
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Сегментация экземпляров с помощью Mask R-CNN
Задача сегментации изображений может решаться в нескольких постановках. Самая распространённая - semantic segmentation с одним классом и фоном, необходимо просто отделить объекты от фона, не различая их между собой. Но часто просто отделения от фона недостаточно, необходимо отделять отдельные образцы друг от друга, например, чтобы оценить размер или расположение каждого отдельного объекта. Как это можно сделать?
Это задача instance segmentation. Её можно решать, как семантическую сегментацию, просто выделяя границы как отдельный класс и присваивая ему больший вес в лоссе. Такое решение подходит для многих ситуаций с простой границей и работает довольно быстро, но может оказаться нестабильным, завестись далеко не “из коробки”. Другой традиционный способ - нахождение объекта через object detection и сегментация внутри найденных ограничивающих рамок. Такой подход, например, используют Mask R-CNN и, с некоторыми модификациями, YOLACT.
Mask R-CNN является наследницей Faster R-CNN, которая используется для выделения ограничивающих рамок. Обе сети дают высокое качество при большом количестве обучающих данных и являются хорошим бейзлайном для большинства задач. Сегодня мы рассмотрим, как можно дообучить модель с torchvision на своих данных и как сделать её инференс.
Полный код можно найти по [ссылке](https://colab.research.google.com/drive/1-epExQsCQUvenJD_c4E4Ji-ZeDteg_z6?usp=sharing#scrollTo=l79ivkwKy357), здесь будут короткие выдержки.
Для начала нужно подготовить датасет. Разметить изображения можно с помощью [VGG](https://www.robots.ox.ac.uk/~vgg/software/via/via.html), он может работать как локально, так и из браузера, отмечать объекты нужно полигонами, а выгрузить результаты в csv, VGG json или COCO json. Затем перегнать аннотации из полигонов в маски с помощью подобного скрипта, [ссылка](https://github.com/comptech-winter-school/coal-composition-control/blob/main/train/converters/vgg_to_mask.py). Итоговая разметка должна быть в формате Penn-Fudan Database. Поскольку процесс разметки трудоёмкий, можно использовать упрощающий трюк - разметить несколько изображений, обучить модель и сделать предразметку ей на необработанных изображения, затем только поправив руками. Пример такого разметчика на основе Mask R-CNN для аннотаций в формате VGG json есть по [ссылке](https://github.com/comptech-winter-school/coal-composition-control/blob/main/train/instance_segmentation/mask_rcnn_annotator.py). Кроме того, некоторые платформы для разметки предоставляют такую услугу.
Можно сразу сохранить маски отдельными файлами, но это может занимать много места, и их загрузка во время обучения может отнимать время, лучше создавать маски прямо во время обучения. Это можно делать так:
```
# маска каждого экземпляра отдельным цветом
mask = get_mask(annotation)
# убираем фон и выделяем номера масок
obj_ids = np.unique(mask)[1:]
# разбиваем общую маску на бинарные
masks = mask == obj_ids[:, None, None]
# переводим в тензор
masks = torch.as_tensor(masks, dtype=torch.uint8)
```
Затем надо сделать стандартные вещи - выбрать оптимизатор и шедулер, изменить количество выходных каналов и backbone, можно настроить и разбиение для anchor boxes. Например, можно настроить модель так:
```
# загружаем предобученную модель
# можно загрузить другой backbone с torchvision, например MobileNetV2
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
# размер входа для детекторной части
in_features_box = model.roi_heads.box_predictor.cls_score.in_features
# размер входа для сегментационной части
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
# выбираем размер для внутреннего представления
# в предикторе для сегментации
hidden_layer = 256
# заменяем последние слои детекции с учётом количества наших классов
# и размера выхода backbone
model.roi_heads.box_predictor = FastRCNNPredictor(in_features_box, num_classes)
# заменяем последние слои для сегментации
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask, hidden_layer, num_classes)
```
Как применить аугментации? Можно применять их к изначальной маске, полученной из аннотаций, либо использовать аугментации из torchvision когда уже будут созданы bbox’ы и прочее, [вот](https://github.com/pytorch/vision/blob/main/references/detection/transforms.py) доступные для второго варианта. Первый вариант больше подходит для [albumentations](https://albumentations.ai/). В полной версии мы используем случайное отражение по горизонтали (RandomHorizontalFlip) и RandomPhotometricDistort, который включает в себя изменение яркости, контрастности и цветовой гаммы, добавление шума.
Сама тренировка проводится с помощью функции train\_one\_epoch из torchvision.references.detection.engine, там же лежит evaluate для проверки на валидационной выборке. Выводятся стандартные метрики для сегментации и детекции отдельно.
Наконец, перейдём к инференсу. Если запустить сразу, то получится вот такая каша:
Это связано с тем, что сеть для object detection выделяет много лишнего и сегментационная часть обрабатывает пустые регионы. Нужно настроить порог по уверенности для bbox’ов и порог для [non maximum suppression](https://paperswithcode.com/method/non-maximum-suppression).
```
model.roi_heads.score_thresh=0.4
model.roi_heads.nms_thresh=0.3
```
И можно предсказывать!
```
img = transforms.ToTensor()(img)
img = img.to(device)
prediction = model([img])
masks = torch.squeeze(prediction[0]['masks'])
masks = masks > segmentation_th
```
На последнем шаге мы оставляем только те пиксели, уверенность в которых выше порога.
С внесёнными изменениями выглядит намного лучше:
Итак, сегодня мы освоили сегментацию экземпляров с Mask R-CNN. Это не самый быстрый в инференсе и обучении, но стабильный алгоритм, который не боится сливающихся границ, легко настраивается и поддерживается. | https://habr.com/ru/post/665300/ | null | ru | null |
# Каким было автоматизированное рабочее место середины 90-х, и как его повторить на современном компьютере
[](https://habr.com/ru/company/ruvds/blog/707220/)
В настоящее время становится популярным отказываться от интернета, социальных сетей, мессенджеров и прочего. Это называется цифровым детоксом.
Я вам предлагаю совершить нечто подобное, разумеется, ненадолго, и если вам за 40, погрузиться в ностальгические воспоминания. А если вы не представляете, как же люди жили раньше без интернета, то узнать, как выглядело рабочее место программиста или студента в далёкие 90-е годы.
Я хочу, чтобы погружение было максимально приближено к реальности, и считаю, что различные эмуляторы и виртуальные машины очень удобны для изучения, разработки и отладки старого программного обеспечения, но для полного погружения лучше работать с программами без них, на реальном компьютере. Вы, к сожалению, уже не ощутите на себе мерцание и размытость монитора с ЭЛТ, не услышите стук дисковода для гибких дисков, громкое шуршание винчестера, но многие эмоции вы переживёте заново.
Для меня середина 90-х в сфере ИТ неразрывно связана с MS-DOS 6.22.
С появлением ОС Windows постепенно использование MS-DOS и программ для неё сошло на нет. Особенно такая тенденция наметилась с появлением Windows 2000. Уход MS-DOS был обусловлен следующим:
1. MS-DOS не поддерживала файловые системы NTFS и FAT32 (MS-DOS 6.22), которые выгодно отличались от FAT16.
2. Работа с периферийными устройствами усложнялась для пользователя. Если для мыши или CD-ROM проблем не было, то со звуковыми и сетевыми картами, устройствами, использующими USB-интерфейс, дела обстояли хуже. Требовалось множество драйверов или поддержка устройства приложением, и мало что работало из коробки. Иными словами, MS-DOS переставала выполнять функции операционной системы.
3. MS-DOS использовала реальный режим работы процессора, и работать можно было с 640 Кб оперативной памяти. Работа с большими объёмами памяти осуществлялась при помощи так называемых менеджеров памяти.
4. MS-DOS не поддерживала многозадачность. В принципе вы могли запустить несколько резидентных программ, но это по сути не являлось многозадачностью.
Сейчас же, когда хочется поностальгировать, эти недостатки не так важны, так как приятное ощущение тех старых добрых времён всё перевешивает.
Если вам будет что-то непонятно в статье, или вы хотите просто запустить у себя на компьютере программы из статьи, вы можете загрузить готовый образ из [моего репозитория на GitHub](https://github.com/artyomsoft/retro-flash-drive), записать его на флеш-накопитель и запустить компьютер с него.
Какими 90-е остались в моей памяти
----------------------------------
### ▍ Какие были компьютеры
Компьютерная мышь, CD-ROМ-привод, принтер, звуковая карта и колонки являлись роскошью, и у большинства счастливых обладателей персональных компьютеров их не было.
Может потому, что я учился в провинциальном вузе, но в 1996 году IBM-PC-совместимый компьютер был только у одного моего одногруппника, и только к 2001 году компьютеры появились у каждого в моей группе. И то, скорее всего, потому что учились мы на компьютерной специальности.
Так как персонального компьютера практически ни у кого не было, мы видели компьютеры только на практических занятиях, связанных с программированием, и ещё два раза в неделю по два часа после занятий по предварительной записи.
Что же из себя представлял компьютерный класс на моей кафедре в далёком 1996 году в моём вузе? Это около десятка разношёрстных IBM-PC-совместимых компьютеров на базе микропроцессоров Intel 286 и Intel 386, c цветным или монохромным монитором, с винчестером или без, объединённых в локальную сеть.
Было ещё несколько компьютерных классов на вычислительном центре вуза, но там даже не было компьютерной сети. В классах стояли компьютеры (хотя их более правильно назвать ЭВМ) EC 1840. Это такая здоровенная бандура, которая не имеет жёсткого диска, гудит как пылесос и использует в качестве накопителей информации два дисковода на гибких магнитных дисках по 360 Кб каждый.
*Компьютер EC 1840*
Если ты хотел поработать (выполнить задания по программированию) на таком компьютере, то ты должен был отдать свой студенческий билет под залог, а тебе выдавали две дискеты: одну загрузочную дискету 5.25 360 Кб с MS-DOS и Norton Commander и вторую с Turbo Pascal.
### ▍ Какие были сетевые технологии
Некоторые классы были объединены в локальную сеть коаксиальным кабелем с общей пропускной способностью 10 Мбит/c. Эти 10 Мбит делились по-братски на все компьютеры, а это целых два класса по 10 компьютеров. Сеть использовала не привычный нам всем TCP/IP, а протокол от Novel IPX/SPX. Общеинститутской локальной сети не было.
Студентам был предоставлен только доступ на чтение к файловому серверу, где располагались задания на лабораторные работы, документация по программированию, необходимые программы. Персонализированного доступа не было, все студенты и даже преподаватели заходили под обычным юзером.
Высокоскоростного интернета не было вообще, к 1998 году появился канал в 115 Кбит/c на весь институт. Разумеется, что студенты его вообще не видели. Интернет того времени для меня ассоциируется с красными глазами невыспавшегося счастливого одногруппника, которому удалось ночью по dial-up выйти на несколько часов в сеть и даже побеседовать кем-то по ICQ.
### ▍ Что читали и откуда брали информацию
Книг по программированию в библиотеке практически не было. Были какие-то книги по советским компьютерам, был даже трёхтомник Дональда Кнута, но ввиду сложности этого труда он мало чем помогал.
Больше всего помогал опыт работы с компьютером, методички, беседы с одногруппниками после занятий. Помню, с каким восторгом мы слушали студента, который рассказывал, что у его родителей на работе есть персональный компьютер с принтером и Windows 95. Для нас, видевших только MS-DOS 6.22, это было какой-то фантастикой. Также помогали добытые распечатки книжек или интерактивная документация, входящая в комплект поставки IDE Borland Turbo C++ или Borland Turbo Pascal.
### ▍ Какими программами пользовались
Время стёрло из памяти структуру директорий и перечень всего, что было на файловом сервере. Запомнилось только то, что сам часто использовал в то время.
Был текстовый редактор WD, электронные таблицы SuperCalc, IDE для разработки программ: Borland Turbo C++ 3.0, Borland Turbo Pascal 7.0, Borland Turbo Assembler 4.0.
Очень популярны были утилиты от Norton (Symantec). Они отличались очень красивым по тем временам интерфейсом и полезными функциями (дефрагментация диска, проверка диска на битые сектора и лечение, редактирование диска, восстановление удалённых файлов).
Часто использовались архиваторы. Самым распространённым был RAR.
### ▍ Как играли в компьютерные игры
Игры, естественно, были под запретом даже после занятий, но кого это тогда волновало. Обычно игру приносил какой-нибудь студент на дискете, и в течение часа она, часто вместе с компьютерным вирусом, становилась достоянием группы. Иногда получалось её сохранить на файловом сервере, мы её прятали от администратора всеми возможными способами. Архивировали, изменяли сигнатуру архива в начале файла, переименовывали и прятали в директориях.
С администратором у нас была постоянная необъявленная война — мы изобретали способы, как его можно обмануть, а он — как нам не дать поиграть в любимую игру. Его сообщником была лаборант, которая постоянно следила за тем, чтобы мы не играли на компьютерах. Самый простой способ скрыть факт игры, который был – это нажать кнопку Reset, когда она появлялась на горизонте.
Как только в класс заходила лаборант, все дружно нажимали кнопку Reset, а потом также дружно изучали, что же находится на диске C в программе Volkov Commander.
### ▍ Как экономили каждый байт
В ту эпоху каждый байт был на счету. Чтобы сохранить побольше информации на диск, мы использовали архиваторы, нестандартное форматирование дискет, виртуальные диски со сжатием.
Ещё был интересный способ, которым пользовалась лаборант нашей кафедры, продавая нам дискеты, – это их просверливание. Не буду утверждать, что именно она просверливала, но при выполнении такой операции над дискетой её ёмкость увеличивалась в два раза с 720 Кб до 1.44 Мб. Да, вы не ослышались, нужно было просверлить дискету.
*Советская дискета ёмкостью 720 Кб, которую можно было просверлить*
Дело в том, что контроллер дисковода гибких дисков 3.5 дюйма определял ёмкость дискеты по наличию и расположению отверстия в правом нижнем углу дискеты. Если отверстия не было, то это дискета с ёмкостью 720 Кб, если было, то 1.44 Мб или 2.88 Мб в зависимости от положения. Поэтому при помощи простой дрели можно было увеличить ёмкость дискеты. Понятно, что надёжность записи на такую дискету, как и чтения с неё, была низкая.
### ▍ Какие неприятности случались, и как их устраняли
Часто на дискетах появлялись дефектные сектора, с которых нельзя было прочитать информацию или на которые нельзя было записать информацию. Появлялись они из-за разных причин: некачественная или ветхая дискета, повидавший виды дисковод.
Если на дискете являлся дефектный сектор, то файл, который располагался на этом секторе, становился некорректным. Если это был архив, то он не распаковывался. Боролись мы с этим двумя способами:
1. Записывали две копии своих программ на две разных дискеты. Поэтому у каждого было несколько дискет. Большим шиком была пластиковая прозрачная коробка, в которой мы хранили и носили с собой дискеты.
2. При создании архива выбирали опцию «добавить информацию для восстановления». Помимо компьютерного вируса, который мог непредсказуемо напакостить, очень разочаровывало случайное удаление файла. Для файловой системы FAT было решение в виде программы UnDelete. Главное — нужно было ничего не записывать на диск после удаления, чтобы повысить шансы на восстановление. Однако для сетевого диска таких решений не было. До сих пор помню дипломницу, которая весь вечер набирала файл со своей работой и, уходя домой, случайно его удалила с сетевого диска.
Думаю, у вас тоже осталось много воспоминаний о тех временах. Будет интересно, если вы поделитесь ими в комментариях.
Программное обеспечение 90-х
----------------------------
Назначение программ в 90-х не отличалось от современных программ, существовали те же категории приложений:
1. Офисные приложения.
2. Файловые менеджеры.
3. IDE и компиляторы.
4. Антивирусы.
5. Различные утилиты.
6. Игры.
Разве что не было браузеров. Может, конечно, где-то и были, но распространены не были.
### ▍ Офисные приложения
Офисные приложения у нас на кафедре были представлены текстовым редактором WD и электронными таблицами SuperCalc. На них мы и проходили практику на первом курсе. Если WD почти не вызывал вопросов, то SuperCalc по юзабилити немного напоминает редактор Vim (запустить легко, а что-то сделать и выйти с сохранением – нужно знать как, с первого раза не догадаешься).
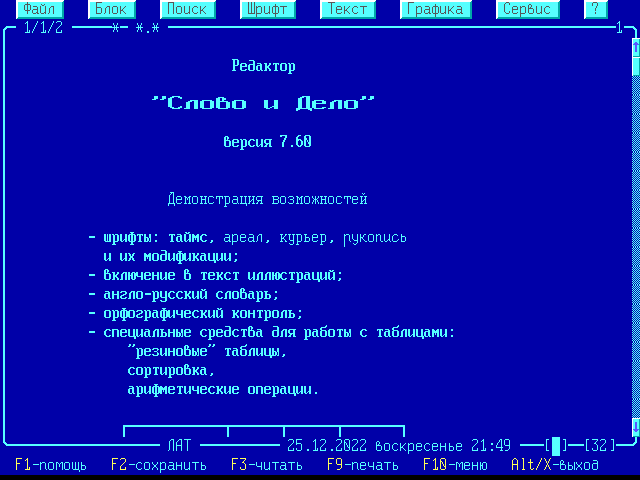*Текстовый редактор WD*
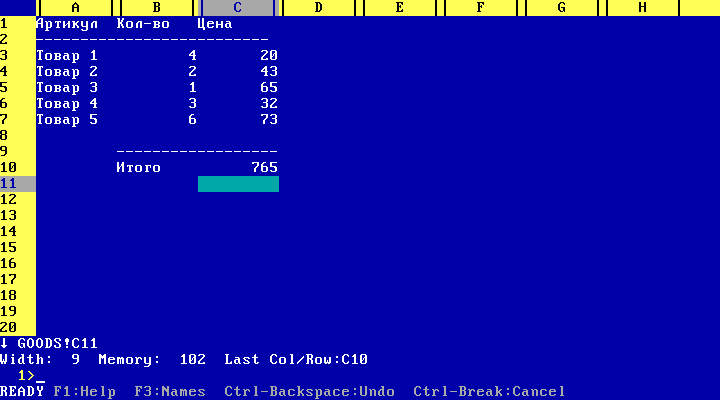*Электронные таблицы SuperCalc*
### ▍ Файловые менеджеры
Несмотря на то, что мы учили командную строку DOS на предмете «Системное программирование», в основном пользовались файловыми менеджерами.
Я помню три файловых менеджера: Norton Commander, Volkov Commander, DOS Navigator. Первый со вторым можно было легко спутать из-за очень похожего внешнего вида, но как-то модно было использовать Volkov Commander.
DOS Navigator мы использовали только для редактирования больших бинарных файлов (первые два портили файл, если он был большого размера). Такую операцию мы выполняли, когда прятали игры от администратора.
*Файловый менеджер Norton Commander*
### ▍ IDE и компиляторы
Когда мы учились, преподаватели не сильно различали IDE и компиляторы. На некоторых других кафедрах были такие случаи, что преподаватель объяснял студенту причину ошибки компиляции программы тем, что в компьютерном классе поставили новые мониторы.
Из IDE было три основных: Borland Turbo Pascal 7.0, Borland Turbo C++ 3.0, Borland Turbo Assembler 4.0, слышали про MASM, но вживую его я не видел, только в книжках.
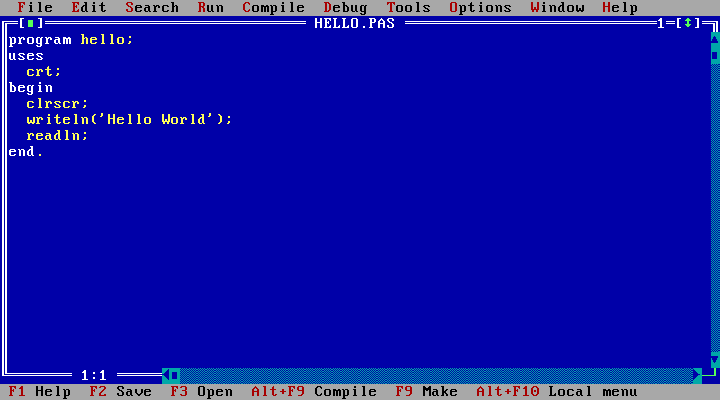
*IDE Borland Turbo Pascal 7.0*
Интересный случай был с компилятором Turbo Pascal 7.0. Некоторые счастливчики, которые уже купили компьютер и могли делать задания по программированию дома, заметили, что у них почти все программы выдают ошибку деления на 0. Оказалось, что дело было в модуле crt (turbo.tpl), который выдавал такую ошибку, если частота процессора была 200 или более МГц.
### ▍ Антивирусы
Компьютерные вирусы были всегда. Тот, кто был попродвинутей, соблюдал элементарные средства безопасности: не совал дискету куда ни попадя, а если не нужно было записывать что-то на дискету, то переключатель на ней был в положении защиты от записи. Иногда проверяли свои дискеты на наличие вирусов. Самыми распространёнными были Doctor Web и Norton Antivirus.
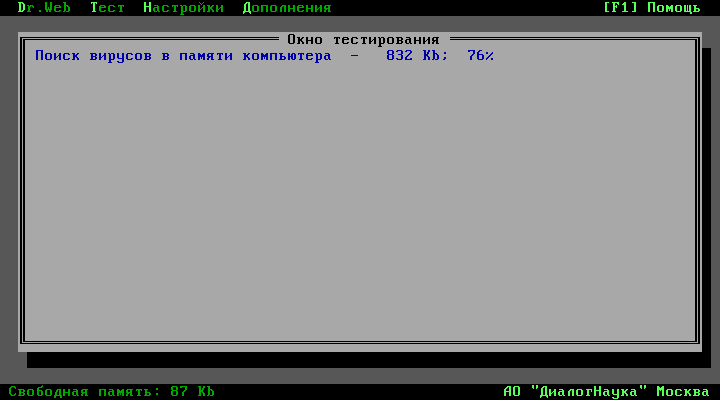*Антивирус Doctor Web*
### ▍ Утилиты
Самой полезной утилитой, наверное, была UnErase из пакета Norton Utilities. Она давала возможность восстановить случайно удалённый файл. Также была интересная утилита DiskEdit, которая позволяла редактировать и просматривать информацию на жёстком диске или дискете на низком уровне (в виде секторов). Для создания архивов использовали rar, реже pkzip/pkunzip. До сих пор помню самый короткий анекдот: «pkunzip.zip».
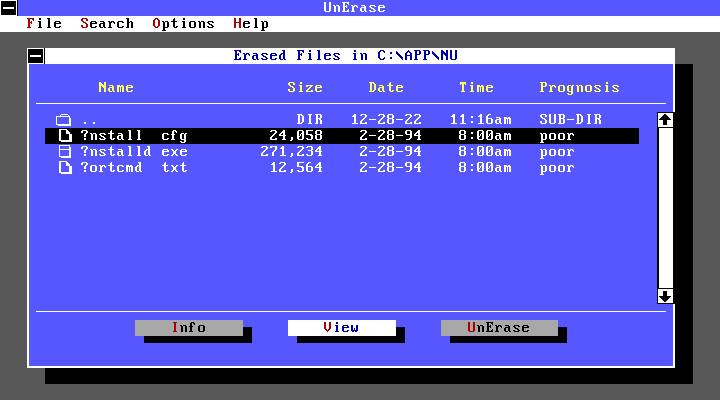*Утилита UnErase*
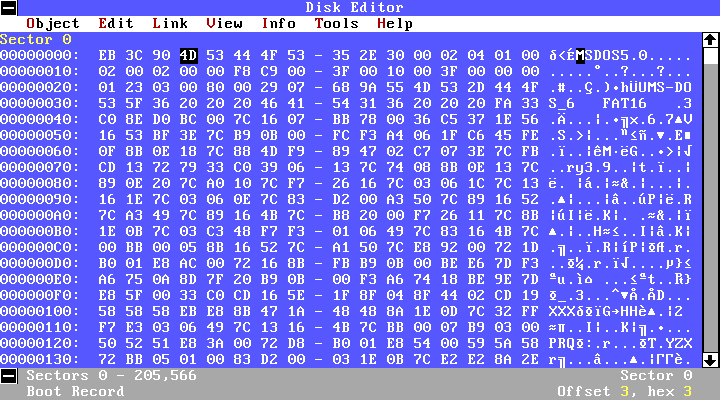*Утилита DiskEdit*
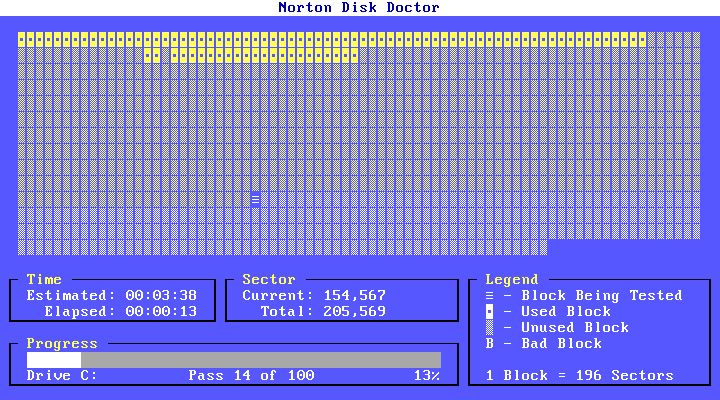*Утилита Norton Disk Doctor*
*Архиватор Rar*
### ▍ Игры
Доступных игр было не сильно много, распространялись они на дискетах, CD-ROM диски только появлялись, но мало где можно было прочитать CD-ROM. Наверное, многим запомнилась легендарная Wolfenstein 3D, а потом Doom, Quake, которые уже требовали более мощные по тем меркам компьютеры.
*Игра Wolfenstein 3D*
*Игра Quake*
Были и отечественные игры, которые создавали энтузиасты, например, «Поле чудес». Естественно, игры, как и обычные программы, никто не покупал — их просто доставали у знакомых и обменивались ими. Сложно судить об оригинальности игр в то время. Игра представляла собой нечто видоизменённое (неизвестно кем), и было хорошо, если игра не содержала вируса в своём составе. Но и такие игры были для многих в диковинку и представляли интерес.
Локализация программ
--------------------
Это было время, когда современные компьютерные технологии только заходили на рынок бывшего СССР. В основном всё программное обеспечение было пиратское и взломанное, если у него предусматривалась защита. Отечественное ПО было, но программы можно было по пальцам пересчитать, по крайней мере у нас: несколько игр и текстовых редакторов, а также KeyRus – резидентная программа, которая позволяла работать с кириллицей.
Программа KeyRus была разработана донецким студентом Дмитрием Гуртяком в 1989 году, к сожалению, рано ушедшем из жизни, но популярность у неё была очень высока, так как в то время использовалась английская версия MS-DOS, которая вообще ничего не знала о кириллице, а программа позволяла очень просто добавить поддержку русского алфавита. Говорят, что была официальная русификация MS-DOS, но я её не видел.
Наверное, из-за нестандартных решений в программе потом у неё были проблемы с работой в Windows NT, да и сейчас в некоторых эмуляторах она не всегда корректно работает.
Воссоздание компьютера из прошлого на современном компьютере
------------------------------------------------------------
В сети много сайтов, которые пытаются сохранить то наследие программ. Например, англоязычные [VentusWare](https://vetusware.com/), [WinWorld](https://winworldpc.com/) или русскоязычный [Old-DOS.ru](http://old-dos.ru/). Я думаю, что вам будет приятно потратить вечер, а может и не один, на их изучение.
После того, как в операционной системе Windows исчезла возможность запускать DOS-программы, самое очевидное решение для запуска старых программ — использовать эмулятор или виртуальную машину, но мы пойдём другим путём – запустим их на современном компьютере в операционной системе MS-DOS 6.22.
Изначально я хотел создать загрузочный ISO с эмуляцией жёсткого диска, но потом от этой идеи отказался, так как флеш-накопитель предоставляет больше возможностей.
Для создания загрузочного флеш-накопителя с DOS мне известны несколько программ:
1. [Rufus](https://rufus.ie) — позволяет, помимо прочего, создать загрузочный накопитель с FreeDOS — современным аналогом MS-DOS, разработка которой прекращена после выхода Windows Me.
2. [RMPrepUSB](https://rmprepusb.com/) — пакет программ, позволяющий записывать различные загрузочные сектора для загрузки ядер MS-DOS и FreeDOS (IO.SYS и KERNEL.SYS), загрузчиков NTLDR (Windows XP), BOOTMGR (Windows Vista, Windows 7), SYSLINUX (простой загрузчик, используемый многими дистрибутивами LINUX для загрузки из BIOS (не UEFI)), проверять работу загрузочного диска в эмуляторе, размечать диск, делать копии разделов, записывать образы разделов на диск.
Разобравшись с вышеперечисленными программами, подготовив необходимые файлы, можно создать загрузочный флеш-накопитель с MS-DOS 6.22 или FreeDOS, но они вам не помогут, если у вас есть образы установочных дискет. Поэтому я решил создать образ флеш-накопителя, используя эмулятор Qemu.
Раньше программы часто не требовали инсталляции — решалось всё простым копированием файлов. Если честно, об установочных дискетах в MS-DOS я узнал уже спустя много лет.
Итак, нам понадобятся:
1. Эмулятор Qemu (только для создания загрузочного флеш-накопителя).
2. Образы инсталляционных дискет MS-DOS 6.22.
3. Программы (образы инсталляционных дискет, директории с программами).
4. Программа для записи образов на флеш-накопитель.
Хотя у меня и получилось запустить многие из программ для MS-DOS 6.22 на своём компьютере, хочу предупредить о сложностях, с которыми вы можете столкнуться.
1. На компьютерах середины 90-х звуковая карта была редкостью, и звук выводился на динамик системного блока. На современных же компьютерах этот динамик может отсутствовать (тогда вы вообще не услышите никакого звука в играх) или эмулироваться звуковой картой (тогда звук может быть искажённым).
2. Некоторые программы, которые напрямую используют порты ввода-вывода, могут не работать.
3. У меня не получилось заставить работать драйвер HIMEM.SYS.
4. DPMI-сервера тех времён, например, для Quake, могут некорректно работать. Я использовал DPMI-сервер с [этого проекта](https://github.com/Baron-von-Riedesel/HX/releases/tag/v2.19).
### ▍ Алгоритм создания загрузочного флеш-накопителя с MS-DOS 6.22
1. Подготавливаем директорию, из которой будем устанавливать программы. Я создал в ней две директории (floppy-images и dos-programs), в которые соответственно поместил программы в виде образов инсталляционных дискет и в виде простых файлов.
2. Загружаем и устанавливаем Qemu.
3. Создаём образ жёсткого диска:
```
$ qemu-img create dos.img 500M
```
4. Запускаем qemu:
```
$ qemu-system-i386 -drive file=dos.img,format=raw,media=disk -m 64 -L . -drive file=fat:rw:"dos-programs",format=raw,media=disk -drive file=floppy-images\dos\disk01.img,format=raw,if=floppy
```
5. Следуем инструкциям, которые предлагает нам установщик DOS.
6. Для смены образа дискеты используем Qemu Monitor Console. В графическом режиме эмулятора это Ctrl+Alt+2. Для возврата из неё – Сtrl+Alt+1.
Для просмотра всех дисковых устройств, используемых в эмуляторе:
```
(qemu) info block
```
Для смены образа дискеты:
```
(qemu) change floppy0 <файл образа>
```
Для извлечения образа дискеты:
```
(qemu) eject floppy0
```
7. Чтобы удобнее было работать в MS-DOS 6.22, первым делом устанавливаем Norton Commander:
```
(qemu) change floppy0 floppy-images\nc\disk01.img
```
```
C:\> mkdir C:\APP
C:\> A:
A:\> dir
A:\> install
```
Путь для установки я меняю с C:\NC на C:\APP\NC, чтобы корневая директория была чище. Я не устанавливал просмотрщики NC, вы можете установить.
8. Аналогичным образом устанавливаем Turbo Pascal 7.0, Turbo C++ 3.0, Turbo Assembler 4.0.
9. Остальные программы копируем просто из директории в директорию.
Из всех программ дополнительной настройки требуют только Turbo Pascal 7.0 и Quake.
### ▍ Настройка Turbo Pascal
Как я говорил ранее, Turbo Pascal, а именно его модуль TURBO.TPL, работает некорректно с процессорами с тактовой частотой 200 мегагерц и выше. Поэтому его нужно пропатчить. Я не буду останавливаться, как это сделать, вы это можете прочесть из прилагаемой к нему инструкции.
### ▍ Настройка Quake
Quake сильно выделяется среди компьютерных игр того времени. Для своей работы она требует прилично по тому времени памяти. Работа с памятью более 640 килобайт всегда была сложной в MS-DOS, поэтому на ней у меня игра Quake не запустилась с первого раза.
Почитав немного о DPMI, я понял, что проблему, скорее всего, можно решить, заменив DPMI-сервер на более новый.
Нужно взять файл HDPMI32.EXE из [этого архива](https://github.com/Baron-von-Riedesel/HX/releases/download/v2.19/HXRT219.zip). Для удобства файлы из этого архива я разместил и в моём репозитории в директории dos-programs\APP\HX.
### ▍ Настройка CONFIG.SYS и AUTOEXEC.BAT
В файлах CONFIG.SYS и AUTOEXEC.BAT осуществляется вся нехитрая настойка DOS 6.22. Я их немного изменил, чтобы DOS работал как надо. Содержимое файлов ниже.
Файл config.sys:
```
FILES=30
```
Файл autoexec.bat:
```
@ECHO OFF
PROMPT $p$g
PATH C:\DOS;C:\APP\TC3\BIN;C:\APP\TP7\BIN;C:\APP\TASM4\BIN;
SET TEMP=C:\DOS
C:\APP\KEYRUS\keyrus.com
C:\APP\NC\nc.exe
```
### ▍ Запуск созданного образа на реальном компьютере
1. Закройте Qemu.
2. На флеш-накопитель запишите образ dos.img, используя balenaEtcher или другую программу для записи образов на флеш-накопитель. При записи будут удалены все файлы, которые были на нём ранее, и пространство под файлы будет ограничено 500 Мб (следствие DOS и FAT16). Поэтому вам будет достаточно старого флеш-накопителя на 1 Гб.
3. В BIOS выберите Legacy Mode и отключите Secure Mode.
4. Выполните загрузку с этого флеш-накопителя.
Если вы создадите в Qemu ещё один пустой образ с FAT 16, вы можете использовать его как дополнительный винчестер, и MS-DOS его будет видеть. Единственное условие, вы должны его вставить в разъём до перезагрузки или включения компьютера.
Заключение
----------
Эпоха DOS для меня длилась всего чуть больше года c сентября 1996-го по декабрь 1997-го. Потом в институте заменили компьютеры на более новые — сначала с Windows 3.1, а потом и с Windows NT 4.0. Но запомнилась эта эпоха очень хорошо. Вообще, обучаясь в институте, я видел, как всё быстро меняется в сфере компьютерных технологий. Когда я поступил, были IBM PC 286 и EC 1840, а когда заканчивал, уже были классы с Pentium II 32 Мб.
Надеюсь, если вы были студентом в те далёкие времена, вы ощутили те чувства, которые ощущали тогда. Я считаю, что именно реальный компьютер с DOS 6.22 позволяет лучше всего это ощутить, а не различные эмуляторы и виртуальные машины, или более поздний DOS 7.0, входивший в поставку Windows 95, или ещё более поздний Free DOS.
Если честно, до этой статьи я сам думал, что в DOS 6.22 уже не поработаешь без виртуальной машины или реального компьютера из 90-х, найденного среди хлама в гараже, но оказалось, что я ошибался.
Не все программы и не на всех компьютерах работают как надо. Но если программу можно запустить на более новом компьютере это, с моей точки зрения, говорит о том, что её правильно спроектировали, раз по прошествии 30 лет она продолжает работать и выполнять то, для чего она задумывалась. Некоторые перестают работать потому, что авторы с целью оптимизации использовали недокументированные возможности и нестандартные решения.
Я думаю, что в 90-х годах студент, у которого все эти программы были на винчестере, мог гордиться этим. Я привёл только те программы, с которыми я работал — вы, вероятнее всего, использовали другие программы. Думаю, вы сможете найти и добавить свои программы, которые использовали в то время.
Если вы всё же хотите поиграть в старые DOS-игры в эмуляторе, то можете использовать [DOSBox](https://www.dosbox.com/), но, несмотря на качественную эмуляцию, ощущения всё же будут не те.
В образ я поместил много программ, не сильно экономя пространство, в реальности же жёсткие диски в то время были по 40 мегабайт, и столько информации вы разместить не могли. Приходилось каким-то образом обходить это ограничение. Из дистрибутивов программ удаляли всё, что считали лишним.
Не знаю как вам, но мне приятно ощущать, что какой бы современный компьютер сейчас ни был, он всё равно может работать под управлением MS-DOS 6.22.
Операционная система Windows 95, которая пришла на смену DOS, обладала большими возможностями, но ввиду сложности её запуск на современном железе более затруднительный и требует больших знаний, если он вообще возможен. То же можно сказать и о Windows NT 4.0, Windows 98, Windows ME, Windows 2000, Windows XP. Но это, как говорится, совсем другая история.
> **[Играй в нашу новую игру прямо в Telegram!](https://t.me/ruvds_community/130)**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=artyomsoft&utm_content=kakim_bylo_avtomatizirovannoe_rabochee_mesto_serediny_90-x_i_kak_ego_povtorit_na_sovremennom_kompyutere) | https://habr.com/ru/post/707220/ | null | ru | null |
# Физика для мобильного PvP шутера, или как мы из двумерной игру в трёхмерную переделывали

В [предыдущей статье](https://habr.com/ru/company/pixonic/blog/481880/) мой коллега рассказал о том, как мы использовали двумерный физический движок в нашем мобильном мультиплеерном шутере. А теперь я хочу поделиться тем, как мы выкинули всё, что делали до этого, и начали с нуля ― иными словами, как мы перевели нашу игру из 2D-мира в 3D.
Всё началось с того, что как-то раз к нам в отдел программистов пришли продюсер и ведущий геймдизайнер поставили перед нами челлендж: мобильный PvP Top-Down шутер с перестрелками в замкнутых пространствах надо было переделать в шутер от третьего лица со стрельбой на открытой местности. При этом желательно, чтобы карта выглядела не так:
А так:

Технические требования при этом выглядели следующим образом:
* размер карты ― 100×100 метров;
* перепад высот ― 40 метров;
* поддержка туннелей, мостов;
* стрельба по целям, находящимся на разной высоте;
* коллизии со статической геометрией (коллизии с другими персонажами в игре у нас отсутствуют);
* физика свободного падения с высоты;
* физика броска гранаты.
Забегая вперед, могу сказать, что на последний скриншот наша игра так и не стала похожа: получилось нечто среднее между первым и вторым вариантом.
Вариант первый: слоистая структура
----------------------------------
Первой была предложена идея не менять физический движок, а просто добавить несколько слоев «этажности» уровней. Получалось что-то вроде планов этажей в здании:
При подобном подходе нам не нужно было радикально переделывать ни клиентское, ни серверное приложение, и вообще казалось, что таким образом задача решается довольно просто. Однако при попытке реализовать его мы столкнулись с несколькими критическими проблемами:
1. После уточнения деталей у левел-дизайнеров мы пришли к выводу, что количество «этажей» в такой схеме может оказаться внушительным: часть карт располагается на открытой местности с пологими склонами и холмами.
2. Расчёт попаданий при стрельбе с одного слоя в другой становился нетривиальной задачей. Пример проблемной ситуации изображен на рисунке ниже: здесь игрок 1 может попасть в игрока 3, но не в игрока 2, так как путь выстрела преграждает слой 2, хотя при этом и игрок 2, и игрок 3 находятся на одном слое.
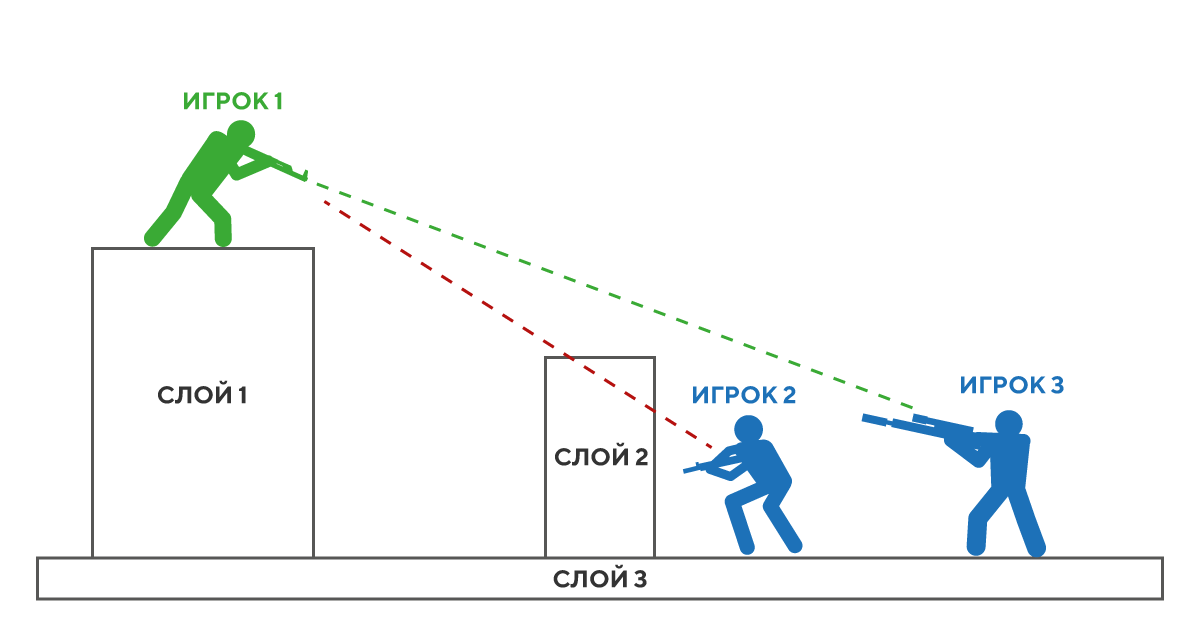
Словом, от идеи разбивать пространство на 2D-слои мы отказались быстро ― и решили, что будем действовать посредством полной замены физического движка.
Что привело нас к необходимости выбрать этот самый движок и встроить его в существующие приложения клиента и сервера.
Вариант второй: выбор готовой библиотеки
----------------------------------------
Так как клиент игры у нас написан на Unity, мы решили рассмотреть возможность использования того физического движка, который встроен в Unity по умолчанию ― PhysX. В целом он полностью удовлетворял требованиям наших геймдизайнеров по поддержке 3D-физики в игре, но всё же была и существенная проблема. Заключалась она в том, что наше серверное приложение было написано на C# без использования Unity.
Был вариант использования C++ библиотеки на сервере ― например, того же PhysX, ― но всерьёз мы его не рассматривали: из-за использования нативного кода при таком подходе была высокая вероятность падения серверов. Также смущала низкая производительность Interop операций и уникальность сборки PhysX чисто под Unity, исключающая использование его в другой среде.
Помимо этого, в попытке внедрить эту идею обнаружились и другие проблемы:
* отсутствие поддержки для сборки Unity с IL2CPP на Linux, что оказалось довольно критичным, поскольку в одном из последних релизов мы перевели наши игровые сервера на .Net Core 2.1 и разворачивали их на машинах с Linux;
* отсутствие удобных инструментов для профилирования серверов на Unity;
* низкая производительность приложения на Unity: нам требовался только физический движок, а не весь имеющийся функционал в Unity.
Кроме того, параллельно с нашим проектом в компании разрабатывался ещё один прототип мультиплеерной PvP-игры. Её разработчики использовали Unity-сервера, и мы получили довольно много негативного фидбека касательно предложенного подхода. В частности, одна из претензий заключалась в том, что Unity-сервера сильно «текут», и их приходится перезапускать каждые несколько часов.
Совокупность перечисленных проблем заставила нас отказаться и от этой идеи тоже. Тогда мы решили оставить игровые сервера на .Net Core 2.1 и подобрать вместо VolatilePhysics, использованного нами ранее, другой открытый физический движок, написанный на C#. А именно движок на C# нам потребовался, так как мы опасались непредвиденных крашей при использовании движков, написанных на C++.
В результате для тестов были отобраны следующие движки:
* [Bepu Physic v1](https://github.com/bepu/bepuphysics1);
* [Bepu Physic v2;](https://github.com/bepu/bepuphysics2)
* [Jitter Physic;](https://github.com/mattleibow/jitterphysics)
* [BulletSharp](https://github.com/ValtoLibraries/BulletSharp).
Основными критериями для нас являлись производительность движка, возможность его интеграции в Unity и его поддерживаемость: он не должен был оказаться заброшенным на случай, если мы найдём в нём какие-то баги.
Итак, мы протестировали движки Bepu Physics v1, Bepu Physics v2 и Jitter Physics на производительность, и среди них наиболее производительным показал себя Bepu Physics v2. К тому же, он единственный из этой тройки всё ещё продолжает активно развиваться.
Однако последнему оставшемуся критерию интеграции с Unity Bepu Physics v2 не удовлетворял: эта библиотека использует SIMD-операции и System.Numerics, и поскольку при сборках на мобильные устройства с IL2CPP в Unity нет поддержки SIMD, все преимущества оптимизаций Bepu терялись. Demo-сцена в билде на iOS на iPhone 5S сильно тормозила. Мы не могли использовать это решение на мобильных устройствах.
Тут следует пояснить, почему нас вообще интересовало использование физического движка. В одной из своих предыдущих [статей](https://habr.com/ru/company/pixonic/blog/415959/) я рассказывал о том, как у нас реализована сетевая часть игры и как работает локальное предсказание действий игрока. Если вкратце, то на клиенте и на сервере исполняется один и тот же код ― система ECS. Клиент реагирует на действия игрока моментально, не дожидаясь ответа от сервера, ― происходит так называемое предсказание (prediction). Когда с сервера приходит ответ, клиент сверяет предсказанное состояние мира с полученным, и если они не совпадают (misprediction), то на основе ответа с сервера выполняется коррекция (reconciliation) того, что видит игрок.
Основная идея заключается в том, что мы исполняем один и тот же код как на клиенте, так и на сервере, и ситуации с misprediction происходят крайне редко. Однако ни один из найденных нами физических движков на C# не удовлетворял нашим требованиям при работе на мобильных устройствах: например, не мог обеспечить стабильную работу 30 fps на iPhone 5S.
Вариант третий, финальный: два разных движка
--------------------------------------------
Тогда мы решились на эксперимент: использовать два разных физических движка на клиенте и сервере. Мы посчитали, что в нашем случае это может сработать: у нас в игре довольно простая физика коллизий, к тому же она была реализована нами как отдельная система ECS и не являлась частью физического движка. Всё, что нам требовалось от физического движка ― это возможность делать рейкасты и свипкасты в 3D-пространстве.
В результате мы решили использовать встроенную физику Unity ― PhysX ― на клиенте и Bepu Physics v2 на сервере.
В первую очередь мы выделили интерфейс для использования физического движка:
**Посмотреть код**
```
using System;
using System.Collections.Generic;
using System.Numerics;
namespace Prototype.Common.Physics
{
public interface IPhysicsWorld : IDisposable
{
bool HasBody(uint id);
void SetCurrentSimulationTick(int tick);
void Update();
RayCastHit RayCast(Vector3 origin, Vector3 direction, float distance, CollisionLayer layer,
int ticksBehind = 0, List ignoreIds = null);
RayCastHit SphereCast(Vector3 origin, Vector3 direction, float distance, float radius, CollisionLayer layer, int ticksBehind = 0,
List ignoreIds = null);
RayCastHit CapsuleCast(Vector3 origin, Vector3 direction, float distance, float radius, float height, CollisionLayer layer, int ticksBehind = 0,
List ignoreIds = null);
void CapsuleOverlap(Vector3 origin, float radius, float height, BodyMobilityField bodyMobilityField, CollisionLayer layer, List overlaps, int ticksBehind = 0);
void RemoveOrphanedDynamicBodies(WorldState.TableSet currentWorld);
void UpdateBody(uint id, Vector3 position, float angle);
void CreateStaticCapsule(Vector3 origin, Quaternion rotation, float radius, float height, uint id, CollisionLayer layer);
void CreateDynamicCapsule(Vector3 origin, Quaternion rotation, float radius, float height, uint id, CollisionLayer layer);
void CreateStaticBox(Vector3 origin, Quaternion rotation, Vector3 size, uint id, CollisionLayer layer);
void CreateDynamicBox(Vector3 origin, Quaternion rotation, Vector3 size, uint id, CollisionLayer layer);
}
}
```
На клиенте и сервере были разные реализации этого интерфейса: как уже говорилось, на сервере мы использовали реализацию с Bepu, а на клиенте ― Unity.
Здесь стоит упомянуть о нюансах работы с нашей физикой на сервере.
Из-за того, что клиент получает обновления мира с сервера с задержкой (лагом), игрок видит мир немного не таким, каким он представляется на сервере: себя он видит в настоящем, а весь остальной мир — в прошлом. Из-за этого получается, что игрок локально стреляет в цель, которая находится на сервере в другом месте. Так что, поскольку мы используем систему предсказания действий локального игрока, нам необходимо компенсировать лаги при стрельбе на сервере.
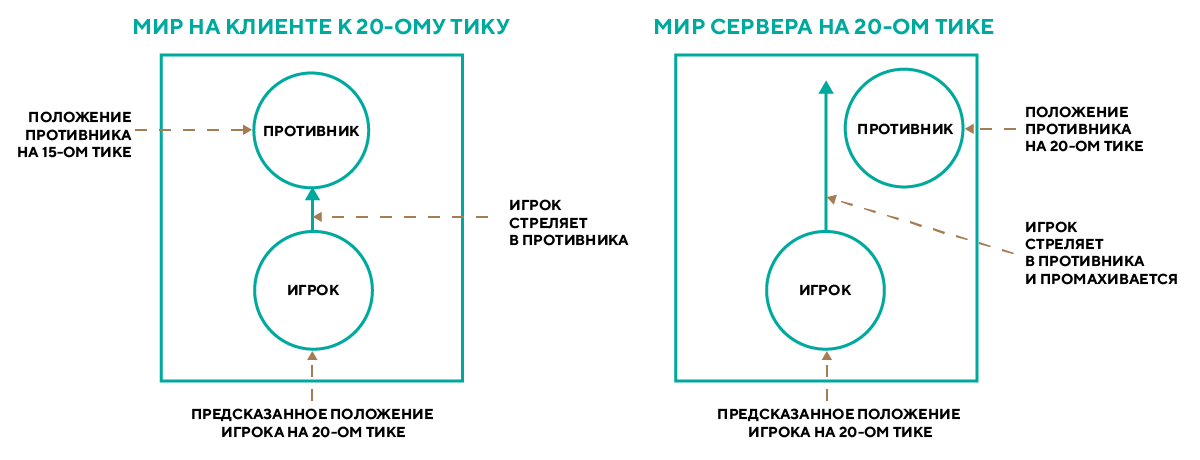
Для того, чтобы их компенсировать, нам необходимо хранить на сервере историю мира за последние N миллисекунд, а также уметь работать с объектами из истории, включая их физику. То есть, наша система должна уметь рассчитывать столкновения, рейкасты и свипкасты «в прошлом». Как правило, физические движки не умеют этого делать, и Bepu с PhysX не исключение. Поэтому нам пришлось реализовать такой функционал самостоятельно.
Так как симуляция игры у нас происходит с фиксированной частотой ― 30 тиков в секунду, ― нам нужно было сохранять данные физического мира за каждый тик. Идея заключалась в том чтобы создавать не один экземпляр симуляции в физическом движке, а N ― на каждый тик, хранящийся в истории, ― и использовать циклический буфер этих симуляций для их хранения в истории:
```
private readonly SimulationSlice[] _simulationHistory = new SimulationSlice[PhysicsConfigs.HistoryLength];
public BepupPhysicsWorld()
{
_currentSimulationTick = 1;
for (int i = 0; i < PhysicsConfigs.HistoryLength; i++)
{
_simulationHistory[i] = new SimulationSlice(_bufferPool);
}
}
```
В нашей ECS существует ряд read-write систем, работающих с физикой:
* InitPhysicsWorldSystem;
* SpawnPhysicsDynamicsBodiesSystem;
* DestroyPhysicsDynamicsBodiesSystem;
* UpdatePhysicsTransformsSystem;
* MovePhysicsSystem,
а также ряд read-only систем, таких как система расчёта попаданий выстрелов, взрывов от гранат и т. д.
На каждом тике симуляции мира первой исполняется InitPhysicsWorldSystem, которая устанавливает физическому движку текущий номер тика (SimulationSlice):
```
public void SetCurrentSimulationTick(int tick)
{
var oldTick = tick - 1;
var newSlice = _simulationHistory[tick % PhysicsConfigs.HistoryLength];
var oldSlice = _simulationHistory[oldTick % PhysicsConfigs.HistoryLength];
newSlice.RestoreBodiesFromPreviousTick(oldSlice);
_currentSimulationTick = tick;
}
```
Метод RestoreBodiesFromPreviousTick восстанавливает положение объектов в физическом движке на момент предыдущего тика из данных, хранящихся в истории:
**Посмотреть код**
```
public void RestoreBodiesFromPreviousTick(SimulationSlice previous)
{
var oldStaticCount = previous._staticIds.Count;
// add created static objects
for (int i = 0; i < oldStaticCount; i++)
{
var oldId = previous._staticIds[i];
if (!_staticIds.Contains(oldId))
{
var oldHandler = previous._staticIdToHandler[oldId];
var oldBody = previous._staticHandlerToBody[oldHandler];
if (oldBody.IsCapsule)
{
var handler = CreateStatic(oldBody.Capsule, oldBody.Description.Pose, true, oldId, oldBody.CollisionLayer);
var body = _staticHandlerToBody[handler];
body.Capsule = oldBody.Capsule;
_staticHandlerToBody[handler] = body;
}
else
{
var handler = CreateStatic(oldBody.Box, oldBody.Description.Pose, false, oldId, oldBody.CollisionLayer);
var body = _staticHandlerToBody[handler];
body.Box = oldBody.Box;
_staticHandlerToBody[handler] = body;
}
}
}
// delete not existing dynamic objects
var newDynamicCount = _dynamicIds.Count;
var idsToDel = stackalloc uint[_dynamicIds.Count];
int delIndex = 0;
for (int i = 0; i < newDynamicCount; i++)
{
var newId = _dynamicIds[i];
if (!previous._dynamicIds.Contains(newId))
{
idsToDel[delIndex] = newId;
delIndex++;
}
}
for (int i = 0; i < delIndex; i++)
{
var id = idsToDel[i];
var handler = _dynamicIdToHandler[id];
_simulation.Bodies.Remove(handler);
_dynamicHandlerToBody.Remove(handler);
_dynamicIds.Remove(id);
_dynamicIdToHandler.Remove(id);
}
// add created dynamic objects
var oldDynamicCount = previous._dynamicIds.Count;
for (int i = 0; i < oldDynamicCount; i++)
{
var oldId = previous._dynamicIds[i];
if (!_dynamicIds.Contains(oldId))
{
var oldHandler = previous._dynamicIdToHandler[oldId];
var oldBody = previous._dynamicHandlerToBody[oldHandler];
if (oldBody.IsCapsule)
{
var handler = CreateDynamic(oldBody.Capsule, oldBody.BodyReference.Pose, true, oldId, oldBody.CollisionLayer);
var body = _dynamicHandlerToBody[handler];
body.Capsule = oldBody.Capsule;
_dynamicHandlerToBody[handler] = body;
}
else
{
var handler = CreateDynamic(oldBody.Box, oldBody.BodyReference.Pose, false, oldId, oldBody.CollisionLayer);
var body = _dynamicHandlerToBody[handler];
body.Box = oldBody.Box;
_dynamicHandlerToBody[handler] = body;
}
}
}
}
```
После этого системы SpawnPhysicsDynamicsBodiesSystem и DestroyPhysicsDynamicsBodiesSystem создают или удаляют объекты в физическом движке в соответствии с тем, как они были изменены в прошлом тике ECS. Затем система UpdatePhysicsTransformsSystem обновляет положение всех динамических тел в соответствии с данными в ECS.
Как только данные в ECS и физическом движке оказываются синхронизированы, мы выполняем расчёт движения объектов. Когда все read-write операции оказываются пройдены, в ход вступают read-only системы по расчёту игровой логики (выстрелов, взрывов, тумана войны...)
Полный код реализации SimulationSlice для Bepu Physics:
**Посмотреть код**
```
using System;
using System.Collections.Generic;
using System.Numerics;
using BepuPhysics;
using BepuPhysics.Collidables;
using BepuUtilities.Memory;
using Quaternion = BepuUtilities.Quaternion;
namespace Prototype.Physics
{
public partial class BepupPhysicsWorld
{
private unsafe partial class SimulationSlice : IDisposable
{
private readonly Dictionary \_staticHandlerToBody = new Dictionary();
private readonly Dictionary \_dynamicHandlerToBody = new Dictionary();
private readonly Dictionary \_staticIdToHandler = new Dictionary();
private readonly Dictionary \_dynamicIdToHandler = new Dictionary();
private readonly List \_staticIds = new List();
private readonly List \_dynamicIds = new List();
private readonly BufferPool \_bufferPool;
private readonly Simulation \_simulation;
public SimulationSlice(BufferPool bufferPool)
{
\_bufferPool = bufferPool;
\_simulation = Simulation.Create(\_bufferPool, new NarrowPhaseCallbacks(),
new PoseIntegratorCallbacks(new Vector3(0, -9.81f, 0)));
}
public RayCastHit RayCast(Vector3 origin, Vector3 direction, float distance, CollisionLayer layer, List ignoreIds=null)
{
direction = direction.Normalized();
BepupRayCastHitHandler handler = new BepupRayCastHitHandler(\_staticHandlerToBody, \_dynamicHandlerToBody, layer, ignoreIds);
\_simulation.RayCast(origin, direction, distance, ref handler);
var result = handler.RayCastHit;
if (result.IsValid)
{
var collidableReference = handler.CollidableReference;
if (handler.CollidableReference.Mobility == CollidableMobility.Static)
{
\_simulation.Statics.GetDescription(collidableReference.Handle, out var description);
result.HitEntityId = \_staticHandlerToBody[collidableReference.Handle].Id;
result.CollidableCenter = description.Pose.Position;
}
else
{
\_simulation.Bodies.GetDescription(collidableReference.Handle, out var description);
result.HitEntityId = \_dynamicHandlerToBody[collidableReference.Handle].Id;
result.CollidableCenter = description.Pose.Position;
}
}
return result;
}
public RayCastHit SphereCast(Vector3 origin, Vector3 direction, float distance, float radius, CollisionLayer layer, List ignoreIds = null)
{
direction = direction.Normalized();
SweepCastHitHandler handler = new SweepCastHitHandler(\_staticHandlerToBody, \_dynamicHandlerToBody, layer, ignoreIds);
\_simulation.Sweep(new Sphere(radius), new RigidPose(origin, Quaternion.Identity),
new BodyVelocity(direction.Normalized()),
distance, \_bufferPool, ref handler);
var result = handler.RayCastHit;
if (result.IsValid)
{
var collidableReference = handler.CollidableReference;
if (handler.CollidableReference.Mobility == CollidableMobility.Static)
{
\_simulation.Statics.GetDescription(collidableReference.Handle, out var description);
result.HitEntityId = \_staticHandlerToBody[collidableReference.Handle].Id;
result.CollidableCenter = description.Pose.Position;
}
else
{
var reference = new BodyReference(collidableReference.Handle, \_simulation.Bodies);
result.HitEntityId = \_dynamicHandlerToBody[collidableReference.Handle].Id;
result.CollidableCenter = reference.Pose.Position;
}
}
return result;
}
public RayCastHit CapsuleCast(Vector3 origin, Vector3 direction, float distance, float radius, float height, CollisionLayer layer, List ignoreIds = null)
{
direction = direction.Normalized();
var length = height - 2 \* radius;
SweepCastHitHandler handler = new SweepCastHitHandler(\_staticHandlerToBody, \_dynamicHandlerToBody, layer, ignoreIds);
\_simulation.Sweep(new Capsule(radius, length), new RigidPose(origin, Quaternion.Identity),
new BodyVelocity(direction.Normalized()),
distance, \_bufferPool, ref handler);
var result = handler.RayCastHit;
if (result.IsValid)
{
var collidableReference = handler.CollidableReference;
if (handler.CollidableReference.Mobility == CollidableMobility.Static)
{
\_simulation.Statics.GetDescription(collidableReference.Handle, out var description);
result.HitEntityId = \_staticHandlerToBody[collidableReference.Handle].Id;
result.CollidableCenter = description.Pose.Position;
}
else
{
var reference = new BodyReference(collidableReference.Handle, \_simulation.Bodies);
result.HitEntityId = \_dynamicHandlerToBody[collidableReference.Handle].Id;
result.CollidableCenter = reference.Pose.Position;
}
}
return result;
}
public void CapsuleOverlap(Vector3 origin, float radius, float height, BodyMobilityField bodyMobilityField, CollisionLayer layer, List overlaps)
{
var length = height - 2 \* radius;
var handler = new BepupOverlapHitHandler(
bodyMobilityField,
layer,
\_staticHandlerToBody,
\_dynamicHandlerToBody,
overlaps);
\_simulation.Sweep(
new Capsule(radius, length),
new RigidPose(origin, Quaternion.Identity),
new BodyVelocity(Vector3.Zero),
0,
\_bufferPool,
ref handler);
}
public void CreateDynamicBox(Vector3 origin, Quaternion rotation, Vector3 size, uint id, CollisionLayer layer)
{
var shape = new Box(size.X, size.Y, size.Z);
var pose = new RigidPose()
{
Position = origin,
Orientation = rotation
};
var handler = CreateDynamic(shape, pose, false, id, layer);
var body = \_dynamicHandlerToBody[handler];
body.Box = shape;
\_dynamicHandlerToBody[handler] = body;
}
public void CreateStaticBox(Vector3 origin, Quaternion rotation, Vector3 size, uint id, CollisionLayer layer)
{
var shape = new Box(size.X, size.Y, size.Z);
var pose = new RigidPose()
{
Position = origin,
Orientation = rotation
};
var handler =CreateStatic(shape, pose, false, id, layer);
var body = \_staticHandlerToBody[handler];
body.Box = shape;
\_staticHandlerToBody[handler] = body;
}
public void CreateStaticCapsule(Vector3 origin, Quaternion rotation, float radius, float height, uint id, CollisionLayer layer)
{
var length = height - 2 \* radius;
var shape = new Capsule(radius, length);
var pose = new RigidPose()
{
Position = origin,
Orientation = rotation
};
var handler =CreateStatic(shape, pose, true, id, layer);
var body = \_staticHandlerToBody[handler];
body.Capsule = shape;
\_staticHandlerToBody[handler] = body;
}
public void CreateDynamicCapsule(Vector3 origin, Quaternion rotation, float radius, float height, uint id, CollisionLayer layer)
{
var length = height - 2 \* radius;
var shape = new Capsule(radius, length);
var pose = new RigidPose()
{
Position = origin,
Orientation = rotation
};
var handler = CreateDynamic(shape, pose, true, id, layer);
var body = \_dynamicHandlerToBody[handler];
body.Capsule = shape;
\_dynamicHandlerToBody[handler] = body;
}
private int CreateDynamic(TShape shape, RigidPose pose, bool isCapsule, uint id, CollisionLayer collisionLayer) where TShape : struct, IShape
{
var activity = new BodyActivityDescription()
{
SleepThreshold = -1
};
var collidable = new CollidableDescription()
{
Shape = \_simulation.Shapes.Add(shape),
SpeculativeMargin = 0.1f,
};
var capsuleDescription = BodyDescription.CreateKinematic(pose, collidable, activity);
var handler = \_simulation.Bodies.Add(capsuleDescription);
\_dynamicIds.Add(id);
\_dynamicIdToHandler.Add(id, handler);
\_dynamicHandlerToBody.Add(handler, new DynamicBody
{
BodyReference = new BodyReference(handler, \_simulation.Bodies),
Id = id,
IsCapsule = isCapsule,
CollisionLayer = collisionLayer
});
return handler;
}
private int CreateStatic(TShape shape, RigidPose pose, bool isCapsule, uint id, CollisionLayer collisionLayer) where TShape : struct, IShape
{
var capsuleDescription = new StaticDescription()
{
Pose = pose,
Collidable = new CollidableDescription()
{
Shape = \_simulation.Shapes.Add(shape),
SpeculativeMargin = 0.1f,
}
};
var handler = \_simulation.Statics.Add(capsuleDescription);
\_staticIds.Add(id);
\_staticIdToHandler.Add(id, handler);
\_staticHandlerToBody.Add(handler, new StaticBody
{
Description = capsuleDescription,
Id = id,
IsCapsule = isCapsule,
CollisionLayer = collisionLayer
});
return handler;
}
public void RemoveOrphanedDynamicBodies(TableSet currentWorld)
{
var toDel = stackalloc uint[\_dynamicIds.Count];
var toDelIndex = 0;
foreach (var i in \_dynamicIdToHandler)
{
if (currentWorld.DynamicPhysicsBody.HasCmp(i.Key))
{
continue;
}
toDel[toDelIndex] = i.Key;
toDelIndex++;
}
for (int i = 0; i < toDelIndex; i++)
{
var id = toDel[i];
var handler = \_dynamicIdToHandler[id];
\_simulation.Bodies.Remove(handler);
\_dynamicHandlerToBody.Remove(handler);
\_dynamicIds.Remove(id);
\_dynamicIdToHandler.Remove(id);
}
}
public bool HasBody(uint id)
{
return \_staticIdToHandler.ContainsKey(id) || \_dynamicIdToHandler.ContainsKey(id);
}
public void RestoreBodiesFromPreviousTick(SimulationSlice previous)
{
var oldStaticCount = previous.\_staticIds.Count;
// add created static objects
for (int i = 0; i < oldStaticCount; i++)
{
var oldId = previous.\_staticIds[i];
if (!\_staticIds.Contains(oldId))
{
var oldHandler = previous.\_staticIdToHandler[oldId];
var oldBody = previous.\_staticHandlerToBody[oldHandler];
if (oldBody.IsCapsule)
{
var handler = CreateStatic(oldBody.Capsule, oldBody.Description.Pose, true, oldId, oldBody.CollisionLayer);
var body = \_staticHandlerToBody[handler];
body.Capsule = oldBody.Capsule;
\_staticHandlerToBody[handler] = body;
}
else
{
var handler = CreateStatic(oldBody.Box, oldBody.Description.Pose, false, oldId, oldBody.CollisionLayer);
var body = \_staticHandlerToBody[handler];
body.Box = oldBody.Box;
\_staticHandlerToBody[handler] = body;
}
}
}
// delete not existing dynamic objects
var newDynamicCount = \_dynamicIds.Count;
var idsToDel = stackalloc uint[\_dynamicIds.Count];
int delIndex = 0;
for (int i = 0; i < newDynamicCount; i++)
{
var newId = \_dynamicIds[i];
if (!previous.\_dynamicIds.Contains(newId))
{
idsToDel[delIndex] = newId;
delIndex++;
}
}
for (int i = 0; i < delIndex; i++)
{
var id = idsToDel[i];
var handler = \_dynamicIdToHandler[id];
\_simulation.Bodies.Remove(handler);
\_dynamicHandlerToBody.Remove(handler);
\_dynamicIds.Remove(id);
\_dynamicIdToHandler.Remove(id);
}
// add created dynamic objects
var oldDynamicCount = previous.\_dynamicIds.Count;
for (int i = 0; i < oldDynamicCount; i++)
{
var oldId = previous.\_dynamicIds[i];
if (!\_dynamicIds.Contains(oldId))
{
var oldHandler = previous.\_dynamicIdToHandler[oldId];
var oldBody = previous.\_dynamicHandlerToBody[oldHandler];
if (oldBody.IsCapsule)
{
var handler = CreateDynamic(oldBody.Capsule, oldBody.BodyReference.Pose, true, oldId, oldBody.CollisionLayer);
var body = \_dynamicHandlerToBody[handler];
body.Capsule = oldBody.Capsule;
\_dynamicHandlerToBody[handler] = body;
}
else
{
var handler = CreateDynamic(oldBody.Box, oldBody.BodyReference.Pose, false, oldId, oldBody.CollisionLayer);
var body = \_dynamicHandlerToBody[handler];
body.Box = oldBody.Box;
\_dynamicHandlerToBody[handler] = body;
}
}
}
}
public void Update()
{
\_simulation.Timestep(GameState.TickDurationSec);
}
public void UpdateBody(uint id, Vector3 position, float angle)
{
if (\_staticIdToHandler.TryGetValue(id, out var handler))
{
\_simulation.Statics.GetDescription(handler, out var staticDescription);
staticDescription.Pose.Position = position;
staticDescription.Pose.Orientation = Quaternion.CreateFromAxisAngle(new Vector3(0, 1, 0), angle);
\_simulation.Statics.ApplyDescription(handler, staticDescription);
}
else if(\_dynamicIdToHandler.TryGetValue(id, out handler))
{
BodyReference reference = new BodyReference(handler, \_simulation.Bodies);
reference.Pose.Position = position;
reference.Pose.Orientation = Quaternion.CreateFromAxisAngle(new Vector3(0, 1, 0), angle);
}
}
public void Dispose()
{
\_simulation.Clear();
}
}
public void Dispose()
{
\_bufferPool.Clear();
}
}
}
```
Также, помимо реализации истории на сервере, нам была необходима реализация истории физики на клиенте. В нашем клиенте на Unity есть режим эмуляции сервера ― мы называем его локальной симуляцией, ― в котором вместе с клиентом запускается код сервера. Этот режим у нас используется для быстрого прототипирования игровых фичей.
Как и в Bepu, в PhysX нет поддержки истории. Здесь мы использовали ту же идею с использованием нескольких физических симуляций на каждый тик в истории, что и на сервере. Однако Unity накладывает свою специфику на работу с физическими движками. Впрочем, тут следует отметить, что наш проект разрабатывался на Unity 2018.4 (LTS), и какие-то API могут поменяться в более новых версиях, так что таких проблем, как у нас, и не возникнет.
Проблема заключалась в том, что Unity не позволял создать отдельно физическую симуляцию (или, в терминологии PhysX, ― сцену), поэтому каждый тик в истории физики на Unity мы реализовали как отдельную сцену.
Был написан класс-обёртка над такими сценами ― UnityPhysicsHistorySlice:
```
public UnityPhysicsHistorySlice(SphereCastDelegate sphereCastDelegate, OverlapSphereNonAlloc overlapSphere, CapsuleCastDelegate capsuleCast,
OverlapCapsuleNonAlloc overlapCapsule, string name)
{
_scene = SceneManager.CreateScene(name, new CreateSceneParameters()
{
localPhysicsMode = LocalPhysicsMode.Physics3D
});
_physicsScene = _scene.GetPhysicsScene();
_sphereCast = sphereCastDelegate;
_capsuleCast = capsuleCast;
_overlapSphere = overlapSphere;
_overlapCapsule = overlapCapsule;
_boxPool = new PhysicsSceneObjectsPool(\_scene, "box", 0);
\_capsulePool = new PhysicsSceneObjectsPool(\_scene, "sphere", 0);
}
```
Вторая проблема Unity ― вся работа с физикой здесь ведётся через статический класс Physics, API которого не позволяет выполнять рейкасты и свипкасты в конкретной сцене. Этот API работает только с одной ― активной ― сценой. Однако сам движок PhysX позволяет работать с несколькими сценами одновременно, нужно только вызвать правильные методы. К счастью, Unity за интерфейсом класса Physics.cs прятала такие методы, оставалось лишь получить к ним доступ. Сделали мы это так:
**Посмотреть код**
```
MethodInfo raycastMethod = typeof(Physics).GetMethod("Internal_SphereCast",
BindingFlags.NonPublic | BindingFlags.Static);
var sphereCast = (SphereCastDelegate) Delegate.CreateDelegate(typeof(SphereCastDelegate), raycastMethod);
MethodInfo overlapSphereMethod = typeof(Physics).GetMethod("OverlapSphereNonAlloc_Internal",
BindingFlags.NonPublic | BindingFlags.Static);
var overlapSphere = (OverlapSphereNonAlloc) Delegate.CreateDelegate(typeof(OverlapSphereNonAlloc), overlapSphereMethod);
MethodInfo capsuleCastMethod = typeof(Physics).GetMethod("Internal_CapsuleCast",
BindingFlags.NonPublic | BindingFlags.Static);
var capsuleCast = (CapsuleCastDelegate) Delegate.CreateDelegate(typeof(CapsuleCastDelegate), capsuleCastMethod);
MethodInfo overlapCapsuleMethod = typeof(Physics).GetMethod("OverlapCapsuleNonAlloc_Internal",
BindingFlags.NonPublic | BindingFlags.Static);
var overlapCapsule = (OverlapCapsuleNonAlloc) Delegate.CreateDelegate(typeof(OverlapCapsuleNonAlloc), overlapCapsuleMethod);
```
В остальном код реализации UnityPhysicsHistorySlice мало чем отличался от того, что было в BepuSimulationSlice.
Таким образом мы получили две реализации игровой физики: на клиенте и на сервере.
Следующий шаг ― тестирование.
Одним из важнейших показателей «здоровья» нашего клиента является параметр количества расхождений (mispredictions) с сервером. До перехода на разные физические движки этот показатель варьировался в пределах 1-2% ― то есть, за бой длительностью 9000 тиков (или 5 минут) мы ошибались в 90-180 тиках симуляции. Такие результаты мы получали на протяжении нескольких релизов игры в софт-лаунче. После перехода на разные движки мы ожидали сильный рост этого показателя ― возможно, даже в несколько раз, ― ведь теперь мы исполняли разный код на клиенте и сервере, и казалось логичным, что погрешности при расчётах разными алгоритмами будут быстро накапливаться. На практике же оказалось, что параметр расхождений вырос лишь 0.2-0.5% и в среднем стал составлять 2-2,5% за бой, что полностью нас устраивало.
В большинстве движков и технологий, которые мы исследовали, использовался один и тот же код как на клиенте, так и на сервере. Однако наша гипотеза с возможностью применения разных физических движков подтвердилась. Основная причина, по которой показатель расхождений вырос так незначительно, заключалась в том, что передвижение тел в пространстве и столкновения мы рассчитываем сами одной из своих систем ECS. Этот код одинаков как на клиенте, так и на сервере. От физического же движка нам требовался быстрый расчёт рейкастов и свипкастов, и результаты этих операций на практике для двух наших движков отличались не сильно.
Что почитать
------------
В заключение, как обычно, приведём несколько ссылок по теме:
* [Физика для мобильного PvP-шутера, часть 1](https://habr.com/ru/company/pixonic/blog/481880/);
* [Сетевой код для мобильного PvP-шутера](https://habr.com/ru/company/pixonic/blog/415959/);
* [Блог Глена Фидлера о том, как писать сетевой код в играх](https://gafferongames.com);
* [Детерминированая симуляция и сетевой код в игре For Honor](https://www.gdcvault.com/play/1026322/Back-to-the-Future-Working). | https://habr.com/ru/post/485150/ | null | ru | null |
# Правила Трех, Пяти и Ноля
Цель этого поста — познакомить вас с Правилами Трех, Пяти и Ноля и объяснить, какое из них и когда вам следует использовать. В следующем посте мы углубимся в применение Правила Пяти в различных сценариях.
Для начала давайте вспомним один из основополагающих принципов C++ — RAII (Resource Acquisition Is Initialization — “получение ресурса есть инициализация”). Этот принцип заключается в возможности управлять ресурсами, такими как память, с помощью пяти *специальных функций-членов*: конструкторов копирования и перемещения, деструкторов и операторов присваивания. Очень часто, когда кто-либо упоминает RAII, речь идет о деструкторах, детерминированно вызываемых в конце области видимости. Немного иронично, учитывая и без того несуразное название. Но остальные особенности RAII не менее важны. В то время как многие языки просто разделяют свои типы на “значимые” и “ссылочные” (например, C# определяет значимые типы в структурах, а ссылочные — в классах), C++ дает нам куда более широкое пространство для работы с идентификаторами и ресурсами посредством этого набора специальных функций-членов.
Но даже до C++11 ценой этой гибкости была сложность. Некоторые взаимодействия довольно тонкие, и в них легко ошибиться. Поэтому еще в 1991 году [Маршалл Клайн (Marshall Cline) сформулировал “Правило Трех”](http://www.ddj.com/cpp/184401400)— простое эмпирическое правило, применимое для большинства сценариев. Когда C++11 представил move семантику (или семантику перемещения), оно было трансформировано в “Правила Пяти”. Затем [Р. Мартиньо Фернандес (R. Martinho Fernandes) сформулировал “Правило Ноля”](https://web.archive.org/web/20130211035910/http://flamingdangerzone.com/cxx11/2012/08/15/rule-of-zero.html), предполагая, что оно по умолчанию превосходит “Правила Пяти”. Но в чем смысл всех этих правил? И должны ли мы им следовать?
### Как Правило Трех стало Правилом Пяти
Правило Трех предполагает, что если вам нужно определить что-либо из конструктора копирования, оператора присваивания копированием или деструктора, то скорее всего вам нужно определить “все три”. Я взял “все три” в кавычки, потому что этот совет устарел начиная с C++11. Теперь, с move семантикой, у нас появилось две дополнительные специальные функции-члены: конструктор перемещения и оператор присваивания перемещением. Таким образом, Правило Пяти — это просто расширение, которое предполагает, что **если вам нужно определить *что-либо* из этой пятерки, то вам, скорее всего, нужно определить или удалить (или, по крайней мере, рассмотреть такую возможность) *все* *пять***.
(Это утверждение не так строго, как Правило Трех, потому что, если вы не определите операции перемещения, они не будут генерироваться, и вызовы будут обрабатываться через операции копирования. И это не будет ошибкой, но, возможно, это будет вашим большим упущением с точки зрения оптимизации.)
Если вы не компилируете код для более ранней версии, чем C++11, вы должны следовать Правилу Пяти.
В любом случае это правило имеет смысл. Если вам нужно определить пользовательскую специальную функцию-член (не являющуюся конструктором по умолчанию), то обычно это из-за того, что вам нужно непосредственно управлять каким-либо ресурсом. В этом случае вам нужно будет отслеживать, что происходит с ним на каждом этапе его жизненного цикла. Обратите внимание, что существуют различные причины, по которым реализации по умолчанию для специальных функций-членов могут быть запрещены или удалены, и мы рассмотрим их подробнее в следующем посте.
Вот пример, вдохновленный `indirect_value` из [P1950](https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2020/p1950r1.html):
```
template
class IndirectValue {
T\* ptr;
public:
// Инициализация и уничтожение
explicit IndirectValue(T\* ptr ) : ptr(ptr) {}
~IndirectValue() noexcept { if(ptr) delete ptr; }
// Копирование (вместе с деструктором дает нам Правило Трех)
IndirectValue(IndirectValue const& other) : ptr(other.ptr ? new T(\*other.ptr) : nullptr) {}
IndirectValue& operator=(IndirectValue const& other) {
IndirectValue temp(other);
std::swap(ptr, temp.ptr);
return \*this;
}
// Перемещение (добавление этих элементов уже дает нам Правило Пяти)
IndirectValue(IndirectValue&& other) noexcept : ptr(other.ptr) {
other.ptr = nullptr;
}
IndirectValue& operator=(IndirectValue&& other) noexcept {
IndirectValue temp(std::move(other));
std::swap(ptr, temp.ptr);
return \*this;
}
// Остальные методы
};
```
Хочу обратить ваше внимание на то, что для реализации операторов присваивания мы использовали [идиомы копирования и замены (copy-and-swap) и перемещения и замены (move-and-swap)](https://en.wikibooks.org/wiki/More_C%2B%2B_Idioms/Copy-and-swap) в целях предотвращения утечек и автоматической обработки самоприсваивания (мы также могли бы объединить эти два оператора в один, который принимает аргумент по значению, но я хотел продемонстрировать в этом примере обе функции).
Также важно отметить, что оба правила начинаются со слов “если вам необходимо определить какой-либо из…”. Иногда оборотная сторона тоже может представлять интерес. Еще один неявный вывод из этих правил заключается в том, что существуют практические случаи, когда нам вообще не нужно определять какие-либо специальные функции-члены, и все будет работать так, как нужно. Оказывается, это вполне может быть самым важным выводом, но чтобы понять почему, нам нужно немного переформулировать правила. Так на сцену выходит Правило Ноля.
### Правило Ноля
Если ничего из специальных функций-членов не определено пользователем, то (с учетом переменных-членов) компилятор предоставит реализации по умолчанию для каждой из них. **Правило Ноля заключается в том, что тот сценарий, когда *не нужно* определять *ничего* из специальных функций-членов, должен быть *предпочтительным***. Отсюда вытекает два сценария:
1. Ваш класс определяет чисто значимый тип, и любое его состояние состоит из чисто значимых типов (например, примитивов).
2. Любые ресурсы, которые приходится задействовать состояниям вашего класса, управляются классами, которые специализируются исключительно на управлении ресурсами (например, умными указателями, файловыми объектами и т. д.).
Второй сценарий требует немного большего пояснений. Мы можем привести еще одну формулировку, которая заключается в том, что любой класс должен непосредственно управлять *не более чем* одним ресурсом. Поэтому, если вам нужно управлять какой-нибудь памятью, вам следует задействовать уже готовый или написать свой класс, специализированный для управления этой памятью — будь то умный указатель, контейнер на основе массива или что-нибудь еще. Эти типы для управления ресурсами в свою очередь уже будут следовать Правилу Пяти. Но такие классы должны быть довольно редким явлением — стандартная библиотека покрывает наиболее распространенные сценарии своими контейнерами, умными указателями и потоковыми объектами. Класс, который *использует* тип для управления ресурсами, должен “просто делать свою работу”, следуя Правилу Ноля.
Соблюдение этого строгого различия делает ваш код проще, чище и специализированнее, а также делает написание корректного кода немного проще. “Нет такого кода, в котором было бы меньше ошибок, чем в его отсутствии”, поэтому необходимость писать меньше кода (особенно кода для управления ресурсами) – это зачастую очень хорошо.
И даже с этой точки зрения Правило Ноля имеет смысл — и, действительно, анализаторы Sonar рекомендуют вам его в [S493 (*“Правило Ноля” следует соблюдать*)](https://rules.sonarsource.com/cpp/RSPEC-4963).
### Когда и какое правило использовать?
В некотором смысле, Правило Ноля включает в себя Правило Пяти, так что вы можете просто следовать ему. Но самый лучший подход — по умолчанию следовать Правилу Ноля, прибегая к Правилу Пяти, если обнаружили, что вам нужно написать какие-либо специализированные классы, управляющие ресурсами (что само по себе должно происходить достаточно редко). Опять же, это уже оговорено в [S3624 (*когда “Правило Ноля” не применимо, следует следовать “Правилу Пяти”*)](https://rules.sonarsource.com/cpp/RSPEC-3624).
Правило Трех применимо только в том случае, если вы работаете строго с версиями до C++11.
Но действительно ли они охватывают все случаи?
### Когда Правил Трех, Пяти и Ноля недостаточно
Полиморфные базовые классы — распространенный случай, когда применяются вышеуказанные правила, но они кажутся несколько тяжеловесными. Почему? Потому что такие классы должны иметь (по умолчанию) виртуальный деструктор ([S1235 — деструктор *полиморфного базового класса должен быть виртуальным public или не виртуальным*](https://rules.sonarsource.com/cpp/RSPEC-1235) [*protected*](https://rules.sonarsource.com/cpp/RSPEC-1235)). Это не означает, что они должны иметь какие-либо другие специальные функции-члены (на самом деле хорошей практикой является использование в качестве полиморфных базовых классов чистых абстрактных базовых классов) без какой-либо функциональности.
Предоставление публичных операций копирования и перемещения для полиморфных иерархий делает их склонными к сплайсингу, когда разница между статическими и динамическими типами теряется при копировании. Если требуется возможность копирования или перемещения, то они должны осуществляться с помощью виртуальных методов. В этом случае обычно используется виртуальный метод `clone()`. Реализации этих виртуальных методов могут использовать операции копирования и перемещения (в этом случае они могут быть реализованы или заданы по умолчанию как *protected* члены), предотвращая случайное использование извне. В противном случае, что составляет подавляющее большинство сценариев, их следует просто удалить.
```
virtual ~MyBaseClass() = default;
MyBaseClass(MyBaseClass const &) = delete;
MyBaseClass(MyBaseClass &&) = delete;
MyBaseClass operator=(MyBaseClass const &) = delete;
MyBaseClass operator=(MyBaseClass &&) = delete;
```
Реализация или удаление всех специальных функций-членов может стать вполне утомительным занятием, особенно если вы работаете с кодовой базой, в которой много полиморфных базовых классов (хотя в наши дни это довольно редко, по крайней мере, в более современном коде). Один из способов обойти это (фактически единственный способ до C++ 11) это приватное наследование от базового класса, который уже имеет все эти пять определений (или, до C++11, делать “удаленные” функции приватными и нереализованными). Это вполне валидный вариант и, пожалуй, возвращает нас к Правилу Ноля.
Однако оказывается, что все, что нам нужно сделать, это удалить оператор присваивания перемещением. Из-за того, как определяются взаимодействия между специальными функциями-членами, это будет иметь тот же эффект (и, на самом деле, может быть, немного лучше, как мы увидим в следующем посте).
```
virtual ~MyBaseClass() = default;
MyBaseClass operator=(MyBaseClass &&) = delete;
```
Если это кажется странным или немного подозрительным, или если вы хотите больше узнать о применении Правила Пяти в ряде разных случаев, читайте вторую часть этой серии, где мы углубимся во все это, а также в то, как определяются эти взаимодействия.
---
Приглашаем всех желающих на открытое занятие, посвященое многопоточному программированию на C++. На примере такой задачи, как подсчет числа простых чисел, мы рассмотрим, как различные элементы многопоточного программирования на C++ помогут получить более производительное решение. Регистрация на вебинар открыта [по ссылке.](https://otus.pw/I6Z4/) | https://habr.com/ru/post/704492/ | null | ru | null |
# Хакинг классического Sonic the Hedgehog для Sega
В этой статье я хочу разобрать внутреннее устройство легендарной игры Sonic the Hedgehog для приставки Sega Mega Drive, а также способы ее модификации или, как еще говорят, хакинга. Эта игра насчитывает порядка [сотни хаков](http://info.sonicretro.org/Sonic_hacks), включающих как действительно достойные работы (такие как [Pana Der Hejhog](https://www.youtube.com/watch?v=24gnW3iAwYU) или [Sonic Remastered](http://info.sonicretro.org/Sonic_1_Remastered_(hack))), так и странные и даже жутковатые (вроде [An Ordinary Sonic ROM Hack](https://www.youtube.com/watch?v=ThSpW33w2gA)). Чтобы понять, как их создавать, нужно разобраться, как писать на языке ассемеблера Motorola 68K (обычно игры для приставок тех времен писались именно на ассемблере), откуда взять дизассемблированный вариант игры и какую архитектуру имеет ее движок.
Дизассемблирование ROM-файлов для Sega осуществляется при помощи коммерческого дизассемблера и дебаггера [IDA Pro](https://www.hex-rays.com/products/ida/). Затем происходит кропотливый процесс разметки, структурирования и причесывания сырого ассемблерного кода с использованием дебаггера (и смекалки). Этот процесс требует хорошего понимания технических особенностей платформы Sega Mega Drive и игр для нее.
К счастью, на GitHub уже есть дизассемблированные и размеченные версии всех игр серии Sonic the Hedgehog, созданные энтузиастами при поддержке сайта [Sonic Retro](https://sonicretro.org). Лучше всего размечен и структурирован исходный код именно первой игры серии. Эта версия кода находится в репозитории [sonicretro / s1disasm](https://github.com/sonicretro/s1disasm) и именно она будет разобрана в статье.
Погружение в внутреннее устройство игрушки начнем с теории.
Технический обзор приставки
---------------------------

Sega Mega Drive (известная в США как Sega Genesis) оснащена 32-битным центральным процессором Motorola MC68000 (сокращенно Motorola 68K) и дополнительным звуковым сопроцессором Zilog Z80 (взамодействие с Z80 происходит через общую память). Объем оперативной памяти (RAM) – 64K. Разрешение экрана в основном режиме (в американской версии) – 320x224 пикселей.
Использованный процессор Motorola 68K в свое время был достаточно распространен. Этот чип применялся в самых разных системах, от популярных домашних компьютеров и игровых приставок до [космических шаттлов](https://history.nasa.gov/computers/Ch4-8.html). Одна из модификаций Motorola 68K даже была [установлена](https://everymac.com/systems/apple/mac_classic/specs/mac_128k.html#macspecs1) в легендарном Apple Macintosh.
Графическая подсистема Mega Drive основана на видеоконтроллере Yamaha YM7101 и поддерживает аппаратную работу с двумя слоями фона и отрисовку до 80 спрайтов поверх них. Подробнее графика в игре будет разобрана далее; прочитать о графике в Sega Mega Drive отдельно можно в статье ["Как работала графическая система Sega Mega Drive: Video Display Processor"](https://habr.com/ru/post/471914/).
Для сборки игры используется [макроассемблер AS](http://john.ccac.rwth-aachen.de:8000/as/). Набор инструкций этой платформы совершенно не сложный и содержит всего 82 инструкции. Для сравнения: по подсчетам пользователя ResearchGate современный Intel Core i7 [имеет 338 инструкций](https://www.researchgate.net/post/What_is_the_number_of_instructions_in_a_modern_CPU).
Процессор имеет восемь 32-битных регистров общего назначения: `D0`–`D7`. Все эти регистры активно используются в играх для хранения промежуточных данных и в качестве операндов арифметических операций. Также существует восемь специальных *адресных регистров* `A0`–`A7`. Адресные регистры оптимизированы для хранения указателей на какие-либо объекты в памяти и их использование в некоторых операциях невозможно. Последний адресный регистр A7 по совместительству работает указателем стека и имеет алиас `SP`.
Большинство инструкций могут работать в одном из трех режимов разрядности. Суффикс `.l` (long) обозначает работу в 32-битном режиме. При использовании суффиксов `.w` (word) и `.b` (byte) процессор будет работать только с младшими 16-ю или 8-ю битами каждого из операндов соответственно.
Разберем основные инструкции Motorola 68K.
### Операция копирования
`move` – скопировать данные из источника в приемник.
Примеры:
* `move.l #48, d4` – поместить десятичное число 48 в регистр `d4`.
* `move.w d5, d6` – скопировать младшие 16 бит регистра `d5` в регистр `d6`.
* `move.w #$12FF, obStatus(a0)` – поместить шестнадцатеричное число 12FF по адресу в памяти, заданному константой `obStatus` со смещением, заданным в регистре `a0`.
Как видно из примеров выше, для записи десятичных чисел в этом ассемблере используется префикс `#`. Для записи шестандатиричных числе используется префикс `#$`.
При записи операнда в скобках вычисление происходит со значением по такому адресу в памяти:
* `move.l #5, (a0)` – поместить десятичное число 5 по адресу в памяти, хранящемуся в регистре `a0`.
* `move.l (a1), d2` – поместить значение по адресу, хранящемуся в регистре `a1`, в регистр `d2`.
Такой режим адресации возможен только для адресных регистров (`a*`).
### Арифметические операции
* `add` – прибавить значения источника к значению приемника.
* `sub` – отнять значение источника от значения приемника.
* `mulu` – беззнаковое умножение; `muls` – знаковое умножение.
* `divu` – беззнаковое деление; `divs` – знаковое деление.
Примеры:
* `add.b #$08, d0` – прибавить шестнадцатеричное число 08 к значению регистра `d0`.
* `sub.w (v_screenposx).w, d1` – разделить значение в регистре `d1` на значение в памяти по адресу `v_screenposx` (в 16-разрядном режиме).
* `mulu.w #10, d0` – умножить значение в регистре `d0` на 10 (число в регистре `d0` считать беззнаковым).
* `divs.w #$68, d2` – целочисленно разделить значение в регистре `d2` на шестнадцатеричное число 68 (число в регистре `d2` считать знаковым).
### Операции управления потоком выполнения
* `jmp`, `bra` – безусловный переход.
* `jsr`, `bsr` – вызов подпрограммы, `rts` – возврат из подпрограммы (аналоги `call` и `ret` в x86).
Примеры:
```
jmp .foo ; безусловный переход на метку .foo
nop ; данная пустая операция (nop) не будет выполнена
.foo: ; метка .foo
```
```
SubRoutine: ; объявление подпрограммы SubRoutine
nop
rts ; возврат из подпрограммы
```
```
bsr SubRoutine ; вызов подпрограммы SubRoutine
```
### Операции ветвления
Для выполнения условных переходов в процессоре 68K используется регистр `CCR` (Condition Code Register). Инструкции `cmp`, `tst` и `btst` позволяют выставить биты (флаги) этого регистра, которые затем используются в операциях условного перехода `beq`, `bne`, `bge`, `ble` и других.
* `cmp` – сравнить значения.
* `tst` – сравнить значение с нулем.
* `btst` – сравнить заданный бит с нулем.
* `beq`/`bne` – перейти, если сравниваемые значения были равны/не равны.
* `bge`/`ble` – перейти, если второе сравниваемое значение было больше/меньше первого.
Примеры:
```
cmp.w #32,d0 ; сравнить d0 и 32
bge.s .foo ; если d0 > 32, перейти на метку .foo
```
```
btst #0,d0 ; сравнить нулевой (младший) бит d0 с нулем
bne.s .foo ; если бит не равен нулю, перейти на метку .foo
```
Более подробно изучить команды Motorola 68K вам поможет [отличный мануал](http://mrjester.hapisan.com/04_MC68/) (с ужасным фоном и шрифтами) автора Марки Джестера, где каждая из команд разобрана максимально подробно.
Сборка игры
-----------
Репозиторий s1disasm содержит Python-скрипт, автоматически запускающий нужную версию ассемблера для текущей операционной системы со всеми необходимыми флагами. Также этот скрипт выполняет специфическую для игры Sonic the Hedgehog операцию ["Kosinski compression"](https://segaretro.org/Kosinski_compression), которая сжимает карты уровней и другие бинарные данные (чтобы они поместились в память картриджа).
Все, что нужно сделать пользователю, это перейти в git-ветку `AS` (`git checkout AS`) и выполнить команду:
```
./build.py
```
Результатом выполнения скрипта должен стать готовый ROM-файл игры с названием `s1built.bin`. Этот файл можно запустить в вашем любимом эмуляторе Sega Mega Drive. Для macOS, например, рекомендуется использовать замечательный [OpenEmu](https://openemu.org).
Архитектура движка игры
-----------------------
Начнем обзор с основной точки входа для сборки игры – файла [`sonic.asm`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm). В нем находятся процедуры инициализации: ожидание готовности сопроцессора Zilog Z80 ([`WaitForZ80`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L183)), установки параметров видеопроцессора ([`VDPSetupGame`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L976)) и проверка [контрольной суммы](https://segaretro.org/Checksum). После инициализации игра выполняет подпрограмму [`GameInit`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L340) и переходит в главный цикл [`MainGameLoop`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L353), задачей которого является считывание переменной глобального игрового режима и запуск соответствующему ему кода.
Полный список глобальных переменных, используемых игрой вынесен в файл [`Variables.asm`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/Variables.asm). Каждая переменная представляет собой константу со ссылкой на адрес в RAM, где должно храниться значение переменной.
Глобальный игровой режим хранится в переменной [`v_gamemode`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/Variables.asm#L107). Список глобальных игровых режимов включает в себя:
* 00 – экран "Sega",
* 01 – титульный экран с Соником,
* 08 – демо,
* 0C – уровень,
* 10 – special stage,
* 14 – экран "Continue",
* 18 – финальная заставка,
* 1C – финальные титры,
* 8C – титр уровня.
В строке `move.b #id_Sega,(v_gamemode).w` подпрограммы [`GameInit`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L340) в переменную `v_gamemode` заносится режим, в котором игра должна стартовать. Если заменить `id_Sega` на `id_Title` и собрать игру командой `./build.py`, то мы получим первый рабочий хак, в котором вместо отображения экрана "Sega" игра сразу приветствует нас титульным экраном, что может сократить время дебага.
Переменная `v_gamemode` определяет подпрограмму для главного цикла, которая должна исполняться в данный момент. Например, в режиме `id_Title` приставка будет исполнять подпрограмму [`GM_Title`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L2097), а в режиме `id_Level` – [`GM_Level`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L2755).
### Игровые параметры
Многие переменные, объявленные в файле [`Variables.asm`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/Variables.asm) представляют интерес для хакинга. Рассмотрим для примера [`v_sonspeedmax`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/Variables.asm#L179), [`v_sonspeedacc`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/Variables.asm#L180) и [`v_sonspeeddec`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/Variables.asm#L181).
Изменяя значения, помещаемые в эти переменные в подпрограмме [`Sonic_Main`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L6927), можно изменять динамические характеристики перемещения Соника: максимальная скорость, значение ускорения и торможения соответственно, получая интересные результаты:
```
move.w #$600,(v_sonspeedmax).w ; Sonic's top speed
move.w #$C,(v_sonspeedacc).w ; Sonic's acceleration
move.w #$80,(v_sonspeeddec).w ; Sonic's deceleration
```
Дробные переменные хранятся в формате с фиксированной точкой, поэтому для получения реальных значений их необходимо разделить на 256. Так, ускорение Соника составит 0xC / 256 = 0.046875, а торможение – 0x80 / 256 = 0.5 (пикселей на игровой цикл в квадрате).
### Графика
Графикой в Mega Drive занимается тайловый графический процессор Sega 315‑5313 (Video Display Processor, VDP). Конфигурирование VDP производится с помощью регистров, запись в которые производится через специальные адеса в памяти [`vdp_data_port`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/Constants.asm#L9) и [`vdp_control_port`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/Constants.asm#L10). Изначальная конфигурация процессора устанавливается в подпрограмме [`VDPSetupGame`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L976), которая берет параметры по адресу [`VDPSetupArray`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L1013). Однако, в каждом из глобальных игровых режимов, некоторые регистры выставляются повторно. Например, на игровых уровнях это [делает](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L2821) подпрограмма `GM_Level`. Подробное описание функций всех регистров VDP приведено в [вики Sega Retro](https://segaretro.org/Sega_Mega_Drive/VDP_registers).
Для примера приведем скриншот игры с включенным режимом Low Color (нулевой бит регистра Mode Register 1 выставлен в ноль):

Video Display Processor позволяет аппаратно работать с двумя фоновыми слоями – background (слой B) и foreground (слой A), а также со слоем спрайтов, которые отображаются поверх фона. Фоновые слои собираются из тайлов 8x8 пикселей с помощью [карт тайлов](https://segaretro.org/Plane_mappings). Спрайты также собираются из тайлов; максимальный размер спрайта – 4x4 тайла. Таким образом, максимальный размер аппаратного спрайта составляет 32x32 пикселя.
Удаление кода из подпрограмм работы с фоновыми слоями ([`LoadTilesAsYouMove`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L4315), [`DrawChunks`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L5153)) и спрайтами ([`BuildSprites`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L6284)) позволяет понять, какие из игровых объектов к какому слою относятся:
Как видно из названия, подпрограмма `LoadTilesAsYouMove` занимается подгрузкой тайлов на фоновые слои по мере продвижения игрока по уровню. В игре Sonic the Hedgehog размер обоих тайловых плоскостей составляет 64x32 тайла или 512x256 пикселей.
**Так выглядит изменяющийся foreground-слой на уровне Green Hill Zone, GIF-анимация, 5 Мб:**

Графический процессор также позволяет устанавливать не только общее смещение фонового слоя, но и смещение его отдельных горизонтальных рядов тайлов, используя так называемую [таблицу скроллинга](https://segaretro.org/Sega_Mega_Drive/Scrolling). Эта возможность позволяет перемещать удаленные элементы фона медленнее, чем близкие. Таким образом создается эффект параллакса, который имитирует 3D-графику и придает сцене объем. Этот эффект используется почти во всех уровнях Sonic the Hedgehog.
Эффект параллакса в фоновом слое уровня Marble Zone:

### Игровые объекты
Движок игры выделяет 8192 байта в RAM на хранение состояния динамических объектов сцены. Вся эта информация хранится по смещению [`v_objspace`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/Variables.asm#L21). К динамическим объектам относится все объекты на уровне, кроме стен и пола. Примеры: Соник, враги Соника, мониторы с бонусами, кольца, пружины, Босс и так далее. При необходимости объекты отрисовывают себя в слое спрайтов при помощи подпрограммы [`DisplaySprite`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/_incObj/sub%20DisplaySprite.asm#L8).

Размер данных состояния игрового объекта статичен и составляет 64 байта. Эта информация формирует структуру, поля которой могут быть получены с использованием макросов, объявленных в файле [`Constants.asm`](https://github.com/sonicretro/s1disasm/blob/6dc32551c3adf49b1ef11ffdec352e8f22e814e4/Constants.asm#L123). Адрес структуры данных текущего обрабатываемого игрового объекта обычно заносится в регистр `a0`. Таким образом, данные игрового объекта могут быть считаны так:
* `ObX(a0)`, `ObY(a0)` – текущие координаты объекта в пикселях.
* `ObVelX(a0)`, `ObVelX(a1)` – текущая скорость объекта в 1/256 пикселя за шаг.
* `obHeight(a0)`, `obWidth(a0)` – высота и ширина объекта.
* `obSubtype(a0)` – подтип объекта (пример: тип бонусного монитора).
* `obStatus(a0)` – байт с флагами состояния объекта.
* `obRoutine(a0)` – номер текущей подпрограммы объекта.
Отметим, что система координат в игре типична для экранной графики и имеет ось X направленную вправо, и ось Y, направленную вниз.
Подпрограмма [`ExecuteObjects`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/sonic.asm#L6217) вызывается на каждом шаге главного цикла уровня. Она последовательно вызывает программный код каждого из игровых объектов, присутствующих на сцене. Список указателей на программный код каждого из объектов задан в таблице в файле [`Object Pointers.asm`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/_inc/Object%20Pointers.asm). Программный код большей части объектов вынесен в отдельный файл в каталоге [`_incObj`](https://github.com/sonicretro/s1disasm/tree/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/_incObj).
Многие из объектов имеют по несколько подпрограмм, которые соответствуют разным этапам жизни объекта (например, только что созданный объект, объект в рабочем состоянии, "предсмертное" состояние). В этом случае номер подпрограммы, которую необходимо выполнять сейчас, хранится в поле [`obRoutine`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/Constants.asm#L148).
При необходимости передвижения объекта с заданной скоростью вызывается специальная подпрограмма [`SpeedToPos`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/_incObj/sub%20SpeedToPos.asm). Она интегрирует скорость текущего объекта, прибавляя ее значение к его координатам.
### Хак: no-ring challenge
В качестве примера реализуем довольно простой хак, который может понравиться самым ярым фанатам игры: no-ring challenge. Этот хак предлагает пройти игру без золотых колец. В результате, каждая атака Соника будет сразу убивать его и заставлять игрока проходить уровень заново (либо с точки сохранения).
Перейдем в главную подпрограмму объекта "Кольцо" – [`Ring_Main`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/_incObj/25%20&%2037%20Rings.asm#L44) и добавим в самое ее начало простейшую инструкцию прыжка (`bra`) на процедуру удаления кольца:
```
Ring_Main: ; Routine 0
bra.w Ring_Delete ; удалить все кольца сразу по созданию
lea (v_objstate).w,a2
moveq #0,d0
move.b obRespawnNo(a0),d0
; ...
```
С бонусными мониторами поступим так же. Главная подпрограмма объекта "Монитор" находится в файле [`26 Monitor.asm`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/_incObj/26%20Monitor.asm#L18). Тип монитора хранится в поле `obSubtype` размером 1 байт. Экспериментальным методом выяснено, что значение для монитора с кольцами равно 6. Добавим простую проверку типа монитора с помощью инструкции `cmp` и условный прыжок `beq` на процедуру его удаления в случае, если его тип равен шести:
```
Mon_Main: ; Routine 0
cmp.b #6,obSubtype(a0) ; монитор с кольцами?
beq DeleteObject ; если да, удаляем объект
addq.b #2,obRoutine(a0)
move.b #$E,obHeight(a0)
; ...
```
Можно убедиться, что в получившемся ROM'е кольца и бонусные мониторы с кольцами на уровнях будут отсутствовать, что усложнит прохождение. Патч целиком можно [посмотреть на GitHub](https://github.com/okalachev/s1disasm/compare/AS...norings). Туда же выложен [готовый бинарник](https://github.com/okalachev/s1disasm/releases/download/norings/sonic-norings.bin) на случай, если кто-то захочет поиграть в такую версию игры, не разбираясь со сборкой.
### Хак: притягивание колец
В первой и второй играх серии бонусный щит только защищает игрока, но при этом не имеет никаких дополнительных функций. Попробуем его улучшить и добавить к нему возможность электрического щита из Sonic the Hedgehog 3 – притягивание колец.
**GIF-анимация, иллюстрирующая действие электрического щита, 1 Мб:**

#### Алгоритм Sonic the Hedgehog 3
Алгоритм, использующийся для этого эффекта, подробно описан [в вики Sonic Retro](http://info.sonicretro.org/SPG:Special_Abilities#Ring_Magnetisation). Если персонаж, обладающий электрическим щитом, находится ближе, чем в 64 пикселях от кольца по каждой из осей, кольцо переходит в режим *намагниченности* и начинает движение. В дальнейшем этот флаг больше не снимается с кольца. В режиме намагниченности кольцо ускоряется на 0.1875 за каждый шаг в сторону игрока, если оно уже движется в нужную сторону по данной оси. Если же кольцо движется от игрока, ускорение составляет 0.75.
Разница в значениях предусмотрена для того, чтобы кольца с одной стороны не слишком перестреливали, но, с другой стороны, если перестрел уже случился либо если игрок движется быстро и резко оказывается с противоположной стороны, быстро "исправлялись" и меняли свое направление движения.
#### Реализация алгоритма
Изучим подробнее исполняемый код объекта "Кольцо", который находится в файле [`25 & 37 Rings.asm`](https://github.com/sonicretro/s1disasm/blob/c1ed7c78f28bb7abee97bf5f3bec66f6f8e4d9c4/_incObj/25%20&%2037%20Rings.asm). Список подпрограмм объекта:
```
Ring_Index:
ptr_Ring_Main: dc.w Ring_Main-Ring_Index
ptr_Ring_Animate: dc.w Ring_Animate-Ring_Index
ptr_Ring_Collect: dc.w Ring_Collect-Ring_Index
ptr_Ring_Sparkle: dc.w Ring_Sparkle-Ring_Index
ptr_Ring_Delete: dc.w Ring_Delete-Ring_Index
```
Кольцо имеет несколько жизненных этапов: `Main` – инициализация; `Animate` – обычное висение с анимацией вращения; `Collect` – момент сбора Соником; `Sparkle` – анимация искр при сборе Соником; `Delete` – удаление кольца. Для того, чтобы изменить поведение кольца в обычном его состоянии, смотрим в сторону подпрограммы `ptr_Ring_Animate`.
Для хранения состояния намагниченности кольца отлично подойдет однобайтное поле `obStatus`. Анализ кода кольца показывает, что в этой версии игры флаги состояния для этого объекта не используются. Назначим нулевой бит `obStatus` (наиболее младший) ответственным за хранение флага намагниченности. Установка отдельного бита ячейки памяти будет возможна с помощью инструкции `bset`, а проверка, установлен ли он – с помощью инструкции `btst`.
Добавим в начало подпрограммы `Ring_Animate` код, устанавливающий флаг намагниченности в случае, если игрок ближе к кольцу, чем на 64 пикселя по каждой оси:
```
Ring_Animate: ; Routine 2
tst.b (v_shield).w ; у Соника есть щит?
beq.s .animate ; если нет, пропускаем
.dist_from_sonic:
; определяем расстояние до Соника
move.w (v_player+obX).w,d0 ; считываем позицию игрока по X в d0
sub.w obX(a0),d0 ; d0 = расстояние по X
move.w (v_player+obY).w,d1 ; считываем позицию игрока по Y в d1
sub.w obY(a0),d1 ; d1 = расстояние по Y
.check_magnetised:
; проверяем, не установлен ли уже флаг намагниченности для кольца
btst #0,obStatus(a0) ; нулевой бит obStatus равен 0?
bne.s .attract ; не равен => флаг установлен, идем на .attract
.check_near_x:
; флаг намагниченности не установлен, проверяем расстояния
cmp.w #64,d0 ; дистанция по X > 64?
bge.s .animate ; если да, пропускаем
cmp.w #-64,d0 ; дистанция по X < -64?
ble.s .animate ; если да, пропускаем
.check_near_y:
cmp.w #64,d1 ; дистанция по Y > 64?
bge.s .animate ; если да, пропускаем
cmp.w #-64,d1 ; дистанция по Y < -64?
ble.s .animate ; если да, пропускаем
; кольцо внутри квадрата 64x64, устанавливаем флаг намагниченности
bset #0,obStatus(a0)
.attract:
; здесь должен быть алгоритм притягивания кольца
.animate:
; ...
```
Реализация алгоритма предполагает разное ускорение в зависимости от того, летит кольцо в сторону игрока или нет, что по сути может быть представлено как сравнение знаков значений скорости кольца и разницы положений кольца и игрока. В псевдокоде такое сравнение может иметь примерно такой вид:
```
if sign(obVelX) == sign(distX):
```
Для простой реализации такого сравнения вспомним, что [способ хранения знаковых](https://ru.wikipedia.org/wiki/%D0%94%D0%BE%D0%BF%D0%BE%D0%BB%D0%BD%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BA%D0%BE%D0%B4) целых чисел в большинстве процессоров (включая Motorola 68K) подразумевает возможность определить знак числа простым считыванием самого старшего бита, причем 0 будет обозначать положительное число, а 1 – отрицательное. Проверить равенство битов в байте можно с помощью операции исключающего "или" – XOR (`eor` на Motorola 68K).
Как уже было отмечено выше, дробные значения (включая скорость игровых объектов) хранятся в формате с фиксированной точкой, поэтому необходимые значения ускорения (0.1875 и 0.75) необходимо домножить на 256 (получив 48 и 192 соответственно).
Реализуем процедуру притягивания колец:
```
.attract:
; рассчитываем ускорение кольца по X
move.w #48,d4 ; записываем в d4 ускорение 48
move.w obVelX(a0),d3 ; считываем скорость кольца по X в d3
eor.w d0, d3 ; сравниваем знаки расстояния и скорости кольца
btst #$F,d3 ; если 15-й бит равен 1 (знаки равны)...
beq.s .x_towards ; идем на x_towards
move.w #192,d4 ; знаки не равны, записываем в d4 ускорение 192
.x_towards:
; если необходимо лететь влево, применяем унарный минус (neg) к ускорению (d4)
cmp.w #0,d0
bge.s .attract_x
neg d4
.attract_x:
; прибавляем значение ускорения по X к скорости по X
add.w d4,obVelX(a0)
; повторяем аналогичную операцию для оси Y:
move.w #48,d4
move.w obVelY(a0),d3
eor.w d1,d3
btst #$F,d3
beq.s .y_towards
move.w #192,d4
.y_towards:
cmp.w #0,d1
bge.s .attract_y
neg d4
.attract_y:
add.w d4,obVelY(a0)
.animate:
; ...
```
Для того, чтобы кольцо действительно осуществляло движение согласно установленным скоростям, необходимо добавить вызов упомянутой выше подпрограммы `SpeedToPos`:
```
.animate:
jsr (SpeedToPos).l
```
Собираем итоговый ROM игры, запускаем и — вуаля — фича из Sonic 3 доступна в Sonic 1!
**GIF-анимация результата, 3.5 Мб:**

На GitHub можно просмотреть [патч целиком](https://github.com/okalachev/s1disasm/compare/AS...magnetic-shield), а также скачать получившийся [бинарник](https://github.com/okalachev/s1disasm/releases/download/magnetic-shield/sonic-magnetic-shield.bin).
Заключение
----------
Эта статья является лишь базовым разбором методов модификации игры. Статья не рассматривает инструменты для редактирования уровней ([SonED2](https://info.sonicretro.org/SonED2), [Chaos](https://info.sonicretro.org/Chaos_(level_editor))), создание новых персонажей, игровых объектов и механик. Также не рассмотрен симулятор/отладчик Motorola 68K [EASy68K](http://www.easy68k.com), который может помочь более пристально разобраться, как работает процессор Sega.
Тем не менее, я получил большое удовольствие, покопавшись в кишках любимой игры детства. Надеюсь, этой статьей мне удастся разбудить в ком-то такую же ностальгию, к тому же черпать вдохновение для работы можно и из сотен уже реализованных хаков, и из последующих игр серии.
Ссылки
------
* [Всеобъемлющая вики про приставки и игры от Sega](https://segaretro.org)
* [Вики со скурпулезнейшим описанием всех игр, связанных с Соником, включая технические аспекты](https://info.sonicretro.org)
* [Полный референс по синтаксису ассемблера Motorola 68K](http://68k.hax.com)
* <https://www.youtube.com/channel/UCfVFSjHQ57zyxajhhRc7i0g> — YouTube-канал [Джона Бертона](https://en.wikipedia.org/wiki/Jon_Burton), основателя компании Traveller's Tales и разработчика игр для Sega, в том числе игры Sonic 3D. | https://habr.com/ru/post/501398/ | null | ru | null |
# Руководство новичка по разработке плагинов для графического редактора Sketch

*Приветствую друзья! Меня зовут Антон, я развиваю сайт [ux.pub](http://ux.pub) посвященный графическому редактору Sketch. Очень часто мне на почту приходят вопросы о тонкостях разработки плагинов для Sketch. Я не разработчик и не специалист в создании плагинов, поэтому я решил сделать перевод самого подробного руководства по созданию плагинов от Mike Mariano.*
Часть 1 — С чего начать?
-------------------------
Вы хотите начать писать Sketch-плагины и не знаете, с чего начать? Продолжайте читать, так как этот пост как раз для вас!
Освоить базу не так просто. Есть масса примеров уже существующих плагинов, но очень сложно понять, с чего нужно начать. В помощь вам я собрал всю нужную информацию, которую только удалось отыскать, в одном месте.
Конечно, это не мануал по написанию плагинов для продвинутых, так как я сам не разработчик. Я UI/UX-дизайнер, которому иногда приходится кодить на довольно неплохом уровне (по крайней мере, я так думаю). Тру-программисты откровенно плачут, видя мой код, но я думаю, что как раз такой код хорошо понятен новичкам.
Если вы — инженер, который ищет более сложные примеры, вам будет полезен [этот пост](http://james.ooo/sketch-plugin-development/), а также [официальный сайт](http://developer.sketchapp.com/) Sketch-разработчиков.
### Зачем писать плагин?
Плагины идеальны для автоматизации повторяющихся задач, они значительно упрощают работу и продакшн. Есть все шансы, что уже существует плагин под ваши нужды, так что сначала поищите готовое решение перед написанием своего. Очень вероятно, что кто-то уже справился с задачей лучше вас. Но если у вас уникальный рабочий процесс создания UI (как у меня с дизайном игровых интерфейсов в Unity), скорее всего вам потребуется кастомное решение.
### Начало
Перед тем, как вы приступите к коду, установите все нужные программы и закладки.
1. Установите текстовый редактор, если у вас его еще нет. (Я использую [Atom](https://atom.io/), но есть много других отличных редакторов, таких как [Sublime](http://www.sublimetext.com/) или [Textmate](https://macromates.com/)).
2. Откройте Консоль для дебага, и добавьте ее в свою панель Dock, вы часто будете ею пользоваться.>

3. Консоль используется вашей машиной для ВСЕГО дебага, так что создайте новый фильтр журнала запросов Sketch: File > New System Query Log
Скопируйте эти настройки и нажмите Ok.

Фильтр Sketch появится в колонке слева.

4. Сделайте закладку папки Sketch Plugins для быстрого доступа, добавив ее в Избранное (Favorites) в окне Finder.
К этой папке вы тоже будете часто обращаться, так что желательно иметь ее под рукой.
> /Library/Application support/com.bohemiancoding.sketch3/Plugins

Вот и все, вы готовы к написанию своего первого плагина!
### Создание плагина за 10 простых шагов
Плагины Sketch — это папки с расширением .sketchplugin, которыми легко обмениваться с другими пользователями.
В этом примере мы создадим базовый скрипт для получения названия страницы. Вам не нужно знать программирование, чтобы реализовать эту задачу, но она поможет понять базовые принципы. В последующих постах я буду документировать разные скрипты для получения разных данных из Sketch и их изменения. Этот пример самый простой.
Плагины Sketch пишутся на CocoaScript, который представляет собой смесь Objective-C/Cocoa и JavaScript. Я неплохо знаком с Javascript, так что тут сложностей не возникло. Не скажу, что я в CocoaScript, как рыба в воде, но моих знаний по JavaScript было достаточно, чтобы разобраться.
Итак, начнем!
**1.** Создайте новую папку в каталоге Sketch Plugins и назовите ее MyPlugin.sketchplugin

*(как только вы добавите расширение .sketchplugin, двойной клик на ней запустит установку плагина вместо открытия папки. Чтобы открыть саму папку, кликните правой кнопкой мышки на плагине и выберите опцию Show Package Contents).*
**2.** Внутри папки создайте еще одну папку и назовите ее Contents
**3.** Внутри Contents создайте папку Sketch
Конечная структура папки плагина будет выглядеть так:
Внутри папки Sketch вы и будете создавать сам плагин, который состоит минимум из 2 файлов – манифеста и скрипта.

Манифест описывает плагин и может содержать разные горячие клавиши и дополнительные скрипты, он всегда называется manifest.json.
В скрипте содержится сам код плагина, и на него ссылается манифест. Имя можно изменять на свое усмотрение, но оно должно совпадать в обоих файлах.
**4.** В текстовом редакторе создайте новый файл под названием manifest.json и сохраните его в MyPlugin.sketchplugin > Contents > Sketch
**5.** Скопируйте и вставьте этот код в manifest.json, и сохраните.
```
{
"name" : "My Plugin",
"identifier" : "my.plugin",
"version" : "1.0",
"description" : "My First Sketch Plugin",
"authorEmail" : "[email protected]",
"author" : "Your Name",
"commands" : [
{
"script" : "MyScript.js",
"handler" : "onRun",
"shortcut" : "command shift y",
"name" : "Get Page Names",
"identifier" : "my.plugin.pagenames"
}
]
}
```
Теперь MyPlugin появится в вашем меню плагинов Sketch. Вы можете изменить название плагина или горячую клавишу его вызова, и это отразится в меню Plugins в Sketch. *Важно выбрать такую горячую клавишу запуска, которая не назначена для других установленных приложений или плагинов, иначе она не будет работать.*
Теперь создадим MyScript.js, на который ссылается manifest. *Убедитесь, что название файла совпадает с названием в файле manifest!*
**6.** Вернитесь в текстовый редактор и создайте новый файл под названием MyScript.js, и также сохраните его в папку MyPlugin.sketchplugin > Contents > Sketch folder
**7.** Скопируйте и вставьте этот код в MyScript.js
```
var onRun = function(context) {
//reference the Sketch Document
var doc = context.document;
//reference all the pages in the document in an array
var pages = [doc pages];
//loop through the pages of the document
for (var i = 0; i < pages.count(); i++){
//reference each page
var page = pages[i];
//get the name of the page
var pageName = [page name];
//show the page name in the console
log(pageName);
}
}
```
Я детальнее поясню этот код в последующих частях. А пока что опирайтесь на комментарии в строках.
**8.** Перейдите в Sketch и откройте новый файл
**9.** В меню Plugins выберите MyPlugin > Get Page Names

**10.** Перейдите в консоль и внизу лога вы должны увидеть название страницы:
```
10:54:42 PM Get Page Names (Sketch Plugin): Page 1
```
Попробуйте изменить название страницы в Sketch-файле и перезапустите плагин. Лог должен показывать новое название. Добавьте еще одну страницу и переименуйте ее, а затем запустите плагин, консоль теперь покажет названия обеих страниц.
### Вот и все!
Я работаю в Sketch всего несколько недель, и уже впечатлен его мощью и возможностями кастомизации. Вы можете скачать текущую версию плагина [здесь](https://www.dropbox.com/s/ozedc78pa1fyee5/MyPlugin.sketchplugin.zip?dl=0).
Часть 2 — Пользовательские уведомления
--------------------------------------
*Я открыл для себя отличный текстовый редактор [Atom](https://atom.io/), на который и переключился. Не знаю, почему до сих пор не пользовался им, но теперь я попрощался со своим старым-добрым TextMate!*
В предыдущей главе мы работали над плагином, который показывал названия всех страниц вашего документа в Консоли. Теперь изучим другие способы отображения информации. Они нужны, если вы хотите уведомлять пользователей (и себя) о разных вещах, например, о том, что плагин отработал, или что пользователю необходимо ввести какие-то данные. Также вам не придется постоянно переключаться в консоль, чтобы протестировать свои скрипты.
Есть два дополнительных способа уведомления пользователей внутри Sketch:
1. **Сообщение** (Message) — короткое ненавязчивое сообщение, которое отображается внизу приложения, прячется через короткий промежуток времени
2. **Окно оповещения** (Alert Box) — стандартное всплывающее окно, которое либо запрашивает от пользователя ввод данных, либо требует какое-то действие для продолжения.
Для каждого способа есть свои случаи применения, и обычно вам не придется перегружать плагин (и пользователей) множеством сообщений. Поэкспериментируйте с обоими, чтобы понять, какой метод лучше для вашего собственного плагина.
Вернемся к скрипту плагина из первого примера и переделаем его.
```
var onRun = function(context) {
//reference the Sketch Document
var doc = context.document;
//reference all the pages in the document in an array
var pages = [doc pages];
//loop through the pages of the document
for (var i = 0; i < pages.count(); i++){
//reference each page
var page = pages[i];
//get the name of the page
var pageName = [page name];
//show the page name in the console
log(pageName);
}
}
```
Если рассматривать этот фрагмент кода, pageName ссылается на название каждой страницы в массиве страниц документа. Это контейнер с данными, содержащий всю информацию о странице. Обычно для доступа к этим массивам используются цикл for, которые итерируют через каждый объект, чтобы извлечь или назначить определенные значения.
В этой строке переменная pageName отправляется в Консоль.
```
log(pageName);
```
Теперь добавим сообщение вниз скрипта, который будет отображать сообщение внутри Sketch, когда скрипт отработает.
Для этого мы добавим строку кода после скобки цикла for:
```
doc.showMessage(“MyPlugin Finished!”);
```
Doc – это переменная вверху скрипта, которая ссылается на документ, а showMessage – это встроенная функция, в которой мы можем передавать переменную или строку (String) для отображения сообщения.
Вот как выглядит ее добавление после цикла for в контексте всего скрипта:
```
var onRun = function(context) {
//reference the Sketch Document
var doc = context.document;
//reference all the pages in the document in an array
var pages = [doc pages];
//loop through the pages of the document
for (var i = 0; i < pages.count(); i++){
//reference each page
var page = pages[i];
//get the name of the page
var pageName = [page name];
//show the page name in the console
log(pageName);
}
//show a message at the bottom of Sketch
doc.showMessage("MyPlugin Finished!");
}
```
Запустите MyPlugin через меню Plugins, чтобы увидеть результат. Внизу окна Sketch вы должны увидеть:
Этот тип сообщений полезен, если вам не хочется постоянно переключаться в консоль, или если есть что-то, что вы бы хотели показать пользователю, но что не требует его участия.
Если вы хотите более выделяющегося сообщения, которое требует от пользователя какого-то действия, лучше использовать alert box. Чтобы добавить его, допишите строку кода в начало скрипта, и еще одну после отображения предыдущих сообщений.
Первая строка добавляется вверх, над объявлением переменной doc, чтобы обратиться к самому приложению:
```
var app = [NSApplication sharedApplication];
```
Вторая строка дает доступ к новой переменной для отправки сообщений в приложение.
```
[app displayDialog:"This is an alert box!" withTitle:"Alert Box Title"];
```
И вот как выглядит конечный код с новыми строками:
```
var onRun = function(context) {
//reference the Application
var app = [NSApplication sharedApplication];
//reference the Sketch Document
var doc = context.document;
//reference all the pages in the document in an array
var pages = [doc pages];
//loop through the pages of the document
for (var i = 0; i < pages.count(); i++){
//reference each page
var page = pages[i];
//get the name of the page
var pageName = [page name];
//show the page name in the console
log(pageName);
}
//show a message at the bottom of Sketch
doc.showMessage("MyPlugin Finished!");
//send an alert message to the application
[app displayDialog:"This is an alert box!" withTitle:"Alert Box Title"];
}
```
Запустите MyPlugin с меню Plugin, и вы должны увидеть что-то такое:

Меняйте сообщения (те, что в кавычках) на что угодно и перезапустите плагин. Полная кастомизация!
Это самое начало отладки и отображения данных внутри Sketch. Вы можете попробовать изменить скрипты сообщений/уведомлений, добавить дополнительные скрипты для показа разных данных — переменных или счетчиков массивов.
Чтобы показать количество страниц в документе, вы можете создать сообщение с отображением pages.count().
```
[app displayDialog:”This document has “ + pages.count() + “ pages.” withTitle:”Alert Box Title”];
```
Вот таким будет результат:

Мы разобрались с пользовательскими уведомлениями! Сначала подготовили среду для разработки, затем разобрались, как дебажить и отображать сообщения внутри Sketch. Далее мы сфокусируемся больше на самом коде, поиске конкретных данных и способах их обработки.
Текущую версию плагина можно скачать [здесь](https://www.dropbox.com/s/9oyycnv26ehvl29/MyPlugin.sketchplugin.zip?dl=0).
Часть 3 — Написание кода для многоразового использования
--------------------------------------------------------
Настало время развернуть мониторы вертикально, потому что мы приступаем к программированию!
В этой части мы раскроем базовые концепты написания кода, создание функций для многократного вызова, а также линкование двух скриптов вместе. Если вы уже освоились в написании скриптов, можете просто проскроллить вниз до конца этой части, скачать исходники и переделать их на свой лад. Если же вы новичок в этом деле, или вам нужно освежить знания, продолжайте читать!
### Базовые концепты написания кода
Есть код, который мы уже написали, и он включает в себя переменные, массивы, функции и циклы for. Эти элементы, а также операторы if/else, и есть фундаментальные кирпичики всего, что я делаю. Как только я освоил эти элементы (особенно, цикл loop), мне стало гораздо проще понимать скрипты. Я пишу свои скрипты на Javascript и Objective-C, но эти концепты довольно универсальны для любого языка программирования. Вам просто нужно выработать определенный способ написания кода.
Я бегло поясню эти понятия:
**Переменная** — это ссылка на какой-то тип информации. Это может быть как строка (кусок текста), так и число или булевское значение (true или false). Это горячая клавиша доступа к значению, и очень удобно использовать именно ее вместо того, чтобы печатать его руками снова и снова.
```
var myName = “Mike”;
var thisYear = 2016;
var givesHighFives = true;
```
Если я задам для myName значение “Mike”, тогда я просто могу писать везде в скрипте myName, и эта переменная будет ссылаться на “Mike”. Но если я захочу, чтобы значением myName стал “Shawn”, мне нужно будет изменить его только один раз в объявлении переменной, и каждая ее сущность в коде также изменится.
**Массив** — это тоже переменная, но обычно он содержит несколько однотипных значений. Как если бы у вас был массив дней недели, вы бы увидели стринговое значение всех дней внутри такого массива.
```
var daysOfTheWeek = {“Sunday”, “Monday”, “Tuesday”, Wednesday”, “Thursday”, “Friday”, “Saturday”};
```
Вы также можете написать его так, будет проще увидеть количество элементов массива, которые начинаются с 0:
```
var daysOfTheWeek[];
daysOfTheWeek[0] = “Sunday”;
daysOfTheWeek[1] = “Monday”;
daysOfTheWeek[2] = “Tuesday”;
daysOfTheWeek[3] = “Wednesday”;
daysOfTheWeek[4] = “Thursday”;
daysOfTheWeek[5] = “Friday”;
daysOfTheWeek[6] = “Saturday”;
```
**Функция** — это многократно используемый фрагмент кода, который выполняет определенную задачу. Обычно вы их задаете, если нужно делать что-то снова и снова. Вы можете передавать в нее переменные, заставлять их возвращать значение или держать их пустыми.
```
var eyesOpen = true;
function closeEyes(){
eyesOpen = false;
}
function openEyes(){
eyesOpen = true;
}
```
В примере выше каждый раз, когда вы хотите закрыть глаза, вы можете вызывать функцию closeEyes(), затем для их открытия вызывать openEyes().
**Оператор if/else** делает именно то, что говорит, т.е. проверяет какое-то условие, производит определенное действие, если условие выполняется, в противном случае выполняет что-то другое.
```
if(daysOfTheWeek == “Sunday”){
watchGameOfThrones();
}else if(daysOfTheWeek == “Wednesday”){
watchMrRobot();
}else{
watchTheNews();
}
```
**Цикл for** используется для повтора определенного блока кода известное количество раз. Например, в массиве daysOfTheWeek, если бы вы хотели вывести значения массива в список, вы бы воспользовались для этого циклом for.
Без цикла вы бы писали так:
```
log(daysOfTheWeek[0]);
log(daysOfTheWeek[1]);
log(daysOfTheWeek[2]);
log(daysOfTheWeek[3]);
log(daysOfTheWeek[4]);
log(daysOfTheWeek[5]);
log(daysOfTheWeek[6]);
```
А с циклом вам бы пришлось написать всего лишь:
```
for(var i = 0; i < daysOfTheWeek.count(); i++){
log(daysOfTheWeek[i];
}
```
Гораздо проще, правда? Для цикла мы задали начальное значение i, равное 0 и считали, пока i не достигнет количества значений в массиве daysOfTheWeek, т.е. 7. То есть начиная с i=0, цикл логирует значение daysOfTheWeek, потом добавляет к i 1, и все повторяется. Всего это проделывается 7 раз, пока не достигается полный набор значений в массиве.
### Создание функции окна оповещения (Alert Box)
Вернемся к кодуMyPlugin. В предыдущей части мы создали окно оповещения, которое отображалось после отработки скрипта.
```
[app displayDialog:”This is an alert box!” withTitle:”Alert Box Title”];
```
Выглядит как что-то, что будет использоваться каждый раз, когда нам понадобится показать сообщения пользователю, и не особо хочется каждый раз прописывать всю строку кода для каждого такого сообщения. Это особенно актуально, если отображаемое сообщение — это комбинация переменных и строк, код может быть довольно длинный.
Отличный повод сделать повторно используемую функцию, и для этого нужно прописать:
```
function alert(title, message){
var app = [NSApplication sharedApplication];
[app displayDialog:message withTitle:title];
}
```
Каждый раз, когда мы вызываем alert() и передаем заголовок и сообщение, будет отображаться окно оповещения.
Добавьте эту функцию в конец скрипта, после скобок функции onRun:
```
var onRun = function(context) {
//reference the Application
var app = [NSApplication sharedApplication];
//reference the Sketch Document
var doc = context.document;
//reference all the pages in the document in an array
var pages = [doc pages];
[app displayDialog:"This document has " + pages.count() + " pages." withTitle:"Alert Box Title"];
//loop through the pages of the document
for (var i = 0; i < pages.count(); i++){
//reference each page
var page = pages[i];
//get the name of the page
var pageName = [page name];
//show the page name in the console
log(pageName);
}
//show a message in app
doc.showMessage("MyPlugin Finished!");
//send an alert message to the application
[app displayDialog:"This is an alert box!" withTitle:"Alert Box Title"];
}
function alert(title, message){
var app = [NSApplication sharedApplication];
[app displayDialog:message withTitle:title];
}
```
И теперь мы можем изменить код, написанный ранее, заменив им исходную ссылку на переменную, так как теперь она прописана в функции. Скрипт теперь выглядит так:
```
var onRun = function(context) {
//reference the Application
var app = [NSApplication sharedApplication];
//reference the Sketch Document
var doc = context.document;
//reference all the pages in the document in an array
var pages = [doc pages];
alert("Number of Pages", "This document has " + pages.count() + " pages.");
//loop through the pages of the document
for (var i = 0; i < pages.count(); i++){
//reference each page
var page = pages[i];
//get the name of the page
var pageName = [page name];
//show the page name in the console
log(pageName);
}
//show a message in app
doc.showMessage("MyPlugin Finished!");
//send an alert message to the application
alert("Plugin Finished!", "This is a message saying the Plugin is finished.")
}
function alert(title, message){
var app = [NSApplication sharedApplication];
[app displayDialog:message withTitle:title];
}
```
Запустите плагин, и вы будете видеть такой же результат, как раньше, но теперь ваш код ссылается на функцию. Ее можно вызвать в любом месте скрипта, и не нужно будет переписывать код снова и снова. Но что если бы у нас был другой скрипт, в котором нужно использовать эту функцию?
### Ссылка на скрипты из других скриптов
И вот тут уместно создать библиотеку. Иногда у вас есть общая функция, которую не стоит привязывать к какому-то одному скрипту. Как в случае с функцией alert(), или с функцией округления числа до ближайшего целого. Это общие функции, которые, скорее всего, будут использоваться в разных скриптах. Поэтому вместо копипаста функции в каждый файл вы можете создать общий файл, и вставлять его по необходимости.
**1.** Сохраните новый JavaScript-файл в ту же папку, в которой хранится MyScript.js, и назовите его common.js. Теперь в папке будет 3 файла:

**2.** Вырежьте функцию alert из MyScript.js и вставьте ее в common.js и сохраните изменения.
В common.js должен быть только этот код:
```
function alert(title, message){
var app = [NSApplication sharedApplication];
[app displayDialog:message withTitle:title];
}
```
**3.** Чтобы запустить этот скрипт из MyScript.js, добавьте эту строку кода вверху скрипта и сохраните:
```
@import 'common.js'
```
Весь скрипт с новой строкой вверху и удаленной функцией alert() выглядит так:
```
@import 'common.js'
var onRun = function(context) {
//reference the Application
var app = [NSApplication sharedApplication];
//reference the Sketch Document
var doc = context.document;
//reference all the pages in the document in an array
var pages = [doc pages];
alert("Number of Pages", "This document has " + pages.count() + " pages.");
//loop through the pages of the document
for (var i = 0; i < pages.count(); i++){
//reference each page
var page = pages[i];
//get the name of the page
var pageName = [page name];
//show the page name in the console
log(pageName);
}
//show a message in app
doc.showMessage("MyPlugin Finished!");
//send an alert message to the application
alert("Plugin Finished!", "This is a message saying the Plugin is finished.")
}
```
Запустите плагин еще раз, он должен работать, как и раньше, но теперь вы запускаете функцию из общего скрипта! Оптимизация завершена!
Теперь у вас есть основы написания и понимания более сложных плагинов. Далее мы изучим доступ к данным документа Sketch через его переменные и массивы, способы прохождения по этим массивам для извлечения и назначения нужных нам значений.
Вы можете скачать текущую версию плагина [здесь](https://www.dropbox.com/s/zg85bt38kpk1mek/MyPlugin.sketchplugin.zip?dl=0).
Часть 4 — Примеры из реального мира
-----------------------------------
Мы уже научились, как организовывать среду для написания и отладки кода, как отображать разные виды пользовательских уведомлений, а также освоили базовые понятия написания кода. Кажется, у нас есть все, чтобы начать писать собственные плагины.
К счастью, Bohemian Coding имеют документацию по своим классам:
<http://developer.sketchapp.com/reference/class/>
К сожалению, как пишется вначале этой страницы, она все еще “в стадии разработки”. Так что не все еще описано, и не так много примеров, что с этим всем делать.
Лично я лучше всего учусь на примерах. Понимание кода может вызывать большие трудности, но когда вы видите, как он используется применительно к вашим знаниям и целям, становится гораздо проще. Я приведу три примера, которые нашел, пока работал со Sketch, надеюсь, вам они окажутся полезными!
### Пример 1: Переключение высоты и ширины артборда.
Странно, но в стандартном функционале Sketch нет смены ориентации артборда с портретной на альбомную и наоборот. Я поискал, и не нашел ни одного плагина, который решает эту проблему, так что самое время создать наш собственный!
Для ясности давайте определимся, что мы будем делать. Это помогает определить цель, способы ее достичь, а также выявить крайние случаи, с которыми придется столкнуться. Это почти как создание UX-сценария, правда?
Для этого плагина мы напишем скрипт, который выполняет следующее:
* Сначала убеждается, что что-то выделено
* Затем убеждается, что выделенный объект — это артборд
* Затем берет исходную высоту и ширину выбранного артборда и сохраняет их в переменные
* Затем задает новую высоту на основе его старой ширины, и новую ширину на основе старой высоты
* В конечном итоге, уведомляет пользователя, что скрипт отработал
#### Добавление еще одного скрипта в MyPlugin
Вместо добавления новой порции кода в MyScript.js, давайте создадим новый скрипт под названием RotateArtboard.js, и сохраните его в папку MyPlugin.sketchplugin.
Добавьте этот код в RotateArtboard.js. Каждый основной скрипт должен быть в функции onRun, так что этот скрипт всегда является хорошей базой для старта:
```
@import 'common.js'
var onRun = function(context) {
//reference the Sketch Document
var doc = context.document;
}
```
Вы увидите, что мы импортируем файл common.js, чтобы использовать ту же функцию alert, которую мы уже создали.
На данный момент в папке плагина должны быть следующие файлы:

Теперь откройте manifest.json, чтобы добавить еще один скрипт в наш манифест.
Скопируйте фрагмент кода со всеми командами MyScript.js, добавьте запятую после блока MyScript, и вставьте перед закрывающейся скобкой commands, вот так:
```
{
"name" : "My Plugin",
"identifier" : "my.plugin",
"version" : "1.0",
"description" : "My First Sketch Plugin",
"authorEmail" : "[email protected]",
"author" : "Your Name",
"commands" : [
{
"script" : "MyScript.js",
"handler" : "onRun",
"shortcut" : "command shift y",
"name" : "Get Page Names",
"identifier" : "my.plugin.pagenames"
},
{
"script" : "RotateArtboard.js",
"handler" : "onRun",
"shortcut" : "command shift u",
"name" : "Rotate Artboard",
"identifier" : "my.plugin.rotateartboard"
}
],
}
```
Теперь вы видите новый скрипт в меню MyPlugin (можете менять горячие клавиши, кстати):

Вернемся к коду! Чтобы узнать, что выделено, используем следующее:
```
var selection = context.selection;
```
Этот код создает переменную типа массив со всеми выделенными слоями. Теперь мы можем проверить этот массив, чтобы узнать, есть ли что-нибудь внутри него. Если там 0, тогда ничего не выделено, и мы скажем пользователю, что нужно что-то выделить.
```
if(selection.count() == 0){
doc.showMessage(“Please select something.”);
}
```
Но если счетчик не 0, тогда внутри массива что-то есть, как минимум, один слой должен быть выделен. Теперь мы можем пройтись циклом по выделенным слоям, чтобы определить, есть ли среди них артборды ([MSArtboardGroup](http://developer.sketchapp.com/reference/class/MSArtboardGroup/)):
```
if(selection.count() == 0){
doc.showMessage(“Please select something.”);
} else {
for(var i = 0; i < selection.count(); i++){
if(selection[i].class() == "MSArtboardGroup"){
//do something
}
}
}
```
*Вы можете использовать эту же технику для проверки, является ли выделение текстовым слоем ([MSTextLayer](http://developer.sketchapp.com/reference/class/MSTextLayer/)), группой ([MSGroupLayer](http://developer.sketchapp.com/reference/class/MSArtboardGroup/)), фигурой (MSShapeGroup / не задокументированная), импортированным изображением ([MSBitmapLayer](http://developer.sketchapp.com/reference/class/MSBitmapLayer/)) или символом (MSSymbolInstance / не задокументированная).*
Чтобы получить высоту и ширину артборда, сначала нужно получить его фрейм. И уже из фрейма можно извлечь значения, и назначить новые.
Создайте переменную под названием artboard на основе элемента массива в цикле for, и так мы сможем получить текущие размеры. *Использование цикла for позволяет работать с несколькими выделенными артбордами одновременно*.
```
var artboard = selection[i];
var artboardFrame = artboard.frame();
var artboardWidth = artboardFrame.width();
var artboardHeight = artboardFrame.height();
```
Теперь создайте две новые переменные со значениями, которые нам нужны, т.е. поменяйте местами ширину и высоту:
```
var newArtboardWidth = artboardHeight;
var newArtboardHeight = artboardWidth;
```
Затем воспользуемся artboardFrame, чтобы задать высоту и ширину новыми переменными:
```
artboardFrame.setWidth(newArtboardWidth);
artboardFrame.setHeight(newArtboardHeight);
```
И, наконец, мы воспользуемся нашим окном уведомлений, чтобы сообщить пользователю об отработке скрипта и отобразить новые значения:
```
var alertMessage = “New Height: “+newArtboardHeight+ “ | New Width: “+newArtboardWidth;
alert(“Artboard Rotated!”, alertMessage)
```
Вот весь скрипт с комментариями:
```
@import 'common.js'
var onRun = function(context) {
//reference the sketch document
var doc = context.document;
//reference what is selected
var selection = context.selection;
//make sure something is selected
if(selection.count() == 0){
doc.showMessage("Please select something.");
}else{
//loop through the selected layers
for(var i = 0; i < selection.count(); i++){
//checks to see if the layer is an artboard
if(selection[i].class() == "MSArtboardGroup"){
//reference the selection
var artboard = selection[i];
//get the artboard frame for dimensions
var artboardFrame = artboard.frame();
//get the width
var artboardWidth = artboardFrame.width();
//get the height
var artboardHeight = artboardFrame.height();
//set a new width variable to the old height
var newArtboardWidth = artboardHeight;
//set a new height variable to the old width
var newArtboardHeight = artboardWidth;
//set the artboard frame with the new dimensions
artboardFrame.setWidth(newArtboardWidth);
artboardFrame.setHeight(newArtboardHeight);
//send an alert message with the new values
var alertMessage = "New Height: "+newArtboardHeight+ " | New Width: "+newArtboardWidth;
alert("Artboard Rotated!", alertMessage);
}else{
doc.showMessage("Please select an artboard.");
}
}
}
}
```
**Подытожим пример 1:**
* Проверяем, выделено ли что-то
* Определяем тип слоя выделенного, и делаем кое-что, если это тот тип, который нам нужен
* Извлекаем исходный фрейм нашего выделенного артборда, высоту и ширину, и сохраняем это в переменных
* Создаем новые переменные c нужными нам значениями
* Задаем для фрейма выделенного артборда эти значения
### Пример 2: Выделение слоев и их переименование на имя символа
Вот еще одна проблема из реального мира, которую я обнаружил, работая с символами. Если я добавляю новый символ из своей библиотеки, имя слоя изменяется на имя символа. Если я переключаюсь на другой символ, название слоя все равно остается без изменений. Иногда я хочу задать свое название слоя, а иногда просто хочу переключить его на название нового символа. Вот еще один идеальный повод написать плагин!
**Для этого примера, скачайте [файл Sketch](https://www.dropbox.com/s/d24wasfwgpo65fm/Example.sketch?dl=0) для справок.**
В файле Sketch на первом артборде вы увидите символ под названием Square, он находится по центру. Также в библиотеке есть еще один символ под названием Circle.
Выделите Square, и используя опции справа измените Square на Circle
Теперь посмотрите на слои слева — слой все еще называется Square! Я думаю, что мог бы изменить название вручную, но это не прикольно, особенно если изменить нужно множество сущностей.
Сценарий для этого плагина такой:
* Сначала убедиться, что что-то выделено
* Затем убедиться, что выделен именно символ
* Получить название символа
* Проверить, совпадает ли название символа с названием слоя
* Если нет, изменить название слоя на название символа
* И, наконец, уведомить пользователя, когда скрипт отработает
Вы заметите, что у нового и предыдущего скрипта много общего – та же проверка на выделение, и определение типа выделенных объектов. Так что мы можем воспользоваться готовыми наработками, но все же это довольно специфический случай, так что будем создавать отдельный скрипт.
Следуя первым шагам из предыдущего примера, давайте добавим еще один скрипт в MyPlugin.sketchplugin, создав новый файл под названием SetLayerNameToSymbolName.js и добавим его в manifest.json. Чтобы сэкономить время, просто используйте RotateArtboard.js и “Save As”. Мы будем использовать этот скрипт очень часто, так что начнем отсюда и сделаем несколько изменений.
Наша папка сейчас содержит такие файлы:

В этом скрипте, вместо проверки, является ли выделение MSArtboardGroup (артбордом), мы проверим, является ли оно MSSymbolInstance (символом). Если является, мы выясним название symbolMaster и сравним его с названием слоя.
И вот вам новый скрипт с парой измененных строк:
```
@import 'common.js'
var onRun = function(context) {
//reference the sketch document
var doc = context.document;
//reference what is selected
var selection = context.selection;
//make sure something is selected
if(selection.count() == 0){
doc.showMessage("Please select something.");
}else{
//loop through the selected layers
for(var i = 0; i < selection.count(); i++){
//checks to see if the layer is a Symbol
if(selection[i].class() == "MSSymbolInstance"){
//reference the selection
var layer = selection[i];
//get the original layer name
var layerName = layer.name();
//get the name of the symbol on the layer
var symbolName = layer.symbolMaster().name();
//check if layer name is not already symbol name
if(layerName != symbolName){
//set the layer name to the symbol name
layer.setName(symbolName);
var alertMessage = "Layer Name Changed from: "+layerName+ " to: "+symbolName;
alert("Layer Name Changed!", alertMessage);
}else{
doc.showMessage("Layer name is already Symbol Name.");
}
}else{
doc.showMessage("Please select a Symbol Layer.");
}
}
}
}
```
**Подытожим пример 2**
В этом примере мы усвоили:
* Проверки, является ли выделение артбордом или символом, выполняются идентично.
* Как получить название symbolMaster и название слоя
* Как сравнить два названия и настроить название слоя, если они отличаются.
### Пример 3: Задание названий символов в качестве названий слоев
Предыдущий скрипт работает идеально, но иногда мне не хочется выделять каждый слой вручную. Иногда после разбрасывания кучи символов по документу я просто хочу привести все названия слоев в соответствие с названиями символов без выделения слоя. Для этого понадобится изменить следующее:
* Сначала получить все страницы документа
* Затем получить все артборды на каждой странице
* Затем получить все слои на каждом артборде
* Затем проверить, является ли какой-то из этих слоев слоем символа
* Затем проверить, не совпадает ли название слоя с названием символа
* Если не совпадает, заменить название слоя и уведомить пользователя
Так как мы теперь не учитываем, что сейчас выделено, нам придется изменить скрипт, чтобы он прошелся по данным страниц документа. Затем мы воспользуемся рядом вложенных петель for, которые будут итерировать по массиву артбордов, затем по массиву слоев, и наконец, дойдут до каждого слоя. Цикл for внутри цикла for, которая внутри цикла for.
Наверное, для этой задачи мы создадим еще один новый скрипт. Начните с нового файла под названием SetAllLayerNamesToSymbolNames.js и также добавьте его в manifest.json, как мы делали раньше.
Теперь в папке MyPlugin.sketchplugin будет столько файлов:

И плагин в вашем списке меню, вместе с предыдущими примерами должен отображать новую опцию, как только вы добавите новый файл в манифест:

Чтобы извлечь данные страниц документа, используйте следующий код:
```
var pages = [doc pages];
```
Чтобы получить артборды страниц, используйте цикл for:
```
var pages = [doc pages];
for (var i = 0; i < pages.count(); i++){
var page = pages[i];
var artboards = [page artboards];
}
```
Чтобы получить слои артборда, используйте цикл for внутри цикла for:
```
var pages = [doc pages];
for (var i = 0; i < pages.count(); i++){
var page = pages[i];
var artboards = [page artboards];
for (var z = 0; z < artboards.count(); z++){
var artboard = artboards[z];
var layers = [artboard layers];
}
}
```
Далее, чтобы извлечь каждый отдельный слой, вам нужно пройтись по слоям внутри цикла for, и затем проверить, что это за слой:
```
var pages = [doc pages];
for (var i = 0; i < pages.count(); i++){
var page = pages[i];
var artboards = [page artboards];
for (var z = 0; z < artboards.count(); z++){
var artboard = artboards[z];
var layers = [artboard layers];
for(var k = 0; k < layers.count(); k++){
var layer = layers[k];
if(layer.class() == "MSSymbolInstance"){
//do something
}
}
}
}
```
Как только мы установили, что это слой символа, мы можем проверить его название и сравнить с названием слоя. Если они отличаются, меняем название слоя на название символа, и все!
Вот как выглядит весь скрипт, для простоты понимания почти каждая строка прокомментирована:
```
@import 'common.js'
var onRun = function(context) {
//reference the sketch document
var doc = context.document;
//reference the pages array in the document
var pages = [doc pages];
//create a variable to hold how many symbol layers we changed
var symbolCount = 0;
//loop through the pages array
for (var i = 0; i < pages.count(); i++){
//reference each page
var page = pages[i];
//reference the artboards array of each page
var artboards = [page artboards];
//loop through the artboards of each page
for (var z = 0; z < artboards.count(); z++){
//reference each artboard of each page
var artboard = artboards[z];
//reference the layers array of each artboard
var layers = [artboard layers];
//loop through the layers array
for(var k = 0; k < layers.count(); k++){
//reference each layer of each artboard
var layer = layers[k];
//check to see if the layer is a Symbol
if(layer.class() == "MSSymbolInstance"){
//get the original layer name
var layerName = layer.name();
//get the name of the symbol on the layer
var symbolName = layer.symbolMaster().name();
//only change the name of layers that don't match the symbol name
if(layerName != symbolName){
//set the layer name to the symbol name
layer.setName(symbolName);
symbolCount = symbolCount + 1;
}
}
}
}
}
var alertMessage = symbolCount + " symbol layer name changed.";
alert("Symbol Layer Names Reset!", alertMessage);
}
```
**Подытожим пример 3, тут мы научились:**
* Проходиться по всем страницам документа, чтобы получить список артбордов
* Проходиться по всем артбордам страницы, чтобы получить слои
* Проходиться по всем слоям артборда и проверять их тип
* Сравнивать имя слоя с именем символов
* И, наконец, если имена отличаются, изменить название слоя на название символа
Вывод
=====
Это всего три примера, как можно начать использовать базовые понятия доступных классов Sketch, изученных ранее. Тут еще многое можно сделать, но мы пока только начинаем! Далее мы рассмотрим еще больше способов доступа к дополнительным классам внутри Sketch, еще больше примеров из реального мира.
Вы можете скачать текущую версию плагина [здесь](https://www.dropbox.com/s/skdnmyuf9vu5a4l/MyPlugin.sketchplugin.zip?dl=0).
Часть 5 — Класс MSLayer
-----------------------
Мы уже ознакомились с реальными, рабочими примерами того, что могут сделать классы в Sketch, так что можно углубиться в их изучение дальше. В этой части мы сфокусируемся на классе MSLayer, а затем изучим классы, наследующие этот.
Класс MSLayer — это базовый класс всех слоев в Sketch, и все другие типы слоев — это подклассы, наследующие его. Все, что вы добавляете в ваш документ, является изначально слоем — страница, артборд, группа, фигура, текст, изображение и т.д. Все это — подклассы класса MSLayer, и они могут все, что может класс MSLayer, и даже больше.
Чтобы лучше понять терминологию, есть два типа данных, доступных через класс:
1. **Атрибуты** — именованное свойство объекта (например, высота, ширина или название)
2. **Методы** — функции, связанные с классами, обычно используется для изменения атрибутов (таких как изменение высоты, ширины или названия)
[Документация](http://developer.sketchapp.com/reference/class/MSLayer/) на сайте разработчиков уже содержит неплохую базу атрибутов и методов классов. Так что мы нет смысла воспроизводить все здесь. Вместо этого я покажу вам самые простые способы просмотра атрибутов слоя и использования его методов в реальном мире.
### Получение атрибутов слоя
В предыдущей части мы рассмотрели два способа получения данных о слое: с помощью цикла по массиву выделения, а также путем гнездования петель for в массиве страниц документа.
Предположим, что вы использовали массив выделения, чтобы получить переменную под названием layer:
```
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
if(selection.count() == 0){
doc.showMessage("Please select something.");
}else{
for(var i = 0; i < selection.count(); i++){
var layer = selection[i];
}
}
};
```
Зная, что все слои — это подклассы базового класса MSLayer, мы можем получить некоторые атрибуты из любого типа слоев, независимо от его специфики, а затем хранить их в виде переменных для доступа в будущем.
Некоторые атрибуты являются на самом деле сущностями других классов, и имеют свои собственные атрибуты и методы на базе этих классов. Для них я покажу пару примеров, как вы можете углубиться в данные. Но для более тщательного изучения вопроса используйте ссылку на документацию.
Вот несколько атрибутов, которые доступны в классе MSLayer:
**Класс (тип слоя):**
```
var layerClass = layer.class();
```
**Фрейм (размер и положение, относительно его артборда, сущность MSRect):**
```
var layerFrame = layer.frame();
var layerWidth = layerFrame.width();
var layerHeight = layerFrame.height();
var layerXpos = layerFrame.x();
var layerYpos = layerFrame.y();
```
**Стиль (границы, заливки, тени, внутренние тени, сущность MSStyle):**
```
var layerStyle = layer.style();
//получение массива цветов заливки
var layerFills = layer.style().fills();
//получение каждого цвета заливки
for(var z = 0; z < layerFills.count(); z++){
var fillColor = layerFills[z].colorGeneric();
}
```
**Название слоя:**
```
var layerName = layer.name();
```
**Видимость:**
```
var layerIsVisible = layer.isVisible();
```
**Статус блокировки:**
```
var layerIsLocked = layer.isLocked();
```
**Отражение (горизонтальное или вертикальное):**
```
//горизонтальное
var layerIsFlippedHorizontal = layer.isFlippedHorizontal();
//вертикальное
var layerIsFlippedVertical = layer.isFlippedVertical();
```
**Поворот:**
```
var layerRotation = layer.rotation();
```
**Родительская группа (страница, артборд или группа):**
```
var layerParent = layer.parentGroup();
```
**Статус выделения:**
```
var layerIsSelected = layer.isSelected();
```
**Absolute Rect (глобальный размер и положение в целом документе, сущность MSAbsoluteRect):**
```
var layerAbsoluteRect = layer.absoluteRect();
var layerAbsoluteWidth = layerAbsoluteRect.width();
var layerAbsoluteHeight = layerAbsoluteRect.height();
var layerAbsoluteXpos = layerAbsoluteRect.x();
var layerAbsoluteYpos = layerAbsoluteRect.y();
```
**CSSAttributeString:**
```
var layerCSSAttributeString = layer.CSSAttributeString();
```
**CSSAttributes:**
```
var layerCSSAttributes = layer.CSSAttributes();
```
В документации есть еще несколько, но это те, которые я обычно использую. Я выбрал на основе нужд скрипта. Но если вы действительно хотите сохранить все эти атрибуты сразу в переменные, вы бы могли сделать нечто такое:
```
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
if(selection.count() == 0){
doc.showMessage("Please select something.");
}else{
for(var i = 0; i < selection.count(); i++){
var layer = selection[i];
var layerClass = layer.class();
var layerFrame = layer.frame();
var layerStyle = layer.style();
var layerName = layer.name();
var layerIsVisible = layer.isVisible();
var layerIsLocked = layer.isLocked();
var layerIsFlippedHorizontal = layer.isFlippedHorizontal();
var layerIsVertical = layer.isFlippedVertical();
var layerRotation = layer.rotation();
var layerParent = layer.parentGroup();
var layerIsSelected = layer.isSelected();
var layerAbsoluteRect = layer.absoluteRect();
var layerUserInfo = layer.userInfo();
var layerCSSAttributeString = layer.CSSAttributeString();
var layerCSSAttributes = layer.CSSAttributes();
}
}
};
```
Затем вы можете использовать консоль для логирования любых переменных, которых хотели бы видеть:
```
log(“Layer Rotation: “ + layerRotation);
```
### Использование методов
Теперь, когда мы научились получать атрибуты слоя, мы можем использовать методы для их настройки. В классе [MSLayer](http://developer.sketchapp.com/reference/class/MSLayer/) есть несколько доступных методов, которые позволяют менять конкретные атрибуты любого слоя. Их названия выдают их действия:
**setName**
```
var newLayerName = "New Layer Name";
layer.setName(newLayerName);
```
**setIsVisible**
```
//показать слой
layer.setIsVisible(true);
//спрятать слой
layer.setIsVisible(false);
//переключить
layer.setIsVisible(!layer.isVisible())
```
**setIsLocked**
```
//заблокировать слой
layer.setIsLocked(true);
//разблокировать слой
layer.setIsLocked(false);
//переключить
layer.setIsLocked(!layer.isLocked());
```
**setRotation**
```
var newLayerRotation = 180;
layer.setRotation(newLayerRotation);
```
**setIsFlippedHorizontal**
```
//отразить по горизонтали
layer.setIsFlippedHorizontal(true);
//сбросить
layer.setIsFlippedHorizontal(false);
//переключить
layer.setIsFlippedHorizontal(!layer.isFlippedHorizontal());
```
**setIsFlippedVertical**
```
//отразить по вертикали
layer.setIsFlippedVertical(true);
//сбросить
layer.setIsFlippedVertical(false);
//переключить
layer.setIsFlippedVertical(!layer.isFlippedVertical());
```
**setIsSelected**
```
//выделить
layer.setIsSelected(true);
//снять выделение
layer.setIsSelected(false);
//переключить
layer.setIsSelected(!layer.isSelected());
```
**дублирование**
```
layer.duplicate();
```
Теперь вы можете создавать разные типы плагинов, просто извлекая атрибут слоя и перенастраивая его.
Например, если вы хотите разблокировать все слои, вы сначала можете проверить, заблокированы ли они, затем можете их разблокировать:
```
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
if(selection.count() == 0){
doc.showMessage("Please select something.");
}else{
for(var i = 0; i < selection.count(); i++){
var layer = selection[i];
var layerIsLocked = layer.isLocked();
if(layerIsLocked == true){
layer.setIsLocked(false);
}
}
}
};
```
Или если бы вы хотели добавить префикс к названию слоя:
```
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
if(selection.count() == 0){
doc.showMessage("Please select something.");
}else{
for(var i = 0; i < selection.count(); i++){
var layer = selection[i];
var layerName = layer.name();
var layerPrefix = "prefix_";
layer.setName(layerPrefix + layerName);
}
}
}
```
И еще много всего, опции действительно бесконечны!
### Методы атрибутов
Атрибуты, которые являются сущностями других классов, таких как фрейм или стиль, также имеют свои методы.
Например, чтобы изменить ширину слоя до 100, вам понадобится использовать setWidth на переменной фрейма:
```
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
if(selection.count() == 0){
doc.showMessage("Please select something.");
}else{
for(var i = 0; i < selection.count(); i++){
var layer = selection[i];
var layerFrame = layer.frame();
var newLayerWidth = 100;
layerFrame.setWidth(newLayerWidth);
}
}
}
```
Если вы хотите добавить на слой заливку, вы можете использовать [addStylePartOfType(0)](http://developer.sketchapp.com/reference/class/MSStyle/) на переменной стиля:
```
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
if(selection.count() == 0){
doc.showMessage("Please select something.");
}else{
for(var i = 0; i < selection.count(); i++){
var layer = selection[i];
var layerStyle = layer.style();
layerStyle.addStylePartOfType(0);
}
}
}
```
### Определение типа подкласса слоя Finding the Layer Subclass Type
Это все вы можете делать с любым MSLayer. Но что если, например, вы хотите считать строку текста из текстового поля? Вам нужно знать сначала, является ли этот объект текстовым полем, иначе код выбросит вам ошибку о несуществовании String.
Не все подклассы описаны в документации, но так как мы можем выяснить класс слоя из атрибута класса, мы можем легко с этим справиться. И чтобы еще больше упростить себе задачу, специально для этого я написал плагин!
Скачайте и установите плагин Show Layer Type Plugin [здесь](https://www.dropbox.com/s/ufh9m23tb3yiumb/ShowLayerType.sketchplugin.zip?dl=0). Затем скачайте и откройте этот [файл Sketch](https://www.dropbox.com/s/d1053j4m8y34q5b/Article4.sketch?dl=0) для тестирования.
В файле Sketch вы увидите артборд с несколькими разными типами слоев — 2 линии, символ, 2 текстовых поля и прямоугольник.
Выделите все слои и запустите плагин **Show Layer Type**. В консоли вы увидите такой вывод:
```
8/28/16 9:07:18.993 AM Show Layer Type (Sketch Plugin)[46515]: Background is a: MSShapeGroup
8/28/16 9:07:18.997 AM Show Layer Type (Sketch Plugin)[46515]: Line is a: MSShapeGroup
8/28/16 9:07:18.999 AM Show Layer Type (Sketch Plugin)[46515]: Author is a: MSTextLayer
8/28/16 9:07:18.999 AM Show Layer Type (Sketch Plugin)[46515]: Icon is a: MSBitmapLayer
8/28/16 9:07:19.000 AM Show Layer Type (Sketch Plugin)[46515]: Oval is a: MSSymbolInstance
8/28/16 9:07:19.001 AM Show Layer Type (Sketch Plugin)[46515]: Title is a: MSTextLayer
8/28/16 9:07:19.002 AM Show Layer Type (Sketch Plugin)[46515]: Line is a: MSShapeGroup
```
Если вы перейдете на страницу Symbols и выберите символ, снова запустите плагин, то увидите следующее:
```
8/28/16 9:10:08.600 AM Show Layer Type (Sketch Plugin)[46515]: Oval is a: MSSymbolMaster
```
Если вы выделите артборд и запустите плагин, вывод будет таким:
```
8/28/16 9:10:48.226 AM Show Layer Type (Sketch Plugin)[46515]: Artboard 1 is a: MSArtboardGroup
```
Если вы сгруппируете все слои на артборде, затем запустите плагин, увидите следующее:
```
8/28/16 9:11:24.234 AM Show Layer Type (Sketch Plugin)[46515]: Group is a: MSLayerGroup
```
Вот и все типы подклассов слоев! Возможно, есть и другие, но это все, которые мне удалось найти (документированные я сопроводил ссылками).
> **MSShapeGroup**
>
> **[MSBitmapLayer](http://developer.sketchapp.com/reference/class/MSBitmapLayer/)**
>
> **[MSTextLayer](http://developer.sketchapp.com/reference/class/MSTextLayer/)**
>
> **MSSymbolInstance**
>
> **MSSymbolMaster**
>
> **[MSArtboardGroup](http://developer.sketchapp.com/reference/class/MSArtboardGroup/)**
>
> **[MSLayerGroup](http://developer.sketchapp.com/reference/class/MSLayerGroup/)**
Теперь мы можем дифференцировать код в зависимости от того, какой этот класс, используя операторы if/else.
```
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
if(selection.count() == 0){
doc.showMessage("Please select something.");
}else{
for(var i = 0; i < selection.count(); i++){
var layer = selection[i];
var layerClass = layer.class();
if(layerClass == "MSShapeGroup"){
//do something
} else if (layerClass == "MSBitmapLayer"){
//do something
} else if (layerClass == "MSTextLayer"){
//do something
} else if (layerClass == "MSSymbolInstance"){
//do something
} else if (layerClass == "MSSymbolMaster"){
//do something
} else if (layerClass == "MSArtboardGroup"){
//do something
} else if (layerClass == "MSLayerGroup"){
//do something
}
}
}
};
```
Каждый из этих подклассов располагает гораздо большим количеством атрибутов и методов доступа, которые мы рассмотрим в других постах. Изучите документацию по подклассам layer, чтобы быть готовым к старту!
### Выводы
В этой части мы научились, как:
* Просматривать атрибуты слоя
* Изменять атрибуты слоя с помощью методов
* Получать доступ к атрибутам атрибутов и методов
* Проверять тип класса слоя и различать их в коде
Часть 6 — Экспорт данных
------------------------
Sketch предоставляет удобный доступ к выходному коду svg и css через клик правой кнопкой мыши на слое. Это очень полезная опция для веб-дизайнеров, но для тех, кто занимается разработкой приложений или игр пользы в этом мало. Также приходится копировать и вставлять значения из одного приложения в другое, что представляет собой огромное поле для ошибок.
Есть много сторонних инструментов-мостиков между дизайном и разработкой (Zeplin, Avocode, Sketch Measure, Sympli и др.), но эти инструменты предоставляют лишь справочное руководство для разработчиков. Было бы куда полезнее, если приложения для дизайна и разработки работали вместе напрямую. Представьте: вы делаете дизайн чего-то в Sketch, нажимаете “экспортировать”, считываете свой проект по разработке и воссоздаете макет. Это избавит от необходимости в попиксельных спецификациях, и даже сэкономит время инженера на воссоздании дизайна в коде.
Набор инструментов, доступный для дизайнеров сейчас, создавался как решения для общих потребностей, они не заточены под каких-то специфические задачи. Но в этом и состоит прелесть разработки плагинов: вы можете создавать инструменты четко под свои нужды, нужно только знать, как это делать.
Мы уже прошлись по базе, получили фундамент для успешного программирования. Теперь же мы можем углубиться в самое сердце разработки плагинов, сделать реальное решение для реальной задачи.
### Плагины Sketch — это инструменты, соединяющие дизайн с разработкой
Чтобы соединить дизайн и разработку, нужно найти общую основу двумя этими сферами. Так как нет родных способов их соединить, что мы можем использовать такое, что понятно обоим? Ответ — XML или JSON. С помощью плагинов Sketch может экспортировать данные в оба формата, и, скорее всего, среда разработки, в которой вы работаете, может их считывать. Так зачем слать разработчику пиксельные спецификации, из которых придется копировать значения вручную, если можно отослать их в файле XML и JSON и импортировать автоматически?
Это действительно одно из лучших решений, возможных для Sketch. В этой части я покажу базовый пример, как экспортировать атрибуты слоя в XML или JSON. По аналогии с предыдущими частями, давайте набросаем план. Наш плагин будет работать в таком порядке:
1. Выделяем слой
2. Создаем модальное окно для выбора папки пользователем и сохранения этого местоположения в переменной.
3. Из выделенного поля создаются переменные для хранения базовой информации (Название, координата X, координата Y, высота и ширина).
4. Сохраняем все эти переменные либо в XML, либо в JSON-объект.
5. И, наконец, сохраняем этот объект в файл XML или JSON в предварительно выбранную папку.
### Экспорт XML
Для начала мы начнем с создания нашего плагина. Создайте плагин под названием Export Layer to XML с основным скриптом под названием ExportLayerToXML.js. Также нужно добавить наш файл common.js для использования кастомного окна уведомлений, который создавали в предыдущих частях.
Мы уже знаем, как определить, выделен ли слой:
```
@import 'common.js'
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
//make sure something is selected
if(selection.count() == 0){
doc.showMessage("Please select a layer.");
}else{
//do something
}
};
```
В операторе else мы создадим панель, где пользователь будет выбирать, в какую папку сохранить файл:
```
//allow xml to be written to the folder
var fileTypes = [NSArray arrayWithObjects:@"xml", nil];
//create select folder window
var panel = [NSOpenPanel openPanel];
[panel setCanChooseDirectories:true];
[panel setCanCreateDirectories:true];
[panel setAllowedFileTypes:fileTypes];
```
Потом создадим переменную, которая будет проверять, нажата ли кнопка, подключим ее к кнопке ОК, затем отформатируем выбранную категорию и сохраним ее в переменную для дальнейшего использования:
```
//create variable to check if clicked
var clicked = [panel runModal];
//check if clicked
if (clicked == NSFileHandlingPanelOKButton) {
var isDirectory = true;
//get the folder path
var firstURL = [[panel URLs] objectAtIndex:0];
//format it to a string
var file_path = [NSString stringWithFormat:@"%@", firstURL];
//remove the file:// path from string
if (0 === file_path.indexOf("file://")) {
file_path = file_path.substring(7);
}
}
```
Когда все будет сделано, пройдемся циклом по выделенным слоям и вызовем функцию, которая записывает данные в XML-файл. Получившийся код будет выглядеть так:
```
@import 'common.js'
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
//make sure something is selected
if(selection.count() == 0){
doc.showMessage("Please select a layer.");
}else{
//allow xml to be written to the folder
var fileTypes = [NSArray arrayWithObjects:@"xml", nil];
//create select folder window
var panel = [NSOpenPanel openPanel];
[panel setCanChooseDirectories:true];
[panel setCanCreateDirectories:true];
[panel setAllowedFileTypes:fileTypes];
//create variable to check if clicked
var clicked = [panel runModal];
//check if clicked
if (clicked == NSFileHandlingPanelOKButton) {
var isDirectory = true;
//get the folder path
var firstURL = [[panel URLs] objectAtIndex:0];
//format it to a string
var file_path = [NSString stringWithFormat:@"%@", firstURL];
//remove the file:// path from string
if (0 === file_path.indexOf("file://")) {
file_path = file_path.substring(7);
}
}
//loop through the selected layers and export the XML
for(var i = 0; i < selection.count(); i++){
var layer = selection[i];
exportXML(layer, file_path);
}
}
};
```
Теперь для функции exportXML передадим 2 значения: выделенный слой и file\_path.
Сначала мы настроим XML:
```
//initialize the root xml element
var root = [NSXMLElement elementWithName:@"document"];
//initialize the xml object with the root element
var xmlObj = [[NSXMLDocument document] initWithRootElement:root];
```
Затем из переданного слоя извлечем нужные переменные:
```
//create the variables
var layerName = layer.name();
var layerFrame = layer.absoluteRect();
var layerXpos = String(layerFrame.x());
var layerYpos = String(layerFrame.y());
var layerHeight = String(layerFrame.height());
var layerWidth = String(layerFrame.width());
```
Сохраним эти переменные в объект XML:
```
//create the first child element and add it to the root
var layerElement = [NSXMLElement elementWithName:@"layer"];
[root addChild:layerElement];
//add elements based on variables to the first child
var layerNameElement = [NSXMLElement elementWithName:@"name" stringValue:layerName];
[layerElement addChild:layerNameElement];
var layerXPosElement = [NSXMLElement elementWithName:@"xPos" stringValue:layerXpos];
[layerElement addChild:layerXPosElement];
var layerYPosElement = [NSXMLElement elementWithName:@"yPox" stringValue:layerYpos];
[layerElement addChild:layerYPosElement];
var layerHeightElement = [NSXMLElement elementWithName:@"height" stringValue:layerHeight];
[layerElement addChild:layerHeightElement];
var layerWidthElement = [NSXMLElement elementWithName:@"width" stringValue:layerWidth];
[layerElement addChild:layerWidthElement];
```
И наконец, запишем XML-файл по переданному пути файла и уведомим пользователя, когда все будет сделано:
```
//create the xml file
var xmlData = [xmlObj XMLDataWithOptions:NSXMLNodePrettyPrint];
//name the xml file the name of the layer and save it to the folder
[xmlData writeToFile:file_path+layerName+".xml"];
var alertMessage = layerName+".xml saved to: " + file_path;
alert("Layer XML Exported!", alertMessage);
```
Скрипт целиком выглядит так:
```
@import 'common.js'
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
//make sure something is selected
if(selection.count() == 0){
doc.showMessage("Please select a layer.");
}else{
//allow xml to be written to the folder
var fileTypes = [NSArray arrayWithObjects:@"xml", nil];
//create select folder window
var panel = [NSOpenPanel openPanel];
[panel setCanChooseDirectories:true];
[panel setCanCreateDirectories:true];
[panel setAllowedFileTypes:fileTypes];
//create variable to check if clicked
var clicked = [panel runModal];
//check if clicked
if (clicked == NSFileHandlingPanelOKButton) {
var isDirectory = true;
//get the folder path
var firstURL = [[panel URLs] objectAtIndex:0];
//format it to a string
var file_path = [NSString stringWithFormat:@"%@", firstURL];
//remove the file:// path from string
if (0 === file_path.indexOf("file://")) {
file_path = file_path.substring(7);
}
}
//loop through the selected layers and export the XML
for(var i = 0; i < selection.count(); i++){
var layer = selection[i];
exportXML(layer, file_path);
}
}
};
function exportXML(layer, file_path){
//initialize the root xml element
var root = [NSXMLElement elementWithName:@"document"];
//initialize the xml object with the root element
var xmlObj = [[NSXMLDocument document] initWithRootElement:root];
//create the variables
var layerName = layer.name();
var layerFrame = layer.absoluteRect();
var layerXpos = String(layerFrame.x());
var layerYpos = String(layerFrame.y());
var layerHeight = String(layerFrame.height());
var layerWidth = String(layerFrame.width());
//create the first child element and add it to the root
var layerElement = [NSXMLElement elementWithName:@"layer"];
[root addChild:layerElement];
//add elements based on variables to the first child
var layerNameElement = [NSXMLElement elementWithName:@"name" stringValue:layerName];
[layerElement addChild:layerNameElement];
var layerXPosElement = [NSXMLElement elementWithName:@"xPos" stringValue:layerXpos];
[layerElement addChild:layerXPosElement];
var layerYPosElement = [NSXMLElement elementWithName:@"yPos" stringValue:layerYpos];
[layerElement addChild:layerYPosElement];
var layerHeightElement = [NSXMLElement elementWithName:@"height" stringValue:layerHeight];
[layerElement addChild:layerHeightElement];
var layerWidthElement = [NSXMLElement elementWithName:@"width" stringValue:layerWidth];
[layerElement addChild:layerWidthElement];
//create the xml file
var xmlData = [xmlObj XMLDataWithOptions:NSXMLNodePrettyPrint];
//name the xml file the name of the layer and save it to the folder
[xmlData writeToFile:file_path+layerName+".xml"];
var alertMessage = layerName+".xml saved to: " + file_path;
alert("Layer XML Exported!", alertMessage);
}
```
Скачайте [плагин](https://www.dropbox.com/s/pjx6wunb640nqze/ExportLayerToXML.sketchplugin.zip?dl=0) или просмотрите его на [GitHub](https://github.com/marianomike/sketch-exportlayertoxml), протестируйте. Если вы создадите прямоугольник на артборде и экспортируете в XML, получится примерно так:
```
Rectangle
550
258
234
235
```
### Экспорт JSON
Сохранение JSON-файла реализуется почти также, кроме пары моментов. Мы можем использовать первую часть скрипта и создать функцию exportJSON, которая выглядит так:
```
function exportJSON(layer, file_path){
//initialize the layer array
var layerArray = [];
//create the variables
var layerName = String(layer.name());
var layerFrame = layer.absoluteRect();
var layerXpos = String(layerFrame.x());
var layerYpos = String(layerFrame.y());
var layerHeight = String(layerFrame.height());
var layerWidth = String(layerFrame.width());
// add the strings to the array
layerArray.push({
name: layerName,
xPos: layerXpos,
yPos: layerYpos,
height: layerHeight,
width: layerWidth,
});
// Create the JSON object from the layer array
var jsonObj = { "layer": layerArray };
// Convert the object to a json string
var file = NSString.stringWithString(JSON.stringify(jsonObj, null, "\t"));
// Save the file
[file writeToFile:file_path+layerName+".json" atomically:true encoding:NSUTF8StringEncoding error:null];
var alertMessage = layerName+".json saved to: " + file_path;
alert("Layer JSON Exported!", alertMessage);
}
```
Скрипт целиком выглядит так:
```
@import 'common.js'
var onRun = function(context) {
var doc = context.document;
var selection = context.selection;
//make sure something is selected
if(selection.count() == 0){
doc.showMessage("Please select a layer.");
}else{
//allow xml to be written to the folder
var fileTypes = [NSArray arrayWithObjects:@"json", nil];
//create select folder window
var panel = [NSOpenPanel openPanel];
[panel setCanChooseDirectories:true];
[panel setCanCreateDirectories:true];
[panel setAllowedFileTypes:fileTypes];
var clicked = [panel runModal];
//check if Ok has been clicked
if (clicked == NSFileHandlingPanelOKButton) {
var isDirectory = true;
//get the folder path
var firstURL = [[panel URLs] objectAtIndex:0];
//format it to a string
var file_path = [NSString stringWithFormat:@"%@", firstURL];
//remove the file:// path from string
if (0 === file_path.indexOf("file://")) {
file_path = file_path.substring(7);
}
}
//loop through the selected layers and export the XML
for(var i = 0; i < selection.count(); i++){
var layer = selection[i];
exportJSON(layer, file_path);
}
}
};
function exportJSON(layer, file_path){
//initialize the layer array
var layerArray = [];
//create the variables
var layerName = String(layer.name());
var layerFrame = layer.absoluteRect();
var layerXpos = String(layerFrame.x());
var layerYpos = String(layerFrame.y());
var layerHeight = String(layerFrame.height());
var layerWidth = String(layerFrame.width());
// add the strings to the array
layerArray.push({
name: layerName,
xPos: layerXpos,
yPos: layerYpos,
height: layerHeight,
width: layerWidth,
});
// Create the JSON object from the layer array
var jsonObj = { "layer": layerArray };
// Convert the object to a json string
var file = NSString.stringWithString(JSON.stringify(jsonObj, null, "\t"));
// Save the file
[file writeToFile:file_path+layerName+".json" atomically:true encoding:NSUTF8StringEncoding error:null];
var alertMessage = layerName+".json saved to: " + file_path;
alert("Layer JSON Exported!", alertMessage);
}
```
Вы можете скачать плагин [здесь](https://www.dropbox.com/s/qvf7ob5qcnnfqqr/ExportLayerToJSON.sketchplugin.zip?dl=0) или посмотреть его на [GitHub](https://github.com/marianomike/sketch-exportlayertojson). Если протестируете скрипт, получите JSON-файл с таким содержимым:
```
{“layer”:[{“name”:”Rectangle”,”xPos”:”550",”yPos”:”258",”height”:”234",”width”:”235"}]}
```
Заключение
----------
По итогу этой части мы научились:
* Создавать модальное окно для сохранения файла
* Создавать объекты XML и JSON для хранения переменных
* Сохранять файлы XML и JSON в определенную папку.
Это всего лишь подсказка, как работать с экспортом данных из Sketch. Я только добавил пару атрибутов для старта, но есть [огромное количество данных](https://github.com/abynim/Sketch-Headers/blob/master/Headers/MSLayer.h), из которых можно выбрать нужные для ваших целей.
Спасибо, что читаете наш урок, делитесь своими достижениями в комментариях. Успехов в создании собственных плагинов!
Удачи вам в создании собственных плагинов, делитесь достижениями под этим постом. Если есть вопросы, можете их [задать тут](https://musli.cc).
*Обо всех найденных ошибках, неточностях перевода и прочих подобных вещах просьба сообщать в личку.* | https://habr.com/ru/post/310968/ | null | ru | null |
# Расширение для Chrome, которое предупредит вас о слежке
Привет, Хабр! Роскомсвобода снова с хорошими новостями.
Умелые руки нашей команды разработали расширение для браузера Google Chrome **[Censor Tracker](https://chrome.google.com/webstore/detail/censor-tracker/gaidoampbkcknofoejhnhbhbhhifgdop?hl=en&authuser=0)** и [запускают](https://github.com/roskomsvoboda/censortracker/releases) его ~~в открытое плавание~~ публичное бета-тестирование.
Несколько месяцев мы проверяли работу [Censor Tracker](https://chrome.google.com/webstore/detail/censor-tracker/gaidoampbkcknofoejhnhbhbhhifgdop?hl=en&authuser=0) с помощью наших друзей, коллег и преданных подписчиков, [обсуждали](https://t.me/CensorTracker_feedback) и [исправляли](https://github.com/roskomsvoboda/censortracker_backend) возникающие ошибки и сейчас готовы представить наше расширение широкой публике.
#### Итак, что умеет Censor Tracker
**1. Искать блокировки сайтов, которые осуществляет (будет осуществлять) Роскомнадзор в рамках закона “О Суверенном интернете” в России.**
Закон о «суверенном интернете» (N 90-ФЗ «О внесении изменений в Федеральный закон „О связи“ и Федеральный закон „Об информации, информационных технологиях и о защите информации“») предусматривает изоляцию российского сегмента интернета и создание национальной системы маршрутизации интернет-трафика. Был принят 1 мая 2019 года, вступил в силу — 1 ноября 2019.
**2. Предупреждать, если вы заходите на сайты из реестра ОРИ.**
[Реестр ОРИ](https://reestr.rublacklist.net/distributors_main/) (Организаторов Распространения Информации) — список сайтов, которых обязали следить за пользователями и сливать госорганам по требованию всё содержимое переписок, звонков и всех любых других действий и взаимодействий пользователей на своих ресурсах.
Если говорить языком российского законодательства, то «Организатор распространения информации в сети «Интернет» обязан хранить на территории РФ:
* информацию о фактах приема, передачи, доставки и (или) обработки голосовой информации, письменного текста, изображений, звуков, видео- или иных электронных сообщений пользователей сети «Интернет» и информацию об этих пользователях в течение одного года с момента окончания осуществления таких действий;
* текстовые сообщения пользователей сети «Интернет», голосовую информацию, изображения, звуки, видео-, иные электронные сообщения пользователей сети «Интернет» до шести месяцев с момента окончания их приема, передачи, доставки и (или) обработки. Порядок, сроки и объем хранения указанной в настоящем подпункте информации устанавливаются Правительством РФ.
Организатор распространения информации в сети «Интернет» обязан предоставлять указанную информацию уполномоченным государственным органам, осуществляющим оперативно-розыскную деятельность или обеспечение безопасности РФ, в случаях, установленных федеральными законами».
Если сайт, который находится в реестре ОРИ публично отказался от слежки за пользователями и сотрудничества с госорганами, Censor Tracker также сообщит вам об этом. Другие сайты, находящиеся в этом реестре могут сливать в том числе сессионные ключи от трафика и некоторые это делают уже сейчас.
**3. Разблокировать сайты, которые сейчас находятся в реестре запрещённых.**
[Реестр запрещённых сайтов](https://reestr.rublacklist.net) — список сайтов, содержащих, по мнению российских госорганов, запрещённую в России информацию.
В день вступления в силу Единого реестра запрещенных сайтов (1 ноября 2012 года) была создана РосКомСвобода, чтобы противостоять незаконным блокировкам и бороться с необоснованной цензурой в сети.
Реестр находится в ведении Роскомнадзора, но пополнять его могут и другие ведомства (Генпрокуратура, МВД, ФНС, ФСКН, Минкомсвязь, Роспотребнадзор, Росалкогольрегулирование, Росмолодежь), в том числе внесудебно.
За последнее полугодие в реестр ежемесячно вносилось 17-18 тысяч новых сайтов. Большинство из них было заблокировано действительно за нарушение российского законодательства, но были и прецеденты, выходящие за рамки здравого смысла. Например, сайты международных неправительственных организаций ([тут](https://roskomsvoboda.org/62118/) и [тут](https://roskomsvoboda.org/57267/)), [форум](https://roskomsvoboda.org/57727/) с анекдотами, [платформа Crunchbase](https://roskomsvoboda.org/60411/), [сервисы](https://roskomsvoboda.org/62290/) электронной почты и даже [госсайт](https://roskomsvoboda.org/57489/) Украины.
### Почему мы это делаем
**1. Готовимся противостоять приближающемуся суверенному Рунету.**
Напомним, что закон о суверенном Рунете вступил в силу 1 ноября 2019 года и одно из его нововведений заключается в том, что Роскомнадзор теперь будет реализовывать «централизованное управление» Рунетом. Главный инициатор принятия этого закона — Андрей Липов — сейчас занимает должность руководителя Роскомнадзора и, судя по всему, будет делать всё возможное, чтобы воплотить в жизнь свою законодательную инициативу. Так, в разработанный Минцифры в апреле документ [обязывает](https://roskomsvoboda.org/57843/) операторов незамедлительно блокировать запрещённые интернет-ресурсы в случае если [организатор распространения информации](https://reestr.rublacklist.net/distributors/) отказывается взаимодействовать с госведомствами по сбору, хранению и выдаче данных пользователей, хотя изначально этот документ должен был избавить операторов связи от ответственности за неблокировку запрещённых сайтов.
По словам других авторов «устойчивого интернета» Андрея Клишаса и Людмилы Боковой, закон направлен на защиту Рунета от опасности отключения извне, однако многие эксперты и пользователи сети воспринимают его как закон об изоляции российского сегмента интернета от всемирной паутины. Хотя с момента вступления закона в силу пользователи не заметили существенных изменений в работе сети, а запланированные на этот год “учения по защите от угроз устойчивости функционирования Интернета” [проходили](https://roskomsvoboda.org/55280/) или со сбоями или [переносились](https://roskomsvoboda.org/56542/) на более поздние сроки, мы всё же реалисты и хотим заранее подготовиться к возможному худшему сценарию.
**2. Мы считаем, что информация о цензуре должна быть публичной и дискуссионной.**
*Именно поэтому, мы осуществляем постоянный мониторинг реестра запрещённых сайтов и реестра ОРИ и всячески противостоим сомнительным законодательным инициативам, которые направлены на ужесточение цензуры в интернете.*
**3. Мы хотим знать, что от нас будут пытаться скрыть в дальнейшем.**
*В принципе мы и так это узнаем, но хотим это делать централизованно и превентивно, знать, в каких регионах какой контент попадает под запрет и какие провайдеры содействуют цензуре в Рунете.*
### Принцип работы [Censor Tracker](https://chrome.google.com/webstore/detail/censor-tracker/gaidoampbkcknofoejhnhbhbhhifgdop?hl=en&authuser=0)
**1. Все запросы перенаправляются на HTTPS и тогда, если сайт заблокирован происходит сброс соединения и в `chrome.webRequest.onErrorOccured` возвращается соответствующая ошибка.**
* Если сайт принудительно перенаправляет обратно на HTTP, то происходит циклическое перенаправление и потому подобные сайты заносятся в список игнорируемых.
* Если сайт имеет проблемы с сертификатом, то сайт также добавляется в список игнорируемых из-за невозможности корректной обработки.
**2. Если сброс соединения произошел, то сайт логируется на бэкенде и добавляется в PAC расширения.**
* На бэкенд отсылается IP адрес с которого сайт недоступен и веб-сайт, с доступностью которого возникли проблемы.
* Каждые n-часов запускается задача, проверяющая наличие пар IP/веб-сайт и выясняющая регион владельца IP, а затем хэш IP-адреса сохраняется, а сам адрес удаляется.
* Затем выявляются ресурсы недоступные у разных пользователей из одного и того же региона или провайдера и заносятся в соответствующую базу данных.
**Наши следующие шаги:**
1. Запуск расширения для браузера Mozilla Firefox
2. После успешного теста на России выйти за пределы страны для выявления, листинга и обхода внереестровых блокировок.
**Чем вы нам можете помочь?**
1. Поставить расширение и попользоваться им. Доступно в Chrome Web Store [по ссылке](https://chrome.google.com/webstore/detail/censor-tracker/gaidoampbkcknofoejhnhbhbhhifgdop?hl=en&authuser=0).
2. Проаудировать наш код.
3. [Присоединиться к разработке](https://github.com/roskomsvoboda/censortracker).
4. Если у вас есть богатый опыт содержания VPN-сервисов или прокси, мы будем рады контактам для экспертных советов.
5. Серверное пространство и трафик подешёвке тоже не будет лишним. Если вы знаете где брать — будем рады совету.
6. Хотите запустить в стране отличной от России? Давайте общаться.
Ещё вы можете придумать свою идею, отвечающую принципам цифрового гражданства, и реализовать её на хакатоне [DemHack](https://demhack.ru), который состоится уже 12-13 сентября в Москве.
А также принять участие в [Privacy Accelerator](https://privacyaccelerator.org/) – онлайн-программе интенсивного развития проектов, которые создают продукты в сфере приватности, анонимности, доступа к информации и свободы слова, а также legaltech-проекты в сфере цифровых прав. Программа продлится 3 месяца, на протяжении которых проекты смогут получить опыт и знания в области маркетинга, разработок, privacy-сферы; выявить узкие места и определить потенциальные точки роста; получить техническую экспертизу и найти финансирование с помощью инвестиций и фандрайзинга.
[Приём заявок](https://docs.google.com/forms/d/e/1FAIpQLSftaXoNMwNFAt3mXqsM0cyASqp-X5F77gjtKjbCSbRmqDHOZA/viewform) на участие – до 15 сентября.
**На случай, если пропустили:**
Страница CensorTracker в Chrome Web Store:
[https://chrome.google.com/webstore/detail/censor-tracker](https://chrome.google.com/webstore/detail/censor-tracker/gaidoampbkcknofoejhnhbhbhhifgdop?hl=en&authuser=0)
Последний актуальный билд:
<https://github.com/roskomsvoboda/censortracker/releases>
Версия из master:
<https://github.com/roskomsvoboda/censortracker>
Бэкенд расширения:
<https://github.com/roskomsvoboda/censortracker_backend>
Если вы обнаружили баг, то мы будем вам признательны за репорт: <https://github.com/roskomsvoboda/censortracker/issues>
Чатик для вопросов, обсуждений, советов и гениальных идей:
<https://t.me/CensorTracker_feedback> | https://habr.com/ru/post/515132/ | null | ru | null |
# Генератор/валидатор паролей по результатам взлома LinkedIn
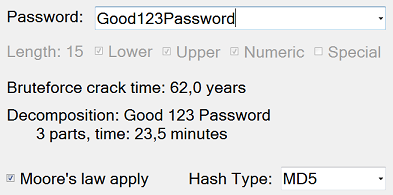После анализа подобранных [паролей к LinkedIn](http://habrahabr.ru/post/145843/) появилась идея создать генератор паролей, совмещенный с валидатором, не допускающим легко подбирающиеся пароли. Простейшего анализа на длину, наличие специальных символов здесь не достаточно — некоторые пароли можно легко собрать из очень вероятных «кусочков» и на их перебор уходит существенно меньшее время, нежели теоретически заявленное. И гарантий, что программа-генератор не выдаст вам подобный пароль нет — случайность, она на то и случайность. Мое творение не претендует на полное решение вопроса, скорее это повод для размышлений, но оно вполне работоспособно (исходники и небольшой разбор тоже присутствуют).
##### Надежность vs доверие
Изначально хотел оформить идею как некий Веб-сервис, однако одумался; грамотный пользователь должен сперва задуматься, куда может попасть его возможный пароль, а для сетевых технологий — этот вопрос без очевидного ответа, и есть все поводы не доверять подобным сервисам вообще. Вы только закончили ввод пароля, а AJAX'ом он уже утянут и сохранен на сервере. Нет, уж, спасибо.
Неизвестное десктопное приложение в этом плане ничем не лучше, у него есть много возможностей незаметно отправить запрос в интернет. Именно из-за этого не пользуюсь программами-генераторами сам. И несмотря на огромные списки источников энтропии, нет гарантий, что твой пароль не окажется в чьей-то базе.
Поэтому сам предлагаю программу в исходных кодах (на C#, исходя из того, что на разработку не хотелось тратить больше пары часов) и настоятельно рекомендую собирать ее из исходников.
##### Генерация паролей
Самая простая и универсальная схема генерации — получить некоторую энтропию и преобразовать ее в строку целевой длины, с заданным набором символов.
Для преобразования есть довольно-таки [стандартное решение](http://habrahabr.ru/post/122711/), сводящееся к вызову хеш-функции, как эффективной свертки пула энтропии (то есть неких случайных значений):
```
string generatePassword(string charset, int length)
{
byte[] result;
SHA1 sha = new SHA1CryptoServiceProvider();
result = sha.ComputeHash(seed); // <--- текущий пул энтропии
// create password
StringBuilder output = new StringBuilder();
for (int i = 0; i < result.GetLength(0) && output.Length < length; i++)
output.Append(charset[result[i] % charset.Length]);
// update seed
for (int i = 0; i < result.GetLength(0); i++)
addToSeed(result[i]);
return output.ToString();
}
```
Сами случайные значения можно набирать разными способами:
* аппаратные решения,
* окружение системы (значения в памяти, свойства процессов),
* получение данных от интернет-сервисов,
* взаимодействие с пользователем.
Но первые три пункта я считаю совершенно избыточными в идеале, а в реальности еще и плохо прогнозируемыми. Нет никакой уверенности, что аппаратный датчик не сломается, и не будет выдавать «одно и то же», окружение системы может не быть достаточно динамичным, а интернет-сервис может специально вернуть (и сохранить) сгенерированные в корыстных целях данные. Это случайные числа, и даже имея возможность на них взглянуть, мы ничего не поймем.
Так что решено было использовать те данные, процесс получения которых зависит от пользователя, и одним из самых простых и удобных вариантов — сохранение перемещений мыши. Каждое перемещение характеризуется координатами и временем, что хоть и имеет предсказуемый в общем вид, но в конкретных числах — всегда различим и практически случаен, особенно если замерять время счетчиком с высоким разрешением (в тиках процессора).
```
void handleMouseData(int x, int y)
{
/* store information in seed array */
addToSeed(x);
addToSeed(y);
addToSeed(ticks());
}
```
Та небольшая часть кода, которая относится к формированию энтропии из окружения, содержится в этой простой функции:
```
int ticks()
{
long timer;
if (QueryPerformanceCounter(out timer) == false)
{
// high-performance counter not supported
throw new Win32Exception();
}
/* ignore significant bits due its stability - we prefer using fast-changing low bits only */
return (int)timer;
}
```
Счетчик QueryPerformanceCounter имеет разное разрешение в зависимости от системы, а его значение меняется в зависимости от текущей загрузки процессора, количества процессов, факта context switch. Одна величина, которая, хоть и имеет прогнозируемый рост, но в конкретных числах его выразить очень сложно.
Как следствие, мы получаем хорошие пароли, не заставляя пользователя нажимать какие-то хитрые комбинации, часами ждать окончания генерации, мучиться со сложным интерфейсом программы. Я не претендую на аккуратность в дизайне интерфейсов (даже смешно стало, после осознания скриншота ниже), но предполагаю, что нет более удобного решения, чем ткнуть в ComboBox и выбрать из сгенеренных вариантов понравившийся.
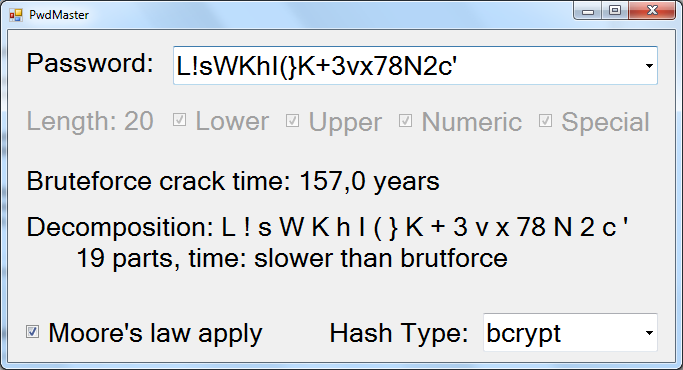
##### Оценка времени на взлом
Для прямого перебора итоговое время можно вычислить, исходя из следующих параметров:
* скорость функции проверки,
* мощность алфавита,
* количество символов.
Мощность алфавита — это минимальное (с разумным критерием описания) множество, содержащее символы конкретного пароля. Как правило это наборы вида:
* маленькие буквы,
* заглавные буквы,
* цифры,
* спецзнаки.
Поэтому для вычисления времени просто проверяем, символы из каких наборов содержит наш пароль, и включаем в мощность множества все символы набора:
```
double bruteforceCombinations = Math.Pow(26 * upper + 26 * lower + 10 * numeric + specials.Length * special, pwd.Length);
```
Скорость хеширования различается для разных алгоритмов, я предоставляю список с грубо оцененными значениями для популярных методов (но в реальности мы не знаем, какой используется на сервере, поэтому корректнее будет оставить только самый быстрый из популярных алгоритм, сейчас это MD5).
И не стоит забывать про [закон Мура](http://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%9C%D1%83%D1%80%D0%B0), отчего все вычисления утверждающие о «миллионах лет на взлом» кажутся очень наивными. Хотя динамику роста вычислительной мощности нельзя предсказать наверняка, но использовать текущий темп роста — лучше чем вообще ничего.
И теперь, собственно, главное — оценка времени [атаки декомпозицией](http://habrahabr.ru/post/122956/).
Это не так сложно, необходимо просто вычислить минимальное разбиение нашего пароля на слова некоторого словаря релевантных комбинаций (достаточно часто встречающиеся подстроки) == длина пароля. И вычислить «мощность» словаря == количество слов в нем. Итоговое количество комбинаций — все так же «мощность» в степени длины.
Если наш пароль вида «Good123Password» — то он раскладывается на «Good», «123», «Password», которые очень распространены по отдельности и время, необходимое для перебора всего лишь «совсем немного» в кубе.
Вопрос, конечно, заключается в качестве такого словаря, но опять же, любой вариант — лучше чем ничего. Я приложил к программе словарь, полученный после аудита на LinkedIn, составленный из самых частых комбинаций, встреченных в 2.5 миллионах найденных паролей. Сам словарь — всего 40 килобайт.
##### Результаты
Ссылка на программу и исходники: [dl.dropbox.com/u/243445/md5h/pwdmaster.zip](https://dl.dropbox.com/u/243445/md5h/pwdmaster.zip)
Одним из приятных результатов является факт, что бо́льшая часть сгенерированных псевдослучайно паролей не раскладывается на вероятные комбинации. Если в других программах генераторах нет явных ошибок, или «лазеек», и по качеству генерации они не хуже моей — то «можно спать спокойно». Доля паролей для 14-символьных алфавитно-цифровых комбинаций, раскладывающихся по словарю (таким образом, что перебор по словарю быстрее прямого перебора) — менее одной тысячной процента. | https://habr.com/ru/post/146068/ | null | ru | null |
# YARG — open-source библиотека для генерации отчётов
Практически каждый разработчик, создающий информационные системы, сталкивается с необходимостью формирования различных отчетов и печатных форм. Это характерно и для большинства приложений разработанных на нашей [платформе](https://www.cuba-platform.com/). Например, в системе, над которой я работаю в настоящее время, их 264. Для того чтобы не писать каждый раз логику формирования отчетов с нуля, мы разработали специальную библиотеку (под катом будет объяснено, почему нам не подошли существующие). Называется она YARG — Yet Another Report Generator.
YARG позволяет:
* Генерировать отчет в формате шаблона или конвертировать результат в PDF;
* Создавать шаблоны отчетов в привычных и распространенных форматах: DOC, ODT, XLS, DOCX,XLSX, HTML;
* Создавать сложные XLS и XLSX шаблоны: с вложенными областями данных, графиками, формулами и т.д.;
* Использовать в отчетах изображения и HTML-разметку;
* Хранить структуру отчетов в формате XML;
* Запускать standalone приложение для генерации отчетов, что делает возможным использование библиотеки вне Java-экосистемы (например для генерации отчетов в PHP);
* Интегрироваться с IoC-фреймворками (Spring, Guice).
Эта библиотека используется в платформе [CUBA](https://www.cuba-platform.com/) в качестве основы для движка отчетов. Мы развиваем ее с 2010 года, но совсем недавно решили сделать ее открытой, и выложили ее код на [GitHub](https://github.com/Haulmont/yarg) с лицензией Apache 2.0.
Данная статья призвана привлечь к ней внимание сообщества.
В основе библиотеки лежит простая идея разделения выборки данных и отображения данных в готовый отчет (data layer & presentation layer). Выборка данных описывается разнообразными скриптами, а отображение данных настраивается прямо в документах-шаблонах. При этом, для того, чтобы создать шаблон не требуются специальные средства, достаточно иметь под рукой Open Office или Microsoft Office.
Отчет состоит из так называемых полос. Полоса одновременно является и набором данных и областью в шаблоне, куда эти данные отображаются (связывает data layer и presentation layer).
Рассмотрим для начала пример в стиле Hello World.
Очень простой пример
--------------------
Представим, что у нас есть фирма и нам нужно вывести список всех сотрудников фирмы, с указанием должности сотрудника.
Мы создаем полосу отчета c именем Staff, в которой указываем, что данные загружаются SQL запросом
```
select name, surname, position from staff
```
**Java code**
```
ReportBuilder reportBuilder = new ReportBuilder();
ReportTemplateBuilder reportTemplateBuilder = new ReportTemplateBuilder()
.documentPath("/home/haulmont/templates/staff.xls")
.documentName("staff.xls")
.outputType(ReportOutputType.xls)
.readFileFromPath();
reportBuilder.template(reportTemplateBuilder.build());
BandBuilder bandBuilder = new BandBuilder();
ReportBand staff= bandBuilder.name("Staff")
.query("Staff", "select name, surname, position from staff", "sql")
.build();
reportBuilder.band(staff);
Report report = reportBuilder.build();
Reporting reporting = new Reporting();
reporting.setFormatterFactory(new DefaultFormatterFactory());
reporting.setLoaderFactory(
new DefaultLoaderFactory().setSqlDataLoader(new SqlDataLoader(datasource)));
ReportOutputDocument reportOutputDocument = reporting.runReport(
new RunParams(report), new FileOutputStream("/home/haulmont/reports/staff.xls"));
```
Далее мы создаем xls-шаблон, в котором отмечаем именованный регион Staff и расставляем алиасы в ячейках.
Примеры посложнее рассматриваются ниже.
Немного истории
---------------
Несколько лет назад у нас возникла потребность в массовом создании отчетов в одном из наших проектов. Нужно было создавать отчеты в формате XLS и DOC, а также конвертировать результат из DOC и XLS в PDF. Нам требовалось, чтобы библиотека:
1. позволяла создавать отчеты (по крайней мере, шаблоны отчетов) обычным пользователям;
2. поддерживала загрузку данных из различных источников;
3. поддерживала различные форматы шаблонов (XLS, DOC, HTML);
4. поддерживала конвертацию отчетов в PDF;
5. была расширяемой (позволяла быстрое добавление новых способов загрузки данных и новых форматов шаблонов);
6. легко встраивалась в различные IoC контейнеры.
Сначала мы пытались использовать JasperReports, но он, во-первых, не умеет создавать DOC отчеты (есть платная библиотека для этого), во-вторых, его возможности по генерации XLS отчетов сильно ограничены (не получится использовать графики, формулы, форматы ячеек), и, в-третьих, создание шаблонов требует определенного навыка и специальных инструментов, а для описания загрузки данных нужно писать Java-код. Существовало также много библиотек, концентрирующихся на каком-то конкретном формате, но единой библиотеки мы не нашли.
Поэтому мы решили создать механизм, позволяющий единообразно описывать отчеты, независимо от типа шаблона и способа загрузки данных.
Первые шаги
-----------
Для работы с XLS уже тогда существовало много разных библиотек (POI-HSSF, JXLS и т.д.) и было решено использовать Apache POI, как самую на тот момент популярную. А вот для работы с DOC файлами такого разнообразия не наблюдалось. Вариантов было совсем немного: использовать UNO Runtime — API для интеграции с сервером Open Office или работать с DOC файлами через COM- объекты. Проект POI-HWPF тогда находился в зачаточном состоянии (недалеко ушел он и сейчас). Мы решили использовать интеграцию с Open Office, потому что увидели много положительных отзывов от людей, которые успешно интегрировались с Open Office на совершенно разных языках (Python, Ruby, C#).
Если с POI-HSSF все было более или менее просто (за исключением полного отсутствия возможности работы с графиками), то с UNO Runtime нам пришлось испытать множество проблем.
1. Отсутствует внятный API для работы с таблицами. Например, чтобы скопировать строку таблицы, нужно использовать системный буфер обмена (выделяя строку, копируя и вставляя ее в нужное место).
2. Для каждой генерации отчета порождается процесс Open Office (и уничтожается после печати). Изначально мы использовали библиотеку bootstrapconnector для порождения процессов, но вскоре убедились, что во многих случаях она оставляет процесс в живых (в зависшем состоянии) или вообще не пытается процесс завершить, что приводило к коллапсу системы через какое-то время. Нам пришлось переписать логику запуска и уничтожения процессов Open Office, воспользовавшись наработками ребят, написавших jodconverter.
3. UNO Runtime (и сам Open Office сервер) имеет проблемы с потокобезопасностью, из-за чего под нагрузкой сервер может зависнуть или внезапно остановиться из-за внутренней ошибки. Это привело к тому, что пришлось делать механизм повторного запуска отчетов (если отчет не напечатался — попробовать напечатать его еще раз). Это, естественно, сказывается на скорости работы данного вида отчетов.
Docx4j
------
Долгое время мы использовали только XLS и DOC шаблоны, но затем было решено поддержать также XLSX и DOCX. Выбор пал на библиотеку DOCX4J, которая к тому времени набрала популярность.
Важным достоинством этой библиотеки для нас стало то, что она предоставляет низкоуровневый доступ к структуре документа (фактически оперируя с XML). С одной стороны это несколько усложнило код и логику, а с другой открыло почти безграничные возможности по управлению документом, так как любые операции над ним были теперь возможны.
Еще более серьезным достоинством стала возможность отказаться от запуска Open Office для генерации DOCX-отчетов.
Пример посложнее
----------------
Представим, что у нас есть книжный магазин. Давайте попробуем с помощью нашей библиотеки сделать отчет, выводящий в XLS список магазинов и список книг проданных в каждом из магазинов.
Представим также, что мы (владельцы магазина) совсем не знаем язык программирования Java, но на наше счастье наш системный администратор знаком с SQL, и у нас даже есть база данных, содержащая информацию обо всех продажах.
В первую очередь давайте создадим шаблон отчета в формате xls. Сразу отметим полосы отчета с помощью именованных регионов.

