
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Тестирование JavaScript кода с Jest для чайников. Часть 1
Здравствуй, Хабр! Данное руководство является первой частью в запланированном цикле статей про такой замечательный фреймворк для тестирования как Jest. Материал будет полезен новичкам и тем, кто только знакомится с тестированием, и хотел бы изучить этот фреймворк. В первой части мы разберём: как начать работу с jest, как написать простой тест, и какие есть методы для сопоставления проверяемых значение с ожидаемыми. Кому интересно — добро пожаловать под кат!
Что такое Jest?
---------------
Как указано на домашней странице проекта:
> Jest — это восхитительная среда тестирования JavaScript с упором на простоту.
И действительно, Jest очень простой. Он не требует дополнительных настроек, легкий в понимании и применении, а так же имеет довольно хорошую документацию. Отлично подходит для проектов использующих Node, React, Angular, Vue, Babel, TypeScript и не только.
Также он имеет открытый исходный код и поддерживается компанией Facebook.
Установка
---------
Для установки Jest в ваш проект выполните:
```
npm install --save-dev jest
```
Если вы используете yarn:
```
yarn add --dev jest
```
После установки можете обновить секцию scripts вашего package.json:
```
“scripts” : {
“test”: “jest”
}
```
С помощью такого простого вызова мы уже можем запустить наши тесты (на самом деле jest потребует существование хотя бы одного теста).
Также можно установить глобально (но так делать я бы не рекомендовал, так как по мне глобальная установка модулей является плохой практикой):
```
npm install jest --global
```
И соответственно для yarn:
```
yarn global add jest
```
После этого вы можете использовать jest непосредственно из командной строки.
При помощи вызова команды jest --init в корне проекта, ответив на несколько вопросов, вы получите файл с настройками jest.config.js. Или можно добавить конфигурацию прямиком в ваш package.json. Для этого добавьте в корень json ключ «jest» и в соответствующем ему объекте можете добавлять необходимые вам настройки. Сами опции мы разберем позже. На данном этапе в этом нет необходимости, поскольку jest можно использовать «сходу», без дополнительных конфигураций.
Первый тест
-----------
Давайте создадим файл first.test.js и напишем наш первый тест:
```
//first.test.js
test('My first test', () => {
expect(Math.max(1, 5, 10)).toBe(10);
});
```
И запустим наши тесты с помощью npm run test или непосредственно командой jest (если он установлен глобально). После запуска мы увидим отчет о прохождении тестов.
```
**PASS** ./first.test.js
✓ My first test (1 ms)
Test Suites: 1 passed, 1 total
Tests: 1 passed, 1 total
Snapshots: 0 total
Time: 0.618 s, estimated 1 s
```
Давайте «сломаем» наш тест и запустим jest повторно:
```
//first.test.js
test('My first test', () => {
expect(Math.max(1, 5, 10)).toBe(5);
});
```
Как мы видим, теперь наш тест не проходит проверки. Jest отображает подробную информацию о том, где возникла проблема, какой был ожидаемый результат, и что мы получили вместо него.
Теперь давайте разберём код самого теста. Функция *test* используется для создания нового теста. Она принимает три аргумента (в примере мы использовали вызов с двумя аргументами). Первый — строка с названием теста, его jest отобразит в отчете. Второй — функция, которая содержит логику нашего теста. Также можно использовать 3-й аргумент — таймаут. Он является не обязательным, а его значение по умолчанию составляет 5 секунд. Задаётся в миллисекундах. Этот параметр необходим когда мы работаем с асинхронным кодом и возвращаем из функции теста промис. Он указывает как долго jest должен ждать разрешения промиса. По истечению этого времени, если промис не был разрешен — jest будет считать тест не пройденным. Подробнее про работу с асинхронными вызовами будет в следующих частях. Также вместо *test()* можно использовать *it()*. Разницы между такими вызовами нету. *it()* это просто алиас на функцию *test()*.
Внутри функции теста мы сначала вызываем *expect()*. Ему мы передаем значение, которое хотим проверить. В нашем случае, это результат вызова *Math.max(1, 5, 10)*. *expect()* возвращает объект «обертку», у которой есть ряд методов для сопоставления полученного значения с ожидаемым. Один из таких методов мы и использовали — *toBe*.
Давайте разберем основные из этих методов:
* **toBe()** — подходит, если нам надо сравнивать примитивные значения или является ли переданное значение ссылкой на тот же объект, что указан как ожидаемое значение. Сравниваются значения при помощи *Object.is()*. В отличие от === это дает возможность отличать 0 от -0, проверить равенство NaN c NaN.
* **toEqual()** — подойдёт, если нам необходимо сравнить структуру более сложных типов. Он сравнит все поля переданного объекта с ожидаемым. Проверит каждый элемент массива. И сделает это рекурсивно по всей вложенности.
```
test('toEqual with objects', () => {
expect({ foo: 'foo', subObject: { baz: 'baz' } })
.toEqual({ foo: 'foo', subObject: { baz: 'baz' } }); // Ок
expect({ foo: 'foo', subObject: { num: 0 } })
.toEqual({ foo: 'foo', subObject: { baz: 'baz' } }); // А вот так ошибка.
});
test('toEqual with arrays', () => {
expect([11, 19, 5]).toEqual([11, 19, 5]); // Ок
expect([11, 19, 5]).toEqual([11, 19]); // Ошибка
});
```
* **toContain()** — проверят содержит массив или итерируемый объект значение. Для сравнения используется оператор ===.
```
const arr = ['apple', 'orange', 'banana'];
expect(arr).toContain('banana');
expect(new Set(arr)).toContain('banana');
expect('apple, orange, banana').toContain('banana');
```
* **toContainEqual()** — проверяет или содержит массив элемент с ожидаемой структурой.
```
expect([{a: 1}, {b: 2}]).toContainEqual({a: 1});
```
* **toHaveLength()** — проверяет или свойство length у объекта соответствует ожидаемому.
```
expect([1, 2, 3, 4]).toHaveLength(4);
expect('foo').toHaveLength(3);
expect({ length: 1 }).toHaveLength(1);
```
* **toBeNull()** — проверяет на равенство с null.
* **toBeUndefined()** — проверяет на равенство с undefined.
* **toBeDefined()** — противоположность *toBeUndefined*. Проверяет или значение !== undefined.
* **toBeTruthy()** — проверяет или в булевом контексте значение соответствует true. Тоесть любые значения кроме false, null, undefined, 0, NaN и пустых строк.
* **toBeFalsy()** — противоположность *toBeTruthy()*. Проверяет или в булевом контексте значение соответствует false.
* **toBeGreaterThan()** и **toBeGreaterThanOrEqual()** — первый метод проверяет или переданное числовое значение больше, чем ожидаемое >, второй проверяет больше или равно ожидаемому >=.
* **toBeLessThan()** и **toBeLessThanOrEqual()** — противоположность *toBeGreaterThan()* и *toBeGreaterThanOrEqual()*
* **toBeCloseTo()** — удобно использовать для чисел с плавающей запятой, когда вам не важна точность и вы не хотите, чтобы тест зависел от незначительной разницы в дроби. Вторым аргументом можно передать до какого знака после запятой необходима точность при сравнении.
```
const num = 0.1 + 0.2; // 0.30000000000000004
expect(num).toBeCloseTo(0.3);
expect(Math.PI).toBeCloseTo(3.14, 2);
```
* **toMatch()** — проверяет соответствие строки регулярному выражению.
```
expect('Banana').toMatch(/Ba/);
```
* **toThrow()** — используется в случаях, когда надо проверить исключение. Можно проверить как сам факт ошибки, так и проверить на выброс исключения определенного класса, либо по сообщению ошибки, либо по соответствию сообщения регулярному выражению.
```
function funcWithError() {
throw new Error('some error');
}
expect(funcWithError).toThrow();
expect(funcWithError).toThrow(Error);
expect(funcWithError).toThrow('some error');
expect(funcWithError).toThrow(/some/);
```
* **not** — это свойство позволяет сделать проверки на НЕравенство. Оно предоставляет объект, который имеет все методы перечисленные выше, но работать они будут наоборот.
```
expect(true).not.toBe(false);
expect({ foo: 'bar' }).not.toEqual({});
function funcWithoutError() {}
expect(funcWithoutError).not.toThrow();
```
Давайте напишем пару простых тестов. Для начала создадим простой модуль, который будет содержать несколько методов для работы с окружностями.
```
// src/circle.js
const area = (radius) => Math.PI * radius ** 2;
const circumference = (radius) => 2 * Math.PI * radius;
module.exports = { area, circumference };
```
Далее добавим тесты:
```
// tests/circle.test.js
const circle = require('../src/circle');
test('Circle area', () => {
expect(circle.area(5)).toBeCloseTo(78.54);
expect(circle.area()).toBeNaN();
});
test('Circumference', () => {
expect(circle.circumference(11)).toBeCloseTo(69.1, 1);
expect(circle.circumference()).toBeNaN();
});
```
В этих тестах мы проверили результат работы 2-х методов — *area* и *circumference*. При помощи метода *toBeCloseTo* мы сверились с ожидаемым результатом. В первом случае мы проверили или вычисляемая площадь круга с радиусом 5 приблизительно равна 78.54, при этом разница с полученым значением (оно составит 78.53981633974483) не большая и тест будет засчитан. Во втором мы указали, что нас интересует проверка с точностью до 1 знака после запятой. Также мы вызвали наши методы без аргументов и проверили результат с помощью *toBeNaN*. Поскольку результат их выполнения будет NaN, то и тесты будут пройдены успешно.
Разберём ещё один пример. Создадим функцию, которая будет фильтровать массив продуктов по цене:
```
// src/productFilter.js
const byPriceRange = (products, min, max) =>
products.filter(item => item.price >= min && item.price <= max);
module.exports = { byPriceRange };
```
И добавим тест:
```
// tests/product.test.js
const productFilter = require('../src/producFilter');
const products = [
{ name: 'onion', price: 12 },
{ name: 'tomato', price: 26 },
{ name: 'banana', price: 29 },
{ name: 'orange', price: 38 }
];
test('Test product filter by range', () => {
const FROM = 15;
const TO = 30;
const filteredProducts = productFilter.byPriceRange(products, FROM, TO);
expect(filteredProducts).toHaveLength(2);
expect(filteredProducts).toContainEqual({ name: 'tomato', price: 26 });
expect(filteredProducts).toEqual([{ name: 'tomato', price: 26 }, { name: 'banana', price: 29 }]);
expect(filteredProducts[0].price).toBeGreaterThanOrEqual(FROM);
expect(filteredProducts[1].price).toBeLessThanOrEqual(TO);
expect(filteredProducts).not.toContainEqual({ name: 'orange', price: 38 });
});
```
В этом тесте мы проверям результат работы функии *byRangePrice*. Сначала мы проверили соответствие длины полученого массива ожидаемой — 2. Следующая проверка требует, чтобы в массиве находился элемент — { name: 'tomato', price: 26 }. Объект в массиве и объект переданный *toContainEqual* — это два разных объекта, а не ссылка на один и тот же. Но *toContainEqual* сверит каждое свойство. Так как оба объекта идентичные — проверка пройдет успешно. Далее мы используем *toEqual* для провеки структуры всего массива и его элементов. Методы *toBeGreaterThanOrEqual* и *toBeLessThanOrEqual* помогут нам проверить price первого и второго элемента массива. И, наконец, вызов *not.toContainEqual* сделает проверку, не содержится ли в массиве элемент — { name: 'orange', price: 38 }, которого по условию там быть не должно.
В данных примерах мы написали несколько простых тестов используя функции проверки описанные выше. В следующих частях мы разберём работу с асинхронным кодом, функции jest которые не затрагивались в этой части туториала, поговорим о его настройке и многое другое. | https://habr.com/ru/post/502302/ | null | ru | null |
# Как усовершенствовать реализацию Компоновщика в .NET

Каждый прогер наверняка использовал паттерн «Компоновщик», а большинство из нас также сталкивалось с необходимостью реализовать его в своем проекте. И часто так получается, что каждая его реализация налагает особые требования на определяемую бизнес-логику, при этом с точки зрения работы с иерархической структурой мы хотим иметь одинаково широкий набор возможностей: одних методов Add и Remove часто недостаточно, так почему бы не добавить Contains, Clear и с десяток других? А если еще нужны специальные методы обхода поддеревьев через итераторы? И вот такую функциональность хочется иметь для различных независимых иерархий, а также не обременять себя необходимостью определять реализацию таких методов в каждом из множества элементов Composite. Ну и листовые компоненты тоже не помешало бы упростить.
Чуть ниже я предложу свой вариант решения такой проблемы, применительно к возможностям C#.
Итак, мы имеем интерфейсный тип Component, который *перегружен двумя областями ответственности*: одна определяет бизнес-логику — то, ради чего и строилась иерархия; вторая обеспечивает прозрачное взаимодействие в иерархии и управляет потомками для композитных элементов. Попробуем одну их них вынести в отдельный интерфейс, к которому можно будет получать доступ по свойству компонента Children (или методу GetChildren). В объекте, который возвращается свойством, будут собраны все операции над коллекцией, включая перечисление, добавление и удаление дочерних элементов, а также все, что нам заблагорассудится.

Мы также определили свойство (метод) IsComposite, чтобы получить быструю и хорошо читаемую проверку на то, является ли элемент композитным или же листовым. Этим свойством можно и не пользоваться: тогда при попытке изменить коллекцию дочерних элементов для листового компонента будет выбрасываться исключение NotSupportedException. Таким образом, мы не теряем *прозрачность интерфейса для всех компонентов* — основное преимущества паттерна «Компоновщик», — и в то же время получаем простой способ определить, могут ли у любого выбранного компонента быть дочерние элементы.
Теперь попробуем определить реализацию интерфейса IComponent, которая была бы хорошо адаптируемой для возможных изменений, и поэтому применимой для построения различных иерархий.
> `using System.Collections.Generic;
>
> using System.Diagnostics.Contracts;
>
> namespace ComponentLibrary
>
> {
>
> [ContractClass(typeof(IComponentContract))]
>
> public interface IComponent<out TComponent, out TChildrenCollection>
>
> where TComponent : IComponent
>
> where TChildrenCollection : class, IEnumerable
>
> {
>
> TChildrenCollection Children { get; }
>
> bool IsComposite { get; }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
От чего интерфейс реализован как шаблонный и что за параметры-типы он принимает? На самом деле идея очень проста: привнести строгую типизацию туда, где действительные типы еще не известны.
*TComponent* — это всего лишь фактический тип того дочернего интерфейса (или класса в более тесно связанной архитектуре), который вы унаследуете от IComponent, чтобы добавить в него обязанности типа Operation( ).
*TChildrenCollection* — интерфейс коллекции, который вы реализуете, чтобы обращаться к дочерним элементам. В этом интерфейсе должен быть определен как минимум только GetEnumerator( ), через который можно получить итератор коллекции. Дело в том, что иногда не нужно предоставлять методы типа Add( ) и Remove( ), т.к. все элементы могут добавляться в конструкторе, а сама иерархическая структура не должна изменяться после создания. А если вам вдруг понадобятся уведомления об изменении коллекции — передайте ObservableCollection в качестве TChildrenCollection, и дело в шляпе!
В контракте типа мы укажем следующие ограничения на возвращаемое значение свойства Children: 1) возвращаемая коллекция не равна null; 2) ни один из ее элементов не равен null; 3) компонент либо указан как композитный, либо не содержит дочерних элементов. Для краткости код контракта здесь не приводится.
Помните, мы говорили, что хотели бы наделить каждый компонент дополнительным методом, возвращающим итератор, реализующий сложную логику обхода поддерева? Допустим, что мы написали такой итератор ComponentDescendantsEnumerator (его код можно скачать по ссылке в конце статьи), а затем обернули его в класс ComponentDescendantsEnumerable, определяющий IEnumerable. Теперь нужно решить, где разместить методы, возвращающие подобные итераторы? К счастью в C# есть очень полезный механизм — методы-расширения. Давайте попробуем его применить.
> `namespace ComponentLibrary.Extensions
>
> {
>
> public static class ComponentExtensions
>
> {
>
> public static IEnumerable GetDescendants(this T component)
>
> where T : IComponentIEnumerable>
>
> {
>
> // здесь был контракт метода
>
> return new ComponentDescendantsEnumerable(component);
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Мы реализуем метод-расширение в отдельном пространстве имен — так мы сможем его вызывать словно метод, принадлежащий интерфейсу IComponent< , >, лишь тогда, когда импортируем это пространство имен.
Далее перед нами еще задача: нужно реализовать способ получения коллекций, которые никогда не содержат элементов, а на все запросы изменения (вроде Add / Remove) выбрасывают NotSupportedException. Сначала сделаем одну такую коллекцию, реализующую ICollection. Однако, если коллекция никогда не изменяется и создается всегда пустой, то нет смысла делать более одной такой коллекции на всю программу (вернее на AppDomain). Идеальный случай, чтобы воспользоваться паттерном «Синглтон»! (реализацию класса Singleton можно узнать в прилагаемых исходниках)
> `sealed internal class ItemsNotSupportedCollection :
>
> Singleton>,
>
> ICollection
>
> {
>
> private ItemsNotSupportedCollection() { }
>
>
>
> public int Count { get { return 0; } }
>
>
>
> public bool IsReadOnly { get { return true; } }
>
>
>
> public bool Contains(T item) { return false; }
>
>
>
> public void CopyTo(T[] array, int arrayIndex) { }
>
>
>
> public void Add(T item) { throw new NotSupportedException(); }
>
>
>
> public void Clear() { throw new NotSupportedException(); }
>
>
>
> public bool Remove(T item) { throw new NotSupportedException(); }
>
>
>
> public IEnumerator GetEnumerator()
>
> {
>
> return ItemsNotSupportedEnumerator.Instance;
>
> }
>
>
>
> IEnumerator IEnumerable.GetEnumerator()
>
> { return this.GetEnumerator(); }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Ради прозрачности используемый класс итератора представляет итератор пустой коллекции, поэтому тоже достаточно одного его экземпляра — вновь синглтон.
> `sealed internal class ItemsNotSupportedEnumerator :
>
> Singleton>,
>
> IEnumerator
>
> {
>
> private ItemsNotSupportedEnumerator() { }
>
>
>
> public T Current { get { return default(T); } }
>
>
>
> public void Dispose() { }
>
>
>
> object IEnumerator.Current { get { return null; } }
>
>
>
> public bool MoveNext() { return false; }
>
>
>
> public void Reset() { throw new NotSupportedException(); }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Осталось только создать статическое свойство, видимое извне сборки и возвращающее доступную только для чтения коллекцию элементов для интерфейса ICollection.
> `public static class ComponentCollections
>
> where TComponent : IComponentIEnumerable>
>
> {
>
> public static ICollection EmptyCollection
>
> {
>
> get
>
> {
>
> // здесь был контракт
>
> return ItemsNotSupportedCollection.Instance;
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Пришло время для самого интересного: применение нашей мини-библиотеки для создания конкретной иерархии классов. Допустим надо организовать систему меню, состоящую из: MenuCommand — конкретная команда, и Menu — подменю, которое может содержать другие команды и подменю. Все классы расположены в отдельной сборке. Шестое чувство подсказывает, что паттерн «Компоновщик» пришелся бы здесь кстати.

Сначала определим интерфейс, общий для всех классов иерархии. Внутри интерфейса мы определяем только методы и свойства, требуемые бизнес-логикой нашего меню (в данном случае каждый элемент имеет имя и умеет отображать себя с указанным отступом).

> `namespace MenuLibrary
>
> {
>
> public interface IMenuItem :
>
> IComponent>
>
> {
>
> string Name { get; }
>
> void Display(int indent = 0);
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В качестве параметра-типа TComponent мы всегда передаем интерфейс компонентов (т.е. этот же IMenuItem), в качестве TChildrenCollection — интерфейс реализуемой коллекции. Мы могли бы для TChildrenCollection создать свой интерфейс, определяющий методы Add, Remove и GetChild (а также GetEnumerator), как и в классическом варианте паттерна. Можно передать например IList, но мы решили, что здесь нам подходит стандартный интерфейс ICollection.
Вот так мы определим листовой компонент MenuCommand:
> `public class MenuCommand : IMenuItem
>
> {
>
> private readonly string name;
>
>
>
> public MenuCommand(string name)
>
> {
>
> // здесь был контракт
>
> this.name = name;
>
> }
>
>
>
> public string Name { get { return this.name; } }
>
>
>
> public void Display(int indent = 0)
>
> {
>
> string indentString = MenuHelper.GetIndentString(indent);
>
> Console.WriteLine("{1}{0} [Command]", this.name, indentString);
>
> }
>
>
>
> public ICollection Children
>
> {
>
> get { return ComponentCollections.EmptyCollection; }
>
> }
>
>
>
> public bool IsComposite { get { return false; } }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Свойство Children возвращает ранее объявленную «синглтоновую» коллекцию для листовых элементов. Теперь объявим композитный компонент Menu.
> `public class Menu : IMenuItem
>
> {
>
> private readonly ICollection children =
>
> new List();
>
>
>
> private readonly string name;
>
>
>
> public Menu(string name)
>
> {
>
> // здесь должен быть контракт
>
> this.name = name;
>
> }
>
>
>
> public string Name { get { return this.name; } }
>
>
>
> public void Display(int indent = 0)
>
> {
>
> string indentString = MenuHelper.GetIndentString(indent);
>
> Console.WriteLine("{1}{0} [Menu]", this.name, indentString);
>
> int childrenIndent = indent + 1;
>
> foreach (IMenuItem child in this.children)
>
> {
>
> child.Display(childrenIndent);
>
> }
>
> }
>
>
>
> public ICollection Children
>
> { get { return this.children; } }
>
>
>
> public bool IsComposite { get { return true; } }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Children неожиданно возвращает использованную стандартную коллекцию List. Это хороший ход, если пользователю нашей иерархии разрешено привести тип объекта Children к List и использовать все дополнительные возможности этого класса. Но если такой расклад недопустим, то надо обернуть List в некий внутренний класс, реализующий только ICollection и недоступный другим сборкам (или даже классам).
Теперь протестируем написанный нами код.
> `using System;
>
> using System.Linq;
>
> using ComponentLibrary.Extensions;
>
> using MenuLibrary;
>
> namespace MenuTest
>
> {
>
> public static class MenuTest
>
> {
>
> public static void Perform()
>
> {
>
> // создаем структуру меню
>
> IMenuItem rootMenu = new Menu("Root");
>
> // ... меню File
>
> IMenuItem fileMenu = new Menu("File");
>
> fileMenu.Children.Add(new MenuCommand("New"));
>
> fileMenu.Children.Add(new MenuCommand("Open"));
>
> // ... меню File->Export
>
> IMenuItem fileExportMenu = new Menu("Export");
>
> fileExportMenu.Children.Add(new MenuCommand("Text Document"));
>
> fileExportMenu.Children.Add(new MenuCommand("Binary Format"));
>
> fileMenu.Children.Add(fileExportMenu);
>
> // ... меню File
>
> fileMenu.Children.Add(new MenuCommand("Exit"));
>
> rootMenu.Children.Add(fileMenu);
>
> // ... меню Edit
>
> IMenuItem editMenu = new Menu("Edit");
>
> editMenu.Children.Add(new MenuCommand("Cut"));
>
> editMenu.Children.Add(new MenuCommand("Copy"));
>
> editMenu.Children.Add(new MenuCommand("Paste"));
>
> rootMenu.Children.Add(editMenu);
>
> // выводим меню на экран
>
> rootMenu.Display();
>
> Console.WriteLine();
>
> // выводим на консоль имена всех составных меню,
>
> // вложенных в Root, начинающихся на буквы "E" или "R"
>
> var compositeMenuNames =
>
> from menu in rootMenu.GetDescendants()
>
> where menu.IsComposite
>
> && (menu.Name.StartsWith("E") || menu.Name.StartsWith("R"))
>
> select menu.Name;
>
> foreach (string menuName in compositeMenuNames)
>
> {
>
> Console.WriteLine(menuName);
>
> }
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Обратите внимание на LINQ-запрос к перечислению, возвращаемому методом-расширением GetDescendants(). Взглянем на результат работы.

Вот так все просто. Причем в логике разработанных компонентов все внимание проектировщика сосредоточено на построении бизнес-логики, а не иерархической структуры или классов-контейнеров.
**Ссылка на исходники:** <http://www.fileden.com/files/2011/10/7/3205975/ComponentLibrary.zip>
**P.S.** Если вам что-то показалось не очевидным, либо вы хотели бы посмотреть на вариант реализации иерархии, доступной только для чтения, то можете обратиться к [расширенному варианту](http://sergeyalikin.blogspot.com/2011/10/net.html) этого же поста.
**P.P.S.** Если честно, я надеюсь, что в комментах кто-нибудь предложит лучший вариант реализации Компоновщика, чем у меня.
**UPD** Как правильно заметил [avalter](https://habrahabr.ru/users/avalter/), здесь я всего лишь применил к Компоновщику Extract Interface, Extract Class и использовал NullObject (желательно закончить Extract Class, вынести используемую коллекцию из композитных компонентов и инкапсулировать ее в отдельный класс). В итоге получается не просто Компоновщик, а более гибкая структура.
**Реализовывать каждый раз паттерн таким образом «с нуля» ни в коем случае не советую!** Но можно взять код сборки ComponentLibrary, скопировать ее в свой проект и автоматически получить некоторые преимущества для своей иерархии: готовые Null-Object коллекции для листовых элементов, дополнительные итераторы для обхода структуры, а также контракт на интерфейс IComponent, о котором тут упоминалось вскользь. Т.о. при реализации очередной иерархии, подобной IMenuItem, можно задумываться лишь над логикой методов Display(), если реализованных в ComponentLibrary интерфейсов структур достаточно (иначе определить свои реализации). | https://habr.com/ru/post/130012/ | null | ru | null |
# Javascript примеси для чайников
После того, как с классическим (от слова класс) наследованием в JS стало вроде-бы [все понятно](http://habrahabr.ru/blogs/javascript/131714/), я решил разобраться с реализацией другого способа повторного использвоания кода — примесями. Несмотря на довольно непривычное название, способ этот чертовски прост.
#### 1. Примеси — это, собственно, что ?
Примесь (mixin) — это объект с набором функций, который сам по себе (отдельно от других объектов) не используется.
Вот, например, прекрасная примесь:
```
var Mixin_Babbler =
{
say: function ()
{
console.log("My name is " + this.name + " and i think:'" + this.THOUGHTS + "'");
},
argue: function() { console.log("You're totally wrong"); }
};
```
При попытке вызвать метод say просто так, нас ждет облом, потому что ни *this.name*, ни *this.THOUGHTS* в нашем объекте, почему-то, просто нет.
На самом деле все правильно, чтобы использовать примесь по назначению нам нужен другой объект, и метод, который копирует все свойства переданных ему объектов-примесей в прототип функции конструктора — обычно такой метод называют extend, или mix, или как-нибудь в этом духе:
```
function extend(object)
{
var mixins = Array.prototype.slice.call(arguments, 1);
for (var i = 0; i < mixins.length; ++i)
{
for (var prop in mixins[i])
{
if (typeof object.prototype[prop] === "undefined")
{
object.prototype[prop] = mixins[i][prop];
}
}
}
}
```
#### 2. Ну и как это использовать?
Легко и не напрягаясь — допустим, у нас есть парочка примесей:
```
var Mixin_Babbler =
{
say: function () { console.log("My name is " + this.name + " and i think:'" + this.THOUGHTS + "'"); },
argue: function() { console.log("You're totally wrong"); }
};
var Mixin_BeverageLover =
{
drink: function () { console.log("* drinking " + this.FAVORITE_BEVERAGE + " *"); }
};
```
И, кому-то, возможно, уже знакомая, эволюционная цепочка:
```
function Man(name)
{
this.name = name;
}
Man.prototype =
{
constructor: Man,
THOUGHTS: "I like soccer"
}
extend(Man, Mixin_Babbler);
function Gentleman(name)
{
this.name = name;
}
Gentleman.prototype =
{
constructor: Gentleman,
THOUGHTS: "I like Earl Grey",
FAVORITE_BEVERAGE: "Tea"
}
extend(Gentleman, Mixin_Babbler, Mixin_BeverageLover);
function Programmer(name)
{
this.name = name;
}
Programmer.prototype =
{
constructor: Programmer,
THOUGHTS: "MVC, MVVM, MVP *___* like it!",
FAVORITE_BEVERAGE: "Cofee",
write_good_code: function () { console.log("*writing best code ever*"); this.drink(); }
}
extend(Programmer, Mixin_Babbler, Mixin_BeverageLover);
```
Каждый «класс» теперь не зависит от другого, а весь повторяющийся функционал реализован с помощью примесей.
Теперь стоит все проверить — вдруг заработает:
```
var man = new Man("Bob");
var gentleman = new Gentleman("Bill");
var programmer = new Programmer("Benjamin");
man.say();
man.argue();
gentleman.say();
gentleman.drink();
programmer.say();
programmer.write_good_code();
```
И консоль говорит что таки да, все как надо:
```
My name is Bob and i think:'I like soccer'
*You're totally wrong*
My name is Bill and i think:'I like Earl Grey'
*drinking Tea*
My name is Benjamin and i think:'MVC, MVVM, MVP like *__* it!'
*writing best code ever*
*drinking Cofee*
```
Собственно все. В отличие от «классического» наследования, реализация примесей очень простая и понятная. Существуют конечно некоторые вариации, но так или иначе ядро выглядит именно так.
**UPD.** Как подсказал один очень хороший человек с ником [lalaki](https://habrahabr.ru/users/lalaki/), метод extend можно реализовать немножко по-другому:
```
function extend_2(object)
{
var mixins = Array.prototype.slice.call(arguments, 1);
for (var i = 0; i < mixins.length; ++i)
{
for (var prop in mixins[i])
{
if (typeof object.prototype[prop] === "undefined")
{
bindMethod = function (mixin, prop)
{
return function () { mixin[prop].apply(this, arguments) }
}
object.prototype[prop] = bindMethod(mixins[i], prop);
}
}
}
}
```
С таким подходом можно на лету подменять методы в примеси, и эти изменения сразу будут доступны для всех объектов эту примесь использующих.
Очень-очень маленьким недостатком является то, что не слишком умная подсказка в среде разработки будет всегда показывать что у методов нет аргументов.
Весь код и примеры лежат себе спокойно [вот тут](https://github.com/L0stSoul/Training/tree/master/MixIn) | https://habr.com/ru/post/132340/ | null | ru | null |
# TeamViewer из подручных материалов
Всем привет!
Сегодня хочу рассказать о двух случайно обнаруженных “фичах” известных протоколов, которые позволили сложиться “пазлу” из темы статьи.
И так, у **сотрудника** техподдержки есть необходимость подключаться к рабочему столу **пользователя**, что бы совместно что-то сделать. Раз нет TeamViewer, значить надо использовать что-то похожее, например VNC.Тут же “выплывают” проблемы:
1. компьютер пользователя может быть недоступен для компьютера сотрудника, например, находится в домашней сети за роутером (который так же может быть не доступен из внешних сетей)
2. пользователю нужно не только заранее установить VNC Server на свой компьютер, но и задать (и не забыть:) пароль от него, что бы сообщить его, когда понадобится, сотруднику
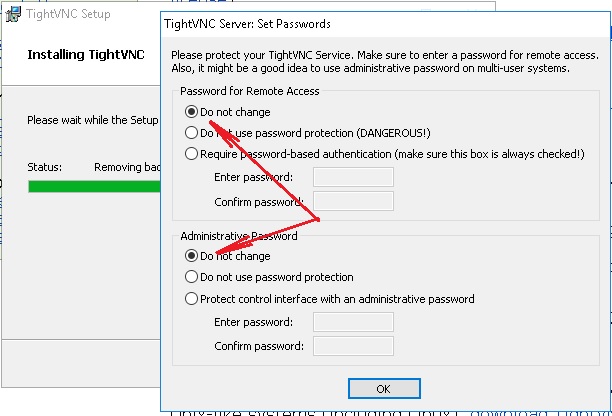
Эти проблемы решает первая “фича” - оказалось, что VNC позволяет организовать подключение “наоборот”, не с клиента на сервер, а с сервера на клиент. В системе Windows пользователь может установить, например, пакет TightVNC оставляя все опции, “по умолчанию”, и, не меняя и не выясняя случайно сгенерированный пароль, который теперь никому не понадобится:
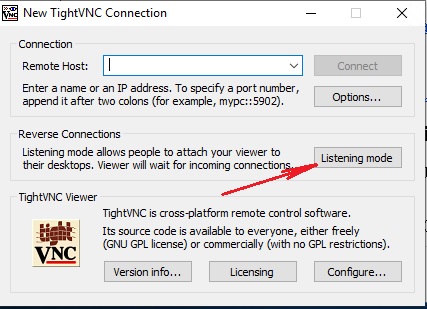
Этот же пакет нужно будет установить сотруднику техподдержки, серверная часть ему не нужна, можно убрать ее из автозагрузки, а понадобится TightVNC Viewer запущенный в Listening mode
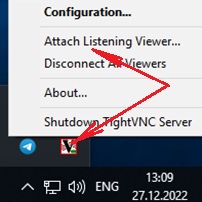
Теперь, по просьбе сотрудника техподдержки, пользователю будет достаточно выбрать меню Attach Listening Viewer
указать "ip\_адрес\_компьютера\_сотрудника\_техподдержки" и нажать на кнопку "Attach"
Если пользователи работают в Linux, то необходимой функциональностью обладает пакет x11vnc, который в debian ориентированных дистрибутивах может быть установлен командой:
```
$ sudo apt install x11vnc
```
Для предоставления своего рабочего стола сотруднику техподдержки пользователю будет достаточно набрать в терминале:
```
$ x11vnc -connect ip_адрес_компьютера_сотрудника_техподдержки
```
Если и сотрудник техподдержки работает в Linux, он может установить пакет tigervnc-viewer
```
$ sudo apt install tigervnc-viewer
```
и, перед оказанием помощи пользователю, запустить в терминале команду:
```
$ vncviewer -listen
```
СТОП! Как это “ip\_адрес\_компьютера\_сотрудника\_техподдержки”? А если (даже наверняка) это такой же “серый” адрес в локальной сети за роутером, как и у сотрудника?
Эту проблему решает вторая “фича” - оказалось что сервис SSH не только позволяет, благодаря опции GatewayPorts yes, установить подключение с компьютера сотрудника к SSH серверу и назначить внешний TCP порт для встречных соединений, которые можно “направить” в VNC viewer, но и сгенерировать этот номер динамически.
Команда будет выглядеть вот так (обратите внимание на 0, там где указывается номер внешнего порта):
```
ssh -R 0:localhost:5500 логин_сотрудника_техподдержки@ip_адрес_ssh_сервера
```
И, да, VNC viewer, в режиме listen, ожидает, по умолчанию, подключения на порту 5500, и теперь его можно ограничить только интерфейсом localhost
Теперь, если “ip\_адрес\_ssh\_сервера” публичный, пользователи смогут предоставить свой рабочий стол, указав вместо “ip\_адреса\_компьютера\_сотрудника\_техподдержки” - “ip\_адрес\_ssh\_сервера:сгенерированный\_номер\_порта”
Некоторой проблемой оказалось “выяснение” назначенного динамического порта, дело в том что в Linux терминале строка:
```
Allocated port NNNNN for remote forward to localhost:5500
```
прекрасно отображается, и сотрудник техподдержки может продиктовать его пользователю, но в Windows, не все SSH клиенты (например PuTTY) это делают, тут могу посоветовать MobaXTerm в нем все как в Linux
В завершении статьи остается только посочувствовать пользователям, которые вместо “каликанья” по “иконке” и сообщения оператору номера подключения в TeamViewer приходится запускать “страшные” программы с непонятными адресами, но мы на работе “боремся” с этим создав bat файл для пользователей Windows и используя Ansible для рабочих станций Linux, после которых на рабочем столе пользователя тоже появляется “иконка”, по которой можно “кликнуть” и ввести там 5 цифр, названных сотрудником техподдержки. Если статья вызовет интерес, можно будет написать продолжение на эту тему.
Еще, из “нехорошего”, трафик между пользовательским VNC и ssh сервером “летит” нешифрованный, тоже в планах поправить в будущем.
Так же, вероятно что MeshCentral или RustDesk окажутся более удобными решениями для тех, кто ищет альтернативу TeamViewer, буду рад почитать статьи на эту тему.
На этом все, всех с Новым годом, всех благ! | https://habr.com/ru/post/709218/ | null | ru | null |
# Пишем современный маршрутизатор на JavaScript
Доброго времени суток, друзья!
Простые одностраничные приложения, основанные на React, Vue или чистом JavaScript, окружают нас повсюду. Хороший «одностраничник» предполагает соответствующий механизм маршрутизации.
Такие библиотеки, как «navigo» или «react-router», приносят большую пользу. Но как они работают? Необходимо ли нам импортировать всю библиотеку? Или достаточно какой-то части, скажем, 10%? В действительности, быстрый и полезный маршрутизатор можно легко написать самому, это займет немного времени, а программа будет состоять менее чем из 100 строчек кода.
### Требования
Наш маршрутизатор должен быть:
* написан на ES6+
* совместим с историей и хешем
* переиспользуемой библиотекой
Обычно в веб приложении используется один экземпляр маршрутизатора, но во многих случаях нам требуется несколько экземпляров, поэтому мы не сможем использовать синглтон (Singleton) в качестве шаблона. Для работы нашему маршрутизатору необходимы следующие свойства:
* маршрутизаторы (routes): список зарегистрированных маршрутизаторов
* режим (mode): хеш или история
* корневой элемент (root): корневой элемент приложения, если мы находимся в режиме использования истории
* конструктор (constructor): основная функция для создания нового экземпляра маршрутизатора
```
class Router {
routes = []
mode = null
root = '/'
constructor(options) {
this.mode = window.history.pushState ? 'history' : 'hash'
if (options.mode) this.mode = options.mode
if (options.root) this.root = options.root
}
}
export default Router
```
### Добавление и удаление маршрутизаторов
Добавление и удаление маршрутизаторов осуществляется через добавление и удаление элементов массива:
```
class Router {
routes = []
mode = null
root = '/'
constructor(options) {
this.mode = window.history.pushState ? 'history' : 'hash'
if (options.mode) this.mode = options.mode
if (options.root) this.root = options.root
}
add = (path, cb) => {
this.routes.push({
path,
cb
})
return this
}
remove = path => {
for (let i = 0; i < this.routes.length; i += 1) {
if (this.routes[i].path === path) {
this.routes.slice(i, 1)
return this
}
}
return this
}
flush = () => {
this.routes = []
return this
}
}
export default Router
```
### Получение текущего пути
Мы должны знать, где находимся в приложении в определенный момент времени.
Для этого нам потребуется обработка обоих режимов (истории и хеша). В первом случае, нам нужно удалить путь к корневому элементу из window.location, во втором — "#". Нам также необходима функция (clearSlash) для удаления всех маршрутизаторов (строки от начала до конца):
```
[...]
clearSlashes = path =>
path
.toString()
.replace(/\/$/, '')
.replace(/^\//, '')
getFragment = () => {
let fragment = ''
if (this.mode === 'history') {
fragment = this.clearSlashes(decodeURI(window.location.pathname + window.location.search))
fragment = fragment.replace(/\?(.*)$/, '')
fragment = this.root !== '/' ? fragment.replace(this.root, '') : fragment
} else {
const match = window.location.href.match(/#(.*)$/)
fragment = match ? match[1] : ''
}
return this.clearSlashes(fragment)
}
}
export default Router
```
### Навигация
Ок, у нас имеется API для добавления и удаления URL. Также у нас имеется возможность получать текущий адрес. Следующий шаг — навигация по маршрутизатору. Работаем со свойством «mode»:
```
[...]
getFragment = () => {
let fragment = ''
if (this.mode === 'history') {
fragment = this.clearSlashes(decodeURI(window.location.pathname + window.location.search))
fragment = fragment.replace(/\?(.*)$/, '')
fragment = this.root !== '/' ? fragment.replace(this.root, '') : fragment
} else {
const match = window.location.href.match(/#(.*)$/)
fragment = match ? match[1] : ''
}
return this.clearSlashes(fragment)
}
navigate = (path = '') => {
if (this.mode === 'history') {
window.history.pushState(null, null, this.root + this.clearSlashes(path))
} else {
window.location.href = `${window.location.href.replace(/#(.*)$/, '')}#${path}`
}
return this
}
}
export default Router
```
### Наблюдаем за изменениями
Теперь нам нужна логика для отслеживания изменений адреса как с помощью ссылки, так и с помощью созданного нами метода «navigate». Также нам необходимо обеспечить рендеринг правильной страницы при первом посещении. Мы могли бы использовать состояние приложения для регистрации изменений, однако в целях изучения сделаем это с помощью setInterval:
```
class Router {
routes = [];
mode = null;
root = "/";
constructor(options) {
this.mode = window.history.pushState ? "history" : "hash";
if (options.mode) this.mode = options.mode;
if (options.root) this.root = options.root;
this.listen();
}
[...]
listen = () => {
clearInterval(this.interval)
this.interval = setInterval(this.interval, 50)
}
interval = () => {
if (this.current === this.getFragment()) return
this.current = this.getFragment()
this.routes.some(route => {
const match = this.current.match(route.path)
if (match) {
match.shift()
route.cb.apply({}, match)
return match
}
return false
})
}
}
export default Router
```
### Заключение
Наша библиотека готова к использованию. Она состоит всего лишь из 84 строчек кода!
Код и пример использования на [Github](https://github.com/thecreazy/create-a-modern-javascript-router).
Благодарю за внимание. | https://habr.com/ru/post/496590/ | null | ru | null |
# Создание Outline эффекта в Unity Universal Render Pipeline
В Universal Render Pipeline, создавая свои RendererFeature, можно легко расширить возможности отрисовки. Добавление новых проходов в конвеер рендеринга позволяет создавать различные эффекты. В этой статье, используя ScriptableRendererFeature и ScriptableRenderPass, создадим эффект обводки объекта (Outline) и рассмотрим некоторые особенности его реализации.

Вступление или пару слов о Render Pipeline
------------------------------------------
Scriptable Render Pipeline позволяет управлять отрисовкой графики посредством скриптов на C# и контролировать порядок обработки объектов, света, теней и прочего. Universal Render Pipeline — это готовый Scriptable Render Pipeline, разработанный Unity и предназначенный на замену старому встроенному RP.
Возможности Universal RP можно расширить, создавая и добавляя свои проходы отрисовки ( ScriptableRendererFeature и ScriptableRenderPass ). Об этом и будет текущая статья. Она пригодится тем, кто собирается переходить на Universal RP и, возможно, поможет лучше понимать работу имеющихся ScriptableRenderPass’ов в Universal RP.
При написании этой статьи использовалась Unity 2019.3 и Universal RP 7.1.8.
План действий
-------------
Мы будем разбираться в работе ScriptableRendererFeature и ScriptableRenderPass на примере создания эффекта обводки непрозрачных объектов.
Для этого создадим ScriptableRendererFeature, выполняющую следующие действия:
* отрисовка указанных объектов
* размытие отрисованных объектов
* получение контуров объектов из изображений, полученных на предыдущих проходах
Исходный кадр — 
И последовательность результатов, которые мы должны достичь:

В ходе работы мы создадим шейдер, в глобальные свойства которого будут сохраняться результаты первого и второго проходов. Последний проход отобразит результат работы самого шейдера на экран.
**Глобальные свойства**
Это свойства, объявленные в шейдере, но не имеющие определения в блоке Properties. В данном примере нет принципиальной разницы как мы будем задавать текстуры — через глобальные или обычные свойства.
Основная причина использования глобальных свойств — нет необходимости передавать материал каждому проходу. А также отладка становится немного удобнее.
Создаём OutlineFeature
----------------------
ScriptableRendererFeature используется для добавления своих проходов отрисовки (ScriptableRenderPass) в Universal RP. Создадим класс OutlineFeature, наследуемый от ScriptableRenderFeature и реализуем его методы.
```
using UnityEngine;
using UnityEngine.Rendering.Universal;
public class OutlineFeature : ScriptableRendererFeature
{
public override void Create()
{ }
public override void AddRenderPasses(ScriptableRenderer renderer, ref RenderingData renderingData)
{ }
}
```
Метод Create() служит для создания и настройки проходов. А метод AddRenderPasses() для внедрения созданных проходов в очередь отрисовки.
**аргументы AddRenderPasses()**
ScriptableRenderer — текущая стратегия рендеринга по умолчанию для Universal RP. На данный момент в Universal RP реализована только стратегия Forward Rendering.
RenderingData содержит данные для настройки проходов отрисовки — данные об отбраковке, камерах, освещении и прочем.
Теперь приступим к созданию проходов отрисовки, а к текущему классу будем возвращаться после реализации каждого из них.
Render Objects Pass
-------------------
Задача этого прохода — отрисовывать объекты из определенного слоя с заменой материала в глобальное свойство-текстуру шейдера. Это будет упрощенная версия имеющегося в Universal RP прохода RenderObjectsPass, с единственным отличием в цели ( RenderTarget ), куда будет производится отрисовка.
Создадим класс MyRenderObjectsPass, наследуемый от ScriptableRenderPass. Реализуем метод Execute(), который будет содержать всю логику работы прохода, а так же переопределим метод Configure().
```
using UnityEngine.Rendering;
using UnityEngine.Rendering.Universal;
public class MyRenderObjectsPass : ScriptableRenderPass
{
{
public override void Configure(CommandBuffer cmd, RenderTextureDescriptor cameraTextureDescriptor)
{ }
public override void Execute(ScriptableRenderContext context, ref RenderingData renderingData)
{ }
}
}
```
Метод Configure() используется для указания цели рендеринга и создания временных текстур. По умолчанию целью является цель текущей камеры и после выполнения прохода она вновь будет указана по умолчанию. Вызов этого метода осуществляется перед выполнение основой логики прохода.
### Замена цели рендеринга
Объявим RenderTargetHandle для новой цели рендеринга. Используя его, создадим временную текстуру и укажем её как цель. RenderTargetHandle содержит в себе идентификатор используемой временной RenderTexture. А также позволяет получить RenderTargetIdentifier, служащий для идентификации цели рендеринга, которая может быть задана, например как объект RenderTexture, Texture, временная RenderTexture или встроенная (используется камерой при отрисовке кадра).
Объект RenderTargetHandle будет создаваться в OutlineFeature и передаваться нашему проходу при его создании.
```
private RenderTargetHandle _destination;
public MyRenderObjectsPass(RenderTargetHandle destination)
{
_destination = destination;
}
public override void Configure(CommandBuffer cmd, RenderTextureDescriptor cameraTextureDescriptor)
{
cmd.GetTemporaryRT(_destination.id, cameraTextureDescriptor);
}
```
Метод GetTemporaryRT() создаёт временную RenderTexture с заданными параметрами и устанавливает её как глобальное свойство шейдера с указанным именем (имя будет задаваться в фиче).
**Удаление RenderTexture**
ReleaseTemporaryRT() удаляет указанную временную RenderTexture. Это можно сделать в конце метода Execute() или в переопределенном методе FrameCleanup.
После завершения рендеринга, все временные RenderTexture, которые не были освобождены явно, будут удалены.
Для создания временной RenderTexture используем дескриптор текущей камеры, содержащий информацию о размере, формате и прочих параметрах цели камеры.
```
public override void Configure(CommandBuffer cmd, RenderTextureDescriptor cameraTextureDescriptor)
{
cmd.GetTemporaryRT(_destination.id, cameraTextureDescriptor);
ConfigureTarget(_destination.Identifier());
ConfigureClear(ClearFlag.All, Color.clear);
}
```
Указание цели и её очистка должны происходить только в Configure() с использованием методов ConfigureTarget() и ClearTarget().
### Рендер
Подробно рассматривать отрисовку не будем, т.к. это может увести нас далеко и надолго от основной темы. Для отрисовки воспользуемся методом ScriptableRenderContext.DrawRenderers(). Создадим настройки для отрисовки только непрозрачных объектов только из указанных слоёв. Маску слоя будем передавать в конструктор.
```
...
private List \_shaderTagIdList = new List() { new ShaderTagId("UniversalForward") };
private FilteringSettings \_filteringSettings;
private RenderStateBlock \_renderStateBlock;
...
public MyRenderObjectsPass(RenderTargetHandle destination, int layerMask)
{
\_destination = destination;
\_filteringSettings = new FilteringSettings(RenderQueueRange.opaque, layerMask);
\_renderStateBlock = new RenderStateBlock(RenderStateMask.Nothing);
}
public override void Execute(ScriptableRenderContext context, ref RenderingData renderingData)
{
SortingCriteria sortingCriteria = renderingData.cameraData.defaultOpaqueSortFlags;
DrawingSettings drawingSettings = CreateDrawingSettings(\_shaderTagIdList, ref renderingData, sortingCriteria);
context.DrawRenderers(renderingData.cullResults, ref drawingSettings, ref \_filteringSettings, ref \_renderStateBlock);
}
```
**Очень кратко о параметрах**
CullingResults — результаты отбраковки (берём из RenderingData)
FilteringSettings — данные о слоях и типе объектов.
DrawingSettings — настройки отрисовки.
RenderStateBlock — набор значений, используемых для переопределения состояния визуализации (глубины, режимов смешивания и т.п.)
**О готовом RenderObjectsPass в UniversalRP**
Данный метод не универсален, т.к содержит много захардкоженных данных. RenderObjectsPass, реализованный в Universal RP, позволяет более гибко настраивать рендер объектов. Но для примера реализации своей составной RenderFeature практичней использовать что-то более простое :)
### Замена материала
Переопределим используемые материалы при отрисовке, так как нам нужны только контуры объектов.
```
private Material _overrideMaterial;
public MyRenderObjectsPass(RenderTargetHandle destination, int layerMask,, Material overrideMaterial)
{
...
_overrideMaterial = overrideMaterial;
...
}
public override void Execute(ScriptableRenderContext context, ref RenderingData renderingData)
{
...
DrawingSettings drawingSettings = CreateDrawingSettings(_shaderTagIdList, ref renderingData, sortingCriteria);
drawingSettings.overrideMaterial = _overrideMaterial;
...
}
```
### Шейдер для отрисовки
Создадим в ShaderGraph шейдер материала, который будет использоваться при отрисовке объектов в текущем проходе.
### Добавляем проход в OutlineFeature
Вернемся в OutlieFeature. Для начала создадим класс для настроек нашего прохода.
```
public class OutlineFeature : ScriptableRendererFeature
{
[Serializable]
public class RenderSettings
{
public Material OverrideMaterial = null;
public LayerMask LayerMask = 0;
}
...
}
```
Объявим поля для настроек MyRenderPass и имени глобального свойства-текстуры, используемой в качестве цели рендеринга нашим проходом.
```
[SerializeField] private string _renderTextureName;
[SerializeField] private RenderSettings _renderSettings;
```
Создадим идентификатор для свойства-текстуры и экземпляр MyRenderPass.
```
private RenderTargetHandle _renderTexture;
private MyRenderObjectsPass _renderPass;
public override void Create()
{
_renderTexture.Init(_renderTextureName);
_renderPass = new MyRenderObjectsPass(_renderTexture, _renderSettings.LayerMask, _renderSettings.OverrideMaterial);
}
```
В методе AddRendererPass добавляем наш проход в очередь на исполнение.
```
public override void AddRenderPasses(ScriptableRenderer renderer, ref RenderingData renderingData)
{
renderer.EnqueuePass(_renderPass);
}
```
**Забегая вперёд**
Следует также указать когда должен выполняться проход. Но это об этом позже, после реализации всех проходов.
Результат прохода для исходной сцены должен получиться следующий:

**Отладка**
Для отладки удобно использовать Frame Debug для просмотра результатов каждого прохода (Windows-Analysis-FrameDebugger).
Blur Pass
---------
Цель этого прохода — размыть изображение, полученное на предыдущем шаге и установить его в глобальное свойство шейдера.
Для этого несколько раз будем копировать исходную текстуру во временные, с применением к ней шейдера размытия. При этом исходное изображение можно уменьшить в размерах (создать уменьшенную копию), что ускорит расчеты и не повлияет на качестве результата.
Создадим класс BlurPass, наследуемый от ScriptableRenderPass.
```
using UnityEngine.Rendering;
using UnityEngine.Rendering.Universal;
public class BlurPass : ScriptableRenderPass
{
public override void Execute(ScriptableRenderContext context, ref RenderingData renderingData)
{ }
}
```
Заведём переменные под исходную, целевую и временные текстуры (и их ID).
```
private int _tmpBlurRTId1 = Shader.PropertyToID("_TempBlurTexture1");
private int _tmpBlurRTId2 = Shader.PropertyToID("_TempBlurTexture2");
private RenderTargetIdentifier _tmpBlurRT1;
private RenderTargetIdentifier _tmpBlurRT2;
private RenderTargetIdentifier _source;
private RenderTargetHandle _destination;
```
Все ID для RenderTexture задаются через Shader.PropertyID(). Это не означает что где-то обязательно должны существовать такие свойства шейдера.
Добавим поля и под остальные параметры, которые сразу же инициализируем в конструкторе.
```
private int _passesCount;
private int _downSample;
private Material _blurMaterial;
public BlurPass(Material blurMaterial, int downSample, int passesCount)
{
_blurMaterial = blurMaterial;
_downSample = downSample;
_passesCount = passesCount;
}
```
\_blurMaterial — материал с шейдером размытия.
\_downSample — коэффициент для уменьшения размера текстуры
\_passesCount — количество проходов размытия, которое будет применено.
Для создания временных текстур создадим дескриптор со всей необходимой информацией о ней — размере, формате и прочем. Высоту и размер будем масштабировать относительно дескриптора камеры.
```
public override void Configure(CommandBuffer cmd, RenderTextureDescriptor cameraTextureDescriptor)
{
var width = Mathf.Max(1, cameraTextureDescriptor.width >> _downSample);
var height = Mathf.Max(1, cameraTextureDescriptor.height >> _downSample);
var blurTextureDesc = new RenderTextureDescriptor(width, height, RenderTextureFormat.ARGB32, 0, 0);
```
Также создадим идентификаторы и сами временные RenderTexture.
```
_tmpBlurRT1 = new RenderTargetIdentifier(_tmpBlurRTId1);
_tmpBlurRT2 = new RenderTargetIdentifier(_tmpBlurRTId2);
cmd.GetTemporaryRT(_tmpBlurRTId1, blurTextureDesc, FilterMode.Bilinear);
cmd.GetTemporaryRT(_tmpBlurRTId2, blurTextureDesc, FilterMode.Bilinear);
```
Мы снова меняем цель рендеринга, поэтому создадим ещё одну временную текстуру и укажем её как цель.
```
cmd.GetTemporaryRT(_destination.id, blurTextureDesc, FilterMode.Bilinear);
ConfigureTarget(_destination.Identifier());
}
```
### Размытие
Некоторые задачи рендеринга могут быть выполнены с помощью специальных методов ScriptableRenderContext, которые настраивают и добавляют в него команды. Для выполнения других команд потребуется использовать CommandBuffer, который можно получить из пула.
После добавления команд и отправки их на выполнение контексту, буфер нужно будет вернуть обратно в пул.
```
public override void Execute(ScriptableRenderContext context, ref RenderingData renderingData)
{
var cmd = CommandBufferPool.Get("BlurPass");
...
context.ExecuteCommandBuffer(cmd);
CommandBufferPool.Release(cmd);
}
```
Конечная реализация метода Execute() будет следующей.
```
public override void Execute(ScriptableRenderContext context, ref RenderingData renderingData)
{
var cmd = CommandBufferPool.Get("BlurPass");
if (_passesCount > 0)
{
cmd.Blit(_source, _tmpBlurRT1, _blurMaterial, 0);
for (int i = 0; i < _passesCount - 1; i++)
{
cmd.Blit(_tmpBlurRT1, _tmpBlurRT2, _blurMaterial, 0);
var t = _tmpBlurRT1;
_tmpBlurRT1 = _tmpBlurRT2;
_tmpBlurRT2 = t;
}
cmd.Blit(_tmpBlurRT1, _destination.Identifier());
}
else
cmd.Blit(_source, _destination.Identifier());
context.ExecuteCommandBuffer(cmd);
CommandBufferPool.Release(cmd);
}
```
**Blit**
Команда Blit() копирует исходную текстуру в указанную с применением к ней шейдера.
### Шейдер
Для размытия создадим простой шейдер, который будет вычислять цвет пикселя с учётом его ближайших соседей ( среднее значение цвета пяти пикселей ).
**Шейдер размытия**
`Shader "Custom/Blur"
{
Properties
{
_MainTex ("Texture", 2D) = "white" {}
}
SubShader
{
HLSLINCLUDE
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct Attributes
{
float4 positionOS : POSITION;
float2 uv : TEXCOORD0;
};
struct Varyings
{
float4 positionCS : SV_POSITION;
float2 uv : TEXCOORD0;
};
TEXTURE2D_X(_MainTex);
SAMPLER(sampler_MainTex);
float4 _MainTex_TexelSize;
Varyings Vert(Attributes input)
{
Varyings output;
output.positionCS = TransformObjectToHClip(input.positionOS.xyz);
output.uv = input.uv;
return output;
}
half4 Frag(Varyings input) : SV_Target
{
float2 offset = _MainTex_TexelSize.xy;
float2 uv = UnityStereoTransformScreenSpaceTex(input.uv);
half4 color = SAMPLE_TEXTURE2D_X(_MainTex, sampler_MainTex, input.uv);
color += SAMPLE_TEXTURE2D_X(_MainTex, sampler_MainTex, input.uv + float2(-1, 1) * offset);
color += SAMPLE_TEXTURE2D_X(_MainTex, sampler_MainTex, input.uv + float2( 1, 1) * offset);
color += SAMPLE_TEXTURE2D_X(_MainTex, sampler_MainTex, input.uv + float2( 1,-1) * offset);
color += SAMPLE_TEXTURE2D_X(_MainTex, sampler_MainTex, input.uv + float2(-1,-1) * offset);
return color/5.0;
}
ENDHLSL
Pass
{
HLSLPROGRAM
#pragma vertex Vert
#pragma fragment Frag
ENDHLSL
}
}
}`
**Почему не ShaderGraph?**
Я считаю ShaderGraph однозначно хорошим инструментом, но не когда пытаешься создать граф на 13 дюймовом экране ноутбука используя тачпад :)
### Добавляем проход в OutlineFeature
Порядок действия будет аналогичен добавлению нашего первого прохода. Сначала создадим настройки.
```
[Serializable]
public class BlurSettings
{
public Material BlurMaterial;
public int DownSample = 1;
public int PassesCount = 1;
}
```
Затем поля.
```
[SerializeField] private string _bluredTextureName;
[SerializeField] private BlurSettings _blurSettings;
private RenderTargetHandle _bluredTexture;
private BlurPass _blurPass;
...
public override void Create()
{
_bluredTexture.Init(_bluredTextureName);
_blurPass = new BlurPass(_blurSettings.BlurMaterial, _blurSettings.DownSample, _blurSettings.PassesCount);
}
```
И добавим в очередь на выполнение.
```
public override void AddRenderPasses(ScriptableRenderer renderer, ref RenderingData renderingData)
{
renderer.EnqueuePass(_renderPass);
renderer.EnqueuePass(_blurPass);
}
```
Результат прохода:

Outline Pass
------------
Конечное изображение с обводкой объектов будет получено с помощью шейдера. И результат его работы будет отображаться поверх текущего изображения на экране.
Ниже представлен сразу весь код прохода, т.к. вся логика заключена в двух строках.
```
public class OutlinePass : ScriptableRenderPass
{
private string _profilerTag = "Outline";
private Material _material;
public OutlinePass(Material material)
{
_material = material;
}
public override void Execute(ScriptableRenderContext context, ref RenderingData renderingData)
{
var cmd = CommandBufferPool.Get(_profilerTag);
using (new ProfilingSample(cmd, _profilerTag))
{
var mesh = RenderingUtils.fullscreenMesh;
cmd.DrawMesh(mesh, Matrix4x4.identity, _material, 0, 0);
}
context.ExecuteCommandBuffer(cmd);
CommandBufferPool.Release(cmd);
}
}
```
RenderingUtils.fullscreenMesh возвращает меш размером 1 на 1.
### Шейдер
Создадим шейдер для получения контура. Он должен содержать два глобальных свойства-текстуры. \_OutlineRenderTexture и \_OutlineBluredTexture для изображения указанных объектов и его размытого варианта.
**код шейдера**
```
Shader "Custom/Outline"
{
Properties
{
_Color ("Glow Color", Color ) = ( 1, 1, 1, 1)
_Intensity ("Intensity", Float) = 2
[Enum(UnityEngine.Rendering.BlendMode)] _SrcBlend ("Src Blend", Float) = 1
[Enum(UnityEngine.Rendering.BlendMode)] _DstBlend ("Dst Blend", Float) = 0
}
SubShader
{
HLSLINCLUDE
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct Attributes
{
float4 positionOS : POSITION;
float2 uv : TEXCOORD0;
};
struct Varyings
{
half4 positionCS : SV_POSITION;
half2 uv : TEXCOORD0;
};
TEXTURE2D_X(_OutlineRenderTexture);
SAMPLER(sampler_OutlineRenderTexture);
TEXTURE2D_X(_OutlineBluredTexture);
SAMPLER(sampler_OutlineBluredTexture);
half4 _Color;
half _Intensity;
Varyings Vertex(Attributes input)
{
Varyings output;
output.positionCS = float4(input.positionOS.xy, 0.0, 1.0);
output.uv = input.uv;
if (_ProjectionParams.x < 0.0)
output.uv.y = 1.0 - output.uv.y;
return output;
}
half4 Fragment(Varyings input) : SV_Target
{
float2 uv = UnityStereoTransformScreenSpaceTex(input.uv);
half4 prepassColor = SAMPLE_TEXTURE2D_X(_OutlineRenderTexture, sampler_OutlineRenderTexture, uv);
half4 bluredColor = SAMPLE_TEXTURE2D_X(_OutlineBluredTexture, sampler_OutlineBluredTexture,uv);
half4 difColor = max( 0, bluredColor - prepassColor);
half4 color = difColor* _Color * _Intensity;
color.a = 1;
return color;
}
ENDHLSL
Pass
{
Blend [_SrcBlend] [_DstBlend]
ZTest Always // всегда рисуем, независимо от текущей глубины в буфере
ZWrite Off // и ничего в него не пишем
Cull Off // рисуем все стороны меша
HLSLPROGRAM
#pragma vertex Vertex
#pragma fragment Fragment
ENDHLSL
}
}
}
```
Так как меш будет отображаться на весь экран, нам не нужно преобразовывать позиции вершин. В некоторых случаях Unity выполняет вертикальный переворот экрана. Чтобы определить это, шейдер проверяет значение \_ProjectionParams.х.
Результат работы шейдера для для двух полученных ранее изображений:

### Добавляем проход в OutlineFeature
Все действия аналогичны предыдущим проходам.
```
[SerializeField] private Material _outlineMaterial;
private OutlinePass _outlinePass;
public override void Create()
{
...
_outlinePass = new OutlinePass(_outlineMaterial);
....
}
public override void AddRenderPasses(ScriptableRenderer renderer, ref RenderingData renderingData)
{
renderer.EnqueuePass(_renderPass);
renderer.EnqueuePass(_blurPass);
renderer.EnqueuePass(_outlinePass);
}
```
RenderPassEvent
---------------
Осталось указать когда будут вызываться созданные проходы. Для этого каждому из них нужно указать параметр renderPassEvent.
**Список событий**
Места в Universal RP, куда могут быть добавлены проходы.
BeforeRendering
BeforeRenderingShadows
AfterRenderingShadows
BeforeRenderingPrepasses
AfterRenderingPrePasses
BeforeRenderingOpaques
AfterRenderingOpaques
BeforeRenderingSkybox
AfterRenderingSkybox
BeforeRenderingTransparents
AfterRenderingTransparents
BeforeRenderingPostProcessing
AfterRenderingPostProcessing
AfterRendering
Создадим соответствующее поле в OutlineFeature.
```
[SerializeField] private RenderPassEvent _renderPassEvent;
```
И укажем его всем созданным проходам.
```
public override void Create()
{
...
_renderPass.renderPassEvent = _renderPassEvent;
_blurPass.renderPassEvent = _renderPassEvent;
_outlinePass.renderPassEvent = _renderPassEvent;
}
```
Настройка
---------
Добавим слой Outline и установим его для объектов, которые хотим обвести.
Создадим и настроим все необходимые ассеты: UniversalRendererPipelineAsset и ForwardRendererData.

Результат
---------
Результат для нашего исходного кадра будет следующим!

Доработка
---------
Сейчас обводка объекта будет видна всегда, даже через другие объекты. Чтобы наш эффект учитывал глубину сцены нужно внести несколько изменений.
### RenderObjectsPass
Указывая цель нашего рендера, мы должны также указать текущий буфер глубины. Создадим соответствующее поле и метод.
```
public class MyRenderObjectsPass : ScriptableRenderPass
{
...
private RenderTargetIdentifier _depth;
public void SetDepthTexture(RenderTargetIdentifier depth)
{ _depth = depth; }
...
}
```
В методе Configure() укажем глубину в настройке цели рендера.
```
public override void Configure(CommandBuffer cmd, RenderTextureDescriptor cameraTextureDescriptor)
{
cmd.GetTemporaryRT(_destination.id, cameraTextureDescriptor);
ConfigureTarget(_destination.Identifier(), _depth);
ConfigureClear(ClearFlag.Color, Color.clear);
}
```
### OutlineFeature
В OutlineFeature передадим MyRenderObjectsPass текущую глубину сцены.
```
public class OutlineFeature : ScriptableRendererFeature
{
...
public override void AddRenderPasses(ScriptableRenderer renderer, ref RenderingData renderingData)
{
var depthTexture = renderer.cameraDepth;
_renderPass.SetDepthTexture(depthTexture);
renderer.EnqueuePass(_renderPass);
renderer.EnqueuePass(_blurPass);
renderer.EnqueuePass(_outlinePass);
}
...
}
```
### UniversalRenderPipelineAsset
В используемом UniversalRenderPipelineAsset поставим галочку напротив пункта DepthTexture.

### Результат
Результат без учета глубины:

Результат с учетом глубины:

Итог
----
ScriptableRendererFeature достаточно удобный инструмент для добавления своих проходов в RP.
В нем можно легко заменять RenderObjectsPass’ы и использовать их в других ScriptableRendererFeature. Не нужно сильно углубляться в реализацию Universal RP и менять его код, чтобы что-то добавить.
P.S.
----
Для того чтобы общий алгоритм работы со ScriptableRendererFeature и ScriptableRenderPass был более понятен, и чтобы статья не сильно разрослась, я намеренно старался создавать код проходов простым, пусть даже в ущерб их универсальности и оптимальности.
Ссылки
------
Исходный код — [ссылка на gitlab](https://gitlab.com/Dimonik333/outline-feature)
Модели и сцена взяты из игры Lander Missions: planet depths
За основу примера была взята следующая реализация обводки — [ссылка на youtube](https://www.youtube.com/watch?v=SMLbbi8oaO8)
Примеры реализации собственных RenderFeature от Unity — [ссылка на github](https://github.com/Unity-Technologies/UniversalRenderingExamples).
Серия уроков по созданию собственного ScriptableRenderPipeline. После прочтения становится ясна общая логика работы RP и шейдеров — [ссылка на туториалы](https://catlikecoding.com/unity/tutorials/custom-srp). | https://habr.com/ru/post/491624/ | null | ru | null |
# Ajax загрузка данных из контейнера
Знаете ли вы, что с помощью jQuery можно загружать не только контент страницы, но и выбранного контейнера на ней? Оказывается можно и делается это следующим образом:
```
$("#area").load("something.html #content");
```
Данный код найдет на странице *something.html* контейнер с id *content*, возьмет его содержимое и загрузит в контейнер с id *area*. Но есть одно но…
И выглядит это но вот таким образом:
```
$("#area").load("something.html #area");
```
Результатом работы такого кода будет такой результат:
```
```
И чем дальше, тем все более вложенным будет этот код.
Решение такое:
```
$("#area").load("something.html #area > *");
```
Демо можно найти [здесь](http://css-tricks.com/examples/AJAXReplaceSamePart/). | https://habr.com/ru/post/112779/ | null | ru | null |
# Реализация кеша с ограничением по числу элементов на Python — решения: простое и посложнее
#### Формулировка задачи
Предположим, что у нас есть необходимость иметь некий сервис, который бы отдавал нам по запросу какую-либо информацию, и отдавал как можно быстрее. Что для этого делает любой нормальный человек? Налаживает кэширование наиболее часто запрашиваемых данных. При этом, если хоть немного задуматься о перспективе, то размеры кэша необходимо ограничивать.
Для простоты реализации в случае Питона сделаем ограничение по числу элементов в кэше (*здесь предполагается, что данные более-менее однородны по размеру, а также учитывается специфика, что определить объём памяти, реально занимаемый каким-либо Питоновским объектом — **весьма** нетривиальная задача, кому интересно, пусть пожалует [сюда](http://packages.python.org/Pympler/asizeof.html)*), а для того, чтобы кэш содержал как можно более часто используемую информацию — построим его по принципу [least recently used](http://en.wikipedia.org/wiki/Cache_algorithms#Least_Recently_Used), т.е. чем более давно запрашивали кусочек информации, тем больше у него шансов «вылететь» из кэша.
О двух решениях (попроще и посложнее) я и расскажу в этой статье.
#### Философское отступление
Я обратил внимание, что зачастую написанный на Питоне код не блещет оптимизациями по потреблению памяти или по скорости (*здесь можно вскользь заметить, что это не только вина программистов-пользователей языка, хорошего инструментария просто нет, или по крайней мере я о таком не знаю (да, я в курсе про cProfile, но он помогает далеко не всегда, например, в нём нет attach-detach; искать же утечки памяти — вообще занятие не для слабонервных, вот если pympler допилят...), если кто подскажет — буду благодарен*). В основном это даже правильно, так как обычно Питон применяют в случае, когда время исполнения программы или потребление памяти не критично, зато критично время написания кода и простота его дальнейшей поддержки, поэтому очевидное, пусть и менее экономичное решение будет удобнее.
Хотя вышесказанное совсем не означает, что любой код на Питоне нужно писать «абы как». Кроме того, иногда производительность и потребление памяти могут стать критичными, даже если код крутится на серверной машине с хорошим процессором и тоннами памяти.
Как раз такой случай (нехватка CPU time) и подвиг меня на исследование этого вопроса и замену одного кэширующего класса другим.
#### Простое решение
Часто говорят — «простое решение — самое верное», хотя в случае с программированием это далеко не всегда так, не правда ли? Однако, если есть задача обеспечения кэша, но нет особых требований к скорости (например, то, что использует этот кэш, само по себе очень медленное, и нет смысла вкладываться в сложную реализацию), то можно обойтись и тривиальными решениями.
##### Реализация
Итак, относительно простое решение:
```
import weakref
class SimpleCache:
def __init__(self, cacheSize):
self.cache = weakref.WeakValueDictionary()
self.cache_LRU = []
self.cacheSize = cacheSize
def __getitem__(self, key):
# no exception catching - let calling code handle them if any
value = self.cache[key]
return self.touchCache(key, value)
def __setitem__(self, key, value):
self.touchCache(key, value)
def touchCache(self, key, value):
self.cache[key] = value
if value in self.cache_LRU:
self.cache_LRU.remove(value)
self.cache_LRU = self.cache_LRU[-(self.cacheSize-1):] + [ value ]
return value
```
##### Использование
Работать с таким кэшем после создания можно, как с обычным dict-ом, но при чтении/записи элемента он будет помещён в конец очереди, а за счёт комбинации WeakValueDictionary() и списка, который хранит не более cacheSize элементов, мы получаем ограничение по количеству сохранённых данных.
Таким образом, после исполнения куска кода
```
cache = SimpleCache(2)
cache[1] = 'a'
cache[2] = 'b'
cache[3] = 'c'
```
в кэше останутся только записи 'b' и 'c' ('a', как самая старая, будет вытеснена).
##### Преимущества и недостатки
Преимущество — относительная простота (около 20 строк кода, после прочтения документации по WeakValueDictionary принцип работы становится понятен).
Недостаток — скорость работы, т.к. при каждом «касании» кэша приходится пересоздавать список целиком, удаляя из произвольного его места элемент (на самом деле там происходит аж целая куча длинных операций по работе со списком, так, «if value in self.cache\_LRU» — линейный поиск по списку, потом .remove() — ещё раз линейный поиск, потом ещё берётся срез — т.е. создаётся почти полная копия списка). Словом, относительно долго.
#### Сложное решение
Теперь вдумаемся — а как можно ускорить такой класс? Очевидно, основные проблемы у нас именно с поддержанием cache\_LRU в актуальном состоянии — как я уже говорил, поиск по нему, последующее удаление элемента и пересоздание — дорогие операции. Тут нам на помощь придёт такая вещь, как [двунаправленный связный список](http://ru.wikipedia.org/wiki/Связный_список#.D0.94.D0.B2.D1.83.D1.81.D0.B2.D1.8F.D0.B7.D0.BD.D1.8B.D0.B9_.D1.81.D0.BF.D0.B8.D1.81.D0.BE.D0.BA_.28.D0.94.D0.B2.D1.83.D0.BD.D0.B0.D0.BF.D1.80.D0.B0.D0.B2.D0.BB.D0.B5.D0.BD.D0.BD.D1.8B.D0.B9_.D1.81.D0.B2.D1.8F.D0.B7.D0.BD.D1.8B.D0.B9_.D1.81.D0.BF.D0.B8.D1.81.D0.BE.D0.BA.29) — он обеспечит нам поддержку «последний использованный — в конце», ну а WeakValueDictionary() поможет с быстрым поиском по этому списку (поиск по словарю идёт куда быстрее линейного перебора, поскольку внутри Питоновские словари реализуют что-то вроде бинарных деревьев по хешам ключей *(тут Остапа понесло — могу честно сказать, что в исходники не смотрел, поэтому только предполагаю, как именно устроен поиск по словарю)*
##### Реализация
Для начала создаём класс — элемент списка, в который будем оборачивать хранимые данные:
```
class Element(object):
__slots__ = ['prev', 'next', 'value', '__init__', '__weakref__']
def __init__(self, value):
self.prev, self.next, self.value = None, None, value
```
Тут надо заметить использование такой штуки, как \_\_slots\_\_, позволяющей существенно сэкономить память и немного — производительность по сравнению с такой же реализацией класса, но без этого атрибута (что это такое и с чем его едят — в [официальной документации](http://docs.python.org/reference/datamodel.html#slots)).
Теперь создаём класс кэша (класс элемента засунем внутрь «во избежание»):
```
import weakref
class FastCache:
class Element(object):
__slots__ = ['prev', 'next', 'value', '__init__', '__weakref__']
def __init__(self, value):
self.prev, self.next, self.value = None, None, value
def __init__(self, maxCount):
self.dict = weakref.WeakValueDictionary()
self.head = None
self.tail = None
self.count = 0
self.maxCount = maxCount
def _removeElement(self, element):
prev, next = element.prev, element.next
if prev:
assert prev.next == element
prev.next = next
elif self.head == element:
self.head = next
if next:
assert next.prev == element
next.prev = prev
elif self.tail == element:
self.tail = prev
element.prev, element.next = None, None
assert self.count >= 1
self.count -= 1
def _appendElement(self, element):
if element is None:
return
element.prev, element.next = self.tail, None
if self.head is None:
self.head = element
if self.tail is not None:
self.tail.next = element
self.tail = element
self.count += 1
def get(self, key, *arg):
element = self.dict.get(key, None)
if element:
self._removeElement(element)
self._appendElement(element)
return element.value
elif len(*arg):
return arg[0]
else:
raise KeyError("'%s' is not found in the dictionary", str(key))
def __len__(self):
return len(self.dict)
def __getitem__(self, key):
element = self.dict[key]
# At this point the element is not None
self._removeElement(element)
self._appendElement(element)
return element.value
def __setitem__(self, key, value):
try:
element = self.dict[key]
self._removeElement(element)
except KeyError:
if self.count == self.maxCount:
self._removeElement(self.head)
element = FastCache.Element(value)
self._appendElement(element)
self.dict[key] = element
def __del__(self):
while self.head:
self._removeElement(self.head)
```
Тут можно обратить внимание на следующие существенные/интересные моменты:
* реализация метода get() — слегка отличается от стандартной для словарей, т.к. если не задано значение по умолчанию, а ключ отсутствует, то выкидывает исключение (работает так же, как cache[key]), а если есть значение по умолчанию, то возвращает его
* наличие метода \_\_del\_\_ обязательно, в противном случае получаем (или можем получить) утечку всего кэша — ведь все элементы списка друг на друга ссылаются, значит, их счётчики ссылок никогда не обнулятся без посторонней помощи; кстати, как выяснилось, встроенный (по крайней мере в 2.6) garbage collector хоть и вроде как собирает простейшие циклы ссылок, но с этим списком не справляется
* при желании можно слегка поднять производительность, выкинув assert'ы
##### Использование
Полностью аналогично предыдущей реализации (да и логика внутри похожа, только использует не простой, встроенный в Питон тип list, а реализует свой двунаправленный список ~~с шахматами и поэтессами~~).
#### Ещё одно простое решение с хорошей производительностью
Спасибо [seriyPS](https://habrahabr.ru/users/seriyps/) за подсказку!
Вырисовалось ещё одно решение, которое выглядит так же просто, как первое (если даже не проще) и при этом работает почти так же быстро, как сложное. Итак, реализация:
```
from collections import OrderedDict
class ODCache(OrderedDict):
def __init__(self, cacheSize):
self.cacheSize = cacheSize
OrderedDict.__init__(self)
def __getitem__(self, key):
value = OrderedDict.__getitem__(self, key)
return self._touchCache(key, value)
def __setitem__(self, key, value):
self._touchCache(key, value)
def _touchCache(self, key, value):
try:
OrderedDict.__delitem__(self, key)
except KeyError:
pass
OrderedDict.__setitem__(self, key, value)
toDel = len(self) - self.cacheSize
if toDel > 0:
for k in OrderedDict.keys(self)[:toDel]:
OrderedDict.__delitem__(self, k)
return value
```
#### Ещё одно решение — хорошая производительность
Решение из комментариев (по использованным мной тестам — лидер по скорости), спасибо [tbd](https://habrahabr.ru/users/tbd/):
```
class ListDictBasedCache(object):
__slots__ = ['__key2value', '__maxCount', '__weights']
def __init__(self, maxCount):
self.__maxCount = maxCount
self.__key2value = {}# key->value
self.__weights = []# keys ordered in LRU
def __updateWeight(self, key):
try:
self.__weights.remove(key)
except ValueError:
pass
self.__weights.append(key)# add key to end
if len(self.__weights) > self.__maxCount:
_key = self.__weights.pop(0)# remove first key
self.__key2value.pop(_key)
def __getitem__(self, key):
try:
value = self.__key2value[key]
self.__updateWeight(key)
return value
except KeyError:
raise KeyError("key %s not found" % key)
def __setitem__(self, key, value):
self.__key2value[key] = value
self.__updateWeight(key)
def __str__(self):
return str(self.__key2value)
```
#### Сравнение
Голословные утверждения — это одно, а беспристрастные цифры — совсем другое. Поэтому я не призываю верить мне на слово, наоборот — измерим эти классы!
Тут нам на помощь приходит встроенный в Питон модуль [timeit](http://docs.python.org/library/timeit.html):
```
class StubClass:
def __init__(self, something):
self.something = something
def testCache(cacheClass, cacheSize, repeat):
d = cacheClass(cacheSize)
for i in xrange(repeat * cacheSize):
d[i] = StubClass(i)
import random
class testCacheReadGen:
def __init__(self, cacheClass, cacheSize):
d = cacheClass(cacheSize)
for i in xrange(cacheSize):
d[i] = StubClass(i)
self.d = d
self.s = cacheSize
def __call__(self, repeat):
cacheSize, d = self.s, self.d
for i in xrange(cacheSize * repeat):
tmp = d[random.randint(0, cacheSize-1)]
def minMaxAvg(lst):
return min(lst), max(lst), 1.0 * sum(lst) / len(lst)
import timeit
def testAllCaches(classes, cacheSize, repeats):
templ = '%s: min %.5f, max %.5f, avg %.5f'
genmsg = lambda cls, res: templ % ((cls.__name__.ljust(20),) + tuple(minMaxAvg(res)))
for cls in classes:
t = timeit.Timer(lambda: testCache(cls, cacheSize, repeats[0]))
print genmsg(cls, t.repeat(*repeats[1:]))
def testAllCachesRead(classes, cacheSize, repeats):
templ = '%s: min %.5f, max %.5f, avg %.5f'
genmsg = lambda cls, res: templ % ((cls.__name__.ljust(20),) + tuple(minMaxAvg(res)))
for cls in classes:
tst = testCacheReadGen(cls, cacheSize)
t = timeit.Timer(lambda: tst(repeats[0]))
print genmsg(cls, t.repeat(*repeats[1:]))
if __name__ == '__main__':
print 'write'
testAllCaches((SimpleCache, FastCache, ODCache, ListDictBasedCache), 100, (100, 3, 3))
print 'read'
testAllCachesRead((SimpleCache, FastCache, ODCache, ListDictBasedCache), 100, (100, 3, 3))
```
Результаты запуска на моей машине (Intel Core i5 2540M 2.6GHz, Win7 64-bit, ActivePython 2.7.2 x64-bit):
```
write
SimpleCache : min 9.36119, max 9.49077, avg 9.42536
FastCache : min 0.39449, max 0.41835, avg 0.40880
ODCache : min 0.79536, max 0.82727, avg 0.81482
ListDictBasedCache : min 0.25135, max 0.27334, avg 0.26000
read
SimpleCache : min 9.61617, max 9.73143, avg 9.66337
FastCache : min 0.19294, max 0.21941, avg 0.20552
ODCache : min 0.22270, max 0.25816, avg 0.23911
ListDictBasedCache : min 0.16475, max 0.17725, avg 0.16911
```
Разница между простым и сложным решениями довольно ощутима — порядка 20 раз! Решение на OrderedDict чуть отстаёт в плане производительности, но совсем незначительно. Для дальнейших выводов нужно делать более сложные измерения, отражающие особенность задачи кэша — быстрый доступ к произвольным кусочкам информации, а не некоторый линейный, как использовался выше.
По потреблению памяти — запускаем предыдущий скрипт с другой секцией main и смотрим потребление памяти интерпретатором Питона через диспетчер задач:
```
if __name__ == '__main__':
import time
print 'measure me - no cache'
try:
while True:
time.sleep(10)
except:
# let user interrupt this with Ctrl-C
pass
testCache(FastCache, 1000, 1)
print 'measure me - cached'
while True:
time.sleep(10)
exit()
```
Результаты измерений — в таблице:
| | | | |
| --- | --- | --- | --- |
| Класс кэша | до создания кэша | после создания кэша | потребление кэша |
| SimpleCache | 4228K | 4768K | 540K |
| FastCache | 4232K | 4636K | 404K |
| ODCache | 4496K | 4936K | 440K |
| ListDictBasedCache | 4500K | 4880K | 380K |
Как видим — сложное решение не только заметно быстрее (в ~20 раз) добавляет элементы, но и потребляет немного меньше памяти, чем простое.
В той конкретной задаче, которую я решал, создавая такой кэш, его замена позволила сократить время отдачи запроса с 90 секунд до 70 примерно (более плотная профилировка и переписывание почти всей логики генерации ответа потом помогла довести время ответа до 30 секунд, но это уже совсем другая история). | https://habr.com/ru/post/147756/ | null | ru | null |
# Использование MapXtreme .Net
Всем привет! Хочу с Вами поделиться своим опытом работы с таким SDK как MapXtreme .Net от фирмы Pitney Bowes. Как сказано у них на сайте:
> MapInfo MapXtreme for .Net — это комплект разработчика программного обеспечения ГИС в среде Microsoft .Net, позволяющий встраивать картографические и ГИС функции в бизнес-приложения.
Установка
---------
Первым шагом была настройка машины к работе. Устанавливаем MS VisualStudio 2015 с сайта [разработчика](https://www.microsoft.com/ru-ru/SoftMicrosoft/vs2015Community.aspx) (на MSVS2010 работает, ниже версии не пробовал).
Скачиваем пакет установки с сайта [разработчика](http://www.pbinsight.com/support/product-downloads/for/mapxtreme). На портале для скачивания доступна триальная версия 7.1 на 60 дней (версия 8 доступна для покупки, разница между ними ощутимая, но затрагивает архитектуру MapXtreme. Основные операции остались неизменными).
Так же необходимо скачать карту мира, иначе зачем нам вообще нужна ГИС, не так ли? Для MapXtreme подходит карта [ADC WorldMap Version 7.1](http://www.adcworldmap.com/).
Ставить именно в таком порядке, так как MapXtreme требует .Net.
Документация
------------
Библиотека очень большая с большим количеством функций, но чтобы добраться до них нужна документация, а с ней у MapXtreme проблемы. После установки в каталоге с SDK можно найти
> MapXtreme Developers Reference
> MapXtreme Version 8.0 Developer Guide
Сами материалы содержат примеры на уровне капитана очевидность, либо отсутствуют вовсе. В интернете данная библиотека так же не содержит множества поясняющих ресурсов. Самый лучший был на сайте самого [разработчика](http://www.pbinsight.com/support/knowledge-base/). Однако где-то полгода назад они закрыли к ней доступ и стали всех отправлять в тех.поддержку.
Кстати, пару слов о ней родимой:

Было 3-4 обращения к ним за помощью, и все разы мне говорили:
> «Мы передали ваш запрос нашим разработчикам»
>
>
> «Пришлите ваш исходный код нам, мы не понимаем вашу проблему» и т.д.
Для карты так же идет руководство, которое полезно. В нем описаны все теги и тпиа значений которые можно устанавливать.
Разработка
----------
Если вы установили все верно, то VisualStudio при создание нового проекта у вас будет доступен тип проекта MapXtreme (у меня версия 8.0, т.к. мы купили лицензию).

Выбираем Windows Form App. Если в ToolBox не появились новые элементы открываем пункт меню
> Tools → Choose ToolBox Items...
И в появившемся окне выбираем нужные нам инструменты:

Итак, мы все установили, настроили и готовы писать код MapXtreme предоставляет уже готовые компоненты для создания приложения. Вы можете сразу сделать панель инструментов MapXteme добавив на главную форму компонент ToolStrip, в котором хранятся необходимые нам кнопки.

Чтобы использовать выбранные нами кнопки свойству MapControl пропишем имя нашего элемента типа MapControl. У меня называется mapControl1, у вас оно может отличаться. Либо в конструкторе формы написать
```
private void Form1_Load(object sender, EventArgs e)
{
addrectangleToolStripButton1.MapControl = mapControl1;
....
}
```
Если все сделано правильно, то у вас должно получится вот так:

> *«Я сделал все правильно, выбрал инструмент для рисования, но у меня ничего не выходит! Почему?»*
Чтобы решить данную проблему необходимо выбрать слой на котором мы будем рисовать и сделать его изменяемым. По умолчанию все слои на mapControl неизменяемые.
Мы можем решить нашу проблему средствами MapXtreme нажав кнопку «Layer Control» и поставив галочки в нужных местах.

Или сделать это прямо в коде:
```
var layerTemp = mapControl1.Map.Layers["wldcty25"];
LayerHelper.SetInsertable(layerTemp, true);//дает возможность рисовать на слое инструментами
LayerHelper.SetEditable(layerTemp, true); //делает наш слой изменяемым
```
Отмечу, что рисовать можно только на «верхнем» слое, то есть чтобы сейчас нарисовать объект мы должны наш слой «wldcty25» переместить вверх:

Или написать в коде:
```
mapControl1.Map.Layers.Move(lastPosition, nextPosition);
```
В результате нарисован наш первый объект:

> Как я говорил ранее любая настройка может быть задана через интерфейс. Однако, заказчик чаще всего привередливый и ему нужны более гибкие/доступные элементы настройки поэтому далее я не буду рассказывать о том как настроить что либо через компоненты MapXtreme. Я покажу как это сделать через код.
Начать хочу со стиля. Основным классом отвечающим за оформление выступает *CompositeStyle*. В MapXtreme мы можем задавать стиль на слой и на объект. Отмечу, что стиль слоя перекрывает стиль объекта.
```
SimpleLineStyle border;//стиль линейного объекта
border= new SimpleLineStyle(<ширина линии в единицах MapXtreme>, <код стиля линии>, <цвет линии>)
SimpleInterior interior;//стиль внутренней области объекта
interior = new SimpleInterior(<код стиля>, <цвет переднего плана>,<цвет фона>)
AreaStyle polygon;//стиль который используя предыдущие два задает стиль для площадного объекта
polygon = new AreaStyle(border, interior);
SimpleLineStyle line;//стиль линейного объекта
line = new SimpleLineStyle(<ширина линии в единицах MapXtreme>, <код стиля линии>, <цвет линии>)
BasePointStyle point;//стиль точечного объекта
point = new SimpleVectorPointStyle(<код стиля>, <цвет точки>, <размер точки>)
CompositeStyle compStyle;//стиль применяемый к слою
compStyle = CompositeStyle(polygon, line, null, point);
```
Применим полученный стиль к слою:
```
FeatureOverrideStyleModifier fosm;
fosm = new FeatureOverrideStyleModifier(parStyleName, parStyleAlias, compStyle);
myLayer.Modifiers.Append(featureOverrideStyleModifier);
```
Применим полученный стиль к объекту:
```
Feature feature = null;
feature = new Feature(<класс описывающий наш объект>, compStyle);
```
#### Создание объекта
Для создания мультилинии или мультиполигона сначала создадим исходные данные:
```
//задаем первую часть мультиобъекта
DPoint[] pts1 = new DPoint[5];
pts1[0] = new DPoint(-20, 10);//произвольные координаты точек взятые для примера
pts1[1] = new DPoint(10, 15);
pts1[2] = new DPoint(15, -10);
pts1[3] = new DPoint(-10, -10);
pts1[4] = new DPoint(-20, 10);
//задаем вторую часть мультиобъекта
DPoint[] pts2 = new DPoint[5];
pts2[0] = new DPoint(-40, 50);
pts2[1] = new DPoint(60, 45);
pts2[2] = new DPoint(65, -40);
pts2[3] = new DPoint(25, 20);
pts2[4] = new DPoint(-40, 50);
//LineString создаем из массива элементов DPoint
LineString lineString1 = new LineString(coordSys, pts1);
LineString lineString2 = new LineString(coordSys, pts2);
```
Используя код выше создадим:
— мультиполигон
```
//Ring в заданной системе координат coordSys создается через LineString
Ring ring1 = new Ring(coordSys, lineString1);
Ring ring2 = new Ring(coordSys, lineString2);
Ring[] rng1 = new Ring[2];
rng1[0] = ring2;
rng1[1] = ring1;
//MultiPolygon состоит из массива Ring
MultiPolygon multiPol = new MultiPolygon(coordSys, rng1);
```
— мультилинию
```
//Curve в заданной системе координат coordSys создается через LineString
Curve curve4 = new Curve(coordSys, lineString1);
Curve curve5 = new Curve(coordSys, lineString2);
Curve[] crv = new Curve[2];
crv[0] = curve5;
crv[1] = curve4;
//MultiCurve состоит из массива Curve
MultiCurve mc = new MultiCurve(coordSys, crv);
```
#### Работа с картографической проекцией
Получение:
```
CoordSys сoordSys= mapControl1.Map.GetDisplayCoordSys();
```
Создание и изменение текущей системы координат:
```
CoordSys cs = Session.Current.CoordSysFactory.CreateCoordSys("EPSG:3395", CodeSpace.Epsg);
mapControl1.Map.SetDisplayCoordSys(cs);
```
На самом деле там очень много перегруженных конструкторов, но обычно двух хватает так как в практических задачах необходима работа в трех-четырех системах координат.
Я еще ничего не сказал про работу с растровыми изображениями. Она здесь так же есть. Однако если вы изменили систему координат, то ваше изображение вряд ли преобразуется если не прописать след. строчку:
```
mapControl1.Map.RasterReprojectionMethod = ReprojectionMethod.Always;
/**
*ReprojectionMethod имеет три состояния
* None = 0, //запрет на изменение растра
* Always = 1,//изменять всегда
* Optimized = 2//так и не понял зачем нужен, в моей практике он ничем не отличался от
* предыдущего
*/
```
Лично я работал только с GeoTiff. MapXtreme не работает напрямую с изображениями. Для того чтобы все было хорошо системе необходим \*.tab файл, который будет содержать описание растра, систему координат, координаты углов.
Как делать \*.tab для растра средствами MapXtreme я так и не нашел, интернет так же подсказки не дал и мне пришлось самому писать метод, который создавал бы этот файл:
```
private string CreateTabFile(List parImageCoordinate)//список координат углов
{
NumberFormatInfo nfi = new CultureInfo("en-US", false).NumberFormat;
var ext = m\_fileName.Split(new Char[] { '.' });
var fileExt = ext[ext.GetLength(0) - 1];
string fileTabName = m\_fileName.Substring(0, m\_fileName.Length - fileExt.Length) + "TAB";
StreamWriter sw = new StreamWriter(fileTabName);
string header = "!table\n!version 300\n!charset WindowsCyrillic\n \n";
sw.WriteLine(header);
string definitionTables = "Definition Table\n ";
definitionTables += "File \"" + m\_fileName + "\"\n ";
definitionTables += "Type \"RASTER\"\n ";
for (var i = 0; i < parImageCoordinate.Count; i++)
{
definitionTables += "(" + parImageCoordinate[i].Longitude.ToString("N", nfi) + "," + parImageCoordinate[i].Latitude.ToString("N", nfi) + ") ";
definitionTables += "(" + parImageCoordinate[i].PixelColumn.ToString() + "," + parImageCoordinate[i].PixelRow.ToString() + ") ";
definitionTables += "Label \"Точка " + (i + 1).ToString() + " \",\n ";
}
definitionTables = definitionTables.Substring(0, definitionTables.Length - 4);
definitionTables += "\n ";
definitionTables += "CoordSys Earth Projection 1, 104\n ";
definitionTables += "Units \"degree\"\n";
sw.WriteLine(definitionTables);
string metaData = "begin\_metadata\n";
metaData += "\"\\IsReadOnly\" = \"FALSE\"\n";
metaData += "\"\\MapInfo\" = \"\"\n";
string hash;
using (MD5 md5Hash = MD5.Create())
{
hash = GetMd5Hash(md5Hash, m\_fileName);
}
metaData += "\"\\MapInfo\\TableID\" = \"" + hash + "\"\n";
metaData += "end\_metadata\n";
sw.WriteLine(metaData);
sw.Close();
return fileTabName;
}
```
Метод *GetMd5Hash* взят с [MSDN](https://msdn.microsoft.com/ru-ru/library/s02tk69a(v=vs.110).aspx). Итак, теперь наш mapControl1 готов к работе с растром.
Пока все. Вышло и объемно, наверное. Почему решил написать? Потому что не нашел ни на хабре, ни в ру/еу сегменте интернета хорошего контента по данному вопросу. | https://habr.com/ru/post/331590/ | null | ru | null |
# Распределённая трассировка с помощью Jaeger
Частая проблема при разработке распределённых систем состоит в следующем. Предположим, вы отправили системе запрос, и этот запрос обрабатывается очень долго. При этом внутри системы он распадается на запросы к нескольким внутренним микросервисам, которые могут превратиться в несколько подзапросов и выполняться параллельно. Как в этом случае определить, что тормозит систему? На помощь приходит Jaeger — сервис для сбора и отображения трейсов в распределённых системах.
### Что такое распределённая трассировка и зачем она нужна
**Распределённая трассировка** — диагностическая методика, позволяющая инженерам локализовать сбои и проблемы с производительностью в приложениях, особенно те, которые охватывают несколько серверов или процессов.
С точки зрения архитектуры микросервисов, один сервис отвечает за одну [бизнес-возможность](https://microservices.io/patterns/decomposition/decompose-by-business-capability.html). Это приводит к необходимости трассировки микросервисной архитектуры, что намного сложнее, чем трассировка монолита. В монолитной архитектуре весь жизненный цикл процесса находится в одном проекте. В микросервисной архитектуре для обработки одного запроса необходимо вызвать n-количество других сервисов.
Кажется, что достаточно создать отдельный лог-сервис, который будет записывать запросы для каждой службы. Но когда API обрабатывает сотни запросов в секунду, откуда вы знаете, что один запрос лога в сервисе A соответствует логу в сервисе B и так далее?
Лучше понять поведение программного обеспечения помогает распределённая трассировка. Она показывает, где происходят сбои и что вызывает неоптимальную производительность.
### Как работает трассировка
Разберём на примере Даши-путешественницы, которой дали задание добраться до замка из песка из дома на дереве. Вот карта:
Чтобы добраться до замка из песка, нужно пройти через лес, пересечь озеро и преодолеть пирамиду. Только после этого Даша окажется в замке. Каждое препятствие, встречающееся на пути, занимает время. Вы хотите знать, сколько всего времени требуется, чтобы преодолеть дистанцию от домика на дереве до замка из песка. Это просто — нужно зафиксировать время перед отъездом и по прибытию.
Предположим, что вы хотите не просто знать, сколько занимает путь, а понимать, какое препятствие требует больше всего времени и почему. Для этого вы можете записывать время начала и время окончания преодоления каждого препятствия, фиксировать любую другую информацию, которую сочтёте полезной для отчёта. Это работает примерно так:
Каждое препятствие похоже на функцию, тогда как путь между ними — это вызовы функций, которые можно не учитывать, так как они должны быть быстрыми.
### Let’s coding!
Перенесём путешествие Даши в код и проанализируем, что она делает на каждом препятствии. Для начала нам нужно создать 4 функции:
```
func startTheJourneyFromTreeHouse(parent context.Context, param int64) (out int64, err error) {
span, ctx := opentracing.StartSpanFromContext(parent, "startTheJourneyFromTreeHouse")
defer func() {
ctx.Done()
span.Finish()
}()
time.Sleep(2 * time.Millisecond)
span.SetTag("message", "prepare some food")
out = param + 2
return
}
func passTheForest(parent context.Context, param int64) (out int64, err error) {
span, ctx := opentracing.StartSpanFromContext(parent, "passTheForest")
defer func() {
ctx.Done()
span.Finish()
}()
time.Sleep(5 * time.Millisecond)
span.SetTag("message", "oh it's a long forest and I'm getting tired now!")
out = param + 5
return
}
func crossTheLake(parent context.Context, param int64, isRainyDay bool) (out int64, err error) {
span, ctx := opentracing.StartSpanFromContext(parent, "crossTheLake")
defer func() {
ctx.Done()
span.Finish()
}()
time.Sleep(10 * time.Millisecond)
out = param + 10
if isRainyDay {
time.Sleep(20 * time.Millisecond)
span.SetTag("message", "It's a rainy day and "+
"I must extra careful since I don't want my boat drowned with me")
} else {
span.SetTag("message", "Clear weather and I enjoy the view from the lake!")
}
span.SetTag("isRainyDay", isRainyDay)
return
}
func enterThePyramid(parent context.Context, param int64) (out int64, err error) {
span, ctx := opentracing.StartSpanFromContext(parent, "enterThePyramid")
defer func() {
ctx.Done()
span.Finish()
}()
time.Sleep(10 * time.Millisecond)
out = param + 10
span.SetTag("message", "Whoa, everywhere's dark!")
return
}
```
* **startTheJourneyFromTreeHouse** — Даша готовит еду своего путешествия;
* **passTheForest** — Даша гуляет с обезьяной Бутом по лесу;
* **crossTheLake** — Даша пересекает озеро. Здесь мы добавим условие: если день дождливый, то процесс будет медленнее. Это условие также показывает, что трассировка позволяет точно определить, где произошло замедление процесса;
* **enterThePyramid** — Даша входит в пирамиду и выходит из темной комнаты внутри пирамиды.
В первом аргументе каждой функции всегда есть параметр context. На его основе вы создаёте интервал, используя opentracing.StartSpanFromContext. Каждый интервал представляет собой функциональный процесс и должен завершаться с использованием отложенной функции. В context есть информация о трассировке, поэтому при вызове функции passTheForest он будет содержать информацию из предыдущего вызова функции startTheJourneyFromTreeHouse.
Вызов функции будет выполнен следующим образом:
```
serverSpan := eCtx.Get("serverSpan").(opentracing.Span)
ctx := opentracing.ContextWithSpan(
context.Background(),
serverSpan,
)
defer ctx.Done()
...
out, _ = startTheJourneyFromTreeHouse(ctx, in)
out, _ = passTheForest(ctx, out)
out, _ = crossTheLake(ctx, out, isRainyDay)
out, _ = enterThePyramid(ctx, out)
```
Переменная serverSpan — значение, которое уже задано в traceMiddleware. Оно содержит родительский интервал, который обертывает весь интервал вызовов функций:
```
spanCtx, _ := opentracing.GlobalTracer().Extract(
opentracing.HTTPHeaders,
opentracing.HTTPHeadersCarrier(req.Header),
)
serverSpan := opentracing.StartSpan(
c.Request().URL.Path,
ext.RPCServerOption(spanCtx),
)
c.Set("serverSpan", serverSpan)
```
Каждый раз, когда вы вызываете функцию, она несет информацию из предыдущего вызова функции. И вы получаете трассировку стека (которая визуализируется с помощью интервала), которая выглядит следующим образом:
В каждом интервале вы записываете информацию и можете увидеть подробности, развернув его:
Самый длинный процесс — функция crossTheLake с параметром is\_rainy\_day true. Чтобы убедиться, что это не аномалия, вы можете попробовать найти другую трассировку в той же конечной точке. С помощью этой подсказки вы можете попытаться оптимизировать функцию, не угадывая, как провидец, а опираясь на данные.
### Заключительные слова
При высоком трафике довольно сложно определить точную проблему в серверной части. Свести к минимуму трудности, связанные с поиском узких мест, помогает трассировка. Она работает путём конвейерной передачи информации с использованием context и отправки этой информации с использованием UDP в Jaeger.
[«DevOps Tools для разработчиков»](https://slurm.club/3VHGngJ)
Материал основан на статье [«Understand Your System Behavior By Implement Distributed Tracing Using Jaeger»](https://yusufs.medium.com/understand-your-system-behavior-by-implement-distributed-tracing-using-jaeger-9041df1104ec) | https://habr.com/ru/post/704464/ | null | ru | null |
# Некоторые аспекты качества обучающих последовательностей
На Хабре появился ряд статей о качестве образования и как процесса и как результата (уровень выпускников).
Тема заинтересовала и руки зачесались проверить, а как это устроено у ~~пчелок~~ ~~роботов~~ искусственного интеллекта, влияет ли качество обучающей последовательности на результат.
Была выбрана простая сеть из [примеров Keras](https://github.com/keras-team/keras/blob/master/examples/mnist_mlp.py) в которую добавил одну строку. Нас интересует насколько упорядоченность входной обучающей последовательности mnist влияет на результат обучения MLP.
Результат получился неожиданным и странным, пришлось перепроверять многократно, но перейдем к делу и конкретике.
Идея эксперимента проста и обычна — обучаем MLP из keras на общедоступном mnist и получаем ориентир, после обучаем на последовательностях 01234567890123..7890123. Как студентов учат — немного бейсик, немного ассемблер, немного fortran, и т.д. и сравним с исходным обучением. Результат вполне ожидаем, исходная последовательность учит лучше, но порядок такой же. Вот график 64 испытаний
А теперь будем учить сеть так, подаем все картинки с «0», потом все «1», потом все «2» и так до «9» и результат получается никакой!, сеть просто не учится. Интуитивно ожидаешь результат сопоставимый, хуже или лучше — это уже детали, но вот таблица результатов обучения 64 раза
**Натив и эксперименты**step 0
('Test accuracy:', 0.9708)
('Test accuracy:', 0.97689999999999999)
('Test accuracy:', 0.1009)
step 1
('Test accuracy:', 0.97689999999999999)
('Test accuracy:', 0.97219999999999995)
('Test accuracy:', 0.1009)
step 2
('Test accuracy:', 0.97330000000000005)
('Test accuracy:', 0.97609999999999997)
('Test accuracy:', 0.1028)
step 3
('Test accuracy:', 0.97040000000000004)
('Test accuracy:', 0.97160000000000002)
('Test accuracy:', 0.1135)
step 4
('Test accuracy:', 0.97370000000000001)
('Test accuracy:', 0.97050000000000003)
('Test accuracy:', 0.098199999999999996)
step 5
('Test accuracy:', 0.96999999999999997)
('Test accuracy:', 0.96909999999999996)
('Test accuracy:', 0.1009)
step 6
('Test accuracy:', 0.97589999999999999)
('Test accuracy:', 0.97540000000000004)
('Test accuracy:', 0.1028)
step 7
('Test accuracy:', 0.97360000000000002)
('Test accuracy:', 0.97350000000000003)
('Test accuracy:', 0.1135)
step 8
('Test accuracy:', 0.97740000000000005)
('Test accuracy:', 0.97109999999999996)
('Test accuracy:', 0.1135)
step 9
('Test accuracy:', 0.97260000000000002)
('Test accuracy:', 0.97089999999999999)
('Test accuracy:', 0.1135)
step 10
('Test accuracy:', 0.96930000000000005)
('Test accuracy:', 0.9708)
('Test accuracy:', 0.1028)
step 11
('Test accuracy:', 0.97419999999999995)
('Test accuracy:', 0.97099999999999997)
('Test accuracy:', 0.1135)
step 12
('Test accuracy:', 0.97419999999999995)
('Test accuracy:', 0.97519999999999996)
('Test accuracy:', 0.1009)
step 13
('Test accuracy:', 0.97719999999999996)
('Test accuracy:', 0.97370000000000001)
('Test accuracy:', 0.1135)
step 14
('Test accuracy:', 0.97489999999999999)
('Test accuracy:', 0.97189999999999999)
('Test accuracy:', 0.1135)
step 15
('Test accuracy:', 0.9758)
('Test accuracy:', 0.97219999999999995)
('Test accuracy:', 0.10489999999999999)
step 16
('Test accuracy:', 0.97419999999999995)
('Test accuracy:', 0.97529999999999994)
('Test accuracy:', 0.1135)
step 17
('Test accuracy:', 0.97819999999999996)
('Test accuracy:', 0.97170000000000001)
('Test accuracy:', 0.1009)
step 18
('Test accuracy:', 0.97850000000000004)
('Test accuracy:', 0.97260000000000002)
('Test accuracy:', 0.1009)
step 19
('Test accuracy:', 0.97419999999999995)
('Test accuracy:', 0.97589999999999999)
('Test accuracy:', 0.0974)
step 20
('Test accuracy:', 0.97699999999999998)
('Test accuracy:', 0.97319999999999995)
('Test accuracy:', 0.1135)
step 21
('Test accuracy:', 0.97309999999999997)
('Test accuracy:', 0.97260000000000002)
('Test accuracy:', 0.1009)
step 22
('Test accuracy:', 0.97560000000000002)
('Test accuracy:', 0.97519999999999996)
('Test accuracy:', 0.1135)
step 23
('Test accuracy:', 0.97619999999999996)
('Test accuracy:', 0.97450000000000003)
('Test accuracy:', 0.1009)
step 24
('Test accuracy:', 0.97689999999999999)
('Test accuracy:', 0.97430000000000005)
('Test accuracy:', 0.1028)
step 25
('Test accuracy:', 0.97609999999999997)
('Test accuracy:', 0.97599999999999998)
('Test accuracy:', 0.1135)
step 26
('Test accuracy:', 0.97840000000000005)
('Test accuracy:', 0.97419999999999995)
('Test accuracy:', 0.1028)
step 27
('Test accuracy:', 0.96909999999999996)
('Test accuracy:', 0.97019999999999995)
('Test accuracy:', 0.1135)
step 28
('Test accuracy:', 0.9738)
('Test accuracy:', 0.97419999999999995)
('Test accuracy:', 0.1009)
step 29
('Test accuracy:', 0.97460000000000002)
('Test accuracy:', 0.97419999999999995)
('Test accuracy:', 0.1135)
step 30
('Test accuracy:', 0.97640000000000005)
('Test accuracy:', 0.97170000000000001)
('Test accuracy:', 0.1042)
step 31
('Test accuracy:', 0.97409999999999997)
('Test accuracy:', 0.95650000000000002)
('Test accuracy:', 0.089200000000000002)
step 32
('Test accuracy:', 0.97689999999999999)
('Test accuracy:', 0.97109999999999996)
('Test accuracy:', 0.1135)
step 33
('Test accuracy:', 0.97370000000000001)
('Test accuracy:', 0.97340000000000004)
('Test accuracy:', 0.1009)
step 34
('Test accuracy:', 0.97699999999999998)
('Test accuracy:', 0.97150000000000003)
('Test accuracy:', 0.1135)
step 35
('Test accuracy:', 0.97250000000000003)
('Test accuracy:', 0.97140000000000004)
('Test accuracy:', 0.1009)
step 36
('Test accuracy:', 0.97589999999999999)
('Test accuracy:', 0.96950000000000003)
('Test accuracy:', 0.1055)
step 37
('Test accuracy:', 0.97519999999999996)
('Test accuracy:', 0.96509999999999996)
('Test accuracy:', 0.1135)
step 38
('Test accuracy:', 0.97299999999999998)
('Test accuracy:', 0.9728)
('Test accuracy:', 0.1028)
step 39
('Test accuracy:', 0.96909999999999996)
('Test accuracy:', 0.97240000000000004)
('Test accuracy:', 0.1009)
step 40
('Test accuracy:', 0.97399999999999998)
('Test accuracy:', 0.96479999999999999)
('Test accuracy:', 0.1135)
step 41
('Test accuracy:', 0.97799999999999998)
('Test accuracy:', 0.97319999999999995)
('Test accuracy:', 0.1135)
step 42
('Test accuracy:', 0.97419999999999995)
('Test accuracy:', 0.96340000000000003)
('Test accuracy:', 0.1009)
step 43
('Test accuracy:', 0.97740000000000005)
('Test accuracy:', 0.97170000000000001)
('Test accuracy:', 0.1009)
step 44
('Test accuracy:', 0.97160000000000002)
('Test accuracy:', 0.97389999999999999)
('Test accuracy:', 0.1135)
step 45
('Test accuracy:', 0.97599999999999998)
('Test accuracy:', 0.97360000000000002)
('Test accuracy:', 0.1033)
step 46
('Test accuracy:', 0.97389999999999999)
('Test accuracy:', 0.97019999999999995)
('Test accuracy:', 0.1135)
step 47
('Test accuracy:', 0.97650000000000003)
('Test accuracy:', 0.97619999999999996)
('Test accuracy:', 0.10290000000000001)
step 48
('Test accuracy:', 0.97409999999999997)
('Test accuracy:', 0.9647)
('Test accuracy:', 0.1009)
step 49
('Test accuracy:', 0.97240000000000004)
('Test accuracy:', 0.97450000000000003)
('Test accuracy:', 0.1135)
step 50
('Test accuracy:', 0.97570000000000001)
('Test accuracy:', 0.97040000000000004)
('Test accuracy:', 0.1135)
step 51
('Test accuracy:', 0.97250000000000003)
('Test accuracy:', 0.97219999999999995)
('Test accuracy:', 0.1135)
step 52
('Test accuracy:', 0.97230000000000005)
('Test accuracy:', 0.97309999999999997)
('Test accuracy:', 0.1135)
step 53
('Test accuracy:', 0.9758)
('Test accuracy:', 0.97230000000000005)
('Test accuracy:', 0.1135)
step 54
('Test accuracy:', 0.97770000000000001)
('Test accuracy:', 0.97260000000000002)
('Test accuracy:', 0.089200000000000002)
step 55
('Test accuracy:', 0.97340000000000004)
('Test accuracy:', 0.96919999999999995)
('Test accuracy:', 0.1135)
step 56
('Test accuracy:', 0.97170000000000001)
('Test accuracy:', 0.97070000000000001)
('Test accuracy:', 0.1028)
step 57
('Test accuracy:', 0.97670000000000001)
('Test accuracy:', 0.97330000000000005)
('Test accuracy:', 0.1135)
step 58
('Test accuracy:', 0.97589999999999999)
('Test accuracy:', 0.97370000000000001)
('Test accuracy:', 0.1033)
step 59
('Test accuracy:', 0.9748)
('Test accuracy:', 0.97419999999999995)
('Test accuracy:', 0.10290000000000001)
step 60
('Test accuracy:', 0.97409999999999997)
('Test accuracy:', 0.97099999999999997)
('Test accuracy:', 0.1009)
step 61
('Test accuracy:', 0.9758)
('Test accuracy:', 0.97450000000000003)
('Test accuracy:', 0.1135)
step 62
('Test accuracy:', 0.97529999999999994)
('Test accuracy:', 0.97260000000000002)
('Test accuracy:', 0.1028)
step 63
('Test accuracy:', 0.97240000000000004)
('Test accuracy:', 0.96809999999999996)
('Test accuracy:', 0.1135)
Не знаю как у людей, но тут чисто только MLP и получается, что обучать её можно не абы как, не на всех последовательностях.
Обучать ИИ так, как обучают в некоторых местах: сначала только бейсик, потом только фортран, потом только ассемблер и т.д. не приведет к успеху. / :-) / Если выявленная особенность присуща всем процессам обучения, как людям так и роботам, то все программы вузов нужно тщательно исследовать.
**Исходный текст**
```
from keras import backend as K_B
from keras.datasets import mnist
from keras.layers import Input, Dense, Dropout
from keras.models import Sequential
from keras.optimizers import RMSprop
from keras.utils import np_utils
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
def MLP(ind):
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(width * height,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
if (ind == 0): # начальные веса в каждой тройке испытаний должны быть одинаковыми
model.save_weights('weights.h5') # натив, сохраняем веса
else:
model.load_weights('weights.h5', by_name = False) # эксперимент, восстанавливаем веса
history = model.fit(X_train, Y_train,
shuffle = False, # добавлена эта строка что бы запретить keras перемешивать батч
batch_size=batch_size,
epochs=epochs,
verbose=0,
validation_data=(X_test, Y_test))
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test accuracy:', score[1])
K_B.clear_session()
# сессию уничтожаем в возрождаем преднамеренно, что бы начальные веса отличались
return(score[1])
batch_size = 12
epochs = 12
hidden_size = 512
(X_train, y_train), (X_test, y_test) = mnist.load_data()
num_train, width, height = X_train.shape
num_test = X_test.shape[0]
num_classes = np.unique(y_train).shape[0]
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255.
X_test /= 255.
X_train = X_train.reshape(num_train, height * width)
X_test = X_test.reshape(num_test, height * width)
XX_train = np.copy(X_train)
yy_train = np.copy(y_train)
Y_train = np_utils.to_categorical(y_train, num_classes)
Y_test = np_utils.to_categorical(y_test, num_classes)
steps = 64
st = np.arange(steps, dtype='int')
res_N = np.arange((steps), dtype='float')
res_1 = np.arange((steps), dtype='float')
res_2 = np.arange((steps), dtype='float')
for n in xrange(steps):
# __ натив
X_train = np.copy(XX_train)
y_train = np.copy(yy_train)
Y_train = np_utils.to_categorical(y_train, num_classes)
print ' step ', n
res_N[n] = MLP(0)
# __ 00..0011..1122..2233.. .. 8899..99
perm = np.arange(num_train, dtype='int')
cl = np.zeros(num_classes, dtype='int')
for k in xrange(num_train):
if (cl[yy_train[k]] * num_classes + yy_train[k] < num_train):
perm[ cl[yy_train[k]] * num_classes + yy_train[k] ] = k
cl[yy_train[k]] += 1
for k in xrange(num_train):
X_train[k,...] = XX_train[perm[k],...]
for k in xrange(num_train):
y_train[k] = yy_train[perm[k]]
Y_train = np_utils.to_categorical(y_train, num_classes)
res_2[n] = MLP(2)
# __ 0123..78901..7890123..789
perm = np.arange(num_train, dtype='int')
j = 0
for k in xrange(num_classes):
for i in xrange(num_train):
if (yy_train[i] == k):
perm[j] = i
j += 1
for k in xrange(num_train):
X_train[k,...] = XX_train[perm[k],...]
y_train[k] = yy_train[perm[k]]
Y_train = np_utils.to_categorical(y_train, num_classes)
res_1[n] = MLP(1)
```
Другие типы сетей не проверял и эта проверка занимает на моей не очень теслистой тесле много часов. | https://habr.com/ru/post/347510/ | null | ru | null |
# Android, PhraseApp и напильник — или о бедных андроид строках замолвите слово
Работая на платформе Android достаточно часто сталкиваешься с необходимостью заполнения строковых констант strings.xml. Всё бы было ничего, но правила которые налагает Android на содержимое этих файлов весьма ограниченны. Некоторые из них очевидны, например знак апострофа необходимо экранировать знаком слеша, другие же связанны как с устройством XML формата так и с особенностями Android. Об этих особенностях и пойдёт речь в статье ниже.
Итак, допустим у нас есть набор строк полученных от заказчика в виде текстового файла или iOS PLIST или даже документа Excel. В моём случае это были строки импортированные в проект из PhraseApp. Поля name заполняются автоматически на базе имён которые дал разработчик локалей и набора правил PhraseApp. Стоит отметить что для других платформ, на которых нет стольких ограничений экспорт происходит успешно, что значительно ускоряет разработку и локализацию в многоплатформенной среде. К несчастью искать ошибки в строках с использованием AndroidStudio всё так же неудобно как и много версий назад, студия просто не показывает номера ошибочных строк в XML, поэтому Eclipse всё ещё может помочь усталому разработчику. Итак, познакомимся с подводными камнями поближе.
Пробелы в именах
----------------
```
Are you sure?
```
пробел между confirm и exit не допустим, заменяем его на знак подчёркивания
```
Are you sure?
```
Точки в именах
--------------
В общем виде точки в именах допустимы, среда с удовольствием примет вариант
```
Male
```
но дьявол, как известно кроется в деталях, попробовав собрать массив строк или plurals с точкой в имени мы получим ошибку вида
Error retrieving parent for item: No resource found that matches the given name 'age'.
```
0-13
14-18
19-21
22+
```
для всех string-array и plurals меняем в именах точку на то же подчёркивание
```
```
Ключевые слова Java в именах
----------------------------
Это не совсем очевидно, но использовать в именах ключевые слова Java нельзя. Следующая строка не даст проекту собраться.
```
Else
```
Выход прежний — снабдим else знаком подчёркивания в начале \_else и проект будет снова собираться.
Форматированный вывод
---------------------
Форматирование вывода значительно облегчает читабельность исходных кодов, но и здесь нас подстерегают проблемы. Выведем в одной строке одновременно два и больше значения с подстановкой, к примеру — время от и до. Получим ошибку
Multiple substitutions specified in non-positional format; did you mean to add the formatted=«false» attribute?
```
Time from %s to %s
```
добавление аттрибута formatted=«false» исправляет ситуацию, но ведь у нас ещё есть plurals и string-array, усложняем пример и пробуем собрать
```
Error %s occured
%s errors ocurreds in %s
```
получаем сразу две ошибки
Multiple substitutions specified in non-positional format; did you mean to add the formatted=«false» attribute?
Found tag where is expected" attribute?
Добавление аттрибута formatted=«false» уже ничего не исправляет, но Google подсказывает что параметры необходимо задать с их порядковыми номерами, дабы система понимала что и куда подставлять. Принцип прост, параметры нумеруются начиная с единицы и используют знак доллара. Для первого параметра замена будет %1$s – для второго %2$s, для последующих %(i+1)$s. Правильная запись
```
Error %s occured
%1$s errors ocurreds in %2$s
```
Вернёмся к PhraseApp, при использовании плагина текущей версии все вышеперечисленные ошибки поджидают неосторожного разработчика, в том случае если строки создавались без учёта специфических требований Android. Эти ошибки требуют исправления при каждом обновлении ресурсов. Это явно неэффективно. Напрашивается автоматизация. К несчастью написать вменяемый скрипт для sed у меня не получилось. Кроме того пользователи Windows не горят желанием искать этот самый sed и добавлять в пути запуска.
В качестве альтернативы предлагаю вашему вниманию очередной велосипед по работе со строками на Java. Проект открыт и лежит на [GitHub](https://github.com/shadwork/Java-Android-Clean-Fix-XML). Весь код находится в одном файле игнорируя ООП, работа с string.xml ведётся в лоб, без DOM или SAX. В утилите три режима работы: скормив на вход каталог мы обработаем все строки во всех подкаталогах в файлах с именем strings.xml, скормив два файла — возьмём первый и скопируем во второй с исправлением ошибок, а подставив один файл мы его обработаем и перезапишем. Для запуска достаточно положить собранную утилиту в корень Eclipse или AndroidStudio и выполнить с параметром в виде точки
java -jar AndroidCleanFixXml.jar.
Для пользователей PhraseApp обойтись без правки исходных текстов утилиты может не получиться. Часто те кто набивает локали создают шаблон для форматного вывода в виде %{location} — %{duration}, такая подстановка не будет работать с String.format, поэтому все их приходится заменять. Так как в общем виде понять какой тип данных будет подставляться невозможно, то в коде присутствует три статический константы PHRASE\_FLOAT, PHRASE\_DECIMAL и PHRASE\_STRING. Все встреченные в ваших файлах локализации подстановки необходимо руками добавлять в константу.
Никаких временных файлов при работе не создаётся — поэтому помните о бекапах или коммите в репозиторий перед использованием. Приятного использования, пишите issue на github, постараюсь исправлять по мере сил. | https://habr.com/ru/post/355460/ | null | ru | null |
# Android Architecture Components. Часть 3. LiveData

**Компонент LiveData** — предназначен для хранения объекта и разрешает подписаться на его изменения. Ключевой особенностью является то, что компонент осведомлен о жизненном цикле и позволяет не беспокоится о том, на каком этапе сейчас находиться подписчик, в случае уничтожения подписчика, компонент отпишет его от себя. Для того, чтобы LiveData учитывала жизненный цикл используется компонент Lifecycle, но также есть возможность использовать без привязки к жизненному циклу.
Сам компонент состоит из классов: *LiveData, MutableLiveData, MediatorLiveData, LiveDataReactiveStreams, Transformations* и интерфейса: *Observer*.
**Класс LiveData**, являет собой абстрактный дженериковый класс и инкапсулирует всю логику работы компонента. Соответственно для создания нашего LiveData холдера, необходимо наследовать этот класс, в качестве типизации указать тип, который мы планируем в нем хранить, а также описать логику обновления хранимого объекта.
Для обновления значения мы должны передать его с помощью метода setValue(T), будьте внимательны поскольку этот метод нужно вызывать с main треда, в противном случае мы получим *IllegalStateException*, если же нам нужно передать значение из другого потока можно использовать *postValue(T)*, этот метод в свою очередь обновит значение в main треде. Интересной особенностью *postValue(T)* является еще то, что он в случае множественного вызова, не будет создавать очередь вызовов на main тред, а при исполнении кода в main треде возьмет последнее полученное им значение. Также, в классе присутствует два колбека:
*onActive()* — будет вызван когда количество подписчиков изменит свое значение с 0 на 1.
*onInactive()* — будет вызван когда количество подписчиков изменит свое значение с 1 на 0.
Их назначение соответственно уведомить наш класс про то, что нужно обновлять даные или нет. По умолчанию они не имеют реализации, и для обработки этих событий мы должны переопределить эти методы.
Давайте рассмотрим, как будет выглядеть наш LiveData класс, который будет хранить wife network name и в случае изменения будет его обновлять, для упрощения он реализован как синглтон.
```
public class NetworkLiveData extends LiveData {
private Context context;
private BroadcastReceiver broadcastReceiver;
private static NetworkLiveData instance;
public static NetworkLiveData getInstance(Context context){
if (instance==null){
instance = new NetworkLiveData(context.getApplicationContext());
}
return instance;
}
private NetworkLiveData(Context context) {
this.context = context;
}
private void prepareReceiver(Context context) {
IntentFilter filter = new IntentFilter();
filter.addAction("android.net.wifi.supplicant.CONNECTION\_CHANGE");
filter.addAction("android.net.wifi.STATE\_CHANGE");
broadcastReceiver = new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent) {
WifiManager wifiMgr = (WifiManager) context.getSystemService(Context.WIFI\_SERVICE);
WifiInfo wifiInfo = wifiMgr.getConnectionInfo();
String name = wifiInfo.getSSID();
if (name.isEmpty()) {
setValue(null);
} else {
setValue(name);
}
}
};
context.registerReceiver(broadcastReceiver, filter);
}
@Override
protected void onActive() {
prepareReceiver(context);
}
@Override
protected void onInactive() {
context.unregisterReceiver(broadcastReceiver);
broadcastReceiver = null;
}
}
```
В целом логика фрагмента следующая, если кто-то подписывается, мы инициализируем BroadcastReceiver, который будет нас уведомлять об изменении сети, после того как отписывается последний подписчик мы перестаем отслеживать изменения сети.
Для того чтобы добавить подписчика есть два метода: *observe(LifecycleOwner, Observer)* — для добавления подписчика с учетом жизненного цикла и *observeForever(Observer)* — без учета. Уведомления об изменении данных приходят с помощью реализации интерфейса *Observer*, который имеет один метод *onChanged(T)*.
Выглядит это приблизительно так:
```
public class MainActivity extends LifecycleActivity implements Observer {
private TextView networkName;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity\_main);
networkName = (TextView) findViewById(R.id.network\_name);
NetworkLiveData.getInstance(this).observe(this,this);
//NetworkLiveData.getInstance(this).observeForever(this);
}
@Override
public void onChanged(@Nullable String s) {
networkName.setText(s);
}
}
```
*Примечание: Этот фрагмент только для примера, не используйте этот код в реальном проекте. Для работы с LiveData лучше использовать ViewModel(про этот компонент в следующей статье) или позаботиться про отписку обсервера вручную.
В случае использования observe(this,this) при повороте экрана мы будем каждый раз отписываться от нашего компонента и заново подписываться. А в случае использование observeForever(this) мы получим memory leak.*
Помимо вышеупомянутых методов в api LiveData также входит *getValue(), hasActiveObservers(), hasObservers(), removeObserver(Observer observer), removeObservers(LifecycleOwner owner)* в дополнительных комментариях не нуждаются.
**Класс MutableLiveData**, является расширением LiveData, с отличием в том что это не абстрактный класс и методы *setValue(T)* и *postValue(T)* выведены в api, то есть публичные.
По факту класс является хелпером для тех случаев когда мы не хотим помещать логику обновления значения в LiveData, а лишь хотим использовать его как Holder.
```
void update(String someText){
ourMutableLiveData.setValue(String);
}
```
**Класс MediatorLiveData**, как понятно из названия это реализация паттерна медиатор, на всякий случай напомню: поведенческий паттерн, определяет объект, инкапсулирующий способ взаимодействия множества объектов, избавляя их от необходимости явно ссылаться друг на друга. Сам же класс расширяет *MutableLiveData* и добавляет к его API два метода: *addSource(LiveData, Observer)* и *removeSource(LiveData)*. Принцип работы с классом заключается в том что мы не подписываемся на конкретный источник, а на наш MediatorLiveData, а источники добавляем с помощью *addSource(..)*. MediatorLiveData в свою очередь сам управляет подпиской на источники.
Для примера создадим еще один класс LiveData, который будет хранить название нашей мобильной сети:
```
public class MobileNetworkLiveData extends LiveData {
private static MobileNetworkLiveData instance;
private Context context;
private MobileNetworkLiveData(Context context) {
this.context = context;
}
private MobileNetworkLiveData() {
}
@Override
protected void onActive() {
TelephonyManager telephonyManager = (TelephonyManager) context
.getSystemService(Context.TELEPHONY\_SERVICE);
String networkOperator = telephonyManager.getNetworkOperatorName();
setValue(networkOperator);
}
public static MobileNetworkLiveData getInstance(Context context) {
if (instance == null) {
instance = new MobileNetworkLiveData(context);
}
return instance;
}
}
```
И перепишем наше приложение так чтоб оно отображало название wifi сети, а если подключения к wifi нет, тогда название мобильной сети, для этого изменим MainActivity:
```
public class MainActivity extends LifecycleActivity implements Observer {
private MediatorLiveData mediatorLiveData;
private TextView networkName;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity\_main);
networkName = (TextView) findViewById(R.id.network\_name);
mediatorLiveData = new MediatorLiveData<>();
init();
}
private void init() {
final LiveData network = NetworkLiveData.getInstance(this);
final LiveData mobileNetwork = MobileNetworkLiveData.getInstance(this);
Observer networkObserver = new Observer() {
@Override
public void onChanged(@Nullable String s) {
if (!TextUtils.isEmpty(s))
mediatorLiveData.setValue(s);
else
mediatorLiveData.setValue(mobileNetwork.getValue());
}
};
Observer mobileNetworkObserver = new Observer() {
@Override
public void onChanged(@Nullable String s) {
if (TextUtils.isEmpty(network.getValue())){
mediatorLiveData.setValue(s);
}
}
};
mediatorLiveData.addSource(network, networkObserver);
mediatorLiveData.addSource(mobileNetwork,mobileNetworkObserver);
mediatorLiveData.observe(this, this);
}
@Override
public void onChanged(@Nullable String s) {
networkName.setText(s);
}
}
```
Как мы можем заметить, теперь наш UI подписан на *MediatorLiveData* и абстрагирован от конкретного источника данных. Стоит обратить внимание на то что значения в нашем медиаторе не зависят напрямую от источников и устанавливать его нужно в ручную.
**Класс LiveDataReactiveStreams**, название ввело меня в заблуждение поначалу, подумал что это расширение LiveData с помощью RX, по факту же, класс являет собой адаптер с двумя static методами: *fromPublisher(Publisher publisher)*, который возвращает объект LiveData и *toPublisher(LifecycleOwner lifecycle, LiveData liveData)*, который возвращает объект Publisher. Для использования этого класса, его нужно импортировать отдельно:
*compile «android.arch.lifecycle:reactivestreams:$version»*
**Класс Transformations**, являет собой хелпер для смены типизации LiveData, имеет два static метода:
*map(LiveData, Function)* - применяет в main треде реализацию интерфейса Function и возвращает объект LiveData, где T — это типизация входящей LiveData, а P желаемая типизация исходящей, по факту же каждый раз когда будет происходить изменения в входящей LiveData она будет нотифицировать нашу исходящую, а та в свою очередь будет нотифицировать подписчиков после того как переконвертирует тип с помощью нашей реализации Function. Весь этот механизм работает за счет того что по факту исходящая LiveData, является MediatiorLiveData.
```
LiveData location = ...;
LiveData locationString = Transformations.map(location, new Function() {
@Override
public String apply(Location input) {
return input.toString;
}
});
```
*switchMap(LiveData, Function>)* - похож к методу map с отличием в том, что вместо смены типа в функции мы возвращаем сформированный объект LiveData.
```
LiveData location = ...;
LiveData getPlace(Location location) = ...;
LiveData userName = Transformations.switchMap(location, new Function>() {
@Override
public LiveData apply(Location input) {
return getPlace(input);
}
});
```
Базовый пример можно посмотреть в репозитории: [git](https://github.com/kb2fty7/Android-Architecture-Components/tree/livedata)
Также полезные ссылки: [раз](https://developer.android.com/topic/libraries/architecture/livedata.html) и [два](https://developer.android.com/reference/android/arch/lifecycle/LiveData.html).
[Android Architecture Components. Часть 1. Введение](https://habrahabr.ru/post/332562/)
[Android Architecture Components. Часть 2. Lifecycle](https://habrahabr.ru/post/332718/)
[Android Architecture Components. Часть 3. LiveData](https://habrahabr.ru/post/333890/)
[Android Architecture Components. Часть 4. ViewModel](https://habrahabr.ru/post/334942/) | https://habr.com/ru/post/333890/ | null | ru | null |
# Прямые в гексагональном растре
Данное исследование не претендует на оригинальность, я полагаю, что на самом деле изобретаю велосипед, но никаких деталей от него при (признаю, довольно поверхностном) изучении интернета мне найти не удалось.
Понаблюдав за разнообразными игрушками, передвижение персонажей в которых производится на плоскости, вымощенной правильными шестиугольниками, меня зацепил вопрос — а как должна выглядеть прямая на такой плоскости. Собственно, задача оптимального перемещения персонажа из шестиугольника A в шестиугольник B (подразумеваю, что на плоскости нет препятствий, под оптимальным перемещением подразумеваю такое, чтобы оно происходило через наименьшее количество шестиугольников) может быть решена кучей разных способов, маршрут далеко не единственен, так же, как, впрочем, и на плоскости, покрытой квадратами. Но мне хотелось бы, чтобы маршрут был приближен к отрезку прямой, как приближено к отрезку прямой изображение, построенное по [алгоритму Брезенхэма](http://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%91%D1%80%D0%B5%D0%B7%D0%B5%D0%BD%D1%85%D1%8D%D0%BC%D0%B0), и в то же время реализация должна быть достаточно прозрачной и простой.
С использованием вычислений в области действительных чисел наиболее прозрачным будет следующий подход: допустим, есть координаты центров начала и конца. Допустим, уже построена часть прямой (например, поставлен начальный шестиугольный «пиксель»). От последнего построенного пикселя нужно выбрать в его окрестности (в которой находится 6 других шестиугольников) тот шестиугольник, сумма расстояний (в смысле обычной геометрии) от центра которого до начала и конца строящегося отрезка минимальна (на самом деле достаточно рассмотреть два случая — либо два нижних, либо нижний правый и правый, в зависимости от некоторого условия, которое будет описано ниже). На сам алгоритм требует вычислений в области действительных чисел, вычислений квадратных корней, чего не очень хочется делать.
Для начала оказывается удобным выбрать систему координат, однозначно идентифицирующую каждый «пиксель» растра. После нескольких рассмотренных вариантов я остановился на простейшем.

В каждом из шестиугольников записаны координаты — x и y — которые для удобства буду называть «растровыми» для отличия от координат точек, которые удобно называть «геометрическими».
В процессе решения задача разбилась на два случая, условие для разделения которых я получил в процессе решения. Ниже станет понятно, почему так происходит, а пока я приведу условие. Если брать координаты начала отрезка как (0, 0), а конца как (x, y), то первый случай получается при выполнении условия x ≥ [y / 2] и, соответственно, x < [y / 2], где квадратные скобки обозначают взятие целой части. Эти условия разбивают мозаику на два неравных участка, граница которого проходит следующим образом:

##### Первый случай: x ≥ [y / 2]
Сначала приведу решение для первого случая, он, пожалуй, наиболее очевидный. Бросается в глаза, что применение алгоритма Брезенхэма «в лоб» не даст нужного эффекта. Дело в том, что в нем x растет на каждой итерации, а y при переполнении значения ошибки. Но при переходе с четной строки на нечетную одновременный рост x и у приведет к разрыву. Например, если в шестиугольнике (2, 2) увеличить обе координаты на единицу, получится шестиугольник (3, 3), не имеющая, как видно на рисунках выше, с первым общих границ. А вот если из (2, 2) перейти к точке (2, 3), а потом к (3, 3), никаких разрывов не будет. Мозаику можно деформировать следующим образом:

А также временно изменить координаты:

На последней картинке видно, что разделяющий отрезок точно проходит по границе октета для алгоритма Брезенхема, поэтому в данной ситуации алгоритм становится уже применим. Более того, каждая следующая точка при итерции в алгоритме является соседней для предыдущей в исходной мозаике. Таким образом, достаточно применить алгоритм Брезенхэма в деформированной мозаике с измененными координатами, после чего вернуть все на исходное место, и получится прямая в гексагональном растре. На картинках ниже пара иллюстраций работы алгоритма.


Длина линии (количество шестиугольников, участвующих в построении) равна x + [(y + 1) / 2] + 1. Квадратные скобки — все то же взятие целой части. Геометрически это количество точек по горизонтали плюс количество переходом с четных строк на нечетные (верхняя строка имеет номер 0, потому она четная).
##### Второй случай: x < [y / 2]
Во втором случае очевидно, что длина линии не должна превышать y + 1. В отличие от классического алгоритма Брезенхэма, этот случай не симметричен первому, однако методика аналогично — произвести описанную выше деформацию и нарисовать отрезок, но уже согласно правилам другого октета, где основные изменения происходят по оси y.


**Код на Java**
```
public final class Line implements Iterable {
private final Point begin;
private final int dx;
private final int dy;
private final int sx;
private final int sy;
public Line(final Point begin, final Point end) {
this.begin = begin;
int dx = end.x - begin.x;
int dy = end.y - begin.y;
if (dx < 0) {
dx = -dx;
sx = -1;
} else {
sx = 1;
}
if (dy < 0) {
dy = -dy;
sy = -1;
} else {
sy = 1;
}
this.dx = dx + (dy + 1) / 2;
this.dy = dy;
}
@Override
public Iterator iterator() {
return dx > dy ? new LineIterator1() : new LineIterator2();
}
private final class LineIterator1 implements Iterator {
private int x = 0;
private int y = 0;
private int error = 0;
@Override
public boolean hasNext() {
return x <= dx;
}
@Override
public Point next() {
if (x > dx)
return null;
Point point = new Point(begin.x + (x - (y + 1) / 2) \* sx, begin.y + y \* sy);
x++;
if (x <= dx) {
error += dy;
if (2 \* error >= dx) {
y++;
error -= dx;
}
}
return point;
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
private final class LineIterator2 implements Iterator {
private int x = 0;
private int y = 0;
private int error = 0;
@Override
public boolean hasNext() {
return y <= dy;
}
@Override
public Point next() {
if (y > dy)
return null;
Point point = new Point(begin.x + (x - (y + 1) / 2) \* sx, begin.y + y \* sy);
y++;
if (y <= dy) {
error = error + dx;
if (2 \* error >= dy) {
error -= dy;
x++;
}
}
return point;
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
}
```
**Класс Point**
```
public final class Point {
public final int x;
public final int y;
public Point(final int x, final int y) {
this.x = x;
this.y = y;
}
}
```
Еще раз повторюсь — я допускаю, что это изобретение велосипеда, и прошу прощения за отнятое время в таком случае. | https://habr.com/ru/post/193668/ | null | ru | null |
# Doctrine, расширяем возможности любимого ORM-фреймворка! Часть 1.а (I18n, быстрый доступ к переводимым атрибутам)
Я думаю многие со мной согласны, что Doctrine — один из самых мощных и удобных ORM для PHP, но с недавнего времени возможностей оного мне перестало хватать. Начнем с того что невозможно использовать ассоциации с условиями фильтрации, «волшебный» поиск с учетом перевода через I18n и много другого.
Всячески экпериментируя с возможностями Doctrine, я написал кучу нужных и ненужных расширений, которые и решил вывести «в мир». Тем самым и начинаю цикл статей, посвященных практическому написанию всяких упрощающих жизнь свистелок. В процессе я также постараюсь раскрыть методологию разработки, так что возможно наличие взаимоисключающих параграфов в течение статьи, но в итоге они разрешатся.
Начну с самого легкого — с расширения для мультиязычности Doctrine\_Template\_I18n. Оговорюсь сразу, текста будет много, как и много сумбурной технической информации
Пара слов относительно названий классов, которые я буду использовать в статье: у меня есть свой фреймворк в котором я и реализовывал рассматриваемые дополнения и имена классов попадают под мой нэймспэйс Of, а, касательно того что я рассматриваю — под Of\_ExtDoctrine (т.е. Extended Doctrine). Соглашения по названиям я использую те же, что и в Doctrine (собственно как и в ZendFramework, бла-бла-бла… много их, почти стандарт)
I18n плагин
-----------
Тут больше всего смущает невозможность прямого обращения к переводимым атрибутам, в случаях когда язык изначально был выбран или получен при запросе на сайт, например:
> `echo $record->my\_translatable\_attribute; // вывод
>
> $record->my\_translatable\_attribute = 'something'; // запись`
Каждый раз приходится писать стандартные конструкции вроде $record['Translation'][$lang]['title'] (кто не в курсе, доступ к записям возможен через array-notation, а также часто используется HYDRATION\_ARRAY для увеличения быстродействия. см. [полезную ссылку](http://www.doctrine-project.org/documentation/manual/1_2/en/improving-performance#conservative-fetching)), что в свою очередь требует передачи значения выбраного языка в шаблон, что часто неудобно.
Добавим эту функциональность, а для этого придется написать свой шаблон для actAs, а также статичный метод для определения языка перевода по умолчанию.
### Бастрый доступ к переводимым атрибутам
Для начала создадим класс записи и окружение для дальнейшей работы
> `class Product extends Doctrine\_Record {
>
>
>
> public function setTableDefinition() {
>
> //....
>
> $this->hasColumn('name', 'string', 255);
>
> $this->hasColumn('description', 'string');
>
> //....
>
> }
>
>
>
> public function setUp() {
>
>
>
> $this->actAs('I18n', array(
>
> 'fields'=>array('name', 'description')
>
> ));
>
>
>
> }
>
>
>
> }`
> `require\_once 'Doctrine.php';
>
> spl\_autoload\_register(array('Doctrine','autoload'));
>
> $connection = Doctrine\_Manager::connection('mysql://user:passw@host/dbname');`
Как видно мы создали простейшую модель с 2мя переводимыми полями name и descritpion, которые будут доступны через аксессоры
> `$record->Translation[$language]->name;
>
> $record->Translation[$language]->description;`
Пришло время создать свой шаблон (пока пустой) и подключить его к нашей модели
> `class Of\_ExtDoctrine\_I18n\_Template extends Doctrine\_Template {
>
>
>
> // пока пусто
>
>
>
> }
>
>
>
> class Product extends Doctrine\_Record {
>
>
>
> public function setTableDefinition() {
>
> //....
>
> $this->hasColumn('name', 'string', 255);
>
> $this->hasColumn('description', 'string');
>
> //....
>
> }
>
>
>
> public function setUp() {
>
>
>
> $this->actAs('I18n', array(
>
> 'fields'=>array('name', 'description')
>
> ));
>
>
>
> // добавляем наш шаблон к модели
>
> $this->actsAs(new Of\_ExtDoctrine\_I18n\_Template());
>
>
>
> }
>
>
>
> }`
Т.к. требуется реализовать интерфейс доступа к переводу для заранее заданного языка, то необходимо определить где это значение будет хранится. Определим методы для уcтановки и доступа к языку в шаблоне:
* setDefaultLanguage($language) — static — будет использоваться для установки языка по умолчанию в любом месте нашего кода. Метод статичный т.к. значение этого языка будет одинаково для всех экземпляров шаблона.
* setLanguage($language) — not static — будет использоваться для конкретной установки языка для моделей по отдельности. Внимание! Т.к. шаблон инициализируется для всей модели один раз и потом используется для каждой записи одинаково, и, если хранить значение текущего языка в каком-либо свойстве класса шаблона, то это значение одно и то же во всех экземплярах модели
* getDefaultLanguage() и getLanguage() — соответственно используются для получения значений языка, причем если конкретный язык для модели не задан — используется общий
Также позволю себе вольность добавить опцию 'lang' для определения текущего языка прямо из модели. В принципе не нужно, но вдруг когда-нибудь понадобится :)
> `class Of\_ExtDoctrine\_I18n\_Template extends Doctrine\_Template {
>
>
>
> protected $\_options = array(
>
> 'lang'=>null,
>
> );
>
>
>
> /\*\*
>
> \* Holds default language for all behaviors
>
> \*
>
> \* @var string
>
> \*/
>
> static protected $\_defaultLanguage;
>
>
>
> /\*\*
>
> \* Holds language for current model behavior
>
> \*
>
> \* @var string
>
> \*/
>
> protected $\_language;
>
>
>
> public function setUp() {
>
>
>
> if ($language = $this->getOption('lang')) $this->setLanguage();
>
>
>
> }
>
>
>
> /\*\*
>
> \* Returns default language for all behaviors
>
> \*
>
> \* @return string
>
> \*/
>
> static public function getDefaultLanguage() {
>
> return (string)self::$\_defaultLanguage;
>
> }
>
>
>
> /\*\*
>
> \* Sets default language for all behaviors
>
> \*
>
> \* @param string $language
>
> \* @return void
>
> \*/
>
> static public function setDefaultLanguage($language) {
>
> self::$\_defaultLanguage = $language;
>
> }
>
>
>
> /\*\*
>
> \* Returns current behavior language
>
> \*
>
> \* @return void
>
> \*/
>
> public function getLanguage() {
>
> if ($this->\_language === null) return self::getDefaultLanguage();
>
> else return (string)$this->\_language;
>
> }
>
>
>
> /\*\*
>
> \* Sets current behavior language
>
> \*
>
> \* @param $language
>
> \* @return string
>
> \*/
>
> public function setLanguage($language) {
>
> $this->\_language = $language;
>
> }
>
>
>
> }`
В принципе, все просто, если нет текущего языка — возвращаем язык по умолчанию. Преобразование (string) для геттеров поставил что бы всегда возвращало строку, т.к. было дело что вместо строки вкинул в язык экземпляр Zend\_Locale, а парсер Translation этого не понял, но про это дальше.
Теперь следует добавить парочку методов для чтения/записи в определенные поля, которые мы будем использовать в дальнейшем:
> `class Of\_ExtDoctrine\_I18n\_Template extends Doctrine\_Template {
>
>
>
> //...
>
>
>
> /\*\*
>
> \* Returns translatable attribute
>
> \*
>
> \* @param string $field - name of attribute/field
>
> \* @param string $language - custom language of translation
>
> \* @return mixed|null
>
> \*/
>
> public function getTranslatableAttribute($field, $language = null) {
>
> if ($language === null) $language = $this->getLanguage();
>
> $translation = $this->getTranslationObject();
>
> if ($translation->contains($language)) {
>
> return $translation[$language][$field];
>
> } else return null;
>
> }
>
>
>
> /\*\*
>
> \* Sets translatable attribute
>
> \*
>
> \* @param string $field - attribute/field name
>
> \* @param mixed $value - value to set
>
> \* @param string $language - custom language of translation
>
> \* @return void
>
> \*/
>
> public function setTranslatableAttribute($field, $value, $language = null) {
>
> if ($language === null) $language = $this->getLanguage();
>
> $translation = $this->getTranslationObject();
>
> $translation[$language][$field] = $value;
>
> }
>
>
>
> }`
Здесь тоже ничего сложного. При чтении аттрибута проверяем существует ли перевод для языка и возвращаем его, если нет то null. Это сделано для того что бы не создавать ненужных переводов, т.к. при доступе к несуществующей записи $translation[$lang] автоматически создается экземпляр новой. При записи эта проверка не нужна, т.к. подразумевается что мы потенциально можем создать новый перевод.
С языками разобрались, теперь приступим к реализации доступа к аттрибутам из записи. Целесообразней всего это делать через пару Accessor/Mutator для записей, следовательно нужны методы для доступа к переведенным аттрибутам с учетом языка, что в свою очередь тянет за собой необходимость генерации своих геттеров/сеттеров для каждого аттрибута. Решение очевидно — использовать \_\_call() метод в шаблоне в котором парсить имя вызываемого метода и перенаправлять на уже созданные getTranslatedAttribute()/setTranslatedAttribute() в зависимости он задачи. Вообще-то говоря логичней это было бы делать через \_\_get() и \_\_set(), как это сделано в Doctrine\_Record, но, увы, нельзя, т.к. трансляция через эти методы не работает с шаблонами actAs.
> `class Of\_ExtDoctrine\_I18n\_Template extends Doctrine\_Template {
>
>
>
> protected $\_options = array(
>
> 'lang'=>null,
>
> 'fields'=>null, // добавим новую опцию
>
> );
>
>
>
> public function setUp() {
>
>
>
> //...
>
>
>
> // определим пары accessor/mutator для модели
>
> $fields = $this->getOption('fields');
>
> if ($fields) {
>
> foreach ($fields as $field) {
>
> $this->getInvoker()->hasAccessorMutator($field, 'getTranslatableAttribute'.$field, 'setTranslatableAttribute'.$field);
>
> }
>
> }
>
>
>
> }
>
>
>
> //...
>
>
>
> /\*\*
>
> \* Covers calls of functions [getTranslatableAttribute|setTranslatableAttribute][fieldname]
>
> \*
>
> \* @param string $method
>
> \* @param array $arguments
>
> \* @return mixed
>
> \*/
>
> public function \_\_call($method, $arguments) {
>
> $methodAction = substr($method,0,24);
>
> if ($methodAction == 'getTranslatableAttribute') {
>
> return call\_user\_func\_array(array($this, $methodAction), array(substr($method, 24)));
>
> } elseif($methodAction == 'setTranslatableAttribute') {
>
> return call\_user\_func\_array(array($this, $methodAction), array(substr($method, 24),$arguments[0]));
>
> }
>
> }
>
>
>
> }`
Как видно, у нас добавилась новая опция 'fields', такая же как и для шаблона I18n. Она определяет какие поля мы будем использовать для быстрого доступа. Изменим класс Product в соответствии с этой опцией.
> `class Product extends Doctrine\_Record {
>
>
>
> public function setTableDefinition() {
>
> //....
>
> $this->hasColumn('name', 'string', 255);
>
> $this->hasColumn('description', 'string');
>
> //....
>
> }
>
>
>
> public function setUp() {
>
>
>
> $this->actAs('I18n', array(
>
> 'fields'=>array('name', 'description')
>
> ));
>
>
>
> $this->actAs(new Of\_ExtDoctrine\_I18n\_Template(array(
>
> 'fields'=>array('name', 'description') // используем все доступные для перевода поля
>
> )));
>
>
>
> }
>
>
>
> }`
Вот, собственно, и все, проверяем:
> `$record = new Product();
>
>
>
> $record->Translation['en']->name = 'notebook'; // зададим какой-то перевод вручную
>
>
>
> Of\_ExtDoctrine\_I18n\_Template::setDefaultLanguage('en');
>
>
>
> echo $record->name; // выведет 'nodebook' - верно
>
>
>
> $record->name = 'nuclear weapon'; // зададим другое название через mutator
>
>
>
> echo $record->name; // выведет 'nuclear weapon' - работает!`
Это не все возможные тесты, но система работает. Конечно стоило оформить это через unit tests, но откровенно лень.
Есть некоторые ньюансы относительно конкретно этой реализации быстрого доступа к переводимым аттрибутам:
* т.к. используется \_\_call() метод прямо в шаблоне, то в итоге все неизвестные методы в модели будут перенаправлятся в этот шаблон и если вдруг вы захотите добавить другой, с аналогичной системой, то обработчик не сработает.
* нет интеграции с HYDRATE\_ARRAY, быстрый доступ будет недоступен. В принципе эта проблема решена уже, и, забегая вперед, совершенно другой архитектурой доступа. Я расскажу об этом в следующей части.
* достаточно медленный движок. Куча if, прыжки между методами и т.д.
Вот такие дела и я надеюсь, что вам было более-менее понятно что к чему. В следующей части займусь модификацией данного движка доступа для более оптимального расходования ресурсов и расширения возможностей интеграции с различными представлениями результатов поиска (hydration modes), загрузки переводов через join во всех dql запросах автоматически, ознакомлю с практикой использования компоненты Doctrine\_Record\_Listener в контексте задачи и много другого.
В этой статье код был подсвечен при помощи [Source Code Highlighter](http://virtser.net/blog/post/source-code-highlighter.aspx). | https://habr.com/ru/post/79878/ | null | ru | null |
# Установка и настройка CentOS Linux 5.5 под Hyper-V
Давайте продолжим серию статей о запуске Unix и Linux систем под Hyper-V R2. Сегодня посмотрим, как устанавливать и настраивать CentOS 5.5 под управлением нашей системы виртуализации. Почему именно CentOS? Все очень просто он является самым популярным среди любителей RedHat подобных дистрибутивов.
Для тех, кому лень читать могу сказать что CentOS работает под Hyper-V очень хорошо и готов к применению в производственной среде. Кстати, все, что я напишу ниже можно с таким же успехом применять и для RHEL.
Ну что приступим?
Создаем виртуальную машину. И добавляем в нее сетевой адаптер Legacy. Он пригодится нам для обновления CentOS и для установки компонентов интеграции Hyper-V.
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/3884.Centos_5F00_hyperv_5F00_network_5F00_settings_5F00_1DAAEB46.png)
Запускаем установку ОС. Для того чтобы сценарий тестирования был наиболее реалистичным будем использовать динамические жесткие диски VHD. Обратите внимание, что гостевая система вполне нормально работает с дисками размера до 2 ТБ. Использование динамических дисков автоматически расширяющихся при необходимости поможет нам реалистичнее посчитать среднюю производительность дисковых операции.
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/2308.Centos_5F00_2TB_5F00_VHD_5F00_Disk_5F00_3194580F.png)
Так же в процессе установки можно настроить сетевой интерфейс Legacy. [](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/1212.Centos_5F00_legacy_5F00_network_5F00_dhcp_5F00_settings_5F00_0934FFEE.png)
После этого установка ОС выполняется, так же как и на обычном физическом оборудовании. После завершения установки и первой перезагрузки, входим в гостевую систему и проверяем работу сети. [](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/1803.Centos_5F00_legacy_5F00_network_5F00_2FD3666E.png)
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/7585.Centos_5F00_legacy_5F00_network_5F00_test_5F00_785D2F72.png)
Сейчас нам доступен сетевой адаптер со скоростью 100 МБит/c. Для многих задач этого достаточно, но ведь хочется более высоких скоростей? Скоро мы и до этого дойдем.
Обратите внимание, что даже без сервисов интеграции с Hyper-V система способна работать с несколькими виртуальными процессорами. Максимальное количество виртуальных процессоров 4.
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/4034.Centos_5F00_SMP_5F00_Hyperv_5F00_030A60FB.png)
Как видите базовый функционал работает вполне нормально. Теперь давайте приступим к установке сервисов интеграции Hyper-V. Что это даст нам?
* Синтетические драйвера для жестких дисков и сетевых контроллеров оптимизированные специально для Hyper-V R2.
* Fastpath Boot позволяет жестким дискам с которых загружается гостевая ОС работать быстрее.
* Синхронизация времени гостевой ОС с часами Hyper-V.
* Правильно завершение работы гостевой ОС Linux по команде Shutdown из Hyper-V, System Center Virtual Machine Manager или Powershell.
* Heartbeat – периодическая проверка сердцебиения гостевой ОС.
Перед установкой сервисов интеграции Hyper-V обновляем гостевую ОС через графический интерфейс или с помощью команд:
`# yum update
# reboot`
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/7288.Centos_5F00_system_5F00_update_5F00_161B67DA.png)
После перезагрузки неплохо было бы сделать мгновенный снимок (snapshot) средствами Hyper-V, если что-то пойдет не так, всегда сможем откатиться назад.
Теперь устанавливаем заголовки ядра и инструменты разработчика
`# yum install kernel-devel
# yum groupinstall "development tools"`
Скачиваем [интеграционные сервисы для Hyper-V](http://www.microsoft.com/downloads/en/details.aspx?FamilyID=eee39325-898b-4522-9b4c-f4b5b9b64551) распаковываем их и подключаем ISO к гостевой CentOS.
Собираем и устанавливаем модули ядра для синтетических устройств
`# mkdir /opt/linux_is
# cp -R /media/CDROM/* /opt/linux_is
# cd /opt/linux_is
# make
# make install`
Проверяем что модули загрузились с помощью команды
`# lsmod | grep vsc`
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/7288.Centos_5F00_hyperv_5F00_integration_5F00_services_5F00_65583A61.png)
Выключаем гостевую ОС с помощью poweroff. Удаляем из нее сетевой адаптер Legacy и добавляем синтетический адаптер. Запускаем ОС и настраиваем новый сетевой адаптер seth0.
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/4034.Centos_5F00_hyperv_5F00_synthetic_5F00_device_5F00_netwok_5F00_4DFD1023.png)
Теперь можно провести тестирование скорости работы синтетического сетевого адаптера с помощью iperf.
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/6683.Centos_5F00_synthetic_5F00_network_5F00_speed_5F00_53A803FC.png)
Как видите скорость на сетевом интерфейсе seth0 в среднем составляет 492,5 Мбит/c. Довольно неплохой результат для виртуальной машины.
К сожалению, выполнять загрузку гостевой ОС Hyper-V умеет только с IDE дисков поэтому рекомендуется на них располагать только раздел /boot. Для всех остальных разделов рекомендуется в качестве жестких дисков использовать SCSI диски. В этом случае мы сможем добиться гораздо более высокого быстродействия.
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/4431.Centos_5F00_scsi_5F00_disk_5F00_07404A8E.png)
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/4527.Centos_5F00_scsi_5F00_disk_5F00_benchmark_5F00_62EB403E.png)
Если вам нужно сделать так чтобы, подключаясь через RDP к консоли Hyper-V вы могли управлять CentOS с помощью мыши в графическом режиме ставим драйвера синтетического устройства мыши.
Скачиваем их со страницы проекта [Citrix Satori](http://www.xen.org/products/satori.html), присоединяем ISO файл к виртуальной машине, копируем исходники и устанавливаем скомпилированный драйвер.
`# mkdir /opt/mouse_is
# cp -R /media/CDROM/* /opt/mouse_is
# cd /opt/mouse_is
# ./setup.pl inputdriver`
На этом установку всех компонентов интеграции можно считать законченной.
Давайте посмотрим, как CentOS чувствует себя в настоящих больших производственных средах. Для этого я дал ему те ресурсы, что были в наличии на тестовом сервере — 44 Гб ОЗУ и 4 процессора. К сожалению больше ресурсов у меня не было. Интересно было бы глянуть, как CentOS чувствует себя, если дать ему 2ТБ ОЗУ.
[](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/2783.Centos_5F00_45gb_5F00_memory_5F00_4_5F00_cpu_5F00_52AF5278.png) [](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-59-42-metablogapi/3750.Centos_5F00_45gb_5F00_memory_5F00_4_5F00_cpu_5F00_1_5F00_54BC2B74.png)
Затем в течении нескольких дней с помощью скриптов запущенных в несколько потоков создавал командой dd файлы размером до 2ТБ и перекачивал их по ftp и scp на другой сервер. Каких либо проблем и сбоев не обнаружилось.
Поэтому я делаю вывод, что CentOS может использоваться как виртуальная система под Hyper-V для проектов с довольно большой нагрузкой. | https://habr.com/ru/post/113993/ | null | ru | null |
# Как установить доверительные отношения между компьютером и основным доменом
Здравствуйте Уважаемые читатели Хабрахабра! В просторах интернета каждый из нас может найти много отдельных статей о не прохождении аутентификации компьютера через домен-контроллер, если точнее сказать, компьютер подключенный к домену теряет связь с ним.
Итак, приступим к изучению этой проблемы.
У многих IT – инженеров, которые работают в больших и малых компаниях, имеются компьютеры с операционной системой Windows 7, 8.1 и т.п. и все эти компьютеры подключены к доменной сети (DC).
Данная проблема происходит из-за того, что сетевой протокол Kerberos не может синхронизироваться и пройти аутентификацию с компьютером (The trust relationship between this workstation and the primary domain failed), который подключен к домену. Тогда мы можем увидеть такую ошибку (см. фото ниже).
После чего мы ищем стороннюю программу, скачиваем ее, создаем загрузочную флешку и локального админа, далее логируемся через него и выходим с домена, добавляем компьютер в Workgroup-у и потом обратно подключаем этот компьютер к домену.
Используя Windows Batch scripting, я хочу создать bat file и автоматизировать процесс создания и добавления локального админа. Единственное, что нам будет необходимо, так это после создания данного файла запустить его.
Открываем наш текстовой редактор, вписываем команду, которая показана внизу.
```
net user admin Ww123456 /add /active:yes
WMIC USERACCOUNT WHERE "Name='admin'" SET PasswordExpires=FALSE
net localgroup Administrators admin /add
net localgroup Users admin /delete
netsh advfirewall set allprofiles state off
```
Пройдем все команды по пунктам для устранения неясных моментов.
• net user admin (вместо слова админ Вы можете добавить любое имя, которое Вас устраивает, по умолчанию ставится administrator, в моем случае это admin).
Далее мы видем пароль, который я там поставил Ww123456(Вы можете поставить любой запоминающийся для Вас пароль).
После мы видем /add /active:yes –добавить и активировать: ДА
• WMIC USERACCOUNT WHERE «Name='admin'» SET PasswordExpires=FALSE – данная команда означает, что админ, который добавляется, имел постоянный пароль без срока действия (см. картинку ниже).

• Третий и четвертый пункт связаны между собой тем, что по умолчанию, когда создается локальный админ в пункте Member Of стоит Users (см. фото). Нам он не нужен (Users), потому что мы создаем полноправного администратора для нашей ОС. Поэтому четвертая команда — net localgroup Users admin /delete – удаляет Users, а предыдущая команда — net localgroup Administrators admin /add, добавляет администратора (см. фото).
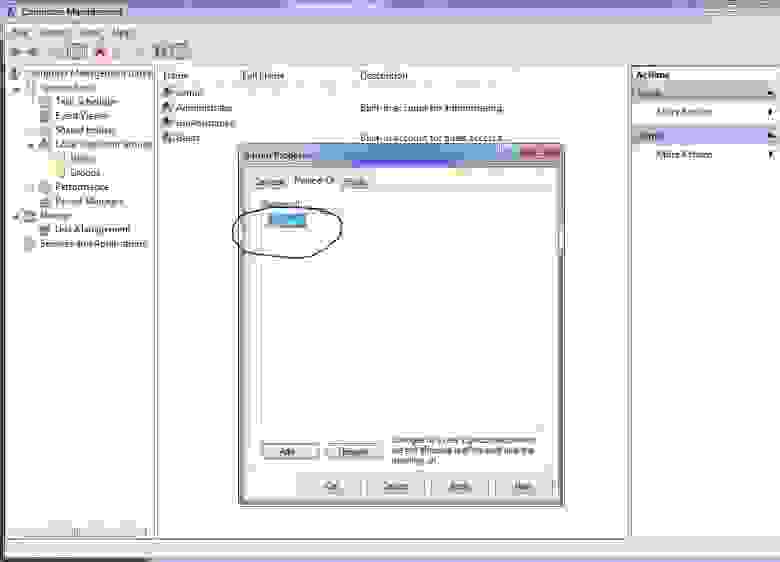
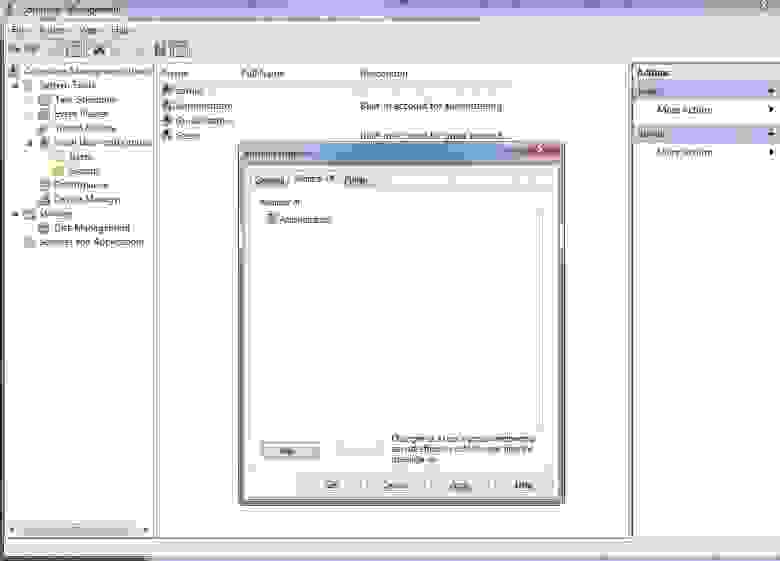
• Последняя команда- netsh advfirewall set allprofiles state off, отключает брандмаузер Windows-a.
Иногда, чтобы установить какую-либо программу или дать какую-либо команду в Windows-e необходимо отключить firewall (После запуска скрипта Вы можете ввести команду- netsh advfirewall set allprofiles state on и включить его заново. У меня по умолчанию стоит off, так как я использую сторонний брандмаузер. Данный момент на усмотрение каждого лично).
Далее идем к нашему блокноту, нажимаем File, save as… (сохранить как...) вводим имя нашего скрипта( в моем случае: localadmin).Затем ставим точку (.) и пишем формат скрипта bat. Выбираем место, где сохранить данную запись и нажимаем save. Более детально показано на картинке.
Получается вот такой скрипт (см. фото).

Данный скрипт при запуске необходимо открывать от имени администратора:
• Нажимаем правую кнопку мыши и Run as administrator (см. фото).
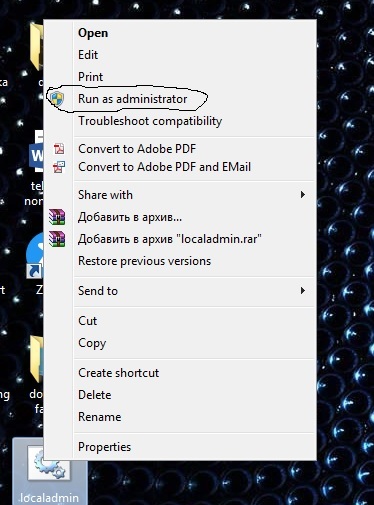
После запуска скрипта у Вас должно появиться вот такое окошко (см. фото).
Если по каким-либо причинам выйдет ошибка, то в 90% таких случаев это связано с тем, что у Вас образ с которого Вы установили Windows, имеет нелицензионный характер, какие-либо repack или т.п. Скачивайте и используйте лицензионный и проверенный софт.
После удачного добавления локального админа, Вы можете этот скрипт запустить на всех рабочих машинах в Вашем офисе, в которых установлена ОС Windows.
Если у Вас когда-нибудь появится такая ошибка: The trust relationship between this workstation and the primary domain failed- Вам нужно будет только сделать switch user и где логин написать.\admin (запомните! В начале до слеша ставится точка!), далее внизу вводите пароль, который Вы добавили в Ваш скрипт (в моем случае: Ww123456). После этого Вы заходите на рабочую ОС.
Осталось снять наш компьютер с домена и добавить в Workgroup-у. Вместо Workgroup-а вписываем любую букву (см. фото).
Далее вводится пароль администратора домена и компьютер просит нас о перезагрузке.
После перезагрузки ещё раз заходим под нашим локальным админом и дальше уже добавляем компьютер к нашему домену. Система в очередной раз требует перезагрузиться и Вуаля! Наш User опять может подключиться к домену без всяких проблем!
P.S – Данная система работает также для серверной части Windows, однако если Вы будете писать такой скрипт для серверов после отключения брандмаузера необходимо будет включить его еще раз (до — netsh advfirewall set allprofiles state off, после netsh advfirewall set allprofiles state on).
Благодарю за внимание! | https://habr.com/ru/post/320348/ | null | ru | null |
# VoxImplant — облачная платформа для разработчиков коммуникационных сервисов и приложений
Доброго времени суток, %USERNAME%! Мы хотим поделится со всем сообществом разработчиков отличной новостью — мы (в лице компании Zingaya) запустили облачную платформу для разработчиков коммуникационных сервисов и приложений, благодаря которой вы теперь можете легко добавить поддержку аудио и видео коммуникаций, а также телефонии в свое веб или мобильное приложение. Итак, встречайте **[VoxImplant](http://voximplant.com)**!
[](http://voximplant.com)
VoxImplant обладает рядом уникальных особенностей, которые вы не встретите в других коммуникационных платформах. Мы подробнее расскажем о них и о том какие возможности вам предоставляет платформа под катом.
Начать стоит с более подробного описания, что же это все-таки такое и зачем оно нужно. **VoxImplant** — это облачная платформа, которая предлагает ряд API, с которыми непосредственно взаимодействует разработчик: Web SDK, Mobile SDK, VoxEngine и HTTP API. Все SDK и HTTP API позволяют взаимодействовать с платформой удаленно, а VoxEngine позволяет запускать в облаке приложения, которые описывают логику обработки звонков, проходящих через VoxImplant Cloud, на Javascript. В дополнение на платформе может быть зарегистрирован любой SIP-клиент, а также можно совершать и принимать звонки через SIP. Например, если у вас уже есть номер телефона с переадресацией на SIP, то вы можете легко направить звонок на VoxImplant и обработать его в соответствии с логикой вашего приложения, а потом прокинуть на какой-нибудь SIP-клиент, подключенный к вашему приложению. Таким образом можно быстро написать функционал простой IP PBX и подстроить логику обработки звонков под свои требования или интегрировать все это с какими-то вашими веб-сервисами, например, CRM.

