
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Как киту съесть Java-приложение и не подавиться
Здравствуйте, уважаемые хабравчане! Сегодня я хотел бы рассказать о том, как «скормить» Java-приложение докеру, как при этом лучше действовать, а чего делать не стоит. Я занимаюсь разработкой на Java более 10 лет, и последние года три провёл в самом тесном общении с Docker, так что у меня сложилось определённое представление о том, что он может и чего не может. Но ведь гипотезы надо проверять на практике, не так ли?
Я представил весь процесс как старую добрую компьютерную игру с тёплым ламповым пиксель-артом.
Начнем мы, как и полагается любой игре, с некоторого брифинга. В качестве вводной возьмем немного рекламы докера.
На сайте [докера](https://www.docker.com/what-docker) можно ознакомиться с рядом рекламных посулов – а именно, с обещанием увеличить скорость разработки и развертывания аж в ***13*** раз и повысить портативность в разработке (в частности, избавиться о сакраментального «работает на моей машине»). Но соответствует ли это реальности?
Сейчас мы попробуем доказать/опровергнуть эти утверждения.
Level 1
-------
Так как мы находимся в игре, то начнем, как и положено, с самого простого уровня.
Какова наша миссия на первом уровне? Наверное, для многих это что-то очень тривиальное и понятное: мы должны «завернуть» в Docker примитивнейшее Java-приложение.

Для этого нам понадобится простой Java-класс, который выводит сакраментальное *Hello JavaMeetup!* Также для того чтобы создать docker-образ нам понадобится [Dockerfile](https://docs.docker.com/engine/reference/builder/). По синтаксису он предельно прост – в качестве базового образа используем **java:8**, добавляем наш Java-класс (команда **ADD**), компилируем его (при помощи команды **RUN**) и указываем команду, которая выполнится при запуске контейнера (команда **CMD**).
**HelloWorld.java**
```
public class HelloWorld {
public static void main (String[] args) {
System.out.println("Hello World!");
}
}
```
**Dockerfile**
```
FROM java:8
ADD HelloWorld.java .
RUN javac HelloWorld.java
CMD ["java", "HelloWorld"]
```
**Docker commands:**
```
$ docker build -t java-app:demo .
$ docker images
$ docker run java-app:demo
```

Чтобы все это дело собрать, нам понадобится, по сути, одна команда – это **docker build**. При сборке указываем имя нашего образа и тег, который мы ему присваиваем (таким образом мы сможем версионировать различные сборки нашего приложения). Далее убедимся, что мы собрали образ, выполнив команду **docker images**. Для того чтобы запустить наше приложение выполним команду **docker run**.
Ура, всё прошло прекрасно, и мы молодцы… Или нет?

Да, миссию мы выполнили. Но баллы с нас снять есть за что. За что, спросите вы, и как избежать подобных промашек в следующий раз?
* Базовый образ докера, который мы использовали, заявлен как нерекомендуемый (deprecated) и не поддерживается [сообществом докера](https://hub.docker.com/_/java/). Даже на [DockerCon17](https://www.youtube.com/watch?v=yHLAaA4gPxw) многим из мира Java EE знакомый Arun Gupta рекомендовал использовать в качестве базового образа openjdk (на что нам также намекают описание и даты обновлений образов <https://hub.docker.com/_/openjdk/> ).
* Для уменьшения размера лучше использовать образы на основе Alpine – образы на основе данного дистрибутива самые легковесные.
* Компилируем при помощи образа jdk, запускаем с помощью jre (бережем место на диске, оно нам еще понадобится).
Вот теперь, можно считать, первый уровень пройден успешно. Поднимаемся на второй.
*[Полезная ссылка для прохождения первого уровня](https://www.tutorialkart.com/docker/docker-Java-application-example/)*
Level 2
-------
Имея дело с Java, мы, скорее всего, будем использовать Maven или Gradle. Поэтому было бы удобно как-то интегрировать наши системы сборки с Docker, чтобы иметь единую среду для сборки проекта и образов докера.
К счастью для нас, большинство плагинов уже написано — как для Maven, так и для Gradle.

Наиболее популярны плагины Maven для Docker [fabric8io](https://github.com/fabric8io/docker-maven-plugin) и [spotify](https://github.com/spotify/docker-maven-plugin). Для Gradle мы можем использовать плагин Бенджамина Мушко – одного из разработчиков Gradle и автора книги «Gradle in Action».
Чтобы подключить докер в систему сборки приложения, в gradle-конфигурации достаточно создать несколько задач, которые будут собирать и запускать наши контейнеры, а также указать некую общую информацию из разряда — какой образ использовать в качестве базового и какое имя дать собранному образу.
Не будем многословными: возьмём плагин [bmuschko/gradle-docker-plugin](https://github.com/bmuschko/gradle-docker-plugin) и Gradle (поклонники Maven и любители XML, подождите немного!).
Выполним наше первое задание, но теперь с помощью данного плагина. Основные части build.gradle, которые нам понадобятся:
```
docker {
javaApplication {
baseImage = 'openjdk:latest'
tag = 'java-app:gradle'
}
}
task createContainer(type: DockerCreateContainer) {
dependsOn dockerBuildImage
targetImageId { dockerBuildImage.getImageId() }
}
task startContainer(type: DockerStartContainer) {
dependsOn createContainer
targetContainerId { createContainer.getContainerId() }
}
```
Запускаем команду **gradle startContainer** и видим сборку нашего образа и даже запуск контейнера. Но вместо желанного сообщения «Hello JavaMeetup!» получаем уведомление об успешном билде!

Мы где-то ошиблись? Не совсем, просто надо перенаправить вывод нашего контейнера в консоль:
```
task logContainer(type: DockerLogsContainer, dependsOn: startContainer) {
targetContainerId { startContainer.getContainerId() }
follow = true
tailAll = true
onNext {
message -> logger.quiet message.toString()
}
}
```
Запускаем команду **gradle logContainer** и… Ура, заветное сообщение и пройденный уровень.
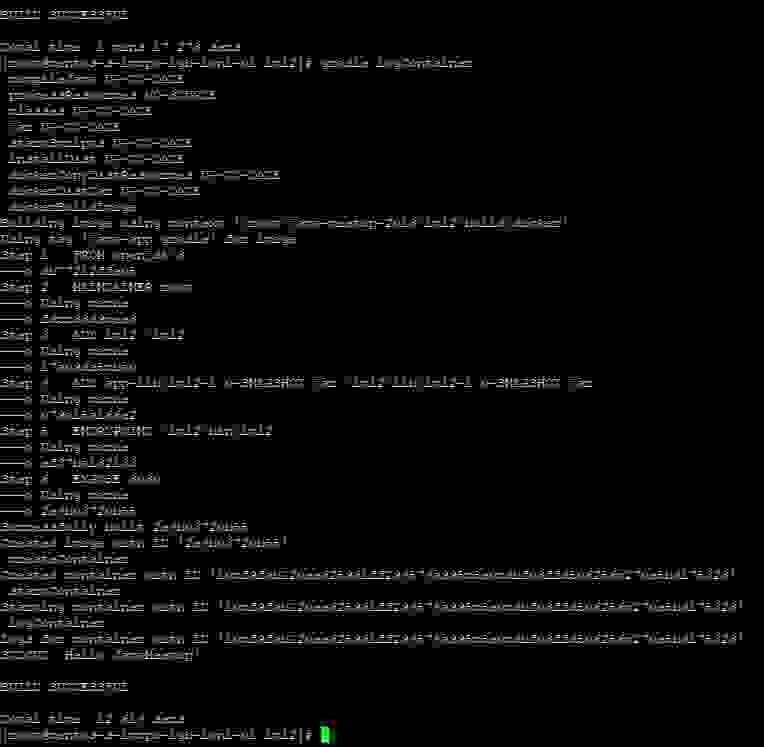
Вот, собственно говоря, и все. Нам даже не нужен Dockerfile (но лишним он не будет — мало ли, Gradle не окажется под рукой).
Двигаемся дальше!
Level 3
-------

Скорее всего, в реальной жизни наше приложение будет делать что-то похитрее, чем вывод на экран «хелло ворлд». Поэтому на следующем уровне мы узнаем, как запустить сложное приложение – Spring веб-приложение, которое выведет нам какие-нибудь записи из базы.
Для того, чтобы поднять базу и само приложение, мы воспользуемся [Docker Compose](https://docs.docker.com/compose/overview/). Для начала создадим новый файл (очередной новый конфигурационный файл, вздохнете Вы, но нас же это не остановит?) – **docker-compose.yml**. В нем мы просто пропишем сервисы для поднятия образа базы и образа приложения. Docker Compose сам найдёт в текущей директории yml-файл и поднимет или соберет нужные нам контейнеры и образы.

Что бы все это дело запустилось, мы предварительно соберем образ. В [данном примере](https://github.com/alexff91/java-meetup-2018/tree/master/lvl3) использован maven-плагин для Docker(ура, XML!) от fabric8io – поэтому для начала выполним команду **mvn install**:
```
io.fabric8
docker-maven-plugin
0.20.1
app
${project.basedir}/src/main/docker
dir
/app
${project.basedir}/src/main/docker/assembly.xml
build
install
build
```
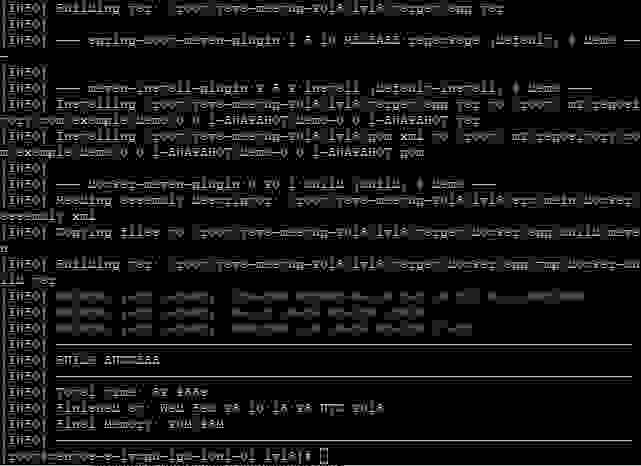
Подождем пока наш проект и образ докера соберутся, перейдем в директорию с yml файликом и запустим команду **docker-compose up -d**.

Проверим, что оба наши контейнера запущены выполнив команду **docker ps**.
Дабы убедиться, что наше веб-приложение работает и достает что-то из базы, мы можем напрямую что-то изменить в базе, а затем перейти по адресу <http://localhost:8080/> и увидеть желаемые данные.
Все это может показаться сложным, но на самом деле оно предельно просто. Третий уровень пройден. Ну, почти.
У нас есть еще бонусный уровень. На нем мы немножко (совсем чуть-чуть) поиграем в Docker Swarm — а если быть точным, то в [Docker Swarm Mode](https://habrahabr.ru/company/redmadrobot/blog/318866/).
Bonus Level
-----------

Docker Swarm Mode не особенно-то сложен – это просто кластер из машинок, на которых стоит Docker. Для пользователя этот кластер выглядит как одна машина, и все команды работают почти так же, как если бы этого Docker Swarm’a не было.
В swarm-режиме можно запускать несколько экземпляров нашего приложения — для распределения нагрузки, например. Также здесь появляется такая абстракция как стек: с помощью Docker Swarm мы можем деплоить целую связку приложений как единое целое. И, аналогично обычному масштабированию, мы можем разворачивать несколько реплик [стека](https://docs.docker.com/engine/swarm/stack-deploy/).
Docker-команды в swarm mode:
```
$ docker service create --name japp --publish 8080:80 --replicas 3 java-app:demo
$ docker stack deploy -c docker-compose.yml javahelloworld
```
По сути, синтаксис команд предельно прост и напоминает создание обычных контейнеров.
Мы можем так же использовать docker compose:
```
$ docker-compose scale jm-app=3
```
Ну что же, за последние три уровня мы вроде как добились портативности java-приложений. Настало время перейти на последний уровень и попробовать подтвердить или опровергнуть утверждение о том, что Docker делает фразу «работает на моей машине» более не актуальной.
Final Level
-----------

Представим, что у нас тяжеловесное приложение. Либо большое количество микросервисов, которые могут находиться на одной машине. В этом случае Java-приложение (если быть точным, то JVM) непременно схватится с нашим маленьким синим китом в борьбе за ресурсы хостовой машины. Об этом, кстати, хорошо рассказано вот в [этой статье](https://habrahabr.ru/company/ruvds/blog/324756/).

На данном уровне будет меньше всего примеров кода, но будут разные конфигурации запуска докер-контейнера. Основными средствами изоляции процессов и ресурсов, используемыми Docker, являются [cgroups](https://en.wikipedia.org/wiki/Cgroups) и [namespaces](https://en.wikipedia.org/wiki/Linux_namespaces). Но основная проблема заключается в том, что джаве на все это немножко по барабану. Она у нас прожорливая и немного жадная, видит, что ресурсов на самом деле больше, даже если мы задаем ограничения по памяти при создании контейнера с java-приложением при помощи флага — memory. В этом можно убедиться просто выполнив команду free внутри контейнера. Отсюда следует довольно общая рекомендация для Java 8 задавать параметр –Xmx, а параметр –memory делать как минимум в два раза большим, чем –Xmx. Приятная новость с полей Java 9 – там поддержку cgroups добавили.

Промоделировать утечку памяти в джаве довольно просто. Мы просто возьмём уже готовый образ **valentinomiazzo/jvm-memory-test** и будем запускать с различными параметрами размера кучи и --memory для докера.
В первом случае памяти контейнеру у нас выдано меньше, чем java приложению, и мы получаем невнятную ошибку. А хотелось бы получить OutOfMemoryException. Если проинспектировать «убитый» контейнер, то можно заметить, что он был убит [OOMKiller](https://linux-mm.org/OOM_Killer), а это может привести к непредсказуемым последствиям, зависанию java-процесса, неправильному закрытию ресурсов и всяким другим обидным вещам (я встречал даже kernel-panic). Не самое приятное, что может случиться.
Повышаем ставки, даем побольше памяти контейнеру. В этот раз можем словить OutOfMemoryException и после инспектирования убедиться, что OOMKiller наш контейнер не трогал, и от всех вышеперечисленных бед мы избавлены.
Последний уровень пройден, попробуем подытожить.
Resume
------
Итак, что же мы получили в результате, пройдя все уровни нашей игры? Что насчёт обещаний Docker свернуть нам горы?
Портативность не так хороша, как нам хотелось бы, но Java 9 вроде как обещает эти проблемы решить. С повышением гибкости все уже поприятнее: с докером мы получаем воспроизводимую конфигурацию окружения в коде, причём недалеко от основного кода. За такими вещами проще следить, нежели за тем, кто, что и когда подправил, заменил или испортил где-то под рутом. Да и в целом можно добиться неплохого сокращения ресурсов за счет возможности запускать множество контейнеров на одной машине — при тестировании это может быть критично.
То есть, я бы сказал, что для тестирования и/или разработки докер подходит идеально. А вот при работе в production нужно быть осторожнее, поскольку нагрузка в этом случае может оказаться гораздо выше. А получить падение по вине докера – это уж совсем неприятно.
Ну и напоследок — те самые флаги, которые нужны для того, чтобы подружить Java 9 с докером!

Game Over
---------
*Полезные ссылки для прохождения последнего уровня:*
<https://hackernoon.com/crafting-perfect-Java-docker-build-flow-740f71638d63>
<https://jaxenter.com/nobody-puts-Java-container-139373.html>
<https://github.com/valentinomiazzo/docker-jvm-memory-test>
**P.S.** Все упомянутые и приведённые выше примеры можно найти здесь:
[github.com/alexff91/Java-meetup-2018](https://github.com/alexff91/Java-meetup-2018) | https://habr.com/ru/post/350138/ | null | ru | null |
# Учебный проект на Python: интерфейс в 40 строк кода (часть 2)
Демонстрация проекта Python с пользовательским интерфейсом никогда не была такой простой. С помощью Streamlit Framework вы можете создавать браузерный пользовательский интерфейс, используя только код Python. В этой статье мы будем создавать пользовательский интерфейс для программы лабиринта, [подробно описанной в предыдущей статье](https://habr.com/ru/company/skillfactory/blog/509304/).
### Streamlit
Streamlit — это веб-фреймворк, предназначенный для исследователей данных для простого развертывания моделей и визуализаций с использованием Python. Это быстро и минималистично, а также красиво и удобно. Есть встроенные виджеты для пользовательского ввода, такие как загрузка изображений, ползунки, ввод текста и другие знакомые элементы HTML, такие как флажки и переключатели. Всякий раз, когда пользователь взаимодействует с потоковым приложением, сценарий python перезапускается сверху вниз, что важно учитывать при рассмотрении различных состояний вашего приложения.
Вы можете установить Streamlit с помощью pip:
```
pip install streamlit
```
И запустите streamlit в скрипте Python:
```
streamlit run app.py
```
### Варианты использования
В [предыдущей статье](https://habr.com/ru/company/skillfactory/blog/509304/) мы создали программу на Python, которая будет проходить лабиринт, учитывая файл изображения и начальное/конечное местоположения. Мы хотели бы превратить эту программу в одностраничное веб-приложение, где пользователь может загрузить изображение лабиринта (или использовать изображение лабиринта по умолчанию), настроить начальное и конечное местоположение лабиринта и увидеть пройденный лабиринт.
Во-первых, давайте создадим пользовательский интерфейс для загрузчика изображений и возможность использовать изображение по умолчанию. Мы можем добавить вывод текста, используя такие функции, как st.write() или st.title(). Мы храним динамически загруженный файл, используя функцию st.file\_uploader(). Наконец, st.checkbox() вернет логическое значение в зависимости от того, установил ли пользователь флажок.
```
import streamlit as st
import cv2
import matplotlib.pyplot as plt
import numpy as np
import maze
st.title('Maze Solver')
uploaded_file = st.file_uploader("Choose an image", ["jpg","jpeg","png"]) #image uploader
st.write('Or')
use_default_image = st.checkbox('Use default maze')
```
Результат:

Затем мы можем вывести наше изображение по умолчанию или загруженное изображение в пригодный для использования формат изображения OpenCV.
```
if use_default_image:
opencv_image = cv2.imread('maze5.jpg')
elif uploaded_file is not None:
file_bytes = np.asarray(bytearray(uploaded_file.read()), dtype=np.uint8)
opencv_image = cv2.imdecode(file_bytes, 1)
```
Как только изображение загружено, мы хотим показать изображение, размеченное с начальной и конечной точками. Мы будем использовать ползунки, чтобы позволить пользователю переместить эти точки. Функция st.sidebar() добавляет боковую панель на страницу, а st.slider() принимает числово в пределах определенного минимума и максимума. Мы можем определить минимальное и максимальное значения слайдера динамически в зависимости от размера нашего изображения лабиринта.
```
if opencv_image is not None:
st.subheader('Use the sliders on the left to position the start and end points')
start_x = st.sidebar.slider("Start X", value= 24 if use_default_image else 50, min_value=0, max_value=opencv_image.shape[1], key='sx')
start_y = st.sidebar.slider("Start Y", value= 332 if use_default_image else 100, min_value=0, max_value=opencv_image.shape[0], key='sy')
finish_x = st.sidebar.slider("Finish X", value= 309 if use_default_image else 100, min_value=0, max_value=opencv_image.shape[1], key='fx')
finish_y = st.sidebar.slider("Finish Y", value= 330 if use_default_image else 100, min_value=0, max_value=opencv_image.shape[0], key='fy')
marked_image = opencv_image.copy()
circle_thickness=(marked_image.shape[0]+marked_image.shape[0])//2//100 #circle thickness based on img size
cv2.circle(marked_image, (start_x, start_y), circle_thickness, (0,255,0),-1)
cv2.circle(marked_image, (finish_x, finish_y), circle_thickness, (255,0,0),-1)
st.image(marked_image, channels="RGB", width=800)
```
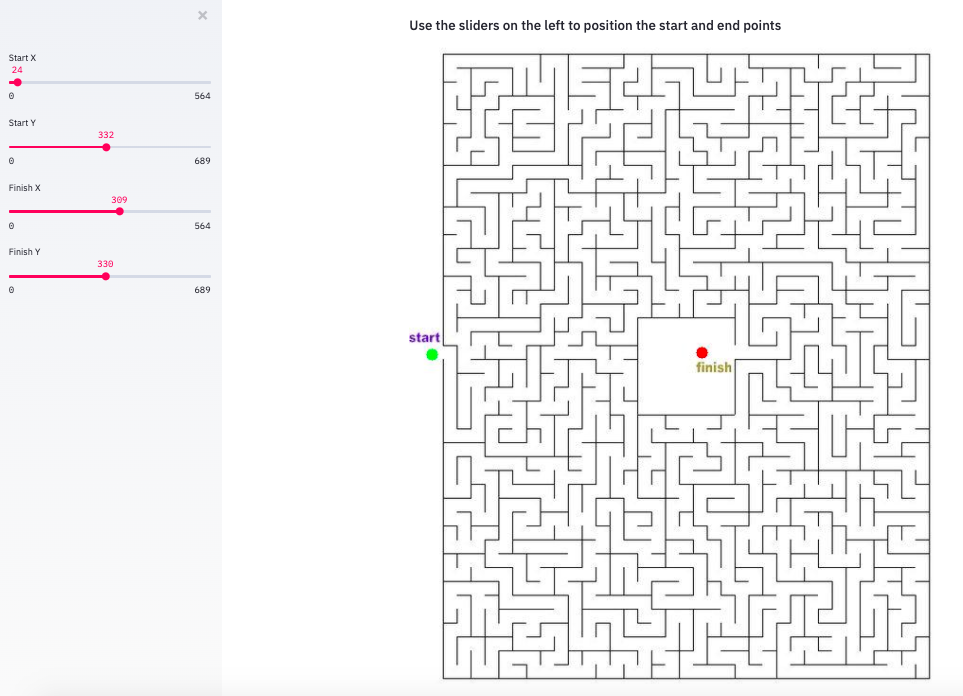
Всякий раз, когда пользователь настраивает ползунки, изображение быстро перерисовывается и точки меняются.
После того, как пользователь определил начальную и конечную позиции, мы хотим кнопку, чтобы решить лабиринт и отобразить решение. Элемент st.spinner () отображается только во время работы его дочернего процесса, а вызов st.image () используется для отображения изображения.
```
if marked_image is not None:
if st.button('Solve Maze'):
with st.spinner('Solving your maze'):
path = maze.find_shortest_path(opencv_image,(start_x, start_y),(finish_x, finish_y))
pathed_image = opencv_image.copy()
path_thickness = (pathed_image.shape[0]+pathed_image.shape[0])//200
maze.drawPath(pathed_image, path, path_thickness)
st.image(pathed_image, channels="RGB", width=800)
```

*Кнопка*
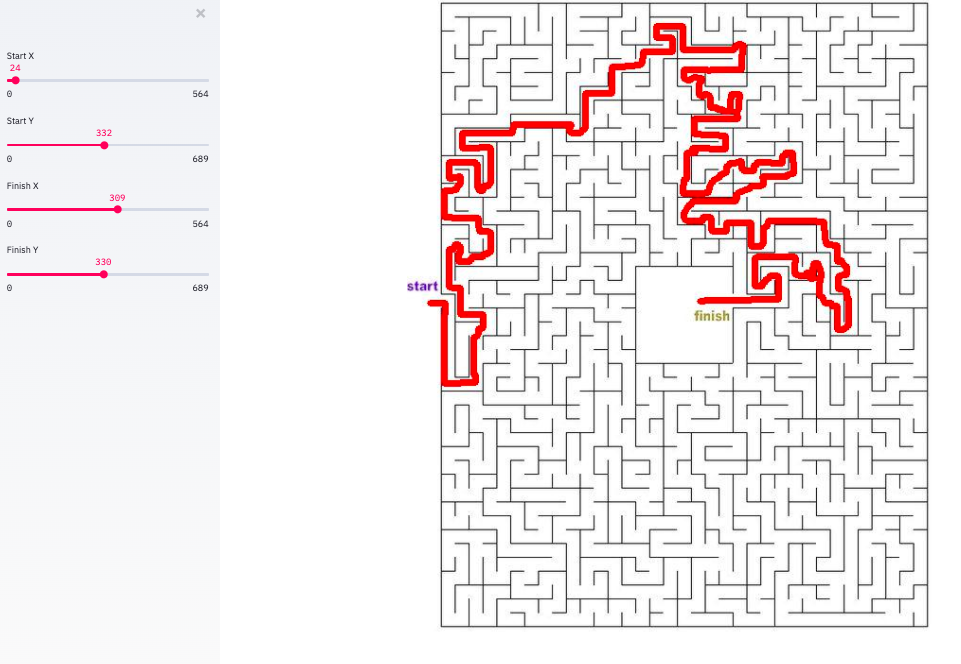
*Вывод решения*
### Вывод
Менее чем в 40 строк кода мы создали простой пользовательский интерфейс для приложения обработки изображений Python. Нам не нужно было писать какой-либо традиционный интерфейсный код. Помимо способности Streamlit переваривать простой код Python, Streamlit интеллектуально перезапускает необходимые части вашего скрипта сверху вниз при каждом взаимодействии пользователя со страницей или при изменении скрипта. Это обеспечивает прямой поток данных и быструю разработку.
Вы можете найти [полный код на Github](https://github.com/maxwellreynolds/Maze/blob/master/ui.py) и первую часть, объясняющую алгоритм решения лабиринта [здесь](https://habr.com/ru/company/skillfactory/blog/509304/). Документация Streamlit, включая важные понятия и дополнительные виджеты находится [здесь](https://docs.streamlit.io/en/stable/).

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=ML&utm_term=regular&utm_content=03072000) (12 недель)
* [Обучение профессии Data Science с нуля](https://skillfactory.ru/data-scientist?utm_source=infopartners&utm_medium=habr&utm_campaign=DST&utm_term=regular&utm_content=03072000) (12 месяцев)
* [Профессия аналитика с любым стартовым уровнем](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=SDA&utm_term=regular&utm_content=03072000) (9 месяцев)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=PWS&utm_term=regular&utm_content=03072000) (9 месяцев)
### Читать еще
* [Тренды в Data Scienсe 2020](https://habr.com/ru/company/skillfactory/blog/508450/)
* [Data Science умерла. Да здравствует Business Science](https://habr.com/ru/company/skillfactory/blog/508556/)
* [Крутые Data Scientist не тратят время на статистику](https://habr.com/ru/company/skillfactory/blog/507052/)
* [Как стать Data Scientist без онлайн-курсов](https://habr.com/ru/company/skillfactory/blog/507024/)
* [Шпаргалка по сортировке для Data Science](https://habr.com/ru/company/skillfactory/blog/506888/)
* [Data Science для гуманитариев: что такое «data»](https://habr.com/ru/company/skillfactory/blog/506798/)
* [Data Scienсe на стероидах: знакомство с Decision Intelligence](https://habr.com/ru/company/skillfactory/blog/506790/) | https://habr.com/ru/post/509340/ | null | ru | null |
# Docker Compose: от разработки до продакшена
***Перевод транскрипции подкаста подготовлен в преддверии старта курса [«Администратор Linux»](https://otus.pw/jHmQ/)***
---

Docker Compose — это удивительный инструмент для создания рабочего
окружения для стека, используемого в вашем приложении. Он позволяет вам определять
каждый компонент вашего приложения, следуя четкому и простому синтаксису в [YAML-
файлах](https://en.wikipedia.org/wiki/YAML).
С появлением [docker compose v3](https://docs.docker.com/compose/compose-file/) эти YAML-файлы могут использоваться непосредственно в рабочей среде, при работе с кластером [Docker Swarm](https://docs.docker.com/engine/swarm/).
Но значит ли это, что вы можете использовать один и тот же docker-compose файл в процессе разработки и в продакшен среде? Или использовать этот же файл для стейджинга? Ну, в целом — да, но для такого функционала нам необходимо следующее:
* Интерполяция переменных: использование переменных среды для некоторых
значений, которые изменяются в каждой среде.
* Переопределение конфигурации: возможность определить второй (или любой
другой последующий) docker-compose файл, который что-то изменит относительно
первого, и docker compose позаботится о слиянии обоих файлов.
Различия между файлами для разработки и продакшена
--------------------------------------------------
Во время разработки вы, скорее всего, захотите проверять изменения кода в
режиме реального времени. Для этого, обычно, том с исходным кодом монтируется в
контейнер, в котором находится рантайм для вашего приложения. Но для продакшн-среды
такой способ не подходит.
В продакшене у вас есть кластер с множеством узлов, а том является локальным по
отношению к узлу, на котором работает ваш контейнер (или сервис), поэтому вы не
можете монтировать исходный код без сложных операций, которые включают в себя
синхронизацию кода, сигналы и т. д.
Вместо этого мы, обычно, хотим создать образ с конкретной версией вашего кода.
Его принято помечать соответствующим тегом (можно использовать семантическое
версионирование или другую систему на ваше усмотрение).
Переопределение конфигурации
----------------------------
Учитывая различия и то, что ваши зависимости могут отличаться в сценариях
разработки и продакшена, ясно, что нам потребуются разные конфигурационные файлы.
Docker compose поддерживает объединение различных compose-файлов для
получения окончательной конфигурации. Как это работает можно увидеть на примере:
```
$ cat docker-compose.yml
version: "3.2"
services:
whale:
image: docker/whalesay
command: ["cowsay", "hello!"]
$ docker-compose up
Creating network "composeconfigs_default" with the default driver
Starting composeconfigs_whale_1
Attaching to composeconfigs_whale_1
whale_1 | ________
whale_1 | < hello! >
whale_1 | --------
whale_1 | \
whale_1 | \
whale_1 | \
whale_1 | ## .
whale_1 | ## ## ## ==
whale_1 | ## ## ## ## ===
whale_1 | /""""""""""""""""___/ ===
whale_1 | ~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
whale_1 | \______ o __/
whale_1 | \ \ __/
whale_1 | \____\______/
composeconfigs_whale_1 exited with code 0
```
Как было сказано, docker compose поддерживает объединение нескольких compose-
файлов, это позволяет переопределять различные параметры во втором файле. Например:
```
$ cat docker-compose.second.yml
version: "3.2"
services:
whale:
command: ["cowsay", "bye!"]
$ docker-compose -f docker-compose.yml -f docker-compose.second.yml up
Creating composeconfigs_whale_1
Attaching to composeconfigs_whale_1
whale_1 | ______
whale_1 | < bye! >
whale_1 | ------
whale_1 | \
whale_1 | \
whale_1 | \
whale_1 | ## .
whale_1 | ## ## ## ==
whale_1 | ## ## ## ## ===
whale_1 | /""""""""""""""""___/ ===
whale_1 | ~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
whale_1 | \______ o __/
whale_1 | \ \ __/
whale_1 | \____\______/
composeconfigs_whale_1 exited with code 0
```
Такой синтаксис не очень удобен в процессе разработки, когда команду
понадобится выполнять множество раз.
К счастью, docker compose автоматически ищет специальный файл с именем
**docker-compose.override.yml** для переопределения значений **docker-compose.yml**. Если
переименовать второй файл, то получится тот же результат, только с помощью изначальной команды:
```
$ mv docker-compose.second.yml docker-compose.override.yml
$ docker-compose up
Starting composeconfigs_whale_1
Attaching to composeconfigs_whale_1
whale_1 | ______
whale_1 | < bye! >
whale_1 | ------
whale_1 | \
whale_1 | \
whale_1 | \
whale_1 | ## .
whale_1 | ## ## ## ==
whale_1 | ## ## ## ## ===
whale_1 | /""""""""""""""""___/ ===
whale_1 | ~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
whale_1 | \______ o __/
whale_1 | \ \ __/
whale_1 | \____\______/
composeconfigs_whale_1 exited with code 0
```
Хорошо, так запомнить проще.
#### Интерполяция переменных
Файлы конфигурации поддерживают [интерполяцию
переменных](https://docs.docker.com/compose/compose-file/#variable-substitution) и значения по умолчанию. То есть вы можете сделать следующее:
```
services:
my-service:
build:
context: .
image: private.registry.mine/my-stack/my-service:${MY_SERVICE_VERSION:-latest}
...
```
И если вы выполняете **docker-compose build (или push)** без переменной окружения
**$MY\_SERVICE\_VERSION**, будет использовано значение *latest*, но если вы установите
значение переменной окружения до сборки, оно будет использовано при сборке или пуше
в регистр **private.registry.mine**.
Мои принципы
------------
Подходы, которые удобны для меня, могут пригодиться и вам. Я следую этим
простым правилам:
* Все мои стеки для продакшена, разработки (или других сред) определяются через
файлы docker-compose.
* Файлы конфигурации, необходимые для охвата всех моих сред, максимально
избегают дублирования.
* Мне нужна одна простая команда для работы в каждой среде.
* Основная конфигурация определяется в файле **docker-compose.yml**.
* Переменные среды используются для определения тегов образов или других
переменных, которые могут меняться от среды к среде (стейджинг, интеграция,
продакшен).
* Значения переменных для продакшена используются в качестве значений по
умолчанию, это минимизирует риски в случае запуска стека в продакшене без
установленной переменной окружения.
* Для запуска сервиса в продакшен-среде используется команда **docker stack deploy — compose-file docker-compose.yml --with-registry-auth my-stack-name**.
* Рабочее окружение запускается с помощью команды **docker-compose up -d**.
Давайте посмотрим на простой пример.
```
# docker-compose.yml
...
services:
my-service:
build:
context: .
image: private.registry.mine/my-stack/my-service:${MY_SERVICE_VERSION:-latest}
environment:
API_ENDPOINT: ${API_ENDPOINT:-https://production.my-api.com}
...
```
И
```
# docker-compose.override.yml
...
services:
my-service:
ports: # This is needed for development!
- 80:80
environment:
API_ENDPOINT: https://devel.my-api.com
volumes:
- ./:/project/src
...
```
Я могу использовать **docker-compose (docker-compose up)**, чтобы запустить стек в
режиме разработки с исходным кодом, смонтированным в **/project/src**.
Я могу использовать эти же файлы на продакшене! И я мог бы использовать точно
такой же файл **docker-compose.yml** для стейджинга. Чтобы развернуть это на
продакшен, мне просто нужно собрать и отправить образ с предопределенным тегом
на этапе CI:
```
export MY_SERVICE_VERSION=1.2.3
docker-compose -f docker-compose.yml build
docker-compose -f docker-compose.yml push
```
На продакшене это можно запустить с помощью следующих команд:
```
export MY_SERVICE_VERSION=1.2.3
docker stack deploy my-stack --compose-file docker-compose.yml --with-registry-auth
```
И если вы хотите сделать то же самое на стейдже, необходимо просто определить
необходимые переменные окружения для работы в среде стейджинга:
```
export MY_SERVICE_VERSION=1.2.3
export API_ENDPOINT=http://staging.my-api.com
docker stack deploy my-stack --compose-file docker-compose.yml --with-registry-auth
```
В итоге мы использовали два разных docker-compose файла, которые без
дублирования конфигураций могут использоваться для любой вашей среды!
---
***Узнать подробнее о курсе [«Администратор Linux»](https://otus.pw/jHmQ/)***
--- | https://habr.com/ru/post/512404/ | null | ru | null |
# Решение задания с pwnable.kr 08 — leg, и 10 — shellshock. ARM ассемблер. Уязвимость bash

В данной статье вспомним синтаксис ARM ассемблера, разберемся с уязвимостью shellshock, а также решим 8-е и 10-е задания с сайта [pwnable.kr](https://pwnable.kr/index.php).
**Организационная информация**Специально для тех, кто хочет узнавать что-то новое и развиваться в любой из сфер информационной и компьютерной безопасности, я буду писать и рассказывать о следующих категориях:
* PWN;
* криптография (Crypto);
* cетевые технологии (Network);
* реверс (Reverse Engineering);
* стеганография (Stegano);
* поиск и эксплуатация WEB-уязвимостей.
Вдобавок к этому я поделюсь своим опытом в компьютерной криминалистике, анализе малвари и прошивок, атаках на беспроводные сети и локальные вычислительные сети, проведении пентестов и написании эксплоитов.
Чтобы вы могли узнавать о новых статьях, программном обеспечении и другой информации, я создал [канал в Telegram](https://t.me/RalfHackerChannel) и [группу для обсуждения любых вопросов](https://t.me/RalfHackerPublicChat) в области ИиКБ. Также ваши личные просьбы, вопросы, предложения и рекомендации [рассмотрю лично и отвечу всем](https://t.me/hackerralf8).
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Решение задания leg
-------------------
Нажимаем на первую иконку с подписью leg, и нам говорят, что нужно подключиться по SSH с паролем guest. Так же предоставляют исходный код на C и ассемблере.

Давайте скачаем оба файла и посмортим исходный код на языке C. По ассемблерным вставкам можно сказать, что использует синтаксис ARM. Про ARM ассемблер на Хабре писали [тут](https://habr.com/ru/post/133808/) и [тут](https://habr.com/ru/post/188712/).

В функции main() от пользователя принимается число и сравнивается с суммой результатов трех функций key(). Разберем их по порядку.

Таким образом в регистр R3 помещается значение из регистра PC. В ARM ассемблере регистр PC содержит адрес следующей инструкции, которая должна быть выполнена. Смотрим дизассемблированный код.

Таким образом, функция key1() вернет значение 0x8ce4. Разберем функцию key2().

В R3 помещается 0x8d08, которое потом увеличивается на 4 и записывается в регистр R0. То есть key2() вернет 0x8d0c. Рассмотрим key3().

По аналогии с первой функцией делаем вывод, что key3() вернет значение из регистра LR. LR содержит адрес возврата функции. Посмотрим, где вызывается функция и возьмем следующий адрес.

Функция key3() вернет 0x8d80. Подключимся по SSH и введем в программу сумму трех найденных чисел.

Сдаем флаг и получаем два очка.
Shellshock aka Bashdoor
-----------------------
Shellshock (Bashdoor) — программная уязвимость, обнаруженная в программе GNU Bash, которая позволяет исполнять произвольные команды при получении некоторых нестандартных значений переменных окружения. Уязвимость получила номер CVE-2014-6271.
В Unix-подобных операционных системах каждая программа имеет переменными среды. Дочерний процесс наследует у родительского список переменных среды. Кроме переменных среды, bash также поддерживает внутренний список функций — именованных скриптов, которые могут вызываться из исполняемого скрипта. При запуске скриптов из других (родительских) скриптов возможен экспорт значений существующих переменных окружения и определений функций. Определения функций экспортируются путём кодирования их в виде новых переменных окружения специального формата, начинающегося с пустых скобок «()», за которыми следует определение функции в виде строки. Новые экземпляры bash при своем запуске сканируют все переменные среды, детектируя данный формат и преобразовывая его обратно в определение внутренней функции. Таким образом, если злоумышленник имеет возможность подать произвольную переменную среды в запуск bash, то появляется возможность исполнения произвольных команд.
Следующий пример напечатает текст VULN.
```
env x=’() { : ; }; echo “VULN”’ bash -c “echo text”
```
Так как при выполнении команды “echo text” будет загружено определение функции, содержащееся в переменной окружения x, а с ним выполнена команда ‘echo “VULN”’.
Решение задания shellshock
--------------------------
Нажимаем на первую иконку с подписью shellshock, и нам говорят, что нужно подключиться по SSH с паролем guest.
При подключении мы видим соответствующий баннер.
Давайте узнаем, какие файлы есть на сервере, а также какие мы имеем права.

Давай просмотрим исход код.

Интерес вызывает строка с вызовом функции system. Исходя из названия, предполагаем, что bash, который находится рядом с программой и вызывается из программы, уязвим. По аналогии с описанной в статье атакой, выполним команду чтения флага.
```
/bin/cat flag
```
Для этого определим функцию в переменной окружения, куда поместим эту команду. А потом запустим программу.
```
export x="() { :; }; /bin/cat flag;"
```

Сдаем флаг и получаем еще одно очко. До встречи в следующей статье.
Мы в телеграм канале: [канал в Telegram](https://t.me/RalfHackerChannel). | https://habr.com/ru/post/461269/ | null | ru | null |
# CSS 3D эффекты

Стивен Виттенс переработал свой сайт Acko.net. Виттенс применил 3D функции CSS 3 и небольшую часть JavaScript для создания ошеломляющего 3D заголовка страницы.
Чтобы увидеть 3D в действии вам надо использовать браузер WebKit (Safari или Chrome) т.к. пока только они поддерживают CSS 3D эффекты. В других браузерах, которые еще не поддерживают 3D эффекты сайт все равно нормально просматривается. Чтобы увидеть полный 3D эффект обязательно прокрутите страницу.
Виттенс в [своем блоге](http://acko.net/blog/making-love-to-webkit/) подробно написал как он создал 3D эффекты и даже сделал 3D редактор, с которым вы можете [поиграть](http://acko.net/editor.html).

Чтобы обойти некоторые ограничения CSS в браузерах Виттенс применил [Three.js](https://github.com/mrdoob/three.js/) — JavaScript 3D библиотека, написана Рикардо Кабелло (его знаменитый проект [Harmony](http://mrdoob.com/projects/harmony/)). Для тех кто заинтересован в исходных кодах некоторых преобразований на Acko.net, Виттенс пообещал выпустить его на GitHub в ближайшее время.
Потестить можно с этим кодом:
```
try{Typekit.load();}catch(e){}
<h1 class="site-name">Habrahabr</h1>
```
~~CSS код в нормальном виде можно взять [здесь](http://acko.net/cache/combo.css), JS [здесь](http://acko.net/cache/combo.js).~~
**UPD:** Перезалил полную версию CSS — [forum.xeksec.com/habr/3d/combo.css](http://forum.xeksec.com/habr/3d/combo.css)
JS — [forum.xeksec.com/habr/3d/combo.js](http://forum.xeksec.com/habr/3d/combo.js) | https://habr.com/ru/post/136475/ | null | ru | null |
# Киллер игорных слотов в браузере своими руками для хабровцев
Здравствуйте!
Я вот заметил, что почти любой софт имеется платный и бесплатный. Но я не видел чтобы был какой-нибудь движок для казино в свободном доступе. Но я это не гуглил, может и имеется. Но что толку если Вы сами не попробовали это сделать? Если не хватает знаний и сил - то дерзайте, покупайте или скачивайте пиратский софт (библиотеку или движок), но мне на разбор чужого детища не хватает сил, да и я никогда таким не занимался. Сейчас уже такое время, что людям трудно даже программу установить на ПК или смартфон, а может разучились и не знают что так можно? Мельчают юзеры, да к тому же печатные машинки сейчас наверное остались только у разработчиков. Везде смартфоны - на андроиде или IOS, но они радуют поддержкой веб-технологий в своих браузерах. Просто открыл сайт и вуаля! Играй не хочу или сёрфь интернет, что-то смотри, читай. Не знаю как сейчас пользователи гаджетов и ПК занимают своё свободное время, как я понял сидят в соцсетях судя по количеству интернет трафика. Но это дело избранных, а тем кому не повезло в жизни ищут как бы заработать. Я кокрас из таких. Насколько я знаю заработать можно своим делом или работая на кого-то. Если рассматривать обычных людей, а не айтишников, то выбор не большой. Смотреть рекламу за копейки, разносить закладки(если понимаете), постить рекламу на всяких сайтах, раскачивать персов в играх на продажу, в случае если ничего не умеете конечно, есть конечно там перепродажа всякой всячины, стать блогером и(или) ютубером, про работу в оффлайне не говорю и наше любимое-вечное: покер и казино. А конкретно слоты - это "однорукий бандит"(запрещены в РФ, если на деньги конечно, да и не только в РФ). Я за всю жизнь играл в них раз, один раз за день когда их запретили в РФ проиграл где-то 3000 рублей ставя на гонку собак.. Это конечно меня разозлило и я решил нанести удар по индустрии. Конечно удар муравьиный, но начало положено.
Немного теории.
Я конечно своими словами.
Игровой автомат - это математическая функция которая возвращает вероятность выигрыша от стоимости хода и бюджета.
Можно даже перефразировать возвращает число у.е. выигрыша в зависимости остался у вас бюджет для получения текущего хода.
То есть, если
Зависит от функции BlackBox, обычно 51 раз выигрывает казино, а 49 раз игрок. Иначе просто разорится крупье. Но бывает, что казино может 100 раз выиграть, а игрок 0. Так что рано радоваться. Конечно если казино грабит игроков, то это сразу заметно и негативный отзыв тут же сделает свое дело. Именно поэтому они меняют адреса(в сети) и добавляют новые "одежды" для слотов, а бывает что и меняют название фирм. Короче дурят как хотят, но что если в сети появятся много сайтов и начнут отъедать у монополистов аудиторию? Конкуренция, что тогда? Если каждому кто захочет склепать сайт например со слотом хотя бы одним, то начнется хаос. Правда тут еще не сильно сделано все. Но я просто хотел привлечь внимание к проблеме. Вернемся к теории, если 0.49\*0.49(умножение вероятностей выигрыша игрока означает вероятность выигрыша игрока подряд для 2х ходов) и так далее
Запомните хотя бы общее правило, предел функции(последовательности) при шагах стремящихся к бесконечности равен 0.(То есть чем дольше играем тем больше проиграем(выигрыш 0)).
```
if(budget - price>=0)
{
step++;
budget -= price;
Win = BlackBox(step,budget,price);
}
else
alert("Пополните счет!");
```
Но этот алгоритм, выше скорее всего остановит Вас раньше.
Теперь рассмотрим проект сам.
Всего 2 играющих символа - буква F и звездочка. Минимальный функционал, по нажатию мышкой или тап с телефона по игровому экрану приведёт к вращению("спину") барабана, через некоторое время он остановится. Во время "спина" происходит смена символов на барабане. Задаются символы генератором случайных чисел. Работает в телефоне(в браузере) и на компьютере. Если у кого IOS, MacOS отпишитесь работает ли?
Не знаю сработает ли медиафайл на странице Хабра, так что продублирую [ссылкой](https://codepen.io/Gremlin_Rage/pen/poPqmxY)
Благодарю за внимание! | https://habr.com/ru/post/665748/ | null | ru | null |
# Работаем с долгими API в ASP.NET Core правильно или тонкости переезда на новую платформу
Microsoft очень постарался, создавая новую платформу для веб-разработки. Новый ASP.NET Core похож на старенький ASP.NET MVC только, быть может, самой MVC-архитектурой. Ушли сложности и привычные вещи из старой платформы, появился встроенный DI и легковесные view-компоненты, HTTP модули и хэндлеры уступили место middleware и т.д. Вкупе с кроссплатформенностью и хорошей производительностью всё это делает платформу очень привлекательной для выбора. В этой статье я расскажу, как мне удалось решить специфическую задачу логирования длительных запросов к сторонним API для повышения удобства анализа инцидентов.
Вместо вступления...
--------------------
В дипломах и диссертациях где-то в начале обычно должна формулироваться проблема. Но то, что я опишу ниже, скорее даже не проблема, а стремление сделать приложение юзабельнее и окружающий мир немножечко прекраснее. Это один из тех моментов в моей жизни, где я спрашиваю себя, а можно ли сделать лучше? А после этого пытаюсь найти способы это сделать. Иногда у меня это получается, иногда я понимаю, что сделать лучше либо невозможно, либо на это стоит затратить столько усилий, что это в конечном итоге потеряет всякий смысл. В конце концов, это ~~не перевернет мир и не решит проблему бедности на планете~~ не то, на что стоит тратить свои силы и время. Но так или иначе, я получаю из этого какой-то опыт, который не может не пригодиться в будущем. В этой статье я опишу то, что мне кажется, у меня получилось сделать лучше.
Формулировка задачи
-------------------
Начну с того, что компания, где я работаю, занимается разработкой высоконагруженных сайтов. Приложения, над которыми на текущий момент мне удалось потрудиться, по своей большей части, являются неким прикрытым авторизацией интерфейсом доступа к внутренним АПИ заказчика. Логики там немного и она распределена примерно в равных пропорциях между frontend'ом и backend'ом. Большинство ключевой бизнес-логики лежит именно в этих АПИ, а сайты, видимые конечному клиенту, являются их консьюмерами.
Иногда получается так, что сторонние по отношению к сайту API отвечают на запросы пользователя весьма продолжительное время. Иногда это временный эффект, иногда постоянный. Так как приложения по природе своей — высоконагруженные, нельзя допустить, чтобы запросы пользователя находились в подвисшем состоянии долгое время, иначе это может грозить нам постоянно увеличивающимся количеством открытых сокетов, быстро пополняющуюся очередь не отвеченных запросов на сервере, а ещё — большим количеством клиентов, волнующихся и переживающих, почему их любимый сайт открывается так долго. С API мы ничего сделать не можем. И в связи с этим с очень давних времен у нас на балансировщике было введено ограничение на длительность выполнения запроса, равное 5 секундам. Это в первую очередь накладывает ограничения на архитектуру приложения, так как подразумевает ещё больше асинхронного взаимодействия, вследствие чего решает вышеописанную проблему. Сам сайт открывается быстро, а уже на открытой странице крутятся индикаторы загрузки, которые в конце концов выдадут какой-то результат пользователю. Будет это тем, что пользователь ожидает увидеть, или же ошибкой уже не играет большого значения, и это будет уже совсем другой историей…
**Совсем другая история**[](https://imgbb.com/)
Внимательный читатель заметит: но если ограничение стоит на все запросы, то оно ведь распространяется и на AJAX-запросы тоже. Все правильно. Я вообще не знаю способа отличить AJAX-запрос от обычного перехода на страницу, 100% работающего во всех случаях. Поэтому долгие AJAX-запросы реализуются по следующему принципу: с клиента мы делаем запрос на сервер, сервер создает Task и ассоциирует с ним определенный GUID, затем возвращает этот GUID клиенту, а клиент получает результат по данному GUID, когда он придет на сервер от API. На этом этапе мы почти подобрались к сути моей ~~надуманной проблемы~~ задачи.
Все запросы и ответы к этим API мы должны логировать и хранить для разбора полетов, а из логов мы должны получать максимум полезной информации: вызванный action/controller, IP, URI, логин пользователя и т.д. и т.п. Когда же я в первый раз с помощью NLog'а залогировал свой запрос/ответ в моем ASP.NET Core приложении, то в принципе я не удивился, увидев в ElasticSearch что-то вроде:
`2017-09-23 23:15:53.4287|0|AspNetCoreApp.Services.LongRespondingService|TRACE|/| DoJob method is starting (AspNetCoreApp.Services.LongRespondingService.DoJob:0)| url:http:///`
В то же время в конфигурации NLog все выглядело достаточно правильно и в качестве layout было установлено следующее:
`${longdate}|${event-properties:item=EventId.Id}|${logger}|${uppercase:${level}}|${aspnet-mvc-controller}/${aspnet-mvc-action}| ${message} (${callsite}:${callsite-linenumber})| url:${aspnet-request-url}`
Проблема здесь в том, что ответ от API приходит уже после окончания выполнения запроса клиентом (ему то возвращается всего лишь GUID). Вот тут то я и начал думать о возможных способах решения этой проблемы…
Возможные решения проблемы
--------------------------
Конечно, любую проблему можно устранить несколькими способами. Причем забить на нее — тоже один из приёмов, которым иногда не стоит пренебрегать. Но поговорим всеж-таки о реальных способах решения и их последствиях.
### Передавать ID задачи в метод обращения к API
Наверное, это первое, что только может прийти в голову. Мы генерируем GUID, логируем этот GUID еще до выхода из action'а и передаем его в сервис работы с API.
Проблемы этого подхода — очевидны. Мы должны передавать этот ID в абсолютно все методы обращения к сторонним API. При этом, если мы захотим переиспользовать данный кусочек где-то еще, где такая функциональность не требуется, то нам это очень сильно будет мешать.
Ситуация усугубляется, если перед отдачей данных клиенту, мы хотим их каким-то образом обработать, упростить или агрегировать. Это относится к бизнес-логике и ее следует вынести в отдельный кусочек. Получается, что этот кусочек, который должен оставаться максимально независимым, будет тоже работать с этим идентификатором! Так дела не делаются, поэтому рассмотрим другие способы.
### Сохранить ID задачи в CallContext
Если мы подумаем, какие средства нам предоставляет фрэймворк для этих целей, то первым делом вспомним про CallContext с его LogicalSetData/LogicalGetData. Используя эти методы, можно сохранить ID задачи в CallContext'e, а .NET (лучше сказать, .NET 4.5) сам позаботится о том, чтобы новые потоки автоматически получили доступ к этим же данным. Внутри фрэймворка это реализуется с помощью паттерна, чем-то напоминающего Memento, который должны использовать все методы запуска нового потока/задачи:
```
// Перед запуском задачи делаем snapshot текущего состояния
var ec = ExecutionContext.Capture();
...
// Разворачиваем сохраненный snapshot в новом потоке
ExecutionContext.Run(ec, obj =>
{
// snapshot на этом этапе уже развернут, поэтому здесь вызывается уже пользовательский код
}, state);
```
Теперь когда мы знаем, как сохранить ID, а затем получить его в нашей task'е, мы можем в каждое наше логируемое сообщение, включить этот идентификатор. Можно сделать это непосредственно при вызове метода логирования. Или, чтобы не засорять слой доступа к данным, можно использовать возможности вашего логгера. В NLog, например, есть [Layout Renderers](https://github.com/nlog/nlog/wiki/Layout-Renderers).
Также в крайнем случае можно написать свой логгер. В ASP.NET Core всё логирование осуществляется с помощью специальных интерфейсов, расположенных в пространстве имен Microsoft.Extensions.Logging, которые внедряются в класс посредством DI. Поэтому нам достаточно реализовать два интерфейса: ILogger и ILoggerProvider. Думаю, такой вариант может оказаться полезным, если ваш логгер не поддерживает расширения.
А чтобы все получилось так, как надо, рекомендую ознакомиться со [статьей Stephen'а Cleary](https://blog.stephencleary.com/2013/04/implicit-async-context-asynclocal.html). В ней нет привязки к .NET Core (в 2013 году его просто-напросто еще не было), но что-то полезное для себя там точно можно подчеркнуть.
Недостаток данного подхода в том, что в лог будут попадать сообщения с идентификатором и чтобы получить полную картину нужно будет искать HTTP-запрос с этим же ID. Про производительность я промолчу, так как, даже если и будет какая-та просадка, то по сравнению с другими вещами это будет казаться несоизмеримо малым значением.
### А что, если подумать, почему это не работает?
Как я уже говорил, в лог к нам сыпятся сообщения вида:
`2017-09-23 23:15:53.4287|0|AspNetCoreApp.Services.LongRespondingService|TRACE|/| DoJob method is starting (AspNetCoreApp.Services.LongRespondingService.DoJob:0)| url:http:///`
Т.е. все, что связано с IHttpContext просто зануляется. Оно вроде как и понятно: выполнение запроса то закончилось, поэтому NLog и не может получить данные, т.е. ссылки на HttpContext просто уже нет.
Наконец-то, я решил посмотреть, а как собственно NLog получает ссылку на HttpContext вне контроллера. Так как с SynchronizationContext'ом и HttpContext.Current в .NET Core [было покончено](https://blog.stephencleary.com/2017/03/aspnetcore-synchronization-context.html) (да, это снова Stephen Cleary), значит должен быть какой-то другой способ это сделать.
Поковырявшись в исходниках NLog, я нашел некий [IHttpContextAccessor](https://docs.microsoft.com/ru-ru/dotnet/api/Microsoft.AspNetCore.Http.IHttpContextAccessor?view=aspnetcore-2.0). Жажда понять, что все таки здесь происходит, заставила меня снова залезть в GitHub и посмотреть, что же представляет из себя эта магическая штука с одним свойством. Оказалось, что это просто [абстракция над AsyncLocal](https://github.com/aspnet/HttpAbstractions/blob/rel/2.0.0/src/Microsoft.AspNetCore.Http/HttpContextAccessor.cs), который по сути является новой версией LogicalCallContext (те самые методы LogicalSetData / LogicalGetData). Кстати, для .NET Framework'а так было [не всегда](https://github.com/aspnet/HttpAbstractions/blob/rel/1.1.2/src/Microsoft.AspNetCore.Http/HttpContextAccessor.cs).
После этого я задал себе вопрос: а почему собственно тогда это не работает? Мы запускаем Task стандартным способом, никакого неуправляемого кода тут нет… Запустив дебаггер, чтобы посмотреть, что происходит с HttpContext в момент вызова метода логирования, я увидел, что HttpContext есть, но свойства в нем все обнулены за исключением Request.Scheme, которое в момент вызова равно «http». Вот и получается, что в логе у меня вместо урла — странное "`http:///`".
Итак, получается, что в целях повышения производительности ASP.NET Core где-то внутри себя обнуляет HttpContext'ы и переиспользует их. Видимо, такие тонкости вкупе и позволяют достичь значительного преимущества по сравнению со стареньким ASP.NET MVC.
Что же я мог с этим сделать? Да просто сохранить текущее состояние HttpContext'а! Я написал простой сервис с единственным методом CloneCurrentContext, который я зарегистрировал в DI-контейнере.
**HttpContextPreserver**
```
public class HttpContextPreserver : IHttpContextPreserver
{
private readonly IHttpContextAccessor _httpContextAccessor;
ILogger _logger;
public HttpContextPreserver(IHttpContextAccessor httpContextAccessor, ILogger logger)
{
\_httpContextAccessor = httpContextAccessor;
\_logger = logger;
}
public void CloneCurrentContext()
{
var httpContext = \_httpContextAccessor.HttpContext;
var feature = httpContext.Features.Get();
feature = new HttpRequestFeature()
{
Scheme = feature.Scheme,
Body = feature.Body,
Headers = new HeaderDictionary(feature.Headers.ToDictionary(kvp => kvp.Key, kvp => kvp.Value)),
Method = feature.Method,
Path = feature.Path,
PathBase = feature.PathBase,
Protocol = feature.Protocol,
QueryString = feature.QueryString,
RawTarget = feature.RawTarget
};
var itemsFeature = httpContext.Features.Get();
itemsFeature = new ItemsFeature()
{
Items = itemsFeature?.Items.ToDictionary(kvp => kvp.Key, kvp => kvp.Value)
};
var routingFeature = httpContext.Features.Get();
routingFeature = new RoutingFeature()
{
RouteData = routingFeature.RouteData
};
var connectionFeature = httpContext.Features.Get();
connectionFeature = new HttpConnectionFeature()
{
ConnectionId = connectionFeature?.ConnectionId,
LocalIpAddress = connectionFeature?.LocalIpAddress,
RemoteIpAddress = connectionFeature?.RemoteIpAddress,
};
var collection = new FeatureCollection();
collection.Set(feature);
collection.Set(itemsFeature);
collection.Set(connectionFeature);
collection.Set(routingFeature);
var newContext = new DefaultHttpContext(collection);
\_httpContextAccessor.HttpContext = newContext;
}
}
public interface IHttpContextPreserver
{
void CloneCurrentContext();
}
```
Я не использовал deep cloner, так как это добавило бы тяжелую рефлексию в проект. А нужно это мне всего в одном единственном месте. Поэтому я просто создаю новый HttpContext на базе существующего и копирую в него только то, что будет полезно увидеть в логе при анализе инцидентов (action|controller, url, ip и т.п.). **Копируется не вся информация**.
Теперь запустив приложение, я увидел примерно следующие счастливые строчки:
```
2017-10-08 20:29:25.3015|0|AspNetCoreApp.Services.LongRespondingService|TRACE|Home/Test| DoJob method is starting (AspNetCoreApp.Services.LongRespondingService.DoJob:0)| url:http://localhost/Test/1
2017-10-08 20:29:34.3322|0|AspNetCoreApp.Services.LongRespondingService|TRACE|Home/Test| DoJob method is ending (AspNetCoreApp.Services.LongRespondingService+d\_\_3.MoveNext:0)| url:http://localhost/Test/1
```
А это означало для меня маленькую победу, которой я и делюсь здесь с вами. Кто что об этом думает?
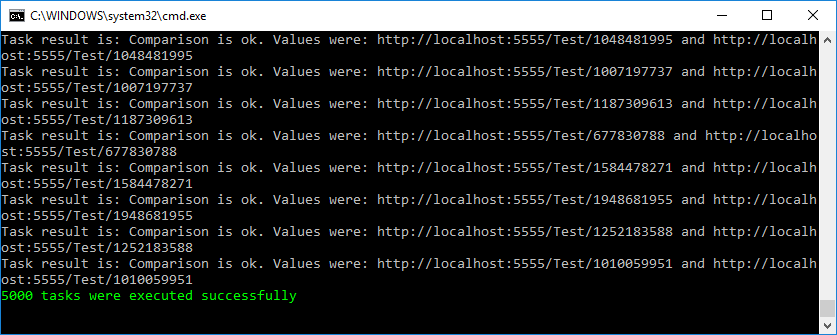
Чтобы удостовериться, что я ничего себе не надумал ложного, я написал маленький функционально-нагрузочный тест, который можно найти в моем репозитории на github'е вместе с сервисом. При запуске 5000 одновременных тасков, тест прошел успешно.
Кстати, благодаря архитектуре ASP.NET Core такие тесты можно писать легко и непринужденно. Нужно всего лишь запустить полноценный сервер внутри теста и обратиться к нему через настоящий сокет:
**Инициализация сервера по URL**
```
protected TestFixture(bool fixHttpContext, string solutionRelativeTargetProjectParentDir)
{
var startupAssembly = typeof(TStartup).Assembly;
var contentRoot = GetProjectPath(solutionRelativeTargetProjectParentDir, startupAssembly);
Console.WriteLine($"Content root: {contentRoot}");
var builder = new WebHostBuilder()
.UseKestrel()
.UseContentRoot(contentRoot)
.ConfigureServices(InitializeServices)
.UseEnvironment(fixHttpContext ? "Good" : "Bad")
.UseStartup(typeof(TStartup))
.UseUrls(BaseAddress);
_host = builder.Build();
_host.Start();
}
```
Еще один довод к использованию ASP.NET Core в своих проектах.
Итоги
-----
Мне очень понравился ASP.NET Core во всех аспектах его реализации. В нем заложена большая гибкость и одновременно лёгкость всей платформы. За счет абстракций для абсолютно всей функциональности можно делать любые вещи и настраивать всю платформу под себя, свою команду и свои методы разработки. Кроссплатформенность пока не доведена до совершенства, но Microsoft к этому стремится, и когда-нибудь (пусть может и не скоро) у них должно это получиться.
[Ссылка на github](https://github.com/Dobby007/aspnetcore-longtask/) | https://habr.com/ru/post/338582/ | null | ru | null |
# Время высокой точности: как работать с долями секунды в MySQL и PHP

Однажды я поймал себя на мысли, что при работе со временем в базах данных почти всегда использую время с точностью до секунды просто потому, что я к этому привык и что именно такой вариант описан в документации и огромном количестве примеров. Однако сейчас такой точности достаточно далеко не для всех задач. Современные системы сложны — они могут состоять из множества частей, иметь миллионы пользователей, взаимодействующих с ними, — и во многих случаях удобнее использовать бОльшую точность, поддержка которой уже давно существует.
В этой статье я расскажу про способы использования времени с дробными частями секунды в MySQL и PHP. Она задумывалась как туториал, поэтому материал рассчитан на широкий круг читателей и местами повторяет документацию. Основную ценность должно представлять то, что я собрал в одном тексте всё, что нужно знать для работы с таким временем в MySQL, PHP и фреймворке Yii, а также добавил описания неочевидных проблем, с которыми можно столкнуться.
Я буду использовать термин «время высокой точности». В документации MySQL вы увидите термин “fractional seconds”, но его дословный перевод звучит странно, а другого устоявшегося перевода я не нашёл.
Когда стоит использовать время высокой точности?
------------------------------------------------
Для затравки покажу скриншот списка входящих писем моего почтового ящика, который хорошо иллюстрирует идею:

Письма представляют собой реакцию одного и того же человека на одно событие. Человек случайно нажал не на ту кнопку, быстро понял это и исправился. В результате мы получили два письма, отправленных примерно в одно и то же время, которые важно правильно отсортировать. Если время отправки совпадает, есть шанс, что письма будут показаны в неправильном порядке и получатель будет сконфужен, так как потом получит не тот результат, на который будет рассчитывать.
Я сталкивался со следующими ситуациями, в которых время высокой точности было бы актуально:
1. Вы хотите замерить время между какими-то операциями. Тут всё очень просто: чем выше точность меток времени на границах интервала, тем выше точность результата. Если вы используете целые секунды, то можете ошибиться на 1 секунду (при попадании на границы секунд). Если же использовать шесть знаков после запятой, то ошибка будет на шесть порядков ниже.
2. У вас есть коллекция, где велика вероятность наличия нескольких объектов с одинаковым временем создания. Примером может служить знакомый всем чат, где список контактов отсортирован по времени последнего сообщения. Если там появляется постраничная навигация, то возникает даже риск потери контактов на границах страниц. Эту проблему можно решить и без времени высокой точности за счёт сортировки и постраничного разбиения по паре полей (время + уникальный идентификатор объекта), но у этого решения есть свои недостатки (как минимум усложнение SQL-запросов, но не только это). Увеличение точности времени поможет снизить вероятность появления проблем и обойтись без усложнения системы.
3. Вам нужно хранить историю изменений какого-то объекта. Особенно важно это в сервисном мире, где модификации могут происходить параллельно и в совершенно разных местах. В качестве примера могу привести работу с фотографиями наших пользователей, где параллельно может осуществляться множество разных операций (пользователь может сделать фотографию приватной или удалить её, она может модерироваться в одной из нескольких систем, обрезаться для использования в качестве фото в чате и т. д.).
Нужно иметь в виду, что нельзя верить полученным значениям на 100% и реальная точность получаемых значений может быть меньше шести знаков после запятой. Это происходит из-за того, что мы можем получить неточное значение времени (особенно при работе в распределённой системе, состоящей из многих серверов), время может неожиданно измениться (например, при синхронизации через NTP или при переводе часов) и т. д. Я не стану здесь останавливаться на всех этих проблемах, но приведу пару статей, где про них можно почитать подробнее:
* [«Заблуждения программистов относительно времени»](https://habr.com/ru/post/146109/) (сама статья очень минималистична, но в дополнение к тезисам из текста можно найти пояснения в комментариях);
* [«Тяжёлое бремя времени»](https://habr.com/ru/company/yandex/blog/463203/).
Работа со временем высокой точности в MySQL
-------------------------------------------
MySQL поддерживает три типа колонок, в которых можно хранить время: `TIME`, `DATETIME` и `TIMESTAMP`. Изначально в них можно было хранить только значения, кратные одной секунде (например, 2019-08-14 19:20:21). В версии 5.6.4, которая вышла в декабре 2011 года, появилась возможность работать и с дробной частью секунды. Для этого при создании колонки нужно указать количество знаков после запятой, которое необходимо хранить в дробной части метки времени. Максимальное количество знаков, которое поддерживается, — шесть, что позволяет хранить время с точностью до микросекунды. При попытке использовать большее количество знаков вы получите ошибку.
Пример:
```
Test> CREATE TABLE `ChatContactsList` (
`chat_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT PRIMARY KEY,
`title` varchar(255) NOT NULL,
`last_message_send_time` timestamp(2) NULL DEFAULT NULL
) ENGINE=InnoDB;
Query OK, 0 rows affected (0.02 sec)
Test> ALTER TABLE `ChatContactsList` MODIFY last_message_send_time TIMESTAMP(9) NOT NULL;
ERROR 1426 (42000): Too-big precision 9 specified for 'last_message_send_time'. Maximum is 6.
Test> ALTER TABLE `ChatContactsList` MODIFY last_message_send_time TIMESTAMP(3) NOT NULL;
Query OK, 0 rows affected (0.09 sec)
Records: 0 Duplicates: 0 Warnings: 0
Test> INSERT INTO ChatContactsList (title, last_message_send_time) VALUES ('Chat #1', NOW());
Query OK, 1 row affected (0.03 sec)
Test> SELECT * FROM ChatContactsList;
+---------+---------+-------------------------+
| chat_id | title | last_message_send_time |
+---------+---------+-------------------------+
| 1 | Chat #1 | 2019-09-22 22:23:15.000 |
+---------+---------+-------------------------+
1 row in set (0.00 sec)
```
В этом примере у метки времени вставленной записи нулевая дробная часть. Это произошло потому, что входящее значение было указано с точностью до секунды. Для решения проблемы нужно, чтобы точность входящего значения была такой же, как у значения в базе данных. Совет кажется очевидным, но он актуален, поскольку подобная проблема может всплыть в реальных приложениях: мы сталкивались с ситуацией, когда значение на входе имело три знака после запятой, а в базе данных хранилось шесть.
Самый простой способ предупредить возникновение этой проблемы — использовать входящие значения с максимальной точностью (до микросекунды). В этом случае при записи данных в таблицу время округлится до требуемой точности. Это абсолютно нормальная ситуация, которая не будет вызывать никаких warning-ов (предупреждений):
```
Test> UPDATE ChatContactsList SET last_message_send_time="2019-09-22 22:23:15.2345" WHERE chat_id=1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
Test> SELECT * FROM ChatContactsList;
+---------+---------+-------------------------+
| chat_id | title | last_message_send_time |
+---------+---------+-------------------------+
| 1 | Chat #1 | 2019-09-22 22:23:15.235 |
+---------+---------+-------------------------+
1 row in set (0.00 sec)
```
При использовании автоматической инициализации и автоматического обновления колонок типа TIMESTAMP с помощью конструкции вида `DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP` важно, чтобы значения имели ту же точность, что и сама колонка:
```
Test> ALTER TABLE ChatContactsList ADD COLUMN updated TIMESTAMP(3) DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;
ERROR 1067 (42000): Invalid default value for 'updated'
Test> ALTER TABLE ChatContactsList ADD COLUMN updated TIMESTAMP(3) DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6);
ERROR 1067 (42000): Invalid default value for 'updated'
Test> ALTER TABLE ChatContactsList ADD COLUMN updated TIMESTAMP(3) DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3);
Query OK, 0 rows affected (0.07 sec)
Records: 0 Duplicates: 0 Warnings: 0
Test> UPDATE ChatContactsList SET last_message_send_time='2019-09-22 22:22:22' WHERE chat_id=1;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
Test> SELECT * FROM ChatContactsList;
+---------+---------+-------------------------+-------------------------+
| chat_id | title | last_message_send_time | updated |
+---------+---------+-------------------------+-------------------------+
| 1 | Chat #1 | 2019-09-22 22:22:22.000 | 2019-09-22 22:26:39.968 |
+---------+---------+-------------------------+-------------------------+
1 row in set (0.00 sec)
```
Функции MySQL для работы со временем поддерживают работу и с дробной частью единиц измерения. Перечислять их все я не буду (предлагаю посмотреть в документации), но приведу несколько примеров:
```
Test> SELECT NOW(2), NOW(4), NOW(4) + INTERVAL 7.5 SECOND;
+------------------------+--------------------------+------------------------------+
| NOW(2) | NOW(4) | NOW(4) + INTERVAL 7.5 SECOND |
+------------------------+--------------------------+------------------------------+
| 2019-09-22 21:12:23.31 | 2019-09-22 21:12:23.3194 | 2019-09-22 21:12:30.8194 |
+------------------------+--------------------------+------------------------------+
1 row in set (0.00 sec)
Test> SELECT SUBTIME(CURRENT_TIME(6), CURRENT_TIME(3)), CURRENT_TIME(6), CURRENT_TIME(3);
+-------------------------------------------+-----------------+-----------------+
| SUBTIME(CURRENT_TIME(6), CURRENT_TIME(3)) | CURRENT_TIME(6) | CURRENT_TIME(3) |
+-------------------------------------------+-----------------+-----------------+
| 00:00:00.000712 | 21:12:50.793712 | 21:12:50.793 |
+-------------------------------------------+-----------------+-----------------+
1 row in set (0.00 sec)
```
Главная проблема, с которой сопряжено использование дробной части секунд в SQL-запросах, — несогласованность точности при сравнениях (`>`, `<`, `BETWEEN`). С ней можно столкнуться в том случае, если данные в базе имеют одну точность, а в запросах — другую. Вот небольшой пример, иллюстрирующий эту проблему:
```
# На вход подаются шесть знаков в дробной части
Test> INSERT INTO ChatContactsList (title, last_message_send_time) VALUES ('Chat #2', '2019-09-22 21:16:39.123456');
Query OK, 0 row affected (0.00 sec)
Test> SELECT chat_id, title, last_message_send_time FROM ChatContactsList WHERE title='Chat #2';
+---------+---------+-------------------------+
| chat_id | title | last_message_send_time |
+---------+---------+-------------------------+
| 2 | Chat #2 | 2019-09-22 21:16:39.123 | <- Сохраняются только три знака из-за точности, указанной в колонке
+---------+---------+-------------------------+
1 row in set (0.00 sec)
Test> SELECT title, last_message_send_time FROM ChatContactsList WHERE last_message_send_time >= '2019-09-22 21:16:39.123456'; <- Это то же значение, что было в INSERT-е
+---------+-------------------------+
| title | last_message_send_time |
+---------+-------------------------+
| Chat #1 | 2019-09-22 22:22:22.000 |
+---------+-------------------------+
1 row in set (0.00 sec) <- Chat #2 не найден из-за того, что точность в базе ниже, чем точность на входе
```
В данном примере точность значений в запросе выше, чем точность значений в базе, и проблема возникает «на границе сверху». В обратной ситуации (если значение на входе будет иметь точность ниже, чем значение в базе) проблемы не будет — MySQL приведёт значение к нужной точности и в INSERT-е, и в SELECT-е:
```
Test> INSERT INTO ChatContactsList (title, last_message_send_time) VALUES ('Chat #3', '2019-09-03 21:20:19.1');
Query OK, 1 row affected (0.00 sec)
Test> SELECT title, last_message_send_time FROM ChatContactsList WHERE last_message_send_time <= '2019-09-03 21:20:19.1';
+---------+-------------------------+
| title | last_message_send_time |
+---------+-------------------------+
| Chat #3 | 2019-09-03 21:20:19.100 |
+---------+-------------------------+
1 row in set (0.00 sec)
```
Согласованность точности значений всегда стоит держать в голове при работе со временем высокой точности. Если подобные граничные проблемы для вас критичны, то нужно следить за тем, чтобы код и база данных работали с одинаковым количеством знаков после запятой.
**Мысли о выборе точности в колонках с дробными частями секунд**Объём места, занимаемого дробной частью единицы времени, зависит от количества знаков в колонке. Кажется естественным выбирать привычные значения: три или шесть знаков после запятой. Но в случае с тремя знаками не всё так просто. Фактически MySQL использует один байт для хранения двух знаков дробной части:
>
>
> | Fractional Seconds Precision | Storage Required |
> | --- | --- |
> | 0 | 0 bytes |
> | 1, 2 | 1 byte |
> | 3, 4 | 2 bytes |
> | 5, 6 | 3 bytes |
>
>
>
>
>
> [Date and Time Type Storage Requirements](https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html#data-types-storage-reqs-date-time)
Получается, что если вы выбираете три знака после запятой, то не в полной мере используете занятое место и при тех же накладных расходах могли бы взять четыре знака. Вообще я рекомендую всегда использовать чётное количество знаков и при необходимости «обрезать» ненужные при выводе. Идеальный же вариант — не жадничать и брать шесть знаков после запятой. В худшем случае (при типе DATETIME) эта колонка займёт 8 байт, то есть столько же, сколько целое число в колонке типа BIGINT.
См. также:
* [“Fractional Seconds in Time Values”](https://dev.mysql.com/doc/refman/8.0/en/fractional-seconds.html);
* [“Automatic Initialization and Updating for TIMESTAMP and DATETIME”](https://dev.mysql.com/doc/refman/8.0/en/timestamp-initialization.html);
* [“Date and Time Functions”](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html).
Работа со временем высокой точности в PHP
-----------------------------------------
Мало иметь время высокой точности в базе данных — нужно уметь работать с ним в коде ваших программ. В этом разделе я расскажу про три основных момента:
1. Получение и форматирование времени: объясню, как получить метку времени перед тем, как положить его в базу данных, получить его оттуда и осуществить какие-то манипуляции.
2. Работа со временем в PDO: покажу на примере, как PHP поддерживает форматирование времени в библиотеке по работе с базой данных.
3. Работа со временем во фреймворках: расскажу про использование времени в миграциях для изменения структуры базы данных.
### Получение и форматирование времени
При работе со временем есть несколько основных операций, которые нужно уметь делать:
* получение текущего момента времени;
* получение момента времени из какой-то отформатированной строки;
* добавление к моменту времени какого-то периода (или вычитание периода);
* получение форматированной строки для момента времени.
В этой части я расскажу, какие возможности для выполнения этих операций есть в PHP.
Первый способ — это работа с **меткой времени как с числом**. В этом случае в PHP-коде мы работаем с численными переменным, которыми оперируем через такие функции, как `time`, `date`, `strtotime`. Этот способ нельзя использовать для работы со временем высокой точности, поскольку во всех этих функциях метки времени представляют собой целое число (а значит, дробная часть в них будет потеряна).
Вот сигнатуры основных таких функций из официальной документации:
> `time ( void ) : int`
>
> <https://www.php.net/manual/ru/function.time.php>
>
>
>
> `strtotime ( string $time [, int $now = time() ] ) : int`
>
> <http://php.net/manual/ru/function.strtotime.php>
>
>
>
> `date ( string $format [, int $timestamp = time() ] ) : string`
>
> <https://php.net/manual/ru/function.date.php>
>
>
>
> `strftime ( string $format [, int $timestamp = time() ] ) : string`
>
> <https://www.php.net/manual/ru/function.strftime.php>
**Любопытный момент про функцию date**Хотя нельзя передать дробную часть секунды на вход этим функциям, в строке шаблона форматирования, передаваемой на вход функции `date`, можно задать символы для отображения милли- и микросекунд. При форматировании на их месте всегда будут возвращаться нули.
| Символ в строке format | Описание | Пример возвращаемого значения |
| --- | --- | --- |
| u | Микросекунды (добавлено в PHP 5.2.2). Учтите, что date() всегда будет возвращать 000000, т.к. она принимает целочисленный параметр, тогда как DateTime::format() поддерживает микросекунды, если DateTime создан с ними. | Например: 654321 |
| v | Миллисекунды (добавлено в PHP 7.0.0). Замечание такое же как и для u. | Например: 654 |
Пример:
```
$now = time();
print date('Y-m-d H:i:s.u', $now);
// 2019-09-11 21:27:18.000000
print date('Y-m-d H:i:s.v', $now);
// 2019-09-11 21:27:18.000
```
Также к этому способу можно отнести функции `microtime` и `hrtime`, которые позволяют получить метку времени с дробной частью для текущего момента. Проблема заключается в том, что нет готового способа форматирования такой метки и получения её из строки определённого формата. Это можно решить, самостоятельно реализовав эти функции, но я не буду рассматривать такой вариант.
> Если вам нужно работать только с таймерами, то хорошим вариантом будет библиотека [HRTime](https://www.php.net/manual/ru/book.hrtime.php), которую я не стану рассматривать подробнее из-за ограниченности её применения. Скажу только, что она позволяет работать со временем с точностью до наносекунды и гарантирует монотонность таймеров, что избавляет от части проблем, с которыми можно столкнуться при работе с другими библиотеками.
Для полноценной работы с дробными частями секунды нужно использовать модуль **DateTime**. С определёнными оговорками он позволяет выполнять все перечисленные ранее операции:
```
// Получение текущего момента времени:
$time = new \DateTimeImmutable();
// Получение момента времени из отформатированной строки:
$time = new \DateTimeImmutable('2019-09-12 21:32:43.908502');
$time = \DateTimeImmutable::createFromFormat('Y-m-d H:i:s.u', '2019-09-12 21:32:43.9085');
// Добавление/вычитание периода:
$period = \DateInterval::createFromDateString('5 seconds');
$timeBefore = $time->add($period);
$timeAfter = $time->sub($period);
// Получение форматированной строки для момента времени:
print $time->format('Y-m-d H:i:s.v'); // '2019-09-12 21:32:43.908'
print $time->format("Y-m-d H:i:s.u"); // '2019-09-12 21:32:43.908502'
```
**Неочевидный момент при использовании `DateTimeImmutable::createFromFormat`**Буква `u` в строке форматирования означает микросекунды, но она корректно работает и в случае с дробными частями меньшей точности. Более того, это единственный способ задать дробные части секунды в строке формата. Пример:
```
$time = \DateTimeImmutable::createFromFormat('Y-m-d H:i:s.u', '2019-09-12 21:32:43.9085');
// => Получаем объект DateTimeImmutable со значением времени 2019-09-12 21:32:43.908500
$time = \DateTimeImmutable::createFromFormat('Y-m-d H:i:s.u', '2019-09-12 21:32:43.90');
// => Получаем объект DateTimeImmutable со значением времени 2019-09-12 21:32:43.900000
$time = \DateTimeImmutable::createFromFormat('Y-m-d H:i:s.u', '2019-09-12 21:32:43');
// => Получаем false
```
Главной проблемой данного модуля является неудобство при работе с интервалами, содержащими дробные секунды (а то и невозможность такой работы). Класс `\DateInterval` хотя и содержит дробную часть секунды с точностью до тех же самых шести знаков после запятой, но инициализировать эту дробную часть можно только через `DateTime::diff`. Конструктор класса DateInterval и фабричный метод `\DateInterval::createFromDateString` умеют работать только с целыми секундами и не позволяют задать дробную часть:
```
// Эта строка выбросит исключение из-за некорректного формата
$buggyPeriod1 = new \DateInterval('PT7.500S');
// Эта строка отработает и вернёт объект периода, но без секунд
$buggyPeriod2 = \DateInterval::createFromDateString('2 minutes 7.5 seconds');
print $buggyPeriod2->format('%R%H:%I:%S.%F') . PHP_EOL;
// Выведет "+00:02:00.000000"
```
Другая проблема может появиться при вычислении разницы между двумя моментами времени с помощью метода `\DateTimeImmutable::diff`. В PHP до версии 7.2.12 был [баг](https://bugs.php.net/bug.php?id=77007), из-за которого дробные части секунды существовали отдельно от других разрядов и могли получить свой собственный знак:
```
$timeBefore = new \DateTimeImmutable('2019-09-12 21:20:19.987654');
$timeAfter = new \DateTimeImmutable('2019-09-14 12:13:14.123456');
$diff = $timeBefore->diff($timeAfter);
print $diff->format('%R%a days %H:%I:%S.%F') . PHP_EOL;
// В PHP версии 7.2.12+ результатом будет "+1 days 14:52:54.135802"
// В более ранних версиях мы получим "+1 days 14:52:55.-864198"
```
В целом я советую проявлять осторожность при работе с интервалами и тщательно покрывать такой код тестами.
См. также:
* [«Дата и время»](https://www.php.net/manual/ru/book.datetime.php);
* [«Функция hrtime»](https://www.php.net/manual/ru/function.hrtime.php).
### Работа со временем высокой точности в PDO
PDO и mysqli — это два основных интерфейса для выполнения запросов к базам данных MySQL из PHP-кода. В контексте разговора про время они похожи друг на друга, поэтому я расскажу только про один из них — PDO.
При работе с базами данных в PDO время фигурирует в двух местах:
* в качестве параметра, передаваемого в выполняемые запросы;
* в качестве значения, приходящего в ответ на SELECT-запросы.
Хорошим тоном при передаче параметров в запрос является использование плейсхолдеров. В плейсхолдеры можно передавать значения из очень небольшого набора типов: булевы значения, строки и целые числа. Подходящего типа для даты и времени нет, поэтому необходимо вручную преобразовать значение из объекта класса DateTime/DateTimeImmutable в строку.
```
$now = new \DateTimeImmutable();
$db = new \PDO('mysql:...', 'user', 'password', [\PDO::ATTR_ERRMODE => \PDO::ERRMODE_EXCEPTION]);
$stmt = $db->prepare('INSERT INTO Test.ChatContactsList (title, last_message_send_time) VALUES (:title, :date)');
$result = $stmt->execute([':title' => "Test #1", ':date' => $now->format('Y-m-d H:i:s.u')]);
```
Использовать такой код не очень удобно, поскольку каждый раз нужно делать форматирование переданного значения. Поэтому в кодовой базе Badoo мы реализовали поддержку типизированных плейсхолдеров в нашей обёртке для работы с базой данных. В случае с датами это очень удобно, так как позволяет передавать значение в разных форматах (объект, реализующий DateTimeInterface, отформатированная строка или число с меткой времени), а уже внутри делаются все необходимые преобразования и проверки корректности переданных значений. В качестве бонуса при передаче некорректного значения мы узнаём об ошибке сразу, а не после получения ошибки от MySQL при выполнении запроса.
Получение данных из результатов запроса выглядит довольно просто. При выполнении этой операции PDO отдаёт данные в виде строк, и в коде нужно дополнительно обработать результаты, если мы хотим работать с объектами времени (и тут нам потребуется функционал получения момента времени из отформатированной строки, о котором я рассказывал в предыдущем разделе).
```
$stmt = $db->prepare('SELECT * FROM Test.ChatContactsList ORDER BY last_message_send_time DESC, chat_id DESC LIMIT 5');
$stmt->execute();
while ($row = $stmt->fetch(PDO::FETCH_ASSOC)) {
$row['last_message_send_time'] = is_null($row['last_message_send_time'])
? null
: new \DateTimeImmutable($row['last_message_send_time']);
// Делаем что-то полезное
}
```
> Примечание
>
>
>
> То, что PDO отдаёт данные в виде строк, — не совсем правда. При получении значений есть возможность задать тип значения для колонки с помощью метода [`PDOStatement::bindColumn`](https://www.php.net/manual/ru/pdostatement.bindcolumn.php). Я не стал рассказывать об этом из-за того, что там есть тот же ограниченный набор типов, который не поможет в случае с датами.
К сожалению, тут есть проблема, о которой нужно знать. В PHP до версии 7.3 есть баг, из-за которого PDO при выключенном атрибуте `PDO::ATTR_EMULATE_PREPARES` «обрезает» дробную часть секунды при её получении из базы. Подробности и пример можно посмотреть в [описании бага на php.net](https://bugs.php.net/bug.php?id=76386). В PHP 7.3 эту ошибку исправили и предупредили о том, что [это изменение ломает обратную совместимость](https://www.php.net/manual/ru/migration73.incompatible.php).
Если вы используете PHP версии 7.2 или старше и не имеете возможности обновить её или включить `PDO::ATTR_EMULATE_PREPARES`, то вы можете обойти этот баг, поправив SQL-запросы, возвращающие время с дробной частью, так, чтобы эта колонка имела строковый тип. Это можно сделать, например, так:
```
SELECT *, CAST(last_message_send_time AS CHAR) AS last_message_send_time_fixed
FROM ChatContactsList
ORDER BY last_message_send_time DESC
LIMIT 1;
```
С этой проблемой можно столкнуться и при работе с модулем `mysqli`: если вы используете подготовленные запросы через вызов метода `mysqli::prepare`, то в PHP до версии 7.3 дробная часть секунды не будет возвращаться. Как и в случае с PDO, можно исправить это, обновив PHP, или обойти через преобразование времени к строковому типу.
См. также:
* [«Подготовленные запросы и хранимые процедуры в PDO»](https://www.php.net/manual/ru/pdo.prepared-statements.php);
* [«Подготавливаемые запросы в mysqli»](https://www.php.net/manual/ru/mysqli.quickstart.prepared-statements.php);
* [Документация на метод mysqli\_stmt::bind\_param](https://www.php.net/manual/ru/mysqli-stmt.bind-param.php) (здесь описаны типы плейсхолдеров, поддерживаемых в mysqli);
* [Пул-реквест к PHP, в котором починили «обрезание» дробной части секунд](https://github.com/php/php-src/pull/3257).
### Работа со временем высокой точности в Yii 2
Большинство современных фреймворков предоставляют функционал миграций, который позволяет хранить в коде историю изменений схемы базы данных и инкрементально изменять её. Если вы используете миграции и хотите использовать время высокой точности, то ваш фреймворк должен его поддерживать. К счастью, это работает из коробки во всех основных фреймворках.
В данном разделе я покажу, как эта поддержка реализована в Yii (в примерах я использовал версию 2.0.26). Про Laravel, Symfony и другие я не стану писать, чтобы не делать статью бесконечной, но буду рад, если вы добавите деталей в комментариях или новых статьях на эту тему.
В миграции мы пишем код, который описывает изменения в схеме данных. При создании новой таблицы мы описываем все её колонки с помощью специальных методов из класса \yii\db\Migration (они объявлены в [трейте SchemaBuilderTrait](https://github.com/yiisoft/yii2/blob/master/framework/db/SchemaBuilderTrait.php)). За описание колонок, содержащих дату и время, отвечают методы `time`, `timestamp` и `datetime`, которые могут принимать на вход значение точности.
Пример миграции, в которой создаётся новая таблица с колонкой времени высокой точности:
```
use yii\db\Migration;
class m190914_141123_create_news_table extends Migration
{
public function up()
{
$this->createTable('news', [
'id' => $this->primaryKey(),
'title' => $this->string()->notNull(),
'content' => $this->text(),
'published' => $this->timestamp(6), // шесть знаков после запятой
]);
}
public function down()
{
$this->dropTable('news');
}
}
```
А это пример миграции, в которой меняется точность в уже существующей колонке:
```
class m190916_045702_change_news_time_precision extends Migration
{
public function up()
{
$this->alterColumn(
'news',
'published',
$this->timestamp(6)
);
return true;
}
public function down()
{
$this->alterColumn(
'news',
'published',
$this->timestamp(3)
);
return true;
}
}
```
При работе с этими колонками через ActiveRecord мне не удалось найти каких-то специфичных нюансов: данные из колонок с датой и временем возвращаются как строки, и при необходимости можно вручную преобразовать их в DateTime-объекты. Единственная вещь, о которой нужно помнить — это баг с «обрезанием» дробной части секунды при выключенном `PDO::ATTR_EMULATE_PREPARES`. По умолчанию Yii не трогает этот атрибут, но его можно выключить через конфигурацию базы данных. Если он выключен, необходимо воспользоваться одним из способов решения проблемы, про которые я рассказывал в разделе про PDO.
См. также:
* [Документация на миграции в Yii 2](https://www.yiiframework.com/doc/guide/2.0/en/db-migrations);
* [Документация на SchemaBuilderTrait](https://www.yiiframework.com/doc/api/2.0/yii-db-schemabuildertrait).
Заключение
----------
Надеюсь, мне удалось показать, что время высокой точности — полезная штука, которую можно использовать уже сегодня. Если после прочтения статьи вы станете более осознанно подходить к работе с точностью времени в своих проектах, то я буду считать, что добился своей цели. Спасибо, что дочитали до конца! | https://habr.com/ru/post/469615/ | null | ru | null |
# Разработчик в стране Serverless: первые шаги, первая лямбда (Часть 1)
Предисловие
-----------
Ссылки на другие части:
* [Разворачиваем БД (Часть 2)](https://habr.com/ru/company/lineate/blog/656695/)
* [Как подружиться с БД (Часть 3)](https://habr.com/ru/company/lineate/blog/657171/)
Serverless подход в разработке уже давно пользуется большой популярностью. По разным опросам, разработчики отмечают следующие преимущества в serverless технологиях:
* гибкое масштабирование;
* быстрота разработки;
* уменьшение времени или затрат на администрирование приложений;
* быстрые релизы.
Преимущества выглядят заманчивыми и многообещающими. Так ли все это? Пришло время познакомиться с serverless технологиями. Буду разбираться с новым подходом через призму опыта создания “классических” приложений. Это значит, что обязательно должны быть тесты, возможность запускать локально, возможность дебажить, несколько окружений, логи, метрики и т.д. Нет смысла знакомиться на уровне hello world приложений, которые красиво выглядят на экране. Я возьму задачу с похожими на реальность сценариями. Конечно, в сети очень много разных статей и инструкций, но нет таких, после которых ты сможешь сделать как надо, подумав обо всех проблемах заранее, а не после релиза. Поехали.
Начнем с задачи. Буду делать REST API для небольшого баг трекера. У нас есть проекты, есть люди, которые работают на этих проектах. Есть карточки - таски, которые назначаются на людей. У карточек, само собой, есть статус выполнения. У каждого проекта есть свой репозиторий на гитхабе. Выглядит это примерно так:
Я буду реализовывать следующие методы:
1. получить проект по идентификатору с информацией о людях, которые на нем работают, а также информацией об открытых PR;
2. обновить информацию о проекте;
3. добавить человека на проект;
4. убрать человека с проекта.
Конечно, задача не боевая, рисковать нервами и чутким сном не хочу, но важно, чтобы она была приближенной к реальности. Я не собираюсь учиться кодировать, не буду весь код показывать, я хочу попробовать serverless подход и буду концентрироваться на этом. А поэтому неважно, какой код у меня используется для выполнения запроса к БД, важно, где и с какими параметрами этот код вызывается . Практически в любом проекте есть хранилище. Я буду использовать MySQL. У меня будет своя интеграция с 3rd party service через REST API в методе про получение информации о проекте.
Какого провайдера выбрать? В последнее время их становится все больше, даже у оракла появляется свой serverless. Начну с флагмана, с Amazon. Хочется верить, что он там максимально стабильный, понятный, обкатанный, да и искать ответы на вопросы будет быстрее и проще.
План будет примерно такой:
1. Разбираемся с лямбда функциями, делаем первую простую лямбда функцию.
2. Разворачиваем БД.
3. Интегрируем лямбда функцию с БД.
4. Создаем REST API и подключаем ранее созданные функции.
5. Выходим в “прод”, нюансы о которых не надо забывать.
Глава 1. Первые шаги. Первая лямбда
-----------------------------------
Для начала мне надо подготовить рабочее место:
* любимая среда разработки (я буду пользоваться [VSCode](https://code.visualstudio.com/));
* система контейнеризации Docker;
* AWS аккаунт с полными правами (в дальнейшем затронем этот вопрос детальнее).
С чего начать? Начнем с кубиков, из которых и состоит классическое serverless приложение - у Amazon это сервис AWS Lambda. Лямбда-функции - это функция, которая обрабатывает события из разных источников, начиная от очередей сообщений и заканчивая событиями от S3 об обновлении/добавлении файла. Лямбда принимает на вход json объект, представляющий это событие, делает с ним, что требуется, и возвращает ответ.
### Выбираем язык программирования
И вот тут у нас возникает первый серьезный вопрос: на каком языке писать? Казалось бы, можно писать на чем угодно, но все не так просто. И для того, чтобы понять, в чем проблема, придется немного погрузиться в документацию и рассмотреть вопрос, как лямбда работает.
Жизненный цикл лямбды состоит из трех фаз:
1. Init
2. Invoke
3. Shutdown
Как следует из названия, в фазе **Init** происходит создание окружения, среды выполнения, где код лямбды будет работать, происходит скачивание кода функции, запускаются конструкторы, код инициализации. Эта фаза “поднимает” лямбду в облаке. Происходит это один раз за все время жизни экземпляра лямбда функции.
После фазы init наступает фаза Invoke. В фазе **Invoke** происходит непосредственный вызов кода обработчика лямбды функции. В отличие от фазы Init, которая происходит один раз, эта фаза может повторяться много раз; зависит от того, сколько событий будет доступно для обработки. Как только обработчик вернул результат, Amazon “замораживает” окружение, пока не появится новое событие для обработки. При появлении нового события, Amazon “размораживает” окружение. Если в процессе работы фазы происходит критическая ошибка или время выполнения выходит за пределы, то Amazon пытается пересоздать среду выполнения.
Ну и фаза **Shutdown** “убивает” лямбду и освобождает все ее ресурсы. Происходит это по прошествии какого-то времени, когда никакие события не приходили, и моя функция ничем не занималась. В документации не описано “время простоя”, но оно есть.
Ну и при чем тут язык программирования? А при том, что он напрямую влияет на фазу Init. У нас есть лямбда, нет никаких созданных экземпляров этой лямбды, не приходят события. Прилетает первое событие. В облаке некому обработать это событие (также это бывает, когда все экземпляры заняты обработкой других событий). Провайдер начинает создавать для моего события экземпляр лямбды. “Срабатывает” фаза init. В этот момент я просто жду, когда появится рабочее окружение для лямбды. После того, как фаза отработала, на следующей фазе Invoke лямбда делает полезную (для клиента) работу. Эта ситуация называется cold start — когда нет доступных для обработки экземпляров функций и тратится время на поднятие этих функций (примерно как мы тратим время на прогрев двигателя автомобиля зимой в -30). Чем быстрее пройдет фаза Init, тем быстрее начнется обработка события, тем быстрее клиент получит ответ, тем меньше будет время ответа. В силу своей природы cold start у разных языков программирования разный. У интерпретируемых языков (python, nodejs) он существенно меньше, чем у компилируемых (java, c#). Но у компилируемых есть преимущество в лучшем использовании ресурсов, у таких лямбд “КПД” выше, если надо использовать несколько ядер, больше памяти. Поэтому, если нужно минимальное время cold start, берем что-то из интерпретируемых языков; если нужно по максимуму выжимать ресурсы из окружения, то лучше взять компилируемые.
Я провел небольшой тест, создал лямбды с hello world обработчиком на разных языках программирования. Ниже представлены длительности init фазы в зависимости от языка:
Основываясь на этих данных и на своих знаниях ЯПов, я остановил свой выбор на NodeJS.
### Структура проекта
Начну с лямбды для получения информации о проекте. Код в принципе можно писать прямо в редакторе в Amazon Console. Достаточно создать hello world лямбду, дальше можно редактировать код этой лямбда функции. Очевидно, что этот вариант в любом не hello-world проекте обречен, не получится построить нормальный CI/CD, да и вообще это будет неудобно. Можно создавать лямбду с нуля, а можно взять за основу готовый шаблон. Поможет мне в этом [SAM framework](https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/what-is-sam.html), расширение AWS Cloudformation (*далее CF*) для Serverless-приложений. Он может создать мне hello-world шаблон для лямбда функции, поможет с деплоем в облако и не только.
Я воспользуюсь hello-world шаблоном. Следующая консольная команда создаст hello world проект с лямбда функцией с использованием Node JS, а созданная лямбда функция при сборке будет упаковываться в zip архив.
```
serverless-bugtracker> sam init --package-type Zip --runtime nodejs14.x --app-template hello-world --name serverless-bugtracker
```
Структура первой лямбда функции получается такой:
template.yaml — это конфиг SAM framework, описывающий компоненты, которые задействованы в моем проекте. SAM шаблон совместим с CF шаблоном. Он добавляет способы быстро и просто создать специфичные для serverless приложений типы ресурсов (лямбды, api gateway, и т.д.). CF развернет из этого конфига ресурсы, которые в нем указаны. Если в template.yaml будет описано 10 лямбда-функций, RDS, SQS, то он это все создаст. Но здесь надо соблюдать грани разумного, ведь даже в serverless мире можно создать serverless-монолит, когда десятки разных ресурсов, которые могут быть не связаны между собой, находятся в одном конфиге. Такой подход делает поддержку приложения сложнее.
Приложение с лямбда функциями очень похоже на приложение с микросервисной архитектурой. Каждую лямбду можно рассматривать как отдельный микросервис. Поэтому для максимальной изоляции и независимости я буду размещать код функций в различных папках, со своими отдельными независимыми package.json. Оставлю корневой package.json для запуска тестов.
Финальная структура проекта:
Сделаю еще одну остановку и чуть подробнее посмотрю на template.yaml. Из каких частей он состоит, для чего они нужны?
### SAM шаблон
Начну с самой неинтересной части, которая содержит информацию о версии формата шаблон CF и о том, что это SAM шаблон:
```
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
```
Есть отдельный блок для текстового описания и глобальных настроек:
```
Description: >
serverless-bugtracker
My bug tracker.Uses Amazon serverless stack
Globals:
Function:
Timeout: 3
```
Один из самых важных блоков — блок описания ресурсов, в нем описываются все ресурсы для развертывания: лямбды, базы данных и прочие сервисы. Например, ниже приведен пример описания лямбда функции:
```
Resources:
GetProjectByIdFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/handlers/get-project-by-id
Handler: app.lambdaHandler
Runtime: nodejs14.x
Events:
HelloWorld:
Type: Api
Properties:
Path: /hello
Method: get
```
Любой ресурс в шаблоне обладает уникальным логическим именем. Используя это имя, можно обращаться к свойствам этого ресурса. В моем примере логическое имя функции GetProjectByIdFunction. Переменная Runtime говорит о том, какую среду надо использовать для запуска кода. CodeUri и Handler определяют путь до файла с кодом и имя функции обработчика. Блок Events описывает виды событий, обрабатываемые функцией.
И последний блок, о котором мне надо сейчас знать — это блок Outputs, своего рода результат выполнения развертывания. Имеет смысл в этот раздел добавлять значения, которые могут потребоваться для дальнейшей работы или для интеграций, например, урлы созданных апишек, хостнейм поднятой БД и так далее. Amazon показывает эти значения в консоли после развертывания. Значения отображаются, как они есть, поэтому ни в коем случае не надо показывать в этом блоке пароли или секретные ключи.
```
Outputs:
GetProjectByIdFunctionApi:
Description: "ApiGateway endpoint URL for Prod stage for GetProjectByIdFunction"
Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/"
GetProjectByIdFunction:
Description: "GetProjectByIdFunction Lambda Function ARN"
Value: !GetAtt GetProjectByIdFunction.Arn
GetProjectByIdFunctionIamRole:
Description: "Implicit IAM Role created for GetProjectByIdFunction function"
Value: !GetAtt GetProjectByIdFunctionRole.Arn
```
Как видно из сниппетов, SAM также создает API, запросы которого обрабатываются лямбда функциями. В Outputs, помимо идентификаторов лямбда функции (все ресурсы в амазоне обладают уникальных идентификатором ARN), возвращается урл для взаимодействия с этим API. Пока сконцентрируюсь на лямбда функциях, к построению API вернусь позже.
### Запуск лямбда функции
Напишу первую лямбда функцию, которая вернет фиксированные данные по идентификатору проекта:
```
// ./src/handlers/get-project-by-id/app.js
exports.lambdaHandler = async (event, context) => {
return {
id: 123,
title: 'My first project',
description: 'First project to work with serverless. No cards. No members.',
cards: [],
members: []
};
};
```
AWS поддерживает несколько подходов в написании обработчиков на nodejs:
* использование async/await конструкций. В этом случае обработчик может вернуть готовое значение или promise;
* использование callback функций. В этом случае в обработчик добавляется третий аргумент callback, используя который, можно возвращать ответ;
* представление обработчика в виде ES модуля (совсем недавно nodejs среда стала поддерживать эту [возможность](https://aws.amazon.com/ru/blogs/compute/using-node-js-es-modules-and-top-level-await-in-aws-lambda/)).
Далее я буду использовать первый подход, так как для организации кода он более удобный и привычный для меня.
Вроде все готово для первого запуска. Я хочу иметь возможность запускать лямбда функции локально в режиме отладки, так я быстрее смогу искать, исправлять ошибки и проверить, что все работает, как надо. В SAM есть возможность запускать лямбды локально. Для локального запуска используется специальный докер образ от Amazon. Созданный таким образом контейнер мало отличается от среды выполнения в облаке.
Запустить код локально можно несколькими способами.
#### Сборка и запуск при помощи SAM
Прежде чем запустить код локально в консоли, его необходимо собрать.
Сборка приложения происходит при помощи команды:
```
serverless-bugtracker> sam build
```
Эта команда подготавливает артефакты для последующего развертывания или запуска. Результат сборки для каждой лямбда функции — это папка, в которой находятся все файлы из директории, прописанной в CodeUri в шаблоне. Если CodeUri отсутствует, то копируются все файлы из корневой директории. Также в этой папке устанавливаются все зависимости из package.json, который расположен в папке прописанной в CodeUri.
При выбранной ранее структуре проекта получается, что все артефакты будут независимыми и не будут содержать код, относящийся к другим лямбда функциям.
Другой подход к структуре проектаВстречаются и другие подходы к структуре проекта. Даже в примерах от Amazon можно встретить вариант, когда файлы всех функций находятся в одной папке с одним package.json, CodeUri параметр тоже указывает на одну и ту же директорию (либо вообще отсутствует). Пример проекта с несколькими функциями от Amazon:
Объявление функции в SAM шаблоне:
```
Resources:
getAllItemsFunction:
Type: AWS::Serverless::Function
Properties:
Handler: src/handlers/get-all-items.getAllItemsHandler
Runtime: nodejs14.x
...
getByIdFunction:
Type: AWS::Serverless::Function
Properties:
Handler: src/handlers/get-by-id.getByIdHandler
Runtime: nodejs14.x
...
putItemFunction:
Type: AWS::Serverless::Function
Properties:
Handler: src/handlers/put-item.putItemHandler
Runtime: nodejs14.x
...
```
При таком подходе артефакты для разных функции будут идентичными. Например, первая лямбда работает с БД, а вторая работает с S3. В артефакте первой и второй лямбды будут обе зависимости. При таком подходе не получается полной изоляции, к тому же одни и те же зависимости повторяются по многу раз.
У команды sam build есть парочка полезных ключей. **Ключ -p** позволяет вести сборку параллельно. По умолчанию все ресурсы собираются последовательно. **Ключ -c** позволяет кешировать сборку. Если не происходило изменений в файлах, то в качестве артефакта будет использован закешированный артефакт. Если используется структура проекта с общей папкой для всех функций, то ключ **-c** работать не будет, SAM каждый раз будет пересобирать все заданные в шаблоне функции, поскольку всегда будет видеть изменения. Использование отдельных папок позволяет SAM четко определять изменения и собирать только измененные части приложения. В целом, эти ключи позволяют ускорить сборку и не делать лишнюю работу.
По умолчанию сборка происходит в папку ./.aws-sam/build. Помимо артефактов функций, в ./.aws-sam/build есть еще template.yaml. Этот файл похож на мой файл из корня проекта, только все функции в нем настроены на сборочную директорию ./.aws-sam/build.
После выполнения команды сборки:
```
serverless-bugtracker> sam build -c -p
```
В консоли можно увидеть подсказки от SAM по дальнейшим действиям:
```
Build Succeeded
Built Artifacts : .aws-sam\build
Built Template : .aws-sam\build\template.yaml
Commands you can use next
=========================
[*] Invoke Function: sam local invoke
[*] Deploy: sam deploy --guided
```
Как видно из этой подсказки, для локального запуска функции необходимо использовать команду local invoke. Для запуска необходимо указать имя функции (логическое имя из шаблона). Опционально можно указать событие, которые должно быть обработано функцией. Для передачи события используется ключ **-e**. Если его не указать, то событие будет пустым. Можно указывать путь до файла с json объектом, представляющим это событие, или указать -, чтобы событие считывалось с stdin.
```
serverless-bugtracker> echo {"message": "Hey, are you there?" } | sam local invoke GetProjectByIdFunction --event -
```
Первый запуск занимает обычно много времени, потому что скачивается [докер образ](https://hub.docker.com/r/amazon/aws-sam-cli-emulation-image-nodejs14.x). По окончанию работы в консоли можно увидеть результат выполнения
```
START RequestId: afebe87a-84a8-4b69-a430-08ec7f06828b Version: $LATEST
END RequestId: afebe87a-84a8-4b69-a430-08ec7f06828b
REPORT RequestId: afebe87a-84a8-4b69-a430-08ec7f06828b Init Duration: 0.29 ms Duration: 98.90 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 128 MB
{"id":123,"title":"My first project","description":"First project to work with serverless. No cards. No members.","cards":[],"members":[]}
```
#### Запуск при помощи VSCode
Запускать локально функцию можно прямо из VSCode. Для этого мне потребуется плагин для VSCode [**AWS Toolkit**](https://aws.amazon.com/ru/visualstudiocode/). Этот плагин позволит быстрее деплоить из любимой среды разработки, ставить точки прерывания и инспектировать свой код. После установки необходимо его настроить — добавить креды аккаунта, чтобы плагин имел доступ к облаку.
После установки плагина, над функцией появляется команда создания конфигурации запуска:
Плагин предлагает несколько режимов:
Первые две опции похожи, обе используют SAM шаблон, отличие только в типе события, с которым вызывается функция. В первом случае это может быть произвольное событие, во втором случае — это http запрос. VSCode создаст файл .vscode/launch.json, в котором будет настройка локального запуска лямбда функции. Я буду запускать лямбду первым способом, к работе с API вернусь в последующих статьях. Получится такой конфиг запуска в VSCode:
```
// .vscode/launch.json
{
"configurations": [
{
"type": "aws-sam",
"request": "direct-invoke",
"name": "serverless-bugtracker:GetProjectByIdFunction",
"invokeTarget": {
"target": "template",
"templatePath": "${workspaceFolder}/template.yaml",
"logicalId": "GetProjectByIdFunction"
},
"lambda": {
"payload": {
"json": {
"id": 123
}
},
"environmentVariables": {}
}
}
]
}
```
Третий вариант просто запускает код из директории, в этом случае игнорируется код в SAM шаблоне. Для работы третьего варианта потребуется установить компилятор typescript. Конфигурация этого запуска:
```
{
"type": "aws-sam",
"request": "direct-invoke",
"name": "get-project-by-id:app.lambdaHandler (nodejs14.x)",
"invokeTarget": {
"target": "code",
"projectRoot": "${workspaceFolder}/src/handlers/get-project-by-id",
"lambdaHandler": "app.lambdaHandler"
},
"lambda": {
"runtime": "nodejs14.x",
"payload": {
"json": {
"id": 123
}
},
"environmentVariables": {}
}
},
```
В секции payload можно указать json объект — событие, которое будет обработано функцией. Результат запуска любого из вариантов один и тот же — приложение запускается локально в режиме отладки.
Плагин использует те же команды sam build и sam local invoke, только с другой сборочной директорией.
### Развертывание в облако
Теперь я попробую сделать первый деплой в облако. Как и с локальным запуском, это можно сделать двумя способами. Первый способ — использовать консоль, второй — использовать плагин. Проверю оба варианта.
#### Развертывание при помощи консольных команд
Попробуем сделать деплой, вооружившись консолью и SAM.
Прежде чем начать разворачивать приложение, необходимо его собрать. Команду я описал выше.
Непосредственно для развертывания мне потребуется команда sam deploy. Команда sam deploy архивирует и копирует собранные артефакты в S3 бакет и разворачивает приложения в облаке. Все собранные ресурсы создаются внутри стека. CF стек (далее просто стек) это набор ресурсов в облаке, которые были развернуты при помощи CF шаблона. Каждый стек имеет уникальное для аккаунта имя. Первый раз лучше запустить команду с ключом **--guided**. Тогда запустится интерактивный режим, где потребуется ввести имя создаваемого стека, регион, имя S3 бакета для хранения кода и прочее. Но самое интересное в этом режиме то, что все выбранные опции можно сохранить в отдельный файл с определенным профилем (по умолчанию файл samconfig.toml, имя профиля по умолчанию default). Тогда в следующий раз не придется указывать никаких параметров, кроме имени профиля. Я сохранил все под профилем chapter1:
```
version = 0.1
[chapter1]
[chapter1.deploy]
[chapter1.deploy.parameters]
stack_name = "serverless-bugtracker-ch1"
s3_bucket = "serverless-bugtracker-sam"
s3_prefix = "serverless-bugtracker-ch1"
region = "us-east-1"
confirm_changeset = true
capabilities = "CAPABILITY_IAM"
```
В следующий раз для развертывания достаточно просто указать имя профиля:
```
serverless-bugtracker> sam deploy --config-env=chapter1
```
#### Развертывание при помощи плагина
При нажатии правой кнопкой мыши на template.yaml файл в контекстном меню появится новый пункт ”Deploy SAM Application”.
Плагин спросит:
* какой template файл развернуть (у меня он только один):
* aws регион:
* s3 bucket, который SAM будет использовать. Можно создать новый:
* имя CF стека:
После прохождения всех шагов, AWS Toolkit запустит sam build, а потом sam deploy. Единственное отличие, что директория для сборки отличается от ./.aws-sam
К сожалению, плагин не умеет запоминать выбор значений параметров, поэтому каждый раз требуется вводить одни и те же данные. В этом плане запуск через консоль удобнее.
В обоих случаях в конце в консоле я увидел заветную строчку Successfully deployed SAM Application to CloudFormation Stack: serverless-bugtracker-ch1. И вот моя лямбда крутится в облаке. Amazon сам придумал имя моей функции:
В SAM шаблоне у меня у функции нет никакого имени. Amazon берет имя стека, логическое имя функции в шаблоне и генерирует какую-то случайную последовательность символов. Избавиться от этого можно, если использовать свойство FunctionName в SAM шаблоне, тогда имя функции будет то, которое указать в этом поле.
Функцию можно протестировать, используя **AWS Console**. Если открыть lambda функцию, у нее будет специальная вкладка **test**. Тут я могу послать любой json в качестве события (похоже на payload json, который я использовал в локальном запуске):
### Подведение итогов
Подведем итог:
* Сделал каркас приложения. Используется подход, при котором лямбда функции независимы и располагаются в разных директориях.
* Реализовал одну лямбда функцию. Она пока не очень умная и умеет возвращать мой фиксированный объект.
* Приложение создано при помощи SAM. Использую подход IaaC.
* Для локальной разработки установлен плагин к VSCode, с помощью которого могу запустить лямбду локально в режиме отладки.
* Лямбду можно развернуть из среды разработки или при помощи консольных команд.
Код можно найти по [ссылке](https://github.com/akoval/serverless-bugtracker/tree/chapter1).
В следующих главах я разверну БД и научу свою функцию взаимодействовать с базой данных. Создам реализации и для других функций.
*P.S. Спасибо* [*oN0*](https://habr.com/ru/users/oN0/) *за помощь в написании статьи.* | https://habr.com/ru/post/655523/ | null | ru | null |
# Руководство по Supabase. Часть 2

Привет, друзья!
В этом цикле из 2 статей я хочу рассказать вам о [Supabase](https://supabase.com/) — открытой (open source), т.е. бесплатной альтернативе [Firebase](https://firebase.google.com/). В [первой статье](https://habr.com/ru/company/timeweb/blog/648761/) мы рассмотрели теорию, в этой — разработаем полноценное `social app` с аутентификацией, базой данных, хранилищем файлов и обработкой изменения данных в режиме реального времени.
[Репозиторий с исходным кодом проекта](https://github.com/harryheman/Blog-Posts/tree/master/supabase-social-app).
Если вам это интересно, прошу под кат.
Что такое Supabase?
-------------------
`Supabase`, как и `Firebase` — это `SaaS` (software as a service — программное обеспечение как услуга) или `BaaS` (backend as a service — бэкенд как услуга). Что это означает? Это означает, что в случае с `fullstack app` мы разрабатываем только клиентскую часть, а все остальное предоставляется `Supabase` через пользовательские комплекты для разработки программного обеспечения (`SDK`) и интерфейсы прикладного программирования (`API`). Под "всем остальным" подразумевается сервис аутентификации (включая возможность использования сторонних провайдеров), база данных ([PostgreSQL](https://www.postgresql.org/)), файловое хранилище, realtime (обработка изменений данных в режиме реального времени) и сервер, который все это обслуживает.
Подготовка и настройка проекта
------------------------------
*Обратите внимание*: для разработки клиента я буду использовать [React](https://ru.reactjs.org/), но вы можете использовать свой любимый `JS-фреймворк` — функционал, связанный с `Supabase`, будет что называется `framework agnostic`. Также *обратите внимание*, что "полноценное `social app`" не означает, что разработанное нами приложение будет `production ready`, однако, по-возможности, я постараюсь акцентировать ваше внимание на необходимых доработках.
Вы готовы? Тогда вперед!
Создаем шаблон проекта с помощью [Vite](https://vitejs.dev/):
```
# supabase-social-app - название приложения
# --template react - используемый шаблон
yarn create vite supabase-social-app --template react
```
Регистрируемся или авторизуемся на [supabase.com](https://supabase.com/) и создаем новый проект:


Копируем ключ и `URL` на главной странице панели управления проектом:

Записываем их в переменные среды окружения. Для этого создаем в корневой директории проекта (`supabase-social-app`) файл `.env` следующего содержания:
```
VITE_SUPABASE_URL=https://your-url.supabase.co
VITE_SUPABASE_KEY=your_key
```
*Обратите внимание*: префикс `VITE_` в данном случае является обязательным.
На странице `Authentication` панели управления в разделе `Settings` отключаем необходимость подтверждения адреса электронной почты новым пользователем (`Enable email confirmation`):

*Обратите внимание*: при разработке нашего приложения мы пропустим шаг подтверждения пользователями своего `email` после регистрации в целях экономии времени. В реальном приложении в объекте `user` будет содержаться поле `isEmailConfirmed`, например — индикатор того, подтвердил ли пользователь свой `email`. Значение данного поля будет определять логику работы приложения в части авторизации.
В базе данных нам потребуется 3 таблицы:
* `users` — пользователи;
* `posts` — посты пользователей;
* `comments` — комментарии к постам.
`Supabase` предоставляет графический интерфейс для работы с таблицами на странице `Table Editor`:

Но мы воспользуемся редактором [SQL](https://ru.wikipedia.org/wiki/SQL) на странице `SQL Editor` (потому что не ищем легких путей)). Создаем новый запрос (`New query`) и вставляем такой `SQL`:
```
CREATE TABLE users (
id text PRIMARY KEY NOT NULL,
email text NOT NULL,
user_name text NOT NULL,
first_name text,
last_name text,
age int,
avatar_url text,
created_at timestamp DEFAULT now()
);
CREATE TABLE posts (
id serial PRIMARY KEY,
title text NOT NULL,
content text NOT NULL,
user_id text NOT NULL,
created_at timestamp DEFAULT now()
);
CREATE TABLE comments (
id serial PRIMARY KEY,
content text NOT NULL,
user_id text NOT NULL,
post_id int NOT NULL,
created_at timestamp DEFAULT now()
);
```
*Обратите внимание*: мы не будем использовать внешние ключи (`FOREIGN KEY`) в полях `user_id` и `post_id`, поскольку это усложнит работу с `Supabase` на клиенте и потребует реализации дополнительной логики, связанной с редактированием и удалением связанных таблиц (`ON UPDATE` и `ON DELETE`).
Нажимаем на кнопку `Run`:

Мы можем увидеть созданные нами таблицы на страницах `Table Editor` и `Database` панели управления:


*Обратите внимание* на предупреждение `RLS not enabled` на странице `Table Editor`. Для доступа к таблицам рекомендуется устанавливать политики безопасности на уровне строк/политики защиты строк ([Row Level Security](https://postgrespro.ru/docs/postgresql/14/ddl-rowsecurity)). Для таблиц мы этого делать не будем, но нам придется сделать это для хранилища, в котором будут находиться аватары пользователей.
Создаем новый "бакет" на странице `Storage` панели управления (`Create new bucket`):

Делаем его публичным (`Make public`):

В разделе `Policies` создаем новую политику (`New policy`). Выбираем шаблон `Give users access to a folder only to authenticated users` (предоставление доступа к директории только для аутентифицированных пользователей) — `Use this template`:

Выбираем `SELECT`, `INSERT` и `UPDATE` и немного редактируем определение политики:

Нажимаем `Review` и затем `Create policy`.
Последнее, что нам осталось сделать для настройки проекта — включить регистрацию изменений данных для всех таблиц.
По умолчанию `Supabase` создает публикацию (`publication`) `supabase_realtime`. Нам нужно только добавить в нее наши таблицы. Для этого переходим в редактор `SQL` и вставляем такую строку:
```
alter publication supabase_realtime
add table users, posts, comments;
```
Нажимаем `RUN`.
Устанавливаем несколько дополнительных зависимостей для клиента:
```
# производственные зависимости
yarn add @supabase/supabase-js dotenv react-icons react-router-dom zustand
# зависимость для разработки
yarn add -D sass
```
* [@supabase/supabase-js](https://www.npmjs.com/package/@supabase/supabase-js) — `SDK` для взаимодействия с `Supabase`;
* [dotenv](https://www.npmjs.com/package/dotenv) — утилита для доступа к переменным среды окружения;
* [react-icons](https://react-icons.github.io/react-icons/) — большая коллекция иконок в виде `React-компонентов`;
* [react-router-dom](https://reactrouter.com/docs/en/v6/getting-started/overview) — библиотека для маршрутизации в `React-приложениях`;
* [zustand](https://github.com/pmndrs/zustand) — инструмент для управления состоянием `React-приложений`;
* [sass](https://sass-scss.ru/) — `CSS-препроцессор`.
На этом подготовка и настройка проекта завершены. Переходим к разработке клиента.
Клиент
======
Структура директории `src` будет следующей:
```
- api - `API` для взаимодействия с `Supabase`
- comment.js
- db.js
- post.js
- user.js
- components - компоненты
- AvatarUploader.jsx - для загрузки аватара пользователя
- CommentList.jsx - список комментариев
- Error.jsx - ошибка (не надо так делать в продакшне))
- Field.jsx - поле формы
- Form.jsx - форма
- Layout.jsx - макет страницы
- Loader.jsx - индикатор загрузки
- Nav.jsx - панель навигации
- PostList.jsx - список постов
- PostTabs.jsx - вкладки постов
- Protected.jsx - защищенная страница
- UserUpdater.jsx - для обновления данных пользователя
- hooks - хуки
- useForm.js - для формы
- useStore.js - для управления состоянием приложения
- pages - страницы
- About.jsx
- Blog.jsx - для всех постов
- Home.jsx
- Login.jsx - для авторизации
- Post.jsx - для одного поста
- Profile.jsx - для профиля пользователя
- Register.jsx - для регистрации
- styles - стили
- supabase
- index.js - создание и экспорт клиента `Supabase`
- utils - утилиты
- serializeUser.js
- App.jsx - основной компонент приложения
- main.jsx - основной файл клиента
```
С вашего позволения, я не буду останавливаться на стилях: там нет ничего особенного, просто скопируйте их из репозитория.
Настроим алиасы (alias — синоним) для облегчения импорта компонентов в `vite.config.js`:
```
import react from '@vitejs/plugin-react'
import { dirname, resolve } from 'path'
import { fileURLToPath } from 'url'
import { defineConfig } from 'vite'
// абсолютный путь к текущей директории
const _dirname = dirname(fileURLToPath(import.meta.url))
export default defineConfig({
plugins: [react()],
resolve: {
alias: {
'@': resolve(_dirname, './src'),
a: resolve(_dirname, './src/api'),
c: resolve(_dirname, './src/components'),
h: resolve(_dirname, './src/hooks'),
p: resolve(_dirname, './src/pages'),
s: resolve(_dirname, './src/supabase'),
u: resolve(_dirname, './src/utils')
}
}
})
```
Начнем создание нашего клиента с разработки `API`.
API
---
Для работы `API` нужен клиент для взаимодействия с `Supabase`.
Создаем и экспортируем его в `supabase/index.js`:
```
import { createClient } from '@supabase/supabase-js'
const supabase = createClient(
// такой способ доступа к переменным среды окружения является уникальным для `vite`
import.meta.env.VITE_SUPABASE_URL,
import.meta.env.VITE_SUPABASE_KEY
)
export default supabase
```
`API` для работы со всеми таблицами базы данных (`api/db.js`):
```
import supabase from 's'
// метод для получения данных из всех таблиц
async function fetchAllData() {
try {
// пользователи
const { data: users } = await supabase
.from('users')
.select('id, email, user_name')
// посты
const { data: posts } = await supabase
.from('posts')
.select('id, title, content, user_id, created_at')
// комментарии
const { data: comments } = await supabase
.from('comments')
.select('id, content, user_id, post_id, created_at')
return { users, posts, comments }
} catch (e) {
console.error(e)
}
}
const dbApi = { fetchAllData }
export default dbApi
```
Утилита для сериализации объекта пользователя (`utils/serializeUser.js`):
```
const serializeUser = (user) =>
user
? {
id: user.id,
email: user.email,
...user.user_metadata
}
: null
export default serializeUser
```
Все данные пользователей, указываемые при регистрации, кроме `email` и `password`, записываются в поле `user_metadata`, что не очень удобно.
`API` для работы с таблицей `users` — пользователи (`api/user.js`):
```
import supabase from 's'
import serializeUser from 'u/serializeUser'
// метод для получения данных пользователя из базы при наличии аутентифицированного пользователя
// объект, возвращаемый методом `auth.user`, извлекается из локального хранилища
const get = async () => {
const user = supabase.auth.user()
if (user) {
try {
const { data, error } = await supabase
.from('users')
.select()
.match({ id: user.id })
.single()
if (error) throw error
console.log(data)
return data
} catch (e) {
throw e
}
}
return null
}
// метод для регистрации пользователя
const register = async (data) => {
const { email, password, user_name } = data
try {
// регистрируем пользователя
const { user, error } = await supabase.auth.signUp(
// основные/обязательные данные
{
email,
password
},
// дополнительные/опциональные данные
{
data: {
user_name
}
}
)
if (error) throw error
// записываем пользователя в базу
const { data: _user, error: _error } = await supabase
.from('users')
// сериализуем объект пользователя
.insert([serializeUser(user)])
.single()
if (_error) throw _error
return _user
} catch (e) {
throw e
}
}
// метод для авторизации пользователя
const login = async (data) => {
try {
// авторизуем пользователя
const { user, error } = await supabase.auth.signIn(data)
if (error) throw error
// получаем данные пользователя из базы
const { data: _user, error: _error } = await supabase
.from('users')
.select()
.match({ id: user.id })
.single()
if (_error) throw _error
return _user
} catch (e) {
throw e
}
}
// метод для выхода из системы
const logout = async () => {
try {
const { error } = await supabase.auth.signOut()
if (error) throw error
return null
} catch (e) {
throw e
}
}
// метод для обновления данных пользователя
const update = async (data) => {
// получаем объект с данными пользователя
const user = supabase.auth.user()
if (!user) return
try {
const { data: _user, error } = await supabase
.from('users')
.update(data)
.match({ id: user.id })
.single()
if (error) throw error
return _user
} catch (e) {
throw e
}
}
// метод для сохранения аватара пользователя
// см. ниже
const userApi = { get, register, login, logout, update, uploadAvatar }
export default userApi
```
Метод для сохранения аватара пользователя:
```
// адрес хранилища
const STORAGE_URL =
`${import.meta.env.VITE_SUPABASE_URL}/storage/v1/object/public/`
// метод принимает файл - аватар пользователя
const uploadAvatar = async (file) => {
const user = supabase.auth.user()
if (!user) return
const { id } = user
// извлекаем расширение из названия файла
// метод `at` появился в `ECMAScript` в этом году
// он позволяет простым способом извлекать элементы массива с конца
const ext = file.name.split('.').at(-1)
// формируем название аватара
const name = id + '.' + ext
try {
// загружаем файл в хранилище
const {
// возвращаемый объект имеет довольно странную форму
data: { Key },
error
} = await supabase.storage.from('avatars').upload(name, file, {
// не кешировать файл - это важно!
cacheControl: 'no-cache',
// перезаписывать аватар при наличии
upsert: true
})
if (error) throw error
// формируем путь к файлу
const avatar_url = STORAGE_URL + Key
// обновляем данные пользователя -
// записываем путь к аватару
const { data: _user, error: _error } = await supabase
.from('users')
.update({ avatar_url })
.match({ id })
.single()
if (_error) throw _error
// возвращаем обновленного пользователя
return _user
} catch (e) {
throw e
}
}
```
`API` для работы с таблицей `posts` — посты (`api/post.js`):
```
import supabase from 's'
// метод для создания поста
const create = async (postData) => {
const user = supabase.auth.user()
if (!user) return
try {
const { data, error } = await supabase
.from('posts')
.insert([postData])
.single()
if (error) throw error
return data
} catch (e) {
throw e
}
}
// для обновления поста
const update = async (data) => {
const user = supabase.auth.user()
if (!user) return
try {
const { data: _data, error } = await supabase
.from('posts')
.update({ ...postData })
.match({ id: data.id, user_id: user.id })
if (error) throw error
return _data
} catch (e) {
throw e
}
}
// для удаления поста
const remove = async (id) => {
const user = supabase.auth.user()
if (!user) return
try {
// удаляем пост
const { error } = await supabase
.from('posts')
.delete()
.match({ id, user_id: user.id })
if (error) throw error
// удаляем комментарии к этому посту
const { error: _error } = await supabase
.from('comments')
.delete()
.match({ post_id: id })
if (_error) throw _error
} catch (e) {
throw e
}
}
const postApi = { create, update, remove }
export default postApi
```
`API` для работы с таблицей `comments` — комментарии (`api/comment.js`):
```
import supabase from 's'
// метод для создания комментария
const create = async (commentData) => {
const user = supabase.auth.user()
if (!user) return
try {
const { data, error } = await supabase
.from('comments')
.insert([{ ...commentData, user_id: user.id }])
.single()
if (error) throw error
return data
} catch (e) {
throw e
}
}
// для обновления комментария
const update = async (commentData) => {
const user = supabase.auth.user()
if (!user) return
try {
const { data, error } = await supabase
.from('comments')
.update({ ...commentData })
.match({ id: commentData.id, user_id: user.id })
if (error) throw error
return data
} catch (e) {
throw e
}
}
// для удаления комментария
const remove = async (id) => {
const user = supabase.auth.user()
if (!user) return
try {
const { error } = await supabase
.from('comments')
.delete()
.match({ id, user_id: user.id })
if (error) throw error
} catch (e) {
throw e
}
}
const commentApi = { create, update, remove }
export default commentApi
```
Хуки
----
Для управления состоянием нашего приложения мы будем использовать `zustand`, который позволяет создавать хранилище в форме хука.
Создаем хранилище в файле `hooks/useStore.js`:
```
import create from 'zustand'
import dbApi from 'a/db'
import postApi from 'a/post'
const useStore = create((set, get) => ({
// состояние загрузки
loading: true,
// функция для его обновления
setLoading: (loading) => set({ loading }),
// состояние ошибки
error: null,
// функция для его обновления
setError: (error) => set({ loading: false, error }),
// состояние пользователя
user: null,
// функция для его обновления
setUser: (user) => set({ user }),
// пользователи
users: [],
// посты
posts: [],
// комментарии
comments: [],
// мы можем "тасовать" наши данные как угодно,
// например, так:
// объект постов с доступом по `id` поста
postsById: {},
// объект постов с доступом по `id` пользователя
postsByUser: {},
// карта "имя пользователя - `id` поста"
userByPost: {},
// объект комментариев с доступом по `id` поста
commentsByPost: {},
// массив всех постов с авторами и количеством комментариев
allPostsWithCommentCount: [],
// далее важно определить правильный порядок формирования данных
// формируем объект комментариев с доступом по `id` поста
getCommentsByPost() {
const { users, posts, comments } = get()
const commentsByPost = posts.reduce((obj, post) => {
obj[post.id] = comments
.filter((comment) => comment.post_id === post.id)
.map((comment) => ({
...comment,
// добавляем в объект автора
author: users.find((user) => user.id === comment.user_id).user_name
}))
return obj
}, {})
set({ commentsByPost })
},
// формируем карту "имя пользователя - `id` поста"
getUserByPost() {
const { users, posts } = get()
const userByPost = posts.reduce((obj, post) => {
obj[post.id] = users.find((user) => user.id === post.user_id).user_name
return obj
}, {})
set({ userByPost })
},
// формируем объект постов с доступом по `id` пользователя
getPostsByUser() {
// здесь мы используем ранее сформированный объект `commentsByPost`
const { users, posts, commentsByPost } = get()
const postsByUser = users.reduce((obj, user) => {
obj[user.id] = posts
.filter((post) => post.user_id === user.id)
.map((post) => ({
...post,
// пользователь может редактировать и удалять свои посты
editable: true,
// добавляем в объект количество комментариев
commentCount: commentsByPost[post.id].length
}))
return obj
}, {})
set({ postsByUser })
},
// формируем объект постов с доступом по `id` поста
getPostsById() {
// здесь мы используем ранее сформированные объекты `userByPost` и `commentsByPost`
const { posts, user, userByPost, commentsByPost } = get()
const postsById = posts.reduce((obj, post) => {
obj[post.id] = {
...post,
// добавляем в объект комментарии
comments: commentsByPost[post.id],
// и их количество
commentCount: commentsByPost[post.id].length
}
// обратите внимание на оператор опциональной последовательности (`?.`)
// пользователь может отсутствовать (`null`)
// если пользователь является автором поста
if (post.user_id === user?.id) {
// значит, он может его редактировать и удалять
obj[post.id].editable = true
// иначе
} else {
// добавляем в объект имя автора поста
obj[post.id].author = userByPost[post.id]
}
return obj
}, {})
set({ postsById })
},
// формируем массив всех постов с авторами и комментариями
getAllPostsWithCommentCount() {
// здесь мы используем ранее сформированные объекты `userByPost` и `commentsByPost`
const { posts, user, userByPost, commentsByPost } = get()
const allPostsWithCommentCount = posts.map((post) => ({
...post,
// является ли пост редактируемым
editable: user?.id === post.user_id,
// добавляем в объект автора
author: userByPost[post.id],
// и количество комментариев
commentCount: commentsByPost[post.id].length
}))
set({ allPostsWithCommentCount })
},
// метод для получения всех данных и формирования вспомогательных объектов и массива
async fetchAllData() {
set({ loading: true })
const {
getCommentsByPost,
getUserByPost,
getPostsByUser,
getPostsById,
getAllPostsWithCommentCount
} = get()
const { users, posts, comments } = await dbApi.fetchAllData()
set({ users, posts, comments })
getCommentsByPost()
getPostsByUser()
getUserByPost()
getPostsById()
getAllPostsWithCommentCount()
set({ loading: false })
},
// метод для удаления поста
// данный метод является глобальным, поскольку вызывается на разных уровнях приложения
removePost(id) {
set({ loading: true })
postApi.remove(id).catch((error) => set({ error }))
}
}))
export default useStore
```
Хук для работы с формами (`hooks/useForm.js`):
```
import { useState, useEffect } from 'react'
// хук принимает начальное состояние формы
// чтобы немного облегчить себе жизнь,
// мы будем исходить из предположения,
// что все поля формы являются обязательными
export default function useForm(initialData) {
const [data, setData] = useState(initialData)
const [disabled, setDisabled] = useState(true)
useEffect(() => {
// если какое-либо из полей является пустым
setDisabled(!Object.values(data).every(Boolean))
}, [data])
// метод для изменения полей формы
const change = ({ target: { name, value } }) => {
setData({ ...data, [name]: value })
}
return { data, change, disabled }
}
```
Компонент поля формы выглядит следующим образом (`components/Field.jsx`):
```
export const Field = ({ label, value, change, id, type, ...rest }) => (
{label}
)
```
А компонент формы так (`components/Form.jsx`):
```
import useForm from 'h/useForm'
import { Field } from './Field'
// функция принимает массив полей формы, функцию для отправки формы и подпись к кнопке для отправки формы
export const Form = ({ fields, submit, button }) => {
// некоторые поля могут иметь начальные значения,
// например, при обновлении данных пользователя
const initialData = fields.reduce((o, f) => {
o[f.id] = f.value || ''
return o
}, {})
// используем хук
const { data, change, disabled } = useForm(initialData)
// функция для отправки формы
const onSubmit = (e) => {
if (disabled) return
e.preventDefault()
submit(data)
}
return (
{fields.map((f) => (
))}
{button}
)
}
```
Рассмотрим пример использования хука для работы с хранилищем состояния и компонента формы на странице для регистрации пользователя (`pages/Register.jsx`):
```
import userApi from 'a/user'
import { Form } from 'c'
import useStore from 'h/useStore'
import { useNavigate } from 'react-router-dom'
// начальное состояние формы
const fields = [
{
id: 'user_name',
label: 'Username',
type: 'text'
},
{
id: 'email',
label: 'Email',
type: 'email'
},
{
id: 'password',
label: 'Password',
type: 'password'
},
{
id: 'confirm_password',
label: 'Confirm password',
type: 'password'
}
]
export const Register = () => {
// извлекаем из состояния методы для установки пользователя, загрузки и ошибки
const { setUser, setLoading, setError } = useStore(
({ setUser, setLoading, setError }) => ({ setUser, setLoading, setError })
)
// метод для ручного перенаправления
const navigate = useNavigate()
// метод для регистрации
const register = async (data) => {
setLoading(true)
userApi
// данный метод возвращает объект пользователя
.register(data)
.then((user) => {
// устанавливаем пользователя
setUser(user)
// выполняем перенаправление на главную страницу
navigate('/')
})
// ошибка
.catch(setError)
}
return (
Register
========
)
}
```
Страница для авторизации пользователя выглядит похожим образом (`pages/Login.jsx`):
```
import userApi from 'a/user'
import { Form } from 'c'
import useStore from 'h/useStore'
import { useNavigate } from 'react-router-dom'
const fields = [
{
id: 'email',
label: 'Email',
type: 'email'
},
{
id: 'password',
label: 'Password',
type: 'password'
}
]
export const Login = () => {
const { setUser, setLoading, setError } = useStore(
({ setUser, setLoading, setError }) => ({ setUser, setLoading, setError })
)
const navigate = useNavigate()
const register = async (data) => {
setLoading(true)
userApi
.login(data)
.then((user) => {
setUser(user)
navigate('/')
})
.catch(setError)
}
return (
Login
=====
)
}
```
Обработка изменения данных в режиме реального времени
-----------------------------------------------------
Вы могли заметить, что на страницах для регистрации и авторизации пользователя мы обновляем состояние загрузки только один раз (`setLoading(true)`). Разве это не приведет к тому, что все время будет отображаться индикатор загрузки? Именно так. Давайте это исправим.
При регистрации/авторизации, а также при любых операциях чтения/записи в БД мы хотим вызывать метод `fetchAllData` из хранилища (в продакшне так делать не надо).
Для регистрации изменения состояния аутентификации клиент `Supabase` предоставляет метод `auth.onAuthStateChanged`, а для регистрации операций по работе с БД — метод `from(tableNames).on(eventTypes, callback).subscribe`.
Обновляем файл `supabase/index.js`:
```
import { createClient } from '@supabase/supabase-js'
import useStore from 'h/useStore'
const supabase = createClient(
import.meta.env.VITE_SUPABASE_URL,
import.meta.env.VITE_SUPABASE_KEY
)
// регистрация обновления состояния аутентификации
supabase.auth.onAuthStateChange((event, session) => {
console.log(event, session)
// одной из прелестей `zustand` является то,
// что методы из хранилища могут вызываться где угодно
useStore.getState().fetchAllData()
})
// регистрация обновления данных в базе
supabase
// нас интересуют все таблицы
.from('*')
// и все операции
.on('*', (payload) => {
console.log(payload)
useStore.getState().fetchAllData()
})
.subscribe()
export default supabase
```
Как мы помним, на последней строке кода метода `fetchAllData` вызывается `set({ loading: false })`. Таким образом, индикатор загрузки будет отображаться до тех пор, пока приложение не получит все необходимые данные и не сформирует все вспомогательные объекты и массив. В свою очередь, пользователь всегда будет иметь дело с актуальными данными.
*Обратите внимание* на то, разработанная нами архитектура приложения не подходит для реальных приложений, в которых используется большое количество данных: большое количество данных означает долгое время их получения и обработки. В реальных приложениях вместо прямой записи данных в базу следует применять оптимистические обновления.
Страницы и компоненты
---------------------
С вашего позволения, я расскажу только о тех страницах приложения, на которых происходит что-нибудь интересное.
Начнем со страницы профиля пользователя (`pages/Profile.jsx`):
```
import { Protected, UserUpdater } from 'c'
import useStore from 'h/useStore'
export const Profile = () => {
// извлекаем из хранилища объект пользователя
const user = useStore(({ user }) => user)
// копируем его
const userCopy = { ...user }
// и удаляем поле с адресом аватара -
// он слишком длинный и ломает разметку
delete userCopy.avatar_url
return (
// страница является защищенной
Profile
=======
{/\* отображаем данные пользователя \*/}
```
{JSON.stringify(userCopy, null, 2)}
```
{/\* компонент для обновления данных пользователя \*/}
)
}
```
Компонент `Protected` перенаправляет неавторизованного пользователя на главную страницу после завершения загрузки приложения (`components/Protected.jsx`):
```
import useStore from 'h/useStore'
import { useEffect } from 'react'
import { useNavigate } from 'react-router-dom'
export const Protected = ({ children, className }) => {
const { user, loading } = useStore(({ user, loading }) => ({ user, loading }))
const navigate = useNavigate()
useEffect(() => {
if (!loading && !user) {
navigate('/')
}
}, [user, loading])
// ничего не рендерим при отсутствии пользователя
if (!user) return null
return {children}
}
```
Компонент для обновления данных пользователя (`components/UserUpdater.jsx`):
```
import { Form, AvatarUploader } from 'c'
import useStore from 'h/useStore'
import userApi from 'a/user'
export const UserUpdater = () => {
const { user, setUser, setLoading, setError } = useStore(
({ user, setUser, setLoading, setError }) => ({
user,
setUser,
setLoading,
setError
})
)
// метод для обновления данных пользователя
const updateUser = async (data) => {
setLoading(true)
userApi.update(data).then(setUser).catch(setError)
}
// начальное состояние
// с данными из объекта пользователя
const fields = [
{
id: 'first_name',
label: 'First Name',
type: 'text',
value: user.first_name
},
{
id: 'last_name',
label: 'Last Name',
type: 'text',
value: user.last_name
},
{
id: 'age',
label: 'Age',
type: 'number',
value: user.age
}
]
return (
Update User
-----------
{/\* компонент для загрузки аватара \*/}
### User Bio
)
}
```
Компонент для загрузки аватара (`components/AvatarUploader.jsx`):
```
import { useState, useEffect } from 'react'
import userApi from 'a/user'
import useStore from 'h/useStore'
export const AvatarUploader = () => {
const { user, setUser, setLoading, setError } = useStore(
({ user, setUser, setLoading, setError }) => ({
user,
setUser,
setLoading,
setError
})
)
// состояние для файла
const [file, setFile] = useState('')
const [disabled, setDisabled] = useState(true)
useEffect(() => {
setDisabled(!file)
}, [file])
const upload = (e) => {
e.preventDefault()
if (disabled) return
setLoading(true)
userApi.uploadAvatar(file).then(setUser).catch(setError)
}
return (
Avatar:
{
if (e.target.files) {
setFile(e.target.files[0])
}
}}
/>
Upload
)
}
```
Рассмотрим страницу для постов (`pages/Blog.jsx`):
```
import postApi from 'a/post'
import { Form, PostList, PostTabs, Protected } from 'c'
import useStore from 'h/useStore'
import { useEffect, useState } from 'react'
// начальное состояние нового поста
const fields = [
{
id: 'title',
label: 'Title',
type: 'text'
},
{
id: 'content',
label: 'Content',
type: 'text'
}
]
export const Blog = () => {
const { user, allPostsWithCommentCount, postsByUser, setLoading, setError } =
useStore(
({
user,
allPostsWithCommentCount,
postsByUser,
setLoading,
setError
}) => ({
user,
allPostsWithCommentCount,
postsByUser,
setLoading,
setError
})
)
// выбранная вкладка
const [tab, setTab] = useState('all')
// состояние для отфильтрованных на основании выбранной вкладки постов
const [_posts, setPosts] = useState([])
// метод для создания нового поста
const create = (data) => {
setLoading(true)
postApi
.create(data)
.then(() => {
// переключаем вкладку
setTab('my')
})
.catch(setError)
}
useEffect(() => {
if (tab === 'new') return
// фильтруем посты на основании выбранной вкладки
const _posts =
tab === 'my' ? postsByUser[user.id] : allPostsWithCommentCount
setPosts(_posts)
}, [tab, allPostsWithCommentCount])
// если значением выбранной вкладки является `new`,
// возвращаем форму для создания нового поста
// данная вкладка является защищенной
if (tab === 'new') {
return (
Blog
====
New post
--------
)
}
return (
Blog
====
{tab === 'my' ? 'My' : 'All'} posts
-----------------------------------
)
}
```
Вкладки постов (`components/PostTabs.jsx`):
```
import useStore from 'h/useStore'
// вкладки
// свойство `protected` определяет,
// какие вкладки доступны пользователю
const tabs = [
{
name: 'All'
},
{
name: 'My',
protected: true
},
{
name: 'New',
protected: true
}
]
export const PostTabs = ({ tab, setTab }) => {
const user = useStore(({ user }) => user)
return (
{tabs.map((t) => {
const tabId = t.name.toLowerCase()
if (t.protected) {
return user ? (
* setTab(tabId)}
>
{t.name}
) : null
}
return (
* setTab(tabId)}
>
{t.name}
)
})}
)
}
```
Список постов (`components/PostList.jsx`):
```
import { Link, useNavigate } from 'react-router-dom'
import useStore from 'h/useStore'
import { VscComment, VscEdit, VscTrash } from 'react-icons/vsc'
// элемент поста
const PostItem = ({ post }) => {
const removePost = useStore(({ removePost }) => removePost)
const navigate = useNavigate()
// каждый пост - это ссылка на его страницу
return (
{
// отключаем переход на страницу поста
// при клике по кнопке или иконке
if (e.target.localName === 'button' || e.target.localName === 'svg') {
e.preventDefault()
}
}}
>
### {post.title}
{/* если пост является редактируемым - принадлежит текущему пользователю */}
{post.editable && (
{
// строка запроса `edit=true` определяет,
// что пост находится в состоянии редактирования
navigate(`/blog/post/${post.id}?edit=true`)
}}
className='info'
>
{
removePost(post.id)
}}
className='danger'
>
)}
Author: {post.author}
{new Date(post.created\_at).toLocaleString()}
{/* количество комментариев к посту */}
{post.commentCount > 0 && (
{post.commentCount}
)}
)
}
// список постов
export const PostList = ({ posts }) => (
{posts.length > 0 ? (
posts.map((post) => )
) : (
### No posts
)}
)
```
Последняя страница, которую мы рассмотрим — это страница поста (`pages/Post.jsx`):
```
import postApi from 'a/post'
import commentApi from 'a/comment'
import { Form, Protected, CommentList } from 'c'
import useStore from 'h/useStore'
import { useNavigate, useParams, useLocation } from 'react-router-dom'
import { VscEdit, VscTrash } from 'react-icons/vsc'
// начальное состояние для нового комментария
const createCommentFields = [
{
id: 'content',
label: 'Content',
type: 'text'
}
]
export const Post = () => {
const { user, setLoading, setError, postsById, removePost } = useStore(
({ user, setLoading, setError, postsById, removePost }) => ({
user,
setLoading,
setError,
postsById,
removePost
})
)
// извлекаем `id` поста из параметров
const { id } = useParams()
const { search } = useLocation()
// извлекаем индикатор редактирования поста из строки запроса
const edit = new URLSearchParams(search).get('edit')
// извлекаем пост по его `id`
const post = postsById[id]
const navigate = useNavigate()
// метод для обновления поста
const updatePost = (data) => {
setLoading(true)
data.id = post.id
postApi
.update(data)
.then(() => {
// та же страница, но без строки запроса
navigate(`/blog/post/${post.id}`)
})
.catch(setError)
}
// метод для создания комментария
const createComment = (data) => {
setLoading(true)
data.post_id = post.id
commentApi.create(data).catch(setError)
}
// если пост находится в состоянии редактирования
if (edit) {
const editPostFields = [
{
id: 'title',
label: 'Title',
type: 'text',
value: post.title
},
{
id: 'content',
label: 'Content',
type: 'text',
value: post.content
}
]
return (
Update post
-----------
)
}
return (
Post
====
{post && (
{post.title}
------------
{post.editable ? (
{
navigate(`/blog/post/${post.id}?edit=true`)
}}
className='info'
>
{
removePost(post.id)
navigate('/blog')
}}
className='danger'
>
) : (
Author: {post.author}
)}
{new Date(post.created\_at).toLocaleString()}
{post.content}
{user && (
### New comment
)}
{/\* комментарии к посту \*/}
{post.comments.length > 0 && }
)}
)
}
```
Компонент для комментариев к посту (`components/CommentList.jsx`):
```
import { useState } from 'react'
import useStore from 'h/useStore'
import commentApi from 'a/comment'
import { Form, Protected } from 'c'
import { VscEdit, VscTrash } from 'react-icons/vsc'
export const CommentList = ({ comments }) => {
const { user, setLoading, setError } = useStore(
({ user, setLoading, setError }) => ({ user, setLoading, setError })
)
// индикатор редактирования комментария
const [editComment, setEditComment] = useState(null)
// метод для удаления комментария
const remove = (id) => {
setLoading(true)
commentApi.remove(id).catch(setError)
}
// метод для обновления комментария
const update = (data) => {
setLoading(true)
data.id = editComment.id
commentApi.update(data).catch(setError)
}
// если комментарий находится в состоянии редактирования
if (editComment) {
const fields = [
{
id: 'content',
label: 'Content',
type: 'text',
value: editComment.content
}
]
return (
### Update comment
)
}
return (
### Comments
{comments.map((comment) => (
{comment.content}
{/\* является ли комментарий редактируемым - принадлежит ли текущему пользователю? \*/}
{comment.user\_id === user?.id ? (
setEditComment(comment)} className='info'>
remove(comment.id)} className='danger'>
) : (
Author: {comment.author}
)}
{new Date(comment.created\_at).toLocaleString()}
))}
)
}
```
И основной компонент приложения (`App.jsx`):
```
import './styles/app.scss'
import { Routes, Route } from 'react-router-dom'
import { Home, About, Register, Login, Profile, Blog, Post } from 'p'
import { Nav, Layout } from 'c'
import { useEffect } from 'react'
import useStore from 'h/useStore'
import userApi from 'a/user'
function App() {
const { user, setUser, setLoading, setError, fetchAllData } = useStore(
({ user, setUser, setLoading, setError, fetchAllData }) => ({
user,
setUser,
setLoading,
setError,
fetchAllData
})
)
useEffect(() => {
// запрашиваем данные пользователя при их отсутствии
if (!user) {
setLoading(true)
userApi
.get()
.then((user) => {
// устанавливаем пользователя
// `user` может иметь значение `null`
setUser(user)
// получаем данные из всех таблиц
fetchAllData()
})
.catch(setError)
}
}, [])
return (
} />
} />
} />
} />
} />
} />
} />
© 2022. Not all rights reserved
)
}
export default App
```
Таким образом, мы рассмотрели все основные страницы и компоненты приложения.
Проверка работоспособности
--------------------------
Давайте убедимся в том, что приложение работает, как ожидается.
Определим функцию для наполнения базы фиктивными данными. В директории `src` создаем файл `seedDb.js` следующего содержания:
```
import { createClient } from '@supabase/supabase-js'
import serializeUser from '../utils/serializeUser.js'
import { config } from 'dotenv'
// получаем доступ к переменным среды окружения
config()
// создаем клиента `Supabase`
const supabase = createClient(
process.env.VITE_SUPABASE_URL,
process.env.VITE_SUPABASE_KEY
)
// создаем 2 пользователей, `Alice` и `Bob` с постами и комментариями
async function seedDb() {
try {
const { user: aliceAuth } = await supabase.auth.signUp(
{
email: '[email protected]',
password: 'password'
},
{
data: {
user_name: 'Alice'
}
}
)
const { user: bobAuth } = await supabase.auth.signUp(
{
email: '[email protected]',
password: 'password'
},
{
data: {
user_name: 'Bob'
}
}
)
const {
data: [alice, bob]
} = await supabase
.from('users')
.insert([serializeUser(aliceAuth), serializeUser(bobAuth)])
const { data: alicePosts } = await supabase.from('posts').insert([
{
title: `Alice's first post`,
content: `This is Alice's first post`,
user_id: alice.id
},
{
title: `Alice's second post`,
content: `This is Alice's second post`,
user_id: alice.id
}
])
const { data: bobPosts } = await supabase.from('posts').insert([
{
title: `Bob's's first post`,
content: `This is Bob's first post`,
user_id: bob.id
},
{
title: `Bob's's second post`,
content: `This is Bob's second post`,
user_id: bob.id
}
])
for (const post of alicePosts) {
await supabase.from('comments').insert([
{
user_id: alice.id,
post_id: post.id,
content: `This is Alice's comment on Alice's post "${post.title}"`
},
{
user_id: bob.id,
post_id: post.id,
content: `This is Bob's comment on Alice's post "${post.title}"`
}
])
}
for (const post of bobPosts) {
await supabase.from('comments').insert([
{
user_id: alice.id,
post_id: post.id,
content: `This is Alice's comment on Bob's post "${post.title}"`
},
{
user_id: bob.id,
post_id: post.id,
content: `This is Bob's comment on Bob's post "${post.title}"`
}
])
}
console.log('Done')
} catch (e) {
console.error(e)
}
}
seedDb()
```
Выполняем этот код с помощью `node src/seed_db.js`. Получаем сообщение об успехе операции (`Done`). В БД появилось 2 пользователя, 4 поста и 8 комментариев.
Находясь в корневой директории проекта (`supabase-social-app`), выполняем команду `yarn dev` для запуска сервера для разработки.

