
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Unittest и абстрактные тесты
### Вместо вступления
Unittest — наверное самый известный фреймворк для написания тестов в Python. Он очень прост в освоении и его легко начать использовать в вашем проекте. Но ничто не бывает идеальным. В этом посте я хочу рассказать об одной возможности, которой лично мне (думаю, не одному) не хватает в unittest.
### Немного о Unit тестах
Прежде чем обсуждать(и осуждать) тестовый фреймворк, считаю нужным немного поговорить о тестировании в целом. Когда я впервые услышал словосочетание «модульное тестирование», то подумал, что это обязанности какой-то службы по контролю качества, которая проверяет программные модули на соответствие требованиям. Каково же было моё удивление, когда я узнал, что эти самые тесты должны писать программисты. Первое время я не писал тесты… вообще. Ничто не заменит тех ощущений, когда просыпаешься утром и читаешь от пользователя «Программа не работает. С этим срочно надо что-то делать». Сперва мне казалось, что это совершенно обычный процесс, пока не написал первый модульный тест, который нашёл ошибку. Модульные тесты вообще кажутся бесполезными ровно до тех пор, пока не обнаруживают проблемы. Теперь я просто не могу закоммитить новую функцию, не написав на неё тест.
Но тесты служат не только для проверки правильности написания кода. Вот список функций, которые, на мой взгляд, выполняют тесты:
* Обнаружение ошибок в программном коде
* Придание программистам уверенности в том, что их код работает
* Следствие из предыдущего пункта: возможность без опаски вносить изменения в программу
* Тесты — своего рода документация, которая наиболее верно описывает поведение системы
В некотором смысле, тесты повторяют структуру программы. Применимы ли принципы построения программ к тестам? Я считаю, что да — это такая же программа, пусть и проверяющая другую.
### Описание проблемы
В какой-то момент мне пришла идея написать абстрактный тест. Что я подразумеваю под этим? Это такой тест, который сам не выполняется, но объявляет методы, зависящие от параметров, определяемых в наследниках. И тут я обнаружил то, что не могу этого сделать по-человечески в unittest. Вот пример:
```
class SerializerChecker(TestCase):
model = None
serializer = None
def test_fields_creation(self):
props = TestObjectFactory.get_properties_for_model(self.model)
obj = TestObjectFactory.create_test_object_for_model(self.model)
serialized = self.serializer(obj)
self.check_dict(serialized.data, props)
```
Думаю, даже не зная реализацию TestObjectFactory и метода check\_dict понятно, что props — это словарь свойств для объекта, obj — объект, для которого мы проверяем сериализатор. check\_dict проверяет рекурсивно словари на совпадение. Думаю, многие, кто знаком c unittest сразу скажут, что этот тест не соответствует моему определению абстрактного. Почему? Потому что метод test\_fields\_creation выполнится из этого класса, чего нам абсолютно не надо. После некоторого поиска информации, я пришёл к выводу, что самый адекватный вариант — не наследовать SerializerChecker от TestCase, а наследников реализовывать как-то так:
```
class VehicleSerializerTest(SerializerChecker, RecursiveTestCase):
model = Vehicle
serializer = VehicleSerialize
```
RecursiveTestCase — потомок TestCase, который реализует метод check\_dict.
Это решение некрасиво сразу с нескольких позиций:
* В классе SerializerChecker мы должны знать, что потомок должен наследоваться от TestCase. Эта зависимость может создать проблемы для тех, кто незнаком с этим кодом
* Среда разработки упорно считает, что я неправ, так как у SerializerChecker нет метода check\_dict

*Ошибка, которую выдаёт среда разработки*
Может показаться, что можно просто добавить заглушку для check\_dict и все проблемы решены:
```
class SerializerChecker:
model = None
serializer = None
def check_dict(self, data, props):
raise NotImplementedError
def test_fields_creation(self):
props = TestObjectFactory.get_properties_for_model(self.model)
obj = TestObjectFactory.create_test_object_for_model(self.model)
serialized = self.serializer(obj)
self.check_dict(serialized.data, props)
```
Но это не является полноценным решением проблемы:
* Мы, по сути, создали интерфейс, который реализует не потомок данного класса, а RecursiveTestCase, что создаёт оправданные вопросы к архитектуре.
* В TestCase много методов assert\*. Неужели нам надо писать заглушку для каждого используемого? Всё ещё кажется хорошим решением?
### Подводя итог
Unittest не предоставляет вменяемой возможности «отключить» класс, отнаследованный от TestCase. Я был бы очень рад, если бы такую функцию добавили в фреймворк. А как вы решаете данную проблему? | https://habr.com/ru/post/447438/ | null | ru | null |
# Проблема с чтением файлов более 1Мб в Android
Добрый день.
При написании одного приложения для Android столкнулся с проблемой загрузки файлов из директории **assets** размер которых превышает 1Мб.
Допустим, в папке проекта, в **assets** лежит файл **file.dat**, который надо загружать в память и читать данные из него.

Открываем файл, и читаем в buffer 8 первых байт
`AssetManager am = context.getAssets();
InputStream is = am.open("file.dat", AssetManager.ACCESS_BUFFER);
// Read file
is.read(buffer, 0, 8);`
В результате выполнения кода на Android 2.2 и ниже, получаем сообщение в **LogCat**
06-14 17:10:48.554: DEBUG/asset(382): Data exceeds UNCOMPRESS\_DATA\_MAX (1048852 vs 1048576)
и **IOException**
06-14 17:10:48.654: WARN/System.err(698): java.io.IOException
Смотрим исходники андроида. В файле **frameworks/base/include/utils/Asset.h** находится та самая константа **UNCOMPRESS\_DATA\_MAX**
`enum {
/* data larger than this does not get uncompressed into a buffer */
#ifdef HAVE_ANDROID_OS
UNCOMPRESS_DATA_MAX = 1 * 1024 * 1024
#else
UNCOMPRESS_DATA_MAX = 2 * 1024 * 1024
#endif
};`
А в файле **frameworks/base/include/utils/Asset.cpp** происходит проверка на размер файла
`if (mUncompressedLen > UNCOMPRESS_DATA_MAX) {
LOGD("Data exceeds UNCOMPRESS_DATA_MAX (%ld vs %d)\n",
(long) mUncompressedLen, UNCOMPRESS_DATA_MAX);
goto bail;
}`
Как видно из комментария, данные, превышающие по размеру **UNCOMPRESS\_DATA\_MAX** в байтах, не распаковываются в буфер из **.apk** файла.
Решить проблему можно несколькими способами:
**1.** Самый простой — изменить расширение файла **file.dat**, на такое, что этот файл не будет сжиматься при упаковке в **.apk** файл. Список этих расширений определён в **Package.cpp**
`/* these formats are already compressed, or don't compress well */
static const char* kNoCompressExt[] = {
".jpg", ".jpeg", ".png", ".gif",
".wav", ".mp2", ".mp3", ".ogg", ".aac",
".mpg", ".mpeg", ".mid", ".midi", ".smf", ".jet",
".rtttl", ".imy", ".xmf", ".mp4", ".m4a",
".m4v", ".3gp", ".3gpp", ".3g2", ".3gpp2",
".amr", ".awb", ".wma", ".wmv"
};`
Либо, можно вручную скомпилировать проект с помощью **aapt** с опцией "-0", указав расширения файлов, которые не надо сжимать в **.apk**. Если использовать пустую строку, вместо расширения, ни один файл не будет сжат.
Этот способ плох тем, что размер загружаемого пользователем установочного файла из маркета значительно вырастает (на разницу между сжатым и несжатым **file.dat**), а объём файла довольно критичен для мобильных устройств. В моём случае, в **file.dat** хранится текстовая информация, используемая в приложении, в нераспакованном виде занимает немного более 1Мб, а в **.apk** файле сжимается до 40Кб.
Если ваши файлы из **assets** плохо сжимаются в zip (медиа), этот способ отлично подойдёт.
**2.** Второй способ заключается в разбиении **file.dat** на кусочки по 1Мб, например из консоли:
`split file.dat --bytes=1024K`
Получившиеся файлы нужно поместить в **assets**, при первом запуске приложения «склеить» по кусочкам и поместить в директорию с приложением. Данный способ хорошо описан на stackoverflow, его предложил человек под именем Seva Alekseyev, поэтому приведу только ссылку *stackoverflow.com/questions/2860157/load-files-bigger-than-1m-from-assets-folder/3093966#3093966*
В этом случае, ваше приложение будет хранить две копии данных, одни в **.apk** файле, другие, выгруженные в директорию с приложением. Также добавляется немного лишнего кода и необходимость следить за существованием и целостностью «распакованных» данных.
Описанной проблемы для Android 2.3.1 и выше нет.
Конечно, можно придумать ещё что-то, например, загрузка файлов по сети (т.н. кэш), что не всегда надёжно, если пользователь отключил интернет, или генерация файла с нуля, но мне двух вышеописанных методов хватило. | https://habr.com/ru/post/122361/ | null | ru | null |
# Вещи, о которых следует помнить, программируя на Python
Дзэн Питона
-----------
Изучение культуры, которая окружает язык, приближает вас на шаг к лучшим программистам. Если вы всё еще не прочли «Zen of Python», то откройте интерпретатор Python и введите **import this**. Для каждого элемента в списке вы найдете пример [здесь](http://artifex.org/~hblanks/talks/2011/pep20_by_example.html)
Однажды моё внимание привлекло:
**Красивое лучше уродливого**
UPDATE: На [Hacker News](http://news.ycombinator.com/item?id=3996708) было много обсуждений этой статьй. Несколько поправок от них.
Дайте мне функцию, которая принимает список чисел и возвращает только четные числа, деленые на два.
```
#-----------------------------------------------------------------------
halve_evens_only = lambda nums: map(lambda i: i/2, filter(lambda i: not i%2, nums))
#-----------------------------------------------------------------------
def halve_evens_only(nums):
return [i/2 for i in nums if not i % 2]
```
Помните очень простые вещи в Python
-----------------------------------
Обмен значений двух переменных:
```
a, b = b, a
```
Шаговый аргумент для срезов. Например:
```
a = [1,2,3,4,5]
>>> a[::2] # iterate over the whole list in 2-increments
[1,3,5]
```
Частный случай **x[::-1]** является средством выражения **x.reverse()**.
```
>>> a[::-1]
[5,4,3,2,1]
```
UPDATE: Имейте в виду **x.reverse()** переворачивает список, а срезы дают вам возможность делать это:
```
>>> x[::-1]
[5, 4, 3, 2, 1]
>>> x[::-2]
[5, 3, 1]
```
* Не используйте изменяемые типы переменных для значений по умолчанию
```
def function(x, l=[]): # Don't do this
def function(x, l=None): # Way better
if l is None:
l = []
```
UPDATE: Я понимаю что не объяснил почему. Я рекомендую прочитать статью [Fredrik Lundh](http://effbot.org/zone/default-values.htm). Вкратце этот дизайн иногда встречается. «Значения по умолчанию всегда вычисляются тогда, и только тогда, когда **def** заявлена на исполнение.»
* Используйте **iteritems** а не **items**
**iteritems** использует **generators** и следовательно это лучше при работе с очень большими списками.
```
d = {1: "1", 2: "2", 3: "3"}
for key, val in d.items() # builds complete list when called.
for key, val in d.iteritems() # calls values only when requested.
```
Это похоже на **range** и **xrange** когда **xrange** вызывает значения только когда попросят.
UPDATE: Заметьте что **iteritems**, **iterkeys**, **itervalues** удалены из Python 3.x. **dict.keys()**, **dict.items()** и **dict.values()** вернут **views** вместо списка. [docs.python.org/release/3.1.5/whatsnew/3.0.html#views-and-iterators-instead-of-lists](http://docs.python.org/release/3.1.5/whatsnew/3.0.html#views-and-iterators-instead-of-lists)
* Используйте **isinstance** а не **type**
Не делайте:
```
if type(s) == type(""): ...
if type(seq) == list or \
type(seq) == tuple: ...
```
лучше:
```
if isinstance(s, basestring): ...
if isinstance(seq, (list, tuple)): ...
```
Почему не стоит делать так: [stackoverflow.com/a/1549854/504262](http://stackoverflow.com/a/1549854/504262)
Заметьте что я использую **basestring** а не **str**, поскольку вы можете пытаться проверить соответствие **unicode** к **str**. Например:
```
>>> a=u'aaaa'
>>> print isinstance(a, basestring)
True
>>> print isinstance(a, str)
False
```
Это происходит потому что в Python версиях < 3.0 существует два строковых типа: **str** и **unicode**:
```
object
|
|
basestring
/ \
/ \
str unicode
```
* Изучите различные [коллекции](http://docs.python.org/library/collections.html)
Python имеет различные типы контейнеров данных являющихся лучшей альтернативой базовым **list** и **dict** в различных случаях.
~~В большинстве случаев используются эти:~~
UPDATE: Я знаю большинство не использовало этого. Невнимательность с моей стороны. Некоторые могут написать так:
```
freqs = {}
for c in "abracadabra":
try:
freqs[c] += 1
except:
freqs[c] = 1
```
Некоторые могут сказать, лучше было бы:
```
freqs = {}
for c in "abracadabra":
freqs[c] = freqs.get(c, 0) + 1
```
Скорее используйте коллекцию типа **defaultdict**:
```
from collections import defaultdict
freqs = defaultdict(int)
for c in "abracadabra":
freqs[c] += 1
```
**Другие коллекции**
```
namedtuple() # factory function for creating tuple subclasses with named fields
deque # list-like container with fast appends and pops on either end
Counter # dict subclass for counting hashable objects
OrderedDict # dict subclass that remembers the order entries were added
defaultdict # dict subclass that calls a factory function to supply missing values
```
UPDATE: Как отметили в нескольких комментария на Hacker News я мог бы использовать **Counter** вместо **defaultdict**.
```
>>> from collections import Counter
>>> c = Counter("abracadabra")
>>> c['a']
5
```
* Создавая классы в Python задействуйте [magic methods](http://www.rafekettler.com/magicmethods.html)
```
__eq__(self, other) # Defines behavior for the equality operator, ==.
__ne__(self, other) # Defines behavior for the inequality operator, !=.
__lt__(self, other) # Defines behavior for the less-than operator, <.
__gt__(self, other) # Defines behavior for the greater-than operator, >.
__le__(self, other) # Defines behavior for the less-than-or-equal-to operator, <=.
__ge__(self, other) # Defines behavior for the greater-than-or-equal-to operator, >=.
```
Существует ряд других магических методов.
* Условные назначения
```
x = 3 if (y == 1) else 2
```
Этот код делает именно то, как и звучит: «назначить **3** для **x** если **y=1**, иначе назначить **2** для **x**». Вы также можете применить это если у вас есть нечто более сложное:
```
x = 3 if (y == 1) else 2 if (y == -1) else 1
```
Хотя в какой то момент оно идет слишком далеко.
Обратите внимание что вы можете использовать выражение if...else в любом выражение. Например:
```
(func1 if y == 1 else func2)(arg1, arg2)
```
Здесь будет вызываться **func1** если **y=1**, и **func2** в противном случае. В обоих случаях соответствующая функция будет вызываться с аргументами **arg1** and **arg2**.
Аналогично, также справедливо следующее:
```
x = (class1 if y == 1 else class2)(arg1, arg2)
```
где class1 и class2 являются классами.
* Используйте **Ellipsis** когда это необходимо.
UPDATE: Один из комментаторов с Hacker News упоминал: «Использование многоточие для получения всех элементов, является нарушением принципа „Только Один Путь Достижения Цели“. Стандартное обозначение это **[:]**». Я с ним согласен. ЛУчший пример использования в NumPy на [stackoverflow](http://stackoverflow.com/a/118508/504262):
Многоточие используется что бы нарезать многомерные структуры данных.
В данной ситуации это означает, что нужно расширить многомерный срез во всех измерениях.
Пример:
```
>>> from numpy import arange
>>> a = arange(16).reshape(2,2,2,2)
```
Теперь у вас есть 4-х мерная матрица порядка 2x2x2x2. Для того что бы выбрать все первые элементы 4-го измерения, вы можете воспользоваться многоточием:
```
>>> a[..., 0].flatten()
array([ 0, 2, 4, 6, 8, 10, 12, 14])
```
что эквивалентно записи:
```
>>> a[:,:,:,0].flatten()
array([ 0, 2, 4, 6, 8, 10, 12, 14])
```
**Предыдущие предложения.**
При создание класса вы можете использовать **\_\_getitem\_\_** для того что бы ваш объект класса вел себя как словарь. Возьмите этот класс в качестве примера:
```
class MyClass(object):
def __init__(self, a, b, c, d):
self.a, self.b, self.c, self.d = a, b, c, d
def __getitem__(self, item):
return getattr(self, item)
x = MyClass(10, 12, 22, 14)
```
Из-за **\_\_getitem\_\_** вы сможете получить значение **a** объекта **x** как **x['a']**. Вероятно это известный факт.
Этот объект используется для расширения срезов Python [docs.python.org/library/stdtypes.html#bltin-ellipsis-object](http://docs.python.org/library/stdtypes.html#bltin-ellipsis-object) Таким образом если мы добавим:
```
def __getitem__(self, item):
if item is Ellipsis:
return [self.a, self.b, self.c, self.d]
else:
return getattr(self, item)
```
Мы сможем использовать **x[...]** что бы получить список всех элементов.
```
>>> x = MyClass(11, 34, 23, 12)
>>> x[...]
[11, 34, 23, 12]
```
---
P.S
---
Это перевод поста [Satyajit Ranjeev](http://satyajit.ranjeev.in/) – "[A few things to remember while coding in python.](http://satyajit.ranjeev.in/2012/05/17/python-a-few-things-to-remember.html)". ~~Но оформить в хаб переводов не хватило 0.5 кармы, и сохранить черновик не позволяет, поэтому выкладываю как есть.~~ Просьба все замечания по переводу и орфографии присылать в личку, и сильно не пинать =) | https://habr.com/ru/post/144614/ | null | ru | null |
# Игра на пустом месте
#### Игра на пустом месте

Пост о нелегком, но чрезвычайно интересном пути из ниоткуда к готовой игре.
##### Введение
Долгое время с игростроем меня связывала только работа среднестатистическим 3d-художником в филиале одной не шибко известной компании, да вялые попытки вырваться, наконец, на ниву инди-разработки с её неограниченной свободой и баснословными доходами. По крайней мере, именно таким казался мне независимый геймдев по прочтении многочисленных success-stories.
Реальность, однако же, всегда охлаждала мой пыл, напоминая об отсутствующих навыках программирования, управления проектами, умении что-то продавать, опыта разработки хоть чего-нибудь… в сущности, об отсутствии всего, что было необходимо для начала работы над своей собственной игрой. За исключением, пожалуй, владения 3d на некотором уровне.
С деньгами тоже была напряжённая ситуация, поэтому опция «взять — и вложить всем известные $70k в разработку, а на выходе получить готовую конфетку, расхватываемую геймерами как горячие пирожки», для меня тоже оказывалась недоступной.
Но в топках энтузиазма вовсю кочегарилось желание. Поэтому было принято решение во что бы то ни стало таки начать (и обязательно закончить!) воплощать в жизнь одну из множества постоянно придумываемых мной идей игры. И вот, в одно прекрасное утро на мой компьютер был неспешно установлен и запущен замечательный инструмент Unity3d, который через несколько секунд уже выжидающе смотрел на меня девственно пустым окном нового проекта.
Следующие месяцы были проведены в невероятно интересной атмосфере изучения огромного количества новой для меня информации и экспериментирования над своим будущим детищем. Об этом процессе я и хотел бы вам рассказать.
##### Концепт и подготовка прототипа
Мне не хотелось браться за что-то большое и сложное. Чем проще, тем лучше — таков был мой девиз. В планах не было вязнуть в непреодолимых задачах и неперелопачиваемых в одиночку объёмах работы. Идея была проста и относительно оригинальна: лабиринт с возможностью прокручивания отдельных квадратных его участков, а-ля plumber game. Поворачивая плитки с участками лабиринта, игрок строит путь к выходу.
Каждый кусочек (плитка) помимо текстуры представляет из себя нехитрый набор характеристик:
* Плитка всегда имеет сквозной проход
* Плитка может иметь глухие внешние стенки и/или один тупиковый ход
* Имя плитки состоит из четырёх цифр, характеризующих её внешние стенки, начиная с верхней по часовой стрелке. Например, имя **0212** говорит о том, что плитка имеет глухую верхнюю стенку, один тупиковый проход снизу и один сквозной проход, соединяющий левую и правую стороны
* Четыре бита (по одному на каждую сторону), описывающие соединение пройденного пути с рассматриваемой плиткой. Например, **0001** означает, что с левой стороны в плитку упирается пройденный игроком путь
* Массив из четырёх целых чисел, полученный поциферным перемножением предыдущих двух чисел. Элементы этого массива показывают, какие проходы в плитке присоединяются к уже построенному пути
**Схематичные примеры плиток**
Не все плитки, показанные на рисунке, соответствуют правилам, поэтому лишь некоторые из них я использовал в игре
**Как плитки выглядят в игре**
Каждая плиточка в игре представляет собой три квада (четырёхугольника), находящихся один над другим. Самый нижний квад отображает подложку — базовую текстуру стенок и тёмного непройденного пути. Два других квада имеют текстуру пройденных участков плитки, «включающихся», если игрок построил путь через неё. Для наглядности прилагаю картинку:
**Что из себя представляет плитка**
Накладываясь один на другой, квады при прямом изометрическом виде дают картинку готовой плитки
Из таких вот плиток и состоит игровое поле, являющееся двумерным массивом. Первый элемент массива всегда представляет начало лабиринта (`[0, 0]` левая нижняя плитка), последний — конец (`[width – 1, height - 1]` правая верхняя плитка).
**Схематичное игровое поле**
Желтая плитка имеет имя **2210** и массив входов **0001**
Самое интересное заключалось в том, чтобы придумать и реализовать алгоритм прорисовки построенного пользователем пути. Здесь я тоже не стал мудрствовать лукаво, и в спойлере ниже можно посмотреть, что у меня получилось.
**Упорщенный алгоритм поиска пути**
##### Добавление плюшек и удержание мысли в узде
Параллельно допиливанию рабочего прототипа полным ходом шла подготовка текстур. Этот этап для меня был самым простым и ничего особенного из себя не представляет. Я старался выдать максимально приятную глазу картинку, попиксельно выверяя каждый свой шаг. Помучиться пришлось разве что с кастомным шрифтом. Дело в том, что я совершенно не хотел использовать TTF и сконцентрировался исключительно на BitMap fonts. Для использования шрифтов, реализованных текстурой с прозрачностью в альфа-канале, в Unity на данный момент нет удобных бесплатных инструментов. И, так как финансовые траты я с самого начала решил свести к нулю, пришлось шрифт делать руками от начала до конца, включая прорисовку и UV-маппинг каждой буквы. Наградой за унылую монотонную работу мне стал полностью готовый к использованию симпатичный шрифт. Подробнее о том, как я делал шрифт, я писал в [другом посте](http://habrahabr.ru/post/212587/).
**Шрифт**
Изначально планировалось, что игра будет выполнена в трёх сеттингах с оригинальными особенностями геймплея в каждом из них, содержать кучу разнообразных монстров, оружие для их уничтожения и много чего ещё. Включая даже возможность лишать вереницу бредущих по пустыне путников некоторых материальных ценностей. Но в процессе работы быстро стало понятно, что мне такой объем контента просто не потянуть в одиночку. Поэтому было принято решение ограничиться одним «каменным» сеттингом, сокровищами, разбросанными по разным углам лабиринта, запертыми на замок сундуками/дверьми и ключами к ним. Такой простенький набор вполне вписывался в стратегию «проще — лучше» и требовал совсем не много сил на реализацию
**Предметы в игре**
##### Завершение процесса
Работа спорилась и, несмотря на то, что я мог уделять проекту лишь свободное от основной работы время, довольно ощутимо подходила к концу. Впору было задуматься о каком-никаком продвижении. Несколько дней поизучав вопрос и прочтя диагональным методом несколько книжек, я снова погрузился в уныние. На повестку выползло понимание, что без приличных затрат на рекламу ни о какой сколь-нибудь интересной прибыли можно даже не думать. Отсутствие денег, в течение всего процесса помогавшее мне оставаться верным правилу «свести затраты на разработку к нулю», не подвело и в этот раз. И на рекламу тратиться не пришлось. Впрочем, на покупку аккаунта продавца Google и домена с хостингом таки пришлось выложить полукруглую сумму в $50.
Еще одним неприятным моментом стала для меня новость, что у меня нет возможности продавать игру в Play Google в связи с отсутствием моей многострадальной страны в соответствующем списке (мне оставили, впрочем, возможность хоть как-то монетизироваться через рекламу в игре).
Но забивать на почти готовый проект смысла уже не было, и остатки сил я бросил на допиливание и вылизывание игры до состояния близкого к идеальному в моём субъективном понимании этого слова. Чем я и занялся. Не за горами был день, когда я с уверенностью мог сказать, что мне удалось осуществить свою мечту.
##### Итоги
И вот, по прошествии полугода со времени старта, игра готова! За месяцы, проведенные в изучении самых различных аспектов игростроя, я получил гигантское количество опыта, научился множеству интересных и увлекательных штук, ~~заработал сколиоз и проблемы со зрением~~, и, главное, получил заряд удовольствия от того, что мне удалось претворить свою мечту в жизнь.
Говорить о популярности игры пока еще слишком рано, равно как и о её интересности для геймеров. Если всё сложится удачно, я посвящу этом отдельный пост.
##### Послесловие
Имеются планы по портированию игры на iOS, если удастся наскрести на аккаунт разработчика Apple. C портом по идее не должно возникнуть трудностей, спасибо могущественному Unity3d. Так же хочется заняться постепенным добавлением новых фич, прощупыванием почвы монетизации через внутриигровые продажи (если я не ошибаюсь, AppStore позволяет совершать валютные операции резидентам Украины), реализацией множества других задумок как в отношении этого проекта, так и относительно новых, которым только предстоит появиться на свет. | https://habr.com/ru/post/212665/ | null | ru | null |
# Проверка проекта LibreOffice
 Предлагаем читателю очередную статью о проверке известного open-source проекта. В этот раз мы проверили проект LibreOffice, представляющий собой офисный пакет. В его разработке принимает участие более чем 480 программистов. Код оказался весьма качественным и регулярно проверяемым статическим анализатором Coverity. Но, как и в любом другом большом проекте, были найдены новые ошибки и недочеты, о которых мы и расскажем в статье. Для разнообразия, в этот раз нас будут сопровождать не единороги, а коровы.
[LibreOffice](http://www.viva64.com/go.php?url=1502) — мощный офисный пакет, полностью совместимый с 32/64-битными системами. Переведён более чем на 30 языков мира. Поддерживает большинство популярных операционных систем, включая GNU/Linux, Microsoft Windows и Mac OS X.
LibreOffice бесплатен и имеет открытый исходный код. Написан на языках: Java, Python, C++. Анализу была подвергнута та часть проекта, которая написана на C++ (и немножко на С, [C++/CLI](http://www.viva64.com/go.php?url=1485)). Version: 4.5.0.0.alpha0+ (Git revision: 368367).
Анализ был выполнен с помощью статического анализатора кода [PVS-Studio](http://www.viva64.com/ru/pvs-studio/).
Рассмотрим, какие ошибки были найдены, и что можно с ними сделать. Хочу отметить, что некоторые ошибки могут оказаться не ошибками. Я не знаком с кодом и мог принять за ошибку вполне корректный код. Однако, раз этот код сбил с толку анализатор и меня, значит что-то не так. Этот код пахнет, и хорошо провести его рефакторинг, чтобы снизить вероятность его неправильного понимания в процессе развитии проекта.
Опечатки
--------
Любой код не обходится без опечаток. Многие, конечно, находятся и исправляются на этапе тестирования, но некоторые остаются жить внутри программ на долгое время. Как правило они находятся в редко используемых функциях или не оказывают сильного влияние на работу программы.
Например, встретилась вот такая функция сравнения, которая работает только на одну треть:
```
class SvgGradientEntry
{
....
bool operator==(const SvgGradientEntry& rCompare) const
{
return (getOffset() == rCompare.getOffset()
&& getColor() == getColor()
&& getOpacity() == getOpacity());
}
....
}
```
Предупреждение PVS-Studio: [V501](http://www.viva64.com/ru/d/0090/) There are identical sub-expressions to the left and to the right of the '==' operator: getColor() == getColor() svggradientprimitive2d.hxx 61
Наверное, это ошибка не приносит много вреда. Возможно, этот оператор '==' вообще не используется. Однако, раз анализатор смог найти эту ошибку, он сможет найти и более серьезные сразу после написания нового кода. Поэтому основная ценность статического анализа не в разовых запусках, а в регулярном использовании.
Как можно было бы попробовать избежать такой ошибки? Не знаю. Возможно, если приучить себя более тщательно выравнивать блоки однотипного кода, то ошибка была бы более заметна. Например, функцию можно оформить так:
```
bool operator==(const SvgGradientEntry& rCompare) const
{
return getOffset() == rCompare.getOffset()
&& getColor() == getColor()
&& getOpacity() == getOpacity();
}
```
Теперь стало более заметно, что в правом столбце не хватает «rCompare». Хотя если честно, заметно не очень сильно. Может и не помочь. Человеку свойственно ошибаться. И поэтому статический анализатор бывает хорошим помощником.
А вот пример, где опечатку явно можно было избежать. Кто-то неудачно написал код для обмена значений между двумя переменными.

```
void TabBar::ImplGetColors(....)
{
....
aTempColor = rFaceTextColor;
rFaceTextColor = rSelectTextColor;
rSelectTextColor = rFaceTextColor;
....
}
```
Предупреждение PVS-Studio: [V587](http://www.viva64.com/ru/d/0190/) An odd sequence of assignments of this kind: A = B; B = A;. Check lines: 565, 566. tabbar.cxx 566
В последней строке вместо 'rFaceTextColor' следовало использовать 'aTempColor'.
Не нужно было писать код для обмена значений «вручную». Было бы проще и надёжней воспользоваться стандартной функцией std::swap():
```
swap(rFaceTextColor, rSelectTextColor);
```
Продолжим. От следующей ошибки думаю защититься невозможно. Опечатка в чистом виде:
```
void SAL_CALL Theme::disposing (void)
{
ChangeListeners aListeners;
maChangeListeners.swap(aListeners);
const lang::EventObject aEvent (static_cast(this));
for (ChangeListeners::const\_iterator
iContainer(maChangeListeners.begin()),
iContainerEnd(maChangeListeners.end());
iContainerEnd!=iContainerEnd;
++iContainerEnd)
{
....
}
}
```
Предупреждение PVS-Studio: V501 There are identical sub-expressions to the left and to the right of the '!=' operator: iContainerEnd != iContainerEnd theme.cxx 439
Цикл выполняться не будет, так как условие «iContainerEnd!=iContainerEnd» всегда ложно. Подвело схожие названия итераторов. На самом деле, нужно было написать: «iContainer!=iContainerEnd». Кстати, здесь кажется есть ещё одна ошибка. Странно, что увеличивается итератор «iContainerEnd».
Рассмотрим другой неудачный цикл:
```
static void lcl_FillSubRegionList(....)
{
....
for( IDocumentMarkAccess::const_iterator_t
ppMark = pMarkAccess->getBookmarksBegin(); <<<<----
ppMark != pMarkAccess->getBookmarksBegin(); <<<<----
++ppMark)
{
const ::sw::mark::IMark* pBkmk = ppMark->get();
if( pBkmk->IsExpanded() )
rSubRegions.InsertEntry( pBkmk->GetName() );
}
}
```
Предупреждение PVS-Studio: V625 Consider inspecting the 'for' operator. Initial and final values of the iterator are the same. uiregionsw.cxx 120
Цикл выполняться не будет. В условии итератор 'ppMark' нужно сравнивать с 'pMarkAccess->getBookmarksEnd()'. Идей, как защититься от такой ошибки с помощью правил написания кода, у меня нет. Просто опечатка.
Кстати, иногда ошибка есть, но она никак не влияет на правильное выполнение программы. Сейчас продемонстрирую одну из таких опечаток:
```
bool PolyPolygonEditor::DeletePoints(....)
{
bool bPolyPolyChanged = false;
std::set< sal_uInt16 >::const_reverse_iterator
aIter;( rAbsPoints.rbegin() );
for( aIter = rAbsPoints.rbegin();
aIter != rAbsPoints.rend(); ++aIter )
....
}
```
Предупреждение PVS-Studio: [V530](http://www.viva64.com/ru/d/0119/) The return value of function 'rbegin' is required to be utilized. polypolygoneditor.cxx 38
Ошибка вот здесь: aIter;( rAbsPoints.rbegin() );
Хотели инициализировать итератор. Но случайно вклинилась точка с запятой. Итератор остался неинициализированным. А выражение "(rAbsPoints.rbegin());" болтается в воздухе и ничего не делает.
Спасает ситуацию то, что в цикле итератор всё-таки инициализируется нужным значением. В общем ошибки нет, но лишнее выражение лучше убрать. Кстати, этот цикл был размножен с помощью Copy-Paste, поэтому стоит заглянуть ещё в строку 69 и 129 в этом же файле.
Напоследок опечатка в конструкторе класса:
```
XMLTransformerOOoEventMap_Impl::XMLTransformerOOoEventMap_Impl(
XMLTransformerEventMapEntry *pInit,
XMLTransformerEventMapEntry *pInit2 )
{
if( pInit )
AddMap( pInit );
if( pInit )
AddMap( pInit2 );
}
```
Предупреждение PVS-Studio: V581 The conditional expressions of the 'if' operators situated alongside each other are identical. Check lines: 77, 79. eventoootcontext.cxx 79
Второй оператор 'if' должен проверять указатель 'pInit2'.
Может быть так и задумано, но очень подозрительно
-------------------------------------------------
Есть несколько фрагментов кода, которые кажется содержат опечатки. Но я не уверен. Возможно, так и задумано.
```
class VCL_DLLPUBLIC MouseSettings
{
....
long GetStartDragWidth() const;
long GetStartDragHeight() const;
....
}
bool ImplHandleMouseEvent( .... )
{
....
long nDragW = rMSettings.GetStartDragWidth();
long nDragH = rMSettings.GetStartDragWidth();
....
}
```
Предупреждение: [V656](http://www.viva64.com/ru/d/0277/) Variables 'nDragW', 'nDragH' are initialized through the call to the same function. It's probably an error or un-optimized code. Consider inspecting the 'rMSettings.GetStartDragWidth()' expression. Check lines: 471, 472. winproc.cxx 472
Не понятно, должны инициализироваться переменные nDragW и nDragH одним и тем же значением, или нет. Если да, то не хватает комментария. Или лучше было бы явно написать:
```
long nDragW = rMSettings.GetStartDragWidth();
long nDragH = nDragW;
```
Похожая ситуация:
```
void Edit::ImplDelete(....)
{
....
maSelection.Min() = aSelection.Min();
maSelection.Max() = aSelection.Min();
....
}
```
V656 Variables 'maSelection.Min()', 'maSelection.Max()' are initialized through the call to the same function. It's probably an error or un-optimized code. Consider inspecting the 'aSelection.Min()' expression. Check lines: 756, 757. edit.cxx 757
Для тех, кто работает с проектом здесь всё сразу понятно. Я не работаю, и поэтому не знаю, есть здесь ошибка или нет.
И последний случай. В классе есть три функции:* GetVRP()
* GetVPN()
* GetVUV()
Однако, вот здесь, для инициализации константы 'aVPN' используется функция GetVRP().
```
void ViewContactOfE3dScene::createViewInformation3D(....)
{
....
const basegfx::B3DPoint aVRP(rSceneCamera.GetVRP());
const basegfx::B3DVector aVPN(rSceneCamera.GetVRP()); <<<---
const basegfx::B3DVector aVUV(rSceneCamera.GetVUV());
....
}
```
Предупреждение PVS-Studio: V656 Variables 'aVRP', 'aVPN' are initialized through the call to the same function. It's probably an error or un-optimized code. Consider inspecting the 'rSceneCamera.GetVRP()' expression. Check lines: 177, 178. viewcontactofe3dscene.cxx 178
Анализатор выдал ещё одно предупреждение V656. Я почти уверен, что там настоящая ошибка. Но приводить код не буду, так как он громоздкий. Прошу разработчиков посмотреть вот сюда:* V656 Variables 'oNumOffset1', 'oNumOffset2' are initialized through the call to the same function. It's probably an error or un-optimized code. Check lines: 68, 69. findattr.cxx 69
Copy-Paste
----------

Вынужден признать, что без Copy-Paste программирование временами будет крайне утомительным и скучным занятием. Без Ctrl-C, Ctrl-V программировать не получится, как бы не хотелось запретить эти сочетания клавиш. Поэтому не буду призывать не копировать код. Но призываю всех: копируя код, будьте аккуратны и бдительны!
```
uno::Sequence< OUString >
SwXTextTable::getSupportedServiceNames(void)
{
uno::Sequence< OUString > aRet(4);
OUString* pArr = aRet.getArray();
pArr[0] = "com.sun.star.document.LinkTarget";
pArr[1] = "com.sun.star.text.TextTable";
pArr[2] = "com.sun.star.text.TextContent";
pArr[2] = "com.sun.star.text.TextSortable";
return aRet;
}
```
Предупреждение PVS-Studio: [V519](http://www.viva64.com/ru/d/0108/) The 'pArr[2]' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 3735, 3736. unotbl.cxx 3736
Классический [эффект последней строки](http://www.viva64.com/ru/b/0260/). Почти уверен, что последняя строчка была получена из предпоследней. Заменили «Content» на «Sortable», а про индекс '2' забыли.
Очень похожий случай:
```
Sequence FirebirdDriver::getSupportedServiceNames\_Static()
{
Sequence< OUString > aSNS( 2 );
aSNS[0] = "com.sun.star.sdbc.Driver";
aSNS[0] = "com.sun.star.sdbcx.Driver";
return aSNS;
}
```
Предупреждение PVS-Studio: V519 The 'aSNS[0]' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 137, 138. driver.cxx 138
Но самое ужасное, что иногда благодаря Copy-Paste ошибки размножаются. Продемонстрирую это на примере. К сожалению, код будет несколько тяжёл для чтения. Потерпите.
Итак, в программе есть вот такая функция:
```
static bool GetPropertyValue(
::com::sun::star::uno::Any& rAny,
const ::com::sun::star::uno::Reference<
::com::sun::star::beans::XPropertySet > &,
const OUString& rPropertyName,
bool bTestPropertyAvailability = false );
```
Обратите внимание, что последний аргумент 'bTestPropertyAvailability' является необязательным.
Ещё надо сказать, что такое 'sal\_True':
```
#define sal_True ((sal_Bool)1)
```
Теперь собственно ошибка. Посмотрите, как вызывается функция GetPropertyValue():
```
sal_Int32 PPTWriterBase::GetLayoutOffset(....) const
{
::com::sun::star::uno::Any aAny;
sal_Int32 nLayout = 20;
if ( GetPropertyValue(
aAny, rXPropSet, OUString( "Layout" ) ), sal_True )
aAny >>= nLayout;
DBG(printf("GetLayoutOffset %" SAL_PRIdINT32 "\n", nLayout));
return nLayout;
}
```
Предупреждение PVS-Studio: [V639](http://www.viva64.com/ru/d/0257/) Consider inspecting the expression for 'GetPropertyValue' function call. It is possible that one of the closing ')' brackets was positioned incorrectly. pptx-epptbase.cxx 442
Если присмотреться, то выяснится, что одна из закрывающихся круглых скобок стоит не на своём месте. В результате, функция GetPropertyValue() в качестве последнего аргумента получает не 'sal\_True', а значение по умолчанию (равное 'false').
Но это только пол беды. Дополнительно испортилась работа оператора 'if'. Условие выглядит так:
```
if (foo(), sal_True)
```
[Оператор запятая](http://www.viva64.com/go.php?url=1503) возвращает свою правую часть. В результате условие всегда истинно.
Ошибка в этом коде не связана с Copy-Paste. Обыкновенная опечатка. Не там поставлена скобка. Бывает.
Печально то, что эта ошибка была размножена по другим участкам программы. Если в одном месте ошибку исправят, то высока вероятность, что в остальных местах оно останется.
Copy-Paste привёл к появлению этой ошибки ещё в 9 местах:* epptso.cxx 993
* epptso.cxx 3677
* pptx-text.cxx 518
* pptx-text.cxx 524
* pptx-text.cxx 546
* pptx-text.cxx 560
* pptx-text.cxx 566
* pptx-text.cxx 584
* pptx-text.cxx 590
В заключении раздела 3 последних некритических предупреждения. Просто одна лишняя проверка:
```
#define CHECK_N_TRANSLATE( name ) \
else if (sServiceName == SERVICE_PERSISTENT_COMPONENT_##name) \
sToWriteServiceName = SERVICE_##name
void OElementExport::exportServiceNameAttribute()
{
....
CHECK_N_TRANSLATE( FORM ); <<<<----
CHECK_N_TRANSLATE( FORM ); <<<<----
CHECK_N_TRANSLATE( LISTBOX );
CHECK_N_TRANSLATE( COMBOBOX );
CHECK_N_TRANSLATE( RADIOBUTTON );
CHECK_N_TRANSLATE( GROUPBOX );
CHECK_N_TRANSLATE( FIXEDTEXT );
CHECK_N_TRANSLATE( COMMANDBUTTON );
....
}
```
Предупреждение PVS-Studio: [V517](http://www.viva64.com/ru/d/0106/) The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 177, 178. elementexport.cxx 177
Ничего страшного, но недочёт. Ещё две лишние проверки можно найти здесь:* querydesignview.cxx 3484
* querydesignview.cxx 3486
Храброе использование функции realloc()
---------------------------------------
Функция realloc() используется столь явно небезопасно, что я не рискую назвать это ошибкой. Видимо, это сознательное решение авторов. Раз не удалось выделить память, используя malloc()/realloc(), то пусть программа лучше сразу упадёт. Нечего «брыкаться». Все равно, если программа продолжит работать, вряд ли что из этого хорошего выйдет. Но не честно засчитать выданные анализатором сообщения за ложные срабатывания. Поэтому рассмотрим, что не понравилось анализатору.
Для примера изучим реализацию функции add() в классе FastAttributeList:
```
void FastAttributeList::add(sal_Int32 nToken,
const sal_Char* pValue, size_t nValueLength )
{
maAttributeTokens.push_back( nToken );
sal_Int32 nWritePosition = maAttributeValues.back();
maAttributeValues.push_back( maAttributeValues.back() +
nValueLength + 1 );
if (maAttributeValues.back() > mnChunkLength)
{
mnChunkLength = maAttributeValues.back();
mpChunk = (sal_Char *) realloc( mpChunk, mnChunkLength );
}
strncpy(mpChunk + nWritePosition, pValue, nValueLength);
mpChunk[nWritePosition + nValueLength] = '\0';
}
```
Предупреждение PVS-Studio: [V701](http://www.viva64.com/ru/d/0340/) realloc() possible leak: when realloc() fails in allocating memory, original pointer 'mpChunk' is lost. Consider assigning realloc() to a temporary pointer. fastattribs.cxx 88
Главная беда этого кода в том, что не проверяется результат работы функции realloc(). Безусловно, ситуация, когда не удастся выделить память весьма редка. Но представим — это случилось. Тогда realloc() возвращает NULL. Далее возникнет аварийная ситуация, когда функция strncpy() начнёт копировать данные не пойми куда:
```
mpChunk = (sal_Char *) realloc( mpChunk, mnChunkLength );
}
strncpy(mpChunk + nWritePosition, pValue, nValueLength);
```
Но анализатору не нравится другое. Предположим, что есть какой-то обработчик ошибок. И программа продолжит своё выполнение. Вот только возникает memory leak. В переменную mpChunk будет записан 0, и освободить память уже невозможно. Поясню этот паттерн ошибки чуть подробнее. Многие не задумываются и неправильно используют realloc().
Рассмотрим искусственный пример кода:
```
char *p = (char *)malloc(10);
....
p = (char *)realloc(p, 10000);
```
Если не удастся выделить память, то переменная 'p' будет «испорчена». Теперь нет никакой возможности освободить память, указатель на которую хранился в 'p'.
В таком виде ошибка очевидна. Но на практике такой код встречается достаточно часто. Анализатор выдаёт ещё 8 предупреждений на эту тему, но рассматривать их смысла нет. Все равно LibreOffice считает, что память можно выделить всегда.
Ошибки в логике
---------------
Встретилось ряд забавных ошибок в условиях. Причины, видимо, разные: невнимательность, опечатки, недостаточное знание языка.

```
void ScPivotLayoutTreeListData::PushDataFieldNames(....)
{
....
ScDPLabelData* pLabelData = mpParent->GetLabelData(nColumn);
if (pLabelData == NULL && pLabelData->maName.isEmpty())
continue;
....
}
```
Предупреждение PVS-Studio: [V522](http://www.viva64.com/ru/d/0111/) Dereferencing of the null pointer 'pLabelData' might take place. Check the logical condition. pivotlayouttreelistdata.cxx 157
Логическая ошибка в условии. Если указатель нулевой, то мы его разыменуем. Как я понимаю, здесь следовало использовать оператор ||.
Аналогичная ошибка:
```
void grabFocusFromLimitBox( OQueryController& _rController )
{
....
vcl::Window* pWindow = VCLUnoHelper::GetWindow( xWindow );
if( pWindow || pWindow->HasChildPathFocus() )
{
pWindow->GrabFocusToDocument();
}
....
}
```
Предупреждение PVS-Studio: V522 Dereferencing of the null pointer 'pWindow' might take place. Check the logical condition. querycontroller.cxx 293
Здесь наоборот, вместо '||' следовало написать '&&'.
Теперь чуть более сложное условие:
```
enum SbxDataType {
SbxEMPTY = 0,
SbxNULL = 1,
....
};
void SbModule::GetCodeCompleteDataFromParse(CodeCompleteDataCache& aCache)
{
....
if( (pSymDef->GetType() != SbxEMPTY) ||
(pSymDef->GetType() != SbxNULL) )
....
}
```
Предупреждение PVS-Studio: [V547](http://www.viva64.com/ru/d/0137/) Expression is always true. Probably the '&&' operator should be used here. sbxmod.cxx 1777
Для простоты перепишу выражение:
```
if (type != 0 || type != 1)
```
Условие всегда истинно.
Две похожих ошибки можно найти здесь:* V547 Expression is always true. Probably the '&&' operator should be used here. sbxmod.cxx 1785
* V547 Expression is always false. Probably the '||' operator should be used here. xmlstylesexporthelper.cxx 223
Встретилось два места, где условие является избыточным. Я думаю это ошибки:
```
sal_uInt16 ScRange::ParseCols(....)
{
....
const sal_Unicode* p = rStr.getStr();
....
case formula::FormulaGrammar::CONV_XL_R1C1:
if ((p[0] == 'C' || p[0] != 'c') &&
NULL != (p = lcl_r1c1_get_col(
p, rDetails, &aStart, &ignored )))
{
....
}
```
Предупреждение PVS-Studio: V590 Consider inspecting the 'p[0] == 'C' || p[0] != 'c'' expression. The expression is excessive or contains a misprint. address.cxx 1593
Условие (p[0] == 'C' || p[0] != 'c') можно сократить до (p[0] != 'c'). Уверен, что это ошибка и условие должно быть таким: (p[0] == 'C' || p[0] == 'c').
Идентичная ошибку можно найти в этом же файле чуть ниже:* V590 Consider inspecting the 'p[0] == 'R' || p[0] != 'r'' expression. The expression is excessive or contains a misprint. address.cxx 1652
Пожалуй, к ошибкам в логике можно отнести ситуацию, когда указатель в начале разыменовывается, а потом только проверяется на равенство нулю. Это весьма [распространенная ошибка](http://www.viva64.com/ru/examples/v595/) во всех программах. Обычно она возникает из-за невнимательности в процессе рефакторинга кода.
Типичный пример:
```
IMPL_LINK(....)
{
....
SystemWindow *pSysWin = pWindow->GetSystemWindow();
MenuBar *pMBar = pSysWin->GetMenuBar();
if ( pSysWin && pMBar )
{
AddMenuBarIcon( pSysWin, true );
}
....
}
```
Предупреждение PVS-Studio: V595 The 'pSysWin' pointer was utilized before it was verified against nullptr. Check lines: 738, 739. updatecheckui.cxx 738
Указатель 'pSysWin' разыменовывается в выражении 'pSysWin->GetMenuBar()'. Затем он проверяется на равенство нулю.
Предлагаю создателям LibreOffice также обратить внимание вот на эти места: [LibreOffice-V595.txt](http://www.viva64.com/external-pictures/txt/LibreOffice-V595.txt).
И последняя, на этот раз более запутанная ситуация. Если устали, то можно пропустить это место. Рассмотрим обыкновенно перечисление:
```
enum BRC_Sides
{
WW8_TOP = 0, WW8_LEFT = 1, WW8_BOT = 2,
WW8_RIGHT = 3, WW8_BETW = 4
};
```
Обратите внимание, именованные константы не являются степенью двойки. Это просто числа. В том числе там есть 0.
А работают с этими константами, как будто они представляют степень двойки. Пытаются по маске выбрать и проверить отдельные биты:
```
void SwWW8ImplReader::Read_Border(....)
{
....
if ((nBorder & WW8_LEFT)==WW8_LEFT)
aBox.SetDistance(
(sal_uInt16)aInnerDist.Left(), BOX_LINE_LEFT );
if ((nBorder & WW8_TOP)==WW8_TOP)
aBox.SetDistance(
(sal_uInt16)aInnerDist.Top(), BOX_LINE_TOP );
if ((nBorder & WW8_RIGHT)==WW8_RIGHT)
aBox.SetDistance(
(sal_uInt16)aInnerDist.Right(), BOX_LINE_RIGHT );
if ((nBorder & WW8_BOT)==WW8_BOT)
aBox.SetDistance(
(sal_uInt16)aInnerDist.Bottom(), BOX_LINE_BOTTOM );
....
}
```
Предупреждение PVS-Studio: [V616](http://www.viva64.com/ru/d/0233/) The 'WW8\_TOP' named constant with the value of 0 is used in the bitwise operation. ww8par6.cxx 4742
Это неправильные действия. Например, условие ((nBorder & WW8\_TOP)==WW8\_TOP) всегда истинно. Для пояснения подставлю числа: ((nBorder & 0)==0).
Неправильно сработает проверка и на WW8\_LEFT, если в переменной nBorder будет значение WW8\_RIGHT, равное 3. Подставляем ((3 & 1) == 1). Получается, что WW8\_RIGHT примем за WW8\_LEFT.
Скелет в шкафу
--------------
Анализатор время от времени обнаруживает аномальные места в коде. Это не ошибки, а хитрая задумка. Трогать их смысла нет, но посмотреть может быть интересно. Вот один из таких случаев, где анализатору не понравился аргумент функции free():
```
/* This operator is supposed to be unimplemented, but that now leads
* to compilation and/or linking errors with MSVC2008. (Don't know
* about MSVC2010.) As it can be left unimplemented just fine with
* gcc, presumably it is never called. So do implement it then to
* avoid the compilation and/or linking errors, but make it crash
* intentionally if called.
*/
void SimpleReferenceObject::operator delete[](void * /* pPtr */)
{
free(NULL);
}
```
Техника безопасности
--------------------

Анализатор выявил ряд моментов, которые делают код программы опасным. Опасности разнообразны по своей природе, но я решил их собрать в один раздел.
```
void writeError( const char* errstr )
{
FILE* ferr = getErrorFile( 1 );
if ( ferr != NULL )
{
fprintf( ferr, errstr );
fflush( ferr );
}
}
```
Предупреждение PVS-Studio: [V618](http://www.viva64.com/ru/d/0235/) It's dangerous to call the 'fprintf' function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf("%s", str); unoapploader.c 405
Если в строке 'errstr' встретятся управляющие символы, то произойти может всё, что угодно. Программа может упасть, может записать в файл мусор или произойдёт что-то ещё ([подробности](http://www.viva64.com/ru/b/0129/)).
Правильно будет написать так:
```
fprintf( ferr, "%s", errstr );
```
Ещё два места, где неправильно используется функция printf():* climaker\_app.cxx 261
* climaker\_app.cxx 313
Теперь про опасное использование [dynamic\_cast](http://www.viva64.com/go.php?url=1504).
```
virtual ~LazyFieldmarkDeleter()
{
dynamic_cast
(\*m\_pFieldmark.get()).ReleaseDoc(m\_pDoc);
}
```
Предупреждение PVS-Studio: [V509](http://www.viva64.com/ru/d/0098/) The 'dynamic\_cast' operator should be located inside the try..catch block, as it could potentially generate an exception. Raising exception inside the destructor is illegal. docbm.cxx 846
При работе с ссылками, если преобразование невозможно выполнить, оператор dynamic\_cast генерирует исключение std::bad\_cast.
Если в программе возникает исключение, начинается свертывание стека, в ходе которого объекты разрушаются путем вызова деструкторов. Если деструктор объекта, разрушаемого при свертывании стека, бросает еще одно исключение, и это исключение покидает деструктор, библиотека C++ немедленно аварийно завершает программу, вызывая функцию terminate(). Из этого следует, что деструкторы никогда не должны распространять исключения. Исключение, брошенное внутри деструктора, должно быть обработано внутри того же деструктора.
По этой же причине опасно в деструкторы вызывать оператор new. Этот оператор при нехватке памяти сгенерирует исключение std::bad\_alloc. Хорошим тоном будет обернуть его в блок try-catch.
Пример опасного кода:
```
WinMtfOutput::~WinMtfOutput()
{
mpGDIMetaFile->AddAction( new MetaPopAction() );
....
}
```
Предупреждения PVS-Studio: V509 The 'new' operator should be located inside the try..catch block, as it could potentially generate an exception. Raising exception inside the destructor is illegal. winmtf.cxx 852
Прочие опасные действия в деструкторе:* V509 The 'dynamic\_cast' operator should be located inside the try..catch block, as it could potentially generate an exception. Raising exception inside the destructor is illegal. ndtxt.cxx 4886
* V509 The 'new' operator should be located inside the try..catch block, as it could potentially generate an exception. Raising exception inside the destructor is illegal. export.cxx 279
* V509 The 'new' operator should be located inside the try..catch block, as it could potentially generate an exception. Raising exception inside the destructor is illegal. getfilenamewrapper.cxx 73
* V509 The 'new' operator should be located inside the try..catch block, as it could potentially generate an exception. Raising exception inside the destructor is illegal. e3dsceneupdater.cxx 80
* V509 The 'new' operator should be located inside the try..catch block, as it could potentially generate an exception. Raising exception inside the destructor is illegal. accmap.cxx 1683
* V509 The 'new' operator should be located inside the try..catch block, as it could potentially generate an exception. Raising exception inside the destructor is illegal. frmtool.cxx 938
Кстати, раз пошла речь про operator new, то отмечу опасность вот такого кода:
```
extern "C" oslFileHandle
SAL_CALL osl_createFileHandleFromOSHandle(
HANDLE hFile,
sal_uInt32 uFlags)
{
if ( !IsValidHandle(hFile) )
return 0; // EINVAL
FileHandle_Impl * pImpl = new FileHandle_Impl(hFile);
if (pImpl == 0)
{
// cleanup and fail
(void) ::CloseHandle(hFile);
return 0; // ENOMEM
}
....
}
```
Предупреждение PVS-Studio: [V668](http://www.viva64.com/ru/d/0293/) There is no sense in testing the 'pImpl' pointer against null, as the memory was allocated using the 'new' operator. The exception will be generated in the case of memory allocation error. file.cxx 663
Оператор 'new' при нехватке памяти генерирует исключение. Таим образом, проверять указатель, который вернул оператор не имеет смысла. Он всегда не равен 0. При нехватке памяти не будет вызвана функция CloseHandle():
```
FileHandle_Impl * pImpl = new FileHandle_Impl(hFile);
if (pImpl == 0)
{
// cleanup and fail
(void) ::CloseHandle(hFile);
return 0; // ENOMEM
}
```
Я могу ошибаться. Я не знаю проект LibreOffice. Возможно разработчики используют специальный вариант библиотек, в которых оператор 'new' не кидает исключение, а возвращает nullptr. Если это так, то прошу просто не обращать внимание на предупреждения с номером V668. Их можно отключить, чтобы они не мешались.
Если оператор new кидает исключение, то рекомендую просмотреть следующие 126 сообщений: [LibreOffice-V668.txt](http://www.viva64.com/external-pictures/txt/LibreOffice-V668.txt).
Следующая опасность кроется в реализации одной из функций DllMain:
```
BOOL WINAPI DllMain( HINSTANCE hinstDLL,
DWORD fdwReason, LPVOID lpvReserved )
{
....
CreateThread( NULL, 0, ParentMonitorThreadProc,
(LPVOID)dwParentProcessId, 0, &dwThreadId );
....
}
```
Предупреждение PVS-Studio: [V718](http://www.viva64.com/ru/d/0359/) The 'CreateThread' function should not be called from 'DllMain' function. dllentry.c 308
Внутри функции DllMain() нельзя вызывать многие функции, так как это может привести к зависанию приложения или иным ошибкам. Именно к таким функциям относится CreateThread().
Ситуация с DllMain хорошо описана в статье на сайте MSDN: [Dynamic-Link Library Best Practices](http://www.viva64.com/go.php?url=1487).
Этот код может работать, но он опасен и когда-нибудь может подвести.
Встретилась ситуация, где функция wcsncpy() может привести к переполнению буфера:
```
typedef struct {
....
WCHAR wszTitle[MAX_COLUMN_NAME_LEN];
WCHAR wszDescription[MAX_COLUMN_DESC_LEN];
} SHCOLUMNINFO, *LPSHCOLUMNINFO;
HRESULT STDMETHODCALLTYPE CColumnInfo::GetColumnInfo(
DWORD dwIndex, SHCOLUMNINFO *psci)
{
....
wcsncpy(psci->wszTitle,
ColumnInfoTable[dwIndex].wszTitle,
(sizeof(psci->wszTitle) - 1));
return S_OK;
}
```
Предупреждение PVS-Studio: [V512](http://www.viva64.com/ru/d/0101/) A call of the 'wcsncpy' function will lead to overflow of the buffer 'psci->wszTitle'. columninfo.cxx 129
Выражение (sizeof(psci->wszTitle) — 1) неверно. Забыли поделить на размер одного символа:
```
(sizeof(psci->wszTitle) / sizeof(psci->wszTitle[0]) - 1)
```
Последний тип ошибки, который мы рассмотрим в этом разделе, являются неработающие вызовы функций memset(). Пример:
```
static void __rtl_digest_updateMD2 (DigestContextMD2 *ctx)
{
....
sal_uInt32 state[48];
....
memset (state, 0, 48 * sizeof(sal_uInt32));
}
```
Предупреждение PVS-Studio: [V597](http://www.viva64.com/ru/d/0208/) The compiler could delete the 'memset' function call, which is used to flush 'state' buffer. The RtlSecureZeroMemory() function should be used to erase the private data. digest.cxx 337
Я уже много раз писал про этот вид ошибки. Поэтому опишу её буквально парой слов, а подробности можно узнать, перейдя по предложенным ссылкам.
Компилятор в праве удалить вызов функции memset(), если после её вызова обнулённая память никак не используется. Именно это здесь и произойдёт. В результате в памяти останутся какие-то приватные данные.
Подробности:1. [V597. The compiler could delete the 'memset' function call, which is used to flush 'Foo' buffer](http://www.viva64.com/ru/d/0208/).
2. [Перезаписывать память — зачем?](http://www.viva64.com/ru/k/0041/)
3. [Zero and forget — caveats of zeroing memory in C](http://www.viva64.com/go.php?url=1028).
Прочие места, где не чистятся приватные данные: [LibreOffice-V597.txt](http://www.viva64.com/external-pictures/txt/LibreOffice-V597.txt).
Всякое разное
-------------
```
Guess::Guess()
{
language_str = DEFAULT_LANGUAGE;
country_str = DEFAULT_COUNTRY;
encoding_str = DEFAULT_ENCODING;
}
Guess::Guess(const char * guess_str)
{
Guess();
....
}
```
Предупреждение PVS-Studio: [V603](http://www.viva64.com/ru/d/0215/) The object was created but it is not being used. If you wish to call constructor, 'this->Guess::Guess(....)' should be used. guess.cxx 56
Программист, написавший этот код, недостаточно хорошо знает язык Си++. Он хотел вызывать один конструктор из другого. Но, на самом деле, он создал временный неименованный объект. Из-за ошибки некоторые поля класса так остаются неинициализированными. [Подробности](http://www.viva64.com/ru/b/0127/).
Ещё один неудачный конструктор: camera3d.cxx 46
```
sal_uInt32 readIdent(....)
{
size_t nItems = rStrings.size();
const sal_Char** pStrings = new const sal_Char*[ nItems+1 ];
....
delete pStrings;
return nRet;
}
```
Предупреждение PVS-Studio: [V611](http://www.viva64.com/ru/d/0226/) The memory was allocated using 'new T[]' operator but was released using the 'delete' operator. Consider inspecting this code. It's probably better to use 'delete [] pStrings;'. profile.hxx 103
Правильно будет: delete [] pStrings;.
Ещё одно предупреждение про неправильное освобождение памяти:* V611 The memory was allocated using 'new T[]' operator but was released using the 'delete' operator. Consider inspecting this code. It's probably better to use 'delete [] pStrings;'. profile.hxx 134
```
static const int kConventionShift = 16;
static const int kFlagMask = ~((~int(0)) << kConventionShift);
```
Предупреждение PVS-Studio: V610 Undefined behavior. Check the shift operator '<<'. The left operand '(~int (0))' is negative. grammar.hxx 56
Имеет место неопределённое поведение из-за сдвига отрицательного значения ([подробности](http://www.viva64.com/ru/b/0142/)).
```
sal_Int32 GetMRest() const {return m_nRest;}
OUString LwpBulletStyleMgr::RegisterBulletStyle(....)
{
....
if (pIndent->GetMRest() > 0.001)
....
}
```
Предупреждение PVS-Studio: [V674](http://www.viva64.com/ru/d/0308/) The '0.001' literal of the 'double' type is compared to a value of the 'long' type. Consider inspecting the 'pIndent->GetMRest() > 0.001' expression. lwpbulletstylemgr.cxx 177
Что-то здесь не так. Нет смысла сравнивать целочисленное значение с 0.001.
Неприятная путаница с типом возвращаемого значения:
```
BOOL SHGetSpecialFolderPath(
HWND hwndOwner,
_Out_ LPTSTR lpszPath,
_In_ int csidl,
_In_ BOOL fCreate
);
#define FAILED(hr) (((HRESULT)(hr)) < 0)
OUString UpdateCheckConfig::getDesktopDirectory()
{
....
if( ! FAILED( SHGetSpecialFolderPathW( .... ) ) )
....
}
```
Предупреждение PVS-Studio: [V716](http://www.viva64.com/ru/d/0357/) Suspicious type conversion: BOOL -> HRESULT. updatecheckconfig.cxx 193
Программист решил, что SHGetSpecialFolderPath() возвращает тип HRESULT. Но, на самом деле, функция возвращает BOOL. Чтобы исправить код, следует убрать из условия макрос FAILED.
Ещё одна такая ошибка: updatecheckconfig.cxx 222
А вот здесь наоборот не хватает макроса FAILED. Так проверять статус типа HRESULT нельзя:
```
bool UniscribeLayout::LayoutText( ImplLayoutArgs& rArgs )
{
....
HRESULT nRC = ScriptItemize(....);
if( !nRC ) // break loop when everything is correctly itemized
break;
....
}
```
Предупреждение PVS-Studio: [V545](http://www.viva64.com/ru/d/0134/) Such conditional expression of 'if' operator is incorrect for the HRESULT type value 'nRC'. The SUCCEEDED or FAILED macro should be used instead. winlayout.cxx 1115
Думаю, здесь следует заменить запятую на точку с запятой:
```
void Reader::ClearTemplate()
{
if( pTemplate )
{
if( 0 == pTemplate->release() )
delete pTemplate,
pTemplate = 0;
}
}
```
Предупреждение PVS-Studio: [V626](http://www.viva64.com/ru/d/0243/) Consider checking for misprints. It's possible that ',' should be replaced by ';'. shellio.cxx 549
Неинтересная мелочь:
```
void TabBar::ImplInit( WinBits nWinStyle )
{
....
mbMirrored = false;
mbMirrored = false;
....
}
```
Предупреждение PVS-Studio: V519 The 'mbMirrored' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 415, 416. tabbar.cxx 416
И здесь ещё: V519 The 'aParam.mpPreviewFontSet' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 4561, 4562. output2.cxx 4562
Неправильно магическая константа, обозначающая длину строки:
```
static bool CallRsc2(....)
{
....
if( !rsc_strnicmp( ...., "-fp=", 4 ) ||
!rsc_strnicmp( ...., "-fo=", 4 ) ||
!rsc_strnicmp( ...., "-presponse", 9 ) || <<<<----
!rsc_strnicmp( ...., "-rc", 3 ) ||
!rsc_stricmp( ...., "-+" ) ||
!rsc_stricmp( ...., "-br" ) ||
!rsc_stricmp( ...., "-bz" ) ||
!rsc_stricmp( ...., "-r" ) ||
( '-' != *.... ) )
....
}
```
Предупреждение PVS-Studio: [V666](http://www.viva64.com/ru/d/0291/) Consider inspecting third argument of the function 'rsc\_strnicmp'. It is possible that the value does not correspond with the length of a string which was passed with the second argument. start.cxx 179
Длина строки "-presponse" 10, а не 9 символов.
Странный 'break' внутри цикла:
```
OUString getExtensionFolder(....)
{
....
while (xResultSet->next())
{
title = Reference(
xResultSet, UNO\_QUERY\_THROW )->getString(1 /\* Title \*/ ) ;
break;
}
return title;
}
```
Предупреждение PVS-Studio: [V612](http://www.viva64.com/ru/d/0228/) An unconditional 'break' within a loop. dp\_manager.cxx 100
Ещё три странных цикла:* V612 An unconditional 'break' within a loop. svdfppt.cxx 3260
* V612 An unconditional 'break' within a loop. svdfppt.cxx 3311
* V612 An unconditional 'break' within a loop. personalization.cxx 454
Маловероятное разыменование нулевого указателя:
```
BSTR PromptNew(long hWnd)
{
....
ADOConnection* piTmpConnection = NULL;
::CoInitialize( NULL );
hr = CoCreateInstance(
CLSID_DataLinks,
NULL,
CLSCTX_INPROC_SERVER,
IID_IDataSourceLocator,
(void**)&dlPrompt
);
if( FAILED( hr ) )
{
piTmpConnection->Release();
dlPrompt->Release( );
return connstr;
}
....
}
```
Предупреждение PVS-Studio: V522 Dereferencing of the null pointer 'piTmpConnection' might take place. adodatalinks.cxx 84
Если вдруг функция CoCreateInstance() вернёт статус ошибки, то произойдёт разыменование указателя 'piTmpConnection' который равен NULL.
Микрооптимизации
----------------
Статический анализатор ни в коей мере не может быть заменой инструментам профилирования. Только профилировщик может показать, где стоит оптимизировать вашу программу.
Тем не менее статический анализатор может показать места в коде, которые можно легко улучшить. Не обязательно, что от этого программа будет работать быстрее. Но хуже точно не будет. Пожалуй, речь идёт скорее о хорошем стиле кодирования.
Посмотрим, какие рекомендации выдаёт PVS-Studio касательно микрооптимизаций.
### Передача объектов по ссылке
Если объект, переданный в функцию не изменяется, то эстетично будет передать его по ссылке, а не значению. Конечно, это относится не ко всем объектам. Однако, если, например, мы имеем дело со строками, то нет смысла зря выделять память и копировать содержимое строки.

Пример:
```
string getexe(string exename, bool maybeempty) {
char* cmdbuf;
size_t cmdlen;
_dupenv_s(&cmdbuf, &cmdlen, exename.c_str());
if(!cmdbuf) {
if (maybeempty) {
return string();
}
cout << "Error " << exename << " not defined. "
"Did you forget to source the environment?" << endl;
exit(1);
}
string command(cmdbuf);
free(cmdbuf);
return command;
}
```
Объект 'exename' используется только для чтения. Поэтому анализатор сообщает: [V813](http://www.viva64.com/ru/d/0303) Decreased performance. The 'exename' argument should probably be rendered as a constant reference. wrapper.cxx 18
Объявление функции можно изменить следующим образом:
```
string getexe(const string &exename, bool maybeempty)
```
Передача сложных объектов по константной ссылке обычно более эффективна и позволяет избежать проблемы «срезки». Для тех, кто недостаточно хорошо понимает суть, предлагаю обратиться к 20 правилу «Предпочитайте передачу по ссылке на const передаче по значению» из книги:
Мэйерс С. «Эффективное использование C++. 55 верных способов улучшить структуру и код ваших программ» — М.: ДМК Пресс, 2006. — 300 с.: ил. ISBN 5-94074-304-8
Ещё одной родственной диагностикой является [V801](http://www.viva64.com/ru/d/0135/). Всего, анализатор выдал 465 предупреждений, где на его взгляд можно передавать объект по ссылке: [LibreOffice-V801-V813.txt](http://www.viva64.com/external-pictures/txt/LibreOffice-V801-V813.txt).
### Использование префиксного инкремента
Для итераторов операция префиксного инкремента немного быстрее. Более подробно про это можно прочитать в «Правило 6. Различайте префиксную форму операторов инкремента и декремента» из книги:
Мейерс С. Наиболее эффективное использование С++. 35 новых рекомендаций по улучшению ваших программ и проектов: Пер. с англ. — М.: ДМК Пресс, 2000. — 304 с.: ил. (Серия «Для программистов»). ISBN 5-94074-033-2. ББК 32.973.26-018.1.
Рекомендация может показаться надуманной и, что на практике между 'A++'и '++A' никакой разницы нет. Я изучил этот вопрос, провёл эксперименты и считаю, что эту рекомендацию следует применять ([подробности](http://www.viva64.com/ru/b/0093/)).
Пример кода:
```
typename InterfaceMap::iterator find(const key &rKey) const
{
typename InterfaceMap::iterator iter = m_pMap->begin();
typename InterfaceMap::iterator end = m_pMap->end();
while( iter != end )
{
equalImpl equal;
if( equal( iter->first, rKey ) )
break;
iter++;
}
return iter;
}
```
Предупреждение PVS\_Studio: [V803](http://www.viva64.com/ru/d/0165/) Decreased performance. In case 'iter' is iterator it's more effective to use prefix form of increment. Replace iterator++ with ++iterator. interfacecontainer.h 405
Выражение «iter++» стоит заменить на "++iter". Не знаю, посчитают ли разработчики рациональным потратить на это время. Если решат, что стоит поправить, то вот ещё 257 мест, где можно заменить постфиксный инкремент на префиксный: [LibreOffice-V803.txt](http://www.viva64.com/external-pictures/txt/LibreOffice-V803.txt).
### Проверка, что строка пустая
Чтобы узнать, что строка пустая, необязательно вычислять её длину. Пример неэффективного кода:
```
BOOL GetMsiProp(....)
{
....
char* buff = reinterpret_cast( malloc( nbytes ) );
....
return ( strlen(buff) > 0 );
}
```
Предупреждение PVS-Studio: [V805](http://www.viva64.com/ru/d/0179/) Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) > 0' construct. A more efficient way is to check: str[0] != '\0'. sellang.cxx 49
Неэффективность в том, что нужно перебрать все символы в строке, пока не встретится [терминальный ноль](http://www.viva64.com/ru/t/0088/). Но достаточно проверить только один байт:
```
return buff[0] != '\0';
```
Такой код не очень красив, поэтому лучше будет завести специальную функцию:
```
inline bool IsEmptyStr(const char *s)
{
return s == nullptr || s[0] == '\0';
}
```
Здесь появилась лишняя проверка на равенства указателя нулю. Мне это не очень нравится и можно подумать над другими вариантами. Но всё равно, эта функция будет работать быстрее чем strlen().
Другие неэффективные проверки: [LibreOffice-V805.txt](http://www.viva64.com/external-pictures/txt/LibreOffice-V805.txt).
### Прочее
Есть ещё несколько предупреждений анализатора, которые могут показаться интересными: [LibreOffice-V804\_V811.txt](http://www.viva64.com/external-pictures/txt/LibreOffice-V804_V811.txt).
Количество ложных срабатываний
------------------------------
В статье я упомянул 240 предупреждений, которые мне показались интересными. Всего анализатор выдал около 1500 предупреждений общего плана ([GA](http://www.viva64.com/ru/general-analysis/)) 1 и 2 уровня. Это значит, что анализатор выдаёт много ложных срабатываний? Нет. Большинство предупреждений вполне по делу, но говорить про них в статье нет никакого смысла.
Время от времени мы получаем от наших пользователей положительные отзывы, в которых они говорят: «Анализатор PVS-Studio выдаёт мало ложных срабатываний, что очень удобно». Мы тоже считаем, что ложных срабатываний мало. Но как же так? В статье рассказано только о 16% сообщений. Что всё остальное? Это ложные срабатывания?
Конечно, есть ложные срабатывания. От этого никуда не денешься. Для их подавления есть ряд [механизмов](http://www.viva64.com/ru/d/0021/). Однако, большая часть предупреждений хотя и не выявило ошибку, но указала на код, который плохо пахнет. Попробую пояснить на примерах.
Анализатор выдал **206** предупреждений [V690](http://www.viva64.com/ru/d/0326/) о том, что в классе реализован конструктор копирования, но не реализован оператор присваивания. Вот один из таких классов:
```
class RegistryTypeReader
{
public:
....
inline RegistryTypeReader(const RegistryTypeReader& toCopy);
....
};
inline RegistryTypeReader::RegistryTypeReader(const RegistryTypeReader& toCopy)
: m_pApi(toCopy.m_pApi)
, m_hImpl(toCopy.m_hImpl)
{ m_pApi->acquire(m_hImpl); }
```
С большой вероятностью никакой ошибки нет. Скорее всего, operator = не используется во всех 206 классах. А вдруг используется?
Здесь программисту надо сделать выбор.
Если он считает, что код опасен, то он должен реализовать оператор присваивания или запретить его. Если на его взгляд опасности нет, то он может отключить диагностику V690, и список подозрительных мест сразу похудеет на 206 предупреждений.
Другой пример. Ранее в статье упоминался следующий подозрительный фрагмент:
```
if( pInit )
AddMap( pInit );
if( pInit )
AddMap( pInit2 );
```
Он выявлен с помощью диагностики V581. Но, если честно, я смотрел предупреждения V581 очень поверхностно и мог что-то пропустить. Дело в том, что их ещё 70 штук. И анализатор не виноват. Откуда ему знать, зачем писать вот так:
```
static bool lcl_parseDate(....)
{
bool bSuccess = true;
....
if (bSuccess)
{
++nPos;
}
if (bSuccess)
{
bSuccess =
readDateTimeComponent(string, nPos, nDay, 2, true);
....
}
```
Два раза проверяется 'bSuccess'. Вдруг второй раз следует проверить другую переменную?
Что делать с такими 70 предупреждениями вновь должен решить программист. Если он любит делать несколько одинаковых проверок, чтобы выделить какие-то логические блоки, то анализатор конечно не прав. Нужно отключить диагностику V581 и сразу исчезнут 70 предупреждений.
Если программист не столь уверен в себе, то ему придётся что-то предпринять. Можно отрефакторить код:
```
static bool lcl_parseDate(....)
{
bool bSuccess = true;
....
if (bSuccess)
{
++nPos;
bSuccess =
readDateTimeComponent(string, nPos, nDay, 2, true);
....
}
```
Самое главное, что нет серьезной проблемы с ложными срабатываниями. Если человеку группа предупреждений кажется бессмысленной для его проекта, он просто отключает их и очень сильно сокращает количество предупреждений, которое ему следует изучать. Если, на его взгляд, код следует посмотреть и поправить, то это никакие не ложные срабатывания, а самые настоящие полезные предупреждения.
**Примечание.** Можно начать использовать анализатор, не просматривая сотни или тысячи предупреждений. Можно воспользоваться новым механизмом [разметки сообщений](http://www.viva64.com/ru/d/0345/). Надо скрыть все предупреждения, которые есть и смотреть только на сообщения, которые будут появляются в новом коде. А к ошибкам в старом коде можно будет вернуться в более свободный от срочных дел момент времени.
Заключение
----------
Хотя как всегда в моей статье перечислена масса ошибок, недочетов и ляпов, код LibreOffice весьма качественный. Да и регулярное использование Coverity говорит о серьёзном подходе к разработке. Для проекта такого объёма ошибок весьма мало.
Что хотел сказать этой статьёй? Да в общем то ничего. Немного рекламы и не более того. Используйте статический анализатор [PVS-Studio](http://www.viva64.com/ru/pvs-studio/) регулярно и будете находить множество ляпов на самых ранних этапах.

Я подобен корове на последней картинке. Пришёл, навалил кучу ошибок и убежал. А авторам LibreOffice их теперь разгребать. Прошу прощения. Уж такова моя работа.
Эта статья на английском
------------------------
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [LibreOffice Project's Check](http://www.viva64.com/en/b/0308/).
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio и CppCat, версия 2014](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/251817/ | null | ru | null |
# FreeBSD versus GRUB
Добрый день. Эта заметка посвящена моей частной борьбе против GRUB'a, ну или за него, это как посмотреть.
Понадобилось поставить grub-загрузчик на freebsd, конечно многие знают про chainloader+1, но этот способ не годился для меня.
##### Прелюдия
Итак, ставим граб (первый, второй мне показался слишком монстроузным):
`# cd /usr/ports/sysutils/grub && make install`
Теперь необходимо собственно прописать его как загрузчик
`# grub-install /dev/ad8`
Вот здесь-то и пошли проблемы. Он сообщает нам прискорбную весть — *«The file /boot/grub/stage1 not read correctly.»*.
Как же так? Я же сам видел этот файлик, когда проверял поставился ли граб.
Ладно, гляну логи:
`# cat /tmp/grub-install.log.XXXXX
grub> dump (hd2,0,a)/boot/grub/stage1 /tmp/grub-install.img.XXXXX
Error 22: No such partition
grub> quit`
Ошибка мне ни о чём не говорит, ибо раздел само собой есть. Гугл не помог, разве что говорилось о баге с большим размером инодов в ext3, но у меня же ufs, а там размер фиксирован и равен 128 байтам. Поэтому я принял решения копать сорцы самому, несмотря на то, что код написан ужасно в плане оформления и структуры.
##### Error 22
Начинаем исследование с определения константы соответствующей этой ошибке, это просто — **ERR\_NO\_PART**, далее глядим кто может возвращать эту ошибку (на самом деле в grub'e реализован некий аналог errno, то есть глобальная переменная, которая содержит номер последней ошибки).
Таких мест всего 2, причём располагаются в 2х соседних лямбда-функциях (привет gcc!) **next\_bsd\_partition()** и **next\_pc\_slice()** по названию всё понятно — вторая перечисляет bsd-слайсы, первая — разделы в этих слайсах.
Я сразу отмел идею статического анализа, из-за структуры кода grub'a — очень, ну просто, очень много глобальных переменных и почти нет аргументов у функций. Отлаживать с gdb мне тоже не очень хотелось, ибо нет большого опыта в этом и всё происходило на удаленном серваке, так что какой-нибудь xxgdb использовать не представлялось возможным. Поэтому я избрал простой подход новичков — в непонятные места вставляем printf'ы. Здесь у меня тоже возникли трудности:
* При компиляции [alpha.gnu.org/gnu/grub/grub-0.97.tar.gz](ftp://alpha.gnu.org/gnu/grub/grub-0.97.tar.gz) получался другой результат по сравнению с компиляцией из портов. Как и по бинарной структуре (например, размер ./grub/grub ~ 350Kb против 150Kb портовых), так и по функционалу — root (hd \_TAB\_ выдавал всего 2 диска, вместо правильных 5.
Этот момент я обошел крайне просто — скомпилировал вариант из портов, но очищать (**make clean**) не стал, и из /usr/src/ports/sysutils/grub/work/grub забрал корректную версию сорцев и правильно сконфигуренную.
* printf у граба свой.
```
#ifndef WITHOUT_LIBC_STUBS
...
#define printf grub_printf
...
#endif
```
Хотел перекомпилировать без этого дефайна, но глянул на их версию, оставил так как есть. Поддерживает только d, x, X, u, c, s, и без всякой точности и ширины, просто %LITERAL, в принципе мне этого вполне хватило.
Хотелось более быстрой проверки, в самом деле — не заходить же каждый раз в консоль граба и не набирать 2 строчки. Это выполняется простой командой (которую я подсмотрел в шел-скрипте grub-install):
`./grub/grub --batch < cmd`
Где cmd содержит список команд, у меня в данном случае это:
`dump (hd2,0,a)/boot/grub/stage1 test_img
quit`
Рабочее место готово, начинаем «отладку». Вставляем printf() в начала тех двух функций и смотрим, на каком уровне иерархии споткнемся.
Споткнулись на разделах, вот такой вот у нас здесь цикл:
```
/* Search next valid BSD partition. */
for (i = bsd_part_no + 1; i < BSD_LABEL_NPARTS (buf); i++)
{
if (BSD_PART_TYPE (buf, i))
{
/* Note that *TYPE and *PARTITION were set
for current PC slice. */
*type = (BSD_PART_TYPE (buf, i) << 8) | (*type & 0xFF);
*start = BSD_PART_START (buf, i);
*len = BSD_PART_LENGTH (buf, i);
*partition = (*partition & 0xFF00FF) | (i << 8);
#ifndef STAGE1_5
/* XXX */
if ((drive & 0x80) && BSD_LABEL_DTYPE (buf) == DTYPE_SCSI)
bsd_evil_hack = 4;
#endif /* ! STAGE1_5 */
return 1;
}
}
```
Кстати, можно обратить внимание на интересную позицию разработчиков — отступы реализованы с использованием комбинации табов и пробелов, то есть 2 таба, 4 пробела, например. Что очень «нравится» редактору, в котором я правил код.
Если ни разу не сработало условие **BSD\_PART\_TYPE (buf, i)**, то выводим что кончились патриции.
```
#define BSD_PART_TYPE(l_ptr, part) \
( *( (unsigned char *) (((int) l_ptr) + BSD_PART_OFFSET + 12 \
+ (part << 4)) ) )
```
Этот дефайн «очень» понятен. За разъяснениями пришлось идти к **«Booting, Partitioning and File Systems»** доктора **C. P. J. Koymans**.
Там представлена структура слайса, в которой мы и видим что по смещению 12 от блока описания одного раздела лежит поле **Partition type**, а у нас оно по-видимому равно 0, раз условие не срабатывает.
Проверяем — **bsdlabel /dev/ad8s1**, действительно — написано что **unused**. Ну что же, поправить дело недолгое — **bsdlavel -e /dev/ad8s1**. А вот не хочет — «class not found».
Само собой перед установкой граба флажок я установил (**sysctl kern.geom.debugflags=16**), погуглил, советуют ставить 17 в последних версиях фряхи, поставил — результата нет.
Копаться еще и в сорцах bsdlabel'a не было никакого желания, поэтому поступил проще **ktrace bsdlabel -e /dev/ad8s1**, затем **kdump | more**.
`74340 bsdlabel CALL open(0x28201030,O_RDWR,[unused]0xbfbfe9e8)
74340 bsdlabel NAMI "/dev/ad8s1"
74340 bsdlabel RET open -1 errno 1 Operation not permitted
74340 bsdlabel CALL open(0x28097653,O_RDONLY,[unused]0x28050629)
74340 bsdlabel NAMI "/dev/geom.ctl"
74340 bsdlabel RET open 3
74340 bsdlabel CALL ioctl(0x3,GEOM_CTL,0x28203040)
74340 bsdlabel RET ioctl 0`
«Operation not permitted», видимо не судьба отредактировать системный диск на лету с помощью bsdlabel.
Но ничего страшного — есть gpart:
`gpart modify -i 1 -t freebsd-ufs /dev/ad8s1`
Индекс 1, ибо правим раздел 'a', такая логика. /dev/ad8s1, а не /dev/ad8, потому что редактируем не таблицу слайсов (MBR в моём случае), а сам слайс.
Проверяем bsdlabel'ом — успех. Скрестив пальцы, проверяем как граб отнесется к этому. Отнесся он положительно, но не до конца. Ошибку 22 заменила новая — *Error 17: Cannot mount selected partition*.
##### Error 17
Из названия всё ясно — ошибка с монтированием ufs. Однако не поленимся и поставим сигнальный printf в **ufs2\_mount()**.
Так и есть. Функция фейлится. Причина тоже ясна — не может найти суперблок. Это структура, которая содержит базовую информацию о ФС (размер нодов, размер кластеров, флажки, и так далее).
Довольно распространенная структура в архитектуре ФС, есть она и в ufs2, однако grub её не находит. Давайте-ка глянем где она «сидит» — **dumpfs / | head -2** выдает такую строчку *«superblock location 65536»*.
Смотрим в grub:
```
#define SBLOCK_FLOPPY 0
#define SBLOCK_UFS1 8192
#define SBLOCK_UFS2 65536
#define SBLOCK_PIGGY 262144
#define SBLOCKSIZE 8192
#define SBLOCKSEARCH \
{ SBLOCK_UFS2, SBLOCK_UFS1, SBLOCK_FLOPPY, SBLOCK_PIGGY, -1 }
```
Видим заветное число, почему же не находим?
65536 — это смещение в байтах, относительно чего оно считается я точно был не уверен, поэтому брал с запасом:
`dd if=/dev/ad8 bs=512 count=200 | hexdump -C | grep 54`
Читаем 200 первых секторов (сам раздел начинался с 16 сектора, 128 (смещение суперблока) + 16 (максимальная точка отсчета) + 16 (размер суперблока) < 200, люфт для надежности).
grep 54 — это мы получаем строки, которые содержат байт 0x54, который есть в сигнатуре суперблока, полный размер подписи — 4 байта.
`#define FS_UFS2_MAGIC 0x19540119 /* UFS2 fast filesystem magic number */`
Но как искать dword'ами сразу в голову не пришло, поэтому просмотрел пару десятков строк. Полностью сигнатура нашлась в 69 секторе, ажно 2 раза, что меня смутило. Пригляделся к dump'у, там дальше идёт упоминание **FS\_UFS1\_MAGIC**, поэтому это скорее всего код лоадера, а не сам суперблок.
Потом мне подумалось что всё же лучше поискать внутри раздела:
`dd if=/dev/ad8s1a bs=512 count=200 | hexdump -C | grep 54`
И здесь меня ждал успех — по смещению 0x10550 (66896) видим нашу сигнатуру.
Смещение не равно ровно 65536, потому что сигнатура лежит в конце суперблока а не в его начале, поэтому добавляется «дельта» (**FIELD\_OFFSET()**), которая меньше 8192.
Как видим суперблок присутствует, и именно по тому смещению от начала раздела, где и ожидается. Определим смещение относительно, Тупо пробежимся по первым n секторам с известной строкой поиска.
Получим — 0001a350 (107344), что равно 209 сектору, Занятно то, что наша прикидочная оценка не добежала совсем чуть-чуть. Это получилось из-за того, что я забыл прибавить начало самого слайса (63), 63 + 16 + 128 == 207,
А 2 сектора занимают остальные поля суперблока.
Целевой сектор вычисляется в **devread(sector, byte\_offset)** просто:
`sector + (byte_offset >> SECTOR_BITS) + part_start`
Переменные **sector** и **byte\_offset** — аргументы и в нашем случае равны 0 и 65536 соответственно, что конечно правильно. А вот **part\_start** выдаёт 16. Что тоже верно. Но граб воспринимает это как абсолютное значение, относительно начала диска, а не начала слайса.
В мане написано "*The offset of the start of the partition from the beginning of the drive in sectors*", но в то же время приводится "*The first partition should start at offset 16*".
Но так как система работает, и всё монтируется успешно, думается что баг в грабе. Поэтому фиксим его, добавляя всего лишь один символ:
`*start += BSD_PART_START (buf, i);`
И теперь всё проходит успешно — **part\_start = 0x4F**, и дамп выполняется.
Использовать будем пересобранный граб, чтоб мой фикс вошёл и в **stage1\_5/stage2**.
**grub\_install** прошёл корректно, всё отлично.
##### Ограничение на размер считываемого файла
Немного не по теме, но касается ufs, grub'a и фряхи.
Максимальный размер файла, который может прочитать grub:
`(12 + superblock.nindir) * superblock.bsize`
Параметры суперблока берутся из лога dumpfs.
У меня на системе получилось ~32 метра, что не очень радует меня, поэтому я вырезал проверку из кода.
Для этого комментируем эту строчки в **fsys\_ufs2.c**:
`fsmax = (NDADDR + NINDIR (SUPERBLOCK)) * SUPERBLOCK->fs_bsize;`
##### Финита
Вот такая вот небольшая история о том как я запускал grub на фряхе.
Что здесь есть полезного:
* Использование связки ktrace/kdump
* Упоминание dumpfs/hexcode/gpart с usecase'ами
* Немножко о формате слайсов и фс. | https://habr.com/ru/post/118894/ | null | ru | null |
# Не изобретайте колёса! 6 причин от Java мастера пользоваться существующими.

— Ну хватит уже этих банальностей про колёса, надоело! — скажешь ты.
А вот и не хватит!
В современном научном мире и мире программирования колёса изобретают только
идиотыбунтари и студенты — в качестве домашнего задания.
Java — это такой особенный язык, разработчики которого очень продуманно подошли к проблеме разработки стандартных библиотек. Так что колес здесь своих достаточно на любой вкус и цвет.
Глотай бери — не хочу!
Вот список из 6 причин использовать существующие наработки для тех, кто еще не уверовал:
**1. Свое колесо — восьмеркой.**Доказательство тривиальное. Чем больше написано кода, тем больше допущено ошибок. Значит, код вашего колеса вероятно будет содержать ошибки. С другой стороны штампованое серийно выпущенное колесо (многократно протестированные библиотеки) содержит минимум ошибок.
Возьмем классическую задачу сортировки массива. Пусть требуется отсортировать массив Person по неубыванию имени.
Сортировка выполняется по имени или фамилии в зависимости от параметра.
> class Person {
>
> String name;
>
> String surname;
>
>
>
> String getName(int index) {
>
> return index == 0? name: surname;
>
> }
>
> }
>
>
>
> void nativeSort(Person[] persons, final int index) {
>
> Arrays.sort(persons, new Comparator() {
>
> public int compare(Person o1, Person o2) {
>
> return o1.getName(index).compareTo(o2.getName(index));
>
> }
>
> });
>
> }
>
>
>
> void mySort(Person[] persons, int index) {
>
> for (int i = 0; i < persons.length — 1; i++) {
>
> for (int k = 0; k < persons.length — 1; k++) {
>
> if (persons[k + 1].getName(index).compareTo(persons[k].getName(index)) <= 0) {
>
> Person buf = persons[k];
>
> persons[k] = persons[k + 1];
>
> persons[k + 1] = buf;
>
> }
>
> }
>
> }
>
> }
>
>
На первый взгляд, оба решения совершенно правильные. Одно из них использует библиотечную функцию сортировки, а второе реализует алгоритм сортировки
пузырьком. Но оказывается, что своё решение обладает серьезным недостатком, который может повлечь неприятные последствия в реальном коде. Каким? Не скажу!
Это задачка для самостоятельной работы :). Ответы просьба писать в комментариях белым шрифтом.
**2. Свое колесо катится медленнее.**
В примере из первого пункта используется сортировка пузырьком. Как известно, она выполняется за квадратичное время. А стандартная сортировка использует
алгоритм merge sort, обладающий сложностью N\*log(N), что работает значительно быстрее.
**3. Свой код дороже поддерживать.**
Код своих библиотек так или иначе придется поддерживать. Потребуется рефакторинг, доработка, отимизация, отладка с чашкой кофе в три ночи.
А использование готовых библиотек позволяет — только задумайтесь — перебросить разработку части функционала на сторонних (часто более надежных) разработчиков.
**4. Знание стандартных библиотек поможет тебе легче понимать чужой код.** Ведь стандартные библиотеки на то и стандартны, что их используют разные команды.
**5. Модули, использующие стандартные библиотеки и интерфейсы, проще интегрируются.**
Интеграция модулей включает обмен данными. Если данные не станадртизованы, то придется писать конвертеры.
Например, вы хотите соединить в своём проекте библиотеку для работы с http соединениями `org.apache.commons.httpclient.*`
и библиотеку для работы с xml `javax.xml.parsers.*`. Гарантирую головную боль, связанную с тем, что в этих
библиотеках используется разный класс для описания URL (`java.net.URL` и `org.apache.commons.httpclient.HttpURL`)
**6. Разработчики библиотек часто лучше тебя знают, в чем ты нуждаешься.** Это похоже на теорию конспирации?
— Вовсе нет. Стандарты в мире java принимаются [консорциумом(en)](http://jcp.org), а, значит,
принятые решения подходят большинству команд разработчиков. А раз они подходят почти всем, то наверняка, подойдут и тебе.
Здесь можно вспомнить про [другие(en)](http://www.microsoft.com/NET/) технологии, которые разрабатываются полностью внутри компаний,
что может (но не обязательно) сделать их недостаточно удобными для тебя.
Полная версия статьи в [блоге Java мастера](http://java-master.livejournal.com). | https://habr.com/ru/post/28136/ | null | ru | null |
# Использование ArcGIS API for Python в Jupyter Notebook

Всем привет! Это блог компании "Техносерв". В процессе производства на проектах, которые мы выполняем, рождаются интересные технологические кейсы. Их скопилось такое количество, что мы решили начать делиться ими с миром. И да, это наша первая публикация.
Честь начать блог выпала мне, и я пишу о том, что мне близко и любимо: о геоинформационных технологиях. Я работаю в департаменте Больших Данных, где занимаюсь разработкой высоконагруженных геоинформационных систем и сервисов на базе движков для распределенных вычислений. О высоких материях мы еще поговорим, а сегодня плавно начнем погружение в ГИС.
Все чаще и чаще у аналитиков данных (или как еще их называют — Data Scientist) появляется потребность в визуализации данных на карте. Какой инструмент сейчас считается наиболее удобным для работы аналитика? Конечно же, тетрадки! До последнего времени возможностей по визуализации геоданных было не так много. Можно было делать статические растры в matplotlib, иногда можно было добавлять даже базовые карты. Интересной оказалась библиотека для работы с Leaflet, где можно открывать geojson-файлы. Сегодня же я хочу рассказать об ArcGIS API for Python от компании Esri.
Эта статья будет полезна как аналитикам, желающим изучить примеры работы с ГИС, так и картографам и ГИС-специалистам, которым интересно попробовать себя в написании кода.
Что такое ArcGIS API for Python?
--------------------------------
Это простая в использовании и богатая по функционалу библиотека для визуализации и анализа геоданных, а также для управления корпоративной ГИС (Географический Информационной Системы), от пространственных данных до администрирования. Важной особенностью этой библиотеки является "питоничность" (Pythonic) с использованием стандартных конструкций, структур и идиом, что выгодно отличает ее от стандартной ArcGIS-библиотеки arcpy, которая порой вызывала ярость у разработчиков как стилем кода, так и быстродействием.
В этой статье пойдет речь о тех функциях, которые доступны без покупки лицензий ArcGIS или подписки ArcGIS Online. Для работы понадобится бесплатный аккаунт ArcGIS Online (я опущу подробности его создания — это довольно просто сделать на <http://www.arcgis.com>). В этом варианте присутствует ограничение на 1000 объектов в слое.
API распространяется в виде conda-пакета arcgis. Внутри пакета, который представляет собой концептуальную модель ГИС, функциональность организована в нескольких различных модулей, что делает его простым в использовании и понимании. Каждый модуль имеет несколько типов и функций, которые охватывают конкретный аспект ГИС.
Я рассмотрю небольшую часть API в качестве вводного материала.
* `arcgis.gis` обеспечивает базовую информационную модель как для корпоративной ГИС, так и для ArcGIS Online. Этот модуль обеспечивает функции управления (создание, чтение, обновление и удаление) пользователями, группами и контентом. Собственно, это ваша точка входа в ГИС.
* `arcgis.widgets` — это, собственно, модуль для управления картографическими виджетами (MapView) в Jupyter notebook.
Установка
---------
На данный момент библиотека распространяется только внутри Anaconda for Python 3x. Ставится все просто.
```
%%cmd
conda install -c esri arcgis
```
Надеюсь, все прошло успешно. Теперь можно начинать использование.
Если нет желания ставить Anaconda, но библиотеку протестировать хочется, то можно попробовать песочницу от Esri: <https://notebooks.esri.com>.
Использование
-------------
Объект GIS в модуле gis — самый главный в ArcGIS API for Python, ваша входная точка. Он олицетворяет ту ГИС, с которой вы работаете, будь ArcGIS Online или корпоративный ArcGIS. Объект позволяет работать с геоконтентом или же администрировать ГИС. Начнем с инициализации объекта GIS
```
import arcgis
from arcgis.gis import GIS
```
Для работы можно использовать как базовое анонимное подключение к ArcGIS Online...
```
gis = GIS()
```
… так и с логином.
```
my_gis = GIS(url='http://arcgis.com', username='andrey_zhukov', password='секрет')
```
Для любого инструмента можно вызывать справку, например
```
gis?
```
Кроме того, поддерживается и контекстный ввод

Встроить карту — это просто!
Давайте инициализируем объект карты hello\_map с центром в Москве и с уровнем зума 15.
```
hello_map = my_gis.map("Москва", zoomlevel = 15)
```
А теперь вызовем его...
```
hello_map
```

Добро пожаловать!
В карте работают базовые элементы — перетаскивание мышью (pan) и изменение масштаба (zoom) как колесом мыши (или соответствующим жестом на тачпаде), так и экранными кнопками.
Последующие манипуляции с объетом hello\_map отразятся во фрейме выше.
Чем можно управлять у карты?
Например, зумом.
```
hello_map.zoom = 10
```
Увеличим площадь карты
```
hello_map.height = '600px'
```
Получится такая картинка:

Посмотрим список доступных базовых карт.
```
hello_map.basemaps
```
```
['streets',
'satellite',
'hybrid',
'topo',
'gray',
'dark-gray',
'oceans',
'national-geographic',
'terrain',
'osm']
```
Можно все посмотреть? Конечно!
```
from time import sleep
for basemap in hello_map.basemaps:
hello_map.basemap = basemap
sleep(5)
```
Во фрейме карты можно будет увидеть примерно такое:

OpenStreetMap — вполне привычно, остановимся на нем.
```
hello_map.basemap = 'osm'
```
Поищем адреса. Найдем адрес БЦ Омега плаза и приблизм карту к нему.
Геокодирование по одному адресу абсолютно бесплатно, но пакетное геокодирование уже требует кредитов на счете организации.
```
location = arcgis.geocoding.geocode('Москва, Ленинская слобода, 19', max_locations=1)[0]
```
```
hello_map.extent = location['extent']
```

На карту можно добавлять контент из галереи ArcGIS Online. Поищем что-нибудь интересное...
```
from IPython.display import display
items = gis.content.search('title:Moscow', item_type='Feature Collection')
for item in items:
display(item)
```

`Moscow Walking Tour` — отлично! Уточним элемент.
```
my_layer = items[2]
display(my_layer)
```

Добавляем сервис и смотрим на наш hello\_map
```
hello_map.add_layer(my_layer)
```
```
hello_map.zoom = 10
```

Мы получили веб-карту, встроенную во фрейм внутри Notebook. В ней поддерживается навигация и вывод информации по клику на объектах. На сегодняшний день многие организации используют технологии ArcGIS не только на корпоративном уровне, но и для публикации открытых данных. Некоторые из этих открытых данных доступны для поиска и использования на ArcGIS Online, другие же можно найти через портал открытых данных (<https://opendata.arcgis.com/>) и подгрузить в ArcGIS Online.
Happy ~~hacking~~ mapping!
Работа с объектами
------------------
Конечно же, каждый Data Scientist, работающий в Jupyter Notebook, привык к pandas и DataFrame. Давайте поработаем уже с полноценным набором данных, используя pandas и ArcGIS.
Для этого сначала импортируем csv в pandas, а потом преобразуем его в слой карты.
В качестве примера я возьму слой паркоматов Москвы. Я уже немного поколдовал с исходным csv. Перекодировал в utf8 и переименовал столбцы, чтобы не возникло неожиданных проблем.
```
import pandas as pd
parkomats = pd.read_csv(r'.\data\data-417-2017-02-14.csv', sep=';')
```
Посмотрим получившийся объект. В нем уже есть широта и долгота, а также псевдо-geojson-поле geoData. При импорте данных ArcGIS сам пытается опознать поля геометрии или адреса. Если бы нам требовалось собрать данные по адресам, то пришлось бы собирать адрес из нескольких полей.
```
parkomats.tail()
```

Теперь импортирум DataFrame из pandas в объекты gis. Для этого просто вызываем функцию import\_data. В результате у нас получается объект FeatureCollection
```
geoparkomats = my_gis.content.import_data(parkomats)
geoparkomats
```
Теперь добавим объекты на карту. Для этого инициализируем новый объект map и в него добавим наш новый слой.
```
parkomat_map = my_gis.map('Москва', zoomlevel=12)
parkomat_map.basemap = 'osm'
parkomat_map.height = '600px'
parkomat_map.add_layer(geoparkomats)
parkomat_map
```

Уже неплохо! Но неплохо было бы эти данные оформить. Давайте попробуем их разукрасить. Для начала просто по зонам парковки
```
parkomat_cat_map = my_gis.map('Москва', zoomlevel=10)
parkomat_cat_map.basemap = 'gray'
parkomat_cat_map.add_layer(geoparkomats, {"renderer":"ClassedColorRenderer", "field_name":"ParkingZoneNumber"})
parkomat_cat_map.height = '600px'
parkomat_cat_map
```
Многие любят теплокарты. Давайте попробуем сделать и ее.
```
parkomat_heat_map = my_gis.map('Москва', zoomlevel=11)
parkomat_heat_map.basemap = 'dark-gray'
parkomat_heat_map.add_layer(geoparkomats, {"renderer":"HeatmapRenderer"})
parkomat_heat_map.height = '600px'
parkomat_heat_map
```

Как видите, добавить и стилизовать слой — это не сложно.
Кроме того, можно расположить все карты рядом. Для этого создадим и настроим три новых фрейма и впишем их в один бокс.
```
just_map = my_gis.map('Москва', zoomlevel=10)
just_map.basemap = 'osm'
just_map.add_layer(geoparkomats)
```
```
cat_map = my_gis.map('Москва', zoomlevel=10)
cat_map.basemap = 'gray'
cat_map.add_layer(geoparkomats, {"renderer":"ClassedColorRenderer", "field_name":"ParkingZoneNumber"})
```
```
heat_map = my_gis.map('Москва', zoomlevel=10)
heat_map.basemap = 'dark-gray'
heat_map.add_layer(geoparkomats, {"renderer":"HeatmapRenderer"})
```
```
from ipywidgets import *
just_map.layout=Layout(flex='1 1', padding='5px')
cat_map.layout=Layout(flex='1 1', padding='5px')
heat_map.layout=Layout(flex='1 1', padding='5px')
box = HBox([just_map, cat_map, heat_map])
box.height = '300px'
box
```

Заключение
----------
Итак, вы узнали, как легко и просто использовать в Jupyter Notebook полноценные веб-карты с помощью ArcGIS API for Python. Это новый продукт, едва вышедший из беты, но уже довольно интересный, с большими перспективами. С вопросами по работе и предложениями по улучшению API вы можете как выступить в комментариях к статье, так и написать российскому представителю Esri в России — esri-cis.ru.
Материалы этой статьи выложены на GitHub (<https://github.com/fall-out-bug/arcgis_python>). Код библиотеки и обширные материалы Esri тоже можно найти на GitHub (<https://github.com/Esri/arcgis-python-api>)
**Happy mapping!** | https://habr.com/ru/post/324124/ | null | ru | null |
# Kanban команды PVS-Studio. Часть 2: YouTrack
Привет всем. Это продолжение истории про переход команды PVS-Studio на работу по методике kanban. На этот раз речь пойдет про YouTrack, как мы выбирали и внедряли этот трекер задач и с какими вызовами столкнулись в процессе. Статья не имеет цели рекламировать или ругать YouTrack. Тем не менее замечу, что по мнению нашей команды ребята из JetBrains проделали (и продолжают делать) отличную работу.
Про историю перехода на kanban и о предпосылках смены трекера задач я рассказывал в предыдущей статье "[Kanban команды PVS-Studio. Часть 1: agile](https://habr.com/ru/company/pvs-studio/blog/549964/)". Рекомендую ознакомиться с ней для лучшего понимания некоторых аспектов текущей статьи. Также хочу заметить, что здесь я не планирую подробно рассказывать обо всех особенностях [YouTrack](https://www.jetbrains.com/youtrack/), так как их очень много. При желании вы можете заглянуть в [документацию](https://www.jetbrains.com/help/youtrack/incloud/YouTrack-InCloud.html) и убедиться в этом сами. Думаю, статья будет интересна в первую очередь тем, кто планирует или уже использует этот трекер.
Предыстория
-----------
Если вам не хочется читать первую часть статьи, то вот краткая предыстория. После внедрения методики kanban нам очень понравилась идея использования kanban-доски для проведения ежедневных митингов. Однако в связи с переходом на удаленный режим работы наша первоначальная физическая доска оказалась не у дел. Немного помучавшись, мы решили форсировать работы по выбору и внедрению альтернативного трекера задач на замену Bitbucket. При выборе отдавалось предпочтение инструментам с электронной доской. На самом деле, выбор изначально был между YouTrack и чем-то другим, так как YouTrack активно лоббировался тимлидом нашей С++ команды (Филипп, привет). В качестве основного конкурента YouTrack рассматривали Jira, но в итоге остановились всё же на YouTrack.
Bitbucket в команде PVS-Studio мы использовали с середины 2014 года. Долгое время он нас вполне устраивал. Но с ростом размера компании мы столкнулись с рядом неудобств, вызванных отсутствием или сложностью реализации некоторых возможностей:
* расширенная настройка оповещений;
* настраиваемые рабочие процессы;
* связи между задачами;
* учёт времени;
* отчёты;
* agile-доски.
Даже при поверхностном изучении YouTrack оказалось, что все эти возможности там доступны уже "из коробки". Воодушевленные, мы приступили к процессу перехода на новый инструмент.
Подготовка
----------
Как я уже упоминал в первой части статьи, за время работы с Bitbucket там было создано более 5500 задач. Конечно, было бы неплохо перенести их в YouTrack, но сделать это оказалось не так-то просто.
Со стороны Bitbucket относительно безболезненный экспорт задач [возможен](https://support.atlassian.com/bitbucket-cloud/docs/export-or-import-issue-data/) только в Jira. Альтернативный вариант – выгрузка задач при помощи Bitbucket API в промежуточный json определенного [формата](https://support.atlassian.com/bitbucket-cloud/docs/issue-import-and-export-data-format/). При этом процесс сохранения всего репозитория в zip-архив через меню экспорта Bitbucket в любом браузере намертво зависает через какое-то время. На тематических форумах говорят, что это старая проблема, связанная с новой версией API Bitbucket. Таким образом, единственным рабочим вариантом является выгрузка задач по одной при помощи скрипта в тот же json (в сети можно найти несколько подобных скриптов). Но это только половина дела. С другой стороны, в YouTrack [предлагается](https://www.jetbrains.com/help/youtrack/standalone/imports.html) импорт задач из Jira, а также некоторых других систем, среди которых нет Bitbucket. Остается аналогичный вариант с импортом через [json](https://www.jetbrains.com/help/youtrack/incloud/custom-imports.html). Для этого источник данных нужно подготовить, преобразовав json от Bitbucket с учётом всех различий в форматах данных.
В итоге предполагаемая трудоёмкость этой работы значительно превысила наше желание иметь архив старых задач непосредственно в YouTrack. Решили вручную перенести из Bitbucket в YouTrack около сотни ещё не начатых задач (бэклог), а также пару десятков задач, которые уже были взяты в работу, но приостановлены. Bitbucket по итогу мы оставили в качестве архива с доступом у пяти сотрудников в рамках бесплатного тарифа.
Определившись с задачами, начали работы по созданию нашего первого рабочего проекта в YouTrack. Остановились на стандартном облачном варианте, поэтому первоначальная настройка не потребовала много времени. До этого у нас уже был тестовый репозиторий YouTrack, так что в целом мы неплохо представляли как устроена эта система. К тому же YouTrack предоставляет множество обучающих возможностей, включающих тестовый проект с подробным описанием всех особенностей трекера, а также подсказки интерфейса.
Поначалу обилие возможностей YouTrack немного сбивало с толку. Также чувствовался иной по сравнению с Bitbucket подход к организации работы с трекером. Если Bitbucket практически закрыт с точки зрения настройки пользователем, то в YouTrack ситуация прямо противоположна. Уведомления, сохраненные поиски, отчёты, agile-доски, статьи для внутреннего портала "Knowledge Base" — всё это можно при необходимости настроить самостоятельно.
Хочу отметить, что в процессе перехода на YouTrack мы не столкнулись с какими-то серьёзными техническими трудностями или неразрешимыми проблемами. В итоге удалось реализовать все наши "хотелки". Более того, начав плотно работать с YouTrack, мы открыли для себя много дополнительных возможностей. Точнее, смогли оценить их реальную пользу. Например, отчёты о затраченном времени. Такие отчёты позволяют посмотреть, какие сотрудники в принципе принимали участие в работе над определенной задачей, а не просто создали или закрыли ее. Про фишки учёта времени в YouTrack я расскажу далее.
Еще одним побочным эффектом стало то, что переход на новый трекер буквально заставил нас навести порядок во многих наших бизнес-процессах. Появились новые подходы к работе, о которых ранее мы даже не задумывались.
Если говорить о технической части, то немного повозиться пришлось с доработкой рабочих процессов (Workflows), которые в YouTrack реализованы на JavaScript. Но основная работа носила административный характер:
* определение очередности перехода: вся команда сразу или по отделам;
* выбор архитектуры: один проект для всех или разные проекты для разработки и маркетинга, например;
* создание пользователей, настройка ролей и групп;
* базовая настройка проекта, определение прав доступа;
* настройка структуры полей;
* создание и настройка kanban-досок;
* выбор стратегии учёта времени;
* настройка рабочих процессов;
* отчёты;
* обучение сотрудников.
Далее в ходе изложения я буду придерживаться этого плана работ.
Очерёдность перехода, организация проектов
------------------------------------------
Основной вопрос перехода на YouTrack для нас состоял в том, какую часть команды мигрировать вначале. Переводить сразу всех мы опасались. Слишком много доработок пришлось бы делать с участием большого количества пользователей. Выбор пал на отдел маркетинга. Во-первых, это отдел, который наравне с разработчиками уже давно привык использовать kanban в повседневной работе. Во-вторых, там около десяти сотрудников, а этого вполне достаточно чтобы опробовать все основные сценарии работы с новым трекером. Наконец, ~~их было просто не так жалко~~ наш отдел маркетинга очень креативен и весьма гибок по части нововведений. Хочу выразить отдельное спасибо руководителю отдела Екатерине за бесконечное терпение и поддержку на этапе экспериментов с YouTrack. :)
Другой вопрос заключался в том, делать ли нам один проект на всю команду или разделить проекты по направлениям работы (отделам). YouTrack предлагает удобные средства для работы с несколькими проектами одновременно, и поначалу нам показалась разумной идея отделить разработку от маркетинга. Можно было бы разделить сущности и таким образом уменьшить общий объём значений в полях, количество тэгов и т. п., что в итоге упростило бы работу с трекером для пользователей. Но был очень важный аргумент против: наши задачи постоянно переназначаются между сотрудниками маркетинга и разработкой. Пример – задача про написание статьи. Первоначально статья пишется, допустим, разработчиком отдела С++. Далее она попадает на сотрудников отдела маркетинга для вычитывания и перевода. Затем снова возвращается автору для публикации. Наконец, после публикации задача вновь назначается на отдел маркетинга для дальнейшего продвижения в соцсетях и на тематических сайтах. Таким образом, наличие двух проектов осложнило бы процесс совместной работы. YouTrack умеет перемещать задачи между проектами, но при этом рекомендуется соблюдать соответствие между полями проектов. А ещё есть рабочие процессы, которые привязаны к проекту и также зависят от полей.
В итоге мы решили создать один общий проект и сразу настраивать его с учётом возможности одновременной работы всех команд. А переход начать с отдела маркетинга. Так третьего декабря 2020 года был создан проект "Marketing", впоследствии переименованный в "PVS-Studio".
Пользователи, группы, роли
--------------------------
Идеология работы с пользователями, группами и правами доступа (ролями) в YouTrack довольно проста, но имеет особенности. Поэтому я остановлюсь на этом вопросе подробнее. Начнём с иерархии.
Облачная реализация YouTrack является одним из сервисов в инфраструктуре JetBrains для командных продуктов. Все такие сервисы объединены в единое целое, могут управляться и обмениваться данными через связующий сервис верхнего уровня [JetBrains Hub](https://www.jetbrains.com/hub/). Там же содержатся все общие настройки, такие как глобальные права доступа, пользователи, группы. Они называются ресурсами.
Родительским для всех проектов является проект c именем "Global". Все создаваемые группы по умолчанию предлагается добавлять как ресурсы к этому проекту. Это позволит использовать их во всех дочерних проектах. Вы можете ограничить видимость группы, добавив ее в конкретный проект.
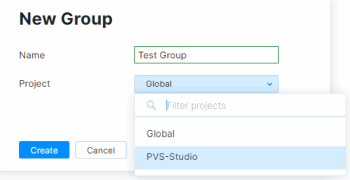
Иерархия групп по умолчанию представлена родительской группой "All Users", куда включены вообще все пользователи. Также есть подгруппа "Registered Users" с признаком автоматического добавления в нее новых пользователей после регистрации. Группы пользователей YouTrack можно использовать для разграничения доступа, в запросах на выборку задач, в рабочих процессах.
Так как мы решили использовать один проект, задача разграничения доступа при помощи групп у нас не стояла. Тем не менее мы добавили несколько групп, которые отражают структуру отделов компании.
Эти группы мы используем главным образом при рассылке уведомлений из рабочих процессов, чтобы уведомление, например, о просроченной задаче получал не только сотрудник, но и его непосредственный руководитель. Реализовали это просто. В группу "Managers" включены все тимлиды. Группа каждого отдела, помимо сотрудников, также содержит одного или нескольких тимлидов. При отправке уведомления пользователю проверяем, в какой группе тот состоит. Если в группе "Managers", то сообщение получит только он. Иначе, производится поиск рабочей группы пользователя. Уведомление получит как пользователь, так и все тимлиды, состоящие в его рабочей группе. Более подробно про наши рабочие процессы я расскажу далее.
Вернёмся к списку групп. Обратите внимание, все группы относятся к проекту "Global" (являются его ресурсами), а группе "Registered Users" назначена роль "Global Observer". Роль в YouTrack – это именованный набор (контейнер) разрешений двух типов: "Hub" и "YouTrack". Тип "Hub" содержит доступы для работы с глобальными сущностями: группы, проекты, роли, пользователи и т.п. Тип "YouTrack" предназначен для настройки доступа к возможностям трекера: работа с задачами (создание, комментирование, добавление вложений и т.п.), отчёты, сохраненные списки и т.п. Мы не стали создавать дополнительных ролей. Имеющихся по умолчанию вполне хватает для работы.
Каждый новый пользователь будет автоматически добавлен в группу "Registered Users" и в соответствии с ролью "Global Observer" получит минимальный набор из трёх разрешений.
Это разрешения уровня "Hub". Нам хотелось максимально автоматизировать процесс добавления новых пользователей, чтобы они сразу получали нужный набор разрешений для работы с проектом "PVS-Studio" (уровень разрешений "YouTrack"). Давайте посмотрим, как это было реализовано. Откроем свойства группы "Registered Users".

Видите, помимо роли "Observer" группе также назначена роль "Developer" в проекте "PVS-Studio". В YouTrack эта роль предлагается по умолчанию для работы с проектом. Она унаследована от родительской группы "All Users", для которой мы её назначили явно.

В общем, довольно бесхитростно. Это были настройки непосредственно групп. Давайте ещё посмотрим, как это выглядит в настройках проекта, чтобы получить полную картину с разрешениями в YouTrack.
У проекта есть такое понятие, как команда. Это группа пользователей, которые могут работать с проектом в соответствии с заданными ролями. У нашего проекта эта настройка выглядит так.
Ничего неожиданного. Видим ту же группу "All Users" и командную роль "Developer". Уровень доступа для участников команды можно настроить (ссылка "Edit"), задав одну или несколько ролей.
Наконец, чтобы увидеть, кто имеет доступ к проекту, необходимо перейти на соседнюю вкладку "Access" в свойствах проекта.
Здесь отображаются не только командные доступы, но и назначенные напрямую роли, а также глобальные доступы.
Роли могут быть дополнительно настроены. Так как у нас одна роль "Developer" для всех пользователей проекта, меняли только её настройки. Внесли незначительные правки для уровня разрешений "Hub", а именно: добавили возможность чтения групп. Это позволило пользователям при желании использовать группы в произвольных фильтрах задач. Обратите внимание, если настройка отличается от дефолтной (была изменена), это будет указано справа от чек-бокса.
Помимо этого, мы внесли изменения и для уровня доступа "YouTrack" роли "Developer". Разрешили вносить правки в чужие статьи внутреннего портала "Knowledge Base", а также удалять и обновлять комментарии к статьям. Запретили удалять задачи, такая возможность у нас доступна только администраторам. Также отключили видимость приватных полей. Пример такого поля у нас – сохраняемое значение таймера задачи (дата и время), которое используется при учёте затраченного времени.
Ну и пара слов про пользователей. Задача создания пользователей и назначения им прав достаточно тривиальна. Нужно запросить требуемое число лицензий в глобальных настройках трекера, создать пользователей, задать им email и временные пароли. Кстати, YouTrack не учитывает лицензии для заблокированных пользователей. Это позволило нам на начальном этапе миграции создать всю структуру компании, а разблокированными оставить только пользователей-маркетологов, не запрашивая дополнительных лицензий до момента миграции всех остальных.
Переходим к настройке ключевого компонента любого трекера – полям задачи.
Поля, теги
----------
Изначально в YouTrack предполагалось создать такую же структуру полей, как в Bitbucket. А затем уже вносить изменения в соответствии с возникающими потребностями. Но просто так сделать это не удалось. Дело в том, что наша старая физическая kanban-доска была своего рода виртуальной надстройкой над Bitbucket. Поэтому многое из того, что мы использовали на физической доске (дополнительные состояния задачи, цвета карточек), просто отсутствовало в Bitbucket.
В свою очередь, электронная agile-доска в YouTrack базируется на сущностях, которые должны быть настроены в трекере. И доску мы хотели начать использовать сразу. Таким образом, стояла задача доработки привычной нам структуры полей с учётом отображения их на электронной доске, то есть некая компиляция полей Bitbucket и сущностей физической доски.
Не буду утомлять подробным описанием процесса сопоставления полей и выбора оптимальной конфигурации. После довольно продолжительного периода доработок нам удалось зафиксировать набор полей, удовлетворяющий всем требованиям. Также отмечу, что для некоторых рабочих процессов YouTrack нужны дополнительно настроенные (служебные) поля. Приведу текущий вариант наших полей в YouTrack и кратко расскажу о них.
**Project**. Этого поля нет в списке, но оно всегда присутствует в карточке любой задачи и содержит имя проекта, к которому задача прикреплена. Мы работаем с единственным проектом "PVS-Studio".
**Assignee**. Исполнитель задачи, текущий ответственный. В перечисление типа "user" должны быть явным образом добавлены все пользователи, которые могут быть назначены исполнителями. Значения данного поля используются для наименования строк на электронной kanban-доске (отображение задач по ответственным).
**State**. Текущее состояние задачи. Может иметь значения:
* Buffer — задача запланирована, но работы по ней ещё не проводились. Если для задачи в статусе Buffer не задан исполнитель, она считается находящейся в бэклоге;
* In progress — задача в работе;
* Review — задача открыта, находится на приёмке (проверке);
* On hold — задача открыта, но работа над ней временно (на короткий период) приостановлена;
* Resolved — задача решена и закрыта (проблема устранена, достигнут ожидаемый результат);
* Suspend — над задачей работали, а затем отложили на длительный период. Далее к задаче планируют вернуться;
* Wontfix — задача не решена, закрыта (не удалось решить по каким-то причинам, завели по ошибке и т.п.);
* Duplicate — задача не решена, закрыта, так как имеется задача-дубликат.
Значения данного поля используются для наименования столбцов на электронной kanban-доске (отображение задач по ответственным).
**Component**. Направление работ по задаче, принадлежность задачи какому-либо отделу или подотделу разработки. Например, "Marketing", "Office", "C++ (Rules)", "C# (Core)" и т.п.
**Type**. Тип задачи: произвольная задача (Task), правка бага (Bug), подготовка мероприятия или доклада (Event), написание статьи (Article) и т.п.
**Priority**. Важность задачи, приоритет. Может иметь следующие значения (по росту приоритета): Minor, Normal, Major, Critical, Blocker.
**Scope**. "Скоуп" — диапазон рабочего времени (продолжительность в часах, днях или неделях), которое планируется затратить на выполнение задачи. Поле заполняется на этапе постановки. Если в ходе работ или при завершении задачи окажется, что на работу было затрачено значительно больше времени, чем планировалось, это будет поводом провести обсуждение. Учёт времени работы система ведёт автоматически, когда задача находится в статусе "In progress" или "Review" (поле "State"). Для этого необходимо включить ведение учёта времени в настройках проекта, а также настроить соответствующий рабочий процесс.
**Spent time**. Содержит диапазон рабочего времени, которое было фактически (суммарно) затрачено на выполнение задачи. Это второе поле, которое потребуется настроить при включении режима учёта времени в настройках проекта. Поле доступно в режиме только чтения. Затраченное на задачу время (единица работы) может быть добавлено двумя способами:
* вручную при помощи комментария особого вида "Добавить затраченное время";
* автоматически (комментарий о затраченном времени будет добавлен также автоматически). В этом режиме время учитывается только когда задача находится в работе (установлено значение "In progress" или "Review" в поле "State"). При переводе задачи в "не рабочее" состояние, например в "On hold" или "Resolved", время, которое задача находилась в работе, будет прибавлено к значению в поле "Spent time". Также время будет учтено при смене ответственного. Наконец, информация о затраченном времени для каждой задачи обновляется автоматически в 9:00 утра каждого рабочего дня. Момент (дата и время) последнего перехода фиксируется в служебном поле "TimerTime". Все это настроено в соответствующем рабочем процессе, о котором я расскажу далее.
Идеология добавления единицы работы очень удобна, так как позволяет указать не только затраченное время, но и пользователя, который выполнил свою часть работы по задаче. Как я упоминал ранее, эту информацию можно использовать в специальных отчётах для получения полной картины вклада каждого сотрудника в работу над задачами.
Если значение в данном поле превышает значение, указанное в поле "Scope", специальный графический индикатор затраченного времени для задачи будет окрашен в красный цвет (отображается в карточке задачи и списке задач). Если превышения нет, графический индикатор отображает круговую пропорцию между потраченным и оставшимся временем.
**TimerTime**. Служебное поле, которое скрыто от пользователей. Хранит дату и время одного из последних событий: смена статуса задачи, смена ответственного. Применяется в рабочем процессе для учёта затраченного времени.
**Due Date**. Содержит дату и время, по достижении которых задача должна быть решена (закрыта). Если в этом поле задано значение и к моменту наступления указанной даты задача не закрыта, ответственный за задачу (а также его руководитель) начнёт получать ежедневные уведомления на почту. Данное поведение также настроено при помощи рабочего процесса.
Для полей с типом перечисления (state или enum) есть дополнительная настройка – выбор цвета значения в поле. Цвета отображаются в списках задач и на досках. Пример такой настройки для поля "State":

Помимо полей, YouTrack предлагает возможность указания специальных меток для задач, называемых тегами. Могут быть задачи как без тегов, так и с несколькими тегами. Это весьма удобно и позволяет увеличить число различных комбинаций возможных состояний задачи. Замечу, что у полей с типом перечисления (enum) тоже есть возможность установки более одного значения, но работа именно с комбинациями полей и тегов кажется более эффективной. На данный момент мы используем около 18 тегов.
Вот так выглядит заголовок карточки задачи с тэгами.

Также обратите внимание на выделение цветом перечислимых полей в легенде этой же задачи.

По комбинации полей и тэгов данной задачи можно понять, что она назначена на Филиппа и временно отложена. Работы ведутся по направлению диагностик для языка C++ (причем идет работа над новой диагностикой по запросу клиента, так как установлены теги "New Rule" и "Client", а сама диагностика относится к классу "General Analysis"). Это обычная задача со средним приоритетом. Трудоемкость (скоуп) задачи на момент создания оценили в четыре рабочих дня (32 часа при восьмичасовом рабочем дне). При этом на работу с задачей уже потратили более 16 рабочих дней и это повод задуматься. :) Отсутствие значения в поле "TimerTime" говорит о том, что в данном состоянии (On hold) учёт времени не ведётся. Дедлайн задаче не задан.
А вот как выглядит список задач.

Кстати, список отфильтрован по задачам компонента С++ (для всех подотделов) при помощи запроса:
```
Component: {C++ *}
```
Запрос получает все задачи, значения компонента которых начинаются со строки "C++". Вообще, поисковые запросы YouTrack – одна из мощнейших возможностей. К тому же, это удобно и интуитивно понятно. Теги и поисковые запросы можно сохранять, настраивать для них оповещения, делиться ими с коллегами или использовать приватно. Мы ещё немного поговорим про запросы, когда доберёмся до рабочих процессов.
Все поля и теги задачи можно использовать в поисковых запросах, а также отчётах.
Kanban
------
Я столько говорил про электронные доски, что просто не могу не показать хотя бы одну. :) Вот фрагмент kanban-доски для команды C++ (отображение задач по ответственным).
Столбец "Resolved" свернут. Доска генерируется на базе запроса, который можно задать в ее настройках:
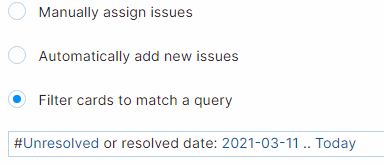
Таким образом, будут отображены все нерешённые задачи, а также задачи, закрытые после 11 марта 2021 года. Это дата одного из последних релизов. Мы решили ограничить период показа закрытых задач одним релизным циклом, чтобы не захламлять доску.
Также список задач будет дополнительно отфильтрован по пользователям, явно заданным для отображения в строках доски. Конечно, это не единственно возможный вариант. Не так давно мы начали использовать другое представление доски, при котором в строках указаны не сотрудники, а направления работы (отделы). Это позволяет больше сосредоточиться на задачах и их движении. Представление доски может быть настроено в соответствии с вашими потребностями.
Расскажу про одну важную особенность работы досок YouTrack. Первоначально мы настроили kanban в режиме "Automatically add new issues", который был предложен по умолчанию. Как и режим "Manually assign issues", он предполагает добавление задачи на доску, при котором между ними образуется связь. То есть задача будет буквально принадлежать доске. Но в этом режиме нет возможности, например, отфильтровать задачи в столбце "Resolved" по дате, как сделано у нас сейчас. Доска отображает все когда-либо добавленные на неё задачи. Это одна из причин, по которой мы не стали использовать первые два режима, а остановились на третьем. Также в режиме "Automatically add new issues" любая новая задача попадала сразу на все доски, что тоже не всегда удобно. Хотя для классического варианта работы с множеством проектов, ограниченных по времени, и одной доской на проект вариант "по умолчанию", наверное, удобнее. Он требует меньше дополнительных настроек.
Другие настройки доски тривиальны, так что больше рассказывать здесь нечего. Kanban — это одна из тех возможностей YouTrack "из коробки", которую можно начать использовать практически сразу. Чего нельзя сказать об учёте времени и настройке рабочих процессов. Переходим к наиболее интересной, на мой взгляд, части повествования.
Учёт времени и рабочие процессы
-------------------------------
Наверное, учёт времени и рабочие процессы – это то, чего нам больше всего не хватало в Bitbucket после kanban-доски. Я объединил эти пункты, так как без настройки рабочих процессов учёт времени возможен только в ручном режиме.
Про рабочие процессы YouTrack подробно рассказано в [документации](https://www.jetbrains.com/help/youtrack/standalone/Workflow-Guide.html). Если в двух словах, то это скрипты на JavaScript, которые позволяют автоматизировать различные виды деятельности в трекере. Предлагается набор рабочих процессов по умолчанию (на данный момент их более 35). Можно менять стандартные рабочие процессы, настраивая их для своих нужд. Любой стандартный рабочий процесс, если он был неудачно модифицирован, легко вернуть в исходное состояние. Можно создавать свои рабочие процессы, а также разделяемые рабочие процессы (для совместного использования из разных скриптов). В общем, есть определенный простор для творчества.
Мы использовали несколько рабочих процессов по умолчанию, которые показались нам необходимыми. Некоторые процессы модифицировали, а также добавили пару своих.
### Учёт времени
Про учёт времени мы начали думать давно. Хотелось иметь хотя бы приблизительное понимание, сколько занимает работа над той или иной задачей. Почему иногда работа затягивается. И как-то анализировать всё это. В Bitbucket мы пытались указывать скоуп задачи прямо в заголовке, в квадратных скобках. Кстати, туда же мы добавляли и другую информацию, которую нельзя было указать в полях Bitbucket. Например, метку, что задача делается по запросу клиента. Заголовок задачи мог иметь вид: "[client][5 дней] Краткое описание задачи". Понятно, что Bitbucket никак не помогал в анализе этих псевдотегов. Поэтому у нас была разработана утилита, которая через API доставала из Bitbucket информацию и генерировала разные отчёты. Также при помощи этой утилиты мы оповещали пользователей о забытых задачах (по которым не было комментариев за последние три-четыре дня, например). В общем, пытались как-то настроить свои рабочие процессы.
Что касается учёта времени, то нам был доступен только ручной анализ задач по требованию. Нужно было смотреть дату создания задачи, искать псевдотег скоупа в описании (а его туда могли забыть добавить) и делать какие-то выводы. Очевидно нерабочая схема. Представьте себе нашу радость, когда мы увидели возможность настройки учёта времени в YouTrack практически за три клика. Всего-то и нужно было включить этот режим в настройках проекта, добавив пару полей.
Сразу после этого в задачах появляется возможность вручную добавлять так называемые единицы работы, а также пользоваться специальными отчётами. Я упоминал про это, когда приводил описание полей. Кстати, единицы работы можно настраивать, задавая свои типы работ. Таким образом, будет видно, какую именно работу делал пользователь в рамках задачи в течение указанного периода.
Но если остановиться только на этом этапе и больше ничего не настраивать, то вся ответственность за фиксацию затраченного времени ложится на пользователей. Поработав над задачей, сотрудник должен самостоятельно добавить единицу работы и указать затраченное время в карточке задачи. Часто люди забывают или банально ленятся делать такие вещи. Поэтому YouTrack предлагает автоматизацию. Для этого на выбор предлагается два стандартных рабочих процесса с несколько разными подходами:
* [In Progress Work Timer](https://www.jetbrains.com/help/youtrack/standalone/Workflow-Work-Timer.html). Рабочий процесс, который отслеживает изменение состояния задачи и соответствующим образом корректирует параметры учёта времени (включает и отключает таймер);
* [Stopwatch-style Work Timer](https://www.jetbrains.com/help/youtrack/standalone/Workflow-Standalone-Work-Timer.html). В этом рабочем процессе предлагается ручное включение и выключение таймера. Для этого используется специальное поле задачи, которое может принимать значения "Start" или "Stop".
Второй рабочий процесс более приближен к ручному режиму, но даже такой полуавтоматический вариант работы значительно лучше ручного. Пользователь должен по-прежнему инициировать процесс, но ему не нужно самостоятельно подсчитывать время, затраченное на работу, так как за него это сделает скрипт.
Мы выбрали первый вариант работы с таймером, который предлагает полную автоматизацию, но и требует гораздо больших усилий для настройки. Подробно про работу этого и других рабочих процессов читайте в следующем разделе.
### Рабочие процессы
Список рабочих процессов, прикрепленных к проекту, можно увидеть в его свойствах. Вот наш текущий набор.

Полный список рабочих процессов можно посмотреть в глобальных настройках трекера. Каждый рабочий процесс может включать несколько правил (модулей). Помимо понятного названия у каждого процесса и его правил есть уникальное имя. Например, "assignee-state". Правила можно увидеть, если развернуть узел процесса.

Для правил имя соответствует файлу сценария js. Например, "check-assignee-state". Имена рабочих процессов с префиксом "@jetbrains/youtrack-workflow-" указывают на стандартные (предустановленные) рабочие процессы YouTrack.
Правило может быть одного из пяти типов:
* On-change: применяется при изменении задачи;
* On-schedule: применяется по расписанию;
* State-machine: контролирует смену значений для настраиваемых полей;
* Action: применяется при выборе пользователем действия (настраиваемой команды для интерфейса);
* Custom: применяется при вызове из модулей других рабочих процессов.
Перейдем к списку наших рабочих процессов и разберем его.
**Assignee and State**
Нестандартный рабочий процесс (был добавлен нами), который содержит единственное правило типа "On-change":
* Block users from setting an invalid assignee.
Правило отслеживает изменение полей "State" и "Assignee" у задачи и препятствует установке некорректной комбинации значений. Например, у задачи нет ответственного, при этом её пытаются взять в работу или сразу закрыть. В этом случае скрипт выведет сообщение об ошибке, а изменения не будут зафиксированы. В YouTrack есть стандартный рабочий процесс "[Issue Property Combinations](https://www.jetbrains.com/help/youtrack/standalone/Workflow-Issue-Properties-Combinations.html)" с похожей функциональностью. Но мы решили, что удобнее будет не модифицировать имеющийся, а сделать свой рабочий процесс. Почему бы и нет? К тому же, данный рабочий процесс использует имена настраиваемых полей, заданные в YouTrack по умолчанию. Мы же заменили многие имена полей на более подходящие, на наш взгляд. Это также осложнило бы модификацию стандартного рабочего процесса.
**Assignee Visibility**
Стандартный (предустановленный) [рабочий процесс](https://www.jetbrains.com/help/youtrack/standalone/Workflow-Assignee-Visibility-Group.html), состоящий из единственного правила типа "On-change":
* Warn when issue is not visible to assignee.
Правило проверяет, чтобы назначаемый ответственный имел доступ к задаче. Ситуация типична для команд, в которых ведётся несколько проектов, доступ к каждому из которых контролируется на уровне групп пользователей. Если пользователя забудут включить в соответствующую группу, он не сможет открыть задачу. Такое лучше проверять на этапе назначения ответственного, что и делает правило. Это не очень актуально для нас, так как при использовании одного проекта, к которому по умолчанию имеют доступ все пользователи, описанная ситуация маловероятна. Тем не менее, правило было предложено к использованию по умолчанию, и мы решили оставить его "на всякий случай".
**Common**
Нестандартный рабочий процесс, который содержит три модуля:
* common-datetime (тип "Custom");
* common-users (тип "Custom");
* DEBUG ACTION (тип "Action").
Для первых двух модулей я привел имена вместо понятных названий. Дело в том, что эти модули содержат разделяемый код, на который ссылаются другие правила. У таких модулей нет понятных названий. Третий модуль отладочный, поэтому для него необязательно (хотя и возможно) указание понятного названия, поэтому я указал такое. Модуль при этом называется "common-debug-action".
Модуль "common-datetime" содержит логику для поддержки учёта времени. В частности, производственный календарь на текущий год, а также нашу версию функции вычисления разницы в минутах между двумя датами с учётом рамок рабочего дня, нерабочих и праздничных дней. Я ещё вернусь к этому модулю, когда буду рассказывать про рабочий процесс для учёта времени.
Модуль "common-users" содержит код, автоматизирующий отправку пользователям критичных уведомлений из других правил. Это уведомления, например, о превышении дедлайна задачи. Также сюда относятся уведомления о забытых задачах, то есть задачах, по которым не было активности (комментариев) за последнее время. Мы решили, что более эффективно отправлять такие уведомления не только ответственному за задачу, но и его руководителю. Я уже упоминал про это в контексте описания групп пользователей.
Наконец, модуль "DEBUG ACTION", как можно догадаться из названия, предназначен для отладки. Это правило типа "Action". При помощи таких правил в YouTrack можно создавать быстрые действия для задач. Список действий доступен в меню карточки задачи при выборе пункта "троеточие".

Также действие может быть выбрано и выполнено в окне действий:
При выборе действия будет сразу же выполнен определенный код. Видимостью таких правил (пунктов меню) можно управлять. Например, отладочное действие "DEBUG ACTION" отображается только для пользователя с определенным именем (меня). Также можно настроить, например, отображение действий лишь при создании новых задач и т.п.
Зачем потребовался такой модуль? Есть определённые нюансы с отладкой скриптов рабочих процессов в облачной версии YouTrack. Собственно, вся отладка заключается в анализе выходных данных консоли в редакторе рабочего процесса после его выполнения. В принципе, этого достаточно. Но хотелось иметь возможность запуска произвольного кода (модулей) прямо в облачной среде. Для решения этой задачи я и использовал отладочное действие. Возможно, есть какие-то более изящные и технически грамотные варианты, но меня вполне устроил такой.
**Dependencies**
Стандартный [рабочий процесс](https://www.jetbrains.com/help/youtrack/standalone/Workflow-Dependencies.html), включающий единственное правило типа "On-change":
* Block users from resolving issues with unresolved dependencies.
Правило контролирует работу связанных задач, а именно связи типа "Depend" (depends on — is required for). При такой связи предполагается, что одна задача зависит от другой и не может быть закрыта, пока другая задача находится в работе. Мы используем связи между задачами, поэтому данное правило полезно.
Интересная особенность: в YouTrack вы можете использовать встроенный (или доработанный) набор типов связей задач, устанавливать связи между задачами. Но без соответствующих рабочих процессов связи не будут работать. Поэтому нужно аккуратно отказываться от рабочих процессов, которые YouTrack предлагает по умолчанию. Похожая история и с именами настраиваемых полей. Все стандартные рабочие процессы настроены на работу с набором полей по умолчанию. Меняя какие-то значения, будьте готовы к внесению множественных правок в рабочие процессы.
Про связи (ссылки) между задачами можно почитать в [документации](https://www.jetbrains.com/help/youtrack/standalone/Link-Issues.html).
**Due Date**
Еще один стандартный [рабочий процесс](https://www.jetbrains.com/help/youtrack/standalone/Workflow-Due-Date.html). Предназначен для работы с дедлайном задачи. По умолчанию он содержит два правила, но мы решили ограничиться только вторым:
* Require due dates for submitted issues (не используем);
* Notify assignee about overdue issues.
Первое правило типа "On-change" требует обязательной установки значения в поле "Due Date" при создании задачи. Мы не стали вводить такое жёсткое требование, поэтому правило было отключено.
Второе правило, которое посчитали полезным, мы используем для оповещения ответственного и его руководителя в случае, если дедлайн задачи превышен. Это правило относится к типу "On-schedule". Оно позволяет обрабатывать задачи по расписанию (параметр "cron"). Список задач будет получен при помощи поискового запроса (параметр "search"). Мы немного доработали это правило, добавив дополнительное условие выполнения только по рабочим дням, так как выполнение по расписанию ограничивает выполнение задачи рабочими днями с понедельника по пятницу, но не учитывает выходные и праздничные дни. Для этого используются функции проверки из разделяемого модуля "common-datetime". В дополнение к этому, как уже говорилось ранее, мы используем расширенную функцию рассылки уведомлений из модуля "common-users".
**Duplicates**
Стандартный [рабочий процесс](https://www.jetbrains.com/help/youtrack/standalone/Workflow-Duplicates.html), который управляет поведением задач-дубликатов. Мы не так часто создаем задачи-дубликаты, но иногда такое всё же случается. Поэтому этот рабочий процесс был подключен к проекту. По умолчанию он содержит пять правил типа "On-change" (одно из правил мы не используем):
* Attach duplicate links to single duplicated issue;
* Raise priority when issue is duplicated by another issue (не используем);
* Reopen issue when all duplicates links are removed;
* Set state to "Duplicate" when duplicates link is added to issue;
* Require links to duplicate issue when state becomes "Duplicate".
Задача в YouTrack может быть отмечена как дубликат другой задачи двумя способами:
* установка дублирующей задаче статуса "Duplicate". При этом необходимо обеспечить установку связи типа "Duplicate" (duplicates — is duplicated by) между задачами;
* обратная ситуация: установка связи типа "Duplicate" между задачами. Здесь необходимо обеспечить установку статуса "Duplicate" дублирующей задаче.
Также необходимо обеспечить корректное поведение при удалении связи между задачами-дубликатами или при смене статуса "Duplicate" задачи на другой. Все эти нюансы контролирует рабочий процесс. Мы не вносили значительных правок в правила данного рабочего процесса. А те, что вносили, были связаны с использованием других названий у статусов задачи (отличных от имён по умолчанию).
**In Progress Work Timer**
Мы подошли к стандартному [рабочему процессу](https://www.jetbrains.com/help/youtrack/standalone/Workflow-Work-Timer.html), настройка которого потребовала несколько больше усилий, чем представлялось сначала. Как я уже говорил ранее, нам хотелось попробовать учёт времени и мы были рады увидеть такую возможность в списке предустановленных. Однако реализация "из коробки" не вполне нас устроила.
По умолчанию процесс включает два правила типа "On-change":
* Start timer when issue is in progress;
* Stop timer when issue is fixed.
Первое правило отслеживает изменение статуса задачи. При установке значения "In Progress" (задача взята в работу) в служебное поле "Timer Time" задачи будут записаны текущие дата и время. Когда работа над задачей будет завершена (статус сменят с "In Progress" на любой другой), автоматически добавится единица работы. Это делает скрипт второго правила. Затраченное время будет подсчитано как разница в минутах между текущей датой и значением, сохраненным ранее в поле "Timer Time" задачи. Алгоритм выглядит достаточно просто, при этом он имеет недостатки:
* предполагается наличие только одного "рабочего" состояния задачи — "In Progress". У нас есть дополнительные состояния, когда требуется учёт времени, например "Review". Эти состояния были дополнительно учтены в скриптах (достаточно простые правки);
* в первоначальном варианте скрипта "Stop timer when issue is fixed" при добавлении единицы работы в качестве автора (исполнителя) будет указан текущий пользователь YouTrack (ctx.currentUser). Это проблема, так как часто задачи может закрывать тимлид. Тогда единица работы будет записана на него. Никак не влияет на подсчет суммарного затраченного на задачу времени, но делает бессмысленным работу с отчётом по единицам работы: [удобный встроенный отчет](https://www.jetbrains.com/help/youtrack/standalone/Time-Report.html), который позволяет увидеть конкретный вклад каждого сотрудника в работу над задачами. Наш вариант правки скрипта предполагает использование текущего ответственного по задаче при создании единицы работы. Наличие ответственного у задач, находящихся в работе, контролирует описанный ранее рабочий процесс "Assignee and State";
* не учитывается смена ответственного. Над задачей могло последовательно работать несколько сотрудников, но при ее закрытии всё рабочее время будет зачислено на того, кто закрыл задачу. Для решения этой проблемы мы добавили дополнительный модуль с именем "Restart timer when the assignee is changed". Это несложное правило отслеживает смену ответственного у задач, находящихся в работе. При этом единица работы создаётся для предыдущего ответственного и учитывается время, которое именно он затратил на работу. Таймер перезапускается;
* скорее, улучшение, а не решение какой-то проблемы. Если задача долго (например, несколько дней) находится в работе у одного ответственного, то нет наглядного отображения того, сколько времени уже было затрачено. Ведь единица работы будет добавлена только при смене статуса или ответственного. И только тогда будет пересчитан общий показатель затраченного на задачу времени, что будет отражено на графическом индикаторе в списке задач:

Допустим, задачу забыли в статусе "In Progress" и работают с другой. Потом про задачу вспомнили и решили ее закрыть. При этом будет начислен большой интервал рабочего времени, в который фактически ничего не делали. Это нестрашно, так как ранее созданные единицы работы для задачи можно править (вручную менять значение начисленного времени). Но мы же хотим полной автоматизации, не так ли? :) Поэтому мы добавили ещё одно небольшое правило типа "On-schedule" с именем "Update timer on schedule". Каждое утро по рабочим дням это правило перезапускает таймер для задач, находящихся в работе. Конечно, это приводит к ежедневному созданию единицы работы. Зато по любой задаче всегда можно посмотреть актуальное значение затраченного времени с точностью до одного дня;
* при добавлении единицы работы в правиле "Stop timer when issue is fixed" используют встроенную функцию "[intervalToWorkingMinutes](https://www.jetbrains.com/help/youtrack/devportal/v1-Project.html)" из класса "Project" для подсчета разницы в минутах между двумя датами. Функция использует минимальный набор настроек YouTrack для учёта времени:

Учитывается только продолжительность рабочего дня и дни недели, указанные как рабочие. Не учитываются начало и конец рабочего дня, продолжительность обеденного перерыва, праздничные дни. Поэтому, несмотря на то, что функция вернёт результат в минутах, он будет достаточно приблизительный. Например, в вашей компании (как у нас) рабочий день начинается в 9:00 и закачивается в 18:00. Вы берете задачу в работу во вторник вечером в 17:45. Утром следующего дня, в среду, вы продолжаете работу над задачей и закрываете ее в 9:15. При использовании функции "intervalToWorkingMinutes" результат составит восемь с половиной рабочих часов (510 минут). Это нормально, так как переход задачи на следующий день сразу же даст нам один рабочий день (1\*8\*60 = 480 минут). Плюс дополнительное время в минутах для выравнивания до полного часа (15 + 15).
Нам хотелось большей точности, поэтому мы написали свой вариант функции "intervalToWorkingMinutes", которая удовлетворяет нашим условиям. Для указанного выше примера она вернёт 30 минут. Также в отдельную функцию мы вынесли проверку переданной даты не только на то, что это выходной день (суббота или воскресенье), но и на то, что это день, объявленный нерабочим праздничным в нашей стране. Это удобно для использования как при расчёте разницы между двумя датами, так и при рассылке уведомлений пользователям из других рабочих процессов (например, "Due Date"), чтобы не тревожить их письмами в нерабочее время. Обе функции помещены в разделяемый модуль "common-datetime".
Таким образом, с учётом всех модификаций, стандартный рабочий процесс "In Progress Work Timer" у нас был расширен до четырех правил:
* Start timer when issue is in progress;
* Stop timer when issue is fixed (было переименовано в "Stop timer when the issue is resolved or paused");
* Update timer on schedule (правило было добавлено);
* Restart timer when the assignee is changed (правило было добавлено).
Может показаться, что мы немного увлеклись учётом времени, и отчасти это так. Но сам YouTrack подталкивает к тому, чтобы максимально кастомизировать рабочие процессы, поэтому мы не смогли устоять :)
К тому же, все эти правки и улучшения были сделаны не одномоментно. Мы и сейчас время от времени там что-то подкручиваем. Расскажу про одну интересную ошибку, с которой мы столкнулись уже после начала активного использования этого рабочего процесса. Это ошибка (или особенность работы) самого трекера. Речь про поле "Scope", которое содержит скоуп задачи.
Изначально мы задали значение по умолчанию для этого поля, равное трём рабочим дням (3d). Спустя какое-то время мы заметили аномалию. У задач, для которых это значение так и оставили без изменений, не отображался индикатор оставшегося времени. Взгляните на скриншот:

У второй и пятой задачи наблюдается указанная проблема. Опытным путем мы выяснили, что нужно явно указывать значение в поле "Scope". При этом что-то происходит "под капотом" YouTrack, и далее это значение будет корректно учтено. Пришлось отказаться от использования дефолтного значения. К тому же, требование обязательно указать скоуп задачи полезно, так как побуждает к проведению большего анализа на этапе постановки задачи. Возможно, это известная проблема и разработчики её уже устранили. Я поленился подробно изучать данный вопрос.
Закрывая тему учёта времени, хочу сказать пару слов об административной стороне вопроса. Кажется, нам удалось создать удобный механизм. Но этого ещё недостаточно. Инструментом нужно научиться правильно пользоваться, выработать оптимальные сценарии работы.
Простой пример – введение практики своевременного перевода задач, над которыми приостановлена работа, в статус отложенных (для остановки таймера) и наоборот. Своевременность переключения статусов позволяет иметь более точную картину происходящего. Но у этого, казалось бы, очевидного подхода есть и обратная сторона. С первых дней использования сотрудники пытались взломать систему: реальная работа часто велась над отложенными задачами (On hold), так как там "не тикает таймер и не портит статистику". Поэтому поначалу можно было наблюдать картину, как команда буквально ни над чем не работает – было всего несколько задач в работе.
Также многие пользователи опасались, что учёт времени будет использован для подсчёта каких-то тайных KPI с целью корректировок заработной платы и т.п. Конечно, такой идеи не было и нет. Главное, для чего сейчас используется данный механизм, повышение эффективности планирования новых задач, более точная оценка возможных трудозатрат.
**Overdue work activities**
Нестандартный рабочий процесс, включающий единственное правило типа "On-schedule":
* Notify assignee on overdue work activities.
По принципу работы этот модуль очень похож на описанный выше модуль "Notify assignee about overdue issues" из рабочего процесса "Due Date". Но здесь мы регулярно оповещаем ответственного и его руководителя в случае, если по задаче не было комментариев за какой-то период. Для этого используется поисковый запрос вида:
```
State:{In progress},Review
commented:-{minus 3d}..Today
created:-{minus 1d}..Today
```
Берутся все задачи в работе, кроме тех, которые комментировали в течение последних трёх дней или недавно создали (днём ранее). Цель рабочего процесса – выявление забытых задач, а также привитие у сотрудников дисциплины описывать работу над задачами в комментариях.
**Subtasks**
Стандартный [рабочий процесс](https://www.jetbrains.com/help/youtrack/standalone/Workflow-Subtasks.html). По умолчанию содержит набор из двух правил типа "On-change", автоматизирующих работу с подзадачами:
* Open parent task when subtask changes to an unresolved state;
* Fix parent task when all subtasks are resolved (не используем).
Для создания иерархии задач в YouTrack используется связь типа "Subtask" (subtask of — parent for). Про связи я уже говорил при описании рабочего процесса "Dependencies". Работа с подзадачами очень удобна и это одна из возможностей, которых нам не хватало в Bitbucket. Интересное наблюдение: в YouTrack мы наблюдаем большее число задач (в среднем по компании), находящихся в работе в единицу времени, по сравнению с Bitbucket. При сопоставимом числе сотрудников. Я думаю, что одна из причин – активное использование подзадач в YouTrack, что даёт возможность более простой декомпозиции. Но вернёмся к правилам.
Первое правило следит за состоянием всех подзадач уже закрытой родительской задачи, и если хотя бы одну из них снова берут в работу, то родительская задача автоматически открывается.
Второе правило автоматически закрывает родительскую задачу при закрытии всех её подзадач. Это правило показалось нам неудобным, так как часто наши родительские задачи являются не просто агрегаторами, а выступают в качестве полноценных задач. По ним ведётся работа, причём это может происходить уже после закрытия всех подзадач. Поэтому данное правило было отключено.
Зато нам не хватило другой возможности: запрещать пользователям закрывать родительскую задачу, если есть хотя бы одна подзадача в работе. Для этого мы расширили стандартный рабочий процесс, добавив свое правило "Block users from resolving issues with unresolved subtasks".
На этом я заканчиваю описание наших рабочих процессов. Возможно, получилось несколько затянуто. Но мне хотелось показать, насколько удобно вы можете настроить YouTrack под себя, даже для нестандартных режимов работы. Кажется, нам это удалось.
Отчёты
------
Полезная возможность, которую также хотелось иметь на борту трекера. Про отчёты в YouTrack можно сказать, что они есть. С их помощью можно решить большинство типовых задач по сбору и анализу статистики. Например, мы активно используем ранее упомянутый [встроенный отчет](https://www.jetbrains.com/help/youtrack/standalone/Time-Report.html) о затраченном времени. Польза этого отчёта для нас, как и от всего механизма учёта времени, не в подсчитывании минуток за людьми, а в понимании вклада каждого сотрудника в работу команды, в эффективном планировании и возможности дальнейшего анализа.
Тем не менее, мы настолько привыкли к своему старому формату отчётов (в Bitbucket использовали собственный генератор отчётов), что решили не отказываться от него. Тем более, в YouTrack есть все возможности для доступа к задачам через API. Таким образом, на данный момент каждый заинтересованный сотрудник может настраивать и использовать любые встроенные отчёты YouTrack. В дополнение к этому каждый месяц менеджеры получают большой сводный отчёт "старого образца".
Обучение сотрудников
--------------------
Напоследок немного расскажу, как происходило внедрение нового трекера с точки зрения команды. Это не первый наш подобный инструмент, поэтому именно с интерфейсом YouTrack особых проблем у пользователей не возникало. Да, там довольно много возможностей, и поначалу теряешься в обилии кнопочек. Но это не проблема. В последнее время команда YouTrack делает определенные шаги по упрощению интерфейса: был введен облегченный режим "Light", изменена структура меню и т.п. Ранее я слышал много отзывов о сложности YouTrack для пользователя и частично согласен с ними. Но повторюсь, что разобраться и привыкнуть к этому инструменту — просто вопрос времени.
Другое дело – смена подхода к организации рабочих процессов, серьезная переработка структуры полей, связи задач, добавление учёта времени. Всё то, что команда внедрения проделывала постепенно и успела освоить, было представлено остальным сотрудникам практически одномоментно. Новшества потребовали от людей дополнительных усилий, что не всегда воспринималось положительно. Понадобилось две больших презентации для сотрудников по разъяснению общих принципов работы с новым трекером. До настоящего времени ведётся планомерная работа с вопросами и возражениями.
Еще хочется оставить тут пасхалку для наших сотрудников. Одна из идей написания данной статьи – дополнительное ознакомление внутренних пользователей с особенностями YouTrack. Прилежный сотрудник PVS-Studio, если ты дочитал до этого момента и готов ответить на дополнительные вопросы о прочитанном, подходи ко мне за подарком. :)
Заключение
----------
Оглядываясь назад, я испытываю гордость и удовлетворение от проделанной работы. Думаю, что и другие сотрудники, которые принимали участие в работах по внедрению kanban и переходу на YouTrack, испытывают подобные чувства. Завершён важный этап на пути развития нашей компании. Это был непростой, но очень увлекательный процесс. Пришлось решать много административных и технических задач: проводить встречи и обсуждения, согласовывать сроки и отстаивать своё видение процессов, программировать на JavaScript.
Хочу поблагодарить всех причастных и пожелать нам всем не расслабляться. Мы ещё только в начале пути. И это здорово!
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Sergey Khrenov. [PVS-Studio team's kanban board. Part 2: YouTrack](https://habr.com/en/company/pvs-studio/blog/572602/). | https://habr.com/ru/post/572604/ | null | ru | null |
# Реализация Swift словаря

*Swift словарь представляет собой контейнер, который хранит несколько значений одного и того же типа. Каждое значение связано с уникальным ключом, который выступает в качестве идентификатора этого значения внутри словаря. В отличие от элементов в массиве, элементы в словаре не имеют определенного порядка. Используйте словарь, когда вам нужно искать значения на основе их идентификатора, так же как в реальном мире словарь используется для поиска определения конкретного слова. (прим.)*
**Swift словарь:**
* Swift словарь состоит из двух общих типов: ключей (должны относиться к категории Hashable) и значений;
* Можно создавать записи посредством введения ключа и его значения;
* Значение может задаваться через ссылку на введенный ранее ключ;
* Можно удалить запись, указав соответствующий ключ;
* Каждый ключ связан с одним единственным значением.
Существует несколько способов хранения данных записей (ключей, значений), один из которых предполагает открытую адресацию посредством линейного пробирования, необходимого для запуска Swift-словаря.
Рассмотрим пример словаря, рассчитанного на 8 элементов: в нем предусмотрено максимум 7 записей (ключей, значений) и, как минимум, одно пустое место (так называемый пробел) в буфере словаря, благодаря которому происходит своеобразная блокировка поиска по выборкам/вставкам (retrivals/insertions).
В памяти это будет выглядеть, примерно, так:

Постоянная память задается через:
`size = capacity * (sizeof(Bitmap) + sizeof(Keys) + sizeof(Values))`
Если систематизировать данные логически, получаем что-то вроде:
Каждая колонка образует сегмент памяти, в котором фиксируется три параметра: bitmap value, ключ и value.
Bitmap value в сегменте указывает, действительны и определены ли ключ и соответствующее значение. Если данные недействительны/неинициализированы, сегмент называется пробелом.
`_HashedContainerStorageHeader (struct)`

Эта структура выступает в качестве заголовка для будущего буфера памяти. В ней прописана емкость и сведения об объеме, где емкость — фактическая емкость выделенной памяти, а сведения об объеме – количество действительных элементов, находящихся в буфере на данный момент.
`maxLoadFactorInverse` — это коэффициент, позволяющий расширять буфер в случае необходимости.
#### `_NativeDictionaryStorageImpl (class)`
Подкласс `ManagedBuffer<_HashedContainerStorageHeader, UInt8>`
Главная задача данного класса — выделить оптимальную для словаря память и создать указатели на bitmap, ключи и значения, которые впоследствии нужно будет обработать. Например:
```
internal var _values: UnsafeMutablePointer {
@warn\_unused\_result
get {
let start = UInt(Builtin.ptrtoint\_Word(\_keys.\_rawValue)) &+
UInt(\_capacity) &\* UInt(strideof(Key.self))
let alignment = UInt(alignof(Value))
let alignMask = alignment &- UInt(1)
return UnsafeMutablePointer(
bitPattern:(start &+ alignMask) & ~alignMask)
}
}
```
Поскольку память Bitmap, ключей и значений смежная, значение для указателей будут иметь вид:
```
internal class func create(capacity: Int) -> StorageImpl {
let requiredCapacity = bytesForBitMap(capacity) + bytesForKeys(capacity)
+ bytesForValues(capacity)
let r = super.create(requiredCapacity) { _ in
return _HashedContainerStorageHeader(capacity: capacity)
}
let storage = r as! StorageImpl
let initializedEntries = _BitMap(
storage: storage._initializedHashtableEntriesBitMapStorage,
bitCount: capacity)
initializedEntries.initializeToZero()
return storage
}
```
В процессе создания буфера все записи в bitmap приравниваются нулю, то есть все сегменты памяти, по сути, представляют собой пробелы. Стоит также отметить, что для подобного способа хранения информации общий тип ключа данного класса вовсе не обязательно должен быть Hashable.
`// Примечание: Предполагается, что здесь используются ключ, значение
// (без: Hashable) - это хранилище должно работать
// с типами, отличными от Hashable.`

#### `_NativeDictionaryStorage (структура)`
Эта структура фиксирует сохраненную информацию в буфере и подбирает функцию, преобразующую смежную выделенную память в массив логического сегмента. Также обратите внимание на то, что окончание массива сегмента связано с началом массива, благодаря чему образуется логическое кольцо. А, значит, если вы в конце массива сегмента и запрашиваете следующую функцию, в итоге, вас перенаправят к началу массива.
Для того, чтобы осуществить вставку или задать значение с помощью ключа, необходимо выяснить, к какому сегменту этот ключ принадлежит. Так как ключ у нас Hashable, подойдет функция hashValue, результатом которой служит Int. Правда указанное hashValue может превышать емкость буфера словаря, а потому, возможно, придется его сжать в пределах от нуля до максимального значения емкости:
```
@warn_unused_result
internal func _bucket(k: Key) -> Int {
return _squeezeHashValue(k.hashValue, 0..
```
Мы можем перемещаться между сегментами, обращаясь к опциям `_next` и `_prev`. **Емкость всегда представляет собой число, которое можно выразить в двоичной системе.** Если мы находимся в конце массива сегмента, при желании откат к исходной позиции задается через вызов `_next`.
```
internal var _bucketMask: Int {
// The capacity is not negative, therefore subtracting 1 will not overflow.
return capacity &- 1
}
@warn_unused_result
internal func _next(bucket: Int) -> Int {
// Bucket is within 0 and capacity. Therefore adding 1 does not overflow.
return (bucket &+ 1) & _bucketMask
}
@warn_unused_result
internal func _prev(bucket: Int) -> Int {
// Bucket is not negative. Therefore subtracting 1 does not overflow.
return (bucket &- 1) & _bucketMask
}
```
Для добавления нового элемента нам понадобится узнать, к какому сегменту он будет принадлежать и затем вызвать функцию, вставляющую соответствующий ключ и значение в выбранный сегмент, а также задающую действительные параметры для записи bitmap.
```
@_transparent
internal func initializeKey(k: Key, value v: Value, at i: Int) {
_sanityCheck(!isInitializedEntry(i))
(keys + i).initialize(k)
(values + i).initialize(v)
initializedEntries[i] = true
_fixLifetime(self)
}
```
#### Функция `_find`
* Функция \_find позволяет выяснить, какой сегмент будет задействован при работе с ключом (вставка или выборка);
* Запрашивает исходный сегмент для ключа, чтобы вызвать `_bucket(key)`;
* В случае, если ключ в параметре совпадает с ключом сегмента, возвращает на исходную позицию объекта;
* Если объект не найден, расположение первого пробела определяется возможным участком для вставки ключа;
* Bitmap позволяет проверять сегменты, отделяя заполненные участки от пробелов;
* Это и есть линейное пробирование ([linear probing](https://en.wikipedia.org/wiki/Linear_probing));
```
/// Поиск для данного ключа начинается с указанного сегмента.
///
///Если ключ не обнаружен, возврат к месту его возможной
/// вставки.
@warn_unused_result
internal
func _find(key: Key, _ startBucket: Int) -> (pos: Index, found: Bool) {
var bucket = startBucket
// The invariant guarantees there's always a hole, so we just loop
// until we find one
while true {
let isHole = !isInitializedEntry(bucket)
if isHole {
return (Index(nativeStorage: self, offset: bucket), false)
}
if keyAt(bucket) == key {
return (Index(nativeStorage: self, offset: bucket), true)
}
bucket = _next(bucket)
}
}
```
* Фактически, squeezeHashValue – индикатор того, что ключ присутствует в массиве сегмента, но возможны, коллизии. Например, у двух ключей могут быть одинаковые значения хеш;
* В таком случае выберите функцию, которая выявит ближайший сегмент для вставки ключа.
#### Именно поэтому при анализе значений хеш Hashable выступает в роли, едва ли не идеальной функции, гарантирующей высокую производительность.
* squeezeHashValue действительно пытается создать отличный хеш с помощью нескольких опций;
* Похоже, для того, чтобы при исполнении программы сохранить различные значения хеш, ядро запуска было привязано к hashValue, указанному в типе ключа. Правда, мы говорим о постоянном значении заполнителя;
* `_BitMap` struct используется в качестве оболочки, позволяющей читать и делать записи в bitmap.
Наглядно получаем, примерно, следующее:

#### `_NativeDictionaryStorageOwner (class)`
Этот класс создан для отслеживания правильного подсчета сносок для копий, сделанных в процессе записи. Так как сохранение данных осуществляется с помощью опций Dictionary и DictionaryIndex, счетчик ссылок будет присваивать вводимой информации значение 2, но, если словарь относится к вышеупомянутому классу и количество ссылок для него отслеживается, вам не о чем беспокоиться.
*/// Данный класс – идентификатор запуска COW. Он
/// необходим исключительно для разделения уникальных счетчиков ссылок для:
/// — `Dictionary` и `NSDictionary`,
/// — `DictionaryIndex`.
///
/// Это важно, поскольку проверка на уникальность для COW проводится исключительно
/// для выявления счетчиков первого вида.*
Так это выглядит не очень приятно:

#### `_VariantDictionaryStorage (перечисляемый тип)`
Этот перечисляемый тип работает с двумя операторами Native/Cocoa в зависимости от сохраняемых в них данных.
```
case Native(_NativeDictionaryStorageOwner)
case Cocoa(\_CocoaDictionaryStorage)
```
Основные характеристики:
* Перечисляемый тип, основанный на Native или Cocoa, задает функции корректировки в процессе сохранения информации в словаре для таких операций, как, как вставка, выборка, удаления и т.д;
* Расширяет объем памяти для хранения данных по мере ее заполнения;
* Обновляет или задает связку ключ-значение.
* Если необходимо удалить Значение из массива сегмента, может появиться пробел, который вызовет побочные эффекты в процессе пробирования, что приведет к его преждевременному прерыванию. Для предотвращения подобных негативных явлений важно учитывать позиции всех элементов словаря.
```
/// - параметр idealBucket: идеальный сегмент, предполагающий возможность удаления элемента.
/// - параметр offset: офсет элемента, который будет удален.
///Необходима инициализация записи на смещение.
internal mutating func nativeDeleteImpl(
nativeStorage: NativeStorage, idealBucket: Int, offset: Int
) {
_sanityCheck(
nativeStorage.isInitializedEntry(offset), "expected initialized entry")
// удалить элемент
nativeStorage.destroyEntryAt(offset)
nativeStorage.count -= 1
// Если в ряду смежных элементов появляется пробел,
// некоторые элементы после пробела могут заполнить промежуток нового пробела.
var hole = offset
// Определите первый сегмент смежного ряда
var start = idealBucket
while nativeStorage.isInitializedEntry(nativeStorage._prev(start)) {
start = nativeStorage._prev(start)
}
// Определите последний сегмент смежного ряда
var lastInChain = hole
var b = nativeStorage._next(lastInChain)
while nativeStorage.isInitializedEntry(b) {
lastInChain = b
b = nativeStorage._next(b)
}
// Перемещайте элементы, перенесенные на новые места в ряду, повторяя процедуру до тех пор,
// пока все элементы не окажутся на соответствующих позициях.
while hole != lastInChain {
// Повторите проверку в обратном направлении, с конца ряда смежных сегментов в поиске
// элементов, оставшихся не на своих местах.
var b = lastInChain
while b != hole {
let idealBucket = nativeStorage._bucket(nativeStorage.keyAt(b))
// Элемент оказался между началом и пробелом? Нам необходимо
// два отдельных теста с учетом возможного появления упаковщиков [начало, пробел]
// в конце буфера
let c0 = idealBucket >= start
let c1 = idealBucket <= hole
if start <= hole ? (c0 && c1) : (c0 || c1) {
break // Found it
}
b = nativeStorage._prev(b)
}
if b == hole { // No out-of-place elements found; we're done adjusting
break
}
// Переместите найденный элемент на место пробела
nativeStorage.moveInitializeFrom(nativeStorage, at: b, toEntryAt: hole)
hole = b
}
}
```

#### И вот как выглядит наш словарь
(всего лишь один из видов перечисляемых данных)
 | https://habr.com/ru/post/275911/ | null | ru | null |
# Обработка больших объемов данных в памяти на C#
Хочу поделиться недавно приобретенным в C# опытом по загрузке и обработке в памяти больших объемов данных. Все нижеуказанное касается Visual Studio 2008 и .Net Framework 3.5.1, на случай каких-либо отличий в других версиях языка или библиотек.
Итак, у нас возникли следующие задачи:
1. Расположить в памяти до 100 миллионов записей, состоящих из строки, длиной 16 символов (уникальный ключ) и двух целочисленных значений, длиной 4 байта каждый;
2. Быстро находить и редактировать запись по ключу.
#### Решение задачи №1. Расположение в памяти.
Начнем с размещения. Суммарный размер полезной информации в записи составляет 24 байта. Весь массив данных должен занять примерно 2,4 Гб (не будем заниматься точными пересчетами по границе 1024). Здесь нас ждет первая неприятность: на x32 процесс ОС Windows может выделить только 2 Гб. На практике, в .Net процессе, это значение еще меньше, у меня получалось выделить где-то в районе 1,8 Гб. Предполагаю, что остальное место занимают библиотеки, которые используются в проекте. Т.о. полностью задачу мы сможем решить только на x64 платформе. В примере мы всё же будем рассматривать x32 для сравнения.
Итак, не мудрствуя лукаво, берем перо (мышь и клавиатуру) и начинаем ваять то, что сразу приходит в голову. Делаем представителя записи в памяти:
```
public class Entry
{
public string Key;
public int IntValue1;
public int IntValue2;
}
```
Псевдоним int – кроссплатформенный и всегда соответсвует Int32, поэтому будет одинаков для x32 и x64.
Делаем простой массив и загружаем в него 10 млн. записей:
```
public Entry[] Entries = new Entry[10000000];
private void btnCreate_Click(object sender, EventArgs e)
{
int i;
for (i = 0; i < Entries.Length; i++)
{
Entries[i] = new Entry() {Key = i.ToString("0000000000000000")};
}
GC.Collect();
var msg = string.Format("Created {0}, Memory {1}",
i.ToString("0,0"), GC.GetTotalMemory(true).ToString("0,0"));
lbLog.Items.Add(msg);
}
```
И видим, что мы заняли примерно 760 Мб (х32) и 1040 Мб (х64), т.е. в аккурат 76/104 Б на запись, полезных из которых только 24. Получается, что 100 млн. займут 7,6/10,4 Гб!
Что же заняло 52/80 Б? Есть несколько моментов: инфраструктура объектов .Net и выравнивание расположения в памяти. Начнем с первого. Неплохую статью можно почитать [здесь](http://www.simple-talk.com/dotnet/.net-framework/object-overhead-the-hidden-.net-memory--allocation-cost/). Получается, что на инфраструктуре класса мы теряем 8/16 Б и еще 4/8 Б на ссылке (наш массив экземпляров классов на самом деле является массивом указателей на экземпляры). Проверим, заменив class на struct:
```
public struct Entry
...
```
Замер показал затраты 64/80 Б на запись. Все сходится – мы сэкономили 12/24 Б. Структура является ValueType, поэтому логично предположить, что в массиве у нас теперь не ссылки, а сами значения. Так и есть, поэтому мы собственно и сэкономили 4/8 Б на ссылке. Сама инфраструктура структуры ничего не занимает. Прежде чем пойти дальше и начать оптимизировать Key, на котором мы, судя по всему, теряем очень много, остановимся на одном важном моменте. Переведя запись на структуру мы вырыли себе яму – если располагать данные в одном массиве структур, то нам понадобится один очень большой блок памяти. Даже если свободной памяти достаточно, из-за фрагментации такого сплошного блока может не оказаться. На практике я начал сталкиваться с проблемами выделения более 500 Мб. Этот вопрос мы будем решать во 2-й задаче. Дополнительно, при каждой передаче записи мы теперь будем терять на клонировании структуры, а при организации ссылки – на упаковке/распаковке(boxing/unboxing). Но деваться некуда, нужно экономить место.
Продолжим с полем Key. Тип String является классом, поэтому мы сходу теряем 12/24 Б на записи. На самом деле строка очень тяжелая, для примера можно почитать [здесь](http://www.yoda.arachsys.com/csharp/strings.html). Практически, сделав массив строк длинной 16, мы убеждаемся в оккупировании полем Key 56/72 Б на запись. Итого:
Для класса: 8 (два int) + 56/72 (Key) +12/24 (инфраструктура класса + ссылка) = 76/104 Б.
Для структуры: 8 (два int) + 56/72 (Key) = 64/80 Б.
Попробуем перевести поле Key на char[]. Получаем выгоду в 8 Б на обеих платформах. Массив – тоже класс, поэтому на инфраструктуре мы не сэкономили, а только на внутренней организации самого string, учитывая, что внутри он тоже хранит массив char. Каждый символ – юникодный и занимает 2 байта. Плюс где-то может сыграть роль выравнивание в памяти. Самое время о нём поговорить.
Думаю, многие знают, что данные в памяти выгодно выравнивать по определенной платформой границе, например по границе Int32. Подробно об этом можно почитать [здесь](http://www.developerfusion.com/article/84519/mastering-structs-in-c/). В нашем случае на расположении класса/структуры Entry мы ничего не потеряли, т.к. все поля ложатся ровно по границе 4 байт (помним, о том, что Key – ссылка). Можно поэкспериментировать, меняя настройки атрибута StructLayout и используя замер Marshal.SizeOf(new Entry()). Но если сделать одно поле типа byte вместо int, окажется, что всего на массив мы занимаем то же количество памяти, что и при int даже если установить у StructLayout свойство Pack = 1. Т.е. структура сама по себе будет упакована по границе 1 байта, но элементы массива будут располагаться по границе 4 байт. Сразу скажу, что задачу упаковки массивов я не решал, т.к. финальное решение задачи этого не потребовало. Поэтому эта тема, равно как и тема строк/символов здесь полностью не раскрывается. Еще хочу добавить, что значение CharSet = CharSet.Ansi атрибута StructLayout никак не повлияло на размер занимаемой памяти ни строки ни char[].
Итак, на данный момент мы сэкономили 20/32 Б на записи. Т.к. строка в этой задаче подразумевалась не юникодная, было решено использовать byte[] вместо char[]. Экономим еще 16 Б на обеих платформах. Одна запись теперь занимает 40/56 Б. Излишек – 16/32 Б на организацию массива. Оказывается в .Net есть возможность организовать статический фиксированный буфер используя небезопасный режим:
```
private unsafe fixed byte _key[16];
```
Вот здесь наконец-то мы добиваемся 100% рациональности – наша запись занимает в памяти ровно 24 Б на обеих платформах. На х32 мы сможем загрузить около 75 млн. (1,8 Гб), на х64 все 100 млн. (2,4 Гб). Максимальное количество на x64 по сути ограничено размером доступной памяти. Использовать это счастье можно только в блоках unsafe и fixed. Есть подозрение, что здесь мы будем терять в производительности, но насколько — я не знаю, замеров не делал, т.к. финальный вариант полностью удовлетворил потребности.
Курим и переходим к решению второй задачи.
#### Решение задачи №2. Быстрый доступ.
Для быстрого доступа к 100 млн. записей нам нужно что-то вроде хештаблицы. Стандартный Hashtable не подходит, т.к. использует Object, а это означает, что каждая запись-структура будет положена в специальный класс (boxing) и мы опять начнем терять на инфраструктуре класса. Нам нужен Generic. Есть такой — Dictionary. После неудачной попытки использования и дизассемблирования обнаруживаем следующее (кто не знаком с принципами работы хештаблиц можно почитать [здесь](http://ru.wikipedia.org/wiki/%D0%A5%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0)):
— избыток 8 Б на вхождение:
```
[StructLayout(LayoutKind.Sequential)]
private struct Entry
{
public int hashCode;
public int next;
public TKey key;
public TValue value;
}
```
Теряем на хранении хешкода и организации связанного списка (используется метод цепочек). Здесь нам кстати нужны две структуры – одна для ключа, другая для значений.
— один сегмент для данных:
```
private Entry[] entries;
```
Тут остро возникает проблема выделения одного большого блока памяти.
— сегмент хеша больше или равен capacity (очень много вопросов возникает):
```
private void Initialize(int capacity) {
…
num = HashHelpers.GetPrime(capacity);
this.buckets = new int[num];
…
```
— при заполнении происходит ресайзинг с минимум двухкратным запасом, подгонка под этот размер хешсегмента и соответсвенно рехешинг:
```
private unsafe void Resize() {
…
num = HashHelpers.GetPrime(this.count * 2);
numArray = new int[num];
…
entryArray = new Entry[num];
…
this.buckets = numArray;
this.entries = entryArray;
}
```
Думаю, не стоит детально описывать к чему это всё приводит. Вдумайтесь хотя бы в логику двукратного роста на миллионных объемах.
Обнаружив такое неадекватное поведение, я уже не стал копаться в родных коллекциях на предмет чего-нибудь более рационального, а написал свой словарь. На самом деле всё достаточно тривиально, тем более мне не нужно 90% функциональности, которую реализует стандартный. Код приводить не буду, укажу лишь ключевые моменты:
— не оспльзуем отдельно ключ и значение, все в одной структуре Entry.
— в структуре Entry перекрыл (и как это в структуре что-то можно перекрывать?!) метод GetHashCode(). Использовал модифицированный метод ФНВ [отсюда](http://bretm.home.comcast.net/~bretm/hash/6.html) (fig.4)
— в структуре Entry перекрыл метод Equals(object obj). Сравнение идет только по ключу.
— размер хешсегмента сделал заказным в конструкторе. Изменение его размера и рехешинг не предусмотрен.
— индекс в хешсегменте высчитывается как остаток от деления хешкода на размер хешсегмента.
— каждая ячейка хешсегмента – обычный List, который наполняется записями с одинаковым хешкодом. Здесь как раз и решается проблема одного большого блока памяти.
Подсчитаем, сколько мы тратим памяти на организацию:
— хешсегмент = массив ссылок на списки (размер хешсегмента \* 4/8 Б);
— экземпляры списков = инфраструктура класса + поля списка (размер хешсегмента \* (8/16 +28/44)).
Итого, на организацию сегмента размером в 1 млн. мы затратим примерно 40/68 Мб.
Все бы замечательно и пора выпить шампанского. Но не тут-то было. Оказывается, что List:
— как и стандартный словарь растет с удвоением:
```
private void EnsureCapacity(int min) {
…
num = (((int) this._items.Length) == null) ? 4 : (((int) this._items.Length) * 2);
…
```
— функция по освобождению избыточно занимаемой памяти не освобождает 0,1 объема:
```
public void TrimExcess()
{
int num;
num = (int) (((double) ((int) this._items.Length)) * 0.9);
if (this._size >= num)
{
goto Label_002A;
}
this.Capacity = this._size;
Label_002A:
return;
}
```
— ну и в довесок избыточен (для наших целей) по полям и тем, что является классом:
```
public class List...
{
private const int _defaultCapacity = 4;
private static T[] _emptyArray;
private T[] _items;
private int _size;
[NonSerialized]
private object _syncRoot;
private int _version;
...
```
Пришлось написать свой список, с заказным линейным ростом, полным освобождением памяти и экономией 8 Б на полях \_syncRoot и \_version. Еще можно перевести его на структуру, сэкономив 12 Б.
Все, задача решена – пьем шампанское!
##### И немного практики
РС Core 2 Quad Q9400 @ 2,66, RAM 4 Gb, Windows Server 2008 R2 Standard x64
Хешсегмент 1 млн., рост списков 25.
Заполнение 100 млн. 5 мин 50 сек. Память 2,46 Гб, пик 3,36 Гб.
Статистика: заполнение 100%, минимальная цепочка 56, максимальная 152, стандартное отклонение 10.
Сравнение 100 млн. в памяти с внешними 100 млн. 4 мин 10 сек.
Хешсегмент 2 млн., рост списков 20.
Заполнение 100 млн. 4 мин 43 сек. Память 2,53 Гб, пик 3,57 Гб.
Статистика: заполнение 100%, минимальная цепочка 20, максимальная 89, стандартное отклонение 7.
Сравнение 100 млн. в памяти с внешними 100 млн. 2 мин 56 сек.
Небольшая ремарка: .Net не сразу освобождает память, даже если мы освободили большое количество объектов. Этого может не произойти и после сбора мусора. Память остается зарезервированной для будущего использования и освободится при острой нехватке памяти в системе (возможно еще по каким-то критериям).
Надеюсь данный опыт пригодится еще кому-то при решении оптимизационных задач. | https://habr.com/ru/post/114495/ | null | ru | null |
# Кукушка на bash своими руками
Привет, %username%.
Для организации моей работы удобно видеть или слышать уведомления о том, что прошел час, полчаса и т.д. Это нужно мне для ориентации во временном пространстве и правильного планирования своей работы.
Поскольку у меня стоит Ubuntu, то и статья будет про то, как сделать такие уведомления стандартными средствами Ubuntu.