#### VoxImplant Web SDK
VoxImplant Web SDK представляет собой Javascript библиотеку с рядом функций по взаимодействию с облаком VoxImplant, а точнее с вашими приложениями, которые вы там развернули. В зависимости от возможностей браузера Web SDK может работать в WebRTC-режиме, или же использовать Flash. Существует возможность жестко задать режим работы, но если ваш браузер не поддерживает его, что особенно актуально для WebRTC (который пока доступен только в Chrome и Firefox + в Yandex-браузере, но там он глючит пока еще), то SDK выкинет exception и работать не будет, поэтому мы рекомендуем дать SDK возможность самому определять технологию, которая будет использоваться, чтобы избежать лишних проблем, за исключением случаев когда вы хотите заставить пользователя работать с вашим приложением в конкретном браузере или какая-то функция доступна только в определенном режиме работы SDK (например, пока видео-звонки работают только во Flash-режиме). Подробное описание функций и возможностей Web SDK доступно [по адресу](http://voximplant.com/docs/references/websdk/).
#### VoxImplant Mobile SDK
То же самое, что и Web SDK, только в виде нативных библиотек для iOS/Android. На текущий момент библиотеки доводятся до ума, а также пишется документация, поэтому они станут доступны чуть позже.
#### VoxEngine
Одна из самых интересных частей платформы — VoxEngine (cloud application engine), который выполняет сценарии, написанные на Javascript. По сути, сценарии — это полноценные Javascript-приложения, которые VoxEngine запускает и выполняет, когда звонок проходит через VoxImplant Cloud. Для написания приложений доступны все функции ECMA5 + дополнительные функции, которые дают доступ к возможностям VoxImplant и позволяют взаимодействовать со внешним миром, например, делать HTTP-запросы или отправлять email. Подробно со списком доступных функций можно ознакомиться [по ссылке](https://voximplant.com/docs/references/voxengine). При создании новой сессии VoxEngine запускает именно те скрипты (Scenarios), которые разработчик описал в правилах (Rules) приложения, то есть в зависимости от типа звонка могут выполнятся совершенно разные скрипты. После завершения сессии (когда в сессии больше нет звонков или разработчик сам вызвал метод уничтожения сессии в скрипте) VoxEngine дает сессии еще какое-то время для освобождения ресурсов (например, для завершения последних нескольких HTTP-запросов), потом сессия уничтожается. Внутри одной сессии может быть сразу несколько разных звонков, которые можно соединять/разъединять друг с другом и делать с ними самые разные вещи, типа проигрывания звукового файла звонящему или записи разговора, но существуют ограничения по количеству звонков, количеству одновременно выполняемых HTTP запросов и использованию других ресурсов платформы на одну сессию. Подробнее об этом можно ознакомиться в документации. Если читатели Хабра сочтут нашу платформу достаточно интересной, то мы займемся циклом туториалов и статей в стиле «How To», чтобы подробнее рассказать что и как можно делать с использованием платформы. Ниже пример самого простого сценария — проброс вызова при звонке с Web SDK на телефон:
```
VoxEngine.forwardCallToPSTN();
```
на самом деле функция forwardCallToPSTN — это хелпер, написанный для упрощения и сокращения кода, если бы этого хелпера не было, то код выглядел бы следующим образом:
```
VoxEngine.addEventListener(AppEvents.CallAlerting, function(e) {
// В качестве второго аргумента нужно указать номер, подтвержденный через верхнее меню панели управления Voximplant
var pstnCall = VoxEngine.callPSTN(e.destination, "+1234567890");
VoxEngine.easyProcess(e.call, pstnCall);
});
```
Кстати, для вашего удобства мы встроили в панель управления VoxImplant редактор скриптов на базе CodeMirror с автокомплитом, поэтому необязательно наизусть помнить все названия функций. См. скриншот ниже:

#### HTTP API
VoxImplant HTTP API предоставляет возможность удаленного создания/редактирования/удаления всех сущностей, с которыми работает VoxImplant, таких как приложения (Applications), пользователи (Identitites), скрипты (Scenarios), правила (Rules), а также дает возможность работать с некоторыми функциями биллинга для распределения средств между аккаунтами пользователей. HTTP API очень полезно для интеграции с уже существующими приложениями и сервисами, иначе все пришлось бы делать в панели управления VoxImplant, что не очень удобно (попробуйте, например, создать вручную 1000 пользователей). Описание HTTP API доступно [на этой странице](http://voximplant.com/docs/references/httpapi/). Мы называем эту часть HTTP API Provisioning API, существует еще одна часть HTTP API, которая сейчас находится в разработке — Control API, она позволит удаленно создавать сессию и вызывать функции, описанные в сценарии для VoxEngine. Такой тип API необходим в случае, когда не используется клиентское приложение, например, если нужно сделать два звонка с платформы и соединить их между собой — стандартный callback-сценарий.
#### VoxImplant Phone Numbers
Мы будем предлагать телефонные номера, подключенные к платформе, которые можно будет арендовать, чтобы принимать на стороне платформы входящие звонки из обычной телефонной сети. В самое ближайшее время можно будет арендовать номера в США и в России (включая toll free). Если у вас уже есть номер телефона, с переадресацией на SIP, то вы сможете легко настроить его так, чтобы входящие на него звонки шли на VoxImplant для дальнейшей обработки.
Используя все эти компоненты платформы, можно создавать самые разнообразные сервисы и приложения. Это короткая обзорная статья и основная ее задача — сообщить про запуск платформы и совсем коротко описать возможности. На voximplant.com мы создали [специальный раздел сайта](https://voximplant.com/docs/introduction/introduction_to_voximplant/basic_concepts), в котором можно почитать о том как начать разрабатывать приложения. Мы активно работаем над документацией, поэтому если чего-то еще не хватает или описано не самым понятным образом — пишите, будем рады добавить/поправить/улучшить. | https://habr.com/ru/post/194354/ | null | ru | null |
# Unity3D + C#, или как переводить скрипты

На [Unity3D](http://unity3d.com/) я натолкнулся сравнительно недавно, до этого работал со своими самописными движками для мобильных телефонов на Java2ME, в остальное время я — дотнетчик.
При переходе на новую платформу я в первую очередь выискивал для себя уже готовую технологическую платформу, и основными критериями для меня были цена (доступная/оправданная) и по возможности — мультиплатформенность, чтобы единожды написанный код можно было использовать вновь и вновь без конвертаций. Почти сразу я наткнулся на Unity.
Про Unity в целом тут уже писали, так что повторяться не буду, отмечу главное — разрабатываемую игру можно (а на мой взгляд — и нужно) скриптовать на C# (спасибо [Mono](http://www.mono-project.com/Main_Page)). Единственное ограничение — следует писать в пределах .NET Framework 1.1 — только он поддерживается на iPhone. [upd: пока я писал этот пост, вышла новая версия Unity3D для iPhone, поддерживающий .NET 2.1]
Итак, ключевые плюсы для меня от использования Unity вообще и C# в частности:
* Использование .NET Framework и C# (лично для меня это очень удобно)
* Возможность сделать сборку сразу на iPhone и для веб-плеера (standalone сборки меня не прельщают по ряду причин, выходящих за рамки поста)
* Уже готовые сценарии поведения на C# можно будет повторно использовать, например, при создании порта игры на XBox при помощи XNA (с изменениями, но все же)
* Удобный интерфейс и не слишком прожорливые редакторы
* Приемлимая цена
Минусы конечно, также имеются, но речь не за них, ибо плюсы в конечном счете перевесили.
Для скриптования используется прикрученный редактор UniSciTE на базе [Scintilla](http://www.scintilla.org), что лично мне пришлось не по душе, а потому я сразу захотел воспользоваться старой доброй Visual Studio. Вот о том, как скриптовать на C# будет речь ниже:
[upd: перенесено в Game Development]
Текущая версия Unity — 2.6.1, и в ней с интеграцией с Visual Studio проблем никаких нет — достаточно в окне обозревателя проекта сделать правый клик и выбрать соответствующий пункт меню. После этого Unity создаст солюшн, а если он уже создан — обновит. В проекте уже будут указаны ссылки на используемые библиотеки UnityEditor и UnityEngine, а все файлы со скриптами (независимо от языка) — добавлены в проект.

Что надо иметь ввиду:
* Каждый отдельный скрипт — это класс, описывающий поведение игровой сущности. Например, то что сущность «мокрая» при касании повышает уровень влажности на 3. Потом в игровом редакторе мы прикручиваем эту сущность к конкретной луже — и при попадании в нее уровень влажности будет повышаться. Каждый такой класс должен быть отнаследован от класса UnityEngine.MonoBehaviour, и если в скриптах на js это подразумевается, то в C# надо указывать явно.
* Unity не переваривает namespace'ы. В будущем обещают исправить, но пока так.
* Имя класса и имя файла скрипта должны совпадать. Если вы создадите класс через Visual Studio, то не забудтье брать namespace И отнаследовать класс от MonoBehaviour (using тоже не забудьте). Если вы создадите класс через Unity, то по умолчанию он будет называться NewBehaviourScript, не забудьте переименовать как файл скрипта, так и имя класса.
Для описания других тонкостей приеду пример простого скрипта, который идет в комплекте с движком и позволяет перемещаться как в FPS, то есть wasd + пробел для прыжка + мышь. Чтобы игровой аватар пользователя не провалился ниже пола, его надо обернуть в простой коллайдер — CharacterController, каковой должен налепиться на игровой объект автоматически при применении к нему сущности FPSWalker.
`> //параметры нашего хождения
>
>
> var speed = 6.0;
>
>
> var jumpSpeed = 8.0;
>
>
> var gravity = 20.0;
>
>
>
>
>
> //внутренние переменные
>
>
> private var moveDirection = Vector3.zero;
>
>
> private var grounded : boolean = false;
>
>
>
>
>
> //обновление по таймеру
>
>
> function FixedUpdate() {
>
>
> //мы на земле
>
>
> if (grounded) {
>
>
> //строим вертор перемещения
>
>
> moveDirection = new Vector3(Input.GetAxis("Horizontal"), 0, Input.GetAxis("Vertical"));
>
>
> //переносим в глобальные координаты
>
>
> moveDirection = transform.TransformDirection(moveDirection);
>
>
> //увеличиваем пропорционально скорости
>
>
> moveDirection \*= speed;
>
>
>
>
>
> //если велено прыгать - прыгаем
>
>
> if (Input.GetButton ("Jump")) {
>
>
> moveDirection.y = jumpSpeed;
>
>
> }
>
>
> }
>
>
>
>
>
> //вычитаем падение
>
>
> moveDirection.y -= gravity \* Time.deltaTime;
>
>
>
>
>
> //берем товарища
>
>
> var controller : CharacterController = GetComponent(CharacterController);
>
>
> //перемещаем
>
>
> var flags = controller.Move(moveDirection \* Time.deltaTime);
>
>
> //и проверям, на земле ли он
>
>
> grounded = (flags & CollisionFlags.CollidedBelow) != 0;
>
>
> }
>
>
> //ах да, если этот скрипт применят к игровому объекту, надо затребовать от объекта наличие компоненты CharacterController
>
>
> @script RequireComponent(CharacterController)`
Итак, при переводе этого скрипта на C# помимо вышесказанного следует учесть:
* вы хотите, чтобы значения параметров можно было менять в игровом редакторе? Тогда делайте их public'ами.

* Не путайте класс CharacterController и его тип typeof(CharacterController)
* инструкции типа "@script RequireComponent(CharacterController)" превращаются в аттрибуты класса — [RequireComponent(typeof(CharacterController))]
* Плавающая запятая предсавлена float'ом, на double даже вектор не помножить =)
* В js не надо было явно приводить типы. C# — **не такой!**
* И если вам нужно что-то сложное инициализировать, воспользуйтесь готовыми функциями Awake() и Start(), перегружать конструктор MonoBehaviour не рекомендуется
После применения всех этих нехитрых правил, наш класс выглядит следующим образом:
`> using UnityEngine;
>
>
>
>
>
> //тот самый аттрибут класса
>
>
> [RequireComponent(typeof(CharacterController))]
>
>
> //не забыли переименовать класс и файл и указать наследование
>
>
> public class FPSWalkerInCS : MonoBehaviour {
>
>
> //это надо показать в редакторе, обращаем внимание на float
>
>
> public float speed = 6.0f;
>
>
> public float jumpSpeed = 8.0f;
>
>
> public float gravity = 20.0f;
>
>
> //а это - не надо
>
>
> private Vector3 moveDirection = Vector3.zero;
>
>
> private bool grounded = false;
>
>
>
>
>
> //сюда класть инициализцию
>
>
> void Start () {
>
>
>
>
>
> }
>
>
>
>
>
> void FixedUpdate() {
>
>
> if (grounded) {
>
>
> moveDirection = new Vector3(Input.GetAxis("Horizontal"), 0, Input.GetAxis("Vertical"));
>
>
> moveDirection = transform.TransformDirection(moveDirection);
>
>
> moveDirection \*= speed;
>
>
>
>
>
> if (Input.GetButton ("Jump")) {
>
>
> moveDirection.y = jumpSpeed;
>
>
> }
>
>
> }
>
>
>
>
>
> moveDirection.y -= gravity \* Time.deltaTime;
>
>
> //не забываем приведение типов
>
>
> CharacterController controller = (CharacterController)GetComponent(typeof(CharacterController));
>
>
> CollisionFlags flags = controller.Move(moveDirection \* Time.deltaTime);
>
>
> grounded = (flags & CollisionFlags.CollidedBelow) != 0;
>
>
> }
>
>
> }`
Все, класс готов. | https://habr.com/ru/post/86456/ | null | ru | null |
# Взлом и обфускация ДНК. Guest Post
**Преуведомление**
Мой [первый пост](https://habr.com/ru/post/531792/) на Хабре (демо-версия авторского хабротекста из разряда «а может, взлетит»?) был посвящен сходству ДНК и программного кода. Такая тема казалась мне максимально «канонической» и «соответствующей тематике Хабра», но при этом непритязательной. Кроме того, я тогда действительно зачитался книгой Сергея Ястребова «От атомов к древу», а начинать со статьи о серповидноклеточной анемии и муковисцидозе, которые во времена повальной малярии и туберкулеза были скорее фичами, чем багами (немножечко увеличивая выживаемость и репродуктивные шансы больного на фоне популяции) — не решился. Тем не менее, до самого последнего времени я ощущал, что тема кода и ДНК требует гораздо более серьезного и профессионального поста, чем мог бы написать я сам. Поэтому я обратился за помощью к уважаемой Анастасии Новосадской [@anastasiamrr](/users/anastasiamrr) , давно желавшей попробовать свои силы на Хабре, и с удовольствием и благодарностью размещаю в блоге её интереснейшую статью о вредоносном генетическом коде и методах его маскировки. Добро пожаловать под кат.
Привет, Хабр!
В этой статье речь пойдет о коде, причем не программном, а генетическом. Выражение «генетический код» стало настолько расхожим, что многие и не задумываются о том, насколько на самом деле похожи биологический код и программный, и какие схожие уязвимости для них характерны. Код — это система знаков, расположенная в определённой последовательности для хранения и передачи какой-либо информации. Он может быть штриховым, радиогенетическим, программным, цифровым. И если генетический код — это основа биологической жизни, то программный в XXI веке проник во все ниши общества на волне цифровизации. Софт буквально повсюду: смартфоны, фитнес-трекеры, рекламные LED-экраны, принтеры, автоматизированные производства. Можно сказать, что программный код в каком-то смысле начал управлять нашей жизнью. А вместе с ним в нашу жизнь вошли киберпреступники — люди, желающие взломать чужой код, скопировать и похитить, т.п. Дело в том, что аналогично им существуют различные организмы, которые способны совершить то же самое с генетическим кодом других клеток и многоклеточных организмов. Таким образом вирус, бактерия, а порой и клетка своего организма (речь сейчас как раз о раковых клетках) может заставить других работать на себя или скопировать особенности чужого кода. Об особенностях программирования и реализации кода клеток как раз и написано в данной статье.
Прежде, чем начать, стоит провести короткий ликбез для всех малознакомых с наукой о жизни нашей:
*Вирус — неживая частица с генетической информацией, которая может заражать живые клетки и менять их ДНК-код.*
*Патоген — бактерия, вирус или что угодно другое, что вызывает болезнь.*
*Клетка — мельчайшая, но самостоятельная живая единица организма. Имеет свои аналоги с ПК такие, как ввод/вывод информации, хранение, передача.*
*Опухолевая клетка — дефектная клетка организма, такой своеобразный «бунтарь» и «борец с системой». У них есть способность к бесконтрольному делению , также они становятся атипичными для своего организма.*
В программировании для борьбы с такими «злоумышленниками» используют обфускацию — намеренное запутывание кода, при котором он сложен для понимания человеком, но при этом функционально ничуть не меняется.
Hidden text*Удивительно, что код программный был написан гораздо раньше, чем люди узнали о том, что все живые организмы также основаны на коде генетическом: Ада Лавлейс, которую считают первым профессиональным программистом, написала код для вычислительной машины уже в 1843 году, а* [*идея*](https://elementy.ru/nauchno-populyarnaya_biblioteka/433216/Skazka_o_vesyolom_fizike_Georgii_Gamove_i_o_kholodnom_dykhanii_goryachey_Vselennoy) *о существовании генетического кода была сформулирована и высказана в 1950-х* [*Даунсом*](https://www.wikiru.wiki/blog/en/Alexander_Dounce#:~:text=%D0%90%D0%BB%D0%B5%D0%BA%D1%81%D0%B0%D0%BD%D0%B4%D1%80%20%D0%9B%D1%8D%D1%82%D1%8D%D0%BC%20%D0%94%D0%B0%D1%83%D0%BD%D1%81%20(7%20%D0%B4%D0%B5%D0%BA%D0%B0%D0%B1%D1%80%D1%8F,%D0%B8%20%D1%85%D0%B8%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5%20%D0%BE%D1%81%D0%BD%D0%BE%D0%B2%D1%8B%20%D1%81%D0%B8%D0%BD%D1%82%D0%B5%D0%B7%D0%B0%20%D0%B1%D0%B5%D0%BB%D0%BA%D0%BE%D0%B2) *и* [*Гамовым*](https://ru.wikipedia.org/wiki/%D0%93%D0%B0%D0%BC%D0%BE%D0%B2,_%D0%93%D0%B5%D0%BE%D1%80%D0%B3%D0%B8%D0%B9_%D0%90%D0%BD%D1%82%D0%BE%D0%BD%D0%BE%D0%B2%D0%B8%D1%87)*, т.е. спустя 110 лет.*
В нашем организме предусмотрены всевозможные варианты обфускации генетического кода, чтобы никакие вирусы, бактерии, «мятежные» опухолевые клетки не смогли помешать нормальному функционированию организма. Только вот в живой природе обфускация идёт не столько на уровне генетического кода, сколько на уровне его продуктов — белков. Белки задействованы буквально ВЕЗДЕ: от считывания кода ДНК и РНК (полимеразы, хеликазы, белки, формирующие рибосомы) до клеточного «общения» (большинство сигнальных систем клеток построено как раз на белках) для регуляции слаженной совместной или одиночной работы. Такое «общение» можно сравнить с работой по локальной сети или же на ПК. А наш организм, по сути, подобен Интернету: каждые отдельные клетки — это хосты, нервные клетки — оптоволокно, скопления нервов — серверы и ЦОД. Как и в реальном интернете, перечисленные узлы могут быть подвержены атакам вредоносных агентов, которыми могут быть вирусы, бактерии и иные организмы. Очевидно, что наш организм знает не только, как защититься от врагов, но и как им противодействовать, ловко пользуясь созданными за миллиарды лет эволюции подходами. (Например, защищаться от белковых DDoS-атак).
Однако биологические зловреды тоже не так просты, и могут пользоваться не только созданным самостоятельно инструментарием для «взлома» клетки, но и использовать то, что атакуемая клетка когда-то создала для себя. Например, вирусы способны пользоваться ферментами инфицированной клетки для сборки новых вирусных частиц, могут встраивать свои генетические программы прямо в геном клетки и размножаться вместе с ней практически бесплатно, находясь в таком спящем состоянии до определённого момента. Такие биологические стилеры находятся в каждом из нас, и мы начинаем замечать их только тогда, когда наша иммунная система слегка ослабляет хватку, например, когда мы проходимся по холодной улице без шапки.
«Преступники» могут точно так же перепрограммировать код наших клеток, порабощая их, как компьютерные вирусы перепрограммируют компьютеры для такой же цели. Когда в организм попадают патогены, наши иммунные клетки, выполняющие функции антивирусного софта, сканируют свойства этих бактерий и вирусов, чтобы понять их потенциальную опасность. А свойства-то обфусцированы! В ходе эволюции велась своего рода «холодная война» между организмами и их «врагами» (патогенами). Она заключалась в том, чтобы запутать код и придумать лазейки для распутывания кода оппонента как можно быстрее. Таким образом, поколение сменяется поколением, а борьба за попытку взломать код друг друга максимально быстро и с минимальным количеством издержек продолжается и будет продолжаться. И если у кого-то получится приобрести невозможную для расшифровки обфускацию, то противодействующая сторона окажется в проигрыше и, скорее всего, вымрет.
Принцип работы генетического кода
---------------------------------
Для того, чтобы понимать, какие варианты обфускации применяются в клетках и как их обходят, нужно разобраться с тем, что же за генетический код такой и чем он схож с программным, а может, и отличается от него.
Разберем ситуацию на классическом примере двоичной системы счисления. У машины есть электрические сигналы: 0 — сигнала нет, 1 — сигнал есть. Представим, что у нас есть машина, в которой сигналы записываются на магнитную ленту в двоичной системе. У живых же организмов информация хранится в виде биохимических молекул (ДНК, например, обладает отрицательным зарядом. Это важно для того, чтобы к ней присоединялись специфичные белки и регулировали экспрессию (реализацию) генетического кода), и если у машин это 2 позиции, то у нас — 4. В молекуле ДНК это четыре нуклеотида (азотистых основания): аденин (А), тимин (Т), гуанин (Г), цитозин (Ц).
Hidden text*Есть ещё такие основания, как урацил (У), инозин (И) и др., которые возникают при копировании/переписывании информации с ДНК на ДНК/РНК, что необходимо, чтобы повысить стабильность самой ДНК. Ферментные системы контроля распознают такие основания и удаляют в случае копирования информации с ДНК на ДНК, т.к. это считается ошибкой (необходимо для деления клетки). Если же происходит переписывание с ДНК на РНК, то разные азотистые основания не являются ошибкой, а не позволяют произвести гибридизацию РНК с ДНК, что аналогично запрету на редактирование и разрешению на чтение соответственно. Этим же запретом на редактирование организм препятствует попаданию вирусов в свой геном.*
Вернемся к нуклеотидам. Они идут в определённом порядке, образуя ДНК. По сути, саму спираль ДНК можно сравнить с магнитной лентой, но с той особенностью, что если на магнитной ленте записан код в двоичной системе счисления, то в ДНК — четверичной. На первый взгляд, разница колоссальная, а на второй и третий математический — нет. :)
Компьютер в своей логике оперирует минимальными кодирующими единицами – битами, которые объединяются в кодирующие группы – байты. За счёт такого разделения удается закодировать необходимую информацию и удобно работать с ней.
Удивительно, но аналогичная логика работает и в нашем организме. У организма биты заменяют нуклеотиды, а байты — кодоны. То, что система счисления в нашем организме четверичная, позволяет сделать генетический код более ёмким при меньшем объёме, что играет большую роль при копировании информации, поскольку это сугубо биохимический процесс. И если у машины 1 байт равняется 8 битам, то у организма 1 кодону соответствуют 3 нуклеотида. Одна тройка нуклеотидов кодирует одну аминокислоту, включаемую в белок, а также обозначает начало и конец трансляции (синтеза белка).
Важно отметить одно из свойств генетического кода (специфичность): один кодон соответствует только одной аминокислоте, а одна аминокислота может кодироваться несколькими кодонами. Аминокислоты объединяются в белок, который имеет свои функции в зависимости от последовательности кодонов и их типов. Также белок может постфактум редактироваться, чтобы принять необходимую конформацию (форму) и/или приобрести дополнительные функции. Эти процессы называются «[фолдинг](https://(https:/farmf.ru/prochee/folding-belka-i-ego-narusheniya-bolezni-svyazannye-s-nim/)» (приобретение формы) и «[посттрансляционные модификации](https://mipt.lectoriy.ru/file/synopsis/pdf/Biology-Genetics-M11-Rebrikov-130429.02.pdf)». Их можно сравнить с использованием декораторов в Python. Если представить получившийся белок как функцию, то способ, позволяющий изменить её поведение, не меняя её код — это применение декораторов, которые будто обёртывают исходную функцию. Благодаря такому врапперу белок-функция приобретает новые свойства, которые нередко являются ключевыми для организма.
Схема реализации генетического кодаБлижайший аналог белка при сравнении его с исходным кодом — это программа для вывода файла на печать либо для конвертации файлов из одного формата в другой. Логика такова: из кода была извлечена информация, преобразованная вывелась в человеко-читаемый или, в нашем случае, «организмо-читаемый» формат.
Вкратце о переменных в коде. В исходном коде есть разные типы переменных: для обозначения массивов, чисел с плавающей запятой и прочих структур данных. Переменные могут занимать довольно большое количество байтов, чтобы вместить достаточное количество информации для реализации команды. И снова в ДНК то же самое! Переменная — это ген. Целая компьютерная программа кодируется огромнейшим количеством байтов и логических конструкций, и в клетке роль такой программы выполняет геном.
Ещё одно свойство генетического кода, для более подобного описания которого был написан этот пост на Хабре, — универсальность. Генетический код един для всех организмов. Абсолютно. Вообразите, будто все программисты внезапно начали писать код на одном языке. И есть логичное объяснение, почему практически все организмы имеют одинаковый генетический код (и нет, горе креационистам, это не из-за божественного вмешательства). Для этого нужно вернуться на 3,5 миллиарда лет назад, когда древние организмы только начинали обзаводиться тем разнообразием биологических инструментов, которое мы имеем сейчас. Как известно, эволюция движется за счёт двух основных факторов: мутаций (случайных изменений в генетическом коде) и естественного отбора. В случае, если какой-то организм получал мутацию, которая меняла логику кодирования генетической информации, данный организм терял возможность пользоваться всем тем многообразием инструментов, которые он уже развил. Это приводило к тому, что он быстро погибал и не мог передать свою мутацию потомкам. Такой эволюционный механизм можно сравнить с процедурным программированием, где всё громоздится в один большой кусок и, если впоследствии появляется необходимость в изменениях, то их внесение становится проблемой. Причём сложность приобретения значимых преобразований растёт экспоненциально с размером кода.
Поэтому кодирование информации в организме — это своеобразный костыль, поставленный несколько миллиардов лет назад, но, как ни парадоксально, всё ещё работающий. Более того, некоторые организмы в процессе эволюции могли делиться между собой генетической информацией, а за счёт того, что код одинаков, он «вставал» без особых проблем. Улавливается сходство с github-репозиторием?
Принципиальное сходство программного и генетического кодаТаким образом, мы разобрали, в чём наиболее схожи генетический и программный код. Можно заметить, что сходств уже достаточно много, но при более детальном разборе их окажется в несколько раз больше. Учёные даже смогли в бактериальной клетке закодировать ту самую фразу «Hello world». Бактерия использовалась как носитель информации, та же флешка, только живая. Вот [тут](https://sci-hub.ru/10.1038/s41589-020-00711-4) можно об этом почитать.
Теперь, разобравшись во всём контексте, переходим к основной теме статьи.
Обфускация патогенов и "бунтующих" клеток
-----------------------------------------
*Начнём, пожалуй, с самого пугающего и ещё довольно неизвестного — опухолевых клеток*
*Что же с ними не так, и почему до сих пор нет эффективного метода лечения рака? Может, всё потому, что ранее предки этих клеток работали на организм и знают, какая обфускация есть у нас? Или тут есть что-то другое, более зловещее?*
Клетка организма перерождается в опухолевую за счёт действия стрессовых факторов, которые повреждают её ДНК (УФ-излучение, активные формы кислорода, радиация и др.). Это приводит к мутациям, изменениям в генетическом коде, о которых вскользь упоминалось выше. Мутации могут быть самыми разными: это вырезание последовательности ДНК или же вставка дополнительных нуклеотидов, замена одних нуклеотидов на другие, неправильное объединение нуклеотидов в пары и многое другое. Второй вариант развития событий, приводящий к злокачественному перерождению клетки связан с транспозонами. [Транспозоны](https://bigenc.ru/biology/text/2221235) — это последовательности ДНК, которые способны перемещаться по хромосоме, встраиваясь в рандомные места. Как будто кто-то просто взял и сделал `ctrl+x` из одной части кода и `ctrl+v` в другую часть. Конечно, после такой операции программа или не будет работать, или будет работать неправильно. С клеткой то же самое. А иногда транспозон не вырезается, а просто копируется в другую часть гена или вообще сам перебирается в другую часть хромосомы.
[Здесь](https://cyberleninka.ru/article/n/transpozonnaya-gipoteza-kantserogeneza/viewer) можно почитать про влияние транспозонов на канцерогенез.
Также инициирующим фактором рака могут быть бактерии. Например, аденокарцинома желудка развивается из-за известной многим *Helicobacter pylori.*
Процесс бесконтрольного перерождения раковой клеткиПосле того, как клетка переродилась в опухолевую, она перепрограммирована на уровне обмена веществ, процессы в ней проходят не как прежде и обычно гораздо быстрее. Такая клетка становится «хозяйкой своей судьбы», постоянно продлевая себе жизнь. Как будто пропадает вручную прописанное ограничение по ресурсам, выдаваемое на функции, обусловленное необходимостью стабильного выполнения других важных клеточных процессов. Клетка может начать неограниченно делиться, поскольку «забудет», что в её программе есть ограничение на рост, который помешал бы соседним клеткам. В итоге она начинает отжирать ресурсы организма, мешая всем вокруг. В норме такого «бунтаря» быстро опознают иммунные клетки по белкам на его поверхности. Но здесь вспомним про обфускацию.
Обманка для иммунной системы
----------------------------
Есть два уровня реализации запутанного опухолевого кода: на уровне внеклеточных продуктов и на уровне мембранно-клеточных. И один, и второй абсолютно необходимы для максимально эффективной обфускации.
Первое и самое простое, что может сделать опухоль, — просто синтезировать меньше поверхностных антигенов, тем самым «закамуфлироваться». Поверхностные антигены — это маркеры, по которым иммунные клетки определяют своих и чужих. Как это происходит? Опять к нам приходят всеми любимые мутации. Всего пара-тройка штук и — вуаля! Произошла обфускация, и иммунные клетки запутались. Они, конечно, потом расшифруют состав антигенов, но на это уйдёт много времени. Другое дело, что это происходит не по инициативе клетки, а по случайности, так как мутации — это случайный процесс. Но стоит также отметить, что инсургенты проворачивают такие фокусы только на начальных этапах развития опухоли, когда в организме имеются только единичные опухолевые клетки, и эта стадия не выявляется при помощи лабораторной диагностики. Но что делать клеткам, у которых такое редактирование кода не произошло? Сделать себе вставку кода (как будто из библиотеки притянули) для подавления ответных сигналов от иммунных клеток.
Второе: [десентизация](http://humbio.ru/humbio/cytology/x01a0194.htm) (снижение чувствительности) клеток. Меняется характер и частота поступающих сигналов. Помните, мы говорили, что клетка подобна ПК с вводом и выводом информации? Всё происходит за счёт шеддинга: компоненты рецепторов попросту сбрасывается во внешнюю среду, тем самым делая инсургента невосприимчивым к сигналам, идущим от иммунных клеток (в качестве носителей сигнала выступают цитокины, небольшие [пептидные молекулы](https://practical-oncology.ru/articles/435.pdf). Это можно сравнить с тем, что компьютер заразился вирусом, и, чтобы на него не установили антивирус, он программно отключил себе DVD-привод, USB-порты и всё остальное, через что антивирусная программа может попасть на ПК и зачистить код, или в крайнем случае, нарушить дееспособность системы, чтобы вирус не успел напакостить. Такие иммунные сигналы должны заставить клетку совершить самоубийство, по-биологически — [апоптоз](https://ru.wikipedia.org/wiki/%D0%90%D0%BF%D0%BE%D0%BF%D1%82%D0%BE%D0%B7), или же в сравнении с компьютерным кодом выдать «синий экран смерти». Более того, отдельные части рецепторов, сброшенные во внешнюю среду, связываются с клетками иммунитета и блокируют их работу. Как если бы диск с «Касперским» вставили бы в DVD, а он закрылся и не открывался, не отдавая диск назад. Или же это похоже на своеобразный биологический эксплойт, который пользуется доступностью рецепторов клеток иммунной системы в случае подходящей структуры самого эксплойта и за счёт когнантных (клетка к клетке) взаимодействий делает их нерабочими.
Также можно адресовать иммунитету сигналы на гибель клеток: да, тот самый «синий экран смерти», только подаваемый уже не от иммунитета на опухоль, а в обратном направлении. Как будто сервер в сети блокирует работу других, выводя из строя операционную систему. Возможность отправки подобных сигналов, которые имеют, как правило, белковую природу, подобно исполнению любого кода и функций на взламываемом устройстве. Использование подобной возможности значительно упрощается тем фактом, что раковая клетка на белковом уровне имеет нужную «документацию» к API клетки, которой она собирается отправлять (само)убийственные сигналы.
Следующим методом обфускации может быть экранирование: антигенные детерминанты (антигены) попросту связываются с другими молекулами и становятся недоступны для рецепторов иммунных клеток. На машинном уровне это похоже на то, что устройства ввода/вывода чем-то будут заняты. То же самое может делать и клетка, если уберет антигены (маркеры), по которым иммунные клетки могут её опознать. Что же за молекулы? Это могут быть, например, [белки теплового шока](https://cyberleninka.ru/article/n/belki-teplovogo-shoka-biologicheskie-funktsii-i-perspektivy-primeneniya), ведь к ним не вырабатываются антитела, и они подавляют действие [фактора некроза опухолей](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%BA%D1%82%D0%BE%D1%80_%D0%BD%D0%B5%D0%BA%D1%80%D0%BE%D0%B7%D0%B0_%D0%BE%D0%BF%D1%83%D1%85%D0%BE%D0%BB%D0%B8) (ФНО), а значит скрыться удастся если и не на 100 %, то на 99 %.
Очень изящным будет такой вариант обфускации: прокачать себе [синтез каталазы](https://%D0%B1%D0%BC%D1%8D.%D0%BE%D1%80%D0%B3/index.php/%D0%9A%D0%90%D0%A2%D0%90%D0%9B%D0%90%D0%97%D0%90). Вставить себе в код эту функцию и начать продуцировать фермент, расщепляющий перекись водорода, которую применяют при борьбе с опухолью наши «защитники» — отличная идея. Добавить к такому нейтрализующему фактору [простагландин](https://translated.turbopages.org/proxy_u/en-ru.ru.841ba2c7-62ec3057-5ba25b4d-74722d776562/https/en.wikipedia.org/wiki/Prostaglandin_E2) Е2 (функция его синтеза также включается в код опухоли) — и вот подавляется иммунный ответ, можно жить, размножаться и метастазировать дальше.
В дальнейшем, уйдя из вида «защитников», обхитрив или даже уничтожив некоторых, опухолевые клетки мутируют и редактируют собственный код до такой неузнаваемости, что могут даже привлекать на свою сторону клетки иммунной системы. После такого, к сожалению, спасти организм от летального исхода вряд ли получится.
Надеюсь, что теперь пазлы сложились и стало понятнее, что же происходит, когда собственные клетки поднимают «бунт». Теперь перейдем к тем, кто является «недоброжелателем» постоянно и чей смысл жизни состоит в том, чтобы жить за счёт нас. Речь именно про бактерии и вирусы (кстати, не все бактерии и вирусы вредны для нас, и без многих мы бы не могли существовать и даже думать; но в данной статье затрагиваются только “злюки", патогены). Что же делают они?
Как бактерии многоклеточных перехитрили
---------------------------------------
Если представлять весь генетический код в виде абстракции программного кода, то внезапно окажется, что большой процент (можно сказать бОльшая часть) кода не исполняется. Напоминает мёртвый код, на первый взгляд. Например, у человека только 1.5 процента ДНК кодирует структурные белки. Вся остальная часть раньше считалась мусором, накопившимся в процессе эволюции. Однако со временем стало понятно, что это далеко не так. Оставшийся гигантский пласт генетического кода ответственен за сложнейшие механизмы регуляции экспрессии (синтеза белков), благодаря которым нога вырастает ногой, а рука рукой, за счёт чего обеспечивается не только сохранение морфологии организма, но и грамотная регуляция всех клеточных процессов. Данные системы регуляции экспрессии позволяют очень точно исполнять отдельные участки генетического кода; неспроста говорят, что жизненная форма организма определяется не генетическим кодом, а его экспрессией.
Бактерии, в свою очередь, имеют значительно более компактный геном, и не могут позволить себе развить сложные системы экспрессии. Однако на уровне нуклеотидов очень распространены естественные перестройки, вставки генома, в том числе из одних организмов в другие. Это называется [горизонтальный перенос генов](https://studopedia.ru/11_76612_gorizontalniy-perenos-genov.html).
С помощью такого переноса могут появляться новые виды живых существ, а «готовые» организмы могут развивать новые свойства, передавая их потомкам. Например, непатогенные бактерии в нашем кишечнике могут «пообщаться» с патогенными (в случае, если человек перенес бактериальную инфекцию), и наша собственная кишечная микрофлора станет злой и патогенной для нас. Аналогичным образом бактерии могут поступать и с эукариотическими организмами. В данном случае бактерии «решили пойти иным путем»: почему бы не выполнять встраивание генетических программ в геном чужого организма, чтобы его защитные системы перепрограммировались и не «трогали» бактерии? Именно такой механизм был обнаружен у бактерий рода [*Agrobacterium*](https://translated.turbopages.org/proxy_u/en-ru.ru.72ec9b7b-62ec3193-bc4f4b12-74722d776562/https/en.wikipedia.org/wiki/Agrobacteria), которые выполняют генетическую трансформацию хозяина. Такая модификация позволяет перестроить метаболизм растения на производство субстратов, доступных только самим Агробактериям, что обеспечивает им конкурентное преимущество перед другими бактериями. Сейчас появляются описания подобного процесса не только для растительных, [но и для человеческих клеток](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3688693/).
Использование генетической трансформации при выведении ГМО-растенийНо, естественно, существуют и иные механизмы, которые позволяют бактериальным клеткам скрываться в организме-носителе. Например, бактерии рода [*Neisseria*](https://cyberleninka.ru/article/n/molekulyarnye-mehanizmy-formirovaniya-lekarstvennoy-ustoychivosti-neisseria-gonorrhoeae-istoriya-i-vzglyad-v-buduschee)продуцируют протеазы для расщепления антител организма, что практически аналогично блокированию сканирующих и детектирующих программ на ПК. Причём такой шаг происходит в результате генетической перестройки, за счёт чего «молчащие» гены экспрессируются.
Особенности вирусных механизмов
-------------------------------
Особенно интересны механизмы, которые применяются вирусами для инфицирования тех или иных организмов. Вирусы не способны к полноценному автономному существованию, что роднит их с объектами неживой природы. Фактически они представляют собой цепочки нуклеотидов, покрывающие себя различными оболочками и способные размножаться только в организме хозяина. Иными словами, всё их существование основано на [облигатном паразитизме](https://ru-ecology.info/term/76384/). Глубже изучая вирусы, рано или поздно сам приходишь к мысли, что мы с вами, как и все существующее живое вокруг, — это лишь оболочки для существования и размножения генов, которые есть в каждой нашей клетке.
Вирусы способны пользоваться не только тем, что сами приносят в клетку внутри своей оболочки, но и тем, что находят внутри хозяина, причём не только структурными веществами, но и ферментными системами и генетической информацией. Вирусы за счёт средств организма хозяина могут копировать свой геном, собирать новые вирусные частицы и изменять метаболизм заражённой клетки до неузнаваемости. Сам подход вирусов к выживанию можно считать максимально низкоуровневым, если рассматривать его с точки зрения абстракций структурной организации клетки. Поскольку вирусы сами являются относительно слаборазвитыми, у них отсутствуют привычные даже для бактерий органеллы, это не мешает им существовать практически в любом живом организме: от крошечных протистов до растений и млекопитающих.
Генетический код вирусов можно сравнить с ассемблерным: кому-то такой код может показаться переусложненным и неэффективным, однако, работая с теми или иными механизмами напрямую, можно добиться более впечатляющих результатов, чем используя высокоуровневые языки, библиотеки и так далее. При этом сами вирусы можно сравнить с USB-накопителем.
Сама по себе флешка не совершает никакой работы, находясь у вас на столе. Однако всё меняется, когда флешка с вирусом подключается к компьютеру. Она, как и биологический вирус, исполняет заложенный в ней вредоносный код, меняя протекающие в компьютере процессы, и заставляет его делать то, что нужно для последующего распространения вируса.
Различные виды вирусов могут содержать в себе все варианты для хранения генетической информации, такие как одноцепочечные РНК положительной и отрицательной полярности, двуцепочечные РНК, [одно-двуцепочечные ДНК](https://ru.wikipedia.org/wiki/%D0%9A%D0%BB%D0%B0%D1%81%D1%81%D0%B8%D1%84%D0%B8%D0%BA%D0%B0%D1%86%D0%B8%D1%8F_%D0%B2%D0%B8%D1%80%D1%83%D1%81%D0%BE%D0%B2_%D0%BF%D0%BE_%D0%91%D0%B0%D0%BB%D1%82%D0%B8%D0%BC%D0%BE%D1%80%D1%83). Однако большая часть из развитых организмов хранит свою информацию в виде двуцепочечной ДНК — как вирусы решают эту проблему? Во-первых, вирусы с положительной РНК-цепью, такие как коронавирус, например, обладают одним интересным свойством: попадая в клетку, такая РНК способна сразу транслироваться (синтезировать на основе информации РНК белок), а результатом такой трансляции является полный набор вирусных белков: от структурных до регуляторных. Вирусы, которые хранят информацию в ДНК, способны копировать её как своими ферментами, так и ферментами клетки хозяина, а также транскрибировать (конвертировать информацию из ДНК в РНК) её похожим образом. Неплохое разнообразие для самых низкоразвитых представителей живой (неживой?) природы?
Особенно на этом фоне выделяются ретровирусы (примером является ВИЧ), которые способны встраиваться в геном клетки и копироваться вместе с клеткой хозяина. При этом сам механизм тоже заслуживает отдельного внимания: геном вируса — одноцепочечная РНК, которая при помощи принесённого вирусом в клетку фермента, называемого «обратная транскриптаза», производит перевод РНК в ДНК. Получившаяся цепочка ДНК за счёт рекомбинации (обмена участками ДНК за счёт схожести их состава) встраивается в геном клетки. При этом клетка хозяина не может сразу обнаружить, что в её геном был встроен посторонний элемент, а замечает она это слишком поздно. Данный встроенный кусок реплицируется и транскрибируется так же, как и родные гены клетки, позволяя собирать новые вирусные частицы, которые продолжат распространение вируса.
Жизненный цикл ретровирусаВстраивание тех или иных генетических элементов не происходит случайно, а привязано к определённым сайтам (местам в геноме, с которыми происходит специфическое взаимодействие). За счёт закономерностей в этом процессе не только обеспечивается существование жизни в целом, но и появляется некая прикладная исследовательская польза: такие отношения нуклеотидов хорошо формализуются с точки зрения моделирования и позволяют предсказать поведение того или иного участка генетического кода, что в свою очередь позволит защитить его при помощи генетической инженерии. Например, мы можем изменить [сайт связывания](https://www.cell.com/molecular-therapy-family/methods/fulltext/S2329-0501(18)30113-X) какого-либо смертельного вируса, за счёт чего он не сможет развиваться в данной клетке, и мы таким образом сломаем его жизненный цикл. Похожим образом это происходит и в дикой природе: появление мутаций может нарушать сайты связывания тех или иных регуляторных факторов или сайты рекомбинации для чужеродной генетической информации, что приводит к изменению экспрессии данного генетического участка. Если такая мутация закрепляется, то организм получает иммунитет. Однако то же самое происходит и у вирусных частиц, они «разрабатывают» новые сайты связывания, причём также при помощи случайных мутаций, но за счёт того, что у вирусных частиц мутации происходят чаще. Поскольку вариантов вирусной стратегии встраивания тоже появляется больше, данную битву между добром и злом, или высокоуровневым и низкоуровневым кодом, вирусы выигрывают. Именно поэтому трудно изобрести идеальную вакцину от вирусов, поскольку потенциально несколько удачных мутаций в геноме вируса делает уже изобретённое нами средство бесполезным. Поэтому нет универсальной вакцины от гриппа, которая могла бы защитить раз и навсегда.
Как оказалось, вирусы являются одними из главных обфускаторов на Земле и говорить о них можно ещё долго и очень много за счёт того огромного количества их особенностей (отмечу, что в данной статье упомянута только мизерная часть). Думаю, это тема для отдельной статьи. | https://habr.com/ru/post/681260/ | null | ru | null |
# Работа с дисковым пространством и файлами
Однажды HR предложили мне в качестве тестового задания сделать проводник на вебе. Примерное описание ТЗ содержится в заголовке. Задание меня заинтересовало.
Непродолжительный поиск в гугле ничего похожего не дал. Тем интереснее.
Для работы с файлами нам достаточно стандартных классов:
* (System.IO) DriveInfo- Предоставляет информацию о дисках. Так мы узнаем какие диски подключены, их имена, емкость и свободное пространство
* (System.IO) DirectoryInfo — Предоставляет информацию о папках. получение информации о вложенных папках и файлах
* (System.IO) FileInfo — Предоставляет информацию о файлах. получение размера
Первое, с чего предлагаю начать – создадим модельку которая смотрит подключенные диски, чтобы смотреть по каким путям нам вообще ходить, показать какие диски есть и отобразить их размеры:
Для этого в папке Models создал папку FilesModels и в ней DisksModel.cs и вставляем код:
```
public class DisksModel
{
public decimal TotalFreeSpace { get; }
public decimal TotalSize { get; }
public List Disks { get; }
public DisksModel()
{
Disks = DriveInfo.GetDrives().Where(r => r.IsReady).Where(r => r.DriveType == DriveType.Fixed).ToList();
TotalSize = Disks.Sum(r => r.TotalSize);
TotalFreeSpace = Disks.Sum(r => r.TotalFreeSpace);
}
}
```
В конструкторе мы получаем информацию по имеющимся дискам, выбираем только готовые к работе и не берем флэшки.
Также дополнительно, чтобы возвращать размерность в нужных единицах измерения заодно вставил статичный класс.
```
public static class DiskMetods
{
public static decimal ToKB(this decimal size, int decimals = 2)
{
return Math.Round(size / 1024, decimals);
}
public static decimal ToMB(this decimal size, int decimals = 2)
{
return Math.Round(size.ToKB(0) / 1024, decimals);
}
public static decimal ToGB(this decimal size, int decimals = 2)
{
return Math.Round(size.ToMB(0) / 1024, decimals);
}
public static decimal ToTB(this decimal size, int decimals = 2)
{
return Math.Round(size.ToGB(0) / 1024, decimals);
}
public static decimal ToKB(this long size, int decimals = 2)
{
return Math.Round((decimal)size / 1024, decimals);
}
public static decimal ToMB(this long size, int decimals = 2)
{
return Math.Round(size.ToKB(0) / 1024, decimals);
}
public static decimal ToGB(this long size, int decimals = 2)
{
return Math.Round(size.ToMB(0) / 1024, decimals);
}
public static decimal ToTB(this long size, int decimals = 2)
{
return Math.Round(size.ToGB(0) / 1024, decimals);
}
}
```
Создаем контролер для работы с файлами в папке FilesControllers создаем FilesController.cs.
Указываем какую страницу открывать и в нем же статично получаем информацию о дисках для дальнейшего использования.
```
public static DisksModel disk = new DisksModel();
[HttpGet]
public IActionResult Files()
{
return View("~/Views/FilesViews/Files.cshtml");
}
```
Далее в папке Views создаем папку FilesViews и страницу Files.cshtml.
И создаём там таблицы, в которых будут отображаться информация о дисках на компьютере заодно в прогресс баре указывается сколько места заполнено. И как раз используется информация из статического класса в контроллере и переводим в гигабайты за счет ранее написанных методов.
```
| | | | | |
| --- | --- | --- | --- | --- |
| |
| |
| --- |
|
Все пространство дисков
|
| |
|
@WebFileManager.Controllers.FilesController.disk.TotalFreeSpace.ToGB() ГБ свободно из @WebFileManager.Controllers.FilesController.disk.TotalSize.ToGB() ГБ
|
|
@{foreach (DriveInfo driveInfo in WebFileManager.Controllers.FilesController.disk.Disks)
{
| | |
| |
| --- |
|
локальный диск (@driveInfo.Name.Replace("\\", ""))
|
| |
|
@driveInfo.TotalFreeSpace.ToGB() ГБ свободно из @driveInfo.TotalSize.ToGB() ГБ
|
|
}
}
```
Добавим скрипт украшательства ради для сворачивания/разворачивания дисков в/из общего объема, а onclick=»getFolder(null,’@(driveInfo.Name+»\» встретится чуть позже.
```
function VieUnvie() {
var table = document.getElementById("allDisk");
if (table.style.display == "none") {
table.style.display = "block";
}
else {
table.style.display = "none";
}
}
```
Прописываем еще одну кнопку в \_Layout.cshtml
```
- Проводник
```
Получим:
Теперь необходимо отобразить размеры файлов и папок. В этом есть проблема, т.к. в DirectoryInfo нет информации о размере, и, как я понял, тот же проводник windows просто каждый раз считает размеры файлов в папке, дальше идет по вложенным папкам и потом возвращает конечную сумму файлов (например, когда вы нажимаете свойство папки, какое-то время идет подсчет размера на ваших глазах и время подсчета зависит в первую очередь от количества файлов внутри). Так же поступим и мы.
Понадобится модель для хранения информации. Предлагаю такую:
```
public class FolderModel
{
public DirectoryInfo ThisDirectoryInfo { get; set; }
public FileInfo[] Files { get; }
public List Folders { get; }
public decimal Size { get; } = 0;
public FolderModel() { }
public FolderModel(string path):this(new DirectoryInfo(path)) { }
public FolderModel(DirectoryInfo directoryInfo)
{
ThisDirectoryInfo = directoryInfo;
Files = directoryInfo.GetFiles();
Folders = ThisDirectoryInfo.GetDirectories().Where(r => !r.Attributes.HasFlag(FileAttributes.System) & !r.Attributes.HasFlag(FileAttributes.Hidden)).ToArray().GetFolderModels();
Size += Files.Sum(r => r.Length) + Folders.Sum(r => r.Size);
}
public static List GetFolderModels()
{
List folderModels = new List();
foreach (var el in WebFileManager.Controllers.FilesController.disk.Disks)
{
folderModels.Add(new FolderModel(el.Name));
}
//folderModels.Add(new FolderModel("C:\\"));
return folderModels;
}
}
```
Мы получили массив файлов в папке с их размерами, рекурсивно ходим по вложенным папкам возвращая их размер (т.е. размер файлов в них), и конечную сумму размеров.
Дополнительные функции, одна из которых понадобится для получения нашей модели по указанному пути:
```
public static class FolderModelMetods
{
///
/// возвращает FolderModel по массиву DirectoryInfo
///
///
///
public static List GetFolderModels(this DirectoryInfo[] directoryInfos)
{
List folderModels = new List();
foreach(DirectoryInfo directoryInfo in directoryInfos)
{
try
{
folderModels.Add(new FolderModel(directoryInfo));
}
catch
{
}
}
return folderModels;
}
///
/// возвращает FolderModel по указанному пути
///
/// откуда ищет
/// путь по которому брать модель
///
public static FolderModel GetCurentFolderModel(this List folderModels, string fullPath)
{
string[] pathEls = fullPath.Split('\\').Where(r=>r!="").ToArray();
FolderModel folderModel = folderModels.FirstOrDefault(r => r.ThisDirectoryInfo.Name.Replace("\\", "") == pathEls[0]);
for (int i = 1; i < pathEls.Length; i++)
{
folderModel = folderModel.Folders.FirstOrDefault(r => r.ThisDirectoryInfo.Name.Trim() == pathEls[i].Trim());
}
return folderModel;
}
}
```
Здесь стоит трай катч. Это был быстрый способ для обхода ошибок связанных с чтением системных закрытых файлов и папок. Теперь вопрос: как это представить и что выводить на экран. Проводник windows обычно выводит имя, дату изменения, тип и размер файлов, значит и мы выведем такое. Первое, что пришло в голову — написать отдельную модель.
```
public class FolderViewModel
{
public string CurentPath { get; set; }
public string Name { get; set; }
public string Type { get; set; }
public decimal Size { get; set; }
public DateTime ChangeDate { get; set; }
}
```
В этой модели мы как раз реализуем все то что хотим увидеть. Ну и заодно сразу добавим методы в статичном классе.
```
public static class FolderViewModelM
{
public static List GetFolderViewModel(this List folderModels, string path, string folderName, string SortName, string SortType)
{
List folderViewModels;
if(folderName==null) { folderViewModels = folderModels.GetFolderViewModel((path).Replace("\\\\", "\\")); }
else { folderViewModels = folderModels.GetFolderViewModel((path + "\\" + folderName).Replace("\\\\", "\\")); }
if (SortName != null)
{
switch (SortName)
{
case "Name":
if (SortType == "Asc") { folderViewModels = folderViewModels.OrderBy(r => r.Name).ToList(); }
else { folderViewModels = folderViewModels.OrderByDescending(r => r.Name).ToList(); }
break;
case "Type":
if (SortType == "Asc") { folderViewModels = folderViewModels.OrderBy(r => r.Type).ToList(); }
else { folderViewModels = folderViewModels.OrderByDescending(r => r.Type).ToList(); }
break;
case "Size":
if (SortType == "Asc") { folderViewModels = folderViewModels.OrderBy(r => r.Size).ToList(); }
else { folderViewModels = folderViewModels.OrderByDescending(r => r.Size).ToList(); }
break;
case "ChangeDate":
if (SortType == "Asc") { folderViewModels = folderViewModels.OrderBy(r => r.ChangeDate).ToList(); }
else { folderViewModels = folderViewModels.OrderByDescending(r => r.ChangeDate).ToList(); }
break;
}
}
return folderViewModels;
}
public static List GetFolderViewModel(this List folderModels, string fullPath)
{
FolderModel folderModel = folderModels.GetCurentFolderModel(fullPath);
return folderModel.ToFolderViewModel();
}
public static List ToFolderViewModel(this FolderModel folderModel)
{
List folderViewModels = new List();
foreach (var folder in folderModel.Folders)
{
folderViewModels.Add(new FolderViewModel()
{
Name = folder.ThisDirectoryInfo.Name,
ChangeDate = folder.ThisDirectoryInfo.LastWriteTime,
Type = "Folder",
Size = folder.Size.ToMB(),
CurentPath = folderModel.ThisDirectoryInfo.FullName
});
}
foreach (var file in folderModel.Files)
{
folderViewModels.Add(new FolderViewModel()
{
Name = file.Name,
ChangeDate = file.LastWriteTime,
Type = "File",
Size = file.Length.ToMB(),
CurentPath = folderModel.ThisDirectoryInfo.FullName
});
}
return folderViewModels;
}
public static string ToJson(this List folderViewModels)
{
return JsonSerializer.Serialize(folderViewModels);
}
}
```
Мы реализуем перевод в json для передачи на страницу и несколько методов перевода из предыдущей модели в нашу новую. Также в одном из методов реализована сортировка.
Надо придумать представление. Самым простым будет использование все той же таблицы. Сначала в наше ранее используемое представление (в то, где мы рисовали диски) записываем:
```
@using WebFileManager.Models.FilesModels;
@using System.IO;
```
Указываем, какую используем модель и дополнительно пространство. Теперь сделаем саму таблицу.
```


@WebFileManager.Controllers.FilesController.folderModels[0].ThisDirectoryInfo.FullName
fff
| Name | Change date | Type | Size |
| --- | --- | --- | --- |
@{
foreach (var folder in WebFileManager.Controllers.FilesController.folderModels[0].Folders)
{
| @folder.ThisDirectoryInfo.Name
|
@folder.ThisDirectoryInfo.LastWriteTime
|
Folder
|
@folder.Size.ToMB() MB
|
}
foreach (var file in WebFileManager.Controllers.FilesController.folderModels[0].Files)
{
| @file.Name
|
File
|
@file.Length.ToMB() MB
|
}
}
| |
```
При открытии страницы сначала показываем содержимое первого диска из списка. Также делаем кнопки назад и вперед, место, где указываем путь.
Также функции:
```
function Back() {
getFolder(null, $('#PathNow')[0].innerText, null, true);
$("#right").prop("disabled", false)
}
```
Соответственно возврат назад:
```
function getFolder(FN, PN, Sor, BK) {
$.ajax({
url: '@Url.Action("NewFolder", "Files")',
data:{
folderName: FN
, pathNow: PN
, orderBy: Sor
, back:BK
}
, type: 'POST'
, success: function (data) {
$(".FileFolderRow").remove();
GetFileFolderRow(data);
pathNow: $('#PathNow')[0].innerText = data[0]["CurentPath"];
setSes("maxPath", data[0]["CurentPath"]);
}
})
}
```
Получение представления по указанному пути — как раз та функция, которая встречалась еще в отображении дисков на странице.
```
function GetFileFolderRow(data) {
for (var i = 0; i < data.length; i++) {
let tr = document.createElement("tr"),
td0 = document.createElement("td"),
td1 = document.createElement("td"),
td2 = document.createElement("td"),
td3 = document.createElement("td"),
img = document.createElement("img");
if (data[i]["Type"] == "File") { img.src = "/img/file.png" }
else { img.src = "/img/folder.png" }
td0.appendChild(img);
td0.appendChild(document.createTextNode(data[i]["Name"]));
td1.innerText = data[i]["ChangeDate"];
td2.innerText = data[i]["Type"];
td3.innerText = data[i]["Size"] + " MB";
tr.className = "FileFolderRow";
tr.append(td0);
tr.append(td1);
tr.append(td2);
tr.append(td3);
$("#FilesAndFolders").append(tr);
}
$(dbClickRow())
}
```
Записываем в таблицу полученную модель.
И функция для нажатия на строку в таблице. Если папка, то пытается пройти дальше, а на файл просто отвечает, что не может его открыть.
```
function dbClickRow () {
$(".FileFolderRow").dblclick(function (e) {
var newFolder = this.getElementsByTagName("td")[0].innerText.trim();
if (this.getElementsByTagName("td")[2].innerText == "Folder") {
getFolder(newFolder, $('#PathNow')[0].innerText, null, false)
}
else {
alert("i can't open files ");
}
})
```
Добавляем совсем короткий скрипт для сортировки, который по сути так же делает запрос на получение страницы и заодно передает по какому полю сортировать.
```
function Sort(e) {
getFolder(null, $('#PathNow')[0].innerText, e.innerText, false);
}
```
Вспомним про метод, возвращающей модель для представления с сортировкой. Он определяет, по какому полю сортировать. Соответственно где-то надо хранить для пользователей их значения. Самым очевидным способом является сессия. Поэтому в startup.cs добавляем services.AddMvc() и app.UseSession(), выглядит примерно так:
Осталось реализовать в контролере как будем возвращать страницы.
В fileController добавляем:
```
public static List folderModels = FolderModel.GetFolderModels();
```
Сам код:
```
[HttpPost]
public ContentResult NewFolder(string folderName, string pathNow, string orderBy=null, bool back=false)
{
if (orderBy != null)
{
if (HttpContext.Session.GetString("OrderBy") == orderBy)
{
if (HttpContext.Session.GetString("SortType") == "Asc") { HttpContext.Session.SetString("SortType", "Desc"); }
else { HttpContext.Session.SetString("SortType", "Asc"); }
}
else
{
HttpContext.Session.SetString("OrderBy", orderBy);
HttpContext.Session.SetString("SortType", "Asc");
}
}
return Content(folderModels.GetFolderViewModel(!back ? pathNow: pathNow.Substring(0, pathNow.LastIndexOf("\\")), folderName, HttpContext.Session.GetString("OrderBy"), HttpContext.Session.GetString("SortType")).ToJson(), "application/json");
}
```
Если запрос приходит с указанием сортировки, то пишем в сессию по какому полю, а если такое поле уже указанно, то меняем порядок и отправляем модель.
Надеюсь, кому-то пригодится данный материал, также каждый желающий может аргументированно провести автора лицом по коду.
→ Весь проект лежит тут [github](https://github.com/DarthDimon/WebFileManager)
Спасибо за внимание.
Автор статьи: [**@Sith\_Lord**](https://habr.com/ru/users/Sith_Lord/) | https://habr.com/ru/post/592681/ | null | ru | null |
# Быстрый приём платежей QIWI в проекте Python
Необходимость добавить возможность оплаты чего-либо в своём проекте всплывает достаточно часто, при этом возня с ИП, банковскими договорами и прочей бюрократией мало кого привлекает, особенно если масштабы проекта сопоставимы с небольшим telegram-ботом или чем-то подобным. На помощь приходят такие сервисы как QIWI, ЮMoney и другие (не рекламирую, просто нахожу удобным для себя).
Подход прочитать документацию API такого сервиса, написать небольшой модуль и использовать в своих проектах - лучший путь, но начинающие программисты зачастую находят это нудным, сложным и ищут простое готовое решение. Так и я решил когда-то и не нашёл, а теперь вместо переписывания одного модуля по 100 раз решил собрать небольшую библиотеку для быстрой интеграции платежей QIWI.
Установка
---------
В терминале пишем команду и ожидаем конца загрузки:
```
pip install PyEasyQiwi
```
Исходный код GitHub<https://github.com/Kur-up/PyEasyQiwi>
Пакет PyPi<https://pypi.org/project/PyEasyQiwi/>
Создание платежа
----------------
Для начала импортируем класс для создания соединения с QIWI аккаунтом:
```
from PyEasyQiwi import QiwiConnection
```
Конструктор класса принимает один аргумент - ваш секретный API ключ, для начала нам понадобится аккаунт QIWI со статусом "Основной", так как сервис запрещает проводить анонимные платежи. Авторизуемся на сайте:
Далее в верхней панели переходим по вкладкам: Ещё > Приём переводов
Нажимаем "Начать приём платежей" и в верхней панели переходим в создание API ключей
Настраиваем новую пару ключей, дав ей любое название:
На этом этапе копируем и сохраняем ваш секретный ключ (тот что на оранжевом фоне), далее возможности посмотреть его снова не будет. **Не забывайте, что секретный ключ даёт доступ к вашему аккаунту** без логинов, паролей и прочего, храните его надёжно и не передавайте третьим лицам. В случае если такое произошло, в этом же разделе можно удалить ранее созданные ключи.
Теперь, когда мы получили API ключ, вернёмся к коду.
Создадим подключение указав наш секретный ключ:
```
api_key = "your_api_key"
conn = QiwiConnection(api_key)
```
Теперь мы можем использовать экземпляр класса для управления приёмом платежей, начнём с создания счёта на оплату для нашего пользователя, используем метод `conn.create_bill()`
```
pay_url, bill_id, response = conn.create_bill(value=1000.00, description="User1")
print(pay_url)
>>> https://oplata.qiwi.com/form/?...
```
> `pay_url` - строка содержащая ссылку для оплаты *(для отправки клиенту или редиректа)*
>
> `bill_id` - строка содержащие полное наименование счёта на оплату, состоит из текста указанного в `conn.create_bill(..., description="User1")` и полной даты создания платежа. *(для идентификации каждого отдельно взятого платежа, фактически его ID в вашей базе данных)*
>
> `response` - словарь содержащий более подробную информацию о деталях созданного платежа *(в некоторых случаях полезно, например для создания подробных логов)*
>
>
Теперь перейдём по ссылке в `pay_url` и увидим страницу с формой для оплаты любым удобным из доступных методов:
Так же все операции проведённые через API отобразятся в сервисе:
Конечно, наш метод позволяет более гибко настроить то, что пользователь увидит на данной странице, разберём по порядку все доступные опции:
`conn.create_bill(value, currency, delay, description, theme_code, comment, qiwi_pay, card_pay)`
1. `value` - Обязательный аргумент, сумма для оплаты. Например 100.59. Допустимые значения 1-1000000 (QIWI ограничивает транзакции на сумму более 1000000 рублей).
2. `currency` - Валюта для проведения платежа. По умолчанию RUB, доступны варианты "RUB" и "KZT".
3. `delay` - Срок действия платежа в минутах. По умолчанию 15 минут. Устанавливает максимальный временной промежуток для оплаты пользователем, после чего закрывает возможность оплаты.
4. `description` - Описание платежа, по умолчанию - unknown. Используется для более точной идентификации каждого платежа. Разумно использовать ID пользователя из вашей базы данных.
5. `theme_code` - Уникальный код оформления страницы платежа. По умолчанию - пустое значение. Подробнее - далее в статье.
6. `comment` - Комментарий который увидит пользователь при оплате. По умолчанию - пустая строка.
7. `qiwi_pay` - Возможность оплаты с кошелька QIWI для пользователя. По умолчанию True.
8. `card_pay` - Возможность оплаты банковской картой для пользователя. По умолчанию True.
Более полный пример создания платежа
------------------------------------
Для начала разберёмся с параметром `theme_code`:
Этот параметр позволяет задать своё (на сколько это возможно) оформление страницы оплаты, и сервис QIWI предлагает небольшой инструмент для настройки кода персонализации: перейдя по [ссылке](https://qiwi.com/p2p-admin/transfers/link) настраиваем всё по своему желанию и сохраняем наш код, позже передадим его в качестве аргумента.
Теперь когда у нас есть всё необходимое попробуем создать новый счёт на оплату, используя всё тот же метод `conn.create_bill():`
```
value = 3010.11
currency = "RUB"
delay = 30
description = "test_user_ID"
theme_code = "my_code"
comment = "Привет Хабр!"
qiwi_pay = False
card_pay = True
pay_url, bill_id, response = conn.create_bill(value, currency, delay, description, theme_code, comment, qiwi_pay, card_pay)
print("Ссылка для оплаты: ", pay_url)
>>> https://oplata.qiwi.com/form/?..............
```
Проверяем, мы отключили оплату с кошелька QIWI, установили код персонализации и добавили комментарий:
Проверка статуса платежа
------------------------
Вообще, откровенно говоря, сервис умеет присылать ответ на ваш сервер как только один из счетов будет оплачен, но ~~я не успел реализовать это в библиотеке~~ это несёт за собой определённые сложности. Поэтому в данной статье я рассмотрю пример ручной проверки статуса платежа, что в целом - вполне будет решать поставленную задачу не забивая голову болью об обработке ответа на сервер и тд.
В качестве примера возьмём счёт на оплату созданный выше, как вы помните метод `conn.create_bill()` вернул нам `bill_id` , он нам и понадобится для отслеживания статуса.
```
status, response = conn.check_bill(bill_id)
print(status)
>>> WAITING
```
> `status` - строка содержащая статус платежа: **WAITING** - счёт ожидает оплаты, **PAID** - счёт ожидает оплаты, **REJECTED** - счёт отклонён, **EXPIRED** - срок оплаты просрочен (Используется для проверки статуса оплаты)
>
> `response` - словарь с более подробной информацией о счёте
>
>
Теперь у нас есть точное понимание, в каком состоянии находится выставленный счёт, как использовать это в своих проектах - решать вам, простейший пример использования:
```
status, response = conn.check_bill(bill_id)
if status == "PAID":
# Пользователь оплатил
else:
# Пользователь не оплатил
```
Отмена выставленных платежей
----------------------------
Помимо выставления платежей, надо уметь их отменять. Зачем хранить открытым счёт на оплату если пользователь уже сообщил вам (нажав кнопку отмена или например закрыв приложение), потенциально это всегда может привести к неожиданному результату - поэтому хорошей практикой будет закрыть счёт и забыть про него.
Для этого нам всё так же понадобится ID счёта, в нашем случае `bill_id` и новый метод `conn.remove_bill()`
```
conn.remove_bill(bill_id)
```
Данный метод ничего не возвращает, но если мы попробуем перейти по ссылке для оплаты которую создавали ранее, то увидим следующее:
Так же при проверке статуса платежа будет понятно, что он уже недействителен:
```
status, response = conn.check_bill(bill_id)
print(status)
>>> REJECTED
```
**Оплаченный или просроченный счёт закрывать не требуется:**
Для ленивых
-----------
Небольшой пример для создания платежа со всеми возможными настройками, проверки его статуса, и закрытия этого счёта.
Код
```
from PyEasyQiwi import QiwiConnection
# Создаём подключение
api_key = "your_api_key"
conn = QiwiConnection(api_key)
# Создаём счёт на оплату
value = 500.01
currency = "RUB"
delay = 30
description = "test_user_ID"
theme_code = "my_code"
comment = "PyEasyQiwi"
qiwi_pay = False
card_pay = True
pay_url, bill_id, response = conn.create_bill(value, currency, delay, description, theme_code, comment, qiwi_pay, card_pay)
print("Ссылка для оплаты: ", pay_url)
# Проверяем статус платежа
status, response = conn.check_bill(bill_id)
print("Текущий статус платежа:", status)
# Закрываем счёт на оплату
conn.remove_bill(bill_id)
print("Счёт закрыт!")
```
Заключение
----------
На этом всё, буду рад если найдёте это полезным для себя. Адекватная критика всегда приветствуется, это мой первый опыт написания статей, так что не судите строго, старался для людей! Ссылки на документацию ниже:
Документация<https://developer.qiwi.com/ru/p2p-payments/#p2p-> | https://habr.com/ru/post/709676/ | null | ru | null |
# Разработка симулятора космического корабля Союз ТМА
Привет! Мы - команда симулятора Союз ТМА, программы, имитирующей орбитальный полёт космического аппарата Союз и Международной Космической Станции, сближение и стыковку КА с МКС, а также расстыковку и спуск. Всё это имитируется как в автоматическом (т.е. под управлением моделями бортовой аппаратуры Системы Управления Движением), так и в ручном режимах полёта, которые по своему алгоритмическому и логическому составу идентичны тем, что использовались на борту КА Союз ТМА.
Нами разработано программное обеспечение под названием "Моделирование и Управление" в среде C++ Builder 6. Почему именно в ней, а не в VS - это наш первый проект и ранее никто из нас не имел опыта в программировании, а тем более в тренажёростроении, поэтому для "пробы пера" была выбрана наиболее простая среда, но при этом код разрабатывается так, чтобы его можно было максимально быстро интегрировать в другую среду (Qt, VS).
В первую очередь мы решили разработать основные оконные формы для отладки работы алгоритмов ПО - журнал протоколирования событий, а также форматы, имитирующие бортовую аппаратуру, с которой взаимодействует космонавт во время выполнения программы полёта.
Первой формой была - "Ввод начальных условий". На данной форме вводятся все необходимые параметры для выставления начального состояния КА и МКС, минимальный набор начальных параметров состояния бортовых систем, оскулирующие элементы и др. параметры, необходимые для начала режима. Сам список какие именно параметры необходимы для моделирования столь сложной системы нам были неизвестны, но изучив статьи на данную тему, имеющиеся в интернете, а также пообщавшись с разработчиками тренажёров подготовки космонавтов мы выяснили приблизительный набор параметров, которые использует ЦПК им. Гагарина и НАСА для задания начальных условий режимов полёта.
В этот список входят несколько групп параметров:
1. Основные характеристики:
* Массив моментов инерции (Jxx, Jyy, Jzz, Jxy, Jyz, Jzx) - который необходим для математической модели движения. Вводится как для корабля, так и для станции.
* Масса корабля и станции (в кг).
* Координаты центра масс корабля и станции.
2. Параметры орбиты:
* Параметры орбиты в виде набора Кеплеровых элементов.
* Параметры орбиты в виде векторов в J2000.
3. Параметры ориентации:
* Начальная система координат корабля и станции (инерциальная текущая или орбитальная СК).
* Углы (тангаж, крен, рыскание).
* Угловые скорости (Wx, Wy, Wz).
4. Параметры режима:
* Признаки занятости стыковочных узлов (наличие пристыкованных кораблей).
* Начальный режим работы Системы Управления Движением и Навигации.
* Конфигурация станции.
* Набор состояния признаков состояния бортовых систем корабля и станции.
* Дата и время начала режима.
Пользовательский интерфейс данного формата выглядит следующим образом:
Формат "Ввод НУ" - КомплексныйПользовательский интерфейс, а также набор и расположение параметров были позаимствованы у тренажёра ДОН Союз-ТМА, как единственные известные нам, по ходу разработки мы от них откажемся и разработаем свой пользовательский интерфейс, основываясь на задачах, поставленных перед симулятором и необходимых параметрах для моделирования.
Из-за обширного количества вводимых значений, в данный формат мы добавили возможность загрузки и сохранения параметров начальных условий в файл. Принцип сохранения и загрузки прост и использует дефолтные компоненты, такие как TSaveDialog и TOpenDialog. Данные сохраняются и загружаются в ini файл (TIniFile), что довольно удобно. Структура файла также разделена на группы в соответствии с логикой набора параметров начальных условий.
Все действия оператора (загрузка и сохранение, а также все возможные ошибки) протоколируются в журнал событий с указанием времени и описанием действия.
Квитанция о загрузке начальных условий из файлаРазработка данного формата позволила нам сформировать структуру начальных условий, для последующей работы с ними.
```
// Структура для математических моделей
struct{
//// Д А Т А ////
TDateTime nu_day; // 2 Модельное время/дата
//// М К С ////
double vec_j2000_mks[3]; // 8 Массив вектора положения Ц.М. МКС в J2000 (X, Y, Z)
double vel_j2000_mks[3]; // 11 Массив скорости Ц.М. МКС в J2000 (X, Y, Z)
double Q_mks[4]; // 14 Массив компонентов кватерниона МКС 0 1 2
double w_j2000_mks[3]; // 18 Массив вектора угловой скорости МКС относительно J2000 в проекциях на ССК РС (Wx Wy Wz)
double vec_mks_PC[3]; // 21 Массив координат Ц.М. МКС в РС (X, Y, Z)
double m_mk; // 24 Масса МКС
double mi_mks[3][3]; // 25 Двумерный массив моментов инерции МКС (Jxx, Jxy, Jxz...)
//// Т К ////
double vec_j2000_tk[3]; // 34 Массив вектора положения Ц.М. ТК в J2000 (X, Y, Z)
double vel_j2000_tk[3]; // 37 Массив скорости Ц.М. ТК в J2000 (X, Y, Z) 0 1 2 3
double Q_tk[4]; // 40 Массив компонентов кватерниона разворота ССК ТК относительно J2000 (Qs, Qx, Qy, Qz)
double w_j2000_tk[3]; // 44 Массив вектора угловой скорости ТК относительно J2000 в проекциях на ССК ТК (Wx Wy Wz)
double vec_tk_TPK[3]; // 47 Массив координат Ц.М. ТГК/ТПК в РС (X, Y, Z)
double m_tk; // 50 Масса ТК
double mi_tk[3][3]; // 51 Двумерный массив моментов инерции ТК (Jxx, Jxy, Jxz...)
//// M I S C ////
double vec_solar[3]; // 60 Единичный вектор из центра J2000 на Солнце в проекциях на J2000 (ex, ey, ez)
unsigned long r_st_mks; // 63 Режим стабилизации МКС
unsigned long n_su_4_dk; // 64 Номер стыковочного узла МКС, к которому выполняется причаливание ТК (резерв, не используется)
unsigned long nu_otor_switch_styk_dk; // 65 № СУ, к которому пристыкован ТК (для задания состояния состыкованного ТК)
double tk_top_zap; // 66 Запас топлива ТК (КДУ О+Г)
double mks_top_zap; // 67 Запас топлива МКС (РС ОДУ О+Г)
unsigned long pr_doking; // 68 Признак состыкованного состояния ТК и МКС по НУ
unsigned long nr_sudn; // 69 Начальный режим работы СУДН ТК
} NU_temp;
// Массив признаков УСО
static bool USO_Booled[20][16]; // Матрица УСО (разблюдовка в ТО_УСО п.п. 3.7)
```
После этого мы изучили некоторые статьи по разработке математических моделей бортовых систем космических аппаратов (Е. А. Микрин - Бортовые комплексы управления космическими аппаратами ISBN 5-7038-2178-9), а также различные технические документы на Союз ТМА (в основном SoyCOM) и составили список основного приборного состава оборудования, которое необходимо реализовать для минимального функционирования системы и отладки основных алгоритмов управления.
В качестве математической модели движения на первом этапе было решено использовать модель SGP4, переработанную под нужды симулятора (вместо входных параметров TLE - массив параметров НУ).
Из приборного состава в первую очередь был реализован Пульт Ручного Ввода Информации (ПРВИ) в UI исполнении, как он был реализован на пульте космонавтов "Нептун" корабля Союз-ТМ
Данный пульт предназначен для информационного обмена оператора с БЦВК "Аргон-16". На кораблях серии ТМА данный пульт был исполнен в программном обеспечении Интегрированного Пульта управления (ИнПУ).
Так как на первом этапе разработки симулятора не предполагалось использовать обмен с моделью ИнПУ, то было решено использовать встроенную модель пульта ПРВИ с сам симулятор.
Логика работы с пультом следующая: оператор последовательно заполняет цифровые Индикаторы Ручного Ввода Информации (ИРВИ) кроме 15-го индикатора (знак + / -), после чего выдает команду на исполнение кнопкой "ИСП" и после обработки введённой информации наблюдает ответ-квитанцию от БЦВК на ИРВИ. Все действия с данным прибором также логируются в журнал. С помощью ПРВИ можно:
* Произвести чтение/запись уставочной информации (состояние логических признаков управляющих слов 16-разрядной ячейки памяти Аргона).
* Управлять форматами дисплея (форматы отображения Блока Формирования Изображения).
* Организовать динамический вывод информации на ИРВИ.
* Чтение/запись восьмеричных или десятичных чисел в память Аргона.
Исходя из вышеперечисленного можно сказать, что данный формат позволяет производить полный информационный обмен с памятью БЦВК, что на этапе отладки модели БЦВК крайне важно.
Для облегчения восприятия информации и ввода вывода уставочной информации, начиная с кораблей серии Союз ТМА-М работу с ПРВИ упразднили, оставив лишь формат отображения ИнПУ "ПРВИ" (индекс 2Ф46), на который выведены основные управляющие слова (В1-ТА1) для контроля их состояния (при выполнении штатной программы полёта, изменение состояния логических признаков происходит по Командной Радио Линии (КРЛ) с Земли группой ГОГУ). Ниже представлен скриншот формата ПРВИ корабля Союз МС с выведенным на экран состоянием логических признаков управляющего слова А20.
Для удобства работы с кодом и последующей миграции кода из C++ Builder 6 в среду Visual Studio (планируется, что итоговое приложение будет MFC + OpenGL в качестве графического движка для системы визуализации) каждый формат имеет помимо своего файла формы (\*\*\*\_form.cpp) также файл с логикой, где описаны все процедуры и функции для данной системы/прибора. Логика работы прибора ПРВИ в симуляторе следующая:
Вначале пользователь должен включить прибор, нажав клавишу ON, тем самым он выставит логический признак brvi\_on = true;
```
void __fastcall TIrBrForm::brvi_on_btnClick(TObject *Sender)
{
brvi_on=true; // Признак включения ПРВИ
Panel1->Color=clLime; // Зажигаем индикатор состояния прибора зеленым цветом
}
```
Далее используя один из кодов ввода-вывода необходимо ввести последовательно режим, адрес и число, а также, если необходимо, то и знак. Знак можно ввести на любом этапе заполнения цифровых индикаторов. Ниже описаны коды ввода-вывода информации, актуальные для ПрО Союз ТМА №228
| | |
| --- | --- |
| Операция | Код |
| Одиночный ввод десятичных чисел | **14** |
| Одиночный ввод восьмеричных чисел | **15** |
| Групповой ввод десятичных чисел | **17** |
| Групповой ввод восьмеричных чисел | **18** |
| Запись "0" в заданный разряд ячейки ОЗУ | **30** |
| Запись "1" в заданный разряд ячейки ОЗУ | **31** |
| | |
| --- | --- |
| Операция | Код |
| Одиночный вывод десятичных чисел | **24** |
| Одиночный вывод восьмеричных чисел | **25** |
| Групповой вывод десятичных чисел | **27** |
| Групповой вывод восьмеричных чисел | **28** |
| Динамический вывод десятичных чисел | **04** |
| Динамический вывод восьмеричных чисел | **05** |
В ПО каждый индикатор является компонентом TPanel, где заполняется свойство Caption. При нажатии на какую-либо цифровую клавишу последовательно проверяется занятость каждого индикатора и заполняется последний свободный индикатор. Ниже приведен участок кода обработки нажатия цифровой клавиши "1":
```
void __fastcall TIrBrForm::brvi_btn_1Click(TObject *Sender)
{
if(brvi_on){
USO_BitType[16][3] = 0111;
if(i1->Caption=="")
i1->Caption="1";
else if(i2->Caption=="")
i2->Caption="1";
else if(i3->Caption=="")
i3->Caption="1";
else if(i4->Caption=="")
i4->Caption="1";
else if(i5->Caption=="")
i5->Caption="1";
else if(i6->Caption=="")
i6->Caption="1";
else if(i7->Caption=="")
i7->Caption="1";
else if(i8->Caption=="")
i8->Caption="1";
else if(i9->Caption=="")
i9->Caption="1";
else if(i10->Caption=="")
i10->Caption="1";
else if(i11->Caption=="")
i11->Caption="1";
else if(i12->Caption=="")
i12->Caption="1";
else if(i13->Caption=="")
i13->Caption="1";
else if(i14->Caption=="")
i14->Caption="1";
else {}
}
}
```
Мы не смогли разобраться, как записать это в виде цикла for, поэтому сделали таким образом. По такой же логике работают обработчики и на остальных клавишах. Если необходимо очистить индикаторы, то для этого надо нажать клавишу "СБР", а если убрать последний введенный индикатор, то клавишу "ГАШ".
После окончания заполнения индикаторов необходимо отправить введенные значения на обработку в БЦВК, ниже представлен код обработчика клавиши ИСП:
```
void __fastcall TIrBrForm::isp_btnClick(TObject *Sender)
{
if(brvi_on) { // Если БРВИ вкл
if(i1->Caption==""&&i2->Caption==""){ // Если первый и второй индикаторы пустые,
i1->Caption=="A"; // Тогда сообщение АА
i2->Caption=="A";
JPS(3,is_irvi,is_operator,"АА",""); // и лог в журнал
} else { // или (если 1И и 2И не пустые)
AnsiString brvi_msg = i1->Caption+i2->Caption+i3->Caption+i4->Caption+ // Создаем строку текущего состояния И ИРВИ
i5->Caption+i6->Caption+i7->Caption+i8->Caption+i9->Caption+i10->Caption+
i11->Caption+i12->Caption+i13->Caption+i14->Caption+i15->Caption;
JPS(1,is_operator,is_irvi,brvi_msg,"");
Timer1->Enabled=true; // Включаем таймер задержки индикации
// Обнуляем индикаторы перед индикацией
i1->Caption="";
i2->Caption="";
i3->Caption="";
i4->Caption="";
i5->Caption="";
i6->Caption="";
i7->Caption="";
i8->Caption="";
i9->Caption="";
i10->Caption="";
i11->Caption="";
i12->Caption="";
i13->Caption="";
i14->Caption="";
i15->Caption="";
irvi_string = brvi_msg; // Присваиваем глобальной переменной значение ИРВИ
ChekIrvi(irvi_string); }} else // Если БРВИ выключен
JPS(3,is_miu,is_operator,cmd_brvi_error,""); // Ошибка в Журнал
}
```
Здесь мы собираем из индикаторов строку, которую после присваиваем глобальной AnsiString переменной irvi\_string. Процедура ChekIrvi принимает в качестве аргумента сформированную строку и производит с ней следующие операции:
```
void ChekIrvi (AnsiString irvi_str){
if(irvi_str.IsEmpty())JPS(3,is_miu,is_operator,"Пустой ввод!",""); else {
irvi_type.mode = StrToInt(irvi_str.SubString(1,2)); // Вырезаем первые два символа строки ирви "режим"
switch (irvi_type.mode) { // Обработчик режима
case 00: /* Приоритетный или принудительный режим выдачи пр-м 1 - 4 */ break;
case 04: /* Динамический вывод 10-х чисел */ break;
case 05: /* Динамический вывод 8-х чисел */ break;
case 10: /* Ввод уставки РУС */ break; // Arg addr RUS AUS data?
case 11: /* Ввод уставки АУС 1-й группы */ break;
case 12: /* Ввод уставки АУС 2-й группы */ break;
case 14: /* Одиночный ввод 10-х чисел */ // Если режим 14, то
if((irvi_str.SubString(3,5)).IsEmpty())JPS(3,is_miu,is_operator,"Пустой адрес!",""); else {
irvi_type.addr = StrToInt(irvi_str.SubString(3,5)); // Присваиваем значение адреса
if(CorrectAddr(irvi_type.addr)) { // Проверяем корректность адреса, если корректен, то
if((irvi_str.SubString(8,7)).IsEmpty())JPS(3,is_miu,is_operator,"Пустое число!",""); else {
irvi_type.value = StrToInt(irvi_str.SubString(8,7)); // Присваиваем значение
ArgonMemoryType[irvi_type.addr] = irvi_type.value; // Записываем его в ячейку памяти Аргона
SetItvi(irvi_type.mode,irvi_type.addr,ArgonMemoryType[irvi_type.addr], irvi_type.z ); // Выставляем результат на ИРВИ
JPS(4,is_argon,is_irvi,"Запись числа "+ // Логируем результат (от имени Аргона)
IntToStr(irvi_type.value)+" по адресу "+IntToStr(irvi_type.addr),"");}}
else { // Если адрес не корректен ,то
irvi_err = true;
JPS(3,is_argon,is_operator,arg_addr_error,""); } } // Логируем превышение допустимого значения памяти А16
break;
case 15: /* Одиночный ввод 8-х чисел */ break;
case 17: /* Групповой ввод 10-х чисел */ break;
case 18: /* Групповой ввод 8-х чисел */
// irvi_type.addr = StrToInt(irvi_str.SubString(3,5)); // Присваиваем значение адреса
// if(CorrectAddr(irvi_type.addr)) { // Проверяем корректность адреса, если корректен, то
//irvi_type.value = StrToInt(irvi_str.SubString(8,7)); // Присваиваем значение
// ArgonMemoryType[irvi_type.addr] = irvi_type.value; // Записываем его в ячейку памяти Аргона
//SetItvi(irvi_type.mode,(irvi_type.addr)+1,ArgonMemoryType[irvi_type.addr], irvi_type.z ); // Выставляем результат на ИРВИ
//mode18act=true;
break;
case 21: /* Вывод уставки АУС 1-й группы */ break;
case 22: /* Вывод уставки АУС 2-й группы */ break;
case 24: /* Одиночный вывод 10-х чисел */ // Если режим 24, то
irvi_type.addr = StrToInt(irvi_str.SubString(3,5)); // Присваиваем значение адреса временной переменной
if(CorrectAddr(irvi_type.addr)) { // Проверяем корректность адреса, если корректен, то
SetItvi(irvi_type.mode,irvi_type.addr,ArgonMemoryType[irvi_type.addr], irvi_type.z ); } // Выставляем результат на ИРВИ
else { // Если адрес не корректен ,то
irvi_err = true;
JPS(3,is_argon,is_operator,arg_addr_error,""); } // Логируем превышение допустимого значения памяти А16
break;
case 25: /* Одиночный вывод 8-х чисел */ break;
case 27: /* Групповой вывод 10-х чисел */ break;
case 28: /* Групповой вывод 8-х чисел */break;
case 30: /* Изменение состояния признака в слове - запись единицы */
irvi_type.addr = StrToInt(irvi_str.SubString(3,5)); // Присваиваем значение адреса временной переменной
if(CorrectAddr(irvi_type.addr)) { // Проверяем корректность адреса, если корректен, то
irvi_type.value = StrToInt(irvi_str.SubString(8,7)); // Присваиваем значение
mode_30(irvi_type.addr,irvi_type.value); } // Выставляем результат на ИРВИ
else { // Если адрес не корректен ,то
irvi_err = true;
JPS(3,is_argon,is_operator,arg_addr_error,""); } // Логируем превышение допустимого значения памяти А16
break;
case 31: /* Изменение состояния признака в слове - запись нуля */
irvi_type.addr = StrToInt(irvi_str.SubString(3,5)); // Присваиваем значение адреса временной переменной
if(CorrectAddr(irvi_type.addr)) { // Проверяем корректность адреса, если корректен, то
irvi_type.value = StrToInt(irvi_str.SubString(8,7)); // Присваиваем значение
mode_31(irvi_type.addr,irvi_type.value); } // Выставляем результат на ИРВИ
else { // Если адрес не корректен ,то
irvi_err = true;
JPS(3,is_argon,is_operator,arg_addr_error,""); } // Логируем превышение допустимого значения памяти А16
break;
case 40: /* */ break;
case 41: /* */ break;
case 42: /* */ break;
case 43: /* */ break;
case 44: /* */ break;
case 45: /* */ break;
case 46: /* */ break;
case 48: /* Сверка времени */
break;
default: irvi_err = true; // Флаг ошибки (для индикации на ИРВИ)
JPS(3,is_argon,is_irvi,"АА",""); // Логируем ошибку о несуществующем режиме
JPS(3,is_miu,is_operator,"Несуществующий режим!","");
irvi_type.addr = StrToInt(irvi_str.SubString(3,5));
irvi_type.value = StrToInt(irvi_str.SubString(8,7));
break;
} } }
```
Все эти операции позволяют нам организовать стандартную логику работы с ПРВИ и контролировать/изменять состояние уставочной информации штатным образом, как это было реализовано на корабле серии ТМА. Все действия оператора также логируются в журнал, что позволяет производить анализ действий по окончанию режима на соответствие требованиям бортовой документации:
Вся необходимая информация (инструкции, аварии, состояние логических признаков и др.) хранится в ячейках памяти и мы можем ее вызвать в любое время используя формат ПРВИ.
Это был первый формат относящийся к модели БЦВК "Аргон-16", но его оказалось недостаточно и в последствии был разработан еще один формат для отладки модели БЦВК "Отладка А16", скриншот которого представлен ниже:
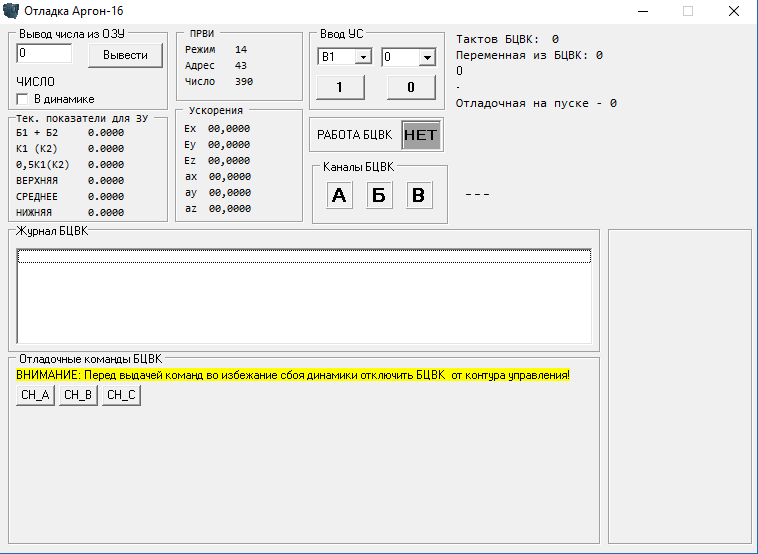На нём можно наблюдать виртуальные клавиши принудительной выдачи команд в БЦВК (имитации релейных команд для отладки некоторых процедур и алгоритмов), вывести число из ОЗУ без использования ПРВИ (если ПРВИ занят, т.к. с ним могут работать 2 оператора - обмен по UDP), наблюдать текущее значение глобальной переменной ИРВИ, наблюдать статусное окно выбранных каналов БЦВК (т.к. он работает по мажоритарной схеме 2 из 3) и др. Пустые поля по мере разработки будут заполнятся отладочными командами. Все компоненты TLabel выводятся в обработчике таймера, который каждый тик присваивает им состояние переменных.
Этот формат позволит нам отслеживать работу алгоритмов БЦВК (как самых сложных в реализации) и прерывать работу модели при нештатной работе (отклонении от нормы).
Следующими основными форматами, без которых невозможно управление кораблём Союз, являются - КСПл и КСПп. Около половины времени работы космонавта с ПрО пульта "Нептун-МЭ" приходится именно на эти форматы. На них представлены основные команды выдаваемые оператором в бортовые системы корабля - включение и пуск БЦВК, команды управления двигательной установкой, управление ССВП и др. Ниже представлены форматы КСПл и КСПп разработанные для симулятора:
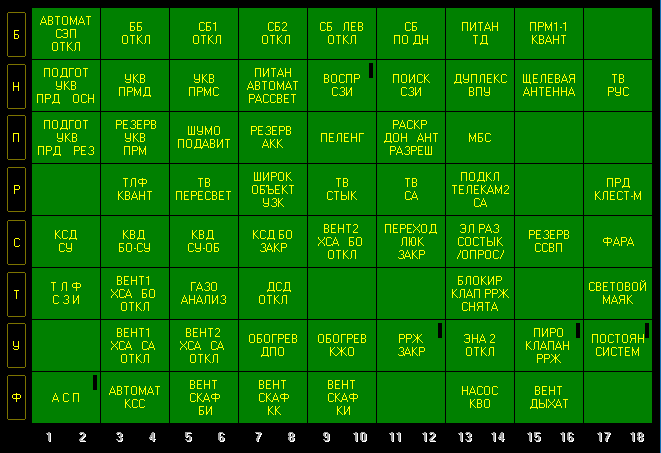Данные форматы по своему информационному обеспечению идентичны одноименным форматам используемым в ПрО и ИО ИнПУ, что также позволяет работать с ними как с штатными форматами отображения, для сравнения - ниже скриншот штатного формата КСПл корабля Союз ТМА №219 (ПО № 5.19, ИО № 5.1)
Логика работы с данным форматом уникальна и разработана [Тяпченко Ю.А.](https://astronaut.ru/bookcase/author/list-tyapchenko.htm) Основным преимуществом данного типа пульта является матричный способ выдачи команд и развернутая форма представления информации. С точки зрения эргономики это довольно удобный способ представления большого количества команд, при малом количестве органов взаимодействия. Логика работы с данным форматом следующая - оператор выбирает вначале строку (букву) и выдает ее, буква загорается и разрешается выбор столбца (цифры), где нечётная цифра включает команду, а чётная ее выключает. К примеру, чтобы выдать команду на включение РУД, необходимо вначале нажать клавишу "В", а потом "7". Таким образом будет подана команда на включение питания ручки управления движением, а в пульт придёт обратная квитанция об успешности исполнения команды, которая "зажжёт" транспарант светло зеленым цветом.
Также можно заметить, что на некоторых транспарантах присутствуют дополнительные символы, обозначение которых описано ниже:
Это обозначает, что если команда без сигнализации - значит обратной квитанции и загорания соответствующего транспаранта не будет, а если команда только прямая, значит при выдаче чётной цифры (выключения) команда не пройдет и транспарант не погаснет. Обычно эти команды выключаются другими командами, к примеру для снятия признака выбора К11 "РРЖ 4С" необходимо выдать Л15 "РРЖ 15С" или Л13 "РРЖ 8С".
В симуляторе логика КСП реализована следующим образом. Объявлен двумерный булевый массив
```
static bool KSP_Booled[16][9];
```
который хранит состояние команд, если мы выдаем ту или иную команду КСП, то присваиваем соответствующему элементу значение true, которое снимается обработчиком получившей его системы. К примеру при выдаче команды А7 "СДД ОТКЛ" мы выставляем признак `KSP_Booled[0][6]=true;` , основной обработчик УСО каждый тик обрабатывает весь массив и при KSP\_Booled[0][6]=1 сразу снимает эту команду и посылает команду в КДУ и другие системы соответствующие признаки, в это время в КСП стоит обработчик квитанций УСО, который в свою очередь опрашивает каждый элемент массива УСО и если видит ответную квитанцию об успешном отключении сигнальных датчиков СДД от системы управления, зажигает транспарант "СДД ОТКЛ", ниже представлен код обработки этой команды:
```
// Модуль КСПл, обработчик нажатия цифры 7
...
if (KSP_Let[0]){ // А Если выбранна буква А
KSP_Booled[0][6]=true; // Тогда выставляем признак А7 - правда
JPS(1,is_operator,is_miu,is_ksp,"А7"); } else // Логируем выдачу команды
...
// Модуль uso_model.cpp процедура USO_work
...
if(KSP_Booled[0][6]) { // A 7
KSP_Booled[0][6] = false;
// 95 Исключение СДД из схемы управления
USO_Booled[0][3]=true;
kdu_sdd = false;
}
...
// Модуль КСПл - тик таймера индикации
...
if(USO_Booled[0][3]){ // KSP A7
A7_LABEL->Color=clLime;
A7_LABEL->Font->Color=clBlack; } else {
A7_LABEL->Color=clGreen;
A7_LABEL->Font->Color=clYellow; }
...
```
Таким образом мы реализуем штатную логику работы с КСП и УСО, конечно если тут есть люди разбирающиеся в УСО корабля Союз, которые нашли ошибку в нашей интерпретации логики работы с КСП, прошу нас поправить, т.к. у нас не имеется материалов по УСО и данную логику мы построили изучая работу моделей ИнПУ и руководство по работу с системой Нептун-МЭ.
Я думаю это довольно много информации для одного поста, поэтому остальные форматы опишу в следующем посте. | https://habr.com/ru/post/532726/ | null | ru | null |
# Эксперимент с голографическим кодированием и декодированием информации
Захотелось мне как-то сделать кодирование информации основываясь на голографическом принципе. Захотелось не просто так, а для проверки кое-каких своих идей и теорий. Теории не подтвердились, идеи не реализовались. Но поскольку подобного алгоритма я «с наскока» не нашёл и пришлось придумывать его самому, основываясь на учебниках по физике, то решил поделиться им на хабре. Алгоритм, кстати, довольно простой.
Итак, приступим.
Как делается голограмма. В общем случае, луч света от [когерентного](http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%B3%D0%B5%D1%80%D0%B5%D0%BD%D1%82%D0%BD%D0%BE%D1%81%D1%82%D1%8C) источника света тем или иным образом делится на две части, одна из которых попадает напрямую на фотопластинку, а другая часть тоже попадает на фотопластинку, но после отражения от объекта, голограмму которого мы желаем получить. В результате, на фотопластинке фиксируется картина интерференции света напрямую пришедшего из источника, и света отражённого от объекта.
Суть голографии в том, что в картине интерференции закодирована не только яркость той или иной точки объекта, но и расстояние до этой точки. Так получается потому что на фотопластинку приходят световые волны в разных фазах (а фаза зависит от расстояния до точки объекта), эти волны складываются в соответствии со своими фазами, за счёт чего собственно говоря и образуется картина интерференции.
Восстанавливается изображение объекта просто осветив проявленную фотопластинку светом той же длины волны. Есть голограммы восстанавливаемые белым некогерентным светом, но их не рассматриваем.
У голограмы есть интересные свойства.
Например, восстановить полное изображение объекта можно по любому кусочку голографического снимка (с ухудшением качества изображения).
Можно на одну фотопластинку записать изображения нескольких объектов, воспользовавшись источниками света с разной длиной волны. И восстановить изображение каждого объекта в отдельности осветив фотопластинку светом с той же длиной волны, который был использован для записи нужного объекта.
Собственно говоря, идея голографического кодирования пришла в голову, так как захотелось таким образом закодировать звуковой файл. Можно было бы отрезать любой кусок такого файла — и по нему воспроизвести полностью исходный звук (в худшем качестве). Можно было бы в один файл записать несколько звуков, и любой кусок файла содержал бы эти звуки, которые можно воспроизвести по отдельности.
Почему эта идея не реализовалась?
Во-первых — звук не картинка, картинку мы видим сразу полностью, и автоматически выделяем знакомые детали. А звук слушаем последовательно, и любая зашумлённость сильно ухудшает восприятие. Тем более, что при голографическом кодировании зашумлённость появляется в виде накладывающихся на исходный звук свистов, шипений и т.п.
Во-вторых сразу не учёл сложность алгоритма. Сложность алгоритма оценивается как O(n^2). Т.е. для кодирования (и декодирования) файла размером в 1 мегабайт требуется триллион (миллион миллионов) итераций, а при каждой итерации надо ещё и производить вычисления… Для примера, WAV-файл размером 10 килобайт (2-3 секунды звука) у меня кодировался около минуты (10 000 \* 10 000 итераций = 100 млн. итераций). И ускорить алгоритм никак не получится. А для кодирования файла в 10 раз большего размера потребуется в 100 раз больше времени.
И в третьих — для получения нормального голографического изображения требуется что бы объект был контрастным. А какая контрастность в звуковом файле? Почти случайный набор чисел.
Но вернёмся к самому алгоритму, и его рабочей демонстрации.
Кодирование и декодирование осуществляется одним и тем же алгоритмом, но при декодировании изменяется пара коэффициентов.
Тестовый алгоритм обработки изображения был реализован на PHP, потому что «так быстрее» (для экспериментов с WAV-файлом использовался язык C).
Исходно: матрица яркости пикселей исходного изображения (для кодирования или декодирования потребуется 2500\*2500 = около 6 миллионов итераций, в моём случае — несколько секунд работы PHP)
$data0[50][50];
На выходе: матрица яркости пикселей «на фотопластинке»
$data1[50][50];
`$W=0.1; //длина волны источника света
//вычислим яркость каждой точки искомого изображения
for($x1=0;$x1<50;$x1++)
for($y1=0;$y1<50;$y1++) {
//опорный свет - считаем, что источник света излучает свет с силой достаточной для освещения
каждого пикселя с силой 256 единиц, но половину света мы отправили на объект, а половину света направили на фотопластинку (128 единиц).
$px=128.0; //эта часть света уже достигла фотопластинки, минуя объект (д.б. =0 при декодировании)
//яркость каждой точки искомого изображения - равна сумме света пришедшего ОТО ВСЕХ точек исходного изображения
for($x0=0;$x0<50;$x0++)
for($y0=0;$y0<50;$y0++) {
//расстояние от точки (x0;y0) до точки (x1;y1) считаем что везде z=1, плоская голограмма
$D=sqrt(1+($x0-$x1)*($x0-$x1)+($y0-$y1)*($y0-$y1));
// Фаза волны достигшей этой точки
$Phase=$D/$W;
//доля света от очередной точки объекта (по поводу коэффициента 0.3 - будет написано далее)
$obj_light=($data[$x0][$y0])*0.3;
//суммируем свет от очередной точки (в соответствии с фазой световой волны пришедшей от этой точки)
$px+=$obj_light*cos($Phase);
}
//волна оставляет пятно в любом случае, плюс она в этой точке или минус.
$px=abs($px);
//на выходе имеем - интенсивность света в точке (x1;y1)
data1[$x1][$y1]=$px;
}`
Коэффициент в этой строке $obj\_light=($data[$x0][$y0])\*0.3; подбирается. Хотя можно для него и формулу вывести, правда отдельно для случая кодирования и случая декодирования.
Декодирование осуществляется этим же алгоритмом, только $px=128.0; изменяется на $px=0.0; (в данном случае, изображение восстанавливается только из отражённого света)
Ну и результаты работы.
Исходное изображение

---
Записанная голограмма и восстановленное по ней изображение
 
---
Затёртая на 1/3 запись голограммы и восстановленное по ней изображение
 
---
Затёртая более чем на 2/3 запись голограммы и восстановленное по ней изображение
 
---
Для случая трёх точек и длины волны светового излучения W=1 пример есть [тут](http://optomopt.ru/holo1/start.php).
Есть две причины сильных шумов:
1. В эксперименте яркости точек округляются до целых в диапазоне 0..255. Часть информации теряется в отбрасываемых дробных частях, да и диапазон, конечно маловат.
2. Малая площадь голограммы, всего лишь 50 на 50 точек. Это намного меньше квадратного миллиметра настоящей голограммы. В реальности для получения голограммы используют фотоматериалы с разрешающей способностью 5000 линий/мм.
Если нужна будет трёхмерность голограммы, то это не усложнит алгоритм, т.к. достаточно будет изменить формулу подсчёта расстояния D (сейчас голограмма плоская, координата Z всегда =1)
Вот такой вот эксперимент. | https://habr.com/ru/post/120051/ | null | ru | null |
# Собираем свою Bluetooth машинку с управлением на Android
На последней сессии я как обычно тщательно готовился к экзаменам (то есть не знал, чем себя занять), и как по счастливой случайности, у меня образовалась радиоуправляемая машинка, большая и красивая, хотя и явно рассчитанная на детей. Поигравшись минут десять, я захотел ее модернизировать, а именно вместо неудобного джойстика с радиусом действия в 3 метра использовать коммуникатор с bluetooth. И удобнее, и дальность действия больше, и явно видны дальнейшие улучшения, о которых, как впрочем и о процессе прикручивания коммуникатора к детской машинке, и пойдет речь в данной статье.

#### Выбираем компоненты
В прошлом мы с приятелями [написали](http://habrahabr.ru/blogs/study/120367/#Embox) собственную прошивку для роботов Lego Mindstorms NXT, поддерживающую удалённое управление роботом по bluetooth с Android-коммуникатора. Для экспериментов тогда была приобретена отладочная плата Olimex SAM7 с ARM7 на борту, которую в этот раз можно использовать в качестве управляющего контроллера.
В качестве шасси используем корпус игрушечной машинки.
Нужен bluetooth-модуль. Результат хотелось получить быстро, поэтому модуль был выбран из единственного доступного в магазине на тот момент [BTM-112](http://www.sparkfun.com/datasheets/Wireless/Bluetooth/BTM112_wATcommands.pdf), хотя он оказался [сравнительно](http://habrahabr.ru/blogs/DIY/125214/) дорогим.
Кроме того, оказалось, что управление с платы не может идти напрямую на моторы, нужен усиливающий контроллер (об этом чуть позже).
В сумме наши компоненты:
* Машинка
* Управляющий контроллер Olimex SAM7
* Bluetooth-модуль BTM-112
* Контроллер для управления моторами L298N
Теперь все необходимое у нас есть.
#### Соединяем bluetooth с управляющей платой
Для начала настроим доставку команд управляющему блоку. Схема соединения bluetooth-модуля и контроллера простая: по сути дела это UART с некоторыми управляющими ножками, то есть надо лишь присоединить модуль к интегрированному UART-контроллеру.
Программная составляющая не сильно сложнее. При соединении модуль пишет строку вида `"CONNECT RE:MO:TE:BT:MA:CC xxx \r\n"`, а при отсоединении — `"DISCONNECT xxx \r\n"`. Задача драйвера состоит в наблюдении за потоком символов и, в случае если сейчас активно соединение, передаче потока управляющему приложению. В итоге драйвер представляет собой конечный автомат, у которого переключение состояния означает переключение функции-обработчика.
#### Удалённое управление
Как было обещано, удаленное управление осуществляется с помощью Android-коммуникатора.
Наше прошлое приложение для Android (которое управляло Lego Mindstorms NXT, тоже посредством bluetooth) с помощью акселерометра отслеживало наклон коммуникатора и посылало соответствующие команды управления на NXT. Так что наиболее простым решением стало добавление протокола управления машинкой в уже существующее приложение. Сам протокол достаточно примитивен: фиксированная длина команды, фиксированный заголовок, после чего управление по осям X и Y.
Итак, на данном этапе мы можем “порулить” нашей платкой, правда моторы пока не подключены, так что индикация движений производится встроенными светодиодами (видео, к сожалению, нет, в этот момент снял только фотку), но всё равно прогресс есть, он виден, и это греет душу.

#### Соединяем управляющую плату с моторами
Изначально я думал, что смогу использовать управление со старой платы (зашитой в саму машинку), но оказалось, что использовать её в чистом виде нельзя, поскольку управление моторами было крепко сцеплено с радиочастью. Управлять моторами напрямую с ног головного контроллера тоже не получится из-за малой выходной мощности микросхемы. К сожалению, опыта в этой области у меня нет никакого (все-таки я программист, а не схемотехник), поэтому пришлось прибегнуть к помощи знакомых. По совету я взял микросхему усилителя L298N (избыточную для моих нужд, зато работающую из коробки) и собрал [референсную схему](http://www.learn-c.com/l298.pdf).
Напомню, препарируемая машинка детская, и управление у нее немного хромает; когда я начал разбираться с моторами, я понял одну из причин. Для механизма поворота используется не сервопривод, а обычный электродвигатель, который может находиться в одном из трех состояний (выкл., вперед и назад). Таким образом, о плавном повороте мечтать не приходится.
В общем, функционально схема простая, один мотор используется как двигатель, второй мотор — как руль (у него стоит блокиратор на определенном угле поворота).
Для управления каждым мотором нужно подать напряжение на соответствующие управляющие ноги (положительное или отрицательное напряжение либо нуль). Напряжение измеряется между двумя точками (входными ногами управления), то есть мне нужно подавать напряжения на пару управляющих ног как-то так:
| | forward | reverse | off |
| --- | --- | --- | --- |
| **PIN1** | 1 | 0 | 0 | 1 |
| **PIN2** | 0 | 1 | 0 | 1 |
Так как Android-приложение передает плавное управление, состояние моторов изменяется по преодолению заданного порога.
Код получился очень простой, я не буду приводить его здесь, но в конце поста есть ссылки на исходники всего проекта.
#### Итог
Ролик с работающей машинкой:
Понятно, есть недостатки:
* Дискретное управление лево/право, вперед/назад. Сейчас управление моторами осуществляется с помощью GPIO, но выбранные для управления линии могут быть переназначены под PWM контроллер. Таким образом, повороты и ускорение будут плавным.
* Дорогой усилитель. Тут всё просто, заменить на более дешёвую микросхему или схему на нескольких транзисторах.
* Скромные возможности. Раз управление осуществляется с помощью смартфона, то можно как-либо расширить функциональность по сравнению с просто пультом управления.
#### Где посмотреть
Весь код есть в открытом доступе.
Прошивка для платы Olimex — [тут](http://code.google.com/p/embox/).
Код Android приложения [тут](http://code.google.com/p/robobot/), собранная версия на [Android Market](http://market.android.com/details?id=org.embox.robobot). | https://habr.com/ru/post/138967/ | null | ru | null |
# Ещё один интерпретатор Brainfuck
[Brainfuck](https://ru.wikipedia.org/wiki/Brainfuck) — язык программирования, созданный с одной целью: написать для него интерпретатор. Их было написано так много, что даже не буду давать на них ссылки. В этой статье на пальцах объясняется простой, но эффективный способ его оптимизации.

Для оптимизации нужно выполнить 3 правила:
1. Обратные инструкции (`+` и `-`, `>` и `<`) взаимоуничтожаются, когда идут одна за другой. Код `>++>><<-` превращается в `>+`. Это, скорее, защита от дурака, чем оптимизация, т.к. такой код бессмысленен.
2. Повторяющиеся инструкции заменяются на команды, в аргументах которых сказано сколько раз конкретную инструкцию выполнить. Например, код `+++` заменяется на команду ADD с аргументом 3, а код `<<<` на MOVE:-3.
3. Добавляется новая команда, у которой в bf нет соответствующий инструкции. Команда присвоения значения. Код `[+]` и `[-]` обнуляет текущую ячейку, а команда ADD за этим кодом присваивает текущей ячейке значение своего аргументы. Код `--[-]+++` заменяется на команду ASSIGN:3.
Список команд с описанием
-------------------------
Каждая команда имеет свой аргумент (далее просто arg). Значение аргумента ограничено только у команды ADD, т.к. размер одной ячейки 256.
| Имя команды | Инструкции | Описание |
| --- | --- | --- |
| ADD | `+` и `-` | Изменяет значение текущей ячейки на arg |
| MOVE | `>` и `<` | Изменяет индекс текущей ячейки на arg |
| READ | `,` | Пропускает из потока ввода arg символов и читает следующий за ними символ |
| PRINT | `.` | Печатает символ соответствующий значению текущей ячейки arg раз |
| GOTO | `[` и `]` | Переходит к выполнению arg по счёту команды относительно текущей |
| ASSIGN | `[+]` и `[-]` | Присваивает текущей ячейке arg |
Пример кода интерпретатора
--------------------------
Интерпретация разделена на 3 этапа. Чтение исходного кода, его преобразование в оптимизированные команды и выполнение этих команд. Это всё происходит в функциях main и parse.
Первый и последний этап происходят сразу в функции main. Её код с комментариями:
```
int main(int argc, char* argv[]){
/* имя файла с исходниками передаётся первым аргументом */
if(argc == 1){
fprintf(stderr, "%s: Wrong argument count\n", argv[0]);
return 1;
};
/* файл открывается для чтения */
FILE* f = fopen(argv[1], "r");
if(f == NULL){
fprintf(stderr, "%s: Can't open %s\n", argv[0], argv[1]);
return 2;
};
/* исходный код читается из файла */
int n = fread(str, sizeof(char), SIZE - 1, f);
if(n == 0){
fprintf(stderr, "%s: Can't read data from %s\n", argv[0], argv[1]);
return 3;
};
str[n] = '\0';
/* проверяется правильность расстановки скобок */
fclose(f);
if(brackets()){
fprintf(stderr, "%s: Wrong brackets sequence\n", argv[0]);
return 4;
};
/* парсинг исходного кода */
parse();
/* выполнение команд */
ptr = mem;
int (*exe[])(int) = {exe_a, exe_b, exe_c, exe_d, exe_e, exe_f};
struct code* p = src + 1;
for(; p->cmd; ++p){
p += (*exe[p->cmd - 1])(p->arg);
};
return 0;
};
```
Оптимизация с помощью преобразования инструкций bf в команды для интерпретатора происходит в функции parse. Её код с комментариями:
```
void parse(){
/* инициализируется массив команд */
struct code *p = src;
p->cmd = 0;
p->arg = 0;
/* указатель на текущую инструкцию */
char* ch = str;
/* указатель на вершину стека необходимый для обработки скобок */
top = stk;
/* массив из указателей на функции обрабатывающих 8 возможных команд и комментарии */
int (*prs[])(struct code*) = {prs_0, prs_1, prs_2, prs_3, prs_4, prs_5, prs_6, prs_7, nothing};
/* парсинг */
for(; *ch != '\0'; ++ch){
p += (*prs[find(*ch)])(p);
};
/* нуль-терминальная команда в конце массива */
(p + 1)->cmd = 0;
};
```
Проверка эффективности
----------------------
Для сравнения взял интерпретатор из официального [репозитория](http://packages.ubuntu.com/ru/trusty/bf) ubuntu и несколько тестов из [этого](https://github.com/rdebath/Brainfuck/tree/master/testing) репозитория. В таблице записано среднее время работы теста в секундах.
| Имя теста | Официальный | Из статьи |
| --- | --- | --- |
| Long | 34 | 20 |
| Mandelbrot | 21 | 26 |
| EasyOpt | 24 | 27 |
| Counter | 34 | 37 |
На всех тестах, кроме первого, официальный интерпретатор работает примерно на 12 процентов быстрее интерпретатора из статьи. В первом тесте, в отличии от остальных, в большинстве циклов количество инструкций `>` не совпадает с количеством инструкций `<`. Это делает циклы несбалансированными и не поддающимися оптимизации (другому виду оптимизации, не описанному в статье). Похоже, официальный интерпретатор оптимизирует сбалансированные циклы и получает от этого 12-процентный прирост к скорости, в то время как интерпретатор из статьи этого не делает и побеждает только на первом тесте. Хотя это неплохой результат для такого простого алгоритма оптимизации.
Исходники на [Github](https://github.com/srbgd/bf) | https://habr.com/ru/post/321630/ | null | ru | null |
# 13 полезных однострочников на JavaScript
Автор статьи, перевод которой мы сегодня публикуем, говорит, что он программирует на JavaScript уже многие годы. За это время он собрал коллекцию отличных однострочников — фрагментов кода, удивительно мощных, учитывая то, что укладываются они в одну строку. По его словам, большие возможности — это и большая ответственность, поэтому пользоваться этими конструкциями нужно осмотрительно, стремясь к тому, чтобы они не вредили бы читабельности программ.
[](https://habr.com/ru/company/ruvds/blog/456338/)
Здесь представлено 13 однострочников. Примеры подготовлены с использованием Node.js v11.x. Если вы будете использовать их в другой среде — это может повлиять на их выполнение.
1. Приведение значений к логическому типу
-----------------------------------------
Вот как привести некое значение к логическому типу:
```
const myBoolean = !!myVariable;
```
Двойное отрицание (`!!`) нужно для того, чтобы значение, являющееся с точки зрения правил JavaScript истинным, было бы преобразовано в `true`, а ложным — в `false`.
2. Избавление от повторяющихся значений в массивах
--------------------------------------------------
Вот как удалить из массива повторяющиеся значения:
```
const deDupe = [...new Set(myArray)];
```
Структуры данных типа `Set` хранят лишь уникальные значения. В результате использование такой структуры данных и синтаксиса spread позволяет создать на основе массива `myArray` новый массив, в котором нет повторяющихся значений.
3. Создание и установка свойств объектов по условию
---------------------------------------------------
Для того чтобы задавать свойства объектов с использованием оператора `&&`, можно воспользоваться синтаксисом spread:
```
const myObject = { ...myProperty && { propName: myProperty } };
```
Если в результате вычисления левой части выражения будет получено нечто, воспринимаемое JS как ложное значение, то `&&` не будет проводить дальнейшие вычисления и новое свойство не будет создано и установлено. Объект `myObject` будет пустым. Если же конструкция `...myProperty` вернёт какой-то результат, воспринимаемый JS как истинный, благодаря конструкции `&&` в объекте появится свойство `propName`, хранящее полученное значение.
4. Слияние объектов
-------------------
Вот как можно создать новый объект, в котором будут скомбинированы два других объекта:
```
const mergedObject = { ...objectOne, ...objectTwo };
```
Этот подход можно использовать для организации слияния неограниченного числа объектов. При этом если у объектов будут свойства с одинаковыми именами, в итоговом объекте останется лишь одно такое свойство, принадлежащее тому из исходных объектов, который расположен правее других. Обратите внимание на то, что здесь используется мелкое копирование свойств объектов.
5. Обмен значений переменных
----------------------------
Для того чтобы обменять значения между двумя переменными без использования вспомогательной переменной можно поступить так:
```
[varA, varB] = [varB, varA];
```
После этого то, что было в `varA`, попадёт в `varB`, и наоборот. Это возможно благодаря использованию внутренних механизмов деструктурирования.
6. Удаление ложных значений из массива
--------------------------------------
Вот как можно убрать из массива все значения, которые считаются в JavaScript ложными:
```
const clean = dirty.filter(Boolean);
```
В ходе выполнения этой операции из массива будут удалены такие значения, как `null`, `undefined`, `false`, `0`, а так же пустые строки.
7. Преобразование чисел в строки
--------------------------------
Для того чтобы преобразовать числа, хранящиеся в массиве, в их строковое представление, можно поступить так:
```
const stringArray = numberArray.map(String);
```
Строковые элементы массива в ходе подобного преобразования так и останутся строковыми.
Можно выполнить и обратное преобразование — преобразовав значения типа `String` к значениям типа `Number`:
```
const numberArray = stringArray.map(Number);
```
8. Извлечение значений свойств объектов
---------------------------------------
Вот как можно извлечь значение свойства объекта и записать его в константу, имя которой отличается от имени этого свойства:
```
const { original: newName } = myObject;
```
Благодаря использованию этой конструкции будет создана новая константа, `newName`, в которую будет записано значение свойства `original` объекта `myObject`.
9. Форматирование JSON-кода
---------------------------
Вот как можно преобразовать JSON-код к виду, удобному для восприятия:
```
const formatted = JSON.stringify(myObj, null, 2);
```
Метод `stringify` принимает три параметра. Первый — это JavaScript-объект. Второй, необязательный, представляет собой функцию, которую можно использовать для обработки JSON-кода, получающегося в ходе преобразования объекта. Последний параметр указывает на то, сколько пробелов нужно использовать при формировании отступов в JSON-коде. Если опустить последний параметр, то весь полученный JSON-код будет представлять собой одну длинную строку. Если в объекте `myObj` есть циклические ссылки, преобразовать его в формат JSON не удастся.
10. Быстрое создание числовых массивов
--------------------------------------
Вот как можно создать массив и заполнить его числами:
```
const numArray = Array.from(new Array(52), (x, i) => i);
```
Первый элемент такого массива имеет индекс 0. Размер массива можно задавать как с помощью числового литерала, так и с помощью переменной. Здесь мы создаём массив из 52 элементов, который, например, можно использовать для хранения данных о колоде карт.
11. Создание кодов для двухфакторной аутентификации
---------------------------------------------------
Для того чтобы сгенерировать шестизначный код, используемый в механизмах двухфакторной аутентификации или в других подобных, можно сделать так:
```
const code = Math.floor(Math.random() * 1000000).toString().padStart(6, "0");
```
Обратите внимание на то, что количество нулей в числе, на которое умножается результат, возвращаемый `Math.random()`, должно соответствовать первому параметру (`targetLength`) метода `padStart`.
12. Перемешивание массива
-------------------------
Для того чтобы перемешать массив, не зная при этом о том, что именно в нём содержится, можно сделать так:
```
myArray.sort(() => { return Math.random() - 0.5});
```
Существуют и более качественные алгоритмы для перемешивания массивов. Например — алгоритм тасования Фишера-Йетса. Почитать о разных алгоритмах для перемешивания массивов можно [здесь](https://medium.com/swlh/the-javascript-shuffle-62660df19a5d).
13. Создание глубоких копий объектов
------------------------------------
Предлагаемый здесь метод глубокого копирования объектов не отличается особенно высокой производительностью. Но если вам нужно решить эту задачу с использованием однострочника — можете воспользоваться следующим кодом:
```
const myClone = JSON.parse(JSON.stringify(originalObject));
```
Надо отметить, что если в `originalObject` есть циклические ссылки, то создать его копию не удастся. Эту технику рекомендуется использовать на простых объектах, которые вы создаёте сами.
Мелкую копию объекта можно создать с помощью синтаксиса spread:
```
const myClone = { ...orignalObject };
```
Итоги: о комбинировании и расширении кода однострочников
--------------------------------------------------------
Существует огромное количество способов комбинации представленных здесь фрагментов кода. Это позволяет решать с их помощью множество задач и при этом пользоваться весьма компактными языковыми конструкциями. Автор этого материала полагает, что в ходе эволюции JavaScript в нём ещё появятся новые возможности, которые будут способствовать написанию компактного и мощного кода.
**Уважаемые читатели!** Какими примерами полезных JS-однострочников вы дополнили бы этот материал?
[](https://ruvds.com/ru-rub/#order)
[](https://ruvds.com/ru-rub/news/read/104) | https://habr.com/ru/post/456338/ | null | ru | null |
# Построение графиков в SwiftUI
> *Перевод подготовлен в рамках курса* [***"iOS Developer. Basic"***](https://otus.pw/Ap8Y/)*. Если вам интересно узнать о курсе больше, приходите на* [***день открытых дверей***](https://otus.pw/zNRV/) *онлайн.*
>
>
Время от времени мне нужно визуализировать данные в виде красивых графиков. В этой статье будет показано, как рисовать графики в SwiftUI-приложении.
Создание пакета для построения графиков с нуля было невозможным из-за ограничений по времени и бюджету, поэтому мне пришлось искать уже существующие решения.
Выбор пал на [SwifUI-Charts](https://github.com/spacenation/swiftui-charts), который предлагает действительно красиво выглядящие графики и простую интеграцию.
### Установка и конфигурация проекта
Сначала мы начнем с создания проекта в XCode.
Отправной точкой является стандартное SwiftUI-приложение, которое будет модифицировано для отображения графика.
На следующем этапе пакет будет добавлен, за счет открытия настройки проекта.
Нажав на кнопку "плюс", можно добавить новый пакет. Здесь необходимо указать полный путь к репозиторию: [https://github.com/spacenation/swiftui-charts.git](https://github.com/spacenation/swiftui-charts.git.).
На следующем экране я оставил все значения по умолчанию.
На последнем экране я также оставил значения по умолчанию такими, какими они были.
### Отображение постоянных данных
Пришло время добавить код. Для первого теста я просто взял несколько фрагментов кода из Github-Readme и добавил их в `ContentView`:
```
import Charts
import SwiftUI
struct ContentView: View {
var body: some View {
Chart(data: [0.1, 0.3, 0.2, 0.5, 0.4, 0.9, 0.1])
.chartStyle(
LineChartStyle(.quadCurve, lineColor: .blue, lineWidth: 5)
)
}
}
```
При запуске этого в симуляторе будет нарисован красивый график, показывающий постоянные значения.
Это считается первым успешным тестом.
### Отображение динамических данных
В той области, в которой я работаю, данные, которые мне нужно визуализировать, меняются со временем, например, в результате сенсорного ввода. Давайте расширим пример, чтобы динамически обновлять графики в соответствии с изменением данных.
В качестве "сенсора" будет использоваться класс `ObservableObject`, который просто публикует случайное значение `Double` каждые 500 миллисекунд.
```
import Foundation
class ValuePublisher: ObservableObject {
@Published var value: Double = 0.0
init() {
Timer.scheduledTimer(withTimeInterval: 0.5, repeats: true) { timer in
self.value = Double.random(in: 0...1.0)
}
}
}
```
Его нужно инстанцировать в `ContentView` как переменную `@State`.
```
@StateObject var valuePublisher = ValuePublisher()
```
`ValuePublisher` выдает только отдельные значения, но нам необходимо, чтобы эти значения были доступны в виде списка. С этой задачей справляется простая очередь структуры данных.
```
struct Queue {
var list = [T]()
mutating func enqueue(\_ element: T) {
list.append(element)
}
mutating func dequeue() -> T? {
if !list.isEmpty {
return list.removeFirst()
} else {
return nil
}
}
func peek() -> T? {
if !list.isEmpty {
return list[0]
} else {
return nil
}
}
}
```
Эта очередь будет инстанцирована как переменная `@State` в `ContentView`
```
@State var doubleQueue = Queue()
```
Основной список должен быть инициализирован при появлении представления.
```
.onAppear {
doubleQueue.list = [Double](repeating: 0.0, count: 50)
}
```
График также должен содержать информацию о списке, в котором хранятся значения.
```
Chart(data: doubleQueue.list)
```
На последнем этапе опубликованные значения `ValuePublisher` должны быть добавлены в очередь, а самое старое значение из очереди должно быть удалено.
```
.onChange(of: valuePublisher.value) { value in
self.doubleQueue.enqueue(value)
_ = self.doubleQueue.dequeue()
}
```
На этом все, вот полный `ContentView`, где я также немного изменил внешний вид графика.
```
import Charts
import SwiftUI
struct ContentView: View {
@State var doubleQueue = Queue()
@StateObject var valuePublisher = ValuePublisher()
var body: some View {
Chart(data: doubleQueue.list)
.chartStyle(
AreaChartStyle(.quadCurve, fill:
LinearGradient(gradient: .init(colors: [Color.blue.opacity(1.0), Color.blue.opacity(0.5)]), startPoint: .top, endPoint: .bottom)
)
)
.onAppear {
doubleQueue.list = [Double](repeating: 0.0, count: 50)
}
.onChange(of: valuePublisher.value) { value in
self.doubleQueue.enqueue(value)
\_ = self.doubleQueue.dequeue()
}
.padding()
}
}
```
Вот скриншот окончательного варианта приложения
Я также загрузил видео, чтобы вы могли посмотреть, как это выглядит, когда значения обновляются динамически.
Видео: [Графики в SwiftUI](https://youtu.be/9cWHGMyeHSc)
**Ресурсы**
* [SwiftUI-](https://github.com/spacenation/swiftui-charts)Графики
* [Структуры Данных в Swift: Очереди и Стеки](https://medium.com/@JoyceMatos/data-structures-in-swift-queues-and-stacks-e7d715634f07) | https://habr.com/ru/post/557222/ | null | ru | null |
# Fault Injection: твоя система ненадежна, если ее не пробовали сломать
Привет, Хабр! Меня зовут Павел Липский. Я инженер, работаю в компании Сбербанк-Технологии. Моя специализация — тестирование отказоустойчивости и производительности бэкендов крупных распределенных систем. Попросту говоря, я ломаю чужие программы. В этом посте я расскажу о fault injection — методе тестирования, который позволяет находить проблемы в системе путем создания искусственных сбоев. Начну с того, как я пришел к этому методу, потом поговорим о самом методе и о том, как мы его используем.

В статье будут примеры на языке Java. Если вы не программируете на Java — ничего страшного, достаточно понять сам подход и основные принципы. В качестве базы данных используется Apache Ignite, но эти же подходы применимы и к любой другой СУБД. Все примеры можно скачать с моего [GitHub](https://github.com/leapsky/FaultInjectionExamples).
Зачем нам это все?
------------------
Начну с истории. В 2005 году я работал в компании Rambler. К тому времени количество пользователей Rambler стремительно росло и наша двухзвенная архитектура «сервер – база данных – сервер – приложения» перестала справляться. Мы думали о том, как решить проблемы с производительностью, и обратили внимание на технологию memcached.

Что такое memcached? Memcached — хэш-таблица в оперативной памяти с доступом к хранимым объектам по ключу. Например, нужно получить профиль пользователя. Приложение обращается в memcached (2). Если в нем объект есть, то он тут же возвращается пользователю. Если объекта нет, то идет обращение в базу данных (3), формируется объект и кладется в memcached (4). Затем, при следующем обращении, нам уже не надо делать дорогое по ресурсам обращение в базу данных — мы получим готовый объект из оперативной памяти — memcached.
За счет memcached мы заметно разгрузили базу, а наши приложения начали работать намного быстрее. Но, как оказалось, радоваться было рано. Вместе с ростом производительности мы получили новые проблемы.

Когда нужно изменить данные, то сначала приложение вносит исправление в базу данных (2), создает новый объект и затем пытается положить его в memcached (3). То есть старый объект должен быть заменен на новый. Представим, что в этот момент происходит страшное — обрывается связь между приложением и memcached, падает сервер memcached или даже само приложение. Значит, приложение не смогло обновить данные в memcached. В итоге пользователь зайдет на страницу сайта (например, своего профиля), увидит старые данные и не поймет, почему так произошло.
Можно ли было обнаружить этот баг во время функционального тестирования или тестирования производительности? Думаю, что, скорее всего, мы бы его не нашли. Для поиска таких багов есть специальный вид тестирования — fault injection.
Обычно во время fault injection тестирования находятся баги, которые в народе называют *плавающими*. Они проявляются под нагрузкой, когда в системе работает больше одного пользователя, когда происходят нештатные ситуации — выходит из строя оборудование, отключается электричество, сбоит сеть и т.п.
Новая ИТ-система Сбербанка
--------------------------
Несколько лет назад Сбербанк начал строить новую ИТ-систему. Зачем? Вот статистика с сайта Центробанка:

Зеленая часть столбца — количество снятий наличных в банкоматах, голубая — количество операций по оплате товаров и услуг. Мы видим, что количество безналичных операций растет из года в год. Через несколько лет мы должны будем способны обработать растущую нагрузку и продолжать предлагать клиентам новые услуги. Это одна из причин создания новой ИТ-системы Сбербанка. Кроме того, мы хотели бы снизить зависимость от западных технологий и дорогих мейнфреймов, которые стоят миллионы долларов, и перейти на технологии с открытым исходным кодом и low-end сервера.
Изначально в основу новой архитектуры Сбербанка мы заложили технологию Apache Ignite. Точнее, мы используем платный плагин Gridgain. Технология обладает достаточно богатой функциональностью: совмещает в себе свойства реляционной базы данных (есть поддержка SQL-запросов), NoSQL, распределенную обработку и хранение данных в оперативной памяти. Причем, при перезагрузке данные, которые были в оперативной памяти, никуда не потеряются. Начиная с версии 2.1 в Apache Ignite появилось распределенное дисковое хранилище Apache Ignite Persistent Data Store с поддержкой SQL.
Перечислю некоторые фичи этой технологии:
* Хранение и обработка данных в оперативной памяти
* Дисковое хранилище
* Поддержка SQL
* Распределенное выполнение задач
* Горизонтальное масштабирование
Технология относительно новая, поэтому требует особого внимания.
Новая ИТ-система Сбербанка физически состоит из множества относительно небольших серверов, собранных в один кластер-облако. Все узлы одинаковые по структуре, равноправные между собой, выполняют функцию хранения и обработки данных.
Внутри кластер разделен на так называемые ячейки. Одна ячейка — это 8 узлов. В каждом дата-центре по 4 узла.

Так как мы используем Apache Ignite, in-memory data grid, то, соответственно, все это хранится в распределенных по серверам кэшах. Причем кэши, в свою очередь, делятся на одинаковые кусочки – партиции. На серверах они представлены в виде файлов. Партиции одного кэша могут хранится на разных серверах. Для каждой партиции в кластере есть основные (primary node) и резервные узлы (backup node).
Основные узлы хранят основные партиции и обрабатывают запросы для них, реплицируют данные на резервные узлы (backup node), где хранятся резервные партиции (backup node).
Проектируя новую архитектуру Сбербанка, мы пришли к тому, что компоненты системы могут и будут выходить из строя. Скажем, если у вас кластер из 1000 железных low-end серверов, то время от времени у вас будут случаться отказы оборудования. Будут выходить из строя планки оперативной памяти, сетевые карты и жесткие диски и т.д. Это поведение мы будем считать совершенно нормальным поведением системы. Такие ситуации должны корректно обрабатываться и наши клиенты не должны их замечать.
Но мало проектировать устойчивость системы к сбою, надо обязательно тестировать системы во время этих сбоев. Как говорит известная исследовательница распределенных систем Caitie McCaffrey из Microsoft Research: «Вы никогда не узнаете, как поведет себя система во время сбоя нештатной ситуации, пока не воспроизведете сбой».
Потерянные обновления
---------------------
Разберем простой пример, банковское приложение, которое симулирует денежные переводы. Приложение будет состоять из двух частей: Apache Ignite сервер и Apache Ignite клиент. Серверная часть – это хранилище данных.
Клиентское приложение подключается к серверу Apache Ignite. Создает кэш, где ключ — ID cчета, а значение — объект счета. Всего в кэше будет храниться десять таких объектов. При этом изначально на каждый счет положим 100 долларов (чтобы было что переводить). Соответственно, общий баланс по всем счетам будет равен 1000 долларов.
```
CacheConfiguration cfg = new CacheConfiguration<>(CACHE\_NAME);
cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC);
try (IgniteCache cache = ignite.getOrCreateCache(cfg)) {
for (int i = 1; i <= ENTRIES\_COUNT; i++)
cache.put(i, new Account(i, 100));
System.out.println("Accounts before transfers");
printAccounts(cache);
printTotalBalance(cache);
for (int i = 1; i <= 100; i++) {
int pairOfAccounts[] = getPairOfRandomAccounts();
transferMoney(cache, pairOfAccounts[0], pairOfAccounts[1]);
}
}
...
private static void transferMoney(IgniteCache cache, int fromAccountId, int toAccountId) {
Account fromAccount = cache.get(fromAccountId);
Account toAccount = cache.get(toAccountId);
int amount = getRandomAmount(fromAccount.balance);
if (amount < 1) {
return;
}
fromAccount.withdraw(amount);
toAccount.deposit(amount);
cache.put(fromAccountId, fromAccount);
cache.put(toAccountId, toAccount);
}
```
Затем делаем 100 случайных денежных переводов между этими 10 счетами. Например, со счета A на другой счет Б переводится 50 долларов. Схематично этот процесс можно изобразить таким образом:

Система замкнутая, переводы делаются только внутри, т.е. сумма общего баланса должна оставаться равной $1000.

Запустим приложение.
Мы получили ожидаемое значение общего баланса — $1000. Теперь давайте немного усложним наше приложение – сделаем его многозадачным. В реальности с одним и тем же счетом одновременно могут работать несколько клиентских приложений. Запустим две задачи, которые параллельно будут делать денежные переводы между десятью счетами.
```
CacheConfiguration cfg = new CacheConfiguration<>(CACHE\_NAME);
cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC);
cfg.setCacheMode(CacheMode.PARTITIONED);
cfg.setIndexedTypes(Integer.class, Account.class);
try (IgniteCache cache = ignite.getOrCreateCache(cfg)) {
// Initializing the cache.
for (int i = 1; i <= ENTRIES\_COUNT; i++)
cache.put(i, new Account(i, 100));
System.out.println("Accounts before transfers");
System.out.println();
printAccounts(cache);
printTotalBalance(cache);
IgniteRunnable run1 = new MyIgniteRunnable(cache, ignite,1);
IgniteRunnable run2 = new MyIgniteRunnable(cache, ignite,2);
List arr = Arrays.asList(run1, run2);
ignite.compute().run(arr);
}
...
private void transferMoney(int fromAccountId, int toAccountId) {
Account fromAccount = cache.get(fromAccountId);
Account toAccount = cache.get(toAccountId);
int amount = getRandomAmount(fromAccount.balance);
if (amount < 1) {
return;
}
int fromAccountBalanceBeforeTransfer = fromAccount.balance;
int toAccountBalanceBeforeTransfer = toAccount.balance;
fromAccount.withdraw(amount);
toAccount.deposit(amount);
cache.put(fromAccountId, fromAccount);
cache.put(toAccountId, toAccount);
}
```
Общий баланс — $1296. Клиенты радуются, банк терпит убытки. Почему это произошло?

Здесь мы видим, как две задачи одновременно меняют состояние счета А. Но вторая задача успевает записать свои изменения раньше, чем это сделает первая. Затем первая задача записывает свои изменения, и все изменения, сделанные второй задачей, сразу пропадают. Такая аномалия называется проблемой потерянных обновлений.
Для того, чтобы приложение работало так, как нужно, необходимо, чтобы наша база данных поддерживала ACID-транзакции и наш код это учитывал.
Давайте разберем свойства ACID применительно к нашему приложению, чтобы понять, почему это так важно.

* *A — Atomicity, атомарность.* Либо все предлагаемые изменения будут внесены в базу данных, либо не будет внесено ничего. То есть, если между шагами 3 и 6 у нас был сбой, изменения не должны попасть в базу данных
* *C — Consistency, целостность.* После выполнения транзакции база данных дожна остаться в консистентном состояние. В нашем примере это означает, что сумма А и Б всегда должно быть одинакова, общий баланс равен $1000.
* *I — Isolation, изолированность.* Транзакции не должны влиять друг на друга. Если одна транзакция делает перевод, а другая получит значение счета А и Б после шага 3 и до шага 6, она думает, что в системе денег меньше, чем надо. Здесь есть нюансы, на которых я остановлюсь позже.
* *D — Durability, устойчивость.* После того, как транзакция зафиксировала изменения в базе данных, эти изменения не должны пропасть в результате сбоев.
Итак, в методе transferMoney будем делать денежный перевод внутри транзакции.
```
private void transferMoney(int fromAccountId, int toAccountId) {
try (Transaction tx = ignite.transactions().txStart()) {
Account fromAccount = cache.get(fromAccountId);
Account toAccount = cache.get(toAccountId);
int amount = getRandomAmount(fromAccount.balance);
if (amount < 1) {
return;
}
int fromAccountBalanceBeforeTransfer = fromAccount.balance;
int toAccountBalanceBeforeTransfer = toAccount.balance;
fromAccount.withdraw(amount);
toAccount.deposit(amount);
cache.put(fromAccountId, fromAccount);
cache.put(toAccountId, toAccount);
tx.commit();
} catch (Exception e){
e.printStackTrace();
}
}
```
Запустим приложение.
Хм. Транзакции не помогли. Общий баланс — $6951! В чем проблема такого поведения приложения?
Во первых, выбрали тип кэша ATOMIC, т.е. без поддержки ACID-транзакций:
```
CacheConfiguration cfg = new CacheConfiguration<>(CACHE\_NAME);
cfg.setAtomicityMode(CacheAtomicityMode.АTOMIC);
```
Во вторых, метод txStart имеет два важных параметра типа enum, которые хорошо бы указать: метод блокировки (concurrency mode в Apache Ignite) и уровень изоляции. В зависимости от значений этих параметров транзакция может по-разному выполнять чтение и запись данных. В Apache Ignite эти параметры задаются таким образом:
```
try (Transaction tx = ignite.transactions().txStart(МЕТОД БЛОКИРОВКИ, УРОВЕНЬ ИЗОЛЯЦИИ)) {
Account fromAccount = cache.get(fromAccountId);
Account toAccount = cache.get(toAccountId);
...
tx.commit();
}
```
В качестве значения параметра МЕТОД БЛОКИРОВКИ можно использовать PESSIMISTIC (пессимистическая блокировка) либо OPTIMISTIC (оптимистическая блокировка). Отличаются они моментом времени наложения блокировки. При использовании PESSIMISTIC блокировка накладывается при первом чтении/записи и удерживается до момента фиксации транзакции. Например, когда транзакция с пессимистической блокировкой делает перевод со счета А на счет Б, другие транзакции не смогут ни прочитать, ни записать значения этих счетов до тех пор, пока транзакция, делающая перевод, не будет зафиксирована. Понятно, что если другие транзакции хотят получить доступ к счетам А и Б, они вынуждены ждать выполнения транзакции, что оказывает отрицательное влияние на общую производительность приложения. Оптимистическая блокировка не ограничивает доступ к данным для других транзакций, однако на фазе подготовки транзакции к фиксации (prepare phase, Apache Ignite использует 2PC протокол) будет выполнена проверка — изменялись ли данные другими транзакциями? И если изменения имели место, то транзакция будет отменена. С точки зрения производительности OPTIMISTIC будет работать быстрее, но больше подходит для приложений, где нет конкурентной работы с данными.
Параметр УРОВЕНЬ ИЗОЛЯЦИИ определяет степень изоляции транзакций друг от друга. В стандарте ANSI/ISO языка SQL определено 4 типа изоляции, и для каждого уровня изоляции один и тот же сценарий транзакции может привести к разном результату.
* READ\_UNCOMMITED – самый низкий уровень изоляции. Транзакции могут видеть «грязные» незафиксированные данные.
* READ\_COMMITTED — когда транзакция видит внутри себя только закомиченные данные
* REPEATABLE\_READ — означает, что, если внутри транзакции выполнено чтение, то это чтение должно быть повторяемым.
* SERIALIZABLE — этот уровень предполагает максимальную степень изоляции транзакций – будто в системе нет других пользователей. Результат работы параллельно выполняющихся транзакций будет такой, как если бы они выполнялись по очереди (упорядоченно). Но вместе с высокой степенью изоляции мы получаем снижение производительности. Поэтому надо осторожно подходить к выбору этого уровня изоляции.
Для многих современных СУБД (Microsoft SQL Server, PostgreSQL и Oracle) уровень изоляции по умолчанию — READ\_COMMITTED. Для нашего примера это было бы фатально, так как не защитит нас от потерянных обновлений. Результат будет такой же, как если бы мы совсем не использовали транзакции.

Из [документации Apache Ignite по транзакциям](https://apacheignite.readme.io/docs/concurrency-modes-and-isolation-levels) следует, что нам подходят такие комбинации метода блокировки и уровня изоляции:
* **PESSIMISTIC REPEATABLE\_READ** — блокировка накладывается при первом чтении или записи данных и удерживается до ей завершения.
* **PESSIMISTIC SERIALIZABLE** — работает аналогично PESSIMISTIC REPEATABLE\_READ
* **OPTIMISTIC SERIALIZABLE** — запоминается версия данных, полученная после первого чтения, и если на фазе подготовке к фиксации эта версия будет отличаться (данные были изменены другой транзакцией), то транзакция будет отменена. Попробуем этот вариант.
```
private void transferMoney(int fromAccountId, int toAccountId) {
try (Transaction tx = ignite.transactions().txStart(OPTIMISTIC, SERIALIZABLE)) {
Account fromAccount = cache.get(fromAccountId);
Account toAccount = cache.get(toAccountId);
int amount = getRandomAmount(fromAccount.balance);
if (amount < 1) {
return;
}
int fromAccountBalanceBeforeTransfer = fromAccount.balance;
int toAccountBalanceBeforeTransfer = toAccount.balance;
fromAccount.withdraw(amount);
toAccount.deposit(amount);
cache.put(fromAccountId, fromAccount);
cache.put(toAccountId, toAccount);
tx.commit();
} catch (Exception e){
e.printStackTrace();
}
}
```
Ура, получили $1000, как и ожидали. С третьей попытки.
Тестируем под нагрузкой
-----------------------
Теперь сделаем наш тест более реалистичным — будем тестировать под нагрузкой. А еще добавим дополнительный серверный узел. Существует множество инструментов для проведения нагрузочного тестирования, в Сбербанке мы используем HP Performance Center. Это достаточно мощный инструмент, поддерживает более 50 протоколов, предназначен для больших команд и стоит много денег. Свой пример я написал на JMeter — он бесплатный и решает нашу задачу на 100%. Я бы не хотел переписывать код на Java, поэтому воспользуюсь семплером JSR223.
Создадим из классов нашего приложения JAR-архив и подгрузим его в тест-план. Чтобы создать и наполнить кэш, запустим класс CreateCache. После инициализации кэша можно запускать скрипт JMeter.
Все классно, получили $1000.
Аварийная остановка узла кластера
---------------------------------
Теперь будем более деструктивны: во время работы кластера аварийно остановим один из двух серверных узлов. Через утилиту Visor, которая входит в поставку Gridgain, мы можем мониторить кластер Apache Ignite и делать разные выборки данных. Во вкладке SQL Viewer выполним SQL-запрос, чтобы получить общий баланс по всем счетам.
Что получается? 553 доллара. Клиенты в ужасе, банк терпит репутационные потери. Что мы на этот раз сделали не так?
Оказывается, в Apache Ignite есть типы кэшей:
* партиционированные — в рамках кластера хранится по одному или несколько экземпляров бэкапа
* реплицированные кэши — в рамках одного сервера хранятся все партиции (все кусочки кэша). Такие кэши подходят прежде всего для справочников — того, что редко меняется и часто читается.
* локальные — все на одном узле

Мы будем наши данные часто менять, поэтому мы выберем партиционированный кэш и добавим в него дополнительный бэкап. То есть у нас будет две копии данных — основная и резервная.
```
CacheConfiguration cfg = new CacheConfiguration<>(CACHE\_NAME);
cfg.setAtomicityMode(CacheAtomicityMode.TRANSACTIONAL);
cfg.setCacheMode(CacheMode.PARTITIONED);
cfg.setBackups(1);
```
Запускаем приложение. Напоминаю, до переводов у нас $1000. Запускаем и во время работы «гасим» один из узлов
В утилите Visor делаем SQL-запрос, чтобы получить общий баланс — $1000. Все отработало замечательно!
Кейсы надежности
----------------
Два года назад мы только начинали тестировать новую ИТ-систему Сбербанка. Как-то пошли мы к нашим инженерам сопровождения и спросили: а что вообще может сломаться? Нам ответили: сломаться может все, тестируйте все! Конечно, нас этот ответ не устроил. Мы вместе сели, проанализировали статистику отказов и поняли, что самый вероятный кейс, с которым мы можем столкнуться — это отказ узла.
Причем, это может произойти по совершенно разным причинам. Например, может отказать приложение, упасть JVM, сбойнуть ОС или выйти из строя оборудование.

Все возможные случаи отказов мы поделили на 4 группы:
1. Оборудование
2. Сетевые
3. Программное обеспечение
4. Другие
Придумали для них тесты и назвали их кейсам надежности. Типичный кейс надежности состоит из описания состояния системы до тестов, шагов воспроизведения сбоя и описания ожидаемого поведения во время сбоя.

#### Кейсы надежности: оборудование
К этой группе относятся такие кейсы как:
* Отказ электропитания
* Полная потеря доступа к жесткому диску
* Сбой одного пути доступа к жесткому диску
* Загрузка CPU, оперативной памяти, дисков, сети
В кластере хранится 4 одинаковых копии каждой партиции: одна основная партиция (primary) и три резервные партиции (backup). Предположим, из-за отказа оборудования из кластера выходит узел. В этом случае основные партиции должны переместиться на другие оставшиеся в живых узлы.
Что еще может произойти? Потеря стойки в ячейке.

Все узлы ячейки находятся в разных стойках. Т.е. выход стойки не приведет к отказу кластера или потерям данных. Мы будем иметь три копии из четырех. Но даже если мы потеряем целый дата-центр, то это также не будет для нас большой проблемой, т.к. у нас остались еще две копии данных из четырех.
Часть кейсов выполняются непосредственно в самом дата-центре при участии инженеров сопровождения. Например, отключение жесткого диска, отключение электропитания сервера или стойки.
#### Кейсы надежности: сеть
Для тестирования кейсов, связанных c сетевой фрагментацией, используем iptables. А с помощью утилиты NetEm эмулируем:
* сетевые задержки с различной функцией распределения
* потерю пакетов
* повтор пакетов
* изменение порядка следования пакетов
* искажение пакетов
Еще одни интересный сетевой кейс, который мы тестируем – split-brain. Это когда все узлы кластера живые, но из-за сетевой сегментации не могут общаться между собой. Термин пришел из медицины и означает, что мозг разделился на два полушария, каждое из которых считает себя единственным. То же самое может произойти и с кластером.

Бывает, что между дата-центрами пропадает связь. Например, в прошлом году из-за повреждения оптоволоконного кабеля экскаватором у клиента банков «Точка», «Открытие» и «Рокетбанк» в течение нескольких часов не проводились операции через интернет, терминалы не принимали карты и не работали банкоматы. Про эту аварию много писали в Twitter.
В нашем случае ситуация split-brain должна корректно обрабатываться. Грид идентифицирует split-brain – разделение кластера на две части. Одна из половин переводится в режим чтения. Это половина, где больше живых узлов или находится координатор (самый старый узел в кластере).
#### Кейсы надежности: программное обеспечение
Это кейсы связанные с отказом различным подсистем:
* DPL ORM — модуль доступа к данным, типа Hibernate ORM
* Межмодульный транспорт — обмен сообщениями между модулями (микросервисами)
* Система логирования
* Система предоставления доступов
* Кластер Apache Ignite
* …
Поскольку большая часть программного обеспечения написана на Java, мы подвержены всем проблемам, присущим Java-приложениям. Тестирует различные настройки сборщика мусора (garbage collector). Проводим тесты с падением java virtual machine.
Для кластера Apache Ignite есть специальные кейсы для off-heap — это такая область памяти, которую контролирует сам Apache Ignite. Она намного больше чем java heap и предназначена для хранения данных и индексов. Здесь можно, например, тестировать переполнение. Мы переполняем off-heap и смотрим, как кластер работает в случае, когда часть данных не влезла в оперативную память, т.е. читается с диска.

#### Другие кейсы
Это кейсы, которые не входят в первые три группы. К ним относятся утилиты, которые позволяют произвести восстановление данных в случае крупной аварии или при миграции данных в другой кластер.
* Утилита создания снапшотов (бэкапа) данных — тестирование полного и инкрементального снапшота.
* Восстановление на определенную точку во времени – механизм PITR (Point in-time recovery).
Утилиты для fault injection
---------------------------
Напомню [ссылку](https://github.com/leapsky/FaultInjectionExamples) на примеры из моего доклада. Дистрибутив Apache Ignite вы можете скачать с официального сайта — [Apache Ignite Downloads](https://ignite.apache.org/download.cgi#binaries). А теперь поделюсь утилитами, которыми мы пользуемся в Сбербанке, если вдруг вас заинтересовала тема.
Фреймворки:
* [Jepsen](https://github.com/jepsen-io/jepsen)
* [Chaos Monkey](https://github.com/Netflix/SimianArmy/wiki/Chaos-Monkey)
Управление конфигурациями:
* [Ansible](https://docs.ansible.com/)
* [Puppet](https://puppet.com/)
Утилиты Linux:
* [NetEm (tc)](https://wiki.linuxfoundation.org/networking/netem)
* [stress-ng](https://manned.org/stress-ng/fd34c972)
* [Iperf](https://iperf.fr/)
* kill -9
* iptables
Инструменты нагрузочного тестирования:
* [JMeter](https://jmeter.apache.org/)
И в современном мире, и в Сбербанке все изменения происходят динамично и сложно предугадать, какие технологии будут использоваться в ближайшие пару лет. Но я точно знаю, что мы будем использовать метод Fault Injection. Метод универсальный — подходит для тестирования любых технологий, действительно работает, помогает отловить много багов и сделать продукты, которые мы разрабатываем, лучше. | https://habr.com/ru/post/433468/ | null | ru | null |
# Архитектура и платформа проекта Одноклассники
#### Архитектура и платформа проекта Одноклассники
В этом посте расскажем о накопленном за 5 лет опыте по поддержанию высоконагруженного проекта. Надеемся, что коллегам-разработчикам будет интересно узнать, что и как мы делаем, какие проблемы и трудности у нас возникают и как мы справляемся с ними.
##### Базовая статистика
До 2.8 млн. пользователей в онлайне в часы пик
7,5 миллиардов запросов в день (150 000 запросов в секунду в часы пик)
2 400 серверов, систем хранения данных
Сетевой трафик в час пик: 32 Gb/s
##### Архитектура
###### Слоеная архитектура:
• presentation layer (презентационный слой или попросту WEB сервера, формирующие HTML)
• business services layer (сервера, обеспечивающие подбор и обработку данных)
• caching layer (кеширование часто используемых данных)
• persistence layer (сервера БД)
• common infrastructure systems (системы логирования статистики, конфигурации приложений, локализация ресурсов, мониторинг)
###### Презентационный слой:
• Используем свой фреймворк, позволяющий строить композицию страниц на языке JAVA, используя собственные GUI фабрики (оформление текста, списки, таблицы, портлеты).
• Композиция страниц состоит из независимых блоков (обычно портлетов), что позволяет обновлять информацию на экране частями, используя AJAX запросы. Такой подход к навигации позволяет избавиться от постоянных перезагрузок страницы, тем самым важные функции сайта (Сообщения, Обсуждения и Оповещения) всегда доступны пользователю. Без javascript страница полностью работоспособна, кроме функциональностей, написанных на GWT — при переходах по ссылкам она просто полностью перерисовывается.
• Функциональные компоненты как Сообщения, Обсуждения и Оповещения, а также все динамичные части (шорткат меню, фотометки, сортировка фотографий, ротирование подарочков) написаны, используя фреймворк Google Web Toolkit.
###### Подбор, обработка и кеширование данных:
Код написан на Java. Есть исключения – некоторые модули для кеширования данных написаны на C и C++.
Java потому, что это удобный для разработки язык, много наработок в различных сферах, библиотек, open source проектов на Java.
На уровне бизнес логики располагаются порядка 25 типов серверов/компонентов и кешей, которые общаются между собой через удаленные интерфейсы. Каждую секунду происходит порядка 3 000 000 удаленных запросов между этими модулями.
Для кеширования данных используется «самописный» модуль odnoklassniki-cache. Он предоставляет возможность хранения данных в памяти средствами Java Unsafe. Кешируем все данные, к которым происходит частое обращение. Например: информацию из профайлов пользователей, группы пользователей, информацию о самих группах, конечно же, граф связей пользователей, граф связей пользователей и групп, праздники пользователей, некоторую мета информацию о фотографиях и т.п.
Для примера, один из серверов, кеширующий граф связей пользователей, в час пик способен обработать около 16 600 запросов в секунду. CPU при этом занят до 7%, максимальный load average за 5 минут — 1.2. Количество вершин графа > 85 миллионов, связей 2 500 миллиона (два с половиной миллиарда). В памяти граф занимает 30 GB.
###### Распределение и балансировка нагрузки:
• взвешенный round robin внутри системы;
• вертикальное и горизонтальное партиционирование данных как в базах данных, так и на кеширующем уровне;
• сервера на уровне бизнес логики разбиты на группы. Каждая группа обрабатывает различные события. Есть механизм маршрутизации событий, т.е. любое событие (или группу событий) можно выделить и направить на обработку на определенную группу серверов.
Управление сервисами происходит через централизованную систему конфигурации. Система самописная. Через WEB интерфейс можно поменять расположение портлетов, конфигурацию кластеров, изменить логику некоторых сервисов и т.д. Измененная конфигурация сохраняется в базе данных. Каждый из серверов периодически проверяет, есть ли обновления для приложений, которые на нем запущены. Если есть – применяет их.
###### Данные, сервера БД, резервные копии:
Общий объем данных без резервирования – 160 TB. Используются два решения для хранения и сервирования данных – MS SQL и BerkeleyDB. Данные хранятся как минимум в двух копиях. В зависимости от типов данных, копий может быть от двух до четырех. Имеется ежесуточный бэкап всех данных. Каждые 15 минут делаются резервные копии накопившихся данных. В результате такой стратегии резервного копирования максимально возможная потеря данных – 15 минут.
###### Оборудование, датацентры, сеть:
Используются двухпроцессорные, 4-х ядерные сервера. Объем памяти от 4 до 48 GB, в зависимости от функционала. В зависимости от типов и использования данных, они хранятся либо в памяти серверов, либо на дисках серверов, либо на внешних системах хранения.
Все оборудование размещено в 3 датацентрах. Всего около 2 400 серверов и систем хранения данных. Датацентры объединены в оптическое кольцо. На данный момент на каждом из маршрутов емкость составляет 30 Gb/s. Каждый из маршрутов состоит из физически независимых друг от друга оптоволоконных пар. Эти пары агрегируются в общую “трубу” на корневых маршрутизаторах.
Сеть разделена на внутреннюю и внешнюю. Сети разделены физически. Разные интерфейсы серверов подключены в разные коммутаторы и работают в разных сетях. По внешней сети WEB сервера, общаются с миром. По внутренней сети все сервера общаются между собой.
Топология внутренней сети – звезда. Сервера подключены в L2 коммутаторы (access switches). Эти коммутаторы подключены как минимум двумя гигабитными линками к agregation стеку маршрутизаторов. Каждый линк идет к отдельному коммутатору в стеке. Для того, чтобы эта архитектура работала, используем протокол [RSTP](http://ru.wikipedia.org/wiki/RSTP). При необходимости, подключения access коммутаторов к agregation стеку осуществляются более чем двумя линками. Тогда используется link aggregation портов.
Agregation коммутаторы подключены 10Gb линками в корневые маршрутизаторы, которые обеспечивают как связь между датацентрами, так и связь с внешним миром.
Используются коммутаторы и маршрутизаторы от компании Cisco. Для связи с внешним миром мы имеем прямые подключения с несколькими крупнейшими операторами связи
Сетевой трафик в часы пик – 32 Gb/s
###### Система статистики:
Существует библиотека, отвечающая за логирование событий. Библиотека используется во всех модулях. Она позволяет агрегировать статистику и сохранять ее во временную БД. Само сохранение происходит с помощью библиотеки log4j. Обычно храним количество вызовов, максимальное, минимальное и среднее время выполнения, количество ошибок, возникших при выполнении.
Из временных баз вся статистика сохраняется в DWH. Каждую минуту сервера DWH ходят во временные базы в production и забирают данные. Временные базы периодически очищаются от данных.
###### Пример кода, который сохраняет статистику об отосланных сообщениях:
```
public void sendMessage(String message) {
long startTime = LoggerUtil.getMeasureStartTime();
try {
/**
* business logic - send message
*/
LoggerUtil.operationSuccess(LogFactory.getLog({log's appender name}), startTime, "messageService", "sendMessage");
} catch (Exception e) {
LoggerUtil.operationFailure(LogFactory.getLog({log's appender name}), startTime, "messageService", "sendMessage");
}
}
```
Наша система DWH хранит всю статистику и предоставляет инструменты для ее просмотра и анализа. Система построена на базе решений от Microsoft. Сервера баз данных – MS SQL 2008, система генерации отчетов – Reporting services. Сейчас DWH – это 13 серверов, находящихся в отделенной от production среде. Некоторые из этих серверов обеспечивают операционную статистику (т.е. онлайн статистику). Некоторые отвечают за хранение и предоставление доступа к исторической статистике. Общий объем статистических данных — 13 TB.
Планируется внедрение мультиразмерного (multi-dimension) анализа статистики на основе OLAP.
##### Мониторинг
###### Мониторинг разделен на две составляющие:
1. Мониторинг сервисов и компонентов сайта
2. Мониторинг ресурсов (оборудование, сеть)
Первичен мониторинг сервисов. Система мониторинга своя, основанная на оперативных данных в DWH. Есть дежурные, чья обязанность мониторить показатели работы сайта и в случае каких-либо аномалий предпринимать действия для выяснения и устранения причин этих аномалий.
В случае с мониторингом ресурсов, следим как за “здоровьем” оборудования (температура, работоспособность компонентов: CPU, RAM, дисков и т.д.), так и за показателями ресурсов серверов (загрузка CPU, RAM, загруженность дисковой подсистемы и т.п.). Для мониторинга “здоровья” оборудования используем Zabbix, статистику по использованию ресурсов серверов и сети накапливаем в Cacti.
Оповещения о наиболее критичных аномалиях приходят по смс, остальные оповещения отсылаются по емейлу.
###### Технологии:
• Операционные системы: MS Windows, openSUSE
• Java, C, C+. Весь основной код написан на Java. На С и С+ написаны модули для кеширования данных.
• Используем GWT для придания динамики WEB интерфейсу. С использованием GWT написаны такие модули как Сообщения, Обсуждения и Оповещения
• WEB сервера – [Apache Tomcat](http://tomcat.apache.org/)
• Сервера бизнес логики работают под [JBoss 4](http://www.jboss.org/)
• Балансировщики нагрузки на WEB слое – [LVS](http://www.linuxvirtualserver.org/). Используем IPVS для балансировки на Layer-4
• Apache Lucene для индексирования и поиска текстовой информации
• Базы данных:
MS SQL 2005 Std edition. Используется во многом потому, что так исторически сложилось. Сервера с MS SQL объединены в failover кластера. При выходе из строя одной из рабочих нод, standby нода берет на себя ее функции
BerkeleyDB – для работы с BDB используется своя, внутренняя библиотека. Используем BDB, C реализацию, версии 4.5. Двухнодовые master-slave кластера. Между мастером и слейвом родная BDB репликация. Запись происходит только в master, чтение происходит с обеих нод. Данные храним в tmpfs, transaction логи хранятся на дисках. Каждые 15 минут делаем бэкап логов. Сервера одного кластера размещены на разных лучах питания дабы не потерять обе копии данных сразу.
В разработке новое решение для хранения данных. Нам необходим еще более быстрый и надежный доступ к данным.
• При общении серверов между собой используем свое решение, основанное на [JBoss Remoting](http://www.jboss.org/jbossremoting)
• Общение с SQL базами данных происходит посредством JDBC драйверов
##### Люди:
Над проектом работают около 70 технических специалистов. Из них 40 разработчиков, 20 системных администраторов и инженеров, 8 тестеров.
Все разработчики разделены на небольшие команды (1-3 человек). Каждая из команд работает автономно и разрабатывает либо какой-то новый сервис, либо работает над улучшением существующих. В каждой из команд есть технический лидер или архитектор. Он ответственен за архитектуру сервиса, выбор технологий и подходов. На разных этапах разработки к команде могут примыкать дизайнеры, тестеры и системные администраторы.
Например, существует отдельная команда сервиса Группы. Или команда, разрабатывающая коммуникационные сервисы сайта (такие как системы сообщений, обсуждений, ленту активности). Есть команда платформы, которая тестирует, обкатывает и внедряет новые технологии, оптимизирует уже существующие решения. В данный момент одна из задач этой команды – разработка и внедрение высокоскоростного и надежного решения для хранения данных.
##### Основные принципы и подходы в разработке
Разработка ведется небольшими итерациями. Как пример жизненного цикла разработки можно привести 3-х недельный цикл:
0 неделя — определение архитектуры
1 неделя — разработка, тестирование на компьютерах разработчиков
2 неделя — тестирование на pre-production среде, релиз на production среду
Практически весь новый функционал делается «отключаемым». Типичный запуск новой «фичи» выглядит следующим образом:
1. функционал разрабатывается и попадает в production релиз
2. через централизованную систему конфигурации функционал включается для небольшой части пользователей. Анализируется статистика активности пользователей, нагрузка на инфраструктуру
3. если предыдущий этап прошел успешно, функционал включается постепенно на все большей аудитории. Если в процессе запуска нам не нравится собранная статистика, либо непозволительно вырастает нагрузка на инфраструктуру, то функционал отключается, анализируются причины, исправляются ошибки, происходит оптимизация и все повторяется с 1-го шага
##### Best practices, tricks & tips
###### Специфика работы с СУБД:
• Мы используем как вертикальное, так и горизонтальное партиционирование, т.е. разные группы таблиц располагаются на разных серверах (вертикальное партиционирование), а данные больших таблицы дополнительно распределяются между серверами (горизонтальное партиционирование). Встроенный в СУБД аппарат партиционирования не используется — вся логика располагается на уровне бизнес сервисов.
• Распределенные транзакции не используются — все транзакции только в пределах одного сервера. Для обеспечения целостности, связанные данные помещаются на 1 сервер или, если это невозможно, дополнительно программируется логика восстановления данных.
• В запросах к БД не используются JOIN даже среди локальных таблиц для минимизации нагрузки на CPU. Вместо этого используется денормализация данных или JOIN происходят на уровне бизнес сервисов. В этом случае JOIN происходит как с данными из БД, так и с данными из кеша.
• При проектировании структуры данных не используются внешние ключи, хранимые процедуры и триггеры. Опять же для снижения нагрузки на CPU серверов БД.
• SQL операторы DELETE также используются с осторожностью — это самая тяжелая операция из DML. Стараемся не удалять данные лишний раз или используем удаление через маркер — запись сначала отмечается как удаленная, а потом удаляется фоновым процессом из таблицы.
• Широко используются индексы. Как обычные, так и кластерные. Последние для оптимизации наиболее частых запросов в таблицу.
###### Кеширование:
• Используются кеш сервера нашей собственной разработки, реализованные на Java. Некоторые наборы данных, как например профили пользователей, социальный граф, и т.п. целиком хранятся в кеше.
• Данные партиционируются на кластер кеш серверов. Используется репликация партиций для обеспечения надежности.
• Иногда требования к быстродействию настолько велики, что используются локальные короткоживущие кеши данных полученных с кеш серверов, расположенные непосредственно в памяти серверов бизнес логики.
• Кеш сервера, кроме обычных операций ключ-значение, могут выполнять запросы по данным, хранящимся в памяти, минимизируют таким образом передачу по сети ненужных данных. Используется map-reduce для выполнения запросов и операций на кластере. В особо сложных случаях, например для реализации запросов по социальному графу, используется язык C. Это помогает повысить производительность.
• Для хранения больших объемов данных в памяти используется память вне кучи Java (off heap memory) для снятия ненужной нагрузки с Java GC.
• Кеши могут использовать локальный диск для хранения данных, что превращает их в высокопроизводительный сервер БД.
###### Оптимизация скорости загрузки и работы страницы
• Кешируем все внешние ресурсы (Expires и Cache-Control заголовки). CSS и JavaScript файлы минимизируем и сжимаем (gzip).
• Для уменьшения количества HTTP запросов с браузера, все JavaScript и CSS файлы объединяются в один. Маленькие графические изображения объединяются в спрайты.
• При загрузке страницы скачиваются только те ресурсы, которые на самом деле необходимы для начала работы.
• Никаких универсальных CSS селекторов. Стараемся не использовать типовые селекторы (по имени тэга).
• Если необходимы CSS expressions, то пишем «одноразовые». По возможности избегаем фильтров.
• Кешируем обращения к DOM дереву, а так же свойства элементов, приводящие к reflow. Обновляем DOM дерево в «оффлайне».
• В GWT используем UIBinder и HTMLPanel для создания интерфейсов.
Полезного чтения! Будем рады вопросам. | https://habr.com/ru/post/115881/ | null | ru | null |
# 0, 0, 1, 0, 2, 0, 2, 2, 1, 6, 0, 5, 0, 2, 6, 5, 4, 0, 5, 3, 0, 3, 2, 9, 0, 4, 9, 3, 6, 14, 0, 6, 3, 5, 15, 0, 5, 3, 5…
Есть два мужика с именами «Van Eck». Первый, в 1985 году показал всему миру как за 15 долларов перехватывать данные с монитора ([Van Eck phreaking](https://en.wikipedia.org/wiki/Van_Eck_phreaking)), второй, в 2010 придумал хитрую последовательность ([Van Eck's sequence](https://en.wikipedia.org/wiki/Van_Eck%27s_sequence)). Круче простоты задания этой последовательности могут быть только её свойства и загадки.
Итак, алгоритм генерации членов последовательности. Берем «стартовое число», например «0», выписываем. Следующий член — это то, сколько шагов назад встречалось это число в предыдущей под-последовательности. Если ни разу, то пишем ноль. Следующее — это сколько шагов назад встречался ноль в предыдущей под-последовательности, то есть один шаг назад. Записываем единицу. Единица впервые — пишем ноль. Опа, ноль встречался два шага назад. Пишем два, и так далее…
Для точки отчета «0» первые 97 членов последовательности:
0, 0, 1, 0, 2, 0, 2, 2, 1, 6, 0, 5, 0, 2, 6, 5, 4, 0, 5, 3, 0, 3, 2, 9, 0, 4, 9, 3, 6, 14, 0, 6, 3, 5, 15, 0, 5, 3, 5, 2, 17, 0, 6, 11, 0, 3, 8, 0, 3, 3, 1, 42, 0, 5, 15, 20, 0, 4, 32, 0, 3, 11, 18, 0, 4, 7, 0, 3, 7, 3, 2, 31, 0, 6, 31, 3, 6, 3, 2, 8, 33, 0, 9, 56, 0, 3, 8, 7, 19, 0, 5, 37, 0, 3, 8, 8, 1
График:
Еще больше график:
Довольно легко доказываются свойства последовательности, что её максимальный член все время возрастает и что в ней бесконечное количество нулей. Или что в ней нет периодов. (Несколько теорем и следствий [тут](https://oeis.org/A181391).)
Логарифмический график:

Прога на Python:
```
A181391 = [0]
last_pos = {}
for i in range(10**4):
new_value = i - last_pos.get(A181391[i], i)
A181391.append(new_value)
last_pos[A181391[i]] = i
# Ehsan Kia, Jun 12 2019
```
Для стартового числа «1» первая сотня такая:
1, 0, 0, 1, 3, 0, 3, 2, 0, 3, 3, 1, 8, 0, 5, 0, 2, 9, 0, 3, 9, 3, 2, 6, 0, 6, 2, 4, 0, 4, 2, 4, 2, 2, 1, 23, 0, 8, 25, 0, 3, 19, 0, 3, 3, 1, 11, 0, 5, 34, 0, 3, 7, 0, 3, 3, 1, 11, 11, 1, 3, 5, 13, 0, 10, 0, 2, 33, 0, 3, 9, 50, 0, 4, 42, 0, 3, 7, 25, 40, 0, 5, 20, 0, 3, 8, 48, 0, 4, 15
График:
Для стартового числа «2» первая сотня такая:
2, 0, 0, 1, 0, 2, 5, 0, 3, 0, 2, 5, 5, 1, 10, 0, 6, 0, 2, 8, 0, 3, 13, 0, 3, 3, 1, 13, 5, 16, 0, 7, 0, 2, 15, 0, 3, 11, 0, 3, 3, 1, 15, 8, 24, 0, 7, 15, 5, 20, 0, 5, 3, 12, 0, 4, 0, 2, 24, 14, 0, 4, 6, 46, 0, 4, 4, 1, 26, 0, 5, 19, 0, 3, 21, 0, 3, 3, 1, 11, 42, 0, 6, 20, 34, 0, 4, 20, 4
График:
### Источники
* [Van Eck's sequence (wikipedia)](https://en.wikipedia.org/wiki/Van_Eck%27s_sequence)
* [The Van Eck Sequence (IB Maths Resources from British International School Phuket)](https://ibmathsresources.com/2019/06/12/the-van-eck-sequence/)
* [A181391 (On-Line Encyclopedia of Integer Sequences)](https://oeis.org/A181391)
* [A171911 (On-Line Encyclopedia of Integer Sequences)](https://oeis.org/A171911)
* [A171912 (On-Line Encyclopedia of Integer Sequences)](https://oeis.org/A171912) | https://habr.com/ru/post/464299/ | null | ru | null |
# Репликация баз данных MySQL. Введение
Редкая современная продакшн система обходится без репликации баз данных. Это мощный инструмент на пути к повышению производительности и отказоустойчивости системы, и современному разработчику очень важно иметь хотя бы общее представление о репликации. В данной статье я поделюсь базовыми знаниями о репликации, и покажу простой пример настройки репликации в MySQL с помощью Docker.