Переходим на страницу регистрации (`Register`) и создаем нового пользователя. *Обратите внимание*: `Supabase` требует, чтобы пароль состоял как минимум из 6 символов.


На панели навигации появилась кнопка для выхода из системы и ссылка на страницу профиля.
Переходим на страницу профиля (`Profile`), загружаем аватар и обновляем данные.


Вместо ссылки на страницу профиля у нас теперь имеется аватар пользователя, а в объекте `user` — заполненные поля `first_name`, `last_name` и `age`.
Переходим на страницу блога (`Blog`), "проваливаемся" в какой-нибудь пост и добавляем к нему комментарий.



Добавленный комментарий можно редактировать и удалять.
Возвращаемся на страницу блога, переключаемся на вкладку для создания нового поста (`New`) и создаем его.


На вкладке `My` страницы блога можно увидеть все созданные нами посты.

Их также можно редактировать и удалять.
Круто! Все работает, как часы.
Таким образом, `Supabase` предоставляет разработчикам довольно интересные возможности по созданию `fullstack app`, позволяя практически полностью сосредоточиться на клиентской части приложения. So give it a chance!
Пожалуй, это все, чем я хотел поделиться с вами в данной статье.
Благодарю за внимание и happy coding!
---
[](http://cloud.timeweb.com/services/timeweb-private-vpn?utm_source=habr&utm_medium=banner&utm_campaign=vpn) | https://habr.com/ru/post/660183/ | null | ru | null |
# Уходим глубже в Underground: история одного экстремального дизайна игры

Хорошо размахнувшись, инженер производил мощный удар кулаком сверху монитора. Раздавался треск и… монитор оживал! Тогда, 30 лет назад, когда в свои десять лет я посещал вечерние занятия школы юных программистов в университете, только инженер имел право так чинить мониторы. Только он знал, в какое место и с какой силой приложить компьютерную технику, чтобы она ожила и мы, дети, которым повезло попасть в школу программистов, продолжили, счастливые, писать свои строчки кода.
В то время я жил в промышленном районе города, в деревянном доме, затерянном среди заводов. Дорога от дома до университета занимала полтора часа, а еще надо было отпроситься из школы. Дело в том, что не пропустив последнего урока, не было шансов успеть на занятия в университете. Как правило, выпадало так, что два последних урока были уроками труда. Пришлось заключить с трудовиком соглашение: на первом уроке труда я делаю уборку всех кабинетов, и тогда он отпускает меня со второго.
Освободившись в школе, я стремительно вклинивался в заснеженные тропы между заводами, чтобы в полумраке сибирских вечеров, за полчаса дойти до автобусной остановки.
Потолкавшись час в заполненных автобусах и сделав одну пересадку, я наконец попадал в другой мир. Это была фантастика. Просторные и ослепительно светлые помещения университета были заполнены волшебством: компьютерами.
На первых занятиях мы изучали Фортран на компьютерах Искра-1256. Информация в нем отображалась на монохромном символьном ЭЛТ-мониторе в 16 строках по 64 символа. Символы имели размер 5×7 точек.

Программы можно было записывать на магнитофонные кассеты. Однако тут был нюанс — невозможно было записать несколько разных программ на одну кассету, при чтении они все считывались непрерывно. По какой-то причине Искра не могла определить конец одной программы и начало следующей. Кассеты для нас школьников были в дефиците, а программы хотелось сохранять и тогда, опытным путем, был открыт такой хак: после того как кто-то записывал свою программу, он доставал кассету и на магнитной ленте прорезал вертикальную полоску с помощью гвоздя. Оказалось, что если нанести значительное физическое повреждение магнитному слою, то в этом случае компьютер определял конец программы. Одной кассеты нам хватало, чтобы несколько месяцев «нарезать» наши небольшие программы. Главное, чтобы был гвоздь!
Потом появились «Корветы» — компьютеры с двумя независимыми видео-контроллерами, выводящими изображение на экран одновременно. Один — алфавитно-цифровой, 16 срок по 64 символа, 8×16 точек каждый. Другой — графический, 512×256 пикселей при 8 цветах. «Корвет» был быстр!

Однако с сохранением программ и здесь был нюанс. Только один «Корвет», учительский, имел 5¼ дюймовый дисковод. Остальные 10 компьютеров в классе подключались к нему по локальной сети со скоростью 19,5 килобит/сек. И сеть эта не была стабильной!
Занятия начинались с того, что с дисковода на локальные компьютеры закачивались наши программы. После нескольких часов работы над своими программами, нам нужно было закачать их обратно на учительский компьютер для сохранения, причем, по очереди. Вот тут разыгрывались подчас настоящие драмы. Достаточно было неосторожно пошевелить клавиатуру, и передача программы могла оборваться, даже если передача была с другого «Корвета». Представляете чувства ребенка, несколько часов «пилившего» свою первую «большую» программу, когда он терял всю свою работу за день? Поэтому период сохранения программ, занимавший иногда до часа-двух, был «карантином». Никто не имел права трогать компьютеры. Обычно все стояли и с замиранием сердца следили за процессом, стараясь потише дышать.
На «Корвете» я впервые сделал игру-платформер и даже с соавторами написал книжку по программированию с примерами спрайтов из этой игры. Тираж был 30 тысяч, который не сразу, но разошелся.

Если «Корветы» открыли для меня графику с несколькими градациями серого, то появившиеся позже MSX и ZX Spectrum открыли бескрайний мир игр с цветной графикой. О, какие там были игры! Помните? Даже сейчас, по прошествии 30-ти лет, я иногда запускаю эмулятор, чтобы поиграть в Zanac Ex, Metal Gear, Vampire Killer (Castlevania). Но до сих пор я с ностальгией вспоминаю те времена, когда мониторы были алфавитно-цифровые, а принтеры — матричные.
### Стиль
Так я нашел свой стиль графики, в котором только год назад решился сделать игру. Вся графика игры выполнена с помощью 94 символов, каждый из которых может принимать цвет из 256-цветовой палитры. Вот эти символы:
```
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
```
При наличии времени и сноровки, с помощью всего лишь этих символов, можно получать вполне атмосферную графику.

Около года назад я решился осуществить «пробу пера» — выпал из жизни на три месяца и сделал пазл-платформер игру Proto Raider. Работая по 10 часов в день, включая выходные, я сделал 64 уровня за три месяца. На каждый уровень уходило не менее одного дня. Это мероприятие подкосило семейный бюджет, но результат того стоил! Не смотря на минимальную ретро графику, игра понравилась моей семье, моим друзьям и потом многим-многим людям. Ресурс Touch Arcade назвал Proto Raider игрой недели.
Графика игры выполнена в стиле ASCII арта, что сразу определило узкую нишу. Не так много людей воспринимают такой стиль графики. Более того, ASCII арт в игре был не классический. Несмотря на «древнюю» графику мне хотелось, чтобы сам процесс игры был современным. Поэтому я отклонился от «канонов» ASCII арта. Движение персонажа, боссов и некоторых других элементов я сделал плавным. Символы перескакивают на соседние позиции текстовой матрицы не рывком, а за несколько кадров. А еще я сделал векторный шлейф за главным героем, за что получил от настоящих ASCII артистов по полной, однако шлейф оказался прикольной фичей, т.к. хорошо отделял человечка от фона и показывал траекторию.
Узость ниши компенсировалась интересом со стороны прессы. К моему удивлению, игра принесла отличные от нуля деньги. Стало понятно, что делать бизнес на таких играх нельзя, но немного заработать можно. Эту идею я попытался сформулировать в кредитсах, которые показывались тем, кто прошел все уровни.
### Новая игра — добавляем историю
Этим летом я начал реализовать еще одну вещь, которую хотел сделать уже несколько лет — написать научно-фантастический рассказ и сделать игру по нему. Идея рассказа давно сложилась, но захотелось сделать необычный ход: в своей ленте на Фейсбуке я спросил, не желает ли кто-нибудь поучаствовать своим персонажем в рассказе. Я обещал изучить профайл друга (если не знал его лично) и вписать его в рассказ под настоящим именем.
Откликнулось 20 человек, что вчетверо превышало изначальное количество персонажей в рассказе. Сейчас рассказ превратился в 100-страничную новеллу и закончен на 80%. Рассказ описывает необычный мир планеты Франго, окруженной одноименной аномалией, затрудняющей к ней доступ. Тем не менее, планета была колонизирована 1500 лет назад, но из-за труднодоступности и вызванной аномалией мутаций, развитие общества на планете проходило весьма не однородно. Экран загрузки новой игры показывает это:
С одной стороны, большая доля 500 миллионного населения планеты достаточно хорошо развита.
Пилотам регулярно приходится проходить через аномалию во внешний космос для осуществления связи с человечеством, а также для доставки туристов. Существует школа космических полетов, куда мечтает попасть большинство мальчишек и девчонок. С другой стороны, значительные по численности группы людей регрессировали.
В этом мире описывается судьба пилота Анри — главного героя рассказа и игры, которого называют лучшим пилотом-человеком во Вселенной. Дело в том, что аномалия, окружающая планету, из поколения в поколение воздействует на мозг жителей, что приводит к мутациям, делающим из пилотов планеты идеальные машины пилотирования. Пилоты планеты Франго могут на равных сражаться с дронами, управляемыми искусственными интеллектами. Это не по душе многим иерархам искусственных супер интеллектов.
С такой историей (Sci-fi), стилем графики (ASCII) и игровой механикой (логический платформер) дизайн новой игры будет по истине экстремальным! Но лично я очень вдохновлен и готов тратить сотни часов на создание атмосферы с помощью 94 символов.
То, что получится, можно будет посмотреть на [ASCIIDENT](http://www.asciident.com?lng=ru). Как вам название, кстати, соответствует ли игре?
Многие родственники и друзья спрашивают — зачем? Зачем тратить столько сил и времени на такую игру? Можно сделать другую, тоже интересную, и заработать в 100 раз больше денег.
С возрастом у мужчины меняется только размер игрушек. Разработка игр — это моя работа. А создание Sci-fi ASCII платформера — это моя дорогостоящая игрушка. Это во-первых. А во вторых, кто-то должен поставить дронов с искусственным интеллектом на место!
Надеюсь, мой рассказ о необычном дизайне игры был интересен. Множество технических моментов было опущено, но я с удовольствием расскажу о них в комментариях если будут вопросы. | https://habr.com/ru/post/314410/ | null | ru | null |
# Готовим статьи для Хабра: скрипт для подтягивания адресов картинок с habrastorage
[](https://habr.com/ru/post/674982/)
*Программист пишет интересную статью. Холст, масло, [ruDALL-E](https://rudalle.ru/).*
Что самое сложное в написании статьи для Хабра? Конечно же сесть и начать писать! А потом вовремя остановиться. Ну а на третьем месте — во всяком случае для меня — стоит загрузка уже готовой статьи на Хабр. Про новый редактор я тактично промолчу, а старый в принципе весьма неплох: статью в markdown можно скопировать в него почти без изменений. Но вот с добавлением картинок есть пара нюансов.
Во-первых, форматирование: markdown не поддерживает ширину-высоту-выравнивание картинок, поэтому если вам захочется красоты, то все теги придется переписать в html. А во-вторых, когда вы зальете картинки на Habrastorage (или в любое другое облако), адреса локальных картинок по всему тексту придется вручную перебивать на ссылки в облаке. Как-то вечером я дописывал статью с ~50 картинками, ужаснулся количеству предстоящей работы, и решил написать простенький скрипт для автоматизации всего этого.
Итак, юзкейз: мы пишем статью в markdown в любимом оффлайновом редакторе и расставляем ссылки на картинки, лежащие где-то рядом на жестком диске.

После этого мы вручную загружаем пачку картинок на Habrastorage, он генерирует ссылки на них. Можно ли вытащить ссылки прямо со страницы Habrastorage? Наверное да, но так как с фронтендом я знаком на уровне

то придется пойти более простым путем. Благо Habrastorage позволяет одним махом скопировать URL всех картинок, которые можно положить в файл (назовем его `cloud.txt`). Они лежат там в каком-то произвольном порядке; чтобы понять, где скрывается какая картинка, нужно сравнить их с локальными копиями. Алгоритм простой:
* вытаскиваем все теги картинок из текста статьи;
* находим в каждом теге адрес, загружаем по нему картинку;
* по очереди сравниваем ее с содержимым ссылок в `cloud.txt`;
* совпадение? ~~не думаю~~ меняем локальный адрес картинки на ссылку в облаке.
В эту же логику хорошо ложится преобразование тегов из markdown в html и обратно. Если мы смогли распарсить тег и вытащить из него адрес картинки и описание, то
```

```
легко превратить в
```

```
и наоборот. Что ж, приступим.
Ищем теги
---------
Теги в тексте статьи проше всего найти регулярками:
```
def find_tags(text):
md_tags = re.findall('!\[.*\]\(.+\)',text)
html_tags = re.findall('',text)
return md\_tags + html\_tags
```
Для работы с тегами создадим класс, который будет отвечать за парсинг тега, его преобразование, а также за загрузку картинок:
```
class ImageTag():
def __init__(self,tag):
self.tag = tag
self.type = ''
self.link = None
self.alt_text = ''
self._parse_tag()
```
Адрес картинки, alt-text и остальные аргументы (в случае html) тоже распарсим регулярками.
```
def _parse_tag(self):
if re.match('!\[.*\]\(.+\)',self.tag):
# this is a markdown tag
self.type = 'md'
... # here goes the parsing
elif re.match('',self.tag):
# HTML tag
self.type = 'html'
... # here goes the parsing
else:
print(f'Tag "{self.tag}" is not recognized')
```
**чуть подробнее**
```
if re.match('!\[.*\]\(.+\)',self.tag):
# markdown tag
self.type = 'md'
# find the link
prefix = re.match('!\[.*\]\(',self.tag)
postfix = re.search('\s*"[^"]*"\s*\)',self.tag)
if postfix:
self.link = self.tag[prefix.end():postfix.start()].strip()
else:
self.link = self.tag[prefix.end():-1].strip()
# find alt text
self.alt_text = re.match('[^\]]*',self.tag[2:]).group(0)
elif re.match('',self.tag):
# HTML tag
self.type = 'html'
# find the link
s = re.search('src\s\*=\s\*"[^"]\*"',self.tag)
if not s:
print(f'Cannot find "src" in "{self.tag}"')
self.type = ''
prefix = re.match('src\s\*=\s\*"',s.group(0))
self.link = s.group(0)[prefix.end():-1].strip()
# find alt text
s = re.search('alt\s\*=\s\*"[^"]\*"',self.tag)
if s:
prefix = re.match('alt\s\*=\s\*"',s.group(0))
self.alt\_text = s.group(0)[prefix.end():-1].strip()
# find optional parameters
s = re.search('width\s\*=\s\*"[^"]\*"',self.tag)
if s:
self.width\_tag = s.group(0)
s = re.search('height\s\*=\s\*"[^"]\*"',self.tag)
if s:
self.height\_tag = s.group(0)
s = re.search('align\s\*=\s\*"[^"]\*"',self.tag)
if s:
self.align\_tag = s.group(0)
```
Почему не BeautifulSoup? Во-первых, он не работает с Markdown. Во-вторых, он возвращает значение аргумента, которое нас не особо интересует: если мы захотим изменить, скажем, ширину картинки, мы можем найти весь тег `width="600"` и заменить его на `width="400"`; какая именно там была ширина, нам безразлично.
Преобразуем теги
----------------
С преобразованием в markdown все просто: если тег уже был в markdown, ничего делать не надо; если он был в html, достаточно взять адрес картинки и alt-text и создать новый тег:
```
def to_markdown(self):
if self.type == 'md':
return self.tag
elif self.type == 'html':
return ''
```
Преобразование из markdown в html аналогично, нужно только не забыть добавить дополнительный аргумент (ширину, высоту, выравнивание), если его задал пользователь:
```
def to_html(self,width=None,height=None,align=None):
if self.type == 'md':
new_tag = '
```
Если же мы преобразовываем html в html, то нужно проверить, не был ли аргумент уже установлен, и в противном случае заменить его. Генерировать заново весь тег не будем, в нем может быть много другой информации:
```
...
elif self.type == 'html':
new_tag = self.tag
if width:
if self.width_tag:
new_tag = new_tag.replace(self.width_tag,f'width="{width}"')
else:
new_tag = new_tag[:-1] + f' width="{width}"' + ">"
if height:
if self.height_tag:
new_tag = new_tag.replace(self.height_tag,f'height="{height}"')
else:
new_tag = new_tag[:-1] + f' height="{height}"' + ">"
if align:
if self.align_tag:
new_tag = new_tag.replace(self.align_tag,f'align="{align}"')
else:
new_tag = new_tag[:-1] + f' align="{align}"' + ">"
return new_tag
```
С преобразованием на этом все. Осталось завернуть все это в функцию `main()`, которую будет вызывать пользователь:
```
def main(file_in,file_out,format=None,
width=None,height=None,align=None):
with open(file_in,'r',encoding="UTF-8") as f:
text = f.read()
tags = find_tags(text)
text_tags = [ImageTag(tag,path=dir_in) for tag in tags]
if format:
if format == 'md':
for tag in text_tags:
new_tag = tag.to_markdown()
text = text.replace(tag.tag, new_tag)
elif format == 'html':
for tag in text_tags:
new_tag = tag.to_html(width=width,height=height,align=align)
text = text.replace(tag.tag, new_tag)
with open(file_out,'w',encoding="UTF-8") as f:
f.write(text)
```
Меняем адреса картинок
----------------------
Habrastorage отдает нам список ссылок на картинки в виде списка тегов markdown, html, или просто URL-адресов. Добавим в класс `ImageTag()` поддержку bare URL и подумаем, как лучше сравнивать картинки. На самом деле оптимизировать тут почти нечего: наибольшее время тратится на загрузку картинок с сервера, места в памяти они занимают немного, а одна картинка может встречаться в тексте много раз. Поэтому выберем самый простой путь: будем по очереди идти по картинкам из текста и искать для каждой первое совпадение на сервере:
```
def main(file_in,file_out,format=None,rename=None,
width=None,height=None,align=None):
...
if rename:
# достаем ссылки на облачные картинки из файла
with open(rename,'r') as f:
content = f.read()
hsto_urls = find_tags(content,bare_urls=True)
hsto_tags = [ImageTag(url) for url in hsto_urls]
# цикл по локальным картинкам и ссылкам в облако
for tag in text_tags:
for hsto_tag in hsto_tags:
if hsto_tag == tag:
text = text.replace(tag.link,hsto_tag.link)
matched = True
break
```
Как сравивать объекты класса `ImageTag()`? Разумеется через сравнение картинок! Их мы будем подгружать по ссылке из тега по первому запросу:
```
def __eq__(self, other: 'ImageTag') -> bool:
return self.img == other.img
@property
def img(self):
if self._img:
return self._img
if self._img_failed:
return None
self._load_img()
return self.img
```
Здесь `_img` содержит собственно картинку, а флаг `_img_failed` устанавливается, если ее не удалось загрузить по указанному адресу. Так как адрес может быть и локальным адресом файла, и URL, то мы будем проверять оба (пожалуй, это не самое красивое решение):
```
def _load_img(self):
try:
if os.path.isfile(os.path.join(self.path,self.link)):
# загружаем как файл
self._img = Image.open(os.path.join(self.path,self.link))
else:
# загружаем по внешей ссылке
response = requests.get(self.link)
image_bytes = io.BytesIO(response.content)
self._img = Image.open(image_bytes)
except:
self._img_failed = True
print(f'Cannot access image "{self.link}"')
```
Вот в принципе и все. Осталось прикрутить [argparse](https://docs.python.org/3/library/argparse.html), чтобы вызывать скрипт как модуль, передавая аргументы через командную строку.
Все вместе
==========
Ключ `-f` или `--format` запускает преобразование в markdown или html:
```
python -m hsto-rename input.md output.md -f md
```
При преобразовании в html можно добавить аргументы `--width`, `--height` и `--align`:
```
python -m hsto-rename input.md output.md -f html --align=center
```
[](https://hsto.org/webt/bs/u7/ic/bsu7icyxi2nofdfb0d18y2bthhs.gif)
*Кликабельно*
Замена локальных адресов на облачные запускается ключом `-r`, `--rename`, который в качестве аргумента принимает имя файла с ссылками на облако:
```
python -m hsto-rename input.md output.md -r cloud.txt
```
[](https://hsto.org/webt/cj/xp/eq/cjxpeqludj70xoobpd-dzl-recg.gif)
*Кликабельно*
Скрипт лежит на [гитхабе](https://github.com/aadiyatul/hsto-rename). Можно установить его глобально, чтобы вызывать через терминал в любом удобном месте:
```
pip install hsto-rename
```
Потренироваться можно на Алисе в стране чудес, которая [лежит](https://github.com/aadiyatul/hsto-rename/tree/main/example) на том же гитхабе. | https://habr.com/ru/post/674982/ | null | ru | null |
# Разнообразие ошибок в C# коде на примере CMS DotNetNuke: 40 вопросов к качеству

Сегодня мы вновь говорим о качестве C# кода и разнообразии возможных ошибок. На нашем операционном столе – CMS DotNetNuke, в исходный код которой мы и залезем. И лучше сразу заварите себе кофе...
DotNetNuke
----------
DotNetNuke – это система управления контентом (CMS) с открытым исходным кодом, преимущественно написанная на C#. Исходный код проекта доступен на [GitHub](https://github.com/dnnsoftware/Dnn.Platform). Также стоит отметить, что проект является частью [.NET Foundation](https://dotnetfoundation.org/).

У проекта есть свой [сайт](https://www.dnnsoftware.com/), [Twitter](https://twitter.com/dnn), [YouTube-канал](https://www.youtube.com/c/dotnetnuke/videos).
Однако для меня остался открытым вопрос, насколько проект живой? Если судить по репозиторию GitHub – в коде делаются какие-то изменения, проходят релизы. Если посмотреть на Twitter или YouTube канал – они достаточно давно не обновлялись.
С другой стороны – есть даже отдельный [сайт сообщества](https://dnncommunity.org/), там же есть новости про какие-то ивенты.
Но, так или иначе, нас в первую очередь интересует код. Код и его качество.
Кстати, на [странице проекта](https://github.com/dnnsoftware/Dnn.Platform) (ниже скриншот с неё) указано, что качество кода контролируется с помощью статического анализатора [NDepend](https://www.ndepend.com/).
Я не могу сказать, как настроен этот анализатор на проекте, обрабатываются ли его предупреждения и так далее, но хочу напомнить, что статический анализатор должен использоваться регулярно. По-хорошему он должен быть тесно вплетён в ваш процесс разработки. Про это написано множество статей, найти которые можно, в том числе, в [нашем блоге](https://pvs-studio.com/ru/blog/posts/).
О проверке
----------
Для проверки проекта я использовал исходники с [GitHub](https://github.com/dnnsoftware/Dnn.Platform) от 22.10.2021. Прошу учитывать, что от момента написания до момента публикации / чтений этой статьи пройдёт определённое время, за которое код может несколько измениться.
Для проверки использовался статический анализатор [PVS-Studio](https://pvs-studio.com/ru/pvs-studio/) версии 7.15. Если хотите попробовать анализатор на своём проекте – переходите на [эту страничку](https://pvs-studio.com/ru/pvs-studio/try-free/), которая проведёт вас по всем необходимым шагам. Появились вопросы или что-то непонятно? Смело [пишите нам](https://pvs-studio.com/ru/about-feedback/?is_question_form_open=true).
А начать мне сегодня хочется с одного из нововведений релиза PVS-Studio 7.15 – списка лучших предупреждений. Фича новая, и в будущем ещё будет улучшаться, но пользоваться можно (и нужно!) уже сейчас.
Best warnings
-------------
Допустим, вы решили попробовать какой-нибудь статический анализатор на своём проекте. Загрузили его, проанализировали проект и… получили кучу предупреждений. Десятки, сотни, тысячи, может, даже десятки тысяч. Ого, вот это номер… Хотелось бы каким-нибудь магическим образом отобрать из них, скажем, Топ-10 наиболее интересных. Таких, чтобы смотришь и понимаешь: "Да, это какая-то ерунда в коде, определённо!". Что ж, теперь в PVS-Studio есть такой механизм, и имя ему – [best warnings](https://pvs-studio.com/ru/docs/manual/6532/).
Пока он реализован только в плагине для Visual Studio, но позже мы планируем добавить его и в плагины для других IDE. Суть проста – анализатор отбирает из всего лога наиболее интересные и правдоподобные предупреждения.
Ну что, посмотрим, что у нас попало в список best warnings на этом проекте?
**Best warnings. Issue 1**
```
public string NavigateURL(int tabID,
bool isSuperTab,
IPortalSettings settings,
....)
{
....
if (isSuperTab)
{
url += "&portalid=" + settings.PortalId;
}
TabInfo tab = null;
if (settings != null)
{
tab = TabController.Instance.GetTab(tabID,
isSuperTab ? Null.NullInteger : settings.PortalId, false);
}
....
}
```
Предупреждение PVS-Studio: [V3095](https://pvs-studio.com/ru/w/v3095/) The 'settings' object was used before it was verified against null. Check lines: 190, 195. DotNetNuke.Library NavigationManager.cs 190
Интересный момент здесь состоит в том, что сначала идёт обращение к экземплярному свойству *settings.PortalId*, а затем идёт проверка *settings* на неравенство *null*. Как следствие, если *settings* – *null* и *isSuperTab* – *true*, получим исключение типа *NullReferenceException*.
Что интересно, в данном фрагменте кода есть и второй контракт, связывающий параметры *isSuperTab* и *settings* – тернарный оператор: *isSuperTab? Null.NullInteger: settings.PortalId*. Но обратите внимание, что в этом случае, в отличие от *if*, *settings.PortalId* будет использоваться тогда, когда *isSuperTab* имеет значение *false*.
И тут можно заметить, что, если *isSuperTab* – *true*, значение *settings.PortalId* не обрабатывается. Может показаться, что вот такой неявный контракт заложен, и в принципе всё ОК.
Нет.
Код должен быть легкочитаем и понятен, чтобы не приходилось играть в Шерлока. Если этот контракт подразумевается – пропишите его явно в коде, чтобы никого не сбивать с толку: ни разработчиков, ни статический анализатор, ни себя спустя какое-то время. ;)
**Best warnings. Issue 2**
```
private static string GetTableName(Type objType)
{
string tableName = string.Empty;
// If no attrubute then use Type Name
if (string.IsNullOrEmpty(tableName))
{
tableName = objType.Name;
if (tableName.EndsWith("Info"))
{
// Remove Info ending
tableName.Replace("Info", string.Empty);
}
}
....
}
```
Предупреждение PVS-Studio: [V3010](https://pvs-studio.com/ru/w/v3010/) The return value of function 'Replace' is required to be utilized. DotNetNuke.Library CBO.cs 1038
Здесь мы опять сталкиваемся сразу с несколькими интересными моментами:
* разработчик хотел удалить подстроку *"Info"* из *tableName*, но забыл про иммутабельность строк в C#. Никакой замены в *tableName* не произойдёт, а изменённая строка просто будет потеряна, так как результат вызова метода *Replace* никуда не сохраняется;
* в коде объявлена переменная *tableName*, инициализированная пустой строкой. Сразу после этого идёт проверка, является ли *tableName* пустой строкой.
На первый кейс и указывает приведённое предупреждение анализатора. Второй кейс, кстати, также был обнаружен анализатором, но предупреждение не попало в список best warnings. Вот оно: [V3022](https://pvs-studio.com/ru/w/v3022/) Expression 'string.IsNullOrEmpty(tableName)' is always true. DotNetNuke.Library CBO.cs 1032
**Best warnings. Issue 3**
```
public static ArrayList GetFileList(...., string strExtensions, ....)
{
....
if ( strExtensions.IndexOf(
strExtension,
StringComparison.InvariantCultureIgnoreCase) != -1
|| string.IsNullOrEmpty(strExtensions))
{
arrFileList.Add(new FileItem(fileName, fileName));
}
....
}
```
Предупреждение PVS-Studio: [V3027](https://pvs-studio.com/ru/w/v3027/) The variable 'strExtensions' was utilized in the logical expression before it was verified against null in the same logical expression. DotNetNuke.Library Globals.cs 3783
В строке *strExtensions* пытаются найти подстроку *strExtension*. Если подстроку найти не удалось, тогда проверяют, а не является ли *strExtensions* пустой или равной *null*. Вот только если *strExtensions* – *null*, уже при вызове экземплярного метода *IndexOf* будет выброшено исключение типа *NullReferenceException*.
Если вдруг подразумевается, что *strExtension* может быть пустой строкой, но никогда не имеет значения *null*, можно более явно выразить свои намерения: *strExtensions.Length == 0*.
Но данный фрагмент кода в любом случае стоит поправить – как и в случае с **Issue 1**, к нему сразу возникают вопросы.
**Best warnings. Issue 4**
```
public static void KeepAlive(Page page)
{
....
var scriptBlock = string.Format(
"(function($){{setInterval(
function(){{$.get(location.href)}}, {1});}}(jQuery));",
Globals.ApplicationPath,
seconds);
....
}
```
Предупреждение PVS-Studio: [V3025](https://pvs-studio.com/ru/w/v3025/) Incorrect format. A different number of format items is expected while calling 'Format' function. Arguments not used: Globals.ApplicationPath. DotNetNuke.Library jQuery.cs 402
Подозрительные операции с форматированными строками – значение переменной *seconds* в результирующую строку подставлено будет, а вот для *Globals.ApplicationPath* в ней места не нашлось из-за отсутствия *{0}* в строке формата.
**Best warnings. Issue 5**
```
private void ProcessRequest(....)
{
....
if (!result.RewritePath.ToLowerInvariant().Contains("tabId="))
....
}
```
Предупреждение PVS-Studio: [V3122](https://pvs-studio.com/ru/w/v3122/) The 'result.RewritePath.ToLowerInvariant()' lowercase string is compared with the '"tabId="' mixed case string. DotNetNuke.Library AdvancedUrlRewriter.cs 2252
По-моему, срабатываний этой диагностики лично я на реальных проектах ещё не встречал. Что ж, всё бывает в первый раз. :)
Из *RewritePath* берут строку, приводят её к нижнему регистру и проверяют, не содержит ли она подстроку *"tabId="*. Вот только проблема в том, что исходная строка у нас в нижнем регистре, а проверяемая содержит, в том числе, символы в верхнем.
**Best warnings. Issue 6**
```
protected override void RenderEditMode(HtmlTextWriter writer)
{
....
// Add the Not Specified Option
if (this.ValueField == ListBoundField.Text)
{
writer.AddAttribute(HtmlTextWriterAttribute.Value, Null.NullString);
}
else
{
writer.AddAttribute(HtmlTextWriterAttribute.Value, Null.NullString);
}
....
}
```
Предупреждение PVS-Studio: [V3004](https://pvs-studio.com/ru/w/v3004/) The 'then' statement is equivalent to the 'else' statement. DotNetNuke.Library DNNListEditControl.cs 380
Классика copy-paste: одинаковые тела *then* и *else*-веток оператора *if*.
**Best warnings. Issue 7**
```
public static string LocalResourceDirectory
{
get
{
return "App_LocalResources";
}
}
private static bool HasLocalResources(string path)
{
var folderInfo = new DirectoryInfo(path);
if (path.ToLowerInvariant().EndsWith(Localization.LocalResourceDirectory))
{
return true;
}
....
}
```
Предупреждение PVS-Studio: [V3122](https://pvs-studio.com/ru/w/v3122/) The 'path.ToLowerInvariant()' lowercase string is compared with the 'Localization.LocalResourceDirectory' mixed case string. Dnn.PersonaBar.Extensions LanguagesController.cs 644
Вновь знакомые грабли, только в этот раз чуть менее очевидные. Значение *path* приводится к нижнему регистру и проверяется, что оно оканчивается на строку, заведомо содержащую символы в верхнем регистре – *"App\_LocalResources"* (литерал, возвращаемый из свойства *LocalResourceDirectory*).
**Best warnings. Issue 8**
```
internal static IEnumerable GetEditorConfigProperties()
{
return
typeof(EditorConfig).GetProperties()
.Where(
info => !info.Name.Equals("Magicline\_KeystrokeNext")
&& !info.Name.Equals("Magicline\_KeystrokePrevious")
&& !info.Name.Equals("Plugins")
&& !info.Name.Equals("Codemirror\_Theme")
&& !info.Name.Equals("Width")
&& !info.Name.Equals("Height")
&& !info.Name.Equals("ContentsCss")
&& !info.Name.Equals("Templates\_Files")
&& !info.Name.Equals("CustomConfig")
&& !info.Name.Equals("Skin")
&& !info.Name.Equals("Templates\_Files")
&& !info.Name.Equals("Toolbar")
&& !info.Name.Equals("Language")
&& !info.Name.Equals("FileBrowserWindowWidth")
&& !info.Name.Equals("FileBrowserWindowHeight")
&& !info.Name.Equals("FileBrowserWindowWidth")
&& !info.Name.Equals("FileBrowserWindowHeight")
&& !info.Name.Equals("FileBrowserUploadUrl")
&& !info.Name.Equals("FileBrowserImageUploadUrl")
&& !info.Name.Equals("FilebrowserImageBrowseLinkUrl")
&& !info.Name.Equals("FileBrowserImageBrowseUrl")
&& !info.Name.Equals("FileBrowserFlashUploadUrl")
&& !info.Name.Equals("FileBrowserFlashBrowseUrl")
&& !info.Name.Equals("FileBrowserBrowseUrl")
&& !info.Name.Equals("DefaultLinkProtocol"));
}
```
Предупреждение PVS-Studio: [V3001](https://pvs-studio.com/ru/w/v3001/) There are identical sub-expressions '!info.Name.Equals("Templates\_Files")' to the left and to the right of the '&&' operator. DNNConnect.CKEditorProvider SettingsUtil.cs 1451
Я немного отформатировал этот код для лучшего восприятия. Анализатор обнаружил подозрительный дубль проверок: *!info.Name.Equals("Templates\_Files")*. Или этот код просто избыточен, или здесь затерялась какая-то нужная проверка.
На самом деле, здесь есть и другие дубли, о которых анализатор почему-то не сообщил (взяли на карандаш). Например, также по два раза встречаются следующие выражения:
* *!info.Name.Equals("FileBrowserWindowWidth")*
* *!info.Name.Equals("FileBrowserWindowHeight")*
Три дублирующиеся проверки в рамках одного выражения – неплохо. На моей памяти это, вроде как, рекорд.
**Best warnings. Issue 9**
```
private void ProcessContentPane()
{
....
string moduleEditRoles
= this.ModuleConfiguration.ModulePermissions.ToString("EDIT");
....
moduleEditRoles
= moduleEditRoles.Replace(";", string.Empty).Trim().ToLowerInvariant();
....
if ( viewRoles.Equals(this.PortalSettings.AdministratorRoleName,
StringComparison.InvariantCultureIgnoreCase)
&& (moduleEditRoles.Equals(this.PortalSettings.AdministratorRoleName,
StringComparison.InvariantCultureIgnoreCase)
|| string.IsNullOrEmpty(moduleEditRoles))
&& pageEditRoles.Equals(this.PortalSettings.AdministratorRoleName,
StringComparison.InvariantCultureIgnoreCase))
{
adminMessage = Localization.GetString("ModuleVisibleAdministrator.Text");
showMessage = !this.ModuleConfiguration.HideAdminBorder
&& !Globals.IsAdminControl();
}
....
}
```
Предупреждение PVS-Studio: [V3027](https://pvs-studio.com/ru/w/v3027/) The variable 'moduleEditRoles' was utilized in the logical expression before it was verified against null in the same logical expression. DotNetNuke.Library Container.cs 273
Мда, многовато кода получилось… Давайте ещё немного сократим.
```
moduleEditRoles.Equals(this.PortalSettings.AdministratorRoleName,
StringComparison.InvariantCultureIgnoreCase)
|| string.IsNullOrEmpty(moduleEditRoles)
```
Вот, теперь другое дело! Кажется, что-то подобное мы сегодня уже видели… Опять сначала проверяют *moduleEditRoles* на равенство другой строке, и лишь затем идёт проверка, а не является ли *moduleEditRoles* пустой строкой или *null*-значением.
Правда, конкретно в текущий момент времени *null*-значение переменная хранить не может, так как содержит результат вызова метода *ToLowerInvariant*. Следовательно – максимум она может быть пустой строкой. Уровень предупреждения анализатора здесь можно и понизить.
Тем не менее, я бы поправил код, перенеся проверку *IsNullOrEmpty* вперёд.
**Best warnings. Issue 10**
```
private static void Handle404OrException(....)
{
....
string errRV;
....
if (result != null && result.Action != ActionType.Output404)
{
....
// line 552
errRV = "500 Rewritten to {0} : {1}";
}
else // output 404 error
{
....
// line 593
errRV = "404 Rewritten to {0} : {1} : Reason {2}";
....
}
....
// line 623
response.AppendHeader(errRH,
string.Format(
errRV,
"DNN Tab",
errTab.TabName
+ "(Tabid:" + errTabId.ToString() + ")",
reason));
....
}
```
Предупреждение PVS-Studio: [V3025](https://pvs-studio.com/ru/w/v3025/) Incorrect format. A different number of format items is expected while calling 'Format' function. Arguments not used: reason. DotNetNuke.Library AdvancedUrlRewriter.cs 623
False positive. Очевидно, что код написан таким образом специально – нужно править на уровне анализатора.
**Summary**
Неплохой результат вышел, на мой взгляд! Да, имеем 1 явный false positive, но во всех остальных случаях к коду возникают вопросы.
Однако вы можете попробовать составить свой список лучших предупреждений – ниже я дам материал для этого. :)
Другие предупреждения
---------------------
Как вы поняли, с предупреждениями мы не закончили. Нет-нет-нет, в проекте нашлось ещё немало мест, заслуживающих внимания и разбора.
**Issue 11**
В best warnings мы уже видели копипаст then/else-веток оператора *if*. То место оказалось не единственным:
```
protected void ExecuteSearch(string searchText, string searchType)
{
....
if (Host.UseFriendlyUrls)
{
this.Response.Redirect(this._navigationManager.NavigateURL(searchTabId));
}
else
{
this.Response.Redirect(this._navigationManager.NavigateURL(searchTabId));
}
....
}
```
Предупреждение PVS-Studio: [V3004](https://pvs-studio.com/ru/w/v3004/) The 'then' statement is equivalent to the 'else' statement. DotNetNuke.Website Search.ascx.cs 432
**Issues 12, 13**
```
private static void LoadProviders()
{
....
foreach (KeyValuePair comp in
ComponentFactory.GetComponents())
{
comp.Value.Name = comp.Key;
comp.Value.Description = comp.Value.Description;
\_providers.Add(comp.Value);
}
....
}
```
Предупреждение PVS-Studio: [V3005](https://pvs-studio.com/ru/w/v3005/) The 'comp.Value.Description' variable is assigned to itself. DotNetNuke.Library SitemapBuilder.cs 231
Иногда встречаются присваивания, в которых переменная записывается в себя же. Это может быть как избыточный код, так и более серьёзная ошибка, когда что-то перепутали. Что-то мне подсказывает, что приведённый выше код не просто избыточен...
*Description* – автореализованное свойство:
```
public string Description { get; set; }
```
Ещё один фрагмент с записью в себя:
```
public SendTokenizedBulkEmail(List addressedRoles,
List addressedUsers,
bool removeDuplicates,
string subject,
string body)
{
this.ReportRecipients = true;
this.AddressMethod = AddressMethods.Send\_TO;
this.BodyFormat = MailFormat.Text;
this.Priority = MailPriority.Normal;
this.\_addressedRoles = addressedRoles;
this.\_addressedUsers = addressedUsers;
this.RemoveDuplicates = removeDuplicates;
this.Subject = subject;
this.Body = body;
this.SuppressTokenReplace = this.SuppressTokenReplace;
this.Initialize();
}
```
Предупреждение PVS-Studio: [V3005](https://pvs-studio.com/ru/w/v3005/) The 'this.SuppressTokenReplace' variable is assigned to itself. DotNetNuke.Library SendTokenizedBulkEmail.cs 109
Не такой подозрительный код, как в предыдущем случае, но выглядит всё равно странно – опять свойство записывают само в себя. Соответствующего параметра нет, и какое значение должно быть записано – вопрос. Предположу, что дефолтное, описанное в комментариях (*false*, то бишь):
```
/// Gets or sets a value indicating whether
shall automatic TokenReplace be prohibited?.
/// default value: false.
public bool SuppressTokenReplace { get; set; }
```
**Issues 14, 15**
Помните, мы видели в best warnings, как кто-то забыл про иммутабельность строк? В общем, забыли про неё не один раз. :)
```
public static string BuildPermissions(IList Permissions, string PermissionKey)
{
....
// get string
string permissionsString = permissionsBuilder.ToString();
// ensure leading delimiter
if (!permissionsString.StartsWith(";"))
{
permissionsString.Insert(0, ";");
}
....
}
```
Предупреждение PVS-Studio: [V3010](https://pvs-studio.com/ru/w/v3010/) The return value of function 'Insert' is required to be utilized. DotNetNuke.Library PermissionController.cs 64
Если строка *permissionsString* не начиналась с ';', то и не будет – *Insert* не меняет исходную строку, а возвращает изменённую. С учётом вышесказанного отдельного внимания заслуживает комментарий. :)
Ещё одно место:
```
public override void Install()
{
....
skinFile.Replace(Globals.HostMapPath + "\\", "[G]");
....
}
```
Предупреждение PVS-Studio: [V3010](https://pvs-studio.com/ru/w/v3010/) The return value of function 'Replace' is required to be utilized. DotNetNuke.Library SkinInstaller.cs 230
**Issue 16**
```
public int Page { get; set; } = 1;
public override IConsoleResultModel Run()
{
....
var pageIndex = (this.Page > 0 ? this.Page - 1 : 0);
pageIndex = pageIndex < 0 ? 0 : pageIndex;
....
}
```
Предупреждение PVS-Studio: [V3022](https://pvs-studio.com/ru/w/v3022/) Expression 'pageIndex < 0' is always false. DotNetNuke.Library ListModules.cs 61
На момент вычисления выражения *pageIndex < 0* значение *pageIndex* всегда будет неотрицательным, так как:
* если *this.Page* лежит в диапазоне [1; *int.MaxValue*], *pageIndex* будет иметь значение в диапазоне [0; *int.MaxValue — 1*]
* если *this.Page* лежит в диапазоне [*int.MinValue*; 0], *pageIndex* будет иметь значение 0.
Следовательно, проверка *pageIndex < 0* будет всегда давать *false*.
**Issue 17**
```
private CacheDependency GetTabsCacheDependency(IEnumerable portalIds)
{
....
// get the portals list dependency
var portalKeys = new List();
if (portalKeys.Count > 0)
{
keys.AddRange(portalKeys);
}
....
}
```
Предупреждение PVS-Studio: [V3022](https://pvs-studio.com/ru/w/v3022/) Expression 'portalKeys.Count > 0' is always false. DotNetNuke.Library CacheController.cs 968
Создали пустой список, после чего проверяют, что он непустой. Нет, ну а вдруг? :)
**Issue 18**
```
public JournalEntity(string entityXML)
{
....
XmlDocument xDoc = new XmlDocument { XmlResolver = null };
xDoc.LoadXml(entityXML);
if (xDoc != null)
....
}
```
Предупреждение PVS-Studio: [V3022](https://pvs-studio.com/ru/w/v3022/) Expression 'xDoc != null' is always true. DotNetNuke.Library JournalEntity.cs 30
Вызвали конструктор, записали ссылку в переменную, после чего вызывают экземплярный метод *LoadXml*. Далее всё ту же ссылку проверяют на неравенство *null*. Нет, ну а вдруг? (2)
**Issue 19**
```
public enum ActionType
{
....
Redirect302Now = 2,
....
Redirect302 = 5,
....
}
public ActionType Action { get; set; }
private static bool CheckForRedirects(....)
{
....
if ( result.Action != ActionType.Redirect302Now
|| result.Action != ActionType.Redirect302)
....
}
```
Предупреждение PVS-Studio: [V3022](https://pvs-studio.com/ru/w/v3022/) Expression is always true. Probably the '&&' operator should be used here. DotNetNuke.Library AdvancedUrlRewriter.cs 1695
Данное выражение будет ложно, только если результат обоих операндов будет *false*. В таком случае должны выполняться оба следующих условия:
* *result.Action == ActionType.Redirect302Now*
* *result.Action == ActionType.Redirect302*
Так как *result.Action* не может иметь двух разных значений, описанное условие невыполнимо, следовательно выражение всегда истинно.
**Issue 20**
```
public Route MapRoute(string moduleFolderName,
string routeName,
string url,
object defaults,
object constraints,
string[] namespaces)
{
if ( namespaces == null
|| namespaces.Length == 0
|| string.IsNullOrEmpty(namespaces[0]))
{
throw new ArgumentException(Localization.GetExceptionMessage(
"ArgumentCannotBeNullOrEmpty",
"The argument '{0}' cannot be null or empty.",
"namespaces"));
}
Requires.NotNullOrEmpty("moduleFolderName", moduleFolderName);
url = url.Trim('/', '\\');
var prefixCounts = this.portalAliasMvcRouteManager.GetRoutePrefixCounts();
Route route = null;
if (url == null)
{
throw new ArgumentNullException(nameof(url));
}
....
}
```
Предупреждение PVS-Studio: [V3022](https://pvs-studio.com/ru/w/v3022/) Expression 'url == null' is always false. DotNetNuke.Web.Mvc MvcRoutingManager.cs 66
С параметром *url* интересная история получается. Мы видим, что, если *url* – *null*, разработчики хотят выбросить исключение типа *ArgumentNullException*, недвусмысленно намекающее на то, что этот параметр должен быть ненулевой ссылкой. Вот только перед этим у *url* вызывается экземплярный метод *Trim*… Как следствие, если *url* – *null*, будет выброшено исключение типа *NullReferenceException*. Поздновато проверку сделали, выходит.
**Issue 21**
```
public Hashtable Settings
{
get
{
return this.ModuleContext.Settings;
}
}
public string UploadRoles
{
get
{
....
if (Convert.ToString(this.Settings["uploadroles"]) != null)
{
this._UploadRoles = Convert.ToString(this.Settings["uploadroles"]);
}
....
}
}
```
Предупреждение PVS-Studio: [V3022](https://pvs-studio.com/ru/w/v3022/) Expression 'Convert.ToString(this.Settings["uploadroles"]) != null' is always true. DotNetNuke.Website.Deprecated WebUpload.ascx.cs 151
*Convert.ToString* либо возвращает результат успешного преобразования, либо *String.Empty*, но не *null*. Как результат, толку от этой проверки нет.
Поверили? Это [false positive](https://pvs-studio.com/ru/blog/terms/6461/).
Для начала стоит сказать про перегрузки метода *Convert.ToString*. Есть такая перегрузка: *Convert.ToString(String value)*. Она просто возвращает *value* as is. Как следствие, если на вход пришёл *null*, то и на выходе будет *null*.
Есть и другая перегрузка – *Convert.ToString(Object value)*. В приведённом выше фрагменте кода как раз используется она. Возвращаемое значение этого метода прокомментировано следующим образом:
```
// Returns:
// The string representation of value,
// or System.String.Empty if value is null.
```
И здесь можно ошибиться в том, что метод всегда будет возвращать какую-то строку, но! Строковое представление объекта вполне может иметь значение *null*, и, как следствие, метод всё же вернёт *null*.
Простейший пример, демонстрирующий это:
Кстати, здесь получается, что:
* если *obj == null*, *stringRepresentation != null* (пустая строка);
* если *obj != null*, *stringRepresentation == null*.
Оу, немного запутанно выходит...
Можно возразить, что это синтетический пример, и кто же вообще возвращает из метода *ToString* значение *null*? Ну, Microsoft порой [этим грешил](https://pvs-studio.com/ru/blog/posts/csharp/0656/) (см. Issue 14 из статьи по ссылке).
Внимание, вопрос! Знали ли авторы кода про эту особенность и учли её или нет? Знали ли про это вы и ожидаете ли, что метод *ToString* может вернуть *null*?
Кстати, хочу здесь похвалить nullable reference types и разметку методов .NET, где из сигнатуры метода сразу понятно, что может быть возвращено значение *null*:
```
public static string? ToString(object? value)
```
Здесь я предлагаю сделать небольшой перерыв, обновить кофеёк и запастись новой порцией печенек, после чего продолжим. Кофе-брейк!