Итак, мне нужно:
* каждый час видеть и слышать уведомление о времени
* уведомление не должно отвлекать
* решение должно быть легким и экономным с точки зрения ресурсов
В процессе поиска перепробовал несколько приложений. Некоторые из них были неплохи, но без нужного мне функционала, некоторые — ужасно неудобны, а что-то — вообще не работало. Почти у всех программ сильно страдала надежность работы.
Нормального инструмента я так и не нашел, и поэтому решил реализовать его сам. Писать свою программу — долго, а потому проще сделать скрипт на коленках.
#### Уведомления в Ubuntu
Как известно, для уведомлений в Ubuntu применяется утилита [notify-send](http://habrahabr.ru/blogs/linux/47892/ "notify send"). В последних версиях Ubuntu notify-send используется как основное средство уведомлений. Это действительно очень удобно, когда все сообщения показываются однообразно. Пользоваться ей так:
```
$ notify-send title message
```
Запустив эту несложную команду в консоли, вы через некоторое время увидите уведомление с заголовком title и сообщением message. У меня это выглядит так:

Отлично, выводить сообщения мы уже умеем, осталось научиться показывать их по расписанию.
#### Задачи по расписанию в linux
Для задач по расписанию есть в linux отличное средство [crontab](http://ru.wikipedia.org/wiki/Cron "crontab википедия")
```
crontab -e
```
отрывается редактор, вбиваем в него строку:
```
0 */1 * * * DISPLAY=:0.0 notify-send "Часовщик" "Прошел 1 час"
```
Сохраняем, любуемся результатом. Если хочется поиграться, то можно поставить уведомления раз в минуту, тогда отладочная запись будет выглядеть как-то так:
```
*/1 * * * * DISPLAY=:0.0 notify-send "Часовщик" "Прошла 1 минута"
```
Теперь через равные промежутки времени мы можем что-нибудь выводить пользователю:
Для пользователей, не умеющих настраивать crontab могу посоветовать online генератор. Например, [такой](http://www.openjs.com/scripts/jslibrary/demos/crontab.php "crontab online").
Отмечу отдельно, что я не стал возиться с определением номера дисплея. Да, он может меняться, но за несколько месяцев работы у меня он не разу не поменялся, т.к. у меня все-таки десктоп, а скрипт все-таки сделан на коленке.
Поделюсь ещё одним рецептом. Пользоваться crontab -e не очень удобно, т.к. открывается редактор по умолчанию. Обычно это nano. По-моему он ужасен. Я обычно делаю так:
```
crontab -l > /tmp/crontab.file && cp /tmp/crontab.file /tmp/crontab.file.backup && gedit /tmp/crontab.file && crontab /tmp/crontab.file
```
Открывается файл в удобном gedit, редактируется, сохраняется или не сохраняется. После закрытия окна gedit настройки попадают в crontab.
Или оформляем все это дело в скрипт и кладем, например, на рабочий стол:
```
#!/bin/sh
# _Nicolay
# file editCrontab.sh
crontab -l > /tmp/crontab.file && cp /tmp/crontab.file /tmp/crontab.file.backup && gedit /tmp/crontab.file && crontab /tmp/crontab.file
rm /tmp/crontab.file
```
#### Диалоги в скриптах linux
Теперь, частично проблема была решена. Но только частично, ведь я не всегда смотрю на экран монитора и могу пропустить сообщение. На помощь мне пришла утилита zenity. Она также уже была в системе. Пишем смело в crontab
```
0 */1 * * * DISPLAY=:0.0 zenity --info --title="Часовщик" --text="Прошел один час"
```
или отладочная запись:
```
*/1 * * * * DISPLAY=:0.0 zenity --info --title="Часовщик" --text="Прошла одна минута"
```
В итоге получилось что-то типа такого:
Какое-то время работать было удобно, но со временем окно-уведомление стало меня доставать. Этот факт заставил меня модернизировать свои крон-скрипты. В итоге я наткнулся на 3-ю полезную утилиту: [ESpeak](http://ru.wikipedia.org/wiki/ESpeak "ESpeak wiki").
Она позволяет синтезировать речевые сообщения на разных языках.
Добавляем новую строчку в crontab:
```
0 */1 * * * espeak -vru -s130 "прошел 1 час"
```
или отладочная строка
```
*/5 * * * * espeak -vru -s130 "прошло 5 минут"
```
#### В итоге, вот что получилось
Синтезатор речи по-русски говорил ужасно. Слушать было противно, и поэтому я переключился на английский и сделал ещё ряд доработок:
* заставил часовщика говорить ещё и время
* добавил напоминания о том, что нужно попить кофе.
Конечный функционал уведомлений меня полностью устроил. Мне не пришлось ничего ставить, все было легковесным и надежным.
Мой файл crontab сейчас выглядит так:
```
# crontab file
# _Nicolay
# ежечасные уведомления о времени
0 */1 * * * /usr/local/scripts/hours.sh
# уведомления о кофе
23 12,16 * * * DISPLAY=:0.0 zenity --info --title="Уведомление" --text="пора бы кофейку!!!"
```
А файл hours.sh:
```
#!/bin/sh
# hours.sh
# _Nicolay
DISPLAY=:0.0 notify-send "часовщик" "`date +%k` часов"
espeak -ven -s130 "`date +%l` hours"
```
Я вынес скрипты в файл hours.sh из-за того, что crontab скрипт не поддерживает обработку [машинописного обратного апострофа](http://ru.wikipedia.org/wiki/Машинописный_обратный_апостроф). Если же вы в crontab укажете машинописный обратный апостроф, то скрипт в указанное время не сработает.
###### Ну и под конец скрины того, как это выглядит у меня.
Каждый час выводится сообщение сколько времени:

Сообщение дублируется звуком. Если я рядом с компьютером, я его услышу. И два раза в день мне отправляется напоминание о том, что нужно все-таки передохнуть.
**UPD:** Доработал скрипт на основе советов и комментариев.
Отдельное спасибо [lionsimba](http://habrahabr.ru/users/lionsimba/) за [комментарий про festival](#comment_4183471).
В итоге, получилась новая версия hours.sh:
```
#!/bin/sh
# hours.sh
# _Nicolay
#HOURS="`date +%l`"
HOURS="`date +%k`"
HOURS_TXT="Сколько времени?"
HOURS_TXT_SAY=$HOURS_TXT
if [ "$HOURS" -eq 11 ]; then
HOURS_TXT="$HOURS часов"
HOURS_TXT_SAY="$HOURS часов"
elif [ "$HOURS" -eq 12 ]; then
HOURS_TXT="$HOURS часов"
HOURS_TXT_SAY="$HOURS часов"
elif [ "$HOURS" -eq 13 ]; then
HOURS_TXT="$HOURS часов"
HOURS_TXT_SAY="$HOURS часов"
elif [ "$HOURS" -eq 14 ]; then
HOURS_TXT="$HOURS часов"
HOURS_TXT_SAY="$HOURS часов"
elif [ "$(($HOURS % 10))" -eq 0 ]; then
HOURS_TXT="$HOURS часов"
HOURS_TXT_SAY="$HOURS часов"
elif [ "$(($HOURS % 10))" -eq 1 ]; then
HOURS_TXT="$HOURS час"
HOURS_TXT_SAY="$HOURS час"
elif [ $(($HOURS % 10)) -lt 5 ]; then
HOURS_TXT="$HOURS часа"
HOURS_TXT_SAY="$HOURS часаa"
else
HOURS_TXT="$HOURS часов"
HOURS_TXT_SAY="$HOURS часов"
fi
DISPLAY=:0.0 notify-send -i "typing-monitor" "Часовщик" "$HOURS_TXT"
#espeak -ven -s130 "`date +%l` hours"
echo "$HOURS_TXT_SAY" | festival --tts --language russian
```
Скрипт вполне сносно сообщает по-русски о времени.
На этом всё, спасибо за внимание. | https://habr.com/ru/post/126849/ | null | ru | null |
# Кармическое проклятье Хабра

### Непредвиденные последствия
 *«Система кармы Хабра и ее влияние на пользователей» — это тема для курсовой как минимум*
[Тема про карму на «Пикабу»](https://pikabu.ru/story/karma_khabra_6449929?cid=131832438)
Я мог бы начать эту статью с того, что я давно читаю Хабр, но это будет не совсем точным высказыванием. Правильный тезис звучал бы так: «я давно читаю статьи с Хабра» — но не интересовался тем, что происходит внутри сообщества, когда этой весной решил наконец-то зарегистрироваться. Это типичная ошибка человека, который приходит на Хабр из поисковика читать полезные статьи о тонкостях программирования или интересные новости из мира технологий. Пока ты видишь портал только с этой, положительной стороны, ты не задаёшься вопросами о том, что происходит под капотом. Конечно, в комментариях или статьях время от времени проскальзывали упоминания кармы — но ведь карма есть почти на всех крупных порталах (наивно полагал я), это нормально для саморегулирующихся интернет-сообществ.
Мне пришлось всерьёз задуматься об этом после того, как я неожиданно потерял возможность писать больше одного комментария в пять минут.
При этом внешне всё шло отлично: мои комментарии всё время плюсовали, мой рейтинг рос — и вдруг оказалось, что у меня отрицательная карма. Весь мой длительный опыт интернет-общения, все пользовательские привычки, да и банальный здравый смысл кричали мне, что это какая-то ошибка: показатель одобрения пользователя сайта другими пользователями сайта не может одновременно расти и падать! Но я решил не рубить сплеча, а провести небольшое исследование, как аналитическое (в виде изучения мнений пользователей о карме), так и статистическое (в виде анализа показателей аккаунтов).
История войны пользователей с кармой оказалась очень богатой. С переменным успехом она длится уже больше десятка лет, на её счету десятки заблокированных жертв и несколько удалённых статей. Причём, как ни странно, моя проблема (расхождение оценок и кармы) практически не используется в аргументации — даже во времена открытого API эти подсчёты не применялись. Ближе всех подобрался только один комментатор в сравнительно недавней записи:
> «Собственно, что интересно найти: есть ли заминусованные за карму люди с большим плюсами к их комментариям?»
>
> <https://habr.com/ru/company/habr/blog/437072/#comment_19650144>
В статистической части вы можете увидеть, что да, такие люди есть. Но даже без статистики пользователи в принципе всё про карму давно понимали.
Вот запись десятилетней давности:
> Большая проблема на хабре, что есть немало юзеров, которые ставят минус в карму по принципу: «Ах, у тебя есть мнение, отличное от моего, вот тебе минус в карму». Хотя по мне так аргументированный комментарий с контраргументами и хорошо изложенной противоположной позицией даже минуса за сам коммент не заслуживает, не то что в карму автору. К сожалению, на Хабре практически отсутствует культура аргументированного диспута и уважения к сильному оппоненту, многие стремятся просто шапками закидать.
>
> У меня вообще есть мнение, что разделение оценок на два счётчика «рейтинг» и «карма» это неинтуитивно и потому некорректно и неэффективно.
>
> <https://habr.com/ru/post/92426/#comment_2800908>
Вот запись пятилетней давности:
> Анализу подверглись лишь случаи, когда карма изменялась минимум на 15 единиц, но картины в целом это не меняет, т.к. и в этом случае отношение 30% на 70%. Как видно, сливают карму большей частью из за комментариев, а поднимают за написанные статьи.
>
> <https://habr.com/ru/post/192376/>
Вот предложение по усовершенствованию трехлетней давности:
> *Предложение:*
>
> Разрешать голосовать за карму авторам статей только в определенный период (например, неделю) после опубликования ими статьи. Если человек не публиковал ничего за последнюю неделю, ему нельзя слить карму за комментарий. Правило можно не распространять на reed-only аккаунты — они набирают карму полезными комментариями.
>
> *Комментарий:*
>
> Слишком часто пользователи хабра жалуются на слив кармы за неугодные комментарии в чужих постах. Для примера, в этом посте проблема описана еще в 2012 году. Воз и ныне там.
>
> <https://github.com/limonte/dear-habr/issues/49>
Вот ещё один диалог трёхлетней давности на ту же тему:
> [DrMetallius](https://habr.com/ru/users/drmetallius/)
>
> Я могу сказать, почему я перестал писать комментарии (этот сделаю исключением): потому что трудно заработать карму, так как для неё нужно постоянно рождать какие-то статьи, зато потерять её очень легко. Это неправда, что если писать корректно, она не тратится. Её могут снизить по множеству причин: не согласился с тобой в споре, посчитал, что в комментарии какой-то факт неверный, или просто у него плохое настроение.
>
>
>
> [maxshopen](https://habr.com/ru/users/maxshopen/)
>
> Да, это древняя болезнь хабрасистемы. Преполагалось, что те, кто имеет положительную карму — адекватны и просто так никого минусовать не будут. Когда то все было еще хуже — чем больше карма, тем больший минус пользователь может поставить, что кончилось тем, что пара «зазвездившихся» хабраюзеров раздавали налево и направо кому попало по -6, -8, после чего возможности порезали до единицы. Создатели экономики кармы изначально видимо не учли порочность анонимности
>
> Как мне кажется эту систему давно надо было еще немного добалансировать тем, что при голосовании кому-то в карму с пользователя списывается какое то ее количество. Много не надо — 0,2-0,5 достаточно. Это сильно повысило бы ответственность голосующих при выборе голосовать за кого то или нет.
>
> <https://habr.com/ru/post/276383/#comment_8761911>
И, наконец, комментарии к посту из начала текущего года:
> Карма — это не очень хороший инструмент саморегулирования системы. В карму ставят оценки чаще те, кто недоволен человеком (или даже его позицией). В результате получается, что набрать карму очень сложно, а слить её — очень легко. Это заставляет людей подумать лишний раз — а стоит ли высказать своё мнение, если оно не очень популярно? Ведь если выскажу один раз, заминусуют и сольют карму, и больше высказывать уже не получится. Это ведет к тому, что на ресурсе остается только одно мнение, а все остальные вытесняются.
>
> <https://habr.com/ru/company/habr/blog/437072/#comment_19647340>
А вот комментарий, который объясняет, почему «написание статей» на самом деле не спасает систему кармы:
> Статья приносит почти ничего в плане кармы, а за один неудачный комментарий человека могут полностью слить.
>
> Тут проблема в разделении рейтинга и кармы. В голове у людей работает так:
>
> 1. Оценка контента это мое отношение к статье или комментарию
>
> 2. Оценка кармы это мое отношение к человеку лично
>
> В итоге
>
> 1. Если ты написал лучшую в мире статью тебе поставят много плюсов к статье (в рейтинг) и посчитают свою миссию выполненной.
>
> 2. Если ты написал комментарий который «не попадет в струю» то тебе минусанут комментарий, да ещё и человек ты видимо так себе раз так считаешь поэтому на тебе и в карму.
>
> <https://habr.com/ru/company/habr/blog/437072/#comment_19649262>
Многие недовольные системой кармы высказываются в том смысле, что это целенаправленная политика администрации — [например в этом комментарии](https://habr.com/ru/company/habr/blog/437072/#comment_19650932) или в [этом](https://habr.com/ru/post/467875/#comment_20639293). Тому есть, конечно, немало косвенных подтверждений:
* Убрали API, чтобы не было возможности следить за динамикой;
* Сделали динамический рейтинг, чтобы нельзя было суммарные оценки посмотреть непосредственно в профиле;
* Постоянно ссылаются на «кармограф», согласно которому плюсов ставят больше чем минусов (о соотношении кармы и оценок речь даже не заходит);
* Много, но безосновательно, говорят о том, будто карма отражает качество публикаций и комментариев (что противоречит статистике, как мы видим по показателям оценок).
Также я напоминаю, что **нигде и никогда не было приведено обоснование существования кармы** в том виде, в котором она существует.
Доказать эти конспирологические теории мы не можем никак. Но мне кажется, что дело и не в них — тут та же проблема, что и с минусующими карму людьми: непробиваемая вера в свою правоту, до такой степени, что несогласный с тобой воспринимается как «плохой человек». Вот руководители Хабра таким же образом решили — мы будем оценивать пользователей отдельно от их сообщений. И им уже больше десяти лет не могут объяснить, что это некорректный подход к ранжированию пользователей. Они умные, они целый портал создали. Вот ты создай свой Хабр — тогда и поговорим (кстати забавно, что [буквально в таких терминах мне защитник кармы на претензии и ответил](https://habr.com/ru/post/467875/#comment_20642033) — «Сперва добейся»)
Лично я предполагаю, что сама схема кармы пришла к нам с [Лепры](https://lurkmore.to/%D0%BB%D0%B5%D0%BF%D1%80%D0%B0), где в своё время тусовалось большинство нынешних владельцев крупных интернет-порталов. Хабр начинался как та же самая Лепра — закрытый клуб с инвайтами и взаимными оценками, недоволен — пошёл прочь из клуба. Те времена давно прошли, клуб уже давным-давно не закрытый, оценки давным-давно ставятся не «другому участнику клуба», а обычному пользователю за обычные комментарии и статьи. Но внутренний элитизм не отпускает администрацию. Все думают — действительно, ребята создали крупный прибыльный портал, много лет пишут статьи на технические темы — разве они могут чего-то не знать? Значит если всё плохо, то ими, злодеями, так и задумано. А на самом деле администраторы просто застряли в детстве. И чем крупнее и прибыльнее портал — тем сложнее признать свои многолетние ошибки, из ложно понимаемой гордости.
### Запутанность

*Это глубокие воды, Ватсон, глубокие воды. Я лишь приступил к погружению.*
[Спецвыпуск «Шерлока Холмса»](https://ru.wikipedia.org/wiki/%D0%91%D0%B5%D0%B7%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BD%D0%B0%D1%8F_%D0%BD%D0%B5%D0%B2%D0%B5%D1%81%D1%82%D0%B0)
Ниже термин «Карма» я буду использовать для кармы, а термин «Оценка» или «Суммарная оценка» — для общей суммы всех плюсов и минусов, которые были получены пользователем, как за статьи, так и за комментарии.
Разобравшись с историей, мы попробуем посмотреть на цифры. Недавно тут был целый цикл анализа статистики, но он касался только текущего года — мне же нужно было понимать суммарную оценку пользователя. Поскольку API у нас нет, а вместо реальных оценок в профиле показывают сомнительный рейтинг — мне оставалось лишь изучить каждый комментарий и собрать из него данные об авторе и оценке. Именно этим я и занялся.
Я открывал каждую публикацию с самого начала времён, доставал из неё ник автора публикации и оценку статьи, а потом ники комментаторов и оценки их комментариев.
**Вот код основного парсера.**
```
import requests
from bs4 import BeautifulSoup
import csv
def get_doc_by_id(pid):
fname = r'files/' + 'habrbase' + '.csv'
with open(fname, "a", newline="") as file:
try:
writer = csv.writer(file)
r = requests.head('https://habr.com/ru/post/' +str(pid) + '/')
if r.status_code == 404: # проверка на существование
pass
else:
r = requests.get('https://habr.com/ru/post/' +str(pid) + '/')
soup = BeautifulSoup(r.text, 'html5lib')
if not soup.find("span", {"class": "post__title-text"}):
pass
else:
doc = []
cmt = []
doc.append(pid) #номер
doc.append(soup.find("span", {"class": "user-info__nickname"}).text) #ник
doc.append(soup.find("span", {"class": "voting-wjt__counter"}).text) #счетчик
writer.writerow(doc)
comments = soup.find_all("div", {"class": "comment"})
for x in comments:
if not x.find("div", {"class": "comment__message_banned"}):
cmt.append(x['id'][8:]) #номер
cmt.append(x.find("span", {"class": "user-info__nickname"}).text) #ник
cmt.append(x.find("span", {"class": "voting-wjt__counter"}).text) #счётчик
writer.writerow(cmt)
cmt = []
except requests.exceptions.ConnectionError:
pass
x = int(input())
y = int(input())
for i in range(x, y):
get_doc_by_id(i)
print(i)
```
Результатом стала такая табличка в файле habrbase:
Я сгруппировал пользователей и получил результат в виде «Пользователь — Сумма его оценок» под названием habrauthors.csv. Потом я начал перебирать этих пользователей и добавлять данные из их профиля. Поскольку иногда связь могла обрываться, или какая-нибудь странная ошибка возникала при загрузке страницы, пришлось смотреть, какой пользователь обрабатывался последним и продолжать с него.
**Вот код вторичной обработки:**
```
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
def len_checker():
fname = r'files/' + 'habrdata' + '.csv'
with open(fname, "r") as file:
try:
authorsList = len(file.readlines())#получаем длину файла даты
except:
authorsList = 0
return authorsList
def profile_check(nname):
try:
r = requests.head('https://m.habr.com/ru/users/' +nname + '/')
if r.status_code == 404: # проверка на существование
pass
else:
ValUsers = []
r = requests.get('https://m.habr.com/ru/users/' +nname + '/')
soup = BeautifulSoup(r.text, 'html5lib') # instead of html.parser
if not soup.find("div", {"class": "tm-user-card"}):
valKarma = 0
valComments = 0
valArticles = 0
else:
valKarma = soup.find("span", {"class": "tm-votes-score"}).text #карма
valKarma = valKarma.replace(',','.').strip()
valKarma = float(valKarma)
tempDataBlock = soup.find("div", {"class": "tm-tabs-list__scroll-area"}).text.replace('\n', '') #показатели активности
mainDataBlock = tempDataBlock.split(' ')
valArticles = mainDataBlock[mainDataBlock.index('Публикации')+1]
if valArticles.isdigit() == True:
valArticles = int(valArticles)
else:
valArticles = 0
valComments = mainDataBlock[mainDataBlock.index('Комментарии')+1]
if valComments.isdigit() == True:
valComments = int(valComments)
else:
valComments = 0
ValUsers.append(valKarma)
ValUsers.append(valComments)
ValUsers.append(valArticles)
except requests.exceptions.ConnectionError:
ValUsers = [0,0,0]
return ValUsers
def get_author_by_nick(x):
finalRow = []
df = pd.DataFrame
colnames=['nick', 'scores']
df = pd.read_csv(r'files\habrauthors.csv', encoding="ANSI", names = colnames, header = None)
df1 = df.loc[x:]
fname = r'files/' + 'habrdata' + '.csv'
with open(fname, "a", newline="") as file:
writer = csv.writer(file)
for row in df1.itertuples(index=True, name='Pandas'):
valName = getattr(row, "nick")
valScore = getattr(row, "scores")
valAll = profile_check(valName)
finalRow.append(valName)
finalRow.append(valScore)
finalRow.append(valAll[0])
finalRow.append(valAll[1])
finalRow.append(valAll[2])
writer.writerow(finalRow)
print(valName)
finalRow = []
n = len_checker()
get_author_by_nick(n)
```
Там много проверок, потому что много странных вещей происходит на страницах хабра, начиная с удалённых комментариев и заканчивая какими-нибудь загадочными пользователями. Например, как появился в моей выборке 2001 год регистрации? Для сбора данных пользователей я парсил мобильную версию сайта, и эта версия для некоторых пользователей не только сообщает, что пользователь удалён, но и выдаёт вот такое сообщение: «Внутренняя ошибка (intermediate value).map is not a function». В комментариях остались все, и удалённые и нечитаемые, вот я и установил им дату регистрации 2001 год. Уже позже я обнаружил, что некоторых таких пользователей видно в обычной версии сайта — если они не были удалены или заблокированы. Но поскольку их всего 250, а половина из них уже не существует — я решил просто их не трогать.
Финальный вариант таблицы habrdata выглядит так: ['nick', 'scores', 'karma', 'comments','articles','regdate']. Его можно скачать [здесь](https://github.com/411an/habrparse/blob/master/habrdata.rar).
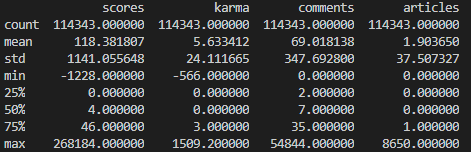
А вот так они распределены по дате регистрации. Я бы сказал, что на длинной дистанции наблюдается некоторый спад регистраций.
| | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Год регистрации | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 |
| Пользователей | 2045 | 11668 | 12463 | 5028 | 5346 | 13686 | 11610 | 9614 | 9703 | 6594 | 8926 | 7825 | 5912 | 3673 |
Всего у нас оказалось 114 343 пользователя, которые когда-либо писали комментарии или статьи. Давайте посмотрим, как выглядит график кармы и оценок для пользователей:
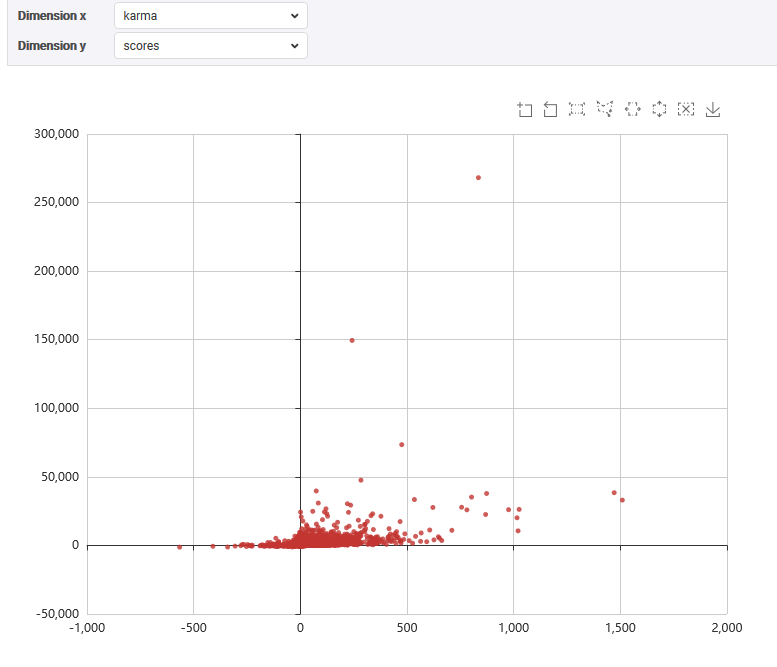
За эти графики, кстати, спасибо шикарному визуализатору [tabloo](https://github.com/bluenote10/tabloo).
У нас есть совершенно безумные выбросы, вы видите их и на графике. Скажем, у пользователя [alizar](https://habr.com/ru/users/alizar/) (UPD) за все его комментарии и публикации набралось больше 268 тысяч плюсов! И он там в этой стратосфере парит совершенно одинокий, остальные более-менее успешные болтаются на высоте около 30 тысяч. С кармой та же история — у пользователя [Zelenyikot](https://habr.com/ru/users/zelenyikot/) карма 1509, а обыденная жизнь начинается где-то на 500. Я не стал урезать выборку, просто немного приблизил график, чтобы вы могли внимательнее рассмотреть распределение обыкновенных пользователей.
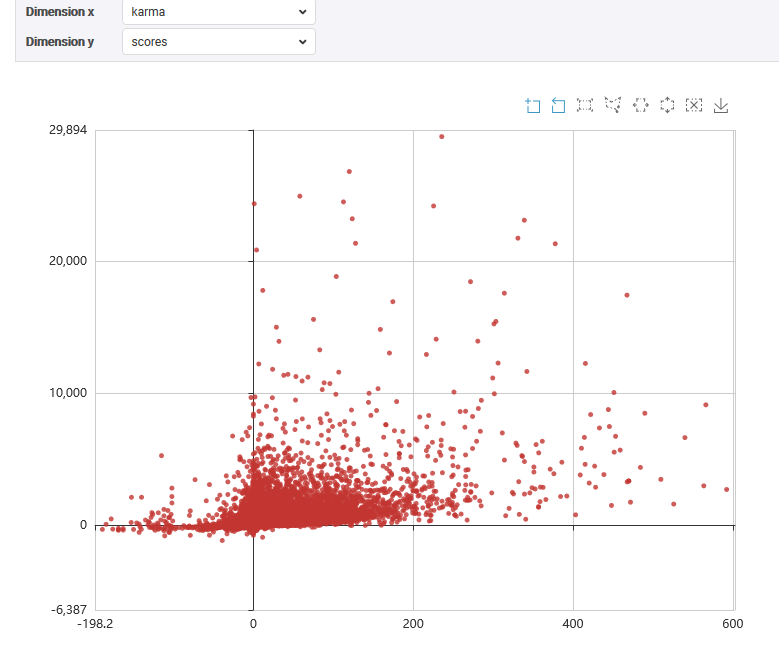
**Здесь по просьбам трудящихся добавлен ТОП-10 пользователей по ключевым показателям**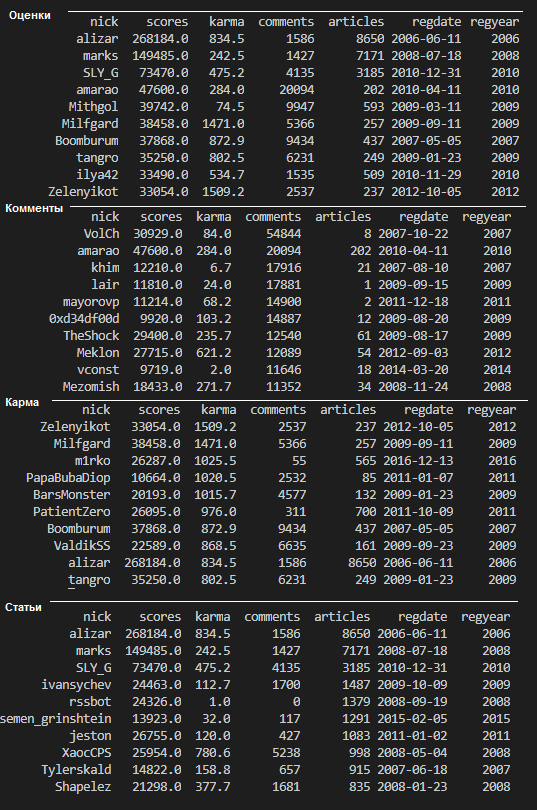
Беглый анализ по всему объёму пользователей показывает нам, что никаких явных корреляций нет, ни в чистом виде, ни с урезанием выбросов, поэтому я не стану останавливаться на этом. Было бы интересно покрутить нелинейные зависимости или посмотреть, нет ли у нас каких-нибудь эдаких кластеров. Всего этого я, конечно, делать не буду — желающие могут скачать CSV и помучить его хоть в R, хоть в SPSS. Я сразу направлюсь к тому, что меня обеспокоило — люди, у которых есть положительные показатели оценок, но отрицательные показатели кармы (и наоборот). Этих голубчиков у нас 4235 пользователей. Вот они на графике. 2866 пользователей из них повторили мой путь, имея плюсы в оценках, но минусы в карме.

3-4 тысячи из 114 это вроде бы несерьёзная цифра, в рамках погрешности. Кстати в рамках той же погрешности находятся вообще все пользователи, имеющие отрицательную карму. Их всего 4652. Но давайте посмотрим на данные не отстранённо, как это любят делать статистики, а как на людей.
**Всего пользователей:** 114 343
**Карма < 5:** 89 447
**В т.ч. нулевая карма:** 67 890
**В т.ч. отрицательная карма:** 4 652
**Карма >= 5 и возможность голосовать:** 24 896
Таким образом мы видим, что сообщество на самом деле не совсем «сообщество». Это "[молчаливое большинство](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D0%BB%D1%87%D0%B0%D0%BB%D0%B8%D0%B2%D0%BE%D0%B5_%D0%B1%D0%BE%D0%BB%D1%8C%D1%88%D0%B8%D0%BD%D1%81%D1%82%D0%B2%D0%BE)", которое ничего не может и потому ничего не делает. Пятая часть пользователей имеют реальные возможности по контролю содержимого портала, они и являются сообществом. Так что, когда перед вами потрясают общим количеством населения Хабра в сотню тысяч и говорят «Сто тысяч человек всё устраивает, а вас нет» — это не совсем правда.
А вот та же самая выкладка для оценок:
**Всего пользователей:** 114 343
**Оценка <5:** 57 223
**В т.ч. нулевая оценка:** 26 207
**В т.ч. отрицательная оценка:** 9 737
**Оценка >=5 и гипотетическая возможность голосовать благодаря оценке:** 57 120
И здесь мы видим, что в случае, если бы право голоса определялось оценками, а не кармой, то голосовать могли бы больше половины пользователей. И это только по мнению тех, кто может ставить оценки, т.е. владельцев кармы! В случае свободного голосования — конечно, голосовать могли бы процентов 90.
Существует довольно распространённое, но ошибочное мнение, будто бы «нужно просто написать статью», чтобы попасть в это избранное сообщество. Это неправда — авторов статей с кармой >=5 всего лишь 24 тысячи (ещё 900 пользователей за какие-то особые заслуги получили карму больше 5 без статей; видимо это отголоски прежних правил и сохранившейся у них кармы с тех давних времён). При том что хотя бы одну статью написали больше 36 тысяч пользователей — треть авторов статей не получили права на жизнь.
Может быть упомянутая треть авторов плохо зарекомендовала себя, может быть их статьи были плохими и не понравились сообществу? Нет, всё та же статистика говорит нам, что 90% из тех, кто написал хотя бы одну статью, а кармы больше 4 не добился — также имеют суммарно положительную оценку. Но оценка ничего не значит, у них ведь «низкая карма». Так что можно иметь положительные оценки, иметь статьи, но при этом не иметь высокой кармы и возможности «регулировать сообщество». Оно не ваше и не наше. [«Это не мой зуб и не твой зуб, это ихний зуб»](https://www.youtube.com/watch?v=C-Uzm-xdzjY) .
Соотношение сохраняется и внутри периодов, например если взять только пользователей с даты регистрации позже 2016 или 2018 года, когда происходили «слияния проектов». 90% пользователей с хотя бы одной статьёй имеют суммарную положительную оценку, но треть из них имеет карму меньше 5 и не может голосовать за статьи. То есть «пишите статьи чтобы поднять карму» работает примерно в 60-70% случаев.
Вот ещё одно простое соотношение, которое скажет о происходящем всё:
**78205** пользователей из **114 343** имеют суммарную оценку больше 0. Так оценивают их статьи и комментарии, то есть полезные для наполнения портала действия.
**24 896** пользователей из **114 343** имеют возможность голосовать. Так оценивают их личность, то есть нравится их личность тем, кто уже может голосовать, или не нравится.
Заодно посмотрите на график зависимости кармы от года регистрации. Многие говорят, мол, дедовщина у нас — да, это она самая и есть. В чистом виде, как в блокчейне. Эти ребята начали первыми, за долгие годы намайнили себе кармы, и теперь именно от них постоянно слышно «да я совсем не обращаю внимания на карму и вам не советую».
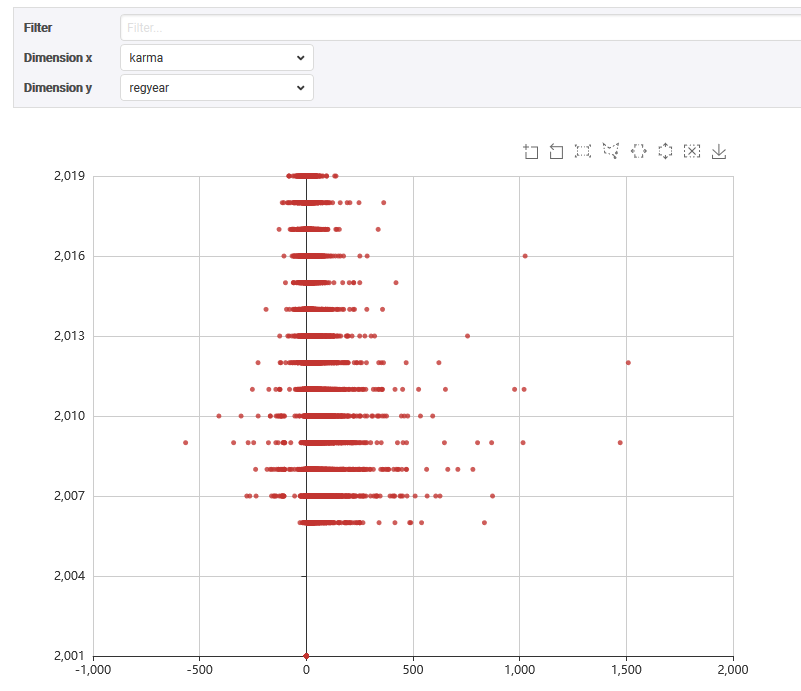
```
Не отдам своего сына в программирование, пока там не решится проблема с хабровщиной!
```
В то же самое время шестьдесят тысяч человек могут в принципе писать интересные или полезные вещи, получать положительные оценки, но при этом вынуждены постоянно оглядываться, чтобы их не высекли за невосторженный образ мыслей.
Итого:
1. Комментатор в принципе не является частью сообщества, даже если развивает и поддерживает его.
2. Автор статей с вероятностью 1/3 тоже не является частью сообщества, даже если развивает и поддерживает его.
3. Даже если действия по развитию и поддержке сообщества были явно одобрены плюсами, автор всё равно может быть заблокирован крайне небольшой частью пользователей (буквально 10-20 человек из тысяч)
Кто же эти злодеи, которые ставят минусы людям, развивающим сообщество?
Когда я готовил эту статью к публикации, появился новый топик на схожую тему. В комментариях ожидаемо начались разговоры о карме, и очередной очевидный вывод:
> Можно сколько угодно кивать на комментаторов, которые ухудшили ресурс, но… Но ведь они то как раз ничего на хабре и не могут:
>
> — не они пишут плохие статьи.
>
> — не они голосуют за кривые перепечатки хаутушек с непониманием что за команды и зачем там вбиваются
>
> — не они голосуют в карму писателям хайповых новостей
>
> — не они оценивают оценивают правильность чужого мнения
>
> Они никак, кроме комментариев, не могут поддержать авторов и выразить свой респект.
>
> И никак не могут защититься от окружающих.
>
> Всё, что происходит на хабре — дело рук именно тех, у кого есть статья и карма.
>
> <https://habr.com/ru/post/467875/#comment_20639397>
Что ж, кто виноват — разобрались, давайте посмотрим почему всё это творится.
### Часть, в которой он вас убивает

*Если каждый человек сможет участвовать напрямую в управлении, что же мы науправляем?*
*Герман Греф*
Как вы поняли из процитированных выше комментариев, существенная проблема кармы не меняется уже много лет. Проблема эта не техническая, а психологическая (может быть именно поэтому на техническом ресурсе её и не могут решить до сих пор).
Давайте рассмотрим её ключевые составляющие и разберём их подробнее.
1. Карма не зависит от реального качества действий на сайте
2. Карма психологически несимметрична
3. Карма потворствует социопатии
*Пункт 1.*
Это та самая проблема. с которой я начал свою статью: заплюсованный человек может оказаться со слитой кармой. Если отбросить разные мелочи, вроде формул расчёта рейтингов — мы увидим ключевое отличие хабра от всех остальных сайтов: разделение пользователя и действий пользователя на две самостоятельные сущности.
Самая распространённая и интуитивно понятная схема выглядит так: пользователь это аккаунт, с этого аккаунта пишутся записи, комментарии, постятся «смищные» картинки или фоточки. Пользователь — это его действия. Другие аккаунты лайкают или дизлайкают эти записи и фоточки. Сумма лайков и дизлайков определяет качество и сообщений, и самого аккаунта. Они неразрывно связаны.
Всё прочее несущественно. В некоторых случаях заминусованные блокируются, в некоторых нет. На одних порталах чтобы поставить оценку — нужно уже иметь высокий рейтинг — на других нет. Иногда авторы оценки отображаются — иногда скрываются. Но нигде нет такого, чтобы человек опубликовал несколько заминусованных постов, комментариев, фоточек — и при этом сохранял высокий рейтинг; равно как и наоборот — если сообщения пользователя заплюсованы читателями, то пользователь не может быть ими же забанен, ведь им нравится то, что он делает. А происходит это благодаря тому, что действия пользователя на сайте и его аккаунт это одно и то же. Твои действия плюсуют — значит плюсуют и тебя. Твои действия минусуют — значит минусуют и тебя.
На хабре ситуация принципиально другая. На хабре искусственно разделена сущность пользователя и его действий. Все твои действия могут быть одобрены и заплюсованы. Но при этом твой аккаунт будет заминусован. И наоборот. Если на других ресурсах кидают плюсы и минусы статьям и комментариям, то на Хабре кидают плюсы и минусы отдельно статьям и комментариям и отдельно — автору.
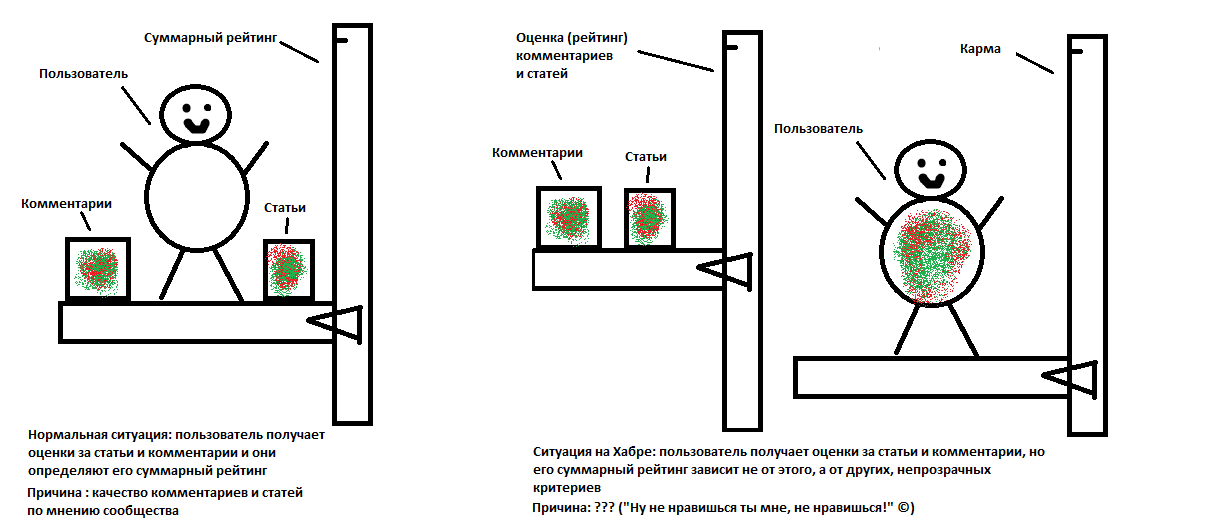
Вот на чём основано кармическое проклятье. А далее оно расползается и начинает наводить порчу на всё сообщество.
*Пункт 2.*
Раздельная система оценки неизбежно попадает под влияние двух психологических искажений.
Искажение первое — это психологическая готовность людей искать негатив и продуцировать негатив. Агрессия это основная реация на всё незнакомое, непонятное или неприятное. В результате готовность поставить минус у человека всегда выше, чем готовность поставить плюс. Вы можете наблюдать это во множестве ситуаций, в маркетинге это классическая проблема обратной связи. Если бизнес не желает писать фальшивые положительные отзывы, он вынужден внедрять кучу сложных методов их добычи: давать скидки и подарки, упрашивать и напоминать — люди, поставьте нам плюс, напишите положительные отзывы. Я видел много ссылок на статью аж 2013 года о том, что на хабре чаще плюсуют карму, чем минусуют. Возможно это и сейчас так; но из той же статьи мы знаем, что карму плюсуют тем, кто написал статью, а комментаторам её минусуют.
Это очень серьёзное искажение — недовольный, агрессивный человек всегда готов потратить силы и время для выражения недовольства, для сброса своей агрессии. Даже с плюсами и минусами для оценок мы имеем постоянную «войну минусов», когда озлобленный собеседник ставит минусы каждому твоему комментарию в текущем топике, да ещё и забегает в твой профиль, чтобы найти старые комментарии и заминусовать их. Но комментарии хотя бы проще плюсовать — если человек согласен, он сдвигает мышку на сантиметр и плюсует. С кармой уже сложнее, до кармы чаще всего добираются на топливе агрессии, чтобы ещё один минус поставить.
Карма работает как оценка только под статьями, потому что там есть большие стрелочки «вверх» и «вниз», и читатель может без труда кликнуть их. Для изменения кармы комментатора нужно сделать несколько дополнительных действий, то есть вопрос в том, как быстро затухает импульс отклика на текст. Негативный импульс затухает медленнее по психологическим и биологическим причинам — поэтому желающие поставить плюс реже добираются до кармы, предпочитая ставить только плюсовые оценки комментариям.
Кстати, большинство ратующих за карму о таких сложных вещах и не задумывается. Например они на полном серьёзе, безо всяких там смайликов, спрашивают у борцов с анонимными минусами — а чего это вы недовольны только минусами? Почему когда вам анонимно плюс ставят — вы довольны, а для минусов хотите обоснования? А вот потому. Потому что у человека готовность поставить минус выше чем готовность поставить плюс, готовность к агрессии выше чем готовность к одобрению. Эту готовность надо офлажковывать и ограничивать хотя бы просто для того, чтобы плюсы и минусы становились равными — уж о том, чтобы они были бы заслуженными, на Хабре давно забыли.
Искажение второе — это появление касты судей. Я напоминаю, что обычно справедливая система это «все пользователи судят всех пользователей», каждый просто оценивает статьи и комментарии других. Но администрация хабра очень сильно переживала за авторов статей, которые могли быть хороши в технических вопросах, но ужасны в социальном взаимодействии с комментаторами. И авторам выдали карт-бланш, отныне их якобы могли судить только другие авторы.
Действительно, такие системы мы можем встретить на разных литературных конкурсах, например: каждый написал свой рассказ, каждый прочитал рассказы остальных и поставил каждому оценку. Это тоже честная система.
Только на Хабре систему опять исказили — других авторов могла судить только часть авторов. Не каждый, кто написал статью, имеет возможность голосовать за карму. А главное — появилось огромное количество пользователей (комментаторов), которые сами никого судить не могут, но вот их могут судить и казнить, причём без права на оправдание. В результате из огромного числа пользователей выделилась маленькая часть «вершителей судеб» — пятая часть от общей численности пользователей — и принялись делать с остальными всё, что захотят.
Существует неявное предположение, будто бы большое количество пользователей сгладит оценки. Это не так. Поскольку судьи могут менять карму таким же, как они сами — рано или поздно неугодные из этой касты вылетают, а угодливые наоборот в неё попадают.
> По сути все положительные примеры, которые мы видим — это ошибка выжившего. Им просто повезло продраться сквозь токсичность сообщества.
>
> <https://habr.com/ru/company/habr/blog/437072/#comment_19649328>
Ситуация усугубляется тем, что в технической области нередко работают люди, довольно плохо ориентирующиеся в области социальной — вот этот весь компьютерный хикки-аутизм, приводящий к «неспособности поддерживать и инициировать социальное взаимодействие и социальные связи ». Вот вам токсичность, вот вам агрессия, вот вам желание с глаз долой убрать всё неприятное и непривычное.
Всё это вместе приводит к следующему пункту.
*Пункт 3.*
Если бы минусы ни на что не влияли, никакой проблемы бы и не было. В комментариях часто пишут — а я и не смотрю на карму, ха-ха, да зачем она нужна, вы все просто кармадрочеры и т.д. Обычно это люди с очень высокой кармой. По факту действительно карма была бы не нужна, если бы низкое её значение не блокировало возможности общения на портале.
А блокируется она вот почему — потому что **в основу кармической системы Хабра заложена идея о том, что есть объективно *плохой* и *хороший* человек**. См. выше — не «плохие или хорошие статьи пользователя», а именно *плохой* и *хороший* пользователь. Мне приведут в пример троллей, «плохих людей»; да, справедливо — но практика показывает, что даже специалист не всегда отличит тролля (или бота) от обычного человека со странным мнением.
Другие порталы для борьбы с этим вводят механизм игнора. Если ты однажды решил, что некий человек *плохой* — ты не лезешь добавлять ему минус в карму, потому что он *плохой*, а просто игноришь, и больше не видишь ни статей его, ни комментариев. Но администраторы хабра далеки от человеческой психологии, поэтому они решили, будто *плохой* и *хороший* это не оценочные категории, а объективная истина, в результате *плохие* просто выкидываются с сайта ~~в ГУЛАГ без права переписки и расстреливаются как враги народа~~.
Вот комментарий пользователя [pragmatik](https://habr.com/ru/users/pragmatik/), сотрудника Хабра
[Если пользователь публикует флуд, необоснованные высказывания и пр., то к нему плохо относятся и он получает минусы, а если публикует что-то полезное/разумное — плюсы.](https://habr.com/ru/company/habr/blog/437072/#comment_19673076)
Как видите, сотрудник свято и искренне верит, будто карма действительно отражает полезность публикаций и комментариев человека. Откуда же берутся люди, у которых суммарная оценка +100, а карма -10? И почему людей с таким отклонением так много? Может быть тысячи пользователей публикуют флуд и необоснованные высказывания, получают за это минусы в карму, но потом прилетает какой-то волшебник и ставит за тот же флуд и необоснованные высказывания плюсы с помощью обычных оценок? Конечно нет.
Просто полезность комментариев и статей показывают оценки возле комментариев и статей. А карма отражает то, *плохой* или *хороший* это человек по мнению касты голосующих. Выше мы разобрали, почему люди будут прикладывать больше усилий, чтобы навредить *плохому* человеку, чем помочь *хорошему*. Поэтому казнь *плохого* человека в такой системе статистически неизбежна. Рано или поздно перебьют всех обычных «плохих», потом начнут искать «наименее хороших» и так далее, и так далее.
Обратите внимание, все эти сложности основаны на полной неспособности администрации понимать и просчитывать действия людей. Сосредоточившись на технической стороне дела, они полностью упустили из виду социальную. Примерно такие же люди спроектировали «Вселенную-25», а потом долгие годы пытались всем рассказать, что там был рай. Некоторые до сих пор в это верят — как верят в то, что «карма делает Хабр лучше». Самое жуткое здесь конечно в том, что администраторы и многие участники даже не понимают, что здесь не так. Да, говорят они, люди и правда бывают плохие и хорошие. Так давайте все хорошие соберутся и убьют всех плохих! И с удовольствием убивают.
> «Как сделали ~~рептилоиды~~ на Хабре:
>
> большому количеству пользователей выдали мелкашки и мотивировали: «Ребята, кто из прохожих вам не понравился, в того пуляйте. Не стесняйтесь, Вам за это ничего не будет, да никто и не узнает, кто был стрелком. Много попаданий — отлично, вы его покалечите и он не сможет много говорить. Сделайте мир лучше и не отказывайте себе ни в чем.»
>
> То, что происходит на Хабре — это рай социопата. Как сказал andorro по другому поводу: «Социальные сети создают асоциальные люди».»
>
> <https://habr.com/ru/company/habr/blog/437072/#comment_19822200>
Интересно, что на Хабре нет игнора. Если ты недоволен человеком — ты можешь только уйти или поставить минус в карму (т.е. заставить таким образом уйти его). Система «убей или умри». Примерно ту же самую схему реализовал Дуров в своём Телеграме — там тоже нет игнора, и единственный способ избежать неприятного человека это покинуть групповой чат или заставить его уйти из группового чата. Очень хорошо виден потребительский подход «успешного человека», идущего по головам других. По сравнению, скажем, с IRC, созданной людьми для людей, Хабр или Телеграм созданы «высокоактивными социопатами» для «целевой аудитории». Не входишь в целевую аудиторию — давай, до свидания.
### Episode Three

*— Что нас может спасти от ревизии?
— Простите, не нас, а вас*
*«Операция Ы»*
Что же можно сделать?
Во-первых, следует наконец принять идею о том, что Хабр больше не закрытое сообщество с инвайтами, а обычный портал, и в нём должна быть обычная для таких порталов простая система оценки. За наличие статей, раз уж они так важны, можно давать удвоенный рейтинг. Но система должна быть единой — за комменты и статьи ставят плюсы и минусы, если ты чаще получаешь плюсы, то ты хорош, если чаще получаешь минусы, то плох. Для борьбы со слишком злобными комментаторами уже не раз предлагалось, чтобы за статьи могли голосовать только те, у кого тоже есть свои статьи, этого вполне достаточно.
Во-вторых, граница блокировок просто нелепа. Что значит 10 или 20 минусов для портала, на котором могут голосовать тысячи человек? Мы видим что среднее значение оценки 118, ну без выбросов будет где-то около 100, вот -100 и нужно делать настоящей границей, после которой начинаются уже комментарии раз в пять минут и прочие ужасы, и дальше шаг в сотню, а не в 10.
В-третьих, тот рейтинг, который используется сейчас, показывает скорее активность (т.е. зависимость от времени). Полезнее было бы показывать рейтинг «плюсов на сообщение в среднем» — тогда и люди не будут лишний раз флудить бессмысленными комментариями, и топ пользователей будет выглядеть корректнее: у кого больше полезных сообщений, тому и в топе находиться.
В-четвёртых, вместо того чтобы искусственно подогревать в сообществе токсичность и взаимную ненависть, в т.ч. почти официально одобряя «войну минусов» — нужно наконец-то просто добавить игнор. Причём не просто сворачивать комментарии под спойлер, а именно скрывать их, что-то вроде «НЛО скрыло эту запись по вашей просьбе». И чтобы отменить игнор нужно лезть в настройки и там вручную вводить ник того, кого заигнорил; то есть включить игнор должно быть просто, а выключить — сложно.
В-пятых, я полагаю, что пора ещё раз поднять вопрос о «цене за оценку». Чтобы поставить минус человеку следует потратить часть своего рейтинга. Причины этого разбирались выше — скорее недовольный человек поставит минус, чем довольный — плюс. Нужно уравнивать шансы плюсов и минусов.
Ну и последнее — можно оставить карму в текущем виде просто как элемент декора и традиции, но убрать её связь с блокировками. Тогда наконец-то все эти шутники и балагуры со своими прибаутками «а чего это вы за карму беспокоитесь, я вот не беспокоюсь, она ж ни на что не влияет» наконец-то смогут это говорить всерьёз. | https://habr.com/ru/post/468491/ | null | ru | null |
# Опыт внедрения кэширования в небольшой проект с сильной социальной составляющей
Хочу поделиться опытом внедрения кэширования при помощи memcached на своем сайте. Текст будет полезен новичкам в веб-разработке, которые задаются вопросом «как же применять на практике те 100500 статей о кэшировании, которые легко находятся в поисковиках». На истину не претендую, просто рассказываю, как получилось у меня.
Исходные данные:
Сайт крутится на одном выделенном сервере, но из-за вероятности в будущем еще подрасти, для кэширования выбран memcached;
Суточная посещаемость: ~23 000 уникальных посетителей и ~300 000 просмотров страниц;
80% посетителей — авторизованные пользователи;
Основной контент: текст (книги, которые авторы пишут и публикуют на сайте по главам, наподобие самиздата).
Сервисы: персонализированные новости, чтение текстов, разбитых на главы, комментарии, профили, блоги, рейтинги, подписка, метки, закладки, личные сообщения, счетчики, почтовые уведомления…
Пользовательская активность: более 10 000 действий, приводящих к изменению контента, в сутки.
Сложность при внедрении кэширования: подавляющее большинство страниц содержит персонализированные данные. Где-то уникально все, вплоть до запросов в базу, где-то можно разделить запросы на общие и уникальные, где-то нельзя, где-то персональные настройки пользователя применяются на данные уже после их выбора из базы.
#### Введение и лирика
Есть у меня велосипед — любимый трехколесный, написанный еще девять лет назад. С тех пор он много раз переписывался, но так как профессионально веб-разработкой или программированием я заниматься так и не стал, проект технологически остался на очень низком уровне и в работе над ним царит принцип «не трож пока работает».
Изначально проект написан на голом PHP, без фреймворков, без ООП, без использования сторонних библиотек, без шаблонизаторов и вообще без шаблонов. База данных, само-собой, MySQL, таблички, само-собой, MyISAM, сервер, само-собой, Apache (позже перед ним встал nginx), на фронт-энде, само-собой, jQuery и довольно много AJAX'а.
Время шло, пользователи прибывали, я развлекался тем, что придумывал, как бы сделать сайт еще более удобным для авторов и читателей (две основные роли, на которые делятся пользователи сайта), авторам и читателям нравилось и они звали друзей. Со временем, на сайте накопилось очень много всевозможных настроек, галочек и функций. И вот, когда по вечерам сервер стал показывать подозрительные 3-4 la, а phpmyadmin рассказал мне о 89 запросах в секунду и 48 Гб/час сетевого трафика, я полез искать информацию по кэшированию.
#### Подготовка — анализируем, что кэшировать
Я полез в liveinternet, взял статистику по страницам за последний месяц и составил табличку с распределением просмотров по разделам сайта.
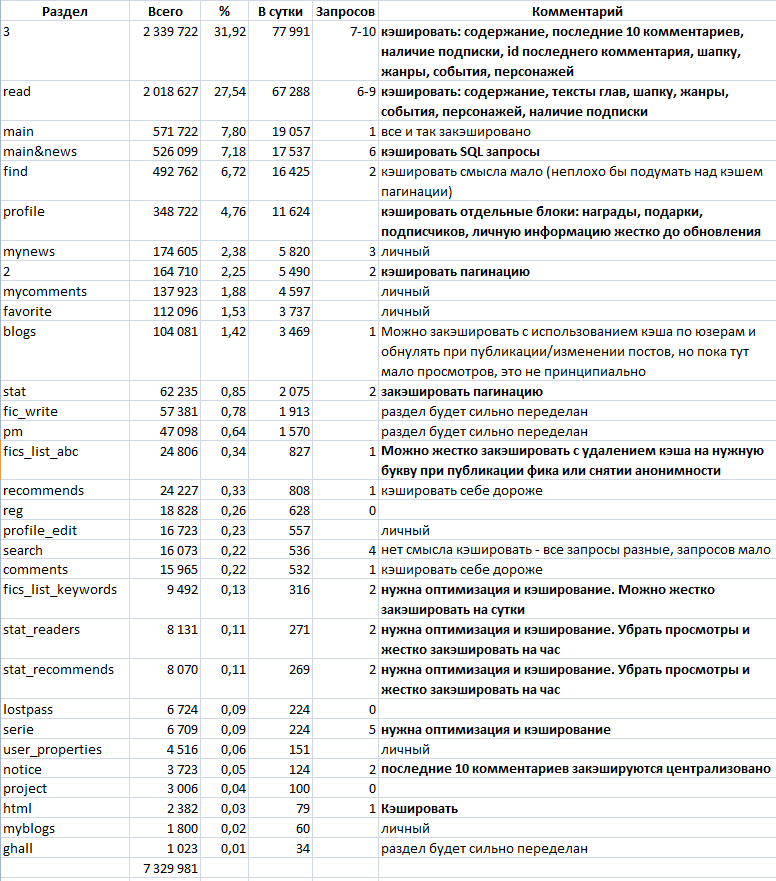
Отлично видно, что в первую очередь надо кэшировать два раздела (3, read), которые в сумме дают почти 60% всех просмотров страниц и, на которых много запросов в базу и много форматирования данных. Затем стоит закешировать main&news, ну а все остальное уже постольку поскольку — для очистки совести и в надежде на многократный рост посещаемости.
#### Сцена первая — кэшируем тексты книг
Раздел — read.
Самая простая часть и самая важная по экономии ресурсов. Итак, тексты книг хранятся в БД в виде одной таблички, где записью является глава книги. Текст главы и мета-информация хранятся вместе, причем текст хранится в сыром виде — перед выводом его еще надо обработать. Почему хранится сырой текст? — Так сложилось исторически, из БД текст может быть выведен во множество мест: на страницу чтения, в простой редактор автору, в визуальный редактор автору, в скрипт для создания fb2 версии. По-хорошему, давно надо переделать БД и хранить рядом с сырым текстом готовый для вывода вариант, но это пока остается заделом для дальнейшей оптимизации.
На страницу может выводится отдельная глава или все главы сразу. Поэтому решено для экономии памяти кэшировать:
1. Массив со списком глав (одномерный массив, содержащий порядковые номера глав). Ключ «f123».
2. Для каждой главы — массив, содержащий мета-информацию о главе и подготовленный к выводу текст главы. Ключ «f123c1».
*Почему не хранится html-ка сразу со всей главой — потому что при выводе всех глав и выводе одной главы разное форматирование названия главы.*
Небольшая сложность в том, что для автора книги и администратора вывод должен идти мимо кэша, так как будет содержать еще и не опубликованные главы.
Алгоритм скрипта прост:
1. Запрошена глава.
```
if($is_author || $is_admin) {
// Вывод главы из БД, без создания кэша
}
else {
$data = cache_get('f'.$id.'c'.$cid); // $id - id книги, $cid - порядковый номер главы в книге, эти параметры передаются скрипту в $_GET
if(!$data) {
// Вывод из БД с созданием кэша
}
else {
// вывод главы
}
}
```
2. Запрошены все главы.
```
if($is_author || $is_admin) {
// Вывод всех глав из БД, без создания кэша
}
else {
$data = cache_get('f'.$id.'conarr'); // $id - id книги передается скрипту в $_GET
if(!$data) {
// Выбираем из БД одним запросом все главы. Но проходя циклом по результатам выбора, ищем каждую главу в кэше, если находим, выводим из кэша, если не находим, тогда только обрабатываем выбранные из БД данные и создаем кэш главы. Создаем кэш списка глав
}
else {
$data = unserialize($data);
foreach($data as $tmp) {
$tmp_data = cache_get('f'.$id.'c'.$tmp['cid']);
if(!$tmp_data) {
// Запрашиваем главу из БД, выводим и создаем кэш
}
else {
// Выводим главу
}
}
}
}
```
###### Обнуление кэша
Кэш глав и содержания создается бессрочный, его обнулением надо управлять.
1. В админке есть функция обнуления всех записей в кэше для конкретной книги.
2. При публикации автором новой главы, удаляется кэш списка глав.
3. При внесении автором изменений в главу, удаляется кэш измененной главы.
#### Сцена вторая — кэшируем содержание книги
Содержание книги выводится в двух разделах (3 и read), но выводятся они по-разному, придется делать две версии кэша.
Сложности кэширования содержания:
1. В разделе read в случае просмотра конкретной главы, в содержании помечается на которой главе мы находимся в данный момент.
2. В разделе 3 могут выводится ссылки на подгрузку аудио версии конкретной главы, если эта аудио версия существует.
3. В разделе 3, если конкретная глава опубликована сегодня, после нее выводится картинка NEW.
4. В обоих разделах в содержании могут выводится закладки, если читатель уже ранее читал эту книгу и отметил какие-то места. Закладок в одной книге и у одного пользователя может быть максимум пять, но на каждой главе может быть несколько закладок (хоть все пять в одной главе).
Решение:
В кэш будет сохраняться шаблон содержания с якорями под дополнительную информацию.
1. Пометкой о нахождении на конкретной главе является спецсимвол, который выводится перед названием главы (в будущем сделаю специальным классом для li, но для описываемого алгоритма ничего не изменится). Якорь имеет вид {Nar}, где N — порядковый номер главы. Соответственно, при выводе:
```
// Заменяем якорь текущей главы на отметку. $cid - порядковый номер текущей главы, передается скрипту в $_GET
$contents_list = str_replace('{'.$cid.'ar}', '>', $contents_list);
// И удаляем все остальные якоря
$contents_list = preg_replace('/{\d+ar}/', '', $contents_list);
```
2. С аудио версиями все просто. В той версии кэша, что предназначена для раздела 3, есть ссылки на аудио версии глав, а в версии для раздела read, их нет.
3. Для вывода картинки NEW, после названия каждой главы в шаблоне вставлены якоря вида {d.m.Y} с датами публикации каждой главы, а при выводе:
```
// Заменяем якорь текущей даты на картинку
$tmp = date('d.m.Y');
$contents_list = str_replace('{'.$tmp.'}', ' ', $contents_list);
// И удаляем все остальные якоря
$contents_list = preg_replace('/{\d+.\d+.\d+}/', '', $contents_list);
```
4. Здесь сначала пришлось реализовать кэширование закладок каждого пользователя. Кратко: создается кэш с массивом закладок конкретного пользователя в конкретной книге, ключ вида «u90000f123bm», где 90000 — id пользователя, а 123 — id книги. Если у пользователя нет закладок в этой книге, кэш все равно создается, значение указывается «no» (это нужно чтобы не запрашивать каждый раз БД, если в кэше не нашлось данных по нужному ключу). Кэш создается бессрочным, при каждом добавлении или удалении закладки производится попытка удаления кэша для книги, которой принадлежит создаваемая/удаляемая закладка. В случае существования закладок, в кэш сохраняется массив, в каждой записи которого находится мета-информация закладки и порядковый номер главы в книге, которой принадлежит закладка.
В шаблоне содержания после названия каждой главы сохраняется якорь вида {Nbm}, где N — порядковый номер главы. При выводе:
```
$bm = LibMember_bm($id); // функция получает кэш закладок текущего пользователя для книги с $id, если кэша не существует, создает его
if($bm != 'no') {
$bm = unserialize($bm);
foreach($bm as $tmp) {
$contents_list = str_replace('{'.$tmp['cid'].'bm}', $tmp['код закладки'].'{'.$tmp['cid'].'bm}', $contents_list); // Заметьте, что якорь не удаляется, это позволяет вставить несколько закладок в одной главе
}
}
// И удаляем все якоря
$contents_list = preg_replace('/{\d+bm}/', '', $contents_list);
```
###### Обнуление кэша
Кэш содержания создается бессрочный. Управлять надо вручную.
Кэш содержания удаляется при публикации автором новых глав или при изменении старых (может измениться название главы).
#### Пока все
Эти два пункта и еще кое-какие мелочи — это пока и все мои шаги на пути внедрения кэширования в работающий проект. Дальше будет больше, если статья вызовет интерес, опишу новые приемы, которые будут придуманы для кэширования данных в оставшихся разделах сайта.
Уже сейчас удалось снизить вечерний la сервера до 0.8-1.5 и показания phpmyadmin до 59 запросов в секунду и 4.6 Гб/час сетевого трафика (правда, это показания через сутки после перезагрузки сервера — показатель трафика в час еще упадет из-за заполнения кэша).
Напомню, что изначальные показатели были таковы:
> 3-4 la, а phpmyadmin рассказал мне о 89 запросах в секунду и 48 Гб/час сетевого трафика | https://habr.com/ru/post/211478/ | null | ru | null |
# Встроенные кнопки в Telegram Bot API — pyTelegramBotAPI
Добрый день уважаемые читатели, давайте рассмотрим, какие основные типы встроенных кнопок предлагают чат-боты telegram и в чем их особенности. Статья будет полезна всем, кто хочет разобраться в возможностях взаимодействия с пользователями telegram в версии bot API 2.0.
Для обзора возможностей нам понадобится установить 3 целых 2 десятых Python`a и пару ложек [pyTelegramBotAPI](https://github.com/eternnoir/pyTelegramBotAPI). Особенности настройки и регистрации чат-бота мы рассматривать не будем, т.к. есть множество статей на эту тему.
И так, что же такое встроенные кнопки(клавиатура) в мессенджере Telegram? Это кнопки которые выводятся во внутренней области чата и привязываются к конкретному сообщению. Они жестко связаны с сообщением(если удалить сообщение, внутренние кнопки так же удаляются вместе с ним.). Они дают возможность динамически видоизменять его.
В данный момент есть три типа встроенных кнопок:
* [URL-кнопки](https://core.telegram.org/bots/2-0-intro#url-buttons)
* [Callback-кнопки](https://core.telegram.org/bots/2-0-intro#callback-buttons)
* [Switch-кнопки](https://core.telegram.org/bots/2-0-intro#switch-to-inline-buttons)
URL-кнопки
----------
Для создания кнопки используется тип [InlineKeyboardMarkup](https://core.telegram.org/bots/api#inlinekeyboardmarkup), давайте создадим кнопку «Наш сайт»:
```
@bot.message_handler(commands = ['url'])
def url(message):
markup = types.InlineKeyboardMarkup()
btn_my_site= types.InlineKeyboardButton(text='Наш сайт', url='https://habrahabr.ru')
markup.add(btn_my_site)
bot.send_message(message.chat.id, "Нажми на кнопку и перейди на наш сайт.", reply_markup = markup)
```
Тут название говорит само за себя, это тип кнопок предназначен для перенаправления пользователя по ссылке, с соответствующим предупреждением. Кнопка имеет соответствующий ярлычок в правом верхнем углу, чтобы дать понять пользователю, что это ссылка.
Switch-кнопки
-------------
Этот тип кнопок предназначен для перенаправления пользователя в какой либо чат, с последующей активацией (встроенного) inline-режима общения с ботом. Данный режим можно активировать вручную: в чате, вводим: "@название бота", но switch-кнопки позволяют это сделать автоматически (помогая знакомиться с inline-режимом новичкам).
Для того что-бы создать подобный переключатель, необходимо указать аргумент *switch\_inline\_query* либо пустой, либо с каким-либо текстом.
```
@bot.message_handler(commands = ['switch'])
def switch(message):
markup = types.InlineKeyboardMarkup()
switch_button = types.InlineKeyboardButton(text='Try', switch_inline_query="Telegram")
markup.add(switch_button)
bot.send_message(message.chat.id, "Выбрать чат", reply_markup = markup)
```
Теперь, если мы нажмем на кнопку и выберем чат, вот что получится:
**Шаг 1:**
*Нажимаем на кнопку.*
**Шаг 2**:
*Выбираем чат.*
**Шаг 3:**
*Активировался встроенный inline-режим.*
Callback-кнопки
---------------
Ну и наконец самое интересное — это кнопки с обратной связью: позволяют динамически обновлять сообщение/встроенные кнопки (не засоряя при этом ленту), а так же отображать уведомление в верху чат-бота или модальном окне.
Например, их можно использовать для просмотра длинного сообщения, аналогично пагинации страниц на сайтах, или например сделать календарь. Я не стану изобретать велосипед, а через поиск по GitHub, найду готовую библиотеку [calendar-telegram](https://github.com/unmonoqueteclea/calendar-telegram). Выполнив указанные инструкции, получаем готовый календарь, который можно динамически изменять по нажатию на соответствующие кнопки:
```
@bot.message_handler(commands=['calendar'])
def get_calendar(message):
now = datetime.datetime.now() #Текущая дата
chat_id = message.chat.id
date = (now.year,now.month)
current_shown_dates[chat_id] = date #Сохраним текущую дату в словарь
markup = create_calendar(now.year,now.month)
bot.send_message(message.chat.id, "Пожалйста, выберите дату", reply_markup=markup)
```
Так же можно добавить уведомление по нажатию на дату, для этого достаточно указать сообщение в ответе:
```
bot.answer_callback_query(call.id, text="Дата выбрана")
```

*(Пример в десктопной версии)*
*(Пример в мобильной версии)*
Если изменить *show\_alert* на *True*, то мы получим модальное окно:
```
bot.answer_callback_query(call.id, show_alert=True, text="Дата выбрана")
```
Заключение
----------
По последним данным, в нашумевшем мессенджере Telegram регистрируются больше 600к пользователей ежедневно. Именно поэтому важно подхватить тренд и разобраться с его основными особенностями, т.к. различные методы взаимодействия с ботами существенно облегчает жизнь разработчиков и пользователей.
Cпасибо за Ваш интерес к данной теме. | https://habr.com/ru/post/335886/ | null | ru | null |
# Препарирование файлов .XLSX: редактирование файла средствами PL/SQL
[Часть 1](https://habrahabr.ru/post/347550/). Введение, стили
[Часть 2](https://habrahabr.ru/post/347616/). Строки, разметка
**Часть 3**. Редактирование через PL/SQL
Доброго дня. Третья часть разговора про формат XLSX подоспела. Я не случайно начал со внутреннего устройства файла. Не понимая где что находится и как выглядит, сложно понять, для чего я сделал то-то и то-то. К тому же, теперь я могу сделать несколько замечаний:
*Первое.* Если я не упомянул какой-то элемент, который нужен именно вам, — создайте пустой файл XLSX, сделайте нужный элемент и сохраните. Теперь вы знаете, где искать код, определяющий этот элемент.
*Второе.* OpenXML допускает наличие в разметке произвольного текста, если он не нарушает структуру тегов (этим мы будем очень активно пользоваться). Сейчас проиллюстрирую. Вот так делать можно:
```
Первая строка
Вторая строка
$Здесь был Вася$
```
А вот так — нельзя:
```
Первая строка
Вторая строка
<Здесь был Вася>
```
Но к делу. Строго говоря, есть два возможных случая. Либо мы имеем некий шаблон, который нам необходимо заполнить данными, либо сами вынуждены составлять файл, что называется, с нуля. Первый случай проще, второй — интереснее. Но при этом оба случая требуют от нас наличия файла-заготовки: поскольку файл .XLSX состоит не только из .XML-файлов, создать его «руками», увы, не выйдет.
Вообще методика, которой я пользуюсь, в значительной степени основывается на библиотеке [Alexandria PL/SQL](https://github.com/mortenbra/alexandria-plsql-utils). Сама библиотека огромна, и если кроме как для целей, описанных ниже, она вам не нужна, то лучше имплантировать ее выборочно.
Для простой подстановки в бланк квитанции ФИО абонента средств, представленных в этой библиотеке, должно вполне хватить. Мне же, с учетом моей специфики, пришлось делать над ней надстройку. Поэтому если вы начали читать, рекомендую дочитать до конца: как знать, быть может, мое решение покажется вам более удобным или эффективным. Общий же алгоритм действий таков:
1. Трансформируем файл-заготовку в BLOB;
2. Заменяем условные метки в XML-файлах внутри него на наши данные;
3. Сохраняем измененный BLOB как новый файл;
4. Возвращаем измененный файл пользователю.
Пройдемся по этим пунктам подробнее. Чтобы различать библиотечные средства и самописные, представим, что библиотечный код я разместил в умозрительном пакете *lib\_utils*.
### Трансформация файла-заготовки в BLOB
Если у нас есть в наличии некий бланк, к примеру, квитанция, в которую надо вставить ФИО абонента и сумму к оплате, то все проще некуда: берем готовую квитанцию и меняем содержимое переменных полей на специальные метки-маячки. По поводу текста этих маячков есть два основных правила — они не должны имитировать теги и вероятность совпадения в исходном тексте документа или в заменяющем тексте должна быть исчезающе малой. В остальном все зависит от вашей фантазии или привычек. Я использую что-то типа *%name%*. Объясню почему. Знак "%" не имитирует разметку, и вероятность того, что где-то будет слово, с двух сторон обособленное этим знаком, — мизерна.
А вот в случае, когда мы заранее не знаем, что может быть в файле на выходе, работы будет больше.
Перво-наперво рекомендую поэксплуатировать Excel и обозначить все стили ячеек, которые нам могут понадобиться (если не понадобятся — ничего страшного, это лучше, чем если чего-то не хватит). После этого лезем блокнотом в стили и записываем индексы конкретных стилей. Так, я сделал себе отдельный стиль для заголовка (серая заливка, полужирное написание и тонкие границы) и отдельный стиль для рядовой строки (без заливки, обычное написание и тонкие границы).
Далее работать придется не через Excel, а руками.
Файл **sharedStrings.xml** должен выглядеть примерно так:
```
%strings%
```
Файл **sheet1.xml** (предполагая, что основным листом у нас будет первый) должен содержать следующее:
```
%attach%
%colsize%
%data%
%filter%
```
Метка *%attach%* расположена там, где должен находиться тег закрепления области. Метка *%colsize%* — там, где находится тег, указывающий ширину занятых столбцов. Это сделано для того, чтобы, допустим, в столбце ФИО ширина была соответствующей. Метка *%data%* будет заменена сгенерированной разметкой ячеек. Метка *%filter%* — на случай, если понадобится встраивать автофильтр.
Сохраняем, закрываем — болванка готова. Далее нам надо трансформировать ее в BLOB. Для этого нам понадобится библиотечная функция **lib\_utils.get\_blob\_from\_file** (на всякий случай напомню, что lib\_utils — это функции из библиотеки по ссылке в начале поста). Функция принимает два параметра: директорию и имя файла. Поскольку это слегка неочевидно, поясню, что под директорией подразумевается оракловый объект DIRECTORY. В нашем примере назовем директорию *FILE\_DIR*. То есть вызов будет выглядеть примерно так:
```
-- Заранее извиняюсь, если мой стиль написания кода и именования объектов кого-то покоробит
v_blobsrc := lib_utils.get_blob_from_file('FILE_DIR', 'src_blank.xlsx');
```
### Замена меток на кастомные данные
В более простом случае с бланком квитанции (или аналогичном случае), просто используем функцию **lib\_utils.multi\_replace**. Библиотека все сделает за вас.
Для сложного случая я построил свою конструкцию. В основе ее лежит составной рукописный тип данных, являющий собой комплексное описание содержимого листа Excel. Поскольку тип составной, пойдем снизу вверх:
```
/* Тип: ячейка */
type tp_cell is record(address varchar2(15),
style number,
val varchar2(4000),
lines number default 1);
/* Тип: строка */
type tp_row is table of tp_cell index by binary_integer;
/* Тип: таблица (лист) */
type tp_table is table of tp_row index by binary_integer;
/* Тип: массивы строковых и числовых значений */
type tp_string is table of varchar2(4000) index by binary_integer;
type tp_number is table of number index by binary_integer;
```
Последний тип напрямую не задействован в построении *tp\_table*, но все равно далее будет нужен. Поясню элементы типа *tp\_cell*.
* **address** — фактический адрес ячейки. Тут надо пояснить кое-что. В комментариях к предыдущему посту выложены результаты экспериментов, показывающие, что при описании ячейки адрес вписывать необязательно. Это так. Однако, на мой взгляд, явное, как правило, лучше неявного.
* **style** — ссылка на индекс стиля описываемой ячейки. Я для себя решил, что все описанные мной стили будут храниться в виде глобальных констант пакета *custom\_utils*.
* **val** — содержимое ячейки.
* **lines** — флажок многострочности. Установка его значения на 2 или выше будет означать, что в содержимом ячейки подразумевается перенос, а как мы помним, для его отображения следует увеличивать высоту ячейки.
Итоговая сигнатура моей процедуры компоновки файла выглядит так:
```
file_build(i_content tp_table,
i_filename varchar2,
i_filter number default 0,
i_attach number default 0);
```
Процедура принимает следующие параметры:
* **i\_content** — содержимое будущего файла.
* **i\_filename** — имя будущего файла.
* **i\_filter** — флажок необходимости автофильтра.
* **i\_attach** — флажок необходимости закрепления области. Поскольку в моем случае требуется закрепление только первой строки, у меня генерируемый из-за этого флага код всегда будет одинаковым.
И прежде чем начать подробный разбор основной процедуры, выложу вспомогательные функции:
**Вспомогательные функции**
```
/* Возвращает буквенный эквивалент числа (имена столбцов Excel) */
function get_literal(i_number number) return varchar2
is
begin
-- Таких не бывает
if i_number < 1 or is_number(i_number) = false then
return '#';
-- 1-символьная выдача
elsif i_number > 0 and i_number < 29 then
return chr(64 + i_number);
-- 2-символьная выдача
else
return chr(64 + trunc(i_number / 28))||chr(64 + (i_number - (28 * trunc(i_number / 28))));
end if;
end get_literal;
/* Проверка: число или строка */
function is_number(i_char char) return boolean
is
begin
if (to_number(i_char) = to_number(i_char)) then
return true;
end if;
exception
when others then
return false;
end is_number;
/* Поиск в текстовом массиве */
function array_search(i_source tp_string,
i_value varchar2) return number
is
begin
for i in 1 .. i_source.count loop
if i_value = i_source(i) then
return i;
end if;
end loop;
return -1;
end array_search;
/* Аккуратное "дописывание" небольшой (до 32767 символов) строки к CLOB-у в нужной кодировке */
procedure clob_append(i_dest in out clob,
i_src in varchar2,
i_encode in varchar2 default 'utf8')
is
begin
if i_src is not null then
if i_dest is null then
i_dest := to_clob(convert(i_src, i_encode));
else
dbms_lob.write(i_dest, length(convert(i_src, i_encode)), length(i_dest) + 1, convert(i_src, i_encode));
end if;
end if;
end clob_append;
```
Сразу хочу кое-что пояснить. Поскольку данных в файле может быть много, работать с varchar-ообразными типами нельзя, их просто не хватит. Поэтому приходится затачивать свое решение под CLOB. В целом же, пока что ничего сверхъестественного. Но — к делу.
**Основная процедура**
```
procedure build_file(i_content tp_table,
i_filename varchar2,
i_filter number default 0,
i_attach number default 0)
is
v_blobsrc blob; -- Заготовка в формате BLOB
v_blobres blob; -- Результат в формате BLOB
c_namesrc constant varchar2(50) := 'src_blank.xlsx'; -- Имя файла-заготовки
v_stringarr tp_string; -- Массив уникальных строковых значений
v_numarr tp_number; -- Массив ширин столбцов
v_index number; -- Для поиска в массиве
v_clobmarkup clob; -- Разметка ячеек
v_clobstring clob; -- Разметка sharedStrings.xml
v_clobcolumns clob; -- Разметка шиниры столбцов
c_letsize constant number := 3; -- Ширина 1 символа в У.Е.
c_padding constant number := 1; -- Запас ширины ячейки
v_rowcount number; -- Фактическое кол-во строк
v_colcount number; -- Фактическое кол-во столбцов
v_multiline number; -- Многострочность
v_filtertag varchar2(50); -- Текст тега фильтра
v_attachtag varchar2(150); -- Текст тега закрепления области
begin
/* Цикл по строкам в таблице */
for l_row in 1 .. i_content.count loop
v_rowcount := l_row; -- Для тега DIMENSION
/* Вычисляем, есть ли в строке многострочные ячейки. Если есть, растягиваем строку по высоте на максимальную величину многострочности */
v_multiline := 1;
for l_col in 1 .. i_content(l_row).count loop
if i_content(l_row)(l_col).lines > v_multiline then
v_multiline := i_content(l_row)(l_col).lines;
end if;
end loop;
clob_append(v_clobmarkup, ' 1 then ' ht="'||(15 \* v\_multiline)||'" customHeight="1"' else null end||'>'||chr(10));
/\* Цикл по ячейкам в строке \*/
for l\_cells in 1 .. i\_content(l\_row).count loop
v\_colcount := l\_cells;
-- Пустая ячейка
if i\_content(l\_row)(l\_cells).val is null then
clob\_append(v\_clobmarkup, ''||chr(10));
else
-- Числовые значения идут как есть
if is\_number(i\_content(l\_row)(l\_cells).val) then
clob\_append(v\_clobmarkup, ''||i\_content(l\_row)(l\_cells).val||''||chr(10));
else
/\* Формируем список строк: "-1" - надо добавить, в противном случае это будет ссылка на индекс записи \*/
v\_index := array\_search(v\_stringarr, i\_content(l\_row)(l\_cells).val);
if v\_index = -1 then
v\_index := v\_stringarr.count + 1;
v\_stringarr(v\_index) := i\_content(l\_row)(l\_cells).val;
end if;
--
-- Формируем код ячейки со ссылкой на массив строк
clob\_append(v\_clobmarkup, ''||(v\_index - 1)||''||chr(10));
end if;
end if;
/\* Подсчет максимальной длины содержимого столбца для рассчета ширины столбца \*/
if v\_numarr.count >= l\_cells then
if length(i\_content(l\_row)(l\_cells).val) > v\_numarr(l\_cells) then
v\_numarr(l\_cells) := length(i\_content(l\_row)(l\_cells).val);
end if;
elsif v\_numarr.count = l\_cells - 1 then
v\_numarr(l\_cells) := length(i\_content(l\_row)(l\_cells).val);
end if;
end loop;
-- Закрываем строку таблицы
clob\_append(v\_clobmarkup, chr(10)||'');
end loop;
-- Формируем код размеров столбцов
clob_append(v_clobcolumns, '');
for l\_cnt in 1 .. v\_numarr.count loop
clob\_append(v\_clobcolumns, '');
end loop;
clob\_append(v\_clobcolumns, '');
-- Формируем код массива строк
for l_cnt in 1 .. v_stringarr.count loop
clob_append(v_clobstring, ''||v\_stringarr(l\_cnt)||''||chr(10));
end loop;
/* Фильтр и закрепление - при необходимости */
if i_filter = 1 then
v_filtertag := '';
end if;
if i_attach = 1 then
v_attachtag := '';
end if;
-- Имплантируем
v_blobsrc := lib_utils.get_blob_from_file('FILE_DIR', c_namesrc);
v_blobres := lib_utils.get_file_from_template(v_blobsrc,
lib_utils.t_str_array('%colsize%',
'%data%',
'%strings%',
'%filter%',
'%attach%',
''),
lib_utils.t_str_array(v_clobcolumns,
v_clobmarkup,
v_clobstring,
v_filtertag,
v_attachtag,
''));
lib_utils.save_blob_to_file('FILE_DIR', i_filename, v_blobres);
exception
when others then
dbms_output.put_line('Ошибка при генерации файла Excel: '||sqlerrm);
end build_file;
```
Собственно, всё. Ну и да, хочу сделать оговорку: эта процедура периодически дополняется в соответствии с текущими потребностями. | https://habr.com/ru/post/348450/ | null | ru | null |
# Построение Android приложений шаг за шагом, часть третья
В [первой](https://habrahabr.ru/company/rambler-co/blog/275943/) и [второй частях](https://habrahabr.ru/company/rambler-co/blog/277343/) статьи мы создали приложение для работы с Github, внедрили Dagger 2 и покрыли код unit тестами. В заключительной части мы напишем интеграционные и функциональные тесты, рассмотрим технику TDD и напишем с ее применением новую функциональность, а также подскажем, что читать дальше.
**Полное содержание*** [Введение](https://habrahabr.ru/company/rambler-co/blog/275943/#1)
* [Шаг 1. Простая архитектура](https://habrahabr.ru/company/rambler-co/blog/275943/#2)
* [Шаг 2. Усложненная архитектура](https://habrahabr.ru/company/rambler-co/blog/275943/#9)
* [Шаг 3. Dependency Injection](https://habrahabr.ru/company/rambler-co/blog/277343/#21)
* [Шаг 4. Модульное тестирование](https://habrahabr.ru/company/rambler-co/blog/277343/#26)
* [Шаг 5. Интеграционное тестирование](https://habrahabr.ru/company/rambler-co/blog/279799/#31)
* [Шаг 6. Функциональное тестирование](https://habrahabr.ru/company/rambler-co/blog/279799/#32)
* [Шаг 7. TDD](https://habrahabr.ru/company/rambler-co/blog/279799/#33)
* [Шаг 8. Что дальше?](https://habrahabr.ru/company/rambler-co/blog/279799/#34)
* [Заключение](https://habrahabr.ru/company/rambler-co/blog/279799/#35)
#### Введение
В первой части статьи мы в два этапа создали простое приложение для работы с github. Архитектура приложения была разбита на две части: простую и сложную. Во второй части мы внедрили Dagger 2 и покрыли код unit тестами с помощью Robolectric, Mockito, MockWebServer и JaCoCo.
**Условная схема приложения**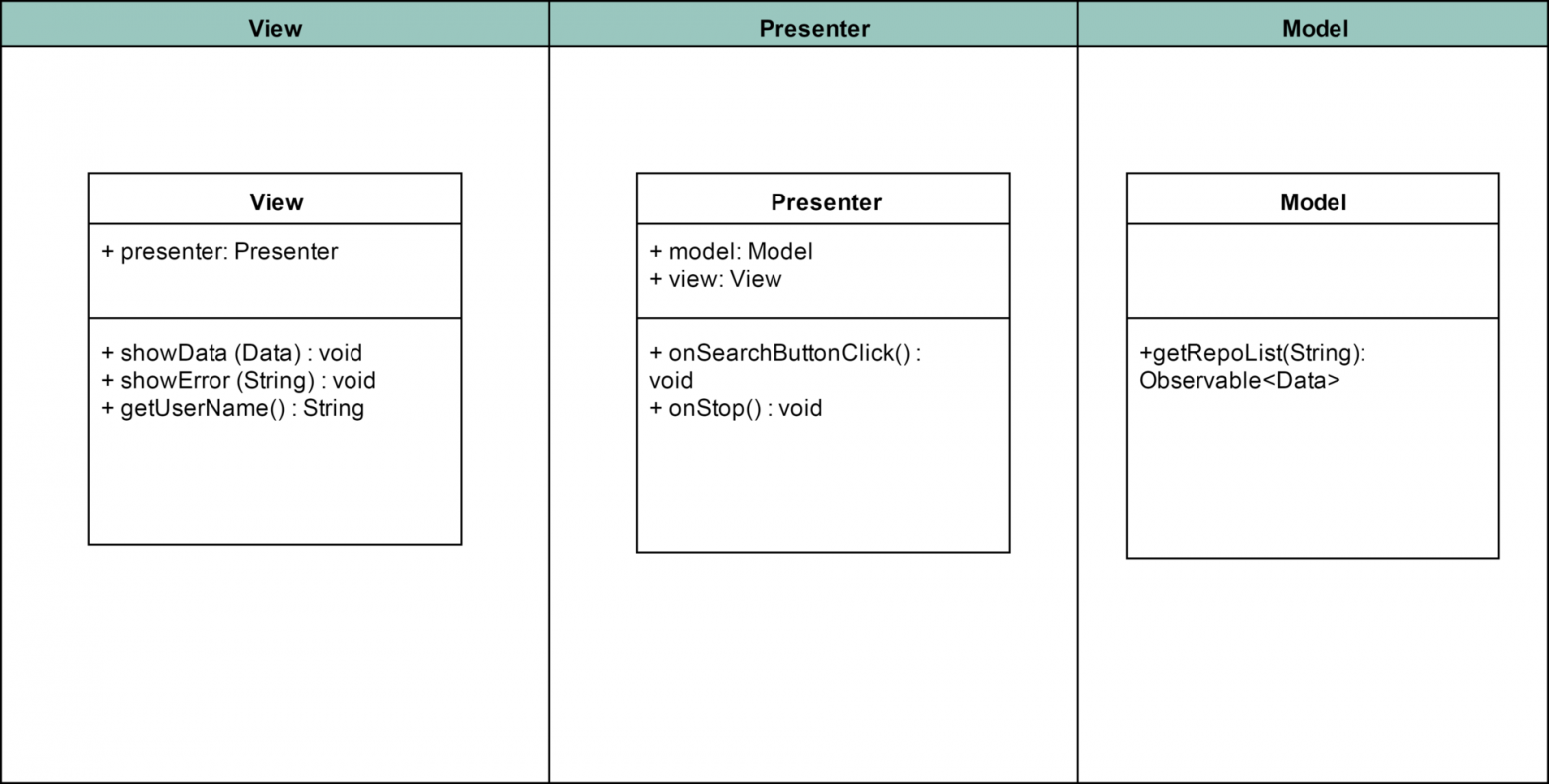
**Диаграмма классов**[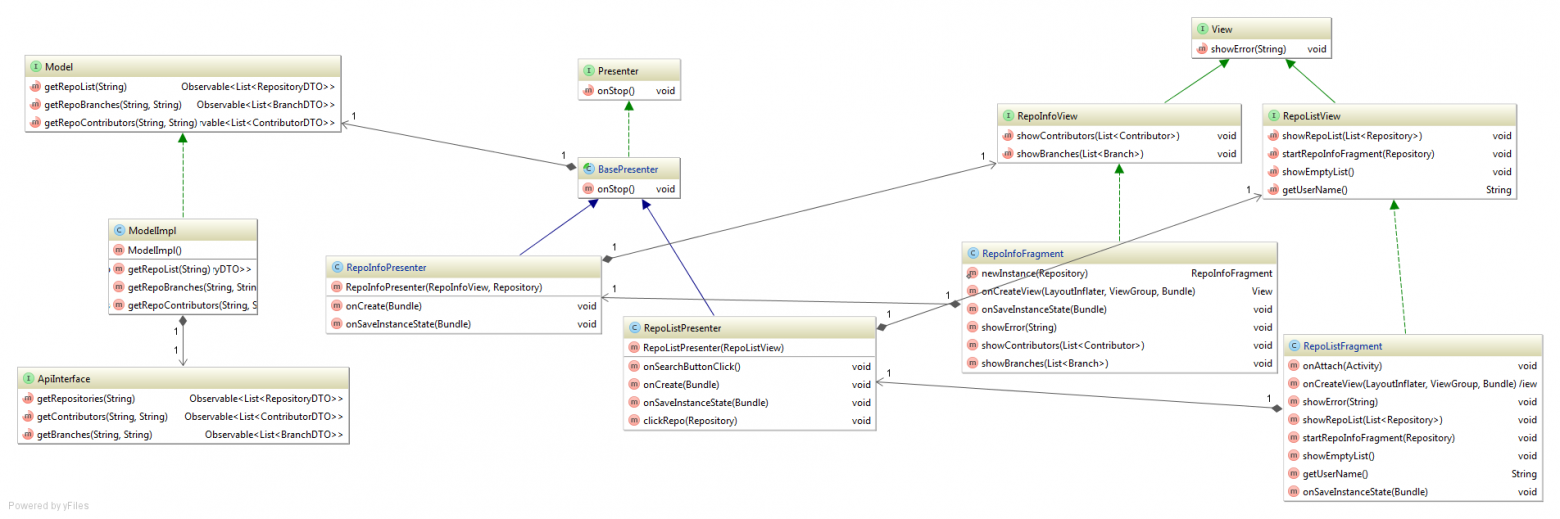](https://habrastorage.org/files/4e0/9f7/802/4e09f78028274958819a59445c3065fd.png)
**Покрытие тестами**[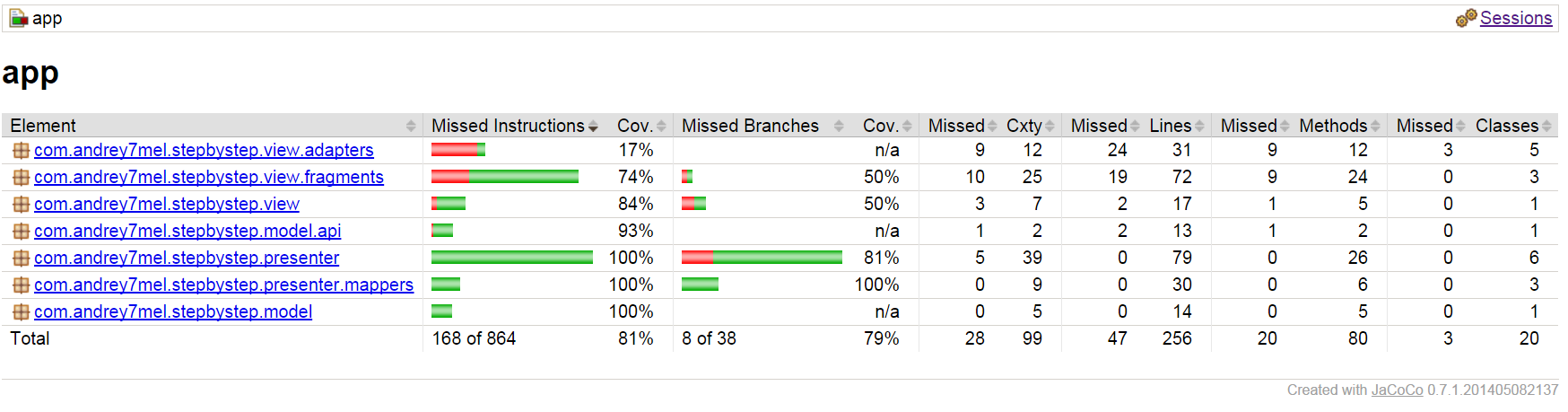](https://habrastorage.org/files/1c5/86b/69a/1c586b69aa204d818e39e5ba22920b33.PNG)
**Схема взаимодействия компонентов**[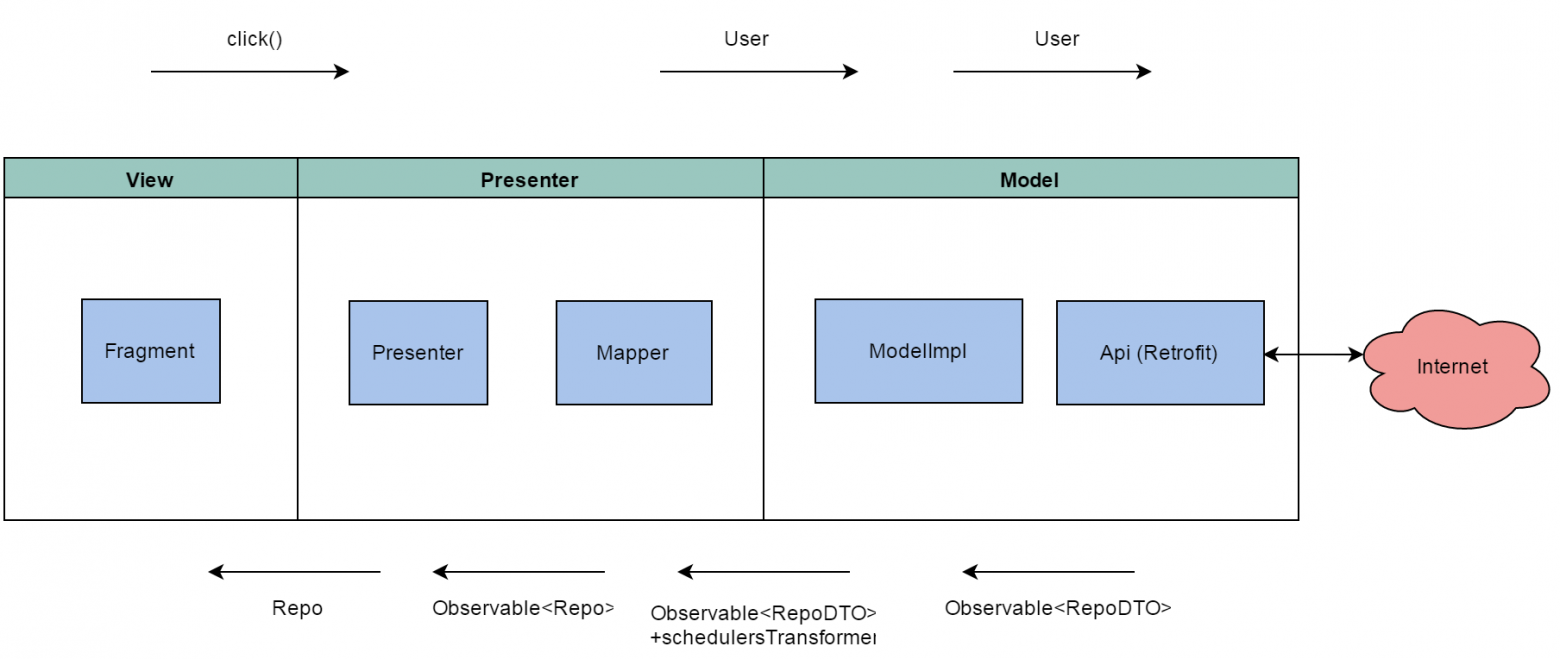](https://habrastorage.org/files/1c5/86b/69a/da6d2cca88424fc2a7aa930a3de2cc8b.PNG)
Все исходники вы можете найти на [Github.](https://github.com/andrey7mel/android-step-by-step)
#### Шаг 5. Интеграционное тестирование
[Интеграционное тестирование (Integration testing)](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D0%B3%D1%80%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%BE%D0%B5_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) — одна из фаз тестирования программного обеспечения, при которой отдельные программные модули объединяются и тестируются в группе.
Выделяется 3 подхода к интеграционному тестированию:
**Снизу вверх (Bottom Up Integration)**
Все низкоуровневые модули, процедуры или функции собираются воедино и затем тестируются. После чего собирается следующий уровень модулей для проведения интеграционного тестирования. Данный подход считается полезным, если все или практически все модули, разрабатываемого уровня, готовы. Также данный подход помогает определить по результатам тестирования уровень готовности приложения.
**Сверху вниз (Top Down Integration)**
Вначале тестируются все высокоуровневые модули, и постепенно один за другим добавляются низкоуровневые. Все модули более низкого уровня симулируются заглушками с аналогичной функциональностью, затем по мере готовности они заменяются реальными активными компонентами. Таким образом мы проводим тестирование сверху вниз.
**Большой взрыв («Big Bang» Integration)**
Все или практически все разработанные модули собираются вместе в виде законченной системы или ее основной части, и затем проводится интеграционное тестирование. Такой подход очень хорош для сохранения времени.
Так как у нас все модули уже готовы, будем использовать подход **снизу вверх**.
##### Итеративный подход
Мы будем использовать итеративный подход, т.е будем подключать модули один за одним, снизу вверх. Сначала проверяем связку api + model, потом api + model + mapper + presenter, затем общую связку api + model mapper + presenter + view
##### Негативный и позитивный сценарий
Для интеграционных тестов мы должны рассмотреть 2 сценария ответа от сервера: нормальный ответ и ошибка. В зависимости от этого меняется поведение компонентов. Перед каждым тестом мы можем настраивать ответ от сервера (MockWebServer) и проверять результаты.
Схема интеграционного теста (api + model):
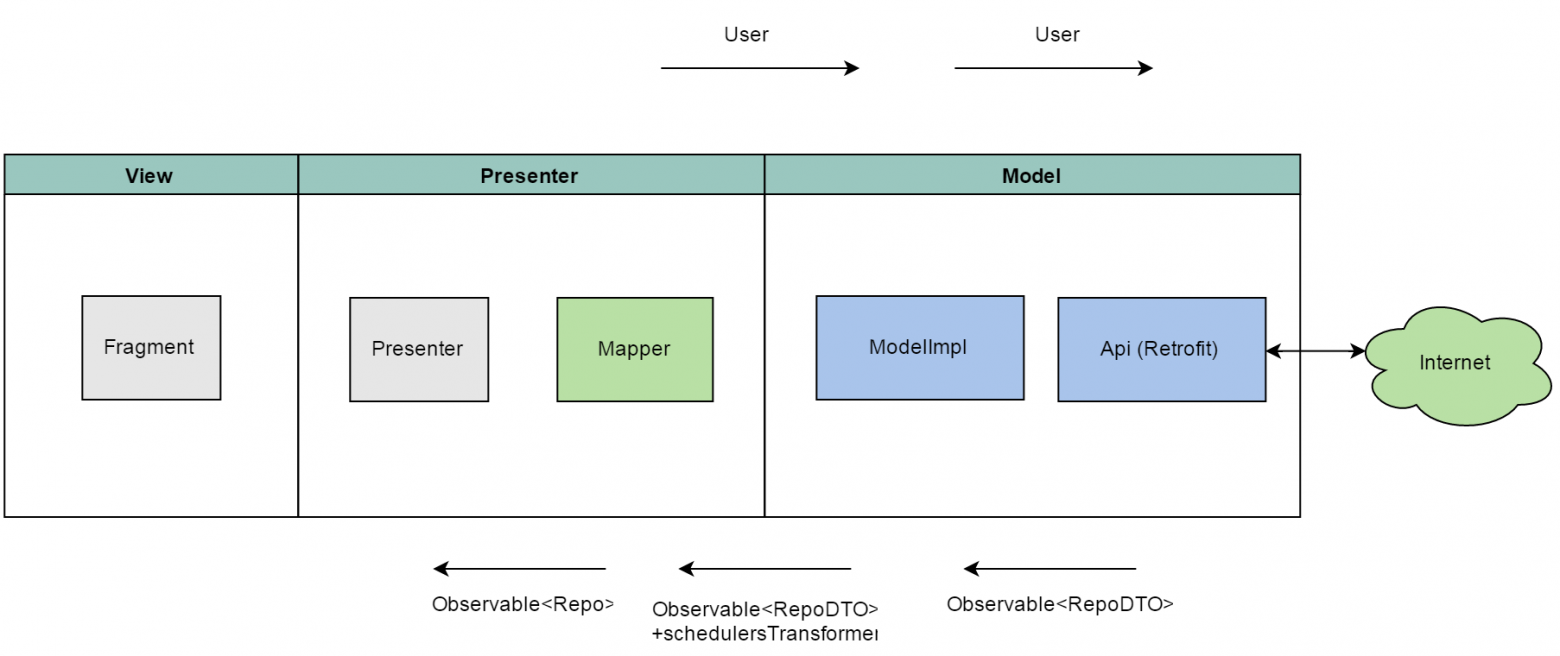
Пример интеграционного теста (api + model), мы проверяем взаимодействие модуля Retrfofit и ModelImpl:
**Пример интеграционного теста**
```
@Test
public void testGetRepoList() {
TestSubscriber> testSubscriber = new TestSubscriber<>();
model.getRepoList(TestConst.TEST\_OWNER).subscribe(testSubscriber);
testSubscriber.assertNoErrors();
testSubscriber.assertValueCount(1);
List actual = testSubscriber.getOnNextEvents().get(0);
assertEquals(7, actual.size());
assertEquals("Android-Rate", actual.get(0).getName());
assertEquals("andrey7mel/Android-Rate", actual.get(0).getFullName());
assertEquals(26314692, actual.get(0).getId());
}
```
Схема интеграционного теста (api + model + mapper + presenter):
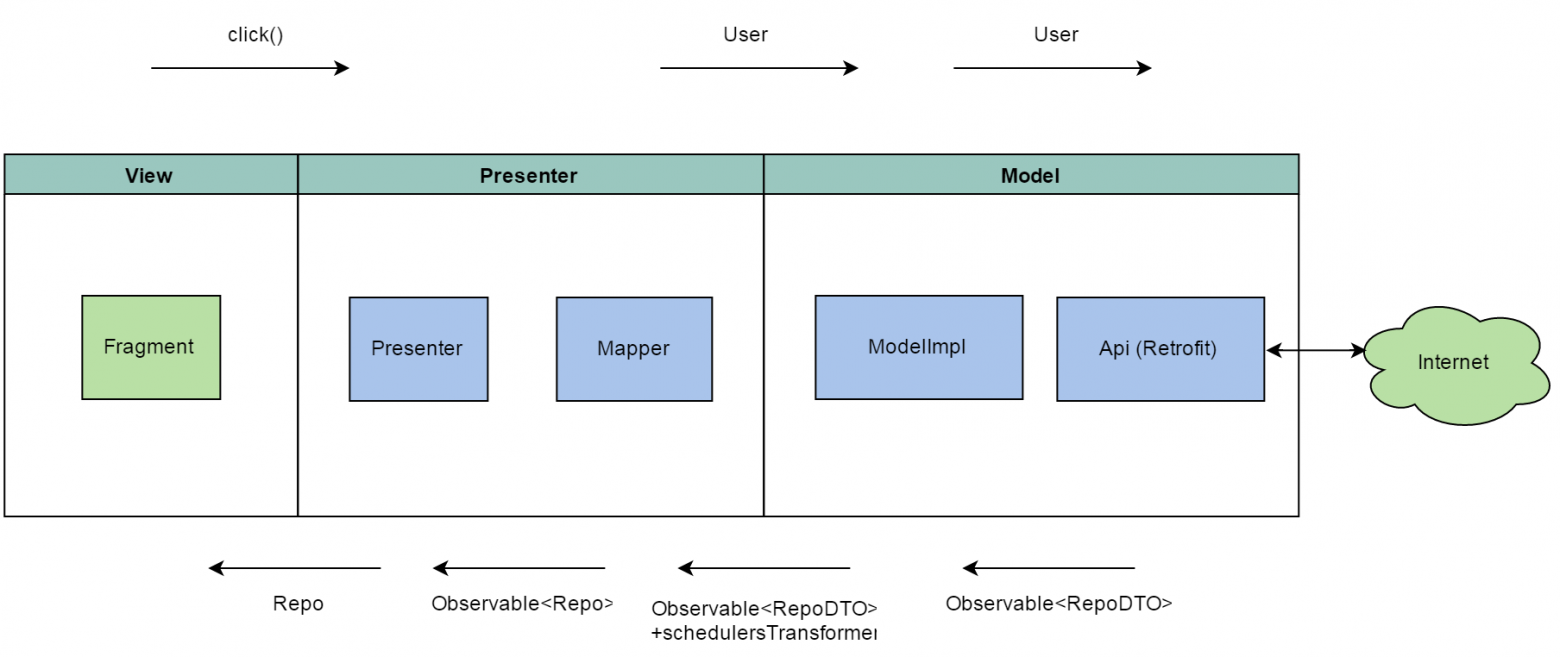
**Пример интеграционного теста (api + model + mapper + presenter)**
```
@Test
public void testLoadData() {
repoInfoPresenter.onCreateView(null);
repoInfoPresenter.onStop();
verify(mockView).showBranches(branchList);
verify(mockView).showContributors(contributorList);
}
@Test
public void testLoadDataWithError() {
setErrorAnswerWebServer();
repoInfoPresenter.onCreateView(null);
repoInfoPresenter.onStop();
verify(mockView, times(2)).showError(TestConst.ERROR_RESPONSE_500);
}
```
В итоге у нас получится полная проверка взаимодействия всех модулей друг с другом, снизу вверх. Если где то модули будут взаимодействовать некорректно, мы быстро увидим это по тестам.
#### Шаг 6. Функциональное тестирование
[Функциональное тестирование](https://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) — это тестирование ПО в целях проверки реализуемости функциональных требований, то есть способности ПО в определённых условиях решать задачи, нужные пользователям. Функциональные требования определяют, что именно делает ПО, какие задачи оно решает.
В рамках нашего Android приложения мы будем проверять работу приложения с точки зрения пользователя. Для начала составим пользовательскую карту приложения:
**Карта приложения**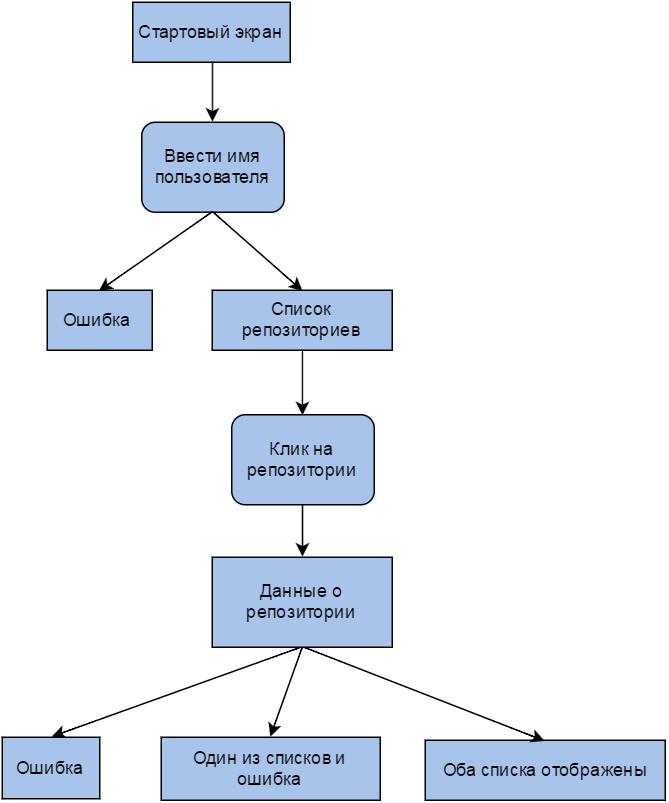
Составим необходимые тест кейсы:
* Открыть приложение, проверить видимость всех элементов
* Ввести тестового пользователя, нажать кнопку Search
+ Данные получены — получить список репозиториев, проверить отображение данных.
+ Данные не получены — проверить отображение ошибки.
* Перейти на второй экран, проверить правильность отображения имени пользователя и названия репозитория.
+ Получить списки бранчей и контрибуторов, проверить отображение данных
+ Какой то из списков не получен (два теста), проверить отображение полученного списка, отображение ошибки
+ Оба списка не получены, проверить отображение ошибки
Для тестирования мы будем использовать Espresso. Также как и для других тестов, изолируем приложение от интернета с помощью моков и заранее подготовленных json файлов. Поможет нам в этом Dagger 2 и подмена компонентов:
**Код MockTestRunner и TestApp**
```
public class MockTestRunner extends AndroidJUnitRunner {
@Override
public Application newApplication(
ClassLoader cl, String className, Context context)
throws InstantiationException,
IllegalAccessException,
ClassNotFoundException {
return super.newApplication(
cl, TestApp.class.getName(), context);
}
}
public class TestApp extends App {
@Override
protected TestComponent buildComponent() {
return DaggerTestComponent.builder().build();
}
}
```
**Пример тестов Espresso**
```
@Test
public void testGetUserRepo() {
apiConfig.setCorrectAnswer();
onView(withId(R.id.edit_text)).perform(clearText());
onView(withId(R.id.edit_text)).perform(typeText(TestConst.TEST_OWNER));
onView(withId(R.id.button_search)).perform(click());
onView(withId(R.id.recycler_view)).check(EspressoTools.hasItemsCount(7));
onView(withId(R.id.recycler_view)).check(EspressoTools.hasViewWithTextAtPosition(0, "Android-Rate"));
onView(withId(R.id.recycler_view)).check(EspressoTools.hasViewWithTextAtPosition(1, "android-simple-architecture"));
onView(withId(R.id.recycler_view)).check(EspressoTools.hasViewWithTextAtPosition(2, TestConst.TEST_REPO));
}
@Test
public void testGetUserRepoError() {
apiConfig.setErrorAnswer();
onView(withId(R.id.edit_text)).perform(clearText());
onView(withId(R.id.edit_text)).perform(typeText(TestConst.TEST_OWNER));
onView(withId(R.id.button_search)).perform(click());
onView(allOf(withId(android.support.design.R.id.snackbar_text), withText(TestConst.TEST_ERROR)))
.check(matches(isDisplayed()));
onView(withId(R.id.recycler_view)).check(EspressoTools.hasItemsCount(0));
}
```
Аналогично пишем остальные тесты по тест кейсам.
Закончив работу с Espresso, мы полностью покроем приложение модульными, интеграционными и функциональными тестами.
#### Шаг 7. TDD
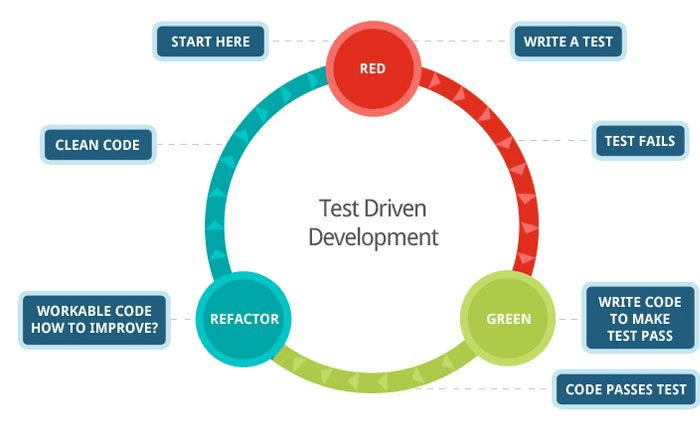
[Разработка через тестирование](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) (Test-driven development) — техника разработки программного обеспечения, которая определяет разработку через написание тестов.
В сущности вам нужно выполнять три простых повторяющихся шага:
— Написать тест для новой функциональности, которую необходимо добавить;
— Написать код, который пройдет тест;
— Провести рефакторинг нового и старого кода.
Если аббревиатура TDD для вас не знакома, рекомендуем почитать [статью от наших коллег из iOS отдела](https://habrahabr.ru/company/rambler-co/blog/263087/) или [статьи из хаба TDD](https://habrahabr.ru/hub/tdd/).
Существуют 3 закона TDD:
* Не пишется production код, прежде чем для него есть неработающий тест;
* Не пишется больше кода юнит теста, чем достаточно для его ошибки.
* Не пишется больше production кода, чем достаточно для прохождения текущего неработающего теста.
Для примера создадим progress bar который будет показывать загрузку из интернета. Он должен появляться когда происходит загрузка данных и исчезать когда данные загружены или появилась ошибка. Всю разработку будем вести по TDD.
Разработка данной функциональности затронет презентеры и фрагменты, мапперы и дата слой остаются без изменений.
##### Презентеры
Начнем со списка репозиториев. Первым делом дополним интерфейсы:
```
public interface RepoListView extends View {
void showRepoList(List list);
void showEmptyList();
String getUserName();
void startRepoInfoFragment(Repository repository);
//New
void showLoading();
void hideLoading();
}
```
###### Первый этап.
Сначала пишем тест, который проверит, что в случае нормальной загрузки был вызван метод showLoading у фрагмента:
```
@Test
public void testShowLoading() {
repoListPresenter.onSearchButtonClick();
verify(mockView).showLoading();
}
```
Как только получили неработающий тест, пишем код, который пройдет его:
```
public void onSearchButtonClick() {
String name = view.getUserName();
if (TextUtils.isEmpty(name)) return;
view.showLoading();
// --- some code ---
}
```
Рефакторить пока нечего.
На этом первая итерация разработки по TDD закончилась. Мы получили новую функциональность и тест для нее.
###### Второй этап.
Напишем тест, который проверит, что после нормальной загрузки был вызван метод hideLoading у фрагмента:
```
@Test
public void testHideLoading() {
repoListPresenter.onSearchButtonClick();
verify(mockView).hideLoading();
}
```
Пишем код, который пройдет тест:
```
//--
view.showLoading();
Subscription subscription = model.getRepoList(name)
.map(repoListMapper)
.subscribe(new Observer>() {
@Override
public void onCompleted() {
view.hideLoading();
}
@Override
public void onError(Throwable e) {
view.showError(e.getMessage());
}
@Override
public void onNext(List list) {
if (list != null && !list.isEmpty()) {
repoList = list;
view.showRepoList(list);
} else {
view.showEmptyList();
}
}
});
```
Рефакторинг не требуется.
###### Третий и четвертый этапы.
Теперь напишем тесты, которые проверят, что при возникновении ошибки, были корректны вызваны необходимые методы.
**Тесты на обработку ошибки**
```
@Test
public void testShowLoadingOnError() {
doAnswer(invocation -> Observable.error(new Throwable(TestConst.TEST_ERROR)))
.when(model)
.getRepoList(TestConst.TEST_OWNER);
repoListPresenter.onSearchButtonClick();
verify(mockView).showLoading();
}
@Test
public void testHideLoadingOnError() {
doAnswer(invocation -> Observable.error(new Throwable(TestConst.TEST_ERROR)))
.when(model)
.getRepoList(TestConst.TEST_OWNER);
repoListPresenter.onSearchButtonClick();
verify(mockView).hideLoading();
}
```
**Код обработки ошибки**
```
//--
@Override
public void onError(Throwable e) {
view.showError(e.getMessage());
view.hideLoading();
}
//--
```
Рефакторинг не требуется. Работа с Repo List Presenter завершена, теперь перейдем к Repo Info Presenter.
##### Repo Info Presenter
Аналогично предыдущему шагу, пишем тесты и код для корректной загрузки данных.
**Тесты для корректной загрузки данных**
```
@Test
public void testShowLoading() {
repoInfoPresenter.onCreateView(null);
verify(mockView).showLoading();
}
@Test
public void testHideLoading() {
repoInfoPresenter.onCreateView(null);
verify(mockView).hideLoading();
}
```
**Код для корректной загрузки данных**
```
public void loadData() {
String owner = repository.getOwnerName();
String name = repository.getRepoName();
view.showLoading();
Subscription subscriptionBranches = model.getRepoBranches(owner, name)
.map(branchesMapper)
.subscribe(new Observer>() {
@Override
public void onCompleted() {
hideInfoLoadingState();
}
@Override
public void onError(Throwable e) {
view.showError(e.getMessage());
}
@Override
public void onNext(List list) {
branchList = list;
view.showBranches(list);
}
});
addSubscription(subscriptionBranches);
Subscription subscriptionContributors = model.getRepoContributors(owner, name)
.map(contributorsMapper)
.subscribe(new Observer>() {
@Override
public void onCompleted() {
hideInfoLoadingState();
}
@Override
public void onError(Throwable e) {
view.showError(e.getMessage());
}
@Override
public void onNext(List list) {
contributorList = list;
view.showContributors(list);
}
});
addSubscription(subscriptionContributors);
}
protected void hideInfoLoadingState() {
countCompletedSubscription++;
if (countCompletedSubscription == COUNT\_SUBSCRIPTION) {
view.hideLoading();
countCompletedSubscription = 0;
}
}
```
Рефакторинг.
Как видно, используется одинаковый код для двух презентеров (показать и скрыть индикатор загрузки, показать ошибку). Необходимо вынести его в общий базовый класс BasePresenter. Выносим методы showLoadingState() hideLoadingState() и showError(Throwable e) в BasePresenter
**Код BasePresenter**
```
protected abstract View getView();
protected void showLoadingState() {
getView().showLoadingState();
}
protected void hideLoadingState() {
getView().hideLoadingState();
}
protected void showError(Throwable e) {
getView().showError(e.getMessage());
}
```
Рефакторим RepoInfoPresenter и проверим, что проходят все тесты. Не забываем сделать рефакторинг RepoListPresenter для работы с базовым классом.
Далее пишем сначала тесты, а потом код для обработки ошибок во время загрузки (для RepoInfoPresenter).
**Тесты для обработки ошибок во время загрузки**
```
@Test
public void testShowLoadingOnError() {
doAnswer(invocation -> Observable.error(new Throwable(TestConst.TEST_ERROR)))
.when(model)
.getRepoContributors(TestConst.TEST_OWNER, TestConst.TEST_REPO);
doAnswer(invocation -> Observable.error(new Throwable(TestConst.TEST_ERROR)))
.when(model)
.getRepoBranches(TestConst.TEST_OWNER, TestConst.TEST_REPO);
repoInfoPresenter.onCreateView(null);
verify(mockView).showLoading();
}
@Test
public void testHideLoadingOnError() {
doAnswer(invocation -> Observable.error(new Throwable(TestConst.TEST_ERROR)))
.when(model)
.getRepoContributors(TestConst.TEST_OWNER, TestConst.TEST_REPO);
doAnswer(invocation -> Observable.error(new Throwable(TestConst.TEST_ERROR)))
.when(model)
.getRepoBranches(TestConst.TEST_OWNER, TestConst.TEST_REPO);
repoInfoPresenter.onCreateView(null);
verify(mockView).hideLoading();
}
@Test
public void testShowLoadingOnErrorBranches() {
doAnswer(invocation -> Observable.error(new Throwable(TestConst.TEST_ERROR)))
.when(model)
.getRepoBranches(TestConst.TEST_OWNER, TestConst.TEST_REPO);
repoInfoPresenter.onCreateView(null);
verify(mockView).showLoading();
}
@Test
public void testHideLoadingOnErrorBranches() {
doAnswer(invocation -> Observable.error(new Throwable(TestConst.TEST_ERROR)))
.when(model)
.getRepoBranches(TestConst.TEST_OWNER, TestConst.TEST_REPO);
repoInfoPresenter.onCreateView(null);
verify(mockView).hideLoading();
}
```
**Код для обработки ошибок во время загрузки**
```
showLoadingState();
Subscription subscriptionBranches = model.getRepoBranches(owner, name)
.map(branchesMapper)
.subscribe(new Observer>() {
@Override
public void onCompleted() {
hideInfoLoadingState();
}
@Override
public void onError(Throwable e) {
hideInfoLoadingState();
showError(e);
}
@Override
public void onNext(List list) {
branchList = list;
view.showBranches(list);
}
});
addSubscription(subscriptionBranches);
Subscription subscriptionContributors = model.getRepoContributors(owner, name)
.map(contributorsMapper)
.subscribe(new Observer>() {
@Override
public void onCompleted() {
hideInfoLoadingState();
}
@Override
public void onError(Throwable e) {
hideInfoLoadingState();
showError(e);
}
@Override
public void onNext(List list) {
contributorList = list;
view.showContributors(list);
}
});
```
На этом разработка презентеров закончена. Переходим к фрагментам.
##### Фрагменты
Progress bar, как общий элемент, будет лежать в activity, фрагменты будут вызывать у activity методы showProgressBar() и hideProgressBar(), которые покажут или спрячут progress bar. Для работы с activity используем интерфейс ActivityCallback. По опыту презентеров, можем сразу догадаться, что нам будет необходим общий базовый класс — BaseFragment. В нем будет содержаться логика взаимодействия с activity.
Сначала пишем тесты, а потом код, для взаимодействия базового фрагмента с activity:
**Тесты Base Fragment**
```
@Test
public void testAttachActivityCallback() throws Exception {
assertNotNull(baseFragment.activityCallback);
}
@Test
public void testShowLoadingState() throws Exception {
baseFragment.showLoading();
verify(activity).showProgressBar();
}
@Test
public void testHideLoadingState() throws Exception {
baseFragment.hideLoading();
verify(activity).hideProgressBar();
}
```
**Код Base Fragment**
```
@Override
public void onAttach(Activity activity) {
super.onAttach(activity);
try {
activityCallback = (ActivityCallback) activity;
} catch (ClassCastException e) {
throw new ClassCastException(activity.toString()
+ " must implement activityCallback");
}
}
@Override
public void showLoading() {
activityCallback.showProgressBar();
}
@Override
public void hideLoading() {
activityCallback.hideProgressBar();
}
```
Рефакторинг не требуется, переходим к activity.
##### Acitivity
Последним шагом реализуем интерфейс Activity. Мы будем изменять видимость (setVisibility) progressBar в зависимости от команды. В тестах необходимо проверить что progressBar найден и работу методов showProgressBar и hideProgressBar.
Сначала пишем тесты:
**Тесты Activity**
```
@Test
public void testHaveProgressBar() throws Exception {
assertNotNull(progressBar);
}
@Test
public void testShowProgressBar() throws Exception {
mainActivity.showProgressBar();
verify(progressBar).setVisibility(View.VISIBLE);
}
@Test
public void testHideProgressBar() throws Exception {
mainActivity.hideProgressBar();
verify(progressBar).setVisibility(View.INVISIBLE);
}
```
Потом пишем код:
**Код Activity**
```
@Bind(R.id.toolbar_progress_bar)
protected ProgressBar progressBar;
//---- some code ----
@Override
public void showProgressBar() {
progressBar.setVisibility(View.VISIBLE);
}
@Override
public void hideProgressBar() {
progressBar.setVisibility(View.INVISIBLE);
}
```
Все достаточно тривиально, рефакторинг не требуется.
На этом мы закончим разработку progress bar с использованием техники TDD.
#### Шаг 8. Что дальше?
Изучив TDD и разработав отображение загрузки, мы закончим разработку приложения. Для дальнейшего развития рекомендую к прочтению следующие статьи:
**Android Clean Architecture**
[Android Clean Architecture](http://fernandocejas.com/2014/09/03/architecting-android-the-clean-way/) — известная статья от Fernando Cejas, на основе [Clean Architecture от Дядюшки Боба](http://blog.8thlight.com/uncle-bob/2012/08/13/the-clean-architecture.html). Рассматривается взаимодействие между 3 слоями Presentation Layer, Domain Layer и Data Layer. Есть [перевод на habrahabr.](https://habrahabr.ru/post/250659/)
**VIPER**
VIPER (View, Interactor, Presenter, Entity и Routing) становится все более популярен, познакомится с ним можно в статье [Android VIPER на реактивной тяге](https://habrahabr.ru/company/rambler-co/blog/277003/) от [VikkoS](https://habrahabr.ru/users/vikkos/). Основные принципы VIPER освещены [в статьях и докладах наших коллег из отдела iOS.](https://habrahabr.ru/company/rambler-co/blog/273949/)
**Mosby**
Mosby — популярная библиотека для создания MVP приложений. Содержит в себе все основные интерфейсы и базовые классы. Сайт: <http://hannesdorfmann.com/mosby/> Github: <https://github.com/sockeqwe/mosby>
**Android Application Architecture**
Хорошая статья про архитектуру от [Ribot team — Android Application Architecture](https://labs.ribot.co.uk/android-application-architecture-8b6e34acda65#.d7yggc7a7). Рассматривается миграция c AsyncTask на RxJava. Совсем недавно вышел [перевод на habrahabr.](https://habrahabr.ru/post/278815/)
**Android Development Culture Document**
[Android Development Culture Document #qualitymatters от [Artem\_zin](https://habrahabr.ru/users/artem_zin/)](http://artemzin.com/blog/android-development-culture-the-document-qualitymatters/). Отличная статья и демонстрационный проект от Artem Zinnatullin. В статье рассматриваются 8 принципов разработки android приложений, подкрепляется все это [примером на Github.](https://github.com/artem-zinnatullin/qualitymatters)
#### Заключение
В этом цикле статей мы прошли все этапы разработки приложения. Начали мы c простой архитектуры на основе MVP, усложняя ее по ходу добавления новых фич. Использовали современные библиотеки: RxJava и RxAndroid для реактивного программирования и избавления от callback-ов, Retrofit для удобной работы с сетью, Butterknife для быстрого и легкого поиска view. Dagger 2 управлял всеми зависимостями и оказал нам неоценимую поддержку при написании тестов. Сами тесты мы писали с помощью jUnit, Robolectric, Mockito и MockWebServer. А Espresso избавил наших тестировщиков от мук регрессионного тестирования.
Мы полностью покрыли наш проект тестами. Unit тесты изолированно проверяют каждый компонент, интеграционные тесты проверяют их общее взаимодействие, а функциональные тесты смотрят на все это со стороны пользователя. При дальнейшем изменении программы мы можем не бояться (ну или почти не бояться), что поломаем какие то компоненты, и что то отвалится, а баги пролезут в релиз. Благодаря TDD, большая часть нашего кода будет покрыта тестами (нет теста, нет и кода). Не будет проблемы частичного покрытия или “код написали, а на тесты времени не осталось”.
Весь код проекта доступен на [Github (https://github.com/andrey7mel/android-step-by-step)](https://github.com/andrey7mel/android-step-by-step)
Надеюсь, эта серия статей вам понравилась и оказалась полезной, спасибо за внимание! | https://habr.com/ru/post/279799/ | null | ru | null |
# Упарываемся по максимуму: от ORM до анализа байткода
Как известно, настоящий программист в своей жизни должен сделать 3 вещи: создать свой язык программирования, написать свою операционную систему и сделать свой ORM. И если язык я написал уже давно (возможно, расскажу как-нибудь в другой раз), а ОС еще ждет впереди, то про ORM я хочу поведать прямо сейчас. А если точнее, то даже не про сам ORM, а про реализацию одной маленькой, локальной и, как изначально казалось, совсем простой фичи.
Мы с вами вместе пройдем весь путь от радости нахождения простого решения до горечи осознания его хрупкости и некорректности. От использования исключительно публичного API до грязных хаков. От "почти без рефлекшена", до "по колено в интерпретаторе байт-кода".
Кому интересно как анализировать байт-код, какие сложности это в себе таит и какой потрясающий результат можно получить в итоге, добро пожаловать под кат.
### Содержание
[1](#1) — С чего все началось.
[2-4](#2) — На пути к байткоду.
[5](#5) — Кто такой байткод.
[6](#6) — Сам анализ. Именно ради этой главы все и затевалось и именно в ней самые кишочки.
[7](#7) — Что еще можно допилить. Мечты, мечты…
[Послесловие](#8) — Послесловие.
*UPD: Сразу после публикации были потеряны части 6-8 (ради которых все и затевалось). Пофиксил.*
### Часть первая. Проблема
Представим, что у нас есть простенькая схема. Существует клиент, у него есть несколько счетов. Один из них является дефолтным. Так же у клиента может быть несколько сим-карт и у каждой симки счет может быть явно задан, а может использоваться дефолтный клиентский.

Вот как эта модель описывается у нас в коде (опуская геттеры/сеттеры/конструкторы/...).
```
@JdbcEntity(table = "CLIENT")
public class Client {
@JdbcId
private Long id;
@JdbcColumn
private String name;
@JdbcJoinedObject(localColumn = "DEFAULTACCOUNT")
private Account defaultAccount;
}
@JdbcEntity(table = "ACCOUNT")
public class Account {
@JdbcId
private Long id;
@JdbcColumn
private Long balance;
@JdbcJoinedObject(localColumn = "CLIENT")
private Client client;
}
@JdbcEntity(table = "CARD")
public class Card {
@JdbcId
private Long id;
@JdbcColumn
private String msisdn;
@JdbcJoinedObject(localColumn = "ACCOUNT")
private Account account;
@JdbcJoinedObject(localColumn = "CLIENT")
private Client client;
}
```
В самом ORM у нас наложено требование на отсутствие проксей (мы должны создать инстанс именно этого класса) и единственный запрос. Соответственно, вот какой sql отправляется в базу при попытке получить карту.
```
select CARD.id id,
CARD.msisdn msisdn,
ACCOUNT_2.id ACCOUNT_2_id,
ACCOUNT_2.balance ACCOUNT_2_balance,
CLIENT_3.id CLIENT_3_id,
CLIENT_3.name CLIENT_3_name,
CLIENT_1.id CLIENT_1_id,
CLIENT_1.name CLIENT_1_name,
ACCOUNT_4.id ACCOUNT_4_id,
ACCOUNT_4.balance ACCOUNT_4_balance
from CARD
left outer join CLIENT CLIENT_1 on CARD.CLIENT = CLIENT_1.id
left outer join ACCOUNT ACCOUNT_2 on CARD.ACCOUNT = ACCOUNT_2.id
left outer join CLIENT CLIENT_3 on ACCOUNT_2.CLIENT = CLIENT_3.id
left outer join ACCOUNT ACCOUNT_4 on CLIENT_1.DEFAULTACCOUNT = ACCOUNT_4.id;
```
Уупс. Клиент и счет задублировались. Правда, если подумать, то это вполне объяснимо — фреймворк ведь не знает что клиент карты и клиент счета карты — это один и тот же клиент. А запрос надо сгенерить статически и только один (помните ограничение в единственность запроса?).
Кстати, ровно по этой же причине здесь вообще нет полей `Card.account.client.defaultAccount` и `Card.client.defaultAccount.client`. Только мы знаем что `client` и `client.defaultAccount.client` всегда совпадают. А фреймворк не знает, для него это произвольная ссылка. И что делать в таких случаях не очень понятно. Я знаю 3 варианта:
1. Явно описывать инварианты в аннотациях.
2. Делать рекурсивные запросы (`with recursive` / `connect by`).
3. Забить.
Угадайте, какой вариант выбрали мы? Правильно. В итоге, все рекурсивные филды сейчас вообще не заполняются и там всегда null.
Но если присмотреться, то за дублированием можно увидеть второю проблему, и она гораздо хуже. Мы ведь что хотели? Номер и баланс карты. А что получили? 4 джойна и 10 колонок. И эта штука растет экспоненциально! Ну т.е. мы реально имеем ситуацию, когда сначала ради красоты и целостности полностью описываем модель на аннотациях, а потом, **ради 5 полей**, идет запрос на **15 джойнов и 150 колонок**. И вот в этот момент становится реально страшно.
### Часть вторая. Рабочее, но неудобное решение
Сразу же напрашивается простое решение. Надо тащить только те колонки, которые будут использоваться! Легко сказать. Самый очевидный вариант (написать селект руками) мы отбросим сразу. Ну не затем же мы описывали модель, чтобы не использовать ее. Довольно давно был сделан специальный метод — `partialGet`. Он, в отличии от простого `get`, принимает `List` — имена полей, которые надо заполнить. Для этого сначала надо прописать алиасы таблицам
```
@JdbcJoinedObject(localColumn = "ACCOUNT", sqlTableAlias = "a")
private Account account;
@JdbcJoinedObject(localColumn = "CLIENT", sqlTableAlias = "c")
private Client client;
```
А потом наслаждаться результатом.
```
List requiredColumns = asList("msisdn", "c\_a\_balance", "a\_balance");
String query = cardMapper.getSelectSQL(requiredColumns, DatabaseType.ORACLE);
System.out.println(query);
```
```
select CARD.msisdn msisdn,
c_a.balance c_a_balance,
a.balance a_balance
from CARD
left outer join ACCOUNT a on CARD.ACCOUNT = a.id
left outer join CLIENT c on CARD.CLIENT = c.id
left outer join ACCOUNT c_a on c.DEFAULTACCOUNT = c_a.id;
```
И вроде бы все хорошо, но, на самом деле, нет. Вот как оно будет использовано в реальном коде.
```
Card card = cardDAO.partialGet(cardId, "msisdn", "c_a_balance", "a_balance");
...
...
...
много много кода
...
...
...
long clientId = card.getClient().getId();//ой, NPE. А что, id клиента не был заполнен?!
```
И получается что пользоваться partialGet сейчас можно только если расстояние между ним и использованием результата только несколько строчек. А вот если результат уходит далеко или, не дай бог, передается внутрь какого-то метода, то понять потом какие поля у него заполнены, а какие нет, уже крайне сложно. Более того, если где-то случился NPE, то еще надо понять действительно ли это из базы null вернулся, или же мы просто данный филд и не заполняли. В общем, очень ненадежно.
Можно, конечно, просто написать еще один объект со своим маппингом специально под запрос, или же вообще полностью руками весь селект и собрать его в какой-нибудь `Tuple`. Собственно, реально сейчас в большинстве мест именно так и делаем. Но все-таки хотелось бы и не писать селекты руками, и не дублировать маппинг.
### Часть третья. Удобное, но нерабочее решение.
Если еще немного подумать, то довольно быстро в голову приходит ответ — надо использовать интерфейсы. Тогда достаточно просто объявить
```
public interface MsisdnAndBalance {
String getMsisdn();
long getBalance();
}
```
И использовать
```
MsisdnAndBalance card = cardDAO.partialGet(cardId, ...);
```
И все. Ничего лишнего больше не вызвать. Более того, с переходом на котлин/десятку/ломбок даже от этого страшного типа можно будет избавиться. Но здесь все еще опущен самый главный момент. Какие аргументы нужно передавать в `partialGet`? Стринги, как раньше, уже не хочется, ибо слишком велик риск ошибиться и написать не те филды, которые нужны. А хочется чтобы можно было как-нибудь так
```
MsisdnAndBalance card = cardDAO.partialGet(cardId, MsisdnAndBalance.class);
```
Или еще лучше на котлине через reified generics
```
val card = cardDAO.paritalGet(cardId)
```
Эхх, ляпота. Собственно, весь дальший рассказ — это именно реализация данного варианта.
### Часть четвертая. На пути к байткоду
Ключевая проблема заключается в том, что из интерфейса идут методы, а аннотации стоят над филдами. И нам нужно по методам найти эти самые филды. Первая и самая очевидная мысль — использовать стандартную Java Bean конвенцию. И для тривиальных свойств это даже работает. Но получается очень нестабильно. Например, стоит переименовать метод в интерфейсе (через идеевский рефакторинг), как все моментально разваливается. Идея достаточно умная чтобы переименовать методы в классах-реализациях, но недостаточно чтобы понять что это был геттер и надо переименовать еще и само поле. А еще подобное решение приводит к дублированию полей. Например, если мне в моем интерфейсе нужен метод `getClientId()`, то я не могу его реализовать единственно правильным способом
```
public class Client implements HasClientId {
private Long id;
@Override
public Long getClientId() {
return id;
}
}
```
```
public class Card implements HasClientId {
private Client client;
@Override
public Long getClientId() {
return client.getId();
}
}
```
А вынужден я дублировать поля. И в `Client` тащить и `id`, и `clientId`, а в карте рядом с клиентом иметь явно `clientId`. И еще следить чтобы все это не разъехалось. Более того, хочется чтобы работали еще и геттеры с нетривиальной логикой, например
```
public class Card implements HasBalance {
private Account account;
private Client client;
public long getBalance() {
if (account != null)
return account.getBalance();
else
return client.getDefaultAccount().getBalance();
}
}
```
Так что вариант с поисками по именам отпадает, нужно что-то более хитрое.
Следующий вариант был совсем безумный и прожил в моей голове недолго, но для полноты истории все же опишу и его. На этапе парсинга мы можем создать пустую сущность и просто по очереди писать какие-нибудь значения в филды, а после этого дергать геттеры и смотреть изменилось что они возвращают или нет. Так мы увидим что от записи в поле `name` значение `getClientId` не меняется, а вот от записи `id` — меняется. Более того, здесь автоматически поддерживается ситуация когда геттер и филд разных типов (типа `isActive() = i_active != 0`). Но здесь есть как минимум три серьезные проблемы (может и больше, но дальше уже не думал).
1. Очевидным требованием к сущности при таком алгоритме является возврат "одного и того же" значения из геттера если "соответствующий" филд не менялся. "Одного и того же" — с точки зрения выбранного нами оператора сравнения. `==` им, очевидно, быть не может (иначе перестанет работать какой-нибудь `getAsInt() = Integer.parseInt(strField))`. Остается equals. Значит, если геттер возвращает какую-нибудь пользовательскую сущность, генерируемую по филдам при каждом вызове, то у нее обязан быть переопределен `equals`.
2. Сжимающие отображения. Как в примере с `int -> boolean` выше. Если мы будем проверять на значениях 0 и 1, то изменение увидим. Но вот если на 40 и 42, то оба раза получим true.
3. Могут быть сложные конвертеры в геттерах, рассчитывающие на определенные инварианты в филдах (например, спец. формат строки). А на наших сгенеренных данных они будут кидать исключения.
Так что в целом вариант тоже не рабочий.
В процессе обсуждения всего этого дела я, изначально в шутку, произнес фразу "ну нафиг, проще в байткод посмотреть, там все написано". На тот момент я даже не продполагал что эта идея поглотит меня, и как далеко все зайдет.
### Часть пятая. Что такое байткод и как он работает
`new #4, dup, invokespecial #5, areturn`
Если вы понимаете, что здесь написано и что данный код делает, то можете сразу переходить к [следующей](#6) части.
*Disclaimer 1.* К сожалению, для понимания дальнейшего рассказа требуется хотя бы базовое понимание того, как выглядит джавовый байткод, так что напишу про это пару абзацев. Ни в коей мере не претендую на полноту.
*Disclaimer 2.* Речь пойдет исключительно про тела методов. Ни про constant pool, ни про структуру класса в целом, ни даже про сами декларации методов, я не скажу ни слова.
Главное, что нужно понимать про байткод — это ассемблер к стековой виртуальной машине Java. Это значит что аргументы для инструкций берутся со стека и возвращаемые значения из инструкций кладутся обратно на стек. С этой точки зрения можно сказать, что байткод записан в [обратной польской нотации](https://en.wikipedia.org/wiki/Reverse_Polish_notation). Помимо стэка в методе есть еще массив локальных переменных. При входе в метод в него записывается `this` и все аргументы этого метода, и в процессе выполнения там же хранятся локальные переменные. Вот простенький пример.
```
public class Foo {
private int bar;
public int updateAndReturn(long baz, String str) {
int result = (int) baz;
result += str.length();
bar = result;
return result;
}
}
```
Я буду писать комментарии в формате
```
# [(:)\*], [()\*]
```
Вершина стэка слева.
```
public int updateAndReturn(long, java.lang.String);
Code:
# [0:this, 1:long baz, 3:str], ()
0: lload_1
# [0:this, 1:long baz, 3:str], (long baz)
1: l2i
# [0:this, 1:long baz, 3:str], (int baz)
2: istore 4
# [0:this, 1:long baz, 3:str, 4:int baz], ()
4: iload 4
# [0:this, 1:long baz, 3:str, 4:int baz], (int baz)
6: aload_3
# [0:this, 1:long baz, 3:str, 4:int baz], (str, int baz)
7: invokevirtual #2 // Method java/lang/String.length:()I
# [0:this, 1:long baz, 3:str, 4:int baz], (length(str), int baz)
10: iadd
# [0:this, 1:long baz, 3:str, 4:int baz], (length(str) + int baz)
11: istore 4
# [0:this, 1:long baz, 3:str, 4:length(str) + int baz], ()
13: aload_0
# [0:this, 1:long baz, 3:str, 4:length(str) + int baz], (this)
14: iload 4
# [0:this, 1:long baz, 3:str, 4:length(str) + int baz], (length(str) + int baz, this)
16: putfield #3 // Field bar:I
# [0:this, 1:long baz, 3:str, 4:length(str) + int baz], (), сумма записана в поле bar
19: iload 4
# [0:this, 1:long baz, 3:str, 4:length(str) + int baz], (length(str) + int baz)
21: ireturn
# возвратили int с вершины стэка, там как раз была наша сумма
```
Всего инструкций очень много. Полный список нужно смотреть в [шестой главе JVMS](https://docs.oracle.com/javase/specs/jvms/se10/html/jvms-6.html), на википедии есть [краткий пересказ](https://en.wikipedia.org/wiki/Java_bytecode_instruction_listings). Большое количество инструкций дублируют друг друга для разных типов, (например, `iload` для инта и `lload` для лонга). Так же для работы с 4 первыми локальными переменными выделены свои инструкции (в примере выше, например, есть `lload_1` и он не принимает аргументов вообще, но еще есть просто `lload`, он будет принимать аргументом номер локальной переменной. В примере выше есть подобный `iload`).
Глобально нас будут интересовать следующие группы инструкций:
1. `*load*`, `*store*` — чтение/запись локальной переменной
2. `*aload`, `*astore` — чтение/запись элемента массива по индексу
3. `getfield`, `putfield` — чтение/запись поля
4. `getstatic`, `putstatic` — чтение/запись статического поля
5. `checkcast` — каст между объектными типами. Нужен т.к. на стэке и в локальных переменных лежат типизированные значения. Например, выше был l2i для каста long -> int.
6. `invoke*` — вызов метода
7. `*return` — возврат значения и выход из метода
### Часть шестая. Главная
Для тех, кто пропустил столь затянувшееся вступление, а так же дле того, чтобы отвлечься от исходной задачи и рассуждать в терминах библиотеки, сформулируем задачу более точно.
> Нужно, имея на руках экземпляр `java.lang.reflect.Method`, получить список всех нестатических филдов (и текущего, и всех вложенных объектов), чтения которых (напрямую или транзитивно) будут внутри данного метода.
Например, для такого метода
```
public long getBalance() {
Account acc;
if (account != null)
acc = account;
else
acc = client.getDefaultAccount();
return acc.getBalance();
}
```
Нужно получить список из двух филдов: `account.balance` и `client.defaultAccount.balance`.
Я буду писать, по-возможности, обобщенное решение. Но в паре мест придется использовать знание об исходной задаче для решения неразрешимых, в общем случае, проблем.
Для начала нужно получить сам байткод тела метода, но напрямую через джаву это сделать нельзя. Но т.к. изначально метод существует внутри какого-то класса, то проще получить сам класс. Глобально я знаю два варианта: вклиниться в процесс загрузки классов и перехватывать уже прочитанный `byte[]` там, либо просто найти сам файл `ClassName.class` на диске и прочитать его. Перехват загрузки на уровне обычной библиотеки не сделать. Нужно либо подключать javaagent, либо использовать кастомный ClassLoader. В любом случае, требуются дополнительные действия по настройке jvm/приложения, а это неудобно. Можно поступить проще. Все "обычные" классы всегда находятся в одноименном файле с расширением ".class", путь к которому — это пакет класса. Да, так не получится найти динамически добавленные классы или классы, загруженные каким-нибудь кастомным класслоадером, но нам это нужно для модели jdbc, так что можно с уверенностью сказать что все классы будут запакованы "дефолтным способом" в джарники. Итого:
```
private static InputStream getClassFile(Class clazz) {
String file = clazz.getName().replace('.', '/') + ".class";
ClassLoader cl = clazz.getClassLoader();
if (cl == null)
return ClassLoader.getSystemResourceAsStream(file);
else
return cl.getResourceAsStream(file);
}
```
Ура, массив байт прочитали. Что будем делать с ним дальше? В принципе в джаве для чтения/записи байткода есть несколько библиотек, но для самой низкоуревневой работы обычно используется [ASM](http://asm.ow2.io). Т.к. он заточен под высокую производительность и работу налету, то основным там является visitor API — асм последовательно читает класс и дергает соответствующие методы
```
public abstract class ClassVisitor {
public void visit(int version, int access, String name, String signature, String superName, String[] interfaces) {...}
public FieldVisitor visitField(int access, String name, String desc, String signature, Object value) {...}
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {...}
...
}
public abstract class MethodVisitor {
protected MethodVisitor mv;
public MethodVisitor(final int api, final MethodVisitor mv) {
...
this.mv = mv;
}
public void visitJumpInsn(int opcode, Label label) {
if (mv != null) {
mv.visitJumpInsn(opcode, label);
}
}
...
}
```
Пользователю же предлагается переопределять интересующие его методы и писать там свою логику анализа/трансформации. Отдельно, на примере `MethodVisitor`, хотелось бы обратить внимание что у всех визиторов есть дефолтная реализация через делегирование.
В дополнение к основному апи из коробки есть еще Tree API. Если Core API является аналогом SAX парсера, то Tree API — это аналог DOM. Мы получаем объект, внутри которого хранится вся информация о классе/методе и можем анализировать ее как хотим с прыжками в любое место. По сути, этот апи является реализациями `*Visitor`, которые внутри методов `visit*` просто сохраняют информацию. Примерно все методы там выглядят так:
```
public class MethodNode extends MethodVisitor {
@Override
public void visitJumpInsn(final int opcode, final Label label) {
instructions.add(new JumpInsnNode(opcode, getLabelNode(label)));
}
...
}
```
Теперь мы, наконец-то, можем загрузить метод для анализа.
```
private static class AnalyzerClassVisitor extends ClassVisitor {
private final String getterName;
private final String getterDesc;
private MethodNode methodNode;
public AnalyzerClassVisitor(Method getter) {
super(ASM6);
this.getterName = getter.getName();
this.getterDesc = getMethodDescriptor(getter);
}
public MethodNode getMethodNode() {
if (methodNode == null)
throw new IllegalStateException();
return methodNode;
}
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
//Проверяем что это именно наш метод
if (!name.equals(getterName) || !desc.equals(getterDesc))
return null;
return new AnalyzerMethodVisitor(access, name, desc, signature, exceptions);
}
private class AnalyzerMethodVisitor extends MethodVisitor {
public AnalyzerMethodVisitor(int access, String name, String desc, String signature, String[] exceptions) {
super(ASM6, new MethodNode(ASM6, access, name, desc, signature, exceptions));
}
@Override
public void visitEnd() {
//Данный метод вызывается в самом конце, после него других вызовов MethodVisitor уже не будет
if (methodNode != null)
throw new IllegalStateException();
methodNode = (MethodNode) mv;
}
}
}
```
**Полный код чтения метода.**Возвращается не напрямую `MethodNode`, а обертка с парой доп. полей, т.к. они нам позже тоже понадобятся. Точка входа (и единственный публичный метод) — `readMethod(Method): MethodInfo`.
```
public class MethodReader {
public static class MethodInfo {
private final String internalDeclaringClassName;
private final int classAccess;
private final MethodNode methodNode;
public MethodInfo(String internalDeclaringClassName, int classAccess, MethodNode methodNode) {
this.internalDeclaringClassName = internalDeclaringClassName;
this.classAccess = classAccess;
this.methodNode = methodNode;
}
public String getInternalDeclaringClassName() {
return internalDeclaringClassName;
}
public int getClassAccess() {
return classAccess;
}
public MethodNode getMethodNode() {
return methodNode;
}
}
public static MethodInfo readMethod(Method method) {
Class clazz = method.getDeclaringClass();
String internalClassName = getInternalName(clazz);
try (InputStream is = getClassFile(clazz)) {
ClassReader cr = new ClassReader(is);
AnalyzerClassVisitor cv = new AnalyzerClassVisitor(internalClassName, method);
cr.accept(cv, SKIP_DEBUG | SKIP_FRAMES);
return new MethodInfo(internalClassName, cv.getAccess(), cv.getMethodNode());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static InputStream getClassFile(Class clazz) {
String file = clazz.getName().replace('.', '/') + ".class";
ClassLoader cl = clazz.getClassLoader();
if (cl == null)
return ClassLoader.getSystemResourceAsStream(file);
else
return cl.getResourceAsStream(file);
}
private static class AnalyzerClassVisitor extends ClassVisitor {
private final String className;
private final String getterName;
private final String getterDesc;
private MethodNode methodNode;
private int access;
public AnalyzerClassVisitor(String internalClassName, Method getter) {
super(ASM6);
this.className = internalClassName;
this.getterName = getter.getName();
this.getterDesc = getMethodDescriptor(getter);
}
public MethodNode getMethodNode() {
if (methodNode == null)
throw new IllegalStateException();
return methodNode;
}
public int getAccess() {
return access;
}
@Override
public void visit(int version, int access, String name, String signature, String superName, String[] interfaces) {
if (!name.equals(className))
throw new IllegalStateException();
this.access = access;
}
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
if (!name.equals(getterName) || !desc.equals(getterDesc))
return null;
return new AnalyzerMethodVisitor(access, name, desc, signature, exceptions);
}
private class AnalyzerMethodVisitor extends MethodVisitor {
public AnalyzerMethodVisitor(int access, String name, String desc, String signature, String[] exceptions) {
super(ASM6, new MethodNode(ASM6, access, name, desc, signature, exceptions));
}
@Override
public void visitEnd() {
if (methodNode != null)
throw new IllegalStateException();
methodNode = (MethodNode) mv;
}
}
}
}
```
Самое время заняться непосредственно анализом. Как его делать? Первая мысль — смотреть все инструкции `getfield`. У каждого `getfield` статически написано какой это филд и какого класса. Можно считать за необходимые все филды нашего класса, к которым был доступ. Но, к сожалению, это не работает. Первая проблема здесь заключается в том, что происходит захват лишнего.
```
class Foo {
private int bar;
private int baz;
public int test() {
return bar + new Foo().baz;
}
}
```
При таком алгоритме мы посчитаем, что филд baz нужен, хотя, на самом деле, нет. Но на эту проблему еще можно было бы и забить. Но что делать с методами?
```
public class Client implements HasClientId {
private Long id;
public Long getId() {
HasClientId obj = this;
return obj.getClientId();
}
@Override
public Long getClientId() {
return id;
}
}
```
Если искать вызовы методов так же, как мы ищем чтение филдов, то `getClientId` мы не найдем. Ибо здесь нет вызова `Client.getClientId`, а есть только вызов `HasClientId.getClientId`. Можно, конечно, считать используемыми все методы на текущем классе, всех его суперклассах и всех интерфейсах, но это уже совсем перебор. Так можно случайно и `toString` захватить, а в нем распечатка вообще всех филдов.
Более того, мы ведь хотим чтобы вызовы геттеров у вложенных объектов тоже работали
```
public class Account {
private Client client;
public long getClientId() {
return client.getId();
}
}
```
И здесь вызов метода `Client.getId` к классу `Account` вообще никак не относится.
При большом желании еще можно какое-то время попридумывать хаки под частные случаи, но довольно быстро приходит понимание, что "так дела не делаются" и нужно полноценно следить за потоком исполнения и перемещением данных. Интересовать нас должны те и только те `getfield`, которые вызываются либо непосредственно на `this`, либо на каком-нибудь филде от `this`. Вот пример:
```
class Client {
public long id;
}
class Account {
public long id;
public Client client;
public long test() {
return client.id + new Account().id;
}
}
```
```
class Account {
public Client client;
public long test();
Code:
0: aload_0
1: getfield #2 // Field client:LClient;
4: getfield #3 // Field Client.id:J
7: new #4 // class Account
10: dup
11: invokespecial #5 // Method "":()V
14: getfield #6 // Field id:J
17: ladd
18: lreturn
}
```
* `1: getfield` нам интересен потому что в момент его выполнения на вершине стэка будет лежать `this`, загруженный туда инструкцией `aload_0`.
* `4: getfield` — потому что он будет вызываться на клиенте, возвращенном из предыдущего `1: getfield`, и, транзативно, на `this`.
* `14: getfield` нам не интересен. Т.к. не смотря на то, что что это филд текущего класса (`Account`), вызывается он не на `this`, а на новом объекте, созданном и положенном на стэк в `7: new`.
Итого, после анализа данного метода видно что филд `Account.client.id` используется, а `Account.id` — нет. Это был пример про филды, с методами больше нюансов, но в целом примерно то же самое.
В этот момент опускаются руки — надо писать полноценный интерпретатор, детектить паттерны не выйдет, ведь между `aload_0` и `getfield` может быть масса кода с перекладыванием этого несчастного `this` в локалы, касты, засовывания его в методы и возврат из них. Короче, боль. Это плохая новость. Но есть и хорошая — такой интерпретатор уже написан! И не где-нибудь, а прямо в асме. И интерпретирует он именно `MethodNode`, полученный нами ранее (вот же неожиданность). В потоковом режиме интерпретировать нельзя, т.к. могут быть джампы (циклы/условия/исключения) и хорошо бы не перечитывать метод после каждого.
Интерпретатор состоит из двух частей:
```
public class Analyzer {
public Analyzer(final Interpreter interpreter) {...}
public Frame[] analyze(final String owner, final MethodNode m) {...}
}
```
`Analyzer` уже написан и в нем (и в `Frame`, но про него позже) реализован сам интерпретатор. Именно он идет последовательно по инструкциям, кладет значения в локалы, читает их оттуда, модифицирует стэк, совершает прыжки если в методе есть цилкы/условия/etc.
```
public abstract class Interpreter {
public abstract V newValue(Type type);
public abstract V newOperation(AbstractInsnNode insn) throws AnalyzerException;
public abstract V copyOperation(AbstractInsnNode insn, V value) throws AnalyzerException;
public abstract V unaryOperation(AbstractInsnNode insn, V value) throws AnalyzerException;
public abstract V binaryOperation(AbstractInsnNode insn, V value1, V value2) throws AnalyzerException;
public abstract V ternaryOperation(AbstractInsnNode insn, V value1, V value2, V value3) throws AnalyzerException;
public abstract V naryOperation(AbstractInsnNode insn, List extends V values) throws AnalyzerException;
public abstract void returnOperation(AbstractInsnNode insn, V value, V expected) throws AnalyzerException;
public abstract V merge(V v, V w);
}
```
Параметр `V` — это наш класс, в котором можно хранить любую информацию, ассоциированную с конкретным значением. `Analyzer` в процессе анализа будет вызывать соответствующие методы для каждой инструкции, передавать на вход значения, которые сейчас лежат на вершине стэка и будут использованы данной инструкцией, а нам остается вернуть новое значение. Например, `getfield` принимает на вход один аргумент — объект, чье поле будет вычитано, и возвращает значение этого поля. Соответственно, будет вызван `unaryOperation(AbstractInsnNode insn, V value): V`, где мы сможем проверить к чьему филду идет доступ и вернуть разные значения в зависимости от этого. В примере выше на `1: getfield` мы вернем `Value`, в котором будет написано "это поле `client`, типа `Client` и нам интересно трэкать дальнейшие доступы к нему", а в `14: getfield` скажем "аргумент — это какой-то неизвестный объект, так что возвращаем скучный инт и плевать на него".
Отдельно хочу обратить внимание на метод `merge(V v, V w): V`. Он вызывается не для конкретных инструкций, а когда поток исполнения снова попадает в место, где он уже был. Например:
```
public long getBalance() {
Account acc;
if (account != null)
acc = account;
else
acc = client.getDefaultAccount();
return acc.getBalance();
}
```
Здесь к вызову `Account.getBalance()` можно попасть двумя разными путями. Но инструкция-то одна. И на вход она принимает единственное значение. Какое из двух? Именно на этот вопрос и призван отвечать метод `merge`.
Что нам осталось перед самым главным шагом — написанием `SuperInterpreter extends Interpreter`? Правильно. Написать этот самый `SuperValue`. Посколько цель у нас — найти все используемые филды и филды филдов, то логичным выглядит хранение именно пути по филдам. Но поскольку в одно и то же место можно прийти разными путями и с разными объектами, то непосредственно в качестве значения мы будем хранить множество уникальных путей.
```
public class Value extends BasicValue {
private final Set refs;
private Value(Type type, Set refs) {
super(type);
this.refs = refs;
}
}
public class Ref {
private final List path;
private final boolean composite;
public Ref(List path, boolean composite) {
this.path = path;
this.composite = composite;
}
}
```
По поводу странного флага `composite`. Нет ни желания, ни необходимости анализировать абсолютно все. Например, тип `String` лучше воспринимать неделимым. И даже если в нашем методе есть вызов `String.length()`, то правильнее считать, что использовано было именно основное поле `name`, а не `name.value.length`. Кстати, `length` — это вообще не филд, а свойство массива, получаемое отдельной инструкцией `arraylength`. Нам надо обрабатывать ее отдельно? Нет! Самое время первый раз вспомнить ради чего все делается — мы хотим понять какие объекты надо грузить из базы. Соответственно, минимальной и неделимой сущностью являются те объекты, которые грузятся из базы целиком, а не через джойн по филдам. Например, это `Date`, `String`, `Long`, и абсолютно плевать что у них внутри довольно сложная структура. Кстати, сюда же идут все типы, для которых у нас есть конвертер. Например может быть написано
```
class Persion {
@JdbcColumn(converter = CustomJsonConverter.class)
private PassportInfo passportInfo;
}
```
И тогда внутрь этого `PassportInfo` тоже смотреть не надо. Он целиком либо будет притянут, либо нет. Так вот, флаг `composite` отвечает именно за это. Надо нам заглядывать внутрь или же нет.
**Полностью**
```
public class Ref {
private final List path;
private final boolean composite;
public Ref(List path, boolean composite) {
this.path = path;
this.composite = composite;
}
public List getPath() {
return path;
}
public boolean isComposite() {
return composite;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Ref ref = (Ref) o;
return Objects.equals(path, ref.path);
}
@Override
public int hashCode() {
return Objects.hash(path);
}
@Override
public String toString() {
if (path.isEmpty())
return "<[this]>";
else
return "<" + path.stream().map(Field::getName).collect(joining(".")) + ">";
}
public static Ref thisRef() {
return new Ref(emptyList(), true);
}
public static Optional childRef(Ref parent, Field field, Configuration configuration) {
if (!parent.isComposite())
return empty();
if (parent.path.contains(field))//пока можно не обращать внимание, дальше объясню
return empty();
List path = new ArrayList<>(parent.path);
path.add(field);
return of(new Ref(path, configuration.isCompositeField(field)));
}
public static Optional childRef(Ref parent, Ref child) {
if (!parent.isComposite())
return empty();
if (child.path.stream().anyMatch(parent.path::contains))//оно же, объясню позже
return empty();
List path = new ArrayList<>(parent.path);
path.addAll(child.path);
return of(new Ref(path, child.composite));
}
}
```
```
public class Value extends BasicValue {
private final Set refs;
private Value(Type type, Set refs) {
super(type);
this.refs = refs;
}
public Set getRefs() {
return refs;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
if (!super.equals(o)) return false;
Value value = (Value) o;
return Objects.equals(refs, value.refs);
}
@Override
public int hashCode() {
return Objects.hash(super.hashCode(), refs);
}
@Override
public String toString() {
return "(" + refs.stream().map(Object::toString).collect(joining(",")) + ")";
}
public static Value typedValue(Type type, Ref ref) {
return new Value(type, singleton(ref));
}
public static Optional childValue(Value parent, Value child) {
Type type = child.getType();
Set fields = parent.refs.stream()
.flatMap(p -> child.refs.stream().map(c -> childRef(p, c)))
.filter(Optional::isPresent)
.map(Optional::get)
.collect(toSet());
if (fields.isEmpty())
return empty();
return of(new Value(type, fields));
}
public static Optional childValue(Value parent, FieldInsnNode childInsn, Configuration configuration) {
Type type = Type.getType(childInsn.desc);
Field child = resolveField(childInsn);
Set fields = parent.refs.stream()
.map(p -> childRef(p, child, configuration))
.filter(Optional::isPresent)
.map(Optional::get)
.collect(toSet());
if (fields.isEmpty())
return empty();
return of(new Value(type, fields));
}
public static Value mergeValues(Collection values) {
List types = values.stream().map(BasicValue::getType).distinct().collect(toList());
if (types.size() != 1) {
String typesAsString = types.stream().map(Type::toString).collect(joining(", ", "(", ")"));
throw new IllegalStateException("could not merge " + typesAsString);
}
Set fields = values.stream().flatMap(v -> v.refs.stream()).distinct().collect(toSet());
return new Value(types.get(0), fields);
}
public static boolean isComposite(BasicValue value) {
return value instanceof Value && value.getType().getSort() == Type.OBJECT && ((Value) value).refs.stream().anyMatch(Ref::isComposite);
}
}
```
Ну что ж, вся подготовительная работа завершена. Поехали!
```
public class FieldsInterpreter extends BasicInterpreter {
```
Чтобы полностью не писать поддержку всех команд, можно относледоваться от `BasicInterpreter`. Он работает с `BasicValue` (именно поэтому можно было заметить, что мой `Value` был `extends BasicValue`) и реализует простую работу с типами.
```
public class BasicValue implements Value {
public static final BasicValue UNINITIALIZED_VALUE = new BasicValue(null);
public static final BasicValue INT_VALUE = new BasicValue(Type.INT_TYPE);
public static final BasicValue FLOAT_VALUE = new BasicValue(Type.FLOAT_TYPE);
public static final BasicValue LONG_VALUE = new BasicValue(Type.LONG_TYPE);
public static final BasicValue DOUBLE_VALUE = new BasicValue(Type.DOUBLE_TYPE);
public static final BasicValue REFERENCE_VALUE = new BasicValue(Type.getObjectType("java/lang/Object"));
public static final BasicValue RETURNADDRESS_VALUE = new BasicValue(Type.VOID_TYPE);
private final Type type;
public BasicValue(final Type type) {
this.type = type;
}
}
```
Это позволит нам не только наслаждаться обилием кастов (`(Value)basicValue`) в коде, но и писать только значимую часть с нашими композитными значениями, а всю тривиальную логику (вида "инструкция `iconst` возвращает инт") не писать.
Начнем с `newValue`. Этот метод отвечает за первичное создание значение, когда они появляются не как результат инструкции, а "из воздуха". Это параметры метода, `this` и исключение в блоке `catch`. В принципе, нас бы устроил дефолтный вариант, если бы не одно но. Для объектных типов `BasicInterpreter` вместо `BasicValue(actualType)` возвращает просто `BasicValue.REFERENCE_VALUE`. А нам хотелось бы иметь реальный тип.
```
@Override
public BasicValue newValue(Type type) {
if (type != null && type.getSort() == OBJECT)
return new BasicValue(type);
return super.newValue(type);
}
```
Теперь entry point. Весь наш анализ начинается с `this`. Соответственно, нужно как-нибудь сказать, что там, где лежит `this`, на самом деле не `BasicValue(actualType)`, а `Value.typedValue(actualType, Ref.thisRef())`. Вообще, как я уже писал выше, изначально значение `this` устанавливается через вызов `newValue`, только вот неизвестно какой именно. И даже на сам тип опираться нельзя, т.к. один из аргументов метода может быть такого же типа, как и `this`. Получается что напрямую записать `this` правильным мы не можем. Ок, можно выкрутиться. Известно, что при вызове метода `this` всегда идет как локальная переменная номер 0. Напрямую с локальными переменными ничего делать нельзя, их можно только читать и записывать. А это значит, что мы можем перехватить чтение данной переменной и вернуть не оригинальное значение, а правильное. Ну и на всякий случай стоит проверить что данная переменная не была перезаписана.
```
@Override
public BasicValue copyOperation(AbstractInsnNode insn, BasicValue value) throws AnalyzerException {
if (wasUpdated || insn.getType() != VAR_INSN || ((VarInsnNode) insn).var != 0) {
return super.copyOperation(insn, value);
}
switch (insn.getOpcode()) {
case ALOAD:
return typedValue(value.getType(), thisRef());
case ISTORE:
case LSTORE:
case FSTORE:
case DSTORE:
case ASTORE:
wasUpdated = true;
}
return super.copyOperation(insn, value);
}
```
Идем дальше. Мержить значения довольно просто. Если они разных типов, то кидаем исключение, если одно нам интересно, а другое — нет, то берем интересное. Если интересны оба, то объединяем все пути.
```
@Override
public BasicValue merge(BasicValue v, BasicValue w) {
if (v.equals(w))
return v;
if (v instanceof Value || w instanceof Value) {
if (!Objects.equals(v.getType(), w.getType())) {
if (v == UNINITIALIZED_VALUE || w == UNINITIALIZED_VALUE)
return UNINITIALIZED_VALUE;
throw new IllegalStateException("could not merge " + v + " and " + w);
}
if (v instanceof Value != w instanceof Value) {
if (v instanceof Value)
return v;
else
return w;
}
return mergeValues(asList((Value) v, (Value) w));
}
return super.merge(v, w);
}
```
Теперь вот какой вопрос. А любая ли операция является "хорошей"? Все ли мы можем делать с интересующими нас объектами? На самом деле нет. Мы не можем сохранять их никуда в глобально доступный стейт. В противном случае уже невозможно будет проконтролировать использование, т.к. оно может быть за пределами анализируемого метода. Инструкций, позволяющих потерять наше значение всего 3 (я сейчас не считаю передачу в аргументы функций): `putfield`, `putstatic`, `aastore`. Здесь сразу стоит оговориться. Из этих инструкций только `putstatic` (запись в статический филд) теряет наш объект гарантированно. Ибо даже если филд приватный, ничто не мешает мне обратиться к нему из соседнего метода. А вот с `putfield` и `aastore` интереснее. В общем случае, если наш объект был записан в нестатический филд или в массив, то действительно неизвестно что будет дальше. Этот объект (чей был филд) или массив могут уйти куда угодно и там с ними будет сделано что угодно. И если в объекте мы хотя бы знаем что это за филд, то в массиве индекс может вычисляться динамически и узнать мы его не сможем. Однако, есть частный случай — если объект или массив являются локальными.
```
public class Account {
private Client client;
public Long getClientId() {
return Optional.ofNullable(client).map(Client::getId).orElse(null);
}
}
```
Не смотря на то, что здесь происходит запись клиента в филд (внутри `ofNullable` создается новый инстанс `Optional` и `client` записывается к нему в поле `value`), утечки здесь не происходит и проследить полный путь можно. Теоретически. На практике этого пока нет. Кстати, конкретно данный пример не будет работать не только из-за `ofNullable(client)`, но еще и из-за `map(Client::getId)`, но про это позже.
Ну а сейчас нам нужно просто запретить `putfield`, `putstatic` и `aastore`.
```
@Override
public BasicValue binaryOperation(AbstractInsnNode insn, BasicValue value1, BasicValue value2) throws AnalyzerException {
if (insn.getOpcode() == PUTFIELD && Value.isComposite(value2)) {
throw new IllegalStateException("could not trace " + value2 + " over putfield");
}
return super.binaryOperation(insn, value1, value2);
}
@Override
public BasicValue ternaryOperation(AbstractInsnNode insn, BasicValue value1, BasicValue value2, BasicValue value3) throws AnalyzerException {
if (insn.getOpcode() == AASTORE && Value.isComposite(value3)) {
throw new IllegalStateException("could not trace " + value3 + " over aastore");
}
return super.ternaryOperation(insn, value1, value2, value3);
}
@Override
public BasicValue unaryOperation(AbstractInsnNode insn, BasicValue value) throws AnalyzerException {
if (Value.isComposite(value)) {
switch (insn.getOpcode()) {
case PUTSTATIC: {
throw new IllegalStateException("could not trace " + value + " over putstatic");
}
...
}
}
return super.unaryOperation(insn, value);
}
```
Еще есть каст. В байткоде для него есть инструкция `checkcast`. С нашей точки зрения у каста может быть два применения: возврат потерянного типа и уточнение типа. Первое — это конструкции вида
```
Client client1 = ...;
Object objClient = client1;
Client client2 = (Client) objClient;
```
Здесь на третьей строчке не смотря на наличие каста, на уровне конкретного объекта уточнения типа не происходит. У нас же в значении записан исходный тип объекта, и от того, что мы переложили клиента из переменной `client1` в `objClient`, информация не потерялась. Соответственно, здесь при `checkcast` достаточно просто проверить что этот тип и так уже был.
А вот с уточнением интереснее.
```
class Foo {
private List list;
public void trimToSize() {
((ArrayList) list).trimToSize();
}
}
```
Обновить тип у значения не проблема. Но гораздо важнее здесь определиться в том, может ли вообще отличаться реальный класс, от того, который написан в декларации филда. Если считать, что такое возможно, то возникнут очень большие проблемы при поддержке вызовов методов, потому что в джаве почти все методы виртуальные, и будет совершенно непонятно, какой метод реально будет вызван. Можем ли мы сказать что тип филда всегда идеально точен? Конечно же, можем! Самое время снова вспомнить про исходную задачу. Нам нужно понять, чтения из каких филдов будут внутри конкретных методов для того, чтобы понять, надо ли их заполнять при запросе в базу или же можно оставить дефолтные null/0/false. И здесь все просто. Композитный объект — это джойн
```
@JdbcJoinedObject(localColumn = "CLIENT")
private Client client;
```
И мы точно знаем, что в таких местах никакого полифорфизма нет, ORM гарантированно создаст инстанс именно того класса, который написан у филда. Теперь с чистой совестью можно написать `checkcast`
```
@Override
public BasicValue unaryOperation(AbstractInsnNode insn, BasicValue value) throws AnalyzerException {
if (Value.isComposite(value)) {
switch (insn.getOpcode()) {
...
case CHECKCAST: {
Class original = reflectClass(value.getType());
Type targetType = getObjectType(((TypeInsnNode) insn).desc);
Class afterCast = reflectClass(targetType);
if (afterCast.isAssignableFrom(original)) {
return value;
} else {
throw new IllegalStateException("type specification not supported");
}
}
}
}
return super.unaryOperation(insn, value);
}
```
Переходим к центральной инструкции — `getfield`. Тут есть один тонкий момент — как глубоко копать?
```
class Foo {
private Foo child;
public Foo test() {
Foo loopedRef = this;
while (ThreadLocalRandom.current().nextBoolean()) {
loopedRef = loopedRef.child;
}
return loopedRef;
}
}
```
Очевидно, что рано или поздно из цикла мы выйдем. Но какие филды считать использованными? `child`, `child.child`, `child.child.child`? Когда останавливаться? Очевидно, что в общем случае это тоже неразрешимо. Прекрасный момент, чтобы в очередной раз вспомнить про оригинальную задачу. Как я уже писал в первой части,
> все рекурсивные филды сейчас вообще не заполняются и там всегда null.
Так что здесь заполненным будет только первый child, а все последующие в любом случае null, а, значит, и анализировать их не надо. Внимательные читатели должны были заметить в методах `Ref.childRef` условие
```
if (parent.path.contains(field))
return empty();
```
Оно именно про это. Если мы через данный филд уже проходили, то путь не считаем.
Сейчас самое время ввести новый термин "интересующий нас филд". Список именно таких филдов в конечном счете мы должны получить. Хочу обратить внимание, что это не любой некомпозитный филд в конце цепочки композитных объектов. Например, в нашей задаче, если над филдом нет никаких аннотаций (ни `@JdbcJoinedObject`, ни `@JdbcColumn`), то даже если этот филд используется, нам на это плевать. ORM все равно не будет выгребать его из базы.
Итого, в обработке `getfield` нужно получить новое значение как доступ к филду у базового значения, затем проверить на отсутствие рекурсии. Если конечный филд нас интересует, то запомнить его, а если значение является композитным, то сохранить его для дальнейшего анализа. Сказано — сделано.
```
@Override
public BasicValue unaryOperation(AbstractInsnNode insn, BasicValue value) throws AnalyzerException {
if (Value.isComposite(value)) {
switch (insn.getOpcode()) {
...
case GETFIELD: {
Optional optionalFieldValue = childValue((Value) value, (FieldInsnNode) insn, configuration);
if (!optionalFieldValue.isPresent())
break;
Value fieldValue = optionalFieldValue.get();
if (configuration.isInterestingField(resolveField((FieldInsnNode) insn))) {
context.addUsedField(fieldValue);
}
if (Value.isComposite(fieldValue)) {
return fieldValue;
}
break;
}
...
}
}
return super.unaryOperation(insn, value);
}
```
Мы почти у цели. Осталась последняя, но не по значению, инструкция. Точнее не инструкция, а группа инструкций `invoke*`. До сих пор весь анализ шел только вокруг филдов, но, тем не менее, в исходной задаче хотелось поддержать и вызов методов. Чтобы работало, например:
```
public long getClientId() {
return getClient().getId();
}
```
Но прежде, чем мы разберемся с вызовами методов, нужно доделать последнюю подготовительную вещь. В получившейся модели один филд не может быть одновременно и композитным, и интересующим нас. И это вполне логично. Нет смысла сначала считать филд используемым, а потом все равно лезть внутрь и анализировать его потроха. Зачем тогда сам филд? И на всех приведенных выше примерах такой подход работал отлично. Но есть одно исключение. Если из метода возвращается композитный объект.
```
class Account implements HasClient {
@JdbcJoinedObject
private Client client;
public Client getClient() {
return client;
}
}
```
Здесь `Account.client` явно композитный и надо смотреть только на использование вложенных филдов. Тем не менее, очевидно что надо получить его целиком. Ведь снаружи может быть вызван любой метод клиента. Решение довольно простое — результат анализа содержит не только перечень использованных значение, но и возвращенное композитное значение.
```
public static class Result {
private final Set usedFields;
private final Value returnedCompositeValue;
}
```
Как узнать это значение? Не просто, а очень просто. Нужно перебрать все инструкции возврата и посмотреть что они возвращают. Строго говоря, т.к. композитным может быть только объект (в терминологии джавы, в смысле — ссылочный тип), а не примитивы, то достаточно было бы проверить только `areturn`, но, на всякий случай, я проверяю все `*return`. От `MethodNode` (это тот, который вышел из асмового Tree API) у нас есть массив всех инструкций метода. От анализатора есть массив фреймов. Фрейм — это состояние локальных переменных и стэка перед выполнением текущей инструкции. Помните, я писал пример байткода и подробно описывал локальные переменные и стэк в комментариях? Вот это ровно фреймы и были. Теперь нам достаточно знаний чтобы собрать возвращенное композитное значение.
```
private static Value getReturnedCompositeValue(Frame[] frames, AbstractInsnNode[] insns) {
Set resultValues = new HashSet<>();
for (int i = 0; i < insns.length; i++) {
AbstractInsnNode insn = insns[i];
switch (insn.getOpcode()) {
case IRETURN:
case LRETURN:
case FRETURN:
case DRETURN:
case ARETURN:
BasicValue value = frames[i].getStack(0);
if (Value.isComposite(value)) {
resultValues.add((Value) value);
}
break;
}
}
if (resultValues.isEmpty())
return null;
return mergeValues(resultValues);
}
```
Ну а сам `analyzeField` выглядит так
```
public static Result analyzeField(Method method, Configuration configuration) {
if (Modifier.isNative(method.getModifiers()))
throw new IllegalStateException("could not analyze native method " + method);
MethodInfo methodInfo = readMethod(method);
MethodNode mn = methodInfo.getMethodNode();
String internalClassName = methodInfo.getInternalDeclaringClassName();
int classAccess = methodInfo.getClassAccess();
Context context = new Context(method, classAccess);
FieldsInterpreter interpreter = new FieldsInterpreter(context, configuration);
Analyzer analyzer = new Analyzer<>(interpreter);
try {
analyzer.analyze(internalClassName, mn);
} catch (AnalyzerException e) {
throw new RuntimeException(e);
}
Frame[] frames = analyzer.getFrames();
AbstractInsnNode[] insns = mn.instructions.toArray();
Value returnedCompositeValue = getReturnedCompositeValue(frames, insns);
return new Result(context.getUsedFields(), returnedCompositeValue);
}
```
И вот теперь, наконец-то, можно приступить к финальному рывку. `invoke*`. Всего инструкций для вызовов методов 5 штук:
1. `invokespecial` — служит для вызова конкретного инстансного метода. Используется для вызова конструктора, приватных методов, методов суперкласса (это если внутри метода написать `super.call()`).
2. `invokevirtual` — обычный вызов обычного инстансного метода. Реальный метод при этом определяется исходя из реального класса объекта. Важно, чтобы сам метод изначально был определен в классе.
3. `invokeinterface` — то же самое, что и `invokevirtual`, с единственным отличием — метод должен быть определен в интерфейсе.
4. `invokestatic` — вызов статического метода
5. `invokedynamic` — специальная инструкция, добавленная в 7 джаве в рамках JSR 292. Если у первых четырех инвоуков логика диспатча зашита в JVM, то в `invokedynamic` она реализуется пользователем в джава коде (именно поэтому он и называется dynamic). Если совсем грубо, то в параметр там передается ссылка на джавовый метод (+ его аргументы), в котором как раз логика диспатча и написана. Кому интересно, рекомендую посмотреть доклад Владимира Иванова [Invokedynamic: роскошь или необходимость?](https://youtu.be/oeFejrCcqDI?list=PLyKg-WHKJImeRoGVHGBzoohWGtDan8Cnr).
Сразу оговорюсь, все дальнейшие рассуждения касаются только вызовов, где композитные значения передаются внутрь вызываемых методов, в противном случае анализ не требуется. С `invokedynamic` одновременно и проще, и сложнее всего. Можно сказать, что раз это полностью динамический диспатч, да еще и написанный в пользовательском коде, то проанализировать ничего нельзя (банально, мы не знаем какой метод будет вызван), и использовать `invokedynamic` мы запрещаем. Это простое решение, и я "реализовал" именно его. В принципе, есть пара мыслей как можно попытаться поддержать даже `invokedynamic`, но про это в самом конце.
Идем дальше. Теоретически, довольно легко сделать поддержку передачи композитных значений как параметров. В принципе, у нас для этого уже почти все есть. Помните, как мы определяем исходное значение `this`, просто читая локальную переменную 0? Собственно, если нас интересует какой-то параметр, то нужно просто сохранить его индекс в конструкторе `FieldsInterpreter` и в `copyOperation` следить за еще одной ячейкой. Более того, сам внешний интерфейс `MethodAnalyzer.analyzeFields` лучше переделать с "анализируй метод относительно использования филдов `this`" на "анализируй метод относительно использования филдов данных параметров" (где `this` — частный случай). Ничего сложного в этом нет, просто нужно сделать. Тем не менее, на текущий момент, так нельзя. И не только потому что хотелось поскорее написать этот пост, но и потому что было замечено что в реальности композитные объекты очень редко уходят куда-нибудь параметрами. А если и уходят, то там все равно будут сохранены в филд (какой-нибудь `Optional.ofNullable(client)`). Так что сама по себе данная фича дает не так уж и много.
Итого, `invokestatic` тоже отвалился (т.к. в параметрах нельзя, а `this` у него нет). Остаются `invokespecial`, `invokevirtual` и `invokeinterface`. Важно понять, а какой же метод на самом деле будет вызван. По сути, надо реализовать тот же самый диспатч, который уже реализован в jvm. С `invokespecial` все хорошо, там логика диспатча зависит только от самой инструкции и не зависит от реального класса объекта, на котором этот метод вызывается. А вот с `invokevirtual` и `invokeinterface` интереснее. В общем случае, без знания реального класса объекта вызываемый метод неизвестен.
```
public String objectToString(Object obj) {
return obj.toString();
}
```
```
public static java.lang.String objectToString(java.lang.Object);
Code:
0: aload_0
1: invokevirtual #104 // Method java/lang/Object.toString:()Ljava/lang/String;
4: areturn
```
Здесь, очевидно, неизвестно какой метод (какого класса) будет вызван. Однако, если в очередной раз вспомнить исходную задачу, то все сразу упрощается. Мы ведь для чего вообще анализируем методы и хотим определить используемые филды? Чтобы понять какие из них необходимо заполнять *автоматически внутри ORM*. А ORM написан нами же, и мы прекрасно знаем что он будет создавать объекты именно того класса, который написан как тип филда. Так что получается что даже `invokevirtual` и `invokeinterface` мы можем обработать.
Ура! Вызываемый метод нашли. Что дальше? А дальше просто анализируем его рекурсивно, после чего сохраняем к себе используемые значения (только не забыв что они считались относительно того композитного значения, которое ушло в качестве `this` в метод), а возвращенное композитное значение (опять же, не забыв про иерархию) записываем к себе как результат вызова метода. И все!
```
@Override
public BasicValue naryOperation(AbstractInsnNode insn, List extends BasicValue values) throws AnalyzerException {
Method method = null;
Value methodThis = null;
switch (insn.getOpcode()) {
case INVOKESPECIAL: {...}
case INVOKEVIRTUAL: {...}
case INVOKEINTERFACE: {
if (Value.isComposite(values.get(0))) {
MethodInsnNode methodNode = (MethodInsnNode) insn;
Class objectClass = reflectClass(values.get(0).getType());
Method interfaceMethod = resolveInterfaceMethod(reflectClass(methodNode.owner), methodNode.name, getMethodType(methodNode.desc));
method = lookupInterfaceMethod(objectClass, interfaceMethod);
methodThis = (Value) values.get(0);
}
List badValues = values.stream().skip(1).filter(Value::isComposite).collect(toList());
if (!badValues.isEmpty())
throw new IllegalStateException("could not pass " + badValues + " as parameter");
break;
}
case INVOKESTATIC:
case INVOKEDYNAMIC: {
List badValues = values.stream().filter(Value::isComposite).collect(toList());
if (!badValues.isEmpty())
throw new IllegalStateException("could not pass " + badValues + " as parameter");
break;
}
}
if (method != null) {
MethodAnalyzer.Result methodResult = analyzeFields(method, configuration);
for (Value usedField : methodResult.getUsedFields()) {
childValue(methodThis, usedField).ifPresent(context::addUsedField);
}
if (methodResult.getReturnedCompositeValue() != null) {
Optional returnedValue = childValue(methodThis, methodResult.getReturnedCompositeValue());
if (returnedValue.isPresent()) {
return returnedValue.get();
}
}
}
return super.naryOperation(insn, values);
}
```
Напоследок хочется сказать пару слов по поводу самого диспатча. Там написано много кода, но сложного в нем ничего нет. По сути, просто открываешь [шестую главу JVMS](https://docs.oracle.com/javase/specs/jvms/se10/html/jvms-6.html) на нужной инструкции и переписываешь 1 в 1. Там в описании каждой команды подробно написан пошаговый алгоритм поиска нужного метода. Единственный момент — алгоритмическая сложность получившегося дела. Честно скажу, вообще не анализировал, но очень похоже что там и экспонента есть. Тем не менее, за проблему не считаю т.к. зависимость там от глубины иерархии, а мы все-таки имеем дело с энтитями, а в них иерархия даже на 2 класса — уже большая редкость. Помимо этого все выполняется один раз на старте приложения, после чего кэшируется, так что время работы не сильно критично. В любом случае, будет тормозить — перепишем. Кому все же интересно, смотрите классы [ResolutionUtil](https://bitbucket.org/Dougrinch/deps/src/default/src/main/java/com/dou/deps/utils/ResolutionUtil.java) и [LookupUtil](https://bitbucket.org/Dougrinch/deps/src/default/src/main/java/com/dou/deps/utils/LookupUtil.java).
ВСЁ!
### Часть седьмая. Что еще можно доделать
Как известно, после первых 80% результата и 20% времени работы остаются еще 20% результата и 80% работы. Собственно, что же еще можно добавить, чтобы было не круто, а очень круто?
* Таки поддержать передачу композитных значений в параметрах методов. Про это я уже писал и ничего сложного там нет.
* Разрешить сохранять значения в филды и массивы. С массивами сложнее (т.к. индексы неизвестны и надо следить за самим массивом), но вот хотя бы с филдами можно разобраться. Собственно, суть в локальных объектах. Нет ничего плохого в сохранении в филд объекта, который является локальным относительно анализируемого метода.
```
public class Account {
private Client client;
public Long getClientId() {
return Optional.ofNullable(client).map(Client::getId).orElse(null);
}
}
```
Можно проследить что объект `Optional`, созданный внутри `ofNullable` на момент выхода из `getClientId` уже уничтожен, а клиент, записанный к нему в филд `value` уже прочитан и использован. В принципе, это довольно сильно похоже на уже имеющийся `returnedCompositeValue` — по сути, это тоже значение, утекающее за границу анализируемого метода. Можно, например, при записи в филд помечать основной объект (чей это филд) как композитный и при выходе из метода следить чтобы все композитные объекты были либо уничтожены, либо возвращены. Главная сложность будет в необходимости написания своего мини-хипа. Если до сих пор все значения хранились либо на стэке, либо в локальных переменных, то информацию о том, что "в филде `value` объекта `Optional@1234` лежит `Client@5678`" сейчас хранить негде.
* Поддержать `invokedynamic`, хотя бы для частных случаев. Если бы через indy делалась только совсем кастомная пользовательская логика, то можно было бы и забить. Но проблема в том, что все больше стандартная джава компилируется с использованием данной инструкции. Так, лямбды компилируются именно через нее. Более того, начиная с девятки конкатенация строк тоже компилируется через invokedynamic. Глобально есть два варианта поддержки. Можно делать точечные хаки. Например, мы знаем что для лямбд в качестве бутстрап метода используется `java.lang.invoke.LambdaMetafactory.metafactory`. Можно детектить именно его, а затем, подсмотрев текущую реализацию, пытаться предугадать что именно он вернет. А для конкатенации `java.lang.invoke.StringConcatFactory.makeConcat/makeConcatWithConstants`. С реализацией здесь даже проще. Мы знаем что просто у всех аргументов будет вызван `toString()`. И, теоретически, подобное решение, скорее всего, будет работать. Не смотря на то, что это является деталями реализации, я не думаю, что оркал/кто-нибудь другой решит данное поведение изменить. Ведь в таком случае старые скомпилированные классы перестанут работать на новых jvm, а такое в джаве не принято. Так что старые версии, скорее всего, работать будут. А для новых в любом случае придется постепенно добавлять поддержку в новых местах. Но это в теории. А на практике, я думаю, не надо объяснять чем плохо такое решение и почему так все же делать не стоит. Альтернативным же вариантом была бы попытка поддержать автоматически большинство indy инструкций. Как вообще они работают? При первой встрече с indy рантайм вызывает бутстрап метод, который возвращает специальный объект — `CallSite`. Внутри этого колсайта написано что же на самом деле нужно вызывать. Так, например, в лябмдах внутри `LambdaMetafactory.metafactory` происходит генерация класса со статическим методом `getValue`, который как раз и возвращает инстанс необходимого функционального интерфейса. А колсайт слинкован на вызов этого `getValue`. И сам бутстрап метод (вместе с аргументами) прописан статически. Более того, он, очевидно, должен быть stateless. Соответственно, можно его просто вызвать! Ну а потом как-нибудь выковырить из колсайта то, что будет вызвано на самом деле. Сами `CallSite` могут быть `ConstantCallSite`, `MutableCallSite` и `VolatileCallSite`. И если с mutable и volatile ничего поделать нельзя, там честная динамика и реальный метод неизвестен, то с `ConstantCallSite` можно попробовать. Но главная проблема в таком решении в строчке "как-нибудь выковырить из колсайта". Ой, не факт, что это вообще возможно. А если и возможно, то вот это уже похоже на совсем внутренности VM, которые могут быть изменены в любой момент.
### Послесловие
Кто-то скажет, что это перебор. И ради какого-то несчастного `partialGet` городить такое не имеет смысла. Возможно, он даже будет прав. Тем не менее, мне хотелось показать, что в самом байткоде ничего страшного нет, и что с его помощью можно делать такие штуки, которые в "стандартной джаве" даже не снились.
Кому интересно, полный код лежит [здесь](https://gitlab.com/Dougrinch/deps). | https://habr.com/ru/post/409043/ | null | ru | null |
# Создание меню для игры на Unity3D на основе State-ов
Всем доброго времени суток! Хотелось бы рассказать о том, как я реализовывал систему игрового UI в небольшом игровом проекте. Данный подход показался мне самым оптимальным и удобным во всех требуемых аспектах.
Вся система является довольно тривиальным представлением недетерминированного конечного автомата.
Для реализации нам понадобится: *набор состояний*, *набор представлений состояний*, *стейт-свитчер, переключающая эти состояния*.
### Реализация сервиса управления меню
Как я уже сказал, вся система может быть описана 3-4 классами: состоянием, визуальным представлением состояния и автоматом, который переключается между этими состояниями.
**Опишем интерфейс состояния:**
**IState**
```
public interface IState
{
void OnEnter(params object[] parameters);
void OnEnter();
void OnExit();
}
```
Метод *OnEnter* будет вызываться в момент перехода в состояние, а его перегрузка создана для того, чтобы передавать в состояние набор параметров. Тем самым можно передавать объекты, которые будут использованы внутри состояния — аргументы событий или, например, делегаты, которые будут вызываться из состояния при том или ином событии. В свою очередь, *OnExit* будет вызван при выходе из состояния.
**Представление состояния:**
У каждого состояния должно быть представление. Задача представления — выводить информацию в UI элементы и уведомлять состояние о пользовательских действиях, касающихся UI (Если такие предусмотрены конкретной страницей интерфейса).
**IUIShowableHidable**
```
public interface IUIShowableHidable
{
void ShowUI();
void HideUI();
}
```
*ShowUI* — метод, инкапсулирующий в себе методы, реализующие отображение (активацию) UI-элементов, относящихся к текущей странице меню.
*HideUI* — метод, позволяющий скрыть все элементы, к примеру, перед переходом на другую страницу.
**Реализация состояний и их представлений:**
Подразумевается, что *IState* и *IUIShowableHidable* работают в связке — в момент вызова OnEnter в стейте уже находится заинжекченый туда IUIShowableHidable. При переходе в состояние вызывается ShowUI, при выходе — HideUI. В большинстве случаев именно так и будет работать переход между состояниями. Исключения, вроде длительных анимаций переходов, при которых требуется задержка между HideUI предыдущей страницы и ShowUI новой страницы можно решить различными способами.
Учитывая факт, описанный выше, мной было решено для удобства и скорости создания новых стейтов сделать абстрактный класс, который будет иметь поле с «вьюшкой» и инкапсулировать показ и сокрытие UI в методы переходов.
**UIState**
```
public abstract class UIState : IState
{
protected abstract IUIShowableHidable ShowableHidable { get; set; }
protected abstract void Enter(params object[] parameters);
protected abstract void Enter();
protected abstract void Exit();
public virtual void OnEnter()
{
ShowableHidable.ShowUI();
Enter();
}
public virtual void OnExit()
{
ShowableHidable.HideUI();
Exit();
}
public virtual void OnEnter(params object[] parameters)
{
ShowableHidable.ShowUI();
Enter(parameters);
}
}
```
Так же имеются абстрактные методы *Enter* и *Exit*, которые будут вызваны после вызова соответсвующих методов *IUIShowableHidable*. Фактической пользы от них нет, так как можно было при надобности обойтись простым override-ом *OnEnter* и *OnExit*, однако мне показалось удобным держать в стейте пустые методы, которые в случае надобности будут заполнены.
Для большей простоты был реализован класс *UIShowableHidable*, который реализует *IUIShowableHidable* и избавляет нас от надобности, каждый раз реализовывать ShowUI и HideUI. Так же, в Awake элемент будет деактивирован, это сделано из соображений, что изначально, все элементы UI включены, с целью получения их инстансов.
**UIShowableHidable**
```
public class UIShowableHidable : CachableMonoBehaviour, IUIShowableHidable
{
protected virtual void Awake()
{
gameObject.SetActive(false);
}
public virtual void ShowUI()
{
gameObject.SetActive(true);
}
public virtual void HideUI()
{
gameObject.SetActive(false);
}
protected bool TrySendAction(Action action)
{
if (action == null) return false;
action();
return true;
}
}
```
**Приступим к проектированию «сердца» игрового меню:**
Нам нужны три основных метода:
* *GoToScreenOfType* — метод, который будет позволять переходить в состояние, передаваемое параметром. Имеет перегрузку, которая будет передавать набор object-ов в целевое состояние.
* *GoToPreviousScreen* — будет возвращать нас на предыдущий «скрин».
* *ClearUndoStack* — даст возможность очистить историю переходов между «скринами».
**IMenuService**
```
public interface IMenuService
{
void GoToScreenOfType() where T : UIState;
void GoToScreenOfType(params object[] parameters) where T : UIState;
void GoToPreviousScreen();
void ClearUndoStack();
}
```
Далее необходимо реализовать механизм, позволяющий переключаться между состояниями.
**StateSwitcher**
```
public class StateSwitcher
{
private IState currentState;
private readonly List registeredStates;
private readonly Stack switchingHistory;
private StateSwitchCommand previousStateSwitchCommand;
public StateSwitcher()
{
registeredStates = new List();
switchingHistory = new Stack();
}
public void ClearUndoStack()
{
switchingHistory.Clear();
}
public void AddState(IState state)
{
if (registeredStates.Contains(state)) return;
registeredStates.Add(state);
}
public void GoToState()
{
GoToState(typeof(T));
}
public void GoToState(params object[] parameters)
{
GoToState(typeof(T), parameters);
}
public void GoToState(Type type)
{
Type targetType = type;
if (currentState != null)
if (currentState.GetType() == targetType) return;
foreach (var item in registeredStates)
{
if (item.GetType() != targetType) continue;
if (currentState != null)
currentState.OnExit();
currentState = item;
currentState.OnEnter();
RegStateSwitching(targetType, null);
}
}
public void GoToState(Type type, params object[] parameters)
{
Type targetType = type;
if (currentState != null)
if (currentState.GetType() == targetType) return;
foreach (var item in registeredStates)
{
if (item.GetType() != targetType) continue;
if (currentState != null)
currentState.OnExit();
currentState = item;
currentState.OnEnter(parameters);
RegStateSwitching(targetType, parameters);
}
}
public void GoToPreviousState()
{
if (switchingHistory.Count < 1) return;
StateSwitchCommand destination = switchingHistory.Pop();
previousStateSwitchCommand = null;
if (destination.parameters == null)
{
GoToState(destination.stateType);
}
else
{
GoToState(destination.stateType, destination.parameters);
}
}
private void RegStateSwitching(Type type, params object[] parameters)
{
if (previousStateSwitchCommand != null)
switchingHistory.Push(previousStateSwitchCommand);
previousStateSwitchCommand = new StateSwitchCommand(type, parameters);
}
private class StateSwitchCommand
{
public StateSwitchCommand(Type type, params object[] parameters)
{
stateType = type;
this.parameters = parameters;
}
public readonly Type stateType;
public readonly object[] parameters;
}
}
```
Тут все просто: *AddState* добавляет стейт в список стейтов, *GoToState* проверяет наличие требуемого стейта в списке, если находит его, то выполняет выход из текущего состояния и вход в требуемое, а так же регистрирует смену состояний, представляя переход классом *StateSwitchCommand*, добавляя ее в стек переходов, что позволит нам возвращаться на предыдущий экран.
Осталось добавить реализацию *IMenuService*
**MenuManager**
```
public class MenuManager : IMenuService
{
private readonly StateSwitcher stateSwitcher;
public MenuManager()
{
stateSwitcher = new StateSwitcher();
}
public MenuManager(params UIState[] states) : this()
{
foreach (var item in states)
{
stateSwitcher.AddState(item);
}
}
public void GoToScreenOfType() where T : UIState
{
stateSwitcher.GoToState();
}
public void GoToScreenOfType(Type type)
{
stateSwitcher.GoToState(type);
}
public void GoToScreenOfType(params object[] parameters) where T : UIState
{
stateSwitcher.GoToState(parameters);
}
public void GoToScreenOfType(Type type, params object[] parameters)
{
stateSwitcher.GoToState(type, parameters);
}
public void GoToPreviousScreen()
{
stateSwitcher.GoToPreviousState();
}
public void ClearUndoStack()
{
stateSwitcher.ClearUndoStack();
}
}
```
Конструктор принимает набор IState'ов, которые будут использованы в вашей игре.
### Использование
**Простой пример использования:**
**Пример состояния**
```
public sealed class GameEndState : UIState
{
protected override IUIShowableHidable ShowableHidable { get; set; }
private readonly GameEndUI gameEndUI;
private Action onRestartButtonClicked;
private Action onMainMenuButtonClicked;
public GameEndState(IUIShowableHidable uiShowableHidable, GameEndUI gameEndUI)
{
ShowableHidable = uiShowableHidable;
this.gameEndUI = gameEndUI;
}
protected override void Enter(params object[] parameters)
{
onRestartButtonClicked = (Action) parameters[0];
onMainMenuButtonClicked = (Action)parameters[1];
gameEndUI.onRestartButtonClicked += onRestartButtonClicked;
gameEndUI.onMainMenuButtonClicked += onMainMenuButtonClicked;
gameEndUI.SetGameEndResult((string)parameters[2]);
gameEndUI.SetTimeText((string)parameters[3]);
gameEndUI.SetScoreText((string)parameters[4]);
}
protected override void Enter()
{
}
protected override void Exit()
{
gameEndUI.onRestartButtonClicked -= onRestartButtonClicked;
gameEndUI.onMainMenuButtonClicked -= onMainMenuButtonClicked;
}
}
```
Конструктор требует входных *IUIShowableHidable* и, собственно, самого *GameEndUI* — представления состояния.
**Пример представления состояния**
```
public class GameEndUI : UIShowableHidable
{
public static GameEndUI Instance { get; private set; }
[SerializeField]
private Text gameEndResultText;
[SerializeField]
private Text timeText;
[SerializeField]
private Text scoreText;
[SerializeField]
private Button restartButton;
[SerializeField]
private Button mainMenuButton;
public Action onMainMenuButtonClicked;
public Action onRestartButtonClicked;
protected override void Awake()
{
base.Awake();
Instance = this;
restartButton.onClick.AddListener(() => { if(onRestartButtonClicked != null) onRestartButtonClicked(); });
mainMenuButton.onClick.AddListener(() => { if (onMainMenuButtonClicked != null) onMainMenuButtonClicked(); });
}
public void SetTimeText(string value)
{
timeText.text = value;
}
public void SetGameEndResult(string value)
{
gameEndResultText.text = value;
}
public void SetScoreText(string value)
{
scoreText.text = value;
}
}
```
**Инициализация и переходы**
```
private IMenuService menuService;
private void InitMenuService()
{
menuService = new MenuManager
(
new MainMenuState(MainMenuUI.Instance, MainMenuUI.Instance, playmodeService, scoreSystem),
new SettingsState(SettingsUI.Instance, SettingsUI.Instance, gamePrefabs),
new AboutAuthorsState(AboutAuthorsUI.Instance, AboutAuthorsUI.Instance),
new GameEndState(GameEndUI.Instance, GameEndUI.Instance),
playmodeState
);
}
...
private void OnGameEnded(GameEndEventArgs gameEndEventArgs)
{
Timer.StopTimer();
scoreSystem.ReportScore(score);
PauseGame(!IsGamePaused());
Master.GetMenuService().GoToScreenOfType(
new Action(() => { ReloadGame(); PauseGame(false); }),
new Action(() => { UnloadGame(); PauseGame(false); }),
gameEndEventArgs.gameEndStatus.ToString(),
Timer.GetTimeFormatted(),
score.ToString());
}
```
### Заключение
В итоге получается довольно практичная, на мой взгляд, и легко расширяемая система управления пользовательским интерфейсом.
Спасибо за внимание. Буду рад замечаниям и предложениям, способным улучшить описаный в статье способ. | https://habr.com/ru/post/310236/ | null | ru | null |
# syncTranslit плагин
Во многих веб проектах используются friendly urls. Например, вместо id статьи в url испольуется его текстовый идентификатор (slug). Обычно slug генерируется автоматически на серверной стороне при создании статьи. Но если вы хотите иметь возможность задавать slug самостоятельно (через форму) — можете использовать мой [плагин syncTranslit](http://snowcore.net/synctranslit "syncTranslit jQuery plugin").