### Что такое репликация, и зачем она нужна
Само по себе, понятие репликации означает процесс синхронизации нескольких копий объекта. В нашем случае, таким объектом является сервер БД, а наибольшую ценность представляют собой сами данные. Если мы имеем два и более серверов, и любым возможным способом поддерживаем синхронизированный набор данных на них — мы реализовали репликацию системы. Даже ручной вариант с `mysqldump -> mysql load` — это также репликация.
Стоит понимать, что сама по себе репликация данных не имеет ценности, и является лишь инструментом решения следующих задач:
* **повышение производительности чтения данных.** С помощью репликации мы сможем поддерживать несколько копий сервера, и распределять между ними нагрузку.
* **повышение отказоустойчивости.** Репликация позволяет избавиться от единственной точки отказа, которой является одиночный сервер БД. В случае аварии на основном сервере, есть возможность быстро переключить нагрузку на резервный.
* **распространение данных.** В современную эпоху глобализации ваше приложение может обслуживать пользователей со всего мира, и мы хотим, чтобы жители и Сиднея, и Хельсинки имели минимальную задержку доступа к нему.
* **распределение нагрузки.** В случае, если БД обслуживает запросы разных типов (быстрые и легкие, медленные и тяжелые), может иметь смысл развести эти запросы по разным серверам, для увеличения эффективности работы каждого типа.
* **тестирование новых конфигураций.** С помощью репликации есть возможность проведения тестирования новых версий сервера БД, изменения параметров конфигурации, и даже изменения типов хранилища данных.
* **резервное копирование.** С помощью репликации есть возможность делать механизмы резервного копирования более гибкими и вносить меньше негативных эффектов в работающую систему.
### Как MySQL реплицирует данные
Процесс репликации подразумевает собой распространение изменений данных с **главного сервера** (обычно он называется как мастер, **master**), на один или более **подчиненных серверов** (слейв, **slave**). Существуют и более сложные конфигурации, в частности с несколькими мастер-серверами, но для каждого изменения на конкретном мастер-сервере остальные мастера условно становятся слейвами, и потребляют эти изменения.
В общем виде, репликация в MySQL состоит из трех шагов:
1. Мастер-сервер записывает изменения данных в журнал. Этот журнал называется двоичным журналом (**binary log**), а изменения — событиями двоичного журнала.
2. Слейв копирует изменения двоичного журнала в свой, который называется журналом ретрансляции (**relay log**).
3. Слейв воспроизводит изменения из журнала ретрансляции, применяя их к собственным данным.
### Виды репликации
Существует два принципиально разных подхода к репликации: **покомандная** и **построчная**. В случае покомандной репликации, в журнал мастера протоколируются запросы изменения данных (INSERT, UPDATE, DELETE), а слейвы в точности воспроизводят те же команды у себя. При построчной же репликации в журнале окажутся непосредственно изменения строк в таблицах, и эти же фактические изменения применятся затем на слейве.
Как нет серебряной пули, так и каждый из этих методов имеет свои преимущества и недостатки. Покомандная репликация проще в реализации и понимании, снижает нагрузку на мастер и на сеть. Но тем не менее, покомандная репликация может приводить к непредсказуемым эффектам, при использовании недетерминированных функций, таких как NOW(), RAND(), и т.д. Могут быть также проблемы, вызванные рассинхронизацией данных между мастером и слейвом. Построчная же репликация приводит к более прогнозируемым результатам, так как фиксируются и воспроизводятся фактические изменения данных. Тем не менее этот метод может значительно увеличивать нагрузку на мастер-сервер, которому приходится фиксировать каждое изменение в журнале, и на сеть, через которую эти изменения распространяются.
В MySQL поддерживаются оба способа репликации, а дефолтный (можно сказать, что и рекомендуемый) изменялся в зависимости от версии. В современных версиях, например MySQL 8, по умолчанию используется построчная репликация.
Второй принцип разделения подходов к репликации — **количество мастер-серверов**. Наличие одного мастер сервера подразумевает, что только он принимает изменения данных, и является неким эталоном, с которого уже распространяются изменения на множество слейвов. В случае же с мастер-мастер репликацией мы получаем как и некоторый профит, так и проблемы. Один из плюсов, например, то, что мы можем давать удаленным клиентам из тех же Сиднея и Хельсинки одинаково быструю возможность записывать свои изменения в базу. Из этого исходит и главный недостаток, если оба клиента одновременно изменили одни и те же данные, чьи изменения считать окончательными, чью транзакцию коммитить, а чью откатывать.
Также, стоит отметить, что наличие мастер-мастер репликации в общем случае не может увеличить производительность записи данных в системе. Представим, что наш единственный мастер может обрабатывать до 1000 запросов в единицу времени. Добавив к нему реплицируемый второй мастер, мы не сможем обрабатывать по 1000 запросов на каждом из них, так как кроме обработки “своих” запросов, им придется применять изменения, сделанные на втором мастере. Что в случае покомандной репликации сделает суммарно возможную нагрузку на оба не больше, чем на самый слабый из них, а с построчной репликацией эффект не совсем предсказуемый, может быть как положительный, так и отрицательный, в зависимости от конкретных условий.
### Пример построения простой репликации в MySQL
А сейчас настало время создать простую конфигурацию репликации в MySQL. Для этого мы будем использовать Docker и MySQL образы из [dockerhub](https://hub.docker.com/_/mysql), а также базу данных [world](https://dev.mysql.com/doc/index-other.html).
Для начала, запустим два контейнера, один из которых позже настроим как мастер, а второй — как слейв. Объединим их в сеть, чтобы они могли обращаться друг к другу.
```
docker run -d --name samplereplication-master -e MYSQL_ALLOW_EMPTY_PASSWORD=true -v ~/path/to/world/dump:/docker-entrypoint-initdb.d mysql:8.0
docker run -d --name samplereplication-slave -e MYSQL_ALLOW_EMPTY_PASSWORD=true mysql:8.0
docker network create samplereplication
docker network connect samplereplication samplereplication-master
docker network connect samplereplication samplereplication-slave
```
Для мастер контейнера указано подключение volume c дампом world.sql, для того, чтобы имитировать наличие некоторой начальной базы на нем. При создании контейнера, mysql загрузит и выполнит sql скрипты, размещенные в директории docker-entrypoint-initdb.d.
Для работы с конфигурационными файлами, нам потребуется текстовый редактор. Можно использовать любой удобный, я предпочитаю vim.
```
docker exec samplereplication-master apt-get update && docker exec samplereplication-master apt-get install -y vim
docker exec samplereplication-slave apt-get update && docker exec samplereplication-slave apt-get install -y vim
```
Первым делом, создадим учетную запись на мастере, которая будет использоваться для репликации:
```
docker exec -it samplereplication-master mysql
```
```
mysql> CREATE USER 'replication'@'%';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'replication'@'%';
```
Далее, изменим конфигурационные файлы для мастер-сервера:
```
docker exec -it samplereplication-master bash
~ vi /etc/mysql/my.cnf
```
В файл my.cnf в секции [mysqld] необходимо добавить следующие параметры:
```
server_id = 1 # назначает серверу уникальный целочисленный идентификатор
log_bin = mysql-bin # включает двоичный журнал и указывает его расположение
```
При включении/выключении двоичного журнала необходима перезагрузка сервера. В случае с Docker перезагружается контейнер.
```
docker restart samplereplication-master
```
Убедимся, что двоичный журнал включен. Конкретные значения, такие как имя файла и позиция, могут отличаться.
```
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 156 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
```
Для того, чтобы начать репликацию данных, необходимо “подтянуть” слейв до состояния мастера. Для этого, нужно временно заблокировать сам мастер, чтобы сделать слепок актуальных данных.
```
mysql> FLUSH TABLES WITH READ LOCK;
```
Далее, с помощью mysqldump сделаем экспорт данных из базы. Конечно, в данном примере можно использовать тот же world.sql, но приблизимся к более реалистичному сценарию.
```
docker exec samplereplication-master mysqldump world > /path/to/dump/on/host/world.sql
```
После этого, необходимо еще раз выполнить команду SHOW MASTER STATUS, и запомнить или записать значения File и Position. Это, так называемые координаты двоичного журнала. Именно от них мы далее укажем стартовать слейву. Начиная с MySQL 5.6 стало возможным использование глобальных идентификаторов транзакций [GTID](https://dev.mysql.com/doc/refman/5.6/en/replication-gtids-concepts.html) вместо координат в виде файл-позиция. Это упростило настройку репликации, а также повысило стабильность ее работы. Но рассмотрение этой темы выходит за рамки данной статьи, и с ней можно ознакомиться в [документации](https://dev.mysql.com/doc/refman/5.6/en/replication-gtids-howto.html).
Теперь можем снова разблокировать мастер:
```
mysql> UNLOCK TABLES;
```
Мастер настроен, и готов реплицироваться на другие сервера. Перейдем теперь к слейву. Первым делом, загрузим в него дамп, полученный с мастера.
```
docker cp /path/to/dump/on/host/world.sql samplereplication-slave:/tmp/world.sql
docker exec -it samplereplication-slave mysql
mysql> CREATE DATABASE `world`;
docker exec -it samplereplication-slave bash
~ mysql world < /tmp/world.sql
```
А затем изменим конфиг слейва, добавив параметры:
```
log_bin = mysql-bin # указываем слейву вести собственный двоичный журнал
server_id = 2 # указываем идентификатор сервера
relay-log = /var/lib/mysql/mysql-relay-bin # указываем расположение журнала ретрансляции
relay-log-index = /var/lib/mysql/mysql-relay-bin.index # этот файл служит перечнем всех имеющихся журналов ретрансляции
read_only = 1 # переводим слейв в режим “только чтение”
```
После этого перезагрузим слейв:
```
docker restart samplereplication-slave
```
И теперь нам нужно указать слейву, какой сервер будет являться для него мастером, и откуда начинать реплицировать данные. Вместо MASTER\_LOG\_FILE и MASTER\_LOG\_POS необходимо подставить значения, полученные из SHOW MASTER STATUS на мастере. Эти параметры вместе называются координатами двоичного журнала.
```
mysql> CHANGE MASTER TO MASTER_HOST='samplereplication-master', MASTER_USER='replication', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=156;
```
Запустим воспроизведение журнала ретрансляции, и проверим статус репликации:
```
mysql> START SLAVE;
mysql> SHOW SLAVE STATUS\G
```
**SLAVE STATUS**
```
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: samplereplication-master
Master_User: replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 156
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 324
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 156
Relay_Log_Space: 533
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: c341beb7-3a33-11eb-9440-0242ac110002
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set, 1 warning (0.00 sec)
```
Если все прошло успешно, ваш статус должен иметь аналогичный вид. Ключевые параметры здесь:
* **Slave\_IO\_State**, **Slave\_SQL\_State** — состояние IO потока, принимающего двоичный журнал с мастера, и состояние потока, применяющего журнал ретрансляции соотвественно. Только наличие обоих потоков свидетельствует об успешном процессе репликации.
* **Read\_Master\_Log\_Pos** — последняя позиция, прочитанная из журнала мастера.
* **Relay\_Master\_Log\_File** — текущий файл журнала мастера.
* **Seconds\_Behind\_Master** — отставание слейва от мастера, в секундах.
* **Last\_IO\_Error**, **Last\_SQL\_Error** — ошибки репликации, если они есть.
Попробуем изменить данные на мастере:
```
docker exec -it samplereplication-master mysql
```
```
mysql> USE world;
mysql> INSERT INTO city (Name, CountryCode, District, Population) VALUES ('Test-Replication', 'ALB', 'Test', 42);
```
И проверить, появились ли они на слейве.
```
docker exec -it samplereplication-slave mysql
```
```
mysql> USE world;
mysql> SELECT * FROM city ORDER BY ID DESC LIMIT 1;
+------+------------------+-------------+----------+------------+
| ID | Name | CountryCode | District | Population |
+------+------------------+-------------+----------+------------+
| 4081 | Test-Replication | ALB | Test | 42 |
+------+------------------+-------------+----------+------------+
1 row in set (0.00 sec)
```
Отлично! Внесенная запись видна и на слейве. Поздравляю, теперь вы создали свою первую репликацию MySQL!
### Заключение
Надеюсь, что в рамках данной статьи мне удалось дать базовое понимание процессов репликации, ознакомить с применением данного инструмента, и попробовать самостоятельно реализовать простой пример репликации в MySQL. Тема репликации, и ее практического применения крайне обширна, и если вас заинтересовала данная тема, могу порекомендовать к изучению следующие источники:
* Доклад [«Как устроена MySQL-репликация»](https://vimeo.com/151816950) Андрея Аксенова (Sphinx)
* Книга “MySQL по максимуму. Оптимизация, репликация, резервное копирование” — Бэрон Шварц, Петр Зайцев, Вадим Ткаченко
* [«Хайлоад»](https://ruhighload.com/) — здесь можно найти конкретные рецепты по репликации данных
Надеюсь, что данная статья была полезна, и буду рад отзывам и комментариям! | https://habr.com/ru/post/532216/ | null | ru | null |
# Check how you remember nullable value types. Let's peek under the hood
Recently nullable reference types have become trendy. Meanwhile, the good old nullable value types are still here and actively used. How well do you remember the nuances of working with them? Let's jog your memory or test your knowledge by reading this article. Examples of C# and IL code, references to the CLI specification, and CoreCLR code are provided. Let's start with an interesting case.
**Note**. If you are interested in nullable reference types, you can read several articles by my colleagues: "[Nullable Reference types in C# 8.0 and static analysis](https://www.viva64.com/en/b/0631/)", "[Nullable Reference will not protect you, and here is the proof](https://www.viva64.com/en/b/0764/)".
Take a look at the sample code below and answer what will be output to the console. And, just as importantly, why. Just let's agree right away that you will answer as it is: without compiler hints, documentation, reading literature, or anything like that. :)
```
static void NullableTest()
{
int? a = null;
object aObj = a;
int? b = new int?();
object bObj = b;
Console.WriteLine(Object.ReferenceEquals(aObj, bObj)); // True or False?
}
```
Well, let's do some thinking. Let's take a few main lines of thought that I think may arise.
**1. Assume that *int?* is a reference type.**
Let's reason, that *int?* is a reference type. In this case, *null* will be stored in *a*, and it will also be stored in *aObj* after assignment. A reference to an object will be stored in *b*. It will also be stored in *bObj* after assignment. As a result, *Object.ReferenceEquals* will take *null* and a non-null reference to the object as arguments, so…
**That needs no saying, the answer is False!**
**2. Assume that *int?* is a value type.**
Or maybe you doubt that *int?* is a reference type? And you are sure of this, despite the *int? a = null* expression? Well, let's go from the other side and start from the fact that *int?* is a value type.
In this case, the expression *int? a = null* looks a bit strange, but let's assume that C# got some extra syntactic sugar. Turns out, *a* stores an object. So does *b*. When initializing *aObj* and *bObj* variables, objects stored in *a* and *b* will be boxed, resulting in different references being stored in *aObj* and *bObj*. So, in the end, *Object.ReferenceEquals* takes references to different objects as arguments, therefore…
**That needs no saying, the answer is False!**
**3. We assume that here we use *Nullable*.**
Let's say you didn't like the options above. Because you know perfectly well that there is no *int?*, but there is a value type *Nullable*, and in this case *Nullable* will be used. You also realize that *a* and *b* will actually have the same objects. With that, you remember that storing values in *aObj* and *bObj* will result in boxing. At long last, we'll get references to different objects. Since *Object.ReferenceEquals* gets references to the different objects…
**That needs no saying, the answer is False!**
**4. ;)**
For those who started from value types — if a suspicion crept into your mind about comparing links, you can view the documentation for *Object.ReferenceEquals* at [docs.microsoft.com](https://docs.microsoft.com/en-us/dotnet/api/system.object.referenceequals?view=netcore-3.1). In particular, it also touches on the topic of value types and boxing/unboxing. Except for the fact that it describes the case, when instances of value types are passed directly to the method, whereas we made the boxing separately, but the main point is the same.
*When comparing value types, if objA and objB are value types, they are boxed before they are passed to the ReferenceEquals method. This means that **if both objA and objB represent the same instance of a value type**, the ReferenceEquals **method nevertheless returns false**, as the following example shows.*
Here we could have ended the article, but the thing is that… the correct answer is **True**.
Well, let's figure it out.
Investigation
-------------
There are two ways — simple and interesting.
### Simple way
*int?* is *Nullable*. Open [documentation on *Nullable*](https://docs.microsoft.com/en-us/dotnet/api/system.nullable-1?view=netcore-3.1), where we look at the section "Boxing and Unboxing". Well, that's all, see the behavior description. But if you want more details, welcome to the interesting path. ;)
### Interesting way
There won't be enough documentation on this path. It describes the behavior, but does not answer the question 'why'?
What are actually *int?* and *null* in the given context? Why does it work like this? Are there different commands used in the IL code or not? Is behavior different at the CLR level? Is it another kind of magic?
Let's start by analyzing the *int?* entity to recall the basics, and gradually get to the initial case analysis. Since C# is a rather "sugary" language, we will sometimes refer to the IL code to get to the bottom of things (yes, C# documentation is not our cup of tea today).
#### int?, Nullable
Here we will look at the basics of nullable value types in general: what they are, what they are compiled into in IL, etc. The answer to the question from the case at the very beginning of the article is discussed in the next section.
Let's look at the following code fragment:
```
int? aVal = null;
int? bVal = new int?();
Nullable cVal = null;
Nullable dVal = new Nullable();
```
Although the initialization of these variables looks different in C#, the same IL code will be generated for all of them.
```
.locals init (valuetype [System.Runtime]System.Nullable`1 V\_0,
valuetype [System.Runtime]System.Nullable`1 V\_1,
valuetype [System.Runtime]System.Nullable`1 V\_2,
valuetype [System.Runtime]System.Nullable`1 V\_3)
// aVal
ldloca.s V\_0
initobj valuetype [System.Runtime]System.Nullable`1
// bVal
ldloca.s V\_1
initobj valuetype [System.Runtime]System.Nullable`1
// cVal
ldloca.s V\_2
initobj valuetype [System.Runtime]System.Nullable`1
// dVal
ldloca.s V\_3
initobj valuetype [System.Runtime]System.Nullable`1
```
As you can see, in C# everything is heartily flavored with syntactic sugar for our greater good. But in fact:
* *int?* is a value type.
* *int?* is the same as *Nullable.* The IL code works with *Nullable*
* *int? aVal = null* is the same as *Nullable aVal =* *new Nullable()*. In IL, this is compiled to an *initobj* instruction that performs default initialization by the loaded address.
Let's consider this code:
```
int? aVal = 62;
```
We're done with the default initialization — we saw the related IL code above. What happens here when we want to initialize *aVal* with the value 62?
Look at the IL code:
```
.locals init (valuetype [System.Runtime]System.Nullable`1 V\_0)
ldloca.s V\_1
ldc.i4.s 62
call instance void valuetype
[System.Runtime]System.Nullable`1::.ctor(!0)
```
Again, nothing complicated — the *aVal* address pushes onto the evaluation stack, as well as the value 62. After the constructor with the signature *Nullable(T)* is called. In other words, the following two statements will be completely identical:
```
int? aVal = 62;
Nullable bVal = new Nullable(62);
```
You can also see this after checking out the IL code again:
```
// int? aVal;
// Nullable bVal;
.locals init (valuetype [System.Runtime]System.Nullable`1 V\_0,
valuetype [System.Runtime]System.Nullable`1 V\_1)
// aVal = 62
ldloca.s V\_0
ldc.i4.s 62
call instance void valuetype
[System.Runtime]System.Nullable`1::.ctor(!0)
// bVal = new Nullable(62)
ldloca.s V\_1
ldc.i4.s 62
call instance void valuetype
[System.Runtime]System.Nullable`1::.ctor(!0)
```
And what about the checks? What does this code represent?
```
bool IsDefault(int? value) => value == null;
```
That's right, for better understanding, we will again refer to the corresponding IL code.
```
.method private hidebysig instance bool
IsDefault(valuetype [System.Runtime]System.Nullable`1 'value')
cil managed
{
.maxstack 8
ldarga.s 'value'
call instance bool valuetype
[System.Runtime]System.Nullable`1::get\_HasValue()
ldc.i4.0
ceq
ret
}
```
As you may have guessed, there is actually no *null* — all that happens is accessing the *Nullable.HasValue* property. In other words, the same logic in C# can be written more explicitly in terms of the entities used, as follows.
```
bool IsDefaultVerbose(Nullable value) => !value.HasValue;
```
IL code:
```
.method private hidebysig instance bool
IsDefaultVerbose(valuetype [System.Runtime]System.Nullable`1 'value')
cil managed
{
.maxstack 8
ldarga.s 'value'
call instance bool valuetype
[System.Runtime]System.Nullable`1::get\_HasValue()
ldc.i4.0
ceq
ret
}
```
Let's recap.
* Nullable value types are implemented using the *Nullable* type;
* *int?* is actually a constructed type of the unbound generic value type *Nullable*;
* *int? a = null* is the initialization of an object of *Nullable* type with the default value, no *null* is actually present here;
* *if (a == null)* — again, there is no *null*, there is a call of the *Nullable.HasValue* property.
The source code of the *Nullable* type can be viewed, for example, on GitHub in the dotnet/runtime repository — a [direct link to the source code file](https://github.com/dotnet/runtime/blob/master/src/libraries/System.Private.CoreLib/src/System/Nullable.cs). There's not much code there, so check it out just for kicks. From there, you can learn (or recall) the following facts.
For convenience, the *Nullable* type defines:
* implicit conversion operator from *T* to *Nullable>;*
* explicit conversion operator from *Nullable* to *T*.
The main logic of work is implemented by two fields (and corresponding properties):
* *T value* — the value itself, the wrapper over which is *Nullable*;
* *bool hasValue* — the flag indicating "whether the wrapper contains a value". It's in quotation marks, since in fact *Nullable* always contains a value of type *T*.
Now that we've refreshed our memory about nullable value types, let's see what's going on with the boxing.
#### Nullable boxing
Let me remind you that when boxing an object of a value type, a new object will be created on the heap. The following code snippet illustrates this behavior:
```
int aVal = 62;
object obj1 = aVal;
object obj2 = aVal;
Console.WriteLine(Object.ReferenceEquals(obj1, obj2));
```
The result of comparing references is expected to be *false*. It is due to 2 boxing operations and creating of 2 objects whose references were stored in *obj1* and *obj2*
Now let's change *int* to *Nullable*.
```
Nullable aVal = 62;
object obj1 = aVal;
object obj2 = aVal;
Console.WriteLine(Object.ReferenceEquals(obj1, obj2));
```
The result is expectedly *false*.
And now, instead of 62, we write the default value.
```
Nullable aVal = new Nullable();
object obj1 = aVal;
object obj2 = aVal;
Console.WriteLine(Object.ReferenceEquals(obj1, obj2));
```
Aaand… the result is unexpectedly *true*. One might wonder that we have all the same 2 boxing operations, two created objects and references to two different objects, but the result is *true*!
Yeah, it's probably sugar again, and something has changed at the IL code level! Let's see.
Example N1.
C# code:
```
int aVal = 62;
object aObj = aVal;
```
IL code:
```
.locals init (int32 V_0,
object V_1)
// aVal = 62
ldc.i4.s 62
stloc.0
// aVal boxing
ldloc.0
box [System.Runtime]System.Int32
// saving the received reference in aObj
stloc.1
```
Example N2.
C# code:
```
Nullable aVal = 62;
object aObj = aVal;
```
IL code:
```
.locals init (valuetype [System.Runtime]System.Nullable`1 V\_0,
object V\_1)
// aVal = new Nullablt(62)
ldloca.s V\_0
ldc.i4.s 62
call instance void
valuetype [System.Runtime]System.Nullable`1::.ctor(!0)
// aVal boxing
ldloc.0
box valuetype [System.Runtime]System.Nullable`1
// saving the received reference in aObj
stloc.1
```
Example N3.
C# code:
```
Nullable aVal = new Nullable();
object aObj = aVal;
```
IL code:
```
.locals init (valuetype [System.Runtime]System.Nullable`1 V\_0,
object V\_1)
// aVal = new Nullable()
ldloca.s V\_0
initobj valuetype [System.Runtime]System.Nullable`1
// aVal boxing
ldloc.0
box valuetype [System.Runtime]System.Nullable`1
// saving the received reference in aObj
stloc.1
```
As we can see, in all cases boxing happens in the same way — values of local variables are pushed onto the evaluation stack (*ldloc* instruction). After that the boxing itself occurs by calling the *box* command, which specifies what type we will be boxing.
Next we refer to [Common Language Infrastructure specification](https://www.ecma-international.org/publications/files/ECMA-ST/ECMA-335.pdf), see the description of the *box* command, and find an interesting note regarding nullable types:
If typeTok is a value type, the box instruction converts val to its boxed form.… *If it is a nullable type, this is done by inspecting val's HasValue property; if it is false, a null reference is pushed onto the stack; otherwise, the result of boxing val's Value property is pushed onto the stack.*
This leads to several conclusions that dot the 'i':
* the state of the *Nullable* object is taken into account (the *HasValue* flag we discussed earlier is checked). If *Nullable* does not contain a value (*HasValue* — *false*), the result of boxing is *null*;
* if *Nullable* contains a value (*HasValue* - *true*), it is not a *Nullable* object that is boxed, but an instance of type *T* that is stored in the *value* field of type *Nullable>;*
* specific logic for handling *Nullable* boxing is not implemented at the C# level or even at the IL level — it is implemented in the CLR.
Let's go back to the examples with *Nullable* that we touched upon above.
First:
```
Nullable aVal = 62;
object obj1 = aVal;
object obj2 = aVal;
Console.WriteLine(Object.ReferenceEquals(obj1, obj2));
```
The state of the instance before the boxing:
* *T* -> *int*;
* *value* -> *62*;
* *hasValue* -> *true*.
The value 62 is boxed twice. As we remember, in this case, instances of the *int* type are boxed, not *Nullable*. Then 2 new objects are created, and 2 references to different objects are obtained, the result of their comparing is *false*.
Second:
```
Nullable aVal = new Nullable();
object obj1 = aVal;
object obj2 = aVal;
Console.WriteLine(Object.ReferenceEquals(obj1, obj2));
```
The state of the instance before the boxing:
* *T* -> *int*;
* *value* -> *default* (in this case, *0* — a default value for *int*);
* *hasValue* -> *false*.
Since is *hasValue* is *false*, objects are not created. The boxing operation returns *null* which is stored in variables *obj1* and *obj2*. Comparing these values is expected to return *true*.
In the original example, which was at the very beginning of the article, exactly the same thing happens:
```
static void NullableTest()
{
int? a = null; // default value of Nullable
object aObj = a; // null
int? b = new int?(); // default value of Nullable
object bObj = b; // null
Console.WriteLine(Object.ReferenceEquals(aObj, bObj)); // null == null
}
```
For the sake of interest, let's look at the CoreCLR source code from the [dotnet/runtime](https://github.com/dotnet/runtime) repository mentioned earlier. We are interested in the file [object.cpp](https://github.com/dotnet/runtime/blob/master/src/coreclr/src/vm/object.cpp), specifically, the *Nullable::Bo*x method with the logic we need:
```
OBJECTREF Nullable::Box(void* srcPtr, MethodTable* nullableMT)
{
CONTRACTL
{
THROWS;
GC_TRIGGERS;
MODE_COOPERATIVE;
}
CONTRACTL_END;
FAULT_NOT_FATAL(); // FIX_NOW: why do we need this?
Nullable* src = (Nullable*) srcPtr;
_ASSERTE(IsNullableType(nullableMT));
// We better have a concrete instantiation,
// or our field offset asserts are not useful
_ASSERTE(!nullableMT->ContainsGenericVariables());
if (!*src->HasValueAddr(nullableMT))
return NULL;
OBJECTREF obj = 0;
GCPROTECT_BEGININTERIOR (src);
MethodTable* argMT = nullableMT->GetInstantiation()[0].AsMethodTable();
obj = argMT->Allocate();
CopyValueClass(obj->UnBox(), src->ValueAddr(nullableMT), argMT);
GCPROTECT_END ();
return obj;
}
```
Here we have everything we discussed earlier. If we don't store the value, we return *NULL*:
```
if (!*src->HasValueAddr(nullableMT))
return NULL;
```
Otherwise we initiate the boxing:
```
OBJECTREF obj = 0;
GCPROTECT_BEGININTERIOR (src);
MethodTable* argMT = nullableMT->GetInstantiation()[0].AsMethodTable();
obj = argMT->Allocate();
CopyValueClass(obj->UnBox(), src->ValueAddr(nullableMT), argMT);
```
Conclusion
----------
You're welcome to show the example from the beginning of the article to your colleagues and friends just for kicks. Will they give the correct answer and justify it? If not, share this article with them. If they do it — well, kudos to them!
I hope it was a small but exciting adventure. :)
**P.S.** Someone might have a question: how did we happen to dig that deep in this topic? We were writing a new diagnostic rule in [PVS-Studio](https://www.viva64.com/en/pvs-studio/) related to *Object.ReferenceEquals* working with arguments, one of which is represented by a value type. Suddenly it turned out that with *Nullable* there is an unexpected subtlety in the behavior when boxing. We looked at the IL code — there was nothing special about the *box*. Checked out the CLI specification — and gotcha! The case promised to be rather exceptional and noteworthy, so here's the article right in front of you.
**P.P.S.** By the way, recently, I have been spending more time on Twitter where I post some interesting code snippets and retweet some news in the .NET world and so on. Feel free to look through it and follow me if you want ([link to the profile](https://twitter.com/_SergVasiliev_)). | https://habr.com/ru/post/525816/ | null | en | null |
# Как установить Ubuntu на ваш Nexus One
Это руководство — для тех, кто хочет установить Ubuntu в качестве подсистемы на свой Nexus One или любое другое устройство с Android (с открытыми правами рута, конечно). Я постарался сделать его как можно более простым, чтобы ни у кого не возникло вопросов.
Как видите, я использовал Nexus One с правами рута. На других устройствах с Android процесс установки может отличаться, но незначительно. В конце концов, не попробуешь — не узнаешь ;)
Также я работаю над запуском Ubuntu на моем HTC Evo 4G и чуть позже опубликую руководство по запуску на сайте HTCEvoHacks.com
Вы можете также попробовать запустить Ubuntu в качестве основной системы на Nexus One или другом Android-устройстве, но это скорее всего будет означать невозможность использования аппарата в качестве телефона, да и камера может перестать работать. Наиболее практично будет запустить Ubuntu поверх Android, что я и покажу.
Установка Ubuntu ни в коей мере не повлияет на Android. Ubuntu будет запущена в фоновом режиме, в виде приложения для Android VNC.
Зачем вообще нужно устанавливать Ubuntu поверх Android? А затем, что можно будет запускать приложения Linux на вашем телефоне! К примеру, это может пригодиться программистам — вряд ли кто-то будет компилировать x86 приложения под Android, а вот под Ubuntu это вполне возможно. Да и при желании телефон можно превратить в компактный веб-сервер.
Да и причин, по которым нужно устанавливать именно Ubuntu именно на Nexus One нет, так что можете поэкспериментировать с другими операционками и устройствами. Только учтите, что в большинстве устройств на Android используются процессоры ARM, а значит, на них системы под платформы x86 или x86-64 запустить нельзя.
*Примечание переводчика: я не стал переводить отдельные куски статьи, типа «что такое chroot?». Думаю, это и так всем понятно.*
#### Итак, как же все-таки установить Ubuntu на Android?
Прежде всего, скачайте ubuntu.zip ([отсюда](http://www.megaupload.com/?d=FALJFT3L) или [отсюда](http://www.filefactory.com/file/b26fg8g/n/ubuntu.zip)) и распакуйте его.
1. Вам нужны будут права рута на вашем устройстве. Если вы не знаете, что это такое и как их получить, погуглите немного (для Nexus One это описывается [здесь](http://nexusonehacks.net/nexus-one-hacks/step-by-step-guide-on-how-to-unlock-bootloader-on-your-nexus-one/)).
2. Надо будет установить последнюю версию Busybox по [этому руководству](http://zedomax.com/blog/2010/07/07/android-hack-how-to-install-busybox-on-your-android/).
3. Вам понадобится Android SDK, который вы можете скачать [отсюда](http://developer.android.com/sdk/index.html).
Скопируйте файлы из архива на карту памяти телефона в папку «ubuntu», после чего отмонтируйте на устройстве карту памяти (Turn off USB storage).
4. Убедитесь, что на устройстве включен режим отладки USB (настройки -> приложения -> разработка), а сам зверек подключен к компьютеру по USB.
5. Теперь нам надо будет запустить консоль ADB. Откройте каталог с Android SDK в консоли, перейдите в директорию tools и выполните команду «adb shell» (или «sudo ./adb shell», если у вас Linux). Если вы увидели символ #, то все сделали правильно.
6. Введите команду «su» для входа в режим рута. Если оно ругнется и выведет ошибку, то это значит, что вы все-таки не получили права рута на своем устройстве и вам надо погуглить на эту тему.
7. При помощи команды «cd /sdcard/ubuntu» перейдем в нашу папку с Ubuntu и запустим установку командой «sh ./ubuntu.sh».
8. Когда программа заверит работу и перед вами предстанет пустая строчка со знаком # в начале, выполните команду «bootubuntu» для запуска Ubuntu.

Если вы видите строчку типа «root@localhost:/#», то вы все сделали верно и запустили-таки Ubuntu! А если что-то пошло не так и вам вывело целую кучу ошибок, то не пугайтесь — у меня так было два дня подряд, так что вы не одиноки. Просто попробуйте повторить все действия, начиная с шага 5. Правда, если у вас не Nexus One, то может и не получиться (к примеру, я до сих пор не могу добиться загрузки в Ubuntu на своем HTC Evo 4G).
#### Как запустить X11
Вообще, я предпочитаю командную строку, потому что GUI жрет слишком много памяти. Но GUI дает возможность использования графических приложений, так что будем его запускать.
9. Первым делом установим Android VNC Viewer (скачать его можно [тут](http://code.google.com/p/android-vnc-viewer/downloads/list)). Если вдруг не умеете устанавливать apk приложения, то воспользуйтесь программой Installer из маркета.
10. Для Ubuntu тоже надо установить пару программ (через терминал):
`apt-get update
apt-get install tightvncserver lxde`
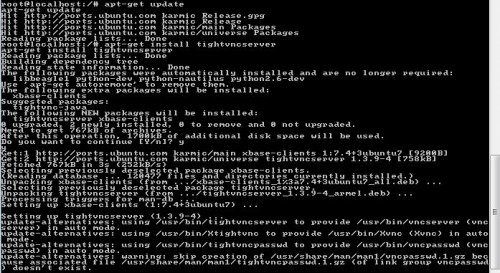
11. Настроим параметры графического режима Ubuntu (также через терминал):
`export USER=root
vncserver -geometry 1024x800`
Разрешение экрана можно указать любое другое.
Когда у вас попросят пароль, можете указать какой хотите, он нужен будет только для подключения к рабочему столу Ubuntu.
12. Теперь надо просто написать вот это:
`cat > /root/.vnc/xstartup
#!/bin/sh
xrdb $HOME/.Xresources
xsetroot -solid grey
icewm &
lxsession`
После чего дважды нажать Ctrl-D и один раз Enter.
13. На устройстве откройте приложение Android VNC. В нем напишите ваш пароль (который вы писали в шаге 11) и укажите порт 5901.
14. Тыкните кнопку Connect и вуаля! перед вами рабочий стол Ubuntu :)
15. Чтобы можно было запускать рабочий стол без дополнительных манипуляций с консолью, выполним в терминале вот эти команды:
`cat > front
export USER=root
cd /
rm -r -f tmp
mkdir tmp
cd /
vncserver -geometry 1024x800`
Разрешение указываем опять любое понравившееся, а после выполнения два раза жмем Ctrl-D и один раз Enter.
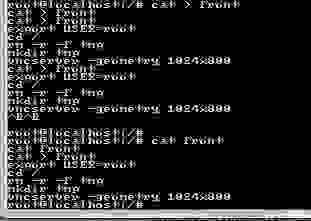
После этого выполним еще две команды:
`cat front /root/.bashrc > temp
cp temp /root/.bashrc`

Все, теперь подключение к рабочему столу Ubuntu будет доступно всегда, если Ubuntu запущена.
#### Как запускать Ubuntu в следующий раз
В эмуляторе терминала под Android напишите это:
`su
bootubuntu`
#### Если у вас есть проблемы с загрузкой
Если у вас возникли какие-то проблемы с загрузкой Ubuntu, то попробуйте скачать [обновленный файл bootubuntu](http://zedomax.com/android/bootubuntu) и через консоль ADB выполнить эти команды для его установки:
`su
cd /sdcard/ubuntu
sh ./ubuntu.sh`
После чего попробуйте запустить Ubuntu.
#### Спасибы
Спасибо разработчикам с XDA Developers за [образ Ubuntu ARM для HTC HD2](http://forum.xda-developers.com/showpost.php?p=5969936&postcount=2).
Огромное спасибо AndroidFanatic за [объяснение](http://www.androidfanatic.com/community-forums.html?func=view&catid=9&id=1615), как запустить X11 через VNC.
И спасибо Saurik (Jay Freeman) за [скрипт Debian G1](http://www.saurik.com/id/10), который помог запустить Ubuntu на Nexus One. | https://habr.com/ru/post/98592/ | null | ru | null |
# Контракты vs Юнит тесты
DISCLAIMER: Эта заметка подразумевает наличие у читателя базовых знаний о юнит тестах, в чем автор этих строк не сомневается, а также базовых знаний о проектирование по контракту, которые можно пополнить начиная [отсюда](http://sergeyteplyakov.blogspot.com/2010/05/design-by-contract.html).
На одном из выступлений, посвященных проектированию по контракту, один из моих коллег задал вполне резонный вопрос о связи контрактов и юнит тестов. Постусловия в контракте класса, как и юнит тесты говорят о гарантиях класса перед его клиентами, а поскольку юнит тесты являются в этом вопросе более мощным механизмом (сложные постусловия выразить в виде контрактов не всегда просто, а иногда и невозможно), то возникает вопрос о необходимости постусловий.
Итак, давайте вкратце рассмотрим, в каком именно месте находится пересечение контрактов и юнит тестов, и постараемся ответить на вопрос: являются ли постусловия избыточными при наличии юнит тестов?
##### **Контракты**
Проблема любого кода заключается в том, что он не самодостаточен. Конечно же, глядя на код сразу же можно увидеть неоптимальность решения, найти банальные глупости или некорректное использование идиом языка программирования, но очень сложно ответить на главный вопрос: **делает ли этот код то, ради чего он был написан или нет?**
Проблема заключается в том, что код сам по себе не является корректным или не корректным, понятие корректности применимо только в связке: код – спецификация. (Подробнее об этом можно почитать в статье: [Проектирование по контракту. Корректность ПО](http://sergeyteplyakov.blogspot.com/2010/05/design-by-contract.html).)
Обычно эта проблема решается с помощью дублирования информации в комментариях, которые очень быстро устаревают и начинают противоречить самому коду; спецификация может быть даже формальной и располагаться на какой-нибудь wiki-странице; она может выражаться в виде утверждений, а также для этих целей могут использоваться юнит тесты.
Последний способ мы рассмотрим позднее, а пока перейдем к предпоследнему: использованию контрактов.
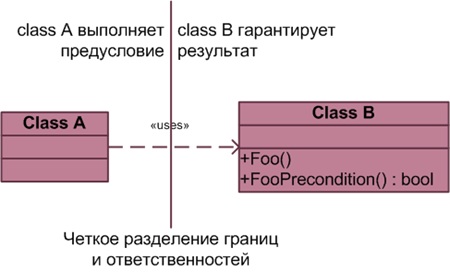
Контракты предназначены для задания спецификации непосредственно в коде в форме утверждений: предусловий, постусловий, инвариантов и утверждений. Сейчас нас не интересуют все тонкости этих вопросов, и на данный момент нам будет достаточно рассмотреть лишь предусловия и постусловия.
Предусловия метода класса B говорят о контракте клиента: **что должны выполнить клиенты класса** **B****, чтобы класс** **B** **приступил к выполнению своих обязанностей**. Постусловия же методов класса B говорят о контракте класса B перед его клиентами: **что гарантирует выполнить класс** **B****, если его клиенты выполнили свою часть контракта**.
Примером контракта может служить контракт метода **Add** интерфейса **IList**: если клиент интерфейса **IList** передаст не нулевой объект (предусловие), то он будет добавлен в данную коллекцию и количество элементов (Count) увеличится на 1 (постусловие).
##### **Юнит тесты**
Юнит тесты являются весьма популярной ныне техникой, при умелом использовании которой разработчик может получить ряд плюшек, начиная от упрощения процесса рефакторинга, заканчивая улучшением дизайна приложения за счет повышения модульности и [ослабления связности](http://sergeyteplyakov.blogspot.com/2011/11/blog-post_23.html).
Еще одним свойством юнит тестов является то, что они по своей сути описывают предполагаемое поведение классов или модулей, что вполне может рассматриваться как их спецификация. Тесты являются замечательной отправной точкой для нового члена команды, который хочет разобраться с работой конкретного класса, ведь с их помощью он увидит способ использования класса, необходимые входные данные и предполагаемые результаты.
Именно последний аспект юнит тестов так сильно напоминает предусловия и постусловия контракта класса. На самом деле, сходство, безусловно, есть, но есть и важные отличия.
**Контракты – декларативны**: они описывают гарантии класса перед его клиентами на высоком уровне, но они ничего не говорят, как эти гарантии обеспечиваются. **Юнит тесты – императивны**: они описывают множество шагов, которые должен выполнить класс или метод, чтобы получить необходимые результаты.
**Контракты – описывают гарантии класса перед его клиентами, а юнит тесты обеспечивают выполнение этих гарантий.**
«Падающий» юнит тест, как и нарушение постусловия, является багом в коде класса, а значит, клиенты наших классов никогда не должны столкнуться с нарушением предусловия. Разработчик класса никак не может гарантировать выполнение предусловий своими клиентами, но он может постараться выполнить свою часть контракта и обеспечить выполнение постусловий. Исключение, возникающее при нарушении постусловия – это такая себе страховка для клиента, которой он никогда не должен воспользоваться. Если метод по какой-то причине не может выполнить свою работу, то он должен четко сигнализировать своим клиентам с помощью соответствующего типа исключения.
Контракты, в отличие от юнит тестов всегда доступны клиентам, и с их помощью клиент может значительно быстрее понять, что ожидать от класса или метода. Даже когда речь идет о внутренней разработке контракты являются более предпочтительным способом описания намерений кода, в то время как на долю юнит тестов останется гарантия их выполнения.
##### **Практический пример. Контракты в интерфейсах**
Необходимость в дополнительных библиотеках для контрактного программирования связана еще и с тем, что системы типов большинства современных языков не столь четко выражают намерения программиста, как хотелось бы. Можно себе только представить насколько уменьшилось бы количество проверок аргументов, будь в нашем распоряжении non-nullable reference типы как в языке Eiffel или в функциональных языках.
Система типов является первым и самым важным средством передачи намерений, однако выразить свои намерения бывает довольно сложно, особенно когда речь касается интерфейсов. Интерфейс моделирует некоторую абстракцию, и каждый его метод обладает определенной семантикой, понять которую можно с помощью его имени, набора аргументов и документации. Другими, не менее важными источниками спецификации интерфейсов могут служить контракты, и, в некотором роде, и юнит тесты.
Давайте рассмотрим метод **Add** интерфейса **IList**, которые были однажды участниками одной из [заметок](http://sergeyteplyakov.blogspot.com/2012/02/lsp.html):
```
// Объявление очень упрощено
[ContractClass(typeof(IListContract<>))]
public interface IList
{
///
/// Adds an item to the ICollection.
///
void Add(T item);
int Count { get; }
// Не нужные члены удалены
}
```
Глядя лишь на имя метода, его параметры, а также на документацию нельзя четко ответить на вопрос о том, какое постусловие метода, т.е. что может ожидать вызывающий код и что должен обеспечить класс, реализующий этот контракт. Обязательно ли должен быть добавлен элемент и только один, или нет. Глядя на контракт – это очевидно, а вот без него понять это очень сложно.
```
[ContractClassFor(typeof(IList<>))]
internal abstract class IListContract : IList
{
void IList.Add(T item)
{
Contract.Ensures(this.Count == (Contract.OldValue(this.Count) + 1),
"Count == Contract.OldValue(Count) + 1");
}
}
```
Конечно, в этом вопросе могут помочь юнит тесты поставщика интерфейса, но проблема здесь заключается в том, что может существовать десятки реализаций интерфейса от разных производителей, что делает юнит тесты не лучшим источником спецификации.
Контракты интерфейсов являются особенно полезными, поскольку основной способ понимания того, для чего служит тот или иной метод класса не работает для интерфейсов. Чтобы понять назначение (семантику) метода класса мы используем reverse engineering, однако этот процесс осложняется для интерфейсов, поскольку для этого нам нужно проанализировать все возможные реализации.
Контракты же дают дополнительную информацию, которую сможет использовать клиент интерфейса, и, что не менее важно, класс, реализующий этот интерфейс.
##### **Заключение**
Контракты и юнит тесты не являются конкурентами друг другу, даже несмотря на то, что и то и другое может использоваться в качестве выражения спецификации. У юнит тестов существует масса забот, в реальной системе их будет довольно много и выкусывать из них элементы спецификации возможно, но не так и просто. Любой инструмент следует использовать по назначению, и наши два героя не исключение.
**Контракты – описывают абстракцию и ничего не говорят о том, как она устроена. Юнит тесты, в свою очередь, гарантируют, что реализация соответствует этому описанию и что гарантии, описанные в контракте, всегда выполняются**. | https://habr.com/ru/post/146702/ | null | ru | null |
# Dashboard Postgresql Overview для postgres_exporter (Prometheus)
Сделал dashboard Postgresql overview для [postgres\_exporter](https://github.com/wrouesnel/postgres_exporter/blob/master/queries.yaml).
Чем отличается от других дашбородов postgres\_exporter?
Я объединил все другие дашборды postgres\_exporter в один.
Этот дашборд показывает общую информацию по кластеру.
Скриншоты и краткая инструкция по установке: postgresql, postgres\_exporter, prometheus, grafana под катом.
Почему бы не использовать [pgwatch2](https://github.com/cybertec-postgresql/pgwatch2) c [influxdb](https://github.com/influxdata/influxdb)?
**Про InfluxDB**
Вот краткий и неполный список проблем на момент версии 1.7 (применимо и к более младшим и скорее всего к старшим, CORE team не поменялась):
* Стабильность. Периодически падает и теряет данные или ломает данные на диске. В последнем случае не может подняться или не может сделать компакшен, от чего количество открытых файлов улетает в космос. Лечится полной остановкой DB и выполнением [команд](https://docs.influxdata.com/influxdb/v1.8/tools/influx_inspect/) в надежде, что хоть одна поможет.
* Скорость. Заявленное в маркетинговых бумажках касается не постоянного рейта, а спайков.
* Не работают внутренние лимиты на запросы вида `SHOW TAG KEYS FROM ALL` или `SHOW EXACT SERIES CARDINALITY` и на средней базе может положить все.
* Потребление ресурсов. Сожрать 256ГБ RAM, закусить 320GB свопа и все равно упасть по OOMу — легко (в момент 6-ти часового запуска, который обусловлен тем, что при старте он читает с диска все индексы в память(InMem)).
* Платная кластеризация (была представлена как часть OSS в версии [0.9 (December 8, 2014)](https://www.influxdata.com/blog/clustering-tags-and-enhancements-to-come-in-0-9-0/) и исчезла в [1.0 (September 26, 2014)](https://www.influxdata.com/blog/one-year-of-influxdb-and-the-road-to-1-0/), став привилегией Enterprise версии).
* Частые breaking changes. За 3 года сменили 5+ движков (закончили это делать на версии [0.9 (December 8, 2014)](https://www.influxdata.com/blog/clustering-tags-and-enhancements-to-come-in-0-9-0/)). Следующий Breaking Changes — это Influx 2.0, где они ушли от База Данных\Ретеншн полиси в сторону [Buckets](https://v2.docs.influxdata.com/v2.0/reference/key-concepts/data-elements/#bucket), поменяли язык запросов на [Flux](https://v2.docs.influxdata.com/v2.0/reference/flux/).
* Периодически выкатывают фичи непонятно зачем сделанные, например сделали [ifql](https://www.influxdata.com/blog/announcing-ifql-v0-0-3/) (Flux) или [Continuous Queries](https://docs.influxdata.com/influxdb/v1.8/query_language/continuous_queries/) (последние выпилили в пользу [task](https://v2.docs.influxdata.com/v2.0/process-data/common-tasks/downsample-data/), по факту те же яйца только с Flux-ом) или Chronograf(буква C в TICK), при живой то графане.
* Безалаберность при подготовке релизов.
* Не самосогласованные утилиты экспорта и импорта из базы — если вы что-то экспортировали через cli, то импортировать обратно файлик не прокатит. restore из backup полностью заменяет всю метаинформацию о базах. Селективности и merge не завезли.
* Телеграф как часть платформы TICK(буква T), например, они ломали поддержку Прометея в телеграфе 1.3.2 ([замена символов](https://github.com/influxdata/telegraf/issues/2937) не попадающих под `[a-z]`). Или, например, невозможность оверрайдить Retention Policy в (input,output).kafka, т.е. организовать полноценную связку `metrics -> telegraf -> kafka -> telegraf -> influx` у вас не получится.
* Капаситор(бука K в TICK), очень неадекватно себя ведет, подстать InfluxDB. Выжирает RAM как не в себя, может говорить, что всё "ок", когда данных нет. Требует нежного обращения и ухода.
### PostgreSQL
```
yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
yum install -y postgresql96 postgresql96-server postgresql96-contrib
```
Инициализируем PostgreSQL.
```
/usr/pgsql-9.6/bin/postgresql96-setup initdb
```
В PostgreSQL добавляем расширение pg\_stat\_statements в postgresql.conf
```
shared_preload_libraries = 'pg_stat_statements'
```
Стартуем PostgreSQL
```
systemctl start postgresql-9.6
```
После этого в БД, выполните следующую команду:
```
CREATE EXTENSION pg_stat_statements
```
Проверяем что pg\_stat\_statements выдает данные.
```
# SELECT * postgres-# FROM pg_stat_statements limit 1;
userid | dbid | queryid | query | calls | total_time | min_time | max_time | mean_time | stddev_time | rows
| shared_blks_hit | shared_blks_read | shared_blks_dirtied | shared_blks_written | local_blks_hit | local_blks_read | local_blks_dirtied | loca
l_blks_written | temp_blks_read | temp_blks_written | blk_read_time | blk_write_time
--------+-------+------------+---------------------------------------+-------+------------+----------+----------+-----------+-------------+-----
-+-----------------+------------------+---------------------+---------------------+----------------+-----------------+--------------------+-----
---------------+----------------+-------------------+---------------+----------------
10 | 16541 | 1215596543 | SELECT pg_catalog.set_config(?, ?, ?) | 1 | 0.043 | 0.043 | 0.043 | 0.043 | 0 | 1
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0
(1 row)
```
### Postgres\_exporter и Prometheus
**Уточнение. Кто будет устанавливать postgres\_exporter из бинарников**
Ознакомьтесь с этим постом: <https://mcs.mail.ru/help/monitoring-with-prometheus/postgresql-exporter>
Конфиг экспортера от mail.ru заточен на k8s
А для большей части запросов в графиках надо подключать queries.yaml
Ссылка на файл в начале статьи есть, но вот в .service нет упоминания extend.query-path
Необходимые файлы вы можете взять здесь: <https://github.com/lest/prometheus-rpm/tree/master/postgres_exporter>
Postgres\_exporter и Prometheus для Redhat систем устанавливаем из этого репозитория: <https://github.com/lest/prometheus-rpm>
Создаем файл `/etc/yum.repos.d/prometheus.repo` со следующим содержимым:
```
[prometheus]
name=prometheus
baseurl=https://packagecloud.io/prometheus-rpm/release/el/$releasever/$basearch
repo_gpgcheck=1
enabled=1
gpgkey=https://packagecloud.io/prometheus-rpm/release/gpgkey
https://raw.githubusercontent.com/lest/prometheus-rpm/master/RPM-GPG-KEY-prometheus-rpm
gpgcheck=1
metadata_expire=300
```
Устанавливаем prometheus2 и postgres\_exporter
```
yum install -y prometheus2 postgres_exporter
```
В файле prometheus.yml для работы с postgres\_exporter в scrape\_configs добавьте следующую секцию:
```
scrape_configs:
- job_name: postgresql
static_configs:
- targets: ['ip-адрес-postgres-exporter:9187']
labels:
alias: postgres
```
Запускаем prometheus2 и postgres\_exporter
```
systemctl start prometheus
systemctl start postgres_exporter
```
Проверяем статус служб prometheus2 и postgres\_exporter
```
systemctl status prometheus
systemctl status postgres_exporter
```
Проверяем статус job postgresql в web-интерфейсе prometheus
Если job postgresql в состоянии down, то либо у вас не работает служба postgres\_exporter либо нет коннективности от prometheus до ip-адрес-postgres-exporter:9187
Если у вас ip-адрес-postgres-exporter:9187 открывается, но метрики такие как под спойлером, значит у postgres\_exporter либо неправильный конфиг либо он не смог подключится к PostgreSQL:
**Заголовок спойлера**
```
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 9.6892e-05
go_gc_duration_seconds{quantile="0.25"} 0.000155543
go_gc_duration_seconds{quantile="0.5"} 0.000238513
go_gc_duration_seconds{quantile="0.75"} 0.000296884
go_gc_duration_seconds{quantile="1"} 0.000348549
go_gc_duration_seconds_sum 0.001311971
go_gc_duration_seconds_count 6
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 12
# HELP go_info Information about the Go environment.
# TYPE go_info gauge
go_info{version="go1.11"} 1
# HELP go_memstats_alloc_bytes Number of bytes allocated and still in use.
# TYPE go_memstats_alloc_bytes gauge
go_memstats_alloc_bytes 3.0422e+06
# HELP go_memstats_alloc_bytes_total Total number of bytes allocated, even if freed.
# TYPE go_memstats_alloc_bytes_total counter
go_memstats_alloc_bytes_total 1.8356112e+07
# HELP go_memstats_buck_hash_sys_bytes Number of bytes used by the profiling bucket hash table.
# TYPE go_memstats_buck_hash_sys_bytes gauge
go_memstats_buck_hash_sys_bytes 1.44586e+06
# HELP go_memstats_frees_total Total number of frees.
# TYPE go_memstats_frees_total counter
go_memstats_frees_total 42761
# HELP go_memstats_gc_cpu_fraction The fraction of this program's available CPU time used by the GC since the program started.
# TYPE go_memstats_gc_cpu_fraction gauge
go_memstats_gc_cpu_fraction 5.846483467559864e-06
# HELP go_memstats_gc_sys_bytes Number of bytes used for garbage collection system metadata.
# TYPE go_memstats_gc_sys_bytes gauge
go_memstats_gc_sys_bytes 2.371584e+06
# HELP go_memstats_heap_alloc_bytes Number of heap bytes allocated and still in use.
# TYPE go_memstats_heap_alloc_bytes gauge
go_memstats_heap_alloc_bytes 3.0422e+06
# HELP go_memstats_heap_idle_bytes Number of heap bytes waiting to be used.
# TYPE go_memstats_heap_idle_bytes gauge
go_memstats_heap_idle_bytes 6.1734912e+07
# HELP go_memstats_heap_inuse_bytes Number of heap bytes that are in use.
# TYPE go_memstats_heap_inuse_bytes gauge
go_memstats_heap_inuse_bytes 4.096e+06
# HELP go_memstats_heap_objects Number of allocated objects.
# TYPE go_memstats_heap_objects gauge
go_memstats_heap_objects 7956
# HELP go_memstats_heap_released_bytes Number of heap bytes released to OS.
# TYPE go_memstats_heap_released_bytes gauge
go_memstats_heap_released_bytes 6.070272e+07
# HELP go_memstats_heap_sys_bytes Number of heap bytes obtained from system.
# TYPE go_memstats_heap_sys_bytes gauge
go_memstats_heap_sys_bytes 6.5830912e+07
# HELP go_memstats_last_gc_time_seconds Number of seconds since 1970 of last garbage collection.
# TYPE go_memstats_last_gc_time_seconds gauge
go_memstats_last_gc_time_seconds 1.5943804951377325e+09
# HELP go_memstats_lookups_total Total number of pointer lookups.
# TYPE go_memstats_lookups_total counter
go_memstats_lookups_total 0
# HELP go_memstats_mallocs_total Total number of mallocs.
# TYPE go_memstats_mallocs_total counter
go_memstats_mallocs_total 50717
# HELP go_memstats_mcache_inuse_bytes Number of bytes in use by mcache structures.
# TYPE go_memstats_mcache_inuse_bytes gauge
go_memstats_mcache_inuse_bytes 27648
# HELP go_memstats_mcache_sys_bytes Number of bytes used for mcache structures obtained from system.
# TYPE go_memstats_mcache_sys_bytes gauge
go_memstats_mcache_sys_bytes 32768
# HELP go_memstats_mspan_inuse_bytes Number of bytes in use by mspan structures.
# TYPE go_memstats_mspan_inuse_bytes gauge
go_memstats_mspan_inuse_bytes 41496
# HELP go_memstats_mspan_sys_bytes Number of bytes used for mspan structures obtained from system.
# TYPE go_memstats_mspan_sys_bytes gauge
go_memstats_mspan_sys_bytes 49152
# HELP go_memstats_next_gc_bytes Number of heap bytes when next garbage collection will take place.
# TYPE go_memstats_next_gc_bytes gauge
go_memstats_next_gc_bytes 4.194304e+06
# HELP go_memstats_other_sys_bytes Number of bytes used for other system allocations.
# TYPE go_memstats_other_sys_bytes gauge
go_memstats_other_sys_bytes 1.538324e+06
# HELP go_memstats_stack_inuse_bytes Number of bytes in use by the stack allocator.
# TYPE go_memstats_stack_inuse_bytes gauge
go_memstats_stack_inuse_bytes 1.277952e+06
# HELP go_memstats_stack_sys_bytes Number of bytes obtained from system for stack allocator.
# TYPE go_memstats_stack_sys_bytes gauge
go_memstats_stack_sys_bytes 1.277952e+06
# HELP go_memstats_sys_bytes Number of bytes obtained from system.
# TYPE go_memstats_sys_bytes gauge
go_memstats_sys_bytes 7.2546552e+07
# HELP go_threads Number of OS threads created.
# TYPE go_threads gauge
go_threads 24
# HELP pg_exporter_last_scrape_duration_seconds Duration of the last scrape of metrics from PostgresSQL.
# TYPE pg_exporter_last_scrape_duration_seconds gauge
pg_exporter_last_scrape_duration_seconds 15.653763958
# HELP pg_exporter_last_scrape_error Whether the last scrape of metrics from PostgreSQL resulted in an error (1 for error, 0 for success).
# TYPE pg_exporter_last_scrape_error gauge
pg_exporter_last_scrape_error 1
# HELP pg_exporter_scrapes_total Total number of times PostgresSQL was scraped for metrics.
# TYPE pg_exporter_scrapes_total counter
pg_exporter_scrapes_total 30
# HELP pg_up Whether the last scrape of metrics from PostgreSQL was able to connect to the server (1 for yes, 0 for no).
# TYPE pg_up gauge
pg_up 0
# HELP postgres_exporter_build_info A metric with a constant '1' value labeled by version, revision, branch, and goversion from which postgres_exporter was built.
# TYPE postgres_exporter_build_info gauge
postgres_exporter_build_info{branch="",goversion="go1.11",revision="",version="0.0.1"} 1
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 0.17
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 1024
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 9
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 8.781824e+06
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.59438020205e+09
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 1.1585536e+08
# HELP process_virtual_memory_max_bytes Maximum amount of virtual memory available in bytes.
# TYPE process_virtual_memory_max_bytes gauge
process_virtual_memory_max_bytes -1
# HELP promhttp_metric_handler_requests_in_flight Current number of scrapes being served.
# TYPE promhttp_metric_handler_requests_in_flight gauge
promhttp_metric_handler_requests_in_flight 2
# HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.
# TYPE promhttp_metric_handler_requests_total counter
promhttp_metric_handler_requests_total{code="200"} 26
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
```
То нужно смотреть логи службы postgres\_exporter:
```
journalctl --full --no-pager -u postgres_exporter
```
### Grafana
Создаем файл `/etc/yum.repos.d/grafana.repo` со следующим содержимым:
```
[grafana]
name=grafana
baseurl=https://packages.grafana.com/oss/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packages.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
```
Устанавливаем grafana
```
yum -y install grafana initscripts urw-fonts wget
```
Запускаем grafana
```
systemctl start grafana-server
```
Берем dashboard здесь
<https://grafana.com/grafana/dashboards/12273>
Исходный код тут:
<https://github.com/patsevanton/postgresql_overview_postgres_exporter>





P.S. В этом дашборде мне не хватает знаний в promql и postgresql. Поэтому я надеюсь на то что вы мне поможете советом как улучшить дашборд или сделаете pull request.
P.S. Как руки дойдут, планирую сделать дашборд для информации по конкретной БД внутри PostgreSQL.
P.S. В телеграме пользователь MAdMAx прислал проверку на распухание индексов. Запрос показывает насколько общий размер индексов таблицы больше объема данных в таблице.
```
/* Схема, таблица, её размер в байтах */ WITH usertables AS
(SELECT nspname AS schemaname,
relname AS tablename,
pg_relation_size(C.oid) AS bytes
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE C.relkind = 'r' /* r - "обычная" таблица */
AND C.relhasindex = TRUE /* у которой есть индексы */
AND nspname NOT IN ('pg_catalog',
'information_schema')/* не системная */ ), /*Схема, таблица, название индекса, его размер в байтах */ userindexes AS
(SELECT schemaname,
tablename,
indexname,
pg_relation_size(C.oid) AS bytes
FROM pg_indexes I
INNER JOIN pg_class C ON I.indexname = C.relname
WHERE schemaname NOT IN ('pg_catalog',
'information_schema') )
SELECT schemaname,
tablename,
pg_size_pretty(S.bytes) AS table_size,
index_count,
pg_size_pretty(sum_bytes) AS sum_index_size,
round((sum_bytes / bytes)::numeric, 1) AS ratio /* коэффициент, на который общий объем всех индексов таблицы, отличается от её объема*/
FROM
(SELECT T.schemaname,
T.tablename,
T.bytes, /* размер таблицы */ count(I.indexname) AS index_count, /* кол-во индексов в таблице */ sum(I.bytes) AS sum_bytes /* их суммарный размер */
FROM usertables T
INNER JOIN userindexes I ON (T.schemaname = I.schemaname
AND T.tablename = I.tablename)
WHERE T.bytes > 0
AND I.bytes > 0 /* исключаем таблицы и индексы с размером 0 */
GROUP BY T.schemaname,
T.tablename,
T.bytes) S
WHERE (sum_bytes / bytes) > 2 /* желаемое значение коэффициента */
AND bytes > 10000000 /* желательный размер таблицы в байтах */
AND S.schemaname NOT IN ('partitions')/* исключение схем */
ORDER BY 6 DESC
```
Дальше нужно отельным запросом смотреть на индексы "подозрительной" таблицы
```
SELECT nspname || '.' || C.relname AS "relation",
pg_size_pretty(pg_relation_size(C.oid)) AS "size",
I.indexrelname, I.idx_tup_read, I.idx_tup_fetch
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
left join pg_tablespace T on C.reltablespace = T.oid
left join pg_stat_user_indexes I on (I.schemaname = nspname and I.indexrelname = C.relname)
WHERE
relkind = 'i' /*только индексы*/
and I.relname = '%TABLE_NAME%'
ORDER BY 2 DESC
``` | https://habr.com/ru/post/501696/ | null | ru | null |
# Нерациональное использование Digitalocean
После раздачи паков студентам Github’ом решил использовать 100 баксов в Digitalocean со смыслом, а точнее в качестве облачного хранилища — качалки всяких мелочей. Памяти, конечно, в дроплетах не так уж и много, (20 — 40 гБ в бюджетных вариантах), но они на то и мелочи, что весят немного. В качестве образа был выбран привычный Ubuntu 14.04 x32, в качестве качалки был избран transmission с его удобной веб-мордой, а как способ шаринга данных был взят apache2 с [webdav](https://ru.wikipedia.org/wiki/WebDAV). Получился Яндекс.Диск на стероидах (ssd, торрент, качающий напрямую в диск, возможности настроить больше плюшек), но с меньшим объемом жесткого диска.
Для начала был создан [дроплет](https://cloud.digitalocean.com/droplets/new) с голой системой. Следом к нему был получен доступ по ssh и установлены нужные программы.
```
sudo apt-get update
sudo apt-get install apache2 transmission-daemon
```
Следом была создана папка, которая и будет хранить данные:
```
mkdir /webdav
```
Далее все проходило в 2 этапа: настройка apache2 и настройка transmission.
Настройка apache2 проходила следующим образом:
Сначала были активированы за bash модули apache, связанные с webdav:
```
sudo a2enmod dav
sudo a2enmod dav_fs
```
Затем в файл /etc/apache2/sites-enabled/000-defaut.conf я записал следующее содержимое:
```
Alias /webdav /webdav
DAV On
Allow from all
Satisfy any
```
В конце настройки apache был перезагружен:
```
sudo service apache2 restart
```
Следом был настроен transmission, в нем нужно было выключить whitelist IP адресов и поменять логин-пароль пользователей веб-морды, а так же выставить папку зарузок — /webdav (та папка, что мы создали ранее и указали в apache). Проблема возникла в том, что при редактировании конфигурации transmission-daemon данные конфигов не сохранялись. Проблема объяснялась в /etc/transmission-daemon/README.json — при выходе конфигурационные файлы перезаписывались, поэтому сначала нужно было остановить демона, затем отредактировать конфиг, затем запустить демона.
```
sudo service transmission-daemon stop
```
Строчки файла .config/transmission-daemon/settings.json, в которые были внесены изменения:
```
"rpc-authentication-required": true,
"rpc-whitelist-enabled": false,
"rpc-username": "",
"rpc-password": "",
"download-dir": "/webdav",
```
Затем был запущен демон:
```
sudo service transmission-daemon start
```
Всё! Сервер запущен, веб-морда доступна по порту 9091 (можно изменить в settings.json).
Дальнейшие операции по монтированию папки различались на различных системах, но в целом это было что-то вроде
```
mount_webdav http:///webdav /mount/
```
Скорость дроплета я не измерял, но 500 МБ архив был скачан за пару минут, которые я наливал кофе. | https://habr.com/ru/post/241247/ | null | ru | null |
# Переезд проекта с SVN на Git
Много лет подряд в качестве системы контроля версий для большого количества проектов использовали только SVN. Но наступил момент, когда количество разработчиков на одном из проектов заметно увеличилось, проект уже запущен в работу, и нужно как активно разрабатывать параллельно несколько фич, так и фиксить уже имеющиеся баги в оперативном режиме. Единый trunk в SVN не позволяет этого делать, а организация бранчей в нем же превращает жизнь разработчиков в ад. Поэтому было принято решение о переезде этого проекта с SVN на Git.
#### 1. Сервер для центрального репозитория
Несмотря на то, что Git — система распределенная, это не отменяет необходимости наличия центрального репозитория, с которым в конечном итоге будут сихронизироваться все разработчики, а также с которого будут разворачиваться как тестовые сборки, так и будет производиться деплой на production. Поэтому нам необходим в первую очередь сервер. Поскольку проект коммерческий, то хранить исходники на чужих серверах как-то не очень хотелось, значит надо поднять свой сервер для хранения git-репозиториев. Сам сервер работает на Gentoo, поэтому нам нужно поставить на него весь необходимый софт.
Здесь выбор особо не велик — gitosis либо gitolite. Поскольку gitosis уже не разрабатывается несколько лет как, то выбор пал на gitolite.
##### 1.1. Установка gitolite
Ставим gitolite 3.03 на сервер:
```
$ emerge gitolite
```
При этом создается пользователь git, который и будет владеть всеми будущими репозиториями.
##### 1.2. Первичная настройка
Теперь нам нужно сгенерировать rsa-ключ для доступа к админскому репозиторию (gitolite хранит все настройки в git-репозитории) и сохранить публичный ключ в общедоступном месте:
```
$ ssh-keygen -t rsa
$ cp ~/.ssh/id_rsa.pub /tmp/admin.pub
```
После этого можно собственно инициализировать gitolite:
```
$ su git
$ cd
$ mkdir -p bin
$ gitolite/install -ln
$ gitolite setup -pk /tmp/admin.pub
```
##### 1.3. Создание репозитория для проекта
Сервер установлен, возвращаемся в своего пользователя и клонируем себе репозиторий с конфигами:
```
$ cd
$ git clone git@server:gitolite-admin.git
```
Здесь и далее server — это hostname сервера, на котором установлен gitolite и хранятся репозитории.
Открываем появившийся файл gitolite-admin/conf/gitolite.conf и добавляем в конец описание репозитория для нашего проекта (пока только с одним пользователем):
```
repo project
RW+ = javer
```
После этого сохраняем наши изменения. Находясь в gitolite-admin, выполняем:
```
$ git add .
$ git commit -am "Repository for project added"
$ git push origin master
```
gitolite автоматически проинициализирует все репозитории, которые описаны в конфиге и еще не существуют.
Все, gitolite установлен и первично настроен, репозиторий для нашего проекта создан, можно двигаться дальше.
#### 2. Импорт проекта из SVN
Непосредственно преобразование SVN-репозитория в Git осуществляется с помощью команды
```
$ git svn clone
```
Для этого git должен быть собран с поддержкой perl.
##### 2.1. Определение стартовой ревизии
Наш проект Project находится в SVN репозитории наряду с множеством других проектов. Поскольку номера ревизий сквозные на весь репозиторий, то находим в svn log первый коммит, который касается именно нашего проекта, и запоминаем. Это нужно для ускорения импорта, чтобы не сканировались все ревизии, начиная с первой. В нашем случае это ревизия 19815, поэтому к команде выше добавляется опция:
```
-r19815:HEAD
```
##### 2.2. Соответствие SVN-пользователей с Git-пользователями
Далее нам необходимо составить соответствие SVN-пользователей с будущими Git-пользователями, чтобы они при импорте успешно заменились. Для этого где-нибудь создаем файл authors примерно такого содержания:
```
javer = javer
developer1 = developer1
...
```
Где [email protected] — это e-mail git-пользователя (в git-е каждый пользователь идентифицируется именем и электропочтой).
Соответственно, к команде импорта добавляется опция:
```
--authors-file=/path/to/authors
```
##### 2.3. Исключение ненужных файлов
Едем дальше. В нашем проекте были случайные коммиты больших бинарных файлов, которые в новом репозитории нам не нужны. При импорте их можно исключить опцией:
```
--ignore-paths="\.(avi|mov)$"
```
##### 2.4. Дополнительные опции
Также нам нужен пользователь в SVN, от имени которого будет производиться доступ к репозиторию:
```
--username javer
```
Добавляем еще опцию --no-metadata, которая нужна для того, чтобы в логе коммитов в каждом комментарии не было добавлений вида:
```
git-svn-id: svn://svn.domain.tld/repo/project/trunk@19815 e13dc095-444b-fa4e-8f24-06838a8318a5
```
В SVN-репозитории нашего проекта полезная информация хранилась только в trunk, немногочисленные бранчи содержали временный код, который в свое время путем невероятных усилий все-таки был смержен с trunk-ом, поэтому более они нам не нужны.
##### 2.5. Клонирование проекта из SVN-репозитория
Собираем все вместе и запускаем:
```
$ cd
$ mkdir project && cd project
$ git svn clone -r19815:HEAD --authors-file=/path/to/authors --ignore-paths="\.(avi|mov)$" --username javer --no-metadata svn://svn.domain.tld/repo/project/trunk .
```
Где svn://svn.domain.tld/repo/project/trunk — адрес trunk-а нашего проекта в SVN-репозитории.
Начинается процесс клонирования, длительность которого зависит от количества коммитов и их объема. В нашем случае было около 4.5 тыс. коммитов, и на их клонирование понадобилось около двух часов.
##### 2.6. Исключение более ненужных файлов и каталогов
По завершении клонирования в нашем каталоге project мы получаем полный клон проекта со всей историей коммитов. После клонирования может внезапно обнаружиться, что мы склонировали также какой-то каталог, который в новом репозитории нам не нужен, например, потому что мы выделим его в отдельный репозиторий. Удалить каталог и все упоминания о нем в истории можно так:
```
$ git filter-branch --tree-filter 'rm -rf unneeded_directory' -f HEAD
```
Этот процесс также достаточно длительный, поскольку пересматривается каждый коммит в отдельности, и в нашем случае это занимало около 1 секунды на каждый коммит.
##### 2.7. Удаление пустых коммитов
В результате всех предыдущих действий мы получили наш склонированный проект со всей историей коммитов, среди которых теперь имеются пустые коммиты, то есть коммиты без единого измененного файла. Они появились в результате исключения некоторых файлов через опцию ignore-paths, либо же из-за последующей фильтрации через tree-filter. Для удаления таких пустых коммитов делаем:
```
$ git filter-branch --commit-filter 'git_commit_non_empty_tree "$@"' HEAD
```
Эта операция занимает примерно столько же времени, как и tree-filter.
##### 2.8. Пустые каталоги и svn:ignore
Далее, нам необходимо сконвертировать бывшие svn:ignore в новые .gitignore. Это делается так:
```
$ git svn create-ignore
```
Не забываем, что git не хранит информацию о каталогах, только о файлах, поэтому во всех пустых каталогах нужно создать пустой файл .gitignore, после чего закоммитить все эти файлы:
```
$ git add .
$ git commit -am "Added .gitignore"
```
##### 2.9. Удаление упоминания об SVN
Поскольку наш проект переезжает с SVN на Git окончательно, то удаляем всяческие упоминания об SVN:
```
$ git branch -rd git-svn
$ git config --remove-section svn-remote.svn
$ git config --remove-section svn
$ rm -rf .git/svn
```
##### 2.10. svn:externals
В нашем проекте некоторые symfony-плагины, как кастомные, так и публичные, были подключены через svn:externals. Поскольку в git такой механизм отсутствует, будем использовать submodules для этого. С публичными плагинами проще:
```
$ git submodule add git://github.com/propelorm/sfPropelORMPlugin.git plugins/sfPropelORMPlugin
$ git submodule add git://github.com/n1k0/npAssetsOptimizerPlugin.git plugins/npAssetsOptimizerPlugin
```
Со своими плагинами чуть сложнее — для них нужно создать отдельные репозитории аналогично описанному выше, после чего точно также подключить к нашему проекту:
```
$ git submodule add git@server:customPlugin.git plugins/customPlugin
```
После подключения submodules их необходимо склонировать в каталог проекта:
```
$ git submodule update --init --recursive
$ git commit -am "Added submodules: sfPropelORMPlugin, npAssetsOptimizerPlugin, customPlugin"
```
##### 2.11. Отправка локальной копии проекта на сервер
Перед отправкой нашего проекта на сервер для ускорения этой операции оптимизируем его:
```
$ git gc
```
Подключаем к проекту наш новый репозиторий:
```
$ git remote add origin git@server:project.git
```
И, наконец, заливаем локальную копию проекта на сервер:
```
$ git push origin master
```
##### 2.12. Обновление submodules в будущем
Поскольку в отличие от svn:externals каждый submodule указывает на конкретный коммит, то при простом обновлении локальной копии через
```
$ git pull
```
содержимое submodules обновляться не будет. Их обновление производится следующим образом:
```
$ git submodule update
```
В случае, если были изменения:
```
$ git submodule foreach git pull
$ git commit -am "Updated submodules"
```
#### 3. Настройка прав доступа к репозиторию
##### 3.1. Пользовательские ключи
Поскольку доступ к удаленному git-репозиторию осуществляется через ssh, то теперь каждый разработчик должен сгенерировать на своей машине rsa-ключ.
###### 3.1.1. Linux/Unix
В случае Linux/Unix или Git bash под Windows это делается так:
```
$ ssh-keygen -t rsa
```
После чего полученный публичный ключ ~/.ssh/id\_rsa.pub передается админу репозитория.
###### 3.1.2. Windows
В случае Windows также можно воспользоваться puttygen, который можно скачать здесь: [puttygen](http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html).
Запускаем puttygen, нажимаем Generate, возим мышкой по окну, пока ключ не будет сгенерирован, потом в поле комментария указываем к чему этот ключ, вводим пароль доступа к ключу при необходимости. После этого копируем содержимое поля Public key, сохраняем в файл user.pub и передаем админу репозитория.
Потом нажимаем Save private key и сохраняем этот ключ в укромном месте для дальнейшего в использования, например, в TortoiseGit.
Также в меню Conversions выбираем пункт Export OpenSSH key и сохраняем его в файл под названием C:\Users\USERNAME\.ssh\id\_rsa, где USERNAME — имя вашего пользователя в системе. Этот ключ нам будет нужен при использовании git из командной строки.
##### 3.2. Настройка прав доступа
Полученные на предыдущем шаге публичные ключи пользователей помещаем в админский репозиторий в каталог ~/gitolite-admin/keydir/ в файлы с названиями USERNAME.pub, где USERNAME — имя пользователя.
Поскольку gitolite имеет достаточно широкие возможности по настройке, используем их для настройки прав доступа к репозиторию нашего проекта. Для этого редактируем файл ~/gitolite-admin/conf/gitolite.conf и приводим его к виду:
`@owners = javer
@project_developers = user1 user2 user3
@deploy = root@production
repo project
- master$ = @project_developers
- refs/tags = @project_developers
RW+ = @project_developers @owners
R = @deploy`
Этим мы даем полный доступ для группы пользователей owners. Для группы project\_developers — также полный доступ с возможностью создания своих веток, за исключением записи в ветку master и создания тегов. Для группы deploy, которая используется для деплоя на продакшн, разрешаем доступ только для чтения.
В конце не забываем сохранить все изменения:
```
$ git add .
$ git commit -am "New users for project: user1, user2, user3..."
$ git push origin master
```
#### 4. Установка и настройка на машинах разработчиков
Серверная часть полностью готова, теперь остается установить и настроить git-клиент на машинах разработчиков.
#### 4.1. Linux/Unix
Тут все просто — устанавливаем git с помощью своего любимого менеджера пакетов.
После установки не забываем указать свое имя и e-mail, такие же, которые использовались при импорте из SVN:
```
$ git config --global user.name "javer"
$ git config --global user.email "[email protected]"
```
#### 4.2. Windows
Здесь существует несколько различных клиентов, я пока остановился на TortoiseGit.
Перед его установкой сначала нужно установить [msysgit](http://code.google.com/p/msysgit/downloads/list?can=2&q=%22Full+installer+for+official+Git+for+Windows%22), желательно самой последней версии, несмотря на надпись Beta. Во время установки на вопрос об интеграции в систему я советую выбирать пункт Git Bash and Command prompt, чтобы можно было запускать git как из Git bash, так и с командной строки.
После этого устаналиваем сам [TortoiseGit](http://code.google.com/p/tortoisegit/downloads/list). Я советую устанавливать последнюю стабильную версию, но не nightly-build.
Теперь заходим в настройки TortoiseGit (правой клик по любому каталогу и TortoiseGit->Settings), находим там раздел Git и справа в блоке User Info вписываем свои имя и e-mail.
#### 5. Переезд завершен. Приступаем к работе
Все, на этом процедура переезда с SVN на Git завершена.
Каждый разработчик клонирует себе на машину проект и начинает с ним работать.
Я бы посоветовал разработчикам ознакомиться с этими статьями:
* [Про Git на пальцах (для переходящих с SVN)](http://habrahabr.ru/post/68341/)
* [Инструкция-шпаргалка для начинающих](http://habrahabr.ru/post/123111/) | https://habr.com/ru/post/144626/ | null | ru | null |
# Headless удаленный рабочий стол за NAT для разработчиков и бесплатно (часть 2, примеры)
Heredes — библиотека для разработчиков
--------------------------------------
**Heredes** — библиотека для облегчения решения ряда конкретных задач, связанных с прямым обменом данных в сети без использования ipv6.
Из встроенных возможностей можно выделить:
* облегченная установка соединения между двумя ПК не зависимо от того есть ли у них «белые» адреса или они за NAT;
* гарантированная (с подтверждением) прямая передача файлов с одного ПК на другой;
* реалтайм аудиосвязь между ПК за NAT;
* реалтайм демонстрация экрана ПК за NAT;
* проброс мыши и клавиатуры между ПК;
* прямая передача произвольных пользовательских данных между ПК за NAT;
* запись звука с удаленного ПК и сохранение скрина с удаленного монитора на локальной машине.
Тема пробоя NAT, на самом деле, не нова. Но она требует от разработчика определенных навыков, наличие STUN сервера, а лучше двух, и времени для реализации.
Heredes берет на себя вышеописанную часть, облегчая тем самым разработку приложений и позволяя сосредоточиться на задаче, будь-то прямой файлообмен, мессенджер или функционал удаленного администрирования, встроенный в Ваше приложение.
Скептики в целом могут возразить — зачем Heredes если есть WebRTC с крайне широкими возможностями.
Тем не менее, если звезды зажигают, значит это кому нибудь нужно.
Прежде всего Heredes не нацелен на межбраузерное взаимодействие и в этом его преимущество в десктопных приложениях. А именно — простота использования при написании «настольных» приложений, неприхотливость в вопросах ресурсов и да, мы постарались облегчить работу с тем, что не стандартизовано в WebRTC.
Разумеется, примеры реализации с помощью WebRTC найдутся и для нашего функционала (например, Screen Capture API реализует захват экрана частично или полностью) и может показаться что нет разницы, чье готовое решение использовать. Попробуйте, выберите наиболее удобное при разработке десктопного приложения решение именно для Вас.
Мы нацелены не на WEB — в приоритете именно десктоп и использование библиотеки в приложениях не требующих установки, экономичность в ресурсах и скорость выполнения задач.
Перейдем к краткому обзору?
**Как писать с использованием Heredes**
Часть 1. Прямая передача файлов за NAT это просто. Или 9 строк кода для передачи 8 эксабайт данных… или чуть более?
-------------------------------------------------------------------------------------------------------------------
Рассмотрим как просто установить прямое соединение на примере вполне жизнеспособной задачи — передача фала между двумя ПК за NAT без использования облачных хранилищ, торрентов, файлообменных ресурсов, личных промежуточных серверов и других вспомогательных средств.
Ситуация вполне жизненная, кому из нас никогда не требовалось передать несколько эксабайт по сети? Задача даже при наличии промежуточного облачного хранилища еще та… ускорим ее в 2 раза, как минимум, за несколько минут...
Пример реализации на С++ ниже
```
//обмен файлами почти неограниченного размера между клиентами за NAT
#pragma comment(linker, "/SUBSYSTEM:windows /ENTRY:mainCRTStartup")
#pragma comment(lib, "C:\\WORK\\P2P\\HEREDES\\heredes.lib")
#include
#include
int main(void)
{
InitIONLibrary(); //инициализация библиотек и интерфейсов HEREDES
DWORD Valid = 0;
DWORD Id = 0;
DWORD HightDword = 0;
RegIONId(&Valid, &Id); //регистрация нового пользователя
//запуск асинхроннго сервера для ожидания входящих соединений
HANDLE hConn = IONWaitConnection(&Valid, &Id, NULL);
//запуск синхронного интерфейса для передачи файла
DWORD lowDword =IONSendFileToId(&Valid, &Id, NULL, &HightDword);
IONTerminate(hConn); //прерывание ожидания входящих соединений
CloseIONHandle(hConn);
return 0;
}
```
Не правда ли, очень лаконично вышло?
Есть явные недостатки, такие как:
* Heredes не нацелен на установление прямого коннекта между двумя ПК из одной локальной сети;
* могут возникнуть сложности в случае если оба ПК за симметричным NAT;
* данный пример не предусматривает передачу нескольких файлов за раз.
Тем не менее есть и очевидный плюс — это вполне рабочий пример с функционалом применимым даже в виде «как есть из коробки». Как минимум удобно перекинуть на край света файл размером… в пределах 8 ЭБт, хотя я лично и не пробовал пробросить такой файл — попробуете Вы и расскажите чем закончилось ))…
Мало кто поспорит с тем что программа копирования файла из каталога в каталог на локальном ПК потребует не на много меньше стулочасов сил, обладая куда меньшей ценностью как самостоятельный продукт.
[Скачать пример](https://download.brodilla.com/index.php?utm_source=habr&utm_campaign=heredes&utm_content=filexchang&utm_term=300821)
Часть 2. Простой UDP сервер и UDP клиент за NAT
-----------------------------------------------
Предположим наличие вполне жизненной ситуации — есть некий ПК, находящийся за NAT и мы хотим что б он периодически принимал входящие соединения из внешнего мира, а конкретно миром для него будет наш же UDP клиент. От слов к делу.
Пример реализации на С++ ниже
```
//UDP сервер, который в течении минуты слушает сеть и ожидает входящих соединений
#pragma comment(linker, "/SUBSYSTEM:windows /ENTRY:mainCRTStartup")
#pragma comment(lib, "C:\\HEREDES\\heredes.lib")
#include
#include
int main(void)
{
InitIONLibrary(); //инициализация библиотек и интерфейсов HEREDES
DWORD Valid = 0;
DWORD Id = 0;
DWORD HightDword = 0;
RegIONId(&Valid, &Id); //регистрация нового пользователя
//запуск асинхроннго сервера для ожидания входящих соединений
HANDLE hConn = IONWaitConnection(&Valid, &Id, NULL);
HANDLE hEv=CreateEventA(NULL,1,NULL,NULL);
WaitForSingleObject(hEv,60000);
CloseHandle(hEv);
IONTerminate(hConn); //прерывание ожидания входящих соединений
CloseIONHandlw(hConn); //прерывание ожидания входящих соединений
return 0;
}
//простейший UDP клиент, который ничего не делает
#pragma comment(linker, "/SUBSYSTEM:windows /ENTRY:mainCRTStartup")
#pragma comment(lib, "C:\\HEREDES\\heredes.lib")
#include
#include
int main(void)
{
InitIONLibrary(); //инициализация библиотек и интерфейсов HEREDES
CHAR SecKey[8]; //8-ми байтный массив с ключем шифрования
DWORD Valid = 0;
DWORD Id = 0;
HANDLE hConn;
RegIONId(&Valid, &Id); //регистрация нового пользователя
hConn=CreateIONHandle();
if (IONConnectToId(hConn, NULL, &Valid, &Id, &SecKey, NULL, NULL, NULL)==TRUE){
MessageBoxA(NULL,"коннет установлен","состояние подключения", 48);
HANDLE hEv=CreateEventA(NULL,1,NULL,NULL);
WaitForSingleObject(hEv,60000);
CloseHandle(hEv);
}else{
MessageBoxA(NULL,"ошибка соединения","состояние подключения", 48);
};
IONDisconnect(hConn); //прерывание ожидания входящих соединений
CloseIONHandle(hConn); //прерывание ожидания входящих соединений
return 0;
}
```
Данный пример очень бесполезен. Причина в том что такой сервер будет тихо реагировать на входящие соединения и обрабатывать все «по умолчанию», то есть игнорировать )), а клиент так же тихо удерживать соединение.
Часть 3. МФУ или клиент и сервер в одном лице
---------------------------------------------
Бывает нужно, что бы приложение могло как реагировать на входящие, так и инициировать исходящие подключение. Такой подход кажется где то даже более универсальным. Напишем еще один бестолковый пример, но на этот раз толк от него будет — в дальнейшем этот код мы будем использовать как каркас, на который вешать всех собак.
```
//клиент-сервер over NAT
#pragma comment(linker, "/SUBSYSTEM:windows /ENTRY:mainCRTStartup")
#pragma comment(lib, "C:\\HEREDES\\heredes.lib")
#include
#include
int main(void)
{
InitIONLibrary(); //инициализация библиотек и интерфейсов HEREDES
CHAR SecKey[8]; //8-ми байтный массив с ключем шифрования
DWORD Valid = 0;
DWORD Id = 0;
RegIONId(&Valid, &Id); //регистрация нового пользователя
HANDLE hCON\_IN=IONWaitConnection(&Valid, &Id, NULL);
HANDLE hCON\_OUT=CreateIONHandle();
if (IONConnectToId(hCON\_OUT, NULL, &Valid, &Id, &SecKey, NULL, NULL, NULL==TRUE)){
}else{
MessageBoxA(NULL,"ошибка соединения","состояние подключения", 48);
};
IONTerminate(hCON\_IN);
IONDisconnect(hCON\_OUT);
CloseIONHandle(hCON\_IN);
CloseIONHandle(hCON\_OUT);
FreeConsole();
return 0;
}
```
Часть 4. Простой консольный мессенджер за NAT
---------------------------------------------
После примера бесполезного будет очень полезно написать что то наглядное. В предыдущих примерах и функция сервера IONWaitConnection и функция клиента IONConnectToId содержат параметр CBUserData установленный в NULL. тем не менее это не обязано быть так и должно так не быть если клиент-сервер обмениваются данными нестандартного формата. При передаче пользовательских данных это должна быть функция обработчик уведомления о пользовательских данных
```
//написать за NAT
#pragma comment(linker, "/SUBSYSTEM:windows /ENTRY:mainCRTStartup")
#pragma comment(lib, "C:\\HEREDES\\heredes.lib")
#include
#include
HANDLE hOutput;
CBUDATA \_\_stdcall UserDataProc(HANDLE hConn, LPVOID pAddrUserData, int datSize)
{
DWORD inSize;
WriteConsoleA(hOutput,pAddrUserData, datSize, &inSize, NULL);
return 0;
}
int main(void)
{
InitIONLibrary(); //инициализация библиотек и интерфейсов HEREDES
CHAR buffer[0x3E0]; //максимальный размер блока пользовательских данных 0х3Е0
DWORD bSize=0;
CHAR SecKey[8]; //8-ми байтный массив с ключем шифрования
DWORD Valid = 0;
DWORD Id = 0;
RegIONId(&Valid, &Id); //регистрация нового пользователя
AllocConsole();
HANDLE hInput=GetStdHandle(-10);
hOutput=GetStdHandle(-11);
HANDLE hCON\_IN=IONWaitConnection(&Valid, &Id, (CBUDATA) &UserDataProc);
HANDLE hCON\_OUT=CreateIONHandle();
if (IONConnectToId(hCON\_OUT, NULL, &Valid, &Id, &SecKey, \
NULL, NULL, (CBUDATA) &UserDataProc)==TRUE){
while (bSize!=-1){
ReadConsoleA(hInput,&buffer,0x3E0,&bSize,NULL);
if (IONGetStatus(hCON\_OUT)==6) {SendUserData(hCON\_OUT,&buffer,bSize);};
if (IONGetStatus(hCON\_IN)==6) {SendUserData(hCON\_IN,&buffer,bSize);};
}
}else{
MessageBoxA(NULL,"ошибка соединения","состояние подключения", 48);
};
IONTerminate(hCON\_IN);
IONDisconnect(hCON\_OUT);
CloseIONHandle(hCON\_IN);
CloseIONHandle(hCON\_OUT);
FreeConsole();
return 0;
}
```
Пусть интерфейс и неказист и прост, но это уже кое-что не оторванное от жизни.
[Скачать пример](https://download.brodilla.com/index.php?utm_source=habr&utm_campaign=heredes&utm_content=cmessange&utm_term=300821)
Часть 5. А поговорить? Попробуем реализовать простую звонику за NAT
-------------------------------------------------------------------
Притянем за уши потребность — пусть нам нужно не много и не мало а позвонить другу в деревню за NAT.
Heredes реализует передачу PCM аудио почти так же просто как и пользовательские данные.
```
//поговорить за NAT
#pragma comment(linker, "/SUBSYSTEM:windows /ENTRY:mainCRTStartup")
#pragma comment(lib, "C:\\HEREDES\\heredes.lib")
#include
#include
int main(void)
{
InitIONLibrary(); //инициализация библиотек и интерфейсов HEREDES
CHAR SecKey[8]; //8-ми байтный массив с ключем шифрования
DWORD Valid = 0;
DWORD Id = 0;
RegIONId(&Valid, &Id); //регистрация нового пользователя
HANDLE hCON\_IN=IONWaitConnection(&Valid, &Id, NULL);
HANDLE hCON\_OUT=CreateIONHandle();
IONSetAudioParam(hCON\_OUT,3,"aud\_in.wav","aud\_sp.wav",NULL);
IONSetAudioParam(hCON\_IN,3,"aud\_in.wav","aud\_sp.wav",NULL);
if (IONConnectToId(hCON\_OUT, NULL, &Valid, &Id, &SecKey, NULL, NULL, NULL)==TRUE){
IONStartAudioStream(hCON\_OUT,11025);
HANDLE hEv=CreateEventA(NULL,1,NULL,NULL);
WaitForSingleObject(hEv,60000);
CloseHandle(hEv);
}else{
MessageBoxA(NULL,"ошибка соединения","состояние подключения", 48);
};
IONStopAudioStream(hCON\_IN);
IONStopAudioStream(hCON\_OUT);
IONTerminate(hCON\_IN);
IONDisconnect(hCON\_OUT);
CloseIONHandle(hCON\_IN);
CloseIONHandle(hCON\_OUT);
return 0;
}
```
[Скачать пример](https://download.brodilla.com/index.php?utm_source=habr&utm_campaign=heredes&utm_content=phone&utm_term=300821)
Часть 6. От разговоров к администрированию или CMD over NAT
-----------------------------------------------------------
Еще один относительно быстро реализуемый пример это командная строка за NAT или удаленное перенаправление ввода/вывода. Приступим?
```
//CMD за NAT
#pragma comment(linker, "/SUBSYSTEM:windows /ENTRY:mainCRTStartup")
#pragma comment(lib, "C:\\HEREDES\\heredes.lib")
#include
#include
CHAR buffer[0x3E0]; //максимальный размер блока пользовательских данных 0х3Е0
HANDLE hOutput;
HANDLE outpipe;
HANDLE inpipe;
HANDLE hEv;
HANDLE hCON\_IN;
HANDLE hCON\_OUT;
CBUDATA \_\_stdcall UserDataProc(HANDLE hConn, LPVOID pAddrUserData, int datSize)
{
DWORD cRcv=1;
if (IONGetStatus(hCON\_IN)==6){
SendCommandLine(outpipe,pAddrUserData);
WaitForSingleObject(hEv,2000);
while(cRcv!=0){
PeekNamedPipe(inpipe,NULL,NULL,NULL,&cRcv,NULL);
if (cRcv!=0){
ReadFile(inpipe,&buffer,cRcv,&cRcv,NULL);
}
SendUserData(hCON\_IN,&buffer,cRcv);
}
};
if (IONGetStatus(hCON\_OUT)==6){
WriteConsoleA(hOutput,pAddrUserData,datSize,&cRcv,NULL);
};
DWORD inSize;
WriteConsoleA(hOutput,pAddrUserData, datSize, &inSize, NULL);
return 0;
}
int main(void)
{
HANDLE hInCons;
HANDLE hOutCons;
hEv=CreateEventA(NULL,1,NULL,NULL);
StartHiddenConsoleProcess("cmd.exe",&outpipe, &inpipe, &hOutCons, &hInCons);
InitIONLibrary(); //инициализация библиотек и интерфейсов HEREDES
DWORD bSize=0;
CHAR SecKey[8]; //8-ми байтный массив с ключем шифрования
DWORD Valid = 0;
DWORD Id = 0;
RegIONId(&Valid, &Id); //регистрация нового пользователя
hCON\_IN=IONWaitConnection(&Valid, &Id, (CBUDATA) &UserDataProc);
hCON\_OUT=CreateIONHandle();
if (IONConnectToId(hCON\_OUT, NULL, &Valid, &Id, &SecKey, \
NULL, NULL, (CBUDATA) &UserDataProc)==TRUE){
AllocConsole();
HANDLE hInput=GetStdHandle(-10);
hOutput=GetStdHandle(-11);
WriteConsoleA(hOutput,"REMOTE CMD >",12,&bSize,NULL);
while (bSize!=-1){
ReadConsoleA(hInput,&buffer,0x3E0,&bSize,NULL);
SendUserData(hCON\_OUT,&buffer,bSize);
}
FreeConsole();
}else{
MessageBoxA(NULL,"ошибка соединения","состояние подключения", 48);
};
IONTerminate(hCON\_IN);
IONDisconnect(hCON\_OUT);
CloseIONHandle(hCON\_IN);
CloseIONHandle(hCON\_OUT);
return 0;
}
```
Из новенького и интересненького здесь функции StartHiddenConsoleProcess и SendCommandLine. Для деталей смотрите документацию (ссылки внизу).
[Скачать пример](https://download.brodilla.com/index.php?utm_source=habr&utm_campaign=heredes&utm_content=remcmd&utm_term=300821)
Часть 7. Займемся фотографией. Сфоткаем часть экрана удаленного рабочего стола
------------------------------------------------------------------------------
Вот мы и приблизились к названию библиотеки и, собственно, к чему все шло до этого. Удаленный рабочий стол без головы. Все слышали про безголовые хромы, проекты вроде селениум, но в памяти не всплывает всадник безголовы — Бил в виде Windows отрисованный на виртуальном DC.
Библиотека так же содержит функционал имитации действий мышей и клавиатур на удаленном ПК, но в данном примере мы ограничимся отрисовкой на виртуальном DC рабочего стола удаленной машины. После чего сохраним содержимое DC в BMP-файл.
Со времени выхода [первой](https://habr.com/ru/post/574300/) статьи кое-что изменилось. Теперь мы все же заморачиваемся с указанием не только координат и размера пробрасываемого прямоугольника, но и указанием DC с которого мы срисовываем. Опустив ностальгические размышления о том, как мы докатились до обезглавливания Windows перейдем к делу.
```
//безголовый скрин
#pragma comment(linker, "/SUBSYSTEM:windows /ENTRY:mainCRTStartup")
#pragma comment(lib, "C:\\HEREDES\\heredes.lib")
#include
#include
int main(void)
{
InitIONLibrary(); //инициализация библиотек и интерфейсов HEREDES
CHAR SecKey[8]; //8-ми байтный массив с ключем шифрования
DWORD Valid = 0;
DWORD Id = 0;
RegIONId(&Valid, &Id); //регистрация нового пользователя
HDC hCDC;
HDC hDC=GetDC(NULL);
HANDLE hCON\_IN=IONWaitConnection(&Valid, &Id, NULL);
HANDLE hCON\_OUT=CreateIONHandle();
SetINVISTParam(hCON\_IN,hDC,64, 64, 256, 256,NULL);//установим параметры прямоугольника
//разрешенного для отправки по сети
if (IONConnectToId(hCON\_OUT, NULL, &Valid, &Id, &SecKey, NULL, NULL, NULL)==TRUE)
{
hCDC=CreateCompatibleDC(hDC);
StartRemoteINVIST(hCON\_OUT,hCDC,512, 512, 1); //размеры изображения
//я решил увеличить,
//но можно было оставить и оригинальные или напротив уменьшить
for (int i=0; i<3; i++){GetRemoteINVISTService(hCON\_OUT);}; //получаю видео из 3х кадра
//из за специфики кодека
int sB=SaveINVISTtoBPM(hCON\_OUT,"screen.bmp");
}else{
MessageBoxA(NULL,"ошибка соединения","состояние подключения", 48);
};
DeleteDC(hCDC);
IONTerminate(hCON\_IN);
IONDisconnect(hCON\_OUT);
CloseIONHandle(hCON\_IN);
CloseIONHandle(hCON\_OUT);
return 0;
}
```
В данном примере я получил несколько кадров для будущего битмепа. Вы можете получить 1,2 и сделать выводы из того что выйдет — лучше один раз пощупать чем 10 раз посмотреть.
[Скачать пример](https://download.brodilla.com/index.php?utm_source=habr&utm_campaign=heredes&utm_content=rembmp&utm_term=300821)
Часть 8. И в заключение статьи — напишем свой маленький TeamViewer.
-------------------------------------------------------------------
Графические приложения для удаленного управления Windows посредством еще более графического интерфейса — прочно засели в быту. Попробуем реализовать этот функционал в нашем маленьком приложении RDP over NAT
```
//свой маленький TeamViewer
#pragma comment(linker, "/SUBSYSTEM:windows /ENTRY:mainCRTStartup")
#pragma comment(lib, "C:\\HEREDES\\heredes.lib")
#include
#include
HANDLE hEv;
WNDPROC \_\_stdcall ProcClose(HWND hwnd, UINT uMsg, WPARAM wParam, LPARAM lParam){
SetEvent(hEv);
return 0;
}
int main(void)
{
hEv=CreateEventA(NULL,1,NULL,NULL);
InitIONLibrary(); //инициализация библиотек и интерфейсов HEREDES
CHAR SecKey[8]; //8-ми байтный массив с ключем шифрования
DWORD Valid = 0;
DWORD Id = 0;
RegIONId(&Valid, &Id); //регистрация нового пользователя
HDC hCDC;
HDC hDC=GetDC(NULL);
HANDLE hCON\_IN=IONWaitConnection(&Valid, &Id, NULL);
HANDLE hCON\_OUT=CreateIONHandle();
SetINVISTParam(hCON\_IN,hDC,64, 64, GetSystemMetrics(0), GetSystemMetrics(1),NULL); //установим параметры прямоугольника
if (IONConnectToId(hCON\_OUT, NULL, &Valid, &Id, &SecKey, NULL, NULL, NULL)==TRUE)
{
hCDC=CreateCompatibleDC(hDC);
StartRemoteINVIST(hCON\_OUT,hCDC,512, 512, 1); //размеры изображения я решил увеличить,
//но можно было оставить и оригинальные или напротив уменьшить
HWND hWin;
CreateINPRT(hCON\_OUT, 64, 32, 512, 300, 0x00CF0000, NULL, &hWin, 1, (WNDPROC) ProcClose);
WaitForSingleObject(hEv,-1);
}else{
MessageBoxA(NULL,"ошибка соединения","состояние подключения", 48);
};
CloseHandle(hEv);
IONTerminate(hCON\_IN);
IONDisconnect(hCON\_OUT);
CloseIONHandle(hCON\_IN);
CloseIONHandle(hCON\_OUT);
return 0;
}
```
[Скачать пример](https://download.brodilla.com/index.php?utm_source=habr&utm_campaign=heredes&utm_content=rdponat&utm_term=300821)
В данном случае мы познакомились с функцией CreateINPRT — это по сути встроенный интерактивный плейер реального времени. Этот же пример можно было реализовать посредством отрисовки на DC какого либо окна и использовать функции передачи мыши и клавиатуры библиотеки Heredes, но так, по моему, даже удобнее.
Ссылки: [на проект](https://brodilla.com/ru/heredes?utm_source=habr&utm_medium=refferal&utm_campaign=heredes;utm_content=text;utm_term=300821), [скачать архив](https://download.brodilla.com/heredes_dev.zip?utm_source=habr&utm_campaign=heredes&utm_content=post2;utm_term=300821), [документация](https://brodilla.com/ru/heredes/about?utm_source=habr&utm_medium=refferal&utm_campaign=heredes&utm_content=text&utm_term=300821). | https://habr.com/ru/post/575442/ | null | ru | null |
# Использование ядерной регрессии для прогноза спроса в сетевых магазинах
Доброго времени суток, уважаемые хабровчане! В данной публикации речь пойдет о модели прогноза спроса на товары в сетевых магазинах и ее реализации на C++.
Постановка задачи
=================
Допустим, у нас имеется сеть магазинов, в каждый из которых завозят товары. Товары (для модели прогноза) попадают в каждый магазин произвольным образом. За некий период времени мы имеем статистику — сколько в каждом магазине продано тех или иных товаров. Требуется спрогнозировать продажи товаров за период времени, аналогичный выбранному, для всех магазинов по всем товарам, которые в них не завозились.
**Примечания и допущения постановки задачи*** Товары, завезенные в магазины, не заканчивались за период сбора статистики.
* Если в магазин завезли новые для него товары (при том, что старые товары остались), продажи не перераспределяться между старыми и новыми товарами. Статистика по старым товарам останется прежней, просто кто-то дополнительно покупает новые товары. Прогнозирование при невыполнении этого условия потребует дополнительных данных о том, как насыщается спрос при увеличении количества товаров.
* Период, за который собирали статистику, и период, для которого нужно сделать прогноз, идентичны по спросу.
Метод решения задачи
====================
Задача решается с помощью метода ядерной регрессии (используя формулу Надарая-Ватсона). В качестве функции ядра используется квадратическая ядерная функция с шириной окна .
«Расстояние» между товарами с разной ценой считается как:

«Расстояние» между двумя магазинами считается как произведение задаваемого вручную коэффициента  и отрицательного десятичного логарифма взвешенной корреляции. Взвешенная корреляция вычисляется как произведение отношения количества типов товаров, которые есть в обоих магазинах к общему количеству типов товаров (вес «правдоподобия») и корреляции количеств проданных товаров (тех, которые общие для этих магазинов):


Расстояние между двумя товарами в двух разных магазинах считается как корень из суммы квадратов расстояний между данными товарами и между данными магазинами.
Задаваемый вручную коэффициент для «расстояния» между двумя магазинами совместно с задаваемой шириной окна позволяют учитывать «расстояния» между товарами и магазинами в нужной нам пропорции.
Я запрограммировал два метода прогнозирования. «Общий» метод учитывает все проданные товары во всех магазинах. «Крестообразный» метод учитывает все проданные товары в текущем магазине и количества проданных прогнозируемых товаров в других магазинах.
Разница в результатах прогнозирования разными методами есть, но, на первый взгляд, небольшая (проверялась при окне , коэффициенте расстояния магазинов  на матрице 20 магазинов \* 20 товаров). При этом, при больших окнах функции ядра второй метод значительно быстрее первого.
Исходный код
============
Статистика представляет собой таблицу, в которой записаны количества проданных товаров (столбцы соответствуют товарам, строки — магазинам). Если товар не поступал в магазин, в соответствующей ячейке таблицы располагается "-1". Для удобства в первой строке таблицы указаны цены товаров.
**Заголовочный файл класса хранения данных DataHolder.h**
```
#pragma once
#include
class DataHolder
{
protected:
// prices vector
std::vector prices;
// mask of initial data: 1 if has init and 0 if not
std::vector> maskData;
// initial data matrix
std::vector> initData;
// full data matrix (with prognosis)
std::vector> fullData;
public:
DataHolder() {}
virtual ~DataHolder() {}
// Load init data from csv file
// calculate range between shops
// @param filename - file path of loading data
void loadData(std::string filename);
// Save full data in csv file
// @param filename - file path of saving data
void saveData(std::string filename);
};
```
**Исходный файл класса хранения данных DataHolder.cpp**
```
#include "DataHolder.h"
void DataHolder::loadData(std::string filename)
{
// Here is loading data from filename to initData
fullData = initData;
}
void DataHolder::saveData(std::string filename)
{
// Here is saving data from fullData to filename
}
```
**Заголовочный файл класса расчета расстояний Prognoser.h**
```
#pragma once
#include
#include
#include "DataHolder.h"
class RangeCalculator :
public DataHolder
{
friend class Prognoser;
private:
// count of shops
int shopsCount;
// count of products
int productsCount;
// marix of range squares between prices
std::vector> priceRanges;
// marix of range squares between shops
std::vector> shopsRanges;
// sums of earn of shops
std::vector shopEarnSums;
public:
RangeCalculator() {}
virtual ~RangeCalculator() {}
// calculate ranges and advanced parameters
void calculateRanges();
private:
// calculate and fill priceRanges
void fillPriceRanges();
// calculate and fill shopsRanges
void fillShopsRanges();
// calculate range between shops
// @param i - first shop index
// @param j - second shop index
double calculateShopsRange(int i, int j);
// calculate earnings of shop
// @param i - shop index
double calculateShopEarnings(int i);
// calculate shopEarnSums
void calculateShopEarnSums();
// calculate range between different shops
// @param i - first shop index
// @param j - second shop index
double calculateShopsRangeByCorrelation(int i, int j);
// calculate correlation between two vectors
double calculateCorrelation(const std::vector &X, const std::vector &Y);
};
```
**Исходный файл класса расчета расстояний Prognoser.cpp**
```
#include "RangeCalculator.h"
void RangeCalculator::calculateRanges()
{
shopsCount = initData.size();
productsCount = initData[0].size();
calculateShopEarnSums();
fillPriceRanges();
fillShopsRanges();
}
void RangeCalculator::fillPriceRanges()
{
// initialize vector
priceRanges.resize(productsCount);
for (int i = 0; i < productsCount; ++i)
priceRanges[i].resize(productsCount);
// calculate and fill
double range = 0, range2 = 0;
for (int i = 0; i < productsCount; ++i)
{
priceRanges[i][i] = 0;
for (int j = i + 1; j < productsCount; ++j)
{
range = log10((double)prices[i] / (double)prices[j]);
range2 = range * range;
priceRanges[i][j] = range2;
priceRanges[j][i] = range2;
}
}
}
void RangeCalculator::fillShopsRanges()
{
// initialize vector
shopsRanges.resize(shopsCount);
for (int i = 0; i < shopsCount; ++i)
shopsRanges[i].resize(shopsCount);
// calculate and fill
double range = 0, range2 = 0;
for (int i = 0; i < shopsCount; ++i)
{
shopsRanges[i][i] = 0;
for (int j = i + 1; j < shopsCount; ++j)
{
range = calculateShopsRange(i, j);
range2 = range * range;
shopsRanges[i][j] = range2;
shopsRanges[j][i] = range2;
}
}
}
double RangeCalculator::calculateShopsRange(int i, int j)
{
if (i != j)
{
return calculateShopsRangeByCorrelation(i, j);
}
else
return 0;
}
double RangeCalculator::calculateShopsRangeByCorrelation(int i, int j)
{
// collects products of shops, that are in both shops
std::vector maskX = maskData[i]; // mask of products in first shop
std::vector maskY = maskData[j]; // mask of products in second shop
std::vector maskXY(productsCount); // mask of products in both shops
for (int k = 0; k < productsCount; ++k)
maskXY[k] = maskX[k] \* maskY[k];
// count of products in first shop
int vecLen = std::accumulate(maskXY.begin(), maskXY.end(), 0);
// weight of correlation calculation
double weightOfCalculation = (double)vecLen / (double)productsCount;
// calculating X and Y vectors
std::vector X(vecLen);
std::vector Y(vecLen);
int p = 0;
for (int k = 0; k < productsCount; ++k)
{
if (maskXY[k])
{
X[p] = initData[i][k];
Y[p] = initData[j][k];
++p;
}
}
// calculating range between shops
double correlation = calculateCorrelation(X, Y); // correlation
double weightedCorrelation = correlation \* weightOfCalculation;
double range = -log10(fabs(weightedCorrelation) + 1e-10);
return range;
}
double RangeCalculator::calculateCorrelation(const std::vector &X, const std::vector &Y)
{
int count = X.size();
double sumX = (double)std::accumulate(X.begin(), X.end(), 0);
double sumY = (double)std::accumulate(Y.begin(), Y.end(), 0);
double midX = sumX / (double)count;
double midY = sumY / (double)count;
double cor1 = 0, cor2 = 0, cor3 = 0;
for (int i = 0; i < count; ++i)
{
cor1 += (X[i] - midX) \* (Y[i] - midY);
cor2 += (X[i] - midX) \* (X[i] - midX);
cor3 += (Y[i] - midY) \* (Y[i] - midY);
}
double cor = cor1 / sqrt(cor2 \* cor3);
return cor;
}
double RangeCalculator::calculateShopEarnings(int i)
{
double earnings = 0;
for (int j = 0; j < productsCount; ++j)
{
earnings += prices[j] \* initData[i][j];
}
return earnings;
}
void RangeCalculator::calculateShopEarnSums()
{
shopEarnSums.resize(shopsCount);
for (int i = 0; i < shopsCount; ++i)
shopEarnSums[i] = calculateShopEarnings(i);
}
```
**Заголовочный файл класса расчета прогнозов Prognoser.h**
```
#pragma once
#include "RangeCalculator.h"
class Prognoser
{
private:
// shared_ptr by RangeCalculator object
std::shared_ptr rc;
// koefficient to multiply by shops ranges
double kShopsR;
// square of kernel window width
double h2;
public:
// constructor
// @param rc - shared\_ptr by RangeCalculator object
// @param kShopsR - koefficient to multiply by shops ranges
// @param h - kernel window width
Prognoser(std::shared\_ptr rc, double kShopsR, double h);
virtual ~Prognoser();
// prognose all missing data
// @param func\_ptr - calculating of weighted sums function pointer
void prognose(void (Prognoser::\*func\_ptr)(int, int, double&, double&));
// calculate weighted sums with "cross" method
// @param shopInd - shop index
// @param prodInd - product index
// @param weightsSum - sum of weights
// @param contribSum - weighted sum of contributions
void calculateWeightSumsCross(int shopInd, int prodInd, double& weightsSum, double &contribSum);
// calculate weighted sums with "total" method
// @param shopInd - shop index
// @param prodInd - product index
// @param weightsSum - sum of weights
// @param contribSum - weighted sum of contributions
void calculateWeightSumsTotal(int shopInd, int prodInd, double& weightsSum, double &contribSum);
private:
// calculate kernel
// @param r2h2 - r\*r/h/h, where r - range and h - window width
double calculateKernel(double r2h2);
// calculate prognosis of selected position with selected method
// @param shopInd - shop index
// @param prodInd - product index
// @param func\_ptr - calculating of weighted sums function pointer
int calculatePrognosis(int shopInd, int prodInd, \
void (Prognoser::\*func\_ptr)(int, int, double&, double&));
};
```
**Исходный файл класса расчета расстояний Prognoser.cpp**
```
#include "Prognoser.h"
Prognoser::Prognoser(std::shared_ptr rc, double kShopsR, double h)
{
this->rc = rc;
this->kShopsR = kShopsR;
this->h2 = h \* h;
}
Prognoser::~Prognoser()
{}
double Prognoser::calculateKernel(double r2h2)
{
if (r2h2 > 1)
return 0;
else
return (1 - r2h2) \* (1 - r2h2) \* 15 / 16;
}
void Prognoser::prognose(void (Prognoser::\*func\_ptr)(int, int, double&, double&))
{
for (int i = 0; i < rc->shopsCount; ++i)
{
for (int j = 0; j < rc->productsCount; ++j)
{
if (!rc->maskData[i][j])
{
rc->fullData[i][j] = calculatePrognosis(i, j, func\_ptr);
}
}
}
}
void Prognoser::calculateWeightSumsCross(int shopInd, int prodInd, double& weightsSum, double &contribSum)
{
double r2 = 0, r2h2 = 0, weight = 0;
// calculate sums by shops
for (int i = 0; i < rc->shopsCount; ++i)
{
if (rc->maskData[i][prodInd] && shopInd!=i)
{
r2 = rc->shopsRanges[shopInd][i];
r2 = r2 \* kShopsR \* kShopsR;
r2h2 = r2 / h2;
weight = 0 ? r2h2 >= 1. : calculateKernel(r2h2);
weightsSum += weight;
contribSum += weight \* rc->initData[i][prodInd] \* \
rc->shopEarnSums[i] / rc->shopEarnSums[shopInd];
}
}
// calculate sums by products
for (int j = 0; j < rc->productsCount; ++j)
{
if (rc->maskData[shopInd][j] && prodInd != j)
{
r2 = rc->priceRanges[prodInd][j];
r2h2 = r2 / h2;
weight = 0 ? r2h2 >= 1. : calculateKernel(r2h2);
weightsSum += weight;
contribSum += weight \* rc->initData[shopInd][j];
}
}
}
void Prognoser::calculateWeightSumsTotal(int shopInd, int prodInd, double& weightsSum, double &contribSum)
{
double r2 = 0, r2h2 = 0, weight = 0;
for (int i = 0; i < rc->shopsCount; ++i)
{
for (int j = 0; j < rc->productsCount; ++j)
{
if (i != shopInd || j != prodInd)
if(rc->maskData[i][j])
{
r2 = rc->shopsRanges[shopInd][i];
r2 = r2 \* kShopsR \* kShopsR;
r2 += rc->priceRanges[prodInd][j];
r2h2 = r2 / h2;
weight = 0 ? r2h2 >= 1. : calculateKernel(r2h2);
weightsSum += weight;
contribSum += weight \* rc->initData[i][j] \* \
rc->shopEarnSums[i] / rc->shopEarnSums[shopInd];;
}
}
}
}
int Prognoser::calculatePrognosis(int shopInd, int prodInd, \
void (Prognoser::\*func\_ptr)(int, int, double&, double&))
{
double weightsSum = 0; // sum of weights
double contribSum = 0; // sum of weighted contributions
//calculateWeightSumsCross(shopInd, prodInd, weightsSum, contribSum);
(this->\*func\_ptr)(shopInd, prodInd, weightsSum, contribSum);
int prognosis = -1;
if (weightsSum > 0)
prognosis = int(contribSum / weightsSum);
return prognosis;
}
```
Ссылки
======
[К. В. Воронцов. Лекции по алгоритмам восстановления регрессии.](http://www.ccas.ru/voron/download/Regression.pdf) | https://habr.com/ru/post/359170/ | null | ru | null |
# PHP-Дайджест № 168 (5 – 25 ноября 2019)
[](https://habr.com/ru/post/477318/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 7.4 RC6, Symfony 5.0 и 4.4, WordPress 5.3 и другие релизы, об обновлении PSR-стандартов, RFC предложения из PHP Internals, порция полезных инструментов, митапы, видеозаписи, подкасты и многое другое.
Приятного чтения!
### Новости и релизы
* [PHP 7.4.0 RC6](https://www.php.net/archive/2019.php#2019-11-14-1) — Последний релиз-кандидат. Финальный релиз запланирован на 28 ноября, a пока можно посмотреть [что нового в PHP 7.4](https://www.phparch.com/2019/11/the-workshop-whats-new-in-php-7-4/), прочитать про  [Стрелочные функции в PHP 7.4](https://habr.com/ru/post/476242/), глянуть [Введение в PHP FFI](https://dev.to/verkkokauppacom/introduction-to-php-ffi-po3).
* [PHP 7.2.25](https://www.php.net/ChangeLog-7.php#7.2.25) — Поддержка ветки заканчивается и релиз 7.2.26, который ожидается 19 декабря, будет последним регулярным выпуском. После этого будут только секьюрити обновления по мере необходимости [в течение года](https://www.php.net/supported-versions.php).
* [PHP 7.3.12](https://www.php.net/ChangeLog-7.php#7.3.12)
* [Обновление стандартов PSR](https://github.com/php-fig/fig-standards/pull/1195/files?short_path=ef021a0#diff-ef021a0820876c95b7b6ec1d4007fe75) — Заканчивается [голосование](https://groups.google.com/forum/#!topic/php-fig/F2-kYPW8UDk/discussion) по процедуре обновления интерфейсов в связи с добавлением тайпхинтов. Предлагается двухэтапный план: выпустить версию 1.1 для стандартов, в которой добавят декларации типов для параметров, и затем v2.0 с тайпхинтами возвращаемых значений. Подробнее [о причинах и рассмотренных альтернативных подходах](https://www.php-fig.org/blog/2019/10/upgrading-psr-interfaces/).
* [WordPress 5.3](https://wordpress.org/news/2019/11/kirk/) — В обновлении улучшения для блочного редактора [Guttenberg](https://wordpress.org/gutenberg/) (кстати доступен для Laravel в виде пакета [VanOns/laraberg](https://github.com/VanOns/laraberg)), новая тема Twenty Twenty, совместимость с PHP 7.4.
* [skyeng/php-communities](https://github.com/skyeng/php-communities) — Открытый список PHP-событий, спикеров и организаторов на GitHub. Ближайшие мероприятия:
• 29 ноября, Уфа:  [Встреча PHP-разработчиков Уфы](https://habr.com/ru/company/skyeng/blog/476488/)
• 30 ноября, Иваново: [PHP: Неправильный путь](https://events.involta.ru/events/show/14)
• 7 декабря, Йошкар-Ола: [PHP Meetup December](https://php-yola.timepad.ru/event/1110295/)
• 10 декабря, Одесса: [PHP OpenSource world. Stable multi-threaded application.](https://www.facebook.com/events/415274049185554)
• 14 декабря, Казань: [Большая встреча PHP-разработчиков](https://leader-id.ru/event/29485/)
### PHP Internals
* [[RFC] Weak maps](https://wiki.php.net/rfc/weak_maps) — В PHP 7.4 была добавлена поддержка [слабых ссылок](https://wiki.php.net/rfc/weakrefs) через специальный класс [WeakReference](https://www.php.net/manual/en/class.weakreference.php). Но в действительности для приложений нужна коллекция WeakMap, которую нельзя реализовать на основе WeakReference. Собственно, её и предлагается добавить. **Скрытый текст**
```
$map = new WeakMap();
$obj = new stdClass();
$map[$obj] = 42;
var_dump($map);
// object(WeakMap)#1 (1) {
// [0]=>
// ["key"] => object(stdClass)#2 (0) {}
// ["value"] => int(42)
// }
// }
// Объект уничтожается здесь,
// и ключ автоматически удаляется из WeakMap
unset($obj);
var_dump($map);
// object(WeakMap)#1 (0) {
// }
```
* [[RFC] Implement new DOM Living Standard APIs in ext/dom](https://wiki.php.net/rfc/dom_living_standard_api) — Предложение о реализации поддержки нового стандарта DOM в расширении ядра принято единогласно.
* [[RFC] Deprecate Backtick Operator (V2)](https://wiki.php.net/rfc/deprecate-backtick-operator-v2) — Отклонено на голосовании.
* [[RFC] Union Types 2.0](https://wiki.php.net/rfc/union_types_v2) — Предложение принято практически единогласно и в PHP 8.0 нас ждут объединённые типы. Синтаксис `T1|T2|...` можно будет использовать везде, где типы можно указывать сейчас.
*  [PHP Internals News podcast #36](https://phpinternals.news/36) — О тех RFC, которые не прошли в PHP 7.4.
### Инструменты
* [lisachenko/z-engine](https://github.com/lisachenko/z-engine) — Экспериментальная библиотека, которая позволяет используя [FFI](https://wiki.php.net/rfc/ffi) получить доступ к внутренним структурам самого PHP, таким как zend\_class\_entry, zval, и подобным, и изменять их в рантайме. Это позволяет делать самые немыслимые манипуляции в рантайме.
* [nette/safe-stream](https://github.com/nette/safe-stream) — Библиотека позволяет производить атомарные и безопасные чтение/запись файлов с помощью стандартных функций PHP.
* [krakjoe/ilimit](https://github.com/krakjoe/ilimit) — Расширение позволяет выполнить функцию наложив при этом ограничения на время и память, которые может потребовать вызов.
* [Twig 3.0](https://github.com/twigphp/Twig) — [Под капотом](https://symfony.com/blog/preparing-your-applications-for-twig-3) много мелких улучшений, повышена производительность, почищен код.
* [fzaninotto/Faker 1.9](https://github.com/fzaninotto/Faker/releases/tag/v1.9.0) — Более сотни улучшений и исправлений в свежем обновлении инструмента для генерации тестовых данных.
* [cekta/di](https://github.com/cekta/di) — Годная реализация PSR-11.
* [tarantool-php/client](https://github.com/tarantool-php/client) — PHP-клиент для Tarantool. [Бенчмарки PHP синхронных коннекторов для Tarantool](https://github.com/tarantool-php/benchmarks) запущенных в асинхронном/параллельном режиме с помощью расширений Swoole, Async и Parallel (и их комбинаций). Прислал [rybakit](https://github.com/rybakit).
* [badoo/jira-client](https://github.com/badoo/jira-client) —  [Badoo Jira API Client: магия в Jira на PHP](https://habr.com/ru/company/badoo/blog/475840/).
### Symfony
* [Symfony 4.4](https://symfony.com/blog/symfony-4-4-0-released) — Подробнее о новых возможностях в [блог постах](https://symfony.com/blog/category/living-on-the-edge/5.0-4.4) и в [полном списке изменений](https://symfony.com/blog/symfony-4-4-curated-new-features)
* [Symfony 5.0](https://symfony.com/blog/symfony-5-0-0-released) — Включает в себя все обновления из 4.4, а также два новых компонента [symfony/string](https://github.com/symfony/string) и [symfony/notifier](https://github.com/symfony/notifier). [Fabien Potencier представляет компонент Notifier](https://symfonycasts.com/screencast/london2019/keynote)
### Laravel
* [thomasjohnkane/snooze](https://github.com/thomasjohnkane/snooze) — Отложенные нотификации. [Пост](https://atymic.dev/blog/laravel-snooze/) в поддержку.
* [mad-web/laravel-initializer](https://github.com/mad-web/laravel-initializer) — Настраиваемый пакет для быстрого создания приложения на Laravel. Прислал [evgwed](https://habr.com/ru/users/evgwed/).
* [Туториал по созданию пакета для Laravel](https://johnbraun.blog/posts/creating-a-laravel-package-1)
* [О создании кастомных отношений в Laravel](https://stitcher.io/blog/laravel-custom-relation-classes) ([перевод](https://laravel.demiart.ru/custom-relationship/))
* [Доменно-ориентированный Laravel](https://stitcher.io/blog/laravel-beyond-crud) — Продолжение серии о разработке крупных приложений на Laravel: [о моделях](https://stitcher.io/blog/laravel-beyond-crud-04-models), [паттерне «состояние»](https://stitcher.io/blog/laravel-beyond-crud-05-states), [управлении доменами](https://stitcher.io/blog/laravel-beyond-crud-06-managing-domains).
* [Как настроить масштабируемое приложение Laravel 6](https://www.digitalocean.com/community/tutorials/how-to-set-up-a-scalable-laravel-6-application-using-managed-databases-and-object-storage) с помощью DBaaS и хранилища объектов.
* [Отключите HTTP сессии в Laravel, чтобы ускорить ваши API](https://ma.ttias.be/disable-http-sessions-in-laravel-to-speed-up-your-api/) ([Перевод](https://laravel.demiart.ru/disable-http-sessions-to-speed-up-api/))
*  [Пишем приложения на Laravel, которые легко поддерживать](https://laravel.demiart.ru/maintainable-laravel-apps/)
*  [Делим Laravel на компоненты](https://habr.com/ru/post/475144/)
*  [Организация маршрутов в Laravel](https://habr.com/ru/post/474788/)
*  [Серия стримов о создании](https://www.youtube.com/playlist?list=PLmwAMIdrAmK5q0c0JUqzW3u9tb0AqW95w) [laravel-shift/blueprint](https://github.com/laravel-shift/blueprint)
### Yii
* [Об оптимизации приложений на Yii 2](https://2amigos.us/blog/yii2-application-optimization)
* [Yii 2.0.30, расширения и Yii 3](https://yiiframework.ru/news/254/yii-2030-rassirenia-i-yii-3)
### Async PHP
* [DriftPHP](https://github.com/driftphp) — PHP-фреймворк на основе ReactPHP и компонентов Symfony. [Демо приложение](https://github.com/driftphp/demo).
* [clue/reactphp-ami](https://github.com/clue/reactphp-ami) — Асинхронный инструмент для управления Asterisk. Вводный [блог пост](https://clue.engineering/2019/introducing-reactphp-ami) в поддержку.
*  [PHP-Watcher: инструмент, который упрощает разработку долгоживущих приложений](https://habr.com/ru/company/skyeng/blog/475624/)
*  Пишем RESTful API с помощью ReactPHP: [Защищённые роуты](https://www.youtube.com/watch?v=Y0Ve5LMr5hA)
### Материалы для обучения
* [5 способов улучшить производительность PHP](https://tideways.com/profiler/blog/5-ways-to-increase-php-performance) — и подкаст [The Undercover ElePHPant #2](https://undercover-elephpant.com/episodes/php-performance-with-marco-pivetta-ocramius) с [Marco «Ocramius» Pivetta](https://twitter.com/Ocramius).
* [Как быстро обновить версию PHPUnit с 4 вплоть до PHPUnit 8](https://www.tomasvotruba.cz/blog/2019/11/04/still-on-phpunit-4-come-to-phpunit-8-together-in-a-day/).
* [Ответы на часто задаваемые вопросы по Serverless PHP](https://mnapoli.fr/serverless-php-faq/) — Как локально запускать серверлесс PHP-приложения? Как на практике масштабируются затраты? Как справиться с дополнительными расходами, связанными с DDoS-атаками или пиковыми нагрузками?
*  [Пишем свой Doctrine Annotation Fixer для PHP-CS-Fixer](https://vtvz.ru/blog/custom-doctrine-annotation-fixer/) — Исследование внутренностей фиксера для создания своего правила. Прислал [vtvz\_ru](https://habr.com/ru/users/vtvz_ru/).
*  [Уровни изолированности транзакций БД для самых маленьких](https://habr.com/ru/post/469415/).
*  [Как добавить проверки в NoVerify](https://habr.com/ru/company/vk/blog/473718/), не написав ни строчки Go-кода.
*  [PHP Composer: фиксим зависимости без боли](https://habr.com/ru/company/badoo/blog/473654/) — О том, какую проблему решают плагины для патчинга зависимостей и почему использовать вместо этого форки неудобно.
### Аудио/Видео
*  [Туториал по использованию HTTP-клиента в PhpStorm](https://blog.jetbrains.com/phpstorm/2019/11/http-client-in-phpstorm-overview/)
 [Laravel Snippet #18: Clear Writing, Great Quality, Low Pain Tolerance](https://blog.laravel.com/laravel-snippet-18-clear-writing-great-quality-low-pain-tolerance) — Продолжение серии подкастов от Тейлора о том, как заработать на опенсорсе.
 [Marco Pivetta: Aggressive PHP Quality Assurance in 2019](https://www.youtube.com/watch?v=8rdTSYljts4)
 [Symfony Camp 2019](https://www.youtube.com/channel/UCd1Ds7u1mAjEwHrZ9jG1Arg/videos?view=0&sort=dd&flow=grid)
 [PHP Internals News podcast #35](https://phpinternals.news/35) — Со [Scott Arciszewski](https://twitter.com/CiPHPerCoder) о недавней [уязвимости в PHP-FPM](https://www.opennet.ru/opennews/art.shtml?num=51749), и криптографии в PHP. | https://habr.com/ru/post/477318/ | null | ru | null |
# МКА (машина конечных автоматов) для чайников на примере класса «кнопка» в arduino
Зачем всё это нужно?
--------------------
Когда чайник, уперевшись в необходимость отойти от простой последовательности действий, задаёт на хабре вопрос типа "как сделать вот это?", ему с вероятностью 70% отвечают "погугли конечные автоматы" и 30% "используй finite state machine" в зависимости от страны работодателя профессионала. На следующий вопрос "а как?" отправляют в гугл. Идёт такой чайник, что только закончил мигать светодиодом и вытер пот со лба, что учил в школе немецкий и всю жизнь работал бульдозеристом в этот гугл и видит там статьи типа [Википедия про конечные автоматы](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D1%8B%D0%B9_%D0%B0%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82) с формулами и в которых понятны только предлоги.
Так как я тоже чайник, но до бульдозера работал программистом 30 лет назад, наступив на множество граблей по мере освоения программирования микроконтроллеров, решил написать эту статью простым языком для начинающих.
Итак, задача стоит, например, научить ардуину понимать нажатие кнопки типа клик, нажатие и удержание, то есть, короткий тык в кнопку, длинный и очень длинный. Любой начинающий может сделать это в функции loop() и гордиться этим, но как быть, если кнопок несколько? А если при этом надо не мешать выполнению другого кода? Я написал библиотеку [SmartButton](https://github.com/nw-wind/SmartButton) для Arduino, чтобы потом не возвращаться к теме кнопок. Здесь же напишу, как она работает.
Что нам мешает жить и как с этим бороться?
------------------------------------------
Нам мешает жить функция delay(), я её поборол при помощи МКА и написал свой класс [SmartDelay](https://github.com/nw-wind/SmartDelay). Я уже сделал новый класс (SmartDelayMs) порождённый от SmartDelay, там всё то же самое, но в миллисекундах. В данной статье я не использую эту библиотеку, просто хвастаюсь.
Чтобы не утомлять читателя повторно рассказом о том, как плохо пользоваться функцией delay() и как жить без неё, я рекомендую сначала прочитать мою старую статейку [Замена delay() для неблокирующих задержек в Arduino IDE](https://habrahabr.ru/post/319184/). Я немножко повторю основные тезисы здесь ещё раз ниже по мере написания кода.
Немного теории
--------------
Так или иначе, но у вас есть **объекты**. Вы можете называть их кнопками, дисплеями, светодиодными лентами, роботами и измерителем уровня воды в бачке. Если ваш код выполняется не в одну ниточку последовательно, а по каким-то событиям, вы храните **состояние** объектов. Вы можете называть это как угодно, но это факт. Для кнопки есть, например, состояния "нажата" и "отпущена". Для робота, например: стоит, едет прямо, поворачивает. Количество этих состояний конечно. Ну, в нашем случае, да. Добавим состояния "клик", "нажатие" и "удержание". Уже пять состояний, которые нам надо различать. Причём, интересны нам лишь последние три. Этими пятью состояниями живёт кнопка. В страшном внешнем мире происходят события, которые от кнопки в общем-то никак не зависят: тыкания в неё пальцем, отпускания, удержания на разное время итп. Назовём их **событие**.
Итак, мы имеем **объект** "кнопка" у которого конечное количество **состояний** и на него действуют **события**. Это и есть **конечный автомат** (КА). В теории КА список возможных событий называют словарём, а события словами. Я дико извиняюсь, я это проходил 30 лет назад и плохо помню терминологию. Вам же не терминология нужна, правда?
В данной статье мы напишем замечательный код, который будет переводить наш КА из состояния в состояние в зависимости от событий. Он и является собственно **машиной конечных автоматов** (МКА).
Не обязательно всё ваше устройство запихивать в один огромный КА, можно разбить на отдельные объекты, каждый из которых обслуживается своей МКА и даже находится в отдельном файле кода. Многие свои объекты вы сможете поместить на [GitHub](http://github.com) в виде готовых библиотек ардуины и использовать потом не вникая в их реализацию.
Если ваш код не требует переносимости и повторного использования, можно всё лепить в один большой файл, что и делают как раз начинающие.
Практика
--------
Основой проектирования МКА является таблица.
* По горизонтали пишем все-все возможные события.
* По вертикали все состояния.
* В клетках действия. Переход в новое состояние — это тоже действие.
Для кнопки это будет выглядеть вот так:
| Состояние \ Событие | Нажата | Отпущена | Нажата 20мс | Нажата 250мс | Нажата 1с | Нажата 3с |
| --- | --- | --- | --- | --- | --- | --- |
| Не Нажата | | | | | | |
| Кликнута | | | | | | |
| Нажата | | | | | | |
| Удержана | | | | | | |
| Слишком долго удержана | | | | | | |
Зачем так сложно? Надо же описать все возможные состояния и учесть все возможные события.
События:
* Нажата — это когда мы обнаружили, что контакт замкнут.
* Отпущена — это когда выяснилось, что контакт разомкнут.
* Нажата 20мс — надо учесть дребезг контактов и игнорировать размыкание какое-то время, дальше уже считатется, что клик.
* Нажата 250мс — для клика 250мс достаточно, всё что дольше — это уже нажатие.
* Нажата 1с — больше 1с это уже удержание.
* нажата 3с — удержание больше 3с посчитаем ошибкой.
Время вы можете поставить своё, как вам удобно. Чтобы не менять потом в разных местах цифры, лучше сразу заменить их буквами :)
```
#define SmartButton_debounce 20
#define SmartButton_hold 250
#define SmartButton_long 1000
#define SmartButton_idle 3000
```
Состояния:
* Не нажата — рапортуем, что никто кнопочку не трогал.
* Дребезг — Ждём конец дребезга контактов.
* Кликнута — был клик.
* Нажата — кнопку нажали.
* Удержана — кнопку нажали и подержали.
* Слишком долго удержана — что-то пошло не так, предлагаю отказаться от нажатия в этом случае.
Итак, переводим русский язык на язык C++
```
// Нога контроллера для кнопки
byte btPin;
// События
enum event {Press, Release, WaitDebounce, WaitHold, WaitLongHold, WaitIdle};
// Состояния
enum state {Idle, PreClick, Click, Hold, LongHold, ForcedIdle};
// Текущее состояния
enum state btState = Idle;
// Время от нажатия кнопки
unsigned long pressTimeStamp;
```
Обращу внимание, что и события и состояния указаны не как целая переменная типа byte или int, а как enum. Такая запись не столь любима профессионалами так как не даёт экономить биты столь дорогой в микроконтроллерах памяти, но, с другой стороны очень наглядна. При использовании enum нас не заботит каким числом закодирована каждая константа, мы пользуемся словами, а не числами.
**Как расшифровать enum?**enum Имя {Константа, Константа, Константа};
Так мы создаём **тип данных** enum Имя, у которого есть набор фиксированных значений из тех, что в фигурных скобках. На самом деле, конечно же, это числовой целый тип, но значение констант нумеруется автоматически.
Можно указать значения и вручную:
enum Имя {КонстантаА=0, КонстантаБ=25};
Для объявления переменной такого нового типа можно написать так:
enum Имя Переменная;
В примере с кнопкой:
* enum event myEvent;
* enum state currentState;
Давайте уже заполним таблицу. Значком -> я обозначу переход в новое состояние.
| Состояние \ Событие | Нажата | Отпущена | Нажата 20мс | Нажата 250мс | Нажата 1с | Нажата 3с |
| --- | --- | --- | --- | --- | --- | --- |
| Не Нажата | ->Дребезг | ->Не Нажата | | | | |
| Дребезг | | ->Не Нажата | ->Кликнута | | | |
| Кликнута | | ->Не Нажата | | ->Нажата | | |
| Нажата | | ->Не Нажата | | | ->Удержана | |
| Удержана | | ->Не Нажата | | | | ->Слишком долго удержана |
| Слишком долго удержана | | ->Не Нажата | | | | |
Для реализации таблицы мы сделаем функцию void doEvent(enum event e). Эта функция получает событие и выполняет действие как описано в таблице.
Откуда берутся события?
-----------------------
Настало время ненадолго покинуть нашу уютную кнопку и окунуться в ужасный внешний мир функции loop().
```
void loop() {
// запоминаем текущий счётчик времени
unsigned long mls = millis();
// генерим события
// нажатие кнопки
if (digitalRead(btPin)) doEvent(Press)
else doEvent(Release)
// ожидание дребезга прошло
if (mls - pressTimeStamp > SmartButton_debounce) doEvent(WaitDebounce);
// ожидание нажатия прошло
if (mls - pressTimeStamp > SmartButton_hold) doEvent(WaitHold);
// ожидание удержания прошло
if (mls - pressTimeStamp > SmartButton_long) doEvent(WaitLongHold);
// совсем перебор по времени
if (mls - pressTimeStamp > SmartButton_idle) doEvent(WaitIdle);
}
```
Итак, имея под рукой генератор событий, можно приступить к реализации МКА.
На самом деле, события могут генерироваться не только по подъёму уровня сигнала на ноге контроллера и по времени. События могут передаваться одним объектом другому. Например, вы хотите, чтобы нажатие одной кнопки автоматически "отпускало" другую. Для этого достаточно вызвать её doEvent() с параметром Release. МКА — это же не только кнопки. Превышение порога температуры является событием для МКА и вызывает включение вентилятора в теплице, к примеру. Датчик неисправности вентилятора меняет состояние теплицы на "аварийное" и так далее.
Три подхода к реализации таблицы в код
--------------------------------------
### План-А: if {} elsif {} else {}
Это первое, что приходит в голову начинающему. На самом деле, это неплохой вариант, если в таблице совсем мало заполненных клеток и действия сводятся только к смене состояний.
```
void doAction(enum event e) {
if (e == Press && btState == Idle) { // нажата кнопка в состоянии кнопка отпущена
btState=PreClick; // переходим в состояние ожидания дребезга
pressTimeStamp=millis(); // запоминаем время нажатия кнопки
}
if (e == Release) { // отпущена кнопка
btState=Idle; // Переходим в состояние кнопка отпущена
}
if (e == WaitDebounce && btState == PreClick) { // Прошло время дребезга
btState=Click; // считаем, что это клик
}
// и так далее для всех сочетаний событий и состояний
}
```
Плюсы:
* Просто писать новичку, который впервые в руки взял ардуину.
* Первое, что приходит в голову.
Минусы:
* Сложно читать код.
* Сложно модифицировать код, если что-то поменялось в таблице.
* Ад, если большая часть клеток таблицы заполнена.
### План-Б: Таблица указателей на функции
Другая крайность — это таблица переходов или функций. Я про такой подход писал в статье [Обработка нажатий кнопок для Arduino. Скрестить ООП и МКА.](https://habrahabr.ru/post/319180/). В двух словах, вы создаёте для каждой **разной** клетки таблицы отдельную функцию и делаете таблицу из указателей на них.
```
// определяем тип, так проще
typedef void (*MKA)(enum event e);
// делаем таблицу
MKA action[6][6]={
{&toDebounce,$toIdle,NULL,NULL,NULL,NULL},
{NULL,&toIdle,&toClick,NULL,NULL,NULL},
{NULL,&toIdle,NULL,&toHold,NULL,NULL},
{NULL,&toIdle,NULL,NULL,&toLongHold,NULL},
{NULL,&toIdle,NULL,NULL,NULL,&toVeryLongHold},
{NULL,&toIdle,NULL,NULL,NULL,NULL}
};
// функция doEvent получается совсем простой
void doEvent(enum event e) {
if (action[btState][e] == NULL) return;
(*(action[btState][e]))(e);
}
// Примеры функций из таблицы
// В состояние "не нажата"
void toIdle(enum event e) {
btState=Idle;
}
// В состояние ожидания дребезга
void toDebounce(enum event e) {
btState=PreClick;
pressTimeStamp=millis();
}
// и так далее
```
**Что за странные слова и значки здесь использованы?**typedef позволяет определить свой тип данных и частенько этим удобно пользоваться. Например, enum event можно определить так:
```
typedef enum event BottonEvent;
```
В программе после этого можно писать:
```
BottonEvent myEvent;
```
Я определил указатель на функцию, которая принимает один аргумент типа enum event и ничего не возвращает:
```
typedef void (*MKA)(enum event e);
```
Так я сделал новый тип данных MKA.
Значок & переводится на русский как "адрес" или "указатель". Таким образом, MKA это не значение функции, а указатель на неё.
```
MKA action[6][6]; // Двумерный массив action переменных типа МКА
```
Я его сразу же заполнил указателями на функции, что выполняют действия. Если действия нет, я ставлю "указатель в никуда" NULL.
Функция doEvent проверяет указатель из таблицы в координатах "текущее состояние" x "случившееся событие" и если для этого есть указатель на функцию — вызывает её с параметром "событие".
```
if (action[btState][e] == NULL) return; // если функции нет - выходим
(*(action[btState][e]))(e); // вызываем функцию по указателю из таблицы
```
Более подробно про указатели и адресную арифметику в языке C можно нагуглить в книжках типа "Язык Си для чайников".
Плюсы:
* Очень читаемый код. Не смейтесь. Достаточно один раз вкурить про массивы с указателями и вы получите простой красивый код. У вас табличка как табличка, ячейки отдельно расписаны — красота.
* Легко писать.
* Очень легко модифицировать логику.
Минусы:
* Жрёт память. Каждый указатель — это от двух до четырёх байтов. 6х6=36 клеток занимают от 72 до 144 байтов памяти и это на каждую кнопку, а если их, скажем, четыре? Напомню, у вас всего 2048 байтов памяти для популярных чипов ардуины.
Минус оказался таким жирным, что я после написания [Обработка нажатий кнопок для Arduino. Скрестить ООП и МКА.](https://habrahabr.ru/post/319180/) и первого же применения кода в деле выпилил это всё нафиг. В итоге я пришёл к золотой середине "switch { switch {}}".
### План-В: Золотая середина или switch { switch {}}
Самый распространённый, средний вариант — это использование вложенных операторов switch. На каждое событие как case оператора switch надо писать switch с текущим состоянием. Получается длинно, но более-менее понятно.
```
void doEvent(enum event e) {
switch (e) {
case Press:
switch (btState) {
case Idle:
btState=PreClick;
pressTimeStamp=millis();
break;
}
break;
case Release:
btState=Idle;
break;
// ... так далее ...
}
}
```
Умный компилятор всё-равно построит таблицу переходов, как описано в плане Б выше, но эта таблица будет в флеше, в коде и не будет занимать столь дорогую нам память переменных.
Плюсы:
* Быстрый код.
* Экономится память.
* Логика понятна. Можно читать.
* Легко менять логику.
Минусы:
* Портянка в несколько экранов при большом количестве состояний и событий, которую сложно распилить на отдельные файлы.
На самом деле, можно использовать план-В и план-А, то есть, switch по событиям, но if внутри по состояниям. На мой вкус, switch и на то и на то понятнее и удобнее, если потребуется что-то потом поменять.
Куда вставлять мой код, который зависит от нажатий кнопки?
----------------------------------------------------------
В табличке мы не учитывали наличие других МКА сосредоточившись на нашем обработчике событий кнопки. На практике же требуется не только радоваться тому, что кнопка работает, но и выполнять другие действия.
У нас есть два важных места для вставки хорошего кода:
```
case Release:
switch(btState) {
case Click:
// Вот здесь был клик и отпустили кнопку. это точно был клик.
break;
```
```
case WaitDebounce:
switch (st) {
case PreClick:
btState=Click;
// Вот здесь случился клик. Кнопка может быть потом ещё нажата и будет ещё и "нажатие" итп.
break;
```
Лучше всего, чтобы не портить красоту, написать свои функции типа offClick() и onClick(), в которых будет обрабатываться уже эти события, возможно, что они передадут его другому МКА :D
Я обернул всю логику работы МКА кнопки в [класс C++](https://github.com/nw-wind/SmartButton). Это удобно, так как не отвлекает от написания основного кода, все кнопки работают самостоятельно, мне не надо изобретать имена кучи переменных. Только это совсем другая история и я могу написать, как оформлять ваши МКА в классы и делать из них библиотеки для Arduino. Пишите в комментариях пожелания.
Что в итоге?
------------
В итоге, в теории, после прочтения этой статьи должно появиться желание заменить в любимом ардуиновом скетче свой нечитаемый глючный говнокод на красивый структурированный и с использованием МКА.
Обратите внимание, что в функции loop(), которая в нашем случае лишь генерит события, нет ни одной задержки. Таким образом, после приведённого кода можно писать что-то ещё: генерить события для других МКА, выполнять ещё какой-то свой код, не содержащий delay();
Я очень надеюсь, что эта статья помогла вам понять, что такое МКА и как их реализовать в вашем скетче. | https://habr.com/ru/post/345960/ | null | ru | null |
# Celery taskcls: новый декоратор, новые возможности
Привет, Хабр! Я расскажу тебе историю своего профессионального подгорания.
Так вышло, что я терпеть не могу рутинных однообразных действий. У меня за плечами несколько проектов, использующих [Celery](https://docs.celeryproject.org/en/latest/). Каждый раз, когда задача становится сложнее вывода `2 + 2 = 5`, шаблон решения сводится к созданию класса, выполняющего задачу, и [функции](https://docs.celeryproject.org/en/latest/userguide/tasks.html#basics)-стартера, с которой умеет работать Celery — бойлерплейта. В этой статье я расскажу, как я боролся с бойлерплейтом, и что из этого вышло.