Надеюсь, вы прислушались к советам и обновили свои запасы. Продолжаем.
**Issues 22, 23**
```
public static ModuleItem ConvertToModuleItem(ModuleInfo module)
=> new ModuleItem
{
Id = module.ModuleID,
Title = module.ModuleTitle,
FriendlyName = module.DesktopModule.FriendlyName,
EditContentUrl = GetModuleEditContentUrl(module),
EditSettingUrl = GetModuleEditSettingUrl(module),
IsPortable = module.DesktopModule?.IsPortable,
AllTabs = module.AllTabs,
};
```
Предупреждение PVS-Studio: [V3042](https://pvs-studio.com/ru/w/v3042/) Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'module.DesktopModule' object Dnn.PersonaBar.Extensions Converters.cs 67
Обратите внимание на инициализацию свойств *FriendlyName* и *IsPortable*. В качестве значений для инициализации используются *module.DesktopModule.FriendlyName* и *module.DesktopModule?.IsPortable* соответственно. Возникает логичный вопрос – а может ли в данном случае *module.DesktopModule* иметь значение *null*? Если да, защита с помощью *?.* не сработает, так как при первом обращении будет сгенерировано исключение типа *NullReferenceException*. Если нет, обращение через *?.* избыточно и только сбивает всех с толку.
Очень похожий фрагмент кода встретился ещё раз.
```
public IDictionary GetSettings(MenuItem menuItem)
{
var settings = new Dictionary
{
{ "canSeePagesList",
this.securityService.CanViewPageList(menuItem.MenuId) },
{ "portalName",
PortalSettings.Current.PortalName },
{ "currentPagePermissions",
this.securityService.GetCurrentPagePermissions() },
{ "currentPageName",
PortalSettings.Current?.ActiveTab?.TabName },
{ "productSKU",
DotNetNukeContext.Current.Application.SKU },
{ "isAdmin",
this.securityService.IsPageAdminUser() },
{ "currentParentHasChildren",
PortalSettings.Current?.ActiveTab?.HasChildren },
{ "isAdminHostSystemPage",
this.securityService.IsAdminHostSystemPage() },
};
return settings;
}
```
Предупреждение PVS-Studio: [V3042](https://pvs-studio.com/ru/w/v3042/) Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'PortalSettings.Current' object Dnn.PersonaBar.Extensions PagesMenuController.cs 47
Когда разработчик инициализировал словарь, он несколько раз использовал *PortalSettings.Current*. Вот только в некоторых случаях при обращении использовалась проверка на *null*, а в некоторых – нет:
```
var settings = new Dictionary
{
....
{ "portalName",
PortalSettings.Current.PortalName },
....
{ "currentPageName",
PortalSettings.Current?.ActiveTab?.TabName },
....
{ "currentParentHasChildren",
PortalSettings.Current?.ActiveTab?.HasChildren },
....
};
```
**Issues 24, 25, 26**
```
private static void HydrateObject(object hydratedObject, IDataReader dr)
{
....
// Get the Data Value's type
objDataType = coloumnValue.GetType();
if (coloumnValue == null || coloumnValue == DBNull.Value)
{
// set property value to Null
objPropertyInfo.SetValue(hydratedObject,
Null.SetNull(objPropertyInfo),
null);
}
....
}
```
Предупреждение PVS-Studio: [V3095](https://pvs-studio.com/ru/w/v3095/) The 'coloumnValue' object was used before it was verified against null. Check lines: 902, 903. DotNetNuke.Library CBO.cs 902
Для переменной *coloumnValue* вызывается экземплярный метод *GetType*, а дальше следует проверка, что *coloumnValue != null*. Ребята, вы чего? :( Это же соседние строчки.
Приведённый выше случай, к сожалению, не единичный. Вот ещё один.
```
private void DeleteLanguage()
{
....
// Attempt to get the Locale
Locale language = LocaleController.Instance
.GetLocale(tempLanguagePack.LanguageID);
if (tempLanguagePack != null)
{
LanguagePackController.DeleteLanguagePack(tempLanguagePack);
}
....
}
```
Предупреждение PVS-Studio: [V3095](https://pvs-studio.com/ru/w/v3095/) The 'tempLanguagePack' object was used before it was verified against null. Check lines: 235, 236. DotNetNuke.Library LanguageInstaller.cs 235
Та же самая история – сначала идёт обращение к свойству *LanguageId* (*tempLanguagePack.LanguageID*), а на следующей строчке идёт проверка *tempLanguagePack != null*.
И ещё...
```
private static void AddLanguageHttpAlias(int portalId, Locale locale)
{
....
var portalAliasInfos = portalAliasses as IList
?? portalAliasses.ToList();
if (portalAliasses != null && portalAliasInfos.Any())
....
}
```
Предупреждение PVS-Studio: [V3095](https://pvs-studio.com/ru/w/v3095/) The 'portalAliasses' object was used before it was verified against null. Check lines: 1834, 1835. DotNetNuke.Library Localization.cs 1834
Конкретно с этим паттерном закончим, хотя подобные срабатывания ещё есть. Взглянем на то, как ещё может выглядеть обращение к членам перед проверкой на *null*.
**Issues 27, 28, 29, 30**
```
private static void WatcherOnChanged(object sender, FileSystemEventArgs e)
{
if (Logger.IsInfoEnabled && !e.FullPath.EndsWith(".log.resources"))
{
Logger.Info($"Watcher Activity: {e.ChangeType}. Path: {e.FullPath}");
}
if ( _handleShutdowns
&& !_shutdownInprogress
&& (e.FullPath ?? string.Empty)
.StartsWith(_binFolder,
StringComparison.InvariantCultureIgnoreCase))
{
ShceduleShutdown();
}
}
```
Предупреждение PVS-Studio: [V3095](https://pvs-studio.com/ru/w/v3095/) The 'e.FullPath' object was used before it was verified against null. Check lines: 147, 152. DotNetNuke.Web DotNetNukeShutdownOverload.cs 147
Обратите внимание на *e.FullPath*. Сначала идёт обращение *e.FullPath.EndsWith(".log.resources")*, а позже – использование оператора *??*: *e.FullPath ?? string.Empty*.
Этот код благополучно размножился через copy-paste:
* V3095 The 'e.FullPath' object was used before it was verified against null. Check lines: 160, 165. DotNetNuke.Web DotNetNukeShutdownOverload.cs 160
* V3095 The 'e.FullPath' object was used before it was verified against null. Check lines: 173, 178. DotNetNuke.Web DotNetNukeShutdownOverload.cs 173
* V3095 The 'e.FullPath' object was used before it was verified against null. Check lines: 186, 191. DotNetNuke.Web DotNetNukeShutdownOverload.cs 186
Если честно, мне уже надоело писать про [V3095](https://pvs-studio.com/ru/w/v3095/), а вам, думаю, читать. Так что пойдём дальше.
**Issue 31**
```
internal FolderInfoBuilder()
{
this.portalId = Constants.CONTENT_ValidPortalId;
this.folderPath = Constants.FOLDER_ValidFolderRelativePath;
this.physicalPath = Constants.FOLDER_ValidFolderPath;
this.folderMappingID = Constants.FOLDER_ValidFolderMappingID;
this.folderId = Constants.FOLDER_ValidFolderId;
this.physicalPath = string.Empty;
}
```
Предупреждение PVS-Studio: [V3008](https://pvs-studio.com/ru/w/v3008/) The 'this.physicalPath' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 29, 26. DotNetNuke.Tests.Core FolderInfoBuilder.cs 29
В поле *physicalPath* сначала записывается значение *Constants.FOLDER\_ValidFolderPath*, однако затем всё в то же поле записывается *string.Empty*. Дополнительно обращаю внимание, что эти значения отличаются, из-за чего данный код выглядит ещё более подозрительно:
```
public const string FOLDER_ValidFolderPath = "C:\\folder";
```
**Issue 32**
```
public int SeekCountry(int offset, long ipNum, short depth)
{
....
var buffer = new byte[6];
byte y;
....
if (y < 0)
{
y = Convert.ToByte(y + 256);
}
....
}
```
Предупреждение PVS-Studio: [V3022](https://pvs-studio.com/ru/w/v3022/) Expression 'y < 0' is always false. Unsigned type value is always >= 0. CountryListBox CountryLookup.cs 210
Значения типа *byte* лежат в диапазоне [0; 255]. Следовательно, проверка *y < 0* всегда будет давать *false* и *then*-ветвь никогда не будет выполнена.
**Issue 33**
```
private void ParseTemplateInternal(...., string templatePath, ....)
{
....
string path = Path.Combine(templatePath, "admin.template");
if (!File.Exists(path))
{
// if the template is a merged copy of a localized templte the
// admin.template may be one director up
path = Path.Combine(templatePath, "..\admin.template");
}
....
}
```
Предупреждение PVS-Studio: [V3057](https://pvs-studio.com/ru/w/v3057/) The 'Combine' function is expected to receive a valid path string. Inspect the second argument. DotNetNuke.Library PortalController.cs 3538
Интересная ошибка. Здесь мы имеем две операции конструирования пути (вызов *Path.Combine*). С первой всё нормально, а вот вторая интереснее. Видно, что во втором случае хотели брать файл admin.template не из директории *templatePath*, а из родительской. Но вот незадача! После того как добавили *..\\*, путь перестал быть валидным, так как образовалась escape sequence:* ..**\a**dmin.template\*.
**Issue 34**
```
internal override string GetMethodInformation(MethodItem method)
{
....
string param = string.Empty;
string[] names = method.Parameters;
StringBuilder sb = new StringBuilder();
if (names != null && names.GetUpperBound(0) > 0)
{
for (int i = 0; i <= names.GetUpperBound(0); i++)
{
sb.AppendFormat("{0}, ", names[i]);
}
}
if (sb.Length > 0)
{
sb.Remove(sb.Length - 2, 2);
param = sb.ToString();
}
....
}
```
Предупреждение PVS-Studio: [V3057](https://pvs-studio.com/ru/w/v3057/) The 'Remove' function could receive the '-1' value while non-negative value is expected. Inspect the first argument. DotNetNuke.Log4Net StackTraceDetailPatternConverter.cs 67
Сейчас этот код работает, но всё равно сразу закрадываются подозрения. В then-ветви оператора *if* значение *sb.Length* >= 1, но при вызове метода *Remove* мы вычитаем из этого значения 2. Соответственно, если *sb.Length == 1*, то вызов будет выглядеть следующим образом: *sb.Remove(-1, 2)*, что приведёт к возникновению исключения.
Конкретно сейчас этот код спасает то, что в *StringBuilder* добавляются строки через формат *"{0}, "*. Следовательно, длина этих строк – как минимум 2 символа. Тем не менее, всё это выглядит достаточно зыбко, а проверка в таком виде только дополнительно сбивает с толку и настораживает.
**Issues 35, 36**
```
public void SaveJournalItem(JournalItem journalItem, int tabId, int moduleId)
{
....
journalItem.JournalId = this._dataService.Journal_Save(
journalItem.PortalId,
journalItem.UserId,
journalItem.ProfileId,
journalItem.SocialGroupId,
journalItem.JournalId,
journalItem.JournalTypeId,
journalItem.Title,
journalItem.Summary,
journalItem.Body,
journalData,
xml,
journalItem.ObjectKey,
journalItem.AccessKey,
journalItem.SecuritySet,
journalItem.CommentsDisabled,
journalItem.CommentsHidden);
....
}
public void UpdateJournalItem(JournalItem journalItem, int tabId, int moduleId)
{
....
journalItem.JournalId = this._dataService.Journal_Update(
journalItem.PortalId,
journalItem.UserId,
journalItem.ProfileId,
journalItem.SocialGroupId,
journalItem.JournalId,
journalItem.JournalTypeId,
journalItem.Title,
journalItem.Summary,
journalItem.Body,
journalData,
xml,
journalItem.ObjectKey,
journalItem.AccessKey,
journalItem.SecuritySet,
journalItem.CommentsDisabled,
journalItem.CommentsHidden);
....
}
```
Тут сразу 2 проблемы, которые, похоже, размножились методом copy-paste. Сможете найти их? Далее привожу картинку для отвлечения внимания, чтобы ответ не бросился в глаза.

Ох, прошу прощения! Кажется, я забыл дать вам ключик для разгадки… Вот он:
```
int Journal_Update(int portalId,
int currentUserId,
int profileId,
int groupId,
int journalId,
int journalTypeId,
string title,
string summary,
string body,
string itemData,
string xml,
string objectKey,
Guid accessKey,
string securitySet,
bool commentsHidden,
bool commentsDisabled);
```
Теперь должно стать немного легче. Нашли проблему? Если нет (или просто ленно это делать), предупреждения анализатора помогут:
* V3066 Possible incorrect order of arguments passed to 'Journal\_Save' method: 'journalItem.CommentsDisabled' and 'journalItem.CommentsHidden'. DotNetNuke.Library JournalControllerImpl.cs 125
* V3066 Possible incorrect order of arguments passed to 'Journal\_Update' method: 'journalItem.CommentsDisabled' and 'journalItem.CommentsHidden'. DotNetNuke.Library JournalControllerImpl.cs 253
Обратите внимание на последние параметры и аргументы – в обоих вызовах аргументы идут в таком порядке: *journalItem.CommentsDisabled*, *journalItem.CommentsHidden*; в то время как параметры перечислены так: *commentsHidden*, *commentsDisabled*. Выглядит достаточно подозрительно, не правда ли?
**Issue 37**
```
private static DateTime LastPurge
{
get
{
var lastPurge = DateTime.Now;
if (File.Exists(CachePath + "_lastpurge"))
{
var fi = new FileInfo(CachePath + "_lastpurge");
lastPurge = fi.LastWriteTime;
}
else
{
File.WriteAllText(CachePath + "_lastpurge", string.Empty);
}
return lastPurge;
}
set
{
File.WriteAllText(CachePath + "_lastpurge", string.Empty);
}
}
```
Предупреждение PVS-Studio: [V3077](https://pvs-studio.com/ru/w/v3077/) The setter of 'LastPurge' property does not utilize its 'value' parameter. DotNetNuke.Library IPCount.cs 96
Здесь подозрительным выглядит то, что *set*-accessor никак не использует *value*-параметр. То есть в это свойство могут что-то записывать, и записываемое значение просто… игнорируется. В коде я нашёл одно место, где идёт запись в это свойство:
```
public static bool CheckIp(string ipAddress)
{
....
LastPurge = DateTime.Now;
....
}
```
Соответственно, текущее время нигде зафиксировано не будет.
**Issue 38**
```
private void DisplayNewRows()
{
this.divTabName.Visible = this.optMode.SelectedIndex == 0;
this.divParentTab.Visible = this.optMode.SelectedIndex == 0;
this.divInsertPositionRow.Visible = this.optMode.SelectedIndex == 0;
this.divInsertPositionRow.Visible = this.optMode.SelectedIndex == 0;
}
```
Предупреждение PVS-Studio: [V3008](https://pvs-studio.com/ru/w/v3008/) The 'this.divInsertPositionRow.Visible' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 349, 348. DotNetNuke.Website Import.ascx.cs 349
Здесь не просто дважды идёт запись в одну переменную – тут целое выражение дублируется. Возможно, оно просто избыточно. Но есть вероятность, что его скопировали, а поменять забыли. [Эффект последней строки](https://pvs-studio.com/ru/blog/posts/cpp/0260/)?
**Issue 39**
```
public enum AddressType
{
IPv4 = 0,
IPv6 = 1,
}
private static void FilterRequest(object sender, EventArgs e)
{
....
switch (varArray[1])
{
case "IPv4":
varVal = NetworkUtils.GetAddress(varVal, AddressType.IPv4);
break;
case "IPv6":
varVal = NetworkUtils.GetAddress(varVal, AddressType.IPv4);
break;
}
....
}
```
Предупреждение PVS-Studio: [V3139](https://pvs-studio.com/ru/w/v3139/) Two or more case-branches perform the same actions. DotNetNuke.HttpModules RequestFilterModule.cs 81
Что-то мне подсказывает, что не должны эти *case*-ветки быть одинаковыми и что во втором случае стоит использовать *AddressType.IPv6*.
**Issue 40**
```
private static DateTime CalculateTime(int lapse, string measurement)
{
var nextTime = new DateTime();
switch (measurement)
{
case "s":
nextTime = DateTime.Now.AddSeconds(lapse);
break;
case "m":
nextTime = DateTime.Now.AddMinutes(lapse);
break;
case "h":
nextTime = DateTime.Now.AddHours(lapse);
break;
case "d":
nextTime = DateTime.Now.AddDays(lapse);
break;
case "w":
nextTime = DateTime.Now.AddDays(lapse);
break;
case "mo":
nextTime = DateTime.Now.AddMonths(lapse);
break;
case "y":
nextTime = DateTime.Now.AddYears(lapse);
break;
}
return nextTime;
}
```
Предупреждение PVS-Studio: [V3139](https://pvs-studio.com/ru/w/v3139/) Two or more case-branches perform the same actions. DotNetNuke.Tests.Core PropertyAccessTests.cs 118
Обратите внимание на тела *case*-ветвей *"d"* и *"w"* – они дублируют друг друга. Copy-paste… Copy-paste никогда не меняется. Стандартного метода *AddWeeks* в типе *DateTime* нет, но очевидно, что в *case*-ветке "w" работа должна идти с неделями.
**Issue 41**
```
private static int AddTabToTabDict(....)
{
....
if (customAliasUsedAndNotCurrent && settings.RedirectUnfriendly)
{
// add in the standard page, but it's a redirect to the customAlias
rewritePath = RedirectTokens.AddRedirectReasonToRewritePath(
rewritePath,
ActionType.Redirect301,
RedirectReason.Custom_Tab_Alias);
AddToTabDict(tabIndex,
dupCheck,
httpAlias,
tabPath,
rewritePath,
tab.TabID,
UrlEnums.TabKeyPreference.TabRedirected,
ref tabPathDepth,
settings.CheckForDuplicateUrls,
isDeleted);
}
else
{
if (customAliasUsedAndNotCurrent && settings.RedirectUnfriendly)
{
// add in the standard page, but it's a redirect to the customAlias
rewritePath = RedirectTokens.AddRedirectReasonToRewritePath(
rewritePath,
ActionType.Redirect301,
RedirectReason.Custom_Tab_Alias);
AddToTabDict(tabIndex,
dupCheck,
httpAlias,
tabPath,
rewritePath,
tab.TabID,
UrlEnums.TabKeyPreference.TabRedirected,
ref tabPathDepth,
settings.CheckForDuplicateUrls,
isDeleted);
}
else
....
}
....
}
```
Предупреждение PVS-Studio: [V3030](https://pvs-studio.com/ru/w/v3030/) Recurring check. The 'customAliasUsedAndNotCurrent && settings.RedirectUnfriendly' condition was already verified in line 1095. DotNetNuke.Library TabIndexController.cs 1097
Анализатор предупреждает о том, что обнаружен паттерн следующего вида:
```
if (a && b)
....
else
{
if (a && b)
....
}
```
Соответственно, в этом фрагменте кода второе условие будет ложным – переменные не изменялись между вызовами.
Но здесь мы наткнулись даже на бОльший куш – дублируются не только условия, но и целые блоки кода. Посмотрите, *if* с его *then*-ветвью был скопирован целиком.
**Issue 42**
```
private IEnumerable GetDescendantsForTabs(
IEnumerable tabIds,
IEnumerable tabs,
int selectedTabId,
int portalId,
string cultureCode,
bool isMultiLanguage)
{
var enumerable = tabIds as int[] ?? tabIds.ToArray();
if (tabs == null || tabIds == null || !enumerable.Any())
{
return tabs;
}
....
}
```
Предупреждение PVS-Studio: [V3095](https://pvs-studio.com/ru/w/v3095/) The 'tabIds' object was used before it was verified against null. Check lines: 356, 357. Dnn.PersonaBar.Library TabsController.cs 356
Подобный кейс я приводил раньше, но решил повторить и разобрать более подробно.
*tabIds* – параметр. Скорее всего, ожидается, что он может иметь значение *null* – не зря же есть проверка *tabIds == null*? Вот только здесь опять что-то напутано...
Представим, что *tabIds* – *null*, тогда:
* вычисляется левый операнд оператора ?? (*tabIds as int[]*);
* *tabIds as int[]* даёт в результате *null*;
* вычисляется правый операнд оператора ?? (*tabIds.ToArray()*);
* исключение при попытке вызова метода *ToArray*, так как *tabIds* – *null*.
Выходит, проверка не сработала.
**Issue 43**
Предлагаю снова поразмяться и найти ошибку самостоятельно. Задача очень сильно упрощена – ниже приведён сокращённый метод, отрезано почти всё лишнее! Оригинальный же метод был на 500 строк – вот в нём поискать проблему было бы настоящим хардкором. Хотя если есть желание – вот [ссылка на него на GitHub](https://github.com/dnnsoftware/Dnn.Platform/blob/05544c719981842c341ec40583be2e149aeb64a9/DNN%20Platform/Providers/HtmlEditorProviders/DNNConnect.CKE/CKEditorOptions.ascx.cs).
Уверен, если сами поймёте, что не так, получите выброс эндорфинов. :)
```
private void SaveModuleSettings()
{
....
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.SKIN}",
this.ddlSkin.SelectedValue);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.CODEMIRRORTHEME}",
this.CodeMirrorTheme.SelectedValue);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.BROWSER}",
this.ddlBrowser.SelectedValue);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.IMAGEBUTTON}",
this.ddlImageButton.SelectedValue);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.FILELISTVIEWMODE}",
this.FileListViewMode.SelectedValue);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.DEFAULTLINKMODE}",
this.DefaultLinkMode.SelectedValue);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.USEANCHORSELECTOR}",
this.UseAnchorSelector.Checked.ToString());
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.SHOWPAGELINKSTABFIRST}",
this.ShowPageLinksTabFirst.Checked.ToString());
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.OVERRIDEFILEONUPLOAD}",
this.OverrideFileOnUpload.Checked.ToString());
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.SUBDIRS}",
this.cbBrowserDirs.Checked.ToString());
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.BROWSERROOTDIRID}",
this.BrowserRootDir.SelectedValue);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.UPLOADDIRID}",
this.UploadDir.SelectedValue);
if (Utility.IsNumeric(this.FileListPageSize.Text))
{
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.FILELISTPAGESIZE}",
this.FileListPageSize.Text);
}
if (Utility.IsNumeric(this.txtResizeWidth.Text))
{
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.RESIZEWIDTH}",
this.txtResizeWidth.Text);
}
if (Utility.IsNumeric(this.txtResizeHeight.Text))
{
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.RESIZEHEIGHT}",
this.txtResizeHeight.Text);
}
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.INJECTJS}",
this.InjectSyntaxJs.Checked.ToString());
if (Utility.IsUnit(this.txtWidth.Text))
{
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.WIDTH}",
this.txtWidth.Text);
}
if (Utility.IsUnit(this.txtHeight.Text))
{
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.HEIGHT}",
this.txtWidth.Text);
}
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.BLANKTEXT}",
this.txtBlanktext.Text);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.CSS}",
this.CssUrl.Url);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.TEMPLATEFILES}",
this.TemplUrl.Url);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.CUSTOMJSFILE}",
this.CustomJsFile.Url);
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.CONFIG}",
this.ConfigUrl.Url);
....
}
```
В таких случаях без картинки для отвлечения внимания не обойтись. За ней будет ответ.

Что ж, время проверить себя!
Предупреждение PVS-Studio: [V3127](https://pvs-studio.com/ru/w/v3127/) Two similar code fragments were found. Perhaps, this is a typo and 'txtHeight' variable should be used instead of 'txtWidth' DNNConnect.CKEditorProvider CKEditorOptions.ascx.cs 2477
Внимательности анализатору не занимать, конечно. Давайте ещё немного сократим код, чтобы ошибка совсем уж оказалась на поверхности.
```
private void SaveModuleSettings()
{
....
if (Utility.IsUnit(this.txtWidth.Text))
{
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.WIDTH}",
this.txtWidth.Text); // <=
}
if (Utility.IsUnit(this.txtHeight.Text))
{
moduleController.UpdateModuleSetting(this.ModuleId,
$"{key}{SettingConstants.HEIGHT}",
this.txtWidth.Text); // <=
}
....
}
```
Обратите внимание, что во втором случае мы уже обрабатываем переменные с 'height' в названии, а не 'width'. Тем не менее, при вызове метода *UpdateModuleSetting* последним аргументом передаётся *this.txtWidth.Text* вместо *this.txtHeight.Text*.
**Issue N**
Нет, конечно, это не все предупреждения, которые нашёл анализатор в проекте. Я постарался отобрать наиболее интересные и ёмкие. Были и межпроцедурные, были похожие на те, которые приводил. Но я исхожу из того, что, скорее, они будут интересны разработчикам проекта, нежели читателям.
Без false positives тоже не обошлось, но они уже интересны скорее разработчикам анализатора, нежели читателям этой статьи, так что их я также оставил за рамками.
Заключение
----------
По-моему, сегодняшняя подборка выдалась достаточно разнообразной. По поводу некоторых ошибок у вас мог возникнуть вопрос: "Как вообще можно было допустить такой косяк?". Но можно, можно! Как? Вопрос открытый, причины разные бывают. Ошибаются ли? Конечно. И мы из раза в раз находим тому [подтверждения](https://pvs-studio.com/ru/blog/inspections/).
Да мы и сами ошибаемся иногда, чего уж тут. И false positives бывают. Важно признавать проблемы и работать над их исправлением. :)
Говоря про качество кода, достаточно ли одной экспертизы разработчиков? Скорее нет. Нужно подходить к проблеме комплексно и использовать разные инструменты/методики как контроля качества кода в частности, так и качества продукта в целом.
Выводы сегодня такие:
* поаккуратнее с copy-paste;
* [используйте статический анализ](https://pvs-studio.com/ru/);
* подписывайтесь на [меня в Twitter](https://twitter.com/_SergVasiliev_).
**P.S.** Кстати, а какой ваш Топ-10 предупреждений из этой статьи? ;)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Sergey Vasiliev. [A variety of errors in C# code by the example of CMS DotNetNuke: 40 questions about the quality](https://habr.com/en/company/pvs-studio/blog/591165/). | https://habr.com/ru/post/591167/ | null | ru | null |
# Микроконтроллеры Megawin серии MG32F02: RTC и сторожевые таймеры IWDT, WWDT
Продолжая цикл публикаций по микроконтроллерам на ядре Cortex-M0 компании Megawin (см. предыдущие статьи [1](https://habr.com/ru/post/674788/), [2](https://habr.com/ru/post/675776/), [3](https://habr.com/ru/post/681702/) и [4](https://habr.com/ru/post/684778/)), сегодня рассмотрим часы реального времени RTC, сторожевые таймеры IWDT и WWDT, а также стандартный для Cortex-M0 таймер SysTick.
Также отметим изменения в организации исходного кода. В структуру кода добавлен файл `src/core.h`, включающий короткие макросы доступа к регистрам МК:
```
/// Макрос 8-битного доступа к ячейке (регистру)
#define RB(addr) (*(volatile uint8_t*)(addr))
/// Макрос 16-битного доступа к ячейке (регистру)
#define RH(addr) (*(volatile uint16_t*)(addr))
/// Макрос 32-битного доступа к ячейке (регистру)
#define RW(addr) (*(volatile uint32_t*)(addr))
```
Для доступа к полям регистров будут применяться макросы из Device Family Pack (структура DFP описана во [второй статье](https://habr.com/ru/post/675776/) цикла). Для каждого периферийного модуля необходимо будет подключать свой заголовочный файл. Все тестовые функции по периферии МК перенесены в отдельные файлы в каталог `test`. Весь исходный код, настроечные файлы проекта, скрипты сборки и прочее будут размещаться в [репозитории GitHub](https://github.com/reug/mg32f02.git) в основной ветке `master`.
### Таймер SysTick
#### Функциональные возможности и принцип работы
МК серии MG32F02 включают стандартный таймер System Tick Timer, являющийся, как и контроллер прерываний NVIC, частью процессорного модуля Cortex-M0 (см. [первую статью](https://habr.com/ru/post/674788/) цикла). Таймер имеет следующие характеристики:
* разрядность: 24 бита,
* режим работы: циклический обратный отсчет от загружаемого значения,
* генерация исключения SysTick (15) при достижении нуля,
* возможность программного сброса,
* возможность получения текущего значения,
* тактирование от ЦПУ или от одного из двух внешних сигналов.
Таймер включает 4 регистра статуса и управления, приведенных в таблице.
| Регистр | Назначение | Описание полей (биты) |
| --- | --- | --- |
| `CPU_SYST_CSR` | Статус и управление | `ENCNT` (0) — включение таймера,`TICKINT` (1) — разрешение генерации исключения (прерывания),`CLKSOURCE` (2) — выбор источника тактирования (0-внешний CK\_ST, 1-от ЦПУ),`COUNTFLAG` (16) — флаг, устанавливается при достижении нуля, сбрасывается при чтении этого регистра |
| `CPU_SYST_RVR` | Загружаемое (начальное) значение | `RELOAD` (0-23) — загружаемое значение, должно быть на 1 меньше требуемого периода счета (коэффициента деления) |
| `CPU_SYST_CVR` | Текущее значение счетчика | `CURRENT` (0-23) — текущее значение, запись любого значения сбрасывает счетчик и флаг `COUNTFLAG` (не вызывает исключение) |
| `CPU_SYST_CALIB` | Калибровочное значения | Все поля доступны только по-чтению.`TENMS` (0-23) — калибровочное загружаемое значение для интервала 10 мс и внешнего тактирования`SKEW` (30) — флаг: 0-значение `TENMS` точное, 1-неточное или не установлено`NOREF` (31) — флаг: 0-имеется эталонный источник тактирования, 1-не имеется |
Адреса регистров стандартные для процессорных модулей Cortex-M0. Значение по-умолчанию для регистра `CPU_SYST_CSR` — 0, для регистров `CPU_SYST_RVR` и `CPU_SYST_CVR` — 0x00FFFFFF. К регистрам возможен только 32-битный доступ.
Выбор внешнего источника тактирования (сигнал CK\_ST) определяется битом `CSC_CR0.CSC_ST_SEL` подсистемы тактирования МК:
* 0 (HCLK/8) — сигнал тактирования процессорного модуля HCLK (фактически CK\_AHB) с делением частоты на 8,
* 1 (CK\_LS/2) — общесистемный низкочастотный сигнал тактирования CK\_LS с делением частоты на 2.
Все варианты выбора источника тактирования приведены в следующей таблице.
| Источник тактирования | `CPU_SYST_CSR.CLKSOURCE` | `CSC_CR0.CSC_ST_SEL` |
| --- | --- | --- |
| HCLK/8 | 0 | 0 |
| CK\_LS/2 | 0 | 1 |
| SCLK (CK\_AHB) | 1 | x |
Прерывание от таймера SysTick относится к исключениям Cortex-M0 (номер 15) и не является внешним прерыванием IRQ, поэтому имеет единственный бит разрешения прерывания только в собственном регистре `CPU_SYST_CSR.TICKINT`. Приоритет прерывания определяется в поле `CPU_SHPR2.PRI_15`. В обработчике прерывания `SysTick_Handler()` никаких флагов сбрасывать не требуется.
Без прерывания таймер SysTick может использоваться в программе для измерения времени работы фрагмента кода. С прерыванием таймер может использоваться в ОС для переключения между задачами или как периодический генератор событий.
#### Тестирование
Прежде всего посмотрим с помощью OpenOCD через telnet, какие значения по-умолчанию находятся в регистрах на примере МК MG32F02A064:
```
> mdw 0xe000e010 4
0xe000e010: 00000000 00ffffff 00ffffff 40028b0a
```
Первые три регистра имеют ожидаемые значения. В регистре `CPU_SYST_CALIB` установленный бит `SKEW` показывает, что калибровочное значение 0x28B0A (166666) не является точным. Оно действительно не подходит под настройки тактирования по-умолчанию, которые предполагают источник тактирования таймера HCLK/8, а частоту ЦПУ 12 МГц. Т.е. тактовая частота таймера получается 1.5 МГц, соответственно для периода 10 мс нужно загружать значение 15000 (минус 1). Проверим это.
Для тестирования таймера SysTick создадим в файле `app.c` функции:
```
// Обработчик исключения SysTick
void systick_hdl() {
RH(PC_SC_h0) = 2; // set PC1
RH(PC_SC_h1) = 2; // clear PC1
}
// Функция тестирования SysTick Timer
void systick_test() {
RH(PC_CR1_h0) = 0x0002; // Выход таймера -> PC1
SVC2(SVC_CHANDLER_SET,15,systick_hdl); // Устанавливаем обработчик исключения 15
RW(CPU_SYST_CSR_w) = 0; // Stop timer
RW(CPU_SYST_RVR_w) = 15000-1; // RELOAD
RW(CPU_SYST_CVR_w) = 1; // Clear CURRENT
RW(CPU_SYST_CSR_w) = 3; // CLKSOURCE = 0 (External), TICKINT=1, ENCNT=1
while (1) ;
}
```
При прерывании будем генерировать единичный импульс на выводе PC1. Для этого в начале функции `systick_test()` настраиваем выход PC1 как push-pull. Далее устанавливаем обработчик исключения (прерывания) `systick_hdl()` (в файле `svr.c` также нужно добавить первичный обработчик `SysTick_Handler()`, исходный код которого прилагается в общем архиве). Затем настраиваем таймер. В начале на всякий случай таймер отключаем (так рекомендуется), затем устанавливаем загрузочное значение, сбрасываем и после запускаем от источника HCLK/8 частотой 1.5 МГц. Убеждаемся, что частота импульсов составляет 100.0 Гц:
Частота сигнала прерывания от таймера SysTickАналогично проверяем частоту 1000.0 Гц для устанавливаемого значения 1500. В завершении тестирования включаем тактирование от SCLK:
```
RW(CPU_SYST_CSR_w) = 7;
```
И убеждаемся, что частота стала ровно в 8 раз выше.
### Часы реального времени RTC
#### Функциональные возможности и принцип работы
МК серии MG32F02 включают модуль часов реального времени RTC (Real Time Clock), имеющий следующие характеристики:
* разрядность: 32 бита,
* основной режим работы: циклический прямой отсчет,
* возможность задания времени срабатывания "будильника" (функция Alarm),
* возможность сохранения временной отметки (Time Stamp) по команде или внешнему сигналу (функция Capture),
* возможность загрузки произвольного значения счетчика по команде или переполнению (функция Reload),
* возможность вывода сигнала тактирования или событий на внешний вывод,
* тактирование от нескольких источников, включая внешний или внутренний часовой генератор.
Отметим, что модуль содержит только счетчик (например, секунд), функцию календаря необходимо реализовывать программно.
Функциональная схема модуля RTC приведена на следующем рисунке.
Функциональная схема модуля RTCОсновным узлом модуля является 32-разрядный счетчик 32-bit Timer, тактируемый от выбираемого источника сигнала. Частота сигнала тактирования предварительно может быть поделена двумя блоками деления PDIV (на 4096) и DIV (на 2, 4 или 8). Модуль содержит следующие программно доступные 32-битные регистры:
* ALARM Register (`RTC_ALM`) для задания времени события Alarm,
* Capture Register (`RTC_CAP`) для сохранения временной отметки,
* Reload Register (`RTC_RLR`) для загрузки произвольного значения счетчика.
В модуле можно использовать внешний управляющий сигнал с вывода RTC\_TS для сохранения временной отметки (Time Stamp).
Один из внутренних сигналов модуля может быть выведен как внешний сигнал на вывод RTC\_OUT. Активный уровень сигнала выбирается в поле `RTC_OUT_STA` (при модификации поля также требуется установить бит защиты `RTC_OUT_LCK`). Источник сигнала определяется полем `RTC_CR0.RTC_OUT_SEL` из следующих значений:
* 0 (ALM) — сигнал по событию Alarm,
* 1 (PC) — сигнал счетных импульсов CK\_RTC\_INT,
* 2 (TS) — сигнал по событию срабатывания триггера Time stamp trigger,
* 3 (TO) — сигнал по событию переполнения Timer overflow.
Все регистры модуля (кроме `RTC_STA`) защищены от случайной модификации. Перед записью в какой-либо регистр необходимо записать код разблокировки 0xA217 в поле `RTC_KEY.RTC_KEY`. Вернуться в состояние блокировки можно записью любого другого значения в это поле.
#### Тактирование
Источник тактирования модуля RTC определяется полем `RTC_CLK.RTC_CK_SEL` из числа следующих:
* 0 — общесистемный НЧ-сигнал CK\_LS,
* 1 — общесистемный НЧ-сигнал CK\_UT,
* 2 — сигнал тактирования шины CK\_APB,
* 3 — выход таймера TM01\_TRGO.
Модуль RTC, в первую очередь, ориентирован на работу от низкочастотных сигналов CK\_LS или CK\_UT (см. [первую статью](https://habr.com/ru/post/674788/) цикла). Сигнал CK\_UT формируется делителем частоты на 8, 16, 32 (по-умолчанию) или 128 (согласно значению поля `CSC_DIV.CSC_UT_DIV`) из сигнала CK\_ILRCO от встроенного в МК низкочастотного RC-генератора частотой 32 кГц. Отметим, что низкие точность (около 4%) и стабильность генератора ILRCO не позволяют использовать его для отсчета временных интервалов, тем более для часов реального времени.
Сигнал CK\_LS может быть получен либо с внешнего генератора EXTCK, либо со встроенного кварцевого генератора XOSC, либо от того же сигнала CK\_ILRCO. Но поскольку генератор XOSC логично использовать как основной задающий генератор МК на высоких частотах порядка мегагерц, а вывод для подключения внешнего генератора совпадает с один из выводов подключения кварцевого резонатора, использование сигнала CK\_LS также проблематично.
Таким образом, в большинстве случаев модуль придется тактировать либо от ВЧ-сигнала CK\_APB с возможным включением значительного деления частоты, либо от таймера TM01. Как вариант, если в приоритете точность RTC, МК можно тактировать от встроенного высокочастотного RC-генератора IHRCO (имеет значительно более высокую точность), а к XOSC подключить часовой кварцевый резонатор на 32768 Гц и получить секундные импульсы на входе счетчика RTC. Для получения миллисекундных импульсов (1000 Гц) на входе RTC можно тактировать весь МК от XOSC или EXTCK с частотой, кратной степени 2 в кГц, т.е. 4.096 МГц, 8.192 МГц или 16.384 МГц (максимально 32.768 МГц для внешнего генератора).
Установка коэффициентов деления частоты сигнала CK\_RTC перед его подачей на вход счетчика (в виде сигнала CK\_RTC\_INT) выполняется в поле `RTC_CLK.RTC_CK_PDIV` (1 или 4096) и в поле `RTC_CLK.RTC_CK_DIV` (1, 2, 4 или 8).
Для включения модуля RTC необходимо:
* включить тактирование модуля установкой бита `CSC_APB0.CSC_RTC_EN` (предварительно нужно разблокировать возможность записи через регистр `CSC_KEY`),
* включить модуль установкой бита `RTC_CR0.RTC_EN` (предварительно нужно разблокировать возможность записи через регистр `RTC_KEY`).
#### Режимы работы и события
В *основном режиме* работы счетчик модуля RTC под действием тактовых импульсов CK\_RTC\_INT выполняет прямой счет от 0 до максимального значения 2^32-1, после чего вновь начинает с 0. В этот момент формируется событие по переполнению и активируется флаг **TOF** (Timer Overflow).
В каждом периоде счетных импульсов CK\_RTC\_INT в модуле RTC активируется флаг **PCF** (Periodic Interrupt), который может быть использован для генерации прерывания. Например, при периоде счета 1 с в обработчике этого прерывания могут обновляться данные, связанные с календарем (минуты, часы, и т.д.).
Если при работе модуля включен бит `RTC_CR0.RTC_ALM_EN`, при совпадении значений счетчика и регистра `RTC_ALM` генерируется *событие Alarm* и активируется флаг **ALMF**. Изменять значение регистра `RTC_ALM` нужно при сброшенном бите `RTC_CR0.RTC_ALM_EN`.
Модуль позволяет сохранять текущее состояние счетчика (временная отметка Time Stamp) в регистре `RTC_CAP` (*функция Capture*) в следующих двух случаях:
* по внешнему сигналу с вывода МК RTC\_TS, активный фронт которого выбирается в поле `RTC_CR0.RTC_TS_TRGS` (если 0, функция отключена);
* из программы при установке бита `RTC_CR0.RTC_RC_START`.
При разрешении и активации внешнего управляющего сигнала RTC\_TS текущее значение счетчика копируется в регистр `RTC_CAP` и активируется флаг **TSF** (Time Stamp).
В поле `RTC_CR0.RTC_RCR_MDS` имеется возможность настроить алгоритм работы модуля, связанный с программным управлением через бит `RTC_RC_START` и загрузкой нового значения в счетчик (*функция Reload*). Имеются следующие варианты:
* 0 (Directly capture) — текущее значение счетчика копируется в регистр `RTC_CAP` в указанных выше двух случаях;
* 1 (Delayed capture) — аналогично предыдущему (отличие не описано в документации);
* 2 (Forced reload) — в счетчик будет загружаться новое значение из регистра `RTC_RLR`, как только оно будет записано в регистр `RTC_RLR`;
* 3 (Auto reload) — в счетчик будет загружаться новое значение из регистра `RTC_RLR` автоматически при переполнении счетчика.
В модуле имеется дополнительный флаг **RCRF**, который активируется в следующих случаях:
* завершено копирование значения счетчика в регистр `RTC_CAP`,
* завершена загрузка нового значения счетчика из регистра `RTC_RLR`.
#### Прерывания
Все события модуля, приводящие к активации флагов, могут быть использованы для генерации прерывания. Все флаги собраны в регистре статуса `RTC_STA`. Модуль RTC не имеет свой номер прерывания IRQ и, соответственно, адрес вектора в таблице векторов. Модуль может генерировать прерывание INT\_RTC, которое может быть использовано для генерации более общего системного прерывания INT\_SYS (IRQ#1). Для использования прерывания от модуля RTC необходимо:
1. Выбрать событие (или события) в регистре `RTC_INT`. Например, для разрешения прерывания по событию Alarm нужно установить бит `RTC_ALM_IE`.
2. Разрешить прерывание самого модуля установкой бита `RTC_INT.RTC_IEA`.
3. Разрешить общесистемное прерывание INT\_SYS установкой бита `SYS_INT.SYS_IEA`.
4. Разрешить прерывание INT\_SYS (IRQ#1) в контроллере прерываний NVIC в регистре `CPU_ISER` установкой бита 1.
5. В обработчике прерываний, если включено более одного источника прерывания INT\_RTC, определять по флагам, какое именно прерывание сработало.
#### Тестирование
Перейдем к тестированию RTC. В исходном коде базовой части (Supervisor) нужно добавить первичный обработчик прерывания `SYS_IRQHandler()` (ISR#1) в файле `svr.c`:
```
__attribute__ ((interrupt))
void SYS_IRQHandler() {
if (hdlr[1]) hdlr[1]();
}
```
Для выходного сигнала RTC\_OUT нам потребуется вывод PD10, поэтому в функции `init_clock()`, наряду с портами PB и PC, нужно включить и тактирование порта PD (код см. в прилагаемом архиве). Весь остальной код, как и прежде, включаем в отлаживаемую часть (Application) для запуска в ОЗУ. В начале создадим несколько функций для работы с RTC и выделим их в отдельный файл `rtc.c`:
```
/// Инициализация RTC
void rtc_init() {
RH(CSC_KEY_h0) = 0xA217; // unlock access to CSC regs
RB(CSC_APB0_b0) |= CSC_APB0_RTC_EN_enable_b0; // CSC_RTC_EN = 1
RH(CSC_KEY_h0) = 0; // lock access to CSC regs
}
/// Включение прерывания INT_SYS по флагам, указанным в flags согласно формату RTC_INT
void rtc_set_int(uint8_t flags) {
RH(RTC_KEY_h0) = 0xA217; // unlock access to regs
// включаем прерывания в модуле:
RB(RTC_INT_b0) = flags | RTC_INT_IEA_enable_b0; // RTC_IEA
RH(RTC_KEY_h0) = 0; // lock access to regs
// включаем прерывание INT_SYS:
RB(SYS_INT_b0) = 1; // SYS_IEA=1
// включаем прерывание в модуле NVIC:
RW(CPU_ISER_w) = (1 << 1); // SETENA 1
}
/// Разблокировка записи
void rtc_write_unlock() {
RH(RTC_KEY_h0) = 0xA217; // unlock access to regs
}
/// Блокировка записи
void rtc_write_lock() {
RH(RTC_KEY_h0) = 0; // lock access to regs
}
/// Подключение выхода. Задаются согласно формату RTC_CR0_b1:
/// RTC_OUT_LCK (7) | RTC_OUT_STA (6) | RTC_TS_TRGS (4-5) | RTC_OUT_SEL (0-1)
/// Разблокировка не требуется. При изменении RTC_OUT_STA также устанавливать RTC_OUT_LCK.
void rtc_set_out(uint8_t out_mode) {
RH(RTC_KEY_h0) = 0xA217; // unlock access to regs
RB(RTC_CR0_b1) = out_mode; // RTC_OUT mode
RH(RTC_KEY_h0) = 0; // lock access to regs
}
```
В первом тесте организуем инициализацию и настройку модуля RTC и выведем его счетные импульсы на выход RTC\_OUT (PD10). Для этого в файле `app.c` создадим следующую функцию:
```
/// Вывод счетных импульсов на RTC_OUT
void rtc_test_clock() {
RH(PD_CR10_h0) = (5 << 12) | 2; // PD10: RTC_OUT, push-pull output
rtc_init();
rtc_write_unlock();
// Вариант на 1000 Гц от CK_UT 4 кГц
csc_set_ck_ut();
RB(RTC_CLK_b0) =
RTC_CLK_CK_PDIV_div1_b0 |
RTC_CLK_CK_DIV_div4_b0 |
RTC_CLK_CK_SEL_ck_ut_b0; // Используем сигнал CK_UT (Unit clock) для тактирования RTC
// Вариант на 1500 кГц от CK_APB 12 МГц
// RB(RTC_CLK_b0) =
// RTC_CLK_CK_PDIV_div1_b0 |
// RTC_CLK_CK_DIV_div8_b0 |
// RTC_CLK_CK_SEL_ck_apb_b0;
RB(RTC_CR0_b0) =
RTC_CR0_EN_enable_b0;// RTC_EN = 1
rtc_write_lock();
rtc_out(RTC_CR0_OUT_SEL_pc_b1); // PC (CK_RTC_INT)
}
```
Здесь предусмотрены два варианта частоты счетных импульсов:
* 1000 Гц от сигнала CK\_UT с частотой 4 кГц,
* 1500 кГц от сигнала CK\_APB с частотой 12 МГц.
В первом варианте мы получаем результат, когда десятые доли и даже единицы герц меняются "на глазах" каждую секунду, что подтверждает вывод о сомнительной возможности применения генератора ILRCO в RTC:
Частота сигнала RTC\_OUT при тактировании от ILRCOВо втором варианте получаем стабильную частоту от кварцевого генератора XOSC:
Частота сигнала RTC\_OUT при тактировании от XOSCВ следующем тесте испытаем функции Alarm и Reload вместе:
```
#define RTC_ALARM_ADD 15000 // 10 мс
void rtc_hdl() {
RH(PB_SC_h0) = (1 << 13); // Тестовый сигнал прерывания PB13 HI
uint32_t d;
d=RW(RTC_ALM_w);
rtc_write_unlock();
if (d == 1000*RTC_ALARM_ADD) {
d=0;
RW(RTC_RLR_w)=0;
RB(RTC_CR1_b0) = 1; // RTC_RC_START
}
// Обновляем значение ALARM:
RB(RTC_CR0_b0) &= ~RTC_CR0_ALM_EN_enable_b0; // RTC_ALM_EN=0
RW(RTC_ALM_w) = d + RTC_ALARM_ADD;
RB(RTC_CR0_b0) |= RTC_CR0_ALM_EN_enable_b0; // RTC_ALM_EN=1
rtc_write_lock();
RB(RTC_STA_b0) = RTC_STA_ALMF_mask_b0; // Clear ALMF flag
RH(PB_SC_h1) = (1 << 13); // Тестовый сигнал прерывания PB13 LO
}
/// Тестирование режима ALARM с прерыванием
void rtc_test_alarm() {
RH(PD_CR10_h0) = (5 << 12) | 2; // PD10: RTC_OUT, push-pull output
rtc_init();
rtc_write_unlock();
// Вариант на 1500 кГц от CK_APB 12 МГц
RB(RTC_CLK_b0) =
RTC_CLK_CK_PDIV_div1_b0 |
RTC_CLK_CK_DIV_div8_b0 |
RTC_CLK_CK_SEL_ck_apb_b0;
RW(RTC_ALM_w) = RTC_ALARM_ADD; // Alarm через 10 мс
RW(RTC_CR0_w) =
RTC_CR0_RCR_MDS_forced_reload_w | // RTC_RCR_MDS = 2 (Force Reload)
RTC_CR0_ALM_EN_enable_w | // Включаем режим ALARM
RTC_CR0_EN_enable_w; // RTC_EN = 1
rtc_write_lock();
SVC2(SVC_HANDLER_SET,1,rtc_hdl); // Устанавливаем обработчик прерывания
rtc_set_int(RTC_INT_ALM_IE_enable_b0); // Разрешаем прерывание по флагу ALMF
rtc_set_out(RTC_CR0_OUT_SEL_alm_b1); // Настраиваем выход RTC_OUT Alarm
}
```
Тактирование счетчика настраиваем от сигнала CK\_APB с итоговой частотой счета 1500 кГц. На выходе модуля RTC\_OUT будем формировать импульсы с периодом 10 мс, в константе `RTC_ALARM_ADD` указано значение счетчика, которое для этого нужно добавлять каждый раз в регистр `RTC_ALM` после события Alarm. В функции `rtc_test_alarm()` устанавливаем прерывание по флагу **ALMF**, а в регистре `RTC_CR0` устанавливаем режим Force Reload и включаем функцию Alarm.
Обработчик прерывания `rtc_hdl()` работает следующим образом. При наступлении прерывания на вывод PB13 выводится дополнительный контрольный импульс индикации прерывания. Далее значение регистра `RTC_ALM` увеличивается на константу `RTC_ALARM_ADD`, после чего сбрасывается флаг прерывания и устанавливается в "0" вывод PB13. Поскольку верхнее значение счетчика не кратно `RTC_ALARM_ADD`, в обработчике оно программно устанавливается на меньшее значение, например на 1000 циклов по `RTC_ALARM_ADD` счетных импульсов. Если достигается это число, счетчик программно сбрасывается путем загрузки в него нового значения 0 из регистра `RTC_RLR`, после чего счетчик перезапускается установкой бита `RTC_RC_START`. Таким образом, на выводах RTC\_OUT (PD10) и PB13 ожидаем импульсы с частотой 100 Гц.
Осциллограммы сигналов на выводах RTC\_OUT и PB13На канал "1" осциллографа подан сигнал RTC\_OUT, на канал "2" — сигнал с вывода PB13. Видно, что прерывание работает как и предполагалось, а вот сигнал RTC\_OUT ведет себя странно. Согласно функциональной схеме ожидались импульсы с длительностью от момента активации флага **ALMF** при наступлении события Alarm до программного сброса флага в обработчике `rtc_hdl()`. В итоге выходной узел формирования сигнала RTC\_OUT стал работать как T-триггер, поделив частоту события на 2. Тем не менее, в программном плане функции Alarm и Reload работают корректно.
### Таймер IWDT (Independent Watch Dog Timer)
МК серии MG32F02 включают независимый сторожевой таймер IWDT (Independent Watch Dog Timer), имеющий следующие характеристики:
* разрядность счетчика: 8 бит;
* тактирование счетчика от генератора ILRCO с предделителем частоты на 1, 2, 4,..., 4096;
* возможность генерации сигнала сброса МК после полного цикла счета;
* генерации дополнительных двух событий для сигнала пробуждения или прерывания.
* работа во всех режимах МК (ON, SLEEP, STOP).
Функциональная схема таймера IWDT приведена на следующем рисунке.
Функциональная схема таймера IWDTОсновным узлом модуля является 8-разрядный счетчик обратного отсчета, тактируемый от генератора ILRCO с опциональным предварительным делением частоты. Коэффициент деления выбирается в 4-битном поле `IWDT_CLK.IWDT_CK_DIV` как степень двух из диапазона от 1 до 4096. Следующая временная диаграмма иллюстрирует работу таймера IWDT.
Временная диаграмма работы таймера IWDTПосле включения модуля счетчик начинает обратный циклический отсчет от 255 до 0. При достижении нуля активируется флаг **TF**, который может быть использован для формирования сигнала сброса RST\_IWDT (момент "C"). Текущее значение счетчика доступно только по чтению в регистре `IWDT_CNT` (младший байт). В модуле также имеются два компаратора, непрерывно сравнивающие значение счетчика с фиксированными константами. При совпадении с числом 0x20 (момент "B") генерируется событие "Early Wakeup 0" и активируется флаг **EW0F**. При совпадении с числом 0x40 (момент "A") генерируется событие "Early Wakeup 1" и активируется флаг **EW1F**. Все три флага могут быть использованы как для формирования сигнала пробуждения WUP\_IWDT, так и для генерации прерывания INT\_IWDT. Флаги собраны в регистре статуса `IWDT_STA`.
Модификация всех регистров модуля (кроме `IWDT_STA`) по-умолчанию заблокирована. Перед записью в какой-либо регистр необходимо записать код разблокировки 0xA217 в поле `IWDT_KEY.IWDT_KEY`, а для восстановления блокировки — любое другое значение.
Основное назначение модуля — формирование сигнала "холодного" или "горячего" сброса при зависании программы. "Холодный" сброс от модуля IWDT разрешается установкой бита `RST_IWDT_CE` в регистре `RST_CE` подсистемы сброса. "Горячий" сброс от модуля IWDT разрешается установкой бита `RST_IWDT_WE` в регистре `RST_WE`. По-умолчанию сброс МК от периферийных модулей запрещен. Общее описание подсистемы сброса МК приведено в [первой статье](https://habr.com/ru/post/674788/) цикла.
В процессе работы программа МК для недопущения формирования сигнала сброса *должна периодически записывать* специальное значение 0x2014 в поле `IWDT_KEY.IWDT_KEY`, что будет приводить к перезапуску счетчика со значения 255. Если временной интервал между этими записями превысит период счета, т.е. счетчик успеет досчитать до нуля, будет выполнен сброс, если он, конечно, был разрешен в подсистеме сброса МК.
*Для включения модуля* IWDT необходимо:
* включить тактирование модуля установкой бита `CSC_APB0.CSC_IWDT_EN` (предварительно нужно разблокировать возможность записи через регистр `CSC_KEY`),
* включить модуль установкой бита `IWDT_CR0.IWDT_EN`.
Модуль IWDT, как и RTC, не имеет свой номер прерывания IRQ и, соответственно, адрес вектора в таблице векторов. Модуль может генерировать прерывание INT\_IWDT, которое может быть использовано для генерации более общего системного прерывания INT\_SYS (IRQ#1). *Для использования прерывания* от модуля IWDT необходимо:
1. Выбрать события в регистре `IWDT_INT`.
2. Разрешить общесистемное прерывание INT\_SYS установкой бита `SYS_INT.SYS_IEA`.
3. Разрешить прерывание INT\_SYS (IRQ#1) в контроллере прерываний NVIC в регистре `CPU_ISER` установкой бита 1.
4. В обработчике прерываний, если включено более одного источника прерывания INT\_RTC, определять по флагам, какое именно прерывание сработало.
### Таймер WWDT (Window Watch Dog Timer)
МК серии MG32F02 включают оконный сторожевой таймер WWDT (Window Watch Dog Timer), имеющий следующие характеристики:
* разрядность счетчика: 10 бит;
* тактирование счетчика от одного из двух источников с двумя предделителями частоты;
* задаваемое разрешенное временное окно для выполнения перезагрузки счетчика со стороны ПО;
* возможность генерации прерывания по событию "предупреждение";
* возможность генерации прерывания или сигнала сброса по завершению цикла счета;
* возможность генерации прерывания или сигнала сброса при преждевременной перезагрузке счетчика;
* работа в режимах МК ON и SLEEP.
Функциональная схема таймера WWDT приведена на следующем рисунке.
Функциональная схема таймера WWDTОсновным узлом модуля является 10-разрядный счетчик обратного отсчета, тактируемый через два настраиваемых делителя частоты от одного из двух сигналов: CK\_APB или CK\_UT. Настройки тактирования счетчика определяются следующими полями регистра `WWDT_CLK`:
* `WWDT_CK_PDIV` (1 бит) — коэффициент первого делителя (1 или 256),
* `WWDT_CK_DIV` (3 бита) — коэффициент второго делителя (1, 2, 4, ..., 128),
* `WWDT_CK_SEL` (1 бит) — выбор исходного сигнала (0 - CK\_APB, 1 - CK\_UT).
Модуль содержит следующие программно доступные 10-битные регистры, определяющие временные параметры:
* Reload Register (`WWDT_RLR`) — начальное значение счетчика (по-умолчанию 0x3FF),
* Window Register (`WWDT_WIN`) — значение счетчика, определяющее начало окна разрешенной перезагрузки счетчика (по-умолчанию 0x3FF),
* Warning Register (`WWDT_WRN`) — значение счетчика, определяющее момент прерывания по событию "предупреждение" (по-умолчанию 0).
Следующая временная диаграмма иллюстрирует работу таймера WWDT.
Временная диаграмма работы таймера WWDTПосле включения модуля счетчик начинает обратный циклический отсчет от значения, записанного в регистре `WWDT_RLR`, до нуля. При достижении значения из регистра `WWDT_WIN` (момент "A") открывается окно разрешенного перезапуска счетчика со стороны ПО. При достижении значения из регистра `WWDT_WRN` (момент "B") активируется флаг **WRNF** и может быть сгенерировано прерывание по событию "предупреждение" (если установлен бит `WWDT_INT.WWDT_WRN_IE`). При достижении нуля (момент "C") окно разрешенного перезапуска закрывается, активируется флаг **TF** (Timeout), что может быть использовано для формирования сигнала сброса RST\_WWDT (если установлен бит `WWDT_CR0.WWDT_RSTF_EN`) или прерывания INT\_WWDT (если установлен бит `WWDT_INT.WWDT_TIE`). Текущее значение счетчика доступно только по чтению в регистре `WWDT_CNT` (биты 0-9).
В процессе работы программа МК для недопущения формирования сигнала сброса должна *в течение времени действия окна разрешенного перезапуска* (от момента "A" до момента "B") записывать специальное значение 0x2014 в поле `WWDT_KEY.WWDT_KEY`, что будет приводить к перезапуску счетчика со значения из регистра `WWDT_RLR`. Если перезапуск счетчика инициируется до начала окна, активируется флаг **WINF**, что также может быть использовано для формирования сигнала сброса RST\_WWDT (если установлен бит `WWDT_CR0.WWDT_RSTW_EN`) или прерывания INT\_WWDT (если установлен бит `WWDT_INT.WWDT_WIN_IE`). Флаги собраны в регистре статуса `WWDT_STA`.
Модификация всех регистров модуля (кроме `WWDT_STA`) по-умолчанию заблокирована. Перед записью в какой-либо регистр необходимо записать код разблокировки 0xA217 в поле `WWDT_KEY.WWDT_KEY`, а для восстановления блокировки — любое другое значение.
Модуль WWDT сбрасывается в исходное состояние после "холодного" сброса МК. Возможность сброса модуля при "горячем" сбросе МК определяется значением бита `RST_CR0.RST_WWDT_DIS`:
* 0 — сброс модуля разрешен (по-умолчанию),
* 1 — сброс модуля запрещен, т.е. счетчик будет продолжать считать после "горячего" сброса МК.
Для *включения модуля* WWDT необходимо:
* включить тактирование модуля установкой бита `CSC_APB0.CSC_WWDT_EN`,
* включить модуль установкой бита `WWDT_CR0.WWDT_EN`.
Для *разрешения сигнала сброса* от модуля WWDT необходимо:
1. Установить биты в регистре `WWDT_CR0` для выбора событий.
2. "Холодный" сброс от модуля WWDT разрешить установкой бита `RST_WWDT_CE` в регистре `RST_CE` подсистемы сброса, "горячий" сброс — установкой бита `RST_WWDT_WE` в регистре `RST_WE`. По-умолчанию оба сброса запрещены.
Для *использования прерывания* от модуля WWDT необходимо:
1. Установить биты в регистре `WWDT_INT` для выбора событий.
2. Разрешить прерывание IRQ от модуля WWDT (IRQ#0) в контроллере прерываний NVIC установкой бита 0 в регистре `CPU_ISER`.
### Тестирование сторожевых таймеров
#### Общий код тестирования
Оба сторожевых таймера, в принципе, решают одну и ту же задачу, поэтому тестировать их логично по общей методике. Все основные функции по работе с таймерами IWDT и WWDT собраны в одном файле `src/wdt.c`, а функции тестирования и обработчики прерываний — в файле `test/wdt_test.c`. Для запуска конечной тестовой функции достаточно ее поместить в файл `app.c`, добавив, разумеется, включение файла `test/wdt_test.h`.
Прежде всего, в основной функции `app()` после вывода в терминал приветствия "Hello" добавим вызов функции `debug_reset_status()`, а ее реализацию поместим в файл `wdt_test.c`:
```
void debug_reset_status() {
uint32_t d;
d = RW(RST_STA_w);
debug32('F',d);
if (d & RST_STA_CRF_mask_w) uart_puts(PORT,"RST:COLD",UART_NEWLINE_CRLF);
if (d & RST_STA_WRF_mask_w) uart_puts(PORT,"RST:WARM",UART_NEWLINE_CRLF);
if (d & RST_STA_WWDTF_mask_w) uart_puts(PORT,"SRC:WWDT",UART_NEWLINE_CRLF);
if (d & RST_STA_IWDTF_mask_w) uart_puts(PORT,"SRC:IWDT",UART_NEWLINE_CRLF);
// Сбрасываем все флаги:
RW(RST_STA_w) = 0xFFFFFFFF;
}
```
Она нам потребуется для чтения флагов регистра статуса `RST_STA` и определения типа и причины сброса при старте МК. В начале выводится в hex-формате содержимое регистра, затем отдельно анализируются 4 интересующих нас флага.
#### Таймер IWDT
Создадим в файле `wdt.c` следующие функции:
```
/// Инициализация IWDT
void iwdt_init() {
RH(CSC_KEY_h0) = 0xA217; // unlock access to CSC regs
RB(CSC_APB0_b0) |= CSC_APB0_IWDT_EN_enable_b0; // CSC_IWDT_EN = 1
RH(CSC_KEY_h0) = 0; // lock access to CSC regs
}
/// Перезагрузка IWDT
void iwdt_reload() {
RH(IWDT_KEY_h0) = 0x2014;
}
/// Разблокировка записи регистров IWDT
void iwdt_write_unlock() {
RH(IWDT_KEY_h0) = 0xA217; // unlock access to regs
}
/// Блокировка записи регистров IWDT
void iwdt_write_lock() {
RH(IWDT_KEY_h0) = 0; // lock access to regs
}
/// Включение прерывания INT_SYS по флагам, указанным в flags согласно формату IWDT_INT
void iwdt_set_int(uint8_t flags) {
RH(IWDT_KEY_h0) = 0xA217; // unlock access to regs
RB(IWDT_INT_b0) = flags; // включаем прерывания в модуле
RH(IWDT_KEY_h0) = 0; // lock access to regs
// включаем прерывание INT_SYS:
RB(SYS_INT_b0) = 1; // SYS_IEA=1
// включаем прерывание в модуле NVIC:
RW(CPU_ISER_w) = (1 << 1); // SETENA 1
}
```
Теперь перейдем собственно к функции тестирования:
```
// Тест сторожевого таймера IWDT
void iwdt_test() {
SVC2(SVC_HANDLER_SET,1,iwdt_hdl); // устанавливаем обработчик прерывания INT_SYS
iwdt_set_int(IWDT_INT_EW0_IE_enable_b0); // разрешаем прерывание IWDT_EW0_IE
iwdt_init(); // включаем общее тактирование IWDT в CSC
iwdt_write_unlock();
RB(IWDT_CLK_b0) = IWDT_CLK_CK_DIV_div1024_b0; // выбираем делитель частоты 4096
RB(IWDT_CR0_b0) = IWDT_CR0_EN_enable_b0; // включаем IWDT_EN=1
iwdt_write_lock();
// Разрешаем горячий сброс:
RH(RST_KEY_h0) = 0xA217; // разблокируем запись в регистры RST
RW(RST_WE_w) |= RST_WE_IWDT_WE_enable_w;
RH(RST_KEY_h0) = 0; // возвращаем блокировку записи в регистры RST
// Выводим в терминал значение счетчика:
while (1) {
__disable_irq();
debug('C',RB(IWDT_CNT_b0));
__enable_irq();
delay_ms(50);
}
}
```
Действия функции следующие. В начале устанавливается обработчик прерывания `iwdt_hdl()` по флагу **EW0F** и происходит инициализация модуля. Включаем делитель частоты 1024 для счетного сигнала CK\_ILRCO частотой 32 кГц и получаем итоговую частоту счета около 31.25 Гц. Полный период таймера составит 256/31.25 ≈ 8.2 с. Разрешаем "горячий" сброс и далее в цикле выводим в терминал значение счетчика с задержкой 50 мс. Чтобы сразу протестировать генерацию события "Early Wakeup 0" используем прерывание с обработчиком:
```
// Обработчик прерывания IWDT (INT_SYS)
void iwdt_hdl() {
uart_puts(PORT,"INT:IWDT",UART_NEWLINE_CRLF);
RB(IWDT_STA_b0) = 0xFF; // Сбрасываем флаги IWDT_STA
}
```
В нем в UART будет выводиться сообщение о его срабатывании, после чего будут сбрасываться все флаги регистра `IWDT_STA`. Для того, чтобы вывод в UART из обработчика прерывания не "вклинивался" в основной вывод счетчика в цикле в функции `iwdt_test()` на время работы `debug()` отключаются прерывания. *Для справки:* макрос библиотеки CMSIS `__disable_irq()` (инструкция `CPSID I`) запрещает прерывания (кроме исключений NMI и HardFault), а макрос `__enable_irq()` (инструкция `CPSIE I`) — разрешает.
Запускаем программу и через несколько секунд в терминале получаем такой вывод (фрагмент в момент сброса МК):
```
C 0008 00008
C 0007 00007
C 0005 00005
C 0004 00004
C 0002 00002
C 0001 00001
Hello
F 40000800
RST:WARM
SRC:IWDT
C 00FA 00250
C 00F8 00248
C 00F7 00247
C 00F5 00245
```
Видно, что таймер запустился и начал отсчет. Спустя около 8 с значение дошло до нуля, и поскольку мы не сбрасывали IWDT, произошел "горячий" сброс МК (`RST:WARM`) по источнику IWDT. Теперь в выводе терминала найдем срабатывание флага **EW0F**:
```
C 0026 00038
C 0025 00037
C 0023 00035
C 0022 00034
C 0020 00032
INT:IWDT
C 001F 00031
C 001D 00029
C 001C 00028
C 001A 00026
C 0019 00025
```
Прерывание сработало как и ожидалось: после перехода счетчика на значение 0x20. Наконец, добавим периодическую перезагрузку счетчика, чтобы не происходило срабатывание IWDT. В начале функции `iwdt_test()` объявим переменную `uint32_t i`, а в цикле добавим вызов функции `iwdt_reload()` с выводом сообщения в терминал:
```
void iwdt_test() {
uint32_t i=0;
// ........
while (1) {
__disable_irq();
debug('C',RB(IWDT_CNT_b0));
__enable_irq();
delay_ms(50);
if (++i==100) {
iwdt_reload();
uart_puts(PORT,"RELOAD",UART_NEWLINE_CRLF);
i=0;
}
}
}
```
Проверяем работу:
```
C 0070 00112
C 006E 00110
C 006D 00109
C 006B 00107
RELOAD
C 00FF 00255
C 00FE 00254
C 00FC 00252
C 00FB 00251
```
Теперь мы не допускаем срабатывания таймера: примерно в середине его периода происходит перезагрузка счетчика и счет начинается заново с 255. Мы также не допускаем события "Early Wakeup 0" и срабатывания прерывания.
#### Таймер WWDT
Создадим в файле `wdt.c` аналогичные функции для таймера WWDT:
```
void wwdt_init() {
RH(CSC_KEY_h0) = 0xA217; // unlock access to CSC regs
RB(CSC_APB0_b0) |= CSC_APB0_WWDT_EN_enable_b0; // CSC_WWDT_EN = 1
RH(CSC_KEY_h0) = 0; // lock access to CSC regs
}
void wwdt_reload() {
RH(WWDT_KEY_h0) = 0x2014;
}
void wwdt_write_unlock() {
RH(WWDT_KEY_h0) = 0xA217; // unlock access to regs
}
void wwdt_write_lock() {
RH(WWDT_KEY_h0) = 0; // lock access to regs
}
```
Для начала запустим такой вариант функции тестирования:
```
// Тест сторожевого таймера WWDT
void wwdt_test() {
wwdt_init(); // включаем общее тактирование WWDT в CSC
wwdt_write_unlock();
RB(WWDT_CLK_h0) =
WWDT_CLK_CK_PDIV_divided_by_256_h0 | // делитель частоты PDIV: 256
WWDT_CLK_CK_DIV_div128_h0; // делитель частоты DIV: 128
RB(WWDT_CR0_b0) =
WWDT_CR0_RSTW_EN_enable_b0 | // разрешаем сброс по выходу из окна
WWDT_CR0_RSTF_EN_enable_b0 | // разрешаем сброс по завершению счета
WWDT_CR0_EN_enable_b0; // включаем IWDT_EN=1
wwdt_write_lock();
// Разрешаем горячий сброс от модуля WWDT:
RH(RST_KEY_h0) = 0xA217; // разблокируем запись в регистры RST
RW(RST_WE_w) |= RST_WE_WWDT_WE_enable_w;
RH(RST_KEY_h0) = 0; // возвращаем блокировку записи в регистры RST
// Выводим в терминал значение счетчика:
while (1) {
__disable_irq();
debug('C',RH(WWDT_CNT_h0));
__enable_irq();
delay_ms(50);
}
}
```
В начале происходит инициализация модуля (включение общего тактирования). Тактирование счетчика оставляем от сигнала CK\_APB, оба делителя включаем на максимальный коэффициент. Таким образом, получаем итоговую частоту счета 12 МГц/256/128 ≈ 366.2 Гц, а полный период таймера 1024/366.2 ≈ 2.8 с. Разрешаем "горячий" сброс по обоим событиям (выходу из окна и таймауту) и далее в цикле выводим в терминал значение счетчика. После запуска в терминале получаем такой результат:
```
C 0045 00069
C 0033 00051
C 0021 00033
C 0010 00016
Hello
F 40001000
RST:WARM
SRC:WWDT
C 03B9 00953
C 03A8 00936
C 0396 00918
C 0384 00900
```
Таймер успешно стартует, и поскольку мы его не перезапускаем, возникает "горячий" сброс МК, при этом сам таймер перезапускается с начального значения. Теперь добавим программный перезапуск таймера:
```
while (1) {
__disable_irq();
debug('C',RH(WWDT_CNT_h0));
__enable_irq();
delay_ms(50);
if (++i==20) {
wwdt_reload();
uart_puts(PORT,"RELOAD",UART_NEWLINE_CRLF);
i=0;
}
}
```
Проверяем работу:
```
C 02E4 00740
C 02D3 00723
C 02C1 00705
C 02AF 00687
RELOAD
C 03FF 01023
C 03EE 01006
C 03DC 00988
C 03CA 00970
```
Сброса не происходит, т.к. мы выполняем перезагрузку примерно на отметке 687/366.2 ≈ 1.88 с, причем укладываемся в окно, которое по-умолчанию начинается от старта.
Теперь проверим главную функцию модуля WWDT — контроль временного окна. Добавим перед вызовом `wwdt_write_lock()`:
```
RH(WWDT_WIN_h0) = 700; // устанавливаем окно
```
Результат работы аналогичен предыдущему случаю: мы попадаем в окно и сброса МК не происходит. Установим окно на значение 500, т.е. сместим нижнюю границу вперед (счет обратный). Посмотрим результат:
```
C 029E 00670
C 028D 00653
C 027B 00635
C 0269 00617
Hello
F 40001000
RST:WARM
SRC:WWDT
C 03B9 00953
C 03A8 00936
C 0396 00918
C 0384 00900
```
Теперь мы не попадаем в окно и генерируется сигнал сброса по выходу за пределы окна — главная функция WWDT работает. Если поставить значение порога окна около 600, через раз будет то срабатывать сброс, то перезагрузка, поскольку в цикле мы не привязывались жестко ко времени.
В завершении тестирования проверим прерывание от модуля WWDT по событию "предупреждение", добавив в начало функции тестирования код:
```
SVC2(SVC_HANDLER_SET,0,wwdt_hdl); // устанавливаем обработчик прерывания
wwdt_set_int(WWDT_INT_WRN_IE_enable_b0); // разрешаем прерывание WWDT_WRN_IE
```
а перед вызовом `wwdt_write_lock()` установим порог предупреждения на значение между началом окна и перезагрузкой:
```
RH(WWDT_WIN_h0) = 700; // устанавливаем окно
RH(WWDT_WRN_h0) = 690; // устанавливаем время предупреждения
```
Добавим также сам обработчик прерывания в файл `wdt_test.c`:
```
void wwdt_hdl() {
uart_puts(PORT,"INT:WRN",UART_NEWLINE_CRLF);
RB(WWDT_STA_b0) = 0xFF; // Сбрасываем флаги
}
```
Кроме того, в файл базовой части `svr.c` нужно добавить первичный обработчик прерывания IRQ#0 `WWDT_IRQHandler()`.
Запускаем тест и смотрим результат:
```
C 02F6 00758
C 02E4 00740
C 02D3 00723
C 02C1 00705
INT:WRN
C 02AF 00687
RELOAD
C 03FF 01023
C 03EE 01006
C 03DC 00988
C 03CA 00970
```
Предупреждение сработало тогда, когда мы его и ожидали. Все тесты выполнены успешно.
На этом мы завершаем пятую статью цикла. В следующий раз рассмотрим общие таймеры МК серии MG32F02. | https://habr.com/ru/post/686416/ | null | ru | null |
# Добавляем рекламу AdMob в Android приложение на платформе Adobe Air
После того, как я разработал свое первое, простейшее приложение для **Android** на **Adobe Air**, мне захотелось добавить в него рекламу, хотя бы для того, чтобы в будущем знать, как это делается. Я потратил на это довольно много времени, не найдя ничего об этом в интернете на русском языке. Поэтому решил написать краткое руководство к действию, для тех, кому это еще понадобится. Добавлять будем рекламу из **Google AdMob**.
#### 1. Загружаем ANE
Для работы со сторонними сервисами (AdMob, GameCenter и тп.), а также с некоторыми техническими возможностями устройств (гироскоп, вибрация и тп.) Adobe предлагает использовать Adobe Native Extensions (ANE) — что-то похожее на внешние библиотеки. ANE — это файлы с расширением .ane, которые содержат описания классов **Action Script 3**, с которыми можно взаимодействовать после подключения расширения.
На сайте ([Adobe](http://www.adobe.com/devnet/air/native-extensions-for-air.html)) есть список рекомендуемых ANE, разработанных как разработчиками компании, так и сторонними разработчиками. Что касается AdMob, то для взаимодействием с этим сервисом Adobe предлагает только коммерческие ANE от Milkman Games ($29,99 на момент написания поста) и от distriqt ($40 на момент написания поста). Разумеется у меня не возникло желания платить такую сумму и я отправился в путешествие по просторам интернета для поиска бесплатной версии.
Поиски в конечном счете привели к AdMobAne от Code-Alchemy. Это расширение представлено в открытом доступе в [в репозитории GitHub](https://github.com/Code-Alchemy/AdMobAne). Загружаем его архивом, распаковываем, находим папку «anes\_builds», выбираем нужный ANE файл (в зависимосте от того пишете вы приложения для Android, iOS или для обеих платформ) и отправляем его в папку со своим проектом.
#### 2. Подключаем ANE
Теперь подключаем ANE к проекту. Если вы используете Flash Professional, нужно перейти на страницу настроек ActionScript 3.0, затем нажать на кнопку «Перейти к файлу с собственным расширением (ANE)» и указать путь к файлу .ane:
Теперь расширение должно появиться в списке ниже.
#### 3. Редактируем манифест приложения
Для того, чтобы в ваше приложение можно было успешно вставить рекламу, нужно во-первых объявить в манифесте, что приложению требуется доступ в интернет, а во-вторых добавить новую активность. Добавляем в манифест следующие строки:
```
<manifest>
<uses-permission android:name="android.permission.INTERNET"/>
<uses-permission android:name="android.permission.ACCESS\_NETWORK\_STATE"/>
<uses-permission android:name="android.permission.ACCESS\_WIFI\_STATE"/>
<application>
<meta-data android:name="com.google.android.gms.version" android:value="4452000"/>
<activity android:name="com.google.android.gms.ads.AdActivity" android:configChanges="keyboard|keyboardHidden|orientation|screenLayout|uiMode|screenSize|smallestScreenSize" />
</application>
</manifest>
```
**Для того, чтобы манифест успешно разбирался парсером, необходимо использовать, как минимум, AIR 3.4**, в случае использования более старой версии будете получать неприятную критическую ошибку. Кроме того, необходимо периодически убеждаться, что в манифесте после очередной публикации приложения остаются строки, описывающие новую активность (то что вы только что добавили), так как после изменения настроек публикации Flash может автоматически переписать манифест и удалить их — а вы будете долго и упорно искать ошибку.
Проверьте также, что в вашем манифесте присутствует следующее:
```
com.codealchemy.ane.admobane
```
#### 4. Пишем код
Подробное описание классов, методов и свойств приведено на [странице ANE в GitHub](https://github.com/Code-Alchemy/AdMobAne). Расскажу, как создать обычный баннер:
1. Импортируем необходимые классы.
```
import com.codealchemy.ane.admobane.AdMobManager;
import com.codealchemy.ane.admobane.AdMobPosition;
import com.codealchemy.ane.admobane.AdMobSize;
```
2. Получаем менеджер.
```
var adMobManager:AdMobManager;
adMobManager = AdMobManager.manager;
```
3. Проверяем, поддерживается ли класс AdMobManager.
```
if (adMobManager.isSupported) { ... }
```
4. Если поддерживается: устанавливаем режим работы в PROD\_MODE (продакшн — отладка не доступна), указываем ID баннера, создаем баннер с размером BANNER и положением BOTTON\_CENTER (определены в классах AdMobSize и AdMobPosition). NULL указывает на то, что мы используем ранее указанный ID баннера, можно вместо NULL указать другой ID. True указывает на то что, что баннер будет показан, как только загрузится. «BottomBanner» — идентификатор баннера в нашем приложении (придумываем сами).
```
adMobManager.operationMode = AdMobManager.PROD_MODE;
adMobManager.bannersAdMobId = "ca-app-pub-3036271947968278/6206838142";
adMobManager.createBanner(AdMobSize.BANNER,AdMobPosition.BOTTOM_CENTER,"BottomBanner", null, true);
```
Не забудьте поменять ID баннера на свой собственный.
5. Для того, чтобы спрятать или показать баннер используем следующие методы:
```
adMobManager.showBanner("BottomBanner");
adMobManager.hideBanner("BottomBanner");
```
Аналогично создаем fullscreen рекламу:
```
adMobManager.interstitialAdMobId = "ADMOB_INTERSTITIAL_ID";
adMobManager.createInterstitial(null,true);
```
Доступные позиции для баннера: TOP\_LEFT, TOP\_CENTER, TOP\_RIGHT, MIDDLE\_LEFT, MIDDLE\_CENTER, MIDDLE\_RIGHT, BOTTOM\_LEFT, BOTTOM\_CENTER, BOTTOM\_RIGHT. Доступные размеры: BANNER, MEDIUM\_RECTANGLE, LARGE\_BANNER, FULL\_BANNER, LEADERBOARD, WIDE\_SKYSCRAPER, SMART\_BANNER, SMART\_BANNER\_PORT, SMART\_BANNER\_LAND.
#### 5. Заключение
Данное расширение позволяет настраивать возраст целевой аудитории, прослушивать события и многое другое. Обо всем этом можно почитать на GitHub. Спасибо за внимание. | https://habr.com/ru/post/267613/ | null | ru | null |
# Mr. Stylin
Вам не кажется, что мы слишком далеко зашли? Да вы, ну те что пишете на реакте. Вначале нам пришла гениальная мысль миксить представление с основным кодом, затем стали писать CSS стили прямо в JS, как в том фильме “[а тут всё в бак можно заливать с бензином”](https://youtu.be/dJrxi1gXPug?t=131). Как сейчас помню вопли и негодование одних и счастье других, признаться честно, позже я и сам не брезгал styled-components-ами. Но на этом вся затея не остановились, нашлись и такие, что решили: “нафиг писать стили отдельно” и стали сразу передавать их в пропсы компонента. Такой подход хорошо отражается в [styled-system](https://styled-system.com/) и жутко напоминает те дикие времена когда балом правили эти господа:
```
Вы думали **я** *не вернусь*?
```
Это безумие можно оправдать тем, что всё развивается спиралью, всё новое это хорошо забытое старое. И возможно в следующей ветви развития мы вновь вернемся к CSS с какой нибудь новизной. Однако. Я не стал ждать того момента и создал ~~своего гомункула~~, свой велосипед.
И вот что вышло:
```
import {render} from 'react-dom'
import {Title} from './styles.scss'
render(
Hello world!
,
document.getElementById('app')
)
```
styles.scss
```
/**
@tag: h1
@component: Title
size: small | medium | large
color: #38383d --color
*/
.title {
--color: #38383d;
color: var(--color);
font-size: 18px;
&.small {
font-size: 14px;
margin: 2px 0;
}
&.medium {
font-size: 18px;
margin: 4px 0;
}
&.large {
font-size: 20px;
margin: 6px 0;
}
}
```
Если вы не заметили, тут есть два абсурда:
```
import {Title} from './styles.scss'
```
Тут мы импортируем реакт компонент сразу из `scss` стилей! Клянусь богом с таким успехом, в будущем мы будем импортировать компоненты из рисованных моков [фигмы](https://www.figma.com/).
Но, а далее следующий фокус в самих стилях. Обратите внимание на секцию комментарий и вы увидите аннотации которые напоминают собой JSDocs, хотя скорее их правильней назвать CSSDocs. Мы как бы говорим, что это за кусок стилей и намекаем для чего он нам нужен.
Возможно эта анимация поможет вам разобраться более наглядно, что к чему:
Если именовать CSS классы также как и значение свойств компонента то их можно сократить до `type: primary | secondary | link`, как было сделано в первом примере, полный список сокращалок можно найти [по ссылке](https://github.com/sultan99/stylin/blob/main/packages/style/README.md).
Конечно, чтобы эта магия заработало, нужен специальный webpack loader и библиотека:
```
npm install @stylin/style
npm install --save-dev @stylin/msa-loader
```
И внести [некоторые изменения](https://github.com/sultan99/stylin/blob/main/packages/msa-loader/README.md) в конфигу вашего webpack-а.
Однако, это еще не всё! Если вы из тех извращенцев, что используют TypeScript, то вы сможете получить авто-генерацию типов бонусом ко своим стилизованным компонентам. И знаете это так избавляет от скучной работы:
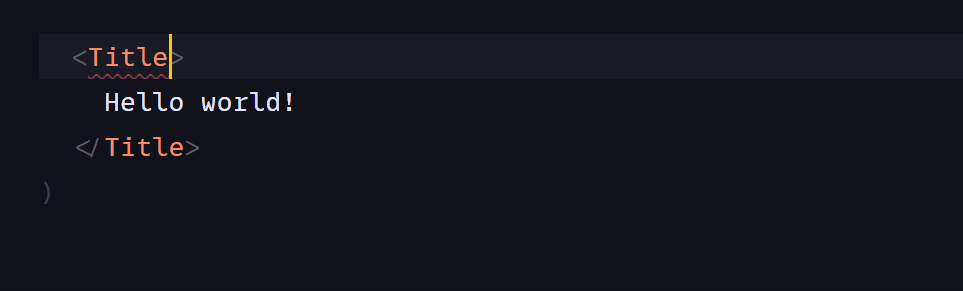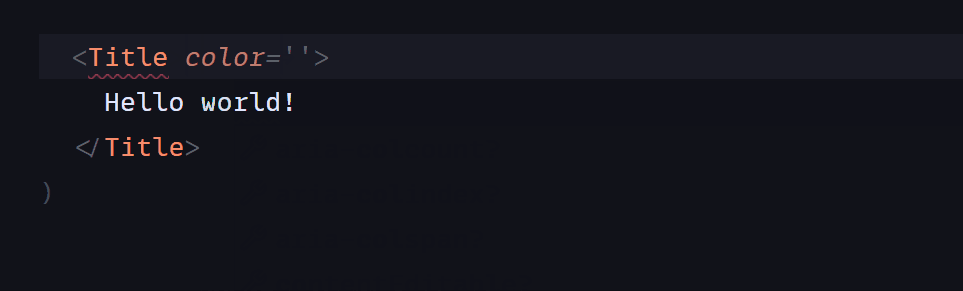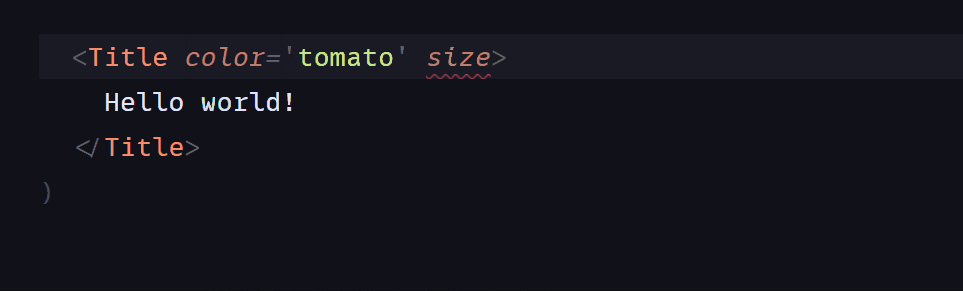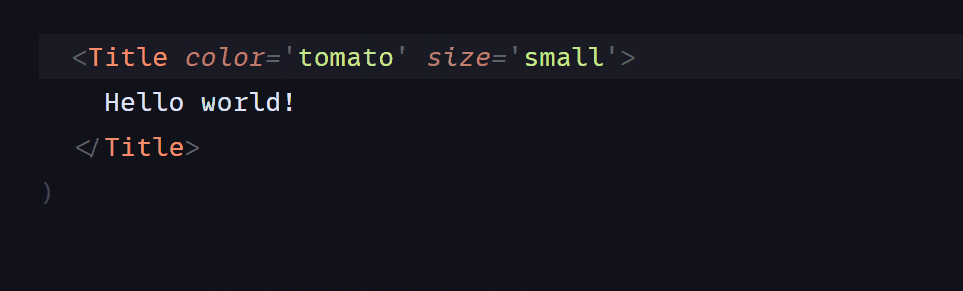Для этого вам надо установить еще один webpack loader и добавить его в конфигу.
```
npm install --save-dev @stylin/ts-loader
```
Полагаю, у вас возник вопрос типа: “[Че там брат, че там под капотом?](https://youtu.be/XmlQ70vx-5I?t=15)”
А там всего [43 строчки кода](https://github.com/sultan99/stylin/blob/main/packages/style/src/index.ts), та часть которая попадает в бандл. Не думаю, что они как то могут повлиять на вес вашего приложения. А вот по скорости предлагаемая библиотека конечно быстрее любых runtime библиотек, так как разбор CSS стилей происходит во время компиляции и сравнивать их несправедливо.
Но я, всё равно сравнил.
[Stylin](https://sultan99.github.io/stylin) быстрее порядком на 30% в сравнении с [styled-components](https://styled-components.com/), а в определенных кейсах он делает styled-components как стоячего в несколько раз!
Передачи значений из JS в CSS происходит через нативные CSS переменные отсюда и скорость и никаких инъекций стилей в рантайм, все происходит так как должно быть - традиционным способом для всех браузеров. Справедливости ради, нужно сказать далеко не [все браузеры это поддерживают](https://caniuse.com/css-variables), к примеру E11 обречен отсюда и минус данной либы.
Пример использования переменных:
`componentPropertyName: default-value --css-variable`
```
/**
@tag: button
@component: SexyButton
width: 150px --btn-width
*/
.sexy-button {
--btn-width: 150px;
width: var(--btn-width);
}
/* JSX */
Love me
```
**Темы**
Благодаря CSS переменным поддержка тем становится гораздо проще, вы полностью избавитесь от какой либо логики в стилях, всё будет в старой и доброй декларативной манере. Проверить это можно в [онлайн демке](https://codesandbox.io/s/github/sultan99/cards/tree/main), правда нужно отметить магия авто-генерации типов там не работает (в codesandbox нет доступа к FS), чтобы их пощупать вам придется стянуть [исходники](https://github.com/sultan99/cards) к себе и уже на локальной машине экспериментировать.
Ах да, чуть ли не забыл, переключая темную тему на светлую и наоборот, вы заметите, что всё приложение не перерисовывается (react render) и это какая то магия!
Естественно есть возможность пере-стилизовать существующие компоненты.
```
import {Button} from 'antd'
import {applyStyle} from './style.scss'
// sexy-button is css-class
const StyledButton = applyStyle(`sexy-button`, Button)
Love me
```
Я бы с удовольствием вам рассказал о всех возможностей данной библиотеки, однако я не хочу показаться, будто я пришел сюда пиариться :D. Я тут только, чтобы избавить вас от боли и послушать вашу критику / предложения. Может вы изволите такую балалайку и для вашего любимого фреймворка типа [next.js](https://nextjs.org/) или [preact](https://preactjs.com/)?
Всем пока, будьте осторожны с реактом и берегите себя! | https://habr.com/ru/post/545994/ | null | ru | null |
# FreeRTOS: введение