Затем опишем загрузку данных с помощью SQL.
```
select shop.id as "id", shop.name as "name", shop.address as "address"
from store shop
select book.author as "author", book.name as "name", book.price as "price", count(*) as "count"
from book book where book.store_id = ${Shop.id}
group by book.author, book.name, book.price
```
Теперь мы должны описать отчет с помощью XML.
```
xml version="1.0" encoding="UTF-8"?
select book.author as "author", book.name as "name", book.price as "price", count(\*) as "count" from book where book.store\_id = ${Shop.id} group by book.author, book.name, book.price
select shop.id as "id", shop.name as "name", shop.address as "address" from store shop
```
Запустив отчет из командной строки, мы получим следующий документ
В данном отчете мы видим, что одна полоса может ссылаться на другую. Полоса Book ссылается на полосу Shop, таким образом для каждого магазина мы выбираем список проданных в нем книг. Полоса Book является вложенной в Shop.
Еще пример
----------
Теперь представим, что наш магазин получил крупный заказ и нам нужно выставить счет заказчику. Попробуем создать отчет, в котором в качестве шаблона используется документ DOCX, а результат конвертируется в PDF. Загрузку данных для разнообразия опишем Groovy-скриптом.
```
xml version="1.0" encoding="UTF-8"?
return [
[
'invoiceNumber':99987,
'client' : 'Google Inc.',
'date' : new Date(),
'addLine1': '1600 Amphitheatre Pkwy',
'addLine2': 'Mountain View, USA',
'addLine3':'CA 94043',
'signature':<![CDATA['<html><body><b><font color="red">Mr. Yarg</font></b></body></html>']]>
]]
return [
['name':'Java Concurrency in practice', 'price' : 15000],
['name':'Clear code', 'price' : 13000],
['name':'Scala in action', 'price' : 12000]
]
```
Можно заметить, что Groovy-скрипт возвращает список ассоциативных массивов в качестве результата (если точнее — **List**). Таким образом, каждый элемент списка представляет собой строку с именованными данными (ключ — имя параметра, значение — параметр).
Теперь создадим шаблон счета. В таблицу сверху поместим имя и адрес клиента, а также дату выставления счета.
Далее создадим таблицу со списком товаров, за которые выставляется счет. Для того чтобы таблица 2 была привязана к списку товаров, вставим в первую ячейку специальный маркер (##band=Items).

Запустив отчет, мы увидим следующее.
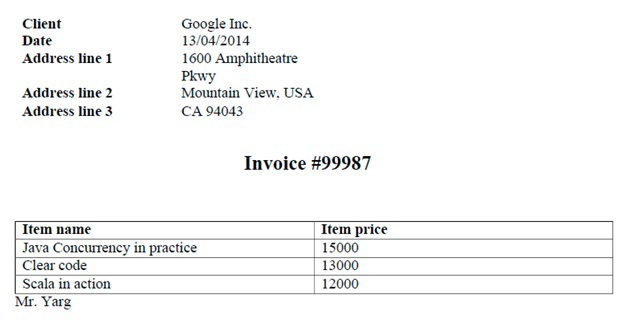
Интеграция и расширение функциональности
----------------------------------------
Библиотека изначально проектировалась для расширения и интеграции в различные приложения. Примером такой интеграции может служить использование YARG в платформе CUBA. В качестве IoC-фреймворка мы используем Spring. Давайте посмотрим как YARG может встраиваться в Spring.
```
8100
8101
8102
8103
${cuba.reporting.displayDeviceAvailable?:false}
${cuba.reporting.openoffice.docFormatterTimeout?:20}
```
Основной bean в данном описании — reporting\_lib\_Reporting. Он предоставляет доступ к основной функциональности библиотеки — созданию отчетов. Для нормального функционирования необходимо определить фабрику форматтеров (работающих с различными типами документов — DOCX, XLSX, DOC и т.д.) и фабрику загрузчиков (загружающих данные). Также, если вы собираетесь использовать DOC отчеты, необходимо задать бин reporting\_lib\_OfficeIntegration, который отвечает за интеграцию с Open Office (с помощью которого обрабатываются DOC и ODT отчеты).
Следует заметить, что для добавления, например, нового загрузчика не нужно переопределять никаких классов библиотеки, достаточно добавить его в описание свойства dataLoaders в бине reporting\_lib\_LoaderFactory. Что мы в принципе и сделали, добавив jpql загрузчик данных ().
Для более серьезных изменений можно наследовать библиотечные классы или создавать свои с нуля, реализуя предоставленные интерфейсы. Практически вся функциональность библиотеки связана через интерфейсы и легко расширяется.
Standalone режим
----------------
Еще одной особенностью библиотеки YARG является то, что ее можно использовать как standalone приложение для генерации отчетов. Таким образом, имея на компьютере установленную JRE, вы можете генерировать отчеты из командной строки. Например, у вас есть серверное приложение на PHP и вы хотите генерировать XLS-отчеты. Вам достаточно создать XLS-шаблон, XML-описание отчета и после этого вы с помощью простой консольной команды сможете генерировать отчет.
Пример команды:
```
yarg -rp ~/report.xml -op ~/result.xls “-Pparam1=20/04/2014”
```
Заключение
----------
В качестве заключения приведу несколько скриншотов UI, который предоставляет платформа CUBA для создания отчетов на движке YARG:
**Фрагменты редактора отчета**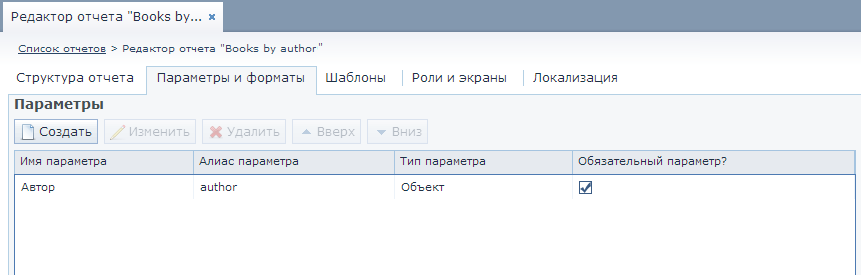

**Мастер создания отчетов**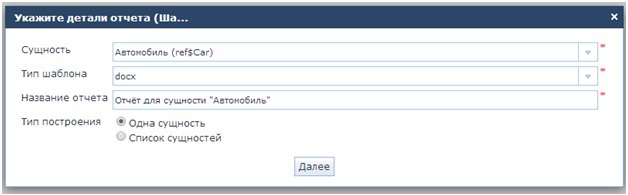
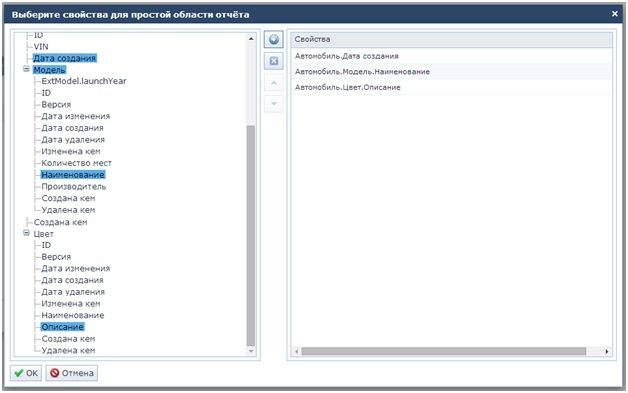
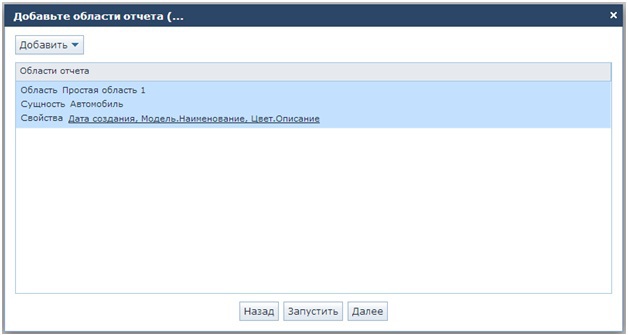
И пример отчета с графиками:
**Отчет с графиками**Шаблон отчета с графиком и диаграммой:
Готовый отчет с графиком и диаграммой
 | https://habr.com/ru/post/224125/ | null | ru | null |
# Эксплоит для уязвимости в Cisco UCS Manager: так ли страшен чёрт?
В сети [опубликован эксплоит](https://www.exploit-db.com/exploits/39568/) для [Cisco UCS Manager](https://habrahabr.ru/company/it-grad/blog/177283/). Указывается, что уязвимы версии 2.1(1b) и, возможно, другие.
На сайте Cisco в разделе [GNU Bash Environment Variable Command Injection Vulnerability](http://www.cisco.com/c/en/us/support/docs/csa/cisco-sa-20140926-bash.html) указано, что доступны обновлённые версии продуктов, исправляющих уязвимость:
* 3.0(1d) (Available)
* 2.2(3b) (Available)
* 2.2(2e) (Available)
* 2.2(1f) (Available)
* 2.1(3f) (Available)
* 2.0(5g) (Available)
Собственное тестирование показало, что уязвимы версии:
* 2.2(1d)
* 2.2(1c)
* 2.1(2a)
Не уязвимы:
* 2.2(6c)
* 2.2(3e)
Мы провели анализ работы эксплоита, а также количество уязвимых устройств. Используя поисковик Shodan и наш собственный поисковый аналог (да здравствует импортозамещение). И вот что получилось.
Судя по коду эксплоита, команды инжектируются в поле User-Agent при работе по специально сформированному URL по протоколу HTTPS. Можно разделить работу эксплоита на 2 этапа. На первом этапе эксплоит пытается определить уязвима ли система. Для этого считывается файл пользователей "/etc/passwd" и ищется пользователь «root». На втором этапе делается реверс-коннект к контролируемому узлу атакующего, [используя особенности псевдо устройства /dev/tcp](https://mtaalamu.ru/blog/admining/1130.html).
У нас нашлось уязвимое оборудование и я смог немного поиграться с эксплоитом.
Выполняем команды.
```
$ who
daemon
```
Считываем содержимое файла "/etc/passwd"
```
$ cat /etc/passwd
root:*:0:0:root:/root:/isanboot/bin/nobash
bin:*:1:1:bin:/bin:
daemon:*:2:2:daemon:/usr/sbin:
sys:*:3:3:sys:/dev:
ftp:*:15:14:ftp:/var/ftp:/isanboot/bin/nobash
ftpuser:*:99:14:ftpuser:/var/ftp:/isanboot/bin/nobash
nobody:*:65534:65534:nobody:/home:/bin/sh
admin:x:2002:503::/var/home/admin:/isan/bin/vsh_perm
svc-isan:*:499:501::/var/home/svc-isan:/isan/bin/vsh_perm
samdme:x:2003:504::/var/home/samdme:/bin/bash
```
Т.е. пользователь root действительно существует, а уязвимое ПО запускается от пользователя daemon.
Также открыто много портов. **Вот лишь краткий список**`$ netstat -ln
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:161 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:2049 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:36738 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:6021 0.0.0.0:* LISTEN
tcp 0 0 127.12.0.1:4101 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:5991 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:7911 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:5961 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:906 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:907 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:6351 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:5871 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:906 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:907 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:6351 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:5871 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:6321 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:5841 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:5781 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:6261 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:51189 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:4023 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:27000 0.0.0.0:* LISTEN`
`uname -a
Linux UCS078A-A-A 2.6.27.10 #1 SMP Fri Nov 15 03:08:09 PST 2013 i686 i686 i386 GNU/Linux
cat /etc/*release
Wind River Linux`
Инжекция кода именно в строку User-Agent — распространённая практика. Например, [скрипт поиска уязвимости типа Shellshock для сетевого сканнера nmap](https://nmap.org/nsedoc/scripts/http-shellshock.html) также пользуется этим подходом в настройках по-умолчанию. Хотя лично мне не удалось настроить данный скрипт так, чтобы он действительно определил уязвимость в тестируемом оборудовании Cisco UCS Manager.
Поисковик Shodan по запросу «Cisco UCS Manager» не выдаёт ничего. А по запросу «Cisco UCS» — много всякого, из чего можно найти 7 адресов, относящихся к искомому устройству. Такое ощущение, что проблема в невозможности поиска по подстроке из нескольких слов: в итоге ищется любое из выражения. Хотя, может быть, я просто неопытный пользователь Shodan.
На конференции PHDays 2015 я и мой коллега [рассказывали про свой поисковик, аналогичный Шодану](http://2015.phdays.ru/program/40864/).
Поиск по банальному запросу в 2-х сетях с маской 16:

В основном мы рассказывали как устроен поисковик. Но также затронули проблему поиска конкретного оборудования: необходимо найти максимальное количество устройств по запросу. При этом в результатах запроса должно быть минимум мусора. В частности, высказывали мысль, про некий цифровой отпечаток. Если вкратце: оборудование бывает по-разному настроено (настройки по-умолчанию, или кастомные настройки, работа оборудования за межсетевым экраном или за NAT). Изучая каждый случай методом проб и ошибок, а также с учётом накопленного опыта создаётся уже совсем не тривиальный запрос. Его результаты могут сильно отличаться от банального первоначального поиска. Так случилось и в этой ситуации. Например, как видно из скриншота выше, при поиске устройства попадается строка «OpenSSL/FIPS». Поиск этой строки в Shodan опять разочаровывает: в результатах опять нет чёткой искомой строки. Поиск в нашем поисковике увеличил количество обнаруженных адресов по сравнению с предыдущим поиском. Хотя, честно скажем: такой поиск всё же выдаёт и мусорные записи. Т.е. записи, при проверке не имеющие ничего общего с Cisco UCS Manager.
В общем и целом вопрос создания цифровых отпечатков (в т.ч. для конкретных устройств) — тема для отдельной статьи. Ограничусь фактом: мы обнаружили около 50 ~~устройств~~ уникальных IP-адреса (говорить про количество найденных устройств не совсем корректно, т.к. у каждого устройства может быть несколько сетевых интерфейсов с разными адресами). В основном в США.
В данный момент прорабатывается вопрос предоставления доступа к нашему поисковику широкой аудитории. Если будет интерес со стороны сообщества. | https://habr.com/ru/post/280364/ | null | ru | null |
# Многозадачная Ардуина: таймеры без боли
Не каждый ардуинщик знает о том, что помимо стартового кода в setup и бесконечного цикла в loop, в прошивку робота можно добавлять такие кусочки кода, которые будут останавливать ход основного цикла в строго определенное заранее запланированное время, выполнять свои дела, затем аккуратно передавать управление в основную программу так, что она вообще ничего не заметит. Такая возможность обеспечена механизмом прерываний по таймеру (обычное дело для любого микроконтроллера), с её помощью в прошивку можно вносить элементы реального времени и многозадачности.
Еще меньше используют такую возможность на практике, т.к. в стандартном не слишком богатом API Arduino она не предусмотрена. И, хотя, доступ ко всем богатствам внутренних возможностей микроконтроллера лежит на расстоянии вытянутой руки через подключение одного-двух системных заголовочных файлов, не каждый пожелает добавить в свой аккуратный маленький скетч пару-тройку экранов довольно специфического настроечного кода (попутно потеряв с ним остатки переносимости между разными платами). Совсем единицы (тем более, среди аудитории Ардуино) решатся и смогут в нем разобраться.
Сегодня я избавлю вас от страданий.
и расскажу, как получить настоящие многозадачность и реальное время в прошивке вашего ардуино-робота, добавив в неё ровно 3 строчки кода (включая #include в шапке). Обещаю, что у вас всё получится, даже если вы только что в первый раз запустили Blink.
Начнем сразу с кода
-------------------
[arduino-timer-api/examples/timer-api/timer-api.ino](https://github.com/sadr0b0t/arduino-timer-api/blob/v0.0.2-habra-08092017/examples/timer-api/timer-api.ino)
Подключаем библиотеку *timer-api.h* (***раз***)
```
#include "timer-api.h"
```
Запускаем таймер с нужной частотой с *timer\_init\_ISR\_XYHz*: здесь XYHz=1Hz — 1 Герц — один вызов прерывания в секунду (***два***)
```
void setup() {
Serial.begin(9600);
// частота=1Гц, период=1с
timer_init_ISR_1Hz(TIMER_DEFAULT);
pinMode(13, OUTPUT);
}
```
(*ISR — interrupt service routine, процедура-обработчик прерывания*)
Добавляем в главный цикл *loop* любую блокирующую или неблокирующую ерунду: печатаем сообщение, ждём 5 секунд (*здесь всё, как обычно, поэтому не считаем*)
```
void loop() {
Serial.println("Hello from loop!");
delay(5000);
// здесь любой код: блокирующий или неблокирующий
}
```
Процедура, вызываемая прерыванием по событию таймера с заданным периодом, — реализация для функции с именем *timer\_handle\_interrupts*: печатаем сообщение, мигаем лампочкой (***три***)
```
void timer_handle_interrupts(int timer) {
Serial.println("goodbye from timer");
// мигаем лампочкой
digitalWrite(13, !digitalRead(13));
}
```
То же самое, только добавим замер времени между двумя вызовами для наглядности и отладки:
```
void timer_handle_interrupts(int timer) {
static unsigned long prev_time = 0;
unsigned long _time = micros();
unsigned long _period = _time - prev_time;
prev_time = _time;
Serial.print("goodbye from timer: ");
Serial.println(_period, DEC);
// мигаем лампочкой
digitalWrite(13, !digitalRead(13));
}
```
Шьем плату, открываем *Инструменты > Монитор порта*, наблюдаем результат:

Как видим, обработчик *timer\_handle\_interrupts* печатает сообщение каждые 1000000 (1 миллион) микросекунд, т.е. ровно раз в секунду. И (о чудо!) постоянная блокирующая задержка на 5 секунд *delay(5000)* в главном цикле никаким образом ему в этом действии не мешает.
Вот вам реальное время и многозадачность в одном скетче в 3 строчки, я обещал.
Варианты частот для timer\_init\_ISR\_XYHz
------------------------------------------
```
//timer_init_ISR_500KHz(TIMER_DEFAULT);
//timer_init_ISR_200KHz(TIMER_DEFAULT);
//timer_init_ISR_100KHz(TIMER_DEFAULT);
//timer_init_ISR_50KHz(TIMER_DEFAULT);
//timer_init_ISR_20KHz(TIMER_DEFAULT);
//timer_init_ISR_10KHz(TIMER_DEFAULT);
//timer_init_ISR_5KHz(TIMER_DEFAULT);
//timer_init_ISR_2KHz(TIMER_DEFAULT);
//timer_init_ISR_1KHz(TIMER_DEFAULT);
//timer_init_ISR_500Hz(TIMER_DEFAULT);
//timer_init_ISR_200Hz(TIMER_DEFAULT);
//timer_init_ISR_100Hz(TIMER_DEFAULT);
//timer_init_ISR_50Hz(TIMER_DEFAULT);
//timer_init_ISR_20Hz(TIMER_DEFAULT);
//timer_init_ISR_10Hz(TIMER_DEFAULT);
//timer_init_ISR_5Hz(TIMER_DEFAULT);
//timer_init_ISR_2Hz(TIMER_DEFAULT);
//timer_init_ISR_1Hz(TIMER_DEFAULT);
```
(*вызов timer\_init\_ISR\_1MHz тоже есть, но он не даёт рабочий результат ни на одном из тестовых контроллеров*)
Код прерывания, очевидно, должен выполняться достаточно быстро для того, чтобы успеть завершиться до следующего вызова прерывания и, желательно, еще оставить немного процессорного времени для выполнения главного цикла.
Полагаю, излишне пояснять, что чем выше частота таймера, тем меньше период вызова прерываний, тем быстрее должен выполняться код обработчика. Я бы не рекомендовал помещать в него вызовы блокирующих задержек *delay*, циклы с неизвестным заранее количеством итераций, любые другие вызовы с плохо предсказуемым временем выполнения (в том числе *Serial.print*).
Суммирование периодов (деление частоты)
---------------------------------------
В том случае, если стандартные частоты из предложенных на выбор вас не устраивают, можно ввести в код прерывания дополнительный счетчик, который будет выполнять полезный код только после определенного количества пропущенных вызовов. Целевой период будет равен сумме пропускаемых базовых периодов. Или можно сделать его вообще переменным.
[arduino-timer-api/examples/timer-api-counter/timer-api-counter.ino](https://github.com/sadr0b0t/arduino-timer-api/blob/v0.0.2-habra-08092017/examples/timer-api-counter/timer-api-counter.ino)
```
#include"timer-api.h"
void setup() {
Serial.begin(9600);
while(!Serial);
// частота=10Гц, период=100мс
timer_init_ISR_10Hz(TIMER_DEFAULT);
pinMode(13, OUTPUT);
}
void loop() {
Serial.println("Hello from loop!");
delay(6000);
// здесь любой код: блокирующий или неблокирующий
}
void timer_handle_interrupts(int timer) {
static unsigned long prev_time = 0;
// дополнильный множитель периода
static int count = 11;
// Печатаем сообщение на каждый 12й вызов прерывания:
// если базовая частота 10Гц и базовый период 100мс,
// то сообщение будет печататься каждые 100мс*12=1200мс
// (5 раз за 6 секунд)
if(count == 0) {
unsigned long _time = micros();
unsigned long _period = _time - prev_time;
prev_time = _time;
Serial.print("goodbye from timer: ");
Serial.println(_period, DEC);
// мигаем лампочкой
digitalWrite(13, !digitalRead(13));
// взводим счетчик
count = 11;
} else {
count--;
}
}
```

Произвольная частота
--------------------
Есть еще вариант установить практически произвольное (в определенных границах) значение частоты таймера при помощи вызова *timer\_init\_ISR(timer, prescaler, adjustment)* с параметрами — системным делителем тактовой частоты процессора *prescaler* и произвольным значением *adjustment* для размещения в регистре счетчика таймера.
Не вдаваясь в подробности, чтобы не перегружать пост, приведу ссылку на пример с подробными комментариями:
[arduino-timer-api/examples/timer-api-custom-clock/timer-api-custom-clock.ino](https://github.com/sadr0b0t/arduino-timer-api/blob/v0.0.2-habra-08092017/examples/timer-api-custom-clock/timer-api-custom-clock.ino)
И только отмечу, что использование такого подхода может привести к потере переносимости кода между контроллерами с разной тактовой частотой, т.к. параметры для получения целевой частоты таймера подбираются в прямой зависимости от частоты системного генератора сигнала на чипе, разрядности таймера, доступных вариантов системных делителей *prescaler*.
Запуск и остановка таймера в динамике
-------------------------------------
Для остановки таймера следует использовать вызов *timer\_stop\_ISR*, для повторного запуска — любой вариант *timer\_init\_ISR\_XYHz*, как и раньше.
[arduino-timer-api/examples/timer-api-start-stop/timer-api-start-stop.ino](https://github.com/sadr0b0t/arduino-timer-api/blob/v0.0.2-habra-08092017/examples/timer-api-start-stop/timer-api-start-stop.ino)
```
#include"timer-api.h"
int _timer = TIMER_DEFAULT;
void setup() {
Serial.begin(9600);
while(!Serial);
pinMode(13, OUTPUT);
}
void loop() {
Serial.println("Start timer");
timer_init_ISR_1Hz(_timer);
delay(5000);
Serial.println("Stop timer");
timer_stop_ISR(_timer);
delay(5000);
}
void timer_handle_interrupts(int timer) {
static unsigned long prev_time = 0;
unsigned long _time = micros();
unsigned long _period = _time - prev_time;
prev_time = _time;
Serial.print("goodbye from timer: ");
Serial.println(_period, DEC);
// мигаем лампочкой
digitalWrite(13, !digitalRead(13));
}
```

Установка библиотеки
--------------------
Клонировать репозиторий прямо в каталог с библиотеками
```
cd ~/Arduino/libraries/
git clone https://github.com/sadr0b0t/arduino-timer-api.git
```
и перезапустить среду Arduino.
Или на странице проекта [arduino-timer-api](https://github.com/sadr0b0t/arduino-timer-api) скачать снапшот репозитория *Clone or download > Download ZIP* или [один из релизов](https://github.com/sadr0b0t/arduino-timer-api/releases) в виде архива, затем установить архив arduino-timer-api-master.zip через меню установки библиотек в среде Arduino (*Скетч > Подключить библиотеку > Добавить .ZIP библиотеку...*).
Примеры должны появиться в меню *File > Examples > arduino-timer-api*
Поддерживаемые чипы и платформы
-------------------------------
— Atmega/AVR 16 бит 16МГц на Arduino
— SAM/ARM 32 бит 84МГц на Arduino Due
— PIC32MX/MIPS 32 бит 80МГц на семействе ChipKIT (PIC32MZ/MIPS 200МГц — частично, в работе)
Ну и, напоследок,
-----------------
Вращение шаговым мотором через интерфейс step-dir:
— в фоне по таймеру генерируем постоянный прямоугольный сигнал для шага по фронту HIGH->LOW на ножке STEP
— в главном цикле принимаем от пользователя команды для выбора направления вращения (ножка DIR) или остановки мотора (ножка EN) через последовательный порт
[arduino-timer-api/examples/timer-api-stepper/timer-api-stepper.ino](https://github.com/sadr0b0t/arduino-timer-api/blob/master/examples/timer-api-stepper/timer-api-stepper.ino)
```
#include"timer-api.h"
// Вращение шаговым моторов в фоновом режиме
// Pinout for CNC-shield
// http://blog.protoneer.co.nz/arduino-cnc-shield/
// X
#define STEP_PIN 2
#define DIR_PIN 5
#define EN_PIN 8
// Y
//#define STEP_PIN 3
//#define DIR_PIN 6
//#define EN_PIN 8
// Z
//#define STEP_PIN 4
//#define DIR_PIN 7
//#define EN_PIN 8
void setup() {
Serial.begin(9600);
// step-dir motor driver pins
// пины драйвера мотора step-dir
pinMode(STEP_PIN, OUTPUT);
pinMode(DIR_PIN, OUTPUT);
pinMode(EN_PIN, OUTPUT);
// Будем вращать мотор с максимальной скоростью,
// для разных настроек делителя шага оптимальная
// частота таймера будет разная.
// Оптимальные варианты задержки между шагами
// для разных делителей:
// https://github.com/sadr0b0t/stepper_h
// 1/1: 1500 мкс
// 1/2: 650 мкс
// 1/4: 330 мкс
// 1/8: 180 мкс
// 1/16: 80 мкс
// 1/32: 40 мкс
// Делилель шага 1/1
// частота=500Гц, период=2мс
//timer_init_ISR_500Hz(TIMER_DEFAULT);
// помедленнее
timer_init_ISR_200Hz(TIMER_DEFAULT);
// Делилель шага 1/2
// частота=1КГц, период=1мс
//timer_init_ISR_1KHz(TIMER_DEFAULT);
// помедленнее
//timer_init_ISR_500Hz(TIMER_DEFAULT);
// Делилель шага 1/4
// частота=2КГц, период=500мкс
//timer_init_ISR_2KHz(TIMER_DEFAULT);
// помедленнее
//timer_init_ISR_1KHz(TIMER_DEFAULT);
// Делилель шага 1/8
// частота=5КГц, период=200мкс
//timer_init_ISR_5KHz(TIMER_DEFAULT);
// помедленнее
//timer_init_ISR_2KHz(TIMER_DEFAULT);
// Делилель шага 1/16
// частота=10КГц, период=100мкс
//timer_init_ISR_10KHz(TIMER_DEFAULT);
// помедленнее
//timer_init_ISR_5KHz(TIMER_DEFAULT);
// Делилель шага 1/32
// частота=20КГц, период=50мкс
//timer_init_ISR_20KHz(TIMER_DEFAULT);
// помедленнее
//timer_init_ISR_10KHz(TIMER_DEFAULT);
/////////
// выключим мотор на старте
// EN=HIGH to disable
digitalWrite(EN_PIN, HIGH);
// просим ввести направление с клавиатуры
Serial.println("Choose direction: '<' '>', space or 's' to stop");
}
void loop() {
if(Serial.available() > 0) {
// читаем команду из последовательного порта:
int inByte = Serial.read();
if(inByte == '<' || inByte == ',') {
Serial.println("go back");
// назад
digitalWrite(DIR_PIN, HIGH);
// EN=LOW to enable
digitalWrite(EN_PIN, LOW);
} else if(inByte == '>' || inByte == '.') {
Serial.println("go forth");
// вперед
digitalWrite(DIR_PIN, LOW);
// EN=LOW to enable
digitalWrite(EN_PIN, LOW);
} else if(inByte == ' ' || inByte == 's') {
Serial.println("stop");
// стоп
// EN=HIGH to disable
digitalWrite(EN_PIN, HIGH);
} else {
Serial.println("press '<' or '>' to choose direction, space or 's' to stop,");
}
}
delay(100);
}
void timer_handle_interrupts(int timer) {
// шаг на фронте HIGH->LOW
digitalWrite(STEP_PIN, HIGH);
delayMicroseconds(1);
digitalWrite(STEP_PIN, LOW);
}
``` | https://habr.com/ru/post/337430/ | null | ru | null |
# Искажение озвучиваемых данных
В этой работе рассмотрен пример искажения данных, передаваемых в виде звукового потока. Схема передачи данных показана на Рисунок 1. Данные упаковываются в звуковой файл WAV. Проигрыватель озвучивает файл. Состояние канала передачи данных отображается звукозаписывателем. Он же записывает отображаемые данные в звуковой файл по команде пользователя.
Рисунок 1. Схема передачи данныхВ качестве носителя исходных данных был выбран формат WAV, который не сжимает данные. Файл состоит из заголовка (44 байт) и области передаваемых данных. Заголовок содержит информацию о количестве каналов (моно или стерео), разрядности амплитуды, частоте дискретизации, размере файла и др. Заголовок (байты в 16-ричном формате) исходного WAV файла показан на Рисунок 2, выделенные байты означают: “01” - моно, “AC 44” - дискретизация 44100 Гц, “08” – разрядность данных.
 и параметры этого заголовка, отображаемые интерпретатором Python (справа)")
Рисунок 2. Пример заголовка передаваемого звукового файла WAV (44 байта, слева) и параметры этого заголовка, отображаемые интерпретатором Python (справа)Для удобства обработки результатов передачи данных исходные данные представлены в виде полуволны амплитудой 100 единиц и длительностью 2 с (**Рисунок 3**), которая рассчитана средствами Python следующим образом.
`dt = 1/44100 # 1/Hz
time_min = 0
time_max = 2
time = np.arange(time_min, time_max, dt)
f = (100 * np.sin((0.25 * 2 * np.pi * time)))`
Размер данных: 88200 байт (как 2[с] \* 44100 [байт\*Гц]), размер WAV файла с заголовком (44 байта) равен 88244 байт.

Рисунок 3. Передаваемые через звуковой WAV файл данныеДля отображения и записи “озвучиваемых” потоков данных использовалась демонстрационная версия Free Audio Recorder 10.1.0 (**Рисунок 4**). Из пакета установленной программы удален MP3 рекламный ролик, который добавлялся в записываемый файл данных. Развертка дисплея: 30 с, цена деления дисплея: 30 с/42. Показанный на дисплее сигнал формируется при запуске на проигрывателе WAV файла с данными **Рисунок 3**. Запись данных выделяется зеленым цветом. Длительность показанного сигнала (2 секунды) совпадает с длительностью полуволны **Рисунок 3**.

Рисунок 4. Дисплей Free Audio Recorder 10.1.0 с отображаемым потоком данныхЗвукозаписыватель, отображающий передаваемую полуволну (**Рисунок 3**) как показано на **Рисунок 4**, создает собственный WAV файл, последовательность байт которого показана на **Рисунок 5**.
")
Рисунок 5. Байтовая последовательность записанного потока данных WAV файла (стерео, 16-разрядов)Оказалось, что демонстрационная версия записывает WAV файл только в “стерео” формате 16-разрядными амплитудами. На это указал заголовок файла:
Расшифровка выделенных байт (16-ричный формат):
“02” – стерео;
“02 B1 10” – частота передачи данных 4 x 44100 байт в секунду;
“04” – 4 канала;
“10” – разрядность амплитуды 16 бит.
Для приведения формата записанных данных (стерео, 16-разрядные данные) к формату исходных данных (моно, 8-разрядные данные) выполнены следующие операции:
1. Удален канал без звука (с 0x00 и 0xFF байтами)
2. Восстановлена 16-разрядная амплитуда по формуле: A16 = байт\_1 \* 256 + байт\_2.
3. Амплитуда уменьшена до 8 разрядов: A8 = A16/256.
4. Удалены данные 0x00 и 0xFF соответствующие состоянию канала до и после “звуковых” данных (**Рисунок 4**).
Выделенный сигнал показан на **Рисунок 6**. Размер сигнала 88160 байт, амплитуда 50 бит (от 191 до 241).

Рисунок 6. Выделенные и отмасштабированные амплитуды моно канала записанного WAV файла Исходный и отфильтрованный шум перехода младшего разряда показан на **Рисунок 7**. Применен низкочастотный фильтр – скользящее среднее из 100 точек. Средняя частота шума в младшем разряде равна половине частоты квантования 44100/2 Гц. Время “дрожания” младшего разряда пропорционально амплитуде сигнала, количество “шумовых” точек одного перехода меняется от 280 до 630.

Рисунок 7. Исходный и отфильтрованный шум перехода младшего разрядаНачало и пример окончания сигнала (**Рисунок 6**) показаны на **Рисунок 8**. Переход с нулевого уровня 0xFF длится 0.01 c (как 400 отсчетов / 44100 Гц). Каждая запись исходной полуволны имеет свое окончание данных – переходный процесс на уровень 0xFF. Было замечено, что записыватель “не видит” короткие последовательности данных, например, линейный сигнал, изменяющийся от 0 до 255, длительностью 256 отсчетов.
 и конец (справа) записанного сигнала (Рисунок 6)")
Рисунок 8. Начало (слева) и конец (справа) записанного сигнала (Рисунок 6)### Выводы
Передача данных (**Рисунок 3**) аудио потоком (**Рисунок 1**) вносит следующие искажения.
1. Амплитуда сигнала уменьшилась в два раза
2. Добавилась постоянная составляющая 191 бит.
3. Изменения младшего разряда сопровождаются шумом, средняя частота которого близка к частоте дискретизации звука, а длительность пропорциональна амплитуде сигнала.
4. Начало и конец сигнала сопровождаются переходными процессами.
5. Переходный процесс окончания сигнала зависит от временного интервала между началами записи и сигнала.
6. Звукозаписыватель “не видит” короткие сигналы порядка 250 отсчетов (записанный файл содержит только 0x00 и 0xFF).
В работе рассмотрена только часть средств потоковой передачи звуковых данных, которая вносит перечисленные искажения. Возможно, что все стандартные кодеки, кодирующие и раскодирующие звуковой сигнал, в той или иной степени вносят искажения в передаваемые потоки данных. | https://habr.com/ru/post/590739/ | null | ru | null |
# Ваш сайт тоже позволяет заливать всё подряд?
Один французский «исследователь безопасности» этим летом опубликовал невиданно много найденных им уязвимостей типа arbitrary file upload в разных «написанных на коленке», но популярных CMS и плагинах к ним. Удивительно, как беспечны бывают создатели и администраторы небольших форумов, блогов и интернет-магазинчиков. Как правило, в каталоге, куда загружаются аватары, резюме, смайлики и прочие ресурсы, которые пользователь может загружать на сайт — разрешено выполнение кода PHP; а значит, загрузка PHP-скрипта под видом картинки позволит злоумышленнику выполнять на сервере произвольный код.
Выполнение кода с правами apache — это, конечно, не полный контроль над сервером, но не стоит недооценивать открывающиеся злоумышленнику возможности: он получает полный доступ ко всем скриптам и конфигурационным файлам сайта и через них — к используемым БД; он может рассылать от вашего имени спам, захостить у вас какой-нибудь незаконный контент, тем подставив вас под абузы; может, найдя параметры привязки к платёжной системе, отрефандить все заказы и оставить вас без дохода за весь последний месяц. Обидно, правда?
Как ему это удастся?
#### Вы не проверяете загружаемые файлы вообще?
Клинический случай: вы скопировали из мануала по PHP строчку
`move_uploaded_file($_FILES["file"]["tmp_name"], "upload/" . $_FILES["file"]["name"]);`
и так её и оставили в продакшн-коде.
Так я могу заливать вообще любые файлы, причём не только в каталог upload, а куда угодно — могу указать в качестве имени файла ../index.html и заменить вашу главную страницу своей. Обидно, правда?
Добавьте хотя бы вызов **basename()** для `$_FILES["file"]["name"]`. В последней версии PHP, судя по моим экспериментам, `$_FILES["file"]["name"]` и так возвращает только basename от переданного в HTTP-запросе значения filename; но осторожность тут лишней не будет.
#### Вы проверяете, является ли файл картинкой?
Перед тем, как сохранить загруженный файл в upload/, вы вызываете **getimagesize()**, чтоб убедиться, что загружена именно картинка. К превеликому удовольствию «исследователей безопасности», PHP позволяет вставлять выполнимый код в любое место любого файла, игнорируя всё, что не заключено в теги ?. Я могу взять фотографию своего любимого котика, дописать в её конец что-нибудь навроде `php passthru($_GET['c']); ?` и залить под именем pwn.php. Тогда **getimagesize()** подтвердит вам, что в файле JPEG-картинка, потому что анализирует только заголовки; и моя «фотография с припиской» пройдёт проверку.
#### Вы проверяете mime-type?
Почему нельзя доверять полю «mime», возвращаемому **getimagesize()**, понятно: оно берётся на основании заголовка файла. Тем более нельзя доверять `$_FILES["file"]["type"]` — ничто не мешает мне передать в HTTP-запросе «Content-Type: image/jpeg» перед PHP-скриптом. Это кажется банальным, но [люди действительно на это полагаются](http://cd34.com/blog/web-security/when-mimetype-validation-isnt-enough/). Вот я только что видел проверку `if(substr($_FILES["file"]["type"], 0, 6)=="image/") {/* сохранить файл */}` в одном самоуверенном проекте. Они, поди, считают изящным и хитроумным то, что смогли одной проверкой покрыть все возможные типы картинок! Но не стоит у них заимствовать этот «передовой опыт».
#### Вы проверяете расширение?
В другом самоуверенном проекте я только что видел проверку
`if(substr($_FILES["file"]["name"], -3)=="jpg" || substr($_FILES["file"]["name"], -3)=="gif" || substr($_FILES["file"]["name"], -3)=="png") {/* сохранить файл */}`
[Особенность Apache](http://httpd.apache.org/docs/2.2/mod/mod_mime.html) — что когда он встречает файлы с незнакомыми расширениями, он эти расширения «откусывает» и ищет знакомые расширения перед ними. Поэтому если я залью файл pwn.php.omgif, то он пройдёт проверку, но Apache увидит в нём PHP-скрипт, потому что для расширения omgif не зарегистрирован ни mime-type, ни модуль-обработчик.
#### Вы проверяете «нехорошие» расширения?
В третьем самоуверенном проекте я видел проверку `if(strpos($_FILES["file"]["name"], ".php")===FALSE) {/* сохранить файл */}` — мол, если в имени файла хоть где-нибудь встретилось расширение .php, значит файл не годится. Но не надо забывать, что по умолчанию интерпретатор PHP вызывается ещё и для расширений .phtml и .php3, а [некоторые хостеры включают его и для других расширений](http://www.sitepoint.com/forums/showthread.php?625287-How-are-gif-files-being-executed-as-PHP) — порой даже для .html, .js, .jpg и так далее, чтобы вставлять в статические ресурсы какой-нибудь SEO-код, или отслеживать статистику хитов. (Можете сами проверить, сколько гугл находит вопросов «как мне сделать, чтоб выполнялся PHP-код в JPEG-файлах?») Кроме того, если злоумышленнику удастся [загрузить свой .htaccess](http://www.justanotherhacker.com/2011/05/htaccess-based-attacks.html), то он сможет исполнять PHP-код в файлах с любыми расширениями — даже в самом этом файле .htaccess. В общем, будьте бдительны.
#### Вы проверяете расширение правильно?
Предположим, вы убедились, что имя файла заканчивается на .jpg (вместе с точкой!) Можно ли быть уверенным, что PHP-код в нём не будет выполняться? Учитывая предыдущий пункт — скорее всего можно, но гарантии нет. Может случиться, что злоумышленник (или криворукий админ) как-то повредил /etc/mime.types, так что расширение .jpg окажется незарегистрированным, и Apache станет анализировать расширение перед ним. Может случиться, что /etc/mime.types [стал недоступен из-за chroot](http://www.webhostingtalk.com/showthread.php?t=588997). Может случиться, что злоумышленник (или криворукий админ) забросил в каталог upload/ такой .htaccess, который позволяет выполнять PHP-код во всех файлах подряд.
Кроме того, до недавних версий PHP можно было загрузить файл с именем «pwn.php\0.jpg», который при сохранении на диск превращался бы в «pwn.php», потому что для системных вызовов строка с именем файла заканчивается на \0, а для функций PHP это обычный допустимый в строке символ. В таком случае проверка расширения тоже ничего не гарантировала бы.
#### И что же делать?
Исчерпывающий чеклист попытались составить [на stackoverflow](http://stackoverflow.com/questions/4166762/php-image-upload-security-check-list). Если коротко: а) запретите явно выполнение PHP в каталоге, куда сохраняются пользовательские файлы; б) переименовывайте пользовательские файлы в неподконтрольные пользователям имена; в) если возможно, пересохраняйте картинки при помощи GD, чтобы удалить ненужные метаданные и непрошенные приписки в конце файла. | https://habr.com/ru/post/148999/ | null | ru | null |
# Grails, jQuery, AJAX: первое знакомство
Добавляем jQuery в Grails
-------------------------
Собственно никаких проблем с AJAX в [Grails](http://grails.org) не наблюдается: контроллеры могут спокойно возвращать JSON-данные, GSP-страницы могут использовать соответствующие [вспомогательные тэги](http://grails.org/doc/latest/guide/6.%20The%20Web%20Layer.html#6.7 Ajax).
По умолчанию Grails дружит с Prototype JS. Однако можно легким движением руки установить [плагин поддержки jQuery](http://grails.org/plugin/jquery).
`grails install-plugin jquery`
Будет установлен jQuery 1.4.x. Далее нам необходимо объявить jQuery как «JavaScript provider» в Grails. В этом случае все встроенные тэги Grails начнут работать через jQuery.
Добавляем в **grails-app/Config.groovy** строчку:
`grails.views.javascript.library="jquery"`
Поскольку мы хотим, чтобы все страницы нашего приложения начали использовать jQuery, сразу добавим в основной layout-файл (по умолчанию это **grails-app/views/layouts/main.gsp**) в секцию HEAD:
```
...
...
...
```
Теперь на каждой странице приложения будет автоматически подгружаться jQuery.
Пишем что-нибудь на jQuery
--------------------------
У нас уже заработали такие, например, конструкции:
```
Nothing here.
Обновить!
```
Если посмотреть это в runtime, то будет видно, что неявно используется функция **jQuery.ajax()**.
Заглянув в **web-app/js/application.js**, обнаруживаем, что сгенерированный (с помощью `grails create-app`) код AJAX-индикатора написан для Prototype. Встроенная индикация выглядит криво (на мой вкус), но если очень хочется, чтобы она заработала, можно переписать код на jQuery:
```
jQuery(document).ready(function() {
jQuery(document).ajaxStart(function(){
$('#spinner').show();
});
jQuery(document).ajaxStop(function(){
$('#spinner').fadeOut(500);
});
});
```
Пишем контроллер
----------------
Напоследок напишем контроллер, пригодный для работы с AJAX. Например, вернем из контроллера случайное число в виде JSON:
```
def random = {
def max = params.int('max')
render(contentType:"text/json") {
rnd = new Random().nextInt(max)
}
}
```
Здесь мы используем [новый вариант](http://blog.lourish.com/2010/01/29/rendering-json-using-grails-part-1-collections-testing-and-the-jsonbuilder/) JSON builder из Grails 1.2.x. Результатом работы контроллера будет JavaScript-массив вида `{rnd: 34}`, который мы можем использовать, например, так:
```
Случайное число:
Генерировать!
```
Здесь из JSON-результата (который в нашем случае попадает в переменную `data`) выбирается значение `rnd` и заносится в текстовое поле.
В скобках замечу, что «прозрачность» замены одного JavaScript-провайдера на другого работает только до определенного момента. Как только вы выходите за пределы встроенных AJAX-тэгов Grails и начинаете использовать функции jQuery (как в примере выше), совместимость с другими провайдерами тут же теряется. | https://habr.com/ru/post/92248/ | null | ru | null |
# Создание станка с ЧПУ из доступных деталей с минимум слесарной работы
Продолжаем обзор деятельности нашего [Хакспейс-клуба](http://vk.com/club71815206).
Мы давно мечтали купить в наш клуб ЧПУ станок. Но решили его сделать сами. С нуля, начиная от железа и кончая программного обеспечение (прошивка контроллера и управляющая программа). И у нас это получилось.
Детали для станка старались выбирать из доступных в свободной продаже, многие из которых даже не требуют дополнительной слесарной обработки.

Контроллер мы выбрали Arduino Mega 2560 и что бы много не думать, драйвер шаговых двигателей использовали RAMPS 1.4 (как у RepRap 3D принтера).

Программу контроллера писали по алгоритму метода конечных автоматов. Последний раз я о нем слышал лет 20 назад в институте, не помню по какому предмету изучали. Это была очень удачная идея. Код получился маленький и легко расширяемый без потери читабельности (если в дальнейшем понадобится не только оси XYZ, или использовать другой G-код). Программа контроллера принимает с USB порта G-код и, собственно, дает команду двигателям осей XYZ двигаться в заданном направлении. Кто не знает, G-код — это последовательность конструкций типа G1X10Y20Z10, которая говорит станку переместится по оси X на 10 мм, Y на 20 мм и Z на 10 мм. На самом деле, в G-коде много различных конструкций (например, G90 — используется абсолютная система координат, G91 — относительная) и много модификаций самого кода. В интернете много о нем описано.
Подробнее остановлюсь на описание скетча (прошивка контроллера).
Вначале в описании переменных прописываем, к какому выходу контроллера будет подключены двигатели и концевые выключатели.
В этом коде метода конечных автоматов переменная принимает значение ждать с USB порта первый байт, во второй конструкции case производится проверка наличия данных и переменная \_s принимает значение get\_cmd. Т.е считать данные с порта.
```
switch(_s){
case begin_cmd: Serial.println("&"); //038
//to_begin_coord();
n_t=0;
_s=wait_first_byte;
len=0;
break;
case wait_first_byte: if(Serial.available()){
Serial.print(">");
_s=get_cmd;
c_i=0;
}
break;
```
Далее считываем все, что есть в порту, переменная \_s устанавливается в get\_tag; т.е. переходим на прием буквенного значение G – кода.
```
case get_cmd: c=Serial.read();
if(c!=-1){
if(c=='~'){
_s=get_tag;
c_i=0;
n_t=0;
break;
}
Serial.print(c);
if((c>=97)&&(c<=122))
c-=32;
if( (c==32)||(c==45)||(c==46)||((c>=48)&&(c<=57))||((c>=65)&&(c<=90)) ){
cmd[c_i++]=c;
len++;
}
}
break;
```
Ну и так далее.
**полный код можно посмотреть здесь.**
```
#include
#define STEPS 48
//#define SHAG 3.298701
#define STEP\_MOTOR 1
double koefx = 1.333333;
double koefy = 1.694915;
Stepper stepper0(STEPS, 5, 4, 6, 3);
Stepper stepper1(STEPS, 8, 9, 10, 11);
Stepper stepper2(STEPS, 13, 12, 7, 2);
int x,y,x1,m;
int motor;
int inPinX = 15; // кнопка на входе 22
int inPinY = 14; // кнопка на входе 23
int inPinZ = 24; // кнопка на входе 24
int x\_en = 62;
int x\_dir = 48;
int x\_step = 46;
int y\_en = 56;
int y\_dir = 61;
int y\_step = 60;
const int begin\_cmd=1;
const int wait\_first\_byte=2;
const int wait\_cmd=3;
const int get\_cmd=4;
const int test\_cmd=5;
const int get\_word=6;
const int get\_tag=7;
const int get\_val=8;
const int compilation\_cmd=9;
const int run\_cmd=10;
int abs\_coord=1;
const int \_X=1;
const int \_Y=2;
//const int =10;
//const int =11;
//const int =12;
int \_s=begin\_cmd;
const int max\_len\_cmd=500;
char cmd[max\_len\_cmd];
char tag[100][20];
char val[100][20];
int n\_t=0;
int c\_i=0;
char c;
int i,j;
int amount\_G=0;
int len=0;
char\*trash;
int n\_run\_cmd=0;
int g\_cmd\_prev; //ya предыдущее значение G
class \_g\_cmd{
public:
\_g\_cmd(){
reset();
}
int n; //ya
int g;
double x;
double y;
double z;
void reset(void){
n=g=x=y=z=99999;
}
};
double \_x,\_y,\_z;
double cur\_abs\_x,cur\_abs\_y,cur\_abs\_z; //ya stoyalo int
int f\_abs\_coord=1;
\_g\_cmd g\_cmd[100];
void setup()
{
stepper0.setSpeed(150);
stepper1.setSpeed(150);
stepper2.setSpeed(1000);
Serial.begin(9600);
pinMode(inPinX, INPUT);
pinMode(inPinY, INPUT);
pinMode(inPinZ, INPUT);
pinMode(x\_en, OUTPUT);
pinMode(x\_dir, OUTPUT);
pinMode(x\_step, OUTPUT);
pinMode(y\_en, OUTPUT);
pinMode(y\_dir, OUTPUT);
pinMode(y\_step, OUTPUT);
digitalWrite(x\_en, 1);
digitalWrite(y\_en, 1);
to\_begin\_coord();
//UNIimpstep(12,13,2,7,3,1000);
//UNIimpstep(12,13,2,7,3,-1000);
}
void to\_begin\_coord(void)
{
impstep(\_X,-10000,1);
impstep(\_Y,-10000,1);
cur\_abs\_x=cur\_abs\_y=cur\_abs\_z=0;
}
void loop()
{
switch(\_s){
case begin\_cmd: Serial.println("&"); //038
//to\_begin\_coord();
n\_t=0;
\_s=wait\_first\_byte;
len=0;
break;
case wait\_first\_byte: if(Serial.available()){
Serial.print(">");
\_s=get\_cmd;
c\_i=0;
}
break;
case get\_cmd: c=Serial.read();
if(c!=-1){
if(c=='~'){
\_s=get\_tag;
c\_i=0;
n\_t=0;
break;
}
Serial.print(c);
if((c>=97)&&(c<=122))
c-=32;
if( (c==32)||(c==45)||(c==46)||((c>=48)&&(c<=57))||((c>=65)&&(c<=90)) ){
cmd[c\_i++]=c;
len++;
}
}
break;
case get\_tag: while((c\_i=65)){
tag[n\_t][i]=cmd[c\_i];
i++;
c\_i++;
while((c\_i=48)&&(cmd[c\_i]<=57)) ) ){
val[n\_t][i]=cmd[c\_i];
i++;
c\_i++;
while((c\_i=len)
\_s=compilation\_cmd;
break;
case compilation\_cmd: Serial.println("");
Serial.print("compilation cmd,input (");
Serial.print(n\_t);
Serial.println("): ");
for(i=0;i=amount\_G) \_s=begin\_cmd; break;}
if(f\_abs\_coord){
Serial.println("zdes kosjak G90 ABS");
if (g\_cmd[n\_run\_cmd].x==99999)
\_x=0;
else
\_x=g\_cmd[n\_run\_cmd].x-cur\_abs\_x;
if (g\_cmd[n\_run\_cmd].y==99999)
\_y=0;
else
\_y=g\_cmd[n\_run\_cmd].y-cur\_abs\_y;
if (g\_cmd[n\_run\_cmd].z==99999)
\_z=0;
else
\_z=g\_cmd[n\_run\_cmd].z-cur\_abs\_z;
}else{
Serial.println("normalno G91 REL");
\_x=g\_cmd[n\_run\_cmd].x;
\_y=g\_cmd[n\_run\_cmd].y;
\_z=g\_cmd[n\_run\_cmd].z;
}
if((\_x==0)&&(\_y==0)&&(\_z==0)){
Serial.println("exit: \_x=0,\_y=0,\_z=0");
if(++n\_run\_cmd>=amount\_G) \_s=begin\_cmd; break;
}
// \_x=\_x\*koefx;
// \_y=\_y\*koefy;
//\_z=\_z\*koef;
double max\_l=abs(\_x); //ya
if(abs(\_y)>max\_l)
max\_l=abs(\_y);
if(abs(\_z)>max\_l)
max\_l=abs(\_z);
double unit\_scale=90; // steps in 1.0
double unit\_len=max\_l\*unit\_scale,unit\_step;
double px=0,py=0,pz=0,x=0,y=0,z=0,kx,ky,kz;
int all\_x\_steps=0,all\_y\_steps=0,all\_z\_steps=0;
kx=\_x/unit\_len;
ky=\_y/unit\_len;
kz=\_z/unit\_len;
// Serial.print("unit\_len - "); Serial.print(unit\_len); Serial.print(" \_x- "); Serial.print(\_x); Serial.print(" max\_l- "); Serial.println(max\_l);
// Serial.print("kx=");Serial.print(kx);Serial.print(" ky=");Serial.print(ky);Serial.print(" kz=");Serial.println(kz);
if((kx==0)&&(ky==0)&&(kz==0)){if(++n\_run\_cmd>=amount\_G) \_s=begin\_cmd; break;}
for(unit\_step=0;unit\_step=1){
impstep(\_X,STEP\_MOTOR\*kx/abs(kx),1); //stepper0.step(STEP\_MOTOR\*kx/abs(kx));
//Serial.print("x\_step ");Serial.println(kx/abs(kx));
all\_x\_steps++;
px=x;
}
if((abs(y-py)\*unit\_scale)>=1){
impstep(\_Y,STEP\_MOTOR\*ky/abs(ky),1); //stepper1.step(STEP\_MOTOR\*ky/abs(ky));
//Serial.print("y\_step ");Serial.println(ky/abs(ky));
all\_y\_steps++;
py=y;
}
if((abs(z-pz)\*unit\_scale)>=1){
UNIimpstep(12,13,2,7,3,10\*kz/abs(kz)); //stepper2.step(STEP\_MOTOR\*kz/abs(kz));
//Serial.print("z\_step ");Serial.println(kz/abs(kz));
all\_z\_steps++;
pz=z;
}
x+=kx; y+=ky; z+=kz;
// Serial.print(unit\_step);Serial.print(" : ");
// Serial.print(x);Serial.print(" | ");Serial.print(y);Serial.print(" | ");Serial.println(z);
}
Serial.println("-----------------------------------------");
Serial.print("all\_steps(");Serial.print(all\_x\_steps);Serial.print(",");Serial.print(all\_y\_steps);Serial.print(",");Serial.print(all\_z\_steps);Serial.print(")");
cur\_abs\_x+=\_x; cur\_abs\_y+=\_y; cur\_abs\_z+=\_z;
Serial.print("cur\_abs(");Serial.print(cur\_abs\_x);Serial.print(",");Serial.print(cur\_abs\_y);Serial.print(",");Serial.print(cur\_abs\_z);Serial.println(")");
Serial.println("-----------------------------------------");
if(++n\_run\_cmd>=amount\_G) \_s=begin\_cmd;
}//switch(\_s)
}
char end\_button(int coord)
{
int but=0;
if(coord==\_X)
but=digitalRead(inPinX);
if(coord==\_Y)
but=digitalRead(inPinY);
if(but){
if(coord==\_X)
Serial.println("[ X out of range ]");
if(coord==\_Y)
Serial.println("[ Y out of range ]");
}
return but;
}
char impstep(int coord,int kol,int f\_test\_coord)
{
int IN\_en,IN\_dir,IN\_step,pause;
pause=2; //35
switch(coord){
case \_X: IN\_en=x\_en; IN\_dir=x\_dir; IN\_step=x\_step;
digitalWrite(IN\_en, 0);
break;
case \_Y: IN\_en=y\_en; IN\_dir=y\_dir; IN\_step=y\_step;
digitalWrite(IN\_en, 0);
break;
}
if(!f\_test\_coord)
Serial.println("[ break step ]");
//delay(100);
if (kol<0)
for (int i=0; i<=abs(kol); i++){
if(f\_test\_coord&&end\_button(coord)){
impstep(coord,200,0);
return 0;
}
digitalWrite(IN\_dir, LOW);
digitalWrite(IN\_step, HIGH);
delay(pause);
digitalWrite(IN\_step, LOW);
delay(pause);
}else
for (int i=0; i <= kol; i++){
if(f\_test\_coord&&end\_button(coord)){
impstep(coord,200,0);
return 0;
}
digitalWrite(IN\_dir, HIGH);
digitalWrite(IN\_step, HIGH);
delay(pause);
digitalWrite(IN\_step, LOW);
delay(pause);
}
digitalWrite(IN\_en, 1);
return 1;
}
void UNIimpstep(int IN1,int IN2,int IN3,int IN4,int pause,int kol)
{
//delay(100);
if (kol<0)
for (int i=0; i<=abs(kol); i++){
digitalWrite(IN1, 0);
digitalWrite(IN2, 1);
digitalWrite(IN3, 0);
digitalWrite(IN4, 0);
delay(pause);
digitalWrite(IN1, 1);
digitalWrite(IN2, 0);
digitalWrite(IN3, 0);
digitalWrite(IN4, 0);
delay(pause);
digitalWrite(IN1, 0);
digitalWrite(IN2, 0);
digitalWrite(IN3, 0);
digitalWrite(IN4, 1);
delay(pause);
digitalWrite(IN1, 0);
digitalWrite(IN2, 0);
digitalWrite(IN3, 1);
digitalWrite(IN4, 0);
delay(pause);
}
else
for (int i=0; i <= kol; i++){
digitalWrite(IN1, 1);
digitalWrite(IN2, 0);
digitalWrite(IN3, 0);
digitalWrite(IN4, 0);
delay(pause);
digitalWrite(IN1, 0);
digitalWrite(IN2, 1);
digitalWrite(IN3, 0);
digitalWrite(IN4, 0);
delay(pause);
digitalWrite(IN1, 0);
digitalWrite(IN2, 0);
digitalWrite(IN3, 1);
digitalWrite(IN4, 0);
delay(pause);
digitalWrite(IN1, 0);
digitalWrite(IN2, 0);
digitalWrite(IN3, 0);
digitalWrite(IN4, 1);
delay(pause);
}
}
```
Завершается конечный автомат конструкцией case run\_cmd: где собственно и подается управляющий сигнал на двигатель. Управлением двигателем можно было бы использовать библиотеку #include но мы написали свою функцию(char impstep -для биполярного двигателя, void UNIimpstep — униполярного ), что бы можно было не ждать пока один двигатель отработает, что бы послать сигнал другому. Ну и на будущее, отдельная процедура позволит гибче использовать возможностями шагового двигателя. Например, если будем использовать другой драйвер двигателя программно задавать полушаг или шаг двигателя. В нынешнем исполнении с RAMPS получается 1/16 шага. Если кому интересно, про управление шаговыми двигателями можно отдельную статью часами писать.
Теперь немного о железе.

Двигатели использовали 17HS8401, самые мощные из NEMA17, которые смогли на ebay найти. Там же купили подшипники и оптические концевики.

Все остальное отечественное, родное. Оригинальная идея с направляющими, сделали их из длинных хромированных ручек для мебели, они как раз диаметром 12 мм под подшипники, длиной они продаются до метра, и прочности вполне хватает. В торцах ручек просверлили отверстия и метчиком нарезали резьбу. Это позволило просто болтом надежно соединить направляющие с несущим конструктивом. Для оси Z так вообще ручку прикрепили к пластине конструктива целиком, Вал продается в любом строительном магазине как шпилька с резьбой любого диаметра. Мы использовали на 8 мм. Соответственно и гайки 8 мм. Гайку с подшипником и несущим конструктивом оси Y соединили с помощью соединительной скобы. Скобы купили в специализированном магазине для витрин. Видели наверно такие хромированные конструкции в магазинах стоят на которых галстуки или рубашки висят, вот там используются такие скобы для соединения хромированных трубок. Двигатель соединили с валом муфтой, которую сделали из куска стального прута диаметром 14мм, просверлив по центру отверстие и пару отверстий сбоку, для зажимания винтами. Можно не заморачиваться и купить готовые на ebay по запросу cnc coupling их куча выпадает. Несущий конструктив нам вырубили на гильотине за 1000 р. Сборка всего этого заняло не много времени и получили на выходе вот такой станок, на фото еще не установлены концевики, контроллер и не установлен двигатель фрезы.

Точность получилась просто изумительная, во-первых шаговый двигатель шагает 1/16 шага, во-вторых вал с мелкой резьбой. Когда в станок вставили ручку вместо фрезы, он нарисовал сложную фигуру, потом еще несколько раз обвел эту фигуру, а на рисунке видно как будто он один раз рисовал, под лупой рассматривали пытались другую линию найти. Жесткость станка тоже хорошая. Шатается только в пошипниках в допустимых пределах их собственого допуска и посадки. Немного шатается еще по оси Y, ну здесь я думаю конструктив оси Z надо доработать.
Фото получилось не качественное, на заднем плане стекло отражает. Не знаю какой я конструктор станка, но фотограф я просто никакой. Вот чуть получше.

Теперь об управляющей программе. Не помню почему, но мы решили сделать свою программу, которая готовый G-код с компьютера передает в контроллер. Может просто не нашли подходящий.
Программа написана на Microsoft Visual C++, использовалась библиотеки:
Module: SERIALPORT.H
Purpose: Declaration for an MFC wrapper class for serial ports
Copyright 1999 by PJ Naughter. All rights reserved.
Программа еще сырая, ну в двух словах используем
```
port.Open(8, 9600, CSerialPort::NoParity, 8, CSerialPort::OneStopBit, CSerialPort::XonXoffFlowControl);
для открытия порта
port.Write(text, l); - запись в порт
port.Read(sRxBuf, LEN_BUF); - чтение порта.
```
Использовался еще стандартный компонент msflexgrid таблица, в которую в реальном времени заносится выполняемый в настоящий момент G-код. Т.е. эта программа просто открывает готовый G-код и маленькими порциями запихивает его в контроллер.
Исходный код управляющей программы можно посмотреть здесь [github.com/konstantin1970/cnc.git](https://github.com/konstantin1970/cnc.git)
Для понимания добавлю еще, что стандартный windows hyperterminal или putty делает то-же самое, запихивает данные в контроллер.
Сам G-код можно сделать в любой CAD/CAM системе например, мне понравился ARTCAM.
В планах у нас сделать более мощный станок на двигателях NEMA 23, но для этого нужно придумать, из чего делать более мощные направляющие. В прошивке контроллера добавить возможность изменять скорость вращения шпинделя. Особенно интересно нам установить камеру и сделать что-то подобное системе технического зрения, что бы станок сам определял размеры заготовки, вычислял начальную координату заготовки по всем осям в программе минимум. В программе максимум, чтобы с помощью камеры станок контролировал все этапы своей работы, возможно даже принимал решения изменить программу. Ну, например, увидел он, что шероховатость больше допустимого, взял и послал фрезу по второму кругу все отшлифовать с более высокой скоростью.
Надеюсь, сможем и в дальнейшем делиться своими разработками с вами уважаемые хаброчитатели. | https://habr.com/ru/post/250385/ | null | ru | null |
# Asychronous Flow Kit — Objective-C тулкит для асинхронных операций
Всем привет.
Это моя первая публикация на Хабре, я взволнован и вообще; и в качестве дебюта хочу представить вам свой пет-проект.
> Краткая предыстория: я давно программирую на C++, C и Obj-C, и всегда хотел иметь под рукой какую-нибудь тулу, чтоб свободно и непринужденно заниматься асинхронным программингом. Помню, когда-то строил я некую аппликашку для OS X. По ходу пьесы мне потребовалось проводить поэтапную обработку потока данных - берем пакет данных, обрабатываем на первом этапе, передаем на второй, а пока что хватаем следующий пакет, пропускаем через первый этап и так далее. Я, разумеется, ухватился в первую очередь за семейство NSOperation, но оно оказалось немного не очень универсальным. А хотелось универсальности, чтоб разные типы данных и много этапов, и чтоб *загружались все наличные ядра*, и чтоб интерфейс был простенький - пришел, бросил кучу данных, подождал, цапнул результат, ушел. Ну ладно, подумал я, пойду подергаю семейство функций dispatch-async из GCD, тем более что NSOperation просто служит им оберткой. Но и там не нашел я удовлетворенья своим хотеньям. Ну что, придется строить велосипед - подумал я и с этого все нача...
>
>
Так я пришел к пакету ASFK (Asynchronous Flow Control Kit). Это программный пакет на Obj-C, который реализует известные мне паттерны асинхронного поведения. Ну не все конечно, но надо ставить себе цели высокие и далекие.
Начать решил с двух вещей, которые понадобились мне в ходе разработки других проектов.
Намбер 1: Конвейер (Pipeline)
-----------------------------
Идея здесь простая: есть набор данных, которые необходимо прогнать через несколько этапов обработки. Критически важно чтобы каждый кусок данных прошел через все этапы в в четко определенном порядке; крайне важно, чтобы каждый этап принимал на входе результаты предыдущего этапа и передавал свой результат следующему; и очень важно чтоб они проходили через этапы в FIFO-порядке. Попутно хотелось, чтобы все этапы могли выполняться параллельно, то есть каждый на своем процессоре. И еще очень хотелось иметь возможность их останавливать и паузить.
> Иллюстрация: представим себе, что мы хотим прочитать из файла длинную строку; поменять в ней все буквы '`а'` на '`б'`; затем все буквы '`б'` заменить на пробелы; затем вычислить для этой строки контрольную сумму; и, наконец, забросить ее в другой файл; вернуться в начало и повторить все операции над следующей строкой. Очевидно, что на каждом этапе работы над строкой можно параллельно работать над следующей.
>
>
Для этого существует обьект Pipeline которые все эти услуги предоставляет.
Работает он следующим образом: сначала создаем пайплайн:
`ASFKPipelinePar* pipeline0=[[ASFKPipelinePar alloc]initWithName:@"Pipeline0"];`
впихиваем в него блоки кода, которые будут обрабатывать наши данные;
`[pipeline0 addRoutine: ^id(id controlBlock, id data) {`
`//Do whatever you need`
`return nil;`
`}];`
Задаем финальный блок который соберет все результаты воедино:
`[pipeline0 setSummary:^id(id controlBlock,NSDictionary\* stats, id data) {`
`NSLog(@“We done !!”);`
`return nil;`
`}];`
Создаем сессию, которая будет использовать это блоки:
`[pipeline0 createSession:nil sessionId:@“session1”];`
затем, кидаем в нее набор данных
`[pipeline0 castArray:@[@(1),@(2),@(3)] session:@“session1” exParam:nil]`
и забываем про них до тех пор, пока все не пройдут обработку.
Как оно устроено внутре?
------------------------
Внутре основной единицей исполнения является сессия. Это объект который содержит копии процедур и очереди с данными. Сессий может быть неограниченное количество.
Планировщик умеет циклически вызывать каждую сессию и заставить ее выполнить очередную процедуру.
Сессии организуются внутри контейнера, который и называется конвеер (pipeline). Возможное количество конвейеров неограничено. Есть и нюансы: например, сессии могут быть постоянными и временными. Постоянные сессии живут до тех пор пока их не прибьют, и в них можно постоянно добавлять новые порции данных; временные самоуничтожаются после прогона одного набора. Также сессию можно отменить, можно ставить на паузу и снимать с паузы, следить за прогрессом исполнения.
Сложностей здесь было порядочно. Требовалось создать механизм, который бы умел распихать исполнение сессий по процессорам более-менее равномерно, чтобы они все выполнялись, в конце концов. Дополнительная сложность была в создании механизма для отмены сессий и паузы/продолжения; и необходимо было добиться правильного порядка выполнения, несмотря на то, что разные этапы могли выполняться на разных процессорах независимо друг от друга.
В самом начале работы я еще точно не знал, что получится, но некоторые ключевые моменты были ясны: хотелось более менее логичный и несложный API; и хотелось заставить работать все наличные процессоры. Насколько этих целей удалось добиться? Более-менее удалось, я считаю.
> Еще две фичи (в разработке): конкурентный мап и композиция. Композиция работает подобно пайплайну: создаем объект композиции, создаем сессию, бросаем в нее данные и ждем результатов. Результат будет состоять из последовательного применения функций к каждому объекту данных. Но при этом все каждый объект данных может проходить через композицию параллельно с другими. Здесь гарантируется, что функции будут применены в строго определенном порядке. То есть, если есть данные d1, d2 ... dn и функции f1, f2…fm, то мы увидим параллельное исполнение такое: fm(… f2(f1(d1))) | fm(….(f2(f1(d2))))... . Мап работает схожим образом, но с нюансом: каждый объект данных проходит параллельно через все наличные функции. Порядок выполнения функций неопределен. А здесь параллельное исполнение примет другой вид: f1(d1) | f2(d1) ... | fm(d1) ; f1(d2) | f2(d2) ... | fm(d2) итд;
>
>
Планы на будущее - продолжить тщательное тестирование, добавить некоторые новые фичи и паттерны использования.
Второй паттерн: Mailbox
-----------------------
Собственно, это альтернатива механизму нотификаций в OS X. Я некоторое время мучился с ними, закрывая глаза на которые недостатки, как-то: необходимость подписываться на конкретный тип сообщения, невозможность доставки сообщения в те уголки, которые вне eventloop-а итп. Но в конце концов я осознал что с закрытыми глазами работать неудобно и принялся проектировать альтернативу...
В поисках более сложного удовольствия я пришел к почтовому ящику. Идея прозрачна: юзер получает FIFO контейнер, куда любой другой юзер может кидать сообщения, а владелец будет их читать. Это главный принцип. Кроме того можно создать групповые ящики - владелец один, но он позволяет посторонним читать сообщения.
Здесь я тоже хотел выжать максимум. Поэтому загрузился несколькими целями: несложный и понятный API; богатый функционал, закрывающий как можно больше возможных сценариев использования; Еще одна сложность заключалась в моем нежелании жестко ограничивать количество контейнеров и сообщений, не заставляя при этом операционную систему давиться. Но при этом использовать наличные вычислительные мощности как можно полнее. Еще важным соображением было чтоб API как можно меньше тормозил систему. Из-за этого пришлось много работы перевести в асинхронный режим.
Звучит амбициозно, знаю.
Вырулилось примерно следующее: во-первых, сообщения могут быть посланы как асинхронно, так и синхронно - в первом случае, сообщение отправляется, пославший тред продолжает работу; во-втором случае, посылающий тред останавливается до тех пор, пока сообщение не прочтут. Есть и обратная возможность - читающий тред может заснуть, пока не придет сообщение.
Во-вторых есть возможность фильтрования сообщений и установления верхнего/нижнего порога для размера очереди - если очередь достигла максимума, то новые сообщения могут заменить старые или быть отвергнутыми. А если размер меньше нижнего порога, то из такой очереди нельзя будет читать, пока не будет достигнут минимум. Кроме того, сообщения могут самоуничтожаться, если их хорошо об этом попросить.
В-третьих, есть система токенов. Мне хотелось создать систему авторизации, которая бы позволяла выполнять операции только тем пользователям, которые заработали на это право. Мне не хотелось для каждой операции создавать список разрешенных пользователей (есть и другие способы конечно), поэтому я решил использовать систему токенов.
Токены характеризуются 2 параметрами: Приватный/Групповой/Мастер; и ролями - например, чтение, запись, бродкаст итп.
И если система сконфигурирована на использование токенов, то операции требуют в качестве параметра правильный токен.
Как ни странно, с токенами я заморочился тоже. Токены одноразовые - они могут потерять валидность через заданный промежуток времени, или через заданной количество использований. Впрочем, другие условия для инвалидации тоже могут быть определены. А потеряв валидность, они становятся бесполезными, ибо восстановить ее невозможно.
Сами контейнеры тоже непростые. Они могут существовать заданное время, а потом самоуничтожаться. Или уничтожать все сообщения, которые живут слишком долго. Или выбрасывать юзеров, по истечении определенного времени.
Вот например как выглядит базовый API
`ASFKMailbox* mail=[ASFKMailbox sharedManager];`
`//Создаем групповой ящик (просто для примера)`
`id gr0=[ mail createGroup:@“group1” withProperties:nil secret:nil];`
`//Создаем персональный ящик (просто для примера)`
`[mail createMailbox:@“user1” secret:nil withProperties:nil];`
`//Забрасываем сообщение в групповой ящик.`
`id msgid=[mail cast:@“msg1” forGroup:@“group1” withProperties:nil secret:nil];`
`//Добавляем пользователя в группу; он ею не владеет, но может писать и читать сообщения.`
`[mail addUser:@“user1" toGroup:@“group1" withProperties:nil secret:nil]`
`//Забрасываем сообщение в персональный ящик.`
`[mail cast:@“msg2” forMailbox:@“user1” withProperties:nil secret:nil];`
`//Тут мы читаем 2 самых свежих сообщения, пропуская самое первое (нумерация с нуля). Результатом должен быть пустой массив:`
`NSArray* a0=[mail readLatestMsg:NSMakeRange(1, 2) fromMailbox:@“user1” withSecret:nil];`
`NSArray* a1=[mail readLatestMsg:NSMakeRange(1, 2) fromGroup:@“group1” forUser:@“user1” withSecret:nil];`
А какие еще фичи есть?
Вообще-то много.
Из ключевых я бы отметил: бродкаст и мультикаст; блокирующий постинг и блокирующее чтение; самоуничтожение контейнеров и сообщений.
И еще управление размером очередей. Бывает так что нужно следить чтоб очередь не раздувалась. Для этого я определил для очереди верхний и нижний предел: если нижний предел выставлен, то из очереди нельзя читать, пока не наберется минимум сообщений. С верхним пределом немного сложнее. Понятно, что если размер очереди достиг максимума, то его нельзя увеличивать. Но что делать с приходящими сообщениями? в общем, я реализовал несколько стратегий решения этой проблемы. Теперь можно либо отбрасывать приходящие сообщения; либо выбрасывать самое последнее и вставлять вместо него новое; или же выбрасывать самое старое из начала и добавлять новое в конец. А можно просто определить собственный алгоритм для регуляции размера.
В планах также операции над множествами - например разослать сообщения юзерам состоящим одновременно в 2 группах или состоящим в одной, но не в другой; модерация контейнеров - например, запретить конкретному юзеру читать или писать сообщения.
Планируются также отложенные сообщения и отмена посланных сообщений; думаю добавить какую-нибудь обратную связь, чтобы регулировать нагрузку со стороны посылки.
Ну и конечно надо продолжить тестирование.
#3
--
Еще одна вещь, которой я уделил меньше внимания статье - FIFO очереди.
Их несколько видов, некоторые позволяют фильтрацию, ограничение по размерам и еще кое-что.
[С кодом можно ознакомиться здесь](https://github.com/pewsou/asyncflow-objc).
Конечно, можно спросить: а на кой надо было так заморачиваться? Ну, мне было интересно выжать из идеи максимум. Так чтобы в конце концов прийти к состоянию, когда уже ни убавить, ни прибавить. Похоже, что я все еще не там. Но останавливаться не собираюсь.
Что еще следует добавить?
Есть много идей, но всему свое время. Например, в планах сделать портинг на С++. Здесь правда неясно, насколько это может быть востребовано.
А что бы вы предложили?
Стоит портировать на C++? | https://habr.com/ru/post/690484/ | null | ru | null |
# Пример создания утилиты для Unigraphics NX с помощью библиотеки NXOpen на языке Java
Решил рассказать, кому интересно, как можно создавать любые утилиты для Unigraphics NX с помощью библиотеки NXOpen и языка программирования Java.В качестве примера моя утилита будет строить 2d сетку на все свободных телах и гранях(это может быть полезно для задачи оптимизации).
Необходимую информацию по библиотеке NXOpen можно найти на [официальном сайте](https://docs.plm.automation.siemens.com/data_services/resources/nx/10/nx_api/en_US/custom/open_java_ref/index.html).
В корневой папки NX лежат необходимые нам библиотеки по умолчанию, а так же примеры:
* C:\Program Files\Siemens\NX 12.0\NXBIN с расширением jar
* C:\Program Files\Siemens\NX 12.0\UGOPEN с расширением jar
* C:\Program Files\Siemens\NX 12.0\UGOPEN\SampleNXOpenApplications\Java.
Для упрощения написания кода можно за основу использовать журнал записи своих действий в текстовый файл.По умолчанию Unigraphics NX записывает на языке Visual Basic, но в настройках можно поменять на Java или на любой другой из списка доступных:
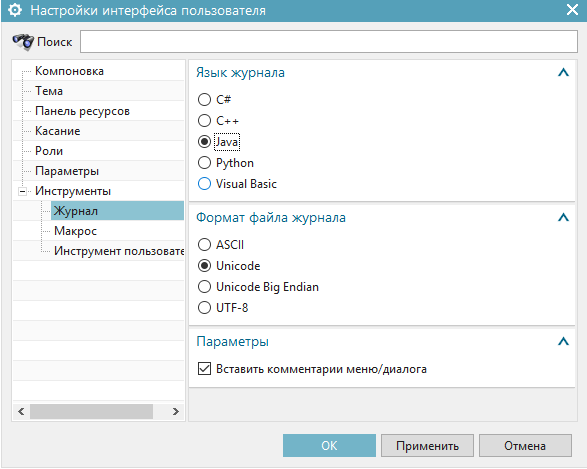
Вот пример записи журнала в текстовый файл.
**Листинг кода**
```
// NX 12.0.1.7
// Journal created by Aleksandr on Sun Nov 3 19:49:32 2019 RTZ 2 (зима)
//
import nxopen.*;
public class journalTT
{
public static void main(String [] args) throws NXException, java.rmi.RemoteException
{
nxopen.Session theSession = (nxopen.Session)nxopen.SessionFactory.get("Session");
nxopen.cae.FemPart workFemPart = ((nxopen.cae.FemPart)theSession.parts().baseWork());
nxopen.cae.FemPart displayFemPart = ((nxopen.cae.FemPart)theSession.parts().baseDisplay());
// ----------------------------------------------
// Меню: Вставить->Сетка->2D сетка...
// ----------------------------------------------
int markId1;
markId1 = theSession.setUndoMark(nxopen.Session.MarkVisibility.VISIBLE, "Начало");
nxopen.cae.FEModel fEModel1 = ((nxopen.cae.FEModel)workFemPart.findObject("FEModel"));
nxopen.cae.MeshManager meshManager1 = ((nxopen.cae.MeshManager)fEModel1.find("MeshManager"));
nxopen.cae.Mesh2d nullNXOpen_CAE_Mesh2d = null;
nxopen.cae.Mesh2dBuilder mesh2dBuilder1;
mesh2dBuilder1 = meshManager1.createMesh2dBuilder(nullNXOpen_CAE_Mesh2d);
nxopen.cae.MeshCollector nullNXOpen_CAE_MeshCollector = null;
mesh2dBuilder1.elementType().destinationCollector().setElementContainer(nullNXOpen_CAE_MeshCollector);
mesh2dBuilder1.elementType().setElementTypeName("CQUAD4");
nxopen.Unit unit1 = ((nxopen.Unit)workFemPart.unitCollection().findObject("MilliMeter"));
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("quad mesh overall edge size", "10", unit1);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("target minimum element edge length", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("surface curvature threshold", "5.05", unit1);
nxopen.Unit nullNXOpen_Unit = null;
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("small feature value", "1", nullNXOpen_Unit);
theSession.setUndoMarkName(markId1, "Диалоговое окно 2D сетка");
nxopen.DisplayableObject [] objects1 = new nxopen.DisplayableObject[1];
nxopen.cae.CAEBody cAEBody1 = ((nxopen.cae.CAEBody)workFemPart.findObject("CAE_Body(14)"));
nxopen.cae.CAEFace cAEFace1 = ((nxopen.cae.CAEFace)cAEBody1.findObject("CAE_Face(14)"));
objects1[0] = cAEFace1;
boolean added1;
added1 = mesh2dBuilder1.selectionList().add(objects1);
nxopen.DisplayableObject [] objects2 = new nxopen.DisplayableObject[1];
nxopen.cae.CAEBody cAEBody2 = ((nxopen.cae.CAEBody)workFemPart.findObject("CAE_Body(3)"));
nxopen.cae.CAEFace cAEFace2 = ((nxopen.cae.CAEFace)cAEBody2.findObject("CAE_Face(3)"));
objects2[0] = cAEFace2;
boolean added2;
added2 = mesh2dBuilder1.selectionList().add(objects2);
nxopen.DisplayableObject [] objects3 = new nxopen.DisplayableObject[1];
nxopen.cae.CAEBody cAEBody3 = ((nxopen.cae.CAEBody)workFemPart.findObject("CAE_Body(2)"));
nxopen.cae.CAEFace cAEFace3 = ((nxopen.cae.CAEFace)cAEBody3.findObject("CAE_Face(2)"));
objects3[0] = cAEFace3;
boolean added3;
added3 = mesh2dBuilder1.selectionList().add(objects3);
nxopen.DisplayableObject [] objects4 = new nxopen.DisplayableObject[1];
nxopen.cae.CAEBody cAEBody4 = ((nxopen.cae.CAEBody)workFemPart.findObject("CAE_Body(1)"));
nxopen.cae.CAEFace cAEFace4 = ((nxopen.cae.CAEFace)cAEBody4.findObject("CAE_Face(1)"));
objects4[0] = cAEFace4;
boolean added4;
added4 = mesh2dBuilder1.selectionList().add(objects4);
int markId2;
markId2 = theSession.setUndoMark(nxopen.Session.MarkVisibility.INVISIBLE, "2D сетка");
theSession.deleteUndoMark(markId2, null);
int markId3;
markId3 = theSession.setUndoMark(nxopen.Session.MarkVisibility.INVISIBLE, "2D сетка");
mesh2dBuilder1.setAutoResetOption(false);
mesh2dBuilder1.elementType().setElementDimension(nxopen.cae.ElementTypeBuilder.ElementType.SHELL);
mesh2dBuilder1.elementType().setElementTypeName("CQUAD4");
nxopen.cae.DestinationCollectorBuilder destinationCollectorBuilder1;
destinationCollectorBuilder1 = mesh2dBuilder1.elementType().destinationCollector();
destinationCollectorBuilder1.setElementContainer(nullNXOpen_CAE_MeshCollector);
destinationCollectorBuilder1.setAutomaticMode(true);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("meshing method", 0);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("quad mesh overall edge size", "10", unit1);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("block decomposition option bool", false);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("mapped mesh option bool", false);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("fillet num elements", 3);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("num elements on cylinder circumference", 6);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("element size on cylinder height", "1", unit1);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("quad only option", 0);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("mesh individual faces option bool", false);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("midnodes", 0);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("geometry tolerance option bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("geometry tolerance", "0", unit1);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("target maximum element edge length bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("maximum element edge length", "1", unit1);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("target minimum element edge length", false);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("split poor quads bool", false);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("move nodes off geometry bool", false);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("max quad warp option bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("max quad warp", "5", nullNXOpen_Unit);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("max jacobian", "5", nullNXOpen_Unit);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("target element skew bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("element skew", "30", nullNXOpen_Unit);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("max included angle quad option bool", false);
nxopen.Unit unit2 = ((nxopen.Unit)workFemPart.unitCollection().findObject("Degrees"));
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("max included angle quad", "150", unit2);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("min included angle quad option bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("min included angle quad", "30", unit2);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("max included angle tria option bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("max included angle tria", "150", unit2);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("min included angle tria option bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("min included angle tria", "30", unit2);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("mesh transition bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("mesh size variation", "50", nullNXOpen_Unit);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("surface curvature threshold", "5.05", unit1);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("alternate feature abstraction bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("minimum feature element size", "0.001", unit1);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("small feature tolerance", "10", nullNXOpen_Unit);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("small feature value", "1", nullNXOpen_Unit);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("suppress hole option bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("hole diameter tolerance", "0", unit1);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("hole suppresion point type", 0);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("merge edge toggle bool", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("edge angle", "15", unit2);
mesh2dBuilder1.propertyTable().setBooleanPropertyValue("quad mesh edge match toggle", false);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("quad mesh edge match tolerance", "0.02", unit1);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("quad mesh smoothness tolerance", "0.01", unit1);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("quad mesh surface match tolerance", "0.001", unit1);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("quad mesh transitional rows", 3);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("min face angle", "20", unit2);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("mesh time stamp", 0);
mesh2dBuilder1.propertyTable().setBaseScalarWithDataPropertyValue("quad mesh node coincidence tolerance", "0.0001", unit1);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("mesh edit allowed", 0);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("transition edge seeding", 0);
mesh2dBuilder1.propertyTable().setIntegerPropertyValue("cylinder curved end num elements", 6);
int id1;
id1 = theSession.newestVisibleUndoMark();
int nErrs1;
nErrs1 = theSession.updateManager().doUpdate(id1);
nxopen.cae.Mesh [] meshes1 ;
meshes1 = mesh2dBuilder1.commitMesh();
theSession.deleteUndoMark(markId3, null);
theSession.setUndoMarkName(id1, "2D сетка");
mesh2dBuilder1.destroy();
// ----------------------------------------------
// Меню: Инструменты->Повторить команду->3 Остановка записи журнала
// ----------------------------------------------
// ----------------------------------------------
// Меню: Инструменты->Журнал->Остановка записи
// ----------------------------------------------
}
public static final int getUnloadOption() { return nxopen.BaseSession.LibraryUnloadOption.IMMEDIATELY; }
}
}
```
Сейчас он строит сетку только на тех поверхностях, которые указаны в коде, а если их меньше или больше будет, а также отличатся будут их названия, то nx выдаст ошибку при запуске нашего кода. Поэтому нам нужно доработать код добавив в него исключения try/catch и придумать способ, чтобы мы не привязывались к количеству полигональных граней.
Я сделал это так:
```
try {
for (int i = 1; i < 20; i++) {
obj="object"+i;
cAEB="cAEBody"+i;
cAEF="cAEFace"+i;
adde="added"+i;
//Object objects = new Object();
nxopen.DisplayableObject [] obj = new nxopen.DisplayableObject[1];
nxopen.cae.CAEBody cAEB = ((nxopen.cae.CAEBody)workFemPart.findObject(("CAE_Body"+"("+i+")")));
nxopen.cae.CAEFace cAEF = ((nxopen.cae.CAEFace)cAEB.findObject("CAE_Face"+"("+i+")"));
obj[0] = cAEF;
boolean adde;
adde = mesh2dBuilder1.selectionList().add(obj);
}
} catch (Exception ex) {
```
Вот конечный результат исполненный в программе:
 | https://habr.com/ru/post/518330/ | null | ru | null |
# Делаем свой friGate с анонимностью и без рекламы
**Введение**
Всем хороши плагины для обхода блокировок вроде популярного friGate, но есть у них один минус — любят встраивать свою [рекламу](https://net.dirty.ru/plagin-frigate-zagruzhaet-vam-reklamu-nezametno-dlia-vas-577981/) и в перспективе следить за всем, что вы делаете в интернете.
VPN имеет свои недостатки: либо весь трафик будет ходить через удаленный сервер, либо нужно будет настраивать сложные правила роутинга.
Ssh-туннель на постоянно засыпающем и просыпающемся ноутбуке приходится каждый раз перезапускать.
Есть решения вроде autossh, но настоящего перфекциониста они не удовлетворят.
Попробуем добиться удобства, аналогичного friGate с использованием сервисов, находящихся полностью под нашим контролем.
Нам понадобятся: выделенный сервер с Linux/FreeBSD (я использовал Ubuntu), домен, letsencrypt, squid и немного магии PAC-файлов.
Домен можно взять бесплатный 3-го уровня от вашего хостера или тут: [freedomain.co.nr](http://www.freedomain.co.nr), [registry.cu.cc](http://www.registry.cu.cc).
Squid поддерживает [шифрованое соединение с браузером](http://wiki.squid-cache.org/Features/HTTPS#Encrypted_browser-Squid_connection) — именно то, что нужно для такого случая.
Эта возможность почему-то практически неизвестна широкой публике, поэтому появился этот пост.

**Установка Squid с поддержкой SSL**
В Ubuntu squid собран без поддержки нужных нам ключей (--enable-ssl)
Если у вас другой дистрибутив и с этим всё хорошо (проверить можно запуском команды squid3 -v | grep -E --color "(ssl|tls)" ) — сразу переходите к следующему пункту.
А мы соберем для Ubuntu свой собственный пакет (использована [эта](https://www.howtoforge.com/filtering-https-traffic-with-squid) инструкция):
```
sudo apt-get install devscripts build-essential fakeroot libssl-dev
apt-get source squid3
sudo apt-get build-dep squid3
```
применяем следующие патчи:
```
--- squid3-3.3.8/debian/rules 2013-11-15 11:49:59.052362467 +0100
+++ squid3-3.3.8/debian/rules.new 2013-11-15 11:49:35.412362836 +0100
@@ -19,6 +19,8 @@
DEB_CONFIGURE_EXTRA_FLAGS := --datadir=/usr/share/squid3 \
--sysconfdir=/etc/squid3 \
--mandir=/usr/share/man \
+ --enable-ssl \
+ --enable-ssl-crtd \
--enable-inline \
--enable-async-io=8 \
--enable-storeio="ufs,aufs,diskd,rock" \
```
**eng**One file in source code of Squid Proxy needs to be adjusted too (src/ssl/gadgets.cc). This change is needed to prevent Firefox error sec\_error\_inadequate\_key\_usage that usually occurs when doing HTTPS filtering with latest Firefox browsers. If you use only Google Chrome, Microsoft Internet Explorer or Apple Safari this step is not required.
```
--- squid3-3.3.8/src/ssl/gadgets.cc 2013-07-13 09:25:14.000000000 -0400
+++ squid3-3.3.8/src/ssl/gadgets.cc.new 2013-11-26 03:25:25.461794704 -0500
@@ -257,7 +257,7 @@
mimicExtensions(Ssl::X509_Pointer & cert, Ssl::X509_Pointer const & mimicCert)
{
static int extensions[]= {
- NID_key_usage,
+ //NID_key_usage,
NID_ext_key_usage,
NID_basic_constraints,
0
```
Собираем и устанавливаем:
```
cd squid3-3.3.8 && dpkg-buildpackage -rfakeroot -b
sudo apt-get install squid-langpack
sudo dpkg -i ../squid-common*.deb ../squid_*.deb
```
**Обретение подписанного сертификата с помощью сервиса [letsencrypt.org](https://letsencrypt.org/)**
Скачиваем скрипты:
```
git clone https://github.com/letsencrypt/letsencrypt
cd letsencrypt
./letsencrypt-auto --help
```
Если у вас уже запущен вебсервер — останавливаем его, т.к. скрипт letsencrypt запустит свой.
В случае сурового продакшна можно верифицировать контроль над доменом без остановки вебсервера, смотрите [документацию](https://letsencrypt.org/getting-started/).
Получаем сертификат:
```
./letsencrypt-auto --authenticator standalone --installer apache -d <наш_домен.ру>
```
В случае успеха pem-файлы можно будет найти в каталоге /etc/letsencrypt/live/<наш домен>/
**Настройка Squid**
Конфиг — дефолтный, добавляем только опцию https\_port
`https_port 3129 cert=/etc/letsencrypt/live/example.com/fullchain.pem key=/etc/letsencrypt/live/example.com/privkey.pem`
По желанию — acl для доступа только с определенных ip или [по паролю](https://moonback.ru/page/squid_ncsa).
Например
`acl mynet src <ваш_внешний_ip>/32
http_access allow mynet`
Запускаем squid
```
sudo /etc/init.d/squid3 start
```
**Учим браузер шифрованным соединениям с прокси**
Как [указано в документации Squid](http://wiki.squid-cache.org/Features/HTTPS#Encrypted_browser-Squid_connection), настроить https-соединение с прокси-сервером в Firefox и Chrome с недавних пор можно, но только с использованием PAC-файла.
> The Chrome browser is able to connect to proxies over SSL connections if configured to use one in a PAC file or command line switch. GUI configuration appears not to be possible (yet).
>
> …
>
> The Firefox 33.0 browser is able to connect to proxies over SSL connections if configured to use one in a PAC file. GUI configuration appears not to be possible (yet).
>
>
PAC (Proxy Auto Configuration) — это файл, содержащий javascript, исполняемый браузером с целью определить прокси для каждого запроса.
Я использовал следующий код:
```
// encrypted_squid.pac
var hosts = 'myip.ru internet.yandex.ru';
var blocked = hosts.split(' ');
function FindProxyForURL(url, host) {
var shost = host.split('.').reverse();
shost = shost[1] + '.' + shost[0];
for(var i = 0; i < blocked.length; i++)
{
if( shost == blocked[i] ) return "HTTPS <ваш_прокси_FQDN>:3129";
}
return "DIRECT";
}
```
Адреса в списке hosts взяты для теста, разбавьте их нужными вам ;)
Подключаем файл в соответствующем поле настроек браузера ( Preferences -> Advanced -> Network -> Settings ), проверяем как теперь выглядит наш внешний адрес на myip.ru, наслаждаемся стабильной работой.
При этом трафик ходит напрямую на все хосты, кроме указанных в строке hosts.
Этот pac-файл можно положить на веб-сервер, подключать через http и изменения в нём будут автоматически подтягиваться на всех хостах, например, на ноутбуке, десктопе и [даже смартфоне](https://www.topbug.net/blog/2015/03/02/configure-proxy-using-pac-files-on-firefox-for-android/).
Также можно использовать [foxyproxy](https://addons.mozilla.org/en-US/firefox/addon/foxyproxy-standard/) для фильтрации хостов, которые должны работать через прокси в сочетании с более простым PAC-файлом — тогда можно будет править этот список прямо в браузере.
**Заключение**
Топик написан по горячим следам исключительно с целью продемонстрировать концепцию шифрованного туннеля в браузере без использования VPN/ssh/сторонних расширений. | https://habr.com/ru/post/280236/ | null | ru | null |
# Высокопроизводительный NIO-сервер на Netty
##### Преамбула
Здравствуйте. Я являюсь главным разработчиком крупнейшего в СНГ сервера Minecraft (не буду рекламировать, кому надо, те знают). Уже почти год мы пишем свою реализацию сервера, рассчитанную на больше чем 40 человек (мы хотим видеть цифру в 500 хотя бы). Пока всё было удачно, но последнее время система начала упираться в то, что из-за не самой удачной реализации сети (1 поток на ввод, 1 на вывод + 1 на обработку), при 300 игроках онлайн работает более 980 потоков (+ системные), что в сочетании с производительностью дефолтного io Явы даёт огромное падение производительности, и уже при 100 игроках сервер в основном занимается тем, что пишет/читает в/из сети.
Поэтому я решила переходить на NIO. В руки совершенно случайно попала библиотека [Netty](http://www.jboss.org/netty), структура которой показалась просто идеально подходящей для того, чтобы встроить её в уже готовое работающее решение. К сожалению, мануалов по Netty мало не только на русском, но и на английском языках, поэтому приходилось много экспериментировать и лазить в код библиотеки, чтобы найти лучший способ.
Здесь я постараюсь расписать серверную часть работы с сетью через Netty, может быть это кому-то будет полезно.
#### Создание сервера
```
ExecutorService bossExec = new OrderedMemoryAwareThreadPoolExecutor(1, 400000000, 2000000000, 60, TimeUnit.SECONDS);
ExecutorService ioExec = new OrderedMemoryAwareThreadPoolExecutor(4 /* число рабочих потоков */, 400000000, 2000000000, 60, TimeUnit.SECONDS);
ServerBootstrap networkServer = new ServerBootstrap(new NioServerSocketChannelFactory(bossExec, ioExec, 4 /* то же самое число рабочих потоков */));
networkServer.setOption("backlog", 500);
networkServer.setOption("connectTimeoutMillis", 10000);
networkServer.setPipelineFactory(new ServerPipelineFactory());
Channel channel = networkServer.bind(new InetSocketAddress(address, port));
```
Используется *OrderedMemoryAwareThreadPoolExecutor* для выполнения задач Netty, по опыту французских коллег они самые эффективные. Можно использовать другие Executor'ы, например *Executors.newFixedThreadPool(n)*. Ни в коем случае не используйте *Executors.newCachedThreadPool()*, он создаёт неоправданно много потоков и ни какого выигрыша от Netty почти нет. Использовать более 4 рабочих потоков нет смысла, т.к. они более чем справляются с огромной нагрузкой (программисты из Xebia-France на 4 потоках тянули более 100 000 одновременных подключений). Босс-потоки должны быть по одному на каждый слушаемый порт. *Channel*, который возвращает функция bind, а так же *ServerBootsrap* необходимо сохранить, чтобы потом можно было остановить сервер.
#### PipelineFactory
То, как будут обрабатываться подключения и пакеты клиента, определяет *PipelineFactory*, которая при открытии канала с клиентом создаёт для него pipeline, в котором определены обработчики событий, которые происходят на канале. В нашем случае, это *ServerPipelineFactory*:
```
public class ServerPipelineFactory implements ChannelPipelineFactory {
@Override
public ChannelPipeline getPipeline() throws Exception {
PacketFrameDecoder decoder = new PacketFrameDecoder();
PacketFrameEncoder encoder = new PacketFrameEncoder();
return Channels.pipeline(decoder, encoder, new PlayerHandler(decoder, encoder));
}
}
```
В данном коде *PacketFrameDecoder*, *PacketFrameEncoder* и *PlayerHandler* — обработчки событий, которые мы определяем. Функция *Channels.pipeline()* создаёт новый pipeline с переданными ей обработчиками. Будьте внимательны: события проходят обработчики в том порядке, в котором Вы передали из функции pipeline!
#### Протокол
Немного опишу протокол, чтобы дальше было понятно.
Обмен данными происходит с помощью объектов классов, расширяющих класс Packet, в которых определены две функции, *get(ChannelBuffer input)* и *send(ChannelBuffer output)*. Соответственно, первая функция читает необходимые данные из канала, вторая — пишет данные пакета в канал.
```
public abstract class Packet {
public static Packet read(ChannelBuffer buffer) throws IOException {
int id = buffer.readUnsignedShort(); // Получаем ID пришедшего пакета, чтобы определить, каким классом его читать
Packet packet = getPacket(id); // Получаем инстанс пакета с этим ID
if(packet == null)
throw new IOException("Bad packet ID: " + id); // Если произошла ошибка и такого пакета не может быть, генерируем исключение
packet.get(buffer); // Читаем в пакет данные из буфера
return packet;
}
public statuc Packet write(Packet packet, ChannelBuffer buffer) {
buffer.writeChar(packet.getId()); // Отправляем ID пакета
packet.send(buffer); // Отправляем данные пакета
}
// Функции, которые должен реализовать каждый класс пакета
public abstract void get(ChannelBuffer buffer);
public abstract void send(ChannelBuffer buffer);
}
```
Пример пары пакетов для наглядности:
```
// Пакет, которым клиент передаёт серверу свой логин
public class Packet1Login extends Packet {
public String login;
public void get(ChannelBuffer buffer) {
int length = buffer.readShort();
StringBuilder builder = new StringBuilder();
for(int i = 0; i < length ++i)
builder.append(buffer.readChar());
login = builder.toString();
}
public void send(ChannelBuffer buffer) {
// Тело отправки пустое, т.к. сервер не посылает этот пакет
}
}
// Пакет, которым сервер выкидывает клиента с указаной причиной, или клиент отключается от сервера
public class Packet255KickDisconnect extends Packet {
public String reason;
public void get(ChannelBuffer buffer) {
int length = buffer.readShort();
StringBuilder builder = new StringBuilder();
for(int i = 0; i < length ++i)
builder.append(buffer.readChar());
reason = builder.toString();
}
public void send(ChannelBuffer buffer) {
buffer.writeShort(reason.length());
for(int i = 0; i < reason.length(); ++i) {
buffer.writeChar(reason.getCharAt(i));
}
}
}
```
**ChannelBuffer** очень похож на DataInputStream и DataOutputStream в одном лице. Большинство функций если не такие же, то очень похожи. Заметьте, что я не забочусь о проверке того, хватает ли в буфере байт для чтения, как будто я работаю с блокирующим IO. Об этом далее…
#### Работа с клиентом
Работа с клиентом в основном определяется классом *PlayerHandler*:
```
public class PlayerHandler extends SimpleChannelUpstreamHandler {
private PlayerWorkerThread worker;
@Override
public void channelConnected(ChannelHandlerContext ctx, ChannelStateEvent e) throws Exception {
// Событие вызывается при подключении клиента. Я создаю здесь Worker игрока — объект, который занимается обработкой данных игрока непостредственно.
// Я передаю ему канал игрока (функция e.getChannel()), чтобы он мог в него посылать пакеты
worker = new PlayerWorkerThread(this, e.getChannel());
}
@Override
public void channelDisconnected(ChannelHandlerContext ctx, ChannelStateEvent e) throws Exception {
// Событие закрытия канала. Используется в основном, чтобы освободить ресурсы, или выполнить другие действия, которые происходят при отключении пользователя. Если его не обработать, Вы можете и не заметить, что пользователь отключился, если он напрямую не сказал этого серверу, а просто оборвался канал.
worker.disconnectedFromChannel();
}
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) {
// Функция принимает уже готовые Packet'ы от игрока, поэтому их можно сразу посылать в worker. За их формирование отвечает другой обработчик.
if(e.getChannel().isOpen())
worker.acceptPacket((Packet) e.getMessage());
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, ExceptionEvent e) {
// На канале произошло исключение. Выводим ошибку, закрываем канал.
Server.logger.log(Level.WARNING, "Exception from downstream", e.getCause());
ctx.getChannel().close();
}
}
```
Worker может посылать игроку данные просто функцией channel.write(packet), где channel — канал игрока, который передаётся ему при подключении, а packet — объект класса Packet. За кодирование пакетов будет отвечать уже Encoder.
#### Decoder и Encoder
Собственно, сама важная часть системы — они отвечают за формирование пакетов Packet из потока пользователя и за отправку таких же пакетов в поток.
Encoder очень прост, он отправляет пакеты игроку:
```
public class PacketFrameEncoder extends OneToOneEncoder {
@Override
protected Object encode(ChannelHandlerContext channelhandlercontext, Channel channel, Object obj) throws Exception {
if(!(obj instanceof Packet))
return obj; // Если это не пакет, то просто пропускаем его дальше
Packet p = (Packet) obj;
ChannelBuffer buffer = ChannelBuffers.dynamicBuffer(); // Создаём динамический буфер для записи в него данных из пакета. Если Вы точно знаете длину пакета, Вам не обязательно использовать динамический буфер — ChannelBuffers предоставляет и буферы фиксированной длинны, они могут быть эффективнее.
Packet.write(p, buffer); // Пишем пакет в буфер
return buffer; // Возвращаем буфер, который и будет записан в канал
}
}
```
Decoder уже гораздо сложнее. Дело в том, что в буфере, пришедшем от клиента, может просто не оказаться достаточного количества байт для чтения всего пакета. В этом случае, нам поможет класс ReplayingDecoder. Нам всего лишь нужно реализовать его функцию decode и читать в ней данные из потока, не заботясь не о чём:
```
public class PacketFrameDecoder extends ReplayingDecoder {
@Override
public void channelClosed(ChannelHandlerContext ctx, ChannelStateEvent e) throws Exception {
ctx.sendUpstream(e);
}
@Override
public void channelDisconnected(ChannelHandlerContext ctx, ChannelStateEvent e) throws Exception {
ctx.sendUpstream(e);
}
@Override
protected Object decode(ChannelHandlerContext arg0, Channel arg1, ChannelBuffer buffer, VoidEnum e) throws Exception {
return Packet.read(buffer);
}
}
```
Спрашивается, как это работает? Очень просто, перед вызовом функции decode декодер помечает текущий индекс чтения, если при чтении из буфера в нём не хватит данных, будет сгенерировано исключение. При этом буфер вернётся в начальное положение и decode будет повторён, когда больше данных будет получено от пользователя. В случае успешного чтения (возвращён не null), декодер попытается вызвать функции decode ещё раз, уже на оставшихся в буфере данных, если в нём есть ещё хотя бы один байт.
Не медленно ли всё это работает, если он генерирует исключение? Медленнее, чем, например, проверка количества данных в буфере и оценка, хватит ли их для чтения пакета. Но он использует кэшированное исключение, поэтому не тратится время на заполнения stacktrace и даже создание нового объекта исключения. Подробнее об и некоторых других, повышающих эффективность, функцийя ReplayingDecoder можно почитать [здесь](http://bruno.biasedbit.com/blag/2010/12/06/netty-tutorial-replaying-decoder/)
Вы так же можете поэкспериментировать с FrameDecoder'ом, если, например, Вы можете заранее определить размер пакета по его ID.
#### Кажется, это всё
Результаты получились отличными. Во-первых, сервер больше не сыпет тысячей потоков — 4 потока Netty + 4 потока обработки данных прекрасно справляются с 250+ клиентами (тестирование продолжается). Во-вторых, нагрузка на процессор стала значительно меньшей и перестала линейно расти от числа подключений. В-третьих, время отклика в некоторых случаях стало меньше.
Надеюсь кому-нибудь это будет полезно. Старалась передать как можно больше важных данных, могла переборщить. Примеров ведь много не бывает? Спрашивайте Ваши ответы и не судите строго — первый раз пишу на хабр.
#### Постскриптум: ещё несколько полезных вещей
У Netty есть ещё несколько интересных особенностей, которые заслуживают отдельного упоминания:
Во-первых, остановка сервера:
```
ChannelFuture future = channel.close();
future.awaitUninterruptibly();
```
Где *channel* — канал, который возвратила функция bind в начале. *future.awaitUninterruptibly()* дождётся, пока канал закроется и выполнение кода продолжится.
Самое интересное: ChannelFuture. Когда мы отправляем на канал пакет, функцией channel.write(packet), она возвращает ChannelFuture — это особый объект, который отслеживает состояние выполняемого действия. Через него можно проверить, выполнилось ли действие.
Например, мы хотим послать клиенту пакет отключения и закрыть за ним канал. Если мы сделаем
```
channel.write(new Packet255KickDisconnect("Пока!"));
channel.close();
```
то с вероятностью 99%, мы получим ChannelClosedException и пакет до клиента не дойдёт. Но можно сделать так:
```
ChannelFuture future = channel.write(new Packet255KickDisconnect("Пока!"));
try {
future.await(10000); // Ждём не более 10 секунд, пока действие закончится
} catch(InterruptedException e) {}
channel.close();
```
То всё будет супер, кроме того, что это может заблокировать поток выполнения, пока пакет не отправится пользователю. Поэтому на ChannelFuture можно повесит listener — объект, который будет уведомлён о том, что событие совершилось и выполнит какие-либо действия. Для закрытия соединения есть уже готовый listener *ChannelFutureListener.CLOSE*. Пример использования:
```
ChannelFuture future = channel.write(new Packet255KickDisconnect("Пока!"));
furute.addListener(ChannelFutureListener.CLOSE);
```
Эффект тот же, блокировок нет. Разобраться в том, как создать свой листенер не сложно — там всего одна функция. Откройте любой готовый класс, здесь я не буду приводить пример.
##### Ещё важная информация
Как правильно было замечено в комментариях, следует предупредить о том, что в обработчиках (handler-ах, которые висят на pipeline) лучше не стоит использовать блокирующие операции или ожидание. В противном случае, Вы рискуете навсегда потерять поток обработки или просто сильно затормозить обработку событий остальных клиентов.
Так же в обработчике ни в коем случае нельзя «ждать будущего», т.е. выполнять .await() или .awaitUninterruptibly() на любом ChannelFuture. Во-первых, у Вас ничего не получится, их нельзя вызывать из обработчиков — система не даст сделать такую глупость и сгенерирует исключение. Во-вторых, если бы этого не было, Ваш поток опять же мог бы умереть оставив других клиентов без обслуживания.
Вообще, все действия, выполняемые в ChannelHandler'ах должны быть как можно более простыми и неблокирующими. Ни в коем случае не обрабатывайте данные прямо в них — кладите пакеты в очередь и обрабатывайте их в другом потоке. | https://habr.com/ru/post/136456/ | null | ru | null |
# Настройка сервиса автообнаружения в Zextras Suite
Сервис автоматического обнаружения, который используется в протоколе ActiveSync позволяет сократить процесс настройки мобильного устройства или MS Outlook для использования с корпоративным почтовым сервером за счет того, что после ввода данных учетной записи смартфон, планшет или MS Outlook в автоматическом режиме загружает все необходимое для подключения к серверу. Это делает процедуру настройки мобильного устройства или почтового клиента по протоколу Exchange ActiveSync максимально простой и понятной для пользователя и, как следствие, значительно сокращает число обращений в поддержку с различными жалобами. Модуль Zextras Mobile, входящий в состав решения Zextras Suite также позволяет использовать функцию автоматического обнаружения Zextras Autodiscover, который является собственной реализацией протокола Autodiscover от компании Zextras. В данной статье мы расскажем о том, по какому принципу работает данная функция, а также о том, как правильно настроить ее в Zextras Suite.
Для использования Zextras Mobile и Exchange ActiveSync Autodiscover вам потребуются действительные лицензии Zextras Suite Mobile или Zextras Suite Pro. Оценить работу данного сервиса можно также в рамках пробного периода Zextras Suite. Также для использования данной функции вам потребуется действительный коммерческий SSL-сертификат. О том, как его установить на ваш сервер Zimbra OSE [мы писали в прошлой статье](https://habr.com/ru/company/zimbra/blog/574378/).
Для того, чтобы включить сервис автообнаружения, нужно отредактировать шаблон файла конфигурации jetty /opt/zimbra/jetty/etc/jetty.xml.in. Необходимо привести его сегмент, в котором описывается работа сервиса Autodiscover, к следующему виду:
```
/autodiscover/\*
/service/extension/autodiscover
/Autodiscover/\*
/service/extension/autodiscover
/AutoDiscover/\*
/service/extension/autodiscover
```
То же самое можно сделать при помощи команды **sed -i 's|/service/autodiscover|/service/extension/autodiscover|g' /opt/zimbra/jetty/etc/jetty.xml.in**
Исходный вид нужного сегмента файла /opt/zimbra/jetty/etc/jetty.xml.inСервис автообнаружения работает следующим образом: после того как пользователь в своем мобильном устройстве или Outlook вводит адрес своей электронной почты, почтовый клиент автоматически опрашивает сервер на наличие готовых настроек. В том случае, если ему удается получить файл конфигурации, он автоматически его применяет, что позволяет пользователю сразу же начать пользоваться электронной почтой. В том случае, если файл конфигурации получить не удастся, пользователю придется самостоятельно вводить все необходимые настройки. Во время опроса почтового сервера, клиент Exchange ActiveSync поочередно обращается к нему по следующим адресам:
* <https://example.ru/Autodiscover/Autodiscover.xml>
* <https://autodiscover.example.ru/Autodiscover/Autodiscover.xml>
* <http://example.ru/Autodiscover/Autodiscover.xml>
Ожидаемый ответ от сервера в данном случае - файл Autodiscover.xml, в котором и содержатся все необходимые настройки для почтового клиента. В том случае, если клиент не получил файл после обращения по первому адресу, он пытается обратиться по второму, а затем и по третьему, который отличается от первого тем, что проходит по незащищенному каналу связи.
Происходит и четвертое обращение, оно основано на DNS-записях. Для того, чтобы оно сработало, необходимо правильно настроить записи в DNS. В нашем случае необходимо настроить DNS CNAME и SRV записи, которые укажут на полное доменное имя сервера Zimbra OSE. Таким образом, используя командную строку или графический интерфейс необходимо добавить в файл доменной зоны запись **autodiscover IN CNAME**[**mail.example.ru**](http://mail.example.ru/).
После этого необходимо добавить запись DNS SRV, в которой необходимо указать полное доменное имя сервера Zimbra OSE, а также используемые службы, протокол, приоритет, вес, порт и имя хоста. Делается это, как и в прошлом случае, добавлением соответствующей строки в файл доменной зоны с помощью CLI или графического интерфейса. В нашем случае данная строка будет выглядеть так: **\_autodiscover.\_tcp IN SRV 0 0 443**[**mail.example.ru**](http://mail.example.ru/).
Для того, чтобы проверить корректность работы Zextras Autodiscover можно попробовать подключиться к серверу по протоколу Exchange ActiveSync используя Outlook или мобильное устройство.
В случае если сервис автообнаружения работает корректно, этих данных будет достаточно для входа в почтовый ящик пользователяВ iPhone перейдите в **Настройки - Почта - Учетные записи - Новая учетная запись - Microsoft Exchange** и в появившемся окне введите имя учетной записи и пароль. В случае, если после их ввода вы подключитесь к своему почтовому ящику, это будет означать, что сервис автообнаружения работает корректно. В случае, если возникнет новое диалоговое окно, в котором потребуется ввести дополнительные данные, сервис автообнаружения работает некорректно.
Если сервис автообнаружения не работает, появляются дополнительные поля при настройке учетной записиО том, как подключить MS Outlook по протоколу Exchange ActiveSync мы рассказывали ранее в одной из наших статей. В случае если сервис автообнаружения работает корректно, для входа в почтовый ящик будет достаточно только имени учетной записи и пароля.
Не все устройства Android имеют поддержку Exchange ActiveSync во встроенных почтовых клиентах. В том случае, если в ваших корпоративных устройствах на Android ее нет, рекомендуем установить MS Outlook for Android и протестировать сервис автообнаружения с его помощью.
Также корректность работы Zextras Autodiscover можно проверить при помощи команды **dig \_autodiscover.\_tcp.example.ru SRV**, которую необходимо выполнить в командной строке Linux. Выводе данной команды будут содержаться данные о полученном от сервера ответе.
Эксклюзивный дистрибьютор Zextras [SVZcloud](https://svzcloud.ru/). По вопросам тестирования и приобретения Zextras Carbonio обращайтесь на электронную почту: [[email protected]](mailto:[email protected]) | https://habr.com/ru/post/575544/ | null | ru | null |
# Удаленное управление роботом Lego Mindstorms по JMX и IP Video
Основной модуль конструктора Lego Mindstorms EV3 может работать с прошивкой [leJOS](http://www.lejos.org/ev3.php), позволяющей запускать Java-приложения. Специально для этого Oracle выпустил и поддерживает [отдельную версию полноценной Java SE](http://www.oracle.com/technetwork/java/embedded/downloads/javase/javaseemeddedev3-1982511.html).
Нормальная JVM позволила мне использовать встроенный в нее протокол Java Management Extensions (JMX), чтобы реализовать удаленное управление роботом-манипулятором. Для объединения управляющих элементов, показаний датчиков и картинок с установленных на роботе IP-камер используется мнемосхема, сделанная на платформе AggreGate.

Сам робот состоит из двух основных частей: шасси и руки-манипулятора. Они управляются двумя полностью независимыми компьютерами EV3, вся их координация осуществляется через управляющий сервер. Прямого соединения между компьютерами нет.
Оба компьютера подключены к IP-сети помещения через Wi-Fi адаптеры NETGEAR WNA1100. Робот управляется восемью двигателями Mindstorms — из них 4 «большие» и 4 «маленькие». Также установлены инфракрасный и ультразвуковой датчики для автоматической остановки у препятствия при движении задним ходом, два датчика прикосновения для остановки поворота манипулятора из-за препятствия, и гироскопический датчик, облегчающий ориентировку оператора при помощи визуализации положения плеча.
В шасси установлены два двигателя, каждый из которых передает усилие на пару гусеничных приводов. Еще один двигатель поворачивает всю руку-манипулятор целиком на 360 градусов.

В самом манипуляторе два двигателя отвечают за подъем и опускание «плеча» и «предплечья». Еще три двигателя занимаются подъемом/опусканием кисти, ее поворотом на 360 градусов и сжиманием/разжиманием «пальцев».

Самым сложным механическим узлом является «кисть». Из-за необходимости выноса трех тяжелых двигателей в район «локтя» конструкция получилась достаточно хитрой.

В целом все выглядит так (коробок спичек был с трудом найден для масштаба):

Для передачи картинки установлены две камеры:
* Обычный Android-смартфон с установленным приложением [IP Webcam](https://play.google.com/store/apps/details?id=com.pas.webcam&hl=en) для общего обзора (на снимке HTC One)
* Автономная Wi-Fi микро-камера [AI-Ball](http://www.thumbdrive.com/aiball/intro.html), установленная прямо на «кисти» манипулятора и помогающая хватать предметы сложной формы

Программирование EV3
====================
ПО самого робота получилось максимально простым. Программы двух компьютеров очень похожи, они запускают JMX сервер, регистрируют MBean'ы, соответствующие двигателям и датчикам, и засыпают в ожидании операций по JMX.
**Код главных классов ПО руки-манипулятора**
```
public class Arm
{
public static void main(String[] args)
{
try
{
EV3Helper.printOnLCD("Starting...");
EV3Helper.startJMXServer("192.168.1.8", 9000);
MBeanServer mbs = ManagementFactory.getPlatformMBeanServer();
EV3LargeRegulatedMotor motor = new EV3LargeRegulatedMotor(BrickFinder.getDefault().getPort("A"));
LargeMotorMXBean m = new LargeMotorController(motor);
ObjectName n = new ObjectName("robot:name=MotorA");
mbs.registerMBean(m, n);
// Registering other motors here
EV3TouchSensor touchSensor = new EV3TouchSensor(SensorPort.S1);
TouchSensorMXBean tos = new TouchSensorController(touchSensor);
n = new ObjectName("robot:name=Sensor1");
mbs.registerMBean(tos, n);
// Registering other sensors here
EV3Helper.printOnLCD("Running");
Sound.beepSequenceUp();
Thread.sleep(Integer.MAX_VALUE);
}
catch (Throwable e)
{
e.printStackTrace();
}
}
}
public class EV3Helper
{
static void startJMXServer(String address, int port)
{
MBeanServer server = ManagementFactory.getPlatformMBeanServer();
try
{
java.rmi.registry.LocateRegistry.createRegistry(port);
JMXServiceURL url = new JMXServiceURL("service:jmx:rmi:///jndi/rmi://" + address + ":" + String.valueOf(port) + "/server");
Map props = new HashMap();
props.put("com.sun.management.jmxremote.authenticate", "false");
props.put("com.sun.management.jmxremote.ssl", "false");
JMXConnectorServer connectorServer = JMXConnectorServerFactory.newJMXConnectorServer(url, props, server);
connectorServer.start();
}
catch (Exception e)
{
e.printStackTrace();
}
}
static void printOnLCD(String s)
{
LCD.clear();
LCD.drawString(s, 0, 4);
}
}
```
Для каждого типа датчика и мотора создан интерфейс MBean'а и реализующий его класс, которые напрямую делегирует все вызовы классу, входящему в leJOS API.
**Пример кода интерфейса**
```
public interface LargeMotorMXBean
{
public abstract void forward();
public abstract boolean suspendRegulation();
public abstract int getTachoCount();
public abstract float getPosition();
public abstract void flt();
public abstract void flt(boolean immediateReturn);
public abstract void stop(boolean immediateReturn);
public abstract boolean isMoving();
public abstract void waitComplete();
public abstract void rotateTo(int limitAngle, boolean immediateReturn);
public abstract void setAcceleration(int acceleration);
public abstract int getAcceleration();
public abstract int getLimitAngle();
public abstract void resetTachoCount();
public abstract void rotate(int angle, boolean immediateReturn);
public abstract void rotate(int angle);
public abstract void rotateTo(int limitAngle);
public abstract boolean isStalled();
public abstract void setStallThreshold(int error, int time);
public abstract int getRotationSpeed();
public abstract float getMaxSpeed();
public abstract void backward();
public abstract void stop();
public abstract int getSpeed();
public abstract void setSpeed(int speed);
}
```
**Пример кода реализации MBean'а**
```
public class LargeMotorController implements LargeMotorMXBean
{
final EV3LargeRegulatedMotor motor;
public LargeMotorController(EV3LargeRegulatedMotor motor)
{
this.motor = motor;
}
@Override
public void forward()
{
motor.forward();
}
@Override
public boolean suspendRegulation()
{
return motor.suspendRegulation();
}
@Override
public int getTachoCount()
{
return motor.getTachoCount();
}
@Override
public float getPosition()
{
return motor.getPosition();
}
@Override
public void flt()
{
motor.flt();
}
@Override
public void flt(boolean immediateReturn)
{
motor.flt(immediateReturn);
}
// Similar delegating methods skipped
}
```
Как ни странно, на этом программирование закончилось. На стороне сервера и операторского рабочего места не было написано ни одной строчки кода.
Подключение к серверу
=====================
Непосредственное управление роботом осуществляет сервер [IoT-платформы AggreGate](http://aggregate.tibbo.com/). Установленная бесплатная версия продукта [AggreGate Network Manager](http://aggregate.tibbo.com/solutions/network_management.html) включает драйвер протокола JMX и позволяет подключить до десяти JMX-хостов. Нам понадобится подключить два — по одному на каждый кирпичик EV3.
Прежде всего, нужно создать аккаунт JMX устройства, указав в настройках URL, заданный при запуске JMX сервера:
**Свойства соединения с JMX-устройством**
После этого выбираем активы (т.е. MBean'ы в данном случае), которые будут добавлены в профиль устройства:
**Выбор MBean'ов**
И через несколько секунд смотрим и меняем текущие значения всех опрошенных свойств MBean'ов:
**Снимок устройства**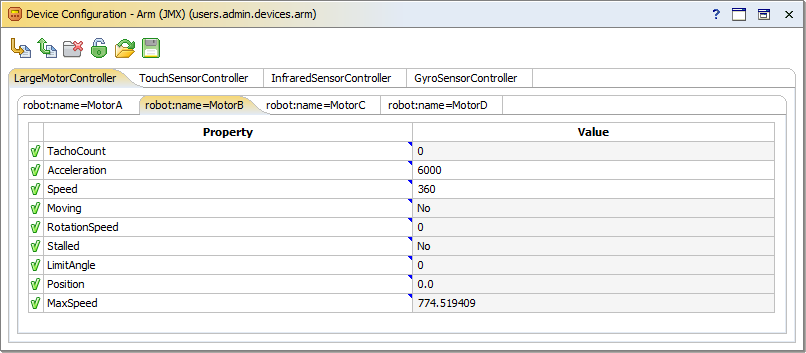
Можно также потестировать различные операции вызывая вручную методы MBean'ов, например forward() и stop().
**Список операций**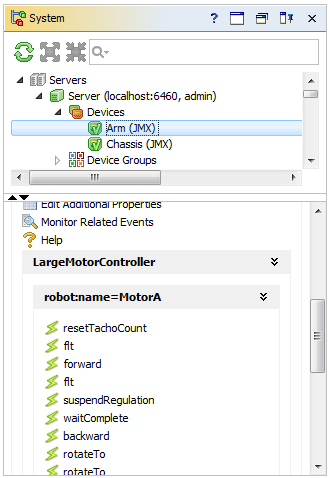
Далее настраиваем периоды опроса для датчиков. Высокая частота опроса (100 раз в секунду) используется, так как управляющий сервер находится в локальной сети вместе с роботом и именно сервер принимает решения об остановке вращения при упоре в препятствие и т.п. Решение, безусловно, не промышленное, но в хорошо работающей Wi-Fi сети в рамках одной квартиры показало себя вполне адекватным.
**Периоды опроса**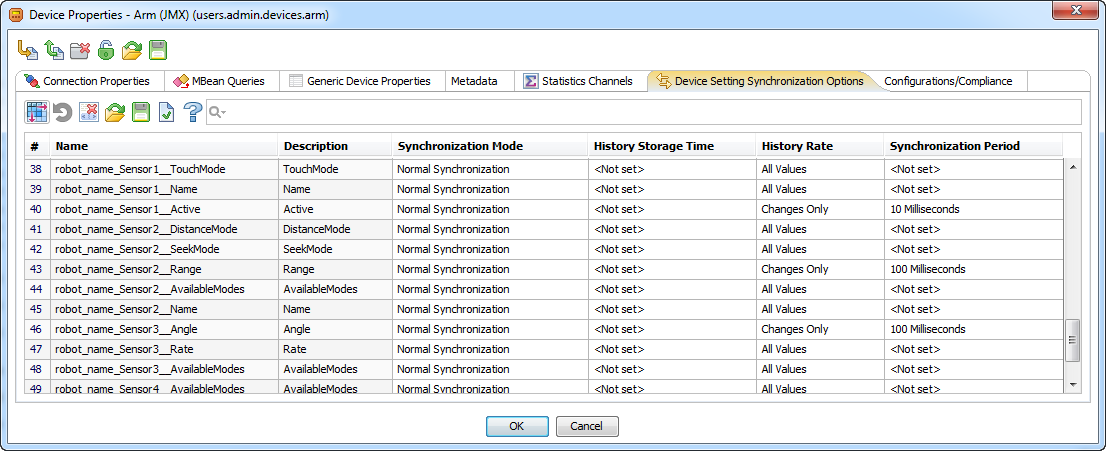
Интерфейс оператора
===================
Теперь переходим к созданию интерфейса оператора. Для этого сначала создаем новый виджет и накидываем в него нужные компоненты. В конечном работающем варианте выглядит он так:
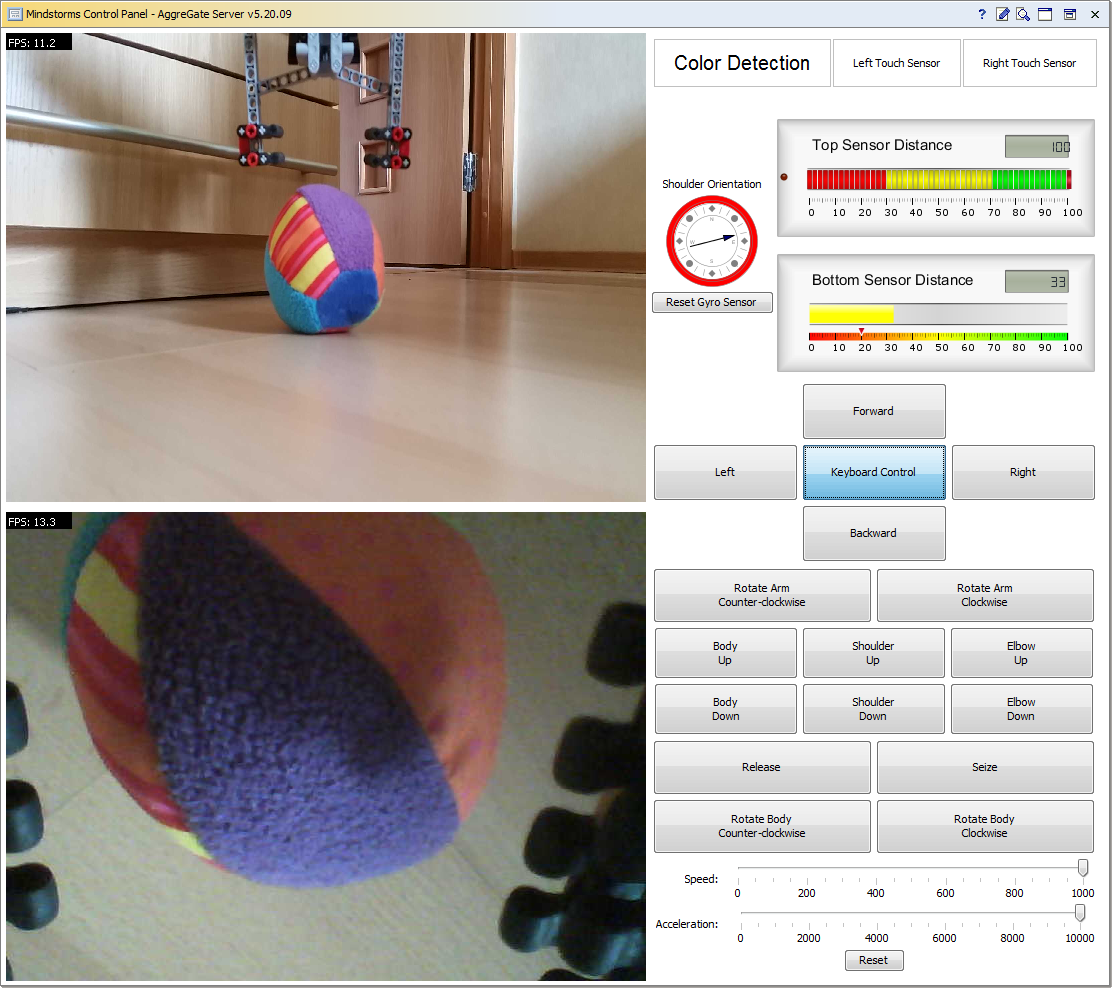
По сути, весь интерфейс состоит из нескольких панелей с кнопками, слайдерами и индикаторами, сгруппированными в различные сеточные раскладки, и двух больших видео-плееров, транслирующих картинки с камер.
**Вид изнутри редактора интерфейсов**Вся форма:
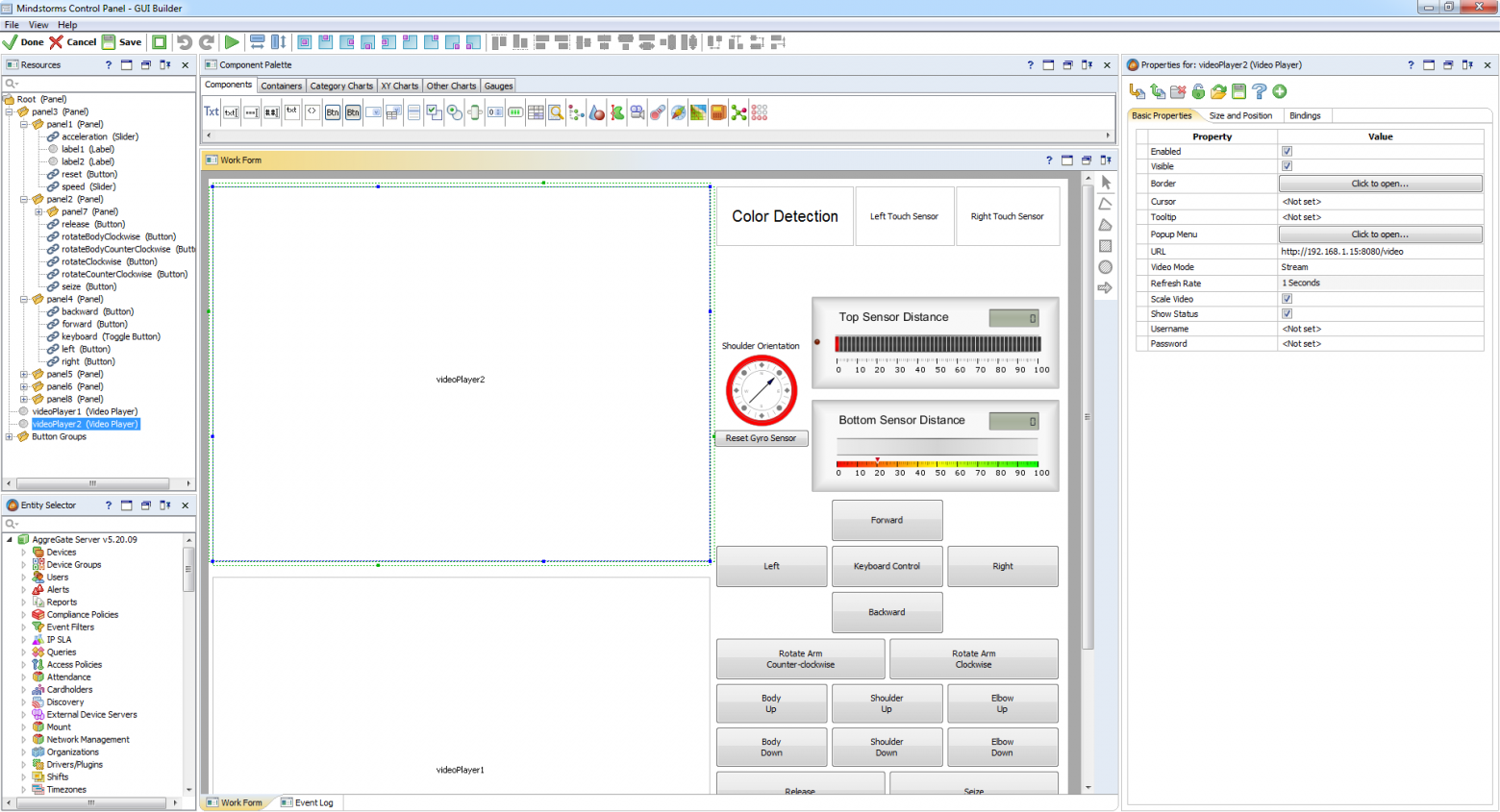
Вид с показанными панелями-контейнерами:
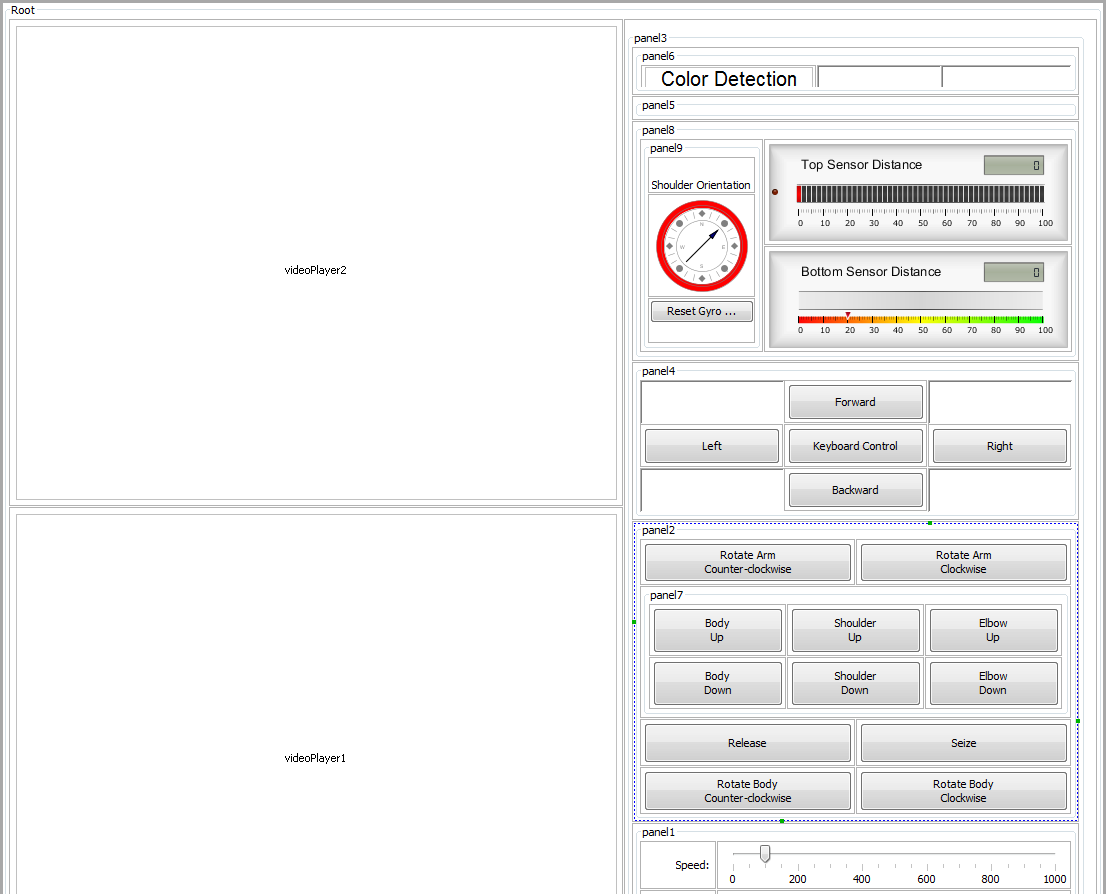
Теперь, как говорят АСУТПшники, осталось «оживить мнемосхему». Для этого применяются так называемые *привязки* связывающие свойства и методы графических компонентов интерфейса со свойствами и методами серверных объектов. Так как компьютеры EV3 уже подключены к серверу, серверными объектами могут быть и MBean'ы нашего робота.
Весь интерфейс оператора содержит около 120 привязок, большая часть из которых однотипна:
Половина однотипных привязок реализует управление при помощи кликов на кнопки, расположенные на мнемосхеме. Это красиво, удобно для тестирования, но совершенно непригодно для реального передвижения робота и перемещения грузов. Активаторами привязок из этой группы являются события **mousePressed** и **mouseReleased** различных кнопок.
Вторая половина привязок позволяет управлять роботом с клавиатуры, предварительно нажав на кнопку Keyboard Control. Эти привязки реагируют на события **keyPressed** и **keyReleased**, а в условии каждой привязки прописано, на какой именно код кнопки нужно реагировать.
Все управляющие привязки вызывают методы **forward()**, **backward()** и **stop()** различных MBean'ов. Поскольку доставка событий происходит асинхронно, важно, чтобы вызовы функций **forward()**/**backward()** и последующие вызовы **stop()** не перепутались. Для этого привязки, вызывающие методы одного MBean'а, добавлены в одну очередь (Queue).
Две отдельные группы привязок выставляют начальные скорости и ускорения двигателей (сейчас это реализовано на стороне сервера при помощи модели, поэтому эти привязки отключены) и меняют скорости/ускорения при перемещении ползунков Speed и Acceleration.
**Привязки скорости и ускорения двигателей**
Все остальные привязки подсвечивают части мнемосхемы при активации сенсоров касания, показывают измеренные сенсорами расстояния до объектов на шкалах и выполняют различные служебные функции.
**Остальные привязки**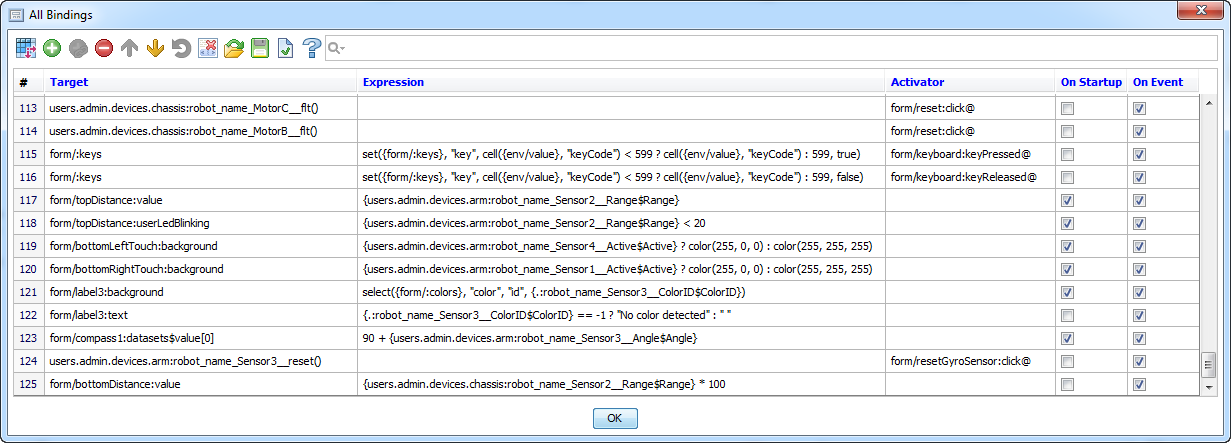
Помимо аккаунтов JMX-устройств и вышеописанного виджета на сервере есть еще один объект, участвующий в управлении роботом. Это [модель](http://aggregate.tibbo.com/technology/management/models.html), которая останавливает двигатели при срабатывании одного из датчиков прикосновения. Осуществляется это также при помощи привязок, различие их с привязками виджета лишь в том, что привязки модели обрабатываются на сервере и связывают одни свойства серверных объектов с другими.
**Привязки модели управления**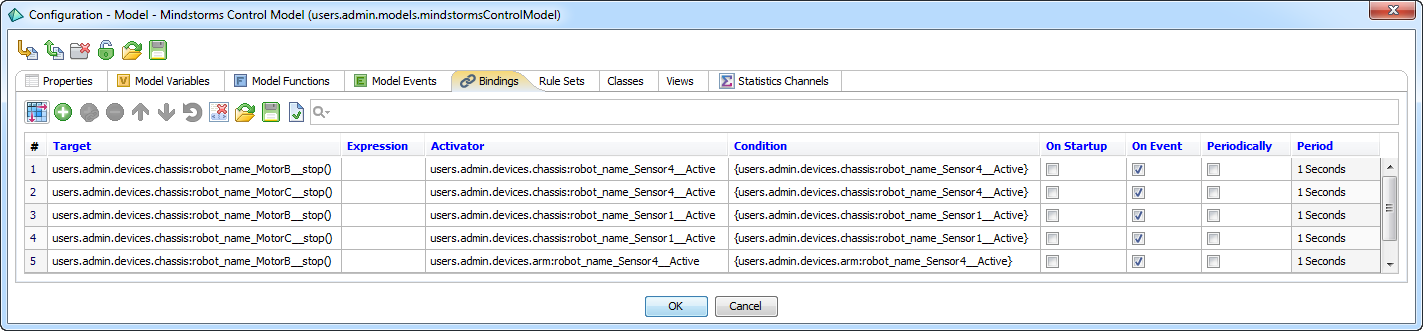
Закончив настройку виджета и модели можно запускать виджет, активировать клавиатурное управление и развлекаться: | https://habr.com/ru/post/254259/ | null | ru | null |
# Tortilla — весь TCP и DNS трафик из виртуальной машины через TOR

Пошаговое руководство по направлению всего TCP и DNS трафика из виртуальной машины через TOR.
Тема уже поднималась в 2012 году: [«Как направить весь tcp-трафик с гостевой Windows системы через Tor»](http://habrahabr.ru/post/145436/) с использованием tun2socks и виртуального сетевого адаптера TUN/TAP от OpenVPN.
Однако на Black Hat USA 2013 был представлен доклад [«TOR… ALL-THE-THINGS!»](http://www.blackhat.com/us-13/briefings.html#Geffner2), в котором анонсировали новый инструмент от Jason Geffner из CROWDSTRIKE INC под названием [Tortilla](http://www.crowdstrike.com/community-tools/index.html#tool-79). Также Tortilla упоминается в официальном Tor FAQ в разделе [What should I do if I can't set a proxy with my application?](https://www.torproject.org/docs/faq.html.en#CantSetProxy). Это виртуальный сетевой адаптер, который просто установить и использовать.
Потребуется:
1. [TOR Expert Bundle](https://www.torproject.org/dist/win32/tor-0.2.4.23-win32.exe)
2. [Tortilla](http://download.crowdstrike.com/tortilla/Tortilla_v1.1.0_Beta.zip)
3. Виртуальная машина
**Все настройки производятся на физическом компьютере (host system).
В операционной системе виртуальной машины (guest system) ничего настраивать не нужно.**
#### Установка TOR Expert Bundle
Скачиваете инсталлятор и для корректной установки запускаете от имени администратора.
По завершении установки запускаете Tor.

Откроется окно, где ожидаете установления полного соединения до сообщения `Bootstrapped 100%: Done.`
#### Установка Tortilla
Драйвер сетевого виртуального адаптера Tortilla имеет специальную тестовую подпись и для его установки и работы во всех 64-bit и некоторых 32-bit версиях Windows Vista и последующих, требуется включить поддержку такой подписи, воспользовавшись [инструкцией Microsoft](http://msdn.microsoft.com/en-us/library/windows/hardware/ff553484(v=vs.85).aspx).
Для этого необходимо запустить командную строку от имени администратора.
И в открывшемся окне командной строки выполнить `Bcdedit.exe -set TESTSIGNING ON`
После чего перезагрузиться.
Затем скачиваете и распаковываете архив. Запускаете Tortilla. Откроется окно.
Появится запрос на установку драйвера Tortilla, который нужно все равно установить.
Если предложение к установке драйвера не появляется, а сразу возникнет ошибка — это означает, что вы не включили поддержку тестовой подписи драйверов (см. начало установки Tortilla).

В итоге после успешной установки драйвера и запуска Tortilla вы должны увидеть окно с сообщением `Ready to receive network traffic from virtual machine`
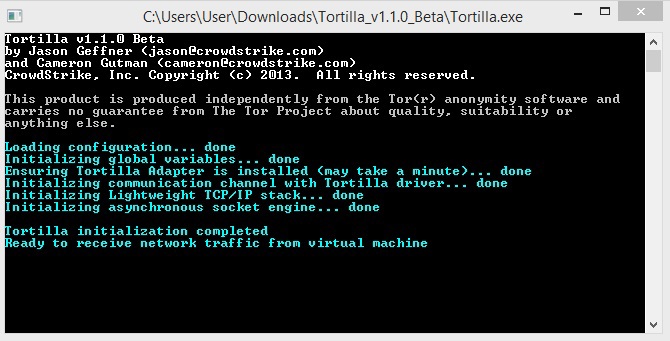
Также в сетевых подключениях вы увидите новый подключенный виртуальный сетевой адаптер Tortilla Adapter.
#### Настройка сети виртуальной машины на примере VMware
В VMware откройте **Virtual Network Editor**. Там выберите сеть **VMnet0** и в настройках укажите тип соединения **Bridged**, выбрав сетевой адаптер из списка **Tortilla Adapter**.
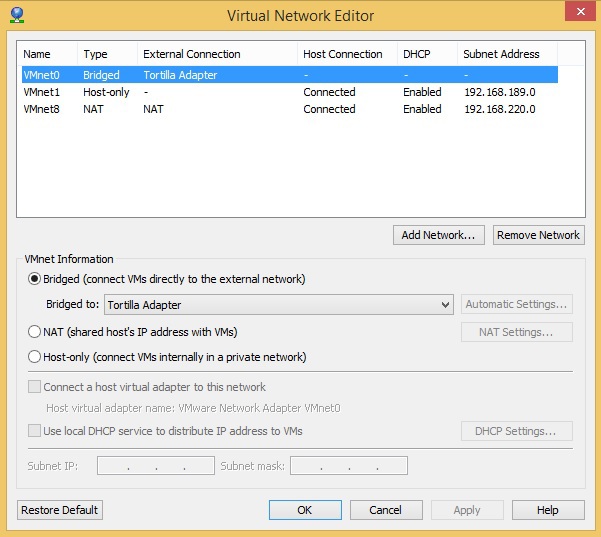
Затем в настройках виртуальной машины укажите в свойствах **Network Adapter** тип соединения **Custom**, выбрав из списка сеть **VMnet0**.