Отправная точка
===============
Рассмотрим рядовую таску Celery. Есть класс, исполняющий задачу, и функция-стартер, выполняющая инстанцирование класса и запуск одного его метода, в котором реализована вся логика задачи и унаследована обработка ошибок:
```
class MyTask(
FirstMixin,
SecondMixin,
ThirdMixin,
):
def main(self):
data = self.do_something()
response = self.remote_call(data)
parsed = self.parser(response)
return self.process(parsed)
@app.task(bind=True)
def my_task(self, arg1, arg2):
instance = MyTask(
celery_task=self,
arg1=arg1,
arg2=arg2,
)
return instance.full_task()
```
При этом метод `full_task` включает в себя вызов `main`, однако также занимается обработкой ошибок, логгированием и прочей чушью, не имеющей прямого отношения к основной задаче.
Идея тасккласса
===============
В корне тасккласса лежит простая идея: в базовом классе можно определить метод класса `task`, в нём реализовать поведение функции-стартера, а после наследоваться:
```
class BaseTask:
def __init__(self, **kwargs):
for key, value in kwargs.items():
setattr(self, key, value)
def full_task(self):
try:
return self.main()
except:
self.celery_task.retry(countdown=30)
@classmethod
def task(cls, task, **kwargs):
self = cls(
celery_task=celery_task,
**kwargs,
)
return self.full_task()
```
Вся вспомогательная скукотища собрана в базовом классе. Больше к ней не возвращаемся. Реализуем логику задачи:
```
@app.taskcls(bind=True)
class MyTask(
BaseTask,
FirstMixin,
SecondMixin,
ThirdMixin,
):
def main(self):
data = self.do_something()
response = self.remote_call(data)
parsed = self.parser(response)
return self.process(parsed)
```
Больше никакой шелухи, уже намного лучше. Однако что же с точкой входа?
```
MyTask.task.delay(...)
```
`MyTask.task` обладает всеми методами обычной таски: `delay`, `apply_async`, и, вообще говоря, ей и является.
Теперь аргументы декоратора. Особенно весело тащить `bind = True` в каждую таску. Можно ли передать аргументы по умолчанию через базовый класс?
```
class BaseTask:
class MetaTask:
bind = True
def __init__(self, **kwargs):
for key, value in kwargs.items():
setattr(self, key, value)
def full_task(self):
try:
return self.main()
except:
self.celery_task.retry(countdown=30)
@classmethod
def task(cls, task, **kwargs):
self = cls(
celery_task=celery_task,
**kwargs,
)
return self.full_task()
```
Вложенный класс `MetaTask` содержит аргументы по умолчанию и будет доступен всем дочерним классам. Интересно, что и его можно унаследовать:
```
class BaseHasTimeout(BaseTask):
class MetaTask(BaseTask.MetaTask):
timeout = 42
```
Наивысшим приоритетом обладают аргументы, переданные декоратору `@app.taskcls`:
```
@app.taskcls(timeout=20)
class MyTask(
BaseHasTimeout,
FirstMixin,
SecondMixin,
ThirdMixin,
):
def main(self):
...
```
В итоге timeout для задачи будет 20.
Выход за рамки
==============
В web-приложениях часто есть необходимость из view запустить таску. В случае высокой сцепленности view и таски их можно совместить:
```
class BaseViewTask:
@classmethod
def task(cls, **kwargs):
# Somehow init View class manually
self = cls(...)
return self.celery()
@app.taskcls
class MyView(
BaseViewTask,
FirstMixin,
SecondMixin,
ThirdMixin,
APIView,
):
queryset = MyModel.objects.all()
def get_some_data(self, *args, **kwargs): # common methed
return self.queryset.filtert(...)
def get(self, request):
data = self.get_some_data(request.field) # used in request handling
return Response(json.dumps(data))
def post(self, request):
self.task.delay(...)
return Response(status=201)
def celery(self):
data = self.get_some_data(...) # also used in background task
return self.do_something(data)
```
Кстати, именно для исключения коллизии имён вложенный класс называется `MetaTask`, а не `Meta`, как в django.
Заключение
==========
Эта функциональность ожидается в [Celery 4.5](https://github.com/celery/celery/pull/5755). Однако я также подготовил [пакет](https://pypi.org/project/celery-decorator-taskcls/), позволяющий попрбовать декоратор `taskcls` уже сегодня. Идея пакета сводится к тому, что при обновлении Celery до версии 4.5 вы сможете убрать его импорт не меняя более ни строчки кода. | https://habr.com/ru/post/470547/ | null | ru | null |
# Сброс пароля и базовая настройка Cisco 1941
Бывает так, что приходится сталкиваться с задачами, к решению которых ты вроде бы и не готов, а получить результат надо здесь и сейчас. Знакомо, да? Добро пожаловать в мир восточноевропейского менеджмента с соответствующей культурой управления.
Итак, допустим, ты представитель местечкового провайдера, уже знающий, как настроить какой-нибудь ASUS, но волею судьбы ещё не получивший сертификат CCNA. Рядом с тобой стоит местный админ, тоже без сертификата, глазами молящий ничего не "сбрасывать в ноль", ибо "всё работает, я просто не знаю пароль, только вы никому не говорите".
Подобные ситуации не редкость в наше ковидном мире, когда отделы со своей инфраструктурой тасуюся ежеквартально, директора направлений таинственно исчезают, а очередной управленец, дабы продемонстрировать собственную эффективность, ссорится с единственным цискарём в округе и заключает договора обслуживания при помощи сайта объявлений.
Проведём же вместе сеанс чёрной айтишной магии с последующим её разоблачением. А именно : сбросим пароль, настроим интерфейсы (локальный и внешний), соединим эти сети маршрутами и трансляцией адресов и прикроем(нет) фаерволом. Кирпич с фирменным шильдиком волшебным образом превратится в полезное сетевое устройство.
### Устройство и нужные нам интерфейсы
Вот она, наша девочка. Как опытные ребята, подходим с правильной стороны:
Нас интересует её правая часть, где все порты. Голубым помечены консольные, жёлтым -- EthernetЕсли подключаться в Ethernet порты, которые жёлтые, то нужно знать IP адреса на этих интерфейсах и пароли на вход -- основной и "повышенный" (под которым, собственно и надо всё настраивать). Если чего-то из этого нет, то добро пожаловать в консоль. Её порты помечены нежно-голубым цветом. Такой же цвет у фирменного консольного кабеля Cisco, который обычно к этому времени потерялся.
Кабель "специальный" Cisco. Распайки есть везде.По нынешним временам COM-порт есть далеко не в каждом ноуте, поэтому придётся к этому шнурку брать стандартный COM-USB переходник. Но можно присмотреться и увидеть, что рядом со "старым" консольным портом есть mini-usb порт с тем же назначением. Переходник в данном случае встроен в циску, и, да, на него нужны [драйвера](https://software.cisco.com/download/home/282774228/type/282855122/release/3.1). Устанавливаем их, ребутимся и подключаемся снова. После подключения Cisco через кабель miniusb в списке оборудования в разделе *Порты (COM и LPT)* появился ***Cisco Serial (COM14)*** (не обязательно именно 14, ну что поделать). Для дальнейшей работы рекомендую терминальную программку [**Putty**](https://putty.org.ru/download.html), ибо в ней есть всё, что необходимо, и она проста, как полено. На сегодня нам от неё нужно будет подключение по интерфейсу Serial (Com14) и впоследствии Telnet (TCP23).
### Сбрасываем пароли
Включаем циску и подключаемся в **Putty** к порту *Serial* (название COM14, Baud Rate 9600). Убеждаемся, что коннект есть. Далее надо перезагрузить маршрутизатор в ROMMON – начальный загрузчик – совсем урезанную версию операционной системы, которая загружается до cisco IOS и используется для сервисных целей (обновление IOS, восстановление пароля). Чтобы перезагрузить маршрутизатор в ROMMON, нужно прервать обычный процесс загрузки в IOS – для этого в самом начале загрузки надо отправить сигнал прерывания.
Выключаем, и не разрывая консольный сеанс, Включаем Cisco 1941 и нажимаем клавишу Break (она же клавиша Pause) или комбинацию Ctrl+Break на клавиатуре (если в ноуте этого нет, в Putty по правой кнопке мыши можно вызвать special command – break). Полная таблица с сигналами прерывания для разных терминалов находится [здесь](http://ciscotips.ru/break-sequence).
Видим приглашение в режим rommon (ROM monitor) :
`rommon 1 >`
Вводим команду изменения конфигурации регистра командой confreg и после перезапускаем роутер командой reset
`rommon 1 > confreg 0x2142`
`rommon 2 > reset`
Повышаем привилегии командой `enable` или просто `en` И пароль она тут не просит :)
`Router1>en`
Копируем «запароленный» конфиг в память роутера:
`Router1#copy startup-config running-config`
После этого применится старый конфиг, который был запаролен, но при этом мы уже находимся в привилегированном режиме, откуда можем выставить новые пароли для привилегированного режима, telnet и консоли.
`Router1#conf terminal`
`Router1(config)#enable secret $$$NewPassword`
`Router1(config)#enable password $$$NewPassword`
`Router1(config)#line vty 0 4`
`Router1(config-line)#password $$$NewPassword`
`Router1(config-line)#login`
`Router1(config-line)#exit`
`Router1(config)#line console 0`
`Router1(config-line)#password $$$NewPassword`
`Router1(config-line)#login`
`Router1(config-line)#exit`
Главное, в конце не забыть вернуть значения регистров по умолчанию. Если этого не сделать, то наш новый конфиг снова будет проигнорирован после перезагрузки роутера.
`Router1(config)# config-register 0x2102`
`Router1(config)#exit`
Копируем загруженный конфиг в стартовый и перезагружаемся:
`Router1# copy running-config startup-config`
`Router1# reload`
Роутер теперь с новым паролем для консоли, телнета и привилегированного режима. Ура. Можно отдать циску просиявшему админу вместе с настройками "нового интернета" (мы же от провайдера приехали, помните?). Если во взгляде местного системного администратора затаились нерешительность и страх, то поможем бедолаге.
### Настройка интерфейсов
Чтоб два раза не приезжать, пробежимся по всем нужным настройкам "чтоб взлетело". У циски два "жёлтых" интерфейса: GigabitEthernet0/0 и GigabitEthernet0/1. Обычно они должны смотреть в сторону WAN и LAN соответственно, да будет так.
Адресация в WAN, допустим 100.200.100.202/30 со шлюзом провайдера 100.200.100.201
Адресация в LAN, как водится, 192.168.1.1/24 с локальным интерфейсом циски 192.168.1.1
Всё делаем из под рута:
`>en`
`#`
Для конфигурации используем команду configure terminal, для выхода - exit:
`#conf t`
`#exit`
**Настраиваем локальный интерфейс:**
`#conf t`
`#interface GigabitEthernet0/1`
`#description LAN`
`#ip address 192.168.1.1 255.255.255.0`
`#no shutdown`
`#exit`
Настраиваем DHCP (на всю подсеть кроме .1-.50 и .200-.254).
Исключения:
`#ip dhcp excluded-address 192.168.1.200 192.168.1.254`
`#ip dhcp excluded-address 192.168.1.1 192.168.1.50`
`#ip dhcp ping packets 4`
Сам пул:
`#ip dhcp pool MY_DHCP_POOL_1`
`#import all`
`#network 192.168.1.0 255.255.255.0`
`#default-router 192.168.1.1`
`#dns-server 77.88.8.8`
`#lease 3`
`#exit`
Всё, после этой настройки можно подключаться телнетом из локалки при желании (удобно для проверок)
При подключении должен примениться адрес из DHCP пула и пинговаться циска. Советую запустить ping -t чтоб мониторить на всякий случай.
**Настраиваем внешний интерфейс**:
`#conf t`
`#interface GigabitEthernet0/0`
`#ip address 100.200.100.202 255.255.255.252`
`#no shutdown`
`#exit`
Тут должен начать пинговаться шлюз прова - 100.200.100.201 - но только от самой циски, не с ноута (между сетями-то пакеты пока не ходят)
`#ip forward-protocol nd`
`#ip route 0.0.0.0 0.0.0.0 100.200.100.201`
Тут от самой циски должен начать **пинговаться 8.8.8.8**
`#ip domain timeout 2`
`#ip name-server 8.8.8.8`
`#ip name-server 77.88.8.8`
`#ip cef`
Тут от самой циски должен начать пинговаться **ya.ru**
`#copy running-config startup-config` (или просто `#wr`)
В итоге мы настроили на циске две сети, в которых она будет жить и трудиться. Далее надо будет их соединить.
### Его величество межсетевой экран
Собственно, его величество фаер. В ипостасях NAT и списков доступа (ACL)
Тут много построено на этих самых списках, ссылки на них вбиваются как в правила интерфейсов (**access-group**), так и в правилах **NAT**, поэтому заносить надо аккуратно. Списки работают строго сверху вниз. Поэтому правила для *any* обычно последние (и они не нужны -- по дефолту для *any* всё запрещено). Список доступа может быть стандантным (access-list standard) , либо расширенным (access-list extended). Отличаются детализацией -- у стандартного только действие и источник пакетов, например.
**Настройка NAT**
Собираем локальную область для маскарадинга (да, я знаю, что это термин для iptables, но суть та же):
`#ip access-list standard 10`
`#permit 192.168.1.0 0.0.0.255`
`#deny any`
`#exit`
Назначаем стороны маскарадинга (интерфейсы):
`#interface gigabitethernet0/1`
`#ip nat inside`
`#exit`
`#interface gigabitethernet0/0`
`#ip nat outside`
`#exit`
Cамое важное: включаем собственно правило (одной строкой):
`#ip nat inside source list 10 interface gigabitethernet0/0 overload`
Закрываемся от атаки по TCPSYN:
`#ip tcp synwait-time 30`
Настраиваем список доступа – для внешнего интерфейса (если настроить для внутреннего, то нужны разрешения для dhcp трафика). Первым делом закроем единственный сетевой доступ -- телнет (tcp 23). Если подняты http(s) или ssh – тоже закрыть
Пишем список (особое внимание – протоколу icmp)
`#ip access-list extended 101`
`#deny tcp any any eq 23`
`#permit tcp any any`
`#permit udp any any`
`#permit icmp any any echo-reply`
`#permit icmp any any time-exceeded`
`#permit icmp any any unreachable`
`#deny ip any any`
`#exit`
Вешаем список на вход во внешний интерфейс:
`#int gigabitethernet0/0`
`#ip access-group 101 in`
`#exit`
`#copy running-config startup-config` (или просто `#wr`)
Так то список только базовую "защиту" обеспечивает, но это головная боль админа уже. После поднятия всех сервисов и их проверки, можно написать построже и применить.
У нас пингуется всё изнутри и циска снаружи. Интернет работает, почта ходит. Все счастливы, танцуют, обнимаются, деньги в карманы засовывают. Твой социальный рейтинг растёт на глазах.
### P.S. Полезные команды
Почти весь мониторинг -- это команда `show.` У неё есть короткая форма `sh`, которую я не рекомендую, ибо такая же короткая форма есть у команды `shutdown`
Собственно, включение чего-либо, например, интерфейса выглядит вот так:
`#no shutdown`
Выведем на почитать/скопировать весь конфиг:
`#show running-config`
Можно посмотреть возможности команды show:
`#show ?`
Да и любой:
`#ip ?`
Просмотр сводной информации по интерфейсам:
`#show ip interface brief`
Просмотр информации по интерфейсам L2:
`#show interface summary`
Просмотр адресов, выданных по DHCP:
`#show ip dhcp bind`
Удаление строк конфига:
`#no [строка конфига]`
Например, удалим шлюз по умолчанию:
`#no ip default-gateway`
Удаляем ВЕСЬ список доступа:
`#no ip access-list extended 101`
Удаление статического маршрута:
`#no ip route [маршрут]`
Что-ж для первого визита вполне достаточно. При помощи этой нехитрой магии ты заведёшь себе много друзей, юный падаван :) И не забудь предупредить местного админа о том, что если он как следует не настроит ACL, их сетку могут в скором времени ждать крупные неприятности. Но это уже совсем другая история.
---
У нас быстрые [серверы](https://macloud.ru/?partner=4189mjxpzx) для любых экспериментов.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!
 | https://habr.com/ru/post/554172/ | null | ru | null |
# Современный C++ нас не спасет
[Я](https://fishinabarrel.github.io/) [часто](https://alexgaynor.net/2017/nov/20/a-vulnerability-by-any-other-name/) [критикую](https://motherboard.vice.com/en_us/article/a3mgxb/the-internet-has-a-huge-cc-problem-and-developers-dont-want-to-deal-with-it) [небезопасные при работе с памятью](https://twitter.com/LazyFishBarrel) [языки](https://fishinabarrel.github.io/), в основном C и C++, и то, как они провоцируют необычайное количество уязвимостей безопасности. Моё резюме, основанное на изучении доказательств из многочисленных крупных программных проектов на С и С++, заключается в том, что нам необходимо мигрировать нашу индустрию на безопасные для памяти языки по умолчанию (такие как Rust и Swift). Один из ответов, который я часто получаю, заключается в том, что проблема не в самих С и С++, разработчики просто неправильно их "готовят". В частности, я часто получаю в защиту C++ ответ типа: "C++ безопасен, если вы не используете унаследованную от C функциональность" [1] или аналогичный ему, что если вы используете типы и идиомы современного C++, то вы будете застрахованы от уязвимостей типа повреждения памяти, от которых страдают другие проекты.
Хотелось бы отдать должное умным указателям С++, потому что они существенно помогают. К сожалению, мой опыт работы над большими С++ проектами, использующими современные идиомы, заключается в том, что этого даже близко недостаточно, чтобы остановить наплыв уязвимостей. Моя цель на оставшуюся часть этой заметки - выделить ряд абсолютно современных идиом С++, которые порождают уязвимости.
---
Скрытая ссылка и use-after-free
-------------------------------
```
#include
#include
#include
int main() {
std::string s = "Hellooooooooooooooo ";
std::string\_view sv = s + "World\n";
std::cout << sv;
}
```
Вот что здесь происходит, `s + "World\n"` создает новую строку `std::string`, а затем преобразует ее в `std::string_view`. На этом этапе временная std::string освобождается, но `sv` все еще указывает на память, которая ранее ей принадлежала. Любое последующее использование `sv` является use-after-free уязвимостью. Упс! В С++ не хватает средств, чтобы компилятор знал, что `sv` захватывает ссылку на что-то, где ссылка живет дольше, чем донор. Эта же проблема затрагивает `std::span`, также чрезвычайно современный тип С++.
Другой забавный вариант включает в себя использование лямбда в С++ для сокрытия ссылки:
```
#include
#include
#include
std::function f(std::shared\_ptr x) {
return [&]() { return \*x; };
}
int main() {
std::function y(nullptr);
{
std::shared\_ptr x(std::make\_shared(4));
y = f(x);
}
std::cout << y() << std::endl;
}
```
Здесь `[&]` в `f` лямбда захватывает значение по ссылке. Затем в `main`, `x` выходит за пределы области видимости, уничтожая последнюю ссылку на данные и освобождая их. В этот момент `y` содержит висячий указатель. Это происходит, несмотря на наше тщательное использование умных указателей. И да, люди действительно пишут код, использующий `std::shared_ptr&`, часто как попытку избежать дополнительного приращения и уменьшения количеств в подсчитывающих ссылках.
Разыменование std::optional
---------------------------
`std::optional` представляет собой значение, которое может присутствовать, а может и не присутствовать, часто заменяя магические значения (например, `-1` или `nullptr`). Он предлагает такие методы, как `value()`, которые извлекают `T`, которое он содержит, и вызывает исключение, если `optional` пуст. Однако, он также определяет `operator*` и `operator->`. Эти методы также обеспечивают доступ к хранимому `T`, однако они не проверяют, содержит ли `optional` значение или нет.
Следующий код, например, просто возвращает неинициализированное значение:
```
#include
int f() {
std::optional x(std::nullopt);
return \*x;
}
```
Если вы используете `std::optional` в качестве замены `nullptr`, это может привести к еще более серьезным проблемам! Разыменование `nullptr` дает segfault (что не является проблемой безопасности, кроме как [в старых ядрах](https://alexgaynor.net/2019/mar/07/chrome-windows-exploit-security-beyond-bugfixes/)). Однако, разыменование `nullopt` дает вам неинициализированное значение в качестве указателя, что может быть серьезной проблемой с точки зрения безопасности. Хотя `T*` также бывает с неинициализированным значением, это гораздо менее распространено, чем разыменование указателя, который был правильно инициализирован `nullptr`.
И нет, это не требует использования сырых указателей. Вы можете получить неинициализированные/дикие указатели и с помощью умных указателей:
```
#include
#include
std::unique\_ptr f() {
std::optional> x(std::nullopt);
return std::move(\*x);
}
```
Индексация std::span
--------------------
`std::span` обеспечивает эргономичный способ передачи ссылки на непрерывный кусок памяти вместе с длиной. Это позволяет легко писать код, который работает с несколькими различными типами; `std::span` может указывать на память, принадлежащую `std::vector, std::array` или даже на сырой указатель. Некорректная проверка границ - частый источник уязвимостей безопасности, и во многих смыслах `span` помогает, гарантируя, что у вас всегда будет под рукой длина.
Как и все структуры данных STL, метод `span::operator[]` не выполняет проверку границ. Это печально, так как `operator[]` является наиболее эргономичным и стандартным способом использования структур данных. `std::vector` и `std::array` можно, по крайней мере, теоретически безопасно использовать, так как они предлагают метод `at()`, который проверяет границы (на практике я этого никогда не видел, но можно представить себе проект, использующий инструмент статического анализа, который просто запрещает вызовы `std::vector::operator[]`). span не предлагает метод `at()`, или любой другой подобный метод, который выполняет проверку границ.
Интересно, что как Firefox, так и Chromium в бэкпортах `std::span` *выполняют* проверку границ в `operator[]`, и, следовательно, никогда не смогут безопасно мигрировать на `std::span`.
Заключение
----------
Идиомы современного C++ вводят много изменений, которые могут улучшить безопасность: умные указатели лучше выражают ожидаемое время жизни, `std::span` гарантирует, что у вас всегда под рукой правильная длина, `std::variant` обеспечивает более безопасную абстракцию для `union`. Однако современный C++ также вводит новые невообразимые источники уязвимостей: захват `лямбд` с эффектом use-after-free, неинициализированные `optional` и не проверяющие границы `span`.
Мой профессиональный опыт написания относительно современного С++ кода и аудита Rust-кода (включая Rust-код, который существенно использует `unsafe`) заключается в том, что безопасность современного С++ просто не сравнится с языками, в который безопасность памяти включена по умолчанию, такими как Rust и Swift (или Python и Javascript, хотя я в реальности редко встречаю программы, для который имеет смысл выбора - писать их на Python, либо на C++).
Существуют значительные трудности при переносе существующих больших кодовых баз на C и C++ на другие языки - никто не может этого отрицать. Тем не менее, вопрос просто должен ставиться в том, *как* мы можем это сделать, а не в том, стоит ли пытаться. Даже при наличии самых современных идиом С++, очевидно, что при росте масштабов просто невозможно [корректно использовать С++](https://www.engadget.com/2010/06/24/apple-responds-over-iphone-4-reception-issues-youre-holding-th/).
[1] Это надо понимать, что речь идет о сырых указателях, массивах-как-указателях, ручном malloc/free и другом подобном функционале Си. Однако, думаю, стоит признать, что, учитывая, что Си++ явно включил в свою спецификацию Си, на практике большинство Си++-кода содержит некоторые из этих "фич". | https://habr.com/ru/post/554376/ | null | ru | null |
# Компактный Java сервлет для мобильного веб
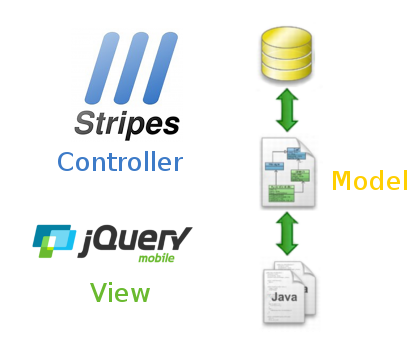
Основная область программирования для меня, это разработка программного обеспечения для автоматизации учёта в торговли. С возможностью использовать для этого сервлеты Java я столкнулся в 2009 году, когда вместе с последней, вышедшей для десктопа, версией Openbravo POS шёл [модуль ресторана для PDA](http://wiki.openbravo.com/wiki/Projects:POS/PDA_Module_Installation_Guide). Основной идей тогда для разработчиков Openbravo POS было, чтобы не усложнять десктопную версию приложения, вынести узкую бизнес-логику в отдельное небольшое приложение, главной изюминкой которого был компактный веб-интерфейс для доступа с любого устройства, а не только того, где может быть запущена Java c Swing. При этом тогда предполагалось, что сервлет не только будет работать с одной и той-же базой, что и десктоп версия, но и контейнер для него будет интегрирован в приложение на десктопе, после запуска которого пользователь автоматический получал доступ к POS в радиусе действия Wi-Fi сети. В рамках комьюнити данная идея дальнейшего развития не получила, но я с 2012 для своих клиентов заложенными тогда принципы продолжаю пользоваться, и в данной статье расскажу читателям, как используя [Stripes Framework](http://www.stripesframework.org) в связке с [jQuery Mobile](http://jquerymobile.com/) и [ORMLite](http://ormlite.com/), получить инструмент для быстрой разработки небольших сервлетов ориентированных на мобильный веб.
#### Инструментарий
Обычно, когда ищешь инструмент разработки, то стараешься найти что-то универсальное, что можно изучив однажды использовать повторно на протяжении достаточно долгого времени. В 2012 года именно с этим я столкнулся, когда попытался переделать исходный код ресторанного модуля Openbravo POS. В его основе лежал фреймворк [Struts 1](http://struts.apache.org/release/1.3.x/), изучать написание XML-схем для которого меня совсем не радовало, но на удачу, как раз в тот момент, мне на глаза попался [обзор технологий экосистемы Java](http://zeroturnaround.com/rebellabs/developer-productivity-report-2012-java-tools-tech-devs-and-data/) от [RebelLabs](http://zeroturnaround.com/rebellabs). [Один из разделов](http://zeroturnaround.com/rebellabs/developer-productivity-report-2012-java-tools-tech-devs-and-data/5/) этого обзора был посвящён популярности веб-фреймворков у разработчиков, в эту 10-ку с почётными 2% входил [Stripes](http://www.stripesframework.org). С его освоения я и начал изучение основ разработки Java сервлетов. Также мне помогло то, что к тому моменту на Хабре в «Песочнице» уже была [обзорная статья](http://habrahabr.ru/sandbox/26093/) про этот фреймворк.
В Stripes всё подчинено логике реакции на контролеры(ActionBean), которые отвечают за получение доступа к модели данных для дальнейшего отображения пользователю через шаблоны страниц JSP. Так как мне нужен был мобильный веб-интерфейс, то для визуальной части я выбрал [jQuery Mobile](http://jquerymobile.com/), главный плюс которого, это возможность практически не касаясь JavaScript использовать только HTML5 разметку для построения динамической реакции на действия контролера.
Третьим элементом, отвечающим за работу с моделью данных, мной сначала был выбран совсем простой [Persist ORM/DAO](https://github.com/MarcosT/persist), но когда его функционала стало недостаточно, я сменил его на более мощный [ORMLite](http://ormlite.com/). Главным при выборе стала лёгкость использования уже существующей модели представления и отсутствия необходимости написания SQL-запросов обходясь, как и в случае Stripes, только аннотациями.
#### Модель-Представление-Контролер
Ключевым в Stripes является 100% ориентированность на концепцию MVC(Model-View-Controller). А главной целью создания данного фреймворка в 2005 году было создание более легковесной реализация MVC концепции для Java EE, чем была реализована в популярном на тот момент фреймворке Struts. К версии 1.5 в 2008 году эта цель авторами Stripes была полностью достигнута и данный фреймворк начал набирать популярность среди разработчиков.
При проектировании структуры исходного кода сервлета следует стараться не выходить за рамки парадигмы Модель-Представление-Контролер, что не очень сложно сделать для большинства задач при создании CRUD-приложений. Для примера, в исходном коде для справочника товаров, это будет выглядеть так:
**Источник данных, исходная SQL-таблица**
```
CREATE TABLE PRODUCTS (
ID VARCHAR(255) NOT NULL,
NAME VARCHAR(255) NOT NULL,
CODE VARCHAR(255) NOT NULL,
PRICESELL DOUBLE NOT NULL,
CATEGORY VARCHAR(255) NOT NULL,
PRIMARY KEY (ID),
CONSTRAINT PRODUCTS_FK_1 FOREIGN KEY (CATEGORY) REFERENCES CATEGORIES(ID)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE UNIQUE INDEX PRODUCTS_CODE_INX ON PRODUCTS(CODE);
CREATE UNIQUE INDEX PRODUCTS_NAME_INX ON PRODUCTS(NAME);
```
**Модель данных с аннотациями для ORMLite**
```
@DatabaseTable(tableName = "PRODUCTS")
public class Product {
public static final String ID = "ID";
public static final String NAME = "NAME";
public static final String CODE = "CODE";
public static final String PRICESELL = "PRICESELL";
public static final String CATEGORY = "CATEGORY";
@DatabaseField(generatedId = true, columnName = ID)
private UUID id;
@DatabaseField(columnName = NAME, unique = true, canBeNull = false)
private String name;
@DatabaseField(columnName = CODE, unique = true, canBeNull = false)
private String code;
@DatabaseField(columnName = PRICESELL, canBeNull = false)
private BigDecimal pricesell;
@DatabaseField(foreign = true,
columnName = CATEGORY,
foreignColumnName = ProductCategory.ID,
foreignAutoRefresh = true,
canBeNull = false)
private ProductCategory productCategory;
// ...
// Перечисления методов get и set.
// ...
}
```
В начале, с помощью ORMLite, задаётся структура модели данных и её связь с реляционной базой данных(значение полей `tableName` и `columnName`). Затем через геттеры и сеттеры модель предоставляет доступ для остальных классов и методов сервлета.
**Контроллер Stripes для ввода/вывода данных**
```
public class ProductCreateActionBean extends ProductBaseActionBean {
private static final String PRODUCT_CREATE = "/WEB-INF/jsp/product_create.jsp";
@DefaultHandler
public Resolution form() {
// Открытие формы для заполнения.
return new ForwardResolution(PRODUCT_CREATE);
}
public Resolution add() {
// ...
// После проверки полученных значений, создание записи в таблице.
// ...
}
@ValidateNestedProperties({
@Validate(on = {"add"},
field = "name",
required = true,
trim = true,
maxlength = 255),
@Validate(on = {"add"},
field = "code",
required = true,
trim = true,
minlength = 8,
maxlength = 13),
@Validate(on = {"add"},
field = "priceSell",
required = true,
converter = BigDecimalTypeConverter.class),
@Validate(field = "productCategory.id",
required = true,
converter = UUIDTypeConverter.class)
})
@Override
public void setProduct(Product product) {
super.setProduct(product);
}
}
```
Контроллер перехватывает данные передаваемые пользователем и обрабатывает их согласно заданных аннотаций. Например, выполняя `Resolution form()`, получив значение ключевого поля `productCategory.id`, он пропускает его через `UUIDTypeConverter`, проверяя соответствует-ли оно допустимым для UUID критериям.
**Шаблон JSP с разметкой jQueryMobile и полями Stripes**
```
*
*
*
*
```
В шаблоне страницы разметка jQuery Mobile также может служить для предварительной проверки вводимых данных, например в визуальной форме предлагая пользователю на мобильном устройстве разные клавиатуры для текста и чисел(в `input` параметр `type` равен `"text"` или `"number"`).
#### Для чего подходит
В конце прошлого 2013 года RebelLabs был опубликован [новый обзор перспектив развития фреймворков в будущем 2014 году](http://zeroturnaround.com/rebellabs/the-2014-decision-makers-guide-to-java-web-frameworks/). Stripes в данный обзор не вошёл, так как в основном внимание было уделено более полярным чем он фреймворкам, таким как Spring, Grails или Vaadin. Но мне кажется, что если совместно с ним использовать jQuery Mobile и ORMLite, то и он сейчас найдёт свою нишу в инструментарии разработчика на Java. По крайней мере в 4 из [7 предложенных RebelLabs сфер применения](http://zeroturnaround.com/rebellabs/the-2014-decision-makers-guide-to-java-web-frameworks/5/) с ним можно чувствовать себя вполне уверенно:
1. Приложения CRUD — об этом было выше, если всё делать последовательно и по одной схеме, то очень сложно сделать плохо. Главное при проектировании стараться каждое действие контроллера делать максимально полным, но не переполненным.
2. Мобильные приложения — тут основная нагрузка лежит на jQuery Mobile, для Java программиста несомненный плюс, что кроме HTML5 можно не трогать JavaScript и CSS.
3. Прототипы приложений — это основное для чего я использую эту связку, набрав с 10-ок сервлетов в портфолио, можно отдельные компоненты каждого из них легко между собой тасовать под разные бизнес-процессы.
4. Портирование десктоп приложений — а с этого у меня всё и началось, и именно для такого применения я могу порекомендовать в первую очередь сплав этих трёх фрейморков.
[](http://habrastorage.org/files/9ec/a0c/726/9eca0c726d6e48cb9a4e039c9b2d370c.png)
Это итог, новый интерфейса с jQuery Mobile версии 1.4 в 2014 году, в сравнении с тем интерфейсом, что был в 2009 году у PDA модуля Openbravo POS.
В качестве примера практической реализации изложенного в статье, небольшой проект CRUD-сервлета для каталог товара: [github.com/nordpos-mobi/product-catalog](http://github.com/nordpos-mobi/product-catalog) | https://habr.com/ru/post/156781/ | null | ru | null |
# Собираем генератор данных на Blender. Часть 4: Сборка проекта и рендеринг
*Привет, Хабр! На связи Глеб, ML-разработчик* [*Friflex*](https://friflex.com/)*. В предыдущих статьях мы научились работать с объектами, настраивать свет и камеры, редактировать материалы (aka. текстуры) через api. В заключительной части знакомства с Blender мы рассмотрим две темы: сборка проекта из разных файлов и запуск рендеринга через консоль. В Friflex мы используем Blender в работе над idChess (интеллектуальной платформой для распознавания и трансляции шахматных партий) и другими проектами по оцифровке спорта.*
**Содержание:**
* [Часть 1: Объекты. В этом блоке научимся взаимодействовать с объектами. Разберем получение доступа через API, перемещение, масштабирование и вращение.](https://habr.com/ru/company/friflex/blog/666958/)
* [Часть 2: Камера. Разберемся, как автоматически настроить фокусное расстояние, навести камеру на предмет и отобразить координаты объекта на кадр.](https://habr.com/ru/company/friflex/blog/668978/)
* [Часть 3: Материалы и освещение. Рассмотрим свойства источников света и работу с материалами через пользовательские свойства и драйверы.](https://habr.com/ru/company/friflex/blog/673322/)
* Часть 4: Сборка проекта и рендеринг. Научимся загружать объекты из разных файлов и запускать рендеринг сцены через консоль.
### Структура файлов.blend
Прежде чем мы начнем, давайте разберемся, как устроены проекты внутри. Предположим, что мы работаем со сценой, на которой находятся такие объекты:
Структура проектаТеперь сохраним этот проект. В результате мы получим файл с расширением «blend», с которым будем работать в дальше.
Это гифка. Чтобы посмотреть, нажмите на изображениеТеперь вернемся обратно в приложение и разберемся, как выглядит внутренняя структура файла, который мы только что создали. Для этого нам нужно открыть вкладку «Blender file» в блоке, который отображает список объектов.
Это гифка. Чтобы посмотреть, нажмите на изображениеКак видите, файл имеет четкую и понятную структуру: все элементы, которые мы используем в нашем проекте, сгруппированы по папкам. Например, в «Materials» лежат все текстуры, с которыми мы работали.
Вкладка «Blender file»Дополнительно замечу, если мы хотим полностью удалить какой-то элемент из нашего проекта, то делать это нужно через вкладку «Blender file». Почему так? Попробуем удалить какой-нибудь объект со сцены.
Это гифка. Чтобы посмотреть, нажмите на изображениеМожет показаться, что этот куб полностью удален и не занимает место в памяти нашего компьютера, но это не так… Давайте заглянем в папку «Mesh». Наш старый знакомый «Cube» все еще тут.
Вкладка «Blender file» с подсветкой кубаСхожая логика работает и с другими элементами, поэтому, если вы заметили, что ваш проект набрал вес, но при этом у вас на сцене практически ничего нет – загляните в «Blender file». Вас ждет приятный сюрприз)
### Загрузка объектов из разных файлов
На данный момент у нас есть файл «project\_42.blend» и понимание того, как он устроен. Теперь предположим, что мы создали новый проект, в котором есть конус, камера и источник света.
Структура нового проектаИ теперь мы хотим загрузить на эту сцену куб из проекта «project\_42.blend». Мы можем сделать это как через интерфейс приложения, так и через консоль. Рассмотрим оба подхода.
### Загрузка через пользовательский интерфейс
Это гифка. Чтобы посмотреть, нажмите на изображение### Загрузка консоль
Чтобы воспользоваться этим подходом нам понадобится примерно такой код.
```
from pathlib import Path
def append(
path: Path,
active_collection: bool = False,
**kwargs
):
bpy.ops.wm.append(
filepath = str(path),
directory = str(path.parent),
filename = str(path.name),
active_collection = active_collection
)
```
Теперь загрузим куб на нашу сцену, но уже через консоль. Для этого используем функцию из предыдущего блока.
```
append(
Path(‘./project_1.blend/Objects/Cube’)
)
```
Чтобы понять что к чему, рассмотрим параметры, которые принимает функция «bpy.ops.wm.append».
1. filepath – полный путь до элемента, который мы хотим загрузить: «./project\_42.blend/Objects/Cube».
2. directory – путь до папки, в которой хранится элемент: «./project\_42.blend/Objects».
3. filename – название элемента: «Cube».
4. active\_collection – если True, то объект будет добавлен в активную коллекцию (выделенную через интерфейс), иначе в «Scene Collection».
В результате мы получили аналогичный результат: куб добавлен на сцену с конусом. Заметим, что помимо самого куба в проект подгружается материал, который к нему прикреплен. Подробнее про параметры функции «bpy.ops.wm.append» можно почитать в [документации](https://docs.blender.org/api/current/bpy.ops.wm.html?highlight=append#bpy.ops.wm.append).
Структура нового проекта после добавления куба### Рендеринг
На данный момент мы изучили все необходимое, чтобы подготовить сцену для генерации через API. Осталось только понять, как запустить рендеринг. Первым делом мы рассмотрим базовые настройки отрисовки, а в конце запустим генерацию через консоль.
### Cycles и Eevee. Сравнение движков для рендеринга
В blender встроены два движка для рендеринга: eevee и cycles. Eevee – движок рендеринга в реальном времени. Но не стоит ждать от него высокого качества отрисовки. Eevee скорее подходит для предварительного просмотра сцены. Ниже привожу пример изображения, созданного с помощью этого движка.
Генерация шахмат на eeveeCycles же пытается как можно лучше соответствовать физике реального мира: вычисляет все световые лучи, отражения и т.д. За счет этого мы получаем фотореалистичный рендеринг. Однако за это качество мы платим временем.
Генерация шахмат на cyclesВыбрать подходящий движок для рендеринга можно и через API. Ниже приведен пример кода.
```
render = bpy.context.scene.render
render.engine = 'CYCLES'
```
Если интересно более детально понять разницу между движками, то советую прочитать эту [публикацию](https://renderguide.com/blender-eevee-vs-cycles-tutorial/).
### Resolution. Разрешение.
В статье про настройку камеры мы уже обсуждали настройку разрешения отрисованного изображения. Но, думаю, не будет лишним повторить это еще раз.
```
render = bpy.context.scene.render
# Меняем разрешение относительно осей x и y в пикселях
render.resolution_x = 1920
render.resolution_y = 1080
```
### Samples. Качество изображения
Samples – свойство движка cycles – отвечает за качество конечного изображения. Чем выше значение этого параметра, тем больше вычислений физики будет произведено. В качестве примера прикрепляю два изображения с разными значениями samples: 5 и 500.
Samples 5samples 500Заметим, что нет единственно верного значение samples. В первую очередь нужно ориентироваться на количество элементов. Чем больше элементов, тем более высокое значение параметра samples нужно, чтобы получить качественное изображение.
Установить значение samples можно через API.
```
bpy.context.scene.cycles.samples = 50
```
### Transparent. Прозрачный фон
В blender есть возможность генерировать изображения с прозрачным задним фоном. Для этого нужно настроить два параметра: transparent и color\_mode.
```
bpy.context.scene.render.film_transparent = True
bpy.context.scene.render.image_settings.color_mode = ‘RGBA’
```
### Device. Запуск рендеринга на GPU
Последнее, но, вероятно, самое важное свойство – тип устройства вычисления. По умолчанию в качестве девайса используется CPU. Чтобы автоматически переключиться на GPU, можно использовать следующий код.
```
preferences = bpy.context.preferences
preferences.addons['cycles'].preferences.get_devices()
cycles = preferences.addons['cycles'].preferences
for compute_device_type in ('CUDA', 'OPENCL', 'NONE'):
try:
cycles.compute_device_type = compute_device_type
break
except TypeError:
pass
```
### Запуск рендеринга через консоль
Предположим, что у нас есть готовый скрипт «some\_script.py», который собирает сцену: расставляет объекты, настраивает материалы и освещение и т.д. Теперь мы хотим запустить этот скрипт и после зарендерить готовую сцену. Для этого выполним следующую команду через консоль.
```
bash
${PATH_TO_BLENDER}/blender -b ${PATH_TO_SCENE} --python-expr "${PYTHON_EXPR}" -noaudio -E CYCLES -o ${OUTPUT_IMAGE_PATH} -F 'PNG' -f 1
```
Теперь разберем параметры, которые используем в этой команде.
1. PATH\_TO\_BLENDER – путь до папки с файлами blender-а.
2. PATH\_TO\_SCENE – путь до сцены, которую блендер должен подгрузить;
3. PYTHON\_EXPR – код, который будет выполнен после подгрузки сцены. С помощью этого выражения запускаем функции из своей python-скрипта: “import some\_script;some\_script.run()”.
4. OUTPUT\_IMAGE\_PATH – путь, по которому будет сохранено изображение. Например, “./my\_image\_#”. На место # блендер автоматически поставит индекс кадра. Расширение будет добавлено автоматически.
5. -E CYCLES. Используем движок Cycles для рендеринга.
6. -f 1. Указываем, какое количество кадров из нашего проекта должен сгенерировать.
### The end
Вы работали с blender и хотите обсудить прочитанное? Или поделиться своим опытом и знаниями, чтобы сделать статью более полной и полезной для новичков? Жду вас в комментариях! | https://habr.com/ru/post/681646/ | null | ru | null |
# Руководство по фоновой работе в Android. Часть 4: RxJava

Обработка событий — это цикл.
В прошлой части мы [говорили](https://habrahabr.ru/company/jugru/blog/351166/) об использовании thread pool executors для фоновой работы в Android. Проблема этого подхода оказалась в том, что отправляющий события знает, как должен быть обработан результат. Посмотрим теперь, что предлагает RxJava.
**Дисклеймер: это не статья о том, как использовать RxJava в Android. Таких текстов в интернете и так прорва. Этот — о деталях реализации библиотеки.**
Вообще говоря, RxJava — даже не инструмент конкретно для работы в фоне, это инструмент для обработки потоков событий.
Фоновая работа — это лишь один из аспектов такой обработки. Общая идея подхода в том, чтобы использовать Scheduler. Давайте посмотрим прямо в код этого класса:
```
public abstract class Scheduler {
@NonNull
public Disposable scheduleDirect(@NonNull Runnable run) { ... }
@NonNull
public Disposable scheduleDirect(@NonNull Runnable run, long delay, @NonNull TimeUnit unit) { ... }
@NonNull
public Disposable schedulePeriodicallyDirect(@NonNull Runnable run, long initialDelay, long period, @NonNull TimeUnit unit) { ... } {
@NonNull
public ~~S when(@NonNull Function>, Completable> combine) { ... }
}~~
```
Довольно сложно, правда? Хорошая новость в том, что не надо самому это реализовывать! Библиотека уже включает целый ряд таких планировщиков: Schedulers.io(), Schedulers.computation(), и так далее. Всё, что требуется от вас — передать экземпляр scheduler в subscribeOn()/observeOn() метод вашей Rx-цепочки:
```
apiClient.login(auth)
// some code omitted
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
```
Затем RxJava сделает остальное за вас: возьмёт лямбды, которые вы передаете в операторы, и исполнит их на нужном планировщике.
Например, если вы хотите, чтобы ваши наблюдатели меняли пользовательский интерфейс, всё, что вам надо сделать — передать AndroidSchedulers.mainThread() в observeOn(). И дело в шляпе: больше никакой излишней связности, никакого платформо-специфичного кода, одно счастье. Конечно, AndroidSchedulers не входит в оригинальную библиотеку RxJava, а подключается в составе отдельной, но это просто ещё одна строчка в вашем build.gradle.
И что тут сложного с потоками? Хитрость в том, что нельзя просто разместить subscribeOn()/observeOn() в любом месте вашей rxChain (а было бы удобно, да?) Вместо этого приходится учесть, как эти операторы получают свои schedulers. Для начала давайте поймем, что каждый раз при вызове map, или flatMap, или filter, или ещё чего, вы получаете новый объект.
Например:
```
private fun attemptLoginRx() {
showProgress(true)
apiClient.login(auth)
.flatMap {
user -> apiClient.getRepositories(user.repos_url, auth)
}
.map {
list -> list.map { it.full_name }
}
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.doFinally { showProgress(false) }
.subscribe(
{ list -> showRepositories(this, list) },
{ error -> Log.e("TAG", "Failed to show repos", error) }
)
}
```
Так что тут почти каждая строчка создаёт новый объект:
```
// new SingleFlatMap()
val flatMap = apiClient.login(auth)
.flatMap { apiClient.getRepositories(it.repos_url, auth) }
// new SingleMap
val map = flatMap
.map { list -> list.map { it.full_name } }
// new SingleSubscribeOn
val subscribeOn = map
.subscribeOn(Schedulers.io())
// new SingleObserveOn
val observeOn = subscribeOn
.observeOn(AndroidSchedulers.mainThread())
// new SingleDoFinally
val doFinally = observeOn
.doFinally { showProgress(false) }
// new ConsumerSingleObserver
val subscribe = doFinally
.subscribe(
{ list -> showRepositories(this@LoginActivity, list) },
{ error -> Log.e("TAG", "Failed to show repos", error) }
)
}
```
И, например, SingleMap получит свой scheduler через цепочку вызовов, начинающуюся с вызова .subscribe() в конце нашей цепочки:
```
@SchedulerSupport(SchedulerSupport.NONE)
@Override
public final void subscribe(SingleObserver super T subscriber) {
ObjectHelper.requireNonNull(subscriber, "subscriber is null");
subscriber = RxJavaPlugins.onSubscribe(this, subscriber);
ObjectHelper.requireNonNull(subscriber, "subscriber returned by the RxJavaPlugins hook is null");
try {
subscribeActual(subscriber);
} catch (NullPointerException ex) {
throw ex;
} catch (Throwable ex) {
Exceptions.throwIfFatal(ex);
NullPointerException npe = new NullPointerException("subscribeActual failed");
npe.initCause(ex);
throw npe;
}
}
```
subsribeActual реализован для каждого Single-оператора так:
```
source.subscribe()
```
где source — оператор, предшествующий текущему, так что создается цепочка, с которой мы работаем и по которой достигаем первого созданного Single. В нашем случае это Single.fromCallable:
```
override fun login(auth: Authorization): Single = Single.fromCallable {
val response = get("https://api.github.com/user", auth = auth)
if (response.statusCode != 200) {
throw RuntimeException("Incorrect login or password")
}
val jsonObject = response.jsonObject
with(jsonObject) {
return@with GithubUser(getString("login"), getInt("id"),
getString("repos\_url"), getString("name"))
}
}
```
Внутри этой лямбды мы осуществляем свои сетевые вызовы.
Но где наш scheduler? Тут, внутри SingleSubsribeOn:
```
@Override
protected void subscribeActual(final SingleObserver super T s) {
final SubscribeOnObserver parent = new SubscribeOnObserver(s, source);
s.onSubscribe(parent);
Disposable f = scheduler.scheduleDirect(parent);
parent.task.replace(f);
}
```
В данном случае scheduler — тот, который мы передали в метод subsribeOn().
Весь этот код показывает, как scheduler, который мы передали в цепь, используется кодом, который мы передали в лямбды оператора.
Также обратим внимание на метод observeOn(). Он создает экземпляр класса (в нашем случае SingleObserveOn), и его subscribeActial для нас уже смотрится тривиально:
```
@Override
protected void subscribeActual(final SingleObserver super T s) {
source.subscribe(new ObserveOnSingleObserver(s, scheduler));
}
```
А вот ObserveOnSingleObserver тут куда интереснее:
```
ObserveOnSingleObserver(SingleObserver super T actual, Scheduler scheduler) {
this.actual = actual;
this.scheduler = scheduler;
}
@Override
public void onSuccess(T value) {
this.value = value;
Disposable d = scheduler.scheduleDirect(this);
DisposableHelper.replace(this, d);
}
```
При вызове observeOn в scheduler-потоке оказывается вызван observer, что, в свою очередь, открывает возможность переключения потоков прямо в rxChain: можно получить данные с сервера на Schedulers.io(), затем произвести ресурсоёмкие вычисления в Schedulers.computation(), обновить UI, посчитать еще что-то, а затем просто перейти к коду в subscribe.
RxJava — довольно сложный «под капотом», очень гибкий и мощный инструмент для обработки событий (и, как следствие, управления фоновой работой). Но, по-моему, у этого подхода есть свои недостатки:
1. На обучение RxJava уходит много времени
2. Количество операторов, которые нужно выучить, большое, а разница между ними неочевидна
3. Стек-трейсы вызовов для RxJava почти не имеют отношения к тому коду, который вы сами пишете
Что дальше? Разумеется, котлиновские корутины!
Предыдущие статьи серии:
* [Часть 1: AsyncTask](https://habrahabr.ru/company/epam_systems/blog/348894/)
* [Часть 2: Loaders](https://habrahabr.ru/company/jugru/blog/350094/)
* [Часть 3: Executors и EventBus](https://habrahabr.ru/company/jugru/blog/351166/)
> От автора: уже завтра и послезавтра пройдёт конференция **Mobius**, где я и [расскажу](https://mobiusconf.com/2018/spb/talks/mt2eecqokiosqguiooouu/) про корутины в Kotlin. Если серия статей заинтересовала и хочется продолжения — ещё не поздно принять решение о её посещении! | https://habr.com/ru/post/353852/ | null | ru | null |
# Dune 2: The Building of a Dynasty
**Разработчик:** Westwood Studios
**Издатель:** Virgin Games
**Жанр:** Strategy (Real-time) / Top-down
**Системные требования:**

#### Вместо введения
[Dune 2](http://ru.wikipedia.org/wiki/Dune_II) — это великолепная стратегия, одна из первых в жанре. Нет смысла распинаться и говорить насколько это великая игра для целого поколения детей 90х. А так как я, неожиданно для себя нахожу в удовольствие возиться с кодом и портировать его в JavaScript, то конечно же моей целью после TTD ([статья](http://habrahabr.ru/post/147138/)) неизбежно стала Dune 2. По счастливой случайности я не додумался начать с неё, поскольку боюсь я бы не справился. Как оказалось, хоть Dune 2 и проще по функционалу чем TTD, но портировать ее было сложнее, но об этом далее.
#### Кодовая база
Выбор «правильной» кодовой базы является главным фактором успешного портирования проекта с применением [emscripten](http://emscripten.org). Например, использование [SDL](http://www.libsdl.org/), отсутствие многопоточности являются хорошим маркером того что портирование пройдет с успехом. Я перебрал похоже все проекты так или иначе связанные с Dune 2, и остановился на [OpenDune](http://www.opendune.org/). Фишка которая меня зацепила — полное копирование всего поведения оригинальной игры включая все её баги. Похоже, код этого проекта изначально был получен полуавтоматическим путем из оригинала. В коде тут и там встречаются переменные с именем *local\_03FF*, очень много глобальных переменных, код читать очень тяжело. Самый серьезный недостаток исходной кодовой базы в многопоточности, она вызвала много проблем при портировании. Но зато результат действительно радует, в браузере игра похожа на оригинал очень сильно, за исключением новой пачки багов.
###### Итак, сухие факты:
Язык: C
Количество исходных файлов: 143
Количество строк кода: 59151
Размер бинарника: 423.2 Кб
Размер эквивалентного JavaScript: ~1000 Кб
Время потраченное на портирование: ~ 2 месяца
Далее в этой статье будут описаны сложности с которыми я столкнулся при портировании. Наверняка это интересно не каждому, если так, то опустите этот подраздел до «известных проблем».
#### Многопоточность VS асинхронность
OpenDune имеет достаточно интересную модель многопоточности основывающуюся на прерываниях. Для обеспечения многопоточности, игровой код в момент простоя крутится в бесконечных циклах, выглядит это примерно так:
```
while (true) {
uint16 key;
key = GUI_Widget_HandleEvents(w);
if (key = 13) {
break;
}
sleepIdle();
}
```
При старте приложения инициализируется интервальный таймер функцией [setitimer](http://www.intuit.ru/department/se/pposix/12/7.html). Этот таймер вызывает прерывание через равные промежутки времени. Оно приостанавливает основной поток выполнения и позволяет выполнить произвольный код. Для JavaScript реализация аналогичного таймера тривиальна, тем не менее был выбран другой путь портирования дабы искусственно не делить проект на JavaScript и C реализации. Было решено полностью отказаться от использования функции *setitimer*, вместо этого вызов *sleepIdle()* был замещен функцией обработки событий по таймеру, т.е. вместо простоя эта функция определяет какие запланированные события подошли и запускает их на выполнение.
Более серьезная проблема — внутрение циклы *while*, любое появление такого цикла в JavaScript вызовет неминуемое зависание открытой вкладки браузера (или браузера в целом). Это связано с тем, что большинство циклов ожидают пользовательского ввода (нажатие кнопки мыши, клавиатуры), однако браузер не может обработать события от устройств ввода, они ставятся в цепочку исполнения уже после текущего исполняемого блока JavaScript. Возможный способ решения этой проблемы — ручная правка кода и перевод проблемного кода в асинхронный режим.
Небольшой примеричик. Вот черновик кода который вызывает проблемы:
```
void someProblemFunction() {
{
//open 1
}
while (true) {
// open 2
while (true) {
// code 2
}
// close 2
}
{
//close 2
}
}
```
После мучительных умозрительных манипуляций, асинхронный код:
```
void asyncSomeProblemFunction() {
Async_InvokeInLoop(
asyncSomeProblemFunctionOpen1,
asyncSomeProblemFunctionCondition1,
asyncSomeProblemFunctionLoop1,
asyncSomeProblemFunctionClose1);
}
void asyncSomeProblemFunctionOpen1() {
// code from open 1
}
void asyncSomeProblemFunctionCondition1() {
// code from loop 1 condition
}
void asyncSomeProblemFunctionLoop1() {
Async_InvokeInLoop(
asyncSomeProblemFunctionOpen2,
asyncSomeProblemFunctionCondition2,
asyncSomeProblemFunctionLoop2,
asyncSomeProblemFunctionClose2);
}
void asyncSomeProblemFunctionClose1() {
// code from close 1
}
```
Адская работа. Ядром всей системы является функция *Async\_InvokeInLoop*.
```
void Async_InvokeInLoop(
void (*open)(),
void (*condition)(bool* ref),
void (*loop)(),
void (*close)());
```
*Async\_InvokeInLoop* — позволяет заменить любой цикл *while (true)* асинхронным эквивалентом. Функция гарантирует вызов *open* до начала цикла, а *close* после завершения цикла. Ссылки на функции *condition* и *loop* являются равноправными участниками асинхронной итерации, что они делают ясно из названия. Итерация реализуется через функцию *Async\_Loop*:
```
void Async_Loop() {
ScheduledAsync *top = STACK_TOP;
switch (top->state) {
case ScheduledAsync_OPEN: {
top->open();
top->state = ScheduledAsync_CONDITION;
return;
}
case ScheduledAsync_CONDITION: {
top->condition(&top->conditionValue);
top->state = ScheduledAsync_LOOP;
return;
}
case ScheduledAsync_LOOP: {
if (top->conditionValue) {
top->loop();
top->state = ScheduledAsync_CONDITION;
} else {
top->state = ScheduledAsync_CLOSE;
}
return;
}
case ScheduledAsync_CLOSE: {
popStack();
top->close();
free(top);
return;
}
default:
abort();
}
}
```
Игровой цикл (или таймер в JavaScript) переодически дергает эту функцию заставляя всё в игре крутится. Если исходная функция должна возвращать результат, то проблемы удваиваются — приходится сохранять результат в памяти глобально, и потом извлекать его в других функциях. Все работает по соглашению. В результате у меня получился адовый фреймворк для асинхронизации проекта, вот его интерфейс:
```
/*
* async.h
*
* Created on: 19.10.2012
* Author: caiiiycuk
*/
#ifndef ASYNC_H_
#define ASYNC_H_
#include "types.h"
extern void async_noop();
extern void async_false(bool *condition);
extern void async_true(bool *condition);
extern void Async_InvokeInLoop(void (*open)(), void (*condition)(bool* ref), void (*loop)(), void (*close)());
extern bool Async_IsPending();
extern void Async_Loop();
extern void Async_InvokeAfterAsync(void (*callback)());
extern void Async_InvokeAfterAsyncOrNow(void (*callback)());
extern void Async_Storage_uint16(uint16* storage);
extern void Async_StorageSet_uint16(uint16 value);
#endif /* ASYNC_H_ */
```
Синхронная природа игры мутировала в асинхронную, что порадило несколько забавных багов:
* Если вызвать меню строительства непосредственно перед тем, как компьютерный противник определит следующее строение для постройки, то можно получить доступ к его сооружениям (исправлено)
* При загрузке сценария существовала возможность что сооружения противника получат 20 000 — 30 000 едениц жизни вместо 150 — 200 (исправлено)
* Из за ошибок синхронизации — игровая карта может перерисоваться прямо поверх диалога с ментатом, правда проявляется это редко (не исправлено)
#### Известные проблемы
Из за того, что штат тестеров состоит из меня и моих вымышленных друзей, известно только что:
* Игра работает в браузерах Firefox, Chrome, Opera, Chrome (Android ~4)
* Игра полностью пройденна за дом Харконненов и серьезных проблем не найденно
* Небольшое количество миссий пройдено за два других дома, проблем так же не было
* Игровой курсор никогда не меняется (вне зависимости от выбранного действия), сделанно намеренно (он подтормаживает)
* Для прокрутки карты используйте миникарту или стрелочки клавиатуры (больше используйте клавиатуру в игре)
* Есть музыка, но эффектов нет
* На игровой карте могут появлятся артефакты (очень редко, вы сразу поймете), в этом случае помогает открытие/закрытие игрового меню
* В меню работают пункты: сохранить, загрузить, рестарт миссии
* В игре только один слот для сохранения (на все дома)
Всё остальное работает, либо должно работать.
Трекер: <https://github.com/caiiiycuk/play-dune>
#### Играем?
<http://play-dune.com/>
71
**UPD1.** Горячие клавиши: [habrahabr.ru/post/159501/#comment\_5516325](http://habrahabr.ru/post/159501/#comment_5516325)
**UPD2.** Сервер просядает, даю прямые ссылки со статикой:
[Игра за дом Atreides](http://play-dune.com/atreides/)
[Игра за дом Ordos](http://play-dune.com/ordos/)
[Игра за дом Harkonnen](http://play-dune.com/harkonnen/)
**UPD3.** Сервер уперся в ограничение tcpsndbuf — cуммарный размер буферов, которых может быть использован для отправки данных через TCP-соединения. Ограничение которое ставит мне провайдер, более производительный сервер позволить себе не могу, извините если вам не удалось поиграть. Ждем когда нагрузка придет в норму.
**UPD4.** Все же проблема была в моих кривых руках, теперь сервер должен справляться с нагрузкой.
**UPD5.** В космопорте не работает кнопка «Invoice», будте внимательны, если вы не заказали ни один юнит в космопорте и нажали «Send Order», то автоматически нажмется кнопка «Invoice» и все зависает.
**UPD6.** Новый [сайт проекта.](http://epicport.com) | https://habr.com/ru/post/159501/ | null | ru | null |
# Превращаем html в нативные компоненты
Доброго дня! Мы, мобильные разработчики компании surfingbird, решили попробовать написать небольшой цикл статей о том с какими трудностями мы сталкиваемся в процессе разработки мобильных приложений (android, ios), и как мы их решаем. Первый пост мы решили посвятить проблеме webview. Сразу оговорюсь, что решили мы эту проблему несколько кардинально… Для того чтобы было более понятно, придется рассказать пару слов о собственно том, чем мы занимаемся. Мы агрегируем контент из различных источников (парсим оригинальные статьи), выделяем значимую часть (контент) и на основе оценок пользователя и всяких сложных алгоритмов рекомендуем их конечному пользователю ну и конечно просто отображаем в более удобном виде.
В мобильных приложениях мы стремимся не только очистить страницы от элементов верстки и назойливых всплывающих окон, но и оптимизировать контент для потребления на мобильных устройствах.
Но при использовании webview для отображения контента мы столкнулись с рядом сложностей. Этот компонент тяжело поддается кастомизации и довольно тяжел и даже, я бы сказал, глючен. Настал день, когда мы поняли, что не хотим больше видеть webview вообще. Но избавиться от него, учитывая то, что контент у нас отдается в html — оказалось не так-то просто. Поэтому мы решили превратить html в нативные компоненты.
Попробую в двух словах описать принцип, прежде чем переходить к примерам кода.
1. Чистим html от стилей и яваскриптов
2. В качестве опорной точки мы используем ссылки на изображения и iframe
3. Все что до и между ссылками на изображения — это текст, который рендерим c помощью textview
4. Непосредственно изображения — рендерим c помощью imageview
5. Для Iframe — анализируем содержимое и видео рендерим как кликабельные картинки на видео, а прочее рендерим как ссылки или, в крайнем случае — вставляем в контейнер webview (например, ссылки на аудио с soundcloud)
6. Получившийся массив компонентов помещаем в listview и адаптер (на самом деле уже в recyclerView, но на момент написания статьи это был listview)
Первым делом необходимо очистить html от всякого мусора в виде javascript и css. Для этих целей мы воспользовались библиотекой [HtmlCleaner](http://htmlcleaner.sourceforge.net/). Заодно создадим массив всех изображений, которые встречаются в контенте (он понадобится нам позже):
```
final ArrayList links = new ArrayList();
HtmlCleaner mHtmlCleaner = new HtmlCleaner();
CleanerTransformations transformations =
new CleanerTransformations();
TagTransformation tt = new TagTransformation("img", "imgs", true);
transformations.addTransformation(tt);
mHtmlCleaner.setTransformations(transformations);
//clean
html = mHtmlCleaner.getInnerHtml(mHtmlCleaner.clean(parsed_content));
TagNode root = mHtmlCleaner.clean(html);
root.traverse(new TagNodeVisitor() {
@Override
public boolean visit(TagNode tagNode, HtmlNode htmlNode) {
if (htmlNode instanceof TagNode) {
TagNode tag = (TagNode) htmlNode;
String tagName = tag.getName();
if ("iframe".equals(tagName)) {
if (tag.getAttributeByName("src") != null) {
Link link = parseTag(tag, "iframe");
if (link != null) {
links.add(link);
}
}
}
if ("imgs".equals(tagName)) {
String src = tag.getAttributeByName("src");
//ico
if (src != null && !src.endsWith("/") && !src.toLowerCase().endsWith("ico")) {
Link link = parseTag(tag, "img");
if (link != null) {
links.add(link);
}
}
}
}
return true;
}
});
```
Здесь мы заменяем теги img на imgs^\_^, во первых, чтобы у textview не было соблазна отрендерить картинки, во вторых, чтобы затем найти все ссылки на картинки и заменить их на imageview.
Раз уж мы решили отображать картинки нативно, то не плохо было бы заодно увеличить их, чтобы средние картинки, например более 1/3 экрана — стали на весь экран смартфона, мелкие картинки — стали более крупными, а совсем маленькими — можно совсем пренебречь (как правило это иконки ссылок на соцсети):
```
public Link parseTag(TagNode tag,String type) {
final String src = tag.getAttributeByName("src");
final String width = tag.getAttributeByName("width");
final String height = tag.getAttributeByName("height");
int iWidth=0, iHeight=0;
try {
iWidth = Integer.parseInt(width.split("\\.")[0]);
iHeight = Integer.parseInt(height.split("\\.")[0]);
}
catch (Exception e) {}
//если картинка больше 1/3 экрана - тянем пропорционально
if (iWidth>((displayWidth*1)/3) && iHeight>0) {
iHeight = (displayWidth * iHeight)/iWidth;
iWidth = displayWidth;
}
//выкидываем мелкие пиписьки
if (iWidth>45 && iHeight>45) {
int scaleFactor = 1;
if (iWidth=4096 || iWidth>=4096 || src.endsWith("gif")) {
type = "iframe";
}
return new Link(type, src, iWidth\*scaleFactor, iHeight\*scaleFactor,"");
}
return null;
}
```
Собственно, половина работы уже сделано. Теперь осталось пройти по массиву линков на изображения, найти контент до изображения и вставить его в textview, после этого вставить картинку.
Для этого мы создали ArrayList в который будем помещать собственно сам контент, с указанием его типа (текст, картинка, iframe).
Некий псевдокод:
```
private ArrayList data = new ArrayList();;
for(int i=0;i0) {
abzats = html.substring(0, pos);
int closeTag = html.indexOf(">",pos)+1;
if (closeTag>0) {
html = html.substring(closeTag);
}
if (!TextUtils.equals("", abzats)) {
data.add(new Link("txt","",0,0,abzats));
}
}
//add text
if (link.type.equals("img")) {
//add image
data.add(link);
}
//add iframe
if (link.type.equals("iframe")) {
data.add(link);
}
}
data.add(new Link("txt","",0,0,html));
```
На этом месте у нас есть великолепный массив, с контентом, разбитым на типы. Все что осталось — отрендерить его. А для рендеренга массивов сложно найти что то более прекрасное чем обычный listview + adapter:
Примерно так выглядит код getView в адаптере:
```
if (link.type.equals("txt")) {
//текст
return getTextView(activity, link.txt);
}
if (link.type.equals("img")) {
// картинка
}
...
//где, textview
public TextView getTextView(Context context,String txt){
TextView textView = new TextView(activity);
textView.setMovementMethod(LinkMovementMethod.getInstance());
textView.setText(Html.fromHtml(txt));
textView.setTextSize(TypedValue.COMPLEX_UNIT_SP,fontSize);
textView.setPadding(UtilsScreen.dpToPx(8),0,UtilsScreen.dpToPx(8),0);
textView.setAutoLinkMask(Linkify.ALL);
textView.setLineSpacing(0, 1.4f);
ColorStateList cl = null;
try {
XmlResourceParser xpp = context.getResources().getXml(R.xml.textview_link_color_selector);
cl = ColorStateList.createFromXml(context.getResources(), xpp);
textView.setLinkTextColor(cl);
} catch (Exception e) {
textView.setLinkTextColor(Color.parseColor("#6fb304"));
}
return textView;
}
```
Итак, текст рендерится как html с помощью textview, картинки превращаются в обычные картинки, но оптимизированные под разрешение устройства. Осталась только боль с iframe. Мы анализируем его содержимое, и если это ссылка на youtube, например — генерируем картинку с плейсхолдером видео, на клик по которой открываем приложение youtube. Вобщем, тут все уже совсем просто:
```
String youtubeVideo = "";
if (link.src.contains("lj-toys") && link.src.contains("youtube") && link.src.contains("vid=")) {
try {
youtubeVideo = link.src.substring(link.src.indexOf("vid=") + 4, link.src.indexOf("&", link.src.indexOf("vid=") + 4));
} catch (Exception e) {
e.printStackTrace();
}
}
//http://www.youtube.com/embed/ZSPyC6Uv9xw
if (link.src.contains("youtube") && link.src.contains("embed/")) {
try {
youtubeVideo = link.src.substring(link.src.indexOf("embed/") + 6);
} catch (Exception e) {
e.printStackTrace();
}
}
if (!youtubeVideo.equals("")) {
//new RelativeLayout
RelativeLayout relativeLayout = new RelativeLayout(activity);
RelativeLayout.LayoutParams layoutParams = new RelativeLayout.LayoutParams(
RelativeLayout.LayoutParams.WRAP_CONTENT, RelativeLayout.LayoutParams.WRAP_CONTENT);
ImageView imageView = new ImageView(activity);
imageView.setLayoutParams(layoutParams);
relativeLayout.addView(imageView);
imageView.setBackgroundColor(Color.parseColor("#f8f8f8"));
if (link.width>0 && link.height>0) {
aq.id(imageView).width(link.width, false).height(link.height, false);
}
String youtubeVideoImage = youtubeVideo;
if (youtubeVideoImage.contains("?")) {
//params
youtubeVideoImage = youtubeVideoImage.substring(0, youtubeVideoImage.indexOf("?"));
}
if (link.width>0) {
aq.id(imageView).image("http://img.youtube.com/vi/" + youtubeVideoImage + "/0.jpg", true, false, link.width, 0, null, AQuery.FADE_IN_NETWORK);
}
else {
aq.id(imageView).image("http://img.youtube.com/vi/" + youtubeVideoImage + "/0.jpg");
}
ImageView imageViewPlayBtn = new ImageView(activity);
relativeLayout.addView(imageViewPlayBtn);
RelativeLayout.LayoutParams playBtnParams = new RelativeLayout.LayoutParams(
ViewGroup.LayoutParams.WRAP_CONTENT, ViewGroup.LayoutParams.WRAP_CONTENT);
playBtnParams.addRule(RelativeLayout.CENTER_IN_PARENT, RelativeLayout.TRUE);
imageViewPlayBtn.setLayoutParams(playBtnParams);
aq.id(imageViewPlayBtn).image(R.drawable.play_youtube);
final String videoId = youtubeVideo;
aq.id(relativeLayout).clickable(true).clicked(new View.OnClickListener() {
@Override
public void onClick(View v) {
try {
Intent intent = new Intent(Intent.ACTION_VIEW, Uri.parse("vnd.youtube:" + videoId));
intent.putExtra("VIDEO_ID", videoId);
activity.startActivity(intent);
} catch (Exception e) {
activity.startActivity(new Intent(Intent.ACTION_VIEW, Uri.parse("http://www.youtube.com/watch?v=" + videoId)));
}
}
});
return relativeLayout;
```
Мы [сняли небольшое видео](http://www.youtube.com/watch?v=U4H9-ol_mNk), с демонстрацией приложения в работе, но лучше конечно скачать приложение и [попробовать самому](https://play.google.com/store/apps/details?id=ru.surf.android.main).
Возможно кому то этот способ покажется несколько кардинальным, но мы довольны конечным результатом. Страницы стали грузиться быстрее, выглядят нативно, единообразно и легко читаемы на любом устройстве. Плюс открывается куча интересных возможностей, нативный предпросмотр фото, настройка шрифтов, открытие видео в родном приложении ну и конечно же нет проблем с различными версиями и зачастую странным поведением webview. | https://habr.com/ru/post/242911/ | null | ru | null |
# Некоторые особенности VimL
В этой статье я хочу рассказать о некоторых особенностях VimL, зачастую неочевидных, которые надо знать человеку, желающему написать хорошее дополнение для Vim. Для понимания статьи требуется знание vimscript и рекомендуется наличие как минимум одного написанного дополнения. Людям, не желающим написать своё собственное дополнение статья будет, по большей части, бесполезна.
Привязки
========
Перепривязки
------------
Начнём с банальных и общеизвестных вещей: перепривязки. В Vim есть два основных семейства команд: `*map` и `*noremap`. Первая позволяет переопределять свою правую часть, вторая нет. В дополнениях должна использоваться только вторая, так как неизвестно, какие привязки имеются у пользователя. Классический пример:
```
noremap : ;
noremap ; :
```
сломает
```
nmap :PluginToggle
```
, но не
```
nnoremap :PluginToggle
```
. Другие команды, о которых надо помнить:* `*map`/`*noremap`, `*abbrev`/`*noreabbrev`, `*menu`/`*noremenu`
* `normal`/`normal!`
* `call feedkeys(string)`/`call feedkeys(string, 'n')`
Также можно отметить наличие настройки ['remap'](http://vimdoc.sourceforge.net/htmldoc/options.html#'remap' "remap"), которая заставляет все команды вида `*map` вести себя так же, как и их `*noremap` эквиваленты. Вы не сможете использовать
```
nnoremap PluginAction :DoAction
if !hasmapto('PluginAction')
nmap a PluginAction
endif
```
для предоставления пользователям возможности переопределения lhs и также поддерживать пользователей, включивших эту настройку, вместо этого вам придётся привести все определения привязок к виду
```
execute 'nnoremap '.get(g:, 'plugin_action_key', 'a').' :DoAction'
```
или более совместимому со старыми версиями Vim
```
if !exists('g:plugin_action_key')
let g:plugin_action_key='a'
endif
execute 'nnoremap '.g:plugin\_action\_key.' :DoAction'
```
Специальные символы
-------------------
* Использование в качестве левой части привязки легко сделает невозможным применение стрелок и функциональных клавиш. Даже
```
nmap
```
уже страдает этим.
* Наличие байта 0x80 в правой части привязки‐выражения может её испортить. Ошибка известна и [документирована](http://vimdoc.sourceforge.net/htmldoc/map.html#:map-<expr>).
Файловые (
---------- | https://habr.com/ru/post/149919/ | null | ru | null |
# Роутер для Matreshka.js 2
[Demo](https://matreshkajs.github.io/matreshka-router/demo.html#!/foo/bar/baz/)
[Репозиторий](https://github.com/matreshkajs/matreshka-router)
tl;dr
=====
Плагин включает синхронизацию свойств объекта и куска урла.
```
Matreshka.initRouter(object, '/a/b/c/');
object.a = 'foo';
object.b = 'bar';
object.c = 'baz'
// location.hash теперь #!/foo/bar/baz/
```
Для использования History API вместо `location.hash`, нужно передать строку `"history"` вторым аргументом.
```
Matreshka.initRouter(object, '/a/b/c/', 'history');
```
Импорт CJS модуля:
```
const initRouter = require('matreshka-router');
initRouter(object, '/a/b/c/', 'history');
```
---
Как работает “традиционный” роутинг? Разработчик указывает правило (роут) и описывает то, как будет себя вести приложение при соответствии урла с указанным правилом.
```
route('books/:id', id => {
// делать что-то
});
```
Matreshka Router работает по-другому. Библиотека синхронизирует часть пути со свойством объекта.
**Дисклеймер:** такой способ роутинга может не покрывать все те задачи, которые обычно ставятся перед обычным роутером. Воспользуйтесь альтернативным решением, если в этом есть необходимость.
Принцип работы плагина в следующем: вы указываете какая часть урла (поддерживается и [hash](https://developer.mozilla.org/ru/docs/Web/API/Window/location), и [HTML5 History](https://developer.mozilla.org/ru/docs/Web/API/History_API)) синхронизируется со свойством.
Скажем, вы хотите синхронизировать свойство `"x"` с первой частью `location.hash`, свойство `"y"` — со второй.
```
Matreshka.initRouter(object, "/x/y/");
```
Теперь когда вы пишете..
```
object.x = 'foo';
object.y = 'bar';
```
… Хеш автоматически изменится на `#!/foo/bar/`
И наоборот, если вы вручную, программно или с помощью стрелок “вперед” и “назад“ меняете адрес, свойства изменятся автоматически.
```
location.hash = '#!/baz/qux/';
// ... через несколько миллисекунд
console.log(object.x, object.y); // ‘bar’, ‘qux’
```
Как и всегда, свойства можно прослушивать с помощью метода [on](https://ru.matreshka.io/#!Matreshka-on).
```
Matreshka.on(object, 'change:x', handler);
// или так, если объект - экземпляр Matreshka: this.on('change:x', handler);
```
В функцию `initRouter` можно передать строку со “звездочками”, для игнорирования части урла.
```
Matreshka.initRouter(object, '/x/*/y');
```
Если хеш выглядит, как `#!/foo/bar/baz/`, то `object.x` становится равным `"foo"`, `object.y` — `"baz"`.
Такая возможность полезна тогда, когда один класс контролирует одну часть адреса, другой — другую.
**class1.js**
```
Matreshka.initRouter(this, '/x/*/');
```
**class2.js**
```
Matreshka.initRouter(this, '/*/y/');
```
Важно помнить две вещи:
**1.** Если при инициализации роутера свойство имеет правдивое значение, адрес изменится сразу после вызова `initRouter`. Иначе — наоборот, свойство получит значение части пути.
```
object.x = 'foo';
Matreshka.initRouter(object, '/x/y/');
```
**2.** Если свойство, указанное в роуте получит лживое значение, все последующие свойства, указанные в роуте, получат значение `null`.
```
Matreshka.initRouter(object, '/x/y/z/u/');
object.y = null; // установит object.z и object.u тоже в null
```
Идея в том, чтоб поддерживать состояния урла и свойств актуалными. Было бы странно иметь свойство `"z"` со значением `"foo"` при условии отсутствующей части адреса, связанной с этим свойством.
HTML5 History API
-----------------
Кроме хеш роутинга, плагин поддерживает возможность работы с HTML5 History. Для инициализации нужно передать в метод `initRoute` дополнительный параметр `type` равный `"history"` (по умолчанию, `type = "hash"`).
```
Matreshka.initRouter(object, '/x/y/z/', 'history');
```
Дополнительная информация
-------------------------
Ядро роутера реализовано в виде класса `Matreshka.Router`. Его конструктор принимает один аргумент: тип роутера `("hash"`, `"history"` или произвольную строку).
При подключении роутера создаётся два экземпляра класса `Matreshka.Router` с типами `hash` и `history`, которые хранятся, соответственно, в `Matreshka.Router.hash` и `Matreshka.Router.history` (используется ленивая инициализация, поэтому подключение без использования ничего не делает). Для этих двух экземпляров реализуется паттерн синглтон, т. е, при создании роутера с типом `hash` возвращается `Matreshka.Router.hash` вместо создания нового экземпляра. Такая логика централизует обработку урла, положительно влияя на производительность и не вызывает коллизии. Объекты, в свою очередь, просто подписываются на изменения и не занимаются парсингом.
"Кастомные" экземпляры `Matreshka.Router` могут быть созданы вручную, на случай, если нужно сгенерировать ссылку для дальнейшего произвольного использования. В этом случае, изменение свойств не повлияет на `hash` и не вызовет `pushState`.
Экземпляры класса `Router` имеют три свойства.
`path` — свойство, которое содержит актуальный урл, например, `/foo/bar/baz/`.
`hashPath` — свойство, которое сожеджит path, с дописанным к ней hashbang, например `#!/foo/bar/baz/`
`parts` — свойство, представленное в виде массива, содержащее актуальные кусочки пути, например, `[‘foo’, ‘bar’, ‘baz’]`.
Все три свойства объявлены с помощью метода [calc](https://ru.matreshka.io/#!Matreshka-calc), так что при изменении одного свойства, меняются и другие:
```
Matreshka.Router.hash.path = '/yo/man/';
```
… И два метода
`subscribe(object, route)` — подписывает объект на изменения в свойствах.
`init()` — используется для ленивой инициализации при вызове `subscribe` (вызывать вручную нет нужды).
```
const customRouter = new Matreshka.Router('myType');
const object = {
a: 'foo',
b: 'bar'
};
customRouter.subscribe(object, '/a/b/');
console.log(customRouter.path); // /foo/bar/
```
Импорт модуля CommonJS
----------------------
Всё описанное выше касается немодульного окружения. Если приложение находится в окружении CommonJS (NodeJS, Webpack, Rollup...) подключение модуля **matreshka-router** не добавляет новых статичных свойств классу `Matreshka`. Вместо этого, `initRouter` импортируется традиционным способом.
```
const initRouter = require('matreshka-router');
initRouter(object, '/x/y/');
```
Импортировать класс `Router` можно так:
```
const Router = require('matreshka-router/router');
const customRouter = new Router('myType');
```
Всем добра. | https://habr.com/ru/post/277171/ | null | ru | null |
# Самое бюджетное видеонаблюдение на даче
Привет, Geektimes! Хочу поделиться моим опытом в организации очень бюджетного видеонаблюдения на даче c 3G с возможностью просмотра онлайн и сохранению архива.
Так как с видеонаблюдением я ранее никогда не сталкивался, то решил начать с простого — купить лишь одну 2M камеру и далее протестировать и посмотреть что из это выйдет.
Почитал отзывов в инете, мой выбор пал вот на [Этот](https://www.aliexpress.com/item/Newest-Security-Camera-CCTV-3PCS-Array-LED-Waterproof-Outdoor-Surveillance-IP-Camera-FULL-HD-1080P-2MP/32610214250.html?spm=2114.13010608.0.0.uoyhyi) экземпляр китайского производства. Устройство вещает по rtsp 1920\*1080 с сжатием h264 основной поток и 540\*340 второй поток.

Покупая устройство я предположил, что программу для записи видео с камеры я найду без проблем хоть под винду, хоть под линукс. В жизни все оказалось намного сложнее.
В моем распоряжении имелся комп с Intel Pentium D (2 core), 1 GB RAM, встроенная видюха, 250 ГБ хард. На момент получения камеры, жила на этом стареньком PC windows XP x86.
Также есть свисток МТС (на даче ловит 3G), есть хостинг с VDS сервером. Понятно, что с таким багажом о качественном видеонаблюдении говорить не приходится, но с чего-то надо же начинать.
Итак, я приступил к домашним тестам. Первое, что пришло в голову — это надо попробовать всеми известный сервис [ivideon](https://ru.ivideon.com/). Быстро регистрируемся, ставим софтинку, раз-два-три все готово, удобно и просто. Жаль что подобный сервис накладывает значительные ограничения на бесплатное использования, впринципе жить можно, но не удобно. Самая печаль это огромный объем передаваемых данных по исходящему аплинку, для 3Г многовато, нужен хороший инет, а его нет и не будет.
**[ZoneMinder](https://zoneminder.com/)**
Когда то давно, ставили на работе данный софт, впечатление очень хорошее, много настроек работает хорошо.
К сожалению, до установки данного софта дело не дошло, так как, со слов людей, знакомых с ситуацией, сервис очень требовательный к ресурсам и на моем старом компе просто мог не взлететь, да и переустанавливать винду не хотелось. Оставил на крайний случай, если ничего не найду подходящего.
**[Axxon next](http://www.itv.ru/products/axxon_next/)**
Судя по всему суровая софтина для суровых компаний. В бесплатной версии до 4-х камер и более никаких ограничений. В тестовом режиме весь функционал со всеми камерами, по пишет только с 8-00 до 20-00 (или что такое).
Честно говоря, юзабилити программы очень неудобное, но да фиг с ним, привыкнем. Столкнулся с проблемами: Пишет видео в один архив в своем формате — видео не достать просто так, не работает по рдп (необходим opengl >1.4). Последняя 4-ая версия не работает в вин ХП, 3-ая работает, но, блин только с консоли, по рдп не пройдет.
**[Xeoma](http://felenasoft.com/ru/)**
Софтина установилась на старое железо, заработало.
В целом софтина не особо удобная, но привыкнуть можно, дело времени.
Из «конструктора» можно собрать разные схемы, логику, добавить какие то обработчики, действия при появлении какого либо события. Но все это теряет смысл в бесплатной версии, где доступно лишь 3 модуля (в платной самой дешевой версии этих модулей уже 6). Один из них камера, один запись в архив. Можно прикрутить детектор движения, но к сожалению это не мой случай — железо не вытянет, просмотра онлайн не будет (об этом позже — решено выдавать статичную картинку по запросу, а не гнать весь трафик в инет).
Для меня также полезной оказалась возможность отредактировать частоту выдачи кадров на экран. Так как по рдп+3г аплинк не быстрый, выдача реальной картинки просто кладёт на глухо канал. В софтине поставил выдачу 1 кадр в минуту, можно выставить и другой, почаще/реже
**FFMPEG**
Самая последняя рабочая версия ffmpeg для Windows XP [тут](https://sourceforge.net/projects/ffmpegwindowsbi/files/).
Вообще очень приятно, когда процесс полностью контролируется, но нужно много всего писать самому. Переподключение, ротация, проверка на зависание и тд. Писать самому не особо хотелось. А вот команда, для захвата потока и записи в файл может кому пригодится:
```
D:\ffmpeg\ffmpeg -i rtsp://192.168.1.10:554/user=admin_password=tlJwpbo6_channel=1_stream=0.sdp?real_stream -reset_timestamps 1 -vcodec copy -acodec copy -y -f segment -segment_time 60 -segment_format mp4 "d:\Xeoma\video\vid-%%05d.mp4"
```
Грусть тоска с софтом господа. Грусть…
Но давайте вернемся к схеме включения всего это безобразия и разберемся что впринципе мы хотим и что можем сделать?
Имеем: 3г свисток. По факту, все операторы сотовой связи уже давно не предоставляют динамические ИП на свистки, а выдают серые адреса и натят. Попасть через инет на комп с 3G можно только через впн.
Но мы же хотим сделать все дешевле. Какой тариф выбрать? Какого оператора выбрать (ловит 3Г на моей даче у всех операторов — свезло)? Платить по 600р/мес за свисток нет желания. Посмотрел тарифы всех операторов — примерно у всех одно и тоже.
Решение было простым. Оказывается, у моего МТС-а есть опция «Поделись инетом» или как то так. Смысл в том, что платишь 100р в мес и делишься своим инетом на тарифе с другим номером. Вот по этому пути я и пошел.
Настроить впн-сервер на дебиане [очень просто](https://www.ylsoftware.com/news/407).
В биосе компа ставим автовключение при возвращении питания, настриваем МТС-соединение через стандартные средства (как dial-up модем со звонком на \*99#) и настраиваем поднятие впн после поднятия МТС-соединения. ГОТОВО! Связь есть, ВПН держит. Можно работать.
Для администрирования сервера достаточно подключиться через ссш тюнель сервера к порту 3389 (рдп) и нет никакой необходимости выставлять 3389 от винхп наружу с пробросом портов через хостинг.
Так как было решено, что выгружать весь архив мы не будем, то остается вопрос — как организовать онлайн просмотр.
Я сделал вот так:
На компе с виндной поставил запись основного потока непрерывно, а дополнительный граблю раз в 30 секунд. Делается это для того, чтобы быстро найти интересующий примерный участок времени, а потом медленно и неспешно тянуть видео файлы по 3Г. На сервер установил апач, php натравил его на директорию с видео фото и включил опцию индексации содержимого директории.
На хостинге приемнике (Куда мы соединяемся по впн) настраиваем форвардинг портов:
```
ProxyPreserveHost On
#ProxyRequests Off
ProxyPass / http://192.168.1.30/
ProxyPassReverse / http://192.168.1.30/
```
Где [192.168.1.30](http://192.168.1.30) это адрес, который мы получили по pptpd.
Для отображения файлов с потока я выбрал такую концепцию:
Онлайн будем хватать один кадр с доп потока в качестве ниже 2МП. Для просмотра картинки в высокой четкости настроим ротацию файлов основного потока раз в минуту (потом так же будет проще качать файлы) и будем выполнять захват кадра с последнего завершенного видео. Таким образом максимальный лаг HD картинки будет составлять 2 минуты, что, вцелом, нормально.
Для получения снапшота с видео файла используем такой код на php:
```
shell_exec ("D:\scripts\convert.cmd $file");
```
Ну и сам процесс получения снапшота:
```
D:\ffmpeg\ffmpeg -y -loglevel 0 -i %1 -ss 00:00:1.1 -r 1 -vframes 1 D:\Xeoma\last.jpeg
```
Итого по затратам:
— Камера 2500
— Инет 100р/мес
— Потребление компом электричества 24/7 = 100Вт\*24\*30 \*4р/квч=288р/мес
— Старый комп (был в наличии) = 3000р
— VDS Хостинг с возможностью приема впн (был) = 2400/год
Наверно не бывает дешевле :)
Надеюсь, данная статья будет кому-либо полезна | https://habr.com/ru/post/370487/ | null | ru | null |
# Internet Explorer перестал отображать многие популярные сайты
Старый браузер Microsoft, Internet Explorer, перестал отображать большинство популярных веб-сайтов, в том числе YouTube, StackOverFlow, Instagram, Twitter и другие. Вместо этого IE принудительно редиректит пользователей в Edge: так компания предполагает «пересадить» пользователей устаревшего браузера, который она пытается «убить» уже несколько лет, на свой актуальный продукт. Принудительный редирект начался с окончанием поддержки IE — 13 ноября.

Подобное поведение софта Microsoft связано с официальной политикой компании по ликвидации Internet Explorer и обеспечению полной миграции пользователей в Edge. В общей сложности IE редиректит в Edge уже не менее тысячи веб-сайтов.
Вместе с отказом отображать веб-сайты, Microsoft лишила IE возможности управления учетными записями и работы с Teams. Полное отстранение Internet Explorer от всех онлайн-сервисов компании произойдет 17 августа 2021 года.
Сам механизм редиректа из IE в Edge реализован динамической библиотекой `ie_to_edge_bho.dll`, которая поставлялась **вместе с обновлениями Edge** с лета этого года, а окончательно стала работать с версией Edge 87. Если вы не получаете обновлений Edge от Microsoft, то и с системой принудительного редиректа не столкнетесь.
Internet Explorer — бесконечный источник головной боли для Microsoft: доля этого устаревшего браузера по различным оценкам составляет до ~4,5% всего рынка, тогда как у нового Edge — не более 9,7%. При этом IE в плане информационной безопасности даже во времена своего расцвета и доминирования был далек от идеала, а в условиях 2020 года он представляет угрозу для всех окружающих. Но глубина проникновения IE в статичные корпоративные системы слишком велика, и перехода на актуальные браузеры не получается уже более пяти лет.
По этой же причине Microsoft еще несколько лет назад пошла на беспрецедентный шаг и внедрила часть движка IE в Edge — для обеспечения полной обратной совместимости с системами, которые были написаны исключительно под IE, в том числе и под IE 6. Этот модуль до сих пор остался в Edge, даже переписанном на Chromium, для того чтобы поддержать старые корпоративные системы. Об этом говорит и сама Microsoft, потому что при редиректе в новый браузер из IE пользователю предлагается соответствующий режим просмотра страницы «Internet Explorer».
Даже если Microsoft удастся пересадить всех пользователей Internet Explorer на Edge — а длиться это будет еще минимум года полтора-два, — то остается вопрос с модулем обратной поддержки IE в движке. Ведь его существование, по своей сути, лишь маскирует проблему устаревших небезопасных систем на местах, а не решает ее. | https://habr.com/ru/post/530034/ | null | ru | null |
# Android Notifications. Оповещения через Status Bar
Добрый день, хабровчане. Давно занимаюсь разработкой под Android и хотелось бы рассказать сообществу о правильном подходе к созданию уведомлений.
На хабре уже есть статья по [уведомлениям в статус баре для андроид](http://habrahabr.ru/blogs/android_development/111238) . В ней рассматриваются основы отображения стандартного и конфигурируемого layout в статус баре.
Ниже, помимо описанного ранее, мы рассмотрим добавление прогрессбара, обработку события по нажатию на уведомлений, различные варианты состояний уведомлений. Рассмотрим добавленный на днях в Compatibility library Notification.Builder. А также поговорим о рекомендациям по UI ([design guidlines](http://developer.android.com/design/index.html)), которые гугл рекомендует соблюдать при создании уведомлений.
Guidlines
Как советуют разработчики Android в [официальном гайдлайне](http://developer.android.com/design/patterns/notifications.html)
##### Когда показывать уведомления:
* Мы показываем уведомления, когда не хотим отвлекать пользователя, перекрывая ему экран нашими [диалогами](http://developer.android.com/guide/topics/ui/dialogs.html) или переходом на экран уведомления. Мы не отвлекаем пользователя, но при этом не лишаем его возможности узнать содержание нашего уведомления в любой момент.
* Чаще всего уведомления не всплывают спонтанно, а появляются в моменты, когда пользователь ожидает реакции от приложения.
* В первую очередь уведомления должны отражать события, зависящие от времени. Как то: события календаря, входящие сообщения, запросы из социальных сетей.
##### Когда не стоит показывать уведомления:
1. Не нужно показывать уведомления для не важных псевдо-зависящих от времени событий. Например, новости из социальных сетей.
2. Нет необходимости показывать то, что уже отображено в UI приложения.
3. Не стоит отображать ход низкоуровневых операций, вроде обращения к БД.
4. Если приложение быстро само исправляет ошибку, то не нужно вовсе показывать эту ошибку, тем более уведомлением.
5. Не показывайте уведомления о сервисах, которые пользователь не может контролировать.
6. Плохим подходом является создание большого числа уведомлений, с целью напоминать пользователю о приложении, показывая постоянно его иконку и имя.
##### Хорошая практика:
1. По клику на уведомление, пользователю должен открываться соответствующий экран приложения. В некоторых случаях достаточно, чтобы по клику уведомление просто убиралось.
2. Указание времени события в уведомлении, также является хорошим подходом.
3. Рекомендуется схожие события складывать в одно уведомление, а не отображать на каждое событие своё.
4. Всегда убирать из статус-бара уведомления, с которыми пользователь уже ознакомился и произвел соответствующие действия.
5. Показывать маленькое превью уведомления при его создании в свёрнутом статус-баре
6. Позволять пользователю отключать уведомления в настройках приложения.
7. Использовать иконки, обозначающие принадлежность уведомления определённому приложению. Иконки делать монохромными. Для этого рекомндуется воспользоваться специальным [онлайн-редактором](http://android-ui-utils.googlecode.com/hg/asset-studio/dist/index.html#group-icon-generators)
8. В случае, если событие требует непосредственной реакции пользователя — вместо уведомлений использовать диалоги.
##### Архитектура:
В качестве утилитки, отвечающей за уведомления, я в своих приложениях использую [singleton](http://habrahabr.ru/post/129494/), к которому можно обратиться из любого класса приложения, нужно лишь иметь ссылку на [context](http://developer.android.com/reference/android/content/Context.html).
В ней всегда хранятся ссылки на все созданные во время работы приложения уведомления, которые ещё отображены в статус-баре.
А для присвоения новому уведомлению уникального id используется нехитрый механизм обращения к приватному целочисленному полю, которое каждый раз увеличивается на единицу.
> `public class NotificationUtils {
>
>
>
> private static final String TAG = NotificationUtils.class.getSimpleName();
>
>
>
> private static NotificationUtils instance;
>
>
>
> private static Context context;
>
> private NotificationManager manager; // Системная утилита, упарляющая уведомлениями
>
> private int lastId = 0; //постоянно увеличивающееся поле, уникальный номер каждого уведомления
>
> private HashMap notifications; //массив ключ-значение на все отображаемые пользователю уведомления
>
>
>
>
>
> //приватный контструктор для Singleton
>
> private NotificationUtils(Context context){
>
> this.context = context;
>
> manager = (NotificationManager) context.getSystemService(Context.NOTIFICATION\_SERVICE);
>
> notifications = new HashMap();
>
> }
>
> /\*\*
>
> \* Получение ссылки на синглтон
>
> \*/
>
> public static NotificationUtils getInstance(Context context){
>
> if(instance==null){
>
> instance = new NotificationUtils(context);
>
> } else{
>
> instance.context = context;
>
> }
>
> return instance;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Создание уведомления с помощью NotificationCompat.Builder:
Для того чтобы воспользоваться классами, входящими в [библиотеку поддержки прошлых версий (Compatibility library)](http://developer.android.com/sdk/compatibility-library.html), нужно добавить в проект библиотеку из папки /extras/android/support/v4/android-support-v4.jar
Если же проект нацелен на Android 3.0 и выше, то добавлять ничего не нужно достаточно обратиться к Notification.Builder
> `public int createInfoNotification(String message){
>
> Intent notificationIntent = new Intent(context, HomeActivity.class); // по клику на уведомлении откроется HomeActivity
>
> NotificationCompat.Builder nb = new NotificationCompat.Builder(context)
>
> //NotificationCompat.Builder nb = new NotificationBuilder(context) //для версии Android > 3.0
>
> .setSmallIcon(R.drawable.ic\_action\_picture) //иконка уведомления
>
> .setAutoCancel(true) //уведомление закроется по клику на него
>
> .setTicker(message) //текст, который отобразится вверху статус-бара при создании уведомления
>
> .setContentText(message) // Основной текст уведомления
>
> .setContentIntent(PendingIntent.getActivity(context, 0, notificationIntent, PendingIntent.FLAG\_CANCEL\_CURRENT))
>
> .setWhen(System.currentTimeMillis()) //отображаемое время уведомления
>
> .setContentTitle("AppName") //заголовок уведомления
>
> .setDefaults(Notification.DEFAULT\_ALL); // звук, вибро и диодный индикатор выставляются по умолчанию
>
>
>
> Notification notification = nb.getNotification(); //генерируем уведомление
>
> manager.notify(lastId, notification); // отображаем его пользователю.
>
> notifications.put(lastId, notification); //теперь мы можем обращаться к нему по id
>
> return lastId++;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Создание уведомления с произвольным отображением (Custom layout):
> `/\*\*
>
> \* Создание уведомления с прогрессбаром о загрузке
>
> \* @param fileName - текст, отображённый в заголовке уведомления.
>
> \*/
>
> public int createDownloadNotification(String fileName){
>
> String text = context.getString(R.string.notification\_downloading).concat(" ").concat(fileName); //текст уведомления
>
> RemoteViews contentView = createProgressNotification(text, context.getString(R.string.notification\_downloading)); //View уведомления
>
> contentView.setImageViewResource(R.id.notification\_download\_layout\_image, R.drawable.ic\_stat\_example); // иконка уведомления
>
> return lastId++; //увеличиваем id, которое будет соответствовать следующему уведомлению
>
> }
>
>
>
> /\*\*
>
> \* генерация уведомления с ProgressBar, иконкой и заголовком
>
> \*
>
> \* @param text заголовок уведомления
>
> \* @param topMessage сообщение, уотображаемое в закрытом статус-баре при появлении уведомления
>
> \* @return View уведомления.
>
> \*/
>
> private RemoteViews createProgressNotification(String text, String topMessage) {
>
> Notification notification = new Notification(R.drawable.ic\_stat\_example, topMessage, System.currentTimeMillis());
>
> RemoteViews contentView = new RemoteViews(context.getPackageName(), R.layout.notification\_download\_layout);
>
> contentView.setProgressBar(R.id.notification\_download\_layout\_progressbar, 100, 0, false);
>
> contentView.setTextViewText(R.id.notification\_download\_layout\_title, text);
>
>
>
> notification.contentView = contentView;
>
> notification.flags = Notification.FLAG\_NO\_CLEAR | Notification.FLAG\_ONGOING\_EVENT | Notification.FLAG\_ONLY\_ALERT\_ONCE;
>
>
>
> Intent notificationIntent = new Intent(context, NotificationUtils.class);
>
> PendingIntent contentIntent = PendingIntent.getActivity(context, 0, notificationIntent, 0);
>
> notification.contentIntent = contentIntent;
>
>
>
> manager.notify(lastId, notification);
>
> notifications.put(lastId, notification);
>
> return contentView;
>
> }`
notification\_download\_layout.xml:
> `</fontxml version="1.0" encoding="utf-8"?>
>
> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
>
> android:layout\_width="fill\_parent"
>
> android:layout\_height="65sp"
>
> android:padding="10dp"
>
> android:orientation="vertical" >
>
>
>
> <LinearLayout
>
> android:layout\_width="fill\_parent"
>
> android:layout\_height="wrap\_content"
>
> android:orientation="horizontal" >
>
>
>
> <ImageView
>
> android:id="@+id/notification\_download\_layout\_image"
>
> android:layout\_width="wrap\_content"
>
> android:layout\_height="wrap\_content"
>
> android:src="@drawable/ic\_stat\_example"
>
> android:layout\_gravity="center\_vertical" />
>
>
>
> <TextView
>
> android:id="@+id/notification\_download\_layout\_title"
>
> style="@style/NotificationTitle"
>
> android:layout\_width="wrap\_content"
>
> android:layout\_height="wrap\_content"
>
> android:layout\_alignParentTop="true"
>
> android:layout\_marginLeft="10dip"
>
> android:singleLine="true"
>
> android:text="notification\_download\_layout\_title"
>
> android:layout\_gravity="center\_vertical" />
>
> LinearLayout>
>
>
>
> <ProgressBar
>
> android:id="@+id/notification\_download\_layout\_progressbar"
>
> style="?android:attr/progressBarStyleHorizontal"
>
> android:layout\_width="fill\_parent"
>
> android:layout\_height="wrap\_content"
>
> android:layout\_marginTop="4dp"
>
> android:progress="0" />
>
>
>
> LinearLayout>`
в андроид 2.3 и выше ( API >10) был создан специальный ресурс, в котором системная тема указывает цвета текста уведомений. Из-за этого в старых версиях приходится использовать костыль:
В файл res/values/styles.xml прописываем:
> `</fontxml version="1.0" encoding="utf-8"?>
>
> <resources>
>
> <style name="NotificationText">
>
> <item name="android:textColor">?android:attr/textColorPrimaryitem>
>
> style>
>
> <style name="NotificationTitle">
>
> <item name="android:textColor">?android:attr/textColorPrimaryitem>
>
> <item name="android:textStyle">bolditem>
>
> style>
>
>
>
> resources>`
А для поддержки API >10 Создаем файл res/values-v9/styles.xml и вписываем:
> `</fontxml version="1.0" encoding="utf-8"?>
>
> <resources>
>
> <style name="NotificationText" parent="android:TextAppearance.StatusBar.EventContent" />
>
> <style name="NotificationTitle" parent="android:TextAppearance.StatusBar.EventContent.Title" />
>
> resources>`
Теперь из кода нашего приложения обращаемся к утилите:
> `NotificationUtils n = NotificationUtils.getInstance(getActivity());
>
> n.createInfoNotification("info notification");`
Создаем уведомление с прогресс-баром:
> `int pbId = NotificationUtils.getInstance(getActivity()).createDownloadNotification("downloading video");`
И во время выполнения потока постоянно обновляем прогресс вызовом:
> `NotificationUtils.getInstance(getActivity()).updateProgress(pbId, YOUR\_PROGRESS);`
В итоге получаем:

Как видно — нижнее уведомление, созданное нами при помощи билдера может быть удалено в любой момент. А уведомление с прогресс-баром размещается в верхнем блоке уведомлений, в котором пользователь не может очистить уведомления.
И напоследок маленькая хитрость:
Если не хотите дублирования в стеке одних и тех же Activity — поставьте в манифесте к нужной activity
`android:launchMode="singleTop"` | https://habr.com/ru/post/140928/ | null | ru | null |
# Используем Resque в Rails
Resque — ruby-библиотека для создания фоновых задач, составления очередей таких задач и их последующего выполнения. Задачи могут быть любым ruby-классом или модулем, содержащим метод perform. В ruby-сообществе Resque пришел на смену Delayed Job (не знаю, кстати, почему проект перестал развиваться, весьма удобная была вещь на мой взгляд) и обладает большим количеством различных преимуществ, таких как разделение задач по разным машинам, приоритеты задач, устойчивость к разным утечкам памяти и еще, и еще, и еще. На этом вступление для тех, кто не может самостоятельно перевести первый абзац из README прошу считать законченным.
В данной статье будет показано как использовать resque и resque-scheduler в rails-приложении.
#### Подключаем resque в rails-проект
Для использования resque необходимо установить Redis — хранилище данных типа ключа-значение. С установкой проблем возникнуть не должно — пользователи Linux и Mac без труда найдут и исходники, и готовые пакеты, пользователи Windows ~~сами выбрали путь мазохистов~~ также должны справиться. Кроме того установить Redis можно с помощью самого Resque, подробнее об этом на [гитхаб-странице](https://github.com/defunkt/resque) проекта. После установки запускается все это простой командой redis-server.
Далее добавляем в Gemfile:
```
gem ‘resque’
gem ‘resue-scheduler’
```
Затем bundle install и поехали!
В config/initializers добавляем файл resque.rb примерно с таким содержанием:
```
uri = URI.parse("redis://localhost:6379/")
Resque.redis = Redis.new(:host => uri.host, :port => uri.port, :password => uri.password)
```
где 6379 — порт, на котором запускается redis по умолчанию.
Для того, чтобы иметь доступ к нашим фоновым задачам через web-интерфейс, добавляем следующие строки в config.ru:
```
require 'resque/server'
run Rack::URLMap.new "/" => AppName::Application, "/resque" => Resque::Server.new
```
и по адресу [localhost](http://localhost):3000/resque вы можете увидеть всю необходимую информацию об очередях, задачах, смысле жизни и т.д.
Добавляем rake-таск(уж простите за такой транслит, но “задача” занята job’ом) — создаем файл lib/tasks/resque.rake со следующим содержимым:
```
require 'resque/tasks'
task "resque:setup" => :environment
```
и запускаем ее:
```
rake resque:work QUEUE=*
```
Теперь в окне терминала вы можете видеть вывод выполняющихся задач.
#### Базовые функции
Для начала создадим некий класс, который и будет представлять из себя задачу, которую нам нужно выполнить. Перед этим создадим директорию для хранения классов задач, например app/jobs и добавим эту папку в config/initializers/resque.rb:
```
Dir["#{Rails.root}/app/jobs/*.rb"].each { |file| require file }
```
Содержимое же класса должно быть примерно таким:
```
class SimpleJob
@queue = :simple
def self.perform
# здесь делаем важные и полезные вещи
…
…
...
puts "Job is done"
end
end
```
Обратите внимание на имя очереди — simple, это обязательно, как и метод perform. Добавить эту задачу в очередь можно так: Resque.enqueue(SimpleJob). Результат выполнения, строка “Job is done” будет выведена в консоль resque, кроме того по адресу [localhost](http://localhost):3000/resque можно увидеть новую добавленную очередь и результат работы воркера.
Передать аргументы в perform также не составляет труда. Например изменяем наш класс следующим образом:
```
def self.perform(str)
# здесь делаем важные и полезные вещи
…
…
...
puts "Job is done! #{str}"
end
```
И добавляем задачу в очередь следующим образом: Resque.enqueue(SimpleJob, “Yahoo!”). После перезпуска rake resque:work QUEUE=\* в консоли вы увидите ожидаемое: “Job is done! Yahoo!”. Следует отметить, что все аргументы передаваемые через enqueue сериализуются в JSON, из-за чего объекты класса Symbol становятся обычными строками, а сложные объекты, например сущности ActiveRecord — хэшами. Соответственно, если вы хотите использовать методы и ассоциации ваших моделей, есть смысл передавать просто id объектов и выбирать их уже внутри perform.
#### Планировщик задач
Resque-scheduler — расширение Resque для задач, которые должны быть выполнены в будущем. Он поддерживает два типа задач — задержанные и задачи по расписанию. Добавим scheduler в наш проект. Добавляем конфигурацию scheduler в resque.rake, теперь он выглядит так:
```
require 'resque/tasks'
require 'resque_scheduler/tasks'
task "resque:setup" => :environment
namespace :resque do
task :setup do
require 'resque'
require 'resque_scheduler'
require 'resque/scheduler'
Resque.redis = 'localhost:6379'
Resque.schedule = YAML.load_file("#{Rails.root}/config/rescue_schedule.yml")
end
end
```
Как видно из этого участка кода, мы грузим расписание из файла config/rescue\_schedule.yml:
```
every_two_minute_job:
cron: "*/2 * * * *"
class: SimpleTask
args: some arg
description: “every two minute job”
```
Для использования scheduler в rails-приложении нужно также добавить в config/initializers/resque.rb строку require 'resque\_scheduler'
Теперь запускаем в консоли rake resque:scheduler и смотрим, как наша задача выполняется каждые 2 минуты. Добавлять задержанные задачи еще проще:
```
Resque.enqueue_at(2.minutes.from_now, SimpleTask, ‘some arg’)
```
чтобы выполнить задачу в определенное время,
```
Resque.enqueue_in(2.minutes, SimpleTask, ‘some arg’)
```
чтобы выполнить задачу через определенное время.
Также можно удалять добавленные задержанные задачи:
```
Resque.remove_delayed(SimpleTask, ‘some arg’)
```
Конечно же работу Resque можно и нужно тестировать, для этого есть соответствующие gem’ы:
[github.com/leshill/resque\_spec](https://github.com/leshill/resque_spec)
[github.com/justinweiss/resque\_unit](https://github.com/justinweiss/resque_unit)
#### Дополнительные ссылки
Код Resque на гитхабе
[github.com/defunkt/resque](https://github.com/defunkt/resque)
Resque-scheduler там же
[github.com/bvandenbos/resque-scheduler](https://github.com/bvandenbos/resque-scheduler)
Документация онлайн
[defunkt.io/resque](http://defunkt.io/resque/)
Скринкаст от Райана Бэйтса
[railscasts.com/episodes/271-resque](http://railscasts.com/episodes/271-resque)
Гостевая статья Дэйва Хувера для RubyLearning Blog
[rubylearning.com/blog/2010/11/08/do-you-know-resque](http://rubylearning.com/blog/2010/11/08/do-you-know-resque/)
Jon Homan — Background Jobs in Rails with Resque
[blog.jonhoman.com/background-jobs-in-rails-with-resque](http://blog.jonhoman.com/background-jobs-in-rails-with-resque/)
Allen Fair — Understanding how Resque works
[girders.org/resque-internals-for-heterogenous-systems](http://girders.org/resque-internals-for-heterogenous-systems) | https://habr.com/ru/post/141964/ | null | ru | null |
# Как заставить сайт летать и сэкономить десятки часов системного администрирования
 Скорость работы вашего сайта, его стабильность и отказоустойчивость всегда зависят от трех составляющих:
1. Платформа (CMS) и ее настройки, которые влияют на производительность (параметры кэширования и т.п.)
2. Конфигурация сервера (реального физического или виртуального) и настройки системного ПО (веб-сервер, база данных и т.д.)
3. Качество разработки, кода, интеграции с платформой.
Зачастую веб-разработчик может написать хороший качественный код, но при этом мало что смыслит в системном администрировании и настройке серверов. А хороший сисадмин редко бывает по совместительству еще и классным программистом.
В общем-то, это — совершенно нормально, каждый должен заниматься своим делом. Но, к сожалению, в небольших веб-студиях, которых большинство, редко есть админы в штате. Настройкам хостинга уделяется мало внимания. В лучшем случае — полагаются на суппорт хостера и настройки «по умолчанию».
В итоге сайт может «хромать» из-за проблем и «узких» мест в любой из составляющих: CMS, хостинг, разработка. Клиент в нюансы не вникает и остается не удовлетворен проектом в целом. Его негатив переносится на всех: «Тормозной хостинг! Ужасная система! Разработчики ничего не умеют!»
Такая картина нас, конечно, никогда не устраивала. И мы решили, что надо что-то делать…
Возможности самой платформы «1С-Битрикс», касающиеся производительности по-настоящему огромны (это и [монитор производительности](http://www.1c-bitrix.ru/products/cms/features/perfmon.php), и инструменты отладки, и несколько вариантов кэширования, и [поддержка веб-кластерных систем](http://www.1c-bitrix.ru/products/cms/features/webcluster.php), и много другое) и требуют отдельной статьи. О многом мы уже писали, о чем-то — расскажем в ближайшее время.
Сегодняшний пост — о хостинге, серверах, VPS и их администрировании.
 Самое простое и, вроде бы, наиболее очевидное решение — написать хорошее подробное руководство по конфигурированию веб-систем, дать его всем желающим. И всё будет хорошо.
И начали мы как раз с этого — написали подробную документацию (было это, кажется, 6 или 7 лет назад). Затем на ее основе было выпущено несколько бесплатных учебных курсов, которые постоянно улучшались и адаптировались. В итоге сейчас они обобщены в общий [«Курс для хостеров»](http://dev.1c-bitrix.ru/learning/course/index.php?COURSE_ID=32).
Несмотря на название и на то, что выпущен он компанией «1С-Битрикс», курс актуален и крайне полезен для всех хостеров вообще и для администраторов, обслуживающих тот или иной парк веб-серверов. Ознакомившись с ним и — тем более — ответив на контрольные вопросы в конце, можно надеяться на то, что каких-то самых грубых ошибок в конфигурировании веб-сервера уже не будет.
Но, к сожалению, даже наличие максимально полной документации и практических рекомендаций по настройке серверов не решает проблему производительности для большинства проектов! Хороших — правильных! — конфигураций все равно очень мало.
Причин тому много…
* У многих администраторов банально нет времени для «тонкой» настройки системы. Поставили, базовое конфигурирование выполнили — уже хорошо...
* Низкая квалификация технических специалистов — даже для того, чтобы все сделать «по мануалу», нужен какой-то технический бэкграунд и понимание происходящих процессов.
* «Историческое наследие» – использование конфигураций 3-5-…-летней давности, в лучшем случае – апгрейд ПО. Четкое следование принципу «работает — не трогай». Который, как оказывается, не всегда применим.
* Шаблонные конфигурации для всех проектов.
* И т.д.
В итоге — как показывает наша практика — остается много типичных проблем, которые почти всегда снижают скорость работы сайта.
Немного отступлю от начальной темы поста и попробую описать самые типовые проблемы, с которыми мы сталкивались на протяжении многих лет. Надеюсь, если даже где-то вы узнаете свой собственный веб-сервер, вам немного поможет понимание сути…
**PHP как CGI**
К счастью, такой режим работы PHP уже становится редкостью. Тем не менее, еще где-то год назад таких конфигураций было достаточно много.
Чем плох CGI? Тем, что на каждое обращение к скрипту запускается отдельный процесс PHP. Это долго и ресурсоемко.
**open\_basedir**
Этот параметр в PHP отвечает за ограничение доступа скриптов в те или иные директории. Очень полезно для конфигураций, в которых на одном сервере могут работать сайты разных клиентов. Благая цель — безопасность, но при этом реализовано решение, мягко говоря, «не очень»…
Во-первых, есть немало вариантов «обойти» ограничения, установленные в [open\_basedir](http://ru.php.net/manual/ru/ini.core.php#ini.open-basedir).
Во-вторых, установка этого параметра (даже в «пустое» значение) очень негативно влияет на скорость работы PHP (файловые операции, например, include). На пустом ненагруженном сервере скорость генерации страниц может снизиться на 20-30%, а при высокой нагрузке — в 2-3 раза.
Есть много альтернатив для open\_basedir. Начиная с отдельной копии веб-сервера для каждого клиента, заканчивая использованием chroot.
**Не установлен прекомпилятор PHP**
[APC](http://pecl.php.net/package/APC), [eAccelerator](http://sourceforge.net/projects/eaccelerator/), [XCache](http://xcache.lighttpd.net/)… Надеюсь, эти слова вам знакомы.
Прекомпилятор служит для оптимизации и ускорения выполнения PHP-скриптов (прекомпилирует интерпретируемый код, кэширует результат и затем исполняет уже прекомпилированный код).
Разница в производительности на разных проектах может достигать нескольких раз.
**Недостаточно памяти прекомпилятору**
Прекомпилятор может быть установлен, но, например, все настройки оставлены «по умолчанию». Чем это может быть чревато? Например, тем, что будет выделено слишком мало памяти для закэшированных скриптов, обращения к новым скриптам будут вытеснять старые данные, и вся работа прекомпилятора будет неэффективной.
**Отсутствует FrontEnd (nginx)**
Двухуровневая архитектура «Backend — Frontend» — практически обязательное требование для стабильной работы любого более-менее нагруженного веб-проекта.
Такая схема работы решает несколько задач:
* всю статику быстро отдают «легкие» (с минимальным потреблением памяти) процессы;
* backend занят обработкой только «тяжелых» запросов к скриптам;
* на медленных каналах у клиентов backend не занят отдачей контента конечному клиенту — он отдает его frontend'у и свободен для обработки последующих запросов.
**Не отрегулировано значение MaxClients в Apache**
На non-threaded серверах этот параметр отвечает за максимальное количество процессов, которые могут быть запущены для параллельной обработки клиентских запросов.
Многие думают, что чем больше — тем лучше. Во многих конфигурациях можно видеть значения и 50, и 150, и 256.
Что это означает на практике. Допустим, один процесс Apache может потребить 40 Мб оперативной памяти. Если MaxClients установлено в 150, то при пиковой нагрузке (DDoS, хабраэффект, ошибки в разработке и т.п.) под все процессы потребуется примерно 6 Гб RAM. Только под Apache.
Если такое количество памяти не доступно, начнет использоваться своп. И начнется общая деградация всей системы. И даже те запросы, которые могли бы быть обработаны быстро, будут обрабатываться очень долго.
Гораздо лучше ограничить MaxClients разумным значением. Если количество запросов будет больше, то они просто «встанут в очередь» и будут обработаны, когда освободятся занятые процессы. Система будет стабильна.
\* \* \*
Список таких типовых ошибок можно продолжать очень долго…
Мы в своей практике сталкивались с ними очень часто.
И в результате в 2009 году мы выступили в достаточно нетипичной для себя роли — не разработчиков, а системных администраторов. И выпустили бесплатный продукт [«1С-Битрикс: Виртуальная машина»](http://www.1c-bitrix.ru/products/vmbitrix/).
**Что это такое?**
VMBitrix (как мы коротко называем виртуальную машину) — это готовый образ VMWare Virtual Appliance, который можно запустить на самых разных продуктах VMware (VMWare Server, VMWare ESX и ESXi, VMWare Workstation, VMWare Player, VMWare Fusion).
**Чтобы было реализовано в этом образе?**
* Конечно, уже установлена операционная система (первые образы были на Ubuntu, в дальнейшем — CentOS).
* Настроена двухуровневая конфигурация веб-сервера (Apache + Nginx).
* Установлен прекомпилятор Zend Optimizer+, входящий в пакет Zend Server CE. По [результатам нагрузочных тестов](http://www.1c-bitrix.ru/products/cms/performance/) он показал наилучшую производительность.
* Установлен и сконфигурирован MySQL.
Изначально мы не планировали широко распространять этот образ. Самые-самые первые версии даже не были публичными, а использовались лишь для внутренних целей.
VMbitrix по сути служил эталонной средой, на которую можно было бы ориентироваться, разворачивая собственную систему.
Тем не менее, «1С-Битрикс: Виртуальная машина» оказалась очень востребованной. Хостеры, которые могли предоставлять тарифы на базе VMware, [стали использовать наш образ для новых тарифов](http://www.1c-bitrix.ru/products/vmbitrix/rent.php), ориентированных на размещение проектов на платформе «1С-Битрикс».
Постепенно стали появляться запросы «а сделайте такой же образ под Hyper-V», «а сделайте темплейт под Virtuozzo»…
Постепенно мы стали поддерживать почти все распространенные среды виртуализации.
Поддержка всех актуальных версий в итоге стала требовать достаточно заметных усилий, и в итоге примерно через год появился еще один бесплатный продукт — [«1С-Битрикс: Веб-окружение» (Linux)](http://www.1c-bitrix.ru/products/env/).
По сути это — RPM пакет, который автоматически можно развернуть на CentOS (5, 6), Fedora (12-16), Red Hat Enterprise Linux (5, 6). Поддерживается и 32-, и 64-разрядная архитектура.
Таким образом, совершенно не важно и не принципиально, используете ли вы реальный физический сервер, или же арендовали виртуальную машину (у [Амазона](http://aws.amazon.com/ec2/), [Scalaxy](http://www.scalaxy.ru/), [Clodo.Ru](http://www.clodo.ru/bitrix-server/bitrix-hosting/) или кого-то еще), или же купили [обычный VPS](http://www.1c-bitrix.ru/partners/hosting.php#tab-vps-link).
На «голой» системе достаточно выполнить:
`# wget repos.1c-bitrix.ru/yum/bitrix-env.sh
# chmod +x bitrix-env.sh
# ./bitrix-env.sh`
… и несколько раз ответить «yes» в процессе установки. :)
(К слову, современные версии виртуальной машины, которая продолжает поддерживаться, собираются именно так — из пакета «1С-Битрикс: Веб-окружение»).
Собственно, все! После такой простой установки вы получаете «Веб-окружение» — сейчас уже версии 3.1.
Как эволюционировал продукт и что он «умеет делать» сейчас (при чем умеет сразу, «из коробки»). Опишу несколько наиболее интересных, на мой взгляд, «фишек».
**Удобный инсталлятор любых продуктов «1С-Битрикс»**
После установки веб-окружения при входе на сервер по HTTP вас встречает очень простой мастер, который позволяет развернуть уже существующий сайт из резервной копии или же установить новый, использовав любой продукт — будь то «Управление сайтом», «Корпоративный портал» или же то или иное тиражное решение.

Мастер доступен на трех языках — русском, английском и немецком.
При этом уже полностью настроено соединение с базой MySQL (в файле /home/bitrix/www/bitrix/php\_interface/dbconn.php), поэтому инсталляция любого продукта проходит по «сокращенной» процедуре: не проверяются параметры системы (мы заранее знаем, что она удовлетворяет техническим требованиям), не запрашиваются параметры соединения с базой (все уже настроено).
**Стартап-меню**
Вот такое меню вы увидите, если зайдете на машину по SSH:
Конечно, выглядит оно несколько аскетично по сравнению с современными красивыми веб-интерфейсами. :) Наверное, когда-нибудь мы сделаем и их для веб-окружения и виртуальной машины — и получим в итоге полноценную панель управления хостингом а-ля ISPmanager, cPanel или Plesk. :)
Но даже в таком варианте — это очень мощный и удобный инструмент.
**Веб-кластер**
Уже около года в платформе «1С-Битрикс» существует и активно развивается [модуль «Веб-кластер»](http://www.1c-bitrix.ru/products/cms/features/webcluster.php), который позволяет развернуть любой проект не на одном, а на нескольких серверах, тем самым обеспечив его масштабирование при росте нагрузке и отказоустойчивость при выходе из строя одного или нескольких серверов.
У нас есть подробное [руководство по настройке веб-кластере](http://www.1c-bitrix.ru/download/manuals/ru/web-cluster_guide.pdf), все желающие могут с ним ознакомиться.
Но для того, чтобы сэкономить свое время, можно воспользоваться мастером, который входит в состав веб-окружения:
* он сконфигурирует и запустит репликацию MySQL;
* сконфигурирует nginx в качестве балансировщика на несколько нод;
* настроит пул серверов memcached для распределенного кэша данных;
* настроит и запустит синхронизацию данных веб-серверов с помощью утилиты csync2.
Процесс настройки получается примерно таким:
* Запускаем виртуальную машину или разворачиваем веб-окружение.
* Устанавливаем через мастер в браузере «1С-Битрикс: Управление сайтом» одной из двух старших редакций (куда входит модуль «веб-кластер»).
* Запускаем настройку master ноды через меню.
* Запускаем еще одну виртуальную машину (или разворачиваем веб-окружение на втором сервере).
* Через меню первой машины добавляем slave ноду.
Далее все настройки будут выполнены автоматически.
На прошедшей недавно партнерской конференции Денис Шаромов, руководитель технической поддержки, наглядно демонстрировал весь процесс разворачивания маленького тестового кластера буквально за 10-15 минут.
Там же он демонстрировал еще одну замечательную возможность — переключение любого слейва в режим мастера в случае аварии на мастер-ноде.
У вас есть замечательная возможность посмотреть все это практически «вживую» — на сайте конференции [выложены видео-записи докладов](http://conf.1c-bitrix.ru/winter2012/about/media/), в том числе и доклад «Виртуальная машина 3.0: Как запустить веб-кластер за 15 минут с практическими примерами».
[**Корпоративный портал**](http://www.1c-bitrix.ru/products/intranet/)
«1С-Битрикс: Веб-окружение» максимально адаптировано для любых проектов, разработанных на платформе «1С-Битрикс» (при этом на нем замечательно будут работать вообще любые сайты, использующие PHP и MySQL).
Но при этом есть целый ряд отдельных «фишек», специально предусмотренных для работы именно с [«Корпоративным порталом»](http://www.1c-bitrix.ru/products/intranet/).
Например, автоматически инсталлируются и конфигурируются в продукте утилиты catdoc и xpdf, которые позволяют «на лету» индексировать и делать доступными для поиска на портале документы самых популярных форматов (MS Word, Excel, PowerPoint, Adobe Acrobat).
Веб-сервер сразу сконфигурирован для работы и по HTTP, и по HTTPS. Можно просто заменить self signed сертификат на свой купленный — и работать в защищенной среде.
Далее… Сразу «из коробки» поддерживается WebDAV для подключения сетевых дисков.
Отдельно можно упомянуть мастер настройки NTLM авторизации:

Если в компании используется Active Directory, и пользователям AD разрешено авторизовываться на портале, то помимо настроек собственно портала зачастую требуется немало «танцев с бубном» вокруг конфигов Apache и Nginx для корректной работы NTLM авторизации.
Теперь это не требуется, весь процесс автоматизирован!
(Подробно весь процесс настройки описан в [блоге Николая Рыжонина](http://dev.1c-bitrix.ru/community/blogs/rns/bitrixvm31-s-podderzhkoy-ntlm-avtorizatsii.php).)
**Автоматическая конфигурация в зависимости от доступных ресурсов**
В веб-окружении есть хитрый скрипт /etc/init.d/bvat.
Запускаясь при старте системы, он определяет количество доступных ресурсов (RAM) и в зависимости от них автоматически оптимально настраивает:
* MySQL (размеры буферов, количество соединений, временные таблицы и т.п.);
* MaxClients и связанные с ним параметры в Apache;
* количество доступной памяти для Zend Optimizer+.
Если после установки виртуальной машины или веб-окружения вы хотите выполнить уже тонкую настройку конкретно под свои задачи, отключите этот скрипт, чтобы он не срабатывал при каждом ребуте сервера.
\* \* \*
Мы как-то попробовали посчитать, а сколько бы понадобилось времени в «человеко-часах» :) на полную настройку всего софта, разворачивание кластера, конфигурирование NTLM-авторизации… Получалось не меньше 200 часов! :)
Конечно, это — верхняя оценка. Тем не менее, даже если вам, например, нужно настроить VPS для стабильной работы обычного сайта, понадобится 1-2 дня для того, чтобы все поставить, настроить и протестировать.
С «Веб-окружением» или «Виртуальной машиной» «1С-Битрикс» это время можно сэкономить и потратить на что-то другое. :)
P.S. Нас часто просят выложить подробное описание веб-окружения: с примерами скриптов, конфигов и т.п.
Такое «описание» — это само [веб-окружение](http://www.1c-bitrix.ru/products/env/). Оно абсолютно бесплатно. Поставьте его на любую машину или же скачайте нашу [виртуальную машину](http://www.1c-bitrix.ru/products/vmbitrix/). Зайдите на нее по ssh — и изучайте! Все конфиги, все скрипты — всё полностью открыто и доступно. :) | https://habr.com/ru/post/137927/ | null | ru | null |
# InterSystems Reports Server
InterSystems Reports
====================
InterSystems Reports – модуль InterSystems IRIS и InterSystems IRIS for Health. Это современное решение для создания и публикации отчетов, которое включает в себя:
* Встроенную оперативную отчетность, которая может быть настроена как разработчиками отчетов, так и конечными пользователями.
* Точное форматирование, позволяющее создавать специализированные формы, например, макеты для счетов, документов и т.д.
* Макеты, обеспечивающие структуру для отображения как агрегированных, так и транзакционных данных.
* Позиционирование заголовков, колонтитулов, агрегированных и подробных данных, изображений и вложенных отчетов.
* Разнообразные типы отчетов.
* Публикация и распространение отчетов, включая экспорт в PDF, XLS, HTML, XML и другие форматы файлов, печать и архивирование для соблюдения нормативных требований.
InterSystems Reports состоит из:
* Дизайнера отчетов, в котором разработчики создают отчёты.
* Сервера отчетов, который предоставляет пользователям доступ через браузер для запуска, планирования, фильтрации и изменения отчетов.
Эта статья продолжает [предыдущую](https://habr.com/ru/company/intersystems/blog/576498/) и посвящена серверной части InterSystems Reports и содержит руководство по запуску Report Server в контейнерах с сохранением конфигурации.
Подготовка
----------
Прежде чем мы начнем, для работы InterSystems Reports должно быть доступно следующее программное обеспечение:
* [Docker](https://docs.docker.com/engine/install/) — хотя InterSystems Reports может работать и без Docker (в операционных системах Windows, Mac, Linux), эта статья посвящена запуску Reports Server в Docker.
* (Опционально) [git](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git) — для клонирования репозитория, можно также загрузить его в виде [архива](https://github.com/eduard93/reports/archive/refs/heads/master.zip).
* (Опционально) [InterSystems Reports Designer](https://wrc.intersystems.com/) — для создания новых отчетов.
Дополнительно вам потребуется:
* [Авторизоваться](https://docs.intersystems.com/components/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_CONTAINERREGISTRY) в Docker registry `containers.intersystems.com`
* Лицензия InterSystems Reports
План
----
Вот что необходимо сделать для запуска Reports Server:
1. Запустить Reports и InterSystems IRIS в режиме настройки, чтобы установить IRIS в качестве базы данных (не источника данных!) для Reports.
2. Настроить Reports и сохранить эту конфигурацию на хосте.
3. Запустить Reports с конфигурацией сохраненными данными.
Первый запуск
=============
Шаги 1-8 используют `docker-compose_setup.yml` в качестве конфигурационного файла docker-compose. Любые дополнительные команды docker-compose во время первого старта должны быть выполнены с аргументом `-f docker-compose_setup.yml`.
1. Склонируйте это репозиторий: `git clone https://github.com/eduard93/reports.git` или скачайте [архив](https://github.com/eduard93/reports/archive/refs/heads/master.zip).
2. Отредактируйте `config.properties` и укажите информацию о лицензии InterSystems Reports Server (User и Key). Если у вас их нет — обратитесь в InterSystems. Существует ряд [других свойств](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GISR_server), описанных в документации. Обратите внимание, что InterSystems IRIS в данном случае является базой данных для InterSystems Reports, а не источником данных для отчетов (который мы добавим позже).
3. Запустите InterSystems Reports Server: `docker-compose -f docker-compose_setup.yml up -d`
4. Подождите, пока InterSystems Reports Server запустится (проверьте статус `docker-compose -f docker-compose_setup.yml logs reports`). Это может занять 5-10 минут. Сервер отчетов готов к работе, если в логах отображается: `reports_1 | Logi Report Server is ready for service.`.
5. Откройте сервер отчетов. (Пользователь/пароль: `admin`/`admin`). В случае, если отображается предупреждение об истекшем сроке действия лицензии, введите информацию о лицензии заново. В результате должен открыться портал InterSystems Reports:

Сохранение конфигурации
=======================
Теперь, когда Reports запущен, нам нужно немного поправить конфигурацию и сохранить ее на хосте (обратите внимание, что конфигурация InterSystems IRIS сохраняется с помощью [Durable %SYS](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=ADOCK#ADOCK_iris_durable)).
1. Отметьте опцию `Enable Resources from Real Paths` в разделе `Administration` > `Configuration` > `Advanced` ([документация](https://devnet.logianalytics.com/hc/en-us/articles/1500009750141-Getting-and-Using-Resources-from-a-Real-Path)). Это позволит нам публиковать отчеты копируя их в папку `reports` в репозитории.

1. Скопируйте конфигурацию InterSystems Reports на хост:
```
docker cp reports_reports_1:/opt/LogiReport/Server/bin .
docker cp reports_reports_1:/opt/LogiReport/Server/derby .
docker cp reports_reports_1:/opt/LogiReport/Server/font .
docker cp reports_reports_1:/opt/LogiReport/Server/history .
docker cp reports_reports_1:/opt/LogiReport/Server/style .
```
1. Остановите InterSystems Reports Server: `docker-compose -f docker-compose_setup.yml down`
Второй запуск
=============
Теперь мы готовы запустить Reports с хранимой конфигурацией — именно так он и будет работать.
1. Запустите InterSystems Reports Server без инициализации: `docker-compose up -d`
2. Создайте новую папку в `Public Reports` с `Real Path`: `/reports` ([документация](https://devnet.logianalytics.com/hc/en-us/articles/1500009750141-Getting-and-Using-Resources-from-a-Real-Path)). Для этого откройте `Public Reports` и выберите `Publish` > `From Server Machine`:
Создайте новую папку `/reports`:

Откройте её:

В папке должен быть `catalog` (в котором настроено соединение с InterSystems IRIS) и два отчета (`reportset1` и `reportset2`). Запустите их (используйте кнопку `Run` для просмотра в браузере и `Advanced Run` для выбора между форматами HTML, PDF, Excel, Text, RTF, XML и PostScript). Вот как выглядят отчеты:


InterSystems Reports поддерживает Unicode из коробки. В этом примере я использую один и тот же инстанс InterSystems IRIS в качестве источника данных, но в общем случае это может быть любой другой сервер InterSystems IRIS — подключение определяется в `catalog`. В этом демо используется набор данных HoleFoods (установлен с помощью `zpm "install samples-bi"`). Чтобы добавить новые источники данных InterSystems IRIS, создайте новый `catalog` в Designer. После этого создайте новые отчеты и экспортируйте все в новую подпапку в папке отчетов. Также можно указать адрес InterSystems Server, тогда InterSystems Designer загрузит отчёт напрямую на сервер. Контейнер InterSystems Server должен иметь сетевой доступ ко всем серверам IRIS — источникам данных.
Вот и все! Теперь, если вы хотите остановить Reports, выполните: `docker-compose stop`. А чтобы снова запустить Reports, выполните: `docker-compose up -d`. После перезапуска все отчеты по-прежнему доступны.
Отладка
-------
Все журналы хранятся в папке `/opt/LogiReport/Server/logs`. В случае возникновения ошибок добавьте ее в `volumes`, перезапустите Reports и воспроизведите ошибку.
В документации описано, как настроить [уровень журналирования](https://documentation.logianalytics.com/rsg17u1/content/html/config/config_log.htm?Highlight=logging). Если загрузка Reports прерывается до запуска пользовательского интерфейса, измените файл `LogConfig.properties`, расположенный в папке `bin`:
```
logger.Engine.level = TRIVIAL
logger.DHTML.level = TRIVIAL
logger.Designer.level = TRIVIAL
logger.Event.level = TRIVIAL
logger.Error.level = TRIVIAL
logger.Access.level = TRIVIAL
logger.Manage.level = TRIVIAL
logger.Debug.level = TRIVIAL
logger.Performance.level = TRIVIAL
logger.Dump.level = TRIVIAL
```
API
===
Чтобы встроить отчеты в ваше веб-приложение, используйте [Embedded API](https://documentation.logianalytics.com/logiinfov12/content/embedded-reports-api.htm).
Другие [доступные API](https://documentation.logianalytics.com/logireportserverguidev17/content/html/api/wkapi_srv.htm).
Заключение
==========
InterSystems Reports представляет собой надежное современное решение для создания отчетов. InterSystems Reports Server предоставляет конечным пользователям доступ через браузер для запуска, планирования, фильтрации и изменения отчетов. InterSystems Reports Server может быть запущен как на хосте, так и в среде Docker.
Ссылки
======
* [Часть I](https://habr.com/ru/company/intersystems/blog/576498/)
* [Документация](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GISR_intro)
* [Репозиторий](https://github.com/eduard93/reports)
* [Логирование](https://documentation.logianalytics.com/rsg17u1/content/html/config/config_log.htm?Highlight=logging) | https://habr.com/ru/post/583002/ | null | ru | null |
# Ansible playbooks — это код: проверяем, тестируем, непрерывно интегрируем. Иван Пономарёв
**Предлагаю ознакомиться с расшифровкой доклада Ивана Пономарёва «Ansible playbooks — это код: проверяем, тестируем, непрерывно интегрируем».**
Рефакторинг кода может быть увлекательным, особенно если это код вашей инфраструктуры. К тому же Ansible-роли почему-то имеют тенденцию к быстрому увеличению сложности. И это добавляет «изюминку» в вашу задачу. Иван расскажет, как можно преодолевать сложность Ansible-кода с помощью тестирования. В Docker-контейнерах.
По мере разрастания кодовой базы в Ansible приходят знакомые проблемы: сложность поддержки кода, ошибки и страх изменений. У знакомых проблем есть знакомое решение: автоматическое тестирование и CI. В докладе Иван покажет, как с использованием ряда инструментов решить проблемы «хрупкости» Ansible-кода, выполнить статический анализ, протестировать Ansible-скрипты и настроить CI-системы для публикации ролей в Ansible Galaxy.
Немного о себе. Я работаю в небольшой софтверной компании, мы делаем софт на заказ. Раз в неделю я преподаю на Физтехе, на той же кафедре, на которой я когда-то учился.

Компания у нас небольшая. Мы работаем с пулом заказчиков. Мы поставляем им различные системы. Расскажу о диапазоне наших работ. Самые простые — это классическая «трёхзвеночка», где один-два сервера и несколько десятков пользователей, но это всё должно стоять и работать. Самый сложный проект, который есть у нас в пуле, — это около сорока серверов в DigitalOcean. И мы используем вот такую связку: Terraform + Ansible. Мы ноды разворачиваем при помощи Terraform, а с помощью Ansible мы конфигурируем все наши виртуальные машины для того чтобы ставить там то что надо.

Когда мы начали использовать Ansible с его низким порогом входа и прекрасной экосистемой, у нас стали появляться роли в соответствии с best practices. И ролей стало накапливаться много-много — для фронта, для бэка, для мониторинга, для кэшей, для логов и т. д.

У нас есть первый проект для одного заказчика, второй проект для второго заказчика. Каждый делается по best practices, но некоторые роли пересекаются. Соответственно, ребята просят дать им роль для установки чего-нибудь, которую можно будет скопировать в репозиторий кода и чуть-чуть подпилить под свои нужды.

И код стал расти как снежный ком, и стали знакомые проблемы возникать. Это:
1. Страх поломать.
* Код не переиспользуется, а копируется в проекты.
* Нет рефакторинга. Действительно: зачем я буду улучшать то, что работает уже и так? А вдруг оно сломается?
2. Нет уверенности в том, что это вообще сработает, если это надо будет запустить.
3. Отладка в процессе деплоя. Запустим playbook, а там посмотрим, что будет.
Нужно делать автоматизированное тестирование и CI. Но как? Ведь это не просто код, на котором unit-tests запускаем, как на Java или на Python. Это же configuration is code. Как это делать?
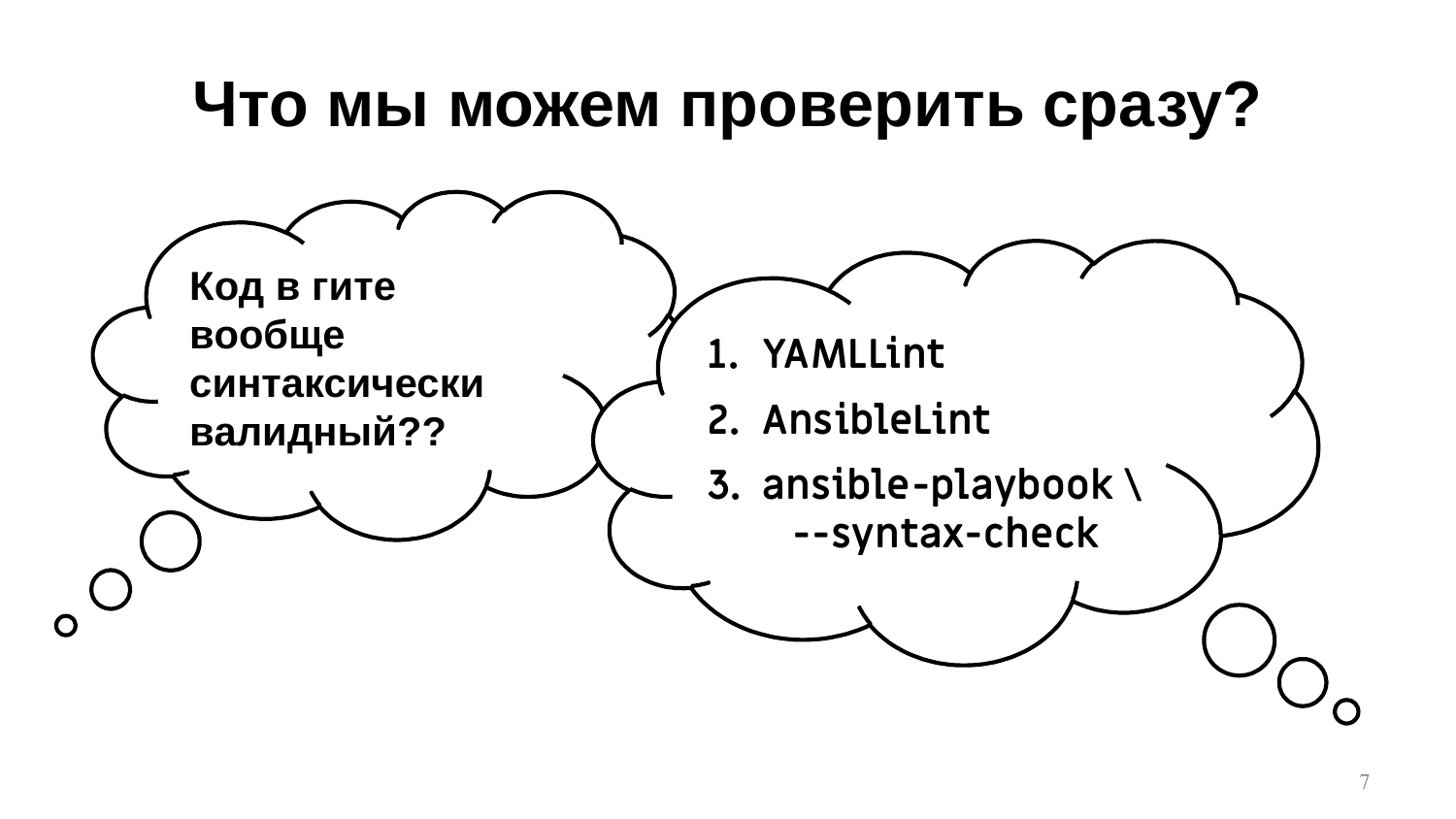
Прежде чем мы перейдём к тестам, давайте упростим проблему и посмотрим, что мы можем проверить, не запуская код, а просто глядя на этот код.
Прежде всего — его well-formedness: является ли он вообще синтаксически валидным. Для этой задачи у нас есть три инструмента, которые можно использовать совместно. Это [YAMLLint](http://www.yamllint.com/), [Ansible-lint](https://docs.ansible.com/ansible-lint/) и [Syntax check](https://docs.ansible.com/ansible/latest/cli/ansible.html) в самом playbook. Сейчас для начала пробежимся по ним.

Проект YAMLLint.
* Проверяет синтаксис YAML. YAML не так прост, как вы знаете. Он проверяет много чего, у него десятки всяких чеков.
* Проверяет лишние пробелы.
* Проверяет переносы строк UNIX-style.
* Проверяет одинаковость отступов, потому что можно сделать валидный YAML, но с разными отступами, и это будет не очень красиво выглядеть.
В принципе он более строг, чем Ansible, к коду, но он позволяет некоторые проблемы убрать. Например, у нас разработка ведётся под Windows, и если попадают переносы строк в Windows-style в конфигурационные файлы, то это беда. YAMLLint это решает.
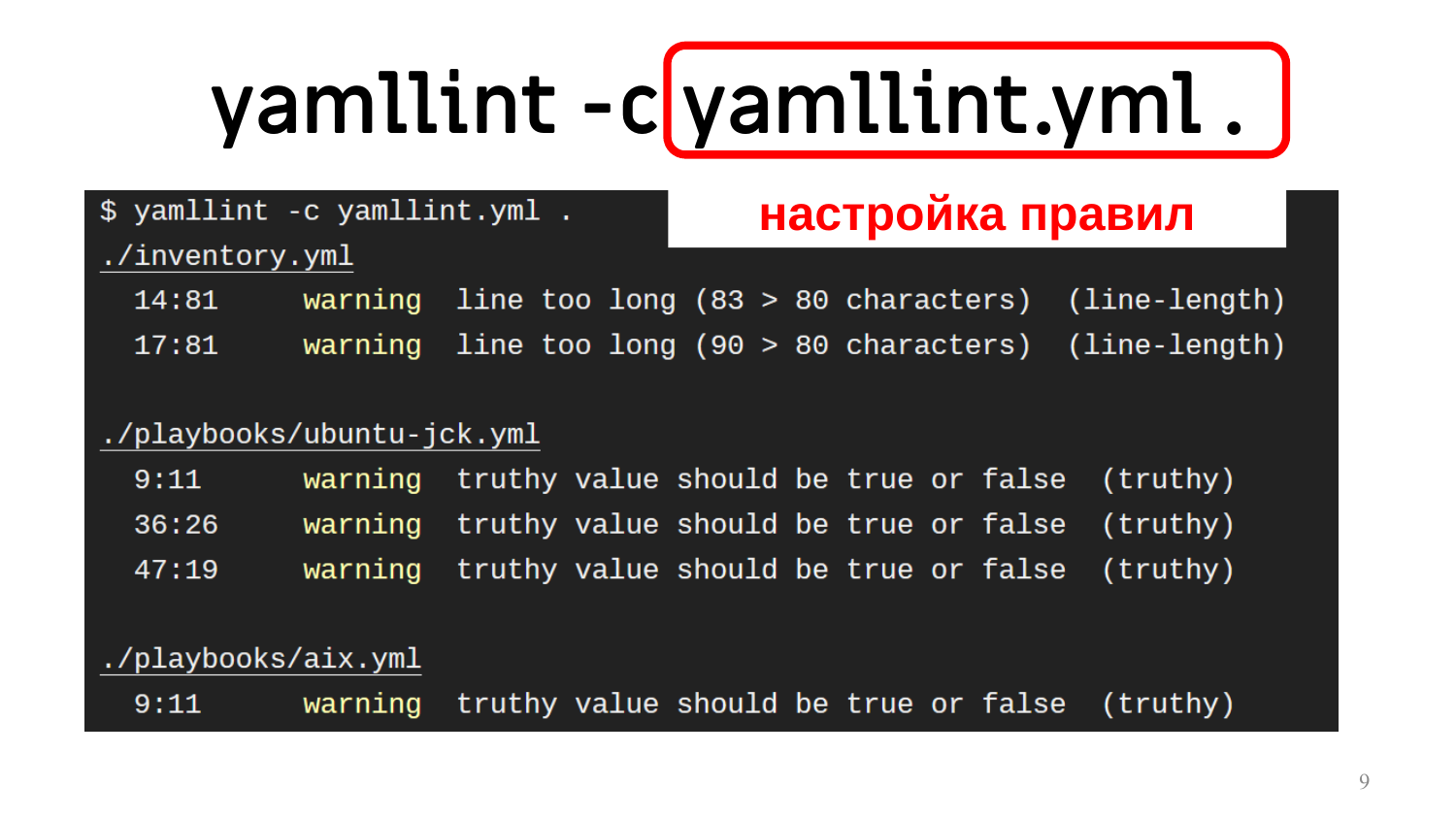
Так выглядит вывод YAMLLint. И обратите внимание: мы эти правила можем настроить, отключить какие-то проверки, например длину строки сделать побольше или ещё что-то. YAMLLint проверяет просто все YAML-файлы в вашей папке, поэтому если это не Ansible playbooks или роли, а просто какие-то конфигурационные файлы, то он тоже их проверяет.

Ansible-lint — это прекрасный проект, который содержит десятка два good practices.
Для примера:
* Когда использовать command module, когда — shell module? Часто с этим путаются новички. Ansible-lint это находит.
* Иногда используется command module, а в нём вызов команд, для которых есть стандартный модуль Ansible. Ansible-lint подскажет, что его возможно заменить на стандартный модуль Ansible.
* Он проверяет idempotence (идемпотентность) вашего использования command и shell. Про idempotence мы чуть-чуть поговорим позже поподробней. Он строже, чем сам Ansible, и он проверяет best practices вашего кода.
* И, кроме того, если вы хотите на Python что-нибудь написать, то там есть фреймворк, который даёт возможность расширять эти правила и добавлять новые.

Запускается это вот так вот. Здесь есть одни «грабли». Если ваш код использует какие-то стандартные роли, то он будет обходить в том числе и стандартные роли. Но в стандартных ролях есть критические ворнинги, и поэтому он завалит вашу CI-сборку. Поэтому стандартные роли исключите.

Вот так выглядит его вывод.

Третий инструмент — это Syntax check, встроенный в сам Ansible. Тут всё просто. Но единственные «грабли», которые также нужно учесть, — это если вы делаете на CI, то установите все свои стандартные роли. Потому что Syntax check хоть и называется Syntax check, но проверяет он не только синтаксис, он заходит внутрь всех ролей и тоже их обходит. И если там какая-то роль не установлена, то у вас завалится сборка.

Всё это вы можете объединить в скрипт вашей любимой CI-системы. У меня это Jenkins, а вы можете использовать что угодно. И получить уже вот такой pipeline. Получить вы его можете прямо сейчас, не вставая с места. Это ничего вам не стоит, вы просто получаете довольно подробный статический анализ всего вашего Ansible-хозяйства.
Но, как известно, возможности статического анализа ограниченны. Всё-таки, чтобы протестировать, программу нужно запускать. Как же тут быть?

История вопроса вот какая. Jeff Geerling — это человек, известный в Ansible-экосистеме. Он автор множества ролей, он автор книги «Ansible for DevOps». В четырнадцатом году он написал вот эту статью, предлагая в Travis разворачивать роли, которые он тестирует.
Два года спустя он в продолжении этой статьи предлагает делать то же самое, но в разных docker-контейнерах. Таким образом за один раз он прогоняет свои роли на семи разных операционных системах.
И в этой же статье он упоминает [Molecule](https://github.com/ansible-community/molecule). Это штука, которая существует где-то с пятнадцатого года. Она сейчас очень активно развивается. И это очень удобный инструмент для тестирования Ansible-ролей.

Это типичный современный OpenSource-проект, который хорошо интегрирует другие проекты.

Устанавливается он в ваш Python environment. Нужно поставить ansible, [molecule](https://github.com/ansible-community/molecule) и, если вы будете тестировать в Docker, — docker-py.
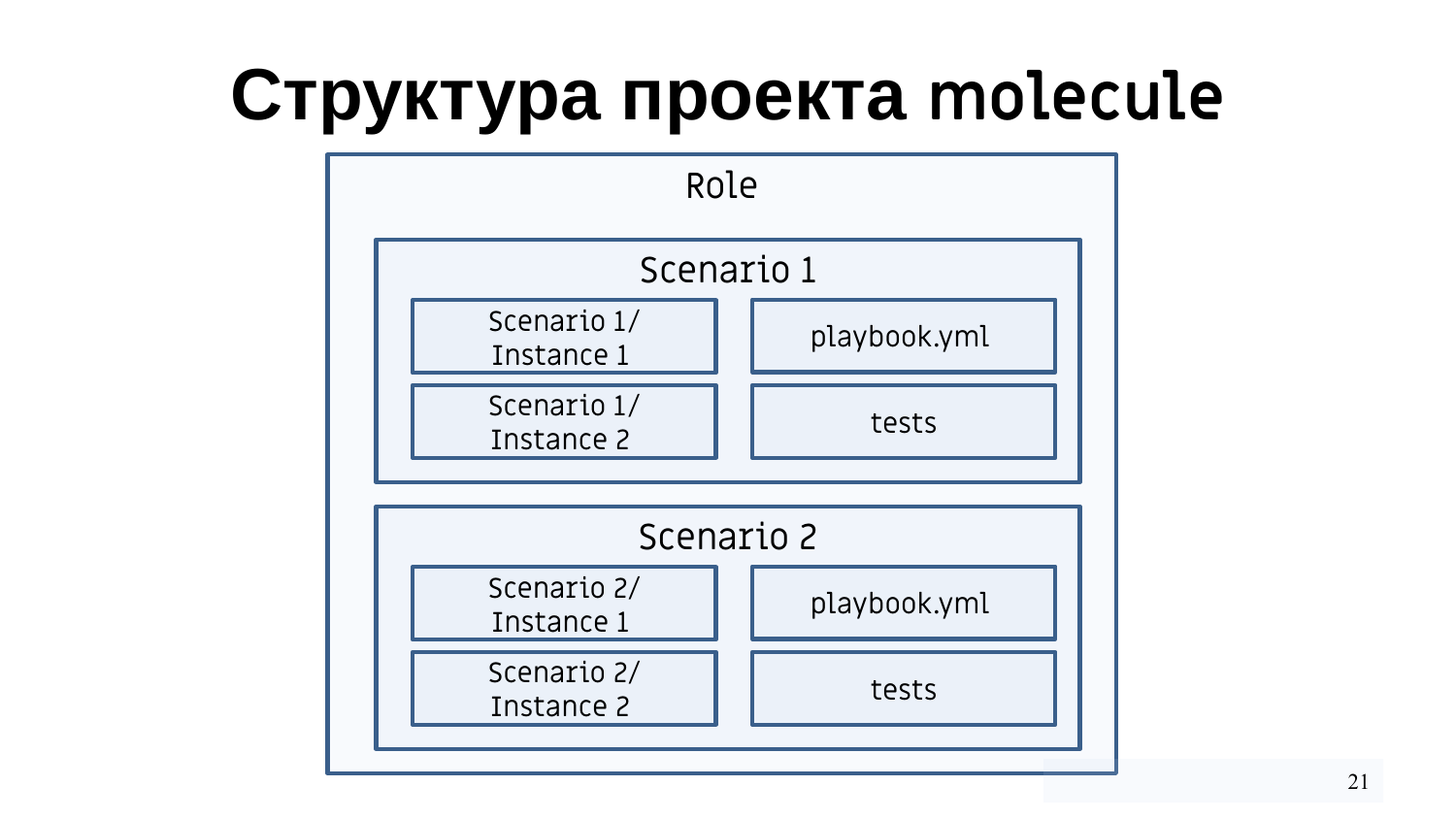
Этот инструмент тестирует роли, то есть он работает внутри отдельной роли. Не проекта Ansible целиком, а внутри роли. Соответственно, внутри роли у вас могут быть разные сценарии. Внутри сценария вы настраиваете instances (сервера, виртуальные машины), на которые вы будете накатывать эту роль. Допустим, на разные операционные системы.
Кроме того, у каждого сценария есть свой playbook. Playbook — это то, что будет выполняться, накатываясь на эти instances.
И есть конфигурационные тесты.

Во-первых, инициализация. Если вы хотите создать новую роль уже с molecule, то вы пишете вот такую команду. И она создаёт вам папку со всеми файлами, даже с readme-файлом, то есть со всеми вещами, необходимыми для создания Ansible-роли. А внутри папки Molecule у них возникает единственный сценарий под названием Default. В принципе, одного сценария под названием Default мне лично всегда хватало, более одного сценария я не писал.

Если вы хотите добавить molecule в вашу существующую роль, то вам надо выполнить вот такую команду. Она тоже добавит вам Default-сценарий. Там никакой магии нет, она просто создаёт папки и прописывает туда файлы. Вы можете просто копировать уже из существующих ролей, которые под Molecule, папки в новые роли. Там всё это переиспользовать очень легко.
После того как мы проинициализировали, заходите в консоль и пишете: `molecule test`. Всё, у вас Molecule тестирует вашу роль. Как правило, это упадёт. Пришло сообщение об ошибке. Непонятно, почему она упала.
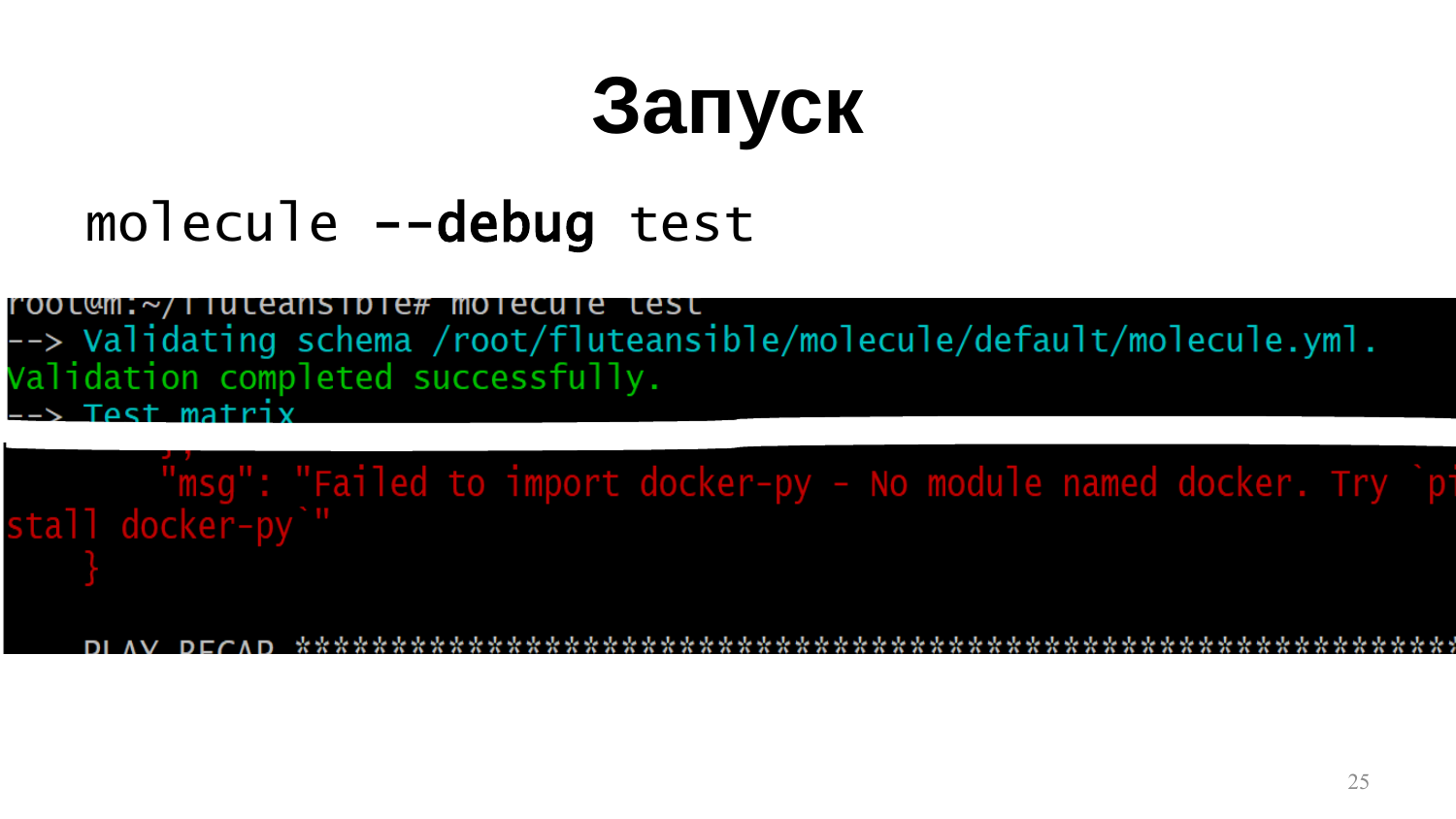
Если мы заполним флажок `--debug`, то она скажет, что вы забыли установить `docker-py`. А я несколькими слайдами ранее говорил, что `docker-py` надо ставить отдельно. Этот `--debug` помогает разобраться: что же пошло не так.

Потом она покажет вам Test matrix. Это некий план или сценарий, по которому Molecule будет работать с вашей ролью. Как видите, она уже предлагает некую матрицу. На первых этапах она проверяет статический анализ, потом она проверяет syntax, converge, idempotence, и заканчивается всё сносом тестовых instances, на которые это всё ставилось.

Самое интересное, конечно, — это на что же, собственно, Molecule накатывает ваши роли, на какие instances, откуда она эти ресурсы берёт? Эти ресурсы настраиваются вот в таком файлике — molecule.yml. Вы можете прописать в разделе Platforms столько instances, сколько вам нужно. Если вы их пропишете три или пять, то их будет три или пять. И Ansible на этапе converge будет их раскатывать сразу на несколько нод, как Ansible обычно это делает.
Если это docker, то здесь вы прописываете базовые image. Заметьте, что здесь image хитрые. Сделано это для того, чтобы у нас работал systemd. Потому что если ваши роли раскатывают какие-то сервисы, которые работают в systemd, а, как известно, docker с этим не работает, то можно воспользоваться хитрыми базовыми контейнерами. Таким образом можно обойтись, и у вас будут тестироваться роли, которые сервисы ставят в systemd.

Кроме docker вы можете использовать другие драйверы.
Во-первых, вы можете создавать тестовые instances в облаках, используя соответствующие модули, встроенные в Ansible.
Во-вторых, вы можете сами написать драйвер. Там есть для этого заготовка.
И есть Vagrant, и есть многое другое.
Заходите в документацию по Molecule, там достаточно большое количество вариантов. Но docker — наиболее простой и лёгкий, его можно прямо здесь и сейчас запустить на машине разработчика.

Следующий важный момент: когда вы начинаете этим пользоваться, вам нужно подключить зависимости. Под зависимостями я имею в виду роли, от которых зависит тестируемая роль.
Это прописывается в файле requirements.yml, как и положено по best practices Ansible. И вы можете указать настройку: какие роли каких версий вам нужны для того чтобы протестировать вашу роль как зависимость. И на первых этапах, на этапе dependency, именно роли именно этих версий будут скачаны.

Этап статического анализа использует эту троицу, о которой я рассказывал в самом начале: YAMLLint, Ansible-lint, Syntax check.

Этап converge на ваши тестовые instances накатывает файл playbook.yml. Вот что вы там напишите, то он и сделает. Вы можете даже вашу тестируемую роль туда не подключать, а что-то другое. То есть этап converge просто выполняет файл playbook.yml. И здесь вы можете несколько ролей выполнить, как-то их сконфигурировать и посмотреть потом, как они будут работать совместно.

Если что-то пошло не так: converge вроде как бы прошёл, или он не прошёл, но непонятно, что происходит, — вы можете запуститься с ключиком `destroy=never` (это значит «никогда не удаляй тестовые instances») и если вы в docker, то обычным образом через interactive-терминал залогиниться в ваш контейнер и посмотреть, какие файлы не туда легли и что там вообще происходит.

Следующий этап после converge. Предположим, роль сработала, на все ваши тестовые instances раскатилась, всё здорово. Molecule ещё раз выполняет вашу роль. Раньше, когда не было diff в Ansible, Jeff Geerling предлагал так: проверять, что ничего не изменено при втором прогоне. Это проверка идемпотентности, то есть что ваша роль написана таким образом, что она не делает лишних операций. Если операции не нужно делать, она их не делает.

Сейчас она использует `--diff`. Если так получится, что роль ваша работает и действительно делает то, что нужно, но при втором прогоне хотя бы одна вещь поменяется, это будет failed на idempotence.

И самая интересная часть в Molecule — это инфраструктурные тесты. Предположим, мы прогнали, роль прошла и всё установилось. Но чтобы узнать, работает там всё или нет, для этого можно использовать инфраструктурные тесты. Molecule поддерживает разные инфраструктурные тесты.
Три вида:
* Testinfra (Python, default).
* Serverspec (Ruby).
* Goss (written in Go, tests in YAML).
Если так случилось, что у вас в команде уже есть какие-то инфраструктурные тесты, например на Serverspec, то вы можете подключить готовые инфраструктурные тесты в Molecule.
Если инфраструктурных тестов ещё нет, я рекомендую Testinfra, потому что она на Python, так же как Molecule и Ansible, и всё будет сделать проще.

Testinfra положит дефолтовый сценарий в Molecule. И вы можете прописывать туда тесты.

Что, например, можно проверить? Ну, что мы обычно проверяем, когда сконфигурировали что-то на сервере и хотим посмотреть, шевелится оно или нет? Мы лезем в shell, выполняем какую-то команду и смотрим, что нам выдала эта команда.
Это можно сделать вот таким вот образом. Вы пишете питоновскую процедуру, получаете аргументом host, у этого host вызываете метод «run» и дальше можете получить return code и можете получить stdout и stderr и проверить этот вывод.

Мы в assert, допустим, написали, что rc=0. Если бы он был равен не нулю или если бы мы что-то там не нашли, то вывод в питоновском assert умный, он показывает вам контекст вашего питоновского кода: где что слетело, что именно чему не равно.

Когда вы гоняете molecule test, то самое длительное время — это накатка Ansible-скриптов на instances. Чтобы не тратить время на накатку тестовых скриптов на instances, вы можете воспользоваться снова флагом `destroy=never` и вызывать `molecule verify`. В этом случае он будет просто выполнять инфраструктурные тесты на ваших готовых instances.

Вот как это выглядит, когда инфраструктурные тесты зелёные. Когда в 2000 году появился JUnit, первая система Unit-тестирования, у них был такой девиз: «keep the bar green to keep your code clean». Так как у нас теперь everything is code, то мы можем то же самое сказать про инфраструктуру.

Что ещё можно проверять? Мы можем проверять всё, что мы можем проверять через командную строку. Установили curl — можем подёргать какие-то сервисы, можем попроверять вывод curl.

Но в Testinfra есть ещё хорошие абстракции для проверки других вещей. Например, процессы. Host.process даёт вам фильтруемую коллекцию процессов, запущенных сейчас на host. Вы можете фильтровать их по какому-то фильтру, по какому-то аргументу, например по названию запущенного файла, и проверить его свойства: например что от правильного пользователя запущен этот процесс, что мы не от root его запускаем, или что он запущен с какими-то определёнными аргументами.

С сервисами всё просто. Можете получить сервис по имени и проверить, запущен он или нет.

Также очень легко проверять файлы и их содержимое. Например, если наш запуск сервиса порождает какие-то логи, в которые мы хотим зайти и проверить, что в этих логах что-то появилось, то это очень легко сделать. Во-первых, по exists мы можем проверить, что файл вообще существует по данному пути, а при помощи contains очень легко можно проверить, что этот файл содержит какую-то подстроку, которая нам сигналит, что всё OK.
Если кто-то любит TDD, то, используя быструю итерацию перезапуска теста, мы можем сначала писать тесты под Ansible, а потом уже сам Ansible.
То есть Ansible-код становится таким же кодом, как код на Java или на Python, и разрабатывать его можно теми же самыми средствами.
Тут, может быть, кто-то вспомнит — пока мы говорили про Testinfra, — что в самом Ansible есть модуль assert. Действительно, хорошая мысль — включить такую проверку прямо в Ansible-роль. Jython — это интерпретатор Python в JVM. Установили, выполнили команду в jython version, проверили, что он даёт какой-то осмысленный вывод.

Хорошая идея. Правда, она не пройдёт, если вы пользуетесь Molecule, потому что Molecule скажет, что этот код не идемпотентный. Почему? Это не пропустит и Ansible-lint. И даже если вы загасите в Ansible-lint эту проверку, то потом Molecule на этапе проверки идемпотентности вас не пропустит.
Поэтому нельзя просто так взять и вставить assert в код Ansible.

Но в принципе его вставить можно, если мы вставим в хэндлер проверку. Например, мы скачиваем эту программу, устанавливаем эту программу в разных местах кода и нотифицируем некоторый хэндлер, который, в случае если мы скачали либо установили новую версию, потом запустится и проверит, что она действительно работает.
Идея использовать проверки в хэндлерах мне кажется очень хорошей. Потому что если всё-таки на production что-то пошло не так, то вы узнаете об этом сразу, то есть ещё в процессе запуска Ansible playbooks у вас будет осмысленный вывод.

Ещё в хэндлерах можно проверить файлы и их содержимое, ещё в хэндлерах можно проверить веб-сервисы. В принципе этого достаточно, чтобы организовать такой аналог инфраструктурных тестов, попроще, чем Testinfra, но достаточно мощный. Это хорошая идея, и я призываю писать Ansible-код таким образом.
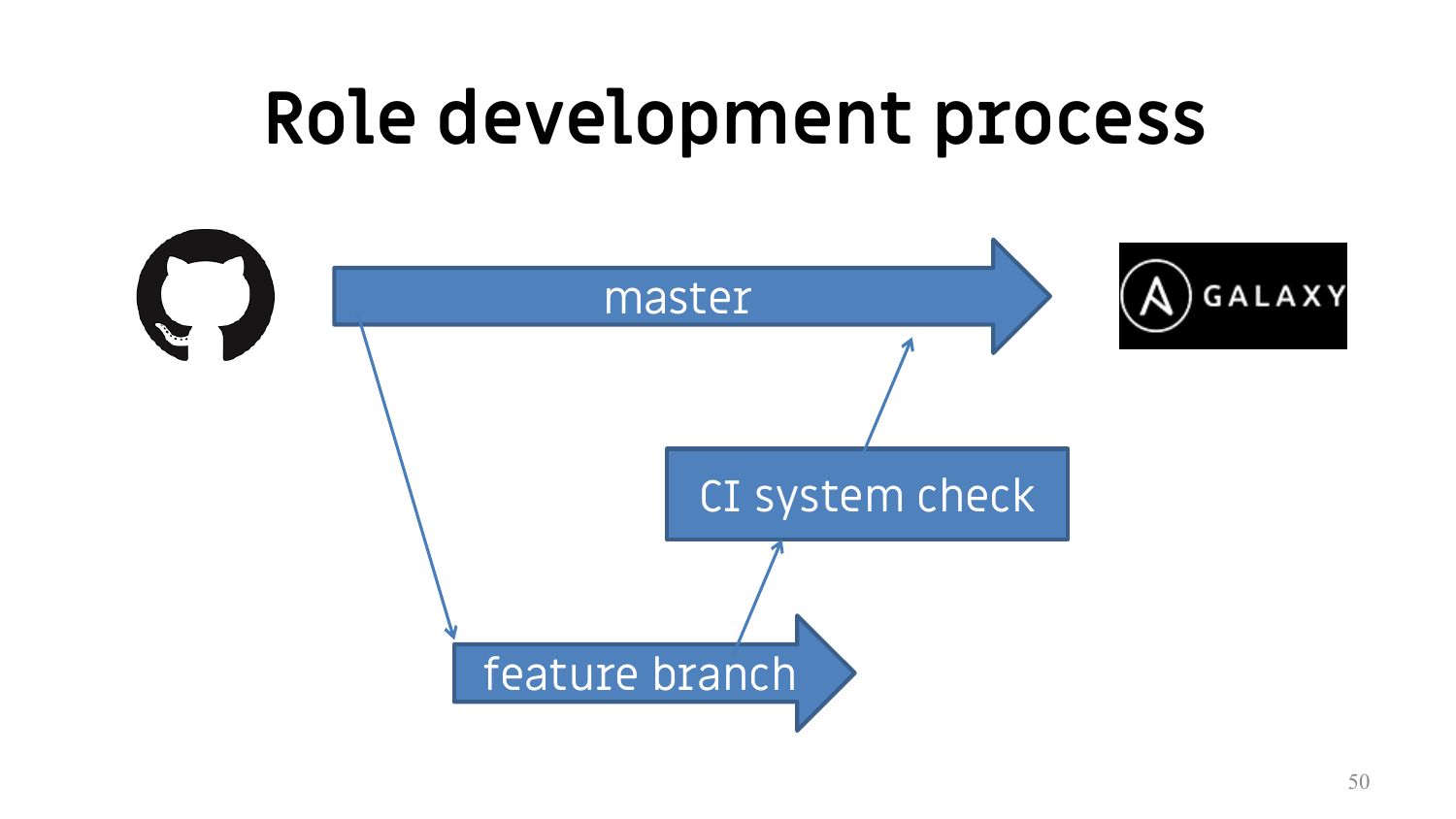
Теперь немножко поговорим про процесс разработки ролей. Он стандартный. Репозиторий для ролей — это Galaxy. И он жёстко привязан к GitHub, то есть если вы разрабатываете роли в OpenSource, то это только лишь GitHub и, соответственно, GitHub-процесс с проверкой на CI на валидность вашей роли. И то, что попадает в Master, то мы считаем релизом. Если мы хотим ссылаться на какую-то версию, то мы можем поставить какой-то тэг на Master, и это будет ссылка на версию вашей роли.
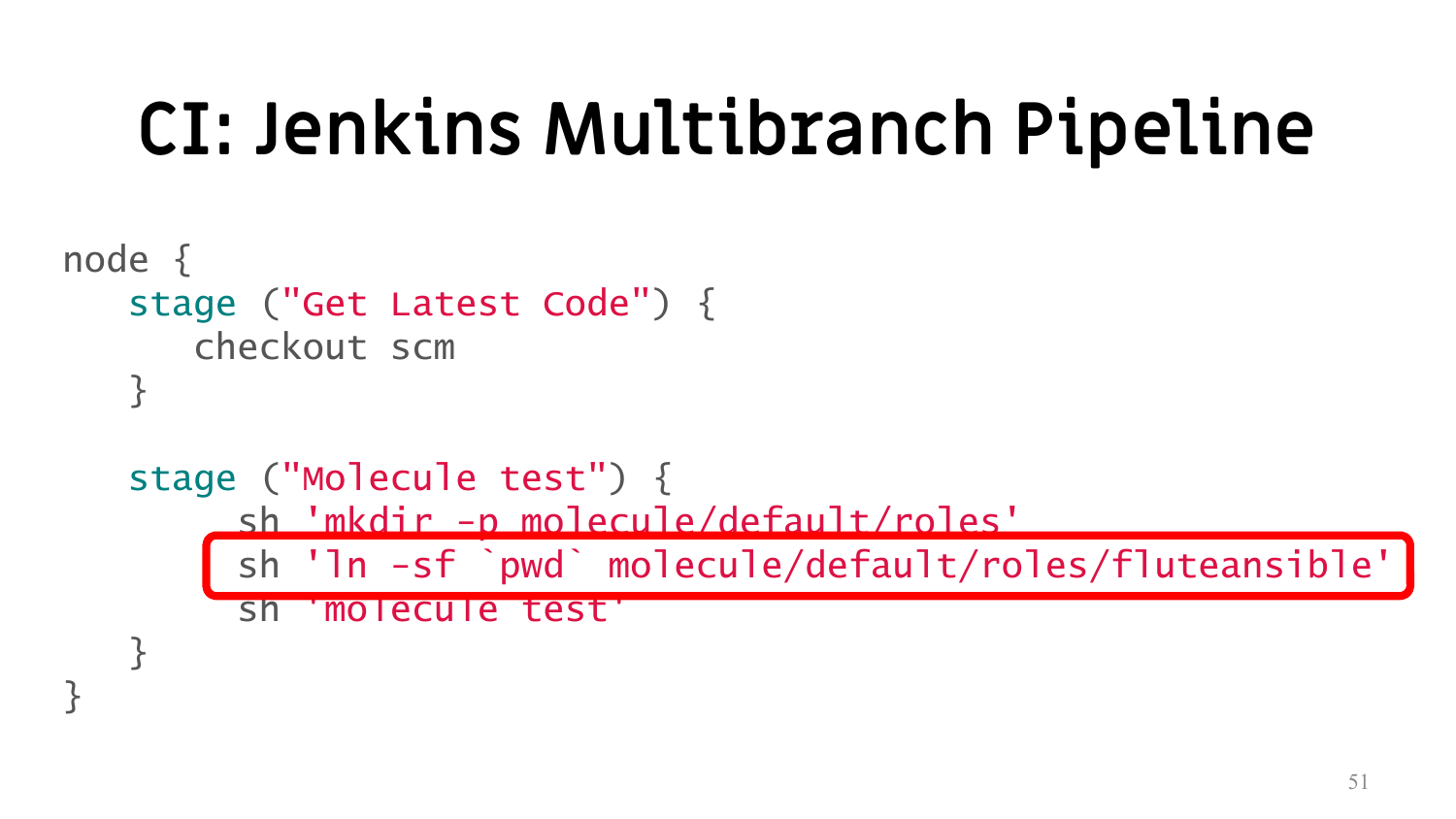
Как это можно сделать? Запуск Molecule легко организовать в вашей CI-системе. Если это Jenkins, то тут есть некоторые «грабли». Если мы используем Jenkins Multibranch, то он делает checkout с контрольной версии вашего проекта не в папку с названием этого проекта MyRole, а в уникальную папку с большим набором цифр и букв, и в результате у Ansible сносит крышу, потому что он ничего не понимает: он ищет роль под названием MyRole, а там другое название. Но это можно исправить небольшим костылём: если ему подсунуть symlink внутри в подпапочку, то это всё решается.

Вы можете заморочиться и разделить выполнение Molecule на стадии.
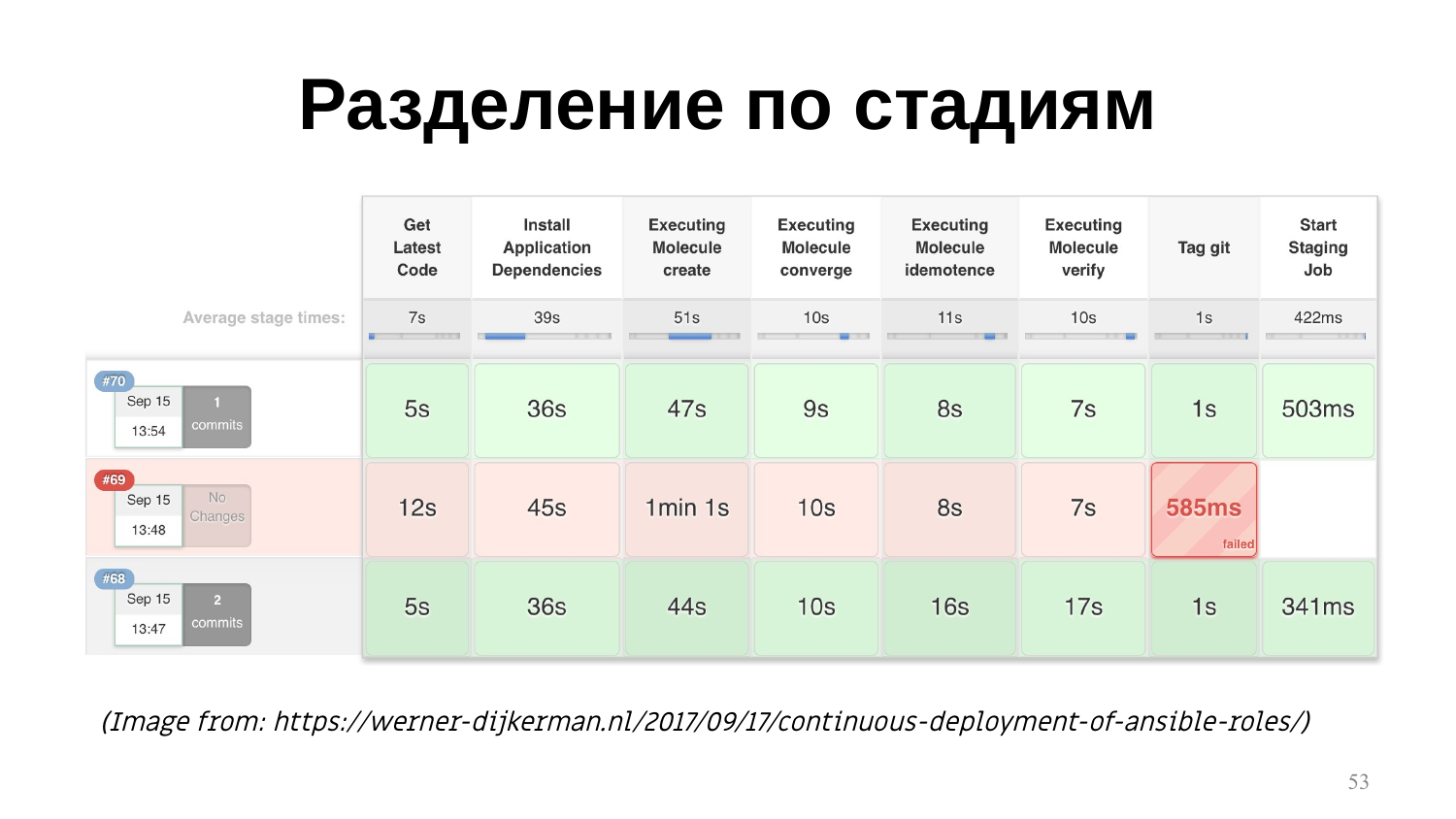
Если вы так сделаете, вы получите вот такую красивую матрицу в Jenkins. И если у вас что-то слетело на каком-то этапе, то вы можете увидеть, на каком этапе это произошло. Но честно скажу, что я так не делал. Я видел статью, где было сказано, что нужно делать именно так, но я ограничиваюсь только molecule test.
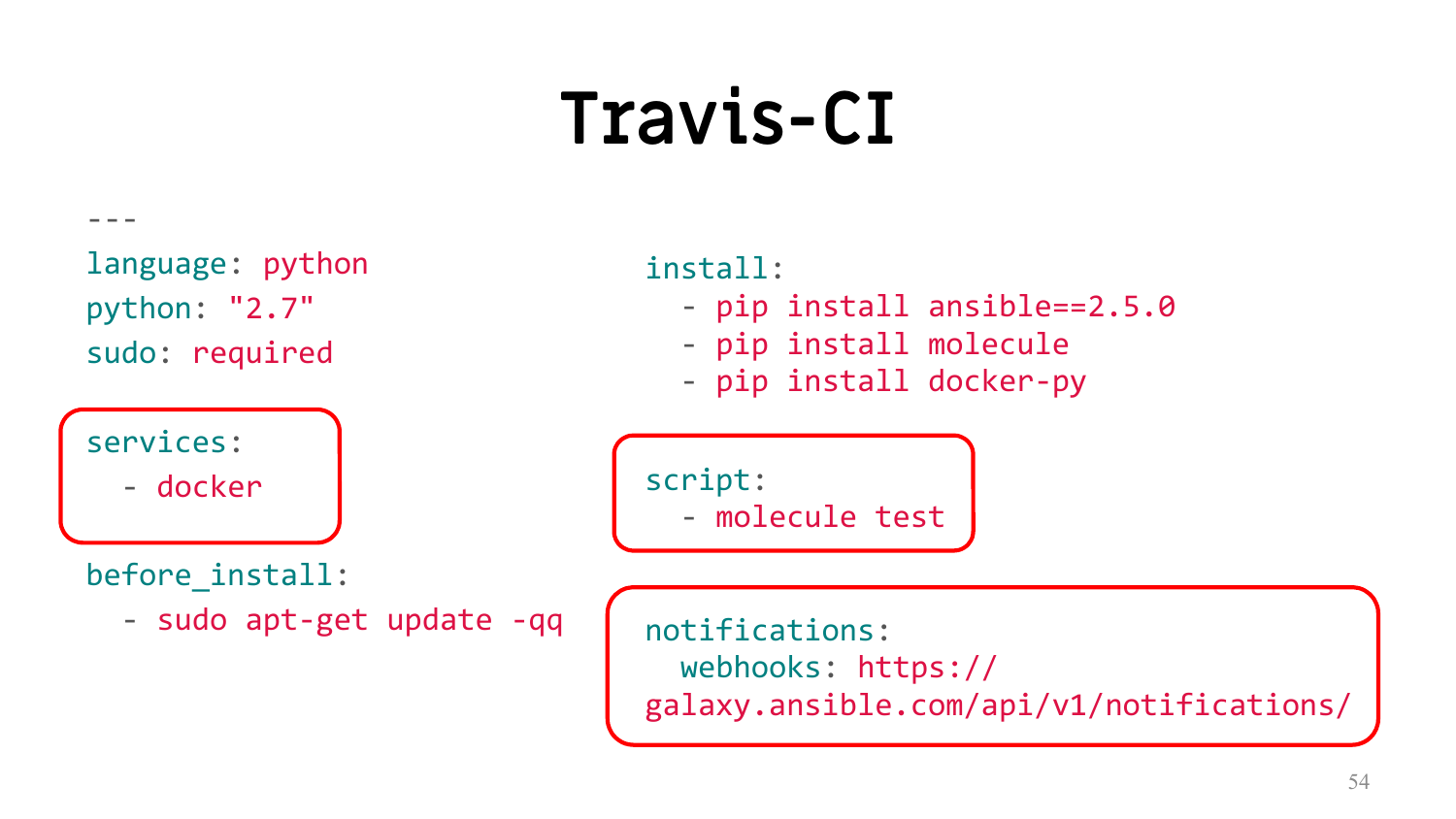
Другая опция, которая будет для вас более актуальной, если вы разрабатываете роли в OpenSource, даже единственная, — это Travis. Тут вообще всё очень просто. Мы указываем в services docker, мы указываем в инсталляцию, что нам нужно поставить Ansible Molecule docker-py. Кстати, это хорошая идея — указывать явные версии того, что вы хотите поставить, иначе у вас сборка сегодня может выполниться, а завтра нет.
И очень простой скрипт — molecule test, если у вас роль, которую вы разрабатываете, находится в GitHub-репозитории.
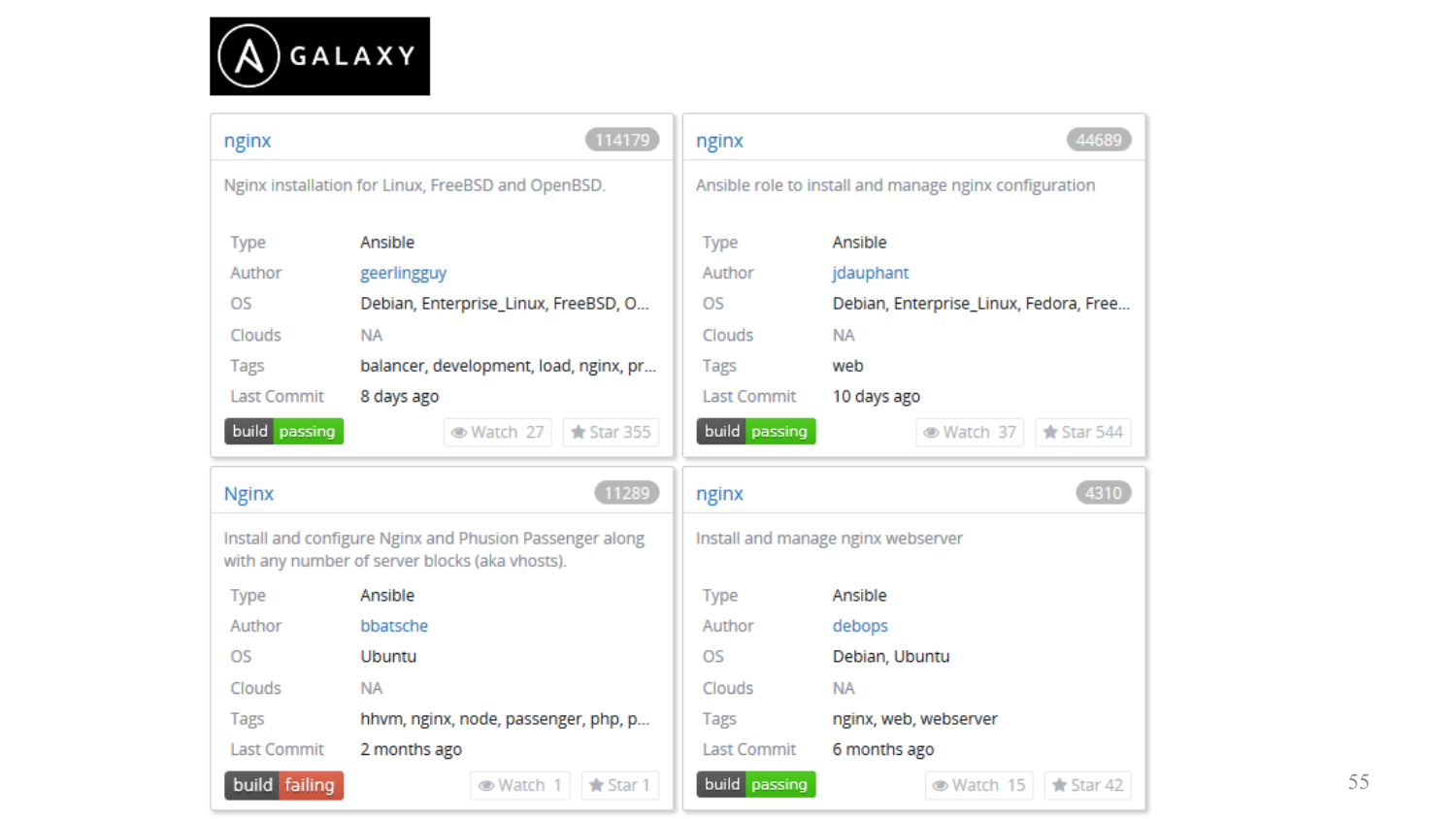
И, используя вот такой webhook, вы нотифицируете Ansible Galaxy тем, что роль ваша хорошая: build passing или build failing.
И в результате вы имеете в окне поиска ролей в Galaxy вот такие бейджики. Это не те бейджики, которые в GitHub, это бейджики именно в Ansible Galaxy. Чтобы их получить, надо пользоваться Travis и тем webhook. Из другого CI это, может быть, и можно сделать, но я не понял пока — как. Задокументированный вариант только через Travis.