Публикую статью со [своего блога](http://snowcore.net/ "Блог веб разработчика Snowcore"). Данный плагин рассчитан на украинскую и русскую аудиторию разработчиков.
Основная задача плагина: генерация slug из кирилличного текста. Плагин позволяет синхронизировать два поля на форме, при этом одно поле является источником данных (например, название статьи), а второе (slug) — принимает траслитерированный текст.
### Использование
Подключаем файл плагина, вызываем метод **syncTranslit** д я элемента-источника, передаем параметр destination — id элемента-приемника:
> `$(document).ready(function(){
>
> $("#articleTitle").syncTranslit({destination: "slug"});
>
> });`
[Демонстрация данного примера](http://snowcore.net/synctranslit)
### Возможные опции
Список доступных опций:
* **destination** — id элемента-приемника
* **type** — url (default) или raw: определяет тип транслитерации. url — для транслитерации в slug (заменяются спец. символы). raw используется для чистого преобразования (с сохранением всех спец. символов)
* **caseStyle** — lower (default), normal, upper: отвечает за регистр транслитерируемых данных
* **urlSeparator** — разделитель слов для slug (default: "-")
Пример с использованием других опций: транслитерация с преобразованием в верхний регистр и с использованием нижнего подчеркивания для разделения слов:
> `$(document).ready(function(){
>
> $("#articleTitle2").syncTranslit({
>
> destination: "slug2",
>
> caseStyle: "upper",
>
> urlSeparator: "\_"
>
> });
>
> });`
[Скачать плагин syncTranslit](http://code.google.com/p/synctranslit/) c Google Code
[Страница проекта на сайте jQuery](http://plugins.jquery.com/project/syncTranslit) | https://habr.com/ru/post/73168/ | null | ru | null |
# Обзор R пакетов для интернет маркетинга, часть 2
Первой моей публикацией на Хабре была ["Обзор R пакетов для интернет маркетинга, часть 1"](https://habr.com/ru/post/425425/), с тех пор прошло почти 3 года. За это время какие-то пакеты стали не актуальны, какие-то сильно изменились и конечно появились новые пакеты, которые могут значительно облегчить жизнь интернет маркетологам и веб аналитикам.
В этой статье мы рассмотрим следующую порцию R пакетов предназначенных для интернет - маркетинга.
Каждый из приведённых в статье пакетов будет рассмотрен по приведённым ниже пунктам:
* основное назначение пакета;
* возможности пакета;
* установка пакета;
* пример кода;
* полезные ссылки.
Содержание
----------
*Если вы интересуетесь анализом данных возможно вам будут полезны мои*[*telegram*](https://t.me/R4marketing)*и*[*youtube*](https://www.youtube.com/R4marketing/?sub_confirmation=1)*каналы. Большая часть контента которых посвящены языку R.*
1. `rgoogleads` - пакет для работы с Google Ads API
2. `googleAnalyticsR` - пакет для работы с Google Analytics API
3. `rappsflyer` - пакет для работы с AppsFlyer Pull API
4. `searchConsoleR` - пакет для загрузки данных из Google Search Console
5. `bigrquery` - пакет для работы с Google BigQuery
rgoogleads - пакет для работы с Google Ads API
----------------------------------------------
Работа над `rgoogleads` пакетом была начата в июне 2021 года. Основной мотивацией для его разработки послужило то, что популярный ранее пакет `RAdwords`, который я рассматривал в [первой части статьи](https://habr.com/ru/post/425425/), прекратит своё существование [27 апреля 2022](https://github.com/jburkhardt/RAdwords/issues/124) года, вместе с отключением Google Adwords API.
**Основные возможности пакета:**
* авторизация в API Google Ads;
* загрузка списка аккаунтов верхнего уровня;
* загрузка всей иерархии аккаунтов из управляющих аккаунтов;
* загрузка объектов рекламного кабинета: кампании, группы объявлений, объявления и другое;
* загрузка статистических данных из рекламных аккаунтов;
* загрузка метаданных ресурсов, полей ресурсов, сегментов и метрик;
* загрузка прогноза и исторических данных из планировщика ключевых слов.
**Установка пакета:**
`install.packages('rgoogleads')`
**Пример кода:**
```
library(rgoogleads)
# авторизация
gads_auth(email = '[email protected]')
# загрузка данных по эффективности рекламных кампаний
data2 <- gads_get_report(
resource = 'campaign',
fields = c('campaign.name',
'segments.date',
'metrics.clicks'),
date_from = '2021-06-01',
date_to = '2021-06-30',
customer_id = 'xxx-xxx-xxxx', # id рекламного аккаунта
login_customer_id = 'xxx-xxx-xxxx' # id управляющего аккаунта (опционально)
)
```
**Полезные ссылки:**
Пакет совсем свежий, поэтому по нему ещё не так много документации, тем не менее следующие ссылки помогут вам в нём более детально разобраться:
* [Миграция с Google AdWords API на Google Ads API: подробный мануал](https://netpeak.net/ru/blog/migratsiya-s-google-adwords-api-na-google-ads-api-podrobnyy-manual/)
* [Официальный сайт пакета](http://selesnow.github.io/rgoogleads/docs)
* [Видео с презентации пакета на конференции 8P 2021](https://www.youtube.com/watch?v=wtXVwOBo518)
googleAnalyticsR - пакет для работы с Google Analytics API
----------------------------------------------------------
Пакет предназначенный для работы с различными API Google Analytics.
**Основные возможности пакета:**
* авторизация в Google Analytics API;
* работа с Core Reporting API 3 и 4 версий;
* работа с Management API;
* работа с Multi Channel Funnels API;
* работа с Real time Reportnig API;
* работа с User Activity API;
* работа с Data API (Google Analytics 4);
* автоматический обход семплирования данных;
* загрузка различны данных в Google Analytics, включая данные о расходах из рекламных кабинетов.
**Установка пакета:**
`install.packages('googleAnalyticsR')`
**Пример кода:**
*Работа с Google Analytics Core API 4:*
```
## подключение пакета
library(googleAnalyticsR)
## авторизация
ga_auth()
## запрос списка представлений
account_list <- ga_account_list()
## просмотр списка идентификаторов доступных представлений
account_list$viewId
## создаём переменную с идентификатором нужного представления
ga_id <- 123456
## запрашиваем отчёт
google_analytics(ga_id,
date_range = c("2017-01-01", "2017-03-01"),
metrics = "sessions",
dimensions = "date")
```
*Работа с Google Analytics Data API (Google Analytics 4):*
```
# подключение пакета
library(googleAnalyticsR)
# авторизация
ga_auth(email="[email protected]")
# запрос списка доступных ресурсов Google Analytics 4
ga_account_list("ga4")
# запрос отчёта из Google Analytics 4
dimensions <- ga_data(
my_property_id,
metrics = c("activeUsers","sessions"),
dimensions = c("date","city","dayOfWeek"),
date_range = c("2020-03-31", "2020-04-27")
)
```
**Полезные ссылки:**
* [Как загрузить данные из API Google Analytics в R: часть 2](https://netpeak.net/ru/blog/kak-zagruzit-dannyye-iz-api-google-analytics-v-r-chast-2/)
* [Доклад: Как работать с API Google Analytics на языке R с помощью пакета googleAnalyticsR (8P Online)](https://www.youtube.com/watch?v=p2D_iLZ1f-8)
* [Сайт пакета googleAnalyticsR](https://code.markedmondson.me/googleAnalyticsR/)
rappsflyer - пакет для работы с AppsFlyer Pull API
--------------------------------------------------
Пакет `rappsflyer` предназначен для работы с AppsFlyer Pull API.
AppsFlyer - сервис аналитики мобильной рекламы, помогающий маркетологам точно определить таргетинг, оптимизировать расходы на рекламу и повысить рентабельность инвестиций.
**Основные возможности пакета:**
* запрос данных из AppsFlyer Pull API;
* запрашивать агрегированный отчёт (привлечение пользователей и ретаргетинг);
* запрашивать отчеты по сырым данным (неорганические);
* запрашивать отчеты по сырым данным (органические);
* запрашивать сырые данные по доходу от рекламы.
**Установка пакета:**
`install.packages('rappsflyer')`
**Пример кода:**
```
library('rappsflyer')
# авторизация
af_set_api_token('ваш API токен')
# запрос отчёта
af_data <- af_get_aggregate_data(
date_from = '2021-08-01',
date_to = Sys.Date() - 1,
report_type = "geo_by_date_report",
additional_fields = c("install_app_store", "match_type", "oaid"),
app_id = 'myapp.app'
)
```
**Полезные ссылки:**
* [Видео урок по работе с пакетом rappsflyer](https://www.youtube.com/watch?v=9Wn8n2A6x2w)
* [Виньетка "Работа с API AppsFlyer на R"](https://cran.r-project.org/web/packages/rappsflyer/vignettes/rappsflyer-intro.html)
* [README пакета](https://github.com/selesnow/rappsflyer/blob/main/README.md)
searchConsoleR - пакет для загрузки данных из Google Search Console
-------------------------------------------------------------------
Пакет `searchConsoleR` предназначен для работы с Google Search Console API.
**Основные возможности пакета:**
* авторизация в Google Search Console API;
* запрос, удаление и добавление веб сайтов в Search Console;
* запрос, удаление и добавление файлов Sitemap в Search Console;
* получение статистики из Google Search Console.
**Установка пакета:**
`install.packages('searchConsoleR')`
**Пример кода:**
```
library(searchConsoleR)
# авторизация
scr_auth(email = '[email protected]')
# список доступных сайтов
list_websites()
# получить данные из Search Console
data <- search_analytics(
siteURL = "http://www.my-site.ru/",
startDate = "2021-01-01",
endDate = "2021-07-31",
dimensions = c("query", "page")
)
```
**Полезные ссылки:**
* [README пакета](https://cran.r-project.org/web/packages/searchConsoleR/readme/README.html)
bigrquery - Пакет для работы с Google BigQuery
----------------------------------------------
Пакет предназначенный для работы с облачной базой данных Google BigQuery, которая очень популярна в решении аналитических задач интернет маркетинга.
**Основные возможности пакета:**
* авторизация в Google BigQuery API;
* возможность запрашивать метаданные объектов Google BigQuery, таких, как проект, набор данных и таблица;
* предоставляет интерфейс для работы с низкоуровневым API, с помощью которого можно запрашивать или загружать данные в BigQuery;
* предоставляет DBI интерфейс для подключения и работы с Google BigQuery;
* предоставляет dbplyr интерфейс для работы с данными, хранящимися в Google BigQuery.
**Установка пакета:**
`install.packages('bigrquery')`
**Пример кода:**
*Работа с низкоуровневым API:*
```
library(bigrquery)
# запросить данные из BigQuery
## текст SQL запроса
sql <- "SELECT year, month, day, weight_pounds FROM `publicdata.samples.natality`"
## загрузка данных в R
tb <- bq_project_query('id проекта', sql) %>%
bq_table_download()
# отправка данных в Google BigQuery
bq_table(project = "id проекта",
dataset = "id набора данных",
table = "название таблицы") %>%
bq_table_upload(values = mtcars,
create_disposition = "CREATE_IF_NEEDED",
write_disposition = "WRITE_APPEND")
```
*Работа через DBI интерфейс:*
```
library(DBI)
# подключение к BigQuery
con <- dbConnect(
bigrquery::bigquery(),
project = "publicdata",
dataset = "samples",
billing = billing
)
# запрос данных
dbGetQuery(con, sql)
# отправка данных в BigQuery
dbWriteTable(
con,
name = "название таблицы",
value = mtcars,
append = FALSE,
overwrite = TRUE
)
# закрываем соединение
dbDisconnect(con)
```
**Полезные ссылки:**
* [Сайт пакета](https://bigrquery.r-dbi.org/)
* [Учимся обращаться к данным и запрашивать их при помощи Google BigQuery. С примерами на Python и R](https://habr.com/ru/company/piter/blog/519816/)
Заключение
----------
В этой статье мы разобрали очередную порцию полезных для интернет маркетологов R пакетов. С помощью представленных в статье пакетов вы сможете быстро начать работать с API таких сервисов как: Google Ads, Google Analytics, AppsFlyer, Google Search Console и Google BigQuery.
Надеюсь материал приведённый в данной статье будет вам полезен. Буду рад видеть вас среди подписчиков своего [telegram](https://t.me/R4marketing) и [youtube](https://www.youtube.com/R4marketing/?sub_confirmation=1) канала R4marketing. | https://habr.com/ru/post/575744/ | null | ru | null |
# Введение в компиляторы, интерпретаторы и JIT’ы
С рождением PHP 7 не прекращаются споры об абстрактных синтаксических деревьях, just-in-time компиляторах, статическом анализе и т. д. Но что означают все эти термины? Это какие-то волшебные свойства, делающие PHP гораздо производительнее? И если да, то как это всё работает? В этой статье мы рассмотрим основы работы языков программирования и разъясним для себя процесс, который должен выполняться до того, как компьютер запустит, например, ваш PHP-скрипт.
Интерпретируя код
=================
Но прежде чем говорить о том, как это всё работает, давайте разберём один простой пример. Представим, что у нас есть новый язык программирования (придумайте любое название). Язык довольно прост:
* каждая строка представляет собой *выражение*,
* каждое выражение состоит из *команды* (оператора)
* и любого количества *значений* (операндов), которыми оперирует команда.
Пример:
`set a 1`
`set b 2`
`add a b c`
`print c`
Это простой язык, так что мы можем без опаски предположить, что этот код всего лишь выводит на экран 3. Оператор `set` берёт переменную и присваивает ей число (совсем как `$a=1` в PHP). Оператор `add` берёт две переменные для добавления и сохраняет результат в третьей. Оператор `print` выводит её на экран.
Теперь давайте напишем программу, которая считывает каждое «выражение», находит оператор и операнды, а затем что-то с ними делает, в зависимости от конкретного оператора. Это довольно просто реализовать на PHP, как вы можете видеть на примере листинга 1.
Листинг 1
```
01. php
02.
03. $lines = file($argv[1]);
04.
05. $linenr = 0;
06. foreach ($lines as $line) {
07. $linenr++;
08. $operands = explode(" ", trim($line));
09. $command = array_shift($operands);
10.
11. switch ($command) {
12. case 'set' :
13. $vars[$operands[0]] = $operands[1];
14. break;
15. case 'add' :
16. $vars[$operands[2]] = $vars[$operands[0]] + $vars[$operands[1]];
17. break;
18. case 'print' :
19. print $vars[$operands[0]] . "\n";
20. break;
21. default :
22. throw new Exception(sprintf("Unknown command in line %s\n", $linenr));
23. }
24. }
</code
```
Это очень простая программа, и вам не придётся писать своё следующее веб-приложение на вашем новом языке. Но данный пример помогает понять, как легко можно создать новый язык и получить программу, которая способна считывать и выполнять этот язык. В нашем случае она построчно считывает исходный файл и выполняет код в зависимости от текущего оператора. Для запуска приложения нам не нужно преобразовывать его в ассемблер или двоичный код, оно и так прекрасно работает. Этот метод выполнения программ называется интерпретированием. Например, таким образом часто выполняются программы на Basic: каждое выражение считывается и сразу же выполняется в высокоуровневом режиме.
Но тут есть ряд проблем. Одна из них заключается в том, что написать подобный языковой процессор довольно легко, а вот выполняться новый язык будет очень медленно. Ведь нам придётся обрабатывать каждую строку и проверять:
* Какой оператор нужно выполнить?
* Это правильный оператор?
* Есть ли у него нужное количество операндов?
А ведь нам нельзя забывать и о других задачах. Например, оператор set может присваивать переменным только числовые значения или строковые тоже? Или даже значения других переменных? Чтобы правильно обработать каждое выражение, нужно ответить на все эти вопросы. Что произойдёт, если написать `set 1` 4? Короче, таким образом практически невозможно создавать быстро работающие приложения.
Но, несмотря на неторопливость, у интерпретирования есть преимущества: мы можем сразу запускать программу после каждого внесённого изменения. Для внимательных: когда я что-то меняю в PHP-скрипте, я сразу могу его выполнить и увидеть изменения; означает ли это, что PHP — интерпретируемый язык? На данный момент будем считать, что да. PHP-скрипт интерпретируется подобно нашему гипотетическому простому языку. Но в следующих разделах мы ещё к этому вернёмся!
Транскомпилирование
===================
Как можно заставить нашу программу «работать быстро»? Это можно сделать разными способами. Один из них, разработанный в Facebook, называется HipHop (я имею в виду «старую» систему HipHop, а не используемую сегодня HHVM). HipHop преобразовывал один язык (PHP) в другой (С++). Результат преобразования можно было с помощью компилятора С++ превратить в двоичный код. Его компьютер способен понять и выполнить без дополнительной нагрузки в виде интерпретатора. В результате экономится ОГРОМНОЕ количество вычислительных ресурсов и приложение работает гораздо быстрее.
Этот метод называется source-to-source компилированием, или транскомпилированием, или даже транспилированием (transpiling). На самом деле происходит не компилирование в двоичный код, а преобразование в то, что может быть скомпилировано в машинный код существующими компиляторами.
Транскомпилирование позволяет напрямую выполнять двоичный код, что повышает производительность. Однако у этого метода есть и обратная сторона: прежде чем выполнить код, нам сначала нужно провести транскомпилирование, а затем настоящее компилирование. Но это нужно делать только тогда, когда в приложение вносятся изменения, т. е. только во время разработки.
Транскомпилирование также используется для того, чтобы сделать «жёсткие» языки более простыми и динамичными. Например, браузеры не понимают код, написанный на LESS, SASS и SCSS. Но зато его можно транспилировать в CSS, который браузеры понимают. Поддерживать CSS проще, но приходится дополнительно транскомпилировать.
Компилирование
==============
Чтобы всё работало ещё быстрее, нужно избавиться от стадии транскомпилирования. То есть компилировать наш язык сразу в двоичный код, который мог бы тут же выполняться, без дополнительной нагрузки в виде интерпретирования или транскомпилирования.
К сожалению, написание компилятора — одна из труднейших задач в информатике. Например, при компилировании в двоичный код нужно учитывать, на каком компьютере он будет выполняться: на 32-битной Linux, или 64-битной Windows, или вообще на OS X. Зато интерпретируемый скрипт может легко выполняться где угодно. Как и в PHP, нам не нужно переживать о том, где выполняется наш скрипт. Хотя может встречаться и код, предназначенный для конкретной ОС, что сделает невозможным выполнение скрипта на других системах, но это не вина интерпретатора.
Но даже если мы избавимся от стадии транскомпилирования, нам никуда не деться от компилирования. Например, большие программы, написанные на С (компилируемый язык), могут компилироваться чуть ли не час. Представьте, что вы написали приложение на PHP и вам нужно ждать ещё десять минут, прежде чем увидеть, работают ли внесённые изменения.
Используя всё лучшее
====================
Если интерпретирование подразумевает медленное выполнение, а компилирование сложно в реализации и требует больше времени при разработке, то как работают языки вроде PHP, Python или Ruby? Они довольно быстрые!
Это потому, что они используют и интерпретирование, и компилирование. Давайте посмотрим, как это получается.
Что, если бы мы могли преобразовывать наш выдуманный язык не напрямую в двоичный код, а в нечто, очень на него похожее (это называется «байт-код»)? И если бы этот байт-код был так близок к тому, как работает компьютер, что его интерпретирование выполнялось бы очень быстро (например, миллионы байт-кодов в секунду)? Это сделало бы наше приложение почти таким же быстрым, как и компилируемое, при этом сохранились бы все преимущества интерпретируемых языков. Самое главное, нам не пришлось бы компилировать скрипты при каждом изменении.
Выглядит очень заманчиво. По сути, подобным образом работают многие языки — PHP, Ruby, Python и даже Java. Вместо считывания и поочерёдного интерпретирования строк исходного кода, в этих языках используется другой подход:
* Шаг 1. Считать скрипт (PHP) целиком в память.
* Шаг 2. Целиком преобразовать/компилировать скрипт в байт-код.
* Шаг 3. Выполнить байт-код посредством интерпретатора (PHP).
На самом деле шагов больше, и в реальности весь процесс гораздо сложнее. Но в целом трёх описанных шагов достаточно для запуска скрипта из командной строки или для выполнения запроса через ваш веб-сервер.
Процесс можно легко оптимизировать: предположим, что мы запустили веб-сервер и каждый запрос выполняет скрипт `index.php`. Зачем каждый раз грузить его в память? Лучше закешировать файл, чтобы можно было быстро преобразовывать его при каждом запросе.
Ещё одна оптимизация: после генерирования байт-кода мы можем использовать его при всех последующих запросах. Так что можно закешировать и его (главное, убедитесь, что при изменении исходного файла байт-код будет перекомпилироваться). Именно это делают кеши кода операций (opcode caches), вроде расширения OPCache в PHP: кешируют скомпилированные скрипты, чтобы их можно было быстро выполнить при последующих запросах без избыточных загрузок и компилирования в байт-код.
Наконец, последний шаг к высокой скорости — выполнение байт-кода нашим PHP-интерпретатором. В следующей части мы сравним это с обычными интерпретаторами. Во избежание путаницы: подобный интерпретатор байт-кода часто называется «виртуальной машиной», потому что в определённой степени он копирует работу машины (компьютера). Не надо путать это с виртуальными машинами, запускаемыми на компьютерах, вроде VirtualBox или VMware. Речь идёт о таких вещах, как JVM (Java Virtual Machine) в мире Java и HHVM (HipHop Virtual Machine) в мире PHP. Свои виртуальные машины есть у Python и Ruby. В некотором роде все они являются высокоспециализированными и производительными интерпретаторами байт-кода.
Каждая ВМ выполняет собственный байт-код, генерируемый конкретным языком, и они несовместимы между собой. Вы не можете выполнять байт-код PHP на ВМ Python, и наоборот. Однако теоретически возможно создать программу, компилирующую PHP-скрипты в байт-код, который будет понятен ВМ Python. Так что в теории вы можете запускать PHP-скрипты в Python (серьёзный вызов!).
Байт-код
========
Как выглядит и работает байт-код? Рассмотрим два примера. Возьмём PHP-код:
```
$a = 3;
echo "hello world";
print $a + 1;
```
Посмотреть его байт-код можно с помощью [3v4l.org](http://3v4l.org) или установив [расширение VLD](https://derickrethans.nl/projects.html#vld). Получим следующее:
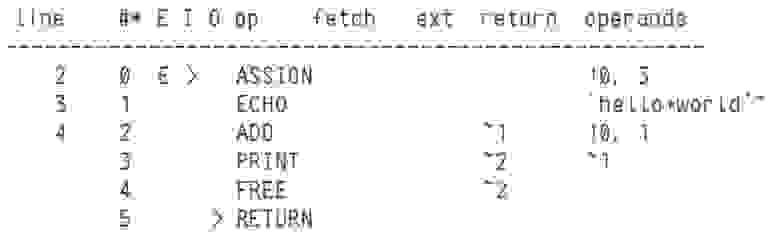
Теперь возьмём аналогичный пример на Python:
```
def foobar():
a = 1
print "hello world",
print a + 4
```
Python может напрямую сгенерировать коды операций ©python:
[dis.dis(func)](https://docs.python.org/2/library/dis.html):
У нас есть два простых скрипта и их байт-коды. Обратите внимание, что байт-коды похожи на язык, который мы «создали» в начале статьи: каждая строка представляет собой оператор с любым количеством операндов. В байт-коде PHP к переменным добавляется префикс !, поэтому !0 означает переменную 0. Байт-коду не важно, что вы используете переменную $a: в ходе компилирования имена переменных теряют значение и преобразуются в числа. Это облегчает и ускоряет их обработку виртуальной машиной. Большинство необходимых «проверок» выполняются на стадии компилирования, что также снимает нагрузку с виртуальной машины и увеличивает скорость её работы.
Поскольку байт-код состоит из простых инструкций, интерпретирование проходит очень быстро. Вместо тысяч двоичных инструкций, которые нужно обработать для каждого выражения интерпретируемого языка, в байт-коде на каждое выражение приходится по несколько сотен инструкций (иногда и того меньше). Поэтому виртуальные машины работают гораздо быстрее интерпретируемых языков.
Иными словами, виртуалки взяли всё лучшее от двух миров. Хотя нам по-прежнему нужно компилировать из исходного кода в байт-код, этот процесс становится быстрым и прозрачным. А после получения байт-кода виртуальная машина быстро и эффективно интерпретирует его без излишних накладных расходов. И в результате мы имеем высокопроизводительное приложение.
От исходного кода к байт-коду
=============================
Теперь, когда мы умеем эффективно выполнять сгенерированный байт-код, остаётся задача компилирования исходного кода в этот байт-код.
Рассмотрим следующие PHP-выражения:
```
$a = 1;
$a=1;
$a
=
1;
```
Все они одинаково верны и должны быть преобразованы в одинаковые байт-коды. Но как мы их считываем? Ведь в нашем собственном интерпретаторе мы парсим команды, разделяя их пробелами. Это означает, что программист должен писать код в одном стиле, в отличие от PHP, где вы можете в одной строке использовать отступления или пробелы, скобки в одной строке или переносить на вторую строку и т. д. В первую очередь компилятор попытается преобразовать ваш исходный код в токены. Этот процесс называется лексингом (lexing) или токенизацией.
Лексинг
=======
Токенизация (лексинг) заключается в преобразовании исходного PHP-кода — без понимания его значения — в длинный список токенов. Это сложный процесс, но в PHP вы можете довольно легко сделать нечто подобное. Представленный в листинге 2 код выдаёт следующий результат:
```
T_OPEN_TAG php
T_VARIABLE $a
T_WHITESPACE
=
T_WHITESPACE
T_LNUMBER 3
;
T_WHITESPACE
T_ECHO echo
T_WHITESPACE
T_CONSTANT_ENCAPSED_STRING "hello world"
;
</code
```
Строковое значение преобразуется в токены:
* php преобразован в токен T\_OPEN\_TAG,</li* $a преобразован в токен T\_VARIABLE, который содержит значение $a.
Токенизатор знает об этом, когда при чтении кода обнаруживает знак $ с буквой a, после которых может следовать любое количество букв и цифр. Числа токенизируются в виде T\_LNUMBER и могут быть одно- и более разрядными. Токенизация позволяет представить исходный код в более структурированном виде, не заставляя делать это самого программиста. Но, как уже упоминалось, токенизатор не понимает значение токенов. Он идеально токенизирует и $a = 1, и 1 = $a. А в следующей части мы научимся парсить — задавать значение потоку токенов.
Парсинг
=======
При парсинге токенов мы должны следовать некоторым «правилам», составляющим наш язык. Например, может быть правило: первый обнаруженный токен в программе должен быть T\_OPEN\_TAG (соответствует php). <br/
Ещё одно возможное правило: присваивание может состоять из любого T\_VARIABLE, после которого идёт символ =, а затем T\_LNUMBER, T\_VARIABLE или T\_CONSTANT\_ENCAPSED\_STRING. Иными словами, мы разрешаем $a = 1, или $a = $b, или $a = 'foobar', но не 1 = $a. Если парсер обнаруживает серию токенов, не удовлетворяющих какому-то из правил, автоматически будет выдана ошибка синтаксиса. В общем, парсинг — это процесс, определяющий язык и позволяющий нам создавать синтаксические правила.
Посмотреть список правил, используемых в PHP, можно [по адресу](http://bit.ly/zend-language-parser). Если ваш PHP-скрипт удовлетворяет синтаксическим правилам, то проводятся дополнительные проверки, чтобы подтвердить, что синтаксис не только правильный, но и осмысленный: определение `public abstract final final private class foo() {}` может быть корректным, но не имеет смысла с точки зрения PHP. Токенизация и парсинг — хитрые процессы, и зачастую для их выполнения берут сторонние приложения. Нередко используются инструменты вроде flex и bison (в PHP тоже). Их можно рассматривать и в качестве транскомпиляторов: они преобразуют ваши правила в С-код, который будет автоматически компилироваться, когда вы компилируете PHP.
Парсеры и токенизаторы полезны и в других сферах. Например, они используются для парсинга SQL-выражений в базах данных, и на PHP также написано немало парсеров и токенизаторов. У объектно-реляционного маппера Doctrine есть свой парсер для DQL-выражений, а также «транскомпилятор» для преобразования DQL в SQL. Многие движки шаблонов, в том числе Twig, используют собственные токенизаторы и парсеры для «компилирования» файлов шаблонов обратно в PHP-скрипты. По сути, эти движки тоже транскомпиляторы!
Абстрактное синтаксическое дерево
=================================
После токенизации и парсинга нашего языка мы можем генерировать байт-код. Вплоть до PHP 5.6 он генерировался во время парсинга. Но привычнее было бы добавить в процесс отдельную стадию: пусть парсер генерирует не байт-код, а так называемое абстрактное синтаксическое дерево (Abstract Syntax Tree, AST). Это древовидная структура, в которой абстрактно представлена вся программа. AST не только упрощает генерирование байт-кода, но и позволяет нам вносить изменения в дерево, прежде чем оно будет преобразовано. Дерево всегда генерируется особым образом. Узел дерева, представляющий собой выражение if, обязательно имеет под собой три элемента:
* первый содержит условие (вроде `$a == true`);
* второй содержит выражения, которые должны быть выполнены, если соблюдается условие `true`;
* третий содержит выражения, которые должны быть выполнены, если соблюдается условие `false` (выражение `else`).
Даже если `else` отсутствует, элемента три, просто третий будет пустым.
В результате мы можем «переписать» программу до того, как она будет преобразована в байт-код. Иногда это используется для оптимизации кода. Если мы обнаружим, что разработчик раз за разом перевычислял переменную внутри цикла, и мы знаем, что переменная всегда имеет одно и то же значение, то оптимизатор может переписать AST так, чтобы создать временную переменную, которую не нужно каждый раз вычислять заново. Дерево можно использовать для небольшой реорганизации кода, чтобы он работал быстрее: удалить ненужные переменные и т. п. Это не всегда возможно, но когда у нас есть дерево всей программы, то такие проверки и оптимизации выполнять куда легче. Внутри AST можно посмотреть, объявляются ли переменные до их использования или используется ли присваивание в условном блоке (`if ($a = 1) {}`). И при обнаружении потенциально ошибочных структур выдать предупреждение. С помощью дерева можно даже анализировать код с точки зрения информационной безопасности и предупреждать пользователей во время выполнения скрипта.
Всё это называется статическим анализом — он позволяет создавать новые возможности, оптимизации и системы валидации, помогающие разработчикам писать гармоничный, безопасный и быстрый код.
В PHP 7.0 появился новый движок парсинга (Zend 3.0), который тоже генерирует AST во время парсинга. Поскольку он достаточно свежий, с его помощью можно сделать не так много. Но сам факт его наличия означает, что мы можем ожидать появления в ближайшем будущем самых разных возможностей. Функция `token_get_all()` уже принимает новую, недокументированную константу TOKEN\_PARSE, которая в будущем может использоваться для возвращения не только токенов, но и отпарсенного AST. Сторонние расширения вроде php-ast позволяют просматривать и редактировать дерево прямо в PHP. Полная переработка движка Zend и реализации AST откроет PHP для самых разных новых задач.
JIT
===
Помимо виртуальных машин, выполняющих высокооптимизированный байт-код, сгенерированный из AST, есть и другая методика повышения скорости. Но это одна из самых сложных в реализации вещей.
Как выполняется приложение? Много времени тратится на его настройку: например, нужно запустить фреймворк, отпарсить маршруты, обработать переменные среды и т. д. По завершении всех этих процедур программа обычно всё ещё не запущена. По сути, куча времени потрачена лишь на функционирование какой-то части вашего приложения. А что, если мы выявим те части, которые могут часто запускаться и способны преобразовывать маленькие куски кода (допустим, всего несколько методов) в двоичный код? Конечно, на это компилирование может уходить относительно много времени, но всё равно метод компилируется куда быстрее, чем всё приложение. Возможно, при первом вызове функции вы столкнётесь с маленькой задержкой, но все последующие вызовы будут выполняться молниеносно, минуя виртуальную машину, и сразу в виде двоичного кода.
Мы получаем скорость компилируемого кода и наслаждаемся преимуществами кода интерпретируемого. Подобные системы могут работать быстрее обычного интерпретируемого байт-кода, иногда гораздо быстрее. Речь идёт о JIT-компиляторах (just-in-time, точно в срок). Название подходит как нельзя лучше. Система обнаруживает, какие части байт-кода могут быть хорошими кандидатами на компилирование в двоичный код, и делает это в тот момент, когда нужно выполнять эти самые части. То есть — точно в срок. Программа может стартовать немедленно, не нужно ждать завершения компилирования. В двоичный код преобразуются только самые эффективные части кода, так что процесс компилирования автоматизируется и ускоряется.
Хотя не все JIT-компиляторы работают таким образом. Некоторые компилируют все методы на лету; другие пытаются только определить, какие функции нужно скомпилировать на ранней стадии; третьи будут компилировать функции, если они вызываются два и больше раза. Но все JIT’ы используют один принцип: компилировать маленькие куски кода, когда они действительно нужны.
Ещё одно преимущество JIT’ов по сравнению с обычным компилированием заключается в том, что они способны лучше прогнозировать и оптимизировать на основании текущего состояния приложения. JIT’ы могут динамически анализировать код во время runtime и делать предположения, на которые неспособны обычные компиляторы. Ведь во время компиляции у нас нет информации о текущем состоянии программы, а JIT’ы компилируют на стадии выполнения.
Если вам доводилось работать с HHVM, то вы уже использовали JIT-компилятор: PHP-код (и надмножественный язык Hack) преобразуется в байт-код, запускаемый на виртуальной машине HHVM. Машина обнаруживает блоки, которые могут быть безопасно преобразованы в двоичный код; если это ещё не было сделано, она это делает и запускает их. По окончании запуска ВМ переходит к следующим байт-кодам, которые могут быть преобразованы в двоичный код.
PHP 7 не выполняется на JIT-компиляторе, но зато его новая система превосходит все предыдущие релизы. Сейчас во всех его компонентах проводятся эксперименты со статическим анализом, динамической оптимизацией, и даже есть простые JIT-системы. Так что не исключено, что однажды даже PHP 7 окажется позади! | https://habr.com/ru/post/304748/ | null | ru | null |
# Windows Phone 8: Создаем приложение. Матрица. Часть 2
[Windows Phone 8: Создаем приложение. Матрица. Часть 1](http://habrahabr.ru/post/195422/)
[Windows Phone 8: Создаем приложение. Матрица. Часть 2](http://habrahabr.ru/post/195760/)
Здравствуйте. Сегодня мы продолжим создание приложения, используем новый шаблон «Панорама», а так же добавим всевозможные настройки, что позволит изменять все параметры матрицы. Сразу оговорюсь, что при задании сильно больших чисел в некоторых настройках, резко понижается производительность, но с этим мы еще будем бороться в следующих частях.
Так же хочу сразу вспомнить основные цели этих статей: это написание приложения с использованием максимального числа всего: различных контролов, техник, шаблонов и т.д. Ну а так же получение конечного продукта с заданными свойствами.
###### Скриншот работы приложения
Хотелось вторую часть написать полностью отточенную, в плане кода, однако размеры ее стали достаточно большими. Если сразу провести еще и оптимизацию, то это усложнит прослеживание логики. Оптимизация будет в следующей части. Начнем.
#### Цели этой части
1. Использовать шаблон Панорама
2. Создание настроек приложения
#### Добавлены следующие настройки
* Скорость смены символов в заданном диапазоне
* Количество змеек в очереди
* Количество одновременно ползущих змеек за нажатие
* Размер шрифта
* Старт / Стоп
* Очистка экрана
* Размер(количество) клеточек в матрице
* Длина змейки в заданном диапазоне
* Горизонтальная / Вертикальная ориентация
* Выбор языка падающих символов
* Цвет фона матрицы
* Цвет первого символа
* Градиент для змейки
Можно посмотреть эти настройки на видео:
#### Перейдем к работе в Visual Studio
Создаем новый проект. Приложение Windows Phone с панорамой.
У меня имя будет SE\_Matrix\_2d\_v\_4.
Остальное как в прошлый раз.
#### MainPage.xaml
Тут у нас добавилось немного кода. В шаблоне Панорама у меня 3 секции:
```
...
...
...
```
В первый элемент добавим непосредственно отображение матрицы. Тут ничего не поменялось, все как и в первой части:
```
```
Во второй элемент управления добавлены первые 9 настроек из 13, описанных в начале статьи. Ничего сложного: название в TextBlock, TextBox для ввода значений и Button для применения заданного значения. Так же все обернуто в ScrollViewer для возможности вертикальной прокрутки, так как список в один экран не влезает. В большинстве TextBox метод ввода выбран как числа, InputScope=«Number». Однако в паре элементов есть возможность вводить отрицательные значения. Временно используется общая клавиатура InputScope=«Default».
**Код. Второй элемент Panorama**
```
```
В третьем элементе остались последние 4 настройки: выбор языка, цвета и задание цвета первому элементу, фону, градиента для змейки. Так же все находится в ScrollViewer для вертикальной прокрутки. Однако тут пришлось использовать один нестандартный элемент управления, а именно ColorPicker. Его можно найти в дополнительной библиотеке элементов с названием [Coding4Fun](http://coding4fun.codeplex.com/).
##### Как установить Coding4Fun
У меня последние пару недель с нугет проблемы, поэтому качал вручную.
Переходим по ссылке.
Нажимаем на большую красную кнопку с надписью «Via CodePlex Current Release Zip».
Качаем архив с именем «Coding4Fun.Toolkit (Windows Phone 8).zip».
Из архива копируем файл с именем «Coding4Fun.Toolkit.Controls.dll» к себе в проект.
Заходим в проект в папочку «References». Жмем на нее правой кнопкой — Добавить ссылку — Справа внизу выбираем Обзор… Находим нашу библиотеку и жмем ОК.
Заходим в Панель элементов. правой кнопкой где угодно в ее приделах — Выбрать элементы… Выбираем вкладку Windows Phone Components. Справа внизу жмем обзор и снова выбираем Coding4Fun.Toolkit.Controls.dll. Новые элементы будут подсвечены. Смотрим, что б возле элемента ColorPicker была галочка.
Убедитесь, что в начале файла добавилась строчка
```
xmlns:Controls="clr-namespace:Coding4Fun.Toolkit.Controls;assembly=Coding4Fun.Toolkit.Controls"
```
Продолжим. Перетаскиваем ColorPicker с Панели элементов. Назначаем имя. Теперь выбирать цвет будем на одном элементе, а применять выбранный цвет разными кнопками к разным характеристикам матрицы.
```
```
Так же добавим кнопку, при нажатии на которую будет появляться всплывающее окно для выбора языка:
```
```
И еще пара кнопок по аналогии со вторым элементом панорамы.
**Код. Третий элемент Panorama**
```
```
**Код. MainPage.xaml**
```
```
Внешне настройки выглядят так:

#### MainPage.xaml.cs
Первым делом создаем свойства класса, которые будут отвечать за настройки:
**Код. Свойства класса**
```
/* ****************************** Свойства класса ****************************** */
// Случайное число
Random random = new Random();
// Количество змеек после нажатия на экран в очереди
int iteration = 5;
// Количество одновременно появляющихся змеек после нажатия
int countSimultaneously = 3;
// Скорость смены символов
int speedFrom = 20;
int speedTo = 40;
// Размер клетки для символа
int addingSize = -6;
// Итоговый размер шрифта
int fontSize;
// Минимальная и максимальная длина змейки
int minLength = 10;
int maxLength = 15;
// Получаем расширение экрана
double ScreenWidth = System.Windows.Application.Current.Host.Content.ActualWidth - 60;
double ScreenHeight = System.Windows.Application.Current.Host.Content.ActualHeight - 100;
// Коеффициент, отвечающий за количесвто ячеек и частично за размер шрифта
int kolich = 30;
// Размер шрифта задается по формуле kolich + addingFontSize.
int addingFontSize = -2;
// Количество смены символов в ячейке
int countSymbol = 3;
// Включить (false), выключить (true) матрицу
bool flagOnOff = false;
// Включить (false), выключить (true) "поворот экрана"
bool turnOnOff = true;
// Количество строк и столбцов
int countWidth = 10;
int countHeight = 10;
// Словарь, в котором хранятся идентификаторы языка и соответствующие ему ASCII коды символов
Dictionary languages = new Dictionary();
// Задаю язык по-умолчанию
string actualLanguage = "Русский";
// Флаг, отвечающий за показывать (true) / не показывать (false) всплывающее окно (PopUp) при выборе языка
bool flagShowLanguages = true;
// Цвет фона матрицы, ARGB
Dictionary colorMatrixBackground = new Dictionary();
// Цвет первого символа, ARGB
Dictionary colorFirstSymbol = new Dictionary();
// Цвет градиента змейки от (второй символ) - до (последний символ), ARGB
Dictionary gradientFrom = new Dictionary();
Dictionary gradientTo = new Dictionary();
```
Рассмотри конструктор класса:
**Код. Конструктор класса**
```
// Конструктор
public MainPage()
{
InitializeComponent();
// Вызываем функцию настройки начальных значений цветов фона, символов и т.д.
BeginColorSettings();
// Инициализируем список доступных языков, а также соответствующие им ASCII коды символов
ListLanguages();
// Количество строк и столбцов
this.countWidth = (int)Math.Round(ScreenWidth / (kolich + addingSize)) + Math.Abs(addingSize);
this.countHeight = (int)Math.Round(ScreenHeight / (kolich + addingSize)) + 5 + Math.Abs(addingSize);
// Создание сетки элементов, в которой будет сыпаться матрица
CreateElement();
// Подсвечиваем кнопку Вкл или Выкл, зависит от флага
if (this.flagOnOff)
{
Button_Stop.Background = new SolidColorBrush(Colors.Cyan);
Button_Start.Background = new SolidColorBrush(Colors.Black);
}
else
{
Button_Stop.Background = new SolidColorBrush(Colors.Black);
Button_Start.Background = new SolidColorBrush(Colors.Cyan);
}
// Меняем цвет фона матрицы
ChangeBackground();
}
```
Давайте начнем с выбора цвета. Для начала инициализируем настройки по умолчанию в методе BeginColorSettings();
**Код. BeginColorSettings**
```
// Начальные настройки цветов фона, символов и т.д
private void BeginColorSettings()
{
// Задаем начальный цвет фона матрицы
colorMatrixBackground["A"] = 0;
colorMatrixBackground["R"] = 0;
colorMatrixBackground["G"] = 0;
colorMatrixBackground["B"] = 0;
// Задаем начальный цвет первого символа
colorFirstSymbol["A"] = 255;
colorFirstSymbol["R"] = 248;
colorFirstSymbol["G"] = 248;
colorFirstSymbol["B"] = 255;
// Задаем начальный цвет градиента от (второго символа в змейке)
gradientFrom["A"] = 255;
gradientFrom["R"] = 1;
gradientFrom["G"] = 255;
gradientFrom["B"] = 1;
// Задаем начальный цвет градиента до (последнего символа в змейке)
gradientTo["A"] = 0;
gradientTo["R"] = 0;
gradientTo["G"] = 0;
gradientTo["B"] = 0;
}
```
##### Цвет фона матрицы
Задаем цвет фона. Просто присваиваем соответствующему атрибуту цвет, состоящий из компонент ARGB. Почему четыре составляющие? Прозрачность (А) нам будет нужна для создания эффекта затухания.
**Код. ChangeBackground**
```
// Метод изменения цвета фона матрицы. По умолчанию черный.
private void ChangeBackground()
{
// Задаю цвет фона матрицы
LayoutRootSecond.Background = new SolidColorBrush(new Color()
{
A = (byte)(colorMatrixBackground["A"]) /*Opacity*/,
R = (byte)(colorMatrixBackground["R"]) /*Red*/,
G = (byte)(colorMatrixBackground["G"]) /*Green*/,
B = (byte)(colorMatrixBackground["B"]) /*Blue*/
});
}
```
Однако это просто метод. Для того, что б цвет действительно поменялся, нужно забрать его из контролла ColorPicker, присвоить свойству и вызвать метод ChangeBackground:
**Код. Event\_Button\_Click\_ChangeBackground**
```
// Меняем цвет фона матрицы
private void Event_Button_Click_ChangeBackground(object sender, RoutedEventArgs e)
{
// Передаем в свойство класса colorMatrixBackground выбранный цвет из элемента ColorPicker для фона матрицы
colorMatrixBackground["A"] = ColorPicker.Color.A;
colorMatrixBackground["R"] = ColorPicker.Color.R;
colorMatrixBackground["G"] = ColorPicker.Color.G;
colorMatrixBackground["B"] = ColorPicker.Color.B;
// Задаем выбранный цвет фона матрицы соответствующей кнопке
Button_BackgroundColor.Background = new SolidColorBrush(new Color()
{
A = (byte)(colorMatrixBackground["A"]) /*Opacity*/,
R = (byte)(colorMatrixBackground["R"]) /*Red*/,
G = (byte)(colorMatrixBackground["G"]) /*Green*/,
B = (byte)(colorMatrixBackground["B"]) /*Blue*/
});
// Задаем выбранный цвет фона матрицы
ChangeBackground();
}
```
##### Цвет первого символа змейки
Изменим цвет первого символа змейки. Первый символ змейки вызывается в методе RandomElementQ\_Async асинхронно:
```
// Вызываем на прорисовку первый, самый яркий падающий элемент. Асинхронно.
// colorFirstSymbol["A"]. Цвет задается через настройку.
await Change(element, timeOut, colorFirstSymbol);
```
**Код. Event\_Button\_Click\_FirstSymbolColor**
```
// Изменение цвета первого символа
private void Event_Button_Click_FirstSymbolColor(object sender, RoutedEventArgs e)
{
// Передаем в свойство класса colorFirstSymbol выбранный цвет из элемента ColorPicker для фона матрицы
colorFirstSymbol["A"] = ColorPicker.Color.A;
colorFirstSymbol["R"] = ColorPicker.Color.R;
colorFirstSymbol["G"] = ColorPicker.Color.G;
colorFirstSymbol["B"] = ColorPicker.Color.B;
// Задаем выбранный цвет фона матрицы соответствующей кнопке
Button_FirstSymbolColor.Background = new SolidColorBrush(new Color()
{
A = (byte)(colorFirstSymbol["A"]) /*Opacity*/,
R = (byte)(colorFirstSymbol["R"]) /*Red*/,
G = (byte)(colorFirstSymbol["G"]) /*Green*/,
B = (byte)(colorFirstSymbol["B"]) /*Blue*/
});
}
```
##### Задание цветов для градиента
Ну вот и добрались до градиента. Первое, что нужно сделать — это в обработчиках событий соответствующих кнопок сохранить цвет в свойства класса:
**Код. Event\_Button\_Click\_Gradient**
```
// Настройки. Задаем градиент змейки. Цвет второго символа.
private void Event_Button_Click_GradientFrom(object sender, RoutedEventArgs e)
{
// Передаем в свойство класса gradientFrom выбранный цвет из элемента ColorPicker для фона матрицы
gradientFrom["A"] = ColorPicker.Color.A;
gradientFrom["R"] = ColorPicker.Color.R;
gradientFrom["G"] = ColorPicker.Color.G;
gradientFrom["B"] = ColorPicker.Color.B;
// Задаем выбранный цвет градиента от змейки соответствующей кнопке
Button_GradientFrom.Background = new SolidColorBrush(new Color()
{
A = (byte)(gradientFrom["A"]) /*Opacity*/,
R = (byte)(gradientFrom["R"]) /*Red*/,
G = (byte)(gradientFrom["G"]) /*Green*/,
B = (byte)(gradientFrom["B"]) /*Blue*/
});
}
/ Настройки. Задаем градиент змейки. Цвет последнего символа.
private void Event_Button_Click_GradientTo (object sender, RoutedEventArgs e)
{
// Передаем в свойство класса gradientTo выбранный цвет из элемента ColorPicker для фона матрицы
gradientTo["A"] = ColorPicker.Color.A;
gradientTo["R"] = ColorPicker.Color.R;
gradientTo["G"] = ColorPicker.Color.G;
gradientTo["B"] = ColorPicker.Color.B;
// Задаем выбранный цвет градиента до змейки соответствующей кнопке
Button_GradientTo.Background = new SolidColorBrush(new Color()
{
A = (byte)(gradientTo["A"]) /*Opacity*/,
R = (byte)(gradientTo["R"]) /*Red*/,
G = (byte)(gradientTo["G"]) /*Green*/,
B = (byte)(gradientTo["B"]) /*Blue*/
});
}
```
Теперь эти цвета нужно применить к нашим символам. Переходим в метод RandomElementQ\_Async и немножко меняем ту часть, которая отвечает за расчет яркости и цвета символов следующим образом:
**Код. RandomElementQ\_Async и Change**Меняем
```
//int greenCoefficient = (int)Math.Round(255 / (double)(count + 1)) - 1;
```
на
```
int A_Coefficient = (int)Math.Round((gradientFrom["A"] - 10) / (double)(count + 1)) - 1;
int R_Coefficient = (int)Math.Round((gradientFrom["R"] - gradientTo["R"]) / (double)(count + 1)) - 1;
int G_Coefficient = (int)Math.Round((gradientFrom["G"] - gradientTo["G"]) / (double)(count + 1)) - 1;
int B_Coefficient = (int)Math.Round((gradientFrom["B"] - gradientTo["B"]) / (double)(count + 1)) - 1;
```
А так же перед вызовом Task dsvv = Change(previousElement, timeOut, SymbolColor); добавляем:
```
// Вызываем извлеченные элементы
// (greenCoefficient * (k + 1)) - 20 Высчитываем яркость так, что б разница между первым и последним была на всех змейках одинаковая
// и равномерно распределялась независимо от ее длины(количества элементов)
SymbolColor["A"] = (gradientFrom["A"] - ((i - k) * A_Coefficient));
SymbolColor["R"] = (gradientFrom["R"] - ((i - k) * R_Coefficient));
SymbolColor["G"] = (gradientFrom["G"] - ((i - k) * G_Coefficient));
SymbolColor["B"] = (gradientFrom["B"] - ((i - k) * B_Coefficient));
```
И меняем определение метода Change, где вместо int Opacity ставим Dictionary SymbolColor:
```
// Метод изменения символов в заданном элеменете
public async Task Change(TextBlock element, int timeOut, Dictionary SymbolColor)
```
А внутри этого метода задаем цвет символа с помощью новых значений. Меняем
```
// Формируем нужный цвет с заданной яркостью
SolidColorBrush NewColor = new SolidColorBrush(new Color()
{
A = (byte)(255) /*Opacity*/,
R = (byte)(0) /*Red*/,
G = (byte)(Opacity) /*Green*/,
B = (byte)(0) /*Blue*/
});
```
на
```
// Формируем нужный цвет с заданной яркостью
SolidColorBrush NewColor = new SolidColorBrush(new Color()
{
A = (byte)(SymbolColor["A"]) /*Opacity*/,
R = (byte)(SymbolColor["R"]) /*Red*/,
G = (byte)(SymbolColor["G"]) /*Green*/,
B = (byte)(SymbolColor["B"]) /*Blue*/
});
```
##### Выбор языка
С цветами разобрались. Теперь давайте решим вопрос с выбором языка. В конструкторе класса мы вызывали метод ListLanguages для инициализации доступных языков. Рассмотрим его более подробно:
**Код. ListLanguages**
```
// Заполняем словарь идентификаторами языка и соответствующие ему ASCII коды символов
public void ListLanguages()
{
// Добавляем в словарь ключь - название языка и значение - массив, состоящий из ASCII кодов символов.
languages.Add("Матрица", new int[] { 64, 127 });
languages.Add("Китаский", new int[] { 19968, 20223 });
languages.Add("Английский", new int[] { 64, 127 });
languages.Add("Цифры", new int[] { 48, 57 });
languages.Add("Случайные символы", new int[] { 0, 1000 });
languages.Add("Русский", new int[] { 1040, 1103 });
// Добавляем языки в всплывающую панель для возможности их выбора
foreach (var language in languages)
{
// Создаю кнопку
Button newLang = new Button();
// Задаю надпись кнопки, соответствует языку
newLang.Content = language.Key.ToString();
// Горизонтальное выравнивание
newLang.HorizontalAlignment = HorizontalAlignment.Stretch;
// Толщина рамки
newLang.BorderThickness = new Thickness(1);
// Смещение
newLang.Margin = new Thickness(0,0,0,0);
// Событие, при нажатии на кнопку. Одно на все.
newLang.Click += Event_Button_Click_SelectLanguageUpdate;
// Добавляю созданую и настроенную кнопку в всплывающее окно
StackPanel_ButtonDropDownSelectLanguage.Children.Add(newLang);
}
}
```
Теперь добавляем обработчик кнопки, в которой показывается выбранный язык и при нажатии на которую появляется всплывающее окно:
**Код. Event\_Button\_Click\_SelectLanguage**
```
// Кнопка, в которой показывается текущее выбранное значение языка. при нажатии на нее всплывает меню для выбора другого языка.
private void Event_Button_Click_SelectLanguage(object sender, RoutedEventArgs e)
{
// Показывать (true) / не показывать (false) всплывающее окно (PopUp) при выборе языка
if (flagShowLanguages)
{
// Показать всплывающее окно
Popup_ButtonDropDownSelectLanguage.IsOpen = true;
flagShowLanguages = false;
}
else
{
// Скрыть всплывающее окно
Popup_ButtonDropDownSelectLanguage.IsOpen = false;
flagShowLanguages = true;
}
}
```
В сплывающем окне находятся кнопки, при нажатии на которые и выбирается нужный язык. У всех кнопок назначен один и тот же обработчик событий, который определяет контент кнопки, который и является ключом в словаре для выбора языка. Задаем значение выбранного языка в свойство класса actualLanguage:
**Код. Event\_Button\_Click\_SelectLanguageUpdate**
```
// Всплывающее меню выбора языка.
private void Event_Button_Click_SelectLanguageUpdate(object sender, RoutedEventArgs e)
{
// Если нажата кнопка выбора языка, но другой язык не выбран, то при повторном нажатии меню свернется.
if (!flagShowLanguages)
{
// Скрыть всплывающее окно
Popup_ButtonDropDownSelectLanguage.IsOpen = false;
flagShowLanguages = true;
}
// Получаем название кнопки, которую нажали
string newLanguagr = (sender as Button).Content.ToString();
// Обновляем название кнопки, отображающей выбранный язык
Button_SelectLanguage.Content = newLanguagr;
// Задаем значение языка, в котором выбирать символы случайным образом
this.actualLanguage = newLanguagr;
}
```
Теперь все готово, для того, что б можно было выбрать случайный символ из заданного диапазона. Напишем метод RandomActualSymbol, который и будет возвращать случайный символ:
**Код. RandomActualSymbol**
```
// Вызываем эту функцию везде, где нужно показать случайный символ из выбранного языка.
public string RandomActualSymbol()
{
// Получаем массив по ключу, содержащий ASCII коды символов языка, заданного в actualLanguage
int[] sd = (languages[actualLanguage]);
// Выбираем случайнфй символ в диапазоне от первого до последнего символа в заданом языке
return char.ConvertFromUtf32(this.random.Next((int)sd.GetValue(0), (int)sd.GetValue(1)));
}
```
И подставим вызов этого метода везде, где нужно задать символ. Например, в методе Change:
```
// Каждый раз разный символ из заданного диапазона
element.Text = RandomActualSymbol();
```
##### Старт / Стоп
Тут все очень просто. В зависимости от флага flagOnOff, который задан как свойство класса завершаем циклы, в которых происходит обработка непосредственно самой матрицы.
Задаем обработчики событий кнопок «Старт» и «Стоп», которые просто меняют состояние флага на противоположный:
**Код. Event\_Button\_Click\_Stop и Event\_Button\_Click\_Start**
```
// Настройки. Выключаем возможность анимирования змеек
private void Event_Button_Click_Stop(object sender, RoutedEventArgs e)
{
this.flagOnOff = true;
// Если flagOnOff в true то подсвечиваем кнопку Stop
if (this.flagOnOff)
{
Button_Stop.Background = new SolidColorBrush(Colors.Cyan);
Button_Start.Background = new SolidColorBrush(Colors.Black);
}
}
// Настройки. Включаем возможность анимирования змеек
private void Event_Button_Click_Start(object sender, RoutedEventArgs e)
{
this.flagOnOff = false;
// Если flagOnOff в false то подсвечиваем кнопку Start
if (!this.flagOnOff)
{
Button_Stop.Background = new SolidColorBrush(Colors.Black);
Button_Start.Background = new SolidColorBrush(Colors.Cyan);
}
}
```
И добавляем внутри нескольких циклов простое условие
```
if (flagOnOff) break;
```
А именно в циклах методов Event\_Grid\_Tap\_LayoutRoot, RandomElementQ\_Async, Change:
**Код. Остановка матрицы**В Event\_Grid\_Tap\_LayoutRoot:
```
// Количество одновременно появляющихся змеек после нажатия
for (int i = 0; i < countSimultaneously; i++)
{
// Останавливаем анимацию
if (flagOnOff) break;
```
В RandomElementQ\_Async тут:
```
// Цикл формирует змейку заданной длины length
for (int i = 0; i <= length; i++)
{
// Останавливаем анимацию
if (flagOnOff) break;
```
и тут:
```
// Перебираем все элементы, составляющие змейку на данном этапе. С каждым циклом она увеличивается, пока не достигнет нужной длины.
for (int k = 0; k <= i; k++)
{
// Останавливаем анимацию
if (flagOnOff) break;
```
В Change:
```
// Количество смены символов в каждой ячейке
for (int i = 0; i < countSymbol; i++)
{
// Останавливаем анимацию
if (flagOnOff) break;
```
Почему аж в четырех местах? Если змеек мало, то все нормально. Но если количество змеек неприлично большое, например, 50+, то матрица останавливается с заметными тормозами. А так мы останавливаем непосредственно каждый элемент, принимающий участие в работе механизма матрицы.
Ну и напоследок добавим красоты, для задания цвета кнопки, которая сейчас нажата. В конструкторе за это отвечает этот код:
```
// Подсвечиваем кнопку Вкл или Выкл, зависит от флага
if (this.flagOnOff)
{
Button_Stop.Background = new SolidColorBrush(Colors.Cyan);
Button_Start.Background = new SolidColorBrush(Colors.Black);
}
else
{
Button_Stop.Background = new SolidColorBrush(Colors.Black);
Button_Start.Background = new SolidColorBrush(Colors.Cyan);
}
```
Точнее сказать, задания цвета кнопки при инициализации приложения.
##### Очистка экрана
При срабатывании события Event\_Button\_Click\_Clear происходит тоже самое, что и в CreateElement, только без создания элементов. Перебираются все элементы и как символ задается пустота:
**Код. Event\_Button\_Click\_Clear**
```
// Настройки. Очистка экрана
private void Event_Button_Click_Clear(object sender, RoutedEventArgs e)
{
// Перебираем сетку ячеек и устанавливаем в каждой ячейке как символ - пустоту
for ( int i = 0; i < countWidth; i++)
{
for (int j = 0; j < countHeight; j++)
{
// Формируем имя элемента, который будем очищать
string elementName = "TB_" + i + "_" + j;
// Получаем элемент по его имени
object wantedNode = LayoutRoot.FindName(elementName);
TextBlock element = (TextBlock)wantedNode;
// Очищаем значение
element.Text = "";
}
}
}
```
##### Горизонтальная / Вертикальная ориентация
Опять все исходит от флага turnOnOff. Что мы делаем? Останавливаем матрицу. Меняем надпись на кнопке. Меняем местами количество строк и столбцов. Удаляем матрицу. Создаем матрицу снова, вызывая метод CreateElement:
**Код. Event\_Button\_Click\_Turn**
```
// Настройки. Вериткальная / горизонтальная матрица
private void Event_Button_Click_Turn(object sender, RoutedEventArgs e)
{
// Включить (true), выключить (false) "поворот экрана"
if (turnOnOff)
{
// Сохраняем значение false в свойство класса turnOnOff
this.turnOnOff = false;
// Надпись на конопке с именем ToggleButton_Turn меняю на Горизонтально
ToggleButton_Turn.Content = "Горизонтально";
// Количество строк и столбцов. Инвертируем для горизонтали.
this.countHeight = (int)Math.Round(ScreenWidth / (kolich + addingSize)) + 5 + Math.Abs(addingSize);
this.countWidth = (int)Math.Round(ScreenHeight / (kolich + addingSize)) + 5 + Math.Abs(addingSize);
}
else
{
// Сохраняем значение true в свойство класса turnOnOff
this.turnOnOff = true;
// Надпись на конопке с именем ToggleButton_Turn меняю на Вертикально
ToggleButton_Turn.Content = "Вертикально";
// Количество строк и столбцов. Возвращаем для вертикали
this.countWidth = (int)Math.Round(ScreenWidth / (kolich + addingSize)) + Math.Abs(addingSize);
this.countHeight = (int)Math.Round(ScreenHeight / (kolich + addingSize)) + 5 + Math.Abs(addingSize);
}
// Останавливаем матрицу
this.flagOnOff = true;
// Удаляем матрицу (сами ячейки)
LayoutRootSecond.Children.Clear();
// Перерисовываем ячейки заново с новыми параметрами
CreateElement();
// Включаем матрицу
this.flagOnOff = false;
}
```
##### Изменение размера матрицы
Логика схожа с поворотом. Единственная разница в том, что мы не меняем местами количество строк и столбцов, а добавляем к расчету количества строк и столбцов коэффициент, введенный пользователем:
**Код. Event\_Button\_Click\_ElementSize**
```
// Настройки. Размер клетки для символа
private void Event_Button_Click_ElementSize(object sender, RoutedEventArgs e)
{
// Сохраняем значение их соответствующего TextBox TextBox_ElementSize в свойство класса addingSize
this.addingSize = int.Parse(TextBox_ElementSize.Text.ToString());
// Количество строк и столбцов. Возвращаем для вертикали
this.countWidth = (int)Math.Round(ScreenWidth / (kolich + addingSize)) + Math.Abs(addingSize);
this.countHeight = (int)Math.Round(ScreenHeight / (kolich + addingSize)) + 5 + Math.Abs(addingSize);
// Останавливаем матрицу
this.flagOnOff = true;
// Удаляем матрицу (сами ячейки)
LayoutRootSecond.Children.Clear();
// Перерисовываем ячейки заново с новыми параметрами
CreateElement();
// Включаем матрицу
this.flagOnOff = false;
}
```
##### Остальные настройки
Выполнены по одному шаблону. Получаем введенное пользователем значение, записываем его в соответствующее свойство класса, которое и подставляем в нужном месте, вместо статических значений которые были в предыдущей части.
Например количество одновременно ползущих змеек:
**Код. Event\_Grid\_Tap\_LayoutRoot**Вместо статики
```
// Событие при нажатии на эелемет Grid (на экран)
private void Event_Grid_Tap_LayoutRoot(object sender, System.Windows.Input.GestureEventArgs e)
{
// Количество одновременно появляющихся змеек после нажатия
for (int i = 0; i < 5; i++)
{
// Останавливаем анимацию
if (flagOnOff) break;
Start();
//Задержка между вызовами. Для красоты матрицы.
Task.Delay(100);
}
}
```
Делаем динамику:
```
// Событие при нажатии на эелемет Grid (на экран)
private void Event_Grid_Tap_LayoutRoot(object sender, System.Windows.Input.GestureEventArgs e)
{
// Количество одновременно появляющихся змеек после нажатия
for (int i = 0; i < countSimultaneously; i++)
{
// Останавливаем анимацию
if (flagOnOff) break;
Start();
//Задержка между вызовами. Для красоты матрицы.
Task.Delay(100);
}
}
```
**Код. MainPage.xaml.cs**
```
using System;
using System.Net;
using System.Collections.Generic;
using System.Linq;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Navigation;
using Microsoft.Phone.Controls;
using Microsoft.Phone.Shell;
using System.Windows.Media;
using System.Threading.Tasks;
using System.Diagnostics;
using System.Collections.ObjectModel;
namespace SE_Matrix_2d_v_4
{
public partial class MainPage : PhoneApplicationPage
{
/* ****************************** Свойства класса ****************************** */
// Случайное число
Random random = new Random();
// Количество змеек после нажатия на экран в очереди
int iteration = 5;
// Количество одновременно появляющихся змеек после нажатия
int countSimultaneously = 3;
// Скорость смены символов
int speedFrom = 20;
int speedTo = 40;
// Размер клетки для символа
int addingSize = -6;
// Итоговый размер шрифта
int fontSize;
// Минимальная и максимальная длина змейки
int minLength = 10;
int maxLength = 15;
// Получаем расширение экрана
double ScreenWidth = System.Windows.Application.Current.Host.Content.ActualWidth - 60;
double ScreenHeight = System.Windows.Application.Current.Host.Content.ActualHeight - 100;
// Коеффициент, отвечающий за количесвто ячеек и частично за размер шрифта
int kolich = 30;
// Размер шрифта задается по формуле kolich + addingFontSize.
int addingFontSize = -2;
// Количество смены символов в ячейке
int countSymbol = 3;
// Включить (false), выключить (true) матрицу
bool flagOnOff = false;
// Включить (false), выключить (true) "поворот экрана"
bool turnOnOff = true;
// Количество строк и столбцов
int countWidth = 10;
int countHeight = 10;
// Словарь, в котором хранятся идентификаторы языка и соответствующие ему ASCII коды символов
Dictionary languages = new Dictionary();
// Задаю язык по-умолчанию
string actualLanguage = "Русский";
// Флаг, отвечающий за показывать (true) / не показывать (false) всплывающее окно (PopUp) при выборе языка
bool flagShowLanguages = true;
// Цвет фона матрицы, ARGB
Dictionary colorMatrixBackground = new Dictionary();
// Цвет первого символа, ARGB
Dictionary colorFirstSymbol = new Dictionary();
// Цвет градиента змейки от (второй символ) - до (последний символ), ARGB
Dictionary gradientFrom = new Dictionary();
Dictionary gradientTo = new Dictionary();
/\* \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* Методы класса \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* \*/
// Конструктор
public MainPage()
{
InitializeComponent();
// Вызываем функцию настройки начальных значений цветов фона, символов и т.д.
BeginColorSettings();
// Инициализируем список доступных языков, а также соответствующие им ASCII коды символов
ListLanguages();
// Количество строк и столбцов
this.countWidth = (int)Math.Round(ScreenWidth / (kolich + addingSize)) + Math.Abs(addingSize);
this.countHeight = (int)Math.Round(ScreenHeight / (kolich + addingSize)) + 5 + Math.Abs(addingSize);
// Создание сетки элементов, в которой будет сыпаться матрица
CreateElement();
// Подсвечиваем кнопку Вкл или Выкл, зависит от флага
if (this.flagOnOff)
{
Button\_Stop.Background = new SolidColorBrush(Colors.Cyan);
Button\_Start.Background = new SolidColorBrush(Colors.Black);
}
else
{
Button\_Stop.Background = new SolidColorBrush(Colors.Black);
Button\_Start.Background = new SolidColorBrush(Colors.Cyan);
}
// Меняем цвет фона матрицы
ChangeBackground();
}
// Создание сетки элементов, в которой будет сыпаться матрица
public void CreateElement()
{
// Вычисляем тоговый размер шрифта для разметки / переразметки
this.fontSize = kolich + addingFontSize + addingSize;
// Создаем сетку ячеек
for (int i = 0; i < countWidth; i++)
{
for (int j = 0; j < countHeight; j++)
{
// Создаем TextBlock
TextBlock element = new TextBlock();
// Задаем имя элемента TextBlock
element.Name = "TB\_" + i + "\_" + j;
// Задаем начальный символ при инициализации сетки ячеек
// element.Text = char.ConvertFromUtf32(random.Next(0x4E00, 0x4FFF)); // Случайный символ из заданного диапазона
// element.Text = random.Next(0, 9).ToString(); // Случайным числом
element.Text = ""; // Пустота
// Задаем смещение каждого нового элемента TextBlock
// Также отвечает за разворот вертикальный / горизонтальный
int turnY = j \* (kolich + addingSize);
int turnX = i \* (kolich + addingSize);
// Включить (false), выключить (true) "поворот экрана"
if (turnOnOff)
{
// Вертикальное, стандартное расположение
element.Margin = new Thickness(turnX, turnY, 0, 0);
}
else
{
// Повернутое, горизонтальное расположение
element.Margin = new Thickness(turnY, turnX, 0, 0);
}
// Задаем цвет символа
element.Foreground = new SolidColorBrush(Colors.Green);
// Задаем размер шрифта
element.FontSize = fontSize;
// Добавляем созданный элемент в Grid
LayoutRootSecond.Children.Add(element);
}
}
}
// Событие при нажатии на эелемет Grid (на экран)
private void Event\_Grid\_Tap\_LayoutRoot(object sender, System.Windows.Input.GestureEventArgs e)
{
// Количество одновременно появляющихся змеек после нажатия
for (int i = 0; i < countSimultaneously; i++)
{
// Останавливаем анимацию
if (flagOnOff) break;
Start();
//Задержка между вызовами. Для красоты матрицы.
Task.Delay(100);
}
}
// Метод запуска змейки
public async void Start()
{
int count;
// Количество змеек после нажатия на экран в очереди
for (count = 0; count < iteration; count++)
{
// Начало змейки по горизонтали случайным образом
int ranX = random.Next(0, countWidth);
// Начало змейки по вертикали случайным образом
int ranY = random.Next(-5, countHeight - 1);
// Длина змейки случайным образом
int length = random.Next(minLength, maxLength);
// Скорость смены символов в змейке случайным образом
int time = random.Next(speedFrom, speedTo);
await Task.Delay(1);
//Обработка змейки
await RandomElementQ\_Async(ranX, ranY, length, time);
}
}
// Определяю элемент, в котором нужно менять символы
public async Task RandomElementQ\_Async(int x, int y, int length, int timeOut)
{
// Словарь для хранения идентификаторов ячеек, которые вызывались на предыдущем этапе.
Dictionary dicElem = new Dictionary();
// Задаем цвет символов
Dictionary SymbolColor = new Dictionary();
// Счетчик, нужен для обработки случаев, когда не выполняется условие if ((y + i) < countHeight && (y + i) >= 0). Смотри на 4 строчки вниз.
// Тоесть элемент в котором нужно менять символы выше или ниже нашей сетки (матрицы элементов).
int count = 0;
// Цикл формирует змейку заданной длины length
for (int i = 0; i <= length; i++)
{
// Останавливаем анимацию
if (flagOnOff) break;
//Проверяем, что б змейка отображалась только в координатах, которые существуют в нашей сетке
if ((y + i) < countHeight && (y + i) >= 0)
{
// Формируем имя элемента, в котором будут меняться символы
string elementName = "TB\_" + x + "\_" + (y + i);
// Получаем элемент по его имени
object wantedNode = LayoutRoot.FindName(elementName);
TextBlock element = (TextBlock)wantedNode;
// Отправляем элемент в словарь, из которого он будет извлекаться для эффекта "падения" и "затухания" змейки
dicElem[count] = (element);
// Определяем коеффициент для подсчета яркости. Первый элемент(который падает) - всега самый яркий, последний - самый темный.
// Отнимаем 1, потому, что последний элемент (когда к - максимальное) в итоге получается больше 255 и становится ярким.
int A\_Coefficient = (int)Math.Round((gradientFrom["A"] - 10) / (double)(count + 1)) - 1;
int R\_Coefficient = (int)Math.Round((gradientFrom["R"] - gradientTo["R"]) / (double)(count + 1)) - 1;
int G\_Coefficient = (int)Math.Round((gradientFrom["G"] - gradientTo["G"]) / (double)(count + 1)) - 1;
int B\_Coefficient = (int)Math.Round((gradientFrom["B"] - gradientTo["B"]) / (double)(count + 1)) - 1;
//int greenCoefficient = (int)Math.Round(255 / (double)(count + 1)) - 1;
// Вызываем на прорисовку первый, самый яркий падающий элемент. Асинхронно.
// colorFirstSymbol["A"]. Цвет задается через настройку.
await Change(element, timeOut, colorFirstSymbol);
// Перебираем все элементы, составляющие змейку на данном этапе. С каждым циклом она увеличивается, пока не достигнет нужной длины.
for (int k = 0; k <= i; k++)
{
// Останавливаем анимацию
if (flagOnOff) break;
// Если змейка начинаеися "выше" начальных координат (например, если y = -5)
if (dicElem.ContainsKey(k))
{
//Извлекаем элементы, которые должны следовать за самым ярким. Создаем эффект "затухания" цвета
TextBlock previousElement = dicElem[k];
// Вызываем извлеченные элементы
// (greenCoefficient \* (k + 1)) - 20 Высчитываем яркость так, что б разница между первым и последним была на всех змейках одинаковая
// и равномерно распределялась независимо от ее длины(количества элементов)
SymbolColor["A"] = (gradientFrom["A"] - ((i - k) \* A\_Coefficient));
SymbolColor["R"] = (gradientFrom["R"] - ((i - k) \* R\_Coefficient));
SymbolColor["G"] = (gradientFrom["G"] - ((i - k) \* G\_Coefficient));
SymbolColor["B"] = (gradientFrom["B"] - ((i - k) \* B\_Coefficient));
Task dsvv = Change(previousElement, timeOut, SymbolColor);
}
}
count++;
}
}
}
// Метод изменения символов в заданном элеменете
public async Task Change(TextBlock element, int timeOut, Dictionary SymbolColor)
{
// Формируем нужный цвет с заданной яркостью
SolidColorBrush NewColor = new SolidColorBrush(new Color()
{
A = (byte)(SymbolColor["A"]) /\*Opacity\*/,
R = (byte)(SymbolColor["R"]) /\*Red\*/,
G = (byte)(SymbolColor["G"]) /\*Green\*/,
B = (byte)(SymbolColor["B"]) /\*Blue\*/
});
// При каждом "падении" на 1 клеточку равномерно "затухает"
element.Foreground = NewColor;
// Количество смены символов в каждой ячейке
for (int i = 0; i < countSymbol; i++)
{
// Останавливаем анимацию
if (flagOnOff) break;
// Каждый раз разный символ из заданного диапазона
element.Text = RandomActualSymbol();
// Размер шрифта
element.FontSize = fontSize;
// Скорость смены символов в ячейке
await Task.Delay(timeOut);
}
}
// Загрузка данных для элементов ViewModel
protected override void OnNavigatedTo(NavigationEventArgs e)
{
if (!App.ViewModel.IsDataLoaded)
{
App.ViewModel.LoadData();
}
}
/\* \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* События \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* \*/
// Настройки. Скорость смены символов.
private void Event\_Button\_Click\_SpeedApplay(object sender, RoutedEventArgs e)
{
// Сохраняем значение их соответствующего TextBox TextBox\_SppeedFrom в свойство класса speedFrom
this.speedFrom = int.Parse(TextBox\_SppeedFrom.Text.ToString());
// Сохраняем значение их соответствующего TextBox TextBox\_SppeedTo в свойство класса speedTo
this.speedTo = int.Parse(TextBox\_SppeedTo.Text.ToString());
}
// Настройки. Количество змеек в очереди
private void Event\_Button\_Click\_CountQueue(object sender, RoutedEventArgs e)
{
// Сохраняем значение их соответствующего TextBox TextBox\_CountQueue в свойство класса iteration
this.iteration = int.Parse(TextBox\_CountQueue.Text.ToString());
}
// Настройки. Количество змеек за нажатие
private void Event\_Button\_Click\_СountSimultaneously(object sender, RoutedEventArgs e)
{
// Сохраняем значение их соответствующего TextBox TextBox\_СountSimultaneously в свойство класса countSimultaneously
this.countSimultaneously = int.Parse(TextBox\_СountSimultaneously.Text.ToString());
}
// Настройки. Размер шрифта
private void Event\_Button\_Click\_FontSize(object sender, RoutedEventArgs e)
{
// Сохраняем значение их соответствующего TextBox TextBox\_FontSize в свойство класса addingFontSize
this.addingFontSize = int.Parse(TextBox\_FontSize.Text.ToString());
// Вычисляем тоговый размер шрифта для разметки / переразметки
this.fontSize = kolich + addingFontSize + addingSize;
}
// Настройки. Количество смены символов в ячейке
private void Event\_Button\_Click\_CountSymbol(object sender, RoutedEventArgs e)
{
// Сохраняем значение их соответствующего TextBox TextBox\_CountSymbol в свойство класса countSymbol
this.countSymbol = int.Parse(TextBox\_CountSymbol.Text.ToString());
}
// Настройки. Выключаем возможность анимирования змеек
private void Event\_Button\_Click\_Stop(object sender, RoutedEventArgs e)
{
this.flagOnOff = true;
// Если flagOnOff в true то подсвечиваем кнопку Stop
if (this.flagOnOff)
{
Button\_Stop.Background = new SolidColorBrush(Colors.Cyan);
Button\_Start.Background = new SolidColorBrush(Colors.Black);
}
}
// Настройки. Включаем возможность анимирования змеек
private void Event\_Button\_Click\_Start(object sender, RoutedEventArgs e)
{
this.flagOnOff = false;
// Если flagOnOff в false то подсвечиваем кнопку Start
if (!this.flagOnOff)
{
Button\_Stop.Background = new SolidColorBrush(Colors.Black);
Button\_Start.Background = new SolidColorBrush(Colors.Cyan);
}
}
// Настройки. Очистка экрана
private void Event\_Button\_Click\_Clear(object sender, RoutedEventArgs e)
{
// Перебираем сетку ячеек и устанавливаем в каждой ячейке как символ - пустоту
for ( int i = 0; i < countWidth; i++)
{
for (int j = 0; j < countHeight; j++)
{
// Формируем имя элемента, который будем очищать
string elementName = "TB\_" + i + "\_" + j;
// Получаем элемент по его имени
object wantedNode = LayoutRoot.FindName(elementName);
TextBlock element = (TextBlock)wantedNode;
// Очищаем значение
element.Text = "";
}
}
}
// Настройки. Размер клетки для символа
private void Event\_Button\_Click\_ElementSize(object sender, RoutedEventArgs e)
{
// Сохраняем значение их соответствующего TextBox TextBox\_ElementSize в свойство класса addingSize
this.addingSize = int.Parse(TextBox\_ElementSize.Text.ToString());
// Количество строк и столбцов. Возвращаем для вертикали
this.countWidth = (int)Math.Round(ScreenWidth / (kolich + addingSize)) + Math.Abs(addingSize);
this.countHeight = (int)Math.Round(ScreenHeight / (kolich + addingSize)) + 5 + Math.Abs(addingSize);
// Останавливаем матрицу
this.flagOnOff = true;
// Удаляем матрицу (сами ячейки)
LayoutRootSecond.Children.Clear();
// Перерисовываем ячейки заново с новыми параметрами
CreateElement();
// Включаем матрицу
this.flagOnOff = false;
}
// Настройки. Задаем максимальную и минимальную длину змейки
private void Event\_Button\_Click\_MaxLength(object sender, RoutedEventArgs e)
{
// Сохраняем значение их соответствующего TextBox TextBox\_MinLength в свойство класса minLength
this.minLength = int.Parse(TextBox\_MinLength.Text.ToString());
// Сохраняем значение их соответствующего TextBox TextBox\_MaxLength в свойство класса maxLength
this.maxLength = int.Parse(TextBox\_MaxLength.Text.ToString());
}
// Настройки. Вериткальная / горизонтальная матрица
private void Event\_Button\_Click\_Turn(object sender, RoutedEventArgs e)
{
// Включить (true), выключить (false) "поворот экрана"
if (turnOnOff)
{
// Сохраняем значение false в свойство класса turnOnOff
this.turnOnOff = false;
// Надпись на конопке с именем ToggleButton\_Turn меняю на Горизонтально
ToggleButton\_Turn.Content = "Горизонтально";
// Количество строк и столбцов. Инвертируем для горизонтали.
this.countHeight = (int)Math.Round(ScreenWidth / (kolich + addingSize)) + 5 + Math.Abs(addingSize);
this.countWidth = (int)Math.Round(ScreenHeight / (kolich + addingSize)) + 5 + Math.Abs(addingSize);
}
else
{
// Сохраняем значение true в свойство класса turnOnOff
this.turnOnOff = true;
// Надпись на конопке с именем ToggleButton\_Turn меняю на Вертикально
ToggleButton\_Turn.Content = "Вертикально";
// Количество строк и столбцов. Возвращаем для вертикали
this.countWidth = (int)Math.Round(ScreenWidth / (kolich + addingSize)) + Math.Abs(addingSize);
this.countHeight = (int)Math.Round(ScreenHeight / (kolich + addingSize)) + 5 + Math.Abs(addingSize);
}
// Останавливаем матрицу
this.flagOnOff = true;
// Удаляем матрицу (сами ячейки)
LayoutRootSecond.Children.Clear();
// Перерисовываем ячейки заново с новыми параметрами
CreateElement();
// Включаем матрицу
this.flagOnOff = false;
}
// Заполняем словарь идентификаторами языка и соответствующие ему ASCII коды символов
public void ListLanguages()
{
// Добавляем в словарь ключь - название языка и значение - массив, состоящий из ASCII кодов символов.
languages.Add("Матрица", new int[] { 64, 127 });
languages.Add("Китаский", new int[] { 19968, 20223 });
languages.Add("Английский", new int[] { 64, 127 });
languages.Add("Цифры", new int[] { 48, 57 });
languages.Add("Случайные символы", new int[] { 0, 1000 });
languages.Add("Русский", new int[] { 1040, 1103 });
// Добавляем языки в всплывающую панель для возможности их выбора
foreach (var language in languages)
{
// Создаю кнопку
Button newLang = new Button();
// Задаю надпись кнопки, соответствует языку
newLang.Content = language.Key.ToString();
// Горизонтальное выравнивание
newLang.HorizontalAlignment = HorizontalAlignment.Stretch;
// Толщина рамки
newLang.BorderThickness = new Thickness(1);
// Смещение
newLang.Margin = new Thickness(0,0,0,0);
// Событие, при нажатии на кнопку. Одно на все.
newLang.Click += Event\_Button\_Click\_SelectLanguageUpdate;
// Добавляю созданую и настроенную кнопку в всплывающее окно
StackPanel\_ButtonDropDownSelectLanguage.Children.Add(newLang);
}
}
// Вызываем эту функцию везде, где нужно показать случайный символ из выбранного языка.
public string RandomActualSymbol()
{
// Получаем массив по ключу, содержащий ASCII коды символов языка, заданного в actualLanguage
int[] sd = (languages[actualLanguage]);
// Выбираем случайнфй символ в диапазоне от первого до последнего символа в заданом языке
return char.ConvertFromUtf32(this.random.Next((int)sd.GetValue(0), (int)sd.GetValue(1)));
}
// Кнопка, в которой показывается текущее выбранное значение языка. при нажатии на нее всплывает меню для выбора другого языка.
private void Event\_Button\_Click\_SelectLanguage(object sender, RoutedEventArgs e)
{
// Показывать (true) / не показывать (false) всплывающее окно (PopUp) при выборе языка
if (flagShowLanguages)
{
// Показать всплывающее окно
Popup\_ButtonDropDownSelectLanguage.IsOpen = true;
flagShowLanguages = false;
}
else
{
// Скрыть всплывающее окно
Popup\_ButtonDropDownSelectLanguage.IsOpen = false;
flagShowLanguages = true;
}
}
// Всплывающее меню выбора языка.
private void Event\_Button\_Click\_SelectLanguageUpdate(object sender, RoutedEventArgs e)
{
// Если нажата кнопка выбора языка, но другой язык не выбран, то при повторном нажатии меню свернется.
if (!flagShowLanguages)
{
// Скрыть всплывающее окно
Popup\_ButtonDropDownSelectLanguage.IsOpen = false;
flagShowLanguages = true;
}
// Получаем название кнопки, которую нажали
string newLanguagr = (sender as Button).Content.ToString();
// Обновляем название кнопки, отображающей выбранный язык
Button\_SelectLanguage.Content = newLanguagr;
// Задаем значение языка, в котором выбирать символы случайным образом
this.actualLanguage = newLanguagr;
}
// Меняем цвет фона матрицы
private void Event\_Button\_Click\_ChangeBackground(object sender, RoutedEventArgs e)
{
// Передаем в свойство класса colorMatrixBackground выбранный цвет из элемента ColorPicker для фона матрицы
colorMatrixBackground["A"] = ColorPicker.Color.A;
colorMatrixBackground["R"] = ColorPicker.Color.R;
colorMatrixBackground["G"] = ColorPicker.Color.G;
colorMatrixBackground["B"] = ColorPicker.Color.B;
// Задаем выбранный цвет фона матрицы соответствующей кнопке
Button\_BackgroundColor.Background = new SolidColorBrush(new Color()
{
A = (byte)(colorMatrixBackground["A"]) /\*Opacity\*/,
R = (byte)(colorMatrixBackground["R"]) /\*Red\*/,
G = (byte)(colorMatrixBackground["G"]) /\*Green\*/,
B = (byte)(colorMatrixBackground["B"]) /\*Blue\*/
});
// Задаем выбранный цвет фона матрицы
ChangeBackground();
}
// Метод изменения цвета фона матрицы. По умолчанию черный.
private void ChangeBackground()
{
// Задаю цвет фона матрицы
LayoutRootSecond.Background = new SolidColorBrush(new Color()
{
A = (byte)(colorMatrixBackground["A"]) /\*Opacity\*/,
R = (byte)(colorMatrixBackground["R"]) /\*Red\*/,
G = (byte)(colorMatrixBackground["G"]) /\*Green\*/,
B = (byte)(colorMatrixBackground["B"]) /\*Blue\*/
});
}
// Начальные настройки цветов фона, символов и т.д
private void BeginColorSettings()
{
// Задаем начальный цвет фона матрицы
colorMatrixBackground["A"] = 0;
colorMatrixBackground["R"] = 0;
colorMatrixBackground["G"] = 0;
colorMatrixBackground["B"] = 0;
// Задаем начальный цвет первого символа
colorFirstSymbol["A"] = 255;
colorFirstSymbol["R"] = 248;
colorFirstSymbol["G"] = 248;
colorFirstSymbol["B"] = 255;
// Задаем начальный цвет градиента от (второго символа в змейке)
gradientFrom["A"] = 255;
gradientFrom["R"] = 1;
gradientFrom["G"] = 255;
gradientFrom["B"] = 1;
// Задаем начальный цвет градиента до (последнего символа в змейке)
gradientTo["A"] = 0;
gradientTo["R"] = 0;
gradientTo["G"] = 0;
gradientTo["B"] = 0;
}
// Изменение цвета первого символа
private void Event\_Button\_Click\_FirstSymbolColor(object sender, RoutedEventArgs e)
{
// Передаем в свойство класса colorFirstSymbol выбранный цвет из элемента ColorPicker для фона матрицы
colorFirstSymbol["A"] = ColorPicker.Color.A;
colorFirstSymbol["R"] = ColorPicker.Color.R;
colorFirstSymbol["G"] = ColorPicker.Color.G;
colorFirstSymbol["B"] = ColorPicker.Color.B;
// Задаем выбранный цвет фона матрицы соответствующей кнопке
Button\_FirstSymbolColor.Background = new SolidColorBrush(new Color()
{
A = (byte)(colorFirstSymbol["A"]) /\*Opacity\*/,
R = (byte)(colorFirstSymbol["R"]) /\*Red\*/,
G = (byte)(colorFirstSymbol["G"]) /\*Green\*/,
B = (byte)(colorFirstSymbol["B"]) /\*Blue\*/
});
}
// Настройки. Задаем градиент змейки. Цвет второго символа.
private void Event\_Button\_Click\_GradientFrom(object sender, RoutedEventArgs e)
{
// Передаем в свойство класса gradientFrom выбранный цвет из элемента ColorPicker для фона матрицы
gradientFrom["A"] = ColorPicker.Color.A;
gradientFrom["R"] = ColorPicker.Color.R;
gradientFrom["G"] = ColorPicker.Color.G;
gradientFrom["B"] = ColorPicker.Color.B;
// Задаем выбранный цвет градиента от змейки соответствующей кнопке
Button\_GradientFrom.Background = new SolidColorBrush(new Color()
{
A = (byte)(gradientFrom["A"]) /\*Opacity\*/,
R = (byte)(gradientFrom["R"]) /\*Red\*/,
G = (byte)(gradientFrom["G"]) /\*Green\*/,
B = (byte)(gradientFrom["B"]) /\*Blue\*/
});
}
// Настройки. Задаем градиент змейки. Цвет последнего символа.
private void Event\_Button\_Click\_GradientTo (object sender, RoutedEventArgs e)
{
// Передаем в свойство класса gradientTo выбранный цвет из элемента ColorPicker для фона матрицы
gradientTo["A"] = ColorPicker.Color.A;
gradientTo["R"] = ColorPicker.Color.R;
gradientTo["G"] = ColorPicker.Color.G;
gradientTo["B"] = ColorPicker.Color.B;
// Задаем выбранный цвет градиента до змейки соответствующей кнопке
Button\_GradientTo.Background = new SolidColorBrush(new Color()
{
A = (byte)(gradientTo["A"]) /\*Opacity\*/,
R = (byte)(gradientTo["R"]) /\*Red\*/,
G = (byte)(gradientTo["G"]) /\*Green\*/,
B = (byte)(gradientTo["B"]) /\*Blue\*/
});
}
}
}
```
#### Выводы
Вторая часть окончена. Знаю, что код немного корявый, но как на меня так наиболее легко проследить логику. В следующей части займемся оптимизацией кода, сохранением настроек при выходе из приложения, локализацией под английский язык, привязкой к данным.
П.С. Если знаете как лучше сделать на данном этапе — прошу в комментарии. И не забывайте, что приложение создается этапами и будут еще как минимум 2 части… Буду благодарен, если подскажете, как решить проблему на последнем видео, так как панорама сдвигается только, если «хватать» за пределами ScrollViewer. | https://habr.com/ru/post/195760/ | null | ru | null |
# Асинхронные шаблоны в Knockout.JS
**Knockout.JS** — хорошая библиотека для создания сложных веб-приложений. Долгое время мне в ней не хватало асинхронного механизма шаблонов. Реализовать его не получалось, пока я не узнал что window.setTimeout вызывает свой callback не раньше окончания работы текущего контекста. Т.е. в коде
```
setTimeout("console.log(window.Value)",0),(function (){while (Math.random() < 0.9999999);window.Value = 1;})()
```
вывод на консоль произойдет только после завершения долгой функции случайного поиска числа очень близкого к единице.
Статья для разбирающихся в механизме биндинга knockout.js и умеющих писать customBindings.
Итак, зная поведение *setTimeout(callback, 0)* реализация очень простая.
Код custom-binding:
```
ko.bindingHandlers['asynctemplate'] = {
update: function (element, valueAccessor, allBindingsAccessor, viewModel, bindingContext) {
$(element).empty();
var template = ko.utils.unwrapObservable(valueAccessor());
if (!template)
return;
setTimeout(function() {
$.ajax({
url: template
}).done(function(result){
var view = $(result).appendTo(element)[0];
ko.applyBindings(bindingContext.$data, view);
});
}, 0);
}
}
```
Применение:
```
// хардкод путь к темлэйту
// или биндинг на переменную
// нельзя одновременно с with или foreach
!ОШИБКА!
```
Без нулевого timeout возникли бы проблемы: если получение шаблона займет небольшое время, то вставка шаблона в дерево DOM может произойти раньше, чем механизм биндинга knockout доберется до соответствующего элемента. В этом случае биндинг произойдет дважды, что ничем хорошим не заканчивается.
Эту проблему можно было бы решить другим способом: создать observable поле template, в которое сначала ставится затычка вроде «loading...», а уже при получении ответа с сервера загружается сам шаблон. Но это провоцирует мигания в интефейсе: на полсекунды появляется индикация загрузки.
Если кого-то заинтересует, могу добавить кэширование шаблонов и поддержку биндинга asynctemplate одновременно с with и foreach.
**UPD:** как пояснил в комментариях [xdenser](http://habrahabr.ru/users/xdenser/) все намного проще. В [документации](http://knockoutjs.com/documentation/custom-bindings-controlling-descendant-bindings.html) Knockout.js изложен более простой путь: нужно добавить init в custom-binding:
```
ko.bindingHandlers['asynctemplate'] = {
init: function () {
return { controlsDescendantBindings: true };
},
update: function (element, valueAccessor, allBindingsAccessor, viewModel, bindingContext) {
$(element).empty();
var template = ko.utils.unwrapObservable(valueAccessor());
if (!template)
return;
$.ajax({
url: template
}).done(function (result) {
$(result).appendTo(element);
ko.applyBindingsToDescendants(bindingContext, element);
});
}
}
```
+исправлена ошибка при биндинге шаблона: в изначальном варианте биндинг происходил только на первый элемент. | https://habr.com/ru/post/176143/ | null | ru | null |
# Как обмануть Робокассу
Если точнее, как обмануть сердобольных физических лиц, берущих комиссию за покупку на себя. Возможно, заголовок слишком громкий, возможно это и не статья вовсе (особенно учитывая, что я никогда не писал статей ранее), а какой-то очерк больного мозга, которому пора наконец выспаться, а не допиливать этот интернет-магазин. И тем не менее, во время интеграции Робокассы в интернет-магазин, была замечена интересная особенность, которая позволяет сэкономить на покупке за счет тех, кто пытается взять обязательства по комиссии в пользу Робокассы на свой счет, и я хотел бы вам об этом поведать.
#### Суть вопроса
Думаю, многие из вас знакомы с таким платёжным сервисом, как «Робокасса». Сервис этот, как водится, работает с двумя типами клиентов: физическими лицами, да юридическими. Рядовой пользователь, покупая нечто в нашем интернет-магазине, ожидает, что ему предъявят счет на сумму, указанную на ценнике. Очевиден тот факт, что требовать от пользователя покрыть еще и комиссию — это прямая дорога вникуда. Вот тут-то и встает вопрос, как переложить обязанность платить робокассе её долю на сам интернет-магазин.
Казалось бы, что может быть проще? Наверняка, такая настройка есть в личном кабинете на сайте платежки. Не тут-то было. Вернее, она есть. Но только в том случае, если вы — юридическое лицо.
В моей ситуации, человек, которому этот магазин создаётся, является лицом физическим. Администрация робокассы предусмотрительно поместила вопрос о комиссии в сайдбар личного кабинета. Видимо, как наиболее актуальный. Дабы не быть голословным:

Я не стану углубляться далеко в подробности о том, как работают транзакции в Робокассе, статья немного не об этом. Если вас интересует техдокументация, она в подробностях разжевана на официальном [сайте.](http://robokassa.ru/ru/Doc/Ru/Interface.asp)
Скажу лишь, что в процессе платежей все держится на нескольких вещах:
* MerchantLogin — ваш логин в системе
* InvId — ID выставляемого счета
* OutSum — сумма, которую мы хотим получить
* MerchantPass1 — технический пароль №1 для транзакций (всего их два, второй — для получения информации о состояниях платежей)
* SignatureValue — md5-хеш строки вида «sMerchantLogin:nOutSum:nInvId:sMerchantPass1»
Собственно, любая хитрая смена одного из значений, входящего в строку SignatureValue не даст транзакции совершиться. К слову, Вы, как разработчик можете добавлять свои параметры вида shp\*, которые «переживут» платеж и будут отправлены вашему серверу назад. Эти параметры также приплюсовываются к подписи транзакции.
Теперь вернемся к теме статьи.
#### Решение вопроса
Решение, предлагаемое работниками Робокассы, настораживает сразу же. Выглядит оно так:
> Для этих целей создан специальный XML-интерфейс:
>
>
>
> Метод расчёта суммы к получению магазином — CalcOutSumm
>
>
>
> Описание метода: Позволяет расчитать сумму к получению, исходя из текущих курсов ROBOKASSA, по сумме, которую заплатит пользователь.
>
>
>
> Параметры метода: MerchantLogin — идентификатор магазина (строка), IncCurrLabel — метка валюты (строка), для которой нужно произвести расчёт суммы. Если оставить его пустым, то расчёт будет произведен для всех доступных валют, IncSum — сумма, которую должен заплатить пользователь.
>
>
>
> Формат запроса: [merchant.roboxchange.com/WebService/Service.asmx/CalcOutSumm?MerchantLogin=string&IncCurrLabel=string&IncSum=string](https://merchant.roboxchange.com/WebService/Service.asmx/CalcOutSumm?MerchantLogin=string&IncCurrLabel=string&IncSum=string)
>
>
Т.е. нам предлагается высчитывать сумму так, чтобы с учетом комиссии она равнялась цене товара. Магазин писался на рельсах, а потому весь дополнительный парсинг отнял бы несколько строчек. И тем не менее, даже при всём нашем желании
#### Где зарыта собака?
Проблемы начинаются сразу же, как только мы хотим воспользоваться этим «интерфейсом». Допустим, мы захотели подсчитать сумму для всех способов оплаты. Как гласит руководство:
> IncCurrLabel — метка валюты (строка), для которой нужно произвести расчёт суммы. **Если оставить его пустым, то расчёт будет произведен для всех доступных валют**
Нет. Неправда. Если оставить его пустым — сервер вернет такой ответ (на примере ссылки [merchant.roboxchange.com/WebService/Service.asmx/CalcOutSumm?MerchantLogin=demo&IncCurrLabel=&IncSum=3500](https://merchant.roboxchange.com/WebService/Service.asmx/CalcOutSumm?MerchantLogin=demo&IncCurrLabel=&IncSum=3500) )
```
`6`
Переданы некорректные значения параметров.
0
```
Первая мысль: «Возможно я дурак и что-то не так делаю. Может, опускать параметр нужно не так?». Но нет, исходя из той же [документации](http://robokassa.ru/ru/Doc/Ru/Interface.aspx#233) (пример для другой функции, лишь демонстрирую отсутствие значения):
> Пример запроса методом HTTP GET:
>
> [merchant.roboxchange.com/WebService/Service.asmx/GetRates?MerchantLogin=demo](https://merchant.roboxchange.com/WebService/Service.asmx/GetRates?MerchantLogin=demo)**&IncCurrLabel=&**OutSum=10.45&Language=ru
Пробуем опустить параметр вовсе:
> Missing parameter: IncCurrLabel.
Беда. Но мы не сдаёмся. Что можно сделать в такой ситуации? Точно! Допустим, мы будем брать идентификатор способа оплаты из коллекции, считать для него сумму оплаты отдельно и запихивать в форму на нашем сайте, после чего менять outSum и пересчитывать подпись при выборе пользователем другого способа.
**Хорошо, что я не кинулся реализовывать это.**
Немного грубого проектирования показало, что на деле всё будет не так уж и радужно. О чём это я? Давайте посмотрим внимательнее на [интерфейс инициализации оплаты](http://robokassa.ru/ru/Doc/Ru/Interface.aspx#222).
> sIncCurrLabel
>
> — предлагаемая валюта платежа. **Пользователь может изменить ее в процессе оплаты.**
>
>
Ничего пока не насторожило? Давайте вдумаемся. Робокасса предлагает нам считать сумму самим, опираясь на выбранный пользователем интерфейс оплаты. Этот самый интерфейс IncCurrLabel в подпись не входит. Это логично, т.к. пользователь имеет право выбрать другой способ на сайте кассы. Тем не менее, комиссия для каждого способа высчитывается своя. Более того, высчитывать её предлагается нам, на стороне нашего сервера. Мы получаем outSum от того самого интерфейса, запихиваем в нашу форму, считаем подпись и отправляем на оплату.
##### Суть всей статьи
Ещё раз.
Робокасса предлагает нам вычитать из нашего дохода сумму комиссии, основываясь на том, какой способ оплаты хочет пользователь. При этом, этот самый способ оплаты она дает менять тогда, когда мы контроля над процессом платежа уже **не имеем**. Что происходит дальше?
А дальше все просто. Пользователь выбирает на нашем сайте способ с самой большой комиссией. На моей памяти — банковская карта. Мы, как добрые дяди, вычитаем порядка 300 рублей из цены нашего товара, дабы снять ношу комиссии с покупателя. Он же, попав на сайт Робокассы, просто выбирает оплату через какой-нибудь Яндекс или Вебмани с мизерной комиссией. Комиссия по новому способу высчитается на сайте робокассы опираясь на отправленный нами «скидочный» вариант цены. **Всё.**

И всё-таки, загвоздка получается в том, что с момента попадания на сайт платежки если пользователь оплатит заказ — нам вернется «успех» по платежу. И никого не волнует, что мы потеряли деньги на этом, по сути. Такая вот нехитрая схема.
#### Что всё-таки можно сделать?
##### Выход номер раз
###### Зверский
Мы можем хранить сумму, нашего товара и способ платежа, указанный пользователем в тех самых shp\* параметрах. Эти параметры защищены от изменения, а значит, мы получим их в целости и сохранности. Получив их назад, мы пересчитываем сумму снова и смотрим, сколько мы получили и сколько должны были. Если получили меньше — значит, нас обманули и мы можем как-то воздействовать на пользователя.
Проблема здесь лишь в том, что типичный покупатель может по чистой случайности, даже если мы напишем, что менять способ в самой кассе нельзя, поступить по своему. Вернуть деньги в полном объеме мы ему уже не сможем, если он подтвердит такую транзакцию. Так что и выходом это назвать сложно.
##### Выход номер два
###### Единственный
Регистрироваться в кассе как юридическое лицо. Собственно, в моем случае заказчик решил поступить именно так. В таком случае вам становится доступен один единственный переключатель, который решает эту проблему раз и навсегда.
##### Выход номер три
###### Несуществующий
Робокасса могла бы сделать возможность запрещать пользователю менять способ оплаты после инициализации оплаты. Например, ввести флаг canChangeCurrLabel, да пихать его в подпись транзакции. Тогда интерфейс расчета стоимости приобрел бы смысл, а мы не теряли бы деньги. Что помешало — неизвестно. | https://habr.com/ru/post/198284/ | null | ru | null |
# Перевод Django Documentation: Models. Part 3

Доброго времени суток!
Еще одна часть серии моих переводов [раздела о моделях](http://docs.djangoproject.com/en/dev/topics/db/models/) из [документации Django](http://docs.djangoproject.com/en/dev/).
[Перевод Django Documentation: Models. Part 1](http://habrahabr.ru/blogs/django/74856/)
[Перевод Django Documentation: Models. Part 2](http://habrahabr.ru/blogs/django/74967/)
\_\_\_*Мета*-параметры
\_\_\_Методы моделей
\_\_\_\_\_Переопределение предопределенных методов
\_\_\_\_\_Использование SQL
\_\_\_Наследование моделей
\_\_\_\_\_Абстрактные базовые классы
\_\_\_\_\_\_\_*Мета*-наследование
\_\_\_\_\_\_\_Будьте аккуратны с *related\_names*
[Перевод Django Documentation: Models. Part 4 (Last)](http://habrahabr.ru/blogs/django/80030/)
***Мета*-параметры**
Добавить вашей модели мета-данные вы можете с помощью внутреннего класса *Meta*:
> `Copy Source | Copy HTML
> class Ox(models.Model):
> horn\_length = models.IntegerField()
>
> class Meta:
> ordering = ["horn\_length"]
> verbose\_name\_plural = "oxen"`
Мета-данные в модели это «что-либо не являющееся полем», например: параметры сортировки ([ordering](http://docs.djangoproject.com/en/dev/ref/models/options/#django.db.models.Options.ordering)), имя таблицы базы данных ([db\_table](http://docs.djangoproject.com/en/dev/ref/models/options/#django.db.models.Options.db_table)), читабельные имена объектов в единственном ([verbose\_name](http://docs.djangoproject.com/en/dev/ref/models/options/#django.db.models.Options.verbose_name)) или множественном ([verbose\_name\_plural](http://docs.djangoproject.com/en/dev/ref/models/options/#django.db.models.Options.verbose_name_plural)) числе и тд. Мета-данные не являются обязательными, добавление класса *Meta* в вашу модель полностью опционально.
Полный список *мета*-параметров вы можете найти в [справке по параметрам модели](http://docs.djangoproject.com/en/dev/ref/models/options/#ref-models-options).
**Методы моделей**
Вы можете определить в модели методы, чтобы добавить собственной функциональности вашим объектам. В то время как методы [Manager](http://docs.djangoproject.com/en/dev/topics/db/managers/#django.db.models.Manager) предназначены для работы с данными всей таблицы, методы модели созданы для действий в отдельном экземпляре модели.
Эта техника полезна для хранения бизнес-логики приложения в одном месте — в модели.
Например, эта модель имеет несколько собственных методов:
> `Copy Source | Copy HTML
> from django.contrib.localflavor.us.models import USStateField
>
> class Person(models.Model):
> first\_name = models.CharField(max\_length=50)
> last\_name = models.CharField(max\_length=50)
> birth\_date = models.DateField()
> address = models.CharField(max\_length=100)
> city = models.CharField(max\_length=50)
> state = USStateField() # Yes, this is America-centric...
>
> def baby\_boomer\_status(self):
> "Returns the person's baby-boomer status."
> import datetime
> if **datetime**.date(1945, 8, 1) <= **self**.birth\_date <= **datetime**.date(1964, 12, 31):
> return "Baby boomer"
> if **self**.birth\_date < **datetime**.date(1945, 8, 1):
> return "Pre-boomer"
> return "Post-boomer"
>
> def is\_midwestern(self):
> "Returns True if this person is from the Midwest."
> return **self**.state in ('IL', 'WI', 'MI', 'IN', 'OH', 'IA', 'MO')
>
> def \_get\_full\_name(self):
> "Returns the person's full name."
> return '%s %s' % (**self**.first\_name, **self**.last\_name)
> full\_name = **property**(\_get\_full\_name)`
Последний метод этом примере — управляемый атрибут ([property](http://docs.djangoproject.com/en/dev/glossary/#term-property)). Более подробно [здесь](http://www.python.org/download/releases/2.2/descrintro/#property).
В [справке по экземплярам моделей](http://docs.djangoproject.com/en/dev/ref/models/instances/#ref-models-instances) содержится полный список [автоматически добавляемых каждой модели методов](http://docs.djangoproject.com/en/dev/ref/models/instances/#model-instance-methods). Вы можете переопределить большую их часть (об этом ниже). Также есть пара методов, которые переопределяют в большинстве случаев:
[\_\_unicode\_\_()](http://docs.djangoproject.com/en/dev/ref/models/instances/#django.db.models.Model.__unicode__)
«Магический метод» языка Python, который возвращает «представление» любого объекта в кодировке unicode. Его используют, когда требуется отобразить экземпляр модели в виде простой, понятной строки. Например, при работе в интерактивной консоли или в интерфейсе администратора.
Переопределение этого метода требуется довольно часто, потому что стандартный не очень полезен.
[get\_absolute\_url()](http://docs.djangoproject.com/en/dev/ref/models/instances/#django.db.models.Model.get_absolute_url)
Этот метод сообщает Django алгоритм вычисления URL для объекта. Он используется в интерфейсе администратора, а также каждый раз, когда нужно выяснить URL некоторого объекта.
Каждый объект, который имеет однозначно определяемый URL, должен содержать данный метод.
##### Переопределение предопределенных методов
Существует еще несколько [методов моделей](http://docs.djangoproject.com/en/dev/ref/models/instances/#model-instance-methods), с помощью которых вы можете изменять поведение базы данных. В частности, нередко требуется изменение алгоритма работы методов [save()](http://docs.djangoproject.com/en/dev/ref/models/instances/#django.db.models.Model.save) и [delete()](http://docs.djangoproject.com/en/dev/ref/models/instances/#django.db.models.Model.delete).
Вы можете переопределять эти методы (так же как и все остальные в модели), и тем самым менять их поведение.
Например, переопределение встроенных методов используется, если вы хотите, чтобы при сохрании объекта совершались некоторые действия (более подробно о принимаемых методом *save()* параметрах вы можете прочитать в [документации](http://docs.djangoproject.com/en/dev/ref/models/instances/#django.db.models.Model.save)):
> `Copy Source | Copy HTML
> class Blog(models.Model):
> name = models.CharField(max\_length=100)
> tagline = models.TextField()
>
> def save(self, force\_insert=False, force\_update=False):
> do\_something()
> **super**(Blog, self).save(force\_insert, force\_update) # The "real" save() method.
> do\_something\_else()`
Также вы можете предотвратить сохранение:
> `Copy Source | Copy HTML
> class Blog(models.Model):
> name = models.CharField(max\_length=100)
> tagline = models.TextField()
>
> def save(self, force\_isert=False, force\_update=False):
> if **self**.name == "Yoko Ono's blog":
> return # Yoko shall never have her own blog!
> else:
> **super**(Blog, self).save(force\_insert, force\_update) # The "real" save() method.`
Важно не забыть вызвать метод наследуемого класса (в нашем примере *super(Blog, self).save()*), чтобы гарантировать сохранение данных в базу данных Если же вы забудете вызвать этот метод, то база данных останется нетронутой.
##### Использование SQL
Еще один частоиспользуемый прием заключается в написании собственных конструкций SQL в методах модели или в методах модуля. Более подробно об использовании «сырого» SQL вы можете прочитать в [документации](http://docs.djangoproject.com/en/dev/topics/db/sql/#topics-db-sql).
**Наследование моделей**
***добавлено в версии Django 1.0**: пожалуйста, прочтите [примечания к релизу](http://docs.djangoproject.com/en/dev/releases/1.0/#releases-1-0).*
Принцип наследования моделей в Django почти полностью идентичен наследованию классов в языке Python. Единственное решение, которое вам придется принимать это, будут ли наследуемые модели представлять собой таблицу базы данных, или же они будут являться лишь хранителями данных, и доступ к ним будет возможен только через производные модели.
В Django существует три вида наследования:
1. Зачастую вам нужно, чтобы базовый класс просто содержал некую информацию, которую вы не хотите определять в каждой производной модели. Такой класс никогда не будет использоваться как самостоятельная единица, а это значит, что лучше всего вам подойдут Абстрактные базовые классы (о них рассказано ниже).
2. Если при создании подклассов вы хотите, чтобы каждая модель имела собственную таблицу в базе данных, смотрите в сторону [Мульти-табличного наследования](http://docs.djangoproject.com/en/dev/topics/db/models/#multi-table-inheritance).
3. И наконец, если вы хотите изменить поведение модели на Python-уровне без изменения ее полей, используйте [прокси-модели](http://docs.djangoproject.com/en/dev/topics/db/models/#proxy-models).
##### Абстрактные базовые классы
Абстрактные базовые классы полезны, когда вы хотите создать несколько моделей с общей информацией. Создайте базовый класс, поместите параметр *abstract=True* в класс *Meta*, и эта модель не будет использоваться при создании таблиц базы данных. Вместо этого, когда он будет использоваться как базовый для некоторой модели, его поля будут добавлены к производному классу. Если же имя поля в базовом и производном классе совпадут, Django возбудит исключение.
Пример:
> `Copy Source | Copy HTML
> class CommonInfo(models.Model):
> name = models.CharField(max\_length=100)
> age = models.PositiveIntegerField()
>
> class Meta:
> abstract = True
>
> class Student(CommonInfo):
> home\_group = models.CharField(max\_length=5)`
Модель *Student* будет содержать три поля: *name, age* и *home\_group*. Так как модель *CommonInfo* — абстрактный базовый класс, она не будет использоваться как обычная модель Django: она не будет генерировать таблицу базы данных, иметь *manager*, нельзя будет сохранить или создать ее экземпляр напрямую.
Во многих случаях этот тип наследования будет удовлетворять вашим требованиям. Данный метод позволяет «вынести за скобки» общую информацию на Python-уровне, в то время как на уровне базы данных будут создаваться отдельные таблицы для каждого производного класса.
*Мета*-наследование
Когда создается абстрактный базовый класс, Django делает внутренний класс *Meta*, который вы определили в базовом классе, доступным как атрибут. Если в производном классе не будет определен собственный класс *Meta*, он будет унаследован от родителя. Однако при желании вы можете расширить базовый класс *Meta*, использовав наследование в классах *Meta*. Например:
> `Copy Source | Copy HTML
> class CommonInfo(models.Model):
> ...
> class Meta:
> abstract = True
> ordering = ['name']
>
> class Student(CommonInfo):
> ...
> class Meta(CommonInfo.Meta):
> db\_table = 'student\_info'`
Django делает лишь одну корректировку в классе *Meta* абстрактного базового класса: перед установлением атрибута *Meta*, параметр *abstract* принмает значение *False*. Это делается для того, чтобы производные классы не становились автоматически абстрактными. Разумеется, вы можете создать абстрактный базовый класс, который наследуется от другого абстрактного базового класса. Для этого вам просто следует явно устанавливать *abstract=True*.
Не имеет смысла добавлять некоторые атрибуты в класс *Meta* абстрактного базового класса. Например, добавление параметра *db\_name*, будет означать, что все производные классы, которые не имеют собственного класса *Meta*, будут использовать одну и ту же таблицу базы данных. Почти наверняка, это совсем не то чего вы хотели.
Будьте аккуратны с *related\_name*
Если вы используете атрибут [related\_name](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ForeignKey.related_name) в поле *ForeignKey* или *ManyToManyField*, вы должны определить *уникальное* обратное имя для каждого поля. Это обычно приводит проблеме в абстрактных базовых классах, так как все поля и их значения добавляются в каждый производный класс.
Чтобы обойти эту проблему, при использовании атрибута [related\_name](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ForeignKey.related_name) в абстрактных базовых классах (и только в них), частью имени должна быть строка *'%(class)s'*. Она будет заменена на имя производного класса в нижем регистре, в котором используется это поле. Так как классы имеют различные имена, каждый атрибут будет иметь уникальное значение. Например:
> `Copy Source | Copy HTML
> class Base(models.Model):
> m2m = models.ManyToManyField(OtherModel, related\_name="%(class)s\_related")
>
> class Meta:
> abstract = True
>
> class ChildA(Base):
> pass
>
> class ChildB(Base):
> pass`
Обратное имя *ChildA.m2m* будет *childa\_related*, а для *ChildB.m2m* — *childb\_related*. Ваше дело как использовать конструкцию *'%(class)s'*, однако если вы забудете про нее, Django возбудит исключение при валидации ваших моделей (или при выполнении *syncdb*).
Если же вы не определили атрибут *related\_name* для поля в абстрактном базовом классе, обратное имя по умолчанию будет именем производного класса в нижнем регистре с добавлением строки *'\_set'*, так будто вы явно определили это поле непосредственно в производном классе. Например, для приведеного выше текста, если бы атрибут [related\_name](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ForeignKey.related_name) был опущен, обратными именами для полей m2m были бы *childa\_set* для класса *ChildA* и *childb\_set* в случае с классом *ChildB*.
**На сегодня все :)** Следущая часть будет последней в данном разделе. Думаю, после ее перевода создать опрос — нужны ли хабру эти самые переводы или нет. Буду ли я продолжать напрямую зависит от его результатов. А пока нужно завершить переводить то, что начал )
**to be continued**
Любые комментарии приветствуются :)
[Перевод Django Documentation: Models. Part 1](http://habrahabr.ru/blogs/django/74856/)
[Перевод Django Documentation: Models. Part 2](http://habrahabr.ru/blogs/django/74967/)
[Перевод Django Documentation: Models. Part 4 (Last)](http://habrahabr.ru/blogs/django/80030/) | https://habr.com/ru/post/75272/ | null | ru | null |
# Язык программирования Глагол
Наткнулся в Википедии на [статью о замечательном языке программирования Глагол](http://ru.wikipedia.org/wiki/Глагол_(язык_программирования)). Я просто не смог пройти мимо, не поделившись радостью с сообществом.
Это феерично:
`ОТДЕЛ Привет+;
ИСПОЛЬЗУЕТ Вывод ИЗ "...\Отделы\Обмен\";
УКАЗ
Вывод.Цепь("Привет!")
КОН Привет.`
P.S. ширвещ и бегунок просто вводят меня в экстаз. | https://habr.com/ru/post/14874/ | null | ru | null |
# Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код
Итак, в [прошлой статье](https://habr.com/ru/post/452656/) мы разработали простейшую процессорную систему, с помощью которой планируем провести тест микросхемы ОЗУ, подключённой к ПЛИС комплекса Redd. Сегодня же мы сделаем для этой аппаратной среды программу на языке С++, а также разберёмся, как эту программу вливать, а главное — отлаживать.

Программа разрабатывается в среде Eclipse. Для её запуска выбираем пункт меню **Tools->Nios II Software Build Tools for Eclipse**.

Нам надо создать проект и BSP для него. Для этого нажимаем правую кнопку «мыши» в области Project Explorer и выбираем пункт меню **New->Nios II Application and BSP from Template**.

Базовый шаблон, на основе которого будет создан проект, был сделан при генерации процессорной системы. Поэтому найдём файл, содержащий его.

Также дадим проекту имя (у меня это **SDRAMtest**) и выберем тип проекта. Я выбрал **Hello World Small**. Очень хочется выбрать **Memory Test**, мы же делаем тест памяти, но сейчас мы занимаемся рассмотрением общего пути создания приложений. Поэтому выбираем общий вариант.

Нам создали два проекта. Первый — наш проект, второй — BSP (Board Support Package, грубо говоря, библиотеки для работы с оборудованием).

Первое, что я обычно делаю, правлю настройки BSP. Для этого я выбираю второй из созданных проектов, нажимаю правую кнопку «мыши» и выбираю пункт меню **Nios II ->BSP Editor**.
В редакторе всё разбито на группы:

Но чтобы не бегать по ним, я выберу корень дерева, элемент **Settings**, и рассмотрю всё линейно. Перечислю то, на что стоит обратить внимание. Первый экран настроек:

Поддержка выхода и поддержка зачистки при выходе отключены, что выкидывает из кода ненужные куски огромного размера, но они отключены исходно. Эти галки отключились, так как я выбрал минимальный вариант **Hello, World**. При выборе других видов кода, лучше эти галки тоже снимать. Не удержусь и включу поддержку С++. Также обязательно надо снять проверку **SysID**, иначе ничего не будет работать. Дело в том, что делая аппаратную систему, я не добавил соответствующий блок. Остальные настройки не требуют пояснений и не изменялись. Собственно, прочие настройки я пока также не изменял. Чуть позже мы сюда ещё вернёмся, а пока нажимаем кнопку Generate. Нам создаётся новый вариант BSP на базе сделанных настроек. По окончании нажимаем Exit.
Теперь начинается самое интересное. Как собирать проект. Нажимаем привычное **Ctrl+B** — получаем ошибку. Расшифровки ошибки нет:

В консоли — тоже ничего разумного:

Выбираем **Build Project** для проекта **SDRAMtest**, получаем разумное объяснение:
На самом деле, нерабочие шаблоны — фирменный стиль Квартуса. Это ещё одна причина, почему я не стал выбирать **Memory Test**. Там всё более запущено. Здесь же понятно, в чём дело.
Сбоит вот эта функция файла **alt\_putstr.c**:
```
/*
* Uses the ALT_DRIVER_WRITE() macro to call directly to driver if available.
* Otherwise, uses newlib provided fputs() routine.
*/
int
alt_putstr(const char* str)
{
#ifdef ALT_SEMIHOSTING
return write(STDOUT_FILENO,str,strlen(str));
#else
#ifdef ALT_USE_DIRECT_DRIVERS
ALT_DRIVER_WRITE_EXTERNS(ALT_STDOUT_DEV);
return ALT_DRIVER_WRITE(ALT_STDOUT_DEV, str, strlen(str), 0);
#else
return fputs(str, stdout);
#endif
#endif
}
```
Починим мы её как-нибудь потом (для этого надо усложнять аппаратную систему). Сегодня она нам просто не нужна. Заменяем её тело на **return 0**. Проект начинает собираться.
Прекрасно. Мы уже имеем готовый **elf файл** (пусть он и не выполняет никаких полезных функций) и имеем аппаратуру, в которую можно залить **hex файл** (помните, как мы сообщили компилятору Quartus, что данные ОЗУ надо загружать из него, настраивая Onchip RAM?). Как нам преобразовать **elf** в **hex**? Очень просто. Встаём на рабочий проект, нажимаем правую кнопку «мыши», выбираем пункт меню **Make Targets->Build**:
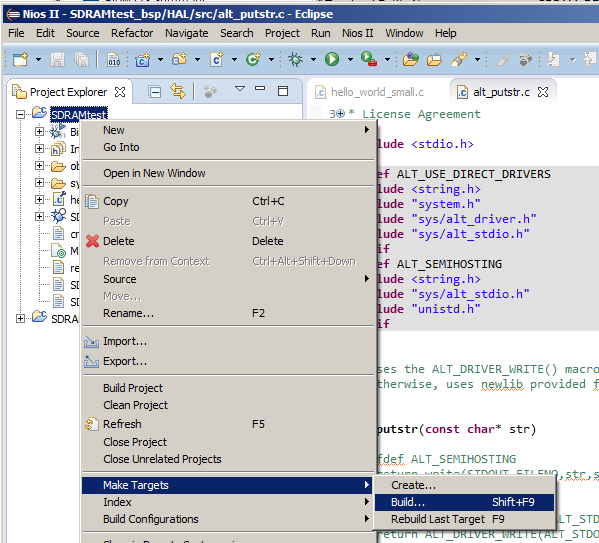
В появившемся окне сначала пробуем выбрать первый вариант (**mem\_init\_install**):

Ничего при этом не произойдёт. Но из выданного нам сообщения об ошибке, мы узнаем, как следует доработать проект для Квартуса:
```
../SDRAMtest_bsp//mem_init.mk:230: *** Deprecated Makefile Target: 'mem_init_install'. Use target 'mem_init_generate' and then add mem_init/meminit.qip to your Quartus II Project. Stop.
```
Выберем **build** уже для цели **mem\_init\_generate**, после чего (именно после!!!) добавим указанный **qip файл** в проект аппаратуры (мы уже научились добавлять файлы, когда добавляли в проект процессорную систему).

Ну, и сам **hex файл** также можно пощупать руками. Вот он:
Прекрасно. У нас есть всё, чтобы начать наполнение программы реальной функциональностью. Идём в файл **hello\_world\_small.c**. Честно говоря, меня немного коробит от работы с чистым Си. Поэтому я его переименую в cpp. А чтобы ничего не испортилось, добавлю в имеющийся текст волшебное заклинание:

**То же самое текстом:**
```
extern "C"
{
#include "sys/alt_stdio.h"
}
int main()
{
alt_putstr("Hello from Nios II!\n");
/* Event loop never exits. */
while (1);
return 0;
}
```
Важно после замены типа файла выполнить операцию **Clean Project**, иначе компилятор будет выдавать сообщения об ошибках, что файл **\*.c** не найден на основании каких-то закэшированных сведений.
Тест памяти мы сделаем простейшим. У меня не стоит задачи научить читателя правильно тестировать микросхему ОЗУ. Мы просто поверхностно убедимся, что шины адреса и данных не залипают и не имеют обрывов. То есть, запишем в каждую ячейку все нули и адрес ячейки. Наша задача — сделать рабочий код, а всё остальное (иные константы заполнения и задержки для проверки, что данные регенерируются) — это детали реализации, которые усложняют текст, но не меняют его сути.
Начнём с простого и естественного вопроса: «А где в адресном пространстве у нас располагается SDRAM?» Помнится, мы вызвали функцию автоматического назначения адресов, но даже не глянули, какие адреса были фактически назначены. На самом деле, мы и сейчас не будем заглядывать именно туда. Вся необходимая информация есть в файле:
**...\SDRAMtest\_bsp\system.h**.
**В итоге, получаем такой код:**
```
extern "C"
{
#include "sys/alt_stdio.h"
#include
#include "../SDRAMtest\_bsp/system.h"
#include
}
int main()
{
bool bRes = true;
volatile static uint32\_t\* const pSDRAM = (uint32\_t\*)NEW\_SDRAM\_CONTROLLER\_0\_BASE;
static const int sizeInDwords = NEW\_SDRAM\_CONTROLLER\_0\_SPAN / sizeof (uint32\_t);
// Зануляем
for (int i=0;i
```
Собираем **hex файл** (напоминаю, что через этот диалог):
После чего компилируем аппаратуру в среде Quartus и входим в программатор, чтобы загрузить получившуюся «прошивку» с получившимся инициализированным программным кодом в кристалл.

Вливаем «прошивку» и получаем сообщение, что система будет жить, только пока она подключена к JTAG (особенности лицензии на ядро SDRAM в бесплатной среде разработки). Собственно, для случая Redd, это не критично. Там этот JTAG всё время имеется.

Результаты теста ОЗУ можно увидеть на разъёме, контакты C21 (успешно) или B21 (ошибка). Подключаемся к ним осциллографом.

Оба выхода — в нуле. Что-то тут не так. Осталось понять, что именно. На самом деле, неработоспособная программа — это просто замечательно, ведь сейчас мы начнём осваивать JTAG-отладку. Наводимся на проект, выбираем **Debug As->Nios II Hardware**.
Первый раз система не находит аппаратуру. Выглядит это так (обратите внимание на красный крестик в выделенном заголовке вкладки):

Переключаемся на вкладку **Target Connection** и устанавливаем флажок **Ignore Mismatching System ID**. Во время последующих опытов мне иногда также приходилось ставить **Ignore Mismatched System Timestamp**. На всякий случай, выделю его на рисунке не красной, а жёлтой рамкой, чтобы подчеркнуть, что сейчас его устанавливать не обязательно, но если кнопка **Debug** не активируется, возможно, пришла пора его установить.

Применяем изменения (**Apply**), затем нажимаем **Refresh Connections** (эта кнопка спряталась, её надо проскроллировать):
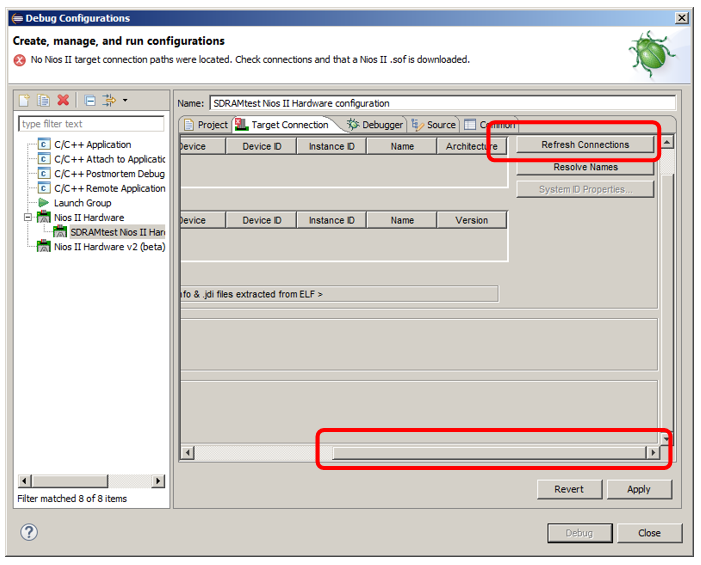
В списке появляется отладчик, можно нажимать **Debug**…
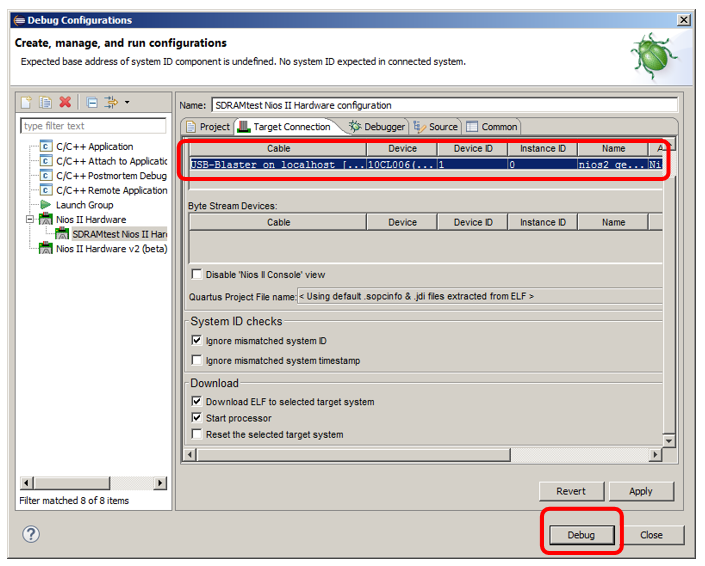
Нас остановили на функции **main()**. При желании, можно поставить точку останова в конце алгоритма и проверить, дойдёт ли программа до неё:

Запускаем программу:

Точка останова не сработала. Остановим программу и посмотрим, где она исполняется.

Всё плохо. Программа явно вылетела. Расставляя последовательно точки останова, после чего останавливая (красной кнопкой «Стоп») и перезапуская программу (кнопкой с жуком), находим проблемный участок.
Умирает всё при исполнении данной строки для самого первого элемента:

**То же самое текстом:**
```
for (int i=0;i
```
С точки зрения С++, здесь всё чисто. Но если открыть дизассемблированный код, видно, что там уж больно однородные команды. Похоже, код сам себя затёр. А сделать он это мог, если компоновщик положил его в SDRAM (содержимое которой этот код и затирает).

Останавливаем отладку, закрываем отладочную перспективу.
Идём в редактор BSP, в котором мы были в начале этой статьи, но на вкладку **Linker Script**. Если бы я поправил эту вкладку в самом начале, мне бы не удалось показать методику входа в JTAG-отладку (и подчеркнуть всю её мощь по сравнению с простым отладочным выводом, ведь факт затёртого кода при JTAG-отладке бросился в глаза сам). Так и есть. Добрый компоновщик кладёт всё в память, размер которой побольше.

Перенаправляем всё в **onchip\_memory**… Сейчас у нас SDRAM — это просто кусок памяти, работоспособность которой нам пока что никто не гарантировал. Нельзя её отдавать под какие-либо автоматизированные действия компилятора.
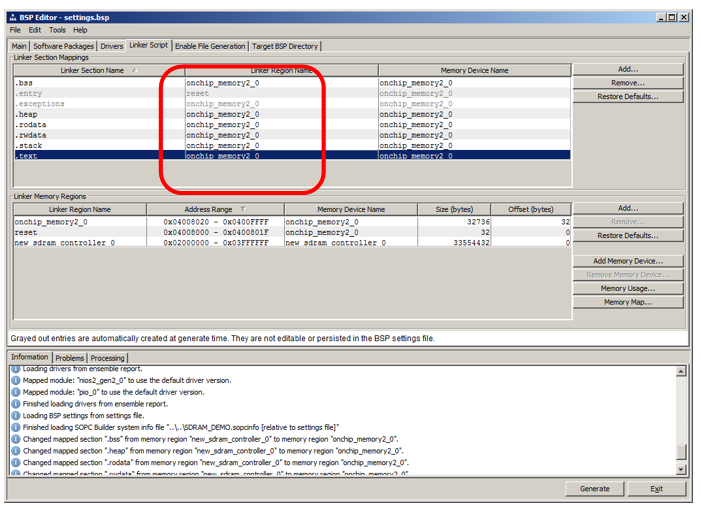
Пересобираем **bsp**, пересобираем проект. Надо ли снова делать образ памяти и перегружать ПЛИС? Потом, для полуавтономной работы, будет надо, но пока идёт отладка — нет. Новый вариант программы будет сразу же загружен в ОЗУ при начале нового сеанса отладки. Но чтобы при следующей загрузке ПЛИС не потребовалось бы запускать отладчик, сделать по окончании отладки новый **HEX файл** и собрать «прошивку» ПЛИС с ним желательно.
Для нового кода точка останова достигнута, результат теста — **true**:

Осциллограф повеселел: жёлтый луч взлетел в единицу.
Тест пройден. Давайте немного похулиганим и попутно проверим быстродействие системы. Сделаем финал таким:
```
// Выдаём результат в GPIO
if (bRes)
{
while (true)
{
IOWR_ALTERA_AVALON_PIO_DATA (PIO_0_BASE,0x01);
IOWR_ALTERA_AVALON_PIO_DATA (PIO_0_BASE,0x00);
}
} else
{
while (true)
{
IOWR_ALTERA_AVALON_PIO_DATA (PIO_0_BASE,0x02);
IOWR_ALTERA_AVALON_PIO_DATA (PIO_0_BASE,0x00);
}
}
```
В результате, имеем на осциллографе такой меандр (всё было подключено через длинный шлейф, поэтому по второй линии появилась емкостная наводка, не обращайте на неё внимание):

Получается частота примерно 8.3 МГц при тактовой частоте 50 МГц без каких-либо тонких настроек процессорного ядра и оптимизации программного кода. То есть, доступ к портам идёт на частоте чуть выше 16 МГц, что соответствует трети системной частоты. Не то, чтобы это было совсем отлично, но всяк лучше, чем 4 МГц при тактовой частоте 925 МГц для Cyclone V SoC… Нет, сам процессор NIOS II работает в разы медленнее, чем ARM ядро пятого Циклона, но процессор, как я уже говорил, у нас в системе и x64 имеется, здесь же нам больше нужно ядро, обеспечивающее логику работы железа. А логика эта обеспечивается именно через работу с портами. Если работа с портами идёт медленно, то всё остальное будет регулярно простаивать, ожидая окончания работы шин. Выявленные характеристики — это предел доступа процессора к портам, но не работы аппаратной части в целом. Однако, как реализовывать работу в целом, рассмотрим в следующей статье.
Заключение
----------
В статье показано, как создать и настроить проект на С++ для простейшей процессорной среды, разработанной для комплекса Redd. Показаны методы доступа к аппаратуре, а также методика JTAG отладки. Скачать полученный при написании статьи аппаратно/программный комплект, можно [здесь](https://yadi.sk/d/hUwlXExGo3Pxyg). | https://habr.com/ru/post/453682/ | null | ru | null |
# Опыт разработки виджетов для сторонних сайтов
Если ваш продукт предоставляет услуги для бизнеса, рано или поздно появится задача создать встраиваемый виджет для сайтов клиентов. Это может быть виджет покупки билетов, прогноза погоды, курса валют, отзывов, комментариев и много чего другого.
В этой статье разберемся, как же сделать качественный виджет, который можно будет легко поддерживать и расширять.
### Библиотека
Не нужно думать, что виджет у вас будет один.
Даже если сейчас это так и других виджетов не предвидится. Или вы уверены, что один виджет может устанавливаться один раз на страницу.
Главная сложность разработки виджетов для сторонних сайтов — сразу верно заложить архитектуру так, чтобы при развитии виджетов не нужно было изменять код, установленный на сайтах. Убедить пользователей виджета заменить код довольно сложно, долго и вызывает волну негатива.
Поэтому сразу проектируем код таким образом, чтобы он позволял вставлять неограниченное число разных виджетов на одну страницу без ограничений. Первое, что приходит в голову: «а давайте просто выведем iframe с нашего сайта?». И сделаем код вида:
```
Ваш браузер не поддерживает фреймы!
```
И это будет большой ошибкой по нескольким причинам.
#### Невозможность расширения
У iframe довольно много ограничений, связанных с защитой конфиденциальности в браузере. Даже просто растянуть iframe под размер его содержимого без внешнего javascript кода не получится. Стилизовать можно будет только то, что лежит непосредственно в iframe, на сам тэг и его обертку никак нельзя будет повлиять.
Может, для начала это не критично, но по мере развития в это легко можно упереться, а код на сайтах уже установлен.
Про то, какие проблемы есть в работе с iframe и их решении, поговорим попозже.
#### Лишние запросы на бэкенд
Если на сайт будет установлено 5 таких одинаковых виджетов, то на ваш сервер придет 5 одинаковых запросов, хотя по факту нужен был только один. Конечно, можно сделать кеш на nginx и не пропускать запрос дальше, но зачем нам самим себе делать паразитные запросы? С таким кодом изменить логику получения данных не получится без изменения кода вставки виджета. Если виджет будет установлен на десятках сайтов, даже не самых популярных, в сумме они могут давать заметную нагрузку.
#### А как надо делать?
Если вы когда-нибудь устанавливали на сайт какой-нибудь виджет, например, от ВК, то могли заметить, что код виджета разделен на две части: библиотеку (SDK) и инициализацию виджетов:
В целом, хорошая практика — посмотреть, как делают другие, так можно сразу перескочить через множество граблей. В этом коде все хорошо, кроме того, что он не асинхронный. Это их право — давать вставлять по умолчанию код, который может заблокировать загрузку страницы, но мы так делать не будем, попозже поговорим об этом. Нам в этом коде важна идея.
Мы видим, что для вставки любого виджета нужно один раз подключить SDK и добавить один пустой тэг с инициализацией виджета. А дальше все делает javascript: он может делать любые запросы и любое их количество на бэкенд, и разработчики виджета могут в любой момент эту логику изменить без изменения кода виджета на сайте. В итоге из html на сайте для виджета должен быть только пустой контейнер с уникальным id. Чтобы не томить вас ожиданием, давайте сразу напишем пример SDK и рендер простого виджета.
А потом поговорим о том, что же у нас получилось и на что стоит обратить внимание.
Код библиотеки
```
namespace MyCompany {
/**
* Виджет кнопки
*/
class Button {
/**
* Внутренний id кнопки
*/
protected id: number;
/**
* DOM элемент контейнера
*/
protected containerElement: HTMLElement;
/**
* Инстанс api
*/
protected apiInstance: Api;
/**
* Constructor
* @param {Api} instance
* @param {string} containerId
*/
public constructor(instance: Api, containerId: string) {
this.apiInstance = instance;
this.containerElement = document.getElementById(containerId);
}
/**
* Инициализация
*/
public init(): void {
this.containerElement.innerHTML = 'Виджет кнопки';
}
}
/**
* Основной класс Api
*/
export class Api {
/**
* Виджет кнопки
* @param {string} containerId
* @return {MyCompany.Button}
*/
public button(containerId: string): Button {
const widget = new Button(this, containerId);
widget.init();
return widget;
}
/**
* Запуск колбеков инициализации
*/
public runInitCallbacks(): void
{
let myCompanyApiInitCallbacks = (window as any).myCompanyApiInitCallbacks;
if (myCompanyApiInitCallbacks && myCompanyApiInitCallbacks.length) {
setTimeout(function () {
let callback;
while (callback = myCompanyApiInitCallbacks.shift()) {
try {
callback();
} catch (e) {
console.error(e);
}
}
}, 0);
}
}
}
}
/**
* Инициализация Api
*/
if (typeof (window as any)['myCompanyApi'] === 'undefined') {
(window as any).myCompanyApi = new MyCompany.Api();
(window as any).myCompanyApi.runInitCallbacks();
}
```
Код вставки
```
(function() {
var init = function() {
myCompanyApi.button('button-container-5ef9b197c865f');
};
if (typeof myCompanyApi !== 'undefined') {
init();
} else {
(myCompanyApiInitCallbacks = window.myCompanyApiInitCallbacks || []).push(init);
}
})();
```
Выглядит страшно и как-то избыточно, давайте разбираться, зачем все это.
### Асинхронность
Сразу в глаза бросается атрибут **async** у тэга script. Он позволит браузеру не ждать загрузки нашего скрипта и продолжить отрисовывать сайт. Это важно: если по каким-то причинам наш скрипт будет недоступен (недоступен сервер, фаервол компании), это не должно влиять на скорость загрузки сайта клиента. Но все не так просто. Раз скрипт загружается асинхронно, это значит, что когда браузер дойдет до места, где инициализируется наш виджет, наш SDK может быть еще не загружен, и если просто вызвать метод из библиотеки — будет ошибка, причем плавающая, в зависимости от того, успел загрузиться скрипт или нет.
Поэтому в месте вызова виджета мы должны обработать оба сценария, когда SDK загрузилось и еще нет.
В первом случае мы просто вызываем функцию init(). Во втором — откладываем выполнение этой функции до момента, когда скрипт загрузится, добавляя замыкание в очередь. А последней строчкой в нашем SDK вызывается метод **runInitCallbacks**, который как раз и выполнит все отложенные инициализации.
Тут же есть защита от повторного подключения SDK, ведь пользователи могут проигнорировать ваши требования и вставить скрипт библиотеки десять раз.
Теперь наш код запускается всегда и не блокирует отрисовку страницы!
### Изоляция
Название объекта SDK и id контейнеров должны быть уникальными, ведь наш код будет выполняться на совершенно разных сайтах. Ни в коем случае нельзя нарваться на совпадения. ID контейнеров желательно генерировать уникальными, например, через uniqid(). Нельзя надеяться и на сторонние библиотеки, установленные на сайте, и совсем не желательно приносить их с собой. Да, я о jQuery, как вы уже догадались.
Код виджетов должен быть легковесным и универсальным, сейчас уже не сложно писать кроссбраузерный код нативно. Кроме того, я настоятельно рекомендую использовать TypeScript, но это есть множество [причин](https://www.internet-design.ru/blog/razrabotka-spa-typescript-ili-javascript-chto-vybrat/).
На кодировку сайта тоже не стоит полагаться, и даже в наше время встречаются сайты на cp1251. Поэтому кодировку скрипта нужно явно задать в ответе сервера в заголовке **Content-Type**.
Код, написанный нами выше, позволяет не останавливаться на одном виджете: сейчас у нас есть только **myCompanyApi.button()**, но ничего не мешает добавить другие виджеты.
### Кеширование
Мы будем постоянно дорабатывать наш SDK, но браузеры кэшируют скрипты, если разработчик не дал других инструкций. Мы должны сами задать время, на которое можно кешировать нашу библиотеку, через заголовок **Expires**, например, час — адекватное время. С кешированием на фронтенде разобрались, теперь поговорим про бэкенд. Как уже обсуждали выше, обслуживание запросов со сторонних виджетов может создавать ощутимую нагрузку просто от количества сайтов, где виджеты установлены. Но чаще всего данные для всех пользователей в этих виджетах одинаковые, нет смысла запускать приложение, а тем более ходить в базу данных за ними на каждый запрос. Такие запросы вообще дальше nginx можно не пропускать, [настроив](https://habr.com/ru/post/428127/) кеширование на нем.
Если для отрисовки виджета нужны данные с бэкенда, но в целом можно отрисовать минимальную версию и без него (например, кнопку покупки билетов, но без признака наличия), хорошим тоном будет сделать fallback: если данные не загрузились за полсекунды, рисовать обрезанную версию виджета, а как только данные получены — дорисовывать. Это визуально ускорит загрузку и покажет виджет даже без работающего бэкенда (вдруг он при взаимодействии уже поднимется?).
### Немного про iframe
Iframe — по сути, отображение сайта в сайте. Вернемся к нашему кейсу с кнопкой покупки билетов. Если мы хотим при клике открывать попап со страницей выбора места — без iframe нам не обойтись. Какие же там есть нюансы?
#### Неработающие cookie
Уже давно многие браузеры по умолчанию начинают запрещать использование cookie для сторонних сайтов (это когда домен iframe отличается от родительского сайта). Это значит, что при переходе между страницами внутри фрейма не получится отследить сессию (localStorage тоже не работает).Тут выход простой — не перезагружать страницы и делать SPA. Идентификатор сессии можно будет легко сохранить в переменной в js.
#### Общение с SDK
Часто требуется организовать общение нашего SDK с приложением внутри iframe, например, мы хотим при открытии виджета растянуть размер фрейма под размер контента. Для этого нам нужно сообщить размер контента из iframe в родительское окно. Это можно легко сделать через [postMessage](https://developer.mozilla.org/ru/docs/Web/API/Window/postMessage). Будьте внимательны при передаче конфиденциальных данных и верно указывайте **targetOrigin**, иначе данные могут «подслушать» другие сайты.
Спасибо за внимание, надеюсь, вы узнали для себя что-то новое.
Сергей Никитченко, Студия Валерия Комягина | https://habr.com/ru/post/549926/ | null | ru | null |
# SMB и NTFS-разрешения. Разбор полетов
Для чего в большинстве случаев в организации нужен сервер? Active Directory, RDS, сервер печати и еще куча мелких и крупных сервисов. Самая заметная всем роль, пожалуй, это файловый сервер. С ним люди, в отличие, от других ролей работают осознаннее всего. Они запоминают в какой папке что лежит, где находятся сканы документов, где их отчеты, где факсы, где общая папка, в которой можно все, куда доступ только одному из отделов, куда другому, а о некоторых они вообще не догадываются
О доступе к сетевым и локальным папкам на сервере я и хочу поговорить.
Доступ к общим ресурсам на сервере осуществляется, как все прекрасно знают, по протоколу SMB уже 3.0. Доступ по сети к папкам можно ограничивать SMB и NTFS-разрешениями. SMB-разрешения работают только при доступе к общей папке по сети и не имеют никакого влияния на доступность той или иной папки локально. NTFS-разрешения работают, как по сети, так и локально, обеспечивая намного больше гибкости в создании прав доступа. SMB и NTFS разрешения работают не отдельно, а дополняют друг друга, по принципу наибольшего ограничения прав.
Для того, чтобы отдать папку в общий доступ в Server 2012 в группе [SMB Share Cmdlets](http://technet.microsoft.com/library/jj635726.aspx), появился командлет New-SMBShare. На примере этого командлета мы увидим все возможности, доступные при создании общей папки, кроме кластерных конфигураций (это отдельная большая тема).
Создание новой общей папки выглядит очень просто:
```
net share homefolder=s:\ivanivanov /grant:"admin",full /grant:"folderowner",change /grant:"manager",read /cache:programs /remark:"Ivanov"
```
или
```
new-smbshare homefolder s:\ivanivanov –cachingmode programs –fullaccess admin –changeaccess folderowner –readaccess manager –noaccess all –folderenumerationmode accessbased -description "Ivanov"
```
#### Разбираемся:
```
-name
```
имя общей папки в сети, может отличаться от имени папки на локальном компьютере. Имеет ограничение в 80 символов, нельзя использовать имена pipe и mailslot.
```
-path
```
путь к локальной папке, которую нужно отдать в общий доступ. Путь должен быть полным, от корня диска.
```
-cachingmode
```
настройка автономности файлов в общей папке.
**Что такое автономный файл?**Автономный файл – это копия файла, находящегося на сервере. Эта копия находится на локальном компьютере и позволяет работать с файлом без подключения к серверу. При подключении изменения синхронизируются. Синхронизируются в обе стороны: если вы сделали изменения в своем автономном файле – при следующем подключении файл на сервере будет изменен; если кто-то сделал изменения на сервере – то ваша локальная копия будет изменена. Если изменения произошли в обоих файлах сразу – получаем ошибку синхронизации и придется выбирать, какую версию сохранить. Для совместной работы использовать эту возможность я бы не стал, но если для каждого пользователя наделать шар и ограничить доступ для других чтением, без возможности записи получаем следующие плюшки:
* Работа не зависит от сети – может сгореть свитч, может перезагружаться сервер, может оборваться провод или выключиться точка доступа – пользователь работает со своей копией, не замечая, что у вас там какая-то авария, при восстановлении сетевого подключения его работа уходит на сервер.
* Пользователь может работать работу где угодно: на даче, в автобусе, в самолете – в тех местах, где подключение к VPN по каким-то причинам недоступно.
* Если даже пользователь работает через VPN, но подключение или очень медленное, или постоянно обрывается – проще работать с автономной копией и синхронизировать изменения, чем пытаться что-то сделать на сервере.
* Пользователь сам может выбирать что и когда синхронизировать, если дать ему такую возможность.
Принимает следующие значения:
* none – файлы недоступны автономно, для доступа к файлам нужен доступ к серверу
* manual – пользователи сами выбирают файлы, которые будут доступны автономно
* programs – все в папке доступно автономно (документы и программы (файлы с расширением \*.exe, \*.dll))
* documents – документы доступны, программы нет
* branchcache – кэширование вместо локального компьютера пользователя происходит на серверах BranchCache, пользователи сами выбирают автономные файлы
```
-noaccess, -readaccess, -changeaccess, -fullaccess
```
разрешения общего доступа (share permissions).
У этих разрешений есть одно большое преимущество – они очень простые.
-noaccess secretary,steward – секретарше и завхозу нечего делать в общих папках бухгалтерии
-readaccess auditor – аудитор, проверяющий работу бухгалтерии может видеть имена файлов и подпапок в общей папке, открывать файлы для чтения, запускать программы.
-changeaccess accountant – бухгалтеры в своей общей папке могут создавать файлы и подпапки, изменять существующие файлы, удалять файлы и подпапки
-fullaccess admin – fullaccess это readaccess+changeaccess плюс возможность изменять разрешения.
При создании общей папки автоматически применяется наиболее ограничивающее правило – группе «Все» дается право на чтение.
Эти разрешения применяются только для пользователей, получивших доступ к общей папке по сети. При локальном входе в систему, например в случае терминального сервера, и секретарша и завхоз увидят в бухгалтерии все, что пожелают. Это исправляется NTFS-разрешениями. SMB-разрешения применяются ко всем файлам и папкам на общем ресурсе. Более тонкая настройка прав доступа осуществляется также NTFS-разрешениями.
```
-concurrentuserlimit
```
c помощью этого параметра можно ограничить максимальное число подключений к папке общего доступа. В принципе, также можно использовать для ограничения доступа к папке, дополняя NTFS-разрешения, только надо быть точно уверенным в необходимом количестве подключений.
```
-description
```
описание общего ресурса, которое видно в сетевом окружении. Описание – это очень хорошая вещь, которой многие пренебрегают.
```
-encryptdata
```
шифрование
В SMB до версии 3.0 единственным способом защитить трафик от файлового сервера клиенту был VPN. Как его реализовать зависело полностью от предпочтений системного администратора: SSL, PPTP, IPSEC-туннели или еще что-нибудь. В Server 2012 шифрование работает из коробки, в обычной локальной сети или через недоверенные сети, не требуя никаких специальных инфраструктурных решений. Его можно включить как для всего сервера, так и для отдельных общих папок. Алгоритмом шифрования в SMB 3.0 является [AES-CCM](http://tools.ietf.org/html/rfc5084), алгоритмом хеширования вместо HMAC-SHA256 стал [AES-CMAC](http://www.ietf.org/rfc/rfc4493.txt). Хорошая новость в том, что SMB 3.0 поддерживает аппаратный AES ([AES-NI](http://www.intel.ru/content/www/ru/ru/architecture-and-technology/advanced-encryption-standard--aes-/data-protection-aes-general-technology.html)), плохая новость в том, что Россия не поддерживает AES-NI.
Чем грозит включение шифрования? Тем, что работать с зашифрованными общими папками смогут только клиенты, поддерживающие SMB 3.0, то есть Windows 8. Причина опять же, максимально допустимое ограничение прав пользователей. Предполагается, что администратор знает, что он делает и при необходимости даст доступ для клиентов с другой версией SMB. Но так как SMB 3.0 использует новые алгоритмы шифрования и хеширования трафик клиентов с другой версией SMB шифроваться не будет, нужен VPN. Пустить всех клиентов на файловый сервер с включенным шифрованием поможет команда
```
set-smbserverconfiguration –rejectunencryptedaccess $false
```
В конфигурации по умолчанию (запрещен нешифрованный трафик к зашифрованным общим папкам), при попытке доступа к папке клиента с версией SMB ниже 3.0 на клиенте мы получим «Ошибку доступа». На сервере в журнал Microsoft-Windows-SmbServer/Operational будет добавлено событие 1003, в котором можно будет найти IP-адрес клиента, пытавшегося получить доступ.
Шифрование SMB и EFS – это разные вещи, никак не связанные друг с другом, то есть его можно применять на FAT и ReFS томах.
```
-folderenumerationmode
```
Это Access-Based Enumeration. С включенным Access-Based Enumeration пользователи, не имеющие доступа к общей папке, просто не увидят ее на файловом сервере и будет меньше вопросов, почему у меня нет доступа к той или этой папке. Пользователь видит свои доступные папки и не пытается лезть в чужие дела. По умолчанию – выключено.
* accessbased – включить
* unrestricted – выключить
```
-temporary
```
Этот ключ создает временную общую папку, доступ к которой будет прекращен после перезагрузки сервера. По умолчанию создаются постоянные общие папки.
#### NTFS-разрешения
С помощью NTFS-разрешений мы можем более детально разграничить права в папке. Можем запретить определенной группе изменять определенный файл, оставив возможность редактирования всего основного; в одной и той же папке одна группа пользователей может иметь права изменения одного файла и не сможет просматривать другие файлы, редактируемые другой группой пользователей и наоборот. Короче говоря, NTFS-разрешения позволяют нам создать очень гибкую систему доступа, главное самому потом в ней не запутаться. К тому же NTFS-разрешения работают, как при доступе к папке по сети, дополняя разрешения общего доступа, так и при локальном доступе к файлам и папкам.
Существует шесть основных (basic) разрешений, которые являются комбинацией из 14 дополнительных (advanced) разрешений.
##### Основные разрешения
**Полный доступ (fullcontrol)** – полный доступ к папке или файлу, с возможностью изменять права доступа и правила аудита к папкам и файлам
**Изменение (modify)** – право чтения, изменения, просмотра содержимого папки, удаления папок/файлов и запуска выполняемых файлов. Включает в себя Чтение и выполнение (readandexecute), Запись (write) и Удаление (delete).
**Чтение и выполнение (readandexecute)** – право открывать папки и файлы для чтения, без возможности записи. Также возможен запуск выполняемых файлов.
**Список содержимого папки (listdirectory)** – право просматривать содержимое папки
**Чтение (read)** – право открывать папки и файлы для чтения, без возможности записи. Включает в себя Содержание папки / Чтение данных (readdata), Чтение атрибутов (readattributes), Чтение дополнительных атрибутов (readextendedattributes) и Чтение разрешений (readpermissions)
**Запись (write)** – право создавать папки и файлы, модифицировать файлы. Включает в себя Создание файлов / Запись данных (writedata), Создание папок / Дозапись данных (appenddata), Запись атрибутов (writeattributes) и Запись дополнительных атрибутов (writeextendedattributes)
##### Дополнительные разрешения
Я ставил на папку только 1 из 14 разрешений и смотрел, что получается. В реальном мире, в большинстве случаев хватает основных разрешений, но мне было интересно поведение папок и файлов с максимально урезанными правами.
**Траверс папок / выполнение файлов (traverse)** – право запускать и читать файлы, независимо от прав доступа к папке. Доступа к папке у пользователя не будет, (что находится в папке останется загадкой) но файлы в папке будут доступны по прямой ссылке (полный, относительный или UNC-путь). Можно поставить на папку Траверс папок, а на файл любые другие разрешения, которые нужны пользователю для работы. Создавать и удалять файлы в папке у пользователя не получится.
**Содержание папки / Чтение данных (readdata)** – право просматривать содержимое папки без возможности изменения. Запускать и открывать файлы в просматриваемой папке нельзя
**Чтение атрибутов (readattributes)** – право просматривать атрибуты ([FileAttributes](http://msdn.microsoft.com/ru-ru/library/system.io.fileattributes(v=vs.110).aspx)) папки или файла.
Просматривать содержимое папки или файлов или изменить какие-либо атрибуты нельзя.
**Чтение дополнительных атрибутов (readextendedattributes)** – право просматривать дополнительные атрибуты папки или файла.
Единственное, что я смог найти по дополнительным атрибутам – это то, что они используются для обеспечения обратной совместимости с приложениями OS/2. ([Windows Internals, Part 2: Covering Windows Server 2008 R2 and Windows 7](http://books.google.ru/books?id=CdxMRjJksScC)). Больше мне о них ничего не известно.
**Создание файлов / запись данных (writedata)** – дает пользователю возможность создавать файлы в папке, в которую у него нет доступа. Можно копировать файлы в папку и создавать в папке новые файлы. Нельзя просматривать содержимое папки, создавать новые папки и изменять уже существующие файлы. Пользователь не сможет изменить какой-либо файл, даже если он является владельцем этого файла – только создавать.
**Создание папок / дозапись данных (appenddata)** – дает пользователю возможность создавать подпапки в папке и добавлять данные в конец файла, не изменяя существующее содержание.
**Проверка**C созданием подпапок все понятно:
```
ni c:\testperms\testappend –itemtype directory
```
отработает, как ожидается — создаст в недоступной для просмотра пользователем папке testperms подпапку testappend. Попробуем добавить строку в конец файла – сэмулируем ведение какого-нибудь лога.
```
newevent >> c:\testperms\user.log
Отказано в доступе.
```
Хм… В CMD не работает. А если так.
```
ac c:\testperms\user.log newevent
ac : Отказано в доступе по пути "C:\testperms\user.log".
```
А по конвейеру?
```
"newevent" | out-file c:\testperms\user.log -append
out-file : Отказано в доступе по пути "C:\testperms\user.log".
```
И так не работает.
Начинаем сеанс черной магии: используем класс File, метод [AppendText](http://msdn.microsoft.com/ru-ru/library/system.io.file.appendtext.aspx). Получаем объект лога.
```
$log = [io.file]::appendtext("c:\testperms\user.log")
Исключение при вызове "AppendText" с "1" аргументами: "Отказано в доступе по пути "c:\testperms\user.log"."
```
Думаю, что [AppendAllText](http://msdn.microsoft.com/ru-ru/library/system.io.file.appendalltext.aspx) пробовать уже не стоит
```
$log = [io.file]::appendalltext("c:\testperms\user.log","newevent")
Исключение при вызове "AppendAllText" с "2" аргументами: "Отказано в доступе по пути "c:\testperms\user.log"."
```
Дело, в принципе, ясное. Только права на дозапись данных в файл вышеперечисленным способам не хватает, им нужна запись в файл. Но вместе с этим мы дадим возможность на изменение файла, а не только добавление записей, то есть открываем потенциальную возможность уничтожить все содержимое файла.
Нам нужно пересмотреть концепцию: давайте будем не получать объект лога, а создадим новый, в котором зададим все интересующие нас параметры. Нам нужно что-то где мы можем явно указать права доступа. Нам нужен [FileStream](http://msdn.microsoft.com/ru-ru/library/system.io.filestream.aspx), а конкретнее нам поможет [FileStream Constructor (String, FileMode, FileSystemRights, FileShare, Int32, FileOptions)](http://msdn.microsoft.com/ru-ru/library/ms143396.aspx). Нужны следующие параметры:
* Путь к файлу – понятно
* Как открывать файл – открыть файл и найти конец файла
* Права доступа к файлу – дозапись данных
* Доступ для других объектов FileStream – не нужен
* Размер буфера – по умолчанию 8 байт
* Дополнительные опции — нет
Получается примерно так:
```
$log = new-object io.filestream("c:\testperms\user.log",[io.filemode]::append,[security.accesscontrol.filesystemrights]::appenddata,[io.fileshare]::none,8,[io.fileoptions]::none)
```
Работает! Объект лога мы создали, попробуем туда что-нибудь [записать](http://msdn.microsoft.com/ru-ru/library/system.io.filestream.write.aspx). Метод FileStream.Write принимает входящие значения в байтах. Перегоняем событие, которое мы хотим записать, в байты – [класс Encoding](http://msdn.microsoft.com/ru-ru/library/system.text.encoding.aspx), метод [GetEncoding](http://msdn.microsoft.com/ru-ru/library/t9a3kf7c.aspx) (нам не нужны кракозябры на выходе) и [GetBytes](http://msdn.microsoft.com/ru-ru/library/ds4kkd55.aspx) (собственно, конвертирование)
```
$event = "Произошло новое событие."
$eventbytes = [text.encoding]::getencoding("windows-1251").getbytes($event)
```
Параметры FileStream.Write:
Что писать; откуда начинать писать; количество байт, которые нужно записать
Записываем:
```
$log.write($eventbytes,0,$eventbytes.count)
```
Проверяем.
```
gc c:\testperms\user.log
gc : Отказано в доступе по пути "C:\testperms\user.log ".
```
Все нормально, у пользователя нет прав на просмотр написанного. Перелогиниваемся под администратором.
```
gc c:\testperms\user.log
Произошло новое событие.
```
Все работает.
Папке, в которой находится файл кроме разрешения Создание папок / дозапись данных должно быть еще выдано разрешение Содержание папки / Чтение данных. На файл хватает только Создание папок / дозапись данных с отключенным наследованием. Полностью оградить пользователя (а пользователем может быть и злоумышленник) от файлов, в которые он должен что-то писать не получится, но с другой стороны, кроме списка файлов в папке, пользователь ничего не увидит и не сможет сделать.
Вывод из этого простой: в батниках реализовать безопасное логирование чего-либо не получится, PowerShell спасает умение работать c .NET объектами.
**Запись атрибутов (writeattributes)** – разрешаем пользователю изменять атрибуты файла или папки. Вроде все просто. Но вот только что ответить на вопрос: «Фотографии моих котиков занимают почти все место в моем профиле и у меня не остается места для деловой переписки. Я бы хотел сжать папку с котиками, но у меня требуют прав администратора. Вы же говорили, что у меня есть право менять атрибуты папок. Это же атрибут? Почему я не могу его поменять?»
Да, пользователю с правом записи атрибутов можно менять почти все видимые атрибуты файлов и папок, кроме атрибутов сжатия и шифрования. Технически, пользователю дается право выполнять функцию [SetFileAttributes](http://msdn.microsoft.com/en-us/library/aa365535(v=vs.85).aspx). А сжатие файлов выполняется функцией [DeviceIOControl](http://msdn.microsoft.com/en-us/library/aa364592(v=vs.85).aspx), которой нужно передать параметр FSCTL\_SET\_COMPRESSION и сжатие файлов является далеко не единственной ее работой. С помощью этой функции мы можем управлять всеми устройствами и их ресурсами в системе и, наверное, дать пользователю это право на выполнение этой функции означает сделать его администратором.
С шифрованием история похожа: функция [EncryptFile](http://msdn.microsoft.com/en-us/library/aa364021(v=vs.85).aspx), которая как раз и отвечает за шифрование, требует, чтобы у пользователя были права Содержание папки / Чтение данных, Создание файлов / Запись данных, Чтение атрибутов, Запись атрибутов и Синхронизация на объект. Без них ничего не получится.
**Запись расширенных атрибутов (writextendedattributes)**. Ну это тех, которые используются для обратной совместимости с приложениями OS/2, ага. Ну, а еще в расширенные атрибуты файла C:\Windows\system32\services.exe с недавних пор начали записывать троянов ([ZeroAccess.C](http://www.symantec.com/connect/blogs/trojanzeroaccessc-hidden-ntfs-ea)). Может быть стоит их отключать на самом верхнем уровне? На этот вопрос я не могу дать ответ, теоретически – может быть и стоит, практически в продакшене – я не пробовал.
**Удаление подпапок и файлов. (deletesubdirectoriesandfiles)** Интересное разрешение, применяемое только к папкам. Суть в том, чтобы разрешить пользователю удалять подпапки и файлы в родительской папке, не давая разрешения Удаление.
Допустим, есть каталог товаров, в который пользователи заносят данные. Есть родительская папка Catalog, внутри подпапки по алфавиту, от A до Z, внутри них какие-нибудь наименования. Наименования меняются каждый день, что-то добавляется, что-то изменяется, что-то устаревает и устаревшую информацию нужно удалять. Но будет не очень хорошо, если кто-нибудь по запарке или злому умыслу грохнет весь каталог K, что очень возможно, если у пользователей есть право Удаление. Если забрать у пользователей право Удаление, то администратору можно смело менять работу, потому что он весь день будет выполнять запросы на удаление того или иного наименования.
Вот тут и включается Удаление подпапок и файлов. На всех буквах алфавита отключается наследование и пользователям добавляется право Удаление подпапок и файлов. В итоге, в папке catalog пользователи не смогут удалить ни одну букву, но внутри букв могут удалять все, что угодно.
**Удаление (delete).** Здесь все просто. Удаление — это удаление. Не работает без права Чтение.
**Чтение разрешений (readpermissions)** дает право пользователю просматривать разрешения на папке или файле. Нет права – пользователь не видит разрешения на вкладке «Безопасность»
**Смена разрешений (changepermissions)** – разрешает пользователю менять разрешения, по сути делает пользователя администратором папки. Можно использовать, например, для делегирования полномочий техподдержке. Без права чтения разрешений не имеет никакого смысла. Смена разрешений не подразумевает смену владельца папки.
**Смена владельца (takeownership)** – для начала, кто такой владелец. Владелец – это пользователь, создавший файл или папку.
Особенностью владельца является то, что у него есть полный доступ к созданной папке, он может раздавать разрешения на свою созданную папку, но что важнее – никто не может лишить владельца права изменять разрешения на его папку или файл. Если Вася создал папку, дал полный доступ Пете, а Петя зашел и грохнул доступ пользователей к папке вообще и Васи в частности, то Вася без особого труда может восстановить статус-кво, так как он является владельцем папки. Изменить владельца папки Петя не сможет, даже если у него есть разрешение Смена владельца. Более того, даже Вася не может изменить владельца, несмотря на то, что папку создал он. Право Смена владельца относится только к группе Администраторы или Администраторы домена.
Но если Петя внутри Васиной папки создал файл и не дал Васе доступа к нему, то Васе остается только думать и гадать, что же внутри этого файла такого секретного. Вася не сможет изменить права доступа к файлу, потому что владельцем файла является Петя. Также Вася не сможет изменить владельца файла – изменение владельца подконтейнеров и объектов также является привилегией группы Администраторы, к которой Вася не относится. Единственный оставшийся у Васи вариант – смотреть на Петин файл внутри своей папки.
#### Управляем
В CMD для управления разрешениями используется хорошо всем известная icacls. В PowerShell управление NTFS-разрешениями выглядит примерно так:
Получить объект, на который мы будем устанавливать разрешения
```
$acl = get-acl c:\testperms
```
Соорудить строку с правами с помощью класса [System.Security.AccessControl.FileSystemAccessRule](http://msdn.microsoft.com/ru-ru/library/system.security.accesscontrol.filesystemaccessrule.aspx). Можем задать следующие параметры:
* группа/имя пользователя – для кого делаем ACL
* разрешение – ACE (принимает значения, указанные в посте)
* применяется к – в GUI это выпадающий список в дополнительных параметрах безопасности. На самом деле принимает всего 3 значения: none (только к этой папке), containerinherit (применяется ко всем подпапкам), objectinherit (применяется ко всем файлам). Значения можно комбинировать.
* применять эти разрешения к объектам и контейнерам только внутри этого контейнера (чекбокс в GUI) – также 3 значения: none (флажок снят), inheritonly (ACE применяется только к выбранному типу объекта), nopropagateinherit (применять разрешения только внутри этого контейнера).
* правило – разрешить (allow) или запретить (deny)
Строка с правами по умолчанию будет выглядеть так:
```
$permission = “contoso.com\admin”,”fullcontrol”,”containerinherit,objectinherit”,”none”,”allow”
```
Сделать новую ACE с определенными выше разрешениями
```
$ace = new-object security.accesscontrol.filesystemaccessrule $permission
```
И применить свежесозданную ACE к объекту
```
$acl.setaccessrule($ace)
$acl | set-acl c:\testperms
```
#### Применяем на практике
Вооружившись знаниями о SMB и NTFS разрешениях, комбинируя их можно создавать правила доступа абсолютно любой сложности. Несколько примеров:
| | | |
| --- | --- | --- |
| Тип | SMB-разрешения | NTFS-разрешения |
| Папка для всех (Public) | Пользователи – Чтение/запись | Пользователи – Изменение |
| Черный ящик. Пользователи скидывают конфиденциальные отчеты, предложения, кляузы – руководство читает. | Пользователи – Чтение/запись
Руководство – Чтение/запись | Пользователи – Запись, применяется Только для этой папки. Предполагается, что запись файла в эту папку – билет в один конец, так как удобного способа редактирования без права Просмотр содержимого папки сохраненных в этой папке файлов не существует (удобного для пользователей способа записи в такую папку, кстати, тоже не существует). А просмотр нарушает конфиденциальность.
Руководство – Изменение. |
| Приложения | Пользователи – Чтение | Пользователи – Чтение, Чтение и выполнение, Просмотр содержимого папки.
Естественно, некоторые приложения могут требовать дополнительных прав для своей работы. Но в общем случае, например, хранение системных утилит для диагностики (того же SysInternals Suite) этого вполне хватает. |
| Профили пользователей | Каждому пользователю – Чтение/запись на его папку | Каждому пользователю – Изменение на его папку. |
Разрешения в Windows – противоречивая штука. С одной стороны – основные разрешения довольно просты и покрывают 90% случаев. Но когда начинает требоваться более тонкая настройка: разные группы пользователей, одна папка, требования безопасности к общим папкам – то разобраться с дополнительными разрешениями, наследованиями и владельцами бывает довольно сложно.
Надеюсь, я не запутал никого еще больше.
Использован материал из:
[MSDN](http://msdn.microsoft.com/ru-ru/ms348103.aspx)
[Technet](http://technet.microsoft.com/) | https://habr.com/ru/post/186240/ | null | ru | null |
# DMX-512 Визуализация передаваемых уровней каналов