#### В итоге
После запуска виртуальной машины в окне Tortilla вы должны увидеть какой трафик побежал через TOR.
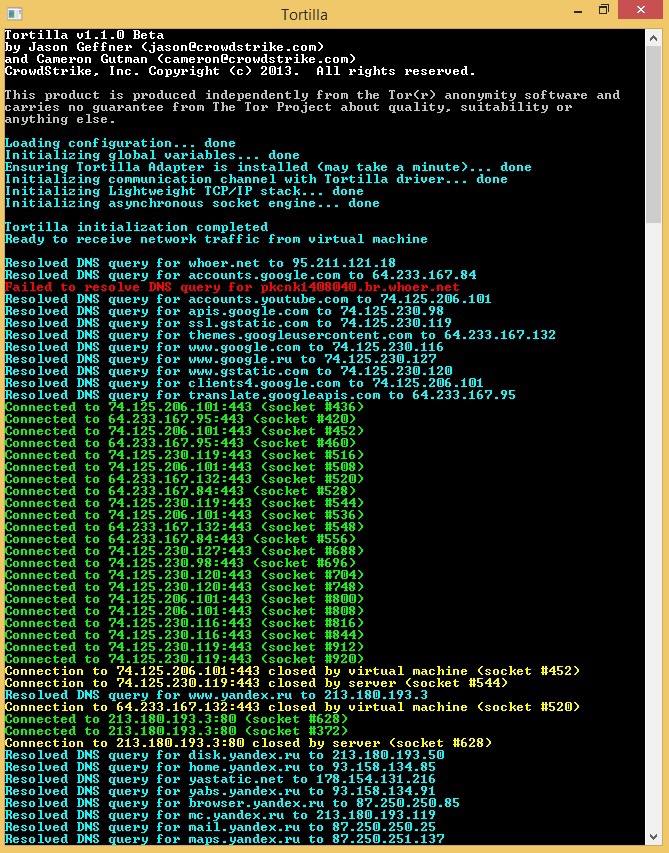
Все.
**UPD. ВАЖНО.**
Для нормальной работы пользуйтесь **TOR BROWSER BUNDLE**.
[Скачайте последнюю версию TOR Browser Bundle](https://www.torproject.org/download/download-easy.html.en) и запустите ее.
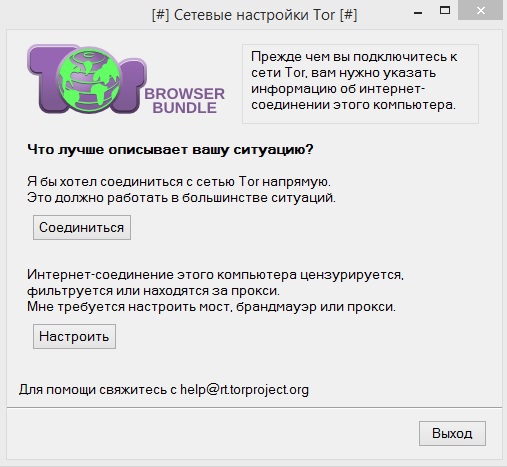 
В файле Tortilla.ini (в каталоге Тортиллы) пропишите вместо порта 9050 порт 9150.
По всей видимости TOR Expert Bundle не обновляется, а для TOR Browser Bundle все время выходят новые версии, видимо связанные с модификацией TOR сети.
В этой связи работа через TOR Expert Bundle связана с постоянными ошибками HTTPS, а т.к. многие сайты сейчас переходят на шифрование, это затрудняет работу.
При работе через TOR BROWSER BUNDLE нет ошибок HTTPS и JAVA приложения работают без сбоев, скорость увеличилась.
**UPD.**
Все же сбои при работе с HTTPS остаются, однако можно перезагрузить TOR соединение опцией «Новая личность», нажав на зеленую луковицу  в браузере TOR.
 | https://habr.com/ru/post/233457/ | null | ru | null |
# Vulkan. Руководство разработчика. Отрисовка

Я занимаюсь техническими переводами в ижевской IT-компании CG Tribe и продолжаю публиковать перевод уроков Vulkan Tutorial на русский язык. Оригинальный текст руководства можно найти [здесь](https://vulkan-tutorial.com).
Моя сегодняшняя публикация посвящена первым двум статьям раздела Drawing, — Framebuffers и Command buffers.
**Содержание**
1. [Вступление](http://habr.com/ru/post/462137/)
2. [Краткий обзор](http://habr.com/ru/post/524992/)
3. [Настройка окружения](https://habr.com/ru/post/526320/)
4. [Рисуем треугольник](https://habr.com/ru/post/531196/)
1. [Подготовка к работе](https://habr.com/ru/post/531196/)
* [Базовый код](https://habr.com/ru/post/531196/#base)
* [Экземпляр (instance)](https://habr.com/ru/post/531196/#two)
* [Слои валидации](https://habr.com/ru/post/535342/)
* [Физические устройства и семейства очередей](https://habr.com/ru/post/537208/#phys)
* [Логическое устройство и очереди](https://habr.com/ru/post/537208/#logic)
2. Отображение на экране
* [Window surface](https://habr.com/ru/post/539174/)
* [Swap chain](https://habr.com/ru/post/542942/)
* [Image views](https://habr.com/ru/post/543288/)
3. [Графический конвейер (pipeline)](https://habr.com/ru/post/547576/)
* [Вступление](https://habr.com/ru/post/547576/)
* [Шейдерные модули](https://habr.com/ru/post/547576/#shader)
* [Непрограммируемые стадии конвейера](https://habr.com/ru/post/554492/)
* [Проходы рендера (Render passes)](https://habr.com/ru/post/560816/)
* [Заключение](https://habr.com/ru/post/560816/#conclusion)
4. Отрисовка
* [Фреймбуферы](https://habr.com/ru/post/564100/#frame)
* [Буферы команд](https://habr.com/ru/post/564100/#buffer)
* [Рендеринг и отображение на экране](https://habr.com/ru/post/567754/)
5. [Пересоздание swap chain](https://habr.com/ru/post/569912/)
5. [Вершинные буферы](https://habr.com/ru/post/571944/)
1. [Описание входных данных вершин](https://habr.com/ru/post/571944/)
2. [Создание вершинного буфера](https://habr.com/ru/post/573920/)
3. [Промежуточный буфер](https://habr.com/ru/post/578956/)
4. [Индексный буфер](https://habr.com/ru/users/alexandra_sky/posts/)
6. Uniform-буферы
1. [Layout дескрипторов и буфер](https://habr.com/ru/post/582838/)
2. Пул дескрипторов и сеты дескрипторов
7. Текстурирование
1. Изображения
2. Image view и image sampler
3. Комбинированный image sampler
8. Буфер глубины
9. Загрузка моделей
10. Создание мип-карт
11. Multisampling
FAQ
Политика конфиденциальности
Фреймбуферы
-----------
В последних главах мы много говорили о фреймбуферах и настроили проход рендера для одного фреймбуфера с таким же форматом, что и image из swap chain. Однако сам фреймбуфер до сих пор не создали.
Буферы (attachments), на которые мы ссылались при создании прохода рендера, необходимо обернуть в **[VkFramebuffer](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkFramebuffer.html)**. Он указывает на все объекты **[VkImageView](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkImageView.html)**, которые мы будем использовать как таргеты. В нашем случае только один буфер: буфер цвета. Однако swap chain содержит множество image, и использовать мы должны именно тот, который получили от swap chain для рисования. Другими словами, нам необходимо создать фреймбуферы для каждого image из swap chain и использовать тот фреймбуфер, к которому прикреплен интересующий нас image.
Для этого добавим еще один член класса:
```
std::vector swapChainFramebuffers;
```
Добавим функцию **`createFramebuffers`** и вызовем ее сразу после создания графического конвейера. Внутри этого метода будем создавать объекты для нашего массива:
```
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
}
...
void createFramebuffers() {
}
```
Сначала выделим необходимое место в контейнере для хранения фреймбуферов:
```
void createFramebuffers() {
swapChainFramebuffers.resize(swapChainImageViews.size());
}
```
Затем обойдем все image views и создадим из них фреймбуферы:
```
for (size_t i = 0; i < swapChainImageViews.size(); i++) {
VkImageView attachments[] = {
swapChainImageViews[i]
};
VkFramebufferCreateInfo framebufferInfo{};
framebufferInfo.sType = VK_STRUCTURE_TYPE_FRAMEBUFFER_CREATE_INFO;
framebufferInfo.renderPass = renderPass;
framebufferInfo.attachmentCount = 1;
framebufferInfo.pAttachments = attachments;
framebufferInfo.width = swapChainExtent.width;
framebufferInfo.height = swapChainExtent.height;
framebufferInfo.layers = 1;
if (vkCreateFramebuffer(device, &framebufferInfo, nullptr, &swapChainFramebuffers[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create framebuffer!");
}
}
```
Как видите, создать фреймбуфер несложно. Сначала нужно указать, с каким **`renderPass`** он должен быть совместим. Фреймбуферы могут быть использованы только с совместимыми проходами рендера, то есть для них используется одинаковое количество и тип буферов.
Параметры **`attachmentCount`** и **`pAttachments`** указывают на объекты **[VkImageView](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkImageView.html)**, которые должны соответствовать описанию **`pAttachments`**, использованному при создании прохода рендера.
Параметры **`width`** и **`height`** не вызывают вопросов. В поле **`layers`** указывается количество слоев для images. Наши images состоят только из одного слоя, поэтому layers = **`1`**.
Фреймбуферы нужно удалить перед image views и проходом рендера, но только после окончания рендеринга:
```
void cleanup() {
for (auto framebuffer : swapChainFramebuffers) {
vkDestroyFramebuffer(device, framebuffer, nullptr);
}
...
}
```
Теперь у нас есть все объекты, необходимые для рендеринга. В следующей главе мы уже сможем написать первые команды рисования.
**[Код C++](https://vulkan-tutorial.com/code/13_framebuffers.cpp)** / **[Вершинный шейдер](https://vulkan-tutorial.com/code/09_shader_base.vert)** / **[Фрагментный шейдер](https://vulkan-tutorial.com/code/09_shader_base.frag)**
Буферы команд
-------------
* [Пул команд](#one)
* [Выделение памяти для буферов команд](#two)
* [Запись буфера команд](#three)
* [Начало прохода рендера](#four)
* [Основные команды рисования](#five)
* [Завершение](#six)
Команды в Vulkan, такие как операции рисования и операции перемещения в памяти, не выполняются непосредственно во время вызова соответствующих функций. Все необходимые операции должны быть записаны в буфер. Это удобно тем, что сложный процесс настройки команд может быть выполнен заранее и в нескольких потоках. В основном цикле вам остается лишь указать Vulkan, чтобы он запустил команды.
### Пул команд
Прежде чем перейти к созданию буфера команд мы должны создать пул команд. Пул команд управляет памятью, которая используется для хранения буферов.
Добавим новый член класса **[VkCommandPool](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkCommandPool.html)**.
```
VkCommandPool commandPool;
```
Теперь создадим новую функцию **`createCommandPool`** и вызовем ее из **`initVulkan`** после создания фреймбуферов.
```
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
}
...
void createCommandPool() {
}
```
Для создания пула команд потребуется только два параметра:
```
QueueFamilyIndices queueFamilyIndices = findQueueFamilies(physicalDevice);
VkCommandPoolCreateInfo poolInfo{};
poolInfo.sType = VK_STRUCTURE_TYPE_COMMAND_POOL_CREATE_INFO;
poolInfo.queueFamilyIndex = queueFamilyIndices.graphicsFamily.value();
poolInfo.flags = 0; // Optional
```
Чтобы запустить буферы команд, их необходимо отправить в очередь, например, в графическую очередь или очередь отображения. Пул команд может выделять буферы команд только для одного семейства очередей. Нам нужно записать команды рисования, поэтому мы используем семейство очередей с поддержкой графических операций.
Есть два возможных флага для пула команд:
* **`VK_COMMAND_POOL_CREATE_TRANSIENT_BIT`**: хинт, сообщающий Vulkan, что буферы из пула будут часто сбрасываться и выделяться (может поменять поведение пула при выделении памяти)
* **`VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT`**: позволяет перезаписывать буферы независимо; если флаг не установлен, сбросить буферы можно будет только все и одновременно
Мы запишем буферы команд только в начале работы программы, а затем будем неоднократно запускать их в основном цикле, поэтому ни один из этих флагов нам не подходит.
```
if (vkCreateCommandPool(device, &poolInfo, nullptr, &commandPool) != VK_SUCCESS) {
throw std::runtime_error("failed to create command pool!");
}
```
Завершим создание пула команд функцией **[vkCreateCommandPool](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/vkCreateCommandPool.html)**. В ней нет никаких специальных параметров. Команды будут использоваться на протяжении всего жизненного цикла программы, поэтому пул нужно уничтожить в самом конце:
```
void cleanup() {
vkDestroyCommandPool(device, commandPool, nullptr);
...
}
```
### Выделение памяти для буферов команд
Теперь мы можем выделить память для буферов команд и записать в них команды рисования. Поскольку каждая из команд рисования привязана к соответствующему **[VkFrameBuffer](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkFramebuffer.html)**, мы должны записать буфер команд для каждого image из swap chain. Для этого создадим список объектов **[VkCommandBuffer](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkCommandBuffer.html)** в виде члена класса. После уничтожения пула команд буферы команд автоматически освобождаются, поэтому нам не требуется явная очистка.
```
std::vector commandBuffers;
```
Перейдем к функции **`createCommandBuffers`**, которая выделяет память и записывает команды для каждого image из swap chain.
```
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
createCommandBuffers();
}
...
void createCommandBuffers() {
commandBuffers.resize(swapChainFramebuffers.size());
}
```
Буферы команд создаются с помощью функции **[vkAllocateCommandBuffers](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/vkAllocateCommandBuffers.html)**, которая принимает структуру **[VkCommandBufferAllocateInfo](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkCommandBufferAllocateInfo.html)** в качестве параметра. В структуре указывается пул команд и количество буферов:
```
VkCommandBufferAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO;
allocInfo.commandPool = commandPool;
allocInfo.level = VK_COMMAND_BUFFER_LEVEL_PRIMARY;
allocInfo.commandBufferCount = (uint32_t) commandBuffers.size();
if (vkAllocateCommandBuffers(device, &allocInfo, commandBuffers.data()) != VK_SUCCESS) {
throw std::runtime_error("failed to allocate command buffers!");
}
```
Параметр **`level`** определяет, первичными или вторичными будут буферы команд.
* **`VK_COMMAND_BUFFER_LEVEL_PRIMARY`**: первичные буферы могут отправляться в очередь, но не могут вызываться из других буферов команд.
* **`VK_COMMAND_BUFFER_LEVEL_SECONDARY`**: вторичные буферы не отправляются в очередь напрямую, но могут вызваться из первичных буферов команд.
Мы не будем использовать вторичные буферы команд, хотя иногда это может быть удобным перенести в них некоторые часто используемые последовательности команд и переиспользовать их в первичном буфере.
### Запись буфера команд
Начнем запись буфера команд с вызова **[vkBeginCommandBuffer](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/vkBeginCommandBuffer.html)**. В качестве аргумента передадим небольшую структуру **[VkCommandBufferBeginInfo](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkCommandBufferBeginInfo.html)**, которая содержит информацию об использовании этого буфера.
```
for (size_t i = 0; i < commandBuffers.size(); i++) {
VkCommandBufferBeginInfo beginInfo{};
beginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
beginInfo.flags = 0; // Optional
beginInfo.pInheritanceInfo = nullptr; // Optional
if (vkBeginCommandBuffer(commandBuffers[i], &beginInfo) != VK_SUCCESS) {
throw std::runtime_error("failed to begin recording command buffer!");
}
}
```
Параметр **`flags`** указывает, как будет использоваться буфер команд. Доступны следующие значения:
* **`VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT`**: после каждого запуска буфер команд перезаписывается.
* **`VK_COMMAND_BUFFER_USAGE_RENDER_PASS_CONTINUE_BIT`**: указывает, что это будет вторичный буфер команд, который целиком находится в пределах одного прохода рендера.
* **`VK_COMMAND_BUFFER_USAGE_SIMULTANEOUS_USE_BIT`**: буфер может быть повторно отправлен в очередь, даже если предыдущий его вызов ещё не выполнен и находится в состоянии ожидания.
На данный момент ни один из флагов нам не подходит.
Параметр **`pInheritanceInfo`** используется только для вторичных буферов команд. Он определяет состояние, наследуемое из первичных буферов.
Если буфер команд однажды уже был записан, вызов **[vkBeginCommandBuffer](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/vkBeginCommandBuffer.html)** неявно сбросит его. Нельзя добавлять команды в уже заполненный буфер.
### Начало прохода рендера
Приступим к отрисовке треугольника, начав проход рендера с помощью **[vkCmdBeginRenderPass](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/vkCmdBeginRenderPass.html)**. Проход рендера настраивается с помощью некоторых параметров в структуре **[VkRenderPassBeginInfo](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkRenderPassBeginInfo.html)**.
```
VkRenderPassBeginInfo renderPassInfo{};
renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_BEGIN_INFO;
renderPassInfo.renderPass = renderPass;
renderPassInfo.framebuffer = swapChainFramebuffers[i];
```
Первые параметры определяют проход рендера и фреймбуфер. Мы создали фреймбуфер для каждого image из swap chain, который используется в качестве цветового буфера.
```
renderPassInfo.renderArea.offset = {0, 0};
renderPassInfo.renderArea.extent = swapChainExtent;
```
Следующие два параметра определяют размер области рендеринга. Область рендеринга (render area) определяет участок фреймбуфера, на котором шейдеры могут сохранять и загружать данные. Пиксели за пределами этой области будут иметь неопределенные значения. Для достижения лучшей производительности область рендеринга должна соответствовать размеру буферов.
```
VkClearValue clearColor = {0.0f, 0.0f, 0.0f, 1.0f};
renderPassInfo.clearValueCount = 1;
renderPassInfo.pClearValues = &clearColor
```
Последние два параметра определяют значения для очистки буферов при использовании операции **`VK_ATTACHMENT_LOAD_OP_CLEAR`**. Заполним фреймбуфер черным цветом со 100% непрозрачностью.
Теперь начнем проход рендера.
```
vkCmdBeginRenderPass(commandBuffers[i], &renderPassInfo, VK_SUBPASS_CONTENTS_INLINE);
```
Функции для записи команд в буфер можно узнать по префиксу **[vkCmd](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/vkCmd.html)**. Все они возвращают **`void`**, поэтому обработка ошибок будет производиться только после окончания записи.
Первый параметр для каждой команды — буфер команд, в который эта команда записывается. Второй параметр — информация о проходе рендера. Последний параметр определяет, как будут предоставляться команды в подпроходе (subpass). Вы можете выбрать одно из двух значений:
* **`VK_SUBPASS_CONTENTS_INLINE`**: команды будут вписаны в первичный буфер команд без запуска вторичных буферов.
* **`VK_SUBPASS_CONTENTS_SECONDARY_COMMAND_BUFFERS`**: команды будут запущены из вторичных буферов команд.
Мы не будем использовать вторичные буферы команд, поэтому выберем первый вариант.
### Основные команды рисования
Теперь мы можем подключить графический конвейер:
```
vkCmdBindPipeline(commandBuffers[i], VK_PIPELINE_BIND_POINT_GRAPHICS, graphicsPipeline);
```
Второй параметр указывает, какой конвейер используется — графический или вычислительный. Осталось нарисовать треугольник:
```
vkCmdDraw(commandBuffers[i], 3, 1, 0, 0);
```
Функция **[vkCmdDraw](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/vkCmdDraw.html)** выглядит весьма скромно, но ее проста связана с тем, что все данные мы указали заранее. Помимо буфера команд в функцию передаются следующие параметры:
* **`vertexCount`**: несмотря на то, что мы не используем вершинный буфер, технически у нас есть 3 вершины для отрисовки треугольника.
* **`instanceCount`**: используется, когда необходимо отрисовать несколько экземпляров одного объекта (instanced rendering); передайте **`1`**, если не используете эту функцию.
* **`firstVertex`**: используется в качестве смещения в вершинном буфере, определяет наименьшее значение **`gl_VertexIndex`**.
* **`firstInstance`**: используется в качестве смещения при отрисовке нескольких экземпляров одного объекта; определяет наименьшее значение **`gl_InstanceIndex`**.
### Завершение
Теперь мы можем закончить проход рендера:
```
vkCmdEndRenderPass(commandBuffers[i]);
```
И завершить запись буфера команд:
```
if (vkEndCommandBuffer(commandBuffers[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to record command buffer!");
}
```
В следующей главе мы напишем код для основного цикла, где image извлекается из swap chain, после чего запускается соответствующий буфер команд, а затем готовый image возвращается в swap chain для вывода на экран.
**[Код C++](https://vulkan-tutorial.com/code/14_command_buffers.cpp)** / **[Вершинный шейдер](https://vulkan-tutorial.com/code/09_shader_base.vert)** / **[Фрагментный шейдер](https://vulkan-tutorial.com/code/09_shader_base.frag)** | https://habr.com/ru/post/564100/ | null | ru | null |
# Шесть загадок по С++
В очередной раз наступив на досадные необязательные грабли, я решил систематизировать свои знания о них. Если вы какое-то время разрабатываете на C++, то можете и не найти здесь ничего нового, но кому-то приведенный в статье материал точно поможет. Если бы я знал это лет пять назад, то однозначно сэкономил бы несколько безвозвратно потерянных дней жизни и нервных клеток.
Чтобы было интереснее, материал представлю в виде простых задачек. Сразу подчеркну, что я не считаю приведенные примеры просчетами языка. Во многом появляется смысл и логика, если вопрос обдумать. Это скорее случаи, когда может отказать интуиция, особенно если голова забита чем-нибудь еще. Есть и пара примеров вида «Ну чего этому компилятору надо, только что то же самое работало!»
И последнее замечание. Это не будут задачи на внимательность типа «Тут я поставил точку с запятой сразу после for — а никто и не заметил». Проблемы не в опечатках. Все необходимые библиотеки можно считать подключенными — не относящийся к описываемой ситуации код я опускал, чтобы не загромождать статью.
##### Условие всех задач.
Дан некоторый код. Иногда он разбит на отдельные листинги. Нужно ответить, скомпилируется ли программа, а если скомпилируется, что будет выведено на экран, и как себя поведет приложение, если компиляция завершится с ошибкой, то по какой причине.
##### Задача 1. Делим на 0
###### Листинг 1.1:
```
int g = 3;
g -= 3;
int f = 1 / g;
std::cout << "f is " << f << std::endl;
```
###### Листинг 1.2:
```
float g = 3;
g -= 3;
float f = 1 / g;
std::cout << "f is " << f << std::endl;
```
**Ответ****Листинг 1.1** Программа аварийно завершает работу. На ноль делить нельзя. Именно то, чего ожидаешь.
**Листинг 1.2** Все работает. Вывод «f is inf». По всей видимости, считается, что float не является точным типом, потому и нуля как такового в нем представлено быть не может. Только бесконечно малое. А на бесконечно малое делить можно. Об этом нужно помнить и не надеяться, что в случае деления на ноль программа упадет, и вы сразу узнаете об ошибке.
##### Задача 2. Switch и класс
###### Листинг 2
```
class SwitchClass
{
public:
static const int ONE;
static const int TWO;
void switchFun(int number)
{
switch(number)
{
case ONE:
std::cout<<"1"<
```
**Ответ**Не компилируется. Статические константные члены класса не являются с точки зрения оператора switch достаточно константными. Проблема решается использованием перечислений (**enum**) вместо "**static const int**"
##### Задача 3. Логические выражения
###### Листинг 3
```
bool update1()
{
std::cout<<"update1"<
```
**Ответ**Вывод на экран будет зависеть от того, какое значение вернет update1. В C++ вычисление логических выражений оптимизируется. Т.е., если на каком-то этапе результат становится очевиден — дальнейшие расчеты не выполняются. В примере используется логическое И. Если один из его операндов ЛОЖЬ, то результат также будет ЛОЖЬ вне зависимости от значения второго операнда. Т.е., если update1 вернет ЛОЖЬ, то update2 даже не будет вызван, и вывод на экран получится
```
update1
```
Если же результатом выполнения update1 будет ИСТИНА, то будет вызвана update2 и программа выведет
```
update1
update2
```
**Мораль**. Функции, выполняющие какие-то побочные действия, в логических выражениях лучше не использовать. Чтобы гарантировать вызов обеих функций с сохранением результата, код листинга 3 нужно переписать следующим образом
```
bool update1Result = update1();
bool update2Result = update2();
bool updatedSuccessfully = update1Result && update2Result ;
```
##### Задача 4. Итератор как параметр
###### Листинг 4.1 Объявление функции
```
typedef std::vector MyVector;
void processIterator(MyVector::iterator& i)
{
std::cout<<\*i<
```
###### Листинг 4.2
```
MyVector v;
v.push_back(1);
for (MyVector::iterator i = v.begin(); i != v.end(); ++i) {
processIterator(i);
}
```
###### Листинг 4.3
```
MyVector v;
v.push_back(1);
processIterator(v.begin());
```
**Ответ****Листинг 4.2** Отработает нормально. На экран будет выведено
```
1
```
**Листинг 4.3** Приведет к ошибке компиляции. Дело в том, что begin возвращает константный итератор, который в листинге 4.2 просто копируется в i. Переменная цикла i уже не является константой и может быть свободно передана в нашу функцию по обычной ссылке. В 4.3 же мы пытаемся «отобрать» у значения спецификатор (qualifier) константности. Чтобы заставить все варианты вызова работать, функцию можно переписать следующим образом
```
void processIterator(const MyVector::iterator& i)
{
std::cout<<*i<
```
##### Задача 5. Вызов метода объекта по указателю
###### Листинг 5
```
class Test
{
public:
void testFun()
{
std::cout<<"testFun"<testFun();
t1->testFun();
return 0;
}
```
**Ответ**На первый взгляд, проблем куча (вызов по нулевому и неинициализированному указателям), и ничего работать не должно. Однако после выполнения программы в консоли мы увидим
```
testFun
testFun
```
А причина проста: хоть метод testFun не является статическим, **обращения к свойствам объекта в нем не происходит**. Если бы метод выглядел следующим образом
```
void testFun()
{
std::cout<<"testFun"<
```
то без проблем бы, конечно, не обошлось.
**Вывод**. Не рассчитывайте, что вызов нестатического метода по неинициализированному или даже нулевому указателю приведет к аварийному завершению программы. Может сложиться так, что все отработает. Конечно, остается вопрос «Зачем делать метод, не использующий свойства объекта, нестатическим». Ответом на него будет: «Мало ли. В жизни и не такое случается».
##### Задача 6.Перегрузка виртуальных функций
###### Листинг 6.1 Определение классов
```
class TestVirtuals
{
public:
virtual void fun(int i)
{
std::cout<<"int"<
```
###### Листинг 6.2
```
TestVirtuals tv;
tv.fun(1);
tv.fun(1.f);
tv.fun(std::string("one"));
```
###### Листинг 6.3
```
TestVirtualsChild tvc;
tvc.fun(1);
tvc.fun(1.f);
```
###### Листинг 6.4
```
TestVirtualsChild tvc;
tvc.fun(std::string("one"));
```
**Ответ****Листинг 6.2** Перегрузка отработает, как и ожидалось. Вывод программы
```
int
float
string
```
**Листинг 6.3** Потомок «не видит» перегрузки родителя. Все вызовы метода fun приводятся к целочисленному варианту (который есть в потомке). Вывод программы
```
int child
int child
```
**Листинг 6.4** Компиляция завершается с ошибкой. Невиртуальная функция как будто исчезает у потомка. Остается возможным только явный ее вызов через явное указание родительского класса.
```
tvc.TestVirtuals::fun(std::string("one"));
```
**Вывод**. От совмещения виртуальных функций с перегруженными лучше держаться подальше. Если другого выхода нет, осторожность должна просто зашкаливать. | https://habr.com/ru/post/197164/ | null | ru | null |
# k-means in Clickhouse
Алгоритм [k-means](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_k-%D1%81%D1%80%D0%B5%D0%B4%D0%BD%D0%B8%D1%85) хорошо известен и применяется когда надо быстро разделить массив данных на группы или т.н. "кластеры". Предполагается, что каждый элемент данных имеет набор численных метрик, и мы можем говорить как о позиции точки в некотором многомерном пространстве, так и о их взаимной близости.
k-means относится к категории EM-алогоритмов (Expectanion-Maximization), где мы попеременно определяем насколько правильно текущее разбиение точек на кластеры, а затем немного его улучшаем.
Этот достаточно простой алгоритм, был сформулирован ещё в 1950-х, и с тех пор реализован на самых разных языках программирования. Есть реализации для MySQL и Postgress, и даже для Excel.
### Зачем Clickhouse
Есть сотни и тысячи реализаций k-means. Почему бы не взять какую-нибудь популярную python библиотеку, вытащить данные через драйвер базы данных, и обработать их в памяти питоновской программы?
Можно и так, если данных мало, и задача найти какую-нибудь особенную область на изображении, чтобы применить к ней более сложный алгоритм. Но бывает, что данных много. Или даже ОЧЕНЬ МНОГО. Да, Clickhouse - это про Big Data.
Big Data - это когда данных настолько много, что они никуда не помещаются. Не только в RAM - об этом даже не надо мечтать. Часто весь массив данных не помещаются даже на один сервер, и приходится ставить несколько (шардировать). Просто написать на sklearn.cluster.KMeans - это прочитать 1Tb данных куда-то в память питоновского процесса, а потом ещё и ещё раз, причем в 1 поток. Не самая лучшая идея. Поэтому на больших объемах данных применяют решения вида MapReduce, Apache AirFlow, Spark и прочие дорогие и солидные инструменты.
Я попробую сделать что-то сравнимое, только просто и дешево, пользуясь возможностями Сlickhouse. И чтобы не тормозило. Покажу как как можно эффективно работать с большими данными на примере одного простого алгоритма. Ведь Сlickhouse - это полноценная среда выполнения заданий по обработке, а не простое хранилище индексированных данных.
Основная сложность в этой задаче заключается в неоднократном чтении огромного массива данных с последующим вычислением евклидова расстояния и группировкой результатов на каждом шаге. В Clickhouse предусмотрено все, чтобы именно эти операции работали быстро и прозрачно для разработчика:
* данные лежат в виде колонок - читаем только то, что нам нужно
* данные лежат в компрессированном виде (lz4) - читаем в разы меньше, снижаем нагрузку на диск
* данные читаются в 8 потоков (по умолчанию, конфигурируется) из отдельных файлов. Без каких-то усилий разработчика задействуется многоядерная архитектура современных серверов.
* тип Tuple эффективно хранит точки многомерного пространства
* специальная функция быстро считает евклидово расстояние
* SQL код компилируется (LLVM) и работает со скоростью C++ кода
* операция group by имеет более 40 различных оптимизаций и работает очень эффективно. Если группировка в памяти невозможна, то автоматически будет задействован диск.
* если данные шардированны по нескольким серверам, то запрос будет отослан на все шарды, частичная группировка будет сделана распределенно, а результаты объединены. Без каких-то усилий со стороны разработчика.
#### Исходные данные
Данные могут находиться в любой таблице, а чтобы алгоритм имел к ним стандартный интерфейс предлагается подготовить обычное SQL View:
```
create or replace view YH as
select i, (toInt32(x),toInt32(y)) as Y
from sourceData;
```
Данные выбираются из таблицы sourceData, формируется две колонки - первичный ключ и Tuple из необходимого количества числовых координат. В данном случае используется две целочисленные координаты 2D пространства. Если данные шардированы, то такое view нужно создать на всех узлах кластера
### Хранение центроидов
Centroids - ключевое понятие алгоритма k-means. Это центры кластеров, которые мы ищем и уточняем последовательными приближениями. Будем хранить в табличке.
```
create table WCR (
ts DateTime,
j Int32,
C Tuple(Int32,Int32)
) engine = MergeTree
order by ts;
```
Храним все итерации, но так как у нас нет автоинкремента, то наш выбор - простой таймстемп. Номер кластера, и координаты центроида в 2D пространстве. Сортировка по времени.
#### Начальная инициализация
В простейшем случае центроиды инициализируются координатами случайно выбранных точек исходного набора данных. Сколько хотите кластеров - столько центроидов и нужно проинициализировать. Алгоритм очень уязвим к начальному расположению центроидов - может и не сойтись.
Поэтому в более сложном варианте инициализации ([k-means++](https://ru.wikipedia.org/wiki/K-means%2B%2B)) центроиды инициализируются хоть и вероятностно, но уже с учетом расстояния между точками в пространстве. Утверждается, что так лучше. Так и будем делать.
Первый центроид выбираем случайным образом (тут число 40) :
```
insert into WCR select now(), 1, Y
from YH
limit 40,1;
```
Последующие центроиды:
```
insert into WCR
select now(), (select j from WCR order by ts desc limit 1)+1 as j, y
from (
select y,
sum(d) over () as total,
sum(d) over (rows between unbounded preceding and current row ) as cum
from (
select argMin(Y, L2Distance(Y,C) as dx2) as y, min(dx2) as d
from YH
cross join (select * from WCR order by ts desc limit 1 by j) as WCR
where Y not in (select C from WCR)
group by Y
)
)
where total * (select rand32()/4294967295) < cum
order by cum
limit 1;
```
Этот insert запускается несколько раз, пока не наберется нужное количество центроидов.
### Пересчет центроидов
* вычисляем расстояние от каждой точки до всех центроидов
* для каждой точки находим ближайший центроид, объединяем точки в группы
* назначаем центр этой группы новой позицией центроида
* повторяем пока движение центроидов не остановится (почти)
```
INSERT INTO WCR SELECT
now(), j,
tuple(COLUMNS('tupleElement') APPLY avg) AS C
FROM (WITH ( SELECT groupArray(j), groupArray(C)
FROM (select j,C from WCR order by ts desc limit 1 by j) ) AS jC
SELECT untuple(Y), i,
arraySort((j, C) -> L2Distance(C, Y), jC.1, jC.2)[1] AS j
FROM YH
)
GROUP BY j
```
* берем центроиды прошлого шага: `select j,C from WCR order by ts desc limit 1 by j`
* делаем из них кортеж (tuple) с двумя массивами внутри (номер и позиция)
* передаем эти массивы функции `arraySort`, которая для каждой точки сортирует центроиды по возрастанию расстояния от точки до центроида. Берем только первый элемент массива - номер ближайшего к точке центроида.
* `untuple(Y)` развертывает координаты точки в отдельные столбцы. Их имена будут вида `tupleElement(Y.1)`
* `COLUMNS('tupleElement')` - берет все столбцы по указанному regex
* `group by j` - группируем все точки по номеру центроида
* `APPLY avg` - применяет к выбранным столбцам аггрегатную функцию - берет среднее по каждой координате, вычисляя новую позицию центроида.
* `tuple()` - полученный список отдельных (но уже аггрегированных) столбцов снова сворачивается в единый кортеж.
* `insert into` - записываем новые центроиды и таймстемп в таблицу.
#### Результат
В таблице WCR сохраняются все шаги работы алгоритма. Есть таймстемп для каждого шага, есть позиция центроида. Чтобы вытащить необходимые для визуализации данные можно написать запрос, похожий на обычную итерацию, который вычислит принадлежность каждой точки к кластеру:
```
with tuple(COLUMNS('tupleElement')) as a
select a.1 as x,
if(j=1,a.2,null) as p1,
if(j=2,a.2,null) as p2,
if(j=3,a.2,null) as p3,
if(j=4,a.2,null) as p4,
if(j=5,a.2,null) as p5
from ( WITH ( SELECT groupArray(j), groupArray(C)
FROM (select j,C from WCR order by ts desc limit 1 by j) ) AS jC
SELECT untuple(Y), i,
arraySort((j, C) -> L2Distance(C, Y), jC.1, jC.2)[1] AS j
FROM YH
)
```
### Заключение
Сам алгоритм работает быстро, с обычной для k-means точностью - трудные для человека ситуации (как на КДПВ) решает логично, а на явно разделенных группах точек - путается. Существуют алгоритмы и поновее, поинтереснее.
Целью статьи было показать как применять некоторые инструменты Сlickhouse для относительно сложной работы с большими данными.
Все описанные выше SQL запросы собраны в bash скрипт, который последовательно инициализирует центроиды, уточняет в цикле, и завершается при остановке блужданий. При желании можно переписать на любой удобный ЯП с учетом особенностей задачи и конкретной архитектуры хранения данных.
[Проект доступен на Github](https://github.com/bvt123/clickhouse-k-means)
Идея реализации k-means на SQL была взята из статьи сотрудников Terradata - [Programming the K-means Clustering Algorithm in SQL](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.109.5005&rep=rep1&type=pdf) Однако там всё написано на классическом SQL. Получилось очень сложно, с дополнительными генераторами SQL кода. Я попробовал сделать проще и лаконичнее, используя специфичный диалект SQL и функции Сlickhouse.
Имена переменных в SQL запросах в общих чертах соответствуют именам в статье. Там предложена интересная схема наименований, я в какой-то степени ей пытался соответствовать. Полезно, если вы хотите понять как работает алгоритм и его реализации. | https://habr.com/ru/post/645291/ | null | ru | null |
# Избавляем игрока от раздражения: правильное использование случайных чисел

Если вам доведётся пообщаться с фанатом RPG, то вскоре вы услышите жалобы на рандомизированные результаты и лут, а также о том, насколько раздражающими они могут быть. Многие геймеры высказывают свою досаду, и пока некоторые разработчики придумывают инновационные решения, большинство по-прежнему заставляет нас проходить приводящие в ярость проверки на усидчивость.
Но есть способ и получше. Используя случайных чисел и их генерирование иным образом, мы можем создавать захватывающий игровой процесс, создающий «идеальный» уровень сложности, не выбешивая при этом игроков. Но прежде чем мы перейдём к этому, давайте рассмотрим основы генераторов случайных чисел (или RNG).
Генератор случайных чисел и его применение
------------------------------------------
Случайные числа встречаются нам повсюду и используются для добавления вариативности в ПО. В общем случае RNG обычно применяются для моделирования хаотических событий, демонстрации непостоянства или являются искусственным ограничителем.
Скорее всего, вы ежедневно взаимодействуете со случайными числами или результатами их действий. Они используются в научных опытах, видеоиграх, анимациях, искусстве и практически в каждом приложении компьютера. Например, RNG скорее всего реализован в простых анимациях в вашем телефоне.
Теперь, когда мы поговорили немного о RNG, давайте взглянем на их реализацию и узнаем, как применять их для улучшения игр.
Стандартный генератор случайных чисел
-------------------------------------
Почти в каждом языке программирования среди прочих функций есть стандартный RNG. Его работа заключается в возврате случайного значения в интервале двух чисел. В разных системах стандартные RNG можно реализовать десятками разных способов, но в общем случае они имеют одинаковый эффект: возвращают случайное число из интервала, каждое значение в котором может быть выбрано с одинаковой вероятностью.
В играх генераторы часто используются для симуляции бросков костей. В идеале они должны использоваться только в ситуациях, когда каждый из результатов должен возникать равное количество раз.
Если вы хотите поэкспериментировать с редкостью или разными степенями рандомизации, то вам больше подойдёт следующий способ.
Взвешенные случайные числа и слоты редкости
-------------------------------------------
Этот тип RNG является основой для любой RPG с системой редкости предметов. В частности, он применяется, когда вам нужен рандомизированный результат, но некоторые значения должны выпадать с меньшей частотой, чем остальные. При изучении вероятностей в пример часто приводят мешок с шариками. При взвешенном RNG в мешке может быть три синих шарика и один красный. Так как нам нужен всего один шарик, мы получим или красный, или синий, но с большей вероятностью он будет синим.
Почему может быть важна взвешенная рандомизация? Давайте в качестве примера возьмём внутриигровые события SimCity. Если бы каждое событие выбиралось невзвешенными способами, то вероятность совершения каждого события статистически было бы одинаковым. То есть с одинаковой вероятностью вам бы предлагали открыть новое казино или происходило бы землетрясение. Добавив веса, мы можем сделать так, чтобы эти события происходили в пропорциональной вероятности, обеспечивающей хороший геймплей.
### Виды и применения
#### Группировка одинаковых предметов
Во многих книгах по информатике такой способ называется «мешком». Имя говорит само за себя — классы или объекты используются для создания визуального представления мешка в буквальном смысле.
По сути, это работает так: есть контейнер, в который можно поместить объекты, функция для помещения объекта в «мешок» и функция для случайного выбора предмета из «мешка». Возвращаясь к нашему примеру с шариками, можно сказать, что наш мешок будет содержать синий, синий, синий и красный шарики.
С помощью этого способа рандомизации мы можем приблизительно задавать частоту возникновения результатов, чтобы усреднить игровой процесс для каждого игрока. Если мы упростим результаты до шкалы от «Очень плохо» до «Очень хорошо», то получим гораздо более приятную систему по сравнению с той, когда игрок может получить ненужную последовательность нежелательных результатов (например, результатов «Очень плохо» 20 раз подряд).
Однако статистически получить серию плохих результатов всё равно возможно, просто вероятность этого снизилась. Мы рассмотрим способ, который для снижения количества нежелательных результатов заходит немного дальше.
Вот краткий пример того, как может выглядеть псевдокод класса мешка:
```
Class Bag {
//Создаём массив для всех элементов, находящихся в мешке
Array itemsInBag;
//Заполняем мешок предметами при его создании
Constructor (Array startingItems) {
itemsInBag = startingItems;
}
//Добавляем предмет в мешок, передавая объект (а затем просто записываем его в массив)
Function addItem (Object item) {
itemsInBag.push(item);
}
//Для возврата случайного предмета используем встроенную функцию random, возвращая предмет из массива
Function getRandomItem () {
return(itemsInBag[random(0,itemsInBag.length-1)]);
}
}
```
#### Реализация слотов редкости
Слоты редкости — это способ стандартизации для задания частоты выпадания объекта (обычно используемый для упрощения процесса создания дизайна игры и вознаграждений игрока).
Вместо задания частоты каждого отдельного предмета в игре мы создаём соответствующую ему редкость — например, редкость «Обычный» может представлять вероятность определённого результата 20 к X, а уровень редкости «Редкий» — вероятность 1 к X.
Этот способ не сильно изменяет функцию самого мешка, зато может использоваться для увеличения эффективности на стороне разработчика, позволяя быстро назначить статистическую вероятность экспоненциально большому количеству предметов.
Кроме того, разделение редкости на слоты полезно для изменения восприятия игрока. Оно позволяет быстро и без необходимости возиться с числами понять, как часто должно происходить событие, чтобы игрок не терял интереса.
Вот простой пример того, как мы можем добавить в наш мешок слоты редкости:
```
Class Bag {
//Создаём массив для всех элементов, находящихся в мешке
Array itemsInBag;
//Добавляем предмет в мешок, передавая объект
Function addItem (Object item) {
//Отслеживаем циклы относительно разделения редкости
Int timesToAdd;
//Проверяем переменную редкости предмета
//(но сначала создаём эту переменную в классе предмета,
//предпочтительно перечислимого типа)
Switch(item.rarity) {
Case 'common':
timesToAdd = 5;
Case 'uncommon':
timesToAdd = 3;
Case 'rare':
timesToAdd = 1;
}
//Добавляем экземпляры предмета в мешок с учётом его редкости
While (timesToAdd >0)
{
itemsInBag.push(item);
timesToAdd--;
}
}
}
```
Случайные числа с переменной частотой
-------------------------------------
Мы рассказали о некоторых из самых распространённых способов работы со случайностями в играх, поэтому давайте перейдём к более сложному. Концепция использования переменных частот начинается аналогично мешку из приведённых выше примеров: у нас есть заданное количество результатов, и мы знаем, насколько часто хотим их возникновения. Разница в реализации в том, что мы хотим изменять вероятность результатов при их возникновении.
Зачем нам это может понадобиться? Возьмём, например, игры с собиранием. Если у нас есть десять возможных результатов для получаемого предмета, когда девять являются «обычными», а один — «редким», то тогда вероятности очень просты: 90% времени игрок будет получать обычный предмет, а 10% времени — редкий. Проблема возникает тогда, когда мы учитываем несколько вытягиваний из мешка.
Давайте посмотрим на наши шансы получения серии обычных результатов:
* При первом вытягивании вероятность получения обычного предмета равна 90%.
* При двух вытягиваниях вероятность получения обоих обычных предметов равна 81%.
* При 10 вытягиваниях по-прежнему существует вероятность 35% всех обычных предметов.
* При 20 вытягиваниях всё равно есть вероятность в 12%.
То есть хотя изначальное соотношение 9:1 казалось нам идеальным, на самом деле оно соответствует только средним результатам, то есть 1 из 10 игроков потратит на получение редкого предмета вдвое больше желаемого. Более того, 4% игроков потратят на получение редкого предмета в три раза больше времени, а 1,5% неудачников — в четыре раза больше.
### Как эту проблему решают переменные частоты
Решение заключается в реализации в наших объектах интервала случайности. Для этого мы задаём максимальную и минимальную редкость каждого объекта (или слоты редкости, если вы хотите соединить этот способ с предыдущим примером). Например, давайте дадим нашему обычному предмету минимальное значение редкости 1, а максимальное — 9. Редкий предмет будет иметь минимальное и максимальное значение 1.
Теперь по показанному выше сценарию у нас будет десять предметов, девять из которых являются экземплярами обычного, а один — редким. При первом вытягивании есть вероятность 90% получения обычного предмета. При переменных частотах после вытягивания обычного предмета мы снижаем его значение редкости на 1.
При этом в следующем вытягивании у нас будет в целом девять предметов, восемь из которых обычные, что даёт вероятность 89% вытягивания обычного. После каждого результата с обычным предметом случайность этого предмета падает, что увеличивает вероятность вытягивания редкого, пока мы не останемся с двумя предметами в мешке, одним обычным и одним редким.
Таким образом, вместо вероятности 35% вытягивания 10 обычных предметов подряд у нас останется вероятность всего в 5%. Вероятность граничных результатов, таких как вытаскивание 20 обычных предметов подряд, снижается до 0,5%, а дальше становится и того меньше. Это создаёт постоянные результаты для игроков, и защищает нас от граничных случаев, в которых игрок постоянно вытягивает плохой результат.
### Создание класса переменных частот
Самой простой реализацией переменной частоты будет извлечение предмета из мешка, а не просто его возвращение:
```
Class Bag {
//Создаём массив для всех элементов, находящихся в мешке
Array itemsInBag;
//Заполняем мешок предметами при его создании
Constructor (Array startingItems) {
itemsInBag = startingItems;
}
//Добавляем предмет в мешок, передавая объект (а затем просто записываем его в массив)
Function addItem (Object item) {
itemsInBag.push(item);
}
Function getRandomItem () {
//pick a random item from the bag
Var currentItem = itemsInBag[random(0,itemsInBag.length-1)];
//Снижаем количество экземпляров этого предмета, если он выше минимума
If (instancesOf (currentItem, itemsInBag) > currentItem.minimumRarity) {
itemsInBag.remove(currentItem);
}
return(currentItem);
}
}
```
Хотя в такой простой версии проявляются некоторые проблемы (например, мешок постепенно переходит в состояние нормального распределения), она отображает незначительные изменения, позволяющие стабилизировать результаты рандомизации.
### Развитие идеи
Мы описали основную идею переменных частот, но в собственных реализациях нам нужно рассмотреть ещё довольно много аспектов:
* Удаление предметов из мешка позволяет добиться постоянных результатов, но со временем возвращает нас к проблемам стандартной рандомизации. Как мы можем изменить функции таким образом, чтобы и увеличение, и уменьшение предметов позволяли этого избежать?
* Что происходит, когда мы имеем дело с тысячами или миллионами предметов? В этом случае решением может быть использование мешка, заполненного мешками. Например, можно создать мешок для каждой редкости (все обычные предметы в одном мешке, редкие в другом) и поместить каждый из них в слоты внутри большого мешка. Это обеспечит широкие возможности для манипуляций.
Менее скучные случайные числа
-----------------------------
Во многих играх по-прежнему для создания сложности используется стандартное генерирование случайных чисел. При этом создаётся система, в которой половина игроков отклоняется в одну или другую сторону от ожидаемых результатов. Если оставить это без внимания, возникнет возможность граничных случаев со слишком большим количеством повторяющихся неудачных результатов.
Ограничивая интервалы разброса результатов, мы можем обеспечить более целостный игровой процесс и позволить получать от неё удовольствие большему количеству игроков.
Подводим итог
-------------
Генерация случайных чисел — один из столпов хорошего геймдизайна. Для улучшения игрового процесса тщательно проверяйте свою статистику и реализуйте наиболее подходящие виды генерирования. | https://habr.com/ru/post/354132/ | null | ru | null |
# Разбор финала конкурса-квиза на стенде hh.ru на #HolyJS18
Привет, это последняя часть разборов вопросов с нашего стенда.
Вопросы по React [тут](https://habr.com/company/hh/blog/431492/).
Разбор первых четырех туров [тут](https://habr.com/company/hh/blog/431698/).

Здесь вопросы по темам практически не сгруппированы, разбираем все по одному.
Поехали:
##### Что будет получено в результате?
```
let i = 0;
let a = 1;
for (; a >= 0; i++) {
a -= 0.1;
}
console.log(i);
a) 1
b) 11
c) ничего
d) 10
```
**Ответ + разбор**b) 11
Тут все достаточно просто. Это больше вопрос на внимательность. Цикл будет выполнен 11 раз, т.к. у нас не строгое
больше `>`, а больше или равно `>=`.
##### Что будет получено в результате?
```
{} + [];
a) 0
b) null
c) '[object Object]'
d) NaN
```
**Ответ + разбор**a) 0
Тут весь фокус в том, что `{}` будет интерпретирован не как объект, а как пустой блок кода. Поэтому выражение преобразовывается в `+[]`, а это `0`, т.к. `+` перед значением преобразовывает его к числу. Хочется заметить, что если код записать как `console.log({} + []);`, то будет уже `[object Object]`, т.к. тут `{}` будет интерпретирован как объект.
##### Что будет получено в результате?
```
[] + {};
```
a) 0
b) null
c) '[object Object]'
d) NaN
**Ответ + разбор**c) '[object Object]'
Тут оба операнда по правилам приводятся к строке у пустого массива — это пустая строка, а у объекта `[object Object]`
##### Что выведет этот код?
```
let response = {
data: '',
errors: { code: 403 }
};
console.log(typeof response.data.link);
a) undefined
b) object
c) string
d) function
```
**Ответ + разбор**d) function
У прототипа строки есть метод [link](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/String/link), поэтому правильный ответ `function`
##### Что выведет этот код?
```
const button = document.querySelector('button');
button.addEventListener('click', () => {
console.log('FUS');
});
button.addEventListener('click', () => Promise.resolve('RO').then((x) => console.log(x)));
button.addEventListener('click', () => {
console.log('DAH!');
});
button.click();
a) FUS RO DAH!
b) FUS DAH! RO
c) RO FUS DAH!
d) DAH! RO FUS
```
**Ответ + разбор**b) FUS DAH! RO
Мы тут триггерим `click` программно, и он попадает в стек вызовов, срабатывает первый обработчик — выводим `FUS`, попадаем во второй — добавляем в очередь `RO`, т.к. `click` еще в стеке — не вызываем промис. Попадаем в следующий обработчик — выводим `DAH!`. `click` отработал, очередь пустая, срабатывает промис.
##### Что выведет этот код при клике на кнопку?
```
const button = document.querySelector('button');
button.addEventListener('click', () => {
console.log('FUS');
});
button.addEventListener('click', () => Promise.resolve('RO').then((x) => console.log(x)));
button.addEventListener('click', () => {
console.log('DAH!');
});
button.click();
a) FUS RO DAH!
b) FUS DAH! RO
c) RO FUS DAH!
d) DAH! RO FUS
```
**Ответ + разбор**a) FUS RO DAH!
Тут пользователь нажимает на кнопку, поэтому в стеке нет `click`, и во втором обработчике промис сработает сразу.
##### Что выведет этот код?
```
console.log(typeof Function````);
a) TypeError
b) SyntaxError
c) 'function'
d) 'undefined'
```
**Ответ + разбор**d) 'undefined'
При использовании шаблонных литералов после имени функции, она вызывается с массивом, где есть переданное значение и массив c `raw` значением. `Function`, то же самое что и `new Function` — конструктор функции. При передаче в него пустой строки мы получим функцию вида `(){}`, соответственно с каким бы аргументом мы ее не вызвали, она вернет `undefined`, здесь она вызывается с с массивом — `['', raw: ['']]`. Это примерно аналогично записи `Function('')('')`
##### Что выведет этот код?
```
function f(a, b, c) {
'use strict';
return f.length;
}
console.log(f(100, 2));
a) undefined
b) 2
c) 3
d) ошибка
```
**Ответ + разбор**c) 3
Исчерпывающее описание с [MDN](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Function/length#Description):
Свойство length является свойством объекта функции и указывает, сколько аргументов ожидает функция, то есть, количество формальных параметров. Это количество не включает остаточные параметры.
##### Что будет получено в результате?
```
const dict = {};
dict[[1]] = 2;
dict[dict] = 3;
dict[1 / 0] = 4;
a) {'1': 2, '[object Object]': 3, 'Infinity': 4}
b) Assignment to constant variable
c) {'[1]': 2, 'dict': 3, '1/0': 4}
d) {'1': 4, '[object Object]': 3}
```
**Ответ + разбор**a) {'1': 2, '[object Object]': 3, 'Infinity': 4}
Ошибки `Assignment to constant variable` тут не будет т.к. `const` не позволяет менять ссылку, а модифицировать объект можно. Все ключи объекта должны быть строками, поэтому для каждого из из них вызывается `toString`. Массив приводится к `1`, объект к `[object Object]`, а при делении на ноль получается `Infinity`.
##### Что выведет этот код?
```
console.log(!![] > [], ![] == []);
a) false false
b) false true
c) true true
d) true false
```
**Ответ + разбор**c) true true
Сравнения `> >= <= <` — вызывают арифметическое сравнение, сначала мы приводим массив к булевому значению и получаем true, и далее получается сравнение 1 > 0, что очевидно дает true. Во второй части вопроса мы приводим массив к `false`, далее `false` приводится к `0`, а массив приводится к примитиву, получается пустая строка `''`, а они равны.
На этом завершаем наши разборы, спасибо за внимание! | https://habr.com/ru/post/431744/ | null | ru | null |
# Реализация асинхронной защищенной системы связи на основе TCP сокетов и центрального OpenVPN сервера
В этой статье я хочу рассказать, о моей реализации мессенджера с двойным шифрованием сообщений на основе tcp сокетов, OpenVPN сервера, PowerDNS сервера.
Суть задачи — обеспечить обмен сообщениями через интернет минуя NAT между клиентами на различных платформах (IOS, Android, Windows, Linux). Также необходимо обеспечить безопасность передаваемых данных.
Моя система состоит из:
* OpenVPN сервера
* PowerDNS сервера
* Прокси. В моем случае это написанный мною на Ruby on Rails Web сервис с реализацией протокола SOAP. То есть на этом SOAP сервере я описываю механизм выполнения неких действий, потом делаю SOAP запрос с клиентского терминала, сервер выполняет некие действия, например апдейт зоны PowerDNS, и возвращает терминалу ответ — успешно или неуспешно. Очень удобно.
* непосредственно клиентские терминалы.
На клиентских терминалах поднимается tcp сокет который слушает определенный порт на предмет входящих сообщений. Если сообщение пришло — сокет выводит его в терминал. В самом сообщении содержится юзернейм отправителя. Для отправки сообщений также открывается tcp сокет клиента.
Сокет открывается непосредственно с терминалом удаленного клиента. Следовательно в моем случае взаимодействие идет в режиме клиент-клиент.
Поиск клиентов происходит по юзернейму. Привязку юзернейма и IP адреса хранит у себя PowerDNS сервер.
PowerDNS – представляет собой высокопроизводительный DNS-сервер, написанный на C++ и лицензируемый под лицензией GPL. Разработка ведется в рамках поддержки Unix-систем; Windows-системы более не поддерживаются.
Сервер разработан в голландской компании PowerDNS.com Бертом Хубертом и поддерживается сообществом свободного программного обеспечения.
PowerDNS использует гибкую архитектуру хранения/доступа к данным, которая может получать DNS информацию с любого источника данных. Это включает в себя файлы, файлы зон BIND, реляционные базы данных или директории LDAP.
PowerDNS по умолчанию настроен на обслуживание запросов из БД.
После выхода версии 2.9.20 программное обеспечение распространяется в виде двух компонентов – (Authoritative) Server (авторитетный DNS) и Recursor (рекурсивный DNS).
Выбор данного решения обусловлен тем, что PowerDNS умеет работать с базой данных без подключения дополнительных модулей, а также более высокой скоростью работы в сравнение с другими свободно распространяемыми решениями.
Для моих целей мне достаточно было только авторитетного модуля, рекурсор я ставить не стал.
Клиентские терминалы взаимодействуют со всеми внутренними компонентами через SOAP Gateway.
Логика работы следующая — клиент включает программу, происходит выполнение SOAP метода на апдейт зоны на PowerDNS сервере. Если клиент хочет с кем-то связаться, он вводит или выбирает в списке соответствующий username, выполняется SOAP метод на получение IP адреса из базы DNS, и происходит подключение к удаленному клиенту по IP адресу.
У меня есть написанные готовые клиенты для IOS, Android, Windows. При их написании я использовал фреймворк xamarin. Очень удобно, потребовались лишь небольшие изменения кода для перевода приложения под другую платформу.
Далее я представлю коды сокетов клиента и сервера, которые у меня используются на клиентских терминалах. Здесь приведены коды для IOS. Для Android и Windows будут почти такие. Разница только в различных типах элементов (кнопок, текстовых блоков и т д)
**Код tcp socket сервера**
```
public class GlobalFunction
{
public static void writeLOG(string loggg)
{
//Размышления над прошлым могут служить руководством для будущего
string path = @"bin\logfile.log";
string time = DateTime.Now.ToString("hh:mm:ss");
string date = DateTime.Now.ToString("yyyy.MM.dd");
string logging = date + " " + time + " " + loggg;
using (StreamWriter sw = File.AppendText(path))
{
sw.WriteLine(logging);
}
}
public static void writeLOGdebug(string loggg)
{
try
{
//Размышления над прошлым могут служить руководством для будущего
string path = @"bin\logfile.log";
string time = DateTime.Now.ToString("hh:mm:ss");
string date = DateTime.Now.ToString("yyyy.MM.dd");
string logging = date + " " + time + " " + loggg;
using (StreamWriter sw = File.AppendText(path))
{
sw.WriteLine(logging);
}
}
catch (Exception exc) { }
}
}
public class Globals
{
public static IPAddress localip = "192.168.88.23";
public static int _localServerPort = 19991;
public const int _maxMessage = 100;
public static string _LocalUserName = "375297770001";
public struct MessBuffer
{
public string usernameLocal;
public string usernamePeer;
public string message;
}
public static List MessagesBase = new List();
public static List MessagesBaseSelected = new List();
}
public class StateObject
{
// Client socket.
public Socket workSocket = null;
// Size of receive buffer.
public const int BufferSize = 1024;
// Receive buffer.
public byte[] buffer = new byte[BufferSize];
// Received data string.
public StringBuilder sb = new StringBuilder();
}
public partial class ViewController : UIViewController
{
public static ManualResetEvent allDone = new ManualResetEvent(false);
public void startLocalServer()
{
//IPHostEntry ipHost = Dns.GetHostEntry(\_serverHost);
//IPAddress ipAddress = ipHost.AddressList[0];
IPAddress ipAddress = Globals.localip;
IPEndPoint ipEndPoint = new IPEndPoint(ipAddress, Globals.\_localServerPort);
Socket socket = new Socket(ipAddress.AddressFamily, SocketType.Stream, ProtocolType.Tcp);
socket.Bind(ipEndPoint);
socket.Listen(1000);
GlobalFunction.writeLOGdebug("Local Server has been started on IP: " + ipEndPoint);
while (true)
{
try
{
// Set the event to nonsignaled state.
allDone.Reset();
// Start an asynchronous socket to listen for connections.
socket.BeginAccept(
new AsyncCallback(AcceptCallback),
socket);
// Wait until a connection is made before continuing.
allDone.WaitOne();
}
catch (Exception exp) { GlobalFunction.writeLOGdebug("Error. Failed startLocalServer() method: " + Convert.ToString(exp)); }
}
}
public void AcceptCallback(IAsyncResult ar)
{
// Signal the main thread to continue.
allDone.Set();
// Get the socket that handles the client request.
Socket listener = (Socket)ar.AsyncState;
Socket handler = listener.EndAccept(ar);
// Create the state object.
StateObject state = new StateObject();
state.workSocket = handler;
handler.BeginReceive(state.buffer, 0, StateObject.BufferSize, 0,
new AsyncCallback(ReadCallback), state);
}
public void ReadCallback(IAsyncResult ar)
{
String content = String.Empty;
// Retrieve the state object and the handler socket
// from the asynchronous state object.
StateObject state = (StateObject)ar.AsyncState;
Socket handler = state.workSocket;
// Read data from the client socket.
int bytesRead = handler.EndReceive(ar);
if (bytesRead > 0)
{
// There might be more data, so store the data received so far.
state.sb.Append(Encoding.UTF8.GetString(
state.buffer, 0, bytesRead));
// Check for end-of-file tag. If it is not there, read
// more data.
content = state.sb.ToString();
if (content.IndexOf("") > -1)
{
// All the data has been read from the
// client. Display it on the console.
string[] bfd = content.Split(new char[] { '|' }, StringSplitOptions.None);
string decrypt = MasterEncryption.MasterDecrypt(bfd[0]);
string[] bab = decrypt.Split(new char[] { '~' }, StringSplitOptions.None);
Globals.MessBuffer Bf = new Globals.MessBuffer();
Bf.message = bab[2];
Bf.usernamePeer = bab[0];
Bf.usernameLocal = bab[1];
string upchat\_m = "[" + bab[1] + "]# " + bab[2];
this.InvokeOnMainThread(delegate {
frm.messageField1.InsertText(Environment.NewLine + "[" + bab[1] + "]# " + bab[2]);
});
//if (Ok != null) { Ok(this, upchat\_m); }
Globals.MessagesBase.Add(Bf);
//GlobalFunction.writeLOGdebug("Received message: " + content);
// Echo the data back to the client.
//Send(handler, content);
}
else
{
handler.BeginReceive(state.buffer, 0, StateObject.BufferSize, 0,
new AsyncCallback(ReadCallback), state);
}
}
}
}
```
Сервер запускается в отдельном потоке, например вот так:
```
public static class Program
{
private static Thread _serverLocalThread;
///
/// The main entry point for the application.
///
///
[STAThread]
static void Main()
{
_serverLocalThread = new Thread(GlobalFunction.startLocalServer);
_serverLocalThread.IsBackground = true;
_serverLocalThread.Start();
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);
Application.Run(new Form1());
}
}
```
**Код tcp socket клиента**
```
public override void DidReceiveMemoryWarning()
{
base.DidReceiveMemoryWarning();
// Release any cached data, images, etc that aren't in use.
}
private void connectToRemotePeer(IPAddress ipAddress)
{
try
{
IPEndPoint ipEndPoint = new IPEndPoint(ipAddress, Globals._localServerPort);
_serverSocketClientRemote = new Socket(ipAddress.AddressFamily, SocketType.Stream, ProtocolType.Tcp);
_serverSocketClientRemote.Connect(ipEndPoint);
GlobalFunction.writeLOGdebug("We connected to: " + ipEndPoint);
}
catch (Exception exc) { GlobalFunction.writeLOGdebug("Error. Failed connectToRemotePeer(string iphost) method: " + Convert.ToString(exc)); }
}
private void sendDataToPeer(string textMessage)
{
try
{
byte[] buffer = Encoding.UTF8.GetBytes(textMessage);
int bytesSent = _serverSocketClientRemote.Send(buffer);
GlobalFunction.writeLOGdebug("Sended data: " + textMessage);
}
catch (Exception exc) { GlobalFunction.writeLOGdebug("Error. Failed sendDataToPeer(string testMessage) method: " + Convert.ToString(exc)); }
}
private void Client_listner()
{
try
{
while (_serverSocketClientRemote.Connected)
{
byte[] buffer = new byte[8196];
int bytesRec = _serverSocketClientRemote.Receive(buffer);
string data = Encoding.UTF8.GetString(buffer, 0, bytesRec);
//string data1 = encryption.Decrypt(data);
if (data.Contains("#updatechat"))
{
//UpdateChat(data);
GlobalFunction.writeLOGdebug("Chat updated with: " + data);
continue;
}
}
}
catch (Exception exc) { GlobalFunction.writeLOGdebug("Error. Failed Client_listner() method: " + Convert.ToString(exc)); }
}
private void sendMessage()
{
try
{
connectToRemotePeer(Globals._peerRemoteServer);
_RemoteclientThread = new Thread(Client_listner);
_RemoteclientThread.IsBackground = true;
_RemoteclientThread.Start();
string data = inputTextBox.Text;
Globals.MessBuffer ba = new Globals.MessBuffer();
ba.usernameLocal = Globals._LocalUserName;
ba.usernamePeer = Globals._peerRemoteUsername;
ba.message = data;
Globals.MessagesBase.Add(ba);
if (string.IsNullOrEmpty(data)) return;
string datatopeer = Globals._peerRemoteUsername + "~" + Globals._LocalUserName + "~" + data;
string datatopeerEncrypted = MasterEncryption.MasterEncrypt(datatopeer);
sendDataToPeer(datatopeerEncrypted + "|");
addLineToChat(data, Globals.\_LocalUserName);
inputTextBox.Text = string.Empty;
}
catch (Exception exp) { GlobalFunction.writeLOGdebug(Convert.ToString(exp)); }
}
private void addLineToChat(string msg, string username)
{
messageField1.InsertText(Environment.NewLine + "[" + username + "]# " + msg);
}
public void addFromServer(string msg, string username)
{
messageField1.InsertText(Environment.NewLine + "[" + username + "]# " + msg);
}
private void listBox1\_Click()
{
messageField1.Text = "";
Globals.MessagesBaseSelected.Clear();
GlobalFunction.ReloadLocalBufferForSelected();
for (int i = 0; i < Globals.MessagesBaseSelected.Count; i++)
{
messageField1.InsertText(Environment.NewLine + "[" + Globals.MessagesBaseSelected[i].usernameLocal + "]# " + Globals.MessagesBaseSelected[i].message);
}
Globals.\_peerRemoteServer = GlobalFunction.getPEERIPbySOAPRequest(Globals.\_peerRemoteUsername);
string Name = Globals.\_LocalUserName;
GlobalFunction.writeLOGdebug("Local name parameter listBox1\_DoubleClick: " + Name);
connectToRemotePeer(Globals.\_peerRemoteServer);
\_RemoteclientThread = new Thread(Client\_listner);
\_RemoteclientThread.IsBackground = true;
\_RemoteclientThread.Start();
}
public static ViewController Form;
```
OpenVPN сервер необходим чтобы преодолеть NAT, а также для дополнительной защиты данных.
В случае с OpenVPN, мы имеем некую адресацию внутри тоннеля, по которой могут связываться клиенты.
Процесс установки OpenVPN сервера описывать не буду, так как на эту тему есть много информации. Приведу только мою конфигурацию. Она полностью оптимизирована для моих целей и полностью рабочая (скопировал с рабочего сервера как есть, без изменений, только IP в конфигурации клиента поменял на фейковый, вместо 1.1.1.1 нужно указывать IP адрес Вашего OpenVPN сервера).
OpenVPN проводит все сетевые операции через TCP или UDP транспорт. В общем случае предпочтительным является UDP по той причине, что через туннель проходит трафик сетевого уровня и выше по OSI, если используется TUN соединение, или трафик канального уровня и выше, если используется TAP. Это значит, что OpenVPN для клиента выступает протоколом канального или даже физического уровня, а значит, надежность передачи данных может обеспечиваться вышестоящими по OSI уровнями, если это необходимо. Именно поэтому протокол UDP по своей концепции наиболее близок к OpenVPN, т.к. он, как и протоколы канального и физического уровней, не обеспечивает надежность соединения, передавая эту инициативу более высоким уровням. Если же настроить туннель на работу по ТСР, сервер в типичном случае будет получать ТСР-сегменты OpenVPN, которые содержат другие ТСР-сегменты от клиента. В результате в цепи получается двойная проверка на целостность информации, что совершенно не имеет смысла, т.к. надежность не повышается, а скорости соединения и пинга снижаются.
**Конфигурация моего OpenVPN сервера**port 8443
proto udp
dev tun
cd /etc/openvpn
persist-key
persist-tun
tls-server
tls-timeout 120
#certificates and encryption
dh /etc/openvpn/keys/dh2048.pem
ca /etc/openvpn/keys/ca.crt
cert /etc/openvpn/keys/server.crt
key /etc/openvpn/keys/server.key
tls-auth /etc/openvpn/keys/ta.key 0
auth SHA512
cipher AES-256-CBC
duplicate-cn
client-to-client
#DHCP information
server 10.0.141.0 255.255.255.0
topology subnet
max-clients 250
route 10.0.141.0 255.255.255.0
#any
mssfix
float
comp-lzo
mute 20
#log and security
user nobody
group nogroup
keepalive 10 120
status /var/log/openvpn/openvpn-status.log
log-append /var/log/openvpn/openvpn.log
client-config-dir /etc/openvpn/ccd
verb 3
**Конфигурация моего OpenVPN клиента**client
dev tun
proto udp
remote 1.1.1.1 8443
tls-client
#ca ca.crt
#cert client1.crt
#key client1.key
key-direction 1
#tls-auth ta.key 1
auth SHA512
cipher AES-256-CBC
remote-cert-tls server
comp-lzo
tun-mtu 1500
mssfix
ping-restart 180
persist-key
persist-tun
auth-nocache
verb 3
Жду комментарии по поводу данной конфигурации OpenVPN.
Все запросы от клиентских терминалов у меня выполняются на тоннельный адрес на стороне OpenVPN сервера, где настроен соответствующий проброс портов и необходимые доступы.
Вот пример:
```
iptables -A INPUT -i ens160 -p tcp -m tcp --dport 8443 -j ACCEPT
iptables -A INPUT -i ens160 -p udp -m udp --dport 8443 -j ACCEPT
iptables -A INPUT -m state --state ESTABLISHED -j ACCEPT
iptables -A INPUT -i ens192 -j ACCEPT
iptables -P INPUT DROP
iptables -t nat -A PREROUTING -p tcp -m tcp -d 10.0.141.1 --dport 443 -j DNAT --to-destination 10.24.184.179:443
#iptables -t nat -A PREROUTING -p udp -m udp -d 10.0.141.1 --dport 53 -j DNAT --to-destination 10.24.214.124:53
```
ДНС сервер у меня служит своеобразным хранилищем привязок IP-username, и не только.
Также приведу здесь конфигурацию моего PowerDNS сервера. Скажу только, что в плане безопасности она не очень оптимизирована, можно было бы разрешить только соответствующие адреса, но тоже полностью рабочая. Скопировал с рабочего сервера, только заменив логины/пароли/адреса на фейковые.
**Конфигурация моего PowerDNS authoritative сервера**launch=gmysql
gmysql-host=10.24.214.131
gmysql-user=powerdns
gmysql-password=password
gmysql-dbname=powerdns
gmysql-dnssec=yes
allow-axfr-ips=0.0.0.0/0
allow-dnsupdate-from=0.0.0.0/0
allow-notify-from=0.0.0.0/0
api=yes
api-key=1234567890
#api-logfile=/var/log/pdns.log
api-readonly=no
cache-ttl=2000
daemon=yes
default-soa-mail=dbuynovskiy.spectrum.by
disable-axfr=yes
guardian=yes
local-address=0.0.0.0
local-port=53
log-dns-details=yes
log-dns-queries=yes
logging-facility=0
loglevel=7
master=yes
dnsupdate=yes
max-tcp-connections=512
receiver-threads=4
retrieval-threads=4
reuseport=yes
setgid=pdns
setuid=pdns
signing-threads=8
slave=no
slave-cycle-interval=60
version-string=powerdns
webserver=yes
webserver-address=0.0.0.0
webserver-allow-from=0.0.0.0/0,10.10.71.0/24,10.10.55.4/32
webserver-password=1234567890
webserver-port=7777
webserver-print-arguments=yes
write-pid=yes
Для обновления зон PowerDNS я использовал встроенный REST API. Написал на Ruby следующую процедуру:
**Метод обновления зоны на PowerDNS через REST**
```
def updatezone(username,ipaddress)
p data = {"rrsets": [ {"name": "#{username}.spectrum.loc.", "type": "A", "ttl": 86400, "changetype": "REPLACE", "records": [ {"content": ipaddress, "disabled": false } ] } ] }
url = 'http://10.24.214.124:7777/api/v1/servers/localhost/zones/spectrum.loc.'
uri = URI.parse(url)
http = Net::HTTP.new(uri.host, uri.port)
req = Net::HTTP::Patch.new(uri.request_uri)
req["X-API-Key"]="1234567890"
req.body = data.to_json
p "fd"
p response = http.request(req)
p content = response.body
end
```
Этот метод я выполняю при запуске клиента. То есть происходит апдейт IP адреса, соответствующего конкретному пользователю. Напоминаю, подобные запросы у меня выполняет SOAP Gateway, написанный на Ruby.
Сама передаваемая между сокетами информация у меня шифруется с помощью алгоритма AES, но не по отдельному паролю, а по случайно выбираемому паролю из списка, что обеспечивает практически абсолютную защиту, даже при наличии у атакующего бесконечных вычислительных ресурсов. Конечно чем длиннее список, тем лучше.
У меня есть метод для проведения такого шифрования/дешифровки.
В дополнение хочу оставить здесь пример моей процедуры на c# для выполнения SOAP запросов.
Может кому-то пригодится. Во всяком случае я долго добивался чтобы SOAP запросы выполнялись на разных платформах. Сперва использовал Service Reference на Windows, но для Xamarin под другие платформы его нету. А эта методика работает везде. Во всяком случае я ее тестировал на IOS, Android и Windows
**Пример выполнения SOAP запроса на c#**
```
public static void registerSession2()
{
try
{
CallWebServiceUpdateLocation();
writeLOG("Session registered on SoapGW.");
}
catch (Exception exc)
{
writeLOG("Error. Failed GlobalFunction.registerSession2() method: " + Convert.ToString(exc));
}
}
private static HttpWebRequest CreateWebRequest(string url, string action)
{
HttpWebRequest webRequest = (HttpWebRequest)WebRequest.Create(url);
webRequest.Headers.Add("SOAPAction", action);
webRequest.ContentType = "text/xml;charset=\"utf-8\"";
webRequest.Accept = "text/xml";
webRequest.Method = "POST";
return webRequest;
}
private static XmlDocument CreateSoapEnvelope()
{
XmlDocument soapEnvelopeDocument = new XmlDocument();
string xml = System.String.Format(@"
{0}
{1}
", Convert.ToString(Globals.localip), Globals._LocalUserName);
soapEnvelopeDocument.LoadXml(xml);
return soapEnvelopeDocument;
}
public static void CallWebServiceUpdateLocation()
{
var _url = "http://10.0.141.1/master/action";
var _action = "master_update_location";
XmlDocument soapEnvelopeXml = CreateSoapEnvelope();
HttpWebRequest webRequest = CreateWebRequest(_url, _action);
InsertSoapEnvelopeIntoWebRequest(soapEnvelopeXml, webRequest);
// begin async call to web request.
IAsyncResult asyncResult = webRequest.BeginGetResponse(null, null);
// suspend this thread until call is complete. You might want to
// do something usefull here like update your UI.
asyncResult.AsyncWaitHandle.WaitOne();
// get the response from the completed web request.
string soapResult;
using (WebResponse webResponse = webRequest.EndGetResponse(asyncResult))
{
using (StreamReader rd = new StreamReader(webResponse.GetResponseStream()))
{
soapResult = rd.ReadToEnd();
}
//Console.Write(soapResult);
}
}
private static void InsertSoapEnvelopeIntoWebRequest(XmlDocument soapEnvelopeXml, HttpWebRequest webRequest)
{
using (Stream stream = webRequest.GetRequestStream())
{
soapEnvelopeXml.Save(stream);
}
}
```
P.S. Всем спасибо за внимание! Надеюсь, что кому-нибудь будет полезна если не идея, то хотя бы примеры процедур. Пишите в комментариях свои мысли по поводу такой реализации обмена сообщениями.
Немного литературы:
1. Полезная статья. Сам ее использовал. Правда предложенная в ней конфигурация мне не подошла, но процесс установки очень подробный — [Настройка OpenVPN сервера на Ubuntu 16.04](https://www.digitalocean.com/community/tutorials/openvpn-ubuntu-16-04-ru)
2. [Установка PowerDNS](https://habrahabr.ru/post/278153/)
3. [Подробно о Xamarin](https://habrahabr.ru/post/188130/) | https://habr.com/ru/post/346792/ | null | ru | null |
# Работа с параметрами в EEPROM, как не износить память
Введение
--------
Доброго времени суток. Прошлая моя [статья](https://habr.com/ru/post/560632/) про параметры в EEPROM была, мягко говоря, немного недопонята. Видимо, я как-то криво описал цель и задачу которая решалась. Постараюсь в этот раз исправиться, описать более подробно суть решаемой проблемы и в этот раз расширим границы задачи.
А именно поговорим о том, как хранить параметры, которые необходимо писать в EEPROM постоянно.
Многим может показаться, что это очень специфическая проблема, но на самом деле множество устройств именно этим и занимаются - постоянно пишут в EEPROM. Счетчик воды, тепловычислитель, одометр, всяческие журналы действий пользователя и журналы, хранящие историю измерений, да просто любое устройство, которое хранит время своей работы.
Особенность таких параметров заключается в том, что их нельзя писать просто так в одно и то же место EEPROM, вы просто израсходуете все циклы записи EEPROM. Например, если, необходимо писать время работы один раз в 1 минуту, то нетрудно посчитать, что с EEPROM в 1 000 000 циклов записей, вы загубите его меньше чем за 2 года. А что такое 2 года, если обычное измерительное устройство имеет время поверки 3 и даже 5 лет.
Кроме того, не все EEPROM имеют 1 000 000 циклов записей, многие дешевые EEPROM все еще производятся по старым технологиям с количеством записей 100 000. А если учесть, что 1 000 000 циклов указывается только при идеальных условиях, а скажем при высоких температурах это число может снизиться вдвое, то ваша EEPROM способно оказаться самым ненадежным элементом уже в первый год работы устройства.
Поэтому давайте попробуем решить эту проблему, и сделать так, чтобы обращение к параметрам было столь же простым как в прошлой статье, но при этом EEPROM хватало бы на 30 лет, ну или на 100 (чисто теоретически).
Итак, в прошлой статье, я с трудом показал, как сделать, так, чтобы с параметрами в EEPROM можно было работать интуитивно понятно, не задумываясь, где они лежат и как осуществляется доступ к ним
Напомню:
```
ReturnCode returnCode = NvVarList::Init(); //инициализируем все наши параметры из EEPROM
returnCode = myStrData.Set(tString6{ "Hello" }); //Записываем Hello в EEPOM myStrData.
auto test = myStrData.Get(); //Считываем текущее значение параметра
myFloatData.Set(37.2F); //Записываем 37.2 в EEPROM.
myUint32Data.Set(0x30313233);
```
Для начала проясню, для чего вообще нужно обращаться по отдельности к каждому параметру, этот момент был упущен в прошлой статье. Спасибо товарищам @[**Andy\_Big**](https://habr.com/users/Andy_Big/) и @[**HiSER**](https://habr.com/users/HiSER/) за замечания.
Все очень просто, существует огромный пласт измерительных устройств, которые используют полевые протоколы такие как HART, FF или PF, где пользовательские команды очень атомарные. Например, в HART протоколе есть отдельные команды - запись единиц изменения, запись верхнего диапазона, запись времени демпфирования, калибровка нуля, запись адрес опроса и т.д. Каждая такая команда должна записать один параметр, при этом успеть подготовить ответ и ответить. Таких параметров может быть до 500 - 600, а в небольших устройствах их около 200.
Если использовать способ, который [предложил](https://habr.com/ru/post/560632/#comment_23109066) пользователь [@HiSER](/users/hiser)- это будет означать, что для перезаписи одного параметра размером в 1 byte, я должен буду переписать всю EEPROM. А если алгоритм контроля целостности подразумевает хранение копии параметров, то для 200 параметров со средней длиной в 4 байта, мне нужно будет переписать 1600 байт EEPROM, а если параметров 500, то и все 4000.
Малопотребляющие устройства или устройства, питающиеся от от токовой петли 4-20мА должны потреблять, ну скажем 3 мА, и при этом они должны иметь еще достаточно энергии для питания модема полевого интерфейса, графического индикатора, да еще и BLE в придачу. Запись в EEPROM очень энергозатратная операция. В таких устройствах писать нужно мало и быстро, чтобы средний ток потребления был не высоким.
Очевидно, что необходимо, сделать так, чтобы микроконтроллер ел как можно меньше. Самый простой способ, это уменьшить частоту тактирования, скажем до 500 КГц, или 1 Мгц (Сразу оговорюсь, в надежных применениях использование режима низкого потребления запрещено, поэтому микроконтроллер все время должен работать на одной частоте). На такой частоте, простая передача 4000 байт по SPI займет около 70 мс, прибавим к этому задержку на сохранение данных в страницу (в среднем 7мс на страницу), обратное вычитывание, и вообще обработку запроса микроконтроллером и получим около 3 секунд, на то, чтобы записать один параметр.
Поэтому в таких устройствах лучше чтобы доступ к каждому параметру был отдельным, и обращение к ним должно быть индивидуальным. Их можно группировать в структуру по смыслу, или командам пользователя, но лучше, чтобы все они не занимали больше одной страницы, а их адреса были выравнены по границам страницы.
Но вернемся к нашей основной проблеме - мы хотим постоянно писать параметры.
Как работать с EEPROM, чтобы не износить её
-------------------------------------------
Те кто в курсе, можете пропустить этот раздел. Для остальных краткое, чисто мое дилетантское пояснение.
Как я уже сказал, число записей в EEPROM ограничено. Это число варьируется, и может быть 100 000, а может и 1 000 000. Так как же быть, если я хочу записать параметр 10 000 000 раз? И здесь мы должны понять, как внутри EEPROM устроен доступ к ячейкам памяти.
Итак, в общем случае вся EEPROM разделена на страницы. Страницы изолированы друг от друга. Страницы могут быть разного размера, для небольших EEPROM это, скажем, 16, 32 или 64 байта. Каждый раз когда вы записываете данные по какому-то адресу, EEPROM копирует все содержимое страницы, в которой находятся эти данные, во внутренний буфер. Затем меняет данные, которые вы передали в этом буфере и записывает весь буфер обратно. Т.е. по факту, если вы поменяли 1 байт в странице, вы переписываете всю страницу. Но из-за того, что страницы изолированы друг от друга остальные страницы не трогаются.
Таким образом, если вы записали 1 000 000 раз в одну страницу, вы можете перейти на другую страницу и записать туда еще 1 000 000 раз, потом в другую и так далее. Т.е. весь алгоритм сводится к тому, чтобы писать параметр не в одну страницу, а каждый раз сдвигаться в следующую страницу. Можно закольцевать эти действия и после 10 раз, снова писать в исходную страницу. Таким образом, вы просто отводите под параметр 10 страниц, вместо 1.
Да придется пожертвовать память, но как сделать по другому, я пока не знаю. Если есть какие мысли - пишите в комментариях.
Анализ требований и дизайн
--------------------------
Итак, мы почти поняли что хотим. Но давайте немного формализуем это. Для начала, назовем наши параметры, которые нужно писать постоянно - `AntiWearNvData` (антиизносные данные). Мы хотим, чтобы обращение к ним было такое же простое и юзер френдли, как и к кешируемым параметрам из [предыдущей статьи](https://habr.com/ru/post/560632/).
```
// читываем из EEPROM все параметры и инициализируем их копии в ОЗУ
ReturnCode returnCode = NvVarList::Init();
returnCode = myStrData.Set(tString6{ "Hello" }); //Записываем Hello в EEPROM myStrData.
auto test = myStrData.Get(); //Считываем текущее значение параметра
myFloatData.Set(37.2F); //Записываем 37.2 в EEPROM.
myUint32Data.Set(0x30313233);
myFloatAntiWearData.Set(10.0F); //Записали в параметр 10.0F в EEPROM первый раз
myFloatAntiWearData.Set(11.0F);
myFloatAntiWearData.Set(12.0F);
myFloatAntiWearData.Set(13.0F);
...
// Записываем этот же параметр в EEPROM 11 000 000 раз.
myFloatAntiWearData.Set(11'000'000.0F);
myUint32AntiWearData.Set(10U); // Тоже самое с int
myStrAntiWearData.Set(tString6{ "Hello" }); // со строкой и так далее
```
Все требования можно сформулировать следующим образом:
* Пользователь должен задать параметры EEPROM и время обновления параметра
+ На этапе компиляции нужно посчитать количество необходимых страниц (записей), чтобы уложиться в необходимое время работы EEPROM. Для этого нужно знать:
- Количество циклов перезаписи
- Размер страницы
- Время обновления параметра
- Время жизни устройства
Хотя конечно, можно было дать возможность пользователю самому задавать количество записей, но что-то я хочу, чтобы все считалось само на этапе компиляции.
* Каждая наша переменная(параметр) должна иметь уникальный начальный адрес в EEPROM
+ Мы не хотим сами руками задавать адрес, он должен высчитываться на этапе компиляции
* При каждой следующей записи, адрес параметра должен изменяться, так, чтобы данные не писались по одному и тому же адресу
+ Это также должно делаться автоматически, но уже в runtime, никаких дополнительных действий в пользовательском коде мы делать не хотим.
* Мы не хотим постоянно лазить в EEPROM, когда пользователь хочет прочитать параметр
+ Обычно EEPROM подключается через I2C и SPI, передача данных по этим интерфейсам тоже отнимает время, поэтому лучше кэшировать параметры в ОЗУ, и возвращать сразу копию из кеша.
+ При инициализации мы должны найти самую последнюю запись, её считать и закешировать.
* За целостность должен отвечать драйвер.
+ За алгоритм проверки целостности отвечает драйвер, если при чтении он обнаружил несоответствие он должен вернуть ошибку. В нашем случае, пусть в качестве алгоритма целостности будет простое хранение копии параметра. Сам драйвер описывать не буду, но приведу пример кода.
Ну кажется это все наши хотелки. Как и в прошлой статье давайте прикинем дизайн класса, который будет описывать такой параметр и удовлетворять нашим требованиям:
Класс `AntiWearNvData` будет похож на, `CachedNvData` из прошлой статьи, но с небольшими изменениям. При каждой записи в EEPROM, нам нужно постоянно сдвигать адрес записи, поэтому необходимо хранить индекс, который будет указывать на номер текущей записи. Этот индекс должен записываться в EEPROM вместе с параметром, чтобы после инициализации можно было найти запись с самым большим индексом - эта запись и будет самой актуальной. Индекс можно сделать `uint32_t` точно хватит на 30 лет - даже при 100 000 циклах записи.
И вот наш класс:
Посмотрим на то, как реализуются наши требования таким дизайном.
#### Пользователь должен задать параметры EEPROM и время обновления параметр
В отличии от `CachedNvData` Из предыдущей статьи здесь появился параметр `updateTime`. На основе этого параметра можно посчитать сколько записей необходимо для того, чтобы уложиться в ожидаемое время жизни EEPROM. Сами параметры EEPROM можно задать в отдельном заголовочнике. Например, так:
```
using tSeconds = std::uint32_t;
constexpr std::uint32_t eepromWriteCycles = 1'000'000U;
constexpr std::uint32_t eepromPageSize = 32U;
// Хотим чтобы EEPROM жила 10 лет
constexpr tSeconds eepromLifeTime = 3600U * 24U * 365U * 10U;
```
Вообще можно было бы обойтись и без `updateTime`. И для каждого параметра задавать необходимое количество самим. Но я решил, все переложить на компилятор, потому что самому считать лень. В итоге сам расчет необходимого количества записей, с учетом, что все они выравнены по границам страницы, будет примерно таким:
```
template
class AntiWearNvData
{
private:
struct tAntiWear
{
T data = defaultValue;
std::uint32\_t index = 0U;
};
inline static tAntiWear nvItem;
public:
// Умножил на 2 чтобы зарезервировать место под копию.
// Но по хорошему надо это убрать в список или драйвер
static constexpr auto recordSize = sizeof(nvItem) \* 2U;
// предполагаем, что параметр не занимает больше страницы и
// все они выравнены по границам страницы, но ничто не запрещает
// сделать более сложный расчет необходимого количества записей,
// для параметров, занимающих больше страницы. Такие ограничения для упрощения.
static\_assert(eepromPageSize/recordSize != 0, "Too big parameter");
static constexpr size\_t recordCounts = (eepromPageSize/recordSize) \*
eepromLifeTime /
(eepromWriteCycles \* updateTime);
```
#### При каждой следующей записи, адрес параметра должен изменяться, так, чтобы данные не писались по одному и тому же адресу
Еще одной особенностью нашего противоизносного параметра является тот факт, что кроме самого значения, мы должны хранить еще и его индекс. Индекс нужен нам для двух вещей:
* По нему мы будет рассчитывать следующий адрес записи
* Для того, чтобы после выключения/включения датчика найти последнюю запись, считать её и проинициализировать значением по адресу этой записи кеширумое значение в ОЗУ.
Для этого заведена специальная структура `tAntiWear`. Её то мы и будем сохранять при вызове метода `Set(...)`, который, кроме непосредственно записи, еще сдвигает индекс текущей записи на 1.
```
template
class AntiWearNvData
{
public:
ReturnCode Set(const T& value) const
{
tAntiWear tempData = {.data = value, .index = nvItem.index};
//На основе текущего индекса расчитывем текущий адрес записи в EEPROM
const auto calculatedAddress = GetCalculatedAdress(nvItem.index);
ReturnCode returnCode = nvDriver.Set(calculatedAddress,
reinterpret\_cast(&tempData),
sizeof(tAntiWear));
//Если запись прошла успешно, то обновляем кэшируемую копию параметра,
//а также смещаем индекс на 1, для следующей записи
if (!returnCode)
{
nvItem.data = value;
nvItem.index ++;
}
return returnCode;
}
...
};
```
Давайте посмотрим как реализован метод расчета текущего адреса записи:
```
template
class AntiWearNvData
{
...
private:
static size\_t GetCalculatedAdress(std::uint32\_t ind)
{
constexpr auto startAddress = GetAddress();
//собственно весь алгоритм расчета сводится к прибавленипю к стартовому адресу
//смещения текущей записи, которое находится по текущему индексу
//как только индекс будет кратен расчитанному количеству, необходимо начать писать
//с начального адреса - такой кольцевой буфер в EEPROM.
size\_t result = startAddress + recordSize \* ((ind % recordCounts));
assert(result < std::size(EEPROM));
return result;
}
constexpr static auto GetAddress()
{
return NvList::template GetAddress>();
}
};
```
#### Мы не хотим постоянно лазить в EEPROM, когда пользователь хочет прочитать параметр
Метод `Get()` - крайне простой, он просто возвращает копию из ОЗУ
```
template
class AntiWearNvData
{
public:
T Get() const
{
return nvItem.data;
}
};
```
Теперь самое интересное, чтобы проинициализировать копию в ОЗУ правильным значением, необходимо при запуске устройства считать все записи нашего параметра и найти запись с самым большим индексом. Наверняка есть еще разные методы хранения данных, например, связанный список, но использование индекса, показалось мне ну прямо очень простым.
```
template
class AntiWearNvData
{
public:
static ReturnCode Init()
{
const auto ind = FindLastRecordPosition();
constexpr auto startAddress = GetAddress();
const auto calculatedAddress = startAddress + recordSize \* ind;
return nvDriver.Get(calculatedAddress, reinterpret\_cast(&nvItem), sizeof(tAntiWear));
}
...
private:
static std::uint32\_t FindLastRecordPosition()
{
// Метод поиска индекса приводить не буду, оставлю на откуп читателям
// Здесь нужно считать все записи парамтера и найти параметр с самым
// большим индексом, пока предположим, что запись с самым большим индексом
// находится на позиции 0.
return 0U;
}
};
```
В общем-то и все класс готов, полный код класса:
Полный код класса
```
template
class AntiWearNvData
{
public:
ReturnCode Set(const T& value) const
{
tAntiWear tempData = {.data = value, .index = nvItem.index};
// К размеру типа прибавляем 4 байта индекса и умножаем на номер индекса записи.
// Умножаем на 2, чтобы драйвер мог хранить копиию записи для проверки целостности
const auto calculatedAddress = GetCalculatedAdress(nvItem.index);
ReturnCode returnCode = nvDriver.Set(calculatedAddress, reinterpret\_cast(&tempData), sizeof(tAntiWear));
// std::cout << "Write at address: " << calculatedAddress << std::endl;
//Если запись прошла успешно, то обновляем кэшируемую копию параметра, а также смещаем индекс на 1, для следующей записи
if (!returnCode)
{
nvItem.data = value;
//если колчиство записей превысило нужное количество, обнуляем индекс, начинаем писать с начального адреса
nvItem.index ++;
}
return returnCode;
}
static ReturnCode Init()
{
const auto ind = FindLastRecordPosition();
constexpr auto startAddress = GetAddress();
const auto calculatedAddress = startAddress + recordSize \* ind;
return nvDriver.Get(calculatedAddress, reinterpret\_cast(&nvItem), sizeof(tAntiWear));
}
T Get() const
{
return nvItem.data;
}
static ReturnCode SetToDefault()
{
ReturnCode returnCode = nvDriver.Set(GetCalculatedAdress(nvItem.index), reinterpret\_cast(&defaultValue), sizeof(T));
return returnCode;
}
private:
static size\_t GetCalculatedAdress(std::uint32\_t ind)
{
constexpr auto startAddress = GetAddress();
size\_t result = startAddress + recordSize \* ((ind % recordCounts));
assert(result < std::size(EEPROM));
return result;
}
static std::uint32\_t FindLastRecordPosition()
{
// Здесь нужно считать все записи парамтера и найти параметр с самым большим индексом, пока предположим,
// что запись с самым большим индексом находится на позиции 1 - Там записано число 15 с индексом 5.
return 1U;
}
constexpr static auto GetAddress()
{
return NvList::template GetAddress>();
}
struct tAntiWear
{
T data = defaultValue;
std::uint32\_t index = 0U;
};
inline static tAntiWear nvItem;
public:
static constexpr auto recordSize = sizeof(nvItem) \* 2U;
static\_assert(eepromPageSize/recordSize != 0, "Too big parameter");
static constexpr size\_t recordCounts = (eepromPageSize/recordSize) \* eepromLifeTime / (eepromWriteCycles \* updateTime);
};
```
По аналогии с `CachedNvData` из прошлой статьи, все параметры должны быть зарегистрированы в едином списке, причем, в этом списке мы можем регистрировать как и `CachedNvData`, так и наши `AntiWearNvData` параметры.
Я немного переделал список, так как IAR компилятор все еще не понимает много фишек из С++17, и собственно теперь список принимает только типы, а не ссылки на параметры. Кроме того, теперь у него появились методы `SetToDefault` и `Init`. Первый нужен, например, чтобы сбросить все параметры в их начальное значение. А второй, чтобы проинициализировать кешируемые в ОЗУ копии.

```
template
struct NvVarListBase
{
static ReturnCode SetToDefault()
{
return ( ... || TNvVars::SetToDefault());
}
static ReturnCode Init()
{
return ( ... || TNvVars::Init());
}
template
constexpr static size\_t GetAddress()
{
return startAddress + GetAddressOffset();
}
private:
template
constexpr static size\_t GetAddressOffset()
{
auto result = 0;
if constexpr (!std::is\_same::value)
{
//можно дописать алгоритм, чтобы все параметры были выравенны по странице.
result = T::recordSize \* T::recordCounts + GetAddressOffset();
}
return result;
}
};
```
Также в `CachedNvData` я добавил параметр `recordSize` и `recordCounts = 1`. Чтобы расчет адреса параметра был унифицирован для разного типа параметров.
Результат
---------
Собственно все, теперь мы можем регистрировать в списке любые параметры:
```
struct NvVarList;
constexpr NvDriver nvDriver;
using tString6 = std::array;
inline constexpr float myFloatDataDefaultValue = 10.0f;
inline constexpr tString6 myStrDefaultValue = { "Popit" };
inline constexpr std::uint32\_t myUint32DefaultValue = 0x30313233;
inline constexpr std::uint16\_t myUin16DeafultValue = 0xDEAD;
constexpr CachedNvData myFloatData;
constexpr CachedNvData myStrData;
constexpr CachedNvData myUint32Data;
constexpr AntiWearNvData myUint32AntiWearData;
constexpr AntiWearNvData myFloatAntiWearData;
struct SomeSubsystem
{
static constexpr auto test = CachedNvData < NvVarList, std::uint16\_t, myUin16DeafultValue, nvDriver>();
};
//\*\*\* Register the Shadowed Nv param in the list \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
struct NvVarList : public NvVarListBase<0,
decltype(myStrData),
decltype(myFloatData),
decltype(SomeSubsystem::test),
decltype(myUint32Data),
decltype(myFloatAntiWearData),
decltype(myUint32AntiWearData)
>
{
};
```
Замечу, что пользователю параметров нужно только объявить параметр и список, а вся портянка с кодом, до этого, пишется один раз. Используются параметры точно также как и `CachedNvData`.
```
int main()
{
NvVarList::SetToDefault();
ReturnCode returnCode = NvVarList::Init();
myFloatData.Set(37.2F);
myStrData.Set(tString6{"Hello"});
myFloatAntiWearData.Set(10.0F);
myFloatAntiWearData.Set(11.0F);
myFloatAntiWearData.Set(12.0F);
myFloatAntiWearData.Set(13.0F);
myFloatAntiWearData.Set(14.0F);
myUint32AntiWearData.Set(10U);
myUint32AntiWearData.Set(11U);
myUint32AntiWearData.Set(12U);
myUint32AntiWearData.Set(13U);
myUint32AntiWearData.Set(14U);
myUint32AntiWearData.Set(15U);
return 1;
}
```
Что произойдет в этом примере, когда мы будем писать 10,11,12...15 в наш параметр. Каждый раз при записи, адрес параметра будет смещаться на размер параметра + размер индекса + размер копии параметра и индекса. Как только количество записей превысит максимальное количество, параметр начнет писаться с начального адреса.
На картинке снизу как раз видно, что число 15 с индексом 5 записалось с начального адреса, а 10 теперь нет вообще.
В данном случае после сброса питания, при инициализации, будет найдена запись с индексом 5 и значением 15 и это значение и индекс будут записаны в кэшируемую копию нашего параметра.
Вот и все, надеюсь в этой статье цель получилось пояснить более детально, спасибо за то, что прочитали до конца.
Как обычно [код с примером](https://godbolt.org/z/oK47o9xjs). | https://habr.com/ru/post/561678/ | null | ru | null |
# Сервис для музыкантов и авторское право: что под капотом у ultimate guitar
Привет, Хабр! Меня зовут Павел Иванцов, я Head of Engineering Muse Group. Мы разрабатываем продукты для тех, кто любит музыку. Наша платформа [Ultimate-guitar.com](http://Ultimate-guitar.com) — один из крупнейших в мире сервисов для музыкантов. В нашей базе более полутора миллионов табулатур, права на которые лицензируются у разных правообладателей.
Еще в 2007 году наша команда столкнулась с серьёзным вызовом, связанным с авторским правом. В то время, не зная, как вести бизнес в новом цифровом мире, издатели начали бороться с сайтами, где пользователи делились табами без разрешения правообладателей. Большинство подобных ресурсов закрылись, потому что не знали, как выйти на легальную операционную деятельность. Но команде Muse Group удалось тогда подписать одно из первых в мире лицензионных соглашений о цифровых табулатурах, а к 2010 году — заключить контракты с десятками музыкальных издателей.
Итак, текст песни, ноты и даже просто использование имени артиста и его трека — всё это объекты авторского права. Без разрешения правообладателя использовать их нельзя: он может потребовать удалить контент, а за неисполнением требования могут последовать различные меры — от штрафа до удаления приложения из стора. Помимо этого нужно собирать и обрабатывать огромное количество статистики. Все это и множество других нюансов ложатся на плечи разработчиков. Этот пост — небольшой экскурс в то, как работать с музыкальным контентом законно.
### Почему контракт — это ТЗ для ИТ-департамента?
Потому что кроме финансовых отношений там прописаны требования к площадке и SLA. Например, по запросу правообладателя контент должен блокироваться (или разблокироваться) в указанной стране в течение некоторого срока. Отчеты об этом должны поступать в определенном виде в определенное время. Контракты с разными правообладателями могут быть разные, и итоговую систему необходимо строить, учитывая их все. Контракт дает правообладателям право управлять своим контентом на нашей площадке и обязует нас отправлять им обезличенную статистику и отчисления по факту потребления контента пользователями.
Вот что нам нужно для нормальной работы.
1. Подключаемся к правообладателям и получаем базу контента.
2. Регулярно получаем от них списки песен и разрешения.
3. Люди пользуются сервисом.
4. Мы собираем статистику.
5. Мы отчисляем деньги правообладателям.
С виду всё просто, но дьявол, как всегда, скрывается в деталях. Погружаемся дальше.
### Что есть у нас
За годы работы мы собрали большую базу контента. У нас он бывает двух видов.
* UGC (user generated content) — пользователи присылают собственные подборы аккордов и табулатур, загружают guitar pro файлы.
* PGC (professional generated content) — в этом случае табулатуры производит команда музыкантов Ultimate-guitar.
Контент отсортирован по артистам и альбомам. Все варианты подборов одного и того же трека заботливо собраны вместе командой редакторов. Они же исправляют ошибки в названиях треков и артистов, которые допускают пользователи. В итоге у нас получается аккуратный каталог. Давайте лицензируем его.
Прежде всего нужно получить разрешение на использование контента. Единого сервиса, с которым можно подписать договор и потом по API получать данные, нет. Нужно заключить контракт с каждым правообладателем. Права на многие аккорды и ноты принадлежат издателям, которые печатают нотные каталоги. Если ноты ещё не издавались, то нужно идти к музыкальному лейблу. Но ноты и аккорды — не их специализация. В итоге мы можем записать ноты сами и получить право их использовать. Таких контрактов с правообладателями может быть несколько сотен. Все они имеют ограниченный срок действия и постоянно перезаключаются. Чтобы это вовремя обрабатывать, у нас трудятся опытные юристы.
### Подключаемся к правообладателям и получаем базу контента
И сразу мы сталкиваемся с первой интересной задачей — правообладатели по-разному подготовлены технически. У кого-то каталоги сделаны в XML формате (у некоторых даже полноценный DDEX), у кого-то — в бинарном CWR, а у некоторых — просто CSV-таблицы. Аналогично и с каналом передачи данных для нас: фид, ftp, а иногда нам самим приходится парсить сайт издателя. Для этого нам нужно реализовать парсеры нескольких форматов и научиться работать с разными каналами получения данных.
Теперь о содержимом каталогов правообладателей. Если обобщить, то внутри что-то в таком духе.
```
{
“Title”: “Track 1”,
“Performer”: “Performer 1”,
“Restrictions”: {
“ALL”:false,
“FR”:“2021-01-01 00:00:00”,
},
//Дальше может идти разный набор из полей
“ISMN”: “979-0-060-11561”,
“ISRC”: “GBARL2001274”,
“ReleaseDate”: “2003-11-21 00:00:00”
}
```
Самое простое и понятное — это Restrictions. Тут правообладатель указывает, в каких странах с какой даты доступен его контент. Или где он не доступен. Так как правообладатель не знает, когда продаст права на трек, то конечной даты, естественно, нет. Это нам ещё доставит проблем дальше.
Title и Performer — название трека и имя артиста. Хорошо, если данные приходят без опечаток и битой кодировки. Особенно этим грешат агрегаторы, через которые много маленьких лейблов распространяют свои треки. В итоге у нас в базе есть около 0,1% композиций, названия которых состоят только из вопросительных знаков.
Как видите, в примере нет ID, но есть другие непонятные числа. Давайте разберемся, что это. Есть понятие ISMN — уникальный номер печатной музыки. Эти номера есть у издателей нот, но ведь вы помните — у нас есть аккорды, которые никто ещё не печатал. Тут мы снова идем к музыкальным лейблам, а у них есть только ISRC — идентификатор релиза (конкретная песня на конкретном альбоме в конкретной стране). То есть в разных странах у одного и того же трека ISRC могут быть разные. Вообще конечно, есть ISWC, который должен идентифицировать музыкальное произведение независимо от числа его переизданий, но на практике им мало кто пользуется. В итоге даже если эти магические идентификаторы есть, единственное, что более-менее надежно идентифицирует трек — это текстовая информация: исполнитель и название трека. Но пока мы находимся на этапе приема данных, нас это мало волнует.
### Регулярно получаем от них списки песен и разрешения
Список контента мы забрали, а дальше нужно его обновлять и выполнять блокировки. Информацию про новые треки мы обычно получаем через тот же канал, откуда и начальный каталог. А вот с блокировками интереснее. У кого-то всё автоматизировано и информация о блокировках поступает тем же способом. Однако многие правообладатели по-прежнему пользуются старой доброй электронной почтой. Вместе с другими обращениями получается приличный поток. Его разбором занимается отдельная небольшая команда.
### Структурируем контент
Вот мы и добрались до самого сложного момента, когда все то, что прислали правообладатели, нужно применить к материалам, присланным пользователями, чтобы определить, можно показывать табулатуру или нет. В нашем каталоге нет никаких юридических идентификаторов типа ISRC или ISWC. У нас есть внутренний song\_id, title и performer. Получается матчить табулатуры нужно по title + performer, больше пересечений нет.
Запускаем текстовый поиск и… находим не более 50% совпадений. Причина — человеческий фактор. В каждом лейбле или издательстве базы заполняются менеджерами вручную. В итоге от разных правообладателей может прийти один и тот же трек, но артист будет написан по-разному. Например, Jay-Z, Jay Z и JayZ. С этим ничего не поделать, входные данные из фидов правообладатели не изменят.
Берем открытые базы музыки: MusicBrainz и Discogs, там есть всевозможные синонимы имен артистов. Пробуем еще раз. Стало сильно лучше, но все еще не идеально. Из того что осталось видим вещи типа:
* Tom Morello, Bring Me the Horizon
* Billie Eilish and Khalid
* Papa Roach ft. FEVER 333
* И прочие варианты написания коллабораций артистов.
Ладно. Вводим разделители и режем по артистам... и благополучно распиливаем коллектив Simon & Garfunkel на двух независимых артистов, что противоречит логике, ведь это название дуэта. Это примерно как разделить название Guns N' Roses — отдельно Guns, отдельно Roses.
В итоге сначала нужно искать по целой строке, и только если не нашли — делить и пытаться искать отдельно. В отличие от стриминговых сервисов, нам ещё повезло. Туда альбом может прийти за месяц до релиза, и еще ни в одной открытой базе о нем нет информации, и никто еще не понимает, тот же это артист или новый с таким же именем. Существует довольно много артистов с одинаковыми именами, но разными песнями. У нас аккорды появляются после релиза альбома, и в базах информация есть. При этом примерно 20% песен не имеет достаточного совпадения с базой. Они отправляются в админку на ручную модерацию.
Потом выясняем следующую особенность. У некоторых песен в одной стране — два правообладателя, и один разрешает нам использовать табулатуры, а другой запрещает. Например, есть большой лейбл, который издает много треков на весь мир, и лейбл поменьше, который выпустил какой-нибудь сборник Best Pop Collection 2015. И последний в итоге имеет права на несколько отдельных песен. В этом случае побеждает прямой правообладатель, а проигрывают все последующие дистрибьюторы. Такие конфликты разрешаются вручную с помощью юристов.
А еще бывает ситуации, когда на определенной территории вообще не оказывается ни одного правообладателя. У одного закончился договор сублицензии, а основной владелец не имеет прав на данной территории. В этом случае официальный контент (присланный или лицензированный правообладателем) должен стать недоступным, а вот пользовательские подборки временно выходят из-под контроля и становятся доступны на данной территории. Но все это до появления нового владельца.
### Сбор статистики
Контент получен, структурирован, все правила применяются корректно. Пользователь, наконец, может обращаться к сервису. Остается собрать данные об использовании и отчислить деньги правообладателям. Просто отправлять с клиентов статистику об открытии табулатур и регистрировать время ее получения на сервере нельзя. При таком подходе мы получим заметное количество открытий табулатур уже после того, как они стали не доступны по требованию владельца. Или еще хуже — сменили владельца, и деньги нужно отчислить уже другому правообладателю. Все из-за асинхронности.
Мы не отправляем статистику сразу после наступления события, мы ожидаем некоторое время, копим несколько событий и отправляем их все в одном пакете данных. Это делается, чтобы не нагружать сеть и серверы. Также в момент отправки статистики может быть недоступна сеть и повторная попытка произойдет через некоторое время или когда появится сеть. Некоторые события приходят с задержкой в неделю. В итоге между открытием табулатуры и получением нами статистики об этом может пройти неопределенное время. А нам нужно отчислить деньги тому, кто владел контентом в момент обращения пользователя. Отчет идет по каждой единице контента, и любая серьезная проверка выявит проблемы. Нам проще использовать клиентское время. И хотя это потенциально уязвимее, практика показывает, что очень небольшой процент пользователей имеет неправильное время на своем устройстве.
### Отчисления
Здесь уже почти нет сложностей. В финансовый отдел нужно отправить статистику и добавить данные о том, какому правообладателю принадлежала табулатура при каждом показе пользователю (помним о том, что со временем владелец таба может меняться). На этом наша работа заканчивается. Дальше финансисты берут отчеты из App Store, Google Play и других платежных систем, приправляют это условиями контрактов и делают свою финансовую магию. Артисты получают деньги, сервис работает для пользователей, законы соблюдаются.
Итого
-----
Это была первая статья от Muse Group на Хабре. Задавайте вопросы в комментариях, делитесь своими решениями, спрашивайте то, что вам интересно узнать о музыкальных сервисах. | https://habr.com/ru/post/596881/ | null | ru | null |
# Что такое Zeroconf и с чем его едят
Я, как старый линуксоид, когда впервые установил Ubuntu и увидел незнакомое слово *avahi*, конечно же сразу посмотрел в [google](http://www.google.com/linux?q=avahi). Потыкался в несколько ссылок, увидел другие непонятные слова, типа *zeroconf*, *multicast dns*, *bonjour*. Сразу понял, что это какая то мутная технология от Apple и нафиг мне ненужная.
Однако, с ростом локальной сети внутри моей квартиры, подумал, что неплохо бы было полюбопытствовать, как можно приспособить *zeroconf*, чтобы облегчить себе жизнь.
Давайте разберемся с терминологией:
1. [Zeroconf](http://ru.wikipedia.org/wiki/Zeroconf) — это протокол, разработанный Apple и призванный решать следующие проблемы:
* выбор сетевого адреса для устройства;
* нахождение компьютеров по имени;
* обнаружение сервисов, например принтеров.
2. [Avahi](http://avahi.org/) — открытая и свободная реализация протокола zeroconf.
3. [Bonjour](http://www.apple.com/macosx/technology/bonjour.html) — open-source реализация протокола zeroconf от Apple.
Для назначения IP-адресов устройствам, zeroconf использует [RFC 3927](http://tools.ietf.org/html/rfc3927 "Dynamic Configuration of IPv4 Link-Local Addresses"). Стандарт описывает назначение, так называемых *link-local* адресов, из диапазона `169.254.0.0/16`. Технология называется *IPv4 Link-Local* или *IPv4LL*.
Для разрешения имен (name resolving) используется протокол *Multicast DNS* или сокращено *mDNS*. Он позволяет устройству выбрать имя в зоне **.local**. Работает это почти как обычный DNS, но с нюансами. Каждый компьютер хранит записи своей зоны (`A`, `MX`, `SRV`) сам и сам же обслуживает запросы к ним. Когда какой либо компьютер хочет узнать запись зоны, скажем определить IP-адрес по имени (получить запись `A` для заданной зоны), он обращается по multicast-адресу `224.0.0.251`. Соответственно, запрос получают все компьютеры в локальной сети, а отвечает тот, кто хранит зону для интересующего нас имени.
Для поиска и обнаружения сервисов используется протокол *DNS based Service Discovery* или *DNS-SD*. Для того, чтобы прорекламировать, какие сервисы доступны на устройстве, используются DNS-записи типа `SRV`, `TXT`, `PTR`.
Как все это заставить работать на Linux? Гораздо проще, чем кажется. Разберем по шагам:
1. Поставить пакеты `avahi-daemon`, `avahi-autoipd`, `libnss-mdns`. Если у вас стоит [Ubuntu](http://ubuntu.com/), то скорее всего эти пакеты уже установлены.
2. Включить IPv4LL. Этот шаг совершенно не обязателен. Если у вас есть любой IP-адрес, который нормально маршрутизируется в локальной сети, то использовать IPv4LL не нужно и даже вредно, так как по стандарту, маршрутизатуры не должны форвардить пакеты с link-local адресами (`169.254.*`). Иными словами, пробросить интернет через NAT скорее всего не удастся (мне не удалось). Но если вы уж решились, то достаточно для сетевого интерфейса локальной сети, в файле `/etc/network/interfaces` поставить тип `ipv4ll`. Что-то типа такого:
```
iface eth0 inet ipv4ll
```
Далее можно сделать `sudo invoke-rc.d networking restart` или даже перезагрузиться (`avahi-autoipd` не будет устанавливать на интерфейсе адрес `169.254.*`, если там уже есть другой IP-адрес, а он после `sudo invoke-rc.d networking restart` скорее всего никуда не исчезнет).
3. Разрешить в брандмауэре прохождение UDP-пакетов через порт `5353` по адресу `224.0.0.251` (это нужно для нормально работы mDNS) на интерфейсах, смотрящих в локальную сеть.
На этом настройку можно считать завершенной. Какие бонусы после этого вы получите? Перечисляю: все компьютеры получат имена в домене \*.local, без лишних телодвижений с вашей стороны; jabber-клиенты [Gajim](http://www.gajim.org/) или [Empathy](http://live.gnome.org/Empathy) будут показывать всех собеседников в локальной сети; [Rhythmbox](http://projects.gnome.org/rhythmbox/) будет расшаривать всю музыку; [Ekiga](http://www.gnomemeeting.org/) позволит находить и звонить всем, у кого она запущена в локалке; [PulseAudio](http://www.pulseaudio.org/) сможет находить все опубликованные звуковые устройства в сети; ну и многое, многое другое. Вы можете ознакомится со [списком программ](http://avahi.org/wiki/Avah4users#SoftwareMakinguseofAvahi), поддерживающих *avahi*.
Несколько замечаний.
1. Просмотреть анонсированные сервисы в сети можно командой `avahi-browse --all`. Она же будет показывать в realtime подключение и отключение этих сервисов.
2. Если у вас стоит брандмауэр, то сервисы могут видеть друг друга, но не общаться, если закрыты нужные для них порты.
3. При помощи демона `avahi-dnsconfd` можно клонировать `/etc/resolv.conf` на все компьютеры локальной сети.
4. Непременно проголосуйте за [идею](http://brainstorm.ubuntu.com/idea/456) внедрения связки **NFS+Zeroconf** в Gnome. | https://habr.com/ru/post/66020/ | null | ru | null |
# Мониторинг событий git clone и git push на локальном GitLab сервере

Иногда возникает желание мониторить локальный GIT сервер на предмет кто (ФИО из LDAP), какой проект и откуда(ip-адрес) клонит или пушит.
Изучив документацию, стало ясно, что такого функционала из коробки нет, точнее есть, но в платной версии GitLab. Под катом мой опыт реализации мониторинга.
Мой рецепт не претендует на универсальность, я надеюсь он многим пригодится как, отправная точка.
**Описание моей конфигурации:**У нас установлен «GitLab Community Edition 10.0.3», авторизация пользователей происходит по LDAP, клон и пуш они делают используя единую SSH учетку 'git'. По сути это стандартная конфигурация для более или менее крупной компании.
При каждом git-clone и git-push в файле '/var/log/auth.log' появляется сообщение о том, что пользователь «git » авторизовался в системе с таким-то 'fingerprint'
**cat auth.log**
```
Oct 17 12:41:11 GitLab-test sshd[25931]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=192.168.111.24 user=git
Oct 17 12:41:13 GitLab-test sshd[25931]: Accepted publickey for git from 192.168.111.24 port 55268 ssh2: RSA 63:3b:ca:8d:23:2f:d2:0c:40:ce:4d:2e:b1:2e:5f:7c
Oct 17 12:41:13 GitLab-test sshd[25931]: pam_unix(sshd:session): session opened for user git by (uid=0)
```
Затем в файле '/var/log/gitlab/gitlab-shell/gitlab-shell.log' появляется сообщение о том, что пользователь с таким-то 'key' склонировал или спушил такой-то проэкт.
**cat gitlab-shell.log**
```
I, [2017-10-19T16:17:32.006429 #1115] INFO -- : POST http://127.0.0.1:8080/api/v4/internal/allowed 0.02417
I, [2017-10-19T16:17:32.006954 #1115] INFO -- : gitlab-shell: executing git command for user with key key-1030.
```
И наконец в файле '/var/log/auth.log' появляется сообщение о том, что пользователь 'git ' вышел из системы:
**cat auth.log**
```
Oct 17 12:41:13 GitLab-test sshd[25944]: Received disconnect from 192.168.111.24: 11: disconnected by user
Oct 17 12:41:13 GitLab-test sshd[25931]: pam_unix(sshd:session): session closed for user git
```
Изучив все таблицы в базе данных стало ясно, что по мифическому 'key', который есть в логах GitLab`a, можно найти вменяемое имя пользователя и его 'fingerprint'.
Т.к. в логах строчки появляются в строгом порядке, то самая последняя запись в '/var/log/auth.log' с нужным нам 'fingerprint' будет содержать IP-адрес пользователя. Даже если сообщения от разных пользователей будут записываться не строго по порядку, сбоя не произойдет т.к. соответствие 'fingerprint' — 'IP-адрес' ищется с конца.
**Имя пользователя находится в таблице 'identities' по 'user\_id', который можно найти в таблице 'keys' по 'key' который мы видим в лог файле 'gitlab-shell.log'.**
```
SELECT extern_uid FROM identities WHERE user_id = (SELECT user_id FROM keys WHERE id = 1030);
```
**В таблице 'keys' по 'key' находится 'fingerprint'**
```
SELECT fingerprint FROM keys WHERE id = 1030;
```
**SQL запрос для поиска реального имени пользователя:**
```
SELECT extern_uid FROM identities WHERE user_id = (SELECT user_id FROM keys WHERE id = 1030);
```
**Воорижившись этими данными был придуман алгоритм, как найти имя пользователя, его ip-адрес, проект и действие которое он совершил.**1. парсим с помощью tail -f новые строчки в логе гита,
2. как только попадается строчка соответствующия регулярке идем в базу данный и ищем по полученому 'key' имя пользователя и его 'fingerprint',
3. по 'fingerprint' в 'auth.log' ищем ip-адрес пользователя и берем самую свежую запись.
Скрипт написан на питоне(Пайтоне, да простят меня фанаты).
Это мой первый опыт написания чего-либо на питоне. Буду признателен за конструктивную критику и рекомендации.
Для его работы необходимы следующие библиотеки и модули:
[python-tail](https://github.com/kasun/python-tail) Для отслеживания новых строчек в файле 'gitlab-shell.log'
[psycopg](http://initd.org/psycopg/docs/install.html) Для работы с PostgreSQL
[gelfHandler](https://github.com/stewrutledge/gelfHandler) Для отправки сообщений в GrayLog сервер
Скрипт получился довольно большой, он умеет выдергивать из конфигурационного файла 'gitlab.rb' данный для подключения к базе PostgreSQL, проверяет наличие лог-файлов SSH и 'gitlab-shell.log', умеет писать результат в файл и отправлять в GreyLog сервер, пишет логи об ошибках в файл и в консоль. Любой из этих параметров можно включить или отключить.
**Скрипт**
```
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
Краткое описание:
1. В '/var/log/gitlab/gitlab-shell/gitlab-shell.log' ищем имя проэкта, действие и 'key' юзера.
2. В базе данных ищем реальное имя пользователя и его 'fingerprint' по найденому ранее 'key'.
3. В "/var/log/auth.log" ищем IP пользователя в самой последней строчке, с нужным нам 'fingerprint'.
Строчка из gitlab-shell.log
I, [2017-10-17T12:19:56.526131 #21521] INFO -- : gitlab-shell: executing git command for user with key key-11.
SQL запрос для поиска 'fingerprint'
SELECT fingerprint FROM keys WHERE id = 11;
SQL запрос для поиска реального имени пользователя:
SELECT extern\_uid FROM identities WHERE user\_id = (SELECT user\_id FROM keys WHERE id = 11);
"""
# Импортируем модули и библиотеки
from gelfHandler import GelfHandler
import logging
import psycopg2
import re
import os
import tail
import subprocess
import sys
import datetime
time=str(datetime.datetime.now())
# Включить/включить дебаг-on или отключить - off
debug = 'on'
#debug = ''
# Включить/включить отображение полного пути до файла GIT. Имя файла соответствует имени проекта.
#pach\_git\_all = 'on'
pach\_git\_all = 'off'
# Пути к лог-файлам:
log\_file\_GuiLab = '/var/log/gitlab/gitlab-shell/gitlab-shell.log'
log\_file\_SSH = '/var/log/auth.log'
# Параметры подключения к SQL. Для автоматического определения параметров, необходимо указать путь до конфигурационного файла гитлаба, либо указать свои параметры.
gitlab\_rb = '/etc/gitlab/gitlab.rb'
#gitlab\_rb = ''
sql\_db = 'gitlab'
sql\_user = 'python\_user'
sql\_password = 'qwer123'
sql\_host = '127.0.0.1'
sql\_port = '5432'
# Параметры грейлог сервера:
out\_GrayLog='yes'
#out\_GrayLog=''
logger = logging.getLogger()
gelfHandler = GelfHandler(
host='192.168.250.145',
port=6514,
protocol='UDP',
facility='Python\_parsing\_log\_file\_GitLab'
)
logger.addHandler(gelfHandler)
#параметры записи результатов в логфайл
out\_log\_file\_name='/home/viktor/pars\_log\_GitLab.log'
#out\_log\_file\_name=''
# Функция обработки ошибки при отсутствии лог-файлов
def funk\_error\_file(log\_file):
print "Файл ", log\_file, "не найден!!!"
out\_log\_file = open(out\_log\_file\_name, 'a')
out\_log\_file.write(time);
out\_log\_file.write(" ");
out\_log\_file.write("Файл ");
out\_log\_file.write(log\_file);
out\_log\_file.write(" не найден!!!");
out\_log\_file.close()
sys.exit()
# Весь скрипт это одна функция tail, она начинает выполняться, когда в файле "gitlab-shell.log" появляется новая строчка
def funk\_pars\_gitlab\_shell(string\_gitlab\_shell):
# Локальные переменные:
action = 'action'
project = 'project'
user\_key = 0
username = 'username'
time\_ssh = 'time\_ssh'
host\_name = 'host\_name'
id\_ssh\_log\_message = 0
usr\_name\_git = 'usr\_name\_git'
ip\_address = 'ip\_address'
fingerprint\_log\_ssh = 'fingerprint\_log\_ssh'
fingerprint = 'fingerprint'
time\_git = 'time\_git'
id\_git\_log\_message = 'id\_git\_log\_message'
# Проверяем регуляркой, чтоб новая строчка соответствовала шаблону, в результате получаем массив с тремя элементами, в том числе и пустыми(предварительно проверка на полный и короткий путь до файла)
if pach\_git\_all == 'on':
regexp\_string\_gitlab\_shell = re.findall(r'^.\*\[([^ ]+)\.[\d]+\s\#([^ ]+)\]\s.\*<([^ ]\*)\s([^ ]\*)>\s{1,}for user with key\s{1,}key-([^ ]\*)\.$', string\_gitlab\_shell)
elif pach\_git\_all == 'off':
regexp\_string\_gitlab\_shell = re.findall(r'^.\*\[([^ ]+)\.[\d]+\s\#([^ ]+)\]\s.\*<([^ ]\*)\s.+repositories/([^ ]\*)\.git>\s{1,}for user with key\s{1,}key-([^ ]\*)\.$', string\_gitlab\_shell)
# Выдергиваем из полученного массива переменные
for arr\_string\_\_gitlab\_shell in regexp\_string\_gitlab\_shell:
time\_git = arr\_string\_\_gitlab\_shell[0] # Время записи сообщения в лог-файл GIT
id\_git\_log\_message = arr\_string\_\_gitlab\_shell[1] # Идентификатор сообщения в лог-файле GIT
action = arr\_string\_\_gitlab\_shell[2] # Действие т.е. клон, пуш или что-то там ещё.
project = arr\_string\_\_gitlab\_shell[3] # Проэкт в который клонили или пушили
user\_key = arr\_string\_\_gitlab\_shell[4] # Некий индетификатор пользователя присвоеный ему гитлабом.
# Проверим есть ли в переменной новые данные дабы не дергать лишний раз базу данный и не присылать пустоту
if action != 'action':
# Подключение к базе данных
connect = psycopg2.connect(database=sql\_db, user=sql\_user, password=sql\_password, host=sql\_host, port=sql\_port)
# Открываем курсор (т.е. подключаемя к базе данных)
curs = connect.cursor()
# Формируем переменную для подстановки в SQL запрос. В запросе по идентификатору пользователя будем искать его user\_id, по которому еже найдем вменяемое имя пользователя
sql\_string\_find\_username="""SELECT extern\_uid FROM identities WHERE user\_id = (SELECT user\_id FROM keys WHERE id = %s);""" %user\_key
curs.execute(sql\_string\_find\_username) # сам запрос
string\_external\_uid = curs.fetchall() # Массив с результтаом запроса
# Формируем переменную для подстановки в SQL запрос. В запросе по идентификатору пользователя будем искать его fingerprint.
sql\_string\_find\_fingerprint="""SELECT fingerprint FROM keys WHERE id = %s;""" %user\_key
curs.execute(sql\_string\_find\_fingerprint) # сам запрос
sql\_string\_fingerprint = curs.fetchall() # Массив с результтаом запроса
# Закрываем соединение с базой
connect.close()
# В следующих двух циклах разбираем полученные массивы от SQL
for fingerprint\_array in sql\_string\_fingerprint:
fingerprint = fingerprint\_array[0]
for username\_array in string\_external\_uid:
username = re.findall(r'^.\*uid=([-\w\.\_]+)', username\_array[0])
username = username[0]
# Формируем переменную и делаем системный вызов для получения последней строчки из лог-файла auth.log с полученным из SQL fingerprint.
command = """grep '%s' %s | tail -n 1""" %(fingerprint, log\_file\_SSH)
p = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
for line in p.stdout.readlines():
str\_line = str(line)
retval = p.wait()
# Разбираем найденную сторочку из auth.log при помощи регулярки на время, IP адрес и остальные не очень нужные данные.(имя сервера, идентификатор сообщения, SSH гит пользователь)
arr\_reg\_exp\_ssh\_info = re.findall(r'^([\w\*\s\d\:\s]+)\s([^ ]+)\ssshd\[(\d+)\]:\sAccepted publickey for\s([^ ]+)\sfrom\s([^ ]+)\sport\s[\s\w]+:\sRSA\s([\w\:]+)$', str\_line)
# Раскладываем массив по переменным
for data\_ssh\_info in arr\_reg\_exp\_ssh\_info:
time\_ssh = data\_ssh\_info[0]
host\_name = data\_ssh\_info[1]
id\_ssh\_log\_message = data\_ssh\_info[2]
usr\_name\_git = data\_ssh\_info[3]
ip\_address = data\_ssh\_info[4]
fingerprint\_log\_ssh = data\_ssh\_info[5]
# Изменим значение переменной 'action' на более привычные нам значения.
if action == 'git-receive-pack':
action = 'push'
elif action == 'git-upload-pack':
action = 'clone'
# Печатаем переменные для отладки
if debug:
print '----'
print ' ', 'time\_ssh', '\t\t', time\_ssh
print ' ', 'time\_git', '\t\t', time\_git
print ' ', 'username','\t\t', username
print ' ', 'action', '\t\t', action
print ' ', 'project', '\t\t', project
print ' ', 'ip\_address', '\t\t', ip\_address
print ' ', 'user\_key', '\t\t', user\_key
print ' ', 'host\_name', '\t\t', host\_name
print ' ', 'id\_ssh\_log\_message','\t', id\_ssh\_log\_message
print ' ', 'id\_git\_log\_message','\t', id\_git\_log\_message
print ' ', 'usr\_name\_git', '\t', usr\_name\_git
print ' ', 'fingerprint\_ssh', '\t', fingerprint\_log\_ssh
print ' ', 'fingerprint\_sql', '\t', fingerprint
print '----'
print '\n'
# Формирование и отправка сообщения в грейлог
if out\_GrayLog != 'no':
logger.warning(
'Now message', extra={'gelf\_props': {
'title\_time\_ssh':time\_ssh,
'title\_time\_git':time\_git,
'title\_username':username,
'title\_action':action,
'title\_project':project,
'title\_ip\_address':ip\_address,
'title\_user\_key':user\_key,
'title\_host\_name':host\_name,
'title\_id\_ssh\_log\_message':id\_ssh\_log\_message,
'title\_id\_git\_log\_message':id\_git\_log\_message,
'title\_fingerprint':fingerprint
}})
# Формирование и отправка сообщения в файл
if out\_log\_file\_name:
out\_log\_file = open(out\_log\_file\_name, 'a')
out\_log\_file.write("{time\_ssh:");
out\_log\_file.write(time\_ssh);
out\_log\_file.write("}{time\_git:");
out\_log\_file.write(time\_git);
out\_log\_file.write("}{username:");
out\_log\_file.write(username);
out\_log\_file.write("}{action:");
out\_log\_file.write(action);
out\_log\_file.write("}{project:");
out\_log\_file.write(project);
out\_log\_file.write("}{ip\_address:");
out\_log\_file.write(ip\_address);
out\_log\_file.write("}{user\_key:");
out\_log\_file.write(user\_key);
out\_log\_file.write("}{host\_name:");
out\_log\_file.write(host\_name);
out\_log\_file.write("}{id\_ssh\_log\_message:");
out\_log\_file.write(id\_ssh\_log\_message);
out\_log\_file.write("}{id\_git\_log\_message:");
out\_log\_file.write(id\_git\_log\_message);
out\_log\_file.write("}{fingerprint:");
out\_log\_file.write(fingerprint);
out\_log\_file.write("}");
out\_log\_file.write("\n");
out\_log\_file.close()
# Выполним проверку на наличие лог файлов, и корректно закроем скрипт если их нет(вызовом соответствующей функции)
if os.path.exists(log\_file\_GuiLab):
if os.path.exists(log\_file\_SSH):
if gitlab\_rb:
command\_searh\_db = """grep "gitlab\_rails\['db\_" %s|tr -s '\\n' '\ '""" %gitlab\_rb
p = subprocess.Popen(command\_searh\_db, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
for line in p.stdout.readlines():
str\_db\_line = str(line)
retval = p.wait()
arr\_db\_con = re.findall(r'^.\*db\_database\'\]\s\=\s\"([^ ]+)\".\*db\_username\'\]\s\=\s\"([^ ]+)\".\*db\_password\'\]\s\=\s\"([^ ]+)\".\*db\_host\'\]\s\=\s\"([^ ]+)\".\*db\_port\'\]\s\=\s([^ ]+)\s.\*$', str\_db\_line)
# Раскладываем массив по переменным
for data\_db\_info in arr\_db\_con:
sql\_db = data\_db\_info[0]
sql\_user = data\_db\_info[1]
sql\_password = data\_db\_info[2]
sql\_host = data\_db\_info[3]
sql\_port = data\_db\_info[4]
# Если включен дебаг, выводим шапку при запуске
if debug:
print '\n'
print 'debug ==> on'
print 'Start', (os.path.basename(\_\_file\_\_))
print '\n'
print 'sql\_db ==> ', sql\_db
print 'sql\_user ==> ', sql\_user
print 'sql\_password ==> ', sql\_password
print 'sql\_host ==> ', sql\_host
print 'sql\_port ==> ', sql\_port
print '----'
# Запускаем главную функцию
t = tail.Tail(log\_file\_GuiLab) # 'log\_file\_GuiLab' - Файл который будем парсить тайлом
t.register\_callback(funk\_pars\_gitlab\_shell) # Вызов сомой функции 'funk\_pars\_gitlab\_shell'
t.follow(s=1) # Частота парсинга файла
funk\_error\_file(log\_file\_SSH)
funk\_error\_file(log\_file\_GuiLab)
```
И как логическое завершение service для systemd:
**cat /lib/systemd/system/pars\_log\_GitLab.service**
```
[Unit]
Description=Python parsing_log_file_GitLab
# стартовать после запуска следующих сервисов
#After=network.target postgresql.service
# Требуемые сервисы
#Requires=postgresql.service
# Необходимые сервисы
#Wants=postgresql.service
[Service]
# Тип запуска
Type=simple
# Перезапуск при сбое
Restart=always
# расположение PID файла
PIDFile=/var/run/appname/appname.pid
# Рабочий каталог
#WorkingDirectory=/home/username/appname
# Пользователь и группа из под которых запускать
User=root
Group=root
# Данный параметр необходим что бы дать права на выполнение следующих
#PermissionsStartOnly=true
# ExecStartPre - выполнить ДО старта приложения
#ExecStartPre=-/usr/bin/mkdir -p /var/run/appname
#ExecStartPre=/usr/bin/chown -R app_user:app_user_group /var/run/appname
# Запуск приложения
ExecStart=/usr/bin/python2 /usr/bin/pars_log_GitLab.py &
# Пауза при необходимости
TimeoutSec=300
[Install]
WantedBy=multi-user.target
```
Теперь скриптом можно управлять следующими командами:
```
systemctl start pars_log_GitLab.service
systemctl status pars_log_GitLab.service
systemctl stop pars_log_GitLab.service
```
Не забудьте отключить дебаг перед запуском.
Всем спасибо за внимание! | https://habr.com/ru/post/340768/ | null | ru | null |
# Ускорение кода на Python средствами самого языка
Каким бы хорошим не был Python, есть у него проблема известная все разработчикам — скорость. На эту тему было написано множество [статей](http://eax.me/python-benchmark/), в том числе и [на](http://habrahabr.ru/blogs/programming/66562/) [Хабре](http://habrahabr.ru/blogs/programming/124346/).
Чаще всего, предлагают следующие решения:
* Использовать [Psyco](http://psyco.sourceforge.net/)
* Переписать часть программы на С используя Python C Extensions
* Сменить ~~мозги~~алгоритм
Безусловно, решения верные. Но у каждого из них есть свои недостатки.
**Psyco** — прекрасный модуль, достигающий ускорения кода в сотни процентов, но: поддерживаются лишь 32-битный Python версий не выше 2.6, [большое потребление памяти](http://stackoverflow.com/questions/575385/why-not-always-use-psyco-for-python-code) и тот факт, что в последнее время разработка psyco сбавила темпы, последнее обновление на [сайте](http://psyco.sourceforge.net/) датировано 16.07.2010. Возможно, с выходом Psyco v2 ситуация изменится, но пока что, этот модуль применим не всегда.
**Python C Extensions** (рекомендую отличную статью [rushman](https://habrahabr.ru/users/rushman/) [Пишем модуль расширения для Питона на C](http://habrahabr.ru/blogs/python/44520/)) — создатели Python'a сделали всем разработчикам, использующим этот язык, неоценимый подарок — Python/С API, дающий возможность относитенльно прозрачной интеграции Си-шного кода в программы на Python'e. Недостатков у этого решения только два:
1. «Порог вхождения» у C и Python/C API все же выше, чем у «голого» Python'a, что отсекает эту возможность для разработчиков, не знакомых с C
2. Одной из ключевых особенностей Python является скорость разработки. Написание части программы на Си снижает ее, пропорционально части переписанного в Си кода к всей программе
Так что, данный метод тоже подойдет не всем.
**Смена алгоритма** же возможна не всегда, часты ситуации, что и самый быстрый алгоритм выдает разочаровывающие результаты по скорости.
##### Так что же делать?
Тогда, если для вашего проекта выше перечисленные методы не подошли, что делать? Менять Python на другой язык? Нет, сдаваться нельзя. Будем оптимизировать сам код. *Примеры будут взяты из программы, строящей [множество Мандельброта](http://ru.wikipedia.org/wiki/%D0%9C%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%BE_%D0%9C%D0%B0%D0%BD%D0%B4%D0%B5%D0%BB%D1%8C%D0%B1%D1%80%D0%BE%D1%82%D0%B0) заданного размера с заданным числом итераций.
Время работы исходной версии при параметрах 600\*600 пикселей, 100 итераций составляло **3.07 сек**, эту величину мы возьмем за 100%*
**Скажу заранее, часть оптимизаций приведет к тому, что код станет менее pythonic, да простят меня адепты python-way.**
###### Шаг 0. Вынос основного кода программы в отдельную
Данный шаг помогает интерпретатору python лучше проводить внутренние оптимизации про запуске, да и при использовании psyco данный шаг может сильно помочь, т.к. psyco оптимизирует лишь функции, не затрагивая основное тело программы.
Если раньше рассчетная часть исходной программы выглядела так:
```
for Y in xrange(height):
for X in xrange(width):
#проверка вхождения точки (X,Y) в множество Мандельброта, itt итераций
```
То, изменив её на:
```
def mandelbrot(height, itt, width):
for Y in xrange(height):
for X in xrange(width):
#проверка вхождения точки (X,Y) в множество Мандельброта, itt итераций
mandelbrot(height, itt, width)
```
мы получили время **2.4 сек**, т.е. **78%** от исходного.
###### Шаг 1. Профилирование
Стандартная библиотека Python'a, это просто клондайк полезнейших модулей. Сейчас нас интересует модуль cProfile, благодаря которому, профилирование кода становится простым и, даже, интересным занятием.
Полную документацию по этому модулю можно найти [здесь](http://docs.python.org/library/profile.html), нам же хватит пары простых команд.
`python -m cProfile sample.py`
*Ключ интерпетатора -m позволяет запускать модули как отдельные программы, если сам модуль предоставляет такую возможность.*
Результатом этой команды будет получение «профиля» программы — таблицы, вида
`4613944 function calls (4613943 primitive calls) in 2.818 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 2.309 2.309 2.766 2.766 mand_slow.py:22(mandelbrot)
...`
С её помощью, легко определить места, требующие оптимизации (строки с наибольшими значениями ncalls (кол-во вызовов функции), tottime и percall (время работы всех вызовов данной функции и каждого отдельного соответственно)).
Для удобства можно добавить ключ `-s time`, отсортировав вывод профилировщика по времени выполнения.
В моем случае интересной частью вывода было (время выполнение отличается от указанного выше, т.к. профилировщик добавляет свой «оверхед»):
`4613944 function calls (4613943 primitive calls) in 2.818 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 2.309 2.309 2.766 2.766 mand_slow.py:22(mandelbrot)
3533224 0.296 0.000 0.296 0.000 {abs}
360000 0.081 0.000 0.081 0.000 {math.atan2}
360000 0.044 0.000 0.044 0.000 {math.cos}
360000 0.036 0.000 0.036 0.000 {math.sqrt}
...`
Итак, профиль получен, теперь займемся оптимизацией вплотную.
###### Шаг 2. Анализ профиля
Видим, что на первом месте по времени стоит наша основная функция mandelbrot, за ней идет системная функция abs, за ней несколько функций из модуля math, далее — одиночные вызовы функций, с минимальными временными затратами, они нам не интересны.
Итак, системные функции, «вылизаные» сообществом, нам врядли удастся улучшить, так что перейдем к нашему собственному коду:
###### Шаг 3. Математика
Сейчас, код выглядит так:
```
pix = img.load() #загрузим массив пикселей
def mandelbrot(height, itt, width):
step_x = (2 - width / 1.29) / (width / 2.6) - (1 - width / 1.29) / (width / 2.6) #шаг по оси х
for Y in xrange(height):
y = (Y - height / 2) / (width / 2.6) #для Y рассчет шага не так критичен как для Х, его отсутствие положительно повлияет на точность
x = - (width / 1.29) / (width / 2.6)
for X in xrange(width):
x += step_x
z = complex(x, y)
phi = math.atan2(y, x - 0.25)
p = math.sqrt((x - 0.25) ** 2 + y ** 2)
pc = 0.5 - 0.5 * math.cos(phi)
if p <= pc: #если лежит в области кардиоиды - отмечаем
pix[X, Y] = (255, 255, 255)
continue
Z_i = 0j
for i in xrange(itt): #проверка на выход за "границы бесконечности"
Z_i = Z_i ** 2 + z
if abs(Z_i) > 2:
color = (i * 255) // itt
pix[X, Y] = (color, color, color)
break
else:
pix[X, Y] = (255, 255, 255)
print("\r%d/%d" % (Y, height)),
```
Заметим, что оператор возведения в степень \*\* — довольно «общий», нам же необходимо лишь возведение во вторую степень, т.е. все конструкции вида x\*\*2 можно заменить на х\*х, выиграв таким образом еще немного времени. Посмотрим на время:
**1.9 сек**, или **62%** изначального времени, достигнуто простой заменой двух строк:
```
p = math.sqrt((x - 0.25) ** 2 + y ** 2)
...
Z_i = Z_i **2 + z
```
на:
```
p = math.sqrt((x - 0.25) * (x - 0.25) + y * y)
...
Z_i = Z_i * Z_i + z
```
###### Шажки 5, 6 и 7. Маленькие, но важные
Прописная истина, о которой знают все программисты на Python — работа с глобальными переменными медленней работы с локальными. Но часто забывается факт, что это верно не только для переменных но и вообще для всех объектов. В коде функции идут вызовы нескольких функций из модуля math. Так почему бы не импортировать их в самой функции? Сделано:
```
def mandelbrot(height, itt, width):
from math import atan2, cos, sqrt
pix = img.load() #загрузим массив пикселей
```
Еще 0.1сек отвоевано.
Вспомним, что abs(x) вернет число типа float. Так что и сравнивать его стоит с float а не int:
```
if abs(Z_i) > 2: ------> if abs(Z_i) > 2.0:
```
Еще 0.15сек. **53%** от начального времени.
И, наконец, грязный хак.
В конкретно этой задаче, можно понять, что нижняя половина изображения, равна верхней, т.о. число вычислений можно сократить вдвое, получив в итоге **0.84сек** или **27%** от исходного времени.
##### Заключение
Профилируйте. Используйте timeit. Оптимизируйте. Python — мощный язык, и программы на нем будут работать со скоростью, пропорциональной вашему желанию разобраться и все отполировать:)
Цель данной статьи, показать, что за счет мелких и незначительных изменения, таких как замен \*\* на \*, можно заставить зеленого змея ползать *до двух раз быстрее*, без применения тяжелой артиллерии в виде Си, или шаманств psyco.
Также, можно совместить разные средства, такие как вышеуказанные оптимизации и модуль psyco, хуже не станет:)
Спасибо всем кто дочитал до конца, буду рад выслушать ваши мнения и замечания в комментариях!
**UPD** Полезную [ссылку](http://wiki.python.org/moin/PythonSpeed/PerformanceTips) в коментариях привел [funca](https://habrahabr.ru/users/funca/). | https://habr.com/ru/post/124388/ | null | ru | null |
# Алгоритмы поиска решений лабиринтов и их практическое применение в реальном мире — Кит Берроуз и Ванесса Клотцман
### Истоки понятия «лабиринт»
Первое упоминание термина “maze” датируется тринадцатым веком, а “labyrinth” — к четырнадцатым. Сама концепция лабиринтов восходит к эпохе греческого мифологического героя Тесея — древнего героя, успешно прошедшего Кносский лабиринт и сразившего Минотавра.
Однако в более современном контексте лабиринты не имеют ничего общего с убийством мифологических существ. Теперь лабиринты чаще всего представляют из себя прямоугольную головоломку, состоящую из коридоров и поворотов, которые в конечном итоге ведут к выходу. И точно так же, как древний герой Тесей путешествовал по лабиринту, чтобы сразить Минотавра, современный человек решает задачу поиска пути в лабиринте не только для того, чтобы найти выход из лабиринта, но и для гораздо более широкого круга целей — решения связанных задач наиболее эффективным и доступным образом.
### Введение
Лабиринты являются неотъемлемой частью нашей реальности. Хотя лабиринты в реальном физическом мире редко походят на стереотипное описание лабиринтов (черно-белая прямоугольная головоломка), общая идея и концепция лабиринтов находят свое отражение во многих аспектах нашего быта. В нашей повседневной жизни мы часто сталкиваемся с ситуациями, в которых необходимо найти самый быстрый и эффективный маршрут к заданному пункту назначения. Например, когда мы ищем в продуктовом магазине отдел с молоком, мы можем просто просмотреть каждый отдел, пока мы не найдем молоко. Однако это не самый эффективный способ. Если воспользоваться подсказками в магазине или полученными ранее воспоминаниями о том, куда ведут разные пути в магазине, поиск молока может стать гораздо более эффективным процессом. В некотором смысле мы должны использовать этот же процесс при решении задачи поиска пути в реальных лабиринтах. Метод/алгоритм, выбранный нами для поиска решения лабиринта, влияет на эффективность процесса.
### Эффективность
Эффективность вычислительного алгоритма — это количество вычислительных ресурсов, используемых указанным алгоритмом, и время, необходимое для получения желаемого результата. Можно повысить эффективность алгоритма, удалив вложенные циклы for, кэшируя промежуточные или предыдущие результаты и уменьшив временную сложность алгоритма.
### Временная сложность
Временная сложность измеряет время выполнения каждого оператора в коде алгоритма. При анализе фрагмента кода на предмет его временной сложности используется нотация большого “O”. Временная сложность — это функция от размера входных данных, равная максимальному количеству элементарных операций, проделываемых алгоритмом для решения экземпляра задачи указанного размера. «Существует связь между объемом входных данных (n) и количеством выполненных операций (N) относительно времени».
*Константное (постоянное) время — O(1)*
*Линейное время — O(n)*
*Логарифмическое время — O(log(n))*
*Квадратичное время — O(n²)*
*Кубическое время — O(n³)*
Как правило, мы стремимся создать алгоритм, который будет выполняться за константное время: O(1). Это значило бы, что время выполнения алгоритма одинаково независимо от размера набора данных или количества входных данных. Логарифмическая временная сложность — O(log (n)) — указывает на то, что по мере роста размера входных данных количество операций растет логарифмически (или достаточно медленно). С другой стороны, алгоритм, который может похвастаться кубической временной сложностью — O (n³) — имеет время выполнения, пропорциональное кубу размера набора данных. В результате добросовестный программист попытается свести к минимуму временную сложность своих алгоритмов и методов, чтобы уменьшить время выполнения и затрачиваемые ресурсы.
На приведенном ниже графике показано сравнение различных временных сложностей:
### Длина кода
Не следует путать временную сложность с количеством строк кода. Такой показатель, как количество строк кода чрезвычайно легко измерить, но почти невозможно интерпретировать. В первую очередь это потому, что один алгоритм может иметь меньшую временную сложность при количестве строк кода большем, чем у другого алгоритма со сравнительно большей временной сложностью. Ошибочно считать, что временная сложность напрямую связана с количеством строк кода.
Давайте рассмотрим это на примере конкретной задачи: даны массив целых чисел *nums* и целое число *target*, нам нужно вернуть индексы двух чисел, которые в сумме равны *target*. Алгоритмы, решающие эту задачу, могут иметь разные временные сложности.
Реализация с временной сложностью O(n²):
Реализация с временной сложностью O(n):
Оба этих подхода возвращают один и тот же результат. Однако мы прекрасно видим, что, несмотря на наличие дополнительной строки кода, второй пример выполняет задачу с временной сложностью O(n), а не O(n²), что в подавляющем большинстве случаев намного быстрее.
Несмотря на это, алгоритмы с меньшим количеством строк кода зачастую менее сложны, более читабельны и проще в использовании. Далее мы будем рассматривать разные алгоритмические подходы к одной и той же задаче, поэтому вполне ожидаемо, что все алгоритмы поиска решения лабиринта будут приблизительно одинакового объема. Следовательно, длину кода алгоритма все таки следует рассматривать как критерий при сравнении и противопоставлении рассматриваемых нами алгоритмов.
### Алгоритмы поиска решения лабиринта
Алгоритмы поиска решения лабиринта представляют собой автоматизированные методы прохода. Отталкиваясь от конкретного лабиринт, можно использовать множество различных алгоритмов для нахождения его решения. В этой статье мы обсудим и проанализируем следующие хорошо известные алгоритмы поиска решения лабиринта:
* Полный перебор/”Грубая сила” (Bruteforce Algorithm)
* Алгоритм Тремо (Trémaux Algorithm)
* Алгоритм случайного поведения мыши (Random Mouse Algorithm)
* Метод следования вдоль стены (Wall-Follower Method)
* Метод обнаружения тупиков (Dead-End Filling)
### Алгоритм полного перебора
Алгоритм поиска решения лабиринта путем полного перебора (в простонародье “брутфорс”) исследует каждый проход, пока не найдет правильный путь. Работа алгоритмов такого типа обычно заключается в проверке всех возможных путей через лабиринт с постоянным перезапуском, когда сгенерированный путь оказывается неудачным. Такой подход зачастую имеет высокую временную сложность и делает программу неэффективной, поскольку она выполняет избыточный код. В результате временная сложность алгоритма такого типа часто составляет O(n!). С другой стороны, алгоритм полного перебора очень легок в реализации, поскольку он не требует маркировки развилок (что требуется для алгоритма Тремо) и зачастую состоит из небольшого количества операторов повторяющихся в цикле.
### Алгоритм Тремо
Алгоритм Тремо, изобретенный Шарлем Пьером Тремо (Charles Pierre Trémaux), представляет из себя метод поиска решения лабиринта, который, чтобы обозначить путь, рисует линии и точки на протяжении всего лабиринта. Существует ряд правил, которым необходимо следовать в рамках этого алгоритма:
* Выберите случайный проход и следуйте по нему до следующей развилки.
* Помечайте начало и конец каждого прохода по мере их прохождения (на анимации ниже в качестве меток используются точки).
* Если вы идете по проходу в первый раз, то вам нужно помечать его одной точкой.
* Если вы зашли в тупик, вернитесь назад по тому же пути до первой развилки, пометив этот проход вторыми точками (на анимации две точки представлены крестом).
* Проход, который отмечен двумя точками (на анимации это крест), не подлежит проходу и считается тупиком.
* На развилке всегда выбирайте проход, отмеченный наименьшим количеством точек (в идеале не отмеченный ни одной точкой).
Этот алгоритм накладывает дополнительное требование помечать каждую пройденную развилку. Однако этот алгоритм более эффективен и имеет меньшую временную сложность, чем алгоритмы полного перебора и случайной мыши. Цена этой эффективности - более высокая сложность реализации. Впоследствии этот алгоритм был обобщен и назван “поиск в глубину”.
*\*Демонстрация работы алгоритма Тремо:*
[Пример реализации алгоритма Тремо](https://github.com/illiterati1/python_maze/blob/master/tremaux.py) на Python:
```
import random
from walker_base import WalkerBase
FOUND_COLOR = 'red'
VISITED_COLOR = 'gray70'
class Tremaux(WalkerBase):
class Node(object):
__slots__ = 'passages'
def __init__(self):
self.passages = set()
def __init__(self, maze):
super(Tremaux, self).__init__(maze, maze.start(), self.Node())
self._maze.clean()
self._last = None # Заготовка на будущее
def _is_junction(self, cell):
return cell.count_halls() > 2
def _is_visited(self, cell):
return len(self.read_map(cell).passages) > 0
def _backtracking(self, cell, last):
return last in self.read_map(cell).passages
def step(self):
# Сердечно прошу простить меня за этот ход
if self._cell is self._maze.finish():
self._isDone = True
self.paint(self._cell, FOUND_COLOR)
return
# print self._cell.get_position()
paths = self._cell.get_paths(last=self._last)
# print paths
random.shuffle(paths)
if self._is_visited(self._cell):
# Мы уже были здесь раньше
if self._backtracking(self._cell, self._last):
# Возвращаемся назад; проверяем, если какие-нибудь непосещенные отрезки пути
unvisited = filter(lambda c: not self._is_visited(c), paths)
if len(unvisited) > 0:
self._last = self._cell
self._cell = unvisited.pop()
else:
# Непосещенных отрезков пути нет
self.paint(self._cell, VISITED_COLOR)
# Ищем путь назад
passages = self.read_map(self._cell).passages
unvisited = set(self._cell.get_paths()).difference(passages)
self._last = self._cell
self._cell = unvisited.pop()
else:
# Мы пришли к уже посещенному ранее отрезку; разворачиваемся назад
self._cell, self._last = self._last, self._cell
else:
# Новый отрезок; двигаемся в случайном порядке
if len(paths) > 0:
# Не тупик
self.paint(self._cell, FOUND_COLOR)
self._last = self._cell
self._cell = paths.pop()
else:
# Тупик; возвращаемся
self.paint(self._cell, VISITED_COLOR)
self._cell, self._last = self._last, self._cell
self.read_map(self._last).passages.add(self._cell)
# print self.read_map(self._cell).passages
# print self.read_map(self._last).passages
# raw_input('...')
```
### Алгоритм случайного поведения мыши
Алгоритм случайного поведения мыши — крайне неинтеллектуальный и простой алгоритм. Часто он реализуется в качестве самого быстрого и простого варианта. В рамках этого алгоритма, как только мы начинаем двигаться по лабиринту и достигает развилки, мы “как мышь в лабиринте” случайным образом выбираем направление, в котором продолжим путь:
* Следуем по текущему проходу, пока на пути нам не встретится развилка.
* Затем мы случайным образом принимаем решение о следующем направлении, по которому мы будем следовать.
Этот алгоритм практически вслепую ищет выход из лабиринта и обычно занимает очень много времени. Несмотря на все это, мы всегда получим решение, так как алгоритм (“мышь”) в конечном итоге обязательно найдет правильный путь через лабиринт. Случайность и неэффективность, связанные с алгоритмами случайного поведения мыши, почти всегда являются причиной высокой временной сложности. Однако, этот алгоритм может случайным образом найти правильный путь с первой попытки/цикла, что дает нам временную сложность в лучшем случае O(1). Но, скорее всего, этот алгоритм будет неоднократно перебирать неудачные варианты, которые мы уже опробовали.
[Пример кода алгоритма случайного поведения мыши](https://github.com/keithhb33/Tremauxs-Algorithm/blob/main/mouse.py) на Python:
```
from random import choice
from maze_constants import *
from walker_base import WalkerBase
MOUSE_COLOR = 'brown'
class RandomMouse(WalkerBase):
def __init__(self, maze):
super(RandomMouse, self).__init__(maze, maze.start())
self._maze.clean()
self._last = None
self._delay = 50
def step(self):
if self._cell is self._maze.finish():
self._isDone = True
return
paths = self._cell.get_paths(last=self._last)
if len(paths) == 0:
# Мы попали в тупик
self._cell, self._last = self._last, self._cell
else:
self._last = self._cell
self._cell = choice(paths)
self.paint(self._cell, MOUSE_COLOR)
self.paint(self._last, OPEN_FILL)
```
### Метод следования вдоль стены
Одним из наиболее широко известных методов поиска решения лабиринтов является метод следования вдоль стены, также известный как “правило левой/правой руки”. Этот метод основан на внешней связности лабиринта — все стены должны быть соединены с внешней границей лабиринта. Если это так, то всегда можно найти выход из лабиринта, непрерывно следуя либо по левой, либо по правой стороне на протяжении всего лабиринта. Однако в тех случаях, когда не все стены соединены с внешними границами, этот метод не всегда будет находить решение. Этот метод/алгоритм полезен, если нам известно, что стены лабиринта связаны между собой. Алгоритм очень эффективен, так как не требует маркировки развилок или перезапуска при неудачных попытках; алгоритм просто следует по левой или правой стороне лабиринта.
Программирование метода следования вдоль стеной, вероятно, будет относительно простым и не потребует большого количества строк кода. В результате временная сложность, несомненно, будет лучше, чем у алгоритма полного перебора или случайного поведения мыши. Тем не менее, явная бесполезность этого метода для множество лабиринтов является большим минусом.
[Пример реализации алгоритма следования вдоль стены](https://github.com/buddhikadesilva/Wall-Maze-Solver-Robot).
### Метод обнаружения тупиков
Алгоритм обнаружения тупиков использует другой подход к поиску решения лабиринта. Вместо того, чтобы пытаться пройти лабиринт как можно быстрее и эффективнее, алгоритм обнаружения тупиков заполняют все тупики, оставляя только правильный(е) путь(и). Правила этого алгоритма:
* Найти все тупики в лабиринте.
* Заполнить каждый путь из каждого тупика.
* Последний (оставшийся) путь является правильным путем.
Преимущества использования алгоритма обнаружения тупиков заключаются в том, что он может найти несколько решений лабиринта, если они существуют, и алгоритм должен работать для любого типа лабиринта. Несмотря на это, алгоритм очень неэффективен, особенно если лабиринт большой. Алгоритм должен проверять каждый тупик, а затем заполнять/отмечать его. Это отнимает много времени и наводит меня на мысль, что любая более-менее разумная программа с реализацией этого алгоритма будет иметь временную сложность не менее O(n²). Видео алгоритма в действии можно посмотреть ниже:
### Пример приложения с роботом
Я решила внедрить вышеперечисленные алгоритмы поиска решения лабиринта в настоящего робота, который будет пытаться найти выход из реального лабиринта. Сделать это можно с помощью Raspberri Pi Pico и MicroPython.
В этом проекте используется робот [Yahboom Raspberry Pi Pico Robot](https://www.amazon.com/dp/B09C3NW8DX?psc=1&ref=ppx_yo2ov_dt_b_product_details):
В рамках этого руководства вам не помешало бы некоторое знание Python. Робот [Yahboom Pico](https://www.amazon.com/dp/B09C3NW8DX?psc=1&ref=ppx_yo2ov_dt_b_product_details) поставляется с Raspberry Pi Pico, и вы также можете докупить множество дополнительных в рамках набора [Pico Sensor Kit](https://www.amazon.com/dp/B09C3NW8DX?ref=ppx_yo2ov_dt_b_product_details&th=1). В этом проекте не будут использоваться датчики из набора Sensor Kit, поэтому вам достаточно приобрести только Pico Robot.
Для начала нам нужно будет собрать робота Yahboom из отдельных частей и Raspberry Pi Pico, а затем подготовить для запуска MicroPython. Колеса должны быть тщательно выровнены, чтобы избежать ошибок в движений при выполнении кода. MicroPython — это язык программирования, написанный на C и оптимизированный для работы на микроконтроллерах и аппаратных средствах. Он позволяет нам управлять оборудованием, подключенным к Raspberry Pi Pico, не сталкиваясь с трудностями, связанными с языками более низкого уровня, такими как C или C++.
После того, как все будет подготовлено, мы сможем протестировать различные алгоритмы на реальном лабиринте, собранном из цветных листов бумаги и пенопласта.
### Установка программного обеспечения
Raspberry Pi Pico можно запрограммировать, подключив его к компьютеру через кабель micro-USB. Но для начала нам нужно установить MicroPython, после чего мы сможем начать программирование на устройстве. Самые актуальные версии файлов MicroPython UF2 можно найти в документации Raspberri Pi по [MicroPython](https://www.raspberrypi.com/documentation/microcontrollers/micropython.html).
\*Обратите внимание, что на Pico нужно удерживать BOOTSEL, чтобы библиотека отобразилась в Windows/Mac.
Кроме того, должны быть установлены компиляторы Thonny Python и MicroPython. Thonny позволит нам общаться с Raspberry Pi Pico и устройствами, подключенными к его контактам. Если MicroPython установлен на Raspberry Pi Pico, то соответствующая опция должна быть доступна в настройках интерпретатора Thonny:
После успешного подключения к Thonny мы сможем получить доступ к Raspberry Pi Pico и начать программирование. Python-библиотека, которую рекомендуют производители робота, называется “Pico\_Car”. Ее можно скачать [здесь](https://drive.google.com/drive/folders/1Xe3tAtfQqAJEU6Ib1ZOgz_-i0MnNNQQv) в разделе “библиотека” и впоследствии установить на Raspberry Pi Pico через Thonny. Кроме того, производители предоставляют приложение YahboomRobot на iOS для управления роботом. Чтобы использовать приложение, на Raspberry Pi Pico нужно загрузить и запустить “Bluetooth Control.py”. Файл можно скачать [здесь](https://drive.google.com/drive/folders/1XO7igQLowOMxBxdqgH5qGhujR5CU7TBD) в каталоге: “3. Robotics Course”. Если все правильно установлено и успешно запущено, то приложение должно выглядеть как на рисунке ниже, предоставляя нам возможность управлять роботом в режиме реального времени:
Чтобы управлять Raspberry Pi Pico без необходимости использовать это IOS-приложение, которое не позволяет нам запускать свой код, нам нужно реализовать управление через Bluetooth самостоятельно. Для этого мы должны использовать приложение для Android - Serial Bluetooth Terminal. Это приложение позволяет нам подключиться к Bluetooth-модулю Raspberry Pi Pico. Как только Pico получает ввод, определенный код может быть запущен или остановлен. Это позволяет нам запускать и останавливать программы по беспроводной связи и без необходимости подключать Pico к компьютеру каждый раз, когда нам нужно запустить фрагмент кода.
Значения M1 и M2 должны быть установлены в шестнадцатеричном формате в 31 и 32, чтобы запустить и остановить лабиринт соответственно.
Теперь наконец настало время реализовать на практике алгоритмы, которые мы обсуждали в первой части этой статьи. Для начала нам нужно написать код полного перебора, адаптированный к аппаратному обеспечению Raspberry Pi Pico. В этом случае нам не нужно беспокоиться об использовании датчика цвета, поскольку мы просто используем уже инициализированный 2D-массив в качестве нашего лабиринта. Используя шаги, которые программа возвращает для решения лабиринта (например, влево, вправо, вверх или вниз), мы можем заставить робота двигаться в этих направлениях. Адаптированный код можно посмотреть [здесь](https://github.com/keithhb33/MazeSolvers/blob/main/bruteforcesolverRPIPICO.py).
Используя реализованный алгоритм поиска решения лабиринта методом полного перебора (ссылка выше), робот может пройти предварительно указанный ей лабиринт. Если немного подкорректировать размеры лабиринта и ввести в код в виде двумерного массива под именем *maze*, то алгоритм может быть приспособлен для решения любого лабиринта. Стены/границы представлены в массиве как 1, а открытое пространство, через которое робот может пройти, представлено как 0:
Если бы это был реальный лабиринт, он выглядел бы следующим образом (начиная с левого верхнего индекса):
Поскольку Raspberry Pi Pico и его код теперь настроены, мы можем воссоздать лабиринт в реальной жизни, чтобы наш робот мог его пройти. Обратите внимание, что для [bruteforcesolverRPIPICO.py](https://github.com/keithhb33/MazeSolvers/blob/main/bruteforcesolverRPIPICO.py), может потребоваться корректировка переменных *speed* и *runtime* в соответствии с масштабом и размерами лабиринта. Значение по умолчанию:
*runtime = 2 #seconds*
*rotate\_pause = 2 #seconds*
*speed = 175*
Теперь робот может успешно пройти описанный выше лабиринт. Однако мы должны воссоздать лабиринт в реальной жизни. В этом случае для строительства стен лабиринта я буду использовать блоки пенопласта.
Пример робота, проходящего через лабиринт, можно найти в видео на YouTube:
В результате мы:
1. Собрали робота
2. Установили необходимое программное обеспечение (MicroPython и Thonny)
3. Убедились, что MicroPython установлен на Raspberry Pi
4. Настроили и запустили [скрипт](https://github.com/keithhb33/MazeSolvers/blob/main/bruteforcesolverRPIPICO.py), не забыв взглянуть на уже готовое приложение под iOS.
5. Построили лабиринт и запустите скрипт с помощью Thonny, подключив робота к ПК
### Реальные сценарии
Способность проходить лабиринты с помощью робота захватывает, но может быть трудно реализовать альтернативные применения этих алгоритмов в реальной жизни. Поиск решения лабиринта — это упрощенная версия задачи навигации, поэтому реализация алгоритмов навигации зиждется на тех же концепциях, что и поиск решения лабиринта.
На примере ниже мы можем увидеть работу навигации Google Maps, где для построения пути от Mcdonald's до Walgreens Google тоже использует алгоритм для определения самого быстрого маршрута. Дороги в этом случае эквивалентны проходам в лабиринте (индексы со значениями 0 в массиве лабиринта). Google также пытается найти самый быстрый маршрут — обычно маршрут с наименьшим количеством поворотов и совокупным расстоянием.
Кроме того, в 2022 году Uber начал эксперименты с доставкой еды при помощи роботов; используя технологию поиска пути и GPS, холодильник на колесах будет доставлять покупателям их еду.
Дело в том, что аналогичные процессы и алгоритмы, используемые для нахождения решений лабиринтов, используются в интересных и очень полезных реальных приложениях. Не следует рассматривать концепцию поиска решения лабиринтов как изолированную область с немногими полезными применениями в реальной жизни, это не так.
### Заключение
Роботы, способные находить путь в лабиринтах, — это концепция, которую многие могут счесть неинтересной или не столь ценной для общества. Однако для реализации этого проекта потребовалось всего около сотни строк кода. Кроме того, если бы алгоритм решения лабиринта полным перебором был адаптирован для использования датчика света или цвета, робот мог бы пройти любой лабиринт, не требуя предварительной информации о его размерах и конфигурации стен. Если бы у меня было больше времени, я бы обязательно реализовала эту идею в данном проекте. В ходе этого исследования я погрузилась в новую область удивительного мира алгоритмов, временной сложности и эффективности программ. Этот проект позволил мне в комфортном для меня темпе открыть для себя ранее неизведанную область исследований и ее связь с системами GPS и множеством перспективных идей и стартапов. В мире, которым вполне вероятно скоро будет править ИИ и сложные роботы, я чувствую себя немного спокойнее, зная, что получила важный опыт, экспериментируя с основами робототехники и алгоритмов.
**Полезные ссылки:**
1. “A Brief History of Mazes: National Building Museum.” National Building Museum |, 17 Mar. 2017, [https://www.nbm.org/brief-history-mazes/.](https://www.nbm.org/brief-history-mazes/)
2. “Simple Maze Solution (Brute Force, Depth First), Python.” Gist, <https://gist.github.com/Chuwiey/1e34ed9e65d41b735d8c.>
3. mikeburnfire. “Trémaux’s Algorithm.” *YouTube*, YouTube, 10 July 2020, <https://www.youtube.com/watch?v=RjWSlz-aEr8.>
4. *Maze Solution #3 — Tremaux’s Algorithm: V19FA Intro to Computer Science (CIS-1100-VU01)*. <https://vsc.instructure.com/courses/6476/modules/items/713459.>
5. Anubabajide. “Anubabajide/Maze-Runner: Autonomous Maze Navigation Robot Using a Raspberry Pi.” *GitHub*, <https://github.com/anubabajide/Maze-Runner.>
6. *Genetic Algorithm for Maze Solving Bot — GitHub Pages*. <https://shepai.github.io/downloads/GeneticAlgorithmVsBrute_by_Dexter_Shepherd.pdf.>
7. *“Trémaux’s Algorithm” Sample Maze Solved [1] — Researchgate*. <https://www.researchgate.net/figure/Tremauxs-algorithm-sample-maze-solved-1_fig8_315969093.>
8. Cedars-Sinai Medical Center. “With Smiles and Beeps.” *Robots Help Nurses Get the Job Done*, Cedars-Sinai Medical Center, 26 Nov. 2021, [https://www.cedars-sinai.org/newsroom/robots-help-nurses-get-the-job-donewith-smiles-and-beeps/.](https://www.cedars-sinai.org/newsroom/robots-help-nurses-get-the-job-donewith-smiles-and-beeps/)
9. “Raspberry Pi Documentation.” *MicroPython*, <https://www.raspberrypi.com/documentation/microcontrollers/micropython.html.>
10. McFarland, Matt. “Uber to Test Delivering Food with Robots.” CNN, Cable News Network, 13 May 2022, <https://www.cnn.com/2022/05/13/cars/uber-robot-delivery-la>
11. Jarednielsen. “Big O Factorial Time Complexity.” *Jarednielsencom RSS*, [https://jarednielsen.com/big-o-factorial-time-complexity/.](https://jarednielsen.com/big-o-factorial-time-complexity/)
---
> Сегодня вечером состоится открытый вебинар на тему **«Создание ассоциативного массива»**, на котором мы начнем реализовывать популярную структуру данных «ассоциативный массив» для хранения пар (ключ, значение). Рассмотрим несколько алгоритмов для решения этой задачи и сравним их эффективность:
>
> 1. Параллельные массивы;
> 2. Отсортированные массивы;
> 3. Двоичные деревья поиска.
>
> Регистрация для всех желающих [доступна по ссылке.](https://otus.pw/VpYo/)
>
> | https://habr.com/ru/post/693036/ | null | ru | null |
# Manipulation Process Efficiency (MPE) Benchmark
**Бенчмарк эффективности решения задач манипуляции предметами (MPE)**
**Назначение:** *Бенчмарк предназначен для оценки эффективности применения робототехнического комплекса в практических задачах манипуляции предметами по сравнению с другими системами автоматизации (в т.ч. роботизации) или использованием ручного человеческого труда.*
**Корректная ссылка на статью:** `https://habr.com/ru/post/534954/` | https://habr.com/ru/post/534934/ | null | ru | null |
# Robot Framework vs Pytest
Я активный сторонник Robot Framework. Уже писал на Хабре о том, что с его помощью можно решить практически любую задачу по автоматизации тестирования, особенно когда разработка ведется на Python. В той же статье я упоминал, что на смежных проектах в компании используется Pytest. Мне пришлось довольно близко познакомиться с этим инструментом, так что теперь я готов провести его полноценное сравнение с Robot Framework, конечно же, со своей персональной колокольни.
")Robot vs. Snake by Beanhex (https://www.weasyl.com/~beanhex)Кстати, на идею статьи меня натолкнул один из комментариев [к предыдущей статье](https://habr.com/ru/company/maxilect/blog/470924/), в котором читатель сравнил jUnit и Robot Framework для проекта на Java. На мой взгляд, в этих условиях Robot Framework (основанный на Python) изначально был не очень применим. Но сама идея сравнения ближайшего аналога jUnit в мире Python (того самого Pytest) и Robot Framework мне понравилась.
Что это за инструменты?
-----------------------
### Pytest
Фактически, Pytest - реализация xUnit фреймворка для Python. Если вы всю жизнь работали с jUnit или nUnit (двумя самыми распространенными представителями этого семейства для Java и .NET соответственно), то в Pytest найдете ровно те же стандарты - быстро поймете, что происходит, будете следовать привычным подходам написания юнит-тестов. xUnit-фреймворки - это надстройки над языком программирования или библиотеки в них, которые удобно использовать самим разработчикам. За счет этого они довольно распространены и популярны.
Для понимания ситуации вместе с Pytest, как и вместе со многими xUnit-фреймворками, необходимо использовать инструмент генерации логов. Уже традиционно в этой роли применяется Allure. Наверное, сегодня это стандарт для логов автотестов, который хочет видеть бизнес. Но надо понимать, что Pytest разрабатывается своим сообществом, а Allure - своим, и векторы этих команд могут в какой-то момент развернуться в разные стороны.
### Robot Framework
В отличие от Pytest, Robot Framework - это domain specific language (DSL) - язык, специфичный для своей предметной области. Это не Python, хотя он на нем построен. Зато на Python можно написать все, что угодно для Robot Framework. И все возможности, о которых я здесь говорю (а также интеграции, настройки), доступны из коробки.
Robot Framework не настолько удобен разработчикам, поскольку требует более глубокого погружения. По сути, это другой подход написания автотестов. Как Cucumber для Java. Зато Robot Framework самостоятельно генерирует развернутые отчеты (мы об этом еще поговорим), т.е. фактически он содержит в себе также слой генерации отчетов, и развивается продукт одним сообществом - неделимо и гармонично.
Кстати, сообщество открытое и довольно отзывчивое. У него есть открытый канал в Slack, где каждый желающий может задать вопрос по Robot Framework и получить на него ответ. Я и сам иногда там отвечаю. Я даже иногда контрибьючу в Robot Framework.
Аргументы в пользу Robot Framework
----------------------------------
### Отсутствие лишних ограничений на наименования
В Pytest и ряде других xUnit фреймворков название тест-кейса всегда должно начинаться с test. Мне кажется логичным, когда используется метод test. Но в остальных случаях ограничения на наименования не помогают процессу.
Предполагаю, что эти ограничения в Pytest появились из желания разделить то, что относится к тест-кейсам, и то, что касается общих методов, вызываемых из тестов. Поскольку Pytest заточен под юнит-тестирование, реальные и тестовые методы приложения могут лежать в одном классе, так что возможна неразбериха.
Но на мой взгляд, здесь проблема именно в выбранном подходе, который “тащит” за собой то, что в XXI веке нам приходится ставить какие-то ограничения на названия тест-кейсов.
Robot Framework никак не заточен на юнит-тесты. В нем предусмотрен раздел Keywords, а сами тесты могут называться как угодно. Мне кажется, так работать удобнее. Более того, в Robot Framework любые сущности, в том числе keywords, можно называть по-русски. Грамотно подобрав названия, текст теста можно превратить в рассказ (“Открой сайт, введи логин, убедись, что результат такой-то”). Это позволяет не писать длинные комментарии, рассказывающие о том, что там происходит. Любой участник разработки или руководитель, никогда не залезавший в недра тестирования, может открыть этот тест и понять его. И время экономится, и понимание ситуации даже через полгода сохраняется.
### Suite setup
Бывает, что для набора тест-кейсов (тест-сьюта) требуются однотипные настройки, например выполнение метода, который готовит некие данные, создает сущности и сохраняет их идентификаторы для использования в тестах. В Robot Framework предусмотрены отдельные настройки suite setup, которые применяются для всех тестов в наборе. Отдельно есть suite teardown, который выполняется после всех тестов в наборе, а также аналогичные настройки для каждого тест-кейса (test setup и test teardown). Это удобно, логично и не требует изобретения велосипедов.
В xUnit фреймворках есть аннотации, заменяющие настройки suite setup, а в Pytest есть фикстуры со `scope=”class”`.
В Pytest тест-кейсы могут быть просто методами (и тогда у них нет никакого suite setup - т.е. нет единой подготовки). Если же нужна единая подготовка, мы можем обернуть эти методы в класс. Но если мы сделаем фикстуру со `scope=”class”` для этого класса (т.е. попытаемся реализовать suite setup), то получим отдельный инстанс класса для каждого теста, так что данные из suite setup никак не попадут в тест-кейсы. Отдельные инстансы, вероятно, создаются из предположения, что данные из разных тест-кейсов не должны влиять друг для друга. Но из-за этого настроить среду для выполнения тестов намного сложнее, чем в Robot Framework, где suite setup предусмотрен априори.
Обычно этот вопрос в Pytest приходится обходить через создание отдельной фикстуры, куда загружаются данные. Эта фикстура впоследствии подтягивается в тесты. Другой путь - воспользоваться средствами Python, создав статическое поле у класса, которое будет общим для всех его инстансов (например, `self.__class__.test_id = 2`). Но на мой взгляд, это тоже костыль - к полям класса через подчеркивание не стоит обращаться извне.
### Логи
Как я отметил выше, в Pytest для генерации логов чаще всего используется Allure. Это красиво и модно. Но из-за описанной выше особенности с инстансами, Allure не понимает, что и как связано с тестом. В отчет не попадают действия из suite setup. Приходится это обходить через написание обработчиков. И с моей точки зрения это уже не просто костыль, а настоящий костылесипед.
Кстати, в других xUnit фреймворках эта проблема тоже есть.
На фоне Pytest+Allure у Robot Framework логи максимально подробны и даже избыточны. Они включают даже то, о чем ты никогда не задумаешься - Robot пишет все, что ты делаешь. С помощью этого лога гораздо проще отлавливать плавающие ошибки, которые так просто не воспроизведешь. Ты точно знаешь, где и какое значение было у переменной, какой API вызвали. Зачастую и перезапускать тест не надо, чтобы понять, что происходит. Для Pytest в таких сложных случаях приходится придумывать инструменты, которые помогают генерировать лог, как у Robot Framework.
### Синтаксический сахар
В Robot Framework не нужно придумывать усложняющих конструкций. Есть выражения, спасающие от лишнего кода.
Я люблю писать keyword-обертки и в них оборачивать другие keyword-ы. Например, в keyword, который из ответа API берет ID, можно будет подсовывать keyword, который дергает разные API (если в компании есть стандарты написания кода, то ответы API будут сходными - поле ID скорее всего будет во всех).
Например, можно написать: “Идентификатор из создание сущности”. Здесь “Идентификатор из” - keyword-обертка, “создание сущности” - это keyword, который вызывает API и отдает весь ответ. В другом случае можно написать “Идентификатор из создание таблицы”, где “создание таблицы” - это другой keyword.
Для меня писать подобным образом удобнее и понятнее. А если изменить keyword с “создание сущности” на “создания сущности”, то конструкция будет читаться даже с литературной точки зрения (“Идентификатор из создания сущности”).
### Теггирование
В заголовке лога Robot Framework показывает статистику по каждому тегу. Если изначально правильно расставить теги, достаточно будет взглянуть на эту статистику, чтобы увидеть, в чем проблема, не забивая себе голову тем, что происходит внутри. Я писал про это в предыдущей статье. Там же я упоминал, что теги можно привязывать к идентификаторам багов в Jira или в любом другом треккере, который у вас используется. Как раз недавно у меня был случай, когда на одном из поддерживаемых тестов, о которых я и думать забыл с полгода назад, “сработали” старые забытые баги, привязанные к тегам. И на их поиски ушло несколько секунд, вместо минут и часов.
В Pytest присутствует теггирование, но оно не попадает в лог. Снова нужны какие-то костыли, чтобы реализовать это своими руками. Поэтому, насколько я знаю, так почти никто не делает.
Кстати, и Allure не дает возможности отобразить статистику по тегам. Вероятно, если бы в нем появилась такая возможность, она в моих глазах приблизила бы связку Pytest+Allure к Robot Framework по функциональности. Плюс был бы в том, что связка Pytest+Allure не требовала бы забивать головы консервативных разработчиков новым DSL. К сожалению, появление таких инструментов маловероятно из-за того, что Pytest и Allure развиваются разными группами.
Аргументы в пользу Pytest
-------------------------
В моем списке всего два аргумента в пользу Pytest. Зато от сторонника другого инструмента они должны прозвучать весомо.
### Отладка
Об этом писал один из читателей в комментариях к предыдущей статье. К сожалению, ты не можешь приостановить выполнение в Robot Framework, чтобы посмотреть значения переменных. Это факт, который можно записать в плюс Pytest.
Но, на мой взгляд, это и не нужно. Все, что можно было бы посмотреть таким образом, доступно в логах. Просто для работы через логи нужно немного поменять мышление, сменить парадигму разработчика (привыкшего к определенному сценарию отладки).
### Параметрические тесты Pytest
Я нашел то, чего нет в Robot Framework - благодаря параметризации Pytest может создавать тест-кейсы на лету. В Robot Framework 10 тестов всегда будут 10-ю тестами, ни больше, ни меньше. В Pytest в некоторых случаях с помощью одного параметрического теста можно покрыть огромное количество кейсов.
На примере реального проекта. Предположим, у нас есть API с двумя параметрами, каждый из которых может принимать несколько вариантов значений (например, один принимает 7 значений, другой - 10). И эти значения друг друга не исключают. В соответствии с теорией тестирования в таком случае надо выбрать несколько кейсов, более-менее равномерно покрывающих сетку из 70 “пересечений” (метод pair-wise). Но я с помощью метода product из модуля itertools (который перемножает списки) написал тест-сетап, который подготавливает 70 комбинаций данных, а потом ходит в API и обеспечивает то самое утопическое exhaustive testing. При появлении еще одного варианта в начальных данных мне достаточно просто добавить строчку в один из первоначальных списков.
В Robot Framework так сделать нельзя. Там можно написать тест-шаблон, который принимает два значения, и сделать 70 вызовов. При появлении новых значений количество вызовов придется увеличивать.
В целом плюсов за Robot Framework получилось больше - я остаюсь его ярым сторонником. Но, конечно, это лишь мое мнение.
Автор статьи: Владимир Васяев
P.S. Мы публикуем наши статьи на нескольких площадках Рунета. Подписывайтесь на наши страницы в [VK](https://vk.com/maxilect), [FB](https://www.facebook.com/maxilectru/), [Instagram](https://www.instagram.com/maxilectteam/) или [Telegram-канал](https://t.me/maxilect), чтобы узнавать обо всех наших публикациях и других новостях компании Maxilect. | https://habr.com/ru/post/521620/ | null | ru | null |
# Как построить “Умный дом" и не сойти с ума

Умная мебель, которая сама заботится о порядке в доме, — must-have почти любой футуристической картины. На самом деле саморегулирующееся климат, автоматическое включение и выключение света и голосовое управление бытовой техникой — всё это можно настроить уже сейчас. Но понадобится немного опыта, базовых знаний в области техники и иногда программирования, а также целое море фантазии. В моем же случае, я сделал так что достаточно только фантазии, но обо всем по порядку…
 Самой идеей «умного дома» я заинтересовался около пяти лет назад. Сначала я сделал самую простую систему. Она управляла светом в коридоре и ванной по датчику движения, вытяжкой по датчику влажности, а также погодной станцией — в то время по ним все сходили с ума. Каждый уважающий себя DIY-щик должен был сделать погодную станцию.
Первым делом я оснастил квартиру управляемым реле для автоматического включения света в коридоре и ванной. Это выглядело следующим образом: один датчик стоял в коридоре, второй в ванной.
Если кто-то шел в ванную комнату, то его движение фиксировал коридорный датчик и тут же включал свет и в коридоре, и в ванной. При этом, если в ванную никто не заходил, то это уже фиксировал датчик, находящийся внутри ванной комнаты. Спустя 15 секунд свет там выключался. Если человек заходил в ванную, то свет в коридоре выключался через минуту.
Я продумал и такие случаи, если кто-то слишком задумывался, сидя на «белом друге» в ванной (у меня был совмещенный санузел). Для этого свет в ванной был поделен на две группы. Одна выключалась через 3 минуты после того, как датчик в ванной переставал фиксировать движения, другая — через 5 минут. Так что больше чем на пять минут оставаться без движения в ванной при свете не получалось. Очень дисциплинирует. Впрочем, можно было всегда пошевелить рукой и продолжить думать о насущном.
В ванной также работал датчик влажности, который автоматически запускал вытяжку, если влажность превышала 50%. Как только помещение проветривалось до 45% влажности, вытяжка выключалась.
Управление шло — а точнее пыталось идти — через платформу Arduino.

*Фото взято с сайта* [*производителя*](https://www.arduino.cc/en/uploads/Main/ArduinoUnoFront240.jpg)
Почти сразу стало понятно, что эта платформа — не совсем про создание умного дома. Основное неудобство работы с Arduino сводилось к тому, что платформа работала без сети, а без нее не получалась никакой по-настоящему единой экосистемы. Конечно, я мог бы переделать Arduino и добавить поддержку сети, но зачем? Я выбрал более простой путь и сменил эту платформу на другую.
Наигравшись с Arduino, я переподключил дом на плату ESP-8266. По сути это тот же Arduino, но с Wi-Fi + компактнее по размерам. Этот модуль до сих пор пользуется популярностью у производителей гаджетов для умного дома.