После того как всё внедрилось, что получается? У нас было вот что — то есть какие-то проекты, какие-то роли, между ними copy-paste-modify и непонятно что.
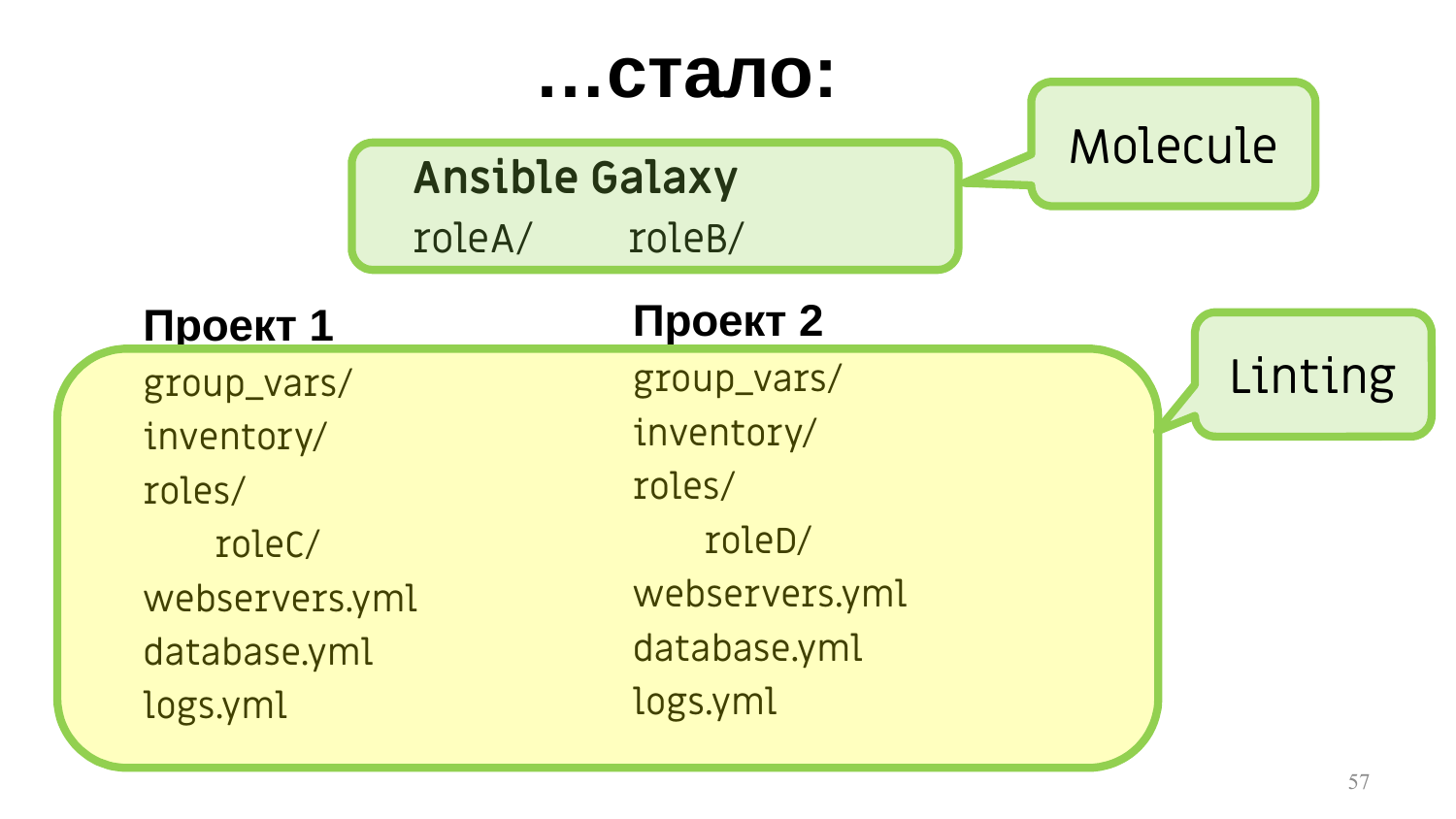
Что стало. Общие роли, которые мы используем между проектами, мы вынесли в Galaxy, они расшариваются. Соответственно, каждая роль тестируется в Molecule, допиливает роль каждый под свой проект сам, и это становится общим достоянием.
На остальную часть, которая уникальна для каждого проекта, навешен linting. Вот эти три инструмента — YAMLLint, Ansible-lint и Syntax Check. И это уже гораздо лучше, чем было.
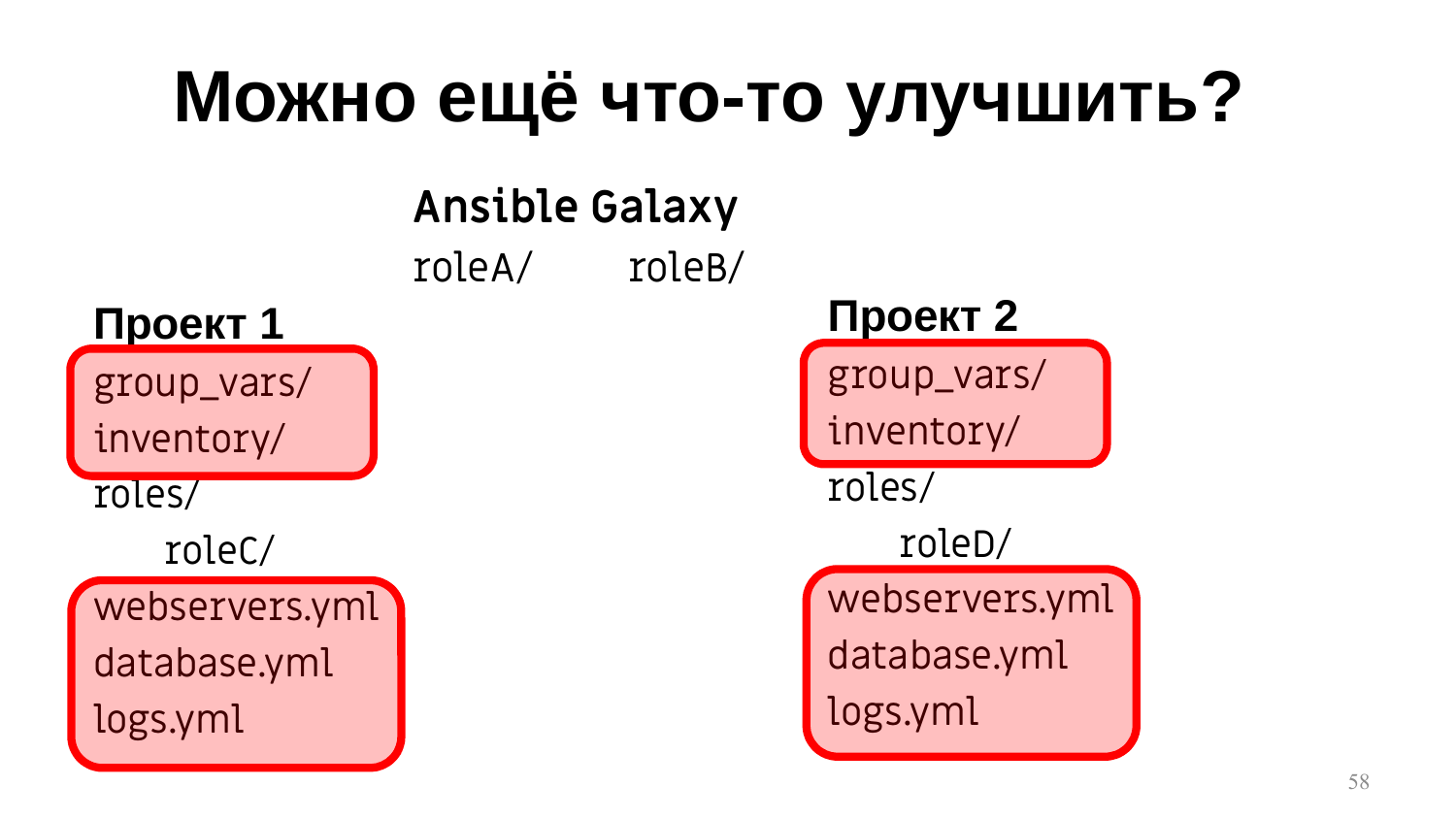
Но возникает вопрос: можно ли здесь пойти дальше и улучшить что-нибудь ещё? У нас есть часть, которая в Ansible Galaxy и которая проверяется Molecule, у нас имеются роли, которые мы в Molecule тоже можем проверить внутри нашей подроли. Но есть большая часть конфигурационного кода, который содержит переменные, всякие конфигурационные файлы, и это достаточно большие куски кода, которые не проверяются никак. Вернее, мы проверили, что YAML в well format, и больше ничего мы не проверили здесь.

Можем ли мы ещё что-то проверить? Как быть с конфигурацией? Плохая новость в том, что Molecule — только для ролей. Но вы можете, правда, проверить в Molecule комбинацию ролей.
Но проверить развёртывание на прод можно только развернув на прод, потому что у вас там прописано, на какие машины вы устанавливаете, как вы связываете это всё, и только в процессе развёртывания на прод это запустится.

Но хорошая новость в том, что вы можете проверить проект, не запуская его.
Это докладчики с конференции по тестированию ПО — Heisenbug. Они рассказывали про такую вещь, как конфигурационное тестирование.

На самом деле идея очень-очень простая. Если у вас имеется некий конфигурационный файл, то что мы можем проверить?
* Мы можем проверить формат значений переменных. Если у нас в значении порт, то это именно порт, а не что-нибудь ещё, если хост, то это хост, если URL, то URL.
* Мы можем проверить, что у нас не утекают в явном виде пароли.
* Мы можем проверить уникальность портов. Потому что если вы назвали две переменные одинаковым портом, то, как правило, это ошибка, в Ansible особенно.
* И другие более специфические вещи. Например, Андрей Сатарин рассказывал в своём докладе о том, что ему необходимо было проверять, что разные instances какого-то сервиса ставятся в машины, расположенные в разных стойках, потому что иначе не будет достаточного failsafe. Потому что если их запихнуть все в одну стойку и стойка отключится, то тогда какая разница, что у нас было три instances?
На самом деле идея очень простая: мы берём и пишем эти проверки, используя тестовые framework, например pytest. Просто это неожиданно, потому что это не исполняемый код, а статический. Сейчас я покажу, как это может выглядеть.

Например, как мы можем проверить валидность портов? Мы можем написать вот такой вот параметризованный тест, являющийся частью pytest, который проверяет для всех пар ключ значений, где ключ — это переменная, которая держит порт, а значение — это значение этой переменной. Мы можем обычные asserts написать: что это интовое поле, что порт находится в разрешённом вами диапазоне. То есть идея очень простая. Магия находится вот где: вам надо написать генератор на Python, который вам будет выдавать все values-значения для переменных, в которых содержатся порты.

Как же мы отличим переменные, которые содержат порты, от других переменных? Мы это можем сделать вот таким вот образом. Мы можем договориться, что наши переменные, в которых прописываются порты, имеют постфикс ‘port$’. И если у вас есть другая функция «var\_values», которая выдаёт вам все переменные, все пары ключ-значений, все переменные в вашем Ansible playbooks, то вот таким вот образом вы можете отфильтровать из этого потока var\_values только те, которые оканчиваются на «port», и, как было показано слайдом ранее, параметризовать тот тест, и тогда этот тест будет выполняться на портах, будет проверять их.
А как написать var\_values? Взять на Python и написать. Это же рекурсивный обход YAML-дерева. Примерно мы знаем, как устроены YAML у Ansible, и надо просто вытащить оттуда все куски, которые содержат переменные.

Это не так сложно, но, так как мы рассчитываем уже на некоторые соглашения, которые есть в вашем коде, то здесь не может быть универсального решения, это решение придётся самим разрабатывать.
Как можно проверить уникальность портов? Очень просто. Если у нас уже есть port\_var\_values, который возвращает нам все переменные с портами, то мы можем просто собрать их в один сет и на каждом шаге проверять, что они задают уникальный порт.
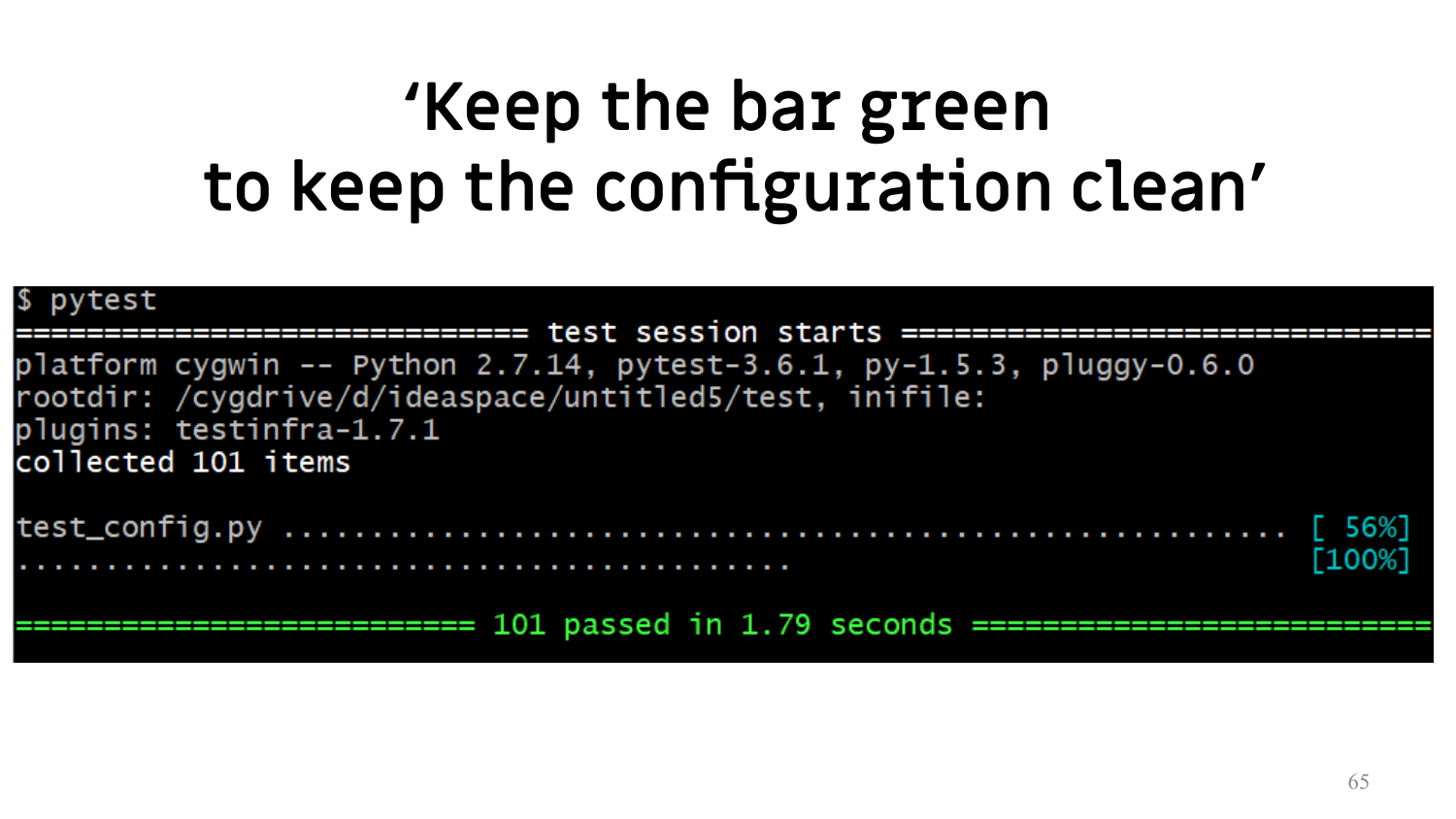
Таким образом мы можем ещё один слоган сделать, теперь уже для тестов конфигурации: «keep the bar green to keep the configuration clean». Вот как это выглядит, когда всё сработало.
Обратите внимание: там внизу написано, что у нас выполнился сто один тест. Это не значит, что мы написали сто один тест. Это значит, что параметризованные тесты выполнились сто один раз для сто одной пары переменной и значения. Он всё просуммировал, естественно. То есть большие количества проверок не означают, что для этих проверок надо много кода писать. На самом деле кода писать надо довольно мало, так же, как и для инфраструктурных текстов.

И напоследок — пример, как можно поймать «утекающий» пароль в таком случае. Во-первых, мы из всего потока ключ-значений переменных выделим те, которые содержать в себе пароль.
Выделить их можно так: они заканчиваются либо на слово «password», либо на слово «pass», либо на «pwd». Во-вторых, мы просто проверяем, что значением должен быть placeholder, который ссылается на что-то, например на какую-то переменную, которая находится в Vault. И всё, этого достаточно.
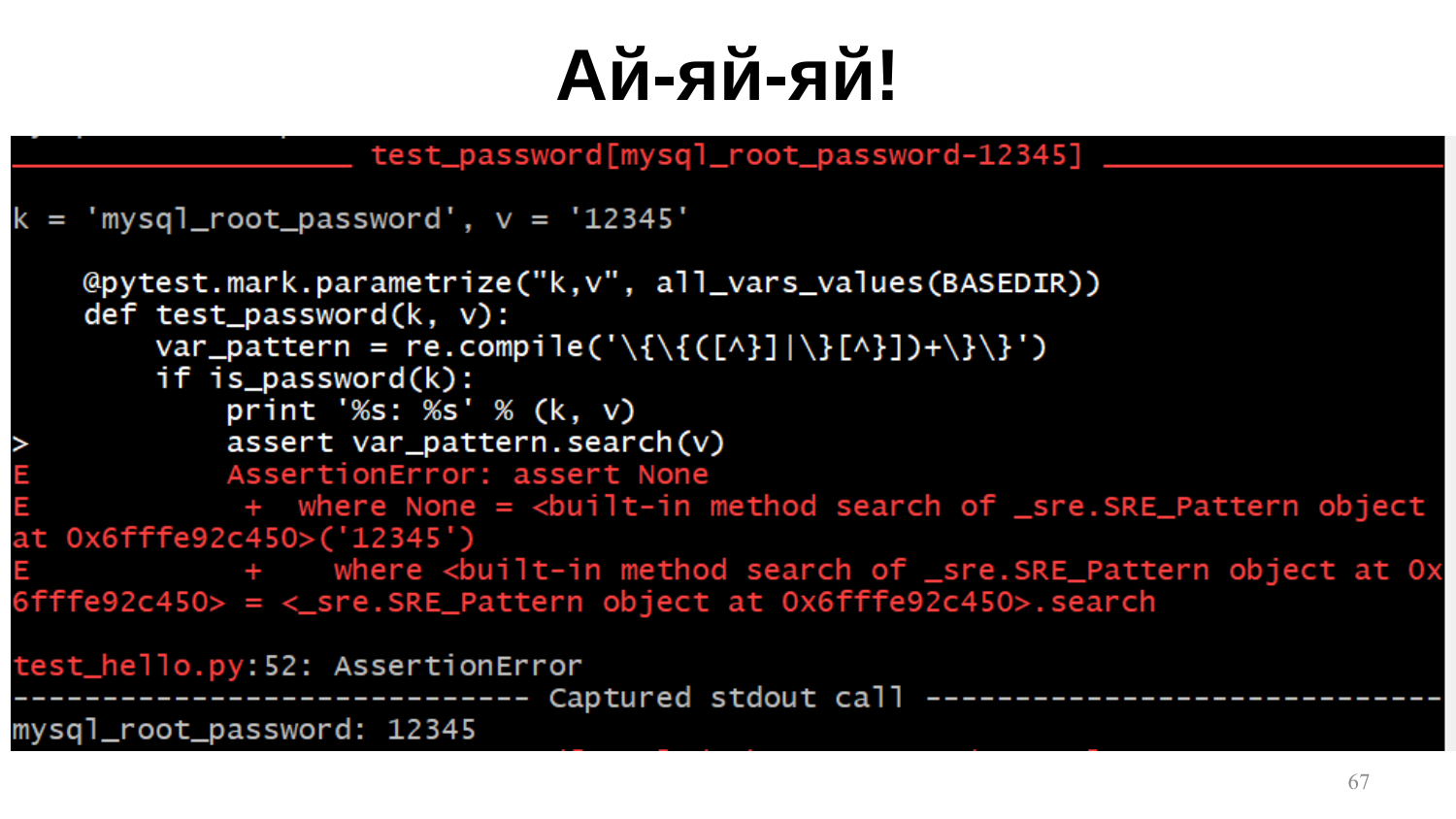
Вот это реальный случай. Был такой pull request. Запустился тест. И этот тест возвращает мне: k=’myskq\_root\_password’, v=’12345’. То есть не то плохо, что password «12345», а то, что он в GitHub теперь. И понятно, что такой pull request мерджить нельзя.
Давайте к выводам переходить.

Первый вывод — тестируйте ваш Ansible.
* Во-первых, эту троицу: YAMLLint + Ansible-lint + Syntax check — вы можете подсоединить прямо сегодня. Если у вас есть какие-то портянки с Ansible-кодом, есть какие-то репозитории, где всё это лежит, просто возьмите и подключите, посмотрите, какие ворнинги там возникнут. Потом у вас будет увлекательное время, чтобы пофиксить. Ansible-lint может вам многое рассказать, многому вас научить, потому что его best practices многие не знают.
* Проверяйте роли на Molecule.
* Вставляйте проверки в хэндлеры. Делайте ваши playbook failed fast. Так, чтобы, если что-то пошло не так, мы бы об этом узнали как можно раньше.
* И тестируйте конфигурацию.

* Если у вас где-то есть роли — попробуйте Molecule. Это просто: `pip install molecule`, `molecule init`, `molecule test`.
* Лень разбираться с тестами? Попробуйте converge и idempotence.
* Лень разбираться с converge и idempotence? Пусть он хотя бы синтаксис проверит.

Я верю, что всё должно быть как код: инфраструктура как код, база данных как код, документация как код. Что это значит — быть как код? Это не только лежать в репозитории, не только лежать в Git, это значит, что должен быть pipeline, должны быть quality gates, должна быть процедура изменения этого кода.

Штатный набор инструментов, который они сами предлагают, — это GitHub + Travis + Galaxy. Это если вы разрабатываете роли в OpenSource. Правда, я вижу мало поводов разрабатывать роли не в OpenSource. Jenkins Multibranch тоже отлично для нас работает.

Ссылки, про которые я упоминал, будут на слайдах, которые будут расшарены.
* **Иван Пономарёв**. Тестирование и непрерывная интеграция для Ansible-ролей при помощи Molecule и Jenkins <https://habr.com/post/351974/>
* **Jeff Geerling**. Testing Ansible Roles with Travis CI on GitHub <https://www.jeffgeerling.com/blog/testing-ansible-roles-travis-cigithub>
* **Werner Dijkerman**. Continuous deployment of Ansible Roles <https://werner-dijkerman.nl/2017/09/17/continuous-deployment-ofansible-roles/>
**Вопросы**
Вопрос: *Спасибо за доклад! Меня зовут Роман. Я хотел бы уточнить: делали ли вы написание тестов обязательным, чтобы, например, выложить роль в общее пользование? И если да, то насколько это увеличило порог вхождения в Ansible? Потому что Ansible всем подаётся как простая система управления конфигурациями, а в итоге человеку нужно знать Python, Testinfra, разобраться с Molecule. И количество боли увеличивается, потому что каждое изменение нужно покрыть тестами на Python, который может ему не нравиться, или он его не знает.*
Ответ: Как инфорсить написание тестов? Оно точно так же форсится, когда вы пишите на Java. Сделали pull request — и решаем: тесты нужны или не нужны. Касательно порога вхождения, роли — это какой-то расшаренный код, то есть это как библиотечный код. Как правило, если человеку нужно что-то быстро подправить, то он работает с кодом, который уже существует, поэтому он просто зайдёт и подправит. Тесты для этого не нужны. Тесты на playbooks не нужны. Есть тесты на ролях, которые именно расшарены между собой. И даже если он что-то подправит, то надо ли менять тесты? Потому что это же не тесты как код. Инфраструктурные тесты очень просты, там два-три стейтмента, которые просто проверяешь. Мы запустили что-то в shell, а этот shell нам что-то вывел. Поэтому мы можем достаточно многое поменять в роли, а тесты не менять.
Вопрос: *Тестировали ли Ansible в Windows? Мы запускаем Ansible playbook на Windows. И как это тестировать? Может быть, есть у вас опыт в этом?*
Ответ: К сожалению, нет у меня опыта разворачивания Ansible чего-то на Windows и тестирования этого в Testinfra. Мы разрабатываем под Windows, то есть Ansible в cygwin запускается и работает. Но все роли мы выкладываем на Linux-сервера и тестируем там, поэтому не могу ответить. Может быть, возможно. Но у меня такого опыта не было.
Вопрос: *Меня зовут Михаил, у меня такой вопрос. Выносить проверки в хэндлер — это хорошая идея. Но как мне поступить, если от результата проверки зависит роль? То есть если логика роли будет меняться. Поможет ли мне в этом changed\_when, например?*
Ответ: Вы имеете в виду, что вы хотите запустить что-то, получить какой-то вывод в консоли, захватить его в переменную и в зависимости от результата этого вывода выполнить либо одно, либо другое?
Вопрос: *Допустим, проверить, есть ли пользователь и могу ли я залогиниться с паролем, который у меня есть. И если пользователя нет, то создать пользователя.*
Ответ: Это не про проверки, это не про asserts, это про идемпотентность вообще. Тут надо писать идемпотентные скрипты. Выход тут один. Если вы пользуетесь command или shell, то у вас есть возможность указать ситуации, при которых он не будет выполняться. И если вы уже создали нужного вам пользователя, то у вас должно быть такое условие, при котором эта ветка даже отрабатываться не будет. То есть идемпотентность — это значит, что мы отработали один раз — создали то, что нам надо. Потом мы отработали второй раз и проверили, что нет этого. И оно никакие модификации Ansible выполнять не будет. В принципе, если подумать, то это всегда можно сделать, так или иначе. Это частности.
Вопрос: *Хотел бы в продолжение заданного вопроса уточнить следующий момент. Насколько мне известно, в Ansible можно писать задачи для gathering facts study, когда он собирает информацию перед тем, как катить…*
Ответ: Ну да.
Вопрос: *И, допустим, проверка JUnit на совпадение версий, — что, если её вынести не в хэндлер, а в gathering tasks, чтобы сначала проверить, та ли это версия, а потом уже накатывать?*
Ответ: Интересная мысль. Но надо посмотреть, будет ли он воспринимать этот код как идемпотентный. Это пред-проверка, а там пост-проверка. Во-первых, чем хороша проверка в хэндлере? Тем, что это пост-проверка. Мы считаем, что мы его установили, но ещё мы дёрнули хэндлер, чтобы он зашёл, выполнил и проверил, что он даёт какой-то осмысленный вывод. Пред-проверка не будет проверять результат действия. Но мысль интересная, надо посмотреть: таски, выполняющиеся на этом этапе, будут ли считаться идемпотентными или нет? Это надо посмотреть.
Вопрос: *Например, у меня есть роль, которая из GitHub качает архив, распаковывает его. И у меня в роли в начале стоит проверка, которая просто проверяет вывод команды на version. Но у меня это является условием, по которому ставить или не ставить.*
Ответ: Правильно. Это нормальный валидный подход. Если вы будете это на Molecule тестировать, она вам ничего плохого не скажет.
Вопрос: *Меня зовут Владимир. Приходилось ли вам писать или тестировать более сложные вещи, как корректность выполнения ролей? Например, написать какую-то роль, которая ставит какой-то сервис, и проверить, что она действительно сделала то, что от неё требовалось.*
Ответ: Это инфраструктурные тесты. Можно в тесте прописать, что service is running. Имеется в виду то, что у меня на слайде «Сервисы»?
Вопрос: *Имеется в виду, что сервис — это довольно просто, а бывают более сложные случаи. Бывает так, что он вроде бы как работает, но на самом деле…*
Ответ: Инфраструктурный тест не проверяет функциональность, он проверяет, что там дым не идёт из щелей, что вместо запроса не вывалился стек-трейс, а вывалился какой-то ответ. Ничего сложнее, чем у нас сервер ответ «200» вернул, когда мы что-то запросили. И ничего сложнее на этом этапе не надо проверять. Мы пишем selenium-тесты в наш интерфейс. И если этот артефакт готов к установке, то мы в Ansible говорим: «ставь эту версию». И если она уставилась, то мы проверяем, что он ответ «200» возвращает, но мы уже не проверяем, что она делает то что надо, потому что мы это уже проверили на более ранних этапах pipeline.
Вопрос: *Используете ли вы в production роли из Ansible Galaxy и тестируете ли вы их? Имеются в виду чужие.*
Ответ: Используем чужие, конечно. Например, nginx, PostgreSQL. Кучу всего мы разворачиваем. Ту же Oracle Java разворачиваем при помощи ролей из Ansible Galaxy. Ролей там очень много. Выбирать её следует обычно по количеству скачиваний. И, как правило, они тестируются. Как правило, роли в Ansible имеют build pipeline. И если не на Molecule, то хотя бы в Travis они запускаются. Можно посмотреть хорошие, признанные роли, например того же Jeff Geerling.
Вопрос: *Не страшно выбирать playbook из Ansible Galaxy?*
Ответ: В тех случаях, когда я их использовал, это были нормальные роли. Их достаточно много. Конечно, есть и мусор, но если отфильтровать по количеству скачиваний, то сразу же видно. Есть роль, которую скачали 150000 раз, а есть роль, которую скачали 150 раз. И если 150000 раз её скачали, то, может быть, кто-то ею даже пользуется в production.
Вопрос: *В моих проектах иногда бывают достаточно сложные навороты с Jinja. Допустим, Jinja может генерировать список хостов, которые я использую как переменные в hosts. Как это будет работать?*
Ответ: Если говорить о хостах, то это не про Molecule точно, потому что Molecule тестирует роль, выполняя её на тестовых хостах. У неё там возникает некий динамический inventory. Molecule сама знает, на какие хосты нагонять эти роли, и она их будет выполнять. Если какие-то другие случаи… Что делает Molecule? Molecule всего лишь в какой-то момент выполняет файл, который называет playbook.yml. И что у вас в playbook.yml, ей не интересно, главное, чтобы там был валидный playbook. Если там какая-то сложная Jinja, то — прекрасно. Она либо будет работать, либо свалится. И тогда у вас Molecule свалит это всё. | https://habr.com/ru/post/488966/ | null | ru | null |
# Прогресс выполнения тяжелой задачи в PHP
Случилось мне как-то иметь дело с тяжелым PHP-скриптом. Нужно было каким-то образом в браузере отображать прогресс выполнения задачи в то время, пока в достаточно длительном цикле на стороне PHP проводились расчёты. В таких случаях обычно прибегают к периодичному выводу строки вроде этой:
```
document.getElementById('progress').style.width = '1%';
```
Этот вариант меня не устраивал по нескольким причинам, к тому же мне в принципе не нравится такой подход.
Итераций у меня было порядка 3000—5000. Я прикинул, что великоват трафик для такой несложной затеи. Кроме того, мне такой вариант казался очень некрасивым с технической точки зрения, а внешний вид страницы и вовсе получался уродлив: футер дойдет еще не скоро — после последнего уведомления о 100% выполнении задачи.
Увернуться от проблемы некрасивой страницы большого труда не составляло, но остальные минусы заставили меня обрадоваться и приступить к поискам более изящного решения.
Несколько наводящих вопросов. Асинхронные HTTP-запросы возможны? — Да. Можно ли с помощью одного-единственного байта сообщить, что часть большой задачи выполнена? — Да. Можем ли мы постепенно (последовательно) получать и обрабатывать данные с помощью `XMLHttpRequest.onreadystatechange`? — Да. Мы даже можем воспользоваться заголовками HTTP для передачи предварительного уведомления об общей продолжительности выполняемой задачи (если это возможно в принципе).
Решение простое. Основанная страница — это пульт управления. С пульта можно запустить и остановить задачу. Эта страница инициирует XMLHttpRequest — стартует выполнение основной задачи. В процессе выполнения этой задачи (внутри основного цикла) скрипт отправляет клиенту один байт — символ пробела. На пульте в обработчике `onreadystatechange` мы, получая байт за байтом, сможем делать вывод о прогрессе выполнения задачи.
Схема такая. Скрипт операции:
```
php
set_time_limit(0);
// допустим, что итераций будет 50:
for ($i = 0; $i < 50; $i++) {
sleep(1); // Тяжелая операция
echo ' ';
}
</code
```
Обработчик `XMLHttpRequest.onreadystatechange`:
```
xhr.onreadystatechange = function() {
if (this.readyState == 3) {
var progress = this.responseText.length;
document.getElementById('progress').style.width = progress + '%';
}
};
```
Однако, итераций всего 50. Об этом мы знаем, потому что сами определили их количество в файле скрипта. А если не знаем или количество может меняться? При `readyState == 2` мы можем получить информацию из заголовков. Давайте этим и воспользуемся для определения количества итераций:
```
header('X-Progress-Max: 50');
```
А на пульте получим и запомним это значение:
```
var progressMax = 100;
xhr.onreadystatechange = function() {
if (this.readyState == 2) {
progressMax = +this.getResponseHeader('X-Progress-Max') || progressMax;
}
else if (this.readyState == 3) {
var progress = 100 * this.responseText.length / progressMax;
document.getElementById('progress').style.width = progress + '%';
}
};
```
Общая схема должна быть ясна. Поговорим теперь о подводных камнях.
Во-первых, если в PHP включена опция `output_buffering`, нужно это учесть. Здесь все просто: если она включена, то при запуске скрипта `ob_get_level()` будет больше 0. Нужно обойти буферизацию. Еще, если вы используете связку Nginx FastCGI PHP, нужно учесть, что и FastCGI и сам Nginx будут буферизовать вывод. ~~Последний это будет делать в том случае, если собирается сжимать данные для отправки~~. Устраняется проблема просто (из PHP-скрипта):
```
header('X-Accel-Buffering: no', true);
```
Кроме того, то ли Nginx, то ли FastCGI, то ли сам Chrome считают, что инициировать прием-передачу тела ответа, которое содержит всего-навсего один байт — слишком расточительно. Поэтому нужно предварить всю операцию дополнительными байтами. Нужно договориться, скажем, что первые 20 пробелов вообще ничего не должны означать. На стороне PHP их нужно просто «выплюнуть» в вывод, а в обработчике `onreadystatechange` их нужно проигнорировать. На мой взгляд — раз уж вся конфигурационная составляющая передается в заголовках — то и это число игнорируемых пробелов тоже лучше передать в заголовке. Назовем это *padding*-ом.
```
php
header('X-Progress-Padding: 20', true);
echo str_repeat(' ', 20);
flush();
// ...
</code
```
На стороне клиента это тоже нужно учесть:
```
var progressMax = 100,
progressPadding = 0;
xhr.onreadystatechange = function() {
if (this.readyState == 2) {
progressMax = +this.getResponseHeader('X-Progress-Max') || progressMax;
progressPadding = +this.getResponseHeader('X-Progress-Padding') || progressPadding;
}
else if (this.readyState == 3) {
var progress = 100 * (this.responseText.length - progressPadding) / progressMax;
document.getElementById('progress').style.width = progress + '%';
}
};
```
Откуда число 20? Если подскажете — буду весьма признателен. Я его установил экспериментальным путем.
Кстати, насчет настройки PHP `output_buffering`. Если у вас сложная буферизация и вы не хотите ее нарушать, можно воспользоваться такой функцией:
```
function ob_ignore($data, $flush = false) {
$ob = array();
while (ob_get_level()) {
array_unshift($ob, ob_get_contents());
ob_end_clean();
}
echo $data;
if ($flush)
flush();
foreach ($ob as $ob_data) {
ob_start();
echo $ob_data;
}
return count($ob);
}
```
С ее помощью можно обойти все уровни буферизации, вывести данные напрямую, после чего все буферы восстанавливаются.
Кстати, а почему именно пробел используется для уведомления о выполненной части задачи? Просто потому что почти любой формат представления данных в вебе такими пробелами не испортишь. Можно применить такой метод передачи уведомления о прогрессе операции, а после всего этого вывести отчет о результатах в JSON.
Если все привести в порядок, немного оптимизировать и дополнить код всеми возможностями, которые могут пригодиться, получится вот что:
**progress-loader.js**
```
function ProgressLoader(url, callbacks) {
var _this = this;
for (var k in callbacks) {
if (typeof callbacks[k] != 'function') {
callbacks[k] = false;
}
}
delete k;
function getXHR() {
var xhr;
try {
xhr = new ActiveXObject("Msxml2.XMLHTTP");
}
catch (e) {
try {
xhr = new ActiveXObject("Microsoft.XMLHTTP");
}
catch (E) {
xhr = false;
}
}
if (!xhr && typeof XMLHttpRequest != 'undefined') {
xhr = new XMLHttpRequest();
}
return xhr;
}
this.xhr = getXHR();
this.xhr.open('GET', url, true);
var contentLoading = false,
progressPadding = 0,
progressMax = -1,
progress = 0,
progressPerc = 0;
this.xhr.onreadystatechange = function() {
if (this.readyState == 2) {
contentLoading = false;
progressPadding = +this.getResponseHeader('X-Progress-Padding') || progressPadding;
progressMax = +this.getResponseHeader('X-Progress-Max') || progressMax;
if (callbacks.start) {
callbacks.start.call(_this, this.status);
}
}
else if (this.readyState == 3) {
if (!contentLoading) {
contentLoading = !!this.responseText
.replace(/^\s+/, ''); // .trimLeft() — медленнее О_о
}
if (!contentLoading) {
progress = this.responseText.length - progressPadding;
progressPerc = progressMax > 0 ? progress / progressMax : -1;
if (callbacks.progress) {
callbacks.progress.call(_this,
this.status,
progress,
progressPerc,
progressMax
);
}
}
else if (callbacks.loading) {
callbacks.loading.call(_this, this.status, this.responseText);
}
}
else if (this.readyState == 4) {
if (callbacks.end) {
callbacks.end.call(_this, this.status, this.responseText);
}
}
};
if (callbacks.abort) {
this.xhr.onabort = callbacks.abort;
}
this.xhr.send(null);
this.abort = function() {
return this.xhr.abort();
};
this.getProgress = function() {
return progress;
};
this.getProgressMax = function() {
return progressMax;
};
this.getProgressPerc = function() {
return progressPerc;
};
return this;
}
```
**process.php**
```
php
function ob_ignore($data, $flush = false) {
$ob = array();
while (ob_get_level()) {
array_unshift($ob, ob_get_contents());
ob_end_clean();
}
echo $data;
if ($flush)
flush();
foreach ($ob as $ob_data) {
ob_start();
echo $ob_data;
}
return count($ob);
}
if (($work = @$_GET['work']) 0) {
header("X-Progress-Max: $work", true, 200);
header("X-Progress-Padding: 20");
ob_ignore(str_repeat(' ', 20), true);
for ($i = 0; $i < $work; $i++) {
usleep(rand(100000, 500000));
ob_ignore(' ', true);
}
echo $work.' done!';
die();
}
```
**launcher.html**
```
ProgressLoader
progress, button {
display: inline-block;
vertical-align: middle;
padding: 0.4em 2em;
margin-right: 2em;
}
Start/Stop
var progressbar = document.getElementById('progressbar'),
btnStart = document.getElementById('start'),
worker = false;
btnStart.onclick = function() {
if (!worker) {
var url = 'process.php?work=42';
worker = new ProgressLoader(url, {
start: function(status) {
progressbar.style.display = 'inline-block';
},
progress: function(status, progress, progressPerc, progressMax) {
progressbar.value = +progressbar.max \* progressPerc;
},
end: function(status, s) {
progressbar.style.display = 'none';
worker = false;
},
});
}
else {
worker.abort();
progressbar.style.display = 'none';
worker = false;
}
};
```
Вместо вступления перед катом: *Прошу не бить ногами. Гугление перед проработкой схемы не дало вменяемых результатов, поэтому ее и понадобилось выдумать, ввиду чего я и решил ее изложить в этой своей первой публикации.* | https://habr.com/ru/post/257053/ | null | ru | null |
# Zen Reports и %XML.Writer для генерации отчётов Excel в Caché
Как известно MS Excel последних версий поддерживает описание структуры документа в формате xml. Это обстоятельство позволяет создавать отчеты в Excel с помощью генерации xml-файлов. В СУБД Caché существует несколько способов создания xml. В этой статье будут рассмотрены два, возможно наиболее удобных, способа эффективной программной генерации отчетов в MS Excel: с помощью Zen Reports и с использованием класса %XML.Writer.
В качестве примера отчета MS Excel взята печатная форма учебного плана из системы управления учебным планированием, о которой [здесь](http://habrahabr.ru/company/intersystems/blog/149704/) уже писалось, поэтому перейдём непосредственно к постановке задачи и способам её решения. Требуется получить отчёт учебного плана в формате MS Excel, который должен состоять из графика учебного процесса (титульный лист) и содержания учебного плана (перечень всех дисциплин, их характеристик и вычисляемых параметров). Фрагмент отчёта учебного плана представлен на рисунке, готовый отчёт можно посмотреть [здесь](https://dl.dropbox.com/u/81078622/Report.xls).
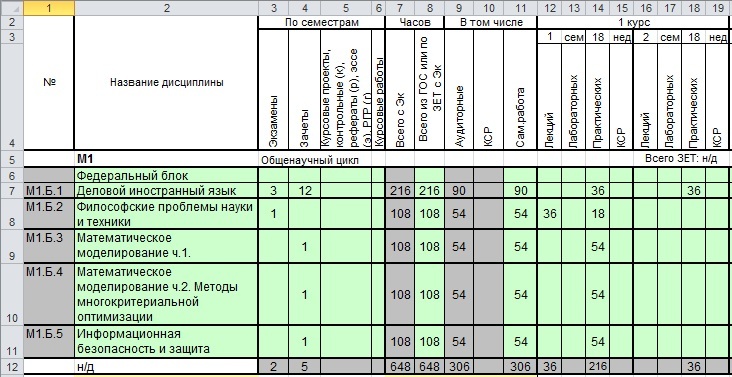
#### Общая схема формирования отчёта
В Cache существует несколько способов ручного изготовления отчётов (здесь не будут рассматрены возможности полуавтоматической сборки на базе DeepSee). Самый удобный способ реализован в ZEN и включает в себя набор средств, обеспечивающий полный цикл процесса формирования отчётов в формате XHTML и PDF. Описание этого процесса можно посмотреть в [документации](http://docs.intersystems.com/cache20122/csp/docbook/DocBook.UI.Page.cls?KEY=GRPT_reports). Тем не менее, для решения нашей задачи этот способ можно задействовать только частично.
Рассмотрим общий механизм формирования отчёта в формате MS Excel с применением как технологии ZEN, так и других возможностей Caché (см. рисунок ниже).
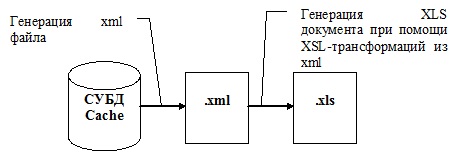
Данная схема формирования xls документа включает три этапа: 1) данные из базы конвертируются при помощи технологии Zen Reports или стандартной технологии Caché в xml файл (входной xml); 2) посредством механизма трансформации XSL (eXtensible Stylesheet Language) модифицируется подготовленный заранее шаблон отчёта в формате xml; 3) генерируется документ Excel (xls) путём заполнения шаблона отчёта xml, расширенного вставками XSL, данными из входного xml.
#### Структура входного xml-файла
Поскольку xml используется в качестве источника данных для нашего отчёта, то структура xml-файла должна быть максимально удобной для прохождения описанных выше этапов и, в конечном счёте, для формирования отчёта. Никаких дополнительных специальных ограничений на структуру xml-файла нет.
Исходя из специфики нашей задачи и структуры базы данных, корневым элементом входного xml является «Curriculum», содержащий всю информацию об учебном плане и включающий следующие элементы:
* Название учебного плана
* Сумма форм контроля за весь учебный план: экзаменов; зачётов; курсовых проектов; курсовых работ
* Сумма часов по всем дисциплинам учебного плана: всего с экзаменом; всего по ГОС (государственный образовательный стандарт); аудиторных часов; КСР (самостоятельная работа на курсовой проект или работу); часов по самостоятельной работе
* Сумма часов по каждой дисциплине за каждый семестр учебного плана: часы на лекции; часы на лабораторные работы; часы на практические занятия; часы на КСР
* Сумма зачётных единиц (ЗЕ) на весь учебный план
Также в «Curriculum» содержатся циклы «Cicl», каждый из которых состоит из своих собственных элементов. Аналогично описываются остальные ветви xml-файла вплоть до дисциплин и их характеристик. **Пример xml-файла для описываемого отчёта.**
```
xmlversion="1.0" encoding="UTF-8"?
Название учебного плана
Название цикла 1
Код цикла
Названиеблока 1
Названиедисциплины 1
. . .
Названиедисциплины 2
. . .
. . .
. . .
. . .
```
#### Формирование исходного xml
Рассмотрим два способа получения исходного xml файла: при помощи класса %XML.Writer и с использованием механизма Zen Reports.
##### Формирование исходного xml с использованием %XML.Writer
Описанная выше структура xml может быть получена посредством класса XML.Writer, который позволяет:
1. Создавать корневой элемент
do fWriter.RootElement("имя корневого элемента")
do fWriter.EndRootElement()
2. Создавать элемент
do fWriter.Element("имя элемента")
do fWriter.Write(значение элемента)
do fWriter.EndElement()
3. Создавать атрибут
do fWriter.WriteAttribute("имя атрибута", "значение атрибута")
Кроме того, XML.Writer обладает методом, позволяющим извлекать все данные из переданного в него объекта.
Writer.RootObject("имя объекта")
В задаче формирования отчёта учебного плана метод RootObject не подошел, т.к. класс дисциплины имеет ссылку сам на себя, и работа этого метода была не корректна. В связи с этим все элементы выходного xml файла были созданы вручную. Для этого был создан класс sp.Report.spExcelWriter, включающий метод genWriterData (iDSelectCur As %Integer) для генерации xml-файла, в который передаётся id выбранного учебного плана. Используя данный метод, с помощью SQL-запросов извлекаются данные из БД, и в нужном месте выполняется их вставка. После этого генерируется выходной xml файл с помощью другого метода OutputToFile(«путь\имя файла.xml»).
##### Формирование исходного xml с использованием механизма Zen Reports
Zen Reports является высокоуровневым механизмом извлечения данных из базы Caché и преобразования их в xml, что накладывает определённые ограничения, о которых будет сказано ниже. Данный способ предполагает создание класса Zen-отчёта через Caché-студию, наследуемый от %ZEN.Report.reportPage, в котором необходимо заполнить блок XData ReportDefinition. Более подробно о правилах формирования блока XData ReportDefinition и выборке данных посредством SQL-запроса для XML-представления можно прочитать в [документации](http://docs.intersystems.com/cache20122/csp/docbook/DocBook.UI.Page.cls?KEY=GRPT_report_definition).
**Здесь приведено содержание блока XData ReportDefinition для рассматриваемого отчёта**XData ReportDefinition [ XMLNamespace = "[www.intersystems.com/zen/report/definition"](http://www.intersystems.com/zen/report/definition)]
{
<report xmlns="[www.intersystems.com/zen/report/definition"](http://www.intersystems.com/zen/report/definition)name="Curriculum" sql = "SELECT \* FROM sp.cCurriculum WHERE ID=?" >
<parameter expression='..idCurr'/>
<element name="CurrName" field="Name" />
<element name="sumСurEx" field="ID" expression = "##class(sp.cCurriculum).getCountFCInCur(%val,1)"/>
<element name="sumСurZa" field="ID" expression="##class(sp.cCurriculum).getCountFCInCur(%val,2)"/>
<element name="sumСurKP" field="ID" expression="##class(sp.cCurriculum).getCountFCInCur(%val,4)"/>
<element name="sumСurKR" field="ID" expression="##class(sp.cCurriculum).getCountFCInCur(%val,3)"/>
<element name="sumСurZET" field="ID" expression="##class(sp.cCurriculum).getComTimeInCur(%val,6)"/>
<element name="sumСurAll" field="ID" expression="##class(sp.cCurriculum).getComTimeInCur(%val,1)"/>
<element name="sumСurGos" field="ID" expression="##class(sp.cCurriculum).getComTimeInCur(%val,2)"/>
<element name="sumСurAud" field="ID" expression="##class(sp.cCurriculum).getComTimeInCur(%val,3)"/>
<element name="sumСurKsr" field="ID" expression="##class(sp.cCurriculum).getComTimeInCur(%val,4)"/>
<element name="sumСurSR" field="ID" expression="##class(sp.cCurriculum).getComTimeInCur(%val,5)"/>
<group name="sumCurseme1" >
<element name="sumCurLec" field="ID" expression="##class(sp.cCurriculum).getTimeInCur(%val,1,1)"/>
<element name="sumCurLab" field="ID" expression="##class(sp.cCurriculum).getTimeInCur(%val,1,2)"/>
<element name="sumCurPra" field="ID" expression="##class(sp.cCurriculum).getTimeInCur(%val,1,3)"/>
<element name="sumCurKsr" field="ID" expression="##class(sp.cCurriculum).getTimeInCur(%val,1,4)"/>
group>
…
<group name="Cicls" sql="SELECT \* FROM sp.cCicl WHERE Curriculum = ?" >
<parameter expression='..idCurr'/>
<group name="Cicl" >
<attribute name="CiclName" field="Name"/>
<attribute name="CodeOfCicl" field="CodeOfCicl" />
<element name="sumCiclEx" field="ID" expression="##class(sp.cCicl).getCountFCInCicl(%val,1)"/>
<element name="sumCiclZa" field="ID" expression="##class(sp.cCicl).getCountFCInCicl(%val,2)"/>
<element name="sumСiclKP" field="ID" expression="##class(sp.cCicl).getCountFCInCicl(%val,4)"/>
<element name="sumСiclKR" field="ID" expression="##class(sp.cCicl).getCountFCInCicl(%val,3)"/>
<element name="sumCiclchAll" field="ID" expression="##class(sp.cCicl).getComTimeInCicl(%val,1)"/>
<element name="sumCiclchGos" field="ID" expression="##class(sp.cCicl).getComTimeInCicl(%val,2)"/>
<element name="sumСiclchAud" field="ID" expression="##class(sp.cCicl).getComTimeInCicl(%val,3)"/>
<element name="sumСiclchKsr" field="ID" expression="##class(sp.cCicl).getComTimeInCicl(%val,4)"/>
<element name="sumСiclchSR" field="ID" expression="##class(sp.cCicl).getComTimeInCicl(%val,5)"/>
<element name="sumСiclZet" field="ID" expression="##class(sp.cCicl).getComTimeInCicl(%val,6)"/>
<group name="sumCiclseme1" >
<element name="sumCiclLec" field="ID" expression="##class(sp.cCicl).getTimeInCicl(%val,1,1)"/>
<element name="sumCiclLab" field="ID" expression="##class(sp.cCicl).getTimeInCicl(%val,1,2)"/>
<element name="sumCiclPra" field="ID" expression="##class(sp.cCicl).getTimeInCicl(%val,1,3)"/>
<element name="sumCiclKsr" field="ID" expression="##class(sp.cCicl).getTimeInCicl(%val,1,4)"/>
group>
…
<group name="Blocks" sql="SELECT \* FROM sp.cBlock WHERE Cicl = ?" breakOnField="ID">
<parameter field="ID"/>
<group name="Block">
<attribute name="BlocName" field="Name"/>
<element name="countEx" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getCountFCInBlock(%val("ID"),%val("Name"),%val("Cicl"),1)'/>
<element name="countZa" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getCountFCInBlock(%val("ID"),%val("Name"),%val("Cicl"),2)'/>
<element name="countKR" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getCountFCInBlock(%val("ID"),%val("Name"),%val("Cicl"),3)'/>
<element name="countKP" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getCountFCInBlock(%val("ID"),%val("Name"),%val("Cicl"),4)'/>
<element name="sumBAll" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getComTimeInBlock(%val("ID"),%val("Name"),%val("Cicl"),1)'/>
<element name="sumBGos" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getComTimeInBlock(%val("ID"),%val("Name"),%val("Cicl"),2)'/>
<element name="sumBAud" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getComTimeInBlock(%val("ID"),%val("Name"),%val("Cicl"),3)'/>
<element name="sumBKSR" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getComTimeInBlock(%val("ID"),%val("Name"),%val("Cicl"),4)'/>
<element name="sumBSR" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getComTimeInBlock(%val("ID"),%val("Name"),%val("Cicl"),5)'/>
<element name="sumBZET" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getComTimeInBlock(%val("ID"),%val("Name"),%val("Cicl"),6)'/>
<group name="sumBseme1" >
<element name="sumBLec" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getTimeInBlock(%val("ID"),%val("Name"),%val("Cicl"),1,1)'/>
<element name="sumBLab" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getTimeInBlock(%val("ID"),%val("Name"),%val("Cicl"),1,2)'/>
<element name="sumBPra" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getTimeInBlock(%val("ID"),%val("Name"),%val("Cicl"),1,3)'/>
<element name="sumBKSR" fields="Cicl,Name,ID" expression= '##class(sp.cBlock).getTimeInBlock(%val("ID"),%val("Name"),%val("Cicl"),1,4)'/>
group>
…
<group name="Disciplines" sql= "SELECT \* FROM sp.cDiscipline WHERE ( Blok=? AND Cicl=? And Parent is null)" breakOnField="ID">
<parameter field="ID"/>
<parameter field="Cicl"/>
<group name="Discipline">
<element name="DiscName" field="Name"/>
<element name="Exam" field="ID" expression= '##class(sp.cDiscipline).getFormContr(%val,1)'/>
<element name="Zachet" field="ID" expression= '##class(sp.cDiscipline).getFormContr(%val,2)'/>
<element name="KR" field="ID" expression= '##class(sp.cDiscipline).getFormContr(%val,3)'/>
<element name="KP" field="ID" expression= '##class(sp.cDiscipline).getFormContr(%val,4)'/>
<element name="chAll" field="ID" expression= '##class(sp.cDiscipline).getComTime(%val,1)'/>
<element name="chGos" field="ID" expression= '##class(sp.cDiscipline).getComTime(%val,2)'/>
<element name="chKsr" field="ID" expression= '##class(sp.cDiscipline).getComTime(%val,4)'/>
<element name="chAud" field="ID" expression= '##class(sp.cDiscipline).getComTime(%val,3)'/>
<element name="chSamRab" field="ID" expression= '##class(sp.cDiscipline).getComTime(%val,5)'/>
<element name="Zet" field="ID" expression='##class(sp.cDiscipline).getComTime(%val,6)'/>
<element name="naBlock" field="ID" expression= '##class(sp.cDiscipline).getNameBlock(..idCurr,%val)'/>
<group name="seme1">
<element name="Lec" field="ID" expression= '##class(sp.cDiscipline).getTime(%val,1,1)'/>
<element name="Lab" field="ID" expression= '##class(sp.cDiscipline).getTime(%val,1,2)'/>
<element name="Pra" field="ID" expression= '##class(sp.cDiscipline).getTime(%val,1,3)'/>
<element name="KSR" field="ID" expression= '##class(sp.cDiscipline).getTime(%val,1,4)'/>
group>
…
group>
group>
group>
group>
group>
group>
report>
}
Zen Report предлагает использование собственного синтаксиса для описания структуры данных для генерируемого xml — это накладывает некоторые ограничения на формат выходного xml. В результате структура полученного xml файла незначительно отличается от описанной выше: в генерируемый xml файл дополнительно добавляются узлы Cicls и Blocks, в которых содержатся подузлы Cicl и Block.
Покажем некоторые особенности вывода связанных данных.
Пример 1. Передача ID выбранного учебного плана в sql запрос элемента .
<report sql = "SELECT \* FROM sp.cCurriculum WHERE ID = ?">
Далее на место «?» передается параметр со значением переменной ..idCurr
<parameter expression = '..idCurr'/>
Переменная является свойством класса ZenReport и при вызове метода генерации отчета, значение idCurr принимает значение переданного в метод параметра id текущего учебного плана.
Пример 2. Передача параметра зависящего от результата выполнения SQL запроса, например связь Цикл – Блок:
<group sql="SELECT \* FROM sp.cCicl WHERE Curriculum = ?">
<parameter expression = '..idCurr'/>
<group sql = "SELECT \* FROM sp.cBlock WHERE Cicl = ?" breakOnField = "ID">
<parameter field = "ID" />
group>
group>
Здесь передача «ID» осуществляется с использованием атрибута breakOnField = «ID».
Покажем выполнение группировки для «Циклов».
<group name="Cicls" sql="SELECT \* FROM sp.cCicl WHERE Curriculum = ?" >
<parameter expression='..idCurr'/>
<group name="Cicl" >
<attribute name="CiclName" field="Name"/>
<attribute name="CodeOfCicl" field="CodeOfCicl" />
…
group>
…
group>
Блоки группируются аналогично.
Изменённый формат сгенерированного XML-файла теперь имеет следующий вид.
```
xml version="1.0" encoding='utf-8'?
…
…
…
…
…
```
Также изменится вызов цикла при XSL трансформациях (общий способ применения XSL трансформаций описан ниже):
```
```
Сформулируем некоторые правила, которые следует учитывать при проектировании структуры выходных данных.
1. Поле Name будет взято из Table1:
<report sql="SELECT Name FROM Table1">
<element name="A" field="Name"/>
2. Поле Name выдаст ошибку:
<report sql="SELECT Name FROM Table1">
<attribute name="A" field="Name"/>
3. Поле Name получится из Table2:
<report sql="SELECT Name FROM Table1">
<group name="Name" sql="SELECT Name FROM Table2 WHERE...">
<element name="A" field="Name"/>
4. Поле Name получится из Table1:
<report sql="SELECT Name FROM Table1">
<group name="Name" sql="SELECT Name FROM Table2 WHERE...">
<attribute name="A" field="Name"/>
#### Создание шаблона Excel
Перед выполнением XSL-трансформации необходимо создать шаблон документа Excel, в который будут вставляться данные из xml. Порядок создания шаблона Excel состоит из трёх шагов.
**Шаг №1.** В Excel создаётся внешний вид отчёта.
**Шаг №2.** Шаблон сохраняется в формате таблицы xml.
**Фрагмент общего вида xml создаваемого отчёта.**
```
xml version="1.0"?
mso-application progid="Excel.Sheet"?
Microsoft Corporation
AlexandeR
2012-10-31T10:28:49Z
1996-10-08T23:32:33Z
2012-11-24T12:30:48Z
11.9999
7320
9720
120
120
False
False
False
<Alignment ss:Vertical="Bottom"/>
<Borders/>
<Font/>
<Interior/>
<NumberFormat/>
<Protection/>
<Alignment ss:Horizontal="Center" ss:Vertical="Bottom"/>
<Font ss:FontName="Arial Cyr" x:CharSet="204" x:Family="Swiss" ss:Bold="1"
ss:Italic="1"/>
<Protection/>
. . .
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
. . .
9
600
600
3
25
74
False
False
. . .
```
В приведённом фрагменте видно, что вначале создаётся список стилей, который затем используется для форматирования ячеек. Например:
```
<Alignment ss:Horizontal="Center" ss:Vertical="Bottom"/>
<Font ss:FontName="Arial Cyr" x:CharSet="204" x:Family="Swiss" ss:Bold="1"
ss:Italic="1"/>
<Protection/>
```
На этот стиль ссылается следующая ячейка:
```
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
```
Элемент «Worksheet» создаёт листы в книге Excel, например:
```
. . .
```
Элемент «Table» создаёт таблицу. Таблица состоит из строк «Row», а строки в свою очередь из ячеек «Cell».
**Шаг 3.** Посредством любого текстового редактора вносятся изменения в структуру xml путём удаления лишних атрибутов. В нашем случае удаляются атрибуты: ss:ExpandedColumnCount = «67»; ss:ExpandedRowCount = «45»; x:FullColumns = «1»; x:FullRows = «1», так как учебный план имеет произвольное количество дисциплин, и если у элемента «Table» сохранить эти атрибуты, возникнет ошибка при генерации документа Excel из-за несоответствия количества строк и столбцов. Также желательно удалить атрибут ss:Height у , так как если строка будет сильно длинная и в ячейке будет указано «переносить по словам», то переноса по словам не будет в сгенерированном Excel-документе.
#### XSL-трансформация
Для использования стандартного метода трансформации (в классе %XML.XSLT.Transformer) xml-данных в формат xls требуется подготовить специальный блок xml со встроенными конструкциями XSL. В нашем случае в качестве основы для XSL взят шаблон Excel, подготовленный в предыдущем пункте. Этот шаблон нужно доработать, используя следующие конструкции XSL:
1. ```
```
2. ```
```
Конструкция используется для выбора каждого xml элемента заданного набора. Конструкция позволяет выводить значения выбранного узла. Ниже приведён простой пример вставки XSL в Excel шаблон:
```
```
В приведённом примере показано, что в Excel таблице во вложенном цикле идёт обращение ко всем элементам «Cicl», затем в каждом цикле (укрупнённая группа дисциплин) ко всем элементам «Block», затем в каждом блоке к элементам /Disciplines/Discipline, и после этого выводится информация соответствующая указанному полю , т.е. названия дисциплин.
После того как выполнилась вставка элементов XSL в нужные места шаблона можно приступать к процессу генерации отчёта. Для этого можно создать специальный метод в некотором классе, который будет выполнять трансформацию данных из xml формата в xls, используя подготовленный шаблон Excel, который можно разместить в блоке XData этого же класса (в приведённом ниже примере блок XData называется «xsl»). Пример этого метода приведён ниже.
ClassMethod generateReportStadyPlan(outFileName As %String) As %Status
{
set xslStream = ##class(%Dictionary.CompiledXData).%OpenId(..%ClassName(1)\_ "||xsl").Data
set xmlStream = ##class(%FileBinaryStream).%New()
set xmlStream.Filename = "Путь к файлу xml"
set outStream = ##class(%FileCharacterStream).%New()
set outStream.TranslateTable = "UTF8"
set outStream.Filename = outFileName
set sc = ##class(%XML.XSLT.Transformer).TransformStream(xmlStream, xslStream, .outStream)
if $$$ISERR(sc) quit sc
quit outStream.%Save()
}
XData xsl
{
<xsl:stylesheet version="1.0" xmlns:xsl="[www.w3.org/1999/XSL/Transform"](http://www.w3.org/1999/XSL/Transform)
xmlns="urn:schemas-microsoft-com:office:spreadsheet"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:x="urn:schemas-microsoft-com:office:excel"
xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet">
<xsl:template match="/">
<xsl:processing-instruction name="mso-application">
<xsl:text>progid="Excel.Sheet"xsl:text>
xsl:processing-instruction>
xsl:template>
xsl:stylesheet>
}
#### Сравнение Zen Reports и %XML.Writer
| Механизм | Преимущества | Недостатки |
| --- | --- | --- |
| Zen Reports | 1. Избавляет от лишней рутинной работы
2. Описание структуры получается более лаконичным, нет излишних нагромождений
3. Простота восприятия | Структура выходного xml хуже контролируется, приходится соблюдать определенные правила |
| %XML.Writer | Можно создавать абсолютно любую структуру xml | Большая трудоёмкость описания структуры |
Исходя из специфики архитектуры [МАС УУП](http://www.osp.ru/os/2012/07/13017640/), в которой создаются java-проекции для классов Caché, к дополнительным преимуществам %XML.Writer можно добавить возможность проецирования класса sp.Report.spExcelWriter, который формирует отчёт. Напротив, в Zen Reports получить проекцию класса отчёта, наследуемого от %ZEN.Report.reportPage, невозможно в силу того, что его методы работают с потоками.
Таким образом, использование XML.Writer целесообразно в случае жёстких требований к структуре выходного xml файла, а использование механизма Zen Reports рекомендуется при создании сложных отчётов, где в первую очередь требуется понятное описание и снижение трудоёмкости. | https://habr.com/ru/post/163981/ | null | ru | null |
# Minecraft protocol VarInt и VarLong. Как из единиц и нулей сделать число на примере Go?
В этой статье я хочу объяснить на пальцах, как из байтов преобразуются числа в нужные типы данных (**VarInt**, **VarLong**). Детально рассмотрим реализацию, примеры и напишем unit-тесты. Вспомним бинарные операции, двоичную и шестнадцатеричную систему счисления.
Предыстория
-----------
Я уже не раз разворачивал свой сервер Minecraft, используя разные ядра: **Vanilla**, **Spigot**, **SpongeForge**, **Paper**, **Velocity**(хотя это прокси, но все же) - все они написаны на **Java**. В один момент мне стало интересно, а можно ли написать свою имплементацию сервера Minecraft с нуля (from scratch). Ответ на мой вопрос лежит по [этой ссылке](https://wiki.vg/How_to_Write_a_Server). Перейдя по ней я увидел заголовок "**Before You Get Started**", в котором есть три небольших тезиса:
* "Убедитесь, что вы не хотите форкнуть, или присоединиться к уже существующему форку", - интересное предложение, но я бы хотел смотреть на форки, как на пример реализации.
* "Подумайте, почему вы хотите это сделать?", - я хочу более углубленно разобраться в логике взаимодействия клиент-сервер Minecraft'а.
* "Выберите язык с хорошим сетевым взаимодействием, например Java, C# или Python", - Хорошо, попробую написать на [Go](https://go.dev/), у него как раз отличные встроенные инструменты для таких задач.
Как вы уже поняли, выбрал я Go, в частности потому что это сейчас мой основной язык, на котором я выполняю свою работу, мне нравится Go потому что он простой, быстрый, да и памяти будет кушать намного меньше чем Java, а значит может стать хорошим вариантом для написания своего собственного сервера. Хочу попробовать!
Реализация
----------
Взаимодействие между клиентом и сервером Minecraft происходит путем установления подключения через TCP протокол, через который обе стороны начинают обмениваться пакетами данных. Структура пакетов описана так же в документации ([ссылка](https://wiki.vg/Protocol#Packet_format)).
Чтобы извлекать информацию из пакетов, нужно научиться их декодировать. Абстрагируемся от лишней информации и сконцентрируемся на двух типах данных **VarInt** и **VarLong**. В документации для них уделено достаточно много внимания и даже описаны примеры, как правильно производить **decode** и **encode**.
> These are very similar to [Protocol Buffer Varints](http://developers.google.com/protocol-buffers/docs/encoding#varints).
> (перевод) Эти два типа очень похожи на [Protocol Buffer Varints](http://developers.google.com/protocol-buffers/docs/encoding#varints).
>
>
В документации сказано, что 7 младших битов используются для кодирования значения, а старший 8 (восьмой) для определения будут ли еще последующие байты числа после текущего. Так же есть условия:
* **VarInt** не может быть больше 5 байтов
* **VarLong** не может быть больше 10 байтов
Давайте приступать к реализации! Напишем код, в котором определим наши два типа
```
// Package packet назвал его именно так,
// потому что типы данным принадлежат пакетам.
// Сейчас мы находимя в файле data_types.go
package packet
const (
// MaxVarIntLen максимальное кол-во байтов для VarInt.
MaxVarIntLen = 5
// MaxVarLongLen максимальное кол-во байтов для VarLong.
MaxVarLongLen = 10
)
type (
// VarInt обычный int (-2147483648 -- 2147483647)
VarInt int
// VarLong обычный int64 (-9223372036854775808 -- 9223372036854775807)
VarLong int64
)
```
Нам нужно будет считывать байты из какого-то буфера, поэтому будем реализовывать интерфейс [io.ReaderFrom](https://pkg.go.dev/io#ReaderFrom). Определим новые методы для наших типов.
```
func (v *VarInt) ReadFrom(r io.Reader) (n int64, err error) {
return 0, nil
}
func (v *VarLong) ReadFrom(r io.Reader) (n int64, err error) {
return 0, nil
}
```
Приступим к разбору реализации. На просторах интернета я нашел библиотеку <https://github.com/Tnze/go-mc>. По словам разработчиков в ней уже реализована имплементация протокола для сервера Minecraft, парсинг пакетов и т.п. Мой код будет очень похожим на реализацию <https://github.com/Tnze/go-mc/blob/master/net/packet/types.go#L265>, но я хочу понять, почему этот алгоритм верный и как вообще из последовательности [101010001] получаются числа.
Сама реализация интерфейса [io.ReaderFrom](https://pkg.go.dev/io#ReaderFrom) для **VarInt** и **VarLong** не отличается, разве что использованием разных констант для максимальной возможной длины последовательности байтов.
Для начала определим две константы, ошибку, если кол-во байтов превышает максимально допустимый размер типа данных и небольшую функцию, которая считывает **один** байт из буфера:
```
const (
// segmentBits 7 бит 01111111 = int(127)
segmentBits byte = 0x7F
// continueBit 8 бит 10000000 = int(128)
continueBit 8 byte = 0x80
)
// ErrTooBig ошибка, если какой-то тип превышает максимально доступное кол-во байтов
var ErrTooBig = errors.New("too big")
// readByte считывает только ОДИН байт из буфера и возвращает его.
func readByte(r io.Reader) (byte, error) {
if r, ok := r.(io.ByteReader); ok {
return r.ReadByte()
}
var b [1]byte
if _, err := io.ReadFull(r, b[:]); err != nil {
return 0, errors.Wrap(err, "failed to perform read full")
}
return b[0], nil
}
```
Реализуем интерфейс [io.ReaderFrom](https://pkg.go.dev/io#ReaderFrom) для **VarInt**.
```
// ReadFrom ...
func (v *VarInt) ReadFrom(r io.Reader) (n int64, err error) {
var val uint32
for sec := continueBit; sec&continueBit != 0; n++ {
if n > VarIntMaxLen {
return 0, ErrTooBig
}
sec, err = readByte(r)
if err != nil {
return 0, errors.Wrap(err, "failed to read a byte")
}
val |= uint32(sec&segmentBits) << uint32(7*n)
}
*v = VarInt(val)
return n, nil
}
```
Давайте подробнее пройдемся по этому коду и посмотрим, как из последовательности байтов, состоящих из нулей и единиц получаются числа.
Рассмотрим на примере числа **25565**.
Число **25565** в нашем буфере можно представить следующими способами:
* В **шестнадцатиричной** системе = `[0xdd, 0xc7, 0x01]`
* В **десятичной** системе = `[221, 199, 1]`
* В **двоичной** системе = `[11011101, 11000111, 00000001]`
В буфере мы имеем`[..., 11011101, 11000111, 00000001, ...].`
Эта последовательность может быть разной длины, для примера мы откинем переднюю часть и будем считать, что мы уже произвели считывание до нашего первого байта,
а наш указатель находится на нем -`11011101`.
Переменная в которую мы будем записывать результат: `var val uint32`
Рассмотрим детально каждую итерацию, их здесь будет всего **3**.
### Итерация #1
Считываем байт `sec, err = readByte(r)`, в результате в **sec** лежит значение `11011101`
`V |= uint32(sec&segmentBits) << uint32(7*n)` будет эквиваленто
`0 |= uint32(11011101 & 01111111) << uint32(7*0)`
```
11011101
&
01111111
--------
01011101
```
В результате получаем число `01011101 = uint32(93)`.
Далее производим логический сдвиг влево на `7*0`, т.е. на `0` битов.
```
01011101 << 0 = 01011101
```
Вычисляем значение val, тут все просто:
```
val |= 01011101
00000000
|
01011101
--------
01011101
```
К концу первой итерации значение `val = uint32(93)`.
### Итерация #2
Считываем байт `sec, err = readByte(r)`, в результате в **sec** лежит значение `11000111`.
`V |= uint32(sec&segmentBits) << uint32(7*n)` будет эквиваленто
`93 |= uint32(11000111 & 01111111) << uint32(7*1)`
```
11000111
&
01111111
--------
01000111
```
В результате получаем число `01000111 = uint32(71)`.
Далее производим логический сдвиг влево на `7*1`, т.е. на `7` битов.
```
01000111 << 7 = 010111010000000
```
Вычисляем значение val:
```
val |= 010111010000000
000000001011101
|
010111010000000
---------------
010001111011101
```
К концу второй итерации значение `val = uint32(9181)`.
### Итерация #3
Считываем байт `sec, err = readByte(r)`, в результате в **sec** лежит значение `00000001`.
`V |= uint32(sec&segmentBits) << uint32(7*n)` будет эквиваленто
`9181 |= uint32(00000001& 01111111) << uint32(7*2)`
```
00000001
&
01111111
--------
00000001
```
В результате получаем число `00000001 = uint32(1)`.
Далее производим логический сдвиг влево на `7*2`, т.е. на `14` битов.
```
00000001 << 7 = 0000000100000000000000
```
Вычисляем значение `val`:
```
val |= 0000000100000000000000
0000000010001111011101
|
0000000100000000000000
----------------------
0000000110001111011101
```
К концу третьей итерации значение `val = uint32(25565)`.
Почему эта итерация последняя? Потому что выражение `sec&continueBit = 0`
```
00000001 - sec
&
10000000 - continueBit
--------
00000000
```
### Реализация для VarLong
Как я уже упомянул раньше, реализация для данного типа практически не отличается:
```
// ReadFrom ...
func (v *VarLong) ReadFrom(r io.Reader) (n int64, err error) {
var val uint64
for sec := continueBit; sec&continueBit != 0; n++ {
if n > VarLongMaxLen {
return 0, ErrTooBig
}
sec, err = readByte(r)
if err != nil {
return 0, errors.Wrap(err, "failed to read a byte")
}
val |= uint64(sec&segmentBits) << uint64(7*n)
}
*v = VarLong(val)
return n, nil
}
```
### Отрицательные числа
Как получаются отрицательные числа? Расписывать такой громоздкий кусок достаточно проблематично, но вкратце на примере числа `-1`: в последней итерации получается `11111111 11111111 11111111 11111111` . Это число в двоичной системе и в формате `uint32 = 4294967295` . Далее мы уже приводим к нужному типу **int32**, в итоге получаем число **-1**.
Unit-тесты
----------
Куда же без них, покроем только те места, которые нас интересуют, а именно упустим случаи возвращения ошибок. Тест кейсы брал из примеров, описанные в [документации](https://wiki.vg/Protocol#VarInt_and_VarLong:~:text=an%20int32.-,Sample%20VarInts,-%3A).
```
package packet
import (
"bytes"
"github.com/stretchr/testify/assert"
"strconv"
"testing"
)
func TestVarInt_ReadFrom(t *testing.T) {
a := assert.New(t)
type testCase struct {
Bytes []byte
Expected VarInt
}
testCases := []testCase{
{
Bytes: []byte{0x00},
Expected: 0,
},
{
Bytes: []byte{0x01},
Expected: 1,
},
{
Bytes: []byte{0x10},
Expected: 16,
},
{
Bytes: []byte{0x7f},
Expected: 127,
},
{
Bytes: []byte{0xac, 0x02},
Expected: 300,
},
{
Bytes: []byte{0xdd, 0xc7, 0x01},
Expected: 25565,
},
{
Bytes: []byte{0xff, 0xff, 0xff, 0xff, 0x07},
Expected: 2147483647,
},
{
Bytes: []byte{0x80, 0x80, 0x80, 0x80, 0x08},
Expected: -2147483648,
},
{
Bytes: []byte{0xff, 0xff, 0xff, 0xff, 0x0f},
Expected: -1,
},
}
for _, tc := range testCases {
t.Run(strconv.FormatInt(int64(tc.Expected), 10), func(t *testing.T) {
var varInt VarInt
n, err := varInt.ReadFrom(bytes.NewReader(tc.Bytes))
// No error should be here.
a.NoError(err)
// Length of the VarInt must be equal to the bytes size.
a.EqualValues(len(tc.Bytes), n)
// Asserting to the expected VarInt value.
a.EqualValues(tc.Expected, varInt)
})
}
}
```
Результат Unit-тестов для VarInt
---
```
func TestVarLong_ReadFrom(t *testing.T) {
a := assert.New(t)
type testCase struct {
Bytes []byte
Expected VarLong
}
testCases := []testCase{
{
Bytes: []byte{0x00},
Expected: 0,
},
{
Bytes: []byte{0x01},
Expected: 1,
},
{
Bytes: []byte{0x10},
Expected: 16,
},
{
Bytes: []byte{0x7f},
Expected: 127,
},
{
Bytes: []byte{0xac, 0x02},
Expected: 300,
},
{
Bytes: []byte{0xdd, 0xc7, 0x01},
Expected: 25565,
},
{
Bytes: []byte{0xff, 0xff, 0xff, 0xff, 0x07},
Expected: 2147483647,
},
{
Bytes: []byte{0x80, 0x80, 0x80, 0x80, 0xf8, 0xff, 0xff, 0xff, 0xff, 0x01},
Expected: -2147483648,
},
{
Bytes: []byte{0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x01},
Expected: -1,
},
{
Bytes: []byte{0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x7f},
Expected: 9223372036854775807,
},
{
Bytes: []byte{0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x01},
Expected: -9223372036854775808,
},
}
for _, tc := range testCases {
t.Run(strconv.FormatInt(int64(tc.Expected), 10), func(t *testing.T) {
var varLong VarLong
n, err := varLong.ReadFrom(bytes.NewReader(tc.Bytes))
// No error should be here.
a.NoError(err)
// Length of the VarInt must be equal to the bytes size.
a.EqualValues(len(tc.Bytes), n)
// Asserting to the expected VarInt value.
a.EqualValues(tc.Expected, varLong)
})
}
}
```
Результать Unit-тестов для VarLongЗаключение
----------
Данная статья получилась достаточно длинной и возможно сложной для понимания, но я постарался все изложить максимально подробно. Думаю над написанием *второй части* про данные два типа, в котором детально разберу как **VarInt** и **VarLong** обратно преобразуются в последовательность байтов. Очень будут рад почитать ваше мнение, ответить на ваши вопросы в комментариях! | https://habr.com/ru/post/677642/ | null | ru | null |
# Дайте две или уязвимость защиты многостраничных PIC18
Эта статья не руководство к действию хакеров, это подсказка, как правильно используя предоставленные MICROCHIP инструменты защитить прошивку внутри чипа.
Не помню уже сколько лет назад это было, натолкнулся я на статью "Heart of darkness - exploring the uncharted backwaters of hid iСlass security by Milosch Meriac". Суть статьи в проблемах безопасности iCLASS card. В общем-то я по быстренькому стал "пробегать" статью, пока не натолкнулся на: "Copy Protection? You’re kidding me!". И меня "скрючило от восторга"... а чё так можно было!!!?
Пардон, ничего не понятно, сейчас объясню.
Не помню какой PIC тогда был под рукой, сейчас есть PIC18F26K20.
Суть уязвимости.
----------------
Запускаем PICKIT и попутно открываем даташит по программированию PIC18F\*K\*.
Смотрим, зеленым биты защиты EEPROM, красным - биты защиты BOOT блока, синим - биты защиты кода, блоки 0-3.
CPB/WRTB, CP[3:0]/WRT[3:0] - защита от чтения/записи кода, сперва BOOT затем блоки с 0-3.
CPD/WRTD - Защита от чтения/записи EEP данных.
А вот самые интересные биты защиты: EBTRB/EBTR[3:0] - защита от чтения секторов из других блоков.
Смотрим на конфигурацию "защищенного" чипа (защита установлена):
Смотрим на конфигурацию, - всё защищено!
Читаем:
Ноль по вдоль! Всё защищено!
И вроде проблем нет.
А они есть, читаем в даташите:
 Написано, - "Биты защиты можно записать только из 1 в 0, наоборот нельзя, чтобы записать в бит защиты 1 нужно стереть все блоки или блок соотв. биту защиты чтобы установить соотв. бит защиты в 1". И опа, оно!
Стираем BOOT блок, записываем в него свой код, который будет для нас читать прошивку и отдавать её по EUSART.
Да, но МЫ ПОТЕРЯЛИ ТО ЧТО БЫЛО В BOOT блоке, и тут появляется тема "ДАЙТЕ ДВЕ", берем второй чип с такой же прошивкой и проделываем то же самое только например с блоком 0, причем код помещаем в самый конец блока, всё остальное заполняем NOP'ами, чтобы с определенной вероятностью наш код начался не "с середины". Вот так:
Затем склеиваем блоки в любом HEX редакторе, и вуаля! Прошивка на руках.
Код есть, вытаскиваем EEP. Точно так же:
Выглядит довольно просто. Однако проверим так ли это на самом деле.
Первая задача, как затереть сектор. Читаем даташит:
Стереть весь чип: 0x3F8F, BOOT: 0x0084, Block0: 0x0180.
Только вот вопрос чем тереть то?
Берем PICKIT3 (а он "из коробки" трет весь чип, нам не подходит):
Ни для кого не секрет что исходный код этого программатора открыт. Идем на Microchip и качаем исходники прошивки (PICkit3 Programmer Application v3.10).
Изучаем исходники... понимаем что это провал, внутри программатора интерпретатор команд, ага, значит сами команды в исходном коде приложения PIC KIT Programmer...
Изучаем исходники (они в том же архиве)... понимаем что и тут интерпретатор!!! Да чтож такое!!! А команды то где?
А они заботливо сложены в базе данных PK2DeviceFile.dat
Первая мысль написать небольшой скрипт править базу данных, собственно давным давно я так и сделал, но теперь в поиске используя PK2DeviceFile.dat неожиданно натолкнулся на редактор этой базы (pickit2-editor, только прежде чем получить результат мне пришлось исправить несколько багов ибо при попытке сохранить подправленный файл базы прога "вылетала" неисправимо файл базы запортив).
Запускаем PicKit2 Editor и находим имя скрипта стирания нашего чипа:
Переходим в скрипты, находим наш, и правим соотв (0x3F8F -> 0x0084).
Правим 0x3F на 0x00, а 0x8F на 0x84. Теперь при нажатии на кнопку ERASE, PicKit Programmer будет стирать не весь чип, а только BOOT блок.
Так, как стереть поняли.
Теперь код ридера, предлагается использовать стандартный интерфейс EUSART установленный в чипе, будем читать код из памяти и отдавать его по EUASRT, подключим его к любому конвертеру интерфейсов RS232->USB (убедившись что конвертер соотв. напряжению питания чипа). Смотрим опять в даташит:
Отлично, 18-ый пин соединяем с конвертером интерфейсов (не забываем объединить земли, у меня всё соединено через общий хаб):
Всё мы готовы. Напишем код ридера:
data\_reader.c
```
#include "pic18fregs.h"
/* CONFIG1L */
#pragma config FOSC = INTIO67
#pragma config FCMEN = OFF
#pragma config IESO = OFF
/* CONFIG2L */
#pragma config PWRT = OFF
#pragma config BOREN = NOSLP
#pragma config BORV = 18
/* CONFIG2H */
#pragma config WDTEN = ON
#pragma config WDTPS = 128
/* CONFIG3H */
#pragma config CCP2MX = PORTC
#pragma config PBADEN = OFF
#pragma config LPT1OSC = OFF
#pragma config HFOFST = OFF
#pragma config MCLRE = OFF
/* CONFIG4L */
#pragma config STVREN = ON
#pragma config LVP = OFF
#pragma config XINST = OFF
#pragma config DEBUG = OFF
/* CONFIG5L */
#pragma config CP0 = ON
#pragma config CP1 = ON
#pragma config CP2 = ON
#pragma config CP3 = ON
/* CONFIG5H */
#pragma config CPB = ON
#pragma config CPD = OFF
/* CONFIG6L */
#pragma config WRT0 = OFF
#pragma config WRT1 = OFF
#pragma config WRT2 = OFF
#pragma config WRT3 = OFF
/* CONFIG6H */
#pragma config WRTD = OFF
#pragma config WRTB = OFF
#pragma config WRTC = OFF
/* CONFIG7L */
#pragma config EBTR0 = OFF
#pragma config EBTR1 = OFF
#pragma config EBTR2 = OFF
#pragma config EBTR3 = OFF
/* CONFIG7H */
#pragma config EBTRB = OFF
typedef __code unsigned char *CODEPTR;
void main()
{
unsigned int uaddr = 0;
CODEPTR c;
TRISA = 0;
TRISB = 0;
TRISC = 0;
/* Set Default State of OSC */
OSCCON = 0b00110000;
PIR2 = PIE2 = OSCTUNE = 0;
IPR2 = 0xFF;
/* Disable IRQs */
INTCONbits.GIE = 0;
/* enable EUSART */
RCSTAbits.SPEN = 1;
/* baud rate to 2400 Baud */
SPBRG = 25;
/* enable TX + only HI byte divisor */
TXSTA = 0b00100100;
c = 0x0;
do
{
TXREG = *c++;
while (!TXSTAbits.TRMT);
ClrWdt();
} while (c != (CODEPTR)0x10000);
while (1)
{
/* Recharge WDT */
ClrWdt();
}
}
```
Компилируем и получаем:
data\_reader.hex:020000040000FA :10000000926A936A946A300ED36E9B6AA06AA16A60 :10001000FF0EA26EF29EAB8E190EAF6E240EAC6E6A :10002000006A016A026A00C0F6FF01C0F7FF02C061 :10003000F8FF0900F5CFADFF002A02E3014A022ACA :10004000ACA2FED70400005005E1015003E10250CC :0C005000010A01E0E8D70400FED712000E :020000040030CA :03000100081D0FC8 :02000500018177 :0600080000C00FE00F40F4 :00000001FF
Записываем в чип и видим что байтики поехали:
Далее если действовать по описанному выше алгоритму получаем всю прошивку целиком.
В общем то и всё. Время для резюме.
Применимость уязвимости:
------------------------
1. EBTRB/EBTR[3:0] - защита от чтения секторов из других блоков не установлена.
2. У вас есть два идентичных многостраничных PIC18 чипа с идентичными прошивками.
Как защититься от уязвимости:
-----------------------------
1. EBTRB/EBTR[3:0] - устанавливать защиту от чтения секторов или хотя бы одного сектора, таким образом получить доступ к "чистой прошивке" будет затруднительно.
Однако необходимо помнить, - если вы устанавливаете защиту чтения из других блоков, Вам необходимо убедиться что данные для одного блока компилятор не будет собирать в другом! А он так может.
За сим разрешите откланяться.
Приятного дня и бодрости духа. | https://habr.com/ru/post/534554/ | null | ru | null |
# Buildroot — часть 2. Создание конфигурации своей платы; применение external tree, rootfs-overlay, post-build скриптов
В данном разделе я рассматриваю часть возможностей по кастомизации, которые потребовались мне. Это не полный список того, что предлагает buildroot, но они вполне рабочие и не требуют вмешательства в файлы самого buildroot.
### Использование EXTERNAL-механизма для кастомизации
[В предыдущей статье](https://habr.com/ru/post/448638/) рассматривался простой пример добавления своей конфигурации, путем добавления defconfig’а платы и нужных файлов непосредственно в каталог Buildroot.
Но этот метод не очень удобен, особенно при обновлении buildroot. Для решения это проблемы есть механизм **external tree**. Суть его в том, что в отдельном каталоге можно хранить каталоги board,configs,packages и прочие( например, я использую каталог patches для наложения патчей на пакеты, подробнее в отдельном разделе) и buildroot будет сам добавлять их к имеющимися в своем каталоге.
*Примечение: можно накладывать сразу несколько external tree, есть пример в руководстве buildroot*
Создадим каталог my\_tree, находящийся рядом с каталогом buildroot’а и перенесём туда нашу конфигурацию. На выходе должны получить следующую структуру файлов:
```
[alexey@alexey-pc my_tree]$ tree
.
├── board
│ └── my_x86_board
│ ├── bef_cr_fs_img.sh
│ ├── linux.config
│ ├── rootfs_overlay
│ └── users.txt
├── Config.in
├── configs
│ └── my_x86_board_defconfig
├── external.desc
├── external.mk
├── package
└── patches
6 directories, 7 files
```
Как видно, в целом структура повторяет структуру buildroot.
Каталог **board** содержит файлы, специфичные каждой плате в нашем случае:
* bef\_cr\_fs\_img.sh — скрипт, который будет выполняться после сборки target-файловой системы, но перед упаковыванием её в образы. В дальнейшем мы его будем использовать
* linux.config — конфигурация ядра
* rootfs\_overlay — каталог для наложения поверх target-файловой системы
* users.txt — файл с описанием создаваемых пользователей
Каталог **configs** содержит defconfig’и наших плат. У нас он всего один.
**Package** — каталог с нашими пакетами. Изначально buildroot содержит описания и правила сборки ограниченного числа пакетов. Позже мы добавим сюда оконный менеджер icewm и менеджер графического входа в систему Slim.
**Patches** — позволяет удобно хранить свои патчи для разных пакетов. Подробнее в отдельном разделе далее.
Теперь нужно добавить файлы описания нашего external-tree. За это отвечают 3 файла: external.desc, Config.in, external.mk.
**external.desc** содержит собственно описание:
```
[alexey@alexey-pc my_tree]$ cat external.desc
name: my_tree
desc: My simple external-tree for article
```
Первая строка — название. В дальнейшем buildroot создать переменную *$(BR2\_EXTERNAL\_MY\_TREE\_PATH)*, которую нужно использовать при конфигурировании сборки. Например, путь к файлу с пользователями можно задать следующим путем:
```
$(BR2_EXTERNAL_my_tree_PATH)/board/my_x86_board/users.txt
```
Вторая строка — краткое, понятное человеку описание.
**Config.in, external.mk** — файлы для описания добавляемых пакетов. Если свои пакеты не добавлять, то эти файлы можно оставить пустыми. Пока что мы так и поступим.
Теперь у нас готово наше external-tree, содержащее defconfig нашей платы и нужные ему файлы. Перейдем каталог buildroot, укажем использовать external-tree:
```
[alexey@alexey-pc buildroot]$ make BR2_EXTERNAL=../my_tree/ my_x86_board_defconfig
#
# configuration written to /home/alexey/dev/article/ramdisk/buildroot/.config
#
[alexey@alexey-pc buildroot]$ make menuconfig
```
В первой команде мы используем аргумент *BR2\_EXTERNAL=../my\_tree/*, указывающий использование external tree.Можно задать одновременно несколько external-tree для использования При этом достаточно сделать это один раз, после чего создается файл output/.br-external.mk, хранящий информацию об используемом external-tree:
```
[alexey@alexey-pc buildroot]$ cat output/.br-external.mk
#
# Automatically generated file; DO NOT EDIT.
#
BR2_EXTERNAL ?= /home/alexey/dev/article/ramdisk/my_small_linux/my_tree
BR2_EXTERNAL_NAMES =
BR2_EXTERNAL_DIRS =
BR2_EXTERNAL_MKS =
BR2_EXTERNAL_NAMES += my_tree
BR2_EXTERNAL_DIRS += /home/alexey/dev/article/ramdisk/my_small_linux/my_tree
BR2_EXTERNAL_MKS += /home/alexey/dev/article/ramdisk/my_small_linux/my_tree/external.mk
export BR2_EXTERNAL_my_tree_PATH = /home/alexey/dev/article/ramdisk/my_small_linux/my_tree
export BR2_EXTERNAL_my_tree_DESC = My simple external-tree for article
```
Важно! В этом файле пути будут абсолютными!
В меню появился пункт External options:
В этом подменю будут содержаться наши пакеты из нашего external-tree. Сейчас этот раздел пустой.
Сейчас нам важнее переписать нужные пути на использование external-tree.
*Обратите внимание, что в разделе Build options → Location to save buildroot config, будет абсолютный путь к сохраняемому defconfig'у. Формируется он в момент указания импользования extgernal\_tree.*
Также в разделе System configuration поправим пути. Для таблицы с создаваемыми пользователями:
```
$(BR2_EXTERNAL_my_tree_PATH)/board/my_x86_board/users.txt
```
В разделе Kernel поменяем путь к конфигурации ядра:
```
$(BR2_EXTERNAL_my_tree_PATH)/board/my_x86_board/linux.config
```
Теперь при сборке будут использоваться наши файлы из нашего external-tree. При переносе в другой каталог, обновлении buildroot у нас будет минимум проблем.
### Добавление root fs overlay:
Данный механизм позволяет легко добавлять/заменять файлы в target-файловой системе.
Если файл есть в root fs overlay, но нет в target, то он будет добавлен
Если файл есть в root fs overlay и в target, то он будет заменён.
Сначала зададим путь к root fs overlay dir. Это делается в разделе System configuration → Root filesystem overlay directories:
```
$(BR2_EXTERNAL_my_tree_PATH)/board/my_x86_board/rootfs_overlay/
```
Теперь проведем создадим два файла.
```
[alexey@alexey-pc my_small_linux]$ cat my_tree/board/my_x86_board/rootfs_overlay/etc/hosts
127.0.0.1 localhost
127.0.1.1 my_small_linux
8.8.8.8 google-public-dns-a.google.com.
[alexey@alexey-pc my_small_linux]$ cat my_tree/board/my_x86_board/rootfs_overlay/new_file.txt
This is new file from overlay
```
Первый файл (my\_tree/board/my\_x86\_board/rootfs\_overlay/etc/hosts) заменит файл /etc/hosts в готовой системе. Второй файл (cat my\_tree/board/my\_x86\_board/rootfs\_overlay/new\_file.txt) добавится.
Собираем и проверяем:
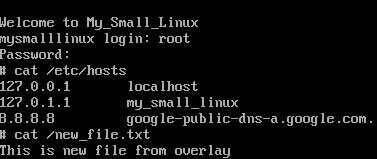
### Выполнение скриптов кастомизации на разных этапах сборки системы
Часто нужно выполнить некоторые действия внутри target-файловой системы до того, как как она будет упакована в образы.
Это можно сделать в разделе System configuration:

Первые два скрипта выполняются после сборки target-файловой системы, но до упаковки её в образы. Разница в том, что fakeroot-скрипт выполняется в контексте fakeroot, те имитируется работа от пользователя root.
Последний скрипт выполняется уже после создания образов системы. В нем можно выполнять дополнительные действия, например, скопировать нужные файлы на nfs-сервер или создать образ своей прошивки устройства.
В качестве примера я создам скрипт, который будет писать версию и дату сборки в /etc/.
Сначала укажу путь к этому файлу в моем external-tree:

А теперь сам скрипт:
```
[alexey@alexey-pc buildroot]$ cat ../my_tree/board/my_x86_board/bef_cr_fs_img.sh
#!/bin/sh
echo "my small linux 1.0 pre alpha" > output/target/etc/mysmalllinux-release
date >> output/target/etc/mysmalllinux-release
```
После сборки можно увидеть этот файл в системе.
На практике, скрипт может стать большим. Поэтому в реальном проекте я пошел более продвинутым путем:
1. Создал каталог (my\_tree/board\_my\_x86\_board/inside\_fakeroot\_scripts), в котором лежат скрипты для выполнения, с порядковыми номерами. Например, 0001-add-my\_small\_linux-version.sh, 0002-clear-apache-root-dir.sh
2. Написал скрипт(my\_tree/board\_my\_x86\_board/run\_inside\_fakeroot.sh), который проходит по этому каталогу и последовательно выполняет скрипты, лежашие в нем
3. Указал этот скрипт в настройках платы в разеле System configuration -> Custom scripts to run inside the fakeroot environment ($(BR2\_EXTERNAL\_my\_tree\_PATH)/board/my\_x86\_board/run\_inside\_fakeroot.sh) | https://habr.com/ru/post/449348/ | null | ru | null |
# Очередная блокировка части IP-адресов GitHub
Вчера и сегодня часть IT-населения нашей страны (России) столкнулась с неожиданной проблемой, при попытке зайти н GitHub, чтобы, например, почитать pull-request или документацию к какой-нибудь библиотеке. Сайт долго тупил, после чего загружался без стилей, картинок и скриптов.

Среди этой части населения оказался и я. Ситуация показалась знакомой. Действительно, зайдя в консоль браузера, я обнаружил, что вся статика отвалилась по таймауту. Ok. Посмотрим, куда ведет assets-cdn.github.com:
```
$ host assets-cdn.github.com
assets-cdn.github.com is an alias for github.map.fastly.net.
github.map.fastly.net is an alias for prod.github.map.fastlylb.net.
prod.github.map.fastlylb.net has address 151.101.36.133
```
Ок. Поглядим внесен ли данный IP-адрес в [единый реестр](https://eais.rkn.gov.ru/)?

Да, похоже, что внесен!
О том же нам говорит и сайт [Универсального сервиса проверки ограничения доступа к сайтам](http://blocklist.rkn.gov.ru/#anchor).
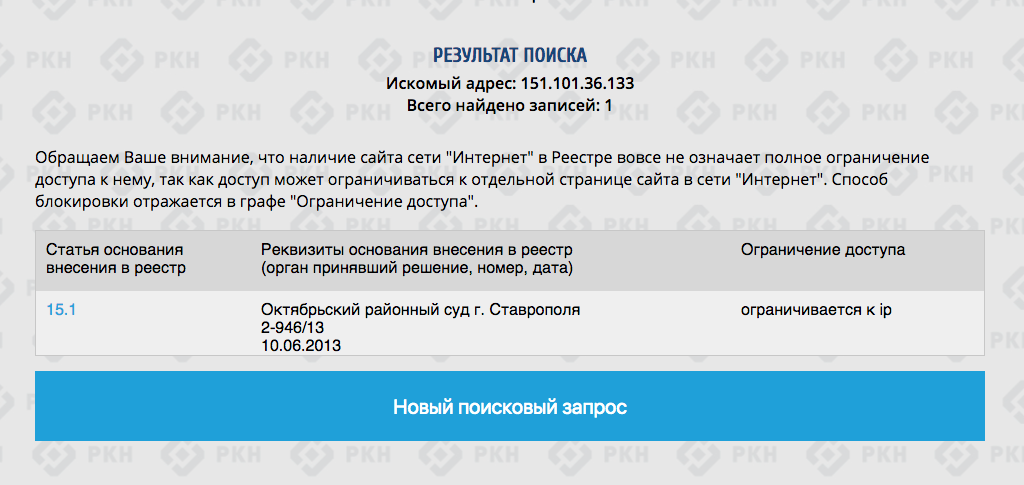
Погодите-ка, 10 июня 2013? Что, решение суда дожидалось исполнения 3 года? 0\_о
[Реестр Роскомсвободы](https://reestr.rublacklist.net/rec/89105/) говорит, что да:
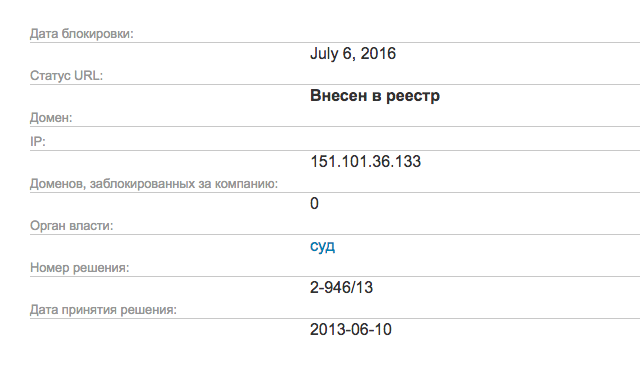
Немного погуглив по данному вопросу (и удивившись, что на хабраресурсах еще ничего не всплывало), нашел [запись в ЖЖ](http://keinkeinkein.livejournal.com/102312.html) с некоторыми дополнительными подробностями:
> Судя по всему, этой же CDN пользовалось в 2013 году какое-то интернет-казино, и наша Роскомцензура в далеком 2013-м решила заблокировать не хосты интернет-казино, а одним росчерком пера IPv4-адрес всего дата-центра CDN. Д..., б...! То есть, власть нас спасла от того, чтобы мы не проигрывали последние деньги в казино, параллельно заблокировав и ненужный с ее духовно-скрепной точки зрения GitHub.
>
>
> Оказывается, GitHub заблокирован на всей территории России Октябрьским районным судом Ставрополя. Районным судом, Карл! Получается, заблокировать любой сайт на всей территории РФ на DPI-оборудовании провайдеров теперь может абсолютно любой районный судья из любого субъекта РФ.
>
>
Еще нагуглилось [небольшое обсуждение](http://vk.com/rublacklist?w=wall-45023092_31289%2Fall) на VK-страничке Роскомсвободы, из которого можно, в частности попасть на [текст решения суда](https://rospravosudie.com/court-oktyabrskij-rajonnyj-sud-g-stavropolya-stavropolskij-kraj-s/act-429825542/), и на [страничку судьи](http://bit.ly/29wxSkn), его вынесшего («Очень грамотный, тактичный и доброжелательный, С ТОНКИМ ЧУВСТОМ ЮМОРА»).
В недрах комментариев к вышеуказанному ЖЖ-посту можно также найти решение данной проблемы (ну, кроме очевидных — использовать прокси или ssh-тоннель): гитхабовские CDN также имеют IP адрес **151.101.12.133**, который в реестр не внесен. Таким образом, можно прописать его в */etc/hosts* и радоваться жизни. Ну… Только по той же CDN раздаются еще аватарки, имеющие разные доменные имена, и, в чем самая подстава — *некоторые* страницы GitHub Pages. На момент написания этой статьи в моем */etc/hosts* были:
```
151.101.12.133 assets-cdn.github.com
151.101.12.133 avatars2.githubusercontent.com
151.101.12.133 avatars0.githubusercontent.com
151.101.12.133 avatars1.githubusercontent.com
151.101.12.133 avatars3.githubusercontent.com
151.101.12.133 google.github.io
151.101.12.133 kangax.github.io
151.101.12.133 eslint.org
```
Наверное, все-таки придется включать VPN…
**UPD 13.07.2016:**
Похоже, [IP был исключен из реестра 12.07.2016](https://reestr.rublacklist.net/rec/89105/). Так что Роскомнадзор, надо отдать им должное, не такой уж и нерасторопный. | https://habr.com/ru/post/356052/ | null | ru | null |
# Geany и пользовательские скрипты
По роду деятельности приходится править куски конфигурационных файлов оборудования Cisco в текстовом редакторе. Я пользуюсь редактором Geany (ОS Linux), поэтому тюнить буду его и скрипт писать под bash
Мой тюнинг прост, я добавил скрипт, который добавляет или убирает в выделенном тексте команду «no»
Я обозвал скрипт cisco\_add\_no и скопировал его в /usr/bin, так же не забываем дать ему права на запуск:
chmod ug+x /usr/bin/cisco\_add\_no
Скрипты для geany можно добавить в
Правка -> Форматирование -> Отправить выделенное в -> Установить пользовательские команды
Там необходимо указать имя скрипта, выделенный текст передается через стандартный stdin
Я указал так (1-й добавляет «no», второй убирает):
**cisco\_add\_no**
**cisco\_add\_no unno**
```
#!/bin/bash
#
# Add or remove "no" from all selected strings in Geany
#
# Usage: cisco_add_no [w/o arguments] - add "no" to all stdin strings
# cisco_add_no unno - remove "no" from all stdin strings
#
#Get stdin strings
my_strings=`xargs -0 echo`
#Get count of strings
num=`echo "$my_strings" | wc -l`
i=0
while [ $i -lt $num ]; do
let i+=1
#If we haven't "unno" argument? add "no" to selected strings, otherwise remove "no"
if [ "$1" != "unno" ]
then
printf "no "
echo "$my_strings" | head -${i} | tail -1
else
echo "$my_strings" | head -${i} | tail -1 | sed -e 's/no //'
fi
done
```
Скрипты можно вызывать либо из меню (там же где и добавляли), либо через хот-кеи Ctrl+1, Ctrl+2 и т.д.
P.S. Друзья, я не претендую на уникальность кода, так же не выдвигаюсь в номинации «самый красивый код года», я просто сделал так как смог. Все предложения по улучшению принимаются с удовольствием. | https://habr.com/ru/post/130151/ | null | ru | null |
# Хотел красивую железку. Получилось
[Часть 1](https://habr.com/post/407581/ "В которой ничего толком не получилось") >> [Часть 2](https://habr.com/post/408899/ "В которой Винни Пух размышляет о красивых железках вообще") >> [Вы находитесь здесь](https://habr.com/post/423775/ "Ну так красивее")
*Однажды любимая жена у друзей на даче нашла радужную пружинку [слинки](https://ru.wikipedia.org/wiki/%D0%A1%D0%BB%D0%B8%D0%BD%D0%BA%D0%B8 "вики нам поможет вспомнить детство"). Вспомнила детство, подошла к лестнице и запустила. Чудо, но пружинка с первого раза идеально пропружинила по каждой ступеньке.
— Получилось! — с радостным удивлением воскликнули все, кто был рядом.
Трёхлетней дочке тоже захотелось попробовать. Она взяла пружинку, забралась на лестницу и запустила её. Пружинка пролетела над лестницей и шмякнулась боком на траву.
— Получилось! — радостно закричала дочка.*
Прошёл год с начала моего фанового проекта. Получилось! Та самая красивая железка выглядит вот так:

На первый взгляд может быть не понятно. Но, допустим, что это топор. И с помощью этого топора и нескольких деталек в конце у меня получится каша.
А для хорошей каши из топора нужна крупа.
WiFi Slot
=========
Все знают про ESP8266. У этой борды несколько отличий.
1. К ней подключаются Troyka-модули. И их разных очень много.
2. Таких модулей туда можно поставить 4.
3. У неё 8 каналов АЦП, с измерением диапазона от 0 до 3.3 В. А для голой ESP8266 это очень не характерно.
4. Здесь есть две шины питания: силовая 5В, цифроаналоговая 3,3 В.
5. Одно в другое превращается через DC/DC. Меня лично задолбали эти кипятильники-регуляторы. Привет высокий КПД.
6. А это значит, что можно драйвить моторы прям с неё. И как-нибудь я покажу как.
7. Она поддерживает Slot Connector. А это круто.
Короче, я могу воткнуть в неё 4 потенциометра, и это будет выглядеть шикарно. Ведь ради крутого лука всё и затевалось.
i2cio
=====
А вот и мой любимый STM32F030F4P6.
На картинке две платы с одной и той же прошивкой i2cio. Это расширитель портов ввода/вывода.
9 управляющих пинов этой штуки умеют:
1. 12-битный АЦП
2. 16-битный ШИМ, с очень круто регулируемой частотой. Хоть сервы туда вешай (DC/DC помогает и тут), хоть моторы постоянного тока крути, хоть звук играй.
Так же эти 9 плюс ещё один могут цифровой ввод/вывод.
Дополнительно Slot Expander поддерживает Troyka-разъёмы и разделение питания на силовую и аналоговую части.
Аааа… Забыл. Таких расширителей можно к железке подключить чуть больше 100 штук. И они все рассортируются по I2C-адресам автоматом, предоставляя плоскую адресацию пинов. То есть вы сможете написать
```
i2cio.digitalWrite(852, HIGH);
int tooMuchForAnalogPinNumber_areYouReallyShureQuestion = i2cio.analogRead(942);
```
И при этом всё получится.
Ну и стоит камень 33 рубля. И можно сделать с ним, например, ездуна по линии с самым большим в мире количеством датчиков оттенка серого. С 12 битным АЦП и 16-битной регулировкой чувствительности. Не меняя прошивку.
**Заголовок спойлера**Что я обязательно и покажу в следующих сериях.
Едем дальше.
Экшн
====
Друг попросил меня сделать ему пульт для Traktor — любимой программы дискжокеев. Я подумал, что если у меня не получится сделать это быстро и красиво, то ерунда у меня получилась, а не красивая железка.
Скручиваем всё вместе
---------------------

*Примечание: здесь и далее подразумевается, что текста сверху никогда не было*
Для этого мне понадобится материнская платка с мозгами esp8266 (*слева*). Её отличие от остальных только в том, что она квадратная, имеет 8 входов АЦП и питается от 5 В через DC/DC преобразователь. А ещё к ней можно подключить такую же квадратную плату расширения на моём любимом stm32f030f4p6 (*справа*) через красивую железку (*центр*).
Добавим кучу потенциометров
---------------------------
Ещё одна особенность этих железок — в них очень просто вставить стандартные модули. Модулей у меня этих много разных. Я взял кучу потенциометров. Потому что *все любят кучу потенциометров*(с).

Больше потенциометров богу потенциометров!

Соль
----
Самый долгий пункт сборки. Если захочется сделать всё в точности как я, понадобится сделать следующее:
1. Купить в Леруа деревянный уголок со стороной 2 см
2. Взять пилу, и попытаться отпилить его под 45 градусов
3. Понять, что это не так то просто. Начать бегать повсюду и искать стусло.
4. Скрутить стусло из советского металлического конструктора.
5. Упилить почти весь уголок в брак, потому что не дано тебе, Василий, делать что-то красивое руками.
6. Купить, наконец, стусло.
7. GOTO 5. Потому что не дано тебе, Василий. Нечего и пытаться.
Вот что получилось:

Ерунда, переделать
------------------
Друг говорит: «Это что это, пульт для трактора, да? Не похоже что-то».
Хороша работа. Начинай сначала.
Берём ещё 4 платы расширения, прикручиваем. Берём кучу модульков, и тыкаем куда попало.
Получилось вот это:

Аккуратно сверлим отверстие для Micro-USB коннектора, чтобы запрограммировать материнскую плату и, в последствии, заряжать батарейку.

Ох, не дано тебе, Василий, не дано...
Демонстрация работы
-------------------
В итоге получился беспроводной пульт для трактора. Он управляет трактором по WiFi через Open Sound Control.
Исходный код
------------
Исходный код на [gitHub](https://github.com/acosinwork/WiFiSlot_OSC/tree/master/traktor_osc). Залил целиком рабочую папку, чтобы не искать библиотеки по всему интернету.
А как вообще это работает?
--------------------------
Красивая железка — это просто коннектор, который при помощи четырёх болтов умеет передавать два сигнала и питание. Два сигнала — это I2C. Материнская плата умеет разбрасывать все платы расширения по последовательно идущим I2C-адресам и, впоследствии, что-то с ними делать. Например, считывать 12-битный аналоговый сигнал с (почти) каждой ножки расширителя. Или управлять 16-битным ШИМ на каждой ножке расширителя. Ну или просто использовать эти ножки как цифровой вход/выход. Можно использовать эти расширители, если вам просто не хватило ног на вашем любимом микроконтроллере.
Прошивка stm32f030f4p6, установленного на плате расширения лежит [здесь](https://github.com/acosinwork/i2cio-firmware).
Библиотека для работы с расширителями портов в Arduino IDE лежит [здесь](https://github.com/acosinwork/I2cio).
Если уважаемым хабравчанам будет интересно, я обязательно расскажу об этом подробнее. Но не сегодня. | https://habr.com/ru/post/423775/ | null | ru | null |
# Как мы анализируем уязвимости с помощью нейронных сетей и нечеткой логики
[](https://habrahabr.ru/company/pt/blog/323436/)
*Изображение: [Daniel Friedman](https://www.flickr.com/photos/daniel_friedman/), Flickr*
В нашем блоге на Хабре мы много пишем о внедрении практик DevOps в процессы разработки и тестирования создаваемых в компании систем информационной безопасности. Задача инженера-автоматизатора не всегда заключается только в установке и поддержки какого-то сервиса, иногда необходимо решать трудоемкие исследовательские задачи.
Для решения одной из таких задач — разбора уязвимостей в ходе [тестов конкурентного анализа](https://habrahabr.ru/company/pt/blog/321354/), мы разработали собственный [универсальный классификатор](https://habrahabr.ru/company/pt/blog/246197/). О том, как работает этот инструмент, и каких результатов позволяет добиваться, и пойдет речь в нашем сегодняшнем материале.
Немного теории
--------------
Для начала разберемся с тем, что такое классификация в общем случае. Под классификацией производного объекта подразумевается отношение этого объекта к одному из двух классов в зависимости от того, насколько он «похож» на эталон, применяемый в предметной области. То есть, для задачи классификации необходимо построить некоторую функцию (классификатор), которая бы указывала на уровень «похожести» нашего объекта на эталонные примеры из разных классов (подробнее [по ссылке](http://math-n-algo.blogspot.ru/2014/08/FuzzyClassificator.html#chapter_2)).
*Диаграмма Эйлера-Венна для задачи классификации уязвимостей*
Для решения широкого класса задач классификации предлагается использовать несколько теорий:
* теорию нечетких множеств;
* инструмент для нечеткой оценки свойств объектов: нечеткие шкалы;
* теорию нейронных сетей.
### Теория нечетких множеств
Основателем теории нечетких множеств и нечеткой логики еще в 60-х годах прошлого века стал [Лотфи Заде](https://ru.wikipedia.org/wiki/%D0%9B%D0%BE%D1%82%D1%84%D0%B8_%D0%97%D0%B0%D0%B4%D0%B5). Смысл понятия «нечеткое множество» лучше всего иллюстрирует простой пример объяснения того, что такое «много». Один экземпляр чего-то — не много, два — тоже, а три, четыре или пять — уже может быть много. Для математического описания нечеткой величины используют так называемую функцию принадлежности, которая для каждого объекта рассматриваемой области ставит в соответствие число, характеризующее величину принадлежности к данному нечеткому множеству.
### Нечеткие шкалы
Это упорядоченная совокупность нечетких множеств, то есть каждое из них должно нести какую-то смысловую нагрузку. Пример — всем известные уровневые шкалы. Вот так выглядит универсальная нечеткая шкала, состоящая из пяти уровней:
> `S = {Min, Low, Med, High, Max}`
При оперировании уровневыми шкалами мы имеем возможность определять, когда то или иное значение находится на каком-то уровне. Такие нечеткие шкалы позволяют интерпретировать значения конкретных свойств в виде числа (подробнее [по ссылке](http://math-n-algo.blogspot.ru/2014/08/FuzzyClassificator.html#chapter_3)).
### Нейронные сети
Известно, что в биологическом нейроне клетки могут накапливать электрические импульсы, которые передаются на синапсы, связывающие между собой несколько нейронов. В зависимости от порога чувствительности клетки электрический сигнал передается или не передается дальше.
Точно также устроены и математические нейронные сети. На вход нейрону могут подаваться какие-либо числа — как четкие, так и нечеткие, они перемножаются с весовыми коэффициентами. Для каждого нейрона устанавливается «порог срабатывания» — сумма произведений входов и весов передается на вход функции активации, которая выдает результат для конкретного нейрона. Такие нейроны, расположенные друг за другом, называют нейронной сетью (подробнее [по ссылке](http://math-n-algo.blogspot.ru/2013/04/blog-post.html#id_1)).

Для повышения качества разбора уязвимостей нашими продуктами, нам необходимо было научиться определять их принадлежность к одному из двух классов — подтвержденных или неподтвержденных уязвимостей. Для этого было проведено множество экспериментов, которые увенчались созданием оптимальной для решения этой задачи нейронной сети.
Она состоит из четырех слоев, на вход которой подаются числа, а на выходе получаем два четких или нечетких числа, которые характеризуют уровень принадлежности к одному из классов — например, минимальный уровень «похожести» или «максимальный» (подробнее [по ссылке](http://math-n-algo.blogspot.ru/2014/08/FuzzyClassificator.html#chapter_6)).
Автоматизация классификации
---------------------------
Для автоматизации процесса классификации объектов мы разработали специальный инструмент — FuzzyClassificator. Это нечеткий нейроклассификатор, в основе которого лежит нейронная сеть, обрабатывающая четкие и нечеткие величины. Код этого инструмента доступен на [GitHub](https://github.com/Tim55667757/FuzzyClassificator/tree/master), для его работы требуется [Pyzo](http://www.pyzo.org/) и [PyBrain](http://pybrain.org/) (подробнее [по ссылке](http://math-n-algo.blogspot.ru/2014/08/FuzzyClassificator.html#chapter_7)).
Сейчас мы используем инструмент FuzzyClassificator для решения конкретной прикладной задачи классификации уязвимостей. Они — отличный пример объектов, имеющих нечеткую природу, и которые не может однозначно классифицировать даже человек.
Существует всего два этапа работы любой системы, в основе которой лежит нейронная сеть — ее обучение и классификация. На первом этапе для решения нашей задачи классификации мы сканируем множество различных CMS множеством сканеров безопасности. На выходе эти сканеры выдают очень много информации об уязвимостях в CMS — на этом этапе невозможно сказать, реальны ли они, либо мы имеем дело с ложными срабатываниями. Полученные данные мы помещаем в базу TFS, откуда их можно получать и кодировать в понятном для нейросети виде.
Затем нейросеть обучается на эталонных данных, после чего ее можно использовать на данных, полученных в ходе тестов сканеров безопасности.
Что в итоге
-----------
Ранее нам приходилось заниматься разбором уязвимостей вручную — только так можно было понять, корректно ли сработали наши продукты, существует ли действительно найденная ими уязвимость и настолько ли она серьезна. Нейронная сеть помогает экономить до 70% времени на разбор. В частности, это позволило увеличить число сканируемых CMS и анализируемых сканеров безопасности для конкурентного анализа.
Этот процесс был автоматизирован в использующейся нами системе TeamCity. Тестировщики используют специальный интерфейс для запуска FuzzyClassificator и использования нейросети в режиме обучения и классификации.

Пример отчета системы на этапе обучения выглядит так:

Он включает данные по качеству обучаемой нейронной сети — насколько сильно может ошибаться сеть при анализе. Отчет в «боевом» режиме разбора уязвимостей выглядит так:

Все уязвимости сведены в таблицу, в которой отражены уровни уверенности нейросети в действительном наличии той или иной уязвимости или ее ложности, а также рекомендации по интерпретации этих данных. Пример — на рисунке выше первую уязвимость нейросеть готова подтвердить с минимальным уровнем уверенности, а отвергнуть ее — с максимальным, поэтому рекомендует эту ошибку отклонить, пометить ее как Rejected, то есть — это false positive для сканера. После того, как нейросеть выдала результат, она отправляет его также в базу TFS.
Ограничения и доработки
-----------------------
Как и любой инструмент, наш FuzzyClassificator имеет свои ограничения. Корректная классификация с его помощью:
* сильно зависит от выбранного метода кодирования входных данных;
* требует хорошего знания предметной области, для которой выполняется классификация;
* требует значительных усилий в подготовке «хороших» входных данных для обучения.
На данный момент для кода инструмента и всех его низкоуровневых методов мы уже провели оптимизацию алгоритмов, но останавливаться на достигнутом не собираемся. В наших ближайших планах:
* перевод инструмента на CPython;
* реализация исполнения кода на GPU.
**Материалы по теме:**
* [Применение нейросетей для решения классических задач линейного и нелинейного разделения элементов множества на классы](http://math-n-algo.blogspot.ru/2013/04/blog-post.html)
* [Подходы к автоматизации процесса валидации уязвимостей, найденных автоматическими сканерами безопасности, при помощи нечётких множеств и нейронных сетей](http://math-n-algo.blogspot.ru/2014/08/FuzzyClassificator.html)
* [Сканеры безопасности: автоматическая валидация уязвимостей с помощью нечетких множеств и нейронных сетей](https://habrahabr.ru/company/pt/blog/246197/)
* [Сканеры безопасности: автоматическая классификация уязвимостей](https://habrahabr.ru/company/pt/blog/274241/)
P.S. Рассказ о нашем опыте создания нечеткого классификатора был представлен в рамках DevOps-митапа, который состоялся осенью 2016 года в Москве.
Видео:
Слайды:
По [ссылке](http://www.slideshare.net/phdays) представлены презентации 16 докладов, представленных в ходе мероприятия. Все презентации и видео выступлений добавлены в таблицу в конце этого [топика-анонса](https://habrahabr.ru/company/pt/blog/310584/).
**Автор**: [Тимур Гильмуллин](https://www.linkedin.com/in/tgilmullin) | https://habr.com/ru/post/323436/ | null | ru | null |
# Поднимаем упрощенную провайдерскую сеть дома
Изначально эта статья была дневником по лабораторной работе, которую я придумал сам для себя. Постепенно мне начало казаться, что данная информация может быть полезна кому-то еще. Поэтому я постарался преобразовать заметку в более-менее приличный вид, добавить описание некоторых команд и технологий.
В статье рассматривается построение простейшей сети с несколькими провайдерами и клиентами, в частности, такие технологии, как NAT, OSPF, BGP, MPLS VPN. Многое, естественно, будет не учтено. Например в статье почти нет описания проблем безопасности, т.к. на эту тему можно говорить бесконечно, а текст и так получается довольно объемным. QoS тоже оставлен в стороне, т.к. в лабораторных условиях его особо не проверишь.
По поводу целевой аудитории. Совсем новичкам в сетях статья, боюсь, будет непонятна. Людям, обладающим знаниями хотя бы на уровне CCNP – неинтересна. Поэтому я примерно ориентируюсь на сертификацию CCNA R&S.
Лабораторная построена на эмуляторе Cisco IOU. По поводу его установки и использования написано уже [много](http://habrahabr.ru/post/199138/) [чего](http://habrahabr.ru/post/196228/), так что повторяться не буду.
Используются образы i86bi\_linux-adventerprisek9-ms.152-4.M1 и i86bi\_linux\_l2-ipbasek9-ms.jan24-2013-B
Определимся с топологией и IP-адресацией.
После некоторых раздумий я решил сделать такую схему:
Теперь осталось придумать легенду:
1. AS1234 – крупный провайдер ISP1. Владеет сетью 50.0.0.0/16.
2. AS67 – провайдер ISP2. Владеет сетью 100.0.0.0/16. Нужен для внесения дополнительной сложности в топологию.
3. AS812 – клиент Customer1. Владеет блоком PI-адресов IPv4 175.0.0.0/24, но внутри своей сети использует исключительно IPv6.
4. AS65000 – клиент Customer2. Получает от провайдера блок адресов 50.0.109.0/24. Внутри сети использует приватные адреса из подсети 192.168.109.0/24. AS65000 — приватная.
5. AS1114 – клиент Customer3. Владеет блоком PI-адресов 150.0.0.0/24. Их же и использует для внутренних нод.
Для простоты на p2p линках между маршрутизаторами в разных AS будем использовать адреса вида 200.0.xy.0/24, где x,y – номера маршрутизаторов, x>y.
p2p линки внутри провайдеров также будут иметь маску /24 (понятно, что это расточительство, но так будет значительно проще настраивать маршрутизацию) и вид 50.0.xy.0 (100.0.xy.0 для AS67), где x,y – номера маршрутизаторов, x>y.
#### Первоначальная настройка
##### Базовая конфигурация
Для начала зальем на все маршрутизаторы примерно одинаковую конфигурацию (пример для R2):
```
enable
configure terminal
```
Включаем aaa и настраиваем возможность заходить на маршрутизатор удаленно с локальными реквизитами:
```
aaa new-model
aaa authentication login default local
username cisco privilege 15 secret cisco
no ip domain-lookup
```
Прописываем все необходимое для ssh v1.99 и разрешаем только его в параметрах линии:
```
ip domain-name isp1.com
hostname R2
crypto key generate rsa modulus 2048
line console 0
exec-timeout 0
line vty 0 4
transport input ssh
exec-timeout 0
```
На каждом маршрутизаторе создадим несколько loopback'ов. lo0 для протоколов маршрутизации, остальные для имитации клиентских подключений, чтобы RIB не выглядела слишком маленькой. Понятно, что если провайдер владеет подсетью 50.0.0.0/16, он не имеет никакого права анонсировать, например, подсеть 2.0.0.0/24, но для наглядности мы сделаем допущение, что такая ситуация возможна:
```
interface loopback 0
ip address 2.2.2.2 255.255.255.255
interface loopback 1
ip address 2.0.0.2 255.255.255.0
interface loopback 2
ip address 2.0.1.2 255.255.255.0
interface loopback 3
ip address 2.0.2.2 255.255.255.0
interface loopback 4
ip address 2.0.3.2 255.255.255.0
```
Присвоим адреса и отключим CDP на тех интерфейсах, которые смотрят не на соседний по AS маршрутизатор:
```
interface ethernet 0/0
ip address 200.0.62.2 255.255.255.0
no cdp enable
no shutdown
interface ethernet 0/1
ip address 50.0.32.2 255.255.255.0
no shutdown
interface ethernet 0/2
ip address 200.0.72.2 255.255.255.0
no cdp enable
no shutdown
interface ethernet 0/3
ip address 50.0.52.2 255.255.255.0
no shutdown
end
write
```
Теперь необходимо настроить наших клиентов.
##### HSRP, Stateful NAT
Начнем с AS65000. Из нее подсеть 192.168.109.0/24 будет транслироваться в блок адресов 50.0.109.0/24, выданный провайдером. При этом автономная система подключена к одному ISP через два маршрутизатора, поэтому для обеспечения избыточности на них необходимо будет настроить HSRP. В связи с этим при использовании обычного NAT может возникнуть проблема ассиметричного роутинга:
1. Приватный адрес транслируется в публичный на одном из маршрутизаторов.
2. Ответ приходит на второй маршрутизатор.
3. У второго маршрутизатора правило трансляции для данного пакета отсутствует, так что он просто отбросит пакет.
4. Для решения данной проблемы официальный сайт Cisco предлагает использовать [Stateful NAT](http://www.cisco.com/c/en/us/products/collateral/ios-nx-os-software/ios-software-releases-12-2-t/prod_white_paper0900aecd8052870b.html).

Для начала настроим HSRP (конфиг на R10).
У больших компаний редко бывает всего один VLAN, так что все настройки будем делать на сабинтерфейсе для 109 VLAN'а:
Создаем HSRP группу:
```
R10(config)#interface ethernet 0/1.109
R10(config-subif)#encapsulation dot1Q 109
R10(config-subif)#ip address 192.168.109.10 255.255.255.0
R10(config-subif)#standby 109 ip 192.168.109.109
R10(config-subif)#standby 109 preempt
R10(config-subif)#standby 109 name SNAT
```
Сконфигурируем ACL и NAT pool для Stateful NAT точно так же, как и для обычного (длина маски 25, а не 24, т.к. решено было оставить половину подсети для других нужд, здесь не рассматриваемых):
```
R10(config)#ip access-list standard SNAT_INSIDE
R10(config-std-nacl)#permit 192.168.109.0 0.0.0.255
R10(config)#ip nat pool SNAT_OUTSIDE 50.0.109.1 50.0.109.126 prefix-length 25
```
Настроим непосредственно Stateful NAT:
```
R10(config)#ip nat stateful id 109
R10(config-ipnat-snat)#redundancy SNAT
R10(config-ipnat-snat-red)#protocol udp
R10(config-ipnat-snat-red)#mapping-id 109
R10(config)#ip nat inside source list SNAT_INSIDE pool SNAT_OUTSIDE mapping-id 109 overload
```
И включим его на интерфейсах:
```
R10(config)#interface ethernet 0/0
R10(config-if)#ip nat outside
R10(config)#interface ethernet 0/1.109
R10(config-subif)#ip nat inside
```
На eth 0/2 применим для того, чтобы в случае, если пакет придет на R10, а R5 не будет доступен, адрес все-таки транслировался и доходил до места назначения:
```
R10(config)#interface ethernet 0/2
R10(config-if)#ip nat outside
```
Можно сделать по другому – применить не ip nat outside на eth0/2 маршрутизатора R10, а ip nat inside на eth0/1 маршрутизатора R9. Результат будет абсолютно одинаковым, главное – понимать, зачем это делается и как работает.
На R9 конфигурация аналогичная.
Конфигурация SW13 не приводится ввиду ее простоты. Интерфейсы, смотрящие на маршрутизаторы сделаем транками с инкапсуляцией в 109 VLAN. Также настроим интерфейс в 109 VLAN'e для проверки нашего решения.
После этого можно для теста поднять маршрутизацию на роутерах R3, R4, R5, R9 и R10 таким образом, чтобы пинг пошел по данному пути:

```
SW13#ping 3.3.3.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 3.3.3.3, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/3/6 ms
```
```
R9#sh ip nat translations
Pro Inside global Inside local Outside local Outside global
icmp 50.0.109.4:35 192.168.109.13:35 3.3.3.3:35 3.3.3.3:35
--- 50.0.109.4 192.168.109.13 --- ---
```
```
R10#sh ip nat translations
Pro Inside global Inside local Outside local Outside global
icmp 50.0.109.4:35 192.168.109.13:35 3.3.3.3:35 3.3.3.3:35
--- 50.0.109.4 192.168.109.13 --- ---
```
Как мы видим, информация синхронизировалась между двумя HSRP маршрутизаторами, и при ассиметричном роутинге пинг прошел обратно через тот маршрутизатор, который не осуществлял прямую трансляцию адреса.
##### IPv6, NAT-PT
Теперь обратимся к AS812. Напомним, что местные инженеры активно внедряют инновации, поэтому вся внутренняя сеть построена на протоколе IPv6. Тем не менее провайдер, к которому подключена данная компания даже не слышал про существование IPv6, поэтому придется использовать на пограничном маршрутизаторе [NAT-PT](http://blog.ine.com/2008/04/18/understanding-ipv6-nat-pt/) (Protocol Translation).
Данная технология, как это понятно из названия, позволяет осуществлять трансляцию из одного сетевого протокола в другой, и, соответственно, общаться хостам, поддерживающим только IPv6 или только IPv4, друг с другом.
Если мы попробуем сделать это без трансляции, то получим примерно такое сообщение:
```
SW12#ping 200.0.86.6
% Unrecognized host or address, or protocol not running.
```
Определимся с адресацией: предположим, что используется одна большая подсеть 2001:0:0:812::/64
Тогда адрес интерфейса eth0/1 на R8 будет 2001:0:0:812::8/64.
Включаем маршрутизацию пакетов IPv6:
```
R8(config)#ipv6 unicast-routing
```
Задаем IPv6 адрес:
```
R8(config)#interface ethernet 0/1
R8(config-if)#ipv6 address 2001:0:0:812::8/64
```
Включаем NAT на интерфейсах:
```
R8(config)#interface range eth 0/0-2
R8(config-if-range)#ipv6 nat
```
Создаем пул IPv4, в который будут транслироваться наши внутренние IPv6 адреса:
```
R8(config)#ipv6 nat v6v4 pool 6TO4 175.0.0.1 175.0.0.254 prefix-length 24
```
ACL, содержащий префикс, при вводе которого перед IPv4 адресом, мы сообщим маршрутизатору, что нам необходима трансляция:
```
R8(config)#ipv6 access-list v6LIST
R8(config-ipv6-acl)#permit ipv6 any 4::/96
```
Применяем этот ACL:
```
R8(config)#ipv6 nat prefix 4::/96 v4-mapped v6LIST
```
И, собственно, включаем NAT-PT:
```
R8(config)#ipv6 nat v6v4 source list v6LIST pool 6TO4 overload
```
Обратите внимание, что длина префикса составляет 96 бит. Если учесть, что суммарная длина IPv6 адреса 128 бит, получаем в остатке 32 бита, что равно длине IPv4 адреса.
Проверяем. Временно создадим на R6 и на R8 необходимые маршруты и попробуем пропинговать R6 с коммутатора SW12:
```
SW12#ping 4::200.0.86.6
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 4::C800:5606, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/3 ms
```
Как мы видим, технология работает. Для того, чтобы выделенная подсеть 175.0.0.0/24 не пропадала зря (все-таки крайне глупо покупать PI-адреса и использовать их только для динамического NAT'a) можно было бы сконфигурировать статические трансляции v6v4 и v4v6, чтобы, например, внутренний сервер имеющий адрес IPv6 был доступен из внешней сети по IPv4 адресу. Тем не менее этого мы делать не будем.
Больше, в данный момент, у клиентов настраивать особо нечего, так что можно перейти к настройке маршрутизации.
#### OSPF, настройка маршрутизации внутри автономной системы
Начнем с IGP, в частности с протокола OSPF. EIGRP рассматривать не будем, т.к. на таких небольших сетях принципиальных отличий в конфигурации немного.
В сети провайдера ISP1 все роутеры кроме R1 соединены по принципу “каждый с каждым”. Так как R1 подключен только одним линком, имеет смысл вынести его в отдельную totally stubby area (т.е. отдавать R1 только маршрут по умолчанию на R3).
Приведем пример настройки OSPF на R3:
```
R3(config)#router ospf 1234
R3(config-router)#router-id 3.3.3.3
```
По умолчанию запретим всем интерфейсам участвовать в OSPF процессе, а затем включим только нужные (конкретно на R3 данные команды не имеют абсолютно никакого смысла, т.к. все его интерфейсы будут задействованы):
```
R3(config-router)#passive-interface default
R3(config-router)#no passive interface e0/1
R3(config-router)#no passive interface e0/2
R3(config-router)#no passive interface e0/3
R3(config-router)#no passive interface e0/4
```
Следующая команда дает возможность при изменении карты сети запускать процесс SPF только частично, для отдельной ветви дерева, что в больших сетях может несколько уменьшить время сходимости топологии:
```
R3(config-router)#ispf
```
Добавляем сеть в тупиковый регион и конфигурируем сам регион:
```
R3(config-router)#network 50.0.31.0 0.0.0.255 area 1234
R3(config-router)#area 1234 stub no-summary
```
Добавляем подсети из магистрального региона:
```
R3(config-router)#network 50.0.32.0 0.0.0.255 area 0
R3(config-router)#network 50.0.43.0 0.0.0.255 area 0
R3(config-router)#network 50.0.53.0 0.0.0.255 area 0
```
Можно, конечно, анонсировать и так:
```
R3(config-router)#network 50.0.0.0 0.0.255.255 area 0
```
но:
* Есть шанс случайно захватить лишнюю подсеть;
* При удалении одной из суммаризованных подсетей могут возникнуть проблемы;
* Это в принципе дает меньше контроля над ситуацией и повышает риск ошибки.
Также можно объявлять принадлежность подсети к процессу ospf непосредственно на интерфейсе (и это единственный путь в IPv6), но используемый мной способ банально быстрее (на мой взгляд), да и нагляднее, когда вся конфигурация, связанная с определенным протоколом хранится в одном месте.
Сети с loopback'ов добавим командой redistribute connected. Делать это надо аккуратно, потому что всегда есть риск объявить что-то, что объявлять бы не хотелось. Поэтому воспользуемся route-map'ом, чтобы установить четкие ограничения:
```
R3(config)#ip access-list standard REDISTRIBUTE_CONNECTED
R3(config-std-nacl)#permit host 3.3.3.3
R3(config-std-nacl)#permit 3.0.0.3 0.0.0.255
R3(config-std-nacl)#permit 3.0.1.3 0.0.0.255
R3(config-std-nacl)#permit 3.0.2.3 0.0.0.255
R3(config-std-nacl)#permit 3.0.3.3 0.0.0.255
R3(config)#route-map REDISTRIBUTE_CONNECTED
R3(config-route-map)#match ip address REDISTRIBUTE_CONNECTED
R3(config-router)#redistribute connected route-map REDISTRIBUTE_CONNECTED subnets
```
Вообще route-map – крайне гибкая и удобная технология, которая позволяет творить с подсетями практически все что угодно: суммаризовать, вешать различные теги, метки, менять всевозможные параметры, пути следования пакетов, etc. В секции про настройку BGP я затрону route-map'ы чуть более детально.
Остановимся подробнее на том, чем еще выделяется команда redistribute:
```
R5(config)#do sh ip route
-----------------------------------------------------------------
3.0.0.0/8 is variably subnetted, 5 subnets, 2 masks
O E2 3.0.0.0/24 [110/20] via 50.0.53.3, 00:19:17, Ethernet0/0
O E2 3.0.1.0/24 [110/20] via 50.0.53.3, 00:19:07, Ethernet0/0
O E2 3.0.2.0/24 [110/20] via 50.0.53.3, 00:19:07, Ethernet0/0
O E2 3.0.3.0/24 [110/20] via 50.0.53.3, 00:19:07, Ethernet0/0
O E2 3.3.3.3/32 [110/20] via 50.0.53.3, 00:19:37, Ethernet0/0
-----------------------------------------------------------------
O 50.0.32.0/24 [110/20] via 50.0.53.3, 00:21:43, Ethernet0/0
O 50.0.43.0/24 [110/20] via 50.0.53.3, 00:21:43, Ethernet0/0
```
Если мы внимательно посмотрим на таблицу маршрутизации, то увидим, что подсети, созданные командой redistribute connected помечены, как внешние для этой AS маршруты, в отличие от тех, которые добавлены командой network. Соответственно R3 становится ASBR (Autonomous System Boundary Router), хотя по факту им не является.
Также при типе маршрута E2 (а данная метка ставится по умолчанию) метрика не будет пересчитываться, как это обычно происходит в процессе SPF (то есть при увеличении длины пути до подсети стоимость линков учитываться не будет).
Избежать этого можно так:
```
R3(config-router)#redistribute connected route-map REDISTRIBUTE_CONNECTED subnets metric-type 1
```
Вернемся к R1. После конфигурации area 1234 как totally stubby в таблице маршрутизации мы увидим только один маршрут, пришедший по OSPF. Как и ожидалось – это default gateway:
```
R1(config-router)#do sh ip route
--------------------------------------------------------------
Gateway of last resort is 50.0.31.3 to network 0.0.0.0
O*IA 0.0.0.0/0 [110/11] via 50.0.31.3, 00:00:00, Ethernet0/1
-------------------------------------------------------------
```
Все остальные маршрутизаторы в лабораторной настраиваются примерно одинаково, так что нет смысла заострять на них внимание.
#### BGP, настройка маршрутизации между автономными системами
Недавно на собеседовании в одном крупном и известном интеграторе мне задали вопрос: “Зачем вообще нужны IGP, когда у нас есть iBGP?”. Ответ про ужасную скорость сходимости протокола по сравнению с IGP, необходимость топологии full-mesh (или Route Reflector), повышенные требования к ресурсам каждого маршрутизатора в топологии их не удовлетворил.
Только выйдя из переговорной я вспомнил, что BGP не будет помещать в RIB маршруты, для которых next-hop недоступен.
Соответственно, без IGP с внутренних маршрутизаторов мы не сможем достучаться до next-hop (который, как правило, является адресом eBGP пира, не присоединенного непосредственно) и маршрутизации у нас не получится. Думаю, что от меня хотели услышать именно это. К слову, должность мне все-таки предложили, но это уже совсем другая история.
Теперь еще немного про отношения соседства. Вообще-то, по-хорошему, стоило бы устанавливать отношения между eBGP пирами с помощью их loopback-адресов. Тем не менее, у нас нет в этом острой необходимости. Каждый маршрутизатор соединен с каждым не более чем одним линком, соответственно на отказоустойчивость это не повлияет.
Для того, чтобы достучаться до соседнего loopback для eBGP пиров нам бы потребовались следующие действия:
1. Static route на loopback соседа;
2. redistribute static в OSPF (можно обойтись без этого, если на всех iBGP пирах делать команду next-hop self, но мне как-то не очень нравится так делать);
3. Команда neighbor n.n.n.n ebgp-multihop 2 для того, чтобы увеличить ttl служебных BGP пакетов (по умолчанию равен 1);
4. Команда neighbor n.n.n.n update-source lo0.
Чтобы сократить конфигурацию будем использовать:
* loopback адреса для коммуникации между iBGP пирами (это действительно имеет смысл, т.к. даже при падении одного из линков TCP-сессия останется живой благодаря избыточным соединениям);
* адреса на физических интерфейсах для eBGP пиров
.
Настроим BGP в автономной системе 1234.
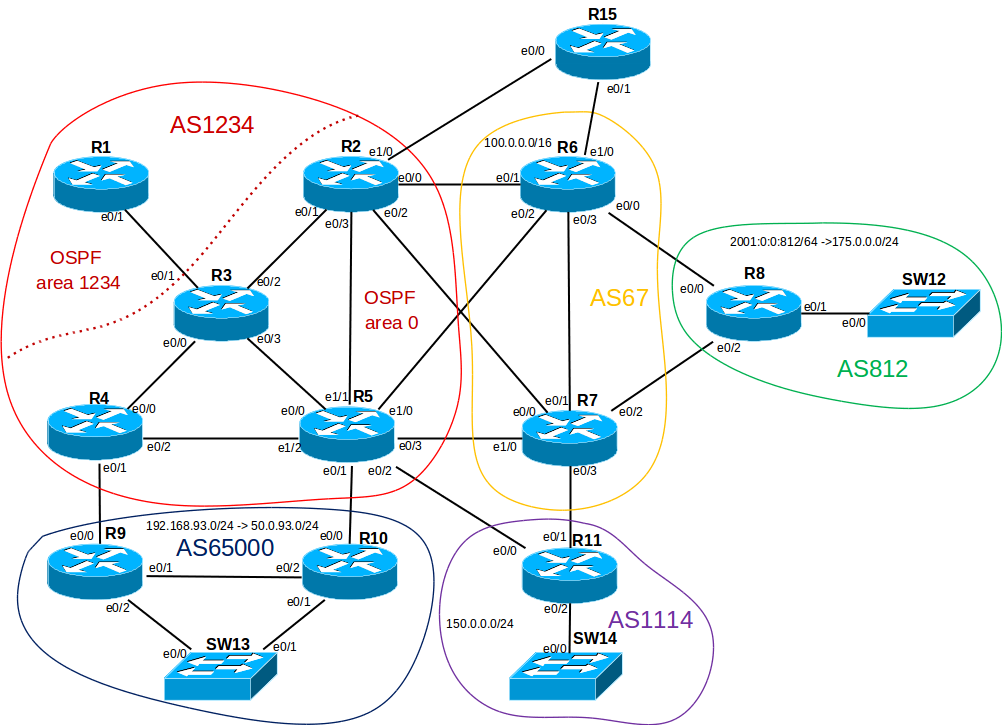
Для начала небольшой чек-лист:
1. prefix-list, фильтрующий приватные сети;
2. prefix-list, фильтрующий p2p-линки;
3. prefix-list, фильтрующий адреса на lo0;
4. prefix-list, фильтрующий адреса, анонсируемые соседней AS;
5. route-map для соседа;
6. route-map для анонса connected сетей (если вдруг мы не захотим анонсировать их командой network);
7. непосредственно конфигурация BGP;
Атрибут community использовать не будем. В данном случае сеть небольшая, пиринговых войн не предвидится, DDOS получить неоткуда, поэтому путаницы от community, на мой взгляд, будет больше, чем пользы.
Зачем вообще мы делаем фильтрацию? Затем, что если клиент неадекватен и вдруг решит анонсировать все, что ему захочется (в нашем случае AS65000 попробует поступить именно так), провайдер ОБЯЗАН пресечь данные действия со своей стороны.
Пойдем по списку. Для примера будем настраивать R4:
1) Т.к. это всего лишь лабораторная, будем фильтровать не все сети, а только 3 самых известных (существует еще куча зарезервированных под разные нужды префиксов, например 127.0.0.0/8):
```
R4(config)#ip prefix-list PRIVATE_IP permit 10.0.0.0/8 le 32
R4(config)#ip prefix-list PRIVATE_IP permit 172.16.0.0/12 le 32
R4(config)#ip prefix-list PRIVATE_IP permit 192.168.0.0/16 le 32
```
2) p2p линки между маршрутизаторами внутри автономной системы, на мой взгляд, информация, которую незачем оглашать, так что лучше оставим ее внутри AS:
```
R4(config)#ip prefix-list P2P permit 50.0.31.0/24 le 32
R4(config)#ip prefix-list P2P permit 50.0.32.0/24 le 32
R4(config)#ip prefix-list P2P permit 50.0.43.0/24 le 32
R4(config)#ip prefix-list P2P permit 50.0.52.0/24 le 32
R4(config)#ip prefix-list P2P permit 50.0.53.0/24 le 32
R4(config)#ip prefix-list P2P permit 50.0.54.0/24 le 32
```
3) Наши lo0 адреса также не должны маршрутизироваться, т.к. таким образом мы можем навредить реальному хосту 1.1.1.1, или, например, сделать недоступным DNS-сервер google с адресом 8.8.8.8 (на самом деле не можем, уже давно все провайдеры фильтруют сети с маской /25 и больше).
```
R4(config)#ip prefix-list LOOPBACK permit 1.1.1.1/32
R4(config)#ip prefix-list LOOPBACK permit 2.2.2.2/32
R4(config)#ip prefix-list LOOPBACK permit 3.3.3.3/32
R4(config)#ip prefix-list LOOPBACK permit 4.4.4.4/32
R4(config)#ip prefix-list LOOPBACK permit 5.5.5.5/32
```
4) Наша соседняя AS65000 транзитной не является, следовательно не может анонсировать ничего, кроме выданной ей подсети 50.0.109.0/24. Проконтролируем это:
```
R4(config)#ip prefix-list ADVERTISED permit 50.0.109.0/24 le 32
```
На этом закончим с фильтрацией. Я никогда (на момент написания этой части статьи) не работал в ISP, но у меня есть очень сильное подозрение, что у них в BGP фильтруется в несколько раз больше маршрутов, и цели для этого могут быть самыми разными.
5) Пришло время настроить route-map. Так как в префикс листах мы писали “permit”, сейчас мы будем писать “deny”.
Фильтрация исходящего трафика:
```
R4(config)#route-map AS65000_OUT deny 10
R4(config-route-map)#match ip address prefix-list LOOPBACK
R4(config-route-map)#match ip address prefix-list P2P
R4(config-route-map)#match ip address prefix-list PRIVATE_IP
R4(config)#route-map AS65000_OUT permit 20
```
Фильтрация входящего трафика:
```
R4(config)#route-map AS65000_IN
R4(config-route-map)#match ip address prefix-list ADVERTISED
R4(config)#route-map AS65000_IN deny 20
```
6) На R4 будем добавлять connected сети 4.0.0.0/24 – 4.0.3.0/24 суммаризованными в одну подсеть 4.0.0.0/22. Сделать это можно несколькими способами, покажем один из них:
```
R4(config)#ip access-list standard REDISTRIBUTE_CONNECTED
R4(config-std-nacl)#permit 4.0.0.0 0.0.3.255
R4(config)#route-map REDISTRIBUTE_CONNECTED
R4(config-route-map)#match ip address REDISTRIBUTE_CONNECTED
R4(config-route-map)#router bgp 1234
R4(config-router)#redistribute connected route-map REDISTRIBUTE_CONNECTED
```
На этом этапе мы получаем такой вывод #sh ip bgp:
```
R4(config-router)#do sh ip bgp
-------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
*> 4.0.0.0/24 0.0.0.0 0 32768 ?
*> 4.0.1.0/24 0.0.0.0 0 32768 ?
*> 4.0.2.0/24 0.0.0.0 0 32768 ?
*> 4.0.3.0/24 0.0.0.0 0 32768 ?
```
Теперь делаем
```
R4(config-router)#aggregate-address 4.0.0.0 255.255.252.0 summary-only
```
и видим следующий вывод:
```
R4(config-router)#do sh ip bgp
-------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
s> 4.0.0.0/24 0.0.0.0 0 32768 ?
*> 4.0.0.0/22 0.0.0.0 32768 i
s> 4.0.1.0/24 0.0.0.0 0 32768 ?
s> 4.0.2.0/24 0.0.0.0 0 32768 ?
s> 4.0.3.0/24 0.0.0.0 0 32768 ?
```
Все маршруты, кроме суммарного, помечены буквой “s” — suppressed, что значит подавленные. Анонсироваться они не будут. Если бы мы по каким то причинам ввели команду aggregate-address без ключевого слова summary-only, то анонсировались бы и суммаризованная подсеть, и каждая из /24 по отдельности.
7) Пришло время непосредственной настройки процесса BGP, установления соседских отношений и конфигурации прочих параметров, описывающих общий характер работы протокола:
```
R4(config)#router bgp 1234
R4(config-router)#bgp router-id 4.4.4.4
R4(config-router)#neighbor 3.3.3.3 remote-as 1234
R4(config-router)#neighbor 3.3.3.3 update-source lo0
R4(config-router)#neighbor 5.5.5.5 remote-as 1234
R4(config-router)#neighbor 5.5.5.5 update-source lo0
R4(config-router)#neighbor 200.0.94.9 remote-as 65000
```
Применим ранее сконфигурированные route-map на соседа:
```
R4(config-router)#neighbor 200.0.94.9 route-map AS65000_IN in
R4(config-router)#neighbor 200.0.94.9 route-map AS65000_OUT out
```
Теперь настало время настроить R3.
Пропустим все пункты про фильтрацию, т.к. у R3 нет eBGP пиров. Вместо этого сконфигурируем R3 как [Route Reflector](http://xgu.ru/wiki/BGP_route_reflector). Дело в том, что iBGP пиры при получении маршрута не отправляют его дальше. Таким образом у нас обязательно должна быть full-mesh топология, чтобы, например, R4 мог получить маршруты с R2.
Посмотрев на нашу топологию можно заметить, что до full-mesh она немного не дотягивает. Поэтому придется использовать Route Reflector, чтобы все iBGP пиры выучили все iBGP маршруты.
Так как соседей у нас целых 3, имеет смысл конфигурировать их с помощью peer-group:
```
R3(config-router)#neighbor LOCAL peer-group
R3(config-router)#neighbor LOCAL remote-as 1234
R3(config-router)#neighbor 2.2.2.2 peer-group LOCAL
R3(config-router)#neighbor 4.4.4.4 peer-group LOCAL
R3(config-router)#neighbor 5.5.5.5 peer-group LOCAL
R3(config-router)#neighbor LOCAL update-source lo0
```
Настроим номер группы для Route Reflector (следует уделять этому особое внимание, если кластеров планируется сделать несколько):
```
R3(config-router)#bgp cluster-id 1
```
И сделаем всех наших соседей клиентами:
```
R3(config-router)#neighbor LOCAL route-reflector-client
```
Обратите внимание, что на самих клиентах настраивать ничего не нужно, достаточно указать RR-соседа как обычный iBGP пир.
Также покажем на R3 второй способ суммаризации подсетей.
Создаем суммарный маршрут на null 0 (напомним, что если маршрута нет в RIB, BGP не будет анонсировать его):
```
R3(config)#ip route 3.0.0.0 255.255.252.0 null 0
```
И просто добавляем его в BGP:
```
R3(config-router)#network 3.0.0.0 mask 255.255.252.0
```
Как мы видим, суммаризованная сеть присутствует в таблице BGP и анонсируется. Также мы уже получили от R4 его суммаризованную сеть 4.0.0.0/22:
```
R3(config-router)#do sh ip bgp
-------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
*> 3.0.0.0/22 0.0.0.0 0 32768 i
*>i 4.0.0.0/22 4.4.4.4 0 100 0 i
```
Какой способ суммаризации лучше – судить не мне, но тот, который мы применяли на R4 однозначно гибче в настройке, поэтому я предпочитаю использовать именно его.
Как мы помним R1 соединен только с R3 и не использует BGP, так что на R3 нам надо анонсировать и сеть 50.0.254.0/24 с R1, чтобы она тоже была доступна. Сделаем это самым простым образом:
```
R3(config-router)#network 50.0.254.0 mask 255.255.255.0
```
Казалось бы все должно пройти отлично, маршрут анонсируется, но посмотрим на R4:
```
R4(config-router)#do sh ip bgp
Network Next Hop Metric LocPrf Weight Path
-------------------------------------------------------------------
r>i 50.0.254.0/24 50.0.31.1 20 100 0 i
-------------------------------------------------------------------
```
Мы поймали RIB-failure. На самом деле абсолютно ничего страшного не случилось. Есть несколько причин по которым может появиться RIB-failure. В данном случае это произошло потому, что в RIB на R4 уже есть маршрут с лучшей AD (полученный через OSPF) до данного префикса. Будет ли этот маршрут анонсироваться в другие AS? Ответ – да, будет, волноваться не о чем.
Например на R9 (если предположить, что BGP там уже настроен):
```
R9(config)#do sh ip bgp
---------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
*> 3.0.0.0/22 200.0.94.4 0 1234 i
*> 4.0.0.0/22 200.0.94.4 0 0 1234 i
*> 50.0.109.0/24 0.0.0.0 0 32768 i
*> 50.0.254.0/24 200.0.94.4 0 1234 i
---------------------------------------------------------------------
```
Кстати говоря, раз уж получилось так, что BGP на R9 уже работает, попробуем чисто ради интереса проанонсировать серую подсеть 192.168.109.0/24 и посмотреть, отработает ли фильтрация на R4:
```
R4#debug ip bgp 200.0.94.9 updates
```
```
R9(config-router)#network 192.168.109.0 mask 255.255.255.0
```
```
R4#
*Nov 28 22:13:31.004: BGP(0): 200.0.94.9 rcvd UPDATE w/ attr: nexthop 200.0.94.9, origin i, metric 0, merged path 65000, AS_PATH
*Nov 28 22:13:31.004: BGP(0): 200.0.94.9 rcvd 192.168.109.0/24 -- DENIED due to: route-map;
```
Как мы видим, R4 попытался получить обновление, но route-map отработал как надо.
К слову, на R9 и R10 ничего фильтровать не будем, переложим эти заботы на провайдера. Предположим, что местные инженеры не обладают достаточной квалификацией (на самом деле мне просто лень, к тому же я обещал, что AS65000 особой адекватностью отличаться не будет).
На R5 и R2 добавим еще одну необходимую нам команду в стандартную конфигурацию BGP:
```
R5(config-router)#neighbor 200.0.115.11 remove-private-as
```
Таким образом мы уберем из анонса приватную AS. Посмотрим, как теперь будет выглядеть путь к подсети 50.0.109.0/24 (префикс из приватной AS 65000) для маршрутизатора R11:
```
R11(config-router)#do sh ip bgp
---------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
*> 3.0.0.0/22 200.0.115.5 0 1234 i
*> 4.0.0.0/22 200.0.115.5 0 1234 i
*> 5.0.0.0/24 200.0.115.5 0 0 1234 i
*> 5.0.1.0/24 200.0.115.5 0 0 1234 i
*> 5.0.2.0/24 200.0.115.5 0 0 1234 i
*> 5.0.3.0/24 200.0.115.5 0 0 1234 i
*> 50.0.109.0/24 200.0.115.5 0 1234 i
*> 50.0.254.0/24 200.0.115.5 0 1234 i
---------------------------------------------------------------------
```
В столбце path для интересующего нас префикса указана только одна AS – 1234, следовательно наша задумка удалась, и приватная AS65000 не отображается.
Кстати говоря, фильтрация на R11 просто жизненно необходима. Дело в том, что AS1114 подключена сразу к двум ISP, но транзитной не является (судя по вики такие AS называются многоинтерфейсными). Поэтому, если вдруг какой-то трафик, не относящийся к этой AS пройдет через нее, плохо будет всем:
* провайдерам, т.к. каналы скорее всего имеют не очень большую пропускную способность, следовательно часть пакетов будет теряться;
* компании владеющей AS, т.к. ее аплинки будут забиты чужим, абсолютно неинтересным ей трафиком.
Как делать фильтрацию на R11 показывать не буду, концептуально этот процесс не отличается от уже описанного. Скажу только, что там будет присутствовать такая команда:
```
R11(config)#ip prefix-list OUTBOUND permit 150.0.0.0/24 le 32
```
Немного по поводу того, почему везде используются префикс-листы, а не ACL:
* Одним префикс-листом мы можем отфильтровать сразу все подсети данной сети (например команда чуть выше фильтрует не только /24 маску, но и всевозможные /25, /26, etc...);
* Я смутно помню, как читал статью, где рассказывалось, что у prefix-list древовидная структура в отличие от ACL, соответственно маршрутизатору требуется несколько меньше ресурсов для лукапа (возможно неправда, полагаюсь на память, статью найти не могу).
Честно говоря, мне очень надоело полноценно конфигурировать BGP на каждом маршрутизаторе, так что на всех остальных настройки будут такими, чтобы поднялось и маршрутизировало (предупреждаю на случай, если где-то в дальнейшем это всплывет).
При полностью настроенной маршрутизации sh ip bgp на R8 выглядит так:
**sh ip bgp**
```
R8(config-router)#do sh ip bgp
------------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
* 2.0.0.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 2.0.1.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 2.0.2.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 2.0.3.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 3.0.0.0/22 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 4.0.0.0/22 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 5.0.0.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 5.0.1.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 5.0.2.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 5.0.3.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 6.0.0.0/24 200.0.87.7 0 67 i
*> 200.0.86.6 0 0 67 i
* 6.0.1.0/24 200.0.87.7 0 67 i
*> 200.0.86.6 0 0 67 i
* 6.0.2.0/24 200.0.87.7 0 67 i
*> 200.0.86.6 0 0 67 i
* 6.0.3.0/24 200.0.87.7 0 67 i
*> 200.0.86.6 0 0 67 i
* 7.0.0.0/24 200.0.87.7 0 0 67 i
*> 200.0.86.6 0 67 i
* 7.0.1.0/24 200.0.87.7 0 0 67 i
*> 200.0.86.6 0 67 i
* 7.0.2.0/24 200.0.87.7 0 0 67 i
*> 200.0.86.6 0 67 i
* 7.0.3.0/24 200.0.87.7 0 0 67 i
*> 200.0.86.6 0 67 i
* 50.0.109.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 50.0.254.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 100.0.0.0/16 200.0.87.7 0 0 67 i
*> 200.0.86.6 0 67 i
* 150.0.0.0/24 200.0.87.7 0 67 1114 i
*> 200.0.86.6 0 67 1114 i
*> 175.0.0.0/24 0.0.0.0 0 32768 i
```
Как мы видим, R8 держит на себе два местных full view (был бы настоящий интернет — был бы настоящий full view).
Проверяя связность я был несколько удивлен этим:
```
SW12#ping 4::3.0.0.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 4::300:3, timeout is 2 seconds:
!.!.!
Success rate is 60 percent (3/5), round-trip min/avg/max = 1/2/4 ms
```
Описание и решение [здесь](http://routersysco.wordpress.com/2011/12/21/nat-pt-network-address-translation-issues/).
Я пошел на крайние меры и выключил CEF на R8 (никогда так не делайте). Ситуация исправилась:
```
SW12#ping 4::3.0.0.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 4::300:3, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/3 ms
```
#### MPLS VPN
Про MPLS будет сказано не так много, как хотелось бы. Мы просто настроим его и попробуем запустить L2 и L3 VPN. Для этих целей задействуем ранее остававшийся в стороне маршрутизатор R15.