По роду деятельности, мне часто приходится разрабатывать всевозможные системы управления световыми эффектами. В случаях, когда для заказчика избыточен функционал представленных на рынке контроллеров, приходится под конкретный объект изобретать простенький контроллер практически на коленке. Задача каждый раз уникальна, начиная от одного канала, пульсирующего словно сердце до управления «гирляндой» декодеров работающих по протоколу DMX-512 или на микросхемах WS28хх:
**Простейший DMX декодер**
[Стоят копейки у китайцев](http://www.ebay.com/itm/3-Channel-300mA-18W-DMX512-Decoder-Board-LED-RGB-Stage-Lighting-Driver-Module-/141701505428?hash=item20fe116194:g:drkAAOSwLVZVin3h). Я очень люблю эти декодеры. С их помощью легко можно масштабировать систему от трех до 512 каналов.
Для меня самый удобный вариант всем известная плата Arduino. Очень удобно держать в ящике десяток-другой клонов Arduino Pro Mini и по мере надобности использовать их в подобных проектах. Люблю его за то что на его базе можно быстро собрать достаточно компактное устройство и стоят эти клоны в Китае, примерно столько же, как и голая Atmaga328.
И вот при разработке эффектов для очередного контроллера на 16 каналов, работающего по протоколу DMX-512, я окончательно замучился раскладывать на столе паутину проводов на скрутках ради того, что бы один раз отладить эффекты и снова все это разобрать. Я озадачился поиском приборов для анализа DMX пакетов, но оказалось, что это весьма редкие и довольно дорогостоящие приборы. Это и подтолкнуло меня к созданию собственного DMX-тестера.
Изначально я решил, что нужен прибор, который будет уметь отображать уровни каналов в реальном времени и этого будет достаточно, но немного пораздумав, я определил следующий список задач:
* Отображение уровней каналов в режиме реального времени в относительных единицах;
* Отображение общего количества каналов, на которые контроллер выдает данные;
* Отображение уровня одного выбранного канала в абсолютных единицах (0-255);
Выводить уровни каналов, было принято в виде столбиков, т. е. если использовать символьный LCD-дисплей 16х2, то в одной строке уже можно наблюдать 16 каналов одновременно. Т.к. каналов может быть до 512, то хорошо бы было иметь возможность прокрутки отображаемого диапазона каналов.
Ну раз задача поставлена, перейдем к железу. В основе, как я уже писал, у меня клон Arduino Pro Mini:
**Данные мы будем получать через простейший переходник TTL to RS-485, основанный на MAX485.**"
Ну и выводить информацию будем на LCD-дисплей 16х2 (сразу оговорюсь, что в момент разработки уже заказал аналогичный дисплей 40х2 который встанет на свое место в конечном устройстве). Управлять всем этим буду посредством клавиатуры, описанной [здесь](http://geektimes.ru/post/255408/) товарищем [kumbr\_87](https://geektimes.ru/users/kumbr_87/).
Сказано — сделано.
**На макетке собрал прототип**
**Написал скетч**
```
#include
#include
#include
#define DMX\_SLAVE\_CHANNELS 512
#define LCD\_W 16 //количество выводимых на дисплей каналов (по идее соответствует символьной ширине дисплея)
LiquidCrystal lcd(12, 11, 5, 4, 3, 2);
DMX\_Slave dmx\_slave ( DMX\_SLAVE\_CHANNELS );
unsigned long lastFrameReceivedTime = 0; //Время последнего получения пакета
unsigned long lastFrameTranceivedTime = 0; // Время последнего отображенного пакета
byte qa[8] =
{
B00000,
B00000,
B00000,
B00000,
B00000,
B00000,
B00000,
B11111
};
byte ws[8] =
{
B00000,
B00000,
B00000,
B00000,
B00000,
B00000,
B11111,
B11111
};
byte ed[8] =
{
B00000,
B00000,
B00000,
B00000,
B00000,
B11111,
B11111,
B11111
};
byte rf[8] =
{
B00000,
B00000,
B00000,
B00000,
B11111,
B11111,
B11111,
B11111
};
byte tg[8] =
{
B00000,
B00000,
B00000,
B11111,
B11111,
B11111,
B11111,
B11111
};
byte yh[8] =
{
B00000,
B00000,
B11111,
B11111,
B11111,
B11111,
B11111,
B11111
};
byte uj[8] =
{
B00000,
B11111,
B11111,
B11111,
B11111,
B11111,
B11111,
B11111
};
byte ik[8] =
{
B11111,
B11111,
B11111,
B11111,
B11111,
B11111,
B11111,
B11111
};
byte outAr [LCD\_W]; // Значения каналов, выводимые на дисплей
unsigned short chRx; // количество принятых каналов
#define KEY\_BUTTON\_1\_PIN A2 //пин к которому подключена клавиатура
unsigned int KeyButton1Value=0; //значение с клавиатуры
unsigned long KeyButton1TimePress=0; //последнее время когда не было нажатых кнопок
unsigned long KeyButton1Latency=100; //задержка перед считыванием состояния панели управления после нажатия
unsigned int KeyButton1WasChecked=0; //метка означающая что нажатие кнопки было обработано
unsigned long KeyButton1RepeatLatency=1500; //время после которого удерживание кнопки начинает засчитываться как многократные быстрые нажатия
unsigned long KeyButton1RepeatTimePress=0; //вспомогательная переменная для обработки повторных нажатий
unsigned long KeyButton1TimeFromPress=0; //переменная для хранения времени между временем когда не было зажатых кнопок и временем проверки
unsigned long KeyBoardTime1=0; //
unsigned long KeyBoardTime2=0; // Переменные для обработки времени для обработки событий клавиатуры
unsigned long KeyBoardTimeInterval=25; //
byte start = 0; // +1 номер канала, который выводится на экран первым
void setup() {
lcd.begin(LCD\_W, 2);
dmx\_slave.enable ();
dmx\_slave.setStartAddress (1);
dmx\_slave.onReceiveComplete ( OnFrameReceiveComplete );
lcd.createChar(0,qa);
lcd.createChar(1,ws);
lcd.createChar(2,ed);
lcd.createChar(3,rf);
lcd.createChar(4,tg);
lcd.createChar(5,yh);
lcd.createChar(6,uj);
lcd.createChar(7,ik);
pinMode (KEY\_BUTTON\_1\_PIN, INPUT);
pinMode (10, OUTPUT);
pinMode (9, OUTPUT);
digitalWrite(9, LOW);
}
void loop()
{
//проверка таймера для обработки нажатий клавиатуры
KeyBoardTime2=millis();
if ((KeyBoardTime2-KeyBoardTime1)>KeyBoardTimeInterval)
{
KeyBoardTime1=KeyBoardTime2;
KeyBoardCalculate();
}
if (lastFrameReceivedTime > lastFrameTranceivedTime){ //если получен новый пакет
printLevel (outAr); // Вывод значений на дисплей
lastFrameTranceivedTime = millis();
}
else if ((lastFrameReceivedTime==0 && lastFrameTranceivedTime ==0)||(KeyBoardTime2-lastFrameReceivedTime>2000)) {
lcd.clear();
delay (500);
lcd.setCursor(0, 0);
lcd.print("NO SIGNAL");
delay (500);
}
}
void OnFrameReceiveComplete (unsigned short channelsReceived) // функция, вызываемая после получения очередного пакета
{
chRx = channelsReceived; // количество калалов, на которые пришли данные в пакете
for (byte i=0; i9) { //
lcd.print((start+1)); //
lcd.print(" "); //
} else lcd.print((start+1)); //
lcd.setCursor(5, 1);
lcd.print("V:"); //
if (lv[0]<10) { //
lcd.print("00"); //
lcd.print(lv[0]); // Отображение уровня первого отображаемого канала в абсолютных единицах
} else if (lv[0]<100 && lv[0]>9) { //
lcd.print("0"); //
lcd.print(lv[0]); //
} else lcd.print(lv[0]); //
lcd.setCursor(11, 1);
lcd.print("T:"); // Отображение общего количества полученных каналов
lcd.print(chRx); //
}
void ButtonPress() // Распознаем, какая кнопка нажата
{
if ((KeyButton1Value>200) and (KeyButton1Value<500))
{
if((start) < (chRx-LCD\_W) && chRx>LCD\_W) start++; // обработка нажатия первой кнопки
}
if ((KeyButton1Value>500) and (KeyButton1Value<1000))
{
if(start > 0) start--; // Обработка нажатия второй кнопки
}
}
void KeyBoardCalculate()
{
//Часть отработки нажатия клавиши
KeyButton1Value=analogRead(KEY\_BUTTON\_1\_PIN);
//если сигнал с кнопки нулевой то обнуляем метку обработки нажатия
if ((KeyButton1Value<=50) or (KeyButton1Value>=1000))
{
//Сохраняем время последнего сигнала без нажатой кнопки
KeyButton1TimePress=millis();
KeyButton1WasChecked=0;
KeyButton1RepeatTimePress=0;
}
KeyButton1TimeFromPress=millis()-KeyButton1TimePress;
//исключаем шумы
if ((KeyButton1Value>50) and (KeyButton1Value<1000))
{
//отработка первого нажатия
if ( ((KeyButton1TimeFromPress)>KeyButton1Latency) and (KeyButton1WasChecked==0))
{
KeyButton1Value=analogRead(KEY\_BUTTON\_1\_PIN);
ButtonPress();
KeyButton1WasChecked=1;
KeyButton1RepeatTimePress=0;
}
//отработка повторных нажатий
if ( ((KeyButton1TimeFromPress)>(KeyButton1RepeatLatency+KeyButton1RepeatTimePress)) and (KeyButton1WasChecked==1))
{
KeyButton1Value=analogRead(KEY\_BUTTON\_1\_PIN);
ButtonPress();
KeyButton1RepeatTimePress=KeyButton1RepeatTimePress+100;
}
}
}
```
И как ни странно, все заработало! Столбики «прыгали» в соответствии с получаемыми данными. К этому времени, как раз пришел дисплей 40х2. Подключил его, переделал скетч под дисплей на 40 символов, залил, и тут произошло необъяснимое.
В момент запуска микроконтроллера в первом отображаемом кадре вся информация верна, при отображении последующих кадров, arduino куда-то съедает несколько каналов. Т.е. если контроллер выдает данные на 60 каналов, то в момент включения или перезагрузки arduino, отображается общее количество каналов 60 и первый канал на дисплее является действительно первым. Но сразу после смены кадров, отображается количество кадров 57, а первым отображается, в реальности пятый. Пробовал еще загонять сигнал на 30 каналов — тоже самое, только сначала все правильно, а потом показывает общее количество каналов 29, а на месте первого показывает вообще непонятно что.
Все остальное работает без проблем — прокрутка листает. Может кто-нибудь свежим взглядом увидит… Да, кстати, если выдавать сигнал на <17 каналов, то отображается все корректно.
Думал над этой проблемой неделю, но так и не нашел решения. В итоге решил остановиться на изначальном дисплее на 16 символов. Запилил корпус, собрал и все работает по сей день. | https://habr.com/ru/post/357888/ | null | ru | null |
# Ручная кофемолка: инструменты командной строки для Java
В книге "[97 вещей, которые должен знать каждый Java-программист](https://medium.com/97-things)" есть глава о некоторых инструментах командной строки в JDK (я дал 2 из 97 советов).
Поскольку я сам часто использую такие помощники, я хотел кратко представить их в сегодняшней статье.
Я предпочитаю командную строку для своей повседневной работы, используя комбинацию команд `git`, `sed`, `grep`, и т. д., `bash` что упрощает выполнение повторяющихся задач.
Уже в «[Прагматическом программисте](https://pragprog.com/titles/tpp20/)» была четкая ссылка на это в разделе 21:
> **Используйте возможности командных оболочек+
> Используйте оболочку, когда графические пользовательские интерфейсы не подходят.**
>
>
Также хотелось бы сослаться на книгу NealFord "[Productive Programmer":](https://www.oreilly.com/library/view/the-productive-programmer/9780596519780/)
> **Вам не нужно бояться командной строки, это как любой язык программирования. Вы выполняете команды или сценарии и можете комбинировать их ввод и вывод в более сложные процессы. В Linux и OSX вас хорошо обслуживают встроенные bash или zsh, в Windows вы можете воспользоваться либо** `cmd`**, либо с недавних пор с подсистемой Windows для Linux (WSL).**
>
>
Большинство инструментов поставляются со встроенной справкой, отображаемой по параметру `-h` или предоставляют страницы справки с помощью `man`. Эти [справочные страницы также можно найти на веб-сайте Oracle](https://docs.oracle.com/en/java/javase/14/docs/specs/man/).
Управление установками JDK с помощью SDKman
-------------------------------------------
Как упоминалось в предыдущих статьях, для меня sdkman — это гений управления установками Java, Groovy, Maven, Gradle, Micronaut и многих других инструментов, а также для активации различных версий.
Для этого вы устанавливаете sdkman, например, с помощью:
`curl -s "https://get.sdkman.io" | bash`.
После этого по команде `sdk list` отображаются устанавливаемые инструменты, и с помощью команды `sdk list java` вы можете увидеть доступные и установленные версии JDK.
У вас есть широкий выбор версий JDK от OpenJDK до Azul Zuulu, GraalVM до Amazon и SAP JDK.
С помощью, например `sdk install java 17-open`, вы можете установить новые версии (вплоть до последней EAP), а с помощью `sdk use java 17-open` вы можете переключиться на текущую оболочку или глобально.
Простые помощники
-----------------
В каждом пакете JRE и JDK помимо компилятора `javac` и среды выполнения `java` есть много полезных помощников в каталоге `bin` дистрибутива. Некоторые из них, как `jarsigner` или `keytool` очень специфичные, и я не буду углубляться в них здесь.
Мы начнем с некоторых полезных инструментов, а затем посвятим более сложным инструментам отдельные разделы.
### jps
Если вы хотите избавиться от зависшего процесса Java, вы можете либо найти его в диспетчере задач и закрыть его там, либо найти PID (идентификатор процесса) с помощью, `ps auxww | grep java`, а затем завершить его с помощью `kill`.
Вместо этого встроенный `jps` может предоставить тот же сервис.
Есть дополнительные параметры: `-l` - для полного доменного имени основного класса или пути к JAR-файлу запуска, `-v` - для аргументов JVM и `-m` - для аргументов командной строки метода `main`.
### jstack
Чтобы получить дамп потока JVM, особенно если он завис в какой-то точке, которую вы хотите изучить более внимательно, есть 2 способа.
Либо `kill -3` производит вывод непосредственно из процесса, либо предпочтительнее с помощью `jstack`.
Таким образом, jstack также может заставить остановившиеся процессы выводить с флагом «force» `-F`, который затем можно перенаправить в файл.
С помощью `jstack -l` вы получаете дополнительный вывод о блокировках, также отображаются взаимоблокировки.
Статус потоков различается между `kill -3`и `jstack`.
| **kill -3** | **jstack** |
| --- | --- |
| `RUNNABLE` | `IN_NATIVE` |
| `TIMED_WAITING` | `BLOCKED` |
| `WAITING` | `BLOCKED (PARK)` |
### jinfo
С помощью `jinfo` вы можете быстро получить доступ к системным свойствам, флагам JVM и аргументам JVM процесса Java.
`jinfo` дает полный обзор, который может помочь в обнаружении странных эффектов. Используя `jinfo -flag name=value` или `-flag [+|-]name` вы можете изменить динамические флаги JVM.
### jshell
Представленная в Java 9, `jshell` - это была первая официальная консоль REPL (read eval print loop) для интерактивного выполнения кода Java.
Можно не только вычислять выражения и назначать переменные, но также можно создавать и динамически переопределять классы с методами.
Можно передать пути к классам в jshell, содержимое которого затем будет доступно для импорта и использования.
`jshell` имеет множество параметров командной строки, а также встроенные команды, которые объясняются с помощью параметра `/?`.
Особенно полезны `/help`, `/save`, `/history` и команды `/vars`, `/types`, `/methods`, `/imports`.
Для редактирования больших фрагментов кода вы можете использовать '/edit', создав свой собственный редактор, используя переменные окружения 'JSHELLEDITOR', 'VISUAL', 'EDITOR' или установить редактор указав '/path/to/editor'.
Важные пакеты `java.util.(*,streams,concurrent)`, такие как `java.math` и некоторые другие, уже импортированы по умолчанию.
Выражения присваиваются заполнителям `$5`, которые можно использовать позже.
Для улучшения читабельности кода лучше использовать `var` начиная с Java 11, тогда переменные можно создавать без объявления типа.
Новые языковые функции, которые все еще доступны в режиме предварительного просмотра, могут быть включены с помощью параметра `--enable-preview`.
Очень удобной функцией `jshell` является автодополнение. Каждое имя класса, метода и переменной можно контекстно завершить, нажав несколько раз клавишу Tab.
Вот пример запуска игры «Жизнь» (Покойся с миром — Джон Конвей) в `jshell`.
```
// GOL Rules: Cell is alive, if it was alive and has 2 or 3 living neighbours or always with 3 living neighbours
import static java.util.stream.IntStream.range;
import static java.util.stream.Collectors.*;
import static java.util.function.Predicate.*;
record Cell(int x, int y) {
Stream nb() {
return range(x()-1,x()+2)
.mapToObj(i -> i)
.flatMap(x -> range(y()-1,y()+2)
.mapToObj(y -> new Cell(x,y)))
.filter(c -> !this.equals(c));
}
boolean alive(Set cells) {
var count = nb().filter(cells::contains).count();
return (cells.contains(this) && count == 2) || count == 3;
}
}
Set evolve(Set cells) {
return cells.stream().flatMap(c -> c.nb()).distinct()
.filter(c -> c.alive(cells))
.collect(toSet());
}
void print(Set cells) {
var min=new Cell(cells.stream().mapToInt(Cell::x).min().getAsInt(),
cells.stream().mapToInt(Cell::y).min().getAsInt());
var max=new Cell(cells.stream().mapToInt(Cell::x).max().getAsInt(),
cells.stream().mapToInt(Cell::y).max().getAsInt());
range(min.y(), max.y()+1)
.mapToObj(y -> range(min.x(), max.x()+1)
.mapToObj(x -> cells.contains(new Cell(x,y)) ? "X" : " ")
.collect(joining(""))).forEach(System.out::println);
}
"""
#
#
###
"""
var cells = Set.of(new Cell(1,0), new Cell(2,1), new Cell(0,2),new Cell(1,2),new Cell(2,2))
void gen(Set cells, int steps) {
print(cells);
if (steps>0) gen(evolve(cells),steps-1);
}
Set parse(String s) {
Arrays.stream(s.split("\n")).mapIndexed((x,l) ->
Arrays.stream(l.split("")).mapIndexed(y,c) -> )
}
```
jar
---
Для работы с jar-файлами (Java ARchive) есть одноименная команда.
Синтаксис командной строки аналогичен команде `tar`.
Хотя `tar` по умолчанию только хранит файлы в архиве, `jar` также сжимает их, что приводит к значительному уменьшению размера.
Вот несколько полезных сценариев использования:
* `jar tf file.jar` - отображать содержимое архива
* `jar xvf file.jar` - распаковать файл архива в текущем каталоге (с отображением по `v`)
* `jar uvf file.jar -C path test.txt` - добавить файл из указанной директории
Поскольку в Java 9 `jar` также может создавать мультирелизные архивы, совместимые с несколькими JDK и могут содержать оптимизированные файлы классов для соответствующей версии Java.
java
----
Команда Java запускает виртуальную машину Java с заданным путем к классам (каталоги, файлы и URL-адреса jar и классов) и основным классом, main метод которого выполняется.
С помощью команды `java -jar file.jar` main класс определяется с помощью метаинформации файла jar.
Начиная с Java 11, доступен [JEP 330](https://openjdk.java.net/jeps/330) (Запуск программ с однофайловым исходным кодом), поэтому исходные файлы можно запускать напрямую.
```
cat > Hello.java < hello <<EOF
#!/usr/bin/java --source 10
public class Hello {
public static void main(String...args) {
System.out.println("Hello "+String.join(" ",args)+"!");
}
}
EOF
chmod +x hello
./hello JEP 330
```
JVM можно контролировать с помощью [сотен флагов](https://foojay.io/command-line-arguments/), от выделения памяти с помощью [флагов](https://foojay.io/command-line-arguments/) `-Xmx` и `-Xms` до выбора сборщика мусора с помощью [флаг](https://foojay.io/command-line-arguments/)а `-XG1GC` и настроек журнала.
Коллекция ресурсов по флагам JVM была опубликована [Betsy Rhodes на Foojay](https://foojay.io/today/top-10-fun-with-jvm-flags/)
Далее следуют несколько полезных флагов, список представляет лишь часть опций JVM.
* `HeapDumpOnOutOfMemoryError`
* `Xshareclasses`- Обмен данными класса
* `verbose:gc`- Ведение журнала GC
* `+TraceClassLoading`
* `+UseCompressedStrings`
Javac
-----
Компилятор `javac` транслирует исходный код Java в один или несколько файлов классов, содержащих байт-код классов, выполняет начальную оптимизацию и запускает обработку аннотаций «процессорами аннотаций».
Чтобы указать все классы, от которых зависит текущий код, они или их архивы должны быть перечислены в пути к классам или пути к модулю.
Для более глубокого изучения `javac` потребуется отдельная статья, поэтому мы остановимся на ее почетном упоминании.
JavaP
-----
Всякий раз, когда вы хотите изучить результат `javac`, `javap` вступает в игру.
Этот инструмент позволяет отображать сигнатуру класса, его расположение в памяти с помощью [флагов](https://foojay.io/command-line-arguments/) `-l -v -constants` или инструкциями байт-кода языка стека JVM с помощью [флаг](https://foojay.io/command-line-arguments/)а`-c`.
Это может быть полезно, если вы хотите увидеть влияние определенных опций компилятора или версий Java, или если изменилось поведение оптимизаций (размер встроенного кода).
В качестве параметра он получает полное имя класса, имя файла или URL-адрес jar.
Вот пример нашего класса `Hello.java`, где вы можете видеть, например, что Java 14 теперь использует операцию «invokedynamic» для конкатенации строк.
```
javap -c Hello
Compiled from "Hello.java"
public class Hello {
// Constructor with Super-Constructor call
public Hello();
Code:
// load "this" on stack
0: aload_0
4: return
public static void main(java.lang.String...);
Code:
0: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #13 // String
// load first parameter on stack, i.e. "args"
5: aload_0
6: invokestatic #15 // Method java/lang/String.join:(Ljava/lang/CharSequence;[Ljava/lang/CharSequence;)Ljava/lang/String;
// string concatenation
9: invokedynamic #21, 0 // InvokeDynamic #0:makeConcatWithConstants:(Ljava/lang/String;)Ljava/lang/String;
14: invokevirtual #25 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
17: return
}
```
### JMAP
Было полезно создавать heapdumps или гистограммы (ссылочных) объектов `jmap`.
В настоящее время рекомендуется использовать `jcmd`.
* `jmap -clstats` выводит статистику загрузчика классов
* `jmap -histo` или `jmap -histo:live` выводит гистограмму
* jmap -dump:live,format=b,file=heap.hprof генерирует дамп кучи.
### JCMD
Используя `jcmd` можно управлять Java процессами удаленно, существует довольно много действий, которые можно инициировать в JVM.
`jcmd` может использоваться интерактивно или с помощью параметров командной строки.
Используя `jcmd`, можно запускать определенные действия, при этом несколько команд разделяются символами новой строки.
Кроме того `jcmd help` дает информацию о том, какие команды имеются.
```
jcmd 14358
```
Вот несколько примеров:
| Команда | Описание |
| --- | --- |
| `GC.class_stats` | Подробная информация обо всех загруженных классах |
| `GC.class_histogram` | Гистограмма количества экземпляров |
| `GC.heap_dump filename=` | Создать дамп кучи. |
| `GC.heap_info` | Обзор использования кучи |
| `GC.run` | Запустить сборку мусора |
| `Thread.print` | Дамп потока |
| `JFR.start name= settings= delay=20s duration=2m` | Начать запись JDK JFR |
| `JFR.dump name= filename=` | Создать дамп JFR |
| `VM.uptime` | Время выполнения JVM |
| `VM.flags` | Активные флаги JVM |
| `VM.system_properties` | Свойства системы |
| `VM.command_line` | Командная строка JVM |
| `VM.version` | JVM-версия |
| `VM.class_hierarchy` | Визуальный вывод иерархии классов |
| `VM.log` | Управление ведением журнала JVM |
```
jcmd 15254 GC.heap_info
15254:
garbage-first heap total 1048576K, used 214334K [0x00000007c0000000, 0x0000000800000000)
region size 1024K, 135 young (138240K), 0 survivors (0K)
Metaspace used 136764K, capacity 142605K, committed 142896K, reserved 1169408K
class space used 19855K, capacity 22505K, committed 22576K, reserved 1048576K
```
```
jcmd GradleDaemon GC.class_histogram | head
14358:
num #instances #bytes class name
----------------------------------------------
1: 42635 4515304 [C
2: 10100 1096152 java.lang.Class
3: 42595 1022280 java.lang.String
4: 27743 887776 java.util.concurrent.ConcurrentHashMap$Node
5: 10598 599128 [Ljava.lang.Object;
6: 26119 417904 java.lang.Object
```
JDK Flight Recorder (jfr)
-------------------------
JDK Flight Recorder — это механизм для трассировки во время выполнения, который позволяет записывать различные события активности, происходящие в JVM, и соотносить их с активностью приложения.
Возможна трассировка всего, включая JIT-оптимизации, сборки мусора, точек сохранения и даже пользовательских событий.
Инструмент `jfr` позволяет читать и отображать файлы JDK Flight Recorder с помощью команд `print`, `summary` и `metadata`.
Выдачу результатов можно представить в удобочитаемом текстовом формате или JSON/XML ( `--json, --xml`).
* `print` представляет весь журнал событий
* `metadata` показывает, какие события были записаны (классы событий)
* `summary` показывает в виде гистограммы, какие события были записаны, как часто
```
jfr summary /tmp/test.jfr
Version: 2.0
Chunks: 1
Start: 2020-06-21 12:06:38 (UTC)
Duration: 7 s
Event Type Count Size (bytes)
===========================================================
jdk.ModuleExport 2536 37850
jdk.ClassLoaderStatistics 1198 35746
jdk.NativeLibrary 506 45404
jdk.SystemProcess 490 53485
jdk.JavaMonitorWait 312 8736
jdk.NativeMethodSample 273 4095
jdk.ModuleRequire 184 2578
jdk.ThreadAllocationStatistics 96 1462
jdk.ThreadSleep 65 1237
jdk.ThreadPark 53 2012
jdk.InitialEnvironmentVariable 40 2432
jdk.InitialSystemProperty 20 16392
jdk.ThreadCPULoad 17 357
```
Чтобы ограничить количество информации, категории можно фильтровать с помощью флага `--categories "GC,JVM,Java*"`, а события с помощью флага `--events CPULoad,GarbageCollection` или `--events "jdk.*"`.
К сожалению, это невозможно с помощью `summary` или `metadata`, только с помощью `print`.
Лучшим инструментом для оценки записей JFR, конечно же, является [JDK Mission Control (JMC)](https://adoptopenjdk.net/jmc.html), который был выпущен как OpenSource, начиная с Java 11, а также предлагается [другими поставщиками, такими как Azul](https://www.azul.com/products/zulu-mission-control/).
jdeprscan
---------
Поскольку в последние годы некоторые компоненты были исключены из JDK (discontinued), `jdeprscan` позволяет сканировать классы, каталоги или файлы jar для определения использования этих API.
Пример:
```
jdeprscan --release 11 testcontainers/testcontainers/1.9.1/testcontainers-1.9.1.jar 2>&1 | grep -v 'error: cannot '
Jar file testcontainers/testcontainers/1.9.1/testcontainers-1.9.1.jar:
class org/testcontainers/shaded/org/apache/commons/lang/reflect/FieldUtils uses
deprecated method java/lang/reflect/AccessibleObject::isAccessible()Z
class org/testcontainers/shaded/org/apache/commons/lang/reflect/MemberUtils uses
deprecated method java/lang/reflect/AccessibleObject::isAccessible()Z
class org/testcontainers/shaded/org/apache/commons/io/input/ClassLoaderObjectInputStream
uses deprecated method java/lang/reflect/Proxy::getProxyClass(Ljava/lang/Class
```
С помощью `jdeprscan --list --release 11` вы можете перечислить API, которые объявлены устаревшими (deprecated) в этом релизе.
```
jdeprscan --release 11 --list | cut -d' ' -f 3- | cut -d. -f1-3 | sort | uniq -c | sort -nr | head -10
132
40 java.rmi.server
34 java.awt.Component
25 javax.swing.text
25 javax.swing.plaf
20 javax.management.monitor
18 java.util.Date
13 java.awt.List
9 javax.swing.JComponent
8 java.util.concurrent
```
Другие инструменты
------------------
Есть, конечно, еще много важных инструментов для работы с JVM, от `async-profiler` и `jol` (Java Object Layout) до графических программ для разбора и отображения журналов GC ([https://gceasy.io](https://gceasy.io/)), записей JFR (jmc) или дампов кучи (jvisualvm, Eclipse-MAT).
Другие инструменты, такие как отладчик Java `jdb`, не так удобны, как возможности IDE для удобной отладки как на локальных, так и на удаленных компьютерах.
Заключение
----------
Помощники, поставляемые с JDK, могут облегчить вашу жизнь, если вы знаете об их возможностях и о том, как их комбинировать друг с другом и с другими инструментами оболочки.
Их определенно стоит попробовать и узнать о них больше. | https://habr.com/ru/post/652985/ | null | ru | null |
# Заметки для построения эффективных Django-ORM запросов в нагруженных проектах
Написано, т.к. возник очередной холивар в комментариях на тему SQL vs ORM в High-Load Project (HL)
#### Преамбула
В заметке Вы сможете найти, местами, банальные вещи. Большая часть из них доступна в документации, но человек современный часто любит хватать все поверхностно. Да и у многих просто не было возможности опробовать себя в HL проектах.
Читая статью, помните:
* Никогда нельзя реализовать HL-проект на основе только одной манипуляции с ORM
* Никогда не складывайте сложные вещи на плечи БД. Она нужна Вам чтобы хранить инфу, а не считать факториалы!
* Если вы не можете реализовать интересующую Вас идею простыми средствами ORM — не используйте ORM для прямого решения задачи. И тем более не лезте в более низкий уровень, костыли сломаете. Найдите более элегантное решение.
* Извините за издевательски-юмористический тон статьи. По другому скучно :)
* Вся информация взята по мотивам Django версии 1.3.4
* Будьте проще!
И-и-и да, в статье будут показаны ошибки понимания ORM, с которыми я столкнулся за три с лишним года работы с Django.
#### Не понятый ORM
Начну с классической ошибки, которая меня преследовала довольно долго. В части верований в племя уругвайских мартышек. Я очень сильно верил во всемогучесть Django ORM, а именно в
```
Klass.objects.all()
```
например:
```
all_result = Klass.objects.all()
result_one = all_result.filter(condition_field=1)
result_two = all_result.filter(condition_field=2)
```
В моих мечтах размышление шло следующим образом:
* Я выбрал все что мне интересно, одинм запросом на первой строке.
* Во второй строке у меня уже не будет запроса, а будет работа с полученным результатом по первому условию.
* В третьей строке у меня так же не будет запроса к БД, а я по результатам первого запроса буду иметь интересующий меня вывод со вторым условием.
Вы, наверное, уже догадываетесь, что волшебных мартышек не существует и в данном случае мы имеем три запроса. Но, я Вас огорчу. В данном случае мы все же имеем два запроса, а если быть еще точнее — то ни одного запроса нет по результатам работы данного скрипта (но в дальнейшем мы конечно так не будем изголяться). Почему, спросите Вы?
Объясняю по порядку. Докажем что в данном коде три запроса:
* Первая строка, при вычислениях, аналог
```
select * from table;
```
* Вторая строка, при вычислениях, аналог
```
select * from table where condition_field=1;
```
* Третяя строка, при вычислениях, аналог
```
select * from table where condition_field=2;
```
Ура! Мы доказали что у нас есть три запроса. Но главное фраза — «при вычислениях». По сути, мы переходим ко второй части — доказательство что у нас всего два запроса.
Для данной задачки нам поможет следующее понимание ORM (в 2х предложениях):
* Пока мы ничего не вычислили — мы только формируем запрос, средствами ORM. Как только начали вычислять — вычисляем по полученному сформированному запросу.
Итак, в первой строке мы обозначили переменную **all\_result** с интересующим нас запросом — выбрать все.
Во второй и третьей строке, мы уточняем наш запрос на выборку доп. условиями. Ну и следовательно получили 2 запроса. Что и следовало доказать
Внимательные читатели (зачем вы еще раз взглянули в предыдущие абзацы?) уже должны были догадаться, что никаких запросов то мы и не сделали. А во второй и третьей строке мы так же просто сформировали интересующий нас запрос, но к базе так с ним и не обратились.
Так что занимались мы ерундой. И вычисления начнутся, например, с первой строки нижестоящего кода:
```
for result in result_one:
print result.id
```
##### Не всегда нужные функции и обоснованные выборки
Попробуем поиграться с шаблонами, и любимой некоторыми функцией **\_\_unicode\_\_()**.
Вы знаете — классная функция! В любом месте, в любое время и при любых обстоятельствах мы можем получить интересующее нас название. Супер! И супер до тех пора, пока у нас в выводе не появится **ForeignKey**. Как только появится, считай все пропало.
Рассмотрим небольшой пример. Есть у нас новости одной строкой. Есть регионы к которым привязаны эти новости:
```
class RegionSite(models.Model):
name = models.CharField(verbose_name="название", max_length=200,)
def __unicode__(self):
return "%s" % self.name
class News(models.Model):
region = models.ForeignKey(RegionSite, verbose_name="регион")
date = models.DateField(verbose_name="дата", blank=True, null=True, )
name = models.CharField(verbose_name="название", max_length=255)
def __unicode__(self):
return "%s (%s)" % (self.name, self.region)
```
Нам нужно вывести 10 последних новостей, с названием, как у нас определено в **News.\_\_unicode\_\_()**
Расчехляем рукава, и пишем:
```
news = News.objects.all().order_by("-date")[:10]
```
В шаблоне:
```
{% for n in news %}
{{ n }}
{% endfor %}
```
И вот тут мы вырыли себе яму. Если это не новости или их не 10 — а 10 тыс, то будьте готовы к тому, что вы получите 10 000 запросов + 1. А все из-за ~~грязнокровки~~ **ForeignKey**.
Пример лишних 10 тыс запросов (и скажите спасибо что у нас мелкая модель — так бы выбирались все поля и значения модели, будь то 10 или 50 полей):
```
SELECT `seo_regionsite`.`id`, `seo_regionsite`.`name` FROM `seo_regionsite` WHERE `seo_regionsite`.`id` = 1
SELECT `seo_regionsite`.`id`, `seo_regionsite`.`name` FROM `seo_regionsite` WHERE `seo_regionsite`.`id` = 1
SELECT `seo_regionsite`.`id`, `seo_regionsite`.`name` FROM `seo_regionsite` WHERE `seo_regionsite`.`id` = 2
SELECT `seo_regionsite`.`id`, `seo_regionsite`.`name` FROM `seo_regionsite` WHERE `seo_regionsite`.`id` = 1
-- итп
```
Почему так происходит? Все до генитальности просто. Каждый раз, когда вы получаете название новости, у нас происходит запрос к **RegionSite**, чтобы вернуть его **\_\_unicode\_\_()** значение, и подставить в скобки для вывода названия региона новости.
Аналогично нехорошая ситуация начинается когда мы, например, в шаблоне средствами ORM пытаемся добраться до нужного нам значения, например:
```
{{ subgroup.group.megagroup.name }}
```
Вы не поверите какой жесткий запрос может там быть :) Я уж и не говорю о том, что таких выборок у Вас в шаблоне может быть десятки!
Нас так просто не возьмешь — всхлипнули мы и воспользовались следующей отличной возможностью ORM — **.values()**.
Наша строчка кода магическо-клавиатурным способом превращается в:
```
news = News.objects.all().values("name", "region__name").order_by("-date")[:10]
```
А шаблон:
```
{% for n in news %}
{{ n.name }} ({{ n.region__name }})
{% endfor %}
```
Обратите внимание на двойное подчеркивание. Оно нам в скором времени пригодится. (Для тех кто не в курсе — двойное подчеркивание, как бы связь между моделями, если говорить грубо)
Такими нехитрыми манипуляциями мы избавились от 10 тыс запросов и оставили лишь один. Кстати да, он получится с JOIN'ом и с выбранными нами полями!
```
SELECT `news_news`.`name`, `seo_regionsite`.`name` FROM `news_news` INNER JOIN `seo_regionsite` ON (`news_news`.`region_id` = `seo_regionsite`.`id`) LIMIT 10
```
Мы до безумства рады! Ведь только что мы стали ORM-оптимизаторами:) Фиг-то там! Скажу Вам я:) Данная оптимизация — оптимизация до тех пор пока у нас не 10 тыс новостей. Но мы можем еще быстрее!
Для этого забъем на наши предрассудки по количеству запросов и в срочном порядке увеличиваем количество запросов в 2 раза! А именно, займемся подготовкой данных:
```
regions = RegionSite.objects.all().values("id", "name")
region_info = {}
for region in regions:
region_info[region["id"]] = region["name"]
news = News.objects.all().values("name", "region_id").order_by("-date")[:10]
for n in news:
n["name"] = "%s (%s)" % (n["name"], region_info[n["region_id"]])
```
И дальше вывод в шаблоне нашей свежезаведенной переменной:
```
{% for n in news %}
{{ n.name }}
{% endfor %}
```
Да, понимаю… Данными строками мы нарушили концепцию MVT. Но это лишь пример, который можно легко переделать в строки, не нарушающие, стандарты MVT.
Что же мы сделали?
1. Мы подготовили данные по регионам и занесли инфо о них в словарь:
```
SELECT `seo_regionsite`.`id`, `seo_regionsite`.`name` FROM `seo_regionsite`
```
2. Выбрали из новостей все что нас интересует + обратите внимание на одинарное подчеркивание.
```
SELECT `news_news`.`name`, `news_news`.`region_id` FROM `news_news` LIMIT 10
```
Именно одинарным подчеркиванием мы выбрали прямое значение связки в базе.
3. Связали средствами питона две модели.
Поверьте, на одинарных ForeignKey Вы прироста в скорости почти не заметите (особенное если выбираемых полей мало). Однако, если Ваша модель имеет связь через фориджн более чем с одной моделью — вот тут и начинается праздник данного решения.
Продолжим изголяться над двойным и одинарным подчеркиванием.
Рассмотрим до банальности простой пример:
```
item.group_id vs. item.group.id
```
Не только при построении запросов, но и при обработке результатов можно напороться на данную особенность.
Пример:
```
for n in News.objects.all():
print n.region_id
```
Запрос будет всего один — при выборке новостей
Пример 2:
```
for n in News.objects.all():
print n.region.id
```
Запросов будет 10 тыс + 1, т.к. в каждой итерации у нас будет свой запрос на id. Он будет аналогичен:
```
SELECT `seo_regionsite`.`id`, `seo_regionsite`.`name` FROM `seo_regionsite` WHERE `seo_regionsite`.`id` = 1
```
Вот такая вот разница из-за одного знака.
Многие продвинутые джанговоды сейчас тыкают пальцем в куклу Вуду с моим кодом. И при этом задают мне вопрос — ты чего за пургу творишь с подготовкой данных, и где **values\_list(«id», flat=True)** ?
Рассмотрим замечательный пример, показывающий необходимость в аккуратности работы с **value\_list**:
```
regions_id = RegionSite.objects.filter(id__lte=10).values_list("id", flat=True)
for n in News.objects.filter(region__id__in=regions_id):
print n.region_id
```
Данными строками кода мы:
1. Подготавливаем список интересующих нас id-шников регионов по какому-то абстрактному условию.
2. Получившийся результат вставляем в наш новостной запрос и получаем:
```
SELECT `news_news`.`id`, `news_news`.`region_id`, `news_news`.`date`, `news_news`.`name` FROM `news_news` WHERE `news_news`.`region_id` IN (SELECT U0.`id` FROM `seo_regionsite` U0 WHERE U0.`id` <= 10 )
```
Запрос в запросе! Уууух, обожаю :) Особенно выбирать 10 тыс новостей при вложенном селекте с IN (10 тыс айдишников)
Вы конечно же понимаете чем это грозит? :) Если нет — то поймите — ничем, совершенно ничем хорошим!
Решение данного вопроса так же до гениальности проста. Вспомним начало нашей статьи — никакой запрос не появляется без вычисления переменной. И сделаем ремарку, например, на второй строке кода:
```
for n in News.objects.filter(region__id__in=list(regions_id)):
```
И таким решением мы получим 2 простых запроса. Без вложений.
У вас еще не захватило дух от падл, припасенных для нас ORM? Тогда капнем еще глубже. Рассмотрим код:
```
regions_id = list(News.objects.all().values_list("region_id", flat=True))
print RegionSite.objects.filter(id__in=regions_id)
```
Данными двумя строками мы выбираем список регионов, по котором у нас есть новости. Все в этом коде замечательно, за исключением одного момента, а именно получившегося запроса:
```
SELECT `seo_regionsite`.`id`, `seo_regionsite`.`name` FROM `seo_regionsite` WHERE `seo_regionsite`.`id` IN (1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9) LIMIT 21
```
Ахаха, ORM, прекрати! Что ты делаешь!
Мало того что он из всех новостей (у меня в примере их 256, вроде) он выбрал id регионов и просто их подставил, так он еще взял откуда-то limit 21. Про лимит все просто — так устроен print большого количества значений массива (я другого оправдания не нашел), а вот со значениями тут явно засада.
Решение, как и в предыдущем примере, просто:
```
print RegionSite.objects.filter(id__in=set(regions_id)).values("id", "name")
```
Убрав лишние элементы через **set()** мы получили вполне адекватный запрос, как и ожидали:
```
SELECT `seo_regionsite`.`id`, `seo_regionsite`.`name` FROM `seo_regionsite` WHERE `seo_regionsite`.`id` IN (1, 2, 3, 4, 9) LIMIT 21
```
Все рады, все довольны.
Пораскинув немного глазами по исторически написанному коду, выделю еще одну закономерность о которой Вы должны знать. И опять пример кода:
```
region = RegionSite.objects.get(id=1)
t = datetime.datetime.now()
for i in range(1000):
list(News.objects.filter(region__in=[region]).values("id")[:10])
# list(News.objects.filter(region__id__in=[region.id]).values("id")[:10])
# list(News.objects.filter(region__in=[1]).values("id")[:10])
# list(News.objects.filter(region__id__in=[1]).values("id")[:10])
print datetime.datetime.now() - t
```
Каждая из строк итерации была последовательно включена (чтобы работала только одна). Итого мы можем получить следующие приближенные цифры:
* 1 строка — 6.362800 сек
* 2 строка — 6.073090 сек
* 3 строка — 6.431563 сек
* 4 строка — 6.126252 сек
Расхождения минимальные, но видимые. Предпочтительные 2 и 4 варианты (я в основном пользуюсь 4м). Основная потеря времени — это то, как быстро мы создадим запрос. Тривиально, но показательно, я считаю. Каждый читатель сделает выводы самостоятельно.
И завершим мы статью страшным словом — **транзакция**.
Частный случай:
* У вас InnoDB
* Вам нужно обновить данные в таблице, в которую клиенты не пишут, а лишь читают (например список товаров)
Делается обновление/вставку на раз-два
1. Подготавливаем 2 словаря — на вставку данных и на обновление данных
2. Каждый из словарей кидаем в свою функцию
3. **PROFIT!**
Пример реальной функции обновления:
```
@transaction.commit_manually
def update_region_price(item_prices):
"""
Обновляем одним коммитом базу
"""
from idea.catalog.models import CatalogItemInfo
try:
for ip in item_prices:
CatalogItemInfo.objects.filter(
item__id=ip["item_id"], region__id=ip["region_id"]
).update(
kost=ip["kost"],
price=ip["price"],
excharge=ip["excharge"],
zakup_price=ip["zakup_price"],
real_zakup_price=ip["real_zakup_price"],
vendor=ip["vendor"],
srok=ip["srok"],
bonus=ip["bonus"],
rate=ip["rate"],
liquidity_factor=ip["liquidity_factor"],
fixed=ip["fixed"],
)
except Exception, e:
print e
transaction.rollback()
return False
else:
transaction.commit()
return True
```
Пример реальной функции добавления:
```
@transaction.commit_manually
def insert_region_price(item_prices):
"""
Добавляем одним коммитом базу
"""
from idea.catalog.models import CatalogItemInfo
try:
for ip in item_prices:
CatalogItemInfo.objects.create(**ip)
except Exception, e:
print e
transaction.rollback()
return False
else:
transaction.commit()
return True
```
Зная эти моменты, можно строить эффективные приложения с использованием Django ORM, и не влезать в SQL код.
##### Ответы на вопросы:
**Раз уж пошла такая пляска, то напишите, когда стоит использовать ORM, а когда не стоит.** (с) [lvo](https://habrahabr.ru/users/lvo/)
Считаю что ОРМ стоит использовать всегда, когда оно просто. Не стоит складывать на плечи ORM, а уж тем более базы запросы типа:
```
User.objects.values('username', 'email').annotate(cnt=Count('id')).filter(cnt__gt=1).order_by('-cnt')
```
Тем более на HL-продакшн. Заведите для себя отдельный системный сервачок, в котором так изголяйтесь.
Если у Вас нет возможности писать простыми «ORM-запросами», то измените алгоритм решения задачи.
Для примера, у клиента в ИМ есть фильтрация по характеристикам, с использованием регулярок. Крутая гибкая штука, до тех пор пока посетителей сайта не стало очень много. Сменил подход, вместо стандартного Клиент-ORM-База-ORM-Клиент, переписал на Клиент-MongoDB-Питон-Клиент. Данные в MongoDB формируются по средствам ORM на системном сервере. Как было сказано раньше — HL нельзя достигнуть путем одних манипуляций с ORM
**Интересно, почему именно Django. Какие преимущества дает этот фреймворк (и его ОРМ) по сравнению с другими фреймворками / технологиями.** (с) [anjensan](https://habrahabr.ru/users/anjensan/)
Исторически. Питон начал изучать вместе с Django. И знания в технологии его использования довожу до максимума. Сейчас в параллельном изучении Pyramid. Сравнить я пока могу только с PHP, и их фреймворками, цмс-ками. Наверное скажу общую фразу — **я неэффективно тратил свое время, когда писал на PHP**.
Сейчас могу назвать пару серьезных недочетов в Django 1.3.4:
1. Постоянное соединение/разъединение с базой (в старших версиях подправлено)
2. Скорость работы template-процессора. По тестам, найденных в сети, она достаточна мала. Нужно менять :)
А вообще, есть один классный прием, как увеличить скорость работы генерации template-процессора.
Никогда не передавайте переменные в шаблон через **locals()** — при объемных функциях и промежуточных переменных — Вы получите молчаливого медленно шевелящегося умирающего монстра :)
**Что это за программист такой которому сложно запрос на SQL написать?** (с) [andreynikishaev](https://habrahabr.ru/users/andreynikishaev/)
Программист, который ценит свое время на программном коде, а не на средстве взаимодействия между База-Код обработки данных. SQL знать нужно — очень часто работаю напрямую с консолью базы. Но в коде — ORM. ORM легче и быстрее подвергается изменениям, либо дополнением. А так же, если пишешь обоснованно-легкими запросами, легко читать и понимать.
**Извините, все!** (Бла-бла… жду замечаний, предложений, вопросов, пожеланий) | https://habr.com/ru/post/175727/ | null | ru | null |
# Спасительный BSOD защитил компьютеры под Windows XP от заражения WannaCry

Новый [отчёт](https://blog.kryptoslogic.com/malware/2017/05/29/two-weeks-later.html) от компании Kryptos Logic подвёл итоги распространения червя-криптовымогателя WannaCry (WannaCrypt) спустя две недели после начала эпидемии. Кстати, именно в Kryptos Logic работает хакер MalwareTech, который заметил новый ботнет в системе раннего детектирования [Kryptos Vantage](https://www.kryptoslogic.com/kryptos_vantage.html), сразу зарегистрировал на себя домен, с которым связывался WannaCry, и тем самым [случайно остановил распространение вируса](https://geektimes.ru/post/289143/).
Один из интересных выводов экспертов: оказывается, операционная система Windows XP была железобетонно защищена от вируса, как многие думали. Выяснилось, что при заражении самым распространённым вариантом WannaCry компьютеры под Windows XP SP3 просто зависали и показывали «синий экран смерти» с последующей перезагрузкой. Никакие файлы не шифровались. Криптовымогатель не мог функционировать в таких условиях.
В первые дни после начала распространения WannaCry многие СМИ [распространили](https://www.nytimes.com/2017/05/12/world/europe/nhs-cyberattack-warnings.html) [информацию](https://www.wired.com/2017/05/still-use-windows-xp-prepare-worst/), что главная вина за заражение лежит на Windows XP. Вероятной причиной такого заблуждение было массовое инфицирование компьютеров Государственной службы здравоохранения Великобритании. Говорят, что в этой организации работает много древних ПК со старыми операционными системами. Служба здравоохранения [решительно отвергла обвинения](https://digital.nhs.uk/article/1493/UPDATED-Statement-on-reported-NHS-cyber-attack-13-May-): она заявила, что на момент атаки всего всего 5% их компьютеров работали под Windows XP.
Одновременно критике подверглась компания Microsoft, которая прекратила выпускать обновления безопасности под Windows XP ещё в 2014 году. Специалисты Microsoft не стали спорить и оперативно выпустили необходимый патч для старых систем.
Две недели тестирования в лабораториях Kryptos Logic показали, что WannaCry действительно мог заразить непропатченные компьютеры с Windows XP, но попытка после этого загрузить полезную нагрузку [DoublePulsar](https://en.wikipedia.org/wiki/DoublePulsar) приводила к зависанию системы.
Сначала тестирование происходило в режиме, приближённом к реальному, когда распространение нагрузки DoublePulsar проверялось через эксплоит [EternalBlue](https://en.wikipedia.org/wiki/EternalBlue). На втором этапе на компьютеры вручную устанавливалась DoublePulsar. Выяснилось, что криптор успешно запускался на машинах Windows 7 64-bit, SP1, а вот машины c Windows XP непрерывно вылетали в BSOD, так что инфицирования не происходило.
Исследователи делают вывод, что машины под Windows XP не могли стать главным средством распространения инфекции, потому что «реализация эксплоита в WannaCry не могла надёжно запустить DoublePulsar и добиться корректного RCE». Соответственно, такой компьютер не имел возможности распространять вредоносный код далее по сети, используя уязвимость в SMB. Эти выводы соответствуют тем, к которым [пришли эксперты «Лаборатории Касперского»](https://twitter.com/craiu/status/865562842149392384) в первые дни. Они выяснили, что 98% всех заражений приходится именно на компьютеры с Windows 7, а доля инфицированных Windows XP «незначительна».
«В самом худшем случае, который является наиболее вероятным, — сказано в отчёте Kryptos, — WannaCry вызвал много неожиданных сбоев с синим экраном смерти».
Наверное, впервые в истории BSOD сделал что-то полезное полезное — защитил компьютеры.
В то же время компьютеры под Windows 7 пострадали довольно серьёзно. Исходя из данных системы Kryptos Vantage, специалисты оценивают количество заражений в 14-16 млн. Общее количество систем, где криптор сработал и зашифровал файлы пользователей до срабатывания стоп-крана, оценивается в несколько сотен тысяч.
Всего WannaCry поразил сети более 9500 IP-диапазонов интернет-провайдеров и/или организаций в 8900 городах 90 стран. Наиболее пострадавшими оказались Китай, США и Россия.
Sinkhole-серверы компании Kryptos до сих пор регистрируют большое количество обращений к стоп-крану, в том числе с новых IP-адресов. Это говорит о том, что червь продолжает распространяться (в основном, в Китае). То есть миллионы пользователей до сих пор не установили патчи, не закрыли уязвимость в Windows и на них не установлены антивирусы. Этот факт могут использовать новые версии червя — и может разродиться новая инфекция.
Специалисты Kryptos рассмотрели [предположение](https://twitter.com/neelmehta/status/864164081116225536) хакера Нила Меты (если помните, он обнаружил Heartbleed), что авторы WannaCry связаны с [группой Lazarus](https://en.wikipedia.org/wiki/Lazarus_Group), которая провела знаменитую атаку на Sony Pictures в 2014 году, а спустя два года выкрала часть золотовалютных резервов банка Бангладеш (101 млн через систему SWIFT). Эта группа связана с Северной Кореей.
Нил Мета указал на одинаковый участок кода в WannaCry и зловреде группы Lazarus.
```
static const uint16_t ciphersuites[] = {
0x0003,0x0004,0x0005,0x0006,0x0008,0x0009,0x000A,0x000D,
0x0010,0x0011,0x0012,0x0013,0x0014,0x0015,0x0016,0x002F,
0x0030,0x0031,0x0032,0x0033,0x0034,0x0035,0x0036,0x0037,
0x0038,0x0039,0x003C,0x003D,0x003E,0x003F,0x0040,0x0041,
0x0044,0x0045,0x0046,0x0062,0x0063,0x0064,0x0066,0x0067,
0x0068,0x0069,0x006A,0x006B,0x0084,0x0087,0x0088,0x0096,
0x00FF,0xC001,0xC002,0xC003,0xC004,0xC005,0xC006,0xC007,
0xC008,0xC009,0xC00A,0xC00B,0xC00C,0xC00D,0xC00E,0xC00F,
0xC010,0xC011,0xC012,0xC013,0xC014,0xC023,0xC024,0xC027,
0xC02B,0xC02C,0xFEFF
};
template
void store\_be(void \* p, T x) {
// store T in p, in big-endian byte order
}
template
void store\_le(void \* p, T x) {
// store T in p, in little-endian byte order
}
bool find(const unsigned char \* list, size\_t n, uint16\_t x) {
for(size\_t i = 0; i < n; ++i) {
uint16\_t t = (list[2\*i + 0] << 8) | packet[2\*i + 1];
if(t == x) return true;
}
return false;
}
void make\_client\_hello(unsigned char \* packet) {
uint32\_t timestamp = time(NULL);
packet[ 0] = 0x01; // handshake type: CLIENT\_HELLO
packet[ 4] = 0x03; // TLS v1.0
packet[ 5] = 0x01; // TLS v1.0
random\_bytes(&packet[6], 32); // random\_bytes
store\_be(&packet[6], timestamp); // gmt\_unix\_time
packet[38] = 0x00; // session id length
const size\_t cipher\_num = 6\*(2 + rand() % 5);
store\_be(&packet[39], cipher\_num \* 2); // ciphersuite length
for(size\_t i = 0; i < cipher\_num;) {
const size\_t index = rand() % 75;
// Avoid collisions
if(find(&packet[41], i, ciphersuites[index])) {
continue;
} else {
store\_be(&packet[41 + 2\*i], ciphersuites[index]);
i += 1;
}
}
store\_be(&packet[41 + cipher\_num \* 2], 0x01); // compression\_method\_len
store\_be(&packet[42 + cipher\_num \* 2], 0x00); // compression\_method
store\_le(&packet[0], 0x01 | ((43 + cipher\_num \* 2) << 8)); // handshake size
}
```
Это фиктивная реализация TLS 1.0, чтобы замаскировать трафик под TLS. Действительно, некоторые особенности этой реализации таковы, что случайно их повторить точно не могли. Это или та же хакерская группа или кто-то другой, кто внимательно проанализировал [выводы аналитического отчёта (pdf) по атаке на Sony](https://web.archive.org/web/20170224084041/https://www.operationblockbuster.com/wp-content/uploads/2016/02/Operation-Blockbuster-Report.pdf) — и решил попробовать в точности такой же метод маскировки трафика. Собственно, это мог быть кто угодно.
Факты таковы, что в наше время такие атаки может провести абсолютно любой человек из любой страны мира, даже в одиночку — благодаря утечкам из АНБ и ЦРУ и другим источникам в руках любого хакера сейчас есть мощные инструменты для проведения хорошей качественной атаки в глобальном масштабе. | https://habr.com/ru/post/357354/ | null | ru | null |
# Композиция vs наследование
Как и всем разработчикам, мне часто приходилось читать и слышать утверждение, что «композиция всегда лучше наследования». Наверное, даже слишком часто. Однако я не склонен принимать что-либо на веру, поэтому давайте разберёмся, так ли это.
Итак, какие же преимущества есть у композиции перед наследованием?
**1.** Нет конфликта имён, возможного при наследовании.
**2.** Возможность смены агрегируемого объекта в runtime.
**3.** Полная замена агрегируемого объекта в классах, производных от класса, включающего агрегируемый объект.
В последних двух случаях очень желательно, чтобы сменяемые агрегируемые объекты имели общий интерфейс. А в третьем – чтобы метод, возвращающий такой объект, был виртуальным.
Если рассматривать, например, C#, не поддерживающий множественное наследование, но позволяющий наследовать от множества интерфейсов и создавать методы расширения для этих интерфейсов, то можно выделить ещё два плюса (речь в данном случае может идти только о *поведениях* (*алгоритмах*) в рамках паттерна «Стратегия»):
**4.** Агрегируемое поведение (алгоритм) может включать в себя другие объекты. Что в частности позволяет переиспользовать посредством агрегации другое поведение.
**5.** При агрегации есть возможность скрыть определённую часть реализации, а также исходные параметры, необходимые поведению, посредством передачи их через конструктор (при наследовании поведению придётся запрашивать их через методы/свойства собственного интерфейса).
Но как же минусы? Неужели их нет?
**1.** Итак, если нам необходима возможность смены поведения извне, то композиция, по сравнению с наследованием, имеет принципиально другой тип отношений между объектом поведения и объектом, его использующим. Если при наследовании от абстрактного поведения мы имеем отношение 1:1, то при агрегации и возможности установки поведения извне мы получаем отношение 1:many. Т.е. один и тот же объект поведения может использоваться несколькими объектами-владельцами. Это порождает проблемы с общим для нескольких таких объектов-владельцев состоянием поведения.
Разрешить эту ситуацию можно, запретив установку поведения извне или доверив его, например, generic-методу:
```
void SetBehavior()
```
запретив тем самым создание поведения кем-либо, кроме объекта-владельца. Однако мы не можем запретить использовать поведение «где-то ещё». В языках без сборщика мусора (GC) это порождает понятные проблемы. Конечно, в таких языках можно неправомерно обратиться по ссылке и на сам объект-владелец, но, раздавая отделённые объекты поведения направо и налево, мы получаем в разы больше шансов получить exception.
**2.** Агрегация (и это, пожалуй, главный нюанс) отличается от наследования в первую очередь тем, что агрегируемый объект не является объектом-владельцем и не содержит информации о нём. Нередки ситуации, когда коду, взаимодействующему с поведением, необходим и сам объект-владелец (например, для получения информации о том, какими ещё поведениями он обладает).
В таком случае, нам придётся или передавать в такой код нетипизированный объект (как object или void\*), или создавать дополнительный интерфейс для объекта-владельца (некий IBehaviorOwner), или хранить в поведении циклическую ссылку на объект-владелец. Понятно, что каждый из этих вариантов имеет свои минусы и ещё больше усложняет код. Более того, различные типы поведений могут зависеть друг от друга (и в это вполне допустимо, особенно если они находятся в некоем закрытом самодостаточном модуле).
**3.** Ну и последний минус — это конечно же производительность. Если объектов-владельцев достаточно много, то создание и уничтожение вместо одного объекта двух или более может не остаться незамеченным.
Получается, что утверждение «композиция всегда лучше наследования» в ряде случаев спорно и не должно являться догмой. Особенно это касается языков, позволяющих множественное наследование и не имеющих GC. Если в какой-либо ситуации перечисленные выше плюсы не важны, и заранее известно, что при работе с определёнными типами у вас не будет возможности их использовать, стоит всё-таки рассмотреть вариант наследования. | https://habr.com/ru/post/177447/ | null | ru | null |
# Писать плагины с AppDomain — весело
Как часто вы писали плагины для своих приложений?
В статье я хочу рассказать как можно написать плагины используя AppDomain, и кросс доменные операции. Плагины будем писать для уже существующего моего приложения TCPChat.
Кто хочет повелосипедить — вперед под кат.
Чат находится [тут](https://github.com/Nirklav/TCPChat).
А об архитектуре приложения можно почитать вот [тут](http://habrahabr.ru/post/228021/). В данном случае нас интересует только модель. Кардинально она не менялась, и достаточно будет знать про основные сущности ([Корень](https://github.com/Nirklav/TCPChat/blob/master/Engine/Model/Client/ClientModel.cs) [модели](https://github.com/Nirklav/TCPChat/blob/master/Engine/Model/Server/ServerModel.cs)/[A](https://github.com/Nirklav/TCPChat/blob/master/Engine/API/StandardAPI/StandardClientAPI.cs)[PI](https://github.com/Nirklav/TCPChat/blob/master/Engine/API/StandardAPI/StandardServerAPI.cs)/[Кома](https://github.com/Nirklav/TCPChat/tree/master/Engine/API/StandardAPI/ClientCommands)[нды](https://github.com/Nirklav/TCPChat/tree/master/Engine/API/StandardAPI/ServerCommands)).
**О том, что необходимо реализовать в приложении:**
Необходимо иметь возможно расширить набор команд с помощью плагинов, при этом код в плагинах должен выполняться в другом домене.
Очевидно, что команды не будут вызываться сами собой, поэтому нужно также добавить возможность изменять UI. Для этого предоставим возможность добавить пункты меню, а также создавать свои окна.
По окончании, я напишу плагин с помощью которого можно будет удаленно делать снимок экрана любого пользователя.
**Для чего нужен AppDomain?**
Домен приложения нужен для выполнения кода с ограниченными правами, а также для выгрузки библиотек во время работы приложения. Как известно сборки из домена приложений выгрузить невозможно, а вот домен — пожалуйста.
Для того, чтобы выгружать домен было возможно, взаимодействие между ними сведено к минимуму.
По сути мы можем:
* Выполнить код в другом домене.
* Создать объект и продвинуть его по значению.
* Создать объект и продвинуть его по ссылке.
**Немного о продвижении:**
Продвижение, может происходить по ссылке или по значению.
Со значением все относительно просто. Класс сериализуется в одном домене, передается массивом байт в другой, десериализуется, и мы получаем копию объекта. При этом необходимо чтобы сборка была загружена в оба домена. Если необходимо чтобы сборка не грузилась в основной домен, то лучше чтобы папка с плагинами не была добавлена в список папок, где ваше приложение будет искать сборки по умолчанию (AppDomain.BaseDirectory / AppDomainSetup.PrivateBinPath). В таком случае будет исключение о том, что тип не удалось найти, и вы не получите молча загруженную сборку.
Для выполнения продвижения по ссылке класс должен реализовывать [MarshalByRefObject](http://msdn.microsoft.com/ru-ru/library/system.marshalbyrefobject%28v=vs.110%29.aspx). Для каждого такого объекта, после вызова метода CreateInstanceAndUnwrap, в вызывающем домене создается представитель. Это объект который содержит все методы настоящего объекта (полей при этом там нет). В этих методах, с помощью специальных механизмов он вызывает методы настоящего объекта, находящегося в другом домене и соответственно методы тоже выполняются в домене в котором объект был создан. Также стоит сказать, что время жизни представителей ограничено. После создания они живут 5 минут, и после каждого вызова какого-либо метода, их время жизни становится 2 минуты. Время аренды можно изменить, для этого у MarshalByRefObject можно переопределить метод [InitializeLifetimeService](http://msdn.microsoft.com/en-us/library/system.marshalbyrefobject.initializelifetimeservice%28v=vs.110%29.aspx).
Продвижение по ссылке не требует загрузки в основной домен сборки с плагином.
Отступление про поля:
Это одна из причин пользоваться не открытыми полями, а свойствами. Доступ к полю через представитель получить можно, но работает это все намного медленнее. Причем, для того чтобы это работало медленнее, не обязательно использовать кросс-доменные операции, достаточно унаследоваться от MarshalByRefObject.
**Детальнее о выполнении кода:**
Выполнение кода происходит с помощью метода [AppDomain.DoCallBack()](http://msdn.microsoft.com/en-us/library/system.appdomain.docallback%28v=vs.110%29.aspx).
При этом выполняется продвижения делегата в другой домен, поэтому нужно быть уверенным, что это возможно.
Это небольшие проблемы на которые я наткнулся:
1. Это экземплярный метод, а класс-хозяин не может быть продвинут. Как известно делегат для каждого подписанного метода хранит 2 основных поля, ссылка на экземпляр класса, а также указатель на метод.
2. Вы использовали замыкания. По умолчанию класс который создает компилятор не помечается как сериализуемый и не реализовывает [MarshalByRefObject](http://msdn.microsoft.com/ru-ru/library/system.marshalbyrefobject%28v=vs.110%29.aspx). (Далее см. пункт 1)
3. Если унаследовать класс от MarshalByRefObject, создать его в домене 1 и пытаться выполнить его экземплярный метод в другом домене 2, то граница доменов будет пересечена 2 раза и код будет выполнен в домене 1.
**Приступим**
В первую очередь нужно узнать какие плагины приложение может загрузить. В одной сборке может быть несколько плагинов, а нам необходимо обеспечить для каждого плагина отдельный домен. Поэтому нужно написать загрузчик информации, который тоже будет работать в отдельном домене, и по окончании работы загрузчика этот домен будет выгружен.
Структура для хранения загрузочной информации о плагине, помечена атрибутом Serializable, т.к. она будет продвигаться между доменами.
```
[Serializable]
struct PluginInfo
{
private string assemblyPath;
private string typeName;
public PluginInfo(string assemblyPath, string typeName)
{
this.assemblyPath = assemblyPath;
this.typeName = typeName;
}
public string AssemblyPath { get { return assemblyPath; } }
public string TypeName { get { return typeName; } }
}
```
Сам загрузчик информации. Можете обратить внимание, что класс Proxy наследуется от MarshalByRefObject, т.к. его поля будут использоваться для входных и выходных параметров. А сам он будет создан в домене загрузчика.
```
class PluginInfoLoader
{
private class Proxy : MarshalByRefObject
{
public string[] PluginLibs { get; set; }
public string FullTypeName { get; set; }
public List PluginInfos { get; set; }
public void LoadInfos()
{
foreach (var assemblyPath in PluginLibs)
{
var assembly = AppDomain.CurrentDomain.Load(AssemblyName.GetAssemblyName(assemblyPath).FullName);
foreach (var type in assembly.GetExportedTypes())
{
if (type.IsAbstract)
continue;
var currentBaseType = type.BaseType;
while (currentBaseType != typeof(object))
{
if (string.Compare(currentBaseType.FullName, FullTypeName, StringComparison.OrdinalIgnoreCase) == 0)
{
PluginInfos.Add(new PluginInfo(assemblyPath, type.FullName));
break;
}
currentBaseType = currentBaseType.BaseType;
}
}
}
}
}
public List LoadFrom(string typeName, string[] inputPluginLibs)
{
var domainSetup = new AppDomainSetup();
domainSetup.ApplicationBase = AppDomain.CurrentDomain.BaseDirectory;
domainSetup.PrivateBinPath = "plugins;bin";
var permmisions = new PermissionSet(PermissionState.None);
permmisions.AddPermission(new ReflectionPermission(ReflectionPermissionFlag.MemberAccess));
permmisions.AddPermission(new SecurityPermission(SecurityPermissionFlag.Execution));
permmisions.AddPermission(new UIPermission(UIPermissionWindow.AllWindows));
permmisions.AddPermission(new FileIOPermission(FileIOPermissionAccess.PathDiscovery | FileIOPermissionAccess.Read, inputPluginLibs));
List result;
var pluginLoader = AppDomain.CreateDomain("Plugin loader", null, domainSetup, permmisions);
try
{
var engineAssemblyPath = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, @"bin\Engine.dll");
var proxy = (Proxy)pluginLoader.CreateInstanceAndUnwrap(AssemblyName.GetAssemblyName(engineAssemblyPath).FullName, typeof(Proxy).FullName);
proxy.PluginInfos = new List();
proxy.PluginLibs = inputPluginLibs;
proxy.FullTypeName = typeName;
proxy.LoadInfos();
result = proxy.PluginInfos;
}
finally
{
AppDomain.Unload(pluginLoader);
}
return result;
}
}
```
Для ограничения возможностей загрузчика, в домен к нему я передаю набор разрешений. Как видно в листинге устанавливается 3 разрешения:
* **ReflectionPermission** разрешение на использование отражений.
* **SecurityPermission** разрешение на выполнение управляемого кода.
* **FileIOPermission** разрешение на чтение файлов переданных во втором параметре.
Некоторым из разрешений (почти всем) можно указать как частичный доступ, так и полный. Частичный дается с помощью конкретных для каждого разрешения перечислений. Для полного доступа или, наоборот, запрета можно отдельно передать состояние:
PermissionState.None — для запрета.
PermissionState.Unrestricted — для полного разрешения.
Детальнее о том какие еще есть разрешения можно почитать [тут](http://msdn.microsoft.com/en-us/library/System.Security.Permissions%28v=vs.110%29.aspx). Также можно посмотреть какие параметры у доменов по умолчанию вот [здесь](http://msdn.microsoft.com/en-us/library/03kwzyfc%28v=vs.90%29.aspx).
В метод для создания домена я передаю экземпляр класса AppDomainSetup. Для него установлено только 2 поля, по которым он понимает где ему нужно по умолчанию искать сборки.
Далее, после ничем не примечательного создания домена, мы вызываем у него метод CreateInstanceAndUnwrap, передавая в параметры полное название сборки и типа. Метод создаст объект в домене загрузчика и выполнит продвижение, в данном случае по ссылке.
**Плагины:**
Плагины в моей реализации разделены на клиентские и серверные. Серверные предоставляют только команды. Для каждого клиентского плагина будет создан отдельный пункт меню и он, как и серверный, может отдать набор команд для чата.
У обоих плагинов есть метод инициализации, в который я проталкиваю обертку над моделью и сохраняю ее в статическом поле. Почему это делается не в конструкторе?
Имя загружаемого плагина неизвестно и обнаружится оно только после создания объекта. Вдруг плагин с таким именем уже добавлен? Тогда он должен быть выгружен. Если же плагина-тезки еще нету, то выполняется инициализация. Таким образом обеспечивается инициализация только в случае удачной загрузки.
Вот собственно базовый класс плагина:
```
public abstract class Plugin : CrossDomainObject
where TModel : CrossDomainObject
{
public static TModel Model { get; private set; }
private Thread processThread;
public void Initialize(TModel model)
{
Model = model;
processThread = new Thread(ProcessThreadHandler);
processThread.IsBackground = true;
processThread.Start();
Initialize();
}
private void ProcessThreadHandler()
{
while (true)
{
Thread.Sleep(TimeSpan.FromMinutes(1));
Model.Process();
OnProcess();
}
}
public abstract string Name { get; }
protected abstract void Initialize();
protected virtual void OnProcess() { }
}
```
CrossDomainObject — это объект который содержит только 1 метод — Process, обеспечивающий продление времени жизни представителя. Со стороны чата менеджер плагинов раз в минуту вызывает его у всех плагинов. Со стороны плагина, он сам обеспечивает вызов метода Process у обертки модели.
```
public abstract class CrossDomainObject : MarshalByRefObject
{
public void Process() { }
}
```
Базовые классы для серверного и клиентского плагина:
```
public abstract class ServerPlugin :
Plugin
{
public abstract List Commands { get; }
}
public abstract class ClientPlugin :
Plugin
{
public abstract List Commands { get; }
public abstract string MenuCaption { get; }
public abstract void InvokeMenuHandler();
}
```
Менеджер плагинов ответственен за выгрузку, загрузку плагинов и владение ими.
Рассмотри загрузку:
```
private void LoadPlugin(PluginInfo info)
{
var domainSetup = new AppDomainSetup();
domainSetup.ApplicationBase = AppDomain.CurrentDomain.BaseDirectory;
domainSetup.PrivateBinPath = "plugins;bin";
var permmisions = new PermissionSet(PermissionState.None);
permmisions.AddPermission(new UIPermission(PermissionState.Unrestricted));
permmisions.AddPermission(new SecurityPermission(
SecurityPermissionFlag.Execution |
SecurityPermissionFlag.UnmanagedCode |
SecurityPermissionFlag.SerializationFormatter |
SecurityPermissionFlag.Assertion));
permmisions.AddPermission(new FileIOPermission(
FileIOPermissionAccess.PathDiscovery |
FileIOPermissionAccess.Write |
FileIOPermissionAccess.Read,
AppDomain.CurrentDomain.BaseDirectory));
var domain = AppDomain.CreateDomain(
string.Format("Plugin Domain [{0}]", Path.GetFileNameWithoutExtension(info.AssemblyPath)),
null,
domainSetup,
permmisions);
var pluginName = string.Empty;
try
{
var plugin = (TPlugin)domain.CreateInstanceFromAndUnwrap(info.AssemblyPath, info.TypeName);
pluginName = plugin.Name;
if (plugins.ContainsKey(pluginName))
{
AppDomain.Unload(domain);
return;
}
plugin.Initialize(model);
var container = new PluginContainer(domain, plugin);
plugins.Add(pluginName, container);
OnPluginLoaded(container);
}
catch (Exception e)
{
OnError(string.Format("plugin failed: {0}", pluginName), e);
AppDomain.Unload(domain);
return;
}
}
```
Аналогично загрузчику, в начале мы инциализируем и создаем домен. Далее уже с помощью метода AppDomain.CreateInstanceFromAndUnwrap создаем объект. После его создания имя плагина анализируется, если такой уже был добавлен, то домен вместе с плагином выгружается. Если же такого плагина нет — он инициализируется.
Детальнее код менеджера можно посмотреть [тут](https://github.com/Nirklav/TCPChat/blob/master/Engine/Plugins/PluginManager.cs).
Одной из проблем, которая решилась достаточно просто, было предоставление доступа плагинов к модели. Корень модели у меня статический, и в другом домене он будет не инициализирован, т.к. типы и статические поля у каждого домена свои.
Решилась проблема написанием обертки, в которую сохраняются объекты модели, и продвигается уже экземпляр этой обертки. Модельным объектам только необходимо было добавить в базовые классы MarshalByRefObject. Исключение это клиентский и серверный (серверный просто из симметрии) API которые пришлось также обернуть. Клиентский API создается после менеджера плагинов, и в момент загрузки дополнений его еще просто нет. [Пример клиентской обертки](https://github.com/Nirklav/TCPChat/blob/master/Engine/Plugins/Client/ClientModelWrapper.cs).
Для клиентских и серверных плагинов я написал 2 различных менеджера, которые реализуют базовый PluginManager. У обоих есть метод TryGetCommand, который вызывается в соответствующем API, если не найдена родная команда с таким айдишником. Ниже реализация метода API GetCommand.
**Код**
```
public IClientCommand GetCommand(byte[] message)
{
if (message == null)
throw new ArgumentNullException("message");
if (message.Length < 2)
throw new ArgumentException("message.Length < 2");
ushort id = BitConverter.ToUInt16(message, 0);
IClientCommand command;
if (commandDictionary.TryGetValue(id, out command))
return command;
if (ClientModel.Plugins.TryGetCommand(id, out command))
return command;
return ClientEmptyCommand.Empty;
}
```
**Написание плагина:**
Теперь на основе написанного кода, можно попробовать реализовать плагин.
Напишу я плагин который, по нажатию на пункт меню, открывает окно с кнопкой и текстовым полем. В обработчике кнопки будет посылаться команда юзеру, ник которого мы ввели в поле. Команда будет делать снимок и сохранять его в папку. После этого выкладывать его в главную комнату и оправлять нам ответ.
Это будет P2P взаимодействие, поэтому написание серверного плагина не понадобится.
Для начала создадим проект, выберем библиотеку классов. И добавим к нему в ссылки 3 основные сборки: Engine.dll, Lidgren.Network.dll, OpenAL.dll. Не забудьте поставить правильную версию .NET Framework, я собираю чат под 3.5, и соответственно плагины тоже должны быть такой же версии, или ниже.
Далее реализуем основной класс плагина, который предоставляет 2 команды. А по обработчику пункта меню открывает диалоговое окно.
Стоит отметить что менеджеры плагинов на своей стороне кешируют команды, поэтому необходимо чтобы плагин удерживал на них ссылки. И свойство Commands возвращало одни и те же экземпляры команд.
```
public class ScreenClientPlugin : ClientPlugin
{
private List commands;
public override List Commands { get { return commands; } }
protected override void Initialize()
{
commands = new List
{
new ClientMakeScreenCommand(),
new ClientScreenDoneCommand()
};
}
public override void InvokeMenuHandler()
{
var dialog = new PluginDialog();
dialog.ShowDialog();
}
public override string Name
{
get { return "ScreenClientPlugin"; }
}
public override string MenuCaption
{
get { return "Сделать скриншот"; }
}
}
```
Диалоговое окно выглядит вот так:
**Код**
```
```
```
public partial class PluginDialog : Window
{
public PluginDialog()
{
InitializeComponent();
}
private void Button_Click(object sender, RoutedEventArgs e)
{
ScreenClientPlugin.Model.Peer.SendMessage(UserNameTextBox.Text, ClientMakeScreenCommand.CommandId, null);
}
}
```
При пересылке файлов я воспользовался уже написанной функциональностью чата, с помощью API.
```
public class ClientMakeScreenCommand : ClientPluginCommand
{
public static ushort CommandId { get { return 50000; } }
public override ushort Id { get { return ClientMakeScreenCommand.CommandId; } }
public override void Run(ClientCommandArgs args)
{
if (args.PeerConnectionId == null)
return;
string screenDirectory = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "screens");
if (!Directory.Exists(screenDirectory))
Directory.CreateDirectory(screenDirectory);
string fileName = Path.GetFileNameWithoutExtension(Path.GetRandomFileName()) + ".bmp";
string fullPath = Path.Combine(screenDirectory, fileName);
using (Bitmap bmpScreenCapture = new Bitmap(Screen.PrimaryScreen.Bounds.Width, Screen.PrimaryScreen.Bounds.Height))
using (Graphics graphic = Graphics.FromImage(bmpScreenCapture))
{
graphic.CopyFromScreen(
Screen.PrimaryScreen.Bounds.X,
Screen.PrimaryScreen.Bounds.Y,
0, 0,
bmpScreenCapture.Size,
CopyPixelOperation.SourceCopy);
bmpScreenCapture.Save(fullPath);
}
ScreenClientPlugin.Model.API.AddFileToRoom(ServerModel.MainRoomName, fullPath);
var messageContent = Serializer.Serialize(new ClientScreenDoneCommand.MessageContent { FileName = fullPath });
ScreenClientPlugin.Model.Peer.SendMessage(args.PeerConnectionId, ClientScreenDoneCommand.CommandId, messageContent);
}
}
```
Самое интересное происходит в последних 3-ех строчках. Здесь мы используем API добавляя в комнату файл. После этого отправляем команду ответ. У пира вызывается перегрузка метода, принимающая набор байт, т.к. наш объект не сможет быть сериализован в основной сборке чата.
Ниже приведена реализация команды, которая будет принимать ответ. Она огласит на всю главную комнату, о том что мы сделали снимок экрана у бедного пользователя.
```
public class ClientScreenDoneCommand : ClientPluginCommand
{
public static ushort CommandId { get { return 50001; } }
public override ushort Id { get { return ClientScreenDoneCommand.CommandId; } }
public override void Run(ClientCommandArgs args)
{
if (args.PeerConnectionId == null)
return;
var receivedContent = Serializer.Deserialize(args.Message);
ScreenClientPlugin.Model.API.SendMessage(
string.Format("Выполнен снимок у пользователя {0}.", args.PeerConnectionId),
ServerModel.MainRoomName);
}
[Serializable]
public class MessageContent
{
private string fileName;
public string FileName { get { return fileName; } set { fileName = value; } }
}
}
```
Полный проект с плагином могу выложить, но не знаю куда. (Для отдельного репозитория на гитхабе, он сильно маленький, как мне кажется).
**UPD**: выложил плагин на [github](https://github.com/Nirklav/ScreenshotPlugin).
**UPD 2**: В статье для поддержки времени жизни плагинов используется пулинг, что странно. В [реализации на github](https://github.com/Nirklav/TCPChat) я **позже** реализовал нормальную модель. | https://habr.com/ru/post/242209/ | null | ru | null |
# Как выглядит рельеф Марса? Выясняем с помощью Python
К старту флагманского [курса по Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_01022022&utm_term=lead) делимся визуализациями марсианского ландшафта на основе изображений, полученных благодаря беспилотным полётам над поверхностью планеты. За подробностями приглашаем под кат.
---
Лучший способ узнавать что-то новое — решать интересные или необычные задачи. Одна из них — создание топографических карт Марса с помощью сложных цветовых карт.
Благодаря шумихе, поднятой одним американским миллиардером, Марс всё чаще появляется в новостях, и наверняка уже скоро люди будут ходить по его поверхности. Многие представляют Марс большим красным шаром в небе, но мало кто знает, как он выглядит на самом деле. А ведь у Марса богатый ландшафт — от каньонов и кратеров до вулканов.
В ходе многочисленных беспилотных полётов карту детализировали. И теперь легко получить реальное представление о том, как выглядит Марс. Создадим карту планеты и с помощью магии цветовых карт представим, как выглядел бы терраформированный Марс, его океаны и реки. А главное — поймём, как правильно использовать цветовые карты для решения конкретных задач.
### Изучение данных
Сначала загружаем данные о ландшафте Марса. Данные правительства США доступны [здесь](https://astrogeology.usgs.gov/search/map/Mars/GlobalSurveyor/MOLA/Mars_MGS_MOLA_Shade_global_463m) и не имеют никаких ограничений для пользователей. Имейте в виду: объём данных огромен — это 2,3 Гб.
Формат данных — tif, загружаются они через rasterio в np.array. Размеры массива: 23040 x 46090. Диапазон значений — это высоты Красной планеты. На Марсе нет океанов, поэтому нет точки отсчёта высоты — уровня моря. Если коротко, «уровень моря» на Марсе определяется как средняя высота на планете. Отрицательные значения рельефа — это области ниже средней высоты, а положительные — выше.
Гора Олимп — самая высокая на планете (21 241 м относительно средней высоты Марса), а равнина Эллада — самая низкая точка — это –8201 м относительно средней высоты Марса. Разница между самой высокой и самой низкой точками на Марсе (~30 км) больше, чем между Эверестом и Марианской впадиной на Земле (~20 км):
```
import rasterio
import numpy as np
mars = rasterio.open('../../Planets/mars/data/Mars_MGS_MOLA_DEM_mosaic_global_463m.tif')
mars = mars.read()
print(mars.shape)
print(np.amin(mars[0]))
print(np.amax(mars[0]))
print(np.amax(mars[0]) + abs(np.amin(mars[0])))
```
Вывод кода:
```
(1, 23040, 46080)
-8201
21241
29442
```
Нанесённые на карту данные дают представление о том, с чем мы имеем дело. Предупреждение: на стандартном ноутбуке выполнение займёт немало времени. Можно успеть выпить чаю.
```
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fig.set_size_inches(14, 7)
ax.imshow(mars[0], cmap="viridis")
ax.axis('off')
plt.show()
```
Стандартная картаПри использовании стандартной цветовой карты возникает проблема: отображая на ней значения рельефа линейно, получаются размытые объекты и большинство из них теряется. На Марсе объекты в основном расположены между –8000 и 12 000 м, а средняя высота намного ближе к равнине Элладе, чем к горе Олимп.
Четыре горы ближе к жёлтому и занимают крошечную по площади часть планеты, но огромны по высоте, и у них четверть всех цветов на цветовой карте. Остальные объекты отображаются в небольшом диапазоне цветов, чёткость плохая:
Марсианские объекты на стандартной цветовой картеОпределение цветовых карт
-------------------------
Решим проблему, создав цветовую карту и нарушив правила визуализации данных. Нормализуем линейную цветовую карту между наименьшими и наибольшими значениями данных. Но в этом случае всего четыре объекта выше 14 000 м и куча объектов ниже. Поэтому создадим цветовую карту для отображения цветов между –8201 (самая низкая точка в данных) и 14 000 м, а всё, что выше, будет в последнем цвете цветовой карты. matplotlib не особо хороша в отображении рельефа на цветовых картах. Вот [что](https://astrogeology.usgs.gov/search/map/Mars/GlobalSurveyor/MOLA/Mars_MGS_MOLA_ClrShade_merge_global_463m) для этого используют в NASA, и мы сделаем то же самое.
Ниже показан раздел кода, в котором создаётся подобная цветовая карта, нормализованная между –8210 и 14 000 м в 10-метровых полосках. Метод LinearSegmentedColormap принимает список цветов, создаётся цветовая карта с N цветами, линейно расположенными между цветами из списка.
Класс BoundaryNorm позволяет сопоставлять на ней цвета с набором заданных значений. В нашем случае создаётся объект BoundaryNorm, отображающий цвета в 10-метровых полосках между –8210 и 14 000 м. Например, значения от 0 до 10 м сопоставляются с одним цветом, значения от 10 до 20 м — с другим и т. д. Всё, что выше 14 000 м, отобразится в последнем цвете карты:
```
from matplotlib.colors import BoundaryNorm, LinearSegmentedColormap
import numpy as np
custom_cmap = LinearSegmentedColormap.from_list('mars', ['#162252',
'#104E8B',
'#00B2EE',
'#00FF00',
'#FFFF00',
'#FFA500',
'#FF0000',
'#8b0000',
'#964B00',
'#808080',
'#FFFFFF'], N=2221)
bounds = np.arange(-8210, 14000, 10)
norm = BoundaryNorm(bounds, custom_cmap.N)
```
Получилась цветовая карта с примерными высотами марсианских объектов. Цветов стало гораздо больше, ведь диапазон значений увеличился:
Марсианские объекты на смоделированной цветовой картеСоставим карту марсианского рельефа с нормализованными значениями и новой цветовой картой. Просто удивительно: это совсем другая карта, а ведь мы изменили только цветовую карту и способ сопоставления цветов со значениями:
```
fig, ax = plt.subplots()
fig.set_size_inches(14, 7)
ax.imshow(mars[0], cmap=custom_cmap, norm=norm)
ax.axis('off')
logo = plt.imread('../../Branding/globe_black.png')
newax = fig.add_axes([0.82, 0.13, 0.08, 0.08], anchor='NE')
newax.imshow(logo)
newax.axis('off')
txt = ax.text(0.0, 0.02, "Martian Topography \n@PythonMaps",
size=4,
color='white',
transform = ax.transAxes)
plt.show()
```
Рельеф Марса на смоделированной цветовой картеДобавим обозначения всех объектов:
```
def label_features(ax):
ax.text(5000, 8400, "Olympus\n Mons")
ax.text(7000, 10000, "Ascreaus\n Mons")
ax.text(6200, 11500, "Pavonis\n Mons")
ax.text(5000, 13000, "Arsia\n Mons")
ax.text(8500, 13000, "Tharsis", rotation=45)
ax.text(12000, 14000, "Vallies\n Marineris")
ax.text(17000, 18000, "Argyre")
ax.text(20000, 2000, "Vastitas Borealis")
ax.text(17000, 8500, "Chryse\n Planitia")
ax.text(20000, 5000, "Acidalia Planitia")
ax.text(30000, 16500, "Hellas", color='white')
ax.text(37000, 5000, "Utopia\n Planitia")
ax.text(41000, 8000, "Elysium")
ax.text(34000, 9800, "Isidis")
ax.text(7000, 5000, "Alba Patera")
ax.text(2000, 6500, "Amazonis\n Planitia")
return ax
fig, ax = plt.subplots()
fig.set_size_inches(14, 7)
ax.imshow(mars[0], cmap=custom_cmap, norm=norm)
ax = label_features(ax)
ax.axis('off')
newax = fig.add_axes([0.82, 0.13, 0.08, 0.08], anchor='NE')
newax.imshow(logo)
newax.axis('off')
txt = ax.text(0.0, 0.02, "Martian Topography \n@PythonMaps",
size=4,
color='white',
transform = ax.transAxes)
plt.show()
```
Рельеф Марса с обозначениями объектовТерраформирование Марса
-----------------------
На самом деле терраформировать Марс мы не будем, а создадим цветовые карты, подобные земным. И представим, каким будет полностью терраформированный Марс. Это цветовые карты с тёмно-синими и голубыми цветами для значений ниже уровня моря и зелёно-коричневыми — для значений выше уровня моря.
В Matplotlib для этого есть цветовая карта terrain, но её синяя часть недостаточно тёмная. Есть ещё карта ocean. Объединив их, мы получим цветовую карту, подобную земным картам. Цель объединения — создать объект BoundaryNorm, чтобы сопоставлять значения ниже уровня моря с картой ocean, а значения выше уровня моря — с картой terrain.
При создании цветовой карты цвета индексируются линейно по шкале от 0 до 1. С помощью списка индексов из цветовой карты извлекается список цветов и исключается её часть. Например, ниже в plt.cm.ocean(np.linspace(0.2, 0.8, 821)) из цветовой карты ocean возвращается список с 821 цветом и исключаются цвета из её части ниже 0,2 и выше 0,8.
То же самое сделано для цветовой карты terrain, но здесь возвращается 1400 цветов. Затем эти два списка объединяются в одну цветовую карту с помощью метода LinearSegmentedColourmap.
Рельеф будет отображаться на цветовой карте 821 цветом ocean и 1400 цветами terrain. Класс BoundaryNorm позволяет сопоставлять цвета карты с набором заданных значений.
В коде ниже создадим цветовую карту с 2221 цветом (821 ocean + 1400 terrain) и объектом BoundaryNorm, с помощью которого сопоставим значения данных с цветовой картой по предопределённым уровням — 821 уровень ниже 0 и 1400 выше 0. Все значения данных ниже 0 будут в цветах части цветовой карты ocean, а все значения выше нуля — в цветах карты terrain:
```
colors_undersea = plt.cm.ocean(np.linspace(0.2, 0.8, 821))
undersea_map = LinearSegmentedColormap.from_list('undersea_map', colors_undersea, N=821)
colors_land = plt.cm.terrain(np.linspace(0.25, 1, 1400))
land_map = LinearSegmentedColormap.from_list('land_map', colors_land, N=1400)
colors = np.vstack((colors_undersea, colors_land))
terrain_map = LinearSegmentedColormap.from_list('cut_terrain', colors, N=2221)
bounds = np.arange(-8210, 14000, 10)
norm = BoundaryNorm(bounds, terrain_map.N)
```
Цветовые карты ocean и terrain вместеДанные этой новой цветовой карты с границами цветов делают Марс очень похожим на Землю:
```
def label_features_terrain(ax):
ax.text(5000, 8400, "Olympus\n Mons")
ax.text(7000, 10000, "Ascreaus\n Mons")
ax.text(6200, 11500, "Pavonis\n Mons")
ax.text(5000, 13000, "Arsia\n Mons")
ax.text(8500, 13000, "Tharsis", rotation=45)
ax.text(12000, 14000, "Vallies\n Marineris")
ax.text(17000, 18000, "Argyre", color='white')
ax.text(20000, 2000, "Vastitas Borealis", color='white')
ax.text(17000, 8500, "Chryse\n Planitia", color='white')
ax.text(20000, 5000, "Acidalia Planitia", color='white')
ax.text(30000, 16500, "Hellas", color='white')
ax.text(37000, 5000, "Utopia\n Planitia", color='white')
ax.text(41000, 8000, "Elysium")
ax.text(34000, 9800, "Isidis", color='white')
ax.text(7000, 5000, "Alba Patera")
ax.text(2000, 6500, "Amazonis\n Planitia", color='white')
return ax
fig, ax = plt.subplots()
fig.set_size_inches(14, 7)
ax.imshow(mars[0], cmap=terrain_map, norm=norm)
ax = label_features_terrain(ax)
ax.axis('off')
newax = fig.add_axes([0.82, 0.13, 0.08, 0.08], anchor='NE')
newax.imshow(logo)
newax.axis('off')
txt = ax.text(0.0, 0.02, "Martian Topography \n@PythonMaps",
size=4,
color='white',
transform = ax.transAxes)
plt.show()
```
Может, так выглядит терраформированный Марс?Изменение уровня моря
---------------------
В качестве уровня моря мы выбрали произвольное значение — среднюю высоту Марса. Но этот уровень можно менять, применяя описанный выше метод создания цветовых карт. Цветовая карта создаётся из 2221 цвета: 821 из карты ocean и 1400 из карты terrain. Меняя количество цветов в каждой карте, но сохраняя их общее число, будем менять уровень моря. Там, где на карте заканчивается синий и начинается зелёный.
В функции ниже принимается значение уровня моря и генерируется цветовая карта с объектом границы цвета. Например, для уровня моря 3000 м, где каждые 10 м отображаются цветом, нужно увеличить ocean на 300 и уменьшить terrain на 300 цветов:
```
def change_sea_level(new_sea_level):
new_sea_level = new_sea_level / 10
undersea = int(800 + new_sea_level)
land = int(1400 - new_sea_level)
colors_undersea = plt.cm.ocean(np.linspace(0.2, 0.8, undersea))
undersea_map = LinearSegmentedColormap.from_list('undersea_map', colors_undersea, N=undersea)
colors_land = plt.cm.terrain(np.linspace(0.25, 1, land))
land_map = LinearSegmentedColormap.from_list('land_map', colors_land, N=land)
colors = np.vstack((colors_undersea, colors_land))
terrain_map = LinearSegmentedColormap.from_list('cut_terrain', colors, N=2221)
bounds = np.arange(-8210, 14000, 10)
norm = BoundaryNorm(bounds, terrain_map.N)
return terrain_map, norm
terrain_map0, norm0 = change_sea_level(new_sea_level = 0)
terrain_map3000, norm3000 = change_sea_level(new_sea_level = 3000)
terrain_map_3000, norm_3000 = change_sea_level(new_sea_level = -3000)
```
Цветовые карты после измененияПосмотрим, как выглядел бы Марс при уровне моря на 1500 м выше средней высоты. Такой Марс на 70% покрыт водой, как и Земля:
```
terrain_map1500, norm1500 = change_sea_level(new_sea_level = 1500)
fig, ax = plt.subplots()
fig.set_size_inches(14, 7)
ax.imshow(mars[0], cmap=terrain_map1500, norm=norm1500)
ax = label_features_terrain(ax)
ax.axis('off')
newax = fig.add_axes([0.82, 0.13, 0.08, 0.08], anchor='NE')
newax.imshow(logo)
newax.axis('off')
txt = ax.text(0.0, 0.02, "Martian Topography \n@PythonMaps",
size=4,
color='white',
transform = ax.transAxes)
plt.show()
```
Терраформированный Марс с уровнем моря на 1500 м выше средней высоты### Отмывка рельефа
Добавим рельефу немного света, чтобы придать карте эффект 3D. Отмывка рельефа — это представление поверхности в 3D, обычно в оттенках серого. Более тёмные и светлые цвета — это тени и освещённые участки, визуально обнаруживаемые на модели рельефа. Отмывку рельефа часто применяют на картах, чтобы подчеркнуть трёхмерность и сделать данные визуально интересными.
Чтобы сгенерировать данные с отмывкой рельефа, воспользуемся функцией earthpy. Есть два параметра, при настройке которых в зависимости от набора данных получаются очень разные результаты:
* Первый — это значение azimuth (азимут), которое варьируется от 0 до 360° и определяет источник света. 0° соответствует источнику света, указывающему строго на север.
* Второй — это altitude (высота), на которой источник света находится. Его значения варьируются от 1 до 90:
```
import earthpy as et
import earthpy.spatial as es
hillshade = es.hillshade(mars[0], azimuth=250, altitude=1)
fig, ax = plt.subplots(facecolor='#FCF6F5FF')
fig.set_size_inches(14, 7)
ax.imshow(mars[0], cmap=terrain_map, norm=norm)
ax.imshow(hillshade, cmap="Greys", alpha=0.2)
ax = label_features_terrain(ax)
ax.axis('off')
newax = fig.add_axes([0.8, 0.78, 0.08, 0.08], anchor='NE')
newax.imshow(logo)
newax.axis('off')
txt = ax.text(0.02, 0.03, "Martian Topography \n@PythonMaps",
size=8,
color='black',
transform = ax.transAxes)
plt.show()
```
Итог — та же карта, но с объектами крупнее, особенно в северных океанах:
Терраформированный Марс с отмывкой рельефа### Заключение
Вот и всё. Мы создали красивую карту с чёткой визуализацией данных Марса. Впереди много статей о том, как делать геопространственные данные такими крутыми с помощью Python.
Пишите комментарии с предложениями или возможными изменениями карты. Подобные статьи о визуализации данных мы регулярно публикуем в наших пабликах, так что [заглядывайте](https://twitter.com/PythonMaps), не появилось ли чего-то интересного по этой теме.
Ссылки
------
Полный [список](https://astrogeology.usgs.gov/search/map/Mars/GlobalSurveyor/MOLA/Mars_MGS_MOLA_Shade_global_463m) использованных материалов.
Продолжить погружение в Data Science или Python вы сможете на наших курсах:
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_01022022&utm_term=conc)
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_01022022&utm_term=conc)
Узнайте подробности [здесь](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_01022022&utm_term=conc).
Другие профессии и курсы**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_01022022&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_01022022&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_01022022&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_01022022&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_01022022&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_01022022&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_01022022&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_01022022&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_01022022&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_01022022&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_01022022&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_01022022&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_01022022&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_01022022&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_01022022&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_01022022&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_01022022&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_01022022&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_01022022&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_01022022&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_01022022&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_01022022&utm_term=cat) | https://habr.com/ru/post/649097/ | null | ru | null |
# Бандл… Пара-пара-па хэй! или Bundle Transformer шагает по планете 2
[](http://taritsyn.files.wordpress.com/2014/01/bundle-transformer-mosaic-jan-2014.png "Открыть полную версию изображения")
Я немного отойду от формата [предыдущей статьи](http://taritsyn.wordpress.com/2013/05/04/bandl-para-para-pa-hjej-ili-bundle-transformer-shagaet-po-planete/) и прежде чем привести подборку интересных упоминаний о [Bundle Transformer](http://bundletransformer.codeplex.com/), я расскажу об изменениях, которые произошли в проекте за последние полгода.
До августа прошлого года библиотека [dotless](http://www.dotlesscss.org/) была основным средством для работы с LESS в сообществе .NET-разработчиком, и входила в состав практически всех инструментов клиентской оптимизации для ASP.NET: [Cassette](http://getcassette.net/), [SquishIt](http://github.com/jetheredge/SquishIt), [Combres](http://github.com/buunguyen/combres) и [RequestReduce](http://requestreduce.org/). Bundle Transformer также не являлся исключением: библиотеки dotless и DotlessClientOnly (облегченная версия) использовались в модулях [BundleTransformer.Less](http://nuget.org/packages/BundleTransformer.Less/) и BundleTransformer.LessLite.
Ситуация в корне изменилась, когда вышел [Twitter Bootstrap 3.0](http://getbootstrap.com/). Исходники таблиц стилей Bootstrap 3.0 были написаны на LESS 1.4.X, а библиотека dotless на тот момент поддерживала более старую версию LESS (поддержка LESS 1.4.X появилась в dotless только в декабре 2013 года). Фактически все перечисленные инструменты для работы с LESS в одночасье стали морально устаревшими.
Для того чтобы исправить сложившуюся ситуацию, я решил реализовать в модулях BundleTransformer.Less и BundleTransformer.LessLite собственную версию LESS-компилятора на основе исходного кода проекта [less.js](http://github.com/less/less.js). К тому времени у меня уже был большой опыт создания компиляторов (трансляторов) и минимизаторов на базе Node.js-библиотек (модули [BundleTransformer.CoffeeScript](http://nuget.org/packages/BundleTransformer.CoffeeScript/), [BundleTransformer.TypeScript](http://nuget.org/packages/BundleTransformer.TypeScript/), [BundleTransformer.UglifyJs](http://nuget.org/packages/BundleTransformer.UglifyJs/) и [BundleTransformer.Csso](http://nuget.org/packages/BundleTransformer.Csso/)). Первоначально в обновленных модулях BundleTransformer.Less и BundleTransformer.LessLite в качестве JavaScript-движка использовалась библиотека [MSIE JavaScript Engine for .Net](http://github.com/Taritsyn/MsieJavaScriptEngine), но с ростом популярности этих модулей я стал получать много сообщений от пользователей, которые просили меня отказаться от MSIE JavaScript Engine for .Net и использовать вместо нее одну из реализаций движка V8 под .NET. Так я начал работу над своим новым проектом — [JavaScript Engine Switcher](http://github.com/Taritsyn/JavaScriptEngineSwitcher).
JavaScript Engine Switcher – это .NET-библиотека, которая определяет унифицированный интерфейс доступа к базовым возможностям популярных JavaScript-движков:
1. MSIE JavaScript Engine for .Net
2. V8 (первоначально в качестве реализации движка использовалась библиотека [Noesis Javascript .NET](http://javascriptdotnet.codeplex.com/), но из-за плохой совместимости с 64-битными версиями IIS 8.X она была заменена на более современную библиотеку — [Microsoft ClearScript.V8](http://clearscript.codeplex.com/))
3. [Jurassic](http://jurassic.codeplex.com/)
JavaScript Engine Switcher позволяет легко и быстро переключить любой .NET-проект на использование другого JavaScript-движка. Кроме того, у вас есть возможность подключить свой любимый JavaScript-движок с помощью JavaScript Engine Switcher. Для этого нужно написать адаптер, который реализует интерфейс `IJsEngine` или наследует класс `JsEngineBase` из пространства имен `JavaScriptEngineSwitcher.Core`, а затем зарегистрировать его в элементе `\configuration\jsEngineSwitcher\core\engines` конфигурационного файла (`Web.config` или `App.config`).
Начиная с версии 1.8.0 все модули Bundle Transformer, созданные на основе кода JavaScript-библиотек, стали использовать JavaScript Engine Switcher. Разработка модуля BundleTransformer.LessLite была прекращена, т.к. он уже ничем не отличался от BundleTransformer.Less. Возможность использования движка V8 позволила на основе кода проекта [Clean-css](http://github.com/GoalSmashers/clean-css) создать модуль [BundleTransformer.CleanCss](http://nuget.org/packages/BundleTransformer.CleanCss/).
Отсутствие прямой зависимости от Internet Explorer и поддержка самых последних версий LESS (на данный момент поддерживается LESS 1.6.1) позволила Bundle Transformer обойти всех своих конкурентов и занять 21-е место в [категории ASP.NET](http://nuget.org/packages?q=Tags%3A%22ASP.NET%22&sortOrder=package-download-count&page=2&prerelease=False) рейтинга сайта NuGet Gallery. Постоянный приток новых пользователей способствовал появлению актуальных технических статей о Bundle Transformer:
1. Статья Дженнифер Семтнер [«Setting up ASP.NET MVC 4 and Twitter Bootstrap 3 with LESS»](http://www.jennifersemtner.com/css/326/setting-up-asp-net-mvc-4-and-twitter-bootstrap-3-with-less/)
2. Статья Тома Дюпона [«Bootstrap 3, LESS, Bundling, and ASP.NET MVC»](http://www.tomdupont.net/2013/10/bootstrap-3-less-bundling-and-aspnet-mvc.html)
3. Пост Евгения Ярославова [«Использование LESS в проектах ASP.NET MVC»](http://ts-soft.ru/blog/less-aspnet/) в блоге компании [«ТиЭс Софт»](http://ts-soft.ru/)
4. Пост пользователя Kalint [«Guide to getting LESS working with Twitter Bootstrap in MVC 5»](http://www.neowin.net/forum/topic/1191221-guide-to-getting-less-working-with-twitter-bootstrap-in-mvc-5/) на форуме сайта [Neowin.net](http://www.neowin.net/)
Помимо этого некоторые разработчики ПО стали включать Bundle Transformer в состав своих продуктов:
1. Демонстрационный проект Майкла Берда [«MVC4 Bootstrap .less{} Demo Project»](http://github.com/michaeljbaird/Mvc4BootstrapLessDemo)
2. Расширение [Sassy](http://our.umbraco.org/projects/backoffice-extensions/sassy) для CMS Umbraco, разработанное Уорреном Бакли
3. Расширение [Optimus](http://our.umbraco.org/projects/developer-tools/optimus) для CMS Umbraco, разработанное Тимом Гейссенсом, Уорреном Бакли и Дживоном Леопольдом
4. Проект [«Open Government Data Initiative v6»](http://github.com/openlab/OGDI-DataLab)
5. CMS [EonicWeb5](http://www.eonicweb.com/)
А теперь перейдем к подборке наиболее ярких упоминаний о Bundle Transformer:
### 1. 77-й выпуск интернет радио-шоу Code Name «APS»

В предыдущей статье я уже рассказывал о 21-м выпуске радио-шоу [Code Name «APS»](http://aps-radio.com/) на [Бинарном Радио](http://binradio.ru/), в эфире которого местные диджеи сделали обзор Bundle Transformer 1.6.5. На этот раз мне посчастливилось стать гостем 77-го выпуска данного радио-шоу. В основном я рассказывал о Bundle Transformer и [WebMarkupMin](http://webmarkupmin.codeplex.com/), но в процессе обсуждения также были затронуты следующие темы: WebMatrix, ASP.NET Web Pages, Web Essentials 2013, TypeScript, Windows 8 и веб-сервисы. Запись данной радио-передачи можно [прослушать в группе Бинарного Радио](http://vk.com/audios-40009810?q=Code%20Name%20%22APS%22) в социальной сети «ВКонтакте» или [скачать в виде MP3-файла](http://www.dropbox.com/s/t6ipjvvhp9y79ce/Code-Name-APS-77.mp3).
### 2. Презентация расширения Optimus на конференции «Umbraco UK Fest 2013»

[Optimus](http://our.umbraco.org/projects/developer-tools/optimus) – это расширение для CMS [Umbraco](http://umbraco.com/), созданное на основе [Microsoft ASP.NET Web Optimization Framework](http://aspnetoptimization.codeplex.com/) и Bundle Transformer. Данное расширение позволяет front-end разработчикам, не знакомым c C# или VB.NET, создавать бандлы через интерфейс административной части Umbraco. Также для Optimus существуют дополнительные модули (провайдеры), которые позволяют добавить поддержку промежуточных языков: LESS, Sass/SCSS, CoffeeScript и TypeScript.
Стоит отметить, что авторы расширения (Тим Гейссенс и Уоррен Бакли) очень творчески подошли к выбору его названия. Название «Optimus» одновременно обыгрывает названия двух базовых продуктов:
1. Оно созвучно со словом «Optimization» из Microsoft ASP.NET Web Optimization Framework.
2. Совпадает с именем одного из главных персонажей вселенной трансформеров — [Оптимуса Прайма](http://ru.wikipedia.org/wiki/%D0%9E%D0%BF%D1%82%D0%B8%D0%BC%D1%83%D1%81_%D0%9F%D1%80%D0%B0%D0%B9%D0%BC).
Даже в логотипе расширения присутствует эмблема [трансформеров-автоботов](http://ru.wikipedia.org/wiki/%D0%90%D0%B2%D1%82%D0%BE%D0%B1%D0%BE%D1%82%D1%8B):
[](http://taritsyn.files.wordpress.com/2014/01/optimus-logo.png)
Не менее креативным было и выступление Тима Гейссенса на конференции [«Umbraco UK Fest 2013»](http://umbracoukfestival.co.uk/):
Более подробную информацию об Optimus вы можете найти в [блоге Тима Гейссенса](http://www.nibble.be/index.php?s=Optimus) и статье Уоррена Бакли [«Transformers! Robots in Disguise»](http://creativewebspecialist.co.uk/2013/07/12/transformers-robots-in-disguise/).
### 3. Обучающий курс «ASP.NET Bundling, Minification & Resource Optimization» от Pluralsight

Обучающий курс Трэвиса Госселина [«ASP.NET Bundling, Minification & Resource Optimization»](http://pluralsight.com/training/Courses/TableOfContents/aspnet-bundling-minification-resource-optimization), содержит практически исчерпывающую информацию о работе с библиотекой Microsoft ASP.NET Web Optimization Framework (не была затронута только тема использования данной библиотеки в ASP.NET Web Pages). Раньше подобную информацию приходилось собирать по крупицам: читать [официальную документацию](http://www.asp.net/mvc/tutorials/mvc-4/bundling-and-minification), следить за [блогом Говарда Дёркинга](http://codebetter.com/howarddierking/), искать ответы на [Stack Overflow](http://stackoverflow.com/) и даже изучать код сборки `System.Web.Optimization.dll` с помощью декомпилятора.
Как вы уже успели догадаться, в таком большом курсе нашлось место и для Bundle Transformer. Работе с Bundle Transformer посвящены два видео-ролика:
[](http://taritsyn.files.wordpress.com/2014/01/pluralsight-aspnet-bundling-minification-resource-optimization-table-of-contents.png)
В видео-ролике «Demo: Bundle Transformer Package» автор курса на примере установки и настройки модулей BundleTransformer.Less и [BundleTransformer.Yui](http://nuget.org/packages/BundleTransformer.Yui/) объясняет основные принципы работы с Bundle Transformer и приводит следующий пример кода:
```
bundles.Add(new Bundle("~/bundles/app", new JsTransformer())
.IncludeDirectory("~/Scripts/app", "*.js"));
bundles.Add(new Bundle("~/styles/site", new CssTransformer()).Include(
"~/Content/bootstrap/bootstrap.css",
"~/Content/site.less",
"~/Content/toastr.css"));
```
В принципе, это корректный код, но его можно сделать более производительным, если в качестве построителя кода по умолчанию использовать экземпляр класса `NullBuilder`:
```
var nullBuilder = new NullBuilder();
bundles.Add(new Bundle("~/bundles/app", new JsTransformer())
{
Builder = nullBuilder
}
.IncludeDirectory("~/Scripts/app", "*.js"));
bundles.Add(new Bundle("~/styles/site", new CssTransformer())
{
Builder = nullBuilder
}
.Include(
"~/Content/bootstrap/bootstrap.css",
"~/Content/site.less",
"~/Content/toastr.css"));
```
Кроме того, объем данного кода можно сократить, если воспользоваться классами `CustomScriptBundle` и `CustomStyleBundle`:
```
bundles.Add(new CustomScriptBundle("~/bundles/app")
.IncludeDirectory("~/Scripts/app", "*.js"));
bundles.Add(new CustomStyleBundle("~/styles/site")
.Include(
"~/Content/bootstrap/bootstrap.css",
"~/Content/site.less",
"~/Content/toastr.css"));
```
Несмотря на то, что я давно использую Microsoft ASP.NET Web Optimization Framework и хорошо знаю его внутреннее устройство, из этого курса я смог подчеркнуть для себя много нового (особенно из двух последних модулей: «Architecting Optimizations» и «Testing Optimizations»).
### Заключение
В заключении, я хотел бы поблагодарить всех технических специалистов, которые помогают мне продвигать Bundle Transformer в широкие массы. | https://habr.com/ru/post/210884/ | null | ru | null |
# Как вызвать утечку памяти в Angular-приложении?
Производительность — это ключ к успеху веб-приложения. Поэтому разработчикам нужно знать о том, как возникают утечки памяти, и о том, как с ними бороться.
Эти знания особенно важны в том случае, когда приложение, которым занимается разработчик, достигает определённого размера. Если уделять утечкам памяти недостаточно внимания, то всё может закончиться тем, что разработчик, в итоге, попадёт в «команду по устранению утечек памяти» (мне доводилось входить в состав такой команды).
[](https://habr.com/ru/company/ruvds/blog/503312/)
Утечки памяти могут возникать по разным причинам. Однако я полагаю, что при использовании Angular можно столкнуться с паттерном, который соответствует самой распространённой причине возникновения утечек памяти. Существует и способ борьбы с такими утечками памяти. А лучше всего, конечно, не бороться с проблемами, а избегать их.
Что такое управление памятью?
-----------------------------
В JavaScript применяется система автоматического управления памятью. Жизненный цикл памяти обычно состоит из трёх шагов:
1. Выделение необходимой памяти.
2. Работа с выделенной памятью, выполнение операций чтения и записи.
3. Освобождение памяти после того, как она больше не нужна.
На [MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Memory_Management) говорится о том, что автоматическое управление памятью — это потенциальный источник путаницы. Это может дать разработчикам ложное ощущение того, что им не нужно заботиться об управлении памятью.
Если вы совершенно не заботитесь об управлении памятью, это значит, что после того, как ваше приложение дорастёт до определённого размера, вы вполне можете столкнуться с утечкой памяти.
В целом, утечки памяти можно представить как выделенную приложению память, которая больше ему не нужна, но и не освобождена. Другими словами, это — объекты, которые не удалось подвергнуть операции сборки мусора.
Как работает сборка мусора?
---------------------------
В ходе процедуры сборки мусора, что вполне логично, выполняется уборка всего того, что можно счесть «мусором». Сборщик мусора очищает память, которая больше не нужна приложению. Для того чтобы выяснить, какие участки памяти ещё нужны приложению, сборщик мусора использует алгоритм «mark and sweep» (алгоритм пометок). Как следует из названия, этот алгоритм состоит из двух фаз — фазы пометки (mark) и фазы очистки (sweep).
### ▍Фаза пометки
Объекты и ссылки на них представлены в виде дерева. Корень дерева — это, на следующем рисунке, узел `root`. В JavaScript это — объект `window`. У каждого объекта есть особый флаг. Назовём этот флаг `marked`. На фазе пометки, в первую очередь, все флаги `marked` устанавливаются в значение `false`.
*В начале флаги объектов marked устанавливаются в false*
Затем осуществляется обход дерева объектов. Все флаги `marked` объектов, достижимых из узла `root`, устанавливаются в `true`. А флаги тех объектов, достичь которых не удаётся, так и остаются в значении `false`.
Объект считается недостижимым в том случае, если до него нельзя добраться из корневого объекта.

*Достижимые объекты помечены как marked=true, недостижимые — как marked=false*
В результате все флаги `marked` недостижимых объектов остаются в значении `false`. Память пока не освобождается, но, после завершения фазы пометки всё оказывается готовым для фазы очистки.
### ▍Фаза очистки
Память очищается именно на данной фазе работы алгоритма. Здесь все недостижимые объекты (те, флаг `marked` которых остался в значении `false`) уничтожаются сборщиком мусора.

*Дерево объектов после сборки мусора. Все объекты, флаг marked которых остался в значении false, уничтожены сборщиком мусора*
Сборка мусора периодически выполняется в процессе работы JavaScript-программы. В ходе выполнения этой процедуры осуществляется освобождение памяти, которая может быть освобождена.
Возможно, тут у вас возникает следующий вопрос: «Если сборщик мусора убирает все объекты, помеченные как недостижимые — как создать утечку памяти?».
Дело тут в том, что объект не будет обработан сборщиком мусора в том случае, если он не нужен приложению, но при этом до него всё ещё можно добраться из корневого узла дерева объектов.
Алгоритм не может знать о том, будет ли приложение пользоваться неким фрагментом памяти, к которому оно может обратиться, или не будет. Такие знания есть только у программиста.
Утечки памяти в Angular
-----------------------
Чаще всего утечки памяти возникают с течением времени, тогда, когда выполняется многократный повторный рендеринг компонента. Например — посредством маршрутизации, или как результат использования директивы `*ngIf`. Скажем, в ситуации, когда некий продвинутый пользователь работает с приложением целый день, не обновляя страницу приложения в браузере.
Для того чтобы воспроизвести этот сценарий, создадим конструкцию из двух компонентов. Это будут компоненты `AppComponent` и `SubComponent`.
```
@Component({
selector: 'app-root',
template: ``
})
export class AppComponent {
hide = false;
constructor() {
setInterval(() => this.hide = !this.hide, 50);
}
}
```
В шаблоне компонента `AppComponent` используется компонент `app-sub`. Самое интересное здесь то, что в нашем компоненте используется функция `setInterval`, которая переключает флаг `hide` каждые 50 мс. Это приводит к тому, что каждые 50 мс выполняется повторный рендеринг компонента `app-sub`. То есть — выполняется создание новых экземпляров класса `SubComponent`. Этот код имитирует поведение пользователя, который весь день работает с веб-приложением, не обновляя страницу в браузере.
Мы, в `SubComponent`, реализовали разные сценарии, при использовании которых, со временем, начинают проявляться изменения в объёме памяти, используемой приложением. Обратите внимание на то, что компонент `AppComponent` всегда остаётся одним и тем же. В каждом сценарии мы выясним, является ли то, с чем мы имеем дело, утечкой памяти, анализируя потребление памяти процессом браузера.
Если потребление памяти процессом со временем растёт — это значит, что мы столкнулись с утечкой памяти. Если процесс использует более или менее постоянный объём памяти, это значит либо то, что утечки памяти нет, либо то, что утечка, хотя и присутствует, не проявляется достаточно очевидным образом.
### ▍Сценарий №1: огромный цикл for
Наш первый сценарий представлен циклом, который выполняется 100000 раз. В цикле осуществляется добавление случайных значений в массив. Не будем забывать о том, что компонент повторно рендерится каждые 50 мс. Взглянем на код и подумаем о том, создали мы утечку памяти или нет.
```
@Component({
selector:'app-sub',
// ...
})
export class SubComponent {
arr = [];
constructor() {
for (let i = 0; i < 100000; ++i) {
this.arr.push(Math.random());
}
}
}
```
Хотя такой код и не стоит отправлять в продакшн, утечку памяти он не создаёт. А именно, потребление памяти не выходит за рамки диапазона, ограниченного значением в 15 Мб. В результате — утечки памяти тут нет. Ниже мы поговорим о том, почему это так.
### ▍Сценарий №2: подписка на BehaviorSubject
В этом сценарии мы подписываемся на `BehaviorSubject` и назначаем значение константе. Есть ли в этом коде утечка памяти? Как и прежде, не забываем о том, что компонент рендерится каждые 50 мс.
```
@Component({
selector:'app-sub',
// ...
})
export class SubComponent {
subject = new BehaviorSubject(42);
constructor() {
this.subject.subscribe(value => {
const foo = value;
});
}
}
```
Здесь, как и в предыдущем примере, утечки памяти нет.
### ▍Сценарий №3: назначение значения полю класса внутри подписки
Тут представлен практически такой же код, как и в предыдущем примере. Основная разница заключается в том, что значение назначается не константе, а полю класса. А теперь, как думаете, есть в коде утечка?
```
@Component({
selector:'app-sub',
// ...
})
export class SubComponent {
subject = new BehaviorSubject(42);
randomValue = 0;
constructor() {
this.subject.subscribe(value => {
this.randomValue = value;
});
}
}
```
Если вы полагаете, что утечки тут нет — вы совершенно правы.
В сценарии №1 нет подписки. В сценариях №2 и 3 мы подписались на поток наблюдаемого объекта, инициализированного в нашем компоненте. Возникает такое ощущение, что мы находимся в безопасности, подписываясь на потоки компонента.
А что если мы добавим в нашу схему сервис?
Сценарии, в которых используется сервис
---------------------------------------
В следующих сценариях мы собираемся пересмотреть вышеприведённые примеры, но в этот раз мы будем подписываться на поток, предоставляемый сервисом `DummyService`. Вот код сервиса.
```
@Injectable({
providedIn: 'root'
})
export class DummyService {
some$ = new BehaviorSubject(42);
}
```
Перед нами — простой сервис. Это — всего лишь сервис, который предоставляет поток (`some$`) в форме общедоступного поля класса.
### ▍Сценарий №4: подписка на поток и присвоение значения локальной константе
Воссоздадим тут ту же схему, которую уже описывали ранее. Но в этот раз подпишемся на поток `some$` из `DummyService`, а не на поле компонента.
Есть ли тут утечка памяти? Опять же, отвечая на этот вопрос, помните о том, что компонент используется в `AppComponent` и рендерится много раз.
```
@Component({
selector:'app-sub',
// ...
})
export class SubComponent {
constructor(private dummyService: DummyService) {
this.dummyService.some$.subscribe(value => {
const foo = value;
});
}
}
```
А вот теперь мы наконец-то создали утечку памяти. Но это — маленькая утечка. Под «маленькой утечкой» я понимаю такую, которая, с течением времени, приводит к медленному увеличению объёма потребляемой памяти. Это увеличение едва заметно, но беглый осмотр снепшота кучи показал наличие там множества неудалённых экземпляров `Subscriber`.
### ▍Сценарий №5: подписка на сервис и назначение значения полю класса
Здесь мы снова подписываемся на `dummyService`. Но в это раз мы назначаем полученное значение полю класса, а не локальной константе.
```
@Component({
selector:'app-sub',
// ...
})
export class SubComponent {
randomValue = 0;
constructor(private dummyService: DummyService) {
this.dummyService.some$.subscribe(value => {
this.randomValue = value;
});
}
}
```
А вот тут мы, наконец, создали значительную утечку памяти. Потребление памяти быстро, в течение минуты, превысило 1 Гб. Поговорим о том, почему это так.
### ▍Когда появилась утечка памяти?
Возможно, вы обратили внимание на то, что в первых трёх сценариях утечку памяти нам создать не удалось. У этих трёх сценариев есть кое-что общее: все ссылки являются локальными по отношению к компоненту.
Когда мы подписываемся на наблюдаемый объект, он хранит список подписчиков. В этом списке есть и наш коллбэк, а коллбэк может ссылаться на наш компонент.
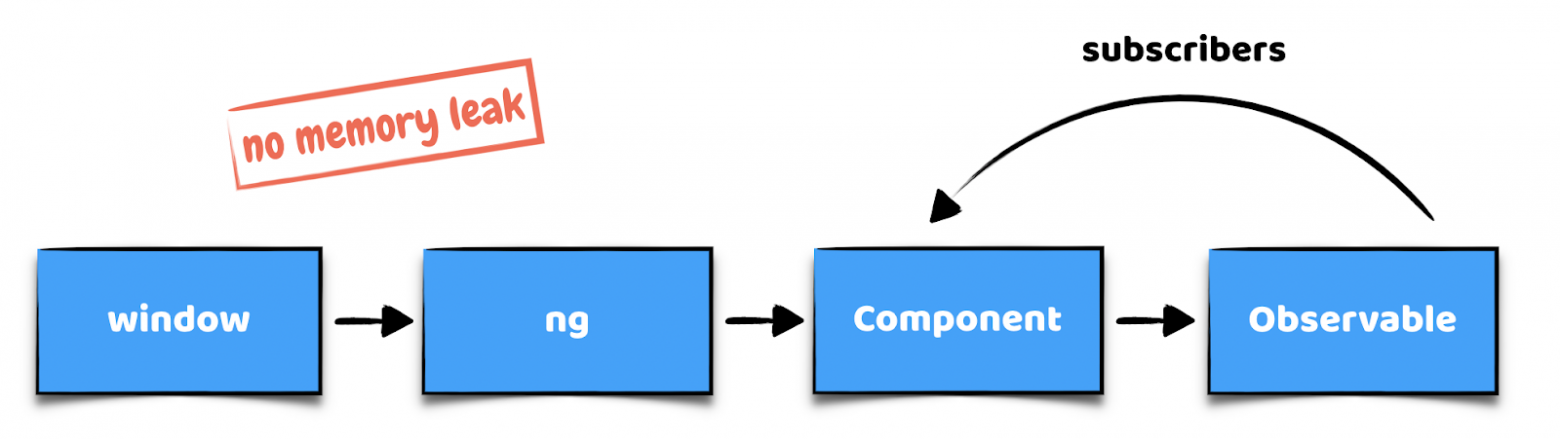
*Отсутствие утечки памяти*
Когда компонент уничтожается, то есть, когда Angular больше не имеет ссылки на него, а значит — до компонента нельзя добраться из корневого узла, до наблюдаемого объекта и его списка подписчиков тоже нельзя добраться из корневого узла. В результате весь объект компонента подвергается сборке мусора.
До тех пор, пока мы подписаны на наблюдаемый объект, ссылки на который есть лишь в пределах компонента, никаких проблем не возникает. А вот когда в игру вступает сервис, ситуация меняется.

*Утечка памяти*
Как только мы подписались на наблюдаемый объект, предоставляемый сервисом или другим классом, мы создали утечку памяти. Это происходит из-за наблюдаемого объекта, из-за его списка подписчиков. Из-за этого коллбэк, а значит, и компонент, оказываются доступными из корневого узла, хотя у Angular и нет прямой ссылки на компонент. В результате сборщик мусора не трогает соответствующий объект.
Уточню: такими конструкциями пользоваться можно, но работать с ними нужно правильно, а не так, как мы.
Правильная работа с подписками
------------------------------
Для того чтобы избежать утечки памяти, важно правильно отписаться от наблюдаемого объекта, сделав это тогда, когда подписка больше не нужна. Например — при уничтожении компонента. Отписаться от наблюдаемого объекта можно разными способами.
Опыт консультирования владельцев крупных корпоративных проектов указывает на то, что в этой ситуации лучше всего использовать сущность `destroy$`, создаваемую командой `new Subject()`, в комбинации с оператором `takeUntil`.
```
@Component({
selector:'app-sub',
// ...
})
export class SubComponent implements OnDestroy {
private destroy$: Subject = new Subject();
randomNumber = 0;
constructor(private dummyService: DummyService) {
dummyService.some$.pipe(
takeUntil(this.destroy$)
).subscribe(value => this.randomNumber = value);
}
ngOnDestroy(): void {
this.destroy$.next();
this.destroy$.complete();
}
}
```
Здесь мы отписываемся от подписки с помощью `destroy$` и оператора `takeUntil` после уничтожения компонента.
Мы реализовали в компоненте хук жизненного цикла `ngOnDestroy`. Каждый раз, когда компонент уничтожается, мы вызываем у `destroy$` методы `next` и `complete`.
Вызов `complete` очень важен из-за того, что этот вызов очищает подписку от `destroy$`.
Затем мы используем оператор `takeUntil` и передадим ему наш поток `destroy$`. Это гарантирует очистку подписки (то есть — то, что мы отписались от подписки) после уничтожения компонента.
Как не забыть об очистке подписок?
----------------------------------
Очень легко забыть добавить в компонент `destroy$`, а также забыть вызвать `next` и `complete` в хуке жизненного цикла `ngOnDestroy`. Даже несмотря на то, что я обучал этому команды, работающие над проектами, я сам часто об этом забывал.
К счастью, существует замечательное правило линтера, входящее в состав [набора правил](https://github.com/angular-extensions/lint-rules), которое позволяет обеспечить правильное отписывание от подписок. Установить набор правил можно так:
```
npm install @angular-extensions/lint-rules --save-dev
```
Затем его надо подключить в `tslint.json`:
```
{
"extends": [
"tslint:recommended",
"@angular-extensions/lint-rules"
]
}
```
Я настоятельно рекомендую вам пользоваться этим набором правил в своих проектах. Это позволит вам сэкономить много часов отладки в поиске источников утечек памяти.
Итоги
-----
В Angular очень легко создать ситуацию, приводящую к утечкам памяти. Даже небольшие изменения кода в местах, которые, вроде бы, не должны иметь отношения к утечкам памяти, могут привести к серьёзным неблагоприятным последствиям.
Лучший способ избежать утечек памяти — это правильно управлять подписками. К сожалению, операция очистки подписок требует от разработчика большой аккуратности. Об этом легко забыть. Поэтому рекомендуется применять правила `@angular-extensions/lint-rules`, которые помогают организовать правильную работу с подписками.
[Вот](https://github.com/macjohnny/angular-memory-leak-demo) репозиторий с кодом, положенным в основу этого материала.
**Сталкивались ли вы с утечками памяти в Angular-приложениях?**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=utechka-pamyati-angular#order) | https://habr.com/ru/post/503312/ | null | ru | null |
# Как перестать беспокоиться и начать работать?
В [прошлый раз](http://habrahabr.ru/blogs/agile/105008/), когда мы рассказывали о работе [нашей](http://www.e-kontur.ru) команды, многих интересовали подробности организации работы непосредственно разработчиков, о чём мы сейчас и расскажем. Не стоит ожидать «срывов покровов» и открытий, ведь всё, что делают разработчики ни раз описывалось и обсуждалось, но то, что мы делаем в совокупности в реальных крупных проектах, делается не так уж часто (честно говоря, я этого вообще больше нигде не видел). То есть ожидать-то не стоит, но «срывы покровов» произойдут :)
Реальность такова, что Agile без правильных инженерных практик очень быстро закончится. Если вы не будете прилагать усилия, которые гарантируют высокий уровень качества разработки и состояния системы в целом, то по мере усложнения проекта контроль будет быстро утрачен. В результате сделать всё, что запланировано в итерации, у вас не получится, а о значимом релизе (значимый — значит, с какой-то новой функциональностью, которая будет доступна пользователям, а не просто рефакторинг) раз в месяц вы будете только мечтать, потому что стабилизация важного релиза будет занимать гораздо больше, чем месяц.
При правильном подходе разработка новой функциональности может происходить довольно быстро и фокус тут в том, как не сломать при этом то, что было сделано раньше или же быстро понять, что именно ты сломал, и быстро это исправить. Каждый раз тестировать все детали и нюансы вручную очень долго и неэффективно, ведь в Эльбе сегодня уже более 400 «экранов». И проблема не только в том, что тестеры должны все это проверить вручную — очень много времени уходит на сценарий «тестер добавил баг — разработчик исправил баг — тестер проверил и закрыл/переоткрыл баг». Можно долго рассуждать о том, как трудно сохранить быстрорастущую систему в стабильном состоянии, почему код превращается в гавно, почему страшно делать исправления и никто не берет на себя смелость сказать дату релиза даже с точностью до месяца (потому что это было бы безответственно), но гораздо интереснее узнать о том, как сделать так, чтобы было хорошо.
#### Тесты, тесты, тесты
Я написал слово «тесты» 3 раза, не потому, что повторять слова по три раза весело, а потому что мы используем 3 вида тестов:
1. Модульные тесты бизнес-логики. Эльба — это совокупность нескольких взаимодействующих друг с другом сервисов (веб, хранилище данных, сервис справочников, сервис печати и т.д.) Все эти сервисы и серверную часть веба мы пишем в TDD стиле. Про TDD сказано и написано очень много. Основным плюсом этой методологии я считаю создание ситуации, в которой написание тестов — это не рутинная и не скучная работа. Постепенно наращивать тесты и фанатично писать кода ровно столько, чтобы текущий набор модульных тестов проходил, но ни строчкой больше — это очень весело, это такая ментальная игра, вроде шахмат. Кроме того, честно покрывая каждую строчку вашего кода модульными тестами, вы получаете более совершенный код. Тут уместен фанатизм: если возник код, который можно стереть и при этом не упало ни одного теста, этот код должен быть стерт немедленно, в воспитательных целях. Стоит сказать, что представление о хорошем коде у каждого свое: студенты считают совершенным код, который компилируется, а некоторые разработчики любой код, который работает. К счастью можно не спорить по этому поводу. Прекраснейший человек [Uncle Bob](http://butunclebob.com) давно обобщил все, что стоит обобщать в области формальных характеристик хорошего кода и написал серию статей об этом. Мы в Эльбе считаем хорошим тот код, который удовлетворяет принципам [SOLID](http://ru.wikipedia.org/wiki/SOLID_%28%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%29). Если вы до сих пор не знаете что это и при этом не являетесь Хаскелл-разработчиком, то есть вероятность, что вы живете неправильно или зря :) Код, покрытый модульными тестами, легко наращивать и модифицировать: тесты гарантируют неизменность старой бизнес-логики, а SOLIDность позволяет делать важные изменения сугубо локально (у вас ведь нет копипастов и 3 классов, которые делают одно и тоже?) — вы достигаете заявленной цели, скорость разработки не снижается и все происходит с заданным качеством.
2. Модульные тесты для клиентского JavaScript. Серверная бизнес-логика это прекрасно, но конечные пользователи видят веб-приложение. И они хотят не просто наблюдать унылые страницы, все должно летать и взрываться. Поэтому мы пишем много клиентской логики. Тут нет ничего нового по сравнению с серверной бизнес-логикой: код должен быть SOLIDным и покрытым тестами, просто язык другой. Такими образом мы тестируем классы и контролы общего назначения (например, клиентские валидаторы).
3. Функциональные тесты веб-приложения. Все модульные тесты могут проходить, но это вовсе не гарантирует, что у пользователя нет никаких проблем с конкретной страницей. Мы не тестируем модульными тестами заполнение полей каждой формы и обработку этих полей на сервере. Чтобы зафиксировать правильное поведение конечных страниц, мы используем функциональные тесты. Фактически мы повторяем поведение пользователя: кликаем на ссылку, ожидаем загрузку страницы с определенным набором полей, заполняем эти поля, проверяем корректность валидации, нажимаем на кнопку «сохранить» и убеждаемся, что именно то, что было вписано в поля, осело в нашем хранилище. Даже если на странице, в зависимости от каких-то условий, меняется какая-нибудь маленькая надпись — на это есть тест. Если разработчик говорит, что невозможно протестировать все условия, под которые он писал код, значит, он писал этот код пьяным или врёт (речь идёт об обычной бизнес-логике, а не о [научных приложениях](http://habrahabr.ru/blogs/development/92038/), например). Вот так понятно может выглядеть тест:
```
[Test]
public void ChangeEmailWithGoodPassword()
{
const string newEmail = "[email protected]";
Prepare();
emailSettingsPage.Email.TypeValueAndWait(newEmail);
emailSettingsPage.Password.TypeValueAndWait("superpassword");
emailSettingsPage.SaveButton.Click();
emailSettingsPage.WaitSaveSucceded();
emailSettingsPage = emailSettingsPage.Refresh();
emailSettingsPage.Email.WaitValue(newEmail);
}
```
А вот что происходит при запуске теста:
Чтобы писать такие понятные тесты, мы для них строим абстракции над страницами и контролами, благодаря которым сильно снижается сложность их поддержки, повышается читаемость и даже появляется возможность писать функциональные тесты по TDD!
#### Запуск тестов
Тесты пишутся для того, чтобы их запускать, поэтому очень важно, чтобы тесты запускались легко (одной кнопкой!), стартовали мгновенно и быстро отрабатывали. Тогда разработчики действительно будут их запускать. Наши модульные тесты именно так себя и ведут, 1700 тестов отрабатывают за 2 минуты. С функциональными тестами все не так просто, ведь каждый тест предполагает загрузку страницы (зачастую нескольких) с последующей проверкой. Это занимает от нескольких до десятков секунд. Но с учётом того, что всего функциональных тестов у нас более 2000, прогон всех тестов на одной машине занимает порядка 7 часов. Очевидно, что еще не родился такой разработчик, которому хватит терпения дождаться прохождения всех функциональных тестов. Поэтому разработчик запускает или только что написанные тесты, или те, которые тестируют модифицированные страницы. После этого разработчик делает коммит, и в дело вступает билд-сервер, который, общаясь с системой контроля версий, понимает, что появилось что-то новенькое и добавляет коммит в очередь. Очередь разгребается агентами — физическими или виртуальными машинами, смысл существования которых заключается в том, чтобы прогонять весь набор тестов по каждому коммиту. Мы используем 20 агентов для того чтобы проверять корректность работы во всех значимых для нас браузерах. Можно легко увидеть список упавших тестов и начать их поднимать. При этом у нас есть несколько веток в системе контроля версий (стабильная и ветки, в которых мы делаем новые фичи). И на каждую крупную ветку мы напускаем агентов.
Отдельного упоминания должно удостоиться время, когда мы поднимаем тесты. Затягивать тут нельзя. Я слышал, что в некоторых командах в Майкрософте вся работа останавливается и не возобновляется, пока есть хотя бы один упавший тест. Так делать мы, честно говоря, не пробовали и поднимаем тесты ежедневно (этим занимается дежурный инженер), а перед каждым релизом, во время стабилизации (в тяжелых случаях — вся команда).
В результате код тестов в строках примерно равен коду системы. Нам удалось выстроить для запуска серьезную инфраструктуру. Что же мотивирует нас это делать? Мы уже давно поняли, что без тестов на длительных временных промежутках мы затратим на разработку больше времени. Многие из вас наверняка не раз участвовали в обсуждениях того, что может поломать очередной большой коммит, а потом в пожарном порядке ночь напролет исправляли то, о чем не подумали и что не было найдено тестерами. Или приходили к выводу, что важный рефакторинг, который ускорит работу или сделает код лучше, вы вообще не можете себе позволить, потому что выявление возникших проблем займет непрогнозируемое время. Очень приятно ощущать контроль над происходящим и понимать, что любое изменение системы реально. Писать комплексные системы задача непростая, а писать всегда качественно работающие, часто меняющиеся, но устойчивые к изменениям системы, сложнее на порядок.
#### Парное программирование
Мы пишем почти весь код в парах и стремимся к общему владению кодом. То есть у нас нет разделения: серверный программист, клиентский или, скажем, разработчик БД. Любой член команды может взять любую задачу. Понятно, что компетентность и вовлеченность в проект или в какую-то его область у всех разная, поэтому чтобы распространить знания мы используем пары. А ещё вдвоем гораздо веселее. Честно. А самое главное, что это ничуть не медленнее — при работе в паре разработчики вообще не отвлекаются на посторонние дела.
#### Pre-commit code review
В ситуации общего владения кодом довольно разумно показать, что пара собирается закоммитить, другому участнику команды, наиболее погруженному в эту тему. Во-первых, объясняя ревьюеру, что они только что написали, пара в итоге сама понимает это окончательно. Во-вторых, ревьюер очень быстро видит какие-то совсем тупые проблемы и указывает на них. В-третьих, информация распространяется от пары еще на одного разработчика — это тоже прекрасно.
#### Планирование
Это, конечно, нельзя назвать инженерной практикой в чистом виде, просто планирование настолько важная часть жизни команды разработки, что не говорить о нем совершенно невозможно. Все, о чем я писал выше, было связано с качеством, но качество не может быть единственной целью. Хороший код, множество тестов и релизы, которые очень стабильны, но происходят раз в полгода или реже, быстро заведут проект в тупик. Это может работать в заказной разработке, если у вас есть клиент, понимающий что он хочет, готовый за это хорошо заплатить и ожидающий просто качественного воплощения своих желаний. Во всех остальных случаях нужны более частые релизы, чтобы была возможность проверить правильность своих идей и подкорректировать их. В итоге нужно понимать, что команда сумеет сделать в ближайшие несколько недель с высокой степенью достоверности. А парное программирование и общее владение кодом требует, чтобы до начала работы все разработчики понимали задачи одинаково. Мы это обеспечиваем с помощью planning poker — широкоизвестной практики команд, применяющих гибкие методологии разработки. Классический подход состоит в том, что команда набирает несколько задач в очередную итерацию разработки (мы используем двухнедельные итерации) и голосует сколько «идеальных» часов займет каждая задача. Наше ноухау состоит в инновационной форме представления результатов голосования, мы используем вот такой mindmap:

Буквы — это название задачи, а цифры — часы, которые возникли в результате игры в покер. Но самое классное, что мы переоцениваем ситуацию каждый день. По каждой задаче определяется прогресс — какая часть уже была сделана. В итоге мы на очень раннем этапе можем отреагировать на любые форс-мажоры, поэтому не нужно ждать окончания итерации, чтобы понять, что команда не успевает, либо наоборот готова взять в итерацию дополнительные задачи.
#### Баги
Багов нет только там, куда не ступала нога разработчика. И если учесть, что у нас есть стремление делать значимый релиз раз в месяц, то есть все шансы утонуть в багах, потому что времени на их исправление нет. Ещё надо учесть, что обычно фикс багов — достаточно внеплановое занятие. Когда количество багов достигнет критической массы, придётся их лихорадочно фиксить, что может разрушить все планы.
Мы лицом к лицу столкнулись с этой проблемой и нашли выход, который вроде бы работает, — дни багов. Сначала у нас был один день багов в итерацию, но количество багов всё равно продолжало расти. Поэтому мы ввели ещё один день багов, который проводится на второй неделе итерации. Таким образом, мы всегда знаем, что у нас два дня в итерацию отведены под баги, и учитываем это при планировании. Надо заметить, что такая ситуация у нас возникла не сразу, а сравнительно недавно. Первое время мы как-то обходились и без этого.
#### Рефакторинг
Какой ~~русский~~ программист не любит рефакторинг? Несмотря на то, что наличие тестов позволяет довольно спокойно проводить любой рефакторинг, всё равно не всегда удаётся уделить этому достаточное количество времени по той же причине, по которой растёт количество багов, — релиз раз в месяц. Если баг можно закрыть (или не закрыть), ничего при этом не потеряв (и даже не демотивироваться), то ввязавшись в рефакторинг, порой отступить уже нельзя и некуда. Чтобы решить данную проблему, ещё один день в итерацию выделяется под «день свободного творчества», в который можно делать всё, что угодно: рефакторить, делать какие-нибудь магические вещи. А кто-то в этот день, как это не парадоксально, по собственному желанию фиксит баги!
#### Дежурный инженер
Не всегда есть возможность отложить исправление бага до специально отведенного для исправлений дня. А у техподдержки, колцентра и аналитиков каждый день возникают различные вопросы и просьбы к разработчикам. Чтобы не отвлекать всю команду, каждую итерацию мы выбираем жертву — дежурного инженера. Смысл его существования — отвечать на все вопросы и выполнять все просьбы Эльба-людей, не являющихся разработчиками.
#### Релиз-инженер
У нас несколько нетрадиционное представление об этой роли. Для каждого релиза мы назначем релиз-инженера из разработчиков. Его цель обеспечить, чтобы все функциональные тесты проходили, патчи были подготовлены и протестированы и ни у кого не было вопросов по релизу вообще. Это не значит, что релиз-инженер сам поднимает все тесты, главное, чтобы он поднимал правильные вопросы и всех мотивировал для получения ответов. И конечно, он обязательно присутствует при релизе, и готов решить любую возникшую проблему.
На самом деле, как правило, дежурный инженер и релиз-инженер — один человек.
#### Результат
Действуя таким образом, нам удается уже почти 2 года делать 1 значимый релиз в месяц. Система развивается очень динамично, но мы не боимся делать несколько апдейтов в неделю (не все удается запланировать: законодательство меняется слишком стремительно и рост пользователей в последние полгода произошел очень существенный), наши инженерные практики делают разработку очень управляемой и прогнозируемой.
Технические детали
IDE: Microsoft VisualStudio + [JetBrains ReSharper](http://www.jetbrains.com/resharper/)
Continuous Integration сервер: [JetBrains TeamCity](http://www.jetbrains.com/teamcity/)
Багтрэкер: [JetBrains YouTrack](http://www.jetbrains.com/youtrack/)
Функциональные тесты: [Selenium](http://seleniumhq.org/)
VCS: Mercurial
Web-сервер: Microsoft IIS + nginx
БД: MS SQL Server
P.S. Может быть, это не очевидно из текста, но у нас есть тестировщик. Он все время загружен работой и работает очень хорошо :)
P.P.S. Спасибо горячо нами любимой компании [ДжетБрейнс](http://www.jetbrains.com/) за отличные инструменты :) | https://habr.com/ru/post/128427/ | null | ru | null |
# Xaraya CMS — глава первая, «Введение»
[Xaraya](http://xaraya.com) (читается «Зарая») — не просто еще одна CMS. Она предоставляет вдумчивому администратору сайта, готовому потратить некоторое время на освоение архитектуры и понимание внутреннего устройства, фактически готовый фреймворк, позволяющий сделать все, что угодно.
Порог входа в Xaraya несколько выше, чем у других известных мне CMS, но, во-первых, ненамного, а во-вторых — поверьте, оно того стоит.
В данной статье я попытаюсь максимально упростить начало работы с Xaraya, а заодно — расскажу о том, как прикрутить к сайту всяких библиотекарш и шахматы. Все нижесказанное относится к ветке 1.\* (последняя на данный момент версия — [1.2.3](http://sourceforge.net/projects/xaraya/files/Core%20plus%20Modules/Xaraya%201.2.3%20Core%20Plus/), качать имеет смысл сразу `full`, чтобы дополнительно не искать модули). Ветка 2.\* как-то меня не впечатлила, очень многое переделано, обратной совместимости нет, многие модули еще не адаптированы — в общем, сыровато для стабильной работы.

Установка
---------
Установить Xaraya очень просто — нужно скачать дистрибутив, содержимое папки `html` распаковать, например, в корень сайта (или не в корень), подготовить пустую базу данных и браузером сходить по адресу `XARAYA_HOME/install.php`. Инсталлятор проведет вас через весь процесс и скоро у вас будет рабочий сайт (не забудьте после этого стереть файлы `install.php` и `upgrade.php`.
Ключевые моменты архитектуры
----------------------------
Xaraya — модульное MVC приложение. В базовую поставку входит все, нужное для развертывания обычного сайта. Единицей информации в Xaraya является «публикация». Публикация состоит из набора «полей» (например, «Заголовок», «Введение», «Текст», «Картинка»). У каждого типа публикаций — несколько шаблонов вывода (например: «в ленте», «на отдельной странице»). Посмотреть на предустановленные типы публикаций можно в (здесь и далее: `XARAYA_HOME` — это что-то наподобие `mybestsite.ru`) `XARAYA_HOME/index.php?module=articles&type=admin&func=pubtypes`.
Набор шаблонов вывода — называется темой («theme») и располагается в папке `themes`. Управление осуществляется через `XARAYA_HOME/index.php?module=themes&type=admin&func=list`. Можно заметить, что RSS и «версия для печати» тоже сделаны через темы, что упрощает редактирование вывода для разных «устройств».
Темы Xaraya
-----------
Создание собственной темы — процесс поначалу нетривиальный, но захватывающий.
Язык шаблонов — XML с дополнительными свистелками (о них — чуть позже). Xaraya будет искать шаблон сначала в соответствующем каталоге вашей темы, потом — если такового там не окажется — в папке `xartemplates` соответствующего модуля. Поиск осуществляется *по имени шаблона*. Например, пытаясь отобразить запись в блоге (модуль `articles`, тип публикации `news`, вид отображения — `display`), Xaraya сначала заглянет в папку `/themes/YOUR_THEME/modules/**articles**` и поищет там файл `user-display-news.xt`. Если не найдет — возьмет стандартный из поставки (`/modules/articles/xartemplates/user-display-news.xd`). Таким образом обеспечивается *каскадность* — переписывать вам придется только те шаблоны, которые вас не устраивают в стандартном представлении.
Главные шаблоны — шаблоны страниц — лежат в папке `/themes/YOUR_THEME/pages`. Основных — три: * `default.xt` — на все про все,
* `frontpage.xt` — отображение главной страницы, и
* `module.xt` — отображение содержимого конкретного модуля (используется реже).
Вот более-менее стандартный вид файла `default.xt`:
```
xml version="1.0" encoding="utf-8"?
xar type="page" ?
#xarTplGetThemeDir()#
```
Блоки могут группироваться (см. `xar:blockgroup name="*" id="*"`). К переменным и функциям контроллера можно обращаться через конструкцию `#PHP_CODE#`. Переменные передаются из контроллера, который лежит в `/modules/MODULE_NAME/xaruser`. Модель располагается в `/modules/MODULE_NAME/xaruserapi`. В Xaraya почти все организовано через naming conventions; например, контроллер вывода отдельной публикации живет в `/modules/articles/xaruser/display.php`, в функции `articles_user_display($args)` и передает в шаблон данные вот так (`$data` и `$template`, разумеется, подготовлены собственно в коде функции):
```
return xarTplModule('articles', 'user', 'display', $data, $template);
```
На время написания и отладки шаблонов — рекомендую включить опцию «Show template filenames in HTML comments» на странице Admin ⇒ Themes ⇒ Modify Config (`XARAYA_HOME/index.php?module=themes&type=admin&func=modifyconfig`). Кстати, ЧПУ могут быть отдельно включены для каждого модуля в настройках, а русская локализация — [скачана](http://mt.xaraya.com/download/nightly/languages/) и распакована в папку `/var/locales/`.
Практика
--------
Собственно, пора бы уже написать какой-нибудь шаблон. Рекомендую создать новую публикацию типа «news», чтобы шаблон проще было отлаживать. Вот код из темы моего блога:
```
#$data['summary']#
#$data['body']#
*#$data['notes']#*
```
Сначала я «подключаю» шаблон вывода заголовка — он у меня одинаковый для всех типов публикаций, а дублировать код я не люблю. Потом вывожу поля записи (если они не пусты). Затем вывожу блок комментариев (я пользуюсь DISQUS для этого, в вызываемом блоке — просто сниппет, который они мне выдали). Затем вызываю хуки преобразований (о хуках нужно писать отдельно, пока же ограничусь тем, что они есть; теги, например, выводятся здесь через соответствующий хук, поскольку модуль `articles` ничего не знает о тегах). Вот как это выглядит в результате:
Обратите внимание: комментарии выводятся через свой шаблон, теги — через свой, и они все могут быть разными.
The Summing Up
--------------
Для введения, мне кажется, достаточно. Какая-то слегка сумбурная получилась заметка, но я честно пытался рассказать про основную архитектуру, дать, что ли, введение.
Если тема окажется интересной — могу продолжить (например, рассказать про создание темы с нуля до «рабочего варианта», либо провести через процедуру «создания модуля»). Свои модули — это то, что превращает Xaraya во фреймворк. Ну а уж своя тема — она настолько легко настраиваема в мельчайших подробностях, что, зачастую, «узнать» движок становится просто невозможно.
Если я упустил что-то важное для понимания механизма работы этой CMS — обязательно спрашивайте в комментариях. Апдейты к статьям пока еще разрешены.
**Upd**: я в легком шоке. Меня [попросили](http://habrahabr.ru/blogs/about_cms/114955/#comment_3715251) рассказать, что я знаю о Xaraya — и теперь я не могу опубликовать ссылку из-за **22** свалившихся минусов в карму.
Ну и сидите без ссылки ;-) | https://habr.com/ru/post/115052/ | null | ru | null |
# День защиты детей от плохого кода
*Пост посвящен дню защиты детей. Любые совпадения – не совпадения.*
В 10 лет у меня появились первый компьютер и диск с Visual Studio 6. С тех пор я придумываю себе задачки — автоматизировать дела, собрать какой-нибудь веб-сервис для трёх человек или написать игру, которую потом удалят из плеймаркета от старости. Конечно, я терял исходники и писал код, который стыдно показывать людям. И в 10 лет я бы точно не отказался получить из будущего архив со всеми косяками — чтобы никогда их не допускать.
Пару недель назад я спросил коллег из Яндекс.Денег, что бы они сейчас посоветовали ребенку, который хочет стать айтишником, а потом вспомнил кое-что о себе. Так появился этот текст. Предлагаю об этом поговорить.
---
*Не рекомендую тратить много сил на муки выбора, лучше всё пробовать и всем заниматься. Когда поймешь, что есть что в общих чертах, сможешь сам решить, в каком направлении надо двигаться, а от какого лучше отказаться.*
*Сергей, младший программист*
---
Детство
-------
Какое самое веселое занятие в программистском детстве, когда ещё нет интернета?
У меня их было два — разобрать все игры с диска «800 игр на русском языке» всеми программами с диска «Всё, что нужно хакеру», а потом переписать все игры, на которые потратил больше 10 часов, с нуля на Бейсике. Нет никакой разницы, что получится, — даже если получится такое.
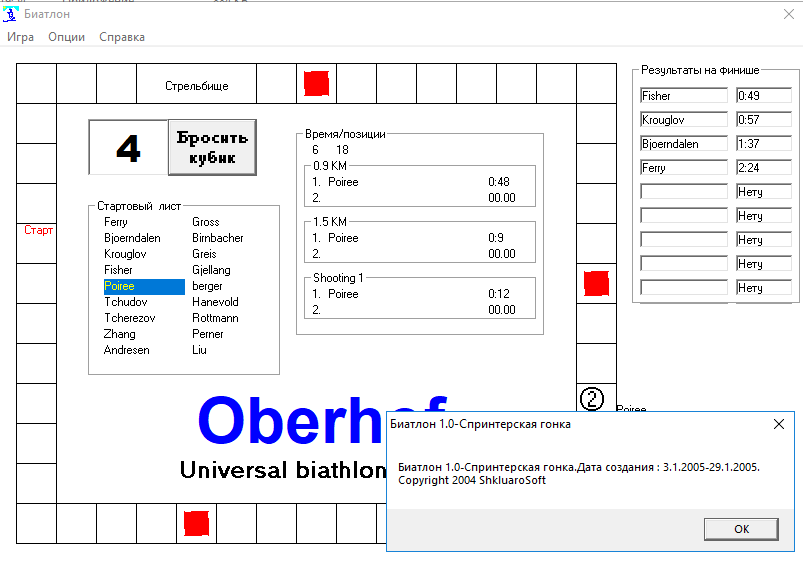
Ты берёшь, пробуешь, переставляешь блоки местами, экспериментируешь и дотягиваешься до всего, до чего можно дотянуться. Сносишь Windows, 10 часов ставишь Windows обратно. Пытаешься вернуть драйверы. Разбираешься, как устроен DOS. Разбираешься, как должны стоять перемычки, чтобы твой хард завелся в компьютере у друга (там 200 мегабайт новых игр!). Крутишь софт, крутишь железо, разбираешь и собираешь компьютер. Пишешь футбольный симулятор 13 лет, в конце концов.
Когда нет ничего, становишься счастливым и от такого.
---
*Нельзя недооценивать важность самопроверки. По-моему, новички в IT недооценивают, как строго придётся контролировать свой продукт (и в аналитике тоже) и как много это занимает времени по сравнению с чисто творческой частью. И чем интереснее то, что ты делаешь, тем сложнее и дольше будет проверка.*
*Это, конечно, несколько абстрактный совет, но если бы я сразу знала.*
*И не рекомендую зацикливаться на одном направлении в IT. Тут тоже кругозор имеет значение.*
*Анна, старший системный аналитик*
---
Средняя школа
-------------
В какой-то момент на форуме уездного города П обсуждали программирование — и там появился тред с заголовком «В крупную компанию ищутся программисты PHP». Текст объявления был таким:
```
В крупную компанию ищутся программисты PHP:
Для того, чтобы понять, стоит ли вам приходить на собеседование, выполните несложное задание: напишите программу на php, которая находит такие целые положительные числа x, y и z, чтобы x^5+y^5=z^5. (^ - степень).
Отвечать можете здесь.
```
В этом треде отписались всего несколько человек — там был и я. Со всей своей шестнадцатилетней наивностью я ответил:
```
Реально чет странное. Да и комп нужен неслабый, штоб ето найти...
Ибо от x,y,z <=1000 таких чисел нет-эт во первых (сел набросал в vb, большего ПОКА не дано), во вторых комп подсаживается намертво.
Не все равно чето нето, ИМХО.
```
Да, розыгрыш, ловушка для новичков, ~~да, падонкафский, ну и што~~. Очевидно, что я потратил сколько-то времени на простой скрипт, но совсем забыл о существовании теоремы Ферма — о чем автор треда, достопочтенный The\_Kid, уточнил в самом конце.
```
Итог печален - в П. практически нет людей, знающих математику, но каждый второй мнит себя мего программистом. За три часа, на все форумах на которых я разместил сообщение, было суммарно около двух сотен просмотров... и всего два правильных ответа. А теорема Ферма - это ведь школьная программа, и условия ее настолько просты, что должны бросаться в глаза. Кстати, параллельно при опросе в аське 6 из 6 знакомых новосибирских студентов ответили «Это же теорема Ферма».
И кого после этого брать на работу?
```
Тогда это вызвало у меня бурю возмущения в духе: «Если я не написал про теорему Ферма, это не значит, что я о ней не знаю», — классическая отмазка. Грустно ли мне сейчас? Нет, это тоже урок на всю жизнь. Как тогда, когда мою игру зафичерили в индонезийском Windows Phone Store, а через две недели удалили, потому что я не обновил какие-то там условия EULA.
И совершенно ведь непонятно: если в одной там крупной компании некого брать на работу — кем же тогда быть? Чем заниматься? Куда расти?
---
*Не стоит думать, что, получив образование, ты будешь программистом/таксировщиком/математиком или ещё кем-то.*
*Пришли времена, когда в дипломе становятся намного более важными базовые предметы (математика, физика, информатика, философия), а не прикладные (программирование, проектирование в конкретных областях, прочее). Высшее образование начало разделяться на слои – базовый (инженерный) и прикладной. Следует учиться не конкретным навыкам, а мышлению, научному подходу, пониманию, как решать проблемы, софт скиллам.*
*Это что касается университета. На прикладные навыки у человека ещё будет вся остальная жизнь.*
*Олег, ведущий системный аналитик*
---
Университет
-----------
Пишешь код на «плюсах», пишешь код на Джаве. Трогаешь ассемблер, отводишь руку, вляпываешься в Qt и думаешь, за что так с тобой поступают. Курсу к четвертому всем становится всё равно, на чём ты пишешь очередные важные лабы, — преподаватели смотрят на код кое-как.
Так, конечно, не везде — есть вузы, где мощно и хорошо, но туда берут ребят, которые в школе решали задачи из ACM, на дополнительных занятиях выжимали всё из теории графов и зубрили, сколько памяти требуют все существующие в мире алгоритмы всего на свете.
Я вот не решал, не ходил на допы, а просто доучился в своём математическом классе, попутно делая интересные штуки. Спойлер — на собеседованиях они будут никому не нужны.
---
*Сначала лучше определиться, что нравится из IT. Если нравятся все направления, то будет сложно. Учить какой-то язык —* *ни к чему не приведет, будет только путаница в дальнейшем.*
*Ян, специалист по фин. мониторингу*
---
Реальная история — за симулятор Windows, сделанный с товарищем на коленке в 10 классе, в универе можно получить пару экзаменов и зачетов автоматом. Можно даже потом рассказывать всем, как это было классно. Проблема в том, что это не было классно — это были запутанная архитектура, отвратительный код и полное отсутствие каких-либо стандартов хоть чего-нибудь.
Такие вещи нужно делать с одной целью — чтобы был собственный каталог граблей. Хотя это и не убережет от синдрома самозванца, когда оказался в большой компании с какими-то своими поверхностными знаниями по всему и думаешь, что тебя сейчас разоблачат.

---
*Поддержу, важнее помогать советами, что можно делать и где брать инфу, а не наоборот. И совершенно не страшно, если он вначале будет на ощупь что-то делать,* — *осознание позже придёт. Важно, чтобы нравилось.*
*Эрик, инженер по тестированию*
---
Все мы пишем планы развития — что нужно изучить, чем заниматься в ближайшем будущем и как себя улучшать. Но кажется, всем нам было бы полезно написать письмо себе из прошлого — вот моё.
1. Потрать время, найди книжку и поставь-таки тот дистрибутив Убунты, который тебе бесплатно прислали из Canonical. Там явно какая-то простая проблема, Убунта заводится везде. А Линукс тебе очень пригодится.
2. Не бойся консоли. Volkov Commander, конечно, помещается на одну дискету, но попробуй разобраться, зачем тебе все эти команды, подружись с командной строкой. А дискеты умрут. Диски умрут. Флешки тоже умрут. Не сильно переживай.
3. Почитай про алгоритмы, разберись в сортировках, деревьях и кучах. Читай книжки.
4. Чтобы разобраться в основах, платные курсы не нужны. Скоро появится Ютуб – вот ты удивишься.
5. Не зацикливайся на Бейсике. В мире есть сотня технологий, которые стоят твоего внимания, и миллион вещей, которые интереснее, чем в очередной раз рисовать юзерформы в Экселе. Возьми хотя бы Python — а дальше разберешься.
6. Научись пользоваться Гитом, забэкапь все исходники. Напиши хотя бы одно клиент-серверное приложение, чтобы понимать, как они работают. Разберись в сетях, свитчах и маршрутизаторах.
7. И если ты сейчас это читаешь, значит всё не зря.
---
Расскажите в комментариях, что бы вы написали себе из прошлого? Посоветуйте что-нибудь нынешним школьникам и студентам, которые пока на распутье и пытаются найти свой путь. Давайте поговорим об этом. | https://habr.com/ru/post/454260/ | null | ru | null |
# Новое в СУБД Caché 2013.1: встроенная поддержка WebSockets
В одной из предыдущих [статей](http://habrahabr.ru/company/intersystems/blog/144311/) уже рассматривалась работа с WebSocket на примере собственной серверной реализации этого протокола поверх обычных сокетов.
В СУБД Caché 2013.1 CSP-Шлюз теперь включает поддержку спецификации HTML 5 для WebSocket-соединений между веб-сервером и HTML 5 совместимым браузером. Эта функция доступна для Apache 2.2 и выше, и для IIS 8.0, который является частью Windows Server 2012.
Поскольку в Caché 2013.1 уже встроен Apache 2.4, мы будем наши примеры запускать именно на нём.
Для реализации клиентской части использовался фреймворк [ZEN](http://www.intersystems.ru/cache/technology/components/zen/index.html), но вы можете переделать примеры и на технологию [CSP](http://www.intersystems.ru/cache/technology/components/csp/index.html) или любую другую.
Итак приступим.
#### Теория
Как уже было сказано выше, теперь всю внутреннюю логику по поддержке WebSocket на стороне сервера СУБД Caché берёт на себя. От программиста требуется лишь создать свой класс, унаследовав его от класса **%CSP.WebSocket**, и переопределить в нём несколько методов.
Объект класса **%CSP.WebSocket** служит в качестве обработчика событий для связи между клиентом и сервером с использованием протокола WebSocket. Все WebSocket-сервера наследуются от **%CSP.WebSocket**.
Подробное описание методов и свойств класса [%CSP.WebSocket](http://docs.intersystems.com/cache20131/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25CSP.WebSocket) можно найти в справочнике классов.
Здесь отмечу кратко лишь некоторые из них:
| Метод/Свойство | Описание |
| --- | --- |
| *Read()* | получить данные от клиента |
| *Write()* | отправить данные клиенту |
| *OnPreServer()* | обработчик события PreServer: вызывается перед стартом WebSocket-сервера |
| *OnPostServer()* | обработчик события PostServer: вызывается после останова WebSocket-сервера |
| *Server()* | собственно сам WebSocket-сервер |
| *EndServer()* | остановить WebSocket-сервер |
| *AtEnd* | свойство принимает значение true (1), когда во время чтения, WebSocket-сервер достигает конца текущего кадра данных |
| *SharedConnection* | свойство определяет, будет ли обмен информацией между клиентом и WebSocket-сервером происходить по выделенному соединению CSP-Шлюза или через пул разделяемых соединений (пока не используется) |
#### Практика
Давайте рассмотрим простой пример, как всё это можно использовать на практике.
Для начала создадим в Студии в области **USER** ZEN-страницу — класс **demo.WebSocket** — и унаследуем её от класса **%CSP.WebSocket**:
> Class demo.WebSocket Extends (%ZEN.Component.page, %CSP.WebSocket)
>
> {
>
>
>
> XData Contents [ XMLNamespace = "[www.intersystems.com/zen"](http://www.intersystems.com/zen)]
>
> {
>
> <page xmlns="[www.intersystems.com/zen"](http://www.intersystems.com/zen)title="">
>
> page>
>
> }
>
>
>
> }
Подключим файл *zenCSLM.js* для поддержки работы с JSON:
> Parameter JSINCLUDES = "zenCSLM.js";
Реализуем методы для подключения клиента по WebSocket и обработки соответствующих событий:
> /// This client event, if present, is fired when the page is loaded.
>
> ClientMethod onloadHandler() [ Language = javascript ]
>
> {
>
> ws=null;
>
>
>
> url=((window.location.protocol == 'https:') ? 'wss:' : 'ws:') + '//' + window.location.host + window.location.pathname;
>
>
>
> wsCtor = window['MozWebSocket'] ? MozWebSocket : window['WebSocket'] ? WebSocket : null;
>
>
>
> if (zenIsMissing(wsCtor)) zenAlert('WebSocket НЕ поддерживается вашим браузером!');
>
> }
>
>
>
> ClientMethod start() [ Language = javascript ]
>
> {
>
> if (!zenIsMissing(wsCtor)) {
>
> if (zenIsMissing(ws)) {
>
> ws = new wsCtor(url);
>
>
>
> ws.onopen = function() {
>
> zenAlert('onopen\n\nreadyState: ',ws.readyState,'\nbinaryType: ',ws.binaryType,'\nbufferedAmount: ',ws.bufferedAmount);
>
> };
>
>
>
> ws.onmessage = function(e) {
>
> zenAlert(e.data);
>
> };
>
>
>
> ws.onclose = function(e) {
>
> zenAlert('onclose\n\nwasClean: ',e.wasClean,'\ncode: ',e.code,'\nreason: ',e.reason);
>
> ws=null;
>
> };
>
>
>
> ws.onerror = function(e) {
>
> zenAlert('onerror');
>
> };
>
> }
>
> }
>
> }
Поскольку реализация WebSocket-сервера находится на этой же странице, строка подключения будет идентичной за исключением протокола. То есть, если url нашей ZEN-странички имеет вид
`localhost:57772/csp/user/demo.WebSocket.cls`
, то для WebSocket-сервера это будет
`ws://localhost:57772/csp/user/demo.WebSocket.cls`
Теперь давайте добавим на нашу страницу немного интерфейса: несколько кнопок для подключения, отключения и отправки данных на сервер:
> XData Contents [ XMLNamespace = "[www.intersystems.com/zen"](http://www.intersystems.com/zen)]
>
> {
>
> <page xmlns="[www.intersystems.com/zen"](http://www.intersystems.com/zen)title="">
>
> <text id="txt" label="Текст для отправки" value="Мир"/>
>
> <button caption="1.Подключиться" onclick="zenPage.start();"/>
>
> <button caption="2.Отправить текст" onclick="if (!zenIsMissing(ws)) ws.send(zenGetProp('txt','value'));"/>
>
> <button caption="3.Отправить длинную строку" onclick="zenPage.sendLongStr(100000);"/>
>
> <button caption="4.Отправить JSON" onclick="zenPage.sendJSON();"/>
>
> <button caption="5.Отключиться" onclick="if (!zenIsMissing(ws)) ws.close();"/>
>
> page>
>
> }
Код метода *sendLongStr* следующий:
> ClientMethod sendLongStr(N) [ Language = javascript ]
>
> {
>
> if (zenIsMissing(ws)) return;
>
>
>
> var s='a';
>
> for(var i=1;i<N;i++) s+='a';
>
> ws.send(s);
>
> }
Код метода *sendJSON*:
> ClientMethod sendJSON() [ Language = javascript ]
>
> {
>
> if (zenIsMissing(ws)) return;
>
>
>
> var obj={
>
> "firstName": "Иван",
>
> "lastName": "Иванов",
>
> "address": {
>
> "streetAddress": "Московское ш., 101, кв.101",
>
> "city": "Ленинград",
>
> "postalCode": 101101
>
> },
>
> "phoneNumbers": [
>
> "812 123-1234",
>
> "916 123-4567"
>
> ]
>
> };
>
>
>
> ws.send(ZLM.jsonStringify(obj));
>
> }
Пришло время реализации собственно нашего WebSocket-сервера. Для этого переопределим методы *OnPreServer*, *OnPostServer* и *Server*, как показано ниже:
> Method OnPreServer() As %Status
>
> {
>
> Do $system.Process.Undefined(2)
>
>
>
> Set ^tmp($Increment(^tmp),"OnPreServer")=""
>
> Quit $$$OK
>
> }
> Method OnPostServer() As %Status
>
> {
>
> Set ^tmp($Increment(^tmp),"OnPostServer")=""
>
> Quit $$$OK
>
> }
> Method Server() As %Status
>
> {
>
> For {
>
>
>
> Set len=32656
>
> Set data=$ZConvert(..Read(.len,.status),"I","UTF8")
>
>
>
> If $$$ISOK(status) {
>
>
>
> If data="Мир" {
>
> Do ..Write($ZConvert("Привет, "\_data\_"!","O","UTF8"))
>
> }ElseIf data="bye" {
>
>
>
> ; принудительно завершаем работу WebSocket-сервера и выходим из бесконечного цикла
>
> ; на клиенте при этом сработает onclose
>
> Do ..EndServer()
>
> Quit
>
>
>
> }Else{
>
>
>
> #Dim obj As %RegisteredObject=$$$NULLOREF
>
>
>
> Set ^tmp=$Increment(^tmp)
>
>
>
> ; преобразовываем строку в объект
>
> If $$$ISOK(##class(%ZEN.Auxiliary.jsonProvider).%ConvertJSONToObject(data,,.obj)) {
>
>
>
> ; если нет ошибки, сохраняем значения свойств
>
> Set ^tmp(^tmp,"Server","firstName")=obj.firstName
>
> Set ^tmp(^tmp,"Server","lastName")=obj.lastName
>
> Set ^tmp(^tmp,"Server","address.streetAddress")=obj.address.streetAddress
>
> Set ^tmp(^tmp,"Server","address.city")=obj.address.city
>
> Set ^tmp(^tmp,"Server","address.postalCode")=obj.address.postalCode
>
> Set ^tmp(^tmp,"Server","phoneNumbers.1")=obj.phoneNumbers.GetAt(1)
>
> Set ^tmp(^tmp,"Server","phoneNumbers.2")=obj.phoneNumbers.GetAt(2)
>
>
>
> ; Меняем фамилию
>
> Set obj.lastName="Сидоров"
>
>
>
> ; Добавляем ещё один телефон
>
> Do obj.phoneNumbers.Insert("111 111-1111")
>
>
>
> ; Добавляем к объекту ещё два новых свойства
>
> Set obj.name="Вася"
>
> Set obj.street="ул. Мира 17"
>
>
>
> ; Конвертируем изменённый объект в строку и отсылаем клиенту обратно
>
> Do ..Write(..Write2Str(.obj))
>
>
>
> }Else{
>
>
>
> ; сохраняем данные при получении длинной строки
>
> Set ^tmp(^tmp,"Server","longStr")=..AtEnd\_":"\_$Length(data)\_":"\_len
>
> }
>
> }
>
> }Else{
>
> Quit:($$$GETERRORCODE(status)=$$$CSPWebSocketClosed)
>
> }
>
> }
>
> Quit $$$OK
>
> }
Служебный метод *Write2Str* служит для сборки в строку, выводимых командой Write, данных:
> ClassMethod Write2Str(ByRef obj) As %String [ Private ]
>
> {
>
> Try{
>
> Set tIO=$IO,tXDEV="|XDEV|"\_+$Job
>
> Do {
>
>
>
> // For $$$IsUnicode use UTF-8
>
> Open tXDEV:($ZF(-6,$$$XSLTLibrary,12):"":"S":/HOSTNAME="XSLT":/IOT=$Select($$$IsUnicode:"UTF8",1:"RAW"):/IBU=16384:/OBU=16384)
>
> Use tXDEV
>
>
>
> Quit:$$$ISERR(obj.%ToJSON(,"aeloiwu"))
>
>
>
> // Flush any remaining output
>
> Write \*-3
>
>
>
> // Now read back a string (up to the maximum possible length, 32k or ~4MB for long strings)
>
> Set s = ""
>
> While (1) {
>
> #Dim tChunk As %String
>
> Read tChunk:0
>
> Quit:'$Length(tChunk)
>
> Set s = s \_ tChunk
>
> }
>
>
>
> } While (0)
>
> }Catch{}
>
>
>
> Close tXDEV
>
> Use tIO
>
> Quit s
>
> }
Осталось скомпилировать наш класс (Ctrl+F7) и открыть его для просмотра в браузере (F5).
После последовательного нажатия на кнопки содержимое глобала ^tmp будет следующим:
`^tmp=7`
`^tmp(1,"OnPreServer")=""`
`^tmp(2,"Server","longStr")="0:32656:32656"`
`^tmp(3,"Server","longStr")="0:32656:32656"`
`^tmp(4,"Server","longStr")="0:32656:32656"`
`^tmp(5,"Server","longStr")="1:2032:2032"`
`^tmp(6,"Server","address.city")="Ленинград"`
`^tmp(6,"Server","address.postalCode")=101101`
`^tmp(6,"Server","address.streetAddress")="Московское ш., 101, кв.101"`
`^tmp(6,"Server","firstName")="Иван"`
`^tmp(6,"Server","lastName")="Иванов"`
`^tmp(6,"Server","phoneNumbers.1")="812 123-1234"`
`^tmp(6,"Server","phoneNumbers.2")="916 123-4567"`
`^tmp(7,"OnPostServer")=""`
Скачать [исходник](http://db.tt/XvYtcXue) класса **demo.WebSocket**. | https://habr.com/ru/post/181113/ | null | ru | null |
# Всё как у больших. Автозагрузка приложений в оконных менеджерах linux
[](https://habr.com/ru/company/ruvds/blog/583328/)
*Вывод systemd-analyze dot --user ‘i3.service’ | dot -Tpng | imv -*
Как-то раз, листая сообщения в профильном *systemd* [чате, в телеграм](https://t.me/ru_systemd), я наткнулся на следующий кусок `man systemd.special`…
```
xdg-desktop-autostart.target
The XDG specification defines a way to autostart applications using XDG desktop files.
systemd ships systemd-xdg-autostart-generator(8) for the XDG desktop files in autostart
directories. Desktop Environments can opt-in to use this service by adding a Wants=dependency
on xdg-desktop-autostart.target.
```
О как интересно, подумалось мне. Можно реализовать функционал полноценных`Desktop Environments`, по автоматическому запуску приложений, при старте. А у меня как раз *i3wm*, который таковым не является и которому такой функционал не помешал бы. Надо это дело исследовать. Тогда я ещё не знал во что ввязался. Как оказалось, не всё так просто.
Переменные XDG, freedesktop.org, desktop-файлы и autostart
----------------------------------------------------------
Пользователям полноценных линуксовых графических окружений (KDE, Gnome, Mate etc) прекрасно известна возможность автозапуска приложений при логине пользователя в систему, разработанную инициативной группой [Freedesktop.org](https://www.freedesktop.org/wiki/) (ранее X Desktop Group, или *XDG*), подобная той, что существует, например, в Windows. Данный функционал обеспечивается обычными `*.desktop` [файлами](https://specifications.freedesktop.org/desktop-entry-spec/latest/), но лежащими по определённым путям:
* `$XDG_CONFIG_DIRS/autostart/` (`/etc/xdg/autostart/` по умолчанию) — общесистемная директория, для всех пользователей. Туда, обычно, попадают десктоп файлы при установке софта пакетным менеджером.
* `$XDG_CONFIG_HOME/autostart/` (`$HOME/.config/autostart/` по умолчанию) — Пользовательская директория, имеющая больший приоритет, нежели общесистемная, то есть если в пользовательской лежит десктоп файл с таким же именем, что и в общесистемной, будет использован именно пользовательский файл.
Если в этих переменных семейства [XDG directories](http://standards.freedesktop.org/basedir-spec/) не указано иное, или эти переменные отсутствуют (так происходит в большинстве **классических** дистрибутивов, привет *NixOS*!), будут использованы значения по умолчанию.
Итак, с директориями определились. Файлы в них можно:
* Симлинкнуть из стандартных путей: `$XDG_DATA_DIRS/applications/` (`/usr/share/applications/` по умолчанию) или из пользовательского `$XDG_DATA_HOME/applications/` (`~/.local/share/applications` по умолчанию), куда, кстати, любят класть свои файлы Steam, Itch.io или Wine.
* Можно создать самому, написав десктоп файлы руками.
* Можно нажать галочку «Запускать при старте системы», в каком-нибудь софте, например, в телеграм клиенте и тогда уже софт сам создаст в `$XDG_CONFIG_HOME/autostart/` свой файл.
Всё хорошо. Одно плохо. Это не работает, как минимум, в *Leftwm*, *Spectrwm*, *xmonad*, *bspwm*, *dwm* (без патчей точно) и, разумеется, в любимом [i3wm](https://i3wm.org/). Просто потому, что у них отсутствует *session manager*. И вот тут мы переходим к самому интересному. Встречайте! *systemd*!
Systemd как спасательный круг тайловых (и не очень) оконных менеджеров
----------------------------------------------------------------------
Эта глава будет самой объёмной. Тут мы разберёмся кто и как может помочь разобрать залежи desktop файлов, кто, как и когда их запустит, и при чём тут вообще *systemd*. Поехали!
### ▍ ~~Developers, developers, developers!~~ Генераторы, генераторы, генераторы!
Systemd, как известно, это не только система инициализации, логгирования событий, но и набор готовых дополнительных утилит, готовых сервисов с их юнитами, система управления сетью, and more… Среди прочего systemd может выступать в качестве системного менеджера для пользовательских сервисов — юнитов, работающих в пространстве пользователя. То есть после логина пользователя в систему запускается ещё один экземпляр `/usr/lib/systemd` только уже от пользователя и позволяет запускать юниты в пространстве пользователя, с наследованием его окружения и правами.
Среди других интересных и полезных вещей в systemd есть такая штука, как генераторы. Маленькие утилиты запускаемые на раннем этапе загрузки системы или сразу после логина пользователя и выполняющие динамическую генерацию юнитов и/или их конфигов. Например, есть генератор, который читает `/etc/fstab` и на его основе генерирует `*.mount` юниты. Или генератор, который вычитывает файлы `*.conf` из `/etc/environment.d/` и `$HOME/.config/environment.d/` и на их основе собирает переменные которые пользователь видит набирая команду `env` и которые наследуются всеми **пользовательскими** юнитами. Среди прочего есть и генератор, который пробегает по `$XDG_CONFIG_DIRS/autostart` и `$XDG_CONFIG_HOME/autostart`, вычитывает `*.desktop` файлы, генерирует пользовательские `*.service` юниты и кладёт их в `/run/user//systemd/generator.late`.
Всё хорошо и замечательно, но есть одно но. Если есть сервисы, их должен кто-то вовремя запустить. То есть запустить ровно тогда, когда будет запущена графическая оболочка… Если посмотреть, произвольный такой юнит, мы увидим там упоминание target-а `graphical-session.target` (Юнит на основе десктоп файла апплета управления Bluetooth `cat /run/user/1000/systemd/generator.late/[email protected]`):
```
# Automatically generated by systemd-xdg-autostart-generator
[Unit]
Documentation=man:systemd-xdg-autostart-generator(8)
SourcePath=/etc/xdg/autostart/blueman.desktop
PartOf=graphical-session.target
Description=Blueman Applet
After=graphical-session.target
[Service]
Type=exec
ExecStart=:/usr/bin/blueman-applet
Restart=no
TimeoutSec=5s
Slice=app.slice
```
Хорошо, но что это за *graphical-session.target*? В выводе `systemctl --user --type=target`, если выполнить команду из-под *i3wm* никакого такого таргета не наблюдается. А вот если запустить из-под, например, *Gnome*, то вполне:
**Многабукв и ничего интересного ;-)**
```
UNIT LOAD ACTIVE SUB DESCRIPTION
basic.target loaded active active Basic System
default.target loaded active active Main User Target
gnome-session-initialized.target loaded active active GNOME Session is initialized
gnome-session-manager.target loaded active active GNOME Session Manager is ready
gnome-session-pre.target loaded active active Tasks to be run before GNOME Session starts
gnome-session-x11-services.target loaded active active GNOME session X11 services
gnome-session-x11.target loaded active active GNOME X11 Session
[email protected] loaded active active GNOME X11 Session (session: gnome)
gnome-session.target loaded active active GNOME Session
[email protected] loaded active active GNOME Session (session: gnome)
graphical-session-pre.target loaded active active Session services which should run early before the graphical session is brought up
graphical-session.target loaded active active Current graphical user session
org.gnome.SettingsDaemon.A11ySettings.target loaded active active GNOME accessibility target
org.gnome.SettingsDaemon.Color.target loaded active active GNOME color management target
org.gnome.SettingsDaemon.Datetime.target loaded active active GNOME date & time target
org.gnome.SettingsDaemon.Housekeeping.target loaded active active GNOME maintenance of expirable data target
org.gnome.SettingsDaemon.Keyboard.target loaded active active GNOME keyboard configuration target
org.gnome.SettingsDaemon.MediaKeys.target loaded active active GNOME keyboard shortcuts target
org.gnome.SettingsDaemon.Power.target loaded active active GNOME power management target
org.gnome.SettingsDaemon.PrintNotifications.target loaded active active GNOME printer notifications target
org.gnome.SettingsDaemon.Rfkill.target loaded active active GNOME RFKill support target
org.gnome.SettingsDaemon.ScreensaverProxy.target loaded active active GNOME FreeDesktop screensaver target
org.gnome.SettingsDaemon.Sharing.target loaded active active GNOME file sharing target
org.gnome.SettingsDaemon.Smartcard.target loaded active active GNOME smartcard target
org.gnome.SettingsDaemon.Sound.target loaded active active GNOME sound sample caching target
org.gnome.SettingsDaemon.Wacom.target loaded active active GNOME Wacom tablet support target
org.gnome.SettingsDaemon.XSettings.target loaded active active GNOME XSettings target
org.gnome.Shell.target loaded active active GNOME Shell
paths.target loaded active active Paths
sockets.target loaded active active Sockets
timers.target loaded active active Timers
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
31 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
```
И что же со всем этим делать и как быть? Как получить заветный *target*?
### ▍ Графическая оболочка тоже сервис. Подсматриваем в Gnome
Если в Gnome запустить `systemctl --user --type=service` можно заметить интересный сервис:
```
UNIT LOAD ACTIVE SUB DESCRIPTION
at-spi-dbus-bus.service loaded active running Accessibility services bus
dbus.service loaded active running D-Bus User Message Bus
...
gnome-shell-x11.service loaded active running GNOME Shell on X11
...
```
Становится всё интереснее. Значит *Gnome* запускается как systemd сервис (`gnome-shell-x11.service`). Ну а уж из сервиса можно реализовывать любые зависимости. В принципе ожидаемо. Но как реализовывать такое для произвольной графической оболочки, которая не заточена под такие тонкие извращения? Надеемся на то не должно быть сложно… Перво-наперво смотрим в юнит (`systemctl cat --user gnome-shell-x11.service`) и понимаем, что ничего не понимаем и что мы немножко попали…
```
# /usr/lib/systemd/user/gnome-shell-x11.service
[Unit]
Description=GNOME Shell on X11
# On X11, try to show the GNOME Session Failed screen
OnFailure=gnome-shell-disable-extensions.service gnome-session-failed.target
OnFailureJobMode=replace
CollectMode=inactive-or-failed
RefuseManualStart=on
RefuseManualStop=on
After=gnome-session-manager.target
Requisite=gnome-session-initialized.target
PartOf=gnome-session-initialized.target
Before=gnome-session-initialized.target
# The units already conflict because they use the same BusName
#Conflicts=gnome-shell-wayland.service
# Limit startup frequency more than the default
StartLimitIntervalSec=15s
StartLimitBurst=3
[Service]
Type=notify
ExecStart=/usr/bin/gnome-shell
# Exit code 1 means we are probably *not* dealing with an extension failure
SuccessExitStatus=1
# On X11 we want to restart on-success (Alt+F2 + r) and on-failure.
Restart=always
```
Ладно, чёрт с ним, идём смотреть в `*.desktop` файл xsessions(`cat /usr/share/xsessions/gnome.desktop`)…
```
[Desktop Entry]
Name=GNOME
Comment=This session logs you into GNOME
Exec=env GNOME_SHELL_SESSION_MODE=gnome /usr/bin/gnome-session --systemd --session=gnome
TryExec=/usr/bin/gnome-shell
Type=Application
DesktopNames=GNOME
X-GDM-SessionRegisters=true
X-Ubuntu-Gettext-Domain=gnome-session-3.0
```
… и понимаем, что попали несколько серьёзнее чем хотелось бы и что гном, в данном случае, нам мало чем поможет. Он изначально заточен под работу с systemd. Идём в эти наши интернеты.
### ▍ Выходим на финишную прямую. Пишем враппер, юнит и наконец удачно стартуем
Не буду затягивать и утомлять читателя подробностями того, как и где приходилось выуживать информацию по крупицам. Это были и маны и `ArchWiki` и чёрт его знает что ещё. Лучше сразу приведу готовые, в меру откомментированные файлы.
Итак, копируем дефолтный `/usr/share/xsessions/i3.desktop` в `/usr/share/xsessions/i3-systemd.desktop` и немного модифицируем.
```
[Desktop Entry]
### Было: ###
# Name=i3
### Стало: ###
Name=i3 via systemd
Comment=improved dynamic tiling window manager
### Было: ###
# Exec=i3
# TryExec=i3
### Стало: ###
Exec=i3-service
TryExec=i3-service
Type=Application
X-LightDM-DesktopName=i3
DesktopNames=i3
Keywords=tiling;wm;windowmanager;window;manager;
```
Теперь нам нужно написать враппер i3-service который будет подготавливать окружение и запускать i3wm в качестве сервиса. Ну и, разумеется, сам `i3.service` файл тоже должен быть написан. Итак враппер `/usr/local/bin/i3-service`:
```
#!/usr/bin/env sh
# Импортируем и загружаем в d-bus сессию переменные из логин менеджера.
/etc/X11/xinit/xinitrc.d/50-systemd-user.sh
systemctl --user import-environment XDG_SEAT XDG_VTNR XDG_SESSION_ID XDG_SESSION_TYPE XDG_SESSION_CLASS
if command -v dbus-update-activation-environment >/dev/null 2>&1; then
dbus-update-activation-environment XDG_SEAT XDG_VTNR XDG_SESSION_ID XDG_SESSION_TYPE XDG_SESSION_CLASS
fi
# Загружаем иксовые ресурсы.
userresources=$HOME/.Xresources
usermodmap=$HOME/.Xmodmap
sysresources=/etc/X11/xinit/.Xresources
sysmodmap=/etc/X11/xinit/.Xmodmap
if [ -f $sysresources ]; then
xrdb -merge $sysresources
fi
if [ -f $sysmodmap ]; then
xmodmap $sysmodmap
fi
if [ -f "$userresources" ]; then
xrdb -merge "$userresources"
fi
if [ -f "$usermodmap" ]; then
xmodmap "$usermodmap"
fi
# Запускаем xinitrc* скрипты.
if [ -d /etc/X11/xinit/xinitrc.d ] ; then
for f in /etc/X11/xinit/xinitrc.d/?*.sh ; do
[ -x "$f" ] && . "$f"
done
unset f
fi
# И собственно запускаем сервис.
exec systemctl --wait --user start i3.service
```
Ну и наконец вишенка на нашем торте, сам `/etc/systemd/user/i3.service`:
```
[Unit]
Description=i3wm tiling window manager for X
Documentation=man:i3(5)
Wants=graphical-session-pre.target
After=graphical-session-pre.target
# Самое главное, биндимся к таргету графической сессии..
BindsTo=graphical-session.target
PartOf=graphical-session.target
# ... и не забываем включить таргет, ради которого всё затевалось.
Before=xdg-desktop-autostart.target
Wants=xdg-desktop-autostart.target
[Service]
Type=simple
# Запускаем i3 через d-bus launcher. Мы же хотим, чтоб у нас работал d-bus?
ExecStart=/usr/bin/dbus-launch --sh-syntax --exit-with-session i3 --shmlog-size 0
Restart=on-failure
RestartSec=5
TimeoutStopSec=10
```
* Записываемся.
* Для проверки добавляем в автозагрузку, например, тот же клиент телеграма.
* Идём на перезагрузку и в дисплейном менеджере при старте системы, выбираем пункт «*i3 via systemd*»
Что в итоге?
------------
* Работает автозагрузка, прямо как в каком-нить гноме.
* Бонусом получили `graphical-session.target`, к которому можно биндить сервисы, зависящие от запущенной графической оболочки. Например, до этого у меня падал, при загрузке юнит *clipboard manager*-а, в результате приходилось костылять таймаут… Теперь не падает.
* Можно выкинуть из конфига i3 всё, что запускается при старте (Директива `exec --no-startup-id` и это вот всё) и упаковать в отдельные аккуратные пользовательские `*.service` и по-человечески рулить ими в процессе работы. Например, отключать и включать *lockscreen* простым `systemctl --user start`/`stop`
* Для автозагружаемых юнитов, сгенерённых из `*.desktop` файлов, в самих этих файлах их можно отключать, добавив строчку `Hidden=true`
Ну и вообще, приятно быть первооткрывателем. Ибо в процессе гугления и чтения манов, готового рецепта обнаружено не было. Так что любители wm, не относящиеся к systemd хейтерам. Пробуйте. За месяц использования был замечен ровно один косяк. Не работает `gvgs-*` функционал в *pcman-fm*, если его запустить хоткеем из `i3` Но если запустить из *rofi*, волшебным образом всё начинает работать. Возможно я забыл импортировать какую-то переменную в *d-bus* Ну и, чтоб не копипастить, [ссылка на гитхаб](https://github.com/Oxyd76/wm_via_systemd-with_xdg).
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Oxyd&utm_content=vsyo_kak_u_bolshix._avtozagruzka_prilozhenij_v_okonnyx_menedzherax_linux) | https://habr.com/ru/post/583328/ | null | ru | null |
# Построение отказоустойчивого SIP-прокси/PBX на базе FreeSWITCH mod_sofia (recover)
Здравствуйте, уважаемые хабравчане.
Вот уже несколько месяцев ковыряюсь в прекрасном продукте FreeSWITCH. Он не перестает меня удивлять функциональностью, надежностью и производительностью (даже в тех областях, в которых от него этого не ждешь).
Один из моих экспериментов, который в скором времени, скорей всего, перейдет в продакшн касался изумительной, с моей точки зрения, функции mod\_sofia recover. Функция recover позволяет FreeSWITCH (FS) восстановить вызовы после краша или же, если FS работает в высоко доступном кластере подхватить вызовы на второй ноде! ВНИМАНИЕ! без обрывов вызовов абонентов, как в случае проксировании RTP, так и без него.
Реализуется это достаточно просто, благодаря использованию внешней СУБД и настройкам mod\_sofia, отвечающего за SIP стэк. Т.е. mod\_sofia хранит всю информацию о текущих вызовах во внешней БД, и при краше у второй ноды кластера есть возможность эти настройки прочесть и подхватить вызовы.
Итак, нам понадобятся:
* FreeSwitch
* Установленная отдельно СУБД (в моем случае mysql)
* unixODBC
* депенденсы, которые потребует FS (описано на [вики](http://wiki.freeswitch.org/wiki/Installation_Guide#CentOS))
* heartbeat
Я не буду подробно останавливаться на процессе установки FS и выпиливании из него ненужных модулей, все эксперементы будут ставиться на конфигурации по умолчанию. В конце только добавим какой-нибудь гейтвей, для осуществления внешних звонков.
Будем считать, что все что нам нужно установлено, приступим к самому интересному! Ковырянию конфигов.
Установка FS по умолчанию уже вполне звонибельна и для тестов нам ее будет более чем достаточно.
На сервере БД выполняем:
```
#mysqladmin -u dba_user -p create fs_cnf
```
Это создаст БД, в которой FS будет хранить свои настройки.
Наш клайстер будет состоять из 2х рабочих нод и сервера базы данных.
Адрес первой ноды 172.16.100.200
Адрес второй ноды 172.16.100.201
Общий адрес 172.16.100.205
Адрес ДБ сервера 172.16.100.210
**Все действия ниже производятся на обоих нодах FreeSWITCH**
В файл /etc/odbc.ini вносим параметры подключения к серверу БД
```
[fsw-cnf]
Description = MySQL ODBC Database
TraceFIle = stderr
Driver = MySQL
SERVER = 172.16.100.210
USER = fs-usr
PASSWORD = super_secure_password
OPTION = 67108864
DATABASE = fs_cnf
```
Мы хотим, чтобы FS работал на общем IP, для этого файл freeswitch\_base\_dir/conf/vars.xml
нужно внести строку:
Для того, чтобы работал recover нужно включить трекинг звонков в sip профилях. Что такое профили прекрасно описано [тут](http://habrahabr.ru/post/50140/). Идем в freeswitch\_base\_dir/conf/sip\_profiles/ и добавляем в настройки обоих профилей (internal, external) строку:
Так же в обоих профилях указываем параметры подключения к серверу БД
Идем в файл freeswitch\_base\_dir/conf/autoload\_configs/switch.conf.xml и добавляем строку или раскоментируем и правим:
Это для core настроек FS.
При старте FS сам создаст нужные для работы таблицы.
Далее настраиваем heartbeat:
vim /etc/ha.d/authkeys
```
auth 1
1 sha1 mega_super_secure_key
```
chmod 600 /etc/ha.d/authkeys
vim /etc/ha.d/ha.cf
```
# Логи
logfacility local0
# Таимауты
keepalive 100ms
deadtime 2
warntime 1
initdead 120
# как будут между собой общаться ноды
udpport 694
bcast eth0
# Какие ноды учавствуют в нашем клайстере
node fs1 fs2
# После востановления должны ли возвращаться ресурсы на первую ноду?
auto_failback on
```
vim /etc/ha.d/haresources (на второй ноде нужно поменять хостнейм (fs1 на fs2))
```
fs1 IPaddr2::172.16.100.205/255.255.255.0/eth0 freeswitch::fsrecover
```
freeswitch::fsrecover — раздел init.d скрипта, который нам подымет наши профили, его мы добавим в следующем шаге
В /etc/init.d/freeswitch между restart и reload добавим
```
fsrecover)
$FS_HOME/bin/fs_cli -x "sofia profile internal start"
$FS_HOME/bin/fs_cli -x "sofia profile external start"
/bin/sleep 1
$FS_HOME/bin/fs_cli -x "sofia recover"
;;
```
Теперь когда одна из нод грохнется вторая подымет общий IP и перезапустит профили FS, после чего выполнит заветную команду и подхватит звонки.
Для проверки исходящего вызова нам нужно отредактировать dialplan и добавить гейтвей.
В моем примере я буду использовать voip.ms c десятизначным номером. Идем в freeswitch\_base\_dir/conf/sip\_profiles/external/ и создаем файл следующего содержания:
```
```
В freeswitch\_base\_dir/conf/dialplan/default.xml добавляем(поменяйте регулярное выражение и параметры caller-id)
```
```
Запускаем демоны:
```
chkconfig heartbeat on
service heartbeat start
chkconfig freeswitch on
service freeswitch start
```
Стартап скрипт фрисвитча его запустит на обоих нодах, но на неактивной ноде не подымутся профили, т.к. нет IP, на котором они запускаются.
Для тестов берем любой экстеншон из freeswitch\_base\_dir/conf/directory/default, регистрируемся:
Proxy: 172.16.100.205
username: 1000
password: 1234 (Это default\_password, его обязательно надо менять в vars.xml)
Набираем любой номер, в процессе разговора кладем одну из нод и вуаля! Heartbeat обнаруживает, что вторая нода лежит, подхватывает общий IP, запускает скрипт, запуская тем самым неактивные профили. Прерывание медиа потока всего 2-3 секунды, т.е. время, которое уходит у хартбита на перехват ресурсов + 1 секунда в freeswitch:fsrecover
Все. Спасибо за внимание, надеюсь статья кому-то пригодится. Пожелания и предложения более чем приветствуются. В планах есть написать про связку mod\_xml\_curl, mod\_lcr и еще кое что.
П.С. Как принято говорить: ”сильно не пинайте, первая статья”.
Литература:
[wiki.freeswitch.org](http://wiki.freeswitch.org) | https://habr.com/ru/post/140517/ | null | ru | null |
# Настраиваем Mozilla Thunderbird в корпоративной среде Windows
Будем следовать принципу: Чем меньше надо настраивать пользователю, тем меньше вероятность того что он что то поломает. Думаю пользователь с вводом своего пароля справится.
#### Необходимо настроить:
1. Файл конфигурации для подключения к серверу.
2. Справочник контактов из LDAP.
3. Подпись сотрудника в письме в соответствии с корпоративными стандартами.
### Имеем на данный момент:
1. Установленный почтовый клиент Thunderbird на рабочих станциях средствами групповой политики.
2. Почта на biz.mail.ru (может быть и другой)
3. Пользователи в AD с логином вида [email protected]
**Установка Thunderbird средствами GPO**Мы не будем качать .msi файлы от сторонних разработчиков, я не доверяю перепакованным программам, тем более что Thunderbird умеет ставиться тихой установкой из командной строки. Этим преимуществом мы и воспользуемся, а чтоб не переустанавливать его каждый раз при загрузке системы будем проверять ключи в реестре.
Скачиваем Thunderbird с [сайта](https://www.mozilla.org/ru/thunderbird/) и закидываем в шару (права должны быть на чтение всем ПК в домене)
Сам скрипт
```
set VERSION=52.7.0
set SHARE="ПАПКА"
if %PROCESSOR_ARCHITECTURE% == x86 (
set REGISTRY_KEY_NAME="HKLM\SOFTWARE\Mozilla\Mozilla Thunderbird"
) else (
set REGISTRY_KEY_NAME="HKLM\SOFTWARE\Wow6432Node\Mozilla\Mozilla Thunderbird"
)
reg query %REGISTRY_KEY_NAME% /v CurrentVersion | find "%VERSION% (ru)"
if ERRORLEVEL 1 "\\%SHARE%\Thunderbird Setup %VERSION%.exe" -ms
```
> Необходимо поменять первые переменные. Версия и папка.
>
> Версия соответствует имени файла, на момент написания статьи актуальная версия 52.7.0.
>
> Имя файла Thunderbird Setup 52.7.0.exe
Сохраняем в ту же папку, обзываем InstallMozillaThunderbird.bat и добавляем в GPO на старт скрипта при запуске системы.
P.S. таким-же методом можно установить и Mozilla Firefox.
### Настраиваем Thunderbird при запуске.
При первом запуске Thunderbird генерирует папку вида 123.default в папке %appdata%\Thunderbird\Profiles\, а в файле %appdata%\Thunderbird\profiles.ini создает ссылку на данную папку.
Поэтому мы создадим данные настройки раньше, при входе пользователя.
Заходим в групповые политики и создаем политику.
Конфигурация пользователей => Настройка =>Конфигурация Windows => INI-файлы.
**Создаем 5 ключей**
| Путь к файлу | Имя раздела | Имя свойства | Значение свойства |
| --- | --- | --- | --- |
| %AppData%\Thunderbird\profiles.ini | Profile0 | Default | 1 |
| %AppData%\Thunderbird\profiles.ini | Profile0 | IsRelative | 1 |
| %AppData%\Thunderbird\profiles.ini | Profile0 | Name | %username% |
| %AppData%\Thunderbird\profiles.ini | Profile0 | Path | Profiles/%username%.default |
| %AppData%\Thunderbird\profiles.ini | General | StartWithLastProfile | 1 |
Файл profiles.ini сконфигурирован, остается создать папку Profiles/%username%.default и заполнить ее файлами конфигураций.
За настройку Thunderbird отвечает файл prefs.js
Его мы и будем генерировать своими данными для доступа к IMAP, а так же к LDAP через KerberOS.
Я начал с написания PowerShell который вставляем в GPO при входе пользователя. Нам важно его запускать правами пользователя который выполнил вход.
Конфигурация пользователей => Политики => Конфигурация Windows => Сценарии (вход/выход из системы) => Вход в систему => Сценарии PowerShell
start.ps1
```
$profiledir = "$env:APPDATA\Thunderbird\Profiles\$env:UserName.default"
md $profiledir #Создаем папку для профиля.
powershell "\\domain.cn\NETLOGON\soft\new_prefs.ps1" #тут мы генерируем файл
```
**new\_prefs.ps1**
```
#Ищем полное имя пользователя (Фамилия Имя Отчество)
$UserName = $env:username
$Filter = "(&(objectCategory=User)(samAccountName=$UserName))"
$Searcher = New-Object System.DirectoryServices.DirectorySearcher
$Searcher.Filter = $Filter
$ADUserPath = $Searcher.FindOne()
$ADUser = $ADUserPath.GetDirectoryEntry()
$ADDisplayName = $ADUser.DisplayName
############################################################################################################################
$domain="mail.ru" #Почтовый домен
$imap="imap.mail.ru" #imap сервер
$dc="dc1.domain.cn" #Контролер домена
$bdn="CN=Users,DC=domain,DC=cn" #Base DN
$file="$env:appdata\Thunderbird\Profiles\$env:username.default\prefs.js"
echo '#######################' | out-file $file -encoding UTF8
echo 'user_pref("ldap_2.autoComplete.directoryServer", "ldap_2.servers.company");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("ldap_2.autoComplete.useDirectory", true);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("ldap_2.servers.company.auth.dn", "");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("ldap_2.servers.company.auth.saslmech", "GSSAPI");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("ldap_2.servers.company.description", "company");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("ldap_2.servers.company.filename", "ldap.mab");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("ldap_2.servers.company.maxHits", 100);' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("ldap_2.servers.company.uri", "ldap://'
$id2 = echo $dc/$bdn'??sub?(objectclass=*)");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.ab_remote_content.migrated", 1);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.account.account1.identities", "id1");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.account.account1.server", "server1");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.account.account2.server", "server2");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.account.lastKey", 2);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.accountmanager.accounts", "account1,account2");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.accountmanager.defaultaccount", "account1");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.accountmanager.localfoldersserver", "server2");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.append_preconfig_smtpservers.version", 2);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.attachment.store.version", 1);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.default_charsets.migrated", 1);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.folder.views.version", 1);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.font.windows.version", 2);' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.identity.id1.draft_folder", "imap://'
$id2 = echo $env:username%40$domain@$imap/Drafts'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.identity.id1.attach_signature", true);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.identity.id1.drafts_folder_picker_mode", "0");' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.identity.id1.fcc_folder", "imap://'
$id2 = echo $env:username%40$domain@$imap/Sent'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.identity.id1.fcc_folder_picker_mode", "0");' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.identity.id1.fullName", "'
$id2 = echo $ADDisplayName'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.identity.id1.htmlSigFormat", true);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.identity.id1.reply_on_top", 1);' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.identity.id1.sig_file", "C:\\Users\\'
$id2 = echo $env:username\\AppData\\Roaming\\Thunderbird\\Profiles\\$env:username.default\\signature.htm'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.identity.id1.sig_file-rel", "[ProfD]signature.htm");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.identity.id1.sign_mail", false);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.identity.id1.smtpServer", "smtp1");' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.identity.id1.stationery_folder", "imap://'
$id2 = echo $env:username%40$domain@$imap/Templates'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.identity.id1.tmpl_folder_picker_mode", "0");' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.identity.id1.useremail", "'
$id2 = echo $env:username@$domain'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.identity.id1.valid", true);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.openMessageBehavior.version", 1);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.rights.version", 1);' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.root.imap", "C:\\Users\\'
$id2 = echo $env:username\\AppData\\Roaming\\Thunderbird\\Profiles\\$env:username.default\\ImapMail'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.root.imap-rel", "[ProfD]ImapMail");' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.root.none", "C:\\Users\\'
$id2 = echo $env:username\\AppData\\Roaming\\Thunderbird\\Profiles\\$env:username.default\\Mail'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.root.none-rel", "[ProfD]Mail");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server1.cacheCapa.acl", false);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server1.cacheCapa.quota", false);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server1.canChangeStoreType", true);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server1.check_new_mail", true);' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.server.server1.directory", "C:\\Users\\'
$id2 = echo $env:username\\AppData\\Roaming\\Thunderbird\\Profiles\\$env:username.default\\ImapMail\\$imap'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.server.server1.directory-rel", "[ProfD]ImapMail/'
$id2 = echo $imap'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.server.server1.hostname", "'
$id2 = echo $imap'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server1.login_at_startup", true);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server1.max_cached_connections", 5);' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.server.server1.name", "'
$id2 = echo $env:username@$domain'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server1.port", 993);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server1.socketType", 3);' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.server.server1.spamActionTargetAccount", "imap://'
$id2 = echo $env:username%40$domain@$imap'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server1.storeContractID", "@mozilla.org/msgstore/berkeleystore;1");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server1.type", "imap");' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.server.server1.userName", "'
$id2 = echo $env:username@$domain'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.server.server2.directory", "C:\\Users\\'
$id2 = echo $env:username\\AppData\\Roaming\\Thunderbird\\Profiles\\$env:username.default\\Mail\\Local Folders'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server2.directory-rel", "[ProfD]Mail/Local Folders");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server2.hostname", "Local Folders");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server2.name", "Локальные папки");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server2.storeContractID", "@mozilla.org/msgstore/berkeleystore;1");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server2.type", "none");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.server.server2.userName", "nobody");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.smtpserver.smtp1.authMethod", 3);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.smtpserver.smtp1.description", "mail.ru");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.smtpserver.smtp1.hostname", "smtp.mail.ru");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.smtpserver.smtp1.port", 465);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.smtpserver.smtp1.try_ssl", 3);' | out-file $file -encoding UTF8 -Append
$id1 = echo 'user_pref("mail.smtpserver.smtp1.username", "'
$id2 = echo $env:username@$domain'");'
echo $id1$id2 | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.smtpservers", "smtp1");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.spam.version", 1);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.taskbar.lastgroupid", "8216C80C92C4E828");' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.ui-rdf.version", 15);' | out-file $file -encoding UTF8 -Append
echo 'user_pref("mail.winsearch.firstRunDone", true);' | out-file $file -encoding UTF8 -Append
```
Теперь при запуске Thunderbird будет запрашиваться только пароль от почты.
Скрипт однозначно работает c imap сервером imap.mail.ru. С другими не пробовал, возможно надо будет допиливать.
Вы могли заметить при генерации prefs.js мы указали что подпись брать с файла signature.htm которая находится в той-же папке где и prefs.js. Будем делать теперь подпись.
### Настраиваем подпись электронной почты.
Для создания красивой подписи нам нужен какой нибудь сервис где можно генерировать подпись и на основе ее будем делать подпись для наших пользователей.
Я пользовался сервисом mailsig(точка)ru (не реклама)
Можно и самому сделать подпись на том же HTML, но мне было лень.
На выходе получаем код
Добавляем еще одну строчку в start.ps1
```
powershell "\\domain.cn\NETLOGON\soft\signature.ps1" #тут мы генерируем подпись
```
Конечно можно было бы всё сразу вместить в один файл, к сожалению я люблю когда все лежит по своим местам. Да и проще разбираться когда файл называется так-же как и файл который он создает.
**signature.ps1**
```
#Находим данные о пользователи из AD
$UserName = $env:username
$Filter = "(&(objectCategory=User)(samAccountName=$UserName))"
$Searcher = New-Object System.DirectoryServices.DirectorySearcher
$Searcher.Filter = $Filter
$ADUserPath = $Searcher.FindOne()
$ADUser = $ADUserPath.GetDirectoryEntry()
$ADDisplayName = $ADUser.DisplayName
$ADEmailAddress = $ADUser.mail
$ADInfo = $ADUser.otherMailbox
$ADTitle = $ADUser.title
$ADTelePhoneNumber = $ADUser.TelephoneNumber
$ADipPhone = $ADUser.ipPhone
$ADOffice = $ADUser.physicalDeliveryOfficeName #Номер Офиса
$ADСompany = $ADUser.company
$ADOffice = $ADUser.physicalDeliveryOfficeName
############################################################################################################
$Site="http://mail.ru"
$Logo="http://mail.ru/logo.png" #85*85px
$Banner="http://mail.ru/banner.png" #440*58px !Можно написать скрипт на сайте который будет рандомно выдавать картинку с предложениями (мини рекламная компания)
$BannerSite="http://mail.ru/" #Адрес куда будет вести баннер под подписью.
$Tel="84951234567"
$Fax="84951234567"
$Address="г. Москва, Красная площадь д. 3"
$signature = "$env:appdata\Thunderbird\Profiles\$env:username.default\signature.htm" #Место куда будем сохранять
$html = '
| |
| --- |
| '+$ADDisplayName+' |
| '+$ADTitle+' |
| |
|
| |
| --- |
| |
| | |
| |
| --- |
| Моб.: ['+$ADTelePhoneNumber+'](tel:'+$ADTelePhoneNumber+') |
| Email: ['+$ADEmailAddress+'](mailto:'+$ADEmailAddress+') |
| |
| '+$ADСompany+' |
| Офис: ['+$Tel+'](tel:'+$Tel+') / Факс: '+$Fax+' |
| ['+$Address+' офис '+$ADOffice+'](https://yandex.ru/maps/?text='+$Address+'&l=map) |
| <'+$Site+'> |
|
| |
|
| |
| |
| |
| |
Информация в этом сообщении предназначена исключительно для конкретных лиц, которым она адресована. В сообщении может содержаться конфиденциальная информация, которая не может быть раскрыта или использована кем-либо, кроме адресатов. Если вы не адресат этого сообщения, то использование, переадресация, копирование или распространение содержания сообщения или его части незаконно и запрещено. Если Вы получили это сообщение ошибочно, пожалуйста, незамедлительно сообщите отправителю об этом и удалите со всем содержимым само сообщение и любые возможные его копии и приложения.The information contained in this communication is intended solely for the use of the individual or entity to whom it is addressed and others authorized to receive it. It may contain confidential or legally privileged information. The contents may not be disclosed or used by anyone other than the addressee. If you are not the intended recipient(s), any use, disclosure, copying, distribution or any action taken or omitted to be taken in reliance on it is prohibited and may be unlawful. If you have received this communication in error please notify us immediately by responding to this email and then delete the e-mail and all attachments and any copies thereof.'
echo $html | out-file $signature -encoding UTF8
```
У нас должно получиться 3 файла.
start.ps1 — Его мы запускаем при входе пользователя.
new\_prefs.ps1 — Создает prefs.js в папке Thunderbird.
signature.ps1 — Создает подпись в почте.
В зависимости от настроек безопасности PowerShell скрипты могут не выполняться. Если видите ошибку что скрипт не имеет цифровой подписи, прошу ознакомиться [с данной инструкцией](http://gpo-planet.com/?p=4621) для решения проблемы. | https://habr.com/ru/post/352384/ | null | ru | null |
# О программировании на 1С Предприятие 8
*> Если пишешь ты на СИ
>
> Будь хоть трижды ламер
>
> Про такого говорят:
>
> «Он — крутой программер!»
>
> (Фидошные песни — «Что Такое Suxxx и Что Такое Rulezzz»)*
#### **Предисловие**
Поводом к написанию данной статьи послужило негативное отношение профессионального сообщества к указанной платформе и программистам.
Как программист, выбравший 1С, считаю данное мнение необоснованным. Платформа 1С — далеко не идеал, но, на мой взгляд, — это лучший, а главное — отечественный продукт!
И уж тем более — неадекватно судить о способностях программиста по тому языку, на котором он пишет.
В данной статье я опишу те преимущества, которые нашел для себя в программе. Статья получится практически рекламой, поэтому сразу дисклеймер:
* Прямого отношения к фирме 1С я не имею;
* Данная статья не является заказной, и написана исключительно на добровольной основе;
* В некоторых случаях высказано личное мнение, которое может не совпадать…;
* Вся статья, за исключением пролога — авторская, любые совпадения — случайность;
* Речь пойдет о платформе 1С Предприятие 8.2 (в настоящее время — актуальна версия 8.3, но я её ещё не изучал — очень много работы на 1С 8.2). Однако, большая часть сказанного применима как к платформе 8.3, так и к более ранним версиям, а часть — и к версии 7.7.
Итак, приступим.
#### **О чем речь?**
Платформа 1С Предприятие 8 — это:
* Работает в двух вариантах — файловый и серверный (трёхзвенка) — у каждого свои достоинства и недостатки;
* Независимая система учета, которая легко устанавливается и настраивается;
* Мощная экосистема для программистов со всеми необходимыми объектами и инструментами;
* Приятный эргономичный интерфейс;
* Сравнительно недорогое решение для бизнеса;
* Сеть франчайзи, начальное обучение;
* Мощная база наработок и знаний, накопленная годами;
* Временами проблемная платформа для системных администраторов;
* Не самое быстрое выполнение алгоритмов (хотя и не самое медленное) — это дань информативности (при ошибках указан номер строки и её содержимое);
* В языке программирования нет классов (наследования, инкапсуляции, полиморфизма), нет анонимных функций и прочих современных фич. Но для решения большинства задач — это и не нужно!
Для организации учета — одной платформы недостаточно. Платформа — это своего рода «движок», промежуточное звено между программой и базой данных. Программы для этого «движка» называются конфигурации. В конфигурации описана структура базы данных в виде объектов, тексты процедур, хранящиеся в отдельных модулях (модулей много, они есть как у каждого объекта, так и у системы в целом, а также имеются общие модули). Платформа представляет такой уровень абстракции, при котором прямого обращения к базе данных не требуется, а также позволяет абстрагироваться от операционной системы и типа базы данных.
#### **Файловая и серверная базы данных**
Платформа состоит из нескольких частей и может работать в файловом или серверном варианте.
В файловом варианте вся база данных содержится в одном файле (с расширением «1cd») — платформа устанавливается на каждом компьютере и напрямую читает/пишет в базу данных.
Плюсы файлового варианта — низкая цена и простота развёртывания.
Минусы — структура файла «1cd» закрыта, нет единой системы, взаимодействующей с БД. В результате — сложно использовать при большом числе пользователей (пробовали на 20+ пользователей — работать можно). Кроме того, при размере базы данных примерно 15 ГБ (и более) возникают сбои при проведении динамического обновления. Решать такие сбои — задача сложная, а утилита для починки базы — не всегда эффективно чинит, а иногда и калечит базу.
Решение есть — это, прежде всего, настройка ежедневного резервного копирования базы данных. Кроме того, народные умельцы не только публикуют формат файла 1cd, но и разработали утилиты для работы с такими файлами и ряд методов по решению подобных проблем.
В серверном варианте, платформа для хранения базы данных использует SQL-сервер (обычно, это MS SQL, но начиная с 8.2.14 — можно использовать и некоторые другие ~~например, Firebird~~ PostgreSQL, IBM DB2, Oracle Database), а сама платформа работает использует трехзвенную архитектуру:

Часть кода выполняется на клиенте, часть на сервере. При этом с базой данных взаимодействует только сервер. При этом, начиная с версии 8.2, помимо стандартного режима работы, который обозвали режимом «толстый клиент», появилось два новых режима работы — «тонкий клиент» и «web-клиент»; также появились «управляемые формы», внешний вид которых строится в виде абстрактного дерева элементов. Программировать под управляемые формы и трехзвенную архитектуру сложнее, но это позволяет перенести почти всю нагрузку на сервер (т.е. можно купить один мощный сервер и сотню самых дешевых офисных компьютеров).
Плюсы платформы: «трёхзвенка» — распределение нагрузки, открытость базы данных (официально фирма 1С отказывается от ответственности за любую порчу данных, если в базу SQL вносились изменения кроме как средствами ихней платформы или сервера, но это мало кого останавливает), отсутствие ограничений.
Минусы — цена: покупать придется отдельно клиентские лицензии на каждый клиентский компьютер, отдельно — одну лицензию на сервер 1С, отдельно лицензию на сервер SQL, если не использовать бесплатный. Также иногда возникают сложности в работе базы данных. Они решаются гораздо быстрее за счет доступности данных и наличия внешних инструментов работы с БД. Кроме того, и в этом случае следует делать бекап базы данных.
Общим плюсом является универсальность кода конфигураций: за некоторыми исключениями, конфигурация разработанная для файловой базы данных будет работать на серверной, и наоборот. Пример исключения — передача мутабельного значения на сервер или с сервера на клиент (в файловом варианте это не вызовет исключений, а в клиент-серверном варианте запрещено).
Ещё один плюс: платформа устанавливается очень просто, примерно так: «Далее-Далее-Далее-Ок», не требуется тонкая настройка и установка каких-либо компонент.
Для серверного варианта несколько больше настроек, но всё делается в диалоге установки и не требует прописывать что-либо в отдельных файлах. Некоторую сложность может представлять установка SQL-сервера, т.к. в этом случае настроек намного больше (и чтобы тонко настроить — требуется изучение дополнительных инструкций). Но это не относится к проблемам платформы 1С. Более того, если установить, например сервер MS SQL со всеми настройками по-умолчанию, то 1С вполне сможет с ним работать.
#### **Это больше, чем бухгалтерия**
Когда речь заходит о платформе 1С, то она представляется, прежде всего, как программа для бухгалтерского учета. Действительно, это — самая популярная область использования платформы 1С. Но не бухгалтерией единой живет 1С!
Те, кто знаком с платформой, говорят, что это система учета (автоматизации учета). Это ближе к истине — существует множество конфигураций, как от фирмы 1С, так и от сторонних разработчиков. Некоторые лишь косвенно связаны с бухучетом, некоторые вообще никак не связаны.
Вообще, правильнее представлять платформу 1С как оболочку для объектного моделирования базы данных, интерфейса и программирования на языке 1С. Единственное ограничение — для каждой конфигурации создается своя база данных, и только одна (однако, есть возможность дополнительно в составе конфигурации подключать внешние источники данных, т.е. другие базы).
#### **Экосистема для программистов**
Рассмотрим теперь язык 1С и платформу с точки зрения разработчика:
**Объектная модель базы данных.** Во-первых, напрямую с базами данных мы не работаем. Это не нужно. Для нашего удобства — все данные представлены в виде взаимосвязанных объектов (справочники, документы, регистры сведений, регистры накопления, …), а «вытаскивание» этих данных из базы выполняет платформа автоматически.
Например, при условии, что в переменной «ЭлементНоменклатуры» содержится ссылка на элемент справочника «Номенклатура», у справочника «Номенклатура» есть реквизит «ОсновнойПоставщик», типа «Справочник.Контрагенты», а у справочника «Контрагенты» есть реквизит «ПолноеНаименование», тогда код:
```
ЭлементНоменклатуры.ОсновнойПоставщик.ПолноеНаименование
```
… приведет к тому, что платформа 1С, используя внутренние механизмы, найдет запись в таблице, соответствующей справочнику «Контрагенты» по идентификатору из поля «ОсновнойПоставщик» элемента номенклатуры и вернёт значения поля, соответствующего полю «ПолноеНаименование» в объектной модели справочника «Контрагенты».
Подобных разыменовываний может быть много — система справится. Единственный нюанс — система не умеет оптимизировать разыменовывания, поэтому следует стремиться выносить их наружу из всевозможных из циклов.
Помимо объектов, описывающих данные, существует огромное число системных объектов — для самых разных функций. Выделю некоторые из них:
##### **Хранилища значений**
Массив — объект, хранящий набор данных, в отличие от классического представления о массивах. Это могут быть данные различного типа (число, строка, ссылка, другой объект). Имеет минимальный функционал и используется, в основном, как временный контейнер для передачи значений между другими хранилищами.
СписокЗначений — объект, преимущественно, для работы с интерфейсом пользователя. Помимо данных также для каждого элемента может содержать представление, признак флажка и картинку (пиктограмму). Также имеет методы «ВыбратьЭлемент()» и «ОтметитьЭлементы()» — при вызове которых пользователю показывается интерфейсный диалог (что удобно — не нужно данный диалог создавать в конфигурации).
Структура и Соответствие — хранилища парных значений «КлючИЗначение». В структуре «Ключ» — это строка, подчиняющаяся правилам наименования переменных в 1С (без пробелов, начинаться не с цифры, состоит только из букв, цифр и знака подчеркивания). В соответствии — «Ключ» — это любое значение. Самый шустрый поиск объектов — в соответствии (быстрее, чем в массиве и индексированной таблице значений).
ТаблицаЗначений — очень удобный, и довольно быстрый, объект для хранения и обработки данных. Колонки в таблице значений можно добавлять и удалять, независимо от количества записей. При этом данные в строках не теряются (или удаляются только данные из ячеек, соответствующих удаляемым колонкам). Также, имеет метод «ВыбратьСтроку()», вызывающий диалог выбора строки. Имеются индексы.
ДеревоЗначений — объект, представляющий иерархические данные. Содержит колонки, набор колонок одинаковый для всех записей на всех уровнях. Удаление/Добавление колонок в дереве значений точно так же легко, как и в таблице значений. Также, имеет метод «ВыбратьСтроку()».
Интерфейсные объекты и объекты для работы с различными данными ТекстовыйДокумент, ТабличныйДокумент, Web-браузер, ЧтениеФайла, ЗаписьФайла, ЧтениеZIPФайла, ЗаписьZIPФайла, ЧтениеXML, ЗаписьXML, HTTPЗапрос и ещё много объектов, и по все в конфигураторе есть встроенная справка. Назначение перечисленных объектов видно из их названий и всё это сразу есть в платформе.
Отдельно следует отметить, что имеется объект «Метаданные» — с помощью которого на языке программирования можно изучить структуру данных, а также у каждой ссылки или объекта для справочника, документа, плана счетов, и т.п. есть метод «Метаданные()» — предоставляющий описание данного справочника/документа/плана счетов/ и т.п. в базе данных (какие реквизиты, табличные части имеются, длина кода/номера и т.п.). Часто бывает очень удобно.
И еще отдельно следует упомянуть про объекты: «Запрос», «КонструкторЗапроса», «ПостроительЗапроса», «ПостроительОтчета», «СхемаКомпоновкиДанных». Это семейство реализует набор объектов для работы с мощным языком запросов 1С.
**Язык запросов.** Запросы в 1С используются только для получения выборки данных с удобным отбором, сортировкой, группировками. В первом приближении это переведенный на русский язык оператор «SELECT» из SQL, однако, в языке запросов 1С имеется и функционал, который отсутствует в SQL, а именно:
* Работа с объектами конфигурирования 1С, вместо таблиц SQL;
* Работа со ссылками, вместо полей-идентификаторов SQL;
* Поддержка разыменовывания, аналогично тому, как это делается в коде;
* Выборка по вхождению в группу (для справочников);
* Иерархические итоги;
* Временные таблицы и вложенные запросы (SELECT \* FROM (SELECT … )));
* Конструктор запросов — удобный, объектный, автоматически оптимизирующий текст запроса для быстрого чтения, который умеет разбирать текст запроса (парсить текст запроса и строить из него объектную модель);
* Построитель отчёта — надстройка над механизмом запросов, в которой добавлен функционал автоматического оформления результатов, а также гибкой настройки самого запроса в режиме «Предприятие» (т.е. пользователем). В результате в стандартных платформах 1С появился универсальный отчёт, в котором пользователь может настроить какие данные и в каком порядке он хочет видеть, что в строках, что в колонках, и отчет сам генерирует выходную таблицу;
* СКД (Система компоновки данных) — следующая модель, вобравшая в себя функционал универсального отчета и дополнившая его некоторыми функциями обработки результатов.
**Язык программирования**
По синтаксису язык 1С похож на «русский Паскаль», однако от «Pascal» отличается меньшей строгостью и отсутствием некоторых конструкций:
* Нет необходимости объявлять переменные — можно инициализировать прямо в тексте модуля;
* Нет жёсткой типизации переменных. В системе есть типы значений, но для переменных нет строгих правил по типизации. Переменная, хранившая ссылку, может через пару строчек кода уже хранить число или строку;
* Можно складывать переменные со значениями разных типов, при этом, тип результата будет таким, каким был тип у первой переменной, например:
```
к = “25”+1; // к = “251”, не 26
```
* Переменные со значениями разных типов можно сравнить на равенство или неравенство (но не на больше-меньше, это вызовет исключение) — естественно, такие переменные не равны;
* Имеются функции и процедуры, допустимо использовать рекурсию (с ограничением по глубине рекурсии);
* При указании функции или процедуры без параметров — всё-равно, обязательно указывать пустые скобки в конце: вот\_так();
* Имеются модули: у каждого справочника и документа их несколько, кроме того, модули есть у регистров, отчетов и обработок и у каждой формы, а также в составе конфигурации имеется возможность создавать общие модули;
* Нет классов, наследования, инкапсуляции, полиморфизма;
* Функцию нельзя передать как ссылку, нет анонимных функций;
* Нет обратного цикла (for i:=5 downto 1 do), а он реально нужен при удалении записей. Обходимся чуть более длинной записью через цикл «Пока».
**Инструментарий**
* В платформе 1С есть возможность выгружать-загружать конфигурацию, сравнивать конфигурацию с другой конфигурацией и частично загружать изменения;
* Есть возможность выгружать тексты модулей для их пакетной обработки и загружать обратно в конфигурацию;
* Если конфигурация находится на поддержке (все конфигурации от 1С изначально на поддержке), то всегда можно выполнить сравнение и посмотреть, что изменялось сторонними разработчиками или местными специалистами;
* Также есть возможность выгружать / загружать базу данных целиком (вместе с данными);
* Для коллективной работы над одной конфигурацией используется хранилище конфигурации;
* Также существует ряд правил внесения изменений в стандартные конфигурации, есть даже документ от 1С, описывающий методики и стандарты изменения типовых конфигураций (да и любых других).
**Общее впечатление**
Язык 1С сочетает в себе ясность текстов языка «Pascal» с фривольностью работы с переменными языка «BASIC». В нем отсутствует ряд возможностей, присущих современным языкам программирования, но без них вполне можно обойтись. Кроме того, в платформе 1С есть мощный сборщик мусора, т.е. не требуется, например, очищать таблицы после использования или удалять их.
#### **Интерфейс 1С Предприятие 8.2**
Фирма 1С уделила особенное внимание интерфейсу своей программы. Прежде всего — это цветовая палитра. Она шикарна! Окна программы узнаваемы даже издалека, при этом за многие годы работы — не вызывают неприязненных ощущений, наоборот — хочется, чтобы все программы были были такими-же классными.
При этом стиль платформы весьма строгий, без рюшечек и прочих излишеств. При этом есть весьма полезные функции, например, запоминание размеров окон (размеры запоминаются только при их изменении пользователем, и, при этом, всегда можно сбросить настройки пользователя — до размеров и позиции по-умолчанию, нажав Alt+Shift+R).
Интерфейс Web-клиента 8.2 вызывает ряд нареканий, но, вроде бы, платформа 8.3 несёт с собой новый переработанный интерфейс — «Такси».
#### **Цены, спрос и предложение, франчайзинг**
Самым «вкусным» плюсом платформы 1С является её цена. Особенно, это актуально сейчас, во время кризиса. Ведь 1С — это полностью наш, отечественный продукт. И продаётся она за наши деревянные. Подобные решения от иностранного производителя будут стоить огромных денег. А лицензии на 1С стоят вполне приемлемо.
Кроме того, у 1С интересная политика лицензирования. Сами лицензии и конфигурации покупаются один раз. При этом, лицензии покупаются на рабочее место и на сервер, но не на базы данных, и даже не на подключения, т.е. по одной лицензии один и тот же пользователь может запускать неограниченное количество сеансов 1С, работая с любым числом баз данных. То же самое касается конфигураций: приобретя одну лицензию на конфигурацию организация может использовать её для создания любого количества баз данных, более того официально разрешается использовать части кода и объекты данной конфигурации при разработке собственных конфигураций (при этом собственные конфигурации можно продавать/передавать — оговаривая, что для их использования нужно купить конфигурацию от 1С).
После этой единовременной покупки нужно только подписаться на обновления и раз в год оплачивать продление подписки, т.н. ИТС. К слову, подписка стоит весьма недорого, примерно как две клиентские лицензии.
В целом, всё это выглядит очень выгодно.
Вторым «вкусным», но уже с ложкой дёгтя, плюсом, является наличие довольно универсальных конфигураций от самой 1С и от партнеров.
**Про универсальность**Понятие «универсальность» определил один школьный учитель по НВП на примере противогазов: существуют универсальные, защищающие от многих поражающих факторов, но степень защиты средняя или ниже среднего, и также существуют специализированные противогазы, которые защищают от одного воздействия, но с высокой степенью защиты. До сих пор я не встречал более точного определения.
И конфигурации от 1С — именно универсальные. Практически, нет задач, где бы их можно было полноценно использовать без доработок. Тем не менее, фирме 1С удалось создать универсальный набор инструментов, покрывающий запросы большинства отраслей современного бизнеса.
Третьим плюсом (и тоже с ложкой «дёгтя») является сеть франчайзи и центров обучения, как для пользователей, так и для начинающих программистов и администраторов. Хорошая идея, но весьма посредственное качество её реализации. Тем не менее, распространённость и агрессивный маркетинг — одна из причин повсеместной популярности 1С в нашей стране (и это-же причина негатива, зависти и ненависти).
#### **Ложка дёгтя**
Расписав во всех красках 1С было бы несправедливо не сказать и о её недостатках, а уж они-то есть:
**Нестабильные релизы** — как в платформе, так и в конфигурациях, присутствует огромное количество ошибок и глюков. И это в официальных релизах. Перед тем, как выпустить официальную версию, выпускается «Версия для ознакомления». Есть также обратная связь для отправки описаний ошибок, чтобы их приняли к исправлению. Однако, то-ли версии для ознакомления не особо популярны, то-ли сама фирма 1С не успевает к сроку релиза обработать все письма, но факт. Каждый раз обновляя платформу или конфигурацию можно наткнуться на самые неожиданные «сюрпризы». К фирме 1С уже неоднократно обращались с призывом более тщательно тестировать свои разработки.
**Франчайзи (далее — франчи)**. В идеале, по задумке, это должны были быть фирмы с квалифицированными специалистами, знающими основные принципы работы конфигураций и платформы. Эти самые фирмы должны были бы продавать платформу, конфигурацию и поддержку, слегка «допиливать» универсальные конфигурации под требования клиента (а временами — корректировать эти требования), стараясь минимально модифицировать стандартную конфигурацию. Так, чтобы не сильно усложнять будущие обновления. А в реальности всё наоборот.
При продаже новых лицензий клиенту франчи получают 50% от их стоимости (за минусом подоходного налога 13% от этих 50%). При этом самим производить ничего не надо, надо только передать ключи от 1С покупателю.
При оказании же услуг франчи не платят фирме 1С ничего (за исключением членских взносов), но зато им нужно платить зарплату сотруднику. Также приходится тратиться на налоги государству — ПФР и подоходный налог.
Выходит, что и 1С, и франчам выгодно продавать лицензии и невыгодно осуществлять дальнейшую поддержку. При этом, чтобы клиент купил программу, нужно её изначально подогнать под его требования. А работу оплачивать надо. И тут с целью экономии привлекаются студенты, ученики, неспециалисты, которым можно заплатить немного, а иногда — и не платить вовсе, их можно даже в штат не оформлять (поработают неофициально, благо есть с чего оплатить). Результат — огромное число продаж при очень низком качестве. Доработки, как правило, затрагивают важные механизмы и усложняют будущее обновление. Но на этапе продажи это ни 1С, ни франчайзи не интересует.
Замечу, что это не столько вина бизнесменов из франчей, сколько фирмы 1С. Ориентируясь на продажи она совершенно не позаботилась о поддержке (я не о школах сейчас, а о том, что осуществлять поддержку должно быть выгодно и самой фирме-франчайзи, и 1С).
**Техподдержка.** В понимании фирмы 1С, техподдержка — это предоставление доступа к разделу «обновление» для платформы и конфигураций, а также к информационным разделам, содержащим описание некоторых механизмов и особенностей работы 1С. Кроме того, при подписке предоставляется диск с указанными материалами. Также имеется форум (весьма скудный в сравнении с народными). Ещё имеется возможность отправить электронное письмо в фирму 1С — но даже не надеясь, что на него ответят (или ответит робот «Письмо передано в отдел разработки». В плане разработки гораздо большую поддержку оказывает Яндекс.Поиск и встроенная в конфигуратор справка.
#### **Эпилог**
**В этом блоке автор рассказывает о себе**Я перешел на 1С в 2008 году, а до этого работал в фирме, разрабатывающей свою программу бухучета (Delphi 5, затем Delphi 7). Сначала я познакомился с платформой 1С Предприятие 7.7 и меня поразила в ней простота разработки отчетов. При этом было видно, что отчеты формируются намного дольше, чем в похожих механизмах на Delphi, но бухгалтеров это особо не волновало. Подождать несколько минут вместо нескольких секунд — не проблема. Наоборот, можно ногти там накрасить, чайку попить или обсудить последние новости не отрываясь от работы. Ведь подавляющее большинство бухгалтеров в наше время — женщины.
Тем не менее, интерфейс 7.7 был весьма ограничен, а набор объектов — весьма скуден. Я искал альтернативы. Познакомился с внешними компонентами, но до практического применения их не дошло, т.к. начальник решил, что пора бы нам переходить на 8.1 (да, 8.2 тогда ещё не было), а в этой платформе, как программист, я нашёл всё, чего мне не хватало ранее.
В настоящее время имею авторитет среди коллег, а также клиентов, которые перешли ко мне от франчей. С франчами они уже, наверное, никогда больше не свяжутся.
В целом, работой в платформе 1С Предприятие 8 я вполне доволен. Она подходит для решения большинства учетных задач и задач с использованием базы данных. | https://habr.com/ru/post/247657/ | null | ru | null |
# Электронная торговля в Universal Analytics
На Хабре уже писали ([1](http://habrahabr.ru/post/156671/),[2](http://habrahabr.ru/post/186076/)) про Universal Analytics от Google.
Электронная торговля и отслеживание событий на сайте — это главные функции аналитиков интернет-магазинов и компаний, которые отслеживают продажу товаров и услуг. В данном топике мы рассмотрим их настройку для Universal Analytics.
Сравнение Universal и классической версии Google Analytics.
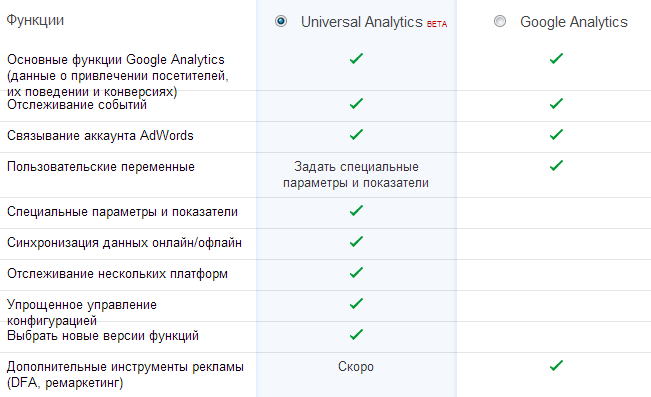
Еще несколько нововведений, которые не отражены в таблице:
* Настройка продолжительности времени ожидания сессий и кампаний. Сделать это можно во вкладке «Администратор» -> «Код отслеживания» -> «Настройки сеанса»
* Настройка источников поискового трафика. Вкладка «Администратор» -> «Код отслеживания» -> «Источники обычных результатов поиска»
* Исключение переходов с определенных доменов. Вкладка «Администратор» -> «Код отслеживания» -> «Список исключаемых источников перехода»
* Исключение определенных поисковых запросов и их учет, как прямой трафик. Вкладка «Администратор» -> «Код отслеживания» -> «Список исключаемых поисковых запросов»
Изменился способ использования пользовательских переменных. Раньше названия и действия параметров указывались в коде, в Universal Analytics это надо делать в настройках. Вкладка «Администратор» -> «Пользовательские параметры» и «Администратор» -> «Пользовательские показатели»
#### Настройка электронной торговли
1. Чтобы начать отслеживание электронной торговли в Universal Analytics сначала нужно его включить в настройках профиля. Для этого перейдите во вкладку “Администратор” -> “Настройки представления”. На этой вкладке надо указать страну, валюту, включить электронную торговлю и также можно настроить отслеживание поисковых запросов пользователей на сайте.
2. Разместить код электронной торговли на странице подтверждения заказа.
Сначала следует разместить основной код Universal Analytics, если его еще нет на сайте. Найти его можно во вкладке «Администратор» -> «Код отслеживания». Выглядит он так, только вместо UA-XXXXXXXX-1 стоит подставить свой ID.
```
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
})(window,document,'script','//www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-XXXXXXXX-1', 'example.com');
ga('send', 'pageview');
```
Затем код электронной торговли, который и будет отправлять данные:
```
ga('require', 'ecommerce', 'ecommerce.js');
ga('ecommerce:addTransaction', {
'id': '1234', // ID заказа
'affiliation': 'example.com', // Название магазина
'revenue': '1500', // Общая стоимость заказа
'shipping': '250', // Стоимость доставки
'tax': '' // Налог
});
// addItem метод вызывается для каждого товара (позиции) в корзине и склеивается с addTransaction по id.
ga('ecommerce:addItem', {
'id': '1234', // ID заказа
'name': 'Mouse Logitech', // Название товара
'sku': 'AAA000', // Артикул или SKU
'category': 'Wireless', // Размер, модель, категория или еще какая-то информация
'price': '750', // Стоимость товара
'quantity': '2' // Количество товара
});
ga('ecommerce:send'); // Отправка данных
```
Отрицательные транзакции создаются также, т.е. используются отрицательные числа при оформлении заказа.
#### Настройка отслеживания событий
Также распространенные действия в Universal Analytics является отслеживание событий. С помощью них можно отслеживать: клики, работу с формами, просмотр видео, загрузка и скачивание файлов и т.д. Самое распространенное событие для отслеживания в электронной торговле — пользователь добавил в корзину товар/услугу. Чтобы эти данные отображались в Universal Analytics, следует выполнять следующий код:
```
ga('send', 'event', 'Категория', 'Действие', 'Ярлык', Значение (число));
```
Описание параметров:
**Категория** — похожие действия на сайте, например, “Корзина”.
**Действие** — обозначение конкретного события/действия на сайте, например, “добавил в корзину” и “удалил из корзины”
**Ярлык** — дополнительное описание действия, например, “клик в карточке товара” и “клик из быстрого просмотра”
**Значение** — числовое значение, которое вам пригодится при анализе.
“Категория” и “Действие” являются обязательными параметрами.
Пример использования отслеживания событий с помощью jQuery:
```
$('#add_to_basket').on('click', function() {
ga('send', 'event', 'Корзина', 'Добавил в корзину', 'Клик в карточке товара');
});
```
На этом все, считайте, анализируйте, отключайте источники трафика, не приносящие заказы.
**P.S.** Если у Вас имеются вопросы или темы для топиков на эту тему, то прошу в ЛС.
Материалы и полезные ресурсы:
* [Переход на Universal Analytics со старой версии](https://developers.google.com/analytics/devguides/collection/upgrade/reference/gajs-analyticsjs?hl=ru)
* [Расширенные настройки Universal Analytics (eng)](https://developers.google.com/analytics/devguides/collection/analyticsjs/) | https://habr.com/ru/post/202824/ | null | ru | null |
# R c H2O на Spark в HDInsight
*H2O* – библиотека машинного обучения, предназначенная как для локальных вычислений, так и с использованием кластеров, создаваемых непосредственно средствами *H2O* или же работая на кластере *Spark*. Интеграция *H2O* в кластеры *Spark*, создаваемые в *Azure HDInsight*, была добавлена недавно и в этой публикации (являющейся дополнением моей прошлой статьи: [R и Spark](https://habrahabr.ru/post/308534/)) рассмотрим построение моделей машинного обучения используя *H2O* на таком кластере и сравним (время, метрика) его с моделями предоставляемых *sparklyr*, действительно ли *H2O* киллер-приложение для *Spark*?
### Обзор возможностей *H20* в кластере *HDInsight Spark*
Как было сказано в предыдущем посте, на тот момент было три способа построения моделей МО используя R на кластере *Spark*, напомню, это:
1) Пакет *sparklyr*, который предлагает разные способы чтения из различных источников данных, удобную *dplyr*-манипуляцию данных и достаточно большой набор различных моделей.
2) *R Server for Hadoop*, ПО от *Microsoft*, использующее свои функции для манипуляций данных и свои реализации моделей МО.
3) Пакет *SparkR*, который предлагает свою реализацию манипуляций данных и предлагал малое число моделей МО (в настоящее время, в версии *Spark 2.2* список моделей значительно расширился).
Подробнее функциональные возможности каждого варианта можно посмотреть в Таблице 1 предыдущего поста.
Теперь появился четвертый способ — использовать *H2O* в кластерах *Spark HDInsight*. Рассмотрим вкратце его возможности:
1. Чтение-запись, манипуляция данными – непосредственно в *H2O* их нет, необходимо передавать (конвертировать) готовые данные из *Spark* в *H20*.
2. Моделей машинного обучения чуть меньше, чем в sparklyr, но все основные имеются, вот их список:
* Generalized Linear Model
* Multilayer Perceptron
* Random Forest
* Gradient Boosting Machine
* Naive-Bayes
* Principal Components Analysis
* Singular Value Decomposition
* Generalized Low Rank Model
* K-Means Clustering
* Anomaly Detection via Deep Learning Autoencoder.
3. Дополнительно можно использовать ансамбли и стекинг нескольких моделей, используя пакет *h2oEnsemble*.
4. Удобство моделей *H2O* в том, что есть возможность сразу оценивать метрики качества, как на тренировочной, так и на валидационной выборке.
5. Настройка гиперпараметров алгоритмов по фиксированной сетке или случайным выбором.
6. Полученные модели можно сохранить в бинарный вид или в чистый *Java* код "*Plain Old Java Object*". (*POJO*)
В целом, алгоритм работы с *H2O* заключается в следующем:
1. Чтение данных, используя возможности пакета *sparklyr*.
2. Манипуляция, трансформация, подготовка данных, используя *sparklyr* и *replyr*.
3. Конвертация данных в *H2O* формат, используя пакет *rsparkling*.
4. Построение моделей МО и предсказывание данных, используя *h2o*.
5. Возвращение полученных результатов в *Spark* и/или локально в R, используя *rsparkling* и/или *sparklyr*.
**Используемые ресурсы**
* Кластер *H2O Artificial Intelligence for HDInsight 2.0.2.*
Данный кластер представляет собой законченное решение с API для *Python* и *Scala*. *R* (видимо пока) не интегрирован, но его добавление не составляет труда, для этого необходимо следующее:
* *R* и пакеты *sparklyr*, *h2o*, *rsparkling* инсталлировать на все узлы: головные и рабочие
* *RStudio* инсталлировать на головной узел
* *putty* клиент локально, для установления *ssh* сессии с головным узлом кластера и туннелирования порта *RStudio* на порт локального хоста для доступа к *RStudio* через веб-браузер.
> Важно: устанавливать пакет *h2o* необходимо из исходников, выбирая версию, соответствующую версии как *Spark*, так и пакета *rsparkling*, при необходимости перед загрузкой *rsparkling* необходимо указывать используемую версию *sparklingwater* (в данном случае *options(rsparkling.sparklingwater.version = '2.0.8'*. Таблица с зависимостями по версиям приведена [здесь](https://github.com/h2oai/rsparkling/blob/master/README.md#install-h2o). Устанавливать ПО и пакеты на головные узлы допустимо непосредственно через консоль узла, а вот на рабочие узлы прямого доступа нет, поэтому разворачивание дополнительного ПО необходимо делать через *Action Script*.
Вначале разворачиваем кластер *H2O Artificial Intelligence for HDInsight*, конфигурация используется такая же, с 2 головными узлами D12v2 и 4 рабочими узлами D12v2 и 1 узел *Sparkling water* (служебный). После успешного разворачивания кластера, используя подключение по *ssh* к головному узлу, устанавливаем туда *R*, *RStudio* (текущая версия *RStudio* уже с интегрированными возможностями по просмотру фреймов *Spark* и состояния кластера), и необходимые пакеты. Для установки пакетов на рабочие узлы создаем скрипт установки (R и пакетов) и инициируем его через *Action Script*. Возможно использовать готовые скрипты, располагающиеся здесь: [на головные узлы](https://bostoncaqs.blob.core.windows.net/scriptaction/scriptaction-head.sh) и [на рабочие узлы](https://bostoncaqs.blob.core.windows.net/scriptaction/scriptaction-worker.sh). После всех успешных установок переустанавливаем ssh соединение, используя туннелирование на *localhost:8787*. Итак, теперь в браузере по адресу *localhost:8787* мы подключаемся к *RStudio* и продолжаем работать.
> Достоинство использования R заключается еще и в том, что установив *Shiny* сервер на эту же головную ноду и, создав простой веб-интерфейс на *flexdashboard*, возможно все вычисления на кластере, подбор гиперпараметров, визуализацию результатов, подготовку отчетов и прочее, инициировать на созданном web-сайте, который уже будет доступен отовсюду по прямой ссылке в браузере (здесь не рассматривается).
### Подготовка и манипуляция данных
Использовать я буду тот же набор данных, что и в прошлый раз, это информация о поездках на такси и их оплате. Скачав данные файлы и поместив их в *hdfs*, читаем их оттуда и делаем необходимые преобразования (код приведен в прошлом посте).
### Модели машинного обучения
Для более-менее сопоставимого сравнения выберем общие модели как в *sparklyr*, так и в *h2o*, для задач регрессии таких моделей оказалось три — линейная регрессия, случайный лес и градиентный бустинг. Параметры алгоритмов использовались по умолчанию, в случае их отличий, они приводились к общим (по возможности), проверка точности модели осуществлялась на холдаут выборке в 30%, по метрике *RMSE*. Результаты приведены в Табл.1 и на Рис.1.
Табл.1. Результаты моделей
| Модель | RMSE | Время, сек |
| --- | --- | --- |
| lm\_mllib | 1,2507 | 10 |
| lm\_h2o | 1,2507 | 5,6 |
| rf\_mllib | 1,2669 | 21,9 |
| rf\_h2o | 1,2531 | 13,4 |
| gbm\_mllib | 1,2553 | 108,3 |
| gbm\_h2o | 1,2343 | 24,9 |
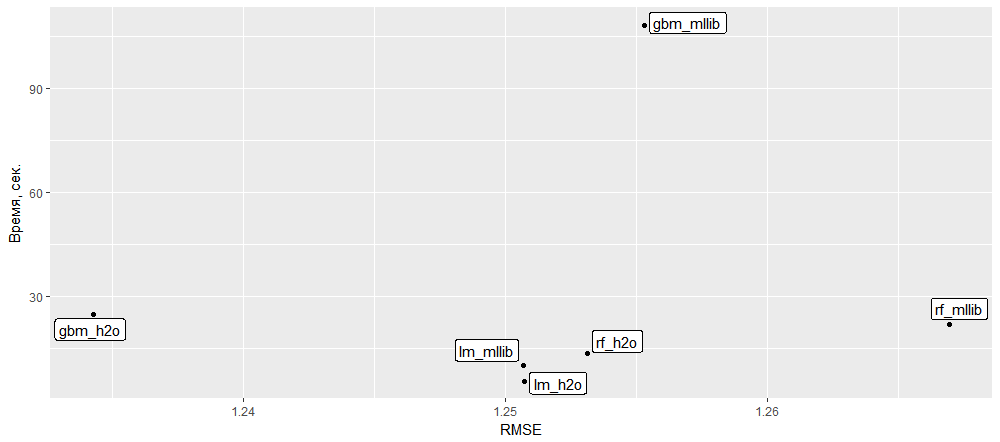
*Рис.1 Результаты моделей*
Как видно из результатов, явно видно преимущество одних и тех же моделей *h2o* перед их реализацией в *sparklyr*, как по времени исполнения, так и по метрике. Безусловный лидер из *h2o* *gbm*, обладает хорошим временем исполнения и минимальным *RMSE*. Не исключено, что осуществляя подбор гиперпараметров по кросс-валидациям, картина могла бы быть иной, но в данном случае «из коробки» *h2o* быстрее и лучше.
### Выводы
В данной статье дополнены функциональные возможности машинного обучения, используя R с *H2O* на кластере *Spark*, используя платформу *HDInsight*, и приведен пример преимущества данного способа в отличие от моделей МО пакета *sparklyr*, но в свою очередь *sparklyr* обладает существенным преимуществом по удобной предобработке и трансформации данных.
**Исходный код**
```
###Подготовительная часть (подготовка данных) приведена в прошлом посте
features<-c("vendor_id",
"passenger_count",
"trip_time_in_secs",
"trip_distance",
"fare_amount",
"surcharge")
rmse <- function(formula, data) {
data %>%
mutate_(residual = formula) %>%
summarize(rmse = sqr(mean(residual ^ 2))) %>%
collect %>%
.[["rmse"]]
}
trips_train_tbl <- sdf_register(taxi_filtered$training, "trips_train")
trips_test_tbl <- sdf_register(taxi_filtered$test, "trips_test")
actual <- trips.test.tbl %>%
select(tip_amount) %>%
collect() %>%
`[[`("tip_amount")
tbl_cache(sc, "trips_train")
tbl_cache(sc, "trips_test")
trips_train_h2o_tbl <- as_h2o_frame(sc, trips_train_tbl)
trips_test_h2o_tbl <- as_h2o_frame(sc, trips_test_tbl)
trips_train_h2o_tbl$vendor_id <- as.factor(trips_train_h2o_tbl$vendor_id)
trips_test_h2o_tbl$vendor_id <- as.factor(trips_test_h2o_tbl$vendor_id)
#mllib
lm_mllib <- ml_linear_regression(x=trips_train_tbl, response = "tip_amount", features = features)
pred_lm_mllib <- sdf_predict(lm_mllib, trips_test_tbl)
rf_mllib <- ml_random_forest(x=trips_train_tbl, response = "tip_amount", features = features)
pred_rf_mllib <- sdf_predict(rf_mllib, trips_test_tbl)
gbm_mllib <-ml_gradient_boosted_trees(x=trips_train_tbl, response = "tip_amount", features = features)
pred_gbm_mllib <- sdf_predict(gbm_mllib, trips_test_tbl)
#h2o
lm_h2o <- h2o.glm(x =features, y = "tip_amount", trips_train_h2o_tbl)
pred_lm_h2o <- h2o.predict(lm_h2o, trips_test_h2o_tbl)
rf_h2o <- h2o.randomForest(x =features, y = "tip_amount", trips_train_h2o_tbl,ntrees=20,max_depth=5)
pred_rf_h2o <- h2o.predict(rf_h2o, trips_test_h2o_tbl)
gbm_h2o <- h2o.gbm(x =features, y = "tip_amount", trips_train_h2o_tbl)
pred_gbm_h2o <- h2o.predict(gbm_h2o, trips_test_h2o_tbl)
####
pred.h2o <- data.frame(
tip.amount = actual,
as.data.frame(pred_lm_h2o),
as.data.frame(pred_rf_h2o),
as.data.frame(pred_gbm_h2o),
)
colnames(pred.h2o)<-c("tip.amount", "lm", "rf", "gbm")
result <- data.frame(
RMSE = c(
lm.mllib = rmse(~ tip_amount - prediction, pred_lm_mllib),
lm.h2o = rmse(~ tip.amount - lm, pred.h2o ),
rf.mllib = rmse(~ tip.amount - prediction, pred_rf_mllib),
rf.h2o = rmse(~ tip_amount - rf, pred.h2o),
gbm.mllib = rmse(~ tip_amount - prediction, pred_gbm_mllib),
gbm.h2o = rmse(~ tip.amount - gbm, pred.h2o)
)
)
``` | https://habr.com/ru/post/334898/ | null | ru | null |
# Как найти «слона» в песочнице на Hadoop: решаем проблему с ограничением объёма выделенной памяти
И снова здравствуй, Хабр! Сегодня поговорим об актуальной для многих из нас проблеме при работе с базами данных. В ходе работы над разными проектами часто приходится создавать базу данных (командное пространство, песочница и т.п.), которую использует как сам автор, так и/или коллеги для временного хранения данных. Как у любого «помещения», в нашей «песочнице» есть своё ограничение по объёму выделенного места для хранения данных. Периодически бывает так, что вы или ваши коллеги забываете об этом маленьком ограничении, из-за чего, к сожалению, заканчивается объём выделенной памяти.
В этом случае можно применить маленький лайфхак, который позволит оперативно просмотреть, какая таблица больше всего занимает место, кто её владелец, как долго она находится в общей песочнице и т.д. Используя его, вы оперативно сможете почистить место в песочнице, предварительно согласовав действия с владельцем данных без нанесения вреда данным остальных коллег. Кроме того, этот инструмент позволит периодически проводить мониторинг наполняемости вашей общей песочницы.
Этап 1
------
Для начала импортируем нужные нам модули библиотек для Python и определим путь к нашей песочнице.
```
import subprocess
import sys, getopt
import re
import pandas as pd
%matplotlib inline
pd.set_option('display.max_colwidth', -1)
path = 'hdfs://arnsdpsbx/user/team/team_sandbox/hive'
```
Модуль subprocess в Python предоставляет простые функции, которые позволяют нам запускать новый процесс и получать их коды возврата.
Модуль getopt — один из вариантов анализа аргументов командной строки. В основном используется для анализа последовательности аргументов.
Модуль re в Python — функции в этом модуле позволяют проверить, соответствует ли строка заданному регулярному выражению (или соответствует ли данное регулярное выражение определённой строке, что сводится к тому же самому).
Модуль pandas — программная библиотека для обработки и анализа данных. Команда %matplotlib inline позволяет построить и вывести нужный вам график прямо в Jupiter notebook (далее в статье).
Этап 2
------
Далее мы пропишем функции, которые позволят нам сформировать статистику по заполняемости нашей песочницы:
*- для определения размера используемой памяти (human\_readable\_size)*
```
def human_readable_size(size, decimal_places=2):
for unit in ['B', 'KiB', 'MiB', 'GiB', 'TiB', 'PiB']:
if size < 1024.0 or unit == 'PiB':
break
size /= 1024.0
return f'{size:.{decimal_places}f} {unit}'
```
*- для поиска и формирования списка пользователей в песочнице (get\_ipa\_login)*
```
def get_ipa_login(domain, login):
if domain == 'Ваш_домен_IPA':
return f'{login}_Ваш_домен_IPA'
return ''
```
*- для определения территориального подразделения (get\_tb)*
```
def get_tb(dept):
try:
return dept.split('/')[2]
except:
return '-'
```
*- для определения наименования таблицы в песочнице (get\_table\_name)*
```
def get_table_name(path):
try:
return path.split('/')[-1]
except:
return '-'
```
*- для определения владельца таблицы (get\_owner\_name)*
```
def get_owner_name(owner, name):
return f'{owner} ({name})'
```
*- для определения таблиц «фантомов» без определения владельца*
```
def get_fix_cmd(merge, path, table_name):
if merge == 'right_only':
return f'DROP TABLE {table_name}'
elif merge == 'left_only':
return f'hdfs dfs -rm -f -R -skipTrash {path}'
return ''
```
Этап 3
------
Далее мы создаем Dataframe, содержащий информацию о данных, размещённых в песочнице (данные о владельце, группе, дате, времени, пути размещения таблицы).
```
out = subprocess.Popen(['hdfs', 'dfs', '-du', path], stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
stdout, stderr = out.communicate()
if 'GSSException' in stdout.decode('utf-8'):
print('GSSException! Run kinit')
exit(1)
lines = stdout.decode('utf-8').split('\n')
list_du = []
for line in lines:
m = re.match(r'^(\d+)\s+(\d+)\s+(.*)$', line)
if m:
list_du.append([
int(m.group(1)),
int(m.group(2)),
m.group(3)
])
df_du = pd.DataFrame(list_du, columns=['fsize', 'disk_space_consumed', 'path'])
out = subprocess.Popen(['hdfs', 'dfs', '-ls', path], stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
stdout, stderr = out.communicate()
lines = stdout.decode('utf-8').split('\n')
del lines[0]
list_ls = []
for line in lines:
list_ls.append(line.split())
df_ls = pd.DataFrame(list_ls, columns=['permission', 'links', 'owner', 'group', 'size', 'date', 'time', 'path'])
df_ls.dropna(how='all', inplace=True)
df_ls.drop(['permission', 'links', 'size'], axis=1, inplace=True)
```
По написанному коду мы получаем данные о владельце, группе, дате, времени, пути размещения таблицы.
Этап 4
------
Не забывая о коллегах, мы добавляем в наш Dataframe подробную информацию о пользователях, которым предоставлены права и которые используют нашу «песочницу». В нашем случае данные о пользователях и их принадлежности к территориальному подразделению мы взяли из сsv файла. В целом скрипт можно улучшить, настроив выгрузку на получение данных из системы учёта пользователей IPA (в нашем случае это Red HAT Identity Management).
```
df_users = pd.read_csv('ad_users.csv', encoding='windows-1251', sep='|', header=None, names=['domain', 'login', 'tn', 'full_name', 'position', 'dept'], index_col=False)
df_users['ipa_login'] = df_users.apply(lambda row: get_ipa_login(row.domain, row.login), axis=1)
```
Этап 5
------
После формирования баз с необходимой для нас информацией о таблицах и пользователях мы объединяем эти данные в единую базу данных.
```
df_hdfs = pd.merge(df_du, df_ls, on='path')
df_hdfs['fsize_h'] = df_hdfs['fsize'].apply(lambda x: human_readable_size(x))
df_hdfs['disk_space_consumed_h'] = df_hdfs['disk_space_consumed'].apply(lambda x: human_readable_size(x))
df_hdfs = df_hdfs.reindex(columns=['path', 'owner', 'group', 'fsize', 'fsize_h', 'disk_space_consumed', 'disk_space_consumed_h', 'date'])
df_hdfs = pd.merge(df_hdfs, df_users, how='left', left_on='owner', right_on='ipa_login')
df_hdfs['owner_name'] = df_hdfs.apply(lambda row: get_owner_name(row.owner, row.full_name), axis=1)
df_hdfs['tb'] = df_hdfs['dept'].apply(lambda x: get_tb(x))
df_hdfs['table_name'] = df_hdfs['path'].apply(lambda x: get_table_name(x))
```
Этап 6
------
Делаем ещё пару шагов для получения более точного наименования таблиц, размещённых в нашей «песочнице», собирая воедино и «отсекая» ненужную информацию.
```
out = subprocess.Popen([
'beeline',
'--outputformat=csv2',
'--silent=true',
'--showHeader=false',
'--verbose=false',
'--showWarnings=false',
'-u',
'"jdbc:hive2://:10000/default;principal=hive/\_HOST@ВАШ домен"',
'-e',
'"show tables in Наименование Песочницы (башей базы);"'
],
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT)
stdout,stderr = out.communicate()
lines = stdout.decode('utf-8').split('\n')
list\_tables = []
for line in lines:
if 'warning:' not in line:
list\_tables.append(line)
df\_tables = pd.DataFrame(list\_tables, columns=['table\_name'])
df\_tables.dropna(how='all', inplace=True)
```
В результате написанный код формирует наименование таблицы, установленное пользователем при её создании.
После проведения подготовительных мероприятий по написанию кода и создания нужных нам данных в DataFrame перейдём к самому интересному — к просмотру результатов и анализу заполняемости нашей «песочницы».
Начнём с самого простого и выведем топ-10 таблиц по размерам использования памяти в «песочнице» с информацией о коллегах, которые их создали.
```
df_hdfs_top = df_hdfs.sort_values(by=['fsize'], ascending=False).head(10)[['path', 'fsize_h', 'owner_name']]
df_hdfs_top
```
Теперь давайте посмотрим на пользователей, которые больше всего занимают место в «песочнице», и выведем топ-10 из них.
```
df_hdfs_size_by_owner = df_hdfs.groupby('owner_name')['fsize'].sum().reset_index().sort_values(by=['fsize']).tail(10)
df_hdfs_size_by_owner.plot(x='owner_name', y='fsize', kind='barh')
```
Одновременно посмотрим на заполняемость «песочницы» в разрезе территориальных подразделений.
```
df_hdfs_size_by_tb = df_hdfs.groupby('tb')['fsize'].sum().reset_index().sort_values(by=['fsize'])
df_hdfs_size_by_tb.plot(x='tb', y='fsize', kind='barh')
```
При необходимости посмотрим на наши таблицы по дате их создания, для уточнения у коллег их актуальности и планов по дальнейшему использованию.
```
df_hdfs_oldest = df_hdfs[df_hdfs.fsize > 10000].sort_values(by=['date'], ascending=False).tail(50) df_hdfs_oldest
```
Для более подробного просмотра результатов выгрузим данные в отдельный файл, который более подробно нам покажет информацию о таблицах, их объёме и владельцах.
```
df_hdfs_top = df_hdfs[df_hdfs.fsize > 10000].sort_values(by=['fsize'], ascending=False)
df_hdfs_top.to_csv('team_sandbox.csv', index=False)
```
Что ещё?
--------
Также вы можете столкнуться с ситуацией, когда в вашей «песочнице» находятся HDFS файлы «фантомы» — таблицы без каталога и/или каталог без таблицы, а также файлы без принадлежности к определённому владельцу. Для их определения воспользуемся следующим кодом:
```
df_fantoms = pd.merge(df_hdfs, df_tables, how='outer', on='table_name', indicator=True).sort_values(by=['fsize'], ascending=False)
df_fantoms['fix_cmd'] = df_fantoms.apply(lambda row: get_fix_cmd(row._merge, row.path, row.table_name), axis=1)
df_fantoms = df_fantoms.reindex(columns=['path', 'table_name', 'owner_name', 'fsize', 'fsize_h', 'fix_cmd', '_merge'])
```
*- для просмотра таблиц без каталога сформируем запрос*
```
df_fantoms[df_fantoms._merge=='right_only']
```
*- для просмотра каталогов без таблиц сформируем следующий запрос*
```
print(human_readable_size(df_fantoms[df_fantoms._merge=='left_only']['fsize'].sum()))
df_fantoms[(df_fantoms._merge=='left_only') & (df_fantoms.fsize > 1000000000)]
```
*- для более подробного просмотра и анализа «фантомов» выгрузим данные в отдельный файл*
```
df_fantoms[(df_fantoms._merge=='left_only') & (df_fantoms.fsize > 1000000000)].to_csv('team_sandbox_fantoms.csv', index=False)
```
Данный подход является не единственным способом найти СЛОНА в «песочнице»: существует множество вариантов его реализации, от использования команд HDFS c её различными параметрами до написания Python кода под другим «углом» в зависимости от особенностей ведения вашей базы. | https://habr.com/ru/post/703608/ | null | ru | null |
# Исследование переменных Mikrotik. Скрипт обновления Dynamic DNS записей FreeDNS.afraid.org
Я использую Mikrotik в качестве домашнего и офисного маршрутизатора, и в целом система очень нравится. RouterOS имеет широкие возможности, которые покрывают 90% моих задач, если чего-то недостает, то можно «дописать» функционал с помощью внутренних скриптов. Но когда начинаешь писать более-менее вменяемый скрипт или пытаешься понять и применить чужой рецепт, становятся заметны очертания подводной части айсберга, всплывают странные особенности языка.
Я провел небольшое исследование переменных в скриптах Mikrotik, рассмотрел под лупой объявление и инициализацию.
Получилась, на мой взгляд, достойная тема для написания статьи. Итак, приступим.
Что же нам говорит Manual:Scripting о переменных в скриптах? А говорит он нам, что переменные бывают двух областей видимости: локальные и глобальные, что объявляются они командами —
**:local**
и
**:global**
Предлагаю сразу сосредоточиться на global переменных, так как их легче исследовать за счет их лучшей «наблюдаемости», а большинство выводов, думаю, можно спокойно перенести и на local.
Прежде чем мы объявим первую глобальную переменную, давайте ознакомимся с особенностями некоторых встроенных типов данных и символьных конструкций, которые можно использовать как значения переменных или аргументы операторов сравнения.
Manual:Scripting говорит нам, что есть около десятка типов, из которых мы рассмотрим только некоторые, важные для понимания переменных. Итак, явные и логичные типы: числовой **num**, строковый **str** и массив **array**. Далее упоминается тип (оно же — значение переменной) **nil**, про который написано, что он будет у переменной по умолчанию, если ей ничего не присвоено. Поверим.
Если поработать с командной консолью в WinBox, можно заметить, что есть еще одно странное ключевое слово **nothing**, которое непонятно что означает, какое-то «ничего».
```
[admin@MikroTik] > :global var0
[admin@MikroTik] > :put [:typeof $var0]
nothing
[admin@MikroTik] > /environment print
var0=[:nothing]
```
Ну и где тут **nil**? Зато полно **nothing**.
Исследование nil
================
В общем, чтобы разобраться с этими особыми типами и значениями, применим системный подход, проанализируем выдачу однотипных запросов, но с разными наборами исходных данных. А исходными данными у нас будут в начале разные «странные» константы и выражения. В результате получается такая таблица:
| № | Что это? | | | :if ( = ) do={:put TRUE} else={:put FALSE} | :put [:typeof ] | :put [:typeof []] | :put [:len ] | :put [:len []] |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1 | **Nothing** в командной обертке | [] / [:nothing] / или даже так [:] | [] | TRUE | nil | nil | 0 | 0 |
| 2 | Пустая строка | "" | "" / {} | TRUE | str | expected command name | 0 | 0 |
| 3 | **Nothing** внутри выражения | (:nothing) / или даже так (:) | [] / "" / {} | FALSE | nothing | nil | 0 | 0 |
| 4 | Массив из **nothing** | {:nothing} / {:} | {} / "" | TRUE | array | nil | 1 | 1 |
| 5 | Элемент массива **nothing** | ({:nothing}->0) | [] / "" / {} | FALSE | nothing | nil | 0 | 0 |
Тут даны результаты сравнения различных констант выражений и команд над константами между собой. Понимание свойств констант поможет при написании правых частей операторов сравнения.
На счет полей таблицы. В языке скриптов Mikrotik квадратные скобки обозначают встраивание результата команды в общее выражение, поэтому в общем смысле value != [value], это важно.
Прокомментирую построчно:
Строка 1: все варианты записи поля **value** синонимичны! В будущем я предлагаю использовать лаконичное **[]**. Повторюсь, что квадратные скобки обозначают встраивание результата команды в общее выражение. Как видите, это один из способов «генерации» **nil** не в чистом виде, а как результат пустой команды в квадратных скобках, который как раз равен **nil**.
Строка 2:
Тут все просто. Пустая строка вполне очевидная вещь. Единственные момент, что она оказывается равна массиву из ничего, но предлагаю не обращать на это особого внимание. И нельзя использовать пустую строку как команду в квадратных скобках, это единственное место, где терминал не проглотил синтаксис по исходным данным таблицы, логично.
Строка 3:
Круглые скобки несут в себе выражение, внутри можно тоже поместить **nothing**, и результат от такого выражения тоже будет **nothing**, по сути это почти чистый **nothing**. Видно, что тип результата выражения **(:nothing)** дает **nothing**, а тип от обертки из командных скобок **[]** дает **nil**, по аналогии со строкой 1. Вообще после повторного осмысления написанного, я понял что это спекуляция, т.к. внутрь **()** можно поместить что угодно, любой бессмысленный набор символов, главное, что результат **(...)** дает **nothing**.
Строка 4:
Массив, который содержит ничего, на самом деле содержит 1 элемент. Тип, как и ожидалось, **array**, тип результата командной обертки также дает **nil**
Строка 5:
Добираемся до элемента массива из ничего, прослеживается полная аналогия выдачи со строкой 3. В общем такой элемент — это тоже чистое **nothing**.
Какие общие выводы можно сделать из этого странного brainfuck-а. **nothing** действительно существует, им можно оперировать, редкие выражения могут его возвращать, но команды в **[]** никогда не возвращают **nothing**, а только **nil**. Другой более важный вывод, что оператор длины значения или кол-ва элементов массива **:len** ведет себя очень стабильно и генерирует предсказуемый результат, поэтому его я могу однозначно рекомендовать для использования в скриптах, когда требуется проверка возвращаемых выражениями и командами значений. И что **[] = [:nothing] = nil**.
Таблица дает представление о том, что могут возвращать различные команды и выражения языка Mikrotik.
Исследование объявлений переменных
==================================
Теперь перейдем к более практическому объявлению переменных.
| № | Что это? | Объявление | | | :put | :if ( = ) do={:put TRUE} else={:put FALSE} | :put [:typeof ] | :put [:typeof []] | :put [:len ] оно же :put [:len []] | /environment print |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1 | Без присвоения | :global var1 | $var1 | [] / (:) | | FALSE / TRUE | nothing | nil | 0 | var1=[:nothing] |
| 2 | Присвоение, удаляющее переменную | :global var2 (:nothing) | $var2 | (:) | | TRUE | nothing | nil | 0 | - |
| 3 | Присвоение **nil** | :global var3 [] | $var3 | [] | | TRUE | nil | nil | 0 | var3=[] |
| 4 | Присвоение пустой строки | :global var4 "" | $var4 | "" / {} | | TRUE / TRUE | str | str | 0 | var4="" |
| 5 (3) | Странный **nil**, аналог 3 | :global var5 [{}] | $var5 | [{}] / [] | | TRUE / TRUE | nil | nil | 0 | var5=[] |
| 6 | Массив из **nothing** | :global var6 {:} | $var6 | "" / {""} / {} | | TRUE / TRUE / TRUE | array | array | 1 | var6={[:nothing]} |
| 7 (6, 8) | Массив из пустой строки | :global var7 {""} | $var7 | "" / {""} / {} | | TRUE / TRUE / TRUE | array | array | 1 | var7={""} |
| 8 (6, 7) | Массив из **nil** | :global var8 {[]} | $var8 | "" / {""} / {} | | TRUE / TRUE / TRUE | array | array | 1 | var8={[]} |
| № | Что это? | Объявление | | | :put | :if ( = ) do={:put TRUE} else={:put FALSE} | :put [:typeof ] | :put [:typeof []] | :put [:len ] оно же :put [:len []] | /environment print |
| 9 | Присвоение числа | :global var9 123 | $var9 | н./и. | 123 | н./п. | num | num | 3 | var9=123 |
| 10 | Присвоение строки | :global var10 "987" | $var10 | н./и. | 987 | н./п. | str | str | 3 | var10="987" |
| 11 | Массив из одного числа | :global var11 {555} / :global var11 {555;} | $var11 | н./и. | 555 | н./п. | array | array | 1 | var11={555} |
| 12 | Массив разнородных элементов | :global var12 {33;"test123"} | $var12 | н./и. | 33;test123 | н./п. | array | array | 2 | var12={33; "test123"} |
| 13 | Элемент массива | -//- | ($var12->0) | н./и. | 33 | н./п. | num | num | 2 | -//- |
| 14 | Элемент массива | -//- | ($var12->1) | н./и. | test123 | н./п. | str | str | 7 | -//- |
| 15 | Массив c **nothing** элементом | :global var13 {33;(:)} | $var13 | н./и. | 33; | н./п. | array | array | 2 | var13={33; [:nothing]} |
| 16 | Элемент массива | -//- | ($var13->0) | н./и. | 33 | н./п. | num | num | 2 | -//- |
| 17 | Элемент массива | -//- | ($var13->1) | н./и. | | н./п. | nothing | nil | 0 | -//- |
| 18 | Массив c **nil** элементом | :global var14 {1012;[]} | $var14 | н./и. | 1012; | н./п. | array | array | 2 | var14={1012; []} |
| 19 | Элемент массива | -//- | ($var14->1) | н./и. | | н./п. | nil | nil | 0 | -//- |
н./и. — не используется; н./п. — не применимо
Построчные комментарии к таблице:
1. Переменная создана, но ей ничего не присвоено. Переменная как бы содержит **nothing**.
2. Если переменной присвоить такое выражение, то это приведет к удалению глобальной переменной из переменных окружения.
3. Стандартный способ создания пустых переменных. Переменная содержит **nil**.
4. Присвоение пустой строки. Тут все очевидно.
5. Получается, что такое выражение аналогично **[]** простому присвоению **nil**, как в 3. Думаю, это потому, что внутри **[]** несуществующая команда и результат этой команды дает **nil**
6, 7, 8. Присвоение фигурных скобок делает из переменной массив, хоть и пустой. Обратите внимание, что записи имеют одинаковые результаты в таблице, но это не касается свойств элементов этих массивов. Свойства элементов массивов рассмотрены ниже.
9, 10. Простые типы данных. Все довольно очевидно.
11. Массив из одного элемента, обратите внимание, что {555;} по результатам равно {555}
12, 13, 14. В массив могут входить элементы разных типов данных. Исследование свойств элементов массива дает предсказуемые результаты.
15, 16, 17. Один из элементов массива **nothing**. Элементы массива обладают теми же свойствами, что и просто переменные и константы данных типов и значений. Прослеживается аналогия с пунктом 2.
18, 19. Прослеживается аналогия с пунктом 3.
Исследование, на мой взгляд, получилось немного спорным, но я очень надеюсь, оно внесет больше порядка в ваше понимание Mikrotik, чем хаоса. В качестве дополнительной компенсации публикую скрипт для работы с динамическим DNS замечательного сервиса FreeDNS.afraid.org.
Скрипт для FreeDNS.afraid.org
=============================
Я видел несколько аналогичных скриптов, но они не понравились мне из-за разных ограничений, поэтому я решил собрать свой велосипед, который меня бы полностью устроил.
За основу я взял скрипт от [LESHIYODESSA](http://forum.mikrotik.com/viewtopic.php?f=13&t=83744&p=444954#p444181). Мне не очень понравился его алгоритм, в котором использовался файл для хранения текущих адресов записей Dynamic DNS и производился его периодический парсинг, кроме того, скрипт не поддерживает обновление разных записей, для этого предлагается размножить скрипт, но это не снимает проблему обновления записи по заданному IP-адресу. Поэтому фактически я написал свой собственный скрипт, в котором заменил работу с файлами на более надежный механизм периодического обновления (с часовым интервалом) и форсированное обновление по изменению отслеживаемых IP-адресов интерфейсов, полученных по DHCP, независимое для нескольких записей.
Объявляем массивы имен субдоменов FreeDNS.afraid.org и их хешей, имен WAN-инетфейсов, у которых мы будем отслеживать IP-адреса. А также задаем кол-во записей (Quant) по размеру массива либо вручную:
```
:local SubdomainHashes {"U3dWVE5V01TWxPcjluEo0bEtJQWjg5DUz=";"U3pWV5VFTWxPcjlOEo0EtJpOE1MAyDc="}
:global DNSDomains {"aaa.xyz.pu";"bbb.xyz.pu"}
:global WANInterfaces {"ether4-WAN-Inet";"ether3-WAN-Beeline"}
:global Quant [:len $DNSDomains]
```
Объявляем вспомогательные переменные:
SkipCounters — массив счетчиков проверок отслеживаемых интерфейсов
LastIPs — массив IP-адресов, которые уже были отправлены в FreeDNS.
Массив счетчиков позволит обновлять Dynamic DNS записи независимо друг от друга.
Сначала я делаю пустое объявление переменной **:global SkipCounters**, такое объявление позволяет либо создать новую глобальную переменную, либо использовать уже существующую в переменных окружения и ее значение без перезаписи.
Следующие конструкции работают для только что созданных переменных, проверяется тип данных, если он не массив, то тип меняется на массив, и присваиваются значения переменных. Таким образом на выходе мы имеем проинициализированные нужными значениями переменные типа массив.
```
:global SkipCounters
:if ([:typeof $SkipCounters] != "array") do={
:set SkipCounters {""}
:for i from=0 to=($Quant-1) do={:set ($SkipCounters->$i) 1}
}
:global LastIPs
:if ([:typeof $LastIPs] != "array") do={
:set LastIPs {""}
:for i from=0 to=($Quant-1) do={:set ($LastIPs->$i) ""}
}
```
Ни и собственно сам алгоритм отслеживания-обновления.
Получаем текущий IP-адрес из dhcp-client. Дальше самое интересное.
Команда **[/ip dhcp-client get [find where interface=($WANInterfaces->$i)] address]** в общем случае может вернуть что угодно кроме строки, содержащей IP-адрес, поэтому она в норме обновит значение переменной CurrentIP. Возвращаемым значением может быть либо строка с IP, либо nil, или будет ошибка выполнения и команда не обновит CurrentIP. Поэтому я строкой выше ввожу явное объявление **:local CurrentIP ""**. И после выполнения команды в CurrentIP будет либо "", либо nil, либо IP-адрес.
Как я писал выше, наибольшей устойчивостью обладает оператор :len, поэтому используем его дальше для проверки адекватности полученных данных **[:len $CurrentIP] > 0**. Еще отслеживаем значение счетчика, и если он >=60, принудительно отсылаем запрос в FreeDNS. Таким образом повышается устойчивость алгоритма к проблемам связи. Скрипт в шедулере у меня выполняется раз в минуту, поэтому период обязательного обновления около 1 часа, что не сильно обременяет сервис FreeDNS.
На что еще стоит обратить внимание. В URL запроса на обновление присутствует параметр "&address=".$CurrentIP, этот параметр позволяет явно указать IP-адрес для субдомена вместо автоматического (по интерфейсу с которого ушел запрос).
```
:for i from=0 to=($Quant-1) do={
:local CurrentIP ""
:set CurrentIP [/ip dhcp-client get [find where interface=($WANInterfaces->$i)] address]
:set CurrentIP [:pick $CurrentIP 0 ([:len $CurrentIP]-3)]
# :log info ("Current SkipCounter$i: ".($SkipCounters->$i))
:if ([:len $CurrentIP] > 0 and ($CurrentIP != ($LastIPs->$i) or ($SkipCounters->$i) > 59)) do={
:if ($CurrentIP != ($LastIPs->$i)) do={
:log info ("Service Dynamic DNS: Renew IP: ".($LastIPs->$i)." for ".($DNSDomains->$i)." to $CurrentIP")
}
/tool fetch url=("http://freedns.afraid.org/dynamic/update.php\?".($SubdomainHashes->$i)."&address=".$CurrentIP) keep-result=no
:set ($LastIPs->$i) $CurrentIP
:set ($SkipCounters->$i) 1
} else={
:set ($SkipCounters->$i) (($SkipCounters->$i) + 1)
}
}
```
**Скрипт MultiFreeDNS целиком**
```
# MultiFreeDNS
:local SubdomainHashes {"U3dWVE5V01TWxPcjluEo0bEtJQWjg5DUz=";"U3pWV5VFTWxPcjlOEo0EtJpOE1MAyDc="}
:global DNSDomains {"aaa.xyz.pu";"bbb.xyz.pu"}
:global WANInterfaces {"ether4-WAN-Inet";"ether3-WAN-Beeline"}
:global Quant [:len $DNSDomains]
:global SkipCounters
:if ([:typeof $SkipCounters] != "array") do={
:set SkipCounters {""}
:for i from=0 to=($Quant-1) do={:set ($SkipCounters->$i) 1}
}
:global LastIPs
:if ([:typeof $LastIPs] != "array") do={
:set LastIPs {""}
:for i from=0 to=($Quant-1) do={:set ($LastIPs->$i) ""}
}
:for i from=0 to=($Quant-1) do={
:local CurrentIP ""
:set CurrentIP [/ip dhcp-client get [find where interface=($WANInterfaces->$i)] address]
:set CurrentIP [:pick $CurrentIP 0 ([:len $CurrentIP]-3)]
# :log info ("Current SkipCounter$i: ".($SkipCounters->$i))
:if ([:len $CurrentIP] > 0 and ($CurrentIP != ($LastIPs->$i) or ($SkipCounters->$i) > 59)) do={
:if ($CurrentIP != ($LastIPs->$i)) do={
:log info ("Service Dynamic DNS: Renew IP: ".($LastIPs->$i)." for ".($DNSDomains->$i)." to $CurrentIP")
}
/tool fetch url=("http://freedns.afraid.org/dynamic/update.php\?".($SubdomainHashes->$i)."&address=".$CurrentIP) keep-result=no
:set ($LastIPs->$i) $CurrentIP
:set ($SkipCounters->$i) 1
} else={
:set ($SkipCounters->$i) (($SkipCounters->$i) + 1)
}
}
``` | https://habr.com/ru/post/270719/ | null | ru | null |
# Антихукинг — теория
Совсем недавно озадачился защитой приложений от перехвата системных api, решил поделиться и обсудить то, к чему пришел. Многие из вас знают, что перехват системных api сводится к перенаправлению оригинальной функции в нужное место, благодаря этому можно модифицировать параметры функции, возвращать результат отличный от оригинала, хранить оригинальный вызов с параметрами и многое другое. Так как это теоретическая часть, примеры в статье будут сопровождаться псевдокодом.
Обычно используются следующие методы перехвата:
1. Вставка безусловного прыжка на месте функции (х86 — 5 байт jmp addr, x64 — 12 байт, mov rax addr, jmp rax)
2. Вставка инструкции вызова (call) на месте вызова оригинальной функции (hooked\_function\_entry: call my\_function)
3. Модификация таблицы импорта приложения, внедрение прокси DLL.
4. Перехват без модификации кода средствами аппаратных точек останова (hardware breakpoints).
5. Перехват через kernel драйвер Zw/Nt функций.
Можно перечислить следующие методы детектирования перехвата из usermode:
1. Сравнение начала функции перед ее вызовом с опкодами машинных инструкций:
```
//0x90 - nop
//0xE9 - jmp
//0xE8 - call
if (*mainFunc == 0xE9 || *mainFunc == 0x90 || *mainFunc == 0xE8 ...)
printf("Hook detected");
```
Метод статичный и легко обходится, более умными переходами.
2. Перечисленные методы перехвата — это модификация памяти, и они могут быть обнаружены посредством crc checksum проверок, но api для чтения памяти тоже могут быть перехвачены и тогда будет возвращен ложный результат.
3. Порождать контролируемый процесс (с активной отладкой самого себя), с восстановлением важных api.
4. Перебор важных для нас api, используя таблицу экспорта в системных библиотеках, сравнивать дизассемблированную длину функции с оригинальной.
5. Восстановление модифицированных api посредством копирования байтов из библиотеки, примерная схема такая:
— получение базы определенного модуля
— итерация экспорта
— получение RVA необходимой функции.
— преобразование RVA->FileOffset.
— чтение оригинала и запись в память.
— в некоторых случаях не забываем про релоки.
6. Просмотр таблицы импорта библиотеки и для каждой импортированной функции из другой системной библиотеки делать проверку на соответствие, если не совпадает так же читаем с диска и записываем в память.
7. Имитирование системных функций Nt / Zw при помощи syscall-ов, int2e в (старых версиях windows), таблица syscall-ов для всех систем, легко находится в гугле.
Остановимся на 7 методе так как Nt / Zw функции так же могут быть перехвачены, этот метод тоже далек от совершенства, но по моему мнению лучше из всего вышеперечисленного.
Посмотрим на реализацию функции NtCreateFile в windows 7 sp1
происходит следующее:
— в еах лежит номер syscall-a.
— обнуляется ecx, (wow64 index?).
— в edx содержится указатель на параметры.
— далее вызов, корректировка стэка и возврат.
x64 вызов в win7 и win8
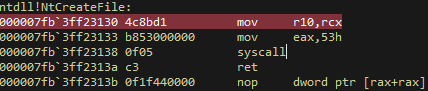
При помощи следующего x86 псевдокода «можно создать файл на диске».
```
//прототип функции NtCreateFile
typedef NTSTATUS (NTAPI * NTCREATEFILE) (OUT PHANDLE FileHandle,
IN ACCESS_MASK DesiredAccess,
IN POBJECT_ATTRIBUTES ObjectAttributes,
OUT PIO_STATUS_BLOCK IoStatusBlock,
IN PLARGE_INTEGER AllocationSize OPTIONAL,
IN ULONG FileAttributes,
IN ULONG ShareAccess,
IN ULONG CreateDisposition,
IN ULONG CreateOptions,
IN PVOID EaBuffer OPTIONAL,
IN ULONG EaLength);
#define InitializeObjectAttributes( p, n, a, r, s ) { \
(p)->Length = sizeof( OBJECT_ATTRIBUTES ); \
(p)->RootDirectory = r; \
(p)->Attributes = a; \
(p)->ObjectName = n; \
(p)->SecurityDescriptor = s; \
(p)->SecurityQualityOfService = NULL; \
}
typedef VOID (NTAPI * RTLINITUNICODESTRING)(IN OUT PUNICODE_STRING,
IN PCWSTR);
unsigned char dNtCreateFile[] =
{0xb8,0x52,0x00,0x00,0x00,0x33,0xc9,0x8d,0x54,0x24,0x04,0x64,
0xff,0x15,0xc0,0x00,0x00,0x00,0x83,0xc4,0x04,0xc2,0x2c,0x00};
...
RtlInitUnicodeString
InitializeObjectAttributes
...
DWORD oldp;
VirtualProtect(&dNtCreateFile, sizeof(dNtCreateFile), PAGE_EXECUTE_READ, &oldp);
auto func = (NTCREATEFILE) ((void*)dNtCreateFile);
Ntstatus = (func)(&fileHandle, DesiredAccess, ObjectAttritubes, ioStatusBlock, 0, FileAttributes, ShareAccess, CreateDisposition ,CreateOptions, Optional_Buffer, 0);
```
Данный псевдокод будет работать только на windows 7 sp1, однако dNtCreateFile можно формировать «динамично», используя метод из пункта 5, и тогда код с небольшими правками будет работать на всех системах, начиная с winxp. Приветствуются любые размышления в комментариях, kernelmode — крайний случай. | https://habr.com/ru/post/186334/ | null | ru | null |
# Стандарт Miracast — старые протоколы в новой обёртке
Не так давно (начиная с JellyBean 4.2) Google добавила в Android поддержку технологии [Miracast](https://ru.wikipedia.org/wiki/Miracast).
Практическому исследованию этой технологии методами reverse engineering и посвящена статья.
Что такое Miracast в двух словах? Это очередное детище Wi-Fi альянса — стандарт для передачи мультимедийного контента по сети Wi-Fi в peer-to-peer режиме. Для пользователя это означает прежде всего то, что для соединения с телевизором (к примеру) ему не понадобится Wi-Fi маршрутизатор. Два устройства по задумке альянса должны связываться друг с другом напрямую. Это обеспечивается использованием стандарта Wi-Fi Direct за авторством той же организации. Иными словами, новый стандарт решает задачи очень похожие на AirPlay от Apple, WiDi от Intel, или старое-доброе DLNA.
Зачем было городить огород — спросите вы. Почему было не воспользоваться уже существующим решением? Тут мне будет трудно ответить. Понятно, что лицензировать решения от прямых конкурентов или даже от Intel — не кошерный вариант имеющий к тому же **фатальный недостаток**, но почему не взять то же DLNA, возможно, чуть доработав рашпилем. Быть может, хотелось чего-то новенького, с модными нонче словами peer-to-peer? Не буду гадать. Так или иначе, технология была реализована в Android, и свежие телефоны типа Nexus 4 и Samsung Galaxy S3 имеют ее на борту.
Хуже обстоит дело с производителями телевизоров. Если поддержка DLNА уже есть практически в каждом современном телевизоре достаточно высокого уровня, то с Miracast дела обстоят хуже. Несмотря на существование чипов, модели телевизоров и проекторов умеющие принимать Miracast можно пересчитать по пальцам. Впрочем, ситуация наверняка изменится в 2014 году, а пока — пользователь может довольствоваться многочисленными гаджетами, принимающими сигнал по Wi-Fi и преобразующими его в HDMI. Такая штука втыкается в HDMI-разъем телевизора, и вот уже у вас есть Miracast-enabled устройство!
Один из инженерных образцов с чипом Broadcom попал в мои цепкие руки:

Убедившись, что с Android-смартфоном все работает на ура, я задумался над вопросом — нельзя ли наладить вещание через Miracast прямо из под Linux? Ведь что такое Android внутри? Тот же Linux…
Для начала, хотелось понять как вообще выглядит стек протоколов Miracast? Что стоит за красивым названием? Гонится ли видео-сигнал напрямую в Ethernet-фреймах или используется IP и еще более высокоуровневые протоколы. К сожалению, [сам стандарт](https://www.wi-fi.org/wi-fi-display-technical-specification-v100), хоть и открытый, но далеко не бесплатный, так что пришлось изыскивать иные, более традиционные пути исследования. В какой-то презентации я ухватил ключевые слова — MPEG-TS и RTSP, и это дало возможность раскрутить клубок дальше. Если я хоть что-то в чем-то смыслю, то [RTSP](https://ru.wikipedia.org/wiki/RTSP) — это TCP, а TCP — это IP. А IP — это подходящий протокол, который можно послушать tcpdump-ом! Сказано-сделано, запустив на Nexus-е tcpdump и включив Wireless display в настройках, через 5 минут я имел дамп пакетов, приемлемый для дальнейшего анализа.
Временно отложив трудности с соединением через Wi-Fi я взялся сразу за анализ TCP-потока. И вот что увидел:
```
OPTIONS * RTSP/1.0
Date: Fri, 08 Mar 2013 12:37:54 +0000
Server: Mine/1.0
CSeq: 1
Require: org.wfa.wfd1.0
RTSP/1.0 200 OK
CSeq: 1
Public: org.wfa.wfd1.0, GET_PARAMETER, SET_PARAMETER
OPTIONS * RTSP/1.0
CSeq: 1
Require: org.wfa.wfd1.0
RTSP/1.0 200 OK
Date: Fri, 08 Mar 2013 12:37:54 +0000
Server: Mine/1.0
CSeq: 1
Public: org.wfa.wfd1.0, SETUP, TEARDOWN, PLAY, PAUSE, GET_PARAMETER, SET_PARAMETER
GET_PARAMETER rtsp://localhost/wfd1.0 RTSP/1.0
Date: Fri, 08 Mar 2013 12:37:54 +0000
Server: Mine/1.0
CSeq: 2
Content-Type: text/parameters
Content-Length: 83
wfd_content_protection
wfd_video_formats
wfd_audio_codecs
wfd_client_rtp_ports
RTSP/1.0 200 OK
CSeq: 2
Content-Type: text/parameters
Content-Length: 751
wfd_content_protection: none
wfd_video_formats: 00 00 02 10 0001bdeb 3fffffff 00000fff 00 0000 0000 11 none none, 02 08 0001bdeb 3fffffff 00000fff 00 0000 0000 11 none none, 02 04 0001bdeb 3fffffff 00000fff 00 0000 0000 11 none none, 02 02 0001bdeb 3fffffff 00000fff 00 0000 0000 11 none none, 02 01 0001bdeb 3fffffff 00000fff 00 0000 0000 11 none none, 01 10 0001bdeb 3fffffff 00000fff 00 0000 0000 11 none none, 01 08 0001bdeb 3fffffff 00000fff 00 0000 0000 11 none none, 01 04 0001bdeb 3fffffff 00000fff 00 0000 0000 11 none none, 01 02 0001bdeb 3fffffff 00000fff 00 0000 0000 11 none none, 01 01 0001bdeb 3fffffff 00000fff 00 0000 0000 11 none none
wfd_audio_codecs: LPCM 00000003 00
wfd_client_rtp_ports: RTP/AVP/UDP;unicast 6500 0 mode=play
SET_PARAMETER rtsp://localhost/wfd1.0 RTSP/1.0
Date: Fri, 08 Mar 2013 12:37:54 +0000
Server: Mine/1.0
CSeq: 3
Content-Type: text/parameters
Content-Length: 248
wfd_video_formats: 28 00 02 02 00000020 00000000 00000000 00 0000 0000 00 none none
wfd_audio_codecs: LPCM 00000002 00
wfd_presentation_URL: rtsp://192.168.16.40/wfd1.0/streamid=0 none
wfd_client_rtp_ports: RTP/AVP/UDP;unicast 6500 0 mode=play
RTSP/1.0 200 OK
CSeq: 3
SET_PARAMETER rtsp://localhost/wfd1.0 RTSP/1.0
Date: Fri, 08 Mar 2013 12:37:54 +0000
Server: Mine/1.0
CSeq: 4
Content-Type: text/parameters
Content-Length: 27
wfd_trigger_method: SETUP
RTSP/1.0 200 OK
CSeq: 4
SETUP rtsp://192.168.16.40/wfd1.0/streamid=0 RTSP/1.0
CSeq: 2
Transport: RTP/AVP/UDP;unicast;client_port=6500
RTSP/1.0 200 OK
Date: Fri, 08 Mar 2013 12:37:55 +0000
Server: Mine/1.0
CSeq: 2
Session: 1219569791;timeout=30
Transport: RTP/AVP/UDP;unicast;client_port=6500;server_port=15550
PLAY rtsp://192.168.16.40/wfd1.0/streamid=0 RTSP/1.0
CSeq: 3
Session: 1219569791
RTSP/1.0 200 OK
Date: Fri, 08 Mar 2013 12:37:55 +0000
Server: Mine/1.0
CSeq: 3
Session: 1219569791;timeout=30
Range: npt=now-
SET_PARAMETER rtsp://localhost/wfd1.0 RTSP/1.0
Date: Fri, 08 Mar 2013 12:38:07 +0000
Server: Mine/1.0
CSeq: 5
Content-Type: text/parameters
Content-Length: 30
wfd_trigger_method: TEARDOWN
RTSP/1.0 200 OK
CSeq: 5
TEARDOWN rtsp://192.168.16.40/wfd1.0/streamid=0 RTSP/1.0
CSeq: 4
Session: 1219569791
RTSP/1.0 200 OK
Date: Fri, 08 Mar 2013 12:38:09 +0000
Server: Mine/1.0
CSeq: 4
Session: 1219569791;timeout=30
Connection: close
```
Неправда ли, напоминает обычный RTSP. Итак, часть дела сделана. Остается понять чем отличается Miracast-овская реализация RTSP от стандартной. Для тех, кто никогда не сталкивался с RTSP (Real Time Streaming Protocol) напомню, что он используется для управления мультимедийным потоком с сервера на клиенте. Сиречь — позволяет выдать такие команды как PLAY, PAUSE, TEARDOWN и т.п. Также имеется возможность обменяться опциями и настроить параметры. Именно {GET|SET}\_PARAMETER и стали основной моей головной болью при анализе. Не имея под рукой стандарта, я не мог знать, что значат все эти wfd\_video\_formats, wfd\_audio\_codecs и т.п. Но мог догадываться!
Поскольку из анализа фреймов MPEG-TS я понял, что использовалось стандартное разрешение 720x480, и кодек H.264 (AVC), то было неплохой идеей создать видеофайл с ровно такими же параметрами, и тогда поля типа wfd\_video\_formats можно оставить без изменения! Порывшись в DVD-дисках я перекодировал небольшой VOB из телесериала «Cracker», в нужный мне формат посредством ffmpeg. Теперь оставалось только скормить файл серверу. Но для этого нужно найти сервер!
Чтобы не писать RTSP-сервер самостоятельно (что никак не входило в мои планы) я начал просматривать Open Source варианты, которые было бы легко доработать до состояния совместимого с Miracast. Если вы внимательно смотрели на логи из tcpdump-а, то могли заметить несколько странностей. Традиционная клиент-серверная модель RTSP заменена «peer-to-peer» взаимодействием. Это значит, что активность в запросах может исходить не только от клиента (им в данном случае выступает телевизор или проектор), а и от «сервера» (то бишь телефона или компьютера). Зачем понадобилось так делать — непонятно, но факт остается фактом — и «клиент» и «сервер» могут слать запросы когда им вздумается, что сводит на нет их традиционные роли. Тем не менее, сторону которая шлет видеосигнал я буду продолжать именовать сервером (в нашем случае это Linix-PC), а сторону, принимающую и декодирующую видео — клиентом (в нашем случае — это будет проектор).
Итак, после нескольких часов поисков я остановился на [live555](http://www.live555.com/). Этот сервер написан на С++, распространяется под лицензией LGPL и поддерживает как RTSP, так и вещание в MPEG-TS. Поглядев на обработчик RTSP я понял, что его вполне реально переработать под peer-to-peer специфику Miracast. Но, оставалось еще заставить клиента (т.е. Мiracast-гаджет) соединяться с Linux!
Эта задача была посложней «Фауста» Гёте. Прежде я никогда не настраивал в Linux-е даже обычный Wi-Fi, справедливо полагая, что провода как-то понадежнее. Что уж говорить про Wi-Fi Direct. Однако, прочитав стопку manual-ов, я понял, что надо рыть в направлении загадочного [WPA supplicant](https://en.wikipedia.org/wiki/Wpa_supplicant). Для чего нужен этот supplicant? Именно он обеспечивает аутентификацию при подключении по Wi-Fi к точке доступа или к другому узлу. Как я уже писал выше, Miracast работает в режиме p2p, т.е. устройства связываются напрямую, минуя маршрутизаторы. Эта возможность, к счастью, поддержана в последних версиях wpa\_supplicant. Не знаю точно, с какого момента была добавлена поддержка p2p, но в версии 2.1-devel она уже есть.
Однако, обновить supplicant мало! Надо еще иметь конфигурационные файлы для него. С грехом пополам я написал конфигурацию приемлемую для моего устройства (NetGear, WNA1100 Wireless-N 150 [Atheros AR9271]), возможно, она подойдет и вам.
Итак, в файле /etc/wpa\_p2p.conf пишем:
```
ctrl_interface=/var/run/wpa_supplicant
ap_scan=1
device_name=JellyFish
device_type=1-0050F204-1
```
Далее, нужен shell-скрип для запуска supplicant:
```
sudo iwconfig wlan0 mode ad-hoc
sudo ip link set wlan0 up
sudo wpa_supplicant -Dnl80211 -c /etc/wpa_p2p.conf -i wlan0 -dt
```
Вот вроде и все (уточню, что данная конфигурация работает в Ubuntu-based дистрибутиве Linux Mint 13 Maya, версия ядра — 3.2.0-57-generic).
Дальше нужно овладеть такой утилитой как wpa\_cli, именно она позволяет управлять соединением «вручную».
После запуска wpa\_supplicant через скрипт, нужно открыть отдельную консоль и выдать что-то вроде:
```
sudo wpa_cli
```
Это командный интерфейс к supplicant-у. Включив гаджет мы можем командой p2p\_find найти все устройства в округе, готовые подключиться к нам в режиме p2p. Далее, используя команду p2p\_connect мы производим само подключение.
Вот пример лога для моего устройства:
```
wpa_cli v2.1-devel
Selected interface 'wlan0'
Interactive mode
> p2p_find
OK
<3>P2P-DEVICE-FOUND 02:90:4c:04:04:04 p2p_dev_addr=02:90:4c:04:04:04 pri_dev_type=7-0050F204-1 name='MLT-52-2123' config_methods=0x4688 dev_capab=0x25 group_capab=0xa
>
> p2p_connect 02:90:4c:04:04:04 pbc
OK
<3>P2P-FIND-STOPPED <--- Тут надо нажать кнопку на устройстве
<3>P2P-GO-NEG-SUCCESS
<4>Failed to initiate AP scan
<4>Failed to initiate AP scan
<4>Failed to initiate AP scan
<4>Failed to initiate AP scan
<3>CTRL-EVENT-SCAN-RESULTS
<3>WPS-AP-AVAILABLE-PBC
<3>SME: Trying to authenticate with 02:90:4c:04:84:04 (SSID='DIRECT-fCMLT-52-2123' freq=2412 MHz)
<3>Trying to associate with 02:90:4c:04:84:04 (SSID='DIRECT-fCMLT-52-2123' freq=2412 MHz)
<3>CTRL-EVENT-SCAN-RESULTS
<3>WPS-AP-AVAILABLE-PBC
<3>SME: Trying to authenticate with 02:90:4c:04:84:04 (SSID='DIRECT-fCMLT-52-2123' freq=2412 MHz)
<3>Trying to associate with 02:90:4c:04:84:04 (SSID='DIRECT-fCMLT-52-2123' freq=2412 MHz)
<3>Associated with 02:90:4c:04:84:04
<3>CTRL-EVENT-EAP-STARTED EAP authentication started
<3>CTRL-EVENT-EAP-PROPOSED-METHOD vendor=14122 method=1
<3>CTRL-EVENT-EAP-METHOD EAP vendor 14122 method 1 (WSC) selected
<3>WPS-CRED-RECEIVED
<3>WPS-SUCCESS
<3>P2P-GROUP-FORMATION-SUCCESS
<3>CTRL-EVENT-EAP-FAILURE EAP authentication failed
<3>CTRL-EVENT-DISCONNECTED bssid=02:90:4c:04:84:04 reason=3 locally_generated=1
<3>CTRL-EVENT-SCAN-RESULTS
<3>WPS-AP-AVAILABLE
<3>SME: Trying to authenticate with 02:90:4c:04:84:04 (SSID='DIRECT-fCMLT-52-2123' freq=2412 MHz)
<3>Trying to associate with 02:90:4c:04:84:04 (SSID='DIRECT-fCMLT-52-2123' freq=2412 MHz)
<3>Associated with 02:90:4c:04:84:04
<3>WPA: Key negotiation completed with 02:90:4c:04:84:04 [PTK=CCMP GTK=CCMP]
<3>CTRL-EVENT-CONNECTED - Connection to 02:90:4c:04:84:04 completed [id=0 id_str=]
<3>P2P-GROUP-STARTED wlan0 client ssid="DIRECT-fCMLT-52-2123" freq=2412 psk=fd435c6683ae5d7c9e3398dab15cc1b80d7f308b3fe7330db044ea90dcf7ac31 go_dev_addr=02:90:4c:04:04:04 [PERSISTENT]
```
В принципе, из лога все понятно, кроме разве что загадочного слова 'pbc' в команде p2p\_connect после адреса устройства. Что же оно значит? Это один из вариантов аутентификации при подключении по Wi-Fi direct. Означает он — Push Button Control. Это упрощенная аутентификация, не требующая от пользователя ввода пароля или даже pin-кода. Просто в момент соединения нужно нажать кнопку на устройстве, и аутентификаця будет считаться успешной.
Итак, из лога мы видим, что соединение успешно произошло. И теперь мы имеем возможность получить IP-адрес для интерфейса wlan0.
DHCP-сервером в данном случае будет выступать телевизор или проектор. Введем в отдельном терминале:
```
sudo dhclient wlan0
```
Если после этого запустить tcpdump, то мы обнаружим попытки посылки SYN-пакета на порт 7236. Этот порт отличается от стандартного порта для RTSP (554), но пугать это нас не должно. Самое главное, что гаджет хочет с нами договориться! Запустив уже слегка доработанный livemedia сервер на этом порту (7236) мы получаем возможность отлаживать собственно «клиент-серверное» взаимодействие.
Я не буду утомлять читателя подробностями отладки протокола, скажу лишь, что все проблемы так или иначе были решены. И вот, наконец, результат налицо — я смог смотреть видео со своего PC через новомодный Miracast!

Нужно ли это вам? Не знаю. Во всяком случае, разобраться в новом стандарте всегда интересно (если конечно это не ASN.1).
Для тех, кому было лень вникать в технические подробности тезисно обрисую процедуру соединения для Miracast-based устройств:
1. Используя Wi-Fi direct, устройства находят друг друга (обычно — источник видео-данных находит устройство отображения)
2. Используя ту или иную форму аутентификации (в нашем случае — pbc) устройства объединяются в P2P-группу
3. Одно из устройств получает IP-адрес по DHCP (в нашем случае — это источник видео-данных)
4. На источнике данных на порту 7236 запускается RTSP-сервер
5. Клиент подключается к RTSP-серверу, и запрашивает некий предопределенный URL (/wfd1.0/streamid=0)
6. RTSP-сервер начинает передавать видео (и, возможно, аудио) данные в форме MPEG-TS упакованных в RTP-пакеты.
7. Клиент распаковывает данные и отображает их на устройстве вывода.
Из явных недостатков Miracast (не упомянутых в Wiki) я бы отметил следующие:
* Если вы подключаетесь к Miracast-устройству то теряете возможность работы через обычный (не P2P) Wi-Fi. Чтобы одновременно пользоваться традиционным Wi-Fi и Wi-Fi direct нужен специальный двух-канальный Wi-Fi адаптер. Он имеется далеко не во всех телефонах!
* Качество картинки на динамичных сценах страдает даже при разрешении 720x480, 30 FPS. Я уж не говорю про Full HD. Разумеется, с появлением более мощных процессоров картина будет меняться, но пока все печально.
Вот собственно и все. Если у вас остались вопросы — задавайте в комментариях. | https://habr.com/ru/post/207456/ | null | ru | null |
# Троян в CS-Cart. Утечка счетов из 35'000 интернет-магазинов
TL;DR: Разрабы второго по популярности (по версии ratingruneta) интернет-магазина встроили в движок код, который делает копии всех счетов клиентов на сервер в Аризоне.
Кто пострадал
-------------
Интернет-магазины и их клиенты, работающие на CS-Cart всех версий.
Сама компания заявляет о 35'000 установок в 170 странах мира.
Какая информация содержится в утечке
------------------------------------
* ФИО покупателя интернет-магазина
* Адрес покупателя
* Телефон покупателя
* email покупателя
* Сумма заказа, заказанные товары и услуги
* Почтовые треки
Подробности
-----------
С CMS можно познакомиться (и скачать демо) по двум адресам: <https://www.cs-cart.ru/>, [https://www.cs](https://www.cs-cart.ru/)[-](https://www.cs-cart.com/)[cart.com/](https://www.cs-cart.ru/).
Последняя версия на сегодня 4.12.2.SP2 ([зеркало](https://drive.google.com/uc?id=1fI7qCJllqxDe71t1oZanIN3MoPZlli0C&export=download)), написана на PHP, ставится как всё, заточенное под LAMP, но нам для наших целей это не обязательно делать.
Скачиваем, распоковываем и сразу идём смотреть **./app/Tygh/Pdf.php** , где видим такой код для отрисовки счёта клиента в виде Pdf-файла:
```
php
...
protected static $url = 'http://converter.cart-services.com';
...
public static function render(...)
{
...
$response = Http::post(self::action('/pdf/render'), json_encode($params), array(
'headers' = array(
'Content-type: application/json',
'Accept: application/pdf'
),
'binary_transfer' => true,
'write_to_file' => $file
));
...
protected static function action($action)
{
return self::$url . $action;
}
```
где `json_encode($params)` содержит всю личную информацию, в т.ч. **персональные данные** покупателя, а `Http::post(self::action('/pdf/render')` после эвалюации превращается в `Http::post("https://converter.cart-services.com/pdf/render")` и все наши данные **отправляются по ссылке выше**, а уже в ответ из Аризоны (см. далее) приходит Pdf, который потом отправляется покупателю и/или используется для других целей системы.
converter.cart-services.com
---------------------------
Если погуглить этот адрес (converter.cart-services.com), то окажется, что первые обращения в форум поддержки датируются [не позже 2018 года](https://forum.cs-cart.com/topic/42289-generated-invoice-comes-from-another-website-hacked/) (вероятно, даже раньше, но администрация форума поддержки удаляет сообщения об этой проблеме), скорее всего с 2006 года, когда этот адрес был зарегестрирован.
Сам сервер, где собираются счета находится в Аризоне, США:
- Resolving "converter.cart-services.com"... 1 IP address found: 184.95.47.28
┌PTR cs-cart.com
├ASN 20454 (SSASN2, US)
├ORG Servstra
├NET 184.95.32.0/19 (SERVSTRA)
├ABU -
├ROA ✓ UNKNOWN (no ROAs found)
├TYP Proxy host Hosting/DC
├**GEO Phoenix, Arizona (US)**
└REP ✓ GOOD
Выводы
------
Компания-разработчик установила закладку, которая все заказы всех своих 35к клиентов, включая информацию о ФИО, емейлах, телефонах, адресах покупателей сливает куда-то в Аризону на сервер, который зарегистрирован уже 15 лет.
Накопленная за, предположительно, 15 лет база - просто клондайк для разного рода преступников, мало того, что имеются персональные данные десятков тысяч (если не сотен тысяч) человек, так ещё есть информация, позволяющая оценить их финансовое состояние.
Как это соотносится с законами о персональных данных (GDPR, № 152-ФЗ), думаю, объяснять не надо.
Обращение на форум поддержки, кстати, заканчивается удалением топиков и открытым признанием, что такое поведение меняться не будет. | https://habr.com/ru/post/558852/ | null | ru | null |
# Opera vs. mailto
Изрядно потрепал сегодня нервы.
Есть Flash, в котором используется ссылка, при клике на которую:
`navigateToURL(new URLRequest("mailto:[email protected]"), "_self");`
Помимо этого в коде есть методы, которые делают post-запрос на адрес:
`loader = new URLLoader();
...
loader.addEventListener(IOErrorEvent.IO_ERROR, errorHandler);
loader.addEventListener(Event.COMPLETE, loaderCompleteHandler);
loader.load(request);`
Так вот, в моей Opera 10 с последним Flash плеером такая ситуация: при клике на линк, который mailto, открывается окно почтового клиента, мы его закрываем и после этого loader.load(request) перестает работать вообще. Он не инициирует никакх ошибок, но запросы не делаются.
Ладно, потратив некоторое время на изучение проблемы и не найдя решения решил пойти иным способом, и именно дергать во Flash JS-функцию, в которой уже делаю вот что:
`window.location.href="mailto:[email protected]";`
Что ж думать, работает везде, кроме Оперы! Чтоб ее… =(
Не знаю, что еще попробовать.
Баг с неработающим loader.load проявляется не у всех, но у многих. | https://habr.com/ru/post/89702/ | null | ru | null |
# Интеграция AJAX в ASP.NET MVC 4
Наверное, уже не существует веб разработчика, который не слышал о Ajax. Microsoft в такой ситуации не может оставаться в стороне, с каждым релизом старается облегчить жизнь именно нам, ASP.NET MVC разработчикам. Но прежде чем я продолжу статью, немного отступлюсь от темы.
Когда я познакомился с MVC фреймворком, он был тогда только во второй версии и, столкнувшись с такими хелперами как `@Ajax....`, честно говоря, их реализация на стороне клиента меня не впечатлила. Нет, так нет, подумал я про себя, у меня есть jQuery со своим `$.ajax`, мне его за глаза. Вот и забыл я про них на несколько лет, к своему великому сожалению проморгав этот момент с третьим релизом. Что было, то было. Благо что взялся за ум и почитал две книги по MVC 4. Далее расскажу, как можно сократить написание строк кода благодаря хелперам, упомянутым мною выше.
Начну с того, что MVC может работать с двумя вариантами Ajax библиотек (конечно я же имею ввиду с коробки, не более того) — jQuery и Microsoft Ajax. Чтобы знать, для какого адаптера создавать разметку, существует настройка в `web.config` `UnobtrusiveJavaScriptEnabled` и соответствующее значение `true` (для работы с jQuery) и f`alse` (для работы с Microsoft Ajax). Если же нам необходимо поменять значение только для одного представления, можно воспользоваться методом — `@{Html.EnableUnobtrusiveJavaScript(bool);}`. Хочу обратить внимание, что данная настройка влияет и на формирование валидационных данных на стороне клиента.
В зависимости от того, каков вариант вам более по душе, вам необходимо подключить соответствующий адаптер. Для Microsoft Ajax
```
```
, a для jQuery
Как я писал выше, вариант с jQuery меня вполне устраивает. Поэтому пойду по пути ненавязчивого JavaScript (т.е. `web.config` с `/>`), и начну с самого простого.
#### ActionLink
Рассмотрим такую задачу. Есть ссылочка, при клике на которую мы хотим обновить содержимое контейнера. Что делал я ранее.
Кусочек метода действия
```
public ActionResult Index()
{
if (Request.IsAjaxRequest())
return PartialView("_IndexPartial");
return View();
}
```
`Index` преставление
```
jQuery(function($) {
$('#update-container').click(function(e) {
e.preventDefault();
$.ajax({
url: '@Url.Action("Index", "Home")',
success: function(data) {
$('#container').html(data);
}
});
})
})
@Html.Partial("\_IndexPartial")
@Html.ActionLink("Поменять данные", "Index", "Home", new {}, new {id = "update-container"})
```
`_IndexPartial` частичное представление
```
Динамическое данные в зависимости от запроса
```
Большинству знаком такой вспомогательный метод как `Html. ActionLink(...)`, представленный выше. Казалось бы, строк кода в принципе не много, да и привык так уже программировать, так что все в порядке, но ведь я очень ленивый программист и в меру своих сил борюсь за чистоту и уменьшение кода. Поэтому мне будет приятно уменьшить представление с 22 строк до 5. И на помощь ко мне приходит `Ajax.ActionLink(...)` (конечно, скептики могут сказать, что вместо `$.ajax` можно было использовать `.load` или `$.get`, но сути это не меняет, мы сократили представление, которое и так порой у нас начинает пухнуть)
Вуаля, `Index` преставление
```
@Html.Partial("\_IndexPartial")
@Ajax.ActionLink("Поменять данные", "Index", "Home", new {}, new AjaxOptions{UpdateTargetId = "container"}, new {id = "update-container"}) //id элемента нам уже не нужно, но для наглядности оставлю
```
Разница между двумя расширенными методами `Html.ActionLink` и `Ajax.ActionLink` заключается только в одном параметре, объекте `AjaxOptions`. Давайте о нем и поговорим.
#### AjaxOptions
Как видно свойств, в принципе, у него не много, с другой стороны это и хорошо, когда начинают создавать серебряную пулю, будь то объект или библиотека, становится просто не вероятно громоздкой и неработоспособной.
Что из свойств за что отвечает, лучше MSDN я сказать не смогу.
Давайте пробежимся по свойствам:
`Confirm` — аналог javascript `confirm(...)`
`HttpMethod` — типа `string`, самое интересное, что же MS заставило ограничиться только 2 методами, ума не приложу почему, и видимо алгоритм таков, все что не `GET`, `null` или пустая строка после `.Trim()` — все `POST`
`InsertionMode` — перечисление со значениями "`InsertAfter`" (вставить в конец контейнера), "`InsertBefore`" (вставить в начало контейнера) или "`Replace`" (заменить содержимое контейнера)
`Loading...` — изначальный скрытый элемент
`On.....` — javascript функции, по аналогии с `$.ajax`
* `OnBegin` — `beforeSend`
* `OnComplete` — `complete`
* `OnFailure` — `error`
* `OnSuccess` — `success`
`Url` — ссылка на отдельный адрес ajax запроса, если нам необходимо развести запрос от ajax запроса по разным роутам/контроллерам/действиям/параметрам (нужное подчеркнуть)
#### Ajax вспомогательные методы
Под конец хотелось бы привести табличку методов, которые нам время от времени облегчат нашу жизнь
| | |
| --- | --- |
| `Ajax.ActionLink` | Создает гиперссылку на действие контроллера, которая при нажатии отправляет запрос Ajax. |
| `Ajax.RouteLink` | Похож на `Ajax.ActionLink`, но создает ссылку на определенный роут, а не действие контроллера |
| `Ajax.BeginForm` | Создает элемент формы, который будет отправлять введенные данные к определенному действию контроллера |
| `Ajax.BeginRouteForm` | Похож на `Ajax.BeginForm`, но отправляет запрос по определенному роуту, а не к действию контроллера |
| `Ajax.GlobalizationScript` | Создает ссылку на скрипт глобализации, в котором содержится информация о языке и региональных параметрах |
| `Ajax.JavaScriptStringEncode` | Кодирует строку для безопасного использования в JavaScript |
#### Обеспечение постепенного ухудшения
Рассмотрим такую ситуацию. Ajax запрос возвращает JSON/XML/Частичное представление — и все хорошо, но такой подход совсем не приемлем, если пользователь отключил JavaScript, либо браузер вообще не поддерживает его. В таких случаях необходимо полностью вернуть страницу пользователю. Одним из решений является вариант использования «разводки» в одном методе действия с определением того, является ли этот запрос запросом Ajax. Это можно сделать, используя `Request.IsAjaxRequest()`, как было рассмотрено выше.
Вторым вариантом решения проблемы является создание двух разных методов действия: одного — для Ajax запроса, а второго — для обычного. Давайте рассмотрим этот вариант подробнее, на упрощенной задаче сохранения полученного от пользователя комментария.
Создаем два метода действия
```
[HttpPost]
public ActionResult AddComment(string comment)
{
//необходимые действия
return View();
}
[HttpPost]
public ActionResult AddCommentAjax(string comment)
{
//необходимые действия
return Json(new {resultMessage = "Ваш комментарий добавлен успешно!"});
}
```
представление `AddComment`
```
### Ваш комментарий добавлен успешно!
```
и наше представление с формой
```
function OnSuccessComment(data) {
alert(data.resultMessage);
}
@using (Ajax.BeginForm("AddComment", new AjaxOptions
{
Url = Url.Action("AddCommentAjax"),
OnSuccess = "OnSuccessComment",
HttpMethod = "POST"
}))
{
@Html.TextArea("comment")
}
```
##### Как это работает
Для браузера рендерится следующая форма
```
```
Мы видим, что отличие от `@using (Html.BeginForm("AddComment", "Home"))` заключается только в дополнительных `data-` атрибутах. Иными словами, для отключенного Javascript форма будет отравляться на `public ActionResult AddComment(string comment)`. Когда же JavaScript включен, адаптер считывает данные с `data-` атрибутов, перехватывает отправку формы и делает запрос на `public ActionResult AddCommentAjax(string comment)`. Успешный результат мы получаем в виде переданного JSON и обрабатываем в указанной js функции `OnSuccessComment`.
#### Резюме
Целью моей статьи было лишь показать, что некоторые вещи можно немного ускорить и не изобретать велосипед (сужу лишь по себе).
---
На написание этой статьи меня сподвигли главы книг:
[Ajax в ASP.NET MVC (ASP.NET MVC 4 в действии)](http://www.smarly.net/asp-net-mvc-4-in-action/working-with-asp-net-mvc/ajax-in-asp-net-mvc)
и
[Вспомогательные методы для URL и Ajax (pro ASP.NET MVC 4)](http://www.smarly.net/pro-asp-net-mvc-4/asp-net-mvc-4-in-detail/url-and-ajax-helper-methods)
--- | https://habr.com/ru/post/180011/ | null | ru | null |
# GammaRay — средство интроспекции Qt-приложений
Фреймворк Qt предоставляет неплохие средства разработки — входящая в него IDE Qt Creator включает дизайнер, отладчик, профайлер и другие удобные вещи. К сожалению, даже со всем этим иногда не очень понятно, почему приложение в данные момент выглядит так, как выглядит: чего-то не видно, что-то выглядит не так, как ожидалось, где-то неподходящий размер шрифта или неверная картинка.
Часть этих проблем может быть решена в Qt Designer, но только часть. Qt Designer имеет несколько существенных недостатков: во-первых, он неверно отображает положение Qt Quick компонентов в случае активного использования Javascript при расчете их координат и размеров, во-вторых в дизайнере мы видим состояние только «пустой» формы, без загруженных в неё данных. В общем, очень не хватает чего-то вроде инструментов разработчика в любом современном браузере: чтобы можно было посмотреть всё дерево компонентов, найти нужный, увидеть его положение относительно других, свойства, поправить на лету что-то, подобрать цвет\шрифт\размер, увидеть какие обработчики повешены на события и т.д.
И такой инструмент в мире Qt появился! Встречайте — [GammaRay](http://www.kdab.com/kdab-products/gammaray/), средство интроспекции приложений на Qt. GammaRay понимает, что такое Qt, из чего состоит ваше Qt-приложение, как в нём взаимодействую компоненты, как они выглядят, как генерируются и обрабатываются события и т.д. Давайте посмотрим, что умеет GammaRay.
По-сути GammaRay это не один, а около 20-и различных инструментов, собранных в одно приложение. Каждый инструмент размещён на своей вкладке. Могут быть активны не все вкладки. К примеру, вкладка Quick Scenes активна только если приложение использует Qt Quick компоненты.
##### Сборка
Бинарников под Windows нет. Исходники здесь: <https://github.com/KDAB/GammaRay>. Для сборки под Windows + Qt 5.4 мне понадобилось поправить файл CMakeLists.txt, добавив в него следующие строки с указанием путей к моей папке с Qt 5.4:
```
set(Qt5Core_DIR "D:/Qt/5.4/msvc2010_opengl/lib/cmake/Qt5Core")
set(Qt5_DIR "D:/Qt/5.4/msvc2010_opengl/lib/cmake/Qt5")
set(QT_QMAKE_EXECUTABLE "D:/Qt/5.4/android_x86/bin/qmake.exe")
```
В остальном всё собирается так, как написано в инструкции (для Windows + Visual Studio):
```
mkdir build
cd build
cmake -G "NMake Makefiles" ..
nmake
nmake install
```
##### Запуск
Теперь нужно собрать какое-нибудь Qt-приложение, вполне подойдут примеры из стандартной поставки Qt. Дальше нужно запустить gammaray, передав ему параметром путь к экзешнику подконтрольного приложения:
```
gammaray.exe D:\Qt\Examples\Qt-5.4\quick\demos\build-stocqt-Desktop_Qt_5_4_0_MSVC2010_OpenGL_32bit-Debug\debug\stocqt.exe
```
##### Вкладка Quick Scenes
Я начну с самой для меня интересной вкладки — Quick Scenes. Именно она является Qt-аналогом тех самых браузерных Developer Tools, о которых я писал выше. В левой верхней части вкладки мы видим дерево Qt Quick компонентов, причём не в «изначальной» его форме, а со всеми созданными на рантайме объектами.
Мы можем выбрать нужный объект в дереве — и он будет подсвечен на превью в нижней части окна.

Мы можем посмотреть свойства этого объекта в правой части окна, изменить их. Таким образом удобно подбирать размеры элементов, шрифты, цвета, смотреть как будет помещаться текст разной длины в отведённых ему границах.
Мы можем вызвать определённый метод компонента. К примеру, для MouseArea мы можем сгенерировать «клик», что приведёт к вызову логики его обработки.
Окно превью имеет несколько режимов и, кстати, является «двунаправленным» — т.е. выполняемые в нём действия влияют не только на превью, но и на само приложение.
Кроме того, мы можем включить вот такой удобный режим отображение контента, позволяющий легче понимать взаимное расположение компонентов.
##### Вкладка Objects
Здесь перечислены вообще все Qt-объекты вашего приложения. Функционал: перечисление свойств, вызов методов, просмотр сигналов-слотов. Немного трудновато найти конкретный объект, но есть фильтр, иногда помогает.
##### Вкладка Models
Должна показывать модели, используемые в приложении (наследников QAbstractListModel). В моём случае приложение падало всякий раз при открытии этой вкладки. Возможно, попалась нестабильная версия GammaRay (брал ведь прямо с GitHub).
##### Вкладка Timers
Все таймеры приложения
##### Вкладка Resources
Позволяет просмотреть все ресурсы Qt-приложения (картинки, звуки, шейдеры, QML-код) а также экспортировать их при необходимости. Не сильно полезная вещь при работе со своим приложением (всё то же самое вы видите в дереве ресурсов в Qt Creator), но может помочь при анализе чужой программы.
##### Signals
Показывает события, генерируемые всеми Qt-объектами в приложении. Интерфейс пока не очень удобен (слабо понятно, какой именно экземпляр определенного типа сгенерировал события, не хватает возможностей группировки и гибкости поиска нужных объектов). Тем ни менее, при определенной сноровке позволяет быстро увидеть последовательность событий, так сказать, «ухватить общую картинку».
##### State Machines
Визуализация конечных автоматов. Показывает автомат в общем, текущее состояние, историю переходов между состояниями — в общем, весьма наглядно.
Остальные вкладки GammaRay показались мне менее интересными, хотя мало ли что кому нужно: просмотр шрифтов, локалей, логов, мета-объектов, мета-типов, переменных окружения, стилей компонентов.
В общем, GammaRay — отличная утилита, хорошо вписывающаяся в инфраструктуру Qt и позволяющая сэкономить несколько минут там, где их действительно легко можно сэкономить. | https://habr.com/ru/post/258411/ | null | ru | null |
# NodeJS Cluster-hub. Обмен сообщениями в cluster, запросы, межпроцессные эксклюзивные блокировки (критические секции)
Работая в очередной раз с модулем cluster, я столкнулся с необходимостью обмена сообщениями между рабочими процессами. К сожалению стандартный функционал модуля позволяет отправлять сообщения только с master процесса на worker, и в обратном направлении. При этом нет возможности получить какой-то ответ на сообщение, а очень хотелось бы. Поэтому я написал модуль cluster-hub. Возможно кому-нибудь он пригодится.
Модуль позволяет
* Отправлять сообщения master->worker, worker->master, master->master
* Отправлять запросы и получать ответы (через callback)
* Использовать эксклюзивные блокировки по ключу (критические секции)
Кому интересно — прошу под кат.
#### Обмен сообщениями
Самый простой функционал — просто отправка сообщений в другие процессы. Есть возможность отправлять сообщения из master в worker, из worker в master, из master->master.
```
var Hub = require('cluster-hub');
var cluster = require('cluster');
var hub = new Hub(cluster);
if (cluster.isMaster) {
var worker = cluster.fork();
hub.on('master-to-master', function (data) {
console.log('master-to-master received');
});
hub.on('worker-to-master', function (data) {
console.log('worker-to-master received');
});
hub.sendToMaster('master-to-master', 1);
hub.sendToWorker(worker, 'master-to-worker');
} else {
hub.on('master-to-worker', function () {
console.log('master-to-worker received');;
process.exit();
});
hub.sendToMaster('worker-to-master', 2);
}
```
#### Отправка запросов
Данный функционал позволяет отправить запрос из одного процесса в другой и получить результат внутри callback функции. Пример сам за себя все скажет:
```
var Hub = require('cluster-hub');
var cluster = require('cluster');
var hub = new Hub(cluster);
if (cluster.isMaster) {
// in master process
hub.on('sum', function (data, sender, callback) {
callback(null, data.a + data.b);
});
var worker = cluster.fork();
} else {
//in worker process
hub.requestMaster('sum', {a: 1, b:2}, function (err, sum) {
console.log('Sum in worker: ' + sum);
process.exit();
});
}
```
По аналогии можно использовать метод requestWorker, чтобы с master процесса вызвать метод на worker процессе.
#### Эксклюзивные блокировки / Критические секции
Данный функционал позволяет получить эксклюзивный доступ к какому-либо ресурсу одному из процессов (неважно — master или один из worker). Если worker процесс прекращает свою работу, не вызвав unlock для заблокированного ресурса — ресурс освободится автоматически.
```
var Hub = require('cluster-hub');
var cluster = require('cluster');
var hub = new Hub(cluster);
if (cluster.isMaster) {
var worker = cluster.fork();
hub.lock('foo', function (unlock) {
console.log('foo lock in master');
setTimeout(unlock, 1000);
});
} else {
hub.lock('foo', function (unlock) {
console.log('foo lock in worker 1');
setTimeout(unlock, 500);
});
hub.lock('bar', function (unlock) {
console.log('bar lock in worker');
unlock();
})
hub.lock('foo', function (unlock) {
console.log('second foo lock in worker');
unlock();
process.exit();
})
}
```
исходные коды модуля доступны тут: [github.com/sirian/node-cluster-hub](https://github.com/sirian/node-cluster-hub) | https://habr.com/ru/post/191192/ | null | ru | null |
# Мозговой штурм: как смотреть на задачи под другим углом
Мозговой штурм с помощью транспонирования
-----------------------------------------
Иногда я захожу в тупик и мне приходится искать способы думать над задачей под другим углом. Бывают задачи, которые можно отобразить в виде матрицы или таблицы. Их структура выглядит примерно так:
| | A | B | C | D | E |
| --- | --- | --- | --- | --- | --- |
| 1 | A1 | B1 | C1 | D1 | E1 |
| 2 | A2 | B2 | C2 | D2 | E2 |
| 3 | A3 | B3 | C3 | D3 | E3 |
| 4 | A4 | B4 | C4 | D4 | E4 |
| 5 | A5 | B5 | C5 | D5 | E5 |
Ячейки, с которыми я работаю, выстроены в столбцы и строки. Давайте возьмём пример из простой игры:
| | Attack | Defend | Special |
| --- | --- | --- | --- |
| Fighter | sword | armor | slam |
| Mage | fireball | reflect | freeze |
| Thief | dagger | dodge | disarm |
*Строки* — это классы персонажей: воин, маг, вор.
*Столбцы* — это типы действий: нападение, защита, особое действие.
*Матрица* содержит весь код для обработки каждого из типов действий для каждого типа персонажа.
Как выглядит код? Обычно подобные структуры упорядочивают в такие модули:
1. `Fighter` будет содержать код для обработки ударов мечом, снижения урона с помощью брони и особого мощного удара.
2. `Mage` будет содержать код обработки фаерболов, отражения урона и особую атаку заморозкой.
3. `Thief` будет содержать код для обработки атак кинжалом, избегания урона уклонением и особую обезоруживающую атаку.
Иногда бывает полезно транспонировать матрицу. Мы можем упорядочить её по другой оси:
| | Fighter | Mage | Thief |
| --- | --- | --- | --- |
| Attack | sword | fireball | dagger |
| Defend | armor | reflect | dodge |
| Special | slam | freeze | disarm |
1. `Attack` будет содержать код обработки ударов мечом, стрельбы фаерболами и атак кинжалом.
2. `Defend` будет содержать код обработки снижения урона, отражения урона и ускользания от урона.
3. `Special` будет содержать код обработки мощного удара, заморозки и обезоруживания.
Меня учили, что один стиль «хорош», а другой «плох». Но мне не очевидно, почему всё должно быть именно так. Причина заключается *предположении*, что мы чаще будем добавлять новые классы персонажей (существительные), и редко добавлять новые виды действий (глаголы). Таким образом я смогу добавить код с помощью нового модуля, не трогая *все* имеющиеся. В вашей игре всё может быть иначе. Взглянув на транспонированную матрицу, я осознаю существование предположения и могу поставить его под сомнение. Затем я задумаюсь о необходимом мне виде гибкости, и уже потом буду выбирать структуру кода.
Давайте рассмотрим ещё один пример.
В интерпретациях языков программирования есть различные типы узлов, соответствующих примитивам: константы, операторы, циклы, ветвление, функции, типы и т.д. Нам нужно сгенерировать код для них всех.
| | Generate Code |
| --- | --- |
| Constant | |
| Operator | |
| Loop | |
| Branch | |
| Function | |
| Type | |
Отлично! Можно создать по одному классу для каждого типа узла, и они все могут наследоваться от базового класса `Node`. Но мы основываемся на предположении, что будем чаще добавлять строки и реже столбцы. Что происходит в оптимизирующем компиляторе? Мы добавляем новые проходы оптимизации. И каждый из них — это новый столбец.
| | Generate Code | Data flow | Constant folding | Loop fusion | … |
| --- | --- | --- | --- | --- | --- |
| Constant | | | | | |
| Operator | | | | | |
| Loop | | | | | |
| Branch | | | | | |
| Function | | | | | |
| Type | | | | | |
Если я хочу добавить новый проход оптимизации, то мне нужно будет добавлять новый метод к каждому классу, и весь код прохода оптимизации будет разнесён по разным модулям. Я хочу избежать такой ситуации! Поэтому в некоторых системах поверх этого добавляется ещё один слой. С помощью паттерна «посетитель» (visitor) я могу хранить весь код слияния циклов в одном модуле, а не разбивать его на множество файлов.
Если взглянуть на транспонированную матрицу, то нам откроется ещё один подход:
| | Constant | Operator | Loop | Branch | Function | Type |
| --- | --- | --- | --- | --- | --- | --- |
| Generate code | | | | | | |
| Data flow | | | | | | |
| Constant folding | | | | | | |
| SSA | | | | | | |
| Loop fusion | | | | | | |
Теперь вместо *классов* с *методами* я могу использовать *меченные объединения (tagged union)* и *сопоставление с образцом (pattern matching)* (они поддерживаются не во всех языках программирования). Благодаря этому весь код каждого прохода оптимизации будет храниться вместе и сможет обойтись без косвенности паттерна «посетитель».
Часто бывает полезно посмотреть на задачу с точки зрения матрицы. Если применить её к объектно-ориентированной структуре, о которой думают все, то это может привести меня к чему-то другому, например, к паттерну «сущность-компонент-система», реляционным базам данным или реактивному программированию.
И это касается не только кода. Вот пример применения этой идеи к продуктам. Допустим, что существуют люди с разными интересами:
| | Nick | Feng | Sayid | Alice |
| --- | --- | --- | --- | --- |
| cars | X | | | X |
| politics | | X | X | |
| math | | | X | X |
| travel | X | X | | |
Если бы я разрабатывал сайт социальной сети, то мог бы позволить людям следить за новостями других *людей*. Ник может подписаться на Алису, потому что им обоим интересны автомобили, и на Феня, потому что они оба интересуются путешествиями. Но Ник будет также получать посты Алисы о математике и посты Феня о политике. Если бы я рассматривал транспонированную матрицу, то мог бы позволить людям подписываться на *темы*. Ник мог бы вступить в группу любителей машин, а также в группу путешественников. Facebook и Reddit начали своё существование примерно в одно время, но они являются транспонированными матрицами друг друга. Facebook позволяет подписываться на людей; Reddit позволяет подписываться на темы.
Когда я захожу в тупик или когда хочу рассмотреть альтернативы, то смотрю на задачу и ищу в ней разные оси упорядочивания. Иногда взгляд на задачу под другим углом способен обеспечить более хорошее решение.
Мозговой штурм при помощи разложения
------------------------------------
Я использую и другую технику, которая называется «разложение».
В алгебре операция *разложения* преобразует многочлен вида 5x² + 8x — 21 в (x + 3)·(5x — 7). Чтобы решить уравнение 5x² + 8x — 21 = 0, мы сначала можем разложить его в (x + 3)·(5x — 7) = 0. Затем мы можем сказать, что x + 3 = 0 *или* 5x — 7 = 0. Разложение превращает сложную задачу в несколько более лёгких задач.
| | x | 3 |
| --- | --- | --- |
| 5x | 5x² | 15x |
| -7 | -7x | -21 |
Давайте взглянем на пример: у меня есть шесть классов: `File`, `EncryptedFile`, `GzipFile`, `EncryptedGzipFile`, `BzipFile`, `EncryptedBzipFile`. Я могу разложить их в матрицу:
| | Uncompressed | Gzip | Bzip |
| --- | --- | --- | --- |
| Unencrypted | File | Gzip(File) | Bzip(File) |
| Encrypted | Encrypt(File) | Encrypt(Gzip(File)) | Encrypt(Bzip(File)) |
С помощью паттерна «декоратор» (или примесей) я превратил шесть разных типов файлов в четыре компонента: plain, gzip, bzip, encrypt. Не похоже, чтобы это позволило много сэкономить, но если я добавлю больше вариаций, то экономия будет увеличиваться. Разложение превращает O(M\*N) компонентов в O(M+N) компонентов.
Ещё один пример: иногда люди задают мне вопросы типа *«как написать на C# линейную интерполяцию?»*. Я могу написать множество потенциальных туториалов:
| | C++ | Python | Java | C# | Javascript | Rust | Idris | … |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Interpolation |
| --- |
| Neighbors |
| Pathfinding |
| Distances |
| River maps |
| Isometric |
| Voronoi |
| Transforms |
| … |
Если есть M тем и N языков, то я могу написать M\*N туториалов. Однако это *куча* работы. Вместо этого я напишу туториал об [интерполяции](https://www.redblobgames.com/grids/line-drawing.html), кто-то другой напишет туториал про C#, а затем читатель объединит знания C# со знаниями об интерполяции, и напишет свою версию интерполяции на C#.
Как и транспонирование, разложение помогает не всегда, но если оно применимо, то может оказаться довольно полезным.
Мозговой штурм движением в обратную сторону
-------------------------------------------
В предыдущих двух частях я рассказал о том, как иногда подхожу к задаче, пытаясь упорядочить её в матрицу. Иногда это не помогает и тогда я пробую посмотреть на задачу в обратном направлении. Давайте например рассмотрим процедурную генерацию карт. Часто я начинаю с функции шума, потом добавляю октавы, настраиваю параметры и добавляю слои. Я делаю так, потому что мне нужны карты, обладающие определёнными свойствами.

Вполне можно начать с экспериментов с параметрами, но пространство параметров довольно велико, и неизвестно, найду ли я параметры, наиболее соответствующие моим требованиям. Поэтому немного поэкспериментировав, я останавливаюсь и начинаю думать в обратном порядке: если я могу описать то, что мне нужно, то это может помочь в поиске параметров.
Именно такая мотивация заставила меня изучать алгебру. Если у нас есть уравнение вида *5x² + 8x — 21 = 0*, то каким будет *x*? Когда я не знал алгебры, я бы решал это уравнение, пробуя подставлять разные значения *x*, сначала выбирая их случайным образом, а затем подстраивая их, когда почувствую, что подобрался к решению близко. Алгебра даёт нам инструмент, позволяющий пойти в другом направлении. Вместо угадывания ответов она даёт мне аппарат (разложение, или квадратные уравнения, или ньютоновский метод итеративного поиска корней), который я могу более осознанно использовать для поиска значений *x* (-3 или 7/5).
Я чувствую, что часто попадаю в такую ситуацию в программировании. При работе над генерацией процедурных карт, какое-то время поэкспериментировав с параметрами, я остановился и составил список того, что должно быть в игровых мирах [одного проекта](https://en.wikipedia.org/wiki/Realm_of_the_Mad_God):
1. Игроки должны начинать игру далеко от берега.
2. При повышении уровня игроки должны подниматься в гору.
3. У игроков не должно быть возможности достичь края карты.
4. С ростом уровня игроки должны объединяться в группы.
5. На побережьях должны быть простые монстры без большой вариативности.
6. На равнинах должно быть большое разнообразие монстров средней сложности.
7. В гористой местности должны быть сложные монстры-боссы.
8. Должен существовать какой-то ориентир, позволяющий игрокам оставаться на одном уровне сложности, и ещё один ориентир, позволяющий подниматься или опускаться в уровне сложности.
Составление этого списка привело к созданию следующих ограничений:
1. Игровые миры должны быть островами со множеством побережий и небольшим пиком в центре.
2. Высота над уровнем моря должна соответствовать сложности монстров.
3. На малой и большой высотах должна быть меньшая вариативность биомов, чем на средних высотах.
4. Дороги должны оставаться на одном уровне сложности.
5. Реки должны течь с большой на малую высоту, и предоставлять игрокам возможность перемещаться вверх/вниз.
Эти ограничения привели меня к созданию дизайна генератора карт. А он привёл к генерации *гораздо* лучшего набора карт, чем те, которые я получал настройкой параметров, как это делаю обычно. А [получившаяся в результате статья](http://www-cs-students.stanford.edu/~amitp/game-programming/polygon-map-generation/) заинтересовала многих людей созданием карт на основе диаграмм Вороного.
Ещё один пример — юнит-тесты. Предполагается, что я должен придумать список примеров для проверки. Например, для сеток из шестиугольников я могу подумать, что мне нужно проверять условие `add(Hex(1, 2), Hex(3, 4)) == Hex(4, 6)`. Потом я могу вспомнить что нужно проверить нули: `add(Hex(0, 1), Hex(7, 9)) == Hex(7, 10)`. Потом я могу вспомнить, что нужно проверять и отрицательные значения: `add(Hex(-3, 4) + Hex(7, -8)) == Hex(4, -4)`. Ну вот, отлично, у меня есть несколько юнит-тестов.
Но если подумать чуть дальше, то *на самом деле* я проверяю `add(Hex(A, B), Hex(C, D)) == Hex(A+C, B+D)`. Я придумал три показанных выше примера, основываясь на этом общем правиле. Я иду в обратном направлении от этого правила, чтобы прийти к юнит-тестам. Если я смогу напрямую закодировать это правило в тестовую систему, то сама система сможет работать в обратном порядке, чтобы создавать примеры для тестирования. Это называется «property-based-тестирование». (См. также: [метаморфическое тестирование](https://www.hillelwayne.com/post/metamorphic-testing/))
Ещё один пример: солверы ограничений. В таких системах пользователь описывает то, что хочет видеть на выходе, и система находит способ удовлетворения этих ограничений. Цитата из Procedural Content Generation Book, [глава 8](http://pcgbook.com/wp-content/uploads/chapter08.pdf):
> С помощью конструктивных методов из Главы 3, а также методов фракталов и шумов из Главы 4 мы можем создавать различные виды выходных данных, настраивая алгоритмы, пока нас не начнёт устраивать их выходные данные. Но если мы знаем, какими свойствами должен обладать генерируемый контент, то будет удобнее непосредственно указать, чего мы хотим, чтобы общий алгоритм нашёл контент, удовлетворяющий нашим критериям.
В этой книге описывается программирование наборов ответов (Answer Set Programming, ASP), при котором мы описываем структуру того, с чем работаем (тайлы являются полом и стенами, тайлы граничат друг с другом), структуру решений, которые мы ищем (подземелье — это группа соединённых тайлов с началом и концом) и свойства решений (боковые проходы должны содержать не более 5 комнат, в лабиринте должно быть 1-2 петли, нужно победить троих помощников, прежде чем добраться до босса). После этого система создаёт возможные решения и позволяет вам решать, что с ними делать.
Недавно был разработан солвер ограничений, который вызвал большой интерес благодаря своему крутому названию и любопытным демо: Wave Function Collapse (коллапс волновой функции). *[Про этот солвер есть [статья](https://habr.com/ru/post/437604/) на Хабре.]* Если передать ему изображения-примеры, чтобы сообщить, какие ограничения накладываются на соседние тайлы, то он создаст новые примеры, соответствующие заданным паттернам. Его работа описана в статье [WaveFunctionCollapse is Constraint Solving in the Wild](https://adamsmith.as/papers/wfc_is_constraint_solving_in_the_wild.pdf):
> WFC реализует метод жадного поиска без возврата назад. В этой статье WFC исследуется как пример методов решений с учётом ограничений.
Мне уже многого удалось добиться с помощью солверов ограничений. Как и в случае с алгеброй, прежде чем я научусь использовать их эффективно, мне нужно многому научиться.
Ещё один пример: [созданный мной космический корабль](https://simblob.blogspot.com/2009/03/game-component-spaceship-editor-part-4.html). Игрок может перетаскивать двигатели, куда угодно, и система будет определять, какие двигатели нужно активировать при нажатии на W, A, S, D, Q, E. Например, в этом корабле:

Если вы хотите полететь вперёд, то включаете два задних двигателя. Если хотите повернуться влево, то включаете правый задний и левый передний двигатели. Я пробовал искать решение, заставляя систему *перебирать множество параметров*:

Система работала, но не идеально. Позже я осознал, что это ещё один пример того, где бы могло помочь решение в обратном направлении. Оказалось, что движение космических кораблей может быть описано [линейной системой ограничений](https://en.wikipedia.org/wiki/Linear_programming). Если бы я это понял, то мог бы использовать готовую библиотеку, точно решающую ограничения, а не свой метод проб и ошибок, возвращающий аппроксимацию.
И ещё один пример: проект G9.js, в котором можно перетаскивать по экрану *выходные данные* некой функции, и он определяет, как изменять *входные данные*, чтобы соответствовать желаемым данным на выходе. [Демки G9.js](http://omrelli.ug/g9/gallery/) выглядят отлично! Обязательно раскомментируйте в демо Rings строку «uncomment the following line».
Иногда бывает полезно подумать о задаче в обратном порядке. Часто выясняется, что это даёт мне *более качественные* решения, чем при рассуждениях в прямом направлении. | https://habr.com/ru/post/453170/ | null | ru | null |
# Mercurial hgwebdir через FCGI + несколько разных хранилищ
#### Введение и отмазка
Доброго времени утра,
Возможно, всё о чём я сейчас буду рассказывать делается проще, правильнее, уже сделано, придумали ещё австралопитеки. Возможно это даже будет воспринято как издевательство над всем упомянутым, а вы зря потратите несколько минут своего драгоценного времени. Знайте — я предупреждал!
Если ещё не закрыли статью — обрисую ситуацию:
#### Что у нас есть
У нас есть nginx, mercurial несколько самостоятельных проектов, на каждый из которых имеется 3-4 репозитория. Ещё у нас иногда могут появляться сторонние разработчики, которым часть этих проектов показывать совершенно не обязательно.
#### Что со всем этим делать?
Для начала напомню (или расскажу, если кто не знает), что у Mercurial [существует довольно много вариантов](http://mercurial.selenic.com/wiki/PublishingRepositories) предоставления доступа к репозиториям.
Одним из самых правильных и удобных является [hgwebdir](http://mercurial.selenic.com/wiki/HgWebDirStepByStep), по ссылке описано множество методов подключения этого интрумента к различным веб-серверам, однако в нашем случае мы будем использовать nginx+fcgi.
#### Конфигурируем nginx
О самом nginx рассказывать не буду, приведу только пример рабочей конфигурации с https:
```
server {
listen <адрес>:443;
server_name hg1.whatever.com;
access_log /var/log/nginx/hg1.access.log;
error_log /var/log/nginx/hg2.error.log;
ssl on;
ssl_protocols SSLv3 TLSv1;
ssl_certificate /etc/nginx/ssl/hg/hgmaincert.pem;
ssl_certificate_key /etc/nginx/ssl/hg/hgmaincert.key;
location / {
fastcgi_pass unix:/var/run/hgwebdir.fcgi.socket;
fastcgi_param PATH_INFO $fastcgi_script_name;
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD $request_method;
fastcgi_param CONTENT_TYPE $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param SERVER_PROTOCOL $server_protocol;
fastcgi_param SERVER_PORT $server_port;
fastcgi_param SERVER_NAME $server_name;
}
}
```
#### Конфигурируем fcgi
Основная задача — получить демона, который бы запускал наше fcgi приложение. Как получить этого демона — зависит от вашей ОС, если попросите — дополню статью описанием для Ubuntu (по сути для Linux вообще).
Сам fcgi гейт выглядит примерно так:
> `*#!/usr/bin/python2.6*
>
>
>
> **from** **mercurial** **import** demandimport; demandimport.enable()
>
> **from** **mercurial.hgweb.hgwebdir\_mod** **import** hgwebdir
>
> **from** **mercurial.hgweb.request** **import** wsgiapplication
>
> **from** **flup.server.fcgi** **import** WSGIServer
>
>
>
> **def** make\_web\_app():
>
> **return** hgwebdir("path\_to/hgweb.config")
>
>
>
> WSGIServer(wsgiapplication(make_web_app)).run()`
#### Поехали!..
Ну а дальше запускаем nginx, fcgi, пишем конфиг hgweb.config, согласно документации, добавляем туда коллекции наших проектов, и радуемся жизни… или не очень радуемся.
Дело в том, что hgwebdir сваливает все проекты в одну кучу — разграничить права то мы можем, но список репозиториев всё равно будет виден всем и непередаваемо ужасен.
#### Допиливаем hgwebdir
Что можно сделать теперь? Создать несколько поддоменов, с разными именами, насоздовать несколько fcgi демонов, добавить правила или даже хосты в nginx… получится не слабый такой зоопарк.
Вот с этого места можно начинать кидать помидоры, но мне в голову пришла мысль — если hgwebdir не умеет работать с несколькими конфигами — надо его заставить. Для этого добавим в конфигурацию хоста в nginx нужные нам алиасы:
```
server_name hg1.whatever.com;
server_name hg2.whatever.com;
server_name hg3.whatever.com;
```
Если же потребуется авторизация — придётся использовать несколько директив server, и include, чтобы вынести общую часть. А когда в nginx можно будет использовать auth\_basic внутри if — можно будет сделать и без инклюда.
Рядом с гейтом, создадим модуль hgtreewebdir.py:
> `**from** **mercurial.hgweb.hgwebdir\_mod** **import** hgwebdir
>
>
>
> **class** **hgtreewebdir**(hgwebdir):
>
>
>
> refreshinterval = 0 # = 0, хабр есть ноли!
>
>
>
> **def** \_\_init\_\_(self, conf, baseui=None, virtuals={}):
>
> self.baseconf = conf
>
> self.virtuals = virtuals
>
> hgwebdir.__init__(self, conf, baseui)
>
>
>
>
>
> **def** run\_wsgi(self, req):
>
> **if** self.virtuals != {}:
>
> virtual = req.env.get("HTTP\_HOST", "")
>
> **if** virtual **in** self.virtuals:
>
> self.conf = self.virtuals[virtual]
>
> **return** hgwebdir.run_wsgi(self, req)
>
> self.conf = self.baseconf
>
> **return** hgwebdir.run_wsgi(self, req)`
Код самого гейта изменим следующим образом:
> `*#!/usr/bin/python2.6*
>
>
>
> **from** **mercurial** **import** demandimport; demandimport.enable()
>
> **from** **hgtreewebdir\_mod** **import** hgtreewebdir
>
> **from** **mercurial.hgweb.request** **import** wsgiapplication
>
> **from** **flup.server.fcgi** **import** WSGIServer
>
>
>
> **def** make\_web\_app():
>
> **return** hgtreewebdir("path\_to\_configs/mainhgweb.config",
>
> virtuals={
>
> "hg2.whatever.com": "path\_to\_configs/hg2hgweb.config",
>
> "hg3.whatever.com": "path\_to\_configs/hg3hgweb.config"
>
> })
>
> WSGIServer(wsgiapplication(make_web_app)).run()`
#### Минусы и заключение
В данном варианте, интервал обновления изменён с 20 до 0, это может привести к нагрузкам на сервер вцелом, но я пока на 3 деревьях ничего особенного не наблюдаю. В принципе, интервалы и конфигурации тоже можно закешировать, что я наверное и сделаю, если возникнут тормоза.
Если за неделю ничего не отвалится — пробовать пропихнуть в официальную ветку, как считаете? | https://habr.com/ru/post/84191/ | null | ru | null |
# Запускаем .NET MicroFramework на STM32F4Discovery (перевод)

Несколько месяцев назад STMicroelectronics бесплатно раздавали отладочную плату STM32F4 Discovery. Я стал одним из тех, кому повезло получить ее бесплатно. Последний семестр я использовал плату для моего проекта (realtime и embedded OS) с применением Keil. У меня так-же есть отладочная плата Netduino, которая является моим фаворитом среди моих отладочных плат потому что я могу использовать Visual Studio и C#. Я знаю об ограничениях управляемого кода, связанных с расходами ресурсов на CLR, но моя программа не является программой реального времени. В последнюю неделю я случайно наткнулся на сайт [netmf4stm32.codeplex.com](http://netmf4stm32.codeplex.com/) и был приятно удивлен тем, что .NET MicroFramework был портирован на отладочные платы STM32F4. Так почему-бы не попробовать? Одновременно я описывал весь процесс, разбавляя текст скриншотами. Источником этой работы стал пост [netmf4stm32.codeplex.com/discussions/400293](http://netmf4stm32.codeplex.com/discussions/400293). Благодарю LouisCPro и членов [netmf4stm32.codeplex.com/team/view](http://netmf4stm32.codeplex.com/team/view). Все это отняло у меня не более 2 часов (включая установку Visual C# Express 2010). Начнем…
Нам понадобится следующее
* Отладочная плату STM32F4 Discovery
* Micro USB и Mini USB кабели (нужны оба)
* STM32 ST-LINK Utility (что-бы залить бутлоадер на отладочную плату, это необходимо для драйвера) [www.st.com/internet/com/SOFTWARE\_RESOURCES/TOOL/DEVICE\_PROGRAMMER/stm32\_st-link\_utility.zip](http://www.st.com/internet/com/SOFTWARE_RESOURCES/TOOL/DEVICE_PROGRAMMER/stm32_st-link_utility.zip)
* Скачайте stm32f4discovery.zip и STM32\_WinUSB\_drivers\_(for\_evaluation\_purposes\_only).zip по этой ссылке [netmf4stm32.codeplex.com](http://netmf4stm32.codeplex.com/)
* Visual C# Express или Visual Studio 2010 (версия 2012 пока не поддерживается) [www.microsoft.com/visualstudio/eng/downloads#d-2010-express](http://www.microsoft.com/visualstudio/eng/downloads#d-2010-express)
* .NET MicroFramework SDK (в нашем случае версии 4.2) [netmf.codeplex.com/releases/view/91594](http://netmf.codeplex.com/releases/view/91594)
* Один LED (будем моргать светодиодами)
После того, как Вы все установили (пожалуйста, установите все), подсоедините кабель MiniUSB.

*Подключение кабеля MiniUSB к STM32F4*
(У меня была установлена другая прошивка, поэтому все легко запустилось)
Как только вы подключите карту, начнется поиск драйверов. Если вы уже установили утилиту STLink, драйвера будут установлены автоматически. Если-же вы пропустили это, пожалуйста установите ее. Запустите STLink (по умолчанию STM32 ST-LINK Utility.exe расположена в папке C:\Program Files (x86)\STMicroelectronics\STM32 ST-LINK Utility\ST-LINK Utility\)

*STLink подключена к плате*
После подключения к утилите очистите STM32F4 (не пугайтесь, вы не получите кирпич) следуя скриншотам ниже (по очереди запустите Erase Chip и Erase Sectors...)

*Меню очистки*
*Очищение секторов*
Сейчас чип очищен. Помните пункт 4 вначале, где указаны ссылки на два архива zip? Распакуйте их в удобное место (мы будем использовать их). В stm32f4discovery.zip вы увидите 3 файла: Tinybooter.hex, ER\_Flash.hex and ER\_Config.hex. Используя утилиту ST Link загрузите Tinybooter.hex в чип (следуйте указаниям на скриншоте ниже)
*Раздел Program*

*Tinibooter.hex*
Затем нажмите кнопку Reset на плате (или вытащите и вставьте кабель usb). После того, как вы загрузили Tinibooter.hex, кабель MiniUSB будет действовать только в качестве источника питания для нашего проекта. После перезагрузки вашей платы подключите кабель Micro USB (другой кабель). Я использовал кабель для зарядки своего смартфона.

*Micro и Mini USB кабели подключены*
Как только вы подключите кабель Micro USB, система запустит поиск драйверов и не найдет их. Установите драйвер, который находится в другом файле с именем «STM32\_WinUSB\_drivers\_(for evaluation purposes only).zip». Руководствуйтесь скриншотами ниже, если вы не знаете как это сделать.
Перейдите в Devices and Printers (Устройства и принтеры) из меню Пуск, а затем

*Нажмите правой кнопкой мыши на ярлык STM32.Net Test*
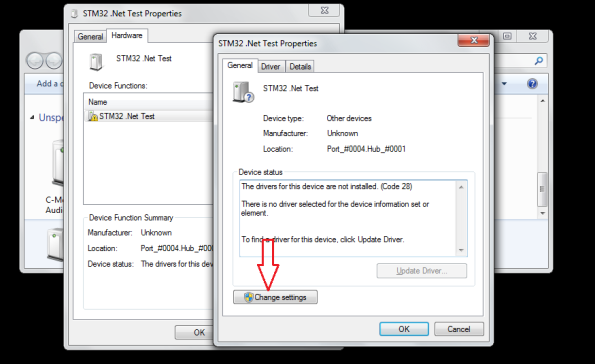
*Свойства -> Изменить настройки*
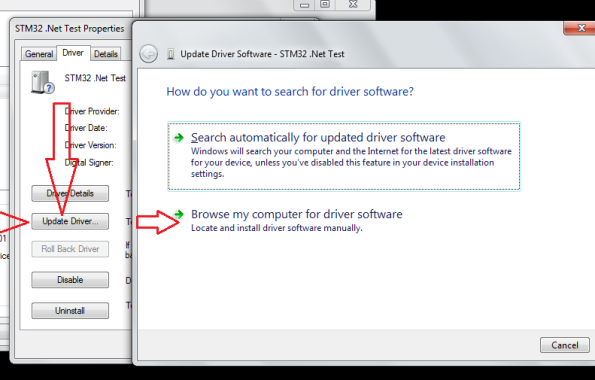
*Поиск нового драйвера*

*Игнорируйте предупреждение (как обычно )))*
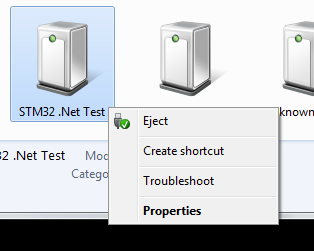
*Сейчас ошибок нет!*
Теперь MFDeploy должна быть в состоянии обнаружить плату. MFDeploy это MicroFramework Deployer. С помощью этой программы мы установим CLR, на котором будет работать наш .net код. Отлично, запустите MFDeploy.exe (вы найдете его в папке C:\Program Files (x86)\Microsoft .NET Micro Framework\v4.2\Tools\), который у вас должен появится после установки SDK. Что-бы убедиться, что MFDeploy видит плату, сделайте как показано ниже.
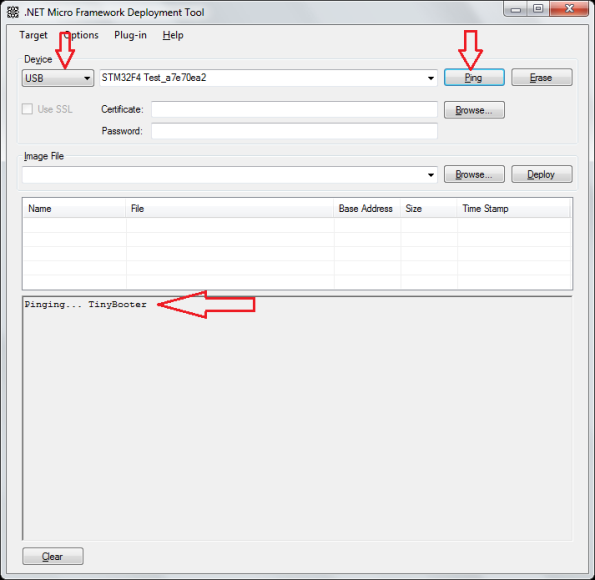
*MFDeploy ping*
Если вы видите ответ, значит все сделано правильно. Загрузите 2 других .hex файла (ER\_Config.hex and ER\_Flash.hex), распакованных из stm32f4discovery.zip в плату иcпользуя MFDeploy как показано далее

*Нажмите Browse для загрузки hex файлов*
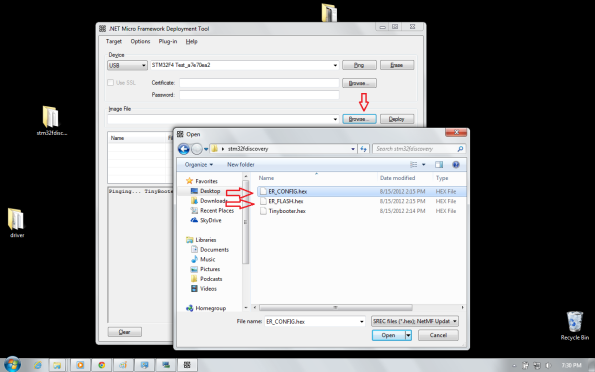
*Установите их в любой последовательности*
Перезагрузите плату.
**Поздравляю! У вас теперь есть плата с .NET Microframework!**
Сейчас необходимо протестировать нашу плату. Откройте Visual C# Express/Visual Studio. Я уверен, что вы уже установили Microframework SDK. Выберите тип проекта
*Проект MicroFramework*
Теперь нам нужно изменить свойства так, что-бы Visual Express/Studio загружал проект в нашу плату. Настройте так, как показано ниже

*Настройки*

*С помощью USB*
Теперь нам нужно добавить класс что-бы мы смогли поморгать светодиодами.
*Добавляем класс*
*Microsoft.SPOT.Hardware*
Мой тестовый код
```
using System;
using System.Threading;
using Microsoft.SPOT;
using Microsoft.SPOT.Hardware;
namespace STM32F_Test
{
public class Program
{
public static void Main()
{
OutputPort led = new OutputPort(Cpu.Pin.GPIO_Pin1, false); //PA1 on discovery board
while (true)
{
led.Write(true);
Thread.Sleep(500);
led.Write(false);
Thread.Sleep(500);
}
}
}
}
```
Узнать карту пинов платы можно в этом файле “C:\MicroFrameworkPK\_v4\_2\DeviceCode\Targets\Native\STM32\ManagedCode\Hardware\CPU.cs” который вы найдете, если установили комплект портирования (не включены в список свыше).
Оригинал статьи: [singularengineer.wordpress.com/category/electronics](http://singularengineer.wordpress.com/category/electronics/) | https://habr.com/ru/post/175989/ | null | ru | null |
# Счастливые билетики до 300 цифр
Началось все с тестового задания на вакансию «js-developer, Node.js-developer», и тут я выпал в осадок: задача на счастливые билетики.
> Посчитать количество счастливых билетиков для 2, 4, 6, 8 и 10 цифрового значения.
>
>
Уверен, многие уже не раз делали эту банальную задачку, но, как правило, для 6-ти цифр ([для тех, кто не понимает о чем пойдет речь](https://ru.wikipedia.org/wiki/%D0%A1%D1%87%D0%B0%D1%81%D1%82%D0%BB%D0%B8%D0%B2%D1%8B%D0%B9_%D0%B1%D0%B8%D0%BB%D0%B5%D1%82)).
Банальное решение:
```
var
sum = function(num){ // функция для получения суммы цифр
var
str = num.toString(),
arr = str.split(''),
s = 0;
arr.forEach(function(value){ s+=parseInt(value); });
return s;
},
luckyTickets = function(len){
var
lenMiddle = len/2,
maxSize = Math.pow(10,lenMiddle),
result = 0;
for(var i=0;i
```
Также можно посмотреть [тут](https://ru.wikibooks.org/wiki/%D0%A0%D0%B5%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D0%B8_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC%D0%BE%D0%B2/%D0%9F%D0%BE%D0%B4%D1%81%D1%87%D1%91%D1%82_%D1%81%D1%87%D0%B0%D1%81%D1%82%D0%BB%D0%B8%D0%B2%D1%8B%D1%85_%D0%B1%D0%B8%D0%BB%D0%B5%D1%82%D0%BE%D0%B2#JavaScript).
А если цифр 10? 30? 200? Беда! Приходиться ооочень долго ждать результата: аналог в PHP (5.3) «умирал», даже когда я давал 10 цифр и set\_time\_limit (3600).
Теперь вернемся в мир JS. Несмотря на то, что простые циклы в Node.js выполняются быстрей, чем в PHP, время выполнения меня все равно не устраивало (1 029 458 ms).
А теперь хватит этого унылого текста, переходим к альтернативному решению.
Сама зацепка оказалась в журнале «Квант», № 12 (1976), с.68–70 ([электронный вариант](http://www.ega-math.narod.ru/Quant/Tickets.htm) ).
Там же можно увидеть вывод — таблица, с помощью которой можно легко узнать «количество счастья» в билетах из 2 (n=1), 4 (n=2), 6 (n=3) и 8 (n=4) цифрами.
Как заполнить таблицу — изображено ниже:

То есть сумма 10 элементов предыдущего столбца, у которых индекс <= нужному значению. Количество счастливых билетов равно сумме каждого значения в квадрате в определенном столбце:
— для n=1 (2 цифры) -> 1^2 + 1^2 +… + 1^2 = 10;
— для n=2 (4 цифры) -> 1^2 + 2^2 +… + 1^2 = 670;
— для n=3 (6 цифр) -> 1^2 + 3^2 +… + 75^2 +… + 1^2 = 55 252;
— для n=4 (8 цифр) -> 1^2 + 3^2 +… + 670^2 +… + 1^2 = 4 816 030;
Дальше наш ход.
```
var
getNextArr = function(prevArr){ // функция для построения следующего массива из предыдущего
var
newLen = prevArr.length + 9, // длинна следующего массива будет больше на 9
arr = []; // заготовка результата
for(var i=0; i
```
Ну и проверить же нужно:
```
console.log( luckyTickets(300) ); // 8.014950093120178e+297 **
```
Собственно то, к чему все велось: время выполнения 106 ms (!!!), страшно представить, что бы случилось при использовании банального способа.
\* все JavaScript-ы проверял на Node.js (x32)
\*\* максимальная длинна номера билета — 310, Больше? — результат переходит в область Infinity.
\*\*\* это моя первая статья на Хабре за последние 3 года, прошу камнями не бросать. | https://habr.com/ru/post/266479/ | null | ru | null |
# Allure TestOps: «Нестандартный» сценарий использования
Привет. Меня зовут Николай, я QA Automation Engineer в мобильной платформенной команде Delivery Club. Эта статья будет о том, как мы интегрировали Allure TestOps (далее Allure TO) в регрессионное тестирование нескольких мобильных приложений и ушли от TestRail. Альтернативу TestRail выбирали мои коллеги, и эту часть мы упомянем вскользь.
Нашей команде требовалось перевести в Allure TO клиентские приложения под Android и iOS, а также Android-приложения для курьеров и сборщиков. В статье будет освещена только специфика Android, так как с ней было больше интересных нюансов. В частности, на сегодня у клиентского приложения около 1000 тест-кейсов. В подавляющем большинстве случаев при регрессионном тестировании у нас используется один тест-кейс для обеих платформ клиентского приложения. Такой багаж не позволял делать какое-либо решение с нуля.
Этот материал будет интересен тем, кому предстоит интегрировать мобильные автотесты в Allure TO и хочется узнать про потенциальные проблемы. А также, возможно, тем, кому не полностью подходят стандартные сценарии использования этой TMS. Цель статьи — не дать конкретное решение, а продемонстрировать наш сценарий использования нетипичных возможностей TMS с небольшими вставками кода.
### Research
Allure TO призван решить проблему ранних Test Management System (TMS), которые создавались с ручным тестированием во главе угла. И с течением времени к этим TMS сбоку прикручивали автоматизацию процессов и тестирования. В Allure TO автоматизация заложена изначально, и при этом инструмент подталкивает к ее использованию.
На этом этапе ручное тестирование в нашей компании пока еще преобладает, и нам предстояло начать использовать новый инструмент и при этом не сломать существующие процессы тестирования.
Наши автотесты преимущественно пишутся на Kotlin с использованием Kaspresso, поэтому поддержка базового Allure достигается за счет паттерна Step и расширения для базового класса тестов [Kaspresso-Allure.md](https://github.com/KasperskyLab/Kaspresso/blob/master/wiki/09_Kaspresso-Allure.md).
До начала интеграции мой коллега [@materkey](https://github.com/materkey) уже реализовал запуск тестов на каждый коммит Pull Request (PR), где при наличии красных тестов для такого PR срабатывает Quality Gate. Следовательно, если мы не успеваем быстро починить сломанный тест, то у нас появляются `@Ignore`-тесты (skipped), ниже я расскажу про них подробнее. В качестве отчета PR уже был отлаженный Allure Report в [allure-docker-service](https://github.com/fescobar/allure-docker-service), и на первом этапе мы не планировали отказываться от него. В качестве CI используется Jenkins, а для работы с эмуляторами — Argo Workflow (k8s). Тесты запускает форк [Avito test runner](https://avito-tech.github.io/avito-android/test_runner/TestRunner/). С такими вводными моя задача становилась проще.
У Allure TO есть богатая [документация](https://docs.qameta.io). Хотя в процессе ее изучения пришел к выводу, что нужного нам сценария использования «из коробки» нет и потребуется дорабатывать интеграцию. На момент написания статьи мы работали с версией 3.193.0. При этом хотелось как можно больше задач переложить на Continuous Integration (CI).
#### Сначала о наших ожиданиях
Одна из ключевых целей перехода на Allure TO — мигрировать бесшовно и быстро. Внутри есть много всего «из коробки», интеграции с кодом и хорошая аналитика. Немаловажно, что TMS сделана в России, а значит не предвидится проблем с отключением и оплатами.
Желаемое нами поведение, аналог которого был ранее сделан для TestRail и которое предстояло поддержать для Allure TO:
* Минимально зависеть от Jenkins-плагинов, поскольку мобильные автотесты запускались в инстансе Jenkins, который имел ряд инфраструктурных ограничений, и на их преодоление могло уйти немало времени. Поэтому несмотря на использование Jenkins планировалось взять allurectl вместо плагина.
allurectlallurectl – оболочка командной строки для API.
* С помощью аннотации `@AllureId` и идентификатора тестового сценария должна быть реализована связь между тест-кейсом и автотестом. В Allure TO это разные сущности, но каждая из них может иметь такое свойство, как результат тестирования.
* Если отведена ветка Release Candidate, то метаинформация автотестов первого multibranch pipeline отправляется в allure-docker-service, а также создается launch по фильтру тест-кейсов, и к нему загружается эта же метаинформация. Плановые релизы у нас обычно происходят раз в неделю.
Метаинформация Метаинформация – файлы определенного формата для единицы автотеста, которые могут содержать выполняемые шаги, результаты тестирования, вложения и многое другое. Исходные данные для отчета, который будет создан впоследствии.
Launch Launch – результаты тестирования в рамках одного или нескольких прогонов тестов. Аналог Test Run в TestRail.
* Фильтр тест-плана будем хранить в коде. Фильтр будет находить как автоматизированные, так и неавтоматизированные тест-кейсы. Тестовый набор будет пересчитываться по мере добавления новых сценариев от релиза к релизу. **Это то важное, аналог чего мы не нашли в существующих интеграциях.**
* В день релиза автотесты запускаются ночью, и к началу рабочего дня должен быть launch с результатами. Неавтоматизированные тест-кейсы ожидаемо допроходим вручную и выносим решение о готовности приложения к релизу.
* Проставление статуса каждым конкретным автотестом в реальном времени для launch’ей не требуется, так как ветку Release Candidate отводим ночью. Результаты автотестов загрузим разом в конце пайплайна.
Уже в процессе исследования я выяснил, что в используемом нами test runner возможность штучно запускать автотесты требует доработки. Поэтому если будет X красных тестов, то в первое время для таких тестов мы будем вручную делать `Rerun` с флагом `Force manual` силами QA-инженеров.
Одной из задач, которые предстояло решить, была необходимость заменить самописную TestRail-аннотацию `@CaseId`на коробочную аннотацию `@AllureId`.
```
// Было
import com.deliveryclub.utils.testrail.CaseId
@CaseId(12345)
@Test fun checkThat() { }
```
```
// Стало
import io.qameta.allure.kotlin.AllureId
@AllureId("67890")
@Test fun checkThat() { }
```
Отмечу, что ранее в процессе работы с TestRail-аннотациями не использовались какие-либо инспекции IDE, поэтому при переходе мы узнали, что не везде был проставлен `@CaseId`, и в этой части предстояло наверстать упущенное, расставив идентификаторы тест-кейсов.
#### Далее рассмотрим доступные сценарии использования «из коробки»
### 1. Без ручных операций при подготовке launch’а
А. TestCase as code — тест-кейсы хранятся в коде, а значит запускаются вместе со всеми автотестами. Такие ручные тесты не будут взаимодействовать с приложением, поэтому будут исполнены быстро и отражены в Allure TO с необходимостью пройти их вручную. Источник правды для тестовой документации в таком случае один, и процесс актуализации тестов становится неразрывным. Получается близкое к идеалу решение, но если уже есть тысячи тест-кейсов, то перенести их в код и мотивировать всех QA-инженеров работать через Git будет не самой простой задачей.
### 2. С ручными операциями при подготовке launch’а
А. QA-инженер выбирает в launch’е нужные тест-кейсы, которые уже были автоматизированы, и запускает их по кнопке в интерфейсе Allure TO.
B. Либо создается launch только из автотестов, и по его завершении QA-инженер вручную добавляет недостающие ручные тест-кейсы.
C. Либо создается launch только из автотестов, и по его завершении QA-инженер вручную объединяет его с другим launch’ем из недостающих ручных тест-кейсов.
Варианты 2A, 2B и 2C не подойдут нам, так как мы осуществляем запуск автотестов ночью и к утру хотим видеть их результаты, а также все ручные тест-кейсы, которые следом предстоит пройти.
### Базовая интеграция
#### 0. Скачивание allurectl
Указываем в ожидаемом состоянии Infrastructure-as-Code-инструмента подходящий дистрибутив [allurectl](https://github.com/allure-framework/allurectl/releases).
#### 1. Наши скрипты
Создаем тест-план ручных и автоматических тестов. Запускаем его и получаем сущность launch. После запуска launch’а удаляем тест-план.
```
PLATFORM_NAME="ANDROID"
ALLURE_TESTOPS_HOST="https://alluretestops.domain"
ALLURE_TESTOPS_PROJECT_ID=1
ALLURE_TESTOPS_TREE_ID=10
ALLURE_TESTOPS_TESTPLAN='cf["Suite"] != "SomeSuite" and tag != "SomeTag" and status != "Outdated" '
# При решении задачи мы поддержали создание динамического тест-плана
# по фильтру на основе встроенного Allure Query Language (он же AQL/RQL)
```
```
if [[ "$CAN_SEND_TO_TMS" == "true" ]]; then
ALLURE_LAUNCH_ID=$(python3 our_scripts/create_launch.py \
--allure_host "$ALLURE_TESTOPS_HOST" \
--allure_token "$ALLURE_TESTOPS_TOKEN" \
--branch_name "$BRANCH_INPUT" \
--commit_hash "$COMMIT_HASH" \
--allure_project_id "$ALLURE_TESTOPS_PROJECT_ID" \
--allure_tree_id "$ALLURE_TESTOPS_TREE_ID" \
--platform_name "$PLATFORM_NAME" \
--base_rql "$ALLURE_TESTOPS_TESTPLAN")
fi
```
#### Детали our\_scripts/create\_launch.py
У инструмента есть swagger-ui, в котором мы нашли нужные нам endpoint’ы для реализации желаемого поведения в скрипте. Написанный код был достаточно простым, поэтому привожу только сами endpoint’ы:
```
1. POST /api/rs/testplan с важным для нас параметром "baseRql"
2. POST /api/rs/testplan/{testplan_id}/run возвращающий "launch_id"
3. DELETE /api/rs/testplan/{testplan_id}
```
#### Флаг CAN\_SEND\_TO\_TMS
В следующем блоке кода Jenkins pipeline вычисляется необходимость выгружать отчет в Allure TO. Выгружаем только один раз для первой успешной сборки, поэтому пытаемся найти ее среди предыдущих сборок multibranch pipeline.
```
def can_send_to_tms() {
previous = currentBuild.getPreviousBuild()
while (previous != null) {
if (previous.result == 'UNSTABLE' || previous.result == 'SUCCESS') {
return false
}
previous = previous.getPreviousBuild()
}
return true
}
```
#### 2. Запускаем тесты и ждем завершения
#### 3. Загружаем разом все результаты
```
allurectl upload --launch-id "$ALLURE_LAUNCH_ID" \
--endpoint "$ALLURE_TESTOPS_HOST" \
--token "$ALLURE_TESTOPS_TOKEN" \
--project-id "$ALLURE_TESTOPS_PROJECT_ID" \
"ci/k8s/allure"
```
### Возникшие проблемы
#### Skipped-тесты
@Ignore@Ignore (skipped) — аннотация в коде, которая сообщает test runner об отсутствии необходимости запускать конкретный автотест.
LiveDoc LiveDoc — автоматическое создание документации тестирования на основе результатов автотестов. В основе этой функциональности лежит идея TestCase as code.
Несколько возникших проблем были связаны с автотестами, отмеченными `@Ignore`. В документации сказано:
> Now, this is important. In order to proceed to further steps, your build job needs to be started at least once, so Allure TestOps server will start gathering the information about your tests.
>
>
Как оказалось, требование первичной синхронизации не охватывает skipped-автотесты, и после отработки LiveDoc у нас начала расходиться структура.
Также после загрузки результатов автотестов и закрытия launch’а с включенным LiveDoc неожиданно появляются тест-кейсы из skipped-автотестов.
Так как мы в тот момент не были готовы к TestCase as code, то временно в Update policies задали использование всех полей из тест-кейсов вместо полей из автотестов.
И все же для синхронизации `AllureId` мы были вынуждены периодически включать и снова выключать LiveDoc с последующим удалением пустых тест-кейсов. Забегая вперед, скажу, что мы уже ушли от этой ручной операции. Если не синхронизировать `AllureId`, то тест-кейс ничего не будет знать про соответствующий ему новый автотест.
В качестве первого решения ребята из Qameta предложили нам не загружать skipped-автотесты, но мы выяснили, что наличие метаинформации для skipped — это стандартное поведение адаптера. Желающие могут посмотреть официальный пример [allure-junit4-gradle-kts](https://github.com/allure-examples/allure-junit4-gradle-kts).
Адаптер Адаптер – надстройка test runner, позволяющая собирать метаинформацию во время выполнения автотестов.
В качестве второго решения нам предложили хак `@AllureId`("-1"), который препятствует созданию тест-кейсов из skipped, а также позволит присвоить тесту признак `Orphan`, который можно отфильтровать перед началом ручного тестирования и дать скорректированную ссылку с параметром на launch для QA-инженера:
Мы подумали, что `@AllureId`("-1") не способствует читаемости автотеста и предсказуемости поведения самой Allure TO.
В качестве третьего решения нам предложили договориться о новой аннотации, решающей проблему со стороны продукта, хотя что-то похожее мы могли сделать и сами, получив новые вводные.
В итоге в качестве временного решения выбрали первый вариант и доработали форк test runner, чтобы в Allure TO не загружать skipped, но при этом загружать в allure-docker-service при PR с сохранением возможности контролировать такие тесты. Пример изменений [прикладываем](https://github.com/materkey/avito-android/pull/1/files) в ознакомительных целях.
#### Сюрприз LiveDoc
Предположим, что все тест-кейсы перенесены из TestRail, или уже написано много новых. Далее они связываются с автотестами по идентификатору. Мы решаем загрузить результаты автотестов и закрыть launch, чтобы в первый раз пройти вручную весь сценарий. Казалось бы, что может пойти не так? Видимо, Qameta предполагала, что пользователь изучит не только блок Quick start, а сразу всю документацию. Если предварительно в настройках вы не «*выключите костылем*» фичу LiveDoc или не сконфигурируете все типы полей в Update policies (описано выше), то будьте готовы к тому, что автотесты перезапишут поля всех связанных тест-кейсов, и это породит хаос.
«выключаем костылем»К сожалению, мы с этой ситуаций столкнулись, обратились к Qameta, и для нас оперативно сделали скрипт для отката состояния затронутых тест-кейсов к предыдущему. Скрипт [прикладываем](https://github.com/eroshenkoam/allure-testops-utils#rollback-testcases-in-allure-testops) только в ознакомительных целях.
### Выводы
На базовую интеграцию четырех мобильных приложений, которую можно использовать в регрессионном тестировании, у нас ушел примерно месяц работы одного вовлеченного инженера и небольшая часть времени остальных членов команды.
Если попытаться рассказать о новом релизном процессе одной картинкой, то она будет такой:
Приведенный выше сценарий с динамическим тест-планом ручных и автоматических тестов мы передали ребятам из Qameta. Они согласились поддержать его у себя, потому что он всем сторонам показался оправданным и полезным.
Думаю, что поведение Allure TO может быть доработано ради упрощения работы пользователя со skipped-автотестами и подстраховки на стороне UX от неожиданной потери данных после срабатывания LiveDoc. Предварительно, ребята из Qameta согласны с необходимостью таких доработок в продукте.
Allure TestOps и видение процесса тестирования его разработчиками привлекательны, но для перехода на него требуются определенные усилия и, конечно же, время. Мы рассказали о первой итерации работы с инструментом и уже видим точки роста в нашем процессе. Если у вас был опыт перехода, делитесь им в комментариях — давайте обсудим. Благодарю за внимание. | https://habr.com/ru/post/691660/ | null | ru | null |
# О практических применениях свойства float

Каждый хороший верстальщик скажет, что только безукоризненное знание собственной работы способно принести позитивные результаты. Собственные наблюдения привели меня к выводу, что не только начинающие верстальщики не совсем понимают сути применения свойства float. На Хабре просмотрел имеющиеся публикации на данную тематику. Появилось желание поделиться некоторыми замечаниями и практическими применениями данного свойства. Приведенные ниже разъяснения в большинстве своем могут стать полезными для начинающего верстальщика.
1. Значения left, right определяют, по какой стороне будет выравниваться элемент;
2. элементы, имеющие значения left, right, становятся блочными (имея больший приоритет над значениями свойства display);
3. плавающий элемент обтекается следующим элементом (и другими вложенными в него элементами), следующими соседними элементами родителя, а также предыдущими соседними строчными элементами;
4. плавающий элемент занимает ширину контента за исключением, если внутренние элементы неплавающие (это было обсуждено в статье [Float'омагия: пробуем не «плавать» в спецификации, чтобы не утонуть в потоке](http://habrahabr.ru/post/136622/));
5. высота отца не зависит от высоты дочернего плавающего элемента, для следующих неплавающих элементов внешние отступы от плавающих элементов не будут действовать;
6. элемент, для которого предыдущий соседний элемент — плавающий, будет обтекать его, если позволит ширина отца, в противном случае — обтекать предыдущий плавающий элемент;
7. элементы не будут флоатиться, если это не позволит ширина отца;
8. значения absolute и fixed свойства position отменяют действие свойства float.
Известно, что блочный элемент располагается на отдельной строке, но зафлоаченный элемент обтекают предыдущие соседние строчные элементы.
##### Пример:
```
2
1
```
##### Результат:
12
Как по мне, вышеуказанный пример не имеет практического применения. Но вывод можно сделать такой: не стоит размещать друг к другу строчные и блочные элементы. На том, как ведут себя зафлоаченные элементы между собой, особо останавливаться не буду, поскольку это хорошо было продемонстрировано в статье [Подробно о свойстве float](http://habrahabr.ru/post/142486/).
#### Но хотелось бы привести еще дополнительные практические применения
##### 1. Какие стили написать для такой разметки
```
Бренд:
Apple
Потребительная мощность:
10Вт
Дополнительные возможности:
Веб-камера FaceTime HD Встроенный микрофон
```
**чтобы выглядело так:**

**Все просто:**
```
dt{
float: left;
}
```
**A если размеры ограничены:**
```
dl{
width: 500px;
}
```
##### Результат:

*микрофон **упал** под Дополнительные возможности:*
**В таком случае стоит лишь добавить**
```
dd{
overflow: hidden;
}
```
##### Результат:

**В итоге получается небольшой код:**
```
dl{
width: 500px;
}
dt{
float: left;
}
dd{
overflow: hidden;
}
```
##### 2. Как упомянуто выше, зафлоаченный элемент занимает ширину содержимого, и если нам нужно сверстать такое меню:

эта особенность нам поможет.
С условием, что цвет фона нужно задать элементу li:
**Розметка:**
```
* [Главная](#)
* [Каталог](#)
* [Контакты](#)
```
**Базовые стили:**
```
ul > li {
float: left;
background-color: #eee;
margin: 4px 0;
padding: 4px;
}
```
float: left — нужен для того, чтобы ограничить ширину до содержимого.
Но не обязательно быть профессионалом верстки, чтобы заметить: если ширина ul позволяет элементам обтекать друг друга, то получится следующее:

Тогда в помощь нам приходит связка свойств float и clear. Стоит селектору ul > li прописать clear: left, и все станет на свои места.
Не все так просто со свойством clear — применение этого свойства из значением left или right приводит к очищению всего потока зафлоаченных элементов данного типа. Приведу наглядный пример:
**Имеем следующую разметку:**
```
lorem ispum
lorem ispum
lorem ispum
lorem ispum
```
**и стили:**
```
.leftColumn {
width: 200px;
height: 200px;
float: left;
background: #f55;
}
.rightColumn {
margin-left: 220px;
background: #5ff;
}
.rightColumn .block1,
.rightColumn .block2 {
float: left;
width: 200px;
margin-right: 20px;
background: #ebde05;
}
.rightColumn .block3 {
background: #9e9;
clear: both;
}
```
**Заметка:** *за задумкой, элемент с классом block3(зеленый) должен расположиться после элементов с классами block1, block2 (желтые) и начинаться с нового рядка.*
##### В результате:

Что здесь произошло? Элемент с классом block3 (зеленый), действием правила clear: both; очистил поток, включая красный блок.
Выходов из этой ситуации много. Все зависит от поставленной задачи:
* задать элементу с классом rightColumn правило overflow: hidden;
результат:

* задать элементу с классом rightColumn правило float: left; но тогда придется убрать margin-left: 220px; и теперь элемент с классом rightColumn не будет занимать остальную ширину окна браузера;
* обвернуть элементы с классами block1, block2 в элемент, задав ему overflow: hidden; или же display: table-cell; (для ie7 — zoom: 1;)
Знакомый метод очищения потока и определения высоты элементу под названием clearfix здесь не подходит.
##### 4. Вооружившись знаниями свойства float и overflow, сверстаем такое меню:
**Разметка:**
```
* [Главная](#)
* [Каталог](#)
* [Контакты](#)
```
Не будет проблемы, если использовать дополнительные селекторы. Но, к примеру, мы не знаем количества пунктов (для использования селектора соседних элементов), не имеем кроссбраузерную поддержку :first-child, :last-child, а использование каких либо выражений, тем более скриптов для IE — запрет;
**стили:**
```
ul li {
float: left;
border-width: 0 3px;
border-style: solid;
border-left-color: #5FF;
border-right-color: red;
padding: 0 5px;
}
```
**В результате получаем:**

Использовав отрицательные внутренние отступы для li и свойства float и overflow для ul, получаем дополнительные стили:
```
ul{
overflow: hidden;
float: left;
}
ul li {
margin: 0 -3px;
}
```

Как можно заметить, border-ы не на своем месте, осталось лишь поменять значения цветов левого и правого бордеров, получается такой код:
```
ul {
overflow: hidden;
float: left;
}
ul li{
float: left;
border-width: 0 3px;
border-style: solid;
border-left-color: red;
border-right-color: #5ff;
padding: 0 5px;
margin: 0 -3px;
}
```

Конечно же, внутренние отступы уменьшились на 3px, поэтому надо их увеличить на 3px:
```
ul {
overflow: hidden;
float: left;
}
ul li{
float: left;
border-width: 0 3px;
border-style: solid;
border-left-color: red;
border-right-color: #5ff;
padding: 0 8px;
margin: 0 -3px;
}
```
**Получаем готовое меню:**
Я не упомянул всего, что касается специфики и практических примеров свойства float, но приведу еще некоторые ссылки на полезные статьи:
* [Подробно о свойстве float](http://habrahabr.ru/post/142486/)
* [Float'омания: разъяснение как работает css свойство float](http://habrahabr.ru/post/136588/)
Раздел блога ImageCMS “Совершенствуемся — [CSS](http://www.imagecms.net/blog/imagecms-lessons/html-css-javascript)!” в статье учебные материалы об эффективной верстке веб-страниц.
В заключение хочу добавить, что применять свойство float надо там, где в этом есть необходимость. Известный фреймворк bootstrap использует специальные вспомогательные классы .pull-left и .pull-right. Я использую .f\_l, .f\_r, это позволяет не только сократить код css, но и дает большую гибкость в построении структуры.
Ко всем вышеуказанным важностям хочу добавить только одно: с Днем программиста, друзья и коллеги! Легкого кодинга, двойной оплаты в восьмой степени вам и нам! | https://habr.com/ru/post/151287/ | null | ru | null |
# Простой графический интерфейс для M5Stack (Arduino)
Привет! Сегодня мы познакомимся с такой штукой как M5 UI. Благодаря M5 UI Вы можете с помощью пары строк кода подключать всевозможные поля, кнопки, ползунки и переключатели, создавать условные слоя. Несмотря на то, что процесс подключения элементов UI очень прост, Вы также можете воспользоваться наглядным инструментом M5 UI Designer for Arduino IDE.

Рисунок 1
Необходимо рассмотреть все существующие на сегодняшний день элементы из библиотеки M5 UI на практике, так же ознакомиться с процессом создания интерфейса в приложении M5 UI Designer.
Краткая справка
---------------
Графический интерфейс представляет собой совокупность функциональных элементов, необходимых для взаимодействия с пользователем. В качестве таких элементов выступают всевозможные поля ввода/вывода текста, кнопки, чекбоксы, ползунки, переключатели и многие другие. В качестве примера графического интерфейса давайте посмотрим на рисунок 2.

Рисунок 2. Элементы пользовательского интерфейса
> Для того, чтобы установить фокус на следующий элемент (выбрать элемент) используйте поочерёдное нажатие клавиш Fn и TAB
**Inputbox** представляет собой область ввода текстовой информации на экране с фиксированной высотой 50 px. Ширина может быть задана пользователем, но не может быть меньше 32 px. В верхней части располагается надпись (например: Enter user name), обратите внимание на то, что в конце автоматически будет добавлен символ '**:**'. В нижней части располагается прямоугольная область, в которую пользователь может вводить данные с клавиатуры. При наведении фокуса на данный элемент — происходит подсветка нижней части. Для того чтобы изменить значение используйте клавиши с буквами и цифрами на клавиатуре.
**Textbox** представляет собой область вывода текстовой информации на экране. Размеры могут быть заданы пользователем, но не могут быть меньше размеров одного символа. Состоит данный элемент из одной части. Текст умещается по всей площади и не выходит за пределы. Наведение фокуса на данный элемент не предусмотрено.
**Waitingbar** представляет собой область вывода графической информации на экране с фиксированной высотой 50 px. Ширина может быть задана пользователем, но не может быть меньше 12 px. В верхней части располагается надпись (например: Connection to Wi-Fi), обратите внимание на то, что в конце автоматически будет добавлен символ '**:**'. В нижней части располагается прямоугольная область, которая закрашивается периодически оранжевыми и черными квадратами. Наведение фокуса на данный элемент не предусмотрено.
**Progressbar** представляет собой область вывода графической информации на экране с фиксированной высотой 50 px. Ширина может быть задана пользователем, но не может быть меньше 12 px. В верхней части располагается надпись (например: Times of the check), обратите внимание на то, что в конце автоматически будет добавлен символ '**:**'. В нижней части располагается прямоугольная область, которая закрашивается в зависимости установленного значения (до 10% — красным, до 30% — оранжевым, до 80% — зелёным, до 100% — синим цветом). Наведение фокуса на данный элемент не предусмотрено.
**Selectbox** представляет собой область выбора текстовой информации на экране с фиксированной высотой 50 px. Ширина может быть задана пользователем, но не может быть меньше 44 px. В верхней части располагается надпись (например: Mode), обратите внимание на то, что в конце автоматически будет добавлен символ '**:**'. В нижней части располагается прямоугольная область выбора, в которой пользователь может выбирать данные с клавиатуры. Для того чтобы изменить значение нажмите клавишу **Fn**, затем **K / M** или аналогично стрелки **вверх / вниз**.
**Checkbox** представляет собой область ввода единственного значения (true/false) на экране с фиксированной высотой 32 px. Ширина может быть задана пользователем, но не может быть меньше 44 px. В левой части расположен флаг (если закрашен, то true, если нет — false). В правой части располагается надпись (например: Remember password). Для того чтобы снять или установить флаг нажмите клавишу **SPACE**.
**Button** представляет собой область вызова любой пользовательской функции (с сигнатурой void (String\*)) с фиксированной высотой 32 px. Ширина может быть задана пользователем, но не может быть меньше 22 px. По центру располагается надпись (например: Launch). Отличительной особенностью данного элемента является поддержка иконок из стандартного набора (рис. 3). Для того чтобы нажать на кнопку нажмите клавишу **SPACE**.

Рисунок 3. Коды стандартных иконок 24 x 24 px
Если будет подключена иконка, то минимальная ширина будет 51 px.
**Rangebox** представляет собой выбора целого числового значения из заданного диапазона с фиксированной высотой 50 px. Ширина может быть задана пользователем, но не может быть меньше 32 px. В верхней части располагается надпись (например: Speed), обратите внимание на то, что в конце автоматически будет добавлен символ '**:**'. В нижней части располагается область содержащая полосу и прилегающий ползунок. Для того чтобы изменить значение нажмите клавишу **Fn**, затем **N / $** или аналогично стрелки **влево / вправо**.
**Перечень компонентов для урока**
* PC/MAC;
* M5STACK;
* FACES;
* FACES Keyboard;
* кабель USB-C из стандартного набора;
* цветные провода из стандартного набора (тип розетка-вилка);
* макетная плата для пайки 5 х 7 см;
* паяльник 40 или 60 Вт;
* канифоль паяльная;
* олово паяльное;
* ножницы;
* резистор 36 ом (1 шт.);
* резистор 160 кОм (1 шт.);
* микросхема 74HC595N (1 шт.);
* резистор 220 Ом (1 шт.);
* светодиоды: оранжевый, зеленый, жёлтый, красный (4 шт.);
* транзистор мощный BC337 (1 шт.);
* резистор 100 кОм (1 шт.);
* электродвигатель постоянного тока (1 шт.).
Начнём!
-------
### Шаг 1. Установка библиотеки M5 UI
Перейдите по ссылке M5 UI for Arduino IDE в разделе **Downloads** (внизу этой страницы) и скачайте архив с библиотекой с GitHub (рис. 3.1).
Рисунок 3.1. Нажмите на кнопку Clone or download, затем Download ZIP
Запустите Arduino IDE и добавьте скаченный архив (рис. 3.2).
Рисунок 3.2. Нажмите Sketch, Include Library, Add .ZIP Library...
После этого библиотека будет успешно добавлена. На этом всё.
### Шаг 2. Установка и инструмента M5 UI Designer
Аналогичным образом перейдите по ссылке M5 UI Designer for Arduino IDE в разделе **Downloads** (внизу этой страницы) и скачайте архив с библиотекой с GitHub в рабочий стол, затем извлеките содержимое и откройте документ index.html с помощью браузера (beta-версия работает исключительно под браузерами на движке Chrome) (рис. 3.4)
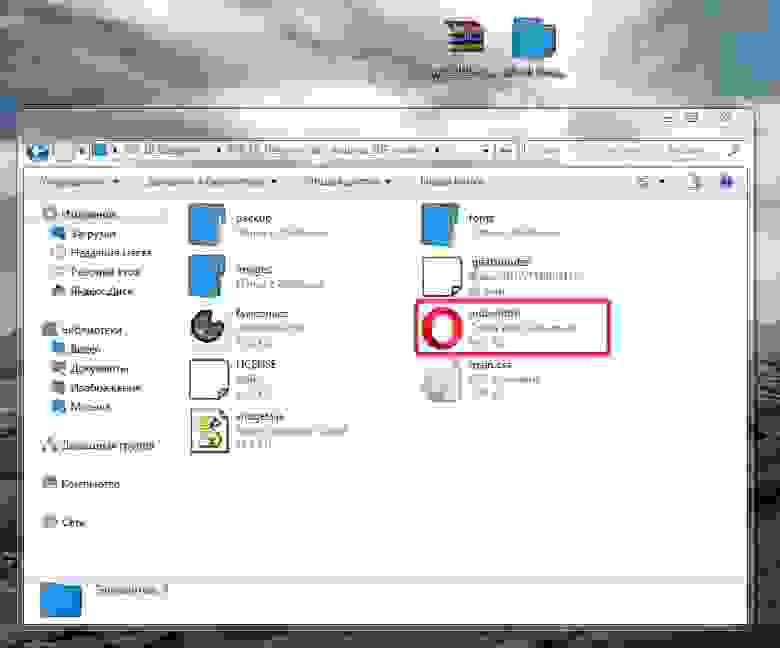
Рисунок 3.4
На этом установка инструмента завершена (рис. 3.5).

Рисунок 3.5. Знакомьтесь — M5 UI Designer
### Шаг 3. Клавиша Enter — особенная (⊙\_⊙)
Представьте себе такую ситуацию — пользователь ввёл необходимую информацию в тот же Inputbox и ему необходимо её обработать, например: отправить куда-нибудь. Как сообщить M5 что пользователь завершил ввод? Верно — нажатием на клавишу Enter (как один из вариантов).
В любом месте кода Вы всегда можете привязать пользовательскую функцию к клавише Enter, главное — чтобы сигнатура пользовательской функции была следующей void (String\*).
```
void userFunction1(String* rootVar) {
// reaction after pressing the Enter key
}
...
UIEnter = userFunction1;
```
### Шаг 4. Азбука морзе, Inputbox и Textbox (^\_^♪)
Давайте добавим первый наш элемент — Inputbox. В него мы будем вводить текст и после нажатия на клавишу Enter будем слышать из динамика код Морзе (рис. 4).
Рисунок 4. Код Морзе
Откройте M5 UI Designer, перетащите Inputbox и Textbox, задайте ширину и заголовки. В разделе Tools > User Functions нажмите на значок "жёлтая молния" и введите имя новой пользовательской функции Morse. Затем в разделе Properties > Enter key выберите Morse (рис. 4.1).
Рисунок 4.1.
Выделите весь текст из раздела Source и скопируйте в Arduino IDE.
```
/* User functions: */
void Morse(String* rootVar) {
int MorseCodes[] =
{
0,1,-1,-1, // A
1,0,0,0, // B
1,0,1,0, // C
1,0,0,-1, // D
0,-1,-1,-1, // E
0,0,1,0, //F
1,1,0,-1, // G
0,0,0,0, // H
0,0,-1,-1, // I
0,1,1,1, // J
1,0,1,-1, // K
0,1,0,0, // L
1,1,-1,-1, // M
1,0,-1,-1, // N
1,1,1,-1, // O
0,1,1,0, // P
1,1,0,1, // Q
0,1,0,-1, // R
0,0,0,-1, // S
1,-1,-1,-1, // T
0,0,1,-1, // U
0,0,0,1, // V
0,1,1,-1, // W
1,0,0,1, // X
1,0,1,1, // Y
1,1,0,0 // Z
};
for (int i = 0; i < UIInputbox_v05700a.length(); i++) {
char chr = UIInputbox_v05700a[i];
if (chr == ' ')
{
M5.Speaker.mute();
delay(350);
}
else
{
int chrNum = (chr - 'a') * 4;
for (int j = chrNum; j < (chrNum + 4); j++)
{
M5.Speaker.tone(440);
if (MorseCodes[j] == 0)
delay(50);
else if (MorseCodes[j] == 1)
delay(200);
M5.Speaker.mute();
delay(150);
}
}
}
}
```
Как видите — весь каркас кода сгенерированный M5 UI Designer остался абсолютно в стандартном виде без изменений. Единственное, что мы изменили — пользовательская функция Morse. Всё очень просто :) (рис. 4.2).