*Фото взято из* [*Интернета*](https://makeradvisor.com/wp-content/uploads/2017/10/aliexpress-esp8266-esp-12e-nodemcu-wi-fi-development-board.jpg)
Параллельно я пытался сделать умный дом еще более умным. Например, решить проблему круглосуточно работающих теплых полов или вечно включенного кондиционера. Для этого я купил китайские WiFi-термостаты Beok. Они позволили отключать подогрев пола дистанционно, но приходилось это делать через специальное приложение в телефоне.
Задачу по дистанционному управлению кондиционером я решил с помощью эмулятора инфракрасных сигналов Broadlink RM Pro. Ничего сложного: записываешь на эмулятор сигнал с пульта управления кондиционером (тут может быть любая техника, управляемая с помощью пульта), а потом в телефоне нажимаешь кнопочку в приложении, и эмулятор воспроизводит ранее записанный сигнал. В случае с кондиционером я получил возможность включать и выключить его, задавать режим работы и выставлять другие параметры удаленно.
Также установил выключатели Livolo. С их помощью я мог также включать и выключать свет по радиоканалу.

Из минусов: для управления пришлось снова установить отдельное приложение и не было обратной связи, то есть я не мог увидеть, что свет включен, если его включил или выключил кто-то вручную с помощью обычного выключателя.
В доме также появились различные управляемые WiFi-реле типа Sonoff или Tuya и даже дорогущий Danalock для замка в квартиру, к которому тоже потребовалось отдельное приложение. Почти все эти мелочи (за исключением Danalock) я покупал на китайской площадке Aliexpress, где они стоили копейки и позволяли мне экспериментировать без серьезных вложений.
Одной из первых относительно серьезных покупок стал бризер от Tion. С автоматическим контролем CO2 он более или менее справлялся, но температуру подогрева воздуха зимой постоянно приходилось регулировать вручную. И снова — для управления пришлось установить отдельное приложение.

*Фото взято с сайта* [*производителя*](https://tion.global/breezer/)
Всех датчиков и контроллеров, которые я тогда испробовал, я даже не могу вспомнить. Мой смартфон был забит приложениями по их управлению. Это был целый зоопарк, за которым постоянно приходилось следить. Я попытался объединить управление этими приложениями через всякие агрегаторы типа HomeBridge/MajorDomo и т.п. Но у всех обнаружились свои существенные недостатки:
* недружелюбный интерфейс, а порой просто ужасный интерфейс
* отсутствие поддержки всех используемых приложений
* сложное подключение
Поиски какого-либо приложения для централизованного управления такого объема датчиков, контроллеров и других систем управления к успеху не привели. Тогда же я попробовал самостоятельно довести до ума одно из «умных» устройств — тот самый бризер Tion. Я написал скрипт для автоматического управления температурой нагрева в зависимости от температуры в помещении. Дело в том, что у системы вентиляции не было автоподстройки температуры нагрева воздуха. Получалось, что в помещении было то супержарко, то суперхолодно. Никак не выходило добиться золотой середины. Вот с помощью написанного скрипта и бризера эту задачу удалось решить.
Успех со скриптом для бризера натолкнул меня на идею создать собственное приложение для управления умным домом. Основной целью было создать прогу с удобной интеграцией умных устройств, многоуровневыми условиями автоматизации и возможностью управлять всеми девайсами в доме.
Около года я самостоятельно занимался back-end и front-end разработкой приложения.
Серверная часть написана на NodeJS. Выбор в пользу NodeJS был сделан из-за развитого сообщества, в котором имеются реализованные протоколы практически ко всем имеющимся на рынке устройствам. Клиентская часть написана на Angular (Ionic) и работает на Android/iOS. В общем классическая клиент-серверная архитектура.
***На заметку:*** В процессе работы над приложением меня посетило техническое озарение по поводу использования примесей при написании драйверов устройств. Не знаю, может для кого-то это элементарно, но мне реально стало легче дышать.
Я многократно переписывал драйвера устройств, пока не пришел к примерно такому виду:
**Пример кода одного из устройств**
```
import {XiaomiSubdeviceV2} from '../xiaomi.subdevice.v2';
import {load_power} from '../capabilities/load_power';
import {power_plug} from '../capabilities/power_plug';
import {PowerPurpose} from '../../base/PowerPurpose';
import {Relay} from '../../base/types/Relay';
import {HomeKitAccessory} from '../../hap/HomeKitAccessory';
import {Lightbulb2Accessory} from '../../hap/Lightbulb2Accessory';
import {Yandex} from '../../yandex/Yandex';
import {YandexLightOrSwitch} from '../../yandex/YandexLightOrSwitch';
export class LumiPlug extends XiaomiSubdeviceV2.with(Relay, power_plug, load_power, PowerPurpose,
HomeKitAccessory, Lightbulb2Accessory,
Yandex, YandexLightOrSwitch) {
onCreate() {
super.onCreate();
this.model = 'Mi Smart Plug';
this.class_name = 'lumi.plug';
this.driver_name = 'Mi Smart Plug';
this.driver_type = 3;
this.parent_class_name = 'lumi.gateway';
}
getIcon() {
return 'socket';
}
}
```
Суть в том, что несмотря на обилие различных устройств, все они делают приблизительно одно и то же и предоставляют примерно одинаковую информацию. Поэтому все возможности устройств были вынесены в отдельные примеси, из которых в конечном итоге и состоит окончательный драйвер. Например, в приложении поддержано множество устройств, имеющих функцию включить/выключить. Она-то и вынесена в отдельную примесь и идентично используется для всех девайсов. Элементарно же, Ватсон!
Что это дало в итоге: любой драйвер нового устройства пишется довольно быстро и легко, т.к. все стандартизировано и не нужно беспокоиться о дальнейшем хранении полученной информации. Для совсем новых протоколов (которых у меня еще не было) также пишутся примеси, которые основаны на имеющихся. Уже они получают информацию устройства и передают ее далее по цепочке. Подобный подход позволил сократить объем кода в десятки раз (изначально каждый драйвер был копией похожего драйвера).
Так постепенно я проходил все круги ада по допиливанию бэка и фронта. Когда приложение приобрело достаточно сносный вид, я подумал: почему бы не поделиться своей разработкой с общественностью? Были найдены партнеры для проекта и помощники для доведения приложения до ума.
В первую очередь, довести до ума надо было дизайн приложения. Для этого пришлось обратиться к профессиональным дизайнерам. Я наивно полагал, что на это уйдет 3-4 месяца, но в итоге процесс затянулся. Не смотря на то что структура приложения не сильно изменилась от первоисточника, переделывать пришлось буквально все.
Параллельно я — уже не в одиночку, а вместе с командой партнеров по проекту — скупал наиболее популярные устройства для умного дома и дописывал приложение, если оно не поддерживало эти гаджеты. Вскоре, впрочем, стало понятно, что денег на все умные устройства не хватит, поэтому мы решили пообщаться с существующими игроками на рынке и договориться о бесплатных тестовых образцах оборудование бесплатно. Нам не отказали, и первыми серьезными поставщиками стали Wirenboard и MiMiSmart.
Так я вместе с ребятами создал новое приложение для автоматизации умного дома с классической клиент-серверной архитектурой, которая ставится на любую платформу, и удобным современным дизайном. **[Знакомьтесь — BARY\*.](https://bary.io)**
*\*Название произошло не от имени Бари Алибасова, а от персонажа книги Артура К.Дойля «Собака Баскервиллей» дворецкого Бэрримора (англ. Barrymore) — ваш личный «умный дворецкий».*
Что получилось: описание приложения с красивыми картиночками и котиками
=======================================================================
Главный экран представляет из себя удобный дашборд с возможностью просмотра и управления параметрами автоматизируемых помещений. Удобный — тут ключевое слово, потому что дашборды в тех приложениях, с которыми я сам пытался работать, было необходимо конфигурировать вручную. Не самое приятное времяпрепровождение
Дом можно поделить на зоны, а зоны — на комнаты. У каждой комнаты есть различные параметры: температура, влажность, текущее потребление электричества и пр., а также избранные действия. Если нажмем на комнату, то провалимся в список подключенных к ней устройств:

Здесь можно включить/выключить устройство, а также увидеть его основной параметр. При переходе на устройство, будет доступно более подробное управление с полным перечнем функций.
Все устройства подключаются при помощи однотипных настроек. Для многих девайсов есть мастер подключения. Никаких конфигов для тех, кто любит погорячее! В основном все сводится к указанию IP-адреса устройства (для многих устройств есть автопоиск). Если IP-адрес вдруг поменяется, то ничего страшного, сервер найдет его по новому адресу автоматически.
Есть интеграция с Apple HomeKit, она используется для голосового управления через Siri. Все девайсы, поддерживаемые в BARY, интегрируются с Apple HomeKit нажатием одной галочки (привет любителям HomeBridge). Не обошлось и без поддержки Яндекс Алисы. Она оказалась более дружелюбна с точки зрения интерфейс-команд. Например, Siri не хочет закрывать шторы по команде «закрой шторы», не может выставить определенное значение громкости на ТВ и прочее. У Яндекс.Алисы таких закидонов нет.
Для удобства управления умными угодьями реализованы автоматизации: правила исполнения каких-либо действий при выполнении комплекса условий. Автоматизации логические, многоуровневые, т.е. можно сделать что-то типа: «Условие 1 и (Условие 2 или Условие 3)». Все в логичном красивом редакторе автоматизаций:
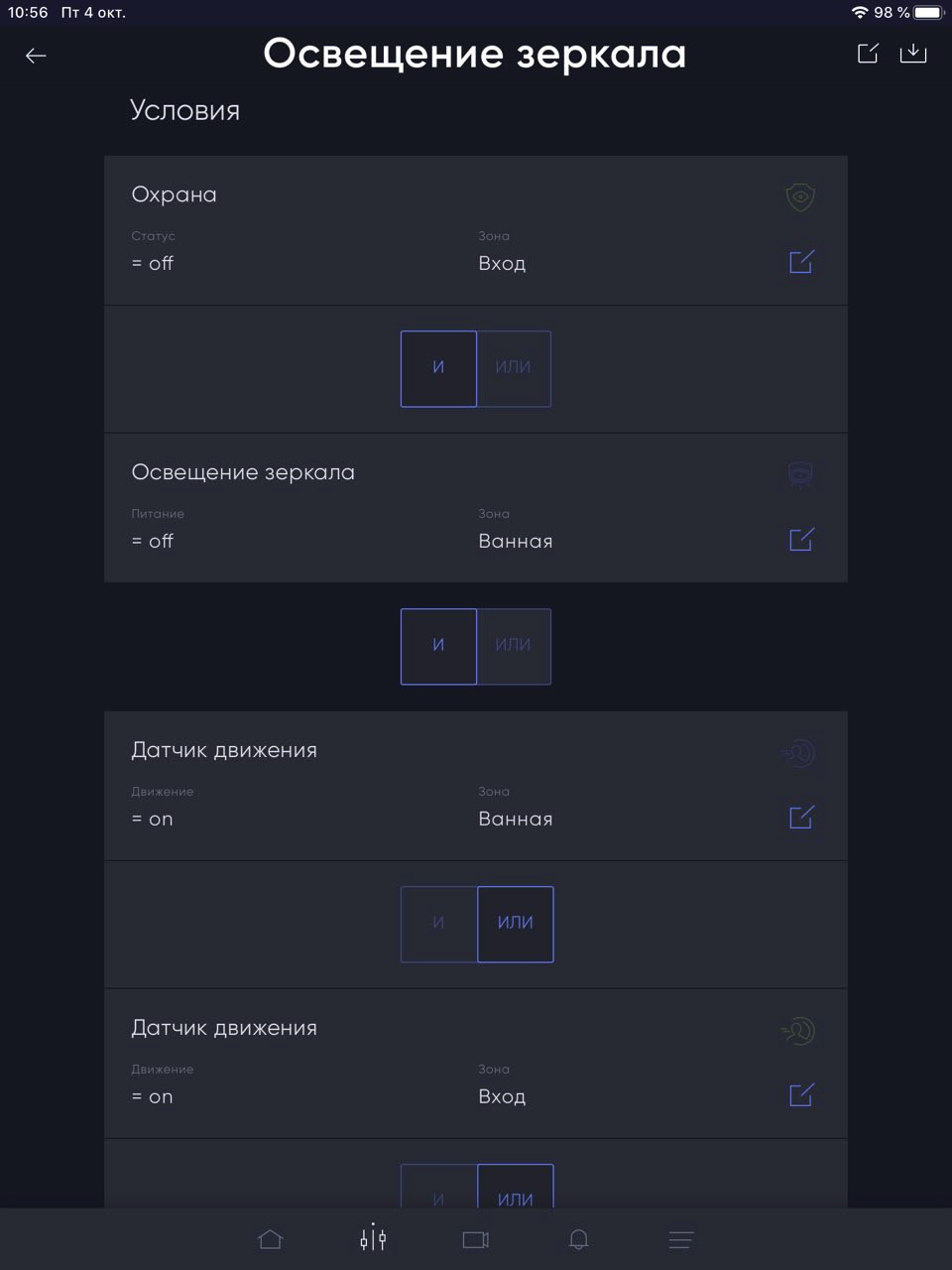
Лично у меня самих автоматизаций набралось уже под сотню, и любую из них можно быстро найти, т.к. все группируется по комнатам и устройствам:
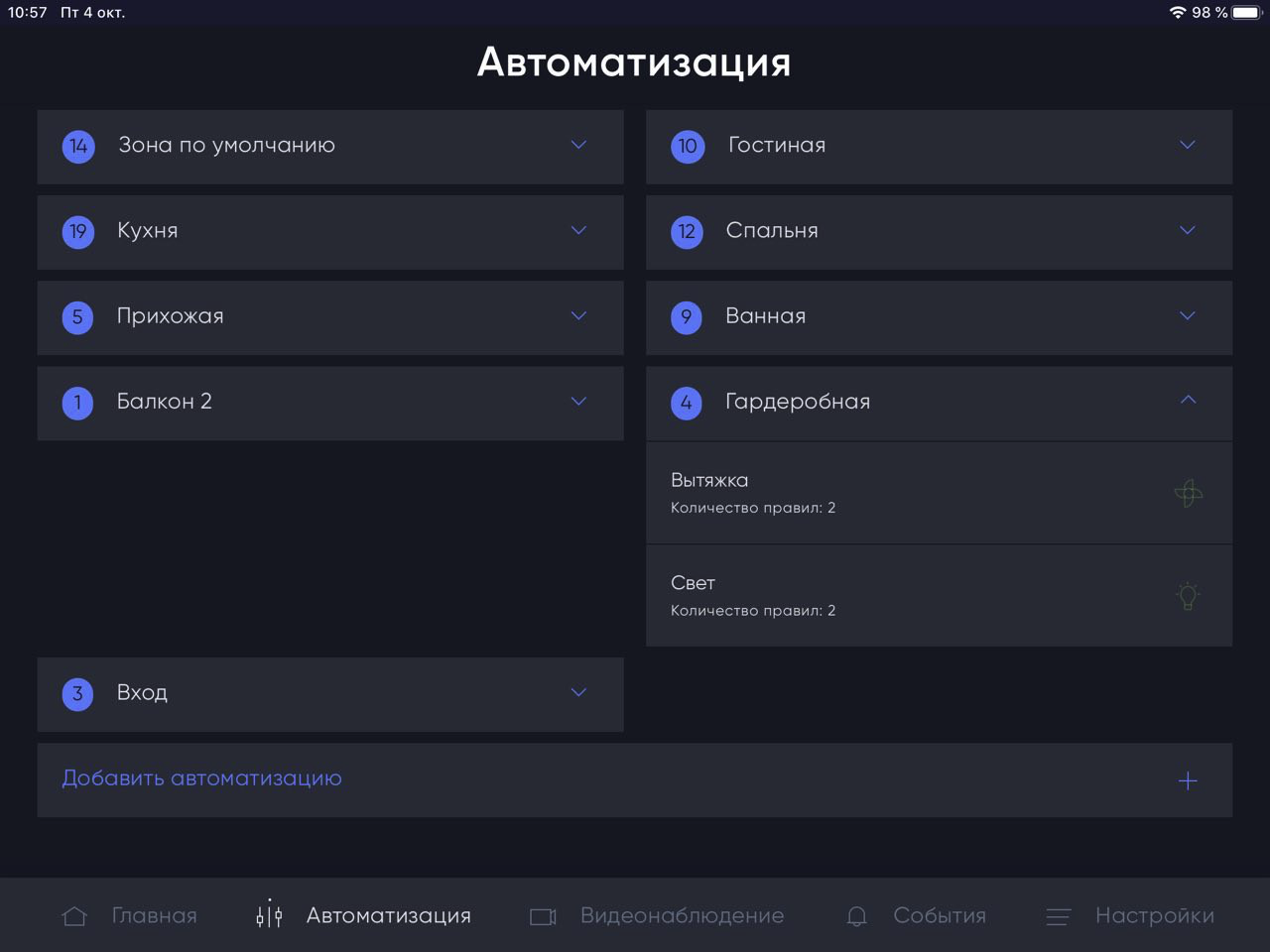
В приложении также поддерживаются сценарии. Сценарий — комплекс действий, выполняющийся при каком-либо условии из автоматизации. Для своего умного дома я использую только стандартный набор:

У меня уход из дома / возвращение домой реализованы через Apple TV — включается/выключается автоматически когда все ушли из дома, или кто-то вернулся домой. Приходишь домой, а тебя там уже встречает диктор с грустными глазами с 1го канала. Ну здорово же?
Ну и какой же умный дом без возможности наблюдать за котиком?

Можно подключить любую камеру, которая способна отдавать RTSP-поток.
Отдельно хочу сказать о блоке статистики. Получилось достаточно информативно:

В легенде красная полоса — отклонение от средних значений за последние полгода, серая полоса — расход в пределах средних значений.
На картинке моя статистика за сентябрь. Было холодно, отопление еще не дали, поэтому у вентиляции постоянно был включен подогрев.
Также статистику можно посмотреть по любому подключенному устройству:
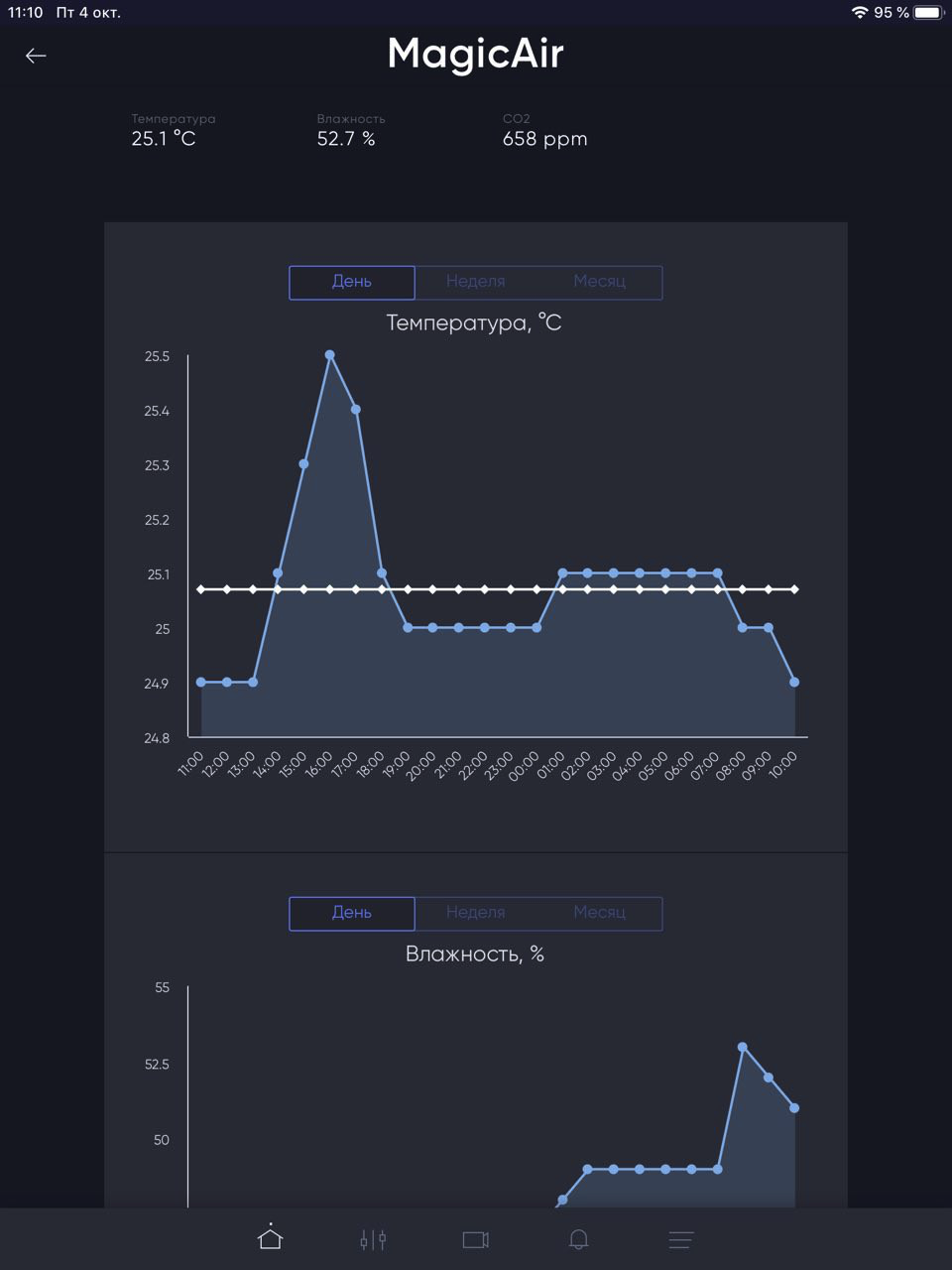
Кстати, наличие автоматизаций и статистики сократили расходы на электричество более чем в 2 раза.
Все возникающие события хранятся, и их можно посмотреть:

Также на главной странице есть особая вкладка, которая собирает все выбранные пользователем основные показатели:
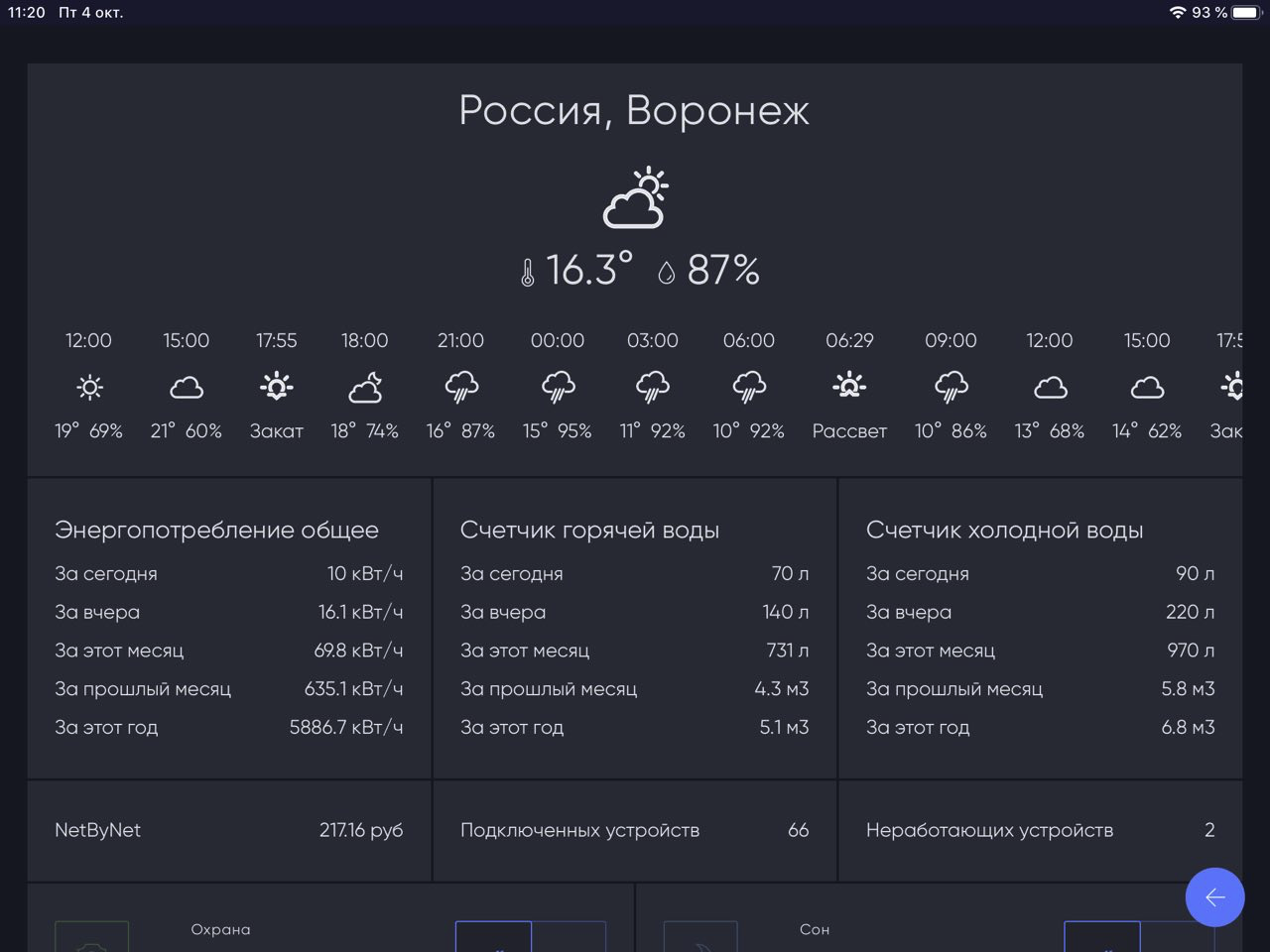
Кстати, учет воды реализован через датчик открытия дверей/окон Xiaomi. Для этого вместо геркона на специальный контакт припаивается выход с импульсного счетчика, а в BARY создается виртуальный счетчик, у которого в качестве источника импульсов можно указать этот датчик.
Архитектура и безопасность
==========================
Обмен клиента с сервером зашифрован по технологии AES, а сервер находится непосредственно внутри автоматизируемого помещения. На мой взгляд, это максимально защищает систему от сторонних нежелательных вмешательств.
Если нет белого IP-адреса, то можно подключить облако. Оно будет являться посредником, без возможности расшифровки команд, т.к. ключи находятся на сервере.
Где взять
=========
Серверная часть может быть запущена практически на любой существующей платформе — спасибо NodeJS. Для самых распространенных платформ мы подготовили скрипты, которые всю работу сделают автоматически.
Для Raspberry Pi на базе Debian Stretch:
`wget -qO- "http://bary.io/install?target=pi" | sudo bash`
Параметр target отвечает за целевую платформу и может иметь следующие значения:
| | |
| --- | --- |
| Raspberry Pi (Debian Stretch) | pi |
| Raspberry Pi (Debian Buster) | pi\_buster |
| Tinker Board (Debian Stretch) | tb |
| Wiren Board (Debian Stretch) | wb |
Если у кого-то будет желание установить на другую платформу, напишите нам, и мы обновим скрипт. Если возникнут какие-то трудности — тоже пишите. Нам очень нужна обратная связь.
Приложение в свободном доступе на [Google Play](https://play.google.com/store/apps/details?id=io.bary) и [App Store](https://apps.apple.com/us/app/bary/id1460539463). Возможно, к концу года, приложение станет платным.
Заключение
==========
Зачем я написал эту статью? Основная цель – получить обратную связь от вас.
В настоящее время проект стремительно развивается, и вся наша команда старается предельно расширить перечень поддерживаемого оборудования, имеющегося на рынке. Хотя над проектом работаю уже не я один, задачи остались те же — создать максимально удобное приложение, которое учитывает пожелания и решает проблемы всех, кто занимался самостоятельной установкой смарт-решений для дома.
Мы открыты к диалогу по возможным интеграциям и готовы в кратчайшие сроки реализовать поддержку оборудования от заинтересованных в партнерстве компаний. Вы получаете готовое приложение и не тратите время на разработку ПО. А мы получаем широкую номенклатуру поддерживаемых устройств на любой вкус и цвет. Всем хорошо.
Ближайшие планы и радужные хотелки
==================================
В настоящее время я и моя команда активно занимаемся разработкой блока хранения видеозаписей. Будет возможность располагать видео в домашнем хранилище, либо в облачном сервисе. Думаю, в начале следующего года можно будет говорить о новом релизе. Должна же быть возможность пересматривать в записи лучшие перлы котика, развлекающего себя самого, пока хозяев нет дома?
В следующем году планируем больше интеграций с различными сервисами: списком покупок и дел, календарем и т.д. Подошел, посмотрел на один экран - и все как на ладони. Несколько проектов, реализованных «под ключ», показали, что эта задача актуальна.
Также планируем старт производства контроллеров с предустановленным ПО для пакетных решений умного дома (в настоящее время пакетное решение «ПО+железо» доступно совместно с нашими партнерами [Wiren Board](https://wirenboard.com/ru/).
А еще поддержка Google Home и Amazon Alexa. Ну и расширение номенклатуры поддерживаемого оборудования, само собой.
Кстати, кому интересно, можете посмотреть перечень поддерживаемых девайсов (не полный) на [нашем сайте](https://bary.io/supported-devices), а если чего-то в списке не нашли, то спросить в [телеграмм-группе](https://ttttt.me/bary_io).
Будем очень благодарны, если вы поделитесь, чего вам не хватает в существующих приложениях и какие функции вы бы добавили на нашем месте.
Всем спасибо, кто дочитал. Давайте сделаем свои дома умнее вместе! | https://habr.com/ru/post/502056/ | null | ru | null |
# Испытания Posit по-взрослому. Спектральный анализ
Обсуждения достоинств и недостатков нового революционного формата с плавающей запятой Posit продолжаются. Следующим аргументом в дискуссии стало [утверждение](https://habr.com/ru/post/467933), что на самом деле задача Posit — это компактно хранить данные, а вовсе не использоваться в вычислениях; при этом сами вычисления делаются в арифметике Quire с бо́льшей точностью, которая также входит в стандарт Posit.
Ну, хранить так хранить. Что вообще значит — «хранить» числа после вычислений, выполненных с бо́льшей точностью, чем допускает формат хранения? Это значит — округлять, а округлять значит вносить погрешности. Погрешности можно оценивать разными способами — и чтобы не повторяться, сегодня мы используем спектральный анализ с помощью преобразования Фурье.
### Очень краткое введение
Если взять сигнал в виде синусоиды и выполнить над ним преобразование Фурье, то в спектре мы должны получить один-единственный пик; по факту же в спектре могут присутствовать как гармоники с частотой кратной основному тону, полученных вследствие нелинейных искажений, так и шумовая полка, полученная вследствие шумов, наводок и оцифровки. Вот уровень этих шумов мы и будем измерять.
### Начало
Чтобы было ещё интереснее, в качестве тестового сигнала возьмём не одну синусоиду, а несколько; при этом необходимо следить, чтобы периоды этих синусоид нацело укладывались в период дискретного преобразование Фурье. В Wolfram Mathematica это можно сделать, например, так:
```
sz = 8192;
data = Table[2 Sum[
Sin[Prime[j] k 2 Pi/sz + j*j]/sz,
{j, 100, 200, 2}] // N,
{k, 0, sz - 1}];
```
Простые числа здесь используются для неравномерного прореживания частот; а j\*j сдвигает фазу синусоиды в зависимости от частоты во избежание сильных выбросов в тестовом сигнале, обеспечивая ему более-менее равномерную амплитуду. Визуально полученный сигнал выглядит вот так:
Далее мы нормируем его к единице по максимальному значению, затем преобразуем в целочисленный 32-битный Int, Float, Posit и снова в Double. Если утверждения авторов верны, то погрешность, вносимая преобразованием Double→Posit→Double будет ближе к Doublе, чем к Float.
Уровень шумов будем анализировать в стандартных для обработки сигналов единицах — децибелах, позволяющих сравнивать величины в логарифмическом масштабе. В качестве инструмента я использовал собственный спектроанализатор, когда-то написанный в исследовательских целях.
**сравнительная таблица**
| | |
| --- | --- |
| Порог слышимости | 0 дБ |
| Шелест листьев | 10 дБ |
| Шепот | 20 дБ |
| Тиканье часов | 30 дБ |
| Тихая комната | 40 дБ |
| Тихая улица | 50 дБ |
| Разговор | 60 дБ |
| Шумная улица | 70 дБ |
| Опасный для здоровья уровень | 75 дБ |
| Пневматический молоток | 90 дБ |
| Поезд метро | 100 дБ |
| Громкая музыка | 110 дБ |
| Болевой порог | 120 дБ |
| Сирена | 130 дБ |
| Старт ракеты | 150 дБ |
| Смертельный уровень | 180 дБ |
| Шумовое оружие | 200 дБ |
Итак:
синий — Float
красный — Posit
фиолетовый — Int32
голубой — Double
Posit, конечно же, оказался чуточку лучше Float — но до уровня Double ему ещё далеко. И при этом — хуже Int32! Логично — ведь часть бит у него уходит на порядок… Давайте используем этот порядок — увеличим амплитуду нашего сигнала до 1000:

Внезапно (а на самом деле вполне ожидаемо) шум у Float и Posit сравнялся. Идём дальше — увеличиваем амплитуду до миллиарда:

Float показывает тот же уровень, а Posit начинает отставать. Дальнейшее увеличение амплитуды (здесь 1015) приводит к дальнейшему повышению шумовой полки:
### Заключение
Чуда по прежнему не произошло. Спектральный анализ не подтвердил заявления авторов о том, что использование формата Posit в качестве хранения может обеспечить точность близкую к Double. Даже в наилучших условиях шумовая полка у Posit оказались лишь на 20 децибел ниже Float, но при этом выше Int32 на 10 децибел, и выше Double — на 60 децибел.
Конечно, Posit-у вполне можно найти полезное применение — в качестве защиты от выхода за пределы допустимого диапазона, когда выбросы, значительно превосходящие нормальные значения, не будут приводить ни к клиппингу, ни к переполнению. Но даже в таком сценарии Posit выступает скорее как компромисс между Int и Float, нежели однозначно лучший формат чисел. | https://habr.com/ru/post/468077/ | null | ru | null |
# AngularJS — разделение приложения на модули и загрузка компонентов с помощью RequireJS
Использование AngularJS в паре с RequireJS — достаточно популярный подход к разработке веб приложений в последнее время. И один из основных вопросов — структура приложения. Существует достаточно известный seed для такого приложения [tnajdek/angular-requirejs-seed](https://github.com/tnajdek/angular-requirejs-seed), но мне это не походит, так как при увеличении функционала приложения — данная структура просто будет засоряться кучей файлов, не будет никакого логического разделения скриптов и достаточно сложно будет их менеджить.
Целью было создать приложение с модульной и гибкой архитектурой (ну скорее просто разбиение приложение не логические части), с простым и понятным описанием зависимостей между частями приложения и уменьшить зависимость кода от структуры приложения.
#### Модуль
В данном случае, это логически отдельная часть приложения, включающая в себя набор компонентов:
* ngModule;
* Controller;
* FIlter;
* Directive;
* Service;
* Template;
* Configs — содержат **config()** и **run()** методы для текущего ngModule.

#### Проблема
При использовании RequrieJS, файлы приложения чаще всего подключаются как-то так:
```
require('modules/foo/controller/foo-controller.js');
require('modules/foo/service/foo-service.js');
require('modules/foo/directive/foo-controller.js');
require('text!modules/foo/templates/foo.html');
require('modules/bar/directive/bar-controller.js');
```
Здесь есть явные минусы:
* Код очень зависит от структуры проекта;
* Код очень зависит от названий модулей;
* Достаточно много нужно писать руками.
#### Решение
Были написаны RequireJS плагины для загрузки компонентов модуля.
К примру есть такая структура приложения (кстати, очень похожая на структуру бандлов в Symfony2):
```
app
|-modules
| |-menu
| | |-controller
| | | |-menu-controller.js
| | |-menu.js
| |
| |-user
| |-controllers
| | |-profile.js
| |-resources
| | |-configs
| | | |-main.js
| | |
| | |-templates
| | | |-user-profile.html
| | |-directives
| | |-user-menu
| | |-user-menu.js
| | |-user-menu.html
| |-src
| | |-providers
| | | |-profile-information.js
| | |-factory
| | |-guest.js
| |-user.js
|
|-application.js
|-boot.js
```
В данном случае у нас есть 2 модуля: **user** и **menu**. Файлы **/app/modules/menu/menu.js** и **/app/modules/user/user.js** — скрипты с инициализацией angularJS модулей. Все остальное — думаю понятно.
Теперь нужно задать конфигурацию для подключения всех компонентов. Делается это с помощью **requirejs.config**:
```
requirejs.config({
baseUrl: '/application',
paths: {
'text': '../bower_components/requirejs-text/text',
// Structure plugins:
'base': '../bower_components/requirejs-angular-loader/src/base',
'template': '../bower_components/requirejs-angular-loader/src/template',
'controller': '../bower_components/requirejs-angular-loader/src/controller',
'service': '../bower_components/requirejs-angular-loader/src/service',
'module': '../bower_components/requirejs-angular-loader/src/module',
'config': '../bower_components/requirejs-angular-loader/src/config',
'directive': '../bower_components/requirejs-angular-loader/src/directive',
'filter': '../bower_components/requirejs-angular-loader/src/filter'
},
structure: {
prefix: 'modules/{module}',
module: {
path: '/{module}'
},
template: {
path: '/resources/views/{template}',
},
controller: {
path: '/controllers/{controller}'
},
service: {
path: '/src/{service}'
},
config: {
path: '/resources/configs/{config}'
},
directive: {
path: '/resources/directives/{directive}/{directive}'
},
filter: {
path: '/resources/filters/{filter}'
}
}
});
```
Все пути каждого компонента определены в рамках модуля. Поле **structure.prefix** — путь к корню модуля, после **baseUrl**.
Теперь, если мы хотим подключить файл `/app/modules/user/user.js из:`
1. **/app.js**:
```
require('module!user')
```
2. **/app/modules/user/controllers/profile.js**:
```
require('module!@')
```
В рамках одного модуля — имя модуля можно не писать, достаточно символа '@'. Тем самым, если придется переименовать модуль — не нужно будет менять код.
Теперь, если мы хотим подключить файл `/app/modules/user/controllers/profile.js` из:
1. **/app.js**:
```
require('controller!user:profile')
```
До двоеточия — название модуля, после двоеточия — название контроллера.
2. **/app/modules/user/user.js**:
```
require('controller!profile')
```
В рамках одного модуля — имя модуля можно не писать, достаточно указать только название контроллера. Так же, если контроллер лежит на уровень ниже, то возможно подключать так:
```
require('controller!additional/path/to/profile')
```
Точно так же и для всех других компонентов.
#### Результат
Получилось очень гибкая структура приложения с поддержкой разделения кода на модули и с минимальной зависимостью кода от структуры проекта даже если придется перенести какой либо компонент из одного модуля в другой — то практически ничего менять не придется. И лишнего кода так же стало меньше.
Так же не возникает никаких проблем при сброке проекта. В тестовом приложение есть пример собранного проекта в папке /build и Gruntfile для сборки, но в нем нету ничего не обычного.
Ссылки:
* Репозиторий с плагинами — [requirejs-angular-loader](https://github.com/tuchk4/requirejs-angular-loader). Устанавливать можно с помощью bower;
* Репозиторий с тестовым приложением — [tuchk4/requirejs-angular-loader-bootstrap](https://github.com/tuchk4/requirejs-angular-loader-bootstrap).
Данный подход используем в большом корпоративном приложении, поддержка и развитие данного подхода будет поддерживаться и развиваться. | https://habr.com/ru/post/216469/ | null | ru | null |
# Рендеринг DOOM с помощью чекбоксов
Скриншот из DOOM, отрендеренного с помощью нативных чекбоксов*Дисклеймер: перевод статьи публикуется* [*с одобрения*](https://disk.yandex.ru/i/uku_zI7sNQLaNQ) *оригинального автора*
Поиграть можно [тут](https://healeycodes.github.io/doom-checkboxes/) (Chrome/Edge), исходный код [здесь](https://github.com/healeycodes/doom-checkboxes), текст статьи ниже.
На этой неделе я прочитал статью Брайана Брауна — ["Я всё ещё продолжаю экспериментировать с чекбоксами"](https://www.bryanbraun.com/2021/09/21/i-keep-making-things-out-of-checkboxes/). Там он рассказывал про свою библиотеку [Checkboxland](https://github.com/bryanbraun/checkboxland).
> JavaScript-библиотека для отображения текста и анимаций на сетке из чекбоксов
>
>
Это довольно приятная библиотека. Её API и документация лучше некоторых библиотек, с которыми мне приходится иметь дело на работе. С её помощью можно рендерить текст, фигуры, изображения и видео. Есть низкоуровневое API. В ней есть всё, что надо. Брайан использовал Checkboxland для создания шикарных интерактивных анимаций.
Кто-то на Hacker News [прокомментировал статью](https://news.ycombinator.com/item?id=28826839):
> Я не думаю, что вы исчерпаете все возможности библиотеки, до тех пор пока не отренедерите с её помощью DOOM
>
>
После проверки, что Брайан [ещё не взялся](https://xkcd.com/356/) за реализацию этой идеи, я начал скрещивать Checkboxland и [WebAssembly-порт DOOM](https://github.com/diekmann/wasm-fizzbuzz) Корнелиуса Дайкменна.
Корнелиус во всех деталях описывает процесс портирования DOOM в [README](https://github.com/diekmann/wasm-fizzbuzz/tree/main/doom). Я взял его порт за основу и написал glue-код для интеграции с Checkboxland.
В моём проекте DOOM запускается с помощью WebAssembly и рендерится в невидимый . Я использую [HTMLCanvasElement.captureStream()](https://developer.mozilla.org/en-US/docs/Web/API/HTMLCanvasElement/captureStream) для его преобразования в `MediaStream`. Элемент отображает `MediaStream` и передаётся методу [renderVideo](https://www.bryanbraun.com/checkboxland/#rendervideo) из Checkboxland. Я экспериментировал с разными [пороговыми значениями](https://www.bryanbraun.com/checkboxland/#renderVideo-arguments), чтобы картинка получилась настолько чёткой, насколько это возможно. Одно из возможных улучшений — использовать что-то похожее на [дизеринг](https://en.wikipedia.org/wiki/Dither).
Элемент тоже можно было спрятать, но по моим наблюдениям пользователи не могли выйти из главного меню без посторонней помощи, если они не видели оригинальную картинку.
Наш экран — это сетка 160 на 100, состоящая из нативных чекбоксов. С более высоким разрешением FPS падал совсем низко. Изображение в начале статьи из ранней версии с разрешением 320x200.
```
const cbl = new Checkboxland({
dimensions: "160x100",
selector: "#checkboxes",
});
```
Стигматизированное CSS-свойство [zoom](https://developer.mozilla.org/en-US/docs/Web/CSS/zoom) используется для уменьшения размера чекбоксов. Использование `transform: scale(x)` приводило к худшей производительности и качеству картинки. К сожалению, это означает, что пользователи Firefox должны вручную уменьшить масштаб страницы.
> Эта нестандартное свойство, и оно не находится в процессе стандартизации. Не используйте его на публичных сайтах — оно не будет работать у всех пользователей.
>
>
События нажатия клавиш форвардятся в скрытый , чтобы избежать проблем с фокусом.
```
const forwardKey = (e, type) => {
const ev = new KeyboardEvent(type, {
key: e.key,
keyCode: e.keyCode,
});
canvas.dispatchEvent(ev);
};
document.body.addEventListener("keydown", function (e) {
forwardKey(e, "keydown");
});
document.body.addEventListener("keyup", function (e) {
forwardKey(e, "keyup");
});
```
На время загрузки и компиляции WebAssembly-модуля на сетке отображается сообщение с помощью метода [print](https://www.bryanbraun.com/checkboxland/#print):
Сообщение о загрузке WebAssembly, отрендеренное с помощью чекбоксовПосле загрузки выводится сообщение о том, что нужно где-нибудь кликнуть, чтобы инициализировать . После клика запускается игра!
Пока вы всё ещё тут, вы знали, что Билл Гейтс однажды поместил себя в DOOM, чтобы прорекламировать Windows 95?
Кадр из рекламы Windows 95, на котором изображён Билл Гейтс c ружьём внутри коридора DOOM*Примечание переводчика: если вам понравися перевод, то вам скорее всего понравится мой* [*телеграм-канал*](https://t.me/defront)*, где я публикую рецензии на статьи про веб-стандарты, производительность и т.п.* | https://habr.com/ru/post/590337/ | null | ru | null |
# Совмещение R и Python: зачем, когда и как?

Наверное, многие из тех, кто занимается анализом данных, когда-нибудь думали о том, возможно ли использовать в работе одновременно R и Python. И если да, то зачем это может быть нужно? В каких случаях будет полезным и эффективным для проектов? Да и как вообще выбрать лучший способ совмещения языков, если гугл выдает примерно 100500 вариантов?
Давайте попробуем разобраться в этих вопросах.
Зачем
-----
* В первую очередь, это **возможность использовать преимущества** двух наиболее популярных языков программирования для анализа данных на сегодняшний день. Совмещая наиболее мощные и стабильные библиотеки R и Python в некоторых случаях можно повысить эффективность расчетов или избежать изобретения велосипедов для реализации каких-либо статистических моделей.
* Во вторую очередь, это **повышение скорости и удобства выполнения проектов**, в случае если разные люди в вашей команде (или вы сами) обладают хорошими знаниями разных языков. Здесь может помочь разумная комбинация имеющихся навыков программирования на R и Python.
Попробуем поговорить подробнее о первом пункте. Summary, которое последует ниже, безусловно, субъективно, и его можно дополнять. Оно создано на основе систематизации ключевых статей о преимуществах языков и личного опыта. Но мир, как мы знаем, очень быстро меняется.
Python создавался умными программистами и является языком общего назначения, уже впоследствии — с развитием data science — адаптированным под специфические задачи анализа данных. Отсюда и следуют главные плюсы этого языка. При анализе данных его использование оптимально для:
* Web scraping и crawling (beautifulsoup, Scrapy, и т.д.)
* Эффективной работы с базами данных и приложениями (sqlachemy, и т.д.)
* Реализации классических ML алгоритмов (scikit-learn, pandas, numpy, scipy, и т.д.)
* Задач Computer Vision
Главное в R — это обширная коллекция библиотек. Этот язык, особенно на начальном этапе, развивался по большей части благодаря усилиям статистиков, а не программистов. Статистики очень старались и их достижения сложно оспорить.
Если вдруг вы подумываете о том, чтобы попробовать новую вкусную статмодель, о которой недавно услышали на конференции, прежде чем садиться писать ее с нуля, загуглите сначала `R package` . Ваши шансы на успех очень велики! Так, несомненным плюсом R являются возможности продвинутого статистического анализа. В особенности, для ряда специфических областей науки и практики (эконометрика, биоинформатика и др.). На мой взгляд, в R на текущий момент все еще существенно более развит анализ временных рядов.
Другим ключевым и пока неоспоримым преимуществом R над Python является интерактивная графика. Возможности для создания и настройки дашбордов и простых приложений для людей без знаний JS поистине огромны. Не верите — потратьте немного времени на изучение возможностей пары библиотек из списка: `htmlwidgets`, `flexdashboard`, `shiny`, `slidify`. Например, изначально, материалы для этой статьи были собраны в виде [интерактивной презентации на slidify](http://irinagoloshchapova.github.io/Progs/D2D_DevPRO2017_R_Py/).
Но как бы статистики ни старались, сильны они не во всем. Такой высокой эффективности управления памятью, как в Python, им достичь не удалось. Вернее, в R хороший и быстроработающий на больших объемах данных код вполне возможен. Но при гораздо больших усилиях и самоконтроле, чем в Python.
Постепенно все различия стираются, и оба языка становятся все более взаимозаменяемы. В Python развиваются возможности визуализации (большим шагом вперед стал `seaborn`) и добавляются ~~не всегда работающие~~ эконометрические библиотеки (`puFlux`, `pymaclab`, и др.), в R — растет эффективность управления памятью и улучшаются возможности обработки данных (`data.table`). Вот тут, например, можно посмотреть [примеры базовых операций с данными на R и Python](https://gist.github.com/conormm/fd8b1980c28dd21cfaf6975c86c74d07). Так что есть ли преимущество в совмещении языков для вашего проекта, решать только вам.
Что касается второго пункта о повышении скорости и удобства выполнения проектов, то здесь речь в основном об организации проекта. К примеру, есть у вас на проект два человека, один из которых больше и сильнее может на R, другой — на Python. При условии, что вы можете обеспечить code review и другой контроль для обоих языков, можно попробовать распределить задачи так, чтобы каждый участник использовал свои лучшие навыки. Конечно, также имеет значение ваш опыт решения конкретных задач на различных языках.
Хотя тут следует уточнить, что речь идет об исследовательских проектах работы с данными. Для продакшен решений важны другие критерии. Совмещение, скорее всего, не будет полезным для устойчивости и масштабируемости расчетов. Так мы плавно и переходим к вопросу о том, когда удобнее совмещать языки.
Когда
-----
С учетом особенностей обоих языков выиграть от совмещения R и Python можно при:
* **Исследовательском анализе данных**
* **Прототипировании**
* **Реализации проекта/набора задач с широким охватом по различным научно-практическим областям**
Приведу примеры для возможного совмещения языков:
* *Исследование региональных рынков труда*. Подключение к [официальному API HH.ru](https://dev.hh.ru/) с помощью Python, исследование трендов и зависимостей (`xgboost`, `xgboostExplainer`) + визуализация (Markdown-отчеты) с помощью R
* *Приложение на данных Bloomberg*. Подключение к [официальному API](https://www.bloomberg.com/professional/support/api-library/) и обработка данных на Python (`numpy`, `pandas`) + вывод результата в dashboard или shiny приложение на R (`flexdashboard`, `htmlwidgets`)
* *Анализ данных социальных медиа*. Парсинг и ML стек с помощью Python + эконометрика, network analysis, визуализация и сайт — с помощью R
* *Модель для прогнозирования спроса на продукцию в отдельных точках*. Блок прогноза спроса на товар в единичных локациях c помощью Python (ML алгоритмы) + макроэкономический прогноз с помощью R (модели общего равновесия и структурные var модели)
* *Анализ новостного потока*. Парсинг на R (`rvest`) + NLP на Python + параметризованный отчет на R (`RMarkdown Parameterized Reports`)
Все приведенные примеры — реальные проекты.
Повторюсь, что даже при том, что с момента моего первого выступления о возможностях совмещения R и Python прошло уже 2 года, я все еще не решусь рекомендовать совмещать языки в продакшене. Разве что если это почти 2 отдельных сущности/модели, не критично завязанные друг на друга.
Если есть счастливчики, запилившие R+Python продакшен что-то — поделитесь, пожалуйста, в комментах!
Как
---
Теперь непосредственно о стульях. Среди подходов к совмещению R и Python можно выделить три основных категории:
* **Command line tools**. Исполнение скриптов с помощью командной строки + промежуточное хранение файлов на диске (filling air gap)
* **Interfacing R and Python**. Одновременный запуск процессов R и Python и передача данных между ними в оперативной памяти (in-memory)
* **Другие подходы**
Рассмотрим подробнее каждый из подходов.
### Command line tools
Суть в разделении проекта на отдельные относительно самостоятельные части, выполняемые на R или Python и передаче данных через диск в каком-либо удобном для обоих языков формате.
По синтаксису все предельно просто. Исполнение скриптов с помощью командной строки осуществляется по схеме:
```
```
— команда для выполнения скрипта R или Python с помощью командной строки
— директория расположения скрипта
— список аргументов на вход скрипту
В таблице ниже более детально показаны схемы выполнения скриптов из командной строки и считывания переданных аргументов. В комментариях указан тип объекта, в который записывается список аргументов.
| Command | Python | R |
| --- | --- | --- |
| Cmd | `python path/to/myscript.py arg1 arg2 arg3` | `Rscript path/to/myscript.R arg1 arg2 arg3` |
| Fetch arguments | `# list, 1st el. - file executed
import sys
my_args = sys.argv` | `# character vector of args
myArgs <- commandArgs(trailingOnly = TRUE)` |
Для желающих есть совсем подробные примеры ниже.
**R script из Python**
Для начала сформируем простой R script для определения максимального числа из списка и назовем его `max.R`.
```
# max.R
randomvals <- rnorm(75, 5, 0.5)
par(mfrow = c(1, 2))
hist(randomvals, xlab = 'Some random numbers')
plot(randomvals, xlab = 'Some random numbers', ylab = 'value', pch = 3)
```
А теперь выполним его на Python, задействовав cmd и передав список чисел для поиска максимального значения.
```
# calling R from Python
import subprocess
# Define command and arguments
command = 'Rscript'
path2script = 'path/to your script/max.R'
# Variable number of args in a list
args = ['11', '3', '9', '42']
# Build subprocess command
cmd = [command, path2script] + args
# check_output will run the command and store to result
x = subprocess.check_output(cmd, universal_newlines=True)
print('The maximum of the numbers is:', x)
```
**Python script из R**
Вначале создадим простой скрипт на Python по разделению текстовой строки на части и назовем его `splitstr.py`.
```
# splitstr.py
import sys
# Get the arguments passed in
string = sys.argv[1]
pattern = sys.argv[2]
# Perform the splitting
ans = string.split(pattern)
# Join the resulting list of elements into a single newline
# delimited string and print
print('\n'.join(ans))
```
А теперь выполним его на R, задействовав cmd и передав текстовую строку для удаления нужного паттерна.
```
# calling Python from R
command = "python"
# Note the single + double quotes in the string (needed if paths have spaces)
path2script ='"path/to your script/splitstr.py"'
# Build up args in a vector
string = "3523462---12413415---4577678---7967956---5456439"
pattern = "---"
args = c(string, pattern)
# Add path to script as first arg
allArgs = c(path2script, args)
output = system2(command, args=allArgs, stdout=TRUE)
print(paste("The Substrings are:\n", output))
```
Для промежуточного хранения файлов при передаче информации от одного скрипта к другому можно использовать множество форматов — в зависимости от целей и предпочтений. Для работы с каждым из форматов в обоих языках есть библиотеки (и не по одной).
**Форматы файлов для R и Python**
| Medium Storage | Python | R |
| --- | --- | --- |
| Flat files | | |
| csv | csv, pandas | readr, data.table |
| json | json | jsonlite |
| yaml | PyYAML | yaml |
| Databases | | |
| SQL | sqlalchemy, pandasql, pyodbc | sqlite, RODBS, RMySQL, sqldf, dplyr |
| NoSQL | PyMongo | RMongo |
| Feather | | |
| for data frames | feather | feather |
| Numpy | | |
| for numpy objects | numpy | RcppCNPy |
Классический формат — это, конечно, flat файлы. Часто csv — это наиболее просто, удобно и надежно. Если хочется структуризации или хранение информации планируется на относительно длительный срок, то, вероятно, оптимальным выбором будет хранение в базах данных (SQL/NoSQL).
Для быстрой передачи `numpy` объектов в R и обратно есть быстрая и устойчивая библиотека `RCppCNPy`. Пример её использования можно посмотреть [тут](http://dirk.eddelbuettel.com/code/rcpp.cnpy.html).
При этом существует также формат `feather`, разрабатываемый специально для передачи дата фреймов между R и Python. Изначальная фишка формата — заточенность на R и Python, легкость обработки на обоих языках и очень быстрая запись и чтение. Идея отличная, но с реализацией, как это иногда бывает, есть нюансы. Сами разработчики формата не раз отмечали, что он пока не подходит для долгосрочных решений. При апдейте библиотек для работы с форматом весь процесс может сломаться и потребовать значительных изменений кода.
Но при этом запись и чтение feather в R и Python действительно быстрые. Тест-сравнение по скорости чтения-записи файла на 10 млн строк представлены на рисунке ниже. В обоих случаях `feather` значимо опережает по скорости ключевые библиотеки для работы с классическим форматом csv.
**Сравнение скорости работы с форматами feather и CSV для R и Python**
**Файл**: data frame, 10 млн. строк. По 10 попыток на каждую библиотеку.
**R**: CSV чтение/запись через пакеты `data.table` и `dplyr`. Работа с feather оказалась наиболее быстрой, но обход по скорости `data.table` не высокий. При этом есть определенные сложности с настройкой и работой с feather для R. И поддержка вызывает сомнения. [`Пакет feather`](https://github.com/wesm/feather) последний раз обновлялся год назад.
**Python**: CSV чтение/запись с помощью `pandas`. Выигрыш feather по скорости оказался значительным, проблем с работой с форматом на Python 3.5 не обнаружилось.
Тут важно отметить, что сравнивать скорость можно только отдельно для R и отдельно для Python. Между языками будет некорректно, потому что весь тест осуществлялся из R — для удобства формирования итогового рисунка.
#### Подведем итоги
*Преимущества*
* Простой метод и поэтому часто наиболее быстрый
* Просто увидеть промежуточный результат
* Возможность чтения/записи большинства форматов реализована в обоих языках
*Недостатки*
* Конструкция быстро становится громоздкой и сложноуправляемой по мере роста числа переходов между языками
* Существенная потеря в скорости записи/чтения файлов при росте объема данных
* Необходимость заранее согласовывать схему взаимодействия между языками и формат промежуточных файлов
### Interfacing R and Python
Этот подход заключается в непосредственном запуске одного языка из другого и предусматривает внутреннюю (in-memory) передачу информации.
За время, в которое народ задумывался о совмещении R и Python вместо их противопоставления, было создано достаточно много библиотек. Из них удачных и устойчивых к разным параметрам, включая использование операционной системы Windows, всего две. Но уже их наличие открывает новые горизонты, значительно облегчая процесс совмещения языков.
Для вызова каждого языка через другой ниже представлено по три библиотеки — по убыванию качества.
#### R from Python
Наиболее популярная, стабильная и устойчивая библиотека — это `rpy2`. Работает быстро, имеет хорошее описание как [часть официальной документации](https://pandas.pydata.org/pandas-docs/stable/r_interface.html) `pandas`, так и на [отдельном сайте](https://rpy2.github.io/doc/latest/html/index.html). Главная фишка — интеграция с `pandas`. Ключевым объектом для передачи информации между языками является `data frame`. Также декларируется прямая поддержка наиболее популярного пакета для визуализации R `ggplot2`. Т.е. пишете код в python, график видите непосредственно в IDE Python. Тема с `ggplot2`, правда, барахлит для Windows.
Недостаток у `rpy2`, пожалуй, один — необходимость потратить некоторое время на изучение туториалов. Для корректной работы с двумя языками это необходимо, поскольку есть неочевидные нюансы в синтаксисе и сопоставлении типов объектов при передаче. К примеру, при передаче числа из Python на вход в R вы получаете не число, а вектор из одного элемента.
Ключевое преимущество библиотеки `pipe`, которая находится на втором месте в таблице ниже, — это скорость. Реализация через пайпы, действительно, в среднем ускоряет работу (на эту тему даже есть [статья в JSS](https://www.jstatsoft.org/article/view/v035c02/v35c02.pdf)), а наличие поддержки работы с pandas объектами в R-Python внушает надежду. Но имеющиеся минусы надежно сдвигают библиотеку на второе место. Ключевой недостаток — это плохая поддержка установки библиотек в R через Python. Если вы хотите воспользоваться какой-либо нестандартной библиотекой в R (а R часто нужен именно для этого), то чтобы она установилась и заработала, нужно последовательно (!!!) загрузить все её dependencies. А для некоторых библиотек их может быть примерно 100500 и маленькая тележка. Второй важный недостаток — неудобная работа с графикой. Построенный график можно посмотреть, только записав его в файл на диске. Третий недостаток — слабая документация. Если случается косяк чуть за границами стандартного набора, решение часто не найдешь ни в документации, ни на stackoverflow.
Библиотека `pyrserve` проста в использовании, но и значительно ограничена по функционалу. Например, не поддерживает передачу таблиц. Обновление и поддержка библиотеки разработчиками также оставляет желать лучшего. Версия 0.9.1 является последней из доступных уже более 2 лет.
| Библиотеки | Комментарии |
| --- | --- |
| [rpy2](https://rpy2.bitbucket.io/) | — C-level interface
— прямая поддержка pandas
— поддержка графики (+ggplot2)
— [слабая поддержка Windows](http://eurekastatistics.com/installing-rpy2/) |
| [pyper](https://pypi.org/project/PypeR/) | — Python code
— use of pipes (в среднем быстрее)
— косвенная поддержка pandas
— ограниченная поддержка графики
— плохая документация |
| [pyrserve](https://pypi.org/project/pyRserve/) | — Python code
— use of pipes (в среднем быстрее)
— косвенная поддержка pandas
— ограниченная поддержка графики
— плохая документация
— низкий уровень поддержки проекта |
#### Python from R
Лучшая библиотека на текущий момент — это официальная разработка RStudio `reticulate`. Минусы в ней пока не просматриваются. А вот преимуществ достаточно: активная поддержка, понятная и удобная документация, вывод результатов выполнения скриптов и ошибок сразу в консоль, легкая передача объектов (как и в `rpy2`, основной объект — дата фрейм). По поводу активной поддержки приведу пример из личного опыта: средняя скорость ответа на вопрос в stackoverflow и github/issues составляет примерно 1 минуту. Для работы можно как выучить синтаксис по туториалу и затем подключать отдельные python-модули и писать функции. Или же выполнять отдельные куски кода в python через функции `py_run`. Они позволяют легко выполнить python-скрипт из R, передав необходимые аргументы и получить объект со всем выходом скрипта.
Второе место по качеству у библиотеки `rPython`. Ключевое преимущество — простота синтаксиса. Всего 4 команды и вы мастер использования R и Python. Документация также не отстает: все изложено понятно, просто и доступно. Главный недостаток — кривая реализация передачи data frame. И в R и в Python требуется дополнительный шаг, чтобы переданный объект стал таблицей. Второй важный недостаток — отсутствие вывода результата выполнения функции в консоль. При запуске какой-то python-команды из R непосредственно из R вы не сможете быстро понять, успешно она выполнилась или нет. Даже в документации был хороший пассаж от авторов, что для того, чтобы увидеть результат выполнения python кода нужно зайти в сам python и посмотреть. Работа с пакетом из Windows возможна только через боль, но возможна. Полезные ссылки есть в таблице.
Третье место у библиотеки `Rcpp`. На самом деле, это очень хороший вариант. Как правило, то, что реализовано в R с помощью C++ работает устойчиво, качественно и быстро. Но требует времени, чтобы разобраться. Поэтому здесь и указано в конце списка.
Еще вне таблицы можно упомянуть [RSPython](http://www.omegahat.net/RSPython/). Идея была хорошая — единая платформа в обе стороны с единой логикой и синтаксисом — но реализация подкачала. Пакет не поддерживается с 2005 г. Хотя в целом старую версию завести и потыкать палочкой можно.
| Библиотеки | Комментарии |
| --- | --- |
| [reticulate](https://rstudio.github.io/reticulate/) | — хорошая документация
— активное развитие (с авг 2016 г.)
— волшебная функция
```
py_run_file("script.py")
```
|
| [rPython](https://rpython.readthedocs.io/en/latest/) | — передача данных через json
— непрямая передача таблиц
— [хорошая документация](https://cran.r-project.org/web/packages/rPython/rPython.pdf)
— [слабая поддержка Windows](https://github.com/cjgb/rPython-win)
— часто падает с Anaconda |
| [Rcpp](http://gallery.rcpp.org/articles/rcpp-python/) | — через C++ ([Boost.Python](https://www.boost.org/doc/libs/1_55_0/libs/python/doc/) и [Rcpp](http://www.rcpp.org/))
— нужны специфические навыки
— [хороший пример](http://gallery.rcpp.org/articles/rcpp-python/) |
Для двух наиболее популярных библиотек ниже приведены подробные примеры использования.
**Interfacing R from Python: rpy2**Для простоты будем использовать скрипт на R, указанный еще в первых примерах — `max.R`.
```
from rpy2.robjects import pandas2ri # loading rpy2
from rpy2.robjects import r
pandas2ri.activate() # activating pandas module
df_iris_py = pandas2ri.ri2py(r['iris']) # from r data frame to pandas
df_iris_r = pandas2ri.py2ri(df_iris_py) # from pandas to r data frame
plotFunc = r("""
library(ggplot2)
function(df){
p <- ggplot(iris, aes(x = Sepal.Length, y = Petal.Length))
+ geom_point(aes(color = Species))
print(p)
ggsave('iris_plot.pdf', plot = p, width = 6.5, height = 5.5)
}
""") # ggplot2 example
gr = importr('grDevices') # necessary to shut the graph off
plotFunc(df_iris_r)
gr.dev_off()
```
**Interfacing Python from R: reticulate**Для простоты будем использовать скрипт на Python, указанный еще в первых примерах — `splitstr.py`.
```
library(reticulate)
# aliasing the main module
py <- import_main()
# set parameters for Python directly from R session
py$pattern <- "---"
py$string = "3523462---12413415---4577678---7967956---5456439"
# run splitstr.py from the slide 11
result <- py_run_file('splitstr.py')
# read Python script result in R
result$ans
# [1] "3523462" "12413415" "4577678" "7967956" "5456439"
```
#### Подведем итоги
*Преимущества*
* Гибкий и интерактивный способ
* Быстрая взаимная передача объектов в рамках оперативной памяти
*Недостатки*
* **Необходимость читать туториалы!**
* Тонкости в сопоставимости объектов и способах их передачи между языками
* Передача больших объемов данных также может быть затруднительной
* Слабая поддержка Windows
* Нестабильность между версиями библиотек
### Другие подходы
В качестве отдельной категории хотелось бы привести еще несколько способов совмещения языков: с помощью специального функционала ноутбуков и отдельных платформ. Обращу внимание, что большинство приведенных ниже ссылок — это практические примеры.
При выборе *ноутбуков* можно использовать:
* Классический jupyter и синтаксис `R majic` вместе с обсуждавшейся выше `rpy2`. [Несложно, в целом](https://github.com/michhar/rpy2_sample_notebooks/blob/master/TestingRpy2.ipynb), но нужно опять же потратить некоторое время на изучение синтаксиса. Другой вариант: установка [`IRKernel`](https://blog.revolutionanalytics.com/2015/09/using-r-with-jupyter-notebooks.html). Но в этом случае получится только запускать кернелы отдельно, передавая файлы через запись на диске.
* R Notebook. Достаточно просто установить уже упомянутую библиотеку `reticulate` и далее указывать для каждой ячейки ноутбука язык, на котором вы будете творить. [Удобная штука!](https://www.r-bloggers.com/rstudio-1-2-preview-reticulated-python/)
* Apache Zeppelin. Говорят, достойно и также [в использовании удобно](https://zeppelin.apache.org/docs/0.6.2/interpreter/r.html).
Был еще замечательный проект Beaker Notebooks, позволявший очень удобно перемещаться между языками в интерфейсе, похожем и на Jupyter и на Zeppelin. Для передачи объектов in-memory авторами была написана отдельная библиотека `beaker`. Плюс можно было сразу удобно публиковать результат (в общий доступ). Но почему-то всего этого больше нет, даже старые публикации удалены — разработчики сконцентрировались на проекте [BeakerX](http://beakerx.com/).
Среди *специального софта, дающего возможность совмещать R и Python* следует выделить:
* Отличную open-source платформу [H2O](https://www.h2o.ai/). Продукт предполагает отдельные библиотеки-коннекторы как для [Python](https://pypi.org/project/h2o/), так и для [R](https://cran.r-project.org/web/packages/h2o/h2o.pdf).
* Возможности [SAS](https://blog.revolutionanalytics.com/2015/05/call-r-and-python-from-base-sas.html)
* [Cloudera](https://www.cloudera.com/documentation/data-science-workbench/latest/topics/cdsw_overview.html)
Расширенный пример
------------------
В завершение статьи хотелось бы также разобрать детальный пример решения небольшой исследовательской задачи, в которой удобно использовать R и Python.
Предположим, поставлена **задача**: сравнить уровни инфляции и темпов экономического роста в странах, реализующих инфляционное таргетирование (или близкий аналог) как режим денежно-кредитной политики с 2013 г. — примерного старта внедрения этого режима в России.
Решить задачу нужно быстро, а как быструю загрузку помним только с Python, обработку и визуализацию — с R.
Поэтому трясущимися руками заводим R Notebook, пишем в верхней ячейке ```python``` и загружаем данные с сайта World Bank. Данные будем передавать через CSV.
**Python: загрузка данных с сайта World Bank**
```
import pandas as pd
import wbdata as wd
# define a period of time
start_year = 2013
end_year = 2017
# list of countries under inflation targeting monetary policy regime
countries = ['AM', 'AU', 'AT', 'BE', 'BG', 'BR', 'CA', 'CH', 'CL', 'CO', 'CY', 'CZ', 'DE', 'DK', 'XC', 'ES', 'EE', 'FI', 'FR', 'GB', 'GR', 'HU', 'IN', 'IE', 'IS', 'IL', 'IT', 'JM', 'JP', 'KR', 'LK', 'LT', 'LU', 'LV', 'MA', 'MD', 'MX', 'MT', 'MY', 'NL', 'NO', 'NZ', 'PK', 'PE', 'PH', 'PL', 'PT', 'RO', 'RU', 'SG', 'SK', 'SI', 'SE', 'TH', 'TR', 'US', 'ZA']
# set dictionary for wbdata
inflation = {'FP.CPI.TOTL.ZG': 'CPI_annual', 'NY.GDP.MKTP.KD.ZG': 'GDP_annual'}
# download wb data
df = wd.get_dataframe(inflation, country = countries, data_date = (pd.datetime(start_year, 1, 1), pd.datetime(end_year, 1, 1)))
print(df.head())
df.to_csv('WB_data.csv', index = True)
```
Далее осуществляется предобработка данных на R: разброс значений инфляции в разных странах (min/max/mean) и средний темп экономического роста (по темпам роста реального ВВП). Изменяем также названия некоторых стран на более короткие — чтобы потом было удобнее сделать визуализацию.
**R: предобработка данных**
```
library(tidyverse)
library(data.table)
library(DT)
# get df with python results
cpi <- fread('WB_data.csv')
cpi <- cpi %>% group_by(country) %>% summarize(cpi_av = mean(CPI_annual), cpi_max = max(CPI_annual),
cpi_min = min(CPI_annual), gdp_av = mean(GDP_annual)) %>% ungroup
cpi <- cpi %>% mutate(country = replace(country, country %in% c('Czech Republic', 'Korea, Rep.', 'Philippines',
'Russian Federation', 'Singapore', 'Switzerland',
'Thailand', 'United Kingdom', 'United States'),
c('Czech', 'Korea', 'Phil', 'Russia', 'Singap', 'Switz', 'Thai', 'UK', 'US')),
gdp_sign = ifelse(gdp_av > 0, 'Positive', 'Negative'),
gdp_sign = factor(gdp_sign, levels = c('Positive', 'Negative')),
country = fct_reorder(country, gdp_av),
gdp_av = abs(gdp_av),
coord = rep(ceiling(max(cpi_max)) + 2, dim(cpi)[1])
)
print(head(data.frame(cpi)))
```
Затем можно с помощью небольшого кода и R создать читабельный и приятный график, позволяющий ответить на исходный вопрос о сравнении уровней инфляции и ВВП в странах, применяющих режим инфляционного таргетирования.
**R: визуализация**
```
library(viridis)
library(scales)
ggplot(cpi, aes(country, y = cpi_av)) +
geom_linerange(aes(x = country, y = cpi_av, ymin = cpi_min, ymax = cpi_max, colour = cpi_av), size = 1.8, alpha = 0.9) +
geom_point(aes(x = country, y = coord, size = gdp_av, shape = gdp_sign), alpha = 0.5) +
scale_size_area(max_size = 8) +
scale_colour_viridis() +
guides(size = guide_legend(title = 'Average annual\nGDP growth, %', title.theme = element_text(size = 7, angle = 0)),
shape = guide_legend(title = 'Sign of\nGDP growth, %', title.theme = element_text(size = 7, angle = 0)),
colour = guide_legend(title = 'Average\nannual CPI, %', title.theme = element_text(size = 7, angle = 0))) +
ylim(floor(min(cpi$cpi_min)) - 2, ceiling(max(cpi$cpi_max)) + 2) +
labs(title = 'Average Inflation and GDP Rates in Inflation Targeting Countries',
subtitle = paste0('For the period 2013-2017'),
x = NULL, y = NULL) +
coord_polar() +
theme_bw() +
theme(legend.position = 'right',
panel.border = element_blank(),
axis.text.x = element_text(colour = '#442D25', size = 6, angle = 21, vjust = 1))
ggsave('IT_countries_2013_2017.png', width = 11, height = 5.7)
```

На полученном графике в полярной системе координат показан разброс значений инфляции в период с 2013 г. по 2017 г., а также средние значения ВВП (над значениями инфляции). Круг означает положительный темп роста ВВП, треугольник — отрицательный.
Рисунок в целом позволяет сделать некоторые предварительные выводы об успешности режима инфляционного таргетирования в России относительно других стран. Но это уже за рамками данной статьи. А если интересно — могу дать ссылки на различные материалы по теме.
Выводы
------
* **Можно и нужно совмещать R и Python!**
В особенности в целях исследовательского анализа данных и прототипирования
* **Внимательно относитесь к выбору способов совмещения**, основываясь на целях проекта:
+ Command line tools: просто, понятно и обязательно будет работать.
+ Отличный способ для начала!
+ Внимание к формату feather!
* **Interfacing R and Python: быстро, гибко и временами интерактивно**.
+ Специфический синтаксис — необходимо читать туториалы, более сложная настройка.
+ Используйте проверенные и стабильные библиотеки: `rpy2` и `reticulate`.
* Другие подходы. **Внимание к ноутбукам!** | https://habr.com/ru/post/348260/ | null | ru | null |
# Amazon Elastic Transcoder
Привет! 
Amazon Web Services предоставили своим пользователям новый сервис обработки видео [Elastic Transcoder](http://aws.amazon.com/elastictranscoder/). Как вы понимаете, основной смысл — транскодирование видео.
Сервис представляет собой некий дата пайплайн. Мы даём ему информацию откуда брать видео, куда и в каком формате класть и всё. Я уже попробовал и хочу вам показать-рассказать что и как.
Во первых нам нужны 2 S3 бакета: один как исходящий, другой как принимающий:
* et\_test\_source
* et\_test\_dest
Далее в консоли Elastic Transecoder создаём новый пайплайн:

Вводим названия бакетов и называем пайплайн:

Далее у нас появится стандартная консоль:

В меню слева мы видим ещё пункты заданий и пресетов. Очень интересно взглянуть на пресеты:

Как видим, сервис даёт нам шаблоны для обычных форматов, ну и для популярных мобильных устройств. Так же можно создать шаблон самому и ввести все параметры видео.
Итак, мы имеем некое видео, залитое в бакет **et\_test\_source**, нам нужно его перекодировать. Создаём задание:

Далее, задание появляется во вкладке **Jobs** со статусом **Processing**.
После того, как задание отработало, в бакете et\_test\_dest у нас появится нужный файл:

Формат файла соответствует используемому пресету:
```
$ ffmpeg -i Downloads/MVI_3237.MOV
ffmpeg version 0.8.4-6:0.8.4-0ubuntu0.12.10.1, Copyright (c) 2000-2012 the Libav developers
built on Nov 6 2012 16:51:11 with gcc 4.7.2
Seems stream 0 codec frame rate differs from container frame rate: 59.94 (2997/50) -> 29.97 (2997/100)
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'Downloads/MVI_3237.MOV':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
encoder : Lavf54.29.104
Duration: 00:00:13.64, start: 0.000000, bitrate: 1037 kb/s
Stream #0.0(eng): Video: h264 (Constrained Baseline), yuv420p, 640x480 [PAR 1:1 DAR 4:3], 903 kb/s, 29.97 fps, 29.97 tbr, 2997 tbn, 59.94 tbc
Stream #0.1(eng): Audio: aac, 44100 Hz, stereo, s16, 128 kb/s
```
**Стоимость.** Elastic Transecode оплачивается поминутно.
* Стандартное разрешение (<720p) $0.015 за минуту видео
* Высокое разрешение (720p+) $0.030 за минуту видео
\* Цены указаны для региона US-EAST-1.
Вот так Amazon Web Services создали ещё один новый сервис, который, на мой взгляд, будет очень интересен нашим клиентам. Мне любопытно, просчитывали ли вы сколько стоит минута видео, используя решения на серверах? Интересен ли для вас этот сервис? | https://habr.com/ru/post/167493/ | null | ru | null |
# PHP: фрактал плохого дизайна
Предисловие
===========
Я капризный. Я жалуюсь о многих вещах. Многое в мире технологий мне не нравится и это предсказуемо: программирование — шумная молодая дисциплина, и никто из нас не имеет ни малейшего представления, что он делает. Учитывая [закон Старджона](http://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%A1%D1%82%D0%B0%D1%80%D0%B4%D0%B6%D0%BE%D0%BD%D0%B0), у нас достаточно вещей для постижения на всю жизнь.
Тут другое дело. PHP не просто неудобен в использовании, плохо мне подходит, субоптимален или не соответствует моим религиозным убеждениям. Я могу рассказать вам много хороших вещей о языках, которых я стараюсь избегать, и много плохих вещей о языках, которые мне нравятся. Вперёд, спрашивайте! Получаются интересные обсуждения.
PHP — единственное исключение. Фактически каждая деталь PHP в какой-то мере поломана. Язык, структура, экосистема: всё **плохо**. И даже нельзя указать на одну убийственную вещь, настолько дефект систематичный. Каждый раз, когда я пытаюсь систематизировать недостатки PHP, я теряюсь в поиске в глубину обнаруживая всё больше и больше ужасных мелочей(отсюда фрактал).
PHP — препятствие, отрава моего ремесла. Я схожу с ума от того, насколько он сломан и насколько воспеваем каждым уполномоченным любителем нежелающим научиться чему-либо ещё. У него ничтожно мало оправдывающих положительных качеств и я бы хотел забыть, что он вообще существует.
Аналогия
========
Я только что выпалил это Мэл, чтобы описать своё расстройство и она настояла на том, чтобы я воспроизвёл это здесь:
> Я даже не могу сказать, что не так с PHP, потому что… Окей. Представьте себе, эмм, коробку с инструментами. Набор инструментов. Выглядит нормально, инструменты как инструменты.
>
>
>
> Вы берёте отвёртку и видите крестовину с тремя лепестками. Окей, не очень полезно для вас, но может когда-нибудь понадобиться.
>
>
>
> Берёте молоток и ужасаетесь тому, что он раздвоен с двух сторон. Он, конечно, всё ещё пригоден, я имею ввиду, что вы можете забивать гвозди серединой бойка, держась за ручку наоборот.
>
>
>
> Берёте плоскогубцы, у которых нет зазубрин; они плоские и гладкие. Не так полезно, как могло бы быть, но ими всё ещё можно выкручивать болты.
>
>
>
> И так далее. Все инструменты чем-то странные и вывернутые, но не настолько, чтобы быть совсем бесполезными. И во всём наборе нет конкретной проблемы; в нём есть все инструменты.
>
>
>
> Теперь представьте себе миллионы плотников, использующих такой вот набор инструментов и говорящих вам: «А что не так с этими инструментами? Я никогда не использовал ничего другого и они отлично работают!». И плотники показывают вам, построенные ими дома с пятиугольными комнатами и крышей кверху ногами. Вы стучитесь в дверь, она просто падает внутрь и они орут на вас за то, что вы сломали их дверь.
>
>
>
> Вот что не так с PHP.
>
>
Расстановка сил
===============
Я утверждаю, что язык должен обладать следующими качествами, дабы быть полезным и продуктивным, и PHP нарушает их с дикой непринуждённостью. Если вы не согласны, что они критичны, честно, я не могу представить, как мы с вами в чём-либо можем достигнуть согласия.
* Язык должен быть **предсказуем**. Язык — носитель для выражения человеческих идей и выполнения их на компьютере, поэтому человеческое понимание правильности программы критично.
* Язык должен быть **целостен**. Похожие вещи должны быть похожи, разные должны различаться. Знание части языка должно помогать в изучении и понимании остальной части.
* Язык должен быть **краток**. Новые языки существуют, чтобы уменьшить шаблонность присущую старым языкам. (Мы все *могли* бы программировать на машинных кодах.) Язык должен в тоже время избегать введения своих собственных шаблонов.
* Язык должен быть **надёжен**. Языки — инструменты для решения задач; проблемы, которые они представляют сами по себе должны быть минимальны. Любые непонятные моменты вызывают смущение.
* Язык должен быть **отлаживаем**. Если что-то идёт не так, программист обязан это *починить*, и нам нужна вся помощь, которую мы можем получить.
Моя позиция такова:
* PHP полон сюрпризов: `mysql\_real\_escape\_string`, `E\_ACTUALLY\_ALL`
* PHP не целостен: `strpos`, `str\_rot13`
* PHP требует шаблонного кода: проверка ошибок вокруг «C API»-вызовов, `===`
* PHP чудной: `==`, `foreach ($foo as &$bar)`
* PHP непрозрачен: без стэктрэйсов по умолчанию и фатальных ошибок, сложный error reporting.
Я не могу привести абзац для каждой проблемы, описывающий почему каждая конкретная проблема попадает в эти категории, статья будет бесконечной. Я верю, что читатель, как бы, думает.
Не нужно следующих комментариев
===============================
Я участвовал во *многих* спорах о PHP. Слышал много общих контраргументов на самом деле предназначенных, чтобы закрыть тему. Пожалуйста воздержитесь от них :(
* Не говорите мне, что «хорошие разработчики могут писать хороший код на любом языке», или что «плохие разработчики что-то там ещё». Это *ничего не значит*. Хороший плотник *может* забить гвоздь камнем или молотком, но где вы видели плотников забивающих что-либо камнями? Один из факторов, определяющих хорошего разработчика, это способность *выбрать* подходящие инструменты.
* Не говорите мне, что разработчик обязан помнить тысячи странных исключений и неожиданных поведений. Да, это обязательно в любой системе, потому что компьтеры сосут. Только это не значит, что нет верхнего предела фигни в системе. В PHP нет *ничего* кроме исключений, и это не круто, если борьба с языком занимает больше усилий нежели написание самой программы. Мои инструменты не должны создавать мне не позитивную работу.
* Не говорите мне, что «так работает C API». Какой вообще тогда смысл использовать высокоуровневый язык, если он даёт только строковые хэлперы и массу дословных C обёрток? Просто пишите на C! Смотрите, для него даже есть [CGI-библиотека](http://www.boutell.com/cgic/).
* Не говорите мне: «Это тебе за то, что делаешь странные вещи». Если две фичи существуют, кто-нибудь когда-нибудь обязательно найдёт причину использовать их вместе. И снова, это не C: спецификации нет, как нет и надобности в «неопределённом поведении».
* Не говорите мне, что Facebook или Wikipedia написаны на PHP. Я в курсе! Они так же могли бы быть написаны на Brainfuck'е, достаточно умные люди *могут* пересилить это всё. Всё, что мы знаем, это то, что время разработки могло быть ополовинено или удвоенно если бы эти продукты были написаны на каком-нибудь другом языке; только этот отдельный аргумент ничего не значит.
* В идеале вы не должны говорить мне ничего! Это мой лучший выстрел; если он не изменит мнения о PHP, тогда его не изменит *ничто*, так что хорош уже спорить с каким-то чуваком в Интернете и иди уже сделай крутой сайт в рекордные сроки, чтобы доказать, что я не прав :)
Кстати: я обожаю Python. И с удовольствием прожужжу тебе уши, ноя о нём, если ты на самом деле этого хочешь. Я не утверждаю, что он *идеален*; я просто взвесил его преимущества и его проблемы и сделал вывод, что он лучше всего подходит для того, что я делаю.
И я никогда не встречал PHP-разработчика, который может сделать тоже самое на PHP. Но я натыкался на достаточное количество тех, кто сразу начинает извинятся за что-то и всё, что делает PHP. Такое мышление ужасает.
PHP
===
Ядро языка
----------
CPAN был назван «стандартной библиотекой Perl». Это не говорит много о стандартной библиотеке Perl, но указывает, что прочное ядро может построить замечательные вещи.
### Философия
* PHP изначально создавался для непрограммистов(и если читать между строк не для программ); он не смог уйти от своих корней. Вот из [документации по PHP 2.0](http://www.php.net/manual/phpfi2.php#overload) цитата о том, как делался выбор относительно приведения типов для `+` и прочих:
> Отдельные операторы для каждого типа сильно усложняют язык, например, вы больше не сможете использовать '==' для строк(что?), вы теперь будете использовать 'eq'. Я не вижу в этом никакого смысла, особенно в таком языке как PHP, где большинство скриптов будут достаточно простыми и в большинстве случаев, написаны непрограммистами, которым нужен язык с простейшим логическим синтаксисом и низким порогом вхождения.
>
>
* PHP построен, чтобы продолжать фурычить при любых обстоятельствах. Если есть выбор между тем, чтобы сделать непонятно что и упасть с ошибкой, он сделает непонятно что. Что-нибудь лучше, чем совсем ничего.
* Дизайн не имеет определённой философии. Ранний PHP был вдохновлён Perl'ом; огромная std-библиотека с «out»-параметрами из C; ОО-часть сделана как в C++ и Java.
* PHP обширно черпает вдохновение из других языков, при этом ему удаётся быть *непонятным* для тех, кто эти языки знает. `(int)` выглядит как C, но `int` не существует. Нэймспэйсы используют `\`. Новый синтаксис массивов получился уникальный среди всех языков с хэш-литералами: `[key=>value]`.
* Слабая типизация(всмысле, тихая автоматическая конверсия между строками/числами/всем остальным) настолько сложная, что она не стоит того, сколько бы усилий начинающего программиста она не сохраняла.
* Новая функциональность реализуется как новый синтаксис, даже если она мала; большинство её делается с помощью функции или чего похожего на функции. Кроме поддержки классов, которая заслуживает множества новых операторов и ключевых слов.
* Некоторые из проблем, описанных в этой статье на самом деле имеют первоклассное решение — если конечно вы хотите платить Zend'у за фиксы к их языку с открытыми исходниками.
* Целая куча событий происходит за сценой. Взять хотя бы вот этот код, откуда-то из PHP-документации:
```
@fopen('http://example.com/not-existing-file', 'r');
```
Что он будет делать?
+ Если PHP скомпилирован с `--disable-url-fopen-wrapper`, он не будет работать. (Документация не говорит, что означает «не будет работать»; вернёт null, бросит исключение?) Заметьте, что этот флаг убрали в PHP 5.2.5.
+ Если `allow\_url\_fopen` выключен в php.ini, он тоже не будет работать. (Как не будет? Нет идей.)
+ Из-за `@`, предупреждение о несуществующем файле не будет выведено.
+ Но будет выведено, если `scream.enabled` установлен в php.ini.
+ Или если `scream.enabled` вручную установлен через `ini\_set`.
+ Но не в том случае, если не установлен корректный `error\_reporting`.
+ Если оно будет выведено, куда оно будет выведено зависит от `display\_errors`, снова в php.ini. Или `ini\_set`.
Я не могу сказать как такой безобидный вызов функции будет себя вести без проверки флагов времени компиляции, глобальной конфигурации сервера и конфигурации в моей программе. И это всё *встроенное* поведение.
* Этот язык полон глобального и неявного поведения. `mbstring` использует глобальную кодировку. `func\_get\_arg` и прочие вроде бы обычная функция, но оперирует над выполняемой в данный момент функцией. Обработка ошибок и исключений имеет глобальные умолчания. `register\_tick\_function` устанавливает глобальную функцию, которая выполняется каждый тик — чего?!
* До сих пор нет поддержки потоков.(Неудивительно, учитывая вышеуказанное.) С отсутствием встроенного `fork`(упомянуто ниже), это очень усложняет парралельное программирование.
* Некоторые части PHP практически *созданы* для производства глючного кода:
+ `json\_decode` возвращает null для невалидного ввода, при том, что null — абсолютно верный объект для декодируемого JSON'а. Эта функция абсолютно *ненадёжна*, если вы конечно не вызываете `json\_last\_error`каждый раз при её использовании.
+ `array\_search`, `strpos` и другие похожие функции возвращают `0`, если находят вхождение на нулевой позиции, но false если не находят его вообще.
Дайте-ка мне чуть расширить последний пункт.
В C, такие функции как `strpos` возвращают `-1`, если элемент не был найден. Если вы не проверите этот вариант и попытаетесь использовать результат в качестве индекса, вы попадёте в мусорную память и ваша программа упадёт. (Скорее всего. Это же C. Хрен его знает. Я уверен, что для этого как минимум есть инструменты.)
В Python'е например эквивалентные методы `.index` бросят исключение, если элемент не найден. Если вы не проверите этот случай, ваша программа упадёт.
В PHP эти функции возвращают false. Если вы используете `FALSE` как индекс, или сделаете с ним почти всё что угодно кроме сравнения с помощью `===`, PHP спокойно сконвертирует его в `0` за вас. Ваша программа не упадёт; она вместо этого будет работать *неправильно без предупреждения*, если конечно вы не забудете вставить нужный шаблонный код вокруг каждого места где вы используете `strpos` и некоторые другие функции.
Это плохо! Языки программирования — это инструменты; я предполагаю, что они будут работать вместе со мной. Здесь же, PHP поставил для меня хитрую ловушку, и должен быть осторожен даже с такими повседневными вещами как операции над строками и сравнения на равенство. PHP — *минное поле*.
Я слышал много замечательных историй про PHP-интерпретатор и [его разработчиков](http://en.wikiquote.org/wiki/Rasmus_Lerdorf) из разных замечательных мест. Они были от людей работавших над [ядром PHP](http://www.reddit.com/r/lolphp/comments/qeq7k/php_540_ships_with_82_failing_tests_in_the_suite/), [отладкой](http://perlbuzz.com/2008/09/optimizing-for-the-developer-not-the-user-php-misses-again.html) ядра PHP и общавшихся с разработчиками ядра. Ни один из рассказов не был хвалебным.
Итак я помещу это сюда, потому что я устал это повторять: PHP — это комьюнити любителей. Очень мало людей, которые его создают, работают над ним или пишут код на нём, вообще представляют, что они делают(о, дорогой читатель, *вы* конечно редкое исключение!). Те, кто начинают что-то *понимать*, сколонны уходить на другие платформы, снижая среднюю компетенцию общего числа. Видите, вот она самая большая проблема PHP: это абсолютно точно слепец ведомый слепцом.
Окей, вернёмся к фактам.
### Операторы
* `==` [бесполезен](http://habnab.it/php-table.html)
+ Он не транзитивен. `"foo" == TRUE`, и `"foo" == 0`… но, конечно же `TRUE != 0`.
+ `==` конвертирует в число, если возможно. Далее конвертирует в float'ы, если возможно. Получается, что большие шестнадцатиричные строки(например, хеши паролей) могут неожиданно [быть равными, когда они не равны](http://phpsadness.com/sad/47).
+ По тем же причинам, `"6" == " 6"`, `"4.2" == "4.20"` и `"133" == "0133"`. Но прошу заметьте, что `133 != 0133`, потому что `0133` восьмеричное.
+ `===` сравнивает значения и тип… но не для объектов, где `===` истинно если оба операнда один и тот же объект! Для объектов, `==` сравнивает оба значения(для каждого аттрибута) и типы, что `===` делает для всех остальных типов. [Чего.](http://developers.slashdot.org/comments.pl?sid=204433&cid=16703529)
* Не лучше и сравнение:
+ Оно даже не согласовано: `NULL < -1`, **и** `NULL == 0`. Сортировка не детерменирована; она зависит от порядка в котором, алгоритм будет сравнивать элементы.
+ Операторы сравнения пытаются сортировать массивы, двумя разными способами: сначала по длине, затем по *элементам*. Вторая сортировка происходит, если у массивов *одинаковое количество* элементов, но *разный* набор ключей. По хорошему, такие массивы вообще нельзя сравнивать.
+ Объекты при сравнении всегда больше всего остального… кроме других объектов, которые не больше и не меньше.
+ Для более типобезопасного `==`, у нас есть `===`. Для типобезопасного `<` у нас… нет ничего. `"123" < "0124"`, всегда, что бы вы не делали.
* Вопреки вышеописанном безумию и чёткому отрицанию Perl'овых пар строковых и числовых операторов, PHP не перегружает `+`, `+` всегда сложение, а `.` всегда конкатенация.
* `[]` оператор индекса может также быть записан как `{}`.
* `[]` может быть применён к любой переменной, не только к строкам и массивам. Он возвращает null и не выдаёт предупреждение.
* `[]` не может слайсить; он только возвращает отдельные элементы.
* `foo()[0]` — синтаксическая ошибка. (Пофикшено в PHP 5.4.)
* В отличие от (почти) всех остальных языков с похожим оператором, `?:` *лево*ассоциативен. Поэтому следующий код:
```
$arg = 'T';
$vehicle = ( ( $arg == 'B' ) ? 'bus' :
( $arg == 'A' ) ? 'airplane' :
( $arg == 'T' ) ? 'train' :
( $arg == 'C' ) ? 'car' :
( $arg == 'H' ) ? 'horse' :
'feet' );
echo $vehicle;
```
выведет `horse`.
### Переменные
* Нет никакого способа объявить переменную. Переменные, которые не существуют создаются со значением null при первом использовании.
* Глобальные переменные должны быть объявлены с ключевым словом `global` перед использованием. Это естественное последствие предыдущего пункта, кроме того, что глобальная переменная даже не может быть *прочитана* без явного объявления — вместо этого PHP просто создаёт локальную переменную с таким же именем. Я не знаю другого языка с такими же проблемами с контекстом.
* Нет ссылок. То, что в PHP называется ссылками, это на самом деле псевдонимы; это шаг назад, прям как ссылки в Perl, не существует передачи через объект, как в Python.
* «Ссылочность» поражает переменные больше всего остального в языке. PHP — динамически типизированный, поэтому у переменных в общем случае нет типа… кроме ссылок, которые украшают определения функций, синтаксис переменных и присваивания. Как только переменная становится ссылкой(что может случится где угодно), она связана с этой ссылкой. Невозможно определить, случилось это или нет и для разыменования ссылки нужно полностью уничтожить переменную.
* Окей, я соврал. Есть "[SPL-типы](http://www.php.net/manual/en/book.spl-types.php)", которые тоже поражают переменные:
Выполнение `$x = new SplBool(true); $x = "foo";` завершится неудачей. Смотрите-ка, выглядит как статическая типизация.
* Можно получить ссылку на несуществующий ключ внутри неопределённой переменной(которая становится массивом). Использование несуществующего массива обычно выводит notice, но не в этом случае.
* Константы определяются с помощью вызова функции; до этого они не существуют. (Возможно, это копия Perl-поведения `use constant`.)
* Имена переменных чувствительны к регистру. Имена функций и классов нет. Включая имена методов, что делает camelCase не лучшим выбором именования.
### Конструкции
* `array()` и пару дюжин других конструкций — не функции. Сама по себе конструкция `array` не означает ничего, `$func = "array"; $func();` не работает.
* Распаковка массивов может быть выполнена операцией `list($a, $b) = ...`. `list()` — синтаксис похожий на функцию так же как `array`. Я не знаю почему для этого был выделен отдельный синтаксис или почему было выбрано такое смутное имя.
* `(int)` очевидно создан, чтобы выглядеть как C, но это отдельный токен; в языке нет никакого `int`. Попробуйте: `var\_dump(int)` не только не работает, но и выбрасывает parse error, потому что аргументы выглядит как оператор приведения типа.
* `(integer)` — синоним `(int)`. Ещё есть `(bool)`/`(boolean)` и `(float)`/`(double)`/`(real)`.
* Есть оператор `(array)` для приведения к массиву и оператор `(object)` для приведения к объекту. Звучит безумно, но у них есть применение: вы можете использовать `(array)` для создания функции с аргументом, который может списком либо одним его элементом, чтобы работать с ним одинаково. Кроме того, что вы не можете сделать это надёжно, потому что если кто-то передаст отдельный *объект*, приведение его к массиву выдаст массив состоящий из аттрибутов объекта. (Приведение к объекту выполняет обратную операцию.)
* `include()` и прочие это просто C-шный `#include`: она дампит другой исходный файл в ваш. Нет системы модулей, даже для PHP-кода.
* Вложенных классов и функций не существует. Только глобальные. `include()` файла дампит переменные из этого файла в текущий контекст функции (и даёт файлу доступ к вашим переменным), но классы и функции дампятся в глобальный контекст.
* Добавление в массив выполняется `$foo[] = $bar`.
* `echo` — выражение, а не функция.
* `empty($var)` настолько не функция, что что угодно кроме переменной, как например `empty($var || $var2)` приводит к parse error'у. Почему вообще парсеру нужно что-то знать о `empty`?
* Существует избыточный синтаксис для блоков: `if (...): ... endif;` и др.
### Обработка ошибок
* Ещё один уникальный оператор PHP `@`(на самом деле взятый из DOS) *заглушает* ошибки.
* У ошибок PHP нет стэктрэйсов. Вы должны установить обработчик, чтобы их генерировать. (Но вы не можете для fatal error'ов — см. ниже.)
* Parse error'ы PHP часто просто выплёвывают состояние парсера и больше ничего, [жутко усложняя отладку](http://phpsadness.com/sad/44), если вы где-то забыли кавычку.
* Парсер PHP внутри ссылается на `::` как на `T\_PAAMAYIM\_NEKUDOTAYIM`, и на `<<` как на `T\_SL`. Я сказал «внутри», но как указано выше это то, что показывается программисту, когда `::` или `<<` встречается в неверном месте.
* Большая часть обработки ошибок состоит в выводе строчки в лог сервера, который никто не читает и не интересуется.
* Уровень `E\_STRICT` как раз то, что нужно, но похоже он на самом деле предотвращает немногое и нет документации, что он на самом деле делает.
* `E\_ALL` включает все категории ошибок — кроме `E\_STRICT`.
* Жутко много противоречий о том, что разрешено, а что нет. Я не знаю, как `E\_STRICT` к этому применяется, но следующее делать можно:
+ пытаться получить доступ к несуществующему свойству объекта, типа `$foo->x`.(warning)
+ использовать переменной как имени функции, или имени переменной, или имени класса.(без сообщений)
+ пытаться использовать неопределённую константу.(notice)
+ пытаться получить доступ свойство чего-нибудь, не являющегося объектом.(notice)
+ пытаться использовать имя переменной, которая не существует.(notice)
+ `2 < "foo"` (без сообщений)
+ `foreach (2 as $foo);` (warning)
А это нельзя:
+ пытаться получить доступ к несуществующей константе класса, типа `$foo::x`. (fatal error)
+ использовать константной строки как имени функции, имени переменной или имени класса. (parse error)
+ пытаться вызвать неопределённую функцию. (fatal error)
+ оставлять точку с запятой в конце блока или файла. (parse error)
+ использовать `list` и разные другие квазиконструкции как названия методов. (parse error)
+ индексировать возвращаемое функцией значение, типа `foo()[0]`. (parse error, пофикшено в 5.4, см. выше)
Во всём этом списке есть ещё несколько хороших примеров странных parse error'ов.
* Метод `\_\_toString` не может бросать исключения. Если вы попробуете PHP… эм, бросит исключение. (На самом деле fatal error, который снова в отличие от всех остальных можно передавать.)
* PHP-ошибки и PHP-исключения абсолютно разные существа. Они, похоже, не могут взаимодействовать *никак*.
+ PHP-ошибки (внутренние и вызванные через `trigger\_error`) не могут быть словлены блоком `try`/`catch`.
+ Точно так же, исключения не приводят к вызову обработчиков установленных через `set\_error\_handler`.
+ Вместо этого, есть отдельная функция `set\_exception\_handler` которая обрабатывает не пойманные исключения, потому что обернуть входную точку вашей программы в блок `try` невозможно в модели `mod\_php`.
+ Fatal error'ы (типа `new ClassDoesntExist()`) не могут быть пойманы ничем. *Многие* вполне невинные вещи бросают fatal error'ы, принудительно завершая вашу программу по сомнительным причинам. Shutdown-функции всё ещё вызываются, но они не могу получить стэктрэйс (потому что выполняются на верхнем уровне), и в них не так просто определить завершилась ли ваша программа с ошибкой или выполнилась до конца.
* Нет конструкции `finally`, создание wrapper-кода(установил обработчик, выполнил код, убрал обработчик; манкипатч, проверил, разманкипатчил) утомительно и сложно для написания. Несмотря на то, что объектная модель и исключения в многом скопированы из Java, это было [сделано намеренно](https://bugs.php.net/bug.php?id=32100), потому что `finally` «не имеет большого смысла в контексте PHP». Да ну?
### Функции
* Вызовы функций явно достаточно [дорогие](http://www.phpwtf.org/php-function-calls-have-quite-some-overhead).
* Некоторые встроенные функции взаимодействуют с функциями возвращающими ссылки, скажем так, [странно](http://www.phpwtf.org/php-function-calls-returning-references).
* Как я замечал ранее, некоторые вещи, похожие на функции или похожие на то, что *должно* быть функцией на самом деле конструкции языка, поэтому всё, что работает с функциями не будет работать с ними.
* Аргументы функций могут иметь «type hint'ы», это попросту статическая типизация. Но вы не можете требовать от аргумента быть `int` или `string` или `object` или другим примитивным типом, хотя каждая встроенная функция использует эти типы, наверное потому что `int` в PHP не существует.(про `(int)` см. выше) Вы также не можете использовать специальные [псевдо-типы](http://www.php.net/manual/en/language.pseudo-types.php#language.types.mixed) используемые повсеместно во встроенных функциях `mixed`, `number` или `callback`.
+ В результате, следующий код:
```
function foo(string $s) {}
foo("hello world");
```
Выводит ошибку:
```
PHP Catchable fatal error: Argument 1 passed to foo() must be an instance of string, string given, called in...
```
+ Вы можете заметить, что указанного «type hint'а» не должно здесь быть. В этой программе нет класса `string`. Если вы воспользуетесь `ReflectionParameter::getClass()`, чтобы исследовать type hint динамически, он *упрётся* в несуществующий класс, делая невозможным получение имени класса.
+ Type hint не может быть применён к возвращаемому функцией значению.
* Передача аргументов функции в другую функцию(dispatch, не такая уж и редкость) делается через `call\_user\_func\_array('другая функция', func\_get\_args())`. Но `func\_get\_args` выбрасывает fatal error в рантайме, жалуясь, чтом `func\_get\_args` не может быть параметром функции. Как и почему такая ошибка вообще существует? (Пофикшено в PHP 5.3.)
* Замыкания требует явного указания всех замыкаемых переменных. Почему интерпретатор сам не может это определить? Калечит всю фичу. (Окей, потому что любое использование переменной переменной, абсолютно любое, создаёт её, если обратное явно не указано.)
* Замыкаемые переменные «передаются» с той же семантикой как остальные аргументы функции. Вот так, массивы, строки и пр. будут переданы по значению. Если не используете `&`.
* Т.к. замыкаемые переменные фактически автоматически передаваемые аргументы и нет вложенных контекстов, замыкание не может использовать private-методы, даже если оно определено внутри класса. (Возможно пофикшено в 5.4? Не уверен.)
* Нет именованных параметров функций. На самом деле [явно отклонено](http://www.php.net/~derick/meeting-notes.html#named-parameters) разработчиками, потому что «ведёт к беспорядочному коду».
* Аргументы со значениями по умолчанию могут быть перед аргументами без них, не смотря на то, что в документации указано, что это странно и бесполезно. (Зачем тогда это позволять?)
* Лишние аргументы игнорируются(кроме лишних аргументов встроенных функций, они вызывают ошибку). Недостающие аргументы предполагаются равными null.
* Функции с переменным числом аргументов требуют возни с `func\_num\_args`, `func\_get\_arg` и `func\_get\_args`. Для этого нет синтаксиса.
### ООП
* Функциональные части PHP сделаны как в C, а объектные как в Java. Даже не могу сказать, как меня это раздражает. Я не нашёл ни одной глобальной функции с заглавной буквой в имени, в то время как [важные встроенные классы](http://www.php.net/manual/en/class.reflectionfunction.php) используют camelCase для имён методов и аксессоры `getFoo` в Java-стиле. Это динамический язык, верно? Perl, Python и Ruby: у каждого из этих языков есть какуя-либо концепция доступа к «свойству» из кода; у PHP же только неуклюжий `\_\_get` и прочие. Система классов создана вокруг *более низкоуровневого* языка Java, который естественно и намеренно *более ограничен*, чем языки-современники PHP, я сбит с толку.
* Классы не объекты. Любой метакод вынужден ссылаться на них по имени, как в случае с функциями.
* Встроенные типы не объекты и (не как в Perl) никоим образом не могут быть представлены ввиде объектов.
* `instanceof` оператор, несмотря на то, что классы были добавлены достаточно поздно и что большая часть языка построена на функциях и функционном синтаксисе. Влияние Java? Классы не first-class объекты?
+ Но *существует* функция `is\_a`. С необязательным аргументом указывающим разрешать ли объекту быть строкой, содержащей имя класса.
+ `get\_class` тоже функция; нет оператора `typeof`. Также как и оператора `is\_subclass\_of`.
+ Тем не менее, `instanceof` не работает для встроенных типов (снова, `int` не существует). Для этого случая вам нужен `is\_int` и пр.
+ И ещё правая часть должна быть переменной или литеральной строкой; не может быть выражением. Это приводит к… parse error'у.
* `clone` — оператор?!
* ООП-дизайн представляет из себя жуткую мешанину Java и Perl.
* Синтаксис аттрибутов объектов `$obj->foo`, а аттрибутов классов `$obj::foo`. Я не в курсе есть ли другой язык в котором сделано так же или какую пользу это приносит.
* Также метод экземпляра может быть вызван статически (`Class::method`). Такой вызов сделать в другом методе(*пер.* или даже другом классе) трактуется как обычный вызов метода в текущем `$this`.
* `new`, `private`, `public`, `protected`, `static` и пр. Хотели привлечь Java-разработчиков? Я в курсе, что это дело вкуса, но я не понимаю зачем это обязательно в динамическом языке — это нужно в C++ в основном для компиляции и разрешения имён во время компиляции.
* Подклассы не могут перегружать private-методы. Перегруженные публичные методы подкласса даже *не видят* private-методы, кроме того, что не могут вызывать. Создаёт проблемы, например, при написании тест-моков.
* Методы не могут называться, например «list», потому что `list()` — специальный синтаксис(не функция) и парсер начинает путаться. Для такой неоднозначности нет никакой причины, и всё работает при динамической модификации(*пер.* monkeypatching).(`$foo->list()` не приводит к ошибке синтаксиса.)
* Если при вычислении аргументов конструктора бросается исключение(например `new Foo(bar())` и `bar()` бросает исключение), конструктор не будет вызван, а деструктор будет.(Пофикшено в PHP 5.3.)
* Исключения в `\_\_autoload` и деструкторах вызывают fatal error.
* Нет никаких конструкторов и деструкторов. `\_\_construct` — это инициализатор, как `\_\_init\_\_` в Python. Нет метода при вызове, которого выделится память и будет создан объект.
* Нет инициализатора по умолчанию. Если суперкласс не определяет собственный `\_\_construct`, Вызов `parent::\_\_construct()` приводит к fatal error'у.
* ООП также вводит интерфейс итераторов, который учитывают некоторые части языка(типа `for...as`), но ни одна встроенная сущность(такая как массивы) этот интерфейс на самом деле не реализует. Если вам нужен итератор массива, вам приходится оборачивать его в `ArrayIterator`. Нет встроенной поддержки сцепления, slice'инга и чего-либо ещё для работы с итераторами, как «first class»-объектами.
* Классы могут перегрузить то, как они конвертируются в строки и как они ведут себя будучи вызванными, но не как они конвертируется в числа и другие встроенные типы.
* Есть конверсия в строки для Строк, чисел и массивов; язык на это очень полагается. Функции и классы *тоже* строки. Тем не менее конверсия встроенного или определённого пользователем объекта(и даже замыкания) в строку вызывает ошибку, если объект не определяет `\_\_toString`. Даже `echo` становится потенциально склонен к ошибке.
* Нет перегрузки сравнения и последовательности(*пер.* ordering).
* Статические переменные внутри методов экземпляра глобальны; одно значение на все экземпляры класса.
Стандартная библиотека
----------------------
Философия стандартной библиотеки Perl «some assembly required»(*пер.* возможный перевод «понадобится некоторая сборка»), Python — «батарейки в комплекте», PHP — «раковина, но канадская с [подписью C на обоих кранах](http://mcguirehimself.com/?p=4146)».
### Общие замечания
* Нет системы модулей. Вы можете компилировать расширения PHP, но какие из них загружать указывается в php.ini, и у вас только две опции: расширение существует(и вносит своё содержимое в глобальное пространство имён) или нет.
* Стандартная библиотека не разбита на namespace'ы, поскольку они были добавлены недавно. В глобальном пространстве имён тысячи функций.
* Части библиотеки дико противоречат друг другу:
+ Подчеркивание против его отсутствия: `strpos`/`str\_rot13`, `php\_uname`/`phpversion`, `base64\_encode`/`urlencode`, `gettype`/`get\_class`
+ «to» против 2: `ascii2ebcdic`, `bin2hex`, `deg2rad`, `strtolower`, `strtotime`
+ объект+действие против действие+объект: `base64\_decode`, `str\_shuffle`, `var\_dump` versus `create\_function`, `recode\_string`
+ Порядок аргументов: `array\_filter($input, $callback)` против `array\_map($callback, $input)`, `strpos($haystack, $needle)` против `array\_search($needle, $haystack)`
+ Путаница с префиксами: `usleep` против `microtime`
+ Варьируется положение `i` в именах функций, нечуствительных к регистру
+ Около половины имен функций работы с массивами начинаются с `array\_`. Другая половина нет.
* Раковина. Библиотека включает:
+ Байндинги для ImageMagick, байндинги для GraphicsMagick(это форк ImageMagick), и пригорошню функций для чтения EXIF-данных(что и так умеет делать ImageMagick).
+ Функции для парсинга bbcode'а, специального маркапа используемого горсткой некоторых форумных пакетов.
+ Слишком много разных XML-пакетов. `DOM`(объектно-ориентированный), `DOM XML`(не объектно-ориентированный), `libxml`, `SimpleXML`, «XML Parser», `XMLReader`/`XMLWriter` и ещё полдюжины акронимов, которые я не могу разобрать. Между ними точно есть какая-то разница, идите и узнайте её сами.
+ Байндинги для двух отдельных процессоров кредитных карт: SPPLUS и MCVE. Зачем?
+ Три способа доступа к базе MySQL: `mysql`, `mysqli` и абстракция `PDO`.
### Влияние C
Оно заслуживает отдельного пункта в этом списке, потому что оно настолько абсурдно и при этом пронизывает язык вдоль и поперёк. PHP — высоко-уровневый, динамически-типизированный язык. В то же время большая часть стандартной библиотеки представляет из себя тонкую обёртку вокруг C API, со следующими результатами:
* «Выходные» параметры, не смотря на то, что PHP вполне способен возвращать специальные хэши или несколько аргументов без особых усилий.
* Как минимумум дюжина функций для получения последней ошибки определённой подсистемы(см. ниже), хотя исключения существуют в PHP уже восемь лет.
* Бородавки типа `mysql\_real\_escape\_string`, несмотря на то, что у неё такие же аргументы как и у сломанной `mysql\_escape\_string`, просто потому что это часть MySQL C API.
* Глобальное поведение для неглобального функционала (например MySQL). Использование нескольких подключений MySQL требует передачи дескриптора подключения в каждый вызов функции.
* Врапперы очень, очень и очень тонкие. Например вызов `dba\_nextkey` без вызова `dba\_firstkey` упадёт с segfault'ом.
* Набор функций `ctype\_\*`(типа `ctype\_alnum`) называется в соответствии C-функциям определения класса символа с похожими именами, вместо того, чтобы называться, например `isupper`.
### Обобщения
Нет никаких обобщений. Если вдруг функции нужно делать две немного разные вещи, в PHP для этого две функции.
Как сортировать в обратном порядке? В Perl, вы можете сделать `sort {$b <=> $a}`. В Python `.sort(reverse=True)`. В PHP, это отдельная функция `rsort()`.
* Функции получения C-ошибки: `curl\_error`, `json\_last\_error`, `openssl\_error\_string`, `imap\_errors`, `mysql\_error`, `xml\_get\_error\_code`, `bzerror`, `date\_get\_last\_errors` и другие.
* Функции сортировки: `array\_multisort`, `arsort`, `ksort`, `krsort`, `natsort`, `natcasesort`, `sort`, `rsort`, `uasort`, `uksort`, `usort`
* Функции для текстового поиска: `ereg`, `eregi`, `mb\_ereg`, `mb\_eregi`, `preg\_match`, `strstr`, `strchr`, `stristr`, `strrchr`, `srcpos`, `stripos`, `strrpos`, `strripos`, `mb\_strpos`, `mb\_strrpos` плюс вариации, выполняющие подстановки.
* К тому же куча бесполезных псевдонимов: `strstr`/`strchr`, `is\_int`/`is\_integer`/`is\_long`, `is\_float`/`is\_double`, `pos`/`current`, `sizeof`/`count`, `chop`/`rtrim`, `implode`/`join`, `die`/`exit`, `trigger\_error`/`user\_error`...
* `scandir` возврщает список файлов в текущей директории. Вместо того, чтобы возвращать сначала директории(что могло бы быть полезно), функция возращает их в алфавитном порядке. Необязательный аргумент позволяет получить их в обратном алфавитном порядке. Очевидно, функций сортировки было недостаточно.
* `str\_split` разбивает строку на равные по длине части. `chunk\_split` разбивает строку на части одинаковой длины и объединяет их через разделитель.
* Для каждого формата архивов используется отдельный набор функций. Всего шесть груп таких функций, с разным API, для bzip2, LZF, phar, rar, zip и gzip/zlib.
* Т.к. вызов функции с массивом аргументов настолько неудобен(`call\_user\_func\_array`), есть несколько пар функций типа `printf`/`vprintf` и `sprintf`/`vsprintf`. Они делают одно и то же только одна принимает аргументы, а другая массив аргументов.
### Текст
* `preg\_replace` с флагом `/e`(eval) выполняет подстановку соответствий на строку подстановки, затем *eval'ит эту строку*.
* `strtok` очевидно создана по образу C-функции, которая считается неудачной по разным причинам. Неважно, что PHP мог бы легко возвращать массив(в C это не так просто), и что хак, используемый `strtok(3)`(модификация строки на месте) в PHP не используется.
* `parse\_str` парсит строку *GET-запроса*, не указывая этого в имени. Также она ведёт себя как `register\_globals` и дампит запрос в виде переменных в локальный контекст, если вы не передадите ей массив для наполнения. (Она, конечно, ничего не возвращает.)
* `explode` отказывается разбивать с пустым разделителем. Любая другая реализация разбиения строки где угодно воспринимает это как разбиение посимвольно; в PHP для этого отдельная функция, непонятно названная `str\_split` и описанная как «конвертирующая строку в массив».
* Для форматирования дат, используется `strftime`, которая ведётся себя как C API и учитывает локаль. Ещё есть `date` с абсолютно другим синтаксисом и работающая только с английским.
* "`gzgetss` — Получить строку из указателя на gz-файл и вырезать HTML-тэги." До смерти хочу узнать какие обстоятельства привели к концепции этой функции.
* `mbstring`
+ Всё дело о «много-байтовости», в то время как проблема в кодировках.
+ Работает с обычными строками. Использует одну глобальную кодировку «по умолчанию». Некоторые функции позволяют указание кодировки, но она применяется ко всем аргументам и возвращаемому значению.
+ Предоставляет функции `ereg\_\*`, но они устарели. Функциям `preg\_\*` не повезло, тем не менее они могут понимать UTF-8, если скормить им кое-какие специфические флаги PCRE.
### Система и reflection
* Вообще целая куча функций стирает грань между текстом и переменными. `compact` и `extract` — только вершина айсберга.
* Существует несколько способов для динамики в PHP, и с первого взгляда нет никакой заметной разницы или опредёлнных приемуществ. `classkit` позволяет модифицировать ползовательские классы, `runkit` заменяет `classkit` и позволяет модифицироет что угодно пользовательское; `Reflection\*`-классы позволяет инспектировать большинство частей языка; очень много функций для работы со свойствами функций и классов. Эти подсистемы независимы, связаны, избыточны?
* `get\_class($obj)` возвращает имя класса объекта. `get\_class()` возвращает имя класса, в котором вызвана функция. Принимая это во внимание, функция делает две абсолютно разные вещи: `get\_class(null)`… ведёт себя так же, как `get\_class()`. Поэтому вы не можете доверять ей при передаче произвольного объекта. Сюрприз!
* Классы `stream\_\*` позволяют реализовывать пользовательские потоковые объекты и прочие встроенные файловые сущности. «tell» не может быть реализован по [внутренним причинам](https://bugs.php.net/bug.php?id=30157). (К тому же в эту систему вовлечена цела [ГОРА](http://www.php.net/manual/en/book.stream.php) функций.)
* `register\_tick\_function` принимает объект замыкания. `unregister\_tick\_function` нет; вместо этого она бросает ошибку, жалуясь, что замыкание не может быть сконвертировано в строку.
* `php\_uname` сообщает о текущей OC. Не в том случае, если PHP не может сказать, где он выполняется; тогда он сообщает на какой ОС он был собран. Произошло ли это не сообщается.
* `fork` и `exec` не встроены. Они идут с расширением pcntl, но оно не включено по умолчанию. `popen` не предоствляет pid.
* `session\_decode` читает произвольную строку сессии, но работает только если уже есть активная сессия. И дампит результат в `$\_SESSION`, вместо того, чтобы его возвращать.
### Разное
* `curl\_multi\_exec` не изменяет `curl\_errno` в случае ошибки, но изменяет `curl\_error`.
* Аргументы `mktime` идут в следующем порядке: час, минута, секунда, месяц, день, год.
Манипуляция данными
-------------------
Программы ничто иное кроме как большие машины поглощающие данные и выплёвывающие больше данных. Очень много языков созданы *вокруг* типов данных, которыми они манипулируют, от awk до Prolog и C. Если язык не может обрабатывать данные, он не может ничего.
### Числа
* Целые — знаковые и 32-битные на 32-битных платформах. В отличие от современников PHP, в нём нет автоматической конверсии в большое целое. Так что ваша математика может работать по разному в зависимости от *архитектуры процессора*. Единственная альтернатива использовать функции обёртки GMP или BC. (Разработчики предложили [добавить новый отдельный 64-битный тип](http://www.php.net/~derick/meeting-notes.html#add-a-64bit-integer). С ума сошли.)
* PHP поддерживает восьмеричный синтаксис с ведущим `0`, так что `012` будет числом десять. Однако, `08` будет числом ноль. `8`(или `9`) и остальные следующие цифры исчезают. `01c` ошибка синтаксиса.
* `pi` — функция. А ещё есть константа, `M\_PI`.
* [Нет оператора возведения в степень](https://bugs.php.net/bug.php?id=13756), только функция `pow`.
### Текст
* Нет поддержики юникода. Надёжно работает только ASCII, честно. Есть вышеупомянутое расширение `mbstring`, но оно как бы не работает.
* Это означает, что использование встроенных строковых функций с UTF-8-текстом создаёт риск их порчи.
* Точно также нет концепции типа сравнения регистра вне ASCII. Несмотря на распространённость нечуствительных к регистру версий функций, ни одна из них не считает `é` равным `É`.
* Ключи нельзя квотировать при интерполяции переменных, например `"$foo['key']"` — ошибка синтаксиса. Вы может не квотировать ключи(*будет* сгенерировано предупреждение) или использовать `${...}`/`{$...}`.
* `"${foo[0]}"` работает. `"${foo[0][0]}"` — синтаксическая ошибка. Работает, если внести `$` внутрь фигурных скобок. Плохо скопированный синтаксис Perl(с абсолютно другой семантикой)?
### Массивы
Ё моё.
* Этот тип данных ведёт себя как список, упорядоченный хэш, упорядоченный набор, разреженный список и время от времени как их странные комбинации. Какая его эффективность? Каков будет расход памяти?(*пер.* [анализ расхода памяти для массивов](http://habrahabr.ru/post/141093/)) Кто знает? У меня всё равно нет других вариантов.
* `=>` — не оператор. Это специальная конструкция, существующая только внутри конструкций `array(...)` и `foreach`.
* Отрицательные индексы не работают, т.к. `-1` точно такой же валидный ключ как и `0`.
* Несмотря на то, что это единственная структура данных языка, для неё нет короткого синтаксиса; `array(...)` — *это* короткий синтаксис. (PHP 5.4 вводит «литералы», `[...]`.)
* Конструкция `=>` базируется на Perl, который позвляет `foo => 1` без квотирования(вот почему конструкция существует Perl; иначе вы можете просто использовать запятую.) В PHP вы не можете так сделать не получив предупреждение; PHP — единственный язык в своей нише, в котором нет проверенного способа создать хэш без квотирования строковых ключей.
* Функции работы с массивами часто ведут себя смутно и противоречиво, потому что вынуждены оперировать списками, хэшами или возможно их комбинацией. Взять хотя бы `array\_diff`, «вычисляющий разность массивов».
```
$first = array("foo" => 123, "bar" => 456);
$second = array("foo" => 456, "bar" => 123);
echo var_dump(array_diff($first, $second));
```
Что будет делать этот код? Если `array\_diff` воспринимает аргументы, как хэши тогда очевидно они разные; одинаковые ключи с разные значения. Если аргументы воспринимаются как списки, тогда они всё равно разные; значения идут в разном порядке.
Фактически `array\_diff` признаёт массивы равными, потому что он воспринимает их как наборы; она сравнивает только значения и игнорирует порядок.
* В той же мере `array\_rand` странно ведёт себя выбирая случайные *ключи*, что не так полезно в общем случае выбора из списка вариантов.
* Несмотря на то, как сильно PHP-код полагается на сохранение порядка ключей:
```
array("foo", "bar") != array("bar", "foo")
array("foo" => 1, "bar" => 2) == array("bar" => 2, "foo" => 1)
```
Оставляю читателю узнать, что случится если массивы смешанные. (Я сам не знаю.)
* `array\_fill` не может создавать массивы нулевой длины, вместо этого она выдаст предупреждение и вернёт false.
* Все из (многих...) функций сортировки оперируют массивом на месте и ничего не возвращают. Нет способа создать отсортированную копию; вы вынуждены копировать массив сами, затем сортировать его и использовать.
* Но `array\_reverse` возвращает новый массив.
* Список отсортированных сущностей и ключи поставленные в соответстивие значениям звучат как отличный способ обрабатывать аргументы функций, но это не так.
### Немассивы
* Стандартная библиотека включает «Quickhash», ООП-реализацию «специфических строго-типизированных классов» для создание хэшей. И на самом деле предоставляет четыре класса, каждый для работы с различными комбинациями типов ключей и значений. Непонятно, почему встроенная реализация массивов не может быть оптимизирована для этих очень частых случаев, и какова относительная эффективность «Quickhash».
* Класс `ArrayObject`(реализующий *пять* различных интерфейсов) может оборачивать массив и позволяет ему вести себя как объект. Пользовательские классы могут реализовывать те же интерфейсы. Беда в том, что у класса жалкая горстка методов, половина которых не похожа на встроенные функции, к тому же встроенные функции не умеют оперировать `ArrayObject`'ом или другим похожим на массив классом.
### Функции
* Функции — не данные. Замыкания всё-таки объекты, но обычные функции нет. Вы даже не можете ссылаться на них по их прямым именам; `var\_dump(strstr)` вызывает предупреждение и предполагает, что вы имели ввиду строковый литерал, `"strstr"`. Нельзя отличить произвольную строку от «ссылки» на функцию.
* `create\_function` просто обёртка вокруг `eval`. Она создаёт функцию с обычным именем и устанавливает её глобально(поэтому эта функция никогда будет собрана сборщиком мусора — не используйте в цикле!). Она на самом деле ничего не знает а текущем контексте, поэтому это не замыкание. Имя содержит NUL-байт, поэтому такая функция никогда не конфликтует с обычными функциями(потому что PHP-парсер отказывает, если где угодно в файле есть `NUL`).
* Если определить функцию `\_\_lambda\_func`, `create\_function` сломается — *на самом деле* реализация создаёт через `eval` функцию с именем `\_\_lambda\_func`, затем внутренними методами переименовывает её. Если `\_\_lambda\_func` уже существует, первая часть процесса бросит fatal error.
### Прочее
* Инкремент (`++`) `NULL`'а выдаёт `1`. Декремент (`--`) `NULL`'а выдаёт `NULL`. Более того декремент строки оставляет её неизменной.
* Нет генераторов.
Web-фрэймворк
-------------
### Выполнение
* Один общий файл, `php.ini` контролирует *огромную* часть функционала PHP и вводит сложные правила относительно того, что и когда перегружается. PHP-приложение которое предполагает внедрение на произвольных машинах вынужден в любом случае заменять настройки, чтобы нормализовать окружение, в любом случая уничтожая полезность такой механики как `php.ini`.
* По существу PHP выполняется как CGI. При каждой загрузке PHP-страницы всё приложение перекомпилируется и выполняется. Даже дев серверы для игрушечных Python-фрэймворков так себя не ведут.
Это создало целый рынок «PHP-акселераторов», выполняющий компиляцию единожды, ускоряя PHP до уровня любого другого языка. Zend, компания, стоящая за PHP, сделала это частью своей [бизнес-модели](http://www.zend.com/products/server/).
* Достаточно долгое время PHP-ошибки по умолчанию шли на клиент — думаю, чтобы для помощи при разработке. Не думаю, что это до сих пор верно, но я всё ещё время от времени вижу mysql-ошибки, выпадающие наверху страницы.
* PHP всё ещё полон странных «пасхальных яиц» типа [выдачи логотипа PHP при передаче соответствующего аргумента в запросе](http://phpsadness.com/sad/11).
Кроме того, что это никак не связано с построением *вашего* приложения, это ещё и позволяет определить используете ли вы PHP(и возможно грубо определить какую версию), в не зависимости от того как много конфигурации в ваших `mod\_rewrite`, FastCGI, обратном проксировании или `Server:`.
* Пробелы вне тэгов `php ... ?`, даже в библиотеках, считаются текстом и включаются в ответ(или приводят к ошибкам «headers already sent»). Популярный фикс — не указывать закрывающий `?>`; PHP не жалуется и у вас нет завершающей новой строки в конце файла.
### Внедрение
Внедрение часто упоминается как наибольшее преимущество PHP; сбросьте несколько файлов и всё. В самом деле это проще, чем выполнение целого процесса, как вы делали бы в Python, Ruby или Perl. Но PHP не даёт много другое.
Со своей стороны я за то, чтобы Web-приложения выполнялись как сервера приложений и запросы реверс-проксировались к ним. Это требует минимальных усилий и даёт множество выгод: вы можете управлять Web-сервером и приложением отдельно, вы может выполнять сколь угодно много или мало процессов приложения на сколь угодно большом количестве машин без дополнительных Web-серверов, вы можете выполнять приложение под собственным пользователем без усилий, вы можете использовать любой Web-сервер, вы можете остановить приложение, не прикасаясь к Web-серверу, вы можете выполнять бесшовное внедрение просто изменив точку проксировния и пр. Спаивать ваше приложение с Web-сервером абсурдно и больше нет причин так делать.
* PHP естественно связан с Apache. Выполнение его по отдельности или с другим Web-сервером требует точно такой же(если не больше) возни как и в других языках.
* `php.ini` применяется ко всем PHP-приложениям, выполняющимся на машине. Есть только один файл `php.ini` и он применяется глобально; если вы на shared-сервере и вам нужно его изменить, или вам нужно выполнять два приложения с различными настройками, тогда вам не повезло; вы должны применять набор всех нужных настроек из самого приложения через `ini\_set`, конфигурационный файл Apache или `.htaccess`. Если можете. Вау, нужно проверить много мест, чтобы определить как же настройка получает своё значение.
* Подобным образом нет простого способа «отделить» PHP-приложение и его зависимости от остальной системы. Выполняете два приложения, требующие разных версий библиотеки или даже самого PHP? Начните со сборки второй копии Apache.
* Подход «сбрось несколько файлов» между прочим делает routing жуткой болью в заднице, также это значит что вы должны осторожно разрешать и запрещать доступ, потому что ваша иерархия URL'ов, также весь ваш код. Конфигурационные файлы и другие «partial'ы» требуют защитных проверок как в C, чтобы избежать их прямой загрузки. Шум контроля версий (типа `.svn`) должен быть также защищён. С `mod\_php` *всё* в вашей файловой системе потенциальная входная точка; с сервером приложений, у вас одна входная точка, и только URL контролирует вызывается ли она.
* Вы не можете бесшовно обновить несколько файлов выполняемых как CGI, если вы не хотите падений и неопределенных поведений, когда пользователи пинают ваш наполовину обновлённый сайт.
* Не смотря на то, как *просто* настроить Apache для выполнения PHP, даже здесь вас поджидает несколько коварных ловушек. В то время, как документация PHP советует использовать `SetHandler` для запуска `.php`-файлов как PHP, `AddHandler` работает так же хорошо, и на самом деле Google выдаёт мне в два раза больше результатов для `AddHandler`. Собственно проблема.
Когда вы используете `AddHandler`, вы указываете Apache, что «выполнение следующего как php» — *один из возможных* способов обработки `.php`-файлов. *Но!* Apache не одного и того же мнения о расширениях файлов, как каждый человек на планете. В нём есть поддержка, например, `index.html.en`, распознаваемого как HTML-файла на английском. Для Apache файл может иметь *сколько угодно* расширений одновременно.
Представьте, что у вас есть форма загрузки файлов, которая выгружает файлы в публичную директорию. Чтобы быть уверенными, что никто не загрузит PHP-файл, вы просто проверяете, что расширение файлов не `.php`. Всё, что атакующий должен сделать это загрузить файл с именем `foo.php.txt`; загрузчик не увидит никаких проблем, но Apache *будет* распознавать файл как PHP, и он выполнится.
Проблема не в том, что «используется исходное имя файла» или «надо было лучше валидировать»; проблема в том, что ваш Web-сервер, настроен выполнять любой старый код, на который он может наткнутся — именно это свойство делает PHP «простым для внедрения». CGI требовал `+x`, это хотя бы *что-то*, но PHP не требует даже этого. И это не теоретическая проблема; я нашёл несколько сайтов с этой проблемой.
### Чего не хватает
Я предполагаю следующее с различными уровнями критичности для построения Web-приложения. Имело бы смысл в PHP, как языке, продаваемом как «Web-язык», реализовать что-нибудь из нижеуказанного.
* Нет системы шаблонов. Есть сам PHP, не нет ничего что бы работало как большой интерполятор, вместо того, чтобы работать как программа.
* Нет XSS-фильтра. Нет, «используй `htmlspecialchars`» — не XSS-фильтр. Вот [это XSS-фильтр](http://pypi.python.org/pypi/MarkupSafe).
* Нет CSRF-защиты. Вы должны делать её сами.
* Нет обобщённого стандартного API для баз данных. Штуки, типа PDO, вынуждены оборачивать отдельные API для абстракции.
* Нет routing'а. Ваш сайт выглядит так же как ваша файловая система. Многие разработчики обмануты, думая, что `mod\_rewrite` (и весь остальной `.htaccess`) подходящая замена.
* Нет аутентификации или авторизации.
* Нет дев сервера.
* Нет интерактивной отладки.
* Нет явного механизма внедрения; только «скопируйте вот эти файлы на сервер».
Безопасность
------------
### В рамках языка
Плохая репутация безопасности PHP в основном связана с тем, что он принимает произвольные данные из одного языка и выдаёт их в другой. Это плохая мысль. `"` | https://habr.com/ru/post/142140/ | null | ru | null |
# НЕ VIM, а круче (xah fly keys) или XAH FLY KEYS. Большой выпуск
Если не хотите потратить время зря!**Пока что**, эта статья только для EMACS-еров, а изначально создана лишь для меня
Насколько я знаю многие программисты используют VIM, а некоторые тоже используют VIM, но они это делают в EMACS-е, EVIL (злом) режиме, это значит, что эти люди понимают все прелести VIM (быстрое редактирование текста без использования мыши, наличие нескольких режимов и т.д.), но им очень нравится возможность добавлять миллиарды плагинов. Но ещё я знаю, что VIM был сделан несколько миллионов лет назад, для программистов того времени и для того чтобы быть отдельным редактором (не для EMACS), поэтому VIM использует не все возможности которые мог бы, например: Клавиша для входа в командный режим находится в ~~самой жопе~~ углу клавиатуры (и. да я знаю что это можно легко поправить в .vimrc), также если я захочу перейти к редактированию другого файла, то мне нужно:
1. Перейти в командный режим (Нажав сами знаете куда)
2. Напечатать `:find` и имя файла
3. Если я ошибся в имени файла ---> во 2 пункт
Это может занять целую вечность, а менять текущий файл приходиться очень часто! А ещё если вы используйте раскладку dvorak, то как возможно вообще пользоваться VIM-ом? И вообще все клавишы VIM настроены не для того чтобы быстро ими пользоваться, а для того чтобы быстрее запомнить это тоже конечно классно, ведь каждая команда в VIM может превращаться в целое красивое и понятное любому носителю языка, предложение, а XAH FLY KEYS таким похвастаться не может, ведь он крут в другом, быстром редактировании текста, причем если вы пользователь какой-то не популярной раскладке, то лучше вы вряд ли найдете!
Переходим к самому главному в этой прекрасной статье.
#### XAH FLY KEYS
Все эти недостатки не имеет наш XAH FLY KEYS, он уже был разработан в наше время и не имеет все недостатки VIM, и по моему скромному мнению это самый лучший в мире способ для редактирования текста!
Чуть-Чуть ИсторииЭтот мощный инструмент разработал XAH LEE, если вы уважающий себя EMACS-ер то вы знаете его имя, ведь этот мудрый китаец придумал ErgoEmacs и возможно вы также пользовались им.
Однако у него есть 1 недостаток (точнее больше, но о них Я вам не расскажу), это не наличие нормальной документации, она конечно есть, но сами посмотрите:
Вам конечно этого может и хватит, но блин XAH FLY KEYS имеет в несколько 10-в раз больше возможностей, которые я попробую объяснить (к сожалению я пользователь QWERTY раскладки и не буду объяснять как всем этим пользоваться на раскладке DVORAK или AZURE).
#### Установка
На github всё описано, но я всё-таки обьясню краткий способ как это сделать:
1. Скачать xah-fly-keys через MELPA package manager для EMACS
2. Вставить и исполнить такой Emacs Lisp код:
```
(require 'xah-fly-keys)
(xah-fly-keys-set-layout "qwerty") ; обязательно
(xah-fly-keys 1)
```
#### Полбзуемся
Вообще XAH-FLY-KEYS имеет 2 режима: COMMAND и INSERT (как в VIM), но в COMMAND есть тоже несколько режимов или не режимов, а префиксов для HOT-KEYS, сейчас всё объясню чуть по подробнее:
* INSERT mode - (для вход из COMMAND наберите f) обычное редактирование файла
* COMMAND mode - (для входа из INSERT наберите Alt+SPACE) режим для набора команд
А если вы в COMMAND mode, то вы можете набрать какую-то буковку и что-то произойдет, например если нажать f, то вы окажетесь в INSERT mode, НО также если вы нажмете SPACE (пробел), то все клавиши изменят свое значения, например если вы нажмете Space f, то вас заставят написать имя буфера для перехода в него, но также есть специальный клавиши и если на них нажать после того как вы нажали SPACE, то клавиши опять изменят свое значение, например если вы напечатайте Space i f, то перейдете в файл путь которого был под курсором.
#### БАЗА
Начнем с чего-то по проще:
**Перемещение**
j - влево на один символ
i - вверх на один символ
k - вниз на один символ
l - вниз на один символ
o - вперёд на 1 слово
u - назад на 1 слово
; - вперёд на 1 предложение, Пример:
h - назад на 1 предложение
m - на прошлую закрывающую скобку
. - на прошлую открывающую скобку
/ - на противоположную скобку, Пример:
0 - перейти на место прошлого перемещения.
Это очень удобно, например если вам надо просто добавить import файла, то вы идете сначала в начало файла, пишите импорта, нажимаете 0, и работайте дальше, думая о том что вы гений.
Ctrl+4 - перейти на место следующей ошибки (работает только flycheck-mode)
Ctrl+3 - перейти на место прошлой ошибки (работает только flycheck-mode)
Space H - перейти в начало файла (Space - пробел)
Space N - перейти в конец файла (Space - пробел)
Space p - проскролить (если нажали первый раз -> расположить текущую строчку по середеине экрана, второй раз -> на начало экрана, третий раз -> на конец экрана)
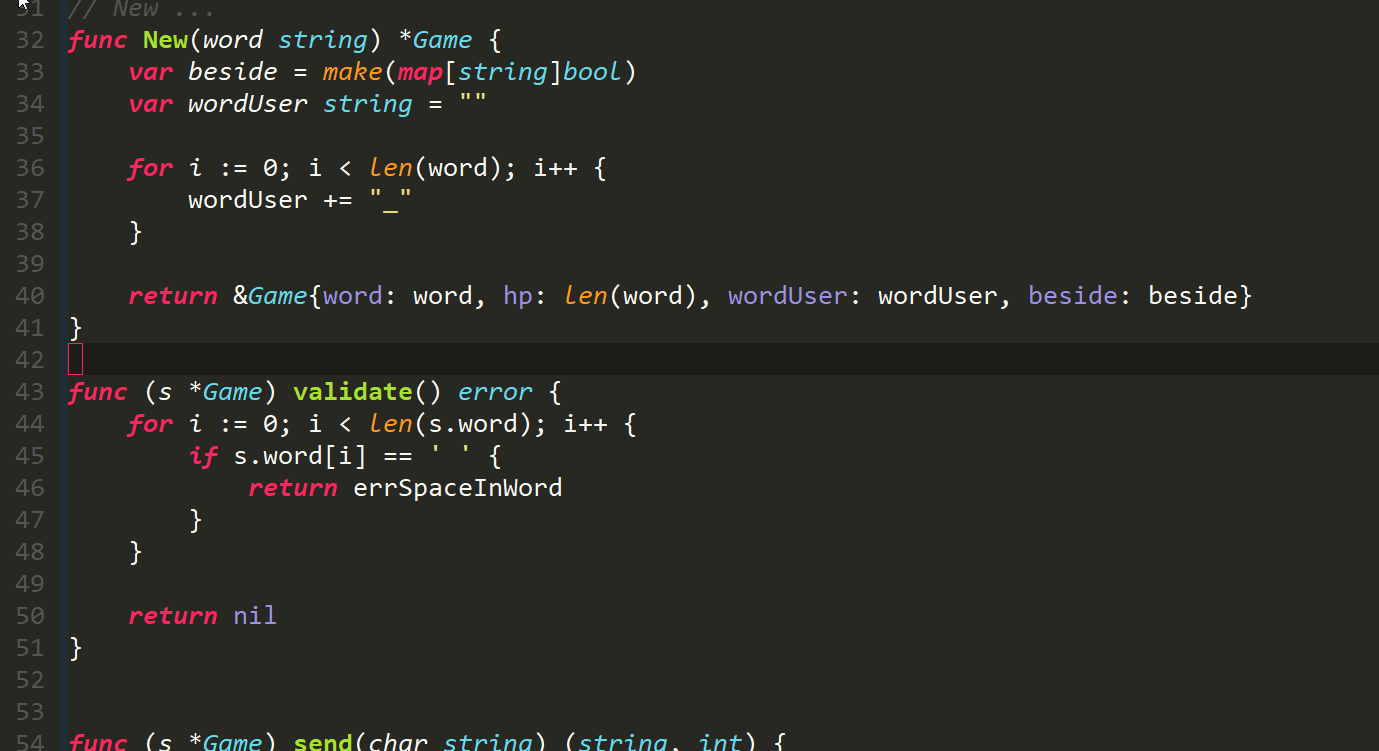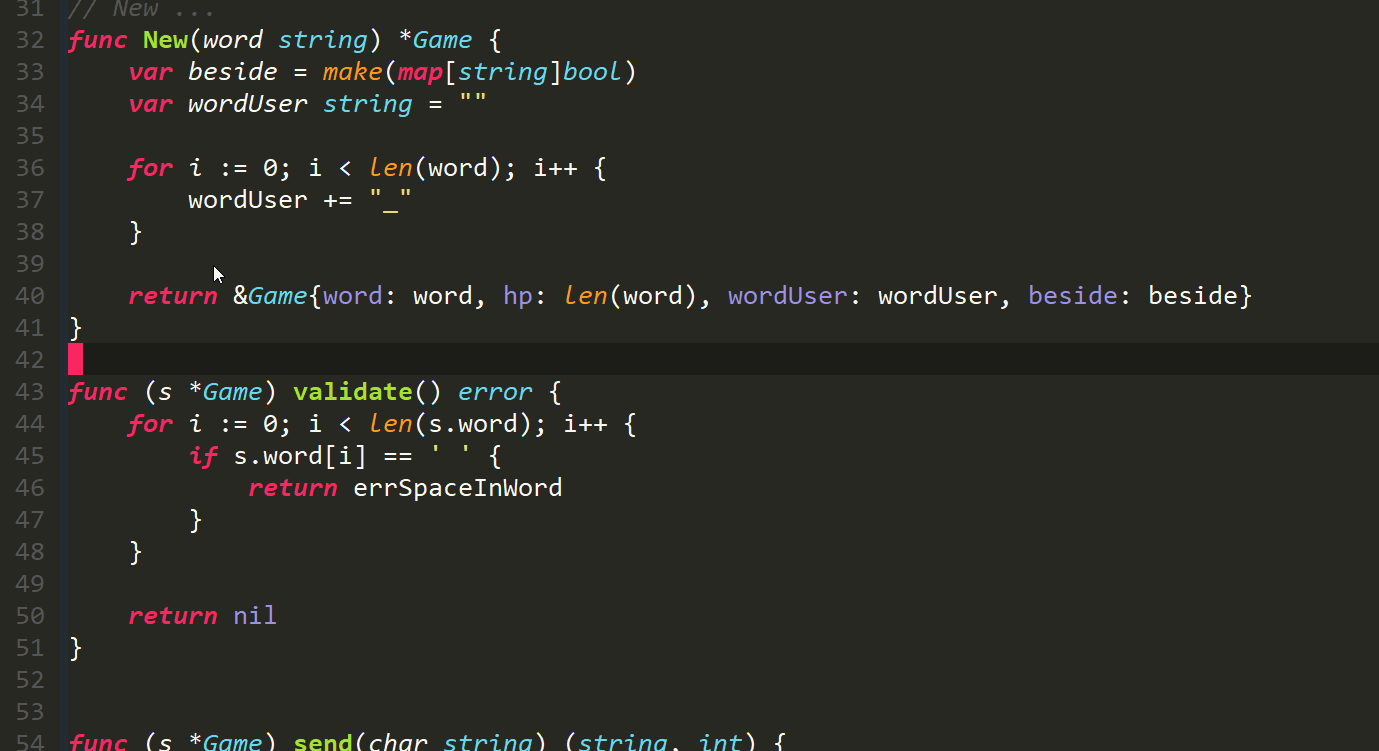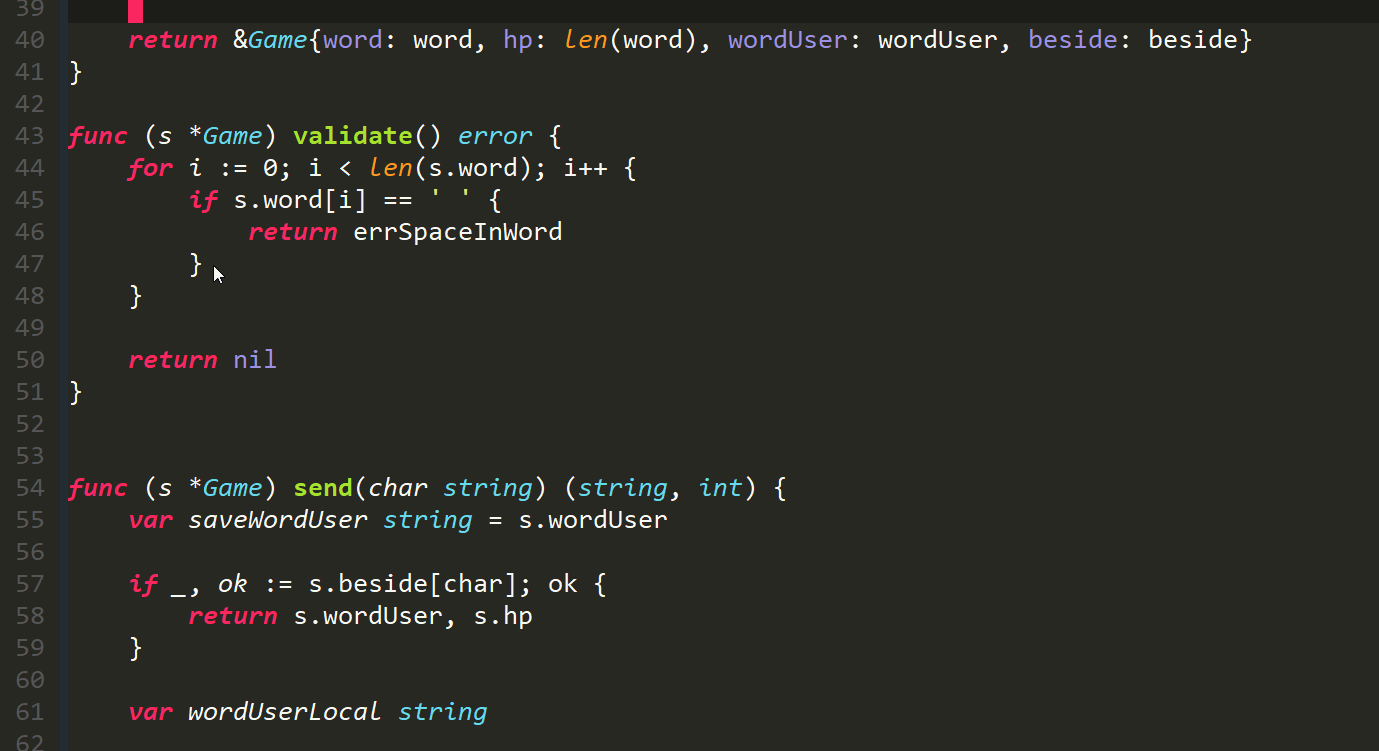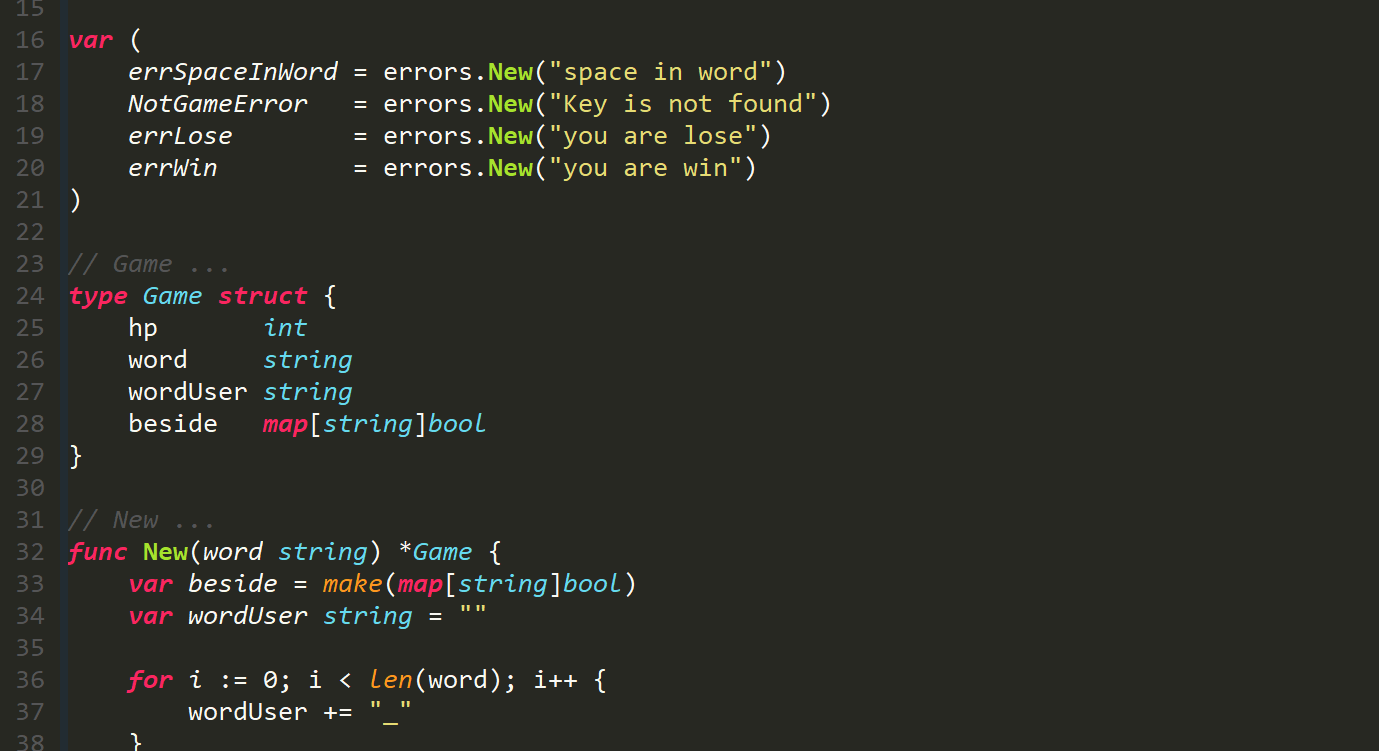**Выделение**
8 - выделить текущее слово, если нажмете снова, то выделится вся строка, а потом по одной строке далее
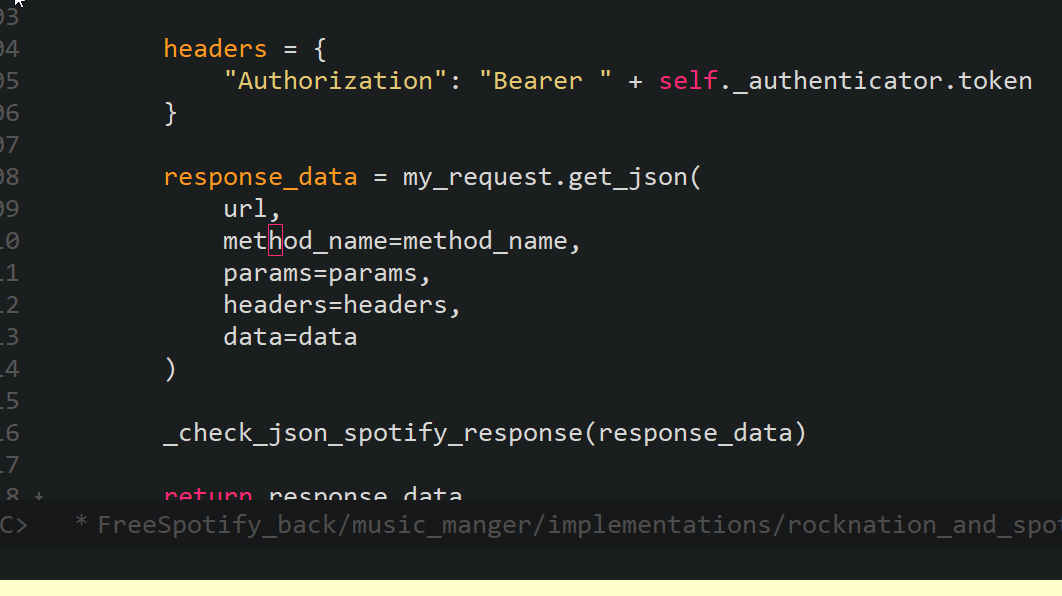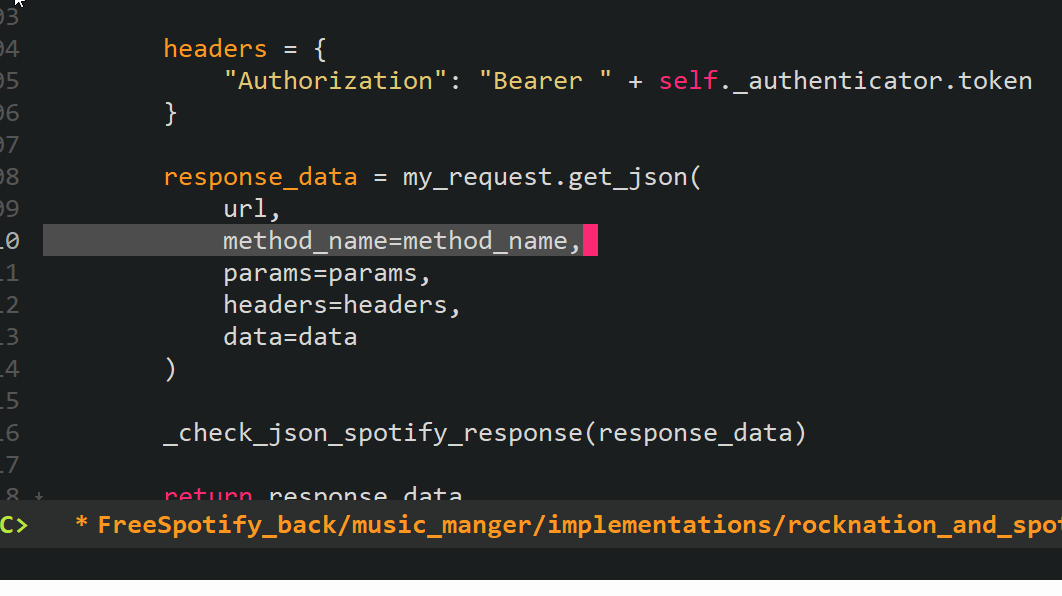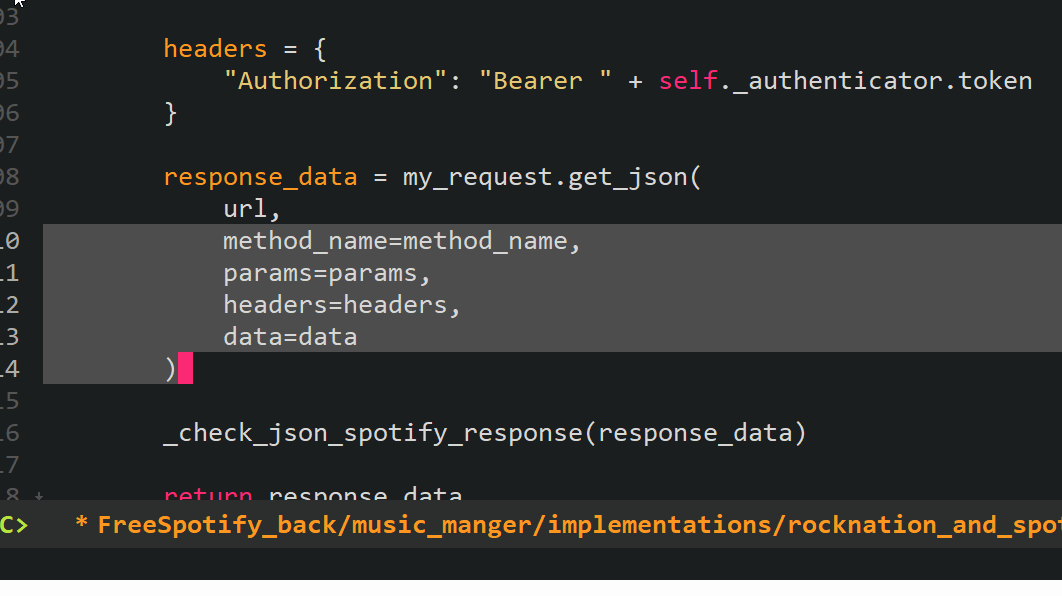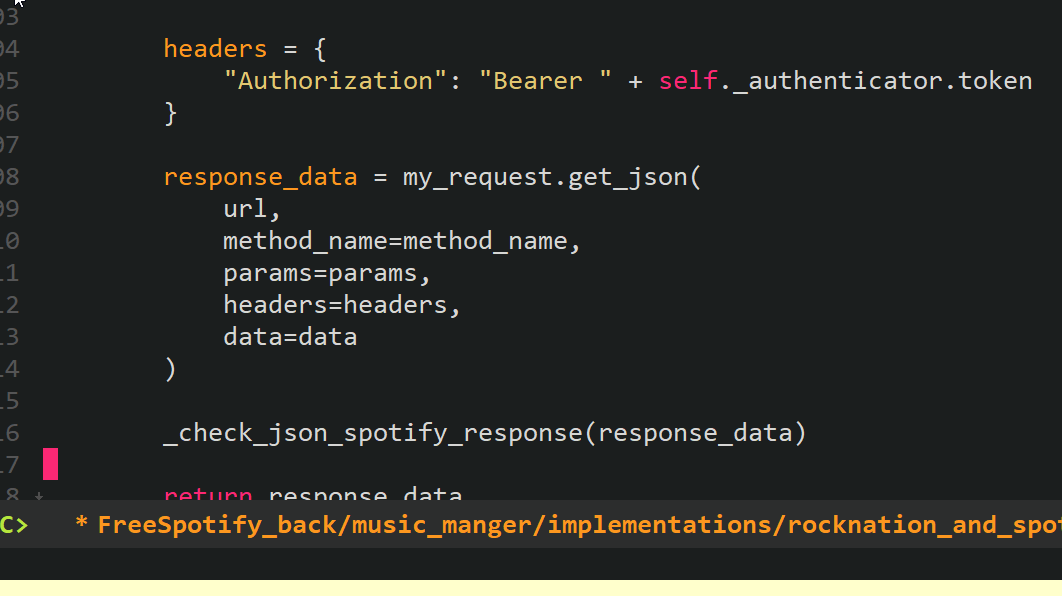1 - выделить то, что возможно или увеличить, то, что уже выделено
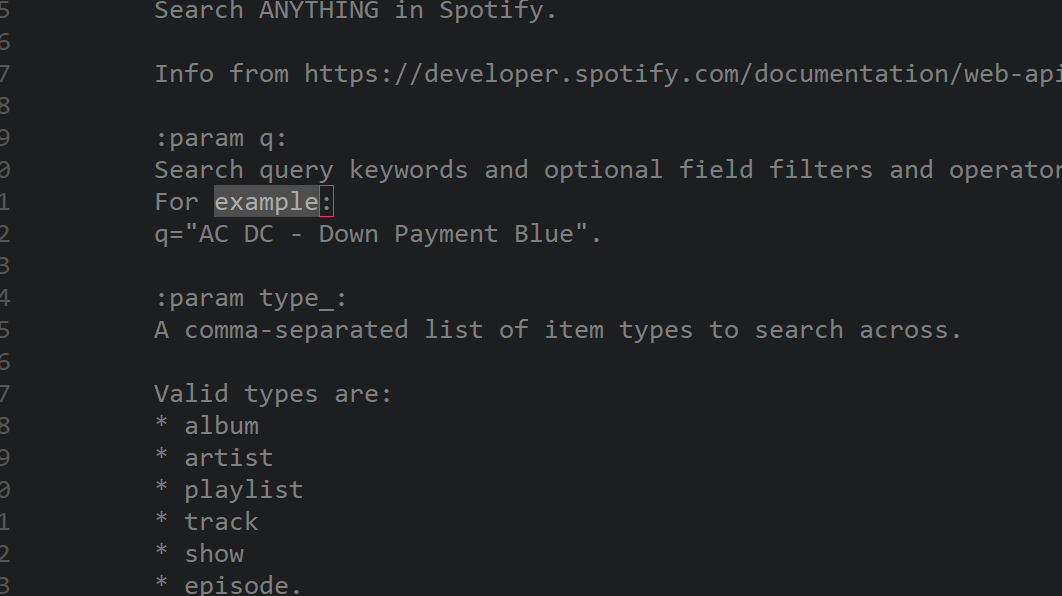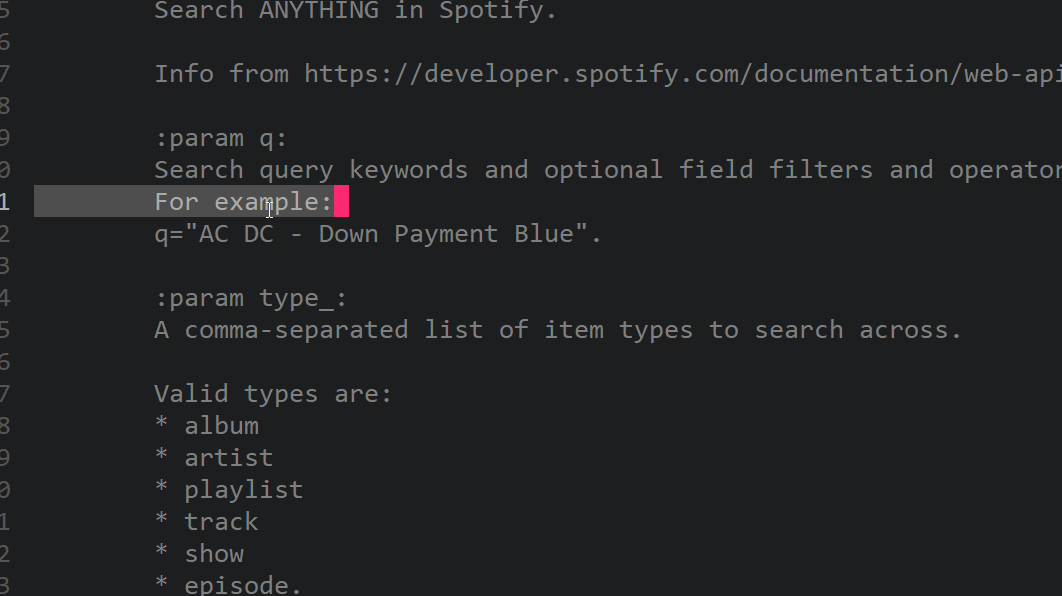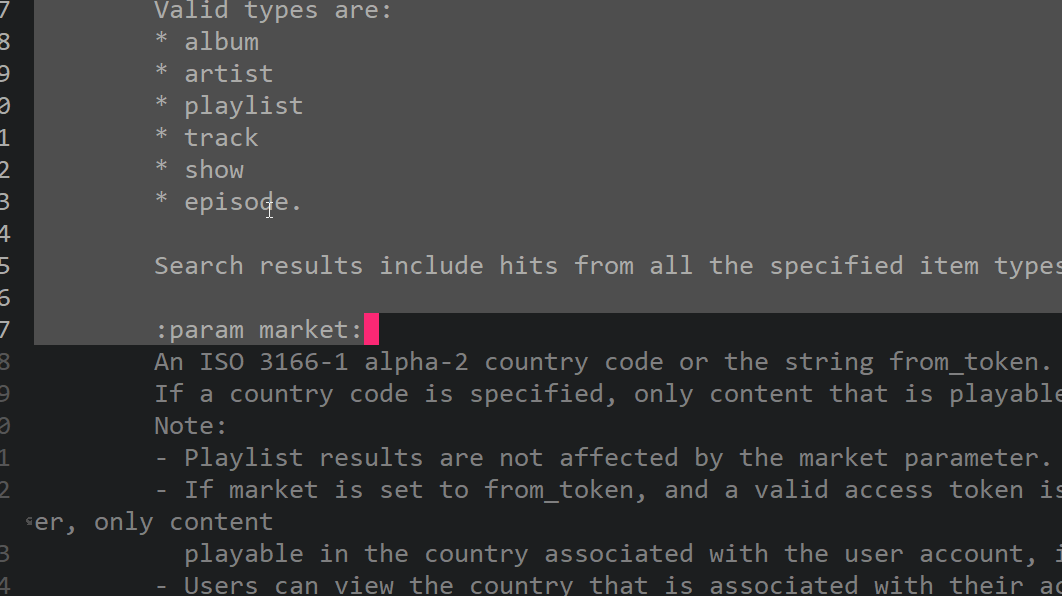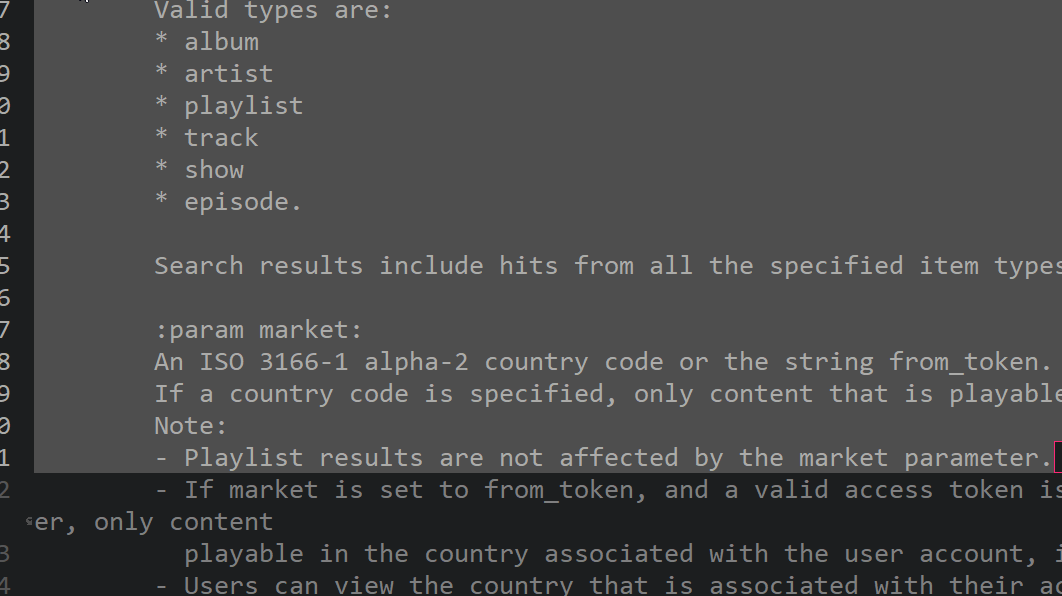2 или 7 - выделить текущую строку
6 - выделить "блок"
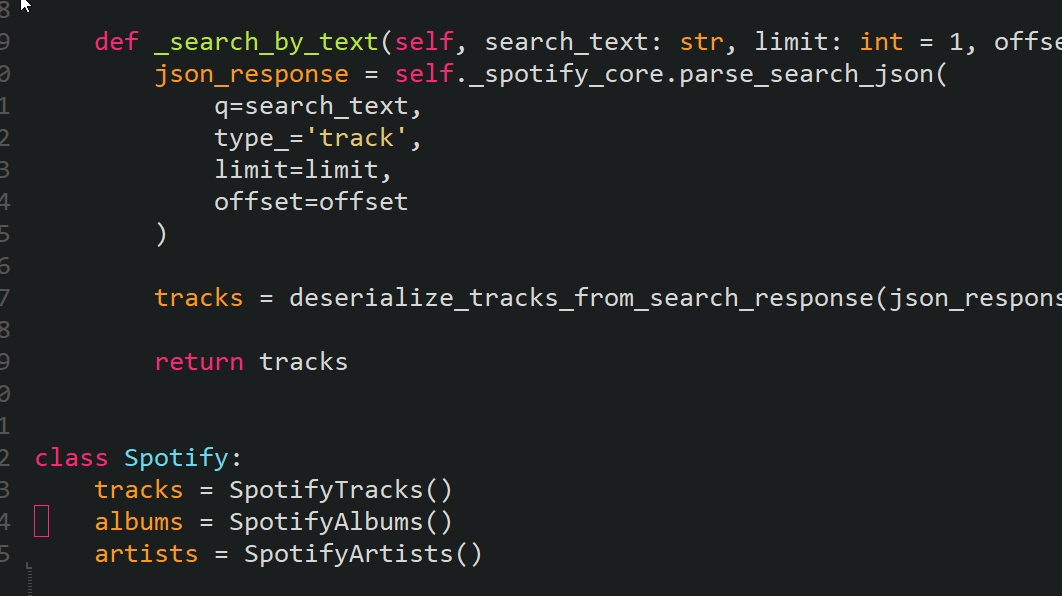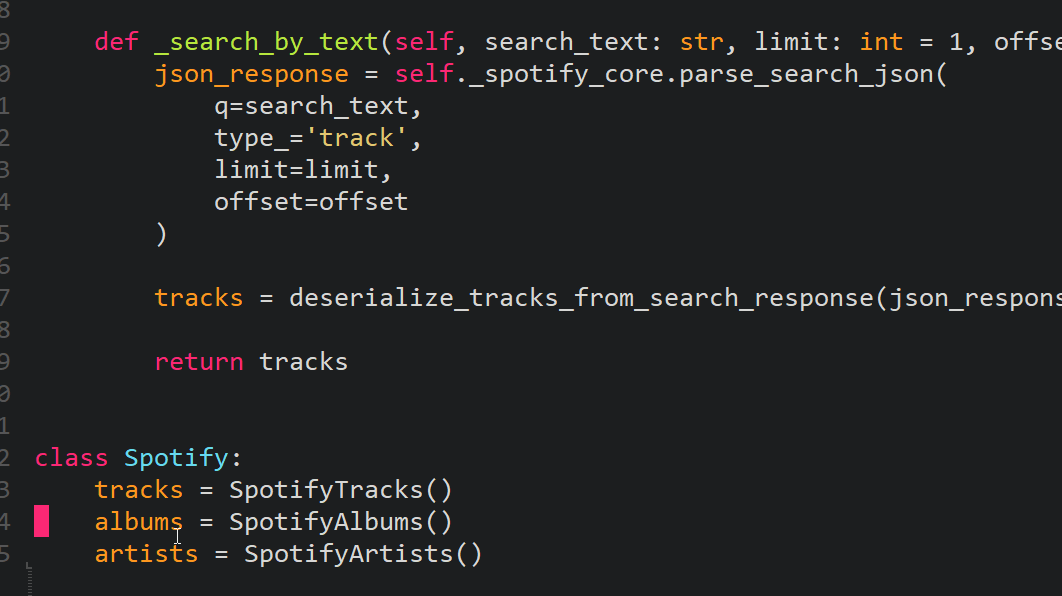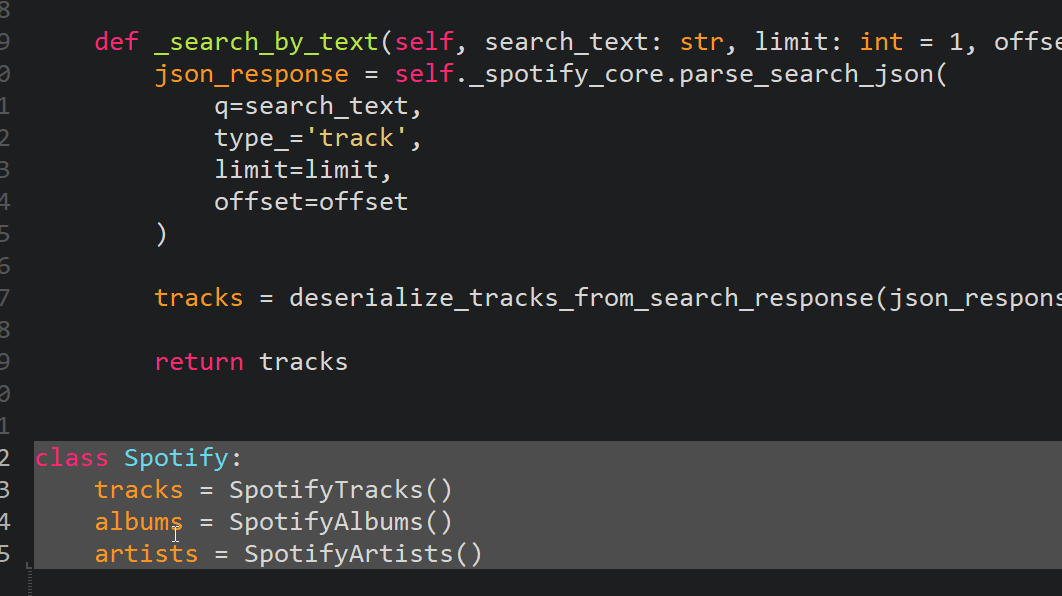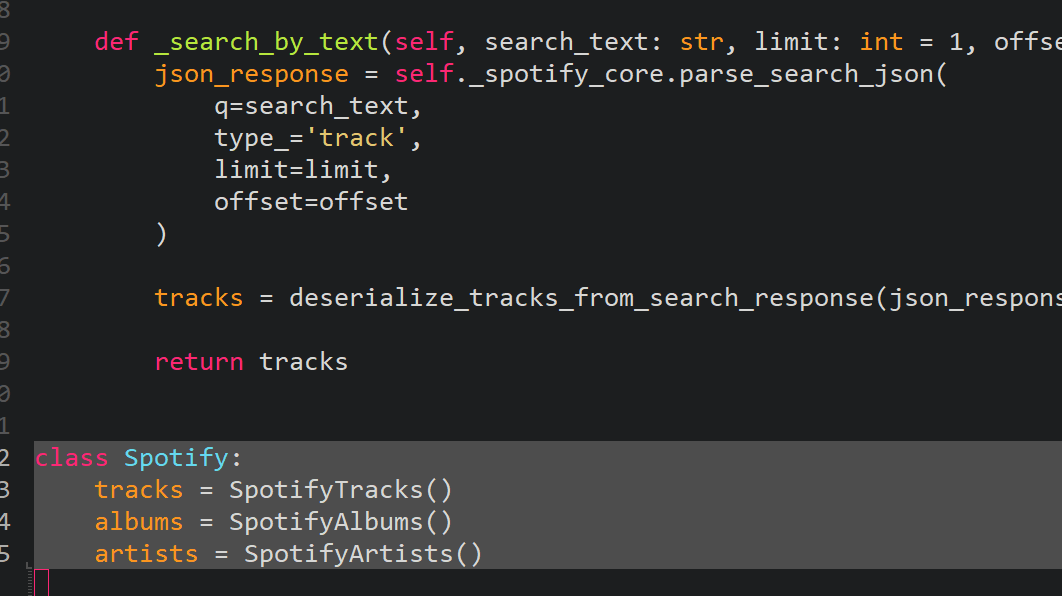9 - выделить текст в ковычках
t - начать выделять то, где ты двигаешься (VISUAL MODE)
Space a - выделить весь файл
Space o Space - включить режим выделение блоком
**Удаление**
d - удалить 1 символ позади
5 - удалить 1 символ впереди
e - удалить слово позади
r - удалить слово впереди
x - вырезать строчку если что-то выделено вырезать то, что выделено (см. Копирование/Вставка)
Space g - удалить всё от положения курсора до конца строки
g - удалить блок:
Space k f - удалить все строки, которые подходят к тому, что мы напишим
Space k t - удалить все строки которые совпадают с текущей
Space k g - удалить все строки которые не совпадают с текущей
Space k a - удалить все "пустые" строчки
**Редактирование**
' - изменить виды разделителей. (Если пробелы -> поменять на подчеркивания, Если подчеркивания -> минусы (тире)), Пример:
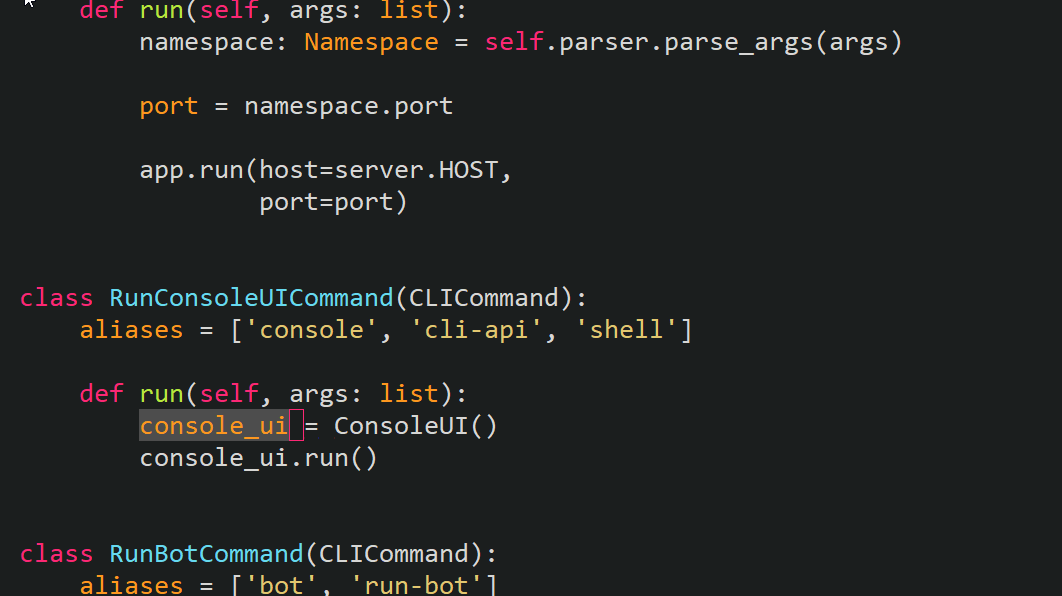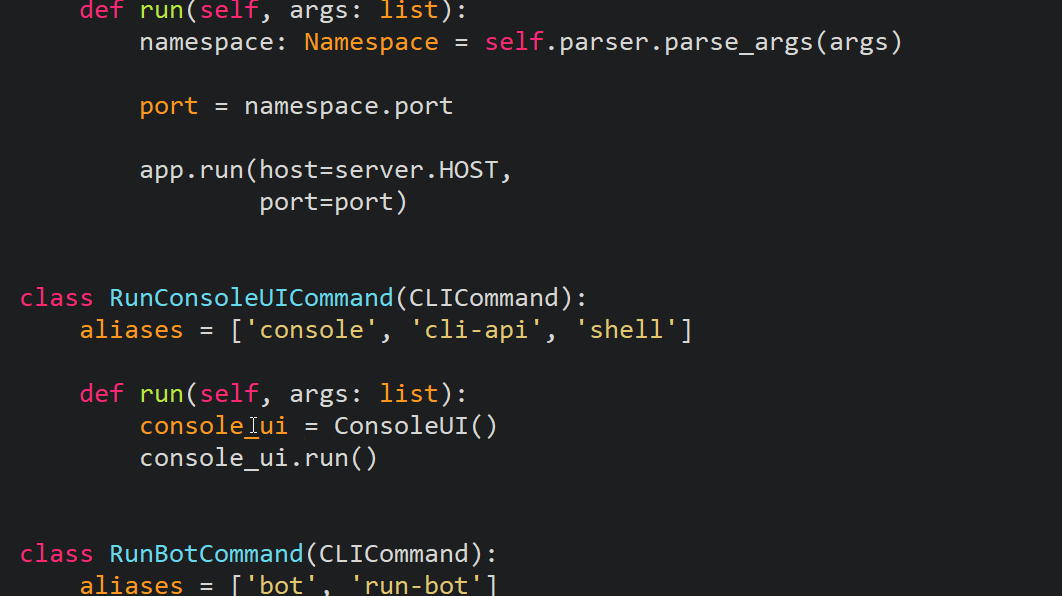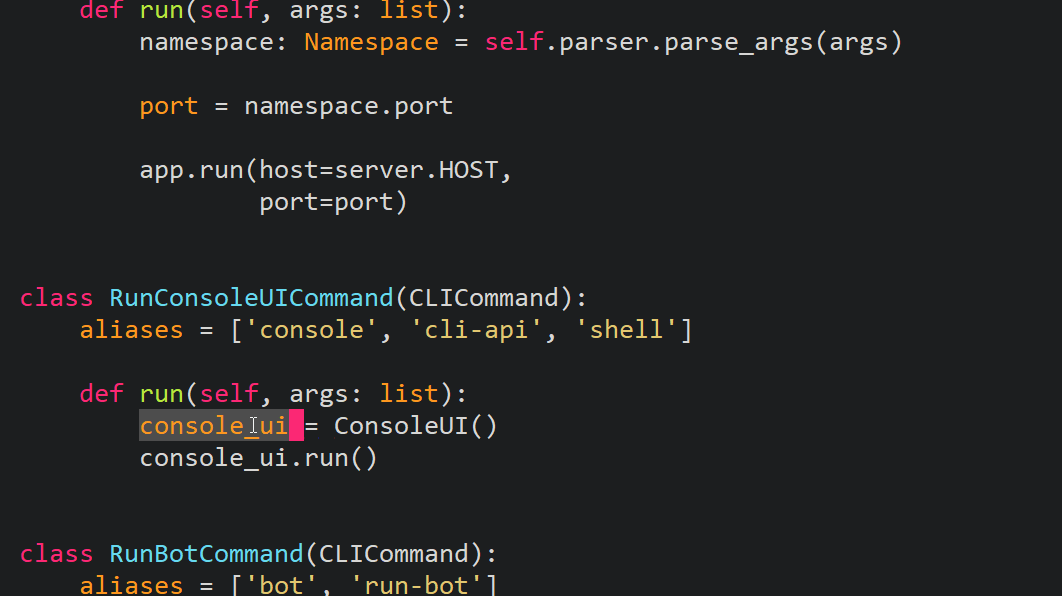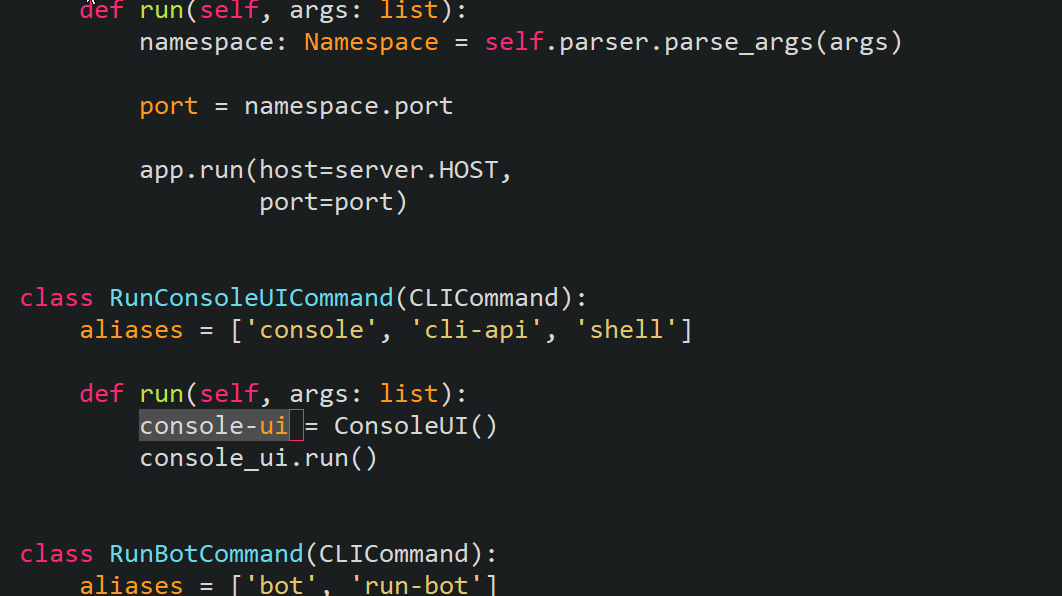z - Закомментировать/Раскомментировать текущую строчку или то, что выделено
w - если нету пробела поставить, если есть удалить.
Очень странная штука.
p - вставить пробел (Для этого не надо переходить в INSERT мод)
b - поменять регистр (Заглавный Регистр, нижний регистр, ВЕРХНИЙ РЕГИСТР)
Space 6 - поменять регистр у всего предложения
Space k e - отсортировать выделенные строчки
Space k p - экранировать все выделенные ковычки (поставить "\" перед ", которые находятся в выделенном тексте)
Space k k - повторить прошлую команду
Space o f - каждую линию обернуть в ковычки или в скобки или в то что вы там напишите, и разделить тем, что вы там выберите
Space o g - превратить пробелы в переходы на новую строку
s - создать новую строчку, но на неё не перейти
**Работа с окнами/файлами (FRAMES)**
, - перейти в другое окно (FRAME)
4 - разделить окно по горизонтальной линии
Space 4 - разделить окно по вертикальной линии
Space 5 - сделать все окна одинакого размера
Ctrl+7 - следующий буфер (открытый файл)
Ctrl+8 - прошлый буфер (открытый файл)
Ctrl+t - новый пустой буфер
Ctrl+w - закрыть текущий буфер (открытый файл)
Ctrl+s - сохранить буфер (открытый файл)
Space m - просмотреть в dired режиме текущую дерикторию
Ctrl+Shift+s - сохранить буфер как...
Space l b - сохранить все файлы
Space i w - открыть в приложение по умолчанию
Space i g - скопировать полный путь до файла
Space i s - открыть в проводнике файл
Space i f - открыть файл путь которого под курсором (путь не обязательно полный)
Space , Del - удалить текущий файл
Space , x - сохранить все файлы + закрыть редактор
Space , c - запустить текущий файл
При старте поддерживаются вот такие, вот языки:php
perl
python
ruby
go
haskell
js
typescript
shell
clojure
racket
ocaml
cscript
tex/latex
java
**Вид**
Space l Space - включить подрисовку пробелов
Space l . - расширить на весь экран (похоже на f11 в вашем браузере)
Space l 2 - подсвечивать текущую строку
Space l 4 - вкл./выкл. показ номера строк
Soace l t - вкл./выкл. перенос строк
Ctrlr+= - увеличить шрифт
Ctrlr+- - уменьшить шрифт
Space l g - создать новое окно и отрыть в нём EMACS с текущим файлом
**Плюшки (от Emacs)**
Space l 6 - календарь (красивый очень)
Space l 7 - калькулятор ([Вот как им пользоваться](https://habr.com/ru/post/279853/))
Space l 9 - выполнить команду в теринале
Space l 0 - выполнить команду в терминале, применить к выделению
Space l c - проверить все орфографические ошибки в файле
Space l , - включить браузер в Emacs
Space l d - включить эмулятор терминала в Emacs
Space 9 - проверить на грамотность слово
a - выполнить команду ELisp (тоже самое, что Alt+X)
**Помощь. HELP**
Space j a - найти все команды совпадающие с нашим шаблоном
Space j j - описать функцию
Space j v - описать горячую клавишу
Space j l - описать переменную
Space j g - дать информацию по всему что у меня есть
**Макросы**
Space o e - запись макроса
Space o r - стоп записи макроса
Space o h - вызвать последний макрос
Space o w - применить макрос ко каждой выделенной строки
**Поиск**
n - поиск с переходом, Я не знаю как объяснить, короче вот:

Space k r - поиск + замена, сначала выделит все совпадения так же как и при поиске с переходм, потом будет спрашивать надо ли заменить слово:
* Напечатайте SPACE, если да
* Напечатайте DEL, ксли нет
* Напечатайте ENTER, если пропустить
Space k d - Поиск строк по шаблону (выделенных строк)
Space y - начать поиск текущего слова
**Копирование/Вставка**
с - копировать (Если ничего не выделено копировать строку)
v - вставить
x - вырезать (Если ничего не выделено вырезать строку)
**Работа с регистром 1. WTF?**
Если, что регистр 1 - очень классная вещь, это такой специальный буфер в который вы можете копировать текст, добавлять текст, вставлять его содержимое в текущий файл и т.д. и т.п.
Space k 1 - добавить в регистр 1 выделенный текст (если ничего не выделено -> добавить строку)
Space k 2 - очистить регистр 1
Space k 3 - копировать в регистр 1 = очистить регистр 1; добавить в регистр 1 текст
Space k 4 - вставить содержимое
#### Кастомизируем
В Emaces любое действие можно сделать через какую-то Eisp фуекцию поэтому настройка также будет на ELisp-е.
1. Чтобы настроить выполнение какой-нибудь функции при нажатии какой-то клавиши в COMMAND режиме, то :
```
(defun my-xfk-addon-command ()
"Modify keys for xah fly key command mode keys
To be added to `xah-fly-command-mode-activate-hook'"
(interactive)
(define-key xah-fly-key-map (kbd "какая-то клавиша") 'имя какой-нибудь функции)
)
(add-hook 'xah-fly-command-mode-activate-hook 'my-xfk-addon-command)
;; Здесь мысоздаем функцию my-xfk-addon-command,
;; которая связывает какую-нибудь функцию с какой-то клавишей.
;; а потом с помощью add-hook выполняем эту функцию перед входом в Command mode
```
2. Чтобы то же самое провернуть только в INSERT ружиме надо выполнить почти такой же код:
```
(defun my-xfk-addon-command ()
"Modify keys for xah fly key command mode keys
To be added to `xah-fly-command-mode-activate-hook'"
(interactive)
(define-key xah-fly-key-map (kbd "какая-то клавиша") 'имя какой-нибудь функции)
)
(add-hook 'xah-fly-insert-mode-activate-hook 'my-xfk-addon-command)
;; Здесь мысоздаем функцию my-xfk-addon-command,
;; которая связывает какую-нибудь функцию с какой-то клавишей.
;; а потом с помощью add-hook выполняем эту функцию перед входом в insert mode
```
Это всё!!! | https://habr.com/ru/post/557892/ | null | ru | null |
# Новый релиз PostgreSQL 9.6: вклад Postgres Professional
Сегодня, 29 сентября 2016 года, [вышел](https://www.postgresql.org/about/news/1703/) новый релиз PostgreSQL, получивший номер 9.6. В нём содержится много весьма полезных фич, и нельзя не рассказать о них, тем более что вклад нашей компании в этот релиз существенен. Поэтому в этой статье мы расскажем о тех разработках Postgres Pro, которые вошли в сегодняшний релиз.
### Производительность и мониторинг
**Улучшение представления pg\_stat\_activity в части информации об ожидающих процессах** (Amit Kapila, Ильдус Курбангалиев).
Ранее в pg\_stat\_activity ожидающими считались процесссы, висящие на тяжелых (heavyweight) блокировках. Теперь там видны также ожидания легких блокировок (lightweight locks) и buffer-pins (как это по-русски?). О разных видах блокировок в постгресе можно прочитать в статье [Александра Короткова](https://habrahabr.ru/company/postgrespro/blog/270827/). Новая информация видна в колонках wait\_event\_type и wait\_event. Подробную информацию об этом патче можно прочитать в нашем [блоге](http://www.postgrespro.ru/blog/301/111807) и в [документации](https://postgrespro.ru/docs/postgresql/9.6/monitoring-stats#WAIT-EVENT-TABLE).
**Эффективное использование памяти при построении GIN-индексов.** (Robert Abraham, Фёдор Сигаев).
Теперь при построении GIN-индексов более эффективно используется память, если ее выделено (maintenance\_work\_mem) более гигабайта. Детали — [в списке рассылки](https://www.postgresql.org/message-id/flat/CABQqHAWYXW%2BNzAYw4uG_FnbjrdEFyRaigLRkQ7AzAtS6AbHnfA%40mail.gmail.com#CABQqHAWYXW+NzAYw4uG_FnbjrdEFyRaigLRkQ7AzAtS6AbHnfA@mail.gmail.com).
**Немедленное освобождение удаляемых страниц GIN-индексов** (Jeff Janes, Фёдор Сигаев).
Удаляемые страницы теперь сразу попадают в список свободных, что помогает сократить объем базы. Полезно при не слишком частом вакууме. Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/CAMkU%3D1xfE1MnGMkv655hB8jCs3PBTb4S5H%2BFnQv8kcmYzyeBDQ%40mail.gmail.com).
**Эффективная обработка мертвых узлов в GiST-индексах** (Анастасия Лубенникова).
Если при индексном скане обнаруживается мертвый узел таблицы, то соответствующий ему узел индекса тоже будет сразу помечен как мертвый. При вставке в индекс занимаемое им место будет использовано. Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/CAP4vRV6FcKVOpPxs_9L327FpTWz75Ly%3DJRUeY-W89amS19BzwQ%40mail.gmail.com).
**Замена спинлоков на атомарные операции** (Александр Коротков, Andres Freund).
Повышает вертикальную масштабируемость за счет более эффективной реализации блокировок. Подробности [в статье Александра Короткова](https://habrahabr.ru/company/postgrespro/blog/270827/).
**Оптимизация ожидания блокировок** (Александр Алексеев).
Изменения в алгоритме ожидания блокировок, дающие заметный вклад на многопроцессорных серверах. Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/20151211170001.78ded9d7@fujitsu).
**Улучшение производительности ResourceOwner** (Александр Алексеев).
Линейный поиск заменен на нечто более эффективное. Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/20151204151504.5c7e4278@fujitsu).
**Вычисление выражений в SELECT после ORDER и LIMIT, если это возможно** (Konstantin Knizhnik).
Теперь, если результаты выражения не попадут в выдачу запроса и не участвуют в условиях выборки и группировки, оно не будет вычисляться. Это сокращает количество вызовов функций (возможно, тяжелых). Кроме того, вызов функций будет осуществляться в порядке, задаваемом ORDER BY, а иногда это важно. Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/9879B786-E011-44A1-91B8-54649B84106D%40postgrespro.ru).
**Добавлены функции оценки селективности для contrib/intarray** (Юрий Журавлев, Александр Коротков).
Это улучшает работу планировщика с запросами, в которых задействованы поля типа int[]. Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/1529951.MrgHGDLjOD%40dinodell).
### Полнотекстовый поиск
**Поиск фраз — новая возможность полнотекстового поиска** (Фёдор Сигаев, Олег Бартунов, Дмитрий Иванов).
Подробности [на слайдах](http://www.pgcon.org/2016/schedule/attachments/436_pgcon-2016-fts.pdf) и в документации [полнотекстового поиска](https://postgrespro.ru/docs/postgresql/9.6/datatype-textsearch).
**Парсер полнотекстового поиска теперь понимает лидирующие цифры в e-mail'ах и именах хостов** (Артур Закиров).
Это помогает правильно индексировать тексты, содержащие e-mail'ы и урлы. Нужно перестроить tsvector'ы, сгенерированные с использованием предыдущей версии. Подробная информация о патче — [в списке рассылки](https://www.postgresql.org/message-id/flat/56CC9C9D.1050603%40postgrespro.ru#[email protected]).
**Поддержка словарей Hunspell и увеличение количества поддерживаемых языков** (Артур Закиров).
Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/[email protected]) и в [документации](https://postgrespro.ru/docs/postgresql/9.6/textsearch-dictionaries).
**Новые полезные функции для работы с tsvector** (Стас Кельвич).
Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/[email protected]) и в [документации](https://postgrespro.ru/docs/postgresql/9.6/functions-textsearch).
**Функции ts\_stat() и tsvector\_update\_trigger() теперь оперируют с данными бинарно совместимых типов** (Фёдор Сигаев).
Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/[email protected]).
### Расширяемость и расширения
**Добавлен класс операторов в SP-GiST для типа box** (Александр Лебедев)
Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/56352972.9020608%40postgrespro.ru).
**Добавление опций в ALTER OPERATOR, позволяющих указывать функции селективности для операторов** (Юрий Журавлев).
Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/3348985.V7xMLFDaJO%40dinodell).
**Новая конструкция CREATE ACCESS METHOD, позволяющая создавать индексные методы доступа в расширениях PostgreSQL** (Александр Коротков, Petr Jelínek).
Подробности [на слайдах](http://www.pgcon.org/2016/schedule/attachments/421_engines.pdf).
**Упрощение API индексных методов доступа** (Александр Коротков, Andrew Gierth).
API индексных методов доступа изменен, чтобы в большей соответствовать концепциям, используемым в FDW и Tablesample. Это упрощает C-шный код и облегчает создание новых методов доступа в устанавливаемые расширения. Количество колонок в системной таблице pg\_am уменьшилось, и появились новые функции для доступа к параметрам методов доступа из SQL. Подробности [на слайдах](http://www.pgcon.org/2016/schedule/attachments/421_engines.pdf).
**Добавлен обобщенный интерфейс для записи WAL** (Александр Коротков, Petr Jelínek, Markus Nullmeier).
Это позволяет расширениям стандартизованным образом делать записи в WAL. Это позволяет расширениям определять свои типы индексов, которые автоматически будут поддерживаться механизмом WAL-логов, т.е., в частности, реплицироваться потоковой репликацией. Подробности [на слайдах](http://www.pgcon.org/2016/schedule/attachments/421_engines.pdf).
**Классы операторов SP-GiST operator classes теперь могут сохранять некоторое значение (“traversal value”) в процессе обхода индекса** (Александр Лебедев, Фёдор Сигаев).
Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/56352972.9020608%40postgrespro.ru).
**Новый модуль [contrib/bloom](https://postgrespro.ru/docs/postgresql/9.6/bloom) реализует метод индексного доступа на основе блумовской фильтрации** (Фёдор Сигаев, Александр Коротков).
Модуль написан, в основном, для проверки новых возможностей по определению методов доступа в расширениях, но может оказаться полезным в реальных многоколоночных запросах. Подробности [на слайдах](http://www.pgcon.org/2016/schedule/attachments/421_engines.pdf).
**В расширении [contrib/cube](https://postgrespro.ru/docs/postgresql/9.6/cube) введен оператор расстояния для кубов и поддержка kNN-поиска для GiST-индексов по колонкам типа cube** (Стас Кельвич)
Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/[email protected]).
### Разное
**В срезе массива теперь можно не указывать левую или правую границу** (Юрий Журавлев)
Например, `array_col[3:]`. Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/2987745.PueTkqGxbO@dinodell).
**Улучшение [pg\_rewind](https://postgrespro.ru/docs/postgresql/9.6/app-pgrewind): возможность работы с измененной целевой линией времени** (Александр Коротков)
Это позволяет, например, откатить бывшую реплику к состоянию старого мастера. Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/CAPpHfdtaqYGz6JKvx4AdySA_ceqPH7Lki=F1HxUeNNaBRC7Mtw@mail.gmail.com).
**Улучшения модуля [pageinspect](https://postgrespro.ru/docs/postgresql/9.6/pageinspect)** (Николай Шаплов)
Функция heap\_page\_items() модуля contrib/pageinspect’s показывает сырые данные записи. Новые функции tuple\_data\_split() и heap\_page\_item\_attrs() позволяют заглянуть внутрь индивидуальных полей.
Подробности [на слайдах](https://pgconf.ru/media/2016/05/13/tuple-internals.pdf).
**Добавлена поддержка “похожести слов” в модуле [contrib/pg\_trgm](https://postgrespro.ru/docs/postgresql/9.6/pgtrgm)** (Александр Коротков, Артур Закиров)
Можно измерить степень похожести между строкой и наиболее похожим на нее словом другой строки.
Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/[email protected]#[email protected]).
**В модуле [contrib/pg\_trgm](https://postgrespro.ru/docs/postgresql/9.6/pgtrgm) добавлен параметр конфигурации pg\_trgm.similarity\_threshold** (Артур Закиров)
Порогом похожести теперь можно управлять через конфигурационный параметр. Раньше это делалось только через специальные функции set\_limit() и show\_limit(). Подробности [в списке рассылки](https://www.postgresql.org/message-id/flat/[email protected]#[email protected]).
---
Если читателям будут особо интересны какие-то из этих пунктов, мы с удовольствием напишем подробнее. | https://habr.com/ru/post/311352/ | null | ru | null |
# Быстрое разверытвание среды разработки для Ruby on Rails
Привет хабражители. Если вам надоело постоянно устанавливать на новых машинах с разными ОС одно и тоже rails окружение с десятками зависимостей и кучей пакетов, то предлагаю вам ознакомится с интересным решением от rails-core разработчиков. На вашей хост-машине нужно иметь лишь Vagrant и Virtual Box.
##### Проблема
Так случилось, что в нашей компании возникла проблема установки всего необходимого окружения на разные оперирующие системы, Mac OS X и Linux в частности.
Казалось бы это тривиальная задача под Linux, немного сложнее под Mac, но всё оказалось еще сложнее, т.к. проект у нас не стандартный. Эдакая адская смесь дрюпала и рельсов. Проект как раз в процессе мигрирования на рельсы. И подружить это всё под маками оказалась не такой простой задачей для фронт-энд программистов, не искушенных в настройке окружения. Ставить убунту или другой линукс они категорически отказывались.
##### Решение

Ну что ж. Как самое быстрое решение был выбран такой замечательный проект как [rails-dev-box](https://github.com/rails/rails-dev-box)
Этот проект автоматизируют установку для разработки ядра Ruby on Rails. Для наших нужд это подходит как нельзя кстати.
Нам потребуется иметь установленный Virtual Box и руби джем Vagrant. Оба установить достаточно легко.
После этого нам лишь нужно выполнить пару команд:
```
host:~$ git clone https://github.com/rails/rails-dev-box.git
host:~$ cd rails-dev-box
host:~$ vagrant up
```
Всё. После чего можно зайти по ssh в уже настроенную ubuntu:
```
vagrant ssh
Welcome to Ubuntu 12.04 LTS (GNU/Linux 3.2.0-23-generic-pae i686)
...
vagrant@rails-dev-box:~$
```
В витуальной системе уже установлено всё что надо, за исключением php и веб-сервера:
* Git
* RVM
* Ruby 1.9.3 (binary RVM install)
* Bundler
* SQLite3, MySQL, and Postgres
* System dependencies for nokogiri, sqlite3, mysql, mysql2, and pg
* Databases and users needed to run the Active Record test suite
* Node.js for the asset pipeline
* Memcached
Установку php и nginx мы не будем рассматривать, это выходить за пределы данной статьи. Это очень просто сделать в линуксе.
Нам лишь осталось скопировать проект в папку с rails-dev-box на хост системе и запустить rails server из под vagrant:
```
vagrant ssh
cd /vagrant/my_project
bundle exec unicorn -E development -D
```
Виртульная система и хост-системы видят одну и ту же папку, что позволяет нам редактировать её своим любимым редактором, а страницы открывать как и раньше через `localhost:3000`
В случае с php нужно еще прокинуть порт 1080 (80 порт мы прокинуть не можем, т.к. тогда нам нужен будет рут доступ)
Это делается довольно просто. Нужно вписать в Vagrantfile лишь одну строку:
```
config.vm.forward_port 80, 1080
```
Каково было мое удивление, когда оказалось что страницы из Rails грузятся чуть ли не по минуте. Drupal работал как ни в чем не бывало. Скорость почти неотличима от родной файловой системы.
Оказалось, что VirtualBox Shared Folders, которые Vagrant использует по умолчанию, очень и очень медленные.
Бенчмарк из документации Vagrant:
```
VirtualBox Shared Folders: 5m 14s
Host File System: 10s
Native VM File System: 13s
NFS Shared Folders: 22s
NFS Shared Folders (warm cache): 14s
```
Как видно, нам ничего не остается как только использовать NFS. В Mac OS этот демон уже предустановлен. Установка в линуксе опять же банальна — нужно установить пакет.
После этого правим наш Vagrantfile, добавляем строки:
```
config.vm.share_folder "v-root", "/home/vagrant/shared-folder", ".", :nfs => true
config.vm.network :hostonly, "33.33.33.100"
```
Опция Host-only используется для создания второго виртуального адаптера, через него и будет работать nfs.
Теперь надо перезагрузить виртуальную машину и проект в виртуальной системе уже будет находиться в `/home/vagrant/shared-folder`
Запускаем юникорн и теперь видим что страницы загружаются с положенной скоростью.
##### Дополнительно
Связка Virtual Box и Vagrant работает замечательно. Вы можете написать дополнительные рецепты(используется puppet), чтобы автоматизировать всё вышеописанное, включая клонирование репозитория вашего проекта со стороннего сервиса, а также настройку конфигов nginx/apache, php, unicorn
Спасибо за внимание и приятной разработки.
##### Ссылки
[rails-dev-box github source code](https://github.com/rails/rails-dev-box)
[Vagrant and NFS Shared Folders](http://docs-v1.vagrantup.com/v1/docs/nfs.html) | https://habr.com/ru/post/173287/ | null | ru | null |
# Cocos2d-x: Пишем на Lua

Доброго времени суток.
Начнем с того, что я не нашел на хабре туториалов по Cocos2d и Lua, поэтому мне пришлось много страдать и чтобы вы не повторяли моих ошибок я решил написать пост. В этой статье я расскажу как создать простую игру используя [Сocos2d-x](http://www.cocos2d-x.org/), Cocos Code IDE и Lua. [Ранее](http://habrahabr.ru/post/202540/), я уже писал про создание игр на Love2d. В этой статье я адаптирую старый туториал для кокоса и как это запустить на андроиде (Ни яблока, ни мака у меня нет).
#### Что нам понадобится?
Список важных вещей:* [Java JDK](http://www.oracle.com/technetwork/java/javase/downloads/index.html)
* Сам Cocos2d-x. На момент выхода этой статьи вышел Cocos2d-x 3.2 и скачать его можно [здесь](http://www.cocos2d-x.org/filedown/cocos2d-x-3.2.zip). Нужно скачать той же разрядности, что и JDK
* IDE для lua. Разработчики движка постарались и выпустили свой IDE на основе Eclipse. Качаем [здесь](http://www.cocos2d-x.org/products/codeide).
* [Windows-only]Python 2.7. Лежит вот [тут](https://www.python.org/download/releases/2.7/).
Если вы хотите писать игры под андроид, то придется скачать еще пару вещей, а именно:* [Android SDK](http://developer.android.com/sdk/index.html). Если вы не собираетесь писать под андроид, то лучше найти вкладку «GET THE SDK FOR AN EXISTING IDE»
* [Android NDK](https://developer.android.com/tools/sdk/ndk/index.html). Я использую Android NDK r9, а с r10 возможны проблемы
* [Apache Ant](http://ant.apache.org/bindownload.cgi). У меня стоит 1.9.4
#### Установка
Сначала поставим Java JDK и Python. После распакуйте cocos2d-x и Cocos Code IDE (Если вы скачивали zip версию, если нет, просто запустите установку) в удобное для вас место. Распаковываем Android SDK, NDK и Apache Ant так же в удобное место. Путь к ним не должен содержать пробелов во избежание проблем. Открываем папку с SDK, находим SDK Manager. Запускаем и ставим нужные для нас версии API и всю папку Tools.
Запускаем Cocos Code IDE. В Window->Preferences->Cocos указываем нужные пути. У меня это выглядит так:
.
Теперь кликаем по вкладке Lua которая находится во вкладке Cocos и выбираем путь к cocos2d-x:
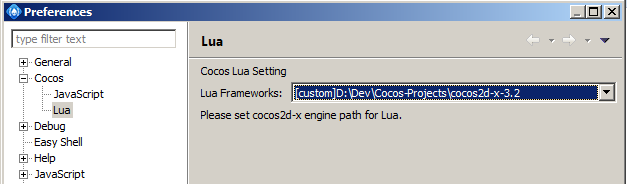
Настроено.
#### Немного теории
Cocos2d-x — кроссплатформенный движок, написанный на С++, был создан как копия Cocos2d. Cocos2d использует Object C и может использоваться [только для iOS](http://habrastorage.org/files/03b/2be/9cb/03b2be9cb00e41669d2baf9716039114.png).
Теперь поговорим о базовой механике движка и сравним ее с Love2D. У кокоса все объекты находятся в слоях, а слои находятся в сценах. В Love2D ни слоев, ни сцен нет. Плюсы сцен и слоев в том, что с их помощью можно создавать гибкое приложение более простыми способами. Минусы в том, что для просто игры это может быть слишком громоздко и неудобно. В кокосе все представленно объектами и чтобы что-то появилось на экране надо просто добавить это на сцену, а в love2d все представленно простыми переменными и чтобы что-то появилось на экране нужно это каждый кадр рисовать. Это можно описывать достаточно долго поэтому я скажу вывод сейчас, а разницу вы сможете почувствовать сами. Cocos2d-x — большой движок с большим количеством возможностей, однако доступ к ним часто сделан не так как хотелось бы. Love2d — простой, не требующий много знаний, движок с отзывчивым коммьюнити, но с отсутствием многих нужных вещей, которые впоследствии пишут сами пользователи, но делают это вполне удачно.
#### А теперь сам код
Создадим новый проект. И у нас будет два файла в исходниках: hello2.lua и main.lua. Если вы не хотите посмотреть на чудо китайского гейм дева, то первый можно сразу удалять, а второй очистить. Он создан для демонстрации возможностей [require](http://www.lua.ru/doc/5.3.html). Открываем main.lua и видим кучу кода которая нужна чтобы понять как использовать порт под lua. Чтобы увидеть, что это такое нажимаем F11. Можно поиграться. Вот это бегающие существо это собака, а не белка как вы могли подумать. Посмотрели, поигрались и хватит. Удалите hello2.lua и весь код в main.lua и очищаем папку res. В папку res добавляем [картинку](http://beta.hstor.org/storage3/c04/948/137/c04948137c958bbbf5cdfb8cf277d1bd.png) и называем ее habr.png. Теперь пишем в main следующий код:
```
--Все классы кокоса
require "Cocos2d"
--Все константы кокоса
require "Cocos2dConstants"
-- Функция вывода сообщений
cclog = function(...)
print(string.format(...))
end
-- Эта функция выводит ошибки
function __G__TRACKBACK__(msg)
cclog("\n----------------------------------------")
cclog("LUA ERROR: " .. tostring(msg))
cclog(debug.traceback())
cclog("----------------------------------------")
return msg
end
collectgarbage("collect")
-- Предотвращает утечку памяти
collectgarbage("setpause", 100)
collectgarbage("setstepmul", 5000)
--Теперь можно использовать файлы которые лежат в папках "src" и "res"
cc.FileUtils:getInstance():addSearchResolutionsOrder("src");
cc.FileUtils:getInstance():addSearchResolutionsOrder("res");
--Записываем в константы ширину и высоту экрана
SCREEN_WIDTH = cc.Director:getInstance():getWinSize().width
SCREEN_HEIGHT = cc.Director:getInstance():getWinSize().height
local function main()
print("Resolution: " .. SCREEN_WIDTH .. "x" .. SCREEN_HEIGHT)
--Запускаем главную сцену
require "mainScene.lua"
end
--Вызываем функцию main
local status, msg = xpcall(main, __G__TRACKBACK__)
if not status then
error(msg)
end
```
В функции main мы вызываем файл mainScene.lua. В нем находится главная сцена игры. Создадим его и напишем туда следующий код:
```
-- Константы
local NONE = 0
local ROTATION = 1
local SCALLING = 2
local MOVING = 3
-- Переменные
local state, rotation, scale, ox, oy, delta, habrImage, moving
-- Эта функция будет вызываться когда палец касается экрана
local function onTouchBegan(touch, event)
-- Включаем следующие состояние
state = (state + 1) % 4
-- И возвращаем переменные к дефолту
resetVariables()
end
-- Эта функция вызывается постоянно, а в dt хранится время с
-- прошлого вызова. Если dt == 1.0, то с прошлого вызова прошла
-- одна секунда
local function update(dt)
if state == ROTATION then
--крутим картинку
rotation = rotation + delta * dt
elseif state == SCALLING then
--увеличиваем
scale = scale + dt * delta
elseif state == MOVING then
--Здесь немного посложнее, но все же просто:
--Каждый раз мы увеличивыем переменную moving, а
--потом берем ее за угол для косинису и синуса
--и крутим картинку по кругу
moving = moving + delta * dt
local radius = 50
ox = radius * math.sin(moving)
oy = radius * math.cos(moving)
end
-- В love2d мы использовали эти параметры при рисовании
-- Здесь у нас спрайт и нам нужно постоянно менять ему
-- все вручную
-- Меняем размер
habrImage:setScale(scale)
-- Меняем угол
habrImage:setRotation(rotation)
-- Меняем позицию
habrImage:setPosition(cc.p(SCREEN_WIDTH / 2 + ox, SCREEN_HEIGHT / 2 + oy))
end
local function init()
print("Creating main scene")
-- Создаем сцену
local mainScene = cc.Scene:create()
-- Создаем слой с фоновым цветом
-- Здесь я бы хотел поставить паузу и рассказать более подробно
-- потому что у меня ушло 2 часа чтобы узнать как мне изменить цвет
-- фона. 1) В C++ нет функции cc.c4b(r,g,b,a) поэтому мне пришлось
-- догадаться, что нужно смотреть не на C++ таких случаях, а на
-- cocos2d-x-js, т.к. он более популярен чем cocos2d-x-lua
-- и если вы не можете найти нужную функцию в C++, то ищите ее в
-- JavaScript версии, однако это не поможет с евентами
local gameLayer = cc.LayerColor:create(cc.c4b(255, 255, 255, 255))
-- Создаем спрайт
habrImage = cc.Sprite:create("res/habr.png")
--Ставим его смещение по центру
habrImage:setAnchorPoint(0.5, 0.5)
--Ставим позицию на центр экрана
habrImage:setPosition(cc.p(SCREEN_WIDTH / 2, SCREEN_HEIGHT / 2))
--Добавляем его к слою
gameLayer:addChild(habrImage)
state = 0
resetVariables()
-- Чтобы функция update вызывалась нужно сообщить кокосу, что ее нужно
-- вызывать
cc.Director:getInstance():getScheduler():scheduleScriptFunc(update, 0, false)
-- Создаем лисениры для событий. Хочу обратить внимание, что для каждого
-- типа событий есть свой лисенер.
local listener = cc.EventListenerTouchOneByOne:create()
-- Говорим лисениру, что такой то тип событий связвн с такой то функцией
listener:registerScriptHandler(onTouchBegan, cc.Handler.EVENT_TOUCH_BEGAN )
-- Добавляем лисенер к слою
local eventDispatcher = gameLayer:getEventDispatcher()
eventDispatcher:addEventListenerWithSceneGraphPriority(listener, gameLayer)
--Добавляем слой к сцене
mainScene:addChild(gameLayer)
--Запускаем или если уже что-либо запущено заменяем сцену
if cc.Director:getInstance():getRunningScene() then
cc.Director:getInstance():replaceScene(mainScene)
else
cc.Director:getInstance():runWithScene(mainScene)
end
end
function resetVariables()
rotation = 0
scale = 1
ox = 0
oy = 0
delta = 20
moving = 0
end
--Запускаем сцену
init()
```
Теперь немного о помощи с поиском ответов. Во-первых: Порт на луа практически идентичен С++ и основные отличия можно прочесть [здесь](http://www.cocos2d-x.org/wiki/How_to_call_c++_from_lua). Во-вторых: как я ранее писал, если вы не можете найти что-либо в порте С++, то попробуйте поискать эту проблему для JS движка. Он более популярен чем луа, однако в нем есть множество отличий, но очень часто он мне помогал. Чтобы запустить то, что у нас вышло нажмите F11. Чтобы запустить на андроид нажмите на кнопку «Debug configurations» и выберите андроид. Для запуска нужен настроенный adb, но про это и так много статей, поэтому я не буду писать здесь об этом. На этом все Спасибо за прочтение (:
Вот что вышло в итоге:
 | https://habr.com/ru/post/232013/ | null | ru | null |
# Как всегда знать свой адрес в сети и не платить за белый IP
**Начало**
Всё началось с покупки одноплатного компьютера. На нём я поднял облачный сервис Seafile, медиа-сервер Jellyfin и вики-движок Wiki.js. Потребляет такой компьютер с подключенным внешним жёстким диском крайне мало. Всё это добро я использую в одном лице для личных нужд. Поэтому платить за белый IP адрес и уж тем более покупать доменное имя считаю лишним. Вот только провайдер постоянно меняет мне внешний IP, а доступ хотелось бы всегда иметь и за пределами домашней сети.
**Идея**
Создать задание Cron, которое периодически будет запускать сценарий, проверяющий, не поменялся ли IP на роутере. В случае изменения отправить его в письме на Yandex Почту.
**Роутер**
* Zyxel Keenetic Viva
**Реализация**
Нам понадобится куда-то сохранять старый и новый IP. Я создал 2 текстовых файла: **old\_ip.txt** и **new\_ip.txt**.
Далее для работы скрипта требуется установить **telnet**:
```
sudo apt update
sudo apt install telnet
```
Создадим следующий shell сценарий **telnet.sh**:
```
#!/bin/sh
HOST='192.168.1.1'
USER='Your user'
PASSWD='Your password'
CMD='show interface PPPoE0'
(
echo open "$HOST"
sleep 2
echo "$USER"
sleep 2
echo "$PASSWD"
sleep 2
echo "$CMD"
sleep 2
echo "exit"
) | telnet | grep -oP 'address: \K.*' >> ./new_ip.txt
```
HOST - адрес роутера. USER и PASSWD - это логин и пароль администратора роутера. В CMD вместо PPPoE0 следует вписать название вашего настроенного интерфейса. У меня это PPPoE0. Сценарий получает текущий внешний IP роутера и сохраняет его в файл new\_ip.txt.
Дальнейшую логику я реализовал на Python. Создадим следующий сценарий **script.py**:
```
#!/usr/bin/python
import subprocess
import smtplib
def CheckFile():
file = open('old_ip.txt', 'r')
if ip != file.readline().strip():
file.close()
open('old_ip.txt', 'w').close()
file = open('old_ip.txt', 'w')
file.write(ip)
file.close()
return True
return False
def SendMail():
content = ip
mail = smtplib.SMTP('smtp.yandex.ru', 587)
mail.ehlo()
mail.starttls()
mail.login('Your Yandex mail login', 'Your Yandex mail password')
mail.sendmail('Your Yandex mail login', 'Your Yandex mail login', content)
def GetIp():
open('new_ip.txt', 'w').close()
subprocess.Popen('./telnet.sh').wait()
GetIp()
ip = open('new_ip.txt', 'r').readline().strip()
if CheckFile() == True:
SendMail()
```
В функции **SendMail** указываем ваш логин и пароль от Yandex Почты. Т.е. мы проходим авторизацию в своём ящике и отправляем письмо сами себе.
Теперь в настройках Yandex Почты разрешим способ авторизации через **портальный пароль**. Это требуется для беспрепятственной авторизации.
**Так же незабываем дать права на запуск нашим скриптам!**
Я создал задание Cron, которое запускает скрипт каждые полчаса:
```
*/30 * * * * python3 script.py
```
Надеюсь, статья оказалась полезной. Спасибо за внимание. | https://habr.com/ru/post/676454/ | null | ru | null |
# Оптимизация Ubuntu (и прочих Linux-ов) под SSD
Доброго времени суток всем читающим. В данной мини-статье мне хотелось бы собрать и рассмотреть основные моменты оптимизации работы (и, конечно, продления жизненного цикла ) твердотельных накопителей. Практически всю информацию можно легко найти в сети, но тут я попытаюсь упомянуть пару подводных камней.
Первое, с чего стоит начать — это выбор файловой системы. Если система на десктопе — то особо вопросов не возникает — брать журналируемую ext4 — у которой масса преимуществ перед остальными ФС. Да, будет больше циклов записи на носитель, но будет гарантия того, что в случае сбоя питания вы не потеряете данные. На ноутбуках, нетбуках — имеются батареи, и вероятность отключения из-за потери питания — практически нулевая (но, конечно, всякое бывает), в связи с чем журналирование, обычно рекомендуют отключать. Если это очень хочется сделать, то после установки системы грузимся с liveCD, и пишем в терминале
`tune2fs -O ^has_journal /dev/sda1
e2fsck -f /dev/sda1`
Другие способы не рекомендуются — потеряете поддержку TRIM. Также не стоит отключать журнал, добавляя параметр "**writeback**" в конфигурацию fstab — система не запустится из-за ошибки монтирования (если до этого был включен трим).
Следующее, что нужно учесть — файл подкачки. Под моим никсом (сейчас — убунту 11.04) обычно пишется код, смотрятся фильмы в HD и активно серфится интернет. За это время файл подкачки не понадобился ни разу, максимальное потребление ОЗУ было 1Гб, из 2х доступных в нетбуке.
Если Ваш сценарий использования системы подобен моему, или у Вас не десктоп — файл подкачки не нужен. Иначе стоит его перенести на HDD. Если журналирование еще можно оставить, ввиду его относительной безобидности, то своп-раздел — однозначно зло, сжирающее как ограниченные циклы перезаписи, так и недешевые гигабайты, количеством которых современные SSD пока не могут похвастаться.
Ну вот, система поставлена — можно заниматься оптимизацией! Самый первый шаг — включение TRIM — главная технология, которая должна продлить жизнь и распределить нагрузку SSD.
Делается очень просто — открываем **fstab** (например так)
`gksudo gedit /etc/fstab`
ищем строчки
*«UUID=[NUMS-AND-LETTERS] / ext4 errors=remount-ro 0 1»*
и заменяем на
*«UUID=[NUMS-AND-LETTERS] / ext4 disсard,errors=remount-ro 0 1»*
Обычно по умолчанию трим отключен, но выкладываю способ проверить — заходим под рут и выполняем команды
1. `dd if=/dev/urandom of=tempfile count=10 bs=512k oflag=direct` //запись 5Мб рандомных данных
2. `hdparm --fibmap tempfile` //Ищем любой стартовый LBA адрес у файла
3. `hdparm --read-sector [ADDRESS] /dev/sdX` //Читаем данные со стартового LBA адреса файла, замените [ADDRESS] на свой Starting LBA address из вывода предыдущей команды
4. rm tempfile //Теперь удалим временный файл и синхронизируем ФС:
5. sync
Повторяем пункт 3 — и смотрим на вывод консоли. Если выведутся нули — то трим работает. Если вы исправили fstab, перезагрузились, но трим не активировался — ищите ошибки в неверном отключении журналирования.
Далее стоит вспомнить о том, что наш никс очень любит вести разнообразные логи. И либо перенести их на HDD, либо держать в ОЗУ до перезагрузки системы. Я считаю, что если у Вас дома не сервер — то оптимален второй вариант, и реализуется он добавлением в **fstab** следующих строчек
*tmpfs /tmp tmpfs defaults 0 0
tmpfs /var/tmp tmpfs defaults 0 0
tmpfs /var/lock tmpfs defaults 0 0
tmpfs /var/spool/postfix tmpfs defaults 0 0*
По умолчанию, после каждого открытия файла — система оставляет отметку времени последнего открытия — лишние операции записи. Отучить просто — добавить в fstab перед параметрами
*disсard,errors=remount-ro 0*
еще парочку опций —
*relatime,nodiratime* Первая разрешает записывать только время изменения (порой необходимо для стабильной работы некоторых программ), вторая — отменяет запись времени доступа к директориям. В принципе, вместо **relatime** можно поставить и **noatime**, который вообще ничего не будет обновлять.
После этого стоит настроить отложенную запись — ядро будет копить данные, ожидающие записи на диск, и записывать их либо при острой необходимости, либо по истечении таймаута. Я ставлю таймаут на 60 секунд, кто-то — на 150.
Для этого открываем */etc/sysctl.conf* и добавляем параметры
*vm.laptop\_mode = 5* // Включение режима
*vm.dirty\_writeback\_centisecs = 6000* время в сСк. Т.е. 100ед = 1секунда
И, напоследок, отключаем I/O планировщик, который был когда-то нужен для лучшего позиционирования головок HDD. Для этого заходит в конфиг граба */etc/default/grub*
и в строчку
*GRUB\_CMDLINE\_LINUX\_DEFAULT=«quiet splash»* вставляем параметр *elevator=noop*
По пути можно убрать ненужный и малоинформатиынй сплэш-скрин, сократив время старта системы еще на секунду, просто убрав *quiet splash*.
Вот, в общем основные моменты. Дальше стоит проявить фантазию — например, перенести куда-нибудь, или вовсе отключить кеш браузеров и тд. В награду за проделанные манипуляции Ваш SSD прослужит вам верой и правдой, и с каждым стартом будет радовать хорошей скоростью.
Update
Многи замечают о необходимости выравнивания разделов. Товарищу isden большое спасибо за ссылку на тему. [wiki.archlinux.org/index.php/SSD#Partition\_Alignment](https://wiki.archlinux.org/index.php/SSD#Partition_Alignment)
Если не хотите рисковать — то журнал лучше не отключать. Тогда гарантированно будет работать трим, и некоторая защита данных от крупных системных сбоев.
Внизу — несколько ссылок, по которым получал информацию.
[vasilisc.com/ssd\_ubuntu](http://vasilisc.com/ssd_ubuntu)
[tokarchuk.ru/2011/01/enable-trim-support-in-ubuntu](http://tokarchuk.ru/2011/01/enable-trim-support-in-ubuntu/)
[sites.google.com/site/linuxoptimization/home/ssd](https://sites.google.com/site/linuxoptimization/home/ssd) | https://habr.com/ru/post/129551/ | null | ru | null |
# Облачное хранилище корпоративного класса на базе NGINX Plus и Minio

В этой статье говорится о том, как настроить [обратный прокси-сервер](https://www.nginx.com/resources/glossary/reverse-proxy-server/?utm_source=enterprise-grade-cloud-storage-nginx-plus-minio&utm_medium=blog&utm_campaign=Cloud) NGINX или NGINX Plus в качестве [балансировщика нагрузки](https://www.nginx.com/resources/glossary/cloud-load-balancing/?utm_source=enterprise-grade-cloud-storage-nginx-plus-minio&utm_medium=blog&utm_campaign=Cloud) для хранилища объектов (object storage) на базе [Minio](https://minio.io/).
Проектирование хранилища объектов
---------------------------------
Практически любому приложению нужно хранилище, но требования к этому компоненту системы могут сильно различаться. Возьмем для примера хранилище документов: возможно, на начальных этапах работы ему не придется обслуживать большое количество запросов на чтение, но впоследствии может понадобиться масштабирование. Другое приложение (такое как, например, галерея изображений) уже с момента запуска должно уметь и быстро обслуживать большое количество запросов, и масштабироваться по мере необходимости.
Эти тонкости осложняют процесс организации хранилища. Но все не так плохо: c приходом хранилища объектов (object storage) в качестве стандартного способа хранения неструктурированных данных (во многом за счет необходимости использования HTTP) начался процесс стандартизации работы приложения с хранилищем.
Но вопрос все еще остается: как организовать заточенное под ваше приложение и в то же время гибкое хранилище объектов?
Поскольку работа с хранилищем объектов подразумевает использование HTTP-серверов и клиентов, для обслуживания HTTP-трафика необходимо выбрать подходящий веб-сервер (например, не нуждающийся в представлении NGINX). В качестве бэкэнда можно использовать легковесный и хорошо масштабируемый сервер хранилища объектов. На эту роль отлично подходит [Minio](https://minio.io/). Гибкость подобной системы является ключевым фактором при создании сервиса корпоративного уровня.
С помощью NGINX Plus администраторы могут не только настроить балансировку входящего трафика, но и кэширование, дросселирование (throttling), завершение SSL/TLS и даже фильтрацию трафика на основе различных параметров. Minio, с другой стороны, предлагает легковесное хранилище объектов, совместимое с [Amazon S3](https://aws.amazon.com/s3/).
Minio создан для размещения неструктурированных данных, таких как фотографии, видеозаписи, файлы журналов, резервные копии, а также образы виртуальных машин и контейнеров. Небольшой размер позволяет включать его в состав стека приложений, аналогичного Node.js, Redis и MySQL. В minio также поддерживается [распределенный режим (distributed mode)](https://docs.minio.io/docs/distributed-minio-quickstart-guide), который предоставляет возможность подключения к одному серверу хранения объектов множества дисков, в том числе расположенных на разных машинах.
В этой статье мы рассмотрим несколько сценариев использования NGINX Plus в сочетании с Minio, которые позволяют настроить хорошо масштабируемое, отказоустойчивое и стабильное хранилище объектов корпоративного класса.
NGINX Plus в качестве обратного прокси и балансировщика нагрузки
----------------------------------------------------------------
NGINX Plus прежде всего известен как обратный прокси (reverse proxy). Но нужен ли обратный прокси для Minio? Давайте посмотрим на несколько сценариев использования:
* Если перед одним или несколькими серверами Minio стоит обратный прокси NGINX Plus, появляется возможность перемещать экземпляры серверов Minio на другие машины/площадки без необходимости изменения настроек клиентов.
* NGINX Plus может балансировать входящий трафик и равномерно раздавать его экземплярам [распределенного сервера Minio](https://docs.minio.io/docs/distributed-minio-quickstart-guide).
* Прокси-сервер NGINX Plus может входить в состав отказоустойчивого хранилища объектов, созданного с помощью команды [`mirror`](https://docs.minio.io/docs/minio-client-complete-guide#mirror) из состава Minio Client (`mc`).
NGINX Plus выполняет обратное проксирование трафика клиента путем передачи запросов на внутренний сервер, который задается директивой [`proxy_pass`](http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_pass). В следующем фрагменте файла конфигурации единственный экземпляр Minio запущен на `localhost` и доступен по ссылке **<http://localhost:9000>**. Все запросы к директории верхнего уровня (/) на **www.example.com**, приходящие на 80-й порт, направляются Minio. NGINX Plus в явном виде устанавливает заголовок `Host` равным этому значению в исходном запросе.
```
server {
listen 80;
server_name www.example.com;
location / {
proxy_set_header Host $http_host;
proxy_pass http://localhost:9000;
}
}
```
Если серверов Minio несколько, имеет смысл настроить балансировку трафика путем перечисления этих серверов в блоке конфигурации [`upstream`](http://nginx.org/en/docs/http/ngx_http_upstream_module.html#upstream) и указания этой группы в директиве `proxy_pass` directive:
```
upstream minio_servers {
server minio-server-1:9000;
server minio-server-2:9000;
}
server {
listen 80;
server_name www.example.com;
location / {
proxy_set_header Host $http_host;
proxy_pass http://minio_servers;
}
}
```
Для получения более подробной информации о настройке NGINX или NGINX Plus в качестве прокси для Minio см. [документацию по Minio](https://docs.minio.io/docs/distributed-minio-quickstart-guide).
Завершение SSL/TLS
------------------
В последнее время HTTPS становится протоколом по умолчанию для передачи большей части веб-трафика, поэтому для Minio имеет смысл разворачивать сразу HTTPS-сервер. NGINX Plus в качестве HTTPS-сервера настроить достаточно просто. Первым делом нужен SSL/TLS-сертификат, который можно получить и интегрировать в NGINX Plus с помощью Let’s Encrypt.
Далее следует отредактировать файл конфигурации NGINX Plus, где необходимо указать параметр `ssl` в директиве [`listen`](http://nginx.org/en/docs/http/ngx_http_core_module.html#listen), которая находится в блоке `server`, а затем прописать файлы с [сертификатом сервера и закрытым ключом](http://nginx.org/en/docs/http/ngx_http_ssl_module.html#ssl_certificate):
```
server {
listen 80;
server_name www.example.com;
return 301 https://www.example.com$request_uri;
}
server {
listen 443 ssl;
server_name www.example.com;
ssl_certificate www.example.com.crt;
ssl_certificate_key www.example.com.key;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers HIGH:!aNULL:!MD5;
location / {
proxy_set_header Host $http_host;
proxy_pass http://localhost:9000;
}
}
```
Для получения более подробной информации о завершении SSL/TLS см. [NGINX Plus Admin Guide](https://www.nginx.com/resources/admin-guide/nginx-ssl-termination/?utm_source=enterprise-grade-cloud-storage-nginx-plus-minio&utm_medium=blog&utm_campaign=Cloud).
Кэширование
-----------
Серверы хранилищ объектов обычно не отличаются быстродействием, но это не означает, что запросы клиентов обрабатываются медленно. При включении кэширования на сервере NGINX Plus он сохраняет часто запрашиваемые данные и может сразу вернуть их клиенту, не перенаправляя запрос на внутренний сервер.
Вот как это работает. Веб-кэш сервера NGINX Plus расположен между клиентом и сервером Minio, и в нем сохраняется копия каждого запрошенного из хранилища файла. Если запрошенный файл есть в кэше, NGINX сразу возвращает его, не обращаясь к Minio. Таким образом уменьшаются время ответа клиенту и нагрузка на сервер Minio.
Чтобы настроить кэш NGINX Plus для работы с Minio, используются директивы [`proxy_cache_path`](http://nginx.org/ru/docs/http/ngx_http_proxy_module.html#proxy_cache_path) и [`proxy_cache`](http://nginx.org/ru/docs/http/ngx_http_proxy_module.html#proxy_cache). Директива `proxy_cache_path` устанавливает расположение и конфигурацию кэша, а `proxy_cache` активирует его. Дополнительную информацию можно найти в [A Guide to Caching with NGINX and NGINX Plus](https://www.nginx.com/blog/nginx-caching-guide/?utm_source=enterprise-grade-cloud-storage-nginx-plus-minio&utm_medium=blog&utm_campaign=Cloud).
```
proxy_cache_path /path/to/cache levels=1:2 keys_zone=my_cache:10m max_size=10g inactive=60m
use_temp_path=off;
server {
...
location / {
proxy_cache my_cache;
proxy_set_header Host $http_host;
proxy_pass http://localhost:9000;
}
}
```
Дросселирование (throttling)
----------------------------
Бывают случаи, когда исходя из требований бизнеса или соображений безопасности некоторых http-клиентов нужно немного «придушить». NGINX Plus позволяет ограничить доступную полосу пропускания, количество запросов и соединений.
Чтобы ограничить полосу пропускания, используйте директиву [`limit_rate`](http://nginx.org/ru/docs/http/ngx_http_core_module.html#limit_rate). В следующем примере скорость загрузки ограничена 200 Кб в секунду:
```
server {
...
location /images/ {
limit_rate 200k;
...
}
}
```
Чтобы ограничить количество запросов, используйте директивы [`limit_req`](http://nginx.org/en/docs/http/ngx_http_limit_req_module.html#limit_req) и [`limit_req_zone`](http://nginx.org/ru/docs/http/ngx_http_limit_req_module.html#limit_req_zone), аналогично этому примеру, в котором каждый уникальный IP-адрес ограничен 10 запросами в секунду с пиками до 20 запросов.
```
limit_req_zone $binary_remote_addr zone=my_req_limit:10m rate=10r/s;
server {
...
location /images/ {
limit_req zone=my_req_limit burst=20;
...
}
}
```
Чтобы ограничить количество соединений, используйте директивы [`limit_conn`](http://nginx.org/en/docs/http/ngx_http_limit_conn_module.html#limit_conn) и [`limit_conn_zone`](http://nginx.org/en/docs/http/ngx_http_limit_conn_module.html#limit_conn_zone). В следующем примере каждый уникальный IP-адрес ограничен пятью одновременными соединениями.
```
limit_conn_zone $binary_remote_addr zone=my_conn_limit:10m;
server {
...
location /images/ {
limit_conn my_conn_limit 5;
...
}
}
```
Для получения более подробной информации см. [NGINX Plus Admin Guide](https://www.nginx.com/resources/admin-guide/restricting-access/?utm_source=enterprise-grade-cloud-storage-nginx-plus-minio&utm_medium=blog&utm_campaign=Cloud).
Заключение
----------
В этой статье мы продемонстрировали несколько функций NGINX Plus, позволяющих организовать балансировку нагрузки (в частности, для сервера хранилища объектов Minio). Связка NGINX Plus и Minio дает возможность настроить гибкое хранилище объектов, заточенное под нужды вашего приложения.
Эта статья была изначально опубликована в [блоге Nginx](https://www.nginx.com/blog/enterprise-grade-cloud-storage-nginx-plus-minio/).
Нас можно найти в Slack: [slack.minio.io](http://slack.minio.io/) | https://habr.com/ru/post/324086/ | null | ru | null |
# Как я писал асинхронные веб-запросы на Python, или почему провайдер считает, что я бандит
На днях по работе потребовалось сделать утилиту, которая прямо вот из консоли ходит в апи нашего клауд сервиса и берет оттуда кое-какую информацию. Подробности что и зачем - вне этого рассказа. Принципиальный вопрос здесь другой - скорость. Скорость реально важна (порядок количества запросов - десятки и сотни). Потому что ждать - не кайф.
Здесь я хочу поделиться своим ресёрчем на тему запросов, как делать круто, а как нет. С примерами кода конечно. А так же рассказать, как я тупил.
Есть только я и неприятностиНачнем, пожалуй, с классики
---------------------------
Последовательные синхронные запросы. Будем использовать всем известную либу **requests** и **tqdm** для красивого вывода в консоль. В качестве игрушечного примера выбрал первую-попавшуюся публичную апишку: `https://catfact.ninja/`. Метрикой качества будет RPS (*Request per second*). Чем выше - тем соотвественно лучше.
```
import time
import requests
from tqdm import tqdm
URL = 'https://catfact.ninja/'
class Api:
def __init__(self, url: str):
self.url = url
def http_get(self, path: str, times: int):
content = []
for _ in tqdm(range(times), desc='Fetching data...', colour='GREEN'):
response = requests.get(self.url + path)
content.append(response.json())
return content
if __name__ == '__main__':
N = 10
api = Api(URL)
start_timestamp = time.time()
print(api.http_get(path='fact/', times=N))
task_time = round(time.time() - start_timestamp, 2)
rps = round(N / task_time, 1)
print(
f"| Requests: {N}; Total time: {task_time} s; RPS: {rps}. |\n"
)
```
Получаем следующий вывод в терминале:
```
Fetching data...: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:06<00:00, 1.52it/s]
[{'fact': 'Despite imagery of cats happily drinking milk from saucers, studies indicate that cats are actually lactose intolerant and should avoid it entirely.', 'length': 148}, {'fact': 'The smallest pedigreed cat is a Singapura, which can weigh just 4 lbs (1.8 kg), or about five large cans of cat food. The largest pedigreed cats are Maine Coon cats, which can weigh 25 lbs (11.3 kg), or nearly twice as much as an average cat weighs.', 'length': 249}, {'fact': 'A cat has 230 bones in its body. A human has 206. A cat has no collarbone, so it can fit through any opening the size of its head.', 'length': 130}, {'fact': "Cats' hearing is much more sensitive than humans and dogs.", 'length': 58}, {'fact': 'The first formal cat show was held in England in 1871; in America, in 1895.', 'length': 75}, {'fact': 'In contrast to dogs, cats have not undergone major changes during their domestication process.', 'length': 94}, {'fact': 'Ginger tabby cats can have freckles around their mouths and on their eyelids!', 'length': 77}, {'fact': 'Cats bury their feces to cover their trails from predators.', 'length': 59}, {'fact': 'While it is commonly thought that the ancient Egyptians were the first to domesticate cats, the oldest known pet cat was recently found in a 9,500-year-old grave on the Mediterranean island of Cyprus. This grave predates early Egyptian art depicting cats by 4,000 years or more.', 'length': 278}, {'fact': 'Relative to its body size, the clouded leopard has the biggest canines of all animals’ canines. Its dagger-like teeth can be as long as 1.8 inches (4.5 cm).', 'length': 156}]
| Requests: 10; Total time: 6.61 s; RPS: 1.5. |
```
RPS - 1.5. Очень грустно. У меня еще и интернет не самый быстрый сейчас дома. Ну тут добавить нечего.
Что можно оптимизировать уже сейчас? Ответ: использовать **requests.Session**
Eсли делать несколько запросов к одному и тому же хосту, базовое TCP-соединение будет использоваться повторно, что приводит к значительному увеличению производительности. (цитата из документации **requests**)
Используем сессию
-----------------
```
def http_get_with_session(self, path: str, times: int):
content = []
with requests.session() as session:
for _ in tqdm(range(times), desc='Fetching data...', colour='GREEN'):
response = session.get(self.url + path)
content.append(response.json())
return content
```
Немного изменив метод, и вызвав его, видим следующее:
```
Fetching data...: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:02<00:00, 3.88it/s]
[{'fact': 'Cats purr at the same frequency as an idling diesel engine, about 26 cycles per second.', 'length': 87}, {'fact': 'Cats eat grass to aid their digestion and to help them get rid of any fur in their stomachs.', 'length': 92}, {'fact': 'A cat’s heart beats nearly twice as fast as a human heart, at 110 to 140 beats a minute.', 'length': 88}, {'fact': 'The world’s rarest coffee, Kopi Luwak, comes from Indonesia where a wildcat known as the luwak lives. The cat eats coffee berries and the coffee beans inside pass through the stomach. The beans are harvested from the cat’s dung heaps and then cleaned and roasted. Kopi Luwak sells for about $500 for a 450 g (1 lb) bag.', 'length': 319}, {'fact': 'There are more than 500 million domestic cats in the world, with approximately 40 recognized breeds.', 'length': 100}, {'fact': 'Cats sleep 16 to 18 hours per day. When cats are asleep, they are still alert to incoming stimuli. If you poke the tail of a sleeping cat, it will respond accordingly.', 'length': 167}, {'fact': 'Since cats are so good at hiding illness, even a single instance of a symptom should be taken very seriously.', 'length': 109}, {'fact': 'At 4 weeks, it is important to play with kittens so that they do not develope a fear of people.', 'length': 95}, {'fact': 'The technical term for a cat’s hairball is a “bezoar.”', 'length': 54}, {'fact': 'Baking chocolate is the most dangerous chocolate to your cat.', 'length': 61}]
| Requests: 10; Total time: 2.58 s; RPS: 3.9. |
```
Почти 4 RPS, в сравнении с 1.5 уже прорыв.
Но не секрет, что для сокращения i/o time есть практика использования асихнронных/многопоточных программ. Это как раз такой случай, потому что во время ожидания ответа от сервера наша программа ничего не делает, хотя могла бы отправлять уже другой запрос, а потом другой и т.д. Попробуем реализовать асинхронный подход к решению кейса.
async / await
-------------
Для удобства вызовов сделаем функцию-оболочку:
```
def run_case(func, path, times):
start_timestamp = time.time()
asyncio.run(func(path, times))
task_time = round(time.time() - start_timestamp, 2)
rps = round(times / task_time, 1)
print(
f"| Requests: {times}; Total time: {task_time} s; RPS: {rps}. |\n"
)
```
И собственно сама реализация метода (не забудьте поставить **aiohttp,** обычные реквесты не работают в асинхронной парадигме):
```
async def async_http_get(self, path: str, times: int):
async with aiohttp.ClientSession() as session:
content = []
for _ in tqdm(range(times), desc='Async fetching data...', colour='GREEN'):
response = await session.get(url=self.url + path)
content.append(await response.text(encoding='UTF-8'))
return content
```
```
if __name__ == '__main__':
N = 50
api = Api(URL)
run_case(api.async_http_get, path='fact/', times=N)
```
Видим:
```
Async fetching data...: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:12<00:00, 3.99it/s]
| Requests: 50; Total time: 12.55 s; RPS: 4.0. |
```
Удивительно, но разницы с предыдущим случаем особо нет. Я думаю выигрыш в i/o тайме компенсируется издержками на передачу управления потоком функциями друг другу (слышал что очень ругают эти моменты в python). Как на самом деле не знаю.
На словах такой подход можно объяснить так.
- В цикле создается корутина, которая отправляет запрос.
- Не дожидаясь ответа, управление потоком отдается снова event loop'у, который создает следующую по "for циклу" корутину, которая тоже отправляет запрос.
- Но теперь прежде чем отдать управление эвент лупу проверяется статус ответа первой корутины. Если она может быть продолжена (получила ответ на запрос), то управление потоком возвращается ей, если нет, то см. пункт 2.
- И так далее
В итоге код-то впринципе асихнронный, но запросы не отправляются "разом". Принципиально иначе подойти к этой ситуации поможет **asyncio.gather.**
Используем asyncio.gather
-------------------------
Gather - как ни банально с английского собирать. Метод gather собирает коллекцию корутин и запускает их разом (тоже условно конечно). То есть, в отличии от предыдущего случая, мы в цикле создаем корутины, а потом их запускаем.
Было:
[cоздали корутину] -> [запустили корутину] -> [cоздали корутину] -> [запустили корутину] ->
[cоздали корутину] -> [запустили корутину] ->[cоздали корутину] -> [запустили корутину]
А стало:
[cоздали корутину] -> [создали корутину] ->[cоздали корутину] -> [создали корутину] ->
[запустили корутину] -> [запустили корутину] -> [запустили корутину] -> [запустили корутину]
```
async def async_gather_http_get(self, path: str, times: int):
async with aiohttp.ClientSession() as session:
tasks = []
for _ in tqdm(range(times), desc='Async gather fetching data...', colour='GREEN'):
tasks.append(asyncio.create_task(session.get(self.url + path)))
responses = await asyncio.gather(*tasks)
return [await r.json() for r in responses]
```
```
if __name__ == '__main__':
N = 50
api = Api(URL)
run_case(api.async_gather_http_get, path='fact/', times=N)
```
И получаем... получаем... ничего не получаем. Курсор продолжает многозначительно мигать в окне терминала. Не работает - подумал Штирлиц.
Путем мучительного дебага и попыток понять, почему мой код не работает, я понял - причина в моем VPN. Его узлы находятся где-то в юрисдикции Cloudflare. А они такое поведение не поощряют, считая, что я бот. Нормальный человек столько запросов в секунду делать не будет, поэтому мои запросы...теряются где-то в пучинах интернета. Ответа на них не будет. Никогда. Корутины просто не заканчиваются.
Окей, поняв откуда ноги растут, запускаем код:
```
Async gather fetching data...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 106834.03it/s]
| Requests: 50; Total time: 2.38 s; RPS: 21.0. |
```
Цифры выросли, круто, 21 не 1.5 - это уж точно.
Однако же есть какой-то предел, увеличим N (число запросов) до 200.
```
| Requests: 200; Total time: 2.97 s; RPS: 67.3. |
```
Это что же получается, можно и так? На самом деле нет. Если внимательно рассмотреть, что же все-таки нам отвечает сервер, то заметим, что большая часть ответов это `{'message': 'Rate Limit Exceeded', 'code': 429}`
Конкретный лимит запросв, который я установил в ходе эксперимента с этим сервисом - это около 60 ответов за раз, остальное он не переваривает. Так что если будете так ходить в сервисы, которые не хотите перегрузить или вообще положить, то подходите к этом вопросу обдуманно, не превышайте определенных рамок.
Что там с threading?
--------------------
Тут особо смысла нет - практический эксперимент показал, что threading показывает такие же результаты (плюс - минус), как асихнронный код из пункта 3.
multiprocessing
---------------
Не буду врать, просто посмотрел как нечто похожее делал какой-то индус с Ютуба. Результаты сильно хуже, чем у предыдущих способов. Да и писать такой код - это насилие над своей психикой. А я свою психику берегу.
Подведу итоги:
--------------
* На днях упал Cloudlfare - извините, это из-за меня, больше не буду.
* Хотите быть чемпионом по запросам - используйте asyncio.gather, но с тщательно подобранными лимитами. Если вы ходите не на один хост, а в разные источники, то вообще не стестяйтесь. | https://habr.com/ru/post/674150/ | null | ru | null |
# Управляем любой AV-техникой с телефона. ИК-приёмопередатчик для Raspberry

Потихоньку делаю свой дом немножко умнее. Сначала сделал управление светом с телефона с помощью платы расширения RaZBerry (Z-Wave) для Raspberry, затем увлекся программирование AVR микроконтроллеров и собрал небольшую метеостанцию, показывающую температуру на LED дисплее. Теперь очередь дошла до управления TV с помощью iPhone.
В качестве медиаплеера использую Raspberry с дистрибутивом Xbian, поэтому сразу же понял как буду управлять телевизором. Raspberry стоит на полочке под телевизором в прямой видимости. На один из выводов GPIO нужно установить ИК LED от пульта и подавать на него сигналы, которые понимает мой телевизор. В реализации затея оказалась не сложной!
Далее речь пойдет о том, как спаять плату ИК приемо-передатчика для Raspberry и как настроить софт, чтобы с телефона переключать каналы, регулировать громкость, включать и выключать телевизор.
Для управления TV нужен ИК передатчик, а чтобы узнать какие сигналы передавать TV нужно просканировать его пульт, для этого нужен ИК приемник, поэтому плата для Raspberry будет содержать и приемник и передатчик. Плата должна занимать мало места и надеваться на GPIO. Приемник использует GPIO 11, передатчик GPIO 9, плюс питание 3.3В и земля, итого задействовано 4 вывода.
Вот принципиальная схема платы:
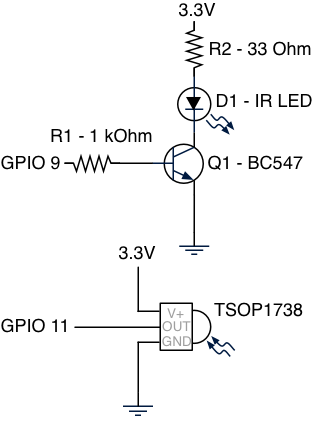
В ее состав входят:
1) R1 — 1 кОм (резистор, ограничивает ток базы до 2.5мА, максимальный ток базы, который может выдержать GPIO и не сгореть 16мА)
2) R2 — 33 Ом (резистор, ограничивает ток на светодиоде до 50мА, благодаря этому сигнал сильный, дальность более 5 метров)
3) Q1 — BC547 (транзистор для усиление сигнала)
4) D1 — IR LED из пульта 36-38 Кгц (ИК передатчик)
5) IR — TSOP1738 (ИК приемник)
На рисунке отмечено какую зону GPIO занимает модуль и какие выводы использует.
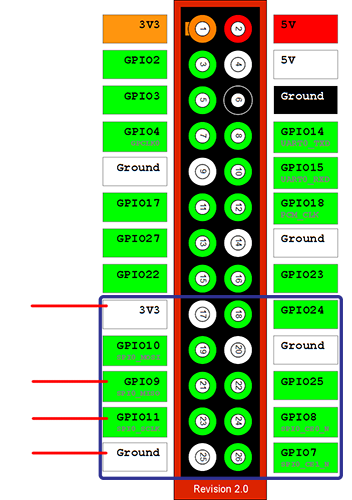
Далее при помощи технологии ЛУТ изготовил маленькую плату. Спаял:

И установил в Raspberry, модуль занимает нижние 5х2 выводов GPIO, чтобы крепче держалась. Можно занять и 5х1 выводов.

Плата готова и установлена, в качестве минуса отмечу, ИК приемник слишком громоздкий и в прозрачный корпус Raspberry не помещается, можно использовать любой другой более компактный ИК приемник на 38Кгц.
Теперь софт, по порядку разложу что нам нужно:
1) Lirc для считывния пульта и для передачи ИК команд
2) Сервер, который принимает HTTP команды, отправляет ИК сигналы через lirc
3) Клиентское приложение для телефона, отправляющее HTTP команды серверу
Для начала сообщим какими выводами должен пользоваться lirc для приема и отправки ИК сигналов, для этого поправим **/etc/modules**, чтобы загружались нужные модули:
**xbian@xbian ~ $** *cat /etc/modules*
```
# /etc/modules: kernel modules to load at boot time.
#
# This file contains the names of kernel modules that should be loaded
# at boot time, one per line. Lines beginning with "#" are ignored.
# Parameters can be specified after the module name.
lirc_dev
lirc_rpi gpio_in_pin=11 gpio_out_pin=9
```
Для создания интерфейса **/dev/lirc0** добавим в **/boot/config.txt**:
```
dtoverlay=lirc-rpi,gpio_in_pin=11,gpio_out_pin=9
```
Перезагружаемся, устанавливаем lirc, если его демон запущен, то останавливаем его. Проверяем работает ли наш модуль командой:
**xbian@xbian ~ $** *sudo mode2 -d /dev/lirc0*
```
space 16777215
pulse 4534
space 4421
pulse 621
space 1642
pulse 582
space 1648
```
Если поползли цифры при нажатии на кнопки, значит ИК приемник работает.
Теперь считаем пульт командой:
**xbian@xbian ~ $** *sudo irrecord tv\_samsung.conf*
Следуйте подсказкам программы и вы получить конфиг **tv\_samsung.conf** с набором кодов от вашего пульта.
Перемещаем полученный конфиг в **/etc/lirc/remotes/**.
Вот мой конфиг для основных кнопок:
**xbian@xbian ~ $** *cat /etc/lirc/remotes/tv\_samsung.conf*
```
# Please make this file available to others
# by sending it to
#
# this config file was automatically generated
# using lirc-0.9.1-git(default) on Tue Sep 3 19:29:12 2013
#
# contributed by
#
# brand: /home/xbian/lircd2.conf
# model no. of remote control:
# devices being controlled by this remote:
#
begin remote
name TV
bits 16
flags SPACE\_ENC|CONST\_LENGTH
eps 30
aeps 100
header 4532 4422
one 591 1650
zero 591 540
ptrail 595
pre\_data\_bits 16
pre\_data 0xE0E0
gap 107530
toggle\_bit\_mask 0x0
begin codes
KEY\_POWER 0x40BF
KEY\_UP 0x48B7
KEY\_DOWN 0x08F7
KEY\_VOLUMEUP 0xE01F
KEY\_VOLUMEDOWN 0xD02F
KEY\_MUTE 0xF00F
end codes
end remote
```
Теперь проверим передатчик. Запускаем демон lirc. Чтобы отправить ИК команды выполним:
**xbian@xbian ~ $** *irsend SEND\_ONCE TV KEY\_POWER*
где,
**SEND\_ONCE** — деректива, отправить один раз
**TV** — Имя телевизора из файла **/etc/lirc/remotes/tv\_samsung.conf**
**KEY\_POWER** — название команды из файла **/etc/lirc/remotes/tv\_samsung.conf**
После выполнения этой команды телевизор должен включиться или выключиться, если все работает, переходим к управлению с телефона.
Нам нужен сервер, который будет принимать HTTP запросы и выполнять команду irsend, я для этого поднял Apache http server и настроил выполнение cgi-bin скриптов. В моем дистрибутиве Xbian это делается в файле **/etc/apache2/sites-enabled/000-default**, разрешил выполнение cgi-bin скриптов и указал где их искать
```
....
ScriptAlias /cgi-bin/ /var/www/cgi-bin/
AllowOverride None
Options +ExecCGI -MultiViews +SymLinksIfOwnerMatch
Order allow,deny
Allow from all
....
```
Затем на bash написал скрипт, который обрабатывает HTTP запрос и выполняет команду irsend:
**xbian@xbian ~ $** *cat /var/www/cgi-bin/main.cgi*
```
#!/bin/bash
echo "Content-type: text/html"
echo ""
echo "Welcome"
echo ""
echo "Send IR code: "
echo $QUERY\_STRING
irsend SEND\_ONCE TV $QUERY\_STRING
echo ""
```
Делаем скрипт исполняемым:
**xbian@xbian /var/www/cgi-bin $** *sudo chmod +x main.cgi*
Запускаем apache и пробуем из браузера включить телевизор:
**[192.168.1.23/cgi-bin/main.cgi?KEY\_POWER](http://192.168.1.23/cgi-bin/main.cgi?KEY_POWER)**
если сервер работает, в ответ получим:
*Send IR code: KEY\_POWER*
Думаю понятно, что после **/cgi-bin/main.cgi?** нужно ввести команду из файла **/etc/lirc/remotes/tv\_samsung.conf**
HTTP API есть, теперь можно управлять телевизором с любого устройства, для браузера можно написать простое приложение с сылками на команды управления телевизором. Я для iPhone написал простое приложение за 15 минут.

Если нет навыков программирования под мобильные платформы, но очень хочется, то можно воспользоваться программным продуктом OpenRemote, с помощью конструктора OpenRemote делаем дизайн приложения, расставляем кнопочки, а затем в свойствах кнопки указываем какую HTTP команду выполнять, как пользоваться этим софтом я уже писал в статье [Мобильное приложения для управления умным домом на базе Z-Wave с помощью OpenRemote](http://habrahabr.ru/post/180749/)
Все замечания и предложения по улучшению статьи принимаю в комментариях!
Приятного управления! | https://habr.com/ru/post/193572/ | null | ru | null |
# Как создать поддомен в VestaCP
Посещая форум поддержки панели VestaCP, заметил, что часто пользователи спрашивают, как создать поддомен в VestaCP. На самом деле, это очень просто. Для начала нужно зайти в саму панель:

Далее нам нужно перейти во вкладку WEB:

Нажимаем кнопку Добавить WEB домен:

В поле Домен вводим имя вашего поддомена (например, если ваш сайт domain.tld, тогда имя поддомена будет sub.domain.tld). Все остальные параметры я решил оставить неизменными:

Теперь, когда мы вернемся к вкладке WEB, то увидим, что наш поддомен теперь в списке доменов:

На этом добавление поддомена закончено.
Интересная особенность VestaCP в том, что для поддоменов создается отдельная папка. Некоторых пользователей это не устраивает, поэтому они задаются вопросом, можно ли сделать так, чтобы поддомен использовал папку с основного домена (например domain.tld есть каталог sub, то есть domain.tld/sub). Решить этот вопрос можно с помощью редактирования файлов конфигурации доменов. Замечу, что на моем сервере установлен CentOS.
Для этого нам нужно соединиться с сервером при помощи SSH:
```
ssh [email protected]
```
Далее нам нужно перейти в папку с файлами конфигураций виртуальных хостов:
```
cd /home/$user/conf/web
```
где $user — это имя вашего пользователя. Далее нужно создать (воспользуемся командой touch filename) файлы httpd.sub.domain.tld.conf, nginx.sub.domain.tld.conf, shttpd.sub.domain.tld.conf, snginx.sub.domain.tld.conf и отредактировать удобным для вас редактором (последние два, если вы используете защищенное SSL соединение на вашем сайте).
Создаем файл httpd.sub.domain.tld.conf со следующим содержимым:
```
DocumentRoot /home/admin/web/domain.tld/public_html/sub
```
Для защищенного соединения создаем файл shttpd.sub.domain.tld.conf, и проводим аналогичную операцию.
Также создаем файл nginx.sub.domain.tld.conf и добавляем в него:
```
root /home/$user/web/domain.tld/public_html/sub;
```
Для защищенного соединения создаем файл snginx.sub.domain.tld.conf, и повторяем действия.
После редактирования файлов, главное сохранять изменения. Чтобы проверить у нас все сделано верно, нужно перезагрузить HTTPd и Nginx:
```
service httpd restart & service nginx restart
```
и посетить наш поддомен.
Для Debian/Ubuntu название файла отличается — вместо httpd будет apache2, то есть apache2.sub.domain.tld.conf. Также отличается команда перезагрузки служб:
```
/etc/init.d/apache2 restart & /etc/init.d/nginx restart
```
На этом все. | https://habr.com/ru/post/251407/ | null | ru | null |
# Большой брат следит за… собой или карта с историей перемещений в HomeAssistant
### Вступление
Для своей домашней автоматизации я уже давно использую HomeAssistant. Однажды товарищ у меня спросил, мол, почему у HomeAssistant есть возможность указывать только текущее положение трекера на карте, но нельзя отобразить весь маршрут следования? С тех пор данная идея захватила меня. И однажды я понял, что и сам очень хочу иметь эту функцию вот прямо сейчас. Всем кому интересно, что из этого вышло, добро пожаловать под кат…
### Разведка
Собственно, чтобы отобразить маршрут нужно иметь набор точек с координатами, поэтому первым шагом было выяснить где HomeAssistant хранит нужные данные (если вообще хранит) и как их оттуда достать. Недолгое изучение первоисточника сразу привело к решению: необходим включенный модуль recorder для записи состояний нужных датчиков в БД в различные моменты времени, а также модуль history, который позволяет получать данные из БД в красивом виде. У модуля history есть хорошо документированный [REST API](https://developers.home-assistant.io/docs/en/external_api_rest.html). То, что нужно!
Далее необходимо полученные данные как-то отобразить на карте. Существует множество различных сервисов, позволяющих отображать историю перемещений. Я наверняка перепробовал далеко не все из них, однако позволю себе пару слов о проверенных мною:
**А**. yandex и google. Собственно для моих нужд там есть все и даже больше, однако в силу платности сервисов и сильных ограничений бесплатных версий, они мне сразу не подошли. Yandex, например, разрешает бесплатное использование только для открытых проектов (то есть любой человек должен иметь возможность в любое время открыть твой ресурс и воспользоваться его возможностями), не говоря уже о других ограничениях в количестве запросов. Про изменения в политике Google по отношению к api не писал только ленивый. На текущий момент, насколько я понял, каждый запрос к maps api или directions api оплачивается, чем больше запросов — тем дешевле. Однако каждому пользователю с подключенной к аккаунту банковской картой дается бесплатный лимит на 200$ в месяц. Все что сверху сразу оплачивается с вашей карты. Привязка карты к аккаунту — это не наш путь.
Поправьте, если я ошибся где то по поводу google и/или yandex.
**Б**. Связка [OpenRouteService](https://openrouteservice.org/) и OpenRouteService maps. В принципе по возможностям мало чем отличается от google или yandex (во всяком случае я не заметил). Полностью бесплатен (есть ограничения по количеству запросов в день и в минуту при превышении которых советуют обратиться в поддержку… описания каких-либо платных тарифов нет вообще). Однако использование ресурса OpenRouteService maps оказалось неудобным (долгая загрузка приложения и назойливое широкое меню слева, открывающееся по умолчанию и не отключаемое средствами API, к тому же сервис не совсем корректно открывается с мобильных устройств). Справедливости ради, OpenRouteService maps можно поставить на свой сервер и вполне возможно, что там позволено сконфигурировать все под себя.
**В**. [Mapbbcode](https://github.com/MapBBCode/mapbbcode). Наткнулся на [хабре](https://habr.com/en/post/207232/) на интересную реализацию карт в простом формате. В принципе для моей задачи проект абсолютно подходит, однако из этой статьи я узнал о [Leaflet](https://leafletjs.com/) и решил обратиться к первоисточнику. На ней в итоге и остановился…
**Г**. Leaflet. Очень хорошая open-source js библиотека для карт, простая в освоении и хорошо документированная. Из фишек: позволяет использовать тайлы от многих сервисов (openstreetmaps, yandex, google, mapbox, microsoft и тд и тп). Дополнительно я использовал плагин [leaflet.polylineDecorator](https://github.com/bbecquet/Leaflet.PolylineDecorator) для указания направления движения на карте.
Стоит упомянуть, что последние два рассматриваемых ресурса не поддерживают «маршруты», то есть не умеют соединять точки вдоль существующих дорог и/или тротуаров, а просто соединяют точки прямой линией. Лично для меня это не проблема, а осознанный шаг. Если нужна именно навигация по дорогам, то нужно смотреть в сторону платных google, yandex или бесплатного openrouteservice.
### Реализация
Запрос к модулю history через REST-API довольно прост (здесь и далее код будет на языке HomeAssistant, т.е. python) и позволяет получить ответ в виде простого для понимания JSON:
```
response = requests.get(self._haddr + '/api/history/period/' + dayBegin + '?filter_entity_id=' + self._myid, headers={'Authorization': 'Bearer ' + self._token, 'content-type': 'application/json'})
data = response.json()[0]
```
здесь self.\_haddr — это адрес вашего HA такой же, как указан в настройках frontend, self.\_myid — это ид устройства device\_tracker, чей маршрут мы будем строить, dayBegin – это начало периода для отображения маршрута, я по умолчанию выбрал начало текущего дня, self.\_token – это long-life токен для доступа к апи, который можно получить в интерфейсе HomeAssistant.
Когда объект, чью историю мы пытаемся отобразить на карте, долгое время находится неподвижно или передвигается крайне медленно, мы получим кучу точек, близко расположенных и забивающих карту. Для исправления ситуации пропустим полученный массив координат через фильтр: если расстояние между предыдущей точкой и следующей менее 100 метров, то не отображать точку на карте. Для расчета расстояний между двумя соседними точками используем упрощенную формулу с [равноугольным приближением](http://www.movable-type.co.uk/scripts/latlong.html). Приближение применимо, когда расстояние между соседними точками не превышает нескольких км:
```
def getDistance(self, latA, lonA, latB, lonB):
dst = 0
latRadA = math.radians(latA)
lonRadA = math.radians(lonA)
latRadB = math.radians(latB)
lonRadB = math.radians(lonB)
x = latRadB - latRadA
y = (lonRadB-lonRadA)*math.cos((latRadB+latRadA)*0.5)
dst = 6371*math.sqrt(x*x+y*y)
return dst
```
Здесь dst расстояние в км.
Описывать API Leaflet здесь не вижу смысла. За этим — на [официальный сайт](https://leafletjs.com/reference-1.4.0.html). Модуль работает следующим образом: Каждые n секунд (у меня настроено на 300) делается запрос к сегодняшней истории интересующего меня объекта. Полученный массив координат прогоняется через фильтр расстояний, уменьшая количество точек. Далее в папке с конфигурацией HomeAssistant в папке www формируются 2 файла: index.html и route.html. В файле route.html прописана вся логика по созданию карты. А файл index.html — это лайфхак по предупреждению кэширования страницы. По умолчанию HomeAssistant кэширует все, что только можно, и только сброс кэша помогал актуализировать данные на карте, что, конечно, неприемлемо. В файле index.html происходит вызов содержимого route.html однако с рендомным динамически формируемым параметром, что позволяет всегда запрашивать с сервера актуальную версию файла route.html:
```
src = 'route.html?datetime=' + (new Date()).getTime() + Math.floor(Math.random() * 1000000)
```
### Немного о безопасности
HomeAssistant устроен так, что все файлы внутри директории www являются публичными, то есть любой файл внутри директории www можно открыть в любом браузере безо всякой авторизации, зная прямую ссылку. В случае с моим модулем эта ссылка такая: [your\_address\_homeassistant/local/route/index.html](https://your_address_homeassistant/local/route/index.html). Если для вас это не критично, то можете пропускать данный раздел. Я же пошел немного дальше и прикрутил таки авторизацию к странице с маршрутами. Для этого я использовал nginx (вы можете выбрать другой веб сервер с поддержкой реверсивного прокси) в качестве прокси сервера. На сайте HomeAssistant есть официальная [инструкция](https://www.home-assistant.io/docs/ecosystem/nginx/) по настройке данной конфигурации. После настройки прокси и проверки работы в конфигурацию nginx нужно добавить авторизацию для нужных страниц:
```
location /local/route/route.html {
proxy_pass http://localhost:8123/local/route/route.html;
proxy_set_header Host $host;
proxy_redirect http:// https://;
proxy_http_version 1.1;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
auth_basic "Unauthorized";
auth_basic_user_file /etc/nginx/.htpasswd;
}
```
Затем создать файл "/etc/nginx/.htpasswd", и в консоли выполнить последовательно команды:
```
sh -c "echo -n 'admin:' >> /etc/nginx/.htpasswd"
sh -c "openssl passwd -apr1 >> /etc/nginx/.htpasswd"
```
admin – заменить на желаемый логин.
После этого перезапускаем nginx и проверяем: при попытке открыть страницу с маршрутом браузер должен запрашивать логин и пароль. Замечу, что это отдельная авторизация, никак не связанная с авторизацией самого HomeAssistant.
### Заключение
Пожалуй и все, что можно рассказать о данном модуле.
Кого заинтересовало, [вот ссылка](https://yadi.sk/d/buRKuNkJ7xDLzg) на модуль. Файл расположить по пути: config\_folder\_homeassistant/custom\_components/route/sensor.py, не забывайте про права.
Если не существует, то создать папку config\_folder\_homeassistant/www и выдать на нее соответствующие права.
В конфигурационном файле configuration.yaml прописать следующие строки:
```
sensor:
- platform: route
name: route
entityid: your_device_tracker_entity_id
haddr: your_address_homeassistant
token: your_long_life_token
```
здесь your\_device\_tracker\_entity\_id – это ID вашего устройства device\_tracker, your\_address\_homeassistant – внешний адрес вашего HomeAssistant, your\_long\_life\_token – предварительно полученный во фронтенде HomeAssistant токен доступа для использования REST API.
После этого перезапустить HomeAssistant и наслаждаться. Карта будет доступна по прямой ссылке: [your\_address\_homeassistant/local/route/index.html](https://your_address_homeassistant/local/route/index.html). При желании вы можете добавить ее в меню HA с помощью panel\_iframe или в любое окно HA через lovelace card “iframe”.
На этом все, спасибо за внимание.
**UPD:**
Добавил [ссылку](https://github.com/mavrikkk/ha_routes) на GitHub. Доработал некоторые места (убрал из конфигурации haddr, автоматом получаю config\_dir, добавил возможность установки своего часового пояса)
**И как это все выглядит? Осторожно, блюр!** | https://habr.com/ru/post/448656/ | null | ru | null |
# Привязка программы к железу + онлайн верификация
Данную статью я представляю вниманию новичков для обеспечения защиты своего софта. Защита реализуется путем привязки к железу компа + онлайн проверка.
Наша защита будет состоять из нескольких частей:
* Генератор серийного номера по системным характеристикам.
* Генератор ключа авторизации по серийнику
* Защищаемая программа
Итак… с структурой мы разобрались, теперь нужно определиться к каким параметрам мы будем осуществлять привязку.
Мы сделаем это через WIN Api функции:
* GetUserName — Имя текущего пользователя.
* GetComputerName — Имя компутора.
* GetVolumeInformation — Получение информации о носителе.
* GlobalMemoryStatus — Информация о используемой системой памяти.
Что бы облегчить вам жизнь, я приведу готовые функции:
`function UserName: string;
var
u: pchar;
i: dword;
begin
i := 1024;
u := StrAlloc(Succ(i));
if GetUserName(u, i) then Result := StrPas(u) else Result := '?';
end;
function ComputerName: string;
var
buffer: array[0..255] of char;
size: dword;
begin
size := 256;
if GetComputerName(buffer, size) then
Result := buffer
else
Result := ''
end;
function GetHard: String;
var
VolumeName, FileSystemName: array [0..MAX_PATH-1] of Char;
VolumeSerialNo: DWord;
MaxComponentLength,FileSystemFlags: Cardinal;
begin
GetVolumeInformation('C:\',VolumeName,MAX_PATH,@VolumeSerialNo,
MaxComponentLength,FileSystemFlags, FileSystemName,MAX_PATH);
Result := IntToHex(VolumeSerialNo,8);
end;
function GetMem: String;
var
MyMem: TMemoryStatus;
begin
MyMem.dwLength:=SizeOf(MyMem);
GlobalMemoryStatus(MyMem);
with MyMem do begin
Result:= IntToStr(dwTotalPhys);
end;
end;`
Итак, мы получили всю интересующую нас информацию. Теперь мы склеим эти данные в hex строку, что бы конечный пользователь не знал, какие параметры мы используем.
Берем функцию преобразования в 16ричный вид.
`function StringToHex(str1,Separator:String):String;
var
buf:String;
i:Integer;
begin
buf:='';
for i:=1 to Length(str1) do begin
buf:=buf+IntToHex(Byte(str1[i]),2)+Separator;
end;
Result:=buf;
end;`
Склеим все параметры —
`function getSerial:string;
begin
Result := StringToHex((UserName + ComputerName + GetHard + GetMem));
end;`
Вывод полученной строки в TEdit
`procedure TForm2.Button1Click(Sender: TObject);
begin
Edit1.Text := getSerial;
end;`
Мои поздравления, готов модуль получения serial кода.
**Генератор регистрационного ключа**
Полученый серийник надо шифрануть, что бы жизнь медом не казалась. Используйте любые методы, я приведу пример MD5.
функция шифрации.
`function getKey(Serial: string):string;
begin
Result := MD5DigestToStr(MD5String(Serial+'123'));
end;`
Теперь кидаем на форму два Tedit и кнопку.
на онклик ставим
`procedure TForm1.Button1Click(Sender: TObject);
begin
Edit2.Text := getKey(Edit1.Text); / в первый Edit вставляем серийник, во втором будет зашифрованый вариант(очевидно)
end;`
Кейген готов.
**Пишем основную программу.**
1) Кидаем все функции сбора инфы о компе и генерации серийника из первого модуля.
2) Кидаем функцию шифрации серийника из генератора рег ключа.
Приступим к регистрации программы и онлайн привязки. Кидаем Tedit(для ввода рег ключа) + 2 кнопки
(1 — проверка на валидность рег ключа 2 — коннект к серверу и проверка на наличия записи там)
`procedure TForm2.Button1Click(Sender: TObject);
begin
if Edit1.Text = getKey(GetSerial) then ShowMessage('RegOk') else ShowMessage('NoFuckinWay');
end;`
При валидности рег ключа — RegOk, если нет, то посылает.
В качестве онлайн проверки будем использовать простейший вариант — txt файл.
Алгоритм — на хосте лежит файл серийник.txt, а в нем же рег ключ. Программа сравнивает содержимое текстовика и ключ, сгенереный программой.
`procedure TForm2.Button2Click(Sender: TObject);
begin
if getKey(GetSerial)= IdHTTP1.Get('http://zzzzzz.com/reg/'+GetSerial+'.txt') then ShowMessage('RegOk') else ShowMessage('NoFuckinWay');
end;`
Вот и все Осталось вам придумать, куда прописывать то, что программа зарегистрирована.
Я лишь описал наглядный пример, как строятся такие методы защиты… вы можете использовать свои способы привязки, совершенствуя код + верификация через txt самый ненадежный способ. используйте php+mysql и т.д.
Будут вопросы — пишите, но я тут разжевал все до процедур онклика.
Всем удачи в начинаниях.
p.s. Напоминаю, что статья для новичков и является пищей для размышления. | https://habr.com/ru/post/715992/ | null | ru | null |
# Codeception — новости проекта
Я уже [писал](http://habrahabr.ru/post/136477/) на Хабре о [Codeception](http://codeception.com/) — фреймворке для тестирования приложений на PHP. Если вы никогда раньше не писали тестов для вашего приложения, вам обязательно стоит взглянуть на Codeception. Он очень прост в использовании и сделан специально, чтобы уберечь разработчиков от рутины.
Сегодня я хотел бы рассказать, какие фичи появились в проекте в последнее время, а также отвечу на пару популярных вопросов.
##### Инсталляция через Composer
Теперь для установки вам больше не нужен PEAR. С ним часто возникает много разных проблем, требующих бубна и шаманских песен. Если вы современный человек и забыли все ритуальные песни древних предков, попробуйте Composer. С его помощью вы легко можете установить сам Codeception, а также все необходимые библиотеки, в том числе Mink и PHPUnit.
Инструкции [тут](http://codeception.com/install).
##### Поддержка фреймворков
Сейчас вы можете писать функциональные тесты для следующих фреймворков: **Symfony2, Zend Framework, symfony, Kohana, SocialEngine**. Последние два модуля, кстати, сделаны сторонними разработчиками, за что им отдельное спасибо. Их пример показывает, что сделать модуль под свой любимый фреймворк не так и сложно.
##### Генерация документации
Многие говорят, что тесты — лучшая документация. Но не всегда тесты пишутся с расчетом на чтение. В Codeception всё иначе, в Cest-тестах вы описываете свои действия и желаемый результат.
```
$I->testMethod('\Service\Group::create');
$I->wantTo('create a group');
$I->executeTestedMethodWith('DemoGroup', 1)
->seeInRepository('Model\Group', array('name' => 'DemoGroup', 'user_id' => 1, 'type' => 'group'))
->seeResultIs('int');
```
Если вы используете систему генерации документации phpDocumentor2 (бывший DocBlox), то с помощью встроенного в Codeception плагина этот тест будет добавлен к описанию метода. Он будет преобразован в текст и примет такой вид:
With this method I can create group
If I execute \Service\Group::create(«DemoGroup»,1)
I will see in repository «Model\Group»,{«name»:«DemoGroup»,«user\_id»: 1, «type»: «group» }
I will see result is «int»
Теперь в документации будет информация о том как ведет себя тот или иной метод в зависимости от параметров. Как подключать плагин — читайте [здесь](http://codeception.com/02-14-2012/generators-release-1-0-3.html).
##### Базовая поддержка CI систем
Теперь Codeception можно подключить к Continious Integration серверам, таким как Jenkins и Bamboo. К сожалению, протестировать интеграцию удалось пока только с Bamboo. Но результат пишется в XML и по идее должен легко подхватываться другими CI системами. Если с ними будут проблемы — сообщайте, всё оперативно подправим.
Всё это, а также много других вкусностей доступно в последней версии **Codeception 1.0.8**.
[Устанавливайте](http://codeception.com/install), используйте.
А теперь ответы на популярные вопросы:
###### Зачем Codeception, если есть PHPUnit?
Открою секрет: Сodeception это не велосипед, а надстройка над PHPUnit. Она позволяет выполнять сценарные тесты на движке PHPUnit. При этом все ваши существующие тесты для PHPUnit Codeception сможет подхватит без каких-либо проблем. К ним вы сможете легко добавить функциональные и приемочные тесты. Очень многие задачи, требующие костылей (например, интеграция с Selenium, с БД) в Codeception уже решены.
###### Зачем Codeception, если есть Selenium?
Codeception умеет выполнять тесты для Selenium. Но тесты в Codeception легче поддерживать, они более гибкие. Например, вы можете часть тестов выполнять не в браузере, а через его эмулятор Goutte. Или вообще не использовать веб-сервер для тестирования, а обращаться к приложению напрямую. Это значительно уменьшит время выполнения ваших тестов. Кроме того, Codeception берет на себя все проблемы связанные с очисткой данных между тестами.
###### Зачем Codeception, если есть Behat?
Вопрос в стиле: зачем Linux, если есть Windows. Наличие альтернатив это всегда хорошо. Как минимум, система позволяющая писать приемочные тесты на PHP будет в экосистеме не лишней.
##### Планы на будущее
В ближайшем будущем добавиться покрытие кода и увеличиться количество поддерживаемых фреймворков. Но предлагайте и свои идеи. Что бы вы хотели видеть в Codeception? | https://habr.com/ru/post/143567/ | null | ru | null |
# SQLite. Готовимся к Windows 10 (Universal App Platform)
Здравствуй, уважаемый All!
Хочу рассказать о небольшой библиотеке для работы с SQLite в Windows Phone 8.0 Silverlight, Windows Phone 8.1, Windows 8.1 а сейчас еще и для Windows 10 UAP. Библиотеке уже больше года и т.к. проблем с ней за все время не возникло, то, я считаю, о ней можно рассказать другим.
**Зачем все это?**
Библиотека в рамках Windows Phone 8.0 Silverlight, Windows Phone 8.1, Windows 8.1 просуществовала больше года. Спрашивается: почему именно сейчас я решил о ней рассказать? Дело в том, что сейчас пора портировать свои приложения для Windows 10, а официального SQLite SDK пока нет.
Вот [здесь](http://sqlite.org/download.html) есть SDK для [Windows Phone 8](http://sqlite.org/2015/sqlite-wp80-winrt-3080803.vsix), [Windows Phone 8.1](http://sqlite.org/2015/sqlite-wp81-winrt-3080803.vsix), [Windows 8](http://sqlite.org/2015/sqlite-winrt-3080803.vsix) и [Windows 8.1](http://sqlite.org/2015/sqlite-winrt81-3080803.vsix). Но не для **Windows 10**.
И скорее всего не будет до выхода Windows 10. Поэтому есть смысл посмотреть на эту библиотеку.
**Поехали**
Библиотека называется **SQLite.WinRT**.
Я не являюсь ее 100% автором. Я лишь собрал многие куски кода, блуждающие по интернету, воедино. Поэтому если вы считаете что я как-то нарушил ваши авторские права, то дайте мне знать — договоримся.
Исходные коды можно посмотреть [здесь](http://sqliteportable.codeplex.com).
Установить библиотеку можно с помощью NuGet. Есть 5 пакетов:
* [SQLite Library Core](https://www.nuget.org/packages/SQLite.WinRT/)
* [SQLite Library for Windows UAP](https://www.nuget.org/packages/SQLite.WinRT.UAP/)
* [SQLite Library for Windows Phone 8.0](https://www.nuget.org/packages/SQLite.WinRT.wp8/)
* [SQLite Library for Windows Phone 8.1](https://www.nuget.org/packages/SQLite.WinRT.wpa81/)
* [SQLite Library for Windows 8.1](https://www.nuget.org/packages/SQLite.WinRT.win81/)
Для успешной компиляции придется избавиться от Any CPU и собирать проект отдельно под каждую платформу: x86, x64, ARM.
Для Windows 10 UAP приложений необходимо добавить ссылку на следующие SDK:
* Microsoft Visual C++ 14 AppLocal Runtime Package for Windows UAP
Для Windows 8.1 приложений необходимо добавить ссылку на следующие SDK:
* Microsoft Visual C++ 2013 Runtime Package for Windows
* SQLite for Windows Runtime (Windows 8.1)
Для Windows Phone 8.1 приложений необходимо добавить ссылку на следующие SDK:
* Microsoft Visual C++ 2013 Runtime Package for Windows Phone
* SQLite for Windows Phone 8.1
Для Windows Phone 8.0 приложений необходимо добавить ссылку на следующие SDK:
* SQLite for Windows Phone
**Как использовать библиотеку?**
Для примера нам понадобятся следующие классы:
```
public sealed class DatabaseContext : BaseDatabaseContext
{
private DatabaseContext(SQLiteConnection connection): base(connection)
{
}
public async static Task CreateContext()
{
const string dbName = "db.sqlite";
var folder = CorePlatform.Current.LocalFolder;
var connectionString = new SQLiteConnectionString(Path.Combine(folder, dbName), true);
var connection = SQLiteConnectionPool.Shared.GetConnection(connectionString);
var ctx = new DatabaseContext(connection);
await ctx.CreateSchemeAsync();
await ctx.UpdateSchemeAsync();
return ctx;
}
public IEntityTable Items { get { return provider.GetTable(); } }
public IEntityTable Categories { get { return provider.GetTable(); } }
}
[Table("Items")]
public class Item
{
[PrimaryKey, AutoIncrement]
public int ItemID { get; set; }
public int CategoryID { get; set; }
public string Title { get; set; }
}
[Table("Categories")]
public class Category
{
[PrimaryKey, AutoIncrement]
public int CategoryID { get; set; }
public string Name { get; set; }
}
```
**Добавление записи**
```
var category = new Category();
category.Name = "category";
await db.Categories.InsertAsync(category);
```
**Обновление записи**
```
category.Name = "category2";
await db.Categories.UpdateAsync(category);
```
Обновляются все поля, кроме основного ключа.
Если очень надо, то можно сделать вот так:
```
var count = db.Categories
.Update()
.Set(t => t.Name).EqualTo("test name")
.Where(t => t.CategoryID).IsBetweenAnd(3, 4)
.Execute();
```
В этом случае будет обновлено только то, что будет указано.
**Удаление записи**
```
var count = db.Items.Delete()
.Where(t => t.CategoryID).IsLessThanOrEqualTo(3)
.And(t => t.Title).IsEqualTo("item0")
.Execute();
```
или так:
```
var category = ...;
await db.Categories.DeleteAsync(category);
```
**Выборка данных**
А здесь нам поможет LINQ:
```
var query =
from c in db.Categories
join i in db.Items on c.CategoryID equals i.CategoryID
select i;
var items = await query.ToListAsync();
```
**Миграция данных**
Внимательный читатель заметил 2 интересных вызова:
```
await ctx.CreateSchemeAsync();
await ctx.UpdateSchemeAsync();
```
Первый создает или обновляет таблицы на основе объявленных свойств контекста. Колонки в таблице могут быть только добавлены. Удалить нельзя.
Второй запускает список миграций, версия которых меньше версии базы данных.
Объявляются миграции вот так:
```
[DatabaseUpdate(typeof(DbChangeset1))]
[DatabaseUpdate(typeof(DbChangeset2))]
[DatabaseUpdate(typeof(DbChangeset3))]
[DatabaseUpdate(typeof(DbChangeset4))]
public sealed class DatabaseContext : BaseDatabaseContext { ... }
```
Пример миграции:
```
public class DbChangeset1 : IDatabaseChangeset
{
public int Version { get { return 1; } }
public void Update(IEntityProvider provider)
{
// так как структура обновляется сама, то тут обновляем только данные.
}
}
```
Вот как-то так. Более подробную информацию можно найти в юнит-тестах.
А теперь я готов выслушать ваши замечания, предложения и возражения. | https://habr.com/ru/post/254313/ | null | ru | null |
# Exasol: опыт использования в Badoo
 [Exasol](http://www.exasol.com/en/) — это современная высокопроизводительная проприетарная СУБД для аналитики. Ее прямые конкуренты: HP Vertica, Teradata, Redshift, BigQuery. Они широко освещены в Рунете и на Хабре, в то время как про Exasol на русском языке нет почти ни слова. Нам бы хотелось исправить эту ситуацию и поделиться опытом практического использования СУБД в компании Badoo.
Exasol базируется на трех основных концепциях:
### 1. Массивно-параллельная архитектура (англ. massive parallel processing, MPP)
SQL-запросы выполняются параллельно на всех нодах, максимально используя все доступные ресурсы: ядра процессоров, память, диски, сеть. Понятие «мастер ноды» отсутствует — все серверы в системе равнозначны.
Отдельные стадии выполнения одного запроса также могут идти параллельно. При этом частично рассчитанные результаты передаются в следующую стадию, не дожидаясь окончания предыдущей.
### 2. Колоночное хранение (англ. columnar store)
Exasol хранит данные в [колоночной форме](http://kejser.org/how-do-column-stores-work/), а не в форме отдельных рядов, как в классических СУБД. Каждая колонка хранится отдельно, разделяется на большие блоки, сортирируется, сжимается и равномерно распределяется по всем нодам.
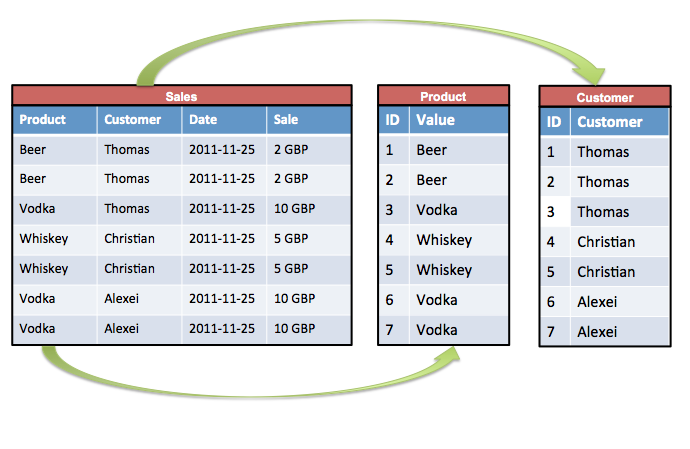
Эффективность сжатия сильно варьируется в зависимости от типов данных и распределения значений в таблицах. В среднем данные в Badoo сжаты в 6,76 раз.
Колоночное хранение позволяет многократно ускорять аналитические запросы, а также вычитывать только те данные, которые необходимы для выполнения запроса. В классических СУБД необходимо прочитать весь ряд целиком, даже если в нем используется всего одна колонка.
### 3. In-memory analytics
В Exasol есть механизм, похожий на buffer pool в MySQL или shared buffer в PostgreSQL. Блоки данных, однажды загруженные с диска, остаются в памяти и могут быть повторно использованы для последующих запросов.
Как правило, в реальной жизни пользователи работают в первую очередь с «горячими» данными (последний день, неделя, месяц). Если у кластера достаточно памяти, чтобы вместить их целиком, то Exasol не будет трогать диск вообще.
Эти три концепции, собранные вместе в одной СУБД, показывают высокую производительность относительно сложности SQL-запросов и используемого «железа». Приведем конкретные цифры.
Сейчас в кластере Badoo используется 8 серверов со следующими характеристиками:
* от 16 до 20 CPU Cores;
* 768 Гбайт RAM;
* 16x1 Тбайт HDD (RAID 1 — 8 Тбайт);
* 10 Гбит сеть.
Общий объем памяти, доступной Exasol, составляет приблизительно 5,6 Тбайт.
Общий объем данных без сжатия — около 85 Тбайт.
Размеры крупных таблиц варьируются от 500 миллионов до 50 миллиардов рядов. Один аналитический запрос обрабатывает в среднем около 4,5 миллиардов рядов.
Производительность на реальных запросах за последний месяц:
| Кол-во объектов в запросе | Все запросы | Запросы длительностью от 1 секунды |
| --- | --- | --- |
| Кол-во | Медиана | Среднее | Кол-во | Медиана | Среднее |
| До 3 | 240914 | 0.021 сек | 9 сек | 34808 | 29 сек | 63 сек |
| От 4 до 10 | 45122 | 13 сек | 47 сек | 30005 | 34 сек | 70 сек |
| От 11 до 30 | 12642 | 24 сек | 69 сек | 5615 | 45 сек | 156 сек |
| От 31 и больше | 740 | 41 сек | 303 сек | 740 | 41 сек | 303 сек |
Это не синтетический тест, а реальная статистика по настоящим запросам живых пользователей. Как можно увидеть, даже в самых сложных случаях, речь чаще всего идет о секундах и минутах, но никак не о часах или днях.
Сложность запроса в этом примере условно рассчитывается путем простого поиска слов FROM и JOIN в тексте SQL. Таким образом, мы находим примерное количество использованных объектов. Чем больше объектов используется, тем сложнее запрос.
Выделение в отдельную группу запросов длительностью от 1 секунды необходимо для того, чтобы снизить влияние слишком быстрых in-memory запросов на результат и показать наиболее близкую к реальности картину для тех случаев, когда все же нужно что-то прочитать с диска.
За счет чего достигается высокая производительность, помимо перечисленных выше концепций.
### Джойны (англ. join) и индексы
Exasol умеет делать очень быстрые джойны, причем совершенно не смущается от их количества.
Эффективный джойн всегда происходит по индексу. Индексы создаются автоматически в тот момент, когда вы впервые пытаетесь объединить две таблицы по определенным ключам. Если индекс не используется долгое время, то он так же автоматически удаляется.
При добавлении или удалении данных в таблицах с уже существующими индексами создаются «дельты», которые содержат только изменения. Если изменений накапливается слишком много (около 20% от общего объема), то происходит INDEX MERGE, который объединяет основной индекс с дельтой, после чего дельта удаляется. Это намного быстрее, чем полное пересоздание индекса с нуля. Механизм чем-то похож на Sphinx.
Индексы занимают относительно небольшой объем памяти. Подавляющее большинство индексов в нашей базе занимает меньше 100 Гбайт, в том числе это справедливо для многомиллиардных таблиц. Размер индекса определяется количеством входящих в него колонок, их типами данных и вариабельностью значений.
### Глобальные джойны vs локальные джойны
Джойны бывают глобальные и локальные. Глобальный джойн происходит в тех случаях, когда объединяемые данные физически хранятся на разных нодах.
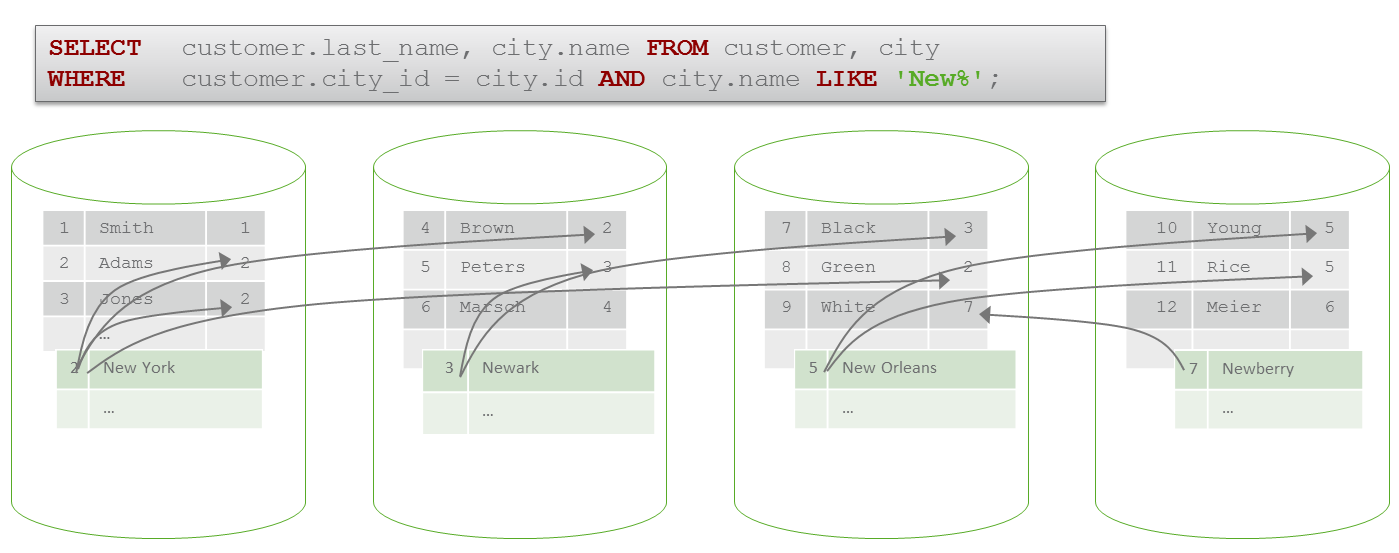
Локальный джойн происходит тогда, когда объединяемые данные хранятся на одной ноде.

Локальные джойны намного быстрее глобальных, потому что в этом случае не используется сеть. Такого эффекта можно добиться, если заранее распределить данные на нодах особым образом. В нашем примере это можно сделать так:
```
ALTER TABLE CUSTOMER DISTRIBUTE BY CITY_ID;
ALTER TABLE CITIES DISTRIBUTE BY ID;
```
При этом гарантируется, что для обеих таблиц ряды с одинаковыми значениями city\_id будут всегда физически находиться вместе на одной ноде.
Также маленькие таблицы автоматически реплицируются (копируются целиком) на все ноды, что автоматически гарантирует быстрые локальные джойны к ним. Это особенно актуально для многочисленных небольших списков.
Главное отличие Exasol от других распределенных СУБД состоит в том, что вам не придется бояться глобальных джойнов и нет нужды создавать специальные проекции, чтобы их избежать. Безусловно, глобальные джойны медленнее локальных, но не настолько, чтобы это создавало проблемы. Подавляющее большинство джойнов в Badoo именно глобальные.
### Условия эффективного джойна
Для того чтобы джойн происходил по наиболее эффективному сценарию, необходимо соблюдать ряд простых правил:
**1. Условия должны быть только в формате columnA = columnB.**
Хорошо:
```
JOIN table2 b ON (a.id=b.id)
```
Плохо:
```
JOIN table2 b ON (a.purchase_date > b.create_date)
```
**2. Нежелательно использовать выражения.**
Хорошо:
```
JOIN table2 b ON (a.purchase_date=b.purchase_date)
```
Плохо:
```
JOIN table2 b ON (a.purchase_date=TO_DATE(b.purchase_time))
```
**3. Несколько условий можно объединять при помощи AND, но следует избегать OR.**
Хорошо:
```
JOIN table2 b ON (a.id=b.id AND a.name=b.name)
```
Плохо:
```
JOIN table2 b ON (a.id=b.id OR a.name=b.name)
```
**4. Типы данных колонок должны совпадать.** DECIMAL к DECIMAL, VARCHAR к VARCHAR, DATE к DATE и так далее.
Если хотя бы одно из условий не выполняется, то происходит следующее:
* либо индекс все равно будет создан, но после выполнения запроса сразу же удален (так называемый Expression Index);
* либо Exasol будет делать джойн «всего ко всему», а затем фильтрацию. Последнее не так уж страшно, пока у вас не получается несколько триллионов рядов в промежуточном результате. Миллиарды — вполне возможно.
### Root filter
Понятие «Root filter» вносит существенный вклад в высокую производительность Exasol. Его нельзя найти в официальной документации, но можно увидеть в секретных системных «вьюшках» и планах выполнения запросов.
Как работает фильтр?
Если в запросе есть достаточно селективное условие WHERE с константами, то Exasol будет читать только те блоки данных, которые подходят под указанное условие. Все остальные блоки он читать не будет.
В этих примерах фильтр будет использоваться:
```
WHERE registration_date BETWEEN '2015-01-01' AND '2015-10-01'
WHERE foo >= 115
WHERE product_type IN ('book','car','doll')
```
А в этих примерах фильтр использоваться не будет:
```
WHERE registration_date BETWEEN CURRENT_DATE – INTERVAL '1' YEAR AND CURRENT_DATE
WHERE foo > (15 + 17)
WHERE email REGEXP_LIKE '(?i)@mail\.ru$'
```
Если Exasol может заранее очертить четкие и простые границы того, какие именно данные ему нужно прочитать, то он воспользуется такой возможностью и в десятки или сотни раз снизит количество операций чтения. Чем меньше чтений и чем меньше размер промежуточных результатов, тем быстрее все работает. При этом никакие специальные индексы не нужны — используется только статистика на базе колоночной структуры хранения данных.
### Возможности и особенности SQL
Exasol полностью поддерживает базовый ANSI SQL. Это включает в себя GROUP BY, HAVING, ORDER BY, LIMIT, OFFSET, MERGE, FULL JOIN, DISTINCT и т.д. — словом, все, что мы привыкли видеть.
С точки зрения аналитического SQL, предлагается следующее:
1. Window-функции, ROW\_NUMBER, медианы, ранги, перцентили на любой вкус;
2. Common Table Expressions;
3. CUBE, ROLLUP, GROUPING SETS;
4. GROUP\_CONCAT;
5. регулярные выражения PCRE, включая поиск, захват паттернов и их замену;
6. функции для работы с датами и таймзонами;
7. Geospatial-функции.
Нам показалось интересным то, что Exasol воспринимает пустую строку как NULL. Это никак нельзя отключить. Судя по всему, преобразование происходит где-то на очень глубоких уровнях, но серьезных проблем это не создает. Просто нужно об этом помнить при импорте.
Exasol жестко валидирует типы данных. Никаких автоматических приведений типов, неявных обрезаний слишком длинных строк, округлений и т.п. не происходит. В таких случаях вы всегда увидите ошибку, и это хорошо.
### Транзакции
Exasol — транзакционная СУБД, [full ACID compliant](https://en.wikipedia.org/wiki/ACID). Уровень изоляции — [serializable](https://en.wikipedia.org/wiki/Isolation_(database_systems)#Serializable). На практике в текущей реализации это означает, что в таблицу параллельно может писать только один писатель. Читателей может быть сколько угодно, и они не блокируются писателем. «Параллельные писатели» будут выполняться последовательно друг за другом, либо, в случае конфликтов и дедлоков, произойдет ROLLBACK.
[DDL](https://en.wikipedia.org/wiki/Data_definition_language)-запросы также транзакционны. Это означает, что вы можете создавать новые таблицы, вьюшки, добавлять колонки и т.д. — все это может происходить в одной транзакции. При необходимости можно легко сделать ROLLBACK и вернуть все как было.
Из-за колоночной структуры хранения, добавление и удаление колонок происходит практически моментально. Никаких простоев из-за долгих «альтеров» при изменении схемы таблиц на практике нет.
### Импорт данных
Наиболее эффективно импортировать данные в Exasol при помощи встроенной утилиты exajload. Она максимально использует возможности управления потоками и параллельного подключения сразу к нескольким нодам.
Разрешается передавать сжатый поток данных без предварительной декомпрессии, что заметно снижает нагрузку на сеть. Поддерживаемые форматы: gz, zip, bz2.
Для аналитических СУБД актуален вопрос эффективной загрузки данных из Hadoop. Exasol позволяет напрямую загружать файлы в несколько потоков при помощи WebHDFS, минуя промежуточные серверы и снижая общий overhead.
Благодаря транзакционности можно также загружать данные напрямую в production-таблицу, целиком минуя staging. Если загрузка прервется (по любой причине), то произойдет ROLLBACK, и у вас останется старая копия таблицы. Если загрузка успешно завершится, то новые данные заменят старые.
Как и во многих других аналитических СУБД, в Exasol намного эффективнее подход ELT (Extract — Load — Transform), нежели классический ETL (Extract — Transform — Load). Лучше загружать «сырые» данные в промежуточную таблицу, а затем трансформировать их средствами самой СУБД, при этом используя все достоинства Massive Parallel Processing.
### Кратко о поддержке
1. В Exasol в настоящий момент нет продвинутой поддержки серверов с разной конфигурацией в рамках одного кластера. Все ноды получают одинаковый объем данных и одинаковый объем вычислительных задач. Весь кластер будет работать со скоростью самой слабой ноды. Поэтому лучше в самом начале поставить 2-4 мощных сервера, чем 10 слабеньких. Расширяться потом вам будет значительно проще.
2. Добавление новой ноды занимает несколько минут. После этого Exasol можно сразу поднимать и пускать пользователей, не дожидаясь окончательного перераспределения данных на дисках. При этом все будет работать чуть медленнее из-за дополнительных сетевых операций, но по мере увеличения количества нод разница становится менее заметной. Процессом реорганизации данных можно управлять вручную, запуская команду REORGANIZE для конкретных схем или таблиц. Таким образом, можно реорганизовать более важные таблицы раньше, чем все остальные.
3. Fault tolerance. В своей практике мы сталкивались с несколькими аварийными сценариями. Например, заканчивалось свободное место, или кто-то случайно физически отключал часть работающих серверов от сети. Никаких существенных проблем с этим мы не заметили. База заранее пишет о проблеме, останавливается и ждет исправления ситуации. В ряде случаев происходит автоматический рестарт, если проблема исчезла. При этом если не заглядывать в логи, можно и не узнать, что вообще что-то происходило.
Exasol способен пережить полную потерю некоторого количества нод без остановки работы. Существует особый параметр «redundancy», который определяет, на сколько нод будет физически сохраняться каждый блок данных. Чем выше значение этого параметра, тем больше нод можно потерять. Но за это ожидаемо приходится платить местом на дисках.
4. SSD диски для Exasol не играют большой роли. Блоки данных очень большие, они читаются и записываются крупными партиями друг за другом. Random disk access практически отсутствует. Вместо SSD лучше поставить больше памяти.
### Цены
К сожалению, Exasol — это не open source software. Необходимо оплачивать лицензию. Фиксированных цен нет — с каждым партнером компания договаривается индивидуально. Скорее всего, стоимость будет зависеть от объема используемой оперативной памяти, что типично для СУБД, позиционирующих себя как in-memory.
Также у Exasol есть [бесплатный trial](https://www.exasol.com/portal/display/DOWNLOAD/Free+Trial). Он представляет собой версию, которая работает только на одной ноде и использует до 10 Гбайт оперативной памяти. Этого достаточно для devel-окружения и для того, чтобы проверить ваши запросы на небольшой части данных и составить общее впечатление.
Кроме того, Exasol запустил специальную [программу для стартапов](http://www.exasol.com/en/solutions/business/startup/), по которой предлагается 500 Гбайт данных в облаке за 500 евро в месяц. При этом не нужно покупать дорогостоящее железо. К сожалению, мы не можем оценить преимущества их облака, т.к. мы с ним не работали.
Физически компания Exasol находится в городе Нюрнберге (Германия). Можно приехать к ним в гости, пройти обучающие курсы, поговорить с разработчиками.
### Заключение
В целом Exasol стал для нас реальным открытием. Вы просто загружаете данные и можете сразу их анализировать на высокой скорости. It just works.
При этом нет никакой возни с индексами, представлениями, какими-то ручными оптимизациями. Можно связать между собой данные из абсолютно разных источников, а не только те, которые заранее были для этого предназначены. Любые джойны к вашим услугам.
Фактически вы ограничены только способностью сформулировать свою задачу в форме SQL-запроса. Если для каких-то особых случаев возможностей SQL окажется недостаточно, то Exasol позволяет создавать custom-функции на Python, LUA, Java, R. При этом сохраняются все плюсы колоночного хранения, общей параллельности всех операций и эффективного использования памяти.
Если вам интересны любые другие аспекты работы с Exasol, а также организация эффективного ETL-процесса — пишите в комментариях, я с удовольствием вам отвечу.
Спасибо за внимание!
### Полезные ссылки
1. [Exasol website](http://www.exasol.com/en/)
2. [User Manual (ver 5.0.11)](https://www.exasol.com/support/secure/attachment/35839/EXASolution_User_Manual-5.0.11-en.pdf)
3. [Technical Whitepaper](http://info.exasol.com/whitepaper-exasolution-1-en.html) — объяснения про Massive Parallel Processing
4. [Free trial](https://www.exasol.com/portal/display/DOWNLOAD/Free+Trial)
5. [Solution center](https://www.exasol.com/portal/display/SOL/Solution+Center) — в основном полезные видео и ответы на частые вопросы | https://habr.com/ru/post/271753/ | null | ru | null |
# Deferred объекты в AngularJS
Доброе время суток!
В этом небольшом посте я хочу рассказать про использование Deferred объектов AngularJS.
Механизм Deferred объектов, а точнее идея была добавлена из библиотеки [Q](https://github.com/kriskowal/q) Криса Ковала. Суть его заключается в том, что если функция не может вернуть значение или исключение без блокировки, то она возвращает Promice объект, который является наблюдателем за результатом выполнения. Как только результат будет получен, либо в момент получения произойдет ошибка, Deferred объект извещает об этом наблюдателя.
Довольно часто перед загрузкой контроллера необходимо получить данные для его работы. Говоря о получение данных я имею в виду данные, получение которых занимает неопределенное время. Наиболее частый случай — это прием данных от сервера приложения. Для решения этой задачи нам нужно передать параметр resolve в $routeProvider при настройке роутинга приложения. Resolve представляет собой объект указывающий контроллеру на зависимость. Как только все зависимости будут решены, они помещаются в контроллер, после чего происходит дальнейшая инициализации контроллера.
Более наглядно это можно увидеть на примере.
```
angular.module('phonecat', ['phonecatFilters', 'phonecatServices', 'phonecatDirectives']).
config(['$routeProvider', function($routeProvider) {
$routeProvider.
when('/phones', {
templateUrl: 'partials/phone-list.html',
controller: PhoneListCtrl,
resolve: PhoneListCtrl.resolve}).
when('/phones/:phoneId', {
templateUrl: 'partials/phone-detail.html',
controller: PhoneDetailCtrl,
resolve: PhoneDetailCtrl.resolve}).
otherwise({redirectTo: '/phones'});
}]);
```
```
function PhoneListCtrl($scope, phones) {
$scope.phones = phones;
$scope.orderProp = 'age';
}
PhoneListCtrl.resolve = {
phones: function(Phone, $q) {
var deferred = $q.defer();
//выполняем запрос на получение данных
//если данные успешно приняты выполним deferred.resolve()
//если произошла ошибка выполним deferred.reject()
Phone.query(function(successData) {
deferred.resolve(successData);
}, function(errorData) {
deferred.reject();
});
return deferred.promise;
},
delay: function($q, $defer) {
var delay = $q.defer();
$defer(delay.resolve, 1000);
return delay.promise;
}
}
```
В выше указанном примере $q.defer() — создает экземпляр объекта Defer. Данный объект имеет два метода, для возврата значения — deferred.resolve(val) и возврата отказа по какой либо причине — deferred.reject(reason). Методы resolve или reject вызываются в callback методах, вызовы которых происходит в случае успешного приема данных или в случае возникновения ошибки.
Как только все Deferred объекты будут выполнены их результаты добавляются в контроллер, после этого происходит событие смены маршрута и мы можем выполнять различные действия с данными внутри контроллера. | https://habr.com/ru/post/183008/ | null | ru | null |
# SeekBar в настройках приложения
Для создания экранов настроек Android предоставляет очень удобный набор виджетов, таких как CheckBoxPreference, EditTextPreference, ListPreference. В случае, если существующие виджеты по каким-либо причинам не соответствуют требованиям, можно создать свой собственный на базе существующих.
Довольно часто встречается ситуация, когда та или иная целочисленная настройка имеет разумные пределы: яркость, громкость и т.д. В этом случае имеет смысл создать собственный виджет, чтобы многократно использовать его в приложении.
##### Подготовка
За основу возьмем класс DialogPreference – базовый класс для виджетов, показывающих двухстрочный элемент в экране настроек и открывающих диалог при нажатии.

Назовем этот класс SeekBarPreference. Параметрами для него будут минимальное значение, максимальное значение и текущее значение по умолчанию, а реальное текущее значение он будет брать из ассоциированных настроек приложения по заданному ключу.
Тогда файл */res/xml/preferences.xml* с разметкой настроек может выглядеть так:
```
xml version="1.0" encoding="utf-8"?
```
Для задания значения по умолчанию можно использовать существующий тег, а вот для минимального и максимального придется создать свои. Для этого в файл */res/values/attrs.xml* следует добавить описание атрибутов.
```
xml version="1.0" encoding="utf-8"?
```
Атрибут name тега должен содержать квалифицированное имя класса нашего виджета.
Это же имя, только в более полном формате (*[schemas.android.com/apk/res/квалифицированное\_имя\_класса](http://schemas.android.com/apk/res/квалифицированное_имя_класса)*) должно быть указано в разметке файла настроек как дополнительное пространство имен (см. выше).
Последний этап работы с xml – это создание разметки диалога, который будет вызываться по нажатию виджета. Код разметки не представляет из себя ничего необычного, поэтому может быть опущен без последствий. Он содержит TextView для минимального значения, максимального значения, текущего значения, и, собственно, SeekBar.
Теперь можно продолжить с реализацией класса SeekBarPreference.
##### Реализация
Для начала необходимо прочитать указанные значения из атрибутов в конструкторе:
```
mMinValue = attrs.getAttributeIntValue(PREFERENCE_NS, ATTR_MIN_VALUE, DEFAULT_MIN_VALUE);
mMaxValue = attrs.getAttributeIntValue(PREFERENCE_NS, ATTR_MAX_VALUE, DEFAULT_MAX_VALUE);
mDefaultValue = attrs.getAttributeIntValue(ANDROID_NS, ATTR_DEFAULT_VALUE, DEFAULT_CURRENT_VALUE);
```
где константы – это имена пространств имен, атрибутов и значения по умолчанию для минимума, максимума и значения по умолчанию (на случай, если они не будут указаны в разметке):
```
private static final String PREFERENCE_NS = "http://schemas.android.com/apk/res/com.mnm.seekbarpreference";
private static final String ANDROID_NS = "http://schemas.android.com/apk/res/android";
private static final String ATTR_DEFAULT_VALUE = "defaultValue";
private static final String ATTR_MIN_VALUE = "minValue";
private static final String ATTR_MAX_VALUE = "maxValue";
```
Для инициализации диалога реализуем метод onCreateDialogView:
```
@Override
protected View onCreateDialogView() {
// Читаем значение из настроек
mCurrentValue = getPersistedInt(mDefaultValue);
// Создаем элемент
LayoutInflater inflater = (LayoutInflater) getContext().getSystemService(Context.LAYOUT_INFLATER_SERVICE);
View view = inflater.inflate(R.layout.dialog_slider, null);
// Выставляем минимум и максимум
((TextView) view.findViewById(R.id.min_value)).setText(Integer.toString(mMinValue));
((TextView) view.findViewById(R.id.max_value)).setText(Integer.toString(mMaxValue));
// Настраиваем SeekBar
mSeekBar = (SeekBar) view.findViewById(R.id.seek_bar);
mSeekBar.setMax(mMaxValue - mMinValue);
mSeekBar.setProgress(mCurrentValue - mMinValue);
mSeekBar.setOnSeekBarChangeListener(this);
// Выставляем текущее значение
mValueText = (TextView) view.findViewById(R.id.current_value);
mValueText.setText(Integer.toString(mCurrentValue));
return view;
}
```
Значение читается по ключу, заданному в *preferences.xml* для виджета. При настройке SeekBar нужно учитывать, что для него минимальное значение – это всегда 0, поэтому приходится производить вычитание, если минимум отличен от нуля. Кстати, данный код верен только для неотрицательных чисел, а так же когда максимум больше минимума.
После этого уже можно запускать приложение и двигать ползунок, но текст текущего значения изменяться не будет, поскольку необходимо обработать изменения.
Для этого реализуем интерфейс OnSeekBarChangeListener у SeekBarPreference. В приведенном выше коде именно на этот интерфейс передается ссылка в `mSeekBar.setOnSeekBarChangeListener(this)`. Необходимо реализовать только один метод из трех возможных:
```
public void onProgressChanged(SeekBar seek, int value, boolean fromTouch) {
mCurrentValue = value + mMinValue;
mValueText.setText(Integer.toString(mCurrentValue));
}
```
И опять же, из-за того, что минимальное значение SeekBar равно нулю, приходится применять сложение.
Следующий шаг – сохранение полученного значения. При применении или отмене изменений вызывается метод `onDialogClosed`, который и нужно переопределить:
```
@Override
protected void onDialogClosed(boolean positiveResult) {
super.onDialogClosed(positiveResult);
if (!positiveResult) {
return;
}
if (shouldPersist()) {
persistInt(mCurrentValue);
}
notifyChanged();
}
```
При положительном варианте текущее значение сохраняется. Проверка `shouldPersist()` анализирует нужно ли это делать. При этом проверяется флаг `android:persistent`, указанный в *preferences.xml*.
Последняя строчка нужна для маленькой хитрости. Дело в том, что по умолчанию вторая строка виджета (*summary*) не динамическая, поэтому если хочется отображать в ней текущее значение, то необходимо добавить следующие строки:
```
@Override
public CharSequence getSummary() {
String summary = super.getSummary().toString();
int value = getPersistedInt(mDefaultValue);
return String.format(summary, value);
}
```
Здесь, при запросе *summary*, оригинальная строка выполняет роль шаблона, в который подставляется текущее значение. Это превосходно работает при открытии экрана настроек. Но чтобы заставить этот код работать после изменения значения, необходимо вызвать `notifyChanged()`.
##### Результат
Полученный виджет подходит для применения к широкому спектру настроек и элегантно дополняет существующие виджеты. Подход с динамической строкой *summary* может использоваться и в других типах настроек.
##### Ссылки
[Архив с проектом примера](https://docs.google.com/leaf?id=0Bxtnvl856FZ_OGVhMmM3Y2EtZWZiYi00ZjFhLWIwMDktNTk1ZWRmMTYzODVk&hl=en)
[Описание SeekBar (en)](http://developer.android.com/reference/android/widget/SeekBar.html)
[Описание DialogPreference (en)](http://developer.android.com/reference/android/preference/DialogPreference.html) | https://habr.com/ru/post/114733/ | null | ru | null |
# Реверс инжиниринг протокола пульта от инверторного кондиционера Electrolux

В этой статье я опишу свой опыт и основные этапы изучения ИК пульта от кондиционера. Из инструмента понадобится Arduino nano на mega328 и приемник ИК сигналов (у меня VS1838B).
**Небольшая предыстория**Решил включить свой кондиционер Electrolux в систему умного дома. Для этого возможны 3 варианта: использование ИК передатчика broadlink, использование самодельного ИК передатчика и интеграция самодельной схемы в сам кондиционер. Как наиболее безопасный, для подопытного кондиционера, и наиболее дешевый, выбор пал на самодельный ИК модуль.
Первым делом нужно разобрать ИК протокол. Поиск в интернете дал лишь 1 результат и тот не подходит, т. к. кондиционер другой фирмы: [ссылка](https://habr.com/post/189142/). Взял осциллограф, посмотрел что к чему. Оказалось протокол схож с NEC, но посылка настолько длинная что не умещается в буфер моего USB осциллографа. Не беда, взял ардуинку, нашел универсальную библиотеку IRremote и… понял что она не понимает команды длиннее 32 бит, а у меня как минимум 3 части подряд по 6 байт (48 бит).
Библиотеку я подправить не смог, слишком она для меня сложна. Немного помучившись, написал код, читающий временные интервалы между изменениями сигнала. В ардуино я не силен, поэтому код вероятно кривоват и гарантированно работает на ардуинах с МК ATMega328 и частотой 16МГц. Вообще то, я мог бы написать более красивый код в CVAVR но тогда повторить мой опыт сможет далеко не каждый, ведь нужен программатор и я решил сделать все же на ардуино. Начну с особенностей моей модели. Некоторые кондиционеры моей линейки имеет функцию «I feel», которая предназначена для того чтобы заданная температура достигалась в той части комнаты? где нахожусь я (на самом деле пульт). В документации указано что именно в моей модели такой функции нет, но оказалось что она есть. Выяснилось это довольно неприятным образом, батарейки в пульте сели и пульт начал завышать температуру на 4 градуса т.е. вместо 28 показывать 32. Я ставлю 28 градусов и кондей холодит до 26. Ладно, решил я, и выставил 32 градуса на охлаждение (это верхний предел), но кондиционер упорно продолжал охлаждать помещение. Я решил что что-то сломалось, или окислился контакт у термодатчика и разобрал кондиционер в поисках поломки. Ничего не обнаружив, на всякий случай, решил поменять батарейки и, о чудо, кондиционер стал работать адекватно. Итак как же это работает? Пульт вместе со всеми настройками отправляет кондиционеру температуру которую измерил и тот корректирует показания внутреннего термодатчика, в зависимости от того что прислал пульт.
Для начала я написал код, который считывает длительности нахождения сигнала с ИК приемника в низком и высоком состоянии, записывает их в массив, а потом выводит в порт компьютера.
**Код**
```
// IR приемник подключается на D2
unsigned int timerValue; // значение таймера
unsigned int data_m[350];
unsigned int i=0;
unsigned int n=0;
byte temp;
void setup() {
Serial.begin(115200); // инициализируем последовательный порт, скорость 115200
// установки таймера 1
TCCR1A = 0;
TCCR1B = 0;
attachInterrupt(0, inter_1, CHANGE); // привязываем 0-е прерывание к функции inter_1
TCCR1B = 2; // разрешение работы таймера
Serial.println("Start");
pinMode(2, INPUT);
}
void loop() {
temp=TIFR1&0x01; // проверяем бит переполнения таймера
if (temp!=0)
{
TIFR1=0x01; // очистить флаг переполнения
if (i!=0)
{while (n<=i) // вывод на компьютер
{
Serial.print(n,DEC);
Serial.print("=");
Serial.print(data_m[n],DEC);
Serial.print("\t");
if ((n&B00000011)==0) { Serial.println(" ");}
n++;
}
Serial.println("End");
}
i=0; // очистить адрес первого значения в массиве
n=0;
}
}
void inter_1()
{
timerValue = (unsigned int)TCNT1L>>1 | ((unsigned int)TCNT1H << 7); // чтение таймера
data_m[i]=timerValue;
i++;
TCNT1H = 0; // сброс таймера
TCNT1L = 0;
}
```
После нажатия на кнопку пульта кондиционера в порт пришли данные:
**Результат приема посылки**`Start
0=20543
1=9038 2=4541 3=548 4=1675
5=548 6=1681 7=545 8=560
9=543 10=614 11=494 12=569
13=543 14=620 15=493 16=624
17=494 18=1688 19=544 20=603
21=494 22=1655 23=571 24=1685
25=545 26=613 27=495 28=568
29=543 30=622 31=493 32=625
33=495 34=613 35=494 36=604
37=494 38=607 39=493 40=561
41=545 42=612 43=495 44=620
45=491 46=622 47=494 48=624
49=494 50=565 51=543 52=602
53=494 54=1679 55=547 56=609
57=494 58=614 59=493 60=619
61=492 62=1693 63=546 64=1698
65=547 66=1685 67=548 68=603
69=494 70=608 71=493 72=609
73=495 74=615 75=493 76=571
77=540 78=620 79=494 80=626
81=493 82=565 83=545 84=605
85=492 86=607 87=493 88=613
89=492 90=596 91=512 92=619
93=492 94=622 95=493 96=624
97=494 98=594 99=521 100=7988
101=550 102=1674 103=546 104=608
105=492 106=1685 107=543 108=611
109=495 110=1689 111=547 112=620
113=495 114=625 115=491 116=1689
117=543 118=605 119=493 120=1654
121=572 122=611 123=494 124=614
125=493 126=1692 127=545 128=621
129=492 130=622 131=496 132=613
133=492 134=604 135=494 136=605
137=496 138=556 139=548 140=614
141=493 142=618 143=494 144=620
145=494 146=624 147=494 148=615
149=493 150=606 151=493 152=608
153=493 154=609 155=496 156=614
157=494 158=566 159=545 160=623
161=493 162=625 163=493 164=564
165=543 166=603 167=494 168=606
169=495 170=609 171=496 172=613
173=494 174=617 175=495 176=620
177=494 178=624 179=496 180=613
181=494 182=604 183=493 184=606
185=494 186=562 187=541 188=613
189=495 190=618 191=493 192=622
193=493 194=623 195=494 196=1663
197=569 198=603 199=494 200=1678
201=547 202=1686 203=543 204=1663
205=570 206=1692 207=545 208=619
209=494 210=624 211=495 212=614
213=494 214=1653 215=569 216=1657
217=571 218=611 219=493 220=1664
221=571 222=1691 223=544 224=1671
225=571 226=1699 227=547 228=1671
229=572 230=7995 231=551 232=603
233=493 234=606 235=493 236=612
237=493 238=608 239=497 240=618
241=494 242=621 243=492 244=626
245=493 246=584 247=524 248=556
249=541 250=1680 251=545 252=610
253=494 254=613 255=495 256=588
257=523 258=620 259=494 260=625
261=494 262=615 263=493 264=604
265=495 266=607 267=495 268=612
269=493 270=616 271=493 272=570
273=542 274=621 275=495 276=625
277=493 278=612 279=496 280=606
281=493 282=607 283=496 284=610
285=494 286=614 287=495 288=618
289=493 290=595 291=519 292=575
293=543 294=616 295=494 296=605
297=495 298=606 299=495 300=613
301=493 302=613 303=494 304=616
305=495 306=569 307=546 308=625
309=493 310=564 311=545 312=602
313=496 314=607 315=495 316=611
317=494 318=613 319=496 320=571
321=541 322=621 323=494 324=624
325=495 326=568 327=539 328=604
329=493 330=1679 331=547 332=610
333=495 334=614 335=493 336=618
337=495 338=572 339=543 340=623
341=496 342=596 343=484 344=0`
End
Мы можем заметить что все нечетные данные одинаковые (кроме стартового импульса) и их можно игнорировать. Далее в код прерывания было довольно условие if (digitalRead(2)==0) которое отбрасывает длительности низкого состояния на входе контроллера.
```
void inter_1()
{
timerValue = (unsigned int)TCNT1L>>1 | ((unsigned int)TCNT1H << 7); // чтение таймера
if (digitalRead(2)==0)
{
data_m[i]=timerValue;
i++;
}
TCNT1H = 0; // сброс таймера
TCNT1L = 0;
}
```
В общем виде программа работает следующим образом: запускается таймер-счетчик с коэфициентом деления 8 (это один из стандартных делителей предусмотренных в МК), и когда изменяется состояние входа D2 выполняется прерывание — функция void inter\_1(). В этом прерывании считывается значение таймера-счетчика и делится на 2, после чего записывается в массив, а сам таймер сбрасывается. Таймер-счетчик работает с частотой в 8 раз меньше тактовой частоты МК (16МГц) т.е. 2МГц и чтобы получить время в микросекундах число считанное со счетчика нужно разделить на 2. В основном теле программы проверяется флаг переполнения таймера и если таймер-счетчик переполнен т.е. досчитал до 65535, проверяется счетчик принятых интервалов. Если он отличен от 0 выводятся все принятые данные и сбрасывается счетчик принятых байт. Новые данные выглядят вот так:
**Результат получения команды**`Start
0=26938
1=4539 2=1675 3=1654 4=610
5=563 6=569 7=567 8=621
9=1687 10=602 11=1679 12=1658
13=613 14=615 15=619 16=576
17=561 18=602 19=591 20=607
21=611 22=615 23=620 24=622
25=611 26=602 27=1678 28=609
29=612 30=615 31=1693 32=1695
33=1659 34=601 35=605 36=610
37=611 38=566 39=564 40=622
41=611 42=601 43=604 44=608
45=614 46=615 47=618 48=620
49=594 50=7970 51=1676 52=604
53=1681 54=613 55=1688 56=620
57=623 58=1685 59=602 60=1680
61=1680 62=612 63=1687 64=619
65=624 66=611 67=602 68=604
69=607 70=558 71=616 72=619
73=624 74=560 75=603 76=605
77=562 78=611 79=615 80=566
81=622 82=612 83=601 84=603
85=606 86=611 87=564 88=618
89=572 90=612 91=601 92=604
93=608 94=611 95=569 96=621
97=622 98=1686 99=552 100=1678
101=1681 102=1660 103=1689 104=618
105=622 106=610 107=1675 108=1677
109=1681 110=1681 111=1691 112=1688
113=1696 114=1668 115=7966 116=599
117=603 118=562 119=558 120=612
121=617 122=621 123=565 124=601
125=1679 126=607 127=612 128=616
129=565 130=622 131=613 132=602
133=604 134=608 135=612 136=615
137=618 138=617 139=611 140=598
141=553 142=607 143=612 144=615
145=617 146=568 147=565 148=600
149=604 150=606 151=559 152=613
153=617 154=622 155=609 156=549
157=605 158=609 159=611 160=613
161=618 162=621 163=609 164=602
165=1679 166=609 167=612 168=615
169=618 170=622 171=595 172=0
End`
Из полученных данных видно, что первое число рандомно — это время от последнего переполнения таймера, до начала посылки. Далее стартовый импульс 4,5мс и данные. Данные передаются побитно, где интервал примерно 1690мкс соответствует логической единице, а интервал 560мкс логическому нулю. Также видно, что посылки разделены на 3 отдельные части, где 50=7970 и 115=7966 являются стартовыми последовательностями.
Добавим в код функции формирования байт и небольшую расшифровку принятых данных. Последнюю строчку я написал уже в самом конце, но не плодить же почти одинаковый код.
**Код на arduino**
```
// IR приемник подключается на D2
unsigned int timerValue; // значение таймера
unsigned int data_m[250];
byte i=0;
byte n=0;
byte temp;
byte k=0;
byte x,y;
byte m1=0;
byte dat[4][12];
byte temp2=0;
char s[5];
void setup() {
Serial.begin(115200); // инициализируем последовательный порт, скорость 9600
// установки таймера 1
TCCR1A = 0;
attachInterrupt(0, inter_1, CHANGE); // привязываем 0-е прерывание к функции inter_1
TCCR1B = 2; // разрешение работы таймера с делителем 8
Serial.println("Start");
pinMode(2, INPUT);
}
void loop() {
temp=TIFR1&0x01; // проверяем бит переполнения таймера
if (temp!=0)
{
TIFR1=0x01; // очистить флаг переполнения
if (i!=0)
{
if (k==0) // проверка что в последнем байте нет данных и установка метки FF как признак конца команды
{dat[y][x]=0xFF;}
else
{dat[y][x+1]=0xFF;
dat[y][x]=m1;
}
/* while (n<=i) // вывод на компьютер
{
Serial.print(n,DEC);
Serial.print("=");
Serial.print(data_m[n],DEC);
Serial.print("\t");
if ((n&B00000011)==0) { Serial.println(" ");}
n++;
}*/
for (int i1 = 0; i1 < 3; i1++) {
for (int j = 0; j < 9; j++) {
sprintf(s, "%02X ", dat[i1][j]);
Serial.print(s);
//dat[i1][j]=0;
}
Serial.println("");
}
if ((dat[0][3]&0x0F)==0x2) Serial.print("Cool ");
if ((dat[0][3]&0x0F)==0x0) Serial.print("Heat ");
if ((dat[0][3]&0x0F)==0x3) Serial.print("Dry ");
if ((dat[0][3]&0x0F)==0x04) Serial.print("Vent ");
if ((dat[0][2]&0x03)==0x0) Serial.print("Vent=Auto ");
if ((dat[0][2]&0x03)==0x1) Serial.print("Vent=Max ");
if ((dat[0][2]&0x03)==0x2) Serial.print("Vent=Mid ");
if ((dat[0][2]&0x03)==0x3) Serial.print("Vent=Min ");
temp=((dat[0][3]&0xF0)>>4)+18;
Serial.print("T=");
Serial.print(temp,DEC);
sprintf(s, " Time=%02d:%02d ",(dat[1][0]&0x7F),(dat[1][1]&0x7F));
Serial.print(s);
Serial.print(" C=");
temp=(dat[1][6]);
Serial.println(temp,DEC);
Serial.println("End");
// очистить массив
for (int i1 = 0; i1 < 3; i1++) {
for (int j = 0; j < 9; j++) {dat[i1][j]=0;}
}
}
i=0; // очистить адрес первого значения в массиве
n=0;
k=0;
m1=0;
x=0;
y=0;
}
}
void inter_1()
{
timerValue = (unsigned int)TCNT1L>>1 | ((unsigned int)TCNT1H << 7); // чтение таймера с одновременным делением на 2, т.к. кварц 16мгц, предделитель 8 и еще нужно разделить на 2
if (digitalRead(2)==0)
{
data_m[i]=timerValue;
i++;
if ((timerValue>4400)&&(timerValue<4700)) {m1=0; k=0;}
if ((timerValue>7500)&&(timerValue<8500))
{if (k==0) // проверка что в последнем байте нет данных и установка метки FF как признак конца команды
{dat[y][x]=0xFF;}
else
{dat[y][x+1]=0xFF;
dat[y][x]=m1;
}
x=0; y++; }
if ((timerValue>1500)&&(timerValue<1800)) {m1=(m1>>1)+0x80; k++;}
if ((timerValue>450)&&(timerValue<800)) {m1=m1>>1; k++;}
if (k>=8)
{k=0;
dat[y][x]=m1;
x++;
m1=0;
}
}
TCNT1H = 0; // сброс таймера
TCNT1L = 0;
}
```
Стоит отметить, что размеры массивов подогнаны под мой пульт, для исследования нового пульта их стоит расширить чтобы все точно влезло. Также стоит проверить число бит в посылках, например у меня 50-2=48 первая посылка, 115-51=64 и 172-116=56 (я вычитаю номера из последнего незначащего бита первый значащий). Итого получаем 6 байт 8 байт и 7 байт. Поскольку все 3 посылки имеют разную длинну я решил обозначить конец посылки значениями FF, поскольку такие данные почти не встречаются в тестируемом пульте.
Как я уже упоминал у моего кондиционера есть функция «I feel» работает это следующим образом пульт каждые 9 минут вместе со всеми настройками отправляет кондиционеру температуру которую измерил и тот, если окажется в зоне действия пульта, корректирует показания внутреннего термодатчика в зависимости от того что прислал пульт.
Вот кстати
**команды, отправленные автоматически**`Start
83 06 00 82 00 00 FF 00 00
16 30 00 00 00 80 1D 39 FF
00 00 00 00 00 00 00 FF 00
Cool Vent=Auto T=26 Time=22:48 C=29
End
83 06 00 82 00 00 FF 00 00
16 31 00 00 00 80 1D 38 FF
00 00 00 00 00 00 00 FF 00
Cool Vent=Auto T=26 Time=22:49 C=29
End
83 06 00 82 00 00 FF 00 00
16 3A 00 00 00 80 1D 33 FF
00 00 00 00 00 00 00 FF 00
Cool Vent=Auto T=26 Time=22:58 C=29
End
83 06 00 82 00 00 FF 00 00
17 07 00 00 00 80 1D 0F FF
00 00 00 00 00 00 00 FF 00
Cool Vent=Auto T=26 Time=23:07 C=29
End`
Дальше все самое простое и интересное — тыкам на кнопочки, получаем результат и пытаемся угадать, что, за что отвечает. Оказалось что биты в моем кондиционере передаются начиная с младшего. Большую часть протокола мне удалось расшифровать.
#### Описание протокола пульта кондиционера Electrolux
**0,1 байты** 0x83 0x06 Видимо адрес
**2 байт** 0b00000000 Режим работы
7 бит=1, если нажата кнопка «swing»
6 5 4 биты в режиме осушения отвечают за «мощность» 110= -7...-2, 101= -1, 000=0, 001=1, 010=2..7
3 бит=1 в режиме «sleep» (одновременно вентилятор устанавливается на минимум)
2 бит установлен, если нажата кнопка включения
1 и 0 биты отвечают режим вентилятора — 00 автоматический, 10 максимальная скорость, 01 средняя скорость, 11 малая скорость.
**3 байт** 0b11000010 Режим работы и температура. В этом примере охлаждение до 30 градусов
Старшие 4 бита содержат заданную температуру по формуле 18+число записанное тут, например 0b1100=12 прибавляем 18 получается 30
Младшие 4 бита отвечают за режим работы 0010 охлаждение, 0000 нагрев, 0011 осушение, 0001 режим «smart»
**4 байт** 0b00000000 неизвестный байт
**5 байт** 0b10010000 Режим супер охлаждения
В режиме супер охлаждения вентилятор на максимум, температура +18 и дополнительно старшие 4 бита 1001 в остальных режиме там нули.
Первые 6 байт закончены далее следует стартовая последовательность 8мс в высоком состоянии +0,5мс в низком состоянии и вторая часть посылки 8 байт.
**0 байт** 0b10000110 Текущее время (часы), в этом примере 6 часов.
7 бит всегда установлен.
5 бит=1 выключить дисплей на внутреннем блоке.
**1 байт** 0b00000010 текущее время (минуты) в этом примере 02 минуты
7 бит установлен когда включен таймер выключения.
**2 байт** 0b00010111 Время автоотключения (часы), тут 23 часа.
**3 байт** 0b10111010 Время автовыключения ( минуты) тут 58
7 бит установлен, когда включен таймер автовключения.
**4 байт** 0b00001100 Время автовключения (часы) тут 12 часов
**5 байт** 0b10000010 Время автоовключения (минуты) тут 2 минуты
7 бит всегда установлен
**6 байт** 0b00011111 Текущая температура измеренная пультом, тут 31.
**7 байт** CRC. ~~Алгоритм CRC не мной не найден. (буду благодарен если кто-то подскажет). Я перепробовал в онлайн калькуляторах все предлагаемые алгоритмы (штук 10), но подходящего не нашел. Очевидно при подсчете CRC считается первая и вторая строка т.к. при изменении любого байта в первой или второй строке CRC меняется.~~
Участник [huhen](https://habr.com/users/huhen/) разгадал метод вычисления CRC: Это операция XOR над всеми байтами первой и второй посылки кроме адреса. Например:83 06 60^73^00^00^00^00^96^04^00^00^00^80^1E=1F
Последняя часть посылки 7 байт
**0 байт**
5 бит режим SOFT
4 бит нажата кнопка switch
3 бит установлен когда включен режим mute (на дисплее горит значек уха)
**1 байт**
0x00= автоматическая посылка, кнопка dimmer и установка времени кнопка clock
0x01=нажата кнопка включения
0x02=нажата кнопка изменения заданной температуры (мощности) + или — 0x03=нажата кнопка sleep
0x04 =нажата кнопка супер охлаждения
0x05=включен или отключен таймер авто включения Timer ON
0x06=нажата кнопка режим
0x07=нажата кнопка swing (качание заслонкой)
0x0B нажата кнопка mute
0x0С нажата кнопка SOFT (энергосбережения)
0x0D нажата кнопка I feel
0x0F нажата кнопка switch (выключить дисплей внутреннего блока)
0x11 нажата кнопка режим вентилятора
0x17=нажата кнопка smart (автоматический режим работы)
0x1D включен или отключен таймер авто отключения Timer OFF
**2 байт** в режиме осушения и smart (автоматический) отвечают за «мощность» вместе с 2 байтом первой посылки
0x14= +-7
0x10= +-6
0x0C= +-5
0x08= +-4
0x02= +-3
0x00= 0, +-1, +-2
**6 байт** Контрольная сумма 0-5 байт (третей строки).
В режиме осушения или smart у кондиционера не выставляется температура, можно лишь выбрать цифру от-7 до +7. Вероятно они отвечают за мощность. И эта мощность передается во втором байте первой посылки и втором байте третьей посылки.
Также у меня есть IR передатчик xiaomi. Он был настроен на кондиционер методом перебора и передает кондиционеру первую посылку длинной 6 байт. Кондиционер на такую укороченную посылку откликается и исправно её выполняет. Но такой вариант управления мне не очень нравится поскольку не позволяет передать кондиционеру текущую температуру, тем самым корректируя его работу.
Тут я просто на кнопочки по нажимал. В подписи под данными T= установленная температура
С= текущая температура измеренная пультом. Vent=режим вентилятора.
**Данные**`83 06 60 73 00 00 FF 00 00
96 04 00 00 00 80 1E 1F FF
00 02 08 00 00 00 0A FF 00
Dry Vent=Auto T=25 Time=22:04 C=30
End
83 06 01 74 00 00 FF 00 00
96 04 00 00 00 80 1E 79 FF
00 06 00 00 00 00 06 FF 00
Vent Vent=Max T=25 Time=22:04 C=30
End
83 06 00 50 00 00 FF 00 00
96 04 00 00 00 80 1E 5C FF
00 06 00 00 00 00 06 FF 00
Heat Vent=Auto T=23 Time=22:04 C=30
End
83 06 00 82 00 00 FF 00 00
96 04 00 00 00 80 1E 8E FF
00 06 00 00 00 00 06 FF 00
Cool Vent=Auto T=26 Time=22:04 C=30
End
83 06 00 73 00 00 FF 00 00
96 04 00 00 00 80 1E 7F FF
00 06 00 00 00 00 06 FF 00
Dry Vent=Auto T=25 Time=22:04 C=30
End
83 06 01 74 00 00 FF 00 00
96 04 00 00 00 80 1E 79 FF
00 06 00 00 00 00 06 FF 00
Vent Vent=Max T=25 Time=22:04 C=30
End
83 06 00 50 00 00 FF 00 00
96 04 00 00 00 80 1E 5C FF
00 06 00 00 00 00 06 FF 00
Heat Vent=Auto T=23 Time=22:04 C=30
End
83 06 00 82 00 00 FF 00 00
96 04 00 00 00 80 1E 8E FF
00 06 00 00 00 00 06 FF 00
Cool Vent=Auto T=26 Time=22:04 C=30
End
83 06 00 92 00 00 FF 00 00
96 04 00 00 00 80 1E 9E FF
00 02 00 00 00 00 02 FF 00
Cool Vent=Auto T=27 Time=22:04 C=30
End
83 06 00 A2 00 00 FF 00 00
96 04 00 00 00 80 1E AE FF
00 02 00 00 00 00 02 FF 00
Cool Vent=Auto T=28 Time=22:04 C=30
End
83 06 00 B2 00 00 FF 00 00
96 04 00 00 00 80 1E BE FF
00 02 00 00 00 00 02 FF 00
Cool Vent=Auto T=29 Time=22:04 C=30
End
83 06 00 C2 00 00 FF 00 00
96 04 00 00 00 80 1E CE FF
00 02 00 00 00 00 02 FF 00
Cool Vent=Auto T=30 Time=22:04 C=30
End
83 06 00 D2 00 00 FF 00 00
96 04 00 00 00 80 1E DE FF
00 02 00 00 00 00 02 FF 00
Cool Vent=Auto T=31 Time=22:04 C=30
End
83 06 00 E2 00 00 FF 00 00
96 04 00 00 00 80 1E EE FF
00 02 00 00 00 00 02 FF 00
Cool Vent=Auto T=32 Time=22:04 C=30
End
83 06 00 E2 00 00 FF 00 00
96 04 00 00 00 80 1E EE FF
00 02 00 00 00 00 02 FF 00
Cool Vent=Auto T=32 Time=22:04 C=30
End
83 06 00 E2 00 00 FF 00 00
B6 05 00 00 00 80 1E CF FF
00 00 00 00 00 00 00 FF 00
Cool Vent=Auto T=32 Time=54:05 C=30
End
83 06 00 E2 00 00 FF 00 00
96 05 00 00 00 80 1E EF FF
10 0F 00 00 00 00 1F FF 00
Cool Vent=Auto T=32 Time=22:05 C=30
End
83 06 03 E2 00 00 FF 00 00
96 05 00 00 00 80 1E EC FF
04 0B 00 00 00 00 0F FF 00
Cool Vent=Min T=32 Time=22:05 C=30
End
83 06 00 71 80 00 FF 00 00
96 05 00 00 00 80 1E FC FF
00 17 00 00 00 00 17 FF 00
Vent=Auto T=25 Time=22:05 C=30
End
83 06 80 71 00 00 FF 00 00
96 05 40 00 00 80 1E BC FF
00 07 00 00 00 00 07 FF 00
Vent=Auto T=25 Time=22:05 C=30
End
83 06 00 82 00 00 FF 00 00
96 05 00 00 00 80 1E 8F FF
00 06 00 00 00 00 06 FF 00
Cool Vent=Auto T=26 Time=22:05 C=30
End
83 06 04 82 00 00 FF 00 00
96 05 00 00 00 80 1E 8B FF
00 01 00 00 00 00 01 FF 00
Cool Vent=Auto T=26 Time=22:05 C=30
End` | https://habr.com/ru/post/419797/ | null | ru | null |
# Pillow 2.7 — Существенное улучшение качества и производительности
 Первого января 2015 года по расписанию вышла новая версия библиотеки для работы с изображениями [Pillow 2.7](https://pypi.python.org/pypi/Pillow/2.7.0). Так как многие изменения в ней были сделаны командой [Uploadcare](https://uploadcare.com/), мы рады представить вам расширенную версию заметок о релизе этой версии.
Для начала вспомним, с чего все началось. Pillow — дружественный форк (как называют его авторы) популярной библиотеки PIL, Python Imaging Library. Последняя версия PIL 1.1.7 вышла в 2009 году и в основном содержала исправления ошибок. Изначально Pillow задумывался как проект только по приведению в порядок сборки PIL, и разработчики рекомендовали отправлять все баги, не связанные со сборкой, в оригинальный PIL. Но время шло, PIL стремительно устаревала, багов не уменьшалось, тут еще Python 3 маячил на горизонте. Поэтому с версией Pillow 2.0 все изменилось. «Pillow 2.0.0 добавляет поддержку Python 3 и включает много багфиксов со всего интернета» гласит [описание проекта](https://pypi.python.org/pypi/Pillow/2.0.0) на PyPI. И с тех пор понеслось. Каждые три месяца выходили версии с огромным количеством багфиксов и другими улучшениями от различных разработчиков. Самым значительным нововведением за это время было, пожалуй, поддержка форматов WebP и JPEG2000. Теперь пришло время следующего большого шага.
Фильтры ресайза изображений
---------------------------
Функции ресайза изображений `Image.resize()` и `Image.thumbnail()` в качестве одного из аргументов принимают фильтр, использующийся для ресайза — `resample`. Его возможные значения: `NEAREST`, `BILINEAR`, `BICUBIC` и `ANTIALIAS`. Поведение практически каждого из них изменилось в новой версии.
### Уменьшение изображения с билинейным и бикубическим фильтрами
Одной из проблем в PIL, а потом и в Pillow, было то, что для ресайза с помощью билинейного и бикубического фильтра использовался метод [аффинных преобразований](http://habrahabr.ru/post/243285/#affine-transformations), который использует одно и то же количество пикселей исходного изображения для формирования одного пикселя конечного (2x2 пикселя для билинейного, 4x4 для бикубического) и фиксированный размер фильтра. Это приводило к неудовлетворительным результатам для уменьшения изображения, практически не отличавшимся от метода [ближайшего соседа](http://habrahabr.ru/post/243285/#nearest-neighbor).

Слева метод ближайшего соседа, справа бикубический фильтр аффинных преобразований. Первый образец — уменьшение в 5,8 раз, различий практически нет. Второй — в 1,8 раз, отличия минимальные, на резких диагональных линиях видна лесенка.
В то же время для фильтра `ANTIALIAS` использовался высококачественный [алгоритм на основе сверток](http://habrahabr.ru/post/243285/#convolution), что давало одинаково хороший результат как для уменьшения, так и для увеличения.
Начиная с Pillow 2.7.0, высококачественный алгоритм на основе сверток используется для всех трех фильтров.


Слева бикубический фильтр на основе аффинных преобразований, справа — свертки. Свертки определенно выигрывают.
Если до того вы использовали какие-то ухищрения для улучшения качества при использовании билинейного или бикубического фильтра (например, уменьшение изображения за несколько шагов или предварительное размытие), теперь в них нет необходимости.
### Antialias переименован в Lanczos
Новая константа `Image.LANCZOS` была добавлена взамен `Image.ANTIALIAS`.
Когда метод `ANTIALIAS` был впервые представлен, он был единственным высококачественным методом, основанным на свертках. И его имя отражало этот факт. Теперь, когда все методы основаны на свертках, они все стали «сглаживающими». А настоящее название фильтра, которое использовалось раньше для этой константы — фильтр Ланцоша.
Само собой, старая константа оставлена для обратной совместимости и является псевдонимом для новой. Шутка для лингвистов: Antialias is alias now.
### Качество фильтра Ланцоша при увеличении
Как ни странно, с качеством сверок тоже было не все в порядке. В предыдущих версиях был баг, из-за которого качество фильтра Ланцоша при увеличении было практически таким же, как у фильтра `BILINEAR`. Этот баг был исправлен.


Слева результат увеличения в 4,3 раза предыдущей версии, справа — Pillow 2.7.0. Картинки слева одновременно более размытые и пикселизованные.
### Качество бикубического фильтра при увеличении
Бикубический фильтр, реализованный для аффинных преобразований, давал резкую, слегка пикселизованную картинку при увеличении. Бикубический фильтр, реализованный для сверток, немного мягче.


Слева результат увеличения в 4,3 раза предыдущей версии, справа — Pillow 2.7.0. Картинки слева более пикселизованные (имеют более ощутимые границы пикселей). В то же время диагональные линии на первом примере более четкие и менее подвержены эффекту лесенки. И то и другое — влияние параметра «a» в [бикубическом уравнении](http://en.wikipedia.org/wiki/Bicubic_interpolation#Bicubic_convolution_algorithm). Избежать обоих эффектов можно только с помощью более качественного фильтра Ланцоша.
### Производительность ресайза
В общем случае [свертки](http://habrahabr.ru/post/243285/#convolution) — более затратный алгоритм для уменьшения, потому что в отличие от [аффинных преобразований](http://habrahabr.ru/post/243285/#affine-transformations), он учитывает все пиксели исходного изображения. Из-за этого чистая производительность билинейного и бикубического фильтров может быть ниже, чем раньше. С другой стороны, если вы до этого были удовлетворены качеством билинейного и бикубического фильтров для уменьшения, возможно вам стоит подумать над использованием `NEAREST` фильтра, который давал практически такой же результат. Это существенно увеличит производительность.
В то же время одно из существенных улучшений Pillow 2.7.0 в том, что производительность сверток для уменьшения была увеличена в среднем в 2 раза по сравнению с предыдущей версией и даже по сравнению с ImageMagick. Производительность увеличения свертками для фильтра `BILINEAR` оказалась быстрее в полтора раза, для `BICUBIC` — в четыре, а для `LANCZOS` осталась на том же уровне.
Т.к. скорее всего вы не использовали в своем приложении ничего, кроме `LANCZOS` (бывший `ANTIALIAS`), то производительность при уменьшении для вас должна увеличиться в среднем в два раза. Если использование Ланцоша для вас было вынужденной мерой из-за низкого качества остальных фильтров, то теперь вы можете перейти, например, на билинейный фильтр. Это увеличит производительность еще примерно в 2 раза для уменьшения и примерно на 30% для увеличения.
### Фильтр по умолчанию для `Image.thumbnail()`
В Pillow 2.5 фильтр по умолчанию для `Image.thumbnail()` был изменен с `NEAREST` на `ANTIALIAS`. Этот фильтр был выбран по причине, неоднократно озвученной выше — низкое качество остальных фильтров. В Pillow 2.7.0 фильтр по умолчанию вновь изменен, в этот раз на `BICUBIC`, потому что он немного быстрее. На самом деле Ланцош не дает каких-либо преимуществ после использования метода `Image.draft()` внутри `Image.thumbnail()`, который уменьшает изображение с помощью библиотеки `libjpeg` и использует для этого [суперсемплинг](http://habrahabr.ru/post/243285/#supersampling), а не свертки.
Транспонирование изображений
----------------------------
Новый метод `Image.TRANSPOSE` был добавлен для функции `Image.transpose()` в дополнение к уже существующим `FLIP_LEFT_RIGHT`, `FLIP_TOP_BOTTOM`, `ROTATE_90`, `ROTATE_180`, `ROTATE_270`. `TRANSPOSE` — это алгебраическое транспонирование, т.е. отражение изображения относительно его основной диагонали.
Производительность методов `ROTATE_90`, `ROTATE_270` и `TRANSPOSE` была существенно увеличена для больших изображений, не помещающихся в кэш процессора.
Эти три метода объединяет то, что в них пиксели берутся из строк, а помещаются в столбцы. Такой шаблон доступа к памяти оказывается очень не эффективным для больших изображений, потому что данные успевают вытесниться из кэша процессора за один проход и их приходится заново загружать из памяти для следующего прохода.
В новой версии изображение разбивается на логические квадраты размером в 128×128 пикселей, и операции над пикселями производятся последовательно внутри каждого квадрата. Это позволяет существенно сократить дистанцию, которую проходит процессор на каждой строке, в результате чего данные не успевают вытесниться из кэша (память, необходимая для одного квадрата, равна 64Кб).
Гауссово размытие и контурная резкость
--------------------------------------
Реализация `ImageFilter.GaussianBlur` была заменена на последовательное применение бокс-фильтров. Новая реализация основана на статье [Theoretical foundations of Gaussian convolution by extended box filtering](http://www.mia.uni-saarland.de/Publications/gwosdek-ssvm11.pdf) от Mathematical Image Analysis Group. Так как реализация `ImageFilter.UnsharpMask` базируется на Гауссовом размытии, все, что описано в этой секции, также применимо и к ней.
### Радиус размытия
В предыдущих версиях Pillow была ошибка, из-за которой радиус размытия (стандартное отклонение Гауссианы) на самом деле задавал его диаметр. Поэтому, например, чтобы размыть изображение на радиус 5, нужно было указывать значение 10. Ошибка была исправлена, и теперь значение радиуса интерпретируется так же, как во всем остальном программном обеспечении.
Если до этого вы использовали Гауссово размытие с определенным радиусом, вам нужно поделить его значение на два.
### Производительность размытия
Время вычисления бокс-фильтра постоянно относительно его радиуса и зависит только от размеров входного изображения. Т.к. новая реализация Гауссового размытия основана на бокс-фильтре, её вычисление также не зависит от радиуса размытия.
Для радиуса в 1 пиксель новая реализация работает 5 раз быстрее, для радиуса 10 — в 18 раз, для радиуса 50 — уже в 85 раз. Ваш дизайнер, рисующий интерфейсы в стиле iOS 8, должен быть доволен.
### Качество размытия
Теоретически при Гауссовом размытии в вычислении каждой точки конечного изображения должны участвовать все точки исходного с определенными коэффициентами. На практике коэффициенты точек дальше 3×стандартное отклонение настолько малы, что учитывать их нет смысла.
Предыдущая реализация учитывала только пиксели в радиусе 2×стандартное отклонение для каждого конечного пикселя. Этого было недостаточно, поэтому качество было хуже в сравнении с другими реализациями Гауссова размытия.
Несмотря на то, что новая реализация является лишь математической аппроксимацией, она не содержит такого бага.


Слева результат размытия с радиусом 5 в предыдущей версии (с учетом бага с удвоением радиуса), справа — в новой. Слева видны резкие границы объектов.
---
Все эти изменения уже работают на наших серверах. Благодаря им мы повысили качество и скорость [API для обработки картинок на лету](https://uploadcare.com/documentation/cdn/#image-operations). Также мы реализовали операцию [быстрого блюра](https://uploadcare.com/documentation/cdn/#operation-blur). Но это еще не все. Мы готовим следующий большой шаг для Pillow, о котором объявим чуть позже. | https://habr.com/ru/post/247219/ | null | ru | null |
# Portable-изируемся на примере Firefox-а
Началось это из-за дружеского многомесячного вялотекущего холивара «Linux vs. Windows» между мной и нашим сис.админом.
Однажды была затронута проблема о защищенности системы и пользовательских каталогах. Встала задача показать что в Windows есть полноценный аналог линуксового %home%.
Старые виндопользователи знают, что пользовательские настройки начали храниться в специально для этого предназначенном каталоге еще в Windows 9х. Но это было мягко говоря «совсем не то». (Update: в комментах поправляют: это появилось еще в NT 3, причем сразу с хорошей реализацией.)
С приходом NT 5 (Win2k, WinXP), где был безопасности уделили больше внимания, все пользовательские профили стали храниться в той самой «Documents and Settings». Правда при желании и прямых руках это может быть и другой каталог, например «Users».
Примерно тогда же появились глобальные переменные для указания текущего пользователя и его домашнего каталога. Видать, навеяло из мира Linux. Имхо, ничего зазарного в этом нет :)
Узнать значение всех глобальных переменных можно выполнив команду SET в командной строке. Для тех кто совсем в танке: Win+R, печатаем cmd, жмем Enter, печатаем set, жмем Enter.
Текущие гайдлайны Майкрософта рекомендуют использовать именно глобальные переменные, для того чтобы выяснить, где программе можно хранить свои настройки. К сожалению, многие это игнорируют, а некоторые и вовсе до сих пор упорно хранят файл с настройками в своей директории. Руки бы поотрывал.
Поспорили мы немного о пользовательских каталогах да забыли до поры до времени.
Пока однажды при очередном обновлении FireFox-а на официальном сайте я не нашел его портативной версии. Хотелось свежую и именно портативную версию. Тут я вспомнил, что FireFox кроссплатформенный, и скорее всего в Linux-е он хранит настройки «там, где надо». И скорее всего в Windows он хранит их там же. И выясняет, куда хранить «как надо» — через глобальные переменные. Чай разработчики FireFox-а профессионалы своего дела.
Итак, у нас на руках Windows XP, установленный FireFox последней версии и желание получить его портативный вариант.
Глобальные переменные иницилизируются при запуске Windows и входе пользователя в систему. Новый процесс получает значение глобальных переменных от родительского. Чаще всего родительским процессом является Explorer. Но каждый процесс может переопределить любую глобальную переменную, но это новое значение переменой будет доступно только этому процессу и его дочерним процессам. У родительского процесса все останется по старому.
Переопределить глобальную переменную в командном интерпретаторе cmd можно той же командой set.
Значит можно в cmd переопределить переменную, запустить нужную программу, завершить работу cmd. Profit!
Мысль только оформилась, а руки уже начали ваять скрипт. Для начала выясняем где FireFox хранит наш настройки/профили. Это оказались
c:\Documents and Settings\Гость\Local Settings\Application Data\Mozilla\
и
c:\Documents and Settings\Гость\Application Data\Mozilla\
Сам FireFox-профиль лежит здесь
c:\Documents and Settings\Гость\Application Data\Mozilla\Firefox\Profiles\
и у меня назывался «6rynxm6u.default». Случайная комбинация символов. У вас может быть другая.
В каталоге FireFox-а создаем папку «toxicdream» (ну или как вы захотите) — это будет нашим тем самым %home%. Внутри нее создаем "\Local Settings\Application Data\" и "\Application Data\Mozilla\". Найденные выше каталоги «Mozilla» переносим в соответствующие.
Смотрим какие переменные Windows могут нам помочь:
`ALLUSERSPROFILE=C:\Documents and Settings\All Users
APPDATA=C:\Documents and Settings\Гость\Application Data
HOMEDRIVE=C:
HOMEPATH=\Documents and Settings\Гость
USERNAME=Гость
USERPROFILE=C:\Documents and Settings\Гость`
Попробуем обойтись малой кровью — перекрываем только APPDATA и смотрим что получилось. Создаем
в каталоге Firefox файл «firefox.cmd» с текстом
````
%~d0%
cd %~dp0%
set APPDATA=%~dp0%toxicdream\Application Data
start firefox.exe
````
Первые две строки указывают, что надо переключиться на диск и перейти в каталог, где лежит сам файл «firefox.cmd», чтобы рабочий каталог для запускаемого FireFox был именно этот каталог.
Запускаем. Ну почти получилось — профиль пользователя грузится.
С «Local Settings» придется повозиться. После перекрытия USERPROFILE и USERNAME лисичка все равно лезет не туда куда ей сказали. Надо перекрыть еще HOMEPATH и соответственно HOMEDRIVE
````
%~d0%
cd %~dp0%
set APPDATA=%~dp0%toxicdream\Application Data
set HOMEDRIVE=%~d0%
set HOMEPATH=%~p0%toxicdream
set USERNAME=toxicdream
set USERPROFILE=%~dp0%toxicdream
start firefox.exe
````
Ну а чтобы уж наверняка перекроем еще ALLUSERSPROFILE и TEMP/TMP. Итоговый скрипт такой
````
%~d0%
cd %~dp0%
set ALLUSERSPROFILE=%~dp0%toxicdream
set APPDATA=%~dp0%toxicdream\Application Data
set HOMEDRIVE=%~d0%
set HOMEPATH=%~p0%toxicdream
set TEMP=%~dp0%toxicdream\Local Settings\Temp
set TMP=%~dp0%toxicdream\Local Settings\Temp
set USERNAME=toxicdream
set USERPROFILE=%~dp0%toxicdream
start firefox.exe
````
Напоминаю — это для Windows 5.x, то есть Windows 2000, Windows XP и Windows 2003.
Текст скрипта для Win7:
````
%~d0%
cd %~dp0%
set ALLUSERSPROFILE=%~dp0%toxicdream
set APPDATA=%~dp0%toxicdream\Application Data
set HOMEDRIVE=%~d0%
set HOMEPATH=%~p0%toxicdream
set LOCALAPPDATA=%~dp0%toxicdream\Application Data\Local
set TMP=%~dp0%toxicdream\Application Data\Local\Temp
set TEMP=%~dp0%toxicdream\Application Data\Local\Temp
set USERNAME=toxicdream
set USERPROFILE=%~dp0%toxicdream
start firefox.exe
````
Ну вот, теперь все работает как часы. Можно даже обновляться с сохранением всех настроек. И не надо никого ждать или мучаться с ThInstall и ему подобными. Правда тут всплывает еще один эффект: все (ну или почти все) программы запущенные из нашего FireFox будут использовать наш каталог «toxicdream» для своей работы. Поэтому не удивляйтесь если вдруг например, Download Master начнет показывает список загрузок то так, то этак.
**PS**
В Viste и Seven профиль Firefox-а хранится в другом месте. Плюс там еще добавили переменную для того самого «Local Settings», вернее уже «Local» — %LOCALAPPDATA%.
Придется при каждой смене системы перемещать файлы из «Local Settings» в «Application Data\Local».
Можно это все также прописать в скрипте. К сожалению у меня сейчас под рукой нет Win7, поэтому оставляю это для доработки следующими энтузиастами.
Для затравки: выяснить версию Windows можно командой ver. Тут есть небольшие грабли — вывод команды отличается от версии к версии, и может быть, от языка системы. Код, выявляющий версию однозначно:
````
echo off
for /f "usebackq tokens=2 delims=[]" %%i in (`ver`) do set osver=%%i
for /f "usebackq tokens=2 delims=. " %%i in (`set osver`) do set osver=%%i
if %osver% == 6 (
echo Win7 or Vista
) else if %osver% == 5 (
echo W2k or XP
)
pause
````
**UPD 1**
> запустив файрфокс вот так: firefox -profile «E:\myprofile» мы достигаем нашей цели. То есть надо создать ярлык и всё будет работать как надо
Минусы:
— жесткая привязка к путям
— создание/модификация ярлыка
— мусор в «Local Settings»
**UPD 2**
> портативный огнелис гуглится не просто быстро, а очень быстро — mozilla-russia.org/products/firefox/ — раз и portableapps.com/apps/internet/firefox\_portable — два.
Минусы:
— не всегда последняя версия
— лишний процесс в памяти
— иногда возникают проблемы при обновлении, например, лично у меня были при переходе на Windows 7
**UPD 3**
> Почему в блоге «Огненый лис»?
Мне показалось для пользователей Огнелиса будет интересней.
Для блога Windows слишком элементарный уровень.
Спасибо за плюсы :) Следующий пост будет про внутреннее устройство FireFox, вернее про то, что, как и где он хранит. | https://habr.com/ru/post/111704/ | null | ru | null |
# Microsoft выпустила накопительный пакет обновлений для Windows 7 SP1

По [многочисленным просьбам](http://www.zdnet.com/article/whatever-happened-to-that-promised-windows-7-convenience-rollup/) компания Microsoft всё-таки сделала хорошее дело и [собрала в единый пакет](https://blogs.technet.microsoft.com/windowsitpro/2016/05/17/simplifying-updates-for-windows-7-and-8-1/) все обновления для операционной системы Windows 7 с момента выхода SP1 в 2011 году. Неофициально пакет обновлений [KB3125574](https://support.microsoft.com/en-us/kb/3125574) уже называют [Windows 7 SP2](http://www.zdnet.com/article/microsoft-comes-through-with-rollup-of-updates-and-fixes-for-windows-7/), хотя это не совсем правильно.
Пакет обновлений не включает в себя только IE11 (он обновляется отдельно), апдейты для .NET и [некоторые другие](https://support.microsoft.com/en-us/kb/3125574) обновления. Но всё остальное там есть: ключевые апдейты ядра, обновления безопасности, исправления и т.д.: [полный список файлов в csv](http://download.microsoft.com/download/E/B/0/EB084E02-4173-444E-9438-53972AE2F9E0/3125574.csv).
Накопительный пакет [опубликован](https://blogs.technet.microsoft.com/windowsitpro/2016/05/17/simplifying-updates-for-windows-7-and-8-1/) на официальном сайте Microsoft Update Catalog. Как уже [предупреждала Microsoft](https://geektimes.ru/post/275246/), сайт работает только в браузере IE6 или более старшей версии.
Установка целого пакета гораздо удобнее, чем обновление в обычном режиме, потому что проходит только с одной перезагрузкой.