Здравствуйте. В короткой серии постов я постараюсь описать возможности, и подходы работы с одной из наиболее популярной и развивающейся РТОС для микроконтроллеров – FreeRTOS. Я предпологаю базовое знакомство читателя с теорией многозадачности, о которой можно почитать в одном из соседних постов на Хабре или ещё где-то.
Ссылки на остальные части:
[FreeRTOS: межпроцессное взаимодействие.](http://habrahabr.ru/blogs/controllers/129180/)
[FreeRTOS: мьютексы и критические секции.](http://habrahabr.ru/blogs/controllers/129445/)
##### Зачем все это? Или введение в многозадачные системы, от создателей FreeRTOS.
Традиционно существует 2 версии многозадачности:
* «Мягкого» реального времени(soft real time)
* «Жесткого» реального времени(hard real time)
К ОСРВ мягкого типа можно отнести наши с Вами компьютеры т.е. пользователь должен видеть, что, например, нажав кнопку с символом, он видит введенный символ, а если же он нажал кнопку, и спустя время не увидел реакции, то ОС будет считать задачу «не отвечающей»( по аналогии с Windows — «Программа не отвечает»), но ОС остается пригодной для использования. Таким образом, ОСРВ мягкого времени просто определяет предполагаемое время ответа, и если оно истекло, то ОС относит таск к не отвечающим.
К ОСРВ жесткого типа, как раз относят ОСРВ во встраиваемых устройствах. В чем-то они похоже на ОСРВ на дестопах(многопоточное выполнение на одном процессоре), но и имеют главное отличие — каждая задача **должна** выполняться за отведенный квант времени, не выполнение данного условия ведет к краху все системы.
###### А все таки зачем?
Если у Вас есть устройство с нетривиальной логикой синхронизации обмена данными между набором сенсоров, если Вам действительно нужно гарантировать время отклика, и наконец-то если Вы думаете, что система может разростись, но не знаете насколько, то РТОС Ваш выбор.
Не стоит применять РТОС, для применения РТОС т.е. не нужно применять РТОС в слишком тривиальных задачах(получить данные с 1 сенсора, и отправить дальше, обработать нажатие 1 кнопки и т.д) т.к. это приведет к ненужной избыточности, как полученного кода, так и решения самой задачи.
##### Работа с тасками(или задачами, процессами).
Для начала приведу несколько определений, для того чтобы внести ясность в дальнейшие рассуждения:
*"**Операционные системы реального времени** (ОСРВ(RTOS)) предназначены для обеспечения интерфейса к ресурсам критических по времени систем реального времени. Основной задачей в таких системах является своевременность (timeliness) выполнения обработки данных".*
*"**FreeRTOS** — многозадачная операционная система реального времени (ОСРВ) для встраиваемых систем. Портирована на несколько микропроцессорных архитектур.
От хабраюзера [andrewsh](http://geektimes.ru/users/andrewsh/), по поводу лицензии: разрешено не публиковать текст приложения, которое использует FreeRTOS, несмотря на то, что OS линкуется с ним. Исходники самой же RTOS должны всегда прикладываться, изменения, внесённые в неё — тоже.".*
FreeRTOS написана на Си с небольшим количеством ассемблерного кода(логика переключения контекста) и ее ядро представлено всего 3-мя C файлами. Более подробно о поддерживаемых платформах можно почитать на [официальном сайте](http://www.freertos.org).
Перейдем к делу.
Любой таск представляет собой Си функцию со следующим прототипом:
```
void vTask( void *pvParametres );
```
Каждый таск – это по сути мини подпрограмма, которая имеет свою точку входу, и исполняется внутри бесконечного цикла и обычно не должна выходить из него, а также имеет собственный стэк. Одно определение таска может использоваться для создания нескольких тасков, которые будут выполняться независимо и также иметь собственный стэк.
Тело таска не должно содержать явных **return;** конструкций, и в случае если таск больше не нужен, его можно удалить с помощью вызова API функции. Следующий листинг, демонстрирует типичный скелет таска:
```
void vTask( void *pvParametres) {
/* Данный фрагмент кода будет вызван один раз, перед запуском таска.
Каждый созданный таск будет иметь свою копию someVar.
Кроме объявления переменных, сюда можно поместить некоторый инициализационный код.
*/
int someVar;
// Так как каждый таск - это по сути бесконечный цикл, то именно здесь начинается тело таска.
for( ;; ) {
// Тело таска
}
// Так как при нормальном поведении мы не должны выходить из тела таска, то в случае если это все таки произошло, мы удаляем таск.
// Функция vTaskDelete принимает в качестве аргумента хэндл таска, который стоит удалить.
// Вызов внутри тела таска с параметром NULL,удаляет текущий таск
vTaskDelete( NULL );
}
```
Для создания таска, и добавления ее в планировщик используется специальная API функция со следующим прототипом:
```
portBASE_TYPE xTaskCreate( pdTASK_CODE pvTaskCode,
const signed portCHAR * const pcName,
unsigned portSHORT usStackDepth,
void *pvParameters,
unsigned portBASE_TYPE uxPriority,
xTaskHandle *pxCreatedTask
);
```
***pvTaskCode*** – так как таск – это просто Си функция, то первым параметром идет ее значение.
***pcName*** – имя таска. По сути это нигде не используется, и полезно только при отладке с соответствующими плагинами для IDE.
***usStackDepth*** – так как каждый таск – это мини подпрограмма, со своим стэком, то данный параметр отвечает за его глубину. При скачивании RTOS и разворачивания системы для своей платформы, вы получаете файл FreeRTOSConfig.h настройкой которого можно конфигурировать поведение самой ОС. В данном файле также объявлена константная величина **configMINIMAL\_STACK\_SIZE**, которую и стоит передавать в качестве usStackDepth с соответствующим множителем, если это необходимо.
***pvParameters*** – при создании, каждый таск может принимать некоторые параметры, значения, или ещё что-то что может понадобиться внутри тела самого таска. С точки зрения инкапсуляции, этот подход наиболее безопасный, и в качестве pvParameters стоит передавать, например, некоторую структуру, или NULL, если ничего передавать не нужно.
***uxPriority*** – каждый таск имеет свой собственный приоритет, от 0(min) до (**configMAX\_PRIORITIES** – 1). Так как, по сути, нет верхнего предела для данного значения, то рекомендуется использовать как можно меньше значений, чтобы не было дополнительно расхода RAM на данную логику.
***pxCreatedTask*** — хэндл созданного таска. При создании таска, опционально можно передать указатель на хэндл будующего таска, для последующего управления работой самого таска. Например, для удаления определенного таска.
Данная функция возвращает **pdTRUE**, в случае успешного создания таска, или **errCOULD\_NOT\_ALLOCATE\_REQUIRED\_MEMORY**, в случае если размер стэка был указан слишком большим, т.е. недостаточно размера хипа для хранения стэка таска, и самого таска.
На следующем листинге я привел, короткий пример законченной программы, которая создает 2 таска, каждый из которых мигает светодиодом:
```
void vGreenBlinkTask( void *pvParametrs ) {
for( ;; ) {
P8OUT ^= BIT7;
// Выполнить задержку в 700 FreeRTOS тиков. Величина одного тика задана в FreeRTOSConfig.h и как правило составляет 1мс.
vTaskDelay( 700 );
}
}
void vRedBlinkTask( void *pvParametrs ) {
for( ;; ) {
P8OUT ^= BIT6;
// Выполнить задержку в 1000 FreeRTOS тиков. Величина одного тика задана в FreeRTOSConfig.h и как правило составляет 1мс.
vTaskDelay( 1000 );
}
}
void main(void) {
// Инициализация микроконтроллера. Данный код будет у каждого свой.
vInitSystem();
// Создание тасков. Я не включил код проверки ошибок, но не стоит забывать об этом!
xTaskCreate( &vGreenBlinkTask,
(signed char *)"GreenBlink",
configMINIMAL_STACK_SIZE,
NULL,
1,
NULL );
xTaskCreate( &vRedBlinkTask,
(signed char *)"RedBlink",
configMINIMAL_STACK_SIZE,
NULL,
1,
NULL );
// Запуск планировщика т.е начало работы тасков.
vTaskStartScheduler();
// Сюда стоит поместить код обработки ошибок, в случае если планировщик не заработал.
// Для примера я использую просто бесконечный цикл.
for( ;; ) { }
}
```
В следующем посте я планирую написать о взаимодействии между тасками, и работе с прерываниями. | https://habr.com/ru/post/129105/ | null | ru | null |
# Алгоритм нахождения N первых простых чисел — Решето Аткина
В процессе реализации одной программы я столкнулся с задачей поиска простых чисел до числа N порядка . На хабре уже неоднократно писали про различные способы и методы, но не упоминали про основной метод решения, что я сегодня и постараюсь исправить.
Алгоритм имеет асимптотическую сложность  и требует  бит памяти. На входных значениях порядка  решето Аткина быстрее решета Эрастофена в 9.2 раза. Приведу график роста превосходства алгоритма Аткина на числах от 2 до :
В результате можно наблюдать следующую скорость выполнения:
| | |
| --- | --- |
| 10 000 000 | 0.15 сек. |
| 100 000 000 | 2.16 сек. |
| 1 000 000 000 | 48.76 сек. |
Для удобства и краткости создадим абстрактный класс, от которого будем наследовать реализации решета Аткина. В дальнейшем будем только создавать различные варианты класса.
> `public abstract class AAtkin
>
> {
>
> internal readonly int \_limit;
>
> public bool[] IsPrimes;
>
>
>
> protected AAtkin(int limit)
>
> {
>
> \_limit = limit;
>
> FindPrimes();
>
> }
>
>
>
> public abstract void FindPrimes();
>
> }`
Создадим базовую реализацию алгоритма:
> `public override void FindPrimes()
>
> {
>
> IsPrimes = new bool[\_limit + 1];
>
> double sqrt = Math.Sqrt(\_limit);
>
> var limit = (ulong) \_limit;
>
> for (ulong x = 1; x <= sqrt; x++)
>
> for (ulong y = 1; y <= sqrt; y++)
>
> {
>
> ulong x2 = x\*x;
>
> ulong y2 = y\*y;
>
> ulong n = 4\*x2 + y2;
>
> if (n <= limit && (n%12 == 1 || n%12 == 5))
>
> IsPrimes[n] ^= true;
>
>
>
> n -= x2;
>
> if (n <= limit && n%12 == 7)
>
> IsPrimes[n] ^= true;
>
>
>
> n -= 2 \* y2;
>
> if (x > y && n <= limit && n%12 == 11)
>
> IsPrimes[n] ^= true;
>
> }
>
>
>
> for (ulong n = 5; n <= sqrt; n += 2)
>
> if (IsPrimes[n])
>
> {
>
> ulong s = n\*n;
>
> for (ulong k = s; k <= limit; k += s)
>
> IsPrimes[k] = false;
>
> }
>
> IsPrimes[2] = true;
>
> IsPrimes[3] = true;
>
> }`
Время исполнения базовой (классической) версии алгоритма:
| | |
| --- | --- |
| 1 000 000 | 0.03 сек. |
| 10 000 000 | 0.39 сек. |
| 100 000 000 | 4.6 сек. |
| 1 000 000 000 | 48.92 сек. |
Вспомним, что в языке C# операции с типом ulong занимают примерно в 3 раза больше времени, чем с типом int. В программе при расчёте больших чисел значения всё-таки переваливают за int.MaxValue, так что найдём эмпирическую планку использования. Здесь она равна 858599509. Вставим условие и получим финальное ускорение:
> `IsPrimes = new bool[\_limit + 1];
>
> double sqrt = Math.Sqrt(\_limit);
>
> if (sqrt < 29301)
>
> {
>
> for (int x = 1; x <= sqrt; x++)
>
> for (int y = 1; y <= sqrt; y++)
>
> {
>
> int x2 = x \* x;
>
> int y2 = y \* y;
>
> int n = 4 \* x2 + y2;
>
> if (n <= \_limit && (n % 12 == 1 || n % 12 == 5))
>
> IsPrimes[n] ^= true;
>
>
>
> n -= x2;
>
> if (n <= \_limit && n % 12 == 7)
>
> IsPrimes[n] ^= true;
>
>
>
> n -= 2 \* y2;
>
> if (x > y && n <= \_limit && n % 12 == 11)
>
> IsPrimes[n] ^= true;
>
> }
>
>
>
> for (int n = 5; n <= sqrt; n += 2)
>
> if (IsPrimes[n])
>
> {
>
> int s = n \* n;
>
> for (int k = s; k <= \_limit; k += s)
>
> IsPrimes[k] = false;
>
> }
>
> }
>
> else
>
> {
>
> var limit = (ulong) \_limit;
>
> for (ulong x = 1; x <= sqrt; x++)
>
> for (ulong y = 1; y <= sqrt; y++)
>
> {
>
> ulong x2 = x\*x;
>
> ulong y2 = y\*y;
>
> ulong n = 4\*x2 + y2;
>
> if (n <= limit && (n%12 == 1 || n%12 == 5))
>
> IsPrimes[n] ^= true;
>
>
>
> n -= x2;
>
> if (n <= limit && n%12 == 7)
>
> IsPrimes[n] ^= true;
>
>
>
> n -= 2 \* y2;
>
> if (x > y && n <= limit && n%12 == 11)
>
> IsPrimes[n] ^= true;
>
> }
>
>
>
> for (ulong n = 5; n <= sqrt; n += 2)
>
> if (IsPrimes[n])
>
> {
>
> ulong s = n\*n;
>
> for (ulong k = s; k <= limit; k += s)
>
> IsPrimes[k] = false;
>
> }
>
> }
>
> IsPrimes[2] = true;
>
> IsPrimes[3] = true;
>
> }`
На этом всё. Спасибо за внимание — я постарался не быть очень сухим. | https://habr.com/ru/post/125620/ | null | ru | null |
# Немного о затенении по Фонгу

> «Мы не можем ожидать, что у нас получится отобразить объект точно таким, каким он является в реальности, с текстурами, тенями и т.д. Мы надеемся только на то, чтобы создать изображение, которое достаточно близко к достижению определённой степени реализма».
>
>
>
> *Буй Тыонг Фонг*
Буй Тыонг Фонг родился в 1941 году и стал учёным-информатиком во время Вьетнамской войны. Должно быть, ему сложно оказалось завершить своё обучение в токсичной среде 60-х, не говоря уже о том, что его призвали на фронт! Но ему удалось выжить и дожить до 1975 года, прежде чем его жизнь забрала лейкемия спустя всего два года после того, как он заложил для мира фундамент современной теории освещения и затенения: *шейдер Фонга*. Вьетнамские имена состоят из трёх частей: фамилии, среднего имени и личного имени. То есть когда люди говорят «шейдер Фонга», они называют личное имя Буй Тыонга. Подробнее о *личных именах* можно прочитать в [Википедии](https://en.wikipedia.org/wiki/Given_name).

*Не уверен, действительно ли это Фонг, но если верить Google, то да.*
> “Softly let the balmy sunshine
>
> Play around my dying bed,
>
> E’er the dimly lighted valley
>
> I with lonely feet must tread. “
>
>
>
> *Let The Light Enter – стихотворение Фрэнсис Харпер*
В основе шейдера Фонга лежит чрезвычайно лаконичная математика. Которую вам, на самом деле, знать не обязательно, если только вы искренне не желаете стать программистом графики. Однако в долгой перспективе её знание будет полезным. Ниже представлены выдержки из *OpenGL Superbible, 7th Edition* Грэма Сэллерса и Kronos Group ARB Foundation.
A) Некоторые концепции
----------------------
Во-первых, давайте разберёмся с концепциями. Если вы хоть минуту имели дело с 3D-моделированием или разработкой игр, то вы наверняка с ними уже сталкивались, но повторение никому ещё не мешало.
##### A-1) Окружающее освещение (Ambient Light)
В большинстве книг, особенно в низкокачественных, это освещение сравнивается с солнечным светом, но это совершенно неверно. Окружающее освещение — это не солнечный свет. Оно поступает *со всех направлений*, то есть оно вездесуще, но в вычислениях это просто вектор с тремя составляющими. В затенении Фонга он добавляется в конце, но не изменяется.
##### A-2) Рассеянное/диффузное освещение (Diffuse Light)
Рассеянное освещение имеет направление. На самом деле, это *направленный компонент источника освещения[sic]*. В кинематографе свет рассеивается с помощью софтбокса, а в компьютерной графике освещение рассеивается с помощью формулы, которую мы покажем ниже. Величина, то есть размер рассеянного освещения зависит от поверхности. Например, если поверхность является матовой, то есть она больше поглощает, чем отражает свет, то величина будет больше, чем в случае гладкой поверхности.

*Рассеяние/поглощение рассеянного освещения от матового экрана*
##### A-3) Блики отражений (Specular Highlight)
Как и рассеянное освещение, отражённый *свет* является направленным, но основан на гладкости (glossiness) поверхности; он оставляет *блик (highlight)*, который называется *блеском (shininess)*. В реальной жизни блеск не является неотъемлемой частью материала. На самом деле, покрытие плёнкой или капля воска добавят к блеску гораздо больше, чем что-либо остальное. Отражённый *блеск* — это фактор, имеющий значение от 0 до 128, потому что при значениях выше 128 он не сильно будет влиять на шейдер.

*Бумага с плёнкой — плотная цветная бумага с глянцевым плёночным покрытием, настоящий подарок для ребёнка.*
##### A- 4) Альбедо (Albedo)
Это доля падающего света, *отражаемая* поверхностью.
##### A-5) Формула Фонга
Формула вычисления материала по Фонгу имеет следующий вид:

Где:
: материал окружающего освещения (Ambient material)
: материал рассеянного освещения (Diffuse material)
: материал отражённого освещения (Specular material) и : показатель блеска
: окружающее освещение
: рассеянное освещение
: отражённое освещение
Вы можете спросить, а что насчёт векторов? Не волнуйтесь, сейчас мы расскажем и о них:
: нормаль к поверхности
: единичный вектор из затеняемой точки к источнику освещения (другими словами, вектор света)
: отражение отрицательного значения вектора света
: вектор, направленный к зрителю

B) Затенение по Гуро (Gouraud Shading)
--------------------------------------
Прежде чем браться за шейдер Фонга, давайте посмотрим, как можно получить на GLSL затенение по Гуро. Учтите, что я использую версию GLSL 4.1, как и в Superbible, однако если вы фанат [www.learnopengl.com](http://www.learnopengl.com), то можете пользоваться 3.3. Это не важно. Итак, давайте посмотрим, что же такое «затенение по Гуро».
Этот метод затенения был изобретён Анри Гуро в 1971 году. Он ни по каким параметрам не превосходит затенение по Фонгу, и сегодня в основном используется как мало нагружающий GPU метод предварительного просмотра в таких пакетах, как Cinema 4D. Его проблема в том, что генерируемый им *блик* выглядит как искра:

Эта проблема вызывается интерполяцией цветов между вершинами, а разрывы между треугольники возникают потому, что цвета интерполируются линейно. Эта проблема была решена только в шейдере Фонга. Давайте посмотрим, как можно реализовать затенение по Гуро на GLSL 4.1.
**Листинг 1**: повершинное затенение по Гуро на GLSL 4.1
```
#version 410 core
// Per-vertex inputs
layout (location = 0) in vec4 position;
layout (location = 1) in vec3 normal;
// Matrices we'll need
layout (std140) uniform constants
{
mat4 mv_matrix;
mat4 view_matrix;
mat4 proj_matrix;
};
// Light and material properties
uniform vec3 light_pos = vec3(100.0, 100.0, 100.0);
uniform vec3 diffuse_albedo = vec3(0.5, 0.2, 0.7);
uniform vec3 specular_albedo = vec3(0.7);
uniform float specular_power = 128.0;
uniform vec3 ambient = vec3(0.1, 0.1, 0.1);
// Outputs to the fragment shader
out VS_OUT
{
vec3 color;
} vs_out;
void main(void)
{
// Calculate view-space coordinate
vec4 P = mv_matrix * position;
// Calculate normal in view space
vec3 N = mat3(mv_matrix) * normal;
// Calculate view-space light vector
vec3 L = light_pos - P.xyz;
// Calculate view vector (simply the negative of the view-space position)
vec3 V = -P.xyz;
// Normalize all three vectors
N = normalize(N);
L = normalize(L);
V = normalize(V);
// Calculate R by reflecting -L around the plane defined by N
vec3 R = reflect(-L, N);
// Calculate the diffuse and specular contributions
vec3 diffuse = max(dot(N, L), 0.0) * diffuse_albedo;
vec3 specular = pow(max(dot(R, V), 0.0), specular_power) * specular_albedo;
// Send the color output to the fragment shader
vs_out.color = ambient + diffuse + specular;
// Calculate the clip-space position of each vertex
gl_Position = proj_matrix * P;
}
```
А теперь фрагментный шейдер.
**Листинг 2:** фрагментный шейдер той же концепции.
```
#version 410 core
// Output
layout (location = 0) out vec4 color;
// Input from vertex shader
in VS_OUT
{
vec3 color;
} fs_in;
void main(void)
{
// Write incoming color to the framebuffer
color = vec4(fs_in.color, 1.0);
}
```
C) Затенение по Фонгу
---------------------
Прежде чем двигаться дальше, давайте запомним, что *затенение* по Фонгу и *освещение* по Фонгу — это две разные концепции. Можно избавиться от «снежинки» блика Гуро, добавив больше вершин, но зачем, если у нас есть затенение по Фонгу? В затенении по Фонгу цвет интерполируется не между вершинами (как это делается в листингах 1 и 2), мы интерполируем между вершинами *нормали к поверхности*, и используем сгенерированную нормаль для выполнения всех вычислений освещения для каждого *пикселя*, а не вершины. Однако это значит, что во фрагментном шейдере придётся выполнить больше работы, как это показано в листинге 4. Но для начала давайте рассмотрим вершинный шейдер.

**Листинг 3:** вершинный шейдер шейдера Фонга на GLSL 4.1.
```
#version 410 core
// Per-vertex inputs
layout (location = 0) in vec4 position;
layout (location = 1) in vec3 normal;
// Matrices we'll need
layout (std140) uniform constants
{
mat4 mv_matrix;
mat4 view_matrix;
mat4 proj_matrix;
};
// Inputs from vertex shader
out VS_OUT
{
vec3 N;
vec3 L;
vec3 V;
} vs_out;
// Position of light
uniform vec3 light_pos = vec3(100.0, 100.0, 100.0);
void main(void)
{
// Calculate view-space coordinate
vec4 P = mv_matrix * position;
// Calculate normal in view-space
vs_out.N = mat3(mv_matrix) * normal;
// Calculate light vector
vs_out.L = light_pos - P.xyz;
// Calculate view vector
vs_out.V = -P.xyz;
// Calculate the clip-space position of each vertex
gl_Position = proj_matrix * P;
}
```
Почти ничего не изменилось. Но во фрагментом шейдере ситуация совершенно другая.
**Листинг 4:** фрагментный шейдер затенения по Фонгу.
```
#version 410 core
// Output
layout (location = 0) out vec4 color;
// Input from vertex shader
in VS_OUT
{
vec3 N;
vec3 L;
vec3 V;
} fs_in;
// Material properties
uniform vec3 diffuse_albedo = vec3(0.5, 0.2, 0.7);
uniform vec3 specular_albedo = vec3(0.7);
uniform float specular_power = 128.0;
uniform vec3 ambient = vec3(0.1, 0.1, 0.1);
void main(void)
{
// Normalize the incoming N, L and V vectors
vec3 N = normalize(fs_in.N);
vec3 L = normalize(fs_in.L);
vec3 V = normalize(fs_in.V);
// Calculate R locally
vec3 R = reflect(-L, N);
// Compute the diffuse and specular components for each fragment
vec3 diffuse = max(dot(N, L), 0.0) * diffuse_albedo;
vec3 specular = pow(max(dot(R, V), 0.0), specular_power) * specular_albedo;
// Write final color to the framebuffer
color = vec4(ambient + diffuse + specular, 1.0);
}
```
Ну вот, на этом статья заканчивается, надеюсь, она вам понравилась. Если она зародила в вас искру интереса к OpenGL, то можете купить *OpenGL Superbible* на Amazon или изучите learnopengl.com. Если вы не можете разобраться с шейдерами, то рекомендую [Book of Shaders](https://thebookofshaders.com/). | https://habr.com/ru/post/441862/ | null | ru | null |
# Изучаем английский с Scala на Future и Actor
Решил тут я подтянуть свой английский язык. В частности, захотелось значительно расширить словарный запас. Я знаю, что существует масса программ, которые в игровой форме помогают это сделать. Загвоздка в том, что я не люблю геймфикацию. Предпочитаю по старинке. Листочек бумаги где таблица со словами, транскрипцией и переводом. И учим его учим. И проверяем свои знания, например, закрывая столбец с переводом. В общем, как я учил это в университете.
Прослышал я про то, что существует 3000 наиболее часто используемых слов, подобранных на OxfordDictionary сайте. Вот тут этот список слов: [www.oxfordlearnersdictionaries.com/wordlist/english/oxford3000/Oxford3000\_A-B](http://www.oxfordlearnersdictionaries.com/wordlist/english/oxford3000/Oxford3000_A-B/) Ну а перевод на русский я решил брать отсюда: [www.translate.ru/dictionary/en-ru](http://www.translate.ru/dictionary/en-ru/) Одна только проблема, все находиться на этих сайтах ну совсем не в том формате, который можно распечатать и учить. В итоге родилась идея это все запрограммировать. Но сделать это не как последовательный алгоритм, а все распаралелить. Что бы выкачивание и парсинг всех слов занял не (3000 слов \* 2 сайта) / 60 секунд = 100 минут. Это если давать по 1 секунде на выкачивание и распарсивание страницы для извлечения перевода и транскрипции (в реальности думаю это в 3 раза дольше, пока соединение откроем, пока закроем и тд и тп).