Рисунок 4.2
### Шаг 5. Bruteforce и Waitingbar ≧(◕ ‿‿ ◕)≦
Аналогичным образом добавим Waitingbar. Будем генерировать 8-битный случайный код, а затем его подбирать. Индикатором процесса будет как раз Waitingbar. После того, как код будет подобран Waitingbar будет скрыт. Запуск процесса будет происходить после нажатия на клавишу Enter (рис. 5).

Рисунок 5.
В этом примере мы несколько модифицируем функцию слоя default добавлением void UIDiable(bool, String\*) после перечисления элементов. Это необходимо для того, чтобы Waitingbar был скрыт на время бездействия.
```
/* Function for layer default: */
void LayerFunction_default(String* rootVar) {
/* UI Elements */
...
UIDisable(true, &UIWaitingbar_yksk2w8);
}
```
> **void UIDisable(bool, String\*)** или **void UISet(String\*, int)** используется для того, чтобы скрыть элемент. Где **bool** — может принимать значения **true**/**false** т.е. **скрыть**/**показать** элемент; **String\*** — указатель на rootVar (корневая переменная) элемента.
Теперь добавим содержимое функции void Brutforce(String\*):
```
/* User functions: */
void Brutforce(String* rootVar) {
/* make random original key */
uint8_t okey = random(0, 256);
String okeyString = "";
for (int i = 0; i < 8; i++) {
okeyString += String((okey >> i) & 1);
}
UISet(&UITextbox_sxjzx0g, okeyString); // set value for Textbox
UIDisable(false, &UIWaitingbar_yksk2w8); // show the Waitingbar
uint8_t key;
while (true) {
key++;
String keyString = String();
for (int i = 0; i < 8; i++) {
keyString += String((key >> i) & 1);
}
UISet(&UITextbox_eyar2x, keyString);
Serial.print(key);
Serial.print(" ");
Serial.println(okey);
if (key == okey) break;
M5.Speaker.tone(800);
delay(40);
M5.Speaker.mute();
}
UIDisable(true, &UIWaitingbar_yksk2w8);
M5.Speaker.tone(600);
delay(75);
M5.Speaker.mute();
M5.Speaker.tone(800);
delay(75);
M5.Speaker.mute();
M5.Speaker.tone(500);
delay(75);
M5.Speaker.mute();
}
```
> Для того, чтобы установить значение для элемента используют функцию **void UISet(String\*, String)** или **void UISet(String\*, int)**. Где **String\*** — указатель на rootVar (корневая переменная) элемента; **String** или **int** — новое значение.
Теперь запустим и посмотрим, что получилось (рис. 5.1).

Рисунок 5.1
### Шаг 6. BatteryCheck и Progressbar Σ(O\_O)
Давайте сделаем тестер заряда обычных пальчиковых батареек типа A, AA, AAA. Индикацию будем осуществлять с помощью Progressbar в процентном соотношении, а в дополнении внизу с помощью Textbox будем отображать напряжение в мВ (рис. 6).
Рисунок 6.
Здесь мы модифицируем функцию слоя
```
/* Function for layer default: */
void LayerFunction_default(String* rootVar) {
/* To open this layer use: */
...
// BattaryCheck
while (true) {
int voltage = analogRead(35) * 3400 / 4096;
int percentage = voltage * 100 / 1600;
UISet(&UIProgressbar_1mlmhcu, percentage);
UISet(&UITextbox_gtaetjh, voltage);
delay(500);
}
}
```
Постоянно, каждые 500 мс, в цикле будем снимать показания с АЦП порт 0 (контакт 35).
Затем будем рассчитывать напряжение: 3400 мВ — это опорное напряжение, 4096 — разрешающая способность АЦП. Схема включения приведена на рисунке 6.1.
> Обратите внимание — используется M5 Bottom вместо FACES
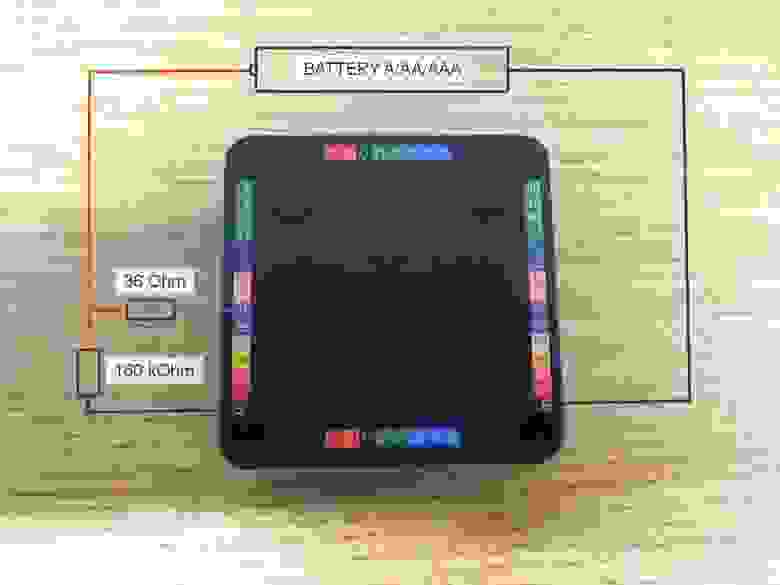
Рисунок 6.1. Наглядная схема включения встроенного АЦП к пальчиковой батарейке
Устройство работает здорово! Теперь у Вас есть отличный инструмент для проверки батареек (рис. 6.2).

Рисунок 6.2
### Шаг 7. LEDshift и Selectbox ( ◡‿◡ \*)
Возьмем четыре светодиода (оранжевый, зелёный, красный и жёлтый) подключим их через сдвиговый регистр 74HC595N к M5 по схеме на рисунке 7.

Рисунок 7. Схема подключения светодиодов к M5 с помощью сдвигового регистра
Создадим графический интерфейс с помощью M5 UI Designer, как в предыдущих примерах, и скопируем код (рис. 7.1).

Рисунок 7.1.
Теперь модифицируем код.
Добавим номера контактов на M5 для подключения сдвигового регистра 74HC595N после RootVar's:
```
/* RootVar's for UI elements (note: not edit manually) */
...
// Shift register pinout
int SH_CP = 17;
int ST_CP = 2;
int DS = 5;
```
Далее добавим содержимое функции void SelectColor(String\*):
```
/* User functions: */
void SelectColor(String* rootVar) {
int led = UIOptionValue(&UISelectbox_6foo6h).toInt();
digitalWrite(ST_CP, LOW);
shiftOut(DS, SH_CP, MSBFIRST, led);
digitalWrite(ST_CP, HIGH);
delay(100);
}
```
> Для того, чтобы получить **значение** выбранной опции из Selectbox используют функцию **String UIOptionValue(String\*)**.
Теперь необходимо наполнить Selectbox опциями. для этого добавим в самое начало функции слоя 5 строк кода:
```
/* Function for layer default: */
void LayerFunction_default(String* rootVar) {
// add options to Selectbox
UIOption("OFF", "0", &UISelectbox_6foo6h);
UIOption("RED", "17", &UISelectbox_6foo6h);
UIOption("YELLOW", "3", &UISelectbox_6foo6h);
UIOption("GREEN", "5", &UISelectbox_6foo6h);
UIOption("ORANGE", "9", &UISelectbox_6foo6h);
...
}
```
> Для того, чтобы добавить опцию в Selectbox используют функцию **void UIOption(String, String, String\*)**. Где первый **String** — подпись опции, которую видит пользователь; второй **String** — значение опции, которое скрыто от пользователя; **String\*** — указатель на rootVar (корневая переменная) элемента
В завершении добавим три строчки после приведенного ниже комментария. Таким образом мы настроим контакты M5 на вывод:
```
void setup() {
...
/* Prepare user's I/O. For example pinMode(5, OUTPUT); */
pinMode(SH_CP, OUTPUT);
pinMode(ST_CP, OUTPUT);
pinMode(DS, OUTPUT);
...
}
```
На этом всё! :) (рис. 7.2).

Рисунок 7.2
### Шаг 8. SmartDrill и команда из Rangebox, Checkbox, Button (´。• ᵕ •。`)
Что может объединить Rangebox, Checkbox и Button? Верно! — станок для сверления. Возьмём электродвигатель постоянного тока (например, от кассетного плеера), транзистор (чтоб по мощности подходил), резистор чтоб перекрывать ток базы, немного проводов, макетную плату и соберём! Бывает необходимо делать несколько отверстий одно за одним, а бывает необходимо сделать всего одно, поэтому возникает идея выделять некоторое время на работу дрели, а потом отключать её автоматически: тут нам на помощь приходит Checkbox.

Рисунок 8
С помощью Rangebox будем регулировать напряжение питания на электродвигателе. Кнопкой будем запускать и останавливать процесс (рис. 8). Обратите внимание — кнопка с иконкой ;)
Кнопка Enter здесь нам не пригодится, поэтому Enter key для всех элементов останется пустым (нулем).
Взамен мы будем вызывать пользовательскую функцию Drill с помощью свойства Callback для кнопки.
Что у нас по коду? После RootVar's добавим bool startStatus, которая позволит программе понимать запущен ли двигатель или нет.
```
/* RootVar's for UI elements (note: not edit manually) */
...
// User's variables
bool startStatus = false;
```
Наполним пользовательскую функцию void Drill(String\*):
```
void Drill(String* rootVar) {
startStatus = (startStatus) ? false : true;
if (startStatus)
{
int power = UIRangebox_ztj619h.toInt() * 255 / 100;
dac_out_voltage(DAC_CHANNEL_1, power);
if (UICheckbox_1n9gs0b == "true")
{
UICaption("WAIT", &UIButton_enhu9fc);
delay(25000);
Drill(0);
return;
}
UICaption("STOP", &UIButton_enhu9fc);
}
else
{
dac_out_voltage(DAC_CHANNEL_1, 0);
UICaption("START", &UIButton_enhu9fc);
}
}
```
> Для того, чтобы установить значение на аналоговом порту используют функцию **dac\_out\_voltage(DAC\_CHANNEL\_1, int)**. Где **DAC\_CHANNEL\_1** — номер канала (контакт 25), **int** — значение
;
> Для того, чтобы изменить заголовок любого из UI-элементов используют функцию UICaption(String, String*). Где **String** — новый заголовок; **String\*** — указатель на rootVar (корневая переменная) элемента
Ура! Теперь можно пробовать сверлить (рис. 8.1).

Рисунок 8.1
### Шаг 9. Запуск!
В разделе **"Ссылки"** прилагаются видео с демонстрацией работы. На этом урок завершён.
Ссылки \ Downloads
------------------
* Узнать больше про M5Stack [тут](http://ru.m5stack.com/)
* M5 UI for Arduino IDE (GitHub): [https://github.com/dsiberia9s/M5\_UI](https://github.com/dsiberia9s/M5_UI "https://github.com/dsiberia9s/M5_UI")
* M5 UI Designer for Arduino IDE (GitHub): [https://github.com/dsiberia9s/M5\_UI\_Designer\_for\_Arduino\_IDE](https://github.com/dsiberia9s/M5_UI_Designer_for_Arduino_IDE "https://github.com/dsiberia9s/M5_UI_Designer_for_Arduino_IDE")
* Видео с демонстрацией работы "Morse" (YouTube): [https://youtu.be/ZYIfTDb\_r80](https://youtu.be/ZYIfTDb_r80 "https://youtu.be/ZYIfTDb_r80")
* Видео с демонстрацией работы "Bruteforce" (YouTube): [https://youtu.be/IfZaFtWYyFA](https://youtu.be/IfZaFtWYyFA "https://youtu.be/IfZaFtWYyFA")
* Видео с демонстрацией работы "BatteryCheck" (YouTube): [https://youtu.be/TgceYjgONd8](https://youtu.be/TgceYjgONd8 "https://youtu.be/TgceYjgONd8")
* Видео с демонстрацией работы "LEDshift" (YouTube): [https://youtu.be/vDMsIPcURgc](https://youtu.be/vDMsIPcURgc "https://youtu.be/vDMsIPcURgc")
* Видео с демонстрацией работы "SmartDrill" (YouTube): [https://youtu.be/uDhNmWwTD4Q](https://youtu.be/uDhNmWwTD4Q "https://youtu.be/uDhNmWwTD4Q") | https://habr.com/ru/post/492458/ | null | ru | null |
# Audio API Quick Start Guide: Playing and Recording Sound on Linux, Windows, FreeBSD and macOS
Hearing is one of the few basic senses that we humans have along with the other our abilities to see, smell, taste and touch. If we couldn't hear, the world as we know it would be less interesting and colorful to us. It would be a total silence - a scary thing, even to imagine. And speaking makes our life so much fun, because what else can be better than talking to our friends and family? Also, we're able to listen to our favorite music wherever we are, thanks to computers and headphones. With the help of tiny microphones integrated into our phones and laptops we are now able to talk to the people around the world from any place with an Internet connection. But computer hardware alone isn't enough - it is computer software that really defines the way how and when the hardware should operate. Operating Systems provide the means for that to the apps that want to use computer's audio capabilities. In real use-cases audio data usually goes the long way from one end to another, being transformed and (un)compressed on-the-fly, attenuated, filtered, and so on. But in the end it all comes down to just 2 basic processes: playing the sound or recording it.
Today we're going to discuss how to make use of the API that popular OS provide: this is an essential knowledge if you want to create an app yourself which works with audio I/O. But there's just one problem standing on our way: there is no single API that all OS support. In fact, there are completely different API, different approaches, slightly different logic. We could just use some library which solves all those problems for us, but in that case we won't understand what's really going on under the hood - what's the point? But humans are built the way that we sometimes want to dig a little bit deeper, to learn a little bit more than what just lies on the surface. That's why we're going to learn the API that OS provide by default: **ALSA (Linux), PulseAudio (Linux), WASAPI (Windows), OSS (FreeBSD), CoreAudio (macOS)**.
Although I try to explain every detail that I think is important, these API are so complex that in any case you need to find the official documentation which explains all functions, identificators, parameters, etc, in much more detail. Going through this tutorial doesn't mean you don't need to read official docs - you have to, or you'll end up with an incomplete understanding of the code you write.
All sample code for this guide is available here: <https://github.com/stsaz/audio-api-quick-start-guide>. I recommend that while reading this tutorial you should have an example file opened in front of you so that you better understand the purpose of each code statement in global context. When you're ready for slightly more advanced usage of audio API, you can analyze the code of ffaudio library: <https://github.com/stsaz/ffaudio>.
Contents:
* [Overview](#overview)
* [Audio Data Representation](#audio-data-representation)
* [Linux and ALSA](#linux-and-alsa)
+ [ALSA: Enumerating Devices](#alsa-enumerating-devices)
+ [ALSA: Opening Audio Buffer](#alsa-opening-audio-buffer)
+ [ALSA: Recording Audio](#alsa-recording-audio)
+ [ALSA: Playing Audio](#alsa-playing-audio)
+ [ALSA: Draining](#alsa-draining)
+ [ALSA: Error Checking](#alsa-error-checking)
* [Linux and PulseAudio](#linux-and-pulseaudio)
+ [PulseAudio: Enumerating Devices](#pulseaudio-enumerating-devices)
+ [PulseAudio: Opening Audio Buffer](#pulseaudio-opening-audio-buffer)
+ [PulseAudio: Recording Audio](#pulseaudio-recording-audio)
+ [PulseAudio: Playing Audio](#pulseaudio-playing-audio)
+ [PulseAudio: Draining](#pulseaudio-draining)
* [Windows and WASAPI](#windows-and-wasapi)
+ [WASAPI: Enumerating Devices](#wasapi-enumerating-devices)
+ [WASAPI: Opening Audio Buffer in Shared Mode](#wasapi-opening-audio-buffer-in-shared-mode)
+ [WASAPI: Recording Audio in Shared Mode](#wasapi-recording-audio-in-shared-mode)
+ [WASAPI: Playing Audio in Shared Mode](#wasapi-playing-audio-in-shared-mode)
+ [WASAPI: Draining in Shared Mode](#wasapi-draining-in-shared-mode)
+ [WASAPI: Error Reporting](#wasapi-error-reporting)
* [FreeBSD and OSS](#freebsd-and-oss)
+ [OSS: Enumerating Devices](#oss-enumerating-devices)
+ [OSS: Opening Audio Buffer](#oss-opening-audio-buffer)
+ [OSS: Recording Audio](#oss-recording-audio)
+ [OSS: Playing Audio](#oss-playing-audio)
+ [OSS: Draining](#oss-draining)
+ [OSS: Error Reporting](#oss-error-reporting)
* [macOS and CoreAudio](#macos-and-coreaudio)
+ [CoreAudio: Enumerating Devices](#coreaudio-enumerating-devices)
+ [CoreAudio: Opening Audio Buffer](#coreaudio-opening-audio-buffer)
+ [CoreAudio: Recording Audio](#coreaudio-recording-audio)
+ [CoreAudio: Playing Audio](#coreaudio-playing-audio)
+ [CoreAudio: Draining](#coreaudio-draining)
* [Final Results](#final-results)
### Overview
First, I'm gonna describe how to work with audio devices in general, without any API specifics.
Step 1. It all starts with **enumerating the available audio devices**. There are 2 types of devices OS have: a playback device, in which we write audio data, or a capture device, from which we read audio data. Every device has its own unique ID, name and other properties. Every app can access this data to select the best device for its need or to show all devices to its user so he can select the one he likes manually. However, most of the time we don't need to select a specific device, but rather just use the default device. In this case we don't need to enumerate devices and we won't even need to retrieve any properties.
Note that there can be a registered device in the system but unavailable, for example when the user disabled it in system settings. If we perform all necessary error checks when writing our code, we won't normally see any disabled devices.
Sometimes we can retrieve the list of all supported audio formats for a particular device, but I wouldn't rely on this info very much - it's not cross-platform, after all. Instead, it's better to try to assign an audio buffer to this device and see if the audio format is supported for sure.
Step 2. After we have determined what device we want to use, we continue with **creating an audio buffer and assigning it to device**. At this point we must know the audio format we'd like to use: sample format (e.g. signed integer), sample width (e.g. 16 bit), sample rate (e.g. 48000 Hz) and the number of channels (e.g. 2 for stereo).
**Sample format** is either signed integer, unsigned integer or a floating point number. Some audio drivers support all integers and floats, while some may support just 16-bit signed integers and nothing else. This doesn't always mean that the device works with them natively - it's possible that audio device software converts samples internally.
**Sample width** is the size of each sample, 16 bit is the standard for CD Audio quality, but it's not the best choice for audio processing use-cases because it can easily produce artifacts (although, it's unlikely that we can really tell the difference). 24 bit is much better and it's supported by many audio devices. But nevertheless, the professional sound apps don't give any chance to sound artifacts: they use 64-bit float samples internally when performing mixing operations and other types of filtering.
**Sample rate** is the number of samples necessary to get 1 whole second of audio data. The most popular rates are 44.1KHz and 48KHz, but audiophiles may argue that 96KHz sample rate is the best. Usually, audio devices can work with rates up to 192KHz, but I really don't believe that anybody can hear any difference between 48KHz and higher values. Note that sample rate is the number of samples per second **for one channel only**. So in fact for 16bit 48KHz stereo stream the number of bytes we have to process is `2 * 48000 * 2`.
```
0 sec 1 sec
| (Sample 0) ... (Sample 47999) |
| short[L] ... short[L] |
| short[R] ... short[R] |
```
Sometimes samples are called *frames*, similar to video frames. An **audio sample/frame** is a stack of numerical values which together form the audio signal strength for each hardware device channel for the same point in time. Note, however, that some official docs don't agree with me on this: they specifically define that a sample is just 1 numerical value, while the frame is a set of those values for all channels. Why don't they call *sample rate* a *frame rate* then? Please take a look at the diagram above once again. There, the sample width (column width) is still 16bit, no matter how many channels (rows below) we have. Sample format (which is a signed integer in our case) always stays the same too. Sample rate is the number of columns for 1 second of audio, no matter how many channels we have. Therefore, my own logic tells me the definition of an audio sample to me (no matter how others may define it), but your logic may be different - that's totally fine.
**Sample size** (or frame size) is another property that you will often use while working with digital audio. This is just a constant value to conveniently convert the number of bytes to the number of audio samples and vice versa:
```
int sample_size = sample_width/8 * channels;
int bytes_in_buffer = samples_in_buffer * sample_size;
```
Of course, we can also set more parameters for our audio buffer, such as the **length of our buffer** (in milliseconds or in bytes) which is the main property for controlling sound latency. But keep in mind that every device has its own limits for this parameter: we can't set the length too low when device just doesn't support it. I think that 250ms is a fine starting point for most applications, but some real-time apps require the minimum possible latency at the cost of higher CPU usage - it all depends on your particular use-case.
When opening an audio device we should always be ready if the API we use returns with a "bad format" error which means that the audio format we chose isn't supported by the underlying software or by physical device itself. In this case we should select a more suitable format and recreate the buffer.
Note that one physical device can be opened **only once**, we can't attach 2 or more audio buffers to the same device - what a mess it would be otherwise, right? But in this case we need to solve a problem with having multiple audio apps that want to play some audio in parallel via the single device. Windows solves this problem in WASAPI by introducing 2 different modes: shared and exclusive. In shared mode we attach our audio buffers to a virtual device, which mixes all streams from different apps together, applies some filtering such as sound attenuation and then passes the data to a physical device. And PulseAudio on Linux works the same way on top of ALSA. Of course, the downside is that the shared mode has to have a higher latency and a higher CPU usage. On the other hand, in exclusive mode we have almost direct connection to audio device driver meaning that we can achieve the maximum sound quality and minimum latency, but no other app will be able to use this device while we're using it.
Step 3. After we have prepared and configured an audio buffer, we can start using it: writing data to it for playback or reading data from it to record audio. Audio buffer is in fact a circular buffer, where reading and writing operations are performed infinitely in circle.
But there is one problem: CPU must be in synchronization with the audio device when performing I/O on the same memory buffer. If not, CPU will work at its full speed and run over the audio buffer some million times while the audio device only finishes its first turn. Therefore, CPU must always wait for the audio device to slowly do its work. Then, after some time, CPU wakes up for a short time period to get some more audio data from the device (when recording) or to feed some more data to the device (in playback mode), and then CPU should continue sleeping. Note that this is where the audio buffer length parameter comes into play: the less the buffer size - the more times CPU must wake up to perform its work. A circular buffer can be in 3 different states: empty, half-full and full. And we need to understand how to properly handle all those states in our code.
**Empty buffer while recording** means that there are no audio samples available to us at the moment. We must wait until audio device puts something new into it.
**Empty buffer while playing** means that we are free to write audio data into the buffer at any time. However, if the audio device is running and it comes to this point when there's no more data available for it to read, it means that we have failed to keep up with it, this situation is called *buffer underrun*. If we are in this state, we should pause the device, fill the audio buffer and then resume the normal operation.
**Half-full buffer while recording** means that there are some audio samples inside the buffer, but it's not yet completely full. We should process the available data as soon as we can and mark this data region as read (or useless) so that the next time we won't see this data as available.
**Half-full buffer for playback** streams means that we can put some more data into it.
**Full buffer for recording** streams means that we are falling behind the audio device to read the available data. Audio device has filled the buffer completely and there's no more room for new data. This state is called *buffer overrun*. In this case we must reset the buffer and resume (unpause) the device to continue normally.
**Full buffer for playback** streams is a normal situation and we should just wait until some free space is available.
A few words about how the waiting process is performed. Some API provide the means for us to subscribe to notifications to achieve I/O with the least possible latency. For example, ALSA can send `SIGIO` signal to our process after it has written some data into audio recording buffer. WASAPI in exclusive mode can notify us via a Windows kernel event object. However, for apps that don't require so much accuracy we can simply use our own timers, or we can just block our process with functions like `usleep/Sleep`. When using these methods we just have to make sure that we sleep not more than half of our audio buffer length, .e.g. for 500ms buffer we may set the timer to 250ms and perform I/O 2 times per each buffer rotation. Of course you understand that we can't do it reliably for very small buffers, because even a slight delay can cause audio stutter. Anyway, in this tutorial we don't need high accuracy, but we need small code that is easier to understand.
Step 4. For playback buffers there's one more thing. After we have completed writing all our data into audio buffer, we must still wait for it to process the data. In other words, we should **drain the buffer**. Sometimes we should manually add silence to the buffer, otherwise it could play a chunk of some old invalid data, resulting in audio artifacts. Then, after we see that the whole buffer has become empty, we can stop the device and close the buffer.
Also, keep in mind that during the normal operation these problems may arise:
* The physical audio device can be switched off by user and become unavailable for us.
* The virtual audio device could be reconfigured by user and require us to reopen and reconfigure audio buffers.
* CPU was too busy performing some other operations (for another app or system service) resulting in buffer overrun/underrun condition.
Careful programmer must always check for all possible scenarios, **check all return codes from API functions** that we call and handle them or show an error message to user. I don't do it in my sample code just because this tutorial is for you to understand an audio API. And this purpose is fulfilled with the shortest possible code for you to read - error checking everywhere will make the things worse in this case.
Of course, after we are done, we must **close the handlers to audio buffers and devices**, free allocated memory regions. But we don't wanna do that in case we just want to play another audio file, for example. Preparing a new audio buffer can take a lot of time, so always try to reuse it when you can.
### Audio Data Representation
Now let's talk about how audio data is actually organized and how to analyze it. There are 2 types of audio buffers: interleaved and non-interleaved. **Interleaved buffer** is a single contiguous memory region where the sets of audio samples go one by one. This is how it looks like for 16bit stereo audio:
```
short[0][L]
short[0][R]
short[1][L]
short[1][R]
...
```
Here, 0 and 1 are the sample indexes, and L and R are the channels. For example, how we can read the values for both channels for sample #9 is we take the sample index and multiply it by the number of channels:
```
short *samples = (short*)buffer;
short sample_9_left = samples[9*2];
short sample_9_right = samples[9*2 + 1];
```
These 16-bit signed values are the signal strength where 0 is silence. But the signal strength is usually measured in dB values. Here's how we can convert our integer values to dB:
```
short sample = ...;
double gain = (double)sample * (1 / 32768.0);
double db = log10(gain) * 20;
```
Here we first convert integer to a float number - this is gain value where 0.0 is silence and +/-1.0 - max signal. Then, using `gain = 10 ^ (db / 20)` formula we convert the gain into dB value. If we want to do an opposite conversion, we may use this code:
```
#include // SSE2 functions. All AMD64 CPU support them.
double db = ...;
double gain = pow(10, db / 20);
double d = gain \* 32768.0;
short sample;
if (d < -32768.0)
sample = -0x8000;
else if (d > 32768.0 - 1)
sample = 0x7fff;
else
sample = \_mm\_cvtsd\_si32(\_mm\_load\_sd(&d));
```
*I'm not an expert in audio math, I'm just showing you how I do it, but you may find a better solution.*
The most popular audio codecs and the most audio API use interleaved audio data format.
**Non-interleaved** buffer is an array of (potentially) different memory regions, one for each channel:
```
L -> {
short[0][L]
short[1][L]
...
}
R -> {
short[0][R]
short[1][R]
...
}
```
For example, the mainstream Vorbis and FLAC audio codecs use this format. As you can see, it's very easy to operate on samples within a single channel in non-interleaved buffers. For example, swapping left and right channels would take just a couple of CPU cycles to swap the pointers.
I think we've had enough theory and we're ready for some real code with a real audio API.
### Linux and ALSA
ALSA is Linux's default audio subsystem, so let's start with it. ALSA consists of 2 parts: audio drivers that live inside the kernel and user API which provides universal access to the drivers. We're going to learn user mode ALSA API - it's the lowest level for accessing sound hardware in user mode.
First, we must install development package, which is `libalsa-devel` for Fedora. Now we can include it in our code:
```
#include
```
And when linking our binaries we add `-lalsa` flag.
#### ALSA: Enumerating Devices
First, iterate over all sound cards available in the system, until we get a -1 index:
```
int icard = -1;
for (;;) {
snd_card_next(&icard);
if (icard == -1)
break;
...
}
```
For each sound card index we prepare a NULL-terminated string, e.g. `hw:0`, which is a unique ID of this sound card. We receive the sound card handler from `snd_ctl_open()`, which we later close with `snd_ctl_close()`.
```
char scard[32];
snprintf(scard, sizeof(scard), "hw:%u", icard);
snd_ctl_t *sctl = NULL;
snd_ctl_open(&sctl, scard, 0);
...
snd_ctl_close(sctl);
```
For each sound card we walk through all its devices until we get -1 index:
```
int idev = -1;
for (;;) {
if (0 != snd_ctl_pcm_next_device(sctl, &idev)
|| idev == -1)
break;
...
}
```
Now prepare a NULL-terminated string, e.g. `plughw:0,0`, which is the device ID we can later use when assigning an audio buffer. `plughw:` prefix means that ALSA will try to apply some audio conversion when necessary. If we want to use hardware device directly, we should use `hw:` prefix instead. For default device we may use `plughw:0,0` string, but in theory it can be unavailable - you should provide a way for the user to select a specific device.
```
char device_id[64];
snprintf(device_id, sizeof(device_id), "plughw:%u,%u", icard, idev);
```
#### ALSA: Opening Audio Buffer
Now that we know the device ID, we can assign a new audio buffer to it with `snd_pcm_open()`. Note that we won't be able to open the same ALSA device twice. And if this device is used by system PulseAudio process, no other app in the system will be able to use audio while we're holding it.
```
snd_pcm_t *pcm;
const char *device_id = "plughw:0,0";
int mode = (playback) ? SND_PCM_STREAM_PLAYBACK : SND_PCM_STREAM_CAPTURE;
snd_pcm_open(&pcm, device_id, mode, 0);
...
snd_pcm_close(pcm);
```
Next, set the parameters for our buffer. Here we tell ALSA that we want to use mmap-style functions to get direct access to its buffers and that we want an interleaved buffer. Then, we set audio format and the buffer length. Note that ALSA updates some values for us if the values we supplied are not supported by device. However, if sample format isn't supported, we have to find the right value manually by probing with `snd_pcm_hw_params_get_format_mask()/snd_pcm_format_mask_test()`. In real life you should check if your higher-level code supports this new configuration.
```
snd_pcm_hw_params_t *params;
snd_pcm_hw_params_alloca(¶ms);
snd_pcm_hw_params_any(pcm, params);
int access = SND_PCM_ACCESS_MMAP_INTERLEAVED;
snd_pcm_hw_params_set_access(pcm, params, access);
int format = SND_PCM_FORMAT_S16_LE;
snd_pcm_hw_params_set_format(pcm, params, format);
u_int channels = 2;
snd_pcm_hw_params_set_channels_near(pcm, params, &channels);
u_int sample_rate = 48000;
snd_pcm_hw_params_set_rate_near(pcm, params, &sample_rate, 0);
u_int buffer_length_usec = 500 * 1000;
snd_pcm_hw_params_set_buffer_time_near(pcm, params, &buffer_length_usec, NULL);
snd_pcm_hw_params(pcm, params);
```
Finally, we need to remember the frame size and the whole buffer size (in bytes).
```
int frame_size = (16/8) * channels;
int buf_size = sample_rate * (16/8) * channels * buffer_length_usec / 1000000;
```
#### ALSA: Recording Audio
To start recording we call `snd_pcm_start()`:
```
snd_pcm_start(pcm);
```
During normal operation we ask ALSA for some new audio data with `snd_pcm_mmap_begin()` which returns the buffer, offset to the valid region and the number of valid frames. For this function to work correctly we should first call `snd_pcm_avail_update()` which updates the buffer's internal pointers. After we have processed the data, we must dispose of it with `snd_pcm_mmap_commit()`.
```
for (;;) {
snd_pcm_avail_update(pcm);
const snd_pcm_channel_area_t *areas;
snd_pcm_uframes_t off;
snd_pcm_uframes_t frames = buf_size / frame_size;
snd_pcm_mmap_begin(pcm, &areas, &off, &frames);
...
snd_pcm_mmap_commit(pcm, off, frames);
}
```
When we get 0 frames available, it means that the buffer is empty. Start the recording stream if necessary, then wait for some more data. I use 100ms interval, but actually it should be computed using the real buffer size.
```
if (frames == 0) {
int period_ms = 100;
usleep(period_ms*1000);
continue;
}
```
After we've got some data, we get the pointer to the actual interleaved data and the number of available bytes in this region:
```
const void *data = (char*)areas[0].addr + off * areas[0].step/8;
int n = frames * frame_size;
```
#### ALSA: Playing Audio
Writing audio is almost the same as reading it. We get the buffer region by `snd_pcm_mmap_begin()`, copy our data to it and then mark it as complete with `snd_pcm_mmap_commit()`. When the buffer is full, we receive 0 available free frames. In this case we start the playback stream for the first time and start waiting until some free space is available in the buffer.
```
if (frames == 0) {
if (SND_PCM_STATE_RUNNING != snd_pcm_state(pcm))
snd_pcm_start(pcm);
int period_ms = 100;
usleep(period_ms*1000);
continue;
}
```
#### ALSA: Draining
To drain playback buffer we don't need to do anything special. First, we check whether there is still some data in buffer and if so, wait until the buffer is completely empty.
```
for (;;) {
if (0 >= snd_pcm_avail_update(pcm))
break;
if (SND_PCM_STATE_RUNNING != snd_pcm_state(pcm))
snd_pcm_start(pcm);
int period_ms = 100;
usleep(period_ms*1000);
}
```
But why do we always check the state of our buffer and then call `snd_pcm_start()` if necessary? It's because ALSA never starts streaming automatically. We need to start it initially after the buffer is full, and we need to start it every time an error such as buffer overrun occurs. We also need to start it in case we haven't filled the buffer completely.
#### ALSA: Error Checking
Most of the ALSA functions we use here return integer result codes. They return 0 on success and non-zero error code on failure. To translate an error code to a user-friendly error message we can use `snd_strerror()` function. I also recommend storing the name of the function that returned with an error so that the user has complete information about what went wrong exactly.
But there's more. During normal operation while recording or playing audio we should handle buffer overrun/underrun cases. Here's how to do it. First, check if the error code is `-EPIPE`. Then, call `snd_pcm_prepare()` to reset the buffer. If it fails, then we can't continue normal operation, it's a fatal error. If it completes successfully, we continue normal operation as if there was no buffer overrun. Why can't ALSA just handle this case internally? To give us more control over our program. For example, some app in this case must notify the user that an audio data chunk was lost.
```
if (err == -EPIPE)
assert(0 == snd_pcm_prepare(pcm));
```
Next case when we need special error handling is after we have called `snd_pcm_mmap_commit()` function. The problem is that even if it returns some data and not an error code, we still need to check whether *all* data is processed. If not, we set `-EPIPE` error code ourselves and we can then handle it with the same code as shown above.
```
err = snd_pcm_mmap_commit(pcm, off, frames);
if (err >= 0 && (snd_pcm_uframes_t)err != frames)
err = -EPIPE;
```
Next, the functions may return `-ESTRPIPE` error code which means that for some reason the device we're currently using has been temporarily stopped or paused. If it happens, we should wait until the device comes online again, periodically checking its state with `snd_pcm_resume()`. And then we call `snd_pcm_prepare()` to reset the buffer and continue as usual.
```
if (err == -ESTRPIPE) {
while (-EAGAIN == snd_pcm_resume(pcm)) {
int period_ms = 100;
usleep(period_ms*1000);
}
snd_pcm_prepare(pcm);
}
```
Don't forget that after handling those errors we need to call `snd_pcm_start()` to start the buffer. For recording streams we do it immediately, and for playback streams we do it when the buffer is full.
### Linux and PulseAudio
PulseAudio works on top of ALSA, it can't substitute ALSA - it's just an audio layer with several useful features for graphical multi-app environment, e.g. sound mixing, conversion, rerouting, playing audio notifications. Therefore, unlike ALSA, PulseAudio can share a single audio device between multiple apps - I think this is the main reason why it's useful.
> Note that on Fedora PulseAudio is not the default audio layer anymore, it's replaced with PipeWire with yet another audio API (though PulseAudio apps will continue to work via the PipeWire-PulseAudio layer). But until PipeWire isn't the default choice on other popular Linux distributions, PulseAudio is more useful overall.
>
>
First, we must install development package, which is `libpulse-devel` for Fedora. Now we can include it in our code:
```
#include
```
And when linking our binaries we add `-lpulse` flag.
A couple words about how PulseAudio is different from others. PulseAudio has a client-server design which means we don't operate on an audio device directly but just issue commands to PulseAudio server and receive the response from it. Thus, we always start with **connecting to PulseAudio server**. We have to implement somewhat complex logic to do it, because the interaction between us and the server is asynchronous: we have to send a command to server and then wait for it to process our command and receive the result, all via a socket (UNIX) connection. Of course, this communication takes some time, and we can do some other stuff while waiting for the server's response. But with our sample code here we won't be that clever: we will just wait for responses synchronously which is easier to understand.
We begin by **creating a separate thread** which will process socket I/O operations for us. Don't forget to stop this thread and close its handlers after we're done with PulseAudio.
```
pa_threaded_mainloop *mloop = pa_threaded_mainloop_new();
pa_threaded_mainloop_start(mloop);
...
pa_threaded_mainloop_stop(mloop);
pa_threaded_mainloop_free(mloop);
```
The first thing to remember when using PulseAudio is that we must **perform all operations while holding the internal lock** for this I/O thread. "Lock the thread", perform necessary calls to PA objects, and then "unlock the thread". Failing to properly lock the thread may at any point result in race condition. This **lock is recursive**, meaning that it's safe to lock it several time from the same thread. Just call the unlocking function the same number of times. However, I don't see how the lock recursiveness is useful in real life. Recursive locks usually mean that we have a bad architecture and they can cause difficult to find problems - I never advise to use this feature.
```
pa_threaded_mainloop_lock(mloop);
...
pa_threaded_mainloop_unlock(mloop);
```
Now begin connection to PA server. Note that `pa_context_connect()` function usually returns immediately even if the connection isn't yet established. We'll receive the result of connection later in a callback function we set via `pa_context_set_state_callback()`. Don't forget to disconnect from the server when we're done.
```
pa_mainloop_api *mlapi = pa_threaded_mainloop_get_api(mloop);
pa_context *ctx = pa_context_new_with_proplist(mlapi, "My App", NULL);
void *udata = NULL;
pa_context_set_state_callback(ctx, on_state_change, udata);
pa_context_connect(ctx, NULL, 0, NULL);
...
pa_context_disconnect(ctx);
pa_context_unref(ctx);
```
After we've issued the connection command we have nothing more to do except waiting for the result. We ask for the connection status, and if it's not yet ready, we call `pa_threaded_mainloop_wait()` which blocks our thread until a signal is received.
```
while (PA_CONTEXT_READY != pa_context_get_state(ctx)) {
pa_threaded_mainloop_wait(mloop);
}
```
And here's how our on-state-change callback function looks like. Nothing clever: we just signal the our thread to exit from `pa_threaded_mainloop_wait()` where we're currently hanging. Note that this function is called not from our own thread (it still keeps hanging), but from the I/O thread we started previously with `pa_threaded_mainloop_start()`. As a general rule, try to keep the code in these callback functions as small as possible. Your function is called, you receive the result and send a signal to your thread - that should be enough.
```
void on_state_change(pa_context *c, void *userdata)
{
pa_threaded_mainloop_signal(mloop, 0);
}
```
I hope this call-stack diagram makes this PA server connection logic a little bit clearer for you:
```
[Our Thread]
|- pa_threaded_mainloop_start()
| [PA I/O Thread]
|- pa_context_connect() |
|- pa_threaded_mainloop_wait() |
| |- on_state_change()
| |- pa_threaded_mainloop_signal()
[pa_threaded_mainloop_wait() returns]
```
The same logic applies to handling all operations results with our callback functions.
#### PulseAudio: Enumerating Devices
After the connection to PA server is established, we proceed by listing the available devices. We create a new operation with a callback function. We can also pass some pointer to our callback function, but I just use `NULL` value. Don't forget to release the pointer after the operation is complete. And of course, this code should be executed only while holding the mainloop thread lock.
```
pa_operation *op;
void *udata = NULL;
if (playback)
op = pa_context_get_sink_info_list(ctx, on_dev_sink, udata);
else
op = pa_context_get_source_info_list(ctx, on_dev_source, udata);
...
pa_operation_unref(op);
```
Now wait until the operation is complete.
```
for (;;) {
int r = pa_operation_get_state(op);
if (r == PA_OPERATION_DONE || r == PA_OPERATION_CANCELLED)
break;
pa_threaded_mainloop_wait(mloop);
}
```
While we're at it, the I/O thread is receiving data from server and performs several successful calls to our callback function where we can access all properties for each available device. When an error occurrs or when there are no more devices, `eol` parameter is set to a non-zero value. When this happens we just send the signal to our thread. The function for listing playback devices looks this way:
```
void on_dev_sink(pa_context *c, const pa_sink_info *info, int eol, void *udata)
{
if (eol != 0) {
pa_threaded_mainloop_signal(mloop, 0);
return;
}
const char *device_id = info->name;
}
```
And the function for listing recording devices looks similar:
```
void on_dev_source(pa_context *c, const pa_source_info *info, int eol, void *udata)
```
The value of `udata` is the value we set while calling `pa_context_get_*_info_list()`. In our code they always `NULL` because my `mloop` variable is global and we don't need anything else.
#### PulseAudio: Opening Audio Buffer
We create a new audio buffer with `pa_stream_new()` passing our connection context to it, the name of our application and the sound format we want to use.
```
pa_sample_spec spec;
spec.format = PA_SAMPLE_S16LE;
spec.rate = 48000;
spec.channels = 2;
pa_stream *stm = pa_stream_new(ctx, "My App", &spec, NULL);
...
pa_stream_unref(stm);
```
Next, we attach our buffer to device with `pa_stream_connect_*()`. We set buffer length in `pa_buffer_attr::tlength` in bytes, and we leave all other parameters as default (setting them to -1). We also assign with `pa_stream_set_*_callback()` our callback function which will be called every time audio I/O is complete. We can use `device_id` value we obtained while enumerating devices or we can use `NULL` for default device.
```
pa_buffer_attr attr;
memset(&attr, 0xff, sizeof(attr));
int buffer_length_msec = 500;
attr.tlength = spec.rate * 16/8 * spec.channels * buffer_length_msec / 1000;
```
For recording streams we do:
```
void *udata = NULL;
pa_stream_set_read_callback(stm, on_io_complete, udata);
const char *device_id = ...;
pa_stream_connect_record(stm, device_id, &attr, 0);
...
pa_stream_disconnect(stm);
```
And for playback streams:
```
void *udata = NULL;
pa_stream_set_write_callback(stm, on_io_complete, udata);
const char *device_id = ...;
pa_stream_connect_playback(stm, device_id, &attr, 0, NULL, NULL);
...
pa_stream_disconnect(stm);
```
As usual, we have to wait until our operation is complete. We read the current state of our buffer with `pa_stream_get_state()`. `PA_STREAM_READY` means that recording is started successfully and we can proceed with normal operation. `PA_STREAM_FAILED` means an error occurred.
```
for (;;) {
int r = pa_stream_get_state(stm);
if (r == PA_STREAM_READY)
break;
else if (r == PA_STREAM_FAILED)
error
pa_threaded_mainloop_wait(mloop);
}
```
While we're hanging inside `pa_threaded_mainloop_wait()` our callback function `on_io_complete()` will be called at some point inside I/O thread. Now we just send a signal to our main thread.
```
void on_io_complete(pa_stream *s, size_t nbytes, void *udata)
{
pa_threaded_mainloop_signal(mloop, 0);
}
```
#### PulseAudio: Recording Audio
We obtain the data region with audio samples from PulseAudio with `pa_stream_peek()` and after we have processed it, we discard this data with `pa_stream_drop()`.
```
for (;;) {
const void *data;
size_t n;
pa_stream_peek(stm, &data, &n);
if (n == 0) {
// Buffer is empty. Process more events
pa_threaded_mainloop_wait(mloop);
continue;
} else if (data == NULL && n != 0) {
// Buffer overrun occurred
} else {
...
}
pa_stream_drop(stm);
}
```
`pa_stream_peek()` returns 0 samples when buffer is empty. In this case we don't need to call `pa_stream_drop()` and we should wait until more data arrives. When buffer overrun occurs we have `data=NULL`. This is just a notification to us and we can proceed by calling `pa_stream_drop()` and then `pa_stream_peek()` again.
#### PulseAudio: Playing Audio
When we write data to an audio device, we first must get the amount of free space in the audio buffer with `pa_stream_writable_size()`. It returns 0 when the buffer is full, and we must wait until some free space is available and then try again.
```
size_t n = pa_stream_writable_size(stm);
if (n == 0) {
pa_threaded_mainloop_wait(mloop);
continue;
}
```
We get the buffer region where into we can copy audio samples with `pa_stream_begin_write()`. After we've filled the buffer, we call `pa_stream_write()` to release this memory region.
```
void *buf;
pa_stream_begin_write(stm, &buf, &n);
...
pa_stream_write(stm, buf, n, NULL, 0, PA_SEEK_RELATIVE);
```
#### PulseAudio: Draining
To drain the buffer we create a drain operation with `pa_stream_drain()` and pass our callback function to it which will be called when draining is complete.
```
void *udata = NULL;
pa_operation *op = pa_stream_drain(stm, on_op_complete, udata);
...
pa_operation_unref(op);
```
Now wait until our callback function signals us.
```
for (;;) {
int r = pa_operation_get_state(op);
if (r == PA_OPERATION_DONE || r == PA_OPERATION_CANCELLED)
break;
pa_threaded_mainloop_wait(mloop);
}
```
Here's how our callback function looks like:
```
void on_op_complete(pa_stream *s, int success, void *udata)
{
pa_threaded_mainloop_signal(mloop, 0);
}
```
### Windows and WASAPI
WASAPI is default sound subsystem starting with Windows Vista. It's a successor to DirectSound API which we don't discuss here, because I doubt you want to support old Windows XP. But if you do, please check out the appropriate code in ffaudio yourself. WASAPI can work in 2 different modes: shared and exclusive. In shared mode multiple apps can use the same physical device and it's the right mode for usual playback/recording apps. In exclusive mode we have an exclusive access to audio device, this is suitable for professional real-time sound apps.
WASAPI include directives must be preceded by `COBJMACROS` preprocessor definition, this is for pure C definitions to work correctly.
```
#define COBJMACROS
#include
#include
```
Before doing anything else we must initialize COM-interface subsystem.
```
CoInitializeEx(NULL, 0);
```
We must link all WASAPI apps with `-lole32` linker flag.
The most of WASAPI functions return 0 on success and non-zero on failure.
#### WASAPI: Enumerating Devices
We create device enumerator object with `CoCreateInstance()`. Don't forget to release it when we're done.
```
IMMDeviceEnumerator *enu;
const GUID _CLSID_MMDeviceEnumerator = {0xbcde0395, 0xe52f, 0x467c, {0x8e,0x3d, 0xc4,0x57,0x92,0x91,0x69,0x2e}};
const GUID _IID_IMMDeviceEnumerator = {0xa95664d2, 0x9614, 0x4f35, {0xa7,0x46, 0xde,0x8d,0xb6,0x36,0x17,0xe6}};
CoCreateInstance(&_CLSID_MMDeviceEnumerator, NULL, CLSCTX_ALL, &_IID_IMMDeviceEnumerator, (void**)&enu);
...
IMMDeviceEnumerator_Release(enu);
```
We use this device enumerator object to get array of available devices with `IMMDeviceEnumerator_EnumAudioEndpoints()`.
```
IMMDeviceCollection *dcoll;
int mode = (playback) ? eRender : eCapture;
IMMDeviceEnumerator_EnumAudioEndpoints(enu, mode, DEVICE_STATE_ACTIVE, &dcoll);
...
IMMDeviceCollection_Release(dcoll);
```
Enumerate devices by asking `IMMDeviceCollection_Item()` to return device handler for the specified array index.
```
for (int i = 0; ; i++) {
IMMDevice *dev;
if (0 != IMMDeviceCollection_Item(dcoll, i, &dev))
break;
...
IMMDevice_Release(dev);
}
```
Then, get set of properties for this device.
```
IPropertyStore *props;
IMMDevice_OpenPropertyStore(dev, STGM_READ, &props);
...
IPropertyStore_Release(props);
```
Read a single property value with `IPropertyStore_GetValue()`. Here's how to get user-friendly name for the device.
```
PROPVARIANT name;
PropVariantInit(&name);
const PROPERTYKEY _PKEY_Device_FriendlyName = {{0xa45c254e, 0xdf1c, 0x4efd, {0x80, 0x20, 0x67, 0xd1, 0x46, 0xa8, 0x50, 0xe0}}, 14};
IPropertyStore_GetValue(props, &_PKEY_Device_FriendlyName, &name);
const wchar_t *device_name = name.pwszVal;
...
PropVariantClear(&name);
```
And now the main reason why we need to list devices: we get the unique device ID with `IMMDevice_GetId()`.
```
wchar_t *device_id = NULL;
IMMDevice_GetId(dev, &device_id);
...
CoTaskMemFree(device_id);
```
To get system default device we use `IMMDeviceEnumerator_GetDefaultAudioEndpoint()`. Then we can get its ID and name exactly the same way as described above.
```
IMMDevice *def_dev = NULL;
IMMDeviceEnumerator_GetDefaultAudioEndpoint(enu, mode, eConsole, &def_dev);
IMMDevice_Release(def_dev);
```
#### WASAPI: Opening Audio Buffer in Shared Mode
Here's the most simple way to open an audio buffer in shared mode. Once again we start by creating a device enumerator object.
```
IMMDeviceEnumerator *enu;
const GUID _CLSID_MMDeviceEnumerator = {0xbcde0395, 0xe52f, 0x467c, {0x8e,0x3d, 0xc4,0x57,0x92,0x91,0x69,0x2e}};
const GUID _IID_IMMDeviceEnumerator = {0xa95664d2, 0x9614, 0x4f35, {0xa7,0x46, 0xde,0x8d,0xb6,0x36,0x17,0xe6}};
CoCreateInstance(&_CLSID_MMDeviceEnumerator, NULL, CLSCTX_ALL, &_IID_IMMDeviceEnumerator, (void**)&enu);
...
IMMDeviceEnumerator_Release(enu);
```
Now we either use the default capture device or we already know the specific device ID. In either case we get the device descriptor.
```
IMMDevice *dev;
wchar_t *device_id = NULL;
if (device_id == NULL) {
int mode = (playback) ? eRender : eCapture;
IMMDeviceEnumerator_GetDefaultAudioEndpoint(enu, mode, eConsole, &dev);
} else {
IMMDeviceEnumerator_GetDevice(enu, device_id, &dev);
}
...
IMMDevice_Release(dev);
```
We create an audio capture buffer with `IMMDevice_Activate()` passing `IID_IAudioClient` identificator to it.
```
IAudioClient *client;
const GUID _IID_IAudioClient = {0x1cb9ad4c, 0xdbfa, 0x4c32, {0xb1,0x78, 0xc2,0xf5,0x68,0xa7,0x03,0xb2}};
IMMDevice_Activate(dev, &_IID_IAudioClient, CLSCTX_ALL, NULL, (void**)&client);
...
IAudioClient_Release(client);
```
Because we want to open WASAPI audio buffer in shared mode, we can't order it to use the audio format that we want. Audio format is the subject of system-level configuration and we just have to comply with it. Most likely this format will be 16bit/44100/stereo or 24bit/44100/stereo, but we can never be sure. To be completely honest, WASAPI can accept a different sample format from us (e.g. we can use float32 format and WASAPI will automatically convert our samples to 16bit), but again, we must not rely on this behaviour. The most robust way to get the right audio format is by calling `IAudioClient_GetMixFormat()` which creates a WAVE-format header for us. The same header format is used in .wav files, by the way. Note that for recoding and for playback there are 2 different settings for audio format in Windows. It depends on which device our buffer is assigned to.
```
WAVEFORMATEX *wf;
IAudioClient_GetMixFormat(client, &wf);
...
CoTaskMemFree(wf);
```
Now we just use this audio format to set up our buffer with `IAudioClient_Initialize()`. Note that we use `AUDCLNT_SHAREMODE_SHARED` flag here which means that we want to configurate the buffer in shared mode. The buffer length parameter must be in 100-nanoseconds interval. Keep in mind that this is just a hint, and after the function returns successfully, we should always get the actual buffer length chosen by WASAPI.
```
int buffer_length_msec = 500;
REFERENCE_TIME dur = buffer_length_msec * 1000 * 10;
int mode = AUDCLNT_SHAREMODE_SHARED;
int aflags = 0;
IAudioClient_Initialize(client, mode, aflags, dur, dur, (void*)wf, NULL);
u_int buf_frames;
IAudioClient_GetBufferSize(client, &buf_frames);
buffer_length_msec = buf_frames * 1000 / wf->nSamplesPerSec;
```
#### WASAPI: Recording Audio in Shared Mode
We initialized the buffer, but it doesn't provide us with an interface we can use to perform I/O. In our case for recording streams we have to get `IAudioCaptureClient` interface object from it.
```
IAudioCaptureClient *capt;
const GUID _IID_IAudioCaptureClient = {0xc8adbd64, 0xe71e, 0x48a0, {0xa4,0xde, 0x18,0x5c,0x39,0x5c,0xd3,0x17}};
IAudioClient_GetService(client, &_IID_IAudioCaptureClient, (void**)&capt);
```
Preparation is complete, we're ready to start recording.
```
IAudioClient_Start(client);
```
To get a chunk of recorded audio data we call `IAudioCaptureClient_GetBuffer()`. It returns `AUDCLNT_S_BUFFER_EMPTY` error when there's no unread data inside the buffer. In this case we just wait then try again. After we've processed the audio samples, we release the data with `IAudioCaptureClient_ReleaseBuffer()`.
```
for (;;) {
u_char *data;
u_int nframes;
u_long flags;
int r = IAudioCaptureClient_GetBuffer(capt, &data, &nframes, &flags, NULL, NULL);
if (r == AUDCLNT_S_BUFFER_EMPTY) {
// Buffer is empty. Wait for more data.
int period_ms = 100;
Sleep(period_ms);
continue;
} else (r != 0) {
// error
}
...
IAudioCaptureClient_ReleaseBuffer(capt, nframes);
}
```
#### WASAPI: Playing Audio in Shared Mode
Playing audio is very similar to recording but we need to use another interface for I/O. This time we pass `IID_IAudioRenderClient` identificator and get the `IAudioRenderClient` interface object.
```
IAudioRenderClient *render;
const GUID _IID_IAudioRenderClient = {0xf294acfc, 0x3146, 0x4483, {0xa7,0xbf, 0xad,0xdc,0xa7,0xc2,0x60,0xe2}};
IAudioClient_GetService(client, &_IID_IAudioRenderClient, (void**)&render);
...
IAudioRenderClient_Release(render);
```
The normal playback operation is when we add some more data into audio buffer in a loop as soon as there is some free space in buffer. To get the amount of used space we call `IAudioClient_GetCurrentPadding()`. To get the amount of free space we use the size of our buffer (`buf_frames`) we got while opening the buffer. These numbers are in samples, not in bytes.
```
u_int filled;
IAudioClient_GetCurrentPadding(client, &filled);
int n_free_frames = buf_frames - filled;
```
The function sets the number of used space to 0 when the buffer is full. Now for the first time we have the full buffer must start the playback.
```
if (!started) {
IAudioClient_Start(client);
started = 1;
}
```
We get the free buffer region with `IAudioRenderClient_GetBuffer()` and after we've filled it with audio samples we release it with `IAudioRenderClient_ReleaseBuffer()`.
```
u_char *data;
IAudioRenderClient_GetBuffer(render, n_free_frames, &data);
...
IAudioRenderClient_ReleaseBuffer(render, n_free_frames, 0);
```
#### WASAPI: Draining
We never forget to drain the audio buffer before closing it otherwise the last audio data won't be played because we haven't given it enough time. The algorithm is the same as for ALSA. We get the number of samples still left to be played, and when the buffer is empty the draining is complete.
```
for (;;) {
u_int filled;
IAudioClient_GetCurrentPadding(client, &filled);
if (filled == 0)
break;
...
}
```
In case our input data was too small to even fill our audio buffer, we still haven't started the playback at this point. We do it, otherwise `IAudioClient_GetCurrentPadding()` will never signal us with "buffer empty" condition.
```
if (!started) {
IAudioClient_Start(client);
started = 1;
}
```
#### WASAPI: Error Reporting
The most WASAPI functions return 0 on success and an error code on failure. The problem with this error code is that sometimes we can't convert it to user-friendly error message directly - we have to do it manually. First, we check if it's `AUDCLNT_E_*` code. In this case we have to set our own error message depending on the value. For example, we may have an array of strings for each possible `AUDCLNT_E_*` code. Don't forget index-out-of-bounds checks!
```
int err = ...;
if ((err & 0xffff0000) == MAKE_HRESULT(SEVERITY_ERROR, FACILITY_AUDCLNT, 0)) {
err = err & 0xffff;
static const char audclnt_errors[][39] = {
"",
"AUDCLNT_E_NOT_INITIALIZED", // 0x1
...
"AUDCLNT_E_RESOURCES_INVALIDATED", // 0x26
};
const char *error_name = audclnt_errors[err];
}
```
But in case it's not a `AUDCLNT_E_*` code, we can get error message from Windows the usual way.
```
wchar_t buf[255];
int n = FormatMessageW(FORMAT_MESSAGE_FROM_SYSTEM | FORMAT_MESSAGE_IGNORE_INSERTS | FORMAT_MESSAGE_MAX_WIDTH_MASK
, 0, err, 0, buf, sizeof(buf)/sizeof(*buf), 0);
if (n == 0)
buf[0] = '\0';
```
And it's always good practice to store names of the functions that return with an error. User must know which function exactly has failed and which code it has returned along with error description.
### FreeBSD and OSS
OSS is the default audio subsystem on FreeBSD and some other OS. It was default on Linux too before ALSA replaced it. Some docs say that OSS layer is still supported on modern Linux, but I don't think it's useful for new software. OSS API is very simple comparing to other API: we only use standard syscalls. I/O with OSS is just like I/O with regular files, which makes OSS quite easy to understand and use.
Include necessary header files:
```
#include
#include
#include
#include
#include
#include
```
#### OSS: Enumerating Devices
Open system mixer device exactly the same way as we open regular files.
```
int mixer = open("/dev/mixer", O_RDONLY, 0);
...
close(mixer);
```
We communicate with this device by issuing commands via `ioctl()`. Get the number of registered devices with `SNDCTL_SYSINFO` device control code.
```
oss_sysinfo si = {};
ioctl(mixer, SNDCTL_SYSINFO, &si);
int n_devs = si.numaudios;
```
We get the properties for each device with `SNDCTL_AUDIOINFO_EX`.
```
for (int i = 0; i != n_devs; i++) {
oss_audioinfo ainfo = {};
ainfo.dev = i;
ioctl(mixer, SNDCTL_AUDIOINFO_EX, &ainfo);
...
}
```
Because we iterate over all devices, both playback and recording, we must use `oss_audioinfo::cap` field to filter what we need: `PCM_CAP_OUTPUT` means this is a playback device and `PCM_CAP_INPUT` means this is a recording device. We get other necessary information, most importantly - device ID, from the same `oss_audioinfo` object.
```
int is_playback_device = !!(ainfo.caps & PCM_CAP_OUTPUT);
int is_capture_device = !!(ainfo.caps & PCM_CAP_INPUT);
const char *device_id = ainfo.devnode;
const char *device_name = ainfo.name;
```
#### OSS: Opening Audio Buffer
We open audio device with `open()` and get the device descriptor. To use default device we pass `"/dev/dsp"` string. We need to pass the correct flags to the function: `O_WRONLY` for playback because we will write data to audio device and `O_RDONLY` for recording because we will read from it. We can also use `O_NONBLOCK` flag here which makes our descriptor non-blocking, i.e. read/write functions won't block and return immediately with `EAGAIN` error.
```
const char *device_id = NULL;
if (device_id == NULL)
device_id = "/dev/dsp";
int flags = (playback) ? O_WRONLY : O_RDONLY;
int dsp = open(device_id, flags | O_EXCL, 0);
...
close(dsp);
```
Let's configure the device for the audio format we want to use. We pass the value we want to use to `ioctl()`, and it updates it on return with the actual value that device driver has set. Of course, this value can be different from the one we passed. In real code we must detect such cases and notify the user about the format change or exit with an error.
```
int format = AFMT_S16_LE;
ioctl(dsp, SNDCTL_DSP_SETFMT, &format);
int channels = 2;
ioctl(dsp, SNDCTL_DSP_CHANNELS, &channels);
int sample_rate = 44100;
ioctl(dsp, SNDCTL_DSP_SPEED, &sample_rate);
```
To set audio buffer length we first get "fragment size" property for our device. Then we use this value to convert the buffer length to the number of fragments. Fragments *are not* audio frames, fragment size *is not* the size of a sample! Then we set the number of fragments with `SNDCTL_DSP_SETFRAGMENT` control code. Note that we can skip this section if we don't want to set our own buffer length and use the default buffer length.
```
audio_buf_info info = {};
if (playback)
ioctl(dsp, SNDCTL_DSP_GETOSPACE, &info);
else
ioctl(dsp, SNDCTL_DSP_GETISPACE, &info);
int buffer_length_msec = 500;
int frag_num = sample_rate * 16/8 * channels * buffer_length_msec / 1000 / info.fragsize;
int fr = (frag_num << 16) | (int)log2(info.fragsize); // buf_size = frag_num * 2^n
ioctl(dsp, SNDCTL_DSP_SETFRAGMENT, &fr);
```
We've finished preparing the device. Now we get the actual buffer length with `SNDCTL_DSP_GETOSPACE` for playback or `SNDCTL_DSP_GETISPACE` for recording streams.
```
audio_buf_info info = {};
int r;
if (playback)
r = ioctl(dsp, SNDCTL_DSP_GETOSPACE, &info);
else
r = ioctl(dsp, SNDCTL_DSP_GETISPACE, &info);
buffer_length_msec = info.fragstotal * info.fragsize * 1000 / (sample_rate * 16/8 * channels);
int buf_size = info.fragstotal * info.fragsize;
frame_size = 16/8 * sample_rate * channels;
```
Finally, we allocate the buffer of the required size.
```
void *buf = malloc(buf_size);
...
free(buf);
```
#### OSS: Recording Audio
There's nothing easier than audio I/O with OSS. We use the usual `read()` function passing to it our audio buffer and the maximum number of bytes available inside it. It returns the number of bytes read. The function also blocks the execution when the buffer is empty, so there's no need in calling sleep functions for us.
```
int n = read(dsp, buf, buf_size);
```
#### OSS: Playing Audio
For playback streams we first write audio samples to our buffer, then pass this region to the device with `write()`. It returns the number of bytes actually written. The functions blocks execution when the buffer is full.
```
int n = write(dsp, buf, n);
```
#### OSS: Draining
To drain the buffer we just use `SNDCTL_DSP_SYNC` control code. It blocks until the playback is complete.
```
ioctl(dsp, SNDCTL_DSP_SYNC, 0);
```
#### OSS: Error Reporting
On failure, `open()`, `ioctl()`, `read()` and `write()` return with a negative value and set `errno`. We can convert the code into an error message as usual with `strerror()`.
```
int err = ...;
const char *error_message = strerror(err);
```
### macOS and CoreAudio
CoreAudio is the default sound subsystem on macOS and iOS. I have little experience with it because I don't like Apple's products. I'm just showing you the way it worked for me, but theoretically there may be better solutions than mine. The necessary includes are:
```
#include
#include
```
When linking we pass `-framework CoreFoundation -framework CoreAudio` linker flags.
#### CoreAudio: Enumerating Devices
We get the array of audio devices with `AudioObjectGetPropertyData()`. But first we need to know the minimum number of bytes to allocate for the array - we get the required size with `AudioObjectGetPropertyDataSize()`.
```
const AudioObjectPropertyAddress prop_dev_list = { kAudioHardwarePropertyDevices, kAudioObjectPropertyScopeGlobal, kAudioObjectPropertyElementMaster };
u_int size;
AudioObjectGetPropertyDataSize(kAudioObjectSystemObject, ∝_dev_list, 0, NULL, &size);
AudioObjectID *devs = (AudioObjectID*)malloc(size);
AudioObjectGetPropertyData(kAudioObjectSystemObject, ∝_dev_list, 0, NULL, &size, devs);
int n_dev = size / sizeof(AudioObjectID);
...
free(devs);
```
Then we iterate over the array to get the device ID.
```
for (int i = 0; i != n_dev; i++) {
AudioObjectID device_id = devs[i];
...
}
```
For each device we can get a user-friendly name, but we have to convert the CoreFoundation's string object to a NULL-terminated string with `CFStringGetCString()`.
```
const AudioObjectPropertyAddress prop_dev_outname = { kAudioObjectPropertyName, kAudioDevicePropertyScopeOutput, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress prop_dev_inname = { kAudioObjectPropertyName, kAudioDevicePropertyScopeInput, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress *prop = (playback) ? ∝_dev_outname : ∝_dev_inname;
u_int size = sizeof(CFStringRef);
CFStringRef cfs;
AudioObjectGetPropertyData(devs[i], prop, 0, NULL, &size, &cfs);
CFIndex len = CFStringGetMaximumSizeForEncoding(CFStringGetLength(cfs), kCFStringEncodingUTF8);
char *device_name = malloc(len + 1);
CFStringGetCString(cfs, device_name, len + 1, kCFStringEncodingUTF8);
CFRelease(cfs);
...
free(device_name);
```
#### CoreAudio: Opening Audio Buffer
If we want to use the default device, here's how we can get its ID.
```
AudioObjectID device_id;
const AudioObjectPropertyAddress prop_odev_default = { kAudioHardwarePropertyDefaultOutputDevice, kAudioObjectPropertyScopeGlobal, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress prop_idev_default = { kAudioHardwarePropertyDefaultInputDevice, kAudioObjectPropertyScopeGlobal, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress *a = (playback) ? ∝_odev_default : ∝_idev_default;
u_int size = sizeof(AudioObjectID);
AudioObjectGetPropertyData(kAudioObjectSystemObject, a, 0, NULL, &size, &device_id);
```
Get the supported audio format. It seems that CoreAudio uses float32 samples by default.
```
const AudioObjectPropertyAddress prop_odev_fmt = { kAudioDevicePropertyStreamFormat, kAudioDevicePropertyScopeOutput, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress prop_idev_fmt = { kAudioDevicePropertyStreamFormat, kAudioDevicePropertyScopeInput, kAudioObjectPropertyElementMaster };
AudioStreamBasicDescription asbd = {};
u_int size = sizeof(asbd);
const AudioObjectPropertyAddress *a = (playback) ? ∝_odev_fmt : ∝_idev_fmt;
AudioObjectGetPropertyData(device_id, a, 0, NULL, &size, &asbd);
int sample_rate = asbd.mSampleRate;
int channels = asbd.mChannelsPerFrame;
```
Create the buffer with 500ms audio length. Note that we use our own ring buffer here to transfer data between the callback function and our I/O loop.
```
int buffer_length_msec = 500;
int buf_size = 32/8 * sample_rate * channels * buffer_length_msec / 1000;
ring_buf = ringbuf_alloc(buf_size);
...
ringbuf_free(ring_buf);
```
Register I/O callback function which will be called by CoreAudio when there's some more data for us (for recording) or when it wants to read some data from us (for playback). We can pass our ring buffer as a user-parameter. The return value is a pointer which we later use to control the stream.
```
AudioDeviceIOProcID io_proc_id = NULL;
void *udata = ring_buf;
AudioDeviceCreateIOProcID(device_id, proc, udata, &io_proc_id);
...
AudioDeviceDestroyIOProcID(device_id, io_proc_id);
```
The callback function looks like this:
```
OSStatus io_callback(AudioDeviceID device, const AudioTimeStamp *now,
const AudioBufferList *indata, const AudioTimeStamp *intime,
AudioBufferList *outdata, const AudioTimeStamp *outtime,
void *udata)
{
...
return 0;
}
```
#### CoreAudio: Recording Audio
We start recording with `AudioDeviceStart()`.
```
AudioDeviceStart(device_id, io_proc_id);
```
Then after some time our callback function is called. While inside it, we must add all audio samples to our ring buffer.
```
const float *d = indata->mBuffers[0].mData;
size_t n = indata->mBuffers[0].mDataByteSize;
ringbuf *ring = udata;
ringbuf_write(ring, d, n);
return 0;
```
In our I/O loop we try to read some data from the buffer. If the buffer is empty, we wait, and then try again. My ring buffer implementation here allows us to use the buffer directly. We get the buffer region, process it, and then release it.
```
ringbuffer_chunk buf;
size_t h = ringbuf_read_begin(ring_buf, -1, &, NULL);
if (.len == 0) {
// Buffer is empty. Wait until some new data is available
int period_ms = 100;
usleep(period_ms*1000);
continue;
}
...
ringbuf_read_finish(ring_buf, h);
```
#### CoreAudio: Playing Audio
Inside the callback function we write audio samples from our ring buffer to CoreAudio's buffer. Note that we read from the buffer 2 times, because once we reach the end of memory region in our ring buffer, we have to continue from the beginning. In case there wasn't enough data in our buffer we pass silence (data region filled with zeros) so that there are no audible surprises when this data is played.
```
float *d = outdata->mBuffers[0].mData;
size_t n = outdata->mBuffers[0].mDataByteSize;
ringbuf *ring = udata;
ringbuffer_chunk buf;
size_t h = ringbuf_read_begin(ring, n, &buf, NULL);
memcpy(buf.ptr, d, buf.len);
ringbuf_read_finish(ring, h);
d = (char*)d + buf.len;
n -= buf.len;
if (n != 0) {
h = ringbuf_read_begin(ring, n, &buf, NULL);
memcpy(buf.ptr, d, buf.len);
ringbuf_read_finish(ring, h);
d = (char*)d + buf.len;
n -= buf.len;
}
if (n != 0)
memset(d, 0, n);
```
In our main I/O loop we first get the free buffer region where we write new audio samples. When the buffer is full we start the stream for the first time and wait until our callback function is called.
```
ringbuffer_chunk buf;
size_t h = ringbuf_write_begin(ring_buf, 16*1024, &buf, NULL);
if (buf.len == 0) {
if (!started) {
AudioDeviceStart(device_id, io_proc_id);
started = 1;
}
// Buffer is full. Wait.
int period_ms = 100;
usleep(period_ms*1000);
continue;
}
...
ringbuf_write_finish(ring_buf, h);
```
#### CoreAudio: Draining
To drain the buffer we just wait until our ring buffer is empty. When it is, I stop the stream with `AudioDeviceStop()`. Remember that in case the input data was less than the size of our buffer, our stream isn't yet started. We start it with `AudioDeviceStart()` if it's the case.
```
size_t free_space;
ringbuffer_chunk d;
ringbuf_write_begin(ring_buf, 0, &d, &free_space);
if (free_space == ring_buf->cap) {
AudioDeviceStop(device_id, io_proc_id);
break;
}
if (!started) {
AudioDeviceStart(device_id, io_proc_id);
started = 1;
}
// Buffer isn't empty. Wait.
int period_ms = 100;
usleep(period_ms*1000);
```
### Final Results
I think we covered the most common audio API and their use-cases, I hope that you've learned something new and useful. There are few things, though, that didn't make it into this tutorial:
* ALSA's SIGIO notifications. Not all devices support this, as far as I know.
* WASAPI notifications via Windows events. This is only useful for real-time low-latency apps.
* WASAPI exclusive mode, loopback mode. Explaining the details around opening audio buffer in exclusive mode would make me invest so much more time, that I'm not sure I can do it right now. And the loopback mode is not cross-platform. You can learn about this stuff, if you want, by reading official docs or ffaudio's source code for example.
The official API documentation links:
* <https://www.alsa-project.org/alsa-doc/alsa-lib/>
* <https://www.freedesktop.org/software/pulseaudio/doxygen/index.html>
* <https://docs.microsoft.com/en-us/windows/win32/coreaudio/wasapi>
* <http://manuals.opensound.com/developer/>
* <https://developer.apple.com/documentation/coreaudio>
P.S. I used some images from here (thanks to the authors!):
* <http://www.camera-sdk.com/p_54-how-to-implement-circular-buffer-video-recording-in-c-onvif.html>
* <https://www.researchgate.net/figure/The-organisation-of-stereo-data-in-interleaved-stereo-files_fig17_326019555> | https://habr.com/ru/post/663352/ | null | en | null |
# Новая жизнь для XMPP. Делаем мессенджер, который не получится заблокировать

Идея сделать независимый от корпораций P2P мессенджер не нова, однако разработка нового протокола и клиентских приложений для него достаточно дорогой и долгий процесс. А что, если использовать старый добрый [XMPP](https://en.wikipedia.org/wiki/XMPP), в котором уже все давно продумано и запилено?
Но это же не настоящий peer-to-peer, скажете вы, для работы XMPP нужен собственный сервер и домен. Это так, но мы можем запустить сервер на локалхосте, а для связи с серверами других пользователей использовать скрытый сервис в [виртуальной сети I2P](https://en.wikipedia.org/wiki/I2P). Использование I2P избавит нас от необходимости платить за домен с хостингом, а так же защитит наши коммуникации от [преступной онлайн-слежки](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%AF%D1%80%D0%BE%D0%B2%D0%BE%D0%B9).
Таким образом, получаем:
* Гибридный P2P мессенджер, который можно запускать и на пользовательских устройствах, и на полноценном сервере.
* Фичи, которых не хватает другим P2P мессенджерам: оффлайн сообщения, хранение контактов и истории "в облаке", работа нескольких клиентов с одним аккаунтом.
* Готовые клиентские приложения на любой вкус.
* За счет использования I2P, неуязвим для различных \*надзоров (сори за мат).
Приступим же к реализации...
Установка I2P и создание серверного тоннеля
===========================================
В данном руководстве, в качестве I2P роутера будем использовать легковесный C++ клиент [i2pd](https://github.com/PurpleI2P/i2pd). Инструкция по установке есть в [документации](https://i2pd.readthedocs.io/en/latest/user-guide/install/).
После установки создаем серверный I2P туннель — это виртуальный адрес, по которому наш XMPP сервер будет доступен для остального мира. В файл [tunnels.conf](https://i2pd.readthedocs.io/en/latest/user-guide/tunnels/) дописываем следующие строки:
```
[prosody-s2s]
type=server
host=127.0.0.1
port=5269
inport=5269
keys=prosody.dat
[prosody-c2s]
type=server
host=127.0.0.1
port=5222
inport=5222
keys=prosody.dat
```
Если планируется использование только на локалхосте, секцию prosody-c2s можно не добавлять. Перезагружаем i2pd, чтобы применить настройки. Ищем I2P адрес созданного туннеля в веб-консоли <http://127.0.0.1:7070/> на странице `I2P tunnels`.
Можно так же узнать b32 адрес нового туннеля, грепнув логи:
```
grep "New private keys file" /var/log/i2pd/i2pd.log | grep -Eo "([a-z0-9]+).b32.i2p" | tail -n1
```
Сохраните этот xxx.b32.i2p адрес, это будет домен для вашего XMPP сервера.
Установка и настройка XMPP сервера
==================================
В качестве XMPP сервера будем использовать [prosody](https://prosody.im/), он самый легкий и под него есть готовый модуль для работы через I2P. Установка описана в официальной [документации](https://prosody.im/download/start), в Ubuntu делается элементарно `apt install prosody`.
Для работы `mod_darknet` нужна lua библиотека bit32. Если у вас lua версии меньше 5.2 (скорее всего) выполняем `apt install lua-bit32`.
Устанавливаем модуль `mod_darknet`. Он нужен, чтобы prosody делал исходящие соединения через Socks5 сервер i2pd. Скачиваем [этот файл](https://raw.githubusercontent.com/majestrate/mod_darknet/master/mod_darknet.lua) в директорию модулей prosody, обычно это `/usr/lib/prosody/modules`.
Теперь редактируем конфиг /etc/prosody/prosody.cfg.lua. Замените `xxx.b32.i2p` на свой адрес:
```
interfaces = { "127.0.0.1" };
admins = { "[email protected]" };
modules_enabled = {
"roster"; "saslauth"; "tls"; "dialback"; "disco"; "posix"; "private"; "vcard"; "ping"; "register"; "admin_adhoc"; "darknet";
};
modules_disabled = {};
allow_registration = false;
darknet_only = true;
c2s_require_encryption = true;
s2s_secure_auth = false;
authentication = "internal_plain";
-- On Debian/Ubuntu
daemonize = true;
pidfile = "/var/run/prosody/prosody.pid";
log = {
error = "/var/log/prosody/prosody.err";
"*syslog";
}
certificates = "certs";
VirtualHost "xxx.b32.i2p";
ssl = {
key = "/etc/prosody/certs/xxx.b32.i2p.key";
certificate = "/etc/prosody/certs/xxx.b32.i2p.crt";
}
```
Последний шаг в настройке prosody — генерация сертификатов шифрования. В никсах это делается так:
```
openssl genrsa -out /etc/prosody/certs/xxx.b32.i2p.key 2048
openssl req -new -x509 -key /etc/prosody/certs/xxx.b32.i2p.key -out /etc/prosody/certs/xxx.b32.i2p.crt -days 3650
chown root:prosody /etc/prosody/certs/*.b32.i2p.{key,crt}
chmod 640 /etc/prosody/certs/*.b32.i2p.{key,crt}
```
Перезагрузите сервер prosody для применения настроек.
Тут нужно небольшое отступление. В сети I2P любые соединения зашифрованы сквозным шифрованием и, казалось бы, дополнительное шифрование тут излишне. Но, на практике, оказалось проще сгенерировать ключи, чем пытаться настроить все программы на использование открытого текста. Вы можете попробовать, но я вас предупреждал.
Создание аккаунтов и подключение клиентов
=========================================
Добавляем админский аккаунт:
```
prosodyctl adduser [email protected]
```
Теперь настраиваем XMPP клиент (например [Pidgin](https://pidgin.im)).
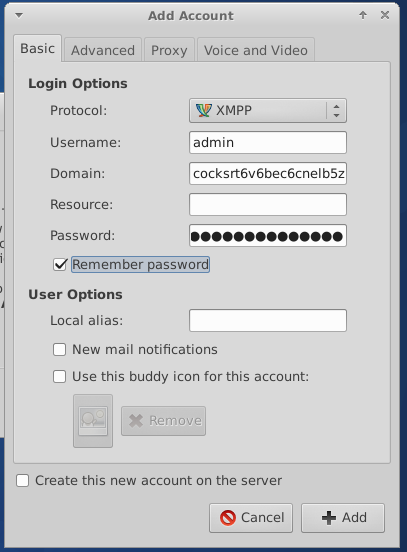
Если вы подключаетесь к локалхосту, то в настройках клиента указываем подключение к серверу 127.0.0.1 порт 5222.
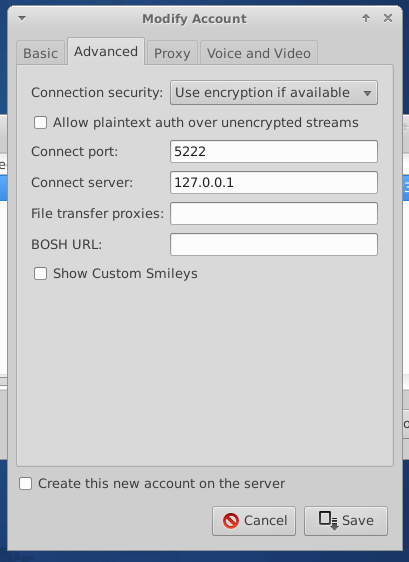
Если подключаетесь к серверу удаленно через I2P, то указывайте в настройках прокси Socks5 127.0.0.1:4447.
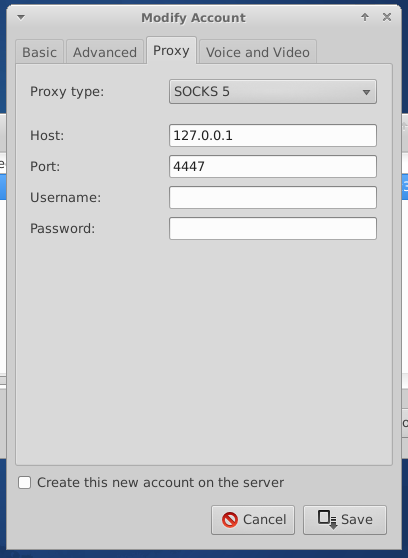
Если все сделано правильно, вы сможете добавлять других пользователей в I2P федерации и переписываться с ними. Так же, возможно настроить ваш уже работающий сервер в обычном интернете на переписку с серверами внутри I2P. Для этого все остальные пользователи должны будут добавить в свой конфиг prosody маппинг для вашего домена. Например, так это сделано у меня для общения с сервером `i2p.rocks`:
```
darknet_map = {
["i2p.rocks"] = "ynkz7ebfkllljitiodcq52pa7fgqziomz4wa7tv4qiqldghpx4uq.b32.i2p";
["muc.i2p.rocks"] = "ynkz7ebfkllljitiodcq52pa7fgqziomz4wa7tv4qiqldghpx4uq.b32.i2p";
}
```
Вот собственно и все. Happy chatting! | https://habr.com/ru/post/351936/ | null | ru | null |
# Делаем Modern Build
Привет, Хабр!
Каждый современный браузер сейчас позволяет работать с ES6 Modules.
На первый взгляд кажется, что это совершенно бесполезная вещь — ведь все мы пользуемся сборщиками, которые заменяют импорты на свои внутренние вызовы. Но если покопаться в спецификации, окажется, что благодаря ним можно подвезти отдельную сборку для современных браузеров.
Под катом рассказ о том, как я смог уменьшить размер приложения на 11% без ущерба для старых браузеров и своих нервов.

Особенности ES6 Modules
-----------------------
ES6 Modules — это всем уже известная и широко используемая модульная система:
```
/* someFile.js */
import { someFunc } from 'path/to/helpers.js'
```
```
/* helpers.js */
export function someFunc() {
/* ... */
}
```
Для использования этой модульной системы в браузерах необходимо добавить тип module к каждому скрипт-тегу. Старые браузеры увидят, что тип отличается от text/javascript, и не станут исполнять файл как JavaScript.
```
```
В спецификации еще есть атрибут nomodule для скрипт-тегов. Браузеры, поддерживающие ES6 Modules, проигнорируют этот скрипт, а старые браузеры скачают его и выполнят.
```
```
Получается, можно просто сделать две сборки: первая с типом module для современных браузеров (Modern Build), а другая — с nomodule для старых (Fallback build):
```
```
Зачем это нужно
---------------
Прежде чем отправить проект в production, мы должны:
* Добавить полифилы.
* Транспилировать современный код в более старый.
В своих проектах я стараюсь поддерживать максимальное количество браузеров, иногда даже IE 10. Поэтому мой список полифилов состоит в том числе и из таких базовых вещей, как es6.promise, es6.object.values и т.п. Но браузеры с поддержкой ES6 Modules имеют все ES6 методы, и им не нужны лишние килобайты полифилов.
Транспиляция тоже оставляет заметный след на размере файлов: для покрытия большинства браузеров babel/preset-env использует 25 трансформаторов, каждый из которых увеличивает размер кода. В это же время для браузеров с поддержкой ES6 Modules количество трансформаторов уменьшается до 9.
Значит, в сборке для современных браузеров мы можем убрать ненужные полифилы и уменьшить количество трансформаторов, что сильно скажется на размере итоговых файлов!
Как добавлять полифилы
----------------------
Прежде чем идти готовить Modern Build для современных браузеров, стоит упомянуть, как я добавляю полифилы в проект.

Обычно, в проектах используют core-js для добавления всех возможных полифилов.
Конечно, вы не хотите все 88 Кбайт полифилов из этой библиотеки, а только те, которые нужны для вашего browserslist. Такая возможность доступна с помощью babel/preset-env и его опции useBuiltIns. Если установить ей значение entry, то импорт core-js заменится на импорты отдельных модулей, необходимых вашим браузерам:
```
/* .babelrc.js */
module.exports = {
presets: [
['@babel/preset-env', {
useBuiltIns: 'entry',
/* ... */
}]
],
/* ... */
};
```
```
/* Исходный файл */
import 'core-js';
```
```
/* Транспилированный файл */
import "core-js/modules/es6.array.copy-within";
import "core-js/modules/es6.array.fill";
import "core-js/modules/es6.array.find";
/* И еще много-много импортов */
```
Но такой трансформацией мы избавились лишь от части ненужных очень старых полифилов. У нас все еще присутствуют полифилы для TypedArray, WeakMap и других странных вещей, которые никогда в проекте не используются.
Чтобы полностью победить эту проблему, для опции useBuiltIns я ставлю значение usage. На этапе компиляции babel/preset-env проанализирует файлы на использование фич, которые отсутствуют в выбранных браузерах, и добавит полифилы к ним:
```
/* .babelrc.js */
module.exports = {
presets: [
['@babel/preset-env', {
useBuiltIns: 'usage',
/* ... */
}]
],
/* ... */
};
```
```
/* Исходный файл */
function sortStrings(strings) {
return strings.sort();
}
function createResolvedPromise() {
return Promise.resolve();
}
```
```
/* Транспилированный файл */
import "core-js/modules/es6.array.sort";
import "core-js/modules/es6.promise";
function sortStrings(strings) {
return strings.sort();
}
function createResolvedPromise() {
return Promise.resolve();
}
```
В примере выше babel/preset-env добавил полифил к функции sort. В JavaScript нельзя узнать, объект какого типа будет передан в функцию — будет это массив или объект класса с функцией sort, но babel/preset-env выбирает худший для себя сценарий и вставляет полифил.
Ситуации, когда babel/preset-env ошибается, случаются постоянно. Чтобы убирать ненужные полифилы, время от времени проверяйте, какие из них вы импортируете, и удаляйте лишние с помощью опции exclude:
```
/* .babelrc.js */
module.exports = {
presets: [
['@babel/preset-env', {
useBuiltIns: 'usage',
// Используйте эту опцию, чтобы узнать, какие полифилы вы используете
debug: true,
// Добавляйте в исключения ненужные полифилы
exclude: ['es6.regexp.to-string', 'es6.number.constructor'],
/* ... */
}]
],
/* ... */
};
```
Модуль regenerator-runtime я не рассматриваю, так как использую fast-async ([и всем советую](https://habr.com/post/425215/#fast-async)).
Создаем Modern Build
--------------------
Приступим к настройке Modern Build.
Убедимся, что у нас в проекте есть файл browserslist, который описывает все необходимые браузеры:
```
/* .browserslistrc */
> 0.5%
IE 10
```
Добавим переменную окружения BROWSERS\_ENV во время сборки, которая может принимать значения fallback (для Fallback Build) и modern (для Modern Build):
```
/* package.json */
{
"scripts": {
/* ... */
"build": "NODE_ENV=production webpack /.../",
"build:fallback": "BROWSERS_ENV=fallback npm run build",
"build:modern": "BROWSERS_ENV=modern npm run build"
},
/* ... */
}
```
Теперь изменим конфигурацию babel/preset-env. Для указания поддерживаемых браузеров в пресете есть опция targets. У нее существует специальное сокращение — esmodules. При его использовании babel/preset-env автоматически подставит браузеры, поддерживающие ES6 modules.
```
/* .babelrc.js */
const isModern = process.env.BROWSERS_ENV === 'modern';
module.exports = {
presets: [
['@babel/preset-env', {
useBuiltIns: 'usage',
// Для Modern Build выбираем браузеры с поддержкой ES6 modules,
// а для Fallback Build берем список браузеров из .browsersrc
targets: isModern ? { esmodules: true } : undefined,
/* ... */
}]
],
/* ... */
],
};
```
Babel/preset-env сделает дальше всю работу за нас: выберет только нужные полифилы и трансформации.
Теперь мы можем собрать проект для современных или старых браузеров просто командой из консоли!
Связываем Modern и Fallback Build
---------------------------------
Последний шаг — это объединение Modern и Fallback Build'ов в одно целое.
Я планирую создать такую структуру проекта:
```
// Директория с собранными файлами
dist/
// Общий html-файл
index.html
// Директория с Modern Build'ом
modern/
...
// Директория с Fallback Build'ом
fallback/
...
```
В index.html будут ссылки на нужные javascript-файлы из обеих сборок:
```
/* index.html */
```
Этот шаг можно разбить на три части:
1. Сборка Modern и Fallback Build в разные директории.
2. Получение информации о путях до необходимых javascript-файлов.
3. Создание index.html со ссылками на все javascript-файлы.
Приступаем!
#### Сборка Modern и Fallback Build в разные директории
Для начала сделаем самый простой шаг — соберем Modern и Fallback Build в разные директории внутри директории dist.
Просто указать нужную директорию для output.path нельзя, так как нам необходимо, чтобы webpack имел пути до файлов относительно директории dist (index.html находится в этой директории, и все остальные зависимости будут выкачиваться относительно него).
Создадим специальную функцию для генерации путей файлов:
```
/* getFilePath.js */
/* Файл содержит функцию, которая поможет создавать пути для файлов */
const path = require('path');
const isModern = process.env.BROWSERS_ENV === 'modern';
const prefix = isModern ? 'modern' : 'fallback';
module.exports = relativePath => (
path.join(prefix, relativePath)
);
```
```
/* webpack.prod.config.js */
const getFilePath = require('path/to/getFilePath');
const MiniCssExtractPlugin = require('mini-css-extract-plugin');
module.exports = {
mode: 'production',
output: {
path: 'dist',
filename: getFilePath('js/[name].[contenthash].js'),
},
plugins: [
new MiniCssExtractPlugin({
filename: getFilePath('css/[name].[contenthash].css'),
}),
/* ... */
],
/* ... */
}
```
Проект стал собираться в разные директории для Modern и Fallback Build'а.
#### Получение информации о путях до необходимых javascript-файлов
Чтобы получить информацию о собранных файлах, подключим webpack-manifest-plugin. В конце сборки он добавит файл manifest.json с данными о путях до файлов:
```
/* webpack.prod.config.js */
const getFilePath = require('path/to/getFilePath');
const WebpackManifestPlugin = require('webpack-manifest-plugin');
module.exports = {
mode: 'production',
plugins: [
new WebpackManifestPlugin({
fileName: getFilePath('manifest.json'),
}),
/* ... */
],
/* ... */
}
```
Теперь у нас есть информация о собранных файлах:
```
/* manifest.json */
{
"app.js": "/fallback/js/app.4d03e1af64f68111703e.js",
/* ... */
}
```
#### Создание index.html со ссылками на все javascript-файлы
Дело осталось за малым — добавить index.html и вставить в него пути до нужных файлов.
Для генерации html-файла я буду использовать html-webpack-plugin во время Modern Build'а. Пути до modern-файлов html-webpack-plugin вставит сам, а пути до fallback-файлов я получу из созданного на предыдущем шаге файла и вставлю их в HTML с помощью небольшого webpack-плагина:
```
/* webpack.prod.config.js */
const HtmlWebpackPlugin = require('html-webpack-plugin');
const ModernBuildPlugin = require('path/to/ModernBuildPlugin');
module.exports = {
mode: 'production',
plugins: [
...(isModern ? [
// Добавим html-страницу в Modern Build
new HtmlWebpackPlugin({
filename: 'index.html',
}),
new ModernBuildPlugin(),
] : []),
/* ... */
],
/* ... */
}
```
```
/* ModernBuildPlugin.js */
// Safari 10.1 не поддерживает атрибут nomodule.
// Эта переменная содержит фикс для Safari в виде строки.
// Найти фикс можно тут:
// https://gist.github.com/samthor/64b114e4a4f539915a95b91ffd340acc
const safariFix = '!function(){var e=document,t=e.createE/* ...И еще много кода... */';
class ModernBuildPlugin {
apply(compiler) {
const pluginName = 'modern-build-plugin';
// Получаем информацию о Fallback Build
const fallbackManifest = require('path/to/dist/fallback/manifest.json');
compiler.hooks.compilation.tap(pluginName, (compilation) => {
// Подписываемся на хук html-webpack-plugin,
// в котором можно менять данные HTML
compilation.hooks.htmlWebpackPluginAlterAssetTags.tapAsync(pluginName, (data, cb) => {
// Добавляем type="module" для modern-файлов
data.body.forEach((tag) => {
if (tag.tagName === 'script' && tag.attributes) {
tag.attributes.type = 'module';
}
});
// Вставляем фикс для Safari
data.body.push({
tagName: 'script',
closeTag: true,
innerHTML: safariFix,
});
// Вставляем fallback-файлы с атрибутом nomodule
const legacyAsset = {
tagName: 'script',
closeTag: true,
attributes: {
src: fallbackManifest['app.js'],
nomodule: true,
defer: true,
},
};
data.body.push(legacyAsset);
cb();
});
});
}
}
module.exports = ModernBuildPlugin;
```
Обновим package.json:
```
/* package.json */
{
"scripts": {
/* ... */
"build:full": "npm run build:fallback && npm run build:modern"
},
/* ... */
}
```
С помощью команды npm run build:full мы создадим один html-файл с Modern и Fallback Build. Любой браузер теперь получит тот JavaScript, который он в состоянии выполнить.
Добавляем Modern Build в свое приложение
----------------------------------------
Чтобы проверить на чем-то реальном свое решение, я подвез его в один из своих проектов. Настройка конфигурации заняла у меня менее часа, а размер JavaScript-файлов уменьшился на 11%. Отличный результат при простой реализации.
Спасибо, что прочитали статью до конца!
### Использованные материалы
* [Speed Essentials: Key Techniques for Fast Websites](https://www.youtube.com/watch?v=reztLS3vomE)
* [Vue CLI Modern mode](https://cli.vuejs.org/guide/browser-compatibility.html#modern-mode) | https://habr.com/ru/post/430950/ | null | ru | null |
# Интеграция 1С с DLL с помощью Python
Привет Хабр! Недавно я разработал алгоритм для логистики, и нужно было его куда-то пристроить. Помимо веб-сервиса решено было внедрить данный модуль в 1С, и тут появилось довольно много подводных камней.
Начнем с того, что сам алгоритм представлен в виде dll библиотеки, у которой одна точка входа, принимающая JSON строку как параметр, и отдающая 2 колбэка. Первый для отображения статуса выполнения, другой для получения результата. С web-сервисом все довольно просто, у питона есть замечательный пакет ctypes, достаточно подгрузить нужную библиотеку и указать точку входа.
Выглядит это примерно так:
```
import ctypes
def callback_recv(*args):
print(args)
lib = ctypes.cdll.LoadLibrary('test.dll')
Callback = ctypes.CFUNCTYPE(None, ctypes.c_int, ctypes.c_char_p)
my_func = getattr(lib, '_ZN7GtTools4testEPKcPFviS1_E')
cb_func = Callback(callback_recv)
my_func(ctypes.c_char_p('some data'), cb_func)
```
Как можно заметить, точка входа не совсем читабельная. Чтобы найти данную строчку в скомпилировнанных данных, нужно открыть соответствующий файл с расширением .lib и применить утилиту objdump с параметром -D, в выводе легко можно найти нужный метод по названию.
Данное коверканье метода происходит из-за того, что компилятор манглит («mangle» — калечить) название всех точек входа, причем разные компиляторы «калечат» по разному. В примере указан метод полученный MinGW
В 1С все оказалось гораздо менее тривиально. Для подключения dll нужно, чтобы у нее был специальный интерфейс Native API, позволяющий зарегестрировать Внешнюю Компоненту. Все написал по примеру, но ничего не взлетало. Я подумал, что это из-за gcc. Все мои попытки поставить Visual Studio были провальны, то ничего не устанавливалось, то не хватало стандартных библиотек.
Уже засыпая мне в голову пришла гениальная гипотеза. Наверное данную проблему не могли не оставить питонисты, ведь на Питон разработно все, что вообще возможно. А-ля правило интернета 34, только по отношению к чудесному Python. И ведь я оказался прав!
Для python существует пакет win32com который позволяет регестрировать Python объекты, как COM объекты. Для меня это было какой то магией, ведь я даже не очень понимаю что такое COM объект, но знаю что он умеет в 1С.
Пакет pypiwin32 не нужно ставить с помощью pip, а скачать его установщик, т.к. почему-то объекты не регестрировались после установки pip'ом.
Разобравшись с небольшим примером, я взялся за разработку. Для начала нужно создать Объект с интерфейсом идентифицирующим COM-Объект в системе
```
class GtAlgoWrapper():
# com spec
_public_methods_ = ['solve','resultCallback', 'progressCallback',] # методы объекта
_public_attrs_ = ['version',] # атрибуты объекта
_readonly_attr_ = []
_reg_clsid_ = '{2234314F-F3F1-2341-5BA9-5FD1E58F1526}' # uuid объекта
_reg_progid_= 'GtAlgoWrapper' # id объекта
_reg_desc_ = 'COM Wrapper For GTAlgo' # описание объекта
def __init__(self):
self.version = '0.0.1'
self.progressOuterCb = None
# ...
def solve(self, data):
# ...
return ''
def resultCallback(self, obj):
# ...
return obj
def progressCallback(self, obj):
# в колбэк необходимо передавать 1С объект, в котором идет подключение
# например ЭтотОбъект или ЭтаФорма
if str(type(obj)) == "":
com\_obj = win32com.client.Dispatch(obj)
try:
# сохраним функцию из 1С (progressCallback) в отдельную переменную
self.progressOuterCb = com\_obj.progressCallback1C;
except AttributeError:
raise Exception('"progressCallback" не найден в переданном объекте')
return obj
```
и конечно опишем его регистрацию
```
def main():
import win32com.server.register
win32com.server.register.UseCommandLine(GtAlgoWrapper)
print('registred')
if __name__ == '__main__':
main()
```
Теперь при запуске данного скрипта в системе появится объект GtAlgoWrapper. Его вызов из 1С будет выглядеть вот так:
```
Функция progressCallback1C(знач, тип) Экспорт
Сообщить("значение = " + знач);
Сообщить("тип = " + тип);
КонецФункции
//...
Процедура Кнопка1Нажатие(Элемент)
//Создадим объект
ГТАлго = Новый COMОбъект("GtAlgoWrapper");
//Установим колбэки
ГТАлго.progressCalback(ЭтотОбъект);
//...
Данные = ...; // JSON строка
ГТАлго.solve(Данные);
КонецПроцедуры
```
Таким образом, все попадающие в колбэки даные можно будет обработать. Единственное, что может еще остаться непонятным — как передать данные из dll в 1C:
```
_dependencies = ['libwinpthread-1.dll',
'libgcc_s_dw2-1.dll',
# ...,
'GtRouting0-0-1.dll']
def solve(self, data):
prefix_path = 'C:/release'
# должны быть подключены все зависимые библиотеки
try:
for dep in self._dependencies:
ctypes.cdll.LoadLibrary(os.path.join(prefix_path, dep))
# запоминаем библиотеку с нужной нам точкой входа
lib = ctypes.cdll.LoadLibrary(os.path.join(prefix_path, 'GtAlgo0-0-1.dll'))
except WindowsError:
raise Exception('cant load' + dep)
solve_func = getattr(lib, '_ZN6GtAlgo5solveEPKcPFviS1_ES3_')
# создаем колбэки
StatusCallback = ctypes.CFUNCTYPE(None, ctypes.c_int, ctypes.c_char_p)
ResultCallback = ctypes.CFUNCTYPE(None, ctypes.c_int, ctypes.c_char_p)
scb_func = StatusCallback(self.progressOuterCb)
rcb_func = ResultCallback(self.resultOuterCb)
# колбэки 1C превратились в функции которые мы передадим в DLL. Magic!
if self.resultOuterCb is None:
raise Exception('resultCallback function is not Set')
if self.progressOuterCb is None:
raise Exception('progressCallback function is not Set')
# запустим алгоритм
solve_func(ctypes.c_char_p(data), scb_func, rcb_func)
```
Для успешной работы, в первую очередь требуется вызов python-скрипта, чтобы зарегистрировать класс GtAlgoWrapper, а затем уже можно смело запускать конфигурацию 1С.
Вот так просто можно связать dll библиотеку и 1C с помощью питона, не уползая в сильные дебри.
Всем Магии!
**Полезные ссылки**[docs.python.org/3/library/ctypes.html](https://docs.python.org/3/library/ctypes.html) — Пакет ctypes
[citforum.ru/book/cook/dll0.shtml](http://citforum.ru/book/cook/dll0.shtml) — Динамические библиотеки для чайников
[habrahabr.ru/post/191014](https://habrahabr.ru/post/191014/) — NativeAPI
[infostart.ru/public/115486](http://infostart.ru/public/115486/) — COM объект на C++
[infostart.ru/public/190166](https://infostart.ru/public/190166/) — COM объект на Python
[pastebin.com/EFLnnrfp](https://pastebin.com/EFLnnrfp) — Полный код скрипта на Python из статьи | https://habr.com/ru/post/332082/ | null | ru | null |
# Список вкладок и просмотр печати в Opera Developer 26
Сегодня у нас есть два вас интересная сборка Opera Developer 26. В ней впервые появляется список вкладок, предпросмотр печати и новые возможности по импорту данных. Обо всём по порядку.
#### Список вкладок

Теперь по сочетанию клавиш `Ctrl K` или `Cmd K` на OS X вы можете вызвать список открытых вкладок. Если вы открыли одновременно много вкладок (да ещё и на одном сайте), то это должно помочь найти нужную. Теперь:
* По заголовкам вкладок теперь удобно ориентироваться.
* Вызвать список и передвигаться по нему можно с клавиатуры (стрелками вверх-вниз).
* Список работает вместе со снимками вкладок: если задержаться ненадолго после открытия списка, то появится снимок выбранной вкладки.
* Список доступен в полноэкранном режиме, так что вы больше не потеряетесь, даже если вкладки скрыты.
#### Просмотр печати

Теперь вы можете просматривать документы перед печатью. Также это даёт возможность генерировать PDF прямо средствами браузера, поэтому результаты будут гораздо лучше. Вот, например, как печатает [презентацию на движке Shower](http://shwr.me) новая Opera Developer в сравнении с Safari:
Каждый слайд аккуратно лежит на своей странице нужного формата, а в Safari всё просто на A4. Происходит это потому, что Safari и другие браузеры не умеют обрабатывать директивы для печати, а новая Opera и Chrome умеют:
```
@page {
margin:0;
size:1024px 640px;
}
```
#### Импорт данных
В предыдущих релизах мы помогали новым пользователям перенести данные из других браузеров с помощью *тихого импорта* (то есть автоматически). Эта возможность так и не появилась в бетах и стабильной версии потому, что мы решили подумать над ней ещё. И вот мы надумали и сегодня эта возможность возвращается, но уже *не по-тихому,* а как часть процесса установки:
Кроме импорта, мы перенесли следующие вопросы пользователям в установщик, чтобы не доставать их после первого запуска:
* Make Opera the default browser
* Share usage data to help improve Opera
#### Обновляйтесь и делитесь впечатлениями
* [Opera Developer для Windows](http://net.geo.opera.com/opera/developer?utm_medium=sm&utm_source=desktop_blog&utm_campaign=developer) ([офлайн-пакет](http://www.opera.com/download/get/?partner=www&opsys=Windows&product=Opera%20Developer&utm_medium=sm&utm_source=desktop_blog&utm_campaign=developer))
* [Opera Developer для Mac](http://net.geo.opera.com/opera/developer/mac?utm_medium=sm&utm_source=desktop_blog&utm_campaign=developer)
* [Opera Developer для Linux](http://www.opera.com/download/get/?partner=www&opsys=Linux&product=Opera%20Developer&utm_medium=sm&utm_source=desktop_blog&utm_campaign=developer) | https://habr.com/ru/post/240741/ | null | ru | null |
# Unity3d, Агенты и Танчики

Всем доброго времени суток!
Еще в универе на старших курсах начал увлекаться интеллектуальными агентами. Даже тема для диплома изначально была связана с созданием агентов, участвующих в боевых действиях, в среде, имитирующей поле боя. Но из-за работы пришлось сменить тему.
Давно хотел этим заняться, но все времени не было. Сейчас наконец-то дошли руки сделать среду для агентов, хотя и не в таком масштабе. Так что если кому-нибудь интересно, присоединяйтесь! Репозитарий открытый, ссылка внизу.
##### Интеллектуальный агент.
Говоря простыми словами, агент — это сущность, помещенная в среду обитания, умеющая воспринимать среду с помощью датчиков и воздействовать на нее с помощью актуаторов.
Схема простейшего агента, как говорит википедия, выглядит так:

У такого агента нет никакого разума, он действует исключительно по списку простейших правил if-then. Есть несколько видов гораздо более сложных агентов, которые умеют анализировать свои действия и обучаться. Но до них мне еще далеко.
##### Unity3d
Я создал в Unity3d проект, в котором есть поле боя (квадрат) и несколько танков. Текстуры танков я взял из старой-доброй игры Battle City. Все, что умеет каждый танк — это ездить по полю и стрелять.
Так выглядит весь проект:

К каждому танку привязаны 2 управляющих скрипта:
— TankBehavior
— BasicTankControls (или его подкласс)
TankBehavior — это главный скрипт, который полностью описывает один танк. В этом скрипте реализованы методы перемещения, стрельбы и все остальные. Также этот скрипт содержит ссылку на BasicTankControls, в котором реализовано управление танком. Базовый скрипт выглядит так:
```
public class BasicTankControls : MonoBehaviour
{
public void Init(TankBehavior tank)
{
this.tank = tank;
}
public virtual void Act(List tanksData)
{
// no operation
}
protected TankBehavior tank;
}
```
Так происходит инициализация скрипта-управления в скрипте TankBehavior:
```
void Start ()
{
...
controls = GetComponent();
if(controls != null)
{
controls.Init(this);
}
...
}
```
Этот метод вызывается каждый физический тик:
```
void FixedUpdate()
{
if(controls != null)
{
GameObject[] tankObjects = GameObject.FindGameObjectsWithTag("Tank");
List tanksData = new List();
foreach (var item in tankObjects)
{
if (item.GetInstanceID() != this.GetInstanceID())
{
tanksData.Add(item.GetComponent().GetData());
}
}
controls.Act(tanksData);
}
}
```
Сначала собираются данные обо всех танках на поле. Таким образом имитируется сбор информации о среде датчиками агента. Затем эта информация передается скрипту-управлению, который уже на основе полученных данных будет оказывать воздействие на среду.
Данные об одном танке выглядят так:
```
public class TankData
{
public TankData(int instanceId, Vector2 position, float health, Direction direction)
{
this.InstanceID = instanceId;
this.Position = position;
this.Health = health;
this.Direction = direction;
}
public readonly int InstanceID;
public readonly Vector2 Position;
public readonly float Health;
public readonly Direction Direction;
}
```
Вот в принципе и все. Теперь задача состоит лишь в том, чтобы написать для танков управляющий скрипт. Я написал один скрипт для управления человеком, если вдруг кто-нибудь захочет вмешаться в ход событий:
```
public class HumanControls : BasicTankControls
{
public override void Act(List tanksData)
{
if(Input.GetButton("Up"))
{
tank.MoveForward();
}
else if (Input.GetButton("Down"))
{
tank.MoveBackward();
}
if (Input.GetButtonDown("Left"))
{
tank.RotateLeft();
}
else if (Input.GetButtonDown("Right"))
{
tank.RotateRight();
}
if (Input.GetButton("Fire"))
{
tank.Fire();
}
}
}
```
##### Поведения танков
Для начала планирую сделать простейшие автономные поведения, например ездить и стрелять в случайные стороны. Потом есть идея добавить стены (может быть, разрушаемые) и тот самый штаб, который одним нужно защищать, а другим разрушить. Может быть, даже будет совместное планирование действий.
Но это очень оптимистичные планы. Сам еще такого никогда не писал, так что придется изучать. Любая помощь и советы приветствуются! :)
[Ссылка](https://bitbucket.org/esin/unityagents) на репозитарий. | https://habr.com/ru/post/151057/ | null | ru | null |
# Самодельный автономный летающий аппарат из Android смартфона

Развлекаться с автономным летательным аппаратом – это, конечно, весело, но создавать их самому еще интереснее! Эта статья адресована тем, кто хочет разработать свой собственный интеллектуальный коптер и содержит набор простых инструкций, как достичь результата с использованием смартфона на Android, OpenCV, C++ и Java. Ну а если вы сможете пройти первые шаги и пожелаете далее совершенствовать свой аппарат – в конце поста вы найдете полезную ссылку и пищу для размышления.
#### Автономный и интеллектуальный?
Для того, чтобы коптер мог самостоятельно летать, он должен включать в себя все необходимые сенсоры, достаточную вычислительную мощность и средства коммуникации. Вроде бы, не так уж и много, однако практически у всех из доступных коммерческих моделей этого нет. Существуют, скажем, модели, движение которых определяют датчики, расположенные в помещении. Другой вариант – управление через GPS. GPS приемник дешев и прост в использовании, но обладает большими задержками в поступлении данных и недостаточно точен. Все это нам не годится.
Чтобы носить звание «интеллектуального» ваш коптер должен уметь воспринимать и анализировать окружающую действительность. Это требует не только мощного процессора, емкого аккумулятора, качественной камеры и достаточного набора датчиков, но и быстрых коммуникационных устройств. Ну и конечно, вся эта система должна хорошо управляться и просто программироваться. Так мы приходим к мысли: а не реализовать ли мозговой центр коптера на базе смартфона? Удобнее всего использовать устройство на базе Android, поскольку под эту ОС имеются удобные средства разработки и программные компоненты, такие, например, как Intel Integrated Performance Primitives (Intel IPP) или OpenCV. Современный смартфон имеет все нужные нам аппаратные компоненты, поэтому изобретать велосипед совершенно нет необходимости.
#### Управление моторами
Итак, центр управления выбран, теперь надо подключить к нему моторы. Мы выбрали [Pololu Maestro servo controller](http://www.pololu.com/product/1350/) стоимостью порядка 5 долларов, он подключается по USB и вдобавок имеет Bluetooth интерфейс. С помощью этой карты будут управляться стандартные серво приводы. С помощью Pololu Maestro servo controller и смартфона сравнительно несложно переделать управляемый летательный аппарат в автономный.

С помощью нескольких строк кода и стандартных Android USB средств мы будем контролировать серво моторы и, таким образом, движение коптера. Еще несколько строк кода – и мы получим доступ к GPS, камере и передаче данных по сети.
Вызовем controlTransfer из UsbDeviceConnection:
```
import android.hardware.usb.UsbDeviceConnection;
// …
private UsbDeviceConnection connection;
// …
connection.controlTransfer(0x40, command, value, channel, null, 0, 5000);
```
Контроллер позволяет управлять серво приводами, устанавливая конечную позицию, скорость и ускорение – все, что нужно для плавного перемещения. Аргумент command может принимать одно из трех значений:
```
public static final int USB_SET_POSITION = 0x85;
public static final int USB_SET_SPEED = 0x87;
public static final int USB_SET_ACCELERATION = 0x89;
```
Выберите подходящие значения и передайте их на нужный серво мотор, используя аргумент channel. Ссылка на полный исходный код и конфигурацию USB доступа в манифесте приложения приведена в конце поста.
#### Особенности квадрокоптеров
До сих пор все идет хорошо. Аппаратные компоненты подключаются друг к другу без проблем, программирование несложно, поскольку все реализуется средствами Android. Однако тут есть одна особенность, связанная с конструированием квадрокоптера. В отличие от более простых моделей, таких как автомобиль или самолет, квадрокоптер должен постоянно следить за своей устойчивостью. Вот почему его необходимым компонентом является модуль стабилизации. Конечно, стабилизатор можно сделать программным, написав кучу кода на C++ или Java. Но гораздо проще купить за несколько долларов карту-стабилизатор, подключаемую непосредственно к Pololu и управляющую четырьмя серво приводами устройства. Всё остальное можно сделать с помощью простых команд типа ± altitude, ± speed/, ± inclination и ± direction.
Если вы создаете квадрокоптер, имейте в виду: эта карта здорово упростит вам жизнь. Все, что вам требуется – провести ее начальную калибровку и потом забыть о ней.
#### Собираем все воедино
Итак, в результате первого этапа конструирования автономного квадрокоптера, мы имеем следующую аппаратную цепочку:
*смартфон <> micro USB-USB адаптер <> кабель USB-mini USB <> Pololu Maestro card <> 4 кабеля JR <> карта стабилизации <> кабели JR <> серво приводы <> двигатели*

В случае более простого устройства цепочка будет покороче:
*смартфон <> micro USB-USB адаптер <> кабель USB-mini USB <> Pololu Maestro card <> кабели JR <> серво приводы <> двигатели*

В дополнение вы можете установить и другие приводы на ваше летающее устройство, например, для закрылков или посадочных шасси. Карта Pololu Maestro имеет поддержку управления до 24 приводов – для нашего проекта это, наверное, даже лишнего.
Базовая платформа создана. Теперь пришло время оснастить наше устройство зрением.
#### Компьютерное зрение
Очевидно, что без системы компьютерного зрения интеллектуальное устройство не может считаться таковым. Наш коптер должен уметь не просто снимать фото, но и анализировать их – для этого воспользуемся возможностями OpenCV.
[OpenCV](http://opencv.org/) – это open source библиотека для программного анализа изображений, лежащая в основе бесчисленных реализаций систем компьютерного зрения и виртуальной реальности. Изначально разработанная Intel, сейчас она доступна для множества аппаратных платформ и ОС.
Для практики попробуем распознать простой знак в виде круга и расположиться перед этим знаком на определенной дистанции. Чтобы упростить тестовое задание, перемещать смартфон будем рукой.

OpenCV не является библиотекой, напрямую доступной Java под Android. Это нативная библиотека, обычно используемая из программ на С++, так что нам понадобится Android NDK. Съемка изображений и визуализация будет выполнена на Java, для взаимодействия между Java и C++ будем использовать JNI. Нам придется установить Android NDK и Android SDK, создать новый проект Circles, добавить компонент C/ C++ и изменить свойства проекта для использования библиотеки OpenCV, как показано на скриншотах ниже:

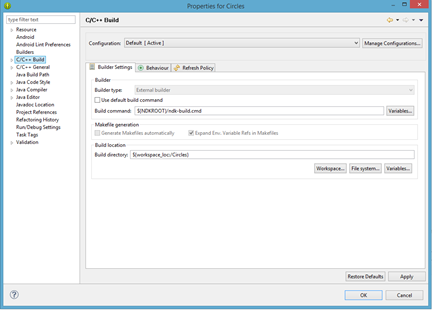

В результате, в вашем проекте будут:
*Основной Java файл « Src/MainActivity.java »
Файл разметки XML « Res/layout/activity\_main.xml » и манифест
Два Makefile « Jni/Android.mk » and « Jni/Application.mk »
Код cpp « Jni/ComputerVision\_jni.cpp » и хедер « Jni/ComputerVision\_jni.h »*
В отличие от Java, C++ должен быть скомпилирован под определенный процессор. Настройка производится путем редактирования переменной APP\_ABI в файле Application.mk. Если у вас смартфон на платформе Intel, корректным значением будет x86. Дальше NDK все сделает сам.
#### Развертывание
OpenCV – библиотека, используемая бесконечным количеством Android приложений, при этом версия библиотеки ими может использоваться разная. Как разработчик, вы можете связать свое приложение с конкретной версией OpenCV, но есть вариант получше. Воспользуйтесь менеджером зависимостей под названием «OpenCV Manager». Это Android приложение, которое определяет, что вам сейчас потребуется OpenCV и загружает именно ту версию, которая необходима.
Мы хотим обнаружить круги в OpenCV, определить их центр и радиус и вывести инструкции оператору смартфона для достижения центрированного круга правильного размера. Следующий Java код получает изображение с камеры с помощью Java API для Android, вызывает функцию на С++ через JNI и прикрепляет указатель на изображение в памяти. Код С++ осуществляет обработку изображения с целью обнаружить круги. Далее опять вызывается Java, чтобы отобразить обнаруженные круги и комментарии.
Код Java:
```
…
// capture images from the camera
import org.opencv.Android.CameraBridgeViewBase;
// load OpenCV native dependancy
import org.opencv.Android.OpenCVLoader;
…
public void onResume()
{
super.onResume();
// OpenCV loading with a callback
// non typical code specific to OpenCV
OpenCVLoader.initAsync(OpenCVLoader.OPENCV_VERSION_2_4_6, this, mLoaderCallback);
}
…
// once the OpenCV manager link established,
// we can load the dynamic library
System.loadLibrary("jni_part");
…
```
Код С++
```
…
// typical for JNI : Java class method name
// pointer to RGB image as argument
JNIEXPORT int JNICALL Java_com_example_circles_MainActivity_process
(JNIEnv *jenv, jobject obj, jlong addrGray, jlong addrRgba)
…
// Get the bitmap from pointer
Mat& mRgb = *(Mat*)addrRgba;
// blur, required before detecting circles
medianBlur(mGr,mGr,5);
// OpenCV detection – Hough transformation
HoughCircles(mGr, //grayscale input image
*circles, //output vector
CV_HOUGH_GRADIENT, //detection method to use
4, //inverse ratio of the accumulator resolution to the image
mGr.rows/8, //min distance between centers of detected circles
220, //higher threshold of the two passed intern canny edge detector
200, //accumulator threshold 100
20, //min radius
mGr.cols/8 //max radius
);
```
Для теста я перемещал смартфон перед листом бумаги с напечатанным кругом. Допустим, с расстояния 20 см изображение круга будет иметь размер 300 пикселей – будем считать это правильным положением. Если круг меньше, смартфон надо пододвинуть ближе, если больше – то дальше. Это самый простой вариант. Можно использовать два концентрических круга, больший для навигации на дальнем расстоянии, меньший – на ближнем. Ничто не мешает распознавать и другие специфические фигуры, например, стрелки. В конечном счете мы должны получить систему, использующую как данные GPS, так и цветовую информацию с камеры.
#### Планы на будущее
Установите OpenCV Manager и ваш APK файл из Eclipse. Запустите его и пройдите все шаги настройки. Оно будет определять круги в поле зрения и руководить перемещением смартфона в центр круга заданного диаметра.
На тестовом смартфоне мы получали и обрабатывали снимок каждые 8 сотых секунды – 12.5 кадров в секунду. Это доказывает, что компьютерное зрение для коптера – вещь совершенно реальная даже при ограниченных временных и финансовых ресурсах.
Возможности дальнейшего развития очень широки. OpenCV – это open source библиотека, портированная на многие платформы. Вдобавок, Intel IPP заменяет некоторые низкоуровневые вызовы OpenCV и ускоряет ваш код, вставляя функции, хорошо оптимизированные под процессоры Intel. Вы можете сохранить переносимость кода – в дальнейшем, возможно, вам понадобится более мощный смартфон.
Ну а что делать дальше – вам подскажут [материалы с сайта Intel](http://intel-software-academic-program.com/pages/courses#drones). Там написано очень подробно, как самому построить летающий аппарат и чему его научить.
Теперь некоторые более конкретные ссылки:
* [Оригинал этой статьи на английском в PDF](http://intel-software-academic-program.com/courses/diy/Intel_Academic_-_DIY_-_Drone/IntelAcademic_DIY_Smart_Autonomous_Drone_White_Paper.pdf)
* [Исходный код коптера](http://intel-software-academic-program.com/courses/diy/Intel_Academic_-_DIY_-_Drone/IntelAcademic_DIY_Smart_Autonomous_Drone_White_Paper.zip)
* [Тестовый АРК](http://intel-software-academic-program.com/courses/diy/Intel_Academic_-_DIY_-_Drone/IntelAcademic_DIY_Smart_Autonomous_Drone_White_Paper.apk) | https://habr.com/ru/post/230299/ | null | ru | null |
# Оптимизации системы разделения прав доступа в веб-приложении
После написания прошлой статьи про [реализацию системы разделения прав доступа в веб-приложении](http://habrahabr.ru/blogs/webdev/51327/), появилось множество интересных комментариев. В них в основном велись споры о том, что можно сделать её ещё лучше.
В действительности, система сейчас не является оптимизированной и не может использоваться на серверах с высокой посещаемостью (так как, прошлая статья писалась больше для ознакомления).
Давайте попробуем это исправить.
В этой статье я рассмотрю:
1. Битовые поля, оптимизация
2. Serialize с денормализацией таблиц БД
3. Вы узнаете, как работает система, подобная Zend ACL
### На чём мы остановились
Остановились мы на том, что для каждого объекта в базе данных у нас хранятся права для конкретного действия пользователем или группой.
Наглядно это выглядит в виде двухмерной таблицы (действие, группа):
| | | | | |
| --- | --- | --- | --- | --- |
| | message\_view | message\_create | message\_delete | message\_edit |
| User21 | + | + | | + |
| Ban | - | - | - | - |
| Users | + | | | |
| Admin | + | + | + | + |
Первое, что пришло в голову, возможность объединения битов для каждого пользователя в группы.
### Превращение первое. Использование битовых масок.
Пользователей и групп у нас может быть сколько угодно. А количество действий с объектом у нас постоянное.
Следовательно, можно записывать в БД сразу все действия для конкретного пользователя в виде двоичной маски.
Вместо плюсов будут 1, отсутствие действия 0.
#### Что мы выигрываем?
Разнообразных действий в веб-приложении обычно не превышает более 64. Следовательно, для большинства случаев, 64 бита будет более чем достаточно. (8 байт)
Для сравнения, каждая ячейка такой базы данных будет занимать по 40 байт. Это столько же, как и если мы будем хранить каждое действие отдельно, только в этом случае, у нас будет несколько записей на одного пользователя. Экономия на лицо :)
Новая таблица будет выглядеть теперь так:
| | | |
| --- | --- | --- |
| | allow | disallow |
| User21 | 1101 | 0000 |
| Ban | 0000 | 1111 |
| Users | 1000 | 0000 |
| Admin | 1111 | 0000 |
Стало менее наглядно для человека, но более наглядно для компьютера.
Теперь наша (описанная в прошлой статье) база данных выглядит:
| rights\_action |
| --- |
| ObjectRightsID: INT(pk) | UserGroupID: INT(fk) | Allow: VARBINARY(4) | Disallow: VARBINARY(4) |
| rights\_group (устанавливает группы пользователям) |
| UserRightsID: INT(pk) | UserGroupID: INT |
При объединении прав подобъектов с глобальными категориями объектов, можно пользоваться простыми OR (A|B для allow) и SUB (A&!B для disallow) операциями.
Теперь разберемся с проблемами интерфейса для программиста, чтобы биты у нас в программе не запутались.
Введем определение бита для действия:
> `public $actions=array();
>
>
>
> /\* SetAction
>
> Добавить новое действие
>
>
>
> @param {string} ActionName - имя действия
>
> @param {int} bitNumber - номер бита в БД
>
> @return {Object ObjRights} - объект с установленными действиями
>
> \*/
>
> public function SetAction($ActionName, $bitNumber){
>
> //проверяем использование бита
>
> if (array\_search($bitNumber, $this->actions))
>
> return false;
>
> //проверяем использование имени
>
> if (isset($this->actions[$ActionName]))
>
> return false;
>
> //Клонируем и добавляем новый бит
>
> $clone = clone $this;
>
> $clone->actions[$ActionName]=$bitNumber;
>
>
>
> return $clone;
>
> }`
Произведем небольшой Рефакторинг класса из прошлой статьи. Во первых разделим классы пользователя и действий. Это необходимо потому, что действия у нас не должны быть связанны с пользователем, но они будут привязаны к объектам. (Например, у объектов сообщений будут действия чтения, удаления, редактирования. У объектов учётных записей — действия объединения, просмотра итд)
#### Что делать, чтобы биты действий не пересекались?
В случае, когда каждое действие определялось не номером бита, а строкой (например 'message\_view'), всё было для программистов совершенно ясно. Была определенная договорённость (например определять действия **Название объекта\_название действия**), что давало ясность, к какому объекту это принадлежит и множественные варианты для отсутствия пересечения.
Чтобы сохранить совместимость в БД, можно использовать, либо отдельную общую БД **Тип объекта->действие->номер бита**, либо договориться для этого использовать один файл на всех.
Я приведу пример такого файла:
> `//Создаём новый объект прав для использования в объектах сообщения
>
> $MessageRights=new ObjRights();
>
>
>
> //добавляем возможные действия с этими объектами
>
> $MessageRights=$MessageRights->SetAction('message\_view',1)->SetAction('message\_read',2)->SetAction('message\_edit',3)->SetAction('message\_delete',4)->SetAction('message\_create',5);
>
>
>
> //Комментарии в сообщениях
>
> $MessageRights=$MessageRights->SetAction('comment\_view',6)->SetAction('comment\_create',7)->SetAction('comment\_delete',8);
>
>
>
> //Пользователи... Здесь нам не нужны работы с комментариями, по этому используем своё поле действий.
>
> //Создаём новый объект прав для использования в объектах пользователей
>
> $UserRights=new ObjRights();
>
>
>
> $UserRights=$UserRights->SetAction('user\_edit',1)->SetAction('user\_delete',2)->SetAction('user\_create',3);`
Теперь пришло время разобраться с нашими пользователями и получить готовую, рабочую программу.
В случае пользователей ничего не меняется. Единственное изменение, что нам необходимо будет использовать объект прав пользователей для разных классов отдельно.
> `//Класс прав для пользователя
>
> class UsrRights{
>
> public $groupID=array();
>
> function \_\_construct($rightsID){
>
> //Чтение из базы данных прав пользователя (ролей) групп, к которым пользователь принадлежит
>
> $result=mysql\_query("SELECT `group\_rights`.groupID FROM `group\_rights` WHERE `group\_rights`.rightsID = $rightsID");
>
>
>
> $this->groupID = array();
>
> while ($t=mysql\_fetch\_assoc($result)){
>
> //Считываем все ID групп
>
> $this->groupID[] = $t['groupID'];
>
> }
>
> mysql\_free\_result($result);
>
> }
>
> }
>
>
>
> //Класс соответствия прав и действий для объектов
>
> class ObjRights{
>
> public $actions=array();
>
> public $groupallow=array(),$groupdisallow=array();
>
> /\* SetAction
>
> Добавить новое действие
>
>
>
> @param {string} ActionName - имя действия
>
> @param {int} bitNumber - номер бита в БД
>
> @return {Object ObjRights} - объект с установленными действиями
>
> \*/
>
> public function SetAction($ActionName, $bitNumber){
>
> //проверяем использование бита
>
> if (array\_search($bitNumber, $this->actions))
>
> return false;
>
> //проверяем использование имени
>
> if (isset($this->actions[$ActionName]))
>
> return false;
>
> //Клонируем и добавляем новый бит
>
> $clone = clone $this;
>
> $clone->actions[$ActionName]=$bitNumber;
>
>
>
> return $clone;
>
> }
>
>
>
> /\* include\_right
>
> Добавить все права подобъекта
>
>
>
> @param {int} RightsID - идентификатор права
>
> @return {Object ObjRights} - объект с установленными правами
>
> \*/
>
> public function include\_right($RightsID){
>
> $clone=clone $this;
>
> $result=mysql\_query("SELECT \* FROM `action\_rights` WHERE `action\_rights`.rightsID = $RightsID");
>
> while ($t=mysql\_fetch\_assoc($result)){
>
> //Добавляем к каждой группе новые права
>
> $clone->calculate\_allow($t['groupID'],$t['allow'],$t['disallow']);
>
> }
>
> mysql\_free\_result($result);
>
>
>
> return $clone;
>
> }
>
>
>
> /\* calculate\_allow
>
> Изменяет права определенной группы, добавляя новые способности
>
>
>
> @param {int} GroupID - идентификатор группы
>
> @param {string} AllowMask - двоичная маска допустимых действий для группы
>
> @param {string} DisallowMask - двоичная маска не допустимых действий для группы
>
> \*/
>
> private function calculate\_allow($GroupID, $AllowMask, $DisallowMask){
>
> if (isset($this->groupallow[$GroupID])){
>
> //Длина - меньшее из масок - для совместимости
>
> $len=min(strlen($this->groupallow[$GroupID]),strlen($AllowMask));
>
> for ($i=0;$i<$len;$i++)
>
> //Allow |= Mask
>
> $this->groupallow[$GroupID]{$i}=chr(ord($this->groupallow[$GroupID]{$i})|ord($AllowMask{$i}));
>
>
>
> //Длина - меньшее из масок - для совместимости
>
> $len=min(strlen($this->groupdisallow[$GroupID]),strlen($DisallowMask));
>
> for ($i=0;$i<$len;$i++)
>
> //Disallow |= Mask
>
> $this->groupdisallow[$GroupID]{$i}=chr(ord($this->groupdisallow[$GroupID]{$i})|ord($DisallowMask{$i}));
>
> }else{
>
> $this->groupallow[$GroupID]=$AllowMask;
>
> $this->groupdisallow[$GroupID]=$DisallowMask;
>
> }
>
> }
>
> /\* isAllow
>
> Проверяет группы пользователя и выдаёт разрешение на определенное действие над объектом
>
>
>
> @param {Object UsrRights} UserRights - идентификатор групп, в которых находится пользователь
>
> @param {string} ActionName - название действия
>
> @return {bool} - может ли пользователь сделать заданное действие?
>
> \*/
>
> public function isAllow($UserRights, $ActionName){
>
> //Существует имя?
>
> if (!isset($this->actions[$ActionName]))
>
> return false;
>
> //Берет номер бита по имени
>
> $Actionbit=$this->actions[$ActionName];
>
>
>
> foreach ($UserRights->groupID as $grpname){
>
> //Проверяем каждую группу
>
> if ($this->checkgrp($grpname,$Actionbit))
>
> //Если хоть в одной есть разрешение, то всё хорошо
>
> return true;
>
> }
>
> return false;
>
> }
>
>
>
> /\* checkgrp
>
> Проверяет бит в группе объекта
>
>
>
> @param {int} GroupID - идентификатор группы
>
> @param {int} bit - номер бита
>
> @return {bool} - может ли заданная группа сделать заданное действие
>
> \*/
>
> private function checkgrp($GroupID, $bit){
>
> //Есть ли группа?
>
> if (isset($this->groupallow[$GroupID])){
>
> //проверяем само действие Allow & NOT Disallow & bit
>
> if ((ord($this->groupallow[$GroupID]{$bit>>3})&(~ord($this->groupdisallow[$GroupID]{$bit>>3}))&(1<<($bit&7)))!=0){
>
> return true;
>
> }
>
> }
>
> return false;
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Использовать данную библиотеку просто. Необходимо сначала распределить допустимые права по классам объектов (пример выше), а затем инициализировав пользователя (меня его идентификатор на группы прав), проверять его с необходимыми правами в объекте:
> `//установка бит действий
>
> $MessageRights = new ObjRights();
>
> $MessageRights = $MessageRights->SetAction('message\_view',0)->
>
> SetAction('message\_read',1)->
>
> SetAction('message\_edit',2)->
>
> SetAction('message\_delete',3)->
>
> SetAction('message\_create',4);
>
> //...
>
>
>
> //получаем все права пользователя (роли)
>
> $CurrentUserRights = new UseRights($CurrentUser->rightsID);
>
>
>
> //...
>
>
>
> //Добавляем права объекта, с которыми должен иметь дело пользователь.
>
> $PageRights = $MessageRights->include\_right($MainPage->rightsID);
>
>
>
> //Проверяем, может ли пользователь просматривать страницу?
>
> if ($PageRights->isAllow($CurrentUserRights,'message\_view')){
>
> //Да, может. Но что делать с сообщениями?
>
>
>
> //Пройдемся по каждому из них
>
> foreach($MainPage->Messages as $msg){
>
> //Добавляем к правам страницы (parent), личные права сообщения (child)
>
> $MsgRights = $PageRights->include\_right($msg->rightsID);
>
>
>
> //И проверяем на читаемость
>
> if ($MsgRights->isAllow($CurrentUserRights,'message\_view')){
>
> //И если оно читается, проверяем можем ли мы редактировать сообщения?
>
> if ($MsgRights->isAllow($CurrentUserRights,'message\_edit'))
>
> $msg->editable\_flag = 1;
>
> //А удалять сообщения?
>
> if ($MsgRights->isAllow($CurrentUserRights,'message\_delete'))
>
> $msg->delete\_flag = 1;
>
>
>
> DrawMessage($msg);
>
> }
>
> }
>
> }`
В результате, по сравнению с примером из первой статьи, мы в несколько раз ускорили доступ к БД и уменьшили количество обращений.
Но можно ли ещё быстрее?
Да, можно сделать ещё несколько оптимизаций кода, но я не буду, чтобы не терять наглядности (и так кода слишком много навалилось :) ).
Мы пойдём просто другим путём, улучшив алгоритм…
### Превращение второе. Получение готовых PHP-объектов из БД.
Сейчас мы поговорим о том, как оптимизируют свой код строители сайтов с большой посещаемостью пользователей.
Создатели PHP создали две функции, с помощью которых можно сохранить и получить готовые структуры(массивы, объекты) данных.
Это функции serialize и unserialize.
#### А чем они нам помогут?
Сейчас в нашем коде, при выборке каждого сообщения (объекта), имеющего (неизменные) свои права, происходит дополнительная выборка из таблицы rights\_action. Для каждого объекта — эта выборка получается одинаковой, пока мы не решим её изменить (добавив новые права объекту). За одно изменение прав нашего объекта, происходит более тысячи/миллионы считываний.
Зачем выполняется несколько лишних преобразований в необходимый нам формат. Так происходит каждое считывание. Таким образом, это можно сделать всего один раз (при генерации/изменении прав) и сохранить готовый результат. Для сохранения результата, и востановления нам помогут функции serialize/unserialize.
Доработаем нашу библиотеку:
> `public function include\_right($grp){
>
> //создаём ещё один такой объект (child)
>
> $clone=clone $this;
>
>
>
> //результат у нас выглядит, как готовая выборка
>
> $result=unserialize($grp);
>
>
>
> //результат лежит как array('GroupID'=>array('allow\_bits','disallow\_bits'),'GroupID2'=>array('allow\_bits','disallow\_bits'),...)
>
> foreach ($result as $groupID=>$allow)
>
> //проходимся по каждой группе, добавляя результаты к клону
>
> $clone->include\_action($groupID,$allow[0],$allow[1]);
>
>
>
> return $clone;
>
> }`
Стало проще и нагляднее!
Правда в этом случае, у нас появляется проблема изменения прав (для каждой маски). Попробуем написать функции для этого:
> `public function export\_object\_rights(){
>
> return serialize($this->selfrights);
>
> }
>
>
>
> public function allow\_group($GroupID, $ActionName){
>
> if (!isset($this->actions[$ActionName]))
>
> return false;
>
> $bit=$this->actions[$ActionName];
>
>
>
> if (isset($this->groupallow[$GroupID])){
>
> $this->groupallow[$GroupID]{$bit>>3}|=(1<<($bit&8));
>
> }else{
>
> $this->groupallow[$GroupID]{$bit>>3}=(1<<($bit&8));
>
> for ($i=0;$i<($bit>>3);$i++)
>
> $this->groupallow[$GroupID]{$i}=chr(0);
>
> }
>
>
>
> if (isset($this->selfrights[$GroupID])){
>
> $this->selfrights[$GroupID][0]{$bit>>3}|=(1<<($bit&8));
>
> }else{
>
> $this->selfrights[$GroupID]=array();
>
> $this->selfrights[$GroupID][0]{$bit>>3}=(1<<($bit&8));
>
> for ($i=0;$i<($bit>>3);$i++)
>
> $this->selfrights[$GroupID][0]{$i}=chr(0);
>
> $this->selfrights[$GroupID][1]="";
>
> }
>
> }
>
>
>
> public function reset\_group($GroupID, $ActionName){
>
> if (!isset($this->actions[$ActionName]))
>
> return false;
>
> $bit=$this->actions[$ActionName];
>
>
>
> if (isset($this->groupallow[$GroupID])){
>
> $this->groupallow[$GroupID]{$bit>>3}&=255^(1<<($bit&8));
>
> }
>
>
>
> if (isset($this->groupdisallow[$GroupID])){
>
> $this->groupdisallow[$GroupID]{$bit>>3}&=255^(1<<($bit&8));
>
> }
>
>
>
> if (isset($this->selfrights[$GroupID])){
>
> $this->selfrights[$GroupID][0]{$bit>>3}&=255^(1<<($bit&8));
>
> $this->selfrights[$GroupID][1]{$bit>>3}&=255^(1<<($bit&8));
>
>
>
> $nul=true;
>
> for ($i=0;$i
> if (selfrights[$GroupID][0]{$i})
>
> $nul=false;
>
>
>
> for ($i=0;$i
> if (selfrights[$GroupID][1]{$i})
>
> $nul=false;
>
>
>
> if ($nul)
>
> unset(selfrights[$GroupID]);
>
> }
>
> }
>
>
>
> public function disallow\_group($GroupID, $ActionName){
>
> if (!isset($this->actions[$ActionName]))
>
> return false;
>
> $bit=$this->actions[$ActionName];
>
>
>
> if (isset($this->groupdisallow[$GroupID])){
>
> $this->groupdisallow[$GroupID]{$bit>>3}|=(1<<($bit&8));
>
> }else{
>
> $this->groupdisallow[$GroupID]{$bit>>3}=(1<<($bit&8));
>
> for ($i=0;$i<($bit>>3);$i++)
>
> $this->groupallow[$GroupID]{$i}=chr(0);
>
> }
>
>
>
> if (isset($this->selfrights[$GroupID])){
>
> $this->selfrights[$GroupID][1]{$bit>>3}|=(1<<($bit&8));
>
> }else{
>
> $this->selfrights[$GroupID]=array();
>
> $this->selfrights[$GroupID][1]{$bit>>3}=(1<<($bit&8));
>
> for ($i=0;$i<($bit>>3);$i++)
>
> $this->selfrights[$GroupID][1]{$i}=chr(0);
>
> $this->selfrights[$GroupID][0]="";
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Жутковато выглядит, не правда-Ли? Я даже не проверял данный код :), я просто испугался — настолько всё жутко. Такой код красным по белому говорит нам о том, что что-то в архитектуре не так.
Предлагаю отрезать лишние и ненужные нам хвосты! Сделать код читаемым и более универсальным.
#### Режим лишние хвосты!
Наша структура сейчас выглядит так:
array(/\*GroupID\*/ 1 => array (allow => 0b100101000100100010 /\*биты\*/, disallow => 0b100010010000010001010), 4 => ...)
В этом виде с ней происходит serialize и она записывается в объект.
Но, во первых, сложно работать с действиями (приходится добавлять новые, редактируя PHP-файл).
Во вторых, вести поиск по битам не так легко. А давайте попробуем вернуться к первоначальному варианту, рассмотренному в предыдущей статье.
То есть теперь права доступа будут выглядеть так:
array(/\*GroupID\*/ 1 => array (/\*Actions\*/ 'message\_read' => 1 /\*+\*/, 'message\_edit' => 0 /\*-\*/), 4 => ...)
За счёт этого:
1) Поиск нужного действия происходит одной командой $array[GroupID][ActionName]. (уверен, что это поможет ускорить процесс поиска)
2) Нет необходимости добавление действий. Все они будут хранится у нас в объекте.
3) Выборка будет происходить одним циклом, только по группам пользователя.
4) Сами группы пользователей могут принять человеческий вид.
Единственный наглядный минус — структура будет занимать больше места. Плохо? Да, но в оптимизации всегда так — либо нагрузка на CPU, либо объемы памяти. Да и памяти БД оно съест не сильно много, по этому приступаем.
> `//Класс соответствия прав и действий для объектов
>
> class ObjRights{
>
> public $groups=array();
>
> public $selfgroups=array();
>
>
>
> /\*Главные функции работы с объектами\*/
>
>
>
> /\* include\_right
>
> Добавить все права подобъекта
>
>
>
> @param {serialize array} RightsID - права объекта массивом
>
> @return {Object ObjRights} - объект с установленными правами
>
> \*/
>
> public function include\_right($RightsID){
>
> $clone=clone $this;
>
>
>
> //Вместо дополнительных SQL-запросов, просто уже имеет готовый двухмерный массив
>
> $clone->selfgroups = unserialize($RightsID);
>
>
>
> foreach ($clone->selfgroups as $groupID=>$actions){
>
> if (isset($clone->groups[$groupID])){
>
> //Если группа присутствует, изменяем правила для действий в данной группе
>
> foreach ($actions as $actname=>$allow){
>
> if (isset($clone->groups[$groupID][$actname]))
>
> // 1 - allow, 0 - disallow
>
> $clone->groups[$groupID][$actname]&=$allow;
>
> else
>
> $clone->groups[$groupID][$actname]=$allow;
>
> }
>
> }else
>
> //Если группа отсутствует, добавляем такую группу
>
> $clone->groups[$groupID]=$actions;
>
>
>
> }
>
>
>
> return $clone;
>
> }
>
>
>
> /\* isAllow
>
> Проверяет группы пользователя и выдаёт разрешение на определенное действие над объектом
>
>
>
> @param {array} UserRights - идентификатор групп, в которых находится пользователь
>
> @param {string} ActionName - название действия
>
> @return {bool} - может ли пользователь сделать заданное действие?
>
> \*/
>
> public function isAllow($UserRights, $ActionName){
>
>
>
> foreach ($UserRights as $groupname){
>
> //Проверяем каждую группу
>
> if (isset ($this->groups[$groupname]) &&
>
> isset ($this->groups[$groupname][$ActionName]) &&
>
> $this->groups[$groupname][$ActionName])
>
> return true;
>
> }
>
> return false;
>
> }
>
>
>
> /\* export\_rights
>
> Возвращает права объекта в формате для БД. (serialize array)
>
>
>
> @return {string} - serialize array
>
> \*/
>
> public function export\_rights(){
>
> return serialize($this->selfgroups);
>
> }
>
>
>
>
>
> /\*Функции работы с правами объекта\*/
>
>
>
> /\* allow
>
> Устанавливает права объекту на определенное действие
>
>
>
> @param {int} GroupID - идентификатор группы
>
> @param {string} ActionName - название действия
>
> \*/
>
> public function allow($GroupID, $ActionName){
>
> if (!isset($this->selfgroups[$GroupID]))
>
> $this->selfgroups[$GroupID]=array();
>
> $this->selfgroups[$GroupID][$ActionName] = 1;
>
> }
>
>
>
> /\* disallow
>
> Устанавливает запрещенные права объекту на определенное действие
>
>
>
> @param {int} GroupID - идентификатор группы
>
> @param {string} ActionName - название действия
>
> \*/
>
> public function disallow($GroupID, $ActionName){
>
> if (!isset($this->selfgroups[$GroupID]))
>
> $this->selfgroups[$GroupID]=array();
>
> $this->selfgroups[$GroupID][$ActionName] = 0;
>
> }
>
>
>
> /\* reset
>
> Убирает любые права объекту на определенное действие
>
>
>
> @param {int} GroupID - идентификатор группы
>
> @param {string} ActionName - название действия
>
> \*/
>
> public function reset($GroupID, $ActionName){
>
> if (isset($this->selfgroups[$GroupID]) && isset($this->selfgroups[$GroupID][$ActionName]))
>
> unset($this->selfgroups[$GroupID][$ActionName]);
>
> if ($this->selfgroups[$GroupID] === array())
>
> unset ($this->selfgroups[$GroupID]);
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В базе данных все эти записи будут храниться, прямо в отдельном поле объекта таблицы. То есть вот так:
| page |
| --- |
| pageID | page\_name | page\_rights
(права в serialize виде) |
| messages |
| messID | pageID | message\_rights
(права в serialize виде) | message\_header | message\_text |
#### Что можно делать ещё?
Для любителей JSON, можно использовать вместо serialize/unserialize => json\_encode/json\_decode, которые по идее должны работать быстрее и занимать меньше места в БД.
Для любителей более человечных названий групп, ничего не потребуется для того, чтобы все GroupID сменить с int на string.
Можно использовать $\_SESSION, если пользователь залогинился, для запоминания всех его прав $User->current\_user->rights (и другой пользовательской информации), чтобы не обращаться к базе данных и не производить лишних действий. Единственный минус — чтобы пользователю сменить права доступа, ему необходимо будет перелогиниваться.
### Работающий пример
Битовые маски:
[Работающий пример](http://zcn.ru/examples/rights2/test0.php)
[test0.php](http://zcn.ru/examples/rights2/#test0.php)
[rights0.php](http://zcn.ru/examples/rights2/#rights0.php)
Serialize:
[Работающий пример](http://zcn.ru/examples/rights2/test.php)
[test.php](http://zcn.ru/examples/rights2/#test.php)
[rights.php](http://zcn.ru/examples/rights2/#rights.php)
### Послесловие
Очень похожие механизмы работы с правами предлагает Zend (последний пример с Serialize).
Основы вы уже узнали здесь (как оно функционирует и откуда растут ноги).
Zend\_Acl предлагает похожую библиотеку описания взаимодействий. Кому именно, как пользоваться Zend\_Acl, может почитать в [интернете](http://www.google.com/search?hl=ru&client=opera&rls=en&hs=XrO&q=Zend_Acl&btnG=%D0%9F%D0%BE%D0%B8%D1%81%D0%BA&lr=). Думаю, что после этой статьи вы быстро разберетесь.
**p.s.** спасибо всем, кто оставил комментарии к прошлой статье на эту тему. Без вас не было бы этой статьи. | https://habr.com/ru/post/51690/ | null | ru | null |
# Что полезно знать Java-разработчику про вывод типов

В Java 8 кардинально переработали процедуру вывода типов выражений. В спецификации появилась целая [новая глава](https://docs.oracle.com/javase/specs/jls/se8/html/jls-18.html) на эту тему. Это весьма сложная штука, изложенная скорее на языке алгебры, чем на языке нормальных людей. Не каждый программист готов в этом разобраться. Я, разработчик IDE, которому приходилось ковыряться в соответствующем коде, к своему стыду тоже довольно плохо разбираюсь в этой теме и понимаю процесс только по верхам. Причём сложно не только мне, но и авторам компилятора Java. После выхода Java 8 обнаружились десятки багов, когда поведение компилятора не соответствовало спецификации, либо текст спецификации был неоднозначен. В средах разработки для Java ситуация обстояла не лучше: там тоже были баги, причём другие, поэтому код мог отображаться ошибочным в вашей IDE, но успешно компилироваться. Или наоборот. С годами ситуация улучшилась, многие баги исправили, хотя всё ещё в спецификации остались тёмные углы.
Если вы просто пишете на Java, вам в целом необязательно знать в деталях, как это всё работает. В большинстве случаев либо результат вывода типов соответствует вашей интуиции, либо вывод типов не работает вообще, и надо ему помочь. Например, указав типы-аргументы в <угловых скобках> при вызове метода, либо указав явно типы параметров лямбды. Тем не менее есть некоторый начальный уровень этого тайного знания, и его несложно освоить. Овладев им, вы будете лучше понимать, почему компилятор не всегда может вывести то, что вы хотите. В частности, вы сможете ответить на вопрос, который мне часто задавали в той или иной форме: какие из следующих строчек не компилируются и почему?
```
Comparator c1 = Comparator.comparing(String::length).reversed();
Comparator c2 = Comparator.comparing(s -> s.length()).reversed();
Comparator c3 = Collections.reverseOrder(Comparator.comparing(s -> s.length()));
```
Первое важное знание: в Java есть два типа выражений (JLS [§15.2](https://docs.oracle.com/javase/specs/jls/se17/html/jls-15.html#jls-15.2)). Первый тип — «автономные выражения» (standalone expression), а второй — «поли-выражения» (poly expression). Тип автономных выражений вычисляется, глядя исключительно на само выражение. Если выражение автономное, совершенно неважно, в каком оно встретилось контексте, то есть что вокруг этого выражения. Для поли-выражений контекст важен и может влиять на их тип. Если поли-выражение вложено в другое поли-выражение, то фактически выбирается самое внешнее из них, и для него запускается процесс вывода типов. По всем вложенным поли-выражениям собираются ограничения (constraints). Иногда к ним добавляется целевой тип. Например, если поли-выражение — это инициализатор переменной, то тип этой переменной является целевым и тоже включается в ограничения. После этого выполняется редукция ограничений и определяются типы для всех поли-выражений сразу. Скажем, простой пример:
```
Comparator c2 = Comparator.comparing(s -> s.length());
```
Здесь лямбда является поли-выражением. Вообще лямбды и ссылки на методы всегда являются поли-выражениями, потому что их нужно отобразить на какой-то функциональный интерфейс, а по содержимому лямбды вы никогда не поймёте, на какой. Вызов метода `Comparator.comparing` тоже является поли-выражением (ниже мы поймём, почему). У лямбды надо определить точный функциональный тип, а у [`Comparator.comparing`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Comparator.html#comparing(java.util.function.Function)) — значения типовых параметров `T` и `U`. В процессе вывода устанавливается, что
* T = String
* U = Integer
* Тип лямбды = Function
* Тип параметра s = String
Только некоторые выражения в Java могут быть поли-выражениями. Вот их полный список (на момент Java 17):
* Выражения в скобках
* Создание нового объекта (new)
* Вызов метода
* Условные выражения (?:)
* switch-выражения (те что в Java 14 появились)
* Ссылки на методы
* Лямбды
Но «могут» не значит «должны». Могут быть, а могут и не быть. Проще всего со скобками: они наследуют «полистость» выражения, которое в скобках. В остальных случаях важен контекст.
Контексты определяются в [пятой главе спецификации](https://docs.oracle.com/javase/specs/jls/se17/html/jls-5.html). Нам будут интересны только три из них:
* Контекст присваивания (assignment context) — это контекст, при котором автоматически выполняется преобразование присваивания. Включает в себя инициализацию переменной (кроме переменной с неявным типом `var`), оператор присваивания, а также возврат значения из метода или лямбды (как с использованием `return`, так и без).
* Контекст вызова (invocation context) — аргумент вызова метода или конструктора.
* Контекст приведения (cast context) — аргумент оператора приведения типа.
Для определения контекста можно подниматься через скобки, условные операторы и switch-выражения. Поли-выражения могут быть только в контексте присваивания и контексте вызова. Для лямбд и ссылок на методы дополнительно разрешён контекст приведения. В любых других контекстах использование лямбд и ссылок на методы недопустимо вообще. Это правило, кстати, приводит к интересным последствиям:
```
Runnable r1 = () -> {}; // можно
Runnable r2 = true ? () -> {} : () -> {}; // можно
Object r3 = (Runnable)() -> {}; // можно
Object r4 = (Runnable)(true ? () -> {} : () -> {}); // нельзя!
Object r5 = true ? (Runnable)() -> {} : (Runnable)() -> {}; // можно
```
Условный оператор во второй строке является поли-выражением, потому что он в контексте присваивания. Поэтому он может посмотреть наружу и увидеть, что результат должен быть типа `Runnable`, а значить использовать эту информацию для вывода типов веток и в итоге присвоить обеим лямбдам тип `Runnable`. Однако четвёртая строчка в таком виде не работает, несмотря на большое сходство. Здесь условный оператор `true ? () -> {} : () -> {}` находится в контексте приведения, что по спецификации делает его автономным выражением. Поэтому мы не можем выглянуть за его пределы и увидеть тип `Runnable`, а значит мы не знаем, какой тип назначить лямбдам — возникает ошибка компиляции. В этом случае придётся переносить приведение типов в каждую ветку условного оператора (или не писать такой код вообще).
Не только контекст, но и вид выражения может влиять на полистость. Например, выражение `new` может быть поли-выражением (в соответствующем контексте), только если используется оператор «ромб» (`new X<>()`, JLS [§15.9](https://docs.oracle.com/javase/specs/jls/se17/html/jls-15.html#jls-15.9)). В противном случае тип результата всё равно однозначен и нет смысла усложнять компиляцию. Аналогичная мысль применяется к выражениям вызова метода, только это приводит к более сложным условиям (JLS [§15.12](https://docs.oracle.com/javase/specs/jls/se17/html/jls-15.html#jls-15.12)):
* Мы вызываем generic-метод
* Этот generic-метод упоминает хотя бы один из своих типовых параметров в возвращаемом типе
* Типы-аргументы не заданы явно при вызове в <угловых скобках>
Если хоть одно из этих условий не выполнено, тип результата метода устанавливается однозначно и разумно считать выражение автономным. Тут ещё дополнительная сложность в том, что мы можем не сразу знать, какой конкретно метод вызываем, если имеется несколько перегруженных методов. Но тут может открыться портал в ад, поэтому не будем копать эту тему.
Интересная история с условным оператором (JLS [§15.25](https://docs.oracle.com/javase/specs/jls/se17/html/jls-15.html#jls-15.25)). Сначала в зависимости от типов выражений в ветках выясняется разновидность оператора: это может быть булев условный оператор, числовой условный оператор или ссылочный условный оператор. Только ссылочный условный оператор может быть поли-выражением, а булев и числовой всегда автономные. С этим связано много странностей. Вот например:
```
static Double get() {
return null;
}
public static void main(String[] args) {
Double x = true ? get() : 1.0;
System.out.println(x);
}
```
Здесь типы веток условного оператора — конкретно `Double` и конкретно `double`. Это означает, что условный оператор числовой (numeric conditional expression, JLS [§15.25.2](https://docs.oracle.com/javase/specs/jls/se17/html/jls-15.html#jls-15.25.2)), то есть автономный. Соответственно, мы не смотрим наружу, нас не волнует, что мы присваиваем результат в объектный `Double`. Мы определяем тип только по самому оператору, и этот тип — примитивный `double`. Соответственно, для балансировки типов добавляется unboxing левой ветки, а потом для присваивания добавляется снова boxing:
```
Double x = Double.valueOf(true ? get().doubleValue() : 1.0);
```
Здесь мы разворачиваем результат метода `get()`, а потом заново сворачиваем. Разумеется, этот код падает с `NullPointerException`, хотя казалось бы мог бы и не падать.
Ситуация в корне меняется, если мы объявим метод `get()` по-другому:
```
static T get() { ... }
```
Теперь в одной из веток не числовой тип `Double`, а неизвестный ссылочный тип `T`. Весь условный оператор становится ссылочным (reference conditional expression, JLS [§15.25.3](https://docs.oracle.com/javase/specs/jls/se17/html/jls-15.html#jls-15.25.3)), соответственно становится поли-выражением и может посмотреть наружу, на целевой тип `Double` и использовать именно его как целевой тип веток. В итоге обе ветки успешно приводятся к типу `Double`, для чего добавляется boxing в правой ветке:
```
Double x = true ? get() : Double.valueOf(1.0);
```
Теперь программа успешно печатает `null` и завершается. Такие нестыковки обусловлены историческими причинами и необходимостью совместимости. В первых версиях Java никаких поли-выражений не было, все были автономными, поэтому надо было выкручиваться, и выкручивались не всегда идеально. К счастью, это не распространяются на более новые switch-выражения. Для них нет дополнительных условий на полистость кроме контекста, поэтому такой код вполне ожидаемо печатает `null` вместо падения с исключением:
```
static Double get() {
return null;
}
public static void main(String[] args) {
Double x = switch (0) {
case 0 -> get();
default -> 1.0;
};
System.out.println(x);
}
```
Вернёмся к нашему примеру с компараторами. Я раскрою карты: второй вариант не компилируется.
```
Comparator c1 = Comparator.comparing(String::length).reversed(); // можно
Comparator c2 = Comparator.comparing(s -> s.length()).reversed(); // нельзя
Comparator c3 = Collections.reverseOrder(Comparator.comparing(s -> s.length())); // можно
```
Вот главное, что следует запомнить:
> Квалификатор никогда не находится в контексте присваивания или контексте вызова, поэтому не может быть поли-выражением.
В первых двух строчках у нас есть квалификаторы: `Comparator.comparing(String::length)` и `Comparator.comparing(s -> s.length())`. При определении типа квалификатора мы не можем смотреть на то что происходит вокруг, нам остаётся пользоваться только самим содержимым квалификатора.
`Comparator.comparing` возвращает `Comparator`, принимая функцию `Function super T, ? extends U`, и нам необходимо определить значения `T` и `U`. В случае со ссылкой на метод у нас есть дополнительная информация: ссылка однозначно указывает на метод `length()` в классе `String`. соответственно, выводу типов хватает этого, чтобы понять, что `T = String` и `U = Integer`. Однако в случае с лямбдой у нас нет никаких указаний на то что `s` — это строка. Соответственно, у нас нет ограничений на `T`, а значит в соответствии с правилами редукции выбирается максимально общий тип: `T = Object`. Далее запускается анализ тела лямбды и мы обнаруживаем, что у класса `Object` нет метода `length()`, из-за чего компиляция останавливается. Вот такое, кстати, бы сработало, потому что `hashCode()` в объекте есть:
```
Comparator cmp = Comparator.comparing(s -> s.hashCode()).reversed();
```
Понятно и почему работает строчка `c3`. Так как `Comparator.comparing` здесь в контексте вызова, мы можем подняться наверх и добраться до контекста присваивания, а значит, использовать целевой тип `Comparator`. Тут вывод сложнее, потому что есть ещё переменная типа в методе `reverseOrder`. Тем не менее компилятор справляется и успешно всё выводит.
Как починить `c2`, если всё-таки хочется использовать квалификатор? Мы уже знаем достаточно, чтобы понять, что вот это не сработает:
```
Comparator c2 =
((Comparator)Comparator.comparing(s -> s.length())).reversed();
```
Приведение типа не чинит результат вызова метода, так как контекст приведения не действует на вызовы. Зато приведение типа срабатывает с лямбдой, хотя и выглядит ужасно:
```
Comparator c2 =
Comparator.comparing((Function) s -> s.length()).reversed();
```
Вариант проще: сделать вызов метода автономным. Для этого надо добавить типы-аргументы. В итоге тип вызова `comparing` устанавливается однозначно, и из него уже выводится тип лямбды:
```
Comparator c2 =
Comparator.comparing(s -> s.length()).reversed();
```
Ещё проще в данном случае — явно указать тип параметра лямбды. Тут у нас вызов `comparing` по-прежнему является поли-выражением, но появляется ограничение на тип `s`, и его хватает, чтобы вывести всё остальное правильно:
```
Comparator c2 =
Comparator.comparing((String s) -> s.length()).reversed();
```
Можно ли было распространить вывод типов на квалификаторы, чтобы `c2` работало без дополнительных подсказок компилятору? Возможно. Но, как я уже говорил, процедура вывода типов и так невообразимо сложная. В ней и так до сих пор есть тёмные места, а даже когда она правильно работает, она может работать ужасно долго. К примеру, возможно написать относительно несложный код, который создаст сотню ограничений и поставит на колени и IDE, и компилятор javac, потому что реализация вывода типов может быть полиномом довольно высокой степени от количества ограничений. Если мы в этот замес добавим квалификаторы, всё станет сложнее на порядок, ведь они будут интерферировать со всем остальным. Также возникнут проблемы из-за того, что мы можем вообще толком не знать, какой метод какого класса мы пытаемся вызвать. Например:
```
T fn(UnaryOperator op) {
return op.apply((T) " hello "); // грязно, но имеем право!
}
String s = fn(t -> t).trim();
```
Если мы выводим тип квалификатора `fn(t -> t)` вместе с типом всего выражения, то мы даже не знаем, у какого класса вызывается метод `trim()`. Нам подходит любой метод `trim()` в любом классе, который не принимает аргументов и возвращает строку. Например, метод `String.trim()` подойдёт. Или ещё какой-нибудь. У этого уравнения может быть много решений. Придётся как-то отдельно обговаривать в спецификации такие случаи. Так или иначе, я не был бы счастлив заниматься поддержкой данной возможности в IDE. | https://habr.com/ru/post/588975/ | null | ru | null |
# Github запустил Code Scanning — функцию сканирования кода на уязвимости
GitHub [запустил](https://github.blog/2022-02-17-code-scanning-finds-vulnerabilities-using-machine-learning/) в тестовом режиме сервис Code Scanning, основанный на алгоритмах машинного обучения. Инструмент сканирует код и выявляет в нем распространенные типы уязвимостей. Пока функция работает только в репозиториях с JavaScript и TypeScript кодом.
По заявлению компании, Code Scanning способен выявлять ошибки, приводящие к межсайтовому скриптингу, искажению путей файлов и подстановке SQL и NoSQL запросов. Функция [реализована](https://codeql.github.com/) на основе инструмента CodeQL. Проверка кода активируется при каждом выполнении команды `git push`, а результат закрепляется к pull-запросу.
Экспериментальный инструмент по умолчанию доступен пользователям наборов для анализа кода `security-extended` и `security-and-quality`. Включить поддержку функции можно и вручную. Для этого необходимо изменить файл конфигурации процесс сканирования кода:
```
[...]
- uses: github/codeql-action/init@v1
with:
queries: +security-extended
[...]
```
Результаты проверки отображаются во вкладке безопасности репозитория. Представители сервиса подчеркивают, что все результаты работы экспериментальных функций явно отмечаются специальным значком `Experimental`.
Пример работы Code ScanningНа прошлой неделе в GitHub [появилась](https://habr.com/ru/news/t/651569/) нативная поддержка генератора динамических диаграмм Mermaid.js. Теперь все блоки кода в README-файлах, отмеченные тегом `mermaid`, автоматически рендерятся в диаграммы. | https://habr.com/ru/post/652661/ | null | ru | null |
# Комонада, она как монада, только комонада
Я подразумеваю, что читатель знает Haskell, по крайней мере, до монад.
**Monad** – это класс типов, позволяющий (неформально говоря) из функций, которые возвращают что то вроде **MyMonad КакойтоТип** выполнять некие функции, взаимодействующие с монадой. Функции, использующие монады, нужно связывать между собой специальными функциями **(>>)**,**(>>=)**,**(=<<)**.
Так вот, **Comonad** – это тоже класс типов, который позволяет функциям взаимодействовать с эффектами комонады, только у этих функций комонада указывается не в возвращаемом типе, а в аргументе. Ни что не мешает указывать одинаковые или разные комонады в каждом аргументе, да ещё и монаду в возвращаемом значении.
Для связки комонадных выражений тоже используются специальные функции — **(=>>)**,**(<<=)**,**(=>=)**,**(=<=)** со своими нюансами.
В общем, схожесть между монадами и комонадами есть, и их применение можно сочетать.
Для того, что бы стало понятно решим практический пример, напишем мини библиотечку для расчёта и отображения гистограммы.
Хотя задача не очень масштабна, мы разделим её на части:
* основная часть (двигатель гистограммы), т.е. расчёт;
* Реализация хранения и накопления данных гистограммы;
* отображение гистограммы (вывод на терминал).
Двигатель гистограммы
---------------------
И так, расчёт. В нём не будет ни монад, ни комонад, однако он важен. В результате предварительного расчёта будет формироваться функция типа
```
type CalcPos x = x -> Maybe Int
```
по заданному исходному значению определяющая номер кармана гистограммы, в который следует добавить единицу (как рассчитывается гистограмма, и что, это, собственно такое легко [навикипедить](https://ru.wikipedia.org/wiki/%D0%93%D0%B8%D1%81%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0)). Если исходное число выходит за заданный диапазон, функцию вернёт **Nothing**.
Весь результат предварительного расчёта по заданным исходным данным будет храниться в структуре
```
data HistoEngine x = HistoEngine { low :: x -- Нижняя граница гистограммы
, step :: x -- Шаг гистограммы
, size :: Int -- кол-во карманов гистограммы
, calcPos :: CalcPos x
}
```
Остальные поля записи не нужны функции **calcPos**, все необходимые ей данные она получит при создании через замыкания, но остальные поля могут потребоваться в других случаях.
Функция **mkHistoEngine** – это то, с чего начинается построения гистограммы. За исходные данные принимаем нижнюю и верхнюю границы анализируемого диапазона и количество карманов гистограммы. Функция **mkHistoEngine** заполняет и возвращает **HistoEngine**, включая **calcPos** задаваемую лямбдой.
```
mkHistoEngine :: (Show x, Ord x, RealFrac x) => x -> x -> Int -> HistoEngine x
```
(определение функции тривиально и будет приведено ниже, в полном коде).
Исходя из принципа инкапсуляции (***Gabriel Gonzalez***, к примеру, полагает что [комонады это объекты](http://www.haskellforall.com/2013/02/you-could-have-invented-comonads.html), так что не погнушаемся одним из принципов ООП). Можно было бы вынести весь вышеприведённый код в отдельный модуль, предоставив извне доступ к **HistoEngine** без её внутреннего содержания. Но тогда нам придётся предоставить функции для получения значений некоторых полей **HistoEngine**.
```
histoEngPosFn:: HistoEngine x -> CalcPos x
histoEngPosFn = calcPos
histoEngSize:: HistoEngine x -> Int
histoEngSize = size
```
В дельнейшем понадобится вывести шкалу гистограммы. Вместо того, что бы создать функции доступа ещё для пары полей целесообразно сформировать сразу значения шкалы.
```
gistoXList:: (RealFrac x, Enum x) => HistoEngine x -> [x]
gistoXList HistoEngine{..} = take size [low+ step*0.5,(low + step*1.5)..]
```
(я использовал расширение **RecordWildCards**, по этому {..}).
Однако, где же комонады? Пора переходить к ним.
Гистограмма как комонада
------------------------
Комонада будет в примере выполнять роль связующего звена между расчётом, хранением и отображением. Тип её данных я сделал таким
```
data Histogram x a = Histogram (HistoEngine x -> a) (HistoEngine x) deriving Functor
```
Не всякий тип подходит для создания комонады. Не обязательно такой, как приведён выше: значение и функция от этого значения в произвольный тип. Но тип должен позволять выполнять с ним некоторую рекурсию. В данном случае, можно рекурсивно вызывать функцию **HistoEngine x -> a**. В других случаях используют рекурсивные типы данных – списки, деревья.
И так, делаем тип **Histogram** комонадой
```
instance Comonad (Histogram x) where
extract (Histogram f x) = f x
duplicate (Histogram f x) = Histogram (Histogram f) x
```
Это всё.
Функция **extract :: w a -> a** (где **w** – комонада, буква **w**, принятое обозначение для комонад – **m** кверх ногами) соответствует в монаде **return**, но делает обратное действие, возвращает значение из комонады. В некоторых статьях её именовали **coreturn** (назвать её **nruter**, кажется, ещё, никто не додумался).
Эта функция далее будет использоваться напрямую. В отличии от функции **duplicate :: w a -> w (w a)**, которая соответствует для монад **join :: (Monad m) => m (m a) -> m a**, только, опять, с противоположным смыслом. **Join** удаляет один слой монады, а **duplicate** дублирует слой комонады. Вызов её непосредственно далее не встретится, но **duplicate** вызывается внутри других функций пакета **comonad**, в частности, в **extend :: (w a -> b) -> w a -> w b**. Собственно, комонаду можно определить, как через **extract**, **duplicate** (и **Functor**), так и через **extract**, **extend**, смотря как удобнее.
И так, сама комонада готова. Переходим к следующему этапу.
В чём хранить
-------------
Будем хранить накапливаемые значения (ячейки или карманы гистограммы) в немутабельном векторе. Подключим
```
import qualified Data.Vector.Unboxed as VU
import qualified Data.Vector.Unboxed.Mutable as VUM
```
И запишем
```
type HistoCounter = VU.Vector Int
type Histo x = Histogram x HistoCounter
```
Пора написать функцию создающую исходную комонаду-гистограмму с пустыми ячейками.
```
mkHisto:: (Show x, Ord x, RealFrac x) => x -> x -> Int -> Histo x
mkHisto lo hi sz = Histogram (\e -> VU.replicate (histoEngSize e) 0)
$ mkHistoEngine lo hi sz
```
Всё просто. Описываем лямбда функцию выделяющую вектор заданного размера заполненный нулями и воспользуемся созданной ранее **mkHistoEngine** для создания **HistoEngine**. Параметры **mkHisto** просто передаются к **mkHistoEngine**.
Теперь напишем функцию накопления отсчётов в гистограмме.
```
histoAdd:: x -> Histo x -> HistoCounter
histoAdd x h@(Histogram _ e) = case histoEngPosFn e x of
Just i -> VU.modify (\v -> VUM.modify v (+1) i) (extract h)
Nothing -> extract h
```
Напомню, что если у монадных функций, монада указывается в типе результата функции, то у комонадных она в аргументе. С помощью **histoEngPosFn** получаем созданную в **mkHistoEngine** функцию типа **CalcPos**. В зависимости от её результата увеличиваем на единицу соотвествующую ячейку вектора или возвращаем вектор неизменным. Сам же вектор получаем выражением **extract h**.
Для того, что бы не привязывать алгоритм отображения гистограммы к её хранению и накоплению, примем, что для отображения она должна быть представлена списком. Это допустимо, т. к. для отображения список будет обрабатываться меньшее число раз и всегда последовательно. (Способ хранения гистограммы при накоплении можно изменить, например, на более эффективный мутабельный вектор, но это не должно привести к изменениям в функциях отображения гистограммы).
И так, комонадная функция преобразования представления данных гистограммы из вектора в список. Она тоже тривиальна.
```
histoToList:: Histo x -> [Int]
histoToList = VU.toList . extract
```
Отображение результата в терминале
----------------------------------
Я использовал вывод гистограммы горизонтально, когда её столбики лежат на боку.
Определение функции приведено ниже, в полном коде. Обратите внимание на то, что функция использует и комонаду (в аргументе, естественно), и монаду (естественно, в выходном значении).
```
histoHorizPrint:: (RealFloat x, Enum x) => Int -> Int -> Histogram x [Int] -> IO ()
```
Её аргументы: ширина поля вывода, ширина поля для отображения значений шкалы исходной величины и, естественно, комонада. Теперь с данными в виде **[Int]** вместо **VU.Vector Int**.
Собираем всё вместе
-------------------
В качестве тестовых данных просто сформируем последовательность синусоидальных отсчётов
```
map sin [0,0.01 .. 314.15]
```
Гистограмму будем накапливать в обычном списковом **foldl**.
```
foldl f (mkHisto (-1::Double) 1 20) (map sin [0,0.01 .. 314.16])
```
(исходные параметры гистограммы – диапазон от -1 до +1, 20 карманов).
Но что из себя будет представлять функция **f**, которая, для **foldl** имеет вид **(b -> a -> b)**, где, в данном случае, **b** — комонада, **а** – очередной, накапливаемый отсчёт. Оказывается, ничего сложного. Ведь мы уже написали функцию **histoAdd**. Так же, как для монад, понадобятся вспомогательные функции похожие на стрелки.
И так, весь тест в функции **main**.
```
main :: IO ()
main = histoHorizPrint 65 5 $ histoToList <<=
foldl (\b a -> b =>> histoAdd a) (mkHisto (-1::Double) 1 20)
(map sin [0,0.01 .. 314.16])
```
**Полный код (понадобятся пакеты comonad и vector)**
```
{-# LANGUAGE DeriveFunctor, RecordWildCards #-}
import Control.Comonad
import qualified Data.Vector.Unboxed as VU
import qualified Data.Vector.Unboxed.Mutable as VUM
import Numeric
type CalcPos x = x -> Maybe Int
data HistoEngine x = HistoEngine { low :: x -- Нижняя граница гистограммы
, step :: x -- Шаг гистограммы
, size :: Int -- кол-во карманов гистограммы
, calcPos :: CalcPos x
}
mkHistoEngine :: (Show x, Ord x, RealFrac x) => x -> x -> Int
-> HistoEngine x
mkHistoEngine lo hi sz
| sz < 2 = error "mkHistoEngine : histogram size must be >1"
| lo>=hi = error $ "mkHistoEngine : illegal diapazone "
++ show lo ++ " - " ++ show hi
| otherwise = let stp = (hi-lo) / fromIntegral sz in
HistoEngine lo stp sz
(\x -> let pos = truncate $ (x - lo) / stp in
if pos<0 || pos >= sz then Nothing
else Just pos)
histoEngPosFn:: HistoEngine x -> CalcPos x
histoEngPosFn = calcPos
histoEngSize:: HistoEngine x -> Int
histoEngSize = size
gistoXList:: (RealFrac x, Enum x) => HistoEngine x -> [x]
gistoXList HistoEngine{..} = take size [low+ step*0.5,(low + step*1.5)..]
------------- Гистограмма как комонада ------------------------
data Histogram x a = Histogram (HistoEngine x -> a) (HistoEngine x)
deriving Functor
instance Comonad (Histogram x) where
extract (Histogram f x) = f x
duplicate (Histogram f x) = Histogram (Histogram f) x
----------- Ф-ии для обработки результата и отображения
histoHorizPrint:: (RealFloat x, Enum x) =>
Int -> Int -> Histogram x [Int] -> IO ()
histoHorizPrint width numWidth h@(Histogram _ e) =
let l = extract h
mx = maximum l
width' = width - numWidth - 1
k = fromIntegral width' / fromIntegral mx ::Double
kPercent = (100 :: Double) / fromIntegral (sum l)
showF w prec v = let s = showFFloat (Just prec) v "" in
replicate (w - length s) ' ' ++ s
in mapM_ (\(x,y)-> do
putStr $ showF numWidth 2 x
putStr " "
let w = truncate $ fromIntegral y * k
putStr $ replicate w 'X'
putStr $ replicate (width'-w+2) ' '
putStrLn $ showFFloat (Just 2)
(fromIntegral y * kPercent) " %")
$ zip (gistoXList e) l
------------- Релизация хранения карманов гистограммы в векторе ----
type HistoCounter = VU.Vector Int
type Histo x = Histogram x HistoCounter
mkHisto:: (Show x, Ord x, RealFrac x) => x -> x -> Int -> Histo x
mkHisto lo hi sz = Histogram (\e -> VU.replicate (histoEngSize e) 0)
$ mkHistoEngine lo hi sz
histoAdd:: x -> Histo x -> HistoCounter
histoAdd x h@(Histogram _ e) = case histoEngPosFn e x of
Just i -> VU.modify (\v -> VUM.modify v (+1) i) (extract h)
Nothing -> extract h
histoToList:: Histo x -> [Int]
histoToList = VU.toList . extract
------------- Тест
main :: IO ()
main = histoHorizPrint 65 5 $ histoToList <<=
foldl (\b a -> b =>> histoAdd a) (mkHisto (-1::Double) 1 20)
(map sin [0,0.01 .. 314.16])
```
Комонадные трансформеры
-----------------------
Так же, как и для монад, для комонад существуют трансформеры (правда их очень мало, но кто нам мешает писать свои). То есть комонады могут быть вложенными.
Предположим, мы хотим установить ширину поля для вывода чисел в самом начале, когда только создали пустую гистограмму.
Подключим ещё один модуль
```
import Control.Comonad.Env
```
который реализует комонаду по смыслу соответствующую монаде **Reader**.
Пример в функции **main** теперь будет выглядеть так
```
(\h-> histoHorizPrint 65 (ask h) (lower h))
$ (histoToList . lower) <<=
foldl (\b a -> b =>> (histoAdd a . lower))
(EnvT 5 (mkHisto (-1::Double) 1 20))
(map sin [0,0.01 .. 314.16])
```
С помощью **(EnvT 5 (…))** мы создаём ещё один комонадный слой и сохраняем в нём значение 5 (желаемую ширину для полей чисел). Поскольку теперь комонадное выражение двухслойное, то, для применения наших функций, использующих комонаду **Histogram**, требуется вспомогательная функция **lower**, подобно тому, как в монадных трансформерах для перехода к предыдущему слою используют **lift**.
Так же обратите внимание на извлечение значения — **(ask h)**. Ну чем не **Reader**!
Последний пример можно записать и по другому, разобрав в конце два слоя комонад на пару (значение, внутренняя комонада) c помощью функции **runEnvT**, название которой жирно намекает на **runReaderT** используемую с **ReaderT**.
```
(\(nw,h)-> histoHorizPrint 65 nw h) $ runEnvT
$ (histoToList . lower) <<=
foldl (\b a -> b =>> (histoAdd a . lower))
(EnvT 5 (mkHisto (-1::Double) 1 20))
(map sin [0,0.01 .. 314.16])
```
Успехов в комонадостроении! | https://habr.com/ru/post/283368/ | null | ru | null |
# ReactiveCocoa. Concurrency. Multithreading
Сегодня хотелось бы поговорить о работе с потоками в ReactiveCocoa. Я не буду вдаваться в подробности основ фреймворка и полагаю, что вы уже знакомы с базовыми принципами реактивного программирования в iOS.
Работа с потоками в мобильном приложении наиважнейшая тема и это все знают. Стандарнтыми инструментами для этого, являются GCD или NSOperation. Но при использовании ReactiveCocoa в нашем проекте, все становится несколько иначе. Нет, вам никто не запрещает использовать стандартные инструменты, но зачем? Мы в каждый блок будем пихать GCD? Для этого в ReactiveCocoa придумали весьма удобную реализацию.
Для работы с многопоточностью в ReactiveCocoa существует класс RACScheduler. По сути, это обертка над GCD… и имеет те же самые приоритеты потоков, что и у GCD:
```
typedef enum : long {
RACSchedulerPriorityHigh = DISPATCH_QUEUE_PRIORITY_HIGH,
RACSchedulerPriorityDefault = DISPATCH_QUEUE_PRIORITY_DEFAULT,
RACSchedulerPriorityLow = DISPATCH_QUEUE_PRIORITY_LOW,
RACSchedulerPriorityBackground = DISPATCH_QUEUE_PRIORITY_BACKGROUND,
} RACSchedulerPriority;
```
Рассмотрим основные методы RACScheduler, которые могут нам понадобиться при работе с ним:
Из названия, в принципе, становится ясно, что нам возвращается RACScheduler, который будет выполнять работу в главном потоке.
```
+ (RACScheduler *)mainThreadScheduler;
```
В данном случае, нам возвращается RACSCheduler с указанным приоритетом и уже не в главном потоке.
```
+ (RACScheduler *)schedulerWithPriority:(RACSchedulerPriority)priority;
```
Возвращает RACScheduler c приоритетом RACSchedulerPriorityDefault.
```
+ (RACScheduler *)scheduler;
```
Возвращает текущий RACScheduler из текущего NSThread.
```
+ (RACScheduler *)currentScheduler;
```
Блок, который RACSсheduler может выполнить где угодно. И к этому мы еще вернемся.
```
- (RACDisposable *)schedule:(void (^)(void))block;
```
Далее приведу основные функции для RACSignal, которые могут использоваться нами для управления многопоточностью:
Данный метод RACSignal, говорит о том, что блоки получения новых значений в subscribeNext/doNext/subscribeError/etc. будут выполняться в том RACSCheduler, который мы вернем.
```
- (RACSignal *)deliverOn:(RACScheduler *)scheduler
```
Данный метод RACSignal, говорит о том, в каком RACScheduler будет выполняться блок, созданный при создании подписки (если мы говорим про ReactiveCocoa 2.5, то это: +[RACSignal createSignal:])
```
- (RACSignal *)subscribeOn:(RACScheduler *)scheduler
```
Приведу два коротких примера и мы на этом закончим
Создадим простой сигнал:
```
RACSignal *signal = [RACSignal createSignal:^RACDisposable *(id subscriber) {
// block executes on other thread with default priority
for (NSInteger i = 0; i < 5000; i++) {
NSLog(@"LOL");
if (i == 5000) {
[subscriber sendNext:@(YES)];
}
}
return nil;
}];
```
Очевидно, что при создании подписки на данный сигнал, пока цикл не закончится, то мы не получим ни единого значения. У кого-то, код выполняющийся в этом блоке, будет довольно ресурсоемким. Попробуем разнести по тредам.
Создадим подписку на сигнал и укажем сигналу subscribeOn/deliverOn
```
[[[signal subscribeOn:[RACScheduler scheduler]]
deliverOn:[RACScheduler mainThreadScheduler]] subscribeNext:^(id x) {
// block executes on main thread
}];
```
В данном случае, как видно по комментариям, значения мы будем получать в главном потоке, где можно, к примеру, обновлять UI. А в блоке создании подписки код будет выполняться в другом потоке, что поможет снизить нагрузку на главный поток.
И последний пример, я покажу вам как из бэкграунд потока запустить код в главном потоке.
С GCD это выглядело бы как все уже знают следующим образом:
```
dispatch_async(dispatch_get_global_queue(0, DISPATCH_QUEUE_PRIORITY_DEFAULT), ^{
// do something
dispatch_async(dispatch_get_main_queue(), ^{
// do something
});
});
```
И как это можно реализовать с RACScheduler:
Как мы помним, при создании подписки на этот сигнал, мы указали, что он будет выполняться не в главном потоке. Но что делать, если в каком то месте, нам все понадобиться выполнить часть кода на главном потоке? Очень просто :) Здесь нам поможет — (RACDisposable \*)schedule:(void (^)(void))block;
```
RACSignal *signal = [RACSignal createSignal:^RACDisposable *(id subscriber) {
// block executes on other thread with default priority
for (NSInteger i = 0; i < 5000; i++) {
NSLog(@"LOL");
if (i == 5000) {
[subscriber sendNext:@(YES)];
}
}
[[RACScheduler mainThreadScheduler] schedule:^(void v) {
// do something on main thread
}];
return nil;
}];
``` | https://habr.com/ru/post/278817/ | null | ru | null |
# Разработка под Microsoft PixelSense #0
Данной статьей я хочу начать цикл статей о разработке под Microsoft PixelSense. Я не уверен, что цикл получится большой, или что кроме этой статьи я вообще что-либо напишу, но все же с чего-то нужно начинать.
Расскажу общие вещи, которые дадут представление о том, что такое PixelSense, где о нем почитать и как начать писать под него. Обо всем по порядку.

**Что такое PixelSense**
PixelSense – это 42 дюймовый сенсорный стол от компании Microsoft, который распознает 42 точки прикосновения, а также во второй версии 256 специальных меток, которые позволяют осуществлять сценарии дополненной реальности. За распознавание касаний и меток отвечает специальная инфракрасная камера. От внешний воздействий экран защищен стеклом Gorilla Glass.
Внутри у стола процессор AMD и видеокарта того же производителя, работает все под управлением Embedded Windows 7 Professional 64-bit.
Писать под стол можно используя 2 технологии: XNA и WPF. Среда разработки Visual Studio 2010.
Изначально проект назывался Surface, поэтому во многих местах будет встречаться именно это название.
**Ресурсы о разработке и не только**
Все ссылки на основные ресурсы о столе можно найти на [www.pixelsense.com](http://www.pixelsense.com). Для нас как для разработчиков самой важной ссылкой является [msdn.microsoft.com/en-US/windows/desktop/hh241326.aspx](http://msdn.microsoft.com/en-US/windows/desktop/hh241326.aspx) — это девелоперская страница PixelSense, где можно найти все, что нужно о разработке: ссылки на SDK, Hands on labs и вообще это центр всего мира =).
**SDK**
SDK PixelSense включает в себя рантайм, шаблоны проектов для VS2010, примеры приложений, а также, пожалуй, самое главное – InputSimulator, который позволяет писать под PixelSense на компьютере без сенсорного экрана (есть одно но – симулятор не работает через RDP сессию).
Где что лежит:
• InputSimulator – в пуске Microsoft Surface 2.0 SDK->Tools->InputSimulator
• Примеры — Microsoft Surface 2.0 SDK->Surface Samples
**Стандартный набор контролов**
Посмотрев на картинку стола, как будто пришедшего из будущего, и почитав, что разрабатывать под него можно даже без самого стола и даже без сенсорного экрана – ты, конечно же, уже поставил на свою винду SDK и пытаешься понять, а что уже написали для тебя разработчики? Лучший ответ на этот вопрос дает одно из приложений примеров, распространяющихся вместе с SDK.
Согласно инструкций примеры вначале нужно собрать, для этого запустив скрипт *InstallSamples.bat* с правами админа, который все сделает хорошо. После того как все собралось запускам скомпилиный проект WPF/ControlsBox. В этом проекте есть все контролы, на них можно посмотреть, потрогать и поиграться с ними с помощью симулятора.
**Как пользоваться симулятором**
Симулятор очень простой и нам для начальной разработки понадобится всего пара кнопок. Важно перед началом его использования перезагрузить компьютер, если после установки SDK этого не сделали, иначе быть беде и ничего работать не будет.

Сверху видна надпись, на каком мониторе будет работать тач ввод и слева — само окошко, на котором можно выбрать текущий способ ввода.
**Создание первого проекта**
Если решимость все еще кипит в кропи – то заходим в VS2010 и создаем новый проект.