Одновременно Microsoft объявила, что с этого момента обновления, не связанные с безопасностью, для Windows 7 SP1, Windows 8.1, Windows Server 2008 R2 SP1, Windows Server 2012 и Windows Server 2012 R2 будут выходить единым пакетом **ежемесячно**. То есть теперь можно устанавливать критические апдейты безопасности в реальном времени через WSUS, а все остальные апдейты — раз в месяц скачивать (или не скачивать) с Microsoft Update Catalog. Такой способ, наверное, удобнее и безопаснее.
Предупреждение. В кумулятивный апдейт Windows 7 входят обновления, которые добавляют функции телеметрии и готовят к обновлению на Windows 10. Будьте осторожны!
> Апдейт для Windows 7 x64 (KB3068708) — KB3068708 устанавливает сервис телеметрии, готовит систему к апгрейду на Windows 10, CEIP Win7, Win8.1, Svr2008R2, Svr2012R2
>
> Апдейт для Windows 7 x64 (KB3075249) — KB3075249 добавляет телеметрию в consent.exe (UAC-трекинг) Win7 Win8.1 RT8.1, Svr2008R2, Svr2012R2
>
> Апдейт для Windows 7 x64 (KB3080149) — исправления часовых поясов, ещё больше телеметрии, возможно CEIP в Win7 SP1, 8.1, Svr2008R2, Svr2012R2
Для удаления ненужных обновлений используйте команду:
`wusa.exe /kb:3080149 /uninstall /quiet /norestart`
Вместо `/kb:3080149` указывайте нужный номер обновления для удаления.
Полный список вредоносных и подозрительных обновлений Windows 7 см. [здесь](http://www.dslreports.com/forum/r30348398-WIN7-Win-7-updates-to-avoid-or-be-careful-with). | https://habr.com/ru/post/394085/ | null | ru | null |
# Определение нечетких дубликатов для коротких документов
Хочу поделиться простым, но эффективным алгоритмом определения нечетких копий документов. Есть много статей об использовании для этой цели [алгоритма шинглов](http://www.codeisart.ru/python-shingles-algorithm/). Ходят слухи, что большие поисковые системы используют очень похожий алгоритм у себя. Однако, все признают, что шинглы плохо подходят для коротких (3-5 предложений) документов. А в моей задаче надо было работать именно с такими документами. В качестве решения предлагают закольцовывать текст, чтобы как бы сделать из него длинный, но мне кажется, что это не очень правильное решение, точность распознавания дублей все равно будет низкая.
Итак, описание алгоритма, который я использовал:
#### Сначала нужно проиндексировать коллекцию текстов
1. Преобразуем каждый текст коллекции в массив из слов этого текста, предварительно вырезав html-тэги, цифры и прочую ненужную информацию.
2. Отберем 15 самых длинных слов, причем те, что короче 4 символов, не берем в любом случае, даже если сам текст короче 15 слов.
3. Для каждого отобранного слова подсчитываем контрольную сумму, например crc32, и пишем суммы в базу данных в формате: «id суммы», «id документа», «сумма».
4. В другую таблицу запишем некоторые характеристики самого текста: «md5» и «кол-во слов, которые попали в таблицу с контрольными суммами». Второе поле нужно для тех текстов, для которых не удалось найти 15 слов подходящей длинны, условно это длинна документа в словах.
Я использую таблицы со следующей структурой:
`CREATE TABLE `items_hashes` (
`id` int(11) NOT NULL auto_increment,
`doc_id` int(11) NOT NULL,
`word_hash` int(11) NOT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `items_hashes_summary` (
`doc_id` int(11) NOT NULL,
`full_hash` char(32) NOT NULL,
`length` smallint(11) NOT NULL,
PRIMARY KEY (`doc_id`)
);`
#### Проверка текста на уникальность
После того, как все документы проиндексированы, мы можем проверить любой текст на уникальность в пределах нашей коллекции. Для этого нужно:
1. Выполнить проверку на полное совпадение с каким-либо документом из коллекции используя данные в таблице items\_hashes\_summary. Если такое совпадение найдено, то следующие шаги смысла не имеют, иначе идем дальше.
2. Для проверяемого текста выполнить первые три шага из предыдущего списка, но пока не записывать контрольные суммы в базу.
3. Найти в базе документы, в которых есть совпадающие с анализируемым документом слова и количество этих совпадений. Сделать это можно примерно вот таким запросом:
`SELECT doc_id, COUNT(id) as intersects FROM items_hashes
WHERE (word_hash = %cur_doc_hash1% OR word_hash = %cur_doc_hash2% OR ... )
GROUP BY doc_id
HAVING intersects > 1`
(на больших коллекциях стоит писать, например HAVING intersects > 5 или даже больше, т.к. иначе дальнейшая обработка может тормозить)
4. Теперь находим «степень схожести» в процентом с каждым из найденных документов, которая вычисляется по формуле:
$similarity = ($intersecs/$length)\*100,
где $length — длинна самого короткого из сравниваемых документов;
$intersecs — количество совпадающих слов.
Я считаю, что документ неуникален если его «степень схожести» с каким-либо документом коллекции более 80%, для ваших задач возможно нужно будет подобрать другое значение.
Если у вас есть задача найти пары похожих текстов уже внутри проиндексированной коллекции, то это тоже можно сделать, надо только модифицировать запрос приведенный в предпоследнем шаге, чтобы не искались пересечения документа с самим собой.
Все это работает довольно быстро. Во всяком случае на коллекции из 12 тыс. документов и очень слабом VPS никаких проблем нет. Тестировал также на 70 тыс. документов в виртуалке, тоже все было очень быстро.
Пощупать как оно реально работает можно [здесь](http://www.terdo.ru/). Можете взять любое объявление, поменять что-то и попробовать добавить как новое. Должно сразу сказать, что очень похожее уже есть в базе. Только если вдруг вы измените объявление слишком сильно и оно добавится, то не забудьте его потом удалить пожалуйста ;)
Пользователи все-таки умудряются публиковать одинаковые по содержанию объявления, но для этого им приходится переписывать практически все другими словами. Ложных срабатываний пока замечено не было.
#### Реализация на PHP
Чтобы было понятнее, выдрал из проекта два класса, которые реализуют этот алгоритм и положил на pastebin.com: [класс, для получения хэшей документа](http://pastebin.com/f34ba590d) (универсальный и готовый к использованию в любом проекте) и [класс модели](http://pastebin.com/f68bfa0ce) (не совсем готов для использования в любом проекте, но думаю не сложно будет модифицировать).
P.S. Это мой первый топик на хабре, так что не бейте больно если что-то не так.
**UPD:** Спасибо всем за карму, теперь могу перенести в блог «Разработка». | https://habr.com/ru/post/52120/ | null | ru | null |
# JavaScript: многоликие функции
Если вы занимаетесь JavaScript-разработкой, о какой бы платформе ни шла речь, это значит, что вы способны оценить значение функций. То, как они устроены, те возможности, которыми они наделяют программиста, делают их поистине универсальным и незаменимым инструментом. Так думают и разработчики [Test262](https://github.com/tc39/test262) — официального набора тестов, который предназначен для проверки JavaScript-движков на совместимость со стандартом EcmaScript.
[](https://habrahabr.ru/company/ruvds/blog/332020/)
В этом материале они дают обзор синтаксических форм определения функций. В частности, речь пойдёт о том, что существует в JS со дня его появления, о том, что появилось в нём за годы развития, и о том, чего стоит ждать в будущем.
Традиционные подходы
--------------------
### ▍Объявление функции и функциональное выражение
Самые известные и широко используемые способы определения функций в JS, кроме того, являются и самыми старыми. Это — объявление функции (Function Declaration) и функциональное выражение (Function Expression). Первый способ был частью исходного варианта языка с 1995-го года и был отражён в [первой редакции](https://www.ecma-international.org/publications/files/ECMA-ST-ARCH/ECMA-262,%201st%20edition,%20June%201997.pdf) спецификации, в 1997-м. Второй представлен в [третьей редакции](https://www.ecma-international.org/publications/files/ECMA-ST-ARCH/ECMA-262,%203rd%20edition,%20December%201999.pdf), в 1999-м.
Если присмотреться к этим способам определения функций, можно увидеть три варианта их использования:
```
// Объявление функции
function BindingIdentifier() {}
```
```
// Именованное функциональное выражение
// (BindingIdentifier недоступно за пределами этой функции)
(function BindingIdentifier() {});
```
```
// Анонимное функциональное выражение
(function() {});
```
Тут, однако, стоит учесть, что у анонимного функционального выражения всё-таки может быть «имя». [Вот](https://bocoup.com/blog/whats-in-a-function-name) хороший материал об именах функций.
### ▍Конструктор Function
Если говорить об «API функций» в JavaScript, то начать такой разговор стоит с конструктора `Function`. Принимая во внимание изначальный подход к проектированию языка, по аналогии с другими конструкциями, рассмотренное выше объявление функции можно интерпретировать в виде «литерала» к API конструктора `Function`.
Конструктор `Function` предоставляет средства для определения функций путём указания параметров и тела функции посредством строковых аргументов. Последний из этих аргументов представляет собой тело функции:
```
new Function('x', 'y', 'return x ** y;');
```
Важно обратить внимание на то, что определяя функции с использованием конструкторов, мы вынуждены прибегать к динамическому исполнению кода, что чревато проблемами с безопасностью.
На практике конструктор `Function` используется очень редко, хотя он присутствует в языке с первой редакции EcmaScript. В большинстве случаев у него есть гораздо более удобные альтернативы.
Новые подходы
-------------
В стандарте [ES2015](https://www.ecma-international.org/ecma-262/6.0/index.html) были представлены несколько новых синтаксических форм определения функций. У них огромное количество вариантов.
### ▍Не такое уж и анонимное объявление функции
Если у вас есть опыт работы с модулями ES, вам должна быть знакома новая форма анонимного объявления функции. Хотя это очень похоже на анонимное функциональное выражение, такая функция, на самом деле, имеет [связанное имя](https://tc39.github.io/ecma262/#sec-function-definitions-static-semantics-boundnames) `"*default*"`. В результате, функция получается не такой уж и анонимной.
```
// Не такое уж и анонимное объявление функции
export default function() {}
```
Кстати, такое «имя» не является корректным идентификатором и привязка тут не создаётся.
### ▍Способы определения методов объектов
В свойствах объектов, представляющих собой функции, легко можно узнать функциональные выражения — именованные и анонимные. Обратите внимание на то, что эти конструкции не являются некими особыми синтаксическими формами определения функций. Это — уже рассмотренные выше функциональные выражения, которые используются в инициализаторах объекта. Эти конструкции были представлены в ES3.
```
let object = {
propertyName: function() {},
};
let object = {
// (BindingIdentifier недоступен за пределами этой функции)
propertyName: function BindingIdentifier() {},
};
```
Вот объявления свойств-аксессоров, представленные В ES5:
```
let object = {
get propertyName() {},
set propertyName(value) {},
};
```
В ES2015 появился сокращённый синтаксис для определения методов объектов, который можно использовать как в формате обычного имени свойства, так и с квадратными скобками, в которые заключено строковое представление имени. То же самое касается и свойств-аксессоров:
```
let object = {
propertyName() {},
["computedName"]() {},
get ["computedAccessorName"]() {},
set ["computedAccessorName"](value) {},
};
```
Похожий подход можно использовать и для определения методов прототипов в объявлениях классов (Class Declarations) и в выражениях классов (Class Expressions):
```
// Объявление класса
class C {
methodName() {}
["computedName"]() {}
get ["computedAccessorName"]() {}
set ["computedAccessorName"](value) {}
}
```
```
// Выражение класса
let C = class {
methodName() {}
["computedName"]() {}
get ["computedAccessorName"]() {}
set ["computedAccessorName"](value) {}
};
```
То же самое применимо и к статическим методам классов:
```
// Объявление класса
class C {
static methodName() {}
static ["computedName"]() {}
static get ["computedAccessorName"]() {}
static set ["computedAccessorName"](value) {}
}
```
```
// Выражение класса
let C = class {
static methodName() {}
static ["computedName"]() {}
static get ["computedAccessorName"]() {}
static set ["computedAccessorName"](value) {}
};
```
### ▍Стрелочные функции
Стрелочные функции, которые появились в ES2015, наделали много шума, однако, в итоге приобрели широкую известность и популярность. Существует две формы стрелочных функций. Первая — это краткая форма (Concise Body), которая не предусматривает наличия фигурных скобок после стрелки, там находится лишь выражение присваивания (Assignment Expression). Вторая — блочная форма (Block Body). Здесь, после стрелки, идёт тело функции в фигурных скобках, которые могут быть пустыми, либо содержать некоторое количество выражений.
Если стрелочная функция не имеет аргументов, или их больше одного, то, что находится перед стрелкой, должно быть заключено в круглые скобки. Если же такая функция имеет лишь один аргумент, использование круглых скобок необязательно.
На практике вышесказанное означает наличие множества вариантов определения стрелочных функций:
```
// Краткая форма Функции без параметров
(() => 2 ** 2);
```
```
// Краткая форма функции с одним параметром
(x => x ** 2);
```
```
// Функция с одним параметром и телом функции
(x => { return x ** 2; });
```
```
// Краткая форма функции со списком параметров в скобках
((x, y) => x ** y);
```
В последней части примера показан набор параметров стрелочной функции в скобках (covered parameters). Такой подход даёт возможность работы со списком параметров, например, позволяя использовать шаблоны деструктуризации:
```
({ x }) => x
```
Параметр без скобок (uncovered parameter), как уже было сказано, позволяет задать стрелочную функцию, имеющую лишь один аргумент. Перед этим единственным аргументом можно использовать ключевые слова `await` или `yield —` если стрелочная функция определена внутри асинхронной функции или генератора, но на этом возможности такого синтаксиса заканчиваются.
Стрелочные функции можно использовать в инициализаторах объектов и при задании их свойств. Тут используются стрелочные функциональные выражения (Arrow Function Expression):
```
let foo = x => x ** 2;
```
```
let object = {
propertyName: x => x ** 2
};
```
### ▍Генераторы
Генераторы имеют особый синтаксис. Заключается он в добавлении звёздочки к определениям функций, за исключением стрелочных функций и объявлений геттеров и сеттеров. В результате получаются объявления функций и методов, функциональные выражения, и даже конструкторы. Взглянем на всё это в следующем примере:
```
// Объявление генератора
function *BindingIdentifer() {}
```
```
// Ещё одно объявление не слишком анонимного генератора
export default function *() {}
```
```
// Выражение генератора
// (BindingIdentifier не доступен за пределами этой функции)
(function *BindingIdentifier() {});
```
```
// Анонимное выражение генератора
(function *() {});
```
```
// Определение методов
let object = {
*methodName() {},
*["computedName"]() {},
};
```
```
// Определение методов в объявлении класса
class C {
*methodName() {}
*["computedName"]() {}
}
```
```
// Определение статических методов в объявлении класса
class C {
static *methodName() {}
static *["computedName"]() {}
}
```
```
// Определение методов в выражении класса
let C = class {
*methodName() {}
*["computedName"]() {}
};
```
```
// Определение статических методов в выражении класса
let C = class {
static *methodName() {}
static *["computedName"]() {}
};
```
ES2017
------
### ▍Асинхронные функции
В июне 2017-го был опубликован стандарт ES2017, в котором, после нескольких лет разработки, были представлены асинхронные функции (Async Functions). Несмотря на то, что стандарт буквально только что «вышел из типографии», множество разработчиков уже пользуется асинхронными функциями благодаря [Babel](https://babeljs.io/).
Асинхронные функции позволяют удобно описывать асинхронные операции. Благодаря их использованию код получается чистым и единообразным. При вызове асинхронной функции будет возвращён промис, который разрешится после того, как асинхронная функция возвратит результат своей работы. Если в асинхронной функции встречается выражение с ключевым словом `await`, она может приостановить работу, и, дождавшись выполнения выражения, например, возвратить его результаты.
Синтаксис асинхронных функций не особенно отличается от того, что уже было рассмотрено. Главная их особенность — префикс `async`:
```
// Объявление асинхронной функции
async function BindingIdentifier() { /**/ }
```
```
// Ещё одно объявление не такой уж анонимной асинхронной функции
export default async function() { /**/ }
```
```
// Именованное асинхронное функциональное выражение
// (BindingIdentifier недоступно за пределами этой функции)
(async function BindingIdentifier() {});
```
```
// Анонимное асинхронное функциональное выражение
(async function() {});
```
```
// Асинхронные методы
let object = {
async methodName() {},
async ["computedName"]() {},
};
```
```
// Асинхронные методы в объявлении класса
class C {
async methodName() {}
async ["computedName"]() {}
}
```
```
// Статические асинхронные методы в объявлении класса
class C {
static async methodName() {}
static async ["computedName"]() {}
}
```
```
// Асинхронные методы в выражении класса
let C = class {
async methodName() {}
async ["computedName"]() {}
};
```
```
// Статические асинхронные методы в выражении класса
let C = class {
static async methodName() {}
static async ["computedName"]() {}
};
```
### ▍Асинхронные стрелочные функции
Ключевые слова `async` и `await` можно использовать не только с традиционными объявлениями функций и функциональными выражениями. Они совместимы и со стрелочными функциями:
```
// Краткая форма функции с одним параметром
(async x => x ** 2);
```
```
// Функция с одним параметром, за которым следует тело функции
(async x => { return x ** 2; });
```
```
// Краткая форма функции со списком параметров в скобках
(async (x, y) => x ** y);
```
```
// Список параметров в скобках, за которым следует тело функции
(async (x, y) => { return x ** y; });
```
Заглянем в будущее
------------------
### ▍Асинхронные генераторы
В будущих версиях спецификации JavaScript применение ключевых слов `async` и `await` будет расширено и на генераторы. За ходом работ по реализации этой функциональности можно наблюдать [здесь](https://github.com/tc39/proposal-async-iteration). Как вы, вероятно, догадались, речь идёт о комбинации ключевых слов `async/await` и существующих форм определения генераторов — через объявления и выражения.
Асинхронный генератор, при вызове, возвращает итератор, метод которого `next()` возвращает промис, который будет разрешён объектом, являющимся тем, что обычно возвращает итератор. В обычных условиях при вызове этого метода выполняется прямой возврат результата.
Асинхронные генераторы можно найти там, где уже имеются обычные функции-генераторы.
```
// Объявление асинхронного генератора
async function *BindingIdentifier() { /**/ }
```
```
// Объявление не такого уж и анонимного асинхронного генератора
export default async function *() {}
```
```
// Асинхронное выражение генератора
// (BindingIdentifier не доступен за пределами этой функции)
(async function *BindingIdentifier() {});
```
```
// Анонимное выражение генератора
(async function *() {});
```
```
// Определение методов
let object = {
async *propertyName() {},
async *["computedName"]() {},
};
```
```
// Определение методов прототипа в объявлении класса
class C {
async *propertyName() {}
async *["computedName"]() {}
}
```
```
// Определение методов прототипа в выражении класса
let C = class {
async *propertyName() {}
async *["computedName"]() {}
};
// Определение статических методов в объявлении класса
class C {
static async *propertyName() {}
static async *["computedName"]() {}
}
```
```
// Определение статических методов в выражении класса
let C = class {
static async *propertyName() {}
static async *["computedName"]() {}
};
```
Итоги. О JavaScript-движках, тестах и функциях
----------------------------------------------
Представим себе путь нового способа определения функции от идеи до рабочего кода. В упрощённом виде это выглядит так. Сначала идея становится предложением к стандарту, потом входит в стандарт, дальше идёт её реализация в JS-движках, потом — изучение программистами и практическое применение.
Вклад в этот процесс тех, кто работает над Test262, заключается в том, чтобы, разобравшись со стандартами, подготовить испытания, проверяющие новые языковые конструкции с учётом уже существующих. Такой подход означает огромнейшую работу по созданию тестов, которую нерационально возлагать на человека. Например, проверка аргументов по умолчанию должна быть проведена со всеми формами функций, в подобных вещах нельзя ограничиться, скажем, только простой формой объявления функции. Всё это привело к разработке инструментария для создания тестов, что позволяет говорить о том, что испытаниям подвергается практически всё, что можно проверить.
Сейчас проект содержит набор [файлов с исходным кодом](https://github.com/tc39/test262/tree/master/src), которые состоят из разных тестовых сценариев и [шаблонов](https://github.com/tc39/test262/tree/master/src/function-forms/default).
Например, [тут](https://github.com/tc39/test262/tree/master/src/arguments) можно посмотреть, как проверяется свойство функции `arguments`, [тут](https://github.com/tc39/test262/tree/master/src/arguments) — тесты различных форм функций. Конечно, в Test262 есть ещё много всего. Скажем, [вот](https://github.com/tc39/test262/tree/master/src/dstr-binding) и [вот](https://github.com/tc39/test262/tree/master/src/dstr-assignment) — тесты, связанные с деструктурированием. В процессе работы над тестами получаются немаленькие pull-запросы, обнаруживаются и исправляются [ошибки](https://github.com/tc39/test262/pull/651). Всё это ведёт к постоянному росту качества Test262, а значит, к улучшению проверок JS-движков на соответствие спецификации EcmaScript. Это имеет прямое воздействие на JavaScript-индустрию. Чем больше программных конструкций будет идентифицировано и покрыто тестами, тем легче разработчикам движков будет внедрять новые возможности, тем стабильнее и надёжнее, в итоге, будут работать программы на JavaScript.
Уважаемые читатели! Какими способами определения функций в JavaScript вы пользуетесь чаще всего? | https://habr.com/ru/post/332020/ | null | ru | null |
# Разворачивание коротких ссылок в Firefox
В какой-то момент мне надоело, что сервисы сокращения ссылок посылают меня неизвестно куда. Не так давно я писал о [pdf эксплойте](http://habrahabr.ru/blogs/infosecurity/65927/), и риск наткнуться на такое чудо, кликая по короткой ссылке в чьём-нибудь твиттере меня совершенно не радовала.
Способов бороться с этим я нашёл два: разворачивание ссылок и контроль переходов (коды HTTP 3xx).
Итак, дано: Огнелис – браузер, bit.ly – объект изучения, Твиттер – среда. Куда пойти для решения проблемы? На официальный сайт [модулей для Firefox](https://addons.mozilla.org/)! Одним из первых нашлось собственное расширение для браузера от сервиса bit.ly, которое при наведении на ссылку показывало, куда она ведёт. Но помимо этого удобства, надстройка добавляла *в контекстное меню каждой ссылки* предложение её сократить. Без возможности это предложение *выключить* в настройках. Фирменное дополнение было с презрением выброшено.
Настало время для более действенных средств.
### Long URL Please
Если короткая ссылка куда-то ведёт – значит, это кому-то нужно. А нам нужно узнать, куда она ведёт. Веб-сайт с понятным названием [Long URL Please](http://www.longurlplease.com/) («Длинную ссылку, пожалуйста») предлагает установить своё [дополнение для Firefox](https://addons.mozilla.org/en-US/firefox/addon/9549), но также согласен работать из букмарклета.
Сервис делает ровно то, о чём говорится в названии: разворачивает в коде страницы короткие ссылки в длинные. Вот как это выглядит до и после:

И в первом, и во втором случае я навёл курсор мыши на первую ссылку в записи. Разница очевидна. Причём общий вид страницы не изменился!
### NoRedirect
[NoRedirect](https://addons.mozilla.org/en-US/firefox/addon/11787) – это плагин сравнимый с тяжёлой артиллерией.
Для начала процитирую официальное описание и комментарии автора:
> NoRedirect даёт пользователю контроль над HTTP перенаправлениями. Его можно использовать для запрета перехвата провайдерском DNS запроса, предпросмотра «сокращённых» ссылок (например, TinyURL), остановки назойливой переадресации «умных» страниц ошибок и т.п.
>
>
>
> *Кай Лю:*
> > Изначальным стимулом к созданию NoRedirect послужило разочарование в поисковом сервисе провайдера Verizon, который не всегда можно было отключить. При каждом столкновении с DNS ошибкой – напечатав несуществующий адрес, щёлкнув ссылку с опечаткой, упустив буквы при копировании адреса – меня перенаправляли на «полезную» страницу поиска Веризона, что означало одно: мне надо набить адрес заново, чтобы исправить опечатку.
> >
> >
> >
> > Такие пользовательско-враждебные сервисы внедрены многими интернет-провайдерами и некоторыми доменными регистраторами. Многие пользователи удивлялись перенаправлению, напечатав ".cm" вместо ".com". Кроме остановки таких редиректов, NoRedirect восстанавливает естественное поведение браузера: показ встроенной ошибки при попытке обратиться к несуществующему домену, и, если включена, активацию встроенной системы поиска по ключевым словам, – они будут защищены от перехвата ошибочных DNS запросов.
>
>
Все настройки аддона чрезвычайно просты. Вы указываете:
1. паттерн обработчика ссылок в виде регулярного выражения (regexp)
2. реагировать на перенаправления при адресации ***с*** контролируемого домена или ***на*** него
3. разрешать или блокировать перенаправление
4. должен ли браузер выдать стандартную DNS ошибку

Настройки по умолчанию защитят американских пользователей от DNS перехватов (провайдеры Роджерс, Веризон, Кокс и даже сервис ОпенДНС засветились в списке), а мы добавим свои правила.
Для безусловной блокировки всех перенаправлений создайте новое правило и переместите его в начало списка: `^http://.\*`, ни одной галочки не ставьте.
Теперь, если вы пойдёте по любой редирект-ссылке, вы увидите предупреждающую полоску, с реальным адресом, на которую можно кликнуть. С примером из обзора предыдущего плагина, это будет выглядеть следующим образом:

> Лирическое отступление: некоторые редирект-сервисы имеют встроенные средства контроля перехода по ссылкам. Так, **[TinyURL](http://tinyurl.com/)** позволяет [добавлить в браузер куки](http://tinyurl.com/preview.php), определяющий, переходить ли по ссылкам напрямую, или через сайт TinyURL с предпросмотром адреса. И теперь ссылка <http://tinyurl.com/hhabr> не приведёт вас неизвестно куда ;) Другой, ещё лучший пример – *курощатель ссылок* **[B23](http://b23.ru/)** при добавлении к любой своей ссылке-сокращению знака вопроса показывает о ней всю информацию <http://b23.ru/ssdv?>. Статистику работы сокращения bit.ly можно неочевидно получить, дописав к ссылке плюсик: [bit.ly/vanM5+](http://bit.ly/vanM5+). Список наверняка можно продолжить...
Если вы отличаетесь параноидальностью, на этом можно и успокоиться. Однако, предположим, подозрение ко всем и вся в вас не сидит. Тогда вы можете довольно гибко настроить плагин, вот ряд примеров:* разрешить все редиректы ***с*** сервиса b23.ru: `^http://b23\.ru [V] [V] [\_]`
* разрешать все редиректы ***на*** ЖЖ: `^http://[\w\-]+\.livejournal\.com [\_] [V] [\_]`
* контролировать все переходы ***с*** сервиса bit.ly: `^http://bit\.ly [V] [\_] [\_]`
Дальше всё ограничено только вашей фантазией. И не забудьте вытавить *ПРАВИЛЬНЫЙ ПОРЯДОК* следования правил: сначала разрешающие, потом запрещающие!
### Неожиданное
Я начал с правила контролировать все редиректы. Скорее всего, я чуть позже добавлю ряд правил, разрешающих редиректы на проверенных сайтах, однако, за время обкатки плагина вылез ряд интереснейших внутренностей веб-сайтов.
К примеру, реклама может выглядеть забавнее, чем обычно:


А конкурирующий, в части корпоративных блогов, сайт livehh.ru гоняет своих пользователей через некий свой hhid.ru:

А если по умолчанию включена запись куки, то добрый hhid.ru ещё и печеньками браузер пользователя накормит.
Если у вас есть подобные смешные примеры – не стесняйтесь постить в комменты!
### Но это ещё не всё!
Как бы ни были хороши ‘Long URL Please’ и ‘NoRedirect’, я всё равно советую вам пользоваться плагином [NoScript](https://addons.mozilla.org/en-US/firefox/addon/722) для большей безопасности ([о нём на Хабре](http://habrahabr.ru/search/?q=noscript&target_type=posts)). | https://habr.com/ru/post/66748/ | null | ru | null |
# Еще одно Canvas руководство [3]: Рисование изображений и текста, сохранение изображения и состояния
Введение
--------
В этой части мы рассмотрим давно избитую тему — рисование изображений, и еще не такую избитую — рисование текста. Рассмотрим все настройки для текста и как пример с использованием изученного рассмотрим написание инструмента построения графиков.
Рисование изображений
---------------------
### Объект изображения
Чтобы нарисовать изображение нужно создать его объект. В качестве конструктора выступает функция Image. Она не принимает аргументов, а чтобы установить путь к изображению нужно изменить свойство src полученного объекта. Давайте добавим в наш скрипт строку:
```
var img = new Image()
img.src = 'path.png'
```
### Загрузим изображение
Теперь стоит заметить что прежде чем рисовать изображение его стоит загрузить для этого добавим обработчик события load для объекта img, добавим его после создания объекта, в итоге получится такой вот код:
```
var img = new Image()
img.onload = function(){
//Тут ваш код для работы с контекстом
}
img.src = 'path.png'
```
### Нарисуем изображение
```
drawImage(object img, float x, float y)
```
— нарисует изображение с исходным размером так чтобы его верхний левый угол был в точке (x;y).
### Масштабируем
```
drawImage(object img, float x, float y, float w, float h)
```
— работает также но вместо исходного размера рисует с шириной w и высотой h.
### Обрежем
```
drawImage(object img, float sx, float sy, float sw, float sh, float cx, float cy, float cw, float ch)
```
— нарисует часть изображения шириной sw и высотой sh расположенную в точке (sx,sy) в исходном изображении на canvas с шириной cw и высотой ch в точке (cx,cy)
Рисование текста
----------------
Очень часто в играх, да и вообще в приложениях нужно показывать пользователю не только картинку, но и некоторую информация, для этого можно воспользоваться функциями рисование текста.
### Нарисуем залитым
```
ctx.fillText(string text, float x, float y)
```
— нарисует текст в точке (x;y).
Примечание: функция fillText имеет необязательный аргумент maxWidth, но он паршиво работает в FF и вообще не работает в Chrome.
### Изменим шрифт

Свойство контекста font управляет стилем текста и имеет [синтаксис схожий с css](http://htmlbook.ru/css/font), для примера добавим в наш скрипт следующие строки:
```
ctx.font = "bold italic 30px sans-serif"
ctx.fillText("Привет Хабр",300,300)
```
Управлять цветом и не только мы можем через свойства fillStyle и strokeStyle
### Нарисуем контуры

Внимательный читатель вероятнее всего логически догадался что для рисования контуров текста применяется функции strokeText, заменим в нашем примере fillText на strokeText.
### Выравняем по горизонтали
Для выравнивания текста существует свойство textAlign, оно может принимать пять возможных значения:
* left — текст выравнивается слева
* right — текст выравнивается справа
* center — текст выравнивается по центру
* start — (значение по умолчанию) текст выравнивается от начала линии слева для письма слева на право и выравнивается справа для письма справа налево
* end — текст выравнивается от начала линии справа для письма слева на право и выравнивается слева для письма справа налево
### Линия основания текста
Для управления линией основания текста существует свойство textBaseline, оно может принимать следующие значения:top,hanging,middle,alphabetic,ideographic,bottom. Смысл этих значений легче показать чем описать, поэтому на WhatWG была найдена картинка:

### Измерим ширину
```
measureText(string text)
```
— вернет специальный объект TextMetrics который на данный момент обладает только одним свойством — width — ширина текста в пикселях.
Сохранение изображений на стороне клиента
-----------------------------------------
Для сохранения изображений существует аж три метода (getAsFile,getBlob,toDataURL), но мы рассмотрим лишь toDataURL поскольку именно он наиболее хорошо поддерживается браузерами. Стоит заметить что метод применяется не к контексту, а к canvas элементу, впрочем его можно получить как свойство 'canvas' контекста, также этот метод принимает как аргумент тип изображения (по умолчанию 'png'). Этот метод вернет изображение в формате base64.
Сохранить нельзя восстановить
-----------------------------
Если какое-то свойство контекста изменить то оно повлияет на все последующие, для упрощения жизни разработчикам в спецификации есть два метода контекста save и restore.
save — сохраняет текущее состояние
restore — восстанавливает последнее сохраненное
Рассмотрим простой пример:
```
ctx.save()
ctx.textAlign = 'center'
ctx.font = "bold italic 30px sans-serif"
ctx.strokeText("Привет Хабр",300,300)
ctx.restore()
ctx.fillText("Привет Хабр",400,400)
```
Как видно, вместо того чтобы сбрасывать все свойства на начальные мы просто использовали save и restore | https://habr.com/ru/post/119305/ | null | ru | null |
# Интерпретатор Python: о чём думает змея? (часть I-III)

**От переводчика**Весьма вольный перевод серии [из](http://akaptur.github.io/blog/2013/11/15/introduction-to-the-python-interpreter/) [трёх](http://akaptur.github.io/blog/2013/11/15/introduction-to-the-python-interpreter-2/) [статей](http://akaptur.github.io/blog/2013/11/17/introduction-to-the-python-interpreter-3/) об устройстве питоновского интерпретатора. Автор занимается разработкой собственного велосипеда по этой теме и решил поделиться знаниями, появившимися в процессе. Посмотрим, что у него из этого получилось.
Данная серия статей рассчитана на тех, кто умеет писать на python в целом, но плохо представляет как этот язык устроен изнутри. Собственно, как и я три месяца назад.
Небольшой дисклеймер: свой рассказ я буду вести на примере интерпретатора python 2.7. Всё, о чем пойдёт речь далее, можно повторить и на python 3.x с поправкой на некоторые различия в синтаксисе и именование некоторых функций.
Итак, начнём.
Часть I. Слушай Питон, а что у тебя внутри?
===========================================
Начнём с немного (на самом деле, с сильно) высокоуровневого взгляда на то, что же из себя представляет наша любимая змея. Что происходит, когда вы набираете строку подобную этой в интерактивном интерпретаторе?
```
>>> a = "hello"
```
Ваш палец падает на enter и питон инициирует 4 следующих процесса: [лексический анализ](http://ru.wikipedia.org/wiki/%D0%9B%D0%B5%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7), [парсинг](http://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7), [компиляцию](http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D0%B8%D0%BB%D1%8F%D1%86%D0%B8%D1%8F_%28%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%29) и непосредственно [интерпретацию](http://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%BF%D1%80%D0%B5%D1%82%D0%B0%D1%86%D0%B8%D1%8F_%28%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0%29). Лексический анализ – это процесс разбора набранной вами строки кода в определенную последовательность символов, называемых токенами. Далее парсер на основе этих токенов генерирует структуру, которая отображает взаимоотношения между входящими в неё элементами (в данном случае, структура это [абстрактное синтаксическое древо](http://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE) или АСД). Далее, используя АСД, компилятор создаёт один или несколько объектных модулей и передаёт их в интерпретатор для непосредственного выполнения.
Я не буду углубляться в темы лексического анализа, парсинга и компиляции, в основном потому, что сам не имею о них ни малейшего представления. Вместо этого, давайте лучше представим, что умные люди сделали всё как надо и данные этапы в питоновском интерпретаторе отрабатывают без ошибок. Представили? Двигаем дальше.
Прежде чем перейти к [объектным модулям](http://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D1%8B%D0%B9_%D0%BC%D0%BE%D0%B4%D1%83%D0%BB%D1%8C) (или объектам кода, или объектным файлам), следует кое-что прояснить. В данной серии статей мы будем говорить об объектах функций, объектных модулях и [байткоде](http://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B9%D1%82%D0%BA%D0%BE%D0%B4) – всё это совершенно разные, хоть и некоторым образом связанные между собой понятия. Хотя нам и необязательно знать, что такое объекты функций для понимания интерпретатора, но я всё же хотел бы остановить на них ваше внимание. Не говоря уже о том, что они попросту крутые.
Итак,
### Объекты функций или функции, как объекты
Если это не первая ваша статья о программировании на питоне, вы должны быть наслышаны о неких «объектах функций». Это именно о них люди с умным видом рассуждают в контексте разговоров о «функциях, как [объектах первого класса](http://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82_%D0%BF%D0%B5%D1%80%D0%B2%D0%BE%D0%B3%D0%BE_%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D0%B0)» и «наличии [функций первого класса](http://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%B8_%D0%BF%D0%B5%D1%80%D0%B2%D0%BE%D0%B3%D0%BE_%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D0%B0) в питоне». Рассмотрим следующий пример:
```
>>> def foo(a):
... x = 3
... return x + a
...
>>> foo
```
Выражение «функции – это объекты первого класса» означает, что функции – это объекты ~~первого класса~~, в том смысле, в коем и списки – это объекты, и экземпляр класса `MyObject` – объект. И так как foo это объект, он имеет значимость сам по себе, безотносительно вызова его, как функции (то есть, `foo` и `foo()` — это разные вещи). Мы можем передать `foo` в другую функцию в качестве аргумента, можем переназначить её на новое имя (`other_function = foo`). С функциями первого класса можно делать, что угодно и они всё стерпят.
Часть II. Объектные модули
==========================
На данном этапе we need to go deeper, чтобы узнать, что объект функции в свою очередь содержит объект кода:
```
>>> def foo(a):
... x = 3
... return x + a
...
>>> foo
>>> foo.func\_code
`", line 1>`
```
Как видно из приведённого листинга, объектный модуль является атрибутом объекта функции (у которого есть и множество других атрибутов, но в данном случае особого интереса они не представляют в силу простоты `foo`).
Объектный модуль генерируется питоновским компилятором и далее передаётся интерпретатору. Модуль содержит всю необходимую для выполнения информацию. Давайте посмотрим на его атрибуты:
```
>>> dir(foo.func_code)
['__class__', '__cmp__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__', 'co_argcount', 'co_cellvars', 'co_code', 'co_consts', 'co_filename',
'co_firstlineno', 'co_flags', 'co_freevars', 'co_lnotab', 'co_name', 'co_names', 'co_nlocals',
'co_stacksize', 'co_varnames']
```
Их, как видите, немало, поэтому все рассматривать не будем, для примера остановимся на трёх наиболее понятных:
```
>>> foo.func_code.co_varnames
('a', 'x')
>>> foo.func_code.co_consts
(None, 3)
>>> foo.func_code.co_argcount
1
```
Атрибуты выглядят довольно интуитивно:
`co_varnames` – имена переменных
`co_consts` – значения, о которых знает функция
`co_argcount` – количество аргументов, которые функция принимает
Всё это весьма познавательно, но выглядит несколько черезчур высокоуровнево для нашей темы, не правда ли? Где же инструкции интерпретатору для непосредственного выполнения нашего модуля? А такие инструкции есть и представлены они байткодом. Последний также является атрибутом объектного модуля:
```
>>> foo.func_code.co_code 'd\x01\x00}\x01\x00|\x01\x00|\x00\x00\x17S'
```
Что за неведомая байтовая фигня, спросите вы?
Часть III. Байткод
==================
Вы наверное и сами понимаете, но я, на всякий случай, озвучу – «байткод» и «объект кода» это разные вещи: первый является атрибутом второго, среди многих других (см. часть 2). Атрибут называется `co_code` и содержит все необходимые инструкции для выполнения интерпретатором.
Что же из себя представляет этот байткод? Как следует из названия, это просто последовательность байтов. При выводе в консоль выглядит она достаточно бредово, поэтому давайте приведём её к числовой последовательности, пропустив через `ord`:
```
>>> [ord(b) for b in foo.func_code.co_code] [100, 1, 0, 125, 1, 0, 124, 1, 0, 124, 0, 0, 23, 83]
```
Таким образом мы получили числовое представление питоновского байткода. Интерпретатор пройдётся по каждому байту в последовательности и выполнит связанные с ним инструкции. Обратите внимание, что байткод сам по себе не содержит питоновских объектов, ссылок на объекты и т.п.
Байткод можно попытаться понять открыв файл интерпретатора CPython (ceval.c), но мы этого делать не будем. Точнее будем, но позже. Сейчас же пойдём простым путём и воспользуемся модулем `dis` из стандартной библиотеки.
### Дизассемблируй это
Дизассемблирование – это перевод байтовой последовательности в нечто более понятное человеческому разуму. Для этой цели в питоне существует модуль `dis`, который подробно покажет вам всё, что скрыто. У модуля нет особого применения в продакшн-коде, результаты его работы нужны только вам, не интерпретатору.
Итак, давайте применим `dis` и снимем паранжу с нашего объектного модуля. Для этого воспользуемся функцией `dis.dis`:
```
>>> def foo(a):
... x = 3
... return x + a
...
>>> import dis
>>> dis.dis(foo.func_code)
2 0 LOAD_CONST 1 (3)
3 STORE_FAST 1 (x)
3 6 LOAD_FAST 1 (x)
9 LOAD_FAST 0 (a)
12 BINARY_ADD
13 RETURN_VALUE
```
**Скрытый текст**Зачастую можно видеть записи вида `dis.dis(foo)`, т.е. объект функции передаётся в дизассемблер напрямую. Это сделано для удобства, под капотом dis всё равно находит и анализирует `func_code`. В нашем примере мы передаём объект кода явно для лучшего понимания процесса.
Числа в первой колонке – это номера строк анализируемых исходников. Вторая колонка отражает смещение команд в байткоде: `LOAD_CONST` находится в позиции «0», `STORE_FAST` в позиции «3» и т.д. Третья колонка даёт байтовым инструкциям человекопонятные названия. Названия эти нужны только ~~жалким людишкам~~ нам, в интерпретаторе они не используются.
Две последние колонки содержат подробности об аргументах для данной команды, если таковые имеются. Четвёртая колонка отражает позицию аргумента в атрибуте объектного модуля. В нашем примере аргумент инструкции `LOAD_CONST` находится на первой позиции атрибута-списка co\_consts, аргумент `STORE_FAST` – на первой позиции `co_varnames`. Наконец, в пятой колонке `dis` отражает значение или название соответствующей переменной. Убедимся в сказанном на практике:
```
>>> foo.func_code.co_consts[1]
3
>>> foo.func_code.co_varnames[1]
'x'
```
Это также объясняет, почему инструкция `STORE_FAST` находится на третьей позиции в байткоде: если где-то в байткоде есть аргумент, следующие два байта будут представлять этот аргумент. Корректная обработка таких ситуаций также ложится на плечи интерпретатора.
**Хинт**Если вас вдруг удивило отсутствие аргументов у `BINARY_ADD` – возьмите печеньку за внимательность, но не беспокойтесь раньше времени. Мы вернёмся к этому моменту чуть позже, когда разговор пойдёт о самом интерпретаторе.
Как `dis` переводит байты (например, 100) в осмысленные имена (например, `LOAD_CONST`) и наоборот? Подумайте, как бы вы сами организовали подобную систему? Если у вас появились мысли, вроде «ну, может там есть какой-то список с последовательным определением байтов» или «по-любому словарь с названиями инструкций в качестве ключей и байтами как значениями», поздравляю – вы абсолютно правы. Именно так всё и устроено. Сами определения происходят в файле opcode.py (можно также посмотреть заголовочный файл opcode.h), где вы сможете увидеть ~полторы сотни подобных строк:
```
def_op('LOAD_CONST', 100) # Index in const list
def_op('BUILD_TUPLE', 102) # Number of tuple items
def_op('BUILD_LIST', 103) # Number of list items
def_op('BUILD_SET', 104) # Number of set items
```
(Какой-то любитель комментариев заботливо оставил нам пояснения к инструкциям.)
Теперь мы имеем некоторое представление о том, чем является (и чем не является) байткод и как использовать `dis` для его анализа. В следующих частях мы рассмотрим, как питон может компилироваться в байткод, оставаясь при этом динамическим ЯП. | https://habr.com/ru/post/206420/ | null | ru | null |
# Исправление и изменение кодировок MySQL
В связи с тем, что довольно много людей обращается с просьбой помочь исправить проблему с кодировками MySQL, решил написать статью с описанием, как «лечить» наиболее часто встречающиеся случаи.
В статье описывается не то, как первоначально правильно настроить кодировки MySQL (об этом уже довольно много написано), а о случаях, когда есть довольно большие таблицы с неправильными кодировками и нужно всё исправить.
Самое плохое в неправильно настроенных кодировках — то, что зачастую проблему сложно обнаружить, и с первого взгляда может казаться, что сайт работает правильно, и никаких проблем нет.
#### Небольшое отступление. Sypex Viewer
В какой-то момент надоело отправлять людей в громоздкий phpMyAdmin, и была написана крошечная утилитка [Sypex Viewer](http://sypex.net/ru/products/browser/). Она представляет собой один PHP-файл, использует современные Web 2.0 технологии AJAX, JSON и другие. Основные задачи, которые ставилась при создании — минимальный вес, и максимальное удобство и скорость работы. В дальнейшем в примерах будут скриншоты из неё, но все те же действия можно сделать и в phpMyAdmin.
#### Данные в cp1251 таблицы в latin1
Наверное, самая популярная проблема. Когда данные в кодировке cp1251 (Windows-1251), а у таблиц указана кодировка по умолчанию latin1. Такие ситуации возникают в следующих случаях:
* при неграмотном обновлении с версии MySQL меньше 4.1 на более новые;
* очень часто возникает в «буржуйских» скриптах, которых вполне устраивает кодировка по умолчанию, и они «забывают», что неплохо бы указывать кодировку, как таблиц, так и соединения;
* также бывают случаи, когда переезжают с одного сервера (у которого установлена дефолтная кодировка cp1251, в частности, так сделано в Денвере) на другой (у которого стоит стандартная кодировка latin1).
В результате на сайте вроде как всё нормально, но если посмотреть в Sypex Viewer, то русские символы будут выглядеть как «кракозябры» (как их обычно называют пользователи).
В статье я рассмотрю один из вариантов преобразование кодировок с помощью бесплатного php-скрипта [Sypex Dumper](http://sypex.net/), в качестве готового решения.
1. На вкладке «Экспорт» выбираем нужные таблицы.
2. Кодировка должна быть auto (остальные параметры неважны, можно комментарий добавить, например, «Дамп перед исправлением кодировки»).
3. Нажимаем «Выполнить». Теперь у нас есть бэкап (его в любом случае желательно делать при любых преобразованиях базы данных).
4. Переходим на вкладку «Импорт»
5. Выбираем только что сделанный файл бэкапа.
6. Выбираем кодировку cp1251 и помечаем опцию «Коррекция кодировки».
7. Нажимаем «Выполнить».
8. Вот и всё заходим в Sypex Viewer, чтобы убедиться, что русские символы выводятся корректно.

#### Данные и таблицы в utf8, но кодировка соединения latin1
Теперь рассмотрим более запущенный случай. Набирающая популярность в последнее время проблема, в связи с повальным увлечением UTF-8. Создатели софта стали переводить свои детища на UTF-8, но и тут не всё так гладко, как хотелось бы.
Возникает проблема в основном в случае, когда у таблиц указана кодировка UTF-8, данные в UTF-8, но кодировка соединения установлена по умолчанию latin1 (типичный пример, vBulletin 4, хоть там и есть в конфигах настройка кодировки соединения, но она закомментирована по умолчанию).
В результате в MySQL присылаются данные в UTF-8, но поскольку указана кодировка соединения latin1, то MySQL пытается преобразовать данные из latin1 в UTF-8. В итоге русские символы выглядят так:
Ситуация более запущенная, но исправляется проблема почти также, как в первом случае, только в пункте 2 нужно выбрать кодировку latin1, а в пункте 6 нужно выбрать utf8 кодировку.
#### Изменение кодировки
Также часто встречающаяся проблема преобразования кодировки из cp1251 в UTF-8. До выполнения этого шага обязательно убедитесь, что русские символы у вас правильно показываются в Sypex Viewer или phpMyAdmin, если это не так, то предварительно исправьте кодировку.
Итак, опять заходим в Sypex Dumper.
1. Во вкладке «Экспорт» выбираем нужные таблицы.
2. Устанавливаем кодировку, в которую хотите преобразовать таблицы, в данном случае utf8.
3. Нажимаем «Выполнить».
4. После чего заходим в «Импорт» и выбираем нужный файл.
5. Выставляем кодировку utf8 и опцию «Коррекция кодировки».
6. Нажимаем «Выполнить».
7. Вот и всё таблицы в UTF-8. Не забываем, что нужно еще установить кодировку соединения, сконвертировать ваши скрипты и шаблоны в UTF-8, выставить правильную кодировку в заголовках.
#### Кодировка соединения
Не забываем, что после исправлений кодировки, нужно убедиться, что ваши скрипты используют правильную кодировку соединения (в принципе, это будет сразу видно, они будут неправильно показывать русские символы без нужной кодировки соединения). У некоторых она выставляется в настройках, в некоторых придется добавить самостоятельно.
Для чего достаточно пройтись поиском по файлам, и найти где вызывается функция mysql\_connect (или mysqli\_connect). После этой строки нужно добавить строку которая укажет кодировку соединения.
```
mysql_query("SET NAMES 'cp1251'");
```
Где вместо cp1251, указать нужную кодировку соединения.
**Не забывайте перед преобразованиями кодировок делать бэкап, тут как с презервативами, лучше пусть он будет и не понадобится, чем когда понадобится — его не будет.**
P.S. Спасибо [Шортикам](http://shortiki.com/) за веселый контент для примеров. | https://habr.com/ru/post/131869/ | null | ru | null |
# Автогенерация музыки без AI
Автоматическое создание музыки по заданным параметрам.
Используется Web Audio API, TypeScript, Android WebView, таблично-волновой синтез и элементарная теория музыки.
* [Открыть в браузере](https://surikov.github.io/rockdice/main.html)
* [Исходники](https://github.com/surikov/rockdice)
* [Андроидная версия](https://play.google.com/store/apps/details?id=rockdice.chord.progression)
Описание работы
---------------
В основном окне можно слайдером выбрать прогрессию. Последовательность аккордов определяет настроение мелодии (слева минорные, справа мажорные, по-середине джазовые септаккорды). Круглыми переключателями можно выбрать риффы для стандартных 4-х слоёв мелодии
* Drums - задает ритм
* Bass - гармоническая основа и ритм
* Lead - создаёт мелодический рисунок
* Pad - контрапункт, протяжные ноты показывающие функцию аккорда
По голубой кнопке с игральным кубиком выбираются рандомные значения.
Приложение делает модуляцию выбранных фрагментов под заданные аккорды. Если покрутить переключатели и прослушать несколько мелодий, можно убедиться что при любом сочетании аккордов и инструментов звучание результата получается вполне "человеческое".
### Похожие проекты
Встроенные функции автогенерации аранжировок появились ещё в первых синтезаторах. Пример исполнения на Cassio MT-100 из 80-х прошлого века:
Современное приложение Captain Plugins Epic, подойдёт только профессионалам:
Web-приложение BandLab SongStarter, никаких настроек не поддерживает, просто генерирует мелодии в одном стиле:
### Настройки
По кнопке с шестерёнкой открывается окно настроек. Можно редактировать громкость по слоям, скорость, менять аккорды, транспонировать:
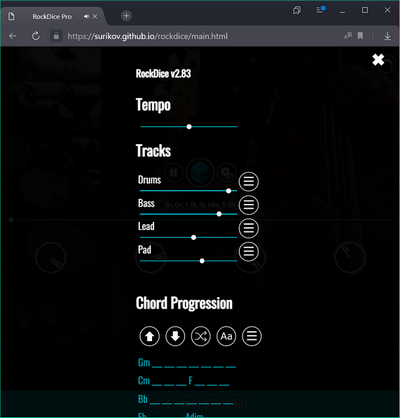Для каждого трека можно выбрать рифф из списка:
Также можно выбрать аккордовую последовательность:
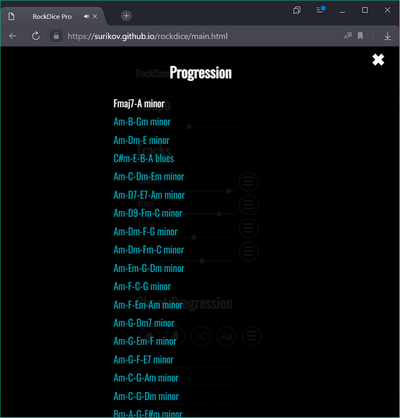### История
Возможность отменить прошлое действие и вернуться в предидущее состояние это типовое требование для любых приложений. По кнопке с иконкой Undo (справа вверху) открывается окно с историей подбора мелодий:
### Публикация и экспорт
Как и любое музыкальное приложение, RockDice позволяет экспортировать созданную мелодию в MIDI-файл или Wav-файл (кнопки в нижней панели). Полученные файлы можно редактировать в других музыкальных приложениях. Пример треков импортированных в BandLab MixEditor (любой трек можно форкнуть и открыть в редакторе):
<https://www.bandlab.com/sss1024/tracks>
#### Совместная работа
Ссылка на мелодию открывается в приложении точно в том виде как её отправил автор.
По кнопке со стандартной иконкой Share открывается окно предпросмотра. В нём можно отослать ссылку на мелодию через e-mail, мессенджер или соц. сети:
В большинстве соц. сетей ссылка корректно распознаётся с описанием и изображением выбранных инструментов:
Описание реализации
-------------------
### Воспроизведение звука
Для воспроизведения звука используется библиотека WebAudioFont:
<https://github.com/surikov/webaudiofont>
В библиотеке содержатся более 2000 оцифрованных инструментов и основные фильтры для обработки звука:
* 10-полосный эквалайзер для настройки тембра
* эхо для объёмного звучания
* динамический компрессор для выделения голосов
Документация:
<https://surikov.github.io/webaudiofont/npm/src/docs/index.html>
### Модуляция фрагментов
Для выбранных (или введённых вручную) аккордов в функции extractMode вычисляется тоника и лад, см.
<https://github.com/surikov/rockdice/blob/main/ts/code/zvoogharmonizer.ts#L1156>
Для воспроизведения музыки в проект добавлено около двухсот риффов с разными инструментами, их можно посмотреть в папке
<https://github.com/surikov/rockdice/tree/main/patterns>
Каждый паттерн кроме нот также содержит описание лада и тоники.
Выбранные риффы в функции morphSchedule транспонируются в тонику выбранных аккордов и проводится модуляция в лад аккордовой прогрессии, см.
<https://github.com/surikov/rockdice/blob/main/ts/code/zvoogharmonizer.ts#L377>
* Транспонирование мелодии это перенос всех нот на равное количество полутонов. По-простому - сделать звук выше или ниже.
* Модуляция мелодии это сдвиг определённых ступеней лада. По-простому - из минора в мажор и т.п.
### Специфика инструментов
При воспроизведении музыкальныз фрагментов учитывается специфика исполнения на конкретных инструментах. Наример:
* при игре на гитаре с дисторшном обычно используют как игру на открытых струнах, так и игру на прижатых струнах (Palm Mute). Т.е. инструемент один, но для реалистичного звучания необходимо два отдельных набора сэмплов [для открытых](https://surikov.github.io/webaudiofontdata/sound/0300_LesPaul_sf2.html) и [приглушенных](https://surikov.github.io/webaudiofontdata/sound/0290_LesPaul_sf2.html) струн
* на аккустической гитаре удары по струнам вниз и вверх ощутимо различаются, см. [пример](https://surikov.github.io/webaudiofont/examples/strum.html)
* наборы нот похожих аккордов (например G и Gm) могут зажиматься на совершенно разных ладах, это нужно учитывать при модуляции фрагментов
* и т.п.
В результате получается сделать звучание сгенерированной музыки менее однообразным.
### Хранение состояний
Выбранные аккорды, фрагменты и другие настройки сохраняются в localStorage брайзера, см. [readObjectFromlocalStorage](https://github.com/surikov/rockdice/blob/main/ts/code/zvoogapp.ts#L2376). В результате при новом открытии приложении его состояние восстанавливается в том же виде как и в последнем сеансе работы.
При создании ссылки для публикации все данные кодируются в длинный-предлинный URL, пример
<https://mzxbox.ru/RockDice/share.php?seed=%7B%22drumsSeed%22%3A21%2C%22bassSeed%22%3A12%2C%22leadSeed%22%3A6%2C%22padSeed%22%3A12%2C%22drumsVolume%22%3A111%2C%22bassVolume%22%3A99%2C%22leadVolume%22%3A66%2C%22padVolume%22%3A77%2C%22chords%22%3A%5B%22Cm%22%2C%222%2F1%22%2C%22Ebm%22%2C%222%2F1%22%5D%2C%22tempo%22%3A130%2C%22mode%22%3A%22Ionian%22%2C%22tone%22%3A%22D%23%22%2C%22version%22%3A%22v2.83%22%2C%22comment%22%3A%22%22%2C%22ui%22%3A%22web%22%7D>
### Разметка ссылок
Публикуемые ссылки соответствуют протоколам Open Graph и Twitter Cards.
Эти протоколы поддерживаются больншинством движков соц. сетей. По сути это требование к страницы на которую ведёт ссылка содержать её описание и картинку предпросмотра.
Картинка и страница для публикации формируются динамически обычным php-скриптом, см.
<https://github.com/surikov/rockdice/blob/main/server/share.php>
вся информация для предпросмотра в тегах узла head:
```
```
Скрипты выложены на обычный хостинг стоимостью примерно 200р в месяц.
### Android
Для создания мобильной версии можно использовать компонент WebView
<https://developer.android.com/reference/android/webkit/WebView>
По сути это обычный Chrome встроенный в Activity. Веб-страницы открываются локально из ресурсов приложения, фоагменты и оцифрованные инструменты так же загружаются локально.
По функционалу мобильная версия ничем не отличается от веб-версии. Вот скомилированное приложение (на давно не обновлялось):
<https://play.google.com/store/apps/details?id=rockdice.chord.progression>
Для WebView есть небольшие ограничения которые следует учитывать.
Например доступ к файловой системе для сохранения мелодий в MIDI- и Wav-файлы. В большом браузере достаточно создать blob с двоичными данными правильным MIME-типом и открыть ссылку на него, например
```
let blob: Blob = new Blob([dataview], { type: 'audio/wav' });
let ourl = URL.createObjectURL(blob);
let a = document.createElement("a");
document.body.appendChild(a);
a.href = ourl;
a.download = 'rockdice';
a.click();
```
Браузер корректно распознает тип файла и покажет обычный диалог сохранения с правильным расширением.
Для встроенного WebView придётся создать функцию сохранения средствами Android, встроить её в JavaScript приложения через [addJavascriptInterface](https://developer.android.com/reference/android/webkit/WebView#addJavascriptInterface(java.lang.Object,%20java.lang.String)) и обращаться к ней из веб-страницы.
Так же необходимо чтоб опубликованные ссылки на мелодии открывались не в браузере телефона, а в мобильной версии приложения. Для этого в AndroidManifest.xml приложения нужно настроить фильтр:
```
```
Можно обойтись и без мобильной версии т.к. Chrome в телефонах ничем не отличается от Chrome на десктопе.
*Ссылки*
* [Открыть в браузере](https://surikov.github.io/rockdice/main.html)
* [Исходники](https://github.com/surikov/rockdice)
* [Андроидная версия](https://play.google.com/store/apps/details?id=rockdice.chord.progression) | https://habr.com/ru/post/696342/ | null | ru | null |
# Love, Spring and HTTP Bugs
Привет, Хабр! Мы команда Marketing Management GlowByte, занимаемся автоматизацией маркетинговых процессов в крупных компаниях. Решили написать небольшую статью, которая будет интересна неравнодушным к Java. Хотим поделиться на первый взгляд простыми особенностями поведения библиотек Spring Security, Spring Web, которые могут сбить с толку разработчиков, которые никогда не сталкивались с такими ситуациями.
Рассмотрим проблему, проведём анализ, тесты, проверяющие наши гипотезы, сделаем выводы и, конечно, оставим ссылку на код, чтобы можно было самостоятельно поиграться.
### Проблематика
Представим себе классические будни энтерпрайзной разработки. Новый спринт – новая задача – необходимо интегрироваться с системой Заказчика. ТЗ ~~на столе~~ ~~в почте~~ в конфлюенсе, вроде ничего сложного – обычная интеграция по HTTP-протоколу. Спринт позади, и вот уже в продакшене вы вдруг обнаруживаете, что все работает медленно и утилизирует много ресурсов CPU, причём для другой системы, которая использует эту же интеграцию, производительность гораздо выше, чем для нашей при одинаковом профиле нагрузки.
Детальнее, как это происходит со стороны **сервиса** (пункт 1) и **клиента** (пункт 2), рассмотрим ниже:
1. Требования со стороны сервиса – самый простой Basic Auth на одного пользователя (интеграцию пилим между backend-сервисами), не нужны ни коробочные решения, ни добавление новых пользователей, достаточно зашифрованного логина/пароля в конфиге. Разработчик добавляет, например, такой конфиг:
```
@EnableGlobalMethodSecurity(prePostEnabled = true)
@EnableWebSecurity
@Configuration
public class SecurityConfig {
@Value("${users.user.name}")
private String userName;
@Value("${users.user.pass}")
private String userPass;
@Value("${users.user.role:HABR}")
private String userRole;
@Value("${encoder.enable}")
private boolean encoderEnable;
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http.csrf().disable().httpBasic();
return http.build();
}
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Bean
public InMemoryUserDetailsManager userDetailsService() {
PasswordEncoder passwordEncoder = passwordEncoder();
UserDetails user = User.builder()
.passwordEncoder(passwordEncoder::encode)
.username(userName)
.password(userPass)
.roles(userRole)
.build();
return new InMemoryUserDetailsManager(user);
}
}
```
Криминального ничего нет (согласны?), такое может пройти и ревью, и юнит-тесты, спокойно уехать на тестовый контур, там пройти интеграционные тесты и в конце концов оказаться в PROD.
И что мы получаем? Приходит боевая нагрузка и выясняется, что сервис очень медленно работает. Разработчик уходит тестироваться локально (на 10 минут, на 1 день или целую неделю) и ничего не находит, тем более что в других проектах такой же код успешно работает.
2. Ситуация со стороны клиента – нужна интеграция с простым web-сервисом, на котором настроен Basic Auth. Сервис для простоты принимает POST-запрос и разворачивает строку. Что получается у разработчика:
```
HttpHeaders header = new HttpHeaders();
header.setBasicAuth(userName, userPass);
for (int j = 0; j < amountThreadMessage; j++) {
String data = UUID.randomUUID().toString();
HttpEntity requestEntity = new HttpEntity<>(data, header);
ResponseEntity entity = restTemplate.postForEntity(url, requestEntity, String.class);
if (entity.getStatusCode() == HttpStatus.OK && new StringBuilder(data).reverse().toString().equals(entity.getBody())) {
amountSuccessExecute.incrementAndGet();
}
}
```
На первый взгляд, и здесь всё хорошо. Будет ли у клиента шанс воспроизвести проблему локально? И какой сервис будет использоваться для тестирования?
Вот таким нехитрым образом получаем проблему, что две стороны уверены в своём коде, но по факту интеграция работает плохо.
### Анализ
Наши проблемы кроются в том, что если клиент не держит постоянное соединение с сервером и каждый запрос открывает и закрывает соединение, то на стороне сервера вызывается дорогая операция для проверки пароля, и производительность падает более чем в 100 раз.
Посмотрим детальнее, почему это происходит, где же скрыта проблема. А базируется она на двух особенностях, первая из них – BcryptPasswordEncoder::matches (выполняется на стороне сервера и заключается в сопоставлении паролей). Достаточно дорогая операция, но разве она должна выполняться на каждый запрос? Нет, конечно! И действительно, Spring заботится, чтобы она выполнялась один раз в рамках установленного соединения.
Значит надо проверить, работает ли keep-alive, и тут мы узнаём, что нет, не работает. А почему? Идём смотреть клиентский код и видим там только new RestTemplate() и больше ничего. Посмотрим, как он работает “под капотом”.
А “под капотом” он дёргает подозрительный HttpURLConnection::close.
Как же можно исправить?
* Использовать клиент, который стабильно держит соединение, например:
```
HttpComponentsClientHttpRequestFactory factory = new HttpComponentsClientHttpRequestFactory(HttpClients.createDefault());
restTemplate = new RestTemplate(factory);
```
* Как временное решение, можно изменить PasswordEnсoder на менее требовательный к ресурсам.
* Ваши предложения пишите в комментариях.
### Тестирование
А теперь предлагаем посмотреть на результаты тестов с различными настройками, чтобы проверить наши предположения из раздела “Анализ”.
Будем включать и выключать keep-alive (постоянное соединение), менять PasswordEncoder (тяжёлая операция по работе с паролем) и проверять, влияет ли на результат использование одного клиента, или концепция **1 thread – 1 HttpClient** надёжнее.
Все цифры условны, они получены на конкретном оборудовании, могут отличаться на вашем и нужны лишь для того, чтобы показать, как влияют те или иные настройки.
Используем виртуальную машину в любимом облаке с таким сайзингом: 8 vCPU, 8 GB vRAM.
Запустим java -Xmx6g -Xms6g -jar Habr-1.0.0.jar
Детальные выкладки результатов под катомОтправим по 10 тысяч запросов в 50 потоков для исправленного варианта.
Execute 500000 from 500000. Time 89366.0 ms, rps 5594.906397215975
Execute 500000 from 500000. Time 80759.0 ms, rps 6191.183754333829
Execute 500000 from 500000. Time 80542.0 ms, rps 6207.864122270092
Отправим по 1 тысяче запросов в 50 потоков вариант без исправлений с утилизацией CPU 95%+.
Execute 50000 from 50000. Time 739863.0 ms, rps 67.57998767341024
Execute 50000 from 50000. Time 735627.0 ms, rps 67.96913657446427
Execute 50000 from 50000. Time 735488.0 ms, rps 67.98198205547601
Отправим по 10 тысяч запросов в 50 потоков вариант с заменой PasswordEncoder и без keep-alive.
Execute 500000 from 500000. Time 45950.0 ms, rps 10881.156014014929
Execute 500000 from 500000. Time 37982.0 ms, rps 13163.783798014902
Execute 500000 from 500000. Time 37585.0 ms, rps 13302.825520140477
Отправим по 10 тысяч запросов в 50 потоков вариант с заменой PasswordEncoder и c keep-alive.
Execute 500000 from 500000. Time 86919.0 ms, rps 5752.416014726185
Execute 500000 from 500000. Time 82718.0 ms, rps 6044.560500006045
Execute 500000 from 500000. Time 83872.0 ms, rps 5961.394012375854
Стоп, а почему в потенциально самом быстром варианте результаты хуже?
Попробуем каждому потоку выдать свой персональный http-клиент.
Отправим по 10 тысяч запросов в 50 потоков вариант с заменой PasswordEncoder и c keep-alive и prototype-клиентом.
Execute 500000 from 500000. Time 52092.0 ms, rps 9598.218570633291
Execute 500000 from 500000. Time 29059.0 ms, rps 17205.781142463868
Execute 500000 from 500000. Time 28339.0 ms, rps 17642.907551164433
Отправим по 10 тысяч запросов в 50 потоков вариант c BCryptPasswordEncoder и c keep-alive и prototype-клиентом.
Execute 500000 from 500000. Time 50892.0 ms, rps 9824.533825869963
Execute 500000 from 500000. Time 29269.0 ms, rps 17082.33686368295
Execute 500000 from 500000. Time 28368.0 ms, rps 17624.872219676407
**Ура**, теперь результаты с разными энкодерами совпадают!
И контрольный: а может, на prototype-клиенте не нужен keep-alive?
Execute 50000 from 50000. Time 738208.0 ms, rps 67.73149609392462
Не-а. Без keep-alive никак.
Результаты тестов показывают, что ошибка в одной-двух строчках кода ухудшает производительность с 17000 rps до 67 rps.
### Заключение
Настройки HTTP-клиента могут совершенно неочевидным образом влиять на производительность сервера. Даже если сервис разработан без багов, можно получить много проблем при неправильной интеграции.
Мы не утверждаем, что приведённые в пример настройки лучшие. Клиент можно настраивать и по-другому. Главное – хотим показать, что настройки могут существенно влиять на производительность. Особенно это будет интересно тем, кто ещё не задавался вопросом, как же быстро может работать пустой сервис, но теперь имеет базовое представление о порядке значений.
P. S. Знаем, что можно изменить подходы, библиотеки и применить другие оптимизации, чтобы работало в рамках этой задачи гораздо быстрее, не бросайтесь за выкладки таких результатов. :)
Ссылка на репозиторий: <https://bitbucket.org/Griphon/security/src/master/>
 | https://habr.com/ru/post/695352/ | null | ru | null |
# Data Science для гуманитариев: что такое «data»
### Размышления об информации, памяти, аналитике и распределениях
Все, что воспринимают наши чувства, — это данные, хотя их хранение в наших черепушках оставляет желать лучшего. Записать это немного надежнее, особенно когда мы записываем это на компьютере. Когда эти записи хорошо организованы, мы называем их данными… хотя я видел, как некоторые ужасно организованные электронные каракули получают то же имя. Я не уверен, почему некоторые люди произносят слово data так, как будто оно имеет заглавную букву D.
> Почему мы произносим data с большой буквы?
Нам нужно научиться быть непочтительно прагматичными в отношении данных, поэтому эта статья поможет новичкам заглянуть за кулисы и помочь практикующим объяснить основы новичкам, у которых проявляются симптомы поклонения данным.
### Смысл и смыслы
Если вы начнете свое путешествие с покупки наборов данных в Интернете, вы рискуете забыть, откуда они берутся. Я начну с нуля, чтобы показать вам, что вы можете делать данные в любое время и в любом месте.
Вот несколько постоянных обитателей моей кладовой, расставленных на полу.

Эта фотография представляет собой данные — она хранится как информация, которую ваше устройство использует для отображения красивых цветов.
Давайте разберемся в том, на что мы смотрим. У нас есть бесконечные варианты того, на что обращать внимание и помнить. Вот что я вижу, когда смотрю на продукты.

Если вы закрываете глаза, вы помните каждую деталь того, что вы только что видели? Нет? И я нет. Вот почему мы собираем данные. Если бы мы могли помнить и обрабатывать это безупречно в наших головах, в этом не было бы необходимости. Интернет мог быть одним отшельником в пещере, рассказывая обо всех твитах человечества и прекрасно передавая каждую из наших миллиардов фотографий кошек.
### Письмо и долговечность
Поскольку человеческая память — это дырявое ведро, было бы лучше записать информацию так, как мы делали это раньше, когда я училась в школе статистики, еще в далекие года. Вот именно, друзья мои, у меня все еще где-то здесь есть бумага! Давайте запишем эти 27 данных.

Что хорошего в этой версии — относительно того, что находится в моем гиппокампе или на моем полу — то, что она более долговечна и надежна.
> Человеческая память — дырявое ведро.
Мы считаем революцию памяти само собой разумеющейся, так как она началась тысячелетия назад с торговцев, нуждающихся в надежном учете того, кто кому продал, сколько бушелей чего. Потратьте немного времени, чтобы понять, как прекрасно иметь универсальную систему письма, которая хранит цифры лучше, чем наш мозг. Когда мы записываем данные, мы производим неверное искажение наших богато воспринимаемых реалий, но после этого мы можем передавать нетленные копии результата другим представителям нашего вида с идеальной точностью. Писать потрясающе! Маленькие кусочки ума и памяти, которые живут вне нашего тела.
> Когда мы анализируем данные, мы получаем доступ к чужим воспоминаниям.
Беспокоитесь о машинах, превосходящих наш мозг? Даже бумага может сделать это! Эти 27 маленьких цифр — большой объем для вашего мозга, но долговечность гарантирована, если у вас есть пишущий инструмент под рукой.
Хотя это и выигрыш в долговечности, но работа с бумагой раздражает. Например, что, если мне вдруг взбредет в голову переставить их от большего к меньшему? Абракадабра, бумага, покажи мне лучший порядок! — Нет? Черт.
### Компьютеры и магические заклинания
Вы знаете, что удивительного в программном обеспечении? Абракадабра на самом деле работает! Итак, давайте перейдем с бумаги на компьютер.
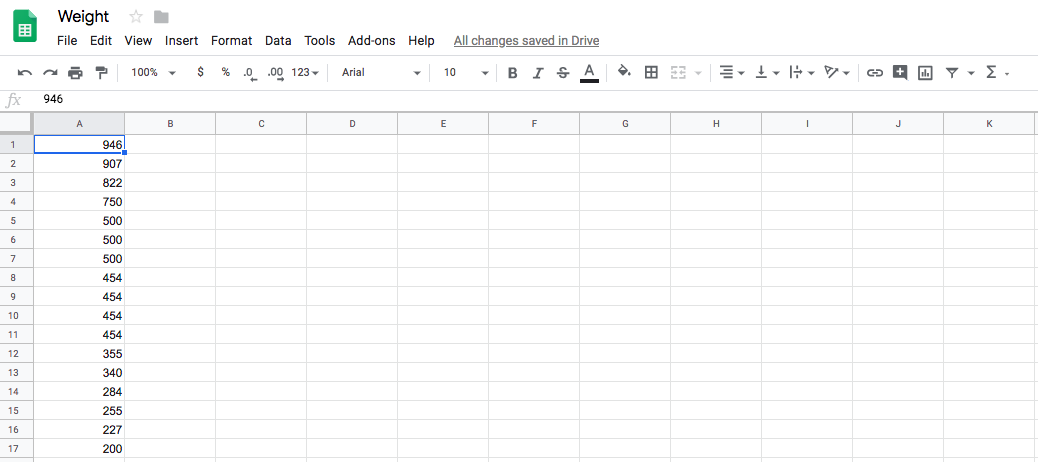
Электронные таблицы оставляют меня равнодушным. Они очень ограничены по сравнению с современными инструментами обработки данных. Я предпочитаю колебаться между R и Python, так что давайте на этот раз возьмем R. Вы можете повторять за мной в вашем браузере с помощью Jupyter: выберите вкладку «with R», затем несколько раз нажмите значок ножниц, пока все не будет удалено. Поздравляю, это заняло 5 секунд, и вы готовы вставить мои фрагменты кода и запустить его [Shift + Enter].
`weight <- c(50, 946, 454, 454, 110, 100, 340, 454, 200, 148, 355, 907, 454, 822, 127, 750, 255, 500, 500, 500, 8, 125, 284, 118, 227, 148, 125)
weight <- weight[order(weight, decreasing = TRUE)]
print(weight)`
Вы заметите, что абракадабра R для сортировки ваших данных не очевидна, если вы новичок в этом.
Ну, это верно для самого слова «абракадабра», а также для меню в программном обеспечении электронных таблиц. Вы знаете эти вещи только потому, что были подвержены им, а не потому, что они являются универсальными законами. Чтобы что-то сделать с компьютером, вам нужно попросить своего местного мудреца о волшебных словах/жестах, а затем попрактиковаться в их использовании. Мой любимый мудрец называется Интернет и знает все на свете.
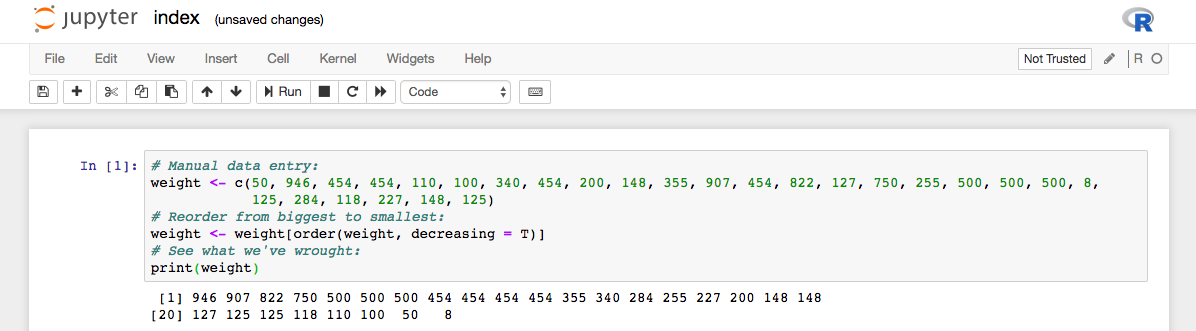
Чтобы ускорить обучение, не просто вставляйте волшебные слова — попробуйте изменить их и посмотреть, что произойдет. Например, что изменится, если вы превратите TRUE в FALSE во фрагменте выше?
Разве не удивительно, как быстро вы получаете ответ? Одна из причин, по которой я люблю программирование, заключается в том, что это нечто среднее между магическими заклинаниями и LEGO.
> Если вы когда-нибудь хотели, чтобы вы могли творить чудеса, просто научитесь писать код.
Вот вкратце о программировании: спросите Интернет, как сделать что-то, возьмите волшебные слова, которые вы только что выучили, посмотрите, что произойдет, когда вы их отрегулируете, а затем соедините их вместе, как блоки LEGO, чтобы выполнить ваш код.
### Аналитика и обобщение
Проблема с этими 27 числами состоит в том, что даже если они отсортированы, они мало что значат для нас. Читая их, мы забываем то, что читали секунду назад. Это человеческий мозг для вас; попросите нас прочитать отсортированный список из миллиона номеров, и в лучшем случае мы запомним последние несколько. Нам нужен быстрый способ сортировки и суммирования, чтобы мы могли понять, на что мы смотрим.
Вот для чего нужна аналитика!
`median(weight)`
При правильном заклинании мы можем мгновенно узнать, каков средний вес. (Медиана означает «среднее».)
Оказывается, ответ 284г. Кто не любит мгновенного удовлетворения? Существуют всевозможные варианты сводки: min(), max(), mean(), median(), mode(), variance()… попробуйте все! Или попробуйте это волшебное слово, чтобы узнать, что происходит.
`summary(weight)`
Кстати, эти вещи называются статистикой. Статистика — это любой способ собрать ваши данные. Это не то, что представляет собой область статистики — [вот 8-минутное введение в академическую дисциплину.](http://bit.ly/quaesita_statistics)
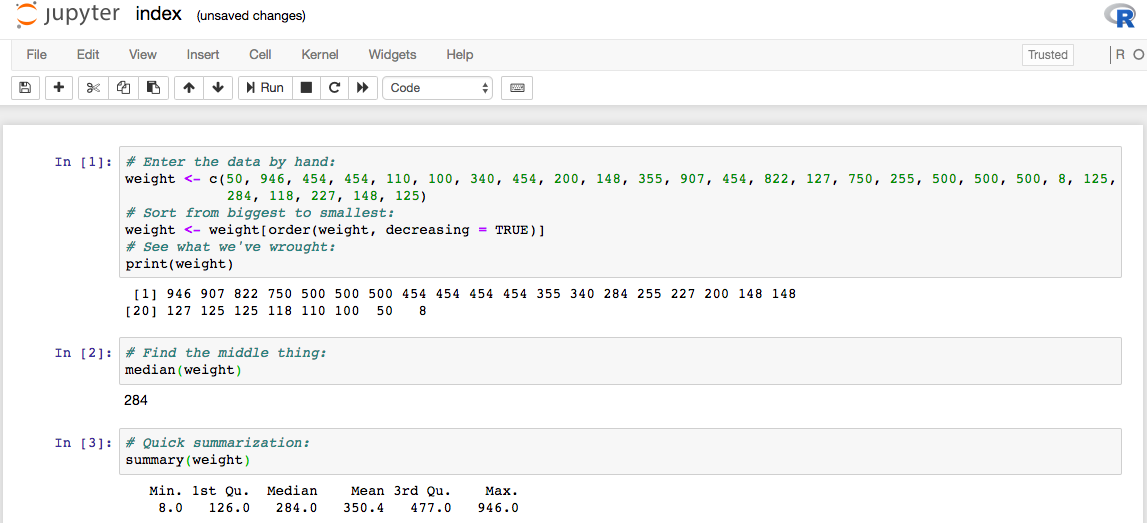
### Построение и визуализация
Этот раздел не о типе заговора, который включает мировое господство (следите за новостями этой статьи). Речь идет о суммировании данных с помощью изображений. Оказывается, картинка может быть информативнее тысячи слов.

Если мы хотим знать, как распределяются веса в наших данных — например, есть ли еще пункты между 0 и 200 г или между 600 и 800 г? — гистограмма — наш лучший друг.
Гистограммы являются одним из способов (среди многих) суммирования и отображения наших выборочных данных. Более высокие блоки для более популярных значений данных.
> Думайте о гистограммах как о конкурсах популярности.
Чтобы создать приложение для работы с электронными таблицами, волшебное заклинание представляет собой долгий ряд нажатий на различные меню. В R это быстрее:
Вот что мы получили с помощью одной строки:
`hist(weight)`
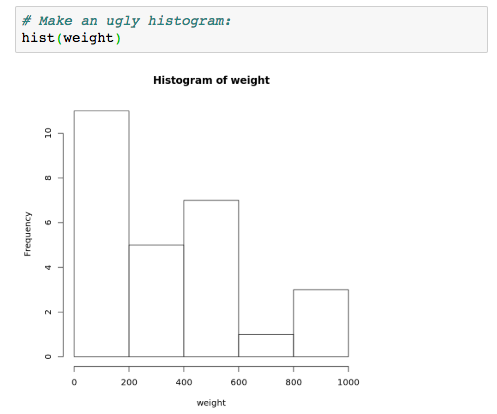
На что мы смотрим?
На горизонтальной оси у нас есть столбцы. По умолчанию они установлены с шагом 200г, но мы изменим это через мгновение. На вертикальной оси находятся отсчеты: сколько раз мы видели вес от 0 до 200 г? График говорит 11. Как насчет между 600 г и 800 г? Только один (это поваренная соль, если память не изменяет).
Мы можем выбрать размер наших столбцов — по умолчанию, которую мы получили без возни с кодом, — 200 г, но, возможно, мы хотим использовать 100 г, вместо этого. Нет проблем! Маги в процессе обучения могут переделать мое заклинание, чтобы узнать, как оно работает.
`hist(weight, col = "salmon2", breaks = seq(0, 1000, 100))`
Вот результат:
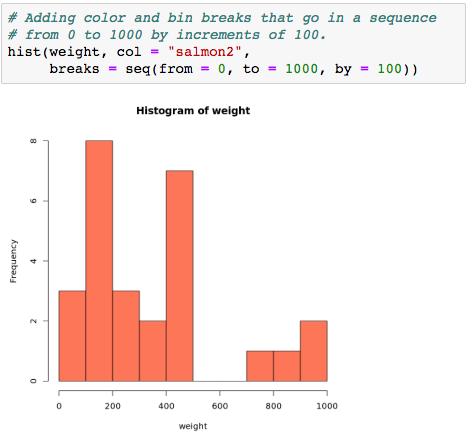
Теперь мы можем ясно видеть, что двумя наиболее распространенными категориями являются 100–200 и 400–500. Кому-нибудь интересно? Возможно нет. Мы сделали это только потому, что могли. Настоящий аналитик, с другой стороны, преуспевает в науке быстрого просмотра данных и искусстве смотреть, где лежат интересные самородки. Если они хороши в своем ремесле, они на вес золота.
### Что такое распределение
Если эти 27 пунктов — это все, что нас волнует, то приведенная мною выборочная гистограмма также отражает распределение совокупности.
Это почти то же самое, что и распределение: это гистограмма, которую вы получили бы, если бы применили Hist() ко всей совокупности (ко всей информации, которая вас интересует), а не только к выборке (данным, которые у вас есть под рукой). Есть несколько сносок, например, шкала по оси Y, но мы оставим их для другого поста в блоге — пожалуйста, не бейте меня, математики!
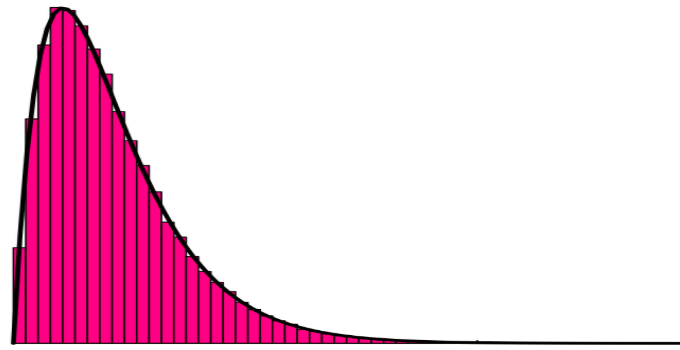
Если бы наше население когда-либо упаковывало все продукты питания, распределение было бы в форме гистограммы всех их весов. Такое распределение существует только в нашем воображении как теоретическая идея — некоторые упакованные продукты питания теряются в глубине веков. Мы не можем сделать этот набор данных, даже если бы захотели, поэтому лучшее, что мы можем сделать, — это угадать, используя хороший пример.
### Что такое Data Science
Существует множество мнений, но я предпочитаю следующее определение: «Наука о данных — это дисциплина, которая делает данные полезными». Три ее подраздела включают анализ большого количества информации для поиска инсайтов (аналитика), разумное принятие решений на основе ограниченной информации (статистика) и использование шаблонов в данных для автоматизации задач (ML/AI).
> Вся наука о данных сводится к следующему: знание это сила.
Вселенная полна информации, ожидающей сбора и использования. Хотя наш мозг прекрасно разбирается в наших реалиях, он не так хорош в хранении и обработке некоторых видов очень полезной информации.
Вот почему человечество обратилось сначала к глиняным табличкам, затем к бумаге и, в конечном итоге, к кремнию за помощью. Мы разработали программное обеспечение для быстрого просмотра информации, и в наши дни люди, которые знают, как ее использовать, называют себя учеными или аналитиками данных. Настоящие герои — это те, кто создает инструменты, которые позволяют этим практикующим лучше и быстрее овладеть информацией. Кстати, даже интернет — это аналитический инструмент — мы просто редко думаем об этом, потому что даже дети могут проводить такой анализ данных.

### Апгрейд памяти для всех
Все, что мы воспринимаем, хранится где-то, по крайней мере, временно. В данных нет ничего волшебного, кроме того, что они записаны более надежно, чем мозг. Некоторая информация полезна, часть вводит в заблуждение, остальное посередине. То же самое касается данных.
> Мы все аналитики данных и всегда ими были.
Мы принимаем наши удивительные биологические возможности как должное и преувеличиваем разницу между нашей врожденной обработкой информации и автоматическим разнообразием. Разница заключается в долговечности, скорости и масштабе… но в обоих случаях применяются одни и те же правила здравого смысла. Почему эти правила выходят в окно при первом знаке уравнения?
Я рада, что мы называем информацию топливом для прогресса, но поклоняться данным как чему-то мистическому для меня не имеет смысла. Лучше просто говорить о данных, так как мы все аналитики данных, и так было всегда. Давайте дадим возможность каждому увидеть себя такими.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
* [Курс по Machine Learning (12 недель)](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=ML&utm_term=regular&utm_content=15062001)
* [Курс «Профессия Data Scientist» (24 месяца)](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=DSPR&utm_term=regular&utm_content=15062001)
* [Курс «Профессия Data Analyst» (18 месяцев)](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=DAPR&utm_term=regular&utm_content=15062001)
* [Курс «Python для веб-разработки» (9 месяцев)](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=PWS&utm_term=regular&utm_content=15062001)
### Читать еще
* [450 бесплатных курсов от Лиги Плюща](https://habr.com/ru/company/skillfactory/blog/503196/)
* [Бесплатные курсы по Data Science от Harvard University](https://habr.com/ru/company/skillfactory/blog/503730/)
* [65 бесплатных курсов по Machine Learning от ведущих университетов мира](https://habr.com/ru/company/skillfactory/blog/504882/)
* [30 лайфхаков чтобы пройти онлайн-курс до конца](https://habr.com/ru/company/skillfactory/blog/503212/)
* [Самый успешный и самый скандальный Data Science проект: Cambridge Analytica](https://habr.com/ru/company/skillfactory/blog/503504/) | https://habr.com/ru/post/506798/ | null | ru | null |
# Использование HCL-конфигурации на примере создания задач в Jira. #2
[Часть 1](https://habr.com/ru/post/697500/)
Сразу оговорюсь, что основная цель статей - пополнить копилку знаний о том, как начать работать с описанием в формате HCL. Возможно это даст стимул для появления новых примеров работы со своим описанием в HCL.
Во-вторых, я не преследую цель показать как писать чистый код на Go.
И в третьих, дать какие-то глубокие объяснения и знания я то же не могу, так как до многих вещей дохожу методом проб и ошибок.
Начнем.
В первой части был показан упрощенный шаблон HCL. Начнем его усложнять и приближать к моим требованиям.
Для начала добавим новые поля, которые могут использоваться в моем случае при создании Issue
```
create "Task" {
project = "AG" # required
# required
summary = "service_A // Обновить библиотеку Library_A до актуальной версии"
# optional
description = <
```
Если немного доработать код из первой части, добавив новые поля в структуру и заполнение их в *jira.Issue*, то таким образом можно создавать по 20+ похожих задач. Но этот вариант имеет кучу неудобств. Поэтому будем улучшать.
Если сейчас запустить скрипт, то получим от парсера сообщения, что обнаружены новые поля:
```
Error: Unsupported argument
on example.hcl line 10, in create "Task":
10: app_layer = "Backend" # optional
An argument named "app_layer" is not expected here.
Error: Unsupported argument
on example.hcl line 11, in create "Task":
11: components = ["service_A"] # optional
An argument named "components" is not expected here.
Error: Unsupported argument
on example.hcl line 20, in create "Task":
20: team_lead = "user_B" # optional
An argument named "team_lead" is not expected here.
...
```
Поэтому доработаем структуру, добавив туда описание новых полей:
```
type config struct {
Type string `hcl:"type,label"`
Project string `hcl:"project"`
Summary string `hcl:"summary"`
Description string `hcl:"description,optional"`
AppLayer string `hcl:"app_layer,optional"`
Components []string `hcl:"components,optional"`
SprintId int `hcl:"sprint,optional"`
Epic string `hcl:"epic,optional"`
Labels []string `hcl:"labels,optional"`
StoryPoint int `hcl:"story_point,optional"`
QaStoryPoint int `hcl:"qa_story_point,optional"`
Assignee string `hcl:"assignee,optional"`
Developer string `hcl:"developer,optional"`
TeamLead string `hcl:"team_lead,optional"`
TechLead string `hcl:"tech_lead,optional"`
ReleaseEngineer string `hcl:"release_engineer,optional"`
Tester string `hcl:"tester,optional"`
Parent string `hcl:"parent,optional"`
}
```
Проверяем:
```
&main.Root{
Create: {
{
Type: "Task",
Project: "AG",
Summary: "service_A // Обновить библиотеку Library_A до актуальной версии",
Description: "Нужно обновить библиотеку Library_A до актуальной версии.\nПосле обновления проверить сервис на regress\n",
AppLayer: "Backend",
Components: {"service_A"},
SprintId: 100,
Epic: "AG-6815",
Labels: {"need-regress"},
StoryPoint: 2,
QaStoryPoint: 1,
Assignee: "user_A",
Developer: "user_A",
TeamLead: "user_B",
TechLead: "user_B",
ReleaseEngineer: "user_C",
Tester: "user_D",
Parent: "",
},
},
}
```
Парсер работает 👌
Теперь перейдем к задачке с переменными. Чтобы каждый раз не вспоминать, как в Jira заведены сотрудники, и избежать опечаток, хочу сделать для них "алиасы", которые проще запомнить.
Способ 1
--------
Самое первое, что приходит на ум, это захардкодить некоторые значения в коде.
Для объявления переменных в коде, в методе *DecodeBody* есть аргумент *context*, в котором можно объявить доступные для использования в шаблоне переменные и функции.
Пример из доки:
```
ctx := &hcl.EvalContext{
Variables: map[string]cty.Value{
"name": cty.StringVal("Ermintrude"),
"age": cty.NumberIntVal(32),
"path": cty.ObjectVal(map[string]cty.Value{
"root": cty.StringVal(rootDir),
"module": cty.StringVal(moduleDir),
"current": cty.StringVal(currentDir),
}),
},
Functions: map[string]function.Function{
"upper": stdlib.UpperFunc,
"lower": stdlib.LowerFunc,
"min": stdlib.MinFunc,
"max": stdlib.MaxFunc,
"strlen": stdlib.StrlenFunc,
"substr": stdlib.SubstrFunc,
},
}
```
```
message = "${name} is ${age} ${age == 1 ? "year" : "years"} old!"
source_file = "${path.module}/foo.txt"
message = "HELLO, ${upper(name)}!"
```
Забегая вперед, скажу, что это нам пригодится. Поэтому придется познакомиться с библиотекой, которая занимается преобразованием типов [zclconf/go-cty](https://github.com/zclconf/go-cty)
Таким образом, можно попробовать захардкодить нужные нам переменные:
```
...
ctx := &hcl.EvalContext{
Variables: map[string]cty.Value{
"tester": cty.StringVal("jira_user_1"),
"team_lead": cty.StringVal("jira_user_5"),
"tech_lead": cty.StringVal("jira_user_5"),
"release_engineer": cty.StringVal("jira_user_6"),
"developers": cty.ObjectVal(map[string]cty.Value{
"Alex": cty.StringVal("jira_user_2"),
"Igor": cty.StringVal("jira_user_3"),
"Denis": cty.StringVal("jira_user_4"),
}),
"services": cty.ObjectVal(map[string]cty.Value{
"service_A": cty.ObjectVal(map[string]cty.Value{
"name": cty.StringVal("service_A"),
}),
"service_B": cty.ObjectVal(map[string]cty.Value{
"name": cty.StringVal("service_B"),
}),
"service_C": cty.ObjectVal(map[string]cty.Value{
"name": cty.StringVal("service_C"),
}),
}),
},
}
var root Root
diags = gohcl.DecodeBody(f.Body, ctx, &root)
...
```
Теперь шаблон будет выглядеть так:
```
create "Task" {
project = "AG" # required
# required
summary = "${services.service_A.name} // Обновить библиотеку Library_A до актуальной версии"
# optional
description = <
```
С полным описанием синтаксиса HCL можно ознакомиться [здесь](https://github.com/hashicorp/hcl2/blob/master/hcl/hclsyntax/spec.md).
Выполняем код:
```
&main.Root{
Create: {
{
Type: "Task",
Project: "AG",
Summary: "service_A // Обновить библиотеку Library_A до актуальной версии",
Description: "Нужно обновить библиотеку Library_A до актуальной версии.\nПосле обновления проверить сервис на regress\n",
AppLayer: "Backend",
Components: {"service_A"},
SprintId: 100,
Epic: "AG-6815",
Labels: {"need-regress"},
StoryPoint: 2,
QaStoryPoint: 1,
Assignee: "jira_user_2",
Developer: "jira_user_2",
TeamLead: "jira_user_5",
TechLead: "jira_user_5",
ReleaseEngineer: "jira_user_6",
Tester: "jira_user_1",
Parent: "",
},
},
}
```
Работает, но не очень удобно.
Способ 2
--------
Следующее, что мне пришло на ум в процессе написания программы, использовать переменные окружения. Добавить либо переменную *env* либо функцию *env*() в *EvalContext*.
Для простоты, пусть будет функция *env*. Смотрим, как реализованы функции в доке, например, *upper*, и делаем по аналогии.
```
var EnvFunc = function.New(&function.Spec{
Params: []function.Parameter{
{
Name: "env",
Type: cty.String,
AllowDynamicType: true,
},
},
Type: function.StaticReturnType(cty.String),
Impl: func(args []cty.Value, retType cty.Type) (cty.Value, error) {
in := args[0].AsString()
out := os.Getenv(in)
return cty.StringVal(out), nil
},
})
...
ctx := &hcl.EvalContext{
Variables: map[string]cty.Value{
"team_lead": cty.StringVal("jira_user_5"),
"tech_lead": cty.StringVal("jira_user_5"),
"release_engineer": cty.StringVal("jira_user_6"),
"services": cty.ObjectVal(map[string]cty.Value{
"service_A": cty.ObjectVal(map[string]cty.Value{
"name": cty.StringVal("service_A"),
}),
"service_B": cty.ObjectVal(map[string]cty.Value{
"name": cty.StringVal("service_B"),
}),
"service_C": cty.ObjectVal(map[string]cty.Value{
"name": cty.StringVal("service_C"),
}),
}),
},
Functions: map[string]function.Function{
"env": EnvFunc,
},
}
```
Объявляем переменные в окружении:
```
export DEVELOPER_ALEX="jira_user_2"
export DEVELOPER_IGOR="jira_user_3"
export DEVELOPER_DENIS="jira_user_4"
export JIRA_TESTER="jira_user_1"
```
Дорабатываем hcl-шаблон
```
create "Task" {
project = "AG" # required
# required
summary = "${services.service_A.name} // Обновить библиотеку Library_A до актуальной версии"
# optional
description = <
```
И проверяем:
```
&main.Root{
Create: {
{
Type: "Task",
Project: "AG",
Summary: "service_A // Обновить библиотеку Library_A до актуальной версии",
Description: "Нужно обновить библиотеку Library_A до актуальной версии.\nПосле обновления проверить сервис на regress\n",
AppLayer: "Backend",
Components: {"service_A"},
SprintId: 100,
Epic: "AG-6815",
Labels: {"need-regress"},
StoryPoint: 2,
QaStoryPoint: 1,
Assignee: "jira_user_2",
Developer: "jira_user_2",
TeamLead: "jira_user_5",
TechLead: "jira_user_5",
ReleaseEngineer: "jira_user_6",
Tester: "jira_user_1",
Parent: "",
},
},
}
```
С этим способом уже больше гибкости. Но, все равно не то, чего я ожидаю.
Способ 3
--------
А что, если нам объявлять переменные в самом HCL, которые мы потом сможем использовать. Например, так:
```
variables {
developers = ["jira_user_2", "jira_user_3", "jira_user_4"]
tester = "jira_user_1"
team_lead = "jira_user_5"
tech_lead = "jira_user_5"
release_engineer = "jira_user_6"
services = [
{ name = "service_A"},
{ name = "service_B"},
{ name = "service_C"},
]
}
# и использовать их в шаблоне
create "Task" {
project = "AG" # required
# required
summary = "${services.0.name} // Обновить библиотеку Library_A до актуальной версии"
# optional
description = <
```
Пробуем запустить:
```
Error: Unsupported block type
on example.hcl line 1, in variables:
1: variables {
Blocks of type "variables" are not expected here.
Error: Invalid index
on example.hcl line 17, in create "Task":
17: summary = "${services.0.name} // Обновить библиотеку Library_A до актуальной версии"
The given key does not identify an element in this collection value. An object
only supports looking up attributes by name, not by numeric index.
...
```
Ок. Нам нужно объявить блок *variables*. Дальше у нас снова развилка вариантов: описать доступные переменные либо сделать их динамическими. Выбираю второе.
Первая мысль, сделать так:
```
type Root struct {
Variables variables `hcl:"variables,block"`
Create []config `hcl:"create,block"`
}
```
Но в этом случае мы обязаны всегда указывать блоки *variables* и *create.* Хочу по-другому, чтобы блок был необязательным, но пойдем по пути от простого к сложному.
Итак, добавляем описание структуры для *variables*:
```
type variables struct {
Variables hcl.Body `hcl:",remain"`
}
```
Проверяем:
```
Error: Invalid index
on example.hcl line 17, in create "Task":
17: summary = "${services.0.name} // Обновить библиотеку Library_A до актуальной версии"
The given key does not identify an element in this collection value. An object
only supports looking up attributes by name, not by numeric index.
Error: Unsuitable value type
on example.hcl line 17, in create "Task":
17: summary = "${services.0.name} // Обновить библиотеку Library_A до актуальной версии"
Unsuitable value: value must be known
...
```
Ок, нужно как-то обработать блок *variables*, добавить из него переменные, после чего снова парсить, но уже блоки *create*.
Значит такая Root-структура нам не очень подходит. Попробуем другую (пришла в голову пока писал статью):
```
type VariablesBlock struct {
Variables variables `hcl:"variables,block"`
Remains hcl.Body `hcl:",remain"`
}
type variables struct {
Remains hcl.Body `hcl:",remain"`
}
type CreateBlocks struct {
Create []createConfig `hcl:"create,block"`
}
type createConfig struct {
Type string `hcl:"type,label"`
Project string `hcl:"project"`
Summary string `hcl:"summary"`
Description string `hcl:"description,optional"`
AppLayer string `hcl:"app_layer,optional"`
Components []string `hcl:"components,optional"`
SprintId int `hcl:"sprint,optional"`
Epic string `hcl:"epic,optional"`
Labels []string `hcl:"labels,optional"`
StoryPoint int `hcl:"story_point,optional"`
QaStoryPoint int `hcl:"qa_story_point,optional"`
Assignee string `hcl:"assignee,optional"`
Developer string `hcl:"developer,optional"`
TeamLead string `hcl:"team_lead,optional"`
TechLead string `hcl:"tech_lead,optional"`
ReleaseEngineer string `hcl:"release_engineer,optional"`
Tester string `hcl:"tester,optional"`
Parent string `hcl:"parent,optional"`
}
```
И попробуем реализовать идею: парсинг *variables*, наполнение контекста переменными, парсинг *create.*
```
parser := hclparse.NewParser()
f, diags := parser.ParseHCLFile(filename)
if diags.HasErrors() {
renderDiags(diags, parser.Files())
return nil, diags
}
var variablesBlock VariablesBlock
diags = gohcl.DecodeBody(f.Body, nil, &variablesBlock)
if diags.HasErrors() {
renderDiags(diags, parser.Files())
return nil, diags
}
...
```
Смотрим в окне дебага, что получили:
Вроде то, что нужно. Пробуем дальше:
```
parser := hclparse.NewParser()
...
// объявляем контекст, чтобы были доступны env в блоке variables
ctx := &hcl.EvalContext{
Variables: map[string]cty.Value{},
Functions: map[string]function.Function{
"env": EnvFunc,
},
}
// парсим блок variables
var variablesBlock VariablesBlock
diags = gohcl.DecodeBody(f.Body, ctx, &variablesBlock)
if diags.HasErrors() {
renderDiags(diags, parser.Files())
return nil, diags
}
// так как variablesBlock.Variables.Remains имеет тип hcl.Body
// и в блоке только атрибуты, чтобы их достать, используем метод hcl.Body.JustAttributes()
variables, diags := variablesBlock.Variables.Remains.JustAttributes()
if diags.HasErrors() {
renderDiags(diags, parser.Files())
return nil, diags
}
// проходимся по переменным и добавляем их в контекст
for _, variable := range variables {
var value cty.Value
// методом проб и ошибок, пришел к такому варианту получения значения с типом cty.Value
diags := gohcl.DecodeExpression(variable.Expr, nil, &value)
if diags.HasErrors() {
return nil, diags
}
ctx.Variables[variable.Name] = value
}
var createBlock CreateBlocks
diags = gohcl.DecodeBody(variablesBlock.Remains, ctx, &createBlock)
if diags.HasErrors() {
renderDiags(diags, parser.Files())
return nil, diags
}
```
Запускаем
```
&main.CreateBlocks{
Create: {
{
Type: "Task",
Project: "AG",
Summary: "service_A // Обновить библиотеку Library_A до актуальной версии",
Description: "Нужно обновить библиотеку Library_A до актуальной версии.\nПосле обновления проверить сервис на regress\n",
AppLayer: "Backend",
Components: {"service_A"},
SprintId: 100,
Epic: "AG-6815",
Labels: {"need-regress"},
StoryPoint: 2,
QaStoryPoint: 1,
Assignee: "jira_user_2",
Developer: "jira_user_2",
TeamLead: "jira_user_5",
TechLead: "jira_user_5",
ReleaseEngineer: "jira_user_6",
Tester: "jira_user_1",
Parent: "",
},
},
}
```
Есть результат 😊 и вроде да же годный.
Сделаем блок *variables* необязательным, для этого просто игнорируем ошибку первичного парсинга и добавляем проверку на наличие *variablesBlock.Variables.Remains*
```
var variablesBlock VariablesBlock
_ = gohcl.DecodeBody(f.Body, ctx, &variablesBlock)
if variablesBlock.Variables.Remains != nil {
variables, diags := variablesBlock.Variables.Remains.JustAttributes()
if diags.HasErrors() {
renderDiags(diags, parser.Files())
return nil, diags
}
for key, variable := range variables {
var value cty.Value
diags := gohcl.DecodeExpression(variable.Expr, nil, &value)
if diags.HasErrors() {
return nil, diags
}
ctx.Variables[key] = value
}
}
```
Проверяем с удаленным блоком *variables* и без переменных
```
create "Task" {
project = "AG" # required
# required
summary = "service_A // Обновить библиотеку Library_A до актуальной версии"
# optional
description = <
```
Результат:
```
&main.CreateBlocks{
Create: {
{
Type: "Task",
Project: "AG",
Summary: "service_A // Обновить библиотеку Library_A до актуальной версии",
Description: "Нужно обновить библиотеку Library_A до актуальной версии.\nПосле обновления проверить сервис на regress\n",
AppLayer: "Backend",
Components: {"service_A"},
SprintId: 100,
Epic: "AG-6815",
Labels: {"need-regress"},
StoryPoint: 2,
QaStoryPoint: 1,
Assignee: "user_A",
Developer: "user_A",
TeamLead: "user_B",
TechLead: "user_B",
ReleaseEngineer: "user_C",
Tester: "user_D",
Parent: "",
},
},
}
```
Способ 4
--------
К этому способу я пришел до написания статьи, после чего и появилось желание поделиться примерами работы с HCL, которые я пробую в процессе написания программы.
Идея такая же, как и в способе 3, с частичными парсингами, но с использованием метода *hcl.Body.PartialContent*.
Минус, *PartialContent* работает со своей структурой *hcl.BodySchema*, поэтому описанные для hcl-файла блоки и структуры использовать не выйдет, придется делать новое описание.
```
var variablesSchema = &hcl.BodySchema{
Blocks: []hcl.BlockHeaderSchema{{Type: "variables"}},
}
```
И сама обработка
```
blocks, body, diags := body.PartialContent(variablesSchema)
if diags.HasErrors() {
renderDiags(diags, parser.Files())
return nil, diags
}
for _, block := range blocks.Blocks {
attrs, _ := block.Body.JustAttributes()
for key, attr := range attrs {
var value cty.Value
diags := gohcl.DecodeExpression(attr.Expr, nil, &hclVar.Value)
if diags.HasErrors() {
renderDiags(diags, parser.Files())
return nil, diags
}
ctx.Variables[key] = value
}
}
```
Вообще работать с BodySchema мне не понравилось из-за "своей" структуры, где можно объявить только блоки и атрибуты. Причем внутри блока атрибуты объявить нельзя, что исключает использование нативной валидации.
```
package hcl
// BlockHeaderSchema represents the shape of a block header, and is
// used for matching blocks within bodies.
type BlockHeaderSchema struct {
Type string
LabelNames []string
}
// AttributeSchema represents the requirements for an attribute, and is used
// for matching attributes within bodies.
type AttributeSchema struct {
Name string
Required bool
}
// BodySchema represents the desired shallow structure of a body.
type BodySchema struct {
Attributes []AttributeSchema
Blocks []BlockHeaderSchema
}
```
Таким образом на текущий момент есть возможность описывать несколько задач, через блоки *create* и использовать переменные.
Следующим шагом в моих хотелках нужно придумать способ использовать итерации для блока *create*. Практическая задача такая: у меня есть массив из названий сервисов (либо описания в виде объектов), нужно по нему запустить цикл, и, используя один шаблон (блок create) создать N issue в Jira.
Псевдо-код выглядит примерно так:
```
{% for service in services %}
create "Task" {
...
summary = "${service.name} // Обновить библиотеку Library_A до актуальной версии"
components = ["${services.name}"]
...
}
{% endfor %}
```
Пока идеи две:
в *create* добавить атрибут for\_each, при анализе которого запускать цикл и как-то внутри цикла создавать переменную *iter*
```
create "Task" {
...
summary = "${iter.name} // Обновить библиотеку Library_A до актуальной версии"
...
for_each = [for i, service in services: service if service.skip == false]
}
```
либо поместить *create* внутрь нового блока, например, *loop*, и в атрибутах *loop* указывать настройки для цикла
```
loop {
list = [for i, service in services: service if service.skip == false]
create "Task" {
...
summary = "${iter.name} // Обновить библиотеку Library_A до актуальной версии"
...
}
}
```
[Продолжение](https://habr.com/ru/post/697590/) | https://habr.com/ru/post/697538/ | null | ru | null |
# Анализ AST c помощью паттернов

Сейчас я работаю [над senjin/gglsl](https://github.com/kravchik/senjin) — библиотекой для программирования шейдеров с помощью Groovy, о которой [недавно писал](http://habrahabr.ru/post/269591/).
Здесь я опишу три подхода к анализу AST (abstract syntax tree), все на примерах под-задач, вытекающих одна из другой и связанных общим контекстом: рекурсивные функции, паттерн Visitor, и паттерн-матчинг.
Паттерн-матчинг реализован на Java и [доступен на GitHub](https://github.com/kravchik/jcommon/wiki/pattern-matching).
Рекурсивные функции
-------------------
*90% функционала делается за 1% времени (или типа того)*
На первом этапе мне было достаточно просто транслировать код на Groovy в код на glsl. Для этого я использовал простые функции разбора дерева, рекурсивно вызывающие друг-друга. Каждая принимает на вход AST-ноду распарсенного Groovy и возвращает строчку, представляющую из себя транслированный код уже на glsl. Этого вполне достаточно т.к. языки очень похожи, в процессе не нужно накапливать никакой информации, а в каждой ноде локально доступна вся необходимая информация.
Пример функций трансляции бинарного выражения и унарного минуса:
```
private String translateExpression(BinaryExpression e) {
def opName = e.operation.getText()
if (opName == "[") return translateExpression(e.leftExpression) + "[" + translateExpression(e.rightExpression) + "]"
return "(" + translateExpression(e.leftExpression) + " " + opName + " " + translateExpression(e.rightExpression) + ")"
}
private String translateExpression(UnaryMinusExpression e) {
return "-" + translateExpression(e.expression)
}
```
Паттерн Visitor
---------------
*Дьявол прячется в деталях*
Вряд ли будет удобно создавать шейдеры если нельзя будет создавать функции. Так что после парочки работающих шейдеров я решил реализовать трансляцию функций. Тут из всех щелей полезли тонкости и детали.
В glsl передача аргументов происходит по значению, а в Groovy по значению мы работаем только с примитивами. Кроме того в glsl с помощью квалификатора out можно передать примитив или вектор обратно, а в Groovy это невозможно. Не помогут и аннотации, т.к. хочется иметь не просто «выглядящий» правильно код, а и запускаемый, и отлаживаемый. Это только пара примеров, на самом деле тонкостей много.
После этапа отчаяния, было принято несколько решений. Например — запретить переписывать непримитивные параметры, запретить возвращать их, если они являются параметрами метода, и т.п.
Приведу код проверки наличия модификации непримитивных параметров с использованием визитёра:
```
for (Parameter parameter : methodNode.getParameters()) if (!isPrimitive(translateType(parameter.getText()))) {
YList rewritten = al(false);
CodeVisitorSupport detectRewrittenVisitor = new CodeVisitorSupport() {
@Override
public void visitBinaryExpression(BinaryExpression expression) {
if (expression.getOperation().getText().equals("=")) {
Expression left = expression.getLeftExpression();
if (left instanceof VariableExpression) {
if (((VariableExpression) left).getName().equals(parameter.getName())) {
rewritten.set(0, true);
}
}
}
super.visitBinaryExpression(expression);
}
};
detectRewrittenVisitor.visitBlockStatement((BlockStatement) methodNode.getCode());
if (rewritten.get(0)) System.out.println(parameter.getName() + " rewritten!");
}
```
Код несложный, но и задача примитивная. И хотя визитёр для таких задач и задумывался — уже здесь кода непозволительно много. Особенно удручают проверки типов дочерних нод и извлечение из них дополнительной информации. Проблема усугубится когда задача станет сложнее — когда нужно, например, проверить наличие в коде чтения поля. При разборе Groovy придётся сначала убедиться что мы находимся в правой ветке присваивания (или ряда других нод), и только ГЛУБЖЕ найти, собственно, ноду, в которой происходит чтение. Т.е. тут — либо придётся вводить в визитёр состояние, либо делать два визитёра, один для поиска ветки «правая часть присваивания», второй — для поиска ноды «чтение поля» где-то в глубине выражений этой ветки.
Паттерн-матчинг
---------------
*Когда становится легче дышать, а от изменений в ТЗ не болит голова*
К сожалению, предыдущие варианты подходят для простых случаев, но заставляют унывать на сложных задачах. Приходится писать много кода для простых понятий, существующий код начинает мешать новому, приходится добавлять различные накопители и промежуточные состояния. А хочется — просто указать кусок AST дерева с переменными, и сказать что нужно делать, если такой найден…
Сказано-сделано! Финальный вариант паттерна для нахождения перезаписи поля в заданной переменной:
```
Object varWritePattern = stairs(
deeper(G_BODY_ACCESSORS),
p(BinaryExpression.class, "operation", p("text", "="), "leftExpression"),
p(VariableExpression.class, "variable", var("VAR_NAME")));
boolean wasWritten = match(methodNode, varWritePattern).notEmpty();
```
*(НЕ ПАНИКОВАТЬ, чуть дальше я опишу детали, сейчас нужно просто насладиться зрелищем)*
Здесь всего одна переменная (var(«VAR\_NAME»)), и она указывает на имя переписываемой (в исходном коде) переменной.
Самое интересное тут то, что добавление довольно сложных (для визитёра) условий — выливается в добавление одной строчки на каждое условие! Т.е. поразительный результат — теперь размер кода линейно зависит от сложности ТЗ (тех-задания) и эта сложность не накапливается! Более сложный паттерн:
```
Object G_FIELD_AS_ARG_PATTERN = stairs(
deeper(G_BODY_ACCESSORS),
p(MethodCallExpression.class,
"getMethod", p("getText", var("METHOD_NAME")),
"getArguments"),
p(ArgumentListExpression.class, "expressions"),
i(),
p(PropertyExpression.class,
"getObjectExpression", p(VariableExpression.class, "variable", var("OBJ_NAME")),
"getProperty", p("value", var("FIELD_NAME"))));
Matcher.match(tree, G_FIELD_AS_ARG_PATTERN)
```
Здесь вычисляется место в дереве, где происходит передача поля какой-то переменной в качестве аргумента в какую-то функцию. Тут уже есть сразу 3 переменные — имя метода (METHOD\_NAME), имя объекта (OBJ\_NAME), и имя поля в нём (FIELD\_NAME). При желании — легко можно добавить ещё переменных (например, var(«ARG\_INDEX») — для получения или связывания номера аргумента). Замечательный факт — в функцию match можно передать предварительно связанные переменные! Тогда не меняя шаблона мы можем находить поддерево с конкретным именем объекта, или с конкретным индексом, по отдельности или всего сразу. Можно только вообразить сколько нужно было бы вписывать в разные места визитёра чтобы достичь тех же целей.
Проход за кулисы
----------------
*Когда магию объясняют, она перестаёт быть магией (но остаётся достаточно развитой технологией)*
Паттерн представляет из себя слепок кусочка дерева, которое нужно найти. Матчер берёт этот слепок и ищет в дереве — какой кусочек подошёл бы.
```
Matcher.match(tree, pattern)
```
Эта функция возвращает список всех совпадений. Каждая запись — это маппинг переменной к тому элементу дерева, который соответствовал ей во время матчинга. Если в паттерне переменных не было, то записи будут пусты, но по их количеству можно увидеть были ли совпадения и сколько (что тоже может быть целью запроса).
Кроме того, в матчинг можно передать заранее связанные переменные, чтобы ограничить варианты:
```
boolean wasWritten = match(methodNode, varWritePattern, hm("VAR_NAME", parameterName)).notEmpty();
```
Здесь мы заранее утверждаем что подойдёт только такое под-дерево, в котором переменная VAR\_NAME соответствует некоему parameterName
*Надо отметить, что под деревом тут подразумевается не какая-то специфическая структура данных (дерево), а что угодно. Это может быть просто массив с числами или объектами. Или просто один объект любого типа.*
Сам паттерн не содержит исчерпывающий 100% совпадающий кусок. В нём указано только то что имеет значение. Кроме того — он состоит не из тех же классов что и дерево, а из специальных. Дальше я приведу примеры таких классов с пояснениями.
```
new Property("getClass", ReturnStatement.class, "getExpression", var("EXPR"));
```
Property — класс, содержащий набор пар имя-значение. Смысл его в том, что нода которую он ищет должна содержать поле или метод с указанным именем, а значение (или результат) должны совпадать с указанным. Значениями могут быть:
1. другие элементы паттерна (может быть снова Property, например), тогда поиск продолжится уже по ним
2. обычные объекты (строка, число, или любой класс), тогда будет просто проведена проверка на совпадение
```
new Var("VAR_NAME", rest);
```
Var та самая переменная, которая содержит имя, и продолжение паттерна. В результате именно по этому имени будет содержаться ссылка на соответствующую ноду дерева.
```
new ByIndex(3, rest);
```
ByIndex — позволяет матчить List и массивы. Причём сам индекс тоже считается «нодой», так что можно матчить, к примеру, «одинаковые значения в двух массивах находящиеся на одном и том же месте».
```
new Deeper(G_BODY_ACCESSORS, rest);
```
Deeper — интересный элемент. Позволяет говорить что «неважно что мы встретим дальше, но в конце-концов найдём...». Он позволяет спускаться по структуре данных на неопределённую изначально глубину. Хороший пример — выражения в языке — не известно сколько уровней BinaryExpression и других ветвлений находится между объявлением метода и конкретным использованием переменной. Так же в нём нужно указать набор мини-паттернов, accessors, с помощью которых он будет прокладывать себе путь.
Я не фанат записей вида new LongJavaClassName(..., поэтому если что-то создаётся больше нескольких раз — я пишу статический метод. Т.о. переписав new Property на p(), new Variable на var(), и т.д., паттерн приобретает вот такой опрятный вид:
```
Object varWritePattern = deeper(G_BODY_ACCESSORS, p(
"getClass", BinaryExpression.class,
"operation", p("text", "="),
"leftExpression", p(
"getClass", VariableExpression.class,
"variable", var("VAR_NAME"))));
```
Как видно, здесь декларативно описан шаблон для нахождения присваиваний. Его можно использовать так:
```
YSet> match1 = match(node, varWritePattern);
YSet> match2 = match(node, varWritePattern, hm("VAR\_NAME", varName));
```
В первом случае мы получаем все варианты, а во втором только те, в которых присваивание происходит в переменную с переданным значением varName (связывание переменной).
Избавляемся от ступеней отступов
--------------------------------
*Когда лестниц в доме больше чем полов*
Мне никогда не нравился в Lisp этот стиль, когда всегда нужно открыть ещё одну скобочку (видимо не только мне, потому что в Clojure есть -> и ->>). Гораздо удобнее когда когда я “вызываю метод” у результата предыдущего вызова как в Scala, Xtend, [моих YCollections](https://github.com/kravchik/jcommon), и много где ещё:
```
String names = al(new File("/home/user/").listFiles())
.filter(File::isDirectory) //only dirs
.map(File::getName) //get name
.filter(n -> n.startsWith(".")) //only invisible
.sorted() //sorted
.foldLeft("", (r, n) -> r + ", " + n); //to print fine
System.out.println(names);
```
Для достижения такого же эффекта я добавил функцию “stairs”, которая (по аналогии с “->>” из Clojure) — просто добавляет то, что идёт позже, в поле rest того, что идёт раньше (не так просто, но суть такова). Теперь достаточно сложный паттерн начинает выглядеть вполне приемлемо:
```
Object G_FIELD_AS_ARG_PATTERN = stairs(
deeper(G_BODY_ACCESSORS),
p(MethodCallExpression.class,
"getMethod", p("getText", var("METHOD_NAME")),
"getArguments"),
p(ArgumentListExpression.class, "expressions"),
i(var("ARG_INDEX")),
p(PropertyExpression.class,
"getObjectExpression", p(VariableExpression.class,
"variable", "OBJ_NAME"),
"getProperty", p("value", var("FIELD_NAME"))));
```
В таком виде очень удобно читать паттерн — просто сверху вниз, ответвления — направо. Легко можно копи-пастить логику из соседних паттернов.
Тот же пример с комментариями
```
Object G_FIELD_AS_ARG_PATTERN = stairs(
//на какой-то глубине
deeper(G_BODY_ACCESSORS),
//есть объект такого класса
p(MethodCallExpression.class,
//с такими параметрами
"getMethod", p("getText", var("METHOD_NAME")),
//а метод getArguments возвращает...
"getArguments"),
// такой объект, у которого есть поле expressions, которое...
p(ArgumentListExpression.class, "expressions"),
//является массивом, а по индексу (который мы запомним) находится...
i(var("ARG_INDEX")),
//такой объект
p(PropertyExpression.class,
//с каким-то ответвлением
"getObjectExpression", p(VariableExpression.class,
"variable", var("OBJ_NAME")),
//и с ещё одним
"getProperty", p("value", var("FIELD_NAME"))));
```
Теперь используем этот паттерн для анализа следующего Groovy кода:
```
public void foo(Vec3f vecA, Vec3f vecB) {
bar(vecA.x, vecA.y)
bar(vecA.x, vecB.x)
}
```
Распарсим его:
```
String src = IO.readFile("src/main/java/yk/senjin/shaders/gshader/analysis/HabraExample.groovy");
//parse kotlin file
Object node = new AstBuilder().buildFromString(CompilePhase.INSTRUCTION_SELECTION, src);
```
И наконец, сделаем несколько запросов:
```
//select method "foo"
for (YMap m : match(node, stairs(deeper(G\_METHOD\_ACCESSORS), var("method"), p(MethodNode.class, "name"), "foo"))) {
//getting methodNode object from select result
Object methodNode = m.get("method");
System.out.println("all variables are free:");
System.out.println(match(methodNode, G\_FIELD\_AS\_ARG\_PATTERN).toString("\n"));
System.out.println("fixed OBJ\_NAME:");
System.out.println(match(methodNode, G\_FIELD\_AS\_ARG\_PATTERN, hm("OBJ\_NAME", "vecB")).toString("\n"));
System.out.println("fixed ARG\_INDEX:");
System.out.println(match(methodNode, G\_FIELD\_AS\_ARG\_PATTERN, hm("ARG\_INDEX", 0)).toString("\n"));
}
```
Вывод в консоли:
```
all variables are free:
{METHOD_NAME=bar, OBJ_NAME=vecA, FIELD_NAME=x, ARG_INDEX=0}
{METHOD_NAME=bar, OBJ_NAME=vecA, FIELD_NAME=y, ARG_INDEX=1}
{METHOD_NAME=bar, OBJ_NAME=vecB, FIELD_NAME=x, ARG_INDEX=1}
fixed OBJ_NAME:
{OBJ_NAME=vecB, METHOD_NAME=bar, FIELD_NAME=x, ARG_INDEX=1}
fixed ARG_INDEX:
{ARG_INDEX=0, METHOD_NAME=bar, OBJ_NAME=vecA, FIELD_NAME=x}
```
Другой пример, для совсем простой структуры данных — массива векторов:
```
Vec3f[] vv = new Vec3f[]{new Vec3f(0, 0, 0), new Vec3f(1, 1, 1)};
System.out.println(match(vv, i(p("x", var("X_VALUE")))));
System.out.println(match(vv, i(var("OBJ_INDEX"), p("x", var("X_VALUE")))));
```
В консоли появится:
```
[{X_VALUE=0.0}, {X_VALUE=1.0}]
[{OBJ_INDEX=0, X_VALUE=0.0}, {OBJ_INDEX=1, X_VALUE=1.0}]
```
Для полноты картины приведу пример аксессоров для Deeper:
```
public static final YArrayList G\_BODY\_ACCESSORS = al(
i(var("access")),
p("methodsList", var("access")),
p(MethodNode.class, "code", var("access")),
p(MethodCallExpression.class, "getReceiver", var("access")),
p(BlockStatement.class, "getStatements", var("access")),
p(ExpressionStatement.class, "expression", var("access")),
p(BinaryExpression.class, "leftExpression", var("access")),
p(BinaryExpression.class, "rightExpression", var("access")),
p(DeclarationExpression.class, "getLeftExpression", var("access")),
p(DeclarationExpression.class, "getRightExpression", var("access")),
p(UnaryMinusExpression.class, "getExpression", var("access")),
p(UnaryPlusExpression.class, "getExpression", var("access")),
p(ReturnStatement.class, "getExpression", var("access")),
p(ConstructorCallExpression.class, "arguments", p("expressions", i(var("access")))),
p(IfStatement.class, "booleanExpression", var("access")),
p(IfStatement.class, "ifBlock", var("access")),
p(IfStatement.class, "elseBlock", var("access"))
```
Можно сказать что он выполняет роль похожую на ту, которую выполняет интерфейс визитёра, только гораздо проще и гибче. Например строчка i(var(«access»)) — позволяет спускаться в любой список или массив, т.е. не привязана конкретно к данному дереву, а является общей. Т.о. легко задать правила о том, куда можно, а куда нельзя спускаться с помощью Deeper — просто указав соответствующий набор аксессоров.
*Интересная идея. Кажется, с помощью паттерн-матчинга можно анализировать не только AST, но и **control-flow**, для этого нужно соответствующим образом описать аксессоры в Deeper и…*
Об оптимизации
--------------
*Уже пора*
Может показаться что подход хорош, но не годится для высоко-нагруженных участков (к примеру, разбора миллионов строк кода). Это верно, но не верно.
Во первых — с паттернами очень легко описать предметную область. А это позволяет разделить задачи — на “реализацию ТЗ”, и на “оптимизацию кода”. Имея на руках отлаженный и покрытый тестами «медленный», простой, правильный вариант — оптимизированный вариант создать гораздо проще и быстрее, чем реализовывать его решая одновременно две задачи — реализации ТЗ и оптимизации. Т.е. тут можно разделить — лёгкость реализации ТЗ и оптимизацию работающего кода.
А это гораздо важнее чем может показаться. У меня были задачи, в которых реализация ТЗ, а ПОТОМ оптимизация может занимать неделю, а реализация ВМЕСТЕ с оптимизацией может занимать месяц. Да, разница может составлять порядок, а на масштабе проекта даже порядки.
Во-вторых, возможности открывает сам факт декларативности в описании предметной области. По декларациям (теоретически) можно сгенерировать оптимизированный код, который хранит весь необходимый стейт в переменных, проходится по дереву один раз выполняя много параллельных задач, и т.п. Т.е. в теории можно сделать генератор оптимизированного, «неприятного» кода. Неприятного — потому что много стейта, много параллельных процессов. Как генератор парсеров.
Просуммирую плюсы
-----------------
*Сам себя не похвалишь — как гугл найдёт?*
* декларативность (можно рисовать, можно анализировать, …)
* лёгкий синтаксис
* ненакапливающаяся сложность кода
* вариативная глубина спуска
* отсутствие привязки к конкретному типу данных
* две роли переменных (результат/связывание)
* потенциал для оптимизаций
* лёгкое переиспользование и копи-паст шаблонов
* можно использовать в роли обычного select
* разделение задач
Вики с мавеном [github.com/kravchik/jcommon/wiki/pattern-matching](https://github.com/kravchik/jcommon/wiki/pattern-matching)
P.S. можно в очередной раз восхититься лиспом, в котором паттерн-матчинг для разбора AST был бы вполне естественным и не стоящим отдельной статьи.
P.P.S. а как разбираете деревья вы? Какие у моего велосипеда промышленные аналоги?
Спасибо [kleshney](https://habrahabr.ru/users/kleshney/) и [oshyshko](https://habrahabr.ru/users/oshyshko/) за вычитку черновика | https://habr.com/ru/post/270173/ | null | ru | null |
# Глобалы MUMPS: Экстремальное программирование баз данных. Часть 2
")
Начало см. [часть 1](/post/175659/).
#### Глава 2. SQL/реляционные БД против MUMPS
В этой главе будут изложены основные различия между обычными SQL реляционными базами данных и БД на основе MUMPS.
Прочитайте [главу 1](/post/175659/#habracut), если вам нужно лучше понять что такое глобалы и как делаются манипуляции с ними.
##### Определим структуры данных
Давайте начнём с основ — определим данные. Для примера мы будем использовать простую БД состоящую из 3-х таблиц:
1. Таблица клиентов (CUSTOMER)
2. Таблица заказов (ORDER)
3. Таблица с перечнем вещей составляющих индивидуальный заказ (ITEM)
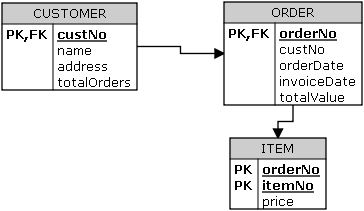
Имена таблиц указаны жирным, первичные ключи подчёркнуты.
**CUSTOMER**
custNo *Уникальный номер клиента*
name *Имя клиента*
address *Адрес клиента*
totalOrders *Общее число заказов клиента*
**ORDER**
orderNo *Номер заказа*
custNo *Номер клиента (внешний ключ из таблицы CUSTOMER)*
orderDate *Дата заказа*
invoiceDate *Дата счёта-фактуры*
totalValue *Стоимость заказа*
**ITEM**
orderNo *Номер заказа (соотвествующий ключу из таблицы ORDER).*
itemNo *Артикул вещи*
price *Цена вещи для клиента (учитывая все скидки).*
Отношение один-ко-многим показано на диаграмме. Каждый клиент может иметь много заказов и каждый заказ может состоять из многих вещей.
Число заказов конкретного клиента (CUSTOMER.totalOrders) это суммарное число размещённых клиентом заказов в таблице ORDERS, которые идентифицируются по его номеру.
Цена заказа (ORDER.totalValue) это сумма стоимости всех вещей в заказе, каждая конкретная стоимость определяется полем ITEM.price.
Поля CUSTOMER.totalOrders и ORDER.totalValue не вводятся напрямую пользователем — это вычисляемые поля.
Для SQL/реляционных БД эти определения таблиц должны быть загружены в БД (с помощью CREATE TABLE) прежде чем с помощью SQL можно будет добавлять, изменять и получать записи.
MUMPS не навязывает использование определений таблиц перед их использованием и, поэтому строки могут быть записаны напрямую в хранилище без того, чтобы быть предварительно формально определены.
Тем не менее важно заметить, что реляционная схема может быть прозрачно наложена на MUMPS-хранилище с целью доступа к данным через SQL-инструменты. Реляционная схема может быть добавлена к существующему MUMPS-хранилищу, когда это станет нужным, предоставляя доступ к записям в нормализованной форме (если структуры поддаются нормализации).
Данные три таблицы будут представлены в MUMPS используя следующие глобалы:
**Таблица CUSTOMER**
^CUSTOMER(custNo)=name|address|totalOrders
**Таблица ORDER**
^ORDER(orderNo)=custNo|orderDate|invoiceDate|totalValue
**Таблица ITEM**
^ITEM(orderNo,itemNo)=price
Связь между CUSTOMER и ORDER будет представлена с помощью глобала:
^ORDERX1(custNo,orderNo)=””
Он будет предоставлять номера заказов по номеру клиента.
В MUMPS вы можете использовать любые имена глобалов. Также вы имеете выбор: использовать по одному глобалу для каждой таблицы (как мы и сделали) или один и тот же глобал для нескольких или всех таблиц.
Для примера мы могли бы использовать один глобал для всей нашу структуры:
```
^OrderDatabase(“customer”,custNo)= name_”~”_address_”~”_totalOrders
^OrderDatabase(“order”,orderNo)= custNo_”~”_orderDate_”~”_invoiceDate_”~”_totalValue
^OrderDatabase(“item”,orderNo,itemNo)=price
^OrderDatabase(“index1”,custNo,orderNo)=””
```
Для обучающих целей данной статьи мы выбрали использовать по глобалу на таблицу.
Также мы выбрали использовать символ тильды (~) как разделитель полей в глобалах (можно выбрать любой другой символ).
**Добавление записи в БД**
Давайте начнём с очень простого примера. Добавим нового клиента в таблицу CUSTOMER.
**SQL**
```
INSERT INTO CUSTOMER (CustNo, Name, Address) VALUES (100, ‘Chris Munt’, ‘Oxford’)
```
**MUMPS**
```
Set ^CUSTOMER(100)= “Chris Munt”_"~"_"Oxford"
```
"\_" — это символ для склеивания (конкатенации) строк.
В правой части мы ввели 2 поля, разделённых символом тильды. К слову говоря, в качестве разделяющего можно использовать действительно любой символ, в том числе служебные (non-printable) символы.
Мы могли бы написать:
```
Set ^CUSTOMER(100)= “Chris Munt”_$c(1)_"Oxford"
```
Функция $c(1) означает «символ ASCII-значение которого 1».
$c — это сокращённое название функции $char.
И в этом случае для разделения поле использовался бы символ ASCII 1.
Конечно, в реальной ситуации данные, которые подставляются в INSERT запрос (или в команду MUMPS), хранятся в переменных.
**SQL**
```
INSERT INTO CUSTOMER (custNo, name, address) VALUES (:custNo, :name, :address)
```
> Прим. переводчика: в ANSI SQL для указания переменных используется предшествующее двоеточие.
**MUMPS**
```
Set ^CUSTOMER(custNo)=name_"~"_address
```
**Выборка записей из БД**
**SQL**
```
SELECT A.name, A.address FROM CUSTOMER A
WHERE A.custNo = :custNo
```
**MUMPS**
```
Set record=$get(^CUSTOMER(custNo))
Set name=$piece(record,"~",1)
Set address=$piece(record,"~",2)
```
Замечание об использовании функции $get(). Это удобный способ извлекать значения из глобалов. Если запрошенного элемента не существует, то $get() вернёт null ("").
Если бы мы не использовали $get(), то нужно было бы делать так:
```
Set record=^CUSTOMER(custNo)
```
Если запрашиваемого элемента глобала не существует, то MUMPS вернёт ошибку периода исполнения (т.е. данные не определены).
Подобно большинству команд и функций в MUMPS вместо $get() можно использовать сокращение $g():
```
Set record=$g(^CUSTOMER(custNo))
```
**Удаление записи из БД**
**SQL**
```
DELETE FROM CUSTOMER A WHERE A.custNo = :custNo
```
MUMPS
```
kill ^CUSTOMER(custNo)
```
Заметим, что этот простой пример пока не содержит проверок, которые позволяют сохранить логическую целостность БД. Далее мы покажем как это делается.
**Выборка нескольких записей**
**SQL**
```
SELECT A.custNo, A.name, A.address FROM CUSTOMER A
```
**MUMPS**
```
s custNo=”” f s custNo=$order(^CUSTOMER(custNo)) Quit:custNo= “” do
. Set record=$get(^CUSTOMER(custNo))
. Set name=$piece(record,"~",1)
. Set address=$piece(record,"~",2)
. Set totalOrders=$piece(record,"~",3)
. ; добавьте свой код для обработки текущей строки
```
Заметьте, что мы используем синтаксис с точками (dot-syntax). Строки начинающиеся с точек представляют собой подпрограмму, вызываемую командой do (см. окончание первой строки)
Вы можете сделать всё что вам нужно с каждой строкой внутри подпрограммы, как показывает комментарий (последня строка начинающаяся с ";")
Функция $order в MUMPS один из столпов силы и гибкости глобалов. Суть её работы обычно как правило непонятна для тех кто знаком только с SQL и реляционными БД, поэтому подробнее о ней читайте [в главе 1](/post/175659/).
С функцией $order и глобалами, мы можем обойти любые строки в таблице, ключи к которым начинаются и заканчиваются с любых значений. Важно понимать, что глобалы представляют собой иерахическое хранилище. Ключ в таблице мы эмулировали через индекс в глобале, так что мы не имеем доступа к строкам в последовательности, в которой они создавались: функция $order может быть применена к каждому индексу (ключу) глобала независимо.
**Использование MUMPS-функций для высокоуровнего доступа к данным**
На практике для повторного использования и исключения избыточности кода MUMPS-команды показанные выше должны быть преобразованы в функции. Примеры таких функций показаны ниже.
**Добавление новой записи в БД**
```
setCustomer(custNo,data) ; Определение заголовка функции
If custNo="" Quit 0
Set ^CUSTOMER(custNo)=data("name")_"~"_data("address")
Quit 1
```
Эта функция может быть вызвана следующим путём::
```
kill data ; удалим локальный массив data (он существует только в RAM)
set data("name")="Rob Tweed"
set data("address")="London"
set custNo=101
set ok=$$setCustomer(custNo,.data) ; $$ означает, что функция пользовательская
```
Обратите внимание на точку перед параметром функции data. Это вызов по ссылке. data — это локальный массив, не простая переменная, так что мы передаём его в функцию по ссылке.
Функция setCustomer может содержаться в другой программе (например в myFunctions). А поскольку программы в MUMPS содержатся в глобалах, то для вызова функции из глобала нужно написать $$setCustomer^myFunctions(custNo,.data)
Пример:
```
kill data ; clear down data local array
set data("name")="Rob Tweed"
set data("address")="London"
set custNo=101
set ok=$$setCustomer^myFunctions(custNo,.data)
```
Функцию $$setCustomer() можно назвать внешней (extrinsic). В терминах ООП это соответствует public. Мы можем обратиться к ней, даже, если она содержится в другой программе. Внешние функции это своего рода методы доступа к данным.
Функция $$setCustomer() возвращает ноль (т.е. false), если в качестве номера клиента мы передадим null. В других случаях запись будет сохранена и $$setCustomer() вернёт 1 (т.е. true). Вы можете проверять переменную ok, чтобы проверить выполнено сохранение или нет.
Поскольку у нас в таблице CUSTOMER есть вычисляемое поле totalOrders, сделаем его поддержку в коде:
```
setCustomer(custNo,data) ;
if custNo="" Quit 0
; Посчитаем число заказов
Set data(“totalOrders”)=0
Set orderNo=””
for set orderNo=$order(^ORDERX1(custNo,orderNo)) Quit:orderNo=”” do
. set data(“totalOrders”)=data(“totalOrders”)+1
set ^CUSTOMER(custNo)=data("name")_"~"_data("address")_”~”_data(“totalOrders”)
Quit 1
```
Мы продолжим обсуждение вычисляемых полей позже в секции «Триггеры».
**Получение записи из БД**
Следующая внешняя функция вернёт строку из таблицы CUSTOMER.
```
getCustomer(custNo,data) ;
new record
kill data ; clear down data array
if custNo="" Quit 0
set record=$get(^CUSTOMER(custNo))
set data("name")=$piece(record,"~",1)
set data("address")=$piece(record,"~",2)
set data("totalOrders")=$piece(record,"~",3)
Quit 1
```
Эта функция может быть использована следующим образом:
```
S custNo=101
set ok=$$getCustomer(custNo,.data)
```
Она вернёт локалный массив (а точнее говоря изменит его, т.к. он передаётся по ссылке), содержащий 3 поля из строки заданного клиента:
data(“name)
data(“address”)
data(“totalOrders”)
**Удаление записи из БД**
Следующая внешняя функция удалит строку из таблицы CUSTOMER:
```
deleteCustomer(custNo) ;
if custNo="" Quit 0
kill ^CUSTOMER(custNo)
Quit 1
```
Эта функция может быть использована следующим образом:
```
S custNo=101
S ok=$$deleteCustomer(custNo)
```
> **Прим. Переводчика:** В 3 части мы поговорим о вторичных индексах, триггерах и транзакциях.
[3-я часть, окончание.](/post/176345/) | https://habr.com/ru/post/176305/ | null | ru | null |
# Разбираемся в нюансах создания оператора на golang
> Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop. — from kubernetes.io
>
>
В данной статье я постарался изложить на что обратить внимание при написании оператора на golang и на нюансы, которые описываются вскользь или вовсе не описываются в официальном [туториале](https://sdk.operatorframework.io/docs/building-operators/golang/tutorial/) или других статьях подобного вида.
В данной статье я кратко покажу:
* Как подготовить окружение для создания оператора
* Как писать программу и что мы можем сделать внутри основной функции обработки событий (реконсилера)
* Когда вызывается реконсилер и как этим управлять
* Как выходить из реконсилера
* Как консистентно создавать и удалять объекты кластера
Для примера мы создадим secret-operator который будет:
* Создавать необходимые секреты во всех неймспейсах кластера
* Создавать секреты при создании нового неймспейса
* Восстанавливать секрет, если его кто-то удалит
* Удалять всех потомков, если удаляется наш корневой объект
Что данный оператор НЕ делает, для упрощения кода:
* Не обрабатываются изменения секретов
* Не реализована логика выбора неймспейса
Немного теории
--------------
Паттерн [оператор](https://kubernetes.io/docs/concepts/extend-kubernetes/operator/) реализуемый [controller-runtime](https://github.com/kubernetes-sigs/controller-runtime) (kubebuilder, operator-sdk) очень похож на паттерн [Наблюдатель](https://refactoring.guru/ru/design-patterns/observer) ([2](https://medium.com/nuances-of-programming/%D0%BF%D0%B0%D1%82%D1%82%D0%B5%D1%80%D0%BD-%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F-%D0%BD%D0%B0%D0%B1%D0%BB%D1%8E%D0%B4%D0%B0%D1%82%D0%B5%D0%BB%D1%8C-%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82-%D0%BF%D0%BE%D0%B4-%D0%BF%D1%80%D0%B8%D1%86%D0%B5%D0%BB%D0%BE%D0%BC-4dc3a453aaa4)). Мы “подписываемся” на события k8s на создание/изменение/удаление объектов на которые мы должны реагировать. При изменении данных ресурсов вызывается функция reconcile в которую передается имя "родительского" объекта к которому относятся данные события. В функции reconcile описывается проверка состояний родительских/дочерних/остальных объектов и реакция на данные события. Более подробно о том как происходит подписка на события и работа reconcile-loop описано далее.
Подготовка окружения разработки
-------------------------------
Установка golang
----------------
Скачайте необходимый архив для необходимой ОС по [ссылке](https://go.dev/dl/).
Распакуйте архив например в директорию /opt/go-1.19.4
Создайте рабочую директорию для go и пропишите переменные окружения
```
mkdir ~/go-1.19
export GOROOT=/opt/go-1.19.4
export GOPATH=~/go-1.19
export PATH=$GOROOT/bin:$GOPATH/bin:$PATH
```
### Установка operator SDK
Скачиваем и проверяем необходимый бинарный исполняемый файл ([ссылка](https://sdk.operatorframework.io/docs/installation/))
```
export ARCH=$(case $(uname -m) in x86_64) echo -n amd64 ;; aarch64)
echo -n arm64 ;; *) echo -n $(uname -m) ;; esac)
export OS=$(uname | awk '{print tolower($0)}')
export OPERATOR_SDK_DL_URL=https://github.com/operator-framework/operator-sdk/releases/download/v1.26.0
curl -LO ${OPERATOR_SDK_DL_URL}/operator-sdk_${OS}_${ARCH}
gpg --keyserver keyserver.ubuntu.com --recv-keys 052996E2A20B5C7E
curl -LO ${OPERATOR_SDK_DL_URL}/checksums.txt
curl -LO ${OPERATOR_SDK_DL_URL}/checksums.txt.asc
gpg -u "Operator SDK (release) " --verify checksums.txt.asc
grep operator-sdk\_${OS}\_${ARCH} checksums.txt | sha256sum -c -
chmod +x operator-sdk\_${OS}\_${ARCH} && sudo mv operator-sdk\_${OS}\_${ARCH} /usr/local/bin/operator-sdk
```
### Установка IDE
Если у вас нет предпочтительной IDE используйте Goland, скачать можно [здесь](https://www.jetbrains.com/go/download). Триал 30 дней при регистрации по электронной почте.
После открытия первого проекта останется только прописать GOROOT|GOPATH в настройках (File -> settings -> Go)
Подготовка проекта operator SDK
-------------------------------
Описание на официальном сайте [тут](https://sdk.operatorframework.io/docs/building-operators/golang/tutorial/)
Исходный код проекта храниться на [github](https://github.com/ddnw/secret-operator)
Создадим новый проект:
```
mkdir -p ~/go-1.19/src/github.com/ddnw/secret-operator
cd ~/go-1.19/src/github.com/ddnw/secret-operator
operator-sdk init --domain ddnw.ml --repo github.com/ddnw/secret-operator
```
Создаем новый API и контроллер:
```
operator-sdk create api --group multi --version v1alpha1 --kind MultiSecret --resource --controller
```
Правим название докер образа на тот что необходим в Makefile
```
IMAGE_TAG_BASE ?= ddnw/secret-operator
IMG ?= $(IMAGE_TAG_BASE):$(VERSION)
```
Подсказка по командам SDK
```
#Запуск кодогенерации
make generate
#Создание манифестов
make manifests
# Сборка и пуш контейнера
make docker-build docker-push
# Установка CRD
make install
# Запуск контроллера в кластере
make deploy
# Удаление CRD и контроллера из кластера
make undeploy
# Удаление CRD
make uninstall
# Создание тестового объекта
kubectl apply -f config/samples/multi_v1alpha1_multisecret.yaml
```
Структура кода оператора
------------------------
Код оператора разделен на 2 основные части:
* api - объявляющую нашу новую "родительскую" сущность для k8s
* controller - код который читает желаемое состояние объектов k8s и стремиться применить его в k8s
API
---
После выполнения команды `operator-sdk create api` сгенерировались файлы по пути api/v1alpha1 в файле multisecret\_types.go описана наша новая “родительская” сущность для которой мы и будем писать большую часть последующего кода.
Добавим в секцию spec необходимые поля, которые мы в последующем будем помещать в наши секреты, не забываем аннотации json - чтобы k8s смог в последующем эти данные сериализовать.
После каждого изменения данной части кода запускаем `make generate` для автогенерации необходимой части кода в файле zz\_generated.deepcopy.go
```
// MultiSecretSpec defines the desired state of MultiSecret
type MultiSecretSpec struct {
Data map[string][]byte `json:"data,omitempty"`
StringData map[string]string `json:"stringData,omitempty"`
Type SecretType `json:"type,omitempty"`
}
```
Так же добавляем описание структуры статусов нашего "родительского" объекта
```
// MultiSecretStatus defines the observed state of MultiSecret
type MultiSecretStatus struct {
Wanted int `json:"wanted"`
Created int `json:"created"`
ChangeTime string `json:"change_time,omitempty"`
}
```
Controller
----------
Основная логика multiSecret контроллера
---------------------------------------
Наш контроллер выполняет следующую логику:
1. По вызову реконсилера запрашивается объект multiv1alpha1.MultiSecret{}
2. Выходим Если он не существует
3. Если "родительский" объект в стадии удаления, удаляем все "дочерние" секреты и выходим (Finalizer)
4. Проверяем какие "дочерние" секреты существуют по всем пространствам (namespace), в соответствии со спецификацией "родительского" объекта создаем или удаляем их.
Reconcile loop
--------------
Reconcile - основная функция внутри которой мы проверяем состояние объектов и приводим их к желаемому состоянию. Функция **обязательно** должна быть идемпотентной, Вы не знаете в какой момент времени жизни объектов она вызовется.
### Выход из функции
Из reconcile функции может быть несколько вариантов выхода в зависимости от того необходимо ли еще перезапустить цикл или нет.
**ctrl.Result{}, err** - случилась ошибка при выполнении из-за которой мы не можем продолжить выполнение, возвращаем ее чтобы перезапустить цикл позже.
**ctrl.Result{Requeue: true}, nil** - ошибки выполнения отсутствуют, но мы возвращаем управление контроллеру, что бы он мог обработать и другие объекты, и позже вернуться к текущему снова.
**ctrl.Result{}, nil** - перезапуск цикла не требуется, желаемое состояние = существующему.
**ctrl.Result{RequeueAfter: 60 \* time.Second}, nil** - перезапустить цикл после определенного времени. Можно использовать для уверенности в том что состояние объектов будет проверено и применено в данный интервал времени.
### Жизненный цикл объекта и кэш
Объект в k8s может быть создан, обновлен или быть в стадии удаления.
Дополнительно к этому контроллер имеет свой кэш состояния объектов, с одной стороны это дает возможность не заботиться о том сколько раз мы запрашиваем состояние объекта, но так же надо понимать что мы можем “успеть” удалить один и тот же объект 2 раза. Либо реконсилер может быть вызван уже на удаленный объект. Для обработки таких ситуаций надо сравнивать возвращаемую ошибку на отсутствие объекта функцией IsNotFound(err)
```
func (r *MultiSecretReconciler) deleteSecret(ctx context.Context, secret *corev1.Secret) error {
log := ctrllog.FromContext(ctx)
err := r.Delete(ctx, secret)
if errors.IsNotFound(err) {
log.Info("corev1.Secret resource not found. Ignoring since object must be deleted",
"NameSpace", secret.Namespace, "Name", secret.Name)
return nil
}
if err != nil {
log.Error(err, "Failed to delete corev1.Secret",
"NameSpace", secret.Namespace, "Name", secret.Name)
return err
}
return nil
}
```
После каждого запроса объекта и удаления, надо понимать какой тип ошибки вернулся, это проблема доступа к API или такого объекта не существует, и уже на основании этого принимать решение что делать далее. В приведенном примере если наш объект multiSecret не существует, то мы ничего не делаем, если же это ошибка доступа к API мы возвращаем ошибку чтобы reconcileLoop снова встал в очередь на выполнение.
```
// Get MultiSecret object
mSecret := &multiv1alpha1.MultiSecret{}
err := r.Get(ctx, req.NamespacedName, mSecret)
if err != nil {
if errors.IsNotFound(err) {
log.Info("MultiSecret resource not found. Ignoring since object must be deleted")
return reconcile.Result{}, nil
}
log.Error(err, "Failed to get MultiSecret")
return reconcile.Result{}, err
}
```
Watching Resources
------------------
Функция SetupWithManager - устанавливает события на которые должен срабатывать reconciler, а так же делает сопоставление, reconciler какого объекта необходимо вызывать.
Первым идет метод For - для "родительского" объекта. Тут нам не надо ничего придумывать, на его события создания/изменения/удаления будет вызываться reconciler
Если Вы задумали контроллер, который будет обрабатывать события только на объекты созданные им самим, и объекты будут находится в том же пространстве (namespace), тогда можно использовать хендлеры через метод Owns
<https://sdk.operatorframework.io/docs/building-operators/golang/tutorial/>
```
func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&cachev1alpha1.Memcached{}).
Owns(&appsv1.Deployment{}).
Complete(r)
}
```
Главное не забывать делать ссылку на “родительский” объект из “дочерних”
```
// deploymentForMemcached returns a memcached Deployment object
func (r *MemcachedReconciler) deploymentForMemcached(m *cachev1alpha1.Memcached) *appsv1.Deployment {
ls := labelsForMemcached(m.Name)
replicas := m.Spec.Size
dep := &appsv1.Deployment{
...
}
// Set Memcached instance as the owner and controller
ctrl.SetControllerReference(m, dep, r.Scheme)
return dep
}
```
Из приведенного ранее ТЗ нам надо отрабатывать:
* События изменений нашего “родительского” объекта
* Объектов которые мы будем создавать (secrets) в разных пространствах (namespace)
* Объекты которые нам не принадлежат, создание новых пространств (namespace)
```
// SetupWithManager sets up the controller with the Manager.
func (r *MultiSecretReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&multiv1alpha1.MultiSecret{}).
Watches(
&source.Kind{Type: &corev1.Secret{}},
handler.EnqueueRequestsFromMapFunc(r.secretHandlerFunc),
builder.WithPredicates(predicate.ResourceVersionChangedPredicate{}),
).
Watches(
&source.Kind{Type: &corev1.Namespace{}},
handler.Funcs{CreateFunc: r.nsHandlerFunc},
).
Complete(r)
}
```
Что мы тут видим - мы следим за объектами corev1.Secret, вызываем функцию secretHandlerFunc - которая делает сопоставление к какому "родительскому" объекту он относится.
```
func (r *MultiSecretReconciler) secretHandlerFunc(a client.Object) []reconcile.Request {
anno := a.GetAnnotations()
name, ok := anno[annotationOwnerName]
namespace, ok2 := anno[annotationOwnerNamespace]
if ok && ok2 {
return []reconcile.Request{
{
NamespacedName: types.NamespacedName{
Name: name,
Namespace: namespace,
},
},
}
}
return []reconcile.Request{}
}
```
Сама функция действует несложно, ищем в объекте необходимые аннотации, и возвращаем вызов необходимого реконсилера "родительского" объекта. Предикат указывает на то когда срабатывать. Данный предикат срабатывает на любое изменение версии объекта, создание и удаление сюда тоже входит.
По corev1.Namespace похожее поведение, но отрабатываем только создание пространства и в nsHandlerFunc отдаем вызовы на все реконсилеры наших “родительских” объектов.
```
func (r *MultiSecretReconciler) nsHandlerFunc(e event.CreateEvent, q workqueue.RateLimitingInterface) {
multiSecretList := &multiv1alpha1.MultiSecretList{}
err := r.List(context.TODO(), multiSecretList)
if err != nil {
return
}
for _, ms := range multiSecretList.Items {
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{
Name: ms.Name,
Namespace: ms.Namespace,
}})
}
}
```
Более подробно о слежении за ресурсами можно почитать [здесь](https://book.kubebuilder.io/reference/watching-resources.html).
Finalizers
----------
Финализаторы ставятся на объект чтобы была возможность выполнить необходимые действия при удалении объекта, например как в нашем случае удалить все "дочерние" секреты.
Если мы создаем "дочерние" объекты в том же пространстве (namespace) что и "родительский" объект, то финализаторы для удаления "дочерних" нам не нужны.
Хватит указания на "родительский" объект, а k8s удалит их сам. [подробнее](https://kubernetes.io/docs/concepts/overview/working-with-objects/owners-dependents/)
В нашем случае при удалении "родительского" объекта мы хотим удалять и все "дочерние" во всех пространствах (namespaces) для этого будем использовать [финализатор](https://kubernetes.io/blog/2021/05/14/using-finalizers-to-control-deletion/).
Идея простая: k8s при удалении объекта проставляет время удаления и смотрит есть ли у него финализаторы. Пока они есть - объект не удаляется и дается время чтобы контролеры могли закончить необходимые действия.
В нашем коде пишем следующую логику:
* Если родительский объект не в стадии удаления и у него нет нашего финализатора, то мы его добавляем
* Если родительский объект в стадии удаления, удаляем все "дочерние" и в случае успеха удаляем запись финализатора
```
inFinalizeStage := false
// Check Finalizer
if mSecret.ObjectMeta.DeletionTimestamp.IsZero() {
if !ctrlutil.ContainsFinalizer(mSecret, FinalizerName) {
ctrlutil.AddFinalizer(mSecret, FinalizerName)
if err := r.Update(ctx, mSecret); err != nil {
return ctrl.Result{}, err
}
changed = true
}
} else {
// The object is being deleted
inFinalizeStage = true
if ctrlutil.ContainsFinalizer(mSecret, FinalizerName) {
// our finalizer is present, so lets handle any external dependency
if err := r.deleteAllSecrets(ctx, genGlobalName(mSecret.Name, mSecret.Namespace, multiSecName), nameSpaces); err != nil {
// if fail to delete the external dependency here, return with error
// so that it can be retried
return ctrl.Result{}, err
}
changed = true
// remove our finalizer from the list and update it.
ctrlutil.RemoveFinalizer(mSecret, FinalizerName)
if err := r.Update(ctx, mSecret); err != nil {
return ctrl.Result{}, err
}
}
}
```
Status
------
Добавим статусы нашему объекту, чтобы они красиво выводились по get запросу:
```
$ k get multisecrets.multi.ddnw.ml
NAME WANTED CREATED CHANGETIME
multisecret-sample 9 9 2022-05-31T12:14:35+03:00
```
По коду добавляем счетчики:
```
// Calculate Wanted Status
sWantedStatus := 0
existedSecrets := 0
changed := false
for _, ns := range nameSpaces {
if nsInList(mSecret, ns) {
sWantedStatus++
}
}
```
Добавляем обновление статуса при выходе из функции. Обновление будет срабатывать только при выходе без ошибок, для этого мы задали имена выходным параметрам:
```
func (r *MultiSecretReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrlRes ctrl.Result, ctrlErr error)
```
Здесь же можно посмотреть как выполняется patch статуса объекта:
```
// Update Status on reconcile exit
defer func() {
if ctrlErr == nil {
if changed || sWantedStatus != mSecret.Status.Wanted || existedSecrets != mSecret.Status.Created {
patch := client.MergeFrom(mSecret.DeepCopy())
mSecret.Status.Wanted = sWantedStatus
mSecret.Status.Created = existedSecrets
mSecret.Status.ChangeTime = time.Now().Format(time.RFC3339)
ctrlErr = r.Status().Patch(ctx, mSecret, patch)
}
if ctrlErr != nil {
log.Error(ctrlErr, "Failed to update multiSecret Status",
"Namespace", mSecret.Namespace, "Name", mSecret.Name)
}
}
}()
```
Дополнительно чтобы работал вывод статуса с get необходимо дополнительно задать маркеры для генерации CRD, [ссылка](https://book.kubebuilder.io/reference/generating-crd.html) на дополнительную информацию.
```
//+kubebuilder:object:root=true
//+kubebuilder:subresource:status
//+kubebuilder:printcolumn:name="Wanted",type=integer,JSONPath=`.status.wanted`
//+kubebuilder:printcolumn:name="Created",type=integer,JSONPath=`.status.created`
//+kubebuilder:printcolumn:name="ChangeTime",type=string,JSONPath=`.status.change_time`
```
### Events
Для того чтобы в последствии понимать, что делает наш контроллер, добавим генерацию событий (Events), которые можно будет видеть, в том числе и в выводе describe объекта multisecret.
Для этого в структуру реконсилера добавляем рекордер и права в маркере:
```
// MultiSecretReconciler reconciles a MultiSecret object
// +kubebuilder:rbac:groups="",resources=events,verbs=create;patch
type MultiSecretReconciler struct {
client.Client
Scheme *runtime.Scheme
Recorder record.EventRecorder
}
```
В main.go добавляем инициализацию рекордера:
```
if err = (&controllers.MultiSecretReconciler{
Client: mgr.GetClient(),
Scheme: mgr.GetScheme(),
Recorder: mgr.GetEventRecorderFor("multisecret-controller"),
}).SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "MultiSecret")
os.Exit(1)
}
```
В последующем при создании и удалении секретов, пишем события:
```
msg := fmt.Sprintf("Created corev1.Secret, NameSpace: %s, Name: %s", newSecret.Namespace, newSecret.Name)
r.Recorder.Event(mSecret, "Normal", "Created", msg)
```
```
k describe multisecrets.multi.itsumma.ru multisecret-sample
Name: multisecret-sample
....
Status:
change_time: 2022-05-31T14:02:18+03:00
Created: 9
Wanted: 9
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Created 2s (x3 over 160m) multisecret-controller Created corev1.Secret, NameSpace: secret-operator-system, Name: multisecret-sample.secret-operator-system.multisec
```
В данной статье я постарался показать как расширить стандартный оператор из примера до рабочего состояния. А так же рассмотрели как следить за ресурсами, как изменять статус ресурса, как управлять реконсилером, как писать события, как сделать свой финализатор.
ЗЫ: Большое спасибо коллегам из ИТ-Сумма за посильный вклад в создание данной статьи. | https://habr.com/ru/post/710588/ | null | ru | null |
# Трамплин вызова магических функций в PHP 7