Для начала базовые (самые базовые, только чтобы заработало) настройки MPLS на маршрутизаторах (в AS67 у нас нет P (Provider) устройств, только PE (Provider Edge), чего вполне достаточно для демонстрации VPN). Конфигурацию покажу только на одной стороне (R7 и R11), на другой все то же самое:
Включаем MPLS на интерфесах, на которых работает OSPF:
```
R7(config)#router ospf 67
R7(config-router)#mpls ldp autoconfig
R7(config)#mpls ldp router-id loopback 0
```
Настраиваем диапазон используемых меток:
```
R7(config)#mpls label range 700 799
```
Включаем MPLS глобально:
```
R7(config)#mpls ip
```
[Тут](http://cisco-lab.by/study/articles/1299-mpls-vpn-atom-eompls.html) про MPLS VPN написано лучше, чем у меня, но я все-таки повторю процесс настройки.
##### Через AS67 мы пробросим L2VPN R11 R15
Для начала надо сконфигурировать VLAN для проброса на R11 и R15:
```
R11(config)#bridge irb
R11(config)#bridge 100 protocol ieee
R11(config)#bridge 100 bridge ip
R11(config)#bridge 100 route ip
R11(config)#int bvi 100
R11(config-if)#ip address 192.168.100.11 255.255.255.0
R11(config)#int eth0/2.100
R11(config-subif)#encapsulation dot1Q 100
R11(config-subif)#bridge-group 100
R11(config)#int eth 0/1.100
R11(config-subif)#encapsulation dot1Q 100
R11(config-subif)#bridge-group 100
```
А теперь ввести всего несколько команд на PE:
```
R7(config)#int eth 0/3.100
R7(config-subif)#encapsulation dot1Q 100
R7(config-subif)#xconnect 6.6.6.6 100 encapsulation mpls
R7(config-subif)#mpls ip
```
Все, L2 связность между VLAN 100 за R11 и R15 поднята. Проверим:
```
SW14#ping 192.168.100.15
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.100.15, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/2/8 ms
```
##### Через AS1234 мы пробросим L3VPN R11 R15
Настройки, в целом, несколько сложнее чем для L2 VPN, но, по большому счету, ничего особого в них нет:
Настраиваем L3VPN только на PE и CE (Customer Edge) маршрутизаторах (трогать P не требуется).
Для проверки маршрутизации создадим приватную подсеть 10.0.150.0/24 на R11 и сеть 10.0.151.0/24 на R15. Наша задача – получить рабочий пинг с Loopback 150 на R11 до Loopback 151 на R15.
Во-первых, необходимо настроить стык PE-CE:
Использовать будем подсеть 10.0.0.0/24 (сконфигурируем на сабинтерфейсах, т.к. в дальнейшем мы привяжем их к VRF, и после этого, если поднимать на физике, понадобится более глобально перенастраивать BGP и переносить соседа в данный VRF).
На CE все просто:
```
R11(config)#router ospf 150
R11(config-router)#network 10.0.0.5 0.0.0.255 area 0
R11(config-router)#network 10.0.150.0 0.0.0.255 area 0
```
А на PE нам потребуется создавать отдельный клиентский VRF (виртуальная сущность, имитирующая отдельный маршрутизатор с собственной таблицей маршрутизации, интерфейсами, etc...):
```
R5(config)#ip vrf AS1114
R5(config-vrf)#rd 1234:1
R5(config-vrf)#route-target export 1234:1
R5(config-vrf)#route-target import 1234:1
```
Также есть необходимость подкрутить BGP:
```
R5(config-router)#address-family vpnv4
R5(config-router-af)#neighbor 2.2.2.2 activate
R5(config-router-af)#neighbor 2.2.2.2 send-community both
R5(config-router-af)#exit-address-family
```
Теперь на PE создадим процесс OSPF в клиентском VRF:
```
R5(config)#router ospf 150 vrf AS1114
```
увидим это:
```
*Nov 29 13:29:51.725: %OSPF-4-NORTRID: OSPF process 150 failed to allocate unique router-id and cannot start
```
и присвоим процессу router-id:
```
R5(config-router)#router-id 10.0.0.5
```
Добавляем необходимую нам сеть:
```
R5(config-router)#network 10.0.0.0 0.0.0.255 area 0
```
и связываем BGP с OSPF:
```
R5(config)#router bgp 1234
R5(config-router)#address-family ipv4 vrf AS1114
R5(config-router-af)#redistribute ospf 150
R5(config-router-af)#exit-address-family
R5(config)#router ospf 150 vrf AS1114
R5(config-router)#redistribute bgp 1234 subnets
```
Привязываем интерфейс к VRF:
```
R5(config-subif)#ip vrf forwarding AS1114
```
И видим, что надо пересоздать ip-адрес на интерфейсе:
```
% Interface Ethernet0/2.10 IPv4 disabled and address(es) removed due to enabling VRF AS1114
R5(config-subif)#ip add 10.0.0.5 255.255.255.0
```
Теперь то же самое на другой паре PE-CE. Единственное отличие – на R15 нет BGP, так что мы можем не создавать сабинтерфейсы для разных VRF, а делать все в одном физическом. В текущей конфигурации это будет работать.
Когда все будет готово, можем посмотреть RIB на R15:
```
R15(config)#do sh ip route ospf
-----------------------------------------------------------------------
O E2 10.0.150.11/32 [110/11] via 200.0.152.2, 00:02:26, Ethernet0/0
O E2 200.0.115.0/24 [110/1] via 200.0.152.2, 00:02:26, Ethernet0/0
-----------------------------------------------------------------------
```
Мы видим, что маршруты через L3 VPN поднялись и доступны:
```
R15(config)#do ping 10.0.150.11 source 10.0.151.15
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.150.11, timeout is 2 seconds:
Packet sent with a source address of 10.0.151.15
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/2/5 ms
```
Loopback адрес на R11 пингуется с R15 (и наоборот), значит цель достигнута.
Кстати говоря, шифровать трафик здесь необходимо. Я попробовал зайти telnet'ом с R11 на R15 и с помощью Wireshark на линке R2 R5 легко нашел пару логин/пароль и все введенные конфигурационные команды.
Конфигурация BGP на R5 в данный момент выглядит таким образом:
**sh run | sec bgp**
```
R5(config-subif)#do sh run | sec bgp
router bgp 1234
bgp router-id 5.5.5.5
bgp log-neighbor-changes
neighbor 2.2.2.2 remote-as 1234
neighbor 2.2.2.2 update-source Loopback0
neighbor 3.3.3.3 remote-as 1234
neighbor 3.3.3.3 update-source Loopback0
neighbor 4.4.4.4 remote-as 1234
neighbor 4.4.4.4 update-source Loopback0
neighbor 200.0.65.6 remote-as 67
neighbor 200.0.75.7 remote-as 67
neighbor 200.0.105.10 remote-as 65000
neighbor 200.0.115.11 remote-as 1114
!
address-family ipv4
network 5.0.0.0 mask 255.255.255.0
network 5.0.1.0 mask 255.255.255.0
network 5.0.2.0 mask 255.255.255.0
network 5.0.3.0 mask 255.255.255.0
neighbor 2.2.2.2 activate
neighbor 3.3.3.3 activate
neighbor 4.4.4.4 activate
neighbor 200.0.65.6 activate
neighbor 200.0.65.6 remove-private-as
neighbor 200.0.75.7 activate
neighbor 200.0.75.7 remove-private-as
neighbor 200.0.105.10 activate
neighbor 200.0.105.10 route-map AS65000_IN in
neighbor 200.0.105.10 route-map AS65000_OUT out
neighbor 200.0.115.11 activate
neighbor 200.0.115.11 remove-private-as
neighbor 200.0.115.11 route-map AS1114_IN in
neighbor 200.0.115.11 route-map AS1114_OUT out
exit-address-family
!
address-family vpnv4
neighbor 2.2.2.2 activate
neighbor 2.2.2.2 send-community both
exit-address-family
!
address-family ipv4 vrf AS1114
redistribute ospf 150
exit-address-family
```
На этом закончим с MPLS и со статьей в целом. | https://habr.com/ru/post/245047/ | null | ru | null |
# Программирование DeFi: Uniswap. Часть 1
Введение
--------
Лучший способ научиться чему-то - научить других. Второй лучший способ научиться чему-то - сделать это самому. Я решил объединить эти два способа и научить себя и вас программировать DeFi сервисы на Ethereum (и любых других блокчейнах, основанных на EVM - Ethereum Virtual Machine).
Мы сосредоточимся на том, как работают эти сервисы, попытаемся понять экономическую механику, которая делает их такими, какие они есть (а все DeFi основаны на экономической механике). Мы будем выяснять, разбирать, изучать и создавать основные механизмы DeFi.
Однако мы будем работать только над смарт-контрактами: создание front-end для смарт-контрактов - тоже большая и интересная задача, но она выходит за рамки этой статьи.
Давайте начнем наше путешествие с Uniswap. *Полный исходный код можно найти* [*здесь*](https://github.com/Jeiwan/zuniswap/tree/part_1)*.*
Различные версии Uniswap
------------------------
По состоянию на июнь 2021 года было запущено три версии Uniswap.
Первая версия (V1) была запущена в ноябре 2018 года и допускала обмен только между eth и токенами. А также были возможны обмены токенов на токены.
Вторая версия (V2) была запущена в марте 2020 года и представляла собой улучшение V1, позволяя осуществлять прямой обмен между любыми токенами ERC20, а также связанный обмен между любыми парами.
Третья версия (V3) была запущена в мае 2021 года и значительно повысила эффективность использования капитала, что позволило поставщикам ликвидности выводить большую часть своей ликвидности из пулов и при этом получать те же вознаграждения (или сжимать капитал в меньших ценовых диапазонах и получать до 4000x прибыли).
В этой серии мы разберем каждую из версий протокола и попробуем построить упрощенные копии каждой из них.
**Эта статья посвящена Uniswap V1,** чтобы соблюсти хронологический порядок и лучше понять, какие были улучшения от версии к версии.
Что такое Uniswap?
------------------
[Uniswap](https://uniswap.org/) - это децентрализованная криптовалютная биржа (DEX), которая призвана стать альтернативой централизованным биржам. Она работает на блокчейне Ethereum и полностью автоматизирована: здесь нет администраторов, менеджеров или пользователей с привилегированным доступом.
На нижнележащем уровне - это протокол, который позволяет создавать пулы, или пары токенов, и наполнять их ликвидностью, чтобы пользователи могли обменивать (торговать) токены, используя эту ликвидность. Такой алгоритм называется *автоматизированным маркет-мейкером* или *автоматизированным поставщиком ликвидности*.
Давайте узнаем больше о **маркет-мейкерах**.
Маркет-мейкеры (рынкоделы, рынкодвижи) - это организации, которые обеспечивают ликвидность (наполенение торговыыми активами) на классических рынках. Ликвидность - это то, что делает возможными сделки: если вы хотите что-то продать, но никто не покупает это, сделки не будет. Некоторые торговые пары имеют высокую ликвидность (например, BTC-USDT), а некоторые - низкую или вообще не имеют ликвидности (например, некоторые мошеннические или сомнительные альткоины).
DEX должна обладать достаточной ликвидностью, чтобы функционировать и служить альтернативой централизованным биржам. Один из способов получить такую ликвидность - это разработчикам вложить свои собственные деньги (или деньги своих инвесторов) в DEX и стать *маркет-мейкером*. Однако это сложно осуществимое решение, поскольку потребуется много денег, чтобы обеспечить достаточную ликвидность для всех пар, учитывая, что на DEX позволяют обмениваться любыми токенами. Более того, это сделает DEX централизованным: будучи единственными маркет-мейкерами, разработчики будут иметь в своих руках большую власть.
Лучшее решение - позволить **каждому стать маркет-мейкером**, и именно это делает Uniswap *автоматизированным маркет-мейкером*: любой пользователь может внести свои средства в торговую пару (и получить от этого выгоду).
Еще одна важная роль Uniswap - это **ценовой оракул**. Ценовые оракулы - это сервисы, которые получают цены на токены с централизованных бирж и предоставляют их смарт-контрактам - такими ценами обычно трудно манипулировать, поскольку объемы на централизованных биржах часто очень велики. Однако, не имея таких больших объемов, Uniswap все же может служить в качестве ценового оракула.
Uniswap действует как вторичный рынок, привлекающий арбитражеров, которые получают прибыль на разнице в ценах между Uniswap и централизованными биржами. Благодаря этому цены в пулах Uniswap максимально приближены к ценам на более крупных биржах. И это было бы невозможно без надлежащих функций ценообразования и балансировки резервов.
Постоянное соотношение торгуемых пар
------------------------------------
Вы, вероятно, уже слышали это определение, давайте посмотрим, что оно означает.
Автоматический маркет-мейкер - это общий термин, который охватывает различные алгоритмы децентрализованных маркет-мейкеров. Самые популярные из них (и те, которые породили этот термин) связаны с рынками предсказаний - рынками, позволяющими получать прибыль на предсказаниях. Uniswap и другие внутрицепочечные биржи являются логичным продолжением этих алгоритмов.
В основе Uniswap лежит формула **постоянного соотношения** *торгуемых пар*:
Где *x* - резерв eth, *y* - резерв токенов (или наоборот), а *k* - константа. Uniswap требует, чтобы *k* оставалось неизменным независимо от того, сколько существует резервов *x* или *y*. Когда вы обмениваете eth на токены, вы вкладываете свои eth в смарт-контракт и получаете взамен некоторое количество токенов. Uniswap гарантирует, что после каждой сделки k остается неизменным (на самом деле это не так, позже мы увидим, почему).
Эта формула также отвечает за расчеты цен.
Разработка смарт-контрактов
---------------------------
Чтобы действительно понять, как работает Uniswap, мы создадим его копию. Мы будем писать смарт-контракты на [Solidity](https://soliditylang.org/) и использовать [HardHat](https://hardhat.org/) в качестве среды разработки. HardHat - это действительно хороший инструмент, который значительно упрощает разработку, тестирование и развертывание смарт-контрактов.
Настройка проекта
-----------------
Сначала создайте пустой каталог (я назвал свой zuniswap), перейдите в него по cd и установите HardHat:
```
$ mkdir zuniswap && cd $_
$ yarn add -D hardhat
```
Нам также понадобится смарт-контракт для создания токенов, давайте воспользуемся смарт-контрактами ERC20, предоставляемыми [OpenZeppelin.](https://openzeppelin.com/)
```
$ yarn add -D @openzeppelin/contracts
```
Инициализируйте проект HardHat и удалите все из папок contract, script и test.
```
$ yarn hardhat
...следуйте инструкциям...
```
Последний штрих: мы будем использовать последнюю версию Solidity, на момент написания статьи это версия `0.8.4`. Откройте свой `hardhat.config.js` и обновите версию Solidity в нижней его части.
Токен-контракт
--------------
Uniswap V1 поддерживает обмен только между eth и токенами. Поэтому нам нужен смарт-контракт токенов и для этого мы возьмем стандарт ERC20. Давайте напишем его!
```
// contracts/Token.sol
pragma solidity ^0.8.0;
import "@openzeppelin/contracts/token/ERC20/ERC20.sol";
contract Token is ERC20 {
constructor(
string memory _name,
string memory _symbol,
uint256 _initialSupply
) ERC20(_name, _symbol) {
_mint(msg.sender, _initialSupply);
}
}
```
Это все, что нам нужно: мы расширяем смарт-контракт ERC20, предоставленный OpenZeppelin, и определяем собственный конструктор, который позволяет нам задать имя токена (`_name`), символ (`_symbol`) и начальное количество токенов (`initialSupply`). Конструктор также создаёт токены в количестве указано в `initialSupply` и отправляет их по адресу создателя токена.
Теперь начинается самое интересное!
Смарт-контракт Exchange
-----------------------
Uniswap V1 имеет только два смарт-контракта: Factory и Exchange.
Factory - это смарт-контракт реестра, который позволяет создавать Биржи (Exchange), отслеживает все развернутые Биржи, позволяет находить адрес Биржи по адресу токена и наоборот. При этом сразу стоит отметить, что каждая обмениваемая пара (eth-токен) развертывается как отдельный смарт-контракт Биржи и этот смарт-контракт позволяет обменивать eth на указанный токен и обратно. Таким образом смарт-контракт Exchange определяет логику проведения обмена на Бирже по одному конкретному токену.
Мы создадим смарт-контракт Exchange, а Factory оставим для другой статьи.
Давайте создадим новый пустой смарт-контракт:
```
// contracts/Exchange.sol
pragma solidity ^0.8.0;
contract Exchange {}
```
Поскольку каждая Биржа позволяет обмениваться только одним токеном (или иначе - каждый токен требует своей отдельной Биржи), нам необходимо указать по какому токену будет происходить обмен:
```
contract Exchange {
address public tokenAddress;
constructor(address _token) {
require(_token != address(0), “Неправильный адрес токена”);
tokenAddress = _token;
}
}
```
Адрес токена - это переменная сохраняемая в состоянии смарт-контракта, что делает её доступной из любой другой функции смарт-контракта. Если сделать ее `public`, пользователи и разработчики смогут прочитать ее и узнать, с каким токеном связана данная Биржа. В конструкторе мы проверяем, что указан правильный адрес токена (не нулевой адрес), и сохраняем его в переменной состояния.
Обеспечение ликвидности
-----------------------
Как мы уже выяснили, ликвидность делает возможными торги по токенам. Таким образом, нам нужен способ добавить ликвидность в смарт-контракт Биржи:
```
import "@openzeppelin/contracts/token/ERC20/IERC20.sol";
contract Exchange {
...
function addLiquidity(uint256 _tokenAmount) public payable {
IERC20 token = IERC20(tokenAddress);
token.transferFrom(msg.sender, address(this), _tokenAmount);
}
}
```
По умолчанию смарт-контракты не могут получать eth, что можно исправить с помощью модификатора `payable`, который позволяет получать eth в функции: любые eth, отправленные вместе с вызовом функции помеченной как `payable`, добавляются к балансу смарт-контракта.
Депонирование токенов - это совсем другое дело: поскольку балансы токенов хранятся на смарт-контрактах токенов, мы должны использовать функцию `transferFrom` (как определено стандартом ERC20) для передачи токенов с адреса отправителя транзакции на смарт-контракт. Кроме того, отправитель транзакции должен будет вызвать функцию `approve` на смарт-контракте токена, чтобы позволить нашему смарт-контракту Биржи получить свои токены.
*Эта реализация* `addLiquidity` *не является полной. Я намеренно сделал ее такой, чтобы больше сосредоточиться на функциях ценообразования. Мы восполним этот пробел в одной из последующих статьей.*
Давайте также добавим вспомогательную функцию, которая показывает баланс токенов на Бирже:
```
function getReserve() public view returns (uint256) {
return IERC20(tokenAddress).balanceOf(address(this));
}
```
И теперь мы можем протестировать addLiquidity, чтобы убедиться, что все правильно:
```
describe("addLiquidity", async () => {
it("добавляет ликвидность", async () => {
await token.approve(exchange.address, toWei(200));
await exchange.addLiquidity(toWei(200), { value: toWei(100) });
expect(await getBalance(exchange.address)).to.equal(toWei(100));
expect(await exchange.getReserve()).to.equal(toWei(200));
});
});
```
Сначала мы позволяем смарт-контракту Биржи воспользоваться 200 токенами, вызывая функцию `approve`. Затем мы вызываем `addLiquidity`, чтобы внести 200 токенов (для их получения смарт-контракт Биржи вызывает `transferFrom`) и 100 eth, которые отправляются вместе с вызовом функции. Затем мы убеждаемся, что биржа действительно получила их.
*Для краткости я опустил много шаблонного кода в тестах. Пожалуйста, проверьте* [*полный исходный код,*](https://github.com/Jeiwan/zuniswap/tree/part_1) *если что-то непонятно.*
Функция ценообразования
-----------------------
Теперь давайте подумаем, как мы будем рассчитывать биржевые цены.
Может возникнуть соблазн думать, что цена - это просто отношение запасов, например:
И это логично: смарт-контракты Биржи не взаимодействуют с централизованными биржами или любыми другими внешними ценовыми оракулами, поэтому они не могут знать правильную цену. Фактически, смарт-контракт Биржи - это сам по себе ценовой оракул. Все что они знают - это запасы eth и токенов, и это единственная информация, которой они располагают для расчета цен.
Давайте придерживаться этой идеи и построим функцию ценообразования:
```
function getPrice(uint256 inputReserve, uint256 outputReserve)
public pure returns (uint256) {
require(inputReserve > 0 && outputReserve > 0, "invalid reserves");
return inputReserve / outputReserve;
}
```
И давайте проверим это:
```
describe("getPrice", async () => {
it("возвращает правильные цены", async () => {
await token.approve(exchange.address, toWei(2000));
await exchange.addLiquidity(toWei(2000), { value: toWei(1000) });
const tokenReserve = await exchange.getReserve();
const etherReserve = await getBalance(exchange.address);
// ETH за токен
expect(
(await exchange.getPrice(etherReserve, tokenReserve)).toString()
).to.eq("0.5");
// токен за ETH
expect(await exchange.getPrice(tokenReserve, etherReserve)).to.eq(2);
});
});
```
Мы внесли 2000 токенов и 1000 eth и ожидаем, что цена токена составит 0,5 eth, а цена eth - 2 токена. Однако тест провалился: он говорит, что мы получаем 0 eth в обмен на наши токены. Почему так?
Причина в том, что Solidity поддерживает целочисленное деление с округлением до целого. Цена 0,5 округляется до 0! Давайте исправим это, увеличив точность:
```
function getPrice(uint256 inputReserve, uint256 outputReserve)
public
pure
returns (uint256)
{
...
return (inputReserve * 1000) / outputReserve;
}
```
После обновления теста он пройдет:
```
// ETH за токен
expect(await exchange.getPrice(etherReserve, tokenReserve)).to.eq(500);
// токен за ETH
expect(await exchange.getPrice(tokenReserve, etherReserve)).to.eq(2000);
```
Таким образом, теперь 1 токен равен 0,5 eth, а 1 eth равен 2 токенам.
Все выглядит правильно, но что произойдет, если мы обменяем 2000 токенов на eth? Мы получим 1000 eth, а это все, что у нас есть по смарт-контракту! **Биржа будет опустошена!**
Видимо, что-то не так с функцией ценообразования: она позволяет опустошить Биржу, а этого мы не хотим.
Причина этого в том, что функция ценообразования принадлежит формуле постоянной **суммы**, которая определяет kkk как постоянную сумму xxx и yyy. Функция этой формулы представляет собой прямую линию:
График функции постоянной суммы
Она пересекает оси *x* и *y*, что означает, что она допускает 0 в любой из них! Мы определенно не хотим этого.
Правильная функция ценообразования
----------------------------------
Напомним, что Uniswap является маркет-мейкером постоянного соотношения торгуемых пар, что означает, что он основан на формуле постоянного соотношения торгуемых пар:
Дает ли эта формула лучшую функцию ценообразования? Давайте посмотрим.
Формула гласит, что kkk остается постоянным независимо от того, каковы резервы (xxx и yyy). Каждая сделка увеличивает резерв eth или токена и уменьшает резерв токена или eth - давайте запишем эту логику в формулу:
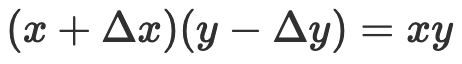Где Δx - количество eth или токенов, которые мы обмениваем на Δy - количество токенов или eth, которые мы получаем в обмен. Имея эту формулу, мы можем теперь найти Δy:
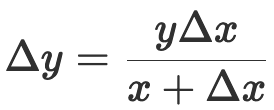Это выглядит интересно: функция теперь учитывает вводимую сумму. Попробуем запрограммировать ее, но учтите, что теперь мы имеем дело с суммами, а не с ценами.
```
function getAmount(
uint256 inputAmount,
uint256 inputReserve,
uint256 outputReserve
) private pure returns (uint256) {
require(inputReserve > 0 && outputReserve > 0, "invalid reserves");
return (inputAmount * outputReserve) / (inputReserve + inputAmount);
}
```
Это низкоуровневая функция, поэтому пусть она будет private. Давайте сделаем две высокоуровневые функции-обертки для упрощения вычислений:
```
function getTokenAmount(uint256 _ethSold) public view returns (uint256) {
require(_ethSold > 0, "ethSold слишком мал");
uint256 tokenReserve = getReserve();
return getAmount(_ethSold, address(this).balance, tokenReserve);
}
function getEthAmount(uint256 _tokenSold) public view returns (uint256) {
require(_tokenSold > 0, "tokenSold слишком мал");
uint256 tokenReserve = getReserve();
return getAmount(_tokenSold, tokenReserve, address(this).balance);
}
```
И проверим их:
```
describe("getTokenAmount", async () => {
it("возвращает правильную сумму токена", async () => {
... addLiquidity ...
let tokensOut = await exchange.getTokenAmount(toWei(1));
expect(fromWei(tokensOut)).to.equal("1.998001998001998001");
});
});
describe("getEthAmount", async () => {
it("возвращает правильную сумму эт", async () => {
... addLiquidity ...
let ethOut = await exchange.getEthAmount(toWei(2));
expect(fromWei(ethOut)).to.equal("0.999000999000999");
});
});
```
Итак, теперь мы получаем 1,998 токена за 1 eth и 0,999 eth за 2 токена. Эти суммы очень близки к тем, которые были получены с помощью предыдущей функции ценообразования. Однако они немного меньше. Почему так?
Формула **постоянного соотношения торгуемых пар**, на которой мы основывали наши расчеты цен, на самом деле является гиперболой:
Гипербола никогда не пересекает xxx или yyy, поэтому ни один из резервов никогда не равен 0. **Это делает резервы бесконечными!**
И есть еще одно интересное следствие: функция ценообразования вызывает проскальзывание (slippage) цены. Чем больше количество торгуемых токенов по отношению к резервам, тем ниже будет цена.
Именно это мы и наблюдали в ходе тестов: мы получили чуть меньше, чем ожидали. Это может показаться недостатком постоянного соотношения торгуемых пар (поскольку каждая сделка имеет проскальзывание), однако это тот же механизм, который защищает пулы от опустошения. Это также согласуется с законом спроса и предложения: чем выше спрос (чем больший объем продукции вы хотите получить) по отношению к предложению (резервам), тем выше цена (тем меньше вы получите).
Давайте улучшим наши тесты, чтобы увидеть, как проскальзывание влияет на цены:
```
describe("getTokenAmount", async () => {
it("возвращает правильную сумму токена", async () => {
... addLiquidity ...
let tokensOut = await exchange.getTokenAmount(toWei(1));
expect(fromWei(tokensOut)).to.equal("1.998001998001998001");
tokensOut = await exchange.getTokenAmount(toWei(100));
expect(fromWei(tokensOut)).to.equal("181.818181818181818181");
tokensOut = await exchange.getTokenAmount(toWei(1000));
expect(fromWei(tokensOut)).to.equal("1000.0");
});
});
describe("getEthAmount", async () => {
it("возвращает правильное количество eth", async () => {
... addLiquidity ...
let ethOut = await exchange.getEthAmount(toWei(2));
expect(fromWei(ethOut)).to.equal("0.999000999000999");
ethOut = await exchange.getEthAmount(toWei(100));
expect(fromWei(ethOut)).to.equal("47.619047619047619047");
ethOut = await exchange.getEthAmount(toWei(2000));
expect(fromWei(ethOut)).to.equal("500.0");
});
});
```
Как вы видите, когда мы пытаемся опустошить пул, мы получаем только половину того, что ожидали.
И последнее, что следует отметить: наша первоначальная функция ценообразования, основанная на соотношении резервов, не была ошибочной. На самом деле, она верна, когда количество токенов, которыми мы торгуем, очень мало по сравнению с резервами. Но для создания AMM нам нужно что-то более сложное.
Функция обмена
--------------
Теперь мы готовы к реализации обмена.
```
function ethToTokenSwap(uint256 _minTokens) public payable {
uint256 tokenReserve = getReserve();
uint256 tokensBought = getAmount(
msg.value,
address(this).balance - msg.value,
tokenReserve
);
require(tokensBought >= _minTokens, "недостаточное количество вывода");
IERC20(tokenAddress).transfer(msg.sender, tokensBought);
}
```
Обмен eth на токены означает отправку некоторого количества eth (хранящихся в переменной `msg.value`) в функцию смарт-контракта и получение токенов взамен. Обратите внимание, что нам нужно вычесть `msg.value` из баланса смарт-контракта, поскольку к моменту вызова функции отправленные eth уже были добавлены к его балансу.
Другой важной переменной здесь является `_minTokens` - это минимальное количество токенов, которое пользователь хочет получить в обмен на свои eth. Эта сумма рассчитывается в пользовательском интерфейсе и всегда включает в себя допуск на проскальзывание; пользователь соглашается получить как минимум столько, но не меньше. Это очень важный механизм, который защищает пользователей от подставных ботов, пытающихся перехватить их транзакции и изменить баланс пула в своих интересах.
Наконец, последняя часть кода на сегодня:
```
function tokenToEthSwap(uint256 _tokensSold, uint256 _minEth) public {
uint256 tokenReserve = getReserve();
uint256 ethBought = getAmount(
_tokensSold,
tokenReserve,
address(this).balance
);
require(ethBought >= _minEth, "недостаточное количество продукции");
IERC20(tokenAddress).transferFrom(
msg.sender,
address(this),
_tokensSold
);
payable(msg.sender).transfer(ethBought);
}
```
Функция передает токены в количестве `_tokensSold` с баланса пользователя на баланс Брижи и в обмен отправляет пользователю eth в количестве указанном в `ethBought`.
Заключение
----------
Вот и все на сегодня! Мы еще не закончили, но мы сделали многое. Наш смарт-контракт Биржи может принимать ликвидность от пользователей, рассчитывать цены таким образом, чтобы защититься от опустошения, и позволяет пользователям обменивать eth на токены и обратно. Это уже много, но некоторых важных частей все еще не хватает:
1. Добавление новой ликвидности может вызвать значительные изменения цен.
2. Поставщики ликвидности не получают вознаграждения; все обмены бесплатны.
3. Нет возможности удалить ликвидность.
4. Нет возможности обмениваться токенами ERC20.
5. Фабрика все еще не реализована.
Мы сделаем это в следующей части.
Серия статей
------------
1. Программирование DeFi: Uniswap. Часть 1
2. [Программирование DeFi: Uniswap. Часть 2](https://habr.com/ru/post/572126/)
3. [Программирование DeFi: Uniswap. Часть 3](https://habr.com/ru/post/572682/)
Полезные ссылки
---------------
1. [Введение в смарт-контракты](https://docs.soliditylang.org/en/latest/introduction-to-smart-contracts.html). Много фундаментальной информации о смарт-контрактах, блокчейне и EVM, которую необходимо изучить перед началом разработки смарт-контрактов.
2. [Давайте запускать децентрализованные биржи на цепочке так же, как мы запускаем рынки предсказаний"](https://www.reddit.com/r/ethereum/comments/55m04x/lets_run_onchain_decentralized_exchanges_the_way/). Сообщение на Reddit от Виталика Бутерина, в котором он предложил использовать механику рынков предсказаний для создания децентрализованных бирж. Это дало идею использовать формулу постоянного соотношения торгуемых пар.
3. [Документация Uniswap V1](https://uniswap.org/docs/v1/)
4. [Техническое описание Uniswap V1](https://hackmd.io/@HaydenAdams/HJ9jLsfTz)
5. [Постоянная функция cоздания рынка: инновации в DeFi](https://medium.com/bollinger-investment-group/constant-function-market-makers-defis-zero-to-one-innovation-968f77022159)
6. [Автоматизированное создание рынка: Теория и практика](http://reports-archive.adm.cs.cmu.edu/anon/2012/CMU-CS-12-123.pdf) | https://habr.com/ru/post/572034/ | null | ru | null |
# Multiple dispatch в C#
Мы уже рассмотрели [две](https://habrahabr.ru/post/280234/) [статьи](https://habrahabr.ru/post/281274/), где функционал C# **dynamic** мог привести к неожиданному поведению кода.
На этот раз я бы хотел показать позитивную сторону, где динамическая диспетчеризация позволяет упростить код, оставаясь при этом строго-типизированным.
В этом посте мы узнаем:
* возможные варианты реализации шаблона множественная диспетчеризация (multiple/double dispatch & co.)
* как ~~избавиться от~~ реализовать Exception Handling Block из Enterprise Library за пару минут. И, конечно же, упростить policy-based модель обработки ошибок
* **dynamic** – эффективнее Вашего кода
### А оно нам надо?
Иногда мы можем столкнуться с проблемой выбора перегрузки методов. Например:
```
public static void Sanitize(Node node)
{
Node node = new Document();
new Sanitizer().Cleanup(node); // void Cleanup(Node node)
}
class Sanitizer
{
public void Cleanup(Node node) { }
public void Cleanup(Element element) { }
public void Cleanup(Attribute attribute) { }
public void Cleanup(Document document) { }
}
```
**[иерархия классов]**
```
class Node { }
class Attribute : Node
{ }
class Document : Node
{ }
class Element : Node
{ }
class Text : Node
{ }
class HtmlElement : Element
{ }
class HtmlDocument : Document
{ }
```
Как мы видим, будет выбран метод только `void Cleanup(Node node)`. Данную проблему можно решить ООП-подходом, либо использовать приведение типов.
Начнем с простого:
**[приведение типов]**
```
public static void Sanitize(Node node)
{
var sanitizer = new Sanitizer();
var document = node as Document;
if (document != null)
{
sanitizer.Cleanup(document);
}
var element = node as Element;
if (element != null)
{
sanitizer.Cleanup(element);
}
/*
* остальные проверки на типы
*/
{
// действие по-умолчанию
sanitizer.Cleanup(node);
}
}
```
Выглядит не очень «красиво».
**Поэтому применим ООП:**
```
public static void Sanitize(Node node)
{
var sanitizer = new Sanitizer();
switch (node.NodeType)
{
case NodeType.Node:
sanitizer.Cleanup(node);
break;
case NodeType.Element:
sanitizer.Cleanup((Element)node);
break;
case NodeType.Document:
sanitizer.Cleanup((Document)node);
break;
case NodeType.Text:
sanitizer.Cleanup((Text)node);
break;
case NodeType.Attribute:
sanitizer.Cleanup((Attribute)node);
break;
default:
throw new ArgumentOutOfRangeException();
}
}
enum NodeType
{
Node,
Element,
Document,
Text,
Attribute
}
abstract class Node
{
public abstract NodeType NodeType { get; }
}
class Attribute : Node
{
public override NodeType NodeType
{
get { return NodeType.Attribute; }
}
}
class Document : Node
{
public override NodeType NodeType
{
get { return NodeType.Document; }
}
}
class Element : Node
{
public override NodeType NodeType
{
get { return NodeType.Element; }
}
}
class Text : Node
{
public override NodeType NodeType
{
get { return NodeType.Text; }
}
}
```
Ну что ж, мы объявили перечисление **NodeType**, ввели одноименное абстрактное свойство в класс **Node**. Задача решена. ~~Спасибо за внимание~~.
Такой шаблон помогает в тех случаях, когда необходимо иметь межплатформенную переносимость; будь то язык программирования, либо среда исполнения. По такому пути пошел стандарт [W3C DOM](https://www.w3.org/TR/DOM-Level-1/level-one-core.html), например.
### Multiple dispatch pattern
Мно́жественная диспетчериза́ция или мультиметод (multiple dispatch) является вариацией концепции в ООП для выбора вызываемого метода во время исполнения, а не компиляции.
Чтобы проникнуться идеей, начнем с простого: double dispatch (больше об этом [здесь](https://habrahabr.ru/post/201996/)).
**Double dispatch**
```
class Program
{
interface ICollidable
{
void CollideWith(ICollidable other);
}
class Asteroid : ICollidable
{
public void CollideWith(Asteroid other)
{
Console.WriteLine("Asteroid collides with Asteroid");
}
public void CollideWith(Spaceship spaceship)
{
Console.WriteLine("Asteroid collides with Spaceship");
}
public void CollideWith(ICollidable other)
{
other.CollideWith(this);
}
}
class Spaceship : ICollidable
{
public void CollideWith(ICollidable other)
{
other.CollideWith(this);
}
public void CollideWith(Asteroid asteroid)
{
Console.WriteLine("Spaceship collides with Asteroid");
}
public void CollideWith(Spaceship spaceship)
{
Console.WriteLine("Spaceship collides with Spaceship");
}
}
static void Main(string[] args)
{
var asteroid = new Asteroid();
var spaceship = new Spaceship();
asteroid.CollideWith(spaceship);
asteroid.CollideWith(asteroid);
}
}
```
Суть double dispatch заключается в том, что привязка метода производится наследником в иерархии классов, а не в месте конкретного вызова. К минусам стоит отнести также и проблему расширяемости: при увеличении элементов в системе, придется заниматься copy-paste.
— *Так и где ~~проблема~~ C# dynamic?!* – спросите Вы.
В примере с приведением типов мы уже познакомились с *примитивной* реализацией шаблона мультиметод, где выбор требуемой перегрузки метода происходит в месте конкретного вызова в отличие от double dispatch.
Но постоянно писать кучу if'ов ~~не по фен-шую~~ — плохо!
Не всегда, конечно. Просто примеры выше — синтетические. Поэтому рассмотрим более реалистичные.
### I'll take two
Прежде чем двигаться дальше, давайте вспомним, что такое Enterprise Library.
[Enterprise Library](https://msdn.microsoft.com/ru-ru/library/ff648951.aspx) — это набор переиспользуемых компонентов/блоков (логирование, валидация, доступ к данным, обработка исключений и т.п.) для построения приложений. Существует отдельная [книга](https://www.microsoft.com/en-us/download/details.aspx?id=41145), где рассмотрены все подробности работы.
Каждый из блоков можно конфигурировать как в XML, так и в самом коде.
Блок по обработке ошибок сегодня мы и рассмотрим.
Если Вы разрабатываете приложение, в котором используется pipeline паттерн а-ля ASP.NET, тогда Exception Handling Block (далее просто «EHB») может сильно упростить жизнь. Ведь краеугольным местом всегда является модель обработки ошибок в языке/фрейворке и т.п.
Пусть у нас есть участок кода, где мы заменили императивный код на более ООП-шный с шаблоном policy (вариации шаблона стратегия).
Было:
```
try
{
// code to throw exception
}
catch (InvalidCastException invalidCastException)
{
// log ex
// rethrow if needed
}
catch (Exception e)
{
// throw new Exception with inner
}
```
Стало (с использованием EHB):
```
var policies = new List();
var myTestExceptionPolicy = new List
{
{
new ExceptionPolicyEntry(typeof (InvalidCastException), PostHandlingAction.NotifyRethrow,
new IExceptionHandler[] {new LoggingExceptionHandler(...),})
},
{
new ExceptionPolicyEntry(typeof (Exception), PostHandlingAction.NotifyRethrow,
new IExceptionHandler[] {new ReplaceHandler(...)})
}
};
policies.Add(new ExceptionPolicyDefinition("MyTestExceptionPolicy", myTestExceptionPolicy));
ExceptionManager manager = new ExceptionManager(policies);
try
{
// code to throw exception
}
catch (Exception e)
{
manager.HandleException(e, "Exception Policy Name");
}
```
Что ж, выглядит более «энтерпрайзно». Но можно ли избежать массивных зависимостей и ограничится возможностями самого языка C#?
— *Императивный подход и есть сами возможности языка*, — можно возразить.
Однако не только.
Попробуем написать свой Exception Handling Block, но только проще.
Для этого рассмотрим реализацию раскрутки обработчиков исключений в самом EHB.
Итак, исходный код еще раз:
```
ExceptionManager manager = new ExceptionManager(policies);
try
{
// code to throw exception
}
catch (Exception e)
{
manager.HandleException(e, "Exception Policy Name");
}
```
Цепочка вызовов, начиная с
`manager.HandleException(e, "Exception Policy Name")`
**ExceptionPolicyDefinition.FindExceptionPolicyEntry**
```
private ExceptionPolicyEntry FindExceptionPolicyEntry(Type exceptionType)
{
ExceptionPolicyEntry policyEntry = null;
while (exceptionType != typeof(object))
{
policyEntry = this.GetPolicyEntry(exceptionType);
if (policyEntry != null)
{
return policyEntry;
}
exceptionType = exceptionType.BaseType;
}
return policyEntry;
}
```
**ExceptionPolicyEntry.Handle**
```
public bool Handle(Exception exceptionToHandle)
{
if (exceptionToHandle == null)
{
throw new ArgumentNullException("exceptionToHandle");
}
Guid handlingInstanceID = Guid.NewGuid();
Exception chainException = this.ExecuteHandlerChain(exceptionToHandle,
handlingInstanceID);
return this.RethrowRecommended(chainException, exceptionToHandle);
}
```
**ExceptionPolicyEntry.ExecuteHandlerChain**
```
private Exception ExecuteHandlerChain(Exception ex, Guid handlingInstanceID)
{
string name = string.Empty;
try
{
foreach (IExceptionHandler handler in this.handlers)
{
name = handler.GetType().Name;
ex = handler.HandleException(ex, handlingInstanceID);
}
}
catch (Exception exception)
{
// rest of implementation
}
return ex;
}
```
И это только вершина айсберга.
Ключевым интерфейсом является IExceptionHandler:
```
namespace Microsoft.Practices.EnterpriseLibrary.ExceptionHandling
{
public interface IExceptionHandler
{
Exception HandleException(Exception ex,
Guid handlingInstanceID);
}
}
```
Возьмем его за основу и ничего более.
---
Объявим два интерфейса (зачем это нужно — увидим чуть позже):
```
public interface IExceptionHandler
{
void HandleException(T exception) where T : Exception;
}
public interface IExceptionHandler where T : Exception
{
void Handle(T exception);
}
```
**А также обработчик для исключений ввода-вывода (I/O):**
```
public class FileSystemExceptionHandler : IExceptionHandler,
IExceptionHandler,
IExceptionHandler,
IExceptionHandler
{
public void HandleException(T exception) where T : Exception
{
var handler = this as IExceptionHandler;
if (handler != null)
handler.Handle(exception);
else
this.Handle((dynamic) exception);
}
public void Handle(Exception exception)
{
OnFallback(exception);
}
protected virtual void OnFallback(Exception exception)
{
// rest of implementation
Console.WriteLine("Fallback: {0}", exception.GetType().Name);
}
public void Handle(IOException exception)
{
// rest of implementation
Console.WriteLine("IO spec");
}
public void Handle(FileNotFoundException exception)
{
// rest of implementation
Console.WriteLine("FileNotFoundException spec");
}
}
```
Применим:
```
IExceptionHandler defaultHandler = new FileSystemExceptionHandler();
defaultHandler.HandleException(new IOException()); // Handle(IOException) overload
defaultHandler.HandleException(new DirectoryNotFoundException()); // Handle(IOException) overload
defaultHandler.HandleException(new FileNotFoundException()); // Handle(FileNotFoundException) overload
defaultHandler.HandleException(new FormatException()); // Handle(Exception) => OnFallback
```
Все сработало! Но как? Ведь мы не написали ни строчки кода для разрешения типов исключений и т.п.
**Рассмотрим схему**
Так, если у нас есть соответствующая реализация IExceptionHandler, тогда используем ее.
Если нет — **multiple dispatch** через **dynamic**.
Так, пример №1 можно решить лишь одной строчкой кода:
```
public static void Sanitize(Node node)
{
new Sanitizer().Cleanup((dynamic)node);
}
```
### Подводя итоги
На первый взгляд, весьма неочевидно, что целый паттерн может поместится лишь в одной языковой конструкции, но это так.
При детальном рассмотрении мы увидели, что построение простого policy-based обработчика исключений вполне возможно. | https://habr.com/ru/post/283522/ | null | ru | null |
# Почти OCR для получения пароля VPNBook. PHP + Mikrotik
Недавно VPNBook стал публиковать пароль вместо прямого текста в виде изображения. «Ну как же так» — подумал я и начал искать пути решения этой проблемы. Распознаем «картиночный» пароль VPNBook на PHP. И, конечно, скрипт для Mikrotik.
Уже давно я у себя на роутере (Mikrotik) настроил автоматический бесплатный PPTP VPN туннель от VPNBook.com и успешно до недавнего времени им пользовался. Не буду вдаваться в подробности, они описаны в статье "[Настраиваем автоматическое получение пароля для VPN на Mikrotik](https://habr.com/post/309892/)". До проблемы пароль для VPNBook можно было просто извлечь из html страницы, например, так:
```
preg_match('/Password: **([^<]+)/', $homepage, $matches);
print($matches[1])**
```
А с недавнего времени пароль стал «картинкой». И первая мысль была воспользоваться оптическим распознаванием текста. Я стал пробовать онлайн и оффлайн сервисы OCR, которыми можно было бы распознать пароль. *Передаю привет хабражителю [Winand](https://habr.com/users/Winand/), с которым у нас на эту тему состоялась переписка.* В общем последний OCR, с которым я возился, был Tesseract, который «из коробки» определял пароль, но с ошибками. Но его можно обучить новым шрифтам, чем я и собирался заняться. Когда я подбирал шрифт, похожий на «картиночный», возникла мысль, что это что-то простое, хотя и похоже на teminal из Windows или terminus font из Linux. И voila — это оказался просто встроенный шрифт PHP под номером (размер) 5. Далее я забросил OCR и написал скрипт на PHP, который ищет символы «картиночного» пароля по сгенерированному словарю. Словарь — это набор изображений возможных символов пароля того же цвета и размера. Поиск делается по совпадению изображений. Вот такой нехитрый реверс-инжиниринг. Предполагаю, что текущий вариант изображения у VPNBook продержится недолго, учитывая его примитивность.
### Скрипт vpnbook.php
Сприпт возвращает строку-пароль.
```
php
// размер символа
$wchar = 9;
$hchar = 13;
$strDict = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789 ';
$imgDict = imagecreatetruecolor(2 + strlen($strDict)* $wchar, $hchar);
$bg = imagecolorallocate($imgDict, 0xF6, 0xF6, 0xF6);
$textcolor = imagecolorallocate($imgDict, 0x4C, 0x4C, 0x4C);
imagefill($imgDict, 0, 0, $bg);
imagestring($imgDict, 5, 2, 0, $strDict, $textcolor);
// инициализируем cURL
$ch = curl_init();
// устанавливаем url, с которого будем получать данные
curl_setopt($ch, CURLOPT_URL, 'https://www.vpnbook.com/password.php');
// устанавливаем опцию, чтобы содержимое вернулось нам в string
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_BINARYTRANSFER, 1); // also, this seems wise considering output is image.
// выполняем запрос
$output = curl_exec($ch);
// закрываем cURL
curl_close($ch);
$imgOCR = imagecreatefromstring($output);
// $imgOCR = imageCreateFromPng('password.png');
// в текущее изображение может поместиться 10 полных символов. 2 + 10*9 = 92 < 100
$maxchar = floor((imagesx($imgOCR) - 2) / 9);
$imgBox = imagecreatetruecolor($wchar, $hchar);
$hashDict = Array();
// генерируем словарь
for ($k = 0; $k < strlen($strDict) ; $k++) {
imagecopy($imgBox, $imgDict, 0, 0, 2 + $k * $wchar, 0, $wchar, $hchar);
$hashStr = "";
for($y = 0; $y < $hchar ; $y++)
for($x = 0; $x < $wchar; $x++) $hashStr .= (imagecolorat($imgBox, $x, $y) != 0xF6F6F6)? '1': '0';
$hashDict[$hashStr] = $strDict[$k];
}
// ищем символы по словарю
for ($k = 0; $k < $maxchar ; $k++) {
imagecopy($imgBox, $imgOCR, 0, 0, 2 + $k * $wchar, 0, $wchar, $hchar);
$hashStr = "";
for($y = 0; $y < $hchar ; $y++)
for($x = 0; $x < $wchar; $x++) $hashStr .= (imagecolorat($imgBox, $x, $y) != 0xF6F6F6)? '1': '0';
$tempchar = $hashDict[$hashStr];
if ($tempchar==' ') break;
print($tempchar);
}
/*header('Content-type: image/png');
imagepng($imgOCR);
*/
//var_dump($hashDict);
imagedestroy($imgDict);
imagedestroy($imgOCR);
imagedestroy($imgBox);
?
```
### План Б. Пароль из twitter
С подсказки [vvsvic](https://habr.com/users/vvsvic/) привожу простую реализацию альтернативного скрипта, для извлечения пароля из твиттера VPNBook (https://twitter.com/vpnbook/)
```
php
function url_get_html($url) {
// инициализируем cURL
$ch = curl_init();
// устанавливаем url с которого будем получать данные
curl_setopt($ch, CURLOPT_URL, $url);
// устанавливаем опцию чтобы содержимое вернулось нам в string
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// выполняем запрос
$output = curl_exec($ch);
// закрываем cURL
curl_close($ch);
// возвращаем содержимое
return $output;
}
$homepage = url_get_html('https://twitter.com/vpnbook');
preg_match('/Password: ([^<]+)/', $homepage, $matches);
// Print the entire match result
// var_dump($matches);
print($matches[1])
// print_r($matches);
?
```
### Скрипт Mikrotik VPNBook
Скрипт нужно вызывать каждую минуту из шедулера. Скрипт мониторит статус PPTP соединения и при разрыве связи вызывает всю процедуру запроса нового пароля, таким образом микротик не«флудит попытками открытия соединение в течении нескольких часов с неправильным паролем, а переподключение делается за 1 минуту. Также тут отслеживаются ошибки on-error для fetch и file get, чтобы точнее определить, что пароль получен.
```
# VPNBookScript v2
:global VPNBookpIfName "pptp-out1"
:global VPNBookServerAddresses {"euro217.vpnbook.com";"euro214.vpnbook.com";"us1.vpnbook.com";"us2.vpnbook.com";"ca1.vpnbook.com";"de233.vpnbook.com";"fr1.vpnbook.com"}
#:if ([:typeof $VPNBookServerAddresses] != "array") do={
# :set VPNBookServerAddresses {"euro217.vpnbook.com";"euro214.vpnbook.com";"us1.vpnbook.com";"us2.vpnbook.com";"ca1.vpnbook.com";"de233.vpnbook.com"}
#}
:global VPNBookErr false
:global VPNBookPassFile "VPNBookPass.txt"
:global VPNBookPass
:global VPNBookRun
#:global TToken "4.....................2"
#:global TChatId "2342432...9"
:global VPNBookServerIndex
:if ([:typeof $VPNBookServerIndex] != "num") do={:set VPNBookServerIndex 0}
:if ([/interface pptp-client get $VPNBookpIfName running]) do={
:set VPNBookRun true
} else {
:if (!$VPNBookRun) do={
:set VPNBookServerIndex ($VPNBookServerIndex + 1)
:if ($VPNBookServerIndex>=[:len $VPNBookServerAddresses]) do={:set VPNBookServerIndex 0}
} else {
:set VPNBookRun false
}
:if (![/interface pptp-client get $VPNBookpIfName disabled]) do={/interface pptp-client set $VPNBookpIfName disabled=yes}
:do {/tool fetch url="http://server/vpnbookpass.php" dst-path=$VPNBookPassFile} on-error={:set VPNBookErr true}
:delay 2
:do {:set VPNBookPass [/file get $VPNBookPassFile contents]} on-error={:set VPNBookErr true}
:if (!$VPNBookErr) do={
:if ([/interface pptp-client get $VPNBookpIfName password] != $VPNBookPass) do={/interface pptp-client set $VPNBookpIfName password=$VPNBookPass}
:if ([/interface pptp-client get $VPNBookpIfName connect-to] != $VPNBookServerAddresses->$VPNBookServerIndex) do={/interface pptp-client set $VPNBookpIfName connect-to=($VPNBookServerAddresses->$VPNBookServerIndex)}
:log info ("VPNBook: Attempt to connect to: ".($VPNBookServerAddresses->$VPNBookServerIndex).". Password: $VPNBookPass")
# /tool fetch url=("https://api.telegram.org/bot$TToken/sendmessage\?chat_id=$TChatId&text=VPNBook: Attempt to connect to: ".($VPNBookServerAddresses->$VPNBookServerIndex).". Password: $VPNBookPass") keep-result=no
/interface pptp-client set $VPNBookpIfName disabled=no
}
}
```
Еще рекомендую добавить отключение PPTP интерфейса по разрыву связи (событие on-down) в PPP-профиле, чтобы переподключение вообще не флудило даже в течении 1 минуты.
Соответственно, основной скрипт в течении 1 минуты в случае удачного получения нового пароля поднимет pptp-out1 соединение.
```
add change-tcp-mss=yes name=VPNBook on-down=\
":if (![/interface pptp-client get pptp-out1 disabled]) do={\r\
\n /interface pptp-client set pptp-out1 disabled=yes\r\
\n}" only-one=yes use-compression=yes use-encryption=required use-ipv6=no use-mpls=no use-upnp=no
``` | https://habr.com/ru/post/420373/ | null | ru | null |
# Скрипты по сусекам: как создать инструмент для контроля количества серверных комплектующих на складе

Всем привет, Хабр. Меня зовут Сергей, в Selectel я работаю в департаменте IaaS-продуктов и отвечаю за [выделенные серверы](https://slc.tl/I4PVz), которые мы сдаем в аренду. Число клиентов растет каждый год — вместе с ними растет потребность в новых серверах и комплектующих. Чем больше становится оборудования, тем сложнее контролировать его наличие на складе и вовремя планировать новые поставки. Но это часть моей работы.
Чтобы облегчить эту задачу, я, не программист, написал скрипт, который стал дополнительным инструментом управления постоянно меняющимися цифрами наличия комплектующих. Об этом скрипте и о том, как мы анализируем число оборудования на складе, пишу под катом.
Для начала поясню, как я дошел до написания скриптов. До Selectel я более 6 лет работал в международной торговой компании. В числе моих задач была аналитика показателей филиала и рынка региона в целом. Инструментом анализа данных о складе и продажах были OLAP-кубы и Excel.
В какой-то момент возможностей этой системы уже не хватало, и я познакомился с библиотекой Pandas, открыв для себя возможности Python для анализа данных. Думаю, дата-аналитики подтвердят, что на сегодняшний день это универсальный и эффективный инструмент.
Полученные знания я решил применить и в Selectel.
Немного контекста
-----------------
Мы в Selectel сами собираем серверы. То есть не получаем собранные вендорами машины в коробочке, а закупаем так называемую «рассыпуху» — комплектующие серверов от процессоров до карт памяти, дисков и так далее. Это более выгодное и гибкое решение: мы не ограничены в возможных конфигурациях и можем предоставлять как фиксированные, так и кастомные сборки.
Чтобы поддерживать рост компании, необходимо регулярно закупать новое железо для выделенных серверов, но и не забывать о том, что уже куплено, но не сдано клиентам. Для анализа таких данных мы используем несколько BI- и ERP-систем. С их помощью получаем информацию о расходе комплектующих, остатках на складе, свободных [серверах фиксированных конфигураций](https://slc.tl/I4PVz) и арендованных серверах.
Однако возможностей систем аналитики не всегда достаточно. В таких случаях приходится лезть в БД и обрабатывать «сырые» данные. В случае, если такие данные необходимы регулярно, аналитика автоматизируется.
Почему понадобился скрипт
-------------------------
2021 год был ознаменован кризисом полупроводников, и это отразилось на регулярности поставок оборудования. Чаще стали возникать ситуации, когда отдельные детали задерживаются и собрать конкретную конфигурацию сервера невозможно. При этом остальное железо лежит на складе и снижает показатели оборачиваемости.
Подвидов комплектующих и вариаций их использования очень много. По очень грубым подсчетам [в конфигураторе серверов](https://slc.tl/IYU6V) можно собрать несколько тысяч серверов в разных вариациях (при наличии всех комплектующих на складе).
На сегодняшний день в арсенале выделенных серверов более пяти линеек актуальных процессоров: Intel® Xeon® Scalable 3rd, AMD EPYC™ 7003, Intel® Xeon® W, Intel® Xeon® E, [десктопный сегмент](https://habr.com/ru/company/selectel/blog/651377/). Менее «свежее» железо также доступно к заказу — начиная от предыдущих поколений масштабируемых процессоров Intel® Xeon® Scalable и AMD EPYC™ и заканчивая Intel® Xeon® E3. Под разные модели процессоров применяются совместимые материнские платы, может отличаться тип оперативной памяти. Также, например, на запасы на складе влияет возможность использования масштабируемых процессоров в материнских платах с разным количеством сокетов и их распределения относительно друг друга. Все это усложняет управление заказами и остатками комплектующих на складе.
При очередном планировании возник вопрос, какое максимальное число готовых серверов мы можем собрать прямо сейчас из имеющихся на складе комплектующих всех поколений? Какое железо остается и что является блокером для его использования?
Готового отчета с ответами не было, но ручную выгрузку никто не отменял. С помощью Excel и данных по остаткам на складах я определил соответствие процессоров и материнских плат, просуммировав по семействам, и рассчитал, сколько серверов и с каким объемом памяти мы можем собрать. На расчеты потратил несколько часов и решил, что подход интересный — стоит пользоваться им чаще.
Для автоматизации отчетов с данными в Selectel можно обратиться к сотрудникам департамента аналитики. Они могут делать сложносочиненные дашборды, которые подтягивают данные десятков источников. Для этого нужно сформулировать задачу, цель дашборда, обсудить нюансы с коллегами и запустить в работу.
На этапе формулирования задачи BI-специалистам мне стало понятно, что требования к отчету не очевидны и мне нужно протестировать детали на уровне заказчика. Python для этого подходит лучше, чем Excel, так как позволяет загрузить входящие данные и обработать их скриптом, быстро внести необходимые правки и изменения. Я решил создать прототип отчета с помощью библиотеки Pandas и проверить, как и с какими данными он будет работать. И уже после этого поставить задачу департаменту аналитики.
Верхнеуровнево в создаваемом отчете было достаточно расчетов по количеству процессоров, совместимых материнских плат и оперативной памяти. Я решил начать с этих компонентов, но впоследствии прибавил к ним корпусы и дополнительные сетевые карты.
Создание скрипта
----------------
> **Дисклеймер 1.** Все данные, продемонстрированные далее, получены с помощью функции random на входе и не отражают реальные запасы компании, так как такие данные относятся к коммерческой тайне.
> **Дисклеймер 2.** Также напомню, что я не программист, а категорийный менеджер. Скрипт я написал, чтобы проверить гипотезу о том, насколько полезен был бы такой отчет. Это MVP, главная задача которого — просто работать. А значит, код может быть неидеальным. Но если вы знаете, как его улучшить, поделитесь в комментариях, будет интересно.
### Входящие данные
На входе в отчет используется файл Excel со следующими данными:
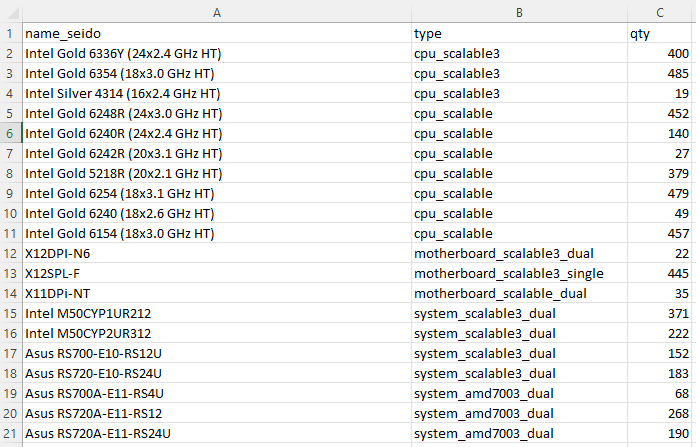
Наименование (name\_seido) и количество комплектующих (qty) выгружаются из учетной системы, столбец type прописывается вручную и содержит в себе тип, семейство комплектующей и количество сокетов для материнских плат. Также доступна выгрузка в Google Sheets, откуда впоследствии можно загрузить датасет в Jupyter Notebook.
После загрузки данных файла в датасет на основе столбца type создаются соответствующие столбцы:

```
data['device'] = data['type'].str.split('_', 1).str[0]
data['family'] = data['type'].str.split('_', 2).str[1]
data['socket'] = data['type'].str.split('_', 3).str[2]
```
### Функции для расчета
Проще всего рассчитать количество доступных для сборки серверов для односокетных материнских плат и совместимых процессоров. Алгоритм функции прост: необходимо определить, чего из двух типов комплектующих меньше, и по этому числу вывести количество серверов. Так же рассчитывается тип и количество «лишних» комплектующих.
```
def cpu_mb(cpu, mb):
print('CPU :',cpu)
print('1 сокетных MB:',mb)
if cpu >= mb:
qty = mb
print('Можем собрать серверов:',qty)
print('Оверсток CPU:',cpu - qty)
else:
qty = cpu
print('Можем собрать серверов:',qty)
print('Оверсток материнских плат:',mb - qty)
return(qty)
```
Для ряда комплектующих масштабируемые процессоры могут устанавливаться как в односокетные материнские платы, так и в двухсокетные. В таком случае задается пропорция. В примере ниже на 60% двухсокетных материнских плат рассчитывается 40% односокетных. Функция усложняется: на первом шаге рассчитываются показатели для односокетных материнских плат, а на следующем — для двухсокетных за вычетом процессоров, использованных на первом шаге.
```
def cpu2_mb2and1(cpu, onesocket, twosocket):
print('CPU :', cpu)
print('односокетные MB :', onesocket)
print('двухсокетные MB :', int(twosocket / 2))
if cpu >= (onesocket + twosocket):
qty = onesocket + twosocket / 2
print('Можем собрать односокетных серверов:', onesocket)
print('Можем собрать двухсокетных серверов:', int(twosocket / 2))
print('Оверсток CPU:', int(cpu - onesocket - twosocket))
elif onesocket <= cpu * 0.25:
qty = int(onesocket + (cpu-onesocket) / 2)
print('Можем собрать односокетных серверов:', int(onesocket))
print('Можем собрать двухсокетных серверов:', int((cpu-onesocket) // 2))
print('Оверсток CPU:', cpu - onesocket - (cpu - onesocket) // 2 * 2)
print('Оверсток двухсокетных MB:', int(twosocket / 2 - int(cpu - onesocket) // 2))
elif twosocket <= cpu * 0.375:
qty = int(twosocket / 2 + cpu-twosocket)
print('Можем собрать односокетных серверов:', int(cpu - twosocket))
print('Можем собрать двухсокетных серверов:', int(twosocket / 2))
print('Оверсток односокетных MB:', onesocket - int(cpu - twosocket))
else:
qty = int(cpu * 0.375)+(cpu - int(cpu * 0.375) * 2)
print('Можем собрать односокетных серверов:', cpu - int(cpu * 0.375) * 2)
print('Можем собрать двухсокетных серверов:', int(cpu * 0.375))
print('Оверсток односокетных MB:', onesocket - (cpu - int(cpu * 0.375) * 2))
print('Оверсток двухсокетных MB:', int(twosocket / 2-int(cpu * 0.375)))
return(qty)
```
Но и это еще не все.
В рамках одного поколения могут существовать масштабируемые процессоры, процессоры, работающие только в одном сокете, и соответствующие материнские платы. Функция для расчета в таком случае предполагает сначала распределение single-процессоров в односокетные системы, затем распределение масштабируемых процессоров в одно- и двухсокетные материнские платы и платформы:
```
def cpu2and1_mb2and1(cpu, cpu1, onesocket, twosocket):
print('масштабируемые CPU :', cpu)
print('single (P) CPU :', cpu1)
print('1 сокетные MB :', onesocket)
print('2 сокетные MB :', int(twosocket / 2))
if cpu1 >= onesocket:
qty_P = onesocket
print('Можем собрать односокетных серверов c single (P) CPU:', int(onesocket))
print('Оверсток single (P) CPU для одного сокета:', cpu1 - onesocket)
onesocket = 0
elif cpu1 <= onesocket:
qty_P = cpu1
print('Можем собрать односокетных серверов c P cpu:', int(cpu1))
onesocket = onesocket - cpu1
if cpu >= (onesocket + twosocket):
qty = onesocket + twosocket / 2
print('Можем собрать односокетных серверов:', onesocket)
print('Можем собрать двухсокетных серверов:', int(twosocket / 2))
print('Оверсток масштабируемых CPU:', int(cpu-onesocket - twosocket))
elif onesocket <= cpu * 0.25:
qty = int(onesocket + (cpu-onesocket) / 2)
print('Можем собрать односокетных серверов:', int(onesocket))
print('Можем собрать двухсокетных серверов:', int((cpu-onesocket) // 2))
print('Оверсток масштабируемых CPU:', cpu-onesocket-(cpu-onesocket) // 2 * 2)
print('Оверсток двухсокетных MB:', int(twosocket / 2 - int(cpu-onesocket) // 2))
elif twosocket <= cpu * 0.375:
qty = int(twosocket / 2 + cpu - twosocket)
print('Можем собрать односокетных серверов:', int(cpu - twosocket))
print('Можем собрать двухсокетных серверов:', int(twosocket / 2))
print('Оверсток односокетных MB:', onesocket - int(cpu - twosocket))
else:
qty = int(cpu * 0.375) + (cpu - int(cpu * 0.375) * 2)
print('Можем собрать односокетных серверов:', cpu - int(cpu * 0.375) * 2)
print('Можем собрать двухсокетных серверов:', int(cpu * 0.375))
print('Оверсток односокетных MB:', onesocket - (cpu - int(cpu * 0.375) * 2))
print('Оверсток двухсокетных MB:', int(twosocket / 2 - int(cpu * 0.375)))
return(qty + qty_P)
```
Ничего не понятно, но жутко интересно.
Как это работает на практике
----------------------------
### Intel® Xeon® E-23xx
Первый пример — для нового поколения процессоров Intel® Xeon® E-23xx.
Минимальная номенклатура комплектующих, только односокетные материнские платы и платформы.
```
data_xeone23 = data.query('family=="xeone23"').copy() #фильтрую только совместимые комплектующие по модели и поколению
cpu_xeone23 = data_xeone23.query('device=="cpu"')['qty'].sum() #считаю число процессоров
mb_xeone23 = data_xeone23.query('device=="motherboard" or device=="system"')['qty'].sum() #считаю число матплат и платформ
print(color.BOLD + 'Intel Xeon E-23xx' + color.END)
display(data_xeone23[['name_seido','device','family','qty']])
print()
qty_xeone23 = cpu_mb(cpu_xeone23,mb_xeone23)
#функция считает кол-во серверов и выводит на экран детали
```
Результат выполнения кода на экране, пора закупать процессоры:
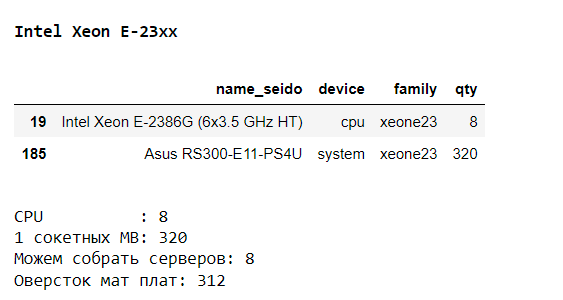
### Intel® Xeon® Scalable 3-го поколения
Усложним задачу и рассмотрим новейшее поколение Intel® Xeon® Scalable.
Это масштабируемые процессоры, которые можно установить как в односокетные, так и в двухсокетные материнские платы или платформы.
```
data_3scalable = data.query('family=="scalable3"').copy()
cpu_3scalable = data_3scalable.query('device=="cpu"')['qty'].sum()
socket1_3scalable = data_3scalable.query('socket=="single"')['qty'].sum()
socket2_3scalable = data_3scalable.query('socket=="dual"')['qty'].sum() * 2
print(color.BOLD + 'Intel 3rd Scalable' + color.END)
display(data_3scalable[['name_seido','device','family','socket','qty']])
qty_3scalable = cpu2_mb2and1(cpu_3scalable,socket1_3scalable,socket2_3scalable)
```
Что видим после выполнения кода:
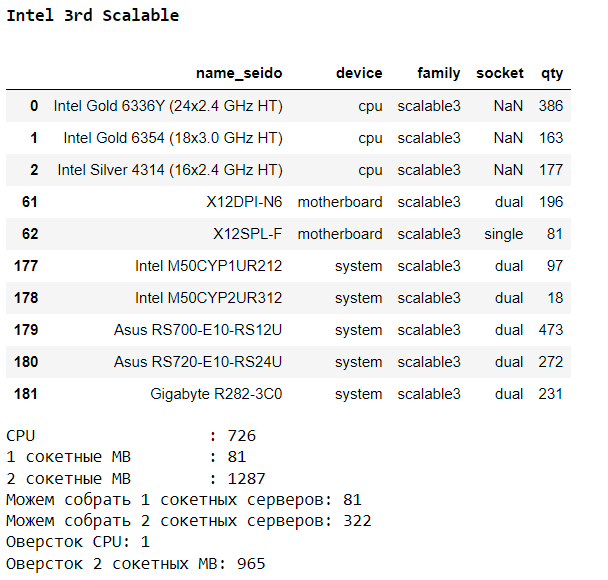
Ситуация с процессорами повторяется: их снова недостаточно. При этом один процессор — лишний, так как число процессоров четное, а односокетных материнских плат — нечетное. В целом видно, что их значительно меньше, чем двухсокетных. Возможно, также стоит докупить односокетные платформы или материнские платы.
Напомню, что **в тестовом датасете число CPU рандомное**, но в реальной жизни процессоры могут задерживаться или частично не приехать вообще. Тогда и возникает оверсток по материнским платам. Об этом, как правило, известно и так, однако скрипт позволяет посчитать показатели быстрее.
### AMD EPYC™ 7003
И наконец, вишенка на торте — AMD EPYC™ 7003. То самое поколение, в котором есть single-процессоры, масштабируемые процессоры и материнские платы с разным количеством сокетов:
```
data_amd7003 = data.query('family=="amd7003" or family=="amd7003p"').copy()
cpu_amd7003 = data_amd7003.query('device=="cpu" and family=="amd7003"')['qty'].sum()
cpu_amd7003p = data_amd7003.query('device=="cpu" and family=="amd7003p"')['qty'].sum()
socket1_amd7003 = data_amd7003.query('socket=="single"')['qty'].sum()
socket2_amd7003 = data_amd7003.query('socket=="dual"')['qty'].sum() * 2
print(color.BOLD + 'AMD EPYC 7003' + color.END)
display(data_amd7003[['name_seido','device','family','socket','qty']])
print()
qty_amd7003 = cpu2and1_mb2and1(cpu_amd7003,cpu_amd7003p,socket1_amd7003,socket2_amd7003)
```
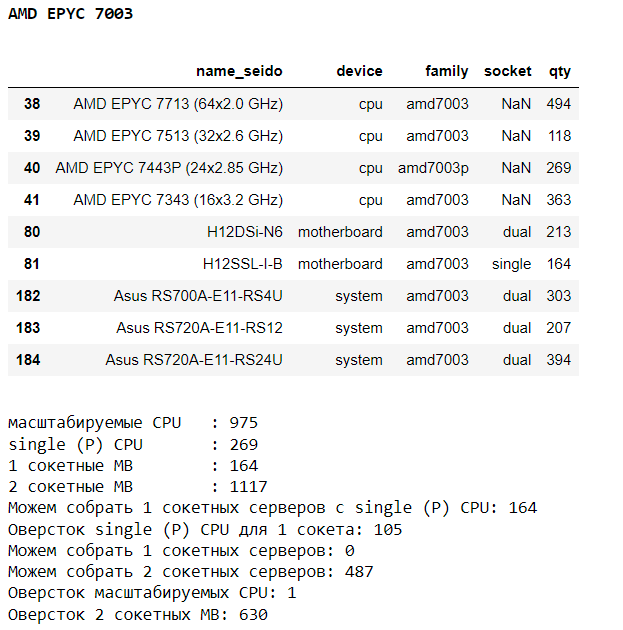
Какие делаем выводы: не хватает односокетных материнских плат и масштабируемых процессоров.
### Общий итог
Общий итог по всем серверам рассчитывается просто:
```
total_servers = ddr4_reg_servers + ddr4_ecc_servers + ddr3_reg_servers + ddr3_ecc_servers
#переменная объявлена ранее в блоке расчета оперативной памяти
print(color.BOLD + 'Всего можем собрать серверов:'+ color.END, int(total_servers))
print('Intel 3rd Scalable: ',int(qty_3scalable))
print('Intel Scalable: ',int(qty_scalable))
print('AMD EPYC 7003: ',int(qty_amd7003))
print('AMD EPYC: ',int(qty_amdepyc))
print('Intel Xeon W: ',int(qty_xeonw))
print('Intel Xeon E-23xx: ',int(qty_xeone23))
print('Intel Xeon E-22xx: ',int(qty_xeone22))
print('Intel Xeon E5: ',int(qty_xeone5))
print('Intel Xeon E5 ddr3: ',int(qty_xeone5ddr3))
print('Intel Xeon E3: ',int(qty_xeone3))
print('Intel Xeon E3 ddr3: ',int(qty_xeone3ddr3))
```
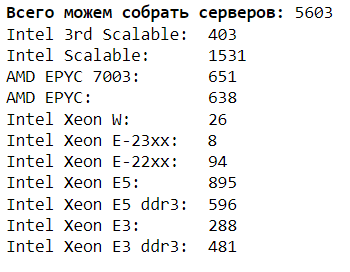
Получаем желаемый результат в виде общего числа потенциальных серверов и разбивку по поколениям.
Расчеты для оперативной памяти, корпусов и сетевых карт.
На примере регистровой памяти DDR4:
```
data_ddr4_reg = data.query('type=="ram_ddr4_reg"').copy()
data_ddr4_reg['size'] = data_ddr4_reg['name_seido'].str.split(' ', 1).str[0].astype(int)
data_ddr4_reg['total'] = data_ddr4_reg['size'] * data_ddr4_reg['qty']
display(data_ddr4_reg[['name_seido','size','qty','total']])
total_ddr4_reg = int(data_ddr4_reg['total'].sum())
```
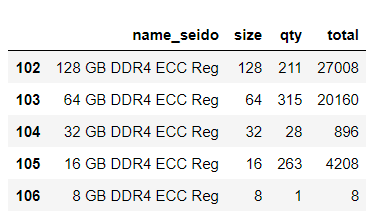
В коде определяется размер памяти по наименованию и рассчитывается общий объем памяти этого типа на складе. Далее происходит пересчет на один сервер исходя из общего количества серверов с данным типом памяти:
```
ddr4_reg_servers = qty_3scalable + qty_xeonw + qty_scalable + qty_amd7003 + qty_amdepyc + qty_xeone5
print(color.BOLD + 'DDR4 ECC REG'+ color.END)
print('Общий объем DDR4 ECC REG:', data_ddr4_reg['total'].sum() / 1000,'TB')
print('Рассчитано серверов:', int(ddr4_reg_servers),'шт')
print('На один сервер:', int(total_ddr4_reg / ddr4_reg_servers),'GB')
```
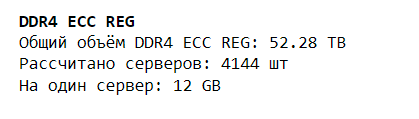
Аналитика поверхностная и не учитывает соотношение планок по размерам, зато она отлично работает как красный флаг для закупки. В нашем примере DDR4 ECC REG на складе недостаточно. Для потенциальной сборки всех серверов не хватит.
Четыре строки кода о корпусах и сетевых картах:
```
print('Всего материнских плат на складе:', data.query('device == "motherboard"')['qty'].sum())
print('Всего корпусов:', data.query('device == "chassis"')['qty'].sum())
print('Расчетное желаемое количество карт 10GE:',int(total_servers*0.4))
print('На складе карт 10GE:',int(data.query('type=="card10ge"')['qty'].sum()))
```

Если после исключения платформ (а они здесь исключены) материнских плат меньше, чем корпусов, необходимо действовать — докупать разницу. В более подробной аналитике, безусловно, также необходимо проверить совместимость и расход разных типов комплектующих. По сетевым картам решение очевидно — пора оформлять заказ.
Что в итоге
-----------
Во-первых, на написание скрипта я потратил несколько часов. И он работает, без привлечения существенных ресурсов компании. Теперь для формирования отчета по остаткам на складе мне не нужно столько же времени «залипать» в Excel.
Во-вторых, при проверке на реальных данных я подсчитал количество доступных к сборке серверов по семействам и поколениям. С удивлением обнаружил дисбаланс комплектующих — например, материнских плат в одном случае и планок памяти в другом. Что примечательно, в обоих случаях для устаревших платформ, например, один из типов DDR3 на складе в избытке. Будем искать ему применение. К работе подключится [отдел сборки](https://habr.com/ru/company/selectel/blog/646261/), так как один из вариантов борьбы с таким оверстоком — создание новой фиксированной конфигурации.
Также ничего не мешает нам добавить к актуальным остаткам информацию о количестве комплектующих, которые находятся в пути и гарантированно приедут в ближайшее время. Результат расчетов меняется, иногда кардинально. Если выявляется недостаток актуального железа, которое мы закупаем, логично отправить заявку в отдел закупок на поставку недостающих комплектующих.
Минус скрипта — в том, что он не интегрирован в общую систему отчетов. Для его запуска необходимо вручную, пусть и в два клика, добавить актуальные остатки и запустить Jupyter Notebook.
Возможно, в дальнейшем мы все-таки сформулируем требование и интегрируем его в BI-систему Selectel. Но сейчас стоимость разработки скрипта в соотношении к выдаваемому результату оптимальна, а тестирование, учет остальных блокеров и поиск новых показателей продолжается.
[](https://slc.tl/I4PVz) | https://habr.com/ru/post/662035/ | null | ru | null |
# Вышел Firebird 4.0

Сегодня, 1 июня 2021 года, выпущен Firebird 4.0 — седьмой основной выпуск СУБД Firebird, разработка которого началась в 2016 году. Ключевой задачей при разработке Firebird 4.0 было повышение доступности баз данных (синхронная и асинхронная логическая репликация).
Одно из важнейших улучшений в Firebird 4.0 — изменение подхода к созданию согласованного представления о состоянии базы данных, видимом для выполняющихся транзакций. Новый подход позволил решить проблему согласованного чтения на уровне запроса в транзакциях Read Committed Read Consistency, а также ввести так называемую промежуточную сборку мусора. Промежуточная сборка мусора позволяет дополнительно сокращать длины цепочек версий при наличии долгих активных транзакций.
* Бинарные комплекты для платформ Windows, Linux и Android (как 32-битные, так и 64-битные) доступны для [загрузки](https://firebirdsql.org/en/firebird-4-0/).
* Также доступна документация по языку SQL Firebird 4.0 на [русском](http://www.ibase.ru/files/firebird/Firebird_4_0_Language_Reference_RUS.pdf) и [английском](https://firebirdsql.org/file/documentation/html/en/refdocs/fblangref40/firebird-40-language-reference.html) языках.
* Для того чтобы администраторы и разработчики могли как можно скорее перейти на новую версию подготовлено краткое руководство по миграции на Firebird 4.0 на [русском](http://www.ibase.ru/files/firebird/fb4migrationshort.pdf) и [английском](https://ib-aid.com/download/docs/fb4migrationguide.pdf) языках.
Далее мы перечислим ключевые улучшения, сделанные в Firebird 4.0, и их краткое описание. Подробное описание всех изменений можно прочитать в [Firebird 4.0 Release Notes](https://firebirdsql.org/file/documentation/release_notes/html/en/4_0/rlsnotes40.html)
Среди важных улучшений также можно отметить поддержку чисел с точностью более 18 цифр, улучшение точности вычислений для более коротких чисел, поддержка часовых поясов, увеличение длины имён метаданных до 63 символов, улучшение подсистемы безопасности, копии постоянной готовности (physical standby) на основе nbackup, таймауты простоя соединения и выполнения SQL запроса, Batch API, а также множество новых возможностей языка SQL.
Далее мы перечислим ключевые улучшения, сделанные в Firebird 4.0, и их краткое описание. Подробное описание всех изменений можно прочитать в "Firebird 4.0 Release Notes".
Логическая репликация
---------------------
В Firebird 4.0 предоставляет встроенную поддержку однонаправленной логической репликации. Репликация, в первую очередь обеспечивает высокую доступность, но может использоваться и для других задач.
Репликация отслеживает следующие события:
* добавление, обновление и удаление записей в таблицах
* изменение последовательностей (генераторов)
* DDL операторы
Поддерживаются синхронный и асинхронный режимы.
При синхронной репликации основная (главная) база данных постоянно подключена к репликам (подчиненным базам данных) и изменения реплицируются немедленно. По сути, базы данных синхронизируются после каждой фиксации каждой транзакции, что может повлиять на производительность из-за дополнительного сетевого трафика.
При асинхронной репликации изменения записываются в файлы локального журнала, передаются по сети и применяются к реплике базы данных. Влияние на производительность намного меньше, но вызывает задержку (отставание репликации) пока изменения ожидают применения к реплике базы данных, т.е. реплика базы данных всегда «догоняет» основную базу данных.
Копии постоянной готовности (nbackup physical standby)
------------------------------------------------------
Утилита nBackup в Firebird 4 может выполнять физическое резервное копирование, которое использует GUID (UUID) самой последней резервной копии базы данных, доступной только для чтения. Изменения (дельты) из исходной базы данных можно последовательно (по одной)
применять к резервной базе данных, без необходимости сохранять и применять (сразу) все дельты с момента последней полной резервной копии.
Новый способ оперативного резервирования можно запустить, не затрагивая действующую многоуровневую схему резервного копирования базы данных.
Пул внешних подключений
-----------------------
Чтобы избежать задержек при создании внешних подключений, подсистема внешних источников
данных (`EXECUTE STATEMENT ... ON EXTERNAL DATA SOURCE`) была дополнена пулом подключений. Пул, в течение некоторого времени, сохраняет бездействующие внешние подключения, чтобы уменьшить накладные расходы для клиентов с одинаковыми строками подключений.
Тайм-ауты
---------
В Firebird 4.0 добавлены настраиваемые тайм-ауты:
* тайм-аут простоя соединения (сеанса)
* тайм-аут выполнения SQL запроса
Тайм-аут простоя сеанса позволяет пользовательскому соединению автоматически закрываться после определенного периода бездействия.
Тайм-аут выполнения SQL запроса, позволяет автоматически останавливать выполнение запроса, если он выполняется дольше заданного периода тайм-аута.
Слепки состояния базы данных (database snapshots) на основе порядка фиксации
----------------------------------------------------------------------------
В Firebird 4.0 кардинально переработана концепция создания слепков состояния базы данных (database snapshot). Ранее для создания слепков (snapshot) требовалось создать копию TIP (transaction inventory page), в Firebird 4 достаточно просто запомнить номер фиксации (Commit Number). Таким образом, процесс создания слепка в Firebird 4 требует значительно меньше ресурсов, чем ранее.
### Режим изолированности READ COMMITTED READ CONSISTENCY
Поскольку процесс создания слепка состояния базы данных в Firebird 4, обходится значительно дешевле чем ранее. Это позволяет создавать такие слепки не только в момент старта транзакции SNAPSHOT, но и для каждого SQL запроса и открытого курсора в новом режиме изолированности транзакции `READ COMMITTED READ CONSISTENCY`. В режиме изолированности `READ COMMITTED READ CONSISTENCY` запросы всегда читают согласованное состояние базы данных на момент старта запроса.
### Промежуточная сборка мусора
Ранее ненужные версии записей (мусор) могли быть удалены только для версий, созданных транзакцией, номер которой меньше чем OST (Oldest Snapshot Transaction). То есть мусор можно было удалить только из конца цепочки версий. Новая концепция создания слепков состояния базы данных (database snapshot) позволила удалять мусор в цепочке версий между активными версиями записи (версий для которых есть активный слепок состояния). Это позволяет значительно сократить длину цепочки версий при наличии длительных активных транзакций и сократить их негативное влияние на производительность.
Совместное использование SNAPSHOT транзакций
--------------------------------------------
С помощью этой функции можно создавать параллельные процессы (с использованием разных соединений), читающие согласованные данные из базы данных. Например, процесс резервного копирования может создать несколько потоков, параллельно считывающих данные из базы данных.
Поддержка международных часовых поясов
--------------------------------------
В Firebird 4.0 введены новые типы данных `TIME WITH TIME ZONE` и `TIMESTAMP WITH TIME ZONE` для поддержки даты и времени с часовыми поясами, а также типы `TIME WITHOUT TIME ZONE` и `TIMESTAMP WITHOUT TIME ZONE` как псевдонимы существующих типов `TIME` и `TIMESTAMP`.
Поддерживаются выражения и операторы для работы с типами с часовыми поясами, а также преобразование между типами данных без/с часовыми поясами.
Повышенная точность хранения и вычисления для типов NUMERIC и DECIMAL
---------------------------------------------------------------------
Типы NUMERIC и DECIMAL теперь могут хранить числа с точностью до 38 цифр. Для хранения чисел с точностью более 18 цифр Firebird 4.0 использует тип INT128 (128 битное целое). Кроме того улучшена обработка промежуточных результатов вычислений с типами данных NUMERIC и DECIMAL. В предыдущих версиях Firebird числа, внутренне представленные типом данных
BIGINT (то есть с точностью от 10 до 18 десятичных цифр), умножались/делились с использованием того же типа данных BIGINT для промежуточных вычислений, что могло вызвать ошибки переполнения из-за ограничения доступной точности. В Firebird 4 такие вычисления выполняются с использованием 128-битных целых чисел, что снижает вероятность неожиданных переполнений.
Тип INT128 также доступен для использования.
Тип данных DECFLOAT
-------------------
DECFLOAT — это числовой тип, соответствующий стандарту SQL:2016, который точно хранит числа с плавающей запятой (десятичный тип с плавающей запятой), в отличие от FLOAT или DOUBLE PRECISION, обеспечивающие двоичное приближение предполагаемой точности. Firebird 4 соответствует типам Decimal64 и Decimal128 из стандарта IEEE 754-1985, обеспечивая для этого типа как 16-значную, так и 34-значную точность.
Все промежуточные вычисления производятся с 34-значными значениями.
Поддержка пакетных операций для параметризованных запросов в API
----------------------------------------------------------------
OO-API в Firebird 4 поддерживает пакетное выполнение SQL операторов (с одним и более наборов параметров). Batch API позволяет производить операции импорта данных по сети более эффективно, поскольку значительно снижается количество сетевых пакетов.
Batch API теперь используется в gbak при восстановлении базы данных из резервной копии. Таким образом процесс восстановления с использованием сетевых протоколов происходит быстрее.
Виртуальная таблица RDB$CONFIG
------------------------------
Добавлена новая виртуальная таблица RDB$CONFIG. В этой таблице перечислены параметры конфигурации, актуальные для текущей базы данных. Таблица RDB$CONFIG заполняется из структур в памяти по запросу, и ее экземпляр сохраняется на время существования SQL запроса.
Улучшение производительности сортировок
---------------------------------------
Исторически сложилось, что когда выполняется внешняя сортировка, Firebird записывает в блоки сортировки как ключевые поля (перечислены в предложениях ORDER BY или GROUP BY), так и не ключевые (все остальные) поля запроса. После завершения сортировки (все) поля запроса вычитываются из блоков сортировки, находящихся в памяти или/и во (временных) файлах. Этот подход обычно считается более быстрым, поскольку записи читаются в порядке хранения вместо случайной выборки страниц данных, соответствующих отсортированным записям. Однако, если не ключевые поля велики (например, задействованы длинные VARCHAR), то они увеличивают размер блоков сортировки, провоцируя их вытеснение на диск и более интенсивный ввод-вывод для временных файлов. Firebird 4 предоставляет альтернативный подход, когда только ключевые поля и записи DBKEY хранятся внутри блоков сортировки, а не ключевые поля повторно выбираются со страниц данных после сортировки. Это улучшает производительность сортировки в случае длинных не ключевых полей.
Улучшения SQL
-------------
### Улучшения DDL
* Увеличена максимальная длина идентификаторов до 63 символов. Метаданные теперь хранятся в кодировке UTF-8 вместо устаревшей кодировки UNICODE\_FSS (ранняя версия реализации UNICODE).
* Новые типы данных: `INT128`, `DECFLOAT`, `TIME WITH TIME ZONE` и `TIMESTAMP WITH TIME ZONE`.
* Добавлены псевдонимы для бинарных строковых типов BINARY(n) и VARBINARY(n). Эти типы данных эквивалентны `[VAR]CHAR(n) CHARACTER SET OCTETS`.
* Расширены опции IDENTITY столбцов. Теперь IDENTITY столбцы могут быть объявлены в двух вариантах: `GENERATED ALWAYS AS IDENTITY` и `GENERATED BY DEFAULT AS IDENTITY`. Ранее существовал только вариант `GENERATED BY DEFAULT AS IDENTITY`.
* Добавлены операторы для настройки набора таблиц, которые включены в публикацию. Публикация — набор таблиц, включенных в процесс репликации.
### Улучшения DML
* Добавлена поддержка LATERAL производных таблиц. Производная таблица, определенная с помощью ключевого слова LATERAL, называется боковой производной таблицей. Если производная таблица определена как боковая, то в этом же предложении FROM разрешено ссылаться на другие таблицы, но только на те, которые были объявлены перед ней в предложении FROM.
```
SELECT
HORSE.NAME,
M.BYDATE,
M.HEIGHT_HORSE,
M.LENGTH_HORSE
FROM HORSE
CROSS JOIN LATERAL (
SELECT
MEASURE.BYDATE,
MEASURE.HEIGHT_HORSE,
MEASURE.LENGTH_HORSE
FROM MEASURE
WHERE MEASURE.CODE_HORSE = HORSE.CODE_HORSE
ORDER BY MEASURE.BYDATE DESC
FETCH FIRST ROW ONLY) M
```
* Добавлена поддержка контекстного значения DEFAULT в операторах `INSERT`, `UPDATE`, `MERGE`, `UPDATE OR INSERT`.
```
UPDATE cars
SET BYYEAR = DEFAULT
WHERE ID = 1;
```
* Добавлена возможность использовать предложение OVERRIDING для IDENTITY полей.
* Добавлена поддержка предложения кадра (frames) для оконных функций. Кадром называется набор строк внутри секции которым оперирует оконная функция.
```
::=
{RANGE | ROWS}
::=
{ | }
::=
{UNBOUNDED PRECEDING | PRECEDING | CURRENT ROW}
::=
BETWEEN AND
::=
{UNBOUNDED PRECEDING | PRECEDING | FOLLOWING | CURRENT ROW}
::=
{UNBOUNDED FOLLOWING | PRECEDING | FOLLOWING | CURRENT ROW}
```
Пример использования кадров (рамки окна):
```
SELECT
id,
salary,
SUM(salary) OVER() AS s1,
SUM(salary) OVER(ORDER BY salary) AS s2,
SUM(salary) OVER(ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS s3,
SUM(salary) OVER(ORDER BY salary ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS s4,
SUM(salary) OVER(ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS s5,
SUM(salary) OVER(ORDER BY salary ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS s6,
SUM(salary) OVER(ORDER BY salary ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS s7,
SUM(salary) OVER(ORDER BY salary ROWS 1 PRECEDING) AS s8
FROM
employee
```
* Именованные окна. Как видно из предыдущего примера, определения окон может быть довольно громоздким, кроме того для нескольких оконных функций может быть указанно одно и то же окно. Чтобы избежать дублирование описания окна, в Firebird 4.0 вы можете воспользоваться предложением WINDOW, которое определяет именованные окна. Именованные окна поддерживают наследование атрибутов, то есть одно именованное окно может ссылаться на другое именованное окно.
```
SELECT
id,
department,
salary,
count(*) OVER w1,
first_value(salary) OVER w2,
last_value(salary) OVER w2,
sum(salary) over (w2 ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS s
FROM employee
WINDOW
w1 AS (PARTITION BY department),
w2 AS (w1 ORDER BY salary)
ORDER BY department, salary;
```
* Поддержка предложения FILTER для агрегатных функций
```
SELECT
invoice_year,
SUM(revenue) FILTER (WHERE invoice_month = 1) AS jan_revenue,
SUM(revenue) FILTER (WHERE invoice_month= 2) AS feb_revenue,
...
SUM(revenue) FILTER (WHERE invoice_month = 12) AS dec_revenue
FROM (
SELECT
EXTRACT(YEAR FROM invoices.invoice_date) AS invoice_year,
EXTRACT(MONTH FROM invoices.invoice_date) AS invoice_month,
invoices.revenue AS revenue
FROM invoices
)
GROUP BY invoice_year
```
### Улучшения PSQL
* Добавлена поддержка "лишних" параметров в EXECUTE STATEMENT. Входные параметры команды EXECUTE STATEMENT могут начинаться с ключевого слова EXCESS. Если указано EXCESS, то данный параметр может быть опущен в тексте запроса.
```
CREATE PROCEDURE P_EXCESS (A_ID INT, A_TRAN INT = NULL, A_CONN INT = NULL)
RETURNS (ID INT, TRAN INT, CONN INT)
AS
DECLARE S VARCHAR(255);
DECLARE W VARCHAR(255) = '';
BEGIN
S = 'SELECT * FROM TTT WHERE ID = :ID';
IF (A_TRAN IS NOT NULL)
THEN W = W || ' AND TRAN = :a';
IF (A_CONN IS NOT NULL)
THEN W = W || ' AND CONN = :b';
IF (W <> '')
THEN S = S || W;
-- будет сгенерипрована ошибка есть A_TRAN или A_CONN равно null
-- FOR EXECUTE STATEMENT (:S) (a := :A_TRAN, b := A_CONN, id := A_ID)
-- Следующий код отработает в любом случае
FOR EXECUTE STATEMENT (:S) (EXCESS a := :A_TRAN, EXCESS b := A_CONN, id := A_ID)
INTO :ID, :TRAN, :CONN
DO SUSPEND;
END
```
* Добавлена поддержка рекурсивных подпроцедур и подфункций.
```
execute block returns (i integer, o integer)
as
declare function fibonacci(n integer) returns integer
as
begin
if (n = 0 or n = 1) then
return n;
else
return fibonacci(n - 1) + fibonacci(n - 2);
end
begin
i = 0;
while (i < 10)
do
begin
o = fibonacci(i);
suspend;
i = i + 1;
end
end
```
* Добавлена возможность получить текст ошибки и имя исключения в блоке обработки ошибок. Для этого введена новая системная функция RDB$ERROR.
```
BEGIN
...
WHEN ANY DO
EXECUTE PROCEDURE P_LOG_EXCEPTION(RDB$ERROR(MESSAGE));
END
```
* В PSQL блоках кода разрешено использовать операторы управления сеансовым окружением.
### Операторы управления сеансовым окружением
В Firebird 4.0 появился новый класс SQL операторов — так называемые операторы управления сеансовым окружением. Обычно такие операторы начинаются с глагола SET, некоторые из них начинаются с ключевого слова ALTER.
Данные SQL операторы работают вне механизма транзакций, и выполненные ими изменения вступают в силу немедленно.
Операторы управления сеансовым окружением доступны, в том числе и в PSQL коде. Они особенно полезны в ON CONNECT триггерах.
Операторы управления сеансовым окружением разбиты на следующие группы:
* управления тайм-аутами (`SET STATEMENT TIMEOUT` и `SET SESSION IDLE TIMEOUT`);
* управление пулом внешних соединений (`ALTER EXTERNAL CONNECTIONS POOL ...`);
* изменение текущей роли (`SET ROLE` и `SET TRUSTED ROLE`);
* управление обработкой типа DECFLOAT (`SET DECFLOAT ROUND` и `SET DECFLOAT TRAPS TO`);
* управление часовым поясом (`SET TIME ZONE`);
* управление привязкой типов (`SET BIND OF`);
* сброс сеансового окружения (`ALTER SESSION RESET`).
Улучшение безопасности
----------------------
### Системные привилегии
Эта функция позволяет предоставлять и отменять некоторые специальные привилегии обычным пользователям для выполнения задач, которые исторически ограничивались только SYSDBA, например: запуск утилит gbak, gfix, nbackup, доступ к таблицам мониторинга, запуск пользовательской трассировки и т.д.
Набор системных привилегий может быть указан при создании/изменении роли.
```
CREATE ROLE SYS_UTILS
SET SYSTEM PRIVILEGES TO USE_GBAK_UTILITY, USE_GSTAT_UTILITY, IGNORE_DB_TRIGGERS;
```
### Выдача ролей другой роли
Firebird 4.0 позволяет назначать роль другой роли. Это явление получило название "Кумулятивные роли". Этот термин относится к ролям, встроенным в другие роли посредством оператора `GRANT ROLE a TO ROLE b`. Оператор GRANT ROLE расширен до следующего синтаксиса
```
GRANT [DEFAULT] role_name
TO [USER user_name | ROLE role_name] [WITH ADMIN OPTION];
REVOKE [DEFAULT] role_name
FROM [USER user_name | ROLE role_name] [WITH ADMIN OPTION];
```
### Ключевое слово DEFAULT в операторах GRANT и REVOKE
Если в операторе GRANT используется ключевое слово DEFAULT, то роли используются пользователем или ролью каждый раз, даже без явного указания. При подключении пользователь получит привилегии всех ролей, которые были назначены с использованием ключевого слова DEFAULT. Если пользователь укажет свою роль при подключении, то получит привилегии этой роли (если она была ему назначена) и привилегии всех ролей, назначенных ему с использованием ключевого слова DEFAULT.
### SQL SECURITY
Все объекты метаданных, содержащие DML или PSQL код, могут выполнятся в одном из следующих режимов:
* С привилегиями вызывающего пользователя (привилегии CURRENT\_USER);
* С привилегиями определяющего пользователя (владельца объекта метаданных).
Исторически сложилось, что все PSQL модули по умолчанию выполняются с привилегиями вызывающего пользователя. Начиная с Firebird 4.0 появилась возможность указывать объектам метаданных с какими привилегиями они будут выполняться: вызывающего или определяющего пользователя. Для этого используется предложение SQL SECURITY, которое можно указать для таблицы, триггера, процедуры, функции или пакета. Если выбрана опция INVOKER, то объект метаданных будет выполняться с привилегиями вызывающего пользователя. Если выбрана опция DEFINER, то объект метаданных будет выполняться с привилегиями определяющего пользователя (владельца). Эти привилегии будут дополнены привилегиями, выданными самому PSQL модулю оператором GRANT.
```
CREATE TABLE t (i INTEGER);
SET TERM ^;
CREATE PROCEDURE p (i INTEGER)
SQL SECURITY DEFINER
AS
BEGIN
INSERT INTO t VALUES (:i);
END^
SET TERM ;^
GRANT EXECUTE ON PROCEDURE p TO USER joe;
COMMIT;
CONNECT 'inet://localhost:test' USER joe PASSWORD 'pas';
EXECUTE PROCEDURE p(1);
```
В данном случае пользователю JOE достаточно только привилегии EXECUTE на процедуру p. Если бы процедура была создана с привилегиями вызывающего пользователя (опция INVOKER), то ещё потребовалось бы выдать привилегию INSERT для процедуры p на таблицу t.
### Встроенные криптографические функции
В Firebird 4.0 добавлено множество встроенные криптографических функций. Вы можете использовать их для шифрования значений отдельных столбцов в таблице или других задач.
```
select encrypt('897897' using sober128 key 'AbcdAbcdAbcdAbcd' iv '01234567')
from rdb$database;
```
### Поддержка шифрования утилитой gbak
Поддержка шифрования базы данных была введена ещё в Firebird 3.0, однако шифровать/дешифровать файлы резервной копии сделанной утилитой gbak можно было только внешними инструментами. В Firebird 4.0 добавлена поддержка шифрования резервной копии с помощью того же плагина шифрования, что используется при шифровании базы данных.
Пример создания шифрованной резервной копии
```
gbak -b -keyholder MyKeyHolderPlugin host:dbname backup_file_name
```
Резервная копия шифруется с помощью того же самого плагина шифрования, с которым зашифрована база данных.
Пример восстановления резервной копии
```
gbak -c -keyholder MyKeyHolderPlugin backup_file_name host:dbname
```
Вы также можете указать плагин шифрования отличный от умолчательного. | https://habr.com/ru/post/559456/ | null | ru | null |
# Подключение IP-телефонов Avaya к IP-АТС 3CX
На этой неделе пришла отличная новость для организаций, в которых установлены достаточно дорогие в сопровождении АТС Avaya. Теперь вы можете заменить Avaya на [бесплатную и постоянно обновляемую АТС 3CX](https://www.3cx.ru/ip-pbx/download-atc/), но при этом сохранить существующий парк IP-телефонов. IP-телефоны Avaya будут работать как с локальной 3CX, так и с установленной а облаке. После подключения вы сможете централизованно управлять телефонами из привычной консоли сервера 3CX.
Модели IP-телефонов, которые можно подключить к 3CX: Avaya 9601, 9608G, 9611G, 9621G и 9641G.

Рассмотрим процедуру подключения пошагово.
### Сбросьте IP-телефоны телефоны в настройки по умолчанию
Для начала подключения, сбросьте телефоны в настройки по умолчанию, чтобы очистить имеющуюся конфигурацию:
* Нажмите кнопку Menu  и перейдите в меню Administration…
* Наберите пароль администратора — по умолчанию 27238
* Прокрутите меню и выберите Clear
* Нажмите Clear еще раз для подтверждения. Телефон сбросится и перезапустится.
### Добавьте DHCP опцию 242
Телефоны Avaya используют для автонастройки опцию DHCP сервера 242, которую вы должны добавить в вашем DHCP сервере. Покажем это на примере Windows DHCP сервера.
В оснастке DHCP в контекстном меню IPv4 выберите Set Predefined Options. Затем нажмите кнопку Add и добавьте следующие параметры (название и описание даны для примера:
* Name: Option 242
* Data Type: String
* Code: 242
* Description: Avaya provisioning

### Создайте резервирование DHCP для телефона
В той же оснастке в контекстном меню Reservations выберите New Reservation…
Укажите параметры резервирования для MAC адреса конкретного телефона, например:
* Reservation Name: Avaya 9611G
* IP address: 10.172.1.232
* MAC address: b0075eb812e9
* Description: Avaya 9611G provisioning

Для созданного резервирования в контекстном меню выберите Configure Options…
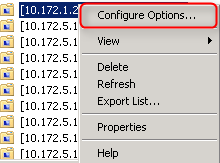
Затем выберите Option 242 и для этой опции укажите строковое значение
```
HTTPDIR=/provisioning/9kb94fwiaf3t/,HTTPPORT=5000,HTTPSRVR=10.172.0.242,SIG=2
```
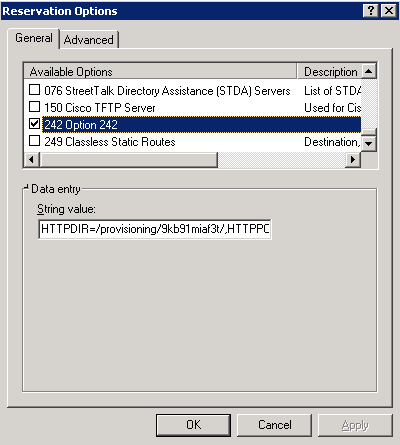
Параметры этой строки:
* /provisioning/9kb94fwiaf3t/ — папка автонастройки сервера 3CX. Папка безопасности (secure folder) 9kb94fwiaf3t — уникальна для каждой инсталляции сервера 3CX.
* 5000 — HTTP порт сервера 3CX. Телефоны Avaya не поддерживают автонастройку по HTTPS, поэтому указывайте порт 5000 (по умолчанию) или 80
* 10.172.0.242 — IP алрес или FQDN имя сервера 3CX
* 2 — указывает тип прошивки. В нашем случае — SIP
### Набор файлов для подключения телефонов Avaya
Для автоматической настройки и подключения телефонов Avaya мы приготовили набор файлов, которые необходимо скачать и разместить в определенных папках на сервере 3CX. Набор включает следующие файлы:
* XML шаблон автонастройки 3CX для телефонов Avaya
* набор прошивок и других файлов для телефонов Avaya от 3CX
* файлы логотипа 3CX для отображения на дисплее телефонов
Загрузите [шаблон автонастройки 3CX для Avaya](http://downloads.3cx.com/downloads/misc/phonefirmware/avaya/avaya.ph.xml) и разместите его в следующих папках на сервере 3CX:
* Windows: C:\ProgramData\3CX\Instance1\Data\Http\Templates\phones
* Linux: /var/lib/3cxpbx/Instance1/Data/Http/Templates/phones
Загрузите [набор прошивок для IP-телефонов Avaya](http://downloads.3cx.com/downloads/misc/phonefirmware/avaya/ProvisioningFiles.zip) и разместите его в следующих папках на сервере 3CX:
* Windows: C:\ProgramData\3CX\Instance1\Data\Http\Interface\provisioning\secure\_folder
* Linux: /var/lib/3cxpbx/Instance1/Data/Http/Interface/provisioning/secure\_folder
Загрузите [логотипы 3CX для Avaya](http://downloads.3cx.com/downloads/misc/phonefirmware/avaya/logos.zip) и разместите их в следующие папки:
* Windows: C:\ProgramData\3CX\Instance1\Data\Http\Interface\provisioning\secure\_folder\logo
* Linux: /var/lib/3cxpbx/Instance1/Data/Http/Interface/provisioning/secure\_folder/logo
Как было сказано, secure\_folder — случайно генерируемая папка безопасности (в данном примере имеет вид 9kb94fwiaf3t).
После этого зайдите в интерфейс управления 3CX и перезапустите сервис 3CX PhoneSystem 01 Configuration Server.
### Подключение IP-телефона Avaya к 3CX
В интерфейсе сервера 3CX добавьте пользователя. Обратите внимание на следующие моменты:
* Добавочный номер телефона и ID аутентификации для телефонов Avaya должны совпадать!
* Укажите пароль аутентификации состоящий из цифр. Это упростит первое подключение телефона.
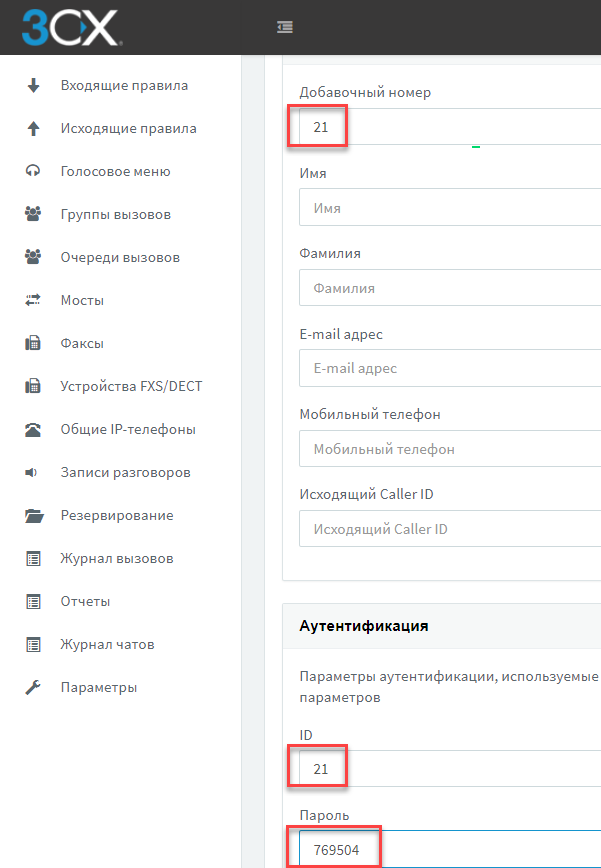
Затем добавьте для пользователя соответствующий телефона Avaya, указав его MAC адрес.
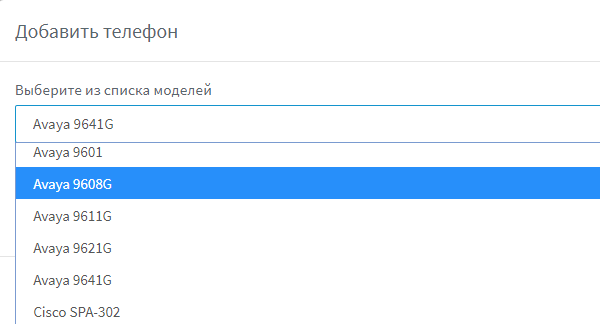
Включите телефон. Он загрузится, получит ссылку автонастройки от DHCP сервера, обновит файлы прошивки и конфигурацию. На дисплее телефона появится запрос ID и пароля SIP аутентификации, которые вы указывали при создании пользователя. Введите эти данные, и телефон автоматически подключится к серверу!
### Заключение
В заключение рассмотрим возможности и ограничения IP-телефонов Avaya при работе с АТС 3CX:
* Полная автонастройка по DHCP Option 242, включая SIP-регистрацию и установку вашего логотипа на дисплее
* Удержание и перевод вызовов, автоответ на вызов (функция пейджинга), конференция
* Поддержка уведомлений голосовой почты (MWI) и часового пояса
* Не поддерживается загрузка адресной книги 3CX
* При работе с 3CX не поддерживаются: сообщения Alert info, синхронизация статуса DND, удаленная перезагрузка и перенастройка, поддержка перехода на летнее время. | https://habr.com/ru/post/353638/ | null | ru | null |
# Пишем Anime Wallpaper Downloader на MacRuby
Просматривая [theotaku.com](http://theotaku.com) в поисках интересных обоев для рабочего стола я поймал себя на мысли о том, что неплохо бы написать софт который по тэгам сам автоматически скачивал бы обои вместо меня. Исходя из того что я пользуюcь **Мac OS X** как основной операционной системой, софт тоже должен быть для этой платформы и желательно иметь **Cocoa** интерфейс. Писать всё это на Java почему-то не захотелось. Альтернатив конечно было много, но почему-то захотелось попробовать чего-то другого и заодно научится чем-то новому. Сразу же вспомнил о **MacRuby** и его тесной интеграции с **Cocoa**. Вооружившись этой идеей, я сразу же полез на <http://www.macruby.org/> и скачал последнюю стабильную версию 0.10. После установки я запустил любимый **XCode** и создал новый проект с названием **AnimeWallpaperDownloader**
Наш проект на **MacRuby** состоит из нескольких файлов, которые **XCode** создаёт за нас. Первый файл это **main.m** который просто запускает **MacRuby** скрипт **rb\_main.rb**
```
#import
#import
int main(int argc, char \*argv[])
{
return macruby\_main("rb\_main.rb", argc, argv);
}
```
**rb\_main.rb** довольно простой скрипт, он подгружает все остальные **Ruby** скрипты и запускает
**NSApplicationMain**
```
framework 'Cocoa'
# Loading all the Ruby project files.
main = File.basename(__FILE__, File.extname(__FILE__))
dir_path = NSBundle.mainBundle.resourcePath.fileSystemRepresentation
Dir.glob(File.join(dir_path, '*.{rb,rbo}')).map { |x| File.basename(x, File.extname(x)) }.uniq.each do |path|
if path != main
require(path)
end
end
# Starting the Cocoa main loop.
NSApplicationMain(0, nil)
```
Последний файл который за нас уже создан это **AppDelegate.rb**, который играет роль **NSApplicationDelegate**. Он содержит пустой метод **applicationDidFinishLaunching** который вызывается когда наша программа закончила запускаться.
```
class AppDelegate
attr_accessor :window
def applicationDidFinishLaunching(a_notification)
# Insert code here to initialize your application
end
end
```
Тут **attr\_accessor :window** играет роль **IBOutlet \*window** и уже привязан к окну нашей программы
Открываем MainMenu.xib и создаём простой интерфейс для нашего wallpaper downloader-а

Далее добавляем методы и outlet-ы в наш **AppDelegate**
```
class AppDelegate
attr_accessor :window
attr_accessor :tags
attr_accessor :size
attr_accessor :number
attr_accessor :saveInto
attr_accessor :startButton
attr_accessor :output
attr_accessor :downprogress
attr_accessor :downloader
attr_accessor :img
def applicationDidFinishLaunching(a_notification)
@startButton.setEnabled(false)
@downprogress.setStringValue('')
@output.setStringValue('')
@saveInto.stringValue = NSHomeDirectory()+"/Pictures"
end
def windowWillClose(a_notification)
NSApp.terminate(self)
end
def controlTextDidChange(notification)
sender = notification.object
if sender == tags
@startButton.setEnabled(@tags.stringValue.size > 0)
elsif sender == number
begin
@number.setIntValue(@number.intValue)
if @number.intValue < 0
@number.setIntValue([email protected])
elsif @number.intValue == 0
@number.setIntValue(20)
end
rescue
@number.setIntValue(20)
end
end
end
def browse(sender)
dialog = NSOpenPanel.openPanel
dialog.canChooseFiles = false
dialog.canChooseDirectories = true
dialog.allowsMultipleSelection = false
if dialog.runModalForDirectory(nil, file:nil) == NSOKButton
@saveInto.stringValue = dialog.filenames.first
end
end
def startStop(sender)
if @downloader == nil
@downloader = Downloader.new(@tags.stringValue,@size.selectedItem.title,@number.stringValue,@saveInto.stringValue,self)
@downloader.start
@startButton.setTitle("Stop Download")
else
@downloader.stop
@downloader = nil
@startButton.setTitle("Start Download")
end
end
def changeImage(file)
@img.setImage(NSImage.alloc.initByReferencingFile(file))
end
def clearStatus
@downprogress.setStringValue('')
end
def setStatus(i,m)
@downprogress.setStringValue("Downloading "+i.to_s()+" of "+m.to_s())
end
def setStatusEnd(i)
@downprogress.setStringValue("Downloaded "+i.to_s()+" wallpapers")
end
def puts(val)
$stdout.puts val
@output.setStringValue(val)
end
def stopped
@startButton.setTitle("Start Download")
down = @downloader
@downloader = nil
down.stop
end
end
```
Тут всё довольно просто. Методы **windowWillClose** и **controlTextDidChange** просто методы делегатов для окна программы и первого текстового поля (пока не впишем тэг ничего скачивать нельзя).
Метод **browse** открывает диалоговое окно для выбора директории куда мы сохраняем наши обои, его мы привязываем к кнопке **Browse**. Метод **startStop** запускает скачку, так что его мы привязываем к кнопке **Start Download**. Остальные методы вспомогательные и будут использоваться классом **Downloader**, который мы будем использовать для нахождения ссылок и скачивания обоев
```
require 'thread'
require 'net/http'
class Downloader
attr_accessor :tags, :size, :number, :saveTo, :thread
attr_accessor :app, :exit
def initialize(tags, size, number, saveTo, app)
@tags = tags.sub(' ','_')
@size = size == 'Any' ? '' : size.sub('x','_')
@number = number
@saveTo = saveTo
@app = app
@exit = false
end
def getIndexPage(page)
walls = {}
url = 'http://www.theotaku.com/wallpapers/tags/'+tags+'/?sort_by=&resolution='+size+'&date_filter=&category=&page='+page.to_s()
@app.puts 'getting index for page: '+page.to_s()
@app.puts url
response = Net::HTTP.get_response(URI.parse(url))
res = response.body
res.each_line { |line|
f = line.index('wallpapers/view')
while f != nil
b = line.rindex('"',f)
e = line.index('"',b+1)
u = line[b+1,e-b].gsub('"','')
walls[u] = u
line = line.sub(u,'')
f = line.index('wallpapers/view')
end
}
@app.puts 'got '+walls.size.to_s()+' wallpapers'
return walls.keys
end
def downloadWall(url)
@app.puts 'downloading '+url
response = Net::HTTP.get_response(URI.parse(url))
res = response.body
b = res.index('src',res.rindex('wall_holder'))+5
e = res.index('"',b)
img = res[b,e-b]
self.downloadFile(img)
end
def downloadFile(url)
name = url[url.rindex('/')+1,1000]
if File.exists?(@saveTo+'/'+name)
@app.puts 'wallpaper already saved '+name
@app.changeImage(@saveTo+'/'+name)
else
@app.puts 'downloading file '+url
response = Net::HTTP.get_response(URI.parse(url))
open(@saveTo+'/'+name, 'wb') { |file|
file.write(response.body)
}
@app.puts 'wallpaper saved '+name
@app.changeImage(@saveTo+'/'+name)
end
end
def getWallUrl(i,url,size)
sizes = {}
i = i+1
@app.puts 'getting '+url+' sizes'
response = Net::HTTP.get_response(URI.parse(url))
res = response.body
res.each_line { |line|
f = line.index('wallpapers/download')
while f != nil
b = line.rindex('\'',f)
e = line.index('\'',b+1)
u = line[b+1,e-b]
u = u.gsub('\'','')
sizes[u] = u
line = line.sub(u,'')
f = line.index('wallpapers/download')
end
}
sizef = @size.sub('_','-by-')
sizes = sizes.keys()
if sizef == ''
maxi = 0
max = 0
i = 0
sizes.each { |s|
f = s.rindex('/')
l = s[f+1,100]
l = l.sub('-by-',' ')
l = l.split(' ')
rs = l[0].to_i()*l[1].to_i()
if rs > max
maxi = i
max = rs
end
i = i+1
}
return sizes[maxi]
else
sizes.each { |s|
if s =~ /#{Regexp.escape(sizef)}$/
return s
end
}
end
return sizes[0]
end
def start
@thread = Thread.new {
@app.puts "Download started"
begin
i = 0
p = 1
@app.clearStatus
while i < @number.to_i() and not @exit
w = self.getIndexPage(p)
if w.size == 0
break
end
w.each { |w|
wallu = self.getWallUrl(i,w,self.size)
if wallu != nil
@app.setStatus(i+1,@number.to_i())
self.downloadWall(wallu)
i = i+1
if i >= @number.to_i() or @exit
break
end
end
}
p = p+1
end
@app.puts ""
@app.setStatusEnd(i)
rescue => e
puts e
end
@app.stopped
}
end
def stop
begin
@app.puts "Download stopped"
if @thread.alive?
if @thread == Thread.current
Thread.exit(0)
else
@exit = true
end
end
rescue => e
puts e
end
end
end
```
Огромный класс неправда ли? Да он нашпигован логикой, но на самом деле всё достаточно тривиально.
Метод **start** просто запускает отдельный поток который и будет скачивать наши обои, **stop** его останавливает. Методы **getIndexPage**, **getWallUrl**, **downloadWall** cпецифичны для сайта [theotaku.com](http://theotaku.com) и содержат достаточно много логики, но по сути достаточно тривиальны и используются для поиска обоeв по тэгу, подбора нужной ссылки на желательный размер обоев и скачивания этих обоев
Итог потраченный воскресный вечер, неплохое чувство самоудовлетворения, а также много интересных мыслей о будущем **МacRuby** как альтернативной платформы для разработки на **Mac OS X**. Конечно же без [граблей](http://stackoverflow.com/questions/8296257/macruby-nstextview-adding-text-hangs-program) не обошлось и некоторые вещи не получилось сделать, но я думаю что платформа **MacRuby** начинает набирать популярность и у неё светлое будущее.
Результат можно посмотреть вот [тут](https://github.com/troydm/AnimeWallpaperDownloader), ну а готовый билд можно скачать вот [отсюда](https://github.com/troydm/AnimeWallpaperDownloader/downloads) (у вас должен быть установлен **MacRuby**)
Cпасибо за внимание
bye-nii

UPD: Cпасибо [Aesthete](https://habrahabr.ru/users/aesthete/) за рефакторинг парсера, выглядит просто замечательно, последнюю версию смотрите на гитхабе | https://habr.com/ru/post/133739/ | null | ru | null |
# Angular cli 6: зачем нужен и как использовать

Всем привет!
Версия Angular 2.0.0 вышла в сентябре 2016 г. И сразу же появилось большое количество подходов к построению и сборке приложений на этом фреймворке. На просторах интернета можно найти Angular seed на любой вкус.
Мы тоже создали свой Angular seed: создали общий project-template, обязали все команды, разрабатывающие фронт-энд, использовать одну структуру приложений.
А уже через полгода, в марте 2017 года, увидела свет версия Angular cli (cli – command-line interface) 1.0.0. Идея, взятая за основу, просто отличная: систематизировать подход к разработке приложений на Angular 2+. Стандартизовать структуру приложения, создание сущностей внутри приложения, а также автоматизировать сборку приложения. Эти задачи и позволяет решить Angular cli, значительно экономя ваше время.
В статье я покажу, как перейти на **Angular cli 6**
Разработка с кастомной структурой проекта имеет довольно много преимуществ:
* полный контроль над приложением;
* возможность настройки webpack / gulp / всего остального с учетом всех особенностей вашего приложения.
Есть и недостатки:
* при наличии нескольких проектов нужно следить за тем, чтобы их структура была идентична;
* необходимо следить за обновлением используемых npm-модулей и библиотек (Angular и Webpack, например, развиваются очень динамично);
* придется заниматься интеграцией npm-модулей и настройкой окружения для работы с Angular, подключать hot module replacement (HMR), использовать сборку Ahead-of-Time (AOT).
Устранить недостатки можно несколькими способами, один из которых – создать общий *project-template*. Выделить разработчика, который время от времени занимался бы его обновлением. Обязать все команды, занимающиеся фронт-эндом, использовать одну структуру приложений, применяя лучшие практики разработки на вашем фреймворке. В данном примере этим фреймворком будет *Angular*, а основой приложения – *angular-cli*.
На момент написания статьи в релиз вышла шестая версия с интеграцией webpack 4. Информации о нововведениях много, упомяну лишь несколько улучшений:
* автоматическое создание библиотеки компонентов;
* появление ng-update, которое делает поддержку проектов на Angular cli ещё проще;
* интеграция с webpack 4, а следовательно, меньший размер финальных бандлов, значительное ускорение времени сборок и т. д. Полный список обновлений можно посмотреть [тут](https://github.com/angular/angular-cli/releases/);
* возможность гибкой настройки Angular cli с помощью [Schematics](https://blog.angular.io/schematics-an-introduction-dc1dfbc2a2b2).
Должен сказать и о том, что в шестой версии angular cli достаточно много багов. О некоторых из них я расскажу. Часть из них связаны с angular cli, часть – с webpack 4. Например, некоторые популярные загрузчики (webpack loaders) на сегодняшний день не поддерживают четвертую версию сборщика. Уверен, что это временные трудности.
Необходимо отметить, что функционала angular cli из коробки хватает, на мой взгляд, для решения 95 % задач стандартного приложения. Если же вам посчастливилось дорабатывать оставшиеся 5 %, не расстраивайтесь – вы сможете сконфигурировать angular cli под свой проект. Правда, в шестой версии фреймворка возможность ng eject, позволяющая вам получить webpack.config, временно отключена, поэтому придется немного поломать голову.
#### Подготовка к переходу
1. Устанавливаем версию *node.js* >= 8.9
2. Выполняем *npm i –g [angular](https://habr.com/users/angular/)/cli* (глобально устанавливаем angular-cli, чтобы выполнять в консоли команды с помощью ng).
3. Переходим в директорию с проектом и выполняем *ng new <название вашего проекта>* (проект назовем: angular-cli-project, пример команды: *ng new angular-cli-project* – в текущей директории появится папка с названием angular-cli-project).
Итог подготовки:
[Подробнее о структуре проекта на Angular cli и не только.](https://github.com/angular/angular-cli/wiki)
Далее мы произведем основные настройки для комфортной разработки.
### Настройка cli
1) **Подключаем HMR** (применяем изменения в коде без перезагрузки страницы) по [гайду](https://github.com/angular/angular-cli/blob/master/docs/documentation/stories/configure-hmr.md). Также в *package.json* добавим *hmr* в scripts и флаг *--open*, чтобы самим не открывать исходную страницу в браузере:

На момент написания статьи в А6 cli при настройке HMR через вышеупомянутый гайд вы можете встретить следующие ошибки:
a) При подключении HMR конфигурации в angular.json
```
…
"configurations": {
"hmr": {
"hmr": true,
"fileReplacements": [{
"src": "src/environments/environment.ts",
"replaceWith": "src/environments/environment.hmr.ts"
}]
},
…
```
К сожалению, вы получите ошибку:
*“Schema validation failed with the following errors:
Data path "" should NOT have additional properties (fileReplacements)”.*
Чтобы ее поправить, делаем так:
```
…
"configurations": {
"hmr": {
"hmr": true,
"browserTarget": "angular-cli-project:build:hmr"
},
…
```
Разница в том, что необходимо указать *«browserTarget»: «angular-cli-project:build:hmr»*, где значение свойства *browserTarget* состоит из *:build:hmr*.
Кроме того, подмену *HMR environment* необходимо делать не в *serve*, а в *architect/build*:
```
…
"architect": {
"build": {
…
"configurations": {
"hmr": {
"fileReplacements": [
{
"src": "src/environments/environment.ts",
"replaceWith": "src/environments/environment.hmr.ts"
}
]
},
…
```
б) Ошибку *ERROR in src/main.ts: Cannot find name 'module'* исправляем так: в *tsconfig.app.json* удаляем строку *«types»: []*.
2. **Подключаем препроцессор**:
В angular.json добавляем:
```
…
"projects": {
…
"prefix": "app",
"schematics": {
"@schematics/angular:component": {
"styleext": "less"
}
}
…
```
Если ваши стили лежат в папке *assets* и объединяются импортами в base.less или scss, а на выходе нужен файл .css, то добавляем *«extractCss»: true* в *angular.json*:
Также на текущий момент в режиме HMR не будет работать обновление в global less файлах, импортированных через [import](https://habr.com/users/import/). Чтобы обойти эту проблему, временно устанавливаем *[email protected]*.
3. **Подключаем *autoprefixer***. Указываем, для каких браузеров нужны префиксы в *package.json*:
```
…
"browserslist": [
"last 2 versions",
"IE 10",
"IE 11"
],
…
```
4. **Добавим обработку иконок** с помощью *gulp и svgstore*, тем более что наконец-то вышел *gulp* четвертой версии. Выполним *npm i [email protected] gulp-inject gulp-rename gulp-svgmin gulp-svgstore --SD* и создадим небольшой *Gulpfile.js* (см. [финальное приложение](https://github.com/maxim1006/angular-cli-project)).
Подробно на *Gulp* останавливаться не будем – все вопросы, пожалуйста, в комментарии.
Укажем в *index.html* нотации для вставки SVG:
```
```
Изменим *package.json*, добавив *task SVG*:
```
…
"scripts": {
...
"svg": "gulp svg",
...
…
```
Теперь мы можем использовать SVG в наших шаблонах так:
```
```
5) **Установим webpack-bundle-analyzer**
Выполнив команду: *npm i webpack-bundle-analyzer –-SD*.
В *angular.json* добавим *«statsJson»: true*:
```
"architect": {
"build": {
"builder": "@angular-devkit/build-angular:browser",
"options": {
...
"statsJson": true,
...
```
Теперь мы сможем посмотреть, из чего, собственно, состоит наш бандл. Чтобы это как-то автоматизировать, добавим скрипт *report* в *package.json*:
```
…
"scripts": {
...
"report": "webpack-bundle-analyzer dist/stats.json"
...
…
```
Пример использования webpack-bundle-analyzer:

Настройка базового функционала закончена.
Теперь открываем наше кастомное angular-приложение и копируем модули, изображения, стили и прочее в подготовленный шаблон. Я же скопирую все из финального проекта [статьи](https://habr.com/company/netcracker/blog/337540/).
Выполняем команду: *npm run hmr* и получаем несколько ошибок от rxjs, который мигрировал с пятой на шестую версию. Исправить их поможет следующий [гайд](https://github.com/ReactiveX/rxjs/blob/master/MIGRATION.md).
[Финальное приложение](https://github.com/maxim1006/angular-cli-project).
Выполняем команду: *npm run build* и получаем результат:

P. S. Как видим, пока что размер бандла достаточно большой, правда, он включает роутинг, rxjs и т. д. Однако команда Angular анонсировала новый render-движок Ivy и hello world приложение размером 2.7 Кб. Ждем с нетерпением.
Спасибо за внимание. | https://habr.com/ru/post/413543/ | null | ru | null |
# Perf и flamegraphs

Огромную популярность набирает тема повышения производительности операционных систем и поиска узких мест. В этой статье мы расскажем об одном инструменте для поиска этих самых мест на примере работы блочного стека в Linux и одного случая траблшутинга работы хоста.
Пример 1. Тестовый
------------------
### Ничего не работает
Тестирование в нашем отделе ― это синтетика на продуктовом железе, а позже ― тесты прикладного ПО. К нам на тестирование поступил диск Intel Optane. Ранее о тестировании дисков Optane мы уже писали [в нашем блоге](https://blog.selectel.ru/tag/intel-optane-ssd/).
Диск был установлен в сервер стандартной комплектации, собранный относительно давно под один из облачных проектов.
Во время тестирования диск показал себя не лучшим образом: при тесте с глубиной очереди в 1 запрос в 1 поток, блоками в 4Кбайта около ~70Kiops. А это значит, что время ожидания ответа огромно: примерно 13 микросекунд на запрос!
Странно, ведь [спецификация](https://ark.intel.com/products/97159/Intel-Optane-SSD-DC-P4800X-Series-1_5TB-12-Height-PCIe-x4-3D-XPoint) обещает “Latency ― Read 10 µs”, а у нас получилось на 30% больше, разница довольно существенная. Диск переставили в другую платформу, более «свежей» сборки, используемую в другом проекте.
### Почему оно работает?
Забавно, но диск на новой платформе заработал как надо. Производительность увеличилась, время ожидания уменьшилось, CPU в полку, в 1 поток в 1 запрос, 4Кбайта блоками, ~106Kiops при ~9 микросекунд на запрос.
И тут самое время ~~сравнить настройки~~ достать из широких штанин **perf**. Ведь нам интересно, почему так? При помощи **perf** можно:
* Снимать показатели аппаратных счетчиков: количество вызовов инструкций, кэш-промахов, неверно предсказанных ветвлений и т.п. (PMU events)
* Снимать информацию со статических трейспоинтов, количество вхождений
* Проводить динамическую трассировку
Для проверки мы воспользовались CPU sampling.
Суть в том, что **perf** может собрать весь стэк трейс запущенной программы. Естественно, запущенный **perf** будет вносить задержку в работу всей системы. Но у нас есть флаг *-F #*, где *#* ― частота сэмплирования, измеряемая в Гц.
Тут важно понимать, что чем выше частота сэмплирования, тем больше шансов поймать вызов какой-то конкретной функции, но тем больше тормозов работа профайлера вносит в систему. Чем меньше частота, тем больше шансов, что часть стека мы не увидим.
При выборе частоты нужно руководствоваться здравым смыслом и одной хитростью — стараться не выставлять четную частоту, чтобы не попасть в ситуацию, когда в сэмплы попадет какая-то работа, выполняющаяся по таймеру с этой частотой.
Ещё один момент, который поначалу вводит в заблуждение ― ПО должно быть собрано с флагом *-fno-omit-frame-pointer*, если это, конечно, возможно. Иначе в трейсе вместо названий функций мы увидим сплошные значения *unknown*. Для некоторого ПО отладочные символы идут отдельным пакетом, например, *someutil-dbg*. Рекомендуется установить их перед запуском **perf**.
Нами были выполнены следующие действия:
* Взят fio из git://git.kernel.dk/fio.git, тэг fio-3.9
* В Makefile к CPPFLAGS добавлена опция *-fno-omit-frame-pointer*
* Запущен *make -j8*
```
perf record -g ~/fio/fio --name=test --rw=randread --bs=4k --ioengine=pvsync2 --filename=/dev/nvme0n1 --direct=1 --hipri --filesize=1G
```
Опция -g нужна для захвата стек трейсов.
Посмотреть полученный результат можно командой:
```
perf report -g fractal
```
Опция *-g fractal* нужна для того, чтобы проценты, отражающие количество сэмплов с этой функцией и показываемые **perf**, были относительны вызывающей функции, количество вызовов которой берется за 100%.
Ближе к концу длинного стека вызовов fio на платформе «свежей сборки» мы увидим:

А на платформе “старой сборки”:

Отлично! Но хочется красивых флеймграфов.
### Построение флеймграфов
Чтобы было красиво, есть два инструмента:
* Относительно более статический [flamegraph](https://github.com/brendangregg/FlameGraph)
* [Flamescope](https://github.com/Netflix/flamescope), который дает возможность из собранных сэмплов выбрать конкретный отрезок времени. Это очень полезно, когда искомый код нагружает CPU короткими всплесками
Эти утилиты принимают на вход вывод **perf script > result**.
Скачиваем *result* и отправляем его через пайпы в *svg*:
```
FlameGraph/stackcollapse-perf.pl ./result | FlameGraph/flamegraph.pl > ./result.svg
```
Открываем в браузере и наслаждаемся кликабельной картинкой.
Можно использовать другой способ:
1. Добавляем *result* в flamescope/example/
2. Запускаем python ./run.py
3. Заходим через браузер на 5000 порт локального хоста
### Что мы видим в итоге?
Хороший fio проводит много времени в [поллинге](https://events.static.linuxfound.org/sites/events/files/slides/lemoal-nvme-polling-vault-2017-final_0.pdf):
А плохой fio проводит время где угодно, но только не в поллинге:
С первого взгляда кажется, что на старом хосте не работает поллинг, но везде стоит ядро 4.15 одной сборки и поллинг по умолчанию включен на NVMe-дисках. Проверить, включен ли поллинг, можно в **sysfs**:
```
# cat /sys/class/block/nvme0n1/queue/io_poll
1
```
Во время тестов используются вызовы *preadv2* с флагом *RWF\_HIPRI* ― необходимое условие для работы поллинга. И, если внимательно изучить флеймграф (или предыдущий скриншот из вывода **perf report**), то его можно найти, но он занимает совсем незначительный промежуток времени.
Второе, что видно ― это отличающийся стек вызовов у функции submit\_bio() и отсутствие вызовов io\_schedule(). Посмотрим поближе на разницу внутри submit\_bio().
Медленная платформа «старой сборки»:

Быстрая платформа «свежей»:

Похоже, что на медленной платформе запрос проходит долгий путь до устройства, заодно попадая в планировщик **kyber**. О планировщиках ввода/вывода подробнее можно прочитать в [нашей статье](https://blog.selectel.ru/blk-mq-tests/).
Как только **kyber** был выключен, тот же тест fio показал среднее время ожидания около 10 микросекунд, прямо как заявлено в спецификации. Отлично!
Но откуда разница еще в одну микросекунду?
### А если чуть глубже?
Как уже было сказано, **perf** позволяет собирать статистику с аппаратных счетчиков. Попробуем посмотреть количество кэш-промахов и инструкций на цикл:
```
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=10
```


Из результатов видно, что быстрая платформа выполняет больше инструкций на цикл CPU и имеет меньший процент кэш-промахов при выполнении. Вдаваться в детали работы разных аппаратных платформ в рамках этой статьи мы, конечно, не будем.
Пример 2. Продуктовый
---------------------
### Что-то идет не так
В работе распределенной системы хранения данных был замечен рост нагрузки на CPU на одном из хостов при росте входящего трафика. Хосты равноправные, равнозначные и имеют идентичные аппаратное и программное обеспечение.
Рассмотрим как выглядит нагрузка на CPU:
```
~# pidstat -p 1441734 1
Linux 3.13.0-96-generic (lol) 10/10/2018 _x86_64_ (24 CPU)
09:23:30 PM UID PID %usr %system %guest %CPU CPU Command
09:23:44 PM 0 1441734 23.00 1.00 0.00 24.00 4 ceph-osd
09:23:45 PM 0 1441734 85.00 34.00 0.00 119.00 4 ceph-osd
09:23:46 PM 0 1441734 0.00 130.00 0.00 130.00 4 ceph-osd
09:23:47 PM 0 1441734 121.00 0.00 0.00 121.00 4 ceph-osd
09:23:48 PM 0 1441734 28.00 82.00 0.00 110.00 4 ceph-osd
09:23:49 PM 0 1441734 4.00 13.00 0.00 17.00 4 ceph-osd
09:23:50 PM 0 1441734 1.00 6.00 0.00 7.00 4 ceph-osd
```
Проблема возникла в 09:23:46 и мы видим, что процесс работал в пространстве ядра исключительно в течении всей секунды. Посмотрим на то, что происходило внутри.
### Почему так медленно?
В данном случае мы сняли сэмплы со всей системы:
```
perf record -a -g -- sleep 22
perf script > perf.results
```
Опция *-a* нужно здесь для того, чтобы **perf** снимал трейсы со всех CPU.
Откроем **perf.results** при помощи **flamescope**, чтобы отследить момент повышенной нагрузки на CPU.
**Тепловая карта**
Перед нами «тепловая карта», обе оси (X и Y) которой представляют собой время.
По оси X пространство разбито на секунды, а по оси Y ― на отрезки по 20 миллисекунд в пределах секунд X. Время идет снизу вверх и слева направо. Наиболее яркие квадраты имеют наибольшее количество сэмплов. То есть, CPU в это время работал активнее всего.
Собственно, нас интересует красное пятно посередине. Выделяем его мышкой, кликаем и смотрим, что оно скрывает:

В целом, уже видно, что проблема заключается в медленной работе *tcp\_recvmsg* и *skb\_copy\_datagram\_iovec* в ней.
Для наглядности сравним с сэмплами другого хоста, на котором тот же объем входящего трафика не вызывает проблем:

Исходя из того, что мы имеем одинаковое количество входящего трафика, идентичные платформы, которые работают уже длительное время без остановки, можно предположить, что проблемы возникли на стороне железа. Функция *skb\_copy\_datagram\_iovec* копирует данные из структуры ядра в структуру в пространстве пользователя, чтобы передать дальше приложению. Вероятно, имеются проблемы с памятью хоста. При этом, в логах ошибок нет.
Перезапускаем платформу. При загрузке BIOS видим сообщение о битой планке памяти. Замена, хост стартует и проблема с перегруженным CPU больше не воспроизводится.
Постскриптум
------------
### Производительность системы с perf
Вообще говоря, на загруженной системе запуск **perf** может внести задержку в обработку запросов. Размер этих задержек зависит в том числе и от нагрузки на сервер.
Попробуем найти эту задержку:
```
~# /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1
test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
fio-3.9-dirty
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=413MiB/s][r=106k IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=109786: Wed Dec 12 17:25:56 2018
read: IOPS=106k, BW=414MiB/s (434MB/s)(4096MiB/9903msec)
clat (nsec): min=8161, max=84768, avg=9092.68, stdev=1866.73
lat (nsec): min=8195, max=92651, avg=9127.03, stdev=1867.13
…
~# perf record /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1
test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
fio-3.9-dirty
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=413MiB/s][r=106k IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=109839: Wed Dec 12 17:27:50 2018
read: IOPS=106k, BW=413MiB/s (433MB/s)(4096MiB/9916msec)
clat (nsec): min=8259, max=55066, avg=9102.88, stdev=1903.37
lat (nsec): min=8293, max=55096, avg=9135.43, stdev=1904.01
```
Разница не сильно заметна, всего около ~8 наносекунд.
Посмотрим, что будет, если увеличить нагрузку:
```
~# /root/fio/fio --clocksource=cpu --name=test --numjobs=4 --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1
test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
...
fio-3.9-dirty
Starting 4 processes
Jobs: 4 (f=4): [r(4)][100.0%][r=1608MiB/s][r=412k IOPS][eta 00m:00s]
~# perf record /root/fio/fio --clocksource=cpu --name=test --numjobs=4 --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1
test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
...
fio-3.9-dirty
Starting 4 processes
Jobs: 4 (f=4): [r(4)][100.0%][r=1584MiB/s][r=405k IOPS][eta 00m:00s]
```
Здесь разница уже становится заметна. Можно сказать, что система замедлилась менее чем на 1%, но по существу потеря около 7Kiops на высоконагруженной системе может привести к проблемам.
Понятно, что данный пример синтетический, тем не менее он весьма показательный.
Попробуем запустить еще один синтетический тест, который вычисляет простые числа ― *sysbench*:
```
~# sysbench --max-time=10 --test=cpu run --num-threads=10 --cpu-max-prime=100000
...
Test execution summary:
total time: 10.0140s
total number of events: 3540
total time taken by event execution: 100.1248
per-request statistics:
min: 28.26ms
avg: 28.28ms
max: 28.53ms
approx. 95 percentile: 28.31ms
Threads fairness:
events (avg/stddev): 354.0000/0.00
execution time (avg/stddev): 10.0125/0.00
~# perf record sysbench --max-time=10 --test=cpu run --num-threads=10 --cpu-max-prime=100000
…
Test execution summary:
total time: 10.0284s
total number of events: 3498
total time taken by event execution: 100.2164
per-request statistics:
min: 28.53ms
avg: 28.65ms
max: 28.89ms
approx. 95 percentile: 28.67ms
Threads fairness:
events (avg/stddev): 349.8000/0.40
execution time (avg/stddev): 10.0216/0.01
```
Здесь видно, что даже минимальное время обработки увеличилось на 270 микросекунд.
### Вместо заключения
**Perf** ― очень мощный инструмент для анализа производительности и отладки работы системы. Однако, как и с любым другим инструментом, нужно держать себя в руках и помнить, что любая нагруженная система под пристальным наблюдением работает хуже.
Ссылки по теме:
* [Примеры однострочников с perf](http://www.brendangregg.com/perf.html)
* [Perf wiki](https://perf.wiki.kernel.org/index.php/Main_Page) | https://habr.com/ru/post/437808/ | null | ru | null |
# Android Vitals — Профилируем запуск приложения
Мои предыдущие статьи были посвящены мониторингу запуска Android-приложений в эксплуатационной среде. После того, как мы разобрались с метриками и сценариями, которые результируют в медленном запуске приложения, следующим шагом будет повышение производительности.
Чтобы понять, почему приложение медленно запускается, нам нужно его профилировать. Android Studio предоставляет несколько типов [конфигураций записи профилирования](https://developer.android.com/games/optimize/cpu-profiler?hl=en#configurations):
* Трассировка системных вызовов (systrace, perfetto): почти не влияет на время выполнения, отлично подходит для понимания того, как приложение взаимодействует с системой и процессорами, но не вызовы методов Java, которые происходят внутри виртуальной машины приложения.
* Сэмплирование функций C/C++ (Simpleperf): не особо меня заинтересовал, приложения, с которыми я работаю, выполняют гораздо больше байт-кода, чем нативного. На Q+ он также должен с минимальными накладными расходами сэмплировать Java-стеки, но мне так и не удалось это реализовать.
* Трассировка методов Java: захватывает все вызовы методов виртуальной машины, что приводит к таким большим накладным расходам, что результаты мало что могут показать.
* Сэмплирование методов Java: меньше накладных расходов, чем при трассировке, но показывает вызовы методов Java, происходящие внутри виртуальной машины. При профилировании запуска приложения это мой предпочтительный вариант.
Как начать записи во время запуска приложения
---------------------------------------------
В профилировщике Android Studio есть пользовательский интерфейс для начала трассировки через подключение к уже запущенному процессу, но нет очевидного способа начать запись во время запуска приложения.
Такая возможность все-таки существует, но она скрывается в конфигурации запуска вашего приложения: поставьте галочку возле *“Start this recording on startup”* на вкладке *profiling* .
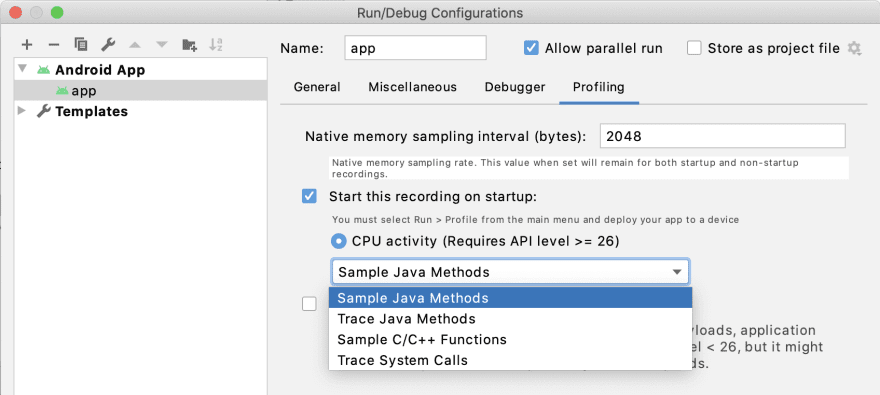Затем запустите приложение через *Run* > *Profile app*.
Профилирование релизных билдов
------------------------------
Android-разработчики в своей повседневной работе обычно используют дебажные билды, а дебажные билды зачастую включают в себя debug drawer, дополнительные библиотеки, такие как LeakCanary и т. д. Разработчикам следует профилировать релизные билды, а не дебажные, чтобы гарантировать, что они работают над актуальными проблемами, с которыми сталкиваются их клиенты.
К сожалению, релизные билды не подлежат отладке, поэтому профилировщик Android не может записывать трейсы релизных билдах.
Есть несколько вариантов решения этой проблемы.
### 1. Создание отлаживаемого релизного билда
Мы могли бы временно сделать наш релизный билд отлаживаемым или создать новый тип релизного билда только для профилирования.
```
android {
buildTypes {
release {
debuggable true
// ...
}
}
}
```
Библиотеки и код Android Framework часто ведут себя иначе, если APK-файл является отлаживаемым. ART отключает множество оптимизаций для подключения дебагера, что значительно и порой непредсказуемо влияет на производительность (смотрите [этот доклад](https://youtu.be/ZffMCJdA5Qc?t=631)). Так что это решение не идеальное.
### 2. Профилирование на рутованном устройстве
Рутованные устройства позволяют профилировщику Android Studio записывать трейсы на недебажных билдах.
Не рекомендую профилировать на эмуляторе - производительность каждого компонента системы будет отличаться (скорость процессора, размер кэша, дисковая производительность), “оптимизация” может даже замедлить работу, переключив работу на что-то, что медленнее телефоне. Если у вас нет рутованого устройства, вы можете создать эмулятор без Play Services, а затем запустить `adb root`.
### 3. Использование simpleperf на Android Q
Есть такой инструмент под названием [simpleperf](https://android.googlesource.com/platform/system/extras/+/master/simpleperf/doc/android_application_profiling.md#prepare-an-android-application), который предположительно позволяет профилировать релизные билды на нерутованных устройства Q+, если у них есть специальный флаг в манифесте. В документации это называется `profileableFromShell`, в примере XML есть тег `profileable` с атрибутом `android: shell`, но в официальной документация по манифесту ничего про это не сказано.
```
```
Я просмотрел код парсинга манифеста на [cs.android.com](https://cs.android.com/android/platform/superproject/+/master:frameworks/base/core/java/android/content/pm/PackageParser.java;l=3878-3885;drc=master):
```
if (tagName.equals("profileable")) {
sa = res.obtainAttributes(
parser,
R.styleable.AndroidManifestProfileable
);
if (sa.getBoolean(
R.styleable.AndroidManifestProfileable_shell,
false
)) {
ai.privateFlags |= ApplicationInfo.PRIVATE_FLAG_PROFILEABLE_BY_SHELL;
}
}
```
Похоже, вы можете запустить профилирование из командной строки, если в манифесте есть (сам я не пробовал). Насколько я понимаю, команда Android Studio все еще работает над интеграцией этой возможности.
Профилирование загруженного APK
-------------------------------
В Square наши релизы создаются в рамках CI. Как мы видели ранее, запуск приложения для профилирования из Android Studio предполагает проверку параметра в конфигурации запуска. Как же сделать это с загруженным APK?
Оказывается, это возможно, но скрыто в *File* > *Profile or Debug APK*. Это откроет новое окно с разархивированным APK, в котором вы можете настроить конфигурацию запуска и начать профилирование.
Профилировщик Android Studio все замедляет
------------------------------------------
К сожалению, когда я тестировал эти методы в реальном приложении, профилирование из Android Studio сильно замедляло запуск приложения (примерно в 10 раз) даже на последних версиях Android. Я не знаю, почему так происходит. Возможно, в этом виновато “расширенное профилирование”, которое, похоже, не может быть отключено. Нам нужно найти другой способ!
Профилирование из кода
----------------------
Вместо профилирования из Android Studio мы можем запустить трассировку непосредственно из кода:
```
val tracesDirPath = TODO("path for trace directory")
val fileNameFormat = SimpleDateFormat(
"yyyy-MM-dd_HH-mm-ss_SSS'.trace'",
Locale.US
)
val fileName = fileNameFormat.format(Date())
val traceFilePath = tracesDirPath + fileName
// Save up to 50Mb data.
val maxBufferSize = 50 * 1000 * 1000
// Sample every 1000 microsecond (1ms)
val samplingIntervalUs = 1000
Debug.startMethodTracingSampling(
traceFilePath,
maxBufferSize,
samplingIntervalUs
)
// ...
Debug.stopMethodTracing()
```
Затем мы можем извлечь файл трассировки из устройства и загрузить его в Android Studio.
### Когда начинать запись
Мы должны начать запись трейсов как можно раньше в жизненном цикле приложения. Как я уже говорил в [Android Vitals — Разбираем холодный запуск](https://habr.com/ru/company/otus/blog/597267/), самый ранний код, который может запускаться при запуске приложения до Android P, - это `ContentProvider`, а на Android P+ - это `AppComponentFactory`.
#### До Android P / API < 28
```
class AppStartListener : ContentProvider() {
override fun onCreate(): Boolean {
Debug.startMethodTracingSampling(...)
return false
}
// ...
}
```
```
xml version="1.0" encoding="utf-8"?
```
К сожалению, мы не можем контролировать порядок, в котором создаются инстансы ContentProvider, поэтому мы можем не захватить часть раннего кода запуска.
*Примечание:* [@anjalsaneen](https://dev.to/anjalsaneen) указал [в комментариях,](https://dev.to/anjalsaneen/comment/1ccod) что при определении провайдера мы можем установить тег [initOrder](https://developer.android.com/guide/topics/manifest/provider-element#init), и провайдер с наибольшим этим значением будет инициализироваться первым.
#### Android P+ / API 28+
```
xml version="1.0" encoding="utf-8"?
```
```
xml version="1.0" encoding="utf-8"?
```
Где хранить трейсы
```
val tracesDirPath = TODO("path for trace directory")
```
* API <28: широковещательный приемник (broadcast receiver) имеет доступ к контексту, в котором мы можем вызвать [Context.getDataDir()](https://developer.android.com/reference/android/content/Context#getDataDir()) для сохранения трейсов в каталоге приложения.
* API 28: [AppComponentFactory.instantiateApplication()](https://developer.android.com/reference/android/app/AppComponentFactory#instantiateApplication(java.lang.ClassLoader,%20java.lang.String)) отвечает за создание нового инстанса приложения, поэтому контекст пока недоступен. Мы можем захардкодить путь к /sdcard/ напрямую, хотя для этого требуется разрешение WRITE\_EXTERNAL\_STORAGE.
* API 29+: при таргетинге на API 29 хардкод /sdcard/ перестает работать. Мы можем добавить флаг [requestLegacyExternalStorage](https://developer.android.com/guide/topics/manifest/application-element#requestLegacyExternalStorage), но он не поддерживается в API 30. Примечание: [Ясин Резгуй (Yacine Rezgui) предложил попробовать MANAGE\_EXTERNAL\_STORAGE](https://twitter.com/yrezgui/status/1330960375865544706) в API 30+. В любом случае [AppComponentFactory.instantiateClassLoader()](https://developer.android.com/reference/android/app/AppComponentFactory#instantiateClassLoader(java.lang.ClassLoader,%20android.content.pm.ApplicationInfo)) передает ApplicationInfo, поэтому мы можем использовать [ApplicationInfo.dataDir](https://developer.android.com/reference/android/content/pm/ApplicationInfo#dataDir) для сохранения трейсов в каталоге приложения.
### Когда прекращать запись
В [Android Vitals - первая отрисовка 👩🎨](https://dev.to/pyricau/android-vitals-first-draw-time-m1d), мы узнали, что холодный запуск заканчивается, когда полностью загружается первый кадр приложения. Мы можем использовать код из этой статьи, чтобы узнать, когда остановить трассировку методов:
```
class MyApp : Application() {
override fun onCreate() {
super.onCreate()
var firstDraw = false
val handler = Handler()
registerActivityLifecycleCallbacks(
object : ActivityLifecycleCallbacks {
override fun onActivityCreated(
activity: Activity,
savedInstanceState: Bundle?
) {
if (firstDraw) return
val window = activity.window
window.onDecorViewReady {
window.decorView.onNextDraw {
if (firstDraw) return
firstDraw = true
handler.postAtFrontOfQueue {
Debug.stopMethodTracing()
}
}
}
}
})
}
}
```
Мы также можем производить запись в течение фиксированного периода времени, превышающего запуск приложения, например 5 секунд:
```
Handler(Looper.getMainLooper()).postDelayed({
Debug.stopMethodTracing()
}, 5000)
```
Профилирование с помощью Nanoscope
----------------------------------
Еще один вариант профилирования во время запуска приложения - [uber/nanoscope](https://github.com/uber/nanoscope). Это образ Android со встроенной трассировкой с минимальными накладными расходами. Что само по себе здорово, но имеет несколько ограничений:
* Отслеживает только основной поток (main thread).
* Большое приложение скорее всего переполнит буфер трассировки в памяти.
> [*@lelandtakamine @Piwai*](https://twitter.com/Piwai)[*@kurtisnelson*](https://twitter.com/kurtisnelson)[*@speekha*](https://twitter.com/speekha) *Круто - с нетерпением жду поста.*
>
> *Да - Nanoscope пока отслеживает только main thread, но мы в* [*@perf\_dev*](https://twitter.com/perf_dev) *работаем над поддержкой многопоточности. Следите за обновлениями.*
>
>
Этапы запуска приложения
------------------------
После того, как у нас на руках будет трассировка запуска, мы можем начать выяснять, на что было потрачено время. Скорее всего это будет что-то из этих трех категорий:
1. `ActivityThread.handlingBindApplication()` отвечает за работу по запуску перед созданием activity. Если он работает медленно, то нам, вероятно, нужно оптимизировать `Application.onCreate()`.
2. `TransactionExecutor.execute()` отвечает за создание и возобновление activity, что включает инфлейтинг иерархии представлений.
3. `ViewRootImpl.performTraversals()` - это то место, где фреймворк выполняет первое измерение, лейаут и отрисовку. Если это происходит медленно, то причиной этому может быть слишком сложная иерархией представлений, или представления с кастомной графикой, которую необходимо оптимизировать.
Если вы заметили, что служба запускается до первого view traversal, возможно, стоит отложить запуск этой службы, чтобы это произошло после view traversal.
Заключение
----------
Выводов несколько:
* Профилируйте релизные билды, чтобы сосредоточиться на актуальных проблемах.
* Состояние профилирования приложения со старта на Android далеко от идеального. По сути, готового хорошего решения нет, но команда Jetpack Benchmark [работает над этим](https://cs.android.com/androidx/platform/frameworks/support/+/androidx-master-dev:benchmark/integration-tests/macrobenchmark/src/androidTest/java/androidx/benchmark/integration/macrobenchmark/ProcessSpeedProfileValidation.kt;l=38;drc=ea99c3ac7be5b54a9493ba9fe00edee9e91baf6e).
* Производите запись из кода, чтобы Android Studio не замедляла работу.
Огромное спасибо многим людям, которые помогали мне в Slack и [Twitter](https://twitter.com/Piwai/status/1330914849019203584): Kurt Nelson, Justin Wong, Leland Takamine, Yacine Rezgui, Raditya Gumay, Chris Craik, Mike Nakhimovich, Artem Chubaryan, Rahul Ravikumar, Yacine Rezgui, Eugen Pechanec, Louis CAD, Max Kovalev.
---
Перевод статьи подготовлен в преддверии старта нового потока курса [Android Developer. Professional](https://otus.pw/WU7I/).
* [Узнать подробнее о курсе](https://otus.pw/WU7I/) | https://habr.com/ru/post/597995/ | null | ru | null |
# Tcl/Tk. Тематические виджеты TTK и дизайнер TKproE-2.20
Просматривая свои [заметки](https://habrahabr.ru/post/333742/) по проектированию GUI с использованием виджетов Tk, я почувствовал какую-то неудовлетворенность. А дело оказалось в том, что я фактически упустил работу с тематическими виджетами ttk (themed tk). Они в скользь были задействованы при рассмотрении пакета Tkinter для Python и использовании дизайнера [Page](https://habrahabr.ru/post/335712/) . Там речь шла о виджете TNotebook (блокнот, записная книжка) из пакета ttk.
Виджет TNotebook это один из новых виджетов, наряду с TCombobox, TProgressbar, TSeparator и TSizegrip, появившихся в ttk. Перевод приложений с классического tk на ttk может потребовать минимальных усилий. Порой бывает достаточно вместо, например, button написать ttk::buton. Отдельно хочется сказать о combobox. Если вы в своих приложениях, написанных на tk, использовали виджет spinbox и теперь замените его на ttk::combobox, то в приложении появится этот виджет, которого вам так не хватало:
Но все же главное в ttk, это не новые виджеты, а их оформление (themеd). Настройка тем, стилей заслуживает отдельного разговора. А здесь бы я отправил разработчиков к вышедшему буквально на днях (11.11.2017 г.) замечательному [учебному пособию](http://www.tcltk.info/einfuehrung_in_tcl_tk_buch.pdf):

Насмотря на то, что оно написано на немецком языке, но я, даже не знаю английского языка, читал его с превеликим удовольствием. Как говорится, написано для «дурака».
Нас интересует, есть ли интегрированная среда разработки/дизайнеры применительно к виджетам ttk. Если говорить о Python и Tkinter, то это [пакет Page](https://habrahabr.ru/post/335712/). Этот пакет поддерживает как классические виджеты, так и тематические виджеты. Правда почему-то отсутствуют поддержка разделителей TSeparator. Средой проектирования является скриптовый язык Tcl. Именно по этой причине мы еще вернемся к этому пакету. Отметим несомненное достоинство Page – это наличие мольберта, на котором можно просто и удобно размещать виджеты.
Но это для Python-а, а нас интересует конечный продукт на Tcl. Оказалось, что ровно год назад (27.11.2016 г.) был анансирован Tcl/Tk-дизайнер [TKproE 2.20](https://groups.google.com/forum/#!topic/comp.lang.tcl/SEnnJTaSwKo):
И в нем присутствуют разделители TSeparator. Уникальной особенностью этого дизайнера является то, что он принимает практически любой tcl/tk скрипт.
Для демонстрации возможностей как виджетов ttk, так и дизайнера TKproE-2.20, был разработан GUI-интерфейс для утилиты «изящной печати» pp из пакета NSS с устраненными [косяками](https://habr.com/ru/post/406037/) и поддержкой oid-ов российской pki (инфраструктура открытых ключей). Тем более, что такая утилита по просмотру сертификатов, включая квалифицированные сертификаты, просмотру электронной подписи документа, является востребованной. И именно для нее был спроектирован и реализован графический интерфейс с помощью TKproE:
Утилиту и графическую обвязку к ней можно скачать здесь. Еще одна очень приятная неожиданность в отличии от других дизайнеров ждала при работе с изображения (image) и иконками. Если раньше приходилось «ручками» переводить изображение в PEM-кодировку и самому вставлять код в скрипт, то теперь достаточно указать файл с изображением и TKproE сам заберет его и конвертирует:
Единственное неудобство здесь – это необходимость ввода имени файла. Но оказалось это легко исправить. Достаточно в скрипте *tkproe.tc*l в строках 7474 и 7516 код (процедура **proc ShowWindow.tpimages** )
```
label .tpimages.propbitmap.frame14.label12 -activebackground {#dcdcdc} \
-anchor {w} - background {#dcdcdc} -borderwidth {2} -font {Helvetica 10} \
-highlightbackground {#dcdcdc} -text {File:} -width {10}
```
заменить на код:
```
button .tpimages.propbitmap.frame14.label12 -activebackground {#dcdcdc} \
-anchor {w} -background {#dcdcdc} -borderwidth {2} -font {Helvetica 10} \
-highlightbackground {#dcdcdc} -text {File:} -width {10} \
-command { global userDir; set fileTypes {{"File image" *}}; \
set file [tk_getOpenFile -title "Find Image" -filetypes $fileTypes \
-initialdir "$userDir"]; \
.tpimages.propphoto.frame14.entry13 delete 0 end; \
.tpimages.propphoto.frame14.entry13 insert end $file; }
```
А чтобы выбор файла начинался с домашнего каталога после 5 строки в скрипт tkproe.tcl добавляем следующий код:
```
global userDir
set userDir $env(HOME)
```
Теперь для выбора файла с изображением достаточно нажать кнопку «File:»:
Желающие могут улучшить и этот код, например, по выбранному файлу заполнять поле «Format», либо наоборот, по формату организовать поиск файла, рассматривая формат как расширение файла («Тип файлов» на скриншоте).
Еще одно неудобство, с которым пришлось столкнуться, это получение домашнего каталога пользователя, например, mHOME set $env(HOME). А домашний каталог, как правило, нужен для обеспечения платформанезависимости скрипта. Оказалось через TKproE вставить его некуда. Глобальные переменные в TKproE определяются через процедуру TPinitVars. Естественно, если определяешь переменную mHOME через область глобальных переменных:
то переменная mHome будеть иметь значение «$env(HOME)». Казалось бы, возьми и вставь вычисление текущего каталога ручками в основное тело скрипта. Можно, если только вы больше не будете править скрипт в TKproE. В противном случае TKproE озаботится оптимизацией и вместо кода set nHOME $env(HOME) вставит в процедуру инициализации глобальных переменных код с домашним каталогом компьютера, на котором создавался/правился скрипт. Это ужасно.
Здесь пришлось во второй раз залезть в код TKproE. Выход из данной ситуации мы нашли в определении глобальной переменной myHOME и включении в генерируемый скрипт дополнительного кода. И так, в процедуру proc TP\_Clone\_app сразу же за строкой (13-ая):
```
set outstr "# Generated by TKproE $TPinfo(revision) - [clock format [clock seconds]]\n\n"
```
добавляем строку
```
append outstr "#Add me\nencoding system utf-8\nglobal myHOME\nset myHOME \$env(HOME)\n\n"
```
а в процедуру proc TP\_Clone\_variables после строки (10-ая)
```
foreach varname $varlist {
```
вставляем код
```
if { $varname == "myHOME" } {
continue
}
```
который отключает переустановление глобальной переменной myHOME.
И вот после этих доработок, и удалось создать графическую оболочку для утилиты PP:
Если выбрать файл с документом и нажать кнопку «Показать в окне», то мы увидим следующее:
Распечатку сертификата, как и любого другого документа, можно сохранить в файле (кнопка «Сохранить в файле» на вкладке «Сертификаты и т.п.»).
Исходный код скрипта GUIPP, а он же является и проектом TKproE, можно скачатьздесь.
Выше мы говорили о том, что вернемся к дизайнеру Page. В дизайнере Page очень удобно проектировать GUI со свободным размещением виджетов (place). Как уже говорилось, проект GUI дизайнер Page хранит как Tcl/Tk скрипт, и было бы заманчиво использовать готовый скрипт из Page в TKproE или дописывать его в ручном режиме. В чистом виде проект из Page нельзя выполнить или загрузить в TKproE-2.20. Для устранения этой «несправедливости» был разработан tcl-скрипт, который приводит проекты из Page в выполняемые скрипты tcl/tk:
```
sh-4.3$ ./fromPageToTcl.tcl
Usage: ./fromPageToTcl.tcl
sh-4.3$
```
Вот код tcl-скрипта fromPageToTcl.tcl:
**Код tcl-скрипта fromPageToTcl.tcl**
```
#!/usr/bin/tclsh
# 1 -- source file
#НЕ ЗАБЫВАТЬ КОММЕНТИРОВТЬ return
# if {[winfo exists $base]} {
#### wm deiconify $base; return
# }
# и строку
## vTcl:FireEvent $base <>
#
namespace eval vTcl::widgets::ttk::sizegrip {
proc CreateCmd {target args} {
grid [ttk::sizegrip $target] -column 999 -row 999 -sticky se
}
}
proc vTcl:font:add\_GUI\_font {font\_name font\_descr} {
# This is called when we load an existing GUI-tcl file. It get rid
# of actual fonts and replaces them with the definitions from the
# GUI-tcl file.
#set font\_descr [font configure $font\_name]
if {[catch {
font delete $font\_name
set newfont [font create $font\_name {\*}$font\_descr ]
} result]} {
# Create failed
set newfont "TkDefaultFont"
}
#set newkey NEEDS WORK
#set ::vTcl(fonts,$newfont,type) $font\_type
#set ::vTcl(fonts,$newfont,key) $newkey
set ::vTcl(fonts,$newfont,font\_descr) $font\_descr
set ::vTcl(fonts,$font\_descr,object) $newfont ;# Rozen 8/24/13
#set ::vTcl(fonts,$newkey,object) $newfont
}
proc {vTcl:font:add\_font} {font\_descr font\_type {newkey {}} {check\_fonts {1}}} {
global vTcl
## This procedure may be used free of restrictions.
## Exception added by Christian Gavin on 08/08/02.
## Other packages and widget toolkits have different licensing requirements.
## Please read their license agreements for details.
# With tk you are not allowed to specify the the font name when
# creating a fomt. So if you want to assign a name to a font then
# specify then the variable ::vTcl(fonts,$newkey,object) will hold
# the correspondance between the actual name of the created name
# and the name you wish to use. Rozen
set defined\_fonts [font names]
if {$newkey != ""} {
if {[info exists ::vTcl(fonts,$font\_descr,object)]} {
set test\_font $::vTcl(fonts,$font\_descr,object)
if {[lsearch $defined\_fonts $newkey] == -1} {
set ::vTcl(fonts,$newkey,object) $test\_font
return $test\_font
}
}
}
if {$check\_fonts} {
if {[info exists ::vTcl(fonts,$font\_descr,object)]} {
# It already exists
return $::vTcl(fonts,$font\_descr,object)
}
if {[lsearch $defined\_fonts $font\_descr] > -1} {
# It's a font already defined..
return $font\_descr
}
}
incr ::vTcl(fonts,counter)
set newfont [eval font create $font\_descr]
lappend ::vTcl(fonts,objects) $newfont
## each font has its unique key so that when a project is
## reloaded, the key is used to find the font descriptio
if {$newkey == ""} {
set newkey vTcl:font$::vTcl(fonts,counter)
## let's find an unused font key
while {[vTcl:font:get\_font $newkey] != ""} {
incr ::vTcl(fonts,counter)
set newkey vTcl:font$::vTcl(fonts,counter)
}
}
set ::vTcl(fonts,$newfont,type) $font\_type
set ::vTcl(fonts,$newfont,key) $newkey
set ::vTcl(fonts,$newfont,font\_descr) $font\_descr
set ::vTcl(fonts,$font\_descr,object) $newfont
set ::vTcl(fonts,$newkey,object) $newfont
lappend ::vTcl(fonts,$font\_type) $newfont
## in case caller needs it
return $newfont
}
proc vTcl:DefineAlias {a b c d e} {
# puts \"$a.$b\"
# puts \"$c.$d.$e\"
return
}
proc Window {type w} {
if {$w == "."} {
return
}
toplevel $w
set base $w
vTclWindow$w $base
}
#END
set largv [llength $argv]
if {$largv != 1} {
puts "Usage: [info script] \n"
exit
}
set fconf [file exists "$argv"]
if { $fconf == "0" } {
puts "File=\"$argv\" don't exist\n"
puts "Usage: [info script] \n"
exit
}
set srcMy [info script]
set fp [open $srcMy r]
while {![eof $fp]} {
gets $fp res
puts $res
if { $res == "#END"} {
break
}
}
close $fp
#Обрабатываем файл из Page
set fp [open $argv r]
while {![eof $fp]} {
gets $fp res
if { [string first "wm deiconify \$base; return" $res] != -1 } {
puts "#Soft"
puts "\t\twm deiconify \$base;"
continue
}
if { [string first "vTcl:FireEvent \$base <>" $res] != -1 } {
puts "#Soft"
puts "#\tvTcl:FireEvent \$base <>"
continue
}
if { [string first "vTcl:toplevel \$top -class Toplevel \\" $res] != -1 } {
puts "#Soft"
puts "#vTcl:toplevel \$top -class Toplevel \\"
puts "\$top configure \\"
continue
}
if { [string first "vTcl::widgets::core::toplevel::createCmd \$top -class Toplevel \\" $res] != -1 } {
puts "#Soft"
puts "#vTcl::widgets::core::toplevel::createCmd \$top -class Toplevel \\"
puts "\$top configure \\"
continue
}
puts $res
}
close $fp
exit
```
И так, берем пример из папки ~/page/examples/complex и получаем посредством скрипта fromPageToTcl.tcl исполняемый tcl-скрипт:
```
sh-4.3$cd ~/page/examples/complex
sh-4.3$ ./fromPageToTcl.tcl complex.tcl > complex_new.tcl
sh-4.3$
```
Теперь, чтобы получить совсем хороший код, открываем полученный скрипт complex\_new.tcl в дизайнере TKproE-2.20 и удаляем из проекта все ненужные теперь процедуры, а это процедура Window и все процедуры с префиксом vTcl, и пересохраняем его:
Отметим, что Page поддерживает еще «Scrolled widgets», мы их, естественно, не поддерживаем.
В целом, дизайнер TKproE оставил очень хорошее впечатление и с ним приятно вести разработку GUI. А тройка Page x TKproE x fromPageToTcl.tcl, состоящая из дизайнеров Page, TKproE и скрипта fromPageToTcl.tcl, это просто великолепная троица. | https://habr.com/ru/post/343930/ | null | ru | null |
# Генератор клиента к базе данных на Golang на основе интерфейса
[Генератор клиента](https://github.com/go-gad/sal) к базе данных на Golang на основе интерфейса.