Как видно из скриншота – в шаблонах проектов для С# добавился новый пункт «Surface», где можно найти и сам шаблон “Surface Application (WPF)”. Создаем!
И видим XAML код первого окна
```
```
Основные отличия от простого WPF окна — окно теперь называется SurfaceWindow и добавилось новое пространство с префиксом s, в котором и находятся все PixelSense контролы.
Для небольшой демонстрации добавим кнопку
```
```
и получим как и ожидалось

Далее ведем разработку на WPF, используя все знания об этой технологии.
Все! Статья получилась совсем простой, для легкого старта с минимальным поиском. Далее постараюсь уже рассказывать о каких-то местах в разработке, подробнее о контролах и прочем. | https://habr.com/ru/post/151021/ | null | ru | null |
# Абстрагируемся от горячих клавиш в десктопных приложениях, или как отлаживаться в любом IDE одними и теми же кнопками
При работе со многими программами использование разнообразных комбинаций горячих клавиш — залог высокой производительности и удобства для пользователя. Для достаточно сложных программ мы заучиваем десятки специфических комбинаций клавиш для различный действий. Это позволяет сосредоточиться на фактической работе, а не на блуждании мышкой по многоэтажным меню в поисках необходимого пункта.
Поэтому, идеальная память под комбинации горячих клавиш — мышечная. Пока комбинация в мышечной памяти, не нужно во время работы переключать внимание на выполнение соответствующего действия — оно делается на автоматизме.
Это хорошо, однако у данного интерфейса пользовательского ввода есть проблемы.
Давайте рассмотрим их на примере работы в знакомой большинству обитателей хабра среде — интегрированной среде разработки (IDE).
Это сложная программная система, имеющая множество аспектов использования (написание кода, навигация по коду, рефакторинг, компиляция и исполнение, отладка, работа с системой контроля версий, и.т.д).
Для каждого из этих аспектов есть свои наборы горячих клавиш, которые не используются в других аспектах (когда я пишу код, мне не нужно помнить, какой комбинацией клавиш открывается окно просмотра локальных переменных в отладчике).
### Первая проблема — забываются нерегулярно используемые комбинации
Первая проблема заключается в том, что если какое-либо действие делается нерегулярно, то соответствующая комбинация клавиш с большой вероятностью забудется к следующему разу её использования. При этом, в тот момент, когда эта комбинация снова станет нужна, она может оказаться использованной не один-два раза, а достаточно активно некоторое время.
Пример: допустим, вы решили провести крупномасштабный рефактроинг вашей программной системы.
Основные действия, которые нужно будет делать — внесение различных полуавтоматизированных изменений в код (переименования символов, извлечения кусков кода в отдельные функции, изменения сигнатур функций, и.т.д). Кроме того, вам гораздо чаще придётся прыгать с места на место по проекту, смотреть на различные диаграммы классов, иерархии вызовов, и.т.д.
Данный набор действий может довольно сильно отличается от того, который используется при обычном написании кода, поэтому, комбинации горячих клавиш для таких действий со временем могут вымываться из головы, поскольку крупные рефакторинги делаются нерегулярно.
Для борьбы с этой проблемой некоторые программисты делают себе разнообразные cheat-sheets со списками команд, которые полезны в редких случаях. Когда такой случай наступает, приходится обращаться к шпаргалке (или гуглить).
### Вторая проблема — сложность миграции между системами
Если вам по какой-либо причине пришлось сменить IDE, заученные на уровне мышечной памяти горячие клавиши старой среды разработки могут оказаться серьёзным барьером. Придётся переучиваться, а это не очень приятное и непродуктивное занятие.
Кроме того, старые комбинации в новой системе могут иметь совершенно другие значения, что особо раздражает.
### Третья проблема — совместное использование нескольких систем
Тут всё может быть совсем плохо. Одни и те же действия в разных системах могут иметь разные комбинации горячих клавиш. В этом случае приходится постоянно держать в голове по набору комбинаций для каждой системы. Кроме того, нужно всё время мысленно контролировать, что за система используется прямо прямо сейчас. Ключевое тут: «держать в голове», — о мышечной памяти можно забыть, что повлечёт за собой падение производительности.
Допустим, вы отлаживаете клиент-серверную систему, где сервер написан на с++ в Visual Studio, а клиент — приложение на java в IDEA или eclipse.
Сервер формирует пакет с данными, отправляет их клиенту, который их каким-то образом обрабатывает. Сначала нам необходимо разобраться, правильно ли серверная часть генерирует пакеты для отправки. Затем, после отправки данных сервером, нужно будет в дебаггере на клиентской стороне смотреть, как полученные данные обрабатываются. Причём, общение сервера с клиентом может не ограничиться пересылом одного пакета. В этом случае вам придётся перескакивать туда-обратно между дебаггерами не один раз. Основные действия, которые будут делаться вами в данном случае — команды пошагового исполнения программы (step over, step into, step out). Концептуально, эти действия одни и те же, однако в каждой из сред разработки за них отвечают свои функциональные клавиши:
| | | | |
| --- | --- | --- | --- |
| | VS | eclipse | IDEA |
| step into | F11 | F5 | F7 |
| step over | F10 | F6 | F8 |
| step out | Shift+F11 | F7 | Shift+F8 |
При этом, например, 'step into' в eclipse делается клавишей F5, которая в VS отвечает за 'resume execution', что может сбить весь процесс отладки по неосторожности.
В таких ситуациях я часто замечал за собой, что начинаю отлаживать практически исключительно мышкой — это гораздо медленнее, но зато я точно знаю, какое действие и в какой среде я сейчас делаю.
Цель
====
Создание системы эмуляции клавиатурного ввода, упрощающей использование программ, имеющих большой набор действий, инициируемых при помощи комбинаций горячих клавиш.
Требования к системе:
* Отсутствие необходимости пользователю помнить фактические значения комбинаций горячих клавиш.
* Простота отправки команд пользователя приложению. Интерфейс должен позволять организовывать команды таким образом, чтобы их можно было легко и быстро находить и выполнять.
* Простота настройки системы — пользователь должен иметь возможность подстраивать интерфейс под свои нужды, ограничивать только актуальными командами в данный конкретный момент.
* Возможность легко переиспользовать конфигурации команд между схожими приложениями.
* Возможность автоматически контролировать, что окно-адресат для команды активно в момент исполнения команды (чтобы избежать ситуаций, таких как проблема описанная выше — клавиша F5 в дебаггерах eclipse и visual studio).
* Кросплатформенность приложения — хотелось абстрагироваться не только от фактических комбинаций горячих клавиш, а также и от операционной системы.
Основная идея системы — на компьютере запускается сервер, который отвечает за генерацию клавиатурных команд. Он работает в бэкграунде и отправляет команды активному в тот момент окну. К этому серверу подключается android устройство, которое используется для пользовательского ввода/вывода. Все команды инициируются нажатиями на кнопки, отображаемые на android устройстве. Когда это происходит, сервер отправляет соответствующую комбинацию клавиш активному окну на своей стороне.
Поскольку сопоставление соответствующей комбинации клавиш для данного действия происходит автоматически на сервере, можно будет определить несколько правил такого сопоставления. Это позволяет единообразно работать с разными программами (если наборы действий, производимых в них, схожи).
Конфигурирование сервера
========================
Для работы данной системе необходимо иметь следующую информацию:
* Данные об окружениях, в которых мы работаем, и для которых мы хотим эмулировать горячие клавиши.
* Данные о комбинациях горячих клавиш. Необходимо для каждого действия указать комбинацию горячих клавиш, которая его инициирует в каждом из окружений.
* Конфигурация элементов на клиентском устройстве: расположение, вид и поведение кнопок, которые будут использоваться для отправки команд.
Данные о горячих клавишах в разных окружениях
---------------------------------------------
Данные из первого и второго пункта хранятся в простой таблице (текстовый csv файл с табуляциями в качестве разделителей), которая выглядит примерно так:

В нём каждая строка представляют всю информацию об определённой команде. Первые четыре столбца — служебные. В них хранятся данные, которые используются программой для построения интерфейса пользователя:
1. command\_id — уникальное строковое представление команды в системе
2. command\_category — строковое представление категории, к которой команда относится
3. command\_note — короткое описание команды, которое будет написано на её кнопке в пользовательском интерфейсе
4. command\_description — более детальное описание команды
Все остальные столбцы таблицы — информация о комбинациях горячих клавиш в различных окружениях. Формат представления комбинаций описан в документации библиотеки, которую я использую для эмуляции клавиатуры. Описание формата можно посмотреть на [сайте документации библиотеки](http://getrobot.net/api/keyboard.html#Compile).
Построение интерфейса пользователя
----------------------------------
Для писания пользовательского интерфейса используется второй текстовый конфигурационный файл. Интерфейс состоит из набора страниц. На страницах расположены кнопки, каждая из которых соответствует какой-либо команде.
### 0. простейший вариант
Вот пример простейшей конфигурации страницы и то, как она будет выглядеть на клиентском устройстве:
**Содержимое конфигурационного файла**
```
page:main page
debug_start
debug_stepInto
debug_stepOver
debug_stepOut
debug_restart
```
В конфигурации интерфейса просто прописаны идентификаторы команд — по одному в строчку. Это транслируется в такой интерфейс для пользователя:
**Gредставление на клиентском устройстве**
Если какое-то из действий не определено для данного окружения, то соответствующая кнопка становится неактивна.
### 1. Несколько кнопок в ряд, промежутки между кнопками
Если в конфигурации указать несколько элементов, разделённых точками с запятой, в одной строке, то соответствующие кнопки будут размещены в один ряд. Между кнопками также можно делать пустые промежутки (для этого достаточно просто не указать идентификатора команды в соответствующем месте).
Следующая конфигурация иллюстрирует данные вещи:
**Вертикальные и горизонтальные промежутки между кнопками**
```
page:main page
debug_start;debug_restart;;
;
;debug_stepOver;;
debug_stepInto;;debug_stepOut
;
```
Интерфейс, в который это транслируется для пользователя:
**Представление на клиентском устройстве**
### 2. Переиспользование кнопок
Бывают случаи, когда какое-то действие не определено для какого-то из окружений, однако не хочется, чтобы место пустовало. Возможно, есть какое-нибудь другое достаточно схожее действие, которое можно поместить в том же месте в этом случае.
Для этого нужно просто написать по порядку идентификаторы через запятую в соответствующем месте. Система автоматически просканирует список и подберёт первый из вариантов, который будет активен в данном окружении:
**Конфигурация с опциями**
```
page:main
debug_start;debug_restart,debug_stopDebugger;;
;
;debug_stepOver;;
debug_stepInto;;debug_stepOut
;
```
Вид интерфейса в различных окружениях:
**Представления различных окружений**
Обратите внимание, как кнопка 'restart' в окружении для VS превращается в 'stop debug' в окружении для eclipse, поскольку для eclipse не определена комбинация для 'restart debug'.
### 3. Опции
Многие команды по факту являются целыми группами команд, которые по смыслу схожи, поэтому хочется их объединить вместе в клиентском UI, однако не хочется, чтобы они занимали слишком много места. Для примера можно привести команды типа 'build something': 'build solution', 'build project', 'compile file'. Для таких групп команд можно определить специальную страницу, которая будет автоматически появляться и исчезать при нажатии кнопки группы. Эта специальная страница отличается от стандартной только заголовком — тело у неё такое же.
**Пример такой конфигурации**
```
page:main page
debug_start;debug_restart;;
;
do_step
;
optionsSelectorPage:do_step;steps
;debug_stepOver;;
debug_stepInto;;debug_stepOut
```
Пример работы в UI:
**Работа с селектором опций**
Этот подход очень удобен с командами типа '[сделать определённое действие] с [чем-то]', где выбирается ровно один вариант из нескольких для [чего-то].
Все варианты областей действия команды переносятся на дополнительную страницу и автоматически отображаются, когда нужно.
Страницы опций можно также вкладывать одна в другую, образуя более глубокую и разветвлённую структуру.
Привязка к определённому окну ввода
-----------------------------------
Для того, чтобы не следить за тем, какое окно сейчас активно (чтобы симулируемый клавиатурный ввод не отправился кому попало), можно попросить программу контролировать это. Для этого системе при запуске передаётся опция 'stickEnvToWindow'.
В этом случае при выборе нового окружения, пользователю будет отображаться такой запрос:
**Запрос активного окна**
Пользователь должен будет сделать нужное ему окно активным и проинформировать об этом программу, нажав кнопку в нижней части экрана клиентского устройства. После этого, всякий раз, когда пользователь запрашивает исполнение команды, сервер будет проверять, правильное ли окно находится в фокусе. Если это не так, то выполнение команды приостанавливается, а пользователю отображается следующая заглушка:
**Активное окно не в фокусе**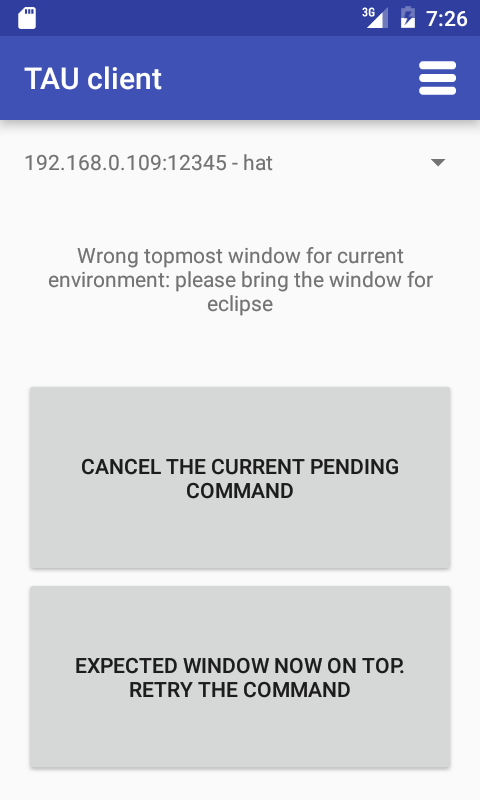
В этом случае пользователь должен либо вернуть фокус нужному окну и снова запросить выполнение команды, либо отменить команду:
**Демонстрация отслеживания окна ввода**
Автоматизация клавиатурного ввода
=================================
Естественно, данный подход может быть использован не только для горячих клавиш. Любое часто повторяемое действие с клавиатуры может быть автоматизированно при помощи данной программы.
Для себя я регулярно использую подобные вещи:
### Вставка слов или фраз на другом языке
Часто при наборе русского текста мне приходится переключаться в английскую раскладку ради одного слова, или даже пары символов. Русская раскладка не признаёт существования следующих символов: ' < > [ ] { } $ # @ & ^ ~, некоторые из которых бывают нужны регулярно. Кроме того, в русском тексте могут встречаться повторяющиеся термины на английском, а, если это html, то ещё и тэги.
Симуляцию набора текста в другой раскладке можно реализовать просто добавив команды переключения раскладки клавиатуры перед и после фактического набора вставляемого текста.
Например, чтобы напечатать тэг , нужно использовать следующую комбинацию: '+{COMMA}html+{PERIOD}'. Она правильно сработает, если включена английская раскладка. Если же включена русская раскладка, то нужно добавить в начало и конец комбинации горячую клавишу переключения раскладки. В моём случае, это '%{SHIFT}' (Alt+Shift). Таким образом, если в текстовом редакторе включена русская раскладка клавиатуры, то следующая последовательность символов: '%{SHIFT}+{COMMA}html+{PERIOD}%{SHIFT}' напечатает там .
Пример работы:
**Ввод текста в двух раскладках**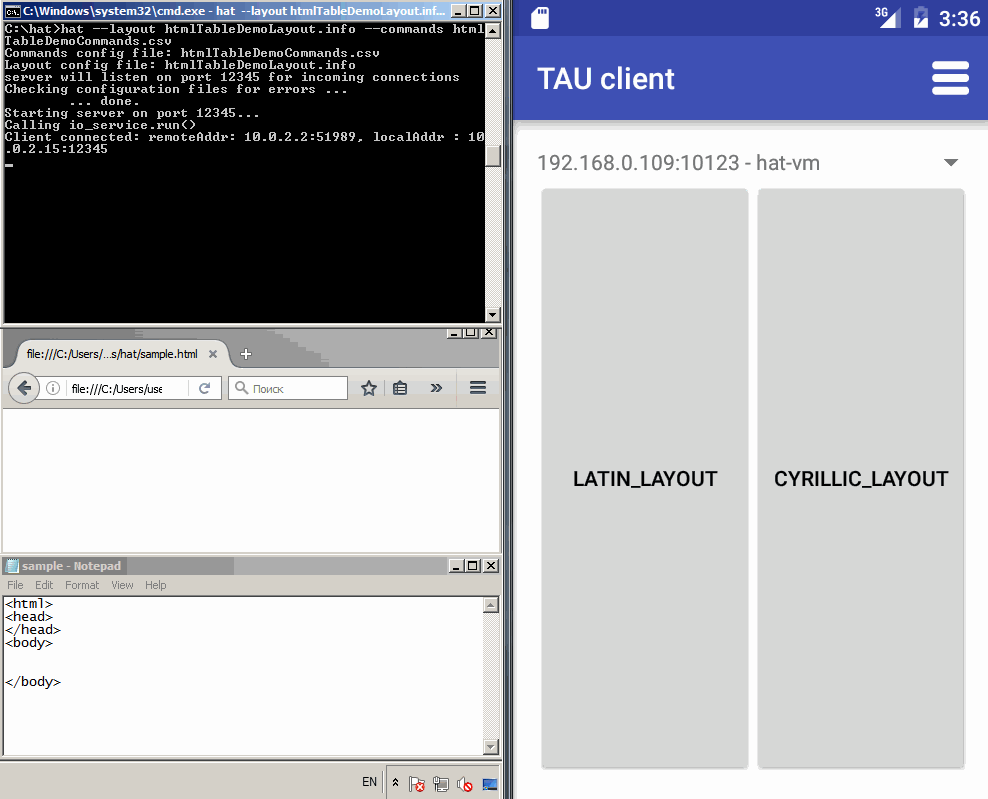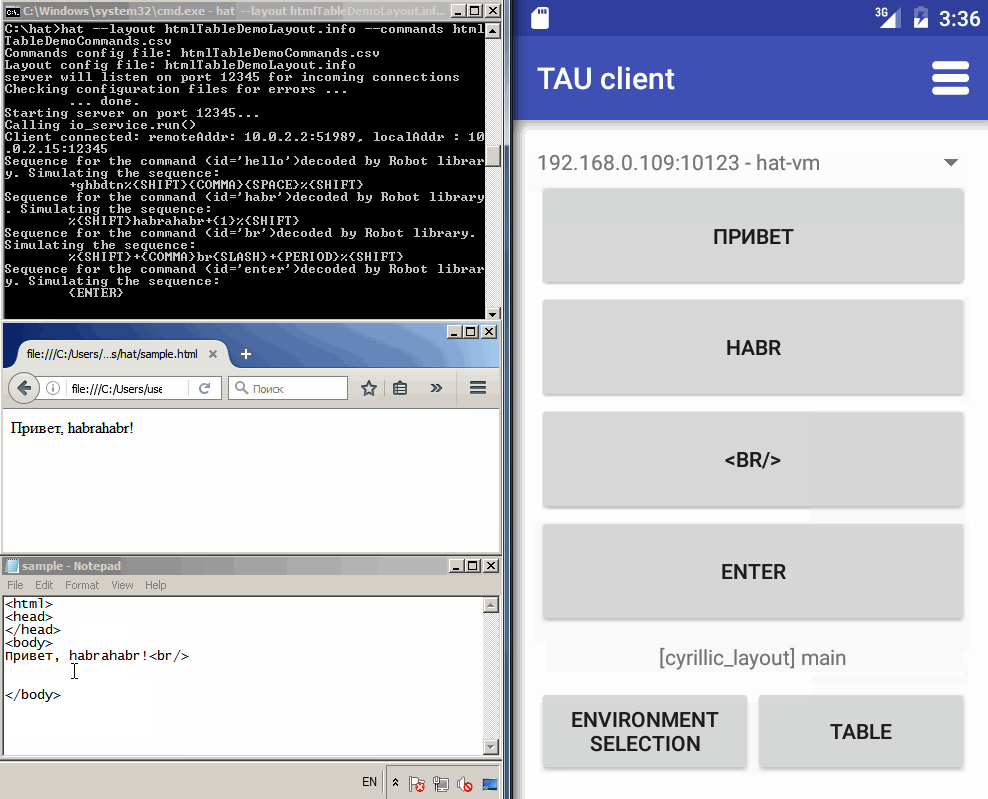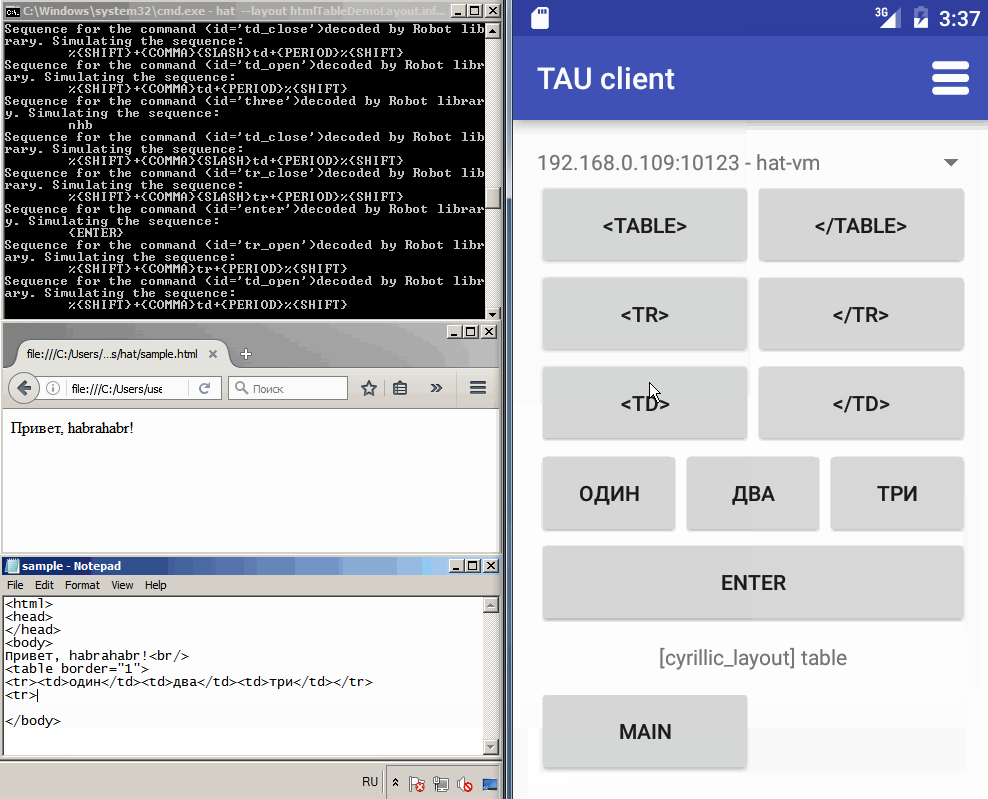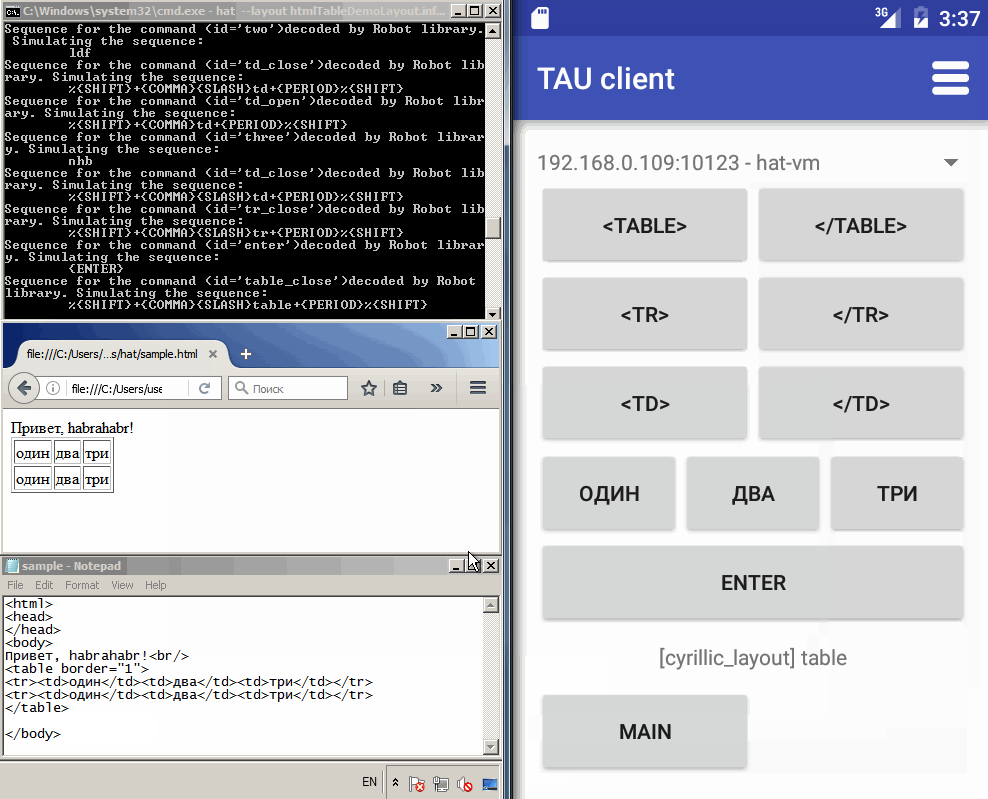
### In-place преобразование выделенного слова
Допустим, мне нужно в большом количестве мест в коде обернуть некоторые переменные в макрос или вызов функции. Например, у какой-то из функций нужно изменить тип параметра, поэтому во всех местах, где эта функция вызывается, нужно сконвертировать то, что туда передавалось в новый тип.
Если подобных изменений нужно сделать хотя бы несколько десятков, то идея это автоматизировать становится очень привлекательной.
Шаги, которые нужно сделать в данном случае:
1. выделяем переменную двойным щелчком мыши
2. симулируем команду «вырезать» (Ctrl+x)
3. симулируем набор текста — название оборачивающей функции и отрывающейся скобки
4. симулируем команду «вставить» (Ctrl+v)
5. закрываем скобку
Шаги 2-5 автоматизируются следующей комбинацией: '^{X}my+function+name+9^{V}+0'. Пример работы:
**Оборачивание выделенного текста**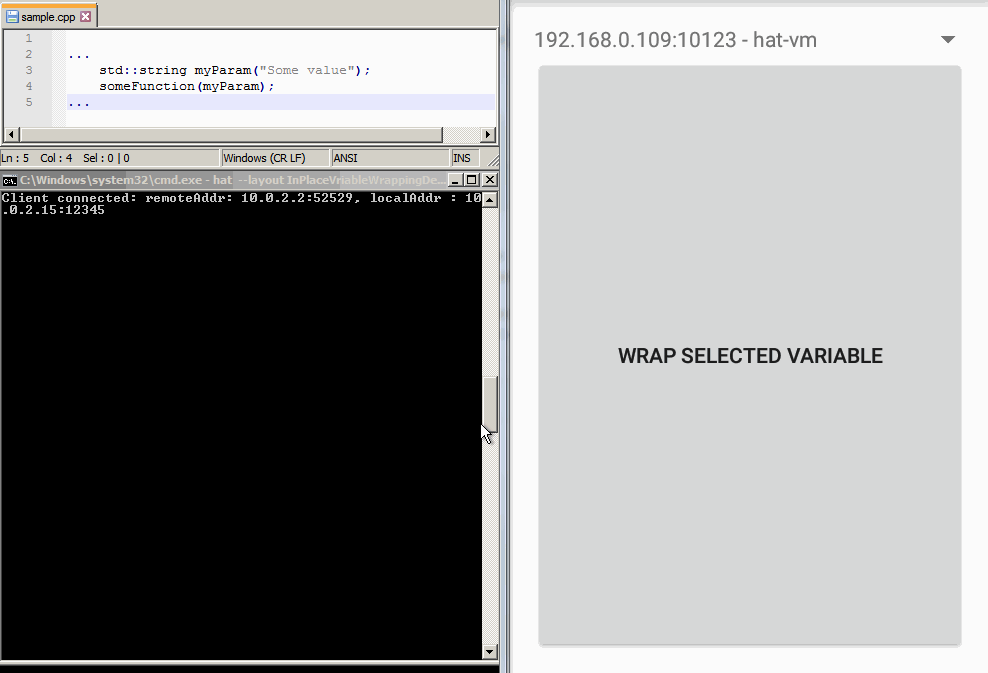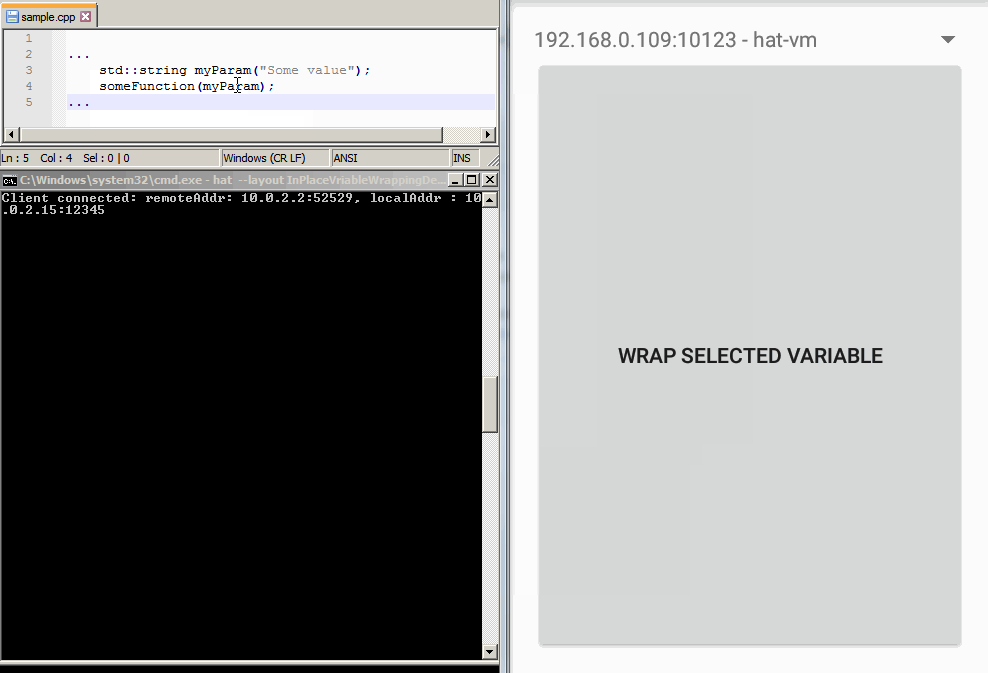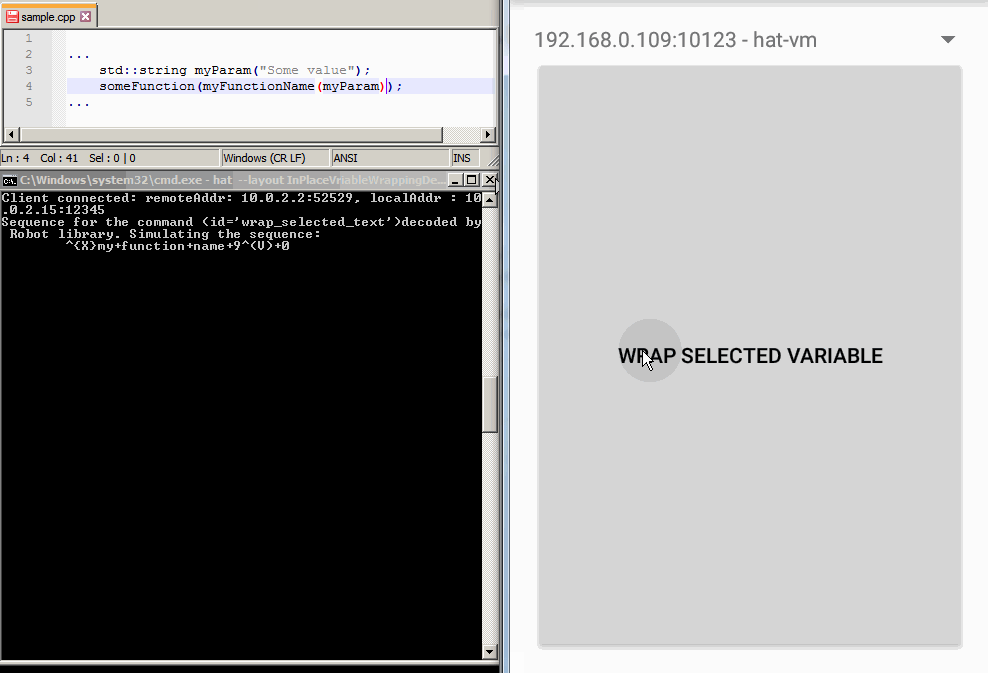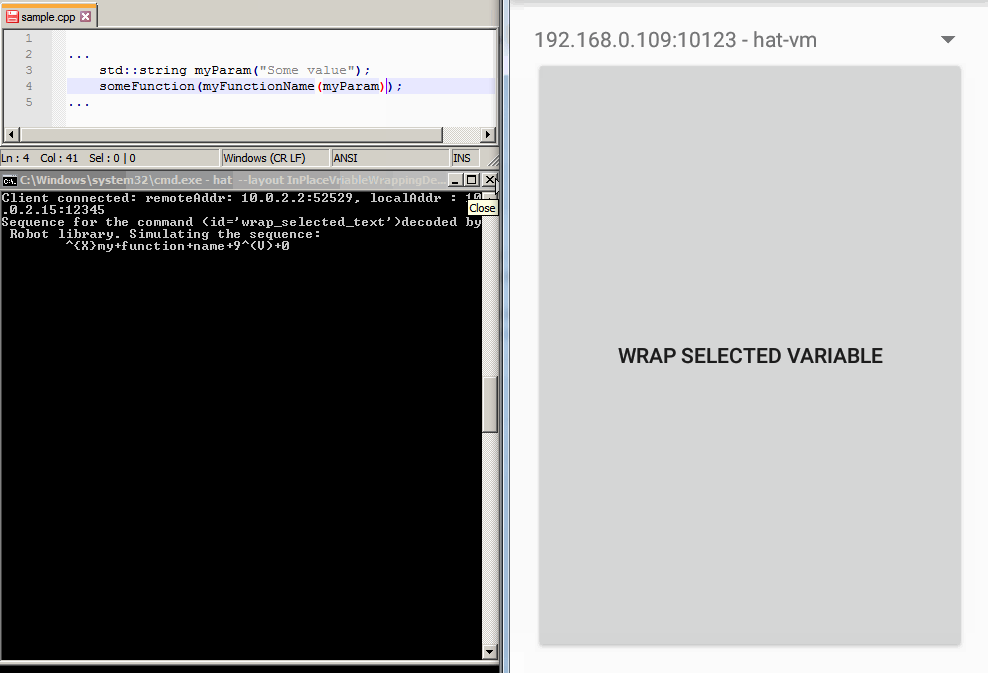
Кроме того, возможно, в разных местах кода вид этих вызовов может немного различаться (возможно, где-то нужно указывать пространство имён вызываемой функции, передавать дополнительные параметры, и.т.д). Всё эти вариации легко реализовать и иметь под рукой.
Заключение
==========
Система пока что сырая — это скорее прототип, а не конечная версия. Но, как мне кажется, уже в её нынешнем состоянии, она способна упростить и повысить эффективность работы с горячими клавишами.
Технические детали реализации я в данной статье не затрагивал, чтобы не раздувать её. Если будет интерес — можно будет сделать статью, посвящённую этому.
Код реализации лежит у меня на [гитхабе](https://github.com/vosel/hat). Там же есть немного более формальной документации о форматах конфигурационных файлов и аргументов командной строки.
Если не хочется качать исходники и компилировать код, есть [собранная для windows версия](https://github.com/vosel/hat/releases/tag/v0.1.0) (для запуска нужно будет поставить [Microsoft Visual C++ 2015 Redistributable](https://www.microsoft.com/en-us/download/details.aspx?id=53840)).
Для самостоятельной компиляции исходников нужен C++14 — совместимый компилятор и boost (используются boost::asio и boost::program\_options). В [документации](https://github.com/vosel/hat/blob/master/README.md#compilation) есть описание того, как собирать проект при помощи gcc и Visual Studio.
Буду рад услышать критику по поводу реализации, а также предложения о том, что можно добавить в систему. Кроме того, сейчас мне не очень нравится формат конфигурационного файла описания UI. Если у кого-нибудь есть идеи, как можно лучше представить подобный интерфейс (предпочтительно в простом текстовом формате), прошу в комментарии.
Что ещё хочется добавить в данной системе:
* Возможность выполнять несколько команд одним запросом (это серьёзно улучшит функциональность по симуляции набора текста).
* Автоматическое отслеживание и переключение раскладки клавиатуры активного окна.
* Улучшение функциональности работы с конфигурационными файлами, добавление новых типов конфигов.
* Рефакторинг кода программы.
* Улучшение системы сообщений пользователю о проблемах в конфигурационных файлах (сейчас сообщения не всегда информативны).
* Багфиксы симуляции некоторых комбинаций клавиш (см. ниже).
Все ссылки в одном месте:
* [Проект на гитхабе](https://github.com/vosel/hat), [exe](https://github.com/vosel/hat/releases/tag/v0.1.0) для windows.
* [Дополнительный репозиторий](https://github.com/vosel/hat-additional) с файлами конфигураций команд для разных задач. Там же можно найти примеры из данной статьи: [link](https://github.com/vosel/hat-additional/tree/master/other/habrahabr_article_01).
* Библиотеки, использованные в проекте: [boost](http://www.boost.org/), [Robot](http://getrobot.net), [tau](https://github.com/vosel/tau) (моя [статья](https://habrahabr.ru/post/309882/) про неё).
* [Microsoft Visual C++ 2015 Redistributable](https://www.microsoft.com/en-us/download/details.aspx?id=53840) — нужно для запуска скомпилированной версии.
* [Клиентское приложение под android](https://play.google.com/store/apps/details?id=com.tau.client).
### P.S.
Проблемы и неочевидности, о которых стоит знать перед использованием:
1. Поддерживается только кодировка UTF-8. Если программе скормить конфиг в другой кодировке, она может выругаться довольно неочевидным сообщением. Пожалуйста, учитывайте это, и сохраняйте файлы в правильной кодировке.
2. В windows замечена проблема с симуляцией нескольких комбинаций формата Shift+'smth'. Она проявляется для клавиш PgUp, PgDn, Home, End, Insert, Delete и стрелочек. Комбинация типа '+{INSERT}', которая должна симулировать Shift+Insert, по факту симулирует просто нажатие Insert.
3. В [примерах конфигураций](https://github.com/vosel/hat-additional) многие комбинации горячих клавиш не проверялись на работоспособность. Я просто нагуглил несколько списков и объединил их в общий файл. Поэтому, там возможны ошибки. Буду признателен сообщениям о найденных проблемах в конфигах, а также pull-реквестам. | https://habr.com/ru/post/318934/ | null | ru | null |
# Ставим GuitarPro 6 на Fedora Linux 22

Около пары месяцев назад перешел с Windows 8.1 на Fedora Linux 22. Все устраивает, но как всегда есть приложения, аналогов которых в мире Linux нету. К счастью, необходимый мне для хобби GuitarPro под Linux есть, но, к сожалению, только deb-пакеты. А в Fedora, как всем известно, надо rpm. Будем исправлять сей досадный факт. Кому интересно — под кат.
**ПРИМЕЧАНИЕ:**В качестве Window Manager'а я использую KDE5. Все версии актуальны на момент написания статьи. Как всегда, вы все делаете на свой страх и риск, автор статьи за вероятный ущерб ответственности не несет.
Итак поехали, обновляем систему до актуальной версии:
```
sudo dnf update
```
1. Качаем дистрибутив GuitarPro с оффициального сайта. Официальный сайт дает только триальную версию **Но есть вариант**Сайт дает ссылку вида *[downloads.guitar-pro.com/gp6/gp6-full-linux-demo-r11683.deb](http://downloads.guitar-pro.com/gp6/gp6-full-linux-demo-r11683.deb)*, а мы схитрим и немного подкорректируем ссылку (удалим demo), в итоге получим что-то наподобие *[downloads.guitar-pro.com/gp6/gp6-full-linux-r11683.deb](http://downloads.guitar-pro.com/gp6/gp6-full-linux-r11683.deb)*.
2. Идем на гитхаб [(https://github.com/dpurgin/guitarpro6-rpm)](https://github.com/dpurgin/guitarpro6-rpm) и качаем [конвертер](https://github.com/dpurgin/guitarpro6-rpm/archive/master.zip) из GuitarPro deb в GuitarPro rpm.
3. Распаковываем архив куда-нибудь, например, в свою домашнюю папку (`~/guitarpro6-rpm-master`, ну или `git clone`, кому как удобно).
4. Копируем скаченный `gp6-full-linux-r11683.deb` в `/home/username/guitarpro6-rpm-master`:
```
cp ~/Downnloads/gp6-full-linux-r11683.deb ~/guitarpro6-rpm-master
```
5. Делаем скрипт `prepare.sh` исполнимым и запускаем его:
```
cd ~/guitarpro6-rpm-master
chmod +x ./prepare.sh
./prepare.sh
```
Если скрипт отработал без проблем, то в папке `~/guitarpro6-rpm-master` появится файл `GuitarPro6-6.1.6.tar.bz2`.
6. Разворачиваем у себя среду сборки rpm пакетов ([оффициальная вики](https://fedoraproject.org/wiki/How_to_create_an_RPM_package#Preparing_your_system)):
**Коротко и по-русски**
```
sudo dnf install @development-tools fedora-packager rpmdevtools
```
Создаем пользователя makerpm и включаем его в группу mock:
```
sudo useradd makerpm
sudo usermod -a -G mock makerpm
sudo passwd makerpm
```
Логинимся в терминале под ним, и выполняем команду `rpmdev-setuptree`:
```
su makerpm
cd ~
rpmdev-setuptree
```
Эта команда создаст необходимую структуру папок в домашней папке пользователя.
7. Копируем `GuitarPro6-6.1.6.tar.bz2` в папку `/home/makerpm/rpmbuild/SOURCES`, `GuitarPro6.spec` в `/home/makerpm/rpmbuild/` (под суперпользователем естесственно).
8. Находясь в папке `/home/makerpm/rpmbuild/`, выполняем команду:
```
QA_RPATHS=$[0x0001 | 0x0002 | 0x0004 ] rpmbuild -bb --target=i686 GuitarPro6.spec
```
После отработки в папке `/home/makerpm/rpmbuild/RPMS/i686` должен появится файл `GuitarPro6-6.1.6-1.fc22.i686.rpm`.
Копируем его куда нибудь в укромное место (например в домашнюю папку вашего постоянного пользователя).
9. Просто поставить полученый RPM не получится. У меня rpm выругался на отсутствующий `gksu-polkit` и `libportaudio.so.2`. Значит будем их ставить.
```
sudo dnf install gksu-polkit
```
По поводу отсутствующей библиотеки поиск в гугле выдал необходимость установить следующее:
```
sudo dnf install libstdc++.i686 mesa-libGL.i686 alsa-lib.i686 portaudio.i686 pulseaudio-libs.i686 libXrender.i686 glib2.i686 freetype.i686 fontconfig.i686 libgnomeui.i686 gtk2-engines.i686
```
10. Теперь ставим GuitarPro:
```
sudo rpm -i GuitarPro6-6.1.6-1.fc22.i686.rpm
```
11. Где искать RSE и лекарство я писать не буду. Сами прекрасно знаете. Чтобы установить банки надо выполнить следующее (естественно подкорректировав путь к Banks-r370.gpbank под вашу систему):
```
sudo /usr/lib/GuitarPro6/GPBankInstaller /home/username/Downloads/Banks-r370.gpbank /usr/lib/GuitarPro6/Data/Soundbanks
```
Появится окошко импортирования. Ждем завершения.
12. Теперь запускаем Guitar Pro (ярлык лежит в K>Application>Multimedia), регистрируем (кейген от Windows версии отлично работает) и радуемся жизни.
**Proof** | https://habr.com/ru/post/383799/ | null | ru | null |
# Тестирование программ в сложных «погодных условиях»

Здравствуй, уважаемый Хабр! Я являюсь участником разработки автоматизированных систем управления высокой надежности, которые применяются на электростанциях, космодромах, сложных производствах и т.п. Однажды передо мной встала задача придумать метод проверки работоспособности программ в условиях загруженности ~~всяких железяк~~, а именно:1. Загруженность процессора
2. Загруженность сети отправкой/приемом
3. Нехватка оперативной памяти
4. Загруженность жесткого диска запросами чтения/записи
а также придумать способ оценки, на сколько та или иная программа может создавать задержки/помехи, для работы других программ. На мой взгляд, наиболее интересный из этих четырех — первый пункт, поэтому речь пойдет именно о нем.
Под катом описываются две утилитки, которые у меня получились и принцип их работы, а так же парочка скриншотов и видео.
##### Итак у нас есть набор тестируемых программ.
Необходимо разработать программу, которая проверяла бы их устойчивость при большой загруженности процессора.
Казалось бы, что может быть проще:
```
while true do
x:=x+1-1;
```
вот и загрузили машину.
Но нужно ли объяснять, что сто процентов загрузки процессора (из диспетчера задач) ста процентам рознь. Во первых, на компьютере, возможно, имеется несколько ядер, и при загрузке одного ядра другое будет спокойно работать. Во вторых, даже если все ядра процессора заняты на 100%, и вентилятор охлаждения, изрыгая раскаленный воздух, вот-вот отправит компьютер в свободный полет по кабинету, нет никаких гарантий, что это окажет хоть какое-то влияние на работу тестируемых программ, что уж говорить о каких-то видимых ~~лагах~~ задержках.
А хочется, чтобы MouseClick был через три секунды после MouseDown, чтобы таймер с периодом секунда срабатывал через 5 секунд, чтобы потокам программы было действительно «трудно» синхронизироваться, и чтобы творился управляемый хаос.
Тут становится ясно, что необходимо создавать для каждого ядра/процессора отдельный поток (class TThread).
Выясняем количество ядер:
```
var info: TSystemInfo;
...
GetSystemInfo(info);
n:=info.dwNumberOfProcessors;
```
Далее создаем n потоков, в которых крутятся какие-нибудь бессмысленные вычисления. Операционная система сама распределяет их по разным ядрам. При этом необходимо, чтобы приоритет созданных потоков случайным образом переключался как минимум между двумя значениями. Если этого не сделать, то при их низком приоритете тестируемые программы могут ничего не «почувствовать», а при слишком высоком — могут почти не получать процессорного времени. Так как приоритеты созданных нами нескольких потоков могут оказаться критичными, для гарантированного переключения из tpTimeCritical во что-нибудь другое необходимо, чтобы этим занялся сам критичный поток.
В своей программке, при создании потоков я делаю один из них «бригадиром», который переключает свой приоритет и приоритеты всех остальных синхронно себе (хорошим бригадиром: и руководит и сам работает).
Для того чтобы помочь управляющему потоку решить, когда и на какой приоритет переключать, при создании я задаю ему необходимые параметры:
* pr1 — значение приоритета 1
* pr2 — значение приоритета 2
* P1 — вероятность переключения в приоритет 1
* P2 — вероятность переключения в приоритет 2
* Tmax — максимальный интервал времени, через который необходимо разыграть переключение приоритетов
Ясно, что P1+p2=100%;
Если определить, что pr1 – критичный приоритет, а pr2 – нормальный, то получим своего рода «управляемый хаос»: **череда почти полных остановок в работе компьютера с заданным распределением**.
Остается это все как-то проверить и зафиксировать.
Итак…
##### Вершим хаос и наблюдаем
Я использовал нечто вроде временной шкалы:

По обычному таймеру с интервалом 100мсек содержимое этой шкалы смещается влево на M пикселей, где M – количество сотен миллисекунд, прошедших с предыдущего такта. Освободившееся справа место заполняется красным цветом, а самый правый столбик пикселей заполняется оттенком зеленого. Таким образом, если никаких задержек нет, т.е. M = 1, содержимое шкалы каждые 100 мсек сползает влево на 1 пиксель, справа дорисовывается зеленый столбик. При появлении существенных задержек M оказывается больше 1 и мы начинаем наблюдать красные полосы, ширина которых пропорциональна случившейся задержке. Цифры справа от шкалы показывают соотношение времени задержек ко времени нормальной работы за последние несколько секунд. Видеозапись иллюстрирует весь процесс:
В «красных зонах» на видео видно, как еле-еле работает мышка.
От себя добавлю, что в видео не показано: не проигрывается музыка, видео, не запускаются программы и т.п.
Ну вот, теперь осталось лишь сделать такую шкалу для каждого ядра процессора отдельно, и можно наблюдать, делать скриншоты, оценивать насколько та или иная программа устраивает задержки в работе того или иного ядра или даже всего процессора.
Для этого создаем столько потоков, сколько ядер в процессоре. Принуждаем систему исполнять их на разных ядрах с помощью API:
```
SetThreadAffinityMask(handle,mask);
```
Каждый такой процесс в памяти держит свою шкалу и дорисовывает её в памяти по вышеуказанному алгоритму. При этом, можно увеличить чувствительность к задержкам, уменьшив время между тактами. Ну а в основной программе, по отдельному таймеру все эти шкалы выводятся подряд одна над другой. Результат можно лицезреть на видео:
Для того чтобы оценить, на сколько тестируемая программа делает задержки в работе других программ, в моем конкретном случае хватило нескольких субъективных оценок изображений этих шкал в стиле:
«шкалы в основном зеленые по всем ядрам, поэтому программа А не сильно мешает другим программам, а для программы Б наоборот — шкалы наполовину красные, что не может не насторожить».
Однако стоит отметить, что для проведения численной оценки задержек, которые делает в системе программа, необходимо выявление таких показателей как: функция распределения времени задержек, мат. ожидание задержек, дисперсия задержек.
Именно эти показатели позволят избежать субъективных оценок, а так же позволят формулировать четкие требования к программам и алгоритмам.
Если уважаемое Хабрасообщество сочтет такую информацию полезной — с удовольствием сделаю это темой следующего топика.
Надеюсь, сей текст окажется кому-то интересным, а если окажется кому-то нужным, то это сделает меня совсем счастливым! ;-)
PS. Я здесь новичок. Честно пересмотрел все разделы сайта, не нашел более подходящего места для размещения. Буду признателен за подсказки.
**UPD**
Спасибо хабралюдям за ссылки на похожие решения и инструменты.
Вот их список:
* [Load Test Analyzer](http://msdn.microsoft.com/en-us/library/ms404677.aspx) — инструмент от Microsoft, входящий в состав VS Ultimate. Благодарим [EndUser](http://habrahabr.ru/users/enduser/)
* [Windows Hardware Quality Labs testing](http://en.wikipedia.org/wiki/WHQL_Testing) — тоже от Microsoft. Благодарим [int80h](http://habrahabr.ru/users/int80h/)
* [Iperf](http://ru.wikipedia.org/wiki/Iperf) — генератор TCP и UDP трафика. Благодарим [amarao](http://habrahabr.ru/users/amarao/) | https://habr.com/ru/post/134398/ | null | ru | null |
# Рендеринг наоборот. Преобразование Хафа на GPU

Преобразование Хафа служит для поиска на изображении фигур, заданных аналитически: прямых, окружностей и любых других, для которых вы сможете придумать уравнение с небольшим количеством параметров. О преобразовании Хафа написано немало, и данная статья не ставит цели подробно осветить все аспекты. Я лишь объясню общий принцип, останавливаясь на особенностях, мешающих его реализации на GPU «в лоб» и, конечно же, предложу решение. Те, кто знают проблемы и хотят сразу видеть решение, могут пропустить пару-тройку разделов.
#### Алгоритм для CPU
Сначала описываем искомую фигуру уравнением. Например, для линии это может быть y = Ax + B.
Затем заводим так называемый аккумулятор: массив с количеством измерений равным количеству параметров в уравнении. В нашем случае – двумерный. Он у нас будет *Пространством Хафа* (по крайней мере, его частью) – в нем прямые будут представлены своими параметрами. Например, A – по горизонтали и B – по вертикали. Одна прямая в обычном пространстве = одна точка в пространстве Хафа.
Исходное изображение бинаризируем, и для каждой непустой точки (x0, y0) определяем множество прямых, которые через эту точку могут проходить: y0=Ax0 + B. Тут x0 и y0 – постоянные, A и B переменные, и это уравнение определяет прямую в пространстве Хафа. Эту прямую нам нужно «нарисовать» в нашем аккумуляторе – добавить по 1 к каждому элементу, через который она проходит. Такая процедура называется голосованием: точка голосует за те прямые, которые могут через нее проходить.
В итоге получается, что в аккумуляторе собраны все голоса ото всех точек, и можно считать, что «победители голосования» присутствуют на исходном изображении. Тут, конечно, можно и нужно применять пороговую фильтрацию и другие методы для того, чтобы найти максимумы в пространстве Хафа, но основное и наиболее трудоемкое занятие – это именно наполнение аккумулятора.
Иллюстрация из википедии:
#### Проблемы с GPU
GPU можно рассматривать как множество (до тысяч) маленьких процессоров, имеющих общую память, и, обычно, алгоритмы делят просто: выделяя каждому процессору свой кусочек работы. Казалось бы, делим исходное изображение на кусочки, даем каждому процессору свой кусочек – и готово. Но нет, мы не можем разделить аккумулятор: в каждом кусочке исходного изображения могут оказаться точки проецирующиеся на любое место пространства Хафа. Писать в общую память процессоры не могут, только читать – иначе будут проблемы с синхронизацией. Выходом было бы дать каждому процессору свой аккумулятор, а после обработки просуммировать аккумуляторы между собой. Но, вы помните, процессоров тысячи. Если даже и найдется столько памяти, время на ее выделение и обработку перекроет выгоды от параллельного выполнения алгоритма.
Другая, меньшая, проблема – алгоритмы «рисования» линий в пространстве Хафа. Они могут быть довольно заковыристыми, но даже самые простые будут содержать циклы и ветвления. А GPU этого не любит: маленькие процессоры не умеют выполнять каждый свою программу, они все выполняют одну (ну не все, но большими группами). Просто каждый оперирует своими данными. Это значит, что выполняются обе ветви ветвления (потом результат ненужной отбрасывается для каждого процессора отдельно). И цикл выполняется столько раз, сколько нужно для наихудшего варианта входных данных. Это ведет к тому, что эффективность использования процессоров падает.
#### Модификация алгоритма для GPU
Исходная моя идея была такая: почему бы не разделить на «зоны влияния» не исходное изображение, а пространство Хафа? То есть, давайте вычислять значение для каждой точки пространства Хафа отдельно. На первый взгляд, это кажется глупо: любая точка исходного изображения может подать «голос», а, значит, нам придется осмотреть их все. Итого, количество операций чтения = *[количество точек исходного изображения]* x *[количество элементов аккумулятора]*, тогда как в традиционном способе это лишь *[количество точек исходного изображения]*.
Но зато потенциально уменьшается количество операций записи – *[количество элементов аккумулятора]* против *[количество непустых точек]* x *[средняя длина образа точки в пространстве Хафа]*. Если непустых точек много – разница существенна.
Итого, чтения становится больше, записи меньше, и она становится более упорядоченной. Теперь вспоминаем, в чем еще сила GPU. В скорости чтения! Видеокарты комплектуются быстрой памятью, доступ к ней «спрямлен» до предела — все с целью накладывать текстуры максимально быстро. Правда, это в ущерб латентности – неупорядоченные запросы на чтение выполняются медленнее. Но у нас таких не будет.
Идея вторая. Если уж в пространстве Хафа надо «рисовать» – почему бы не использовать «рисовательные» таланты видеокарт? Давайте наложим исходное изображение на пространство Хафа как текстуру.
Это приводит к тому, что в моем методе не нужны ни код на OpenCL или CUDA, ни шейдеры. Видеокарта даже не обязана их поддерживать, чтобы получить изображение пространства Хафа. Платой за это является неуниверсальность: практически, это два существенно разных метода: один для окружностей и другой, для прямых. Кажется, метод «окружностей» можно применить для любых замкнутых линий и любых фигур с тремя и более параметрами в уравнении, но эффективность может быть разной.
#### Метод «окружностей»
Окружность описывается уравнением с тремя параметрами – (x-x0)2 + (y-y0)2 = R2. Здесь (x0, y0) – координаты центра, а R – радиус. Пространство Хафа должно иметь три измерения, но мы пока ограничимся двумя и зафиксируем R (допустим, мы его знаем). В этом случае все, что нам нужно найти – это координаты центра(ов).
Возьмем такое исходное изображение (все окружности одного радиуса)

и, сделав почти прозрачным, наложим само на себя следующим образом:

Все изображения смещены от исходного на радиус окружности. Угол между соседними радиусами смещения одинаковый. То есть, допустим, верхние левые углы изображений распределены по окружности того же радиуса, что искомая.
Для наглядности иллюстрации я положил снизу инверсное исходное изображение и отметил важные места красным.
Каждая окружность каждого изображения проходит через центр соответствующей окружности исходного изображения. В этих точках они накладываются друг на друга и получается максимум яркости.
Вот что будет, если проделать эту операцию 32 раза:

И после пороговой фильтрации:

Таким образом, два измерения пространства Хафа мы заполнили. Теперь, варьируя радиус, можно легко заполнить третье. А можно не пытаться накопить все 3 измерения в памяти, а обработать полученную картинку, сохранив положение центров и радиус и освободить память.
Код (Managed DirectX, полная версия – по ссылке ниже), создающий правильно расположенные прямоугольники:
```
float r = (float)rAbs / targetSize;
for (int i = 0; i < n; i++)
{
double angle = 2 * Math.PI / n * i;
rectangles.Add(new TexturedRect(new Vector2(1f, 1f), new Vector2((float)(Math.Cos(angle) * r), (float)(Math.Sin(angle) * r)), new Vector2(1f, 1f), new Vector2(0f, 0f), 0));
}
```
Код, устанавливающий альфа-прозрачность правильным образом:
```
device.RenderState.AlphaBlendEnable = true,
device.RenderState.BlendFactor = (byte)(256.0 * brightness / n)
device.RenderState.BlendOperation = BlendOperation.Add;
device.RenderState.SourceBlend = Blend.BlendFactor;
device.RenderState.DestinationBlend = Blend.One;
```
Здесь `rAbs` задает искомый радиус, `brightness` – яркость, `n` – количество слоев.
Рендерить все можно в текстуру
```
new Microsoft.DirectX.Direct3D.Texture(device, targetSize, targetSize, 1, Usage.RenderTarget, cbGray.Checked ? Format.L8 : Format.X8R8G8B8, Pool.Default);
dxPanel.RenderToTexture(new Options()
{
AlphaBlendEnable = true,
BlendFactor = (byte)(256.0 * (tbBrightness.Value / 100.0) / n)
},
rectangles);
```
А можно использовать 3D текстуру и несколько комплектов слоев для того, чтобы отрендерить все интересующие радиусы и за раз получить трехмерное пространство Хафа (я так делать не пытался).
С прозрачностью есть такой нюанс, что если использовать 8 битный цвет и достаточно большое количество слоев, то BlendFactor будет меньше 10, вплоть до 1. Это может привести к большим погрешностям округления, и ступенчатому изменению яркости, если регулировать общую яркость с помощью BlendFactor. Однако, если яркость не регулировать, то сложно будет подобрать пороговое значение для фильтрации все из-за тех же погрешностей округления. Также, если использовать изображение с оттенками серого, оттенки пострадают, и даже буду потеряны при BlendFactor=1.
Эту проблему можно решить, используя большую глубину цвета для render target (например, 16 или 32 бита), если видеокарта это поддерживает.
Вот еще пример работы на зашумленном изображении. Исходное:

Результат (64 слоя):

Можно заметить, что алгоритм, скорее всего, опрашивает не все точки, составляющие окружность (если только окружность не слишком маленькая). С увеличением количества слоев, процент опрошенных точек и точность определения увеличивается, но возрастает время работы и появляются проблемы описанные выше.
#### Метод «прямых»
##### Анизотропная фильтрация
Прежде, чем перейти к описанию самого метода, нужно сделать отступление и рассказать подробнее об анизотропной фильтрации в видеокартах. При накладывании текстуры может случиться, что цвет одного экранного пикселя должны определять несколько точек текстуры (текселей). Это обычно случается либо при большом отдалении полигона от зрителя, либо при сильном наклоне полигона (хороший пример – текстура дороги). И если в первом случае можно заранее отмасштабировать текстуру на несколько разрешений, и потом брать нужный вариант (мип-маппинг), то во втором так сделать не получится так как текстура может оказаться повернута «в сторону зрителя» любой своей стороной.
И тут видеокарты применяют всяческие ухищрения, но самый честный путь – взять все тексели из проекции пикселя на текстуру и посчитать их среднее значение. Это называется анизотропной (зависящей от направления) фильтрацией.
Максимальный традиционно поддерживаемый уровень анизотропной фильтрации – 16 (видимо, текселей).
##### О самом методе
Возьмем наше изображение и «сплющим» его, например, по вертикали. Т.е. отрендерим его целиком на прямоугольнике высотой в 1 пиксель. В идеале, вертикальные прямые превратятся в точки (максимумы). Все остальное размажется. Таким образом, значение одного параметра мы уже получили – это расстояние от левого края изображения до точки (до прямой на исходном изображении).
Теперь возьмем свежий экземпляр изображения, но перед сплющиванием повернем его на некоторый небольшой угол вокруг центра изображения по часовой стрелке. Потом сплющим. Некоторые прямые перейдут в точки. Это будут те прямые, которые наклонены на тот самый угол поворота изображения.
Таким образом, перебрав все углы от 0 до Пи, мы получим значения второго параметра – угла поворота картинки. По этим двум параметрам можно восстановить любую исходную прямую.
Остался только вопрос, как же грамотно сплющить изображение. Если сделать это в лоб – останется только шум – анизотропная фильтрация сработает, но возьмет лишь 16 текселей (пикселей исходной картинки). Это, скорее всего, слишком мало.
Можно порезать изображение на прямоугольники по 16 пикселей шириной, сплющить каждый отдельно,
а потом отрисовать их поверх друг друга, как мы это делали в методе с окружностями. Вот это сработает, причем в результате будет учтен каждый пиксел.

(Можно считать, что картинки увеличены в 4 раза, чтоб было видно детали)
Если изображение выше, чем 16\*256=4096 пикселей, можно нарезать его на прямоугольники большей высоты, либо использовать большую глубину цвета. Но, скорее всего, такое изображение просто не влезет в текстуру.
Для того, чтобы не потерять линии, находящиеся в углах, либо возле коротких сторон неквадратного изображения нужно брать render target шириной равной диагонали исходного изображения.
Код, настраивающий семплер текстур (поворот я делаю поворотом текстурных координат, поэтому нужно, чтобы семплер возвращал черный цвет, если текстуры где-то просто нет из-за поворота).
```
device.SamplerState[0].MinFilter = TextureFilter.Anisotropic;
device.SamplerState[0].MaxAnisotropy = 16;
device.SamplerState[0].AddressU = TextureAddress.Border;
device.SamplerState[0].AddressV = TextureAddress.Border;
device.SamplerState[0].AddressW = TextureAddress.Border;
device.SamplerState[0].BorderColor = Color.Black;
```
Создание прямоугольников
```
double sourceRectPixelWidth = sourceSize / n;
double targetRectPixelWidth = Math.Ceiling(sourceRectPixelWidth / anizotropy);
int angleValues = (int)Math.Floor(targetSize / targetRectPixelWidth);
float sourceRectWidth = (float)(sourceRectPixelWidth / sourceSize);
float tarectRectWidth = (float)(targetRectPixelWidth / targetSize);
for (int angleNumber = 0; angleNumber < angleValues; angleNumber++)
{
double angle = Math.PI / angleValues * angleNumber;
float targetShift = tarectRectWidth * angleNumber;
for (int sliceNumber = 0; sliceNumber < n; sliceNumber++)
{
float sourceShift = sourceRectWidth * sliceNumber;
rectangles.Add(new TexturedRect(
new Vector2(tarectRectWidth, 1f),
new Vector2(targetShift, 0f),
new Vector2(sourceRectWidth, 1f),
new Vector2(sourceShift, 0f),
(float)angle));
}
}
```
То же зашумленное изображение, что и в прошлом разделе, но теперь ищем линии (32 слоя, 512 шагов угла поворота):

#### Расширение метода «окружностей»
Изображения можно смещать не по радиусам окружностей, а более прихотливым способом. Например, выбираем некий произвольный искомый контур (даже не выражаемый с помощью формулы) и некую точку O.
Затем, последовательно выбирая точки A1, A2 на контуре, смещаем слои изображения на вектора AO. Получается, что угол изображений описывает фигуру наподобие такой.

В этом случае будут найдены все мишки на изображении – максимумы придутся на точку, соответствующую точке O оригинального контура.
#### Дополнительные преимущества перед традиционным способом
* Экономия памяти (можно не копить все измерения в памяти)
* Можно не делать бинаризацию, а использовать оттенки серого. Это не повлияет на скорость работы и может увеличить точность
* Можно равномерно игнорировать часть точек в пользу скорости (В традиционном способе тоже можно так поступить, но придется прибегать к всяческим изощрениям, чтобы добиться равномерности, а не просто пропустить какой-нибудь угол)
* Можно работать с сильно зашумленными изображениями, это не уменьшит скорость
* Бонус. Можно использовать цветные изображения для получения красивых картинок наподобие той, что на КПДВ
#### Производительность
Будет не очень честно сравнивать производительность чистого подсчета между CPU и GPU, так как одна из тяжелых частей работы с GPU – это загрузка и выгрузка данных. Вряд ли стоит выгружать результаты работы в сыром виде обратно на CPU. Можно попробовать их сначала компактизовать, чтобы выгружать только найденные параметры фигур, а не точки. Однако, компактизация данных — тоже достаточно хитро реализуется на GPU, поэтому я даже не брался за нее пока.
Чисто производительность преобразования Хафа. Вход и выход – 2048\*2048, GPU – GeForce GTS250:

Для сравнения результаты детектирования линий с помощью OpenCV. Вход – 2048\*2048, выход 2048 шагов расстояния между линиями, CPU — Core i5 750 @ 3700Mhz.

Из этого времени 50-80 ms уходит на детектор границ Канни (после чего обрабатывается уже двуцветное изображение).
Вывод: в детектировании прямых на изображениях с малым количеством деталей GPU быстрее в 5-20 раз. На зашумленных/детализированных изображениях прирост скорости может составлять 100 – 300 раз.
Сравнить скорость детектирования окружностей не получилось, так как OpenCV использует не обычный, а *градиентный метод Хафа*.
#### Материалы по теме
[Исходники проекта](https://gpuhough.codeplex.com/) (Чтобы собрать нужен DirectX SDK June 2010)
[Преобразование Хафа](http://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%A5%D0%B0%D1%84%D0%B0)
[Алгоритм Хафа для обнаружения произвольных кривых на изображениях](http://habrahabr.ru/post/102948/)
[Hough Transform on GPU](http://parse.ele.tue.nl/system/attachments/21/original/Fast%20Hough%20Transform%20on%20GPUs%20-%20Exploration%20of%20Algorithm%20Trade-offs.pdf)
[Градиентный метод Хафа в OpenCV](http://locv.ru/wiki/6.6.2_%D0%9F%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%A5%D0%B0%D1%84%D0%B0_%D0%B4%D0%BB%D1%8F_%D0%BE%D0%BA%D1%80%D1%83%D0%B6%D0%BD%D0%BE%D1%81%D1%82%D0%B8)
UPD: Да, для того, чтобы запустить приложенный пример нужен .NET и DirectX, но сам принцип к ним не привязан. С тем же успехом можно реализовать его на c++ и OpenGL. CUDA и OpenCL все так же не понадобятся. | https://habr.com/ru/post/141438/ | null | ru | null |
# Практика внедрения PHPunit
Уже достаточно сказано о пользе автоматизированного тестирования (например, [тут](http://habrahabr.ru/blogs/php/56289/) и [тут](http://habrahabr.ru/blogs/zend_framework/60428/)), но до сих пор многие так и не пишут тестов. Одна из причин, как мне кажется, в том что предлагаемые способы автоматизации тестирования сложнее чем необходимо для большинства случаев. Сегодня я хочу рассказать о том как это сделано у нас.
Статья носит исключительно практический характер и расчитана на то что вы имеете представление о phpunit. Для реализации используются ZF, mysql + innodb, но при желании это можно использовать с любым инструментарием. Дополнительно используется [dklab.ru/lib/PHP\_Exceptionizer](http://dklab.ru/lib/PHP_Exceptionizer/) (преобразует нотисы и варнинги в эксепшены).
Подготовка
----------
В дереве проекта создается папка tests со следующей структурой.
d- application
d- models
d- triggers
…
run.php
Содержимое папок application и models повторяет структуру контроллеров и моделей в проекте. Мы не используем тестовые наборы, поэтому добавляя новый файл с тестами в систему нам не нужно добавлять этот тест в набор. В папке triggers лежат папки по именам таблиц, внутри которых файлы, названные как триггеры.
Файл run.php содержит в себе код необходимый для выполнения тестов: автозагрузка классов, подключение к базе и т.п. Скрипт должен работать и в дев среде и в боевой. Это можно сделать с помощью Zend\_Console\_Getopt. В конце файла строчки
> `PHPUnit\_Util\_Filter::addFileToFilter(\_\_FILE\_\_, 'PHPUNIT');
>
> PHPUnit\_TextUI\_Command::main();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для того чтобы они заработали phpunit должен быть установлен в системе и настроен на автозагрузку.
Для запуска тестов(-а) из папки tests можно будет так:
php run.php models/Article (запустятся все тесты из папки Article)
php run.php models/ArticleTest.php (запустятся все тесты из файла ArticleTest.php)
Тестирование моделей
--------------------
Все тесты наследуются от класса Ext\_Db\_Table\_Test\_Abstract, который содержит в себе соединение с базой. Методы setUp и TearDown объявлены как final, а их заменяют \_start и \_finish. В setUp стартует транзакция, а в tearDown она откатывается. Таким образом каждый тест выполняется в своей транзакции, что избавляет нас от необходимости следить за объектами и чистить базу.
<blockquote`1. php</li-
- abstract class Ext\_Db\_Table\_Test\_Abstract extends PHPUnit\_Framework\_TestCase
- {
- /\*\*
- \* @var Zend\_Db\_Adapter\_Abstract
- \*/
- protected static $\_db;
-
- public static function setDbAdapter(Zend\_Db\_Adapter\_Abstract $db = null)
- {
- if (empty($db)) {
- $db = Zend\_Db\_Table\_Abstract::getDefaultAdapter();
- }
-
- self::$\_db = $db;
- }
-
- /\*\*
- \* Zend\_Db\_Profiler
- \*
- \* @return Zend\_Db\_Profiler
- \*/
- public function getProfiler()
- {
- return self::$\_db->getProfiler();
- }
-
- final public function setUp()
- {
- if (empty(self::$\_db)) {
- self::setDbAdapter();
- }
- self::$\_db->beginTransaction(); // Каждый тест в своей транзакции!
- $this->\_start();
- }
-
- final public function tearDown()
- {
- $this->\_finish();
- self::$\_db->rollBack();
- }
-
- protected function \_start()
- {
- }
-
- protected function \_finish()
- {
- }
- }
\* This source code was highlighted with Source Code Highlighter.`
Следующий важный момент это созадние фикстуры. Все статьи посвященные тестированию предлагают для этого использовать расширение [PHPUnit и его Database Extension](http://habrahabr.ru/blogs/php/61710/). В целом это правильно, но мы хотели проще.
Для создания тестовых данных существует специальный класс Test\_Object, представленный в виде singletone.
Если нам нужна статья мы пишем так $article = Test\_Object::getInstance()->addArticle();
> `1. public function addArticle(array $data = array())
> 2. {
> 3. $base = array(
> 4. 'key' => md5(mt\_rand()),
> 5. 'content' => md5(mt\_rand()),
> 6. 'name' => md5(mt\_rand()),
> 7. 'published' => 1,
> 8. 'file\_id' => $this->addFile()->file\_id, // Создаем зависимый объект
> 9. 'created' => now()
> 10. );
> 11. $article\_table = Article::getInstance();
> 12. if (empty($data['article\_category\_id'])) { // Если не передали id категории, то категория создается автоматически
> 13. $base['article\_category\_id'] = $this->addArticleCategory($data)->article\_category\_id; // Массив $data передается и в метод создающий категорию.
> 14. }
> 15.
> 16. return $this->\_createRow($article\_table, $base, $data);
> 17. }
> 18.
> 19. protected function \_createRow(Ext\_Db\_Table\_Abstract $table, array $base, array $data = array())
> 20. {
> 21. $data = array\_merge($base, $data);
> 22. $row = $table->createRow($data);
> 23. $row->save();
> 24.
> 25. return $row;
> 26. }
> \* This source code was highlighted with Source Code Highlighter.`
Здесь видно что мы легко можем переопределить те данные которые нам нужны передав их в addArticle. Так же метод создает внутри себя объекты от которых зависит (если вы их ему не передали в $data). На данный момент Test\_Object содержит около 4000 строк кода из-за большого количества сущностей создающихся в системе. Представьте что было бы используй мы xml файлы. Еще одно преимущество данного подхода в том что создание объектов сосредоточено в одном месте и позволяет легко создавать любой граф объектов. Например нам нужен комментарий к статье, для этого пишется метод addArticleComment(), который внутри себя создает все необходимые объекты addUser, AddArticle и т.д. и возвращает нужный нам коммент.
И теперь сам тест.
> `1. php</li-
> - class ArticleTest extends Ext\_Db\_Table\_Test\_Abstract
> - {
> - public function testFindByKey()
> - {
> - $article = Test\_Object::getInstance()->addArticle();
> -
> - $row = Article::getInstance()->findByKey($article->key);
> - $this->assertEquals($article, $row);
> - }
> - }
> \* This source code was highlighted with Source Code Highlighter.`
Запуск и проверка php run.php models/Article/ArticleTest.php
Ниже приводится пример запуска всех тестов моделей. Всего в нашей системе порядка 1200 тестов и около 4000 проверок (Общее покрытие больше 90%).
`php run.php model/
PHPUnit 3.3.12 by Sebastian Bergmann.
E........................................................... 60 / 356
............................................................ 120 / 356
............................................................ 180 / 356
F..........................................................I 240 / 356
............................................................ 300 / 356
........................................................
Time: 42 seconds
FAILURES!
Tests: 356, Assertions: 800, Failures: 1, Errors: 1, Incomplete: 1.`
Тестирование контроллеров
-------------------------
Проще понять на примере.
> `1. php</li-
> - class Frontend\_Tender\_EditControllerTest extends ControllerTestCase // Класс в котором поднимается окружение acl, routing, и т.п.
> - {
> - public function testAddAction() // Проверяем что страница открывается.
> - {
> - $this->dispatch('/tender/add');
> -
> - $this->assertNoErrors(); // Проверяет что plugin error не зарегистрировал ошибок.
> - $this->assertModuleFromParams('tender');
> - $this->assertControllerFromParams('edit');
> - $this->assertActionFromParams('add');
> - }
> -
> - public function testAddActionWithPost() // Проверяем форму
> - {
> - $data = array(
> - 'name' => 'name',
> - 'content' => md5(mt\_rand()),
> - 'phone' => '12345',
> - 'country\_id' => 3159,
> - 'region\_id' => 4312,
> - 'city\_id' => 4400,
> - 'email' => md5(mt\_rand()) . '@testemail.ru',
> - );
> - $this->getRequest()->setMethod('post')
> - ->setParams($data);
> -
> - $this->dispatch('/tender/add');
> -
> - $this->assertNoErrors();
> -
> - $table = Tender::getInstance();
> - $row = $table->selectByEmail($data['email'])->fetchRow(); // Об этом я расскажу в следующем топике)
> - foreach ($data as $key => $value) {
> - $this->assertEquals($value, $row->$key); // Проверяем что в базе наши данные
> - }
> - }
> - }
> \* This source code was highlighted with Source Code Highlighter.`
Методы assertModuleFromParams, assertControllerFromParams, assertActionFromParams проверяют $request->getParam(blabla).
Мы активно используем actionStack, а он все время меняет реквест, поэтому проверять $request->getModuleName() нецелесообразно.
Заключение
----------
Представленный здесь способ, всего лишь один из возможных. Для нас он показался очень удобным и, можно сказать, что прошел проверку временем. И если вы еще не писали тесты самое время начать это делать).
p.s. Первый пост на хабре. Если будет интересно напишу про архитектуру проекта в котором участвую.
p.s.s Эта схема опробована и используется для [www.okinfo.ru](http://www.okinfo.ru) | https://habr.com/ru/post/72716/ | null | ru | null |
# Рейтрейсер четырёхмерного пространства
Недавно я делал простой рейтрейсер 3-х мерных сцен. Он был написан на JavaScript и был не очень быстрым. Ради интереса я написал рейтрейсер на C и сделал ему режим 4-х мерного рендеринга — в этом режиме он может проецировать 4-х мерную сцену на плоский экран. Под катом вы найдёте несколько видео, несколько картинок и код рейтрейсера.
Зачем писать отдельную программу для рисования 4-х мерной сцены? Можно взять обычный рейтрейсер, подсунуть ему 4D сцену и получить интересную картинку, однако эта картинка будет вовсе не проекцией всей сцены на экран. Проблема в том, что сцена имеет 4 измерения, а экран всего 2 и когда рейтрейсер через экран запускает лучи, он охватывает лишь 3-х мерное подпространство и на экране будет виден всего лишь 3-х мерный срез 4-х мерной сцены. Простая аналогия: попробуйте спроецировать 3-х мерную сцену на 1-мерный отрезок.
Получается, что 3-х мерный наблюдатель с 2-х мерным зрением не может увидеть всю 4-х мерную сцену — в лучшем случае он увидит лишь маленькую часть. Логично предположить, что 4-х мерную сцену удобнее разглядывать 3-х мерным зрением: некий 4-х мерный наблюдатель смотрит на какой то объект и на его 3-х мерном аналоге сетчатки образуется 3-х мерная проекция. Моя программа будет рейтрейсить эту трёхмерную проекцию. Другими словами, мой рейтрейсер изображает то, что видит 4-х мерный наблюдатель своим 3-х мерным зрением.
#### Особенности 3-х мерного зрения
Представьте, что вы смотрите на кружок из бумаги который прямо перед вашими глазами — в этом случае вы увидите круг. Если этот кружок положить на стол, то вы увидите эллипс. Если на этот кружок смотреть с большого расстояния, он будет казаться меньше. Аналогично для трёхмерного зрения: четырёхмерный шар будет казаться наблюдателю трёхмерным эллипсоидом. Ниже пара примеров. На первом вращаются 4 одинаковых взаимноперпендикулярных цилиндра. На втором вращается каркас 4-х мерного куба.
Перейдём к отражениям. Когда вы смотрите на шар с отражающей поверхностью (на ёлочную игрушку, например), отражение как бы нарисовано на поверхности сферы. Также и для 3-х мерного зрения: вы смотрите на 4-х мерный шар и отражения нарисованы как бы на его поверхности. Только вот поверхность 4-х мерного шара трёхмерна, поэтому когда мы будем смотреть на 3-х мерную проекцию шара, отражения будут внутри, а не на поверхности. Если сделать так, чтобы рейстрейсер выпускал луч и находил ближайшее пересечение с 3-х мерной проекцией шара, то мы увидим чёрный круг — поверхность трёхмерной проекции будет чёрная (это следует из формул Френеля). Выглядит это так:
Для 3-х мерного зрения это не проблема, потому что для него виден весь этот 3-х мерный шар целиком и внутренние точки видны также хорошо как и те, что на поверхности, но мне надо как то передать этот эффект на плоском экране, поэтому я сделал дополнительный режим рейтрейсера когда он считает, что трёхмерные объекты как бы дымчатые: луч проходит через них и постепенно теряет энергию. Получается так:
Тоже самое верно для теней: они падают не на поверхность, а внутрь 3-х мерных проекций. Получается так, что внутри 3-х мерного шара — проекции 4-х мерного шара — может быть затемнённая область в виде проекции 4-х мерного куба, если этот куб отбрасывает тень на шар. Я не придумал как этот эффект передать на плоском экране.
#### Оптимизации
Рейтрейсить 4-х мерную сцену сложнее чем 3-х мерную: в случае 4D нужно найти цвета трёхмерной области, а не плоской. Если написать рейтрейсер «в лоб», его скорость будет крайне низкой. Есть пара простых оптимизаций, которые позволяют сократить время рендеринга картинки 1000×1000 до нескольких секунд.
Первое, что бросается в глаза при взгляде на такие картинки — куча черных пикселей. Если изобразить область где луч рейтрейсера попадает хоть в один объект, получится так:
Видно, что примерно 70% — черные пиксели, и что белая область связна (она связна потому что 4-х мерная сцена связна). Можно вычислять цвета пикселей не по порядку, а угадать один белый пиксель и от него сделать заливку. Это позволит рейтрейсить только белые пиксели + немного черных пикселей которые представляют собой 1-пиксельную границу белой области.
Вторая оптимизация получается из того, что фигуры — шары и цилиндры — выпуклы. Это значит, что для любых двух точек в такой фигуре, соединяющий их отрезок также целиком лежит внутри фигуры. Если луч пересекает выпуклый предмет, при этом точка A лежит внутри предмета, а точка B снаружи, то остаток луча со стороны B не будет пересекать предмет.
#### Ещё несколько примеров
Здесь вращается куб вокруг центра. Шар куба не касается, но на 3-х мерной проекции они могут пересекаться.
На этом видео куб неподвижен, а 4-х мерный наблюдатель пролетает через куб. Тот 3-х мерный куб что кажется больше — ближе к наблюдателю, а тот что меньше — дальше.
Ниже классическое вращение в плоскостях осей 1-2 и 3-4. Такое вращение задаётся произведением двух матриц Гивенса.
#### Как устроен мой рейтрейсер
Код написан на ANSI C 99. Скачать его можно [здесь](http://dl.dropbox.com/u/18189361/Habr/rt.c.zip). Я проверял на ICC+Windows и GCC+Ubuntu.
На вход программа принимает текстовый файл с описанием сцены.
```
scene =
{
objects = -- list of objects in the scene
{
group -- group of objects can have an assigned affine transform
{
axiscyl1,
axiscyl2,
axiscyl3,
axiscyl4
}
},
lights = -- list of lights
{
light{{0.2, 0.1, 0.4, 0.7}, 1},
light{{7, 8, 9, 10}, 1},
}
}
axiscylr = 0.1 -- cylinder radius
axiscyl1 = cylinder
{
{-2, 0, 0, 0},
{2, 0, 0, 0},
axiscylr,
material = {color = {1, 0, 0}}
}
axiscyl2 = cylinder
{
{0, -2, 0, 0},
{0, 2, 0, 0},
axiscylr,
material = {color = {0, 1, 0}}
}
axiscyl3 = cylinder
{
{0, 0, -2, 0},
{0, 0, 2, 0},
axiscylr,
material = {color = {0, 0, 1}}
}
axiscyl4 = cylinder
{
{0, 0, 0, -2},
{0, 0, 0, 2},
axiscylr,
material = {color = {1, 1, 0}}
}
```
После чего парсит это описание и создаёт сцену в своём внутреннем представлении. В зависимости от размерности пространства рендерит сцену и получает либо четырёхмерную картинку как выше в примерах, либо обычную трёхмерную. Чтобы превратить 4-х мерный рейтрейсер в 3-х мерный надо изменить в файле vector.h параметр vec\_dim с 4 на 3. Можно его также задать в параметрах командной строки для компилятора. Компиляция в GCC:
`cd /home/username/rt/
gcc -lm -O3 *.c -o rt`
Тестовый запуск:
`/home/username/rt/rt cube4d.scene cube4d.bmp`
Если скомпилировать рейтрейсер с vec\_dim = 3, то он выдаст для сцены cube3d.scene обычный [куб](http://habrastorage.org/storage/592fd86d/2ef3153e/897ea88f/665f0bea.jpg).
#### Как делалось видео
Для этого я написал скрипт на Lua который для каждого кадра вычислял матрицу вращения и дописывал её к эталонной сцене.
```
axes =
{
{0.933, 0.358, 0, 0}, -- axis 1
{-0.358, 0.933, 0, 0}, -- axis 2
{0, 0, 0.933, 0.358}, -- axis 3
{0, 0, -0.358, 0.933} -- axis 4
}
scene =
{
objects =
{
group
{
axes = axes,
axiscyl1,
axiscyl2,
axiscyl3,
axiscyl4
}
},
}
```
Объект group помимо списка объектов имеет два параметра аффинного преобразования: axes и origin. Меняя axes можно вращать все объекты в группе.
Затем скрипт вызывал скомпилированный рейтрейсер. Когда все кадры были отрендерены, скрипт вызывал mencoder и тот собирал из отдельных картинок видео. Видео делалось с таким расчётом, чтобы его можно было поставить на автоповтор — т.е. конец видео совпадает с началом. Запускается скрипт так:
`luajit animate.lua`
Ну и напоследок, в [этом архиве](http://dl.dropbox.com/u/18189361/Habr/rt-avi.zip) 4 avi файла 1000×1000. Все они циклические — можно поставить на автоповтор и получится нормальная анимация. | https://habr.com/ru/post/114698/ | null | ru | null |
# Как проимпортировать неимпортируемое
#### Проблема, идея, и решение
Здравствуйте, дорогие мои детишечки. Спешу сообщить вам, что в мою голову пришла еще одна идея, которая вылилась вот в эту заметку. Идея, собственно говоря, пришла из проблемы, которую подкинула горячо мной любимая и уважаемая компания Microsoft и их новый продукт Windows Server 2012 R2. И тут я нисколько не иронизирую, мне они действительно нравятся. Но начнем по порядку.
Прежде всего отмечу, что я, кроме всего прочего еще и тренер по всякого рода продуктам Microsoft, и соответственно имею доступ к определенным плюшкам в виде готовых виртуальных машин для подготовки к курсам, в рамках учебного центра. И вот, собственно, решил я попробовать погонять новый сервер, ну и, как водится, развернуть на нем виртуалочки от одного курса. Выкачал эти машины, все подготовил, распаковал. И тут меня поджидало ужасное. Они категорически отказывались импортироваться.

В общем, оказалось, что машины экспортированы на Windows Server 2008 и в Windows 2012 R2 импортироваться не будут. [Не поддерживается это](http://blogs.technet.com/b/rmilne/archive/2013/10/22/windows-hyper-v-2012-amp-8-1-hyper-v-did-not-find-virtual-machine-to-import.aspx) по определенным техническим причинам.
Что же делать, как они могли, спросите вы, и будете правы. В моем случае у меня не было под рукой Windows Server 2008 и я стал искать альтернативный вариант. В общем и целом он прост. В одном из подкаталогов экспортированной машины нашелся файл с именем вида {GUID}.exp. Он представляет собой конфигурацию экспортированной виртуальной машины. Именно из-за него она не импортируется, и мы это собираемся изменить. Я решил просто взять нужные мне настройки из этого файла, привести их к подходящему виду и просто создать новые виртуальные машины с теми же настройками, что и исходные. Чтобы долго не заморачиваться, я решил выбрать из файла имя машины, пути к файлам VHD, конфигурацию памяти и имя виртуальной сети, к которой эти машинки должны подключаться. Но не делать же это руками, верно. Тем более если открыть этот файл и посмотреть на его содержимое, то волосы на голове встают дыбом и пропадает желание искать что-то в нем вручную. А если их больше одного. В общем решено, пишем скрипт
##### Скрипт
На чем пишем? Конечно, на старом добром powershell 4, который поставляется в комплекте с новым сервером и WIndows 8.1. С чего начнем? А начнем сразу в лоб, а как же иначе. Открываем файл, благо есть тип [xml] который упрощает ковыряние во внутренностях и дебрях экспортированной конфигурации. Вкратце, файлик этот содержит кучу WMI классов со значениями свойств. Содержимое этих классов выгружено в XML и записано в файл. Поскольку я не сильно знаком с этими WMI классами, та и с XLM тоже, пришлось помучаться, добывая эти параметры в лоб. Вот что вышло:
```
cls
$tmp = dir "C:\Program Files\Microsoft Learning\20413\*\*.exp" -Recurse
$tmp | % {
# read file
[xml]$vm = gc $_.fullname
# parsing of the various of different internal XML structures using "properties" notation
# CLASSNAME Msvm_VirtualSystemGlobalSettingData
$disks = ($vm.DECLARATIONS.DECLGROUP.'VALUE.OBJECT'.instance | where classname -like "*resource*") |
where {$_.property | where name -like "*units*" |
where value -eq "disks"}
$newVM = @{}
# CLASSNAME Msvm_VirtualSystemGlobalSettingData
$newVM.Global = $vm.DECLARATIONS.DECLGROUP.'VALUE.OBJECT'.instance |
where classname -like "*Msvm_VirtualSystemGlobalSettingData*" |
select -ExpandProperty property |
# below passage is most exciting
% {$obj=@{}} {$obj["$($_.name)"]=$_.value} {new-object psobject -prop $obj}
# disks configuration contains some internal nodes, extractiong them to get the paths to VHDs
$newVM.Disks = $disks | % { $prop = @{}; $disk = $_; $disk | select -ExpandProperty property |
% {$obj=@{}} {$obj["$($_.name)"]=$_.value};
$obj."Path" = ($disk | select -expand property.array)."value.array".value;
New-object psobject -prop $obj}
# CLASSNAME Msvm_MemorySettingData
$newVM.Memory = $vm.DECLARATIONS.DECLGROUP.'VALUE.OBJECT'.instance |
where classname -like "*memory*" | select -ExpandProperty property |
% {$obj=@{}} {$obj["$($_.name)"]=$_.value} {new-object psobject -prop $obj}
# CLASSNAME Msvm_SwitchPort
$newVM.Network = $vm.DECLARATIONS.DECLGROUP.'VALUE.OBJECT'.instance |
where classname -like "*switch*" | select -ExpandProperty property |
% {$obj=@{}} {$obj["$($_.name)"]=$_.value} {new-object psobject -prop $obj}
# as far as $newVM is a hashtable, making an object from it
$vmObj = New-object psobject -prop $newVM
# variables, just to see what we've got
$vmName = $vmObj.Global.ElementName
#$vmObj.Disks.Path
[int64]$vmMemoryReservation = [int64]$vmObj.Memory.Reservation * 1MB
[int64]$vmMemoryLimit = [int64]$vmObj.Memory.Limit * 1MB
$vmNetwork = $vmObj.Network.ElementName
$vmName
$vmObj.Disks.Path
$vmMemoryReservation
$vmMemoryLimit
$vmNetwork
#actual import
New-VM -Name $vmName -MemoryStartupBytes $vmMemoryLimit #-VHDPath $vmObj.Disks.Path[0]
$vmObj.Disks.Path | % {Add-VMHardDiskDrive -VMName $vmName -Path $_}
Set-VMMemory -VMName $vmName -MaximumBytes $vmMemoryLimit -DynamicMemoryEnabled $true
Get-vm -Name $vmName | Get-VMNetworkAdapter | Connect-VMNetworkAdapter -SwitchName $vmNetwork
checkpoint-vm -Name $vmName
"========== $vmName =========="
}
```
И это сработало. Но глядя на все это, и вспоминая не несколько часов, которые я потратил на поиск нужных частей текста я понял что все это ужасно. Мне тут же вспомнился комментарий камрада [Pinsky](http://habrahabr.ru/users/Pinsky/) о паралимпийских играх по программированию. А что, я ж не программист, таки. Все равно ведь работает. Но хотелось чего-то большего, более краткого, красивого и лаконичного. В общем, тут я вспомнил знакомое слово XPATH. Честно говоря, до этого момента, о самой технологии кроме самого слова, я ничего не знал. Я подозревал, что эта штука должна делать но пользоваться не приходилось. Я подумал, что стоило бы попробовать. Как это счастье работает с powershell и работает ли. Пара часов прошли в поисках по гуглу и тестах. И вот оно, почти счастье:
```
[xml]$vm = gc $path
#class 'Msvm_VirtualSystemGlobalSettingData'
$vmName = ($vm.SelectNodes("//INSTANCE[@CLASSNAME='Msvm_VirtualSystemGlobalSettingData']/PROPERTY") |
% {$obj=@{}} {$obj["$($_.name)"]=$_.value} {new-object psobject -prop $obj}).elementname
#class 'Msvm_ResourceAllocationSettingData'
$hardDrives = $vm.SelectNodes("(//INSTANCE[@CLASSNAME='Msvm_ResourceAllocationSettingData'])/PROPERTY.ARRAY[@NAME='Connection']/VALUE.ARRAY").value
#class 'Msvm_MemorySettingData'
$memory = $vm.SelectNodes("//INSTANCE[@CLASSNAME='Msvm_MemorySettingData']/PROPERTY") |
% {$obj=@{}} {$obj["$($_.name)"]=$_.value} {new-object psobject -prop $obj} | select Limit,Reservation
#class 'Msvm_SwitchPort'
$network = ($vm.SelectNodes("//INSTANCE[@CLASSNAME='Msvm_SwitchPort']/PROPERTY") |
% {$obj=@{}} {$obj["$($_.name)"]=$_.value} {new-object psobject -prop $obj}).ElementName
$vmName
$hardDrives
$memory
$network
```
Вот такая вот штука. Значительно короче, приятней читать, понятней. И еще и работает.
PS. К слову стоит отметить, что в конфигурациях машины были неправильно указаны пути к самим файлам VHD. То есть самораспаковывающийся архив складывает файлы в каталог [..]\1234**В**-XX-YY1\[..]\file.vhd а в конфигурации они были совсем другие [..]\1234**А**-XX-YY1\[..]\file.vhd. На то чтобы разглядеть эту разницу вместо того чтобы биться головой о стену в поисхах ошибки в скрипте ушло около часа с копейками. | https://habr.com/ru/post/199228/ | null | ru | null |
# Работа сети в пошаговой игре
Три года назад я приступил к разработке [**Swords & Ravens**](https://swordsandravens.net/) — многопользовательской онлайн-адаптации в open source моей любимой стратегической игры [A Game of Thrones: The Board Game (Second Edition)](https://boardgamegeek.com/boardgame/103343/game-thrones-board-game-second-edition), разработанной Кристианом Питерсеном и изданной [Fantasy Flight Games](https://www.fantasyflightgames.com/en/). На февраль 2022 года на платформе ежедневно собирается примерно 500 игроков и с момента её выпуска было сыграно больше 2000 партий. Хотя я перестал активно разрабатывать S&R, благодаря сообществу open source на платформе всё равно появляются новые функции.

*Напряжённая партия в A Game of Thrones: The Board Game на Swords & Ravens*
В процессе разработки S&R я многому научился и мне бы хотелось поделиться своими знаниями с людьми, которых может заинтересовать создание похожего проекта. О его работе можно сказать многое, но в этой статье я сосредоточусь на том, как проектировалась сетевая часть игры. Сначала я опишу задачу формально. Затем объясню, как она решается в S&R, а также опишу другие возможные решения, придуманные или найденные мной. Я подробно расскажу о достоинствах и недостатках каждого способа, а в конце скажу, какой из них считаю лучшим.
Формулирование задачи
---------------------
В однопользовательской игре вся информация находится внутри одного компьютера. Действия игрока применяются к состоянию игры, и изменения в этом состоянии игры отражаются на экране игрока. В многопользовательской онлайн-среде всё иначе. Каждый игрок играет на своём компьютере, хранящем собственную текущую информацию об игре и имеющем собственный UI для отображения текущего состояния игры.
Общую архитектуру онлайн-игры можно вкратце описать следующей схемой:

`UI` отображает игроку текущее состояние игры на основании локальной копии состояния игры. `Клиенты` отвечают за взаимодействие с сервером, и отправляя действия игрока, и получая новую информацию о состоянии игры.
Нам нужно решить задачу синхронизации различных локальных состояний игры клиентов с состоянием игры сервера. Если конкретнее, нам нужно решить, как сервер должен передать изменения в состоянии игры клиентам, когда он применяет действия игрока к его состоянию игры.
Методика Update propagation
---------------------------
Самое очевидное решение заключается в том, чтобы применять к игре любые действия, полученные сервером, и передавать различные обновления состояния игры клиентам. Этот способ показан на схеме ниже.

Именно этот способ используется в Swords & Ravens. Он прост, интуитивно понятен и легко даёт понять, какие данные нужно и не нужно отправлять разным клиентам. Также он тривиально позволяет хранить секретные данные (т. е. данные, которые должны быть известны только подмножеству игроков). Если игрок тянет карту и берёт её в свою руку (в закрытую), то можно передать, какая карта вытянута, только этому игроку, чтобы ни один другой игрок не знал, что это за карта.
Первый недостаток этого способа заключается в том, что нужно прописать в коде все возможные обновления состояния игры. Хотя и существуют способы автоматизирования этого в JS, например, при помощи декораторов, чтобы управлять доступом к переменным состояния игры, это может снизить читаемость кода.
Второй недостаток заключается в том, что поскольку мы можем отправлять несколько обновлений для одного действия, локальное состояние игры клиента до получения всех обновлений может временно находиться в недопустимом состоянии. На показанной выше схеме между обновлением `Убрать пехоту из Винтерфелла` и `Добавить пехоту в Королевскую Гавань` есть отсутствующая пехота, которая изменит количество пехоты, отображаемое в UI. Хотя эту конкретную проблему можно решить отправкой комбинированного обновления (например, `Переместить пехоту из Винтерфелла в Королевскую Гавань`), не все обновления конкатенировать легко.
Более правильным способом решения было бы комбинирование всех обновлений, выполняемых из-за действия, и их одновременная отправка. По сути, в этом и заключается второй способ.
Методика Delta-update propagation
---------------------------------
Способ применения дельты обновления заключается в вычислении дельты между новым состоянием игры и состоянием игры до применения действия. Затем эта дельта передаётся клиентам, чтобы они могли применить её к своему локальному состоянию игры. Именно так работает игровой движок [boardgame.io](https://boardgame.io/).

Это устраняет два недостатка, описанные в предыдущем способе. Нам больше не надо прописывать в коде все возможные обновления, поскольку после того, как что-то изменилось, это будет вычислено в дельте после обработки действия. Больше у вас не будет промежуточных недопустимых состояний, потому что обновления будут применяться одновременно, атомарно.
Однако при этом мы теряем простоту управления секретным состоянием. Если мы хотим препятствовать передаче некой секретной информации конкретному клиенту, сервер перед отправкой дельты клиентам должен отфильтровать из неё любую потенциально приватную информацию.
Методика action propagation method
----------------------------------
Источником вдохновения для создания этого способа стал способ deterministic lockstep, используемый в онлайн-играх реального времени. [Хотя может показаться, что из-за наличия случайности в игре (перемешивание колоды, броски костей и т. п.) мы теряем свойство детерминированности, можно использовать генератор псевдослучайных чисел с порождающим значением, гарантирующий, что случайный бросок будет всегда одинаков и на стороне клиента, и на стороне сервера.]
В нём используется допущение о том, что обработка действий игрока детерминирована, то есть при конкретном состоянии игры применение к нему действия всегда будет давать нам одинаковое итоговое состояние игры. Мы можем воспользоваться этим свойством, чтобы избежать необходимости распространения обновлений состояния игры на клиентов. Вместо этого сервер может применять действие, полученное от клиента, а затем распространять это действие на клиентов, которые далее могут использовать это действие для вывода собственного нового состояния игры. Так как применение действия детерминировано, клиенты придут к тому же состоянию, что и состояние игры на сервере. [Качественно изложенный и проиллюстрированный разбор этого способа можно найти [здесь](https://gafferongames.com/post/deterministic_lockstep/).]

Это решение имеет множество преимуществ по сравнению с предыдущими.
Во-первых, нам не нужно кодировать дополнительную сетевую логику в коде. Единственное, что нужно реализовать — это распространение действия, выполненного игроками.
Во-вторых, потребление канала не привязано к размеру изменений, которым подвергается состояние игры. Если действие одного игрока меняет 1000 сущностей в состоянии игры, нам всё равно нужно передать только действие, а не изменения. Именно поэтому [deterministic lockstep используется в стратегиях реального времени, например, в Age of Empires](https://www.gamedeveloper.com/programming/1500-archers-on-a-28-8-network-programming-in-age-of-empires-and-beyond) [[перевод](https://habr.com/ru/post/417703/) на Хабре]. Хотя в пошаговых играх довольно редко происходит перемещение множества сущностей при выполнении действия (не говоря уже о настольных играх), благодаря такому подходу открываются новые возможности для пошаговых игр.
В-третьих, поскольку код геймплея выполняется в клиенте, мы можем выполнять анимации различных обновлений, происходящих с состоянием игры. Например, если действие игрока уменьшит сумму его денег на 10, а затем увеличит её на 40, мы можем воспроизвести две разные анимации на стороне клиента, в то время как в предыдущем решении мы получим от сервера только информацию о том, что количество денег увеличилось на 30, поэтому клиент не сможет этого сделать.
В-четвёртых, когда игрок решает выполнить действие, клиент после отправки его на сервер напрямую может применить действие к собственному состоянию игры, не дожидаясь подтверждения сервером. Этот процесс, называемый «оптимистичным обновлением», позволяет нам избавить игровой процесс от задержек.
В целом это решение достаточно изящно. Нам достаточно лишь реализовать распространение действий на игрока, после чего мы можем сосредоточиться на реализации геймплея и нам вообще не нужно больше будет трогать сетевой код!
Однако тут есть один серьёзный недостаток. Чтобы гарантировать, что все клиенты и сервер придут к одному состоянию игры после обработки действия, нам нужно сделать так, чтобы они изначально обладали совершенно одинаковым состоянием игры. Поначалу кажется, что при этом невозможно будет хранить секретность. И в самом деле, как создать состояние, хранящееся только на сервере, если в сетевом коде используется тот факт, что состояние игры одинаково для всех акторов?
### Работа с секретным состоянием
Мы можем решить эту проблему довольно изящно — позволив клиентам слегка отличаться от сервера. Если действие требует состояния, которое ранее было скрыто от одного или нескольких клиентов, то мы можем заставить сервер согласовать различия, отправив клиентам эту конкретную часть состояния игры.
Давайте проиллюстрируем это на примере из Swords & Ravens. Когда игрок двигает свою армию на территорию другого игрока, это приводит к бою. Для разрешения боя в S&R оба игрока одновременно выбирают из руки генерала своего дома, который поведёт их армии. Эта механика приводит к активному просчитыванию ходов: оба игрока пытаются догадаться, какого генерала выберет их противник, чтобы выбрать противодействующего ему персонажа, в то же время думая о том, не запланирует ли это противник и не выберет ли он генерала, противодействующего выбранному, и так далее.
Очевидно, что важно хранить секретность выбора одного из противников, если другой игрок пока не сделал свой выбор.
На показанной ниже схеме показано, как мы можем решить эту проблему.

Когда `Клиент A` отправляет своё действие серверу (выбор Тайвина Ланнистера), мы распространяем это действие на обоих игроков, но прежде отфильтровываем выбранного лидера из сообщения, отправляемого `Клиенту Б`. На этом этапе состояние игры `Клиента Б` отличается от состояния игры `Сервера`, потому что он не знает, какого лидера выбрал `A`. Когда `Клиент Б` отправляет своё действие (выбор Маргери Тирелл), мы используем ту же логику и отфильтровываем выбранного лидера из сообщения, передаваемого `Клиенту А`. Так как оба игрока выбрали своих лидеров, мы можем согласовать разницу в состоянии игры, отправив информацию о выборе другого игрока. После этого небольшого манёвра у всех клиентов имеется одинаковое состояние игры и мы можем разрешить остальную часть боя детерминированным образом.
Стоит заметить, что мы могли бы решить не отправлять ничего `Клиенту Б` после выбора лидера `Клиентом A`, отправка этой информации позволяет отобразить в UI `Клиента B` сообщение о том, что `A` уже выбрал своего лидера.
Заключение
----------
Если бы мне пришлось разрабатывать Swords & Ravens с нуля, я выбрал бы способ с детерминированностью. Возможность реализации сетевого кода только один раз — привлекательная и изящная особенность. Так как AGoT:TBG — довольно сложная игра со множеством разных фаз, из-за сетевой обработки каждого взаимодействия возникло много бойлерплейта, составляющего большую часть кода. Кроме того, мне так и не удалось удобно добавить в UI анимации (перемещение фигур, переход карт из руки на поле и т. п.), что не идёт на пользу AGoT:TBG, в которой одно действие может приводить к множеству обновлений состояния.
Ещё один удобный аспект использования детерминированного способа заключается в том, что можно легко создать библиотеку, обрабатывающую всю сетевую часть пошаговой игры, позволив разработчику сосредоточиться на разработке механик самой игры. Я начал создавать такую библиотеку под названием [Ravens](https://ravens.dev/). К сожалению, по объективным причинам я не могу продолжить её разработку.
Если вы сейчас занимаетесь реализацией пошаговой игры, то я надеюсь, что эта статья поможет вам выбрать надёжную архитектуру. Если же нет, то пусть её содержание хотя бы покажется вам интересным! | https://habr.com/ru/post/651987/ | null | ru | null |
# Стоит ли использовать кастомные исключения в Python
В Python имеется так много встроенных исключений, что программисты редко нуждаются в создании и использовании пользовательских исключений. Или это не так?
Какие исключения стоит применять — пользовательские или встроенные? Это, на самом деле, очень хороший вопрос. Одни отвечают на него так:
> *Всеми силами избегайте пользовательских исключений. Существует так много встроенных исключений, что вам редко понадобятся пользовательские исключения, если вообще понадобятся.*
>
>
А другие — так:
> *Применяйте пользовательские исключения в своих проектах. Оставьте встроенные исключения для типичных ситуаций, в которых они генерируются. Пользовательские исключения вызывайте для выдачи информации о том, что что-то пошло не так в связи с приложением, а не с самим кодом.*
>
>
Авторы книги «Python. Искусственный интеллект, большие данные и облачные вычисления» Пол Дейтел и Харви Дейтел утверждают, что программисту следует пользоваться встроенными исключениями. Автор книги «Clean Python: Elegant Coding in Python» Сунил Капиль рекомендует применять пользовательские исключения при создании интерфейсов или библиотек, так как подобные исключения помогают диагностировать проблемы, произошедшие в коде. Так же считает и автор книги «Python Tricks: A Buffet of Awesome Python Features» Дэн Бадер, обосновывая это тем, что пользовательские исключения помогают пользователям тогда, когда код следует стратегии [EAFP](https://devblogs.microsoft.com/python/idiomatic-python-eafp-versus-lbyl/) (Easier to ask for forgiveness than permission, проще просить прощения, чем получить разрешение).
Если вас мучают сомнения по поводу разных видов исключений, или если вам просто интересны пользовательские исключения — значит, эта статья написана специально для вас. Здесь мы поговорим о том, стоит или не стоит применять пользовательские исключения в своих проектах вместо того, чтобы всегда, когда это возможно (то есть, в общем-то, просто «всегда»), прибегать к встроенным исключениям. Прежде чем мы двинемся дальше — обратите внимание на то, что мы не будем пытаться сделать выбор между «правильным» и «неправильным». Мы, скорее, будем заниматься поисками золотого правила, которое поможет нам найти правильный баланс исключений.
### Определение пользовательского исключения
Для начала поговорим о том, как определить пользовательское исключение в Python. Это просто — достаточно создать класс, наследующий от встроенного класса `Exception`:
```
>>> class PredictionError(Exception):
... pass
```
Как вы увидите ниже, при определении пользовательского исключения можно сделать не только это; но суть в том, что в большинстве случаев я использую лишь пустой класс (на самом деле — не пустой, так как он является наследником `Exception`), так как это — всё, что мне нужно. Часто я добавляю к такому классу описательную строку документации:
```
>>> class PredictionError(Exception):
... """Error occurred during prediction."""
```
Как видите, если к классу добавляют строку документации, нет нужды в использовании выражения `pass`. Ещё выражение `pass` можно заменить на многоточие (`…`). Эти три варианта работают одинаково. Выбирайте тот, что лучше всего показывает себя в конкретной ситуации, или тот, который вы предпочитаете.
Обратите внимание на важность правильного именования исключений. Пользовательское исключение `PredictionError` (ошибка в прогнозе) выглядит как довольно универсальное, общее исключение, которое подойдёт для случаев, когда что-то идёт не так при нахождении некоего прогноза. Можно, в зависимости от ваших нужд, создавать более конкретные исключения. Но, в любом случае, всегда помните о том, что исключениям надо давать информативные имена. В Python существует общее правило, в соответствии с которым имена сущностей должны быть короткими, но информативными. По иронии судьбы, пользовательские исключения являются исключением из этого правила, так как они часто имеют длинные имена. Это так из-за того, что большинство людей — включая меня — предпочитают использовать самодостаточные имена исключений. Полагаю, вам тоже стоит придерживаться этого правила. Взгляните на следующие пары имён исключений — информативных и недостаточно ясных:
* `NegativeValueToBeSquaredError` в сравнении с `SquaredError`.
* `IncorrectUserNameError` в сравнении с `InputError`.
* `OverloadedTruckError` и `NoLoadOnTruckError` в сравнении с `LoadError`.
Имена, находящиеся слева, более специфичны и информативны, чем те, которые находятся справа. С другой стороны, «правые» имена можно рассматривать как общие ошибки, наследниками которых могут быть исключения, имена которых находятся слева. Например:
```
class LoadError(Exception):
"""General exception to be used when there is an error with truck load."""
class OverloadTruckError(LoadError):
"""The truck is overloaded."""
class NoLoadOnTruckError(LoadError):
"""The truck is empty."""
```
Это называют иерархией исключений. У встроенных ошибок тоже имеется иерархия. Иерархия исключений может служить важной цели: когда создают такую иерархию, пользователю необязательно знать обо всех конкретных исключениях (из книги Марка Лутца «Изучаем Python»). Вместо этого достаточно знать и перехватывать общие исключения (в нашем примере это — `LoadError`); это позволит перехватывать все исключения, наследующие от них (`OverloadTruckError` и `NoLoadOnTruckError`). Автор книги «Clean Python: Elegant Coding in Python» Сунил Капиль эту рекомендацию подтверждает, но он предупреждает читателя о том, что такую иерархию не следует делать слишком сложной.
Иногда, правда, достаточно пойти самым простым путём:
```
class OverloadTruckError(Exception):
"""The truck is overloaded."""
class NoLoadOnTruckError(Exception):
"""The truck is empty."""
```
Если вы думаете, что исключение `NoLoadOnTruckError` (сообщающее о том, что в грузовике ничего нет) не должно рассматриваться как ошибка, так как грузовики иногда ездят и пустыми, то вы правы. Но помните о том, что исключения и не обязаны олицетворять собой ошибки. Их возникновение означает… возникновение исключительной ситуации. Правда, по правилам Python в конце имён классов исключений должно быть слово `Error`, так устроены имена всех встроенных исключений (например — `ValueError` или `OSError`).
### Выдача пользовательского исключения
Пользовательские исключения выдаются так же, как и встроенные. Но стоит помнить о том, что сделать это можно разными способами.
#### Выдача исключения после проверки условия
Исключение выдаётся после проверки некоего условия. Сделать это можно как с сообщением, так и без него:
```
# без сообщения
if load == 0:
raise NoLoadOnTruckError
# с сообщением
truck_no = 12333
if load == 0:
raise NoLoadOnTruckError(f"No load on truck {truck_no}")
```
#### Перехват встроенного исключения и выдача пользовательского исключения
```
class EmptyVariableError(Exception):
pass
def get_mean(x):
return sum(x) / len(x)
def summarize(x):
try:
mean = get_mean(x)
except ZeroDivisionError:
raise EmptyVariableError
total = sum(x)
n = len(x)
```
Здесь, вместо выдачи `ZeroDivisionError`, мы выдаём пользовательское исключение `EmptyVariableError`. С одной стороны — этот подход может быть более информативным, так как он позволяет сообщить пользователю о сути возникшей проблемы. С другой стороны — он не позволяет сообщить пользователю всю информацию. То есть, иными словами, выдача только исключения `EmptyVariableError` не сообщит пользователю о том, что переменная не содержала значение, и по этой причине произошло деление на ноль при вычислении среднего значения с использованием функции `get_mean()`. Разработчику программы нужно решить — должен ли её пользователь знать такие обширные подробности о её работе. Иногда это не нужно. Но в некоторых случаях оказывается так, что чем больше сведений содержится в отчётах о трассировке стека — тем лучше.
Донести до пользователя подобные сведения можно посредством сообщения, сопутствующего исключению `EmptyVariableError`. Но есть лучший способ решить эту задачу. Он описан в следующем разделе.
#### Перехват встроенного исключения и выдача из него пользовательского исключения
```
class EmptyVariableError(Exception):
pass
def get_mean(x):
return sum(x) / len(x)
def summarize(x):
try:
mean = get_mean(x)
except ZeroDivisionError as e:
raise EmptyVariableError from e
total = sum(x)
n = len(x)
```
Тут в отчёт о трассировке стека попадает и `EmptyVariableError`, и `ZeroDivisionError`. Здесь, в сравнении с предыдущим примером, изменено всего две строчки.
Раньше было так:
```
except ZeroDivisionError:
raise EmptyVariableError
```
Теперь стало так:
```
except ZeroDivisionError as e:
raise EmptyVariableError from e
```
Эта версия кода даёт гораздо более информативные сведения пользователю, так как сообщает ему больше деталей: о том, что переменная была пустой и что в ней не было данных, о том, что из-за этого было выдано исключение `ZeroDivisionError` при вычислении среднего значения в функции `get_mean()`. Даёт ли ту же информацию сообщение вида `ZeroDivisionError: division by zero`? Напрямую об этом тут, понятно, не сообщается. Чтобы получить те же сведения, нужно тщательно проанализировать отчёт о трассировке стека.
Следовательно, выдача пользовательских исключений из встроенных исключений помогает донести до пользователя гораздо более подробные сведения о том, что произошло.
### Расширение возможностей пользовательских исключений
До сих пор мы использовали пользовательские исключения, выполняя лишь минимальные их настройки. Несмотря на простоту такого подхода, он отличается широкими возможностями настройки исключений благодаря тому, что при выдаче исключения можно использовать любое сообщение. Но можно применять сообщения, встроенные в класс исключения. А значит — при выдаче исключения передавать ему сообщение не нужно. Взгляните на этот код:
```
class NoLoadOnTruckError(Exception):
"""The truck is empty."""
def __init__(self, truck_no=None):
self.msg = f"The {truck_no} is empty" if truck_no else ""
def __str__(self):
return self.msg
truck_no = 12333
if load == 0:
raise NoLoadOnTruckError(truck_no)
```
Получается, что если не передать исключению значение `truck_no`, это исключение сообщение не выводит. А если передать это значение (например — `12333`) — исключение `NoLoadOnTruckError` будет выдано с сообщением `«The truck 12333 is empty»`. Это — простой пример, подробнее об этом можно почитать [здесь](https://towardsdatascience.com/how-to-define-custom-exception-classes-in-python-bfa346629bca).
Я применяю этот подход лишь в одной ситуации: тогда, когда иначе мне пришлось бы использовать одно и то же длинное сообщение в нескольких местах кода при выдаче некоего исключения. В результате появляется смысл в расширении класса этого исключения за счёт встраивания в него текста сообщения. Но я стараюсь, чтобы подобные классы были бы устроены настолько просто, насколько это возможно, стремясь не усложнять их код.
В других ситуациях, на самом деле — в большинстве случаев, я просто использую пустой класс, наследующий от базового класса `Exception`. Это — самое простое решение, дающее мне то, что мне нужно. Классы исключений, возможности которых расширены за счёт встроенных сообщений, могут оказаться куда сложнее «пустых» классов исключений, и это при том, что они не дают пользователю каких-то особых возможностей. К тому же — такие классы, как в вышеприведённом примере, нельзя подвергать дальнейшей настройке. При выдаче исключения можно либо опустить сообщение, либо использовать то, что встроено в класс, а использовать что-то другое нельзя. Чтобы сделать это возможным, класс придётся усложнить ещё сильнее.
### Пример
Теперь, когда вы знаете о том, как определять пользовательские исключения, пришло время увидеть их в деле.
```
>>> import datetime
>>> from typing import List
>>> TimeSeriesDates = List[datetime.datetime.date]
>>> TimeSeriesValues = List[float]
>>> class IncorrectTSDataError(Exception):
... """Incorrect data, a forecasting model cannot be built."""
>>> def build_model(ts: TimeSeriesDates, y: TimeSeriesValues):
... if not ts:
... raise IncorrectTSDataError("No dates available for time series")
... if not y:
... raise IncorrectTSDataError("No y values available for time series")
... if len(ts) != len(y):
... raise IncorrectTSDataError("Values (y) and dates (ts) have different lengths")
... try:
... model = run_model(ts, y)
... except Exception as e:
... raise PredictionError("Error during the model-building process") from e
... return model
```
Для начала обратите внимание на то, что я поменял форматирование представленного кода. Теперь команды начинаются с `>>>`. Именно так форматируют код и результаты его работы при использовании стандартного Python-модуля [doctest](https://docs.python.org/3/library/doctest.html), применяемого для тестирования документации. Модуль `doctest` позволяет «запускать» документы, проверяя приведённые в них примеры кода, при его использовании, кроме того, легко отличать код от формируемых им выходных данных.
Я решил использовать в аннотациях типов псевдонимы типов. [Я полагаю](https://betterprogramming.pub/pythons-type-hinting-friend-foe-or-just-a-headache-73c7849039c7), что подобные аннотации типов отличаются лучшей читабельностью, чем сложные аннотации, включённые непосредственно в сигнатуру функции. В результате у нас имеются типы `TimeSeriesDates` и `TimeSeriesValues`. Оба — это списки. Первый — список объектов `datetime.datetime.date`, а второй — список чисел с плавающей запятой.
Далее — я создал пользовательское исключение `IncorrectTSDataError`, которое планируется использовать в том случае, если данные временной последовательности некорректны. Обратите внимание на то, что мы используем один и тот же класс исключения в трёх различных ситуациях, в которых данные являются некорректными. Мы могли бы создать иерархию исключений с тремя пользовательскими исключения, классы которых являются наследниками `IncorrectTSDataError`. Но мы ограничились одним исключением, а в вашем проекте, возможно, лучше покажет себя более сложная иерархия исключений.
Затем объявляется главная функция для построения модели — `build_model()`. Это, конечно, функция упрощённая. Выполняет она всего два действия:
* Проверяет — корректны ли данные, а именно: имеются ли в распоряжении функции списки значений `ts` и `y`, и имеют ли эти списки одинаковую длину.
* Строит модель (представленную функцией `run_model()`).
Мы могли бы переместить код проверок в выделенную функцию (например — `check_data()`) и, определённо, сделали бы это, если бы код функции `build_model()` стал бы гораздо длиннее.
Если одна из проверок завершится неудачно, функция выбросит исключение `IncorrectTSDataError` с сообщением, зависящим от того, что именно пошло не так. В противном случае функция продолжит работу и вызовет функцию `run_model()`. Конечно, наши проверки данных чрезмерно упрощены, они нужны лишь для демонстрационных целей. Мы могли бы проверить, действительно ли данные являются списком значений `datetime.datetime.date`; могли бы проверить, достаточно ли у нас точек данных для построения модели прогнозирования; могли бы провести и другие подобные проверки.
А теперь обратите внимание на то, как именно мы вызываем функцию `run_model()`. Мы это делаем, применяя блок `try-except` — чтобы иметь возможность перехватить любую ошибку, выброшенную в ходе выполнения функции. Если мы перехватим ошибку — наш код не станет молча её «проглатывать» — мы выдадим её повторно, выдав из неё исключение `PredictionError`, воспользовавшись конструкцией `raise PredictionError from e`. Я, ради простоты, не использовал сообщение при выдаче этого исключения. При таком подходе в отчёт о трассировке стека будет включена исходная ошибка.
Для того чтобы всё это запустить и посмотреть, как это работает, нам нужна функция `run_model()`. Создадим её мок (mock, имитацию реализации), который не делает ничего, кроме выдачи ошибки (здесь — это `ValueError`).
[Мок](https://en.wikipedia.org/wiki/Mock_object) объекта — это его искусственное представление, которое имитирует поведение исходного объекта, в данном случае — функции `run_model()`. Смысл использования мок-объекта в том, что нам не нужен весь объект (функция), а лишь его модель, которая имитирует интересующие нас аспекты его поведения. В нашем случае моку достаточно выдать исключение `ValueError`.
```
>>> def run_model(ts: TimeSeriesDates, y: TimeSeriesValues):
... raise ValueError("Something went wrong")
```
Таким образом, всякий раз, когда мы запускаем функцию, она выдаёт `ValueError`:
```
>>> run_model([], [])
Traceback (most recent call last):
...
ValueError: Something went wrong
```
Это — наше приложение в действии. Мы сгенерируем значения из одномерного распределения, поэтому в них вряд ли будет присутствовать тренд.
```
>>> from random import uniform
>>> first_date = datetime.datetime.strptime("2020-01-01", "%Y-%m-%d")
>>> ts = [first_date + datetime.timedelta(i) for i in range(366)]
>>> y = [uniform(-50, 150) for _ in range(1, 367)]
>>> ts[-1]
datetime.datetime(2020, 12, 31, 0, 0)
>>> build_model([], y)
Traceback (most recent call last):
...
IncorrectTSDataError: No dates available for time series
>>> build_model(ts, [])
Traceback (most recent call last):
...
IncorrectTSDataError: No y values available for time series
>>> build_model(ts, y[:200])
Traceback (most recent call last):
...
IncorrectTSDataError: Values (y) and dates (ts) have different lengths
>>> build_model(ts, y) #doctest: +ELLIPSIS
Traceback (most recent call last):
...
PredictionError: Error during the model-building process
```
Полный отчёт о трассировке стека из последних трёх строк предыдущего примера кода выглядит так (вместо путей, имён и прочего подобного использованы многоточия):
```
Traceback (most recent call last):
File "...", line 5, in build_model
model = run_model(ts, y)
File "...", line 2, in run_model
raise ValueError("Something went wrong")
ValueError: Something went wrong
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "...", line 1336, in __run
exec(compile(example.source, filename, "single",
File "...", line 1, in
build\_model(ts, y)
File "...", line 7, in build\_model
raise PredictionError("Error during the model-building process") from e
PredictionError: Error during the model-building process
```
А теперь посмотрим на то, как выглядел бы отчёт о трассировке стека в том случае, если бы вместо исключения `PredictionError` было бы выдано встроенное исключение. Для того чтобы это сделать — сначала надо поменять код функции `build_model()`:
```
>>> def build_model(ts: TimeSeriesDates, y: TimeSeriesValues):
... model = run_model(ts, y)
... return model
```
Эта версия функции `build_model()`, на самом деле, не имеет особого смысла, так как она просто вызывает `run_model()`. Она, правда, могла бы делать куда больше. Например — могла бы проверять данные или выполнять предварительную обработку данных.
Посмотрим на отчёт о трассировке стека, выполняемый в тех же самых условиях, которые рассматривались выше:
```
>>> build_model([], y)
Traceback (most recent call last):
...
ValueError: Something went wrong
>>> build_model(ts, y) #doctest: +ELLIPSIS
Traceback (most recent call last):
File "...", line 1336, in __run
exec(compile(example.source, filename, "single",
File "...", line 1, in
build\_model(ts, y) #doctest: +ELLIPSIS
File "...", line 2, in build\_model
model = run\_model(ts, y)
File "...", line 2, in run\_model
raise ValueError
ValueError: Something went wrong
```
Взгляните на нижеприведённый рисунок — с его помощью можно сравнить два отчёта о трассировке стека.
")Слева показан отчёт о трассировке стека при применении пользовательского исключения. Справа — при использовании встроенного исключения ValueError (изображение подготовлено автором материала)Обратите внимание на следующее:
* Отчёт о трассировке стека, полученный при применении пользовательского исключения, содержит сведения об исходной ошибке (`ValueError`), но раскрывает эти сведения, используя пользовательское исключение `PredictionError` с заданным нами сообщением.
* В то же время, та часть отчёта, которая получена при использовании исходного исключения `ValueError`, получилась краткой и точной, её легче читать, чем отчёт, полученный с использованием встроенного класса исключения.
Согласны ли вы со мной в том, что отчёт о трассировке стека, полученный с помощью пользовательского исключения, получился понятнее?
Синтаксическая конструкция `raise MyException from AnotherExcepion` — это чрезвычайно мощный инструмент, так как он позволяет программисту показать и отчёт о трассировке стека исходного исключения, и отчёт трассировки стека пользовательского исключения. При таком подходе отчёты о трассировке стека могут быть гораздо информативнее в плане выяснения того, что именно привело к возникновению ошибки, чем отчёты, полученные только при использовании встроенных исключений.
### Итоги
Пользовательские исключения легко создавать — особенно, когда программист не усложняет себе жизнь добавлением в их код методов `.init()` и `.str()`. Это — одна их тех довольно редких ситуаций, о которых можно сказать так: «меньше кода — больше функционала». В большинстве случаев это означает, что при создании пользовательского исключения лучше всего воспользоваться пустым классом, унаследованным от `Exception`.
Но, кроме того, при использовании пустого класса, нужно решить — писать ли код строки документации. (Решение заключается в том — использовать ли выражение `pass,` или многоточие не имеет никакого смысла, то есть — его можно проигнорировать). Ответ на этот вопрос зависит от каждой конкретной ситуации. Зависит он от того, что программист ожидает от своего класса. Если это должен быть универсальный класс, предназначенный для обслуживания нескольких исключений, тогда может понадобиться строка документации, сообщающая об этом. Правда, если выбран именно этот вариант — надо подумать о том, что, возможно, несколько более узконаправленных классов исключений покажут себя лучше, чем один универсальный. Я не утверждаю, что так оно и будет, так как во многих случаях разработчики не стремятся применять по 50 пользовательских исключений. В отличие от 100-долларовых купюр в бумажнике, в случае с исключениями, иногда 5 лучше, чем 50.
Тут имеет значение и ещё кое-что: хорошее, информативное имя исключения. Если воспользоваться хорошим именем, класс исключения может оказаться самодостаточным даже без строки документации и без сообщения. Но даже если без строки документации и без сообщения не обойтись, пользовательским исключениям, всё равно, нужны хорошие имена. Отрадно то, что классы исключений могут иметь более длинные имена, чем типичные Python-объекты. Поэтому, в случае с исключениями, имена вроде `IncorrectAlphaValueError` и `MissingAlphaValueError` даже не кажутся слишком длинными.
И ещё, меня прямо-таки восхищает конструкция `raise from`, которая позволяет выдавать пользовательские исключения из исключений, вызываемых внутри кода. Это позволяет включать в отчёт о трассировке стека два блока информации. Первый — имеющий отношение к изначально выданному исключения (оно, правда, не обязательно должно быть встроенным), который сообщает о том, что и где произошло; мы можем называть его базовым источником ошибки. Второй блок — это то, что относится к нашему пользовательскому исключению, который, на самом деле, раскрывает пользователю сведения о том, что именно произошло, пользуясь терминами, имеющими отношение к конкретному проекту. Комбинация этих двух блоков информации превращает отчёты о трассировке стека в серьёзный инструмент разработчика.
Правда, у разных проектов есть свои особенности. Разные подходы к применению пользовательских исключений используются в работе над пакетами, предназначенными для других программистов, над бизнес-проектами, над чем-то своим (вроде Jupyter-блокнота с каким-нибудь отчётом). Объясню подробнее:
* Пакет, предназначенный для использования другими программистами. Таким пакетам применение пользовательских исключений часто идёт на пользу. Эти исключения должны быть хорошо спроектированными, пользоваться ими нужно с умом — чтобы они могли бы точно сообщать о том, что и где пошло не так.
* Бизнес-проект. В подобных проектах пользовательские исключения — это, обычно, стоящее вложение сил. Встроенные исключения дают сведения о проблемах, имеющих отношение к Python, а пользовательские исключения добавляют к этим сведениям данные о проблемах, имеющих отношение к конкретному проекту. При таком подходе код (и то, что попадает в отчёт о трассировке стека при выдаче исключения) можно проектировать так, что при возникновении проблем пользователь проекта узнает не только о неполадках общего характера, но и о специфических проблемах проекта.
* Код для небольших собственных проектов, вроде того, что пишут в Jupyter-блокнотах. Это может быть и код некоего скрипта, или даже фрагмент кода, который планируется использовать не больше пары раз. Чаще всего в таких случаях пользовательские исключения — это уже перебор, они безосновательно усложняют код. Блокноты обычно не нуждаются в мощных системах обработки исключений. Поэтому в подобных случаях программисты редко нуждаются в пользовательских исключениях.
Конечно, всегда есть исключения из этих правил. Поэтому рекомендую выбирать наиболее адекватный подход в каждой конкретной ситуации, основываясь на собственном опыте и на особенностях своего проекта. Но не бойтесь применять пользовательские исключения, так как они способны принести вашему проекту огромную пользу.
Надеюсь, вам понравилась эта статья. Почему-то во многих книгах эту тему незаметно обходят вниманием, даже не упоминая о пользовательских исключениях. Есть, конечно, книги, вроде тех, что я упоминал в начале статьи, к которым вышесказанное не относится. Но, несмотря на это, у меня возникает такое ощущение, что многие авторы не считают пользовательские исключения темой, достаточно интересной или важной для того, чтобы её обсуждать. Я придерживаюсь прямо противоположного мнения по той простой причине, что нашёл пользовательские исключения полезными в порядочном количестве проектов. Если кто-то ещё даже не пробовал пользовательские исключения — возможно, пришло время их попробовать и проверить их на своём проекте.
На мой взгляд, пользовательские исключения предлагают нам фантастический инструмент для диагностирования проблем. Python известен хорошей читабельностью кода и дружественностью по отношению к пользователю. Применение пользовательских исключений может помочь нам сделать Python ещё читабельнее и ещё дружелюбнее, особенно — при разработке собственных пакетов. Если вы решили любой ценой избегать пользовательских исключений, используя лишь встроенные исключения, вы рискуете ухудшить читабельность Python-кода.
Поэтому я надеюсь, что с этого момента тот, кто боялся создавать классы собственных исключений, избавится от этого страха. Когда вы будете работать над интерфейсом или пакетом — не бойтесь создавать вложенные иерархии классов исключений. Иногда, правда, пользовательские исключения вам не понадобятся. Смысл тут в том, что всегда, прежде чем их применять, стоит поразмыслить о том — способны ли они принести пользу конкретному проекту. Если вы решите, что они вам нужны — помните о том, что не стоит злоупотреблять сложными конструкциями, и никогда не забывайте о «[Дзен Python](https://peps.python.org/pep-0020/)»: «Простое лучше, чем сложное», «Плоское лучше, чем вложенное»
О, а приходите к нам работать? 🤗 💰Мы в [**wunderfund.io**](http://wunderfund.io/) занимаемся [высокочастотной алготорговлей](https://en.wikipedia.org/wiki/High-frequency_trading) с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
[Присоединяйтесь к нашей команде.](http://wunderfund.io/#join_us) | https://habr.com/ru/post/697818/ | null | ru | null |
# Разбираем уязвимость CVE-2017-0263 для повышения привилегий в Windows
Май оказался богат на интересные уязвимости в популярной операционной системе. На днях злоумышленники массово заражали компьютеры вирусом-вымогателем WannaCry, эксплуатируя недостаток безопасности в протоколе SMB и инструмент, известный как Eternalblue. Чуть ранее, 9 мая, компания Microsoft устранила [CVE-2017-0263](https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2017-0263), позволяющую получить максимальные привилегии на машинах под управлением Windows 10, Windows 8.1, Windows 7, Windows Server 2008, Windows Server 2012 и Windows Server 2016.
Уязвимость CVE-2017-0263 уже использовалась в фишинговой рассылке. Письмо содержало вложенный эксплойт, который задействовал сначала некорректную обработку EPS-файлов в Microsoft Office ([CVE-2017-0262](https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2017-0262)) для попадания в систему, а оказавшись внутри, получал с помощью CVE-2017-0263 полные права администратора. Два года назад мы уже [препарировали](https://habrahabr.ru/company/pt/blog/257879/) похожую уязвимость в Windows, а в этом материале расскажем о том, как свежая CVE-2017-0263 позволяет стать хозяином чужой рабочей станции или сервера.
Если коротко, то эта уязвимость относится к типу use after free ([CWE-416](https://cwe.mitre.org/data/definitions/416.html)) и возникает из-за того, что в момент закрытия окон контекстного меню и освобождения занимаемой этим меню памяти указатель на освобожденную память не обнуляется. В результате указатель можно использовать повторно.
Все дальнейшее повествование посвящено процессу обработки окон в драйвере `win32k.sys` и тому, как данный процесс позволяет эксплуатировать указанную уязвимость.
Контекстные меню
----------------
Пожалуй, каждый пользователь Windows знаком с контекстными меню. Это тот самый ниспадающий список, появляющийся всякий раз, когда мы кликаем правой кнопкой мыши.
Вид контекстного меню и условия его отображения находятся полностью на совести разработчика конкретного приложения, который волен поступать здесь, как велит ему сердце. WinAPI предоставляет для этого ему в пользование функцию [TrackPopupMenuEx](https://msdn.microsoft.com/en-us/library/windows/desktop/ms648003.aspx), вызов которой приводит к появлению указанного в параметрах контекстного меню в указанном же положении на экране.
В ядре состояние контекстного меню хранится в переменной `win32k!gMenuState`, которая представляет собой структуру `win32k!tagMENUSTATE`:
> 0: kd> dt win32k!tagMenuState
>
> +0x000 pGlobalPopupMenu: Ptr32 tagPOPUPMENU
>
> +0x004 flags: Int4B
>
> +0x008 ptMouseLast: tagPOINT
>
> +0x010 mnFocus: Int4B
>
> +0x014 cmdLast: Int4B
>
> +0x018 ptiMenuStateOwner: Ptr32 tagTHREADINFO
>
> +0x01c dwLockCount: Uint4B
>
> +0x020 pmnsPrev: Ptr32 tagMENUSTATE
>
> +0x024 ptButtonDown: tagPOINT
>
> +0x02c uButtonDownHitArea: Uint4B
>
> +0x030 uButtonDownIndex: Uint4B
>
> +0x034 vkButtonDown: Int4B
>
> +0x038 uDraggingHitArea: Uint4B
>
> +0x03c uDraggingIndex: Uint4B
>
> +0x040 uDraggingFlags: Uint4B
>
> +0x044 hdcWndAni: Ptr32 HDC\_\_
>
> +0x048 dwAniStartTime: Uint4B
>
> +0x04c ixAni: Int4B
>
> +0x050 iyAni: Int4B
>
> +0x054 cxAni: Int4B
>
> +0x058 cyAni: Int4B
>
> +0x05c hbmAni: Ptr32 HBITMAP\_\_
>
> +0x060 hdcAni: Ptr32 HDC\_\_
Здесь стоит сразу оговориться, что все представленные в данной статье описания структур и стеки вызовов созданы на системе Windows 7 x86. 32-битная версия системы выбрана из соображений удобства: аргументы большинства функций хранятся на стеке и отсутствует прослойка WoW64, которая во время системных вызовов переключается на 64-битный стек, благодаря чему при распечатке стека вызовов теряются 32-битные стековые фреймы. Полный список подверженных описываемой уязвимости систем можно найти [на соответствующей странице](https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2017-0263) сайта компании Microsoft.
Как видно, структура `win32k!tagMENUSTATE` хранит, например, такую информацию, как кликнутая область экрана, номер последней отосланной меню команды, а также указатели на окна, по которым был совершен клик или которые были выбраны для перетаскивания (drag-and-drop). Сам список окон ниспадающего меню хранится в первом поле, `pGlobalPopupMenu`, имеющем тип `win32k!tagPOPUPMENU`:
> 0: kd> dt win32k!tagPopupMenu
>
> +0x000 flags: Int4B
>
> +0x004 spwndNotify: Ptr32 tagWND
>
> +0x008 spwndPopupMenu: Ptr32 tagWND
>
> +0x00c spwndNextPopup: Ptr32 tagWND
>
> +0x010 spwndPrevPopup: Ptr32 tagWND
>
> +0x014 spmenu: Ptr32 tagMENU
>
> +0x018 spmenuAlternate: Ptr32 tagMENU
>
> +0x01c spwndActivePopup: Ptr32 tagWND
>
> +0x020 ppopupmenuRoot: Ptr32 tagPOPUPMENU
>
> +0x024 ppmDelayedFree: Ptr32 tagPOPUPMENU
>
> +0x028 posSelectedItem: Uint4B
>
> +0x02c posDropped: Uint4B
>
> +0x030 ppmlockFree: Ptr32 tagPOPUPMENU
В обеих структурах цветом выделены поля, которые представляют для нас интерес и далее будут использоваться при описании варианта эксплуатации.
Переменная `win32k!gMenuState` инициализируется в момент создания контекстного меню, то есть во время выполнения ранее упомянутой функции `TrackPopupMenuEx`. Инициализация происходит при вызове `win32k!xxxMNAllocMenuState`:
> 1: kd> k
>
> # ChildEBP RetAddr
>
> 00 95f29b38 81fe3ca6 win32k!xxxMNAllocMenuState+0x7c
>
> 01 95f29ba0 81fe410f win32k!xxxTrackPopupMenuEx+0x27f
>
> 02 95f29c14 82892db6 win32k!NtUserTrackPopupMenuEx+0xc3
>
> 03 95f29c14 77666c74 nt!KiSystemServicePostCall
>
> 04 0131fd58 7758480e ntdll!KiFastSystemCallRet
>
> 05 0131fd5c 100015b3 user32!NtUserTrackPopupMenuEx+0xc
>
> 06 0131fd84 7756c4b7 q\_Main\_Window\_Class\_wndproc (call TrackPopupMenuEx)
И наоборот, когда контекстное меню уничтожается, потому, например, что пользователь выбрал один из пунктов меню или совершил клик вне отображаемой на экране области меню, вызывается функция `win32k!xxxMNEndMenuState`, ответственная за освобождение состояния меню:
> 1: kd> k
>
> # ChildEBP RetAddr
>
> 00 a0fb7ab0 82014f68 win32k!xxxMNEndMenuState
>
> 01 a0fb7b20 81fe39f5 win32k!xxxRealMenuWindowProc+0xd46
>
> 02 a0fb7b54 81f5c134 win32k!xxxMenuWindowProc+0xfd
>
> 03 a0fb7b94 81f1bb74 win32k!xxxSendMessageTimeout+0x1ac
>
> 04 a0fb7bbc 81f289c8 win32k!xxxWrapSendMessage+0x1c
>
> 05 a0fb7bd8 81f5e149 win32k!NtUserfnNCDESTROY+0x27
>
> 06 a0fb7c10 82892db6 win32k!NtUserMessageCall+0xcf
>
> 07 a0fb7c10 77666c74 nt!KiSystemServicePostCall
>
> 08 013cfd90 77564f21 ntdll!KiFastSystemCallRet
>
> 09 013cfd94 77560908 user32!NtUserMessageCall+0xc
>
> 0a 013cfdd0 77565552 user32!SendMessageWorker+0x546
>
> 0b 013cfdf0 100014e4 user32!SendMessageW+0x7c
>
> 0c 013cfe08 775630bc q\_win\_event\_hook (call SendMessageW(MN\_DODRAGDROP))
Важно здесь то, что поле `gMenuState.pGlobalPopupMenu` обновляется только в момент инициализации в функции `xxxMNAllocMenuState`, но не обнуляется при уничтожении структуры.
Функция xxxMNEndMenuState
-------------------------
Указанной функции и будет посвящена основная часть нашего повествования. В нескольких строчках ее кода таится исследуемая уязвимость.
`xxxMNEndMenuState` начинает выполнение с деинициализации и освобождения информации, связанной с ниспадающим меню. Для этого вызывается функция `MNFreePopup`, к которой мы еще вернемся в следующем разделе. Основная задача `MNFreePopup` заключается в уменьшении значений счетчиков ссылок (reference counters) на окна, относящиеся к данному ниспадающему меню. Уменьшение счетчика ссылок может, в свою очередь, приводить к уничтожению окна, когда счетчик ссылок на него опускается до нуля.
Затем функция `xxxMNEndMenuState` обращением к флагу `fMenuWindowRef` поля pGlobalPopupMenu проверяет, не осталось ли на основное окно ниспадающего меню ссылок. Этот флаг очищается в момент удаления окна, содержащегося в поле `spwndPopupMenu` ниспадающего меню:
> 3: kd> k
>
> # ChildEBP RetAddr
>
> 00 95fffa5c 81f287da win32k!xxxFreeWindow+0x847
>
> 01 95fffab0 81f71252 win32k!xxxDestroyWindow+0x532
>
> 02 95fffabc 81f7122c win32k!HMDestroyUnlockedObject+0x1b
>
> 03 95fffac8 81f70c4a win32k!HMUnlockObjectInternal+0x30
>
> 04 95fffad4 81f6e1fc win32k!HMUnlockObject+0x13
>
> 05 95fffadc 81fea664 win32k!HMAssignmentUnlock+0xf
>
> 06 95fffaec 81fea885 win32k!MNFreePopup+0x7d
>
> 07 95fffb14 8202c3d6 win32k!xxxMNEndMenuState+0x40
>
>
>
> xxxFreeWindow+83f disasm:
>
> .text:BF89082E loc\_BF89082E:
>
> .text:BF89082E and ecx, 7FFFFFFFh; ~fMenuWindowRef
>
> .text:BF890834 mov [eax+tagPOPUPMENU.flags], ecx
Как видно из представленного рисунка, сбрасывание вышеуказанного флага приводит к освобождению занимаемой полем `pGlobalPopupMenu` памяти, но обнуления самого указателя не происходит. Таким образом, получаем dangling pointer, который при выполнении определенных условий можно использовать в дальнейшем.
Сразу после освобождения памяти из-под ниспадающего меню поток выполнения переходит к удалению сохраненных в структуре состояния контекстного меню ссылок на окна, которые были кликнуты (поле `uButtonDownHitArea`) в момент работы меню или выбраны для перетаскивания (поле `uDraggingHitArea`).
Вариант эксплуатации
--------------------
Как мы уже рассказывали ранее в [статье](https://habrahabr.ru/company/pt/blog/257879/), посвященной CVE-2015-1701, в ядре объект окна описывается структурой `tagWND`. В той же статье описано и понятие kernel callbacks, которое нам далее понадобится. Количество действующих ссылок на окно содержится в поле `cLockObj` структуры `tagWND`.
Удаление ссылок на окно, как было указано в предыдущем разделе, может приводить к уничтожению самого окна. Перед уничтожением окну посылается оповещающее о смене состояния окна сообщение `WM_NCDESTROY`.
Это означает, что при выполнении `xxxMNEndMenuState` управление может быть передано на пользовательский код приложения, а именно — оконной процедуре уничтожаемого окна. Так происходит в случае, когда на окно, указатель на которое хранится в поле `gMenuState.uButtonDownHitArea`, больше не остается ссылок.
> 2: kd> k
>
> # ChildEBP RetAddr
>
> 0138fc34 7756c4b7 q\_new\_SysShadow\_window\_proc
>
> 0138fc60 77565f6f USER32!InternalCallWinProc+0x23
>
> 0138fcd8 77564ede USER32!UserCallWinProcCheckWow+0xe0
>
> 0138fd34 7755b28f USER32!DispatchClientMessage+0xcf
>
> 0138fd64 77666bae USER32!\_\_fnNCDESTROY+0x26
>
> 0138fd90 77564f21 ntdll!KiUserCallbackDispatcher+0x2e
>
> 95fe38f8 81f56d86 nt!KeUserModeCallback
>
> 95fe3940 81f5c157 win32k!xxxSendMessageToClient+0x175
>
> 95fe398c 81f5c206 win32k!xxxSendMessageTimeout+0x1cf
>
> 95fe39b4 81f2839c win32k!xxxSendMessage+0x28
>
> 95fe3a10 81f2fb00 win32k!xxxDestroyWindow+0xf4
>
> 95fe3a24 81f302ee win32k!xxxRemoveShadow+0x3e
>
> 95fe3a64 81f287da win32k!xxxFreeWindow+0x2ff
>
> 95fe3ab8 81f71252 win32k!xxxDestroyWindow+0x532
>
> 95fe3ac4 81f7122c win32k!HMDestroyUnlockedObject+0x1b
>
> 95fe3ad0 81f70c4a win32k!HMUnlockObjectInternal+0x30
>
> 95fe3adc 81f6e1fc win32k!HMUnlockObject+0x13
>
> 95fe3ae4 81fe4162 win32k!HMAssignmentUnlock+0xf
>
> 95fe3aec 81fea8c3 win32k!UnlockMFMWFPWindow+0x18
>
> 95fe3b14 8202c3d6 win32k!xxxMNEndMenuState+0x7e
Например, в указанном стеке вызовов сообщение `WM_NCDESTROY` обрабатывает оконная процедура окна класса `SysShadow`. Окна этого класса предназначены для отрисовки тени и уничтожаются обычно вместе с окнами, эту тень отбрасывающими.
Рассмотрим теперь наиболее интересную часть обработки данного оконного сообщения в том виде, в котором она представлена в семпле, изъятом из поддельного документа .docx:
При получении управления злоумышленнику первым делом необходимо занять только что освобожденную память из-под `gMenuState.pGlobalPopupMenu`, чтобы задействовать возможность воспользоваться данным указателем впоследствии. В попытке аллоцировать указанный блок памяти эксплойт совершает множество вызовов `SetClassLongW`, устанавливая специальным образом сформированное наименование меню заранее созданным для этой цели классам окон:
> 2: kd> k
>
> # ChildEBP RetAddr
>
> 00 9f74bafc 81f240d2 win32k!memcpy+0x33
>
> 01 9f74bb3c 81edadb1 win32k!AllocateUnicodeString+0x6b
>
> 02 9f74bb9c 81edb146 win32k!xxxSetClassData+0x1d1
>
> 03 9f74bbb8 81edb088 win32k!xxxSetClassLong+0x39
>
> 04 9f74bc1c 82892db6 win32k!NtUserSetClassLong+0xc8
>
> 05 9f74bc1c 77666c74 nt!KiSystemServicePostCall
>
> 06 0136fac0 7755658b ntdll!KiFastSystemCallRet
>
> 07 0136fac4 775565bf user32!NtUserSetClassLong+0xc
>
> 08 0136fafc 10001a52 user32!SetClassLongW+0x5e
>
> 09 0136fc34 7756c4b7 q\_new\_SysShadow\_window\_proc (call SetClassLongW)
После того, как память занята, можно переходить к следующей стадии. Здесь эксплойт обращается к системной процедуре `NtUserMNDragLeave`, которая, в свою очередь, совершает вложенный вызов (nested call) функции `xxxMNEndMenuState`, т. е. очистка структуры `gMenuState` начинает выполняться заново:
> 2: kd> k
>
> # ChildEBP RetAddr
>
> 00 9f74bbf0 8202c3d6 win32k!xxxMNEndMenuState
>
> 01 9f74bc04 8202c40e win32k!xxxUnlockMenuStateInternal+0x2e
>
> 02 9f74bc14 82015672 win32k!xxxUnlockAndEndMenuState+0xf
>
> 03 9f74bc24 82001728 win32k!xxxMNDragLeave+0x45
>
> 04 9f74bc2c 82892db6 win32k!NtUserMNDragLeave+0xd
>
> 05 9f74bc2c 100010a9 nt!KiSystemServicePostCall
>
> 06 0136fafc 10001a84 q\_exec\_int2e (int 2Eh)
>
> 07 0136fc34 7756c4b7 q\_new\_SysShadow\_window\_proc (call q\_exec\_int2e)
Как было описано в предыдущем разделе, процедура начинается с деинициализации поля `pGlobalPopupMenu`, которая производится вызовом `MNFreePopup`, выполняющим уменьшение значений счетчиков ссылок на окна, содержащиеся в различных полях `tagPOPUPMENU`. При этом содержимое данной структуры после предыдущего шага контролируется атакующим. Таким образом, при выполнении описанной цепочки действий злоумышленник получает примитив декремента (decrement primitive) на произвольный адрес ядра.
В рассматриваемом эксплойте подменяется адрес в поле `tagPOPUPMENU.spwndPrevPopup` и примитив используется для декремента поля флагов одного из окон, что приводит к возведению у этого окна флага `bServerSideProc`, означающего выполнение его оконной процедуры в ядре.
На рисунке показано, что сразу после возврата из `NtUserMNDragLeave` такому окну вызовом SendMessage посылается сообщение, что приводит к выполнению произвольного кода в ядре (kernel code execution). Обычно, используя эту возможность, злоумышленник ворует токен системного процесса, получая системные привилегии. Именно это и происходит в описываемом эксплойте.
Завершение
----------
Итак, перечислим ключевые особенности эксплойта. Обращение к коллбекам в пользовательском пространстве в моменты времени, когда какие-либо структуры ядра находятся в промежуточном состоянии посреди изменяющей их транзакции, является наиболее частой причиной уязвимостей в библиотеке `win32k.sys`. Выставление флага `bServerSideProc` у окна также является популярным методом получения возможности выполнения кода в ядре. И третье, при выполнении кода в ядре копирование ссылки на системный токен — наиболее удобный способ поднятия привилегий.
В этом смысле представленный эксплойт выглядит довольно обыденным. В то же время многие нюансы эксплуатации были лишь мельком упомянуты в статье либо сознательно пропущены.
Например, мы не останавливались на точном виде контекстного меню, а также выполняемых над ним действиях, которые приводят к правильному положению флагов и заполнению полей переменной `win32k!gMenuState` при выполнении процедуры `xxxMNEndMenuState`. Обошли стороной и то, что устанавливаемые при вызовах SetClassLong наименования меню должны, с одной стороны, представлять из себя юникодную строку, не имеющую нулевых символов, а с другой — являться легитимной структурой `tagPOPUPMENU`. Это также означает, что и адрес окна в ядре, на которое будет указывать поле для декремента, не должен содержать нулевых символов wchar\_t. Это всего лишь несколько примеров из довольно внушительного списка.
В завершение стоит сказать несколько слов об [обновлении](https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2017-0263), исправляющем исследуемую уязвимость. Беглый осмотр патча показал, что теперь освобождение буфера, адресуемого полем `gMenuState.pGlobalPopupMenu`, происходит ближе к окончанию функции `xxxMNEndMenuState`, много позже вызовов `MNFreePopup` и `UnlockMFMWPWindow`, и сопровождается обнулением самого указателя. Таким образом, патч исключает сразу две причины, одновременное наличие которых приводило к появлению уязвимости. | https://habr.com/ru/post/328804/ | null | ru | null |
# Inotify или автоматизация рутинных операций с помощью incron
До сих пор на хабре еще никто не упоминал о такой удобной подсистеме ядра linux, как **inotify** и использовании ее в автоматизации работы системного администратора. Хотелось бы восполнить этот пробел.
#### Что такое inotify
**Inotify** — это подсистема ядра Linux, которая позволяет получать уведомления об изменениях в файловой системе. Т.е. простыми словами — эта штука дает нам информацию о создании или изменении любого файла или директории в используемой файловой системе.
Inotify появилась в ядре аж в версии 2.6.13 и прошла проверку временем. Для ее использования написано несколько утилит, работу с одной из которых мы и рассмотрим.
#### incron
**incron** — это демон, который следит за событиями в файловой системе с помощью inotify и выполняет команду при наступлении указанного в задании события, аналогично тому, как делает это его тезка **cron** при наступлении указанного времени.
Устанавливаем демон средствами своего дистрибутива. У меня это выглядит вот так:
*kolvir ~ # emerge incron*
После установки стартуем демон и добавляем его в списк служб, которые запускаются при старте системы.
Теперь можно добавлять задания. Выполняется это командой **incrontab -e**. Можно конечно редактировать файлы и вручную… они находятся в директории **/var/spool/incrontab**, но лучше все же воспользоваться специально предназначенной для этого утилитой.
Здесь существует небольшая тонкость. Если при установке у вас создался файл **/etc/incron.allow** и в нем нету вашего имени пользователя, то следует его туда добавить, иначе вам будет запрещено работать с incron и incrontab. Если же этого файла в системе нет, то по умолчанию доступ будет разрешен всем пользователям.
Итак, проблемы с доступом мы решили. Теперь набираем incrontab -e и видим перед собой, пока еще, чистый файл, открытый в текстовом редакторе, который у вас в системе прописан по умолчанию.
Сейчас я расскажу, что туда нужно писать:
##### формат crontab-файла для incron
Cинтаксис crontab будет даже проще чем у классического cron.
Каждая строчка конфига должна быть следующего вида:
***<путь> <событие> <команда>***
Теперь расшифруем что же здесь нужно писать в каждом столце: **Путь** — здесь надо указать полный путь к файлу или директории, за которыми мы намерены следить. **Команда** — тут указывается какой скрипт или какую команду требуется выполнить по наступлении события. **Событие** — здесь нужно указать одно из следующих видов событий:
**IN\_ACCESS** — К файлу обращались (чтение)
**IN\_ATTRIB** — Изменены метаданные (права, дата создания/редактирования, расширенные атрибуты, и т.д.)
**IN\_CLOSE\_WRITE** — Файл, открытый для записи, был закрыт
**IN\_CLOSE\_NOWRITE** — Файл, не открытый для записи, был закрыт
**IN\_CREATE** — Файл/директория создан(а) в отслеживаемой директории
**IN\_DELETE** — Файл/директория удален(а) в отслеживаемой директории
**IN\_DELETE\_SELF** — Отслеживаемый(ая) файл/директория был(а) удален(а)
**IN\_MODIFY** — Файл был изменен
**IN\_MOVE\_SELF** — Отслеживаемый(ая) файл/директория был(а) перемещен(а)
**IN\_MOVED\_FROM** — Файл был перемещен из отслеживаемой директории
**IN\_MOVED\_TO** — Файл перемещен в отслеживаемую директорию
**IN\_OPEN** — Файл был открыт
Также в команде можно использовать следующие внутренние переменные (очень удобные для логирования ИМХО):
$$ знак $
$@ объект нашей слежки (директория)
$# имя созданного файла
$% флаг события (текстом)
$& флаг события (цифрой)
##### Несколько примеров
Итак. Знаниями вооружились, теперь можно начинать автоматизировать. Наверняка многие уже поняли что и как можно сделать с помощью incron, но я все же напишу несколько примеров, для остальных.
Возьмем для примера crontab-файл взятый с моего домашнего сервера:
`/etc IN_MODIFY /bin/backup
/etc/bind/pri/ IN_MODIFY rndc reload
/etc/bind/pri/named.conf IN_MODIFY /etc/init.d/named restart
/etc/apache2/ IN_MODIFY /etc/init.d/apache2 restart
/etc/squid/squid.conf IN_MODIFY /etc/init.d/squid restart
/etc/squidGuard/ IN_MODIFY /etc/init.d/squid restart
/etc/conf.d/firewall.sh IN_MODIFY /etc/conf.d/firewall.sh`
В первой строке, при модификации любого файла из директории /etc запускается скрипт резервного копирования, который сохраняет все важные файлы из /etc. Благодаря утилите rsync я могу копировать только измененные файлы экономя трафик и не загружая канал попусту, но сейчас речь не об этом =).
Далее идут обычные операции перезапуска служб, при изменении их конфигурационных файлов. **Как же здорово не делать это вручную каждый раз!**
И в последней строчке происходит запуск скрипта конфигурации файрвола, если тот был изменен.
Как видите тут все довольно просто и банально, но зато какая подстраховка памяти =). Особенно, когда увлечен чем-то другим или еще не совсем проснулся, или наоборот очень устал.
В моем примере везде используется только событие IN\_MODIFY, но я могу привести несколько надуманный, но все же рабочий пример использования другого события:
`/mnt/samba/public/shutdown IN_CLOSE_WRITE shutdown now`
Здесь мы выключаем компьютер, если в расшаренной папке, кто-то создал или отредактировал файл shutdown.
##### Ссылки
Подробнее о программном интерфейсе, а также об остальных утилитах можно узнать здесь: [ru.wikipedia.org/wiki/Inotify](http://ru.wikipedia.org/wiki/Inotify) или здесь: [www.ibm.com/developerworks/ru/library/l-ubuntu-inotify](http://www.ibm.com/developerworks/ru/library/l-ubuntu-inotify/) | https://habr.com/ru/post/66569/ | null | ru | null |
# Продолжаем бороться с frontend-рутиной

Прошло полгода с [последней новости о TARS на хабре](http://habrahabr.ru/company/2gis/blog/254105/).
Напомню, что TARS — это сборщик html-верстки, основанный на gulp, в помощь любому frontend-разработчику (или даже целой команде), для создания проектов любой сложности. За последние шесть месяцев было закрыто 88 issue, выпущено 7 версий, появился [CLI](http://www.wikiwand.com/ru/CLI), так вышло, что с yeoman’ом отношения не сложились, поэтому появилась своя версия. TARS переехал в свой новый дом на [github](https://github.com/tars), обзавелся командой из 4 разработчиков + небольшой армией фанатов. Кстати, огромное вам спасибо за мгновенные фидбеки после релизов и не только. TARS был внедрен в нескольких вебстудиях России и за рубежом. Сборщик научил компонентному подходу не один десяток разработчиков, привлек в ряды frontend’еров тех, кто боялся всей рутины верстки. В общем, появилось много всего нового, и об этом хотелось бы рассказать.
Небольшой план статьи:
* кратенько напомним о том, что такое TARS;
* поговорим о новинках;
* поговорим о том, что чаще всего понимают не так. Как использовать TARS, чтобы получить максимум пользы;
* что ждет проект впереди;
* слова благодарности.
Что такое TARS?
---------------
Итак, для начала все же ответим на вопрос, что такое TARS, более развернуто. Небольшая копипаста из прошлой статьи: «TARS — это набор gulp-тасков для автоматизации большинства задач frontend’а + возможность лёгкого добавления новых, если будет чего-то не хватать. TARS можно назвать фреймворком для gulp. Подходит как отдельным разработчикам, так и большим командам. С ним легко разрабатывать проекты любой сложности: от лендинга до огромного портала. Вам даже не нужно знать, как работает gulp, так как всё что можно было вынесено в опции, весь код и варианты использования задокументированы.
Больше информации можно получить из прошлой статьи и записи выступления с FrontTalks.
Что нового?
-----------
Прежде всего скажу: используйте новинки с любой версией TARS, так как в рамках одной мажорной версии гарантируется 100% совместимость вашего проекта. Гайд по обновлению в [документации проекта](https://github.com/tars/tars/blob/master/docs/ru/update-guide.md).
Главная новинка — это CLI для TARS. Что представлял проект на TARS до появления CLI: файлы проекта + все node\_modules для TARS. И так в каждом проекте. Размер каждого увеличивался до 250 МБ, что было крайне неудобно, если проектов больше 5. При создании нового проекта на Windows зависимости устанавливались более 5 минут.
Необходимо было помнить названия команд, название ключей, не было проверки правильности используемых ключей, что можно использовать вместе, а что нет. В общем, одну рутину TARS убирал и добавлял немного другой. Чтобы это исправить, мы создали [TARS-CLI](https://github.com/tars/tars-cli).
TARS-CLI — npm-пакет (ставится глобально), который позволяет:
* заинитить проект;
* запускать таски для сборки (как дев, так и релизной) проекта;
* добавлять модуль в проект с различным набором файлов и папок, больше не нужно делать это руками;
* добавлять страницы в проект, как копии существующего шаблона, так и абсолютно пустые;
* запускать вообще любой таск из gulpfile.js в текущей директории.
При запуске команды с некорректными флагами вы получите сообщение об ошибке. При инициализации проекта теперь не нужно руками править tars-config.js, достаточно ответить на пару вопросов в весьма удобном (для консоли) интерфейсе. При этом сохранили работу с флагами, если вам не хочется каждый раз выбирать режим работы или вы производите автоматическое тестирование. Как и TARS, у TARS-CLI хорошая документация на двух языках: [русском](https://github.com/tars/tars-cli/blob/master/README_RU.md) и [английском](https://github.com/tars/tars-cli/blob/master/README.md). Перевод документации (как для CLI, так и для основного проекта) на английский — тоже новинка. Причина перевода — TARS заинтересовал разработчиков из Чехии, США, стран Южной Америки. Не солидно не иметь документации на английском языке.
Общий список наиболее значительных изменений:
* добавили поддержку Babel;
* поддерживается директива import, sourcemaps, несмотря на то, что происходит конкатинация стилей;
* добавили поддержку PostCSS;
* ускорили процесс сборки;
* вычистили уйму багов, провели серьезный рефакторинг, добавили много полезных мелочей.
На самом деле, [список изменений куда больше](https://github.com/tars/tars/blob/master/docs/ru/changelog.md). Новые пользователи хорошо повлияли на развитие TARS. Мы реализовали новые идеи, приняли pull request’ы, а один из разработчиков через TARS устроился работать в 2ГИС.
Также стоит упомянуть, что каждый релиз теперь проходит через автоматическое тестирование на Windows, Linux и OS X, что позволяет выпускать более надежный код. Статус сборки выводится на бейджи в readme проекта.
Кстати, сборщик успешно применятся для разработки приложений на Cordova, расширений для браузеров и т.д.
FAQ
---
Для разработки желательно использовать именно TARS-CLI. Если вы практикуете сборку проекта на сервере, то используйте TARS отдельно. В этом случае не будет глобальных зависимостей. Но и TARS-CLI использовать никто не мешает.
Вместе с TARS-CLI можно использовать любую сборку TARS. Форкайте, добавляйте таски, модифицируйте сборщик, чтобы он покрывал ваши нужды. Чтобы заинитить проект, выполните:
```
tars init -s http://url.to.zip.with.tars
```
Таким образом, TARS-CLI — интерфейс к TARS, с которым стало гораздо удобнее. Теперь перейдем к самым частым вопросам и недопониманиям, которые мы получали по почте или в гиттер.
**Вопрос**: можно ли пользоваться TARS без опаски, что останусь у «разбитого корыта»? Не будет ли проект заброшен?
**Ответ**: пользоваться точно можно без опаски. Проблемы могут встречаться, но все они решаемы. В самом крайнем случае наша команда сможет сбилдить вам проект и отправить на почту. Ближайшее время планируется сделать сервис онлайн сборки, если локально что-то пошло не так. Бросать проект мы точно не собираемся, каждую неделю появляются новые issue + вторая версия на носу. Ни нам, ни вам скучать не придется. За последний месяц TARS-CLI поставили больше тысячи человек, если верить статистике из npm.
**Вопрос**: у нас в команде есть свой сборщик на gulp/grunt, хотелось бы использовать наработки из него в TARS.
**Ответ**: можете перенести необходимые таски в user-tasks. Для использования grunt-тасков, если не хотите переписывать на gulp, есть пакет [gulp-grunt](https://www.npmjs.com/package/gulp-grunt), который запускает grunt-таск в gulp. Но все же рекомендуем портировать grunt-таск в gulp. Тем более, все плагины для grunt доступны в gulp. Если необходимо, чтобы проект инитился всегда с этими дополнительными тасками, то рекомендую создать форк TARS, добавить в нем необходимые изменения, инитить проект, с указанием ссылки на ваш форк. При этом, для упрощения обновления форка, все кастомные таски следует складывать в users-tasks, а зависимости для этих тасков указывать в user-package.json. Они будут ставится с каждым заиниченым проектом.
Кроме того, если ваши таски будут полезны большому числу разработчиков, очень просим сделать pull request. Описание, как с нами работать, доступно по [ссылке](https://github.com/tars/tars/blob/master/docs/ru/for-contributors.md).
**Вопрос**: как лучше построить процесс разработки с помощью TARS?
**Ответ**: единого ответа тут нет. Все зависит от специфики разработки.
Рассмотрим несколько типов проектов.
1. Долгоиграющий и единственный. В этом случае все просто. Создавайте модули, страницы, храните все в какой-либо CVS — в общем, этот сценарий самый скучный.
2. Много проектов с повторяющейся функциональностью. В этом случае есть несколько путей работы с TARS.
* Создать библиотеку переиспользуемых блоков и включить ее сразу в собственный форк TARS. Таким образом, при ините нового проекта в нем сразу будут все нужные блоки.
* Использовать git или любую другую CVS. Пусть заиниченный TARS находится в git, а каждый новый проект — отдельная ветка.
* Хранить библиотеку повторяющихся блоков отдельно.
Первый вариант самый удобный. Но в этом случае нужно следить за состоянием форка и вовремя брать изменения из оригинального репозитория.
3. Много разных проектов. Также весьма простой сценарий, при котором каждый проект может быть отдельным репозиторием в git (или другой CVS).
Указанные способы выше — не догма, а лишь пример, как получить больше пользы от TARS.
**Вопрос**: кажется, что стек технологий, который вы предлагаете — это прошлый век. Все уже на webpack пересели, а скрипты через npm запускают без всяких gulp/grunt/broccoli/что-то еще.
**Ответ**: начнем с того, что тот же gulp имеет на github более чем в два раза больше звезд, чем webpack или что-то подобное. Называть gulp устаревшим — это как минимум не корректно. Для каждой задачи есть свои инструменты.
Если у вас очень простой проект, вам нужно только стили склеить, да js сжать, то можно написать все самому и запускать через npm. А можно не тратить время на это и заниматься собственно проектом, а все остальное поручить инструментам, которые как раз сделаны для этих нужд. На самом деле, удивляет, что разработчики готовы использовать менеджер пакетов, как таск-раннер. Но это уже вкусовщина.
Вернемся к вопросу о webpack. Ничего не мешает использовать gulp вместе с webpack. Собственно в планах есть внедрение или webpack, или browserify.
**Вопрос**: ничего не понятно, какие-то модули, страницы, куча ошибок, ничего не ставится, что происходит вообще?
**Ответ**: почитайте документацию на [русском](https://github.com/tars/tars/blob/master/README_RU.md) или [английском](https://github.com/tars/tars/blob/master/README.md). Или напишите на почту [email protected] или в наш [чатик в gitter](https://gitter.im/tars/tars). Все оперативно фиксим. Обратная связь будет совсем не лишней, так что если вы обнаружили какую-либо ошибку в работе сборщика, сообщите о ней
Планы на будущее
----------------
За дальнейшими планами следите на [github](https://github.com/tars/tars/issues). Там же можно и повлиять на проект. Мы всегда рады новым идеям.
В самое ближайшее время мы планируем:
* сделать промо-сайт;
* webpack, browserify, что-то ещё;
* переехать на четвертую версию gulp, когда ее выпустят;
* дать возможность собирать React-приложения;
* сделать онлайн версию сборщика;
* начать работать над второй версией TARS;
* создать инфраструктуру для TARS-плагинов.
Последние две идеи — самые интересные. Если со второй версией еще пока не все ясно, то про плагины уже можно рассказать. Система плагинов — различные дополнения к TARS, которые нужны, чтобы решать «узкие» задачи. Самый простой пример — таски для верстки писем. Представьте, вы просто набираете tars install tars-email, и в ваш локальный TARS загружаются таски для комфортной работы с версткой электронных писем.
В ближайшее время мы научим TARS разговаривать. Правда синтетическим голосом и только на Mac и Linux. Попробуем добавить ему характера, научим сарказму. Естественно, это все будет опционально: если вы захотите тишины — достаточно поменять 1 опцию в конфиге.
Credits
-------
В конце благодарности: [Lence\_l](http://habrahabr.ru/users/lence_l/) за кропотливую работу над документацией и ее переводом, [owanturist](http://habrahabr.ru/users/owanturist/) за работу над js-тасками, [oleks](http://habrahabr.ru/users/oleks/) за отличные идеи и помощь в разработке, всем ребятам из гиттера за мгновенные фидбеки, после выпуска очередной версии сборщика, за отличные идеи и поддержку.
Пользуйтесь, форкайте, ставьте звездочки в github и продолжайте уменьшать уровень frontend-рутины с TARS. | https://habr.com/ru/post/269743/ | null | ru | null |
# Актуальность принципов SOLID
Впервые принципы SOLID были представлены в 2000 году в статье [Design Principles and Design Patterns](https://web.archive.org/web/20150906155800/http://www.objectmentor.com/resources/articles/Principles_and_Patterns.pdf) Роберта Мартина, также известного как Дядюшка Боб.
С тех пор прошло два десятилетия. Возникает вопрос - релевантны ли эти принципы до сих пор?
Перед вами перевод [статьи](https://blog.cleancoder.com/uncle-bob/2020/10/18/Solid-Relevance.html) Дядюшки Боба, опубликованной в октябре 2020 года, в которой он рассуждает об актуальности принципов SOLID для современной разработки.
Недавно я получил письмо с примерно следующими соображениями:
*Годами знание принципов SOLID было стандартом при найме. От кандидатов ожидалось уверенное владение этими принципами. Однако позже один из наших менеджеров, который уже почти не пишет код, усомнился, разумно ли это. Он утверждал, что принцип открытости-закрытости стал менее важен, так как по большей части мы уже не пишем код для крупных монолитов. А вносить изменения в компактные микросервисы - безопасно и просто.*
*Принцип подстановки Лисков давно устарел, потому что мы уже не уделяем столько внимания наследованию, сколько уделяли 20 лет назад. Думаю, нам стоит рассмотреть* [*позицию Дена Норса*](https://speakerdeck.com/tastapod/why-every-element-of-solid-is-wrong) *о SOLID - “Пишите простой код”*
В ответ я написал следующее письмо.
Принципы SOLID сегодня остаются такими же актуальными, как они были 20 лет назад (и до этого). Потому что программное обеспечение не особо изменилось за все эти годы, а это в свою очередь следствие того, что программное обеспечение не особо изменилось с 1945 года, когда Тьюринг написал первые строки кода для электронного компьютера. Программное обеспечение - это все еще операторы `if`, циклы `while` и операции присваивания - *Последовательность, Выбор, Итерация*.
Каждому новому поколению нравится думать, что их мир сильно отличается от мира поколения предыдущего. Каждое новое поколение ошибается в этом, о чем они узнают, как только появляется следующее поколение, чтобы сказать им, насколько все изменилось. <смешок>
Итак, пройдемся по принципам по порядку.
**SRP - Single Responsibility Principle** Принцип единственной ответственности.
*Объединяйте вещи, изменяющиеся по одним причинам. Разделяйте вещи, изменяющиеся по разным причинам.*
Трудно представить, что этот принцип не релевантен при разработке ПО. Мы не смешиваем бизнес-правила с кодом пользовательского интерфейса. Мы не смешиваем SQL-запросы с протоколами взаимодействия. Код, меняющийся по разным причинам, мы держим отдельно, чтобы изменения не сломали другие части. Мы следим, чтобы модули, которые изменяются по разным причинам, не включали запутывающих зависимостей.
Микросервисы не решают эту проблему. Вы можете создать запутанный микросервис или запутанное множество микросервисов, если смешаете код, который изменяется по разным причинам.
Слайды Дена Норса полностью упускают этот момент и убеждают меня в том, что он вообще не понимает сам принцип (либо иронизирует, что более вероятно предположить, зная Дена). Его ответ на SRP - “Пишите простой код”. Я согласен. SRP - один из способов сохранять код простым.
**OSP - Open-Closed Principle** Принцип открытости-закрытости
*Модуль должен быть открытым для расширения, но закрытым для изменения.*
Мысль о том, что из всех принципов кто-то может подвергнуть сомнению этот, наполняет меня ужасом за будущее нашей отрасли. Конечно, мы хотим создавать модули, которые можно расширять, не изменяя их. Можете ли вы представить себе работу в зависимой от устройства системе, где запись в файл на диске принципиально отличается от вывода на принтер, печати на экран или записи в канал? Хотим ли мы видеть операторы `if`, разбросанные по всему коду, и вникать сразу во все мельчайшие детали?
Или... хотим ли мы отделить абстрактные понятия от деталей реализации? Хотим ли мы изолировать бизнес-правила от надоедливых мелких деталей графического интерфейса, протоколов связи микросервисов и тонкостей поведения различных баз данных? Конечно хотим!
И снова [слайд](https://speakerdeck.com/tastapod/why-every-element-of-solid-is-wrong?slide=7) Дэна преподносит это совершенно неправильно.
*(Примечание. На слайде Ден утверждает, что при изменении требований существующий код становится неверным, и его нужно заменить на работающий)*
При изменении требований неверна только *часть* существующего кода. Бóльшая часть существующего кода по-прежнему верна. И мы хотим убедиться, что нам не нужно менять правильный код только для того, чтобы снова заставить работать неправильный. Ответ Дэна - “Пишите простой код”. И снова я согласен. По иронии, он прав. *Простой код одновременно открыт и закрыт.*
**LSP - Liskov Substitution Principle** Принцип подстановки Лисков
*Программа, использующая интерфейс, не должна путаться в реализациях этого интерфейса.*
Люди (включая меня) допустили ошибку, полагая что речь идет о наследовании. Это не так. Речь о подтипах. Все реализации интерфейсов являются подтипами интерфейса, в том числе при утиной типизации. Каждый пользователь базового интерфейса, объявлен этот интерфейс или подразумевается, должен согласиться с его смыслом. Если реализация сбивает с толку пользователя базового типа, то будут множиться операторы `if/switch`.
Этот принцип - о сохранении абстракций четкими и хорошо определенными. Невозможно вообразить такую концепцию устаревшей.
Слайды Дэна по этой теме полностью верны, он просто упустил суть принципа. Простой код - это код, который поддерживает четкие отношения подтипов.
**ISP - Interface Segregation Principle** Принцип разделения интерфейса
*Интерфейсы должны быть краткими, чтобы пользователи не зависели от ненужных им вещей.*
Мы по-прежнему работаем с компилируемыми языками. Мы все еще зависим от дат изменений, чтобы определить, какие модули должны быть перекомпилированы и перевыпущены. Покуда это справедливо, нам придется столкнуться с проблемой - когда модуль A зависит от модуля B во время компиляции, но не во время выполнения, изменения в модуле B ведут к перекомпиляции и перевыпуску модуля A.
Проблема особенно остро стоит в статически типизированных языках, таких как Java, C#, C++, GO, Swift и т.д. Динамически типизированные языки страдают гораздо меньше, но тоже не застрахованы от этого - существование Maven и Leiningen тому доказательство.
[Слайд](https://speakerdeck.com/tastapod/why-every-element-of-solid-is-wrong?slide=13) Дэна на эту тему ошибочен.
*(Примечание. На слайде Ден обесценивает утверждение “Клиенты не должны зависеть от методов, которые они не используют” фразой “Это же и так правда!!”)*
Клиенты *зависят* от методов, которые они *не вызывают*, если нужно перекомпилировать и перевыпускать клиент при изменении одного из этих методов. [Финальное замечание](https://speakerdeck.com/tastapod/why-every-element-of-solid-is-wrong?slide=14) Дэна по этому принципу в целом справедливо.
*(Примечание. Речь о фразе “Если классу нужно много интерфейсов - упрощайте класс!”)*
Да, если вы можете разбить класс с двумя интерфейсами на два отдельных класса, то это хорошая идея (SRP). Но такое разделение часто недостижимо и даже нежелательно.
**DIP - Dependency Inversion Principle** Принцип инверсии зависимостей
*Направляйте зависимости согласно абстракциям. Высокоуровневые модули не должны зависеть от низкоуровневых деталей.*
Сложно представить архитектуру, которая активно не использовала бы этот принцип. Мы не хотим зависимости бизнес-правил высокого уровня от низкоуровневых деталей. Это, надеюсь, совершенно очевидно. Мы не хотим, чтобы вычисления, которые приносят нам деньги, были замусорены SQL-запросами, проверками низкого уровня или проблемами форматирования. Мы хотим изолировать абстракции высокого уровня от низкоуровневых деталей. Это разделение достигается за счет аккуратного управления зависимостями внутри системы, чтобы все зависимости исходного кода, особенно те, которые пересекают архитектурные границы, указывали на абстракции высокого уровня, а не на низкоуровневые детали.
В каждом случае слайды Дена заканчиваются фразой “Пишите простой код”. Это хороший совет. Однако если годы и научили нас чему-то, так это тому, что простота требует дисциплины, руководствующейся принципами. Именно эти принципы определяют простоту. Именно эта дисциплина заставляют программистов создавать простой код.
Лучший способ создать путаницу - сказать всем “будьте проще” и не дать никаких дальнейших инструкций. | https://habr.com/ru/post/561216/ | null | ru | null |
# Исследование Crackme Chiwaka1
В данной статье сделана попытка подробно описать исследование одного занимательного crackme. Занимательным он будет в первую очередь для новичков в реверс-инжиниринге (коим и я являюсь, и на которых в основном рассчитана статья), но возможно и более серьезные специалисты сочтут используемый в нем приём интересным. Для понимания происходящего потребуются базовые знания ассемблера и WinAPI.
### Предисловие
Университетский курс ассемблера пробудил дремавший пару лет дух исследователя, зародившийся ещё в средней школе. Этому духу быстро были принесены в жертву несколько простеньких crackme, но вскоре на жестком диске нашелся экземпляр поинтересней. К сожалению, за давностью лет, первоисточник этого crackme найти не удалось, поэтому залил [архив](https://drive.google.com/open?id=0BwNfG861C7W8TzhWOGxuN0U1MVU) на Google Drive.
**Применявшиеся инструменты:**
* Отладчик (я использовал [OllyDbg](http://www.ollydbg.de/))
* Утилита для получения дескрипторов окон запущенных программ (например, [Zero Dump](https://tuts4you.com/download.php?view.432) или поставляющийся с Visual Studio Spy++)
* Некоторые файлы, входящие в [архив fasm'a](http://flatassembler.net/fasmw17139.zip)
### Первый взгляд на противника
Внешний вид главного окна подопытного очень прост: два edit'a и несколько кнопочек. Причем первое поле ввода предназначено для того, чтобы дать возможность писать во второе, которое, судя по расположенной рядом кнопке Check, и будет основным препятствием на пути к регистрации крэкми.
Окошко About содержит одну интересную надпись *«Patching is allowed, but where??»*, предваряющую самое интересное. Вся суть этой надписи раскроется в процессе исследования, а пока спойлерить не будем.
Кстати говоря, если кто-нибудь уже видел этот crackme и нашел способ его пропатчить (ну или если кому-то это показалось очень простым и он сделал это одной левой в процессе чтения статьи), то прошу рассказать всем об успехе, желательно еще и с комментариями.
Попытки вызвать хоть какую-то реакцию программы не увенчиваются успехом: никакой реакции на нажатия кнопок Enable и Check не следует. Однако бросается в глаза то, что в активном поле ввода можно писать только латиницей и ставить значок минус. Замечаем этот факт и начинаем работу.
### В бой!
Для победы данного crackme нам потребуется разобраться с двумя полями ввода.
#### Первый edit и кнопка Enable
Загрузив программу в OllyDbg, сразу замечаем интересный [GetProcAddress](https://msdn.microsoft.com/en-us/library/windows/desktop/ms683212(v=vs.85).aspx) неподалеку от точки входа:
```
00401086 |. 68 56504000 PUSH OFFSET 00405056 ; /Procname = ""10,"&7",14,"*-',4",0F,",-$",02
0040108B |. FF35 9C504000 PUSH [DWORD DS:40509C] ; |hModule = NULL
00401091 |. E8 C0020000 CALL ; \KERNEL32.GetProcAddress
```
Чтобы посмотреть, что же в неё передается, поставим бряк непосредственно на вызове GetProcAddress. Остановившись здесь, увидим, что в Procname «нарисовалась» функция [SetWindowLongA](https://msdn.microsoft.com/en-us/library/windows/desktop/ms633591(v=vs.85).aspx), а в hModule — дескриптор user32.dll:
```
00401086 |. 68 56504000 PUSH OFFSET 00405056 ; /Procname = "SetWindowLongA"
0040108B |. FF35 9C504000 PUSH [DWORD DS:40509C] ; |hModule = 767F0000 ('USER32')
00401091 |. E8 C0020000 CALL ; \KERNEL32.GetProcAddress
```
Вызов этой функции через GetProcAddress намекает, что от нас хотели его скрыть и тут происходит нечто важное. Чтобы разобраться, что именно там происходит, посмотрим на параметры, передаваемые этой функции. Это можно сделать очень быстро, поставив бряк на call eax, расположенный несколькими командами ниже.
**Почему call eax?**По соглашению вызова [stdcall](https://msdn.microsoft.com/ru-ru/library/zxk0tw93.aspx), используемого в WinAPI функциях, целочисленное значение (т. е. адрес нужной функции), которое вернет GetProcAddress, должно находиться в регистре eax.
После остановки на call eax можно повнимательней присмотреться к тому, что легло в стек. Olly любезно предлагает нам расшифровку передаваемых значений:
```
0018FC04 /00020876 ; |hWnd = 00020876, class = Edit
0018FC08 |FFFFFFFC ; |Index = GWL_WNDPROC
0018FC0C |0040302B ; \NewValue = Chiwaka1.40302B
```
Беглый взгляд на описание функции и становится понятно, что тут происходит замена оконной процедуры одного из edit'ов. Чутье подсказывает, что это активный edit, но чтобы убедиться наверняка, нужно воспользоваться утилитой Zero Dump (оказавшийся под рукой аналог Spy++). Перетянув прицел Finder Tool на активный edit, обнаруживаем, что его дескриптор совпадает с переданным в SetWindowLongA.
*При перезапуске крэкми это значение изменится, так что проверку надо проводить за один присест.*
Теперь становится ясно, откуда ноги растут у фильтрации ввода, которую мы обнаружили ранее. Посмотрим, что еще интересного делает новая оконная процедура. Перейдем к адресу (Go To -> Expression или Ctrl+G в OllyDbg), который передавался параметром NewValue (40302b):
```
0040302B 55 PUSH EBP
0040302C 8BEC MOV EBP,ESP
0040302E 817D 0C 0201000 CMP [DWORD SS:EBP+0C],102
00403035 75 61 JNE SHORT 00403098
00403037 8B45 10 MOV EAX,[DWORD SS:EBP+10]
```
Константа 102, с которой происходит сравнение на 40302E, это [WM\_CHAR](https://msdn.microsoft.com/en-us/library/windows/desktop/ms646276(v=vs.85).aspx). Список всех констант, обозначающих тип сообщения, я смотрел в файле `%fasm_directory%\INCLUDE\EQUATES\USER32.INC` (ссылка на архив с fasm'ом в списке применявшихся инструментов), так как интернета под рукой не было, а вот fasm в ~~джентльменском~~ студенческом наборе имелся.
Проследуем дальше по коду, как будто следующий прыжок JNE не выполняется. Код после JNE будет выполняться в случае прихода сообщения WM\_CHAR, которое отправляется окну после нажатия (а точнее после того, как будет обработано сообщение WM\_KEYDOWN) клавиши, в соответствие которой поставлен ASCII-код. В данном сообщении нас интересует wParam, в котором содержится код символа нажатой клавиши. Далее происходит запись этого значения в EAX и начинается серия проверок, не допускающих ввод чего-то кроме латиницы и минуса.
```
0040303A 3C 41 CMP AL,41
0040303C 72 04 JB SHORT 00403042
0040303E 3C 5A CMP AL,5A
00403040 76 10 JBE SHORT 00403052
00403042 3C 61 CMP AL,61
00403044 72 04 JB SHORT 0040304A
00403046 3C 7A CMP AL,7A
00403048 76 08 JBE SHORT 00403052
0040304A 3C 08 CMP AL,8
0040304C 74 04 JE SHORT 00403052
0040304E 3C 2D CMP AL,2D
00403050 75 61 JNE SHORT 004030B3
00403052 3C 08 CMP AL,8
00403054 75 12 JNE SHORT 00403068
00403056 833D D5504000 0 CMP [DWORD DS:4050D5],0
0040305D 74 09 JE SHORT 00403068
0040305F 832D D5504000 0 SUB [DWORD DS:4050D5],1
```
Интересна реакция на backspace (код 8 в ASCII): на 403056 происходит проверка некоторого значения в памяти на равенство нулю и декрмент этого значения на единицу в случае, если там не ноль. Такое поведение означает, что происходит подсчет длины введенной строки. И да, это действительно происходит чуть далее (последняя команда):
```
00403069 8B0D D5504000 MOV ECX,[DWORD DS:4050D5]
0040306F 8881 70504000 MOV [BYTE DS:ECX+405070],AL
00403075 8305 D5504000 0 ADD [DWORD DS:4050D5],1
```
Также тут хорошо видно, что введенный символ записывается в память в конец уже введенной последовательности. В вычислении места для записи символа фигурирует тот же адрес (4050D5), значение по которому является длиной введенной строки.
**Вывод:** для поиска места, где происходит проверка введенных данных, не поможет поиск подходящего GetDlgItemText (так как его здесь и не будет), зато поможет бряк на памяти, в которую происходит запись.
Итак, установим бряк на чтение нескольких байтов, начиная с адреса 405070. Также имеет смысл перестраховаться и поставить брейкпоинт ещё и на чтение количества введенных символом (ранее установлено, что это 4050D5). Второе сделать лучше всего непосредственно перед нажатием Check, чтобы не отвлекаться на остановки во время ввода строки. Теперь запустим программу, введем что-нибудь в первый edit и нажмем на Check.
**Скрытый текст**Байты, расположенные в месте срабатывания бряка (а также много еще где в этом крэкми), идут в такой последовательности, что она может интерпретироваться по-разному. Если попытаться сместиться выше по командам, то место срабатывания бряка переанализируется и станет выглядеть по-другому. Чтобы исправить это, достаточно командой Go to -> Expression (Ctrl+G) перейти на адрес срабатывания бряка.
Видим, что остановка произошла на записи количества введенных символов в EAX, а следующей командой идет сравнение 11-ого символа (405070 + A) введенной строки с минусом (2D — код минуса в ASCII).
```
00402007 A1 D5504000 MOV EAX,[DWORD DS:4050D5] <--memory breakpoint when reading 4050D5
0040200C 803D 7A504000 2 CMP [BYTE DS:40507A],2D
00402013 75 1E JNE SHORT 00402033
00402015 33C9 XOR ECX,ECX
00402017 33DB XOR EBX,EBX
00402019 80B9 70504000 0 CMP [BYTE DS:ECX+405070],0
00402020 74 11 JE SHORT 00402033
00402022 8A99 70504000 MOV BL,[BYTE DS:ECX+405070]
00402028 03C3 ADD EAX,EBX
0040202A 83C1 03 ADD ECX,3
0040202D EB EA JMP SHORT 00402019
0040202F 33C0 XOR EAX,EAX
00402031 5E POP ESI
00402032 58 POP EAX
00402033 C605 7A504000 0 MOV [BYTE DS:40507A],0
0040203A C3 RETN
```
Хорошо заметно, что прыжок нам после сравнения не нужен, так как далее (с 402019) запускается некоторый цикл, который нам вряд ли хочется пропускать. Проверим это предположение и сфальсифицируем результат сравнения 11-ого символа с минусом через модификацию флага ZF (ну или просто перезапустим проверку с подходящей для этого сравнения строкой).
В данном цикле происходит проверка каждого третьего введенного символа до первого нуля и сложение кодов этих символов с регистром EAX, в котором, как мы помним, лежит длина введенной строки. На 4020300 вместо минуса записывается ноль и проверка завершается.
Проследуем по RETN.
```
004010F8 /. 3D 0A030000 CMP EAX,30A
004010FD |. 0F85 C6000000 JNE 004011C9
00401103 |. FF75 08 PUSH [DWORD SS:EBP+8]
00401106 |. E8 380F0000 CALL 00402043
0040110B |. C605 A4504000 MOV [BYTE DS:4050A4],1
00401112 |. 68 12504000 PUSH OFFSET 00405012 ; /Text = "Well done! Keep going ;-)"
00401117 |. 6A 65 PUSH 65 ; |ControlID = 101.
00401119 |. FF75 08 PUSH [DWORD SS:EBP+8] ; |hDialog => [ARG.EBP+8]
0040111C |. E8 23020000 CALL ; \USER32.SetDlgItemTextA
```
Первой командой видим сравнение значения EAX c 30A и прыжок куда-то в случае неравенства. Далее же видится желанное *«Well done! Keep going ;-)»*. Теперь нужно посмотреть, как туда попасть. Рядом с заветным SetDlgItemTextA заметен call, в который нам обязательно нужно сходить. Чтобы попасть туда, необходимо пройти проверку на 30A. Проще всего это сделать модификацией флага ZF перед прыжком JNE.
Выполнив Call, видим следующее:
```
00402043 55 PUSH EBP
00402044 8BEC MOV EBP,ESP
00402046 53 PUSH EBX
00402047 68 70504000 PUSH OFFSET 00405070 ; начало введенной строки
0040204C FF35 9C504000 PUSH [DWORD DS:40509C]
00402052 E8 FFF2FFFF CALL ; Jump to kernel32.GetProcAddress
00402057 6A 66 PUSH 66
00402059 FF75 08 PUSH [DWORD SS:EBP+8]
0040205C FFD0 CALL EAX
0040205E 50 PUSH EAX
0040205F 68 7B504000 PUSH OFFSET 0040507B ; 12-ый символ введенной строки
00402064 FF35 9C504000 PUSH [DWORD DS:40509C]
0040206A E8 E7F2FFFF CALL ; Jump to kernel32.GetProcAddress
0040206F 5B POP EBX
00402070 53 PUSH EBX
00402071 FFD0 CALL EAX
00402073 68 70504000 PUSH OFFSET 00405070 ; начало введенной строки
00402078 FF35 9C504000 PUSH [DWORD DS:40509C]
0040207E E8 D3F2FFFF CALL ; Jump to kernel32.GetProcAddress
00402083 68 E8030000 PUSH 3E8
00402088 FF75 08 PUSH [DWORD SS:EBP+8]
0040208B FFD0 CALL EAX
0040208D 50 PUSH EAX
0040208E 68 7B504000 PUSH OFFSET 0040507B ; 12-ый символ введенной строки
00402093 FF35 9C504000 PUSH [DWORD DS:40509C]
00402099 E8 B8F2FFFF CALL ; Jump to kernel32.GetProcAddress
0040209E 5B POP EBX
0040209F 6A 00 PUSH 0
004020A1 53 PUSH EBX
004020A2 FFD0 CALL EAX
```
Четыре GetProcAddress, в которые передаются части введенной нами строки! Первый раз передается адрес начала строки, второй — адрес 12 символа, и далее снова начало и снова 12-ый символ. Как мы помним, на место 11 символа (которым должен быть минус) записывается ноль. Теперь понятно, что это нужно для того, чтобы передавать в GetProcAddress null-terminated строку.
Теперь можно поставить вполне определенную задачу: найти две функции из user32.dll (об этом свидетельствует хэндл, передаваемый GetProcAddress), у каждой из которых два параметра (количество push'ей перед call eax), причем первая имеет длину десять символов.
Сузим круг поиска, посмотрев на передаваемые параметры, и сопоставив их с тем, что должно произойти после нажатия кнопки Enable. Мы уже видели SetDlgItemTextA с подбадривающей надписью, и есть вероятность, что она отобразится в первом поле ввода, так как второе нам еще нужно. А второе поле надо бы сделать активным, мы ведь все-таки на кнопку Enable жмем!
Чтобы быстро посмотреть на все функции, имеющие длину 10 символов, из user32.dll, я использовал поиск во встроенном редакторе фара по файлу `%fasm_directory%\INCLUDE\API\USER32.INC`. Для поиска применил регэксп `'\s\i{10}\,'`. Можно было далее выбирать из найденных функций те, которые имею два параметра, но в этом не было необходимости, так как «по смыслу» идеально подходит [GetDlgItem](https://msdn.microsoft.com/en-us/library/windows/desktop/ms645481(v=vs.85).aspx). Подтверждением этой мысли служит «волшебная константа» 66h, являющаяся ID второго, пока еще неактивного поля ввода (это можно увидеть с помощью zDump или аналогичной утилиты). Это значение является первым параметром у GetDlgItem.
Осталось только активировать второе поле ввода. За два параметра это отлично сможет сделать [EnableWindow](https://msdn.microsoft.com/en-us/library/windows/desktop/ms646291(v=vs.85).aspx).
Проверка найденной строки **GetDlgItem-EnableWindow** и… успех!