В этой статье мы подробно рассмотрим оптимизацию в виртуальной машинe в PHP 7 (виртуальной машине Zend). Сначала коснёмся теории трамплинов вызовов функций, а затем узнаем, как они работают в PHP 7. Если вы хотите полностью во всём разобраться, то лучше иметь хорошее представление о работе виртуальной машины Zend. Для начала можете [почитать](http://jpauli.github.io/2015/02/05/zend-vm-executor.html), как устроена ВМ в PHP 5, а здесь мы поговорим о ВМ PHP 7. Хотя она и была переработана, но действует практически так же, как и в PHP 7. Поэтому если вы разберётесь в ВМ PHP 5, то разобраться с ВМ PHP 7 не составит никакого труда.
Всё дело в рекурсии
===================
Если вы никогда не слышали о трамплинах, то наверняка и не прикасались к языкам вроде Haskell или Scala. Трамплины вызовов функций — это трюк, о котором обычно рассказывают на курсах углублённого обучения программированию. Задача трамплина — предотвратить рекурсивность вызовов функций. Это теоретическая основа. Если вы не знаете, что такое рекурсия, то сначала полюбопытствуйте. В ней нет ничего сложного.
Существует много способов внедрения механизма трамплинов в приложениях. Начнём с простого примера:
```
function factorial($n)
{
if ($n == 1) {
return $n;
}
return $n * factorial($n-1);
}
```
Проще всего понять рекурсию на всем известной функции factorial. У неё очень мало инструкций, и прежде всего — она вызывает саму себя.
Как вы знаете, при каждом вызове функции происходит много вещей. На нижнем уровне компилятор готовится к вызову, пользуясь [соглашением о вызове функции](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%B3%D0%BB%D0%B0%D1%88%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BE_%D0%B2%D1%8B%D0%B7%D0%BE%D0%B2%D0%B5). По сути, компилятор сначала передаёт в стек аргументы и адрес возврата, а затем генерирует опкод CALL, переводящий процессор на первую инструкцию тела функции. Когда она будет завершена, используется опкод RETURN (если его нет в теле функции, то он генерируется компилятором), говорящий процессору избавиться от стека аргументов (сбрасывается указатель стека) и вернуться к адресу возврата.
Проблема этой модели заключается в том, что стек — часть памяти, конечная и небольшая по размеру. В Linux под стек обычно выделяют 8 Мб (*ulimit -a*). Рекурсивные функции очень активно используют стек, потому что каждая запись на рекурсивном уровне создаёт в стеке новый фрейм. Если слишком увлечься, то можно заполнить весь стек. В этом случае ядро обычно выдаёт процессору сигнал SIGBUS и завершает стек, если до этого он сам не упадёт (например, если вы используете `alloca()`).
Хотя место в стеке заканчивается редко (если не считать багов в программе), помимо рекурсивных функций вам может навредить создание в стеке и последующее уничтожение (при возврате функции) фрейма вызова. Это отъедает часть циклов процессора (для ориентированных на стек инструкций вроде `mov`, `pop`, `push` и `call`) и всегда подразумевает обращения к основной памяти. И — это медленно. Если ваша программа может работать с одиночной функцией, без вызова дочерних, то она будет действовать быстрее: процессору не нужно бесконечно создавать и удалять стеки, перемещая блоки памяти, которые программа не использует напрямую, они просто являются частью архитектуры. Сегодня процессоры обычно применяют регистры для хранения аргументов стека или адреса возврата (например, LP64 в Linux), но всё равно избегайте рекурсии, хотя бы её самых глубоких уровней.
Предотвращение рекурсии
=======================
Предотвратить рекурсию при вызове функций можно несколькими способами. Для знакомства с простыми способами мы воспользуемся PHP. Более традиционный способ изучим с помощью функции-трамплина, а затем на примере исходного кода PHP рассмотрим работу этого механизма, добавленного в сердцевину PHP 7.
### Функции хвостового вызова и циклы
Рекурсия — это разновидность цикла «пока ХХХ, вызываю самого себя». Следовательно, рекурсивную функцию можно переписать с помощью цикла (иногда даже нескольких) без какого-либо вызова самой себя. Однако имейте в виду, что это непростая задача, всё зависит от самой функции: сколько раз и как она себя вызывает.
К счастью, можно легко «дерекурсировать» факториальную функцию. Для этого мы воспользуемся способом, который называется преобразованием хвостового вызова (tail-call transformation). Можно раскрутить (unroll) факториальную функцию, превратив её в рекурсивную функцию хвостового вызова и применив некое правило. Давайте сначала выполним превращение:
```
function tail_factorial($n, $acc = 1)
{
if ($n == 1) {
return $acc;
}
return tail_factorial($n-1, $n * $acc);
}
```
Здесь мы использовали так называемый аккумулятор. В конце мы должны получить функцию хвостового вызова. Напомню: так называется функция, которая, когда дело доходит до возвращения себя, делает это без выполнения каких-либо других операций. То есть выражение возврата передаёт **только** рекурсивную функцию, без дополнительных операций. Например, повторный вход с одним потоком инструкций (single-instruction reentrant). Таким образом компилятор оптимизирует последний вызов: функция просто возвращает саму себя, следовательно, создание стека упрощается за счёт повторного использования текущего фрейма стека вместо создания нового. Также мы теперь можем преобразовать эту функцию хвостового вызова, тело которой представляет собой просто цикл. Вместо обратного вызова функции с изменёнными аргументами нужно прыгнуть снова к началу функции (как это сделал бы рекурсивный вызов), но при этом изменив аргументы, чтобы следующий цикл выполнялся с правильными значениями аргументов (как это делает рекурсивная функция). Получаем:
```
function unrolled_factorial($n)
{
$acc = 1;
while ($n > 1) {
$acc *= $n--;
}
return $acc;
}
```
Эта функция делает то же самое, что и оригинальная `factorial()`, но больше не вызывает саму себя. В ходе runtime это получается гораздо производительнее рекурсивной альтернативы.
Также мы могли бы использовать ветку `goto`:
```
function goto_factorial($n)
{
$acc = 1;
f:
if ($n == 1) {
return $acc;
}
$acc *= $n--;
goto f;
}
```
И снова никакой рекурсии.
Попробуйте запустить `factorial()` с огромным числом: у вас кончится стек, и вы упрётесь в ограничение памяти движка (поскольку фреймы стека в виртуальной машине размещены в куче (heap)). Если отключить ограничение (*memory\_limit*), то PHP упадёт, потому что ни у него, ни у виртуальной машины Zend нет защиты от бесконечной рекурсии. Следовательно, процесс рухнет. Теперь попробуйте запустить с тем же аргументом `unrolled_factorial()` или даже `goto_factorial()`. Система не упадёт. Выполняться может не слишком быстро, но не упадёт, а место в стеке (размещённом в куче PHP) не закончится. Хотя скорость выполнения будет куда выше, чем в случае с рекурсивной функцией.
### Управляющие трамплинные функции хвостового вызова
Иногда бывает так, что функцию непросто дерекурсировать. Факториальную — просто, но некоторые другие — куда сложнее. Например, функции, вызывающие себя в разных местах, в разных условиях и так далее (вроде простой реализации `bsearch()`).
В таких случаях, чтобы обуздать рекурсию, может понадобиться [трамплин](https://en.wikipedia.org/wiki/Trampoline_%28computing%29). Надо будет переписать базовую рекурсивную функцию (как при дерекурсировании), но в этот раз она может вызывать сама себя. Мы просто замаскируем эти вызовы, выполняя их с помощью трамплина, а не напрямую. Таким образом, рекурсия будет раскручиваться (unroll) при наличии потока управления (трамплина), обеспечивая контроль над каждым вызовом нашей функции. Больше не нужно ломать голову над тем, как дерекурсировать сложную функцию: просто оберните её и запускайте через управляющий код, называемый трамплином.
Давайте рассмотрим пример использования этой концепции в PHP. Идея заключается в преобразовании нашей функции, чтобы вызывающий её код (caller) мог определить, когда она входит в рекурсию, а когда выходит из неё. Если применить это к самому рекурсивному вызову, то трамплин будет вызываться им и станет управлять его стеком. Если он вернёт результат, то трамплин должен заметить это и остановить.
Вот так:
```
function trampo_factorial($n, $acc = 1)
{
if ($n == 1) {
return $acc;
}
return function() use ($n, $acc) { return trampo_factorial($n-1, $n * $acc); };
}
```
Здесь функция всё ещё вызывает себя. Однако не делает это напрямую, а оборачивает рекурсивный вызов в замыкание (closure). Ведь теперь мы хотим запускать рекурсивную функцию не напрямую, а через трамплин. Когда тот видит, что вернулось замыкание, он запускает функцию. Если не замыкание — возвращает функцию.
```
function trampoline(callable $c, ...$args)
{
while (is_callable($c)) { $c = $c(...$args); } return $c;
}
```
Готово. Используйте подобным образом:
`echo trampoline('trampo_factorial', 42);`
Трамплин — это нормальное решение проблемы рекурсии. Если вы не можете рефакторить функцию, чтобы исключить рекурсивные вызовы, то преобразуйте её в функцию хвостового вызова, которую можно запускать через трамплин. Конечно, трамплины работают только с функциями хвостового вызова, как же иначе.
При использовании трамплина вызываемые функции запускаются столько раз, сколько нужно, при этом им не дают вызывать себя рекурсивно. Трамплин выступает в роли вызываемого. Мы решили проблему рекурсии гораздо более универсальным способом, который может применяться к любой рекурсивной функции.
Здесь я использовал PHP только для того, чтобы объяснить вам суть идеи (полагаю, вы достаточно часто сталкиваетесь с PHP, раз читаете эти строки). Но я не рекомендую создавать трамплины в этом языке. PHP — высокоуровневый язык, и такие конструкции не требуются в повседневной работе. Вам не так часто могут быть нужны рекурсивные функции, и не таким легковесным получается цикл с вызовом `is_callable()` внутри.
Тем не менее давайте углубимся в движок PHP и посмотрим, как здесь реализованы трамплины для предотвращения рекурсии стека в главном цикле диспетчеризации (dispatch loop) виртуальной машины PHP.
Рекурсия в виртуальной машине Zend
==================================
Надеюсь, вы не забыли, что такое [цикл диспетчеризации](http://jpauli.github.io/2015/02/05/zend-vm-executor.html#a-giant-loop)?
Позвольте освежить это в вашей памяти. Все виртуальные машины строятся на нескольких общих идеях, среди которых есть и цикл диспетчеризации. Запускается бесконечный цикл, и в каждой его итерации выполняется (`handler()`) одна инструкция (`opline`) виртуальной машины. В рамках этой инструкции может происходить многое, но в конце всегда идёт команда циклу, обычно это команда перехода к следующей итерации (goto next). Также может быть команда возвращения из бесконечного цикла или команда перехода к этой операции.
По умолчанию цикл диспетчеризации виртуальной машины движка хранится в функции `execute_ex()`. Вот пример для PHP 7 с некоторыми оптимизациями для моего компьютера (использованы регистры IP и FP):
```
#define ZEND_VM_FP_GLOBAL_REG "%r14"
#define ZEND_VM_IP_GLOBAL_REG "%r15"
register zend_execute_data* volatile execute_data __asm__(ZEND_VM_FP_GLOBAL_REG);
register const zend_op* volatile opline __asm__(ZEND_VM_IP_GLOBAL_REG);
ZEND_API void execute_ex(zend_execute_data *ex)
{
const zend_op *orig_opline = opline;
zend_execute_data *orig_execute_data = execute_data;
execute_data = ex;
opline = execute_data->opline;
while (1) {
opline->handler();
if (UNEXPECTED(!opline)) {
execute_data = orig_execute_data;
opline = orig_opline;
return;
}
}
zend_error_noreturn(E_CORE_ERROR, "Arrived at end of main loop which shouldn't happen");
}
```
Обратите внимание на структуру `while(1)`. Что насчёт рекурсии? В чём тут дело?
Всё просто. Вы запустили цикл `while(1)` как часть функции `execute_ex()`. Что случится, если одна инструкция (`opline->handler()`) запустит саму `execute_ex()`? Возникнет рекурсия. Это плохо. Как обычно: да, если она будет многоуровневой.
В каком случае `execute_ex()` вызывает `execute_ex()`? Здесь я не стану слишком углубляться в движок виртуальной машины, потому что вы можете упустить много важной информации. Для простоты будем считать, что это вызов PHP-функции вызывает `execute_ex()`.
Каждый раз, когда вы вызываете PHP-функцию, она создаёт новый фрейм стека на уровне языка С и запускает новую версию цикла диспетчеризации, повторно входя в новый вызов `execute_ex()` с новыми инструкциями для выполнения. Когда появляется этот цикл, завершается вызов PHP-функции, что приводит к процедуре возврата в коде. Следовательно, завершается текущий цикл текущего фрейма в стеке с возвращением предыдущего. Только учитывайте, что это происходит только в случае с PHP-функциями в пользовательском пространстве. Причина в том, что определяемые пользователями PHP-функции представляют собой опкоды, которые после своего запуска работают в цикле. Но внутренним PHP-функциям (разработанным на С и находящимся в ядре или в расширениях) не нужно выполнять опкоды. Это инструкции на чистом С, следовательно, они не создают другой цикл диспетчеризации и другой фрейм.
Способ применения \_\_call()
============================
Теперь я объясню, как можно использовать `__call()`. Это PHP-функция из пользовательского пространства. Как и в случае с любой пользовательской функцией, её выполнение приводит к новому вызову `execute_ex()`. Но дело в том, что `__call()` может вызываться многократно, создавая много фреймов. Каждый раз, когда вызывается неизвестный метод в контексте объекта с помощью `__call()`, определённым в его классе.
В PHP 7 движок был оптимизирован с помощью дополнительных трамплинных управляющих (mastering) вызовов `__call()`, а также с помощью предотвращения рекурсивных вызовов `execute_ex()` в случае с `__call()`.
`Стек __call()` в PHP 5.6:
Здесь три вызова `execute_ex()`. Это взято из PHP-скрипта, который вызывает неизвестный метод в контексте объекта, который, в свою очередь, вызывает неизвестный метод в контексте другого объекта (в обоих случаях классы содержат `__call()`). Так что первый `execute_ex()` — это исполнение основного скрипта (позиция 6 в стеке вызовов), а в верху списка мы видим два остальных `execute_ex()`.
Теперь запустим тот же скрипт в PHP 7:
Разница очевидна: фрейм стека куда тоньше, и у нас остался только один вызов `execute_ex()`, то есть один цикл диспетчеризации, управляющий всеми инструкциями, включая вызовы `__call()`.
Превращение вызовов \_\_call() в трамплинные вызовы
===================================================
В PHP 5 мы вызывали `execute_ex()` в контексте `__call()`. То есть мы приготовили новый цикл диспетчеризации для выполнения текущих запрошенных опкодов `__call()`.
Пусть выполняется метод, вызванный, например, `fooBarDontExist()`. Нам нужно поместить в память ряд структур и выполнить классический вызов функции из пользовательского пространства. Примерно так (упрощённо):
```
ZEND_API void zend_std_call_user_call(INTERNAL_FUNCTION_PARAMETERS)
{
zend_internal_function *func = (zend_internal_function *)EG(current_execute_data)->function_state.function;
zval *method_name_ptr, *method_args_ptr;
zval *method_result_ptr = NULL;
zend_class_entry *ce = Z_OBJCE_P(this_ptr);
ALLOC_ZVAL(method_args_ptr);
INIT_PZVAL(method_args_ptr);
array_init_size(method_args_ptr, ZEND_NUM_ARGS());
/* ... ... */
ALLOC_ZVAL(method_name_ptr);
INIT_PZVAL(method_name_ptr);
ZVAL_STRING(method_name_ptr, func->function_name, 0); /* Копируем имя функции */
/* Делаем вызов нового цикла диспетчеризации: будет вызван execute_ex() */
zend_call_method_with_2_params(&this_ptr, ce, &ce->__call, ZEND_CALL_FUNC_NAME, &method_result_ptr, method_name_ptr, method_args_ptr);
if (method_result_ptr) {
RETVAL_ZVAL_FAST(method_result_ptr);
zval_ptr_dtor(&method_result_ptr);
}
zval_ptr_dtor(&method_args_ptr);
zval_ptr_dtor(&method_name_ptr);
efree(func);
}
```
Выполнение этого вызова требует большого объёма работы. Поэтому мы часто слышим «постарайтесь избегать `__call()` ради повышения производительности» (и по ряду других причин). Это действительно так.
Теперь про PHP 7. Помните теорию трамплина? Здесь всё примерно так же. Нам нужно избежать рекурсивных вызовов `execute_ex()`. Для этого дерекурсируем процедуру, оставаясь в том же контексте `execute_ex()`, а также перенаправив (rebranch) его в его начало, изменив необходимые аргументы. Давайте снова посмотрим на `execute_ex()`:
```
ZEND_API void execute_ex(zend_execute_data *ex)
{
const zend_op *orig_opline = opline;
zend_execute_data *orig_execute_data = execute_data;
execute_data = ex;
opline = execute_data->opline;
while (1) {
opline->handler();
if (UNEXPECTED(!opline)) {
execute_data = orig_execute_data;
opline = orig_opline;
return;
}
}
zend_error_noreturn(E_CORE_ERROR, "Arrived at end of main loop which shouldn't happen");
}
```
Итак, для предотвращения рекурсивных вызовов нам нужно изменить как минимум переменные `opline` и `execute_data` (содержит следующий опкод, а opline — это «текущий» опкод для выполнения). Когда мы встречаем `__call()`, то:
1. Изменяем `opline` и `execute_data`.
2. Делаем возврат.
3. Возвращаемся к текущему циклу диспетчеризации.
4. Продолжаем его выполнение для наших свежеизменённых новых опкодов.
5. И в результате заставляем его вернуться в исходную позицию (поэтому у нас есть `orig_opline` и `orig_execute_data`; диспетчер виртуальной машины должен всегда помнить, откуда пришёл, чтобы он мог перейти (branch) туда откуда угодно).
Именно это делает в PHP 7 новый опкод `ZEND_CALL_TRAMPOLINE`. Он используется везде, где должны выполняться вызовы `__call()`. Давайте посмотрим на упрощённую версию:
```
#define ZEND_VM_ENTER() execute_data = (executor_globals.current_execute_data); opline = ((execute_data)->opline); return
static ZEND_OPCODE_HANDLER_RET ZEND_FASTCALL ZEND_CALL_TRAMPOLINE_SPEC_HANDLER(ZEND_OPCODE_HANDLER_ARGS)
{
zend_array *args;
zend_function *fbc = EX(func);
zval *ret = EX(return_value);
uint32_t call_info = EX_CALL_INFO() & (ZEND_CALL_NESTED | ZEND_CALL_TOP | ZEND_CALL_RELEASE_THIS);
uint32_t num_args = EX_NUM_ARGS();
zend_execute_data *call;
/* ... */
SAVE_OPLINE();
call = execute_data;
execute_data = EG(current_execute_data) = EX(prev_execute_data);
/* ... */
if (EXPECTED(fbc->type == ZEND_USER_FUNCTION)) {
call->symbol_table = NULL;
i_init_func_execute_data(call, &fbc->op_array,
ret, (fbc->common.fn_flags & ZEND_ACC_STATIC) == 0);
if (EXPECTED(zend_execute_ex == execute_ex)) {
ZEND_VM_ENTER();
}
/* ... */
```
Можно заметить, что переменные `execute_data` и `opline` эффективно изменены с помощью макроса `ZEND_VM_ENTER()`. Следующие `execute_data` подготовлены в переменной `call`, а их привязку (bind) осуществляет функция `i_init_func_execute_data()`. Далее с помощью `ZEND_VM_ENTER()` выполняется новая итерация цикла диспетчеризации, которая переключает переменные на следующий цикл, причём войти в него они должны с «возвратом» (текущего цикла).
Круг замкнулся, всё закончилось.
Как теперь попасть обратно в главный цикл? Это делается в опкоде `ZEND_RETURN`, который завершает любую определённую пользователем функцию.
```
#define LOAD_NEXT_OPLINE() opline = ((execute_data)->opline) + 1
#define ZEND_VM_LEAVE() return
static ZEND_OPCODE_HANDLER_RET ZEND_FASTCALL zend_leave_helper_SPEC(ZEND_OPCODE_HANDLER_ARGS)
{
zend_execute_data *old_execute_data;
uint32_t call_info = EX_CALL_INFO();
if (EXPECTED(ZEND_CALL_KIND_EX(call_info) == ZEND_CALL_NESTED_FUNCTION)) {
zend_object *object;
i_free_compiled_variables(execute_data);
if (UNEXPECTED(EX(symbol_table) != NULL)) {
zend_clean_and_cache_symbol_table(EX(symbol_table));
}
zend_vm_stack_free_extra_args_ex(call_info, execute_data);
old_execute_data = execute_data;
execute_data = EG(current_execute_data) = EX(prev_execute_data);
/* ... */
LOAD_NEXT_OPLINE();
ZEND_VM_LEAVE();
}
/* ... */
```
Как видите, при возврате из вызова определённой пользователем функции мы задействуем `ZEND_RETURN`, который заменяет следующие в очереди на выполнение инструкции предыдущими из предыдущего вызова `prev_execute_data`. Затем он подгружает opline и возвращается в главный цикл диспетчеризации.
Заключение
==========
Мы рассмотрели теорию, лежащую в основе раскрутки (unroll) рекурсивных вызовов функций. Можно исправить любые рекурсивные вызовы, но это бывает очень трудно. Универсальное решение — разработка трамплина: системы, которая управляет запуском каждого этапа рекурсивной функции, не позволяя ей вызывать саму себя и, следовательно, мешая ей бесконтрольно плодить фреймы стека. «Трамплинный» код расположен в диспетчере и управляет им ради предотвращения рекурсии.
Также мы рассмотрели общую реализацию в PHP и изучили реализацию трамплинов в новом движке Zend 3, являющемся частью PHP 7. Больше не бойтесь вызывать `__call()`, они работают быстрее, чем в PHP 5. Они не создают при каждом вызове новые стеки фрейма (на С-уровне), это одно из улучшений в движке PHP 7. | https://habr.com/ru/post/311068/ | null | ru | null |
# Фильтр Калмана: разбор навигационной системы БПЛА + исходный код
В статье я бы хотел объяснить принципиальную разницу между Фильтром Калмана (ФК) и классическими фильтрами, кратко рассмотреть преимущество выбранного ФК поделиться опытом использования данного ФК во встраиваемой системе квадрокоптера для навигации на основе инерциального и ГНСС датчиков и поделится исходным кодом с демкой для самостоятельного изучения.
Всем привет! Меня зовут Илья, я работаю программистом-инженером в компании "SID Logic", мы занимаемся разработкой электроники и сопутствующего ПО для различных применений, мои области интересов касаются систем навигации (оптические, инерциальные, ГНСС, UWB, GSM/LTE), систем управления (ПИД, MRAC, MPC) преимущественно для задач робототехники, беспилотников. Одну из важных тем в навигации занимает тема Фильтра Калмана.
На Хабре фильтру Калману (ФК) посвящено уже много статей, но я пока не встречал объяснения (возможно, плохо смотрел?:))принципиального преимущества его использования перед, например, альфа-бета, различными комбинациями фильтров низкой частоты (ФНЧ), фильтров высокой частоты (ФВЧ), интеграторами, дифференциаторами и т.д... Однако, даже если вы знали, то о чем я буду дальше говорить, возможно, вам будет полезен код, которым я пользуюсь уже несколько лет, на основе которого было проверено множество гипотез, подтверждено их применение.
Теоретическому объяснению основ посвящено уже много статей, поэтому не будем касаться этой темы, а попробуем разобраться в сути алгоритма с инженерной, прикладной точки зрения.
Для начала нужно рассмотреть такую формулировку задачи. Абстрактной задачи.
Представьте, у вас есть большой пульт с вращающимися крутилками, а на выходе некоторая температура, у вас есть таблица по каждой крутилке, как каждая крутилка влияет на температуру. Но нет обратной формулы - какие положения у крутилок должны быть, чтобы установить необходимую температуру. И вам говорят, что нужно выставить определенную температуру, после чего вы начинаете подкручивать крутилки, одну вторую, третью, туда-сюда, пока наконец не установите нужную температуру.
Или другой пример, более реальной задачи – у вас есть 2 фотографии, сделанные под разным углом (части панорамы), вы открываете фотошоп и пытаетесь сместить второе фото так, чтобы с виду обе фотографии не имели разрыва между собой, иначе говоря пытаетесь сшить панораму.
Сшивка панорамыВ обоих примерах вы можете регулировать переменные (крутилки и смещения фото) и смотреть, как они влияют на результат, и вы можете оценить, как далеко вы от цели или близко (близка ли установленная температура к желаемой, сильно ли видно границу стыка двух фотографий). То есть у вас есть функция прямой зависимости (температура = f(крутилки) и визуальная сходимость стыка = f(смещение 2 фото)), но нет обратной зависимости.
Такого рода задачи возникают повсеместно в инженерной практике в любых областях – поиск оптимальной конструкции моста, поиск коэффициентов искажения линзы камеры для нивелирования данных искажений, оптимальное управление химическим процессом, картографирование, обучение нейросетей и т.д.
В общем случае поиск оптимальных (по какому- то критерию в математическом смысле) параметров математической модели это огромная отдельная область, где могут использоваться самые разные реализации в зависимости от кол-ва оптимизируемых параметров (веса нейросети, коэффициенты линзы камеры), требований к вычислительной сложности (микроконтроллеры, GPU кластеры), самой физической природы функции оптимизации (кол-во локальных минимум, их разброс в случае поиска минимума функции, ограничения и род величин).
Итак, фильтр Калмана является частным упрощенным случаем большого семейства алгоритмов поиска оптимальных параметров и состояния системы на основе математической модели.
ФК помогает решать задачи:
* преимущественно рассматриваемые в эволюции во времени;
* с относительно малым количеством оптимизируемых параметров (относительно весов нейросетей, например) до ~100;
* имеющие глобальный минимум, то есть одно решение (с множеством локальных минимумов лучше справляется частичный фильтр Particle Filter, например);
* непрерывная природа величин параметров (не дискретная);
* оптимизируемые параметры не должны иметь ограничений (например, масса не может быть отрицательной и для использования в ФК, должна быть специальная математическая модель).
Итак, основная мысль данной статьи, на которой я хотел бы акцентировать внимание:
***Суть данного алгоритма — это поиск оптимальных значений (с точки зрения наименьших квадратов) состояния и параметров системы, которые бы удовлетворяли реальным измеренным данным и эволюции системы во времени. Зависимость состояния и параметров от модели измеряемых данных может быть нелинейной. При этом описать явно в аналитическом виде зависимость искомого состояния или параметра от измеряемой датчиком величины не всегда возможно.***
Или проще говоря, ФК подбирает такие параметры, чтобы на выходе получить тоже самое, что показывают датчики, при этом не противореча предыдущим состояниям.
Будем работать с более применительным к реальности видом ФК – то есть нелинейным, так как большинство систем имеют нелинейные взаимосвязи.
Как и многие оптимизационные алгоритмы, нелинейные ФК должны понимать в какую сторону им нужно менять параметры, чтобы максимально приблизиться к минимуму функции (минимальное расхождение между предыдущим состоянием системы и минимальное расхождение между тем, что мы ожидаем увидеть от моделируемого датчика (модель датчика) и самими данными от реального датчика). Для этого им нужен виртуальный градиент (направление, двигаясь против которого можно достичь минимума функции). Поиск этого градиента зависит от вида линеаризации.
Все нелинейные виды ФК так или иначе используют линеаризацию. Распространены 2 вида линеаризации ФК:
* Рассчитанные человеком матрицы Якоби записанные в аналитическом виде (Extented Kalman Filter EKF). Другими словами – это линеаризация по касательной.
* Линеаризация методом пробных точек (Sigma Point Kalman Filter, Unscented Kalman Filter UKF). Другими словами – это линеаризация по секущей.
EKF и UKF линеаризацииВ инженерном контексте для нас можно выделить следующие особенности:
В первом случае из преимуществ – быстрая скорость работы. Из недостатков – ручная запись в аналитическом виде матрицы Якоби, меньшая стабильность и точность на сильных нелинейных взаимосвязях, функции эволюции и модели датчика должны быть дифференцируемы.
Во втором случае из преимуществ – лучшая стабильность и точность на сильных нелинейных взаимосвязях, отсутствие необходимости записи матриц Якоби, нужна лишь запись в прямом виде эволюции и модели датчика.
Согласно целям статьи, понизить порог вхождения в тему, дать универсальный алгоритм для быстрого прототипирования и проверки гипотез в условиях слабой вычислительной базы и малого кол-ва памяти лучшим выбором будет являться второй вид ФК – UKF.
Помимо UKF, существуют следующие вариации сигма-точечного фильтра Калмана: CDKF (central difference Kalman filter – фильтр Калмана центральной разности), SRUKF (square-root unscented Kalman filter – ансцентный фильтр Калмана квадратного корня), SRCDKF (square-root central difference Kalman filter – фильтр Калмана квадратного корня центральной разности) и их итеративные модификации IUKF, ICDKF, ISRUKF, ISRCDKF, которые рассматриваются в работах [1, 2].
В инженерном контексте задачи оптимальным выбором я считаю т.н. Square Root Central Difference Kalman Filter (SRCDKF). Выбор сигма точек осуществляется согласно центральной разности (в отрицательное направление от линеаризуемой точки и в положительное направление) пропорционально матрице квадратного корня ковариации. При этом не используется разложение Холецкого для матрицы ковариации, которое может быть не стабильным в условиях с присутствием одновременно малых и больших значений в матрице.
Я решил не загромождать статью лишними формулами, кому будет интересно может почитать литературу в списке.
Это универсальное ядро SRCDKF, которое можно использовать в разных приложениях, реализуя разные математические модели.
Исходный код ядра можно скачать:
[Ядро SRCDKF](https://gitlab.com/open_source/kalman_core)
С Теорией пока всё. Теперь практика.
Пример, иллюстрирующий суть ФК
Начнем сразу с реальной инженерной задачи, без примеров на одномерных случаях, так как в них не проявится вся мощь таких алгоритмов. Параллельно разберем исходный код.
Допустим, есть квадрокоптер, который может лететь в любую сторону, любой стороной борта, то есть у него нет переда или зада. На квадрокоптере установлен акселерометр и датчик угловой скорости (IMU), датчик глобальной навигационной системы (GNSS), в нашем примере нету магнитометра и барометра, хотя это не принципиально.
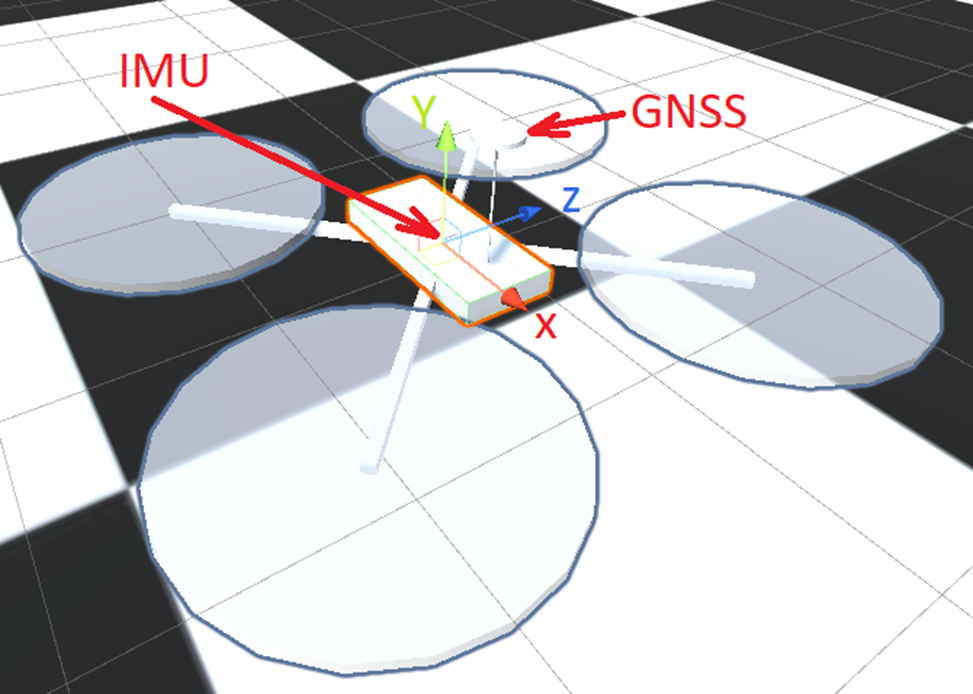Нам для управления квадрокоптером нужно знать положение и ориентацию в пространстве в каждый момент времени.
Раз уж я сказал, что задача из реального мира, а реальный мир трехмерный, то мы будем рассматривать математическую модель описания вращения и положения в трехмерном пространстве. Для описания вращения в трехмерном пространстве воспользуемся кватернионом, можно сказать стандартом для таких случаев. А для описания положения – обычным 3-х мерным вектором.
![Q=[q_w\ q_x\ q_y\ q_z]^T\\ \\ P=[p_x\ p_y\ p_z]^T](https://habrastorage.org/getpro/habr/upload_files/7d5/43c/8e7/7d543c8e7ede087230534df7a2a37dad.svg)Кто работал с дешевыми MEMS IMU знает о необходимости калибровки для нивелирования масштабных искажений, межосевых взаимосвязей, а также смещений (biases).
. Сам эллипсоид масштабно искажен.")Так выглядят данные с акселерометра, при вращении по всем осям. Центр эллипсоида смещен на некоторый вектор (bias). Сам эллипсоид масштабно искажен.Упрощенная, но достаточная для нашей точности математическая модель (без масштабных и межосевых коэффициентов) акселерометра и ДУСа одинаковая и имеет вид:
Где - 3-х мерный вектор данных непосредственно с сенсора (ускорения и угловой скорости соответственно),  - истинный 3-х мерный вектор данных, - 3-х мерный вектор смещения (bias).
Модель IMU у нас есть.
Далее начинается творчество от которого зависит насколько точно, стабильно будет работать алгоритм. Нужно придумать математическую модель эволюции системы, то есть как она будет меняться со временем, какие данные от сенсоров будут являться моделируемыми, какие данные будут априорными, в какой системе координат будет выражаться вектор состояния (глобальной, привязанной к географическим осям север-восток или локальной, в системе координат квадрокоптера), какая модель датчика GNSS. На эту тему написано множество статей и реализовано множество математических моделей. Однако, чтобы не загромождать статью и не усложнять пример, я предлагаю воспользоваться не слишком сложной и в то же время рабочей математической моделью.
Для более-менее достаточной для нашей точности математической модели нужно 3 параметра для описания смещения (bias) акселерометра (в СК IMU), 3 параметра для описания смещения (bias) датчика угловой скорости (в СК IMU), 3 параметра описания положения (3-х мерный вектор в глобальной СК), 4 параметра для описания кватерниона ориентации ( кватернион, выражающий вектор из СК коптера в глобальную СК), дополнительно включим 3-х мерный вектор скорости (в глобальной СК). Итого 16 параметров. Это называется вектор состояния системы, так как он описывает полное состояние (в контексте нашей задачи) нашего квадрокоптера в конкретный момент времени, то есть какое он имеет положение, ориентацию, скорость и т.д.
![X=[A_{bias}^T \ W_{bias}^T \ P^T \ Q^T \ V^T]^T](https://habrastorage.org/getpro/habr/upload_files/80a/473/8d7/80a4738d7e57bf952050b35359a5c960.svg)![A_{bias}=[a_{bx} \ a_{by} \ a_{bz}]^T\\W_{bias}=[w_{bx} \ w_{by} \ w_{bz}]^T\\Q=[q_w\ q_x\ q_y\ q_z]^T\\ \\ P=[p_x\ p_y\ p_z]^T\\V=[v_x \ v_y \ v_z]^T](https://habrastorage.org/getpro/habr/upload_files/8af/c85/92b/8afc8592bbfeb87b14c8be2bbc46c03b.svg)Эволюция системы описывается тем, как будет меняться вектор состояния во времени, то есть зависимость нынешнего момента времени от прошлого, еще этот этап называется прогнозом.  - текущий момент времени,  - прошлый момент времени.
Здесь просто интегрируется по времени положение по скорости - шаг дискретизации.
 - временный вектор ускорений, состоящий из - вектора непосредственно из акселерометра - смещение акселерометра в прошлый прогноз,  - операция вращения вектора кватернионом, в данном случае выражает локальный вектора ускорения в глобальную СК.  - кватернион в прошлый прогноз.
 - вектор стандартных отклонений шумов прогноза для линейной скорости.
- вектор угловой скорости, состоящий из - вектора данных непосредственно с ДУСа, - рассчитанный на предыдущем шаге вектор смещения, - вектор стандартных отклонений шумов прогноза для угловой скорости.
- символ, обозначающий перемножение кватернионов, - это функция перевода 3-х мерного вектора вращения, находящегося в касательной плоскости относительно сферы кватерниона в пространство кватерниона, подробнее распишу попозже.
Смещения IMU не зависят от других переменных в векторе состояния, поэтому в нынешнем моменте времени они почти равны прошлым значениям. Почти, потому что все-таки они немного меняются со временем (температура может меняться), нужно чтобы ФК понимал, что это не константы и имел некоторую неопределенность в значении, для этого есть два параметра  - которые являются векторами стандартных отклонений шумов прогноза для смещений IMU.
Код этапа прогноза
```
void TimeUpdate(float *in, float *noise, float *out, float *u, float dt, int n) {
float tmp[3], acc[3];
float rate[3];
float mat3x3[3 * 3];
float q[4];
int i;
float qRate[4], qRes[4];
// assume out == in
out = in;
for (i = 0; i < n; i++)
{
// create rot matrix from current quat
q[0] = in[UKF_STATE_Q1*n + i];
q[1] = in[UKF_STATE_Q2*n + i];
q[2] = in[UKF_STATE_Q3*n + i];
q[3] = in[UKF_STATE_Q4*n + i];
quatToMatrix(mat3x3, q, 1);
// pos
out[UKF_STATE_POSX*n + i] = in[UKF_STATE_POSX*n + i] + in[UKF_STATE_VELX*n + i] * dt;
out[UKF_STATE_POSY*n + i] = in[UKF_STATE_POSY*n + i] + in[UKF_STATE_VELY*n + i] * dt;
out[UKF_STATE_POSZ*n + i] = in[UKF_STATE_POSZ*n + i] + in[UKF_STATE_VELZ*n + i] * dt;
// acc
tmp[0] = u[0] + in[UKF_STATE_ACC_BIAS_X*n + i];
tmp[1] = u[1] + in[UKF_STATE_ACC_BIAS_Y*n + i];
tmp[2] = u[2] + in[UKF_STATE_ACC_BIAS_Z*n + i];
// rotate acc to world frame
rotateVecByMatrix(acc, tmp, mat3x3);
acc[1] -= GRAVITY;
out[UKF_STATE_VELX*n + i] = in[UKF_STATE_VELX*n + i] + acc[0] * dt + noise[UKF_V_NOISE_VEL_X*n + i];
out[UKF_STATE_VELY*n + i] = in[UKF_STATE_VELY*n + i] + acc[1] * dt + noise[UKF_V_NOISE_VEL_Y*n + i];
out[UKF_STATE_VELZ*n + i] = in[UKF_STATE_VELZ*n + i] + acc[2] * dt + noise[UKF_V_NOISE_VEL_Z*n + i];
// rate = rate + bias + noise
rate[0] = (u[3] + in[UKF_STATE_GYO_BIAS_X*n + i] + noise[UKF_V_NOISE_RATE_X*n + i]) * dt;
rate[1] = (u[4] + in[UKF_STATE_GYO_BIAS_Y*n + i] + noise[UKF_V_NOISE_RATE_Y*n + i]) * dt;
rate[2] = (u[5] + in[UKF_STATE_GYO_BIAS_Z*n + i] + noise[UKF_V_NOISE_RATE_Z*n + i]) * dt;
// rotate quat
exp_mapQuat(rate, qRate);
quatMultiply(qRes, q, qRate);
out[UKF_STATE_Q1*n + i] = qRes[0];
out[UKF_STATE_Q2*n + i] = qRes[1];
out[UKF_STATE_Q3*n + i] = qRes[2];
out[UKF_STATE_Q4*n + i] = qRes[3];
// acc bias
out[UKF_STATE_ACC_BIAS_X*n + i] = in[UKF_STATE_ACC_BIAS_X*n + i] + noise[UKF_V_NOISE_ACC_BIAS_X*n + i] * dt;
out[UKF_STATE_ACC_BIAS_Y*n + i] = in[UKF_STATE_ACC_BIAS_Y*n + i] + noise[UKF_V_NOISE_ACC_BIAS_Y*n + i] * dt;
out[UKF_STATE_ACC_BIAS_Z*n + i] = in[UKF_STATE_ACC_BIAS_Z*n + i] + noise[UKF_V_NOISE_ACC_BIAS_Z*n + i] * dt;
// gbias
out[UKF_STATE_GYO_BIAS_X*n + i] = in[UKF_STATE_GYO_BIAS_X*n + i] + noise[UKF_V_NOISE_GYO_BIAS_X*n + i] * dt;
out[UKF_STATE_GYO_BIAS_Y*n + i] = in[UKF_STATE_GYO_BIAS_Y*n + i] + noise[UKF_V_NOISE_GYO_BIAS_Y*n + i] * dt;
out[UKF_STATE_GYO_BIAS_Z*n + i] = in[UKF_STATE_GYO_BIAS_Z*n + i] + noise[UKF_V_NOISE_GYO_BIAS_Z*n + i] * dt;
}
}
```
Пару слов о векторах стандартных отклонений шумов прогноза. Чем больше будут эти значения шумов, тем меньше доверие прогнозу, неопределенность соответствующей переменной вектора состояния будет расти с каждой итерацией прогноза и этап коррекции будет вносить существенную корректировку в них. То есть эта переменная будет подвержена большой волатильности. ФК будет пользоваться данной "крутилкой" больше, чем теми, у которых малое значение стандартного отклонения шума.
Также стоит отметить, что в отличии от других видов ФК модель шума (как процесса, так и датчика) может быть не аддитивной, и данный вид ФК сможет учесть и нелинейную природу шума. Это преимущество обеспечено способом линеаризации с помощью сигма-точек, которые пропускаются в том, числе и через модель шума.
По поводу . Кватернион - это гиперпараметризированная модель вращения, так как имеет 4 параметра в пространстве вращения с 3 степенями свободы. Так как полноценно описать вращение 3 параметрами не получается (Gimbal lock), приходится прибегать к таким математическим конструкциям, как кватернионы. Для перехода из 4-х мерного пространства в 3-х мерное пространство и обратно есть специальные операции . Это можно представить как сферу (кватернион) и касательную плоскость (3-х мерный вектор вращения).
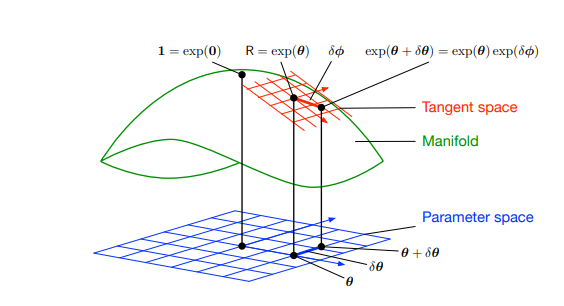Отсюда же проистекает проблема, которую я описывал выше (ФК не умеет работать с параметрами, у которых есть ограничения), у кватерниона должна быть единичная длина. В таком случае можно пойти на небольшую хитрость и после каждой итерации прогноза нормализовывать кватернион. Для нашей мат. модели такой способ сгодится, однако для более нелинейных систем, придется использовать специальную арифметику и операции с кватернионами внутри ФК. Подробнее про касательные пространства и фильтрацию с кватернионами в [3, 4].
В нашем случае есть только 2 датчика IMU и GNSS. IMU - используется непосредственно в модели прогноза как априорные значения и не моделируются.
GNSS моделируется так:
  - кватернион из вектора состояния, - вектор из IMU в GNSS в СК IMU, - вектор позиции из вектора состояния, - вектор стандартного отклонения шума GNSS.
Чем выше  тем меньше доверие GNSS, данную величину можно варьировать в зависимости от качества данных с датчика.
Код, модели GNSS
```
void navUkfPosUpdate(float *u, float *x, float *noise, float *y) {
float vglov[3];
rotateVectorByQuat(vglov, &u[0], &x[UKF_STATE_Q1]);
y[0] = x[UKF_STATE_POSX] + vglov[0] + noise[0]; // return position
y[1] = x[UKF_STATE_POSY] + vglov[1] + noise[1];
y[2] = x[UKF_STATE_POSZ] + vglov[2] + noise[2];
}
```
Вектора стандартных отклонений шумов прогноза и модели датчиков можно взять из даташитов, либо провести эксперимент с реальными датчиками, рассчитать самому. В нашем случае они уже рассчитаны, если захотите использовать другую мат. модель - будет от чего отталкиваться.
Кроме настоящих реальных датчиков, можно моделировать псевдодатчики. Например, при старте, когда коптер еще не взлетел, и мы точно уверены, что он не движется, можно использовать псевдоизмерения угловой и линейной скоростей, которые равны нулю. Тем самым сообщая ФК, что сейчас движения нет, и эта информация, в свою очередь, поможет в уточнении вектора состояния.
Итак, для демонстрации данного ФК был написана демка на Unity.
Кратко расскажу подробности симулятора:
Сам ФК в Unity используется как динамическая библиотека, для WebGL - сырые исходники. Коптер не управляется по физическим законам, используются просто силы и моменты для имитации полета коптера в скрипте Control.cs. Для имитации IMU и GNSS созданы 2 скрипта IMUModel.cs и GNSSModel.cs. Обертка и взаимодействие с Unity ФК реализована в KalmanFilter.cs. Для графиков использовался открытый [Asset](https://assetstore.unity.com/packages/tools/gui/dynamic-line-chart-108651).
Для физики используется внутренний движок PhysX. Для демонстрации 60 Гц - достаточно.
Вот видео демки и графики вектора состояния.
Вектор смещений ДУСаВектор смещений акселерометраГрафик углов ЭйлераВектор положенияВектор скоростейПояснение по графикам: Estimate - это оценка ФК, Reference - это фактическая величина, Uncertainty - дисперсия из матрицы ковариации \*100.
В центре графиков видно, что ошибка возросла, это произошло из-за уменьшения влияния GNSS данных (на видео видно, где я увеличил дисперсию GNSS corr).
Демку, что на видео можно скачать из репа:
[Исходный код демки](https://gitlab.com/open_source/kalman_copter)
А также можно [поиграть интерактивно](https://ilyaprok.github.io/demo/).
Можно заметить, что не использовался магнитометр для коррекции курса. Если применять обычный фильтр Magwick или Mahony тангаж и крен более менее наблюдаемы, когда нет линейных ускорений, то угол курса будет плыть и взять его неоткуда. А если постоянно присутствуют линейные, центростремительные ускорения, то все углы уплывут при коррекции акселерометром, это актуально для самолетов, например.
В случае применения ФК и данной мат. модели, такого не будет: при наличии движения с помощью датчика GNSS будет происходить разделение сырого вектора ускорения из акселерометра на линейную часть и на вектор ускорения свободного падения, из-за чего углы тангажа и крена будут максимально точными, а угол курса не будет уплывать. К тому же мы получаем еще и более точные векторы положения и скорости. Данную особенность приметил не только я:
В этом и заключается преимущество ФК - нахождении неявных полезных обратных зависимостей между вектором состояния и датчиками.
Вот график и видео иллюстрирующие коррекцию курсового угла, даже при начальном неправильном значении в 45 градусов.
Угол курса с начальной ошибкой в 45 градусовВ интерактивной демке, много чего нет, с чем можно поиграть непосредственно в Unity Edior, а именно: различные значения bias IMU, их изменения во времени, различные величины стандартных отклонений шумов прогноза и датчика GNSS, задержки между датчиками, неверные начальные условия и т.д. Так что советую скачать исходник и непосредственно в Unity Editor поиграть с различными условиями.
Самое полезное, это то, что тот же самый C++ код, который работает в демке (kalman lib), можно целиком без переделок запустить на микроконтроллере, на реальном железе в реальных условиях.
Вот например коптер, который я собрал, который летает почти с таким же ФК:
Суть ФК можно расширить на оптимизацию не только текущего вектора состояния в конкретный момент времени, но и оптимизацию, например, целого набора состояний, включенных в разные моменты времени (Sliding-Window Optimization, bundle adjustment/graph optimization). Такой подход требует гораздо большей вычислительной мощности и реализуется другими методами, однако гораздо более точен и стабилен.
За рамками статьи остались такие темы, как:
* моделирование других различных датчиков, например видеокамеры, лидаров, колесных одометров;
* учет задержки в ФК между получением данных с различных датчиков;
* применение параметров с ограничениями (вектора единичной длины, кватернионы) в ФК с высоко нелинейными моделями;
* Регистрация некачественных данных с датчика на основе мат. модели;
* Алгоритмы нелинейной оптимизации во временном окне (Sliding-Window Optimization)
Если вам будет интересно можно продолжить цикл статей по практическому применению ФК.
Список литературы:
1. Van Der Merwe, R. Sigma-point Kalman filters for probabilistic inference in dynamic state-space models
2. Chaabane, M. Nonlinear State and Parameter Estimation Using Iterated Sigma Point Kalman Filter: Comparative Studies
3. Christoph Hertzberga, Integrating Generic Sensor Fusion Algorithms with Sound State Representations through Encapsulation of Manifolds
4. Joan Sol`, Quaternion kinematics for the error-state Kalman filter | https://habr.com/ru/post/567042/ | null | ru | null |
# Создаем портфолио на основе фотографий из Instagram

Здравствуй, дорогой хабрадруг! В этом уроке мы создадим простой сайт-портфолио, который будет базироваться на фотографиях из вашего аккаунта в Instagram. Дизайн сайта сделал [Tomas Laurinavicius](https://webdesign.tutsplus.com/tutorials/designing-a-simple-instagram-based-portfolio-in-photoshop--cms-21402), и он получился у него простым, функциональным и просторным. Итак, начнем.
[**Скачать исходники**](https://github.com/tutsplus/building-an-instagram-based-portfolio-with-bootstrap) | [**Демо**](http://pavel.shimansky.ru/instagram/)
**Инструменты**
---------------
Чтобы облегчить себе жизнь, мы доверимся нескольким полезным инструментам и библиотекам. Перед началом работы нам необходимо подготовить пару инструментов:
* [Sass](http://sass-lang.com/)
* [Twitter Bootstrap](http://getbootstrap.com/) (версия Sass)
* [Instafeed.js](http://instafeedjs.com/)
* [Modernizr](http://modernizr.com/)
Прежде всего вам необходим инструмент Sass, работающий у вас на компьютере. Проще всего использовать приложение [Koala](http://koala-app.com/), оно кросс-платформенное, бесплатное и, что самое важное, легкое в использовании. Кроме того существуют альтернативные программы: [Scout](http://mhs.github.io/scout-app/), [Prepros](http://alphapixels.com/prepros/) и [Compass app](http://compass.kkbox.com/). Все они предлагают схожий функционал, поэтому выбор на ваш вкус!
Теперь Bootstrap. Мы будем использовать Bootstrap на базовом уровне для управления некоторыми элементами страницы. Необходимо скачать *Sass версию,*чтобы включить ее в нашу таблицу стилей.
Почти готово! Теперь нужно загрузить Instafeed.js, плагин, который берет фотографии из Instagram. Стоит заметить, что для того чтобы скрипт мог забирать фотографии из Instagram, необходимо предоставить ему *client ID,* который может быть сгенерирован на [страничке для разработчиков](http://instagram.com/developer).
Ну и наконец, нам необходимо скачать последнюю версию Modernizr, JavaScript-библиотеку, которая узнаёт, что из HTML5 и CSS3 умеет браузер пользователя.
Итак, мы собрали все необходимые инструменты, начинаем конструирование сайта.
**Структура сайта**
-------------------
Нам нужно создать несколько файлов и папок для нашего проекта:
* css/
* images/
* js/
* index.html
Это наш фундамент. Теперь откройте папку `assets`, которую вы можете найти в архиве с Bootstrap:
Скопируйте папку `fonts`в корневую папку проекта. Откройте папку `javascripts` и скопируйте файл `bootstrap.js`в папку `js`. Наконец, откройте папку `stylesheets` и скопируйте файл `bootstrap.scss`и папку `bootstrap`в директорию `css`. Структура нашего проекта должна выглядеть следующим образом:
Отлично! Теперь скопируйте файлы `instafeed.min.js` и `Modernizr` в папку `js`. Сейчас нам нужно еще кое-что настроить перед тем, как начать строить шаблон.
Настройка Sass
--------------
Теперь настало время настроить наш проект для использования Sass. В приложении Koala вся настройка заключается в переносте папок в окно приложения. Думаю, что такой же процесс характерен и для других подобных программ.
#### Добавление файлов
Откройте проект в программе, которую вы выбрали, чтобы мы смогли добавить необходимые файлы.
Сначала в папке `css`добавьте файл под названием `style.scss`. Затем в папке `js` добавьте файл под названием `app.js`.
Советую вам обновить приложение, которое вы используете для настройки Sass, чтобы оно «подхватило» новые файлы. Некоторые приложения делают это автоматически, но все же лучше перестраховаться.
Думаю, что с предварительной настройкой мы закончили. Теперь приступим непосредственно к каркасу!
Начинаем строительство
----------------------
Откройте файл `index.html` и вставьте следующий код HTML:
```
Instagram Portfolio
```
Давайте детально рассмотрим наш шаблон.
Итак, секция содержит необходимый тэг [viewport](https://webdesign.tutsplus.com/articles/quick-tip-dont-forget-the-viewport-meta-tag--webdesign-5972)для корректной работы media queries. Затем мы назначили тэг для различных [Google шрифтов](https://www.google.com/fonts#UsePlace:use/Collection:Lato|Kaushan+Script|Montserrat). Далее мы прописали тэги, содержащие `style.css` и Modernizr.
Секция с тэгом содержит четыре основных элемента, к которым мы применили классы, чтобы понимать, что для чего служит.
### Добавляем файлы JavaScript
Добавьте следующий код ниже секции `footer-bottom`:
```
```
### Стили
Давайте настроим наш файл `style.scss`.
```
/*
* Кастомные переменные
*/
$main-font: 'Lato', sans-serif;
$sub-font: 'Montserrat', sans-serif;
$fancy-font: 'Kaushan Script', cursive;
$font-size: 16px;
$black: #000;
$white: #FFF;
$grey: #585c65;
$mediumgrey: #9b9b9b;
$lightgrey: #eeeeee;
$blue: #3466a1;
$padding: 10px;
$margin: 10px;
/*
* Отменяем переменные Bootstrap
*/
$font-family-sans-serif: $main-font;
@import 'bootstrap';
```
Здесь мы настроили шрифты, затем цвета нашего сайта, а также переменные padding и margin.
### Больше стилей
Продолжим прописывать необходимые нам стили:
```
* {
position: relative;
box-sizing: border-box;
}
body {
color: $grey;
font-size: $font-size;
}
header {
max-height: 600px;
height: 600px;
overflow: hidden;
}
```
Здесь мы используем универсальный селектор `*`, чтобы придать всем объектам параметр `position: relative`. Кроме того практично устанавливать параметр `box-sizing` на `border-box`, чтобы в дальнейшем мы могли использовать проценты при установке ширины объектов.
Далее мы устанавливаем цвет шрифта и размер по умолчанию, и также выставляем высоту нашей секции .
Придаем форму шапке сайта
-------------------------
Так как дизайн нашей шапки довольно-таки простой, то и писать для него код не составит труда:
```

Jonathan
Hello! I'm Jonathan
===================
I love to travel all around the world and design beautiful things
-----------------------------------------------------------------
[Facebook](#)
[Twitter](#)
[Instagram](#)
```
Этот код пойдет в секцию .
### Стили шапки
Начнем с добавления нескольких строчек кода в секцию `header`, которая находится в нашем файле Sass.
```
img {
position: fixed; /* Это придаст нашему сайт эффект глубины */
top: 0px;
left: 50%;
margin-left: -600px;
width: 1200px;
@media screen and (min-width: $screen-lg) {
top: auto; /* Вмещаем наше изображение в маленькие экраны */
left: auto;
margin: 0;
width: 100%;
}
}
```
Вот, что у нас получается!
 | https://habr.com/ru/post/242643/ | null | ru | null |
# Почему стоит выбрать Git для управления документацией?
Иногда важно не только содержание документации, но и процесс ее подготовки. В некоторых проектах с этим процессом связана львиная доля работы, а его нарушения могут приводить к ошибкам, утрате информации и в конечном итоге к временным и финансовым потерям. И даже если обозначенная тема не является вашей основной задачей, правильная организация этого процесса поможет вам улучшить качество документации и сэкономить время.
Метод, описанный ниже, отличается низким порогом вхождения: фактически уже завтра вы сможете начать работать по-новому.
### Постановка задачи
Итак, вам нужно создать один или несколько документов. Возможно, это проектная документация, выдержки из сетевых логов или что-то более простое. Допустим, вы хотите описать процессы, происходящие в компании или в вашем отделе. Такие документы обычно содержат текст, рисунки, таблицы и т. д. Усложним задачу, добавив следующие условия:
1. Работа над документом требует совместных усилий нескольких сотрудников или даже нескольких групп.
2. В результате должен получиться документ определенного формата, созданный по шаблону и содержащий элементы фирменного стиля. Для большей конкретики возьмем формат MS Word (.docx).
10 лет назад схема работы была довольно однозначной: нужно было создать документ (или документы) MS Word и организовать процесс внесения правок.
Такой подход все еще актуален — даже крупные интеграторы используют его при создании проектной документации. Однако интуитивно понятно, что он не очень удобен, если работа над документом занимает много времени и включает множество правок и обсуждений.
### Пример
Я впервые столкнулся с этой проблемой, работая с одним крупным интегратором. Процесс внесения правок в проектную документацию у нас выглядел так:
1. Инженер загружает последнюю версию документа MS Word (.docx)
2. Меняет название документа
3. Вносит правки в режиме отслеживания изменений
4. Отправляет документ с правками архитектору
5. Также прикладывает список всех изменений с комментариями
6. Архитектор анализирует изменения
7. Если все в порядке, он вносит эти правки в последнюю версию файла, меняет номер версии и загружает документ на общий ресурс
8. Если же у архитектора появляются замечания, начинается их обсуждение (по электронной почте или на собраниях)
9. Наконец, все участники процесса приходят к единому мнению
10. Повторяются шаги с 3-го по 9-й
Эта схема более-менее оправдывала себя, пока работа шла не очень интенсивно, но затем она стала узким местом для целого проекта. Это случилось, когда изменения в документ начали вносить сразу несколько команд — одновременно и с высокой частотой.
Когда мы перешли к предварительному тестированию, начали возникать проблемы. И хотя они были небольшими, нам приходилось постоянно вносить изменения в документацию. Каждый день четыре разные команды практически в одно и то же время занимались внесением правок, сопровождая этот процесс обсуждениями. Все изменения проходили через согласование с единственным инженером — архитектором. Поскольку файл проектного решения был огромным, наш архитектор оказался перегружен механической работой — копированием и правкой. Он делал много ошибок. Нам приходилось все перепроверять и отправлять назад. Рабочий процесс превратился в полный хаос.
Итак, работа с документацией на основе MS Word давалась нам с большим трудом, поэтому такой подход создавал проблемы.
### Git и Markdown
Столкнувшись с проблемой, описанной выше, я решил исследовать этот вопрос.
Я заметил, что люди все чаще используют при создании документов язык разметки [Markdown](https://ru.wikipedia.org/wiki/Markdown) в сочетании с системой управления версиями [Git](https://ru.wikipedia.org/wiki/Git).
Вообще Git — это инструмент разработки. Но почему бы не использовать его и для подготовки документации? В этом случае проблема с одновременной работой нескольких пользователей будет решена. Лучше всего преимущества Git раскрываются в работе с документами на основе обычного текста, поэтому вместо MS Word нам придется использовать другой инструмент. Markdown отлично подойдет для этих целей.
Это простой язык разметки, который позволяет создавать эстетично оформленные документы в виде обычных текстовых файлов. При создании документов в формате Markdown будет довольно естественно использовать Git для управления версиями.
И все бы хорошо, если бы не наше второе условие: «в результате должен получиться документ определенного формата, созданный по шаблону и содержащий элементы фирменного стиля» (как мы определились в самом начале, это должен быть документ MS Word). Таким образом, если мы решим использовать Markdown, придется найти способ конвертировать наш файл в требуемый формат — .docx.
Для конвертации документов в разные форматы существуют специальные программы, например [Pandoc](https://ru.wikipedia.org/wiki/Pandoc). С помощью этой программы можно конвертировать файл Markdown в .docx. Однако тут нужно понимать два момента. Первый: не все, что есть в Markdown, можно перенести в MS Word. И второй: MS Word — это целая страна по сравнению с маленьким городком Markdown: в Word есть огромное количество вещей, которых нет в Markdown. Не получится просто указать в командной строке Pandoc какие-то параметры и сразу конвертировать файл Markdown в документ MS Word желаемого вида. Как правило, после конвертации документ .docx приходится дорабатывать вручную, что также отнимает время и может привести к появлению ошибок.
Было бы здорово написать скрипт, который бы автоматически «доделывал» все, с чем не справился Pandoc.
Учитывая принципиальную разницу между MS Word и Markdown, я думаю, что эту проблему невозможно решить в целом. Но возможно ли сделать это в контексте определенных ситуаций и требований? Мой опыт показывает, что возможно, — причем во многих, а то и в большинстве ситуаций.
### Решение конкретной проблемы
Итак, в моем случае после конвертации файлов через Pandoc их приходилось дополнительно обрабатывать вручную, а именно:
* Добавлять поля Word для автоматической нумерации таблиц и рисунков;
* Менять стили таблиц.
Я не нашел способа это сделать с помощью стандартных инструментов (включая Pandoc) или каких-либо других известных средств. Поэтому я применил скрипт на Python, в котором используется пакет [pywin32](https://github.com/mhammond/pywin32), и в результате добился полной автоматизации. У меня получилось наладить конвертацию файлов Markdown в документы MS Word желаемого вида с помощью всего одной команды.
За счет pywin32 можно получить практически полный контроль над документом MS Word, что позволяет привести его к тому виду, которого требует корпоративный стандарт. Конечно, этого результата можно добиться и с помощью других инструментов — например, макросов на VBA, — но мне было удобнее использовать Python.
Вот короткая формула этого подхода:
`Markdown + Git − (нечто) → MS Word`
На месте этого «нечто» может быть что угодно. В моем случае это были Pandoc и скрипт на Python, работающий с пакетом pywin32. У вас могут быть другие предпочтения. Важно одно — формула работает. Это основная мысль всей статьи.
Если коротко, идея такого подхода заключается в том, чтобы работать только с файлами Markdown, используя Git для взаимодействия с другими участниками проекта и управления версиями. При необходимости (например, если нужно предоставить документацию клиенту) можно автоматически создать файл желаемого формата (скажем, MS Word).
### Процесс
Думаю, многим читателям будет достаточно приведенной выше формулы, чтобы понять, как можно организовать работу с документацией. Но я все же обычно ориентируюсь на сетевых инженеров, поэтому в общих чертах расскажу, как может выглядеть рабочий процесс и чем он отличается от внесения правок в файлы MS Word.
Возьмем GitHub в качестве рабочей платформы для Git. Необходимо создать репозиторий и добавить в главную ветку файл или файлы Markdown, с которыми вы собираетесь работать.
Допустим, подготовкой документации занимаются четыре человека, и вы один из них. Тогда нужно создать четыре дополнительные ветки — например, с именами участников. Каждый из них будет работать локально, в собственной ветке, используя все необходимые команды Git.
Завершив какую-то часть работы, вы создадите pull-запрос, чтобы начать обсуждение предлагаемых изменений с другими участниками. Возможно, в процессе выяснится, что вам нужно добавить или поменять что-то еще. В таком случае вы внесете необходимые правки и создадите еще один pull-запрос. В конечном итоге ваши изменения будут объединены с главной веткой (или отвергнуты).
Конечно, это довольно общее описание. Для создания детально проработанного процесса рекомендую подключить к делу разработчиков или найти специалистов с опытом в этой области. Но я хотел бы заметить, что у системы Git довольно низкий порог вхождения. Хотя принцип функционирования системы не так прост, с ней легко начать работать. Я думаю, что, даже если вы столкнетесь с ней впервые, вы сможете начать ее использовать, потратив несколько часов или дней на изучение и установку.
В чем преимущество этого подхода перед процессом из примера выше?
На самом деле, они довольно схожи, просто одни понятия заменяются другими:
* Копировать файл → создать ветку (branch)
* Копировать текст в целевой файл → выполнить слияние (merge)
* Копировать последние изменения к себе → git pull/fetch
* Обсуждение в чате → pull-запросы
* Режим отслеживания изменений → git diff
* Последняя утвержденная версия → главная ветка (master)
* Резервное копирование (создание копии на удаленном сервере) → git push
Таким образом, вы автоматизируете операции, которые до этого приходилось выполнять вручную.
На более высоком уровне это позволит:
* Создать четкий, простой и управляемый процесс внесения правок в документы
* Снизить риск возникновения ошибок, связанных с форматированием, поскольку итоговый документ (в нашем случае документ MS Word) создается автоматически
С учетом вышесказанного становится очевидно: даже если вы единственный человек, которому приходится заниматься документацией, использование Git может значительно облегчить вашу работу.
### Как запустить новый процесс?
В начале статьи я упомянул, что начать работать по-новому вы сможете уже завтра. Как это сделать?
Вот наиболее вероятная последовательность шагов:
* Если документ слишком большой, разделите его на части
* Конвертируйте каждую из них в формат Markdown (например, с помощью Pandoc)
* Установите редактор Markdown (я использую Typora)
* Скорее всего, вам придется поправить полученные документы Markdown
* Следуйте инструкциям, описанным в предыдущей части
* Начните изменять скрипт конвертации для вашей задачи (или создайте свой собственный)
Необязательно ждать момента, когда механизм конвертации Markdown в документы нужного вида будет досконально отлажен. Даже если у вас не получится быстро автоматизировать процесс конвертации файлов Markdown, всегда можно преобразовать их хотя бы в какой-то вид с помощью Pandoc, а затем вручную привести к нужной форме. Как правило, это не приходится делать слишком часто — только по завершении определенных этапов. Работать вручную не так удобно, но я считаю, что на этапе отладки это вполне допустимо и не слишком сказывается на скорости процесса.
Остальные инструменты (Markdown, Git, Pandoc, Typora) уже готовы к использованию и не требуют много сил или времени на освоение.
---
Перевод статьи подготовлен в преддверии старта курса [PHP Developer. Basic](https://otus.pw/cdji/).
* [**УЗНАТЬ ПОДРОБНЕЕ О КУРСЕ**](https://otus.pw/cdji/) | https://habr.com/ru/post/568726/ | null | ru | null |
# Функции Terraform

В этом посте мы обсудим функции Terraform. Язык Terraform включает ряд встроенных функций, которые можно вызывать из выражений для преобразования и комбинирования значений. Общий синтаксис для вызовов функций — это имя функции, за которым следуют аргументы, разделенные запятыми, в круглых скобках.
```
(, , …)
```
Далее мы собираемся объяснить функции Terraform на примерах. Мы будем использовать консоль terraform для этой демонстрации.
Функции Terraform:
Откройте terraform console
`terraform console`
**Числовые функции**
**abs(number)**: возвращает абсолютное значение заданного числа.
`abs(-19.86)` #возвращает `19.86`
**ceil(number)**: возвращает ближайшее целое число, которое больше или равно заданному значению
`ceil(7.1)` #возвращает `8`
**floor(number):** возвращает ближайшее целое число, которое меньше или равно заданному значению
`floor(7.1)` #возвращает `7`
**log(number, base)**: log возвращает логарифм заданного числа по заданному основанию.
`log(16,2)` #возвращает `4`
**max(N1,N2,..Nn):** берет одно или несколько чисел и возвращает наибольшее число из набора.
`max(3,2,6,8.8,7)` #возвращает `8.8`
**min(N1,N2,..Nn):** принимает одно или несколько чисел и возвращает наименьшее число из набора.
`min(3,2,6,8.8,7)` #возвращает `2`
**pow(number,power):** вычисляет показатель степени, возводя свой первый аргумент в степень второго аргумента.
`pow(8,2)` #возвращает `64`
**signum(number):** определяет знак числа, возвращая число от -1 до 1 для представления знака.
`signum(-4)` #возвращает `-1`
`signum(4)` #возвращает `1`
**Строковые функции**
**chomp("string"):** удаляет символы новой строки в конце строки.
`chomp("cloudaffaire\n")` #возвращает `cloudaffaire` (\*\*удаляет только \ n с конца)
**format(spec, values...):** создает строку путем форматирования ряда других значений в соответствии со строкой спецификации
`format("Welcome, to %s", "CloudAffaire")` #возвращает `Welcome, to CloudAffaire`
`format("The year is %d", 2019)` #возвращает The year is 2019
`format("%4.4f+", 3.86)` #возвращает `3.8600+`
[Спецификация форматирования](https://www.terraform.io/docs/configuration/functions/format.html)
**formatlist(spec, values...):** formatlist создает список строк путем форматирования ряда других значений
в соответствии со строкой спецификации. Строка спецификации использует тот же синтаксис, что и формат.
`formatlist("www.%s.com",list("azure","aws","google"))` #возвращает `[www.azure.com,www.aws.com,www.google.com]`
**indent(num\_spaces, string):** добавляет заданное количество пробелов в начало всех строк, кроме первой, в данной многострочной строке.
`indent(8,"hi, \n welcome \n to \n cloudaffaire")` #1st line hi has no indentaton
**join(separator, list):** создает строку, объединяя вместе все элементы заданного списка строк с заданным разделителем.
`join(".",list("www","google","com"))` #возвращает `www.google.com`
**lower(string):** преобразует все буквы в заданной строке в нижний регистр.
`lower("CLOUDAFFAIRE")` #возвращает `cloudaffaire`
**upper(string):** преобразует все буквы в заданной строке в верхний регистр.
`upper("cloudaffaire")` #возвращает `CLOUDAFFAIRE`
**replace(string, substring, replacement):** ищет в заданной строке другую заданную подстроку,
и заменяет каждое вхождение заданной строкой замены.
`replace("www.google.com","google","cloudaffaire")` #возвращает `www.cloudaffaire.com`
**split(separator, string):** создает список, разделяя заданную строку на все вхождения заданного разделителя.
`split(".","www.google.com")` #возвращает `["www","google","com"]`
**strrev(string):** меняет местами символы в строке. Обратите внимание, что символы обрабатываются как символы Unicode.
`strrev("google")` #возвращает: `elgoog` (поддерживается только в terraform версии 0.12 или новее)
**substr(string, offset, length):** извлекает подстроку из заданной строки по смещению и длине.
`substr("www.google.com",4,6)` #возвращает `google`
**title(string):** преобразует первую букву каждого слова в заданной строке в верхний регистр.
`title("welcome to cloudaffaire")` #возвращает `Welcome To Cloudaffaire`
**trimspace(string):** удаляет любые пробелы из начала и конца данной строки.
`trimspace(" hello, all ")` #возвращает "`hello, all`"
Функции по работе с коллекциями
**chunklist(list, chunk\_size):** разбивает один список на фрагменты фиксированного размера, возвращая список списков.
`chunklist(list("a","b","c","d","e","f"),3)` #возвращает `[["a","b","c"],["d","e","f"]]`
**coalesce(strings\numbers):** принимает любое количество аргументов и возвращает первый, который не является нулем или пустой строкой.
`coalesce("",1,"a")` #возвращает `1`
**coalescelist(list1, list2,… listn):** принимает любое количество аргументов списка и возвращает первый непустой аргумент.
`coalescelist(list(),list("a","b","c"),list("d","e"))` #возвращает `["a","b","c",]`
**compact(list(string)):** принимает список строк и возвращает новый список с удаленными пустыми строковыми элементами.
`compact(list("a","","c","","d"))` #возвращает `["a","c","d"]`
**concat(list1, list2,… listn):** берет два или более списка и объединяет их в один список.
`concat(list("a","b"),list("c","d"),list("e","f"))` #возвращает `["a","b","c","d","e","f"]`
**contains(list, value):** определяет, содержит ли данный список или набор заданное единственное значение в качестве одного из своих элементов.
`contains(list("a","b","c"),"a")` #возвращает `true`
`contains(list("a","b","c"),"d")` #возвращает `false`
**distinct(list):** принимает список и возвращает новый список с удаленными повторяющимися элементами.
`distinct(list("a","b","b","c"))` #возвращает `["a","b","c",]`
**element(list, index):** извлекает один элемент из списка.
`element(list("a","b","c"),2)` #возвращает c #index start from 0
**index(list, value):** находит индекс элемента для данного значения в списке.
`index(list("a","b","c"),"b")` #возвращает `1`
**flatten(list(list1,list2,..,listn)):** принимает список и заменяет любые элементы, которые являются списками сглаженной последовательностью содержимого списка.
`flatten(list(list("a","b"),list("c"),list(),list("d","e")))` #возвращает `["a","b","c","d","e",]`
**keys(map):** берет карту и возвращает список, содержащий ключи из этой карты.
`keys(map("name","debjeet","sex","male"))` #возвращает `["name","sex",]`
**length(list\map\string):** определяет длину данного списка, карты или строки.
`length(list("a","b"))` #возвращает `2`
`length("debjeet")` #возвращает `7`
`length(map("name","debjeet","sex","male"))` #возвращает `2`
**list():** принимает произвольное количество аргументов и возвращает список, содержащий эти значения в том же порядке.
`list("a","b","c")` #возвращает `["a","b","c",]`
**lookup(map, key, default):** извлекает значение одного элемента из карты, учитывая его ключ. Если данный ключ не существует, вместо него возвращается заданное значение по умолчанию.
`lookup(map("name","debjeet","sex","male"),"sex","not found!")` #возвращает `male`
`lookup(map("name","debjeet","","male"),"gender","not found!")` #возвращает `not found!`
**map("key1","value1","key2","value2",...,"keyn","valuen"):** принимает четное количество аргументов и возвращает карту, элементы которой
построены из последовательных пар аргументов.
`map("name","debjeet","sex","male")` #возвращает `{"name" = "debjeet" "sex" = "male"}`
**matchkeys(valueslist, keyslist, searchset):** создает новый список, беря подмножество элементов из одного списка, индексы которого
сопоставляет соответствующие индексы значений в другом списке.
`matchkeys(list("a","b","c"),list("one","two","three"),list("two"))` #возвращает `b`
`matchkeys(list("a","b","c"),list("one","two","three"),list("one"))` #возвращает `a`
`matchkeys(list("a","b","c"),list("one","two","three"),list("three"))` #возвращает `c`
**merge(map1,map2,..,mapn):** берет произвольное количество карт и возвращает одну карту
содержит объединенный набор элементов со всех карт.
`merge(map("a","one"),map("b","two"),map("c","three"))` #возвращает `{"a" = "one" "b" = "two" "c" = "three"}`
**reverse(list):** берет последовательность и создает новую последовательность такой же длины со всеми.
те же элементы, что и заданная последовательность, но в обратном порядке.
`reverse(list("a","b","c"))` #возвращает: `["c","b","a",]` (поддерживается только в terraform версии 0.12 или новее)
**setintersection(sets...):** принимает несколько наборов и создает один набор, содержащий только элементы, которые являются общими для всех данных наборов.
`setintersection(list("a","b"),list("b","c"),list("b","d"))` #возвращает `["b",]` (поддерживается только в terraform версии 0.12 или новее)
**setproduct(sets...):** находит все возможные комбинации элементов из всех заданных наборов, вычисляя декартово произведение.
`setproduct(list("a","b"),list("c","d"))` #возвращает `[["a","c"],["a","d"],["b","c"],["b","d"],]` (поддерживается только в terraform версии 0.12 или новее)
**setunion(sets...)**: берет несколько наборов и создает один набор, содержащий элементы из всех данных наборов.
Другими словами, он вычисляет объединение множеств.
`setunion(list("a","b"),list("c","d"))` #возвращает `["a","b","c","d",]` (поддерживается только в terraform версии 0.12 или новее)
**slice(list, startindex, endindex):** извлекает несколько последовательных элементов из списка
`slice(list("zero","one","two","three"),1,3)` #возвращает `["one","two"]`
**sort(list):** принимает список строк и возвращает новый список с этими строками, отсортированными лексикографически.
`sort(list("d","c","a","b"))` #возвращает `["a","b","c","d",]`
**transpose():** берет карту списков строк и меняет местами ключи и значения, чтобы создать новую карту списков строк.
`transpose(map("a",list("one","two"),"b",list("three","four")))` #возвращает `{"four"=["b",] "one"=["a",] "three"=["b",] "two"=["a",]}`
**values(map):** берет карту и возвращает список, содержащий значения элементов в этой карте.
`values(map("name","debjeet","sex","male"))` #возвращает `["debjeet","male",]`
**zipmap(keyslist, valueslist):** создает карту из списка ключей и соответствующего списка значений.
`zipmap(list("name","sex"),list("debjeet","male"))` #возвращает `{"name" = "debjeet" "sex" = "male"}`
**Функции кодирования**
**base64encode(string):** применяет кодировку Base64 к строке.
`base64encode("cloudaffaire")` #возвращает `Y2xvdWRhZmZhaXJl`
**base64gzip(string):** сжимает строку с помощью gzip, а затем кодирует результат в кодировке Base64.
`base64gzip("cloudaffaire")` #возвращает `H4sIAAAAAAAA/0rOyS9NSUxLS8wsSgUAAAD//wEAAP//38z9sQwAAAA=`
**base64decode(string):** принимает строку, содержащую последовательность символов Base64, и возвращает исходную строку.
`base64decode("Y2xvdWRhZmZhaXJl")` #возвращает `cloudaffaire`
**csvdecode(string):** декодирует строку, содержащую данные в формате CSV, и создает список карт, представляющих эти данные.
`csvdecode("a,b,c\n1,2,3\n")` #возвращает `[{"a"="1" "b"="2" "c"="3"},]` (поддерживается только в terraform версии 0.12 или новее)
**jsonencode():** кодирует заданное значение в строку, используя синтаксис JSON.
`jsonencode(map("name","debjeet"))` #возвращает `{"name":"debjeet"}`
**jsondecode():** интерпретирует заданную строку как JSON, возвращая представление результата декодирования этой строки.
`jsondecode("{\"name\":\"debjeet\"}")` #возвращает {"name" = "debjeet"} (поддерживается только в terraform версии 0.12 или новее)
**urlencode():** применяет кодировку URL к заданной строке.
`urlencode("https://cloudaffaire.com/?s=terraform")` #возвращает `https%3A%2F%2Fcloudaffaire.com%2F%3Fs%3Dterraform`
**Функции для работы с файловой системой**
**dirname(string):** берет строку, содержащую путь к файловой системе, и удаляет из нее последнюю часть.
`dirname("/home/ec2-user/terraform/main.tf")` #возвращает `/home/ec2-user/terraform`
**pathexpand():** принимает путь к файловой системе, который может начинаться с сегмента ~,
и если это так, он заменяет этот сегмент на путь к домашнему каталогу текущего пользователя.
`pathexpand("~/.ssh/id_rsa")` #возвращает `/home/ec2-user/.ssh/id_rsa`
**basename(string):** берет строку, содержащую путь к файловой системе, и удаляет из нее все, кроме последней части.
`basename("/home/ec2-user/terraform/main.tf")` #возвращает `main.tf`
**file(path):** читает содержимое файла по заданному пути и возвращает его в виде строки
`file("/home/ec2-user/terraform/main.tf")` #возвращает `content of main.tf`
**fileexists(path):** определяет, существует ли файл по заданному пути.
`fileexists("/home/ec2-user/terraform/main.tf")` #возвращает `true if main.tf exist` (поддерживается только в terraform версии 0.12 или новее)
**filebase64(path):** читает содержимое файла по заданному пути и возвращает его в виде строки в кодировке base64.
`filebase64("/home/ec2-user/terraform/main.tf")` # возвращает содержимое main.tf как данные base64. (поддерживается только в terraform версии 0.12 или новее)
**templatefile(path, vars):** читает файл по заданному пути и отображает его содержимое как шаблон, используя предоставленный набор переменных шаблона.
**Функции по работе с датой и временем**
**formatdate(spec, timestamp):** преобразует метку времени в другой формат времени.
`formatdate("MMM DD, YYYY", "2018-01-02T23:12:01Z")` #возвращает `Jan 02, 2018` (поддерживается только в terraform версии 0.12 или новее). [Спецификация](https://www.terraform.io/docs/configuration/functions/formatdate.html).
**timeadd(timestamp, duration):** добавляет продолжительность к отметке времени, возвращая новую отметку времени.
Продолжительность — это строковое представление разницы во времени, состоящее из последовательностей пар чисел и единиц, например «1,5 часа» или «1 час 30 минут».
Принятые единицы: "ns", "us" (or "µs"), "ms", "s", "m", and "h".
Первое число может быть отрицательным, чтобы указать отрицательную продолжительность, например "-2h5m".
`timeadd("2019-05-10T00:00:00Z", "10m")` #возвращает `2019-05-10T00:10:00Z`
**timestamp():** возвращает текущую дату и время
`timestamp()`
**Функции по работе с IP сетями**
**cidrhost(prefix, hostnum):** вычисляет полный IP-адрес хоста для данного номера хоста в пределах данного префикса IP-адреса сети.
`cidrhost("10.0.0.0/16", 4)` #возвращает `10.0.0.4`
`cidrhost("10.0.0.0/16", -4)`` #возвращает`10.0.255.252`
**cidrnetmask(prefix):** преобразует префикс IPv4-адреса, указанный в нотации CIDR, в адрес маски подсети.
`cidrnetmask("10.0.0.0/16")` #возвращает `255.255.0.0`
`cidrnetmask("10.0.0.0/24")` #возвращает `255.255.255.0`
**cidrsubnet(prefix, newbits, netnum):** cidrsubnet вычисляет адрес подсети в пределах заданного префикса IP-адреса сети.
префикс должен быть указан в нотации CIDR
`newbits` — это количество дополнительных битов, с помощью которых можно расширить префикс.
`netnum` — это целое число, которое может быть представлено как двоичное целое число, состоящее не более чем из двоичных разрядов newbits
`cidrsubnet("10.0.0.0/16",8,2)` #возвращает `10.0.2.0/24`
`cidrsubnet("10.0.0.0/24",8,1)` #возвращает `10.0.0.1/32`
Выйти из консоли терраформа
`exit`
Полный список функций terraform смотрите ниже в документации terraform. | https://habr.com/ru/post/538660/ | null | ru | null |
# Использование Docker для сборки и запуска проекта на C++
В этой публикации речь пойдет о том, как выполнить сборку C++ проекта, использующего GTest и Boost, при помощи Docker. Статья представляет собой рецепт с некоторыми поясняющими комментариями, представленное в статье решение не претендует на статус Production-ready.
Зачем и кому это может понадобиться?
Предположим, что вам, как и мне очень нравится концепция Python [venv](https://docs.python.org/3/library/venv.html), когда все нужные зависимости расположены в отдельной, строго определенной директории; или же вам необходимо обеспечить простую переносимость среды сборки и тестирования для разрабатываемого проекта, что очень удобно, например, при присоединении нового разработчика к команде.
Эта статья будет особенно полезна начинающим разработчикам, кому необходимо выполнить базовую настройку окружения для сборки и запуска C++ проекта.
Представленное в статье окружение можно использовать как каркас для тестовых заданий или лабораторных работ.
Установка Docker
----------------
Все, что вам понадобится, для реализации проекта, представленного в этой статье — это Docker и доступ в интернет.
Docker доступен под платформы Windows, Linux и Mac. [Официальная документация](https://docs.docker.com/).
Так как я использую машину с Windows на борту, мне было достаточно скачать инсталятор и запустить.
Следует учесть, что на данный момент Docker под Windows использует Hyper-V для своей работы.
Проект
------
В качестве проекта будем подразумевать CommandLine приложение, выводящее строку "Hello World!" в стандартный поток вывода.
В проекте будет использован необходимый минимум библиотек, а также [CMake](https://cmake.org/) в качестве системы сборки.
Структура нашего проекта будет выглядеть следующим образом:
```
project
| Dockerfile
|
\---src
CMakeLists.txt
main.cpp
sample_hello_world.h
test.cpp
```
Файл CMakeLists.txt содержит описание проекта.
Исходный код файла:
```
cmake_minimum_required(VERSION 3.2)
project(HelloWorldProject)
# используем C++17
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++17")
# используем Boost.Program_options
# дабы не переусложнять, в качестве статической библиотеки
set(Boost_USE_STATIC_LIBS ON)
find_package(Boost COMPONENTS program_options REQUIRED)
include_directories(${BOOST_INCLUDE_DIRS})
# исполняемый файл нашего приложения
add_executable(hello_world_app main.cpp sample_hello_world.h)
target_link_libraries(hello_world_app ${Boost_LIBRARIES})
# включаем CTest
enable_testing()
# в качестве фреймворка для тестирования используем GoogleTest
find_package(GTest REQUIRED)
include_directories(${GTEST_INCLUDE_DIRS})
# исполняемый файл тестов
add_executable(hello_world_test test.cpp sample_hello_world.h)
target_link_libraries(hello_world_test ${GTEST_LIBRARIES} pthread)
# добавим этот файл в тестовый набор CTest
add_test(NAME HelloWorldTest COMMAND hello_world_test)
```
Файл sample\_hello\_world.h содержит описание класса HelloWorld, отправляя экземпляр которого в поток, будет выводиться строка "Hello World!". Такая сложность обусловлена необходимостью тестирования кода нашего приложения.
Исходный код файла:
```
#ifndef SAMPLE_HELLO_WORLD_H
#define SAMPLE_HELLO_WORLD_H
namespace sample {
struct HelloWorld {
template
friend OS& operator<<(OS& os, const HelloWorld&) {
os << "Hello World!";
return os;
}
};
} // sample
#endif // SAMPLE\_HELLO\_WORLD\_H
```
Файл main.cpp содержит точку входа нашего приложения, добавим также [Boost.Program\_options](https://www.boost.org/doc/libs/1_67_0/doc/html/program_options.html), чтобы симулировать реальный проект.
Исходный код файла:
```
#include "sample_hello_world.h"
#include
#include
// Наше приложение будет иметь один параметр командной строки - "--help"
auto parseArgs(int argc, char\* argv[]) {
namespace po = boost::program\_options;
po::options\_description desc("Allowed options");
desc.add\_options()
("help,h", "Produce this message");
auto parsed = po::command\_line\_parser(argc, argv)
.options(desc)
.allow\_unregistered()
.run();
po::variables\_map vm;
po::store(parsed, vm);
po::notify(vm);
// В C++17 больше нет необходимости использовать std::make\_pair
return std::pair(vm, desc);
}
int main(int argc, char\* argv[]) try {
auto [vm, desc] = parseArgs(argc, argv);
if (vm.count("help")) {
std::cout << desc << std::endl;
return 0;
}
std::cout << sample::HelloWorld{} << std::endl;
return 0;
} catch (std::exception& e) {
std::cerr << "Unhandled exception: " << e.what() << std::endl;
return -1;
}
```
Файл test.cpp содержит необходимый минимум — тест функциональности класса HelloWorld. Для тестирования используем [GoogleTest](https://github.com/google/googletest).
Исходный код файла:
```
#include "sample_hello_world.h"
#include
#include
// Простой тест, выводим HelloWorld в поток, сравниваем вывод с ожидаемым
TEST(HelloWorld, Test) {
std::ostringstream oss;
oss << sample::HelloWorld{};
ASSERT\_EQ("Hello World!", oss.str());
}
// Точка входа в тестовое приложение
int main(int argc, char \*\*argv) {
testing::InitGoogleTest(&argc, argv);
return RUN\_ALL\_TESTS();
}
```
Далее, переходим к самому интересному — настройке сборочного окружения при помощи Dockerfile!
Dockerfile
----------
Для сборки будем использовать [gcc](https://hub.docker.com/_/gcc/) последней версии.
Dockerfile содержит два этапа: сборка и запуск нашего приложения.
Для запуска используем Ubuntu последней версии.
Содержимое Dockerfile:
```
# Сборка ---------------------------------------
# В качестве базового образа для сборки используем gcc:latest
FROM gcc:latest as build
# Установим рабочую директорию для сборки GoogleTest
WORKDIR /gtest_build
# Скачаем все необходимые пакеты и выполним сборку GoogleTest
# Такая длинная команда обусловлена тем, что
# Docker на каждый RUN порождает отдельный слой,
# Влекущий за собой, в данном случае, ненужный оверхед
RUN apt-get update && \
apt-get install -y \
libboost-dev libboost-program-options-dev \
libgtest-dev \
cmake \
&& \
cmake -DCMAKE_BUILD_TYPE=Release /usr/src/gtest && \
cmake --build . && \
mv lib*.a /usr/lib
# Скопируем директорию /src в контейнер
ADD ./src /app/src
# Установим рабочую директорию для сборки проекта
WORKDIR /app/build
# Выполним сборку нашего проекта, а также его тестирование
RUN cmake ../src && \
cmake --build . && \
CTEST_OUTPUT_ON_FAILURE=TRUE cmake --build . --target test
# Запуск ---------------------------------------
# В качестве базового образа используем ubuntu:latest
FROM ubuntu:latest
# Добавим пользователя, потому как в Docker по умолчанию используется root
# Запускать незнакомое приложение под root'ом неприлично :)
RUN groupadd -r sample && useradd -r -g sample sample
USER sample
# Установим рабочую директорию нашего приложения
WORKDIR /app
# Скопируем приложение со сборочного контейнера в рабочую директорию
COPY --from=build /app/build/hello_world_app .
# Установим точку входа
ENTRYPOINT ["./hello_world_app"]
```
Полагаю, пока переходить к сборке и запуску приложения!
Сборка и запуск
---------------
Для сборки нашего приложения и создания Docker-образа достаточно будет выполнить следующую команду:
```
# Здесь docker-cpp-sample название нашего образа
# . - подразумевает путь к директории, содержащей Dockerfile
docker build -t docker-cpp-sample .
```
Для запуска приложения используем команду:
```
> docker run docker-cpp-sample
```
Увидим заветные слова:
```
Hello World!
```
Для передачи параметра достаточно будет добавить его в вышеприведенную команду:
```
> docker run docker-cpp-sample --help
Allowed options:
-h [ --help ] Produce this message
```
Подводим итоги
--------------
В результате мы создали полноценное C++ приложение, настроили окружение для его сборки и запуска под Linux и завернули его в Docker-контейнер. Таким образом, освободив последующих разработчиков от необходимости тратить время на настройку локальной сборки. | https://habr.com/ru/post/414109/ | null | ru | null |
# Создание единой адресной книги Exchange для двух и более лесов Active Directory
Маленькое предисловие.
Почтовая организация Exchange существует только в пределах леса AD. Адресные списки, которые видит пользователь, тоже строятся только в пределах того леса, в котором инсталлирован Exchange. В случае поглощения компании или, наоборот, расщепления возникают случаи, когда люди из некогда разных организаций и лесов очень сильно хотят видеть друг друга в своих адресных списках, да не подключаемых через скрипты и запрашиваемые по LDAP.
Удивлён, что на Хабре ничего нет про Forefront Identity Management(FIM 2010).
Вот, как построить единый адресный список, состоящий из пользователей двух разных лесов AD с использованием FIM 2010, я постараюсь рассказать ниже.
Думаю, многие системные администраторы Windows окружения в многолесовой архитектуре знают, что получить легко и просто общую адресную книгу не просто.
Существуют самописные скрипты, которые решают эту же задачу. Есть продукты сторонних производителей. Ну и, конечно же, есть бесплатные инструменты от MS. В некоторых случаях можно подключить внешнюю адресную книгу через LDAP, но это решение сложно поддерживать, т.к. настройка происходит на стороне пользователя и имеет кучу других недостатков.
Мне бы хотелось рассказать про решение Enterprise уровня, которое умеет намного больше, чем просто синхронизировать контакты между лесами, но и объединять разные источники данных о пользователях в одном месте, наделять пользователей полномочиями, управлять членством в группах и куча всего другого. Сегодня остановимся просто на синхронизации контактов.
Прежде всего немного о самом продукте — **Forefront Identity Management 2010**.
Данный продукт уже неоднократно переименовывался. В районе 2003 года был продукт Microsoft Identity Integration Server (MIIS). Далее его переименовали в Identity Lifecycle Manager (ILM), кажется, в 2007 году, и вот сейчас это всё выродилось в Forefront Identity Management. Функционал продукта возрастал и улучшался.
Как говорилось выше, в нашем кейсе есть два леса AD, в каждом из которых существует своя почтовая организация Exchange 2010.
Буду заурядным и назову свои компании fabrikam.com и всеми любимый contoso.com.
Сам продукт поставлю на отдельный сервер в лес fabrikam.com. Для установки понадобится дистрибутив с официального сайта, MS SQL Server 2008 и выше, установленный на этой же машине или на другом сервере. Я поставил SQL 2008 R2 на эту же машину. Стандартным требованием является установка .NET Framework 3.5.
Создам в настройках DNS сервера обоих лесов перекрёстные Conditional Forwarding записи. И сразу же проверим, что адреса обоих лесов разрешаются с сервера, на котором установлен FIM. Можно, конечно, обойтись и без этого и просто прописать в hosts файле сервера, на котором установлен FIM необходимые записи.
Создам служебную учётную запись в обоих лесах fimacc, как на рисунке:
Дополнительно к имеющимся правам дадим право Replicating Directory Changes командой `dsacls dc=contoso,dc=com" /G contoso\fimacc:CA;"Replicating Directory Changes"`. Это же действие можно сделать и через adsiedit, но займет значительно больше времени.
Создадим иерахию OU в Active Directory обоих доменов. Под корнем каждого домена будет OU — GAL, а под ней Contacts.
На этом подготовительные мероприятия свернём и приступим к настройке Management Agent в интерфейсе FIM.
Вот так выглядит главное окно, где и будем трудиться:
Откроем оснастку Synchronization Service Manager и в разделе Management Agents перейдём к созданию Management Agent.
Укажем имя — Contoso GAL и выберем тип синхронизации — Active Directory global address list (GAL)
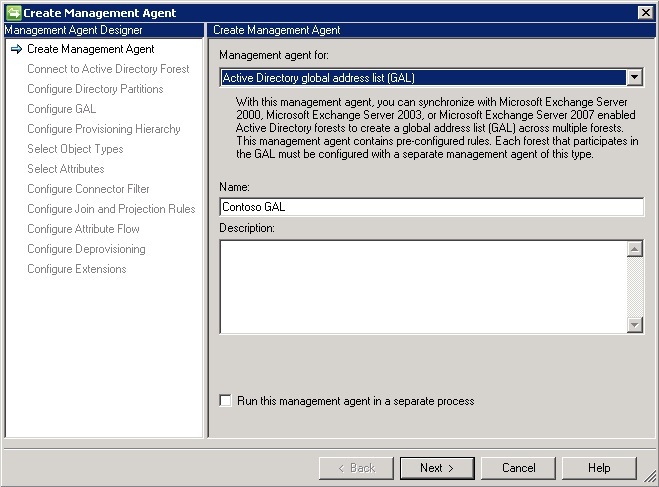
На следующем шаге вводим учётные данные пользователя того домена, к которому планируем подключаться, т.е. fimacc из contoso.com.
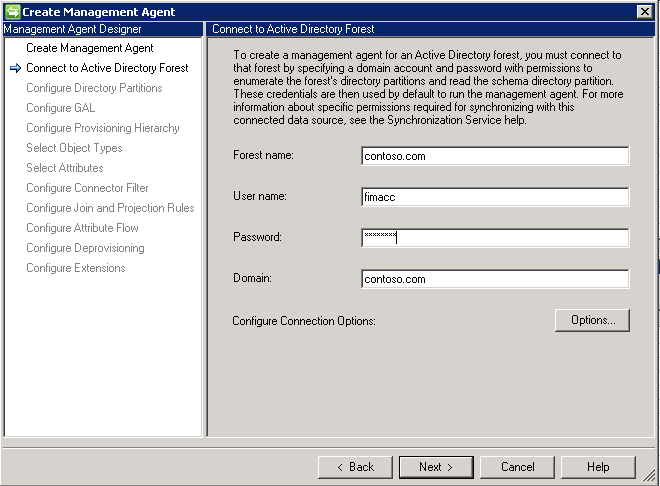
Если на прошлом шаге подключения не произошло, то надо убедиться в том, что адрес домена разрешается корректно, учётная запись создана и ей делегированы все нужные права.
Далее выберем в верхней части окна наш домен, в нижней части окна через кнопку Containers вызовём диалог выбора нужного контейнера GAL. Необходимо снять выделение с корня домена и выделить GAL, не снимая выделения с дочерних OU.
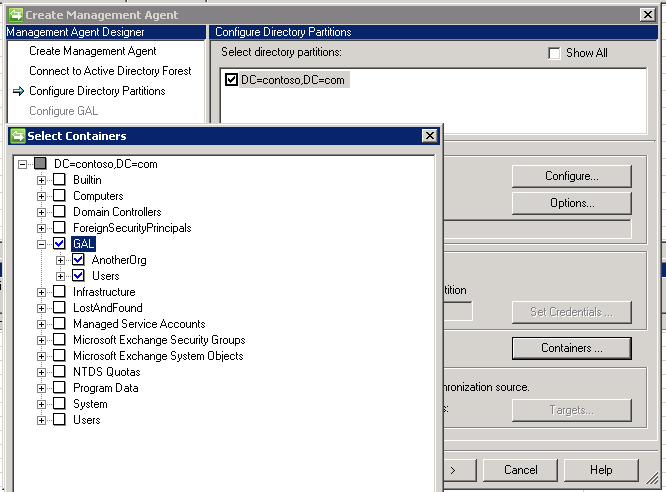
Следующим шагом станет выбор контейнера, где будут размещаться будущие контакты(Target OU). Я выбрал contoso.com\GAL\AnotherOrg
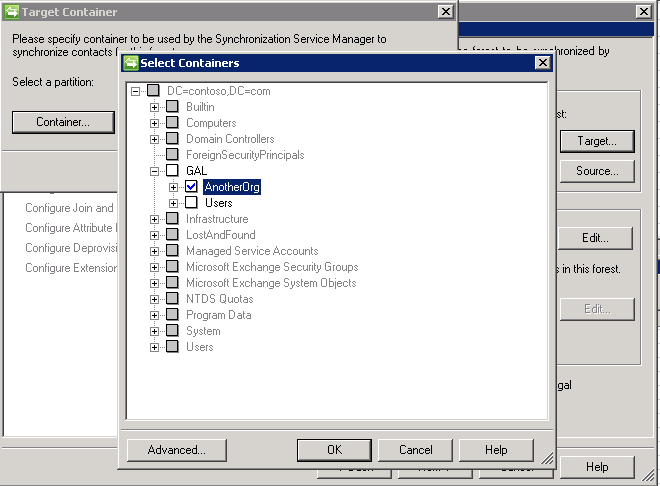
В этом же шаге добавим SMTP адрес того домена, к которому подключаемся, т.е. contoso.com
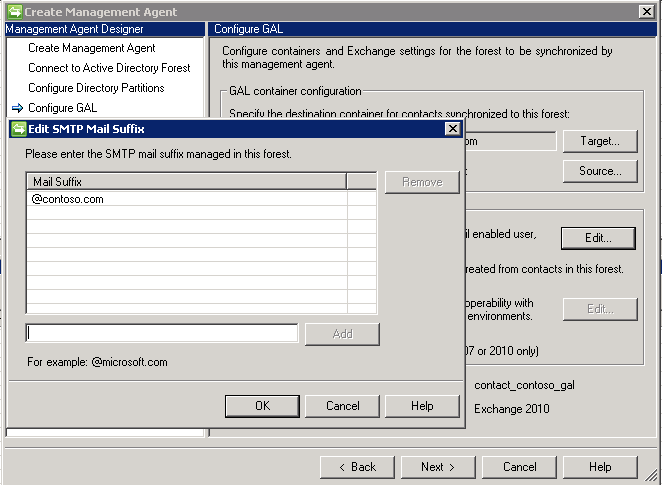
И теперь самая простая часть — нажимаем Next,Next,Next до шага Configure Extensions. Тут необходимо указать имя сервера Exchange с ролью CAS. У меня это — [W2012T3.contoso.com/PowerShell](http://W2012T3.contoso.com/PowerShell).
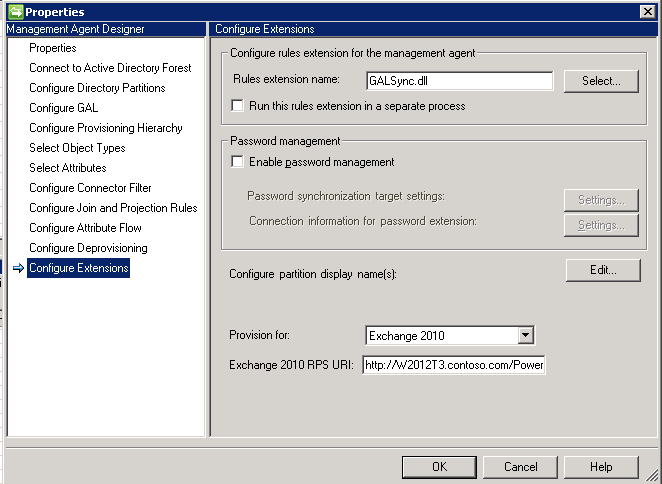
Следует сразу после создания Management Agent его испытать и выполнить Run-Full Import(Stage Only)
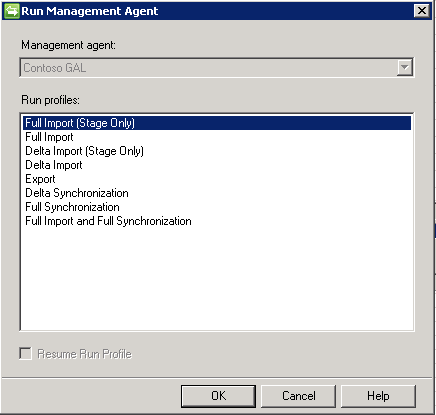
Результат подключения к серверу должен быть success. Количество объектов в строчке Adds не равно нулю.
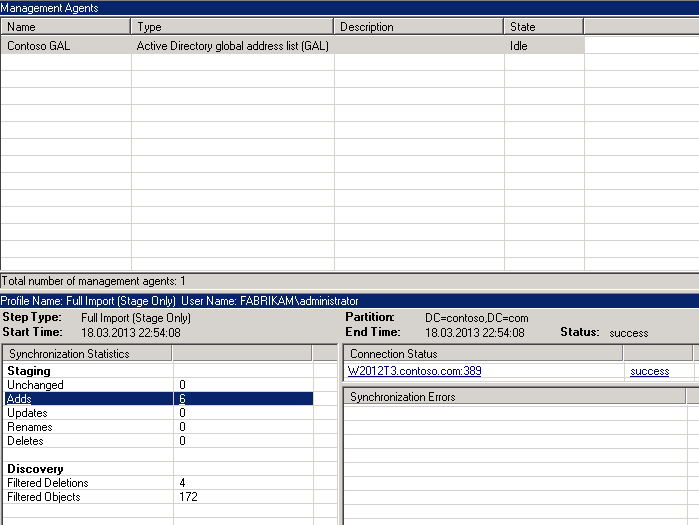
Проделать всё тоже самое для второй организации fabrikam.com
В этот раз укажу учётную запись fimacc из домена fabrikam.com, домен fabrikam.com. Выберу все те же самые OU только в другом домене. Отличий еще два от предыдущей организации: имя сервера, на котором доступен PowerShell, и электронные адреса — @fabrikam.com.
Сделаем Run-Full Import(Stage Only) и получим не нулевой результат.
После успешного завершения предыдущего шага каждый Management Agent необходимо запустить Run-Full Synchronization.
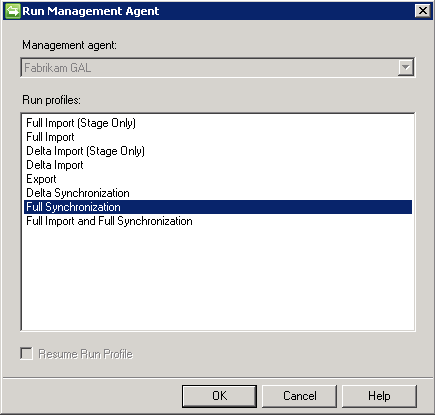
И вновь получить не нулевой результат
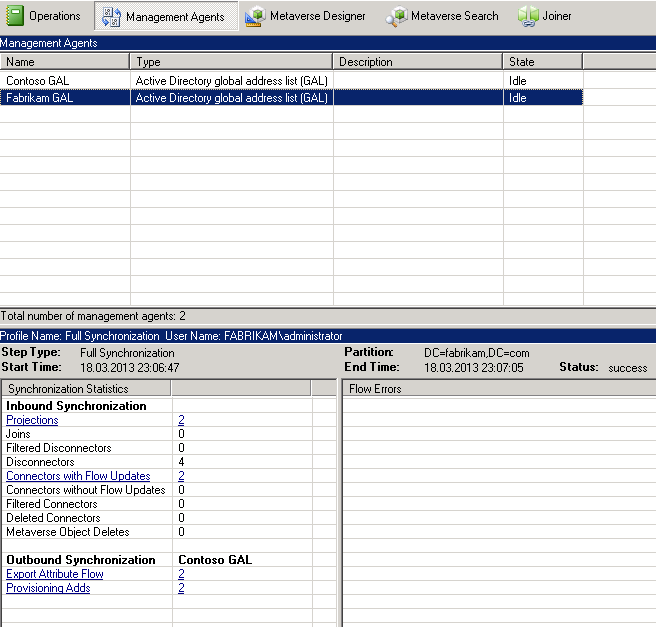
Ну и заключительным шагом станет экспорт контактов в целевые леса. Run-Export.
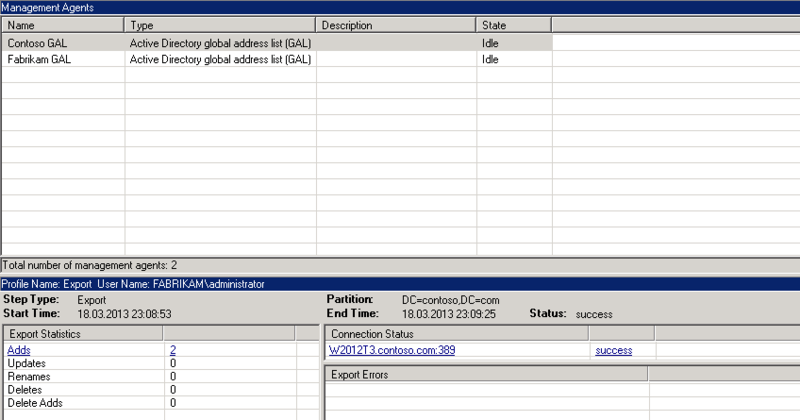
Ну и самое приятное — проверка результата.
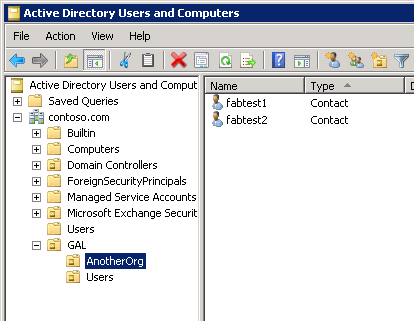
Эта заметка иллюстрирует простоту и функциональность данного продукта.
P.S. Мой первый пост, могут быть ошибки форматирования. | https://habr.com/ru/post/173437/ | null | ru | null |
# Triton vs Kao’s Toy Project. Продолжаем хорошую традицию

В данной статье речь пойдет про SMT-решатели. Так сложилось, что в исследовательских материалах, посвященных данной теме, появилась хорошая традиция. Уже несколько раз в качестве подопытного алгоритма для SMT-решателей разные исследователи выбирали один и тот же пример – [крякми, придуманное некогда человеком с ником kao](https://tuts4you.com/e107_plugins/download/download.php?view.3293). Что ж, продолжим эту традицию и попробуем использовать для решения этого крякми еще один инструмент для символьных вычислений – [Triton](https://triton.quarkslab.com).
Пара слов про SMT-решатели
--------------------------
> Задача выполнимости формул в теориях (англ. satisfiability modulo theories, SMT) — это задача выполнимости для логических формул с учётом лежащих в их основе теорий. Примерами таких теорий для SMT-формул являются: теории целых и вещественных чисел, теории списков, массивов, битовых векторов и т. п. — [wikipedia](https://ru.wikipedia.org/wiki/SMT)
Задача SMT является расширением задачи SAT (Boolean satisfiability problem или Propositional Satisfiability Problem, в англоязычной литературе называется SATISFIABILITY или SAT, в русской литературе иногда называется ВЫП).
Еще одна цитата из Википедии:
> Экземпляром задачи SAT является булева формула, состоящая только из имен переменных, скобок и операций И, ИЛИ и HE. Задача заключается в следующем: можно ли назначить всем переменным, встречающимся в формуле, значения "ложь" и "истина" так, чтобы формула стала истинной. — [wikipedia](https://ru.wikipedia.org/wiki/SMT)
Поскольку SMT-решатели работают с различными теориями, становится возможным их применение для алгоритмов в традиционных процессорных архитектурах. Таким образом, SMT-решатели позволяют решить две задачи:
* ответить на вопрос, возможны ли данные выходные значения алгоритма при данных входных значениях;
* определить, при каких входных значениях результатом алгоритма будут данные выходные значения.
SMT-решатели имеют прикладные применения в различных областях науки и техники. Существуют отдельные инструменты для решения формул SMT, например, [Z3](https://github.com/Z3Prover/z3), [miniSAT](http://minisat.se), [CVC4](https://github.com/CVC4/CVC4) и др., и для представления алгоритмов на машинном языке в [синтаксисе формулы SMT](http://smtlib.cs.uiowa.edu/language.shtml), например, [BAP](https://github.com/BinaryAnalysisPlatform/bap/), [radare2](http://radare.org/r/) или [angr](http://angr.io). Инструменты постоянно совершенствуются, API становится мощнее, и теперь достаточно буквально нескольких кликов для применения всего математического аппарата SMT в задачах реверс-инжиниринга.
Отметим также, что существует несколько видов символьного исполнения. Статическое символьное исполнение (SSE, Static symbolic execution) основывается только на символьных переменных и использует только символьные формулы. Динамическое символьное исполнение (DSE, Dynamic symbolic execution), также называемое concolic execution, использует символьные вычисления наряду с конкретными значениями численных переменных в ходе выполнения программы. В данной работе мы будем использовать только статическое символьное исполнение.
История крякми Kao's Toy Project
--------------------------------
Крякми Kao’s Toy Project устроено предельно просто. В одном окне оно выводит некоторую шестнадцатеричную последовательность и предлагает ввести ключ, валидный для данной последовательности.
Его историю можно представить в виде следующей хроники:
**04.03.2012 — [Kao’s Toy Project and Algebraic Cryptanalysis](https://tuts4you.com/e107_plugins/download/download.php?view.3293) — dcoder, andrewl — алгебраический криптоанализ, SAT**
Первая работа, посвященная этому крякми, появилась в 2012 году. В ней человек с ником dcoder опубликовал решение с помощью алгебраического криптоанализа, а соавтор этой работы andrewl успешно применил SAT-решатель.
**06.03.2012 — [Semi-Automated Input Crafting by Symbolic Execution, with an Application to Automatic Key Generator Generation](http://www.openrce.org/blog/view/2049/%5Bvideo%5D_Semi-Automated_Input_Crafting_by_Symbolic_Execution,_with_an_Application_to_Automatic_Key_Generator_Generation) — Rolf Rolles — z3, самописный конвертер**
Потом известный исследователь Rolf Rolles впервые применил для решения SMT-решатель. Сначала он вручную составил формулу на языке Z3, а потом представил на языке OCaml инструмент для автоматической генерации формулы из промежуточного представления машинного кода. Промежуточный язык, который он использовал, был разработан им самим.
> I use an IR very similar to the one used by BitBlaze and BAP, but I wrote my own IR translator rather than using VEX. My implementation is written-from-scratch and shares no code with the open-source frameworks. — [openrce.org](http://www.openrce.org/blog/view/2049/%5Bvideo%5D_Semi-Automated_Input_Crafting_by_Symbolic_Execution,_with_an_Application_to_Automatic_Key_Generator_Generation)
**11.2013 — [SMT Solvers for Software Security](http://www.slideshare.net/DefconRussia/georgy-nosenko-an-introduction-to-the-use-smt-solvers-for-software-security) — Георгий Носенко — BAP, z3**
Потом появилась работа моего коллеги Георгия Носенко, где для генерации формулы уже использовался фреймворк BAP и тот же решатель Z3.
**03.2015 — [Automated algebraic cryptanalysis with OpenREIL and Z3](http://blog.cr4.sh/2015/03/automated-algebraic-cryptanalysis-with.html) — Cr4sh — OpenREIL, z3**
Дмитрий Олексюк, также известный как Cr4sh, в своем исследовании использовал конвертацию в промежуточный язык OpenREIL с последующей генерацией формулы в Z3.
**04.2016 — [Solving kao's toy project with symbolic execution and angr](https://0xec.blogspot.ru/2016/04/solving-kaos-toy-project-with-symbolic.html) — Extreme Coders Blog — angr**
И, наконец, еще одна работа появилась в 2016 году, и в ней описывается решение с использованием фреймворка angr. Angr применяет промежуточный язык VEX и библиотеку claripy для символьного исполнения.
На арене SMT теперь появился еще один игрок – Triton, и мы в данной работе воспользуемся им, чтобы решить знаменитое крякми.
[Triton](https://triton.quarkslab.com)
--------------------------------------
Triton создан компанией [Quarkslab](https://quarkslab.com), создавшей немало интересных инструментов для реверс-инжиниринга.
Сначала немного о том, как устроен Triton. В ходе своей работы он выполняет следующие действия:
1. парсит трассу выполнения бинарного кода и генерирует абстрактное синтаксическое дерево кода с учетом всех побочных эффектов машинных инструкций;
2. обходит абстрактное синтаксическое дерево и генерирует формулу SMT в формате SMT-LIB;
3. решает формулу с помощью решателя z3.
При построении абстрактного синтаксического дерева Triton не использует промежуточного представления машинного кода (в отличие от bap или angr), и на данный момент поддерживает только работу с архитектурами x86 и x86-64.
Triton может работать в одном из двух режимов. В первом – online mode – трасса выполнения записывается с помощью специального трассировщика, который входит в состав Triton и использует [DBI-фреймворк pin](https://software.intel.com/en-us/node/256675/docs). Во втором – offline mode – трасса записывается внешними средствами. Трасса должна содержать последовательность инструкций и их опкоды. Во втором случае уже необходимо самостоятельно создать начальный контекст, то есть определить значения регистров и используемую память.
API, который предоставляет Triton, очень богатый и … очень нестабильный. С момента появления API менялся уже раза четыре, конечно, не сохраняя обратную совместимость. Из-за этого код старых инструментов, использующих Triton, для запуска на новых версиях надо переписывать. Приятным моментом является то, что API имеет binding’и для Python. В репозитории есть несколько примеров, демонстрирующих использование API на С++ и на Python, благодаря которым с ним довольно несложно разобраться.
Итак, приступим к решению.
Решение
-------
Сначала нам надо найти алгоритм, по которому выполняется проверка введенного ключа. Бегло пробежав по коду, видим, что генерируемая последовательность представляет собой на самом деле восемь 32-разрядных целых чисел, и лежит в памяти последовательно в представлении little-endian, в то время как в окне показывается как big-endian. Узнаем, что ключ имеет формат XXXXXXXX-XXXXXXXX, где X – шестнадцатеричный разряд. Если ключ введен в таком формате, происходит вызов процедуры проверки. Так она выглядит в дизассемблере IDA Pro.
В процедуре проверки сначала происходит инициализация входных данных: cipher – 32-байтовая исходная последовательность в представлении little-endian, String1 – буфер для выходной последовательности после преобразования, в регистрах edx и ebx находятся две половинки ключа, представленные как 32-разрядные целые числа. Далее идет сам алгоритм преобразования – 32 цикла с операциями xor и rol – и затем полученная строка из буфера String1 сравнивается со строкой “0how4zdy81jpe5xfu92kar6cgiq3lst7”. Если они идентичны, ключ считается верным.
Таким образом, формируется следующая задача для SMT-решателя: определить, на каких входных значениях регистров edx и ebx заданная шестнадцатеричная последовательность после выполнения алгоритма преобразуется в строку “0how4zdy81jpe5xfu92kar6cgiq3lst7”.
Поскольку крякми написано для Windows, трассировщик Triton не подойдет, ведь он поставляется только скомпилированным для Linux. Можно, конечно, попытаться скомпилировать его самостоятельно для Windows, но это те еще приключения. Поэтому мы будем использовать режим offline и байндинги Triton’а для Python.
Сначала введем необходимые константы:
```
ADDR_CIPHER = 0x4093A8
ADDR_TEXT = 0x409185
ADDR_EBP = 0x18f980
TEXT = "0how4zdy81jpe5xfu92kar6cgiq3lst7"
cipher = None
```
и произведем начальную инициализацию:
```
ctx = TritonContext()
ctx.setArchitecture(ARCH.X86)
ctx.setConcreteRegisterValue(ctx.registers.ebp, ADDR_EBP)
ctx.setConcreteRegisterValue(ctx.registers.esp, 0x18f95b)
ctx.setConcreteRegisterValue(ctx.registers.eip, 0x4010ec)
ctx.setConcreteMemoryAreaValue(ADDR_CIPHER, cipher)
ctx.setConcreteMemoryAreaValue(ADDR_TEXT, list(map(ord, TEXT)))
edx = ctx.convertRegisterToSymbolicVariable(ctx.getRegister(REG.X86.EDX))
ebx = ctx.convertRegisterToSymbolicVariable(ctx.getRegister(REG.X86.EBX))
keys = [ctx.convertMemoryToSymbolicVariable(MemoryAccess(ADDR_EBP-0x21, 1)) for i in xrange(32)]
```
Во время инициализации мы создаем контекст, устанавливаем архитектуру, инициализируем регистры и память и, конечно, создаем символьные переменные: регистры edx и ebx и буфер для преобразованной последовательности, на значения которого будут наложены ограничения в формуле.
Теперь создаем трассу выполнения. Для этого в режиме offline достаточно загрузить бинарный код:
```
code = {0x4010EC: '\x55', # push ebp
0x4010ED: '\x8b\xec', # mov ebp, esp
0x4010EF: '\x83\xc4\xdc', # add esp, -24h
0x4010F2: '\xb9\x20\x00\x00\x00', # mov ecx, 20h
0x4010F7: '\xbe\xa8\x93\x40\x00', # mov esi, offset cipher
0x4010FC: '\x8d\x7d\xdf', # lea edi, [ebp+string1]
0x4010FF: '\x8b\x55\x08', # mov edx, [ebp+arg_0]
0x401102: '\x8b\x5d\x0c', # mov ebx, [ebp+arg_4]
# loc_401105:
0x401105: '\xac', # lodsb
0x401106: '\x2a\xc3', # sub al, bl
0x401108: '\x32\xc2', # xor al, dl
0x40110A: '\xaa', # stosb
0x40110B: '\xd1\xc2', # rol edx, 1
0x40110D: '\xd1\xc3', # rol ebx, 1
0x40110F: '\xe2\xf4'} # loop loc_401105
```
и запустить процессинг инструкций:
```
ip = 0x4010ec
while ip < 0x401111:
inst = Instruction()
inst.setOpcode(code[ip])
inst.setAddress(ip)
ctx.processing(inst)
ip = ctx.buildSymbolicRegister(ctx.registers.eip).evaluate()
```
Во время процессинга инструкций Triton переводит их в символьную форму и добавляет полученные символьные инструкции в контекст. В данном коде мы еще используем символьную эмуляцию регистра ip, чтобы вычислить следующую инструкцию по порядку выполнения.
После этого осталось ввести в контекст необходимые ограничения на значения переменных. У нас это условие равенства преобразованной строки со строкой “0how4zdy81jpe5xfu92kar6cgiq3lst7”, которую мы поместили в константу TEXT.
```
for i in xrange(32):
r_ast = ast.bv(ord(TEXT[i]), 8)
l_id = ctx.getSymbolicMemoryId(ADDR_EBP-0x21 + i)
l_ast = ctx.getAstFromId(l_id)
ex = ast.equal(l_ast, r_ast)
expr.append(ex)
expr = ast.land(expr)
```
Ограничения задаются в виде узлов абстрактного синтаксического дерева (АСД). У нас в цикле создается узел АСД для одного символа из строки и узел АСД для одного элемента преобразованной последовательности. Затем создается новый узел АСД с операцией сравнения этих двух узлов. Так как нам надо, чтобы условия равенства всех элементов выполнялись одновременно, после получения их в цикле они объединяются в одно АСД под операцией логического «И» expr = ast.land(expr).
Все готово для вычисления решения. Получаем модель данных для символьной формулы с заданными ограничениями expr.
```
model = ctx.getModel(expr)
```
Весь скрипт кейгена целиком можно скачать [отсюда](https://github.com/pickecat/kao_triton/blob/master/keygen_v1.py).
Запускаем скрипт и … ничего не происходит. Отладка показывает, что выполнение зацикливается на этапе процессинга инструкций, и быстро становится понятно, что не выполняется обработка инструкции loop. Оказывается, Triton [даже не знает эту инструкцию](https://triton.quarkslab.com/documentation/doxygen/SMT_Semantics_Supported_page.html). Как справиться с этой проблемой? Можно добавить семантику новой инструкции в исходники Triton и пересобрать его. Но мы уже отмечали, что пересборка на Windows — довольно кропотливое дело. Хм, ну ладно, не будем сразу расстраиваться, и попытаемся переделать наш код. Можно попробовать заменить loop на такой же по действию набор инструкций, например:
```
dec ecx
jz 0401105h
```
А можно попробовать развернуть цикл вручную, и сделать процессинг не блока с циклом внутри, а только тела цикла столько раз, сколько записано в регистре ecx, то есть 32. Тогда код будет выглядеть так:
```
code = ['\xac', # lodsb
'\x2a\xc3', # sub al, bl
'\x32\xc2', # xor al, dl
'\xaa', # stosb
'\xd1\xc2', # rol edx, 1
'\xd1\xc3'] # rol ebx, 1
ctx.setConcreteRegisterValue(ctx.registers.esi, ADDR_CIPHER)
ctx.setConcreteRegisterValue(ctx.registers.edi, ADDR_EBP - 0x21)
ctx.setConcreteRegisterValue(ctx.registers.eip, 0x401105)
ctx.setConcreteMemoryAreaValue(ADDR_CIPHER, cipher)
ctx.setConcreteMemoryAreaValue(ADDR_TEXT, list(map(ord, TEXT)))
edx = ctx.convertRegisterToSymbolicVariable(ctx.registers.edx)
ebx = ctx.convertRegisterToSymbolicVariable(ctx.registers.ebx)
ip = 0x401105
for i in xrange(32):
for c in code:
inst = Instruction()
inst.setOpcode(c)
inst.setAddress(ip)
ctx.processing(inst)
ip = ctx.buildSymbolicRegister(ctx.registers.eip).evaluate()
```
Итак, запускаем новый вариант. На этот раз процессинг выполняется целиком и успешно доходит до вычисления модели, в которое она погружается, ожидаемо, на некоторое время. Ждем… ждем… уже очень долго ждем. Я так и не дождался. На этот раз, проблема в функции вычисления модели, и тут ошибку может быть не так просто обнаружить. Можно предположить, что получившаяся формула очень большая, и ее вычисление действительно может занимать очень много времени. Чтобы проверить это, сократим число итераций в цикле, где происходит процессинг. Действительно, при меньшем числе итераций, результат выдается. Методом подбора было обнаружено, что верхняя граница числа итераций, при котором вычисления занимают обозримое время, на опытном ноутбуке это 12. Да, это очень мало, и с их увеличением время растет экспоненциально. 32 итерации — это намного больше 12, и, кажется, даже если переписать код на С++, все равно вычисление модели будет неприемлемо долгим.
Если попробовать посмотреть в отладке, что же в функции getModel занимает так много времени, мы увидим, что это рекурсивные вызовы функции `triton::ast::TritonToZ3Ast::convert`.
Как написано в документации, Triton использует свое кастомное дерево АСД:
> An abstract syntax tree (AST) is a representation of a grammar as tree. Triton uses a custom AST for its expressions. As all expressions are built at runtime, an AST is available at each program point. — [Triton documentation](https://triton.quarkslab.com/documentation/doxygen/py_AstContext_page.html)
Данная функция конвертирует АСД Triton’а в выражение для z3.
Можно попробовать посмотреть на выражения, которые составляют АСД Triton’а. Добавим перед получением модели следующие строки:
```
tsym = ctx.getSymbolicExpressions()
for ek in sorted(tsym.keys()):
e = tsym[ek].getAst()
print str(e)
```
После этого в консоли появятся выражения Triton’а такого вида:
```
ref!0 = SymVar_0
ref!1 = SymVar_1
ref!2 = SymVar_33 ; Byte reference
ref!3 = (concat ((_ extract 31 8) (_ bv0 32)) (_ bv29 8)) ; LODSB operation
ref!4 = (ite (= (_ bv0 1) (_ bv0 1)) (bvadd (_ bv4232104 32) (_ bv1 32)) (bvsub (_ bv4232104 32) (_ bv1 32))) ; Index operation
ref!5 = (_ bv4198662 32) ; Program Counter
ref!6 = (concat ((_ extract 31 8) ref!3) (bvsub ((_ extract 7 0) ref!3) ((_ extract 7 0) ref!1))) ; SUB operation
ref!7 = (ite (= (_ bv16 8) (bvand (_ bv16 8) (bvxor ((_ extract 7
…
```
Чтобы получить выражения в синтаксисе SMT-LIB, надо добавить еще один вызов.
```
print ctx.unrollAst(e)
```
В этом месте – `unrollAst` – происходит та же конвертация выражений Triton’а в выражения SMT-LIB, и здесь вы также не дождетесь завершения, как и с функцией getModel.
Знакомые с синтаксисом SMT-LIB заметят, что выражения Triton’а представляют собой выражения SMT-LIB, только в форме SSA (Single Static Assignment). В SMT-LIB нет операции присваивания переменных — их заменяет функциональный оператор let. А что, если попробовать самостоятельно сконвертировать синтаксис Triton’а в синтаксис SMT-LIB без разворачивания АСД, а заменяя форму SSA на форму с операторами let, и потом попытаться скормить это z3py? Звучит довольно громоздко и избыточно, но выходить из сложившегося положения надо, пока разработчики не допилили Triton.
Итак, с получившимся выражением мы проводим следующие действия:
* Объявляем переменные в синтаксисе SMT-LIB;
* Заменяем операторы присваивания на операторы let;
* Получившиеся выражения соединяем в общую формулу на языке SMT-LIB.
В результате получается функция конвертации из синтаксиса Triton в синтаксис SMT-LIB. Она, конечно, не универсальна, но, по-крайней мере, для нашей задачи работает.
```
def convert(ctx, asserts):
zsym = ""
tsym = ctx.getSymbolicExpressions()
for ek in sorted(tsym.keys()):
e = tsym[ek].getAst()
if e.getKind() == AST_NODE.VARIABLE:
zsym += "(declare-fun ref!%d () (_ BitVec %d))\n" % (ek, e.getBitvectorSize())
nodes = []
for ek in sorted(tsym.keys()):
e = tsym[ek].getAst()
if e.getKind() <> AST_NODE.VARIABLE:
nodes.append("let ((ref!%d %s))" % (ek, e))
# print reduce(lambda x, y: "%s (%s)" % (x, y), reversed(nodes))
def fold(x, y):
if not isinstance(y, list):
raise TypeError
if len(y) == 1:
return y[0]
return "%s\n(%s)" % (x, fold(y[0], y[1:]))
nodes = ["assert"] + nodes
nodes[-1] += '\n' + str(asserts)
zsym = zsym + '(' + fold(nodes[0], nodes[1:]) + ')'
return zsym
```
Результат функции необходимо отправить на вычисление решателю z3py.
```
s = z3.Solver()
cs = z3.parse_smt2_string(expr)
s.assert_exprs(cs)
s.check()
m = s.model()
edx, ebx = m.decls()
```
Теперь в переменных edx и ebx хранятся объекты класса `z3.z3.FuncDeclRef`. Получаем их численное представление, и, поскольку преобразования в крякми выполняются после того, как они поксорились друг с другом, необходимо их также поксорить.
```
edx, ebx = m[edx].as_long(), m[ebx].as_long()
print "%x-%x" % (edx, edx ^ ebx)
```
Код второй версии можно взять также с [гитхаба](https://github.com/pickecat/kao_triton/blob/master/keygen_v2.py).
Итак, мы получим строку, которую надо просто скопировать в поле ввода в окне крякми. Руки чешутся уже это сделать.


Ура! Наш кейген работает правильно.
[Ponce](https://github.com/illera88/Ponce)
------------------------------------------
На основе Triton построен еще один классный инструмент – плагин Ponce для IDA Pro. Он позволяет делать очень заманчивые вещи – символьное исполнение и taint-анализ прямо в дизассемблере IDA. К сожалению, из-за наличия в нашем крякми инструкции loop, проверить Ponce на нем нельзя. Может быть все-таки есть желающие добавить loop в Triton? :) Или есть еще один вариант. Поскольку крякми kao поставляется с исходниками на ассемблере, можно заменить там loop на вышеупомянутый аналогичный набор инструкций. Тогда получится использовать Ponce и почувствовать его силу. Для заинтересованного читателя это будет классной задачей.
Выводы
------
Откровенно говоря, Triton с задачей не справился. Но давайте не будем слишком строгими: инструкцию loop легко добавить самостоятельно, а конвертацию формулы, судя по истории сборок, разработчики [уже начали делать итеративной](https://ci.appveyor.com/project/JonathanSalwan/triton/history).
Современный реверс-инжиниринг и поиск уязвимостей в программном обеспечении без символьного исполнения отходит в прошлое. Это доказывают, например, автоматические системы по поиску уязвимостей и генерации эксплойтов, созданные в ходе конкурса DARPA Cyber Grand Challenge. Поэтому такие инструменты, как Triton, сейчас очень востребованы. Развиваясь, они становятся все более простыми в использовании, так что символьное исполнение становится очень доступным и эффективным инструментом в работе исследователя. | https://habr.com/ru/post/351648/ | null | ru | null |
# Тонкости nodejs. Часть I: пресловутый app.js
Я работаю с node.js более трех лет и за это время успел хорошо познакомиться с платформой, ее сильными и слабыми сторонами. За это время платформа сильно изменилась, как, собственно, и сам javascript. Идея использовать одну среду и на сервере и на клиенте пришлась многим по душе. Еще бы! Это удобно и просто! Но, к сожалению, на практике все оказалось не так радужно, вместе с плюсами платформа впитала в себя и минусы используемого языка, а разный подход к реализации практически свел на нет плюсы от использования единой среды. Так все попытки реализовать серверный js до ноды не взлетели, взять тот же Rhino. И, скорее всего, node ждала та же участь, если бы не легендарный V8, неблокирующий код и потрясающая производительность. Именно за это его так любят разработчики. В этой серии статей, я постараюсь рассказать о неочевидных на первый взгляд проблемах и тонкостях работы, с которыми вы столкнетесь в разработке на nodejs.
Сразу оговорюсь, что рекомендации больше применимы к большим проектам со сложной структурой.
Начать хочется с наиболее часто встречаемой и распространенной реализации приложения – главной точкой входа – app.js, на примере веб-приложения с использованием express. Обычно выглядит она так:
```
// config.js
exports.port = 8080;
// app.js
var express = require('express');
var config = require('./config.js');
var app = express();
app.get('/hello', function(req, res) {
res.end('Hello world');
});
app.listen(config.port);
```
На первый взгляд все отлично, код понятный, конфигурация вынесена в отдельный файл и может быть изменена для дева и продакшна. Подобная реализация встречается на всех ресурсах посвященных созданию веб-приложений на nodejs. Вот мы и заложили фундамент нашей ошибки в десяти строках чистейшего кода. Но обо всем по порядку.
И так, мы написали hello world. Но, это чересчур абстрактный пример. Давайте добавим конкретики и напишем приложение которое будет выводить список файлов из указаной директории и отображать содержимое отдельных файлов, запрашивая данные из mongo.
```
// config.js
exports.port = 8080;
exports.mongoUrl = 'mongodb://localhost:27017/test';
// app.js
var express = require('express');
var MongoClient = require('mongodb').MongoClient;
var config = require('./config.js');
// Создаем соединение с базой
var db;
MongoClient.connect(config.mongoUrl, function(err, client){
if (err) {
console.error(err);
process.exit(1);
}
db = client;
});
// Создаем веб-сервер
var app = express();
app.get('/', function(req, res, next) {
db.collection('files').find({}).toArray(function(err, list){
if (err) return next(err);
res.type('text/plain').end(list.map(function(file){
return file.path;
}).join('\r'));
});
});
app.get('/file', function(req, res, next){
db.collection('files').findOne({path:req.query.file}).toArray(function(err, file){
if (err) return next(err);
res.type('text/plain').end(file.content);
});
});
app.listen(config.port);
```
Отлично, все просто и наглядно: соединяемся с базой, создаем сервер, назначаем обработчки для путей. Но давайте подумаем, какими недостатками обладает код:
1. Его тяжело тестировать, так как нет возможности напрямую проверить результат возвращаемый методами.
2. Его тяжело конфигурировать – невозможно изменить конфигурацию для двух экземпляров приложения.
3. Компоненты приложения недоступны для внешнего кода, а значит и для расширения.
4. Ошибки никуда не передаются и должны быть обработаны на месте или же выброшены на самый верхний уровень.
На практике это приводит к монолитному коду. И скорому рефакторингу. Что можно сделать? Необходимо разделить логику и интерфейс.
Все что касается работы приложения давайте оставим в app.js, а все что касается веб-http-интерфейса в http.js.
```
// app.js
var MongoClient = require('mongodb').MongoClient;
var EventEmitter = require('event').EventEmitter;
var util = require('util');
module.exports = App;
function App(config) {
var self = this;
// Инициализируем event emitter
EventEmitter.call(this);
MongoClient.connect(config.mongoUrl, function(err, db){
if (err) return self.emit("error", err);
self.db = db;
});
this.list = function(callback) {
self.db
.collection('files')
.find({})
.toArray(function(err, files){
if (err) return callback(err);
files = files.map(function(file){
return file.path
});
callback(null, files);
});
};
this.file = function(file, callback) {
self.db
.collection('files')
.findOne({path:file})
.toArray(callback);
};
}
util.inherits(App, EventEmitter);
// config.js
exports.mongoUrl = "mongo://localhost:27017/test";
exports.http = {
port : 8080
};
// http.js
var App = require('./app.js');
var express = require('express');
var configPath = process.argv[2] || process.env.APP_CONFIG_PATH || './config.js';
var config = require(configPath);
var app = new App(config);
app.on("error", function(err){
console.error(err);
process.exit(1);
});
var server = express();
server.get('/', function(req, res, next){
app.list(function(err, files){
if (err) return next(err);
res.type('text/plain').end(files.join('\n'));
});
});
server.get('/file', function(req, res, next){
app.file(req.query.file, function(err, file){
if (err) return next(err);
res.type('text/plain').end(file);
});
});
server.listen(config.http.port);
```
Что мы сделали? Добавили событийную модель для отлова ошибок. Добавили возможность указывать путь к конфигурации для каждого экземпляра приложения.
Таким образом мы избавились от перечисленых выше проблем:
1. Любой метод доступен напрямую через объект app.
2. Управление конфигурацией стало гибким: можно указать путь в консоли или через export APP\_CONFIG\_PATH=…
3. Появился централизованный доступ к компонентам.
4. Ошибки приложения отлавливаются объектом app и могут быть обработаны с учетом контекста.
Теперь мы можем легко добавить новый интерфейс для командной строки:
```
// cli.js
var App = require('./app.js');
var program = require('commander');
var app;
program
.version('0.1.0')
.option('-c, --config ', 'Config path', 'config.js', function(configPath){
var config = require(configPath);
app = new App(config);
app.on("error", function(err){
console.error(err);
process.exit(1);
});
});
program.command('list')
.description('List files')
.action(function(){
app.list(function(err, files){
if (err) return app.emit("error", err);
console.log(files.join('\n'));
});
});
program.command('print ')
.description('Print file content')
.action(function(cmd){
app.file(cmd.file, function(err, file){
if (err) return app.emit("error", err);
console.log(file);
});
});
```
или тест
```
// test.js
var App = require('App');
var app = new App({
mongoUrl : "mongo://testhost:27017/test"
});
// Пусть тестовая база содержит только один документ:
// {path:'README.md', content:'This is README.md'}
app.on("error", function(err){
console.error('Test failed', err);
process.exit(1);
});
// Тест написан для библиотеки nodeunit
module.exports = {
"Test file list":function(test) {
app.list(function(err, files){
test.ok(Array.isArray(files), "Files is an Array.");
test.equals(files.length, 1, "Files length is 1.");
test.equals(file[0], "README.md", "Filename is 'README.md'.");
test.done();
});
}
}
```
Конечно, приложение теперь выглядит не таким минималистичным, как в примерах, зато является боле гибким. В следующей части я расскажу про отлов ошибок. | https://habr.com/ru/post/241788/ | null | ru | null |
# История одного CRUD'а
В 2015 году, когда я пришёл на своё текущее место работы, мне было непривычно от необыкновенной свободы действий. Буквально, на новом месте можно было проявить весь творческий потенциал как DevOps-евангелиста. Мне нравилось выстраивать процессы, автоматизировать рутину, делать разработку удобной. Больше всего я люблю оптимизации, а больше всего ненавижу - рутину.
Эта история одной боли и попытке не просто "принять обезболивающее", а реально излечить её. Поэтому готовьтесь переварить лонгрид.
Предистория
-----------
Когда Роман ещё работал со мной, то я предложил ему написать [статью](https://habr.com/ru/post/456146/) на эту тему. В каком-то смысле, она раскрывает суть и видение на тот момент времени. Но всё идёт своим чередом и много воды утекло с тех пор. Если Роман описывал ситуацию с большим уклоном в сторону технических деталей, то я хочу сделать акцент больше на архитектурных и управленческих. Проще говоря, я хочу изложить взгляд как руководителя на проблему автоматизации разработки.
Итак, чтобы прийти к тому, где мы сейчас находимся и получить качественный инструмент и опыт, нам пришлось пройти через 6 итераций, чтобы понять как выстраивать наши процессы.
---
Итерация первая: сгружаем общий код
-----------------------------------
Первой попыткой было просто избавиться от шаблонного кода, выделив наиболее популярные части в общей библиотеке. На тот момент, было несколько проектов, в которых раз за разом приходилось копировать код из одного в другой. Это порядком надоедало. В конце концов, для чего придумали наследование?
Так появилась нулевая версия проекта vstutils. По большому счёту это был и не проект вовсе. Там хранились какие-то наработки по созданию новых проектов, подключалась директория со статикой, которую так же можно было включать в шаблонах по мере необходимости. Базовые классы моделей, наработки для создания REST API вьюх, базовый класс для тестов... Конечно у искушённого читателя это вызывает улыбку (или скорее ухмылку), но это был первый шаг, а проект был больше файлопомойкой.
О сборке статики при помощи каких-то инструментов типа webpack или gulp даже не было и речи на тот момент. Это просто код, который мы не хотели подключать со сторонних ресуров, чтобы приложения работали даже без интернета в закрытом контуре. Тут надо понимать, что большинство наших проектов были как раз таки для подобных условий работы и были простыми админками. Admin LTE (тогда ещё версии 2) был выбран случайно и лишь из-за того, что предыдущие проекты были с его участием. Не сказать, что это шедевр дизайна или там есть какие-то сверхкрутые инструменты, но для наших целей было достаточно, а что-то новое изучать и поддерживать (мигрировать) старые проекты совсем не хотелось.
В общем и целом, процесс разработки был следующий:
1. Бэкендер пишет код, покрывает его тестами.
2. Фронтендер пытается из этого что-то осмысленное нарисовать.
3. Бэкендер дописывает логику, которой нехватает Фронтендеру для реализации чувства прекрасного.
4. Фронтендер доделывает админку и выкатывает это в общую ветку.
Как вы уже поняли п.2 и 3 повторялись несколько раз и зацикливались. Т.к. к тому времени я уже руководил командой, меня больше всего напрягали ситуации, когда backend уже готов, а фронтенд чем-то другим занят и не может сделать маленькое исправление, которое на поверке оказывалось порой очень большим.
Одним ужасным утром......я получил на почту заявление на отпуск от своего коллеги на один месяц. По большому счёту это был единственный, кто знал весь фронт и меня охватил ужас, потому что я больше всего ненавижу писать код на JS. Не поймите меня неправильно, я ничего против языка не имею против (на самом деле имею, но не до ненависти), просто я вырос в разработчики из админов, а потом долго писал на C# и Python, а для JS'а я совсем не заточен.
Если прям совсем сократить эту историю до минимума, то всё вылилось в то, что я полез таки вы этот код и меня охватил ужас. Не знаю, что именно мне нужно было выпить или скурить, чтоб понять логику этого кода, но даже простые задачи решались с болью. В тот раз, работа практически встала колом на месяц, а бизнес это не порадовало.
От задачи к задачи, на фронте решались тривиальные задачи в виде рисования формочек и полей, которые были друг на друга похожи и отличались лишь некоторыми условиями. Запросы ходили такими окольными путями, что понять где и в какой момент происходит запрос можно было только лютым дебагом. Тогда я задумался, а почему мы должны это делать снова и снова? Неужели этот процесс никак не автоматизировать? В конце концов, почему мы пишем один и тот же код просто на двух языках? Это же контрпродуктивно!
Итерация вторая: связываем backend с frontend
---------------------------------------------
Первый мажорный релиз был далёк от идеала, но это был первый большой шаг к нему. Меня как автоматизатора и руководителя больше всего раздражала проблема дублирующего кода. Раз за разом мы что-то меняли в коде на backend'е, что практически всегда приводило к поломкам фронта. При этом, если код на сервере был оттестирован и хотя бы покрыт на 100%, то клиентская часть тестировалась методом научно-ненаучного тыка.
Как только проблема была обозначена и выделена, я отправился в глубокое поисковое исследование, ища наиболее оптимальный способ сообщить клиенту о том, как работать с API. На самом деле, вы удивитесь как много различных способов это сделать. Перейдя от поискового исследования к описательному, я остановился на следующих технологиях:
* Protocol Buffers - по своей сути это бинарный протокол сериализации структурированных данных. Может не совсем точно выразился, но суть в том, что он говорит о том, какие данные летают у нас между клиентом и сервером, собирают это в некоторые классы и реализуют сериализацию/десериализацию. Опустим детали реализации протокола HTTP (ключевое слово "текст") и понятия бинарности данных. Самое главное, почему решили отказаться от данного решения, это громоздкость, необходимость что-то компилировать, прежде чем начать обрабатывать запросы (т.е. все недостатки статической типизации). Но самая главная причина - сложность для последующего взаимодействия. Если REST API можно использовать даже curl'ом, то с protobuf взаимодействовать сильно сложнее.
* SOAP (*Simple Object Access Protocol)*, который ни разу не simple, да ещё и XML. Одна из причин, почему мы отказались от этого варианта описана в Википедии: "*Использование SOAP для передачи сообщений увеличивает их объём и снижает скорость обработки. В системах, где скорость важна, чаще используется пересылка XML-документов через HTTP напрямую, где параметры запроса передаются как обычные HTTP-параметры.*"
* [HATEOAS](https://habr.com/ru/post/483328/) - перспективный протокол (хотя это больше архитектура построения REST API), где сам ответ с сервера говорит о том, что можно дальше сделать. В каждом ответе от сервера содержатся глаголы и ссылки на взаимосвязанные данные. Протокол ближе всего к идее HTTP и того как рисуются страницы веб-приложений, но в машиночитаемом виде. В общем-то этот вариант был долго моим фаворитом, потому что позволял довольно динамично менять интерфейс в зависимости от данных и клиента, который запрашивает или отправляет эти данные. Более того, не пришлось бы менять архитектуру API, кроме схемы отправляемых данных, а формат "летающих" данных мог быть разнообразным. Однако самой большой проблемой был объём передаваемых данных. Там, где прилетало всего два коротких поля, был огромный оверхед ссылок на действия с этой сущностью. При всём при этом, набор ссылок мог быть идентичным от запроса к запросу, а как-то закешировать данные было невозможно или потенциально ошибочно.
* [Swagger 2.0](https://swagger.io/specification/v2/) или [OpenAPI](https://swagger.io/specification/) - спецификация описывающая REST API с помощью формализованной схему. Сама спецификация построена так, чтобы её мог легко прочитать как человек, так и машина. Такой формат схемы позволяет динамически синхронизировать интерфейсы со структурой API, сохранив объём передаваемых данных на прежнем уровне. Как и у HATEOAS формат передаваемых данных не зависит от структуры API и может быть любой. Схема расширяема и позволяет передавать нестандартные (неформализованные в community) настройки, что нам в последствии очень пригодилось, хоть и делали мы это не правильно. Особенность этой спецификации в том, что из неё можно сгенерировать практически любое клиентское или даже серверное приложение на огромном списке ЯП, хотя мы этим ни разу не пользовались. Это была любовь практически с первого взгляда. Почему практически? Потому что сперва мы напоролись на CoreAPI, что вообще никак нам не помогло решить проблему взаимодействия. Возможно мы неправильно её (спецификацию) приготовили, но история забвения coreapi говорит о том, что некоторый смысл в нашем решении был.
Собственно на Swagger 2.0 мы и остановились. Так как наш стек базируется на Django Rest Framework, то мы решили воспользоваться библиотекой [drf-yasg](https://drf-yasg.readthedocs.io/en/stable/), даже не смотря на то, что она [не поддерживает OpenAPI 3ей версии](https://drf-yasg.readthedocs.io/en/stable/readme.html#openapi-3-0-note). Возможно это было ошибкой, потому что сейчас мы частенько облизываемся на функции в новом стандарте, но всё делалось практически "на лету", поэтому выбирали из того, что легче всего изучить и применить.
Где-то на этом же этапе родился так называемый bulk endpoint, который должен был решить проблему агрегации запросов в один. Хотелось организовать набор запросов так, чтобы можно было выполнить их последовательно и откатить транзакцию в случае ошибки в одном из запросов. Идея родилась в момент, когда нам нужно было наполнить одну сущность набором других сущностей, которые в этом же запросе и создавались. При этом мы не хотели делать это на backend'е в каком-то конкретном action, а именно использовать имеющиеся endpoint'ы. В скоре, нам понравилось так агрегировать запросы и мы сделали так же нетранзакционную точку входа. Оказалось, что некоторые действия по обработке данных запроса можно оптимизировать. Например, можно было один раз авторизовать пользователя, а не делать это на каждый запрос в наборе. Потом появились зависмые запросы (когда данные предыдущего запроса использовались в следующем) и куча полезного "сахара". Наверное мы изобрели свой велосипед, но он нам очень понравился.
Не буду вдаваться в подробности остальных ошибочных решений, но в идеале с релизом наш процесс разработки должен был выглядеть так:
1. Backend'ер создаёт модель, сериализаторы и вьюхи, которые наружу торчат некоторым набором endpoint'ов. Это всё появляется в схеме, которую можно использовать как документацию к API, делать оттуда запросы и т.д.
2. Клиент при загрузке web-приложения при первом запросе скачивает схему и на её основе рисует интерфейс.
3. Если стандартных средств автогенерации нехватает, то подключается frontend'ер и дописывает через сигналы нужную функциональность.
Звучит как план, правда? На деле же мы столкнулись с большими проблемами, которые были связаны с ошибками проектирования. Самой главной ошибкой было использование шаблонизатора, который был форкнут и дописан нашим коллегой, а не популярного решения. Количество костылей в этом шаблонизаторе превзошло все наши ожидания. Верите или нет, но vDOM может быть медленнее, чем DOM. Естественно с увольнением сотрудника, чьё это было решение ушла и компетенция. Наверное это был мой самый большой fail как руководителя.
Однако, решение как никак, но работало. Большинство стандартных CRUD'ов делались автоматически и даже работали. Это была маленькая, но победа над рутиной.
Итерация третья: избавляемся от костылей
----------------------------------------
Версия 2.0 принесла освобождение от костыля в виде старого самописного шаблонизатора и первую попытку сделать всё с Vue.js. Хотя Роман довольно неплохо [описал](https://habr.com/ru/post/456146/#:~:text=%D0%A0%D0%B5%D1%84%D0%B0%D0%BA%D1%82%D0%BE%D1%80%D0%B8%D0%BD%D0%B3%20%E2%80%93%20%D0%B2%D1%8B%D0%B1%D0%BE%D1%80%20JS%20%D1%84%D1%80%D0%B5%D0%B9%D0%BC%D0%B2%D0%BE%D1%80%D0%BA%D0%B0), почему мы выбрали именно Vue, я попробую всё же не сильно повторяясь резюмировать.
Основным критерием была сложность. Хотелось подобрать такую экосистему, которая позволит как находить новых сотрудников, так и обучать, если определённых компетенций не было. У Vue просто потрясающая документация, которую довольно легко читать. Сам проект довольно простой, а community довольно доброжелательное, не пропитанное "кровавым enterprise".
Простота, так же залог скорости. Если сравнивать кодовую базу Vue с тем же React, то разница в gzipped версии в 5-6 раз. И так со всей экосистемой. Более того, оглядываясь назад и [смотря на производительность Vue 3](https://habr.com/ru/post/572250/#:~:text=%D0%BA%D0%BE%D0%BC%D0%BF%D0%BE%D0%BD%D0%B5%D0%BD%D1%82%D0%BE%D0%B2%20%D0%B2%20Vue.-,%D0%A3%D0%BB%D1%83%D1%87%D1%88%D0%B5%D0%BD%D0%B8%D1%8F%20%D0%BF%D1%80%D0%BE%D0%B8%D0%B7%D0%B2%D0%BE%D0%B4%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE%D1%81%D1%82%D0%B8,-3.2%20%D0%B2%D0%BA%D0%BB%D1%8E%D1%87%D0%B0%D0%B5%D1%82%20%D0%B2), я убедился в правильности своего решения при выборе фреймворка.
На этой итерации, я принял решение, что нужно сделать код Frontend'а более понятный для разработчика на DRF. Это позволило бы backend'еру быстро сориентроваться в коде и понять какие изменения ему потребуется внести без участия frontend'ера. Звучит как утопия, но, отчасти, нам удалось это реализовать привнеся некоторый шарм в архитектуру js кода. Единый шаблон проектирования (по сути MVT - Model+View+Template) позволил убрать разделение на Frontend и Backend разработчиков и перейти к управлению акцентами в компетенции.
Кропотливый труд и ~~несколько бессоных ночей~~ сильная мотивация дали свои плоды. Интерфейс стал заметно озывчивие, разработка ускорилась, а поиск новых сотрудников стал заметно проще. На этом этапе статья Романа и обрывается. Не вдаваясь в подробности, мы расстались с ним на добром, а я остался с SRE, backend'ером и стажёром с горящими глазами. Ну и тремя проектами, которые одновременно требовали внимания...
Итерация четвёртая: делаем фронт лучше
--------------------------------------
Версия 3.0 была новой попыткой сделать разработку удобнее. Отсутствие инструментов сборки фронта превращало в ад создание новых и редактирование старых компонентов. Более того, мы столкнулись с тем, что наш код переставал работать на некоторых версиях браузера, а при разработке приходилось из раза в раз лазись в caniuse для того, чтобы убедиться, что этот синтаксический сахар можно использовать. Ещё большей болью были обновления зависимостей на фронте. Так же, механизм bulk-запросов нуждался в обновлении и переосмыслении. Мы увидели, что сделали в принципе хорошо, но ещё рок-н-ролл.
#### Webpack и однофайловые компоненты
Собственно сперва нужно было решить проблему сборки. Я с большим скрипом добавил в CI'ные базовые образы node и yarn. Оказалось не всё так плохо, особенно после большого рефакторинга самих образов.
Самой чувствительной частью была сборка пакета. Так как мы используем setuptools и рассчитываем, что установка нашего пакета должна происходить на системе без node.js, то необходимо было реализовать сложный механизм компиляции статики в момент сборки образа и учёта того, что статика может быть уже собрана. Т.к. тут много разных "но", пришлось действовать практически на ощупь. Постановили так: если есть конфиг webpack'а, то это значит надо собирать статику. Проблема в том, что собралась статика или нет, чаще всего узнаёшь на проде, а это всегда больно. Более того, мы практически лишились возможности собирать проекты с зависимостью от git-репозитория, потому что это требовало огромного набора пакетов для сборки.
Однако преодолев все эти трудности, нам удалось достичь дзена и постичь всю мощь и удобство сборки клиентского кода. При этом удалось сохранить возможность по простому подкинуть файл с каким-то кастомным кодом и даже оптимизировать процесс загрузки. Мы переработали загрузчик приложения так, чтобы он задействовал всю мощь и скорость браузера, при этом сохранили (а возможно и добавили) даже совместимость с IE11 (работало из рук вон плохо и медленно, но работало). Старый код продолжал работать даже после обновления, но уже так не хотелось его поддерживать, так что мы прошлись по проектам выпустив обновления.
Самое главное улучшение было как раз внедрение однофайловых компонентов. Переработав код, оказалось что сжатая вресия не только меньше, но и быстрее. Разработчики выдохнули, потому что теперь стало хорошо с подсветкой синтакисиса шаблонов компонентов, куча ошибок было исправлено, а код стал похож на код, а не на лапшу.
#### Единый endpoint
Bulk-запросы были прекрасны, но отсутствовал потенциал к улучшению и развитию. Более того, поддержка нескольких версий API был проблемной частью, хоть и не был необходим. Хотелось переработать систему так, чтобы все запросы можно было направить в одну точку и на один путь, добавить возможность выполнять запросы асинхронно, а так же стандартизировать выработанную схему передаваемых параметров. Помимо всего прочего, обнаружилось неэффективное использование БД при большом количестве обращений и отсутствие поддержки работы сессий.
Мы решили не ломать старый механизм, а написать новый ~~костыль~~, где мы задействуем всю мощь DRF в виде сериализаторов и полей. На выходе нам удалось получить лучшее решение, а конкретно:
* Единая точка входа для всех приложений.
* Поддержка разных версий API внутри каждого запроса, а не всей пачки.
* Добавили тайминги по работе каждой операции, чтобы можно было отследить проблемные.
* Поддержку выполнения запросов асинхронно.
* Добились идентичного разультата работы как напрямую, так и через endpoint.
С этого момента мы начали уже не работать на инструмент, а использовать его со всей мощью и усердием. Теперь, прежде чем реализиовать что-либо в проекте, мы задумывались о том, чтобы принести этот код во все проекты. Релизы выкатывались как вода из крана: от 5 до 10 в день. Можно сказать, что в каком-то виде я достиг своей цели, если бы не одно но... Код работал как-то не так, как мы этого ожидали и было много исправляющих релизов, оттуда и много релизов для скромной команды и трёх проектов. Оказалось, что очень многие вещи, которые были реализованы просто не работали и были "для красоты". Такого фейла я не ожидал, но нужно было действовать.
Итерация пятая: Авен-Езер
-------------------------
Можно сказать, что версия 4.0 это некоторое подведение итогов автоматизации процесса разработки и этап оптимизации. Мы полностью переработали JS-код, чтобы он был похож на MVT и работал предсказуемо. Тут же стояла задача покрыть новый код тестами настолько, насколько возможно. На этом же этапе, мы переосмыслили процесс разработки на backend'е. Но обо всём по порядку.
#### Frontend
Был переботан код с учётом желаемой спецификации. Мы агрегировали все наработки, дропнули старый код и постарались сделать новый код стройным и понятным. На этом этапе мы занимались оптимизацией загрузки, кешированием и обновлением версии.
Мы постарались написать код так, чтобы задействовать возможности bulk'а на максимум. Там где это было возможно, мы ускорили работу с перерисовкой списков, добавили возможность как можно меньше писать кода на js и как можно больше решать проблемы с помощью модификации схемы или полей сериализаторов на backend'е.
В какой-то момент, мы обнаружили что механизм работы с полями, который мы хотели использовать для сериализации/десериализации просто не работал, поэтому мы переписали код с поддержкой этих возможностей. Теперь были конкретные точки входа и выхода, с помощью которых можно было 100% получить ожидаемый результат.
#### Backend
Тут произошло больше всего работы. Когда взаимодействие уже автоматизировано, то становится скучно и хочется писать кода ещё меньше. Итак, как выглядит типичная задача для CRUD endpoint?
1. Пишем тест.
2. Рисуем модель (тест не ходит).
3. Пишем сериализаторы (тест не ходит).
4. Пишем вьюху и подключаем сериализаторы и модель (тест ходит частично).
5. Рисуем фильтры и пермишены (тесты проходят полностью).
Видите как много ручной работы нужно сделать прежде чем тест хотя бы заработает? Знаете сколько ошибок возникает в процессе написания этой лапши шаблонного кода у типичных джунов? Т.к. определение модели данных в схеме зависело от имени сериализатора, некоторые части ломались просто по невнимательности, при этом поломка выглядела весьма неочевидной для неопытных кодеров без навыка диагностики проблем.
На помощь пришла моя любовь к метаклассам. Я решил, что если переработать метакласс модели, то можно было бы получить из неё максимально автоматическим образом View-класс с сгенерированными сериализаторами, фильтрами и полями. В каком-то смысле меня вдохновили однофайловые компоненты: весь код компонента можно уложить в один файл. В нашем случае это был не файл, а класс. Вот пример кода из [документации](https://vstutils.vstconsulting.net/backend.html#vstutils.models.BModel):
Портянка кода
```
from django.db import models
from rest_framework.fields import ChoiceField
from vstutils.models import BModel
class Stage(BModel):
name = models.CharField(max_length=256)
order = models.IntegerField(default=0)
class Meta:
default_related_name = "stage"
ordering = ('order', 'id',)
# fields which would be showed on list.
_list_fields = [
'id',
'name',
]
# fields which would be showed on detail view and creation.
_detail_fields = [
'id',
'name',
'order'
]
# make order as choices from 0 to 9
_override_detail_fields = {
'order': ChoiceField((str(i) for i in range(10)))
}
class Task(BModel):
name = models.CharField(max_length=256)
stages = models.ManyToManyField(Stage)
_translate_model = 'Task'
class Meta:
# fields which would be showed.
_list_fields = [
'id',
'name',
]
# create nested views from models
_nested = {
'stage': {
'allow_append': False,
'model': Stage
}
}
```
На выходе, если подключить модель Task в API, то получится 4 endpoint'а (два списка и две детальных записи), где Stage вложен в Task. При этом будут фильтры по полям из списка автоматически. Согласитесь круто, за 47 строк кода?
В итоге процесс решения простых задач сократился до скромных размеров и большую часть времени разработчик пишет тест на проверку переданных и принятых параметров согласно заданию. Это сильно понизило квалификацию отчасти, но такие задачи стали появляться всё реже, а на решение уходить всё меньше времени. Начался настоящий рок-н-ролл и мы поняли, что нужно поднимать квалификацию разработчиков.
Итерация шестая: доводим до абсурда
-----------------------------------
Фактически это текущий этап (правда в beta-обёртке). Ещё никогда я не выпускал бета-релиз под трёхзначным номером. Но нам постоянно кажется, что ещё вот чуть-чуть и наступит дзен.
На этом этапе мы сконцентрировались на трёх вещах.
#### Интерфейс
Оказалось, что для многих проектов необходимо перерабатывать интерфейс по одному лекалу. Мы проанализировали эти наработки и оказалось легче перенести это в базовый проект и избавиться от кучи шаблонного кода в рабочих проектах.
Углубившись в оптимизацию пространства, оказалось, что можно сделать адаптивный и удобный интерфейс даже для небольших экранов. Мы агрегировали кнопки по типам "действия" и "ссылки" и получилость очень стройно даже для большого количества вложений. Нашлось даже место для поля полнотекстового поиска.
Чтобы легче было перерабатывать весь интерфейс, мы разделили код настолько, что можно заменить практически весь интерфейс так и не притронувшись к основному шаблону.
Благодаря одному из проектов, удалось перевести интерфейс на китайский и вьетнамский языки. Таким образом из коробки основные части интерфейса переводятся на четырёх языках. В дальнейшем список планируется только расширять.
#### Сервисы
Каждую боль, мы решили по возможности решать внешними сервисами или системой плагинов. Мы проработали этот механизм так, чтобы можно было основное приложение превратить в один пакет с одним модулем `settings.py`.
Например, решить боль автообновления интерфейса мы собираемся через `Centrifugo`. Мы проработали механизм подключения внешних хранилищ с помощью `django-storages`. Доработав механизм подключения БД, теперь можно с лёгкостью реализовывать любые задумки по шардированию данных.
#### Оптимизация
Оказалось, что если поотключать кучу неоптимизированного кода, то агрегация запросов может быть быстрее, чем непосредственно сами запросы напрямую. Множество различных мест в коде, удалось оптимизировать и получить максимальную производительность "из коробки". С учётом размера команды, это позволяет малыми усилиями делать максимальный результат.
Конечно, это не всё, что мы сделали на данный момент. Нам пришлось переработать весь код, чтобы он стал ещё более понятным и простым для разработчиков, потому что мы делаем это в первую очередь для себя и команды. Поэтому мы поработали и над документацией, чтобы она стала более понятной и актуальной в свете наших задач. Но самое главное, мы стали спать спокойнее, потому что покрыли 85% всего кода тестами и не занимаемся постоянными фиксами базовой функциональности.
---
Подводя итоги
-------------
Всё началось с одного CRUD'а, который заставил меня задуматься над эффективностью работы, а закончилось созданием целой платформы. За последние годы количество кода стало такое, что если бы мне сказали, что мы такой скромной командой сможем написать такой объём, то я бы ни за что не поверил. У всего этого решения есть свои плюсы и минусы.
#### Плюсы:
* Избавились от шаблонного кода (не полностью, но до разумного предела). Теперь большая часть рутины это написание тестов. Разве не здорово? Можно заниматься самой интересной частью проекта и не тратить время на ерунду.
* В следствие предыдущего пункта, скорость разработки увеличилась, а количество релизов в день умножилось вдвое, при этом размер команды остался тот же. Всего один бекэндер может создавать довольно сложное веб-приложение. А при минимальных знаниях JS можно творить по-настоящему крутые штуки.
* Вся базовая логика и оптимизации сконцентрированы в одном проекте, что автоматически подхватывается на оконечных проектах. Тут же получается и упрощение контроля безопасности (хотя тут конечно палка о двух концах).
* Качество проектов улучшилось за счёт того, что большая часть кода протестирована на платформе, а основной код по сути декларативный. Конечно, без багов совсем кода не бывает, но большинство ошибок удаётся избежать как раз за счёт декларативности.
* Проще подбирать и обучать персонал. Найти людей, которые бы знали Django или Vue довольно легко, поэтому можно сделать упор именно на важном - на людях (коллектив и коммуникации это основа DevOps Way же!). В конце концов простые вещи обычный бэкендер может сделать даже без участия фронтендера, что исключает проблемы взаимодействия. В тех же случаях, когда нужно исправить front, есть чёткий контракт в виде схемы API, с описаниями и документацией.
* Поддерживать проекты стало сильно проще, особенно те, где вообще не задействован или не реализован js-код сверх базового.
* Делая проект получается автоматически хорошее REST API в довесок к довольно не плохому (имхо) интерфейсу. Т.е. это не уродливая нефункциональная джанго-админка, а качественный backoffice и хорошее API.
#### Минусы:
* Более высокий уровень абстракции может заблокировать или усложнить низкоуровневую логику. Это встречается довольно редко, но когда встречается требует резкого повышения уровня квалификации разработчика.
* Из-за высокого уровня абстракции создаётся иллюзия простоты, но это не всегда так. Да, какие-то вещи можно получить абсолютно бесплатно, просто накидав модель с полями и связями. Но появляется искушение делать порой не самые удачные решения в угоду нежелания уходить от простоты.
* Поддерживать проекты переходящих на новую мажорную версию платформы просто до тех пор, пока фронтовая часть там или простая, или отсутствует вообще. Но как только есть что-то довольно сложное и сильно кастомное, то переход становится очень болезненным.
* Холодная загрузка приложения это пока что наибольшая проблема. Генерация схемы занимает довольно приличное время (на одном из проектов с огромным количеством endpoint'ов генерация схемы занимает 800мс). Но справедливости ради, схема генерируется только в момент обновления или первого входа в приложение. В дальнейшем схема приходит из кеша.
В планах так же перевести всё оставшееся на SPA (всё что связанно с учёткой, паролями, авторизацией, регистрацией и т.д.), вынести фронтовые наработки в NPM-пакет (чтобы можно было прикручивать любой backend написанный на чём угодно, хоть на Go или, не дай Бог, PHP), добавить возможность собирать мобильные приложения из проектов (сейчас можно, но пока сложно), избавиться от кучи legacy-кода, перейти на OpenAPIv3 и многое другое.
Конечно проекту есть куда расти (да и ещё ой-ой-ой как много расти). Множество проблемных мест и огромное наследие, в следствие эволюции платформы под воздействием задач, дают о себе знать именно тогда, когда совсем не хочется. Но этот проект показал, что здоровая лень, может двигать прогресс и помогать развитию любого начинания. Нежелание тратить время на рутину можно направить и сделать что-то хорошее, было бы желание.
Хотелось бы так же добавить, что как DevOps объединяет разработчиков и администраторов, так и настоящий FullStack не обязательно должен пытаться захватить не свою нишу. Напротив, тесное сотрудничество front и back позволяет использовать сильные стороны друг друга и делать что-то хорошее.
---
### Полезные ссылки
* [Документация vstutils](https://vstutils.vstconsulting.net/)
* Исходники на [Github](https://github.com/vstconsulting/vstutils) и [Gitlab](https://gitlab.com/vstconsulting/vstutils)
* [Спецификация OpenAPI](https://swagger.io/docs/specification/)
* [Предыдущая статья о проекте](https://habr.com/ru/post/456146/) | https://habr.com/ru/post/660847/ | null | ru | null |
# Сканирование с поддержкой JavaScript/Ajax/DomMutation или SlimerJS + CasperJS + Magic = Profit
Сегодня вновь очень активно развивается тема автоматизации тестирования безопасности веб-приложений с использованием PhantomJS в связке с BurpSuite, ModSecurity, Garmr и т.д. Я не стал исключением, о своём опыте разработки относительно рабочего прототипа сканера с поддержкой Javascript, Ajax и DomMutation я бы и хотел с вами поделится. Может это поможет кому-то разработать собственное решение, которое будет гораздо лучше. Всех заинтересованных прошу под кат:-)
Надеюсь, никто не станет спорить, что существующие веб-приложения это адское варево из различных технологий и чем дальше тем больше логики перемещается с серверной части на клиентскую. Разумеется, это не могло не сказаться на отделах ИБ, которые и без того зачастую не столь велики, а тут еще и привычные методики автоматизированного тестирования просто обламываются на корню. В один момент стало ясно, что для первичного анализа решений уже не хватает статического анализа и привычной схемы html-парсер+фаззер. Так было принято решение исследовать этот вопрос и попробовать что-то с этим сделать.
#### Почему поддержка Javascript, Ajax и мутаций столь важна?
Потому как иначе никак:-) История знает массу примеров, когда отсутствие даже простейшей поддержки Javascript в сканерах безопасности сводила их эффективность на нет. К примеру, CSRF в Яндекс.Почта — если в GET параметрах передать изменение настроек пользователя, бекенд честно ответит ошибкой о невалидном CSRF-токене и тогда JavaScript движок переотправлял(!) этот же запрос, но уже дополнив запрос валидным токеном:) Получается, с позиции бекенда все более чем правильно, но с позиции клиента… Или XSS при переводе письма на любой из языков — история аналогичная, примитивная уязвимость которую не смог бы обнаружить w3af и иже с ним. Отсутствие поддержки JavaScript на текущий момент времени, кажется просто недопустимым и необходимо всеми силами стараться это исправить.
#### Как быть?
Я решил воспользоваться существующими идеями и взять за основу любимые SlimerJS и CasperJS и попробовать получить на выходе crawler с возможностью рекурсивного обхода событий элементов DOM + мониторинг мутаций для выявления «патологий», XSS уязвимостей и прочего. Почему не PhantomJS? Потому как в нем пока нет поддержки MutationObserver, который был мне нужен для анализа мутаций. И так, я представил себе целостную систему состоящую из четырёх больших блоков:
\* Кровлер, который как обезьянка обходит все нужные нам события и отслеживает мутации на основе формальных правил
\* Прокси, который смог бы собрать данные для дальнейшего фаззинга и запуска остальной части проверок зависящих от контекста
\* Фикстуры в веб-приложении, с заранее подготовленными метками, на которые сможем ориентироваться в процессе тестирования.
\* Отчет на основе diff'а с предыдущими результатами сканирования
Большая часть из них у меня было реализована ранее и поэтому я сконцентрировался на первой части (если будет интерес, я расскажу и о остальных). Общий алгоритм работы, который видится мне, разбит на два больших участка — обработка страниц и обработка событий, в упрощенном виде выглядит примерно так:
Как видите все достаточно просто, хоть пока и не идеально, для простоты восприятия я рисовал только основные блоки. Представим себе веб-приложение которое выводит пользователей и по клику отображает дополнительную инфу полученную Ajax-запросом:
Доступно тут: <http://crawl-test.mmmkay.info/>.
Исходный ход: <https://github.com/dharrya/monkey-crawler/tree/master/tests>
К примеру, если запустить w3af, с плагином webSpider, то никаких Ajax запросов обнаружено не будет, а между тем они не редко уязвимы по ряду очевидных причин.У Skipfish будет примерно такой же результат.
Я подготовил небольшой прототип для подтверждения работоспособности алгоритма, доступен на [github](https://github.com/dharrya/monkey-crawler). В корне проекта есть тестовый скрипт «test.js»:
```
(function start(require) {
"use strict";
var Spider = require('lib/spider').Spider;
var utils = require('utils');
var startTime = new Date().getTime();
var spider = new Spider();
var url = 'https://github.com/dharrya';
if (spider.cli.has(0))
url = spider.cli.get(0);
spider.initialize({
targetUri: url,
eventContainer: undefined
});
spider.start(url);
spider.then(spider.process);
spider.run(function() {
this.echo('\n<---------- COMPLETED ---------->\n');
var deltaTime = new Date().getTime() - startTime;
deltaTime = (deltaTime / 1000).toFixed(2);
this.echo('time: ' + deltaTime + 'sec');
this.echo('Processed pages:' + this.pagesQueue.length);
utils.dump(this.pages);
spider.exit();
});
})(require);
```
Суть которого запустить процесс и вывести «сырой» результат, опробуем на моём примере:
```
$ ./test.sh http://crawl-test.mmmkay.info
<---------- COMPLETED ---------->
time: 3.61sec
Processed pages:1
[
{
"url": "http://crawl-test.mmmkay.info/",
"opened": true,
"processed": true,
"reloadCount": 0,
"status_code": 200,
"jsErrors": [],
"xss": [],
"xssHashMap": [],
"pages": [],
"events": [
{
"eventType": "click",
"path": "id(\"user-Lisa\")/DIV[3]/BUTTON[1]",
"parentEvent": null,
"depth": 0,
"status": "completed",
"completed": true,
"deleted": false,
"xss": [],
"xssHashMap": [],
"events": [
{
"eventType": "click",
"path": "//DIV[4]",
"parentEvent": null,
"depth": 1,
"status": "completed",
"completed": true,
"deleted": false,
"xss": [],
"xssHashMap": [],
"events": [],
"resourses": []
}
],
"resourses": [
"http://crawl-test.mmmkay.info/user/Lisa.json"
]
},
{
"eventType": "click",
"path": "id(\"user-Jimmy\")/DIV[3]/BUTTON[1]",
"parentEvent": null,
"depth": 0,
"status": "completed",
"completed": true,
"deleted": false,
"xss": [
{
"innerHtml": "Another XSS...",
"path": "id(\"userInfoDescription\")/XSSMARK[1]",
"initiator": null,
"dbRecord": null
}
],
"xssHashMap": [
0
],
"events": [],
"resourses": [
"http://crawl-test.mmmkay.info/user/Jimmy.json"
]
},
{
"eventType": "click",
"path": "id(\"user-Mark\")/DIV[3]/BUTTON[1]",
"parentEvent": null,
"depth": 0,
"status": "completed",
"completed": true,
"deleted": false,
"xss": [],
"xssHashMap": [],
"events": [],
"resourses": [
"http://crawl-test.mmmkay.info/user/Mark.json"
]
},
{
"eventType": "click",
"path": "id(\"user-Tommy\")/DIV[3]/BUTTON[1]",
"parentEvent": null,
"depth": 0,
"status": "completed",
"completed": true,
"deleted": false,
"xss": [],
"xssHashMap": [],
"events": [],
"resourses": [
"http://crawl-test.mmmkay.info/user/Tommy.json"
]
}
],
"deferredEvents": [],
"startTime": 1391266464847,
"endTime": 1391266466787,
"resourses": [
"http://crawl-test.mmmkay.info/"
]
}
]
```
Видите у событий Ajax запросы за данными о пользователе? Это как раз то, что нам нужно! Согласен, текущий отладочный вывод немного избыточен, зато информативен. Из него видно, что он успешно обнаружил дополнительные запросы при обработке событий кнопок «More info», которые можно пофаззить в будущем. В довесок благодаря фикстурам в веб-приложении он смог сразу же обнаружить и XSS в мутациях, о чем любезно сообщил. Пока работает не очень быстро, но я активно работаю над этим в свободное время. Другой отличный пример это linkedin, вот результат работы для 5ти его страниц (начиная с главной):

Зеленные узлы — обработанные события элементов
Синие — ресурсы которые были запрошены при их обработке
Как видите, в подобных веб-приложениях с множеством «цепочных» событий этот подход может быть эффективен!
#### Итог
Я думаю в будущем развить эту идею до полноценного сканера безопасности веб-приложений и дополнив остальной обвязкой выложить (если руководство разрешит), может в виде плагина для W3af или Minion. Но перед этим остается еще множество не решенных вопросов связанных с производительностью и критически важными фичами.
Надеюсь не очень вас утомил и мои попытки будут кому-то полезны, если у меня не вышло что-то внятно донести — говорите, я постараюсь сорвать покров. | https://habr.com/ru/post/211060/ | null | ru | null |
# О Core Bluetooth замолвите слово… или что делать с загадочным девайсом, когда задач много, а девелопер один
Начну с себя. Я и есть тот самый iOS девелопер, работающий в компании Orion Innovation, которому посчастливилось разбирать функционал и придумать универсальный инструмент, применимый в разных кейсах. И у меня есть вопросы:
* Как часто вам приходится работать с реальными устройствами в мире мобильных девайсов?
* А что, если ваше приложение отличается от типичных клиент-серверных?
На всё про всё – массив байт. В нем заложены команды, и они отправляются на блютуз девайс. Как же нам конвертировать это в неклассическую модель данных, совсем непохожую на привычный Json? Интересно? Мои идеи и работающие решения в этой статье.
А если серьезно, то продолжительное время мой проект занимается разработкой приложения для управления чипом по протоколу BLE. Отдельная группа инженеров работает непосредственно с железом, занимаясь тем, что готовит API для нас. Сам чип управляет различными девайсами в зависимости от того, с какой платой его сконнектить. Инженеры создали свой функционал, а мы… на стороне клиента должны работать четко по предоставленной ими инструкции.
Я нарисовал схему, которая может помочь понять, как же все устроено:
Казалось бы все просто – есть сервис, у него есть характеристики, берешь, считываешь данные в конкретной характеристике, меняешь/записываешь новое свойство.
Но!
А что если у тебя есть интересный девайс, для которого умные инженеры написали универсальный протокол, позволяющий решить потрясающую задачу– избавить **Core Bluetooth** от потребности «помнить» массу данных (сервисов) и использовать всего лишь один, читая и записывая ВСЕ данные в одну характеристику. При этом учитывая, что форматы передачи данных могут отличаться, да и сами сообщения тоже. Получаем настоящий швейцарский нож!
Функционал этого чипа настолько велик, что по большому счету не важно, с какими именно девайсом его интегрировать. Важно только, КАК именно он работает.
Инженеры, безусловно, крайне умные и решили свою задачу с элегантностью пантеры. Но что же делать девелоперу?
Я имею более 20 типов сообщений, представляющих собой байтовые массивы. Они легковесны и универсальны – достаточно одной характеристики. Все просто.
Но вот задача – на стороне iOS нужен механизм. Желательно, столь же простой, удобный и универсальный.
Напомню – тип девайса, на котором установлен конкретный чип, не имеет значения. Приложение должно умело и четко коммуницировать, используя Bluetooth.
Что имеем: инженеры написали «протокол», единый для всех типов девайсов. Реализован на стороне девайса. Несет в себе более чем 20 видов сообщений.
Вывод: необходимо покаверить их все. Задача не из простых.
### Что-то придумали инженеры, настала очередь iOS.
Стандартный формат пакетаДля начала все запросы нужно классифицировать, используя предоставленную документацию.
Задача реализована следующим способом:
```
protocol PeripheralPacketProtocol {
var header: PeripheralHeader { get set }
var payload: Payload { get set }
var crcLow: Byte { get set }
var crcHight: Byte { get set }
func toData() -> [Byte]
}
struct PeripheralPacket: PeripheralPacketProtocol {
var header: PeripheralHeader
var payload: Payload
var crcLow: Byte
var crcHight: Byte
init(header: PeripheralHeader, payload: Payload) {
self.header = header
self.payload = payload
var packet = header.toData()
packet.append(contentsOf: payload.toData())
let data = Data(packet)
let crc = CRCCalculator.calculateCRCUInt8(data: data)
self.crcLow = crc.crcLow
self.crcHight = crc.crcHight
}
func toData() -> [Byte] {
var packet = header.toData()
packet.append(contentsOf: payload.toData())
packet.append(crcLow)
packet.append(crcHight)
return packet
}
}
```
У Вас может возникнуть вопрос – что же такое toData? Это – непосредственно наш массив байт, который в конечном итоге отправится на девайс. В коде это выглядит, как typealias к UINT8.
```
typealias Byte = UInt8
struct Uuid {
var value: [Byte] = []
}
```
Можно заметить, что выделена общая часть запроса. Она будет статичной всегда.
Мы назвали ее header (неизменяемая часть сообщения)
```
protocol PeripheralHeaderProtocol {
var destinationAdress: Address { get set }
var destinationBus: Byte { get set }
var sourceAddress: Address { get set }
var sourceBus: Byte { get set }
var dataLength: Int { get set }
var reserved1: Byte { get set }
var reserved2: Byte { get set }
var command: Command { get set }
func toData() -> [Byte]
}
struct PeripheralHeader: PeripheralHeaderProtocol {
var destinationAdress: Address
var destinationBus: Byte
var sourceAddress: Address
var sourceBus: Byte
var dataLength: Int
var reserved1: Byte
var reserved2: Byte
var command: Command
init(destinationAdress: Address,
destinationBus: Byte,
sourceAddress: Address,
sourceBus: Byte,
dataLength: Int,
reserved1: Byte = 0x00,
reserved2: Byte = 0x00,
command: Command) {
self.destinationBus = destinationBus
self.destinationAdress = destinationAdress
self.sourceAddress = sourceAddress
self.sourceBus = sourceBus
self.dataLength = dataLength
self.reserved1 = reserved1
self.reserved2 = reserved2
self.command = command
}
func toData() -> [Byte] {
var header = destinationAdress.rawValue.value
header.append(destinationBus)
header.append(contentsOf: sourceAddress.rawValue.value)
header.append(sourceBus)
header.append(Byte(dataLength))
header.append(reserved1)
header.append(reserved2)
header.append(contentsOf: command.rawValue.value)
return header
}
}
```
Она хранит адреса (source и destination), длину ожидаемого сообщения, а также типы передаваемых параметров.
Все просто – есть протокол, которому соответствует структура, формирующая заголовок.
Header имеет неизменяемую структуру. По большому счету, мы просто объединяем ВСЕ возможные варианты, раскладываем их по enum и выбираем, чем конкретно нам следует воспользоваться.
Перейдем к более сложной части – изменяемой.
Payload:
```
protocol PayloadProtocol {
var packetType: PacketType? { get set }
var object: Object? { get set }
var objects: [Object]? { get set }
var objectValue: IEEEFloat? { get set }
var valueData: Value? { get set }
func toData() -> [Byte]
}
struct Payload: PayloadProtocol {
//Request Only Fields
var packetType: PacketType?
//Data type (full command model)
var object: Object?
//Multyple data type (full command model)
var objects: [Object]?
//Response only fields
// If packetClass Data
var dataType: DataType?
var valueData: Value?
// If packetClass MultiData
var valueDataArray: [Value]?
//If it for write data
var objectValue: IEEEFloat?
var rejectionStatus: RejectionStatus?
//Reaponse Init
// ToData to send
func toData() -> [Byte] {
var payload = packetType?.toData() ?? []
payload.append(contentsOf: object?.toData() ?? [])
payload.append(contentsOf: objects?.toByteArray() ?? [])
payload.append(contentsOf: objectValue?.toData() ?? [])
payload.append(contentsOf: dataType?.rawValue.value ?? [])
payload.append(contentsOf: rejectionStatus?.rawValue.value ?? [])
payload.append(contentsOf: valueData?.toData() ?? [])
return payload
}
}
```
В этой части передаются полезные данные, поэтому назовем ее “payload”. На ее состав влияет пара десятков (не преувеличиваю) свойств от типа и параметра запроса, до того, в каком типе данных мы будем передавать/принимать сообщение. В наследие получили 5 типов, и если честно, эта часть требует провести аналитику.
Это непосредственно те данные, которые нам нужно считать/записать на девайс. Соответственно, они комбинируемые. К тому же, сообщения бывают single и multi (то есть, мы просим либо одно значение, либо несколько). Также в этой части хранятся: тип данных, тип команды и непосредственно формат, в котором мы отправляем данные. Завершаем мы пакет сообщения контрольной суммой (про нее отдельно).
Самое приятное в части создания сообщений: понять типы кодировки и написать всевозможные хелперы для них. Ниже я приведу код реализации хелперов, полезных для девелоперов. Может пригодится.
Как было сказано, в проекте данные можно хранить в 5 различных типах, и все они отличаются набором передаваемых параметров.
Покажу на примере IEEFloat, как читать и конвертировать его в запрос.
```
struct IEEEFloat: IEEEFloatProtocol {
var forceCode: Byte?
var dataType: Byte?
var object: Object?
var statusCode: Byte?
var lowerLimitIEEEFloat: Float?
var upperLimitIEEEFloat: Float?
var dataValue: Float?
func toData() -> [Byte] {
var ieeeFloat: [Byte] = []
if let dataType = dataType {
ieeeFloat.append(dataType)
}
if let forceCode = forceCode {
ieeeFloat.append(forceCode)
}
if let statusCode = statusCode {
ieeeFloat.append(statusCode)
}
ieeeFloat.append(contentsOf: object?.toData() ?? [])
ieeeFloat.append(contentsOf: lowerLimitIEEEFloat?.bytes.reversed() ?? [])
ieeeFloat.append(contentsOf: upperLimitIEEEFloat?.bytes.reversed() ?? [])
ieeeFloat.append(contentsOf: dataValue?.bytes.reversed() ?? [])
return ieeeFloat
}
}
```
Также уделю отдельное внимание калькулятору. На моей стороне это выглядело так:
```
import Foundation
typealias CRC = (crc: UInt16, crcLow: UInt16, crcHight: UInt16)
typealias ByteCRC = (crc: Byte, crcLow: Byte, crcHight: Byte)
class CRCCalculator {
static func calculateCRCUInt16(data: Data) -> CRC {
let length = data.count
var crcHighByte: UInt16 = 0
var crcLowByte: UInt16 = 0
var carryFlag1: UInt16 = 0
var carryFlag2: UInt16 = 0
let numOfBytes = length
for byte in 0..> 1
carryFlag1 = carryFlag1 ^ (crcLowByte & 0x01)
if carryFlag1 == 1 {
crcHighByte = crcHighByte ^ 0x40
crcLowByte = crcLowByte ^ 0x02
}
carryFlag2 = 0
if (crcHighByte & 0x01) == 1 {
carryFlag2 = 1
}
crcHighByte = crcHighByte >> 1
if carryFlag1 == 1 {
crcHighByte = crcHighByte | 0x80
}
crcLowByte = crcLowByte >> 1
if carryFlag2 == 1 {
crcLowByte = crcLowByte | 0x80
}
}
}
return ((crcHighByte \* 256) + crcLowByte, crcLowByte, crcHighByte)
}
static func calculateCRCUInt8(data: Data) -> ByteCRC {
let res = CRCCalculator.calculateCRCUInt16(data: data)
let crc = res.crc.data.byteArray[0] as Byte
let crcLow = res.crcLow.data.byteArray[0] as Byte
let crcHight = res.crcHight.data.byteArray[0] as Byte
return (crc, crcLow, crcHight)
}
}
```
Для того, чтобы не городить много бесполезного кода, процесс создания payload, header и подсчет CRC были вынесены в отдельные классы, отвечающие за общий тип сборки данных, а каждый частный соответствует общему протоколу, что делает код легко масштабируемым и изменяемым.
Дженеричность решения реализована с помощью протоколов. Каждый вид сообщения соответствует общему протоколу, что позволяет легко комбинировать их части.
Немного притормозим и подведем первый итог.
Вот что же мы дописали? Ничего. Это просто две виртуальные коробки Lego. Из них можно собрать все что угодно, только нужна инструкция… Чувствуете, о чем я? Так давайте напишем класс, который будет иметь инструкцию, КАК собрать запрос. Он будет знать МЕХАНИЗМ, по которому он будет собирать, как из кубиков, наше сообщение, а также парсить полученный ответ. При этом, такой подход позволяет нам максимально универсально подходить к вопросу сборки сообщений.
Достаточно слов – я приведу конкретный пример того, как собирается сообщение на ieefloat:
```
func toPeripheralPackageRequest(forPacketClass: PacketClass) -> PeripheralPacket? {
//ToDo: Here we always convert response
guard let destinationAdress = Address(rawValue: Uuid(value: Array(self.bytetoArray[0...3]))),
let sourceAddress = Address(rawValue: Uuid(value: Array(self.bytetoArray[5...8]))),
let command = Command(rawValue: Uuid(value: [self.bytetoArray[13]]))
else {
return nil
}
let sourceBusByte = self.bytetoArray[9]
let destinationBusByte = self.bytetoArray[4]
let dataLength = Int(self.bytetoArray[10])
let reserved1 = self.bytetoArray[11]
let reserved2 = self.bytetoArray[12]
let header = PeripheralHeader(destinationAdress: destinationAdress,
destinationBus: destinationBusByte,
sourceAddress: sourceAddress,
sourceBus: sourceBusByte,
dataLength: dataLength,
reserved1: reserved1,
reserved2: reserved2,
command: command)
switch command {
case .read:
switch forPacketClass {
case .data:
guard let packetProperty = DataProperty(rawValue: Uuid(value: [self.bytetoArray[15]])) else {
return nil
}
let packetType = PacketType(packetClass: forPacketClass,
packetProperty: packetProperty)
let payload = Payload(packetType: packetType,
object: Object(objectNumberHighByte: self.bytetoArray[16],
objectNumberLowByte: self.bytetoArray[17],
objectName: Array(self.bytetoArray[18...25])))
return PeripheralPacket(header: header, payload: payload)
case .multiData:
// At this moment it is only ieee float elements, but in future it can be different types
let length = (Int(dataLength) - 2) / 10
var valueDataArray: [Value] = []
var itemLength = Int(self.bytetoArray[14])
for _ in 1...length {
itemLength = Int(self.bytetoArray[14 + itemLength * length - 1])
let ieeeFloat = IEEEFloat(forceCode: self.bytetoArray[15 + itemLength * length - 1],
statusCode: self.bytetoArray[16],
lowerLimitIEEEFloat: Data(Array(self.bytetoArray[17...20])).floatValue,
upperLimitIEEEFloat: Data(Array(self.bytetoArray[21...24])).floatValue,
dataValue: Data(Array(self.bytetoArray[25...28])).floatValue)
let value = Value(dataType: .ieeeFloat, ieeeFloat: ieeeFloat)
valueDataArray.append(value)
}
let payload = Payload(valueDataArray: valueDataArray)
return PeripheralPacket(header: header, payload: payload)
default:
return nil
}
...
default:
return nil
}
}
```
Как вы видите, есть пакет и его компоненты. Для конкретного сообщения.
Все очень просто: начинаем сборку с header. Берем из enum destination и source адреса, выбираем также из перечисления команду, вычисляем длину сообщения, расставляем зарезервированные байты по стандарту. И… вызываем инициализатор.
Аналогичную процедуру проделываем для payload, но! Я УЖЕ учитываю ТИП команды, ТИП запроса и расписываю КАЖДЫЙ способ сборки пакета (ниже приведу только один из 12 вариантов).
Собственно, это мультишот даты определенного типа. Лишнего нам и не нужно)
Отдельно разберу именно сборку ieeFloat:
```
struct IEEEFloat: IEEEFloatProtocol {
var forceCode: Byte?
var dataType: Byte?
var object: Object?
var statusCode: Byte?
var lowerLimitIEEEFloat: Float?
var upperLimitIEEEFloat: Float?
var dataValue: Float?
func toData() -> [Byte] {
var ieeeFloat: [Byte] = []
if let dataType = dataType {
ieeeFloat.append(dataType)
}
if let forceCode = forceCode {
ieeeFloat.append(forceCode)
}
if let statusCode = statusCode {
ieeeFloat.append(statusCode)
}
ieeeFloat.append(contentsOf: object?.toData() ?? [])
ieeeFloat.append(contentsOf: lowerLimitIEEEFloat?.bytes.reversed() ?? [])
ieeeFloat.append(contentsOf: upperLimitIEEEFloat?.bytes.reversed() ?? [])
ieeeFloat.append(contentsOf: dataValue?.bytes.reversed() ?? [])
return ieeeFloat
}
}
```
Force code, Status code, нижний и верхний лимиты, а также значение.
Согласно приложенным инструкциям, калькулятор считает чек сумму в моменте инициализации сообщения и сборки массива.
Прошу обратить внимание, что каждый сборщик имеет подобный метод:
```
func toData() -> [Byte] {
var packet = header.toData()
packet.append(contentsOf: payload.toData())
packet.append(crcLow)
packet.append(crcHight)
return packet
}
```
Он переводит нашу модель в массив байт. Что в конечном итоге дает итоговый массив, который **CoreBluetooth**отправляет на девайс в указанную характеристику. Следующим способом:
```
func write(bytes: [Byte], for Characteristic: Characteristic, type: CBCharacteristicWriteType = .withoutResponse) {
guard let characteristic = cbPeripheral?.characteristics.first(where: {
$0.Characteristic == Characteristic
}) else {
return
}
cbPeripheral?.writeValue(Data(bytes), for: characteristic, type: type)
}
```
Мы берем конкретный массив байт и передаем его в известную характеристику, ожидая получить ответ после записи на девайс.
Конструкция получается достаточно громоздкой. Но в ней есть известные плюсы – легко масштабируемый код, в котором есть возможность изменить любое из свойств.
### Выводы
По факту статья получилась даже не совсем о Core Bluetooth, а скорее о том, какой инструмент можно создать для работы с порой катастрофически большим объёмом данных, которые можно последовательно передавать на девайс в легковесном формате байтовых массивов.
Кроме того, я думаю Вы сможете воспользоваться простыми, но удобными хелперами для конвертации данных.
До скорых встреч.
Хелперы:
```
extension Data {
var byteArray: [Byte] {
let bufferPointer = UnsafeBufferPointer(start: (self as NSData).bytes.assumingMemoryBound(to: Byte.self), count: count)
return Array(bufferPointer)
}
var floatValue: Float {
return Float(bitPattern: UInt32(bigEndian: self.withUnsafeBytes { $0.load(as: UInt32.self) }))
}
var intValue: Int {
return self.reduce(0) { value, byte in
return value << 8 | Int(byte)
}
}
var stringValue: String {
if let str = NSString(data: self, encoding: String.Encoding.utf8.rawValue) as String? {
return str
} else {
return ""
}
}
}
extension UInt16 {
var data: Data {
var int = self
return Data(bytes: ∫, count: MemoryLayout.size)
}
}
extension Float {
var bytes: [UInt8] {
withUnsafeBytes(of: self, Array.init)
}
}
func hexToString() -> String {
var finalString = ""
let chars = Array(self)
for count in stride(from: 0, to: chars.count - 1, by: 2){
let firstDigit = Int.init("\(chars[count])", radix: 16) ?? 0
let lastDigit = Int.init("\(chars[count + 1])", radix: 16) ?? 0
let decimal = firstDigit \* 16 + lastDigit
let decimalString = String(format: "%c", decimal) as String
finalString.append(Character.init(decimalString))
}
return finalString
}
func base64Decoded() -> String? {
guard let data = Data(base64Encoded: self) else { return nil }
return String(data: data, encoding: .init(rawValue: 0))
}
func ranges(of string: String) -> [NSRange] {
var ranges = [NSRange]()
var searchStartIndex = self.startIndex
while searchStartIndex < self.endIndex,
let range = self.range(of: string, range: searchStartIndex.. [NSRange] {
do {
let regex = try NSRegularExpression(pattern: pattern)
return regex
.matches(in: self, range: NSRange(startIndex..., in: self))
.compactMap { $0.range }
} catch {
return []
}
}
```
--- | https://habr.com/ru/post/572846/ | null | ru | null |
# Блого-социальная сеть на основе XenForo
В этой статье я постараюсь вкратце рассказать о построении аналога Livestreet на основе XenForo. Вся блого-социальная сеть представляет собой плагин для XenForo под названием Social. [Обзор архитектуры движка](http://habrahabr.ru/post/105751/) и [основы плагинописания](http://habrahabr.ru/post/106046/) описаны в статьях [FractalizeR](https://habrahabr.ru/users/fractalizer/).
Проанализировав архитектуру XenForo, мы поняли, что принципиальных отличий форума от блогов не так уж и много. Действительно, первое сообщение темы легко превращается в статью, а остальные сообщения — в комментарии. Определенные разделы форума можно превратить в блоги.
Перечислю основные преимущества данного решения.
* Встроенный форум.
* Готовая система ббкодов и обработки сообщений.
* Превращения статьи в темы, а темы в статьи путем переноса в нужный раздел.
* Код плагина получился очень компактный.
Конечно, у такого подхода есть и недостатки.
* Для правильного разделения функционала пришлось изучить движок от и до.
* Меньше свободы действий, поскольку статьи расширяют темы.
В целом идея о том, что любое обсуждение есть тема, показалось нам очень логичной. Разделение тем и статей в итоге оказалось не таким уж сложным. Теперь об основных моментах технической реализации плагина.
#### Блоги
Сделаем настройку `socialBlogRoot`, определяющую родительский узел для всех блогов. Т.е. все дочерние форумы узла `socialBlogRoot` должны превращаться в блоги, а темы этих форумов — в статьи. Добавим поле `parent_post_id` к таблице `xf_post` для древовидных комментариев.
##### Контроллер
Расширяем классы `XenForo_ControllerPublic_Thread` и `XenForo_ControllerPublic_Forum`. Если текущий форум является дочерним от `socialBlogRoot`, делаем запись в реестр:
`XenForo_Application::set('blogView', 1);`
Теперь в любом месте скрипта мы знаем, что находимся внутри блога.
##### Вид
Расширяем класс `XenForo_ViewPublic_Thread_View`:
````
class Social_ViewPublic_Thread_View extends XFCP_Social_ViewPublic_Thread_View
{
public function renderHtml()
{
parent::renderHtml();
// Если тема является статьей, делаем древовидные комментарии
if (XenForo_Application::isRegistered('blogView'))
{
$firstPostId = $this->_params['firstPost']['post_id'];
$this->_params['firstPost'] = $this->_params['posts'][$firstPostId];
// Оставляем все посты, кроме первого
unset($this->_params['posts'][$firstPostId]);
// Строим дерево комментариев
$commentTree = Social_ViewPublic_Helper_Comment::buildCommentTree($this->_params['posts']);
$this->_params['commentsTemplate'] = Social_ViewPublic_Helper_Comment::createCommentsTemplateObject($this, $commentTree);
// В шаблон подается первый пост и рендеренное дерево комментрариев
$this->_params['posts'] = array($this->_params['firstPost']['post_id'] => $this->_params['firstPost']);
}
}
}
````
##### Шаблон
В качестве параметров шаблона переданы первый пост и рендеренное дерево комментариев. Остается лишь вставить это дерево в конец первого поста, используя template hook под названием `ad_message_below` в щаблоне `message`.
#### Модуль комментариев на основе тем
Оказывается, темы можно использовать как универсальный способ коментирования любого контента. Покажем это на примере фотоальбомов. Из коробки фотографии можно загружать как вложения к сообщениям, а просматривать с помощью встроенного лайтбокса.
Опять же создадим настройку `socialAlbumRoot` для корня всех альбомов. Для блогов мы сделали древовидные комментарии. Теперь же сообщение может относиться не только к другому сообщению, но и к вложению. Для этого вместо добавления одного поля `parent_post_id` к таблице `xf_post`, добавим два поля `target_id` и `target_type`. Последнее указывает на тип контента, к которому относится сообщение (post или attachment).
Все альбомы одного пользователя теперь можно уместить в одну древовидную тему следующим образом:
* Album (post: target\_id=0, target\_type=post, post\_id=200 )
+ Photo (attachment: target\_id=200, target\_type=post, attachment\_id = 1000)
- Comment (post: target\_id=1000, target\_type=attachment, post\_id=201 )
- Comment (post: target\_id=1000, target\_type=attachment, post\_id=202 )
- Comment (post: target\_id=1000, target\_type=attachment, post\_id=203 )
+ Photo (attachment: target\_id=200, target\_type=post, attachment\_id = 1001)
- Comment (post: target\_id=1001, target\_type=attachment, post\_id=204 )
- Comment (post: target\_id=1001, target\_type=attachment, post\_id=205 )
- Comment (post: target\_id=1001, target\_type=attachment, post\_id=206 )
* Album (post: target\_id=0, target\_type=post, post\_id=201 )
+ Photo (attachment: target\_id=201, target\_type=post, attachment\_id = 1002)
- Comment (post: target\_id=1002, target\_type=attachment, post\_id=207 )
- Comment (post: target\_id=1002, target\_type=attachment, post\_id=208 )
- Comment (post: target\_id=1002, target\_type=attachment, post\_id=209 )
+ Photo (attachment: target\_id=201, target\_type=post, attachment\_id = 1003)
- Comment (post: target\_id=1003, target\_type=attachment, post\_id=210 )
- Comment (post: target\_id=1003, target\_type=attachment, post\_id=211 )
- Comment (post: target\_id=1003, target\_type=attachment, post\_id=212 )
Далее можно действовать аналогично блогам: делаем запись в реестр, расширяем вид и меняем шаблон. В технические подробности вдаваться нет смысла.
#### Новости (главная)
Новостная лента имеет собственный контроллер, вид и шаблон. Каждая новость представляет собой обработанное первое сообщение какой-либо темы. Обработка заключается в автоматической обрезке, а также в ограничении числа вложенных картинок и видео. Новость появляется на главной, если первое сообщение темы собирает больше заданного количества лайков. Благодаря такому подходу новостью может быть статья, фотоальбом, опрос или простое обсуждение.
#### Заключение
XenForo показался нам одним из самых продуманных и технологичных скриптов не только среди форумных движков, но и среди CMS. Теперь я убежден, что на основе XenForo можно сделать как крупный портал, так и социальную сеть.
Проект развивается. Основная часть блогов готова. В планах фотоальбомы, CMS, интернет-магазин, вики, афиша. Если кому-то интересно поучаствовать — пишите. Если интересно посмотреть демо, добавлю ссылку. | https://habr.com/ru/post/140346/ | null | ru | null |
# Элемент Date Picker стал доступен в Chrome Canary и Chromium
Последнее обновление билдов Chrome Canary и Chromium включило поддержку нового элемента для форм — **Date Picker**. Задав **type="date"** для input, мы увидим небольшой треугольник рядом с текстовым полем. Кликнув на него, пользователь сможет использовать date picker для выбора даты и ее параметров, и все это без использования JavaScript.
```
```
В [комментариях к новости](https://plus.google.com/102860501900098846931/posts/hTcMLVNKnec) Пол Айриш пояснил, что это не последний вариант имплементации этого элемента и что разработчики прислушаются к любому конструктивному фидбеку.
Так как это нативный контрол браузера, пока нет никакой возможности, чтобы применить к нему пользовательские стили.
Стоит также отметить, что впервые такой календарь был внедрён в Opera 9.0. В Opera 11 он выглядит примерно так:
 | https://habr.com/ru/post/142271/ | null | ru | null |
# Тюнинг Леопарда
Неважно насколько хорош OS X Leopard, всегда найдутся вещи которые людям не нравятся и они хотели бы их изменить. И чем выше уровень пользователя, тем больше у него запросов и желания изменить что-то на свой вкус. В этой заметке, я попытаюсь рассказать о небольших советах, которые позволят вам улучшить внешний вид Леопарда.
**The Dock**
*3D/2D Док*
Начнем с классики. Если вам не нравится новый вид Дока, вы можете изменить его на 2D вариант выполнив следующую команду в терминале:
`$ defaults write com.apple.dock no-glass -boolean YES ; killall Dock`
*[DockColor](http://www.elgebar.com/dockcolor.html)*
Если вам все же нравится 3D Dock, то вы можете настроить цвета дока этой маленькой программкой.
*[Leopardocks.com](http://leoparddocks.com/), [Dockulicious.com](http://www.dockulicious.com/)*
Эти два замечательных сайта позволяют полностью изменить внешний вид дока (собрано большое кол-во тем).