Для работы с базами данных Golang предлагает пакет `database/sql`, который является абстракцией над программным интерфейсом реляционной базы данных. С одной стороны пакет включает мощную функциональность по управлению пулом соединений, работе с prepared statements, транзакциями, интерфейсом запросов к базе. С другой стороны приходится написать немалое кол-во однотипного кода в веб приложении для взаимодействия с базой данных. Библиотека go-gad/sal предлагает решение в виде генерации однотипного кода на основе описанного интерфейса.
Motivation
----------
Сегодня существует достаточное количество библиотек, которые предлагают решения в виде ORM, помощников построения запросов, генерации хелперов на основе схемы базы данных.
* <https://github.com/jmoiron/sqlx>
* <https://github.com/go-reform/reform>
* <https://github.com/jinzhu/gorm>
* <https://github.com/Masterminds/squirrel>
* <https://github.com/volatiletech/sqlboiler>
* <https://github.com/drone/sqlgen>
* <https://github.com/gocraft/dbr>
* <https://github.com/go-gorp/gorp>
* <https://github.com/doug-martin/goqu>
* <https://github.com/src-d/go-kallax>
* <https://github.com/go-pg/pg>
Когда я переходил несколько лет назад на язык Golang, у меня уже был опыт работы с базами данных на разных языках. С использованием ORM, например ActiveRecord, и без. Пройдя путь от любви до ненависти, не имея проблем с написанием нескольких дополнительных строчек кода, взаимодействие с базой данных в Golang пришло к нечто похожему на repository pattern. Описываем интерфейс работы с базой данных, реализуем с помощью стандартных db.Query, row.Scan. Использовать дополнительные обертки просто не имело смысла, это было непрозрачно, заставляло бы быть на чеку.
Сам язык SQL уже представляет из себя абстракцию между вашей программой и данными в хранилище. Мне всегда казалось нелогичным пытаться описать схему данных, а потом строить сложные запросы. Структура ответа в таком случае отличается от схемы данных. Получается что контракт надо описывать не на уровне схемы данных, а на уровне запроса и ответа. Этот подход в веб разработке мы используем, когда описываем структуры данных запросов и ответов API. При обращении к сервису по RESTful JSON или gRPC, мы декларируем контракт на уровне запроса и ответа с помощью JSON Schema или Protobuf, а не схемы данных сущностей внутри сервисов.
То есть взаимодействие с базой данных свелось к подобному способу:
```
type User struct {
ID int64
Name string
}
type Store interface {
FindUser(id int64) (*User, error)
}
type Postgres struct {
DB *sql.DB
}
func (pg *Postgres) FindUser(id int64) (*User, error) {
var resp User
err := pg.DB.QueryRow("SELECT id, name FROM users WHERE id=$1", id).Scan(&resp.ID, &resp.Name)
if err != nil {
return nil, err
}
return &resp, nil
}
func HanlderFindUser(s Store, id int) (*User, error) {
// logic of service object
user, err := s.FindUser(id)
//...
}
```
Такой способ делает вашу программу предсказуемой. Но будем честны, это не мечта поэта. Мы хотим сократить количество шаблонного кода для составления запроса, наполнения структур данных, использовать связывание переменных и так далее. Я попробовал сформулировать список требований, которым должна удовлетворять желанный набор утилит.
Requirements
------------
* Описание взаимодействия в виде интерфейса.
* Интерфейс описывается методами и сообщениями запросов и ответов.
* Поддержка связывания переменных и подготовленных выражений (prepared statements).
* Поддержка именованных аргументов.
* Связывание ответа базы данных с полями структуры данных сообщения.
* Поддержка нетипичных структур данных (массив, json).
* Прозрачная работа с транзакциями.
* Встроенная поддержка промежуточных обработчиков (middleware).
Имплементацию взаимодействия с базой данных мы хотим абстрагировать с помощью интерфейса. Это позволит нам реализовать нечто похожее на такой шаблон проектирования как репозиторий. В примере выше мы описали интерфейс Store. Теперь можем использовать его как зависимость. На этапе тестирования мы можем передать сгенерированный на базе этого интерфейса объект заглушку, а в продуктиве будем использовать нашу имплементацию на базе структуры Postgres.
Каждый метод интерфейса описывает один запрос к базе данных. Входные и выходные параметры метода должны быть частью контракта для запроса. Строку запроса нужно уметь форматировать в зависимости от входных параметров. Это особенно актуально при составлении запросов со сложным условием выборки.
При составлении запроса мы хотим использовать подстановки и связывание переменных. Например в PostgreSQL вместо значения вы пишите `$1`, и вместе с запросом передаёте массив аргументов. Первый аргумент будет использован в качестве значения в преобразованном запросе. Поддержка подготовленных выражений позволит не заботиться об организации хранения этих самых выражений. Библиотека database/sql предоставляет мощный инструмент поддержки подготовленных выражений, сама заботится о пулле соединений, закрытых соединениях. Но со стороны пользователя необходимо совершить дополнительное действие для повторного использования подготовленного выражения в транзакции.
Базы данных, такие как PostgreSQL и MySQL, используют разный синтаксис для использования подстановок и связывания переменных. PostgreSQL использует формат `$1`, `$2`,… MySQL использует `?` вне зависимости от расположения значения. Библиотека database/sql предложила универсальный формат именованных аргументов <https://golang.org/pkg/database/sql/#NamedArg>. Пример использования:
```
db.ExecContext(ctx, `DELETE FROM orders WHERE created_at < @end`, sql.Named("end", endTime))
```
Поддержка такого формата предпочтительнее в использовании по сравнению с решениями PostgreSQL или MySQL.
Ответ от базы данных, который обрабатывает программный драйвер условно можно представить в следующем виде:
```
dev > SELECT * FROM rubrics;
id | created_at | title | url
----+-------------------------+-------+------------
1 | 2012-03-13 11:17:23.609 | Tech | technology
2 | 2015-07-21 18:05:43.412 | Style | fashion
(2 rows)
```
С точки зрения пользователя на уровне интерфейса удобно описать выходной параметр как массив из структур вида:
```
type GetRubricsResp struct {
ID int
CreatedAt time.Time
Title string
URL string
}
```
Далее спроецировать значение `id` на `resp.ID` и так далее. В общем случае этот функционал закрывает большинство потребностей.
При декларации сообщений через внутренние структуры данных, возникает вопрос о способе поддержки нестандартных типов данных. Например массив. Если при работе с PostgreSQL вы использует драйвер github.com/lib/pq, то при передаче аргументов запроса или сканировании ответа вы можете использовать вспомогательные функции, как `pq.Array(&x)`. Пример из документации:
```
db.Query(`SELECT * FROM t WHERE id = ANY($1)`, pq.Array([]int{235, 401}))
var x []sql.NullInt64
db.QueryRow('SELECT ARRAY[235, 401]').Scan(pq.Array(&x))
```
Соответственно должны быть способы подготовки структур данных.
При выполнении любого из методов интерфейса может быть использовано соединение с базой данных, в виде объекта `*sql.DB`. При необходимости выполнить несколько методов в рамках одной транзакции хочется использовать прозрачный функционал с аналогичным подходом работы вне транзакции, не передавать дополнительные аргументы.
При работе с реализаций интерфейса нам жизненно необходимо иметь возможность встроить инструментарий. Например логирование всех запросов. Инструментарий должен получить доступ к переменным запроса, ошибке ответа, времени выполнения, названию метода интерфейса.
По большей части требования были сформулированы как систематизация сценариев работы с базой данных.
Solution: go-gad/sal
--------------------
Один из способов борьбы с шаблонным кодом – это сгенерировать его. Благо в Golang есть инструментарий и примеры для этого <https://blog.golang.org/generate>. В качестве архитектурного решения для генерации был позаимствован подход GoMock <https://github.com/golang/mock>, где анализ интерфейса осуществляется с помощью рефлексии. На основе этого подхода согласно требованиям была написана утилита salgen и библиотека sal, которые генерируют код реализации интерфейса и предоставляют набор вспомогательных функций.
Для того, чтобы начать использовать это решение необходимо описать интерфейс, который описывает поведение слоя взаимодействия с базой данных. Указать директиву `go:generate` с набором аргументов и запустить генерацию. Будет получен конструктор и куча шаблонного кода, готовые к использованию.
```
package repo
import "context"
//go:generate salgen -destination=./postgres_client.go -package=dev/taxi/repo dev/taxi/repo Postgres
type Postgres interface {
CreateDriver(ctx context.Context, r *CreateDriverReq) error
}
type CreateDriverReq struct {
taxi.Driver
}
func (r *CreateDriverReq) Query() string {
return `INSERT INTO drivers(id, name) VALUES(@id, @name)`
}
```
#### Interface
Всё начинается с декларирования интерфейса и специальной команды для утилиты `go generate`:
```
//go:generate salgen -destination=./client.go -package=github.com/go-gad/sal/examples/profile/storage github.com/go-gad/sal/examples/profile/storage Store
type Store interface {
...
```
Здесь описывается, что для нашего интерфейса `Store` из пакета будет вызвана консольная утилита `salgen`, с двумя опциями и двумя аргументами. Первая опция `-destination` определяет в какой файл будет записан сгенерированный код. Вторая опция `-package` определяет полный путь (import path) библиотеки для сгенерированной имплементации. Далее указаны два аргумента. Первый описывает полный путь пакета (`github.com/go-gad/sal/examples/profile/storage`), где расположен искомый интерфейс, второй указывает собственно название интерфейса. Отметим, что команда для `go generate` может быть расположена в любом месте, не обязательно рядом с целевым интерфейсом.
После выполнения команды `go generate` мы получим конструктор, имя которого строится путем добавления префикса `New` к названию интерфейса. Конструктор принимает обязательный параметр, соответствующий интерфейсу `sal.QueryHandler`:
```
type QueryHandler interface {
QueryContext(ctx context.Context, query string, args ...interface{}) (*sql.Rows, error)
ExecContext(ctx context.Context, query string, args ...interface{}) (sql.Result, error)
PrepareContext(ctx context.Context, query string) (*sql.Stmt, error)
}
```
Этому интерфейсу соответствует объект `*sql.DB`.
```
connStr := "user=pqgotest dbname=pqgotest sslmode=verify-full"
db, err := sql.Open("postgres", connStr)
client := storage.NewStore(db)
```
#### Methods
Методы интерфейса определяют набор доступных запросов к базе данных.
```
type Store interface {
CreateAuthor(ctx context.Context, req CreateAuthorReq) (CreateAuthorResp, error)
GetAuthors(ctx context.Context, req GetAuthorsReq) ([]*GetAuthorsResp, error)
UpdateAuthor(ctx context.Context, req *UpdateAuthorReq) error
}
```
* Количество аргументов всегда строго два.
* Первый аргумент это контекст.
* Второй аргумент содержит данные для связывания переменных и определяет строку запроса.
* Первый выходной параметр может быть объектом, массивом объектов или отсутствовать.
* Последний выходной параметр всегда ошибка.
Первым аргументом всегда ожидается объект `context.Context`. Этот контекст будет передан при вызовах базы данных и инструментария. Вторым аргументом ожидается параметр с базовым типом `struct` (или указатель на `struct`). Параметр обязан удовлетворять следующему интерфейсу:
```
type Queryer interface {
Query() string
}
```
Метод `Query()` будет вызван перед выполнением запроса к базе данных. Полученная строка будет преобразована к специфичному для базы данных формату. То есть для PostgreSQL `@end` будет заменено на `$1`, и в массив аргументов будет передано значение `&req.End`
В зависимости от выходных параметров определяется какой из методов (Query/Exec) будет вызван:
* Если первый параметр с базовым типом `struct` (или указатель на `struct`), то будет вызван метод `QueryContext`. Если ответ от базы данных не содержит ни одной строки, то вернется ошибка `sql.ErrNoRows`. То есть поведение схожее с `db.QueryRow`.
* Если первый параметр с базовым типом `slice`, то будет вызван метод `QueryContext`. Если ответ от базы данных не содержит строк, то вернется пустой список. Базовый тип элемента списка должен быть `stuct` (или указатель на `struct`).
* Если выходной параметр один, с типом `error`, то будет вызван метод `ExecContext`.
#### Prepared statements
Сгенерированный код поддерживает подготовленные выражения. Подготовленные выражения кэшируются. После первой подготовки выражения оно помещается в кэш. Библиотека database/sql сама заботится о том, чтобы подготовленные выражения прозрачно применялись на нужное соединение с базой данных, включая обработку закрытых соединений. В свою очередь библиотека `go-gad/sal` забоится о повторном использовании подготовленного выражения в контексте транзакции. При выполнении подготовленного выражения аргументы передаются с помощью связывания переменных, прозрачно для разработчика.
Для поддержки именованных аргументов на стороне библиотеки `go-gad/sal` запрос преобразуется в вид, пригодный для базы данных. Сейчас есть поддержка преобразования для PostgreSQL. Имена полей объекта запроса используются для подстановки в именованных аргументах. Чтобы указать вместо имени поля объекта другое название, необходимо использовать тэг `sql` для полей структуры. Рассмотрим пример:
```
type DeleteOrdersRequest struct {
UserID int64 `sql:"user_id"`
CreateAt time.Time `sql:"created_at"`
}
func (r * DeleteOrdersRequest) Query() string {
return `DELETE FROM orders WHERE user_id=@user_id AND created_at<@end`
}
```
Строка запроса будет преобразована, а с помощью таблицы соответствия и связывания переменных в аргументы выполнения запроса будет передан список:
```
// generated code:
db.Query("DELETE FROM orders WHERE user_id=$1 AND created_at<$2", &req.UserID, &req.CreatedAt)
```
#### Map structs to request's arguments and response messages
Библиотека `go-gad/sal` забоится о том, чтобы связать строки ответа базы данных со структурами ответа, колонки таблиц с полями структур:
```
type GetRubricsReq struct {}
func (r GetRubricReq) Query() string {
return `SELECT * FROM rubrics`
}
type Rubric struct {
ID int64 `sql:"id"`
CreateAt time.Time `sql:"created_at"`
Title string `sql:"title"`
}
type GetRubricsResp []*Rubric
type Store interface {
GetRubrics(ctx context.Context, req GetRubricsReq) (GetRubricsResp, error)
}
```
И если ответ базы данных будет:
```
dev > SELECT * FROM rubrics;
id | created_at | title
----+-------------------------+-------
1 | 2012-03-13 11:17:23.609 | Tech
2 | 2015-07-21 18:05:43.412 | Style
(2 rows)
```
То нам вернется список GetRubricsResp, элементами которого будут указатели на Rubric, где поля заполнены значениями из колонок, которые соответствуют названиям тегов.
Если в ответе базы данных будут колонки с одинаковыми именами, то соответствующие поля структуры будут выбраны в порядке объявления.
```
dev > select * from rubrics, subrubrics;
id | title | id | title
----+-------+----+----------
1 | Tech | 3 | Politics
```
```
type Rubric struct {
ID int64 `sql:"id"`
Title string `sql:"title"`
}
type Subrubric struct {
ID int64 `sql:"id"`
Title string `sql:"title"`
}
type GetCategoryResp struct {
Rubric
Subrubric
}
```
#### Non-standard data types
Пакет `database/sql` предоставляет поддержку базовым типам данных (строки, числа). Для того, чтобы обработать такие типы данных как массив или json в запросе или ответе, необходимо поддержать интерфейсы `driver.Valuer` и `sql.Scanner`. В различных реализациях драйверов есть специальные вспомогательные функции. Например `lib/pq.Array` (<https://godoc.org/github.com/lib/pq#Array>):
```
func Array(a interface{}) interface {
driver.Valuer
sql.Scanner
}
```
По умолчанию библиотека `go-gad/sql` для полей структуры вида
```
type DeleteAuthrosReq struct {
Tags []int64 `sql:"tags"`
}
```
будет использовать значение `&req.Tags`. Если же структура будет удовлетворять интерфейсу `sal.ProcessRower`,
```
type ProcessRower interface {
ProcessRow(rowMap RowMap)
}
```
то используемое значение можно скорректировать
```
func (r *DeleteAuthorsReq) ProcessRow(rowMap sal.RowMap) {
rowMap.Set("tags", pq.Array(r.Tags))
}
func (r *DeleteAuthorsReq) Query() string {
return `DELETE FROM authors WHERE tags=ANY(@tags::UUID[])`
}
```
Этот обработчик можно использовать для аргументов запроса и ответа. В случае со списком в ответе, метод должен принадлежать элементу списка.
#### Transactions
Для поддержки транзакций интерфейс (Store) должен быть расширен следующими методами:
```
type Store interface {
BeginTx(ctx context.Context, opts *sql.TxOptions) (Store, error)
sal.Txer
...
```
Реализация методов будет сгенерирована. Метод `BeginTx` использует соединение из текущего объекта `sal.QueryHandler` и открывает транзакцию `db.BeginTx(...)`; возвращает новый объект реализации интерфейса `Store`, но в качестве хэндлера использует полученный объект `*sql.Tx`
#### Middleware
Для встраивания инструментария предусмотрены хуки.
```
type BeforeQueryFunc func(ctx context.Context, query string, req interface{}) (context.Context, FinalizerFunc)
type FinalizerFunc func(ctx context.Context, err error)
```
Хук `BeforeQueryFunc` будет вызван до выполнения `db.PrepareContext` или `db.Query`. То есть на старте программы, когда кэш подготовленных выражений пуст, при вызове `store.GetAuthors`, хук `BeforeQueryFunc` будет вызван дважды. Хук `BeforeQueryFunc` может вернуть хук `FinalizerFunc`, который будет вызван перед выходом из пользовательского метода, в нашем случае `store.GetAuthors`, с помощью `defer`.
В момент выполнения хуков контекст наполнен служебными ключами со следующими значениями:
* `ctx.Value(sal.ContextKeyTxOpened)` булево значение определяет, что метод вызван в контексте транзакции или нет.
* `ctx.Value(sal.ContextKeyOperationType)`, строковое значение типа операции, `"QueryRow"`, `"Query"`, `"Exec"`, `"Commit"` и т.д.
* `ctx.Value(sal.ContextKeyMethodName)` строковое значение метода интерфейса, например `"GetAuthors"`.
В качестве аргументов хук `BeforeQueryFunc` принимает строку sql запроса и аргумент `req` метода пользовательского запроса. Хук `FinalizerFunc` в качестве аргумента принимает переменную `err`.
```
beforeHook := func(ctx context.Context, query string, req interface{}) (context.Context, sal.FinalizerFunc) {
start := time.Now()
return ctx, func(ctx context.Context, err error) {
log.Printf(
"%q > Opeartion %q: %q with req %#v took [%v] inTx[%v] Error: %+v",
ctx.Value(sal.ContextKeyMethodName),
ctx.Value(sal.ContextKeyOperationType),
query,
req,
time.Since(start),
ctx.Value(sal.ContextKeyTxOpened),
err,
)
}
}
client := NewStore(db, sal.BeforeQuery(beforeHook))
```
Примеров вывода:
```
"CreateAuthor" > Opeartion "Prepare": "INSERT INTO authors (Name, Desc, CreatedAt) VALUES($1, $2, now()) RETURNING ID, CreatedAt" with req took [50.819µs] inTx[false] Error:
"CreateAuthor" > Opeartion "QueryRow": "INSERT INTO authors (Name, Desc, CreatedAt) VALUES(@Name, @Desc, now()) RETURNING ID, CreatedAt" with req bookstore.CreateAuthorReq{BaseAuthor:bookstore.BaseAuthor{Name:"foo", Desc:"Bar"}} took [150.994µs] inTx[false] Error:
```
### What's next
* Поддержка связывания переменных и подготовленных выражений для MySQL.
* Хук RowAppender для корректировки ответа.
* Возврат значения `Exec.Result`. | https://habr.com/ru/post/431984/ | null | ru | null |
# PyUNO — быстрое незначительное редактирование xls-отчета из Python
Просто и быстро
---------------
Не так давно я столкнулся с необходимостью запротоколировать список изменений в нашем ПО. Заказчик прислал мне формуляр, который я должен был заполнить в соответствии с их внутренними требованиями к документации. Я открыл прилагавшийся к письму файл «`Изменения 1.xls`» и немного приуныл. Точнее, мне в голову последовательно пришли мысли об увольнении, а затем — о самоубийстве. Формуляр состоял из 14 колонок. Быстро перемножив в уме количество колонок с числом внесенных нами атомарных изменений (около пятисот), я пошел курить.
Сделать такую работу руками мне не под силу. Большинство данных (номера новых версий, описания изменений и т. п.) у меня, конечно, имелись в наличии, но в разных местах и самых причудливых форматах. Но семьсот копипастов — увольте. Поэтому мне пришлось немного освоить [PyUNO](http://wiki.services.openoffice.org/wiki/PyUNO_bridge). На всякий случай — опишу вкратце процесс управления документом `OOo` из питоновского биндинга, вдруг кому пригодится.
Нам потребуются сам `Open Office`, `python` и, собственно, биндинги:
```
$ sudo yum search pyuno ure
```
Запускаем `OOo` (нам нужны электронные таблицы, но метод работает для всех приложений — см. пример 2) с включенной опцией «слушать сокет»:
```
$ oocalc "-accept=socket,host=localhost,port=8100;urp;" &
$ soffice "-accept=socket,host=localhost,port=8100;urp;" -writer -headless &
```
…и отправляемся писать код. Для начала — получим инстанс документа:
```
import uno
from os.path import abspath, isfile, splitext
def getDocument(inputFile) :
localContext = uno.getComponentContext()
resolver = localContext.ServiceManager.createInstanceWithContext( \
"com.sun.star.bridge.UnoUrlResolver", localContext)
try:
context = resolver.resolve( \
"uno:socket,host=localhost,port=%s;urp;StarOffice.ComponentContext" % 8100)
except NoConnectException:
raise Exception, "failed to connect to OpenOffice.org on port %s" % 8100
desktop = context.ServiceManager.createInstanceWithContext( \
"com.sun.star.frame.Desktop", context)
document = desktop.loadComponentFromURL( \
uno.systemPathToFileUrl(abspath(inputFile)), "_blank", 0, tuple([]))
```
Получение данных для заполнения итогового документа из текстовых файлов и change-логов я оставлю за рамками данной заметки. Пусть они у нас просто появляются в псевдополе `data` по мановению волшебной палочки. Итак, приступим к заполнению нашего документа (заполняем столбец №2):
```
from com.sun.star.beans import PropertyValue
def fillDocument(inputFile, col, data) :
try:
sheet = getDocument(inputFile).getSheets().getByIndex(0)
row = 2
while True:
row = row + 1
val = sheet.getCellByPosition(col, row).getFormula()
if val != '' :
sheet.getCellByPosition(col, row).setFormula(val.replace(%VERSION%, data))
else :
break;
'''
All the rows are now filled, It's time to save our modified document
'''
props = []
prop = PropertyValue()
prop.Name = "FilterName"
prop.Value = "MS Excel 97"
props.append(prop)
document.storeToURL(uno.systemPathToFileUrl(abspath(inputFile)) + ".out.xls", tuple(props))
finally:
document.close(True)
```
Точно так же можно обойтись с любым другим столбцом. Можно даже в дороге сходить в [Google Translate](http://translate.google.com) [за переводом](http://code.activestate.com/recipes/576890-python-wrapper-for-google-ajax-language-api/).
Еще некоторые полезные возможности
----------------------------------
### Вставка другого документа
```
'''
Required for Ctrl+G :-)
'''
from com.sun.star.style.BreakType import PAGE_BEFORE, PAGE_AFTER
def addAtTheEnd(inputFile) :
cursor.gotoEnd(False)
cursor.BreakType = PAGE_BEFORE
cursor.insertDocumentFromURL(uno.systemPathToFileUrl(abspath(inputFile)), ())
```
### Поиск и замена
```
def findAndReplace(pattern, substTo, replaceAll, caseSensitive) :
search = document.createSearchDescriptor()
search.SearchRegularExpression = True
search.SearchString = pattern
search.SearchCaseSensitive = caseSensitive
result = document.findFirst(search)
while found:
result.String = string.replace(result.String, pattern, substTo)
if not replaceAll :
break
result = document.findNext(result.End, pattern)
```
### Экспорт в PDF
```
def exportToPDF(outputFile)
props = []
prop = PropertyValue()
prop.Name = "FilterName"
prop.Value = "writer_pdf_Export"
props.append(prop)
document.storeToURL(uno.systemPathToFileUrl(abspath(outputFile)), tuple(props))
```
Disclaimer
----------
Сразу хочу оговориться: код претендует на звание наколеночного говнокода, выполняемого один раз. Но в качестве «ну-ка быстро обновим файл отчета» — мне лично сэкономил уже кучу времени.
— Вот тут и вокруг можно собрать еще какие-то обрывки информации: <http://wiki.services.openoffice.org/wiki/Uno/FAQ>
— Шаблонизатор на питоне для OOo: [appyframework.org](http://appyframework.org/)
— То же самое, только для C++: [habrahabr.ru/blogs/cpp/116228](http://habrahabr.ru/blogs/cpp/116228/)
**Upd:** В комментариях подсказывают другой способ: [xlwt](https://secure.simplistix.co.uk/svn/xlwt/trunk/xlwt/examples/).
**Upd2:** Для генерации в более «новомодный» формат xlsx, есть такая полезная либа: [xlsx.dowski.com](http://xlsx.dowski.com).
За оба дополнения — огромная благодарность [tanenn](https://habrahabr.ru/users/tanenn/). | https://habr.com/ru/post/116409/ | null | ru | null |
# История одного исследования в log4net и ускорение его более чем в 10 раз
Начну с того, что данная оптимизация будет работать только, если вы используете значения взятые из Properties (например: NDC, MDC) и не используете UserName.
Введение
========
Я работаю на продуктовую компанию, где есть множество маленьких сервисов, связанных между собой. Так как компании более 10 лет, то и сервисы успели обрасти историей. Для логирования данных используется log4net. Раньше все сервисы писали свои логи в базу данных, используя буферизацию и отдельный диспетчер для записи, чтобы не утруждать рабочий поток логированием. Со временем появилась связка nxlog + elasticsearch + kibana, что сделало поддержку сервисов намного приятней. Началась постепенная миграция сервисов на новый стек. С этого момента у нас было уже две конфигурации для log4net:
* писать в базу данных
* писать в nxlog
Задача
======
Иногда у нас возникает ситуация, когда какой-то сервис записывает сообщение об ошибке и нам надо разобраться, что стало этому причиной. Чтобы получить полную картину и сделать правильные выводы, нам нужны все связанные с этим заказом логи со всех сервисов. Но вот проблема: у нас нет никаких меток чтобы их связать. Поэтому, мы стали генерировать уникальное значение и передавать его между нашими сервисами вместе с заказом. Перед тем, как запустить обработку заказа, мы вызываем в упрощенном варианте приведенный ниже код, чтобы он смог попасть в логи.
```
LogicalThreadContext.Properties["CorrelationId"] = Guid.NewGuid();
```
Пример нашей конфигурации log4net в web.config:
```
```
Проблема
========
Но когда мы начали добавлять данный функционал в старые сервисы заменяя запись в базу данных на запись в nxlog. Наши изменения не прошли на code review по причине того, что данная конфигурация на 100 000 записях в лог занимала 15 секунд машинного времени, в то время, как конфигурация с записью в базу данных всего 1.2 секунды. Тогда мы попытались сохранить CorrelationId в базу данных и потерпели поражение. При буферизации не запоминались Properties, где хранилось наше значение, а только Message и Exception.
```
```
И как только мы добавили к свойству Fix еще и Properties, то на 100 000 записей в лог стало уходить чуть более 12 секунд машинного времени. И это только на буферизацию, не говоря уже про сохранение в базу данных в фоне. Честно говоря, мы были сильно удивлены этим и еще больше мы были удивлены результатами профилировщика:
```
namespace log4net.Core
{
public class LoggingEvent : ISerializable
{
private void CreateCompositeProperties()
{
this.m_compositeProperties = new CompositeProperties();
this.m_compositeProperties.Add(this.m_eventProperties);
this.m_compositeProperties.Add(LogicalThreadContext.Properties.GetProperties(false));
this.m_compositeProperties.Add(ThreadContext.Properties.GetProperties(false));
PropertiesDictionary propertiesDictionary = new PropertiesDictionary();
propertiesDictionary["log4net:UserName"] = (object) this.UserName; // <- около 70% времени уходило на получение имени пользователя
propertiesDictionary["log4net:Identity"] = (object) this.Identity;
this.m_compositeProperties.Add(propertiesDictionary);
this.m_compositeProperties.Add(GlobalContext.Properties.GetReadOnlyProperties());
}
}
}
```
По какой-то не понятной нам причине класс LoggingEvent, который в себе хранит всю информацию о записи, пытается запомнить имя пользователя в Properties, хотя мы его об этом точно не просили, так как для этого в этом же классе есть соответствующее не используемое нами свойство.
Краткосрочное решение
=====================
В результате появился на свет AccelerateForwardingAppender, в котором при создании запоминаются UserName и Identity значения и копируются во все LoggingEvent объекты, не тратя время на вычисление каждый раз. Хочу вас предупредить, что у нас сервис запущен под IIS\_IUSRS и он у нас не меняется, поэтому это работает для нас. Но может не работать для вас, если у вас Windows авторизация, например.
**AccelerateForwardingAppender.cs**
```
using System;
using System.Linq.Expressions;
using System.Runtime.CompilerServices;
using System.Security.Principal;
using System.Threading;
using log4net.Appender;
using log4net.Core;
namespace log4net.ext.boost
{
public sealed class AccelerateForwardingAppender : ForwardingAppender
{
private static readonly FieldAccessor LoggingEventDataAccessor;
static AccelerateForwardingAppender()
{
LoggingEventDataAccessor = new FieldAccessor(@"m\_data");
}
public AccelerateForwardingAppender()
{
CacheUsername = true;
CacheIdentity = true;
Username = WindowsIdentity.GetCurrent().Name ?? string.Empty;
Identity = Thread.CurrentPrincipal.Identity?.Name ?? string.Empty;
}
public bool CacheUsername { get; set; }
public bool CacheIdentity { get; set; }
public string Username { get; set; }
public string Identity { get; set; }
protected override void Append(LoggingEvent loggingEvent)
{
Accelerate(loggingEvent);
base.Append(loggingEvent);
}
protected override void Append(LoggingEvent[] loggingEvents)
{
for (var i = 0; i < loggingEvents.Length; i++)
{
Accelerate(loggingEvents[i]);
}
base.Append(loggingEvents);
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private void Accelerate(LoggingEvent loggingEvent)
{
if (CacheUsername || CacheIdentity)
{
var loggingEventData = LoggingEventDataAccessor.Get(loggingEvent);
if (CacheUsername)
{
loggingEventData.UserName = Username;
}
if (CacheIdentity)
{
loggingEventData.Identity = Identity;
}
LoggingEventDataAccessor.Set(loggingEvent, loggingEventData);
}
}
private sealed class FieldAccessor
{
public readonly Func Get;
public readonly Action Set;
public FieldAccessor(string fieldName)
{
Get = FieldReflection.CreateGetDelegate(fieldName);
Set = FieldReflection.CreateSetDelegate(fieldName);
}
}
private static class FieldReflection
{
public static Func CreateGetDelegate(string fieldName)
{
var owner = Expression.Parameter(typeof(TSubject), @"owner");
var field = Expression.Field(owner, fieldName);
var lambda = Expression.Lambda>(field, owner);
return lambda.Compile();
}
public static Action CreateSetDelegate(string fieldName)
{
var owner = Expression.Parameter(typeof(TS), @"owner");
var value = Expression.Parameter(typeof(TF), @"value");
var field = Expression.Field(owner, fieldName);
var assign = Expression.Assign(field, value);
var lambda = Expression.Lambda>(assign, owner, value);
return lambda.Compile();
}
}
}
}
```
Исходный код с тестами я залил на [github](https://github.com/kolbasik/log4net.ext.boost), также я использовал [BenchmarkDotNet](http://www.nuget.org/packages/BenchmarkDotNet) библиотеку, чтобы сравнить производительность.
**Benchmark.cs**
```
using System;
using System.Diagnostics;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Columns;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
using log4net.Appender;
using log4net.Core;
using log4net.Layout;
namespace log4net.ext.boost.benchmark
{
public static class Program
{
private static void Main(string[] args)
{
var config = ManualConfig.Create(DefaultConfig.Instance)
.With(PlaceColumn.ArabicNumber)
.With(StatisticColumn.AllStatistics)
.With(Job.Default);
BenchmarkRunner.Run(config);
Console.WriteLine("Press any key to exit...");
Console.ReadKey(true);
}
public class BoostBenchmark
{
public BoostBenchmark()
{
Trace.AutoFlush = Trace.UseGlobalLock = false;
Trace.Listeners.Clear();
TraceAppender = new TraceAppender { Layout = new PatternLayout("%timestamp [%thread] %ndc - %message%newline") };
AccelerateForwardingAppender = new AccelerateForwardingAppender();
AccelerateForwardingAppender.AddAppender(TraceAppender);
}
private TraceAppender TraceAppender { get; }
private AccelerateForwardingAppender AccelerateForwardingAppender { get; }
[Benchmark]
public void TraceAppenderBenchmark()
{
Perform(TraceAppender);
}
[Benchmark]
public void AcceleratedTraceAppenderBenchmark()
{
Perform(AccelerateForwardingAppender);
}
private static void Perform(IAppender appender)
{
appender.DoAppend(new LoggingEvent(new LoggingEventData { TimeStamp = DateTime.UtcNow, Message = "TEST" }));
}
}
}
}
```
```
Host Process Environment Information:
BenchmarkDotNet.Core=v0.9.9.0
OS=Microsoft Windows NT 6.2.9200.0
Processor=Intel(R) Core(TM) i7-6700HQ CPU 2.60GHz, ProcessorCount=8
Frequency=2531255 ticks, Resolution=395.0609 ns, Timer=TSC
CLR=MS.NET 4.0.30319.42000, Arch=32-bit RELEASE
GC=Concurrent Workstation
JitModules=clrjit-v4.6.1586.0
Type=BoostBenchmark Mode=Throughput
```
| Method | Median | StdDev | Mean | StdError | StdDev | Op/s | Min | Q1 | Median | Q3 | Max | Place |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| TraceAppenderBenchmark | 104.5323 us | 4.5553 us | 105.4234 us | 0.8934 us | 4.5553 us | 9485.56 | 98.7720 us | 102.2095 us | 104.5323 us | 107.0166 us | 116.3275 us | 2 |
| AcceleratedTraceAppenderBenchmark | 2.6890 us | 0.1433 us | 2.7820 us | 0.0236 us | 0.1433 us | 359456.73 | 2.6134 us | 2.6629 us | 2.6890 us | 2.9425 us | 3.0275 us | 1 |
По результатам видно, что прирост довольно солидный в 359456.73 / 9485.56 = 37.9 раз. Такое большое значение обусловлено тем, что в тесте логи никуда не сохраняются. На наших сервисах логи пересылаются в nxlog и поэтому для нас реальный прирост получился в 10 раз, 15 секунд машинного времени превратились в 1.5 секунды.
Долгосрочное решение
====================
Воодушевленный таким результатом и я сделал [pull request](https://github.com/apache/log4net/pull/28) для log4net, где предложил удалить дублирующий код, и получил ожидаемый ответ:
```
bodewig: and break existing code and patterns that need those properties, doesn't it?
```
С одной стороны автор прав: любое изменение может быть критичным для кого-то, но с другой стороны обидно, что тратится столько времени впустую. Хотелось бы узнать ваше мнение. | https://habr.com/ru/post/311224/ | null | ru | null |
# Парсим любой сайт за считанные секунды. Как достать нужную информацию с сайта используя Selenium, XPath и Proxy Sever
Дарова, Хабр! Около года назад я решил заработать на ставках на спорт используя свои знания математики и программирования и тогда я наткнулся на небольшую проблему — как же достать нужную мне информацию с сайта? Как парсить веб-страницы? В этой статье я расскажу простыми словами каким тонкостям я научился.
#### Парсинг
Что ж такое парсинг? Это собирание и систематизирование информации, которая размещена на веб-сайтах с помощью специальных программ, автоматизирующих процесс.
Парсинг обычно используется для анализа ценовой политики и получения контента.
#### Начало
Чтобы забрать деньги у букмекеров мне надо было оперативно получать информацию про коэффициенты на определённые события с нескольких сайтов. В математическую часть вдаваться не будем.
Поскольку я изучал С# у себя в шараге, я решил всё писать на нём. Ребята со Stack Overflow посоветовали использовать Selenium WebDriver. Это драйвер браузера(программная библиотека), который позволяет разрабатывать программы, управляющие поведением браузера. То что надо, подумал я.
Установил библиотеку и побежал смотреть гайды в интернете. Спустя некоторое время я написал программу, которая могла открыть браузер и переходить по некоторым ссылкам.
Ура! Хотя стоп, а как на кнопки нажимать, как доставать нужную информацию? Тут нам поможет XPath.
#### XPath
Если простыми словами, то это язык запросов к элементам XML и XHTML документа.
В этой статье я буду использовать Google Chrome. Однако в других современных браузерах должен быть если не такой же, то очень похожий интерфейс.
Чтобы посмотреть код страницы, на которой вы находитесь надо нажать F12.

Чтобы посмотреть, в каком месте кода находиться элемент на странице(текст, картинка, кнопка) надо нажать на стрелочку в левом верхнем углу и выбрать данный элемент на странице. Теперь перейдем к синтаксису.
Стандартный синтаксис для написания XPath:
**//tagname[@attribute='value']**
**//**: Выбирает все узлы в html документе начиная от текущего узла
**Tagname**: Тег текущего узла.
**@**: Выбирает атрибуты
**Attribute**: Имя атрибута узла.
**Value**: Значение атрибута.
Может быть поначалу непонятно, но после примеров всё должно встать на свои места.
Рассмотри несколько простых примеров:
//input[@type='text']
//label[@id='l25’]
//input[@value= '4']
//a[@href= 'www.walmart.com']
Рассмотрим более сложные примеры для заданного html'я:
```
[habr](habr.com)
cool site
"text2"
[habrhabr](habr.com)
the same site
"text1"
```
XPath = //div[@class= 'contentBlock']//div
Для этого XPath’а будут выбраны следующие элементы:
```
```
XPath = //div[@class= 'contentBlock']/div
```
```
Обратите внимание на разницу между /(выбирает от корневого узла) и //(выбирает узлы от текущего узла независимо от их местонахождения). Если непонятно, то посмотрите на примеры выше ещё раз.
//div[@class= 'contentBlock']/div[@class= 'listItem']/a[@class= 'link']/span[@class= 'name']
Этот запрос равносилен этим при таком html’е:
//div/div/a/span
//span[@class= 'name']
//a[@class= 'link']/span[@class= 'name']
//a[@class='link' and [href](https://habr.com/ru/users/href/)= 'habr.com']/span
//span[text() = 'habr' or text() = 'habrhabr']
//div[@class= 'listItem']//span[@class= 'name']
//a[contains([href](https://habr.com/ru/users/href/), 'habr')]/span
//span[contains(text(),'habr')]
Результат:
```
habr
habrhabr
```
//span[text()='habr']/parent::a/parent::div
Равносилен
//div/div[@class= 'listItem'][1]
Результат:
**parent::** — возвращает предка на один уровень выше.
Есть ещё супер крутая фича, такая как **following-sibling::** — возвращает множество элементов на том же уровне, следующих за текущим, аналогично **preceding-sibling::** — возвращает множество элементов на том же уровне, предшествующих текущему.
//span[@class= 'name']/following-sibiling::text()[1]
Результат:
```
"text1"
"text2"
```
Думаю, теперь стало понятнее. Для закрепления материала советую зайти на этот [сайт](http://xpather.com/) и написать несколько запросов, чтобы найти некоторые элементы этого html’я.
```
[Pickup and delivery](https://www.walmart.com/grocery/?veh=wmt "Pickup & delivery")
[Walmart.com](https://www.walmart.com/ "Walmart.com")
[Savings spotlight](https://www.walmart.com/grocery/?veh=wmt "Savings spotlight")
[Walmart.com(Italian)
"italian virsion"](https://www.walmartethics.com/content/walmartethics/it_it.html "Walmart.com")
```
Теперь зная, что такое XPath, вернемся к написанию кода. Поскольку модераторам хабра не нравятся букмекерские конторы, то будет парсить цены на кофе в Walmart'е
```
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
IWebDriver driver = new ChromeDriver(pathToFile);
driver.Navigate().GoToUrl("https://walmart.com");
Thread.Sleep(5000);
IWebElement element = driver.FindElement(By.XPath("//button[@id='header-Header sparkButton']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//button[@data-tl-id='GlobalHeaderDepartmentsMenu-deptButtonFlyout-10']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//div[text()='Coffee']/parent::a"));
driver.Navigate().GoToUrl(element.GetAttribute("href"));
Thread.Sleep(10000);
List names = new List(), prices = new List();
List listOfElements =driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-title']/div")).ToList();
foreach (IWebElement a in listOfElements)
names.Add(a.Text);
listOfElements = driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-price']/span/span[contains(text(),'$')]")).ToList();
foreach (IWebElement a in listOfElements)
prices.Add(a.Text);
for (int i = 0; i < prices.Count; i++)
Console.WriteLine(names[i] + " " + prices[i]);
```
Thread.Sleep'ы были написаны, чтобы веб-страничка успевала загрузиться.
Программа откроет сайт магазина Walmart, нажмёт пару кнопок, откроет отдел с кофе и получит название и цены на товары.
Если веб-страничка довольно таки большая и поэтому XPath'ы долго работают или их сложно написать, то надо воспользоваться каким-то другим методом.
#### HTTP запросы
Для начала рассмотрим как на сайте появляется контент.

Если простыми словами, то браузер делает запрос серверу с просьбой дать нужную информацию, а сервер в свою очередь, эту информацию предоставляет. Всё это осуществляется с помощью HTTP запросов.
Чтобы посмотреть на запросы, которые отправляет ваш браузер на конкретном сайте, то просто откройте этот сайт, нажмите F12 и перейдите во вкладку Network, после этого перезагрузите страницу.
Теперь осталось найти нужный нам запрос.
Как это делать? – рассмотрите все запросы с типом fetch(третья колонка на картинке выше) и смотрите на вкладку Preview.

Если она не пустая, то она должна быть в формате XML или JSON, если нет – продолжайте поиски. Если да, то посмотрите, есть ли здесь нужная вам информация. Чтобы это проверить советую использовать какой – то JSON Viewer или XML Viewer(загуглите и откройте первую ссылку, скопируйте текст с вкладки Response и вставьте в Viewer). Когда вы найдёте нужный вам запрос, то сохраните у себя где то его название(левая колонка) или хост URL'а(вкладка Headers), чтоб потом не искать. Например если на сайте walmart’а открыть отдел кофе, то будет отправляться запрос, юрл которого начинается с walmart.com/cp/api/wpa. Там будет вся информация про кофе в продаже.

Полпути пройдено, теперь этот запрос можно «подделывать» и отправлять сразу через программу, получая нужную информацию за считанные секунды. Осталось распарсить JSON или XML, а это делается намного проще, чем писание XPath'ов. Но зачастую формирование таких запросов вещь довольно таки неприятная(смотри на URL на картинке выше) и если у вас даже всё получиться, то в некоторых случаях вы будете получать такой ответ.
```
{
"detail": "No authorization token provided",
"status": 401,
"title": "Unauthorized",
"type": "about:blank"
}
```
Сейчас вы узнаете, как можно избежать проблем с подражанием запроса используя альтернативу — прокси сервера.
#### Прокси сервер
Прокси сервер — устройство, являющееся посредником между компьютером и интернетом.

Было б замечательно, если б наша программа была прокси сервером, тогда можно быстро и удобно обрабатывать нужные респонсы с сервера. Тогда была б такая цепочка Браузер – Программа – Интернет(сервер сайта, который парсим).
Благо для си шарпа есть замечательная библиотека для таких нужд – Titanium Web Proxy.
Создадим класс PServer
```
class PServer
{
private static ProxyServer proxyServer;
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")){
Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
}
```
Теперь пройдемся по каждому методу отдельно.
```
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
```
**proxyServer.BeforeRepsone += OnRespone** – добавляем метод обработки ответа с сервера. Он будет вызываться автоматически, когда будет приходить респонс.
**explicitEndPoint** — Конфигурация прокси сервера,
**ExplicitProxyEndPoint(IPAddress ipAddress, int port, bool decryptSsl = true)**
IPAddress и port, на котором работает прокси сервер.
**decryptSsl** – стоит ли расшифровывать SSL. Иначе говоря, если decrtyptSsl = true, то прокси сервер будет обрабатывать все запросы и ответы.
**explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest** — добавляем метод обработки запроса перед его отправкой на сервер. Он также будет вызываться автоматически перед отправкой запроса.
**proxyServer.Start()** — «запуск» прокси-сервера, с этого момента он начинает обрабатывать запросы и ответы.
```
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
```
**e.DecryptSsl = false** — текущий запрос и ответ на него не будут обрабатываться.
Если нас не интересует запрос или ответ на него(например картинка или какой – то скрипт), то зачем его расшифровывать? На это тратиться довольно много ресурсов, и если будут расшифровываться все запросы и ответы, то программа будет долго работать. Поэтому если текущий запрос не содержит хост интересующего нас запроса, то расшифровывать его нет смысла.
```
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")) Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
```
**await e.GetResponseBodyAsString()** – возвращает респонс в виде строки.
Чтобы WebDriver подключился к прокси серверу, то надо написать следующие:
```
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
ChromeOptions options = new ChromeOptions();
options.AddArguments("--proxy-server=" + IPAddress.Loopback + ":8000");
IWebDriver driver = new ChromeDriver(pathToFile, options);
```
Теперь можно обрабатывать нужные вам запросы.
#### Заключение
С помощью WebDriver'а можно переходить по страницам, нажимать на кнопки и подражать поведение обычного юзера. С помощью XPath'ов можно извлекать нужную информацию с веб-страниц. Если XPath'ы не работают, то всегда может помочь прокси сервер, который может перехватывать запросы между браузером и сайтом. | https://habr.com/ru/post/516104/ | null | ru | null |
# Избавляемся от лишних $watch'еров
Хотел бы поделиться небольшой заметкой о том, как ускорить выполнение $digest() путем замены стандартных директив эквивалентами, которые не вызывают $watch.
Смысл в том, что часто на странице очень много элементов для которых нужно выпонить биндинг данных только один раз используя данные моделей которые не изменяются, например:
```
```
```
```
Эти и другие стандартные директивы любезно будут проверять не изменилось ли значение выражения при каждом $digest. Исправить ситуацию можно набором довольно простых кастомных директив, например для текста:
```
app.directive("staticText", function() {
return {
restrict: "A"
link: function(scope, element, attrs) {
element.text(scope.$eval(attrs.customText));
}
};
})
```
```
```
Результат — минус один $watch.
Выдумывать свой велосипед конечно же не нужно, на GitHub лежат два достойных модуля:
* **$watch fighters** — [GitHub](https://github.com/abourget/abourget-angular)
* **Bindonce** — [GitHub](https://github.com/Pasvaz/bindonce)
Первый ($watch fighters) совсем простой, включает в себя такие директивы:
* set-title
* set-href
* set-text
* set-html
* set-class
* set-if
Второй же (Bindonce) интереснее, т.к. разработчики подумали о том, что данные для биндинга могут быть недоступны в момент рендеринга шаблона директивы (например, они подгружаются ajax-запросом). Выглядит это так:
```
```
Для родительской директивы **bindonce** создается времменый $watch, когда значение переданной в неё переменной становится отличным от *undefined* запускаются вложенные bo-\* директивы, а временный $watch удаляется.
Модуль **Bindonce** включает:
* bo-if
* bo-show
* bo-hide
* bo-text
* bo-html
* bo-href
* bo-src
* bo-class
* bo-alt
* bo-title
* bo-id
* bo-style
* bo-value
* bo-attr bo-attr-foo
Более подробно можно почитать на [странице репозитория](https://github.com/Pasvaz/bindonce), там довольно развернутый readme.
На последок приведу функцию, которую нашел [здесь](http://stackoverflow.com/questions/18499909/how-to-count-total-number-of-watches-on-a-page). Она ~~примерно~~ подсчитывает общее количество $watch'еров на странице.
```
(function () {
var root = $(document.getElementsByTagName('body'));
var watchers = [];
var f = function (element) {
if (element.data().hasOwnProperty('$scope')) {
angular.forEach(element.data().$scope.$$watchers, function (watcher) {
watchers.push(watcher);
});
}
angular.forEach(element.children(), function (childElement) {
f($(childElement));
});
};
f(root);
console.log(watchers.length);
})();
```
Ради интересы можно сравнить количество до и поле внедрения zero-watch директив.
Надеюсь кому-то пригодится. Спасибо. | https://habr.com/ru/post/208768/ | null | ru | null |
# Автотесты в функциональном стиле
Элементы функционального программирования появились в Java сравнительно недавно, но приобретает все большую популярность. Особенно в части stream API – наверное нет Java разработчика, который бы не слышал/читал/применял этот API для работы с коллекциями. К сожалению, большинство и не идет дальше использования Stream API, тогда как функциональный подход позволяет значительно упростить жизнь разработчикам автотестов. Ниже я расскажу про два примера такого упрощения – словари проверок и специализированные матчеры
Словари проверок.
-----------------
Если Вы используете BDD подход, то наверняка, применяли параметризированные шаги проверки.
```
Когда нажимаем на кнопку «Кнопка»
Тогда проверить значения полей по БД
|Поле1|
|Поле2|
|Поле3|
```
Для реализации шага такой проверки с использованием ООП/процедурного подхода можно применить набор методов и switch для определения имени поля для проверки:
```
private void checkMinBalanceAmount(String checkMinAmount) throws Exception {
String minBalanceAmountStr = checkMinAmount;
String minBalanceAmount = String.format("%.2f", Double.parseDouble(minBalanceAmountStr));
String amountMinIF = amountLink.getText().replaceAll("(руб.|\\$|€)", "").replaceAll(" ", "");
Assert.assertEquals(minBalanceAmount, amountMinIF);
}
private void checkMaxBalanceAmount(String checkMaxAmount) throws Exception {
String maxBalanceAmountStr = checkMaxAmount;
String maxBalanceAmount = String.format("%.2f", Double.parseDouble(maxBalanceAmountStr));
String amountmaxIF = maxAmountDepositLink.getText().replaceAll("(руб.|\\$|€)", "").replaceAll(" ", "");
Assert.assertEquals(maxBalanceAmount, amountmaxIF);
}
private void checkBalanceAmount(String checkBalanceAmount) throws Exception {
String maxBalanceAmountStr = checkBalanceAmount;
String maxBalanceAmount = String.format("%.2f", Double.parseDouble(maxBalanceAmountStr));
String amountmaxIF = amountDepositLink.getText().replaceAll("(руб.|\\$|€)", "").replaceAll(" ", "");
Assert.assertEquals(maxBalanceAmount, amountmaxIF);
}
public void проверяет_значение_поля(String name) throws Throwable {
String query = "select * from deposit_and_account_data";
List> fetchAll = Db.fetchAll(query, "main");
switch (name) {
case "Имя счета":
Assert.assertEquals(fetchAll.get(0).get("ACCOUNT\_NAME"), nameDepositLink.getText());
break;
case "Дата закрытия":
checkDate(fetchAll.get(0).get("CLOSE\_DATE"));
break;
case "Код валюты":
checkCurrency(fetchAll.get(0).get("NAME"));
case "Сумма неснижаемого остатка":
checkMinBalanceAmount(fetchAll.get(0).get("MIN\_BALANCE\_AMOUNT"));
break;
case "Максимальная сумма для снятия":
checkMaxBalanceAmount(fetchAll.get(0).get("MAX\_SUM\_AMOUNT"));
break;
case "Сумма вклада":
checkBalanceAmount(fetchAll.get(0).get("BALANCE\_AMOUNT"));
break;
default:
throw new AutotestError("Неожиданное поле");
}
```
В коде выше нет ничего плохого, он хорошо структурирован. Но у него есть проблема – трудоемкое добавление еще одной проверки: нужно, во-первых, реализовать проверку, а, во-вторых, добавить ее в свитч. Второй шаг представляется избыточным. Если применить «словарь проверок», то можно обойтись только первым шагов.
Словарь проверок – это Map, в которой ключом является имя проверки, а значением – функция, которая принимает в качестве параметров запись из БД, а возвращает Boolean. То есть java.util.function.Predicate
```
Map>> checkMap = new HashMap<>();
```
Переписываем проверки:
```
checkMap.put("Имя счета",exp -> exp.get("ACCOUNT_NAME").equals(nameDepositLink.getText()));
```
Переписываем метод вызова проверок:
```
public void проверяет_значение_поля(String name) throws Throwable {
String query = "select * from deposit_and_account_data";
Map expected = Db.fetchAll(query, "main").get(0);
Assert.assertTrue(name,
Optional.ofNullable(checkMap.get(name))
.orElseThrow(()->new AutotestError("Неожиданное поле"))
.test(expected));
}
```
Что происходит во фрагменте выше: Пытаемся получить проверку из по имени поля Optional.ofNullable(checkMap.get(name)), если она NULL, то выбрасываем исключение. Иначе выполняем полученную проверку.
Теперь для того, чтобы добавить новую проверку ее достаточно добавить в словарь. В методе вызова проверок она становится доступна автоматически. Полный исходный код примера и другие примеры исполльзования ФП для автотестов доступны в репозитории на GitHub:
<https://github.com/kneradovsky/java8fp_samples/>
Custom Matchers
---------------
Практика показывает, что ассерты достаточно редко применяются в автотестах Selenuim WebDriver. На мой взгляд, наиболее вероятной причиной этого является то, что стандартные Matchers не предоставляют функциональности для проверки состояния WebElement. Почему нужно применять assertions? Это стандартный механизм, который поддерживается любыми средствами генерации отчетов и представления результатов тестирования. Зачем изобретать велосипед, если можно его доработать.
Как функциональный подход может сделать использование assertions для проверки свойств и состояние WebElement’ов удобным? И зачем ограничиваться только веб элементами?
Представим, что у нас есть функция, которая принимает 2 аргумента: сообщение об ошибке в случае провала и функцию-предикат (принимает проверяемый WebElement и возвращает результат проверки), а возвращает Matcher.
```
public static BiFunction, BaseMatcher> customMatcher =
(desc, pred) -> new BaseMatcher() {
@Override
public boolean matches(Object o) {
return pred.test((WebElement) o);
}
@Override
public void describeTo(Description description) {
description.appendText(desc);
}
};
}
```
Это позволяет конструировать любые проверки со специализированными сообщениями об ошибке.
```
BaseMacther m1 = customMatcher.apply("Результаты должны содержать qaconf.ru",e -> e.getAttribute("href").contains("qaconf.ru"));
```
Но зачем ограничивать себя только веб элементами? Сделаем статический generic метод, который примет тип объекта, вернет функцию от 2 аргументов: сообщение об ошибке в случае провала и функция-предикат (принимает объект заданного тип и возвращает результат проверки) и возвращающую Matcher.
```
public static BiFunction, BaseMatcher> typedMatcher2(Class cls) {
return (desc, pred) -> new BaseMatcher() {
@Override
public boolean matches(Object o) {
return pred.test((T) o);
}
@Override
public void describeTo(Description description) {
description.appendText(desc);
}
};
}
```
Теперь у нас есть специализированный матчер, который можно применять в assert’aх:
```
BiFunction, BaseMatcher>> webElMatcherSupp = typedMatcher2(WebElement.class);
BaseMatcher shouldBeTable = apply("Should be Table",e->e.getTagName().equalsIgnoreCase("table"));
assertThat(elem2Test,shouldBeTable);
```
В комбинациях с другими матчерами:
```
assertThat(elem2test,not(shouldBeTable));
```
Или так
```
BaseMatcher hasText1 = webElMatcherSupp.apply("Should be contain text1",e->e.getText().equalsIgnoreCase("text1"));
assertThat(elem2test,allOf(not(shouldBeTable),hasText1));
```
Кроме этого матчеры можно использовать в допущениях (assumptions)
```
assumeThat(elem2test,not(shouldBeTable));
```
Но и это еще не все. Можно создать параметризованный специализированный матчер:
```
Function textEquals = str -> webElMatcherSupp.apply("Text should equals to: " + str,e-> e.getText().equals(str));
assertThat(elem2test,textEquals.apply("text2"));
assertThat(elem2test,not(textEquals.apply("text3")));
```
Таким образом получаем специализированный матчер, у которого сообщение и проверка параметризуется любым значением, передаваемым на этапе выполнения.
Заключение:
Применение функционального подхода в разработке автотестов позволяет с одной стороны сократить количество кода, с другой – повысить его читаемость. Собственные матчеры позволяют легко создавать наборы типизированных проверок, дополняя стандартный механизм assertions. Словари проверок избавляют от необходимости выполнения ненужной работы.
Полный код примеров находится в репозитории: <https://github.com/kneradovsky/java8fp_samples/> | https://habr.com/ru/post/301166/ | null | ru | null |
# К какому уровню это принадлежит: прикладному или домена?
### Куда мне это поместить?
Если вы один из тех людей, в кодовой базе которых есть разделение (как и у меня) на уровни приложения (прикладной) и домена, то у вас достаточно часто возникает вопрос: в каком уровне должна находиться эта служба: приложения или домена? Иногда это заставляет задуматься, а не является ли различие между этими слоями все-таки чем-то чересчур необстоятельным. Я не собираюсь в очередной раз писать о том, что подразумевают под собой эти уровни, я расскажу вам как решаю, какому уровню принадлежит служба - *приложения* или *домена*:
> *Будет ли она использоваться на уровне инфраструктуры? Если да, то она принадлежит к прикладному уровню.*
>
>
### Правило зависимости 2
Мне нравится следовать правилу зависимости (Dependency rule): уровни могут иметь только направленные внутрь зависимости. Это гарантирует, что уровни разделены. Уровень *инфраструктуры* (*Infrastructure*) может использовать службы уровня *приложения* (*Application*). Уровень *приложения* может использовать службы уровня *домена* (*Domain*). Теоретически *инфраструктура* могла бы использовать службы уровня *домена*, но я бы не хотел этого допускать. Я хочу, чтобы уровень *приложения* определял программный интерфейс/API, который может использоваться *инфраструктуры* уровнем. Это делает уровень *домена,* том числе модель *домена,* деталями *реализации* *прикладного* уровня. Что я считаю довольно крутым. Не нужно ничего делать с агрегатами или событиями домена; при условии, что все может быть скрыто за приложением-как-интерфейс (Application-as-an-interface).
Чтобы можно было говорить более конкретно, рассмотрим пример «покупка электронной книги». В коде он будет представлен как `PurchaseEbookController`, находящийся в *инфраструктурном* уровне, который создает объект команды `PurchaseEbook`, который он передает в `PurchaseEbookService`. Эта служба является прикладной службой, находящаяся на уровне *приложения.* Служба создает объект `Purchase` и сохраняет его с помощью `PurchaseRepository`, находящегося на уровне *домена*. Во время выполнения будет использоваться находящийся на уровне *инфраструктуры* `PurchaseRepositoryUsingSql`, который реализует интерфейс `PurchaseRepository`.
Почему интерфейс `PurchaseRepository` находится в уровне *домена*? Потому что он не будет и не должен использоваться напрямую из *инфраструктуры* (например, контроллера). То же самое и с сущностью `Purchase`. Она должна создаваться или управляться службами приложений только посредством контроллеров. Но с точки зрения уровня *инфраструктуры* нам все равно, использует ли прикладная служба сущность, интерфейс репозитория или любой другой шаблон проектирования до тех пор, пока она выполняет свою работу изолированно. То есть она не связана с конкретной инфраструктурой ни кодом, ни необходимостью своей доступности во время выполнения.
Почему прикладная служба находится на уровне *приложения*? Потому что она вызывается непосредственно из контроллера, то есть уровня *инфраструктуры*. Сама прикладная служба является частью API, определенного на уровне *приложения* .
### Приложение-как-интерфейс или ApplicationInterface?
Это подводит нас к интересной возможности, которая носит несколько экспериментальный характер: мы можем определить API, которое *прикладной* уровень предлагает окружающей его инфраструктуре, как фактический `interface`. Например,
```
namespace Application;
interface ApplicationInterface
{
public function purchaseEbook(PurchaseEbook $command): void;
/**
* @return EbookForList[]
*/
public function listAvailableEbooks(): array;
}
```
Этот второй метод, `listAvailableEbooks()`, является примером модели представления, которая также может быть доступна через `ApplicationInterface`.
Я думаю, что приложение-как-интерфейс - это хороший дизайнерский трюк, заставляющий *инфраструктуру* быть отделенной от кода уровней *приложения* и *домена*. *Инфраструктура*, как и контроллеры, может вызывать логику уровня *приложения* только через этот интерфейс. Еще одно преимущество состоит в том, что создание приемочных тестов для приложения становится невероятно простым. Вам нужен только `ApplicationInterface` в вашем тесте, и вы можете запускать команды и запросы к нему, чтобы проверить, что он ведет себя корректно. Вы также можете создать лучшие интеграционные тесты для левых операндов или входных адаптеров, потому что вы можете заменить все ядро своего приложения, смоделировав один интерфейс. Обсуждение вариантов оставлю для другой статьи.
---
*Какое ключевое качество отличает успешного PHP-разработчика? — любознательность.
Чтобы решать задачи на Middle+ уровне, необходимо уметь работать с экосистемой PHP.
Приглашаем всех желающих на* [*бесплатное демо-занятие*](https://otus.pw/VHdK/)*, в рамках которого разберем: “Какие темы и когда нужно изучать? Почему надо задавать вопросы и исследовать все вокруг?”*[**ЗАПИСАТЬСЯ НА ДЕМО-УРОК**](https://otus.pw/VHdK/)
--- | https://habr.com/ru/post/551370/ | null | ru | null |
# .NET 6: PriorityQueue
В .NET 6 появилась новая коллекция — PriorityQueue. До этого очереди с приоритетами уже были в .NET, но только в виде внутренних классов — они использовались под капотом разных механизмов в WPF, Rx.NET и в других частях фреймворка.
Но в .NET 6 PriorityQueue стала новой коллекцией, которой теперь можно пользоваться из клиентского кода. Давайте посмотрим, что предлагает эта очередь, как она устроена внутри и насколько быстро работает. Под катом будет постепенное погружение: от примеров использования в коде к введению n-арные деревья.
Что это такое
-------------
[PriorityQueue](https://docs.microsoft.com/en-us/dotnet/api/system.collections.generic.priorityqueue-2?view=net-6.0) — это коллекция элементов, каждый из которых имеет значение и приоритет. Элементы добавляются в очередь с определенным приоритетом и извлекаться из неё “последовательно” — вначале будут извлечены элементы с **наименьшим** приоритетом, добавленные первыми. То есть, PriorityQueue — это модификация обычной FIFO (first-in-first-out) очереди, в которой элементы с меньшим приоритетом будут оказываться перед всеми элементами с большим приоритетом и извлекаться первыми.
В каких задачах может пригодиться PriorityQueue? Если коротко, то в тех же, что и обычная очередь, когда часть элементов нужно обработать “вне очереди”. С большой вероятностью такой сценарий понадобится как часть инфраструктурного кода. Вот пара примеров использования PriorityQueue:
1. Организация очереди обработки запросов веб-сервером, в которой входящие запросы из Lisnter’а складываются в очередь и приоритезириуются на основе оставшегося лимита времени запроса или явного приоритета запроса (запрос демона или запрос фронта).
2. Алгоритм Дейкстры — если пишите логистический сервис или просто ищите путь в графе обработчиков в вашем workflow (а это может быть и вывод правил в экспертных системах, и парсинг сайтов/данных).
3. Любая абстрактная система асинхронной обработки данных/событий/запросов, в которой может быть класс обслуживания — например, если вы хотите дать возможность выполнить в своей системе какой-то служебный запрос перед всеми на случай забитой очереди.
Как работает PriorityQueue
--------------------------
Обычная очередь извлекает элементы в порядке их добавления — first in first out. Очередь с приоритетами извлекает элементы в порядке приоритета от меньшего к большему и также реализует first in first out для элементов с одинаковым приоритетом:
```
var queue = new PriorityQueue();
queue.Enqueue("Миша", 30);
queue.Enqueue("Маша", 29);
queue.Enqueue("Дима", 31);
queue.Enqueue("Коля", 30);
queue.Enqueue("Паша", 31);
while (queue.TryDequeue(out var name, out var age))
{
Console.WriteLine($"{name}, age {age}");
}
```
Вывод на консоль:
```
Маша, age 29
Миша, age 30
Коля, age 30
Дима, age 31
Паша, age 31
```
Как PriorityQueue сравнивает приоритеты
---------------------------------------
Чтобы определить наименьший приоритет нужно как-то сравнивать приоритеты между собой. PriorityQueue использует для этого стандартный интерфейс `IComparer`:
```
public interface IComparer
{
int Compare(T? x, T? y);
}
```
По умолчанию используется дефолтный компоратор `System.Collections.Generic.Comparer.Default`. Если приоритет задается сложным типом (например, классом `ServerHealthState`), то можно передать в конструктор `PriorityQueue` свою реализацию компоратора:
```
// ServerHealthStateComparer реализует IComparer
var comparer = new ServerHealthStateComparer();
var queue = new PriorityQueue(comparer);
```
Контракт PriorityQueue
----------------------
Создать новый экземпляр PriorityQueue можно тремя способами: инициализировать пустую очередь, задать начальное количество элементов чтобы избежать дополнительного расширения массива при добавлении новых элементов или инициализировать очередь готовым набором значений с приоритетом:
```
public PriorityQueue()
public PriorityQueue(int initialCapacity)
public PriorityQueue(IEnumerable> items)
```
Каждый конструктор имеет перегрузку с компаратором в качестве дополнительного элемента:
```
public PriorityQueue(IComparer? comparer)
public PriorityQueue(int initialCapacity, IComparer? comparer)
public PriorityQueue(IEnumerable> items, IComparer comparer)
```
Интересной особенностью очереди с приоритетом является то, что в случае пустой очереди начальное хранилище оказывается пустым и расширяется до 4 элементов при первом добавлении:
```
_nodes = Array.Empty<(TElement, TPriority)>();
```
У PriorityQueue есть несколько свойств для получения информации об очереди:
```
// Получает компоратор приоритетов, используемый в текущем экземпляре PriorityQueue
public IComparer Comparer { get; }
// Получает количество элементов в очереди
public int Count { get; }
// Получает коллекцию, которая перечисляет элементы очереди в неупорядоченном виде.
public PriorityQueue.UnorderedItemsCollection UnorderedItems { get; }
```
Новые элементы можно добавить либо по одному, либо сразу множеством — с общим приоритетом или отдельным значением приоритета для каждого элемента:
```
// Добавляет в очередь элемент с заданным приоритетом
public void Enqueue(TElement element, TPriority priority);
// Добавляет в очередь последовательность элементов с заданным приоритетом
public void EnqueueRange(System.Collections.Generic.IEnumerable elements, TPriority priority);
// Добавляет в очередь последовательность элементов с заданными приоритетами
public void EnqueueRange(System.Collections.Generic.IEnumerable<(TElement Element, TPriority Priority)> items);
```
Кроме извлечения очередного элемента из очереди есть привычный метод Peek, который получает элемент из очереди, не удаляя его. В случае с пустой очередью попытка извлечения элемента закончится исключением InvalidOperationException, для безопасного извлечения есть аналогичные методы с префиксом Try:
```
// Удаляет из очереди и возвращает элемент с наименьшим приоритетом
public TElement Dequeue();
// Пытается удалить из очереди и возвращает элемент с наименьшим приоритетом.
// Возвращает результат операции: true при успешном удалении и false если очередь пуста
public bool TryDequeue(out TElement element, out TPriority priority);
// Возвращает элемент с наименьшим приоритетом, не удаляя его из очереди
public TElement Peek();
// Пытается вернуть элемент с наименьшим приоритетом, не удаляя его из очереди
// Возвращает результат операции: true при успешном извлечении и false если очередь пуста
public bool TryPeek(out TElement element, out TPriority priority);
```
Можно быстро очистить очередь при помощи метода Clear:
```
// Удаляет все элементы из очереди
public void Clear();
```
Есть и несколько специализированных методов, которые можно использовать для увеличения эффективности работы с очередью — быстро расширить внутреннее хранилище до определенного значения, обрезать внутреннее хранилище или одновременно извлечь элемент и добавить новый:
```
// Добавляет в очередь элемент с заданным приоритетом и извлекает элемент с наименьшим приоритетом
public TElement EnqueueDequeue(TElement element, TPriority priority);
// Гарантирует, что очередь может хранить capacity элементов без дополнительного расширения внутреннего хранилища
// Расширяет текущее внутреннее хранилище до размера capacity, если его ёмкость была меньше
// Возвращает capacity внутреннего хранилища
public int EnsureCapacity(int capacity);
// Устанавливает capacity внутренннего хранилища на фактическое количество элементов в очереди, если это меньше 90% от текущей capacity
public void TrimExcess ();
```
Что внутри PriorityQueue
------------------------
Как устроена очередь с приоритетами внутри?
Самая простая реализация “в лоб”, которую можно придумать — это связный список элементов. Новые элементы добавляются в хвост списка за константное время, а при извлечении нужно найти первый элемент с наименьшим приоритетом, перебрав для этого все элементы за линейное время. `Peek` тоже будет линейным.
Можно ли сделать извлечение элементов быстрее, чем O(n)? Для этого понадобится держать список в отсортированном упорядоченном состоянии. Если мы используем в качестве структуры данных связный список, то для добавления понадобится последовательно перебирать элементы в поиске нужного места для вставки и асимптотика Enqueue будет O(n), так что теперь добавление в очередь становится слишком дорогостоящей операцией. Если заменять список на динамический массив, то вставка потребует “раздвигания” элементов и всё равно останется O(n)-операцией.
На самом деле, для решения задачи хранения элементов с приоритетом, “быстрого” добавления новых элементов и извлечения первого элемента с наименьшим приоритетом идеально подходит такая структура данных, как куча. Есть несколько типов универсальных куч, а ещё [специализированные кучи](https://en.wikipedia.org/wiki/Priority_queue#Specialized_heaps), которые предоставляют дополнительную функциональность или работают эффективнее, но имеют ограничения. Например, в качестве типа приоритета могут использоваться только целочисленные значения.
https://neerc.ifmo.ru/wiki/index.php?title=Приоритетные\_очередиЧаще всего в библиотеках разных языков программирования используются универсальные кучи — бинарные или d-арные. Во-первых, они позволяют извлекать и добавлять элемент за O(log n), а, во-вторых, благодаря свойствам кучи для их хранения достаточно массива элементов. Навигация между родительскими и дочерними элементами для каждого узла происходит по простым формулам.
Пример навигации между элементами бинарной min-кучи с помощью формул для индексов массиваВ .NET 6 в основе PriorityQueue лежит 4-арная min-куча (то есть куча, где каждый узел может иметь 4 элемента уровнем ниже и содержит минимальный элемент своего поддерева), представленная в виде массива кортежей `(TElement Element, TPriority Priority)[] _nodes`, которая инициализируются пустым массивом по-умолчанию и расширяется при недостаточном Capacity по стандартному правилу `List` — в 2 раза, но не менее, чем на 4 элемента.
4-арная min-куча всегда удовлетворяет двум свойствам:
1. Свойство формы: 4-арная куча — это **полное** 4-арное дерево, то есть такое дерево, где все уровни полностью заполнены, за исключением, возможно, последнего уровня. Узлы заполняются слева направо.
2. Свойство кучи: значение (приоритета), хранящееся в каждом узле, меньше или равно его дочерним элементам.
Сложность операций в PriorityQueue связана с сложностью операций в куче:
* `Enqueue(TElement, TPriority)`: O(log4 N)
* `Dequeue()`: O(log4 N)
* `Peek()`: O(1)
* `Count`: O(1)
> Читать словесное описание алгоритмов кучи — сомнительное удовольствие, а иллюстрации для 4-арной кучи не прибавляют понятности, поэтому иллюстрации к алгоритмам будут на основе биарной min-кучи, а в примерах кода можно увидеть, что работа бинарной и 4-арной кучи отличается только методами навигации по куче, то есть получения индекса родительского и дочерних элементов.
>
>
Методы для навигации по куче в PriorityQueue:
```
private const int Arity = 4;
private const int Log2Arity = 2;
private static int GetParentIndex(int index) => (index - 1) >> Log2Arity;
private static int GetFirstChildIndex(int index) => (index << Log2Arity) + 1;
```
Чтобы добавить элемент в кучу, нужно выполнить операцию увеличения кучи (есть разные термины: up-heap, bubble-up, heapify-up):
1. Если куча пуста, то новый элемент становится её корнем (root)

2. Добавляем новый элемент на нижний уровень кучи в первое доступное место.

3. Сравниваем добавленный элемент с его родителем. Если они в правильном порядке, то операция завершена.
4. Если нет, то меняем добавленный элемент с родительским элементом местами и возвращаемся к предыдущему шагу.

Добавление нового элемента с приоритетом 18 в бинарную min-кучу с 14-ю элементами
```
private void MoveUpCustomComparer((TElement Element, TPriority Priority) node, int nodeIndex)
{
while (nodeIndex > 0)
{
int parentIndex = GetParentIndex(nodeIndex);
(TElement Element, TPriority Priority) parent = _nodes[parentIndex];
if (_comparer.Compare(node.Priority, parent.Priority) < 0)
{
_nodes[nodeIndex] = parent;
nodeIndex = parentIndex;
}
else
break;
}
_nodes[nodeIndex] = node;
}
```
Количество требуемых операций зависит только от количества уровней, на которые должен подняться новый элемент чтобы привести кучу в согласованное состяоние.
Итоговая временная сложность в худшем случае составляет O(log N).
Состояние бинарной min-кучи после добавления нового элементаДля извлечения минимального значения из min-heap достаточно обратиться к \_nodes[0]. Алгоритм удаления корневого (минимального) элемента из кучи:
1. Удаляем значение корневого элемента

2. Заменяем текущий удаляемый (корневой) элемент последним элементом кучи (\_nodes[0] = \_nodes[\_size - 1];

3. Сравниваем текущий элемент с его потомками. Если они не в правильном порядке (то есть, существуют потомки меньше текущего элемента), то меняем текущий элемент с **наименьшим** из потомков и повторяем шаг.
4. Если они в правильном порядке, то операция завершена.
На примере бинарного min-дерева из иллюстрации после извлечения значения [0]-го элемента на его место встает последний ([14]-ый). Из потомков [1]-го и [2]-го выбирается наименьший — [2]-ой, т.к. приоритет [0]-го 26, а [2]-го 18, то они заменяются местами, а [2]-ой элемент становится текущим. Затем из его потомков, [5]-го и [6]-го элементов выбирается тот, у которого приоритет ниже, это [6]-ой элемент. Так как приоритет [2]-го теперь 26, а [6]-го 22, то они меняются местами, а [6]-ой элемент становится текущим. Теперь у текущего элемента только 1 потомок, [13]-ый. Его приоритет выше, чем приоритет текущего, поэтому алгоритм заканчивается.
Извлечение корневого элемента из бинарной min-кучи и последующее перестроение кучи
```
// node = _nodes[--_size] — последний элемент кучи,
// nodeIndex = 0 — корневой элемент
private void MoveDownCustomComparer((TElement Element, TPriority Priority) node, int nodeIndex)
{
int i;
while ((i = GetFirstChildIndex(nodeIndex)) < size)
{
// Ищем дочернюю ноду с минимальным приоритетом
(TElement Element, TPriority Priority) minChild = _nodes[i];
int minChildIndex = i;
int childIndexUpperBound = Math.Min(i + Arity, _size);
while (++i < childIndexUpperBound)
{
(TElement Element, TPriority Priority) nextChild = _nodes[i];
if (_comparer.Compare(nextChild.Priority, minChild.Priority) < 0)
{
minChild = nextChild;
minChildIndex = i;
}
}
if (_comparer.Compare(node.Priority, minChild.Priority) <= 0)
{
break;
}
_nodes[nodeIndex] = minChild;
nodeIndex = minChildIndex;
}
_nodes[nodeIndex] = node;
}
```
Состояние бинарной min-кучи после удаления корневого элементаВ PriorityQueue есть пара интересных оптимизаций. Например, при добавлении множества элементов с помощью `public void EnqueueRange(IEnumerable<(TElement Element, TPriority Priority)> items!!)`, фактически коллекция копируется в исходном виде в `_nodes`, а уже потом массив `_nodes` один раз перестраивается в кучу с помощью приватного метода `Heapify`, что позволяет получить итоговую сложность O(log4 N) вместо O(k \* log4 N), где k — количество добавляемых элементов.
```
private void Heapify()
{
int lastParentWithChildren = GetParentIndex(_size - 1);
if (_comparer == null)
for (int index = lastParentWithChildren; index >= 0; --index)
MoveDownDefaultComparer(_nodes[index], index);
else
for (int index = lastParentWithChildren; index >= 0; --index)
MoveDownCustomComparer(_nodes[index], index);
}
```
Метод EnqueueDequeue сравнивает добавляемый элемент с текущим корневым элементов. Если добавляемый элемент имеет меньший приоритет, то он сразу будет извлечен и перестроения кучи не понадобится, а если нет — то вместо двух перестроений для извлечения и добавления элемента понадобится только одно:
```
public TElement EnqueueDequeue(TElement element, TPriority priority)
{
// Если очередь пустая, то сразу вернется добавляемый элемент
if (_size != 0)
{
(TElement Element, TPriority Priority) root = _nodes[0];
if (_comparer == null)
{
// Если приоритет добавляемого элемента меньше приоритета корневого,
// то куча не будет перестраиваться
if (Comparer.Default.Compare(priority, root.Priority) > 0)
{
MoveDownDefaultComparer((element, priority), 0);
\_version++;
return root.Element;
}
}
else
{
// Если приоритет добавляемого элемента меньше приоритета корневого,
// то куча не будет перестраиваться
if (\_comparer.Compare(priority, root.Priority) > 0)
{
MoveDownCustomComparer((element, priority), 0);
\_version++;
return root.Element;
}
}
}
return element;
}
```
Да кто такой этот ваш UnorderedItemsCollection
----------------------------------------------
У новой PriorityQueue есть свойство, которое возвращает элементы очереди в неупорядоченном виде. Но возвращает свойство не массив или енумератор, а вложенный в очередь тип `UnorderedItemsCollection`. Всё из-за специального енумератора, который отслеживает, что очередь не изменилась во время перебора (не изменилась переменная `_version`, а перечисление не вышло за пределы очереди) поскольку внутренний массив содержит `capacity` элементов, а не `_size` элементов.
```
public bool MoveNext()
{
PriorityQueue localQueue = \_queue;
if (\_version == localQueue.\_version && ((uint)\_index < (uint)localQueue.\_size))
{
\_current = localQueue.\_nodes[\_index];
\_index++;
return true;
}
return MoveNextRare();
}
private bool MoveNextRare()
{
if (\_version != \_queue.\_version)
throw new InvalidOperationException(SR.InvalidOperation\_EnumFailedVersion);
\_index = \_queue.\_size + 1;
\_current = default;
return false;
}
```
Итератор перебирает элементы внутреннего представления кучи `_nodes`, так что говорить, что `UnorderedItemsCollection` действительно Unordered не совсем правильно. На самом деле, итератор будет всегда упорядочен в соответствии с правилами хранения 4-арной min-кучи в массиве.
(Очевидные?) ограничения
------------------------
`TPriority` может быть любым типом, в том числе изменяемым. Можно, например, сделать такую очередь:
```
public class TaskPriority
{
public TaskPriority(int businessValue)
{
BusinessValue = businessValue;
}
public int BusinessValue { get; set; }
}
public class TaskPriorityComparer : IComparer
{
public int Compare(TaskPriority x, TaskPriority y) => x.BusinessValue.CompareTo(y.BusinessValue);
}
var queue = new PriorityQueue(new TaskPriorityComparer());
```
И очередь перестраивает кучу при каждой операции. Но, например, при извлечении элемента куча будет перестраиваться только после извлечения элемента с минимальным приоритетом, даже если приоритет другого элемента изменился и стал минимальным:
```
var mutablePriority = new TaskPriority(30);
queue.Enqueue("Фронтенд", new TaskPriority(10));
queue.Enqueue("Бэкенд", new TaskPriority(20));
queue.Enqueue("CI", mutablePriority);
mutablePriority.BusinessValue = 5;
queue.Dequeue(); // (Фронтенд, 10)
queue.Dequeue(); // (CI, 5)
queue.Dequeue(); // (Бэкенд, 20)
```
При добавлении нового элемента куча перестраивается только до уровня, который нужен добавляемому элементу и всё ломается ещё сильнее:
```
var mutablePriorityCI = new TaskPriority(30);
var mutablePriorityDocs = new TaskPriority(40);
queue.Enqueue("Фронтенд", new TaskPriority(10));
queue.Enqueue("Бэкенд", new TaskPriority(20));
queue.Enqueue("CI", mutablePriorityCI);
queue.Enqueue("Документация", mutablePriorityCI);
mutablePriorityCI.BusinessValue = 5;
mutablePriorityDocs.BusinessValue = 15;
queue.Enqueue("Тесты", new TaskPriority(12));
queue.Dequeue(); // (Фронтенд, 10)
queue.Dequeue(); // (CI, 5)
queue.Dequeue(); // (Документация, 15)
queue.Dequeue(); // (Тесты, 12)
queue.Dequeue(); // (Бэкенд, 20)
```
Поэтому ну их изменяемые приоритеты, лучше используйте для TPriority что-нибудь иммутабельное.
> Хорошая новость об этом ограничении: в план работ по .NET 7 добавлен [issue](https://github.com/dotnet/runtime/issues/44871), позволяющий работать с элементами с изменяемым приоритетом.
>
>
[Интерактивная иллюстрация бинарной min-кучи](https://www.cs.usfca.edu/~galles/visualization/Heap.html)
[Исходный код PriorityQueue на github](https://github.com/dotnet/runtime/blob/main/src/libraries/System.Collections/src/System/Collections/Generic/PriorityQueue.cs) | https://habr.com/ru/post/666018/ | null | ru | null |
# Apache Kafka + Spring Boot: Hello, microservices
Привет, Хабр! В этом посте мы напишем приложение на Spring Boot 2 с использованием Apache Kafka под Linux, от установки JRE до работающего микросервисного приложения.
Коллеги из отдела фронтэнд-разработки, увидевшие статью, сетуют на то, что я не объясняю, что такое Apache Kafka и Spring Boot. Я полагаю, что всякий, кому понадобится собрать готовый проект с использованием вышеперечисленных технологий, знают, что это и зачем они им нужны. Если для читателя вопрос не праздный, вот отличные статьи на Хабре, что такое [Apache Kafka](https://habr.com/ru/company/piter/blog/352978/) и [Spring Boot](https://habr.com/ru/post/333756/).
Мы же обойдёмся без пространных объяснений, что такое Kafka, Spring Boot и Linux, а вместо этого запустим Kafka-сервер с нуля на Linux-машине, напишем два микросервиса и сделаем так, чтобы одно из них посылало сообщения на другое — в общем, настроим полноценную микросервисную архитектуру.

Пост будет состоять из двух разделов. В первом мы настроим и запустим Apache Kafka на Linux-машине, во втором — напишем два микросервиса на Java.
В стартапе, в котором я начинал свой профессиональный путь программиста, были микросервисы на Kafka, и один из моих микросервисов тоже работал с другими через Kafka, но я не знал, как работает сам сервер, был ли он написан как приложение или это уже полностью коробочный продукт. Каково же было моё удивление и разочарование, когда выяснилось, что Kafka — всё-таки коробочный продукт, и моей задачей будет не только написание клиента на Java (что я обожаю делать), а также деплой и настройка готового приложения в качестве devOps (что я ненавижу делать). Впрочем, если даже я смог поднять на виртуальном сервере Kafka меньше чем за день, значит, сделать это действительно довольно просто. Итак.
Наше приложение будет иметь следующую структуру взаимодействия:
В конце поста, как обычно, будут ссылки на git с рабочим кодом.
Деплой Apache Kafka + Zookeeper на виртуальной машине
=====================================================
Я пытался поднять Kafka на локальном линуксе, на маке и на удалённом линуксе. В двух случаях (линукс) у меня получилось довольно быстро. С маком пока ничего не вышло. Поэтому поднимать Kafka будем на Linux. Я выбрал Ubuntu 18.04.
Для того, чтобы Kafka заработала, ей нужен Zookeeper. Для этого, Вы должны скачать и запустить его раньше, чем запустите Kafka.
Итак.
#### 0. Устанавливаем JRE
Это делается следующими командами:
```
sudo apt-get update
sudo apt-get install default-jre
```
Если всё прошло ок, то Вы можете ввести команду
```
java -version
```
и убедиться, что Java установилась.
#### 1. Качаем Zookeeper
Я не люблю магических команд на линуксе, особенно когда просто дают несколько команд и непонятно, что они делают. Поэтому я буду описывать каждое действие — что конкретно оно делает. Итак, нам надо скачать Zookeeper и распаковать его в удобную папку. Желательно, если все приложения будут храниться в папке /opt, то есть, в нашем случае, это будет /opt/zookeeper.
Я воспользовался командой ниже. Если Вы знаете другие команды на Linux, которые, на Ваш взгляд, позволят это сделать более расово правильно, воспользуйтесь ими. Я же разработчик, а не девопс, и с серверами общаюсь на уровне «сам козёл». Итак, качаем приложение:
```
wget -P /home/xpendence/downloads/ "http://apache-mirror.rbc.ru/pub/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz"
```
Приложение скачается в ту папку, которую Вы укажете, я создал папку /home/xpendence/downloads для скачивания туда всех нужных мне приложений.
#### 2. Распаковываем Zookeeper
Я воспользовался командой:
```
tar -xvzf /home/xpendence/downloads/zookeeper-3.4.12.tar.gz
```
Эта команда распаковывает архив в ту папку, в которой Вы находитесь. Возможно, Вам потом придётся перенести приложение в /opt/zookeeper. А можно сразу перейти в неё и оттуда уже распаковать архив.
#### 3. Правим настройки
В папке /zookeeper/conf/ есть файл zoo-sample.cfg, предлагаю переименовать его в zoo.conf, именно этот файл будет искать JVM при запуске. В этот файл нужно в конце дописать следующее:
```
tickTime=2000
dataDir=/var/zookeeper
clientPort=2181
```
Также, создайте директорию /var/zookeeper.
#### 4. Запускаем Zookeeper
Переходим в папку /opt/zookeeper и запускаем сервер командой:
```
bin/zkServer.sh start
```
Должна появиться надпись «STARTED».
После чего, предлагаю проверить, что сервер заработал. Пишем:
```
telnet localhost 2181
```
Должно появиться сообщение, что коннект удался. Если у Вас слабый сервер и сообщение не появилось, повторите попытку — даже когда появилась надпись STARTED, приложение начинает слушать порт намного позже. Когда я испытывал всё это на слабом сервере, у меня случалось это каждый раз. Если всё подключилось, вводим команду
```
ruok
```
Что означает: «Ты ок?» Сервер должен ответить:
```
imok (Я ок!)
```
и отключиться. Значит, всё по плану. Переходим к запуску Apache Kafka.
#### 5. Создаём юзера под Kafka
Для работы с Kafka нам потребуется отдельный юзер.
```
sudo adduser --system --no-create-home --disabled-password --disabled-login kafka
```
#### 6. Загружаем Apache Kafka
Существует два дистрибутива — бинарный и sources. Нам нужен бинарный. С виду архив с бинарником отличается размером. Бинарник весит 59 МБ, сорцы весят 6,5 МБ.
Качаем бинарник в нужную там директорию по ссылке ниже:
```
wget -P /home/xpendence/downloads/ "http://mirror.linux-ia64.org/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz"
```
#### 7. Распаковываем Apache Kafka
Процедура распаковки ничем не отличается от такой же для Zookeeper. Мы также распаковываем архив в директорию /opt и переименовываем в kafka, чтобы путь к папке /bin был /opt/kafka/bin
```
tar -xvzf /home/xpendence/downloads/kafka_2.11-2.1.0.tgz
```
#### 8. Правка настроек
Настройки находятся в /opt/kafka/config/server.properties. Добавляем одну строчку:
```
delete.topic.enable = true
```
Эта настройка вроде не является обязательной, работает и без неё. Эта настройка позволяет удалять топики. Иначе, Вы просто не сможете удалять топики через командную строку.
#### 9. Даём доступ юзеру kafka к директориям Kafka
```
chown -R kafka:nogroup /opt/kafka
chown -R kafka:nogroup /var/lib/kafka
```
#### 10. Долгожданный запуск Apache Kafka
Вводим команду, после которой Kafka должен запуститься:
```
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
```
Если в лог не посыпались привычные эксепшены (Kafka написана на Java и Scala), значит, всё заработало и можно протестировать наш сервис.
#### 10.1. Проблемы слабого сервера
Я взял для опытов над Apache Kafka слабый сервер с одним ядром и 512 Мб оперативки (зато всего за 99 рублей), что обернулось для меня несколькими проблемами.
Нехватка памяти. Конечно, с 512 Мб не разгонишься, и сервер не смог развернуть Kafka из-за нехватки памяти. Дело в том, что по умолчанию Kafka потребляет 1 Гб памяти. Неудивительно, что ему не хватило :)
Заходим в kafka-server-start.sh, zookeeper-server-start.sh. Там уже есть строчка, регулирующая память:
```
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
```
Меняем её на:
```
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
```
Это сократит аппетиты Kafka и позволит запустить сервер.
Вторая проблема слабого компьютера — нехватка времени на подключение к Zookeeper. По умолчанию на это даётся 6 секунд. Если железо слабое, этого, конечно, не хватит. В server.properties увеличиваем время подключения к зукиперу:
```
zookeeper.connection.timeout.ms=30000
```
Я поставил полминуты.
#### 11. Тест работы Kafka-сервера
Для этого мы откроем два терминала, на одном запустим продюсер, на другом — консьюмер.
В первой консоли вводим по одной строчке:
```
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
/opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
```
Должен появиться вот такой значок, означающий, что продюсер готов спамить сообщения:
```
>
```
Во второй консоли вводим команду:
```
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
```
Теперь, набирая текст в консоли-продюсере, при нажатии на Enter, он будет появляться в консоли-консьюмере.
[](https://habrastorage.org/webt/k7/uu/kf/k7uukff1u2kyygrgetrnvjnqmmg.png)
Если Вы видите на экране приблизительно то же, что и я — поздравляю, самое страшное позади!

Теперь нам осталось написать пару клиентов на Spring Boot, которые будут общаться друг с другом через Apache Kafka.
Пишем приложение на Spring Boot
===============================
Мы напишем два приложения, которые будут обмениваться сообщениями через Apache Kafka. Первое сообщение будет называться kafka-server и будет содержать в себе и продюсер, и консьюмер. Второе будет называться kafka-tester, оно предназначено, чтобы у нас была микросервисная архитектура.
### kafka-server
Для наших проектов, созданных через Spring Initializr, нам потребуется модуль Kafka. Я дополнительно добавил Lombok и Web, но это уже дело вкуса.
Kafka-клиент состоит из двух компонентов — продюсера (он отправляет сообщения на Kafka-сервер) и консьюмера (слушает Kafka-сервер и берёт оттуда новые сообщения по тем темам, на которые он подписан). Наша задача — написать оба компонента и заставить их работать.
Consumer:
```
@Configuration
public class KafkaConsumerConfig {
@Value("${kafka.server}")
private String kafkaServer;
@Value("${kafka.group.id}")
private String kafkaGroupId;
@Bean
public KafkaListenerContainerFactory batchFactory() {
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true);
factory.setMessageConverter(new BatchMessagingMessageConverter(converter()));
return factory;
}
@Bean
public KafkaListenerContainerFactory singleFactory() {
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(false);
factory.setMessageConverter(new StringJsonMessageConverter());
return factory;
}
@Bean
public ConsumerFactory consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public KafkaListenerContainerFactory kafkaListenerContainerFactory() {
return new ConcurrentKafkaListenerContainerFactory<>();
}
@Bean
public Map consumerConfigs() {
Map props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP\_SERVERS\_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY\_DESERIALIZER\_CLASS\_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE\_DESERIALIZER\_CLASS\_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP\_ID\_CONFIG, kafkaGroupId);
props.put(ConsumerConfig.ENABLE\_AUTO\_COMMIT\_CONFIG, true);
return props;
}
@Bean
public StringJsonMessageConverter converter() {
return new StringJsonMessageConverter();
}
}
```
Нам потребуется 2 поля, инициализированных статическими данными из kafka.properties.
```
kafka.server=localhost:9092
kafka.group.id=server.broadcast
```
kafka.server — это адрес, на котором висит наш сервер, в данном случае, локальный. По умолчанию Kafka слушает порт 9092.
kafka.group.id — это группа консьюмеров, в рамках которой доставляется один экземпляр сообщения. Например, у Вас есть три консьюмера в одной группе, и все они слушают одну тему. Как только на сервере появляется новое сообщение с данной темой, оно доставляется кому-то одному из группы. Остальные два консьюмера сообщение не получают.
Далее, мы создаём фабрику консьюмеров — ConsumerFactory.
```
@Bean
public ConsumerFactory consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
```
Проинициализированная нужными нам свойствами, она будет служить стандартной фабрикой консьюмеров в дальнейшем.
```
@Bean
public Map consumerConfigs() {
Map props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP\_SERVERS\_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY\_DESERIALIZER\_CLASS\_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE\_DESERIALIZER\_CLASS\_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP\_ID\_CONFIG, kafkaGroupId);
props.put(ConsumerConfig.ENABLE\_AUTO\_COMMIT\_CONFIG, true);
return props;
}
```
consumerConfigs — это просто Map конфигов. Мы указываем адрес сервера, группу и десериализаторы.
Далее, один из самых важных моментов для консьюмера. Консьюмер может получать как единичные объекты, так и коллекции — например, как StarshipDto, так и List. И если StarshipDto мы получаем как JSON, то List мы получаем как, грубо говоря, как JSON-массив. Поэтому у нас как минимум две фабрики сообщений — для одиночных сообщений и для массивов.
```
@Bean
public KafkaListenerContainerFactory singleFactory() {
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(false);
factory.setMessageConverter(new StringJsonMessageConverter());
return factory;
}
```
Мы создаём экземпляр ConcurrentKafkaListenerContainerFactory, типизированный Long (ключ сообщения) и AbstractDto (абстрактное значение сообщения) и инициализируем его поля свойствами. Фабрику мы, понятно, инициализируем нашей стандартной фабрикой (которая уже содержит Map конфигов), далее помечаем, что не слушаем пакеты (те самые массивы) и указываем в качестве конвертера простой конвертер из JSON.
Когда же мы создаём фабрику для пакетов/массивов (batch), то главное отличие (не считая того, что мы помечаем, что слушаем именно пакеты) заключается в том, что мы указываем в качестве конвертера специальный конвертер пакетов, который будет конвертировать пакеты, состоящие из JSON-строк.
```
@Bean
public KafkaListenerContainerFactory batchFactory() {
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true);
factory.setMessageConverter(new BatchMessagingMessageConverter(converter()));
return factory;
}
@Bean
public StringJsonMessageConverter converter() {
return new StringJsonMessageConverter();
}
```
И ещё один момент. При инициализации бинов Spring может не досчитаться бина под именем kafkaListenerContainerFactory и запороть запуск приложения. Наверняка есть более изящные варианты решения проблемы, пишите о них в комментариях, я же пока просто создал не обременённый функционалом бин с таким названием:
```
@Bean
public KafkaListenerContainerFactory kafkaListenerContainerFactory() {
return new ConcurrentKafkaListenerContainerFactory<>();
}
```
Консьюмер настроен. Переходим к продюсеру.
```
@Configuration
public class KafkaProducerConfig {
@Value("${kafka.server}")
private String kafkaServer;
@Value("${kafka.producer.id}")
private String kafkaProducerId;
@Bean
public Map producerConfigs() {
Map props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP\_SERVERS\_CONFIG, kafkaServer);
props.put(ProducerConfig.KEY\_SERIALIZER\_CLASS\_CONFIG, LongSerializer.class);
props.put(ProducerConfig.VALUE\_SERIALIZER\_CLASS\_CONFIG, JsonSerializer.class);
props.put(ProducerConfig.CLIENT\_ID\_CONFIG, kafkaProducerId);
return props;
}
@Bean
public ProducerFactory producerStarshipFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate kafkaTemplate() {
KafkaTemplate template = new KafkaTemplate<>(producerStarshipFactory());
template.setMessageConverter(new StringJsonMessageConverter());
return template;
}
}
```
Из статических переменных нам потребуются адрес kafka-сервера и ID продюсера. Он может быть любым.
В конфигах, как мы видим, ничего особенного нет. Почти то же самое. Но в отношении фабрик есть существенное различие. Мы должны прописать шаблон для каждого класса, объекты которого мы будем отправлять на сервер, а также, фабрику для него. У нас такая пара одна, но их могут быть десятки.
В шаблоне мы помечаем, что будем сериализовать объекты в JSON, и этого, пожалуй, достаточно.
У нас есть консьюмер и продюсер, осталось написать сервис, который будет отправлять сообщения и получать их.
```
@Service
@Slf4j
public class StarshipServiceImpl implements StarshipService {
private final KafkaTemplate kafkaStarshipTemplate;
private final ObjectMapper objectMapper;
@Autowired
public StarshipServiceImpl(KafkaTemplate kafkaStarshipTemplate,
ObjectMapper objectMapper) {
this.kafkaStarshipTemplate = kafkaStarshipTemplate;
this.objectMapper = objectMapper;
}
@Override
public void send(StarshipDto dto) {
kafkaStarshipTemplate.send("server.starship", dto);
}
@Override
@KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory")
public void consume(StarshipDto dto) {
log.info("=> consumed {}", writeValueAsString(dto));
}
private String writeValueAsString(StarshipDto dto) {
try {
return objectMapper.writeValueAsString(dto);
} catch (JsonProcessingException e) {
e.printStackTrace();
throw new RuntimeException("Writing value to JSON failed: " + dto.toString());
}
}
}
```
В нашем сервисе всего два метода, их нам хватит для объяснения работы клиента. Мы автовайрим нужные нам шаблоны:
```
private final KafkaTemplate kafkaStarshipTemplate;
```
Метод-продюсер:
```
@Override
public void send(StarshipDto dto) {
kafkaStarshipTemplate.send("server.starship", dto);
}
```
Всё, что требуется для того, чтобы отправить сообщение на сервер — это вызвать метод send у шаблона и передать туда топик (тему) и наш объект. Объект будет сериализован в JSON и под указанным топиком улетит на сервер.
Слушающий метод выглядит так:
```
@Override
@KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory")
public void consume(StarshipDto dto) {
log.info("=> consumed {}", writeValueAsString(dto));
}
```
Мы помечаем такой метод аннотацией @KafkaListener, где указываем любой ID, который нам нравится, слушаемые топики и фабрику, которая будет конвертировать полученное сообщение в то, что нам нужно. В данном случае, поскольку мы принимаем один объект, нам нужен singleFactory. Для List указываем batchFactory. В итоге, мы отправляем объект на kafka-сервер при помощи метода send и получаем его при помощи метода consume.
Можно за 5 минут написать тест, который позволит продемонстрировать всю силу Kafka, но мы пойдём дальше — потратим 10 минут и напишем ещё одно приложение, которое будет отправлять на сервер сообщения, которые будет слушать наше первое приложение.
kafka-tester
------------
Имея опыт написания первого приложения, мы легко можем написать второе, особенно если скопипастить проперти и пакет dto, прописать только продюсер (мы будем только отправлять сообщения) и добавить в сервис единственный метод send. По ссылке ниже Вы легко сможете скачать код проекта и убедиться, что ничего сложного там нет.
```
@Scheduled(initialDelay = 10000, fixedDelay = 5000)
@Override
public void produce() {
StarshipDto dto = createDto();
log.info("<= sending {}", writeValueAsString(dto));
kafkaStarshipTemplate.send("server.starship", dto);
}
private StarshipDto createDto() {
return new StarshipDto("Starship " + (LocalTime.now().toNanoOfDay() / 1000000));
}
```
По истечении первых 10 секунд kafka-tester начинает каждые 5 секунд слать сообщения с названиями звездолётов на сервер Kafka (картинка кликабельна).
[](https://habrastorage.org/webt/oo/ri/gk/oorigkqltxuntytvhzbarlninhk.png)
Там их слушает и получаает kafka-server (картинка так же кликабельна).
[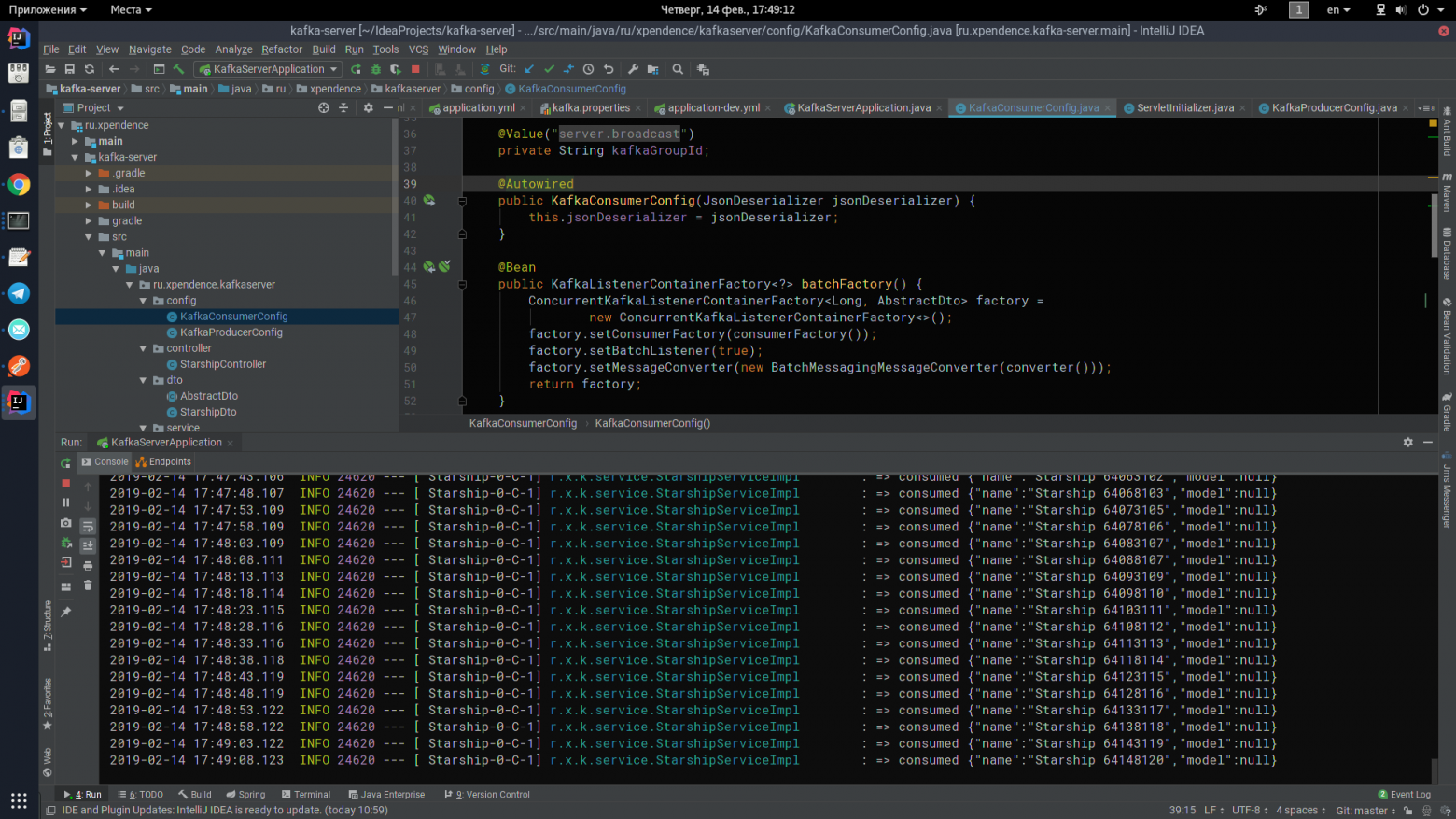](https://habrastorage.org/webt/cs/w-/vc/csw-vcgajjpjymkdxcwibqllnoi.png)
Надеюсь, у мечтающих начать писать микросервисы на Кафке получится так же легко, как это получилось у меня. А вот ссылки на проекты:
→ [kafka-server](https://github.com/promoscow/kafka-server)
→ [kafka-tester](https://github.com/promoscow/kafka-tester) | https://habr.com/ru/post/440400/ | null | ru | null |
# CSS GuideLines, часть 3. Именование классов

Соглашения по именованию CSS позволяют писать строгий, чистый и красивый код. При соблюдении правил именования вы всегда будете знать:
* Для чего используется класс;
* Где класс может быть использован;
* С какими другими классами связан этот класс.
Правила именования, которым я следую, весьма просты: я использую дефис в качестве разделителя, а в сложных местах использую БЭМ-подобное именование.
Следует отметить, что сами по себе правила именования не дадут особой выгоды при написании CSS; но зато они весьма полезны при просмотре разметки.
#### **Разделение дефисом**
Все слова в названиях классов должны быть разделены дефисом:
```
.page-head {}
.sub-content {}
```
CamelCase и знак подчеркивания не используются для классов, следующий пример неправилен:
```
.pageHead {}
.sub_content {}
```
#### **БЭМ-подобное именование**
Для более крупных взаимосвязанных частей интерфейса я использую БЭМ-подобное именование классов.
БЭМ, то есть *Блок, Элемент, Модификатор*, это методология, созданная разработчиками Яндекса. Несмотря на то, что БЭМ — это довольно крупная методология, в данный момент мы заинтересованы только в ее способе именования элементов. Причем, мое соглашение по именованию немного отличается от оригинального БЭМ'a: принципы одни и те же, но синтаксис разный.
БЭМ разделяет компоненты верстки на три группы:
* Блок: главный корневой элемент.
* Элемент: часть блока.
* Модификатор: вариант или модификация блока.
Проведем аналогию:
```
.person {}
.person__head {}
.person--tall {}
```
В начале класса всегда ставится название блока, для обозначения элемента мы отделяем название блока от названия элемента двумя подчеркиваниями (\_\_), а для обозначения модификатора используем два дефиса (--).
В примере выше мы можем видеть, что `.person {}` — это блок; у него нет предков. `.person__head {}` — это элемент, часть блока; наконец, `.person--tall` — это модификатор, разновидность блока `.person {}`.
##### **Использование блоков**
Блок должен быть логической, самостоятельной единицей. Продолжая наш пример с классом `.person {}`: мы не можем создать класс `.room__person`, потому что `.room {}` — это самостоятельная единица. В таком случае стоит разделять блоки:
```
.room {}
.room__door {}
.room--kitchen {}
.person {}
.person__head {}
```
Если нам потребуется обозначить человека внутри комнаты, было бы правильнее использовать такой селектор — `.room .person`, который позволяет не городить кашу из кучи разных непонятных элементов и блоков.
Более реалистичный пример правильного использования блоков может выглядеть следующим образом:
```
.page {}
.content {}
.sub-content {}
.footer {}
.footer__copyright {}
```
Каждая часть кода представляет свой собственный блок. Неправильный пример использования:
```
.page {}
.page__content {}
.page__sub-content {}
.page__footer {}
.page__copyright {}
```
Важно уметь различать, где стоит применять БЭМ, а где нет. Как правило, я использую блоки для описания автономных частей пользовательского интерфейса.
##### **Множество слоев**
Если бы мы добавили к нашему блоку `.person {}` еще один элемент, скажем, `.person__eye`, то нам не нужно было бы при именовании элемента делать шаг назад, добавляя названия предыдущих элементов, вплоть до корневого элемента. То есть, правильно будет писать `.person__eye`, а не `.person__head__eye`.
##### **Добавляем модификации элементов**
Вам может потребоваться добавлять вариации элементов, это может быть сделано несколькими способами, в зависимости от того, как и почему эти элементы должны быть изменены. Опять же, если человек имеет голубые глаза, то в CSS это может быть описано так:
```
.person__eye--blue {}
```
Однако, в реальных проектах все бывает несколько сложнее. Прощу прощения за такую аналогию, но давайте себе представим человека с красивым лицом. Сам по себе он не особо красив, поэтому лучшим решением будет добавить модификатор к элементу `.person__face {}`:
```
.person__face--handsome {}
```
Но что делать, если мы хотим описать лицо красивого человека? То есть человек красив сам по себе, в отличие от предыдущего примера, и нам нужно описать его лицо? Это делается следующим образом:
```
.person--handsome .person__face {}
```
Это один из немногих случаев, когда мы можем менять элемент в зависимости от модификации блока. При использовании Sass получился бы такой код:
```
.person {}
.person__face {
.person--handsome & {}
}
.person--handsome {}
```
Заметьте, что мы не добавляем новый элемент `.person__face` внутрь элемента `.person--handsome`; вместо этого мы используем родительский селектор Sass внутри уже существующего селектора `.person__face`. Это значит, что все правила, связанные с `.person__face` будут находиться в одном месте, и нам не придется разбрасывать их по всему файлу. Это хорошая практика при работе с вложенным кодом: храните все нужные стили внутри одного контекста (в нашем случае, внутри `.person__face`).
#### **Именование в разметке**
Как ранее было замечено, соглашение по именованию классов наиболее полезно при работе с разметкой. Взгляните на следующий кусок разметки, не следующий нашему соглашению:
```
![]()
...
```
Как классы `.box` и `.profile` связаны друг с другом? Как классы `.profile` и `.avatar` связаны друг с другом? Связаны ли они вообще? Зависит ли класс `.bio` от класса `.pro-user`? Можно ли использовать класс `.avatar` вне этой разметки?
При просмотре такой разметки очень сложно ответить на все эти вопросы. Использование соглашения об именовании меняет дело:
```
![]()
...
```
Теперь нам сразу видно, какие классы связаны друг с другом и как, а какие нет; мы знаем, какие классы мы не можем использовать вне этой разметки; наконец, мы знаем, какие классы могут быть использованы в любом другом месте.
#### **JavaScript-хуки**
Как правило, неразумно привязывать JS- и CSS-код к одному и тому же классу в разметке, потому что удалив или изменив один класс с целью, например, изменения поведения скрипта, вы непременно затронете CSS, и наоборот. Намного чище, прозрачнее и в целом лучше привязывать JS к отдельным классам.
Я сталкивался со случаями, когда удаление каких-то классов с целью переработки стилей, ломало работу всех скриптов на странице, а все потому что разработчик не подумал и привязал стили со скриптами к одному и тому же классу.
Как правило, разработчики используют отдельный класс для js, начинающийся с префикса «js-», например:
```
```
Такая разметка позволяет использовать стили `.btn` в любом другом месте, при этом не затрагивая поведения `.js-btn`.
##### **data-\* атрибуты**
Также довольно часто разработчиками используются data-\* атрибуты в качестве js-хуков, но это неправильно. data-\* атрибуты, согласно спецификации, предназначены для хранения данных, недоступных на странице. data-\* атрибуты созданы для хранения данных, а не для для привязки к js.
#### **В продолжение темы...**
Как уже было сказано, все правила, представленные выше весьма просты. Я призываю вас не останавливаться на изученном и читать другие материалы по этой теме — это позволит вам получить больше возможностей по именованию классов.
#### **Материалы для дополнительного изучения**
* [Головокружительное погружение в БЭМ](http://csswizardry.com/2013/01/mindbemding-getting-your-head-round-bem-syntax/) (есть [перевод](http://frontender.info/MindBEMding/))
Предыдущая часть: [CSS GuideLines, часть 2. Комментирование кода](http://habrahabr.ru/post/235893/) | https://habr.com/ru/post/236047/ | null | ru | null |
# Ember.js: отличный фреймворк для веб-приложений
Ember.js — это JavaScript-фреймворк для разработки клиентской части веб-приложений, амбициозный проект, который в последнее время привлекает к себе много внимания. Сегодня мы хотим рассказать о некоторых ключевых концепциях, лежащих в основе Ember.js, продемонстрировав их в ходе создания простого приложения.
[](https://habrahabr.ru/company/ruvds/blog/341076/)
Это будет программа Dice Roller, которая позволяет «бросать» игральные кости, предварительно задавая их параметры, и просматривать историю предыдущих «бросков». Её код можно найти на [Github](https://github.com/sazzer/dice-roller).
Фреймворк Ember.js включает в себя множество современных концепций и технологий из мира JavaScript. Среди его возможностей хотелось бы отметить следующие:
* Использование транспилятора [Babel](https://babeljs.io/) для обеспечения поддержки ES2016.
* Поддержка средств тестирования [Testem](https://github.com/testem/testem) и [QTest](https://qunitjs.com/), что открывает возможности по модульному, интеграционному и приёмочному тестированию.
* Поддержка сборщика [Broccoli.js](http://broccolijs.com/).
* Интерактивная перезагрузка веб-страниц, что ускоряет процесс разработки.
* Поддержка шаблонизатора [Handlebar](http://handlebarsjs.com/).
* Использование модели разработки, при реализации которой в первую очередь создаются URL-маршруты. Это обеспечивает полную поддержку глубоких ссылок.
* Наличие слоя для работы с данными, основанного на JSON API, но поддерживающего подключение к любому API, с которым нужно наладить работу.
Для того, чтобы приступить к работе с Ember.js, понадобятся свежие версии Node.js и npm. Всё это можно загрузить с сайта [Node.js](https://nodejs.org/).
Кроме того, стоит сказать, что Ember.js — это фреймворк, ориентированный исключительно на фронтенд. Он поддерживает множество способов взаимодействия с различными бэкендами, но всё, что относится к серверному коду, не входит в сферу ответственности Ember.
Знакомство с ember-cli
----------------------
 Интерфейс командной строки Ember.js, `ember-cli`, открывает доступ ко множеству возможностей этого фреймворка. `Ember-cli` поддерживает программиста на всех этапах работы. Он упрощает создание приложения, расширение его функциональности, тестирование и запуск проекта в режиме разработки.
Практически всё, чем вы будете заниматься в ходе создания Ember-приложения, будет, в определённой степени, включать в себя использование `ember-cli`. Поэтому важно изучить этот инструмент. Мы, в ходе работы над учебным проектом, будем постоянно пользоваться им.
Первый шаг нашей работы заключается в установке `ember-cli`, или, если он уже установлен — в проверке актуальности имеющейся версии. Установить `ember-cli` можно из реестра `npm` с помощью следующей команды:
```
$ npm install -g ember-cli
```
Для того, чтобы проверить, успешно ли прошла установка, а заодно узнать то, какая версия `ember-cli` установлена, можно воспользоваться следующей командой:
```
$ ember --version
ember-cli: 2.15.0-beta.1
node: 8.2.1
os: darwin x64
```
Создание первого приложения на Ember.js
---------------------------------------
После того, как `ember-cli` установлен, мы готовы к тому, чтобы приступить к созданию приложения. Это — первая ситуация, в которой мы будем пользоваться `ember-cli`. Он создаёт структуру приложения, настраивает его и даёт нам работающий проект. Создадим приложение `dice-roller` следующей командой:
```
$ ember new dice-roller
installing app
create .editorconfig
create .ember-cli
create .eslintrc.js
create .travis.yml
create .watchmanconfig
create README.md
create app/app.js
create app/components/.gitkeep
create app/controllers/.gitkeep
create app/helpers/.gitkeep
create app/index.html
create app/models/.gitkeep
create app/resolver.js
create app/router.js
create app/routes/.gitkeep
create app/styles/app.css
create app/templates/application.hbs
create app/templates/components/.gitkeep
create config/environment.js
create config/targets.js
create ember-cli-build.js
create .gitignore
create package.json
create public/crossdomain.xml
create public/robots.txt
create testem.js
create tests/.eslintrc.js
create tests/helpers/destroy-app.js
create tests/helpers/module-for-acceptance.js
create tests/helpers/resolver.js
create tests/helpers/start-app.js
create tests/index.html
create tests/integration/.gitkeep
create tests/test-helper.js
create tests/unit/.gitkeep
create vendor/.gitkeep
NPM: Installed dependencies
Successfully initialized git.
$
```
Выполнение вышеприведённой команды приводит к созданию работоспособного макета приложения. Она даже настраивает систему контроля версий Git. Обратите внимание на то, что интеграцию с Git можно и отключить, кроме того, вместо менеджера пакетов `npm` можно использовать `yarn`. Подробности об этом можно найти в документации к Ember.
Теперь посмотрим на то, что у нас получилось. Запуск Ember-приложения для целей разработки, как уже было сказано, выполняется с использованием `ember-cli`. Делается это так:
```
$ cd dice-roller
$ ember serve
Livereload server on http://localhost:49153
'instrument' is imported from external module 'ember-data/-debug' but never used
Warning: ignoring input sourcemap for vendor/ember/ember.debug.js because ENOENT: no such file or directory, open '/Users/coxg/source/me/writing/repos/dice-roller/tmp/source_map_concat-input_base_path-2fXNPqjl.tmp/vendor/ember/ember.debug.map'
Warning: ignoring input sourcemap for vendor/ember/ember-testing.js because ENOENT: no such file or directory, open '/Users/coxg/source/me/writing/repos/dice-roller/tmp/source_map_concat-input_base_path-Xwpjztar.tmp/vendor/ember/ember-testing.map'
Build successful (5835ms) – Serving on http://localhost:4200/
Slowest Nodes (totalTime => 5% ) | Total (avg)
----------------------------------------------+---------------------
Babel (16) | 4625ms (289 ms)
Rollup (1) | 445ms
```
Теперь всё готово, приложение доступно по адресу [http://localhost:4200](http://localhost:4200/) и выглядит оно так:
Помимо самого приложения запускается сервис [LiveReload](http://livereload.com/), который наблюдает за изменениями файлов проекта и автоматически перезагружает страницу в браузере. Это означает, что в ходе модификации сайта вы очень быстро увидите результат изменений.
Первая страница сообщает нам о том, что можно сделать дальше, прислушаемся к этим сообщениям, изменим главную страницу и посмотрим, что из этого получится. Для этого приведём файл `app/templates/application.hbs` к такому виду:
```
This is my new application.
{{outlet}}
```
Обратите внимание на то, что тег `{{outlet}}` является частью того, как в Ember работает процесс маршрутизации. Подробнее об этом мы поговорим ниже.
После изменения файла сразу стоит посмотреть на то, что выведет в консоль `ember-cli`. Это должно выглядеть примерно так:
```
file changed templates/application.hbs
Build successful (67ms) – Serving on http://localhost:4200/
Slowest Nodes (totalTime => 5% ) | Total (avg)
----------------------------------------------+---------------------
SourceMapConcat: Concat: App (1) | 9ms
SourceMapConcat: Concat: Vendor /asset... (1) | 8ms
SimpleConcatConcat: Concat: Vendor Sty... (1) | 4ms
Funnel (7) | 4ms (0 ms)
```
Здесь нам сообщают, что система обнаружила изменение шаблона, перестроила и перезапустила проект. Это полностью автоматический процесс, мы в нём участия не принимаем.
Теперь посмотрим в браузер. Если у вас установлен и запущен `LiveReload`, то вам даже не нужно вручную перезагружать страницу для того, чтобы увидеть изменения. В противном случае страницу приложения придётся перезагрузить самостоятельно.
Нельзя сказать, что внешний вид страницы поражает воображение, но то, что мы с ней сделали, потребовало минимума усилий с нашей стороны.
Кроме того, у нас имеется полностью готовая к использованию подсистема тестирования. Для того, чтобы её запустить, надо воспользоваться соответствующим средством Ember:
```
$ ember test
⠸ Building'instrument' is imported from external module 'ember-data/-debug' but never used
⠴ BuildingWarning: ignoring input sourcemap for vendor/ember/ember.debug.js because ENOENT: no such file or directory, open '/Users/coxg/source/me/writing/repos/dice-roller/tmp/source_map_concat-input_base_path-S8aQFGaz.tmp/vendor/ember/ember.debug.map'
⠇ BuildingWarning: ignoring input sourcemap for vendor/ember/ember-testing.js because ENOENT: no such file or directory, open '/Users/coxg/source/me/writing/repos/dice-roller/tmp/source_map_concat-input_base_path-wO8OLEE2.tmp/vendor/ember/ember-testing.map'
cleaning up...
Built project successfully. Stored in "/Users/coxg/source/me/writing/repos/dice-roller/tmp/class-tests_dist-PUnMT5zL.tmp".
ok 1 PhantomJS 2.1 - ESLint | app: app.js
ok 2 PhantomJS 2.1 - ESLint | app: resolver.js
ok 3 PhantomJS 2.1 - ESLint | app: router.js
ok 4 PhantomJS 2.1 - ESLint | tests: helpers/destroy-app.js
ok 5 PhantomJS 2.1 - ESLint | tests: helpers/module-for-acceptance.js
ok 6 PhantomJS 2.1 - ESLint | tests: helpers/resolver.js
ok 7 PhantomJS 2.1 - ESLint | tests: helpers/start-app.js
ok 8 PhantomJS 2.1 - ESLint | tests: test-helper.js
1..8
# tests 8
# pass 8
# skip 0
# fail 0
# ok
```
Обратите внимание на то, что основная масса выводимых данных поступает от [Phantom.js](http://phantomjs.org/). Так происходит из-за того, что здесь имеется полная поддержка интеграционного тестирования, которое, по умолчанию, производится в браузере PhantomJS без графического интерфейса. Присутствует и возможность запускать тестирование в других браузерах, если в этом есть необходимость. Настраивая систему непрерывной интеграции (CI, Continuous Integration), стоит воспользоваться этой возможностью для того, чтобы убедиться в том, что приложение правильно работает во всех поддерживаемых браузерах.
Структура Ember.js-приложения
-----------------------------
Прежде чем мы займёмся работой над приложением, разберёмся со структурой папок и файлов, на которой оно основано. Вышеприведённая команда `ember new` создаёт необходимые приложению папки и файлы, которых довольно много. Понимание того, как это всё устроено, важно для организации эффективной работы с Ember и для создания проектов любого масштаба.
На самом верхнем уровне структуры приложения можно обратить внимание на следующие файлы и папки:
* README.md – стандартный readme-файл с описанием приложения.
* package.json – конфигурационный файл `npm`, описывающий приложение. Он, в основном, используется для того, чтобы обеспечить корректную установку зависимостей.
* ember-cli-build.js – конфигурационный файл для `ember-cli`, который отвечает за сборку приложения.
* testem.js – Это конфигурационный файл для подсистемы тестирования. Он позволяет, кроме прочего, задавать браузеры, которые следует использовать для организации испытаний приложения в разных средах.
* app/ – тут хранится логика приложения. В этой папке происходит много всего интересного, ниже мы об этом поговорим.
* config/ – здесь находятся настройки приложения.
* public/ – тут хранятся статические ресурсы, которые нужно включить в приложение. Например, это изображения и шрифты.
* vendor/ – сюда попадают зависимости фронтенда, которыми не управляет система сборки.
* tests/ – здесь расположены тесты.
Структура страницы
------------------
Прежде чем продолжать, займёмся структурой страницы. В данном случае мы будем пользоваться фреймворком [Materialize CSS](http://materializecss.com/), что позволяет придать странице приятный вид и сделать работу с ней удобнее для конечного пользователя.
Для того, чтобы добавить в приложение поддержку дополнительных средств, можно воспользоваться одним из следующих подходов:
* Подключить то, что нужно, напрямую, воспользовавшись внешней службой вроде какой-нибудь CDN.
* Использовать менеджер пакетов наподобие `npm` или `Bower` для установки необходимого пакета.
* Включить необходимые ресурсы непосредственно в приложение.
* Использовать подходящий [аддон](https://guides.emberjs.com/v2.14.0/addons-and-dependencies/managing-dependencies/#toc_addons) для Ember.
К сожалению, аддон для Materialize пока не работает с самой свежей версией Ember.js, поэтому мы подключим этот фреймворк на главной странице приложения, пользуясь ссылкой на CDN-ресурс. Для того, чтобы это сделать, нужно отредактировать файл `app/index.html`, который описывает структуру главной страницы, в которой выводится приложение. Мы собираемся добавить CDN-ссылки на jQuery, на шрифт с иконками Google, и на Materialize.
```
```
Теперь можно изменить главную страницу таким образом, чтобы она отображала базовый шаблон приложения. Делается это путём приведения файла `app/templates/application.hbs` к такому виду:
```
[*filter\_6*
Dice Roller](#)
{{outlet}}
```
Благодаря этому коду в верхней части страницы окажется навигационная панель, подготовленная средствами Materialize. На странице имеется и контейнер, в котором расположен упомянутый выше тег `{{outlet}}`.
Теперь, если заглянуть в браузер, можно обнаружить, что страница выглядит так, как показано на рисунке ниже.
Пришло время поговорить о теге `{{outlet}}`. Работа Ember основана на маршрутах. Каждый маршрут считается потомком какого-то другого маршрута. Корневой маршрут обрабатывается автоматически, он выводит шаблон `app/templates/application.hbs`.
Тег `{{outlet}}` задаёт место, где Ember выведет содержимое, соответствующее следующему маршруту в текущей иерархии — в итоге маршрут первого уровня выводится в этот тег в `application.hbs`, маршрут второго уровня выводится в таком же теге в шаблоне первого уровня, и так далее.
Создание нового маршрута
------------------------
Доступ к каждой странице приложения на Ember.js организован через маршрут (Route). Существует прямое соответствие между URL, который открывает браузер, и материалами, относящимися к маршруту, которые выводит на экран приложение.
Легче всего ознакомиться с этой концепцией на примере. Добавим в приложение новый маршрут, который позволяет пользователю «бросать» игральные кости. Этот шаг, опять же, выполняется с помощью `ember-cli`:
```
$ ember generate route roll
installing route
create app/routes/roll.js
create app/templates/roll.hbs
updating router
add route roll
installing route-test
create tests/unit/routes/roll-test.js
```
Вот что было создано благодаря вызову этой команды:
* Обработчик для маршрута — `app/routes/roll.js`
* Шаблон для маршрута — `app/templates/roll.hbs`.
* Тест для маршрута — `tests/unit/routes/roll-test.js`
* Обновление конфигурации роутера, дающее ему сведения об этом новом маршруте — `app/router.js`
Посмотрим на то, как это работает. Пока у нас будет очень простая страница, содержащая элементы, описывающие игральную кость и кнопку, которая, немного позже, позволит её «бросить». Для того, чтобы сформировать эту страницу, поместим следующий код в файл шаблона `app/templates/roll.hbs`:
```
Name of Roll
Number of Dice
Number of Sides
Roll Dice
*send*
{{outlet}}
```
После этого посетим страницу <http://localhost:4200/roll> и посмотрим что получится.
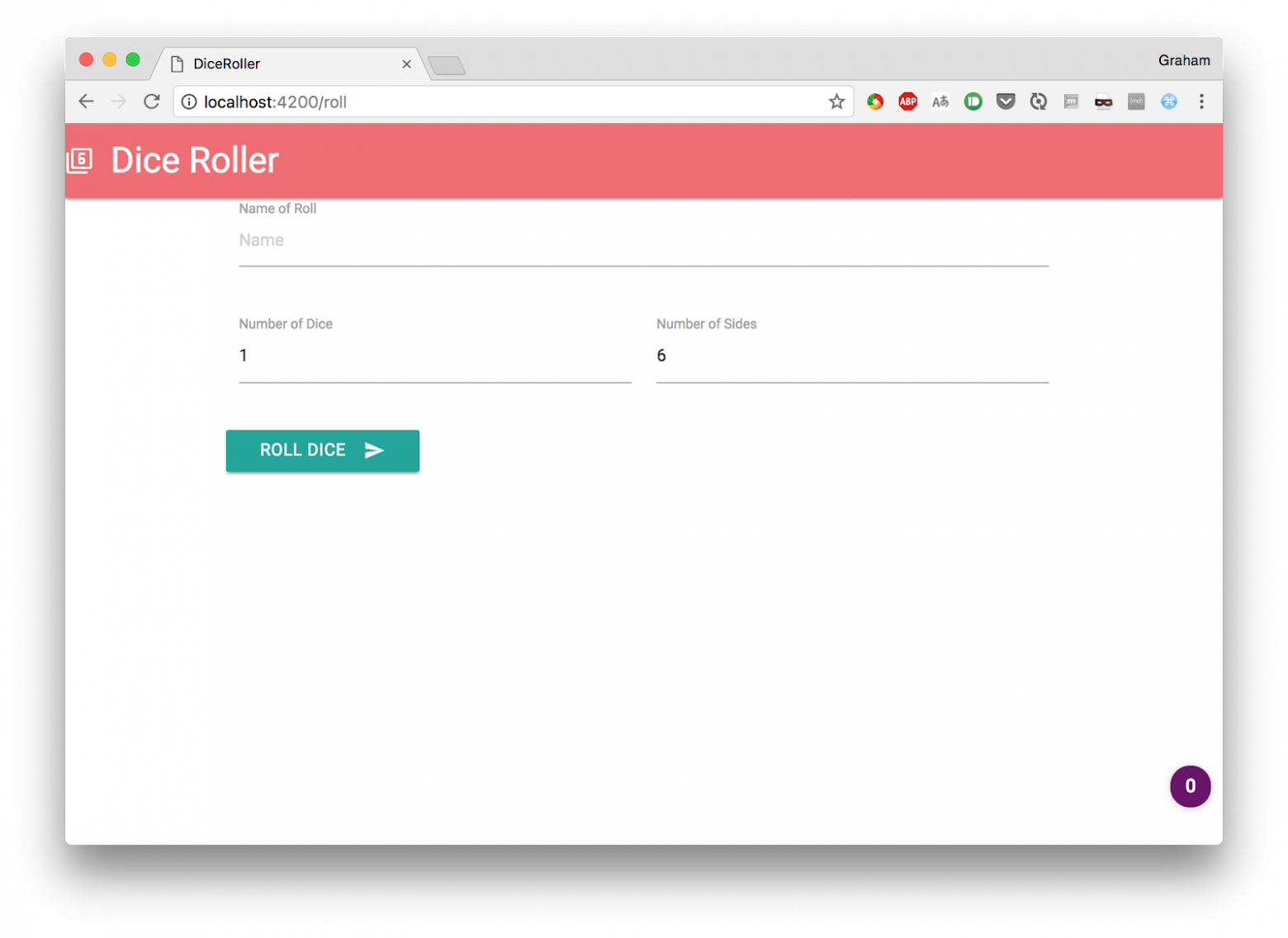
Теперь нам нужен способ организации перехода на эту страницу через интерфейс приложения. Ember упрощает решение этой задачи благодаря использованию тега `link-to`. Он, кроме прочего, принимает имя маршрута, по которому мы отправляем пользователя, и выводит элементы, позволяющие пользователю перейти по этому маршруту.
Включим в файл `app/templates/application.hbs` следующее:
```
{{#link-to 'roll' tagName="li"}}
[Roll Dice](roll)
{{/link-to}}
```
Это приведёт к тому, что навигационная панель в верхней части страницы примет вид, показанный на рисунке ниже.
В правой части панели появилась новая ссылка, `Roll Dice`, при щелчке по которой пользователь переходит по маршруту `/roll`. Именно этого мы и пытались добиться.
Разработка модульных компонентов
--------------------------------
Если вы попробуете поработать с приложением, испытать его, вы заметите проблему. Домашняя страница открывается нормально, ссылка `/roll` работает, но подписи полей на форме выровнены неправильно. Так происходит из-за того, что Materialize надо вызвать определённый JS-код для того, чтобы соответствующим образом расположить элементы, но, из-за особенностей динамической маршрутизации, страницы не перезагружаются. Сейчас мы это исправим.
Поработаем с компонентами. Компоненты — это фрагменты пользовательского интерфейса, имеющие полный жизненный цикл, с которыми можно взаимодействовать. Кроме того, используя компоненты, можно, при необходимости, создавать элементы пользовательского интерфейса, подходящие для повторного использования. Мы поговорим об этом позже.
Сейчас мы собираемся создать единственный компонент, представляющий собой форму `Roll Dice`. Как обычно в подобных ситуациях, для создания компонента обратимся к `ember-cli`:
```
$ ember generate component roll-dice
installing component
create app/components/roll-dice.js
create app/templates/components/roll-dice.hbs
installing component-test
create tests/integration/components/roll-dice-test.js
```
В результате система создаёт следующее:
* Код, реализующий логику компонента — `app/components/roll-dice.js`
* >Шаблон, определяющий внешний вид компонента — `app/templates/components/roll-dice.hbs`
* Тест для проверки правильности работы компонента — `tests/integration/components/roll-dice-test.js`
Теперь мы собираемся переместить всю разметку в компонент. Это напрямую не повлияет на то, как работает приложение, но в дальнейшем поможет нам настроить его так, как нам нужно.
Приведём файл `app/templates/components/roll-dice.hbs` к такому состоянию:
```
Name of Roll
Number of Dice
Number of Sides
Roll Dice
*send*
```
Теперь поместим следующий код в файл `app/templates/roll.hbs`:
```
{{roll-dice}}
{{outlet}}
```
В шаблон компонента попала та же самая разметка, которая раньше располагалась в файле шаблона маршрута. Файл шаблона маршрута при этом стал значительно проще. Тег `roll-dice` указывает Ember место, в которое нужно вывести компонент.
Если посмотреть сейчас на то, как приложение выглядит в браузере, никакой разницы мы не увидим. Однако, поменялось устройство кода, он стал модульным. Мы собираемся воспользоваться только что созданным компонентом, для того, чтобы исправить неправильную вёрстку страницы и добавить нашему приложению некоторые новые возможности.
Жизненный цикл компонента
-------------------------
Компоненты в Ember отличаются особым жизненным циклом, при этом предусмотрено наличие хуков, вызываемых на различных стадиях их жизненного цикла. Мы собираемся, для того, чтобы дать возможность Materialize правильно вывести подписи, воспользоваться хуком `didRender`, который вызывается после вывода компонента на экран. Причём, делается это как при первом показе компонента, так и при последующих его показах.
Для того, чтобы это сделать, отредактируем код компонента, который можно найти в файле `app/components/roll-dice.js`:
```
/* global Materialize:false */
import Ember from 'ember';
export default Ember.Component.extend({
didRender() {
Materialize.updateTextFields();
}
});
```
Теперь каждый раз, когда мы посещаем маршрут `/roll`, используя прямую ссылку или ссылку из панели навигации, выполняется этот код, и Materialize правильно выводит подписи текстовых полей.
Привязка данных
---------------
Нам хотелось бы, используя компонент, загружать данные в пользовательский интерфейс и выгружать их из него. Сделать это очень просто, но, что интересно, в руководстве по Ember об этом ничего нет. В результате процедуры привязки данных в Ember выглядят сложнее, чем есть на самом деле.
Каждый фрагмент данных, с которым мы хотим работать, существует в виде поля класса `Component`. Зная это, мы можем использовать вспомогательные средства, которые позволяют отображать поля ввода для компонента и привязывать эти поля к переменным компонента. В результате можно взаимодействовать с данными напрямую, не задумываясь о работе с DOM.
В данном случае имеется три поля, поэтому нужно добавить в `app/components/roll-dice.js`, внутри блока определения компонента, три строки кода:
```
rollName: '',
numberOfDice: 1,
numberOfSides: 6,
```
Затем настроим шаблон на вывод этих данных, используя вспомогательные механизмы вместо обычной HTML-разметки. Для того, чтобы это сделать, нужно заменить теги на следующий код:
```
{{input placeholder="Name" id="roll\_name" class="validate" value=(mut rollName)}}
Name of Roll
{{input placeholder="Number of dice" id="number\_of\_dice" type="number" class="validate" value=(mut numberOfDice)}}
Number of Dice
{{input placeholder="Number of sides" id="number\_of\_sides" type="number" class="validate" value=(mut numberOfSides)}}
Number of Sides
```
Обратите внимание на то, что синтаксис атрибута `value` выглядит необычно. Подобные конструкции можно использовать для любых атрибутов тега, а не только для `value`. Вот три способа их использования:
* В виде строки, заключённой в кавычки. При таком подходе значение выводится в том виде, в котором оно представлено в коде.
* В виде строки без кавычек. В этом случае значение берётся из соответствующего фрагмента данных компонента, но элемент, выводящий данные, не влияет на компонент.
* В виде конструкции `(mut )`. Благодаря этому соответствующее значение берётся из компонента, и компонент меняется (mutate) при изменении значения в браузере.
Всё это значит, что теперь мы можем работать с тремя полями компонента так, как будто бы они являются значениями полей ввода, а всю остальную работу выполнят внутренние механизмы Ember.
Действия компонента
-------------------
Теперь мы хотим наладить взаимодействие с компонентом. В частности, нам хотелось бы обрабатывать событие нажатия на кнопку `Roll Dice`. В Ember подобное реализуется с помощью действий (Actions). Это — фрагменты кода компонента, которые можно подключать к шаблону. Действия — это функции, реализующие необходимую реакцию приложения, определённые в классе компонента, внутри специального поля, которое называется `actions`.
Сейчас мы просто собираемся сообщить пользователю о том, какие данные он ввёл в форму, но больше делать пока ничего не будем (этим займёмся ниже). Тут будет использоваться действие самой формы `OnSubmit`. Это означает, что действие будет вызвано, если пользователь щёлкнет по кнопке или нажмёт клавишу `Enter` в одном из полей ввода.
Вот фрагмент кода, относящийся к действиям, расположенный в файле шаблона `app/components/roll-dice.hbs`:
```
actions: {
triggerRoll() {
alert(`Rolling ${this.numberOfDice}D${this.numberOfSides} as "${this.rollName}"`);
return false;
}
}
```
Здесь мы возвращаем `false` для предотвращения [всплытия событий](https://www.sitepoint.com/event-bubbling-javascript/). Это — стандартный подход, применяемый в HTML-приложениях. Именно в такой ситуации это не даёт операции отправки формы перезагрузить страницу.
Можно заметить, что тут мы обращаемся к переменным, которые описали ранее и используем их для доступа к полям ввода. Работа с DOM здесь не применяется — всё, чем мы тут занимаемся — это просто взаимодействие с JS-переменными.
Теперь осталось лишь связать всё воедино. В файле шаблона нужно сообщить тегу формы о том, что ему нужно вызывать заданное действие при вызове события `onsubmit`. Это выражается в добавлении одного атрибута к тегу формы с использованием вспомогательного средства Ember для подключения формы к действию. В файле `app/templates/components/roll-dice.hbs` это выглядит так:
Теперь, заполнив поля формы, мы можем щёлкнуть по кнопке и увидеть всплывающее окно, отображающее те данные, которые были введены на форме.
Управление передачей данных между клиентом и сервером
-----------------------------------------------------
Теперь мы хотим, чтобы приложение всё-таки позволило «бросать» игральные кости. Эта операция подразумевает взаимодействие с сервером. Именно сервер ответственен за «броски» и за сохранение результатов. Вот какую последовательность действий мы собираемся реализовать:
* Пользователь задаёт параметры кости, которую он хочет «бросить».
* Пользователь нажимает на кнопку Roll Dice.
* Браузер отправляет данные, введённые пользователем, серверу.
* Сервер «бросает» кость, запоминает результат и отправляет результат клиенту.
* Браузер выводит результат «броска».
Выглядит не так уж и сложно, к тому же, Ember даёт простые и удобные средства для решения этих задач.
Ember позволяет реализовать вышеописанный сценарий с использованием встроенного хранилища (Store), заполняемого с использованием моделей (Models). Хранилище — это единственный источник истинной информации во всём приложении, а каждая модель (Model) представляет отдельный фрагмент информации, находящийся в хранилище. Модели содержат сведения о том, как сохранять свои данные на сервере, а хранилище знает как создавать модели и как с ними работать.
Передача управления от компонентов маршрутам
--------------------------------------------
Работая над приложением важно поддерживать разделение сфер ответственности его подсистем. Маршруты (и контроллеры, о которых мы не говорили), должны иметь доступ к хранилищу. Модели же такого доступа иметь не должны.
Причина такого разделения ответственности заключается в том, что маршрут представляет собой определённый фрагмент функциональности приложения, в то время как компонент — это лишь описание некоего фрагмента пользовательского интерфейса. Для того, чтобы с этим работать, у компонентов есть возможность передавать сигналы сущностям, расположенным выше в иерархии объектов, о том, что произошло некое событие. Это очень похоже на то, как компоненты DOM могут отправлять сообщения компонентам Ember о том, что что-то произошло.
Для того, чтобы передать управление маршруту, сначала переместим код, который занимается выводом окна сообщения, из кода компонента в код маршрута. Для того, чтобы это сделать, нужно изменить некоторые файлы.
В файл, ответственный за логику маршрута, а именно, в `app/routes/roll.js`, нужно добавить следующий блок, выполняющий регистрацию действия, которое мы собираемся выполнить.
```
actions: {
saveRoll: function(rollName, numberOfDice, numberOfSides) {
alert(`Rolling ${numberOfDice}D${numberOfSides} as "${rollName}"`);
}
}
```
В файле кода компонента, `app/components/roll-dice.js`, нам нужно вызвать обработчик действия при наступлении соответствующего события. Делается это с использованием средства `sendAction` в уже существующем обработчике действия:
```
triggerRoll() {
this.sendAction('roll', this.rollName, this.numberOfDice, this.numberOfSides);
return false;
}
```
И, наконец, нужно связать воедино то, что мы сделали в компоненте и в маршруте. Делается это в шаблоне маршрута — `app/templates/roll.hbs`. Тут надо изменить то, как выводится компонент:
```
{{roll-dice roll="saveRoll" }}
```
Эта конструкция сообщает компоненту, что свойство `roll` связано с действием `saveRoll` внутри маршрута. Это имя, `roll`, затем используется в компоненте для того, чтобы указать вызывающему объекту на то, что был выполнен «бросок» кости. Это имя имеет смысл для нашего компонента, так как он знает, что оно используется для запроса «броска» кости, но связанное с ним действие не заботится ни о работе другого кода, ни о судьбе переданной информации.
Проверив приложение мы, как уже бывало, не заметим разницы, но, если на данном этапе всё работает, это означает, что мы готовы продолжать.
Размещение данных в хранилище
-----------------------------
Прежде чем мы сможем поместить данные в хранилище, нам нужно описать модель, которая будет эти данные представлять. Делается это с помощью уже знакомого нам `ember-cli` путём создания структуры в файловой системе и последующего её заполнения.
Для того, чтобы создать класс модели, выполним следующую команду:
```
$ ember generate model roll
installing model
create app/models/roll.js
installing model-test
create tests/unit/models/roll-test.js
```
Затем сообщим модели об атрибутах, с которыми она должна работать. Для этого внесём изменения в файл `app/models/roll.js`:
```
import DS from 'ember-data';
export default DS.Model.extend({
rollName: DS.attr('string'),
numberOfDice: DS.attr('number'),
numberOfSides: DS.attr('number'),
result: DS.attr('number')
});
```
Вызовы `DS.attr` определяют новые атрибуты заданного типа. Среди поддерживаемых типов — `string`, `number`, `date` и `boolean`, хотя можно описать и собственные типы, если в этом возникнет необходимость.
Теперь мы можем всем этим воспользоваться для того, чтобы наконец «бросить» кость и сохранить результат. Делается это путём работы с хранилищем из действия, которое имеется в `app/routes/roll.js`:
```
saveRoll: function(rollName, numberOfDice, numberOfSides) {
let result = 0;
for (let i = 0; i < numberOfDice; ++i) {
result += 1 + (parseInt(Math.random() * numberOfSides));
}
const store = this.get('store');
// Запрашиваем у хранилища экземпляр модели "roll" с данными.
const roll = store.createRecord('roll', {
rollName,
numberOfDice,
numberOfSides,
result
});
// Этой командой сообщаем модели о том, чтобы она сохранила себя на сервере.
roll.save();
}
```
Если всё это испытать, можно отметить, что нажатие на кнопку `Roll Dice` вызывает сетевой запрос к серверу. Запрос этот, однако, даёт сбой, так как сервера у нас пока нет, но даже то, что уже сделано — большой шаг вперёд.
Этот материал посвящён Ember.js, вопросы организации серверной части приложения мы тут не обсуждаем. Если вам нужно разработать приложение на Ember.js вообще без серверной части, хранение данных можно организовать локально, например, с использованием [ember-localstorage-adapter](https://github.com/locks/ember-localstorage-adapter), который организует работу с данными исключительно средствами браузера. В противном случае можно просто написать подходящее серверное приложение. Если сервер и клиент будут правильно функционировать, приложение заработает.
Загрузка данных из хранилища
----------------------------
Теперь, когда в хранилище оказались какие-то данные, нам нужно извлечь их оттуда. В то же время, мы собираемся создать маршрут `index` — он используется для работы с домашней страницей.
В Ember есть встроенный маршрут, `index`, который используется для вывода первой страницы приложения. Если файлы для этого маршрута не существуют, система не выдаст сообщение об ошибке, однако, и на экран ничего выведено не будет. Мы собираемся использовать этот маршрут для вывода истории «бросков» костей из хранилища.
Так как маршрут `index` уже существует, для его подготовки нет нужды использовать `ember-cli`. Достаточно просто создать необходимые файлы и система использует их для этого маршрута.
Обработчик маршрута будет находиться в файле `app/routes/index.js`, в котором надо разместить следующий код:
```
import Ember from 'ember';
export default Ember.Route.extend({
model() {
return this.get('store').findAll('roll');
}
});
```
Код маршрута обладает непосредственным доступом к хранилищу и может использовать метод `findAll` для загрузки данных обо всех сохранённых результатах «бросков» костей. Затем мы передаём эти данные в шаблон, используя метод `model`.
Шаблон маршрута index опишем в файле `app/templates/index.hbs`:
```
| Name | Dice Rolled | Result |
| --- | --- | --- |
{{#each model as |roll|}}
| {{roll.rollName}} | {{roll.numberOfDice}}D{{roll.numberOfSides}} | {{roll.result}} |
{{/each}}
{{outlet}}
```
Этот код обеспечивает прямой доступ к модели непосредственно из маршрута, а затем перебирает набор данных и генерирует строки таблицы. В итоге у нас получилась такая страница с результатами предыдущих «бросков»:
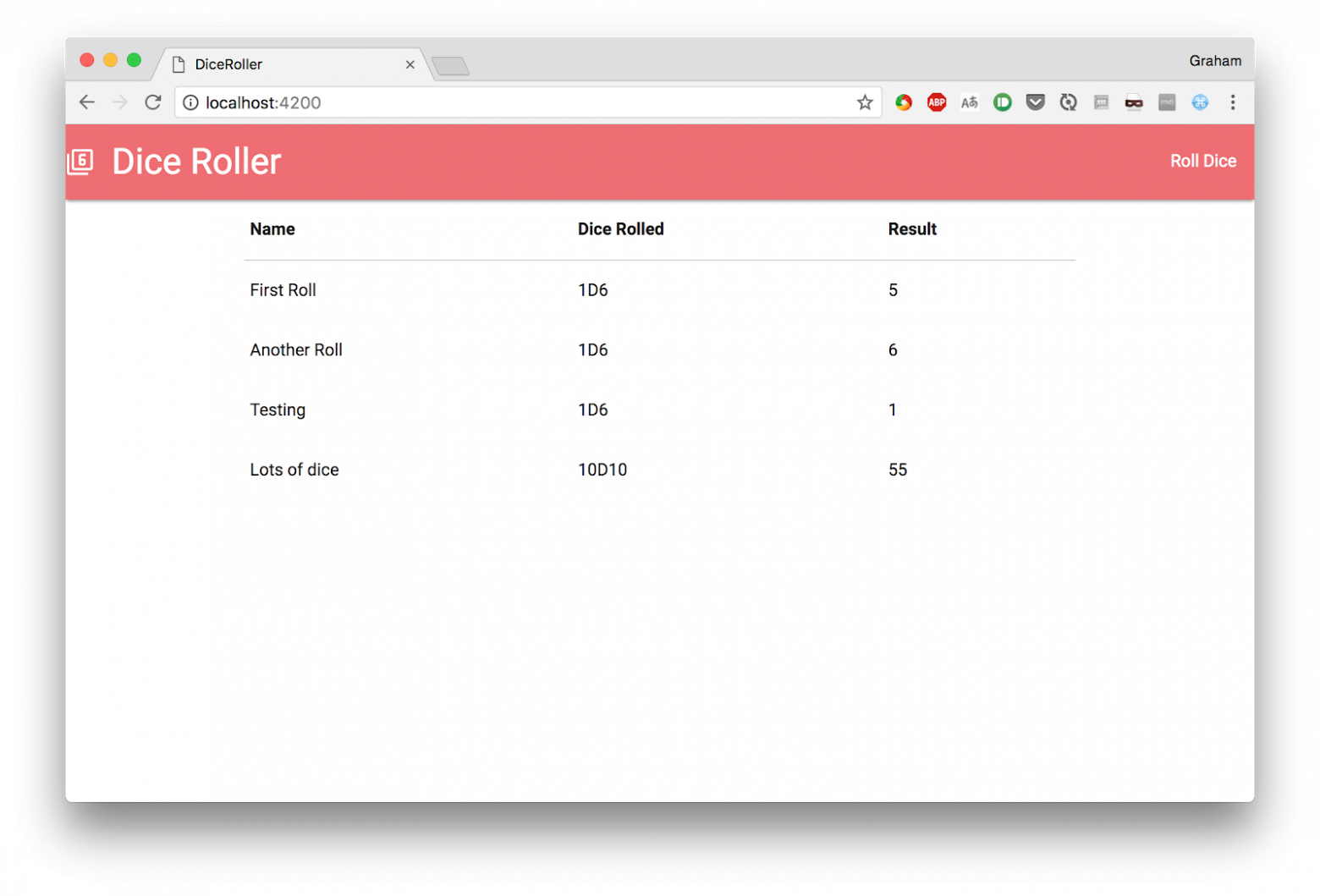
Итоги
-----
К этому моменту, приложив не так уж и много усилий, мы разработали приложение, которое позволяет задавать параметры костей, «бросать» эти кости и просматривать историю бросков. В ходе работы мы пользовались такими методами, как привязка данных, запись данных в хранилище и их чтение, вывод страниц с использованием шаблонов и использование маршрутов для организации навигации. Это приложение можно создать с нуля меньше чем за час.
Использование Ember может значительно повысить эффективность разработки фронтенда. В отличие от библиотек, таких, как React, Ember даёт целостную инструментальную среду, которая предназначена для разработки полнофункционального приложения без необходимости применения каких-либо дополнительных средств. Наличие `ember-cli` и предварительной настройки проекта — это очень удобно, это упрощает процесс разработки и сокращает количество ошибок на всех этапах работы. Если добавить сюда [поддержку сообщества](https://www.emberjs.com/community/), то окажется, что на Ember можно сделать всё, что угодно.
К сожалению интеграция Ember в существующий проект может оказаться непростой или попросту невозможной задачей. Лучше всего, если Ember используется с самого начала работы над новым проектом. Кроме того, что называется, «из коробки», Ember весьма своеобразно работает с серверной частью приложения. Если существующий сервер не соответствует модели Ember, разработчик может потратить очень много времени и усилий на то, чтобы либо переработать бэкенд, либо найти (или написать) плагины, которые позволят работать с тем, что есть.
Ember — мощный фреймворк, он позволяет очень быстро создавать полнофункциональные клиентские части веб-приложений. Он накладывает множество требований к структуре кода проекта, но часто на практике эти требования оказываются не такими уж и жёсткими, как может показаться на первый взгляд, так как, в любом случае, код приходится структурировать.
Уважаемые читатели! Пользуетесь ли вы Ember.js? | https://habr.com/ru/post/341076/ | null | ru | null |
# 16 советов по разработке для андроид на языке Kotlin. Часть 3
*И еще раз здравствуйте! В преддверии старта [базового курса по Android-разработке](https://otus.pw/kbuv/), делимся заключительной частью статьи «16 советов по разработке для андроид на языке Kotlin».*

---
[Читать первую часть](https://habr.com/ru/company/otus/blog/479406/)
[Читать вторую часть](https://habr.com/ru/company/otus/blog/480534/)
### LATEINIT
Одной из ведущих особенностей Kotlin является его приверженность нулевой безопасности. Оператор lateinit предоставляет простой способ обеспечить нулевую безопасность и инициализировать переменную так, как этого требует Android. Эта функция прекрасна, тем не менее, к ней следует привыкнуть после работы на Java. Одна из идей заключается в том, что поле сразу объявляется с возможностью быть нулевым:
```
var total = 0
var toolbar: Toolbar? = null
```
Эта языковая функция может вызвать сложности при работе с макетами Android, потому что мы не знаем как объявить представления, до того как макет объявлен, потому что неясно где они будут существовать, в `Activity` или `Fragment`. Это компенсируется при помощи дополнительных проверок на возможность нулевого значения в каждом месте, с которым мы взаимодействуем, но этот тот ещё геморрой. Поэтому лучше использовать модификатор `lateinit`:
```
lateinit var toolbar: Toolbar
```
Теперь вы, как разработчик, не должны ссылаться на Toolbar, пока она не будет фактически инициализирована. Это прекрасно работает, когда используется вместе библиотекой, например [Butter Knife](https://github.com/JakeWharton/butterknife):
```
@BindView(R.id.toolbar) lateinit var toolbar: Toolbar
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
ButterKnife.bind(this)
// теперь можно без проблем обращаться к toolbar
toolbar.setTitle("Hello There")
}
```
### Безопасность типов
Некоторые соглашения Android требуют безопасной типизации, потому что обычная типизация не исключает ошибки кода. Например, типичный способ создания фрагмента в действии предполагает проверку через FragmentManager на исключение того, что он уже существует. И только если это не так, вы создадите его и добавите в действие. При первом взгляде на типизацию в Kotlin вы можете реализовать это следующим образом:
```
var feedFragment: FeedFragment? = supportFragmentManager
.findFragmentByTag(TAG_FEED_FRAGMENT) as FeedFragment
но это может привести к сбою. Оператор as получит объект с нулевым значением, которое в данном случае исключено.
Правильный вариант такой:
var feedFragment: FeedFragment? = supportFragmentManager
.findFragmentByTag(TAG_FEED_FRAGMENT) as? FeedFragment
if (feedFragment == null) {
feedFragment = FeedFragment.newInstance()
supportFragmentManager.beginTransaction()
.replace(R.id.root_fragment, feedFragment, TAG_FEED_FRAGMENT)
.commit()
}
```
### LEVERAGING LET
Leveraging let позволяет вам выполнить блок, если значение объекта не равно нулю. Это позволяет вам избегать нулевых проверок и делает код более читабельным. В Java это выглядит так:
```
if (currentUser != null) {
text.setText(currentUser.name)
}
А в Kotlin это выглядит так:
user?.let {
println(it.name)
}
```
Этот код намного более удобный для чтения плюс автоматически создает переменную с ненулевым значением без опасности её обнуления.
### SNULLOREMPTY | ISNULLORBLANK
Мы должны проверять поля много раз на протяжении разработки приложения для Android. Если вы справились с этим без использования Kotlin, возможно, вы знаете про класс TextUtils в Android. Класс TextUtils выглядит следующим образом:
```
if (TextUtils.isEmpty(name)) {
// тут информируем пользователя
}
```
В этом примере вы можно заметить, что пользователь может установить в качестве имени пользователя даже просто пробелы, и он пройдет проверку. `isNullOrEmpty` и `isNullOrBlank` встроены в язык Kotlin, устраняют необходимость в `TextUtils.isEmpty` (`someString`) и обеспечивают дополнительное преимущество проверки только пробелов. Вы можете использовать при необходимости что-то типа такого:
```
// Если нам не важны пробелы в имени...
if (number.isNullOrEmpty()) {
// Просим пользователя ввести имя
}
//если пробелы критичны...
if (name.isNullOrBlank()) {
// Просим пользователя ввести имя
}
```
Проверка правильности заполнения полей часто встречается при необходимости регистрации в приложении. Эти встроенные методы отлично подходят для проверки поля и оповещения пользователя, если что-то не так. Для более сложных проверок можно использовать методы расширения, например, для адресов электронной почты:
```
fun TextInputLayout.isValidForEmail(): Boolean {
val input = editText?.text.toString()
if (input.isNullOrBlank()) {
error = resources.getString(R.string.required)
return false
} else if (emailPattern.matcher(input).matches()) {
error = resources.getString(R.string.invalid_email)
return false
} else {
error = null
return true
}
}
```
### Советы для продвинутых
Вы знали, что для создания более чистого и лаконичного кода можете использовать лямбда-выражения?
Например, при работе в Java типично иметь простой класс прослушивателя, такой как:
```
public interface OnClickListener {
void onClick(View v);
}
```
Отличительной особенностью Kotlin является то, что он выполняет преобразования SAM (Single Abstract Method) для классов Java. Слухач кликов в Java, который выглядит как:
```
textView.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
// что-то делаем
}
});
В Kotlin он может быть сокращён до:
textView.setOnClickListener { view ->
// что-то делаем
}
```
Как ни странно, такое преобразование невозможно для интерфейсов SAM, созданных в Kotlin. Это может удивить и даже немного разочаровать новых пользователей Kotlin. Если бы тот же самый интерфейс определен в Kotlin, слухач выглядит примерно так:
```
view.setOnClickListener(object : OnClickListener {
override fun onClick(v: View?) {
// что-то делаем
}
})
```
Чтобы сократить такой код, можно записать своих слухачей в класс следующим образом:
```
private var onClickListener: ((View) -> Unit)? = null
fun setOnClickListener(listener: (view: View) -> Unit) {
onClickListener = listener
}
// обращаемся у ним позже
onClickListener?.invoke(this)
```
Это вернет вас к простому лямбда-синтаксису, который делает возможным автоматическое преобразование SAM.
### Заключение
Я собрал самые полезные лайфхаки из всего, что узнал с тех пор как начал интересоваться языком Kotlin. Надеюсь, знание этих советов существенно поможет вам в разработке собственных проектов.
На этом все. До встречи на [курсе](https://otus.pw/kbuv/)! | https://habr.com/ru/post/481010/ | null | ru | null |
# Создание адаптивных изображений
В Интернете найдется немало статей, посвященных адаптивным логотипам. Наиболее популярным примером является сайт [Responsive Logos](http://responsivelogos.co.uk), который показывает различные варианты известных логотипов для разных размеров экрана. Когда я впервые увидел это, я подумал, что это не более, чем просто ловкий трюк. В конце концов, это просто `div` для спрайта большого изображения в качестве фона. Так было до того момента, пока я не услышал доклад на Smashing Conference от [MikeRiethmuller](https://twitter.com/MikeRiethmuller) под названием «[За пределами медиазапросов](https://vimeo.com/235428198)». Кроме того, я настоятельно рекомендую прочитать его же статью «[Большой потенциал SVG](https://www.madebymike.com.au/writing/svg-has-more-potential)».
[](https://habr.com/company/poiskvps/blog/429116#habracut)
Я узнал две вещи, которые меня потрясли:
1. При использовании SVG вы можете отказаться от атрибута `viewBox` и установить новую систему координат на вложенных элементах SVG путем применения нового `viewBox`. (Да, я знаю. Это звучит странно. Ниже я объясню все более подробно).
2. Когда вы используете медиазапросы внутри SVG-файлов, а затем вставляете изображение через тег img или в качестве фонового изображения CSS, медиазапросы привязаны к ширине изображения. Практически такое же поведение, как и при использовании [контейнерных запросов](https://alistapart.com/article/container-queries-once-more-unto-the-breach).
### Рождение идеи
После того, как я прочитал обо всем этом, у меня возникла идея создать логотип для нашей компании, который бы не только реагировал на ширину браузера, но и мог бы пропорционально изменяться. Тем самым его можно было бы использовать повсеместно, и сам файл выбирал бы какую версию показывать в зависимости от заданных размеров.
#### Итоговый результат
Если вы заинтересовались, то загрузите последнее [демо](https://www.ichimnetz.com/responsive-logo/9e-anywhere.svg) или посмотрите его на [CodePen](https://codepen.io/enbee81/full/QrNRdm).

### Шаг за шагом
Далее я собираюсь показать вам каждый шаг, который необходимо выполнить, чтобы создать свой собственный адаптивный логотип. Вы должны обладать базовыми знаниями о SVG, а также CSS. Но есть и хорошая новость: JavaScript вообще не понадобится. По большому счету, нам просто нужно будет скопировать код из одного файла в другой.
### 1. Разработка логотипа
Начнем с разработки четырех версий нашего логотипа. Я выбрал для этого [Sketch](https://www.sketchapp.com).

Варианты логотипа: вертикальный — портрет — квадрат — горизонтальный
Всякий раз, когда есть элементы, которые можно найти в нескольких версиях, я рекомендую использовать символы в редакторе Sketch. Это облегчит работу в дальнейшем, т.к. в графике SVG будут использоваться те же самые символы (Если вы еще не знакомы с символами в редакторе Sketch, то я настоятельно рекомендую [статью](https://medium.com/ux-power-tools/this-is-without-a-doubt-the-coolest-sketch-technique-youll-see-all-day-ddefa65ea959) от [Джона Мура](https://medium.com/@jon.moore)).
Как видите, логотип состоит из визуального элемента и названия компании. Только в квадратной версии я решил не использовать название компании. Это было сделано по той причине, что я хотел сделать логотип различимым, даже когда он будет использоваться как крошечная миниатюра размерами 32px на 32px.
### 2. Настройка SVG-файла
Прежде чем экспортировать изображения, мы должны создать новый SVG-файл. Может быть вас несколько испугает необходимость создать SVG-файл с написания кода, но, в конце концов, ничего сложного тут нет. Обещаю. Нам нужно только открыть и закрыть тег:
```
```
Если вы посмотрите на атрибуты, то заметите, что атрибут `viewBox` отсутствует. Мы только устанавливаем 100% ширину и высоту.
(*Примечание. Есть также два атрибута xmlns. Если честно, я точно не знаю, почему их необходимо использовать, надо бы загуглить… в любом случае, если их удалить, то нельзя будет использовать какие-либо символы в SVG, и вместо них вы будете получать сообщения об ошибках*).
### 3. Экспорт SVG-символов
Поскольку мы будем использовать оба элемента в качестве символов в финальном SVG, мы должны поместить каждый из них в свою область и экспортировать как SVG.

Поместим все символы в отдельные области перед экспортом в SVG
Крайне важно, чтобы вы не экспортировали объекты, а всегда создавали новую область редактирования. Если вы экспортируете элементы из более крупной области редактирования, то получите странные параметры преобразования, прикрепленные к вашим группам. Это также помогает отделить все символы и удалить все неиспользуемые группы. Наконец, подберите подходящее наименование.
**Смотрите, как выглядит экспортированный код**
```
xml version="1.0" encoding="UTF-8"?
ix
Created with Sketch.
```
Я бы рекомендовал использовать что-то вроде [SVGOMG](https://jakearchibald.github.io/svgomg), чтобы уменьшить размер файла и удалить все ненужные вещи. Но не удаляйте ID. Если вы как-то обозначили слои в Sketch, то сможете их идентифицировать по ID в конечном файле.
**Вот как будет выглядеть ваш оптимизированный файл**
```
```
Если все правильно, то вы увидите группу, которая имеет имя области редактирования в качестве ID. Нас интересует контент внутри этой группы. В данном примере это прямоугольник, который служит фоном и образованная сложным путем цифра IX (римская цифра 9 вращается против часовой стрелки на 90 градусов… поясняю на всякий случай).
### 4. Построение символов
Все наши файлы готовы и могут быть собраны вместе. Начнем с написания тэгов некоторых символов в конечном файле и укажем для каждого символа уникальный ID, так же, как и атрибут viewBox, который соответствует viewBox экспортируемых файлов.
```
```
Наконец, вставим содержимое экспортируемых файлов (внутри группы, названной как область редактирования) внутрь тегов символов.
**Когда это будет сделано, файл должен выглядеть следующим образом**
```
```
### 5. Использование символов
Все идет по плану. К сожалению, если вы откроете файл в браузере, вы ничего не увидите. На данный момент мы определили символы, но еще нигде их не разместили. Чтобы вставить символ, нужно использовать в файле тег `use`:
Давайте посмотрим, что именно происходит.
Во-первых, `xlink: href` указывает на символ с уникальным ID и будет отображать его содержимое… точнее, не реально отображать, а клонировать, и внезапно появляется странная вещь под названием **Shadow DOM**. Это звучит несколько странно, но не стоит бояться. До тех пор, пока вы не захотите что-нибудь поменять внутри символов через CSS, вам не о чем беспокоиться.
Также у нас есть атрибуты **x**, **y**, **width** и **height**. Думаю, вы уже догадались, что эти атрибуты определяют положение и размеры отображаемого символа. Но не указана единица измерения, насколько большой будет наш символ? Внутри SVG единицы измерения определяются атрибутом `viewBox`, установленным в теге SVG. Поскольку мы не установили `viewBox`, а только определили ширину и высоту (100%), то единица измерения соответствует одному пикселю и наш символ будет в ширину 100 пикселей. И неважно, измените ли вы ширину в SVG. Символ всегда будет иметь ширину 100 пикселей.
Попробуйте изменить атрибуты width и height в [CodePen](https://codepen.io/enbee81/pen/BxKrdb). Вы заметите, что символ всегда будет соответствовать коэффициенту пропорциональности. К счастью, именно это нужно для нашего логотипа. Если вы хотите изменить поведение при изменении размера, вам нужен атрибут под названием `preserveAspectRatio`. Познакомьтесь со статьей [SaraSoueidan](https://twitter.com/SaraSoueidan) о [Системе координат и ее трансформации в SVG](https://www.sarasoueidan.com/blog/svg-coordinate-systems), если хотите узнать больше.
Помимо безразмерных значений, вы также можете использовать процентные для определения позиции и размеров объекта. Чтобы символ выглядел как квадрат, просто используйте ширину 90% и расположите его верхний левый угол в 5% от ограничивающей изображение рамки:
(*Может быть, вы думаете, что автонастройка ширины или высоты — хорошая идея… но это не так. Safari и Firefox просто игнорируют ее, а Chrome ничего не отрисует*)
### 6. Объединение символов внутри нового символа
Для портретной версии нам нужны оба символа. Чтобы убедиться, что они масштабируются пропорционально и всегда расположены на одинаковом расстоянии от границ и по отношению друг к другу, мы просто создаем еще один символ. Этот символ имеет свой собственный атрибут viewBox, который позволяет разместить наши символы в новой системе координат. Чтобы понять, где именно символы должны быть размещены, можете просто вернуться в свой файл и проверить размеры и расстояния.