С первым полем ввода разобрались, переходим к «основному блюду».
#### Второй edit и решающий удар по кнопке Check
Так как замена оконной процедуры выполнялась только для одного edit'a, текст из второго должен (во всяком случае есть основания на это надеяться) извлекаться более тривиальным путем. Воспользуемся командой Search for -> All intermodular calls и посмотрим, что может использоваться для получения текста из второго поля ввода.
**All intermodular calls**
```
0040103C CALL 7684CB0C USER32.DialogBoxParamA TemplateName = 1, hParent = NULL, DialogProc = Chiwaka1.401061, InitParam = 0
004011B2 CALL 7684CB0C USER32.DialogBoxParamA TemplateName = 2, hParent = NULL, DialogProc = Chiwaka1.401206, InitParam = 0
004011C4 CALL 7682B99C USER32.EndDialog Result = 0
00401214 CALL 7682B99C USER32.EndDialog Result = 1
0040123D CALL 7682B99C USER32.EndDialog Result = 1
0040104C CALL 765779C8 kernel32.ExitProcess
00401072 CALL 7682F1BA USER32.GetDlgItem ItemID = 101.
00401002 CALL 76571245 kernel32.GetModuleHandleA ModuleName = NULL
00401091 CALL 76571222 kernel32.GetProcAddress Procname = ""10,"&7",14,"\*-',4",0F,",-$",02
00401168 CALL 76571222 kernel32.GetProcAddress Procname = ""04,"&7",07,"/$",LF,"7&.",17,"&;7",02
00401268 CALL 76571222 kernel32.GetProcAddress
004010C4 CALL 7681612E USER32.SendMessageA Msg = WM\_COMMAND
0040111C CALL 7681C4D6 USER32.SetDlgItemTextA ControlID = 101., Text = "Well done! Keep going ;-)"
004011DC CALL 7681C4D6 USER32.SetDlgItemTextA ControlID = 101., Text = "Careful now !!"
```
Самым подходящим кандидатом на функцию, достающую текст из второго поля ввода, кажется один из GetProcAddress, который вероятно получает адрес [GetDlgItemTextA](https://msdn.microsoft.com/en-us/library/windows/desktop/ms645489(v=vs.85).aspx). Чтобы убедиться в этом, запустим программу, разблокируем второе поле найденной строкой, а затем поставим бряки на все три GetProcAddress. Теперь можно нажать на Check и убедиться, что прогнозы оказались верны.
```
0040115D |> \68 46504000 PUSH OFFSET 00405046 ; /Procname = "GetDlgItemTextA"
00401162 |. FF35 9C504000 PUSH [DWORD DS:40509C] ; |hModule = 767F0000 ('USER32')
00401168 |. E8 E9010000 CALL ; \KERNEL32.GetProcAddress
0040116D |. 6A 40 PUSH 40
0040116F |. 68 70504000 PUSH OFFSET 00405070
00401174 |. 6A 66 PUSH 66
00401176 |. FF75 08 PUSH [DWORD SS:EBP+8]
00401179 |. FFD0 CALL EAX
```
Далее происходит проверка количества введенных символов (GetDlgItemText возвращает его в EAX), запись этого значения в память и вызываются четыре функции. Вероятнее всего, именно в этих четырех функциях происходят какие-то действия со строкой, поэтому исследуем их по очереди.
Заглянув в первый call, наблюдаем некоторые махинации с символами в строке, выполняемые в цикле до обнаружения первого нуля (402126):
**CALL 00402101**
```
00402101 8D05 70504000 LEA EAX,[405070] ; введенная строка
00402107 EB 1D JMP SHORT 00402126
00402109 8038 40 CMP [BYTE DS:EAX],40 ; 40h = @ (последний символ в ASCII перед латиницей в верхнем регистре)
0040210C 76 0A JBE SHORT 00402118
0040210E 8038 5B CMP [BYTE DS:EAX],5B ; 5Bh = [ (первый символ после латиницы в верхнем регистре)
00402111 73 05 JAE SHORT 00402118
00402113 8000 20 ADD [BYTE DS:EAX],20 ; 20h - разница между буквой в разных регистрах
00402116 EB 0D JMP SHORT 00402125
00402118 8038 60 CMP [BYTE DS:EAX],60 ; 60h = ' (последний символ перед латиницей в нижнем регистре)
0040211B 76 08 JBE SHORT 00402125
0040211D 8038 7B CMP [BYTE DS:EAX],7B ; 7Bh = { (первый символ после латиницы в нижнем регистре)
00402120 73 03 JAE SHORT 00402125
00402122 8028 20 SUB [BYTE DS:EAX],20 ; 20h - разница между буквой в разных регистрах
00402125 40 INC EAX
00402126 8038 00 CMP [BYTE DS:EAX],0
00402129 75 DE JNE SHORT 00402109
0040212B C3 RETN
```
Присмотревшись к константам, которые тут встречаются, а потом к таблице ASCII, легко заметить, что этот call инвертирует регистр каждого из введенных символов. Тут все оказалось очень просто.
**CALL 00402133**
```
00402133 53 PUSH EBX
00402134 33DB XOR EBX,EBX
00402136 33D2 XOR EDX,EDX
00402138 8D05 70504000 LEA EAX,[405070] ; введенная строка
0040213E 50 PUSH EAX
0040213F 8B0D A5504000 MOV ECX,[DWORD DS:4050A5]
00402145 51 PUSH ECX
00402146 49 DEC ECX
00402147 8A1401 MOV DL,[BYTE DS:EAX+ECX]
0040214A 8893 A9504000 MOV [BYTE DS:EBX+4050A9],DL
00402150 43 INC EBX
00402151 83F9 00 CMP ECX,0
00402154 ^ 75 F0 JNE SHORT 00402146
00402156 59 POP ECX
00402157 58 POP EAX
00402158 49 DEC ECX
00402159 33DB XOR EBX,EBX
0040215B 33D2 XOR EDX,EDX
0040215D 33C0 XOR EAX,EAX
0040215F EB 1A JMP SHORT 0040217B
00402161 8A99 70504000 MOV BL,[BYTE DS:ECX+405070] ; введенная строка
00402167 8A90 70504000 MOV DL,[BYTE DS:EAX+405070] ; введенная строка
0040216D 8891 70504000 MOV [BYTE DS:ECX+405070],DL
00402173 8898 70504000 MOV [BYTE DS:EAX+405070],BL
00402179 49 DEC ECX
0040217A 40 INC EAX
0040217B 83F8 05 CMP EAX,5
0040217E ^ 72 E1 JB SHORT 00402161
00402180 C605 7A504000 4 MOV [BYTE DS:40507A],41
00402187 5B POP EBX
00402188 C3 RETN
```
Второй call чуть побольше, и в нём совершается несколько действий. Первым делом происходит копирование введенной строки задом наперед в другое место в памяти с помощью следующего цикла:
```
00402146 49 DEC ECX
00402147 8A1401 MOV DL,[BYTE DS:EAX+ECX]
0040214A 8893 A9504000 MOV [BYTE DS:EBX+4050A9],DL
00402150 43 INC EBX
00402151 83F9 00 CMP ECX,0
00402154 ^ 75 F0 JNE SHORT 00402146
```
Далее происходит то же самое с исходной строкой, однако инвертируется только 10 символов. Это может указывать на то, что в дальнейшем только они и будут использоваться, но загадывать рано.
Ну и наконец выполняется запись на 11-ую позицию исходной строки символа 'A':
```
00402180 C605 7A504000 4 MOV [BYTE DS:40507A],41
```
Вспомнив, какой прием уже использовался в этом крэкми, можно предположить, что и тут будет нечто похожее, однако WinAPI функция будет вводиться не в готовом виде.
CALL 00401285 выводит нас еще на один call:
**CALL 004012C4**
```
004012C4 /$ 8D05 BD504000 LEA EAX,[4050BD]
004012CA |. 33D2 XOR EDX,EDX
004012CC |. 8A15 F0204000 MOV DL,[BYTE DS:4020F0]
004012D2 |. 8810 MOV [BYTE DS:EAX],DL
004012D4 |. 8A15 31214000 MOV DL,[BYTE DS:402131]
004012DA |. 8850 01 MOV [BYTE DS:EAX+1],DL
004012DD |. 8A15 AE204000 MOV DL,[BYTE DS:4020AE]
004012E3 |. 8850 02 MOV [BYTE DS:EAX+2],DL
004012E6 |. 8A15 CF204000 MOV DL,[BYTE DS:4020CF]
004012EC |. 8850 03 MOV [BYTE DS:EAX+3],DL
004012EF |. 8A15 41204000 MOV DL,[BYTE DS:402041]
004012F5 |. 8850 04 MOV [BYTE DS:EAX+4],DL
004012F8 |. 8A15 40204000 MOV DL,[BYTE DS:402040]
004012FE |. 8850 05 MOV [BYTE DS:EAX+5],DL
00401301 |. 8A15 31214000 MOV DL,[BYTE DS:402131]
00401307 |. 8850 06 MOV [BYTE DS:EAX+6],DL
0040130A |. 8A15 05204000 MOV DL,[BYTE DS:402005]
00401310 |. 8850 07 MOV [BYTE DS:EAX+7],DL
00401313 |. 8A15 83124000 MOV DL,[BYTE DS:401283]
00401319 |. 8850 08 MOV [BYTE DS:EAX+8],DL
0040131C |. 8A15 5B124000 MOV DL,[BYTE DS:40125B]
00401322 |. 8850 09 MOV [BYTE DS:EAX+9],DL
00401325 \. C3 RETN
```
Тут происходят манипуляции с памятью, которая не связана ни с исходной строкой, ни с её копией, поэтому не вникая в тонкости происходящего, посмотрим, что происходит после возврата. А после возврата происходит обработка копии введенной строки с помощью xor'a. Скорее всего что-то из этих двух строк должно в итоге оказаться WinAPI функцией, а что-то — сообщением об успешной регистрации.
Всё прояснит последний call.
**CALL 0040125D**
```
0040125D /$ 68 70504000 PUSH OFFSET 00405070 ; /Procname = "введенная строка задом-наперед с инвертированным регистром и символом 'A' на конце"
00401262 |. FF35 9C504000 PUSH [DWORD DS:40509C] ; |hModule = 767F0000 ('USER32')
00401268 |. E8 E9000000 CALL ; \KERNEL32.GetProcAddress
0040126D |. 6A 30 PUSH 30
0040126F |. 68 BB124000 PUSH 004012BB ; ASCII "API-API"
00401274 |. 68 A9504000 PUSH OFFSET 004050A9 ; ASCII "введенная строка задом-наперед с инвертированным регистром, к которой применен xor"
00401279 |. 6A 00 PUSH 0
0040127B |. FFD0 CALL EAX
0040127D \. C3 RETN
```
Осталось совсем чуть-чуть: снова решить задачку по поиску подходящей WinAPI функции. Вот, что нам о ней известно:
* длина имени — 11 символов, на конце буква A
* находится в user32.dll
* передается четыре параметра, из них два параметра — строки
Для поиска подходящей функции я использовал поиск по файлу `%fasm_directory%\INCLUDE\PCOUNT\USER32.INC` по следующему регулярному выражению `'^\i{10}\%\s\=\s\s4'`. В данном файле не дублируются ANSI-версии функций, поэтому большую A в конце указывать нельзя. Подходяших функций оказалось не так уж и много, а по смыслу отлично подходит лишь одна: [MessageBoxA](https://msdn.microsoft.com/en-us/library/windows/desktop/ms645505(v=vs.85).aspx).
Вспомнив, какие операции выполняются с ней перед передачей в GetProcAddress, преобразуем соответствующим образом: MessageBox — (инверсия регистра) — mESSAGEbOX — (инверсия порядка символов) — **XObEGASSEm**.
Введем заветную строку во второе поле ввода и получаем победный MessageBox с заголовком окна, напоминающем о приключениях!

### Вместо заключения
В исследованном крэкми демонстрируется интересный способ прочной «привязки» защиты к работе самой программы. Используемый механизм достаточно сильно затрудняет патчинг. Мне трудно представить себе применение такого способа в коммерческой защите (однако буду рад, если кто-то расскажет о примерах), но для головоломки на пару деньков она очень даже хороша, особенно для начинающих. | https://habr.com/ru/post/263093/ | null | ru | null |
# Поиск изображений с помощью AffNet
Перед нами стояла задача сравнения изображений (image matching) для поиска изображения максимально подобного данному изображению из коллекции. В этой статье я расскажу как мы использовали для этой задачи подход на основе нейронных сетей под названием AffNet. Кому интересно, прошу под кат.
В нашем случае нам нужно было найти для заданного изображения наиболее похожее с целью последующего вычисления позиции камеры на основе метода фундаментальной матрицы трансформации в OpenCV.
Первоначально мы попробовали стандартный матчинг изображений с использованием дескрипторов признаков SIFT и матчера FLANN из библиотеки OpenCV, а также Bag-of-Words. Оба подхода давали слабые результаты. Bag-of-Words к тому же требует огромный датасет изображений и много времени для обучения.
### Обзор подхода AffNet
На использование подхода нас вдохновил [вебинар](https://www.youtube.com/watch?v=xyM-ebZ4T-Y&feature=youtu.be) «Points & Descriptors», который прошлым летом проводил CVisionLab. Для всех заинтересованных [здесь](https://docs.google.com/presentation/d/17M39q3sez9UD4FPHgEoio43lXqD91nCf1ghuqn1ZPf8/edit) доступны слайды с этого вебинара. На этом вебинаре представили интересный подход: AffNet + HardNet. Результаты матчинга, представленные на слайдах нас впечатлили и мы решили попробовать его в нашей задаче. По словам авторов AffNet это инновационный метод для обучения регионов ковариантных к афинной трансформации с функцией постоянной отрицательной потери (hard negative-constant loss), который обходит state-of-the-art подходы типа Bag-of-Words на задачах матчинга изображений и wide baseline stereo.

HardNet это новый компактный обучаемый дескриптор признаков, показавший лучшую эффективность state-of-art в сравнении с классическими и обучаемыми дескрипторами признаков и который возможно быстро вычислять на GPU ([ссылка](https://arxiv.org/pdf/1705.10872.pdf) на статью). Он доступен публично на [github](https://github.com/DagnyT/hardnet). Здесь есть хороший пример матчинга изоображений с большой афинной трансформацией с использованием AffNet.

Авторы AffNet объясняют подход более детально в своей [статье](https://arxiv.org/pdf/1711.06704.pdf).
### Тестирование подхода AffNet
Клонируем репозиторий с github:
```
git clone https://github.com/ducha-aiki/affnet.git
```
Затем переходим в папку affnet.
Запустим Jupyter :
```
jupyter notebook
```
и откроем ноутбук SIFT-AffNet-HardNet-kornia-matching.ipynb в папке examples. Сначала установим все завивисимости. Создадим ячейку в верху ноутбука и запустим ее
```
!pip install kornia pydegensac extract_patches
```
Если у вас установлен OpenCV версии 4 вы можете получить ошибку из-за функции SIFT\_create:
```
The function/feature is not implemented) This algorithm is patented and is excluded in this configuration;
```
Дело в том, что начиная с версии 3.4.2.16 SIRF и SURF больше недоступны в основном репозитории opencv, они были вынесены в отдельный пакет opencv-contrib. Установим OpenCV и opencv-contrib:
```
pip install opencv-python==3.4.2.16
pip install opencv-contrib-python==3.4.2.16
```
Когда мы запустим матчинг изображений с AffNet на изображениях, предоставленных авторами, мы получим примерно такой результат:
```
30.0 inliers found
```

Довольно неплохой результат для таких изображений.
Для пайплайна DoG-AffNet-OriNet-HardNet
```
18.0 inliers found
```
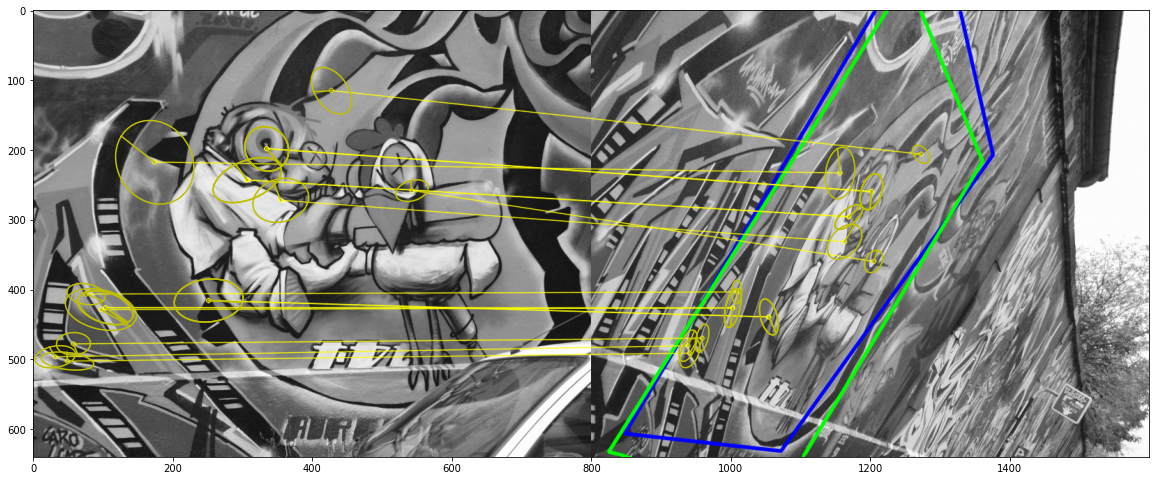
И наконец для пайплайна DoG-OriNet-HardNet
```
25.0 inliers found
```

Когда мы применили подход на своих изображениях сцен домашей обтановке (комнаты в доме), мы были удивлены результатами. AffNet находил соответствия между двумя изображениями с очень плохим освещением и большей разницей в угле обхора камеры. AffNet показал хорошие результаты без дополнительного дообучения.
Теперь осталось попробовать AffNet на своих изображениях.
Чтобы интегрировать AffNet в свою программу вам нужно только установить все необходимые библиотеки, скачать предобученные веса модели и скопировать несколько функций из ноутбука SIFT-AffNet-HardNet-kornia-matching.ipynb.
Можно легко сконвертировать Jupyter ноутбук в скрипт python с помощью утилиты jupyter nbconvert. Установим ее через pip:
```
pip install nbconvert
```
и запустим конвертацию:
```
jupyter nbconvert SIFT-AffNet-HardNet-kornia-matching.ipynb --to python
```
На этом все. Удачи в использовании AffNet для матчинга изоображений и до новых встреч. | https://habr.com/ru/post/535162/ | null | ru | null |
# Как НЕ надо делать информер с внешнего сайта на PHP
Добрый день всем читающим!
Сразу хочу оговориться, здесь я расскажу об очевидных вещах для любого опытного PHP-программиста. Но в последнее время постоянно натыкаюсь у новичков на эту ошибку в том или ином ее проявлении.
**UPD**: господа, ну что за манера молча плевать в карму! неужели трудно написать, что конкретно не нравится в посте?
Человек делает свой первый (второй, третий) сайт. Называет все это дело информационным порталом. Начинание полезное. И вот человек решает разместить у себя на сайте информер со стороннего сайта. Многие сайты предоставляют специальный сервис для этих целей. Например Гисметео раздает html-код для вставки на свои страницы, многие банки тоже дают код для информера с курсами валют. Но что делать, если нужный сайт не дает такого сервиса?
Тут следует оговориться еще раз. Давайте мы опустим обсуждение правомерности размещения информации с чужого сайта без разрешения. Я не приветствую такие действия, но вот если человеку надо…
Итак, наш новичек решает вставить в нужном ему месте страницу с нужного URL. Что я вижу в исходнике:
`...
include "http://...";
...`
Это ужасно. Это очень и очень плохо. Тем, кто не понимает, чем это ужасно:
* Как правило, если удаленный сайт не дает легальный код для информера, то в ответ мы получаем полноценную HTML-страницу, со своими заголовками, в своей кодировке и т.д. Как минимум это будет ужасно выглядеть, не впишется в общий дизайн сайта. А скорей всего это просто поломает макет страницы.
* Команда inсlude просто берет текст, полученный по запросу URL, и вставляет его в текущее место программы, как исходник PHP. Это означает, что если с той стороны админ сайта отдаст специально сформированную страницу с кодом на PHP, этот код исполнится тут же на вашем сервере. Это самая банальнейшая инъекция. На глазах у изумленного новичка я сделал страницу, которая при таком инклюде перезагружала его сервер. Тут еще можно сказать, что на большинстве хостингов удаленный инклюд отключают, и правильно.
И в завершение расскажу как надо делать вставку стороннего контента, это сделал бы я.
В PHP есть поддержка такого приятного инструмента, как curl, который позволяет дергать контент с удаленных веб-серверов, причем с очень гибкими настройками, практически позволяя имитировать работу браузера. Контент помещается в переменную и затем обрабатывается. Можно обработать контент с помощю регулярных выражений, можно разобрать HTML с помощью XPath или другого парсера. В любом случае, нужно избавиться от всего лишнего и оставить голый полезный контент: текст, цифры и т.п. Затем эти данные проверяются на валидность и просто вставляются в родной макет страницы.
Никакого нарушения дизайна, никакой поломки макета, никаких инъекций в PHP.
PS. Стоит отметить, что мои доводы и демонстрация уязвимости не оказали нужного эффекта на начинающего коллегу, уязвимость не была исправлена. Через несколько дней сайт был взломан как раз с использованием этой уязвимости. Не повторяйте ошибок, учитесь на чужих. Удачи! | https://habr.com/ru/post/65277/ | null | ru | null |
# Интеграция с маркетплейсами или как я научился не волноваться и полюбил API-интеграцию
В нашей компании принято устраивать звонки-знакомства — на них клиенты могут напрямую пообщаться с командами, которые будут им помогать или сопровождать. Во время таких встреч поднимается множество вопросов, в том числе связанных с интеграцией. Чаще всего вопросы одни и те же, поэтому я даже имею заготовленный спич, который позволяет на пальцах объяснить принцип работы нашей интеграции и быстро оценить сложность её реализации на своей стороне. Спич долго был только в моей голове, но для Хабра я решил изложить его в письменном виде и поделиться с вами.
💡 Сначала материал не разрешили публиковать — сочли его рекламным. Но когда узнали все детали — что через наш API можно формировать до 500 запросов в сутки бесплатно (а этого по опыту хватает в среднем на обработку 50 заказов), — «дали зеленый свет» и попросили указать все это в начале материала. Что я и делаю 🙂 Заявку на подключение доступа можно оформить на сайте компании через форму обратной связи.
---
Шаг 1. Обновление цен и стоков
------------------------------
Первый поток данных, который нужно запустить. Информация о ценах и остатках должна транслироваться из системы клиента во все маркетплейсы. Инициатором обмена выступает система клиента — именно в ней происходит изменение цен и стоков.
Алгоритм работы сильно зависит от возможностей системы клиента, обычно реализуются следующие варианты:
#### Мгновенное обновление при событии
1. В учётной системе клиента произошло изменение цены или стока.
2. Учётная система клиента отслеживает это событие и в тот же момент вызывает методы передачи цены или стока (в зависимости от того, что изменилось) и отправляет новые значения в XWAY API.
3. XWAY API доставляет данные до маркетплейсов.
Таким образом, время, прошедшее с момента изменения данных в учётной системе клиента до обновления данных на маркетплейсе, составляет сотни миллисекунд, максимум 1-2 секунды. Это самый правильный сценарий, к которому стоит стремиться. Так сказать, идеальный мир интеграции 🙂
#### Запуск рекуррентного обновления по времени
У многих наших клиентов учётная система не может отследить изменение цены или стока, а значит, не может мгновенно запустить обмен и передать новые данные на маркетплейс. Поэтому они реализуют следующую логику:
1. Раз в N минут (параметр целиком и полностью зависит от конкретной системы) запускается сборщик, который пробегает по всей базе и выделяет массив товаров, где изменилась цена или сток за последние N минут.
2. Для найденных массивов товаров формируются соответствующие запросы на обновление цен или стоков и передаются в XWAY API.
3. XWAY API доставляет данные до маркетплейсов.
Очевидным минусом такого подхода является его дискретность. По опыту, наши клиенты, использующие данную схему, осуществляют отправку данных раз в 5 минут и реже. Если сделать чаще, то появляется высокая нагрузка на учётную систему клиента. Если сделать реже — увеличится вероятность продажи большего количества товаров, чем есть на складе.
#### Запуск полного обновления по времени
Самый печальный случай. Учётная система клиента по тем или иным причинам не может выделить товары, в которых произошли изменения цены или стока, поэтому производится отправка всего массива информации о товарах, ценах и остатках.
1. Раз в N минут (параметр целиком и полностью зависит от конкретной системы) запускается обмен по всем товарам, которые есть у клиента.
2. Для всех товаров формируются соответствующие запросы на обновление цен или стоков и передаются в XWAY API.
3. XWAY API доставляет данные до маркетплейсов.
Конечно же, дикие объемы передаваемых данных. Естественно, такой обмен невозможно сделать быстрым, хотя бы потому, что тут же начинаем упираться в лимиты по запросам маркетплейсов. Но если по другому нельзя, то можно и так сделать 🙂
Примеры методов
---------------
*Обновление цен*
Возможны 2 модели асинхронного взаимодействия, с использованием Webhook и без него.
***Если используется Webhook:***
1. В запросе продавец передаёт URL своего эндпоинта в параметре request\_url.
```
{
"request_url": "https://seller.com/webhook/",
"shop_id": 2145,
"items": [
{
"external_id": "204245576795",
"price": 99987,
"discount_price": 95000,
"available": true,
"batch_count": 1
},
{
"external_id": "204245576797",
"price": 39342,
"discount_price": 30999,
"available": false,
"batch_count": 1
}
]
}
```
2. После обработки запроса на указанный эндпоинт продавца придёт request\_id.
3. Используя метод [https://seller-api.xway.ru/api/v2/requests/{request\_id}](https://seller-api.xway.ru/api/v2/requests/%7Brequest_id%7D) продавец получает результат выполнения запроса.
***Если не используется Webhook:***
1. В запросе продавец не передаёт параметр request\_url.
```
{
"shop_id": 2145,
"items": [
{
"external_id": "204245576795",
"price": 99987,
"discount_price": 95000,
"available": true,
"batch_count": 1
},
{
"external_id": "204245576797",
"price": 39342,
"discount_price": 30999,
"available": false,
"batch_count": 1
}
]
}
```
2. В ответе на запрос продавец сразу получает request\_id
3. Используя метод [https://seller-api.xway.ru/api/v2/requests/{request\_id}](https://seller-api.xway.ru/api/v2/requests/%7Brequest_id%7D) продавец получает результат выполнения запроса.
💡 В одном запросе нельзя передавать цену на один и тот же товар более одного раза.
💡 В одном запросе нельзя передавать *массив более чем* из 500 элементов.
Шаг 2. Получение заказов
------------------------
Следующий поток данных, который нам нужно организовать для полноценной работы с маркетплейсами по схеме FBS — обмен информацией о заказах. Чем быстрее продавец получит заказ с маркетплейса и его обработает (зарезервирует товар под этот заказ), тем быстрее он сможет протранслировать новые значения остатков для товаров, которые были в заказе. И тем меньше вероятность оверсейла (продажи большего числа товара, чем есть на складе).
Однако зачастую маркетплейсы не выступают инициатором обмена и ждут, когда учётная система продавца обратится к ним за новыми заказами. Мы поддерживаем несколько схем получения заказа.
#### Продавец запрашивает новые заказы по расписанию
Продавец при разработке интеграции реализует в своей учётной системе метод, который с определённой периодичностью обращается к XWAY API и получает список новых заказов. То есть в качестве инициатора обмена выступает система продавца.
Понятно, что такая схема приводит к задержкам, напрямую зависящим от частоты запросов.
* Если сделать частоту запросов слишком большой, то задержка уменьшится, но при этом увеличится нагрузка как на учётную систему продавца, так и на сервер XWAY API.
* Если сделать частоту запросов слишком низкой, то задержка увеличится, что приведёт к оверсейлам.
Запрос на получение списка заказов достаточно простой. Это GET запрос, в котором можно с помощью параметров добавить дополнительную фильтрацию, например, по дате создания, дате изменения, статусу заказа и так далее.
Пример запроса на получение списка заказов для магазина с id 6414 и статусом delivered:
```
curl --request GET \
--url 'https://seller-api.xway.ru/api/v2/orders/?shop_id=6414&status=delivered' \
--header 'authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGci587IUzI1NiJ9.eyJ1c2VyX2lkIjo2MDQ1LCJ1c2VyX2d1aWQiOiI2ZWQzNDE2Yy03YmQzLTQyNTctYmQzYi1hZjRlNTYzNzE2OGEiLCJleHAiOjE2OTI4MDQyNTgsImF1dGhfbWV0aG9kX3R5cGUiOiJFTUFJTCIsImFjY291bnRzIjp7IlBBU1NQT1JUIjo2MDQ1LCJVTklDT1JOIjo1NTY2fSwicGVybWlzc2lvbnMiOnt9LCJpc194d2F5X2VtcGxveWVlIjpmYWxzZX0.Qf63EQ_kF-ZwIzJYIdC_izro1uTsh6q1zJslxsGcpuc' \
--header 'content-type: application/json
```
В ответ на подобный запрос XWAY API выдаст список заказов для данного магазина:
```
{
"meta": {
"request_id": "a4a17610-9ee9-48f5-a33d-e888eb1846d2",
"message": null
},
"result": {
"orders": [
{
"id": 34511146,
"shop_id": 6414,
"order_id": "107586281",
"marketplace_code": "beru",
"created_at": "2022-04-27T03:00:00.000000Z",
"modified_at": "2022-05-01T13:24:01.165000Z",
"status": "delivered"
},
{
"id": 34511144,
"shop_id": 6414,
"order_id": "107857757",
"marketplace_code": "beru",
"created_at": "2022-04-29T03:00:00.000000Z",
"modified_at": "2022-05-01T13:10:49.838000Z",
"status": "delivered"
}
]
},
"pagination": {
"limit": 100,
"offset": 0,
"total": 482
}
}
```
#### Продавец получает информацию о новых заказах на webhook
Продавец при разработке интеграции реализует в своей учётной системе дополнительный эндпойнт (урл, webhook), адрес которого прописывается в XWAY API. Как только в XWAY API появляется информация о том, что у продавца на любом из маркетплейсов появился новый заказ, в тот же момент XWAY API отправляет уведомления на webhook продавца и селлер тут же вызывает метод получения нового заказа.
Такая схема работы чуть более сложна в реализации для продавца (ему нужно делать отдельный webhook и писать дополнительный обработчик), но обладает рядом важных преимуществ:
* Оптимизация трафика между двумя системами. Обмен начинается только в том случае, если поступил заказ.
* Ускорение обмена между двумя системами. Как только пришёл новый заказ, в тот же момент XWAY API отправляет соответствующее уведомление учётной системе продавца и запускается обмен информацией по заказу. Задержка между появлением заказа в XWAY API и в системе продавца уменьшается до 1 секунды.
#### Получения полной информации о заказе
Независимо от того, каким образом продавец получает информацию о новом заказе, в ней не содержится полная информация. XWAY API отдаёт только базовую информацию о том, что появился заказ или произошло изменение в существующем. Для получения полной информации продавец должен вызвать метод получения полной информации о заказе:
```
curl --request GET \
--url 'https://seller-api.xway.ru/api/v2/orders/34511146?shop_id=6414' \
--header 'authorization: Bearer eyJ0eXAiOiJKV1QiLCJ589GciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjo2MDQ1LCJ1c2VyX2d1aWQiOiI2ZWQzNDE2Yy03YmQzLTQyNTctYmQzYi1hZjRlNTYzNzE2OGEiLCJleHAiOjE2OTI4MDQyNTgsImF1dGhfbWV0aG9kX3R5cGUiOiJFTUFJTCIsImFjY291bnRzIjp7IlBBU1NQT1JUIjo2MDQ1LCJVTklDT1JOIjo1NTY2fSwicGVybWlzc2lvbnMiOnt9LCJpc194d2F5X2VtcGxveWVlIjpmYWxzZX0.Qf63EQ_kF-ZwIzJYIdC_izro1uTsh6q1zJslxsGcpuc' \
--header 'content-type: application/json'
```
В ответ XWAY API отдаст подробную информацию о заказе:
```
{
"meta": {
"request_id": "d1268645-be96-4634-b814-07933c2dc819"
},
"result": {
"id": "42486407",
"shop_id": 2848,
"marketplace_code": "SMM",
"order_id": "747378127",
"created_at": "2022-08-01T11:56:45.000000Z",
"modified_at": "2022-08-01T11:59:10.670598Z",
"status": "delivered",
"antifraud_status": null,
"total_amount": 95.0,
"memo": null,
"order_items": [
{
"id": 43273407,
"xway_offer_id": 22763052,
"external_id": "84.140",
"sku_code": "22763052",
"seller_price": 718.0,
"buyer_price": 95.0,
"subsidy": 623.0,
"currency_code": "RUB",
"name": "Антимоскитная сетка \"Герберы\" для дверного проема 2,1х1,0м",
"quantity": 1,
"is_cancel": false,
"memo": null,
"properties": []
}
],
"buyer_info": {
"name": null,
"phone": null
},
"delivery": {
"delivery_status": null,
"service_type": "fbs",
"shipment_date": "2022-08-04T15:00:00+00:00",
"warehouse_id": null,
"delivery_price": 0.0,
"delivery_type": null,
"delivery_service": "delivery_by_goods",
"customer": {
"name": "Мина Мария",
"phone": null,
"address_full": "г Киров, ул Пушкина, д 15А",
"address_detail": null
},
"delivery_interval": {
"from_date": "2022-08-07",
"to_date": "2022-08-07",
"from_time": "21:00",
"to_time": "21:00",
"timezone": "UTC+0"
},
"shipments": []
},
"requirements": {
"gtd": [],
"country": [],
"mandatory_mark": [],
"rnpt": []
}
}
}
```
Шаг 3. Обработка заказа
-----------------------
Ну что же, заказ получили — теперь его нужно обработать :) Если бы вы делали интеграцию с каждым маркетплейсом отдельно, то тут бы было множество алгоритмов обработки заказа, каждый из которых бы зависел от конкретного маркетплейса.
Забудьте как страшный сон!
Мы всё уже сделали: свели все методы к единому набору, а все статусы — к единой статусной модели.
Вам без разницы, заказ с какого маркетплейса вы хотите обрабатывать. Просто всегда делайте одну и ту же последовательность шагов на складе и одну и ту же последовательность вызовов XWAY API:
1. Подтверждаем или отменяем товары в заказе.
2. Собираем заказ.
3. Получаем наклейку на упакованное отправление.
4. Создаём поставку.
5. Получаем документы на поставку.
ВСЁ! 🙂
Всего пять шагов, всегда стандартные пять шагов 🙂
Конечно, я мог бы далее расписать каждый из шагов, привести примеры кода…но мне кажется, это уже лишнее. Если вам действительно интересны технические детали, вы можете ознакомиться с ними в нашей документации<https://seller-api.xway.ru/redoc>
В заключении хочется выразить простую мысль, которую я хотел донести в этой статье:
> **Интеграция может быть простой и понятной.**
>
>
---
Забудьте об особенностях каждого маркетплейса, о куче методов, механизмов авторизации, множестве ключей и кредов для каждого маркетплейса, о разных айди, каждый из которых называется по-своему и каждый из которых надо передавать в свои методы и в свои параметры. Просто сделайте одну интеграцию — и работайте спокойно, а всю эту головную боль можно делегировать экспертам :) Если у вас есть вопросы, буду рад ответить на них в комментариях или в Телеграм [@anton\_batashov](https://habr.com/users/anton_batashov) | https://habr.com/ru/post/686904/ | null | ru | null |
# CSS-переменные в медиазапросах
Поскольку я являюсь новичком в разработке, мне достаточно трудно считывать используемую в препроцессорах вложенность свойств с помощью символа `"&"`. Вместо формул и миксинов я предпочитаю писать обычные правила. А вместо SASS-переменных использую кастомные свойства CSS. Единственной причиной, по которой я продолжал использовать SASS, была возможность подставлять в медиазапросы переменные с контрольными точками смены раскладки страницы. Например, `$tablet: 768px` или `$dektop: 1100px`.
Именно по этой причине для меня было большой радостью узнать о существовании PostCSS-плагина "[PostCSS Custom Media](https://github.com/postcss/postcss-custom-media)", который уже сейчас позволяет использовать синтаксис кастомных медиазапросов из черновика спецификации "[Media Queries Level 5](https://drafts.csswg.org/mediaqueries-5/#custom-mq)", преобразуя их в синтаксис с числовыми значением, который поддерживается браузерами.
Кроме базового описания на [основной странице](https://github.com/postcss/postcss-custom-media) плагина, в [отдельном документе](https://github.com/postcss/postcss-custom-media/blob/HEAD/INSTALL.md#gulp) присутствуют примеры его использования как с помощью интрументов Gulp, Webpack и других, так и в самом NodeJS.
Выдержка из спецификации
------------------------
При создании документов, в которых применяются медиазапросы, нередко одни и те же выражения многократно указываются в разных местах. Например, для задания нескольких операторов `@import`. Повторение медиазапросов может быть рискованным. Если понадобится изменить контрольную точку, разработчику придётся изменять значения во всех встречающихся случаях. Если же изменение нужно было внести не везде, то потом придётся ещё и мучиться, отлавливая возникшие ошибки.
Чтобы избежать этого, в данной спецификации описаны методы определения [кастомных медиазапросов](https://drafts.csswg.org/mediaqueries-5/#custom-media-query), которые являются упрощёнными псевдонимами более длинных и сложных обычных медиазапросов. Таким образом, медиазапрос, используемый в нескольких местах, может быть заменён одним кастомным, который будет переиспользован столько раз, сколько понадобится. А если понадобится изменить его значение, это нужно будет сделать только в одном месте.
Пример
------
Чтоб увидеть, как именно работает плагин, давайте рассмотрим простенький пример его использования. Я буду использовать Gulp.
**Объявление**
Как показано на странице плагина, первым делом объявим кастомный медиазапрос. Это будет размер экрана, на котором будет применяться альтернативное CSS-правило.
```
@custom-media --desktop (min-width: 900px);
```
1. Объявление кастомного медиазапроса начинается с инструкции `@ custom-media` и является некоторой альтернативой ключевому слову `var` в языке JavaScript, создающем переменную
2. На втором месте помещается название кастомного медиазапроса `--desktop`, которое, как и CSS-переменные, начинается с двух дефисов
3. На последнем месте размещается непосредственно условие, являющееся в данном случае контрольной точкой ширины экрана
**Использование в стилях**
После создания переменной, её можно подставлять в медиазапрос вместо условия
```
body {
background-color: gray;
}
@media (--desktop) {
body {
min-block-size: 100vh;
background-color: red;
}
}
```
**Конфигурация Gulp**
Лично у меня приведённый в документации код настроек `gulpfile.js` не сработал, поэтому я его немного изменил
```
const gulp = require("gulp")
const postcss = require("gulp-postcss");
const postcssCustomMedia = require("postcss-custom-media");
const rename = require("gulp-rename");
gulp.task("css", function() {
return gulp.src("./src/style.css")
.pipe(postcss([
postcssCustomMedia()
]))
.pipe(rename("style.css"))
.pipe(gulp.dest("."))
});
```
**Результат**
После обработки мы получаем привычно оформленные стили
```
body {
background-color: gray;
}
@media (min-width: 900px) {
body {
min-block-size: 100vh;
background-color: red;
}
}
```
Заключение
----------
Очень рад, что последняя преграда для перехода на чистый CSS преодолена. Хотя я и не зарекаюсь, что со временем могу снова вернуться или хотя бы периодически прибегать к работе с препроцессорами.
Желаю всем приятной разработки. | https://habr.com/ru/post/579054/ | null | ru | null |
# Распознавание объектов в режиме реального времени на iOS с помощью YOLOv3

Всем привет!
В данной статье мы напишем небольшую программу для решения задачи детектирования и распознавания объектов (object detection) в режиме реального времени. Программа будет написана на языке программирования Swift под платформу iOS. Для детектирования объектов будем использовать свёрточную нейронную сеть с архитектурой под названием YOLOv3. В статье мы научимся работать в iOS с нейронными сетями с помощью фреймворка CoreML, немного разберемся, что из себя представляет сеть YOLOv3 и как использовать и обрабатывать выходы данной сети. Так же проверим работу программы и сравним несколько вариаций YOLOv3: YOLOv3-tiny и YOLOv3-416.
Исходники будут доступны в конце статьи, поэтому все желающие смогут протестировать работу нейронной сети у себя на устройстве.
Object detection
----------------
Для начала, вкратце разберемся, что из себя представляет задача детектирования объектов (object detection) на изображении и какие инструменты применяются для этого на сегодняшний день. Я понимаю, что многие довольно хорошо знакомы с этой темой, но я, все равно, позволю себе немного об этом рассказать.
Сейчас очень много задач в области компьютерного зрения решаются с помощью свёрточных нейронных сетей (Convolutional Neural Networks), в дальнейшем CNN. Благодаря своему строению они хорошо извлекают признаки из изображения. CNN используются в задачах классификации, распознавания, сегментации и еще во множестве других.
Популярные архитектуры CNN для распознавания объектов:
* **R-CNN.** Можно сказать первая модель для решения данной задачи. Работает как обычный классификатор изображений. На вход сети подаются разные регионы изображения и для них делается предсказания. Очень медленная так как прогоняет одно изображение несколько тысяч раз.
* **Fast R-CNN.** Улучшенная и более быстрая версия R-CNN, работает по похожему принципу, но сначала все изображение подается на вход CNN, потом из полученного внутреннего представления генерируются регионы. Но по прежнему довольно медленная для задач реального времени.
* **Faster R-CNN.** Главное отличие от предыдущих в том, что вместо selective search алгоритма для выбора регионов использует нейронную сеть для их «заучивания».
* **YOLO.** Совсем другой принцип работы по сравнению с предыдущими, не использует регионы вообще. Наиболее быстрая. Более подробно о ней пойдет речь в статье.
* **SSD.** По принципу похожа на YOLO, но в качестве сети для извлечения признаков использует VGG16. Тоже довольная быстрая и пригодная для работы в реальном времени.
* **Feature Pyramid Networks (FPN).** Еще одна разновидность сети типа Single Shot Detector, из за особенности извлечения признаков лучше чем SSD распознает мелкие объекты.
* **RetinaNet.** Использует комбинацию FPN+ResNet и благодаря специальной функции ошибки (focal loss) дает более высокую точность (аccuracy).
В данной статье мы будем использовать архитектуру YOLO, а именно её последнюю модификацию YOLOv3.
Почему YOLO?
------------

YOLO или You Only Look Once — это очень популярная на текущий момент архитектура CNN, которая используется для распознавания множественных объектов на изображении. Более полную информацию о ней можно получить на [официальном сайте](https://pjreddie.com/darknet/yolo/), там же можно найти публикации в которых подробно описана теория и математическая составляющая этой сети, а так же расписан процесс её обучения.
Главная особенность этой архитектуры по сравнению с другими состоит в том, что большинство систем применяют CNN несколько раз к разным регионам изображения, в YOLO CNN применяется один раз ко всему изображению сразу. Сеть делит изображение на своеобразную сетку и предсказывает bounding boxes и вероятности того, что там есть искомый объект для каждого участка.
Плюсы данного подхода состоит в том, что сеть смотрит на все изображение сразу и учитывает контекст при детектировании и распознавании объекта. Так же YOLO в 1000 раз быстрее чем R-CNN и около 100x быстрее чем Fast R-CNN. В данной статье мы будем запускать сеть на мобильном устройстве для онлайн обработки, поэтому это для нас это самое главное качество.
Более подробную информацию по сравнению архитектур можно посмотреть [тут](https://pjreddie.com/media/files/papers/YOLOv3.pdf).
#### YOLOv3
YOLOv3 — это усовершенствованная версия архитектуры YOLO. Она состоит из 106-ти свёрточных слоев и лучше детектирует небольшие объекты по сравнению с её предшествиницей YOLOv2. Основная особенность YOLOv3 состоит в том, что на выходе есть три слоя каждый из которых расчитан на обнаружения объектов разного размера.
На картинке ниже приведено её схематическое устройство:
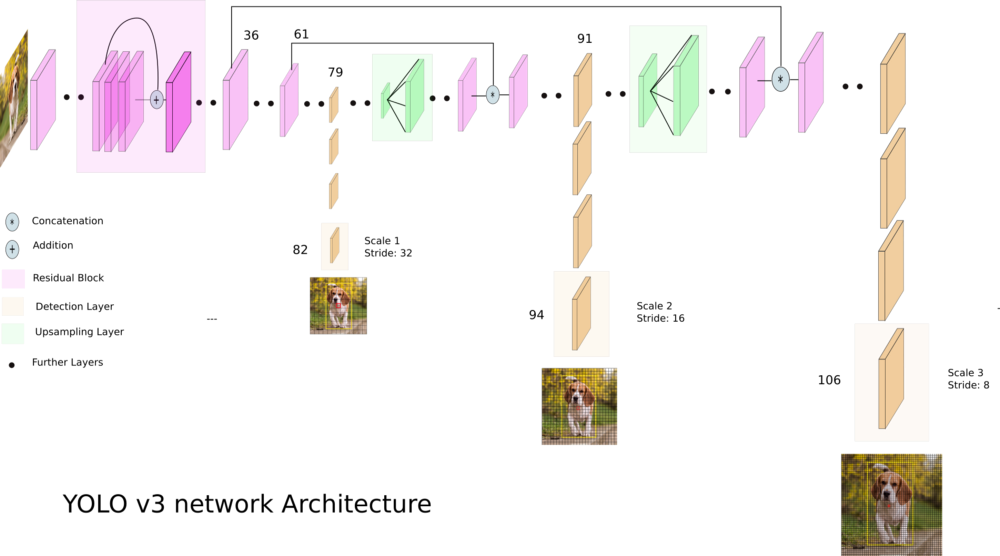
**YOLOv3-tiny** — обрезанная версия архитектуры YOLOv3, состоит из меньшего количества слоев (выходных слоя всего 2). Она более хуже предсказывает мелкие объекты и предназначена для небольших датасетов. Но, из-за урезанного строения, веса сети занимают небольшой объем памяти (~35 Мб) и она выдает более высокий FPS. Поэтому такая архитектура предпочтительней для использования на мобильном устройстве.
Пишем программу для распознавания объектов
------------------------------------------
Начинается самая интересная часть!
Давайте создадим приложение, которое будет распознавать различные объекты на изображении в реальном времени используя камеру телефона. Весь код будем писать языке программирования Swift 4.2 и запускать на iOS устройстве.
В данном туториале мы возьмём уже готовую сеть с весами предобученными на [COCO](https://cocodataset.org/) датасете. В нем представлено 80 различных классов. Следовательно наша нейронка будет способна распознать 80 различных объектов.
#### Из Darknet в CoreML
Оригинальная архитектура YOLOv3 реализована с помощью фремворка [Darknet](https://github.com/pjreddie/darknet).
На iOS, начиная с версии 11.0, есть замечательная библиотека [CoreML](https://developer.apple.com/documentation/coreml), которая позволяет запускать модели машинного обучения прямо на устройстве. Но есть одно ограничение: **программу можно будет запустить только на устройстве под управлением iOS 11 и выше.**
Проблема в том, что CoreML понимает только определённый формат модели *.coreml*. Для большинства популярных библиотек, таких как Tensorflow, Keras или XGBoost, есть возможность напрямую конвертировать в формат CoreML. Но для Darknet такой возможности нет. Для того, что бы преобразовать сохраненную и обученную модель из Darknet в CoreML можно использовать различные варианты, например сохранить Darknet в [ONNX](https://onnx.ai/), а потом уже из ONNX преобразовать в CoreML.
Мы воспользуемся более простым способом и будем использовать Keras имплементацию YOLOv3. Алгоритм действия такой: загрузим веса Darknet в Keras модель, сохраним её в формате Keras и уже из этого напрямую преобразуем в CoreML.
1. **Скачиваем Darknet.** Загрузим файлы обученной модели Darknet-YOLOv3 [отсюда](https://pjreddie.com/darknet/yolo/). В данной статье я буду использовать две архитектуры: YOLOv3-416 и YOLOv3-tiny. Нам понадобится оба файла cfg и weights.
2. **Из Darknet в Keras.** Сначала склонируем [репозиторий](https://github.com/qqwweee/keras-yolo3), переходим в папку репо и запускаем команду:
```
python convert.py yolov3.cfg yolov3.weights yolo.h5
```
где yolov3.cfg и yolov3.weights скачанные файлы Darknet. В итоге у нас должен появиться файл с расширением *.h5* — это и есть сохраненная модель YOLOv3 в формате Keras.
3. **Из Keras в CoreML.** Остался последний шаг. Для того, что бы сконвертировать модель в CoreML нужно запустить скрипт на python (предварительно надо установить библиотеку coremltools для питона):
```
import coremltools
coreml_model = coremltools.converters.keras.convert(
'yolo.h5',
input_names='image',
image_input_names='image',
input_name_shape_dict={'image': [None, 416, 416, 3]}, # размер входного изображения для сети
image_scale=1/255.)
coreml_model.input_description['image'] = 'Input image'
coreml_model.save('yolo.mlmodel')
```
Шаги которые описаны выше надо проделать для двух моделей YOLOv3-416 и YOLOv3-tiny.
Когда мы все это сделали у нас есть два файла: yolo.mlmodel и yolo-tiny.mlmodel. Теперь можно приступать к написанию кода самого приложения.
#### Создание iOS приложения
Полностью весь код приложения я описывать не буду, его можно посмотреть в репозитории ссылка на который будет приведена в конце статьи. Скажу лишь что у нас есть три UIViewController-a: OnlineViewController, PhotoViewController и SettingsViewController. В первом идет вывод камеры и онлайн детектирование объектов для каждого кадра. Во втором можно сделать фото или выбрать снимок из галереи и протестировать сеть на этих изображениях. В третьем находятся настройки, можно выбрать модель YOLOv3-416 или YOLOv3-tiny, а так же подобрать пороги IoU (intersection over union) и object confidence (вероятность того, что на текущем участке изображения есть объект).
**Загрузка модели в CoreML**
После того как мы преобразовали обученную модель из Darknet формата в CoreML, у нас есть файл с расширением *.mlmodel*. В моем случае я создал два файла: *yolo.mlmodel* и *yolo-tiny.mlmodel*, для моделей YOLOv3-416 и YOLOv3-tiny соответсвенно. Теперь можно подгружать эти файлы в проект в Xcode.
Создаем класс ModelProvider в нем будет хранится текущая модель и методы для асинхронного вызова нейронной сети на исполнение. Загрузка модели осуществляется таким образом:
```
private func loadModel(type: YOLOType) {
do {
self.model = try YOLO(type: type)
} catch {
assertionFailure("error creating model")
}
}
```
Класс YOLO отвечает непосредственно за загрузку *.mlmodel* файлов и обработку выходов модели. Загрузка файлов модели:
```
var url: URL? = nil
self.type = type
switch type {
case .v3_Tiny:
url = Bundle.main.url(forResource: "yolo-tiny", withExtension:"mlmodelc")
self.anchors = tiny_anchors
case .v3_416:
url = Bundle.main.url(forResource: "yolo", withExtension:"mlmodelc")
self.anchors = anchors_416
}
guard let modelURL = url else {
throw YOLOError.modelFileNotFound
}
do {
model = try MLModel(contentsOf: modelURL)
} catch let error {
print(error)
throw YOLOError.modelCreationError
}
```
**Полный код ModelProvider.**
```
import UIKit
import CoreML
protocol ModelProviderDelegate: class {
func show(predictions: [YOLO.Prediction]?,
stat: ModelProvider.Statistics,
error: YOLOError?)
}
@available(macOS 10.13, iOS 11.0, tvOS 11.0, watchOS 4.0, *)
class ModelProvider {
struct Statistics {
var timeForFrame: Float
var fps: Float
}
static let shared = ModelProvider(modelType: Settings.shared.modelType)
var model: YOLO!
weak var delegate: ModelProviderDelegate?
var predicted = 0
var timeOfFirstFrameInSecond = CACurrentMediaTime()
init(modelType type: YOLOType) {
loadModel(type: type)
}
func reloadModel(type: YOLOType) {
loadModel(type: type)
}
private func loadModel(type: YOLOType) {
do {
self.model = try YOLO(type: type)
} catch {
assertionFailure("error creating model")
}
}
func predict(frame: UIImage) {
DispatchQueue.global().async {
do {
let startTime = CACurrentMediaTime()
let predictions = try self.model.predict(frame: frame)
let elapsed = CACurrentMediaTime() - startTime
self.showResultOnMain(predictions: predictions, elapsed: Float(elapsed), error: nil)
} catch let error as YOLOError {
self.showResultOnMain(predictions: nil, elapsed: -1, error: error)
} catch {
self.showResultOnMain(predictions: nil, elapsed: -1, error: YOLOError.unknownError)
}
}
}
private func showResultOnMain(predictions: [YOLO.Prediction]?,
elapsed: Float, error: YOLOError?) {
if let delegate = self.delegate {
DispatchQueue.main.async {
let fps = self.measureFPS()
delegate.show(predictions: predictions,
stat: ModelProvider.Statistics(timeForFrame: elapsed,
fps: fps),
error: error)
}
}
}
private func measureFPS() -> Float {
predicted += 1
let elapsed = CACurrentMediaTime() - timeOfFirstFrameInSecond
let currentFPSDelivered = Double(predicted) / elapsed
if elapsed > 1 {
predicted = 0
timeOfFirstFrameInSecond = CACurrentMediaTime()
}
return Float(currentFPSDelivered)
}
}
```
**Обработка выходов нейронной сети**
Теперь разберемся как обрабатывать выходы нейронной сети и получаться соответсвующие bounding box-ы. В Xcode если выбрать файл модели то можно увидеть, что они из себя представляет и увидеть выходные слои.
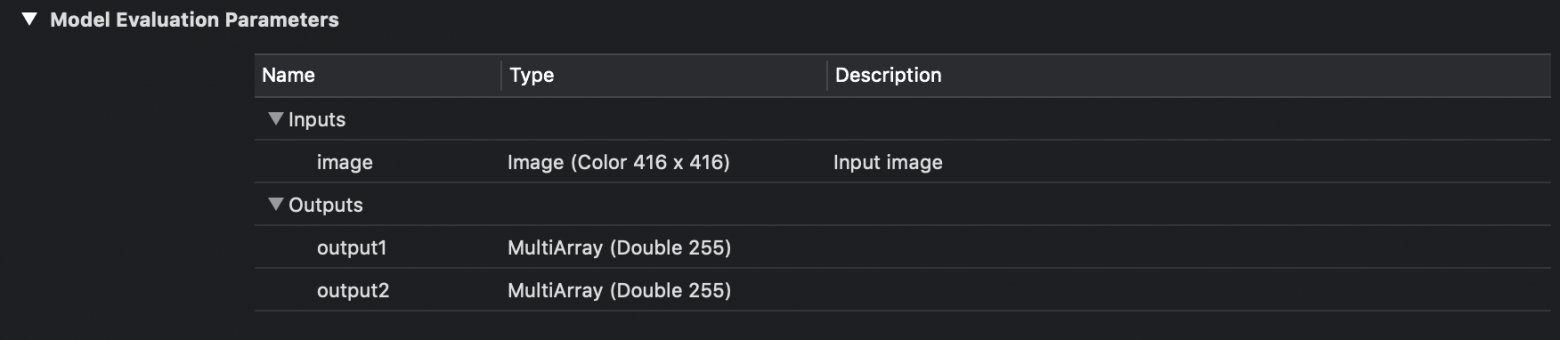
*Вход и выход YOLOv3-tiny.*

*Вход и выход YOLOv3-416.*
Как можно видеть на изображении выше у нас есть три для YOLOv3-416 и два для YOLOv3-tiny выходных слоя в каждом из которых предсказываются bounding box-ы для различных объектов.
В данном случае это обычный массив чисел, давайте же разберемся как его парсить.
Модель YOLOv3 в качестве выхода использует три слоя для разбиения изображения на различную сетку, размеры ячеек этих сеток имеют такие значения: 8, 16 и 32. Допустим на входе у нас есть изображение размером 416x416 пикселей, тогда выходные матрицы (сетки) будут иметь размер 52x52, 26x26 и 13x13 (416/8 = 52, 416/16 = 26 и 416/32 = 13). В случае с YOLOv3-tiny все тоже самое только вместо трех сеток имеем две: 16 и 32, то есть матрицы размерностью 26x26 и 13x13.
После запуска загруженно CoreML модели на выходе мы получим два (или три) объекта класса MLMultiArray. И если посмотреть свойство shape у этих объектов, то увидим такую картину (для YOLOv3-tiny):![$[1, 1, 255, 26, 26]\\ [1, 1, 255, 13, 13]$](https://habrastorage.org/getpro/habr/formulas/488/7dd/83e/4887dd83eca6084e10147790f4367aed.svg)
Как и ожидалось размерность матриц будет 26x26 и 13x13.Но что обозначат число 255? Как уже говорилось ранее, выходные слои это матрицы размерностью 52x52, 26x26 и 13x13. Дело в том, что каждый элемент данной матрицы это не число, это вектор. То есть выходной слой это трех-мерная матрица. Этот вектор имеет размерность B x (5 + C), где B — количество bounding box в ячейке, C — количество классов. Откуда число 5? Причина такая: для каждого box-a предсказывается вероятность что там есть объект (object confidence) — это одно число, а оставшиеся четыре — это x, y, width и height для предсказанного box-a. На рисунке ниже показано схематичное представление этого вектора:

*Cхематичное представление выходного слоя (feature map).*
Для нашей сети обученной на 80-ти классах, для каждой ячейки сетки разбиения предсказывается 3 bounding box-a, для каждого из них — 80 вероятностей классов + object confidence + 4 числа отвечающие за положение и размер этого box-a. Итого: 3 x (5 + 80) = 255.
Для получения этих значений из класса MLMultiArray лучше воспользоваться сырым указателем на массив данных и адресной арифметикой:
```
let pointer = UnsafeMutablePointer(OpaquePointer(out.dataPointer)) // получение сырого указателя
if out.strides.count < 3 {
throw YOLOError.strideOutOfBounds
}
let channelStride = out.strides[out.strides.count-3].intValue
let yStride = out.strides[out.strides.count-2].intValue
let xStride = out.strides[out.strides.count-1].intValue
func offset(ch: Int, x: Int, y: Int) -> Int { // функция доступа по оффсетам
return ch \* channelStride + y \* yStride + x \* xStride
}
```
Теперь необходимо обработать вектор из 255 элементов. Для каждого box-a нужно получить распределение вероятностей для 80 классов, сделать это можно сделать с помощью функции softmax.
**Что такое softmax**Функция преобразует вектор  размерности K в вектор той же размерности, где каждая координата  полученного вектора представлена вещественным числом в интервале [0,1] и сумма координат равна 1.
где K — размерность вектора.
Функция softmax на Swift:
```
private func softmax(_ x: inout [Float]) {
let len = vDSP_Length(x.count)
var count = Int32(x.count)
vvexpf(&x, x, &count)
var sum: Float = 0
vDSP_sve(x, 1, ∑, len)
vDSP_vsdiv(x, 1, ∑, &x, 1, len)
}
```
Для получения координат и размеров bounding box-a нужно воспользоваться формулами:
где  — предсказанные x, y координаты, ширина и высота соответственно,  — функция сигмоиды, а  — значения якорей(anchors) для трех box-ов. Эти значения определяются во время тренировки и заданы в файле Helpers.swift:
```
let anchors1: [Float] = [116,90, 156,198, 373,326] //якоря для первого выходного слоя
let anchors2: [Float] = [30,61, 62,45, 59,119] //якоря для второго выходного слоя
let anchors3: [Float] = [10,13, 16,30, 33,23] //якоря для третьего выходного слоя
```
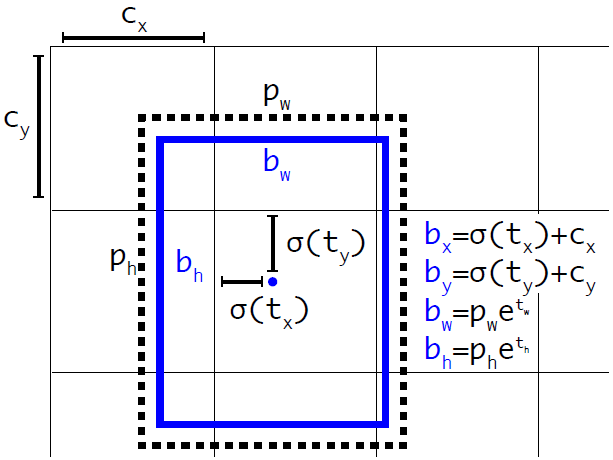
*Схематическое изображение расчета положения bounding box-а.*
**Полный код обработки выходных слоев.**
```
private func process(output out: MLMultiArray, name: String) throws -> [Prediction] {
var predictions = [Prediction]()
let grid = out.shape[out.shape.count-1].intValue
let gridSize = YOLO.inputSize / Float(grid)
let classesCount = labels.count
print(out.shape)
let pointer = UnsafeMutablePointer(OpaquePointer(out.dataPointer))
if out.strides.count < 3 {
throw YOLOError.strideOutOfBounds
}
let channelStride = out.strides[out.strides.count-3].intValue
let yStride = out.strides[out.strides.count-2].intValue
let xStride = out.strides[out.strides.count-1].intValue
func offset(ch: Int, x: Int, y: Int) -> Int {
return ch \* channelStride + y \* yStride + x \* xStride
}
for x in 0 ..< grid {
for y in 0 ..< grid {
for box\_i in 0 ..< YOLO.boxesPerCell {
let boxOffset = box\_i \* (classesCount + 5)
let bbx = Float(pointer[offset(ch: boxOffset, x: x, y: y)])
let bby = Float(pointer[offset(ch: boxOffset + 1, x: x, y: y)])
let bbw = Float(pointer[offset(ch: boxOffset + 2, x: x, y: y)])
let bbh = Float(pointer[offset(ch: boxOffset + 3, x: x, y: y)])
let confidence = sigmoid(Float(pointer[offset(ch: boxOffset + 4, x: x, y: y)]))
if confidence < confidenceThreshold {
continue
}
let x\_pos = (sigmoid(bbx) + Float(x)) \* gridSize
let y\_pos = (sigmoid(bby) + Float(y)) \* gridSize
let width = exp(bbw) \* self.anchors[name]![2 \* box\_i]
let height = exp(bbh) \* self.anchors[name]![2 \* box\_i + 1]
for c in 0 ..< 80 {
classes[c] = Float(pointer[offset(ch: boxOffset + 5 + c, x: x, y: y)])
}
softmax(&classes)
let (detectedClass, bestClassScore) = argmax(classes)
let confidenceInClass = bestClassScore \* confidence
if confidenceInClass < confidenceThreshold {
continue
}
predictions.append(Prediction(classIndex: detectedClass,
score: confidenceInClass,
rect: CGRect(x: CGFloat(x\_pos - width / 2),
y: CGFloat(y\_pos - height / 2),
width: CGFloat(width),
height: CGFloat(height))))
}
}
}
return predictions
}
```
**Non max suppression**
После того как получили координаты и размеры bounding box-ов и соответсвующие вероятности для всех найденных объектов на изображении можно начинать отрисовывать их поверх картинки. Но есть одна проблема! Может Возникнуть такая ситуация когда для одного объекта предсказано несколько box-ов c достаточно высокими вероятностями. Как быть в таком случае? Тут нам на помощь приходит довольно простой алгоритм под названием Non maximum suppression.
Порядок действия алгоритма такой:
1. Ищем bounding box с наибольшей вероятностью принадлежности к объекту.
2. Пробегаем по всем bounding box-ам которые тоже относятся к этому объекту.
3. Удаляем их если Intersection over Union (IoU) с первым bounding box-ом больше заданного порога.
IoU считается по простой формуле:
**Расчет IoU.**
```
static func IOU(a: CGRect, b: CGRect) -> Float {
let areaA = a.width * a.height
if areaA <= 0 { return 0 }
let areaB = b.width * b.height
if areaB <= 0 { return 0 }
let intersection = a.intersection(b)
let intersectionArea = intersection.width * intersection.height
return Float(intersectionArea / (areaA + areaB - intersectionArea))
}
```
**Non max suppression.**
```
private func nonMaxSuppression(boxes: inout [Prediction], threshold: Float) {
var i = 0
while i < boxes.count {
var j = i + 1
while j < boxes.count {
let iou = YOLO.IOU(a: boxes[i].rect, b: boxes[j].rect)
if iou > threshold {
if boxes[i].score > boxes[j].score {
if boxes[i].classIndex == boxes[j].classIndex {
boxes.remove(at: j)
} else {
j += 1
}
} else {
if boxes[i].classIndex == boxes[j].classIndex {
boxes.remove(at: i)
j = i + 1
} else {
j += 1
}
}
} else {
j += 1
}
}
i += 1
}
}
```
После этого работу непосредственно с результатами предсказания нейронной сети можно считать законченной. Далее необходимо написать функции и классы для получение видеоряда с камеры, вывода изображения на экран и отрисовки предсказанных bounding box-ов. Весь этот код в данной статье описывать не буду, но его можно будет посмотреть в репозитории.
Еще стоит упомянуть, что я добавил небольшое сглаживание bounding box-ов при обработки онлайн изображения, в данном случае это обычное усреднение положения и размера предсказанного квадрата за последние 30 кадров.
#### Тестирование работы программы
Теперь протестируем работу приложения.
Еще раз напомню: В приложении есть три ViewController-а, один для обработки фотографий или снимков, второй для обработки онлайн видео потока, третий для настройки работы сети.
Начнем с третьего. В нем можно выбрать одну из двух моделей YOLOv3-tiny или YOLOv3-416, подобрать confidence threshold и IoU threshold, так же можно включить или выключить онлайн сглаживание.

Теперь посмотрим как работает обученная нейронка с реальными изображениями, для этого возьмем фотографию из галереи и пропустим её через сеть. Ниже на картинке представлены результаты работы YOLOv3-tiny с разными настройками.

*Разные режимы работы YOLOv3-tiny. На левой картинке обычный режим работы. На средней — порог IoU = 1 т.е. как будто отсутствует Non-max suppression. На правой — низкий порог object confidence, т.е. отображаются все возможные bounding box-ы.*
Далее приведен результат работы YOLOv3-416. Можно заметить, что по сравнению с YOLOv3-tiny полученные рамки более правильные, а так же распознаны более мелкие объекты на изображении, что соответствует работе третьего выходного слоя.

*Изображение обработанное с помощью YOLOv3-416.*
При включении онлайн режима работы обрабатывался каждый кадр и для него делалось предсказание, **тесты проводились на iPhone XS** поэтому результат получился довольно приемлемый для обоих вариантов сети. **YOLOv3-tiny в среднем выдает 30 — 32 fps, YOLOv3-416 — от 23 до 25 fps.** Устройство на котором проходило тестирование довольно производительное, поэтому на более ранних моделях результаты могут отличатся, в таком случае конечно предпочтительнее использовать YOLOv3-tiny. Еще один важный момент: yolo-tiny.mlmodel (YOLOv3-tiny) занимает около 35 Мб, в свою очередь yolo.mlmodel (YOLOv3-416) весит около 250 Мб, что очень существенная разница.
Заключение
----------
В итоге было написано iOS приложение которое с помощью нейронной сети может распознавать объекты на изображении. Мы увидели как работать с библиотекой CoreML и как с её помощью исполнять различные, заранее обученные, модели (кстати обучать с её помощью тоже можно). Задача распознавания объекта решалась с помощью YOLOv3 сети. На iPhone XS данная сеть (YOLOv3-tiny) способна обрабатывать изображения с частотой ~30 кадров в секунду, что вполне достаточно для работы в реальном времени.
Полный код приложения можно посмотреть на [GitHub](https://github.com/moonl1ght/iOS-ObjectDetection). | https://habr.com/ru/post/460869/ | null | ru | null |
# Функции XPath для динамических XPath в Selenium
> **Будущих студентов курса** [**"Java QA Automation Engineer"**](https://otus.pw/NISP/) **и всех интересующихся приглашаем посмотреть** [**подарочное демо-занятие**](https://otus.pw/9x9f/) **в формате открытого вебинара.
>
> А также делимся переводом полезной статьи.**
>
>

---
В данной статье рассматриваются примеры использования функций XPath для идентификации элементов.
Автоматизация взаимодействия с любым сайтом начинается с корректной идентификации объекта, над которым будет выполняться какая-либо операция. Как нам известно, легче всего идентифицировать элемент по таким атрибутам, как ID, Name, Link, Class, или любому другому уникальному атрибуту, доступному в теге, в котором находится элемент.
Но правильно идентифицировать объект можно только в том случае, если такие атрибуты присутствуют и (или) являются уникальными.
**=>**[**Руководство по Selenium для новичков см. здесь**](https://www.softwaretestinghelp.com/selenium-tutorial-1/)
**Чему вы научитесь:**[[показать](https://www.softwaretestinghelp.com/xpath-functions/)]
### Обзор функций XPath
Обсудим сценарий, при котором атрибуты недоступны напрямую.
#### Постановка задачи
Как идентифицировать элемент, если такие локаторы, как ID, Name, Class и Link, недоступны в теге элемента?
Суть проблемы демонстрирует следующий пример:
Авторизация в[**Twitter**](https://twitter.com/login)
Как видно из скриншота выше, заголовок «Log in to Twitter» не имеет дополнительных атрибутов. Поэтому мы не можем использовать ни один из локаторов, таких как `ID`, `Class`, `Link` или `Name`, для идентификации этого элемента.
**Плагин Firepath для Firefox сгенерировал следующий путь XPath:**
> //*[@id=’page-container’]/div/div[1]/h1*
>
>
*Мы бы не рекомендовали использовать указанный выше путь XPath, поскольку структура страницы или id могут меняться динамически. Если все же использовать этот нестабильный XPath, вероятно, потребуется чаще его обновлять, что подразумевает лишнюю трату времени на поддержку. Это один из случаев, когда мы не можем использовать общее выражение XPath с такими локаторами, как ID, Class, Link или Name.*
***Решение***
#### Идентификация элемента с помощью функций XPath по тексту
Поскольку у нас есть видимый текст «Log in to Twitter», мы могли бы использовать следующие функции `XPath` для идентификации уникального элемента.
1. *contains() [по тексту]*
2. *starts-with() [по тексту]*
3. *text()*
Функции `XPath`, такие как `contains()`, `starts-with()` и `text()`, при использовании с текстом «Log in to Twitter» помогут нам корректно идентифицировать элемент, после чего мы сможем произвести над ним дальнейшие операции.
#### 1. Метод Contains()
**Синтаксис.** Чтобы найти на веб-странице элемент «Log in to Twitter», воспользуйтесь одним из следующих выражений XPath на основе метода `contains()`.
**Поиск по тексту:**
* `//h1[contains(text(),’ Log in to’)]`
* `//h1[contains(text(),’ in to Twitter’)]`
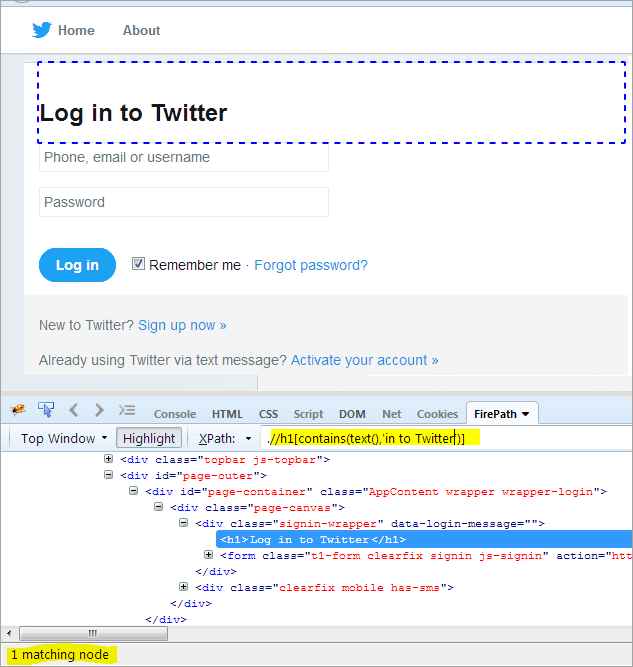
> Примечание. Наличие одного совпадающего узла свидетельствует об успешной идентификации веб-элемента.
>
>
Из примера выше видно, что методу `contains()` не требуется весь текст для правильной идентификации элемента. Достаточно даже части текста, но эта часть текста должна быть уникальной. Используя метод `contains()`, пользователь может легко идентифицировать элемент, даже после смены ориентации страницы.
Обратите внимание, что при указании всего текста «Log in to Twitter» с методом `contains()` элемент будет также идентифицирован корректно.
#### 2. Метод starts-with()
**Синтаксис.** Чтобы найти на веб-странице элемент «Log in to Twitter», используйте следующие выражения XPath на основе метода starts-with().
**Поиск по тексту:**
* `//h1[starts-with(text(),’Log in’)]`
* `//h1[starts-with(text(),’Log in to’)]`
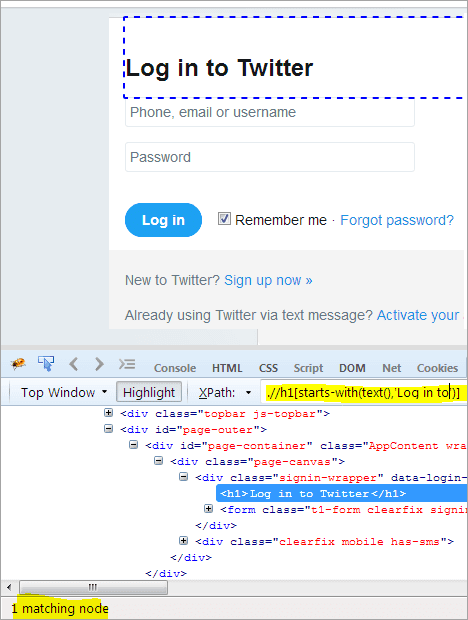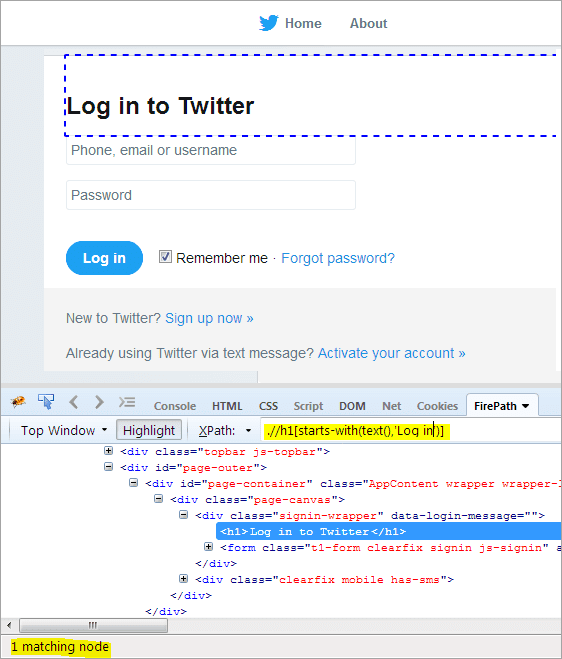Из приведенного выше примера видно, что XPath-функции `starts-with()` требуется по крайней мере первое слово («Log») видимого текста для однозначной идентификации элемента. Функция работает даже с неполным текстом, но он должен как минимум включать первое слово частично видимого текста.
Обратите внимание, что при использовании всего текста «Log in to Twitter» с методом `starts-with()` элемент будет также идентифицирован корректно.
**Недействительный XPath для** `starts-with()`**:** `//h1[starts-with(text(),’in to Twitter’)]`

> Примечание.Отсутствие совпадающих узлов свидетельствует о том, что элемент на веб-странице не был идентифицирован.
>
>
#### 3. Метод text()
**Синтаксис.** Чтобы найти на веб-странице элемент «Log in to Twitter», воспользуйтесь следующим выражением `XPath` на основе метода `text()`.
В этом выражении мы указываем весь текст, содержащийся между открывающим тегом и закрывающим тегом . Если использовать функцию `text()` с частью текста, как в случае с методами `contains()` и `starts-with()`, то мы не сможем найти данный элемент.
**Недействительное выражение Xpath для** `text()`**:**
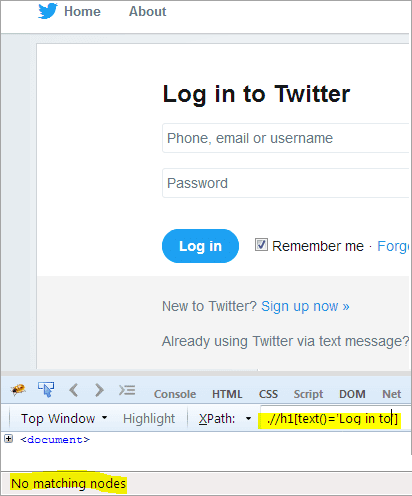#### Идентификация элемента с помощью функций XPath по атрибуту
Мы используем функции `XPath` (`contains` или `starts-with`) с атрибутом в тех случаях, когда в теге содержатся уникальные значения атрибутов. Доступ к атрибутам производится с помощью символа «`@`».
Для лучшего понимания рассмотрим следующий пример:
**Авторизация в**[**Google**](https://www.google.com/)
#### 1. Метод Contains()
**Синтаксис.** Чтобы точно идентифицировать кнопку «I’m Feeling Lucky» («Мне повезет») с помощью XPath-функции `contains()`, можно указать следующие атрибуты.
**Вариант А — поиск по значению атрибута** `Value`
* `//input[contains(@value,’Feeling’)]`
* `//input[contains(@value,’Lucky’)]`
На скриншотах выше видно, что поиск по атрибуту `Value` слов «Feeling» или «Lucky» с помощью функции `contains()` позволяет однозначно идентифицировать данный элемент. Стоит отметить, что, даже если мы используем полное содержимое атрибута `Value`, мы сможем корректно идентифицировать элемент.
**Вариант Б — поиск по содержимому атрибута** `Name`
`//input[contains(@name=’btnI’)]`
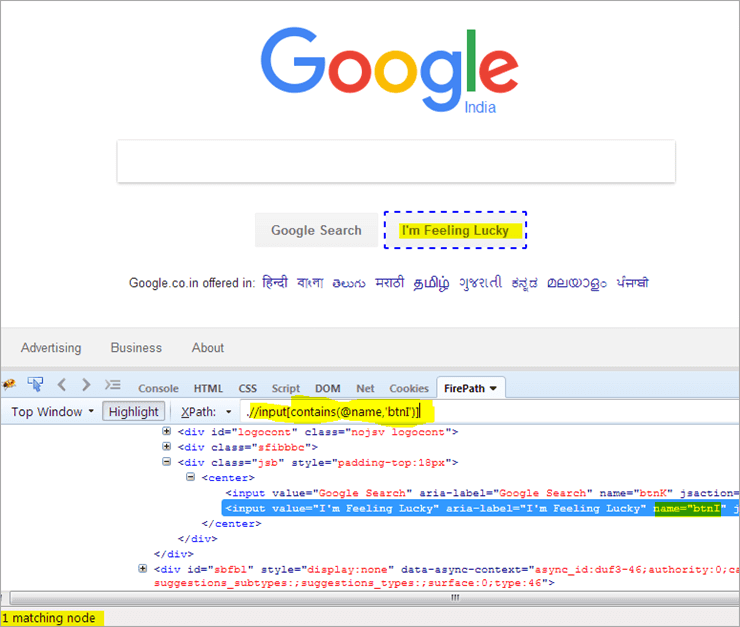**Неправильное использование функции XPath с атрибутом:**
Нужно быть крайне внимательным при выборе атрибута для поиска с помощью методов `contains()` и `starts-with()`. Если значение атрибута не уникальное, мы не сможем однозначно идентифицировать элемент.
Если мы воспользуемся атрибутом `type` при идентификации кнопки «I'm Feeling Lucky», то XPath не сработает.
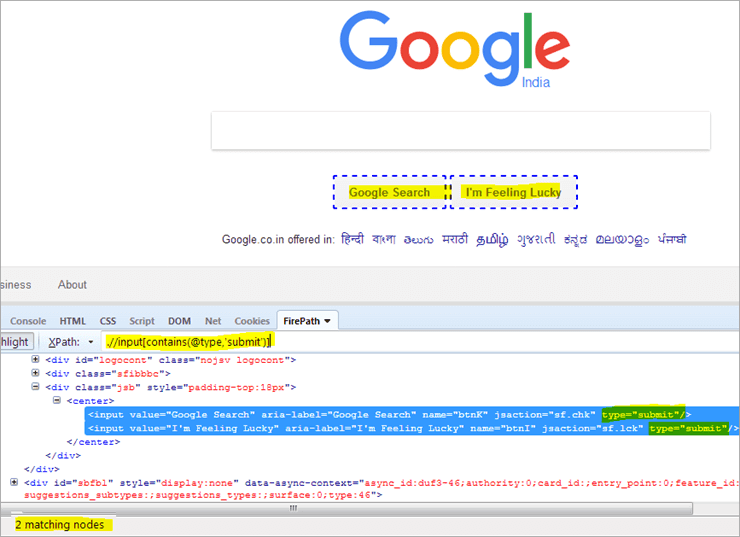Наличие двух совпадающих узлов свидетельствует о том, что нам не удалось корректно идентифицировать элемент. В данном случае значение атрибута `type` не является уникальным.
#### 2. Метод starts-with()
Метод `starts-with()` в сочетании с атрибутом может пригодиться для поиска элементов, у которых начало атрибута постоянное, а окончание изменяется. Такой метод позволяет работать с объектами, динамически изменяющими значения своих атрибутов. Его также можно использовать для поиска однотипных элементов.
Перейдите на страницу авторизации [**Facebook**](https://www.facebook.com/).
Изучите первое текстовое поле First Name (Имя) и второе текстовое поле Surname (Фамилия) формы авторизации.
Первое текстовое поле First Name идентифицировано.
Второе текстовое поле Surname идентифицировано.
В случае обоих текстовых полей, из которых состоит форма авторизации Facebook, первая часть атрибута `id` всегда остается неизменной.
**First Name id="u*0*2"**
**Surname id="u*0*4"**
Это тот случай, когда мы можем использовать атрибут вместе с функцией `starts-with()`, чтобы получить все элементы такого типа с атрибутом `id`. Обратите внимание, что мы рассматриваем эти два поля только для примера. На экране может быть больше полей с `id`, которые начинаются с «u*0*».
**Starts-with() [по атрибуту id]**
`//input[starts-with(@id,"u0")]`
> Важное примечание. Здесь мы использовали двойные кавычки вместо одинарных. Но одиночные кавычки тоже будут работать с методом `starts-with`.
>
>
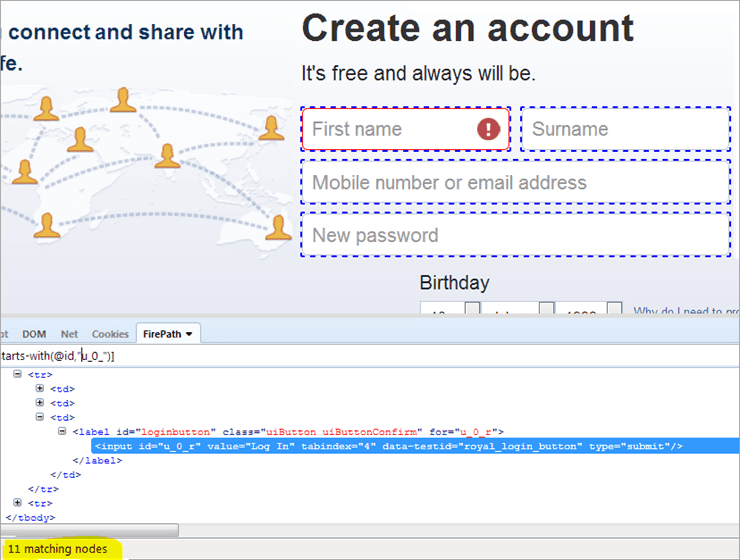11 найденных узлов указывают на то, что данное выражение XPath позволило идентифицировать все элементы, `id` которых начинается с «u*0*». Вторая часть `id` («2» для имени, «4» для фамилии и т. д.) позволяет однозначно идентифицировать элемент.
Мы можем использовать атрибут с функцией `starts-with` там, где нам нужно собрать элементы похожего типа в список и динамически выбрать один из них, передавая аргумент в обобщенный метод, чтобы однозначно идентифицировать элемент.
На примере ниже показано использование функции `starts-with`.
*Пример кода*
| |
| --- |
| / **Generic Method** */**public void xpathLoc(String identifier){**//The below step identifies the element “First Name” uniquely when the argument is “2”**WebElement E1=d1.findElement(By.xpath("//input[starts-with(@id,”u0”+identifier )]"));**E1.sendKeys(“Test1”); /* This step enters the value of First Name as “Test 1” */**}**/* **Main Method**\*/ public static void main(String[] args) { xpathLoc(“2”); --- This step calls the xpathLoc() method to identify the first name. } |
> Примечание. Eclipse может не допускать использование двойных кавычек. Возможно, вам придется прибегнуть к другому коду, чтобы сформировать динамический XPath.
>
>
Приведенный код является лишь примером. Вы можете усовершенствовать его, чтобы он работал со всеми элементами, выполняемыми операциями и вводимыми значениями (в случае текстовых полей), сделав код более универсальным.
### Заключение
В этой статье мы рассмотрели, как можно использовать функции XPath `contains()`, `starts-with()` и `text()` с атрибутом и текстом для однозначной идентификации элементов в структуре HTML DOM.
#### Ниже приведены некоторые замечания касательно функций XPath:
1. Используйте метод `contains()` в XPath, если известна часть постоянно видимого текста или атрибута.
2. Используйте метод `starts-with()` в XPath, если известна первая часть постоянно видимого текста или атрибута.
3. Вы также можете использовать методы `contains()` и `starts-with()` со всем текстом или полным атрибутом.
4. Используйте метод `text()` в XPath, если вам известен весь видимый текст.
5. Нельзя использовать метод `text()` с частичным текстом.
6. Нельзя использовать метод `starts-with()`, если начальный текст не используется в XPath или если начальный текст постоянно изменяется.
В следующем уроке мы узнаем, как использовать оси XPath с функциями XPath для более точного определения расположения элементов на веб-странице.
---
> Все знают как написать хороший тест, а может быть даже несколько. Но вот что делать, когда этих тестов у вас больше 100 или возможно даже несколько тысяч?
>
> **Об этом расскажем на открытом вебинаре.** [**Регистрируйтесь**](https://otus.pw/9x9f/) **Узнать подробнее о курсе "Java QA Automation Engineer" можно** [**здесь.**](https://otus.pw/NISP/)
>
>
[**ЗАБРАТЬ СКИДКУ**](https://otus.pw/EipQ/) | https://habr.com/ru/post/533354/ | null | ru | null |
# Планетарный ландшафт
Трудно поспорить, что ландшафт — неотъемлемая часть большинства компьютерных игр на открытых пространствах. Традиционный метод реализации изменения рельефа окружающей игрока поверхности следующий — берем сетку (Mesh), представляющую из себя плоскость и для каждого примитива в этой сетке производим смещение по нормали к этой плоскости на значение, конкретное для данного примитива. Говоря простыми словами, у нас есть одноканальная текстура размером 256 на 256 пикселей и сетка плоскости. Для каждого примитива по его координатам на плоскости берем значение из текстуры. Теперь просто смещаем по нормали к плоскости координаты примитива на полученное значение(рис.1)
*Рис.1 карта высот + плоскость = ландшафт*
Почему это работает? Если представить, что игрок находится на поверхности сферы, и радиус этой сферы чрезвычайно велик по отношению к размеру игрока, то искривлением поверхности можно пренебречь и использовать плоскость. Но что если не пренебрегать тем фактом, что мы находимся на сфере? Своим опытом построения такого рода ландшафтов я хочу поделиться с читателем в данной статье.
### 1. Сектор
Очевидно, что не разумно строить ландшафт сразу для всей сферы — большую ее часть не будет видно. Поэтому нам нужно создать некую минимальную область пространства — некий примитив, из которых будет состоять рельеф видимой части сферы. Я назову его сектор. Как же нам его получить? Итак, посмотрите на рис.2a. Зеленая ячейка — это наш сектор. Далее построим шесть сеток, каждая из которых является гранью куба (рис.2b). Теперь давайте нормализуем координаты примитивов, которые формируют сетки (рис.2с).
*Рис.2*
В итоге мы получили спроецированный на сферу куб, где сектором является область на одной из его граней. Почему это работает? Рассмотрим произвольную точку на сетке как вектор от начала координат. Что есть нормализация вектора? Это преобразование заданного вектора в вектор в том же направлении, но с единичной длиной. Процесс следующий: сперва найдем длину вектора в евклидовой метрике согласно теореме Пифагора

Затем поделим каждый из компонентов вектора на это значение

Теперь спросим себя, что такое сфера? Сфера — это множество точек, равноудаленных от заданной точки. Параметрическое уравнение сферы выглядит так

где x0, y0, z0 — координаты центра сферы, а R — ее радиус. В нашем случае центр сферы — это начало координат, а радиус равен единице. Подставляем известные значения и берем корень от двух частей уравнения. Получается следующее
Буквально последнее преобразование говорит нам следующее: «Для того, чтобы принадлежать сфере, длина вектора должна быть равна единице». Этого мы и добились нормализацией.
А что если сфера имеет произвольный центр и радиус? Найти точку, которая ей принадлежит, можно с помощью следующего уравнения
где pS — точка на сфере, C — центр сферы, pNorm — ранее нормализованный вектор и R — радиус сферы. Говоря простыми словами, здесь происходит следующее — «мы перемещаемся от центра сферы по направлению к точке на сетке на расстояние R». Так как каждый вектор имеет единичную длину, то в итоге все точки равноудалены от центра сферы на расстояние ее радиуса, что делает истинным уравнение сферы.
### 2. Управление
Нам нужно получить группу секторов, которые потенциально видны из точки обзора. Но как это сделать? Предположим, что у нас есть сфера с центром в некоторой точке. Также у нас есть сектор, который расположен на сфере и точка P, расположенная в пространстве около сферы. Теперь построим два вектора — один направлен от центра сферы до центра сектора, другой — от центра сферы до точки обзора. Посмотрите на рис.3 — сектор может быть виден только если абсолютное значение угла между этими векторами меньше 90 градусов.

*Рис.3 a — угол меньше 90 — сектор потенциально виден. b — угол болше 90 — сектор не виден*
Как получить этот угол? Для этого нужно использовать скалярное произведение векторов. Для трехмерного случая оно вычисляется так:

Скалярное произведение обладает дистрибутивным свойством:

Ранее мы определили уравнение длины вектора — теперь мы можем сказать, что длина вектора равна корню от скалярного произведения этого вектора самого на себя. Или наоборот — скалярное произведения вектора самого на себя равно квадрату его длины.
Теперь давайте обратимся к закону косинусов. Одна из двух его формулировок выглядит так(рис.4):

*Рис.4 закон косинусов*
Если взять за a и b длины наших векторов, тогда угол alfa — то, что мы ищем. Но как нам получить значение с? Смотрите: если мы отнимем a от b, то получим вектор, направленный от a к b, а так как вектор характеризуется лишь направлением и длиной, то мы можем графически расположить его начало в конце вектора a. Исходя из этого, мы можем сказать, что с равен длине вектора b — a. Итак, у нас получилось

выразим квадраты длин как скалярные произведения

раскроем скобки, пользуясь дистрибутивным свойством

немного сократим
и наконец, поделив обе чести уравнения на минус два, получим
Это еще одно свойство скалярного произведения. В нашем случае надо нормализовать векторы, чтобы их длины были равны единице. Угол нам вычислять не обязательно — достаточно значения косинуса. Если оно меньше нуля — то можно смело утверждать, что этот сектор нас не интересует
### 3. Сетка
Пора задуматься о том, как рисовать примитивы. Как я говорил ранее, сектор является основным компонентом в нашей схеме, поэтому для каждого потенциально видимого сектора мы будем рисовать сетку, примитивы которой будут формировать ландшафт. Каждую из ее ячеек можно отобразить с помощью двух треугольников. Из-за того, что каждая ячейка имеет смежные грани, значения большинства вершин треугольников повторяются для двух или более ячеек. Чтобы не дублировать данные в буфере вершин, заполним буфер индексов. Если индексы используются, то с их помощью графический конвейер определяет, какой примитив в буфере вершин ему обрабатывать. (рис.5) Выбранная мной топология — triangle list (D3D11\_PRIMITIVE\_TOPOLOGY\_TRIANGLELIST)

*Рис.5 Визуальное отображение индексов и примитивов*
Создавать для каждого сектора отдельный буфер вершин слишком накладно. Гораздо эффективнее использовать один буфер с координатами в пространстве сетки, то есть x — столбец, а у — строка. Но как из них получить точку на сфере? Сектор представляет из себя квадратную область с началом в некой точке S. Все секторы имеют одинаковую длину грани — назовем ее SLen. Сетка покрывает всю площадь сектора а также имеет одинаковое количество строк и столбцов, поэтому для нахождение длины грани ячейки мы можем построить следующее уравнение

где СLen — длина грани ячейки, MSize — количество строк или столбцов сетки. Делим обе части на MSize и получаем CLen

Идем далее. Пространство грани куба, которой принадлежит сектор, можно выразить как линейную комбинацию двух векторов единичной длины — назовем их V1 и V2. У нас выходит следующее уравнение(см. рис.6)


*Рис.6 Наглядное отображение формирования точки на сетке*
чтобы получить точку на сфере, воспользуемся уравнением, выведенным ранее
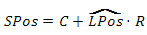
### 4. Высота
Все, чего мы добились к этому моменту, мало напоминает ландшафт. Пришло время добавить то, что сделает его таковым — разность высот. Давайте представим, что у нас есть сфера единичного радиуса с центром в начале координат, а также множество точек {P0, P1, P2… PN}, которые расположены на этой сфере. Каждую из этих точек можно представить как единичный вектор от начала координат. Теперь представьте, что у нас есть набор значений, каждое из которых является длиной конкретного вектора (рис.7).

Хранить эти значения я буду в двухмерной текстуре. Нам нужно найти связь между координатами пикселя текстуры и вектором-точкой на сфере. Приступим.
Помимо декартовой, точка на сфере также может быть описана с помощью сферической системы координат. В этом случае ее координаты будут состоять из трех элементов: азимутного угла, полярного угла и значения кратчайшего расстояния от начала координат до точки. Азимутный угол — это угол между осью X и проекцией луча от начала координат до точки на плоскость XZ. Он может принимать значения от нуля до 360 градусов. Полярный угол — угол между осью Y и лучом от начала координат до точки. Он также может называться зенитным или нормальным. Принимает значения от нуля до 180 градусов. (см. рис.8)

*Рис.8 Сферические координаты*
Для перехода из декартовой системы в сферическую я пользуюсь следующими уравнениями(я полагаю, что ось Y направлена вверх):
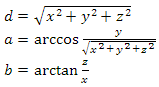
где d — расстояние до точки, a — полярный угол, b — азимутный угол. Параметр d также можно описать как «длина вектора от начала координат до точки»(что видно из уравнения). Если мы используем нормализованные координаты, то можем избежать деления при нахождении полярного угла. Собственно, зачем нам эти углы? Разделив каждый из них на его максимальный диапазон, мы получим коэффициенты от нуля до единицы и с их помощью произведем выборку из текстуры в шейдере. При получении коэффициента для полярного угла необходимо учитывать четверть, в которой расположен угол. «Но ведь значение выражения z / x не определено при x равном нулю» — скажете вы. Я более того скажу — при z равном нулю угол будет нулевым независимо от значения x.
Давайте добавим несколько специальных случаев для этих значений. У нас есть нормализованные координаты(нормаль) — добавим несколько условий: если значение X нормали равно нулю и значение Z больше нуля — тогда коэффициент равен 0.25, если X нулевое и Z меньше нуля — то будет 0.75. Если же значение Z равно нулю и X меньше нуля, то в этом случае коэффициент будет равен 0.5. Все это легко проверить на окружности. Но как поступить, если Z нулевое и X больше нуля — ведь в таком случае будут корректными как 0 так и 1? Представим, что мы выбрали 1 — чтож, давайте возьмем сектор с минимальным азимутным углом 0 и максимальным — 90 градусов. Теперь рассмотрим первые три вершины в первой строке сетки, которая этот сектор отображает. Для первой вершины у нас выполнилось условие и мы установили для текстурной координаты X значение 1. Очевидно, что для последующих двух вершин это условие не выполнится — углы для них находятся в первой четверти и в результате мы получим примерно такой набор — (1.0, 0.05, 0.1). Но для сектора с углами от 270 до 360 для последних трех вершин в той же строке все будет корректно — сработает условие для последней вершины, и мы получим набор (0.9, 0.95, 1.0). Если же мы выберем в качестве результата ноль, то получим наборы (0.0, 0.05, 0.1) и (0.9, 0.95, 0.0) — в любом случае это приведет к довольно заметным искажениям поверхности. Поэтому давайте применим следующее. Возьмем центр сектора, затем нормализуем его центр, переместив тем самым на сферу. Теперь вычислим скалярное произведение нормализованного центра на вектор (0, 0, 1). Формально говоря, этот вектор является нормалью к плоскости XY, и вычислив его скалярное произведение с нормализованным вектором центра сектора, мы сможем понять, с какой стороны от плоскости центр находится. Если оно меньше нуля, то сектор находится позади плоскости и нам нужно значение 1. Если скалярное произведение больше нуля, то сектор находится спереди от плоскости и поэтому граничным значением будет 0.(см. рис.9)

*Рис.9 Проблема выбора между 0 и 1 для текстурных координат*
Вот код получения текстурных координат из сферических. Обратите внимание — из-за погрешности в вычислениях мы не можем проверять значения нормали на равенство нулю, вместо этого мы должны сравнивать их абсолютные величины с неким пороговым значением (например 0.001)
```
//norm - нормализованные координаты точки, для которой мы получаем текстурные координаты
//offset - нормализованные координаты центра сектора, которому принадлежит norm
//zeroTreshold - пороговое значение (0.001)
float2 GetTexCoords(float3 norm, float3 offset)
{
float tX = 0.0f, tY = 0.0f;
bool normXIsZero = abs(norm.x) < zeroTreshold;
bool normZIsZero = abs(norm.z) < zeroTreshold;
if(normXIsZero || normZIsZero){
if(normXIsZero && norm.z > 0.0f)
tX = 0.25f;
else if(norm.x < 0.0f && normZIsZero)
tX = 0.5f;
else if(normXIsZero && norm.z < 0.0f)
tX = 0.75f;
else if(norm.x > 0.0f && normZIsZero){
if(dot(float3(0.0f, 0.0f, 1.0f), offset) < 0.0f)
tX = 1.0f;
else
tX = 0.0f;
}
}else{
tX = atan(norm.z / norm.x);
if(norm.x < 0.0f && norm.z > 0.0f)
tX += 3.141592;
else if(norm.x < 0.0f && norm.z < 0.0f)
tX += 3.141592;
else if(norm.x > 0.0f && norm.z < 0.0f)
tX = 3.141592 * 2.0f + tX;
tX = tX / (3.141592 * 2.0f);
}
tY = acos(norm.y) / 3.141592;
return float2(tX, tY);
}
```
приведу промежуточный вариант вершинного шейдера
```
//startPos - начало грани куба
//vec1, vec2 - векторы направления грани куба
//gridStep - размер ячейки
//sideSize - длина ребра сектора
//GetTexCoords() - преобразует сферические координаты в текстурные
VOut ProcessVertex(VIn input)
{
float3 planePos = startPos + vec1 * input.netPos.x * gridStep.x
+ vec2 * input.netPos.y * gridStep.y;
float3 sphPos = normalize(planePos);
float3 normOffset = normalize(startPos + (vec1 + vec2) * sideSize * 0.5f);
float2 tc = GetTexCoords(sphPos, normOffset);
float height = mainHeightTex.SampleLevel(mainHeightTexSampler, tc, 0).x;
posL = sphPos * (sphereRadius + height);
VOut output;
output.posH = mul(float4(posL, 1.0f), worldViewProj);
output.texCoords = tc;
return output;
}
```
### 5. Освещение
Чтобы реализовать зависимость цвета ландшафта от освещения, воспользуемся следующим уравнением:

Где I — цвет точки, Ld — цвет источника света, Kd — цвет материала освещаемой поверхности, a — угол между вектором на источник и нормалью к освещаемой поверхности. Это частный случай закона косинусов Ламберта. Давайте разберемся, что здесь и почему. Под умножением Ld на Kd подразумевается покомпонентное умножение цветов, то есть (Ld.r \* Kd.r, Ld.g \* Kd.g, Ld.b \* Kd.b). Возможно будет проще понять смысл, если представить следующую ситуацию: допустим, мы хотим осветить объект зеленым источником света, поэтому мы ожидаем, что цвет объекта будет в градациях зеленого. Результат (0 \* Kd.r, 1 \* Kd.g, 0 \* Kd.b) дает (0, Kd.g, 0) — ровно то, что нам нужно. Идем далее. Как было озвучено ранее, косинусом угла между нормализованными векорами является их скалярное произведение. Давайте рассмотрим его максимальное и минимальное значение с нашей точки зрения. Если косинус угла между векторами равен 1, то этот угол равен 0 — следовательно, оба вектора коллинеарны (лежат на одной прямой).
То же самое справедливо и для значения косинуса -1, только в этом случае векторы указывают в противоположных направлениях. Получается, чем ближе вектор нормали и вектор к источнику света к состоянию коллинеарности — тем выше коэффициент освещенности поверхности, которой принадлежит нормаль. Также предполагается, что поверхность не может быть освещена, если ее нормаль указывает в противоположную по отношению к направлению на источник сторону — именно поэтому я использую только положительные значения косинуса.
Я использую параллельный источник, поэтому его позицией можно пренебречь. Единственное, что нужно учесть -то, что мы используем вектор на источник света. То есть, если направление лучей (1.0, -1.0, 0) — нам надо использовать вектор (-1.0, 1.0, 0). Единственное, что для нас представляет трудность — вектор нормали. Вычислить нормаль к плоскости просто — нам надо произвести векторное произведение двух векторов, которые ее описывают. Важно помнить что векторное произведение антикоммутативно — нужно учитывать порядок множителей. В нашем случае получить нормаль к треугольнику, зная координаты его вершин в пространстве сетки, можно следующим образом (Обратите внимание, что я не учитываю граничные случаи для p.x и p.y)
```
float3 p1 = GetPosOnSphere(p);
float3 p2 = GetPosOnSphere(float2(p.x + 1, p.y));
float3 p3 = GetPosOnSphere(float2(p.x, p.y + 1));
float3 v1 = p2 - p1;
float3 v2 = p3 - p1;
float3 n = normalzie(cross(v1, v2));
```
Но это еще не все. Большинство вершин сетки принадлежат сразу четырем плоскостям. Чтобы получить приемлемый результат, надо вычислить усредненную нормаль следующим образом:
```
Na = normalize(n0 + n1 + n2 + n3)
```
Реализовывать данный метод на GPU довольно затратно — нам потребуется два этапа на вычисление нормалей и их усреднение. К тому же эффективность оставляет желать лучшего. Исходя из этого я выбрал другой способ — использовать карту нормалей.(рис.10)

*Рис.10 Карта нормалей*
Принцип работы с ней такой же, как и с картой высот — преобразуем сферические координаты вершины сетки в текстурные и делаем выборку. Только вот напрямую эти данные мы использовать не сможем — ведь мы работаем со сферой, и у вершины есть своя нормаль, которую нужно учитывать. Поэтому данные карты нормалей мы будем использовать в качестве координат TBN базиса. Что такое базис? Вот вам такой пример. Представьте, что вы космонавт и сидите на маячке где-то в космосе. Вам из ЦУПа приходит сообщение: «Тебе нужно переместиться от маячка на 1 метр влево, на 2 метра вверх и на 3 метра вперед». Как это можно выразить математически? (1, 0, 0) \* 1 + (0, 1, 0) \* 2 + (0, 0, 1) \* 3 = (1,2,3). В матричной форме данное уравнение можно выразить так:

Теперь представьте, что вы также сидите на маячке, только теперь вам из ЦУПа пишут: «мы там тебе векторы направлений прислали — ты должен продвинуться 1 метра по первому вектору, 2 метра по второму и 3 — по третьему». Уравнение для новых координат будет таким:

покомпонентная запись выглядит так:

Или в матричной форме:

так вот, матрица с векторами V1, V2 и V3 — это базис, а вектор (1,2,3) — координаты в пространстве этого базиса.
Представим теперь, что у вас есть набор векторов (базис M) и вы знаете, где вы находитесь относительно маячка (точка P). Вам нужно узнать ваши координаты в пространстве этого базиса — на сколько вам нужно продвинуться по этим векторам, чтобы оказаться в том же месте. Представим искомые координаты (X)

Будь P, M и X числами, мы бы просто разделили обе части уравнения на M, но увы… Пойдем другим путем — согласно свойству обратной матрицы
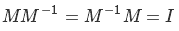
где I это единичная матрица. В нашем случае она выглядит так

Что это нам дает? Попробуйте умножить это матрицу на X и вы получите
Также надо уточнить, что умножение матриц обладает свойством ассоциативности
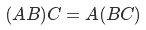
Вектор мы вполне законно можем рассматривать как матрицу 3 на 1
Учитывая все вышесказанное, можно слелать вывод, что чтобы получить Х в правой части уравнения, нам нужно в правильном порядке умножить обе части на обратную M матрицу

Этот результат понадобится нам в дальнейшем.
Теперь вернемся к нашей проблеме. Я буду использовать ортонормированный базис — это значит, что V1, V2 и V3 ортогональны по отношению друг к другу(образуют угол 90 градусов) и имеют единичную длину. В качестве V1 будет выступать tangent вектор, V2 — bitangent вектор, V3 — нормаль. В традиционном для DirectX транспонированном виде матрица выглядит так:

где T — tangent вектор, B — bitangent вектор и N — нормаль. Давайте найдем их. С нормалью проще всего-по сути это нормализованные координаты точки. Bitangent вектор равен векторному произведению нормали и tangent вектора. Сложнее всего придется с tangent вектором. Он равен направлению касательной к окружности в точке. Давайте разберем этот момент. Сперва найдем координаты точки на единичной окружности в плоскости XZ для некоторого угла a

Направление касательной к окружности в этой точке можно найти двумя способами. Вектор до точки на окружности и вектор касательной ортогональны — поэтому, так как функции sin и cos периодические — мы можем просто прибавить pi/2 к углу a и получим искомое направление. Согласно свойству смещения на pi/2:

у нас получился следующий вектор:
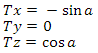
Мы также можем воспользоваться дифференцированием — подробнее см. в Приложении 3. Итак, на рисунке 11 вы можете видеть сферу, для каждой вершины которой построен базис. Синими векторами обозначены нормали, красными — tangent векторы, зелеными — bitangent векторы.

*Рис.11 Сфера с TBN базисами в каждой вершине. Красные — tangent векторы, зеленые — bitangent векторы, синие векторы — нормали*
С базисом разобрались — теперь давайте получим карту нормалей. Для этого воспользуемся фильтром Собеля. Фильтр Собеля вычисляет градиент яркости изображения в каждой точке(грубо говоря, вектор изменения яркости). Принцип действия фильтра заключается в том, что нужно применить некую матрицу значений, которая назвается «Ядром», к каждому пикселю и его соседям в пределах размерности этой матрицы. Предположим, что мы обрабатываем пиксель P ядром K. Если он не находится на границе изображения, то у него есть восемь соседей — левый верхний, верхний, правый верхний и так далее. Назовем их tl, t, tb, l, r, bl, b, br. Так вот, применение ядра K к этому пикселю заключается в следующем:
Pn = tl \* K(0, 0) + t \* K(0,1) + tb \* K(0,2) +
 l \* K(1, 0) + P \* K(1,1) + r \* K(1,2) +
 bl \* K(2, 0) + b \* K(2,1) + br \* K(2,2)
Этот процесс называется «Свертка». Фильтр Собеля использует два ядра для вычисления градиента по вертикали и горизонтали. Обозначим их как Kx и Kу:

Основа есть — можно приступать к реализации. Сперва нам надо вычислить яркость пикселя. Я пользуюсь преобразованием из цветовой модели RGB в модель YUV для системы PAL:
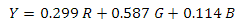
Но так как наше изображение изначально в градациях серого, то этот этап можно пропустить. Теперь нам нужно «свернуть» исходное изображение с ядрами Kx и Ky. Так мы получим компоненты X и Y градиента. Также очень полезным может оказаться значение нормали этого вектора — его мы использовать не будем, но у избражений, содержащих нормализованные значения нормали градиента, есть несколько полезных применений. Под нормализацией я имею ввиду следующее уравнение

где V — значение, которое нормализуем, Vmin и Vmax — область этих значений. В нашем случае минимальное и максимальное значения отслеживаются в процессе генерации. Вот пример реализации фильтра Собеля:
```
float SobelFilter::GetGrayscaleData(const Point2 &Coords)
{
Point2 coords;
coords.x = Math::Saturate(Coords.x, RangeI(0, image.size.width - 1));
coords.y = Math::Saturate(Coords.y, RangeI(0, image.size.height - 1));
int32_t offset = (coords.y * image.size.width + coords.x) * image.pixelSize;
const uint8_t *pixel = &image.pixels[offset];
return (image.pixelFormat == PXL_FMT_R8) ? pixel[0] : (0.30f * pixel[0] + //R
0.59f * pixel[1] + //G
0.11f * pixel[2]); //B
}
void SobelFilter::Process()
{
RangeF dirXVr, dirYVr, magNormVr;
for(int32_t y = 0; y < image.size.height; y++)
for(int32_t x = 0; x < image.size.width; x++){
float tl = GetGrayscaleData({x - 1, y - 1});
float t = GetGrayscaleData({x , y - 1});
float tr = GetGrayscaleData({x + 1, y - 1});
float l = GetGrayscaleData({x - 1, y });
float r = GetGrayscaleData({x + 1, y });
float bl = GetGrayscaleData({x - 1, y + 1});
float b = GetGrayscaleData({x , y + 1});
float br = GetGrayscaleData({x + 1, y + 1});
float dirX = -1.0f * tl + 0.0f + 1.0f * tr +
-2.0f * l + 0.0f + 2.0f * r +
-1.0f * bl + 0.0f + 1.0f * br;
float dirY = -1.0f * tl + -2.0f * t + -1.0f * tr +
0.0f + 0.0f + 0.0f +
1.0f * bl + 2.0f * b + 1.0f * br;
float magNorm = sqrtf(dirX * dirX + dirY * dirY);
int32_t ind = y * image.size.width + x;
dirXData[ind] = dirX;
dirYData[ind] = dirY;
magNData[ind] = magNorm;
dirXVr.Update(dirX);
dirYVr.Update(dirY);
magNormVr.Update(magNorm);
}
if(normaliseDirections){
for(float &dirX : dirXData)
dirX = (dirX - dirXVr.minVal) / (dirXVr.maxVal - dirXVr.minVal);
for(float &dirY : dirYData)
dirY = (dirY - dirYVr.minVal) / (dirYVr.maxVal - dirYVr.minVal);
}
for(float &magNorm : magNData)
magNorm = (magNorm - magNormVr.minVal) / (magNormVr.maxVal - magNormVr.minVal);
}
```
Надо сказать, что фильтр Собеля обладает свойством линейной сепарабельности, поэтому данный метод может быть оптимизирован.
Сложная часть закончилась — осталось записать X и Y координаты направления градиента в R и G каналы пикселей карты нормалей.Для координаты Z я использую еденицу. Также я использую трехмерный вектор коэффициентов для настройки этих значений. Далее приведен пример генерации карты нормалей с комментариями:
```
//ImageProcessing::ImageData Image - оригинальное изображение. Структора содержит формат пикселя и данные изображения
ImageProcessing::SobelFilter sobelFilter;
sobelFilter.Init(Image);
sobelFilter.NormaliseDirections() = false;
sobelFilter.Process();
const auto &resX =sobelFilter.GetFilteredData(ImageProcessing::SobelFilter::SOBEL_DIR_X);
const auto &resY =sobelFilter.GetFilteredData(ImageProcessing::SobelFilter::SOBEL_DIR_Y);
ImageProcessing::ImageData destImage = {DXGI_FORMAT_R8G8B8A8_UNORM, Image.size};
size_t dstImageSize = Image.size.width * Image.size.height * destImage.pixelSize;
std::vector dstImgPixels(dstImageSize);
for(int32\_t d = 0 ; d < resX.size(); d++){
//используем вектор настроечных коэффициентов. У меня он равен (0.03, 0.03, 1.0)
Vector3 norm = Vector3::Normalize({resX[d] \* NormalScalling.x,
resY[d] \* NormalScalling.y,
1.0f \* NormalScalling.z});
Point2 coords(d % Image.size.width, d / Image.size.width);
int32\_t offset = (coords.y \* Image.size.width + coords.x) \* destImage.pixelSize;
uint8\_t \*pixel = &dstImgPixels[offset];
//переводим значения из области [-1.0, 1.0] в [0.0, 1.0] а затем в область [0, 256]
pixel[0] = (0.5f + norm.x \* 0.5f) \* 255.999f;
pixel[1] = (0.5f + norm.y \* 0.5f) \* 255.999f;
pixel[2] = (0.5f + norm.z \* 0.5f) \* 255.999f;
}
destImage.pixels = &dstImgPixels[0];
SaveImage(destImage, OutFilePath);
```
Теперь приведу пример использования карты нормалей в шейдере:
```
//texCoords - текстурные коорлинаты которые мы получили способом, описанным в п.4
//normalL - нормаль вершины
//lightDir - вектор на источник света
//Ld - цвет источника света
//Kd - цвет материала освещаемой поверхности
float4 normColor = mainNormalTex.SampleLevel(mainNormalTexSampler, texCoords, 0);
//переводим значение из области [0.0, 1.0] в [-1.0, 1.0] и нормализуем результат
float3 normalT = normalize(2.0f * mainNormColor.rgb - 1.0f);
//переводим текстурную координату Х из области [0.0, 1.0] в [0.0, Pi*2.0]
float ang = texCoords.x * 3.141592f * 2.0f;
float3 tangent;
tangent.x = -sin(ang);
tangent.y = 0.0f;
tangent.z = cos(ang);
float3 bitangent = normalize(cross(normalL, tangent));
float3x3 tbn = float3x3(tangent, bitangent, normalL);
float3 resNormal = mul(normalT, tbn);
float diff = saturate(dot(resNormal, lightDir.xyz));
float4 resColor = Ld * Kd * diff;
```
### 6. Level Of Detail
Ну вот, теперь наш ландшафт освещен! Можно лететь на Луну — загураем карту высот, ставим цвет материала, загружаем секторы, устанавливаем размер сетки равным {16, 16} и… Да, что-то маловато — поставлю ка я {256, 256} — ой, что-то все тормозит, да и зачем высокая детализация на дальних секторах? К томуже, чем ближе наблюдатель к планете, тем меньше секторов он может увидеть. Да… походу у нас еще много работы! Давайте сперва разберемся, как отсечь лишние секторы. Определяющей величиной здесь будет высота наблюдателя от поверхности планеты — чем она выше, тем больше секторов он может увидеть (рис.12)

*Рис.12 Зависимость высоты наблюдателя от кол-ва обрабатываемых секторов*
Высоту находим следующим образом — строим вектор от позиции наблюдателя на центр сферы, вычисляем его длину и отнимаем от нее значение радиуса сферы. Ранее я говорил, что если скаларное произведение вектора на наблюдателя и вектора на центр сектора меньше нуля, то этот сектор нас не интересует — теперь вместо нуля мы мы будем использовать значение, линейно зависимое от высоты. Сперва давайте определимся с переменными — итак, у нас будут минимальное и максимальное значения скалярного произведения и минимальное и максимальное значение высоты. Построим следующую систему уравнений
Теперь выразим А во втором уравнении

подставим А из второго уравнения в первое
выразим B из первого уравнения
подставим B из первого уравнения во второе

Теперь подставим переменные в функцию

и получим
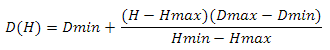
Где Hmin и Hmax-минимальное и максимальное значение высоты, Dmin и Dmax — минимальное и максимальное значения скалярного произведения. Эту задачу можно решить иначе — см. приложение 4.
Теперь нужно разобраться с уровнями детализации. Каждый из них будет определять область значения скалярного произведения. В псевдокоде процесс определения принадлежности сектора определенному уровню выглядит так:
```
цикл по всем секторам
вычисляем скалярное произведение вектора на наблюдателя и вектора на центр сектора
если скалярное произведение меньше минимального порога, вычисленного ранее
переходим к следующему сектору
цикл по уровням детализации
если скалярное произведение находится в рамках определенных для этого уровня
добавляем сектор к этому уровню
конец цикла по уровням детализации
конец цикла по всем секторам
```
Нам надо вычислить область значения для каждого уровня. Сначала построим систему из двух уравнений

решив ее, получим
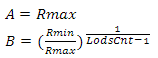
Используя эти коэффициенты, определим функцию

где Rmax это область значения скалярного произведения (D(H) — Dmin), Rmin — минимальная область, определяемая уровнем. Я использую значение 0.01. Теперь нам нужно отнять результат от Dmax

C помощью этой функции мы получим области для всех уровней. Вот пример:
```
const float dotArea = dotRange.maxVal - dotRange.minVal;
const float Rmax = dotArea, Rmin = 0.01f;
float lodsCnt = lods.size();
float A = Rmax;
float B = powf(Rmin / Rmax, 1.0f / (lodsCnt - 1.0f));
for(size_t g = 0; g < lods.size(); g++){
lods[g].dotRange.minVal = dotRange.maxVal - A * powf(B, g);
lods[g].dotRange.maxVal = dotRange.maxVal - A * powf(B, g + 1);
}
lods[lods.size() - 1].dotRange.maxVal = 1.0f;
```
Теперь мы можем определить, к какому уровню детализации принадлежит сектор (рис.13).

*Рис.13 Цветовая дифференциация секторов согласно уровням детализации*
Далее надо разобраться с размерами сеток. Хранить для каждого уровня свою сетку будет очень накладно — гораздо эффективнее менять детализацию одной сетки на лету с помощью тесселяции. Для этого нам надо помимо превычных вершинного и пиксельного, также реализовать hull и domain шейдеры. В Hull шейдере основная задача — подготовить контрольные точки. Он состоит из двух частей — основной функции и функции, вычисляющей параметры контрольной точки. Обязательно нужно указать значения для следующих атрибутов:
> domain
>
> partitioning
>
> outputtopology
>
> outputcontrolpoints
>
> patchconstantfunc
Вот пример Hull шейдера для разбиения треугольниками:
```
struct PatchData
{
float edges[3] : SV_TessFactor;
float inside : SV_InsideTessFactor;
};
PatchData GetPatchData(InputPatch Patch, uint PatchId : SV\_PrimitiveID)
{
PatchData output;
flloat tessFactor = 2.0f;
output.edges[0] = tessFactor;
output.edges[1] = tessFactor;
output.edges[2] = tessFactor;
output.inside = tessFactor;
return output;
}
[domain("tri")]
[partitioning("integer")]
[outputtopology("triangle\_cw")]
[outputcontrolpoints(3)]
[patchconstantfunc("GetPatchData")]
VIn ProcessHull(InputPatch Patch,
uint PointId : SV\_OutputControlPointID,
uint PatchId : SV\_PrimitiveID)
{
return Patch[PointId];
}
```
Видите, основная работа выполняется в GetPatchData(). Ее задача — установить фактор тесселяции. О нем мы поговорим позднее-сейчас перейдем к Domain шейдеру. Он получает контрольные точки от Hull шейдера и координаты от тесселятора. Новое значение позиции или текстурных координат в случае разбиения треугольниками нужно вычислять по следующей формуле
N = C1 \* F.x + C2 \* F.y + C3 \* F.z
где C1, C2 и C3 — значения контрольных точек, F — координаты тесселятора. Также в Domain шейдере нужно установить атрибут domain, значение которого соответствует тому, которое было указано в Hull шейдере. Вот пример Domain шейдера:
```
cbuffer buff0 : register(b0)
{
matrix worldViewProj;
}
struct PatchData
{
float edges[3] : SV_TessFactor;
float inside : SV_InsideTessFactor;
};
[domain("quad")]
PIn ProcessDomain(PatchData Patch,
float3 Coord : SV_DomainLocation,
const OutputPatch Tri)
{
float3 posL = Tri[0].posL \* Coord.x +
Tri[1].posL \* Coord.y +
Tri[2].posL \* Coord.z;
float2 texCoords = Tri[0].texCoords \* Coord.x +
Tri[1].texCoords \* Coord.y +
Tri[2].texCoords \* Coord.z;
PIn output;
output.posH = mul(float4(posL, 1.0f), worldViewProj);
output.normalW = Tri[0].normalW;
output.texCoords = texCoords;
return output;
}
```
Роль вершинного шейдера в этом случае сведена к минимуму — у меня он просто «прокидывает» данные на следующий этап.
Теперь нужно реализовать нечто подобное. Наша первостепенная задача — вычислить фактор тесселяции, а если точнее, то построить его зависимость от высоты наблюдателя. Снова построим систему уравнений

решив ее таким же способом, как и ранее, получим

где Tmin и Tmax — минимальный и максимальный коэффициенты тесселяции, Hmin и Hmax — минимальное и максимальное значения высоты наблюдателя. Минимальный коэффициент тесселяции у меня равен единице. максимальный устанавливается отдельно для каждого уровня
(например 1, 2, 4, 16).
В дальнейшем нам будет необходимо, чтобы рост фактора был ограничен ближайшей степенью двойки. то есть для значений от двух до трех мы устанавливаем значение два, для значений от 4 до 7 установим 4, при значениях от 8 до 15 фактор будет равен 8 и т.д. Давайте решим эту задачу для фактора 6. Сперва решим следующее уравнение

давайте возьмем десятичный логарифм от двух частей уравнения

согласно свойству логарифмов, мы можем переписать уравнение следующим образом

теперь нам остается разделить обе части на log(2)

Но это еще не все. Х равен приблизительно 2.58. Далее нужно сбросить дробную часть и возвести двойку в степень получившегося числа. Вот код вычисления факторов тесселяции для уровней детализации
```
float h = camera->GetHeight();
const RangeF &hR = heightRange;
for(LodsStorage::Lod &lod : lods){
//derived from system
//A + B * Hmax = Lmin
//A + B * Hmin = Lmax
//and getting A then substitution B in second equality
float mTf = (float)lod.GetMaxTessFactor();
float tessFactor = 1.0f + (mTf - 1.0f) * ((h - hR.maxVal) / (hR.minVal - hR.maxVal));
tessFactor = Math::Saturate(tessFactor, RangeF(1.0f, mTf));
float nearPowOfTwo = pow(2.0f, floor(log(tessFactor) / log(2)));
lod.SetTessFactor(nearPowOfTwo);
}
```
### 7. Шум
Давайте посмотрим, как можно увеличить детализацию ландшафта, не изменяя при этом размер карты высот. Мне на ум приходит следующее — изменять значение высоты на значение, полученное из текстуры градиентного шума. Координаты, по которым мы будем осуществлять выборку, будут в N раз больше основных. При выборке будет задействован зеркальный тип адресации (D3D11\_TEXTURE\_ADDRESS\_MIRROR) (см. рис.14).

*Рис.14 Сфера с картой высот + сфера с шумовой картой = сфера с итоговой высотой*
В этом случае высота будет вычисляться следующим образом:
```
//float2 tc1 - текстурные координаты, полученные из нормализованной точки, как было
//рассказано ранее
//texCoordsScale - множитель текстурных координат. В моем случае равен значению 300
//mainHeightTex, mainHeightTexSampler - текстура карты высот
//distHeightTex, distHeightTexSampler - текстура градиентного шума
//maxTerrainHeight - максимальная высота ландшафта. В моем случае 0.03
float2 tc2 = tc1 * texCoordsScale;
float4 mainHeighTexColor = mainHeightTex.SampleLevel(mainHeightTexSampler, tc1, 0);
float4 distHeighTexColor = distHeightTex.SampleLevel(distHeightTexSampler, tc2, 0);
float height = (mainHeighTexColor.x + distHeighTexColor.x) * maxTerrainHeight;
```
Пока что периодический характер выражается значительно, но с добавлением освещения и текстурирования ситуация изменится в лучшую сторону. А что такое из себя представляет текстура градиентного шума? Грубо говоря это решётка из случайных значений. Давайте разберемся, как сопоставить размеры решетки размеру текстуры. Предположим мы хотим создать шумовую текстуру размера 256 на 256 пикселей. Все просто, если размеры решетки совпадают с размерами текстуры — у нас получится что-то подобное белому шуму в телевизоре. А как быть, если наша решетка имеет размеры, скажем, 2 на 2? Ответ прост — использовать интерполяцию. Одна из формулировок линейной интерполяции выглядит так:

Это самый быстрый, но в тоже время наименее подходящий нам вариант. Лучше использовать интерполяцию на основе косинуса:
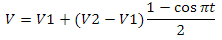
Но мы не можем просто интерполировать между значениями по краям диагонали (левым нижним и правым верхним углом ячейки). В нашем случае интерполяцию нужно будет применять дважды. Давайте предствим одну из ячеек решетки. У нее есть четыре угла — назовем их V1, V2, V3, V4. Также внутри этой ячейки будет своя двухмерная система координат, где точка (0, 0) соответствует V1 и точка (1, 1) — V3 (см. рис.15a). Для того, чтобы получить значение с координатами (0.5, 0.5), нам сперва нужно получить два интерполированных по Х значения — между V1 и V4 и между V2 и V3, и наконец интерполировать по Y между этими значениями(рис.15b).
Вот пример:
```
float2 coords(0.5f, 0.5f)
float4 P1 = lerp(V1, V4, coords.x);
float4 P2 = lerp(V2, V3, coords.x);
float4 P = lerp(P1, P2, coords.y)
```

*Рис.15 a — Изображение ячейки решетки с координатами V1, V2, V3 и V4. b — Последовательность двух интерполяций на примере ячейки*
теперь давайте сделаем следующее — для каждого пикселя шумовой текстуры возьмем интерполированное значение для сетки 2х2, затем прибавим к нему интерполированное значение для сетки 4х4, умноженное на 0.5, затем для сетки 8х8, умноженное на 0.25 и т.д до определенного предела — это назвается сложение октав (рис.16). Формула выглядит так:
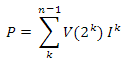

*Рис.16 Пример сложения октав*
Вот пример реализации:
```
for(int32_t x = 0; x < size.width; x++)
for(int32_t y = 0; y < size.height; y++){
float val = 0.0f;
Vector2 normPos = {(float)x / (float)(sideSize - 1),
(float)y / (float)(sideSize - 1)};
for(int32_t o = 0; o < octavesCnt; o++){
float frequency = powf(2.0f, (float)(startFrequency + o));
float intencity = powf(intencityFactor, (float)o);
Vector2 freqPos = normPos * frequency;
Point2 topLeftFreqPos = Cast(freqPos);
Point2 btmRightFreqPos = topLeftFreqPos + Point2(1, 1);
float xFrac = freqPos.x - (float)topLeftFreqPos.x;
float yFrac = freqPos.y - (float)topLeftFreqPos.y;
float iVal = GetInterpolatedValue(topLeftFreqPos,
btmRightFreqPos,
xFrac,
yFrac);
val += iVal \* intencity;
}
noiseValues[y \* size.width + x] = val;
}
```
Также для V1, V2, V3 и V4 вы можете получить сумму от самого значения и его соседей следующим образом:
```
float GetSmoothValue(const Point2 &Coords)
{
float corners = (GetValue({Coords.x - 1, Coords.y - 1}) +
GetValue({Coords.x + 1, Coords.y - 1}) +
GetValue({Coords.x - 1, Coords.y + 1}) +
GetValue({Coords.x + 1, Coords.y + 1})) / 16.0f;
float sides = (GetValue({Coords.x - 1, Coords.y}) +
GetValue({Coords.x + 1, Coords.y}) +
GetValue({Coords.x, Coords.y - 1}) +
GetValue({Coords.x, Coords.y + 1})) / 8.0f;
float center = GetValue(Coords) / 4.0f;
return center + sides + corners;
}
```
и использовать эти значения при интерполяции. Вот остальной код:
```
float GetInterpolatedValue(const Point2 &TopLeftCoord,
const Point2 &BottomRightCoord,
float XFactor,
float YFactor)
{
Point2 tlCoords(TopLeftCoord.x, TopLeftCoord.y);
Point2 trCoords(BottomRightCoord.x, TopLeftCoord.y);
Point2 brCoords(BottomRightCoord.x, BottomRightCoord.y);
Point2 blCoords(TopLeftCoord.x, BottomRightCoord.y);
float tl = (useSmoothValues) ? GetSmoothValue(tlCoords) : GetValue(tlCoords);
float tr = (useSmoothValues) ? GetSmoothValue(trCoords) : GetValue(trCoords);
float br = (useSmoothValues) ? GetSmoothValue(brCoords) : GetValue(brCoords);
float bl = (useSmoothValues) ? GetSmoothValue(blCoords) : GetValue(blCoords);
float bottomVal = Math::CosInterpolation(bl, br, XFactor);
float topVal = Math::CosInterpolation(tl, tr, XFactor);
return Math::CosInterpolation(topVal, bottomVal, YFactor);
}
```
В заключении подраздела хочу сказать, что все описанное мной до этого момента — несколько отличающаяся от канонической реализация шума Перлина.
С высотой разобрались — теперь давайте посмотрим, как быть с нормалями. Как и в случае с основной карты высот, из текстры шума нам надо сгенерировать карту нормалей. Затем в шейдере мы просто складываем нормаль из основной карты с нормалью из шумовой текстуры. Надо сказать, что это не совсем корректно, но дает приемлимый результат. Вот пример:
```
//float2 texCoords1 - текстурные координаты, полученные из нормализованной точки, как было рассказано ранее
//mainNormalTex, mainNormalTexSampler - основная карта нормалей
//distNormalTex, distNormalTexSampler - карта нормалей градиентного шума
float2 texCoords2 = texCoords1 * texCoordsScale;
float4 mainNormColor = mainNormalTex.SampleLevel(mainNormalTexSampler, TexCoords1, 0);
float4 distNormColor = distNormalTex.SampleLevel(distNormalTexSampler, TexCoords2, 0);
float3 mainNormal = 2.0f * mainNormColor.rgb - 1.0f;
float3 distNormal = 2.0f * distNormColor.rgb - 1.0f;
float3 normal = normalize(mainNormal + distNormal);
```
### 8. Hardware Instancing
Займемся оптимизацией. Сейчас цикл отрисовки секторов в псевдокоде выглядит так
```
цикл по всем секторам
вычисляем скаларное произведение вектора на точку и вектора на центр сектора
если оно больше нуля
устанавливаем значение S в данных шейдера
устанавливаем значение V1 в данных шейдера
устанавливаем значение V2 в данных шейдера
отрисовываем сетку
конец условия
конец цикла по всем секторам
```
производительность даного подхода чрезвычайно мала. Вариантов оптимизации несколько — можно построить квадродерево для каждой плоскости куба, чтобы не вычислять скалярное произведение для каждого сектора. Также можно обновлять значения V1 и V2 не для каждого сектора, а для шести плоскостей куба, кторым они принадлежат. Я выбрал третий вариант — Instancing. Вкратце о том, что это такое. Допустим, вы хотите нарисовать лес. У вас есть модель дерева, также имеется набор матриц преобразований — позиции деревьев, возможное масштабирование или поворот. Вы можете создать один буфер, в котором будут содержаться преобразованные в мировое пространство вершины всех деревьев — вариант неплохой, лес по карте не бегает. А что если вам надо реализовывать преобразования — скажем, покачивания деревьев на ветру. Можно сделать так — копируем данные вершин модели N раз в один буфер, добавляя к данным вершины индекс дерева (от 0 до N). Далее обновляем массив матриц преобразований и передаем его как переменную в шейдер. В шейдере мы выбираем нужную матрицу по индексу дерева. Как можно избежать дублирования данных? Для начала хочу обратить ваше внимание, что данные вершины можно собрать из нескольких буферов. Для при описании вершины нужно указать индекс источника в поле InputSlot структуры D3D11\_INPUT\_ELEMENT\_DESC. Это можно использовать при реализации морфирующей лицевой анимации — скажем у вас есть два буфера вершин, содержаших два состояния лица, и вы хотите линейно интерполировать эти значения. Вот как нужно описать вершину:
```
D3D11_INPUT_ELEMENT_DESC desc[] = {
/*part1*/
{"POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D11_INPUT_PER_VERTEX_DATA, 0},
{"NORMAL", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 12, D3D11_INPUT_PER_VERTEX_DATA, 0},
{"TEXCOORD", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 24, D3D11_INPUT_PER_VERTEX_DATA, 0},
/*part2*/
{"POSITION", 1, DXGI_FORMAT_R32G32B32_FLOAT, 1, 0, D3D11_INPUT_PER_VERTEX_DATA, 0},
{"NORMAL", 1, DXGI_FORMAT_R32G32B32_FLOAT, 1, 12, D3D11_INPUT_PER_VERTEX_DATA, 0},
{"TEXCOORD", 1, DXGI_FORMAT_R32G32B32_FLOAT, 1, 24, D3D11_INPUT_PER_VERTEX_DATA, 0}
}
```
в шейдере вершину нужно описать так:
```
struct VIn
{
float3 position1 : POSITION0;
float3 normal1 : NORMAL0;
float2 tex1 : TEXCOORD0;
float3 position2 : POSITION1;
float3 normal2 : NORMAL1;
float2 tex2 : TEXCOORD1;
}
```
далее вы просто интерполируете значения
```
float3 res = lerp(input.position1, input.position2, factor);
```
К чему я это? Вернемся к примеру с деревьями. Вершину будем собирать из двух источников — первый будет содержать позицию в локальном пространстве, текстурные координаты и нормаль, второй — матрицу преобразования в виде четырех четырехмерных векторов. Описание вершины выглядит так:
```
D3D11_INPUT_ELEMENT_DESC desc[] = {
/*part1*/
{"POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D11_INPUT_PER_VERTEX_DATA, 0},
{"NORMAL", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 12, D3D11_INPUT_PER_VERTEX_DATA, 0},
{"TEXCOORD", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 24, D3D11_INPUT_PER_VERTEX_DATA, 0},
/*part2*/
{"WORLD", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 0, D3D11_INPUT_PER_INSTANCE_DATA, 1},
{"WORLD", 1, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 16, D3D11_INPUT_PER_INSTANCE_DATA, 1},
{"WORLD", 2, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 32, D3D11_INPUT_PER_INSTANCE_DATA, 1},
{"WORLD", 3, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 48, D3D11_INPUT_PER_INSTANCE_DATA, 1},
}
```
Обратите внимание, что во второй части поле InputSlotClass равно D3D11\_INPUT\_PER\_INSTANCE\_DATA и поле InstanceDataStepRate равно единице (Краткое описание поля InstanceDataStepRate см. в приложении 1). В этом случае сборщик будет использовать данные всего буфера из источника с типом D3D11\_INPUT\_PER\_VERTEX\_DATA для каждого элемента из источника с типом D3D11\_INPUT\_PER\_INSTANCE\_DATA. При этом в шейдере данные вершины можно описать следующим образом:
```
struct VIn
{
float3 posL : POSITION;
float3 normalL : NORMAL;
float2 tex : TEXCOORD;
row_major float4x4 world : WORLD;
};
```
Создав второй буфер с атрибутами D3D11\_USAGE\_DYNAMIC и D3D11\_CPU\_ACCESS\_WRITE, мы сможем обновлять его со стороны CPU. Отрисовывать такого рода геометрию нужно с помощью вызовов DrawInstanced() или DrawIndexedInstanced(). Есть еще вызовы DrawInstancedIndirect() и DrawIndexedInstancedIndirect() — про них см. в приложении 2.
Приведу пример установки буферов и использования функции DrawIndexedInstanced():
```
//vb - вершинный буфер
//tb - "истансный" буфер
//ib - индексный буфер
//vertexSize - размер элемента в вершинном буфере
//instanceSize - размер элемента в "инстансном" буфере
//indicesCnt - количество индексов
//instancesCnt - количество "инстансев"
std::vector buffers = {vb, tb};
std::vector strides = {vertexSize, instanceSize};
std::vector offsets = {0, 0};
deviceContext->IASetVertexBuffers(0,buffers.size(),&buffers[0],&strides[0],&offsets[0]);
deviceContext->IASetIndexBuffer(ib, DXGI\_FORMAT\_R32\_UINT, 0);
deviceContext->IASetPrimitiveTopology(D3D11\_PRIMITIVE\_TOPOLOGY\_TRIANGLELIST);
deviceContext->DrawIndexedInstanced(indicesCnt, instancesCnt, 0, 0, 0);
```
Теперь давайте наконец вернемся к нашей теме. Сектор мужно описать точкой на плоскости, которой он принадлежит и двумя векторами, которые эту плоскость описывают. Следовательно вершина будет состоять из двух источников. Первый — координаты в пространстве сетки, второй — данные сектора. Описание вершины выглядит так:
```
std::vector meta = {
//координаты в пространстве сетки
{"POSITION", 0, DXGI\_FORMAT\_R32G32B32\_FLOAT, 0, 0, D3D11\_INPUT\_PER\_VERTEX\_DATA, 0}
//первый вектор грани
{"TEXCOORD", 0, DXGI\_FORMAT\_R32G32B32\_FLOAT, 1, 0, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1},
//второй вектор грани
{"TEXCOORD", 1, DXGI\_FORMAT\_R32G32B32\_FLOAT, 1, 12, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1},
//начало грани
{"TEXCOORD", 2, DXGI\_FORMAT\_R32G32B32\_FLOAT, 1, 24, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1}
}
```
Обратите внимание, что для хранения координат в пространстве сетки я использую трехмерный вектор (координата z не используется)
### 9. Frustum culling
Еще один важный компонент оптимизации — отсечение по пирамиде видимости (Frustum culling). Пирамида видимости — это та область сцены, которую «видит» камера. Как ее построить? Сперва вспомним, что точка может быть в четырех системах координат — локальной, мировой, видовой и системе координат проекции. Переход между ними осуществляется посредством матриц — мировой, видовой и матрицы проекции, причем преобразования должны проходить последовательно — от локального в мировое, из мирового в видовое и наконец из видового в пространство проекции. Все эти преобразования можно объединить в одно посредством умножения этих матриц.
Мы используем перспективную проекцию, которая подразумевает так называемое «однородное деление» — после умножения вектора (Px, Py, Pz, 1) на матрицу проекции его компоненты следует разделить на компонент W этого вектора. После перехода в пространство проекции и однородного деления точка оказывается в NDC пространстве. NDC пространство представляет из себя набор из трех координат x, y, z, где x и y принадлежат [-1, 1], а z — [0,1] (Надо сказать, что в OpenGL параметры несколько иные).
Теперь давайте приступим к решению нашей задачи. В моем случае пирамида расположена в видовом пространстве. Нам нужно шесть плоскостей, которые ее описывают (рис.17а). Плоскость можно описать с помощью нормали и точки, которая этой плоскости принадлежит. Сперва давайте получим точки — для этого возьмем следующий набор координат в NDC пространстве:
```
std::vector pointsN = {
{-1.0f, -1.0f, 0.0f, 1.0f}, {-1.0f, 1.0f, 0.0f, 1.0f},
{ 1.0f, 1.0f, 0.0f, 1.0f}, {1.0f, -1.0f, 0.0f, 1.0f},
{-1.0f, -1.0f, 1.0f, 1.0f}, {-1.0f, 1.0f, 1.0f, 1.0f},
{ 1.0f, 1.0f, 1.0f, 1.0f}, {1.0f, -1.0f, 1.0f, 1.0f}
};
```
Посмотрите, в первых четырех точках значение z равно 0 — это значит что они принадлежат ближней плоскости отсечения, в последних четырех z равно 1 — они принадлежат дальней плоскости отсечения. Теперь эти точки нужно преобразовать в видовое пространство. Но как?
Помните пример про космонавта — так вот тут тоже самое. Нам нужно умножить точки на обратную матрицу проекции. Правда, после этого нужно еще поделить каждый из них на его координату W. В результате мы получим нужные координаты (рис.17b). Давайте теперь разберемся с нормалями — они должны быть направлены внутрь пирамиды, поэтому нам надо выбрать необходимый порядок вычисления векторного произведения.
```
Matrix4x4 invProj = Matrix4x4::Inverse(camera->GetProjMatrix());
std::vector pointsV;
for(const Point4F &pN : pointsN){
Point4F pV = invProj.Transform(pN);
pV /= pV.w;
pointsV.push\_back(Cast(pV));
}
planes[0] = {pointsV[0], pointsV[1], pointsV[2]}; //near plane
planes[1] = {pointsV[4], pointsV[5], pointsV[6]}; //far plane
planes[2] = {pointsV[0], pointsV[1], pointsV[4]}; //left plane
planes[3] = {pointsV[2], pointsV[3], pointsV[6]}; //right plane
planes[4] = {pointsV[1], pointsV[2], pointsV[6]}; //top plane
planes[5] = {pointsV[0], pointsV[3], pointsV[7]}; //bottom plane
planes[0].normal \*= -1.0f;
planes[5].normal \*= -1.0f;
```

*Рис.17 Пирамида видимости*
Пирамида построена — настало время ее использовать. Те секторы, которые не попадают внутрь пирамиды, мы не рисуем. Для того, что бы определить, находится ли сектор внутри пирамиды видимости, мы будем проверять ограничивающую сферу, расположенную в центре этого сектора. Это не дает точных результатов, но в данном случае я не вижу ничего страшного в том, что будут нарисованы несколько лишних секторов. Радиус сферы вычисляется следующим образом:

где TR — правый верхний угол сектора, BL — левый нижний угол. Так как все секторы имеют одинаковую площадь, то радиус достаточно вычислить один раз.
Как нам определить, находится ли сфера, описывающая сектор, внутри пирамиды видимости? Сперва нам нужно определить, пересекается ли сфера с плоскостьтю и если нет, то с какой стороны от нее она находится. Давайте получим вектор на центр сферы

где P — точка на плоскости и S — центр сферы. Теперь вычислим скалярное произведение этого вектора на нормаль плоскости. Ориентацию можно определить с помошью знака скалярного произведения — как говорилось ранее, если он положительный, то сфера находится спереди от плоскости, если отрицательный, то сфера находится позади. Осталось определить, пересекает ли сфера плоскость. Давайте возьмем два вектора — N (вектор нормали) и V. Теперь построим вектор от N до V — назовем его K. Так вот, нам надо найти такую длину N, чтобы он с K образовывал угол 90 градусов (формально говоря, чтобы N и K были ортогональны). Оки доки, посмотрите на рис.18a — из свойств прямоугольного треугольника мы знаем, что

Нужно найти косинус. Используя ранее упомянутое свойство скалярного произведения

делим обе части на |V|\*|N| и получаем

используем этот результат:

так как |V| это просто число, то можно сократить на |V|, и тогда мы получим

Так как вектор N нормализован, то последним шагом мы просто умножем его на получившееся значение, в противном случае вектор следует нормализовать — в этом случае конечное уравнение выглядит так:

Где D это наш новый вектор. Этот процес называется «Векторная проекция»(рис.18b). Но зачем нам это? Мы знаем, что вектор определяется длиной и направлением и никак не меняется от его положения — это значит, что если мы расположим D так, чтобы он указывал на S, то его длина будет равна минимальному расстоянию от S до плоскости (рис.18с)

*Рис.18 a Проекция N на V, b Наглядное отображение длины спроецированного N применительно к точке, с Наглядное отображение
длины спроецированного N применительно к сфере с центром в S*
Так как у нас нет необходимости в спроецированном векторе, достаточно лишь вычислить его длину. Учитывая, что N это единичный вектор, нам нужно лишь вычислить скалярное произведение V на N. Собрав все воедино, мы можем наконец заключить, что сфера пересекает плоскость, если значение скалярного произведения вектора на центр сферы и нормали к плоскости больше нуля и меньше значения радиуса этой сферы.
Для того, чтобы утверждать, что сфера находится внутри пирамиды видимости, нам надо убедиться, что она либо пересекает одну из плоскостей, либо находится спереди от каждой из них. Можно поставить вопрос подругому — если сфера не пересекает и находится позади хотябы одной из плоскостей — она определенно вне пирамиды видимости. Так мы и сделаем. Обратите внимание, что я перевожу центр сферы в тоже пространство, в котором расположена пирамида — в пространство вида.
```
bool Frustum::TestSphere(const Point3F &Pos,
float Radius,
const Matrix4x4 &WorldViewMatrix) const
{
Point3F posV = WorldViewMatrix.Transform(Pos);
for(const Plane &pl : planes){
Vector3 toSphPos = posV - pl.pos;
if(Vector3::Dot(toSphPos, pl.normal) < -Radius)
return false;
}
return true;
}
```
### 10. Трещины
Еще одна проблема, которую нам предстоит решить — трещины на границах уровней детализации (рис.19).

*Рис.19 демонстрация трещин ландшафта*
В первую очередь нам надо определить те секторы, которые лежат на границе уровней детализации. На первый взгляд кажется, что это ресурсоемкая задача — ведь количество секторов на каждом из уровней постоянно меняется. Но если использовать данные смежности, то решение значительно упрощается. Что такое данные смежности? Смотрите, у каждого сектора есть четыре соседа. Набор ссылок на них — будь то указатели или индексы — и есть данные смежности. С их помощью мы легко определим, какой сектор лежит на границе — достаточно проверить, какому уровню принадлежат его соседи.
Ну что же, давайте найдем соседей каждого сектора. И опять же нам не нужно переберать в цикле все секторы. Представим, что мы работаем с сектором с координатами X и Y в пространстве сетки.
Если он не касается ребра куба, то координаты его соседей будут такими:
Сосед сверху — (X, Y — 1)
Сосед снизу — (X, Y + 1)
Сосед слева — (X — 1, Y)
Сосед справа — (X + 1, Y)
Если же сектор касается ребра, то мы помещаем его специальный контейнер. После обработки всех шести граней в нем будут содержаться все граничные секторы куба. Вот в этом контейнере нам и предстоит осуществлять перебор. Заранее вычислим ребра для каждого сектора:
```
struct SectorEdges
{
CubeSectors::Sector *owner;
typedef std::pair Edge;
Edge edges[4];
};
std::vector sectorsEdges;
//borderSectors - контейнер с граничными секторами
for(CubeSectors::Sector &sec : borderSectors){
// каждый сектор содержит два вектора, которые описывают грань куба,
// которой он принадлежит
Vector3 v1 = sec.vec1 \* sec.sideSize;
Vector3 v2 = sec.vec2 \* sec.sideSize;
//sec.startPos - начало сектора в локальном пространстве
SectorEdges secEdges;
secEdges.owner = &sec
secEdges.edges[ADJ\_BOTTOM] = {sec.startPos, sec.startPos + v1};
secEdges.edges[ADJ\_LEFT] = {sec.startPos, sec.startPos + v2};
secEdges.edges[ADJ\_TOP] = {sec.startPos + v2, sec.startPos + v2 + v1};
secEdges.edges[ADJ\_RIGHT] = {sec.startPos + v1, sec.startPos + v2 + v1};
sectorsEdges.push\_back(secEdges);
}
```
Далее идет сам перебор
```
for(SectorEdges &edgs : sectorsEdges)
for(size_t e = 0; e < 4; e++)
if(edgs.owner->adjacency[e] == nullptr)
FindSectorEdgeAdjacency(edgs, (AdjacencySide)e, sectorsEdges);
```
Функция FindSectorEdgeAdjacency() выглядит так
```
void CubeSectors::FindSectorEdgeAdjacency(SectorEdges &Sector,
CubeSectors::AdjacencySide Side,
std::vector &Neibs)
{
SectorEdges::Edge &e = Sector.edges[Side];
for(SectorEdges &edgs2 : Neibs){
if(edgs2.owner == Sector.owner)
continue;
for(size\_t e = 0; e < 4; e++){
SectorEdges::Edge &e2 = edgs2.edges[e];
if((Math::Equals(e.first, e2.first) && Math::Equals(e.second, e2.second)) ||
(Math::Equals(e.second, e2.first) && Math::Equals(e.first, e2.second)))
{
Sector.owner->adjacency[Side] = edgs2.owner;
edgs2.owner->adjacency[e] = Sector.owner;
return;
}
}
}
}
```
Обратите внимание, что мы обновляем данные смежности для двух секторов — искомого (Sector) и найденного соседа.
Теперь, используя полученные нами данные смежности, нам предстоит найти те ребра секторов, которые принадлежат границе уровней детализации. План такой — перед отрисовкой найдем граничные секторы. Затем для каждого сектора в Instance buffer помимо основной
информации запишем коэффициент тесселяции и четырехмерный вектор коэффициентов тесселяции для соседних секторов. Описание вершины теперь будет выглядеть так:
```
std::vector meta = {
//координаты в пространстве сетки
{"POSITION", 0, DXGI\_FORMAT\_R32G32B32\_FLOAT, 0, 0, D3D11\_INPUT\_PER\_VERTEX\_DATA, 0}
//первый вектор грани
{"TEXCOORD", 0, DXGI\_FORMAT\_R32G32B32\_FLOAT, 1, 0,D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1},
//второй вектор грани
{"TEXCOORD", 1, DXGI\_FORMAT\_R32G32B32\_FLOAT, 1, 12, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1},
//начало грани
{"TEXCOORD", 2, DXGI\_FORMAT\_R32G32B32\_FLOAT, 1, 24, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1},
//коэффициенты тесселяции соседних секторов
{"TEXCOORD", 3, DXGI\_FORMAT\_R32G32B32A32\_FLOAT, 1, 36, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1},
//коэффициент тесселяции сектора
{"TEXCOORD", 4, DXGI\_FORMAT\_R32\_FLOAT, 1, 52, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1}
}
```
После того, как мы распределили секторы по уровням детализации, определим соседние коэффициенты тесселяции для каждого сектора:
```
for(LodsStorage::Lod &lod : lods){
const std::vector §ors = lod.GetSectors();
bool lastLod = lod.GetInd() == lods.GetCount() - 1;
for(Sector \*s : sectors){
int32\_t tessFacor = s->GetTessFactor();
s->GetBorderTessFactor() = {
GetNeibTessFactor(s, Sector::ADJ\_BOTTOM, tessFacor, lastLod),
GetNeibTessFactor(s, Sector::ADJ\_LEFT, tessFacor, lastLod),
GetNeibTessFactor(s, Sector::ADJ\_TOP, tessFacor, lastLod),
GetNeibTessFactor(s, Sector::ADJ\_RIGHT, tessFacor, lastLod)
};
}
}
```
Функция, которая ищет соседний фактор тесселяции:
```
float Terrain::GetNeibTessFactor(Sector *Sec,
Sector::AdjacencySide Side,
int32_t TessFactor,
bool IsLastLod)
{
Sector *neib = Sec->GetAdjacency()[Side];
int32_t neibTessFactor = neib->GetTessFactor();
return (neibTessFactor < TessFactor) ? (float)neibTessFactor : 0.0f;
}
```
Если мы возвращаем ноль, то сосед на стороне Side не представляет для нас интерес. Забегу вперед и скажу, что нам нужно устранять трещины со стороны уровня с большим коэффициентом тесселяции.
Теперь передем к шейдеру. Напомню, что сперва нам нужно получить координаты сетки, используя координаты тесселятора. Затем эти координаты преобразуются в точку на грани куба, эта точка нормализуется — и вот мы имеем точку на сфере:
```
float3 p = Tri[0].netPos * Coord.x + Tri[1].netPos * Coord.y + Tri[2].netPos * Coord.z;
float3 planePos = Tri[0].startPos + Tri[0].vec1 * p.x * gridStep.x
+ Tri[0].vec2 * p.y * gridStep.y;
float3 sphPos = normalize(planePos);
```
Сперва нам надо выяснить, принадлежит ли вершина либо первой или последней строке сетки, либо первому или последнему столбцу — в этом случае вершина принадлежит ребру сектора. Но этого не достаточно — нам нужно определить, принадлежит ли вершина границе уровней детализации. Для этого используем информацию о соседних секторах, а точнее их уровни тесселяции:
```
float4 bTf = Tri[0].borderTessFactor;
bool isEdge = (bTf.x != 0.0f && p.y == 0.0f) || //bottom
(bTf.y != 0.0f && p.x == 0.0f) || //left
(bTf.z != 0.0f && p.y == gridSize.y) || //top
(bTf.w != 0.0f && p.x == gridSize.x) //right
```
Теперь главный этап — собственно, устранение трещин. Посмотрите на рис.20. Красная линия — грань вершины, принадлежащей второму уровню детализации. Две синие линии — грани третьего уровня детализации. Нам нужно, чтобы V3 принадлежала красной линии — то есть лежала на грани второго уровня. Как как высоты V1 и V2 равны для обоих уровней, V3 можно найти с помощью линейной интерполяции между ними


*Рис.20 Демонстрация граней, которые образуют трещину, в виде линий*
Пока мы не имеем ни V1 и V2, ни коэффициента F. Сначала нам нужно найти индекс точки V3. Тоесть если сетка имеет размер 32 на 32 и коэффициент тесселяции равен четырем, то этот индекс будет от нуля до 128 (32 \* 4). У нас уже есть координаты в пространстве сетки p — в рамках данного примера они могут быть например (15.5, 16). Для получения индекса нужно умножить одну из координат p на коэффициент тесселяции. Нам также понадобится начало грани и направление на ее конец — один из углов сектора.
```
float edgeVertInd = 0.0f;
float3 edgeVec = float3(0.0f, 0.0f, 0.0f);
float3 startPos = float3(0.0f, 0.0f, 0.0f);
uint neibTessFactor = 0;
if(bTf.x != 0.0f && p.y == 0.0f){ // bottom
edgeVertInd = p.x * Tri[0].tessFactor;
edgeVec = Tri[0].vec1;
startPos = Tri[0].startPos;
neibTessFactor = (uint)Tri[0].borderTessFactor.x;
}else if(bTf.y != 0.0f && p.x == 0.0f){ // left
edgeVertInd = p.y * Tri[0].tessFactor;
edgeVec = Tri[0].vec2;
startPos = Tri[0].startPos;
neibTessFactor = (uint)Tri[0].borderTessFactor.y;
}else if(bTf.z != 0.0f && p.y == gridSize.y){ // top
edgeVertInd = p.x * Tri[0].tessFactor;
edgeVec = Tri[0].vec1;
startPos = Tri[0].startPos + Tri[0].vec2 * (gridStep.x * gridSize.x);
neibTessFactor = (uint)Tri[0].borderTessFactor.z;
}else if(bTf.w != 0.0f && p.x == gridSize.x){ // right
edgeVertInd = p.y * Tri[0].tessFactor;
edgeVec = Tri[0].vec2;
startPos = Tri[0].startPos + Tri[0].vec1 * (gridStep.x * gridSize.x);
neibTessFactor = (uint)Tri[0].borderTessFactor.w;
}
```
Далее нам нужно найти индексы для V1 и V2. Представтье что у вас есть число 3. Вам нужно найти два ближайших числа, кратных двум. Для этого вы вычисляете остаток от деления трех на два — он равен еденице. Затем вы вычитаете либо прибавляете этот остаток к трем и получаете нужный результат. Также с индексами, только вместо двух у нас будет соотношение коэффициентов тесселяции уровней детализации. Тоесть если у третьего уровня коэффициент равен 16, а у второго 2, то соотношение будет равно 8. Теперь, чтобы получить высоты, сперва надо получить соответствующие точки на сфере, нормализовав точки на грани. Начало и направление ребра мы уже подготовили — осталось вычислить длину вектора от V1 до V2. Так как длина ребра ячейки оригинальной сетки равна gridStep.x, то нужная нам длина равна gridStep.x / Tri[0].tessFactor. Затем по точкам на сфере мы получим высоту, как было рассказано ранее.
```
float GetNeibHeight(float3 EdgeStartPos, float3 EdgeVec, float VecLen, float3 NormOffset)
{
float3 neibPos = EdgeStartPos + EdgeVec * VecLen;
neibPos = normalize(neibPos);
return GetHeight(neibPos, NormOffset);
}
float vertOffset = gridStep.x / Tri[0].tessFactor;
uint tessRatio = (uint)tessFactor / (uint)neibTessFactor;
uint ind = (uint)edgeVertInd % tessRatio;
uint leftNeibInd = (uint)edgeVertInd - ind;
float leftNeibHeight = GetNeibHeight(startPos,
edgeVec,
vertOffset * leftNeibInd,
normOffset);
uint rightNeibInd = (uint)edgeVertInd + ind;
float rightNeibHeight = GetNeibHeight(startPos,
edgeVec,
vertOffset * rightNeibInd,
normOffset);
```
Ну и послендний компонент — фактор F. Его мы получим разделив остаток от деления на соотношение коэффициентов (ind) на соотношение коэффициентов (tessRatio)
```
float factor = (float)ind / (float)tessRatio;
```
Завершающий этап — линейная интерполяция высот и получение новой вершины
```
float avgHeight = lerp(leftNeibHeight, rightNeibHeight, factor);
posL = sphPos * (sphereRadius + avgHeight);
```
Также может появиться трещина в месте, где граничат секторы с текстурными координатами ребер равными 1 или 0. В этом случае я беру среднее значение между высотами для двух координат:
```
float GetHeight(float2 TexCoords)
{
float2 texCoords2 = TexCoords * texCoordsScale;
float mHeight = mainHeightTex.SampleLevel(mainHeightTexSampler, TexCoords, 0).x;
float dHeight = distHeightTex.SampleLevel(distHeightTexSampler, texCoords2, 0).x;
return (mHeight + dHeight) * maxTerrainHeight;
}
float GetHeight(float3 SphPos, float3 NormOffset)
{
float2 texCoords1 = GetTexCoords(SphPos, NormOffset);
float height = GetHeight(texCoords1);
if(texCoords1.x == 1.0f){
float height2 = GetHeight(float2(0.0f, texCoords1.y));
return lerp(height, height2, 0.5f);
}else if(texCoords1.x == 0.0f){
float height2 = GetHeight(float2(1.0f, texCoords1.y));
return lerp(height, height2, 0.5f);
}else
return height;
}
```
### 11. Обработка на GPU
Давайте перенесем обработку секторов на GPU. У нас будет два Compute шейдера — первый выполнит отсечение по пирамиде видимости и определит уровень детализации, второй получит граничные коэффициенты тесселяции для устранения трещин. Разделение на два этапа нужно потому, что как и в случае с CPU, мы не можем коректно определить соседей для секторов до тех пор, пока не произведем отсечение. Так как оба шейдера будут использовать данные уровней детализации и работать с секторами, я ввел две общих структуры: Sector и Lod
```
struct Sector
{
float3 vec1, vec2;
float3 startPos;
float3 normCenter;
int adjacency[4];
float borderTessFactor[4];
int lod;
};
struct Lod
{
RangeF dotRange;
float tessFactor;
float padding;
float4 color;
};
```
Мы будем использовать три основных буфера — входной(содержит изначальную информацию о секторах), промежуточный(в нем находятся данные секторов, полученных в результате работы первого этапа) и итоговый(Будет передаваться на отрисовку). Данные входного буфера не будут меняться, поэтому в поле Usage структуры D3D11\_BUFFER\_DESC разумно использовать значение D3D11\_USAGE\_IMMUTABLE Мы просто запишем в него данные всех секторов с единственной разницей, что для данных смежности мы будем использовать индексы секторов, а не указатели на них. Для индекса уровня детализации и граничных коэффициентов тесселяции установим нулевые значения:
```
static const size_t sectorSize = sizeof(Vector3) + //vec1
sizeof(Vector3) + //vec2
sizeof(Point3F) + //normCenter
sizeof(Point3F) + //startPos
sizeof(Point4) + //adjacency
sizeof(Vector4) + //borderTessFactor
sizeof(int32_t);//lod
size_t sectorsDataSize = sectors.GetSectors().size() * sectorSize;
std::vector sectorsData(sectorsDataSize);
char\* ptr = §orsData[0];
const Sector\* firstPtr = §ors.GetSectors()[0];
for(const Sector &sec : sectors){
Utils::AddToStream(ptr, sec.GetVec1());
Utils::AddToStream(ptr, sec.GetVec2());
Utils::AddToStream(ptr, sec.GetStartPos());
Utils::AddToStream(ptr, sec.GetNormCenter());
Utils::AddToStream(ptr, sec.GetAdjacency()[0] - firstPtr);
Utils::AddToStream(ptr, sec.GetAdjacency()[1] - firstPtr);
Utils::AddToStream(ptr, sec.GetAdjacency()[2] - firstPtr);
Utils::AddToStream(ptr, sec.GetAdjacency()[3] - firstPtr);
Utils::AddToStream(ptr, Vector4());
Utils::AddToStream(ptr, 0);
}
inputData = Utils::DirectX::CreateBuffer(§orsData[0],//Raw data
sectorsDataSize,//Buffer size
D3D11\_BIND\_SHADER\_RESOURCE,//bind flags
D3D11\_USAGE\_IMMUTABLE,//usage
0,//CPU access flags
D3D11\_RESOURCE\_MISC\_BUFFER\_STRUCTURED,//misc flags
sectorSize);//structure byte stride
```
Теперь пара слов о промежуточном буфере. Он будет играть две роли — выходного для первого шейдера и входного для второго, поэтому мы укажем в поле BindFlags значение D3D11\_BIND\_UNORDERED\_ACCESS | D3D11\_BIND\_SHADER\_RESOURCE. Также создадим для него два отображения — UnorderedAccessView, которое позволит шейдеру записывать в него результат работы и ShaderResourceView, с помощью которого мы будем использовать буфер как входной. Размер его будет таким же, как у ранее созданного входного буфера
```
UINT miscFlags = D3D11_BIND_UNORDERED_ACCESS | D3D11_BIND_SHADER_RESOURCE;
intermediateData = Utils::DirectX::CreateBuffer(
sectors.GetSectors().size() * sectorSize,//Buffer size
miscFlags,
D3D11_USAGE_DEFAULT,//usage
0,//CPU access flags
D3D11_RESOURCE_MISC_BUFFER_STRUCTURED,//misc flags
sectorSize);//structure byte stride
intermediateUAW = Utils::DirectX::CreateUnorderedAccessView(
intermediateData,
D3D11_BUFFER_UAV{0, sectors.GetSectors().size(), 0});
intermediateSRV = Utils::DirectX::CreateShaderResourceView(
intermediateData,
D3D11_BUFFEREX_SRV{0, sectors.GetSectors().size(), 0});
```
Далее я приведу основную функцию первого шейдера:
```
StructuredBuffer inputData : register(t0);
RWStructuredBuffer outputData : register(u0);
[numthreads(1, 1, 1)]
void Process( int3 TId : SV\_DispatchThreadID )
{
int ind = TId.x;
Sector sector = inputData[ind];
float dotVal = dot(toWorldPos, sector.normCenter);
if(dotVal < dotRange.minVal || dotVal > dotRange.maxVal){
outputData[ind] = sector;
return;
}
if(!IsVisible(sector.normCenter)){
outputData[ind] = sector;
return;
}
for(int l = 0; l < 4; l++){
Lod lod = lods[l];
if(dotVal >= lod.dotRange.minVal && dotVal <= lod.dotRange.maxVal)
sector.lod = l + 1;
}
outputData[ind] = sector;
}
```
После вычисления скалярного произведения мы проверяем, находится ли сектор в потенциально видимой области. Далее мы уточняем факт его видимости с помощью вызова IsVisible(), который идентичен вызову Frustum::TestSphere(), показанному ранее. Работа функции зависит от переменных worldView, sphereRadius, frustumPlanesPosV и frustumPlanesNormalsV, значения для которых нужно передать в шейдер заранее. Далее мы определяем уровень детализации. Обратите внимание, что индекс уровня мы указываем от еденицы — это нужно для того, чтобы на втором этапе отбросить те секторы, уровень детализации которых равен нулю.
Теперь нам нужно подготовить буферы для второго этапа. Мы хотим использовать буфер, как выходной у Compute шейдера и входной для тесселятора — для этого нам нужно указать в поле BindFlags значение D3D11\_BIND\_UNORDERED\_ACCESS | D3D11\_BIND\_VERTEX\_BUFFER. Нам придется работать с данными буфера напрямую, поэтому укажем в поле MiscFlags значение D3D11\_RESOURCE\_MISC\_BUFFER\_ALLOW\_RAW\_VIEWS Для отображения такого буфера мы будем использовать значение DXGI\_FORMAT\_R32\_TYPELESS в поле Flags, а в поле NumElements укажем всего буфера, деленный на четыре
```
size_t instancesByteSize = instanceByteSize * sectors.GetSectors().size();
outputData = Utils::DirectX::CreateBuffer(instancesByteSize,
D3D11_BIND_UNORDERED_ACCESS | D3D11_BIND_VERTEX_BUFFER,
D3D11_USAGE_DEFAULT,
0,
D3D11_RESOURCE_MISC_BUFFER_ALLOW_RAW_VIEWS,
0);
D3D11_BUFFER_UAV uavParams = {0, instancesByteSize / 4, D3D11_BUFFER_UAV_FLAG_RAW};
outputUAW = Utils::DirectX::CreateUnorderedAccessView(outputData,
uavParams,
DXGI_FORMAT_R32_TYPELESS);
```
Нам также потребуется счетчик. С его помощью мы осуществим адресацию памяти в шейдере и используем его конечное значение в аргументе instanceCount вызова DrawIndexedInstanced(). Счетчик я реализовал в виде буфера размером 16 байтов. Также при создании отображения в поле Flags поля D3D11\_BUFFER\_UAV я использовал значение D3D11\_BUFFER\_UAV\_FLAG\_COUNTER
```
counter = Utils::DirectX::CreateBuffer(sizeof(UINT),
D3D11_BIND_UNORDERED_ACCESS,
D3D11_USAGE_DEFAULT,
0,
D3D11_RESOURCE_MISC_BUFFER_STRUCTURED,
4);
D3D11_BUFFER_UAV uavParams = {0, 1, D3D11_BUFFER_UAV_FLAG_COUNTER};
counterUAW = Utils::DirectX::CreateUnorderedAccessView(counter, uavParams);
```
Настало время привести код второго шейдера
```
StructuredBuffer inputData : register(t0);
RWByteAddressBuffer outputData : register(u0);
RWStructuredBuffer counter : register(u1);
[numthreads(1, 1, 1)]
void Process( int3 TId : SV\_DispatchThreadID )
{
int ind = TId.x;
Sector sector = inputData[ind];
if(sector.lod != 0){
sector.borderTessFactor[0] = GetNeibTessFactor(sector, 0); //Bottom
sector.borderTessFactor[1] = GetNeibTessFactor(sector, 1); //Left
sector.borderTessFactor[2] = GetNeibTessFactor(sector, 2); //Top
sector.borderTessFactor[3] = GetNeibTessFactor(sector, 3); //Right
int c = counter.IncrementCounter();
int dataSize = 56;
outputData.Store(c \* dataSize + 0, asuint(sector.startPos.x));
outputData.Store(c \* dataSize + 4, asuint(sector.startPos.y));
outputData.Store(c \* dataSize + 8, asuint(sector.startPos.z));
outputData.Store(c \* dataSize + 12, asuint(sector.vec1.x));
outputData.Store(c \* dataSize + 16, asuint(sector.vec1.y));
outputData.Store(c \* dataSize + 20, asuint(sector.vec1.z));
outputData.Store(c \* dataSize + 24, asuint(sector.vec2.x));
outputData.Store(c \* dataSize + 28, asuint(sector.vec2.y));
outputData.Store(c \* dataSize + 32, asuint(sector.vec2.z));
outputData.Store(c \* dataSize + 36, asuint(sector.borderTessFactor[0]));
outputData.Store(c \* dataSize + 40, asuint(sector.borderTessFactor[1]));
outputData.Store(c \* dataSize + 44, asuint(sector.borderTessFactor[2]));
outputData.Store(c \* dataSize + 48, asuint(sector.borderTessFactor[3]));
outputData.Store(c \* dataSize + 52, asuint(sector.lod));
}
}
```
Код функции GetNeibTessFactor() практически идентичен ее CPU аналогу. Единственное различие в том, что мы используем индексы соседей а не указатели на них. Буфер outputData имеет тип RWByteAddressBuffer, поэтому для работы с ним мы используем метод Store(in uint address, in uint value). Значение переменной dataSize равно размеру данных вершины с классом D3D11\_INPUT\_PER\_INSTANCE\_DATA, Описание вершины можно посмотреть в разделе 10. В общем это традиционная для C/С++ работа с указателями. После выполнения двух шейдеров мы можем использовать outputData как InstanceBuffer. Процесс отрисовки выглядит так
```
Utils::DirectX::SetPrimitiveStream({vb, outputData},
ib,
{vertexSize, instanceByteSize},
D3D11_PRIMITIVE_TOPOLOGY_3_CONTROL_POINT_PATCHLIST);
DeviceKeeper::GetDeviceContext()->CopyStructureCount(indirectArgs, 4, counterUAW);
Shaders::Apply(terrainShaders, [&]()
{
DeviceKeeper::GetDeviceContext()->DrawIndexedInstancedIndirect(indirectArgs, 0);
});
Utils::DirectX::SetPrimitiveStream({nullptr, nullptr}, nullptr, {0, 0});
```
За более подробной информацией о методах DrawIndexedInstancedIndirect() и CopyStructureCount() обращайтесь к приложению 2
### 12. Камера
Наверняка вам известно, как помтроить модель простой FPS(First Person Shooter) камеры. Я действую по такому сценарию:
* **1.** Из двух углов получаю вектор направления
* **2.** с помошью вектора направления и вектора (0, 1, 0) получаю базис
* **3.** согласно вектору направления и вактору вправо, полученному в п.2 изменяю позицию камеры

В нашем случае ситуация несколько осложняется — во первых мы должны двигаться относительно центра планеты, во вторых, при построении базиса вместо вектора (0, 1, 0) мы должны использовать нормаль сферы в точке, которой сейчас находимся. Чтобы достичь желаемых результатов, я буду использовать два базиса. Согласно первому будет изменяться позиция, второй будет описывать ориентацию камеры. Базисы взаимозависимы, но первым я вычисляю базис позиции, поэтому начну с него. Предположим, что у нас есть начальный базис позиции (pDir, pUp, pRight) и вектор направления vDir, по которому мы хотим продвинуться на некоторое расстояние. Прежде всего нам надо вычислить проекции vDir на pDir и pRight. Сложив их, мы получим обновленный вектор направления (рис.21).

*Рис.21 Наглядный процесс получения projDir*
Далее мы движемся по этому вектору

где P это позиция камеры, mF и mS — коэффициенты, означающе на сколько нам нужно продвинуться вперед либо вбок.
Мы не можем использовать PN как новую позицию камеры, потому что PN не принадлежит сфере. Вместо этого мы находим нормаль сферы в точке PN, и эта нормаль будет являться новым значением вектора вверх. Теперь мы можем сформировать обновленный базис
```
Vector3 nUp = Vector3::Normalize(PN - spherePos);
Vector3 nDir = projDir
Vector3 nRight = Vector3::Normalize(Vector3::Cross(pUp, pDir))
```
где spherePos — центр сферы.
Нам надо сделать так, чтобы каждый из его векторов был ортогональным по отношению к двум другим. Согласно свойству векторного произведения nRight удовлетворяет этому условию. Осталось добиться тогоже для nUp и nDir. Для этого спроецируем nDir на nUp и отнимим получившийся вектор от nDir (рис.22)
*Рис.22 Ортогонализация nDir по отношению к nUp*
Мы могли бы проделать тоже самое с nUp, но тогда он бы изменил свое направление, что в нашем случае неприемлимо. Теперь нормализуем nDir и получим обновленный ортонормированный базис направления.
Вторым ключевым этапом является построение базиса ориентации. Основную сложность представляет получение вектора направления. наиболее подходящее решение — перевести точку с полярным углом a, азимутным углом b и расстоянием от начала координат равным единице из сферических координат в декартовые. Только если мы осуществим такой переход для точки с полярным углом равным нулю, то получим вектор, смотрящий вверх. Нам это не совсем подходит, так как мы будем инкрементировать углы и предполагаем, что такой вектор будет смотреть вперед. Банальное смещение угла на 90 градусов решит проблему, но более элегантно будет воспользоваться правилом смещения угла, которое гласит, что

так и сделаем. В итоге у нас выходит следующее

где a — полярный угол, b — азимутный угол.
Этот результат нам не совсем подходит — нам нужно построить вектор направления относительно базиса позиции. Давайте перепишем уравнение для vDir:

Все, как у космонавтов — по этому направлению столько, по тому столько. Теперь должно быть очевидно, что если мы заменим векторы стандартного базиса на pDir, pUp и pRight, то получим нужное нам направление. Вот так

Можно представить тоже самое в виде матричного умножения
Вектор vUp изначально будет равен pUp. Вычислив векторное произведение vUp и vDir, мы получим vRight

Теперь мы сделаем так, что бы vUp был ортогональным по отношению к остальным векторам базиса. Принцип тот же, что и при работе с nDir
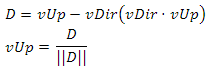
С базисами разобрались — осталось вычислить позицию камеры. Это делается так
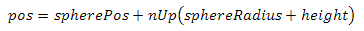
где spherePos — центр сферы, sphereRadius — радиус сферы и height — высота над поверхностью сферы. Приведу код работы описанной камеры:
```
float moveFactor = 0.0f, sideFactor = 0.0f, heightFactor = 0.0f;
DirectInput::GetInsance()->ProcessKeyboardDown({
{DIK_W, [&](){moveFactor = 1.0f;}},
{DIK_S, [&](){moveFactor = -1.0f;}},
{DIK_D, [&](){sideFactor = 1.0f;}},
{DIK_A, [&](){sideFactor = -1.0f;}},
{DIK_Q, [&](){heightFactor = 1.0f;}},
{DIK_E, [&](){heightFactor = -1.0f;}}
});
if(moveFactor != 0.0f || sideFactor != 0.0f){
Vector3 newDir = Vector3::Normalize(pDir * Vector3::Dot(pDir, vDir) +
pRight * Vector3::Dot(pRight, vDir));
Point3F newPos = pos + (newDir * moveFactor + pRight * sideFactor) * Tf * speed;
pDir = newDir;
pUp = Vector3::Normalize(newPos - spherePos);
pRight = Vector3::Normalize(Vector3::Cross(pUp, pDir));
pDir = Vector3::Normalize(pDir - pUp * Vector3::Dot(pUp, pDir));
pos = spherePos + pUp * (sphereRadius + height);
angles.x = 0.0f;
}
if(heightFactor != 0.0f){
height = Math::Saturate(height + heightFactor * Tf * speed, heightRange);
pos = spherePos + pUp * (sphereRadius + height);
}
DirectInput::MouseState mState = DirectInput::GetInsance()->GetMouseDelta();
if(mState.x != 0 || mState.y != 0 || moveFactor != 0.0f || sideFactor != 0.0f){
if(mState.x != 0)
angles.x = angles.x + mState.x / 80.0f;
if(mState.y != 0)
angles.y = Math::Saturate(angles.y + mState.y / 80.0f,
RangeF(-Pi * 0.499f, Pi * 0.499f));
vDir = Vector3::Normalize(pRight * sinf(angles.x) * cosf(angles.y) +
pUp * -sinf(angles.y) +
pDir * cosf(angles.x) * cosf(angles.y));
vUp = pUp;
vRight = Vector3::Normalize(Vector3::Cross(vUp, vDir));
vUp = Vector3::Normalize(vUp - vDir * Vector3::Dot(vDir, vUp));
}
viewMatrix = Matrix4x4::Inverse({{vRight, 0.0f},
{vUp, 0.0f},
{vDir, 0.0f},
{pos, 1.0f}});
```
Обратите внимание, что мы обнуляем angles.x после того, как обновили базис позиции. Это критически важно. Давайте представим, что мы одновременно изменяем угол обзора и перемещаемся по сфере. Сперва мы спроецируем вектор направления на pDir и pRight, получим смещение (newPos) и на его основе обновим базис позиции. Также сработает второе условие, и мы начнем обновлять базис ориентации. Но так как pDir и pRight уже был изменены в зависимости от vDir, то без сброса азимутного угла (angles.x) поворот будет более «крутым»
### Заключение
Я благодарю читателя за проявленный интерес к статье. Надеюсь, что информация, в ней изложенная, была ему доступна, интересна и полезна. Предложения и замечания можете присылать мне по почте [email protected] или оставлять в виде комментариев.
Желаю вам успеха!
**Приложение 1**в поле InstanceDataStepRate содержится информация о том, сколько раз рисовать данные D3D11\_INPUT\_PER\_VERTEX\_DATA для одного элемента D3D11\_INPUT\_PER\_INSTANCE\_DATA. В нашем примере все просто — один к одному. «Но зачем нам рисовать одно и тоже по несколько раз?» — спросите вы. Разумный вопрос. Армянское радио отвечает — предположим, у нас есть 99 шаров трех разных цветов. Мы можем описать вершину таким образом:
```
UINT colorsRate = 99 / 3;
std::vector meta = {
{"POSITION", 0, DXGI\_FORMAT\_R32G32B32\_FLOAT, 0, 0, D3D11\_INPUT\_PER\_VERTEX\_DATA, 0},
{"NORMAL", 0, DXGI\_FORMAT\_R32G32B32\_FLOAT, 0, 12, D3D11\_INPUT\_PER\_VERTEX\_DATA, 0},
{"TEXCOORD", 0, DXGI\_FORMAT\_R32G32\_FLOAT, 0, 24, D3D11\_INPUT\_PER\_VERTEX\_DATA, 0},
{"WORLD", 0, DXGI\_FORMAT\_R32G32B32A32\_FLOAT, 1, 0, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1},
{"WORLD", 1, DXGI\_FORMAT\_R32G32B32A32\_FLOAT, 1, 16, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1},
{"WORLD", 2, DXGI\_FORMAT\_R32G32B32A32\_FLOAT, 1, 32, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1},
{"WORLD", 3, DXGI\_FORMAT\_R32G32B32A32\_FLOAT, 1, 48, D3D11\_INPUT\_PER\_INSTANCE\_DATA, 1},
{"COLOR", 0, DXGI\_FORMAT\_R32G32B32A32\_FLOAT, 2, 0, D3D11\_INPUT\_PER\_INSTANCE\_DATA, colorsRate},
};
```
Обратите внимание, что вершина собирается из трех источников, причем данные последнего обновляются раз в 33 «инстанса». В итоге мы получим 33 инстанса первого цвета, еще 33 — второго и т.д. Теперь создадим буферы. Причем, так как цвета не будут меняться, буфер с цветами можем создать c флагом D3D11\_USAGE\_IMMUTABLE. Это значит, что после того как буфер будет инициализирован, только GPU будет иметь доступ к его данным, при чем только для чтения. Вот код создания буферов:
```
matricesTb = Utils::DirectX::CreateBuffer(sizeof(Matrix4x4) * 99,
D3D11_BIND_VERTEX_BUFFER,
D3D11_USAGE_DYNAMIC,
D3D11_CPU_ACCESS_WRITE);
colorsTb = Utils::DirectX::CreateBuffer(colors,
D3D11_BIND_VERTEX_BUFFER,
D3D11_USAGE_IMMUTABLE,
0);
```
далее по надобности обновляем буфер с матрицами(я использую функции своей библиотеки — надеюсь, что все будет ясно)
```
Utils::DirectX::Map(matricesTb, [&](Matrix4x4 \*Data)
{
//сначала записываем в буфер данные для шаров первого цвета
//затем для второго и т.д. Обратите внимание, что нужное соответсвие
//данных цветам нужно обеспечить на этапе формирования данных буфера
});
```
Доступ к данным в шейдере можно реализовать также, как я описал ранее
**Приложение 2**В отличие от DrawIndexedInstanced() вызов DrawIndexedInstancedIndirect() принимает в качестве аргумента буфер, который содержит всю информацию, которую вы используете для вызова DrawIndexedInstanced(). Причем создавать это буфер надо с флагом D3D11\_RESOURCE\_MISC\_DRAWINDIRECT\_ARGS. Вот пример создания буфера:
```
//indicesCnt - кол-во индексов, которое мы хотим отобразить
//instancesCnt - кол-во "инстансев", которое мы хотим отобразить
std::vector args =
{
indicesCnt, //IndexCountPerInstance
instancesCnt,//InstanceCount
0,//StartIndexLocation
0,//BaseVertexLocation
0//StartInstanceLocation
};
D3D11\_BUFFER\_DESC bd = {};
bd.Usage = D3D11\_USAGE\_DEFAULT;
bd.ByteWidth = sizeof(UINT) \* args.size();
bd.BindFlags = 0;
bd.CPUAccessFlags = 0;
bd.MiscFlags = D3D11\_RESOURCE\_MISC\_DRAWINDIRECT\_ARGS;
bd.StructureByteStride = 0;
ID3D11Buffer\* buffer;
D3D11\_SUBRESOURCE\_DATA initData = {};
initData.pSysMem = &args[0];
HR(DeviceKeeper::GetDevice()->CreateBuffer(&bd, &initData, &buffer));
пример вызова DrawIndexedInstancedIndirect():
DeviceKeeper::GetDeviceContext()->DrawIndexedInstancedIndirect(indirectArgs, 0);
```
вторым аргументом мы передаем смещение в байтах от начала буфера, с которого нужно начинать читать данные. Как это можно использовать? Например, при реализации отсечения невидимой геометрии на GPU. В общем хронология такая — сперва в Compute шейдере мы заполняем AppendStructuredBuffer, который содержит данные видимой геометрии. Затем с помощью CopyStructureCount() мы устанавливаем значение количества «инстансев», которые хотим отбразить равным количеству записей в этом буфере и вызываем DrawIndexedInstancedIndirect()
**Приложение 3**Давайте предположим, что значение координаты х равно результату функции X с аргументом a, а значение координаты z — результату функции Z с тем же аргументом:

Теперь нам нужно для каждой функции вычислить производную. По сути, производная функции в заданной точке равна скорости изменения значений функции именно в этой точке. Согласно правилам дифференцирования тригонометрических функций:
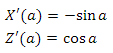
что в итоге дает нам тот же результат:

Почему мы можем использовать значения скорости как компоненты вектора направления? Я понимаю это так. Представьте, что у нас есть векторная функция (для t >= 0):

Вычислим производную для координаты X

Теперь для Y

у нас получилось, что вектор скорости равен (2, 3), теперь найдем начальную точку

в итоге функцию P(t) мы можем выразить так:

что простыми словами можно описать как «точка двигается от начала с координатами (3, 2) на t по направлению (2, 3)». Теперь давайте другой пример:

Снова вычислим производную для координаты X
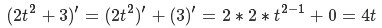
И для координаты Y

Теперь вектор скорости меняется в зависимости от аргумента. В этому случае простыми словами ситуацию можно описать так: «Точка движется от начала с координатами (3, 2), и направление ее движения постоянно меняется».
**Приложение 4**Давайте определим функцию F(H), которая будет принимать высоту в области [Hmin, Hmax] и возвращать значение от 0 до 1, где F(Hmin) = 0 и F(Hmax) = 1. Решив систем уравнений

я получил
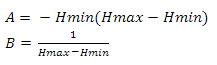
в результате этого функция F приобретает вид

Теперь нам нужна функция, которая принимает коэффициент высоты от 0 до 1 и возвращает минимальное значение для скалярного произведения. Нам надо учесть, что чем ближе наблюдатель к поверхности — тем оно больше. Получается следующее уравнение:

Раскроем скобки

Упростим и получим

Теперь выразим D(F(H)) и получим
 | https://habr.com/ru/post/335588/ | null | ru | null |
# Встречаем третий PowerShell (часть I)
Темпы развития современных технологий таковы, что мы за ними еле-еле поспеваем. Но сегодня мы забежим чуть-чуть вперед, узнаем о новшествах PowerShell v3, причем оглядим их не только глазами, но и пощупаем руками.
##### Стенд
Я собрал под Hyper-V две машины на базе Windows Server 2012 RC, создал лес из одного домена под названием `litware.inc`. Две машины в домене называются, соответственно, `w2012dc1.litware.inc` и `w2012cl1.litware.inc`. На `w2012dc1` вертятся доменные службы и DNS, а на `w2012cl1` не вертится ничего, кроме, собственно, самой операционки. Также в домене есть пользователь `user1`, член группы `domain users`. Можно, конечно, было установить на вторую машину Windows 8 RC, так сказать, для красоты, но я решил сэкономить немножечко дискового пространства, взяв один родительский виртуальный жесткий диск, а к нему прицепив два дочерних вместо использования двух независимых виртуальных жестких дисков.
Также, должен упомянуть, что не все термины, которые я использую, уже локализованы и есть на [языковом портале Microsoft](http://www.microsoft.com/Language), поэтому я даю их перевод ровно так, как я эти термины понимаю, а в скобках даю оригинальное название на английском языке.
##### Новые возможности
Сначала давайте их просто перечислим, это:
* **Рабочие процессы** (англ. *Workflows*) – это некие процессы, запущенные последовательно или же параллельно, выполняющие комплексные задачи управления. Собственно в PowerShell v3 теперь включена поддержка Windows Workflow Foundation, а сами рабочие процессы PowerShell повторяемы, параллелизуемые, прерываемые и восстановимые.
* **Надежные сессии** (англ. *Robust sessions*) – это сессии PowerShell, которые автоматически восстанавливаются после сетевых неурядиц и им подобных прерываний. Также эта технология позволяет отключиться от сессии на одной машине и подключиться к той же сессии на другой.
* **Запланированные задания** (англ. *Scheduled jobs*) – задания PowerShell, которые могут выполняться с определенным интервалом, или же в ответ на какое-либо событие.
* **Специальная конфигурация для сессии** (англ. *Custom session configurations*) – Для каждой PowerShell-сессии можно предопределить определенный набор параметров и сохранить их в специальном конфигурационном файле, чтобы потом войти в сессию на готовеньком.
* **Упрощенный языковой синтаксис** (англ. *Simplified language syntax*) – как утверждается, упрощенный синтаксис позволяет скрипту PowerShell выглядеть менее похожим на программу и более похожим на натуральный человеческий язык.
* **Поиск командлетов** (англ. *Cmdlet discovery*) – автоматическая подгрузка модуля, в котором находится командлет, если этот модуль, конечно, установлен на машину.
* **Show-Command** – это просто один из новых командлетов, с которого мы, пожалуй, и начнем.
##### Show-Command
После его запуска, без параметров, появляется окно, от которого веет грандиозностью и шиком:
Если раньше приходилось искать по TechNet тот или иной командлет, а то и вовсе использовать объекты .NET, то тут вот пожалуйста, все модули, все командлеты, ищи – не хочу.
Вот, извольте, командлеты управления DNS-сервером и службой DNS-клиента, а если выбрать какой-либо модуль, например сетевой, можно узнать командлеты настройки таблицы маршрутизации или, допустим, параметры TCP/IP сетевых интерфейсов.

Также я пробовал поискать слова «share», «user», «acl», «policy», «adapter», и так далее, и тому подобное, попробуйте, это интересно.
##### Cmdlet discovery
Связанное с предыдущим, но напрямую не зависящее. В PowerShell v2 в Windows Server 2008 R2, для того, чтобы производить те или иные операции, необходимо подключать тот или иной модуль, PowerShell v3 же автоматически определяет, какой модуль отвечает за запуск командлета и в фоне этот модуль подгружает, безо всяких вопросов.
Сравним. Я решил получить список групповых политик домена, если я в PowerShell v2 пытаюсь их загрузить:
```
Get-GPO -All | ft Id #Пусть нас просто столбец с Id интересует, без изысков
```
То мы получаем ошибку, потому что не подгружен модуль GroupPolicy:
```
Import-Module GroupPolicy
```
Теперь, если повторить, то все проходит нормально:
В PowerShell v3 же все прекрасно изначально:

##### Simplified language syntax
Тут, как мне показалось, разработчики решили приблизить язык к SQL, ну по крайней мере прослеживается некая аналогия. Дело в том, что они представили новые синтаксисы для командлетов `Foreach-Object` и `Where-Object`. Хотя практическая ценность `Foreach`:
```
Get-Service | Foreach Name
```
вместо
```
Get-Service | Foreach {$_.Name}
```
на мой взгляд, сомнительна.
Другое дело `Where`:
```
Get-Service | Where Status -eq Running
```
вместо
```
Get-Service | Where {$_.Status -eq "Running"}
```
уже ничего, безо всяких скобочек фигурных с долларами-кавычками.
Также появилась пара новых операторов: `-In` и `-NotIn`, указывающие на диапазон. С ними, я думаю, все более, чем понятно:

##### Custom session configurations
Самое замечательное новшество, о котором я хочу рассказать в первой части, это конфигурация сессии в связке с делегированием административных полномочий. Собственно файл с конфигурацией является файлом с расширением .pssc, в котором всего лишь содержится хэш-таблица свойств и значений: авторство, язык, переменные, определения функций, прочее. В самой же конфигурации сессии есть и иные свойства:
```
Get-PSSessionConfiguration | Get-Member
```
Появится картинка, похожая на эту:

Видите сколько настраиваемых параметров? Можно даже сравнить с картинкой, которая появится при запуске этой команды в PowerShell v2 и ощутить разницу.
Но как это использовать? А сейчас покажу, признаться, я достаточно долго ковырялся, чтобы написать вот эти несколько строчек. Итак, последовательно выполняем:
```
$defSSDL = (Get-Item WSMan:\localhost\Service\RootSDDL).Value #Берем SSDL "по умолчанию"
$SecDescriptor = New-Object -TypeName Security.AccessControl.CommonSecurityDescriptor $false, $false, $defSSDL #Создаем дескриптор безопасности
$user = Get-ADUser "user1" #Находим в Active Directory нужного пользователя, но лучше, конечно, полномочия давать группам
$SecDescriptor.DiscretionaryAcl.AddAccess([System.Security.AccessControl.AccessControlType]::Allow, $user.SID.Value, 268435456, [System.Security.AccessControl.InheritanceFlags]::None, [System.Security.AccessControl.PropagationFlags]::None) #Добавляем SID нашего пользователя
$sddl = $SecDescriptor.GetSddlForm("All") #Забираем то, что получилось
$creds = Get-Credential "[email protected]" #Вводим учетные сведения администратора
New-PSSessionConfigurationFile -Path .\DnsRead.pssc -SessionType RestrictedRemoteServer -VisibleCmdlets "Show-DnsServer*" -ModulesToImport DnsServer #Создаем конфигурационный файл
Register-PSSessionConfiguration -Name DnsRead -Path .\DnsRead.pssc -AccessMode Remote -SecurityDescriptorSddl $sddl -RunAsCredential $creds #Регистрируем конфигурацию
```
Заметьте, я ограничил конфигурацию лишь модулем `DnsServer` и лишь командлетами, начинающимися на `Show-DnsServer`, это гарантирует, что хотя сама оболочка и будет выполняться с привилегиями пользователя `[email protected]`, но удаленный пользователь `user1` с удаленной машины `w2012cl1` не сможет сделать ничего, кроме разве что этого:
Удобная штука, правда? Ограничив модули и командлеты внутри PowerShell, мы легко и непринужденно можем внутри нашей команды администраторов одних сотрудников сделать ответственными за DNS, других за сеть, а пользователям, например, дать право делать снэпшоты их машин Hyper-V внутри VDI, и при этом никто не будет знать учетные данные пользователя, из-под которого выполняется задача! А готовый конфигурационный файл просто переносится из одного места на все другие сервера со сходными функциями.
В следующей части мы пойдем далее, а вернее вверх по списку, разберем надежные сессии, запланированные задания и, конечно, рабочие процессы. Ну и, быть может, чуть-чуть коснемся новой PowerShell ISE, там тоже есть, на что посмотреть. | https://habr.com/ru/post/146247/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.