Задачу я разбил сразу на два крупных блока. Первый блок, это операции ввода/вывода блокирующие — выкачивание страницы с сайта. Второй блок, это операции вычислительные, не блокирующие, но нагружающие CPU: парсинг страницы для извлечения перевода и транскрипции и добавление в словарь результатов парсинга.
Блокирующие операции я решил делать в пуле нитей, используя Future от Scala. Вычислительные задачи, решил раскидать на 3 актера Akka. Применяя методику TDD, cначала я написал тест к своим кирпичикам будущего приложения.
```
class Test extends FlatSpec with Matchers {
"Table Of Content extractor" should "download and extract content from Oxford Site" in {
val content:List[String] = OxfordSite.getTableOfContent
content.size should be (10)
content.find(_ == "A-B") should be (Some("A-B"))
content.find(_ == "U-Z") should be (Some("U-Z"))
}
"Words list extractor" should "download words from page" in {
val future: Future[Try[Option[List[String]]]] = OxfordSite.getWordsFromPage("A-B", 1)
val wordsTry:Try[Option[List[String]]] = Await.result(future,60 seconds)
wordsTry should be a 'success
val words = wordsTry.get
words.get.find(_ == "abandon") should be (Some("abandon"))
}
"Words list extractor" should "return None from empty page" in {
val future: Future[Try[Option[List[String]]]] = OxfordSite.getWordsFromPage("A-B", 999)
val wordsTry:Try[Option[List[String]]] = Await.result(future,60 seconds)
wordsTry should be a 'success
val words = wordsTry.get
words should be(None)
}
"Russian Translation" should "download translation and parse" in {
val page: Future[Try[String]] = LingvoSite.getPage("test")
val pageResultTry: Try[String]= Await.result(page,60 seconds)
pageResultTry should be a 'success
val pageResult = pageResultTry.get
pageResult.contains("тест") should be(true)
LingvoSite.parseTranslation(pageResult).get should be("тест")
}
"English Translation" should "download translation and parse" in {
val page: Future[Try[String]] = OxfordSite.getPage("test")
val pageResultTry: Try[String] = Await.result(page,60 seconds)
pageResultTry should be a 'success
val pageResult = pageResultTry.get
pageResult.contains("examination") should be(true)
OxfordSite.parseTranslation(pageResult).get should be(("test", "an examination of somebody’s knowledge or ability, consisting of questions for them to answer or activities for them to perform"))
}
}
```
Обратите внимание. Функции, которые могут вернуть результат вычислений имеют Try[…]. Те либо Success результат или Failure и эксепшен. Функции, которые будут часто вызывать и имеют блокирующие i/o операции имеют результат, как Future[Try[…]]. Те при вызове функции сразу возвращается Future в которой идут долгие i/o операции. Притом они идут внутри Try и могут завершится с ошибок (например соединение порвалось).
Само приложение инициализируется в Top3000WordsApp.scala. Поднимается система актеров. Создаются актеры. Запускается парсинг списка слов, который в параллель запускает выкачивание английских и русских страниц с транскрипцией и переводом. В случае успешной скачки страниц, срабатывает передача содержимое страниц актерам для парсинга, извлекающих перевод и транскрипцию. Результат перевода актеры передают конечному актеру-словарю, который акамулирует все результаты в одном месте. И по нажатию enter, система актеров идет в shutdown. И актер DictionaryActor, получая сигнал об этом, сохраняет собраный словарь в файл dictionaty.txt
```
object Top3000WordsApp extends App {
val system = ActorSystem("Top3000Words")
val dictionatyActor = system.actorOf(Props[DictionaryActor], "dictionatyActor")
val englishTranslationActor = system.actorOf(Props(classOf[EnglishTranslationActor], dictionatyActor), "englishTranslationActor")
val russianTranslationActor = system.actorOf(Props(classOf[RussianTranslationActor], dictionatyActor), "russianTranslationActor")
val mapGetPageThreadExecutionContext = ExecutionContext.fromExecutor(Executors.newFixedThreadPool(16))
val mapGetWordsThreadExecutionContext = ExecutionContext.fromExecutor(Executors.newFixedThreadPool(16))
start()
scala.io.StdIn.readLine()
system.terminate()
def start() = {
import concurrent.ExecutionContext.Implicits.global
Future {
OxfordSite.getTableOfContent.par.foreach(letterGroup => {
getWords(letterGroup, 1)
})
}
}
def getWords(letterGroup: String, pageNum: Int): Unit = {
implicit val executor = mapGetWordsThreadExecutionContext
OxfordSite.getWordsFromPage(letterGroup, pageNum).map(tryWords => {
tryWords match {
case Success(Some(words)) => words.par.foreach(word => {
parse(word,letterGroup,pageNum)
})
case Success(None) => Unit
case Failure(ex) => println(ex.getMessage)
}
})
}
def parse(word: String, letterGroup: String, pageNum: Int)= {
implicit val executor = mapGetPageThreadExecutionContext
OxfordSite.getPage(word).map(tryEnglishPage => {
tryEnglishPage match {
case Success(englishPage) => {
englishTranslationActor ! (word, englishPage)
getWords(letterGroup, pageNum + 1)
}
case Failure(ex) => println(ex.getMessage)
}
})
LingvoSite.getPage(word).map(_ match {
case Success(russianPage) => {
russianTranslationActor !(word, russianPage)
}
case Failure(ex) => println(ex.getMessage)
})
}
}
```
Обратите внимание, что алгоритм разбит на start, getWords, parse функции. Это сделано из-за того, что для каждой фазы задачи требуется свой пул нитей, который передается неявно, как ThreadExecutionContext. Сначала, у меня была всего одна функция getWords, для рекурсивного вызова. Но все работало очень медленно, так как на верхнем уровне алгоритма распаралеливание выжирало весь пул нитей и в самом низу были вечные ожидания, когда же мне дадут свободную нить, что бы поработать. А как раз в низу самое большое число операций.
Вот реализация скачивания и парсинга с сайтов.
```
object OxfordSite {
val getPageThreadExecutionContext = ExecutionContext.fromExecutor(Executors.newFixedThreadPool(16))
def parseTranslation(content: String): Try[(String, String)] = {
Try {
val browser = new Browser
val doc = browser.parseString(content)
val spanElement: Element = doc >> element(".phon")
val str = Jsoup.parse(spanElement.toString).text()
val transcription = str.stripPrefix("BrE//").stripSuffix("//").trim
val translation = doc >> text(".def")
(transcription,translation)
}
}
def getPage(word: String): Future[Try[String]] = {
implicit val executor = getPageThreadExecutionContext
Future {
Try {
val html = Source.fromURL("http://www.oxfordlearnersdictionaries.com/definition/english/" + (word.replace(' ','-')) + "_1")
html.mkString
}
}
}
def getWordsFromPage(letterGroup: String, pageNum: Int): Future[Try[Option[List[String]]]] = {
import ExecutionContext.Implicits.global
Future {
Try {
val html = Source.fromURL("http://www.oxfordlearnersdictionaries.com" +
"/wordlist/english/oxford3000/Oxford3000_" + letterGroup + "/?page=" + pageNum)
val page = html.mkString
val browser = new Browser
val doc = browser.parseString(page)
val ulElement: Element = doc >> element(".wordlist-oxford3000")
val liElements: List[Element] = ulElement >> elementList("li")
if (liElements.size > 0) Some(liElements.map(_ >> text("a")))
else None
}
}
}
def getTableOfContent: List[String] = {
val html = Source.fromURL("http://www.oxfordlearnersdictionaries.com/wordlist/english/oxford3000/Oxford3000_A-B/")
val page = html.mkString
val browser = new Browser
val doc = browser.parseString(page)
val ulElement: Element = doc >> element(".hide_phone")
val liElements: List[Element] = ulElement >> elementList("li")
List(liElements.head >> text("span")) ++ liElements.tail.map(_ >> text("a"))
}
}
object LingvoSite {
val getPageThreadExecutionContext = ExecutionContext.fromExecutor(Executors.newFixedThreadPool(16))
def parseTranslation(content: String): Try[String] = {
Try {
val browser = new Browser
val doc = browser.parseString(content)
val spanElement: Element = doc >> element(".r_rs")
spanElement >> text("a")
}
}
def getPage(word: String): Future[Try[String]] = {
implicit val executor = getPageThreadExecutionContext
Future {
Try {
val html = Source.fromURL("http://www.translate.ru/dictionary/en-ru/" + java.net.URLEncoder.encode(word,"UTF-8"))
html.mkString
}
}
}
}
```
Структуры данных с которыми работают актеры.
```
case class Word (word: String, transcription: Option[String] = None, russianTranslation:Option[String] = None, englishTranslation: Option[String] = None)
case class RussianTranslation(word:String, translation: String)
case class EnglishTranslation(word:String, translation: String)
case class Transcription(word:String, transcription: String)
```
Актеры, которые принимают на входе скачанные страницы для парсинга и пересылают перевод и транскрипцию актеру DictionaryActor
```
class EnglishTranslationActor (dictionaryActor: ActorRef) extends Actor {
println("EnglishTranslationActor")
def receive = {
case (word: String, englishPage: String) => {
OxfordSite.parseTranslation(englishPage) match {
case Success((transcription, translation)) => {
dictionaryActor ! EnglishTranslation(word,translation)
dictionaryActor ! Transcription(word,transcription)
}
case Failure(ex) => {
println(ex.getMessage)
}
}
}
}
}
class RussianTranslationActor (dictionaryActor: ActorRef) extends Actor {
println("RussianTranslationActor")
def receive = {
case (word: String, russianPage: String) => {
LingvoSite.parseTranslation(russianPage) match {
case Success(translation) => {
dictionaryActor ! RussianTranslation(word, translation)
}
case Failure(ex) => {
println(ex.getMessage)
}
}
}
}
}
```
Актер который накапливает в себе словарь с переводами и транскрипцией и после shutdown системы актеров записывает весь словарь в dictionary.txt
```
class DictionaryActor extends Actor {
println("DictionaryActor")
override def postStop(): Unit = {
println("DictionaryActor postStop")
val fileText = DictionaryActor.words.map{case (_, someWord)=> {
val transcription = someWord.transcription.getOrElse(" ")
val russianTranslation = someWord.russianTranslation.getOrElse(" ")
val englishTranslation = someWord.englishTranslation.getOrElse(" ")
List(someWord.word, transcription , russianTranslation , englishTranslation).mkString("|")
}}.mkString("\n")
scala.tools.nsc.io.File("dictionary.txt").writeAll(fileText)
println("dictionary.txt saved")
System.exit(0)
}
def receive = {
case Transcription(wordName, transcription) => {
val newElement = DictionaryActor.words.get(wordName) match {
case Some(word) => word.copy(transcription = Some(transcription))
case None => Word(wordName,transcription = Some(transcription))
}
DictionaryActor.words += wordName -> newElement
println(newElement)
}
case RussianTranslation(wordName, translation) => {
val newElement = DictionaryActor.words.get(wordName) match {
case Some(word) => word.copy(russianTranslation = Some(translation))
case None => Word(wordName,russianTranslation = Some(translation))
}
DictionaryActor.words += wordName -> newElement
println(newElement)
}
case EnglishTranslation(wordName, translation) => {
val newElement = DictionaryActor.words.get(wordName) match {
case Some(word) => word.copy(englishTranslation = Some(translation))
case None => Word(wordName,englishTranslation = Some(translation))
}
DictionaryActor.words += wordName -> newElement
println(newElement)
}
}
}
object DictionaryActor {
var words = scala.collection.mutable.Map[String, Word]()
}
```
Какие выводы? На моем Mac Book Pro этот скрипт работал в течение примерно 1 часа, пока я писал эту статью. Я его прервал нажав enter и вот какой результат:
```
bash-3.2$ cat ./dictionary.txt |wc -l
1809
```
Потом, я еще раз запустил скрипт и оставил на несколько часов. Когда вернулся, то у меня был процессор загружен 100% и были ошибки в консоле про гарбаж коллектор, по нажатию на enter моя программа не смогла сохранить результат своей работы в файл. Диагноз такой, писать на Future и par.map или par.foreach, конечно красиво и удобно, но реально очень тяжело понять как на самом деле на уровне нитей это все работает и где же узкое горлышко бутылки. В итоге я планирую все переписать на актеры. Притом, буду использовать пулы актеров. Что бы, например, 4 актера выкачивало и парсило страницы со списками слов, 18 актеров выкачивало страницы с переводами, 4 актера парсило страницы извлекая переводы и транскрипцию, ну и 1 актер складывал все в словарь.
Текущая реализация в бранче v0.1 [github.com/evgenyigumnov/top3000words/tree/v0.1](https://github.com/evgenyigumnov/top3000words/tree/v0.1) Версия где все переписано на актеры с пулами будет в бранче v0.2, ну и в master, чуть позже. Может есть у кого соображения, что я делал не так, в текущей версии? Ну и может советы подкините по новой версии?
Проект на гитхабе доступен: [github.com/evgenyigumnov/top3000words](https://github.com/evgenyigumnov/top3000words)
Запустить тесты проекта: sbt test
Запустить приложение: sbt run
Ну и как надоест ждать, нажать enter и ознакомиться с содержимым файла dictionary.txt в текущей папке
PS
В итоге сделал финальную версию v0.2, которая парсит за 10 минут в 30 потоков. [github.com/evgenyigumnov/top3000words/tree/v0.2](https://github.com/evgenyigumnov/top3000words/tree/v0.2)
По окончанию работы enter нажимать не нужно. Все сделано на актерах. В Future обвернуты только блокирующие i/o тяжелые. | https://habr.com/ru/post/273431/ | null | ru | null |
# Собственный Security Realm в GlassFish
Ни для кого не секрет что сервера приложений существуют для того чтобы снять некоторую часть работы с разработчика и возложить её на уже готовые механизмы. В частности механизм аутентификации в сервере приложений Glassfish можно организовать с помощью так называемых Security Realms. Существуют несколько встроенных вариантов, такие как аутентификация через СУБД, LDAP, PAM, Certificate и обычное чтение из файла. Однако они могут нас не устроить ввиду своей ограниченности (LDAP, например, может работать только с одним наперед заданным доменом). Поэтому мы и рассмотрим создание собственного security realm’а.
Custom security realm состоит минимум из двух классов. Один из которых расширяет класс AppservRealm (com.sun.appserv.security.AppservRealm), а второй соответственно AppservPasswordLoginModule (com.sun.appserv.security.AppservPasswordLoginModule). Для получения com.sun.appserv.security.\* нужно импортировать в качестве библиотеки /glassfish/modules/security.jar
```
package ru.khmb.security;
import com.sun.appserv.security.AppservRealm;
import com.sun.enterprise.security.auth.realm.BadRealmException;
import com.sun.enterprise.security.auth.realm.InvalidOperationException;
import com.sun.enterprise.security.auth.realm.NoSuchRealmException;
import com.sun.enterprise.security.auth.realm.NoSuchUserException;
import java.util.Enumeration;
import java.util.Properties;
import java.util.Vector;
public class Realm extends AppservRealm {
private static final String PARAM_JAAS_CONTEXT = "jaas-context";
private static final String GROUP_ALL = "Authenticated";
@Override
public void init(Properties properties)
throws BadRealmException, NoSuchRealmException {
String propJaasContext = properties.getProperty(PARAM_JAAS_CONTEXT);
if (propJaasContext != null) {
setProperty(PARAM_JAAS_CONTEXT, propJaasContext);
}
}
@Override
public String getAuthType() {
return "KHMB Realm";
}
@Override
public Enumeration getGroupNames(String user)
throws InvalidOperationException, NoSuchUserException {
Vector vector = new Vector();
vector.add(GROUP_ALL);
return vector.elements();
}
}
```
В классе realm'а необходимо переопределить методы получения типа аутентификации (обычно это название realm'а) и получение групп пользователя по его имени — в данной статье мы умышленно упускаем обзор Java EE авторизации.
Соответственно здесь мы и можем реализовать гибкость механизма в получении групп по имени пользователя, например из СУБД. В данном примере используется одна группа, которая показывает что пользователь прошел аутентификацию. Property jaas-context указывается здесь чтобы связать данный класс со следующим.
```
package ru.khmb.security;
import com.sun.appserv.security.AppservPasswordLoginModule;
import java.util.Enumeration;
import java.util.LinkedList;
import java.util.List;
import javax.security.auth.login.LoginException;
public class LoginModule extends AppservPasswordLoginModule {
@Override
protected void authenticateUser() throws LoginException {
if (!(_currentRealm instanceof Realm)) {
throw new LoginException("Realm not KHMBRealm");
}
Realm realm = (Realm) _currentRealm;
authenticate(_username, _password);
Enumeration enumeration = null;
List authenticatedGroups = new LinkedList();
try {
enumeration = realm.getGroupNames(\_username);
} catch (Exception e) {
throw new LoginException("Get groups exception");
}
for (int i = 0; enumeration != null && enumeration.hasMoreElements(); i++) {
authenticatedGroups.add((String) enumeration.nextElement());
}
commitUserAuthentication(authenticatedGroups.toArray(new String[0]));
}
private static void authenticate(String login, String password) throws LoginException {
try {
LDAP.authenticate(login, password);
} catch (Exception e) {
throw new LoginException("Authenticate exception:" + e.getMessage());
}
}
}
```
В данном классе необходимо реализовать метод аутентификации. Он состоит из получения и проверки использующего его realm'а, проверки правильности введенных логина и пароля (либо других реквизитов) и наконец, получения и передачи групп пользователя.
Скомпилированные классы (пакеты с соответствующими классами внутри) кладем в директорию <домен glassfish>/lib/classes
Также мы должны определить что наш AppservPasswordLoginModule относится к определенному контексту. Нужно отредактировать файл <домен glassfish>/config/login.conf добавив «ссылку»:
```
KHMBRealm {
ru.khmb.security.LoginModule required;
};
```
В котором мы определяем контекст и ссылаемся на необходимость модуля.
Смело запускаем/перегружаем наш сервер приложений и открываем GUI администратора.
Создаем новый Security Realm. Теперь нам не нужно выбирать класс из списка, а вводим полный класс реалма: ru.khmb.security.Realm. Не забываем указать опцию jaas-context которая связывает наш realm с модулем аутентификации через контекст указанный в файле login.conf, т.е. в нашем случаи jaas-context = KHMBRealm
Всё, теперь можно пользоваться Realm'ом.
При реализации механизма источником была запись в [блоге](https://blogs.oracle.com/nithya/entry/groups_in_custom_realms).
Update 02.08.2013:
Есть хорошее описание создания различных Security Realm'ом (областей безопасности) в книге Дэвида Хеффельфингера «Java EE 6 и сервер приложений GlassFish 3» | https://habr.com/ru/post/152483/ | null | ru | null |
# MATLAB + Git: как управлять изменениями скриптов и моделей Simulink без бардака и боли
Все мы знаем, что среда MATLAB заточена под людей, которые не обязательно являются профессиональными программистами, – математиков, инженеров, аналитиков и даже студентов.
С одной стороны, это большой плюс – люди просто решают свою прикладные задачи без заморочек с выбором библиотек, архитектурой ПО и прочим ООП.
С другой стороны, часто можно наблюдать, что, находясь в песочнице Матлаба, люди оказываются оторваны от мира «большого программирования» со своими устоявшимися подходами и инструментами.
Понятно, что не всем условным математикам нравится глубоко в это все погружаться. Но при этом мне очень досадно наблюдать, как суровые инженеры, которые программируют микроконтроллеры для самонаводящихся ракет, не могут даже настроить систему контроля версий, не говоря уже об автоматизированном тестировании и прочих девопсах.
В этой статье я хочу показать инженерам, как можно без боли контролировать изменения скриптов MATLAB и моделей Simulink. А также попытаюсь донести матлаберам, не знакомым с системой контроля версий (а таких большинство), что для них это *необходимый инструмент на каждый день*.
Чтобы не потерять вас в самом начале, привожу краткую серию ответов на вопросы, которые мне часто задают новички в этой теме.
Что такое «система контроля версий»?Это отдельная бесплатная программа, которая работает вместе с MATLAB и сохраняет всю историю того, что вы изменяли в своем проекте: какой добавляли код, как изменяли настройки модели и т. д.
Самая популярная и мощная называется **Git**, сегодня будем говорить о ней.
Зачем она мне нужна?Чтобы ваш проект не выглядел так
Бардак и больНамного комфортнее хранить старые версии моделей и кода где-то в *истории изменений*, чем в куче в одной папке. Ведь вы на следующий же день забываете, какой именно файл актуальный и почему нельзя удалять старые. Контроль версий – самый удобный способ превратить проект из помойки во что-то понятное и приятное.
Круто. И все?Нет, не все. Только с системой контроля версий вы сможете нормально работать над одним проектом всей командой. Вы имеете полную историю изменений всех файлов проекта. Вы видите кто, когда и что конкретно изменил.
А еще без этого вы в принципе не сможете полноценно автоматизировать тестирование и использовать прочие прелести из мира DevOps.
Наконец, работа с системой контроля версий – это один из самых базовых и необходимых навыков, если вы захотите перейти в IT-отрасль или серьезную зарубежную компанию.
А для студентов, которые наше все, это вообще мастхэв – стыдно не владеть Гитом в 2021.
Ладно, попробую. Это сложно?Не очень, за вечер можно освоить базу. Если вы совсем не знаете, что такое Git, то уйдет пара вечеров. Хорошая новость – в Гугле и на Ютубе вы найдете тонны материалов, где все объясняют на пальцах.
**Предупреждение**
Когда вы более-менее освоитесь с контролем версий и Git, то **по-другому вы не сможете и на захотите работать в принципе**. При создании каждого нового проекта вы первым делом будете добавлять его в Git. Вы перетащите все старые проекты в Git. Вы научите коллег работать в Git. Вы будете вспоминать старые времена как свои темные века.
Я сам все это проходил. И многие коллеги проходили. Поэтому я и пишу об этом так уверенно.
Итак, я постарался максимально вас мотивировать, чтобы вы смогли преодолеть тот небольшой порог, с которым сейчас столкнетесь. К делу.
### Установка GitHub Desktop
Предположим, что MATLAB у вас уже установлен. Осталось научить его контролю версий с помощью Git.
И если вы еще не в курсе, то знайте, что сам Git – это консольная утилита, то есть работать с ним нужно из черного окна терминала. Поэтому все уроки по Гиту, что вы найдете в интернете, изобилуют разными командами.
Хорошая новость в том, что сегодня мы писать команды не будем и обойдемся исключительно возможностями Матлаба и еще одного специального приложения с функционалом Git.
Этого вам хватит, чтобы войти в тему и освоить самые базовые принципы контроля версий. Ну а продолжив освоение, вы в любом случае установите [Git](https://git-scm.com/downloads) и освоите парочку команд, без этого никуда.
А пока что мы скачаем так называемый Git GUI-клиент. Подобных приложений создано десятки, если не сотни. Их задача – позволить вам работать с Гитом быстро и удобно с помощью мышки и без командной строки.
Моим любимым Git-приложением является GitHub Desktop. Оно сильно упрощает работу с Гитом и делает ее приятной рутиной. Оно красивое, удобное и без излишеств. Я пользуюсь им буквально каждый день и вам советую.
Честно говоря, я сомневаюсь, что до сих пор остались люди, которые работают с Гитом на десктопе исключительно из командной строки (а если и есть, то они меня пугают 😨).
Скачиваем GitHub Desktop с [официального сайта](https://desktop.github.com/) и устанавливаем. Для начала пропускаем этап, связанный с созданием аккаунта, а затем вводим свое имя и почту (эти данные нужны для Гита и **никуда не передаются**, пока вы сами не захотите).
**Важно:** при желании приложение GitHub Desktop также может загрузить ваш код в интернет на портал GitHub.com (сначала нужно там зарегистрироваться), чтобы вы его там бесплатно хранили и имели возможность работать совместно. Об этом поговорим в другой статье. Без вашего ведома, приложение **никуда отправлять код не будет**.
Итак, у нас установлены MATLAB и GitHub Desktop. Пора внедрить контроль версий в наш проект.
### Создание репозитория
Repository переводится как «хранилище». В Гите репозиторием называется папка, в которой хранится ваш проект (код, модели, данные…) **плюс** полная история изменений всех файлов проекта.
Давайте сначала создадим пустой Git-репозиторий, а затем перенесем в него проект. Для создания нового репо используем GitHub Desktop. Выбираем**File -> New Repository…** и затем обязательно вводим название новой папки проекта *MyProject*, а также указываем путь родительской папки, в которой будет создана папка проекта (например, папка *Документы\MATLAB*):
Открываем созданную папку в Матлабе и видим там какой-то непонятный файл *.gitattributes*:
Это служебный файл Гита, который для нас создал GitHub Desktop. Подобные файлы используют, чтобы тонко настроить репозиторий и то, как Гит с ним работает. В нашем случае .gitattributes не особо нужен, но трогать его не будем, чтобы не запутаться.
Тут у вас возникает вопрос: а что тогда делает нашу обычную пустую папку *MyProject* Гит-репозиторием, который будет хранить все изменения?
Ответ: наличие скрытой директории *.git*, которая также автоматом создалась в нашей папке. Именно в ней и будет храниться вся история изменений. Лазить в эту папку лишний раз не стоит, менять в ней что-то вручную нельзя, удалять – тем более, потеряете всю историю. Просто знайте, что она существует и делает всю работу, хоть вы ее и не видите:
Мы ее не видим, а она есть, только вы ее не трогайтеДальнейшие действия вы можете выполнять для любого своего проекта MATLAB/Simulink. Просто выберите проект и скопируйте все его файлы в *MyProject*.
Я же для наглядности создам простейший проект с нуля, чтобы не отвлекать вас от сути.
Для начала создаем простейший скрипт *sin\_params.m*, допустим, с параметрами модели:
```
A = 10;
w = pi / 2;
```
И простейшую Симулинк-модель *sin\_model.slx*:
Скачать скрипт и модель вы можете по [**ссылке**](https://github.com/roslovets/MATLAB-Git-Demo).
Итак, мы имеем не что иное, как локальный репозиторий Git с нашим проектом. Осталось добавить ему истории!
### Учёт изменений
Теперь посмотрим, как вы будете работать с Git каждый день.
Переходим в GitHub Desktop, в котором уже открыта наша папка с проектом. Это приложение скорее всего будет запущено у вас постоянно вместе с Матлабом.
Мы видим, что изменилось в вашем проекте – добавилось аж 6 новых файлов! При этом полезных из них только два – скрипт и модель, остальные файлы временные, их создал Симулинк для ускорения симуляции.
Новые файлы в репозиторииПримем простое правило: всякие временные и прочие левые файлы в историю изменений добавлять не надо. Добавляйте только те файлы, которые вы разрабатываете. А чтобы остальные не мешались, сразу добавим их в игнор Гита. Для этого выберем в меню **Repository -> Repository settings…**, в окошке выбираем Ignored files и вводим в текстовое поле следующее:
```
slprj
*.slxc
```
Теперь Гит не будет обращать внимания на всю папку slprj и файлы с расширением slxc. А в списке добавленных файлов мы видим скрипт, модель и новый файл *.gitignore*, в котором и хранится список игнорируемых файлов.
Теперь давайте зафиксируем наши изменения проекта в истории. Как вы видите в списке, из изменений у нас – создание трех новых файлов.
В терминологии Гита фиксация любых изменений называется «коммит» (commit). Поэтому вместо «зафиксировать изменения» будем говорить просто «закоммитить», привыкайте.
Итак, галочками уже отмечены изменения, которые хотим закоммитить. Осталось придумать им ёмкое описание. Например, напишем: «Добавил скрипт с параметрами и модель». Что писать и на каком языке – решайте сами. Только помните, что названия коммитов помогут и пригодятся вам в будущем, потому не пишите откровенную ерунду.
Описание коммита при желании тоже можете добавитьПосле этого жмём кнопку **Commit** и тем самым сохраняем наши изменения в истории. На сами файлы проекта это никак не влияет. Просто изменения сохранены куда-то в недра в папки .git.
Теперь полюбуемся нашим коммитом в истории изменений на вкладке **Commits**. Вы можете посмотреть название коммита и что конкретно было изменено. Такое исследование истории никак не влияет на файлы проекта и не изменяет их. Считайте, что вы просто читаете логи.
Первый Initial commit создал GitHub Desktop при создании репозиторияКстати, обратите внимание, что, когда Матлаб понимает, что в текущей папке есть контроль версий, он цветными иконками показывает статус файлов по сравнению с последним коммитом (не изменён, изменён, удален, конфликтует и т. д.). Это одна из фич интеграции MATLAB и Git:
Если вы измените файл, иконка поменяетсяТеперь поменяем параметры в нашем скрипте:
```
A = 10;
w = pi / 4;
```
А в модели поменяем sin на cos. Не забываем сохранить.
Можете внести еще пару любых измененийОдна из стратегий работы с Гитом (которой не обязательно придерживаться) – делать отдельный коммит на каждое изменение. Так и поступим. Сначала пометим галочкой и закоммитим изменение скрипта, потом также поступим с моделью. История стала интереснее:
### Анализ изменений
Теперь посмотрим, как Гит позволяет вспомнить, какие конкретно изменения были когда-то внесены в наш репозиторий.
Для этого выделим коммит, в котором мы меняли параметры, и приложение тут же показывает нам, что конкретно в этом текстовом файле поменялось:
А вот с моделью Симулинк это полноценно не сработает, потому что файл бинарный и Гит не может его расшифровать. Зато Матлаб сможет. В Матлабе кликаем правой кнопкой на модели в окне *Current Folder* и в меню выбираем **Source Control -> Compare to Revision**. Выбираем один из старых коммитов и жмем **Compare to Local**.
Открывается инструмент анализа изменений Simulink-модели. Все изменения показаны в дереве, и вы тут же можете посмотреть, как модель выглядела до и после изменения:
### Заключение
Я думаю, этого пока достаточно. Мы рассмотрели самые-самые основы Git, чтобы вы просто могли начать. За кадром остались такие важные вопросы, как откат к старым версиям, отправка репозитория на сервер для совместной работы и не только.
Мы поговорим о них следующих статьях, если эта тема вам зайдет. Так что не стесняйтесь задавать вопросы в комментариях, делиться опытом и ставить плюсики. Спасибо за прочтение, все материалы можете скачать по [ссылке](https://github.com/roslovets/MATLAB-Git-Demo).
Продолжение: [MATLAB + Git: с чего начать командную работу](https://habr.com/ru/company/etmc_exponenta/blog/598377/) | https://habr.com/ru/post/578172/ | null | ru | null |
# Centrifuge — я больше не буду обновлять страницу перед отправкой комментария
Прошло некоторое время с тех пор, как я писал про [Центрифугу](https://github.com/FZambia/centrifuge) в [предыдущий](http://habrahabr.ru/company/mailru/blog/197044/) раз. Произошло множество изменений за этот период. Многое из того, что было описано в ранних статьях ([1](http://habrahabr.ru/post/184262/), [2](http://habrahabr.ru/company/mailru/blog/194640/)) кануло в лету, но суть и идея проекта остались прежними — это сервер рассылки real-time сообщений пользователям, подключенным из веб-браузера. Когда на вашем сайте возникает событие, о котором вам нужно моментально сообщить некоторым вашим пользователям, вы постите это событие в Центрифугу, а она, в свою очередь, отправляет его всем заинтересованным пользователям, подписанным на нужный канал. В самом простом виде это показано на схеме:
[](http://habrahabr.ru/company/mailru/blog/237257/)
Проект написан на Python с использованием асинхронного веб-сервера Tornado. Использовать можно даже если бекенд вашего сайта написан не на Python. Хотелось бы рассказать о том, что Центрифуга представляет собой на данный момент.
[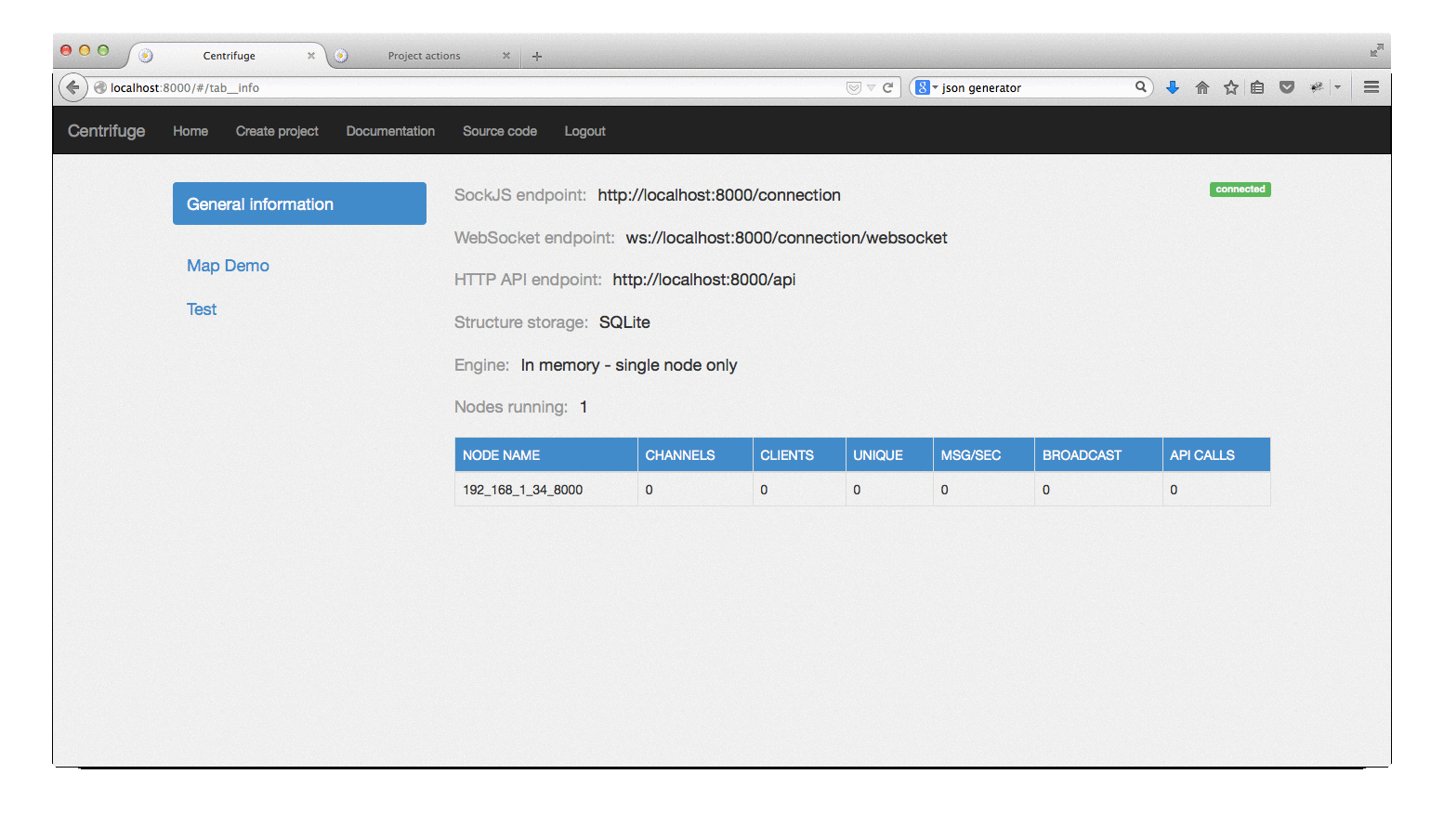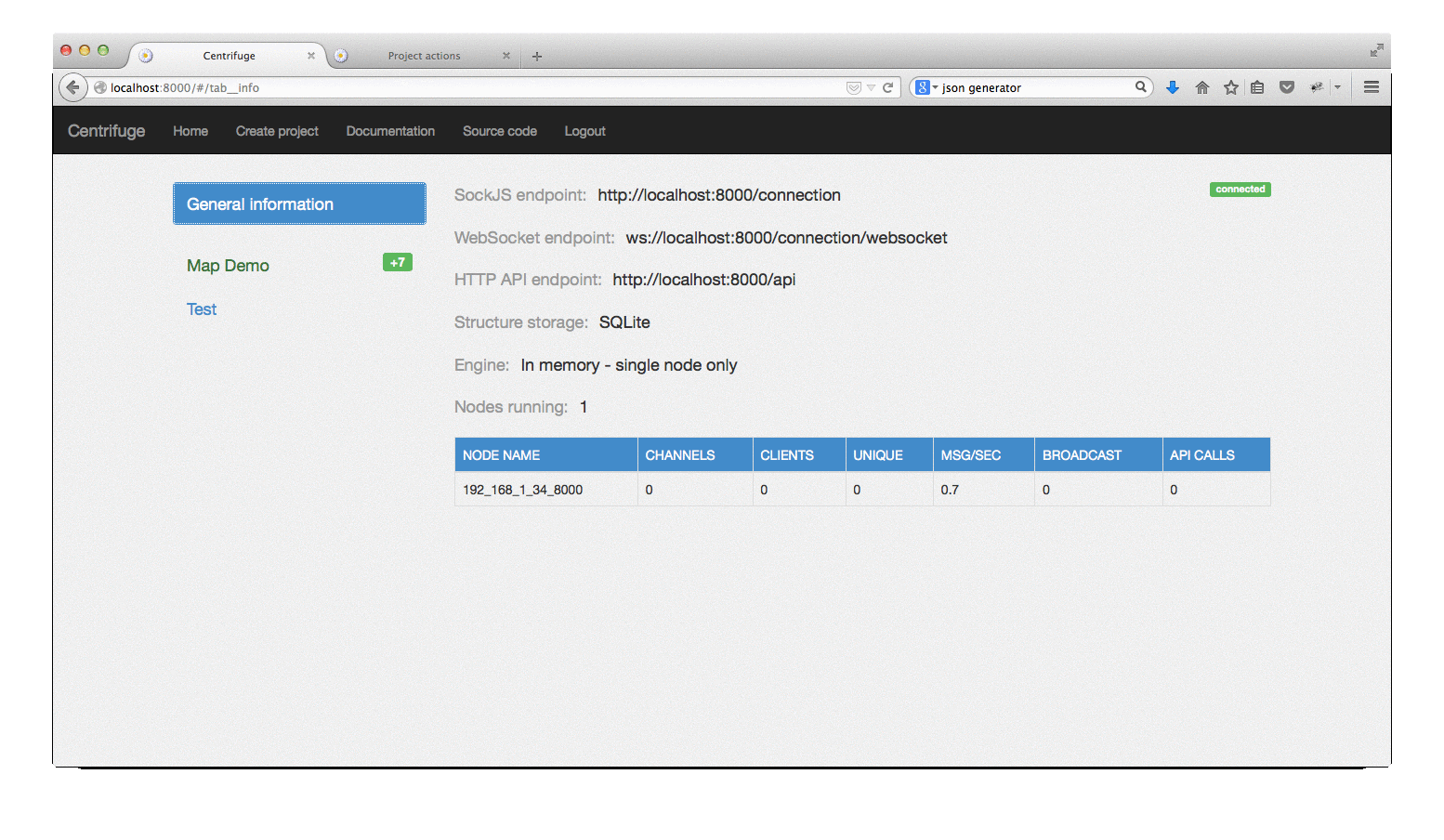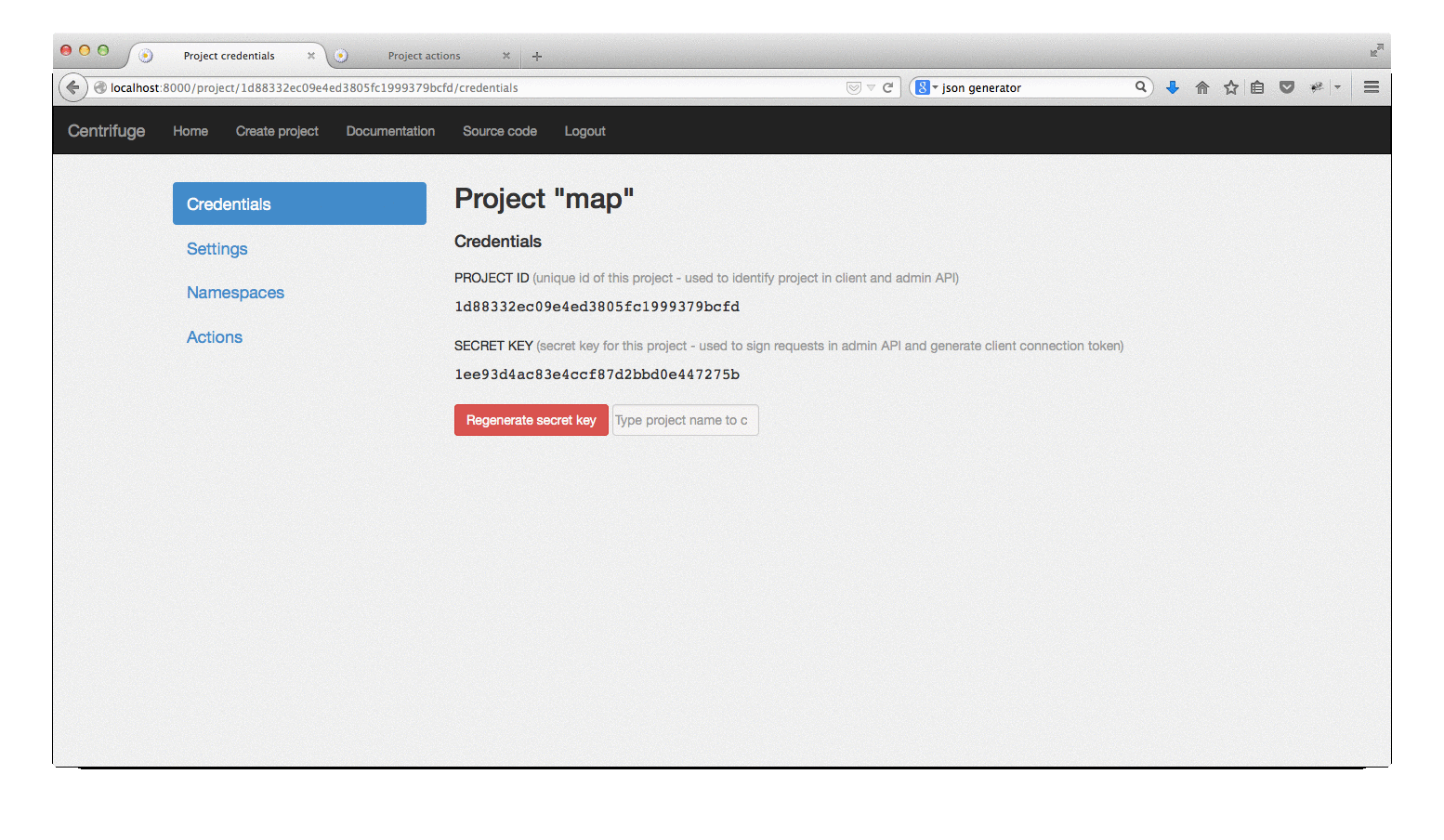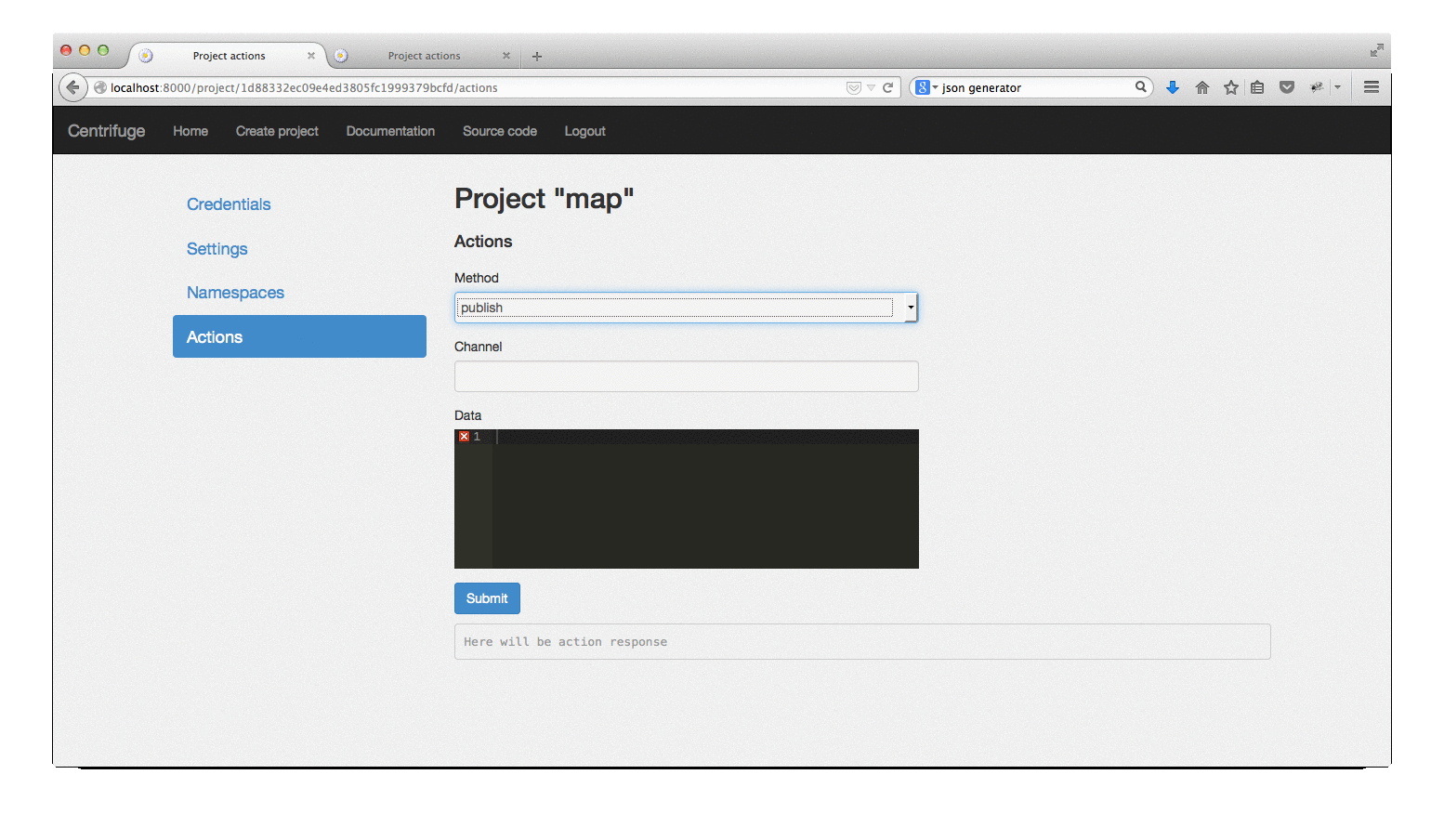](http://hsto.org/files/33a/0c8/efa/33a0c8efa5f1414fbaf738fbbae5513e.gif)
Попробовать проект в действии совсем несложно, если вы знакомы с установкой Python-пакетов. Внутри virtualenv:
```
$ pip install centrifuge
```
Запуск:
```
$ centrifuge
```
После этого по адресу <http://localhost:8000> будет доступен административный интерфейс процесса Центрифуги, который вы только что запустили.
Специально для статьи я запустил инстанс Центрифуги на Heroku — [habrifuge.herokuapp.com](http://habrifuge.herokuapp.com). Пароль — habrahabr. Я надеюсь на вашу честность и благоразумие — демо никак не защищено от попыток все поломать и не дать остальным оценить проект. Запущено на бесплатном дино со всеми вытекающими. Heroku, конечно, не лучшее место для хостинга такого рода приложений, но для целей демонстрации сойдет.
Думаю, я не буду далек от истины, если скажу, что аналогов Centrifuge, как минимум в open-source мире Python, нет. Попробую пояснить, почему я так считаю. Существует масса способов добавить real-time события на сайт. Из того, что приходит на ум:
* отдельно стоящий асинхронный сервер;
* облачный сервис (pusher.com, pubnub.com);
* gevent (gunicorn, uwsgi);
* модули/расширения Nginx;
* BOSH, XMPP.
В JavaScript есть Meteor, Derby — совсем другой подход. Еще есть замечательный Faye — сервер, легко интегрирующийся с вашим JavaScript или Ruby бекендом. Но это решение для NodeJS и Ruby. Центрифуга реализует первый из перечисленных выше подход. Преимущество отдельно стоящего асинхронного сервера (и облачного сервиса) в том, что вам не нужно менять код и философию существующего бекенда, что неизбежно произойдет, как только вы, например, решите использовать Gevent, пропатчив стандартные библиотеки Python. Подход с отдельным сервером позволяет легко и безболезненно интегрировать real-time сообщения в уже существующую архитектуру бекенда.
Недостаток — на выходе при подобной архитектуре получается немного «урезанный» real-time. Ваше веб-приложение должно выдерживать HTTP запросы от клиентов, генерирующие события: новые события попадают первоначально на ваш бекенд, проходят валидацию, сохраняются в базу данных, если необходимо, и только потом отправляются в Centrifuge (в pusher.com, в pubnub.com и др.). Однако это ограничение в большинстве случаев никак не сказывается на задачах веба, от этого могут пострадать динамичные real-time игры, где один клиент генерирует очень большое количество событий. Для таких случаев, пожалуй, нужна более тесная интеграция real-time приложения и бекенда, возможно, что-то вроде gevent-socketio. Если события на сайте генерирует не клиент, а сам бекенд, то в этом случае озвученный выше недостаток роли не играет.
Говоря, что аналогов Центрифуги в open-source мире Python нет, я не имею в виду то, что нет другой реализации отдельно стоящего сервера рассылки сообщений через веб-сокеты и полифиллы к ним. Я просто не нашел ни одного подобного проекта, в полной мере из коробки решающего большинство проблем реального использования.
Набрав в поисковике "*python real-time github*" вы получите массу ссылок на примеры подобных серверов. Но! Большинство из этих результатов лишь демонстрируют подход к решению проблемы, не вдаваясь вглубь. Вам не хватает одного процесса и нужно как-то масштабировать приложение — хорошо, если в документации проекта будет написано, что для этих целей нужно использовать PUB/SUB брокер — Redis, ZeroMQ, RabbitMQ — это правда, но придется реализовывать это самостоятельно. Зачастую все такие примеры ограничиваются переменной класса типа set, в которую добавляются новые объекты соединений и рассылка нового сообщения всем клиентам из этого сета подключений.
Основная цель Центрифуги — из коробки предоставлять решение проблем реального использования. Давайте посмотрим на некоторые моменты, с которыми придется иметь дело подробнее.
Полифиллы
=========
Одних вебсокетов недостаточно. Если не верите, посмотрите выступление с говорящим названием «Websuckets» от одного из разработчиков Socket.io. Вот [слайды](https://speakerdeck.com/3rdeden/websuckets). А вот видео:
Конечно, есть проекты (опять же, динамичные real-time игры), для которых использование именно веб-сокетов — критично. Центрифуга использует SockJS для эмуляции веб-сокетов в старых браузерах. Это означает поддержку браузеров вплоть до IE7 с помощью использования таких транспортов как xhr-streaming, iframe-eventsource, iframe-htmlfile, xhr-polling, jsonp-polling. Для этого используется замечательная реализация SockJS сервера — [sockjs-tornado](https://github.com/mrjoes/sockjs-tornado).
Cтоит также отметить, что к Центрифуге также можно подключаться, используя «чистые» вебсокеты — без оборачивания взаимодействия в SockJS-протокол.
В репозитории есть JavaScript-клиент с простым и понятным API.
Масштабирование
===============
Вы можете запустить несколько процессов — они будут общаться между собой, используя Redis PUB/SUB. Хотелось бы отметить, что Centrifuge совсем не претендует на инсталляцию внутри огромных сайтов с миллионами посетителей. Пожалуй, для таких проектов нужно найти другое решение — те же облачные сервисы или свои разработки. Но для подавляющего большинства проектов нескольких инстансов сервера за балансировщиком, связанных PUB/SUB механизмом Redis, будет более чем достаточно. У нас, например, один инстанс (Redis не нужен в таком случае) выдерживает 1000 одновременных подключений без проблем, среднее время отправки сообщений при этом менее 50мс.
Вот, кстати, график из Graphite за недельный период работы Центрифуги, используемой интранетом Mail.Ru Group. Синяя линия — количество активных подключений, зеленая — среднее время рассылки сообщений в миллисекундах. Посередине – выходные. :)
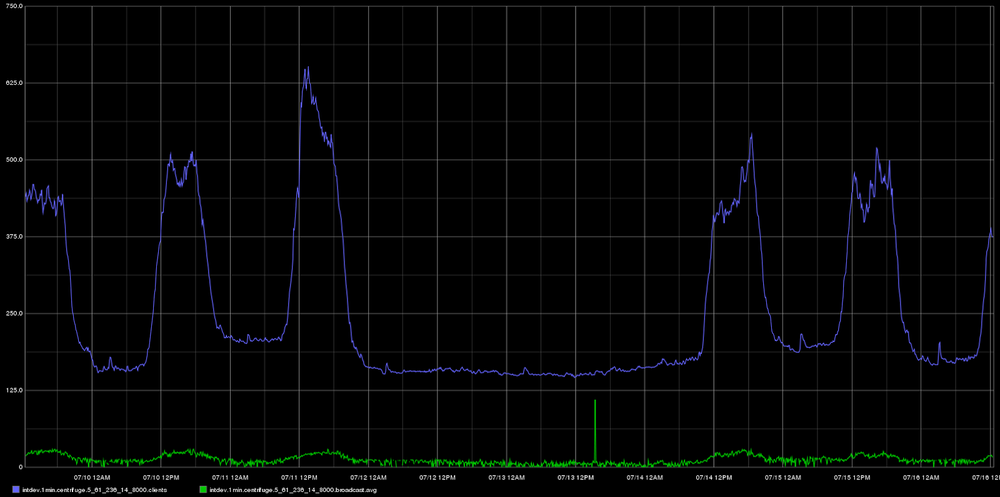
Аутентификация и авторизация
============================
Подключаясь к Центрифуге, вы используете симметричное шифрование на основе секретного ключа проекта для генерации токена (HMAC). Этот токен валидируется при подключении. Также при подключении передаются ID пользователя и, по желанию, дополнительная информация о нем. Поэтому Центрифуга знает достаточно о ваших пользователях, чтобы обрабатывать подключение к приватным каналам. Этот механизм по своей сути очень похож на [JWT](http://self-issued.info/docs/draft-ietf-oauth-json-web-token.html) (JSON Web Token).
Хотелось бы отметить одно из недавних нововведений. Как я рассказывал в предыдущих статьях, если клиент подписывается на приватный канал, то Центрифуга отправит POST запрос вашему приложению, спрашивая, можно ли пользователю с таким-то ID подключиться к определенному каналу. Сейчас появилась возможность создать приватный канал, при подписке на который ваше веб-приложение вообще не будет задействовано. Просто назовите канал как вам удобно и в конце после специального символа # напишите ID пользователя, которому позволено подписываться на этот канал. Только пользователю с ID 42 будет позволено подписаться на этот канал:
```
news#42
```
А еще можно делать вот так:
```
dialog#42,56
```
Это приватный канал для 2-х пользователей с ID 42 и 56.
В последних версиях был также добавлен механизм истечения срока действия подключения — он по умолчанию выключен, так как для большинства проектов не нужен. Механизм стоит рассматривать как экспериментальный.
Пожалуй, в процессе развития проекта было два наиболее сложных решения: как синхронизировать состояние между несколькими процессами (в итоге был выбран самый простой путь — использование Redis) и проблема с клиентами, подключившимися к Центрифуге до того, как их деактивировали (забанили, удалили) в веб-приложении.
Сложность тут в том, что Центрифуга вообще не хранит ничего кроме настроек проектов и неймспейсов проектов в постоянном хранилище. Поэтому нужно было придумать способ надежно отключать невалидных клиентов, не имея при этом возможности сохранять идентификаторы или токены этих клиентов, учитывая возможные даунтаймы Центрифуги и веб-приложения. Этот способ в конечном итоге удалось найти. Однако применить его в реальном проекте пока не довелось, отсюда экспериментальный статус. Попробую описать, как решение работает в теории.
Как я уже описывал раньше, для того чтобы из браузера подключиться к Центрифуге, нужно передать, помимо адреса подключения, некоторые обязательные параметры — ID текущего пользователя и ID проекта. Также в параметрах подключения должен присутствовать HMAC токен, сгенерированный на основе секретного ключа проекта на бекенде веб-приложения. Этот токен подтверждает корректность переданных клиентом параметров.
Беда в том, что раньше, единожды получив подобный токен, клиент мог без проблем пользоваться им и в будущем: подписываться на публичные каналы, читать из них сообщения. Благо не писать (так как сообщения изначально проходят через ваш бекенд)! Это для многих публичных сайтов вполне нормальная ситуация. Тем не менее, я был уверен, что дополнительный механизм защиты данных нужен.
Поэтому среди обязательных параметров при подключении появился параметр `timestamp`. Это Unix секунды (`str(int(time.time()))`). Этот `timestamp` также участвует в генерации токена. То есть подключение теперь выглядит вот так:
```
var centrifuge = new Centrifuge({
url: 'http://localhost:8000/connection',
token: 'TOKEN',
project: 'PROJECT_ID',
user: 'USER_ID',
timestamp: '1395086390'
});
```
В настройках проекта появилась опция, отвечающая на вопрос: сколько секунд новое соединение должно считаться корректным? Центрифуга периодически ищет соединения, у которых истек срок действия и добавляет их в специальный список (на самом деле set) для проверки. Раз в определенный интервал времени Центрифуга отправляет POST запрос вашему приложению со списком ID пользователей, нуждающихся в проверке. Приложение в ответ отправляет список ID пользователей эту проверку не прошедших — эти клиенты будут сразу же насильно отключены от Центрифуги, при этом автоматического реконнекта на стороне клиента не будет.
Но не все так просто. Существует вероятность, что «злоумышленник», подправив, например, JavaScript на клиенте, моментально переподключится после того, как его насильно выгнали. И если `timestamp` в его параметрах подключения всё еще валиден — соединение будет принято. Но на следующем же цикле проверки, после того как его соединение просрочится, его ID будет по тому же механизму отправлен веб-приложению, оно скажет, что юзер невалиден, и после этого он будет отключен навсегда (так как срок действия `timestamp` уже истек). То есть существует небольшая щель во времени, в течение которой у клиента есть возможность продолжать читать из публичных каналов. Но её величина конфигурируется — думаю, совсем не страшно, если после фактической деактивации пользователь еще некоторое время сможет читать сообщения из каналов.
Возможно, с помощью схемы понять этот механизм будет гораздо проще:

Деплой
======
В репозитории есть примеры реальных конфигурационных файлов, которые используются у нас для деплоя Центрифуги. Мы запускаем ее на CentOS 6 за Nginx под супервизором (Supervisord). Есть spec-файл — если у вас CentOS, то вы можете собрать rpm на его основе.
Мониторинг
==========
В последней версии Центрифуги появилась возможность экспортировать различные метрики в Graphite по UDP. Метрики агрегируются в заданном интервале времени, à la StatsD. Выше по тексту была как раз картинка с графиком из Graphite.
В предыдущей статье про Центрифугу я рассказывал, что в ней используется ZeroMQ. И комментарии были единодушны — ZeroMQ не нужен, используй Redis, производительности которого хватит с головой. Сначала я немного подумал и добавил Redis в качестве опционального PUB/SUB бекенда. А потом был вот этот бенчмарк:
Я был удивлен, правда. Почему ZeroMQ оказался настолько хуже для моих задач, чем Redis? Я не знаю ответа на этот вопрос. Поискав в интернете, нашел статью, где автор также сетует на то, что ZeroMQ для быстрого real-time веба подходит плохо. К сожалению, сейчас уже потерял ссылку на эту статью. В итоге — ZeroMQ в Центрифуге уже не используется, осталось только 2 так называемых engine-а — Memory и Redis (первый подойдет, если вы запускаете один инстанс Центрифуги, и вам ни к чему Redis и его PUB/SUB).
Как вы могли видеть на гифке выше, веб-интерфейс никуда не исчез, он по-прежнему используется для того, чтобы создавать проекты, менять настройки, следить за сообщениями в некоторых каналах. Через него также можно отправлять Центрифуге команды, например, опубликовать сообщение. В общем-то, это было и раньше, я просто решил повторить, если вы вдруг не в курсе.
Из других изменений:
* MIT лицензия вместо BSD;
* рефакторинг неймспейсов: теперь это не отдельная сущность и поле в протоколе, а просто префикс в имени канала, отделенный двоеточием (`public:news`);
* улучшения в JavaScript-клиенте;
* работа с JSON теперь может быть значительно ускорена, если дополнительно установить модуль ujson;
* организация [Centrifugal](https://github.com/centrifugal) на GitHub — с репозиториями, имеющими отношение к проекту, помимо Python-клиента для Центрифуги — там сейчас в том числе есть пример как развернуть проект на Heroku и первая версия библиотеки adjacent — небольшая обертка для интеграции с Django (упрощает жизнь с генерацией параметров подключения, есть методы для удобной отправки сообщений в Центрифугу);
* поправлена/расширена [документация](http://centrifuge.readthedocs.org/en/latest/) в соответствии с изменениями/добавлениями;
* множество других изменений отражены в [changelog](https://github.com/FZambia/centrifuge/blob/master/CHANGELOG.md).
Как уже [упоминалось](http://habrahabr.ru/company/mailru/blog/232577/) ранее в блоге Mail.Ru Group на Хабре, Центрифуга используется в нашем корпоративном интранете. Real-rime сообщения добавили удобства использования, красок и динамики нашему внутреннему порталу. Пользователям не нужно обновлять страничку перед отправкой комментария (не нужно обновлять, не нужно обновлять...) — разве это не прекрасно?
Заключение
==========
Как и любое другое решение, использовать Центрифугу нужно с умом. Это не серебряная пуля, нужно понимать, что по большому счету это лишь брокер сообщений, единственная задача которого держать соединения с клиентами и отправлять им сообщения.
Не стоит ждать гарантированной доставки сообщения клиенту. Если, например, пользователь открыл страничку, потом погрузил свой ноутбук в сон, то когда он «разбудит» свою машинку, соединение с Центрифугой вновь установится. Но все события, которые произошли, пока ноутбук находился в спящем режиме, будут потеряны. И пользователю нужно либо обновлять страничку, либо вам самостоятельно дописывать логику догрузки потерянных событий с вашего бекенда. Также нужно помнить, что практически все объекты (подключения, каналы, история сообщений) хранятся в оперативной памяти, поэтому за ее потреблением важно следить. Нужно не забывать о лимитах операционной системы на открытые файловые дескрипторы и увеличить их при необходимости. Необходимо думать о том, какой канал создать в той или иной ситуации — приватный или публичный, с историей или без, какова должна быть длина этой истории и т.д.
Как я упоминал выше, способов добавить real-time на ваш сайт — масса, выбирать нужно с умом, возможно в вашем случае более выигрышным окажется не вариант с отдельным асинхронным сервером.
P.S. В конце весны я посетил конференцию python-разработчиков в Санкт-Петербурге Piter Py. В одном из докладов зашла речь о мгновенных уведомлениях пользователей о том, что их задача, которая выполнялась асинхронно в Celery-воркере, готова. Докладчик сказал, что для этих целей они используют как раз Tornado и вебсокеты. Далее последовало несколько вопросов о том, как это работает в связке с Django, как запускается, какая авторизация… Парни, задававшие те вопросы, если вы читаете эту статью, дайте Центрифуге шанс, она замечательно подходит для подобных задач. | https://habr.com/ru/post/237257/ | null | ru | null |
# Сериализация .NET объекта в JavaScript variable на HTML странице внутрь Script-блока
#### Старые добрые hidden inputs
Часто приходится передавать в HTML страницу данные, которые необходимо потом использовать из JavaScript. Издавна для этого используется самый простой способ: **hidden inputs**. То есть, если нам нужно передать Uri адрес веб сервиса, мы на странице рендерим что-то вроде
```
```
и можем при помощи jQuery или plain old JavaScript найти этот input по имени и прочитать переданное значение.
Но когда нужно передавать много параметров или даже массивы, то этот способ становится не удобным. Можно конечно сделать REST сервис, который отдает все данные по AJAX-запросу со страницы (сессионные данные), но в большенстве случаев это излишне.
В настоящее время часто используется другой способ — на стороне сервера отрендерить в HTML все необходимые данные в виде JavaScript переменной внутри Script-блока.
#### Рассмотрим как это сделать в ASP.NET MVC.
Сценарий использования будет таким:
* у нас есть .NET класс который инкапсулирует в себе требуемые настройки и мы можем использовать любой класс для этого
* у нас есть Extension метод для MVC HtmlHelper, который принимает имя JavaScript переменной и объект, который нужно сериализовать
* сериализуемый класс передается во View внутри ViewModel или ViewBag
* имя JavaScript переменной может передаватся во View из контроллера или хард-кодится во View
После рендеринга страницы мы получаем код аналогичный следующему:
```
var settings = {"WebServiceUri":"URI we need","UserId":"1212"};
```
Extension метод для MVC HtmlHelper получился таким:
```
///
/// This class provides the extension methods to ASP.NET MVC HtmlHelper.
///
public static class HtmlHelperExtensions
{
///
/// This method renders the given model class as JavaScript variable within Html Script tag.
///
/// HtmlHelper instance we extend by this method.
/// The name of JavaScript variable the rendered Json object will be assigned to.
/// The model class to be rendered to Json and assigned to the variable.
/// Html representation of Html Script tag.
public static MvcHtmlString RenderJsToScriptBlock(this HtmlHelper htmlHelper, string variableName, object model)
{
#region Pre-conditions
if (string.IsNullOrWhiteSpace(variableName)) { throw new ArgumentNullException("variableName"); }
#endregion Pre-conditions
if (null == model) { return MvcHtmlString.Empty; }
TagBuilder tagBuilder = new TagBuilder(@"script");
tagBuilder.MergeAttribute(@"type", @"text/javascript");
// use InnerHtml because it doesn't encode characters
tagBuilder.InnerHtml = string.Format("var {0} = {1};", variableName, htmlHelper.Raw(Json.Encode(model)));
return new MvcHtmlString(tagBuilder.ToString());
}
}
```
Немного Unit-тестов с использованием moq фреймворка и MSTest:
```
[TestMethod, TestCategory("Unit")]
[ExpectedException(typeof(ArgumentNullException))]
public void Should_Not_Accept_Null_VariableName()
{
HtmlHelper helper = new HtmlHelper(new Mock().Object, new Mock().Object);
helper.RenderJsToScriptBlock(null, null);
}
[TestMethod, TestCategory("Unit")]
[ExpectedException(typeof(ArgumentNullException))]
public void Should\_Not\_Accept\_Empty\_VariableName()
{
HtmlHelper helper = new HtmlHelper(new Mock().Object, new Mock().Object);
helper.RenderJsToScriptBlock(string.Empty, null);
}
[TestMethod, TestCategory("Unit")]
public void Should\_Return\_Empty\_MvcHtmlString\_For\_NullModel()
{
HtmlHelper helper = new HtmlHelper(new Mock().Object, new Mock().Object);
MvcHtmlString mvcHtmlString = helper.RenderJsToScriptBlock("variableName", null);
Assert.AreEqual(mvcHtmlString, MvcHtmlString.Empty);
}
[TestMethod, TestCategory("Unit")]
public void Should\_Return\_Correct\_Result\_For\_Correct\_Input()
{
const string expectedHtmlString = "var variableName = {\"UserName\":\"Alex\"};";
HtmlHelper helper = new HtmlHelper(new Mock().Object, new Mock().Object);
var model = new { UserName = "Alex" };
MvcHtmlString mvcHtmlString = helper.RenderJsToScriptBlock("variableName", model);
Assert.AreEqual(mvcHtmlString.ToHtmlString(), expectedHtmlString);
}
``` | https://habr.com/ru/post/163239/ | null | ru | null |
# Кунг-фу стиля Linux: наблюдение за файлами
Linux или Unix приятно отличаются от многих других операционных систем тем, что Linux-программы часто выдают сообщения, которые записываются в какой-нибудь журнал. А многие команды даже можно настроить так, чтобы они генерировали бы больше сообщений, чем обычно. Я знаю о том, что в Windows есть средство для просмотра событий, но множество программ не особенно охотно делятся сведениями о своей работе. Это усложняет поиск источников проблем в тех случаях, когда что-то идёт не так, как ожидалось.
[](https://habr.com/ru/company/ruvds/blog/528430/)
В случае с Linux проблема заключается в том, что иногда программы сообщают нам слишком много сведений о своей работе. Как найти в этом море информации именно то, что нужно? Когда киношный хакер сидит перед терминалом и смотрит на текст, прокручивающийся со скоростью 500 строк в секунду, выглядит это впечатляюще. Но в реальной жизни почти бесполезно изучать логи, выводимые на экран с такой скоростью. Хотя, если попрактиковаться, из этого потока информации можно иногда, рискуя ошибиться, выхватить какое-нибудь ключевое слово. Но задачу анализа логов в реальном времени это не решает.
**Все переводы серии**
[Кунг-фу стиля Linux: удобная работа с файлами по SSH](https://habr.com/ru/company/ruvds/blog/520752/)
[Кунг-фу стиля Linux: мониторинг дисковой подсистемы](https://habr.com/ru/company/ruvds/blog/527238/)
[Кунг-фу стиля Linux: глобальный поиск и замена строк с помощью ripgrep](https://habr.com/ru/company/ruvds/blog/527242/)
[Кунг-фу стиля Linux: упрощение работы с awk](https://habr.com/ru/company/ruvds/blog/527244/)
[Кунг-фу стиля Linux: наблюдение за файловой системой](https://habr.com/ru/company/ruvds/blog/528422/)
[Кунг-фу стиля Linux: наблюдение за файлами](https://habr.com/ru/company/ruvds/blog/528430/)
[Кунг-фу стиля Linux: удобный доступ к справке при работе с bash](https://habr.com/ru/company/ruvds/blog/528432/)
[Кунг-фу стиля Linux: великая сила make](https://habr.com/ru/company/ruvds/blog/528434/)
[Кунг-фу стиля Linux: устранение неполадок в работе incron](https://habr.com/ru/company/ruvds/blog/529828/)
[Кунг-фу стиля Linux: расшаривание терминала в браузере](https://habr.com/ru/company/ruvds/blog/529836/)
[Кунг-фу стиля Linux: синхронизация настроек](https://habr.com/ru/company/ruvds/blog/531088/)
[Кунг-фу стиля Linux: бесплатный VPN по SSH](https://habr.com/ru/company/ruvds/blog/530944/)
[Кунг-фу стиля Linux: превращение веб-приложений в полноценные программы](https://habr.com/ru/company/ruvds/blog/529838/)
[Кунг-фу стиля Linux: утилита marker и меню для командной строки](https://habr.com/ru/company/ruvds/blog/529840/)
[Кунг-фу стиля Linux: sudo и поворот двух ключей](https://habr.com/ru/company/ruvds/blog/532334/)
[Кунг-фу стиля Linux: программное управление окнами](https://habr.com/ru/company/ruvds/blog/532342/)
[Кунг-фу стиля Linux: организация работы программ после выхода из системы](https://habr.com/ru/company/ruvds/blog/533336/)
[Кунг-фу стиля Linux: регулярные выражения](https://habr.com/ru/company/ruvds/blog/533334/)
[Кунг-фу стиля Linux: запуск команд](https://habr.com/ru/company/ruvds/blog/536958/)
[Кунг-фу стиля Linux: разбираемся с последовательными портами](https://habr.com/ru/company/ruvds/blog/544512/)
[Кунг-фу стиля Linux: базы данных — это файловые системы нового уровня](https://habr.com/ru/company/ruvds/blog/568302/)
[Кунг-фу стиля Linux: о повторении кое-каких событий сетевой истории](https://habr.com/ru/company/ruvds/blog/568308/)
[Кунг-фу стиля Linux: PDF для пингвинов](https://habr.com/ru/company/ruvds/blog/567158/)
Как и во многих других случаях, в Unix-подобных системах есть инструменты для решения вышеописанной задачи. И, что неудивительно, таких инструментов существует довольно много. Если вы, например, пользовались командой `tail`, то вы уже видели один из таких инструментов. Но `tail` — это лишь вершина айсберга.
Давайте рассмотрим пример анализа файла, который можно назвать «матерью всех логов». Это — `/var/log/syslog`. Попробуйте вывести его на экран с помощью команды `cat` или `less` (я, в своих системах, всегда создаю псевдоним `more` для команды `less`, поэтому если я вдруг упомяну команду `more` — знайте, что я имею в виду `less`). Этот файл, вероятнее всего, будет очень большим, его размеры будут постоянно расти. В обычной настольной системе он ведёт себя довольно спокойно, но в некоторых старых системах и на серверах в нём можно увидеть последствия бурной деятельности разных программ. В любом случае, за исключением тех ситуаций, когда система только что загружена, в нём будут многие страницы данных.
*Хакерский подход к анализу логов*
Поиск информации, которая уже присутствует в этом файле, особых сложностей не вызывает. Тут можно воспользоваться `grep`, или можно загрузить копию файла в текстовый редактор. Проблема заключается в анализе свежей информации. Попробуйте подключить USB-устройство к системе (или отключите его от неё). Вы увидите, как в `syslog` появились новые записи. А что если в него постоянно добавляются десятки сообщений? Как за ними уследить?
И эта проблема характерна далеко не только для файла `syslog`. Например, интересно может быть наблюдать за файлом листинга в ходе выполнения долгой компиляции кода. То же относится и к наблюдению за перестроением RAID-массива. В общем-то, в Linux всегда можно найти некий большой файл, постоянно пополняемый свежими сведениями, за которым нужно понаблюдать.
Команда tail
------------
Традиционный подход к наблюдению за файлами, постоянно пополняемыми информацией, заключается в использовании команды `tail`. Она берёт большой файл и возвращает лишь некоторое количество его последних строк. Эту команду можно вызвать с опцией `-f`. Тогда она будет ждать появления в файле новых данных и выводить их. Эта опция весьма полезна для наблюдения за файлами, в которые постоянно добавляется что-то новое. Опция `-F` приводит к практически такому же эффекту, но благодаря ей `tail`, если не может сразу открыть файл, будет продолжать пытаться открыть его. С помощью опции `-m` можно задавать количество выводимых последних строк файла, а с помощью опции `-c` — количество байтов. Опция `-s` позволяет задавать частоту проверки изменений файла.
Как по мне, так всё это выглядит очень даже хорошо. Попробуйте такую команду:
```
tail -f /var/log/syslog
```
Вы увидите несколько строк из конца файла системного журнала. А если подключить к компьютеру USB-устройство или отключить такое устройство от компьютера, можно увидеть, как сведения, попавшие в журнал, практически мгновенно выводятся на экране. Повторно запускать `tail` при этом не нужно.
Возможно, вы уже пользовались этим приёмом. Вышеописанная конструкция хорошо справляется со своей задачей, она известна и применяется довольно часто. Но есть и другие способы наблюдения за файлами, которыми вы, возможно, ещё не пользовались.
Меньше — значит больше: полезные возможности команды less
---------------------------------------------------------
У команды `less` есть опция `+F`, которая превращает эту команду в хорошую замену команды `tail`. На самом деле, если вы испытаете команду, приведённую ниже, вас может посетить мысль о том, что результаты её работы не очень-то и отличаются от результатов работы `tail`. Вот эта команда:
```
less +F /var/log/syslog
```
Вот как вывод этой команды выглядит на моём компьютере.

*Результаты работы команды less*
Обратите внимание на то, что в нижней части экрана имеется надпись `Waiting for data…`. В данный момент утилита `less` работает практически так же, как и `tail`. Но если нажать `CTRL+C` — произойдёт кое-что интересное. Ну — что-то, возможно, и произойдёт. Попробуйте. Если `less` переходит в командный режим — значит всё в порядке. Теперь можно заниматься всем тем, чем обычно занимаются, просматривая файлы с помощью `less`. Если же по нажатию `CTRL+C` работа `less` прекратится, это будет означать, что ваш Linux-дистрибутив «помог» вам, установив некоторые стандартные опции `less` с использованием переменной окружения `LESS`. Попробуйте такую команду:
```
set | grep LESS
```
Если вы увидите, что в списке опций имеется `--quit-on-intr`, это будет значить, что проблема заключается именно в данной строке. Её надо убрать. После этого переключиться в командный режим можно с использованием `CTRL+C`. Это, кроме того, означает, что вам нужно запомнить, что для выхода из `less` используется команда `q`. Если вы вышли из режима наблюдения за файлом и хотите снова в него вернуться — просто нажмите `F`.
Если вы пользуетесь `less` в обычном режиме (то есть — не использовали при запуске утилиты опцию `+F`), вы можете нажать клавишу `F` на клавиатуре для перехода в «tail-режим». А ещё интереснее то, что, нажав `ESC-F` можно в этом режиме что-то искать, при этом, если в поступающих данных найдётся совпадение с тем, что вас интересует, система вам об этом сообщит.
Команду `less` можно ещё использовать с ключом `--follow-name`. Это позволит добиться того же эффекта, что и использование опции `-F` команды `tail`.
Наблюдение за файлами с помощью команды watch
---------------------------------------------
Иногда файл, за которым нужно наблюдать, не пополняется новыми данными, добавляемыми в его конец, а просто иногда меняется. Например, это файл `/proc/loadavg` или многие другие файлы из директории `/proc`. Использование команд `tail` или `less` не особенно хорошо подходит для наблюдения за такими файлами. Тут нам на помощь придёт команда `watch`:
```
watch -n 5 cat /proc/loadavg
```

*Результат выполнения команды watch*
Эта команда вызывает `cat` каждые 5 секунд и аккуратно выводит результат. Команда `watch` поддерживает множество полезных опций. Например, опция `-d` позволяет выделять отличия, а `-p` позволяет задействовать высокоточный таймер. Опция `-c` включает поддержку цвета.
Использование текстового редактора для наблюдения за файлами
------------------------------------------------------------
Возможно, используемый вами текстовой редактор поддерживает tail-режим. При работе с `emacs`, например, есть несколько способов это организовать. Не буду рассказывать о том, как это сделать. Просто порекомендую вам [эту](https://writequit.org/articles/working-with-logs-in-emacs.html) отличную статью. Я не отношу себя к экспертам в области `vim`, но полагаю, что если вы пользуетесь этим редактором и хотите наблюдать за файлами, вам понадобится специальный [плагин](https://www.vim.org/scripts/script.php?script_id=1714).
Если вы не ищете лёгких путей, то вам, возможно, подойдёт инструмент наподобие [lnav](https://github.com/tstack/lnav), который сделан специально для просмотра логов. Просмотрщики журналов имеются, кроме того, в KDE и Gnome.
Итоги
-----
Как это обычно бывает в Linux и Unix, у задачи организации наблюдения за файлами есть множество решений. Какое из этих решений «лучше» других? У каждого будет собственный ответ на этот вопрос. Именно это и делает Linux системой, привлекательной для продвинутых пользователей. Каждый из них может выбрать именно то, что подходит ему лучше всего.
Те команды, о которых мы говорили, могут пригодиться и тем, кто пользуется настольным дистрибутивом Linux, и тем, кто работает с серверами или с Raspberry Pi.
Как вы наблюдаете за постоянно изменяющимися файлами в Linux?
**Все переводы серии**
[Кунг-фу стиля Linux: удобная работа с файлами по SSH](https://habr.com/ru/company/ruvds/blog/520752/)
[Кунг-фу стиля Linux: мониторинг дисковой подсистемы](https://habr.com/ru/company/ruvds/blog/527238/)
[Кунг-фу стиля Linux: глобальный поиск и замена строк с помощью ripgrep](https://habr.com/ru/company/ruvds/blog/527242/)
[Кунг-фу стиля Linux: упрощение работы с awk](https://habr.com/ru/company/ruvds/blog/527244/)
[Кунг-фу стиля Linux: наблюдение за файловой системой](https://habr.com/ru/company/ruvds/blog/528422/)
[Кунг-фу стиля Linux: наблюдение за файлами](https://habr.com/ru/company/ruvds/blog/528430/)
[Кунг-фу стиля Linux: удобный доступ к справке при работе с bash](https://habr.com/ru/company/ruvds/blog/528432/)
[Кунг-фу стиля Linux: великая сила make](https://habr.com/ru/company/ruvds/blog/528434/)
[Кунг-фу стиля Linux: устранение неполадок в работе incron](https://habr.com/ru/company/ruvds/blog/529828/)
[Кунг-фу стиля Linux: расшаривание терминала в браузере](https://habr.com/ru/company/ruvds/blog/529836/)
[Кунг-фу стиля Linux: синхронизация настроек](https://habr.com/ru/company/ruvds/blog/531088/)
[Кунг-фу стиля Linux: бесплатный VPN по SSH](https://habr.com/ru/company/ruvds/blog/530944/)
[Кунг-фу стиля Linux: превращение веб-приложений в полноценные программы](https://habr.com/ru/company/ruvds/blog/529838/)
[Кунг-фу стиля Linux: утилита marker и меню для командной строки](https://habr.com/ru/company/ruvds/blog/529840/)
[Кунг-фу стиля Linux: sudo и поворот двух ключей](https://habr.com/ru/company/ruvds/blog/532334/)
[Кунг-фу стиля Linux: программное управление окнами](https://habr.com/ru/company/ruvds/blog/532342/)
[Кунг-фу стиля Linux: организация работы программ после выхода из системы](https://habr.com/ru/company/ruvds/blog/533336/)
[Кунг-фу стиля Linux: регулярные выражения](https://habr.com/ru/company/ruvds/blog/533334/)
[Кунг-фу стиля Linux: запуск команд](https://habr.com/ru/company/ruvds/blog/536958/)
[Кунг-фу стиля Linux: разбираемся с последовательными портами](https://habr.com/ru/company/ruvds/blog/544512/)
[Кунг-фу стиля Linux: базы данных — это файловые системы нового уровня](https://habr.com/ru/company/ruvds/blog/568302/)
[Кунг-фу стиля Linux: о повторении кое-каких событий сетевой истории](https://habr.com/ru/company/ruvds/blog/568308/)
[Кунг-фу стиля Linux: PDF для пингвинов](https://habr.com/ru/company/ruvds/blog/567158/)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=kung_fu_stilya_linux_nablyudenie_za_fajlami#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=kung_fu_stilya_linux_nablyudenie_za_fajlami) | https://habr.com/ru/post/528430/ | null | ru | null |
# Сравни меня полностью. Рефлексия на службе .NET разработчика