Портретная версия: Purple: viewBox — Red: Position — Turquoise: Width and Height
Теперь нам нужно перевести все числа в новый символ SVG, который будет выглядеть следующим образом:
```
```
Когда мы используем этот символ, мы не хотим, чтобы его ширина была 100%, поэтому просто масштабируем его как квадрат.
### 7. Скрыть и показать
**Мы создали три символа и использовали два тега use в SVG**
```
```
Наконец, начинается интересная часть, когда мы можем сделать изображение отзывчивым. Сейчас оба символа визуализируются поверх друг друга. Чтобы скрыть части, которые мы не хотим отображать, необходимо добавить некоторые классы в тег `use`.
```
```
Единственное, чего теперь не хватает — это CSS, чтобы показывать только одну версию логотипа в каждый момент времени. Вы можете добавить тег `style` в SVG и использовать медиа-запросы точно так же, как и в обычном файле CSS.
В CSS вы, скорее всего, используете что-то вроде `@media (min-width: 768px) {...}`, но тогда вы рассматриваете только ширину изображения. Мы же заинтересованы в пропорциональности, а не в ширине, поэтому наши медиа-запросы должны выглядеть следующим образом: `@media (min-aspect ratio: 1/2) {...}`.
Для наших первых двух версий по умолчанию сделаем портретную версию и покажем IX-версию только тогда, когда ширина изображения будет такой же, как и высота. Другими словами, в момент, когда изображение меняется с портретного формата на горизонтальное, мы не будем показывать типографию, а только графический логотип.
```
.square { visibility: hidden; }
.portrait { visibility: visible; }
@media (min-aspect-ratio: 1/1) {
.square { visibility: visible; }
.portrait { visibility: hidden; }
}
```
Если вы создадите еще один символ для горизонтальной версии, то, вероятно, захотите продемонстрировать его при условии, что ширина изображения будет как минимум в два раза больше высоты. Посмотрим, как изменится стиль:
```
.square,
.landscape { visibility: hidden; }
.portrait { visibility: visible; }
@media (min-aspect-ratio: 1/1) {
.portrait,
.landscape { visibility: hidden; }
.square { visibility: visible; }
}
@media (min-aspect-ratio: 2/1) {
.portrait,
.square { visibility: hidden; }
.landscape { visibility: visible; }
}
```
Вот и все. Мы закончили создание собственного адаптивного логотипа в формате SVG.
**Вот полный код с тремя версиями, начиная с портретного и заканчивая горизонтальным**
```
.square,
.landscape { visibility: hidden; }
.portrait { visibility: visible; }
@media (min-aspect-ratio: 1/1) {
.portrait,
.landscape { visibility: hidden; }
.square { visibility: visible; }
}
@media (min-aspect-ratio: 2/1) {
.portrait,
.square { visibility: hidden; }
.landscape { visibility: visible; }
}
```
### 8. Немного о трансформации
Да, я знаю, что вертикальная версия отсутствует в приведенном выше примере. Причина в том, что потребуется выполнить некоторое преобразование, чтобы создать необходимый символ. Я не буду вдаваться в детали, просто дам вам необходимый код:
```
```
Я надеюсь, что все это было полезно и я, конечно, был бы рад увидеть ваши результаты.
> [](https://vps.today/)
>
> Заглядывайте на [VPS.today](https://vps.today/) — сайт для поиска виртуальных серверов. 1500 тарифов от 130 хостеров, удобный интерфейс и большое число критериев для поиска самого лучшего виртуального сервера.
>
>
>
> [](https://vps.today/) | https://habr.com/ru/post/429116/ | null | ru | null |
# Flutter 3.3 — Что нового во Flutter
Статья представляет из себя композицию нескольких авторских переводов статей, по причине собрать всю важную информацию в одной статье, ссылки на оригинальные материалы будут даны в конце статьи.
Кратко об анонсе
----------------
**Flutter** обработал 5687 пул-реквестов в преддверии новой версии Flutter 3.3, добавив больше виджетов Material & Dart, новый доступный рендер-движок Impeller для ускорения работы приложения и многие другие изменения, которые повышают производительность. В этом обновлении также представлены 3 новых компонента материального дизайна и поддержка ~~каракулей~~ рукописного ввода без каких-либо дополнительных действий для пользователей iPad, группировка текста на выбор, Dart 2.18, включая поддержку FFI для библиотек и кода, написанного на Swift и Objective-C. Ниже собраны основные события, нововведения и изменения как в структуре самого фреймворка и языка, так и в жизни сообщества. Добро пожаловать под каст!
Анонс Flutter 3.3 на Flutter Vikings
------------------------------------
Привет из прекрасной норвежской столицы Осло, где члены сообщества Flutter собираются на [конференцию Flutter Vikings](https://fluttervikings.com/) . Flutter Vikings — это двухдневное мероприятие для разработчиков, организованное сообществом, с тремя треками контента от экспертов, которые путешествовали со всего мира. На данный момент зарегистрировалось более пяти тысяч разработчиков, и пока билеты на очное мероприятие распроданы, можно [бесплатно посмотреть все сессии онлайн](https://www.youtube.com/playlist?list=PL4dBIh1xps-EWXK28Qn9kiLK9-eXyqKLX) .
Flutter продолжает расти как по количеству пользователей, так и по размеру экосистемы. **Каждый день более 1000 новых мобильных приложений, использующих Flutter, публикуются** в магазинах Apple и Google Play, а также все чаще используются в Интернете и на ПК. Экосистема пакетов Flutter [теперь включает более 25 000 пакетов](https://pub.dev/packages?q=sdk%3Aflutter) , что является еще одним свидетельством зрелости и широты охвата.
Фреймворк
---------
### Глобальный выбор (Global Selection)
До сих пор веб-приложения Flutter не соответствовали ожидаемому поведению при попытке выделить текст. Как и приложения Flutter, нативные веб-приложения состоят из дерева элементов. В традиционном веб-приложении вы можете выбрать несколько веб-элементов одним широким жестом, что нелегко сделать в веб-приложении Flutter.
С введением `SelectableArea`виджета любой дочерний `SelectableArea`элемент виджета получил возможность свободного выделения текста.
")Глобальный выбор (Global Selection)Чтобы воспользоваться преимуществами этой мощной новой функции, просто оберните тело маршрута (например, `Scaffold`) `SelectionArea`виджетом и позвольте Flutter сделать все остальное.
Для более подробного изучения этой замечательной новой функции посетите страницу `SelectableArea`[API](https://api.flutter.dev/flutter/material/SelectionArea-class.html) .
### Ввод с трекпада
Flutter 3.3 обеспечивает улучшенную поддержку ввода с помощью трекпада. Это не только обеспечивает более функциональный и плавный контроль, но, в некоторых случаях, также уменьшает количество неверных интерпретаций. Для проверки такой неверной интерпретации проверьте [Drag a UI element](https://docs.flutter.dev/cookbook/effects/drag-a-widget) в [Flutter cookbook](https://docs.flutter.dev/cookbook). Прокрутите страницу вниз, чтобы перейти к экземпляру DartPad, и выполните следующие действия:
1. Уменьшите размер окна, чтобы в верхней части была полоса прокрутки.
2. Наведите курсор на верхнюю часть
3. Используйте трекпад для прокрутки
4. До установки Flutter 3.3 прокрутка на трекпаде перетаскивала элемент, потому что Flutter отправлял эмулированные общие события.
5. После установки Flutter 3.3 прокрутка на трекпаде правильно прокручивает список, потому что Flutter обеспечивает жест «прокрутки», который не распознается карточками, но *распознается* прокруткой.
Перетаскивание элемента из прокручиваемого списка
Для получения дополнительной информации см. документ по дизайну [Flutter Trackpad Gesture](https://docs.google.com/document/d/1oRvebwjpsC3KlxN1gOYnEdxtNpQDYpPtUFAkmTUe-K8/edit?resourcekey=0-pt4_T7uggSTrsq2gWeGsYQ) и следующие PR на GitHub:
* PR 89944: [Поддержка жестов трекпада в фреймворке .](https://github.com/flutter/flutter/pull/89944)
* PR 31591: [жесты трекпада iPad](https://github.com/flutter/engine/pull/31591)
* PR 34060: [повторная посадка «Жесты трекпада ChromeOS/Android»](https://github.com/flutter/engine/pull/34060)
* PR 31594: [жесты трекпада Win32](https://github.com/flutter/engine/pull/31594)
* PR 31592: [жесты трекпада Linux](https://github.com/flutter/engine/pull/31592)
* PR 31593: [жесты трекпада MacOS](https://github.com/flutter/engine/pull/31593)
### Рукописный ввод
Благодаря замечательному вкладу члена сообщества [fbcouch](https://github.com/fbcouch) , Flutter теперь поддерживает рукописный ввод [Scribble](https://support.apple.com/guide/ipad/enter-text-with-scribble-ipad355ab2a7/ipados) с помощью Apple Pencil на iPadOS. Эта функция включена по умолчанию в `CupertinoTextField`, `TextField`и `EditableText`. Чтобы включить эту функцию для ваших конечных пользователей, просто обновите ее до Flutter 3.3.
Рукописный ввод Scribble### Ввод текста
Для улучшения поддержки редактирования форматированного текста в этом выпуске появилась возможность получать детализированные текстовые обновления из файла `TextInputPlugin`. Раньше `TextInputClient`доставлялось только новое состояние редактирования без разницы между старым и новым `TextEditingDeltas`и `DeltaTextInputClient`заполняло этот информационный пробел. Теперь, имея доступ к этим дельтам, вы можете создать поле ввода со стилизованными диапазонами, которые расширяются и сужаются по мере ввода. Чтобы узнать больше, ознакомьтесь с [демонстрацией Rich Text Editor](https://flutter.github.io/samples/rich_text_editor.html) .
Rich Text Editor .Материальный дизайн 3
---------------------
Команда Flutter продолжает переносить больше компонентов Material Design 3 во Flutter. Этот выпуск включает обновления для `IconButton`, `Chips`, а также большие и средние варианты для `AppBar`.
Чтобы проследить за ходом миграции Material Design 3, ознакомьтесь с [Bring Material 3 to Flutter](https://github.com/flutter/flutter/issues/91605) .
### Иконки (Flutter Icon)
Flutter IconЧипы (Flutter Chip)
-------------------
Flutter Chip### AppBar среднего и большого размера
Десктоп
-------
### Windows
Ранее, представление версии настольно приложения Windows отличалось от других платформ. Версия Windows приложения представлялась в виде файла, имеющего специфику приложения Windows.
Версии настольных приложений Windows теперь можно задавать из `pubspec.yaml`файла проектов и аргументов сборки. Это упрощает включение автоматических обновлений для конечных пользователей, чтобы они могли получать самые последние и лучшие обновления.
Для получения дополнительной информации о настройке версии ваших приложений следуйте документации на [docs.flutter.dev](https://docs.flutter.dev/deployment/windows#updating-the-apps-version-number) и [руководству по миграции](https://docs.flutter.dev/development/platform-integration/windows/version-migration) . Проекты, созданные до Flutter 3.3, необходимо обновить, чтобы получить эту функцию.
Пакеты
------
### go\_router
Разработка приложения со сложной системой навигации сама по себе сложна. Чтобы расширить собственный API навигации Flutter, команда опубликовала [новую версию](https://pub.dev/packages/go_router) `go_router`пакета, упрощающую разработку логики маршрутизации, которая работает на мобильных устройствах, десктопе и веб.
Пакет `go_router`, поддерживаемый командой Flutter, упрощает маршрутизацию, предоставляя декларативный API на основе URL-адресов, облегчая навигацию и обработку глубоких ссылок. Последняя версия (4.3) позволяет приложениям выполнять перенаправление с использованием асинхронного кода и включает другие критические изменения, описанные в [руководстве по миграции](https://docs.google.com/document/d/10l22o4ml4Ss83UyzqUC8_xYOv_QjZEi80lJDNE4q7wM/edit?usp=sharing&resourcekey=0-U-BXBQzNfkk4v241Ow-vZg) .
Для получения дополнительной информации посетите страницу [навигации и маршрутизации](https://docs.flutter.dev/development/ui/navigation) на docs.flutter.dev.
Усовершенствования расширения VS Code
-------------------------------------
Расширение Visual Studio Code для Flutter имеет несколько обновлений, включая улучшения для добавления зависимостей. Теперь вы можете добавить несколько зависимостей, разделенных запятыми, за один шаг, используя **Dart: Add Dependency** .
Усовершенствования расширения VS CodeВы можете прочитать об улучшениях расширения Visual Studio Code, сделанных после выхода последней стабильной версии Flutter, по ссылкам:
* [Расширения кода VS v3.46](https://groups.google.com/g/flutter-announce/c/u1iSDMtKMVg)
* [Расширения кода VS v3.44](https://groups.google.com/g/flutter-announce/c/x4m9o93-Dng)
* [Расширения кода VS v3.42](https://groups.google.com/g/flutter-announce/c/45Wsk5pISx4)
Обновления Flutter DevTools
---------------------------
DevTools поставляется с рядом обновлений с момента последней стабильной версии Flutter, включая улучшения пользовательского интерфейса и производительности таблиц отображения данных для более быстрой и менее дрожащей прокруткой больших списков событий ( [#4175](https://github.com/flutter/devtools/pull/4175) ).
Полный список обновлений, начиная с Flutter 3.0, можно найти здесь:
* [Примечания к выпуску Flutter DevTools 2.16.0](https://docs.flutter.dev/development/tools/devtools/release-notes/release-notes-2.16.0)
* [Примечания к выпуску Flutter DevTools 2.15.0](https://docs.flutter.dev/development/tools/devtools/release-notes/release-notes-2.15.0)
* [Примечания к выпуску Flutter DevTools 2.14.0](https://docs.flutter.dev/development/tools/devtools/release-notes/release-notes-2.14.0)
Производительность
------------------
Этот выпуск повышает производительность загрузки изображений из ресурсов за счет устранения копий и уменьшения нагрузки на сборку мусора (GC) Dart. Раньше при загрузке изображений из assets `ImageProvider`API требовал многократного копирования сжатых данных. Вначале это копировалось в нативную кучу, потом открывалась assets и предоставляла Дарту данные в виде типизированного массива. Затем это копировалось во второй раз, когда этот типизированный массив данных копировался во внутреннюю память файла `ui.ImmutableBuffer`.
С [добавлением](https://github.com/flutter/engine/pull/32999) байты сжатого изображения `ui.ImmutableBuffer.fromAsset`могут быть загружены непосредственно в структуру, используемую для декодирования. Этот подход [требует изменений](https://github.com/flutter/flutter/pull/103496) в конвейере загрузки байтов `ImageProviders`. Этот процесс также быстрее, потому что он обходит некоторые дополнительные накладные расходы планирования, необходимые для загрузчика на основе канала предыдущего метода. В частности, в микробенчмарках разработчиков время загрузки изображений сократилось почти в 2 раза.
 и новое (ниже) время загрузки изображений.")Прежнее (выше) и новое (ниже) время загрузки изображений.Дополнительные сведения и руководство по миграции см. в разделе [Добавление ImageProvider.loadBuffer](https://docs.flutter.dev/release/breaking-changes/image-provider-load-buffer) на docs.flutter.dev.
Стабильность
------------
### Отключено сжатие указателей в iOS
В стабильной версии 2.10 разработчики включили [оптимизацию сжатия указателей](https://medium.com/dartlang/dart-2-15-7e7a598e508a#0c15) Dart на iOS. Однако [Yeatse](https://github.com/Yeatse) на GitHub [предупредил](https://github.com/flutter/flutter/issues/105183) о непредвиденных последствиях оптимизации. Сжатие указателя Dart работает за счет резервирования большой области виртуальной памяти для кучи Dart. Поскольку общее выделение виртуальной памяти, разрешенное на iOS, меньше, чем на других платформах, это большое резервирование уменьшает объем памяти, доступной для использования другими компонентами, которые резервируют собственную память, например, плагинами Flutter.
Хотя отключение сжатия указателя увеличивает объем памяти, потребляемой объектами Dart, он также увеличивает объем памяти, *доступный* для не-Dart частей приложения Flutter, что в целом более желательно.
Apple предоставляет возможность, которая поможет увеличить максимально допустимое выделение виртуальной памяти для приложения, однако эта возможность поддерживается только в более новых версиях iOS и не будет работать на устройствах с версиями iOS, которые по-прежнему поддерживает Flutter. Когда получится использовать эту возможность повсеместно, разработчики планируют вернуться к этой оптимизации.
Улучшения API
-------------
### PlatformDispatcher.onError
В предыдущих выпусках приходилось вручную настраивать пользовательские настройки `Zone`, чтобы перехватывать все исключения и ошибки приложения. Однако пользовательские настройки `Zone` мешали ряду оптимизаций в основных библиотеках Dart, что замедляло время запуска приложения. **В этом выпуске вместо использования пользовательского**`Zone`**, следует перехватывать все ошибки и исключения, устанавливая колбэк**`PlatformDispatcher.onError`**.**Для получения дополнительной информации ознакомьтесь с обновленной страницей [обработки ошибок во Flutter](https://docs.flutter.dev/testing/errors) на docs.flutter.dev.
### Изменения в FragmentProgram
Фрагментные шейдеры, написанные на GLSL и перечисленные в `shaders:`разделе манифеста Flutter `pubspec.yaml`файла приложения, теперь будут автоматически компилироваться в правильный формат, понятный движку, и объединяться с приложением в качестве assets. Благодаря этому изменению больше не придется вручную компилировать шейдеры с помощью сторонних инструментов. В будущем, следует рассматривать `FragmentProgram`API-интерфейс Engine как принимающий только выходные данные инструментов сборки Flutter. Это еще не так, но это изменение запланировано для будущего выпуска, как описано в документе по дизайну [улучшений поддержки API FragmentProgram .](http://flutter.dev/go/fragment-program-support)
Пример такого изменения см. в этом [примере шейдера Flutter](https://github.com/zanderso/fragment_shader_example) .
Частичное преобразование (Fractional translation)
-------------------------------------------------
Ранее Flutter Engine всегда выравнивал составные слои по точным границам пикселей, поскольку это улучшало производительность рендеринга на более старых (32-разрядных) моделях iPhone. После добавления поддержки десктопов было замечено, что это привело к заметному усилению привязки, поскольку соотношение пикселей экранного устройства обычно намного ниже. Например, на экранах с низким значением DPR всплывающие подсказки могли заметно привязываться при затухании. Определив, что эта привязка пикселей больше не нужна для производительности на новых моделях iPhone, [разработчики удалили эту привязку пикселей](https://github.com/flutter/flutter/issues/103909) из Flutter Engine, чтобы улучшить точность воспроизведения на рабочем столе. Кроме того, разработчики также обнаружили, что удаление этой привязки к пикселям стабилизировало ряд тестов «золотого изображения», которые часто менялись с небольшими различиями в рендеринге.
Изменения в поддерживаемых платформах
-------------------------------------
### Прекращение поддержки 32-разрядной версии iOS
Как сообщалось ранее в стабильном выпуске 3.0, из-за сокращения использования этот выпуск был [последним, поддерживающим 32-разрядные устройства iOS и версии iOS 9 и 10](http://flutter.dev/go/rfc-32-bit-ios-unsupported) . Это изменение коснется iPhone 4S, iPhone 5, iPhone 5C, а также устройств iPad 2-го, 3-го и 4-го поколения. Стабильная версия Flutter 3.3 и все последующие стабильные выпуски больше не поддерживают 32-разрядные устройства iOS и версии iOS 9 и 10. Это означает, что приложения, созданные для Flutter 3.3 и более поздних версий, не будут работать на этих устройствах.
### Закрытие macOS 10.11 и 10.12
Ожидается, что в стабильном выпуске за четвертый квартал 2022 года будет прекращена поддержка macOS версий 10.11 и 10.12. Это означает, что после этого приложения, созданные для стабильных SDK Flutter, больше не будут работать в этих версиях, а минимальная версия macOS, поддерживаемая Flutter, увеличится до 10.13 High Sierra.
### Прекращение поддержки битового кода
Биткод [больше не будет приниматься для отправки приложения iOS в предстоящем выпуске Xcode 14](https://developer.apple.com/documentation/xcode-release-notes/xcode-14-release-notes) , а проекты с включенным биткодом будут выдавать предупреждение о сборке в этой версии Xcode. В свете этого Flutter прекратит поддержку биткода в будущей стабильной версии.
По умолчанию в приложениях Flutter не включен биткод, и не ожидается, что это повлияет на многих разработчиков. Однако, если биткод включен вручную в проекте Xcode, его следует отключить при обновлении до Xcode 14. Это можно сделать, открыв `ios/Runner.xcworkspace`и установив для параметра сборки **Enable Bitcode** значение **No** . Разработчики дополнений к приложению должны отключить его в хост-проекте Xcode.
Отключение биткода в XcodeСм [документацию Apple,](https://help.apple.com/xcode/mac/11.0/index.html?localePath=en.lproj#/devde46df08a) чтобы узнать больше о распространении битового кода.
Импеллер (Impeller): новый графический движок
---------------------------------------------
Новый движок рендеринга в качестве экспериментальной пробы — в этой версии также доступен Impeller, заменяющий движок рендеринга skia с настраиваемой средой выполнения, чтобы оправдать полное использование современных графических API с аппаратным ускорением, таких как [**Metal**](https://github.com/flutter/engine/tree/main/impeller)[на](https://developer.apple.com/metal/) iOS и [Vulkan](https://developer.android.com/ndk/guides/graphics) на Android, обеспечивающих переходную анимацию, обеспечивающую более быстрое обновление. скорость и искоренение роли **компиляции шейдеров во время выполнения** , главной проблемы современных приложений, делающей прокрутку плавной. Хотя он все еще находится в стадии производства, и для него ведется большая оптимизация, но он доступен в качестве раннего предварительного просмотра в iOS.
Узнать, как включить его [можно здесь.](https://github.com/flutter/flutter/wiki/Impeller)
Протестировать на : [Wonderous для iPhone](https://apps.apple.com/us/app/wonderous/id1612491897) из Apple App Store .
Сообщайте о любых проблемах, если они обнаружены по адресу: [воспроизводимые отчеты о проблемах](https://github.com/flutter/flutter/issues/new?assignees=&labels=created+via+performance+template&labels=impeller&template=4_performance_others.md&title=%5BImpeller%5D)
Критические изменения
---------------------
#### Еще не выпущен в стабильную версию
* [iOS FlutterViewController splashScreenView стал обнуляемым](https://docs.flutter.dev/release/breaking-changes/ios-flutterviewcontroller-splashscreenview-nullable)
* [Свойство toggleableActiveColor объекта ThemeData устарело.](https://docs.flutter.dev/release/breaking-changes/toggleable-active-color)
#### Выпущено во Flutter 3.3
* [Добавление ImageProvider.loadBuffer](https://docs.flutter.dev/release/breaking-changes/image-provider-load-buffer)
* [PrimaryScrollController по умолчанию на рабочем столе](https://docs.flutter.dev/release/breaking-changes/primary-scroll-controller-desktop)
#### Выпущено во Flutter 3
* [Устаревший API удален после версии 2.10](https://docs.flutter.dev/release/breaking-changes/2-10-deprecations)
* [Переходы страниц заменены на ZoomPageTransitionsBuilder](https://docs.flutter.dev/release/breaking-changes/page-transition-replaced-by-ZoomPageTransitionBuilder)
* [Перенос useDeleteButtonTooltip в deleteButtonTooltipMessage of Chips](https://docs.flutter.dev/release/breaking-changes/chip-usedeletebuttontooltip-migration)
Dart, выпуск версии 2.18
------------------------
* Представлено [взаимодействие Objective-C и Swift](https://dart.dev/guides/libraries/objective-c-interop) , теперь можно использовать пакеты Dart для вызова API из этих языков.
* Добавлено временное решение в [Исправление распространенных проблем с типами](https://dart.dev/guides/language/sound-problems) для редкого случая, когда вывод типа может привести к неправильному выводу, что тип аргумента равен null.
* Удалены все упоминания о прекращенных `.packages`файлах из [What not to commit](https://dart.dev/guides/libraries/private-files) . Если вам все еще нужно сгенерировать `.packages`файл из-за сторонних устаревших зависимостей, см . `dart pub get`Параметры .
* `dart2js`и `dartdevc`инструменты [удалены](https://github.com/dart-lang/sdk/issues/46100), как было объявлено ранее. `dart2js`заменяется `dart compile js`командой, `dartdevc` больше не отображается как инструмент командной строки.
* Добавлена поддержка загрузки экспериментальных сборок Windows ARM в [архив Dart SDK](https://dart.dev/get-dart/archive) .
* Обновлен [тур по библиотеке](https://dart.dev/guides/libraries/library-tour) , чтобы включить информацию о слабых ссылках и финализаторах.
* Добавлен раздел по [настройке](https://dart.dev/tools/dart-fix) `dart fix`.
Об остальных изменениях подробнее в [этой статье](https://medium.com/dartlang/dart-2-18-f4b3101f146c) и в [документации](https://github.com/dart-lang/sdk/blob/main/CHANGELOG.md#2160)
[Детальная хронология введенных изменений между версиями 3.0.0 и 3.3.0](https://github.com/flutter/flutter/wiki/Hotfixes-to-the-Stable-Channel)
Wonderous: новое справочное приложение
--------------------------------------
В партнерстве с командой дизайнеров [gskinner](https://gskinner.com/) **запущено приложение Wonderous**, созданное для демонстрации способности Flutter предоставлять высококачественные, красивые впечатления. Несмотря на то, что оно демонстрирует мощь Flutter, приложение прекрасно само по себе. От потрясающего Тадж-Махала в индийском городе Агра до руин майя Чичен-Ица на полуострове Юкатан в Мексике, Wonderous перенесет некоторые из самых замечательных мест в мире на ваш телефон, используя видео и изображения, чтобы исследовать пересечение искусства, истории и культуры.
Чтобы узнать больше о мотивах разработчиков для создания Wonderous и ссылках на связанный с ним веб-сайт, приложения для Android и iPhone и исходный код, ознакомьтесь с [отдельной статьей](https://medium.com/flutter/wonderous-explore-the-world-with-flutter-f43cce052e1) здесь, в блоге Flutter.
Прощание с Эриком
-----------------
Конец церемонии представления версии 3.3 разбавился эмоциональным прощанием с Эриком Зайделем. Эрик Зайдель был первым, кто представил миру Flutter еще до того, как у него появилось имя, на [саммите разработчиков Dart в 2015 году](https://www.youtube.com/watch?v=PnIWl33YMwA) ; он руководил командой инженеров Flutter на протяжении большей части ее существования, и, проще говоря, без Эрика не было бы Flutter в том виде, в каком мы его знаем. Более подробно о прощании с Эриком Зайделем можно почитать и посмотреть на видео в публикации разработчиков [здесь](https://medium.com/flutter/announcing-flutter-3-3-at-flutter-vikings-6f213e068793) и [здесь](https://youtu.be/5SZZfpkVhwk).
Использованные материалы для перевода:
--------------------------------------
<https://medium.com/flutter/whats-new-in-flutter-3-3-893c7b9af1ff>
<https://medium.flutterdevs.com/flutter-3-3-whats-new-in-flutter-e0f02172acc9>
<https://medium.com/flutter/announcing-flutter-3-3-at-flutter-vikings-6f213e068793>
<https://docs.flutter.dev/release/breaking-changes#released-in-flutter-33>
<https://medium.com/dartlang/dart-2-18-f4b3101f146c>
<https://docs.flutter.dev/development/tools/sdk/release-notes>
Любые исправления и дополнения статьи приветствуются в комментариях! | https://habr.com/ru/post/687186/ | null | ru | null |
# Первый видеокодек на машинном обучении кардинально превзошёл все существующие кодеки, в том числе H.265 и VP9
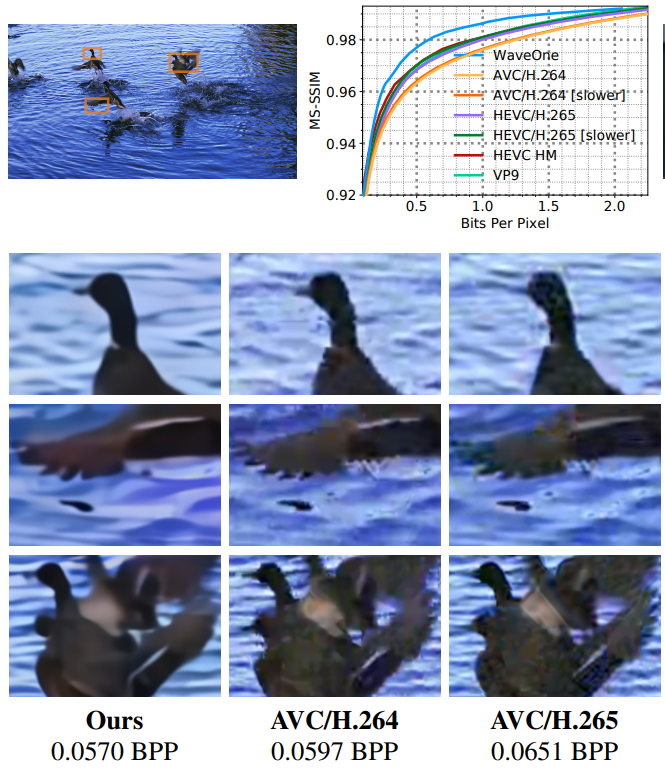
*Примеры реконструкции фрагмента видео, сжатого разными кодеками с примерно одинаковым значением BPP (бит на пиксель). Сравнительные результаты тестирования см. под катом*
Исследователи из компании WaveOne [утверждают](https://www.technologyreview.com/s/612462/deep-learning-will-help-keep-video-from-clogging-up-the-internet/), что близки к революции в области видеокомпрессии. При обработке видео высокого разрешения 1080p их [новый кодек на машинном обучении](https://arxiv.org/abs/1811.06981) сжимает видео примерно на 20%лучше, чем самые современные традиционные видеокодеки, такие как H.265 и VP9. А на видео «стандартной чёткости» (SD/VGA, 640×480) разница достигает 60%.
Разработчики называют нынешние методы видеокомпрессии, которые реализованы в H.265 и VP9, «древними» по стандартам современных технологий: «За последние 20 лет основы существующих алгоритмов сжатия видео существенно не изменились, — пишут авторы научной работы во введении своей статьи. — Хотя они очень хорошо спроектированы и тщательно настроены, но остаются жёстко запрограммированными и как таковые не могут адаптироваться к растущему спросу и всё более разностороннему спектру применения видеоматериалов, куда входят обмен в социальные СМИ, обнаружение объектов, потоковое вещание виртуальной реальности и так далее».
Применение машинного обучения должно наконец перенести технологии видеокомпрессии в 21 век. Новый алгоритм сжатия значительно превосходит существующие видеокодеки. «Насколько нам известно, это первый метод машинного обучения, который показал такой результат», — говорят они.
Основная идея сжатия видео заключается в удалении избыточных данных и замене их более коротким описанием, которое позволяет воспроизводить видео позже. Большая часть сжатия видео происходит в два этапа.
Первый этап — сжатие движения, когда кодек ищет движущиеся объекты и пытается предсказать, где они будут в следующем кадре. Затем вместо записи пикселей, связанных с этим движущимся объектом, в каждом кадре алгоритм кодирует только форму объекта вместе с направлением движения. Действительно, некоторые алгоритмы смотрят на будущие кадры, чтобы определить движение ещё более точно, хотя это явно не сможет работать для прямых трансляций.
Второй шаг сжатия удаляет другие избыточности между одним кадром и следующим. Таким образом, вместо того, чтобы записывать цвет каждого пикселя в голубом небе, алгоритм сжатия может определить область этого цвета и указать, что он не изменяется в течение следующих нескольких кадров. Таким образом, эти пиксели остаются того же цвета, пока не сказали, чтобы изменить. Это называется остаточным сжатием.
Новый подход, который представили учёные, впервые использует машинное обучение для улучшения обоих этих методов сжатия. Так, при сжатии движения методы машинного обучения команды нашли новые избыточности на основе движения, которые обычные кодеки никогда не были в состоянии обнаружить, а тем более использовать. Например, поворот головы человека из фронтального вида в профиль всегда даёт аналогичный результат: «Традиционные кодеки не смогут предсказать профиль лица исходя из фронтального вида», — пишут авторы научной работы. Напротив, новый кодек изучает эти виды пространственно-временных шаблонов и использует их для прогнозирования будущих кадров.
Другая проблема заключается в распределении доступной полосы пропускания между движением и остаточным сжатием. В некоторых сценах более важно сжатие движения, а в других остаточное сжатие обеспечивает наибольший выигрыш. Оптимальный компромисс между ними отличается от кадра к кадру.
Традиционные алгоритмы обрабатывают оба процесса отдельно друг от друга. Это означает, что нет простого способа отдать преимущество тому или другому и найти компромисс.
Авторы обходят это путём сжатия обоих сигналов одновременно и на основе сложности кадра определяют, как распределить пропускную способность между двумя сигналами наиболее эффективным способом.
Эти и другие усовершенствования позволили исследователям создать алгоритм сжатия, который значительно превосходит традиционные кодеки (см. бенчмарки ниже).

*Примеры реконструкции фрагмента, сжатого разными кодеками с примерно одинаковым значением BPP показывает заметное преимущество кодека WaveOne*
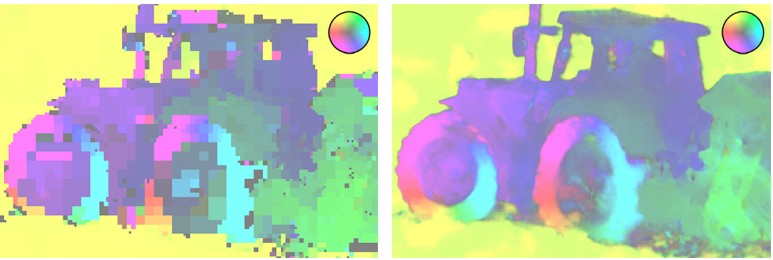
*Карты оптического потока H.265 (слева) и кодека WaveOne (справа) на одинаковом битрейте*
Однако новый подход не лишен некоторых недостатков, [отмечает](https://www.technologyreview.com/s/612462/deep-learning-will-help-keep-video-from-clogging-up-the-internet/) издание *MIT Technology Review*. Пожалуй, главным недостатком является низкая вычислительная эффективность, то есть время, необходимое для кодирования и декодирования видео. На платформе Nvidia Tesla V100 и на видео VGA-размера новый декодер работает со средней скоростью около 10 кадров в секунду, а кодер и вовсе со скоростью около 2 кадров в секунду. Такие скорости просто невозможно применить в прямых видеотрансляциях, да и при офлайновом кодировании материалов новый кодер будет иметь весьма ограниченную сферу использования.
Более того, скорости декодера недостаточно даже для *просмотра* видеоролика, сжатого этим кодеком, на обычном персональном компьютере. То есть для просмотра этих видеороликов даже в минимальном качестве SD в данный момент требуется целый вычислительный кластер с несколькими графическими ускорителями. А для просмотра видео в качестве HD (1080p) понадобится целая компьютерная ферма.
Остаётся надеяться только на увеличение мощности графических процессоров в будущем и на совершенствование технологии: «Текущая скорость не достаточна для развёртывания в реальном времени, но должна быть существенно улучшена в будущей работе», — пишут они.
Бенчмарки
---------
В тестировании принимали участие все ведущие коммерческие кодеки HEVC/H.265, AVC/H.264, VP9 и HEVC HM 16.0 в эталонной реализации. Для первых трёх использовался Ffmpeg, а для последнего — официальная реализация. Все кодеки были максимально настроены, насколько позволили знания исследователей. Например, для удаления B-фреймов использовался H.264/5 с опцией `bframes=0`, в кодеке аналогичная процедура осуществлялась настройкой `-auto-alt-ref 0 -lag-in-frames 0` и так далее. Для максимизации производительности на соответствие метрике MS-SSIM, естественно, кодеки запускались с флагом `-ssim`.
Все кодеки проверяли на стандартной базе видеороликов в форматах SD и HD, которые часто используются для оценки алгоритмов сжатия видео. Для SD-качества использовалась библиотека видео в разрешении VGA от e Consumer Digital Video Library (CDVL). Она содержит 34 видеоролика с общей длиной 15 650 кадров. Для HD использовался набор данных Xiph 1080p: 22 видеоролика общей длиной 11 680 кадров. Все видеоролики 1080p были обрезаны по центру до высоты 1024 (в данный подход нейросеть исследователей способна обрабатывать только измерения с размерностями, кратными 32 по каждой стороне).
Различные результаты тестирования показаны на диаграммах ниже:
* средние значения MS-SSIM для всех видеороликов в наборе для каждого кодека;
* сравнение размеров файла при усреднении значения MS-SSIM для всех кодеков;
* влияние различных компонентов кодека WaveOne на качество сжатия (нижняя диаграмма).
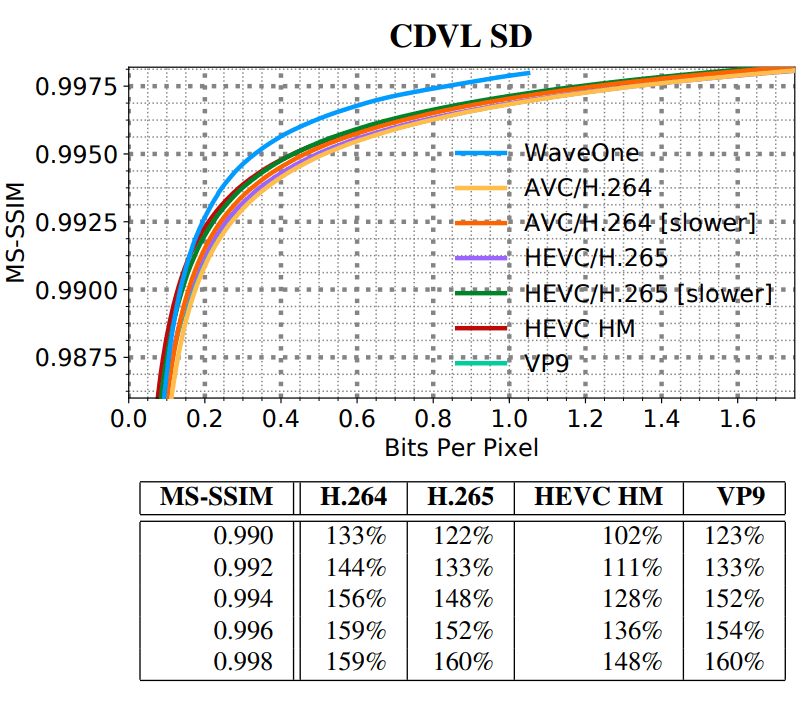
*Результаты тестирования на наборе видеороликов низкого разрешения (SD)*
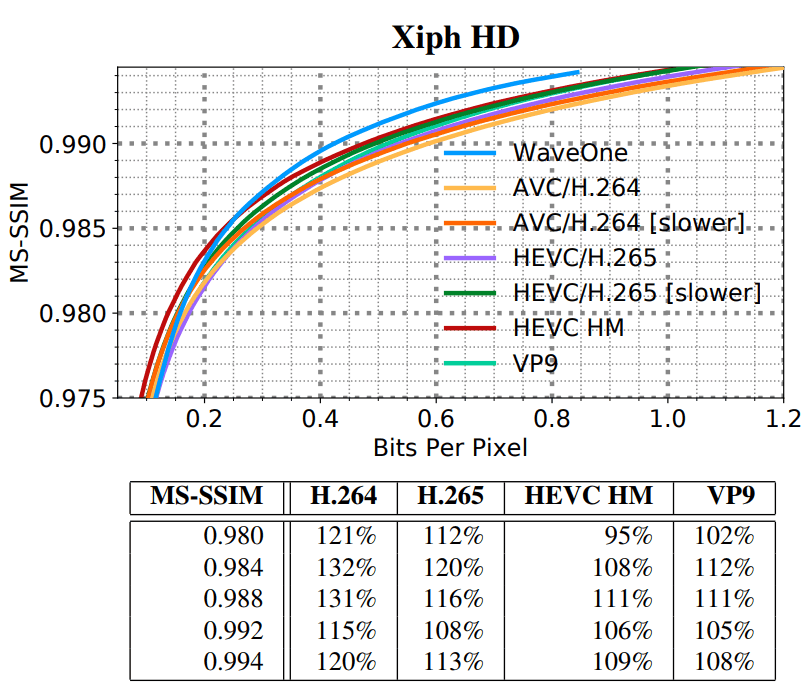
*Результаты тестирования на наборе видеороликов высокого разрешения (HD)*
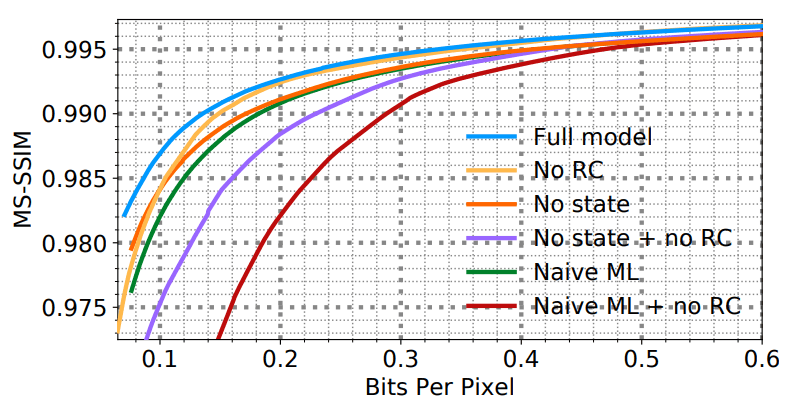
*Влияние различных компонентов кодека WaveOne на качество сжатия*
Не стоит удивляться такому высокому уровню сжатия и кардинальному превосходству над традиционными видеокодеками. Данная работа во многом основана на предыдущих научных статьях, где описываются различные методы сжатия статичных изображений на базе машинного зрения. Все они намного превосходят по уровню и качеству сжатия традиционные алгоритмы. Например, см. работы G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, R. Sukthankar. [Variable rate image compression with recurrent neural networks](https://arxiv.org/abs/1511.06085), 2015; G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, M. Covell. [Full resolution image compression with recurrent neural networks](https://arxiv.org/abs/1608.05148), 2016; J. Balle, V. Laparra, E. P. Simoncelli. [End-to-end optimized image compression](https://arxiv.org/abs/1611.01704), 2016; N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. J. Hwang, J. Shor, G. Toderici. [Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks](https://arxiv.org/abs/1703.10114), 2017 и другие. В этих работах показано, как обученные нейросети заново изобретают многие техники сжатия изображений, которые были изобретены человеком и раньше вручную прописывались для применения традиционными алгоритмами сжатия.
Прогресс в области ML-сжатия статических изображений неизбежно привёл к появлению первых видеокодеков, основанных на машинном обучении. С увеличением производительности графических ускорителей именно реализация видеокодеков стала первым кандидатом. До настоящего момента существовала только единственная попытка создать видеокодек на машинном обучении. Она описана в работе C.-Y. Wu, N. Singhal, and P. Krahenbuhl. *Video compression through image interpolation*, которая опубликована в ECCV (2018). Та система сначала кодирует ключевые кадры, а затем использует иерархическую интерполяцию кадров между ними. Она демонстрирует эффективность кодирования примерно как у традиционного кодека AVC/H.264. Как видим, сейчас исследователям удалось значительно превзойти это достижение.
Статья [«Выученное сжатие видео»](https://arxiv.org/abs/1811.06981) опубликована 16 ноября 2018 года на сайте препринтов arXiv.org (arXiv:1811.06981). Авторы научной работы — Орен Риппель (Oren Rippel), Санджей Наир (Sanjay Nair), Карисса Лью (Carissa Lew), Стив Брэнсон (Steve Branson), Александер Андерсон (Alexander G. Anderson), Любомир Бурдев (Lubomir Bourdev).
---
> Лучший [комментарий](https://habr.com/post/431354/#comment_19428740) [Stas911](https://habr.com/users/stas911/):
>
> Altaisky: Статья про видеокодек и ни одного видео. Нечего было показать?
>
> Stas911: Они ещё декодируют первый кадр. Проявите терпение. | https://habr.com/ru/post/431354/ | null | ru | null |
# Кластеризация СХД NetApp используя подручные свичи
Кластеризация систем хранения данных сейчас набирает оборотов, особенно в свете бурно развивающихся Flash технологий, которые требуют наличия большего количества контроллеров способных обрабатывать выскокопроизводительные накопители. Кроме поддерживаемых кластерных свичей есть множетсво других, которые временно можно исспользовать для этих целей. В этой статье я хотел бы привести пример настройки нескольких свичей, которые мною протестированны для кластерной сети. Многие другие свичи, уверен, тоже будут работать, ведь это обычный Ethernet
Схема подключения свичей для Cluster Interconnect
Когда у вас есть на руках (хотябы временно) больше двух контроллеров FAS, кластерный свич может понадобится, в случае:
* Конвертации FAS2240/255x в полку с последующим подключением к новой FAS истеме (у которой тоже есть полка с дисками), при этом требуется онлайн перенос без останова доступа к данным. На обоих системах должны работать ОС cDOT
* Обновление 7M до cDOT с последующей *онлайн миграцией* данных *назад*. Подробнее о [преимуществах Cluster-Mode](http://habrahabr.ru/post/270625/).
* Обновление прошивки контроллеров (хотя его и можно выполнять без останова, исспользуя всего два контроллера, но если у вас есть ещё пара контроллеров с дисками, почему бы их не задейстовать)
* В случае если нужно выполнить более рациональную перезазбивку дисков (к примеру для получения фичи ADP: [Root-Data Partitioning](http://habrahabr.ru/post/269635/) или [Storage Pool](http://habrahabr.ru/post/270169/))
* И др.
Как для временных конфигураций кластера сосстоящего из более двух контроллеров, так и для постоянных, требуется наличие поддерживаемого кластерного свича. На данный момент таких свича всего два это NetApp CN1610 и Cisco Nexus 5596. Если вы покупали сразу четыре или более контроллера, то этот свич у вас конечно же есть. А если это временная конфигурация из примеров выше, скорее всего такого свича нет. И что делать? Ответ очевиден: настроить тот свич, который у вас есть сейчас под рукой для создания временной конфигурации.
Не смотря на то, что другие свичи официально не поддержуются, они конечно же работают:
Тестировались следующие свичи с **MTU 1500**:
* HP Pro Curve 6120XG (Image stamp Z.14.44, 1564) from HP c7000 with 10Gb links to 2240 and 8020
* Cisco WS-C3850-48T (IOS 03.03.03SE RELEASE SOFTWARE (fc2)) with 1Gb links to 2240 and 8020
**Настройки HP Pro Curve 6120XG from HP c7000**
```
# HP Pro Curve 6120XG from HP c7000
swbl2# sh ver
Image stamp: /ws/swbuildm/Z_zinfandel_fip_t4b_qaoff/code/build/vern(Z_zinfandel_fip_t4b_qaoff)
Aug 26 2013 16:32:58
Z.14.44
1564
Boot Image: Primary
swbl2# sh vlan
Status and Counters - VLAN Information
Maximum VLANs to support : 256
Primary VLAN : TECH
Management VLAN :
VLAN ID Name | Status Voice Jumbo
------- -------------------- + ---------- ----- -----
1 DEFAULT_VLAN | Port-based No No
210 NetApp-Cluster | Port-based No No
vlan 210
name "NetApp-Cluster"
untagged 19-20,22
tagged Trk1-Trk2
# Trk1-Trk2 - connection of both HP switches to each other and to Cisco WS-C3850-48T
no ip address
exit
wbl1# sh vlans 210
Status and Counters - VLAN Information - VLAN 210
VLAN ID : 210
Name : NetApp-Cluster
Status : Port-based
Voice : No
Jumbo : Yes
Port Information Mode Unknown VLAN Status
---------------- -------- ------------ ----------
22 Untagged Learn Up
swbl2# sh cdp neighbors 22 detail
CDP neighbors information for port 22
Port : 22
Device ID : clA-02
Address Type : IP
Address : 169.254.166.38
Platform : NetApp Release 8.3RC1: Fri Oct 31 20:13:33 PDT 2014FAS8020
Capability :
Device Port : e0b
Version : NetApp Release 8.3RC1: Fri Oct 31 20:13:33 PDT 2014FAS8020
```
**Настройка Cisco WS-C3850**
```
#Cisco WS-C3850-48T
interface Vlan210
description NetApp-Cluster
no ip address
interface GigabitEthernet2/0/10
switchport access vlan 210
switchport mode access
flowcontrol receive on
spanning-tree portfast
!
core1-co2#sh cdp neighbors
Capability Codes: R - Router, T - Trans Bridge, B - Source Route Bridge
S - Switch, H - Host, I - IGMP, r - Repeater, P - Phone,
D - Remote, C - CVTA, M - Two-port Mac Relay
Device ID Local Intrfce Holdtme Capability Platform Port ID
netapp2 Gig 1/0/10 149 H FAS2240-2 e0b
netapp2 Gig 1/0/9 149 H FAS2240-2 e0a
netapp2 Gig 2/0/9 149 H FAS2240-2 e0d
netapp2 Gig 2/0/10 149 H FAS2240-2 e0c
netapp2 Gig 1/0/40 149 H FAS2240-2 e0M
netapp1 Gig 2/0/8 166 H FAS2240-2 e0d
netapp1 Gig 2/0/7 166 H FAS2240-2 e0c
netapp1 Gig 1/0/8 166 H FAS2240-2 e0a
netapp1 Gig 1/0/7 166 H FAS2240-2 e0b
netapp1 Gig 1/0/39 166 H FAS2240-2 e0M
clA-02 Gig 2/0/12 142 H FAS8020 e0f
clA-02 Gig 2/0/6 142 H FAS8020 e0e
clA-01 Gig 2/0/11 168 H FAS8020 e0f
clA-01 Gig 1/0/6 168 H FAS8020 e0e
core1-co2#sh vlan
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Te1/1/3, Te1/1/4, Gi2/0/37, Gi2/0/38, Gi2/0/41, Gi2/0/48, Te2/1/3
Te2/1/4
210 NetApp-Cluster active Gi1/0/6, Gi1/0/7, Gi1/0/8, Gi1/0/9, Gi1/0/10, Gi2/0/6, Gi2/0/7
Gi2/0/8, Gi2/0/9, Gi2/0/10, Gi2/0/11, Gi2/0/12
VLAN Type SAID MTU Parent RingNo BridgeNo Stp BrdgMode Trans1 Trans2
---- ----- ---------- ----- ------ ------ -------- ---- -------- ------ ------
210 enet 100210 1500 - - - - - 0 0
ore1-co2#sh ver
Cisco IOS Software, IOS-XE Software, Catalyst L3 Switch Software
(CAT3K_CAA-UNIVERSALK9-M), Version 03.03.03SE RELEASE SOFTWARE (fc2)
Technical Support: http://www.cisco.com/techsupport
Copyright (c) 1986-2014 by Cisco Systems, Inc.
Compiled Sun 27-Apr-14 18:33 by prod_rel_team
ROM: IOS-XE ROMMON
BOOTLDR: CAT3K_CAA Boot Loader (CAT3K_CAA-HBOOT-M) Version 1.2, RELEASE SOFTWARE (P)
Ipbase
License Type: Permanent
Next reload license Level: Ipbase
cisco WS-C3850-48T (MIPS) processor with 4194304K bytes of physical memory.
Processor board ID FOC1801U0WU
11 Virtual Ethernet interfaces
104 Gigabit Ethernet interfaces
8 Ten Gigabit Ethernet interfaces
2048K bytes of non-volatile configuration memory.
4194304K bytes of physical memory.
250456K bytes of Crash Files at crashinfo:.
250456K bytes of Crash Files at crashinfo-2:.
1609272K bytes of Flash at flash:.
1609272K bytes of Flash at flash-2:.
0K bytes of Dummy USB Flash at usbflash0:.
0K bytes of Dummy USB Flash at usbflash0-2:.
0K bytes of at webui:.
Base Ethernet MAC Address : 50:1c:bf:6c:65:00
Motherboard Assembly Number : 73-14444-06
Motherboard Serial Number : FOC180112WY
Model Revision Number : M0
Motherboard Revision Number : A0
Model Number : WS-C3850-48T
System Serial Number : FOC1801U0WU
Switch Ports Model SW Version SW Image Mode
------ ----- ----- ---------- ---------- ----
* 1 56 WS-C3850-48T 03.03.03SE cat3k_caa-universalk9 INSTALL
2 56 WS-C3850-48T 03.03.03SE cat3k_caa-universalk9 INSTALL
```
С **MTU 9000** Cisco Nexus 5548UP[:](#Nexus5548)
**Nexus 5548UP Software version 7.1(1)N1(1)**
```
banner motd # Nexus 5548 NetApp Reference Configuration File (RCF) version 1.3-48p (2012-10-15)
#
feature lacp
cdp enable
cdp advertise v1
cdp timer 5
snmp-server community cshm1! ro
errdisable recovery interval 30
errdisable recovery cause pause-rate-limit
policy-map type network-qos cluster
class type network-qos class-default
mtu 9216
system qos
service-policy type network-qos cluster
spanning-tree port type edge default
port-channel load-balance ethernet source-dest-port
interface port-channel1
switchport mode trunk
spanning-tree port type network
interface Ethernet1/1
description Cluster Node 1
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/2
description Cluster Node 2
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/3
description Cluster Node 3
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/4
description Cluster Node 4
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/5
description Cluster Node 5
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/6
description Cluster Node 6
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/7
description Cluster Node 7
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/8
description Cluster Node 8
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/9
description Cluster Node 9
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/10
description Cluster Node 10
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/11
description Cluster Node 11
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/12
description Cluster Node 12
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/13
description Cluster Node 13
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/14
description Cluster Node 14
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/15
description Cluster Node 15
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/16
description Cluster Node 16
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/17
description Cluster Node 17
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/18
description Cluster Node 18
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/19
description Cluster Node 19
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/20
description Cluster Node 20
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/21
description Cluster Node 21
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/22
description Cluster Node 22
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/23
description Cluster Node 23
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/24
description Cluster Node 24
no lldp transmit
no lldp receive
spanning-tree port type edge
spanning-tree bpduguard enable
interface Ethernet1/25
description Inter-Cluster Switch ISL Port 25 (port channel)
no lldp transmit
no lldp receive
switchport mode trunk
channel-group 1 mode active
interface Ethernet1/26
description Inter-Cluster Switch ISL Port 26 (port channel)
no lldp transmit
no lldp receive
switchport mode trunk
channel-group 1 mode active
interface Ethernet1/27
description Inter-Cluster Switch ISL Port 27 (port channel)
no lldp transmit
no lldp receive
switchport mode trunk
channel-group 1 mode active
interface Ethernet1/28
description Inter-Cluster Switch ISL Port 28 (port channel)
no lldp transmit
no lldp receive
switchport mode trunk
channel-group 1 mode active
interface Ethernet1/29
description Inter-Cluster Switch ISL Port 29 (port channel)
no lldp transmit
no lldp receive
switchport mode trunk
channel-group 1 mode active
interface Ethernet1/30
description Inter-Cluster Switch ISL Port 30 (port channel)
no lldp transmit
no lldp receive
switchport mode trunk
channel-group 1 mode active
interface Ethernet1/31
description Inter-Cluster Switch ISL Port 31 (port channel)
no lldp transmit
no lldp receive
switchport mode trunk
channel-group 1 mode active
interface Ethernet1/32
description Inter-Cluster Switch ISL Port 32 (port channel)
no lldp transmit
no lldp receive
switchport mode trunk
channel-group 1 mode active
end
```
Тестировались следующие операционные cисиетмы cDOT 8.3RC1, 8.3.1RC1 с хранилищами:
* FAS2240
* FAS8020
При необходимости перенастраиваем MTU для кластерных портов NetApp:
```
network port broadcast-domain modify -broadcast-domain Cluster -mtu 1500-or-9000 -ipspace Cluster
```
**При необходимости конвертируем SwitchLess-Cluster в Switched:**
```
cluster1::*> network options switchless-cluster modify -enabled true
```
**При необходимости мигрируем кластерные LIF'ы**Если у ноды только один кластерный LIF, создайте второй и мигрируйте их по-очереди, так чтобы все ноды видели друг-друга хотябы по одному пути: через swichless коммутацию или через свичи.
Не мигрируйте все LIF'ы одной ноды сразу, отвалившаяся нода с включённым HA сразу ребутнётся!
HA конечно же сработает, но зачем, если можно без этого обойтись?
```
cluster1::> network interface show -role cluster
cluster1::> network interface modify -vserver vsm0 -lif clus1_1 -home-node node01 -home-port e0c -auto-revert false
cluster1::> network interface modify -vserver vsm0 -lif clus2_1 -home-node node02 -home-port e0c -auto-revert false
#Мигрируем LIF
#Выполняем из Cluster Node Management консоли, той ноды на которой расположен LIF.
cluster1-01::> network interface revert -vserver vsm0 -lif clus1_1
cluster1-02::> network interface revert -vserver vsm0 -lif clus2_1
```
**Обязательно тестируем кластреную сеть из advanced режима:**
```
cluster1::*> cluster ping-cluster -node local
Host is node1
Getting addresses from network interface table...
Local = 10.254.231.102 10.254.91.42
Remote = 10.254.42.25 10.254.16.228
Ping status:
....
Basic connectivity succeeds on 4 path(s)
Basic connectivity fails on 0 path(s)
................
Detected 1500 byte MTU on 4 path(s):
Local 10.254.231.102 to Remote 10.254.16.228
Local 10.254.231.102 to Remote 10.254.42.25
Local 10.254.91.42 to Remote 10.254.16.228
Local 10.254.91.42 to Remote 10.254.42.25
Larger than PMTU communication succeeds on 4 path(s)
RPC status:
2 paths up, 0 paths down (tcp check)
2 paths up, 0 paths down (udp check)
```

В продакшн, NetApp не рекомендует исспользовать Cluster Interconnect свичи для чего бы то ни было, кроме как для кластерного подключения хранилищ NetApp, для этого необходимо иметь отдельные свичи, хотя технически возможно исспользовать те же свичи для обоих задач.
#### [Блочный доступ:](#SAN)
Напомню, что начиная с cDOT 8.3 по-умолчанию работает [новая фича](http://blog.aboutnetapp.ru/archives/1416) SLM и в случае онлайн миграции необходимо, на нодах которые принимают мигрирующий лун, [разрешить «рассказывать»](https://library.netapp.com/ecmdocs/ECMP1636035/html/GUID-62ABF745-6017-40B0-9D65-CE9F7FF66AB3.html) драйверам мультипасинга хостов, что лун теперь доступен по новым, дополнительным путям.
```
cluster1::> lun mapping add-reporting-nodes -vserver vserver_name -path lun_path -igroup igroup_name [-destination-aggregate aggregate_name | -destination-volume volume_name]
```
Удостоверьтесь, что драйвер мультипасинга на хосте обнаружил эти новые пути.
#### [NAS:](#NAS)
В случае миграции вольюма, который исспользуется для файловых протоколов NFS/CIFS(SMB), после миграции не забудьте переместить LIF на ноду, куда переехал вольюм.
```
cluster1::> network interface migrate -vserver vs0 -lif datalif1 -source-node vs0 -dest-node node2 -dest-port e0c
```
Подробнее том, как [вывести ноды из кластера](http://habrahabr.ru/post/265855/).
Подробнее том, как настроить [зонинг для кластерного хранилища](http://habrahabr.ru/post/260107/).
**Замечания по ошибкам и предложения правок в тексте прошу направлять в ЛС.** | https://habr.com/ru/post/265763/ | null | ru | null |
# Используем телетайп Consul 254 вместо клавиатуры для Arduino
Из документации:
> Электрифицированная пишущая машина Consul 254 предназначена:
>
> а) **для ввода алфавитно-цифровой информации в ЭВМ при печатании оператора на клавиатуре машины**
>
> б) для вывода алфавитно-цифровой информации в порядке печати на лист или рулон бумаги по сигналам, посылаемым от ЭВМ
>
> в) для применения в устройствах подготовки данных или в других устройствах, параметры которых соответствуют параметрам указанной машины
>
>
Сегодня мы займёмся пунктом "а" - будем читать данные с клавиатуры с помощью ЭВМ Arduino Uno.
В семидесятых годах подобные машины были основным интерфейсом для взаимодействия человека с компьютерами. Поэтому первые игры, в частности, были полностью диалоговыми, без аркадных механик или огромных лабиринтов на экране.
Сеанс игры в бейсбол из книги 1973 года "101 компьютерная игра на бейсике"Хотя Consul 254 и называется "пишущей машиной", сама эта машина ничего писать не умеет - клавиатура никак не соединена с печатающим механизмом. Никакого кабеля типа нуль-модема, чтобы просто печатать, тоже не существует. Поэтому без компьютера тут никак.
Зато если подключить ЭВМ, то можно будет вводить в неё информацию с помощью клавиатуры. С печатью я пока разбираться не стал, а просто взял символьный ЖК-дисплей, чтобы выводить набираемый текст.
Берём три таких разъёма и втыкаем их в Arduino.
В каждом разъёме 26 контактов, помеченных буквами от A до ZРазъёмы для подключения к ЭВМ имеют нумерацию (внезапно) I, IV, V. По соединяющимся буквам I V или по их интерпретации в качестве римских чисел можно было бы предположить, что I слева, V справа, а IV посередине, но это не так. К счастью, эти номера выгравированы снизу корпуса.
Телетайп, вид снизу. Скан документацииКлавиши машины подключены к шифратору, выдающему восьмибитный код. При нажатии на кнопку, внутри машины щёлкают релюшки, и на выходе шифратора можно увидеть код этой клавиши. Чтобы узнать, что пора считывать выходной символ, есть ещё пара контактов.
Выход с шифратора клавиатурыИнтересующие нас выходные контакты шифратора (который чехословаки перевели как комбинатор) обозначены буквами от C до K. В документации приведена таблица сканкодов, с помощью которой мы и переведём их в ASCII. Сканкод формируется выходами DEFGHIKJ (именно в таком порядке!), на которые попадает напряжение с выхода (или входа?) C. То есть, если подключить C к питанию, то с соответствующих выходов D-J можно будет это питание "прочитать". Или то же самое можно проделать с "землёй".
Цифровые входы контроллера AVR имеют внутренний притягивающий к питанию резистор. Поэтому коммутировать их будем на землю, чтобы схема была проще.
Схема того, что получилосьДля обозначения того, что символ пора читать, машина с помощью реле замыкает цепь AB. Контакт B в нашей схеме соединён с "землёй". Поэтому A тоже притягивается к "земле" при переключении реле. Для борьбы с дребезгом контактов к этой линии подключен конденсатор - множественных срабатываний не будет.
Временная диаграмма сигналов на выходе с клавиатурыИз временной диаграммы следует, что на выходе шифратора данные появляются как раз перед тем, как замыкаются контакты AB (что вполне логично). Поэтому в цепях C-D..K бороться с дребезгом не нужно.
Чтобы дождаться прихода символа, программа мониторит напряжение на 12 цифровом входе, подключенном к A. Можно было бы направить сигнал с A на вход контроллера прерываний, чтобы сэкономить электричество, но для демонстрационных целей это ни к чему.
Код считывания нажатий клавиш и вывода на экран
```
void loop() {
if (!digitalRead(12)) {
unsigned int v = 0;
for (int i = 2 ; i <= 9 ; ++i)
v = (v << 1) + digitalRead(i);
if (v == LOWREG) {
reg = false;
} else if (v == HIGHREG) {
reg = true;
} else {
if (reg) {
v = v ^ 3;
}
lcd.write(table[v]);
if (x == 16) {
lcd.scrollDisplayLeft();
} else {
++x;
}
}
delay(50);
}
}
```
Полученные коды клавиш декодируются в символы с помощью захардкоженной таблицы и выводятся на ЖК-дисплей. После этого процессор ждёт 50 мс, потому что в документации сказано, что чаще читать нельзя. Заодно и линия AB разомкнётся за это время.
Раскладка клавиатурыНа каждой клавише нарисовано по 2 символа - один для верхнего регистра, другой для нижнего. Русские буквы дисплей сам по себе показывать не умеет, а добавлять их мне было лень. Если что, для этого есть отдельная [библиотека](https://github.com/ssilver2007/LCD_1602_RUS_ALL). Поэтому текст для демонстрации я набираю по-английски. Но чтобы набирать латиницу, нельзя просто переключить язык. Некоторые из нужных символов находятся в нижнем регистре, а некоторые в верхнем (те, которые совпадают по начертанию с кириллицей).
Клавиши переключения регистра (НР, ВР) на клавиатуре, вопреки ожиданиям, не меняют состояния машины, а просто посылают соответствующий сканкод наружу, в ЭВМ. Компьютер большой, ему видней.
Пришлось реализовывать переключение регистра в программе. Сканкоды для разных регистров одной клавиши отличаются инвертированными последними двумя битами. Поэтому чтобы найти код верхнего символа, зная нижний (и наоборот), надо всего лишь выполнить с ним "xor 3".
Ниже видео, как это всё работает. Надеюсь, в реальной жизни никто не набирал на этой клавиатуре тексты программ латиницей. Пару раз переключать регистр во время набора одного слова - сомнительное удовольствие.
Итак, печатать оператор может, а что же с выводом на бумагу? Это немного сложнее. Для поступающих от ЭВМ данных дешифратора нет. Нужно напрямую управлять входами матрицы, составленной из электромагнитных реле. То есть, добыть питание 12 вольт и 20 выводов, которые будут включать эти реле через разъём I. Оставим это на следующий раз.
Ссылки
------
1. [Репозиторий с кодом для Arduino](https://github.com/Dovgalyuk/ArduinoConsul254/).
2. [Consul 254. Техническое описание](https://djvu.online/file/yNTCDJPc25J3y).
3. [101 BASIC Computer Games](http://www.bitsavers.org/pdf/dec/_Books/101_BASIC_Computer_Games_Mar75.pdf). | https://habr.com/ru/post/687964/ | null | ru | null |
# Ежедневная работа с Git
Я совсем не долго изучаю и использую git практически везде, где только можно. Однако, за это время я успел многому научиться и хочу поделиться своим опытом с сообществом.
Я постараюсь донести основные идеи, показать как эта VCS помогает разрабатывать проект. Надеюсь, что после прочтения вы сможете ответить на вопросы:
* можно ли git «подстроить» под тот процесс разработки, который мне нужен?
* будет ли менеджер и заказчик удовлетворён этим процессом?
* будет ли легко работать разработчикам?
* смогут ли новички быстро включиться в процесс?
* можно ли процесс относительно легко и быстро изменить?
Конечно, я попытаюсь рассказать обо всём по-порядку, начиная с основ. Поэтому, эта статья будет крайне полезна тем, кто только начинает или хочет разобраться с git. Более опытные читатели, возможно, найдут для себя что-то новое, укажут на ошибки или поделятся советом.
#### Вместо плана
Очень часто, для того чтобы с чем-то начать я изучаю целую кучу материалов, а это — разные люди, разные компании, разные подходы. Всё это требует много времени на анализ и на понимание того, подойдёт ли что-нибудь мне? Позже, когда приходит понимание, что универсальное решение отсутствует, появляются совершенно другие требования к системе контроля версий и к разработке.
Итак, выделю основные шаги:
* [Окружение](#environment)
* [Перестаём бояться экспериментировать](#getstarted)
* [Строим репозитории](#buildingrepo)
* [Начало GIT](#gitbegin)
* [Включаемся в проект](#gotoproject)
* [Типичные сценарии при работе над проектом](#typicalscenario)
#### Окружение
Для работы нам нужно:
1. Git
2. Консоль
3. Человек по ту сторону монитора, который сумеет это всё поставить под свою любимую ось
На текущим момент моё окружение это Debian + KDE + Git + Bash + GitK + KDiff3.
Если вы обнаружили на своём компьютере Windows, то у вас скорее всего будет Windows + msysgit (git-bash) + TortoiseGit и т.д.
Если вы открываете консоль, пишите `git` и получаете вот это:
**справка git**
```
usage: git [--version] [--exec-path[=]] [--html-path] [--man-path] [--info-path]
[-p|--paginate|--no-pager] [--no-replace-objects] [--bare]
[--git-dir=] [--work-tree=] [--namespace=]
[-c name=value] [--help]
[]
The most commonly used git commands are:
add Add file contents to the index
bisect Find by binary search the change that introduced a bug
branch List, create, or delete branches
checkout Checkout a branch or paths to the working tree
clone Clone a repository into a new directory
commit Record changes to the repository
diff Show changes between commits, commit and working tree, etc
fetch Download objects and refs from another repository
grep Print lines matching a pattern
init Create an empty git repository or reinitialize an existing one
log Show commit logs
merge Join two or more development histories together
mv Move or rename a file, a directory, or a symlink
pull Fetch from and merge with another repository or a local branch
push Update remote refs along with associated objects
rebase Forward-port local commits to the updated upstream head
reset Reset current HEAD to the specified state
rm Remove files from the working tree and from the index
show Show various types of objects
status Show the working tree status
tag Create, list, delete or verify a tag object signed with GPG
See 'git help ' for more information on a specific command.
```
Значит вы готовы.
#### Перестаём бояться экспериментировать
Наверняка, большинство команд уже где-то подсмотрено, какие-то статьи прочитаны, вы хотите приступить но боитесь ввести не ту команду или что-то поломать. А может ещё ничего и не изучено. Тогда просто помните вот это:
> Вы можете делать всё что угодно, выполнять любые команды, ставить эксперименты, удалять, менять. Главное не делайте `git push`.
>
> Только эта команда передаёт изменения в другой репозиторий. Только так можно что-то сломать.
Строго говоря, даже неудачный git push можно исправить.
Поэтому, спокойно можете клонировать любой репозиторий и начать изучение.
#### Строим репозитории
В первую очередь нужно понять что такое git-репозиторий? Ответ очень прост: это набор файлов. Папка `.git`. Важно понимать, что это только набор файлов и ничего больше. Раз 20 наблюдал проблему у коллег с авторизацией в github/gitlab. Думая, что это часть git-системы, они пытались искать проблему в конфигруации git, вызывать какие-то git-команды.
А если это просто файлы, то к ним нужно как-то получить доступ, иметь возможность оттуда читать и туда писать? Да! Я называю это «транспортом». Это может и некорректно, но мне так было удобно запомнить. Более правильный вариант: «Протокол передачи данных». Самые распространённые варианты:
1. FILE — мы имеем прямой доступ к файлам репозитория.
2. SSH — мы имеем доступ к файлам на сервере через ssh.
3. HTTP(S) — используем http в качестве приёма/передачи.
Вариантов намного больше. Не важно какой транспорт будет использован, важно чтобы был доступ на чтение или чтение/запись к файлам.
Поэтому, если вы никак не можете клонировать репозиторий с github, и нет в логах никаких подсказок, возможно у вас проблема с транспортом.
В частности, при клонировании вот так:
```
git clone [email protected]:user/repo.git
```
урл «превращается» в
```
git clone ssh://[email protected]:user/repo.git
```
Т.е. используется SSH и проблемы нужно искать в нём. Как правило, это неправильно настроенный или не найденный ssh-ключ. Гуглить надо в сторону «SSH Auth Key git» или, если совсем по взрослому, проверить, что же происходит:
```
ssh -vvv [email protected]
```
Какие протоколы поддерживаются поможет справка (раздел GIT URLS):
```
git clone --help
```
Репозиторий можно клонировать, но для начала поиграемся со своими:
1. Придумаем свой удалённый репозиторий
2. Сделаем два клона с него, от имени разработчиков (dev1 и dev2)

Кроме самого репозитория есть ещё и **workspace**, где хранятся файлы с которыми вы работаете. Именно в этой папке лежит сам репозиторий (папка .git ). На серверах рабочие файлы не нужны, поэтому там хранятся только голые репозитории (bare-repo).
Сделаем себе один (будет нашим главным тестовым репозиторием):
```
$ mkdir git-habr #создадим папку, чтоб не мусорить
$ cd git-habr
$ git init --bare origin
Initialized empty Git repository in /home/sirex/proj/git-habr/origin/
```
Теперь клонируем его от имени разработчиков. Тут есть только один нюанс, которого не будет при работе с сервером: git, понимая, что репозитории локальные и находятся на одном разделе, будет создавать ссылки, а не делать полную копию. А нам для изучения нужна полная копия. Для этого можно воспользоваться ключом `--no-hardlinks` или явно указать протокол:
```
$ git clone --no-hardlinks origin dev1
Cloning into 'dev1'...
warning: You appear to have cloned an empty repository.
done.
$ git clone --no-hardlinks origin dev2
Cloning into 'dev2'...
warning: You appear to have cloned an empty repository.
done.
```
Итог: у нас есть 3 репозитория. Там ничего нет, зато они готовы к работе.
#### Начало GIT
##### Скандалы! Интриги! Расследования!
* Git не хранит папки
* Git не хранит файлы
* Ревизии (Revision) не имеют порядкового номера
* Редакции (правки, commits) могут идти не по-порядку
* В Git нет веток\* *(с небольшой оговоркой)*
Можно дальше продолжить список, но и этого уже достаточно, чтобы задать вполне закономерные вопросы:
> Как это всё работает?
>
> Как это всё можно понять и запомнить?
Для этого нужно заглянуть под капот. Рассмотрим всё в общих чертах.
##### Git. Почти под капотом
Git сохраняет в commit содержимое всех файлов (делает слепки содержимого каждого файла и сохраняет в objects). Если файл не менялся, то будет использован старый object. Таким образом, в commit в виде новых объектов попадут только **изменённые файлы**, что позволит хорошо экономить место на диске и даст возможность быстро переключиться на любой commit.
Это позволяет понять, почему работают вот такие вот забавные штуки:
```
$ git init /tmp/test
Initialized empty Git repository in /tmp/test/.git/
$ cd /tmp/test
$ cp ~/debian.iso . # iso весит 168 метров
$ du -sh .git #считаем размер папки .git
92K .git
$ git add debian.iso
$ git commit -m "Added iso"
[master (root-commit) 0fcc821] added iso
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 debian.iso
$ du -sh .git #опять считаем
163M .git
# Добавилось. Копируем файлы под другим именем (но то же содержание)
$ cp debian.iso debian2.iso
$ cp debian.iso debian3.iso
$ git add debian2.iso debian3.iso
$ git commit -m "Copied iso"
[master f700ab5] copied iso
2 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 debian2.iso
create mode 100644 debian3.iso
$ du -sh .git #опять считаем
163M .git #место почти не изменилось. Это всё тот же объект, просто у него разные имена.
```
Да, не стоит хранить «тяжёлые» файлы, бинарники и прочее без явной необходимости. Они там останутся навсегда и будут в каждом клоне репозитория.
Каждый коммит может иметь несколько коммитов-предков и несколько дочерних-коммитов:
Мы можем переходить (восстанавливать любое состояние) в любую точку этого дерева, а точнее, графа. Для этого используется git checkout:
```
git checkout
```
Каждое слияние двух и более коммитов в один — это merge (объединение двух и более наборов изменений).
Каждое разветвление — это появление нескольких вариантов изменений.
> Кстати, тут хочется отметить, что нельзя сделать тэг на файл/папку, на часть проекта и т.д. Состояние восстанавливается только целиком. Поэтому, рекомендуется держать проекты в отдельном репозитории, а не складывать Project1, Project2 и т.д. просто в корень.
Теперь к веткам. Выше я написал:
> В Git нет веток\* *(с небольшой оговоркой)*
Получается, что так и есть: у нас есть много коммитов, которые образуют граф. Выбираем любой путь от parent-commit к любому child-commit и получаем состояние проекта на этот коммит. Чтобы коммит «запомнить» можно создать на него именованный указатель.
Такой именованный указатель и есть ветка (branch). Так же и с тэгом (tag). `HEAD` работает по такому же принципу — показывает, где мы есть сейчас. Новые коммиты являются продолжением текущей ветки (туда же куда и смотрит HEAD).
Указатели можно свободно перемещать на любой коммит, если это не tag. Tag для того и сделан, чтобы раз и навсегда запомнить коммит и никуда не двигаться. Но его можно удалить.
Вот, пожалуй, и всё, что нужно знать из теории на первое время при работе с git. Остальные вещи должны показаться теперь более понятными.
##### Терминология
**index** — область зафиксированных изменений, т.е. всё то, что вы подготовили к сохранению в репозиторий.
**commit** — изменения, отправленные в репозиторий.
**HEAD** — указатель на commit, в котором мы находимся.
**master** — имя ветки по-умолчанию, это тоже указатель на определённый коммит
**origin** — имя удалённого репозитория по умолчанию (можно дать другое)
**checkout** — взять из репозитория какое-либо его состояние.
##### Простые правки
Есть две вещи которые должны быть у вас под рукой всегда:
1. git status
2. gitk
Если вы сделали что-то не так, запутались, не знаете, что происходит — эти две команды вам помогут.
`git status` — показывает состояние вашего репозитория (рабочей копии) и где вы находитесь.
`gitk` — графическая утилита, которая показывает наш граф. В качестве ключей передаём имена веток или `--all`, чтобы показать все.
Вернёмся к нашим репозиториям, которые создали раньше. Далее обозначу, что один разработчик работает в dev1$, а второй в dev2$.
Добавим README.md:
```
dev1$ vim README.md
dev1$ git add README.md
dev1$ git commit -m "Init Project"
[master (root-commit) e30cde5] Init Project
1 file changed, 4 insertions(+)
create mode 100644 README.md
dev1$ git status
# On branch master
nothing to commit (working directory clean)
```
Поделимся со всеми. Но поскольку мы клонировали пустой репозиторий, то git по умолчанию не знает в какое место добавить коммит.
Он нам это подскажет:
```
dev1$ git push origin
No refs in common and none specified; doing nothing.
Perhaps you should specify a branch such as 'master'.
fatal: The remote end hung up unexpectedly
error: failed to push some refs to '/home/sirex/proj/git-habr/origin'
dev1$ git push origin master
Counting objects: 3, done.
Writing objects: 100% (3/3), 239 bytes, done.
Total 3 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
To /home/sirex/proj/git-habr/origin
* [new branch] master -> master
```
Второй разработчик может получить эти изменения, сделав pull:
```
dev2$ git pull
remote: Counting objects: 3, done.
remote: Total 3 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
From /home/sirex/proj/git-habr/origin
* [new branch] master -> origin/master
```
Добавим ещё пару изменений:
```
dev1(master)$ vim README.md
dev1(master)$ git commit -m "Change 1" -a
dev1(master)$ vim README.md
dev1(master)$ git commit -m "Change 2" -a
dev1(master)$ vim README.md
dev1(master)$ git commit -m "Change 3" -a
```
Посмотрим, что же мы сделали (запускаем gitk):
**Скрытый текст**
Выделил первый коммит. Переходя по-порядку, снизу вверх, мы можем посмотреть как изменялся репозиторий:
```
@@ -2,3 +2,4 @@ My New Project
--------------
Let's start
+Some changes
```
```
@@ -3,3 +3,5 @@ My New Project
Let's start
Some changes
+Some change 2
+
```
```
@@ -2,6 +2,5 @@ My New Project
--------------
Let's start
-Some changes
-Some change 2
+Some change 3
```
До сих пор мы добавляли коммиты в конец (там где *master*). Но мы можем добавить ещё один вариант README.md. Причём делать мы это можем из любой точки. Вот, например, последний коммит нам не нравится и мы пробуем другой вариант. Создадим в предыдущей точке указатель-ветку. Для этого через git log или gitk узнаем commit id. Затем, создадим ветку и переключимся на неё:
```
dev1(master)$ git branch
# А можно и git branch HEAD~1
# но об этом позже
dev1(master)$ git checkout
```
Для тех, кто любит GUI есть вариант ещё проще: выбрать нужный коммит правой кнопкой мыши -> «create new branch».
Если кликнуть по появившейся ветке, там будет пункт «check out this branch». Я назвал ветку «v2».
Сделаем наши тестовые изменения:
```
dev1(v2)$ vim README.md
dev1(v2)$ git commit -m "Ugly changes" -a
[v2 75607a1] Ugly changes
1 file changed, 1 insertion(+), 1 deletion(-)
```
Выглядит это так:

Теперь нам понятно, как создаются ветки из любой точки и как изменяется их история.
##### Быстрая перемотка
Наверняка, вы уже встречали слова **fast-forward**, **rebase**, **merge** вместе. Настало время разобраться с этими понятиями. Я использую rebase, кто-то только merge. Тем «rebase vs merge» очень много. Авторы часто пытаются убедить, что их метод лучше и удобнее. Мы пойдём другим путём: поймём, что же это такое и как оно работает. Тогда сразу станет ясно, какой вариант использовать в каком случае.
Пока, в пределах одного репозитория, сделаем ветвление: создадим файл, положим в репозиторий, из новой точки создадим два варианта файла и попробуем объединить всё в master:
```
dev1(v2)$ git checkout master
Switched to branch 'master'
Your branch is ahead of 'origin/master' by 3 commits. # Да, мы впереди по сравнению с master в репозитории origin
```
Создадим файл collider.init.sh с таким содержанием:
```
#!/bin/sh
USER=collider
case $1 in
*)
echo Uknown Action: $1
;;
esac
```
Добавим, закоммитим и начнём разработку в новой ветке:
```
dev1(master)$ git add collider.init.sh
dev1(master)$ git commit -m "Added collider init script"
[master 0c3aa28] Added collider init script
1 file changed, 11 insertions(+)
create mode 100755 collider.init.sh
dev1(master)$ git checkout -b collider/start # пояснение ниже
Switched to a new branch 'collider/start'
dev1(collider/start)$ git checkout -b collider/terminate # пояснение ниже
Switched to a new branch 'collider/terminate'
```
**git checkout -b** создаёт указатель (ветку) на текущую позицию (текущая позиция отслеживается с помощью специального указателя HEAD) и переключается на него.
Или проще: сделать с текущего места новую ветку и сразу же продолжить с ней.
Обратите внимание, что в имени ветки не запрещено использовать символ '/', однако, надо быть осторожным, т.к. в файловой системе создаётся папка с именем до '/'. Если ветка с таким названием как и папка существует — будет конфликт на уровне файловой системы. Если уже есть ветка *dev*, то нельзя создать *dev/test*.
A если есть *dev/test*, то можно создавать *dev/whatever*, но нельзя просто *dev*.
Итак, создали две ветки *collider/start* и *collider/terminate*. Запутались? **gitk --all** спешит на помощь:

Как видно, мы в одной точке имеем 3 указателя (наши ветки), а изменения в коммите такие:
```
@@ -0,0 +1,11 @@
+#!/bin/sh
+
+
+USER=collider
+
+
+case $1 in
+ *)
+ echo Uknown Action: $1
+ ;;
+esac
```
Теперь, в каждой ветке напишем код, который, соответственно, будет запускать и уничтожать наш коллайдер. Последовательность действий приблизительно такая:
```
dev1(collider/start)$ vim collider.init.sh
dev1(collider/start)$ git commit -m "Added Collider Start Function" -a
[collider/start d229fa9] Added Collider Start Function
1 file changed, 9 insertions(+)
dev1(collider/start)$ git checkout collider/terminate
Switched to branch 'collider/terminate'
dev1(collider/terminate)$ vim collider.init.sh
dev1(collider/terminate)$ git commit -m "Added Collider Terminate Function" -a
[collider/terminate 4ea02f5] Added Collider Terminate Function
1 file changed, 9 insertions(+)
```
**Сделанные изменения***collider/start*
```
@@ -3,8 +3,17 @@
USER=collider
+do_start(){
+ echo -n "Starting collider..."
+ sleep 1s
+ echo "ok"
+ echo "The answer is 42. Please, come back again after 1 billion years."
+}
case $1 in
+ start)
+ do_start
+ ;;
*)
echo Uknown Action: $1
;;
```
*collider/terminate*
```
@@ -3,8 +3,17 @@
USER=collider
+do_terminate() {
+ echo -n "Safely terminating collider..."
+ sleep 1s
+ echo "oops :("
+
+}
case $1 in
+ terminate)
+ do_terminate
+ ;;
*)
echo Uknown Action: $1
;;
```
Как всегда, посмотрим в **gitk --all** что наделали:

Разработка закончена и теперь надо отдать все изменения в master (там ведь старый коллайдер, который ничего не может). Объединение двух коммитов, как и говорилось выше — это **merge**. Но давайте подумаем, чем отличается ветка *master* от *collider/start* и как получить их объединение (сумму)? Например, можно взять общие коммиты этих веток, затем прибавить коммиты, относящиеся только к *master*, а затем прибавить коммиты, относящиеся только к *collider/start*. А что у нас? Общие коммиты — есть, только коммиты *master* — нет, только *collider/start* — есть. Т.е. объединение этих веток — это *master* + коммиты от *collider/start*. Но *collider/start* — это *master* + коммиты ветки *collider/start*! Тоже самое! Т.е. делать ничего не надо! Объединение веток — это и есть *collider/start*!
Ещё раз, только на буквах, надеюсь, что будет проще для восприятия:
master = C1 + C2 +C3
collider/start = master + C4 = C1 + C2 +C3 + C4
master + collider/start = Общие\_коммиты(master, collider/start) + Только\_у(master) + Только\_у(collider/start) = (C1 + C2 +C3) + (NULL) + (C4) = C1 + C2 +C3 + C4
Когда одна ветка «лежит» на другой, то она уже как бы входит в эту, другую ветку, и результатом объединения будет вторая ветка. Мы просто перематываем историю вперёд от старых коммитов к новым. Вот эта перемотка (объединение, при котором делать ничего не надо) и получила название fast-forward.
Почему fast-forward — это хорошо?
1. При слиянии ничего делать не надо
2. Автоматическое объединение, причём гарантированное
3. Конфликты не возможны и никогда не возникнут
4. История остаётся линейной (как будто объединения и не было), что часто проще для восприятия на больших проектах
5. Новых коммитов не появляется
Как быстро узнать, что fast-forward возможен? Для этого достаточно посмотреть в gitk на две ветки, которые нужно объединить и ответить на один вопрос: существует ли прямой путь от ветки А к B, если двигаться только вверх (от нижней к верхней). Если да — то будет fast-forward.
В теории понятно, пробуем на практике, забираем изменения в *master*:
```
dev1(collider/terminate)$ git checkout master
Switched to branch 'master'
Your branch is ahead of 'origin/master' by 4 commits.
dev1(master)$ git merge collider/start
Updating 0c3aa28..d229fa9
Fast-forward # то что надо
collider.init.sh | 9 +++++++++
1 file changed, 9 insertions(+)
```
Результат (указатель просто передвинулся вперёд):

##### Объединение
Теперь забираем изменения из *collider/terminate*. Но, тот, кто дочитал до сюда (дочитал ведь, да?!) заметит, что прямого пути нет и так красиво мы уже не отделаемся. Попробуем git попросить fast-forward:
```
dev1(master)$ git merge --ff-only collider/terminate
fatal: Not possible to fast-forward, aborting.
```
Что и следовало ожидать. Делаем просто merge:
```
dev1(master)$ git merge collider/terminate
Auto-merging collider.init.sh
CONFLICT (content): Merge conflict in collider.init.sh
Automatic merge failed; fix conflicts and then commit the result.
```
Я даже рад, что у нас возник конфликт. Обычно, в этом момент некоторые теряются, лезут гуглить и спрашивают, что делать.
Для начала:
> Конфликт возникает при попытке объединить два и более коммита, в которых в одной и той же строчке были сделаны изменения. И теперь git не знает что делать: то ли взять первый вариант, то ли второй, то ли старый оставить, то ли всё убрать.
Как всегда, две самые нужные команды нам спешат помочь:
```
dev1(master)$ git status
# On branch master
# Your branch is ahead of 'origin/master' by 5 commits.
#
# Unmerged paths:
# (use "git add/rm ..." as appropriate to mark resolution)
#
# both modified: collider.init.sh
#
no changes added to commit (use "git add" and/or "git commit -a")
dev1(master)$ gitk --all
```

Мы находимся в *master*, туда же указывает *HEAD*, туда же и добавляются наши коммиты.
Файл выглядит так:
```
#!/bin/sh
USER=collider
<<<<<<< HEAD
do_start(){
echo -n "Starting collider..."
sleep 1s
echo "ok"
echo "The answer is 42. Please, come back again after 1 billion years."
}
case $1 in
start)
do_start
=======
do_terminate() {
echo -n "Safely terminating collider..."
sleep 1s
echo "oops :("
}
case $1 in
terminate)
do_terminate
>>>>>>> collider/terminate
;;
*)
echo Uknown Action: $1
;;
esac
```
Нам нужны оба варианта, но объединять вручную не хотелось бы, правда? Здесь то нам и помогут всякие merge-тулы.
Самый простой способ решить конфликт — это вызвать команду **git mergetool**. Почему-то не все знают про такую команду.
Она делает примерно следующие:
1. Находит и предлагает для использования на выбор diff- или merge-программы
2. Создаёт файл filename.orig (файл как есть до попытки объединить)
3. Создаёт файл filename.base (какой файл был)
4. Создаёт файл filename.remote (как его поменяли в другой ветке)
5. Создаёт файл filename.local (как поменяли его мы)
6. После разрешения конфликтов всё сохраняется в filename
Пробуем:
```
dev1(master)$ git mergetool
merge tool candidates: opendiff kdiff3 tkdiff xxdiff meld tortoisemerge gvimdiff diffuse ecmerge p4merge araxis bc3 emerge vimdiff
Merging:
collider.init.sh
Normal merge conflict for 'collider.init.sh':
{local}: modified file
{remote}: modified file
Hit return to start merge resolution tool (kdiff3):
```
Из-за того что изменения были в одних и тех же местах конфликтов получилось много. Поэтому, я брал везде первый вариант, а второй копировал сразу после первого, но с gui это сделать довольно просто. Вот результат — вверху варианты файла, внизу — объединение (простите за качество):
Сохраняем результат, закрываем окно, коммитим, смотрим результат:

Мы создали новый коммит, который является объединением двух других. Fast-forward не произошёл, потому, что не было прямого пути для этого, история стала выглядеть чуть-чуть запутаннее. Иногда, merge действительно нужен, но излишне запутанная история тоже ни к чему.
Вот пример реального проекта:
| | | |
| --- | --- | --- |
| | | |
Конечно, такое никуда не годится! «Но разработка идёт параллельно и никакого fast-forward не будет» скажете вы? Выход есть!
##### Перестройка
Что же делать, чтобы история оставалась красивой и прямой? Можно взять нашу ветку и перестроить её на другую ветку! Т.е. указать ветке новое начало и воспроизвести все коммиты один за одним. Этот процесс и называется rebase. Наши коммиты станут продолжением той ветки, на которую мы их перестроим. Тогда история будет простой и линейной. И можно будет сделать fast-forward.
Другими словами: мы повторяем историю изменений с одной ветки на другой, как будто бы мы действительно брали другую ветку и заново проделывали эти же самые изменения.
Для начала отменим последние изменения. Проще всего вернуть указатель *master* назад, на предыдущее состояние. Создавая merge-commit, мы передвинули именно *master*, поэтому именно его нужно вернуть назад, желательно (а в отдельных случаях важно) на тот же самый commit, где он был.
Как результат, наш merge-commit останется без какого-либо указателя и не будет принадлежать ни к одной ветке.
Используя `gitk` или консоль перемещаем наш указатель. Поскольку, ветка *collider/start* уже указывает на наш коммит, нам не нужно искать его id, а мы можем использовать имя ветки (это будет одно и тоже):
```
dev1(master)$ git reset --hard collider/start
HEAD is now at d229fa9 Added Collider Start Function
```
**Что случилось с merge-commit?**Когда с коммита или с нескольких коммитов пропадает указатель (ветка), то коммит остаётся сам по себе. Git про него забывает, не показывает его в логах, в ветках и т.д. Но физически, коммит никуда не пропал. Он живёт себе в репозитории как невостребованная ячейка памяти без указателя и ждёт своего часа, когда git garbage collector её почистит.
Иногда бывает нужно вернуть коммит, который по ошибке был удалён. На помощь придёт **git reflog**. Он покажет всю историю, по каким коммитам вы ходили (как передвигался указатель *HEAD*). Используя вывод, можно найти id пропавшего коммита, сделать его checkout или создать на коммит указатель (ветку или тэг).
Выглядит это примерно так (история короткая, поместилась вся):
```
d229fa9 HEAD@{0}: reset: moving to collider/start
80b77c3 HEAD@{1}: commit (merge): Merged collider/terminate
d229fa9 HEAD@{2}: merge collider/start: Fast-forward
0c3aa28 HEAD@{3}: checkout: moving from collider/terminate to master
4ea02f5 HEAD@{4}: commit: Added Collider Terminate Function
0c3aa28 HEAD@{5}: checkout: moving from collider/start to collider/terminate
d229fa9 HEAD@{6}: commit: Added Collider Start Function
0c3aa28 HEAD@{7}: checkout: moving from collider/launch to collider/start
0c3aa28 HEAD@{8}: checkout: moving from collider/terminate to collider/launch
0c3aa28 HEAD@{9}: checkout: moving from collider/stop to collider/terminate
0c3aa28 HEAD@{10}: checkout: moving from collider/start to collider/stop
0c3aa28 HEAD@{11}: checkout: moving from master to collider/start
0c3aa28 HEAD@{12}: commit: Added collider init script
41f0540 HEAD@{13}: checkout: moving from v2 to master
75607a1 HEAD@{14}: commit: Ugly changes
55280dc HEAD@{15}: checkout: moving from master to v2
41f0540 HEAD@{16}: commit: Change 3
55280dc HEAD@{17}: commit: Change 2
598a03a HEAD@{18}: commit: Change 1
d80e5f1 HEAD@{19}: commit (initial): Init Project
```
Посмотрим, что получилось:

Для того, чтобы перестроить одну ветку на другую, нужно найти их общее начало, потом взять коммиты **перестраиваемой** ветки и, в таком же порядке, применить их на **основную** (base) ветку. Очень наглядная картинка (*feature* перестраивается на *master*):

Важное замечание: после «перестройки» это уже будут новые коммиты. А старые никуда не пропали и не сдвинулись.
> Для самопроверки и понимания: можно было бы вообще не отменять merge-commit. А взять ветку *collider/terminate* и перестроить на *collider/start*.
>
> Тогда ветка *collider/terminate* была бы продолжением *collider/start*, а *master* с merge-commit остался бы в стороне. В конце, когда работа была бы готова, *master* просто переустанавливается на нужный коммит (**git checkout master && git reset --hard collider/terminate**). Смысл тот же, просто другой порядок действий. Git очень гибок — как хочу, так и кручу.
>
>
В теории разобрались, пробуем на практике. Переключаемся в *collider/terminate* и перестраиваем на тот коммит, куда указывает *master* (или *collider/start*, кому как удобнее). Команда дословно «взять текущую ветку и перестроить её на указанный коммит или ветку»:
```
dev1(master)$ git checkout collider/terminate
Switched to branch 'collider/terminate'
dev1(collider/terminate)$ git rebase -i master # -i означает в интерактивном режиме, т.е. показать git rebase todo list и дать возможность вмешаться в процесс
```
Откроется редактор в котором будет приблизительно следующее:
```
pick 4ea02f5 Added Collider Terminate Function
# Rebase d229fa9..4ea02f5 onto d229fa9
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
# However, if you remove everything, the rebase will be aborted.
#
```
Если коротко: то в процессе перестройки мы можем изменять комментарии к коммитам, редактировать сами коммиты, объединять их или вовсе пропускать. Т.е. можно переписать историю ветки до неузнаваемости. На данном этапе нам это не нужно, просто закрываем редактор и продолжаем. Как и в прошлый раз, конфликтов нам не избежать:
```
error: could not apply 4ea02f5... Added Collider Terminate Function
When you have resolved this problem run "git rebase --continue".
If you would prefer to skip this patch, instead run "git rebase --skip".
To check out the original branch and stop rebasing run "git rebase --abort".
Could not apply 4ea02f5... Added Collider Terminate Function
dev1((no branch))$ git status
# Not currently on any branch.
# Unmerged paths:
# (use "git reset HEAD ..." to unstage)
# (use "git add/rm ..." as appropriate to mark resolution)
#
# both modified: collider.init.sh
#
no changes added to commit (use "git add" and/or "git commit -a")
```
Решаем конфликты с помощью **git mergetool** и продолжаем «перестройку» — **git rebase --continue**. Git в интерактивном режиме даёт нам возможность изменить и комментарий.
Результат:

Теперь уже не сложно обновить master и удалить всё ненужное:
```
dev1(collider/terminate)$ git checkout master
Switched to branch 'master'
Your branch is ahead of 'origin/master' by 5 commits.
dev1(master)$ git merge collider/terminate
Updating d229fa9..6661c2e
Fast-forward
collider.init.sh | 11 +++++++++++
1 file changed, 11 insertions(+)
dev1(master)$ git branch -d collider/start
Deleted branch collider/start (was d229fa9).
dev1(master)$ git branch -d collider/terminate
Deleted branch collider/terminate (was 6661c2e).
```
На данном этапе мы удаляли, редактировали, объединяли правки, а на выходе получили красивую линейную историю изменений:
##### Перерыв
Довольно много информации уже поступило, поэтому нужно остановиться и обдумать всё. На примерах мы познакомились со следующими возможностями git:
* Лёгкое создание репозиториев
* Клонирование репозиториев
* Git работает только с изменениями
* Один проект/библиотека/плагин — один репозиторий
* Ветки, комментарии, коммиты легко изменяются
* Можно выбрать любое состояние и начать от него новую историю
* Если изменения «лежат на одной прямой» то можно делать fast-forward (перемотка, объединение без конфликтов)
Дальше примеры пойдут по сложнее. Я буду использовать простой скрипт, который будет в файл дописывать случайные строки.
На данном этапе нам не важно, какое содержимое, но было бы очень неплохо иметь много различных коммитов, а не один. Для наглядности.
Скрипт добавляет случайную строчку к файлу и делает git commit. Это повторяется несколько раз:
```
dev1(master)$ for i in `seq 1 2`; do STR=`pwgen -C 20 -B 1`; echo $STR >> trash.txt; git commit -m "Added $STR" trash.txt; done
[master e64499d] Added rooreoyoivoobiangeix
1 file changed, 1 insertion(+)
[master a3ae806] Added eisahtaexookaifadoow
1 file changed, 1 insertion(+)
```
#### Передача и приём изменений
Настало время научиться работать с удалёнными репозиториями. В общих чертах, для работы нам нужно уметь:
* добавлять/удалять/изменять информацию о удалённых репозиториях
* получать данные (ветки, тэги, коммиты)
* отправлять свои данные (ветки, тэги, коммиты)
Вот список основных команд, которые будут использоваться:
1. `git remote` — управление удалёнными репозиториями
2. `git fetch` — получить
3. `git pull` — тоже самое что `git fetch` + `git merge`
4. `git push` — отправить
##### git remote
Как отмечалось выше, **origin** — это имя репозитория по умолчанию. Имена нужны, т.к. репозиториев может быть несколько и их нужно как-то различать. Например, у меня была копия репозитория на флешке и я добавил репозиторий **flash**. Таким образом я мог работать с двумя репозиториями одновременно: **origin** и **flash**.
Имя репозитория используется как префикс к имени ветки, чтоб можно было отличать свою ветку от чужой, например *master* и *origin/master*
**Небольшой трюк***master* в репозитории **origin** будет показываться как *origin/master*. Но как уже известно, можно дать ветке имя содержащее '/'.
Т.е. можно создать ветку с именем "*origin\/master*", которая будет являться просто обычной веткой и ничего общего с удалённой веткой *master* иметь не будет. Git послушный, сделает всё, что вы попросите. Конечно, не стоит так делать.
В справке по `git remote` достаточно хорошо всё описано. Как и ожидается, там есть команды: add, rm, rename, show.
`show` покажет основные настройки репозитория:
```
dev1(master)$ git remote show origin
* remote origin
Fetch URL: /home/sirex/proj/git-habr/origin
Push URL: /home/sirex/proj/git-habr/origin
HEAD branch: master
Remote branch:
master tracked
Local branch configured for 'git pull':
master merges with remote master
Local ref configured for 'git push':
master pushes to master (fast-forwardable)
```
Чтобы добавить существующий репозиторий используем `add`:
```
git remote add backup_repo ssh://user@myserver:backups/myrepo.git # просто пример
git push backup_repo master
```
##### git fetch
Команда говорит сама за себя: получить изменения.
Стоит отметить, что локально никаких изменений не будет. Git не тронет рабочую копию, не тронет ветки и т.д.
Будут скачены новые коммиты, обновлены только удалённые (remote) ветки и тэги. Это полезно потому, что перед обновлением своего репозитория можно посмотреть все изменения, которые «пришли» к вам.
Ниже есть описание команды push, но сейчас нам нужно передать изменения в origin, чтобы наглядно показать как работает fetch:
```
dev1(master)$ git push origin master
Counting objects: 29, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (21/21), done.
Writing objects: 100% (27/27), 2.44 KiB, done.
Total 27 (delta 6), reused 0 (delta 0)
Unpacking objects: 100% (27/27), done.
To /home/sirex/proj/git-habr/origin
d80e5f1..a3ae806 master -> master
```
Теперь от имени dev2 посмотрим, что есть и получим все изменения:
```
dev2(master)$ git log
commit d80e5f1746856a7228cc27072fa71f1c087d649a
Author: jsirex
Date: Thu Apr 4 04:21:07 2013 +0300
Init Project
# вообще ничего нет, получаем изменения:
dev2(master)$ git fetch origin
remote: Counting objects: 29, done.
remote: Compressing objects: 100% (21/21), done.
remote: Total 27 (delta 6), reused 0 (delta 0)
Unpacking objects: 100% (27/27), done.
From /home/sirex/proj/git-habr/origin
d80e5f1..a3ae806 master -> origin/master
```
Выглядит это так:

Обратите внимание, что мы находимся в *master*.
Что можно сделать:
`git checkout origin/master` — переключиться на удалённый master, чтобы «пощупать» его. При этом нельзя эту ветку редактировать, но можно создать свою локальную и работать с ней.
`git merge origin/master` — объединить новые изменения со своими. Т.к. у нас локальных изменений не было, то merge превратится в fast-forward:
```
dev2(master)$ git merge origin/master
Updating d80e5f1..a3ae806
Fast-forward
README.md | 2 ++
collider.init.sh | 31 +++++++++++++++++++++++++++++++
trash.txt | 2 ++
3 files changed, 35 insertions(+)
create mode 100755 collider.init.sh
create mode 100644 trash.txt
```
Если в origin появятся новые ветки, само собой fetch их тоже скачает. Также можно попросить **fetch** обновить только конкретную ветку, а не все.
**Важный момент**: когда кто-то удаляет ветку из origin, у вас локально всё равно остаётся запись о ней. Например, вы продолжаете видеть *origin/deleted/branch*, хотя её уже нет. Чтобы эти записи удалить используйте `git fetch origin --prune`.
##### git pull
`git pull` тоже самое что и git fetch + git merge. Разумеется, что изменения будут объединяться с соответствующими ветками: *master* с *origin/master*, *feature* с *origin/feature*. Ветки объединяются не по имени, как кто-то может подумать, а за счёт *upstream tracking branch*. Когда мы делаем checkout любой ветки для работы, git делает приблизительно следующее:
1. смотрит есть ли уже такая ветка локально и если есть берёт её
2. если ветки нет, смотрит есть ли она удалённо *origin/*
3. если есть, создаёт локально там же, где и *origin/* и «связывает» эти ветки (branch now is tracking remote *origin/*)
В файле **.git/config** можно это увидеть:
```
[branch "master"]
remote = origin
merge = refs/heads/master
```
В 95% случаев, вам не нужно менять это поведение.
Если были локальные изменения, то `git pull` автоматически объединит их с удалённой веткой и будет merge-commit, а не fast-forward. Пока мы что-то разрабатывали код устарел и неплохо было бы сначала обновиться, применить все свои изменения уже поверх нового кода и только потом отдать результат. Или пока продолжить локально. И чтоб история не смешивалась. Вот это и помогает делать `rebase`.
Чтобы git по умолчанию использовал `rebase`, а не `merge`, можно его попросить:
```
git config branch..rebase true
```
##### git push
`git push origin` — передать изменения. При этом все отслеживаемые (tracking) ветки будут переданы. Чтобы передать определённую ветку, нужно явно указать имя: `git push origin branch_name`.
На данном этапе могут возникнуть вопросы:
* как мне передать определённые изменения?
* как мне удалить ветку?
* как мне создать новую ветку с определённого коммита?
* и т.д.
На все вопросы может ответить расширенный вариант использования команды:
`git push origin <локальный_коммит_или_указатель>:<имя_ветки_в_origin>`
Примеры:
```
git push origin d80e5f1:old_master # удалённо будет создана или обновлена ветка old_master. будет указывать на коммит d80e5f1
git push origin my_local_feature:new_feature/with_nice_name # создать или обновить ветку new_feature/with_nice_name моей my_local_feature
git push origin :dead_feature # буквально передать "ничего" в dead_feature. Т.е. ветка dead_feature смотрит в никуда. Это удалит ветку
```
**Важно**: когда вы обновляете ветку, предполагается, что вы сначала забрали все последние изменения и только потом пытаетесь передать всё обратно. Git предполагает, что история останется линейной, ваши изменения продолжают текущие (fast-forward). В противном случае вы получите:`rejected! non fast-forward push!`.
Иногда, когда вы точно знаете, что делаете, это необходимо. Обойти это можно так:
```
git push origin master --force # когда вы точно понимаете, что делаете
```
#### Включаемся в проект
К этому моменту уже более-менее понятно, как работает push, pull. Более смутно представляется в чём разница между merge и rebase. Совсем непонятно зачем это нужно и как применять.
Когда кого-нибудь спрашивают:
— Зачем нужна система контроля версий?
Чаще всего в ответе можно услышать:
— Эта система помогает хранить все изменения в проекте, чтобы ничего не потерялось и всегда можно было «откатиться назад».
А теперь задайте себе вопрос: «как часто приходится откатываться назад?» Часто ли вам нужно хранить больше, чем последнее состояние проекта? Честный ответ будет: «очень редко». Я этот вопрос поднимаю, чтобы выделить гораздо более важную роль системы контроля версий в проекте:
> Система контроля версий позволяет вести совместную работу над проектом более, чем одному разработчику.
То, на сколько вам удобно работать с проектом совместно с другими разработчиками и то, на сколько система контроля версий вам помогает в этом — самое важное.
Используете %VCS\_NAME%? Удобно? Не ограничивает процесс разработки и легко адаптируется под требования? Быстро? Значит эта %VCS\_NAME% подходит для вашего проекта лучше всего. Пожалуй, вам не нужно ничего менять.
##### Типичные сценарии при работе над проектом
Теперь поговорим о типичных сценариях работы над проектом с точки зрения кода. А это:
* Выпуск релизов (release)
* Исправление ошибок (bug fixing)
* Срочные исправления (hotfix)
* Разработка нескольких фич одновременно (features development)
* Выпуск определённых фич или выпуск по готовности
Чтобы добиться такого процесса, нужно чётко определиться где и что будет хранится. Т.к. ветки легковесные (т.е. не тратят ресурсов, места и т.д.) под все задачи можно создать отдельные ветки. Это является хорошей практикой. Такой подход даёт возможность легко оперировать наборами изменений, включать их в различные ветки или полностью исключать неудачные варианты.
В *master* обычно хранится последняя выпущенная версия и он обновляется только от релиза к релизу. Не будет лишним сделать и tag с указанием версии, т.к. *master* может обновиться.
Нам понадобится ещё одна ветка для основной разработки, та самая в которую будет всё сливаться и которая будет продолжением *master*. Её будут тестировать и по готовности, во время релиза, все изменения будут сливать в *master*. Назовём эту ветку *dev*.
Если нам нужно выпустить hotfix, мы можем вернуться к состоянию *master* или к определённому тэгу, создать там ветку *hotfix/version* и начать работу по исправлению критических изменений. Это не затрагивает проект и текущую разработку.
Для разработки фич удобно будет использовать ветки *feature/*. Начинать эту ветку лучше с самых последних изменений и периодически «подтягивать» изменения из *dev* к себе. Чтобы сохранить историю простой и линейной, ветку лучше перестраивать на *dev* (`git rebase dev`).
Исправление мелких багов может идти напрямую в *dev*. Но даже для мелких багов или изменений рекомендуется создавать локально временные ветки. Их не надо отправлять в глобальный репозиторий. Это только ваши временные ветки. Такой подход даст много возможностей:
* Вы можете работать над несколькими задачами. Застряли на одном баге, переключились в dev, создали новую ветку и исправляете другой, потом обратно к первому. Обновились, бросили всё и начали делать третий.
* Проблема стала критичной на продакшене — перестроили (rebase) ветку с исправлением на *master* или определённый *hotfix* и выпустили новую версию только с одним исправлением.
* Таким же образом можно перенести работу на другие ветки, например на *feature*-ветки
* Перед тем как отправить изменения, ветку можно немного причесать, убрав оттуда лишние коммиты, исправив комментарии и т.д.
##### Исправление багов
Создадим ветку *dev* и рассмотрим типичный сценарий исправления багов.
```
dev1(master)$ git status
# On branch master
nothing to commit (working directory clean)
dev1(master)$ git checkout -b dev
Switched to a new branch 'dev'
dev1(dev)$ git push origin dev
Total 0 (delta 0), reused 0 (delta 0)
To /home/sirex/proj/git-habr/origin
* [new branch] dev -> dev
```
И второй разработчик «забирает» новую ветку к себе:
```
dev2(master)$ git pull
From /home/sirex/proj/git-habr/origin
* [new branch] dev -> origin/dev
Already up-to-date.
```
Пусть 2 разработчика ведут работу каждый над своим багом и делают несколько коммитов (пусть вас не смущает, что я таким некрасивым способом генерирую множество случайных коммитов):
```
dev1(dev)$ for i in `seq 1 10`; do STR=`pwgen -C 20 -B 1`; echo $STR >> trash.txt; git commit -m "Added $STR" trash.txt; done
[dev 0f019d0] Added ahvaisaigiegheweezee
1 file changed, 1 insertion(+)
[dev c715f87] Added eizohshochohseesauge
1 file changed, 1 insertion(+)
[dev 9b9672c] Added aitaquuerahshiqueeph
1 file changed, 1 insertion(+)
[dev 43dad98] Added zaesooneighufooshiph
1 file changed, 1 insertion(+)
[dev 9da2de3] Added aebaevohneejaefochoo
1 file changed, 1 insertion(+)
[dev e93f93e] Added rohmohpheinugogaigoo
1 file changed, 1 insertion(+)
[dev 54ba433] Added giehaokeequokeichaip
1 file changed, 1 insertion(+)
[dev 05f72db] Added hacohphaiquoomohxahb
1 file changed, 1 insertion(+)
[dev 8c03e0d] Added eejucihaewuosoonguek
1 file changed, 1 insertion(+)
[dev cf21377] Added aecahjaokeiphieriequ
1 file changed, 1 insertion(+)
```
```
dev2(master)$ for i in `seq 1 6`; do STR=`pwgen -C 20 -B 1`; echo $STR >> trash.txt; git commit -m "Added $STR" trash.txt; done
[master 1781a2f] Added mafitahshohfaijahney
1 file changed, 1 insertion(+)
[master 7df3851] Added ucutepoquiquoophowah
1 file changed, 1 insertion(+)
[master 75e7b2b] Added aomahcaashooneefoavo
1 file changed, 1 insertion(+)
[master d4dea7e] Added iexaephiecaivezohwoo
1 file changed, 1 insertion(+)
[master 1459fdb] Added quiegheemoighaethaex
1 file changed, 1 insertion(+)
[master 1a949e9] Added evipheichaicheesahme
1 file changed, 1 insertion(+)
```
Когда работа закончена, передаём изменения в репозиторий. Dev1:
```
dev1(dev)$ git push origin dev
Counting objects: 32, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (30/30), done.
Writing objects: 100% (30/30), 2.41 KiB, done.
Total 30 (delta 19), reused 0 (delta 0)
Unpacking objects: 100% (30/30), done.
To /home/sirex/proj/git-habr/origin
a3ae806..cf21377 dev -> dev
```
Второй разработчик:
```
dev2(master)$ git push origin dev
error: src refspec dev does not match any.
error: failed to push some refs to '/home/sirex/proj/git-habr/origin'
```
Что произошло? Во-первых мы хоть и сделали `pull`, но забыли переключиться на *dev*. А работать стали в *master*.
Когда работаете с git старайтесь «командовать» как можно конкретнее.
Я хотел передать изменения именно в *dev*. Если бы вместо `git push origin dev` я использовал просто `git push`,
то git бы сделал то, что он должен был бы сделать — передал изменения из нашего *master* в *origin/master*. Такую ситуацию можно исправить, но сложнее. Намного проще исправлять всё локально.
Как и говорилось выше, ничего страшного, всё поправимо. Как обычно, посмотрим что наделали `gitk --all`:

У нас вперёд «поехал» *master*, а должен был «поехать» *dev*. Вариантов исправить ситуацию несколько.
Вот можно, например, так:
1. Поскольку, никаких других изменений не было, переключимся на *dev*
2. Объединим все изменения из *master* в *dev*, где они и должны были быть (прямой путь, *fast-forward*, никаких проблем не будет)
3. Правильный *dev* мы запушим, а неправильный *master* «установим» в старую, правильную позицию, где он раньше и был (на *origin/master*)
На первый взгляд, кажется, что здесь много действий и всё как-то сложно. Но, если разобраться, то описание того, что нужно сделать намного больше, чем самой работы. И самое главное, мы уже так делали выше. Приступим к практике:
```
dev2(master)$ git checkout dev # переключаемся
Branch dev set up to track remote branch dev from origin.
Switched to a new branch 'dev'
dev2(dev)$ git merge master # наш fast-forward
Updating a3ae806..1a949e9
Fast-forward
trash.txt | 6 ++++++
1 file changed, 6 insertions(+)
dev2(dev)$ git checkout master # переключаемся на master чтобы...
Switched to branch 'master'
Your branch is ahead of 'origin/master' by 6 commits.
dev2(master)$ git reset --hard origin/master # ... чтобы сдвинуть его в правильное место
HEAD is now at a3ae806 Added eisahtaexookaifadoow
dev2(master)$ git checkout dev # вернёмся в dev
Switched to branch 'dev'
Your branch is ahead of 'origin/dev' by 6 commits.
```
Посмотрим на результат:

Теперь, всё как положено: наши изменения в *dev* и готовы быть переданы в origin.
Передаём:
```
dev2(dev)$ git push origin dev
To /home/sirex/proj/git-habr/origin
! [rejected] dev -> dev (non-fast-forward)
error: failed to push some refs to '/home/sirex/proj/git-habr/origin'
hint: Updates were rejected because the tip of your current branch is behind
hint: its remote counterpart. Merge the remote changes (e.g. 'git pull')
hint: before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
```
Передать не получилось, потому что кто-то другой (dev1) обновил репозиторий, передав свои изменения и мы просто «отстали». Нам нужно актуализировать своё состояние, сделав `git pull` или `git fetch`. Т.к. git pull сразу будет объединять ветки, я предпочитаю использовать git fetch, т.к. он даёт мне возможность осмотреться и принять решение позже:
```
dev2(dev)$ git fetch origin
remote: Counting objects: 32, done.
remote: Compressing objects: 100% (30/30), done.
remote: Total 30 (delta 19), reused 0 (delta 0)
Unpacking objects: 100% (30/30), done.
From /home/sirex/proj/git-habr/origin
a3ae806..cf21377 dev -> origin/dev
```

Есть несколько вариантов, чтобы передать наши изменения:
1. Принудительно передать наши изменения, стерев то, что там было: `git push origin dev --force`
2. Продолжить ветку, используя `git merge origin/dev` и потом `git push origin dev` (объединить новые изменения со своими и передать)
3. Перестроить нашу ветку наверх новой, что сохранит последовательность разработки и избавит от лишнего ветвления: `git rebase origin/dev` и потом `git push origin dev`.
Наиболее привлекательным является 3ий вариант, который мы и попробуем, причём в интерактивном режиме:
```
dev2(dev)$ git rebase -i origin/dev # перестраиваем текущую локальную ветку на origin/dev
```
Нам откроется редактор и даст возможность исправить нашу историю, например, поменять порядок коммитов или объединить несколько. Об этом писалось выше. Я оставлю как есть:
```
pick 1781a2f Added mafitahshohfaijahney
pick 7df3851 Added ucutepoquiquoophowah
pick 75e7b2b Added aomahcaashooneefoavo
pick d4dea7e Added iexaephiecaivezohwoo
pick 1459fdb Added quiegheemoighaethaex
pick 1a949e9 Added evipheichaicheesahme
# Rebase cf21377..1a949e9 onto cf21377
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
# However, if you remove everything, the rebase will be aborted.
#
```
В процессе перестройки возникнут конфликты. Решаем их через `git mergetool` (или как вам удобнее) и продолжаем перестройку `git rebase --continue`
Т.к. у меня всё время дописываются строчки в один файл, конфликтов не избежать, но на практике в проектах, когда работа над разными частями проекта распределена, конфликтов вообще не будет. Или они будут довольно редкими.
Отсюда можно вывести **пару полезных правил**:
* Каждый коммит должен содержать в себе не более одного логического изменения. Если вы делали фичу и заметили баг в коде, лучше исправить его отдельным коммитом. Позже, при объединении, конфликты будет очень просто решать, т.к. будет видно отдельный коммит с конфликтом и к чему он относится. Думайте о коммитах, как о кирпичиках, из которых можно построить проект. Каждый кирпич сам по себе логичен и завершён.
* Старайтесь распределять работу так, чтобы она не пересекалась, т.е. не редактировались одни и те же файлы в одних и тех же местах. Если логика какого-то класса будет меняться одновременно в двух ветках, то после объединения какие-то системы, использующие этот класс перестанут работать. А то и вовсе всё перестанет работать.
После того как все конфликты решены, история будет линейной и логичной. Для наглядности я поменял комментарии (интерактивный rebase даёт эту возможность):

Теперь наша ветка продолжает origin/dev и мы можешь отдать наши изменения: актуальные, адаптированные под новые коммиты:
```
dev2(dev)$ git push origin dev
Counting objects: 20, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (18/18), done.
Writing objects: 100% (18/18), 1.67 KiB, done.
Total 18 (delta 11), reused 0 (delta 0)
Unpacking objects: 100% (18/18), done.
To /home/sirex/proj/git-habr/origin
cf21377..8212c4b dev -> dev
```
Далее история повторяется. Для удобства или в случае работы над несколькими багами, как говорилось выше, удобно перед началом работы создать отдельные ветки из *dev* или *origin/dev*.
**Короткий итог**: обычное исправление багов может быть осуществлено по следующему простому алгоритму:
1. Исправление в ветке *dev* или отдельной
2. Получение изменений из origin (`git fetch origin`)
3. Перестройка изменений на последнюю версию (`git rebase -i origin/dev`)
4. Передача изменений в origin (`git push origin dev`)
##### Feature branch
Бывает так, что нужно сделать какой-то большой кусок работы, который не должен попадать в основную версию пока не будет закончен. Над такими ветками могут работать несколько разработчиков. Очень серьёзный и объёмный баг может рассматриваться с точки зрения процесса работы в git как фича — отдельная ветка, над которой работают несколько человек. Сам же процесс точно такой же как и при обычном исправлении багов. Только работа идёт не с *dev*, а с *feature/name* веткой.
Вообще, такие ветки могут быть коротко-живущими (1-2 неделя) и долго-живущими (месяц и более). Разумеется, чем дольше живёт ветка, тем чаще её нужно обновлять, «подтягивая» в неё изменения из основной ветки. Чем больше ветка, тем, вероятно, больше будет накладных расходов по её сопровождению.
###### Начнём с коротко-живущих (short-live feature branches)
Обычно ветка создаётся с самого последнего кода, в нашем случае с ветки dev:
```
dev1(dev)$ git fetch origin
remote: Counting objects: 20, done.
remote: Compressing objects: 100% (18/18), done.
remote: Total 18 (delta 11), reused 0 (delta 0)
Unpacking objects: 100% (18/18), done.
From /home/sirex/proj/git-habr/origin
cf21377..8212c4b dev -> origin/dev
dev1(dev)$ git branch --no-track feature/feature1 origin/dev # сделать ветку feature/feature1 из origin/dev, но не связывать их вместе
dev1(dev)$ git push origin feature/feature1 # отдать ветку в общий репозиторий, чтобы она была доступна другим
Total 0 (delta 0), reused 0 (delta 0)
To /home/sirex/proj/git-habr/origin
* [new branch] feature/feature1 -> feature/feature1
```
Теперь работу на feature1 можно вести в ветке *feature/feature1*. Спустя некоторое время в нашей ветке будет много коммитов, и работа над feature1 будет закончена. При этом в *dev* тоже будет много изменений. И наша задача отдать наши изменения в *dev*.
Выглядеть это будет приблизительно так:

Ситуация напоминает предыдущую: две ветки, одну нужно объединить с другой и передать в репозиторий. Единственное отличие, это две публичные (удалённые) ветки, а не локальные. Это требует небольшой коммуникации. Когда работа закончена, один разработчик должен предупредить другого, что он собирается «слить» изменения в *dev* и, например, удалить ветку. Таким образом передавать в эту ветку что-либо будет бессмысленно.
А дальше алгоритм почти такой как и был:
```
git fetch origin # обновиться на всякий
git rebase -i origin/dev # перестраиваемся, теперь история у нас линейная, как будто бы feature1 сделали прямо в dev за одно мгновение. Пишу origin/dev, а не dev потому что после обновления ветка ушла вперёд, а наша локальная осталась на месте
git checkout dev # переключаемся на ветку, куда будем принимать все изменения
git merge feature/feature1 # или даже git reset --hard feature/feature1. Результат должен быть один и тот же. Обязательно убедитесь, что был fast-forward.
```
Картинка, feature1 стала частью dev, то что на и нужно было:
Делаем push и чистим за собой ненужное:
```
dev1(dev)$ git push origin dev
Counting objects: 11, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (9/9), done.
Writing objects: 100% (9/9), 878 bytes, done.
Total 9 (delta 6), reused 0 (delta 0)
Unpacking objects: 100% (9/9), done.
To /home/sirex/proj/git-habr/origin
3272f59..e514869 dev -> dev
dev1(dev)$ git push origin :feature/feature1 # удаляем удалённую ветку, если нужно
To /home/sirex/proj/git-habr/origin
- [deleted] feature/feature1
dev1(dev)$ git branch -d feature/feature1 # удаляем локально
Deleted branch feature/feature1 (was e514869).
```
###### Долго-живущие ветки (long-live feature branches)
Сложность долго-живущих веток в их поддержке и актуализации. Если делать всё как описано выше то, вероятно быть беде: время идёт, основная ветка меняется, проект меняется, а ваша фича основана на очень старом варианте. Когда настанет время выпустить фичу, она будет настолько выбиваться из проекта, что объединение может быть очень тяжёлым или, даже, невозможным. Именно поэтому, ветку нужно обновлять. Раз dev уходит вперёд, то мы будем просто время от времени перестраивать нашу ветку на dev.
Всё бы хорошо, но только нельзя просто так взять и перестроить публичную ветку: ветка после ребэйза — это уже новый набор коммитов, совершенно другая история. Она не продолжает то, что уже было. Git не примет такие изменения: два разных пути, нет fast-forward'а. Чтобы переписать историю разработчикам нужно договориться.
Кто-то будет переписывать историю и принудительно выкладывать новый вариант, а в этот момент остальные не должны передавать свои изменения в текущую ветку, т.к. она будет перезаписана и всё пропадёт. Когда первый разработчик закончит, все остальные перенесут свои коммиты, которые они успеют сделать во время переписи уже на новую ветку. ~~Кто говорил, что нельзя ребэйзить публичные ветки?~~
Приступим к практике:
```
dev1(dev)$ git checkout -b feature/long
Switched to a new branch 'feature/long'
dev1(feature/long)$ git push origin dev
Everything up-to-date
dev1(feature/long)$ генерируем_много_коммитов
dev1(feature/long)$ git push origin feature/long
Counting objects: 11, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (9/9), done.
Writing objects: 100% (9/9), 807 bytes, done.
Total 9 (delta 6), reused 0 (delta 0)
Unpacking objects: 100% (9/9), done.
To /home/sirex/proj/git-habr/origin
* [new branch] feature/long -> feature/long
```
Второй разработчик подключается к работе всё стандартно:
```
dev2(dev)$ git pull
remote: Counting objects: 11, done.
remote: Compressing objects: 100% (9/9), done.
remote: Total 9 (delta 6), reused 0 (delta 0)
Unpacking objects: 100% (9/9), done.
From /home/sirex/proj/git-habr/origin
* [new branch] feature/long -> origin/feature/long
Already up-to-date.
dev2(dev)$ git checkout feature/long
Branch feature/long set up to track remote branch feature/long from origin.
Switched to a new branch 'feature/long'
dev2(feature/long)$ делаем много коммитов
dev2(feature/long)$ git pull --rebase feature/long # fetch + rebase одной строчкой
dev2(feature/long)$ git push origin feature/long
Counting objects: 11, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (9/9), done.
Writing objects: 100% (9/9), 795 bytes, done.
Total 9 (delta 6), reused 0 (delta 0)
Unpacking objects: 100% (9/9), done.
To /home/sirex/proj/git-habr/origin
baf4c6b..ce9e58d feature/long -> feature/long
```
Добавим ещё несколько коммитов в основную ветку *dev* и история будет такая:
Настало время актуализировать *feature/long*, но при этом разработка должна продолжиться отдельно. Пусть перестраивать будет dev1. Тогда он предупреждает dev2 об этом и начинает:
```
dev1(feature/long)$ git fetch origin
dev1(feature/long)$ git rebase -i origin/dev
... решение конфликтов, если есть, и т.д.
```
В это время dev2 продолжает работать, но знает, что ему нельзя делать push, т.к. нужной ветки ещё нет (а текущая будет удалена).
Первый заканчивает rebase и история будет такой:
Ветка перестроена, а *origin/feature/long* остался там, где и был. Цели мы достигли, теперь нужно поделиться со всеми:
```
dev1(feature/long)$ git push origin feature/long
To /home/sirex/proj/git-habr/origin
! [rejected] feature/long -> feature/long (non-fast-forward)
error: failed to push some refs to '/home/sirex/proj/git-habr/origin'
hint: Updates were rejected because the tip of your current branch is behind
hint: its remote counterpart. Merge the remote changes (e.g. 'git pull')
hint: before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
```
Git лишний раз напоминает, что что-то не так. Но теперь, мы точно знаем, что мы делаем, и знаем, что так надо:
```
dev1(feature/long)$ git push origin feature/long --force
Counting objects: 20, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (18/18), done.
Writing objects: 100% (18/18), 1.58 KiB, done.
Total 18 (delta 12), reused 0 (delta 0)
Unpacking objects: 100% (18/18), done.
To /home/sirex/proj/git-habr/origin
+ ce9e58d...84c3001 feature/long -> feature/long (forced update)
```
Теперь можно работать дальше предупредив остальных об окончании работ.
Посмотрим, как эти изменения отразились на окружающих и на dev2 в частности:
```
dev2(feature/long)$ git fetch origin
remote: Counting objects: 20, done.
remote: Compressing objects: 100% (18/18), done.
remote: Total 18 (delta 12), reused 0 (delta 0)
Unpacking objects: 100% (18/18), done.
From /home/sirex/proj/git-habr/origin
+ ce9e58d...84c3001 feature/long -> origin/feature/long (forced update)
```
История разошлась, наши коммиты перестроены, кроме одного. Если бы коммитов вообще не было, т.е. разработчик dev2 читал бы хабр, пока первый работает, то достаточно было бы передвинуть указатель `feature/long` на `origin/feature/long` и продолжить работу. Но у нас есть один коммит, который надо добавить. Тут нам опять поможет rebase, вместе с ключом `--onto`:
`git rebase --onto <на_какую_ветку_перестроить> <по\_какой\_коммит\_или\_имя\_ветки>`
Такой подход позволяет взять только часть (некоторую последовательность коммитов) для перестроения. Бывает полезно, когда нужно перенести несколько последних коммитов.
Вспомним также про запись `HEAD~1`. К указателю можно применить оператор ~N, чтобы указать на предыдущий N-ый коммит.
`HEAD~1` — это предыдущий, а `HEAD~2` — это предпредыдущий. `HEAD~5` — 5 коммитов назад. Удобно, чтобы не запоминать id.
Посмотрим, как теперь нам перестроить только один коммит:
```
git rebase -i --onto origin/feature/long feature/long~1 feature/long
```
Разберём подробнее:
1. мы находимся на feature/long, которая полностью отличается от новой, но содержит нужный нам коммит (1, последний)
2. мы командуем перестроить на origin/feature/long (новое начало у ветки)
3. сама ветка эта feature/long
4. но перестраивать её надо не всю (поиск общего начала и перестройка всех коммитов не нужна, они там уже есть), а только начиная с предыдущего коммита (не включительно). Т.е. с *feature/long~1*
Если бы нам надо было перетянуть 4 коммита, то было бы `feature/long~4`.
```
dev2(feature/long)$ git rebase -i --onto origin/feature/long feature/long~1 feature/long
Successfully rebased and updated refs/heads/feature/long.
```

Осталось продолжить работу.
Есть ещё одна **полезная** команда, которая могла бы пригодиться и в этом случае, и во многих других — `git cherry-pick`.
Находясь в любом месте можно попросить git взять любой коммит и применить его в текущем месте. Нужный нам коммит можно было «утащить»:
```
git reset --hard origin/feature/long && git cherry-pick commit_id # commit_id обязательно нужно запомнить, т.к. после reset он будет сам по себе
```
###### Hotfixes
Hotfixы нужны, т.к. бывают очень критичные баги, которые нужно исправить как можно быстрее. При этом нельзя передать вместе с hotfix-ом последний код, т.к. он не оттестирован и на полное тестирование нет времени. Нужно только это исправление, максимально быстро и оттестированное. Чтобы это сделать, достаточно взять последний релиз, который был отправлен на продакшен. Это тот, где у вас остался *tag* или *master*. Тэги играют очень важную роль, помогая понять что именно было собрано и куда это попало.
Тэги делаются командой ````
git tag и тоже могут содержать '/' в своём имени.
Для выпуска hotfix-а нам нужно:
1. создать ветку hotfix из tag или master
2. сделать исправление (или cherry-pick конкретного коммита, вдруг уже где-то это исправили)
3. сделать тэг
4. выпустить билд
5. и возможно с помощью cherry-pick передать изменения в основную ветку, если его там не было. Чтоб не потерялось.
Превратим наш план в команды git:
dev2(feature/long)$ git checkout master
Switched to branch 'master'
dev2(master)$ git tag release/1.0 # тэг для примера, пусть он уже был
dev2(master)$ git checkout -b hotfix/1.0.x
Switched to a new branch 'hotfix/1.0.x'
dev2(hotfix/1.0.x)$ .. исправления и коммиты
dev2(hotfix/1.0.x)$ git push origin hotfix/1.0.x
Counting objects: 5, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 302 bytes, done.
Total 3 (delta 1), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
To /home/sirex/proj/git-habr/origin
* [new branch] hotfix/1.0.x -> hotfix/1.0.x
dev2(hotfix/1.0.x)$ git tag release/1.0.1 # делаем тэг
dev2(hotfix/1.0.x)$ git checkout dev # переключаемся в основную ветку
Switched to branch 'dev'
dev2(dev)$ git cherry-pick release/1.0.1 # лень запоминать id, зато есть указатель на нужный нам коммит.
# если были конфликты, то после разрешения наберите git commit
dev2(dev)$ git commit
[dev 9982f7b] Added rahqueiraiheinathiav
1 file changed, 1 insertion(+)
dev2(dev)$ git push origin dev
Counting objects: 5, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 328 bytes, done.
Total 3 (delta 2), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
To /home/sirex/proj/git-habr/origin
b21f8a5..9982f7b dev -> dev
```
Быстро и просто, не так ли? Если у вас было 2 коммита в *hotfixes*, возможно проще будет сделать 2 раза `cherry-pick` в *dev*. Но если их было много, можно опять воспользоваться командой `git rebase --into ...` и перестроить целую цепочку коммитов.
#### Всякие полезности
Git позволяет настраивать aliasы для различных команд. Это бывает очень удобно и сокращает время набора команд. Приводить здесь примеры не буду, в Интернете их полно, просто поищите.
Перед тем, как отдавать свои изменения их можно перестроить на самих себя, чтобы привести историю в порядок.
Например, в логах может быть такое:
```
9982f7b Finally make test works
b21f8a5 Fixed typo in Test
3eabaab Fixed typo in Test
e514869 Added Test for Foo
b4439a2 Implemented Method for Foo
250adb1 Added class Foo
```
Перестроим сами себя, но начиная с 6 коммитов назад:
```
dev2(dev)$ git rebase -i dev~6 # т.к. нам всё равно отдавать это в origin/dev мы можем перестроить прямо на него
dev2(dev)$ git rebase -i origin/dev
```
Теперь в интерактивном режиме можно объединить (squash) первые два коммита в один и последние четыре. Тогда история будет выглядеть так:
```
0f019d0 Added Test for class Foo
a3ae806 Implemented class Foo
```
Такое намного приятнее передавать в общим репозиторий.
Обязательно посмотрите, что умеет `git config` и `git config --global`. Перед тем, как начнёте работать с реальным проектом, неплохо было бы настроить свой username и email:
```
git config --global user.name sirex
git config --global user.email [email protected]
```
На одном проекте у нас велась параллельная разработка очень многих фич. Они все разрабатывались в отдельных ветках, но тестировать их нужно было вместе. При этом на момент выпуска билда для тестирования не было понятно, готовы фичи или нет: могли поменяться требования или найтись серьёзные баги. И стал вопрос: как продолжить работу над всеми фичами не объединяя их в принципе никогда, но объединяя всё перед релизом? Противоречие? Git красиво помогает решить эту проблему и вот как:
1. для выпуска билда была создана отдельная ветка, куда все фичи мержились (`git merge --no-ff`)
2. ветка отдавалась на тестирование
3. разработка продолжалась в своих ветках
4. новые изменения опять объединялись (`git merge --no-ff`)
5. Если тестируемую временную ветку просто удалить, все связанные коммиты с ней исчезнут и история опять распадётся на много отдельных веток. А их потом можно снова пересобрать
6. Когда какая-то фича абсолютна готова к релизу, только её одну можно перестроить на *dev* и протолкнуть в релиз.
7. Операция с остальными, неготовыми ветками, повторяется
#### Выводы
* Git очень гибкая система, она не лучше, не хуже других. Она просто другая сама по себе.
* Если вы работаете над проектом и используете git, то не будет никакой халявы или магии, что оно само как-то разберётся и сделает то, что вы захотите. Вам **придётся** его выучить.
* Чтобы выучить git и все его команды не надо месяц или два "ходить вокруг, да около". Потратьте пару часов сегодня и пару завтра. Всё будет намного проще.
* Пользуйтесь консольным клиентом. Так вы быстрее запомните команды, будете лучше понимать git, сможете наиболее быстро и точно командовать git'у то, что вы хотите сделать. Не надо гадать, что делает та или иная кнопочка в git gui plugin for %YOUR\_IDE%, не надо искать нужный пункт меню.
* Договоритесь о процессе разработке в команде. 2 часа, митинг, доска - вот что вам нужно. В конце небольшая памятка на wiki для вновь прибывших или в качестве справки тоже будет не лишней.
* Пишите в своё удовольствие, делайте коммиты так часто, как вам хочется, перестраивайте их, делайте патчи, объединяйте, шарьте историю напрямую с разработчиками - в git всё это очень легко.
* Придумывайте новые процессы, которые вам подходят, которые требует проект - скорее всего git сможет вам помочь этого достичь.
#### Причемания и апдейты
[gcc](https://habr.com/ru/users/gcc/) рекомендовал посмотреть на [Git Extensions](https://code.google.com/p/gitextensions/).
[borNfree](https://habr.com/ru/users/bornfree/) подсказал ещё один GUI клиент [Source Tree](http://sourcetreeapp.com/).
[zloylos](https://habr.com/ru/users/zloylos/) поделился ссылкой на [визуализатор для git](https://github.com/gurugray/git-trainer)
[olancheg](https://habr.com/ru/users/olancheg/) предложил посмотреть на [ещё один туториал для новичков](http://githowto.com/ru).
*PS. Что тут обычно пишут, когда первый пост на хабре? Прошу не судить строго, писал как мог.*` | https://habr.com/ru/post/174467/ | null | ru | null |
# Руководство разработчика Prism — часть 8.1, навигация на основе представлений (View-Based Navigation)
> **Оглавление**
>
> 1. [Введение](http://habrahabr.ru/post/176851/)
> 2. [Инициализация приложений Prism](http://habrahabr.ru/post/176853/)
> 3. [Управление зависимостями между компонентами](http://habrahabr.ru/post/176861/)
> 4. [Разработка модульных приложений](http://habrahabr.ru/post/176863/)
> 5. [Реализация паттерна MVVM](http://habrahabr.ru/post/176867/)
> 6. [Продвинутые сценарии MVVM](http://habrahabr.ru/post/176869/)
> 7. [Создание пользовательского интерфейса](http://habrahabr.ru/post/176895/)
>
> 1. [Рекомендации по разработке пользовательского интерфейса](http://habrahabr.ru/post/177925/)
> 8. [Навигация](http://habrahabr.ru/post/178009/)
> 1. [Навигация на основе представлений (View-Based Navigation)](http://habrahabr.ru/post/182052/)
> 9. [Взаимодействие между слабо связанными компонентами](http://habrahabr.ru/post/182580/)
>
### Навигация на основе представлений (*View-Based Navigation*)
Несмотря на то, что навигация на основе состояний может быть полезна в сценариях, описанных ранее, тем не менее, навигация в приложении часто требует замены одного представления на другое. В Prism, такой вид навигации называется «навигация на основе представлений (*view-based navigation*)».
В зависимости от требований к приложению, процесс навигации может быть довольно сложным и требующим аккуратной координации. Ниже перечислены некоторые из трудностей, с которыми можно столкнуться при реализации навигации на основе представлений:
* Цель навигации — контейнер для добавляемых, или удаляемых представлений — может обрабатывать навигацию разными способами при добавлении и удалении представлений, или может визуализировать процесс навигации по-разному. Во многих случаях, целью навигации является обычный `Frame`, или `ContentControl`, и представления просто отображаются внутри этих элементов управления. Однако существует множество сценариев, когда целью навигации является другой вид элементов управления, таких как `TabControl`, или `ListBox`. В таких случаях, навигация может потребовать активации или выделения уже существующего представления, или добавление нового представления.
* Приложению часто будет требоваться, каким-либо образом идентифицировать представление, к которому должна быть выполнена навигация. Для примера, в web-приложениях, страница, к которой выполняется навигация, напрямую идентифицируется по URI. В клиентских приложениях, представление может быть идентифицировано по имени его типа, по расположению файла ресурсов, или множеством других способов. В составных приложениях, состоящих из слабо связанных модулей, представления зачастую определены в раздельных модулях. Отдельные представления, в таких случаях, должны иметь возможность быть идентифицированы без создания дополнительных зависимостей между модулями.
* После идентификации представления, процесс его создания и инициализации должен быть тщательно скоординирован. Это особенно важно при использовании паттерна MVVM. В таком случае, представления и соответствующая модель представления должны быть созданы и ассоциированы друг с другом во время совершения навигации. В случае использования контейнера внедрения зависимостей, такого как Unity, или MEF, при создании модели представления и/или представления может потребоваться использование особого механизма конструирования.
* MVVM паттерн позволяет отделить UI приложения от его логики взаимодействия с пользователем и бизнес-логики. Однако процесс навигации может охватывать как UI, так и логику приложения. Пользователь может начать навигацию внутри представления, в результате чего представление будет обновлено. Но часто будет требоваться возможность инициировать и скоординировать навигацию из модели представления. Важным аспектом для рассмотрения, является способность чётко разделить навигационное поведение между представлением и моделью представления.
* Приложению часто может потребоваться передавать параметры, или контекст, представлению для его корректной инициализации. Для примера, если пользователь производит навигацию к представлению для редактирования информации о выбранном клиенте, ID этого клиента, или его данные, должны быть переданы в представление, для отображения в нем корректной информации.
* Многим приложениям необходимо тщательно координировать навигацию для уверенности, что будут выполнены определённые бизнес-требования. К примеру, пользователю может быть показано всплывающее сообщение о некорректности введённых им данных, во время попытки навигации к другому представлению. Этот процесс требует координации между предыдущим и новым представлениями.
* Наконец, большинство современных приложений позволяют пользователю производить навигацию к предыдущему, или к следующему представлению. Аналогично, некоторые приложения реализуют свой рабочий процесс, используя последовательность представлений, или форм и позволяют пользователю производить по ним навигацию вперёд или назад, добавляя или редактируя данные, перед тем, как завершить задачу и отправить все сделанные изменения одним пакетом. Такие сценарии требуют некоторого механизма журналирования, для того, чтобы последовательность навигации могла быть сохранена, повторена, или предопределена.
Prism предоставляет руководство по решению этих проблем, расширяя механизм регионов для поддержки навигации. Следующие разделы содержат краткую сводку о регионах Prism и рассказывают о том, как они были расширены для поддержки навигации на основе представлений.
#### Обзор регионов (*Region*) Prism
Регионы Prism были спроектированы для поддержки разработки составных приложений (приложений, состоящих из нескольких модулей), позволяя конструировать пользовательский интерфейс слабо связанным образом. Регионы позволяют отображать представления, определённые в модулях, в UI приложения, причём модули не обязаны знать о полной структуре пользовательского интерфейса. Это позволяет легко менять разметку UI приложения, без необходимости вносить изменения в сами модули.
Регионы Prism, по большей части, являются именованными заполнителями, в которых отображаются представления. Любой элемент управления может быть объявлен как регион, с помощью простого добавления присоединенного свойства `RegionName`, как показано ниже.
```
```
Для каждого элемента управления, определённого как регион, Prism создаёт объект `Region` (регион), представляющий сам регион, и объект `RegionAdapter` (адаптер региона), задачей которого является управление расположением и активацией представлений в заданном элементе управления. Prism Library предоставляет реализацию `RegionAdapter` для большинства элементов управления Silverlight и WPF. Вы можете создать свой собственный `RegionAdapter` для поддержки дополнительных элементов управления, или для реализации особого поведения. Класс `RegionManager` (менеджер регионов) предоставляет доступ к объектам `Region` приложения.
Во многих случаях, регионом может быть простой элемент управления, такой как `ContentControl`, который может отображать только одно представление в один момент времени. В других случаях, это может быть элемент управления, позволяющий отображать сразу несколько представлений, такой как `TabControl`, или `ListBox`.
Адаптер региона управляет списком представлений, ассоциированных с этим регионом. Одно, или несколько из этих представлений, могут быть отображены в элементе управления региона, в соответствии с его стратегией отображения содержимого. Представлениям могут быть назначены имена, которые могут быть использованы для их поиска в дальнейшем. Адаптер региона также управляет тем, какое представление является активным в данном регионе. Активным, является то представление, которое выделено в данный момент, или является самым верхним. К примеру, в `TabControl`, активным является то представление, которое отображено на выделенной вкладке, в `ContentControl` — то, которое отображается на экране в данный момент.
> **Заметка.**
>
> Определение того, какое представление является активным, особенно важно в процессе навигации. Часто может понадобиться, чтобы активное представление принимало участие в навигации, к примеру, чтобы оно сохраняло данные перед тем, как пользователь уйдёт с него, или, чтобы оно запросило отмену, или подтверждение операции.
>
>
Предыдущие версии Prism позволяли отображать представления в регионах двумя различными способами. Первый способ, называемый внедрение представления (*view injection*), позволял программно отображать представления в регионе. Данный подход полезен при отображении динамического содержания, когда представление, которое необходимо отобразить в регионе, часто изменяется, отображая логику приложения.
Внедрение представлений поддерживается через предоставление метода `Add` в классе `Region`. Следующий код показывает, как вы можете получить ссылку на объект `Region` через класс `RegionManager`, и программно добавить в него представление. В примере, представление создаётся с помощью DI контейнера.
```
IRegionManager regionManager = ...;
IRegion mainRegion = regionManager.Regions["MainRegion"];
InboxView view = this.container.Resolve();
mainRegion.Add(view);
```
Следующий метод, называемый обнаружение представления (*view discovery*), позволяет модулям регистрировать сопоставление типов представлений с именами регионов. В момент, когда регион с заданным именем будет отображён на экране, будет автоматически создан экземпляр соответствующего представления и отображён в этом регионе. Этот поход полезен для отображения сравнительно статического содержания, когда представление, отображённое в регионе, не меняется.
Обнаружение представления поддерживается через метод `RegisterViewWithRegion` в классе `RegionManager`. Этот метод позволяет задать метод обратного вызова, который будет вызван при отображении региона с заданным именем. Следующий пример показывает, как можно создать представление (использую контейнер внедрения зависимостей) при отображении региона с именем *«MainRegion»*.
```
IRegionManager regionManager = ...;
regionManager.RegisterViewWithRegion("MainRegion", () => container.Resolve());
```
Для более подробного обзора регионов Prism, смотрите главу "[Создание пользовательского интерфейса](http://habrahabr.ru/post/176895/)". Далее в статье будут рассмотрено, как регионы были расширены для поддержки навигации, и как преодолеть описанные ранее проблемы.
#### Базовая навигация в регионах
Оба описанных выше способа отображения представлений в регионах, могут быть расценены, как некоторая ограниченная форма навигации — внедрение представления является формой явной, программной навигации, а обнаружение представления — неявной, или отложенной навигацией. Однако в Prism 4.0 регионы были расширены для поддержки более общего понятий навигации, основанного на URI и расширяемом механизме навигации.
Навигация в пределах региона означает отображение нового представления в нём. Отображаемое представление идентифицируется с помощью URI, который, по умолчанию, ссылается на имя представления, к которому осуществляется навигация. Вы можете инициировать навигацию программно, используя метод `RequestNavigate`, определённый в интерфейсе `INavigateAsync`.
> **Заметка.**
>
> Несмотря на название, интерфейс `INavigateAsync` не подразумевает асинхронную навигацию, выполняемую в отдельном потоке. Наоборот, `INavigateAsync` подразумевает проведение псевдо-асинхронной навигации. Метод `RequestNavigate` может завершиться синхронно, после окончания навигации, или он может завершиться до окончания навигации, например, когда пользователю нужно подтвердить навигацию. Позволяя вам задавать метод обратного вызова во время навигации, Prism даёт возможность поддержки таких сценариев без сложностей обращения с фоновыми потоками.
>
>
Интерфейс `INavigateAsync` реализует класс `Region`, позволяя инициировать навигацию в этом регионе.
```
IRegion mainRegion = ...;
mainRegion.RequestNavigate(new Uri("InboxView", UriKind.Relative));
```
Вы также можете вызвать метод `RequestNavigate` на объекте `RegionManager`, задав имя региона, на котором производится навигация. Этот метод находит ссылку на соответствующий регион и вызывает на нём метод `RequestNavigate`. Это показано на примере ниже.
```
IRegionManager regionManager = ...;
regionManager.RequestNavigate("MainRegion", new Uri("InboxView", UriKind.Relative));
```
По умолчанию, навигационный URI задаёт имя представления, по которому оно зарегистрировано в контейнере. Код ниже иллюстрирует взаимоотношения между именем регистрации представления в контейнере Unity и использования этого имени во время навигации.
```
container.RegisterType("InboxView");
regionManager.Regions[Constants.MainRegion].RequestNavigate(new Uri("InboxView", UriKind.Relative));
```
> **Заметка.**
>
> При создании представления навигационным сервисом, он запрашивает объект тип `Object` из контейнера, с именем, предоставленном в навигационном URI. Различные контейнеры используют различные механизмы регистрации для поддержки этого. К примеру, в Unity, вам нужно зарегистрировать представления, сопоставив тип `Object` с этим представлением, и предоставив имя регистрации, соответствующее имени в навигационном URI. В MEF нужно всего лишь задать имя контракту в атрибуте `ExportAttribute`.
>
>
Пример. При использовании Unity для регистрации представления:
**Не используйте:**
```
container.RegisterType("InboxView");
```
**Используйте вместо этого:**
```
container.RegisterType("InboxView");
```
> **Заметка.**
>
> Имя, используемое для регистрации и навигации, не обязательно должно быть связано с именем типа представления, подойдёт любая строка. Для примера, вместо строки, вы можете явно использовать полное имя типа: `typeof(InboxView).FullName`;
>
>
В MEF, вы просто можете экспортировать представление с требуемым именем.
```
[Export("InboxView")]
public partial class InboxView : UserControl { ... }
```
Во время навигации, заданное представление запрашивается из контейнера вместе с соответствующей моделью представления и другими зависимостями. После этого, оно добавляется в заданный регион и активируется (подробности про активацию будут далее в статье).
> **Заметка.**
>
> Предшествующее описание иллюстрирует *view-first* навигацию, когда URI ссылается на имя представления, с которым оно было экспортировано или зарегистрировано в контейнере. С *view-first* навигацией, зависимая модель представления создаётся как зависимость представления. Альтернативным подходом является использование *view model–first* навигацию, когда навигационный URI ссылается на имя модели представления, с которым она была зарегистрирована в контейнере. Такой подход может быть полезен, когда представления определены, как шаблоны данных, или когда вы хотите, чтобы схема навигации была определена независимо от представлений.
>
>
Метод `RequestNavigate` также позволяет задать метод обратного вызова, который будет вызван при завершении навигации.
```
private void SelectedEmployeeChanged(object sender, EventArgs e) {
...
regionManager.RequestNavigate(RegionNames.TabRegion, "EmployeeDetails", NavigationCompleted);
}
private void NavigationCompleted(NavigationResult result) {
...
}
```
Класс `NavigationResult` имеет свойства, через которые можно получить информацию о навигационной операции. Свойство `Result` показывает, завершилась ли навигация. Если навигация завершилась с ошибкой, то свойство `Error` будет содержать ссылку на любые исключения, вброшенные во время навигации. Через свойство `Context` можно получить доступ к навигационному URI и любым параметрам, которые он содержит, а также к ссылке на сервис, координирующий навигационные операции.
#### Участие представления и модели представления в навигации
Часто бывает, что и представление, и модель представления в вашем приложении захотят принять участие в навигации. Сделать это позволяет интерфейс `INavigationAware`. Вы можете реализовать этот интерфейс в представлении, или (более часто) в модели представления. Реализовав его, ваше представление, или модель представления могут принять непосредственное участие в процессе навигации.
> **Заметка.**
>
> В последующем описании делается предположение, что навигация происходит между представлениями. Но нужно отметить, что интерфейс `INavigationAware` во время навигации будет вызываться вне зависимости от того, реализован ли он в представлении, или в модели представления. Во время навигации, Prism проверяет, реализует ли представление `INavigationAware`, если да, то на нём вызываются необходимые методы. Также, Prism делает проверку реализации этого интерфейса на объекте, в который установлено свойство `DataContext` представления, и, в случае успеха, вызывает необходимые методы.
>
>
Этот интерфейс позволяет представлению, или модели представления принять участие в операции навигации. В интерфейсе `INavigationAware` определены три метода:
```
public interface INavigationAware {
bool IsNavigationTarget(NavigationContext navigationContext);
void OnNavigatedTo(NavigationContext navigationContext);
void OnNavigatedFrom(NavigationContext navigationContext);
}
```
Метод `IsNavigationTarget` позволяет существующему в регионе представлению, или модели представления, показать, может ли оно обработать запрос навигации. Это может быть полезным в случаях, когда вы хотите повторно использовать уже существующее представление для обработки навигации, или хотите совершить навигацию к уже существующему представлению. Для примера, представление, отображающее информацию о клиенте, может обновляться при выборе различных клиентов. Для получения более подробной информации, смотрите раздел «Навигация к существующим представлениям» далее в статье.
Методы `OnNavigatedFrom` и `OnNavigatedTo` вызываются во время операции навигации. Если текущее активное представление в регионе (или его модель представления) реализует этот интерфейс, метод `OnNavigatedFrom` вызывается до начала навигации. Метод `OnNavigatedFrom` позволяет предыдущему представлению сохранить своё состояние, или подготовиться к деактивации или удалению из пользовательского интерфейса. Для примера, представление может сохранить сделанные пользователем изменения в базу данные, или отослать их web-сервису.
Если только что созданное представление (или модель представления) реализует этот интерфейс, его метод `OnNavigatedTo` вызывается после совершения навигации. Метод `OnNavigatedTo` позволяет только что отображённому представлению провести инициализацию, возможно, используя параметры, переданные вместе с навигационным URI. Для получения дополнительной информации, смотрите следующий раздел «Передача параметров во время навигации».
После создания, инициализации и добавления в целевой регион нового представления, оно становится активным, а предыдущее представление деактивируется. Иногда, может понадобиться удалить деактивированное представление из региона. В Prism существует интерфейс `IRegionMemberLifetime`, позволяющий контролировать время жизни представлений в регионах, задавая, следует ли сразу же удалять деактивированные представления из региона, или просто помечать их как деактивированные.
```
public class EmployeeDetailsViewModel : IRegionMemberLifetime {
public bool KeepAlive { get { return true; } }
}
```
Интерфейс `IRegionMemberLifetime` определяет единственное свойство `KeepAlive`, доступное только для чтения. Если оно установлено в `false`, представление будет удалено из региона при его деактивации. Так как регион после этого перестаёт хранить ссылку на представление, оно будет достижимо для сборщика мусора (если, конечно, на него не ссылаются другие части вашего приложения). Вы можете реализовать этот интерфейс, как в представлении, так и в модели представления. Хотя интерфейс `IRegionMemberLifetime` предназначен, по большей части, для управления временем жизни представлений в регионах во время активации и деактивации, свойство `KeepAlive` также используется во время навигации после создания и активации представления в целевом регионе.
> **Заметка.**
>
> Регионы, способные отображать несколько представлений, такие как `ItemsControl`, или `TabControl`, будут показывать как активные, так и неактивные представления. Удаление неактивного представления из региона, для этих элементов управления, приведёт к удалению его из пользовательского интерфейса.
>
>
#### Передача параметров во время навигации
Для реализации необходимого поведения при навигации, вам зачастую может понадобиться задавать дополнительные данные, передаваемые во время запроса навигации, кроме имени целевого представления. Объект `NavigationContext` предоставляет доступ к навигационному URI и ко всем параметрам, которые были переданы вместе с ним. Вы можете получить доступ к `NavigationContext` в методах `IsNavigationTarget`, `OnNavigatedFrom`, и `OnNavigatedTo`.
Для помощи в задании и получении параметров навигации, в Prism существует класс `UriQuery`. Вы можете использовать его при необходимости добавить навигационные параметры к URI перед началом навигации и для доступа к этим параметрам во время навигации. `UriQuery` создаёт список с парами имя-значение для каждого параметра.
Следующий пример кода показывает, как добавить параметры к `UriQuery` и присоединить их к навигационному URI.
```
Employee employee = Employees.CurrentItem as Employee;
if (employee != null) {
UriQuery query = new UriQuery();
query.Add("ID", employee.Id);
_regionManager.RequestNavigate(RegionNames.TabRegion,
new Uri("EmployeeDetailsView" + query.ToString(), UriKind.Relative));
}
```
Вы можете получить навигационные параметры, используя свойство `Parameters` объекта `NavigationContext`. Это свойство возвращает экземпляр класса `UriQuery`, у которого есть свойство-индексатор для упрощения доступа к индивидуальным параметрам.
```
public void OnNavigatedTo(NavigationContext navigationContext) {
string id = navigationContext.Parameters["ID"];
}
```
#### Навигация к существующим представлениям
Довольно часто, повторное использование представления, его обновление, или активация во время навигации, является более предпочтительным поведением, чем его замена на новое представление. Это типичный случай, когда производится навигация к представлению того же самого типа, но в котором требуется отобразить другие данные, или когда необходимое представление уже доступно, но требует активации (для выделения, или перемещения наверх).
Примером к первому сценарию может служить ситуация, когда приложению позволяет пользователю изменять информацию о клиенте, используя представление `EditCustomer`, и пользователь уже использует это представление для редактирования клиента с ID 123. Если пользователь решит отредактировать запись о клиенте с ID 456, он может просто совершить навигацию к представлению `EditCustomer` и ввести новый ID. После этого, представление `EditCustomer` запросит данные о новом клиенте и обновит свой UI соответствующим образом.
Для примера использования второго сценария, допустим, что приложение позволяет редактировать информацию сразу о нескольких клиентах одновременно. В этом случае, приложение отображает несколько представлений `EditCustomer` в `TabControl`, к примеру, клиентов с ID 123 и ID 456. При навигации к `EditCustomer` и вводе ID 456, соответствующее представление будет активировано (то есть, соответствующая вкладка будет выделена). Если пользователь совершит навигацию к представлению `EditCustomer` и введёт ID 789, то новый экземпляр будет создан и отображён в UI.
Способность совершать навигацию к уже существующим представлениям является полезной по множеству причин. Зачастую, гораздо эффективнее обновить существующее представление, а не заменять его новым того же типа. Аналогично, активация существующего представление заместо создания нового, делает интерфейс более согласованным. К тому же, способность обрабатывать такие сценарии без необходимости написания дополнительного кода, упрощает разработку и поддержку приложения.
Prism поддерживает оба описанных выше сценария через метод `INavigationAware.IsNavigationTarget`. Этот метода вызывается во время навигации на представлениях в регионе, имеющих тот же тип, что и целевое представление. В предыдущем примере, целевое представление было типа `EditCustomer`, поэтому метод `IsNavigationTarget` будет вызван на всех существующих представлениях типа `EditCustomer`, находящихся в регионе. Prism определяет целевой тип представления с помощью навигационного URI, предполагая, что он является коротким именем типа целевого представления.
> **Заметка.**
>
> Для того, чтобы Prism определила тип целевого представления, имя представления в навигационном URI должно соответствовать короткому имени его типа. К примеру, если представление имеет класс `MyApp.Views.EmployeeDetailsView`, то имя представления, заданное в навигационном URI должно быть *EmployeeDetailsView*. Это является стандартным поведением Prism. Вы можете изменить его, создав свой класс загрузчика контента. Сделать это можно реализовав интерфейс `IRegionNavigationContentLoader`, или унаследовав свой класс от `RegionNavigationContentLoader`.
>
>
Реализация метода `IsNavigationTarget` может использовать параметр `NavigationContext` для определения, может ли представление обработать навигационный запрос. `NavigationContext` даёт доступ к навигационному URI и навигационным параметрам. В предыдущем примере, реализация этого метода в модели представления `EditCustomer`, сравнивала текущий ID клиента с ID, заданном в навигационном запросе, возвращая `true` при совпадении.
```
public bool IsNavigationTarget(NavigationContext navigationContext) {
string id = navigationContext.Parameters["ID"];
return _currentCustomer.Id.Equals(id);
}
```
Если метод `IsNavigationTarget` всегда возвращает `true`, вне зависимости от навигационных параметров, это представление всегда будет использоваться повторно. Такой подход может гарантировать, что в определённом регионе будет существовать только одно представление определённого типа.
#### Подтверждение, или отмена навигации
Часто может возникнуть необходимость взаимодействия с пользователем во время навигации, позволяя пользователю подтвердить, или отменить её. Во многих приложениях, пользователь, к примеру, может начать навигацию во время ввода или редактирования данных. В таких ситуациях, может потребоваться спросить у пользователя, хочет ли он сохранить, или отменить сделанные изменения, перед тем, как уйти со страницы, или не хочет ли он вообще отменить навигацию. Prism поддерживает такие сценарии через интерфейс `IConfirmNavigationRequest`.
Интерфейс `IConfirmNavigationRequest` унаследован от интерфейса `INavigationAware` и добавляет метод `ConfirmNavigationRequest`. Реализуя этот интерфейс в вашем представлении, или модели представления, вы позволяете им участвовать в процессе навигации, позволяя взаимодействовать с пользователем так, чтобы он мог отменить, или подтвердить навигацию. Вам также может понадобиться использовать объект *Interaction Request*, о котором было рассказано в части 6 "[Продвинутые сценарии MVVM](http://habrahabr.ru/post/176869/)", для показа всплывающего окна с подтверждением.
> **Заметка.**
>
> Метод `ConfirmNavigationRequest` вызывается на активном представлении (или модели представления), аналогично методу `OnNavigatedFrom`, описанному ранее.
>
>
Метод `ConfirmNavigationRequest` принимает два параметра, ссылку на текущий навигационный контекст, описанный выше, и делегат, который необходимо будет вызвать для продолжения навигации. По этой причине, данный делегат часто называют делегатом-продолжением (*continuation callback*). Вы можете сохранить ссылку на делегат-продолжение, для его вызова после окончания взаимодействия с пользователем. Если приложение взаимодействует с пользователем через объекты *Interaction Request*, вы можете использовать этот делегат в качестве метода обратного вызова запроса взаимодействия. Следующая диаграмма иллюстрирует полный процесс.
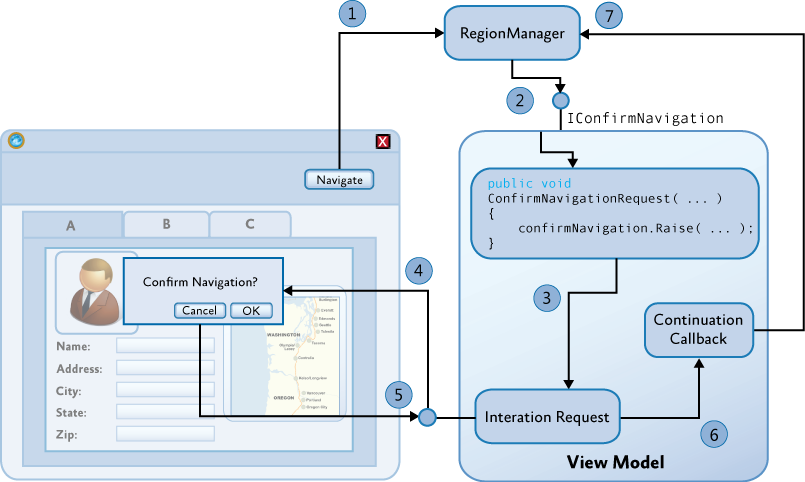
Следующие шаги описывают процесс подтверждения навигации при использовании объекта `InteractionRequest`:
1. Навигация инициируется через вызов метода `RequestNavigate`.
2. Если представление, или модель представления реализуют интерфейс `IConfirmNavigation`, вызывается метода `ConfirmNavigationRequest`.
3. Модель представления вызывает событие начала взаимодействия (*interaction request event*).
4. Представление отображает всплывающее окно с подтверждением и ждёт ответа от пользователя.
5. Метод обратного вызова запроса взаимодействия вызывается после того, как пользователь закрывает всплывающее окно.
6. Делегат-продолжение вызывается для продолжения, или отмены прерванной операции навигации.
7. Операция навигации завершается, или отменяется.
Чтобы увидеть иллюстрацию этому, посмотрите *View-Switching Navigation Quick Start*. Это приложение позволяет пользователю создавать сообщения электронной почты, используя классы `ComposeEmailView`, и `ComposeEmailViewModel`. Класс модели представления реализует интерфейс `IConfirmNavigation`. Если пользователь совершает навигацию, к примеру, нажимая кнопку *Calendar*, в время создания сообщения, будет вызван метод `ConfirmNavigationRequest` для того, чтобы модель представления могла запросить подтверждение у пользователя. Для поддержки этого, модель представления задаёт объект запроса взаимодействия, как показано в примере ниже.
```
public class ComposeEmailViewModel : NotificationObject, IConfirmNavigationRequest {
private readonly InteractionRequest confirmExitInteractionRequest;
public ComposeEmailViewModel(IEmailService emailService) {
this.confirmExitInteractionRequest = new InteractionRequest();
}
public IInteractionRequest ConfirmExitInteractionRequest { get { return this.confirmExitInteractionRequest; } }
}
```
В классе `ComposeEmailVew` задан триггер `InteractionRequestTrigger`, привязанный к свойству `ConfirmExitInteractionRequest` модели представления. При запросе взаимодействия, пользователю показывается простое всплывающее окно.
```
...
```
Метод `ConfirmNavigationRequest` класса `ComposeEmailVewMode` вызывается при попытке пользователя совершить навигацию во время написания сообщения. Реализация этого метода вызывает запрос взаимодействия, определённый ранее, так, чтобы пользователь мог подтвердить, или изменить операцию навигации.
```
void IConfirmNavigationRequest.ConfirmNavigationRequest(
NavigationContext navigationContext, Action continuationCallback) {
this.confirmExitInteractionRequest.Raise(
new Confirmation {Content = "...", Title = "..."},
c => {continuationCallback(c.Confirmed);});
}
```
Метод обратного вызова для запроса взаимодействия вызывается, когда пользователь нажимает кнопку на всплывающем окне подтверждения. Он просто вызывает делегат-продолжение, передавая в него значение флага `Confirmed`, что заставляет подтвердить, или отменить навигацию.
> **Заметка.**
>
> Нужно заметить, что после вызова метода `Rise` объекта запроса взаимодействия, метод `ConfirmNavigationRequest` сразу же возвращается, чтобы позволить пользователю продолжить взаимодействие с UI приложения. При нажатии кнопки *OK*, или *Cancel* на всплывающем окне, вызывается метод обратного вызова на объекте запроса взаимодействия, который, в свою очередь, вызывает делегат-продолжение для завершения навигации. Все методы вызываются в потоке UI. При использовании такой техники не требуется создания фоновых потоков.
>
>
Используя этот механизм, вы можете контролировать, будет ли запрос навигации осуществлён сразу же, или с задержкой, ожидая реакции пользователя, или другой асинхронной операции, такой как запрос к web-серверу. Для продолжения и подтверждения навигации, необходимо просто вызвать делегат-продолжение, передав в него `true`, для отмены навигации, необходимо передать `false`.
```
void IConfirmNavigationRequest.ConfirmNavigationRequest(
NavigationContext navigationContext, Action continuationCallback) {
continuationCallback(true);
}
```
Если вы хотите отложить навигацию, вы можете сохранить ссылку на делегат-продолжение, который можно будет вызвать после окончания взаимодействия с пользователем, или асинхронного запроса (к примеру, к web-серверу). Операция навигации будет находиться в состоянии ожидания до вызова делегата-продолжения.
Если пользователь начнёт другую навигация в это время, запрос навигации будет отменён. В этом случае, вызов делегата-продолжения не вызовет никакого эффекта. Аналогично, если вы решите не вызывать делегат-продолжение, операция навигации будет находиться в состоянии ожидания до замены её на новую операцию навигации.
#### Использование журнала навигации (*Navigation Journal*)
Класс `NavigationContext` предоставляет доступ к сервису навигации региона, который ответственен за координирование последовательности операций во время навигации в регионе. Он предоставляет доступ к региону, в котором производится навигация, и к журналу навигации, ассоциированным с этим регионом. Сервис навигации реализует интерфейс `IRegionNavigationService`, показанный ниже.
```
public interface IRegionNavigationService : INavigateAsync {
IRegion Region { get; set; }
IRegionNavigationJournal Journal { get; }
event EventHandler Navigating;
event EventHandler Navigated;
event EventHandler NavigationFailed;
}
```
Так как этот интерфейс унаследован от интерфейса `INavigateAsync`, вы можете инициировать навигацию в родительском регионе, вызывая метод `RequestNavigate`. Событие `Navigating` вызывается при инициации операции навигации. Событие `Navigated` вызывается при завершении навигации в регионе. `NavigationFailed` вызывается при возникновении ошибки во время навигации.
Свойство `Journal` даёт доступ к навигационному журналу, ассоциированному с регионом. Навигационный журнал реализует интерфейс `IRegionNavigationJournal`, показанный ниже.
```
public interface IRegionNavigationJournal {
bool CanGoBack { get; }
bool CanGoForward { get; }
IRegionNavigationJournalEntry CurrentEntry { get; }
INavigateAsync NavigationTarget { get; set; }
void Clear();
void GoBack();
void GoForward();
void RecordNavigation(IRegionNavigationJournalEntry entry);
}
```
Вы можете получить и сохранить ссылку на навигационный сервис региона в представлении во время навигации через вызов метода `OnNavigatedTo`. По умолчанию, Prism предоставляет простой стековый журнал, который позволяет совершать навигацию вперёд и назад в пределах региона.
Вы можете использовать навигационный журнал для того, чтобы позволить пользователю совершать навигацию внутри самого представления. В следующем примере, модель представления реализует команду `GoBack`, которая использует навигационный журнал родительского региона. Следовательно, представление может отобразить кнопку *Back*, которая позволяет пользователю переместиться к предыдущему представлению в регионе. Аналогично, вы можете реализовать команду `GoForward` для создания рабочего процесса в стиле мастера (*wizard style workflow*).
```
public class EmployeeDetailsViewModel : INavigationAware {
...
private IRegionNavigationService navigationService;
public void OnNavigatedTo(NavigationContext navigationContext) {
navigationService = navigationContext.NavigationService;
}
public DelegateCommand GoBackCommand { get; private set; }
private void GoBack(object commandArg) {
if (navigationService.Journal.CanGoBack) {
navigationService.Journal.GoBack();
}
}
private bool CanGoBack(object commandArg) {
return navigationService.Journal.CanGoBack;
}
}
```
Вы можете создать свой собственный журнал для региона для реализации специфичного рабочего процесса для этого региона.
> **Заметка.**
>
> Навигационный журнал может использоваться только в операциях навигации в регионе, которые координируются навигационным сервисом региона. Если вы используете технику обнаружения или внедрения представления для реализации навигации в регионе, навигационный журнал не будет обновляться во время навигации и его нельзя использовать для навигации назад, или вперёд в регионе.
>
>
#### Использование *WPF* и *Silverlight Navigation Frameworks*
Навигация на основе регионов в Prism была спроектирована для поддержки большого диапазона сценариев и проблем, которые вы можете встретить при реализации навигации в слабо связанных модульных приложениях, использующих паттерн MVVM и контейнер внедрения зависимостей, такой как Unity, или MEF. Также, она была спроектирована для поддержки подтверждения и отмены навигации, навигации к существующим представлениям, передачи параметров во время навигации и ведения журнала навигации.
Поддерживая навигацию для регионов, Prism предоставляет возможность совершения навигации внутри множества элементов управления, и даёт возможность изменять разметку пользовательского интерфейса приложения, не нарушая структуры навигации. Также поддерживается псевдо-синхронная навигация, что позволяет производить расширенное взаимодействие с пользователем во время навигации.
Однако Prism навигация не была спроектирована для замены *Silverlight navigation framework* (представленного в Silverlight 3.0), или *WPF's navigation framework*. Вместо этого, навигация в регионах Prism была спроектирована для работы вместе с *Silverlight и WPF navigation frameworks*.
*Silverlight navigation framework* предоставляет поддержку глубоких ссылок, интеграция с браузером и проекцию навигационных URI. Навигация возможно внутри элемента управления `Frame`. `Frame` может при необходимости отображать адресную строку, которая позволяет пользователю совершать навигацию назад, или вперёд между представлениями, отображаемыми в `Frame`. Обычным подходом является использование *Silverlight navigation framework* для реализации высокоуровневой навигации в оболочке приложения и использование навигации Prism для всех остальных частей приложения. В таком случае, ваше приложение будет поддерживать глубокие ссылки и будет интегрировано с журналом браузера и его адресной строкой, а также будет пользоваться всеми преимуществами навигации в регионах Prism.
*WPF navigation framework* не является таким расширяемым, как в Silverlight. Соответственно, поддержка внедрения зависимостей и шаблона MVVM существенно затрудняется. Он также основывается на элементе управления `Frame`, имеющем схожую функциональность, с точки зрения журналирования и навигационного UI. Вы можете использовать *WPF navigation framework* вместе с навигацией Prism, хотя, реализация навигации, используя только регионы Prism, возможно, будет более простым и гибким решением.
#### Последовательность навигации в регионе
Следующая иллюстрация даёт обзор последовательности операций во время навигации. Она даётся как справка, чтобы вы могли видеть, как различные элементы навигации Prism взаимодействую друг с другом во время запроса навигации.
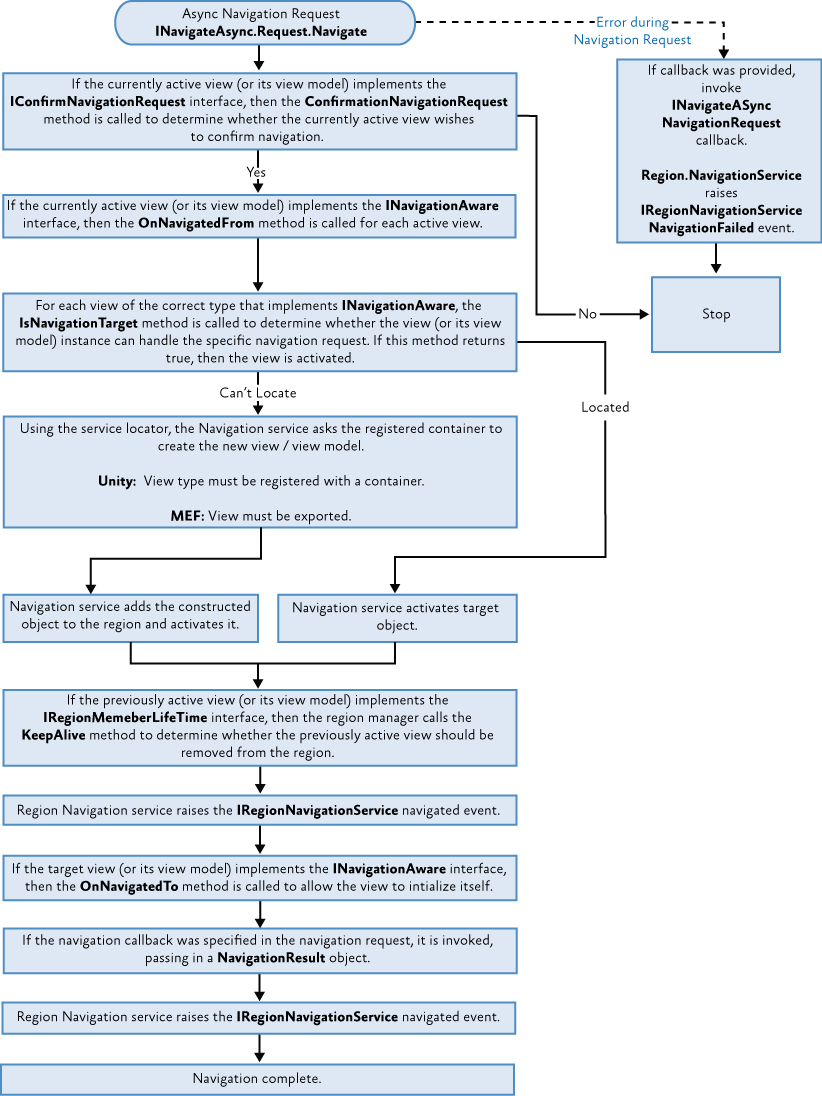
### Дополнительная информация
Для получения дополнительной информации о Visual State Manager, смотрите «VisualStateManager Class» на MSDN: <http://msdn.microsoft.com/en-us/library/cc626338(v=VS.95).aspx>.
Для получения дополнительной информации об использовании поведений Microsoft Expression Blend, смотрите «Working with built-in behaviors» на MSDN: <http://msdn.microsoft.com/en-us/library/ff724013(v=Expression.40).aspx>.
Для получения дополнительной информации о создании поведений Microsoft Expression Blend, смотрите «Creating Custom Behaviors» на MSDN: <http://msdn.microsoft.com/en-us/library/ff724708(v=Expression.40).aspx>.
Для получения дополнительной информации о Silverlight *Navigation Framework*, смотрите «Navigation Overview» на MSDN: <http://msdn.microsoft.com/en-us/library/cc838245(VS.95).aspx>.
Для получения дополнительной информации об интеграции Silverlight's Navigation Framework с Prism, смотрите «Integrating Prism v4 Region Navigation with Silverlight Frame Navigation» в блоге Karl Schifflett's: <http://blogs.msdn.com/b/kashiffl/archive/2010/10/05/integrating-prism-v4-region-navigation-with-silverlight-frame-navigation.aspx>. | https://habr.com/ru/post/182052/ | null | ru | null |
# Стерео плеер из VLC
 Все началось с того что я купил себе новый монитор с поддержкой 3D ASUS VG23AH и в какой то момент мне захотелось воспользоваться возможностью посмотреть 3D фильм на нем. Подуглил бесплатные виде плееры для Mac OS, оказалось их не так много — всех чаще попадался плеер [Bino](http://bino3d.org/). Скачал этот Bino, но посмотреть нормально так и не получилось, т.е. к плееру претензий нет, картинка была 3D, но видео страшно тормозило, картинка дергалась. Я воспользовался советом по повышению производительности к этой программе — там сказано — проверьте, как проигрывается этот фильм в [VLC](http://www.videolan.org) плеере, если уж и там будет тормозить, значит, мощностей вашего компьютера недостаточно/замените компьютер. В VLC все показывалось отлично без тормозов но, конечно, в моно режиме. Поскольку VLC — это opensource проект, я решил его немного подправить, чтоб он смог показывать стерео-фильмы, оказалось это сделать довольно просто.
Для начала я сделал fork [этого](https://github.com/videolan/vlc) репозитория и начал читать документы и howto. Сразу простроить проект у меня не получилось, были конфликты с установленным у меня mac ports, пришлось снести. Потом пришлось сделать up-merge для extras/tools/ragel/aapl компоненты, после этого все собралось по [инструкции](http://wiki.videolan.org/OSXCompile) .
Дальше первое, что мне бросилось в глаза — это возможно добавлять в VLC — плагины (это такие модули, которые позволяют делать пост-обработку декодированных виде фреймов). Ну что-ж, я подумал, что этого будет достаточно для преобразования стерео изображения.
***Отступление:** исходный файл, который мне хотелось проиграть, имел в каждом видео фрейме 2 ракурса (слева картинка для левого глаза, справа — для правого) в общем, довольно стандартный формат для стерео-фильма.*
Обработка сводилась к тому, что я формировал выходной видео буфер линия за линией из левого и правого полукадра соответственно. Ожидалось, что левый глаз будет видеть нечетные строчки, правый — четные.
Реализовать этот фильтр было просто (прочитал [инструкцию](http://wiki.videolan.org/Documentation:Hacker%27s_Guide/Video_Filters) взял за основу один из существующих). Но, конечно же, к успеху это не привело. На экране картинка выглядела полосатой, но линии не были синхронизированы с пикселями экрана, поэтому эффекта 3D в очках не наблюдалось.
***Отступление:** Хочу пояснить, как работает 3D режим на пассивных 3D мониторах. Я не специалист в этой технологии, поэтому буду описывать как дилетант.
В мониторах типа моего используется технология FPR (Film-type Patterned Retarder) для разделения ракурсов видео потока. Я ее представляю себе так, как будь то каждая линия пикселей на мониторе закрыта поляризационным фильтром, условно можно представить, что нечетные линии закрыты фильтром с вертикальной поляризацией, а четные с горизонтально, такие же фильтры стоят в очках, в результате один глаз видит только нечетные линии, второй четные.*
Поняв это, я понял, что мне нужно делать пост-обработку непосредственно в рендере, чтоб я мог гарантировать попиксельно расположение выходного видео фрейма.
Посмотрел как реализован рендер в VLC для Mac. Оказалось все довольно просто. Каждый декодированный видео фрейм загружается в виде текстуры, которая в последствие отображается на экране средствами open GL. Преобразование графического формата из YUV в RBG происходит непосредственно в пиксельном шейдере. Это сразу натолкнуло меня на мысль — что нужно сделать. Поскольку известно, что пиксельный шейдер как раз формирует цвет для каждого пикселя экрана, мне остается только поправить этот шейдер, чтоб он при формирование цвета брал данные из нужной части текстуры, для четных и нечетных линий.
Вот пример кода (написано схематично, рабочий пример можно посмотреть [тут](https://github.com/mikhail-angelov/vlc) ):
```
void main(void) {
vec4 x,y,z,result;
vec4 tc = TexCoord0;
+ float d = mod((floor(height*(tc.y+1.0))),2.0); //odd or even, height - is new uniform to get viewport height
+ if(d>0.1) tc.x += 0.5; //shift texture
x = texture2D(Texture0, tc.st);
y = texture2D(Texture1, tc.st);
z = texture2D(Texture2, tc.st);
result = x * Coefficient[0] + Coefficient[3]; //Coefficient - const coefficients for convert YUV to RGB
result = (y * Coefficient[1]) + result;
result = (z * Coefficient[2]) + result;
+ if(TexCoord0.x > 0.5) result = vec4(0,0,0,1); //cut off right side
gl_FragColor = result;
};
```
Если сравнивать с исходным кодом, то я добавил только строчки помеченные +.
После этого я уже получил правильное стерео изображение в левой части экрана.
В дальнейшем осталось только поправить размер картинки, и отрезать правую часть, и все — стерео-плеер готов.
Всем кому интересно — можно посмотреть [код на github](https://github.com/mikhail-angelov/vlc).
Фактически, чтоб получить стерео-плеер из VLC в общей сумме пришлось написать около 30 строк кода, это меня сильно поразило, и явилось причиной написания этой статьи.
***PS:** Уже потом, когда моя версия была сделана, я нашел отличный opensource стерео-плеер — [sview.ru](http://sview.ru/), на MacOS работает неплохо.* | https://habr.com/ru/post/211468/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.