**Stacks**
*[Stack Drawers](http://t.ecksdee.org/post/19001860)*
Основная задача стэков — разгрузить рабочий стол, но порой становится очень сложно отличить сами стеки. Stack Drawers поможет вам организовать их внешний вид.
*[Stacks In Da Place](http://www.eagle-of-liberty.com/stacksindaplace/)*
А данная программа является замечательным дополнением к Stack Drawers. Она автоматически определяет все ваши стеки и позволяет вам выбрать иконку для стека всего лишь при помощи drag'n'drop.

*[HierarchicalDock](http://www.eternalstorms.at/utilities/hierdock/index.html)*
Многие жаловались на то что в Леопарде убрана возможность навигации по каталогам через док. Данное приложение поможет вам вернуть справедливость.

*Recent Items Stack*
Вы часто используете Recent Items? Ну тогда этот тюнинг для вас. Выполнив данную команду, вы добавите новый стек, в котором будет 10 последних документов, приложений, серверов и т. д.
`defaults write com.apple.dock persistent-others -array-add '{ "tile-data" = { "list-type" = 1; }; "tile-type" = "recents-tile"; }' ; killall Dock`
*Activate Mouse Over Gradient*
Данная команда добавляет градиент для активного элемента в стеке.
`defaults write com.apple.dock mouse-over-hilte-stack -boolean YES ; killall Dock`

**The Menu Bar**
*[OpaqueMenuBar](http://www.eternalstorms.at/utilities/opaquemenubar/)*
Одно из самых спорных изменений в Леопарде — это полупрозрачное меню. OpaqueMenuBar позволит вам изменить коэффициент прозрачности меню.

*[Leo ColorBar](http://homepage.mac.com/mdsw/md%20softworks.html)*
Данная утилита позволяет вам выбирать цвета для меню, более того, она позволяет сделать меню закругленным или маcштабировать картинку на фоне так, чтобы она не попадала под меню.

**Finder**
*Черезстрочная подсветка*
Если вам не нравится голубоватая черезстрочная подсветка, вы можете удалить ее простым действием в терминале:
`defaults write com.apple.finder FXListViewStripes -bool FALSE ; killall Finder`

*Заголовки сайдбара*
Для этого вам нужно открыть файл (средствами XCode) — /System/Library/CoreServices/Finder.app/Contents/Resources/English.lproj/LocalizableCore.strings и найти строки SD5, SD6…. Изменив их на свой вкус, перезапустите finder:
`killall Finder`
*Иконки в Тулбаре*
Оказывается, в тулбар Finder'а можно добавлять иконки приложений. Скажем, иногда вам приходится использовать VLC для файлов, который QT не может открыть, но распологать иконку VLC в доке вам не хочется. Тогда вы можете расположить ее в тулбаре Finder'а. Просто перетащите приложения которые вам нужны. Дальше можно использовать эти иконки так же как иконки дока.

**Icons**
*[Candybar 3](http://www.panic.com/candybar/)*
Candybar — это замечательное приложение, которое позволяет изменять системные иконки OS X.

*[IconFactory](http://iconfactory.com/search/freeware/leopard)*
IconFactory — это гигантский архив ресурсов иконок для Mac, который можно использовать совместно с CandyBar.
**Login Window**
*[Visage Login](http://keakaj.com/visagelogin.html)*
Используя это приложение, вы сможете полностью настроить вход в систему (login window). Вы можете менять фоновую картинку, иконки, имя и ввести любую информацию для отображения.

*DefaultDesktop.jpg*
Если вы хотите только поменять картинку на фоне, то для этого вам нужно всего лишь заменить вот этот файл /System/Library/CoreServices/DeafaultDesktop.jpg и в следующий раз, осуществляя вход в систему, вы увидите новый фон.
**QuickLook**
*[Folder QuickLook Plugin](http://d.hatena.ne.jp/t_trace/20071124/p3)*
QuickLook это одно из важнейших нововведений Леопарда. Используя этот плагин, вы сможете удобно просматривать каталоги.

*[Zip QuickLook Plugin](http://d.hatena.ne.jp/t_trace/20071125/p2)*
Еще один плагин к QuickLook который позволит просматривать вам файлы в Zip архивах, не открывая их.

**Other**
*[Displaperture](http://www.manytricks.com/displaperture/)*
Еще одна фишка, которая была удалена из Леопарад — это скругленый вид углов. Dispalperture — это фоновый процесс, который позволяет скруглять углы как в старом добром Тигре.

*[fonts500](http://fonts500.com/)*
Это не относится к Леопарду, но данный сайт заслуживает внимания, так как содержит 500 высококачественных бесплатных шрифтов.
*[InterfaceLift](http://interfacelift.com/)*
Еще один сайт заслуживающий внимания. Он содержит тысячи постоянно обновляющихся иконок, тем и прочего для Mac и PC.
Разумеется, это не полный список того, что можно сделать, но тут собраны наиболее яркие примеры. Надеюсь вам понравилось :-)
ЗЫ. Я знаю, что тут должно быть безумное количество опечаток и ошибок. Не ругайте сильно, старался как мог (multilingual spell checker работает безумно плохо). Надеюсь с вашей помощью я их исправлю 8-)
По материалам
[www.appletell.com/apple/comment/ultimate-leopard-tweaking-guide](http://www.appletell.com/apple/comment/ultimate-leopard-tweaking-guide/)
[www.usingmac.com/2007/11/18/leopard-tweaking-terminal-codes](http://www.usingmac.com/2007/11/18/leopard-tweaking-terminal-codes)
[www.macworld.com/article/60944/2007/11/leopardfirsttweaks.html](http://www.macworld.com/article/60944/2007/11/leopardfirsttweaks.html)
[lifehacker.com/344376/customize-your-mac-with-leopard-power-tweaks](http://lifehacker.com/344376/customize-your-mac-with-leopard-power-tweaks) | https://habr.com/ru/post/26383/ | null | ru | null |
# Первый стабильный выпуск низкоуровневого корректора раскладок в linux «xswitcher»
Спустя год разработки удалось*(у меня нашлась пара недель)* довести до рабочего состояния задуманное в [предыдущей публикации](https://habr.com/ru/post/499560/). *А спустя ещё пару месяцев я пишу наконец эту статью.*
В общем, ура! "Мы строили-строили и наконец построили". И оно даже работает/переключает. Причём, и в gnome3 тоже *(не без помощи костыля)*.
TL.DR
-----
Кому совсем не терпится, идёт на <https://github.com/ds-voix/xswitcher> и либо собирает по инструкции, либо качает статически слинкованный бинарь из подкаталога `"bin/"`. Встроенная конфигурация циклически переключает первые 2 языка по левому `CTRL`, включает 1-й язык по левому `SHIFT` и 2-й язык по правому `SHIFT`. Перепечатывание последнего введённого слова в изменённой раскладке выполняется по нажатию `Pause` или `F12` *(осторожно с браузерами, это я просто не нашёл лучшего для кастрированной клавиатуры своего Lenovo X1)*.
Пользователи gnome должны ~~страдать~~ использовать хак из подкаталога `"gnome3/"`. Тут уже́ встроенной конфигурацией не обойтись. Придётся положить `"xswitcher.conf"` в папку `"/etc/xswitcher/"` (предварительно её создав), а хэлпер `"switch.gnome"` — в папку `"/usr/local/bin/"`. *И дать права на исполнение.*
Напоминаю, что т.к. xswitcher по своей природе ~~троян~~ низкоуровневый кейлоггер в паре с виртуальной клавиатурой, для работы ему нужны права суперпользователя. Я сам запускаю из-под KDE (прописав в автостарт), для этого бинарю нужен suid-бит в разрешениях `"chmod u+s вот_этому"`. Альтернативно можно пускать из systemd (upstart|rc.d|etc.), написав соответствующий конфиг (к релизу не прилагается). Вот здесь <https://github.com/ds-voix/xswitcher/issues/1> товарищ экспериментировал.
*С wayland — увы, пока помочь не могу. Но готов посодействовать, об этом см. ниже "Что делать с wayland".*
FAQ (часто задаваемые вопросы)
------------------------------
**Q:** Эта штука только вручную переключает раскладки?
**A:** Она умеет перепечатывать слово в изменённой раскладке.
yf,bhftv `<нажимаем "Break">` → "набираем"
Т.е. ту ключевую функциональность punto switcher, от отсутствия которой у меня "подгорало" в linux после "ухода со сцены" xneur. *Смотри* [*"содержание предыдущих серий"*](https://habr.com/ru/post/495748/)*.*
**Q:** Программа умеет по нажатию клавиши менять язык выделенного участка текста?
**A:** В xswitcher можно задать желаемое сочетание/последовательность клавиш для вызова внешней программы. Которая, в свою очередь, сделает нужную обработку.
Детали (что под капотом)
------------------------
В целом, реализовано почти всё намеченное в "предыдущей части сериала".
За основу я взял гипотезу о том что процесс "алфавитного" ввода текста с клавиатуры может быть описан с использованием только регулярных грамматик. Так как мой *моск* не в силах "переваривать" цепочки "голых" скен-кодов, я постарался ему в этом помочь. Сделал трансляцию скен-кодов в ±человекочитаемые аббревиатуры клавиш. А чтобы не биться о восприятие всяких жутких последовательностей вида `"([0-9A-Z=-]|GRAVE|APOSTROPHE|SEMICOLON|[LR]_BRACE|COMMA|DOT|(BACK)?SLASH|KP[0-9])"`, вынес их задание в именованные шаблоны. *Один раз побился над составлением шаблона, и хватит.*
Ешё одной задумкой "как сделать удобнее" было вынести "состояние клавиш состояния" *(извините за тавтологию)* "за скобки" регулярных выражений. Этот приём в итоге почти не понадобился, но в процессе оказалось удобным ввести понятие "виртуальной клавиши состояния". Такая сейчас одна: "WORD". Включается сразу после перепечатывания слова и сохраняет состояние пока не сработает детектор "нового слова". Дальше на сконструированные регулярные выражения вешается набор "детекторов совпадения" ("match"). Предусмотрены пара встроенных функций ("NewWord", "NewSentence") и **неограниченный** набор подключаемых "хуков" "Action.Name". *Работу с юникодом в конфигурации я не закладывал и не проверял, так что советую использовать только ASCII в именах.*
"Хуки" также могут вызывать как несколько встроенных функций, так и друг друга. Таким образом можно описывать схемы без ветвлений (и циклов соответственно). *(Я не придумал зачем оно здесь надо. Кому надо, у меня есть* [*https://github.com/ds-voix/VX-PBX/tree/master/VX*](https://github.com/ds-voix/VX-PBX/tree/master/VX) *с примерами из области телефонии. Правда, там perl. Хотя вот прямо сейчас пользуюсь этой штукой для проключения SAN в гипервизоры.)*
Встроенная функция "Exec" позволяет запустить внешний бинарь и (опционально) отдать ему в stdin записанные скен-коды из буфера последнего слова или "предложения". *Возможно следовало бы также добавить в качестве параметра текущий номер раскладки. Сделаю если кто-нибудь объяснит зачем это ему надо.* *"Exec" уже́ пригодился, чтобы закостылить гнома.*
Основной встроенной функцией, из-за которой весь этот сыр-бор, является "RetypeWord" (забить слово и напечатать ещё раз). Смену раскладки можно полностью вынести наружу, как это и пришлось сделать для gnome. Есть ещё встроенная функция "Respawn". Она перезапускает xswitcher, в процессе переподключаясь ко всем нужным устройствам ввода. Используйте после подключения внешней клавиатуры/мышки (отключится оно само, ругнувшись в консоль).
Форк keybd\_event
-----------------
Для реализации "виртуальной клавиатуры" я не стал изобретать свой велосипед, а взял удобную (как мне показалось) библиотечку `"github.com/micmonay/keybd_event"`. В случае с linux она цепляется к `"/dev/uinput"`, создаёт "устройство" через syscall `"SYS_IOCTL(_UI_DEV_CREATE)"` ну и дальше использует по назначению.
Всё крайне удобно, если бы не одно "но". В погоне за кроссплатформенностью авторы переборщили с уровнем абстракции. Вызовы "нажать" и "отпустить" кнопку скрыты. Вместо них — абстракция "нажать и отпустить" без возможности различать некоторые "клавиши состояния" (правую и левую "WIN"). Я, не долго думая, просто обернул вызовы "нажать" и "отпустить" "публичной" функцией. К сожалению, в таком виде коммит от меня принять не согласны т.к. он не будет работать под Windows. А у меня нет желания делать как-то лучше. Если кому-нибудь интересно посодействовать в улучшении функциональности "keybd\_event" — помогайте. А пока, чтобы всё собралось, нужно подложить файл `keybd_linux_export.go`в каталог с библиотекой. *Или тянуть с меня форк, но это нехорошо т.к. я его в случае чего обновлять не буду.*
Совместная работа с IBus/Fcitx
------------------------------
*IBus навязывают всем подряд. При том что в большинстве случаев ("европейские" азбуки слева направо) это просто ненужная блоатварь.* *Fcitx не навязывают, его просто используют те кому приходится писа́ть на языках ЮВА. (Я в т.ч.)*
Здесь я знаю две проблемы.
* IBus: Завязана на gnome и в связке с ней (по идее) должен работать костыль, см. выше "TL.DR.".
* Fcitx: При загрузке перед xswitcher он умудряется как-то изменять характеристики клавиатуры. "Отваливаются" некоторые клавиши состояния. Мне он нужен лишь изредка и я его просто не загружаю при старте системы. *Если кто-нибудь активно использует и fcitx и "3-й/5-й ряды"/"compose"-клавиши, я прошу потратить немного внимания на изучение данного нюанса. Возможно, проблема выеденного яйца не сто́ит и я просто "не умею готовить".*
Что дальше
----------
Текущее состояние xswitcher *меня* устраивает (оно просто работает и *почти* не "путается под ногами"). Но это никак не отменяет кучу открытых вопросов. Ниже я перечислю те их них, которые вижу сам. Если в обсуждении будут выдвинуты другие интересные вопросы — дополню текст статьи.
### В пакет и на свалку^w^w в репозиторий
Большинство из пользователей linux *этим вашим linux* просто пользуются. *И даже хабра не читают.* Запакуйте и опубликуйте пакет для вашего любимого дистрибутива. На словах всё просто, и запаковать-то надо всего пару файлов. Но вопрос в том **как это хорошо интегрировать с тем или иным DE**.
### Графический (GUI) конфигуратор
Вероятно, кому-то *(как мне в 90х)* интересно писать GUI. Придумать и реализовать GUI для настройки xswitcher — вполне достойная задача. *Я, со своей стороны, торжественно обещаю "не ломать API".*
Посмотрел ещё раз на абзац про гуй и понял что так не годитсяПотому что инструменты для работы с языками нужно интегрировать в DE. Как *опциональные* модули. В самих DE правильной работы с "горячими клавишами" *(да и вообще, грамотного проектирования)* не предвидится. Потому что их пишут (большей частью) очень молодые люди. А хорошим конструктором есть шансы *начать становиться* годам к 40. *Так вообще бывает с многими профессиями, где кроме "просто знаний" нужно набирать опыт.* В общем, вот так. Подмножество тех кто что-то соображает в проектировании/конструировании крайне слабо пересекается с подмножеством разработчиков GUI. И "старшее поколение" должно принимать меры, если не хочет плеваться от UI *и гордо смотреть в чёрную консоль*.
Теперь конкретика. Не скажу за все окружения рабочего стола, но KDE вполне допускает интеграцию функциональности из внешних модулей. С гномом сложнее, но что-то тоже можно. *Про остальные — не в курсе. Дополняйте/поправляйте кто знает.* Не нужно лезть к молодым людям (разработчикам DE) с категоричным "всё тут неверно, давайте перепишем". Нужно постараться сделать достаточно автономный модуль. Скажем, "расширенная поддержка горячих клавиш". *(А корректор раскладок — доп. плюшка.)* И вот это уже́ предлагать конечному пользователю *(+много к опыту интеграции тому кто так сможет)*.
### Безопасность
*"А чего оно рута требует? Это ж не безопасно!"*
Я так не считаю т.к. при штатном использовании поверхность атаки сводится к подключению "нехорошего" устройства ввода, что само по себе является привилегированной операцией. Код на GO достаточно компактный и чего-то типа `"if (uid = 0)"` туда не особо внедришь. Так что, эта сторона достаточно легко подвергается аудиту. Просто не берите абы-чьи бинарные сборки (мои в т.ч.).
В то же время, приведённые выше соображения ни один (вменяемый) аудитор не примет как доказательства безопасности. В этом и состоит ещё одна *(надеюсь, кому-то интересная)* задача. — "Что (и **как**) нужно изменить в схемотехнике/коде, чтобы подобное изделие перестало рассматриваться как топовая угроза безопасности?"
### Развитие функциональности
Я сделал хорошо ровно две вещи *(ну ладно, три)*.
* Контроль событий клавиатуры *(и чуть-чуть мышиных)* через регулярные выражения с поддержкой шаблонов (и понятия "состояния").
* Модель для отсекания "последнего введённого слова" (и его перенабор).
* Конфигурацию в виде блок-схемы на TOML.
*То есть (глядя с другой стороны бесконечности) не сделано почти ничего.* Зато есть каркас, на который можно крепить свои конструкции.
* А можно перепечатывать целиком строку/предложение?
* А может, надо цеплять ввод "как у всех" к "оконным" библиотекам?
* А будет автокоррекция *(как у punto switcher)*?
* Хочется принудительно включать определённую раскладку при получении фокуса определённым окном.
Всё можно, если кому-то покажется интересным потратить часть своего времени на реализацию хотя бы одной функции. Я уже́ как-то писа́л что не вижу способа сделать хороший linux-десктоп классическими "коммерческими" приёмами. *Потому что "где здесь деньги"?* Но можно попробовать вот такой обходной манёвр.
Создаётся "аттрактор" в той области которую желаем улучшить (ну вот как Линус когда-то нащупал способ). Дальше, если каркас вышел удачным, его потихоньку дополняют те кому понравилось. Этот "фокус" работает и с большими коммерческими продуктами ("asterisk", "firefox" пока его не принялись толерастить), и с мелкими (в принципе) проектами ("far manager"). Попробуем с xswitcher?
Что делать с wayland (он наступает)
-----------------------------------
*Как "хорошо информированный оптимист" предполагаю момент когда поддержку Х порежут "потому что не модно".*
С самим wayland — ничего делать не надо (как я понимаю, это "фундамент" для всего остального).
* Чтобы работали подобные этой переключалки *(ну и кейлоггеры, куда уж без них)*, нужно обеспечить вывод потоков скен-кодов от подключенных клавиатур в какие-нибудь символьные устройства. *(И от мышек/трекболов etc., заодно.)*
Это — уровень ядра и должно быть в наличии (если специально не отключать).
* Чтобы иметь возможность перепечатать, нужен интерфейс "виртуальная клавиатура" ("/dev/uinput" или "/dev/input/uinput").
Это опять же уровень ядра и должно быть в наличии (если специально не отключать).
* Чтобы переключать язык, **нужен API для переключения**. Вот его — таки надо. И тут я не помощник.
*И ещё хорошо бы получать класс окна при смене фокуса, чтобы регулировать поведение переключалки.* Если всё в наличии, просто ткните меня носом в соответствующую документацию/примеры использования. Я обязательно постараюсь помочь в адаптации кода. *(В случае с гномом — допускаю, что переключаться можно через описанный выше костыль. А остальным что делать?)*
Известные ошибки
----------------
* Если хорошенько подёргать туда/сюда внешние клавиатуры/мыши, можно "уронить" xswitcher. *Если кому-то удастся отдефектовать проблему, я исправлю.*
* Переключение раскладки по нажатию функциональных клавиш (и иной какой экзотики) чревато феерическими багами. Потому что хswitcher не занимается MITM-порчей событий ввода.
*На "недоклавиатурах" лучше придумайте для перепечатывания что-нибудь более нейтральное. "Двойной шифт" к примеру.*
* Если в вашей программе реализовано автодополнение (не по табулятору), xswitcher может напакостить при перепечатывании. Лучше для таких окон отключать "RetypeWord".
* Также можно нарваться в терминале, начав ввод с "Esc" и затем вызвав "RetypeWord".
Это надо переписать на rustДа хоть на idris. Весь код открыт, заимствуйте как хотите. Замечу, что любой написанный "по мотивам" код не будет подпадать под "антипатент" AGPL, можно лицензировать хоть EULA хоть CPL. *Главное, написать работающее.*
Благодарности
-------------
Отдельное спасибо хочу сказать уважаемым [elfmz](https://habr.com/ru/users/elfmz/) и [unxed](https://habr.com/ru/users/unxed/) за [появление моего любимого FAR в linux](https://github.com/elfmz/far2l/).
И одновременно…выразить надежду на скорейшую реализацию <https://github.com/elfmz/far2l/issues/892> (Очень хочу выделение мышкой как было под виндой, и ведь уже́ почти всё работает!) Несмотря на ряд шероховатостей far2l, весь код для релиза xswitcher я написал именно в его редакторе. *Пользование far2l уже сейчас не кажется актом мазохизма, но две вещи из "старого" FAR хочется увидеть в новом far2l:*
* Функциональность плагина "trucer": обрезка пробелов/табуляций в конце строки и "пустых строк" в конце документа
* Качественный "автодополнитель" слов (в старом far таким был плагин ["Editor Word Completion"](https://github.com/trexinc/evil-programmers/tree/master/ecompl/src)). Он имел достаточное окно поиска и не ломал текст "редактированием поверху".
Как всегда, буду крайне признателен за любую "обратную связь".
Удачи! | https://habr.com/ru/post/577110/ | null | ru | null |
# Эффективные надежные микросервисы

В Одноклассниках запросы пользователей обслуживает более 200 видов уникальных типов сервисов. Многие из них совмещают в одном JVM-процессе бизнес-логику и распределенную отказоустойчивую базу данных Cassandra, превращая обычный микросервис в микросервис с состоянием. Это позволяет нам строить высоконагруженные сервисы, управляющие сотнями миллиардов записей с миллионами операций в секунду на них.
Какие преимущества появляются при совмещении бизнес-логики и БД? Какие нюансы надо учесть, прибегая к такому подходу? Что с надёжностью и доступностью сервисов? Расскажем подробно об этом всём.
Те, кому удобнее видеоформат, могут посмотреть запись, а для всех остальных дальше идёт текстовая версия.
Меня зовут Олег Анастаcьев, я работаю главным инженером в Одноклассниках. А кроме меня, в Одноклассниках есть более 6 000 машин, на которых работает 15 000 задач, как просто на железных серверах, так и в виде контейнеров — в наших собственных четырёх облаках, о которых я ранее уже [рассказывал](https://habr.com/ru/company/odnoklassniki/blog/346868).
Эти задачи предоставляют более двух сотен различных сервисов. Сегодня мы вместе с вами попытаемся построить один из таких микросервисов, связанных с задачей мессенджинга.
Итак, в мессенджере каждый пользователь имеет какие-то чаты. Может создать чат один на один с пользователем, а может сразу с несколькими.

Вариантом чата с несколькими пользователями являются каналы (здесь просто есть ограничение, могут ли пользователи писать или только читать).
Очевидно, что средний пользователь участвует в ограниченном количестве чатов одновременно. По нашим данным, 95% активности пользователя приходится на 5% чатов.
Основное, что хранят чаты — это сообщения. В 80% случаев мы видим в чате не более 13 последних сообщений. На примере выше видно только три и часть четвёртого, но для этой иллюстрации окно браузера было уменьшено — при его обычном размере мы видим приблизительно 13 сообщений.
Но эти цифры не работают, когда нужно получить последние сообщения для отображения в списке чатов:

Маловероятно, что эти сообщения будут востребованы второй раз. В web-клиенте такие сообщения нужно достать только для пары десятков видимых чатов, а для мобильных устройств их может понадобиться значительно больше.
Мы будем строить сервис для хранения сообщений, который сам по себе достаточно масштабный и нагруженный:
* 600 миллиардов сообщений
* 5 миллиардов чатов
* Около 100 терабайт чистых данных без учёта репликации
* Около 120 тысяч запросов в секунду на чтение
* Около 8 тысяч запросов в секунду на запись
Как и любой современный мессенджер, наш должен поддерживать полнотекстовый поиск. Введя запрос в поле поиска, можно получить все чаты с соответствующими сообщениями. А это значит, что сообщения нужно периодически обходить для индексирования. Есть и другие задачи, связанные с обходом и анализом полного набора данных, вроде антиспама.
Сами сообщения — это не только текст, но и множество другой необходимой информации:

В разных колонках этой таблицы — ID чата, ID сообщения в чате (я обозначил его временем создания этого сообщения), автор, тип сообщения (оно может быть текстом, видеозвонком, может быть помеченным как спам), далее текст или какие-то данные, относящиеся к сообщению определённого типа, и прикреплённые файлы.
То есть у нас вот такая табличка передаёт структуру этих сообщений:
```
CREATE TABLE Messages (
chatId, msgId
user, type, text, attachments[], terminal, deletedBy[], replyTo…
PRIMARY KEY ( chatId, msgId )
)
```
И на эти данные у нас поступают следующие операции:
* **getMessages(viewer, chat, from, to)**, который для указанного пользователя в указанном чате получает список последних сообщений за определённый промежуток времени. Разные пользователи могут видеть разный набор сообщений (например, не видеть спам).
* **getLastMessages(viewer, chats)** получает список последних сообщений для большого списка чатов. Это самый тяжёлый запрос в системе, поскольку он идёт по списку чатов.
* Естественно, для мессенджинга у нас есть операция добавления сообщения **add(chat, message)**, операция поиска **search(viewer, text)** и операция индексации сообщений для поиска **indexMessages()**.
Давайте попробуем реализовать это всё с использованием микросервисной архитектуры.
---
Современные микросервисы
------------------------
Пользователи с мобилки или с веба (либо напрямую, либо через какие-то фронты) работают с нашим сервисом сообщений, в котором реализована бизнес-логика, через какой-нибудь наш любимый протокол.
Данные же мы храним отдельно в постоянном хранилище. Отказоустойчивом и надёжном, естественно. Мы используем Cassandra.
Для администрирования этой самой Кассандры мы наняли солидного бородатого дядьку DBA, а мы, нашей хипстерской персоной в кепке, отвечаем только за свой сервис:

Всё, пора запускаться. Попробуем для начала реализовать самый частый запрос getMessages().
Для этого нам нужно выполнить приблизительно вот такой запрос в базу данных:
```
SELECT FROM Messages
WHERE chatId = ? AND
msgId BETWEEN :from AND :to
```
Есть одна небольшая проблема: таких запросов поступает более ста тысяч в секунду. Есть некоторая нагрузка, и сервис у нас начинает ложиться.
Ну что ж. Масштабирование — это то, что мы умеем в микросервисах, правильно? Добавляем инстансов нашего сервиса. И обнаруживаем, что нагрузка проваливается в базу и ложится теперь уже она:
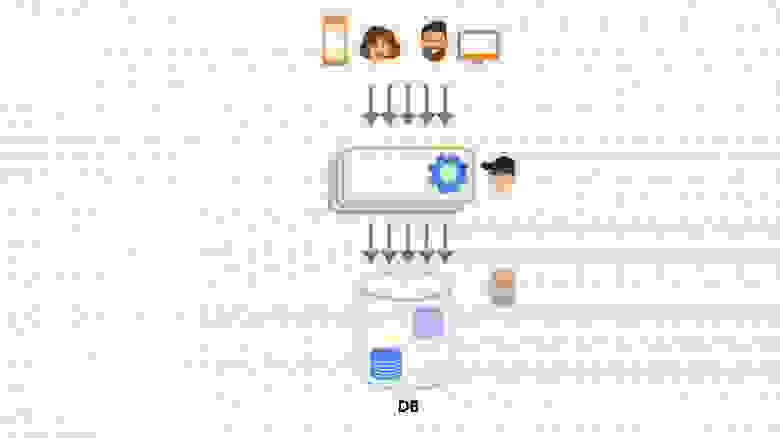
Что дальше? Мы можем либо масштабировать базу, либо воспользоваться знанием, что на 5% активных чатов приходится 95% активности. Будем кешировать.
Вот и бородатый DBA подсказывает, что в нашей базе данных есть кеш часто используемых данных. Пробуем, помогает, но немного.
Оказывается, есть тонкости в других методах сервиса. Вызовы **getLastMessages()** и **indexMessages()** работают не только с активными, но с абсолютно всеми чатами. И хоть вызовов мало, они приводят к тому, что в кеш попадают те 95% записей, которые нам в общем-то не нужны, и вытесняют оттуда нужные нам 5%. Встроенные алгоритмы кеширования БД не могут учитывать специфику приложения и чаще всего ограничены каким-нибудь [общим алгоритмом](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC%D1%8B_%D0%BA%D1%8D%D1%88%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F), как, например, LRU. То есть в нашем сервисе происходит замусоривание кеша ненужными данными.
Чтобы не увеличивать на порядок количество памяти, расходуемой под кеш базы данных, мы должны управлять кешами явно из прикладного кода, помещая туда только те сообщения и тогда, когда это нужно приложению.
Для этого мы можем использовать любое внешнее хранилище ключей-значений в оперативной памяти, например, Memcached, Redis или Tarantool, полностью сняв кеширование с базы данных. При росте нагрузки можем масштабировать кластер memcache независимо.
Вот мы и пришли к типовой архитектуре, к которой приходят многие при построении нагруженного сервиса: прикладной микросервис без состояния, реализующий прикладную логику и использующий внешнюю БД для постоянного хранения состояния и внешний кеш для кеширования:
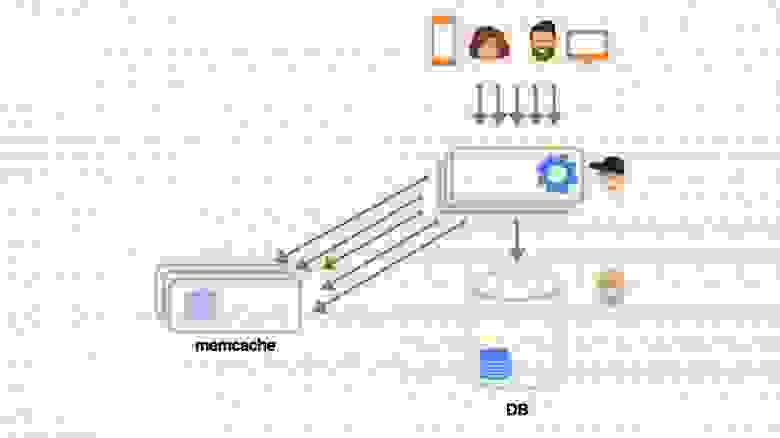
Давайте проанализируем потери, возникающие в такой архитектуре.
---
Потери типовых микросервисов
----------------------------
**Первая проблема — затрата ресурсов CPU на маршалинг и демаршалинг**. [Маршалинг](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%80%D1%88%D0%B0%D0%BB%D0%B8%D0%BD%D0%B3) — это процесс преобразования данных, хранящихся в оперативной памяти, в формат, пригодный для хранения или передачи. Прикинем, где он происходит в нашей схеме.
Наше приложение, обращаясь к memcache, должно замаршаллировать данные и запрос. Кеш должен демаршаллировать эти данные, понять, что это за запрос, обработать, замаршаллировать ответ. Приложение же, получив этот ответ, должно его демаршаллировать на своей стороне.
Те же самые операции маршалинга и демаршалинга будут происходить и при взаимодействии приложения с БД:
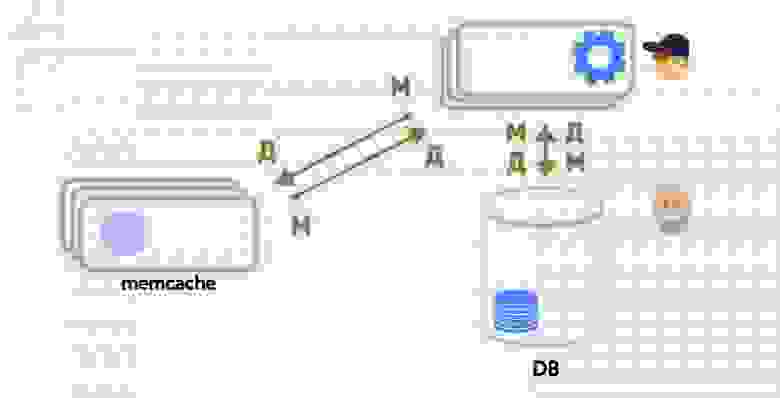
Насколько велики потери при этом? Интуитивно кажется, что немного.
Есть недавно проведенные исследования. Atul Adya, Robert Grandl, Daniel Myers
из Google и Henry Qin из Стэнфордского университета, переписывая одну из своих систем с подобной архитектуры, замерили это и [обнаружили](https://research.google/pubs/pub48030/), что маршалинг и демаршалинг увеличивают нагрузку на процессор на 85%.
И это даёт плюс 27% к медианной задержке, что не очень хорошо, если мы строим low-latency сервис.
**Вторая проблема — чрезмерные чтения и запись**. Они возникают, когда приложение читает больше данных из memcache, чем это необходимо.
В нашем примере с хранением последних 13 сообщений чата в memcache, чтобы получить последнее сообщение из каждого чата, нам пришлось бы прочитать все 13, сериализовать, передать их по сети, десериализовать на стороне сервиса, после чего отбросить 12 из 13, оставив только одно самое свежее сообщение.
Согласно тому же исследованию, если запись содержит только 10% необходимой информации, то мы тратим на 46% больше ресурсов CPU и на 86% больше ресурсов сети, чем это действительно необходимо.
**Третья проблема — сетевые задержки**. Тут мы теряем время как просто на удалённые походы на memcache и базу данных, так и на время передачи нужного объёма данных в запросе-ответе, особенно в сочетании с излишними чтениями.
Но хуже всего, что эти потери растут прямо пропорционально тому, сколько обращений в кеш и базу данных необходимо для обслуживания единственного запроса от клиента.
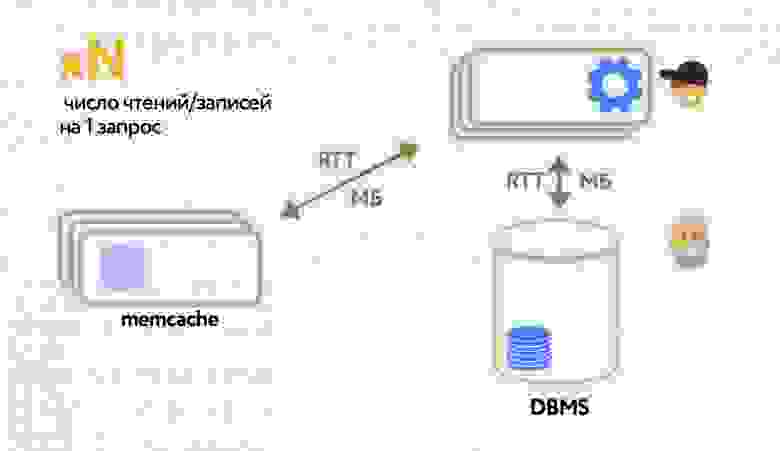
Это число N может быть достаточно большим, оно сильно зависит от креативности разработчика. В нашем примере с получением последних сообщений оно легко может достигать десятков.
Кто виноват — разобрались. Теперь давайте разберёмся, что с этим делать.
---
Чтожеделать
-----------
Поскольку большинство нагрузки попадает на memcache и его связь с прикладной логикой, в индустрии в последнее время большинство усилий было направлено на оптимизацию именно этого: memcache и этой связи.
Некоторые компании концентрируют усилия на [оптимизации](https://www.youtube.com/watch?v=QH1jr8Y1FTQ) перцентильных задержек memcache до 99.99.
[Redis](https://redis.io) и [Tarantool](https://tarantool.io) пытаются уменьшить чрезмерные чтения путём поддержки структуры данных на стороне memcache, что позволяет выбирать не всё значение под ключом, а только часть.
NetCache — решение, которое [пытается](https://www.cs.cornell.edu/~jnfoster/papers/netcache.pdf) уменьшить сетевые задержки путём построения memcache прямо на инфраструктуре сетевых свитчей.
KV-Direct [борется](https://ring0.me/files/KV-Direct/kv-direct-paper.pdf) с демаршаллингом путем переноса задач маршалинга и демаршалинга на сетевые карты.
Тут легко заметить, что большинство проблем возникает именно из-за факта удалённости необходимых данных от приложений. И таким образом, мы можем решить проблемы, просто двинув данные к нашей логике. Так мы приходим к микросервису с состоянием.
---
Микросервис с состоянием
------------------------
Микросервис с состоянием объединяет прикладную логику сервиса с кешем в памяти одного и того же процесса. Это специализированный кеш, в нём реализуются операции, необходимые для прикладной логики.
Это решает все перечисленные выше проблемы:
Во-первых, позволяет полностью избавиться от потерь, связанных с сетевыми задержками. Теперь между этими компонентами нет сети.
Во-вторых, прикладной интерфейс встроенного кеша позволяет реализовать нужную функциональность без чрезмерных операций чтения/записи.
В-третьих, так как теперь прикладная логика и кеш обмениваются данными в памяти одного процесса, мы можем выбрать приемлемый для обоих формат данных, что позволяет полностью убрать или сильно снизить затраты на демаршалинг.
Совмещение базы данных в одном процессе с сервисом решает абсолютно те же самые проблемы, но просто на второй «ноге» нашей архитектуры. И позволяет просто интегрировать все компоненты в случае необходимости.
Ну и вредный дядька DBA нам больше не нужен. Теперь мы сами себе [девопсы](https://www.youtube.com/watch?v=Pa_tFjLyW8s) и отвечаем за все компоненты системы.
Таким образом, микросервис с состоянием будет всегда быстрее при одинаковой реализации приложения за счёт экономии почти в два раза на потерях, которых в этом случае просто нет. Но не может же быть всё хорошо, правильно? Может, оно будет глючить, если не будет тормозить?
Давайте посмотрим, что там с отказоустойчивостью.
---
Отказоустойчивость
------------------
Давайте [вспомним](https://www.youtube.com/watch?v=TXqbALlEI88), какие проблемы возможны в простейшей распределённой системе, состоящей из двух машин — клиента и сервера. Клиент посылает запрос серверу, сервер его обрабатывает и возвращает. Что может пойти не так?
**1, 2** Это внезапная пропажа участника (сервера или клиента) из сети: остановка приложения, падение, ребут сервера.
**3, 4**: Потеря исходящего и входящего сообщения.
**5** Таймаут. Участник отвечает вне указанных временных рамок.
**6** Неправильный ответ — участник отвечает таким значением, которое другой участник не может понять. Например, неправильный формат данных в memcache.
**7** Произвольный отказ, он ещё называется [византийским](https://en.wikipedia.org/wiki/Byzantine_fault). Участник отправляет произвольные сообщения в произвольное время. Это могут быть какие-то умышленные действия, типа различных атак, а могут быть retries, вышедшие из-под контроля.
Итак, давайте посчитаем, какие сценарии отказов будут у нашей системы, построенной как микросервис без состояния. Запрос поступает на наш сервис, в рамках обработки которого он обращается в memcache и базу данных.
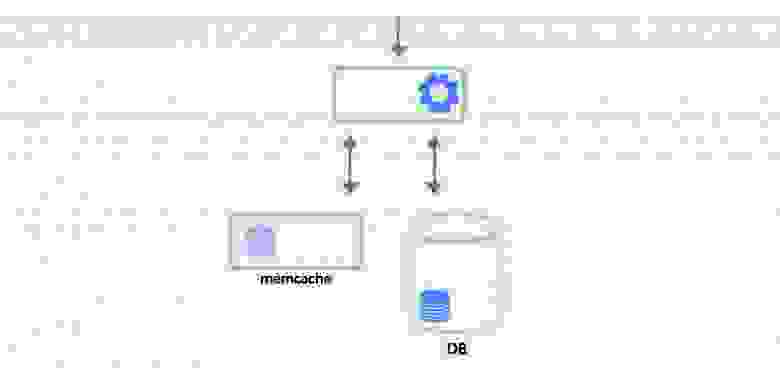
Что в этой схеме может отказать? Может ли отказать memcache? Допустим, memcache пишут волшебные эльфы, и его софт не отказывает. Но может отказать машина или сеть (мы пока не рассматриваем репликацию).
База данных? Ещё более волшебные эльфы пишут ещё более волшебно базу данных, она вообще никогда не крэшится. Но сеть и машина всё равно могут отказать.
И memcache и БД могут отказать либо по-отдельности, либо одновременно, в любой последовательности. Естественно, по [закону Мёрфи](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%9C%D0%B5%D1%80%D1%84%D0%B8) они будут отказывать в самой неблагоприятной.
Таким образом, на обеих «ногах» архитектуры у нас получается по семь сценариев отказа. И наш микросервис тоже может отказать, там уже волшебных эльфов не водилось, и с этим тоже надо как-то иметь дело.
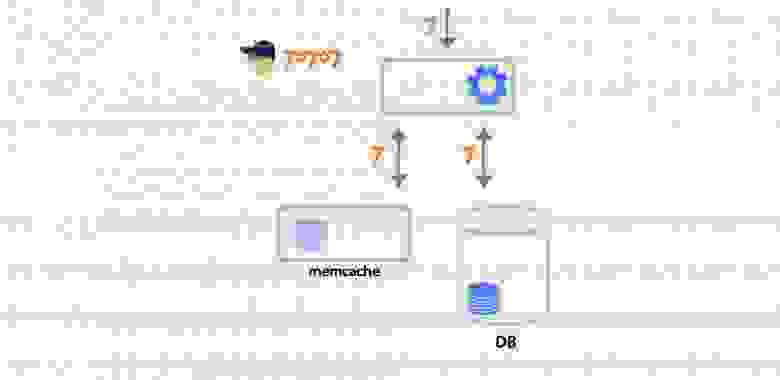
Интересно здесь то, что все эти отказы связаны между собой, они не независимые.
Поэтому для того, чтобы правильно запрограммировать нужную обработку, нам необходимо отдельно рассматривать все отказы и комбинации между ними. Что не делает наш код проще, а вероятность ошибиться и накосячить в таких случаях всегда не равна нулю.
Давайте посмотрим, что будет с отказами в нашей системе, построенной как микросервис с состоянием. Те же самые три машины, организованные по варианту сервиса с состоянием. Здесь схема шардирования будет немного другой. Если в первом случае все три машины отвечали за множество ключей K, то во втором случае каждая из машин будет отвечать только за диапазон равный 1/3 K, которые не пересекаются друг с другом.
Соответственно, коммуникация будет идти только в прикладную логику, ведь кэш и база данных более не требуют сетевой коммуникации. На каждой из этих связей тоже возможны те же самые сценарии отказа.
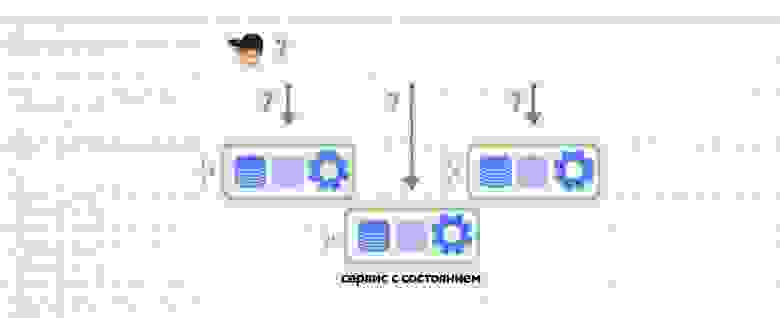
Но действия, которые необходимо предпринять разработчику при отказе первой трети и остальных одинаковы. Если вы обработали отказы по первой трети, остальные надо обрабатывать точно также. Это потому, что эти отказы никак не связаны между собой в рамках обработки одной операции. А значит, комбинации отказов рассматривать не надо и код становится проще.
Давайте теперь посчитаем вероятность отказа машины. Сначала для микросервиса без состояния. Пока предположим для простоты, что репликации у нас нет.
Что будет, если откажет база данных? Будет ли работать у нас сервис по всем ключам? Не будет. Если откажет memcache или сервис, тоже не будет. То есть при отказе любого из компонентов мы получим недоступность сервиса по всем ключам из множества K.
Значит, если вероятность отказа любой конкретной машины обозначим p, то общая вероятность отказа P будет приблизительно вот такой:
**P(K) = 1 – (1 – p)3**
В варианте же сервиса с состоянием при отказе любой машины из трех мы получим недоступность только тех ключей, за которые отвечает эта машина. То есть такой будет вероятность недоступности не всех ключей, а только трети:
**P(1/3 K) = 1 – (1 – p)3**
А чтобы получить отказ по всему множеству K, должны отказать все три машины. То есть формула вероятности отказа для всех ключей сразу будет приблизительно такой:
**P(K) = p3**
По формулам не очень очевидно, что лучше, для наглядности подставим цифры.
Допустим, у нас вероятность отказа конкретной машины p составляет 0.1 (то есть 10%), это очень много, но здесь мы возьмем эту величину для наглядности:
Для сервиса без состояния получим
**P(K) = 1 – (1 – p)3 = 1 – (1 – 0.1)3 = 0.271**
А для сервиса с состоянием:
**P(K) = p3 = 0.13 = 0.001**
Так получается, что архитектура сервиса с состоянием на порядки надежнее.
Конечно, в реальности никто не ставит по одной реплике. Каждая реплика, добавляемая к БД, memcache или микросервису в идеальном случае снижает вероятность отказа каждого компонента на порядок. Но это непринципиально: взаимосвязи компонентов никуда не делись, а поэтому формулы, по которым мы считаем вероятности тоже — мы просто будем подставлять вместо вероятности отказа компонента p = 0.01 для 2 реплик, p = 0.001 для трех, и т.п. Но точно так же мы можем реплицировать и сервис с состоянием, реплицировав каждую уникальную 1/3 K в две (получив вероятность недоступности каждой трети ключей p = 0.01), три (p = 0.001) реплики.
Получается, что сервис с состоянием всегда будет надёжнее при одинаковом и даже меньшем количестве машин.
---
Вперёд, к реализации!
---------------------
С чего начнём? Мы хотим:
* Чтобы наш сервис был высокодоступным. Значит, должна быть обеспечена репликация и определены какие-то гарантии консистентности данных между репликами.
* Чтобы он был масштабируемым, и при увеличении нагрузки мы могли на ходу добавлять мощности. А поскольку сервис теперь совмещён с данными, решардинг, то есть перераспределение данных по масштабируемым нодам, тоже должен поддерживаться.
Конечно, это можно реализовать самим, это интересная задача, работы тут примерно на несколько лет, но намного быстрее взять что-то готовое и допилить. Слова «репликация», «консистентность» и «решардинг» намекают, что мы можем взять что-то в современных БД, поэтому в первую очередь надо определиться с ней.
У нас есть еще одно важное требование к базе данных — она должна быть на языке приложения. Это позволит нам минимизировать демаршалинг и упростить интеграцию с нашим приложением. У нас в Одноклассниках почти всё пишется на Java, соответственно, мы хотим иметь базу данных на Java. Также БД должна иметь открытый код: мы собираемся её использовать нестандартным способом — а значит, будем что то допиливать.
Итак: open source, на Java, высокодоступное масштабирование — исходя из всего этого, в качестве БД мы и выбрали [Cassandra](https://cassandra.apache.org).
Теперь её нужно встроить в наш сервис. Если посмотреть скрипты запуска Cassandra, становится понятно, что запуском занимается класс [CassandraDaemon](https://github.com/apache/cassandra/blob/cassandra-3.11/src/java/org/apache/cassandra/service/CassandraDaemon.java).
А значит, всё, что нам нужно сделать — включить необходимые библиотеки в classpath нашего сервиса ( -cp cassandra/lib/\*.jar ) и вызвать Кассандра-демона вот таким заклинанием:
```
System.setProperty( "cassandra.config", "file://whatever/cassandra.yaml" );
CassandraDaemon.instance.activate();
```
В первой строчке мы устанавливаем, откуда CassandraDaemon будет брать конфигурацию (тот, кто запускал Cassandra, знает, что cassandra.yaml — это её конфигурационный файл). Во второй строчке делается вызов activate(), которым мы и запускаем ноду базы данных.
Файл сassandra.yaml использовать необязательно, есть интерфейс [ConfigurationLoader](https://github.com/apache/cassandra/blob/cassandra-3.11/src/java/org/apache/cassandra/config/ConfigurationLoader.java), который можно реализовать, чтобы интегрировать ноду Cassandra с системой централизованного управления.
Вот и все — мы встроили базу данных в наш сервис — а значит теперь у нашего сервиса есть состояние. Давайте посмотрим, как это меняет маршрутизацию клиентских запросов.
Маршрутизация запросов
----------------------
Предположим, у нас есть пользователь Лёха. Он хочет попереписываться в чате, ключ которого попадает в определённое множество ключей B. Для этого Лёха использует какой-то фронт, который должен решить, куда отправить запрос Лёхи для обработки. Для сервиса без состояния фронту всё равно, какой конкретно работоспособный инстанс сервиса выбрать, последовательные запросы Лёхи могут в итоге попасть на каждый из них:
Со всех этих инстансов цена обслуживания запроса будет одинаковой. Каждому нужно будет отправлять запросы за необходимыми для обработки запросов данными по сети на кеши и на базу данных.
А у микросервисов с состоянием каждый из инстансов сервиса имеет какую-то часть данных локально — один из интервалов ключей, которые я обозначил A, B и C. И теперь инстансу, владеющему интервалом ключей В, незачем куда-то ходить по сети: все данные для выполнения запросов доступны либо в памяти процесса, либо на локальных дисках.
У остальных же инстансов нет данных нужного Лёхе интервала B, и им придётся доставать эти данные по сети. А значит, цена обработки запроса сразу увеличится на демаршалинг и сеть.
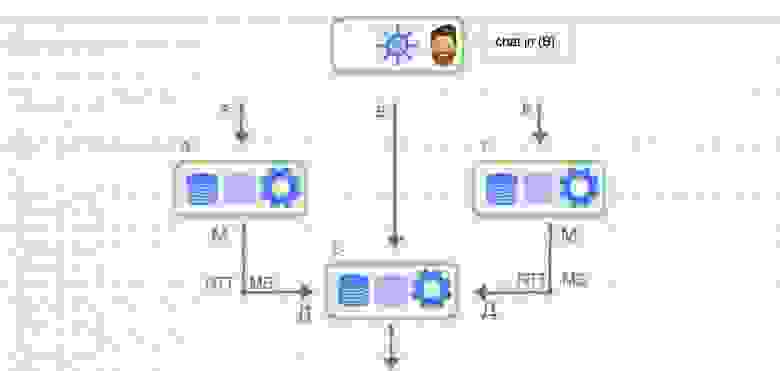
Для того, чтобы запрос по интервалу ключей обрабатывался эффективно, мы не должны обращаться к нелокальным данным. А сделать мы можем это только в случае, если клиенты будут вызывать сразу нужный инстанс сервиса B. Нам нужна маршрутизация запросов, учитывающая топологию кластера, то есть информацию о распределении данных по нодам.
Мы можем реализовать такой роутинг на фронте в виде библиотеки. Она делала бы запросы по ключам сразу на нужные ноды, и эти ноды могли бы работать только с локальными данными.
Распределение данных диктует база данных. Мы только что встроили Cassandra в наш сервис. Давайте посмотрим, как она распределяет данные.
В Cassandra каждый ряд имеет ключ, составленный из двух компонентов:
Partition Key (chatId) — на основании него выбирается нода.
Clustering Key (msgId), который в распределении данных по нодам не участвует, но определяет порядок, в котором записи будут упорядочены внутри партиции.
```
CREATE TABLE Messages (
chatId, msgId
user, type, text, attachments[], terminal, deletedBy[], replyTo…
PRIMARY KEY ( chatId, msgId )
)
```
Записи с разным Partition Key попадают в разные партиции и могут быть распределены на разные ноды. А записи, где различается только Clustering Key, находятся в одной партиции и никак не могут быть распределены по разным нодам — то есть всегда будут находиться вместе. Подробнее об этом можно почитать [тут](https://thelastpickle.com/blog/2013/01/11/primary-keys-in-cql.html).
Поскольку в мессенджере порядок следования сообщений в чате важен, а порядок разных чатов между собой — нет, то для нас в качестве Partition Key правильно будет выбрать ID чата, а Clustering Key — ID сообщения.
С точки зрения кода в распределении данных в Cassandra участвуют следующие компоненты:
* [Partitioner](https://github.com/apache/cassandra/blob/cassandra-3.11/src/java/org/apache/cassandra/dht/IPartitioner.java#L74) — на основании значения Partition Key вычисляет токен, все доступные значения которого принято отображать в виде кольца. Partitioner задаётся один раз на весь кластер и не может быть изменён впоследствии. Среди всех вариантов Partitioner наиболее общеприменим тот, который получает токен путем применения hash-функции [murmur3](https://en.wikipedia.org/wiki/MurmurHash) к значению ключа.
* [TokenMetadata](https://github.com/apache/cassandra/blob/cassandra-3.11/src/java/org/apache/cassandra/locator/TokenMetadata.java#L55) — глобальная структура, в которой хранится разбиение кольца на интервалы значений токенов и соответствие этих интервалов нодам, на которых хранится соответствующая токену партиция.
* [Replication Strategy](https://github.com/apache/cassandra/blob/cassandra-3.11/src/java/org/apache/cassandra/locator/AbstractReplicationStrategy.java#L104) определяет, как организуется хранение реплик партиции и сколько их вообще должно быть. Можно указать разные Replication Strategy для разных таблиц, поместив их в разные keyspace.
Этой информации достаточно для того, чтобы в три строчки составить полную карту нахождения всех данных и их реплик в нашем кластере.
```
SortedMap> endpointMap = …
AbstractReplicationStrategy replication = …
for (Token token : tokenMetadata.sortedTokens() ) {
endpointMap.put( token, replication.getNaturalEndpoints( token ) );
}
```
В приведённом примере endpointMap будет содержать соответствие между максимальным токеном интервала и адресами всех реплик попадающих в интервал ключей. Передав этот endpointMap клиенту, легко сделать нужную нам маршрутизацию. Стоит иметь в виду, что топология кластера меняется время от времени, ноды добавляются и уходят, поэтому эту информацию нужно периодически обновлять.
Мы, например, обновляем её раз в 30 секунд. Также стоит подумать о том, что делать, если клиент вызывает сервис, пользуясь устаревшей топологией. Например, вскоре после расширения кластера, запросы могут уйти не на те ноды. Тут могут быть несколько вполне очевидных стратегий: и редирект, и push-нотификации с новыми нодами. Стоит подумать, какая конкретно подходит под задачу.
С клиентами теперь всё нормально, давайте разберёмся, как нам работать с данными.
Работаем со встроенной БД
-------------------------
У нас есть вот такая таблица:
```
CREATE TABLE Messages (
chatId, msgId
user, type, text, attachments[], terminal, deletedBy[], replyTo…
PRIMARY KEY ( chatId, msgId )
)
```
И нам нужно получить список сообщений, то есть выполнить вот такой запрос:
```
SELECT FROM Messages
WHERE chatId = ? AND
msgId BETWEEN :from AND :to
```
Возможно, отфильтровав ненужные записи потом.
Как мы сделали бы это через драйвера базы данных? Вот пример, который я взял прямо из [мануала](https://github.com/datastax/java-driver/tree/4.x/manual/core#quick-start).
```
import com.datastax.oss.driver.api.core.CqlSession;
import com.datastax.oss.driver.api.core.cql.*;
try (CqlSession session = CqlSession.builder().build()) { // (1)
ResultSet rs = session.execute("select release_version from system.local"); // (2)
Row row = rs.one();
System.out.println(row.getString("release_version")); // (3)
}
```
Что тут происходит (в строках, помеченных числами 1-3):
1. Строим сессию с кластером, устанавливаем соединение с кластером
2. Выполняем запрос, получаем ResultSet
3. Используем его
На самом деле всё немного сложнее, потому что нужно где-то хранить конфигурацию куда на какой кластер ходить, работать с сессиями и прочее.
Для работы же со встроенной в наше приложение Cassandra мы будем работать с классом [QueryProcessor, у которого есть метод execute](https://github.com/apache/cassandra/blob/cassandra-3.11/src/java/org/apache/cassandra/cql3/QueryProcessor.java#L322) , который достаточно вызвать для выполнения запроса:
```
package org.apache.cassandra.cql3;
import java.nio.ByteBuffer;
public class QueryProcessor
{
public static UntypedResultSet execute(String query,
ConsistencyLevel cl, Object… values)
throws RequestExecutionException
}
```
Обратите внимание, что он — статический. Почему? Дело в том, что нам не нужна никакая сессия ни с каким кластером. Наша локальная нода и есть уже член кластера, ей никуда не нужно устанавливать соединение. Поэтому этот метод статический, вы его вызываете и, естественно, вызываете в контексте своего собственного кластера.
Соответственно, для getMessages() получится примерно такой код выполнения этого запроса:
```
UntypedResultSet rs = QueryProcessor.execute(
"SELECT * FROM Messages "
+ "WHERE chatId = ? AND msgId < ? AND msgId > ?"
ConsistencyLevel.QUORUM, chatId, from, to );
rs.forEach ( row -> {} );
```
Аналогичным способом для add() мы должны выполнить запрос добавления записи приблизительно таким же образом:
```
QueryProcessor.execute( "INSERT INTO Messages VALUES (?,?,?,...)", cl, values );
```
Всё просто. Если покопаться в QueryProcessor, можно найти и более эффективный способ получения записей из базы данных. Он не так просто выглядит, поэтому здесь я его не показал, но даже этот вариант будет быстрее стандартного драйвера за счет экономии на маршалинге и сетевой задержке.
---
Кеш сообщений
-------------
Как мы определились ранее, скорости БД нам не хватает и мы решили реализовывать прикладной кеш сообщений. Для начала давайте посчитаем, сколько данных он будет хранить. Итак, у нас всего:
* 600 миллиардов сообщений
* 100 терабайт данных
* 5 миллиардов чатов
* Из этих чатов только 5% активных
* И из каждого мы хотим хранить в кеше 13 последних сообщений
Все исходные данные есть, можем посчитать, что в память у нас попадает довольно большое количество сообщений и данных:
* 3+ миллиарда сообщений
* 250 миллионов чатов
* 500 гигабайт данных
Это без учёта репликации. Нужно их ещё поделить на количество нод в кластере и умножить на replication factor.
Такой кеш сообщений должен обладать прикладным интерфейсом, соответственно, мы должны реализовать какие-то методы из нашего списка (getMessages(), getLastMessages(), add(), search(), indexMessages()). На практике нужны только первые три, потому что мы хотим, чтобы поиск и индексация никогда ходили в кеш.
Начнём с реализации getMessages() на примере чатика Лизы с Лёхой:
* Пользователь Лиза открывает ok.ru и выбирает чат с Лёхой. То есть, мы через веб-фронт получаем на некоторый инстанс запрос getMessages().
* Далее прикладной код проверяет, есть ли этот чат у нас в кеше.
* Обнаруживает, что нет, вызывает QueryProcessor, получает данные из БД.
* Помещает его в кеш.
* Наконец, возвращает актуальное состояние чата Лизе.
Вот эти пять шагов:
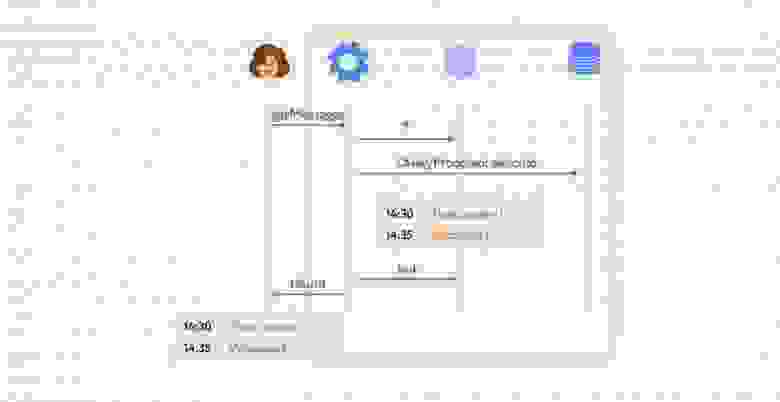
Лёха через мобильное приложение делает то же самое и удачно попадает на другую реплику.
Выполняет тот же самый запрос, точно так же в кеше другой реплики данных нужного чата нет, загружаем его, получаем актуальное состояние чата:
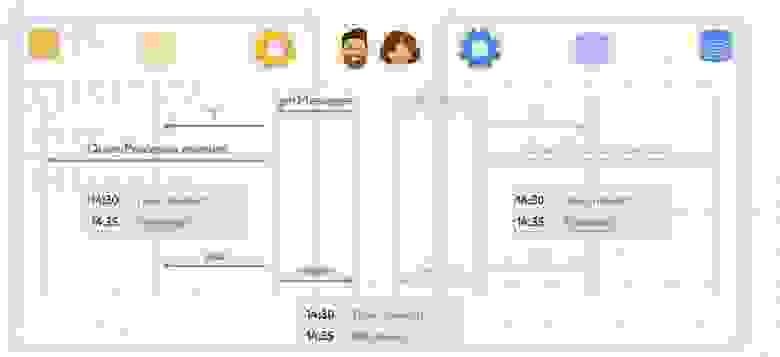
Заботясь о состоянии Лёхи, Лиза предлагает ему сходить пообедать, то есть вызывает метод add(). Нода помещает запись о новом сообщении и в базу данных, и в кеш:
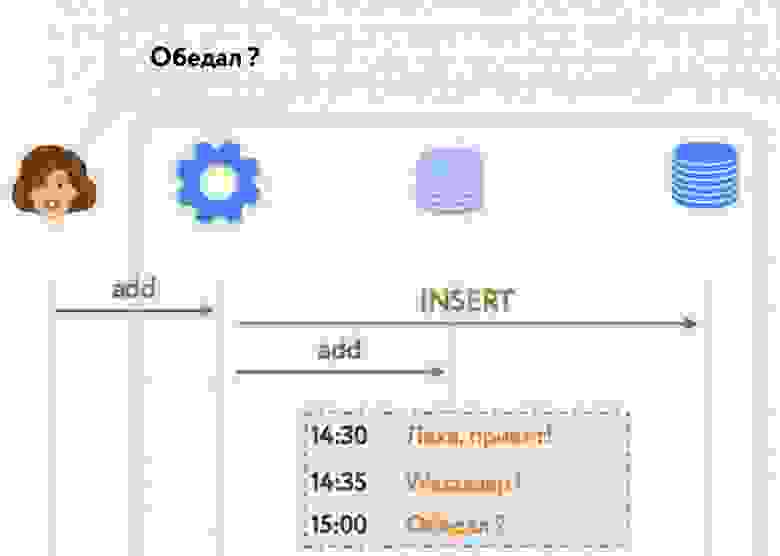
Теперь в кеше этой реплики у нас три сообщения, а в кеше Лёхиной по-прежнему два:
Лёха, получив пуш на телефон, спрашивает getMessages(), обращается в кеш. А там уже есть данные, но они устаревшие. Мы получаем их, и Лёха остаётся голодным:
Актуальность данных
-------------------
Очевидно, мы должны как-то сообщать другим репликам, что появилось новое сообщение.
Мы можем использовать информацию о топологии кластера: точно так же, как мы это делали на клиенте, вычислить все реплики и нотифицировать их все с новым сообщением. Например, вызвав какой-то спецметод added():
И тогда мы вставим новое сообщение кеши всех остальных реплик, и на всех репликах всегда будет актуальное состояние кешей. Или нет?
Проблема в том, что этот запрос пойдёт через сеть на другую реплику, а, следовательно, он может не пройти:
И что на самом деле произошло с репликой, до которой не удалось доставить это сообщение, мы не знаем. Может быть, она крэшнулась? У нее вылетели диски? Может, какие-то нарушения в сети произошли?
Время восстановления удаленной реплики спрогнозировать невозможно, а ждать до бесконечности завершения операции add() мы не можем. Однозначно то, что при такой схеме не все нотификации будут достигать всех реплик, поэтому для некоторых записей состояние кешей будет устаревшим. А такая несогласованность имеет тенденцию к накапливанию со временем.
Давайте посмотрим, как эту же ситуацию будет отрабатывать Cassandra. При выполнении INSERT она тоже определит необходимые реплики данных, которые нужно изменить, сформирует для них требования об изменении (мутацию) и попытается послать это требование по сети.
Поскольку наш кеш и нода желтой реплики — это один процесс, то такая мутация не может быть доставлена точно в силу тех же самых сетевых и прочих проблем.
В этом случае Cassandra сохраняет такие мутации локально и персистентно.
Когда связь с желтой репликой снова восстановится, такие пропущенные мутации будут отосланы ей при первой же возможности. Это называется [Hint](http://cassandra.apache.org/doc/latest/operating/hints.html).
Обычно такие пропущенные мутации сохраняются некоторое ограниченное время, иначе место на дисках работоспособных нод могло бы закончиться из-за одной-единственной достаточно долго не работающей ноды.
Для восстановления согласованности в случаях долгой неработоспособности ноды служит [Read Repair](http://cassandra.apache.org/doc/latest/operating/read_repair.html) — сравнение реплик при чтении. В результате обнаружения расхождения версий формируется мутация на устаревшие реплики.

И, наконец, [Streaming Repair](http://cassandra.apache.org/doc/latest/operating/repair.html) — это пакетный фоновый процесс обхода и сравнения всех или какой-то части данных всех реплик.
В результате такого процесса формируется файл, содержащий несовпадающие между репликами данные, который передаётся на устаревшую ноду целиком через отдельное соединение. Это называется Streaming.
Очевидно, что мы могли бы всё вот это реализовать сами. Это ещё одна интересная задача на несколько лет.
Но мы с вами люди занятые, давайте посмотрим, что мы хотим. Мы хотим, чтобы, когда база данных любым способом (Hint, Read Repair или Streaming Repair) получает данные, локальная нода база данных могла бы нотифицировать нашу прикладную логику, а она в ответ на это могла бы сделать необходимые действия и добавить новые данные в кеш.
То есть мы хотели бы определить такой интерфейс для listener'а изменений в Cassandra и реализовать его в нашей прикладной логике:
```
interface ApplyMutationListener
{
void onApply(ByteBuffer key,
DeletionTime deletion,
Iterator atoms);
}
```
Естественно, сам по себе такой интерфейс работать не будет, и нам надо дописать в Cassandra немного кода. Оказывается, таких мест всего два.
Все мутации, независимо от того, какая подсистема их сформировала, проходят через [вот этот метод](https://github.com/apache/cassandra/blob/cassandra-3.11/src/java/org/apache/cassandra/db/Keyspace.java#L470).
```
package org.apache.cassandra.db
public class Keyspace
{
public void apply( Mutation mutation,
boolean writeCommitLog,
boolean updateIndexes.
boolean isDroppable )
// ...
}
```
Объект Mutation здесь содержит список новых данных для различных таблиц ноды. Соответственно, можно просто брать эти данные и передавать его в listener.
Весь Streaming, независимо от причины, по которой он был запущен (из-за Repair, бутстрапа новых нод в кластере или из-за выемки нод из кластера), заканчивается вот таким [OnCompletionRunnable](https://github.com/apache/cassandra/blob/cassandra-3.11/src/java/org/apache/cassandra/streaming/StreamReceiveTask.java#L183):
```
package org.apache.cassandra.streaming
public class StreamReceiveTask extends StreamTask
{
// holds references to SSTables received
protected Collection sstables;
private static class OnCompletionRunnable implements Runnable {
// ...
}
}
```
Взяв список таблиц, достаточно просто пройтись по ним итератором и передать данные в наш ApplyMutationListener.
Потеря состояния кеша
---------------------
Давайте рассмотрим ту же ситуацию с другого ракурса: мы добавляем запись, мутация не может быть доставлена, но не потому, что были какие-то временные проблемы на сети, а потому, что сервер пошел в ребут.
Это означает, что состояние нашего кеша в памяти пропало. И тогда Hints нам не помогут, потому что они содержат только новые данные:
А для получения старых мы должны были бы на getMessages() их дочитать из базы данных. После старта это привело бы к лавинообразному пику чтений из базы данных, и есть шанс, что мы просто уложим весь кластер возросшей нагрузкой.
Очевидно, мы должны сохранять текущее состояние кеша для последующего восстановления. В системах, ориентированных на хранение данных в памяти, для этого часто используют [периодический снапшот кеша и постоянно пишущиеся WAL](https://www.tarantool.io/en/doc/1.10/dev_guide/internals_index/#data-persistence-and-the-wal-file-format). Тогда в момент старта состояние кеша можно восстановить, загрузив последний снапшот и дочитав изменения с момента его записи из WAL. В Cassandra подобное, оказывается, уже есть, и нам это отдельно программировать не нужно. Мы можем создать вот такой keyspace, указав для него недокументированную стратегию репликации [LocalStrategy](https://github.com/apache/cassandra/blob/cassandra-3.11/src/java/org/apache/cassandra/locator/LocalStrategy.java):
```
CREATE KEYSPACE Caches
WITH REPLICATION = {
'class': 'LocalStrategy'
}
```
LocalStrategy устанавливает, что таблицы такого keyspace не нужно реплицировать, это локальные данные ноды.
И в таком keyspace мы можем создать вот такую таблицу:
```
CREATE TABLE Caches.MessagesSnapshot (
rowkey blob,
value blob,
PRIMARY KEY ( rowkey )
)
```
Дальше мы на каждый put в кеш можем делать в неё запись о том, что у нас есть новые данные в кеше, а на каждый eviction из кеша — удалять из неё запись:
И тогда при старте приложения мы проверяем, пустой ли наш кеш, если пустой, мы его грузим таким вот способом:
```
SELECT * FROM MessagesSnapshot
```
Загружаем все старые данные с диска в кеш, а через хинты к нам приезжают новые данные — те, которые нода приложения не видела, пока лежала.
Всё это происходит достаточно быстро для нашей задачи — около полумиллиона чатов в секунду — что позволяет загрузить кеш с диска за несколько минут.
Но быстро — понятие относительное, и мы не очень хотим ждать вот этой загрузки с диска при плановом рестарте (допустим, из-за выкладки новой версии). Это можно сделать с помощью разделяемой памяти.
Разделяемая память для нас интересна тем, что данные в ней не пропадают при рестарте приложения. Для нас самый простой способ получить туда доступ — открыть mapped byte buffer например на такой файл: /dev/shm/msgs-cache.mem.
Но лучше использовать уже готовую структуру, например, доступную в нашей библиотеке one-nio, которая уже давно есть [на GitHub](https://github.com/odnoklassniki/one-nio). Обратите внимание на [SharedMemoryMap](https://github.com/odnoklassniki/one-nio/blob/master/src/one/nio/mem/SharedMemoryMap.java) и его потомков, там есть кеши на разный вкус и цвет, умеющие использовать SharedMemory.
Этот класс можно использовать, замонтировав /dev/shm под tmpfs, обычно это делается по дефолту. Но чаще мы используем [hugetlbfs](https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt), что позволяет нам делать более крупные страницы в памяти на уровне операционной системы, а, значит, уменьшить количество TLB misses и ускорить работу с памятью.
Так, при плановом рестарте данные никуда ниоткуда грузить не нужно, SharedMemoryMap очень быстро только проверяет валидность данных в разделяемой памяти, это происходит практически мгновенно.
Ожидание согласованности
------------------------
Итак, наша ситуация с рестартом реплики: теперь старт стал быстрым, и часть запросов успевает проходить до того, как придут хинты. Иии… Лёха снова получает устаревшую версию кеша и снова остаётся голодным.
Почему так? Процесс посылки хинтов в Кассандре асинхронный by design. Поскольку при чтении Cassandra обращается к нескольким репликам для определения согласованности данных и может отбросить устаревшие данные с рестартнутой ноды, хинты не обязательны для соблюдения согласованности.
Наше же приложение в 15 раз больше нагружено именно на чтение, чем на запись, и вариант разрешения согласованности при чтении для нас слишком тяжёл.
Поэтому мы делаем так: Мы запускаем сначала сетевые сервисы нашей встроенной БД, ждём, пока она примет хинты от остальных нод кластера, и только после этого запускаем обслуживание прикладных запросов сервиса. С этого момента на сервис могут поступать запросы от клиентов, нода теперь находится в согласованном состоянии.
В принципе, такое ожидание, получение всех нод — это задача распределённой координации. Мы должны координировать все реплики и решить для себя, все ли хинты мы получили.
Мы пробовали применять несколько различных стратегий, но в итоге остановились на самой простой: нода как после старта периодически опрашивает другие ноды, которые могут иметь реплики, «есть ли хинты для меня». И повторяет этот запрос до тех пор, пока все ноды не ответят «Нет». После этого старт продолжается.
Логика на самом деле не настолько простая: нужно учитывать отказы остальных нод, которые могут произойти в момент ожидания, изоляцию ноды от всех реплик тоже нужно учитывать, массовые аварии нужно учитывать, но всё это решаемые вопросы.
---
Мы хотим большего!
------------------
С этим разобрались, поехали дальше.
Теперь мы можем подступиться к самому тяжёлому запросу **getLastMessages(chats[])** — получить последнее сообщение для каждого чата из списка.
Этот запрос должен рассмотреть списки сообщений по множеству чатов, разные чаты могут быть расположены на разных нодах. А значит, нет одной ноды, владеющей всеми данными.
В большинстве случаев загружаются данные неактивных чатов, а значит, этих данных в кеше нет. И загружать их в кеш смысла мало, потому что маловероятно, что они станут активными в ближайшее время.
Данные таких чатов, если они не в кеше, скорее всего, уже согласованы. Так как на старых данных, скорее всего, уже произошли все необходимые процедуры согласования в Cassandra: и hints, и read repair, и streaming repair.
А если чат становится активным, то он будет помещён в кеш и перестанет быть старым. Возможно, мы что-то сможем сэкономить на этом в будущем, посмотрим.
Как бы мы реализовали этот метод в сервисе без состояния? Клиент вызвал бы в сервисе метод, прикладная логика которого опросила бы все memcaches для каждого чата из списка, и базы данных для тех старых чатов, которые уже были вытеснены из кеша:
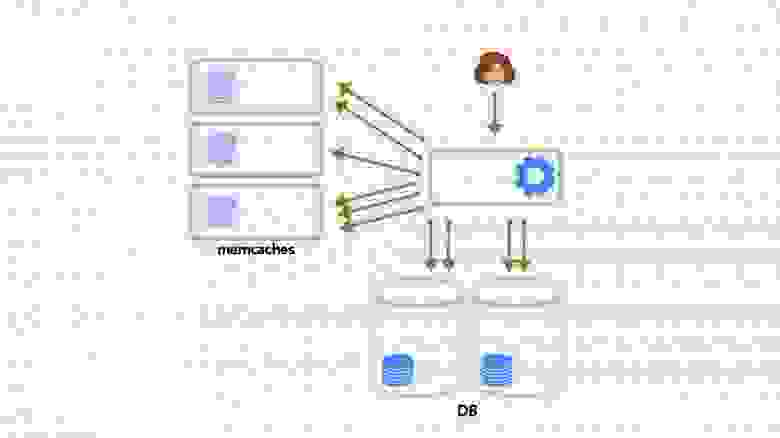
В сервисе с состоянием нет единого сервиса с полным набором данных, а проксировать вызовы с одного инстанса на другие неэффективно. Наиболее эффективно иметь реализацию этого метода на всех участниках — и на сервисах, и на фронте клиента.
Такая «клиентская» реализация использует информацию о топологии кластера и разбивает список ключей чатов на несколько списков (для каждого инстанса сервиса свой), выбирает реплику и вызывает её, передав ей список с её ID чатов.
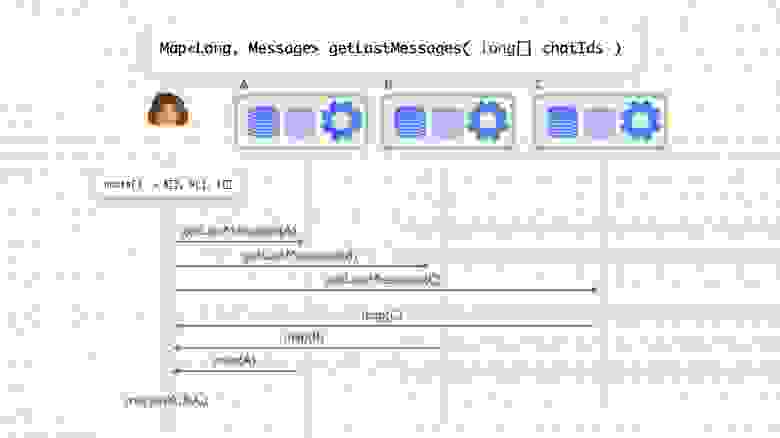
То же самое с остальными репликами — сервисы отрабатывают запросы и возвращают данные (каждый свою часть), а клиент, дождавшись ответа по всем нужным ключам, объединяет результат.
Такая реализация выглядит сложной, но не обязательно писать её каждый раз руками, мы вполне можем реализовать такой алгоритм один раз для всех подобных случаев.
Локальные чтения
----------------
Внутри же каждой реплики выполнение было бы таким. Бизнес-логика обращается в кеш, оттуда получает данные для активных чатов, а из базы данных мы запрашиваем неактивные. Но, поскольку наша база данных распределённая, при обработке запроса будет происходить сетевой запрос для возможного согласования реплик данных, а это дополнительная сетевая коммуникация:
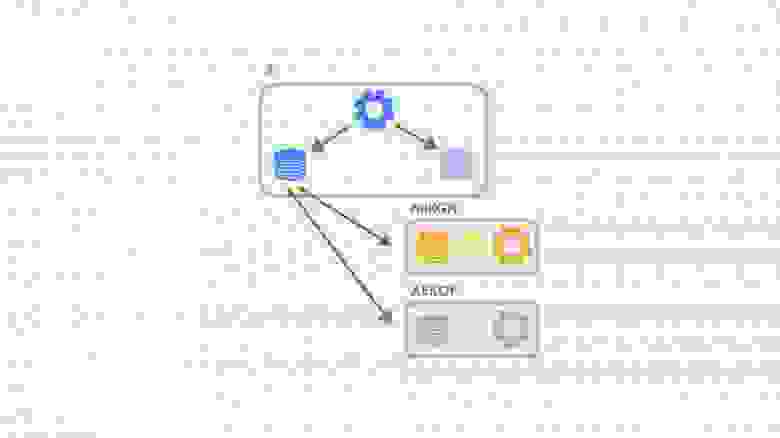
Мы знаем, что согласованность на старых чатах нам не так важна, скорее всего, данные согласованы. Поэтому мы могли бы убрать большую часть сетевой коммуникации в нашем самом тяжёлом запросе, запросив данные у базы данных только с локальной реплики:
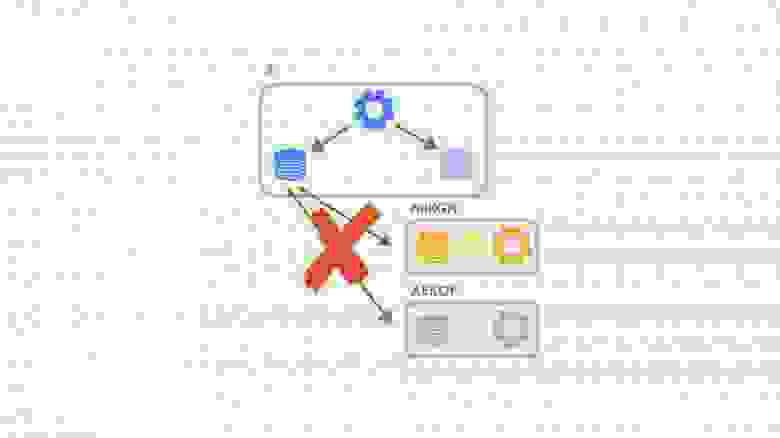
В стандартном API Cassandra нет способа сделать такое. Но наш-то сервис работает вместе с Cassandra в одной и той же JVM, поэтому он не ограничен публичным API.
Мы можем выполнить какой-то такой код:
```
public Message getLastMessage(Long chatId) {
Prepared prepared = QueryProcessor.prepareInternal( "SELECT … WHERE chatId=?" );
SelectStatement select = (SelectStatement) prepared.statement;
QueryOptions opt = QueryProcessor.makeInternalOptions( prepared, chatId );
ReadQuery query = select.getQuery( opt, FBUtilities.nowInSeconds() );
UnfilteredPartitionIterator partitions = query.executeLocally( query.executionController() );
UnfilteredRowIterator partition = partitions.next();
partition.forEachRemaining( atom -> { /* unmarshalling code */ } );
}
```
Здесь очень много какой-то магии, но на самом деле всё то же самое: мы делаем statement, передаём параметры, а отличие только в вызове executeLocally(). Он значительно быстрее, так как много накладных расходов, связанных с сетевой коммуникацией, просто не возникает.
Полнотекстовый Поиск
--------------------
Теперь мы добрались до самого сложного: полнотекстового поиска. Мы хотим ввести что-то в поисковой строке и быстро получить список чатов и сообщений.
Искать простым просмотром всех чатов, даже с использованием локального чтения — не вариант. Сто терабайт данных быстро не просмотришь даже на кластере из ста машин (если, конечно, пользователь не один-единственный и очень терпеливый).
Соответственно, нам нужно построить полнотекстовый индекс с использованием, например, Apache Lucene.
Один большой инвертированный индекс на сто терабайт [будет глючить и тормозить](https://www.youtube.com/watch?v=EkkzSLstSAE). Это отдельная интересная тема, но обсуждение этого выйдет далеко за рамки этой статьи ( о проблемах в эксплуатации больших индексов можно посмотреть еще [тут](https://www.youtube.com/watch?v=0SJo61K3WF0) ). Поэтому мы хотим строить много отдельных индексов — для каждого чата свой собственный.
Строить индексы заранее ( а значит и хранить их ) стоит только для больших чатов, для маленьких чатов мы можем построить эти индексы в момент поиска.
Итак, как бы мы могли это сделать. Давайте попробуем по-простому. При добавлении записи в методе add(), как только мы вставляем сообщение в таблицу, и, как часть бизнес-логики, вызываем IndexWriter.addDocument(), и IndexWriter.commit():

Но есть одна большая проблема: мы сделали слишком много коммитов, восемь тысяч в секунду.
А слишком частые коммиты приводят к тому, что у нас будет слишком много сегментов этого индекса. А для того, чтобы сегменты слить, требуется дисковая операция. То есть мы таким способом уложим диски нашей ноды.
Не получается. Хорошо. Вызовем IndexWriter.addDocument(), но вызывать IndexWriter.commit() не будем. Будет работать? Недолго, поскольку переписка идёт в реальной системе по множеству чатов одновременно, у нас будет открыто очень много индексных сегментов множества чатов. Они будут в открытом состоянии и соответственно будут жрать память, и мы уложим нашу ноду по памяти.
Что же делать? То, что мы на самом деле хотели бы, это какой-то фоновый процесс, который предварительно объединял бы множество сообщений одного чата в один пакет по мере их появления. Но не очень часто, так, чтобы мы могли успевать коммитить индексы, чтобы они успевали мерджиться друг с другом.
Такой процесс в Cassandra уже есть, нам не нужно делать его самим. Он называется [Compaction](http://cassandra.apache.org/doc/latest/operating/compaction.html). Это процесс слияния различных поколений данных, который Cassandra делает сама по себе для поддержания необходимой ей структуры данных на диске.
Данные при этом в пределах чата просматриваются в порядке следования их Clustering Key, что для нас означает, что, вклинившись в этот процесс, мы получим данные в нужном нам порядке.
В Cassandra этим процессом занимается [вот такой класс](https://github.com/apache/cassandra/blob/cassandra-3.11/src/java/org/apache/cassandra/db/compaction/CompactionManager.java):
```
package org.apache.cassandra.db.compaction;
public class CompactionManager implements CompactionManagerMBean {
// …
}
```
Дописать туда небольшой дополнительный процессинг нетрудно, и теперь у нас есть бесплатная массовая обработка данных, причём локальная, которую можно использовать в этом и других подобных случаях.
Когда пользователь делает поиск, мы используем основной индекс, сформированный в процессе Compaction, а для того, чтобы искать и среди свежих сообщений — доиндексируем сообщения добавленные с момента последнего компакшена непосредственно перед поиском. Надеюсь в будущем расскажем о том как работает поиск более подробно.
---
Эксплуатация
------------
Понаписали мы тут кода, давайте теперь попробуем с этим всем пожить и поэксплуатировать.
**Первое, с чем столкнёмся — увеличившееся время раскатки новой версии**.
Это происходит из-за того, что теперь наш сервис стартует дольше. Почему?
* Потому что теперь у нас в сервисе есть база данных, а ей нужно инициализировать свои данные на дисках. То есть скорость старта зависит от скорости диска с нашими данными и скорости проигрывания write-ahead лога.
* Вторая часть, которую нам нужно ждать — загрузка кеша из той самой локальной таблицы Caches.MessagesSnapshot. Тут зависит от размера этого кеша — чем больше, тем дольше ждать. Ещё влияют коллизии ключей в кеше и мощность CPU.
* Мы должны подождать согласованности, то есть, подождать, пока все пропущенные хинты к нам придут.
* И время выкладки растет пропорционально количеству обновляемых реплик.
Что будем делать?
Если раньше мы выкладывали реплики по одной, то имеет смысл параллелизовать выкладку реплик по зонам доступности.
Мы делаем так: сначала выкладываем одну реплику для проверки того, что новая версия работает, а затем все остальные реплики первого дата-центра мы выкладываем параллельно. Потом параллельно перекладываются все реплики второго дата-центра, затем все третьего.
**Вторая проблема: более частые рестарты базы данных.**
Понятно: база данных теперь вместе с приложением, и когда мы обновляем приложение, то выключаем и его базу данных и перезапускаем по дата-центрам.
Внутренний DBA нам говорит: нельзя перезапускать базу данных.

Можно уволить DBA из компании, но нужно ещё выжечь его внутри себя. Что же делать?
А на самом деле, ничего не делать, это хорошо. Это позволяет нам регулярно тестировать отказоустойчивость нашего сервиса в контролируемых условиях — в тот момент, когда мы на него смотрим и делаем контролируемые перезапуски. Лучше так, чем Вселенная протестирует отказоустойчивость сама, ночью, когда у нас внезапно выключится дата-центр.
**А вот что является реальной проблемой — взаимное влияние прикладного кода на базу данных.**
Опять же, база данных у нас теперь вместе с приложением, в той же самой JVM. И в нашей прикладной логике можно легко написать что-нибудь такое, от чего, например, закончится хип. И, выложив на все базы данных наш новый классный код, который пожирает память огромными темпами, мы можем уложить весь кластер базы данных.
Что делать? Когда есть такой код, или есть подозрение на него, или просто в качестве дефолтной практики можно делать так: нам нужно выложить наш новый код на один дата-центр и некоторое время подождать, что же будет.
Максимум, что мы можем сломать — это один дата-центр, но все остальные будут работать и обслуживать клиентов. А мы сможем откатить проблемную версию, если что-то пошло не так.
Второй вариант — если есть какая-то совсем опасная ситуация, то у вас должны быть [рубильники](https://en.wikipedia.org/wiki/Feature_toggle), которым вы можете на ходу отключить опасную функциональность.
**Ну и ещё одна фобия, с которой придётся столкнуться — это апгрейд на новую версию встроенной базы данных.**
Мы тут понаписали всякого кода и поиспользовали внутренние API, которые незадокументированны. Что говорит наш внутренний DBA: они же всё поменяют там в этом незадокументированном API, мы застрянем на старой версии и всё потеряем! Что же делать?
На самом деле, архитектура базы данных остается неизменной годами. Наблюдение за Cassandra, за развитием их внутреннего API, показало, что сущности как были, так и остались. Максимум, что поменялось — они переименовываются время от времени.
Хорошие распределённые базы данных, в том числе и Cassandra, поддерживают rolling upgrades. Для них нормальная ситуация, когда на некоторых нодах кластера стоят разные версии базы данных. И это хорошо. Потому что для нас в микросервисах c состоянием апгрейд базы данных означает просто то, что мы подключаем нашу новую базу данных как новую версию встраиваемой библиотеки, выкатываем всё это на один дата-центр, ждём, что сломается, и откатываем, если что-то сломалось.
Если мы ещё и данные умудрились запороть — тоже небольшая проблема, мы можем их откатить и восстановить эти данные из других дата-центров с помощью [штатной процедуры замены отказавшей ноды](https://docs.datastax.com/en/cassandra-oss/3.0/cassandra/operations/opsReplaceNode.html).
---
Итог
----
* Микросервисы с состоянием эффективнее и надёжнее, потому что у них отсутствуют потери на маршалинг и нет сети между компонентами.
* Теперь у нас есть бо́льшие гарантии консистентности кеша. Поскольку мы совмещаем кеш и базу данных в одном процессе, мы можем гарантировать, что наш кеш будет консистентен с базой данных. Вопросы консистентности кеша часто вообще не адресуются в микросервисах без состояния.
* Всё это относительно просто реализуется, самое сложное есть в Cassandra и в one-nio.
* Мы это давно и широко используем. Множество сервисов построены именно по этому паттерну, есть высоконагруженные, есть сервисы, в которых очень много данных: лента, обсуждения, посты, нотификации, классы.
Если вы хотите узнать больше об Одноклассниках или о том, как применяется этот паттерн, то вы можете посмотреть еще вот эти доклады:
* [Распределённые системы в Одноклассниках](https://ok.ru/video/97105087088) (Олег Анастасьев)
* [Новый граф Одноклассников](https://www.youtube.com/watch?v=Z3zRKfIyIYs) (Антон Иванов)
* [Китайские товары: просто, дешево, надежно](https://youtu.be/qjrOnwzY9zo) (Александр Тарасов) | https://habr.com/ru/post/499316/ | null | ru | null |
# Ещё одна метеостанция, пошаговая видеоинструкция
Последнее время все более популярна стала тема метеостанций. Наверное создание собственной погодной станции является хорошей практикой в освоении ардуинки. Хочу внести свой небольшой вклад в это благое дело.
Хочу представить Вам видео урок по работе с датчикам температуры, влажности, давления, и выводу этих данных на дисплей.Возможно эта информация кому — то поможет начать свой путь в мир микроконтроллеров.
Станция собиралась по этой схеме.
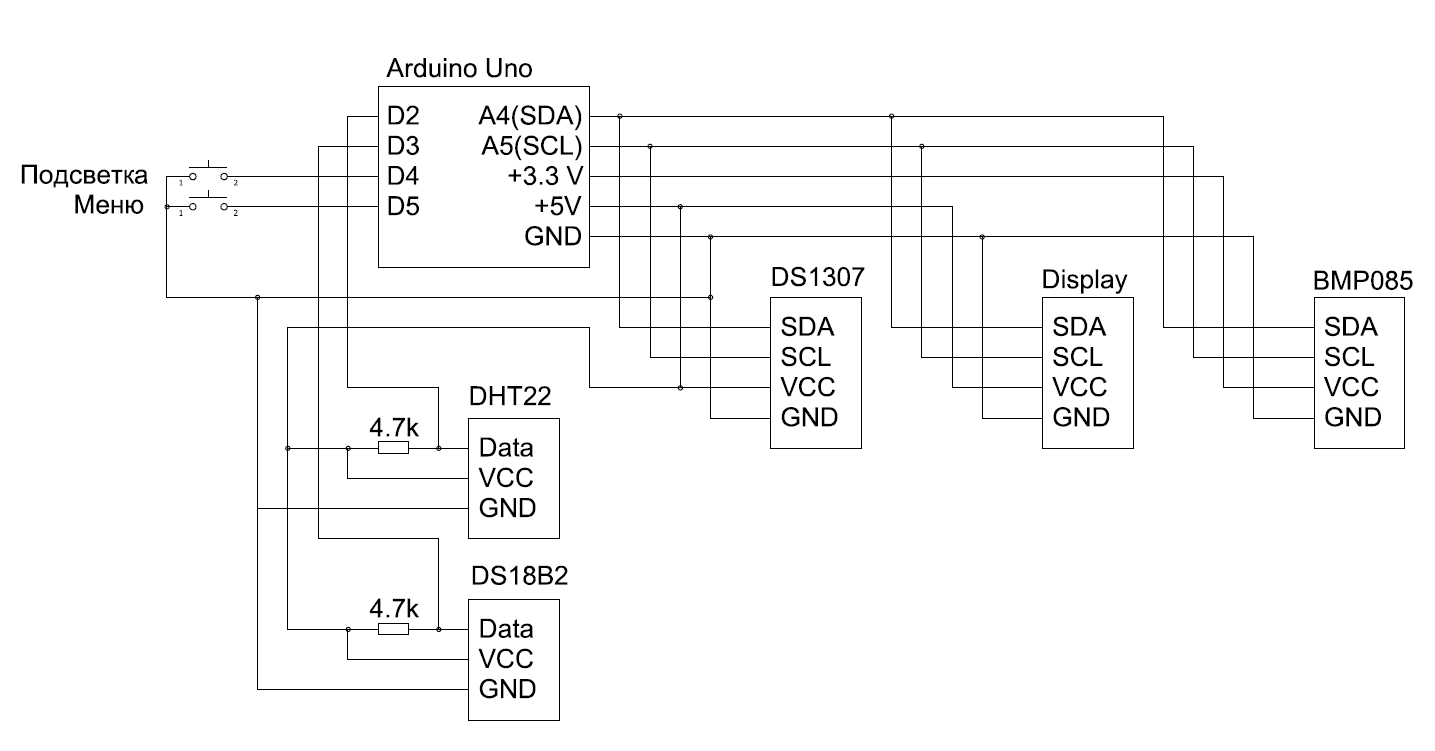
Ну а вот и сам урок
[Проект](http://flprog.ru/images/hostingFiles/150994904.flp) созданный в процессе урока
**Созданный скетч**
```
#include
#include
#include "DHT.h"
#include
#include "RTClib.h"
#include
BMP085 \_bmp085 = BMP085();
long \_bmp085P = 0;
long \_bmp085T = 0;
long \_bmp085A = 0;
byte \_d18x2x1Addr[8] = {0x28, 0xFF, 0x11, 0x94, 0x3C, 0x4, 0x0, 0x48};
RTC\_DS1307 \_RTC1;
DateTime \_tRTC1;
LiquidCrystal\_I2C \_lcd1(0x3F, 20, 4);
int \_dispTempLength1 = 0;
boolean \_isNeedClearDisp1;
DHT \_dht1(2, DHT22);
OneWire \_ow3(3);
String \_gtv1;
String \_gtv2;
String \_gtv3;
String \_gtv4;
String \_gtv5;
String \_gtv6;
bool \_gtv7 = 0;
int \_gtv8 = 0;
bool \_gtv9 = 0;
unsigned long \_d18x2x1Tti = 0UL;
float \_d18x2x1O = 0.00;
unsigned long \_bmp0851Tti = 0UL;
unsigned long \_dht1Tti = 0UL;
float \_dht1t = 0.00;
float \_dht1h = 0.00;
bool \_count1I = 0;
int \_count1P = 0;
bool \_trgs1 = 0;
bool \_D1B1 = 0;
bool \_tim1I = 0;
bool \_tim1O = 0;
unsigned long \_tim1P = 0UL;
int \_disp1oldLength = 0;
int \_disp2oldLength = 0;
String \_mux1;
int \_disp3oldLength = 0;
String \_mux2;
int \_disp4oldLength = 0;
String \_mux3;
int \_disp5oldLength = 0;
bool \_bounseInput5S = 0;
bool \_bounseInput5O = 0;
unsigned long \_bounseInput5P = 0UL;
bool \_bounseInput4S = 0;
bool \_bounseInput4O = 0;
unsigned long \_bounseInput4P = 0UL;
void setup()
{
Wire.begin();
\_bmp085.init(MODE\_ULTRA\_HIGHRES, 300, true);
\_RTC1.begin();
pinMode(5, INPUT);
digitalWrite(5, HIGH);
pinMode(4, INPUT);
digitalWrite(4, HIGH);
\_lcd1.init();
\_lcd1.noBacklight();
\_bounseInput5O = digitalRead(5);
\_bounseInput4O = digitalRead(4);
\_dht1.begin();
}
void loop()
{ \_tRTC1 = \_RTC1.now();
if (\_isTimer(\_dht1Tti, 8000)) {
\_dht1Tti = millis();
float tempDht2;
tempDht2 = \_dht1.readTemperature();
if (!(isnan(tempDht2))) {
\_dht1t = tempDht2;
}
tempDht2 = \_dht1.readHumidity();
if (!(isnan(tempDht2))) {
\_dht1h = tempDht2;
}
} if (\_isNeedClearDisp1) {
\_lcd1.clear();
\_isNeedClearDisp1 = 0;
}
if (\_isTimer(\_bmp0851Tti, 6000)) {
\_bmp0851Tti = millis();
\_bmp085.getAltitude(&\_bmp085A);
\_bmp085.getPressure(&\_bmp085P);
\_bmp085.getTemperature(&\_bmp085T);
}
bool \_bounceTmp5 = (digitalRead (5));
if (\_bounseInput5S)
{
if (millis() >= (\_bounseInput5P + 40))
{
\_bounseInput5O = \_bounceTmp5;
\_bounseInput5S = 0;
}
}
else
{
if (\_bounceTmp5 != \_bounseInput5O )
{
\_bounseInput5S = 1;
\_bounseInput5P = millis();
}
}
bool \_bounceTmp4 = (digitalRead (4));
if (\_bounseInput4S)
{
if (millis() >= (\_bounseInput4P + 40))
{
\_bounseInput4O = \_bounceTmp4;
\_bounseInput4S = 0;
}
}
else
{
if (\_bounceTmp4 != \_bounseInput4O )
{
\_bounseInput4S = 1;
\_bounseInput4P = millis();
}
}
if (\_isTimer(\_d18x2x1Tti, 5000)) {
\_d18x2x1Tti = millis();
\_d18x2x1O = \_readDS18\_ow3(\_d18x2x1Addr, 0);
}
\_gtv1 = ((String("T-")) + (( \_floatToStringWitRaz((\_d18x2x1O), 2))) + (String("C")));
\_gtv2 = ((String("T-")) + (( \_floatToStringWitRaz((\_bmp085T) / (10.00), 1))) + (String("C")));
\_gtv3 = ((String("P-")) + ((String((\_bmp085P) / (1000)))) + (String("kPa")));
\_gtv4 = ((String("A")) + ((String(\_bmp085A))) + (String("cm")));
\_gtv5 = ((String("T-")) + (( \_floatToStringWitRaz(\_dht1t, 2))) + (String("C")));
\_gtv6 = ((String("H-")) + (( \_floatToStringWitRaz(\_dht1h, 2))) + (String("%")));
if (!(\_bounseInput5O))
{
if (! \_count1I)
{
\_count1P = \_count1P + 1;
\_count1I = 1;
}
}
else
{
\_count1I = 0;
}
if (\_count1P < 0 ) \_count1P = 0;
if (\_gtv7) \_count1P = 0;
\_gtv7 = \_count1P >= 3;
\_gtv8 = \_count1P;
if ( (!(\_bounseInput4O)) || (!(\_bounseInput5O)) ) \_trgs1 = 1;
if (\_gtv9) \_trgs1 = 0;
if ( (\_trgs1) && (\_bounseInput5O) )
{
if (\_tim1I)
{
if ( \_isTimer(\_tim1P, 20000)) \_tim1O = 1;
}
else
{
\_tim1I = 1;
\_tim1P = millis();
}
}
else
{
\_tim1O = 0;
\_tim1I = 0;
}
if (\_trgs1) {
if (! \_D1B1) {
\_lcd1.backlight();
\_D1B1 = 1;
}
} else {
if (\_D1B1) {
\_lcd1.noBacklight();
\_D1B1 = 0;
}
}
\_gtv9 = \_tim1O;
if (1) {
\_dispTempLength1 = (((((String((\_tRTC1.hour())))) + (String(":")) + ((String((\_tRTC1.minute())))) + (String(":")) + ((String((\_tRTC1.second()))))))).length();
if (\_disp1oldLength > \_dispTempLength1) {
\_isNeedClearDisp1 = 1;
}
\_disp1oldLength = \_dispTempLength1;
\_lcd1.setCursor(0, 0);
\_lcd1.print(((((String((\_tRTC1.hour())))) + (String(":")) + ((String((\_tRTC1.minute())))) + (String(":")) + ((String((\_tRTC1.second())))))));
} else {
if (\_disp1oldLength > 0) {
\_isNeedClearDisp1 = 1;
\_disp1oldLength = 0;
}
}
if (1) {
\_dispTempLength1 = (((((String((\_tRTC1.day())))) + (String("-")) + ((String((\_tRTC1.month())))) + (String("-")) + ((String((\_tRTC1.year()))))))).length();
if (\_disp2oldLength > \_dispTempLength1) {
\_isNeedClearDisp1 = 1;
}
\_disp2oldLength = \_dispTempLength1;
\_lcd1.setCursor(9, 0);
\_lcd1.print(((((String((\_tRTC1.day())))) + (String("-")) + ((String((\_tRTC1.month())))) + (String("-")) + ((String((\_tRTC1.year())))))));
} else {
if (\_disp2oldLength > 0) {
\_isNeedClearDisp1 = 1;
\_disp2oldLength = 0;
}
}
if ((\_gtv8) == 0) {
\_mux1 = String("DS18B2");
}
if ((\_gtv8) == 1) {
\_mux1 = String("Bmp-085");
}
if ((\_gtv8) == 2) {
\_mux1 = String("DHT-22");
}
if (1) {
\_dispTempLength1 = ((\_mux1)).length();
if (\_disp3oldLength > \_dispTempLength1) {
\_isNeedClearDisp1 = 1;
}
\_disp3oldLength = \_dispTempLength1;
\_lcd1.setCursor(int((20 - \_dispTempLength1) / 2), 1);
\_lcd1.print((\_mux1));
} else {
if (\_disp3oldLength > 0) {
\_isNeedClearDisp1 = 1;
\_disp3oldLength = 0;
}
}
if ((\_gtv8) == 0) {
\_mux2 = \_gtv1;
}
if ((\_gtv8) == 1) {
\_mux2 = \_gtv2;
}
if ((\_gtv8) == 2) {
\_mux2 = \_gtv5;
}
if (1) {
\_dispTempLength1 = ((\_mux2)).length();
if (\_disp4oldLength > \_dispTempLength1) {
\_isNeedClearDisp1 = 1;
}
\_disp4oldLength = \_dispTempLength1;
\_lcd1.setCursor(0, 2);
\_lcd1.print((\_mux2));
} else {
if (\_disp4oldLength > 0) {
\_isNeedClearDisp1 = 1;
\_disp4oldLength = 0;
}
}
if ((\_gtv8) == 0) {
\_mux3 = String("-----");
}
if ((\_gtv8) == 1) {
\_mux3 = ((\_gtv3) + (String("/")) + (\_gtv4));
}
if ((\_gtv8) == 2) {
\_mux3 = \_gtv6;
}
if (1) {
\_dispTempLength1 = ((\_mux3)).length();
if (\_disp5oldLength > \_dispTempLength1) {
\_isNeedClearDisp1 = 1;
}
\_disp5oldLength = \_dispTempLength1;
\_lcd1.setCursor(0, 3);
\_lcd1.print((\_mux3));
} else {
if (\_disp5oldLength > 0) {
\_isNeedClearDisp1 = 1;
\_disp5oldLength = 0;
}
}
}
bool \_isTimer(unsigned long startTime, unsigned long period )
{
unsigned long endTime;
endTime = startTime + period;
return (millis() >= endTime);
}
String \_floatToStringWitRaz(float value, int raz)
{
float tv;
int ti = int(value);
String ts = String(ti);
if (raz == 0) {
return ts;
}
ts += ".";
float tf = abs(value - ti);
for (int i = 1; i <= raz; i++ )
{
tv = tf \* 10;
ti = int(tv);
ts += String(ti);
tf = (tv - ti);
}
return ts;
}
float \_convertDS18x2xData(byte type\_s, byte data[12])
{
int16\_t raw = (data[1] << 8) | data[0];
if (type\_s)
{
raw = raw << 3;
if (data[7] == 0x10) {
raw = (raw & 0xFFF0) + 12 - data[6];
}
}
else
{
byte cfg = (data[4] & 0x60);
if (cfg == 0x00) raw = raw & ~7; else if (cfg == 0x20) raw = raw & ~3; else if (cfg == 0x40) raw = raw & ~1;
}
return (float)raw / 16.0;
}
float \_readDS18\_ow3(byte addr[8], byte type\_s)
{ byte data[12];
byte i;
\_ow3.reset();
\_ow3.select(addr);
\_ow3.write(0xBE);
for ( i = 0; i < 9; i++) {
data[i] = \_ow3.read();
}
\_ow3.reset();
\_ow3.select(addr);
\_ow3.write(0x44, 1);
return \_convertDS18x2xData(type\_s, data);
}
```
PS. В следующем видео уроке планируется подключение SD картридера для логгирования показаний датчиков. | https://habr.com/ru/post/241913/ | null | ru | null |
# Квантовые компьютеры: без математики и философии
В этой статье я разберу по косточкам все тайны квантовых компьютеров: что такое суперпозиция (бесполезна) и запутанность (интересный эффект), могут ли они заменить обычные компьютеры (нет) и могут ли они взломать RSA (нет). При этом я не буду упоминать волновую функцию и столь раздражающих [Bob и Alice](https://en.wikipedia.org/wiki/Alice_and_Bob), которых вы могли встречать в других статьях про квантовые машины.
Первое и самое главное, что нужно знать - квантовые компьютеры не имеют ничего общего с обычными. Квантовые компьютеры по своей природе - аналоговые, там нет бинарных операций. Вероятно, вы уже слышали про Кубиты, что у них есть состояние 0, 1 и 0-1 одновременно, и благодаря этому вычисления выполняются очень быстро: это заблуждение. Кубит - это [магнит](https://physics.stackexchange.com/questions/204090/understanding-the-bloch-sphere) (обычно атом или электрон), подвешенный в пространстве, который может вращаться по всем трем осям. Собственно, вращение магнита в пространстве - это и есть операции квантового компьютера. Почему это может ускорить вычисления? Было очень сложно найти ответ, но самые стойкие читатели увидят его в конце статьи. Начнем разоблачения.
Суперпозиция
------------
Прежде чем говорить про волшебное состояние 0-1 (суперпозиция), сначала разберемся, как положение магнита в 3D вообще становится нулем и единицей. При создании квантового компьютера принимается решение, что если полюс магнита N (на картинках ниже - синий) смотрит вверх - то это значение ноль, если вниз - единица. Когда запускается квантовая программа, все кубиты с помощью внешнего магнитного поля выстраиваются в ноль (вверх). После завершения квантовой программы (серии вращений кубитов) надо получить конечное значение кубитов (выполнить Измерение), но как это сделать? Кубиты крайне маленькие и нестабильные, на них негативно влияет тепловое излучение (поэтому их сильно охлаждают) и космические лучи. На кубит нельзя просто посмотреть и сказать, где у него сейчас полюс N. Измерение выполняется опосредованно, например, можно к кубиту снизу и сверху поднести магниты с полюсом N.
Если полюс кубита N был направлен вверх, то кубит упадет вниз, и как раз это падение можно зарегистрировать. После этого состояние кубита измерено (Ноль) и он физически больше непригоден для дальнейшего использования в квантовой программе. Это лишь иллюстративный пример, в каждом квантовом компьютере измерение выполняется своими методами и очень сложно найти описание - как именно, но суть остается та же.
Теперь самое интересное, вспоминаем, что наш магнит может вращаться в любом направлении, давайте положим его на бок? Именно с этого начинаются все квантовые алгоритмы.
Браво, мы перевели кубит в состояние суперпозиции, знаменитое "0-1 одновременно". При попытке измерить такой кубит он будет падать вверх или вниз с вероятностью примерно 50% (зависит от точности построения квантового компьютера). Как вы видите, состояние кубита более чем конкретное, мы его только что просто повернули на 90o. Заявления о том, что он в нуле и единице одновременно (или мечется между ними) выглядят странно, ведь при измерении всегда сработает только один сенсор. Поворот еще на 90o выводит кубит из волшебного состояния.
Еще один важный момент: если кубит из вертикального положения повернуть не на 90o, а только на пару градусов, то при измерении он с очень высокой вероятностью будет падать на "Сенсор 0", а в редких случаях на "Сенсор 1". Это доказано опытами, я проверял это сам (IBM дает бесплатный доступ), одиночный атом ведет себя сложнее, чем обычный магнит.
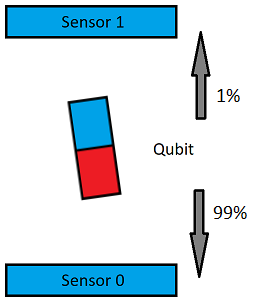Любое отклонение от вертикали приводит к вероятности измерить единицу вместо нуля. Соответственно, исходную инициализацию кубитов и все вращения кубитов надо делать очень точно, защищать кубиты от внешнего воздействия надо очень надежно, иначе вы будете получать ошибку вычислений. Современные квантовые компьютеры имеют крайне низкую точность, это их большая проблема.
Теперь рассмотрим очень популярное, но ложное утверждение, что суперпозиция ускоряет вычисления. Все квантовые алгоритмы начинаются с перевода группы кубитов (регистра) в состояние суперпозиции (укладывания магнитов на бок), начиная с этого момента официальная наука заявляет нам, что каждый кубит хранит в себе 0-1 одновременно, два кубита хранят 0-3 одновременно, восемь кубитов 0-255 одновременно и т.д. Любое математическое действие над этой группой кубитов будет выполнено сразу для всех чисел, хранимых кубитами.
Пример: у нас есть две группы по 32 кубита (два регистра памяти), мы хотим посчитать сумму чисел из этих двух регистров. Выполнив сложение один раз мы получаем абсолютно все возможные комбинации сумм чисел, которые только можно разместить в двух регистрах по 32 бита, т.е. было выполнено около 18 квинтиллионов операций сложения за одну физическую операцию. Звучит очень круто, но есть подвох.
После завершения квантового алгоритма нам надо как-то вытащить результат вычисления, да вот беда - квантовый компьютер ни за что не отдаст нам все 18 квинтиллионов результатов за один раз. После измерения он вернет только один из них, причем рандомно. Процесс измерения разрушает кубиты, и чтобы получить еще один результат, нам придется выполнить операцию заново. Чтобы вытащить из квантовой машины все 18 квинтиллионов результатов придется запустить его как минимум 18 квинтиллионов раз. Звучит как фуфло.
Что там со взломом паролей? Аналогично, чтобы хэш-сумму перевести в пароль нужно запустить квантовую программу очень-очень много раз (как и на классическом компьютере). Таким образом, суперпозиция (даже если она реальна) сама по себе не имеет никакого эффекта на производительность квантовой машины.
Запутанность
------------
Квантовая запутанность - второй кит, на котором держится квантовый компьютер, и это действительно любопытный эффект, который современная наука пока не может объяснить. Но мы пойдем издалека. Давайте взглянем на типичный кусок исходного кода для традиционного компьютера:
```
if (n > 50) then n = 50
```
Эту строчку проблематично выполнить на квантовом компьютере, т.к. после операции (n>50) кубиты переменной n будут тут же физически разрушены (ведь их надо было измерить для операции сравнения), а эта переменная нужна нам дальше по коду. Условные переходы (как и циклы) недоступны для квантовых компьютеров, как они тогда вообще выживают? Одна операция IF все же может быть выполнена, без проведения измерения: контролируемое NOT (CNOT), это аналог классической операции [XOR](https://en.wikipedia.org/wiki/Exclusive_or). В этой операции участвуют два кубита, контролирующий и контролируемый:
* если полюс N контролирующего кубита направлен вниз (значение 1), то контролируемый кубит вращается на 180 градусов
* если полюс N контролирующего кубита направлен вверх (значение 0), то контролируемый кубит не изменяется
Данная операция позволяет выполнять банальное сложение целых чисел для двух регистров кубитов. Чтобы выполнить эту операцию два кубита кратковременно [подносят поближе друг к другу](https://physics.stackexchange.com/questions/173776/how-is-cnot-operation-realized-physically), после чего выполняют серию отдельных вращений. Измерения не требуются, т.е. с кубитами можно работать дальше. После этой операции кубиты запутаны. Как это проявляется? Начнем с банального:
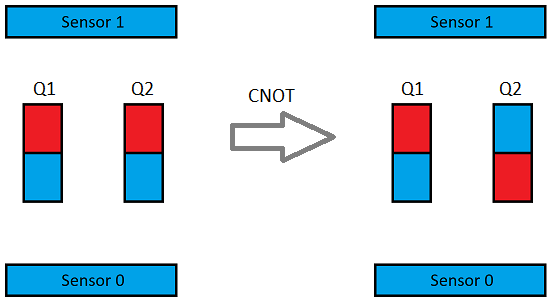После того, как мы запутали кубиты, они становятся зависимыми друг от друга. Если кубит Q1 был измерен как Единица, то кубит Q2 будет измерен как Ноль. Но этот случай очевиден и не интересен, давайте перед CNOT уложим кубиты на бок:
Если контролирующий кубит лежит на боку, то контролируемый будет либо повернут на 180 градусов с вероятностью 50%, либо останется в прежнем состоянии. Точное итоговое положение кубитов в 3D пространстве после такой операции не известно (они якобы сразу во многих состояниях), ведь на кубиты нельзя посмотреть непосредственно. Но если запутанные кубиты измерить, то Q1 будет рандомно падать на сенсор 0 или 1, а Q2 будет всегда падать на противоположный сенсор.
Почему так происходит никто не знает. По логике, оба кубита лежат на боку, после операции CNOT они оба должны рандомно падать на оба сенсора, без какой-либо зависимости. По факту же прослеживается четкая связь при измерении (с некоторой погрешностью, система все-таки аналоговая). На этот счет есть две теории:
* Официальная наука говорит, что кубиты обмениваются информацией между собой (неизвестно как, но мгновенно, больше скорости света). Когда первый кубит измеряют (бьют об сенсор), он сообщает второму кубиту куда именно упал, а тот его запоминает и при измерении ударится о противоположный сенсор. Эта теория выглядит весьма странно, но здесь надо понимать, что официальная наука цепко держится за принцип суперпозиции, что кубиты находятся в состоянии 0-1 одновременно: при измерении первого кубита второй не может больше оставаться в 0-1, ему надо срочно определиться с ориентацией.
* Теория скрытых переменных: она говорит, что при взаимодействии кубиты сразу договариваются, кто на какой сенсор упадет, происходит это за счет изменения физического параметра кубита, который науке пока не известен. Эта теория выглядит более логичной, здесь уже не требуются сверхсветовые взаимодействия. Но данная теория отрицает наличие принципа суперпозиции, который является Святым Граалем для современной науки, поэтому всерьез эту теорию не прорабатывают.
На мой взгляд само явление Запутанности является главным доказательством, что Суперпозиции не существует, но я не физик-теоретик, поэтому оставим эту тему. В конце концов когда-то официальная наука высмеивала теорию движения литосферных плит, но в конце концов ребята во всем разобрались.
Пара заключительных моментов про запутанность:
* Запутать можно сразу много кубитов, и это обычное дело для квантовых компьютеров, для этого надо прогнать CNOT поочередно для нескольких кубитов.
* После операции CNOT контролирующий кубит на самом деле тоже меняет свою ориентацию в 3D пространстве. Его полюс N не двигается вверх-вниз, но сам кубит вращается вокруг оси Z, это явление называется [Phase Kickback](https://towardsdatascience.com/quantum-phase-kickback-bb83d976a448) и оно имеет огромное значение для квантовых алгоритмов, именно оно дает ускорение вычислений. Об этом мы поговорим ниже.
* Если после запутывания один из кубитов с помощью внешнего магнитного поля перевести в состояние Ноль (повторить первичную инициализацию), то это никак не повлияет на второй кубит, состояние запутанности будет разорвано. Т.е. обмен информацией на сверхсветовой скорости нельзя обеспечить за счет эффекта запутывания.
* Запутанные частицы иногда сравнивают с носками: я надеваю один на правую ногу, второй автоматически становится левым. Это некорректное сравнение, запутанные частицы больше похожи на две монетки, стоящие на боку. Если одна из них упадет на Орла, то вторая точно упадет на Решко, даже если прошло несколько часов.
Чего не могут квантовые компьютеры
----------------------------------
Квантовые компьютеры довольно медленные, типичная рабочая частота 100 МГц, но это поправимо. Они также довольно маленькие, 66 кубитов считается мега круто (можно разместить в памяти пару int), но это тоже поправимо. На физическом уровне квантовые компьютеры не поддерживают (и возможно, никогда не поддержат):
* условные переходы и циклы (об этом я писал ранее);
* умножение и деление;
* возведение в степень и тригонометрию.
Все взаимодействие между кубитами сводится к операции CNOT, на которой далеко не уедешь. Но если они такие ограниченные, то почему вокруг них столько шума? При решении задачи в лоб никакого превосходства над классическими компьютерами не будет, но есть очень узкий перечень алгоритмов, где квантовый компьютер может себя проявить. Напомню, каждая квантовая операция - это вращение одного или двух кубитов, для ее выполнения достаточно одного кратковременного импульса. С другой стороны для моделирования вращения магнита на классическом компьютере нужно вычислить много синусов и косинусов. Примерно на этой особенности и строятся эффективные квантовые алгоритмы.
Алгоритм Шора
-------------
Алгоритмом Шора давно пугают интернеты, т.к. он теоретически может довольно быстро взломать RSA. Сама задача взлома сводится к поиску двух простых чисел, из которых состоит открытый ключ RSA, т.е. надо найти два делителя для очень большого числа (порядка 512 бит для RSA-512). Простой перебор на классическом или квантовом компьютере займет очень много времени, и как мы видели выше, принцип суперпозиции тут не спасает.
На самом деле есть два Алгоритма Шора, классический и с квантовым дополнением, начнем с первого. Математики определили, что задачу простого перебора можно заменить на следующее уравнение:
* **a** - число 2 или 3 (на самом деле любое число, но 2 или 3 точно подойдут, какое именно из них - заранее нельзя сказать);
* **N** - число, для которого ищем делители (условно - открытый ключ RSA);
* **mod** - операция, которая возвращает остаток от целочисленного деления;
* **x** - вспомогательное число, найдя его (простым перебором), мы быстро найдем делители числа N. Искомое **x** должно быть больше нуля, четным и минимальным из всех возможных.
Математики определили, что количество шагов по перебору числа x будет существенно меньше, чем простой перебор чисел a и b по формуле a\*b=N. Я проверил как это работает, загнал формулы в Excel и нашел делители для числа 15: достаточно перебрать всего два числа x, проигнорировав 0 и все нечетные:
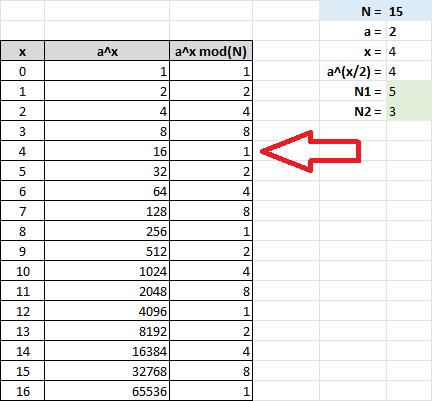Этот эффект должен быть более выраженным для больших чисел, но есть подвох. Опытный глаз конечно же заметил операцию возведения в степень, а также поиск остатка от деления. Шагов перебора может и стало меньше, но каждый шаг сам по себе стал очень сложным, и их сложность будет расти экспоненциально для больших чисел N. Также вы уже наверняка задаетесь вопросом, причем тут квантовые компьютеры, если и в Excel все получилось?
Квантовый алгоритм Шора
-----------------------
Квантовый алгоритм Шора также начинается с вычисления формулы axmod(N), но тут возникает очень много проблем:
* возведение в степень, умножение и деление (в том числе целочисленное с остатком) не поддерживаются на аппаратном уровне;
* количество кубитов сильно ограничено и держать в памяти результат ax проблематично;
* циклы не поддерживаются, значит перебор x надо делать без их участия.
Ребята не стали отчаиваться и придумали набор костылей. Число x на вход квантовой программы подается как рандомное. Если быть точнее, то набор кубитов (регистр) для хранения числа x переводится в суперпозицию (кубиты укладываются на бок). Начиная с этого момента официально заявляется, что axmod(N) будет выполнена сразу для всех возможных чисел x за одну операцию. Как мы видели выше, толку от этого мало, т.к. измерить мы сможем только один результат из всех, причем рандомный.
Далее, сама формула axmod(N) заменяется на очень странный код (показана симуляция квантового компьютера):
```
X = Register('X', 8)
F = Register('F', 4)
X.H()
F[3].X()
for i in range(8):
for j in range(2**i):
Fredkin(X[i], F[0], F[1])
Fredkin(X[i], F[1], F[2])
Fredkin(X[i], F[2], F[3])
```
* функция Register инициализирует указанное число кубитов (8 и 4), на выходе регистр кубитов, в которых можно хранить числа, по умолчанию сохраняется 0х0 (все полюса N направлены вверх);
* метод H - [Hadamard gate](https://www.quantum-inspire.com/kbase/hadamard/), укладывает кубиты на бок (переводит в суперпозицию);
* метод X поворачивает кубит на 180o (аналог бинарного NOT);
* функция Fredkin стандартная для квантовых вычислений, она меняет местами значения двух кубитов, если первый параметр (контролирующий) установлен в единицу. Функция [сводится](https://quantumcomputing.stackexchange.com/questions/9342/how-to-implement-a-fredkin-gate-using-toffoli-and-cnots) к 8 операциям CNOT и 9 одиночным вращениям кубитов;
* входной регистр кубитов X хранит число x;
* регистр F будет хранить результат вычисления axmod(N).
Полный исходный код доступен в моем [репозитории](https://github.com/zashibis/FastQubit).
Вы наверное очень удивлены, как это вообще может работать? Это костыль, который позволяет выполнять формулу axmod(N) для a=2 и N=15. Число x может быть любым. Есть отдельные [методики](https://arxiv.org/abs/1207.0511), которые позволяют подобрать перечень вращений кубитов для любых чисел a и N. Как это работает, я не стал разбираться, поскольку документация на квантовые алгоритмы традиционно крайне низкого качества, но мои собственные опыты подтвердили, что вычисления выполняются корректно.
Соответственно, если мы хотим взломать какой-то ключ RSA-512, то сначала для этого конкретного ключа мы должны составить схему, которая будет включать в себя очень много вращений. Но сколько раз мы должны запустить такую схему? Вы обратили внимание на два вложенных цикла в исходном коде выше? Для числа N=15 схема запускается 255 раз, для N=21 - 511 раз, для пока недостижимого квантовым компьютерам N=35 будет 2047 запусков. Количество операций резко возрастает, в чем же профит квантового компьютера?
Quantum Phase Estimation
------------------------
Поздравляю всех самых терпеливых читателей, пройдя долгий путь непонимания мы добрались до самой сути квантовых компьютеров. Когда мы вычисляем формулу F=axmod(N) на обычном компьютере, мы ждем появления значения F=1, чтобы объявить о взломе ключа RSA. Но когда мы работаем на квантовой машине, нам на самом деле не важно, что по итогу хранится в регистре F, решение задачи будет хранится во входном регистре X.
В классическом компьютере в операторе XOR (аналог CNOT) значение контролирующей переменной не меняется, но напомню, что когда в квантовой машине мы выполняем операцию CNOT, она меняет оба кубита:
* полюс N контролируемого кубита двигается вверх-вниз, в зависимости от состояния контролирующего;
* полюс N контролирующего кубита не двигается вверх-вниз, но сам кубит вращается по оси Z.
Отклонения кубита по оси Z называется фазой. За время выполнения квантовой программы все кубиты накапливают некоторое изменение фазы. Математики доказали, что, измерив итоговую фазу всех кубитов во входном регистре, можно с очень высокой вероятностью найти делители числа N (взломать RSA), даже если в F получилась не единица. Для RSA-512 нужно всего порядка 2000 запусков алгоритма на квантовом компьютере. Но есть подвох. Даже два.
Первая проблема заключается в том, что надо как-то суметь измерить фазу. Для этого используется алгоритм QFE ([Quantum Phase Estimation](https://qiskit.org/textbook/ch-algorithms/quantum-phase-estimation.html)), который требует дополнительных вращений кубитов на очень маленькие углы поворота. Для N=15 нужно вращать кубиты на 1.4o, для N=35 повороты будут уже 0.175o. Для RSA-512 нужно повернуть кубит на ничтожные 180/21022 градуса, сделав это 1022 раза. Кубиты - это аналоговая система, если ошибиться с углом поворота - на выходе мы получим ошибку. Современные квантовые компьютеры не могут справиться с числом N=35, им уже на этом этапе не хватает точности поворотов. Но это еще не так страшно, совсем ничтожными поворотами можно просто пренебречь, почти не потеряв точность всего алгоритма.
Вторая проблема заключается в вычислении axmod(N). Да, для RSA-512 надо вычислить ее всего лишь 2000 раз, но посмотрите еще раз на два вложенных цикла: одно такое вычисление - это более 21022 последовательных вращений кубитов. Это более чем фуфло. Квантовые компьютеры не способны взломать RSA, даже если они вырастут до миллиона кубитов. Есть большое количество научных статей, которые рассказывают нам, как им удалось оптимизировать эту часть и выполнить ее в сотни раз быстрее, но они всегда скромно умалчивают, сколько именно операций требуется, когда N = 2512.
Симуляторы квантовых компьютеров
--------------------------------
Симуляторы квантовых компьютеров работают существенно медленнее своих реальных собратьев. Происходит это потому, что симуляторы делают свою работу гораздо честнее. Когда в симуляторе вы создаете регистр из 8 кубитов, то в памяти сохраняются все возможные значения для этих кубитов (создается массив на 256 ячеек). Если вы создадите два регистра по 8 бит и выполните операцию A+B, то симулятор посчитает и сохранит в памяти все возможные комбинации сложений (создаст массив на 65536 ячеек). Это будет существенно дольше, чем единичная операция, но после этого симулятор может вернуть вам все эти значения, не уничтожая данные при каждом "измерении".
Чтобы получить все варианты сложения на настоящем квантовом компьютере, вы будете запускать его как минимум 65536 раз (результат возвращается рандомно, могут быть повторы), и в целом, это займет даже больше времени, чем на симуляторе.
Но если кубиты - это просто магниты в 3D пространстве, можно ли создать симулятор, который вращает их в виртуальной реальности? Я попытался и создал библиотеку [FastQubit](https://github.com/zashibis/FastQubit). Большая часть операций действительно успешно работает (даже состояния [Белла](https://en.wikipedia.org/wiki/Bell_state)), и такой симулятор обладает существенным превосходством над обычным квантовым компьютером:
* кубитов может быть много и они совершенно стабильны, никаких ошибок;
* на кубиты можно посмотреть в любой момент времени, определить точное положение в 3D, при этом не разрушая их.
Но есть подвох. Phase Kickback в моей библиотеке работает не верно:
```
Q[0].H()
Q[1].X()
Q[0].P_pi(8)
Q[1].P_pi(8)
CNOT(Q[0], Q[1])
Q[1].P_pi(-8)
CNOT(Q[0], Q[1])
```
Вот эта цепочка операций должна по итогу сдвинуть фазу кубита Q[0] на 45o, но в моем случае сдвиг выполнялся на 90o. Дело в том, что точное положение кубитов в 3D после первой операции CNOT науке не известно, тут обычно приплетают суперпозицию, что кубиты сразу много где. Я воспользовался документацией на квантовые операции, и сделал повороты ровно так, как они там описаны. Но нет, на самом деле [никто не знает](https://quantumcomputing.stackexchange.com/questions/26257/rxx-gate-as-a-set-of-rotations), какие повороты выполняются на самом деле.
Если вы заставите этот короткий код работать верно, то можете смело претендовать на Нобелевскую премию. Но не пытайтесь костылить: вы конечно можете добавить хак, который доворачивает фазу на нужный угол при определенных условиях, но это перестанет работать, когда в квантовую программу добавят запутанность сразу между несколькими кубитами.
Итоги
-----
Документация на квантовые компьютеры максимально пафосная, даже элементарные вещи оборачиваются сложными формулами. Я потратил недели, чтобы разобраться, что на самом деле в них скрыто. Статьи в новостях и блогах наоборот крайне поверхностные, философские, и очень часто содержат ложную информацию. Никто и никогда не публикует цифру, сколько операций нужно выполнить, чтобы взломать RSA-512 (причем, он не самый стойкий), вместо этого вам покажут несколько формул вычисления сложности алгоритма, сделав это максимально непонятно.
Я не призываю немедленно прекратить финансирование всех программ по квантовым компьютерам, это фундаментальные исследования, которые могут принести неожиданные полезные результаты в других областях. Но необходимо прекратить публиковать страшилки про пост-квантовую эру. | https://habr.com/ru/post/690786/ | null | ru | null |
# Гайд по архитектуре приложений для Android. Часть 5: слой данных
> В конце декабря 2021-го Android обновил рекомендации по архитектуре мобильных приложений. Публикуем перевод гайда в пяти частях:
>
> [Обзор архитектуры](https://go.surf.dev/hr/android/habr/architecture_guide_data_layer)
>
> [Слой UI](https://go.surf.dev/hr/android/habr/architecture_guide_data_layer1)
>
> [Обработка событий UI](https://go.surf.dev/hr/android/habr/architecture_guide_data_layer2)
>
> [Доменный слой](https://go.surf.dev/hr/android/habr/architecture_guide_data_layer3)
>
> Слой данных *(вы находитесь здесь)*
>
>
Слой UI содержит UI-состояние и логику UI, а слой данных — *данные приложения* и *бизнес-логику*. Бизнес логика наделяет приложение ценностью: она состоит из бизнес-правил, решающих практические задачи. Эти бизнес-правила определяют процесс создания, хранения и изменения данных приложения.
Такое разделение ответственностей позволяет использовать слой данных на нескольких экранах, передавать информацию из одной части приложения в другую и воспроизводить бизнес логику вне UI для unit-тестов. Более подробно о преимуществах слоя данных вы можете почитать [в гайде по архитектуре](https://go.surf.dev/hr/android/habr/architecture_guide_data_layer).
### Архитектура слоя данных
Слой данных состоит из классов *Repository. В каждом из них может содержаться множество классов data source — или не быть ни одного*. Отдельный класс Repository следует создать для каждого уникального типа данных в приложении. Например, у вас может быть класс `MoviesRepository` для данных, связанных с фильмами, или класс `PaymentsRepository` для данных, связанных с платежами.
Роль слоя данных в архитектуре приложенияКлассы Repository выполняют следующие задачи:
* Предоставляют доступ к данным для остальных элементов приложения.
* Централизуют изменения в данных.
* Разрешают конфликты между несколькими классами DataSource.
* Абстрагируют источники данных от остальных элементов приложения.
* Содержат бизнес-логику.
Каждый data source-класс должен отвечать за работу только с одним источником данных. Им может оказаться файл, сетевой источник или локальная база данных. Data source-классы — это связующее звено между приложением и системой для работы с данными.
Остальные слои в иерархии ни в коем случае не должны получать доступ к классам data source напрямую. Переход на слой данных всегда должен осуществляться через Repository классы. State holder классы (см. [гайд «Слой UI»](http://architecture_guide_data_layer1)) или UseCase классы (см. [гайд «Доменный слой»](https://go.surf.dev/hr/android/habr/architecture_guide_data_layer3)) ни в коем случае не должны иметь в непосредственной зависимости класс data source. Используя Repository-классы в качестве точек входа, мы даём различным слоям архитектуры возможность масштабироваться независимо от остальных слоёв.
**Данные, к которым открывается доступ в этом слое, должны быть неизменяемыми,** чтобы их не смогли исказить остальные классы. Иначе могут возникнуть противоречия. Кроме того, неизменяемые данные можно безопасно передавать в нескольких потоках. Более подробно об этом рассказано в разделе [«Потоки»](https://developer.android.com/jetpack/guide/data-layer?continue=https%3A%2F%2Fdeveloper.android.com%2Fcourses%2Fpathways%2Fandroid-architecture%23article-https%3A%2F%2Fdeveloper.android.com%2Fjetpack%2Fguide%2Fdata-layer#threading).
Согласно рекомендациям по [Dependency Injection](https://developer.android.com/training/dependency-injection), в конструкторе репозитория источники данных располагаются в виде зависимостей:
```
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... / }
```
> **Важно:** Зачастую, когда класс Repository содержит только один класс data source и не зависит от других классов Repository, разработчики объединяют ответственности классов Repository и data source в класс Repository. Если будете так делать, не забудьте разделить функциональности, когда в более поздней версии приложения классу Repository потребуется обрабатывать данные из другого источника.
>
>
### Как предоставить доступ к API
Классы в слое данных, как правило, предоставляют доступ к функциям в случае однократных вызовов Create, Read, Update и Delete (CRUD) или чтобы получить уведомления о периодических изменениях данных. Слой данных должен предоставить доступ к следующим сущностям в каждом из двух случаев ниже:
* **Однократные операции.** В Kotlin слой данных должен открывать доступ к suspend-функциям, а в случае с языком программирования Java — к функциям, которые с помощью callback уведомляют класс о результате операции, или к типам RxJava `Single`, `Maybe` или `Completable`.
* **Уведомления о периодических изменениях данных.** В Kotlin слой данных должен предоставлять доступ к [flow](https://developer.android.com/kotlin/flow), а в случае с Java – к callback, который отправляет новые данные, или к типам RxJava `Observable` или `Flowable`.
```
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow = ...
suspend fun modifyData(example: Example) { ... }
}
```
### Правила именования в гайде
В этом гайде Repository-классы именуются с указанием данных, за которые они отвечают. Правило выглядит следующим образом:
*тип данных + Repository*
Например: `NewsRepository`, `MoviesRepository` и `PaymentsRepository`.
Data source-классы именуются с указанием данных, за которые они отвечают, и используемого ими источника. Правило:
*тип данных + тип источника + DataSource*
В типе данных рекомендуем указывать *Remote или Local*, так как со временем реализации могут меняться. Пример: `NewsRemoteDataSource` или `NewsLocalDataSource`. Если источник имеет крайне важное значение, можно дать ему более подробное наименование. В таком случае укажите тип источника. Например: `NewsNetworkDataSource` или `NewsDiskDataSource`.
Не называйте класс data source, исходя из детали реализации (антипример: `UserSharedPreferencesDataSource`). Классам Repository, которые используют этот класс data source, не нужно знать, как сохраняются эти данные. Если следовать этому правилу, можно изменить реализацию класса data source (например, мигрировать с [SharedPreferences](https://developer.android.com/training/data-storage/shared-preferences) на [DataStore](https://developer.android.com/topic/libraries/architecture/datastore)) без ущерба для слоя, вызывающего этот источник.
> **Важно:** в процессе миграции на новую реализацию класса data source некоторые создают для него интерфейс и оставляют две реализации: одну для старой технологии резервирования, а вторую для новой. В таком случае нормально использовать название технологии в названии data source-класса (хоть это и деталь реализации), так как Repository-класс видит только интерфейс, а не сами data source-классы. Завершив миграцию, новый класс можно переименовать, чтобы не держать в названии деталь реализации.
>
>
### Несколько уровней классов Repository
В некоторых случаях с более сложными бизнес-требованиями нужно, чтобы один класс Repository зависел от других. Так бывает, когда данные собираются из нескольких источников, а затем объединяются, или когда ответственность необходимо инкапсулировать в другой Repository-класс.
К примеру, чтобы выполнить поставленные перед ним требования, класс Repository, который работает с данными аутентификации пользователей (`UserRepository`), можно поместить в зависимость от других классов Repository: `LoginRepository` и `RegistrationRepository`.
Схема зависимости одного класса Repository от других
> **Важно:** по сложившейся традиции некоторые разработчики называют одни Repository-классы, которые зависят от других, *менеджерами*: к примеру, **UserManager** вместо **UserRepository**. Если хотите, можете использовать это правило именования.
>
>
### Source of truth
Каждый класс Repository обязательно должен описывать только один source of truth. Данные, содержащиеся в source of truth, всегда консистентны, верны и актуальны. Собственно, данные, к которым открывает доступ класс Repository, всегда должны быть получены напрямую из source of truth.
Source of truth может представлять собой класс data source. Например, базу данных или даже расположенный в памяти кэш, который может содержаться в классе Repository. Для того, чтобы регулярно обновлять единственный source of truth, или в случаях, когда пользователь вводит новую информацию, классы Repository объединяют различные классы data source и разрешают потенциальные конфликты между ними.
У разных классов Repository в вашем приложении могут быть разные source of truth. К примеру, класс `LoginRepository` может использовать в качестве source of truth свой кэш, а класс `PaymentsRepository` — сетевой источник данных.
Чтобы приложение поддерживало подход offline-first, рекомендуется использовать **в качестве source of truth локальный источник данных — например, базу данных**.
### Потоки
Вызов классов data source и repository должен быть *main-safe*. Другими словами, вызывать их из главного потока должно быть безопасно. Данные классы отвечают за перенос выполнения своей логики в соответствующий поток, когда выполняемые ими операции занимают продолжительное время и блокируют поток. К примеру, если класс data source считывает файл или если класс Repository выполняет ресурсозатратную фильтрацию длинного списка, эти процессы должны быть main-safe.
Заметьте: большинство классов data source предоставляют готовые main-safe API: например, вызовы suspend методов в [Room](https://developer.android.com/training/data-storage/room) или [Retrofit](https://square.github.io/retrofit/). Если вам доступны такие API, имеет смысл воспользоваться их преимуществами в своих классах Repository.
Более подробно о потоках можно почитать в [гайде «Фоновая обработка данных»](https://developer.android.com/guide/background). Пользователям Kotlin рекомендуется использовать [корутины](https://developer.android.com/kotlin/coroutines). Чтобы ознакомиться с рекомендациями для языка Java, почитайте [«Выполнение задач Android в фоновых потоках»](https://developer.android.com/guide/background/threading).
### Жизненный цикл
Экземпляры классов в слое данных остаются в памяти до тех пор, пока до них можно добраться из корня графа сборщика мусора — как правило, когда ссылку на него хранит другой объект в приложении.
Если класс содержит хранящиеся в памяти данные (к примеру, кэш), рекомендуем переиспользовать тот же экземпляр этого класса в течение некоторого промежутка времени. Этот промежуток также называют *жизненным циклом* экземпляра класса.
Если ответственность класса имеет ключевое значение для приложения в целом, экземпляр этого класса можно ограничить жизненным циклом класса `Application`. Таким образом, у экземпляра класса и приложения будут равные жизненные циклы. Однако, если в приложении вам нужно переиспользовать один и тот же экземпляр в определённом flow экранов (например, registration flow или login flow), ему следует присвоить жизненный цикл класса, который распоряжается жизненным циклом данного flow. К примеру, жизненный цикл `RegistrationRepository`, содержащего сохранённые в памяти данные, можно ограничить циклом `RegistrationActivity` или [навигационного графа](https://developer.android.com/guide/navigation/navigation-getting-started#create-nav-graph) registration flow.
Жизненный цикл каждого экземпляра играет крайне важную роль, если нужно решить, как предоставлять зависимости в своём приложении. Следуйте рекомендациям по [Dependency Injection](https://developer.android.com/training/dependency-injection), в которых зависимости управляются и могут быть ограничены жизненным циклом контейнера зависимостей. Более подробно об ограничении жизненного цикла зависимостей в Android можно почитать в посте [«Ограничение жизненного цикла зависимостей в Android и Hilt»](https://medium.com/androiddevelopers/scoping-in-android-and-hilt-c2e5222317c0).
### Как представлять бизнес-модели
Модели данных, к которым вы решаете открыть доступ из слоя данных, могут быть выборкой информации, которую вы получили из различных источников данных. В идеале различные источники данных, сетевые и локальные, должны возвращать только информацию, которая нужна вашему приложению. Но зачастую выходит иначе.
К примеру, представим сервер новостного API, который возвращает не только информацию о статье, но и историю изменений, комментарии пользователей и ещё какие-то метаданные:
```
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array,
val comments: Array,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
```
Приложению столько информации не нужно: на экране оно отображает только содержимое статьи и основную информации об авторе. Рекомендуется разделять классы моделей и делать так, чтобы классы Repository открывали доступ только к информации, которая нужна остальным слоям в иерархии.
К примеру, чтобы предоставить доменному слою и слою UI доступ к классу модели `Article`, можно вырезать `ArticleApiModel` из сетевого источника данных следующим образом:
```
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
```
Разделять классы моделей рекомендуют, потому что это:
* Экономит память приложения, сводя объём данных к необходимому минимуму.
* Подстраивает типы внешних данных под типы данных в приложении. К примеру, приложение может использовать другой тип данных для отображения дат.
* Обеспечивает более качественное разделение ответственностей. К примеру члены большой команды могут заниматься сетевым слоем и слоем UI по отдельности, если определили класс модели заранее.
Можно пойти дальше и точно так же определять отдельные классы моделей в других частях архитектуры своего приложения, например, в data source-классах и ViewModel. Однако для этого потребуется описать дополнительные классы и логику, которую нужно тщательно задокументировать и протестировать. **Как минимум, новые модели рекомендуется создавать, когда данные, которые получает класс data source, не совпадают с тем, чего ожидают остальные элементы приложения.**
### Типы операций над данными
Типы операций, с которыми умеет работать слой данных, различают по важности. Выделяют операции, ориентированные на:
* UI (UI-oriented),
* приложение (app-oriented),
* бизнес-процессы (business-oriented).
#### UI-oriented операции
UI-oriented операции выполняются только тогда, когда пользователь находится на определённом экране, и отменяются, когда он покидает экран. Пример: отображение данных, полученных из базы данных.
UI-oriented операции, как правило, запускаются из слоя UI и ограничены жизненным циклом вызывающего компонента: к примеру, жизненным циклом ViewModel. Пример UI-oriented операции можно посмотреть в разделе [«Как выполнить сетевой запрос»](#network-request).
#### App-oriented операции
App-oriented операции выполняются, пока приложение открыто. Если приложение закрывают или процесс завершается, операции отменяются. Пример: кэширование результата сетевого запроса, чтобы использовать его позднее при необходимости. Более подробно об этом можно почитать в разделе [«Как реализовать кэширование в памяти»](#cash-in-memory).
Как правило, такие операции ограничены жизненным циклом класса `Application` или слоя данных. Пример можно посмотреть в разделе [«Как сделать так, чтобы операция жила дольше, чем экран»](#longer-than-screen).
#### Business-oriented операции
Business-oriented операции нельзя отменить. Они должны переживать смерть процесса. Пример: успешная загрузка фотографии, которую пользователь хочет запостить в профиле.
Для business-oriented операций рекомендуется использовать WorkManager. Подробнее об этом можно почитать в разделе [«Как планировать задачи с помощью WorkManager»](#workmanager).
### Обработка ошибок
Взаимодействия с классами Repository и источниками данных могут пройти успешно или, в случае неудачи, выбросить исключение. В случае с корутинами и flow рекомендуем использовать [встроенный механизм обработки ошибок](https://kotlinlang.org/docs/exception-handling.html) Kotlin. В случае с ошибками, которые могут быть спровоцированы suspend функциями, при возможности используйте блоки `try/catch`, а с flow используйте оператор `catch`. Предполагается, что при использовании этого подхода слой UI сможет обработать исключения, когда он обращается к слою данных.
Слой данных способен распознавать различные виды ошибок, обрабатывать их при помощи собственных исключений, таких как `UserNotAuthenticatedException`.
> **Важно:** смоделировать результат взаимодействия со слоем данных также можно при помощи класса **Result**. Данный шаблон моделирует ошибки и прочие сигналы, способные возникнуть в процессе обработки результата. В этом шаблоне слой данных возвращает тип **Result** вместо **T**, таким образом сообщая UI об известных ошибках, которые могут возникнуть при определённых сценариях. Использовать такой шаблон необходимо с API реактивного программирования, у которых нет надлежащих механизмов обработки исключений, например, с [LiveData](https://developer.android.com/jetpack/guide/topic/libraries/architecture/livedata).
>
>
Подробнее об ошибках в корутинах можно почитать в посте [«Исключения в корутинах»](https://medium.com/androiddevelopers/exceptions-in-coroutines-ce8da1ec060c).
### Распространённые задачи
В следующих разделах рассмотрим примеры того, как использовать и построить слой данных для выполнения задач, часто встречающихся при разработке приложений под Android. Все примеры основаны на стандартном новостном приложении, которое уже упоминалось в этом гайде.
#### Как выполнить сетевой запрос
Сетевые запросы — одна из самых распространённых задач в приложении для Android. Новостному приложению нужно показать пользователю свежие новости, которые оно нашло в сети. Следовательно, приложению нужен data source-класс для управления сетевыми операциями: `NewsRemoteDataSource`. Чтобы предоставить доступ к информации всему приложению, нужно создать новый класс Repository, который будет обрабатывать операции с новыми данными: `NewsRepository`.
Свежие новости должны обновляться каждый раз, когда пользователь открывает экран. Следовательно это *UI-oriented операция*.
#### Как создать класс data source
Класс data source должен предоставлять доступ к функции, которая возвращает свежие новости: список экземпляров `ArticleHeadline`. Этот класс data source должен обеспечивать безопасную для главного потока возможность получать свежие новости из сети. Для этого ему нужно получить в качестве зависимости `CoroutineDispatcher` или `Executor` и на них выполнить задачу.
Сетевой запрос – это однократный вызов, который обрабатывается новым методом `fetchLatestNews()`:
```
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
/
suspend fun fetchLatestNews(): List =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List
}
```
Интерфейс `NewsApi` скрывает реализацию сетевого клиента API; вне зависимости от того, реализован этот интерфейс с помощью [Retrofit](https://square.github.io/retrofit/) или `HttpURLConnection`. Благодаря зависимости от интерфейсов, API реализации становятся взаимозаменяемыми.
> **Ключевой момент:** **благодаря зависимости от интерфейсов API реализации становятся взаимозаменяемыми.** Помимо того, что данный подход обеспечивает масштабируемость и даёт возможность с большей лёгкостью заменять зависимости, он облегчает тестирование, так как в тесты можно внедрить фиктивные реализации класса data source.
>
>
#### Как создать класс Repository
Так как для этой задачи Repository классу не требуется дополнительной логики, NewsRepository выступает в роли посредника для сетевого источника данных. Преимущества такого дополнительного слоя абстракции рассмотрим в разделе о [кэшировании в памяти](#cash-in-memory).
```
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List =
newsRemoteDataSource.fetchLatestNews()
}
```
Чтобы научиться использовать Repository-класс непосредственно из слоя UI, можете почитать гайд [«Слой UI»](https://developer.android.com/jetpack/guide/ui-layer).
#### Как реализовать кэширование в памяти
Представим, что для новостного приложения ввели новое требование: когда пользователь открывает экран, приложение должно показать ему кэшированные новости, если они запрашивались ранее. В противном случае приложение должно выполнить сетевой запрос и собрать свежие новости.
С учетом нового требования приложение должно хранить свежие новости в памяти, пока оно открыто. Следовательно, это *app-oriented* операция.
#### Кэш
Чтобы хранить данные, пока приложение открыто, нужно реализовать в нём кэширование в памяти. Кэш сохраняет информацию в памяти на определённый срок (в данном случае — пока приложение открыто). Кэширование можно реализовать различными способами: от простой изменяемой переменной до более сложного класса, который защищает данные от выполнения операций read/write в нескольких потоках. В зависимости от ситуации, кэширование можно реализовать в Repository или классах data source.
#### Как кэшировать результат сетевого запроса
Для простоты `NewsRepository` использует для кэширования свежих новостей изменяемую переменную. Чтобы данные нельзя было считать или переписать из различных потоков, используйте [Mutex](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.sync/-mutex/). Подробнее об общем изменяемом состоянии и многопоточности можно почитать в [документации к Kotlin](https://kotlinlang.org/docs/shared-mutable-state-and-concurrency.html#shared-mutable-state-and-concurrency).
Представленная ниже реализация кэширует свежие новости в переменной, расположенной в классе Repository, который защищён от записи мьютексом. Если результат сетевого запроса успешен, данные присваиваются переменной `latestNews`.
```
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
```
#### Как сделать так, чтобы операция жила дольше, чем экран
Если пользователь уходит с экрана, пока выполняется сетевой запрос, запрос отменится, а результат не кэшируется. `NewsRepository` не должен использовать для этой логики `CoroutineScope` вызывающего компонента. Вместо этого ему нужен `CoroutineScope`, который ограничен его же жизненным циклом. **Получение свежих новостей должно быть app-oriented операцией.**
В соответствии с рекомендациями по Dependency Injection, `NewsRepository` должен получать `CoroutineScope` в качестве параметра в конструкторе, а не создавать свой собственный `CoroutineScope`. Так как классы Repository должны выполнять основную часть работы в фоновых потоках, рекомендуем добавить в `CoroutineScope` `Dispatchers.Default` или использовать в качестве диспетчера собственный пул потоков.
```
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
```
Теперь `NewsRepository` готов к выполнению app-oriented операций с внешним `CoroutineScope`, а значит он должен отправить запрос в класс data source и сохранить результат в новой корутине, которая запущена в том же внешнем scope:
```
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/ ... */
suspend fun getLatestNews(refresh: Boolean = false): List {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
```
`async` используется, чтобы запустить корутину во внешнем scope. `await` вызывается на новой корутине, чтобы приостановить выполнение, пока сетевой запрос не вернётся и результат не сохранится в кэш. Если к тому моменту пользователь ещё не ушёл с экрана, приложение покажет ему свежие новости; если он уже перешёл на другой экран, `await` отменяется, но логика внутри `async` продолжает выполняться.
[Подробнее о паттернах CoroutineScope](https://medium.com/androiddevelopers/coroutines-patterns-for-work-that-shouldnt-be-cancelled-e26c40f142ad)>>
#### Как сохранить данные на диске и извлечь их оттуда
Представим, что вам нужно сохранить пользовательские настройки и статьи, которые пользователь добавил в избранное. Нужно, чтобы этот тип данных пережил смерть процесса и оставался доступен, даже когда устройство пользователя не подключено к сети.
Если нужно, чтобы данные пережили смерть процесса, нужно хранить их на диске одним из следующих способов:
* Если это *крупный массив данных* (в него нужно отправлять запросы, в нём требуется сохранять cсылочную целостность или выполнять частичное обновление), сохраняйте данные в базе данных *Room*. В новостном приложении из примера можно сохранить в базы данных новостные статьи или имена их авторов.
* Если это *небольшие массивы данных,* которые нужно только извлекать или устанавливать (без запросов и частичных обновлений), используйте *DataStore*. В новостном приложении из примера формат времени и другие настройки отображения, выбранные пользователем, можно сохранить в DataStore.
* Если это *фрагмент данных* (например, JSON-объект), используйте *файл*.
Как уже упоминалось в разделе [«Source of truth»](#source-of-truth), каждый класс data source работает только с одним источником и соответствует определённому типу данных (например, `News`, `Authors`, `NewsAndAuthors` или `UserPreferences`). Классы, использующие этот источник, не должны знать, как сохраняются данные (скажем, в базе данных или в файле).
#### Room как источник данных
Так как каждый класс data source должен отвечать за работу только с одним источником с определённым типом данных, источник данных Room получает в качестве параметра [объект доступа к данным (DAO)](https://developer.android.com/training/data-storage/room/accessing-data) или саму базу данных. Например, `NewsLocalDataSource` может получить в качестве параметра экземпляр `NewsDao`, а `AuthorsLocalDataSource` – экземпляр `AuthorsDao`.
В некоторых случаях, если не требуется дополнительной логики, можно внедрить DAO непосредственно в репозиторий, так как DAO – это интерфейс, который легко можно заменить в тестах.
Подробнее о том, как работать с Room API, можно почитать в [гайдах по Room](https://developer.android.com/training/data-storage/room).
#### DataStore как источник данных
[DataStore](https://developer.android.com/topic/libraries/architecture/datastore) идеально подходит для хранения таких пар ключ-значение, как пользовательские настройки. К примерам можно отнести формат времени, настройки уведомлений и флаг «скрыть/показывать» для статей, которые пользователь уже прочитал. DataStore также умеет хранить типизированные объекты с [буферами протоколов](https://developers.google.com/protocol-buffers).
Как и в случае с любым другим объектом, источник данных, хранящихся в DataStore, должен содержать данные, соответствующие определённому типу или определённой части приложения. В DataStore это правило ещё более важно выполнять, так как доступ к чтению из DataStore предоставляется как к flow, который отправляется каждый раз, когда значение обновляется. По этой причине связанные между собой настройки лучше хранить в одном DataStore.
К примеру, у вас будет `NotificationsDataStore`, который работает только с настройками уведомлений, и `NewsPreferencesDataStore`, который работает только с настройками экрана с новостями. Таким образом вы сможете сделать обновления данных более концентрированным, так как условный поток `newsScreenPreferencesDataStore.data` будет отправляться только когда пользователь изменит настройку экрана. Кроме того, это значит, что вы сможете сократить жизненный цикл объекта: он будет жить только пока у пользователя открыт экран с новостями.
Подробнее о том, как работать с DataStore API, читайте в [гайдах к DataStore](https://developer.android.com/topic/libraries/architecture/datastore).
#### Файл как источник данных
При работе с крупными объектами вроде объекта JSON или растрового изображения вам потребуется использовать объект `File` и переключать потоки.
Подробнее о работе с файловым хранением можно почитать в гайде [«Обзор методов хранения»](https://developer.android.com/training/data-storage).
#### Как планировать задачи с помощью WorkManager
Представим, что для новостного приложения ввели ещё одно требование: у пользователя должна быть возможность получать свежие новости регулярно и автоматически, если устройство заряжается и подключено к сети без ограничений по трафику. В этом случае операция становится *business-oriented*. Согласно новому требованию, даже если устройство не подключено к интернету, открыв приложение, пользователь всё равно сможет прочитать свежие новости.
С [WorkManager](https://developer.android.com/topic/libraries/architecture/workmanager) легче планировать асинхронные и бесперебойные процессы, кроме того, он сам сможет проверить, выполняются ли условия. Настоятельно рекомендуется использовать эту библиотеку, если вы хотите, чтобы приложение работало надёжно. Для выполнения указанной выше задачи создаётся класс [Worker](https://developer.android.com/topic/libraries/architecture/workmanager/advanced/coroutineworker): `FetchLatestNewsWorker`. Этот класс получает `NewsRepository` в качестве зависимости, извлекает свежие новости и кэширует их на диск.
```
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
```
Бизнес-логику подобной задачи следует инкапсулировать в её класс и обращаться с ней, как с отдельным классом data source. Так WorkManager будет отвечать только за то, чтобы работа выполнялась в фоновом потоке, когда для этого выполнены все условия. Следуя данному шаблону, при необходимости можно легко заменить реализации в зависимости от условий.
В этом примере задачу (task), связанную с новостями, нужно вызывать из `NewsRepository`, который получит в качестве зависимости новый класс DataSource (`NewsTasksDataSource`), реализованный следующим образом:
```
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder(
REFRESH\_RATE\_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY\_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG\_FETCH\_LATEST\_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH\_LATEST\_NEWS\_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG\_FETCH\_LATEST\_NEWS)
}
}
```
Эти типы классов именуются согласно данным, за которые они отвечают, например, `NewsTasksDataSource` и `PaymentsTasksDataSource`. Все задачи, относящиеся к определённому типу данных, лучше инкапсулировать в один класс.
Если задачу необходимо запустить, когда приложение стартует, рекомендуется активировать запрос WorkManager с помощью библиотеки [App Startup](https://developer.android.com/topic/libraries/app-startup), которая обращается к репозиторию из [инициализатора](https://developer.android.com/reference/kotlin/androidx/startup/Initializer).
Подробнее о работе с WorkManager API можно почитать в [гайдах к WorkManager](https://developer.android.com/topic/libraries/architecture/workmanager).
### Тестирование
Следуя рекомендациям по [Dependency Injection](https://developer.android.com/training/dependency-injection), можно облегчить тестирование приложения. Также можно использовать интерфейсы классов, которые обмениваются данными с внешними ресурсами. В unit-тестах можно сделать тест надёжнее, а его результаты однозначнее, если внедрить фиктивные версии зависимостей модуля.
#### Unit-тесты
Если вы тестируете слой данных, можно воспользоваться [общим руководством по тестированию](https://developer.android.com/training/testing). Для unit-тестов при необходимости используйте реальные объекты и внедряйте фиктивные зависимости, которые обращаются к внешним источникам, к примеру считывают информацию из файла или сети.
#### Интеграционное тестирование
Интеграционные тесты, которые получают доступ к внешним источникам, как правило, менее детерминированы, так как их нужно выполнять на реальном устройстве. Рекомендуется выполнять такие тесты в контролируемой среде, чтобы получать надёжные результаты.
Что касается баз данных, Room позволяет создавать в памяти базу данных, которую можно полностью контролировать в процессе теста. Подробнее об этом можно почитать в гайде [«Как протестировать и отладить базу данных»](https://developer.android.com/training/data-storage/room/testing-db#android).
Для работы с сетью существуют популярные библиотеки вроде [WireMock](http://wiremock.org/) или [MockWebServer](https://github.com/square/okhttp/tree/master/mockwebserver), которые позволяют сымитировать HTTP- и HTTPS-вызовы и подтвердить, что запросы выполнены ожидаемым образом.
> **Предыдущие статьи**
>
> [Обзор архитектуры](https://go.surf.dev/hr/android/habr/architecture_guide_data_layer)
>
> [Слой UI](https://go.surf.dev/hr/android/habr/architecture_guide_data_layer1)
>
> [Обработка событий UI](https://go.surf.dev/hr/android/habr/architecture_guide_data_layer2)
>
> [Доменный слой](https://go.surf.dev/hr/android/habr/architecture_guide_data_layer3)
>
> | https://habr.com/ru/post/655389/ | null | ru | null |
# IE против всех или игра в Прятки
Столкнулся с одной (очередной) проблемой отрисовки таблиц с помощью DOM в Internet Explorer (текущая версия у меня 7.0.5730.13).
Я ее назвал **Прятки**, хотя рабочее название было **Синдром слепого родителя**
Сначала код:
> `<html>
>
> <head>
>
> head>
>
> <body>
>
> <button onclick="add\_row()">Addbutton>
>
> <button onclick="alert(document.getElementById('place').innerHTML)">Show innerbutton>
>
> <div id="place">div>
>
>
>
> <script type="text/javascript">
>
> var place = document.getElementById("place");
>
> var table = document.createElement("table");
>
> place.appendChild(table);
>
>
>
> function add\_row() {
>
> var row = document.createElement("tr");
>
> var c1 = document.createElement("td");
>
> var c2 = document.createElement("td");
>
>
>
> row.appendChild(c1);
>
> row.appendChild(c2);
>
>
>
> table.appendChild(row);
>
>
>
> c1.innerHTML = "cell1";
>
> c2.innerHTML = "cell2";
>
> }
>
> script>
>
> body>
>
> html>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Также [ссылка](http://aregeda.narod.ru/bug_ie_2.html "Прятки") для *собственноручного* тестирования.
А теперь расскажу *вкратце*. При нажатии кнопки *Add* создается новая строка в таблице с двумя ячейками. Все это можно увидеть по нажатию кнопки *Show inner*. Но проблема в том, что **IE** не отрисовывает это строку на странице, хотя бережно и ответственно о них помнит и даже возвражает в *innerHTML*.
Решения пока не нашел :( | https://habr.com/ru/post/55850/ | null | ru | null |
# JPEG 2000, JPEG-XR и WebP в стране упущенных возможностей
Ни для кого не секрет, что первым пунктом в оптимизации сайтов стоит [графика](http://habrahabr.ru/company/io/blog/258363/). Потому многие крупные корпорации годами пыхтят над разработкой оптимальных форматов, в перспективе способных заменить [существующие](http://habrahabr.ru/company/io/blog/257533/) и разом осчастливить и разработчиков, и пользователей. Но лягушка все никак не превратится в царевну, и в распределении форматов по сети из года в год ничего интересного не происходит:
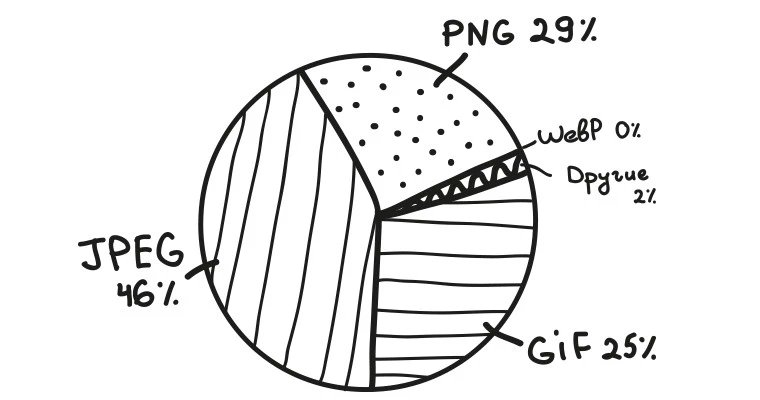
Попробуем разобраться, почему JPEG 2000, JPEG-XR и WebP все еще пасут задних, и действительно ли они такие классные, как заявлено.
#### JPEG 2000
Отличный формат сжатия, поддерживает компрессию как с потерями качества, так и без, а также прозрачность и прогрессивное сжатие. Заявлено сжатие на 20% лучше, чем в [обычном JPEG](https://onthe.io/learn+10+%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D0%BB+%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D1%8B+%D1%81+JPEG), и при этом главной фишкой является отсутствие артефактов при сильной компрессии.
Недостаток – слабая поддержка, и от этого очень скудное распространение в сети.
#### JPEG-XR
Жмет фотки еще лучше и еще быстрее, чем JPEG 2000, возможен вариант [lossless](https://onthe.io/learn+%D0%A1%D0%B6%D0%B0%D1%82%D0%B8%D0%B5+%D0%BA%D0%B0%D1%80%D1%82%D0%B8%D0%BD%D0%BE%D0%BA+%D1%81+%D0%BF%D0%BE%D1%82%D0%B5%D1%80%D1%8F%D0%BC%D0%B8+%D0%B8+%D0%B1%D0%B5%D0%B7#1), при этом поддерживает разные степени прозрачности и прогрессивное сжатие. Сжимает якобы на 50…75% лучше, чем JPEG, при этом сохраняя приличное качество. Так заявлено. В конце материала поэкспериментируем и проверим, не разводят ли нас.
[Поддержка](http://caniuse.com/#search=jpeg%20xr) — только старым добрым IE 9 и старше.

#### [WebP](https://onthe.io/learn+%D0%A7%D1%82%D0%BE+%D1%82%D0%B0%D0%BA%D0%BE%D0%B5+WebP)
Является полностью открытым стандартом. Поддерживает как lossy, так и lossless, и компрессит картинки на 30…40% лучше JPEG’а. Единственный минус по сравнению с двумя предыдущими – не поддерживает прогрессивное сжатие. Зато [гораздо лучше поддерживается браузерами](http://caniuse.com/#search=webp) и имеет более светлое будущее.
#### Поддержка
Не смотря на очевидные преимущества, ни JPEG 2000, ни JPEG-XR, ни WebP пока не светит занять место среди самых популярных форматов сети. Почему? Потому что договориться не могут. Посмотрим на поддержку:

#### Использование
Неправильно:
```

```
Так картинка правильно отобразится только в дружественном браузере.
Правильно:
```
![myimage]()
```
Встроенную поддержку <picture> имеют только Chrome, Opera и последняя версия Firefox, но с помощью [picturefill](https://github.com/scottjehl/picturefill) подстраиваемся и под другие браузеры. После загрузки скрипта добавьте к <head> следующее:
```
```
Сработает для WEBP and SVG. Для остальных форматов сразу после тега <script> добавляем:
```
```
Ура. Картинка корректно отобразится в разных браузерах.
#### Сравниваем JPEG-XR и Webp
Мы решили на конкретном примере проверить, кто же лучше жмет картинки — JPEG-XR или WebP. Для этого мы собрали JPEG-картинки из лучших публикаций Хабры за последний месяц, и каждую поочередно сжали в WebP и в JPEG-XR с помощью [этого](https://i.onthe.io/webp) и [этого](https://i.onthe.io/jxr) инструментов.
Средний показатель сжатия для JPEG-XR составил 48%, а для WebP — 60%. Если рассматривать каждую картинку отдельно, то в 80% случаев WebP справился с задачей лучше, чем JPEG-XR на 10...25%.
Вот, например, один и тот же манул, сжатый в [JPEG-XR](https://i.onthe.io/jxr?r=9fb910bd75e5c679d51ba87445408078) и в [WebP](https://i.onthe.io/webp?r=b0fe7251f59a180207c3851e565abe31).
Как видим, данные отличаются от заявленных.
#### Конспект
* JPEG 2000, JPEG-XR и WebP — инновационные форматы, не получившие должного признания в вебе.
* Ни один из браузеров не поддерживает хотя бы два из этих форматов.
* К общему знаменателю можно прийти с помощью picturefill.
* Вопреки заявленным значениям, WebP сжимает фотки в среднем на 10...25% лучше, чем JPEG-XR. | https://habr.com/ru/post/258545/ | null | ru | null |
# App.Config и Custom Configuration Sections
*Данная статья может показаться банальной, но иногда что-то полезное забывается, а читать на импортном языке лень и книжки под рукой нет. Поэтому я, обратившись к гуглу, нашел хорошее описание процесса создания обработчика конфигурационной секции файла app.config в .net приложениях, перевел его, дополнил замечаниями (курсив) и комментариями и решил опубликовать.*
Я уверен, что многим из вас приходилось использовать файл конфигурации App.Config для хранения инициализирующих или конфигурационных данных приложения. И я так же уверен в том, что многим из вас хотелось создать в данном файле свои собственные структуры для хранения настроек. Но в итоге приходилось использовать встроенные возможности секции и получать значения, используя конструкцию вида:
```
ConfigurationManager.AppSettings["MyKey"]
```
Что ж, я давно хотел выяснить, как использовать возможности класса ConfigurationSection для описания и загрузки данных, определенных в моем собственном формате. После нескольких часов экспериментов и гугления я смог создать свою структуру данных в файле конфигурации и воспользоваться ей в своем приложении.
Итак, для того что бы загрузить свою структуру данных из файла App.Config нам потребуются следующие классы:
1. ConfigurationSection — Этот объект вернет нам пользовательскую секцию.
2. ConfigurationElementCollection — Это собственно коллекция элементов, которые мы определим в пользовательской секции.
3. ConfigurationElement — Это сам элемент, описывающий какую-от определенную вами сущность.
Первое, что нам потребуется сделать, это добавить в наше приложение файл app.Config (если, конечно, вы этого еще не сделали). После чего открываем данный файл и копипастим следующий код между тегами :
```
```
***Замечание:** данная секция должна располагаться в самом начале файла конфигурации, т.е. сразу после тега , иначе будут ошибки инициализации конфигурации.*
Далее создадим нашу собственную секцию, которая будет реализовывать нашу собственную модель данных:
```
```
***Замечание:** если кому-то не нравиться добавление узлов командой add в данном примере, то всегда можно сделать свой собственный префикс, используя следующий код:*
```
[ConfigurationCollection( typeof( FolderElement ) ), AddItemName = "Folder"]
public class FoldersCollection : ConfigurationElementCollection
{
```
*при определении коллекции элементов в структуре данных. Тогда в конфигурационном файле можно будет писать так:
```
```*
Закончим модификации в файле конфигурации и перейдем к организации взаимодействия нашего приложения с ним.
Первым делом создадим класс-наследник от ConfigurationSection, что позволит нам взаимодействовать с нашей секцией в файле конфигурации через ConfigurationManager во время исполнения программы.
```
public class StartupFoldersConfigSection : ConfigurationSection
{
[ConfigurationProperty( "Folders" )]
public FoldersCollection FolderItems
{
get { return ( (FoldersCollection)( base[ "Folders" ] ) ); }
}
}
```
Атрибут ConfigurationProperty( «Folders» ) требуется для сопоставления свойства FolderItems с корневым узлом нашей структуры данных.
Класс FoldersCollection является наследником ConfigurationElementCollection, который обеспечивает взаимодействие с коллекцией наших элементов, описанных в app.config. Определяется класс так:
```
[ConfigurationCollection( typeof( FolderElement ) )]
public class FoldersCollection : ConfigurationElementCollection
{
protected override ConfigurationElement CreateNewElement()
{
return new FolderElement();
}
protected override object GetElementKey( ConfigurationElement element )
{
return ( (FolderElement)( element ) ).FolderType;
}
public FolderElement this[int idx ]
{
get{return (FolderElement) BaseGet(idx); }
}
}
```
Последним нам нужно создать ConfigurationElement, класс который свяжет нас с конечными данными, определенными в конфигурационном файле.
```
public class FolderElement : ConfigurationElement
{
[ConfigurationProperty("folderType", DefaultValue="", IsKey=true, IsRequired=true)]
public string FolderType
{
get {return ((string) (base["folderType"]));}
set{base["folderType"] = value; }
}
[ConfigurationProperty( "path", DefaultValue = "", IsKey = false, IsRequired = false )]
public string Path
{
get{return ( (string)( base[ "path" ] ) ); }
set{base[ "path" ] = value; }
}
}
```
Атрибут ConfigurationProperty(«folderType») требуется для того, что бы проассоциировать имя xml-атрибута в файле конфигурации. Остальные параметры атрибута такие как DefaultValue="", IsKey=true, IsRequired=true определяют только различные опции применимые к свойствам.
***Замечание:** автор умалчивает, что при стандартном способе использования сеттер свойства FolderType, работать не будет, т.к. файл конфигурации обычно доступен только на чтение. Для того что бы представлялось возможным производить запись в файл конфигурации следует делать, например, так:*
```
Configuration cfg = ConfigurationManager.OpenExeConfiguration(ConfigurationUserLevel.None);
StartupFoldersConfigSection section = (StartupFoldersConfigSection)cfg.Section["StartupFolders"];
if ( section != null )
{
System.Diagnostics.Debug.WriteLine( section.FolderItems[0].FolderType );
System.Diagnostics.Debug.WriteLine( section.FolderItems[0].Path );
section.FolderItems[0].Path = "C:\\Nanook";
cfg.Save(); //устанавливает перенос на новую строку и производит проверку .vshost.exe.config файла в вашей отладочной папке.
}
```
Итак, мы имеем все необходимые данные и классы, которые предоставляют нам возможность хранить в конфигурационном файле app.config пользовательскую структуру данных.
Использовать данный подход можно так:
```
StartupFoldersConfigSection section = (StartupFoldersConfigSection)ConfigurationManager.GetSection( "StartupFolders" );
if ( section != null )
{
System.Diagnostics.Debug.WriteLine( section.FolderItems[ 0 ].FolderType );
System.Diagnostics.Debug.WriteLine( section.FolderItems[ 0 ].Path );
}
```
При этом не забываем прописать System.Configuration в список подключаемых пространств имен.
Автор: [Derik Whittaker](http://devlicio.us/blogs/derik_whittaker/archive/2006/11/13/app-config-and-custom-configuration-sections.aspx) | https://habr.com/ru/post/128517/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.