Недавно передо мной встала следующая задача: необходимо сравнить множество пар объектов. Но есть один нюанс: объекты — самые что ни на есть `object`'ы, а сравнивать нужно по всему набору публичных свойств. Причём совершенно необязательно, что типы сравниваемых объектов реализуют интерфейс [`IEquatable`](https://msdn.microsoft.com/en-us/library/ms131187(v=vs.110).aspx).
Было очевидно, что следует использовать рефлексию. Однако при реализации я столкнулся со множеством тонкостей и в конечном счёте прибегнул к ~~чёрной магии~~ динамической генерации IL. В этой статье я хотел бы поделиться опытом и рассказать о том, как я решал эту задачу. Если Вас заинтересовала тема, то прошу под кат!
##### Часть 1. Объект в отражении
> «Подать сюда ~~MFC~~ IEqualityComparer!», — кричал он, топая всеми четырьмя лапами
>
>
В .NET принято, что классы, выполняющие сравнение объектов, реализуют интерфейс [IEqualityComparer](https://msdn.microsoft.com/en-us/library/ms132151(v=vs.110).aspx). Это позволяет внедрять их в классы коллекций, например, списки и словари, и использовать кастомную проверку равенства при поиске. Мы не будем отступать от этого соглашения и приступим к реализации интерфейса `IEqualityComparer`, использующей механизм рефлексии. Напомним, что рефлексией называется инспектирование метаданных и скомпилированного кода в процессе выполнения программы (читателю, незнакомому с рефлексией, настоятельно рекомендуется ознакомиться с главой «Рефлексия и метаданные» книги Джозефа и Бена Албахари [«C# 5.0. Справочник. Полное описание языка»](http://www.williamspublishing.com/Books/978-5-8459-1819-2.html)).
```
public class ReflectionComparer : IEqualityComparer
{
public new bool Equals(object x, object y)
{
public new bool Equals(object x, object y)
{
return CompareObjectsInternal(x?.GetType(), x, y);
}
}
public int GetHashCode(object obj)
{
return obj.GetHashCode();
}
private bool CompareObjectsInternal(Type type, object x, object y)
{
throw new NotImplementedException();
}
}
```
Заметим, что метод `Equals` мы отметили как `new`. Это сделано потому, что он перекрывает метод `Object.Equals(object, object)`.
Теперь сделаем шаг назад и точнее определим, что именно мы будем сравнивать. Объекты могут быть сколь угодно сложными, всё нужно учесть. Комбинируя следующие типы свойств мы сможем покрыть широкий класс входных данных:
* все примитивные типы (Boolean, Byte, SByte, Int16, UInt16, Int32, UInt32, Int64, UInt64, IntPtr, UIntPtr, Char, Double, Single);
* строки;
* массивы (для простоты будем рассматривать только одномерные массивы);
* перечисления;
* коллекции, реализующие интерфейс IEnumerable;
* структуры;
* классы.
Напишем каркас метода `CompareObjectsInternal`, а затем рассмотрим некоторые частные случаи.
```
private bool CompareObjectsInternal(Type type, object x, object y)
{
// Если ссылки указывают на один и тот же объект
if (ReferenceEquals(x, y)) return true;
// Один из объектов равен null
if (ReferenceEquals(x, null) != ReferenceEquals(y, null)) return false;
// Объекты имеют разные типы
if (x.GetType() != y.GetType()) return false;
// Строки
if (Type.GetTypeCode(type) == TypeCode.String) return ((string)x).Equals((string)y);
// Массивы
if (type.IsArray) return CompareArrays(type, x, y);
// Коллекции
if (type.IsImplementIEnumerable()) return CompareEnumerables(type, x, y);
// Ссылочные типы
if (type.IsClass || type.IsInterface) return CompareAllProperties(type, x, y);
// Примитивные типы или типы перечислений
if (type.IsPrimitive || type.IsEnum) return x.Equals(y);
// Обнуляемые типы
if (type.IsNullable()) return CompareNullables(type, x, y);
// Структуры
if (type.IsValueType) return CompareAllProperties(type, x, y);
return x.Equals(y);
}
```
Приведённый выше код достаточно понятен: сначала проверяем объекты на ссылочное равенство и равенство `null`, затем проверяем типы, а после этого рассматриваем различные случаи. Причём для строк, примитивных типов и типов перечислений мы, не мудрствуя лукаво, вызываем метод `Equals`. Для проверки типов на принадлежность к обнуляемым типам и типам коллекций мы используем методы расширения `IsNullable` и `IsImplementIEnumerable`, исходный код которых можно посмотреть ниже.
**Код методов расширения**
```
public static bool IsImplementIEnumerable(this Type type) => type.GetInterface("IEnumerable`1") != null;
public static Type GetIEnumerableInterface(this Type type) => type.GetInterface("IEnumerable`1");
public static bool IsNullable(this Type type) => type.IsGenericType && type.GetGenericTypeDefinition() == typeof (Nullable<>);
```
В случае классов, интерфейсов и структур мы сравниваем все соответствующие свойства. Заметим, что индексаторы в .NET также представляют собой свойства, однако мы ограничимся простыми (parameterless) свойствами, имеющими геттеры, а сравнение коллекций будем обрабатывать отдельно. Проверить, является ли свойство индексатором мы можем с помощью метода [PropertyInfo.GetIndexParameters](https://msdn.microsoft.com/en-us/library/system.reflection.propertyinfo.getindexparameters(v=vs.110).aspx). Если метод вернул массив ненулевой длины, значит мы имеем дело с индексатором.
```
private bool CompareAllProperties(Type type, object x, object y)
{
var properties = type.GetProperties(BindingFlags.Instance | BindingFlags.Public);
var readableNonIndexers = properties.Where(p => p.CanRead && p.GetIndexParameters().Length == 0);
foreach (PropertyInfo propertyInfo in readableNonIndexers)
{
var a = propertyInfo.GetValue(x, null);
var b = propertyInfo.GetValue(y, null);
if (!CompareObjectsInternal(propertyInfo.PropertyType, a, b)) return false;
}
return true;
}
```
Следующий случае — сравнение объектов nullable-типов. Если нижележащий тип примитивный, то мы можем сравнить значения методом `Equals`. Если же внутри объектов лежат структуры, тогда необходимо сначала извлечь внутренние знаения, а затем сравнить их по всем публичным свойствам. Мы безопасно можем обращаться к свойству `Value`, поскольку проверка на равенства уже была выполнена ранее в методе `CompareObjectsInternal`.
```
private bool CompareNullables(Type type, object x, object y)
{
Type underlyingTypeOfNullableType = Nullable.GetUnderlyingType(type);
if (underlyingTypeOfNullableType.IsPrimitive)
{
return x.Equals(y);
}
var valueProperty = type.GetProperty("Value");
var a = valueProperty.GetValue(x, null);
var b = valueProperty.GetValue(y, null);
return CompareAllProperties(underlyingTypeOfNullableType, a, b);
}
```
Перейдём к сравнению коллекций. Реализацию можно выполнить как минимум двумя способами: написать свой необобщённый метод, работающий с IEnumerable, либо использовать метод расширения [Enumerable.SequenceEqual](https://msdn.microsoft.com/en-us/library/vstudio/bb342073(v=vs.100).aspx). Для коллекций, элементами которых являются тип-значения, очевидно, что необобщённый метод будет работать медленее, т.к. ему постоянно придётся выполнять упаковку/распаковку значений. При использовании же метода LINQ нам нужно сначала подставить тип элементов коллекции в параметр-типа TSource с помощью метода [MakeGenericMethod](https://msdn.microsoft.com/en-us/library/system.reflection.methodinfo.makegenericmethod(v=vs.110).aspx)), а затем вызвать метод передав две сравниваемые коллекции. Причём, если коллекция содержит элементы непримитивных типов, то мы можем передать дополнительный аргумент — компарер — текущий экземпляр нашего класса `ReflectionComparer` (не зря же мы реализовывали интерфейс `IEqualityComparer`!). Поэтому для сравнения коллекций выбираем LINQ:
```
private static MethodInfo GenericSequenceEqualWithoutComparer = typeof(Enumerable)
.GetMethods(BindingFlags.Public | BindingFlags.Static)
.First(m => m.Name == "SequenceEqual" && m.GetParameters().Length == 2);
private static MethodInfo GenericSequenceEqualWithComparer = typeof(Enumerable)
.GetMethods(BindingFlags.Public | BindingFlags.Static)
.First(m => m.Name == "SequenceEqual" && m.GetParameters().Length == 3);
private bool CompareEnumerables(Type collectionType, object x, object y)
{
Type enumerableInterface = collectionType.GetIEnumerableInterface();
Type elementType = enumerableInterface.GetGenericArguments()[0];
MethodInfo sequenceEqual;
object[] arguments;
if (elementType.IsPrimitive)
{
sequenceEqual = GenericSequenceEqualWithoutComparer;
arguments = new[] {x, y};
}
else
{
sequenceEqual = GenericSequenceEqualWithComparer;
arguments = new[] {x, y, this};
}
var sequenceEqualMethod = sequenceEqual.MakeGenericMethod(elementType);
return (bool)sequenceEqualMethod.Invoke(null, arguments);
}
```
Последний случай — сравнение массивов — во многом похож на сравнение коллекций. Отличие состоит в том, что вместо использования стандартного метода LINQ мы используем самописный обобщённый метод. Реализация сравнения массивов представлена ниже:
**Сравнение массивов**
```
private static MethodInfo GenericCompareArraysMethod =
typeof(ReflectionComparer).GetMethod("GenericCompareArrays", BindingFlags.NonPublic | BindingFlags.Static);
private static bool GenericCompareArrays(T[] x, T[] y, IEqualityComparer comparer)
{
var comp = comparer ?? EqualityComparer.Default;
for (int i = 0; i < x.Length; ++i)
{
if (!comp.Equals(x[i], y[i])) return false;
}
return true;
}
private bool CompareArrays(Type type, object x, object y)
{
var elementType = type.GetElementType();
int xLength, yLength;
if (elementType.IsValueType)
{
// Массивы типов-значений не приводятся к массиву object, поэтому используем Array
xLength = ((Array) x).Length;
yLength = ((Array) y).Length;
}
else
{
xLength = ((object[]) x).Length;
yLength = ((object[]) y).Length;
}
if (xLength != yLength) return false;
var compareArraysPrimitive = GenericCompareArraysMethod.MakeGenericMethod(elementType);
var arguments = elementType.IsPrimitive ? new[] {x, y, null} : new[] {x, y, this};
return (bool) compareArraysPrimitive.Invoke(null, arguments);
}
```
Итак, все части пазла собраны — наш рефлексивный компарер готов. Ниже представлены результаты сравнения производительности рефлексивного компарера по сравнению с ручной реализацией на «тестовых» данных. Очевидно, что время выполнения сравнения **очень** сильно зависит от типа сравниваемых объектов. В качестве примера здесь сравнивались объекты двух типов — условно «посложнее» и «попроще». Для оценки времени выполнения использовалась библиотека [BenchmarkDotNet](https://github.com/PerfDotNet/BenchmarkDotNet), за которую особую благодарность хочется выразить Андрею Акиньшину [DreamWalker](https://habrahabr.ru/users/dreamwalker/).
**Код тут**
```
public struct Struct
{
private int m_a;
private double m_b;
private string m_c;
public int A => m_a;
public double B => m_b;
public string C => m_c;
public Struct(int a, double b, string c)
{
m_a = a;
m_b = b;
m_c = c;
}
}
public class SimpleClass
{
public int A { get; set; }
public Struct B { get; set; }
}
public class ComplexClass
{
public int A { get; set; }
public IntPtr B { get; set; }
public UIntPtr C { get; set; }
public string D { get; set; }
public SimpleClass E { get; set; }
public int? F { get; set; }
public int[] G { get; set; }
public List H { get; set; }
public double I { get; set; }
public float J { get; set; }
}
[BenchmarkTask(platform: BenchmarkPlatform.X86, jitVersion: BenchmarkJitVersion.LegacyJit)]
[BenchmarkTask(platform: BenchmarkPlatform.X64, jitVersion: BenchmarkJitVersion.LegacyJit)]
[BenchmarkTask(platform: BenchmarkPlatform.X64, jitVersion: BenchmarkJitVersion.RyuJit)]
public class ComparisonTest
{
private static int[] MakeArray(int count)
{
var array = new int[count];
for (int i = 0; i < array.Length; ++i)
array[i] = i;
return array;
}
private static List MakeList(int count)
{
var list = new List(count);
for (int i = 0; i < list.Count; ++i)
list.Add(i);
return list;
}
private ComplexClass x = new ComplexClass
{
A = 2,
B = new IntPtr(2),
C = new UIntPtr(2),
D = "abc",
E = new SimpleClass { A = 42, B = new Struct(42, 3.14, "meow") },
F = 1,
G = MakeArray(100),
H = MakeList(100),
I = double.MaxValue,
J = float.MaxValue
};
private ComplexClass y = new ComplexClass
{
A = 2,
B = new IntPtr(2),
C = new UIntPtr(2),
D = "abc",
E = new SimpleClass { A = 42, B = new Struct(42, 3.14, "meow") },
F = 1,
G = MakeArray(100),
H = MakeList(100),
I = double.MaxValue,
J = float.MaxValue
};
private ReflectionComparer comparer = new ReflectionComparer();
[Benchmark]
public void ReflectionCompare()
{
var \_ = comparer.Equals(x, y);
}
[Benchmark]
public void ManualCompare()
{
var \_ = CompareComplexObjects();
}
private bool CompareComplexObjects()
{
if (x == y) return true;
if (x.A != y.A) return false;
if (x.B != y.B) return false;
if (x.C != y.C) return false;
if (x.D != y.D) return false;
if (x.E != y.E)
{
if (x.E.A != y.E.A) return false;
var s1 = x.E.B;
var s2 = y.E.B;
if (s1.A != s2.A) return false;
if (!s1.B.Equals(s2.B)) return false;
if (s1.C != s2.C) return false;
}
if (x.F != y.F) return false;
if (x.G != y.G)
{
if (x.G?.Length != y.G?.Length) return false;
int[] a = x.G, b = y.G;
for (int i = 0; i < a.Length; ++i)
{
if (a[i] != b[i]) return false;
}
}
if (x.H != y.H)
{
if (!x.H.SequenceEqual(y.H)) return false;
}
if (!x.I.Equals(y.I)) return false;
if (!x.J.Equals(y.J)) return false;
return true;
}
}
[BenchmarkTask(platform: BenchmarkPlatform.X86, jitVersion: BenchmarkJitVersion.LegacyJit)]
[BenchmarkTask(platform: BenchmarkPlatform.X64, jitVersion: BenchmarkJitVersion.LegacyJit)]
[BenchmarkTask(platform: BenchmarkPlatform.X64, jitVersion: BenchmarkJitVersion.RyuJit)]
public class SimpleComparisonTest
{
private SimpleClass x = new SimpleClass { A = 42, B = new Struct(42, 3.14, "meow") };
private SimpleClass y = new SimpleClass { A = 42, B = new Struct(42, 3.14, "meow") };
private ReflectionComparer comparer = new ReflectionComparer();
[Benchmark]
public void ReflectionCompare()
{
var \_ = comparer.Equals(x, y);
}
[Benchmark]
public void ManualCompare()
{
var \_ = CompareSimpleObjects();
}
private bool CompareSimpleObjects()
{
if (x == y) return true;
if (x.A != y.A) return false;
var s1 = x.B;
var s2 = y.B;
if (s1.A != s2.A) return false;
if (!s1.B.Equals(s2.B)) return false;
if (s1.C != s2.C) return false;
return true;
}
}
```
**Результаты тут**BenchmarkDotNet=v0.7.8.0
OS=Microsoft Windows NT 6.2.9200.0
Processor=Intel® Core(TM) i5-2410M CPU @ 2.30GHz, ProcessorCount=4
HostCLR=MS.NET 4.0.30319.42000, Arch=64-bit [RyuJIT]
**Результаты сравнения объектов ComplexClass**
| Method | Platform | Jit | AvrTime | StdDev | op/s |
| --- | --- | --- | --- | --- | --- |
| ManualCompare | X64 | LegacyJit | 1,364.3835 ns | 47.6975 ns | 732,941.68 |
| ReflectionCompare | X64 | LegacyJit | 36,779.9097 ns | 3,080.9738 ns | 27,188.92 |
| ManualCompare | X64 | RyuJit | 930.8761 ns | 43.6018 ns | 1,074,294.12 |
| ReflectionCompare | X64 | RyuJit | 36,909.7334 ns | 3,762.0698 ns | 27,093.98 |
| ManualCompare | X86 | LegacyJit | 936.3367 ns | 38.3831 ns | 1,067,992.54 |
| ReflectionCompare | X86 | LegacyJit | 32,446.6969 ns | 1,687.8442 ns | 30,819.81 |
**Результаты сравнения объектов SimpleClass**
| Method | Platform | Jit | AvrTime | StdDev | op/s |
| --- | --- | --- | --- | --- | --- |
| Handwritten | X64 | LegacyJit | 131.5205 ns | 4.9045 ns | 7,603,376.64 |
| ReflectionComparer | X64 | LegacyJit | 3,859.7102 ns | 269.8845 ns | 259,087.15 |
| Handwritten | X64 | RyuJit | 61.2438 ns | 1.9025 ns | 16,328,222.24 |
| ReflectionComparer | X64 | RyuJit | 3,841.4645 ns | 374.0006 ns | 260,317.46 |
| Handwritten | X86 | LegacyJit | 71.5982 ns | 5.4304 ns | 13,966,823.95 |
| ReflectionComparer | X86 | LegacyJit | 3,636.7963 ns | 241.3940 ns | 274,967.76 |
Естественно, прозводительность рефлексивного компарера ниже самописного. Рефлексия медленна и её API работает с `object`'ами, что незамедлительно сказывается на производительности, если в сравниваемых объектах присутствуют типы-значения, из-за необходимости выполнять boxing/unboxing. И тут уже необходимо исходить из собственных потребностей. Если рефлексия используется не часто, то с ней можно жить. Но в конкретном моём случае, рефлексивный компарер был недостаточно быстр. «Давай по новой~~, Миш~~», — сказал я себе и принялся за второй вариант.
##### Часть 2. Игра в emitацию

> Можно жить так, но лучше ускориться
>
> *Группа Ленинград, «Мне бы в небо»*
>
>
>
> Нео: И ты это читаешь?
>
> Сайфер: Приходится. Со временем привыкаешь. Я даже не замечаю код. Я вижу блондинку, брюнетку, рыженькую.
>
> *Фильм «Матрица» (The Matrix)*
>
>
Рефлексия позволяет нам извлечь всю необходимую информацию о типах сравниваемых объектов. Но эти типы мы не можем использовать напрямую для получения нужных нам свойств или вызова требуемого метода, что приводит нас к использованию медленного API рефлексии (PropertyInfo.GetValue, MethodInfo.Invoke и т.д.). А что, если бы мы могли, используя информацию о типах, единожды сгенерировать код сравнения объектов и вызывать его каждый раз, не прибегая более к рефлексии? И, к счастью, мы можем это сделать! Пространство имён [System.Reflection.Emit](https://msdn.microsoft.com/en-us/library/system.reflection.emit(v=vs.110).aspx) предоставляет нам средства для создания динамических методов — [DynamicMethod](https://msdn.microsoft.com/en-us/library/system.reflection.emit.dynamicmethod(v=vs.110).aspx) с помощью генератора [IL](https://ru.wikipedia.org/wiki/Common_Intermediate_Language) — [ILGenerator](https://msdn.microsoft.com/en-us/library/system.reflection.emit.ilgenerator(v=vs.110).aspx). Именно такой же подход используется, к примеру, для компиляции регулярных выражений в самом .NET Framework (реализацию можно посмотреть [тут](http://referencesource.microsoft.com/#System/regex/system/text/regularexpressions/RegexCompiler.cs)).
О генерации IL на Хабре уже [писали](http://habrahabr.ru/post/172487/). Поэтому лишь вкратце напомним об особенностях IL.
[Intermediate Language (IL)](https://ru.wikipedia.org/wiki/Common_Intermediate_Language) представляет собой объектно-ориентированный язык ассемблера, используемый платформой .NET и Mono. Высокоуровневые языки, например, C#, VB.NET, F#, компилируются в IL, а IL в свою очередь компилируется JIT'ом в машинный код. Из-за своего промежуточного положения в этой цепочке язык и имеет своё название. IL использует стековую модель вычислений, то есть все входные и выходные данные передаются через стек, а не через регистры, как во многих процессорных архитектурах. IL поддерживает инструкции загрузки и сохранения локальных переменных и аргументов, преобразование типов, создание и манипулирование объектами, передачу управления, вызов методов, исключения и многие другие.
К примеру, инкрементация целочисленной переменной будет на IL записана следующим образом:
```
ldloc.0 // Загружаем переменную
ldc.i4.1 // Загружаем единицу
add // Складываем
stloc.0 // Сохраняем результат обратно в переменную
```
Посмотреть результат комплияции C# в IL можно посмотреть различными средствами, например, ILDasm (утилита, поставляемая вместе с Visual Studio) или [ILSpy](http://ilspy.net/). Но мой любимый способ — это с помощью замечательного веб-приложения [Try Roslyn](http://tryroslyn.azurewebsites.net/), написанного Андреем Щёкиным [ashmind](https://habrahabr.ru/users/ashmind/).
Вернёмся к нашей задаче. Мы опять будем делать делать реализацию интерфейса `IEqualityComparer`:
```
public class DynamicCodeComparer : IEqualityComparer
{
// Делегат для сравнения объектов
private delegate bool Comparer(object x, object y);
// Кэш сгенерированных компареров
private static Dictionary ComparerCache = new Dictionary();
public new bool Equals(object x, object y)
{
// Если ссылки указывают на один и тот же объект
if (ReferenceEquals(x, y)) return true;
// Один из объектов равен null
if (ReferenceEquals(x, null) != ReferenceEquals(y, null)) return false;
Type xType = x.GetType();
// Объекты имеют разные типы
if (xType != y.GetType()) return false;
//
// Проверяем наличие компарера в кэше. Если нет, то создаём его и сохраняем в кэш
//
Comparer comparer;
if (!ComparerCache.TryGetValue(xType, out comparer))
{
ComparerCache[xType] = comparer = new ComparerDelegateGenerator().Generate(xType);
}
return comparer(x, y);
}
public int GetHashCode(object obj)
{
return obj.GetHashCode();
}
}
```
Метод `Equals` использует словарь для поддержки кэша сгенерированных делегатов — компареров, выполняющих сравнение объектов. Если компарера для определённого типа ещё нет в словаре, то мы генерируем новый делегат. Вся логика по динамической генерации делегата будет сосредоточена в классе `ComparerDelegateGenerator`.
```
class ComparerDelegateGenerator
{
// Генератор кода динамического метода
private ILGenerator il;
public Comparer Generate(Type type)
{
// Создаём динамический метод в том же модуле, что и сравниваемый тип
var dynamicMethod = new DynamicMethod("__DynamicCompare", typeof(bool), new[] { typeof(object), typeof(object) },
type.Module);
il = dynamicMethod.GetILGenerator();
//
// Загружаем аргументы и прикастовываем их к типу времени выполнения
//
il.LoadFirstArg();
var arg0 = il.CastToType(type);
il.LoadSecondArg();
var arg1 = il.CastToType(type);
// Сравниваем объекты
CompareObjectsInternal(type, arg0, arg1);
// Если управление дошло до этого места, значит объекты равны
il.ReturnTrue();
// Создаём делегат для выполнения динамического метода
return (Comparer)dynamicMethod.CreateDelegate(typeof(Comparer));
}
}
```
В методе `Generate` выше есть один маленький нюанс. Нюанс состоит в том, чтобы создавать динамический метод в том же модуле, что и тип сравниваемых объектов. В противном случае код динамического метода не сможет получить доступ к типу и получит исключение `TypeAccessException`. Класс `ILGenerator` позволяет генерировать инструкции с помощью метода [Emit(OpCode)](https://msdn.microsoft.com/en-us/library/system.reflection.emit.ilgenerator.emit(v=vs.110).aspx), принимающего в качестве аргумента код команды. Но, чтобы не засорять наш класс такими деталями мы будем использовать методы расширения, из названия которых будет понятно, что они делают. Код методов расширения `LoadFirstArg, LoadSecondArg, CastToType` и `ReturnTrue` представлен ниже. Следует пояснить, что вызываемый в `Generate` метод `CompareObjectsInternal` будет генерировать `return false` сразу же, как только встретит отличающиеся значения. Поэтому последним операторам динамического метода будет `return true`, чтобы обрабатать ту ситуацию, когда объекты равны.
**Код методов расширения**
```
// Загружает в стек первый аргумент текущего метода
public static void LoadFirstArg(this ILGenerator il) => il.Emit(OpCodes.Ldarg_0);
// Загружает в стек второй аргумент текущего метода
public static void LoadSecondArg(this ILGenerator il) => il.Emit(OpCodes.Ldarg_1);
// Извлекает из стека значение и приводит его к заданному типу
public static LocalBuilder CastToType(this ILGenerator il, Type type)
{
var x = il.DeclareLocal(type);
// В случае типов-значений и примитивных типов выполняем распаковку
if (type.IsValueType || type.IsPrimitive)
{
il.Emit(OpCodes.Unbox_Any, type);
}
// В случае ссылочных типов выполняем приведение
else
{
il.Emit(OpCodes.Castclass, type);
}
il.SetLocal(x);
return x;
}
// Загружает в стек ноль (он же false)
public static void LoadZero(this ILGenerator il) => il.Emit(OpCodes.Ldc_I4_0);
// Загружает в стек единицу (она же true)
public static void LoadOne(this ILGenerator il) => il.Emit(OpCodes.Ldc_I4_1);
// Возвращает из метода значение false
public static void ReturnFalse(this ILGenerator il)
{
il.LoadZero();
il.Emit(OpCodes.Ret);
}
// Возвращает из метода значение true
public static void ReturnTrue(this ILGenerator il)
{
il.LoadOne();
il.Emit(OpCodes.Ret);
}
```
Далее рассмотрим метод `CompareObjectsInternal`, который будет генерировать различный код сравнения в зависимости от типа объектов:
```
private void CompareObjectsInternal(Type type, LocalBuilder x, LocalBuilder y)
{
// Объявляем метку, на которую будем прыгать в случае, если объекты равны
var whenEqual = il.DefineLabel();
// Если объекты не являются типами-значений
if (!type.IsValueType)
{
// Тут же возвращаем true, если ссылки равны между собой
JumpIfReferenceEquals(x, y, whenEqual);
// Если один из объектов равен null, а второй нет возвращаем false
ReturnFalseIfOneIsNull(x, y);
// Массивы
if (type.IsArray)
{
CompareArrays(type.GetElementType(), x, y);
}
// Классы или интерфейсы
else if (type.IsClass || type.IsInterface)
{
// Строки
if (Type.GetTypeCode(type) == TypeCode.String)
{
CompareStrings(x, y, whenEqual);
}
// Коллекции
else if (type.IsImplementIEnumerable())
{
CompareEnumerables(type, x, y);
}
// Любые другие классы или интерфейсы
else
{
CompareAllProperties(type, x, y);
}
}
}
// Обнуляемые типы
else if (type.IsNullable())
{
CompareNullableValues(type, x, y, whenEqual);
}
// Примитивные типы или перечисления
else if (type.IsPrimitive || type.IsEnum)
{
ComparePrimitives(type, x, y, whenEqual);
}
// Структуры
else
{
CompareAllProperties(type, x, y);
}
// Ставим метку, на которую будем прыгать в случае, если объекты равны
il.MarkLabel(whenEqual);
}
```
Как видно из кода, мы обрабатываем те же ситуации, что и в рефлексивном компарере, но в немного другом порядке. Это связано с тем, что сравнение с `null` генерируется только для ссылочных типов, но не для обнуляемых. В случае обнуляемых объектов вместо этого генерируется проверка свойства `HasValue`.
Подробно разбирать каждый случай в статье не будем, в конце я дам ссылку на исходники. Но представим код сравнения массивов, чтобы прочувствовать, что из себя представляет разработка в условиях примитивных команд.
```
private void CompareArrays(Type elementType, LocalBuilder x, LocalBuilder y)
{
var loop = il.DefineLabel(); // Объявляем метку начала цикла сравнения элементов
il.LoadArrayLength(x); // Загружаем длину первого массива
il.LoadArrayLength(y); // Загружаем длину второго массива
il.JumpWhenEqual(loop); // Если длины равны, то переходим к циклу
il.ReturnFalse(); // Иначе возвращаем false
il.MarkLabel(loop); // Отмечаем метку начала цикла
var index = il.DeclareLocal(typeof(int)); // Объявляем счётчик цикла - индекс
var loopCondition = il.DefineLabel(); // Объявляем метку на проверку условия выхода из цикла
var loopBody = il.DefineLabel(); // Объявляем метку на тело цикла
il.LoadZero(); //
il.SetLocal(index); // Обнуляем индекс
il.Jump(loopCondition); // Прыгаем на проверку условия цикла
il.MarkLabel(loopBody); // Отмечаем начало тела цикла
{
var xElement = il.GetArrayElement(elementType, x, index); // Получаем элемент первого массива
var yElement = il.GetArrayElement(elementType, y, index); // Получаем элемент второго массива
CompareObjectsInternal(elementType, xElement, yElement); // Сравниваем элементы
il.Increment(index); // Увеличиваем счётчик
}
il.MarkLabel(loopCondition); // Отмечаем метку проверки условия выхода из цикла
{
il.LoadLocal(index); // Загружаем текущее значение индекса
il.LoadArrayLength(x); // Загружаем длину массива
il.JumpWhenLess(loopBody); // Если индекс не вышел за пределы диапазона, то прыгаем в тело цикла
}
}
```
Как мы уже отмечали выше, чтобы не ~~травмировать психику~~ засорять исходный текст кодами команд, мы будем использовать метода расширения. Поэтому представленный выше код выглядит не так уж и страшно. Как можно заметить в самом начале `CompareArrays` сравнивает длины массив и переходит к дальнейшему сравнению только в том случае, если они равны. Далее выполняется цикл поэлементного сравнения массивов, но так как в IL нет таких высокоуровневых операторов, как циклы, то мы определяем в нашем коде несколько базовых блоков: инициализацию счётчика, тело и проверку условия выхода из цикла. Переход же между этими блоками осуществляется с помощью инструкций условного перехода (`Jump, JumpWhenLess`) на метки `loopBody, loopCondition`.
**Код методов расширения**
```
// Загружает в стек значение заданной переменной
public static void LoadLocal(this ILGenerator il, LocalBuilder x) => il.Emit(OpCodes.Ldloc, x);
// Извлекает из стека значение и присваивает его заданной переменной
public static void SetLocal(this ILGenerator il, LocalBuilder x) => il.Emit(OpCodes.Stloc, x);
// Загружает в стек длину заданного массива
public static void LoadArrayLength(this ILGenerator il, LocalBuilder array)
{
il.LoadLocal(array);
il.Emit(OpCodes.Ldlen);
il.Emit(OpCodes.Conv_I4);
}
// Извлекает из стека массив и индекса, а загружает в стек элемент массива с заданным индексом
public static void LoadArrayElement(this ILGenerator il, Type type)
{
if (type.IsEnum)
{
type = Enum.GetUnderlyingType(type);
}
if (type.IsPrimitive)
{
if (type == typeof (IntPtr) || type == typeof (UIntPtr))
{
il.Emit(OpCodes.Ldelem_I);
}
else
{
OpCode opCode;
switch (Type.GetTypeCode(type))
{
case TypeCode.Boolean:
case TypeCode.Int32:
opCode = OpCodes.Ldelem_I4;
break;
case TypeCode.Char:
case TypeCode.UInt16:
opCode = OpCodes.Ldelem_U2;
break;
case TypeCode.SByte:
opCode = OpCodes.Ldelem_I1;
break;
case TypeCode.Byte:
opCode = OpCodes.Ldelem_U1;
break;
case TypeCode.Int16:
opCode = OpCodes.Ldelem_I2;
break;
case TypeCode.UInt32:
opCode = OpCodes.Ldelem_U4;
break;
case TypeCode.Int64:
case TypeCode.UInt64:
opCode = OpCodes.Ldelem_I8;
break;
case TypeCode.Single:
opCode = OpCodes.Ldelem_R4;
break;
case TypeCode.Double:
opCode = OpCodes.Ldelem_R8;
break;
default:
throw new ArgumentOutOfRangeException();
}
il.Emit(opCode);
}
}
else if (type.IsValueType)
{
il.Emit(OpCodes.Ldelema, type);
}
else
{
il.Emit(OpCodes.Ldelem_Ref);
}
}
// Возвращает новую переменную, содержащую элемент массива с заданным индексом
public static LocalBuilder GetArrayElement(this ILGenerator il, Type elementType, LocalBuilder array, LocalBuilder index)
{
var x = il.DeclareLocal(elementType);
il.LoadLocal(array);
il.LoadLocal(index);
il.LoadArrayElement(elementType);
il.SetLocal(x);
return x;
}
// Увеличивает значение заданной переменной на единицу
public static void Increment(this ILGenerator il, LocalBuilder x)
{
il.LoadLocal(x);
il.LoadOne();
il.Emit(OpCodes.Add);
il.SetLocal(x);
}
```
Попробуем применить `DynamicCodeComparer` к типу `SimpleClass`, который мы использовали для сравнения прозводительности рефлексивного компарера:
**Сгенерированный метод - IL**
```
.method public static
bool __DynamicCompare (
object '',
object ''
) cil managed
{
// Method begins at RVA 0x2050
// Code size 215 (0xd7)
.maxstack 15
.locals init (
[0] class SimpleClass,
[1] class SimpleClass,
[2] int32,
[3] int32,
[4] valuetype Struct,
[5] valuetype Struct,
[6] int32,
[7] int32,
[8] float64,
[9] float64,
[10] string,
[11] string
)
IL_0000: ldarg.0
IL_0001: castclass SimpleClass
IL_0006: stloc.0
IL_0007: ldarg.1
IL_0008: castclass SimpleClass
IL_000d: stloc.1
IL_000e: ldloc.0
IL_000f: ldloc.1
IL_0010: beq IL_00d5
IL_0015: ldloc.0
IL_0016: ldnull
IL_0017: ceq
IL_0019: ldloc.1
IL_001a: ldnull
IL_001b: ceq
IL_001d: beq IL_0024
IL_0022: ldc.i4.0
IL_0023: ret
IL_0024: ldloc.0
IL_0025: callvirt instance int32 SimpleClass::get_A()
IL_002a: stloc.2
IL_002b: ldloc.1
IL_002c: callvirt instance int32 SimpleClass::get_A()
IL_0031: stloc.3
IL_0032: ldloc.2
IL_0033: ldloc.3
IL_0034: beq IL_003b
IL_0039: ldc.i4.0
IL_003a: ret
IL_003b: ldloc.0
IL_003c: callvirt instance valuetype Struct SimpleClass::get_B()
IL_0041: stloc.s 4
IL_0043: ldloc.1
IL_0044: callvirt instance valuetype Struct SimpleClass::get_B()
IL_0049: stloc.s 5
IL_004b: ldloca.s 4
IL_004d: call instance int32 Struct::get_A()
IL_0052: stloc.s 6
IL_0054: ldloca.s 5
IL_0056: call instance int32 Struct::get_A()
IL_005b: stloc.s 7
IL_005d: ldloc.s 6
IL_005f: ldloc.s 7
IL_0061: beq IL_0068
IL_0066: ldc.i4.0
IL_0067: ret
IL_0068: ldloca.s 4
IL_006a: call instance float64 Struct::get_B()
IL_006f: stloc.s 8
IL_0071: ldloca.s 5
IL_0073: call instance float64 Struct::get_B()
IL_0078: stloc.s 9
IL_007a: ldloc.s 8
IL_007c: call bool [mscorlib]System.Double::IsNaN(float64)
IL_0081: ldloc.s 9
IL_0083: call bool [mscorlib]System.Double::IsNaN(float64)
IL_0088: and
IL_0089: brtrue IL_0099
IL_008e: ldloc.s 8
IL_0090: ldloc.s 9
IL_0092: beq IL_0099
IL_0097: ldc.i4.0
IL_0098: ret
IL_0099: ldloca.s 4
IL_009b: call instance string Struct::get_C()
IL_00a0: stloc.s 10
IL_00a2: ldloca.s 5
IL_00a4: call instance string Struct::get_C()
IL_00a9: stloc.s 11
IL_00ab: ldloc.s 10
IL_00ad: ldloc.s 11
IL_00af: beq IL_00d5
IL_00b4: ldloc.s 10
IL_00b6: ldnull
IL_00b7: ceq
IL_00b9: ldloc.s 11
IL_00bb: ldnull
IL_00bc: ceq
IL_00be: beq IL_00c5
IL_00c3: ldc.i4.0
IL_00c4: ret
IL_00c5: ldloc.s 10
IL_00c7: ldloc.s 11
IL_00c9: call instance bool [mscorlib]System.String::Equals(string)
IL_00ce: brtrue IL_00d5
IL_00d3: ldc.i4.0
IL_00d4: ret
IL_00d5: ldc.i4.1
IL_00d6: ret
} // end of method Test::__DynamicCompare
```
**Сгенерированный метод - C# (декомпилирован с помощью ILSpy)**
```
public static bool __DynamicCompare(object obj, object obj2)
{
SimpleClass simpleClass = (SimpleClass)obj;
SimpleClass simpleClass2 = (SimpleClass)obj2;
if (simpleClass != simpleClass2)
{
if (simpleClass == null != (simpleClass2 == null))
{
return false;
}
int a = simpleClass.A;
int a2 = simpleClass2.A;
if (a != a2)
{
return false;
}
Struct b = simpleClass.B;
Struct b2 = simpleClass2.B;
int a3 = b.get_A();
int a4 = b2.get_A();
if (a3 != a4)
{
return false;
}
double b3 = b.get_B();
double b4 = b2.get_B();
if (!(double.IsNaN(b3) & double.IsNaN(b4)) && b3 != b4)
{
return false;
}
string c = b.get_C();
string c2 = b2.get_C();
if (c != c2)
{
if (c == null != (c2 == null))
{
return false;
}
if (!c.Equals(c2))
{
return false;
}
}
}
return true;
}
```
Декомпилированный метод выглядит достаточно понятно, чтобы проверить, что он корректно выполняет сравнение. Единственное к чему можно было бы придраться, так это обилие временных переменных, но это, как говорится, издержки производства.
##### Результаты
Ниже представлены результаты сравнения производительности `DynamicCodeComparer, ReflectionComparer` и написанного вручную сравнения на тех же входных данных, на которых мы проводили наш микробенчмарк для рефлексивного компарера. Как видно генерация IL позволяет получить гораздо более эффективную реализацию по сравнению с рефлексией.
**Код микробенчмарка**
```
public struct Struct
{
private int m_a;
private double m_b;
private string m_c;
public int A => m_a;
public double B => m_b;
public string C => m_c;
public Struct(int a, double b, string c)
{
m_a = a;
m_b = b;
m_c = c;
}
}
public class SimpleClass
{
public int A { get; set; }
public Struct B { get; set; }
}
public class ComplexClass
{
public int A { get; set; }
public IntPtr B { get; set; }
public UIntPtr C { get; set; }
public string D { get; set; }
public SimpleClass E { get; set; }
public int? F { get; set; }
public int[] G { get; set; }
public List H { get; set; }
public double I { get; set; }
public float J { get; set; }
}
[BenchmarkTask(platform: BenchmarkPlatform.X86, jitVersion: BenchmarkJitVersion.LegacyJit)]
[BenchmarkTask(platform: BenchmarkPlatform.X64, jitVersion: BenchmarkJitVersion.LegacyJit)]
[BenchmarkTask(platform: BenchmarkPlatform.X64, jitVersion: BenchmarkJitVersion.RyuJit)]
public class ComplexComparisonTest
{
private static int[] MakeArray(int count)
{
var array = new int[count];
for (int i = 0; i < array.Length; ++i)
array[i] = i;
return array;
}
private static List MakeList(int count)
{
var list = new List(count);
for (int i = 0; i < list.Count; ++i)
list.Add(i);
return list;
}
private ComplexClass x = new ComplexClass
{
A = 2,
B = new IntPtr(2),
C = new UIntPtr(2),
D = "Habrahabr!",
E = new SimpleClass { A = 42, B = new Struct(42, 3.14, "meow") },
F = 1,
G = MakeArray(100),
H = MakeList(100),
I = double.MaxValue,
J = float.MaxValue
};
private ComplexClass y = new ComplexClass
{
A = 2,
B = new IntPtr(2),
C = new UIntPtr(2),
D = "Habrahabr!",
E = new SimpleClass { A = 42, B = new Struct(42, 3.14, "meow") },
F = 1,
G = MakeArray(100),
H = MakeList(100),
I = double.MaxValue,
J = float.MaxValue
};
private ReflectionComparer reflectionComparer = new ReflectionComparer();
private DynamicCodeComparer dynamicCodeComparer = new DynamicCodeComparer();
[Benchmark]
public void ReflectionCompare()
{
var \_ = reflectionComparer.Equals(x, y);
}
[Benchmark]
public void DynamicCodeCompare()
{
var \_ = dynamicCodeComparer.Equals(x, y);
}
[Benchmark]
public void ManualCompare()
{
var \_ = CompareComplexObjects();
}
private bool CompareComplexObjects()
{
if (x == y) return true;
if (x.A != y.A) return false;
if (x.B != y.B) return false;
if (x.C != y.C) return false;
if (x.D != y.D) return false;
if (x.E != y.E)
{
if (x.E.A != y.E.A) return false;
var s1 = x.E.B;
var s2 = y.E.B;
if (s1.A != s2.A) return false;
if (!s1.B.Equals(s2.B)) return false;
if (s1.C != s2.C) return false;
}
if (x.F != y.F) return false;
if (x.G != y.G)
{
if (x.G?.Length != y.G?.Length) return false;
int[] a = x.G, b = y.G;
for (int i = 0; i < a.Length; ++i)
{
if (a[i] != b[i]) return false;
}
}
if (x.H != y.H)
{
if (!x.H.SequenceEqual(y.H)) return false;
}
if (!x.I.Equals(y.I)) return false;
if (!x.J.Equals(y.J)) return false;
return true;
}
}
[BenchmarkTask(platform: BenchmarkPlatform.X86, jitVersion: BenchmarkJitVersion.LegacyJit)]
[BenchmarkTask(platform: BenchmarkPlatform.X64, jitVersion: BenchmarkJitVersion.LegacyJit)]
[BenchmarkTask(platform: BenchmarkPlatform.X64, jitVersion: BenchmarkJitVersion.RyuJit)]
public class SimpleComparisonTest
{
private SimpleClass x = new SimpleClass { A = 42, B = new Struct(42, 3.14, "meow") };
private SimpleClass y = new SimpleClass { A = 42, B = new Struct(42, 3.14, "meow") };
private ReflectionComparer reflectionComparer = new ReflectionComparer();
private DynamicCodeComparer dynamicCodeComparer = new DynamicCodeComparer();
[Benchmark]
public void ReflectionCompare()
{
var \_ = reflectionComparer.Equals(x, y);
}
[Benchmark]
public void DynamicCodeCompare()
{
var \_ = dynamicCodeComparer.Equals(x, y);
}
[Benchmark]
public void ManualCompare()
{
var \_ = CompareSimpleObjects();
}
private bool CompareSimpleObjects()
{
if (x == y) return true;
if (x.A != y.A) return false;
var s1 = x.B;
var s2 = y.B;
if (s1.A != s2.A) return false;
if (!s1.B.Equals(s2.B)) return false;
if (s1.C != s2.C) return false;
return true;
}
}
```
**Результаты сравнения объектов ComplexClass**
| Method | Platform | Jit | AvrTime | StdDev | op/s |
| --- | --- | --- | --- | --- | --- |
| DynamicCodeComparer | X64 | LegacyJit | 1,104.7155 ns | 32.9474 ns | 905,210.51 |
| Handwritten | X64 | LegacyJit | 1,360.3273 ns | 39.9703 ns | 735,117.32 |
| ReflectionComparer | X64 | LegacyJit | 38,043.3600 ns | 2,261.3159 ns | 26,290.11 |
| DynamicCodeComparer | X64 | RyuJit | 834.8742 ns | 58.1986 ns | 1,197,785.93 |
| Handwritten | X64 | RyuJit | 968.3789 ns | 33.1622 ns | 1,032,653.82 |
| ReflectionComparer | X64 | RyuJit | 37,751.3104 ns | 1,763.3172 ns | 26,489.20 |
| DynamicCodeComparer | X86 | LegacyJit | 776.0265 ns | 22.8038 ns | 1,288,615.79 |
| Handwritten | X86 | LegacyJit | 915.5713 ns | 26.0536 ns | 1,092,214.32 |
| ReflectionComparer | X86 | LegacyJit | 32,382.2746 ns | 1,748.4016 ns | 30,881.10 |
**Результаты сравнения объектов SimpleClass**
| Method | Platform | Jit | AvrTime | StdDev | op/s |
| --- | --- | --- | --- | --- | --- |
| DynamicCodeComparer | X64 | LegacyJit | 215.7626 ns | 8.2063 ns | 4,634,725.08 |
| Handwritten | X64 | LegacyJit | 160.4945 ns | 6.8949 ns | 6,230,741.94 |
| ReflectionComparer | X64 | LegacyJit | 6,654.3290 ns | 380.7790 ns | 150,278.15 |
| DynamicCodeComparer | X64 | RyuJit | 168.4194 ns | 9.4654 ns | 5,937,569.56 |
| Handwritten | X64 | RyuJit | 87.8513 ns | 3.3118 ns | 11,382,874.20 |
| ReflectionComparer | X64 | RyuJit | 6,954.6437 ns | 387.1803 ns | 143,789.85 |
| DynamicCodeComparer | X86 | LegacyJit | 180.4105 ns | 6.5036 ns | 5,542,914.59 |
| Handwritten | X86 | LegacyJit | 93.0846 ns | 4.0584 ns | 10,742,923.17 |
| ReflectionComparer | X86 | LegacyJit | 6,431.5783 ns | 314.5633 ns | 155,483.09 |
##### Заключение
Фред Брукс в своей знаменитой статье «No silver bullet» подчёркивает разницу между ненужными случайными сложностями (accidental complexity) и имманентными сложностями (essential complexity), внутренне присущими самой решаемой задаче. Использование рефлексии зачастую является примером такой ненужной сложности, возникшей из-за того, что в какой-то момент дизайну программной системы не было уделено достаточно внимания. Поэтому прежде чем кидаться скорее использовать рефексию или кодогенерацию проверьте, может быть ещё не поздно подкорректировать проектное решение. Конкретно в моём случае сравнение могло было бы выполняться одной строчкой, если бы все сравниваемые объекты реализовывали бы интерфейс `IEquatable`. Тем не менее я получил решение, которое возможно кому-нибудь ещё окажется полезным.
Засим откланиваюсь, дорогие читатели. Приятного программирования!
Полезные ресурсы:
* [Исходный код к статье](https://github.com/akarpov89/DynamicComparer)
* [Джозеф Албахари, Бен Албахари. C# 5.0. Справочник. Полное описание языка](http://www.williamspublishing.com/Books/978-5-8459-1819-2.html)
* [Serge Lidin. Expert .NET 2.0 IL Assembler](http://www.apress.com/9781590596463)
* MSDN — [System.Reflection.Emit Namespace](https://msdn.microsoft.com/en-us/library/system.reflection.emit%28v%3Dvs.110%29.aspx)
* Библиотека [BenchmarkDotNet](https://github.com/PerfDotNet/BenchmarkDotNet)
* [Try Roslyn](http://tryroslyn.azurewebsites.net/) | https://habr.com/ru/post/269699/ | null | ru | null |
# Миграция кода с Oracle на PostgreSQL: особенности и пути обхода, средства конвертации, вспомогательные модули
Эта статья завершает цикл о миграции с СУБД Oracle на СУБД PostgreSQL. В первых двух статьях рассматривались вопросы и устоявшиеся способы переноса данных из одной СУБД в другую ([часть 1](https://habr.com/ru/company/postgrespro/blog/676792/), [часть 2](https://habr.com/ru/company/postgrespro/blog/679808/)). [В третьей статье](https://habr.com/ru/company/postgrespro/blog/683748/) представлена часть особенностей, которые нужно учесть при переводе хранимого кода с PL/SQL на PL/pgSQL. В сегодняшнем материале рассматриваются:
1. Оставшаяся часть особенностей.
2. Адаптация и конвертация кода.
3. Выбор средств для конвертации кода.
### Глобальные структуры данных уровня пакета
Для таких структур рекомендуется использовать [**модуль** **pg\_variables**](https://github.com/postgrespro/pg_variables). Он позволяет сохранять как скалярные значения, так и множество записей, массивы.
При этом нужно понимать, требуется ли собирать статистику для планировщика. Если да, то придётся пользоваться временными таблицами. По возможности, их **лучше не использовать слишком интенсивно**. Создание и удаление временных таблиц ведёт к изменениям в системном каталоге и сообщениям об инвалидации. Может возникнуть ситуация, когда серверным процессам для своей работы придётся многократно перечитывать системный каталог.
**Пример**: у одного клиента процессы СУБД тратили большое количество времени на планирование запросов, поскольку они многократно пытались прочитать данные [pg\_statistic](https://postgrespro.ru/docs/postgresql/14/catalog-pg-statistic) и [pg\_class](https://postgrespro.ru/docs/postgresql/14/catalog-pg-class) и при этом взять соответствующие блокировки. pg\_statistic и pg\_class являются одними из наиболее часто используемых объектов СУБД, поэтому время ожидания получения блокировки было существенным. Соответственно, **от создания и удаления временных таблиц на каждую транзакцию пришлось отказаться**.
**pg\_variables можно использовать на реплике** – работа с модулем не приводит к изменениям в системном каталоге. Временные таблицы использовать не получится, поскольку реплика не позволяет делать изменения в словаре данных.
### Пользовательские исключения
В языке PL/SQL разработчик может создать свои собственные пользовательские исключения для обработки ошибок. Они могут быть созданы в блоке объявлений подпрограммы, при этом использовать их можно только внутри неё. Вызвать исключение нужно явно с помощью оператора[RAISE](https://docs.oracle.com/en/database/oracle/oracle-database/21/lnpls/RAISE-statement.html) или процедуры [RAISE\_APPLICATION\_ERROR](https://docs.oracle.com/en/database/oracle/oracle-database/19/lnpls/plsql-error-handling.html#GUID-48F88C61-8CE9-4821-91CB-48A8F1BC09E11-91CB-48A8F1BC09E1) пакета DBMS\_STANDARD. Ниже приведён пример:
```
CREATE TABLE customers (
id INTEGER,
name VARCHAR2(100),
address VARCHAR2(2000)
);
INSERT INTO customers VALUES(1, 'Тестовый пользователь 1', 'Тестовый адрес 1');
INSERT INTO customers VALUES(2, 'Тестовый пользователь 2', 'Тестовый адрес 2');
INSERT INTO customers VALUES(3, 'Тестовый пользователь 3', 'Тестовый адрес 3');
ALTER TABLE customers ADD CONSTRAINT customers_pk PRIMARY KEY (id);
DECLARE
c_id customers.id%type := &cc_id;
c_name customers.name%type;
c_addr customers.address%type;
ex_invalid_id EXCEPTION;
BEGIN
IF c_id <= 0 THEN
RAISE ex_invalid_id;
END IF;
SELECT c.name, c.address INTO c_name, c_addr
FROM customers c
WHERE c.id = c_id;
dbms_output.put_line('Имя: '|| c_name);
dbms_output.put_line('Адрес: ' || c_addr);
EXCEPTION
WHEN ex_invalid_id THEN
dbms_output.put_line('Идентификатор клиента не может быть отрицательным');
WHEN no_data_found THEN
dbms_output.put_line('Клиент не найден');
END;
```
Ниже приведён пример перевода кода на СУБД PostgreSQL:
```
CREATE TABLE customers (
id bigint,
name VARCHAR(100),
address VARCHAR(2000)
);
INSERT INTO customers VALUES(1, 'Тестовый пользователь 1', 'Тестовый адрес 1');
INSERT INTO customers VALUES(2, 'Тестовый пользователь 2', 'Тестовый адрес 2');
INSERT INTO customers VALUES(3, 'Тестовый пользователь 3', 'Тестовый адрес 3');
ALTER TABLE customers ADD CONSTRAINT customers_pk PRIMARY KEY (id);
CREATE OR REPLACE FUNCTION ex_invalid_id() RETURNS text AS
$$
SELECT '06502';
$$
LANGUAGE SQL IMMUTABLE;
DO
$$
DECLARE
c_id customers.id%type := 5;
c_name customers.name%type;
c_addr customers.address%type;
BEGIN
IF c_id <= 0 THEN
RAISE EXCEPTION USING errcode = ex_invalid_id();
END IF;
SELECT c.name, c.address INTO STRICT c_name, c_addr
FROM customers c
WHERE c.id = c_id;
RAISE NOTICE 'Имя: %', c_name;
RAISE NOTICE 'Адрес: %', c_addr;
EXCEPTION
WHEN no_data_found THEN
RAISE NOTICE 'Клиент не найден';
WHEN others THEN
CASE SQLSTATE
WHEN ex_invalid_id() THEN
RAISE NOTICE 'Идентификатор клиента не может быть отрицательным';
END CASE;
END
$$
LANGUAGE plpgsql;
```
Но есть один нюанс, касающийся исключений и их обработки. **Во время выполнения BEGIN создаётся точка сохранения (**[**SAVEPOINT**](https://postgrespro.ru/docs/postgresql/14/sql-savepoint)**), т.е. подтранзакция**. Если главная транзакция успешно завершена, то будут подтверждены изменения всех её подтранзакций. Но если подтранзакция по какой-то причине прервалась, то её изменения отменяются. При обработке блока EXCEPTION неявно вызывается команда [ROLLBACK TO SAVEPOINT](https://postgrespro.ru/docs/postgresql/14/sql-rollback-to).
При этом у каждой транзакции есть свой кеш подтранзакций, в котором хранятся их статусы. При создании снимка данных и проверки того, видно ту или иную строку или нет, нужно посмотреть статусы транзакции и её подтранзакций. В Postgres **у каждого процесса кеш из 64 подтранзакций**.
Если у хотя бы одной транзакции **кэш переполнится**, **все процессы будут обращаться к структуре pg\_subtrans**. Был случай, когда все процессы ждали, когда в общий буферный кэш запишется нужная информация из **pg\_subtrans**. То есть вместо выполнения расчётов все процессы ждали, это негативно сказалось на производительности приложения. Чтобы не попасть в такую ситуацию, разработчику приложения придётся думать над тем, сколько точек сохранения будет создано при обработке PL/pgSQL кода.
Если в хранимом коде много таких блоков, нужно попытаться снизить их количество или всё-таки вынести обработку на сторону приложения без их использования, исключения при этом можно обрабатывать средствами прикладного языка программирования.
### Операторы MERGE, INSERT FIRST и INSERT ALL
В СУБД Oracle часто применяется оператор [MERGE](https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/MERGE.html) для добавления новых записей и изменения существующих. Ниже приведён пример:
```
CREATE TABLE members (
member_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50) NOT NULL,
last_name VARCHAR2(50) NOT NULL,
rank VARCHAR2(20)
);
CREATE TABLE member_staging AS
SELECT * FROM members;
INSERT INTO members(member_id, first_name, last_name, rank)
VALUES(1, 'Имя1', 'Фамилия1', 'Золото');
INSERT INTO members(member_id, first_name, last_name, rank)
VALUES(2, 'Имя2', 'Фамилия2', 'Платина');
INSERT INTO member_staging(member_id, first_name, last_name, rank)
VALUES(1, 'Имя1', 'Фамилия1', 'Золото1');
INSERT INTO member_staging(member_id, first_name, last_name, rank)
VALUES(2, 'Имя2', 'Фамилия2', 'Платина1');
INSERT INTO member_staging(member_id, first_name, last_name, rank)
VALUES(3, 'Имя3', 'Фамилия3', 'Серебро1');
MERGE INTO member_staging x
USING (SELECT member_id, first_name, last_name, rank FROM members) y
ON (x.member_id = y.member_id)
WHEN MATCHED THEN
UPDATE
SET x.first_name = y.first_name
, x.last_name = y.last_name
, x.rank = y.rank
WHERE x.first_name <> y.first_name OR
x.last_name <> y.last_name OR
x.rank <> y.rank
WHEN NOT MATCHED THEN
INSERT (x.member_id, x.first_name, x.last_name, x.rank)
VALUES (y.member_id, y.first_name, y.last_name, y.rank);
```
В СУБД PostgreSQL оператор [**MERGE**](#commit_7103ebb7) добавлен в 15-ую версию, в ранних выпусках **вместо него в ряде случаев возможно использовать** [**INSERT ON CONFLICT DO UPDATE**](https://postgrespro.ru/docs/postgresql/14/sql-insert#SQL-ON-CONFLICT)**:**
```
CREATE TABLE members (
member_id bigint,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
rank VARCHAR(20)
);
CREATE TABLE member_staging (
member_id bigint,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
rank VARCHAR(20)
);
INSERT INTO members(member_id, first_name, last_name, rank)
VALUES(1, 'Имя1', 'Фамилия1', 'Золото');
INSERT INTO members(member_id, first_name, last_name, rank)
VALUES(2, 'Имя2', 'Фамилия2', 'Платина');
INSERT INTO member_staging(member_id, first_name, last_name, rank)
VALUES(1, 'Имя1', 'Фамилия1', 'Золото1');
INSERT INTO member_staging(member_id, first_name, last_name, rank)
VALUES(2, 'Имя2', 'Фамилия2', 'Платина1');
INSERT INTO member_staging(member_id, first_name, last_name, rank)
VALUES(3, 'Имя3', 'Фамилия3', 'Серебро1');
ALTER TABLE members ADD CONSTRAINT members_pk PRIMARY KEY(member_id);
ALTER TABLE member_staging
ADD CONSTRAINT member_staging_pk PRIMARY KEY(member_id);
INSERT INTO member_staging AS x
SELECT m.member_id
, m.first_name
, m.last_name
, m.rank
FROM members m
ON CONFLICT (member_id)
DO UPDATE
SET first_name = EXCLUDED.first_name
, last_name = EXCLUDED.last_name
, rank = EXCLUDED.rank
WHERE x.member_id = EXCLUDED.member_id
AND (x.first_name <> EXCLUDED.first_name OR
x.last_name <> EXCLUDED.last_name OR
x.rank <> EXCLUDED.rank);
```
В СУБД PostgreSQL при одновременном выполнении нескольких команд вида **INSERT ON CONFLICT DO UPDATE** не происходит нарушений целостности данных, в отличии от СУБД Oracle. Там при одновременном выполнении нескольких команд **MERGE** возможно появление дубликатов, что приводит к нарушениям ограничений первичного ключа.
В СУБД Oracle конструкция [**INSERT ALL**](https://www.oracletutorial.com/oracle-basics/oracle-insert-all/) позволяет добавлять данные в несколько таблиц одновременно при выполнении одного запроса. При этом можно добавлять условия, что позволяет добавлять строки в определённую таблицу:
```
CREATE TABLE orders_t (
order_id NUMBER(12) PRIMARY KEY,
customer_id NUMBER(6) NOT NULL,
status VARCHAR2(20) NOT NULL,
salesman_id NUMBER(6),
order_date DATE NOT NULL
);
CREATE TABLE order_items_t (
order_id NUMBER(12),
item_id NUMBER(12),
product_id NUMBER(12) NOT NULL,
quantity NUMBER(8) NOT NULL,
unit_price NUMBER(8, 2) NOT NULL
);
CREATE TABLE small_orders (
order_id NUMBER(12) NOT NULL,
customer_id NUMBER(6) NOT NULL,
amount NUMBER(8,2)
);
CREATE TABLE medium_orders AS
SELECT *
FROM small_orders;
CREATE TABLE big_orders AS
SELECT *
FROM small_orders;
INSERT ALL
WHEN amount < 10000 THEN INTO small_orders
WHEN amount BETWEEN 10000 AND 30000 THEN INTO medium_orders
WHEN amount > 30000 THEN INTO big_orders
SELECT o.order_id
, o.customer_id
, oi.quantity * oi.unit_price AS amount
FROM orders_t o
JOIN order_items_t oi
ON oi.order_id = o.order_id;
```
Ниже приведён пример команды **INSERT FIRST,** при выполнении которой каждая строка подзапроса проверяется на выполнение условий **WHEN**. При выполнении условия строка запишется в соответствующую таблицу, остальные условия проверяться не будут.
```
INSERT FIRST
WHEN amount > 30000 THEN INTO big_orders
WHEN amount >= 10000 THEN INTO medium_orders
WHEN amount > 0 THEN INTO small_orders
SELECT o.order_id
, o.customer_id
, oi.quantity * oi.unit_price AS amount
FROM orders_t o
JOIN order_items_t oi
ON oi.order_id = o.order_id;
```
В СУБД PostgreSQL применяются [**общие табличные выражения**](https://postgrespro.ru/docs/postgresql/14/queries-with) **(CTE) и, при необходимости, ключевое слово RETURNING.**
```
CREATE TABLE orders_t (
order_id bigint PRIMARY KEY,
customer_id int NOT NULL,
status VARCHAR(20) NOT NULL,
salesman_id int,
order_date timestamp NOT NULL
);
CREATE TABLE order_items_t (
order_id bigint,
item_id bigint,
product_id bigint NOT NULL,
quantity int NOT NULL,
unit_price numeric(8,2) NOT NULL
);
CREATE TABLE small_orders (
order_id bigint NOT NULL,
customer_id int NOT NULL,
amount numeric(8,2)
);
CREATE TABLE medium_orders AS
SELECT *
FROM small_orders;
CREATE TABLE big_orders AS
SELECT *
FROM small_orders LIKE small_orders(all);
WITH orders AS (
SELECT o.order_id
, o.customer_id
, oi.quantity * oi.unit_price AS amount
FROM orders_t o
JOIN order_items_t oi
ON oi.order_id = o.order_id
),
so AS (
INSERT INTO small_orders
SELECT s.*
FROM orders s
WHERE s.amount < 10000
),
mo AS (
INSERT INTO medium_orders
SELECT s.*
FROM orders s
WHERE s.amount BETWEEN 10000 AND 30000
)
INSERT INTO big_orders
SELECT s.*
FROM orders s
WHERE s.amount > 30000;
```
Стоит отметить, что начиная с 12-ой версии СУБД PostgreSQL [поведение CTE можно контролировать в плане материализации полученного множества](https://habr.com/ru/company/postgrespro/blog/451344). Также запросы в WITH в общем случае могут выполняться параллельно и потому порядок их выполнения непредсказуем. В частности, для контроля порядка выполнения и используется конструкция RETURNING.
Пользуясь случаем, остановимся подробнее на **INSERT ON CONFLICT DO UPDATE**. Часто возникают ситуации, при которых разработчики применяют конструкции **INSERT INTO TABLE VALUES** следующим образом.
```
insert into "user_sequence" ("user_id","seq","timestamp","rkey","mapping")
values ($1,$2,$3,$4,$5),($6,$7,$8,$9,$10),($11,$12,$13,$14,$15),
($16,$17,$18,$19,$20),($21,$22,$23,$24,$25),($26,$27,$28,$29,$30),
($31,$32,$33,$34,$35),($36,$37,$38,$39,$40),($41,$42,$43,$44,$45),
($46,$47,$48,$49,$50),($51,$52,$53,$54,$55),($56,$57,$58,$59,$60),
($61,$62,$63,$64,$65),($66,$67,$68,$69,$70),($71,$72,$73,$74,$75),
($76,$77,$78,$79,$80),($81,$82,$83,$84,$85),($86,$87,$88,$89,$90),
($91,$92,$93,$94,$95),($96,$97,$98,$99,$100),
($101,$102,$103,$104,$105),($106,$107,$108,$109,$110),
($111,$112,$113,$114,$115),($116,$117,$118,$119,$120),
($121,$122,$123,$124,$125),($126,$127,$128,$129,$130),
($131,$132,$133,$134,$135),($136,$137,$138,$139,$140),
($141,$142,$143,$144,$145),($146,$147,$148,$149,$150),
($151,$152,$153,$154,$155),($156,$157,$158,$159,$160);
```
При этом разработчики используют связанные переменные (**bind variables**) и надеются на хорошую производительность. Но её не будет, поскольку текст запроса меняется в зависимости от количества строк. PostgreSQL будет постоянно разбирать и планировать эти запросы, производительность будет не очень высокой.
Существуют два подхода, которые позволяют избежать этой проблемы.
Во-первых, можно использовать команду [COPY](https://postgrespro.ru/docs/postgresql/14/sql-copy). Если известно, что данные только добавляются, но никогда не меняются, можно заменить этот длинный INSERT на команду COPY. Она работает быстрее, вопросов с планированием здесь не возникнет.
Во-вторых, если требуется **INSERT ON CONFLICT DO UPDATE**, можно поступить так:
1. Взять промежуточную таблицу.
2. Опустошить её с помощью [TRUNCATE](https://postgrespro.ru/docs/postgresql/14/sql-truncate).
3. Сохранить туда данные командой COPY.
4. Сделать INSERT INTO (таблица) SELECT FROM (промежуточная таблица) DO UPDATE.
**Конструкция** [**DECODE**](https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/DECODE.html)
Конструкция **DECODE** очень распространена в мире Oracle, **для её замены в Postgres можно использовать CASE**. В работе DECODE есть нюансы.
Предположим, что в DECODE есть 12 условий и четвёртое из них первой прошла проверку. В этом случае будет вычислено выражение, соответствующее ему, а все остальные условия от 5-го до 12-го не будут вычисляться.
**В модуле** [**orafce**](https://github.com/orafce/orafce) **есть DECODE, но в виде функции.** Это означает, что до вызова функции нужно вычислить все её аргументы. В процессе функционального тестирования одной из конструкций **DECODE** выяснилось, что её последним выражением является деление единицы на ноль. В Oracle ошибки не было, потому что до этого выражения DECODE бы не дошёл. PostgreSQL же считает все аргументы функции до её выполнения ,поэтому возникла ошибка деления на ноль. Пришлось переписывать конструкцию, используя CASE. Код стал чуть более громоздким, но ошибки при этом перестали появляться.
**Вложенные определения функций**
Следует запомнить, что в PostgreSQL **вложенные определения функций не поддерживаются** и требуют оформления в виде отдельных функций.
**Функция определения схожести строк**
Иногда возникает потребность проверки строк на фонетическую схожесть. Для этого существуют различные алгоритмы, такие как:
* Jaro-Winkler.
* Levenshtein.
* Soundex distance.
**Схожий функционал предлагает** [**модуль pg\_similarity**](https://github.com/eulerto/pg_similarity)
Алгоритм **Levenshtein** **также поддерживается** **модулем** [**fuzzystrmatch**](https://postgrespro.ru/docs/postgresql/14/fuzzystrmatch), входящий в стандартную поставку СУБД PostgreSQL.
### Автономные транзакции
Для создания аналога автономных транзакций Oracle в СУБД PostgreSQL существуют три способа:
1. [**dblink**](https://postgrespro.ru/docs/postgresql/14/dblink). Создаётся отдельное подключение и отдельная независимая транзакция. Но стоит помнить, что при подключении к СУБД создаётся обслуживающий процесс, что является дорогой операцией.
2. **Использование фоновых процессов при помощи** [**pg\_background**](https://github.com/vibhorkum/pg_background). Потребуется оформить бизнес-логику в виде функции и поручить фоновому процессу её выполнить с помощью функции **pg\_background\_launch()**. Проверить результат выполнения можно с помощью функции **pg\_background\_result()**.
3. [Механизм автономных транзакций уже реализован в Postgres Pro Enterprise с версии 9.6.](https://postgrespro.ru/docs/enterprise/14/atx)
### Регрессионное тестирование хранимого кода
Ни одно приложение не обходится без тестов. Как минимум, нужно убедиться в том, что разработанное приложение корректно выполняет требования бизнеса. Это так называемое функциональное тестирование. Для него в PostgreSQL предусмотрено два решения -[**pgtap**](https://github.com/theory/pgtap)и[**pg\_prove**](https://metacpan.org/dist/TAP-Parser-SourceHandler-pgTAP/view/bin/pg_prove).
Что касается [**pgtap**](https://github.com/theory/pgtap)**, то это набор PL/pgSQL функций для написания тестов**. В частности, если есть функция и некоторые значения параметров, то можно прописать, что данная функция при таких-то условиях должна возвращать определённое значение или выбрасывать исключения.
Если говорить о [**pg\_prove**](https://metacpan.org/dist/TAP-Parser-SourceHandler-pgTAP/view/bin/pg_prove)**, то это написанная на Perl утилита для запуска разработанных с помощью pgtap регрессионных тестов.**
### Выполнение задач по расписанию
Здесь тоже есть ряд решений на выбор:
* [**pg\_cron**](https://github.com/citusdata/pg_cron)**.**
* [**pgAgent**](https://github.com/postgres/pgagent)**.**
* Модуль СУБД Postgres Pro Enterprise [**pgpro\_scheduler**](https://postgrespro.ru/docs/enterprise/14/pgpro-scheduler)**.**
* Любой планировщик заданий прикладного ЯП.
[В третьей части цикла было указано](https://habr.com/ru/company/postgrespro/blog/683748/), что [pgAgent](https://github.com/postgres/pgagent) можно устанавливать и использовать отдельно от [pgAdmin](https://github.com/postgres/pgadmin4). Он используется только для того, чтобы задавать задания для **pgAgent** в графическом интерфейсе. Для корректной работы **pgAgent** совсем необязательно использовать **pgAdmin**, можно обойтись обычным SQL-интерфейсом.
Если Вы клиент Postgres Professional и у Вас установлена версия Postgres Pro Enterprise, можно пользоваться [**pgpro\_scheduler**](https://postgrespro.ru/docs/enterprise/14/pgpro-scheduler).
Можно также использовать любой реализованный на прикладном языке программирования планировщик заданий и адаптировать его под свои требования.
### Конструкции-подсказки планировщику
Для конструкций-подсказок существует **модуль** [**pg\_hint\_plan**](https://github.com/ossc-db/pg_hint_plan), но он не является серебряной пулей. Во многих случаях запрос придётся оптимизировать и даже переписывать, причём не с точки зрения создания недостающего индекса, а с точки зрения его упрощения**.**
**pg\_hint\_plan** позволяет управлять:
* Методами доступа к строкам таблицы.
* Методами соединения множеств.
* Порядком соединения множеств (этого же можно добиться с помощью параметрами [join\_collapse\_limit](https://postgrespro.ru/docs/postgresql/14/runtime-config-query#GUC-JOIN-COLLAPSE-LIMIT) и [from\_collapse\_limit](https://postgrespro.ru/docs/postgresql/14/runtime-config-query#GUC-FROM-COLLAPSE-LIMIT)).
* Методами исправления количества возвращаемых строк.
* Параметрами GUC во время работы планировщика.
### Утилиты для автоматизации конвертации хранимого кода
Поговорим о решениях, позволяющих обеспечить автоматическую конвертацию хранимого кода:
* [ora2pg](https://github.com/darold/ora2pg) и производные от него решения ([LUI4ORA2PG](http://lui.fors.ru/LUI4ORA2PG)).
* [ANTLR4](https://github.com/antlr/antlr4) и грамматика для PL/SQL кода.
Уже упоминавшийся в предыдущих статьях [**модуль** **ora2pg**](https://github.com/darold/ora2pg)может преобразовать часть хранимого кода, но при работе со сложными вещами возможны нюансы, о которых будет рассказано далее. [**LUI4ORA2PG**](http://lui.fors.ru/LUI4ORA2PG) **- разработка компании «ФОРС»**. Это дорабатываемый инструмент, в котором можно создавать свои проекты миграции, в качестве основы разработчики используют ora2pg.
Пожалуй, **наиболее правильным подходом является использование грамматики для PL/SQL кода и техники** [**ANTLR4**](https://github.com/antlr/antlr4). В этом случае исходный код фактически преобразуется в дерево разбора. Разработчику придётся разработать логику обхода этого дерева самостоятельно, в результате, хранимый код исходной СУБД будет преобразован в соответствующий код целевой СУБД.
**Платные конвертеры сделаны на основе упомянутой выше технологии**. [В данном докладе](https://pgconf.ru/2020/271655) описан процесс автоматического перевода кода с PL/SQL на PL/pgSQL с помощью ANTLR4.
### Особенности конвертации кода утилитой ora2pg
Инструмент ora2pg не покрывает всевозможные конструкции хранимого кода. Приведём несколько примеров:
1. **Не поддерживается конвертация старого синтаксиса соединения таблиц в СУБД Oracle.**
2. **Частичная конвертация конструкции DECODE в CASE.**
3. **При конвертации строки в число исходная СУБД (Oracle) убирает лидирующие нули**. Речь идёт о неявном преобразовании типов. В PostgreSQL их надо убирать самостоятельно, в противном случае, запрос будет работать неверно. В частности, при соединении множеств нужно убедиться, что поля соединения одинакового типа и при этом корректно сравниваются. В противном случае, может быть синтаксическая ошибка или неверный результат выполнения.
4. **Не поддерживается конвертация старого и нового синтаксиса рекурсивных запросов.**
5. **Не всегда корректно преобразуются запросы с использованием двойных кавычек**. **Возможна потеря регистра.** Иногда ora2pg меняет регистр идентификаторов, заключённых в двойные кавычки. В некоторых случаях регистр имеет значение.
6. **Не поддерживается конвертация конструкции KEEP (DENSE\_RANK LAST ORDER BY) OVER(PARTITION BY ), нужно использовать расширение** [**first\_last\_agg**](https://github.com/wulczer/first_last_agg)**.**
7. **Не всегда корректно преобразуется код динамических запросов**. Иногда в хранимом коде требуется динамически формировать команды внутри функций, поскольку при каждом выполнении могут использоваться разные таблицы или типы данных. В СУБД Oracle для этого используется команда [**EXECUTE IMMEDIATE**](https://docs.oracle.com/en/database/oracle/oracle-database/21/lnpls/EXECUTE-IMMEDIATE-statement.html), а в СУБД PostgreSQL - [EXECUTE](https://postgrespro.ru/docs/postgresql/14/plpgsql-statements#PLPGSQL-STATEMENTS-EXECUTING-DYN).
Были случаи, когда динамический код просто оставался в исходном виде, нужно было его переписывать. В частности, в СУБД Postgres нет таких типов, как BLOB, VARCHAR, CLOB.
8. **Не конвертируется код с использованием пакетов** [**dbms\_xmldom**](https://docs.oracle.com/en/database/oracle/oracle-database/21/arpls/DBMS_XMLDOM.html)**,** [**dbms\_lob**](https://docs.oracle.com/en/database/oracle/oracle-database/21/arpls/DBMS_LOB.html) **и.т.д.**
### Модуль orafce
[**Модуль orafce**](https://github.com/orafce/orafce) **предоставляет функции и операторы для замены части функций и пакетов**:
* Тип [date](#oracledate-data-type) для хранения значений "дата + время”.
* [Функции](#date-functions) для работы с типом date (add\_months, next\_day, last\_day, months\_between, trunc).
* Пакеты [dbms\_output](#package-dbms_output), [utl\_file](#package-utl_file), [dbms\_pipe](#package-dbms_pipe), [dbms\_alert](#package-dbms_alert).
* [PLVstr и PLVchr](https://github.com/orafce/orafce#package-plvstr-and-plvchr) для работы со строками.
### Использование вспомогательных функций при работе планировщика
Стоит сказать пару слов и о функциях, которые возвращают множества. В Oracle речь идёт о конвейерной (pipeline) функции, которая на выходе возвращает множество. Рассмотрим пример.
```
CREATE OR REPLACE TYPE varchar_t AS TABLE OF VARCHAR2(4000);
CREATE OR REPLACE FUNCTION split_str(p_str VARCHAR, p_delim VARCHAR)
RETURN varchar_t PIPELINED AS
BEGIN
FOR v_row IN
(SELECT regexp_substr(p_str, '[^' || p_delim || ']+', 1, level) AS elem
, '[^' || p_delim || ']+' AS delim
FROM DUAL
CONNECT BY regexp_substr(p_str, '[^' || p_delim || ']+', 1, level) is not null
ORDER BY LEVEL
)
LOOP
PIPE ROW(v_row.elem);
END LOOP;
END;
SELECT * FROM TABLE(split_str('XXX,Y,ММ,AAAAA,B,CCC,D,E,F,GGG', ','));
```
Как правило, данный код заменяется в СУБД PostgreSQL на конструкцию вида:
```
SELECT * FROM regexp_split_to_table('XXX,Y,ММ,AAAAA,B,CCC,D,E,F,GGG', ',');
```
Ниже приведён её план выполнения.
```
QUERY PLAN
-----------------------------------------------------------------------------
Function Scan on regexp_split_to_table (cost=0.00..10.00 rows=1000 width=32)
(actual time=0.025..0.025 rows=10 loops=1)
```
Видно, что расчётное количество строк в 100 раз превышает фактическое. До 12-ой версии СУБД PostgreSQL с точки зрения планировщика функции были чёрным ящиком, в качестве расчётного количества строк бралось значение **prorows** из **pg\_proc**. Для функции **regexp\_split\_to\_table** данное значение = 1000. При дальнейшем использовании этого расчётного количества, например, при соединении с другим множеством существует возможность выбора некорректного метода соединения, что приведёт к деградации работы запроса в целом.
В 12-ой версии команда CREATE FUNCTION была расширена следующим образом:
```
CREATE FUNCTION name (...) RETURNS ...
SUPPORT supportfunction
AS
```
Т.е, появилась возможность предоставления вспомогательной функции, обладающей информацией об основной функции и способствующей выбору лучшего плана выполнения. При работе с функцией, возвращающей множество, PostgreSQL вызывает вспомогательную функцию для оценки количества получаемых строк. Это было разработано для функции **unnest()**, что позволяет заменить **regex\_split\_to\_table**() на следующую конструкцию:
```
SELECT * FROM unnest(regexp_split_to_array('XXX,Y,ММ,AAAAA,B,CCC,D,E,F,GGG', ','));
```
Ниже приведён план выполнения.
```
EXPLAIN(ANALYZE)
SELECT * FROM unnest(regexp_split_to_array('XXX,Y,ММ,AAAAA,B,CCC,D,E,F,GGG', ','));
QUERY PLAN
-----------------------------------------------------------------------------
Function Scan on unnest (cost=0.00..0.10 rows=10 width=32)
(actual time=0.012..0.014 rows=10 loops=1)
Planning Time: 2.591 ms
Execution Time: 0.353 ms
```
В этом случае расчётное количество строк не отличается от фактического.
[**Расширенная статистика в СУБД PostgreSQL**](#PLANNER-STATS-EXTENDED)
В СУБД Postgres предусмотрено **три вида расширенной статистики**:
1. **dependencies (функциональные зависимости).**
2. **n\_distinct (многовариантное число различных значений).**
3. **mcv (многовариантные списки MCV).**
Первый тип, **dependencies**, появился ещё в PostgreSQL 10 и служит для отслеживания функциональных зависимостей между столбцами. Например, если город - Казань, то его код 843, если город Москва, код - 495. **Эта расширенная статистика подходит для операций равенства, сравнивающих значения столбцов с константами, и условий IN с константами.** Она не используется при:
1. Проверке равенства двух столбцов или сравнении столбца с выражением.
2. Проверке условий диапазонов.
3. Проверке условий LIKE.
Для чего нужен **ndistinct**? Изначально в статистике СУБД PostgreSQL хранится информация о количестве уникальных значений столбца, но не для нескольких столбцов. Данный вид расширенной статистики **используется в оценке количества уникальных групп, полученных при выполнении GROUP BY.**
Статистика **mcv - список наиболее часто встречающихся значений**. Она доступна в PostgreSQL с версии 12 и позволяет определить наиболее часто встречающиеся значения для комбинации столбцов. Раньше они хранились только по одиночным столбцам. Если до этого в запросе было много условий фильтрации, объединённых логическими И (AND), то планировщик, как правило, ошибался в оценке расчётного количества строк. mcv позволяет планировщику оценить количество строк более точно.
**Расширенные статистики можно комбинировать между собой**. Пусть есть запрос с несколькими условиями фильтрации, объединённых операцией И (AND), с конструкцией GROUP BY по нескольким столбцам. Тогда можно создать расширенную статистику типа **mcv** и **ndistinct**, планировщик воспользуется ими для определения расчётного количества строк.
Также **в PostgreSQL 14 появилась возможность создавать статистику на набор вычисляемых столбцов**. Подробнее можно прочитать об этом [здесь](https://habr.com/ru/company/postgrespro/blog/550632/).
### Поиск некорректного PL/pgSQL кода и зависимостей
Существуют средства для проверки PL/pgSQL кода. [**Модуль plpgsql\_check**](https://github.com/okbob/plpgsql_check) позволяет отследить:
1. Некорректное использование типов параметров функций. Из-за этого, например, может использоваться полное сканирование таблицы вместо сканирования по индексу.
2. Неиспользуемые переменные и функции.
3. Отсутствие команды возврата значения.
4. Недостижимый код.
Ниже приведён пример вывода результата проверки функции.
Также **можно определять зависимости между объектами**.
### Модуль plprofiler
Иногда хранимый код работает недостаточно быстро, при этом причина сходу непонятна. В таких условиях можно использовать [**plprofiler**](https://github.com/bigsql/plprofiler)**.**
Во-первых, он предоставляет **визуальное отображение профилей нагрузки с указанием проблемных мест в хранимом коде**.
Во-вторых, он генерирует **HTML-отчёты**, которые можно проанализировать. Они создаются **для профилей производительности PL/pgSQL функций и процедур**.
В-третьих, для той или иной функции с помощью этого модуля можно узнать **процент от общего времени выполнения**. Вот как это выглядит.
Проблема здесь заключается в том, что у таблицы **pgbench\_accounts** нет индекса, у которого ключевое поле **aid** является лидирующим. Там есть индекс с полем **aid**, но оно не лидирующее. В результате запрос выполняется неоптимально.
Ещё один визуальный пример. Видно, что у **tpcb\_upd\_accounts()** есть некие проблемы, да и у **tpcb\_fetch\_abalance()** тоже, потому что её выполнение занимает половину общего времени. Причина также заключается в отсутствии индекса в таблице pgbench\_accounts, в котором столбец aid является лидирующим.
Стоит отметить, что **модуль plprofiler можно использовать в рамках трёх сценариев**:
1. Проверка и замер скорости работы определённой функции.
2. Замер скорости работы пользовательских процессов, оценка общего профиля нагрузки.
3. Использование модуля в промышленном окружении. Стоит отметить, что в промышленном окружении нельзя включить замеры работы для всех сессий, иначе просядет производительность. Тем не менее, профилирование можно включить на время. Есть риск, что часть нужной информации не будет записана. Некоторые функции могут начать свою работу до включения замеров.
Поэтому **для точного анализа сессий, которые выбиваются из общей картины, можно использовать модуль** [**pg\_query state**](https://github.com/postgrespro/pg_query_state). Он покажет запрос, выполняемый в настоящий момент времени, и его план выполнения.
В рамках цикла о миграции с СУБД Oracle и СУБД PostgreSQL была рассмотрена лишь часть случаев. На деле каждый случай миграции уникален. Многие клиенты всё чаще задумываются о переходе на PostgreSQL, но могут не учесть всех особенностей перевода. Специалисты компании Postgres Professional готовы восполнить эти пробелы. | https://habr.com/ru/post/683764/ | null | ru | null |
# Создаем HeatMap с помощью Google Spreadsheets
Новый гаджет в SpreadSheets позволяет создавать heatmap, то есть карту, показывающую, сколько пользователей в разных странах, например, ищут в гугле определенные слова. GoogleShare оценивает, как соответствуют друг другу два слова. Например, вы взяли количество индексированных страниц по запросу «Beatles» и «Beatles John Lennon», нашли их отношение и получили GoogleShare.
Для того, чтобы пользоваться GoogleShare, необходимо иметь список стран, который должен выглядеть примерно так.
| Country name | Country code | Googleshare | PageCount for country name | PageCount for country name + keyword |
| --- | --- | --- | --- | --- |
| China | CN | | | |
| India | IN | | | |
| USA | US | | | |
| *etc. ...* | *etc. ...* | | | |
Собираем информацию
-------------------
Попробуем собрать информацию о запросе «habrahabr». Для этого нам надо как-то получить количество страниц. В этом нам поможет функция importXml, имеющая два входных параметра: URL и XPath (язык запроса для XML-документов)
То есть, для того, чтобы показать, сколько страниц имеется для запроса habrahabr, впишем в ячейку следующее:
`=importXml("http://www.google.com/search?hl=en&q=habrahabr", "//td/font/b[3]")`
Добавляем мобильность
---------------------
Нам необходимо собрать информацию о том, сколько проиндексированных страниц имеется по запросу Russia, Britain и т.д. Вбиваем в колонку «PageCount for country name» следующий код, который берет информацию из ячейки и добавляет её к запросу:
`=importXml("http://www.google.com/search?hl=en&q=" & A2, "//td/font/b[3]")`
Больше мобильности — лучше результаты
-------------------------------------
Для того, чтобы не писать постоянно q=habrahabr и быть более универсальным, поместим наш запрос в какую-либо ячейку. Затем перейдем во вкладку Formulas, и назначим переменную для нашей ячейки (Formulas -> Range Names -> Define New).
Перепишем наш запрос, добавляя в него страну, чтобы определить, сколько страниц гугль проиндексировал для каждой страны.
`=importXml("http://www.google.com/search?hl=en&q=" & A2 & "+" & keyword, "//td/font/b[3]")`
Растягиваем содержимое этой формулы на весь столбец, чтобы получить сведения для других стран
Добавляем карту
---------------
Для добавления карты необходимо найти GoogleShare. Выделяем первую ячейку в соответствующем столбце и вставляем в неё формулу:
`=E2 / D2 * 100`
Которая подсчитает отношение общего числа страниц для страны и числа страниц для запроса, например, habrahabr+Russia. Применяем формулу для каждой страны из списка и получаем необходимый нам индекс.
Теперь все готово для того, чтобы добавить гаджет. Выделяем ячейки, содержащие краткий код страны и столбец GoogleShare. Выбираем Insert -> Gadget на панели, затем в открывшемся диалоге выбираем Maps -> HeatMap. Карта готова! :) Теперь сидим и думаем, зачем нам все это надо.
PS: Этот текст основан на статье [Creating a Googleshare Map With Google Spreadsheets](http://blogoscoped.com/archive/2008-03-21-n10.html) | https://habr.com/ru/post/22205/ | null | ru | null |
# Анализ производительности накопителя Intel Optane SSD 750ГБ
Летом прошлого года мы опубликовали [статью](https://blog.selectel.ru/intel-optane-ssd?utm_source=blog_selectel_ru&utm_medium=inner_referral) о дисковых накопителях Intel Optane SSD и предложили всем желающим принять участие в [бесплатном тестировании](https://selectel.ru/promo/intel-optane?utm_source=blog_selectel_ru&utm_medium=inner_referral). Новинка вызвала большой интерес: наши пользователи пробовали применять Optane для [научных расчётов](https://blog.selectel.ru/intel-optane-ssd-application-in-science?utm_source=blog_selectel_ru&utm_medium=inner_referral), для [работы с in-memory базами данных](https://blog.selectel.ru/in-memory-database-with-intel-optane?utm_source=blog_selectel_ru&utm_medium=inner_referral), для проектов в области машинного обучения.
Мы сами давно собирались написать подробный обзор, но всё не доходили руки. Но совсем недавно подходящая возможность появилась: коллеги из Intel предоставили нам для тестирования новый [Optane, ёмкостью 750 ГБ](https://www.intel.com/content/www/us/en/products/memory-storage/solid-state-drives/data-center-ssds/optane-dc-p4800x-series/p4800x-750gb-aic.html). О результатах наших экспериментов пойдёт речь ниже.
Intel Optane P4800X 750ГБ: общая информация и технические характеристики
------------------------------------------------------------------------
Накопители Intel Optane SSD выпускаются по 20-нм технологическому процессу. Он существует в двух форм-факторах: в виде карты (HHHL (CEM3.0) — подробнее о том, что это такое, см. [здесь](https://nvmexpress.org/new-pcie-form-factor-enables-greater-pcie-ssd-adoption)) и U.2 15 мм.
У нас имеется диск в виде карты:


Он виден в BIOS и определяется системой без установки каких-либо драйверов и дополнительных программ (приводим пример для ОС Ubuntu 16.04):
```
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 149.1G 0 disk
├─sda2 8:2 0 1K 0 part
├─sda5 8:5 0 148.1G 0 part
│ ├─vg0-swap_1 253:1 0 4.8G 0 lvm [SWAP]
│ └─vg0-root 253:0 0 143.3G 0 lvm /
└─sda1 8:1 0 976M 0 part /boot
nvme0n1 259:0 0 698.7G 0 disk
```
Более подробную информацию можно просмотреть с помощью утилиты nvme-cli (она включена в репозитории большинства современных дистрибутивов Linux, но в очень устаревшем варианте, поэтому мы рекомендуем собрать свежую версию из [исходного кода](https://github.com/linux-nvme/nvme-cli)).
А вот его основные технические характеристики (взяты с [официального сайта Intel](https://ark.intel.com/products/97154/Intel-Optane-SSD-DC-P4800X-Series-750GB-2_5in-PCIe-x4-20nm-3D-XPoint)):
| | |
| --- | --- |
| **Характеристика** | **Значение** |
| Объём | 750ГБ |
| Производительность при выполнении операций последовательного чтения, МБ/с | 2500 |
| Производительность при выполнении операций последовательной записи, МБ/с | 2200 |
| Производительность при выполнении операций случайного чтения, IOPS | 550000 |
| Производительность при выполнении операций случайной записи, IOPS | 550000 |
| Задержка при выполнении операции чтения (latency) | 10 µs |
| Задержка при выполнении операции записи | 10 µs |
| Износостойкость, PBW\* | 41.0 |
*\*PBW — сокращение от Petabytes written. Эта характеристика обозначает количество информации, которое можно записать на диск в течение всего жизненного цикла.*
На первый взгляд все смотрится очень впечатляюще. Но цифрам, приводимым в маркетинговых материалах, многие (и не без оснований) привыкли не доверять. Поэтому не лишним будет их проверить, а также провести некоторые дополнительные эксперименты.
Начнём мы с достаточно простых синтетических тестов, а затем проведём испытания в условиях, максимально приближенных к реальной практике.
Конфигурация тестового стенда
-----------------------------
Коллеги из Intel (за что им огромное спасибо) предоставили нам сервер со следующими техническими характеристиками:
* материнская плата — Intel R2208WFTZS;
* процессор — Intel Xeon Gold 6154 (24.75M Cache, 3.00 GHz);
* память — 192GB DDR4;
* Intel SSD DC S3510 (на этот диск была установлена ОС);
* Intel Optane™ SSD DC P4800X 750GB.
На сервере была установлена ОС Ubuntu 16.04 с ядром 4.13.
**Обратите внимание! Чтобы получить хорошую производительность NVMe-накопителей, требуется версия ядра не ниже 4.10. С более ранними версиями ядра результаты будут хуже: поддержка NVMe в них надлежащим образом не реализована.**
Для тестов мы использовали следующее ПО:
* утилиту [fio](https://github.com/axboe/fio), которая является де-факто стандартом в области измерения производительности дисков;
* диагностические инструменты, разработанные [Бренданом Греггом](http://www.brendangregg.com/) в рамках проекта [iovisor](https://www.iovisor.org/);
* утилита [db\_bench](https://github.com/facebook/rocksdb/blob/master/tools/db_bench_tool.cc), созданная в Facebook и используемая для измерения производительности в хранилище данных [rocksdb](http://rocksdb.org/).
Синтетические тесты
-------------------
Как уже было сказано выше, сначала мы рассмотрим результаты синтетических тестов. Их мы проводили с помощью утилиты fio версии 3.3.31, которую мы собирали из [исходного кода](https://github.com/axboe/fio).
В соответствии с принятой у нас методикой в тестах использовались следующие профили нагрузок:
* случайная запись/чтение блоками по 4 Kб, глубина очереди — 1;
* случайная запись/чтение блоками по 4 Kб, глубина очереди — 16;
* случайная запись/чтение блоками по 4 М, глубина очереди — 32;
* случайная запись/чтение блоками по 4 Kб, глубина очереди — 128.
Приведём пример конфигурационного файла:
```
[readtest]
blocksize=4M
filename=/dev/nvme0n1
rw=randread
direct=1
buffered=0
ioengine=libaio
iodepth=32
runtime=1200
[writetest]
blocksize=4M
filename=/dev/nvme0n1
rw=randwrite
direct=1
buffered=0
ioengine=libaio
iodepth=32
```
Каждый тест выполнялся в течение 20 минут; по завершении мы заносили все интересующие нас показатели в таблицу (см. ниже).
Наибольший интерес для нас будет представлял такой параметр, как число операций ввода-вывода в секунду (IOPS). В тестах на чтение и запись блоков по 4M в таблицу внесен размер полосы пропускания (bandwidth).
Для наглядности мы приводим результаты не только для Optane, но и для других NVMe-накопителей: это Intel P 4510, а также диск другого производителя — [Micron](https://www.micron.com/~/media/documents/products/product-flyer/9200_ssd_product_brief.pdf):
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| **Модель диска** | **Ёмкость диска, ГБ** | **randread**
**4k**
**iodepth**
**=128** | **randwrite**
**4k**
**iodepth**
**=128** | **randread**
**4M**
**iodepth**
**=32** | **randwrite**
**4M**
**iodepth**
**=32** | **randread**
**4k**
**iodepth**
**=1** | **randwrite**
**4k**
**iodepth**
**=16** | **randread**
**4k**
**iodepth**
**=1** | **randwrite**
**4k**
**iodepth**
**=1** |
| Intel P4800 X | 750 ГБ | 400k | 324k | 2663 | 2382 | 399k | 362k | 373k | 76.1k |
| Intel P4510 | 1 TБ | 335k | 179k | 2340 | 504 | 142k | 143k | 12.3k | 73.5k |
| Micron MTFDHA
X1T6MCE | 1.6 ТБ | 387k | 201k | 2933 | 754 | 80.6k | 146k | 8425 | 27.4k |
Как видим, в некоторых тестах Optane показывает цифры, в несколько раз превышающие результаты аналогичных тестов для других накопителей.
Но чтобы выносить более или менее объективные суждения о производительности диска, одного только количества IOPS явно недостаточно. Этот параметр сам по себе ничего не значит вне связи с другим — временем задержки (latency).
**Latency** — это промежуток времени, в течение которого выполняется запрос на операцию ввода-вывода, отправленный приложением. Измеряется он при помощи всё той же утилиты fio. По завершении всех тестов она выдаёт на консоль следующий вывод (приводим лишь небольшой фрагмент):
```
Jobs: 1 (f=1): [w(1),_(11)][100.0%][r=0KiB/s,w=953MiB/s][r=0,w=244k IOPS][eta 00m:00s]
writers: (groupid=0, jobs=1): err= 0: pid=14699: Thu Dec 14 11:04:48 2017
write: IOPS=46.8k, BW=183MiB/s (192MB/s)(699GiB/3916803msec)
slat (nsec): min=1159, max=12044k, avg=2379.65, stdev=3040.91
clat (usec): min=7, max=12122, avg=168.32, stdev=98.13
lat (usec): min=11, max=12126, avg=170.75, stdev=97.11
clat percentiles (usec):
| 1.00th=[ 29], 5.00th=[ 30], 10.00th=[ 40], 20.00th=[ 47],
| 30.00th=[ 137], 40.00th=[ 143], 50.00th=[ 151], 60.00th=[ 169],
| 70.00th=[ 253], 80.00th=[ 281], 90.00th=[ 302], 95.00th=[ 326],
| 99.00th=[ 363], 99.50th=[ 379], 99.90th=[ 412], 99.95th=[ 429],
| 99.99th=[ 457]
```
Обратите внимание на следующий фрагмент:
```
slat (nsec): min=1159, max=12044k, avg=2379.65, stdev=3040.91
clat (usec): min=7, max=12122, avg=168.32, stdev=98.13
lat (usec): min=11, max=12126, avg=170.75, stdev=97.11
```
Это и есть значения latency, которые мы получили во время теста. Наибольший интерес для нас представляет
Slat — это время отправки запроса (т.е. параметр, который имеет отношение к производительности подсистемы ввода-вывода в Linux, но не диска), а clat — это так называемая complete latency, т.е. время выполнения запроса, поступившего от устройства (именно этот параметр нас и интересует). О том, как анализировать эти цифры, неплохо написано в [этой статье](https://habrahabr.ru/post/154235/), опубликованной пять лет назад, но актуальности при этом не утратившей.
**Fio** — это общепринятая и хорошо зарекомендовавшая себя утилита, однако иногда в реальной практике возникают ситуации, когда нужно получить более точную информации о времени задержки и выявить возможные причины, если значение этого показателя слишком высоко. Инструменты для более точной диагностики разрабатываются в рамках проекта [iovisor](https://www.iovisor.org/) (см. также [репозиторий на GitHub](https://github.com/iovisor). Все эти инструменты построены на базе механизма [eBPF (extended Berkeley Packet Filters](http://prototype-kernel.readthedocs.io/en/latest/bpf/). В наших тестах мы попробовали утилиту biosnoop (см. исходный код [здесь](https://github.com/iovisor/bcc/blob/master/tools/biosnoop.py)). Она отслеживает все операции ввода-вывода в системе и измеряет время задержки для каждой из них.
Это бывает очень полезно, если возникают проблемы с производительностью диска, к которому выполняется большое количество запросов на чтение и запись (например, на диске размещена база данных для какого-нибудь высоконагруженного веб-проекта).
Мы начали с самого простого варианта: запускали стандартные тесты fio и замеряли latency для каждой операции с помощью biosnoop, которую запускали в другом терминале. Во время работы biosnoop пишет в стандартный вывод следующую таблицу:
```
TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms)
300.271456000 fio 34161 nvme0n1 W 963474808 4096 0.01
300.271473000 fio 34161 nvme0n1 W 1861294368 4096 0.01
300.271491000 fio 34161 nvme0n1 W 715773904 4096 0.01
300.271508000 fio 34161 nvme0n1 W 1330778528 4096 0.01
300.271526000 fio 34161 nvme0n1 W 162922568 4096 0.01
300.271543000 fio 34161 nvme0n1 W 1291408728 4096 0.01
```
Эта таблица состоит из 8 столбцов:
* **TIME** — время совершения операции в формате Unix Timestamp;
* **COMM** — имя процесса, выполнившего операцию;
* **PID** — PID процесса, выполнившего операцию;
* **T** — тип операции (R — read, W — write);
* **SECTOR** — сектор, куда осуществлялась запись;
* **BYTES** — размер записываемого блока;
* **LAT (ms)** — время задержки для операции.
Мы провели много измерений для разных дисков и обратили внимание на следующее: для Optane в течение всего теста (а продолжительность тестов при этом варьировалась от 20 минут до 4 часов) значение параметра latency оставалось неизменным и соответствовало заявленному в таблице выше значению 10 µs, в то время как у других накопителей наблюдались колебания.
По полученным результатам синтетических тестов вполне можно вполне предположить, что Optane и под высокой нагрузкой будет показывать хорошую производительность и самое главное — низкое время задержки. Поэтому мы решили на чистой “синтетике” не останавливаться и провести тест с реальными (или по крайней мере максимально приближенными к реальным) нагрузками.
Для этого мы воспользовались утилитами для измерения производительности, которые входят в состав RocksDB — интересным и набирающим популярность хранилищем пар “ключ — значение”, разработанным в Facebook. Ниже мы подробно опишем проведённые тесты и проанализируем их результаты.
Optane и RocksDB: тесты производительности
------------------------------------------
### Почему RocksDB
В последние годы широкое резко возросла потребность в отказоустойчивых хранилищах больших объёмов данных. Они находят применение в самых разных областях: социальные сети, корпоративные информационные системы, мессенджеры, облачные хранилища и других. Программные решения для таких хранилищ, как правило, построены на базе так называемых [LSM-деревьев](https://en.wikipedia.org/wiki/Log-structured_merge-tree) — в качестве примера можно привести Big Table, HBase, Cassandra, LevelDB, Riak, MongoDB, InfluxDB. Работа с ними сопряжена с серьёзными нагрузками, в том числе и на дисковую подсистему — см., например, [здесь](https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf). Optane со всей износостойкостью и долговечностью мог бы стать вполне подходящим решением.
**RocksdDB** (см. также [репозиторий на GitHub](https://github.com/facebook/rocksdb)) — это хранилище типа «ключ-значение», разработанное в Facebook и являющееся форком небезызвестного проекта [LevelDB](http://leveldb.org/). Оно используется для решения широкого круга задач: от организации [storage engine для MySQL](http://myrocks.io/) до кэширования данных приложений.
Мы выбрали именно его для наших тестов, руководствуясь следующими соображениями:
* RocksDB позиционируется как хранилище, **созданное специально для быстрых накопителей, в том числе и NVMe**;
* RocksDB успешно используется в высоконагруженных проектах Facebook;
* в состав RocksDB входят интересные утилиты для тестирования, создающие очень серьёзную нагрузку (подробности см. ниже);
* наконец, нам было просто интересно взглянуть, как Optane с его надёжностью и устойчивостью выдержит большие нагрузки.
Все описанные ниже тесты проводились на двух дисках:
* Intel Optane SSD 750 GB
* Micron MTFDHAX1T6MCE
### Подготовка к тестированию: компиляция RocksDB и создание базы
RocksDB мы собрали из исходного кода, опубликованного на GitHub (здесь и далее приводятся примеры команд для Ubuntu 16.04):
```
$ sudo apt-get install libgflags-dev libsnappy-dev zlib1g-dev libbz2-dev liblz4-dev libzstd-dev gcc g++ clang make git
$ git clone https://github.com/facebook/rocksdb/
$ cd rocksdb
$ make all
```
После установки требуется подготовить к тесту диск, куда будут записываться данные.
В официальной документации с RocksDB рекомендуется использовать файловую систему XFS, которую мы и создадим на нашем Optane:
```
$ sudo apt-get install xfsprogs
$ mkfs.xfs -f /dev/nvme0n1
$ mkdir /mnt/rocksdb
$ mount -t xfs /dev/nvme0n1 /mnt/rocksdb
```
На этом подготовительная работа завершена, и можно переходить к созданию базы данных.
RocksDB не является СУБД в классическом смысле слова, и чтобы создать базу данных, потребуется написать небольшую программу на C или С++. Примеры таких программ (1 и 2) имеются в официальном репозитории RocksDB в директории examples. В исходный код нужно будет внести некоторые изменения и указать правильный путь к базе. В нашем случае это выглядит так:
```
$ cd rockdb/examples
$ vi simple_example.cc
```
В этом файле нужно найти строку
```
std::string kDBPath ="/tmp/rocksdb_simple_example"
```
И прописать в ней путь к нашей базе:
```
std::string kDBPath ="/mnt/rocksdb/testdb1"
```
После этого нужно переходить к компиляции:
```
$ make
$ ./simple_example
```
В результате выполнения этой команды в указанной директории будет создана база. Мы будем в неё записывать (и считывать из неё) данные в наших тестах. Тестировать мы будем с помощью утилиты db\_bench; соответствующий бинарный файл есть в корневой директории RocksDB.
Методика тестирования подробно описана на [официальной wiki-странице проекта](https://github.com/facebook/rocksdb/wiki/Performance-Benchmarks).
Если вы внимательно прочтёте текст по ссылке, то увидите, что смысл теста заключается в записи одного миллиарда ключей в базу (и в последующем чтении данных из этой базы). Суммарный объём всех данных составляет около 800 ГБ. Мы такого себе позволить мне можем: объём нашего Optane составляет всего 750 ГБ. Поэтому число ключей в нашем тесте мы сократили ровно вдвое: не один миллиард, а 500 миллионов. Для демонстрации возможностей Optane и этой цифры вполне достаточно.
В нашем случае объём записываемых данных составит примерно 350 ГБ.
Хранятся все эти данные в формате [SST](https://github.com/facebook/rocksdb/wiki/A-Tutorial-of-RocksDB-SST-formats)(сокращение от [Sorted String Table](https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/); см. также [эту статью](http://mezhov.com/2013/09/sstable-lsm-tree.html)). На выходе мы получим несколько тысяч так называемых SST-файлов (подробнее можно почитать [здесь](https://github.com/facebook/rocksdb/wiki/Creating-and-Ingesting-SST-files).
Перед запуском теста нужно обязательно увеличить лимит на число одновременно открытых файлов в системе, иначе ничего не получится: примерно через 15 — 20 минут после начала теста мы увидим сообщение Too many open files.
Чтобы всё прошло, как надо, выполним команду ulimit c опцией n:
```
$ ulimit -n
```
По умолчанию в системе установлен лимит на 1024 файла. Во избежание проблем мы сразу увеличим его до миллиона:
```
$ ulimit -n 1000000
```
Обратите внимание: после перезагрузки этот лимит не сохраняется и возвращается к значению по умолчанию.
Вот и всё, подготовительные работы завершены. Переходим к описанию непосредственно тестов и разбору результатов.
Описание тестов
---------------
### Вводные замечания
Опираясь на методику, описанную по ссылке выше, мы провели следующие тесты:
* массовая загрузка ключей в последовательном порядке;
* массовая загрузка ключей в случайном порядке;
* случайная запись;
* случайное чтение.
Все тесты проводились с помощью утилиты db\_bench, исходный код которой можно найти в [репозитории rocksdb](https://github.com/facebook/rocksdb).
Размер каждого ключа составляет 10 байт, а размер значения — 800 байт.
Рассмотрим результаты каждого теста более подробно.
### Тест 1. Массовая загрузка ключей в последовательном порядке
Для запуска этого теста мы использовали те же параметры, что указаны в инструкции по ссылке выше. Изменили мы только количество записываемых ключей (об этом мы уже упоминали): не 1 000 000 000, а 500 000 000.
В самом начале база пуста; она заполняется во время теста. Во время загрузки данных никакого чтения не производится.
Команда db\_bench для запуска теста выглядит так:
```
bpl=10485760;mcz=2;del=300000000;levels=6;ctrig=4; delay=8; stop=12; wbn=3; \
mbc=20; mb=67108864;wbs=134217728; sync=0; r=50000000 t=1; vs=800; \
bs=4096; cs=1048576; of=500000; si=1000000; \
./db_bench \
--benchmarks=fillseq --disable_seek_compaction=1 --mmap_read=0 \
--statistics=1 --histogram=1 --num=$r --threads=$t --value_size=$vs \
--block_size=$bs --cache_size=$cs --bloom_bits=10 --cache_numshardbits=6 \
--open_files=$of --verify_checksum=1 --sync=$sync --disable_wal=1 \
--compression_type=none --stats_interval=$si --compression_ratio=0.5 \
--write_buffer_size=$wbs --target_file_size_base=$mb \
--max_write_buffer_number=$wbn --max_background_compactions=$mbc \
--level0_file_num_compaction_trigger=$ctrig \
--level0_slowdown_writes_trigger=$delay \
--level0_stop_writes_trigger=$stop --num_levels=$levels \
--delete_obsolete_files_period_micros=$del --min_level_to_compress=$mcz \
--stats_per_interval=1 --max_bytes_for_level_base=$bpl \
--use_existing_db=0 --db=/mnt/rocksdb/testdb
```
Команда содержит множество опций, которые просто необходимо прокомментировать: они будут использоваться и в последующих тестах. В самом начале мы задаём значения важных параметров:
* bpl ― максимальное количество байт на один уровень;
* mcz ― минимальный уровень сжатия;
* del ― промежуток времени, по истечении которого нужно удалять устаревшие файлы;
* levels ― количество уровней;
* ctrig ― количество файлов, по достижении которого нужно начинать сжатие;
* delay ― время, по истечении которого нужно замедлить скорость записи;
* stop ― время, по истечении которого нужно прекратить запись;
* wbn ― максимальное число буферов записи;
* mbc ― максимальное число фоновых сжатий;
* mb ― максимальное число буферов записи;
* wbs ― размер буфера записи;
* sync ― включить/отключить синхронизацию;
* r ― количество пар “ключ-значение”, которые будут записываться в базу;
* t ― количество потоков;
* vs ― величина значения;
* bs ― размер блока;
* сs ― размер кэша;
* оf ― количество открытых файлов (не работает, см. комментарий по этому по поводу выше);
* si ― периодичность сбора статистики.
Об остальных параметрах можно подробнее прочитать, выполнив команду
```
./db_bench --help
```
Подробные описания всех опций также приведены [здесь](https://github.com/facebook/rocksdb/wiki/Benchmarking-tools).
Какие результаты показал тест? Операция последовательной загрузки была выполнена за **23 минуты**. Скорость записи при этом составила **536,78 МБ/с**.
Для сравнения: на NVMe-накопителе Micron эта же процедура занимает чуть больше **30 минут**, а скорость записи составляет **380.31 МБ/с**.
### Тест 2. Массовая загрузка ключей в случайном порядке
Для тестирования случайной записи использовались следующие настройки db\_bench (приводим полный листинг команды):
```
bpl=10485760;mcz=2;del=300000000;levels=2;ctrig=10000000; delay=10000000; stop=10000000; wbn=30; mbc=20; \
mb=1073741824;wbs=268435456; sync=0; r=50000000; t=1; vs=800; bs=65536; cs=1048576; of=500000; si=1000000; \
./db_bench \
--benchmarks=fillrandom --disable_seek_compaction=1 --mmap_read=0 --statistics=1 --histogram=1 \
--num=$r --threads=$t --value_size=$vs --block_size=$bs --cache_size=$cs --bloom_bits=10 \
--cache_numshardbits=4 --open_files=$of --verify_checksum=1 \
--sync=$sync --disable_wal=1 --compression_type=zlib --stats_interval=$si --compression_ratio=0.5 \
--write_buffer_size=$wbs --target_file_size_base=$mb --max_write_buffer_number=$wbn \
--max_background_compactions=$mbc --level0_file_num_compaction_trigger=$ctrig \
--level0_slowdown_writes_trigger=$delay --level0_stop_writes_trigger=$stop --num_levels=$levels \
--delete_obsolete_files_period_micros=$del --min_level_to_compress=$mcz \
--stats_per_interval=1 --max_bytes_for_level_base=$bpl --memtablerep=vector --use_existing_db=0 \
--disable_auto_compactions=1 --allow_concurrent_memtable_write=false --db=/mnt/rocksdb/testb1
```
Выполнение этого теста заняло у нас **1 час 6 минут**, а скорость записи при этом составила 273.36 МБ/с. На Microne тест выполняется за **3 часа 30 минут**, а скорость записи при этом колеблется: среднее значение — **49.7 МБ/с**.
### Тест 3. Случайная запись
В этом тесты мы попробовали перезаписать 500 миллионов ключей в созданную ранее базу данных.
Приводим полный листинг команды db\_bench:
```
bpl=10485760;mcz=2;del=300000000;levels=6;ctrig=4; delay=8; stop=12; wbn=3; \
mbc=20; mb=67108864;wbs=134217728; sync=0; r=500000000; t=1; vs=800; \
bs=65536; cs=1048576; of=500000; si=1000000; \
./db_bench \
--benchmarks=overwrite --disable_seek_compaction=1 --mmap_read=0 --statistics=1 \
--histogram=1 --num=$r --threads=$t --value_size=$vs --block_size=$bs \
--cache_size=$cs --bloom_bits=10 --cache_numshardbits=4 --open_files=$of \
--verify_checksum=1 --sync=$sync --disable_wal=1 \
--compression_type=zlib --stats_interval=$si --compression_ratio=0.5 \
--write_buffer_size=$wbs --target_file_size_base=$mb --max_write_buffer_number=$wbn \
--max_background_compactions=$mbc --level0_file_num_compaction_trigger=$ctrig \
--level0_slowdown_writes_trigger=$delay --level0_stop_writes_trigger=$stop \
--num_levels=$levels --delete_obsolete_files_period_micros=$del \
--min_level_to_compress=$mcz --stats_per_interval=1 \
--max_bytes_for_level_base=$bpl --use_existing_db=/mnt/rocksdb/testdb
```
В этом тесте был получен очень хороший результат: **2 часа 51 минута** со скоростью **49 МБ/с** (в моменте снижалась до **38 МБ/c**).
На Microne выполнение теста занимает чуть больше — **3 часа 16 минут**; скорость примерно такая же, но колебания выражены более отчётливо.
### Тест 4. Случайное чтение
Смысл этого теста заключается в случайном чтении 500 000 000 ключей из базы. Приведём полный, со всеми опциями, листинг команды db\_bench:
```
bpl=10485760;mcz=2;del=300000000;levels=6;ctrig=4; delay=8; stop=12; wbn=3; \
mbc=20; mb=67108864;wbs=134217728; sync=0; r=500000000; t=1; vs=800; \
bs=4096; cs=1048576; of=500000; si=1000000; \
./db_bench \
--benchmarks=fillseq --disable_seek_compaction=1 --mmap_read=0 \
--statistics=1 --histogram=1 --num=$r --threads=$t --value_size=$vs \
--block_size=$bs --cache_size=$cs --bloom_bits=10 --cache_numshardbits=6 \
--open_files=$of --verify_checksum=1 --sync=$sync --disable_wal=1 \
--compression_type=none --stats_interval=$si --compression_ratio=0.5 \
--write_buffer_size=$wbs --target_file_size_base=$mb \
--max_write_buffer_number=$wbn --max_background_compactions=$mbc \
--level0_file_num_compaction_trigger=$ctrig \
--level0_slowdown_writes_trigger=$delay \
--level0_stop_writes_trigger=$stop --num_levels=$levels \
--delete_obsolete_files_period_micros=$del --min_level_to_compress=$mcz \
--stats_per_interval=1 --max_bytes_for_level_base=$bpl \
--use_existing_db=0
bpl=10485760;overlap=10;mcz=2;del=300000000;levels=6;ctrig=4; delay=8; \
stop=12; wbn=3; mbc=20; mb=67108864;wbs=134217728; sync=0; r=500000000; \
t=32; vs=800; bs=4096; cs=1048576; of=500000; si=1000000; \
./db_bench \
--benchmarks=readrandom --disable_seek_compaction=1 --mmap_read=0 \
--statistics=1 --histogram=1 --num=$r --threads=$t --value_size=$vs \
--block_size=$bs --cache_size=$cs --bloom_bits=10 --cache_numshardbits=6 \
--open_files=$of --verify_checksum=1 --sync=$sync --disable_wal=1 \
--compression_type=none --stats_interval=$si --compression_ratio=0.5 \
--write_buffer_size=$wbs --target_file_size_base=$mb \
--max_write_buffer_number=$wbn --max_background_compactions=$mbc \
--level0_file_num_compaction_trigger=$ctrig \
--level0_slowdown_writes_trigger=$delay \
--level0_stop_writes_trigger=$stop --num_levels=$levels \
--delete_obsolete_files_period_micros=$del --min_level_to_compress=$mcz \
--stats_per_interval=1 --max_bytes_for_level_base=$bpl \
--use_existing_db=1
```
Как видно из приведённых команд, этот тест состоит из двух операций: сначала мы записываем в базу ключи, а потом их читаем. По завершении записи утилита db\_bench случайным образом выбирала из базы ключ и выполняла операцию чтения.
Операция чтения осуществлялась в 32 потока. При каждой операции чтения осуществлялась проверка контрольной суммы.
На Optane выполнение теста заняло **5 часов 2 минуты**, на Microne — около **6 часов**.
Заключение
----------
В этой статье мы описали тесты производительности накопителя Intel Optane SSD объёмом 750 ГБ. Как показывают результаты, диск показывает высокую производительность и стабильность. Даже при большой загрузке мы не наблюдали деградации производительности, а время задержки оставалось практически неизменным. Ещё раз выражаем коллегам из Intel огромную благодарность за предоставленную возможность познакомиться с новинкой.
Как мы уже писали, диски Optane хорошо подойдут для использования в высоконагруженных сервисах или корпоративных СХД. Но лучше один раз увидеть, чем сто раз услышать. Мы до сих пор предлагаем Optane для бесплатного тестирования всем желающим. Условия те же: мы даём вам доступ к тестовому серверу, а вы пишете обзор и публикуете его в любом открытом источнике.
А если вы уже готовы использовать Optane на постоянной основе, то выделенные серверы соответствующей конфигурации уже [доступны для заказа в наших дата-центрах](https://selectel.ru/services/dedicated/?utm_source=blog_selectel_ru&utm_medium=inner_referral).
В этой статье мы не затронули вопросы использования технологии [IMDT (Intel Memory Drive)](https://www.intel.com/content/www/us/en/software/intel-memory-drive-technology.html). Это очень сложная тема, которая требует отдельного рассмотрения. Публикация на эту теме появится в нашем блоге в ближайшее время. | https://habr.com/ru/post/352622/ | null | ru | null |
# Опыт замены Microsoft Outlook на Mozilla Thunderbird с сервером Exchange
#### Задача
Имеется компания с серверами Windows Server. На них поднят DNS, WINS, Active Directory, CA, Exchange. На пользовательских местах установлен Office с Outlook для обмена информацией, поскольку прямой связи у отделов нет и возможность записи на внешние носители существенно ограничена. Всё лицензионное. Довольно типичная ситуация для средних компаний.
В условиях экономии средств возник вопрос достаточной замены компонента Microsoft Office — Outlook. Преимуществ Outlook достаточно много: сквозная аутентификация, удобный и понятный интерфейс, автоматическая архивация, гибкая и полноценная интеграция с Exchange, в которую входят динамические адресные книги, общие папки и прочее. Заменить такой продукт достаточно сложно без потерь в функциональности.
#### Реализация
После некоторых сравнений альтернативным клиентом был выбран Mozilla Thunderbird (в данный момент версия 31) как бесплатный, открытый проект, поддерживающий IMAP и адресную книгу LDAP, а также с возможностью использования дополнений.
##### Пароль
Пароль зашивается в клиент и его можно посмотреть в настройках. Да, это снижает безопасность, но пользователи почты Thunderbird имеют гостевые доменные учётные записи, а также не являются администраторами на локальных компьютерах. Кроме того, планируется внедрить централизованную настройку, где просмотр пароля будет заблокирован. Это посчиталось приемлемым.
##### Учётная запись почты
Thunderbird некорректно работает с русскими логинами Windows. Поэтому предварительно придётся переименовать доменные логины пользователей Thunderbird в английский эквивалент. Рекомендуется делать логины точно такими, как и почты, для упрощения настройки, хотя это и не обязательно, тем более если хост доменный, это не имеет значения.
На сервере Exchange имеется IIS для доступа к почте через веб-интерфейс — Outlook Web Access. Удобная вещь для удалённой работы с почтой при условии, что почта за какой-то период хранится на сервере. Но отсутствие возможности архивирования почты из обозревателя не позволяет сделать этот режим работы постоянным, поскольку аппаратные ресурсы сервера Exchange не безграничны, да и не предназначен он для хранения. У Thunderbird имеется несколько режимов для помощи [настройки учётной записи](https://wiki.mozilla.org/Thunderbird:Autoconfiguration). Проще всего сделать псевдоним (CNAME) DNS *autoconfig* на сервере Exchange: *autoconfig.company.loc*. А на самом сервере в IIS создать папку *mail* с файлом *config-v1.1.xml*. Содержимое файла настраиватся достаточно просто и описано [на сайте Mozilla](https://wiki.mozilla.org/Thunderbird:Autoconfiguration:ConfigFileFormat). В моём случае получилось такое:
```
xml version="1.0" encoding="UTF-8"?
company.loc
Company Exchange Server
Company e-mail
mail.company.loc
993
SSL
NTLM
%EMAILLOCALPART%
mail.company.loc
143
STARTTLS
NTLM
%EMAILLOCALPART%
mail.company.loc
995
SSL
NTLM
%EMAILLOCALPART%
true
true
14
mail.company.loc
587
STARTTLS
NTLM
%EMAILLOCALPART%
```
Папку *mail* стоит сделать виртуальной и явно отключить требование SSL для неё.
Стоит упомянуть, что у нас, как и у многих, имя домена извне отличается от имени локального домена внутри периметра. Но почта должна именоваться везде одинаково. Поэтому внутри Exchange учётные записи имеют по два адреса: внешний и внутренний. Внешний используется по умолчанию. (Exchange также умеет использовать разные DNS для внутренней и внешней пересылки). Отсюда тонкость; адреса пользователей при настройке указываются внешние, поэтому в файле настройки для имени пользователя используется только имя *%EMAILLOCALPART%*. Кроме того, псевдоним (CNAME) *autoconfig* необходимо также создать в копии внешнего домена корневой зоны локального DNS.
Видно, что я решил использовать два типа доступа к почте: IMAP и POP3. Дело в том, что иногда попадаются очень активные пользователи с очень большим объёмом почты. Если такой пользователь не использует почту нигде, кроме своего ПК на рабочем месте (не забываем про OWA), то в случае Outlook создаются локальные папки и назначаются основными для всех учётных записей. Таким образом вся почта будет удаляться с сервера Exchange и храниться непосредственно на ПК пользователя, что не потребует какой-то дополнительной архивации, но привязывает пользователя к ПК и повышает вероятность потери почты, в случае порчи жёсткого диска. В противном случае требуется индивидуальная настройка лимитов на Exchange для таких пользователей, чего я всячески пытаюсь избежать. Но всего не предусмотришь. Поэтому для Thunderbird также оставил возможность простой работы с почтой в виде POP3. Хотя до сих пор ещё не пригодился, откровенно говоря.
Всё это позволит быстро выбирать необходимый способ доступа при настройке учётной записи в Thunderbird. Если хост входит в домен AD, то лучше, всё же, подстроить, выбрав способ аутентификации «Kerberos / GSSAPI» и не указывать пароль в в форме.
Доступ к Exchange по IMAP и POP3 настраивается очень просто и не требует особого рассмотрения. Разве что дополнительно придётся настроить сертификат с соответствующими масками имени сервера для коннекторов. А также потребовалась некоторая дополнительная настройка коннектора SMTP c TLS на Exchange 2007:
```
Get-ReceiveConnector “Client TLS” | Add-ADPermission –User “authenticated users” -ExtendedRights ms-Exch-SMTP-Accept-Authoritative-Domain-Sender
```
Иначе Thunderbird не мог получить доступ по SMTP как не авторизованный.
##### Профиль и сертификат
Первый запуск свежеустановленного клиента Thunderbird производится с ключом *-p* для указания пути для профиля почты. Профиль почты по умолчанию создаётся на системном разделе, что для нас является неприемлемым. Ключ позволяет указать папку на пользовательском разделе для хранения профиля Thunderbird (в нашем случае — папка d:\Mail). Предварительно стоит убедиться, что пользователь имеет право изменения в данной папке (права NTFS).
```
"c:\Program Files (x86)\Mozilla Thunderbird\thunderbird.exe" -p
```
Стоит напомнить, что команду нужно выполнять из пользовательского контекста, а не административного. Были прецеденты.
Первым действием для настройки запущенного клиента нужно отказаться от предложений мастера настройки и добавить корневой сертификат организации в Thunderbird, поскольку Thunderbird, почему-то, не использует системную базу сертификатов.
##### Адресная книга LDAP
Затем необходимо настроить адресную книгу LDAP. В интернете масса материалов по данной теме, но я не нашёл ни одного полноценного документа с адекватными параметрами, поэтому привожу здесь свой.
1. Открываем окно *Адресная книга*.
2. Вызываем Инструменты -> Настройки -> Составление -> Автодополнение адресов и ставим галочку на *Сервере каталогов*
Переключатели Microsoft Exchange Global Addressbook и Contacts на картинке имеются из-за тестируемого дополнения [ExQuilla](https://addons.mozilla.org/ru/thunderbird/addon/exquilla-exchange-web-services/) — подключение к Exchange через http. Результат — скорость работы неудовлетворительна при большом объёме почты.
3. Собственно создаём подключение к LDAP:
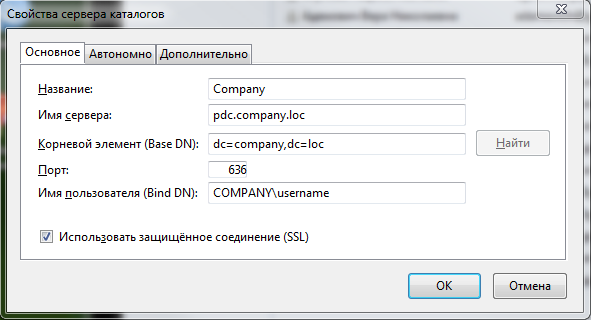
Всё очевидно. Порт без SSL: **3268**. Нужно учитывать, что настройка с SSL работает ощутимо медленнее.
Далее переключаемся на вкладку *Дополнительно*:
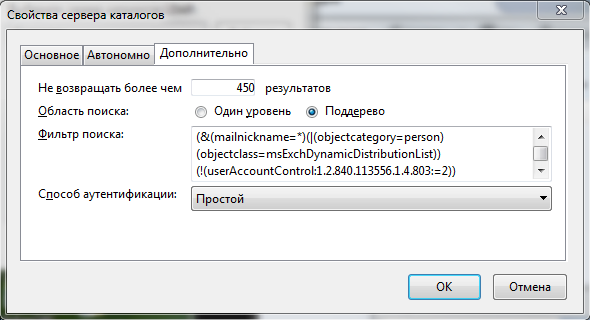
Здесь нужно сказать, что количество отображаемых результатов выбиралось из соображений количества клиентских лицензий на Exchange плюс контакты Active Directory с группами и небольшой запас. Способ аутентификации лучше выбрать «Простой» если ПК не входит в домен AD, иначе рекомендую Kerberos (GSSAPI), при этом необходимо убрать имя пользователя на вкладке «Основное».
Насчёт [фильтра](http://social.technet.microsoft.com/wiki/contents/articles/5392.active-directory-ldap-syntax-filters.aspx). Самое интересное. Я использую в Exchange динамические списки рассылки, кроме того в Active Directory имеются множество временно или постоянно отключенных учётных записей, а также некоторые учётные записи исключены из видимости в адресной книге по разным необходимостям, плюс контакты. Получается следующий фильтр:
```
(&(mailnickname=*)(|(objectcategory=person)(objectclass=msExchDynamicDistributionList))(!(userAccountControl:1.2.840.113556.1.4.803:=2))(!(msExchHideFromAddressLists=TRUE)))
```
Закрываем диалоги. Теперь откроем свежесозданную адресную книгу и набираем @ в строке поиска **не нажимая** Enter, поскольку ввод пойдёт в диалог с паролем. В диалоге следует набрать пароль пользователя и поставить галочку *Сохранить пароль*. Должен появиться список адресатов. Вполне хорошо работает. Достаточно начать набирать имя или адрес получателя в строке *Кому:* нового письма, чтобы получить список возможных вариантов.
Внимание! Если в Active Directory вы ограничили список хостов для учётной записи, на которые ей можно заходить, то для доступа к LDAP на PDC потребуется добавить имя контроллера в этот список.
Далее. Создаём учётную запись пользователя. Если всё предварительно настроено правильно, то вариант с правильной настройкой предложится моментально.
Остаётся нажать готово и, если ранее был подключен корневой сертификат, получим подключенную почту. Иначе придётся подтверждать каждый сертификат.
##### Архивирование и другие дополнения
Настраиваем подписанные папки. Пока идёт синхронизация, настраиваем архивирование в локальные папки: *Параметры учётной записи -> Копии и папки -> Архивы сообщений — Хранить архивированные сообщения в: — папке «Архивы» на: Локальные папки.* Архивирование можно разделяя по папкам годов, месяцев. В обычном режиме Thunderbird может архивировать письма только вручную. Автоархивирования можно добиться установив специальное дополнение (plugin) [Awesome Auto Archive](https://addons.mozilla.org/ru/thunderbird/addon/awesome-auto-archive/). Настраивается вполне просто.
Также устанавливаю следующие дополнения:
* [MinimizeToTray revived](https://addons.mozilla.org/ru/thunderbird/addon/minimizetotray-revived/) — Сворачивает текущее окно в трей
* [Lightning](https://addons.mozilla.org/ru/thunderbird/addon/lightning/) — Органайзер
Получаем работоспособный почтовый клиент. Доступ к общим папкам можно получить через OWA, создав ссылку в обозревателе или на рабочем столе на соответствующий раздел OWA:
```
https://mail.company.loc/Public
```
##### Импорт PST
Теперь к вопросу о [импорте ранее архивированной почты Outlook в Thunderbird](http://kb.mozillazine.org/Import_.pst_files). Описанный способ с установкой 30-дневнего Outlook не работает. Thunderbird вываливается, генерируя исключение. Проверено множество различных конфигураций. Кроме того, исключён импорт на Windows x64. Пришлось идти кружным путём. Есть рабочий способ, но он достаточно насыщен манипуляциями.
1. Скачивается бесплатное приложение [Outlook Viewer](http://www.coolutils.com/OutlookViewer), которое умеет читать .pst файлы — архивы Outlook. Устанавливается на ПК для манипуляций.
2. По сети берётся клиентский pst, открывается и письма экспортируются в папку с подпапками (подпапки могут быть внутри архива) в формате EML с вложениями. Это ещё полдела!
3. Затем во временно установленном Thunderbird с установленным дополнением [ImportExportTools](https://addons.mozilla.org/ru/thunderbird/addon/importexporttools/) создаём локальную папку, например *Архив-Outlook* и, правым кликом на ней вызываем меню импорта дополнения:
4. 
5. Выбираем папку с экспортированными ранее письмами и импортируем.
6. Теперь правым кликом на папке *Архив-Outlook* вызываем свойства папки и смотрим где она находится. Определив, переносим (файлы с именем папки, и подкаталоги с именем папки) на ПК пользователя в профиль пользователя в локальные папки. Наша папка с почтой из архива должна появиться у пользователя в Thunderbird после перезапуска.
Думаю внедрить централизованную конфигурацию пользователей.
Работа по обкатке ещё идёт, так что могу вносить дополнения и изменения. | https://habr.com/ru/post/233963/ | null | ru | null |
# Искусственный интеллект? Или не совсем искусcтвенный?
Салам!
А вы бы хотели, чтобы в вашем мозге поселился CPUЗдесь я, в поисках идей для искуственного интеллекта, постараюсь провести параллель между человеческим интеллектом и машинным.
Нас с ЭВМ обьединяет то, что мы реагируем на события. Человек и животное реагирует на раздражители, ЭВМ - на сигналы от периферии. В ЭВМ или МК эффект человекоподобного искусственного интеллекта даёт набор обработчиков различных ситуаций (прерываний, ошибок, исключений) - этаких машинных рефлеков. Но, как можно заметить, контекст выстраивается в машинном и человеческом интеллекте разными способами. Человек и ЭВМ сохраняют контекст по разному. В ЭВМ пришёл сигнал от периферии - выполнение предыдущей программы прерывается. Обработчик завершается - ЭВМ возвращается в прерванную программу. Человек контекст не сохраняет. Если человек возвращается к какой то прерванной задаче, то это потому что есть стойкий раздражитель. Вы читаете книгу, вам кто то звонит. А по завершении разговора, вы возвращаетесь к книге, если вы никуда не ушли, ведь книга лежит на том же месте.
Попробуем построить аналогии с ощущением голода и опасности. Вы ощущаете голод и ищете пропитание (идёте в магазин и начинаете готовить). Но по дороге из магазина вас настигает дождь и вы начинаете искать укрытие, так как до дома далеко добираться.
Ваша программа прерывает планы на поиск пропитания, она более приоритетна. Однако, голод не тётка и вы решаете перекусить в укрытии, так как исполнение планов в первозданном виде уже невозможно.
Обратите внимание на особенности. Ваше поведение строится асинхронно, т.е. вы его не планируете. Логика вашего поведения непредсказуема, но зато она адаптируется под актуальные потребности. Перекус не стоит выделять в отдельную подпрограмму, это изменённый, в ответ на изменившиеся условия, поиск пропитания. Хотя, если у вас плохая привычка всегда перекусывать вместо того, чтобы нормально пообедать, можете выделить, перекус будет иметь приоритет. Ключевое обстоятельство здесь то, что ваше поведение является ответом на что-то, а не появляется неизвестно откуда.
Вы обратили внимание на то, что я описал человеческое поведение лишь в общих чертах - на самом деле здесь много деталей? Меня интересуют лишь особенности, объявленные выше. Я не собираюсь вдаваться далеко в биологию?
А как бы всё выглядело в программном варианте? Выполнение обработчиков прерываний, аналогично вашему поведению, было бы асинхронно, но не предусматривало возврата. Контекст здесь выстраивается внешними факторами. Функция какого-нибудь интерфейса программирования возвращает значение вызывающей программе, но всегда синхронно. При этом программа сама изменяет своё поведение, если нужно, основываясь на возвращаемом значении. Мы же хотим, вызывая очередной обработчик прерывания Б, изменить поведение другого обработчика А, при этом мы не знаем в какой момент времени завершится обработчик Б и какому обработчику А будет передано управление. Как вариант, можно оставлять значение в регистре процессора, стандартное назначение которого мы знаем, так как значение регистров проверяется регулярно, в отличии от ячеек памяти.
Пример
`#define DEFAULT 0
#define PAGE_ERROR 1`
`volatile int parameter;`
`void page_error(void)
{
volatile int parameter;
// этот обработчик был вызван
//при ошибке страницы
parameter=PAGE_ERROR;
//но он не успел обработать ошибку
//b вызван повторно таймером
parameter=DEFAULT;
}`
`void a1(void)
{
parameter=2;`
`parameter=DEFAULT;
}`
`void b(void)
{
//этот обработчик был вызван
//
switch (parameter)
{
case PAGE_ERROR: //обработка в условиях ошибки страницы
case 2
case DEFAULT: //здесь сгенерирована ошибка отсутствия страницы
}
}`
Но это я описываю готовые программы вашего поведения. Но они откуда то ещё должны взяться. В ЭВМ и у человека это происходит по разному. В ЭВМ программу набирает программист, а человек до неё доходит через опыт.
Отталкиваемся от факта, что человек имеет набор безусловных рефлексов. Уже на их базе сформируются условные. А на базе существующих условных рефлексов сформируются новые при наличии своевременной обратной связи. Это и будет памятью. Причём старые рефлекторные связи могут со временем разрушиться, например в условиях недостатка энергии.
Сейчас будет ~~мясо~~ пример формирования памяти человека. Реакцией человека на низкочастотный импульс может являться сердечный выброс, т.к. такой импульс механически воздействует на диафрагму грудной клетки. А сокращающаяся диафрагма заставляет сердечную мышцу работать в более стеснённых условиях и увеличивать частоту сокращения. Тем временем формируется условный рефлекс - реакция нервной системы на низкочастотный импульс. И впредь в ответ на импульс увеличивается частота сокращения сердечной мышцы, причём это происходит уже без участия диафрагмы. Т. е. диафрагму мы заколебали, однако реакция на импульс необходима. И не только с точки зрения природы, пожары, к примеру, сопровождаются низкочастотными звуками.
Человекоподобную память в ЭВМ можно создать, встраивая вызовы обработчиков прерываний (ошибок, исключений) . Если, допустим, при выполнении обработчика прерывания возникает исключение, мы до выполнения команды, которая вызвала исключение, вставляем вызов обработчика исключения.
Пример
`void page_error(void)
{
// это обработчик ошибки страницы
}
void interrupt(void)
{
//это обработчик прерывания
//
//здесь сгенерирована ошибка отсутствия страницы
}`
`//запоминаем ошибку
void interrupt_saferity(void)
{
//это обработчик прерывания
page_error(); //
//ошибки отсутствия страницы больше не будет
}`
И всё же, цифровые устройства не позволят реализовать полный аналог человеческого интеллекта. А человеческий интеллект не подчиняется детерминированным алгоритмам. Что уж говорить про описание человеческого интеллекта на каком либо языке программирования. Для того, чтобы создать искусственный интеллект, нужно определиться, мы хотим создать полный аналог человеческого интеллекта? Или всего лишь самообучающуюся систему? Но первый вариант однозначно неосуществим. | https://habr.com/ru/post/648639/ | null | ru | null |
# Реализуем http/2 server push с помощью nghttp2
Всем привет, сегодня я расскажу о том, как настроил server push на своём сайте и добился увеличения скорости рендеринга страниц. Для начала о том, что же такое **server push в HTTP/2**. Это технология, позволяющая серверу «протолкнуть» дополнительные данные клиенту, в момент запроса основного документа. То есть в обычной ситуации запрашивает браузер html-страничку, затем обрабатывает её и приходит к выводу, что ему для корректного отображения необходимо подгрузить дополнительные файлы: стили, скрипты, изображения. После чего скачивает их и отображает конечный результат. Server push позволяет отправить дополнительные файлы уже в момент получения основного документа, и они уже будут иметься в кэше, когда они потребуются браузеру. За счёт этого возрастает скорость загрузки сайта.
На этот раз схема будет следующая:

Теперь непосредственно о самой реализации. В данный момент nginx в режиме HTTP/2 не поддерживает технологию server push. Для этих целей я буду использовать nghttp2 — именно его используют в CloudFlare для реализации push'ей для своих клиентов. nghttp2 — это набор инструментов, реализующих HTTP/2 протокол. А именно: standalone-сервер, клиент и обратный прокси-сервер. Нас интересует часть, реализующая прокси-сервер, программа называется nghttpx.
### Настройка
Устанавливаем nghttp2:
```
apt-get install nghttp2
```
Настраиваем nghttpx. Файл конфигурации **/etc/nghttpx/nghttpx.conf** приводим к виду
```
frontend=93.170.104.204,443 #IP и порт нашей веб-морды
backend=127.0.0.1,6081 #IP и порт бэкенд-сервера
private-key-file=/etc/ssl/ssl.webshake.ru.key #Закрытый ключ
certificate-file=/etc/ssl/ssl.webshake.ru.pem #Файл с сертификатом сайта и сертификатами УЦ, аналогично nginx
http2-proxy=no #Иначе server push будет недоступен
workers=1 #Число воркеров
```
Проверяем что сайт работает. Теперь для того, чтобы «запушить» файл стилей в браузер клиенту достаточно передать на nghttpx с бэкенда заголовок вида:
```
Link: /path/to/file.css; rel=preload; as=stylesheet
```
Для JS-файла заголовок будет таким:
```
Link: /path/to/file.js; rel=preload; as=script
```
Я добавил 14 таких заголовков, реализовав это на PHP. В файл index.php добавил строки:
```
php
header("link: </wp-content/themes/shootingstar/style.css; rel=preload; as=stylesheet", false);
header("link: ; rel=preload; as=stylesheet", false);
header("link: ; rel=preload; as=stylesheet", false);
header("link: ; rel=preload; as=stylesheet", false);
header("link: ; rel=preload; as=stylesheet", false);
header("link: ; rel=preload; as=script", false);
header("link: ; rel=preload; as=script", false);
header("link: ; rel=preload; as=script", false);
header("link: ; rel=preload; as=script", false);
header("link: ; rel=preload; as=script", false);
header("link: ; rel=preload; as=script", false);
header("link: ; rel=preload; as=script", false);
header("link: ; rel=preload; as=script", false);
header("link: ; rel=preload; as=script", false);
```
и перезапустил Varnish для сброса всего кэша.
### Результат
После этого в браузере загрузил главную страницу своего сайта и увидел пушнутые файлы:
А вот так выглядит загрузка с отключенными пушами:

Файл, который был отправлен с помощью server push имеет соответствующий заголовок.
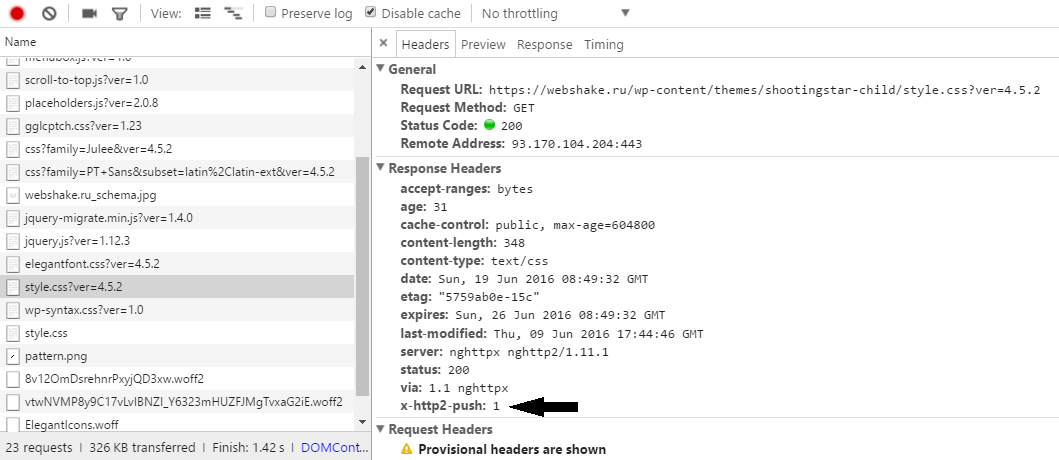
Вот в виде сравнения скорости рендеринга главной страницы при push'е файлов со стилями и JS и без push'ей:
Замеры проводились инструментом [WebPagetest/](http://www.webpagetest.org/), о котором я узнал от своего коллеги. Проект open-source, доступна куча метрик, настроек и тестовых серверов. Всем советую!
Также в процессе работы я накодил мини-сервис, позволяющий быстро проверить список пушаемых файлов, введя url сайта. Может быть кому пригодится — [webshake.ru/post/480](https://webshake.ru/post/480)
### Вывод
Технология server push'ей позволила сократить загрузку и отрисовку моего сайта с 1.7 до 1.4 секунд, а это аж 17%! Это работает и должно быть использовано.
Напоследок еще немного метрик с WebPagetest.

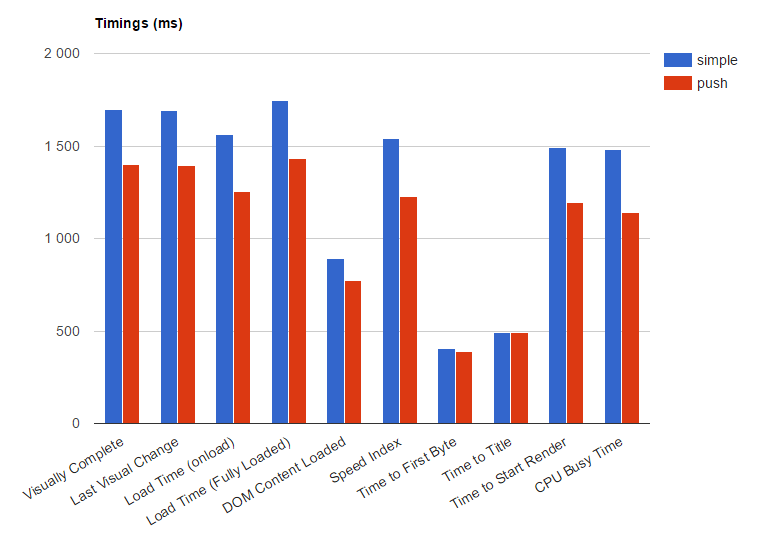
Источник: [webshake.ru/post/480](https://webshake.ru/post/480) | https://habr.com/ru/post/304422/ | null | ru | null |
# Opensource контроллер умного дома на базе Arduino Mega 2560 с поддержкой MQTT, DMX-512, 1-Wire, Modbus и Openhab
 Сегодня я решился вынести на суд общественности проект, работу над которым вел на протяжении последней пары лет: [«LightHub»](http://www.lazyhome.ru/index.php/14-myhome/18-lighthub). То, что получилось в итоге, можно назвать, пожалуй, самым дешевым решением для создания Умного дома, которое, тем не менее, умеет:
* Управлять освещением и силовыми устройствами(Реле, диммеры DMX-512 и Modbus RTU)
* Управлять теплыми полами (в качестве термодатчиков используются полтора десятка дешевых DS18B20, разведенных по квартире)
* Управлять задвижками вентиляции/кондиционера
* Управлять самодельной системой приточной вентиляции.
* Многое такого, о чем я изначально не задумывался, просто в силу того, что контроллер получился абсолютно открытым, гибко конфигурируемым, и прекрасно дополняющим Опенсорсные решения Openhab+Mosquitto+NodeRed
На вход контроллера подключаются обычные выключатели, кнопки, контактные датчики, датчики протечки и пр. которые могут управлять как локальными нагрузками так и устройствами, подключенными к другим таким же контроллерам или ко всему, что понимает протокол MQTT. У меня, например, подключен геркон, установленный в коробке входной двери. Когда закрываю замок на три оборота — выключаются свет, теплые полы, бойлеры, AV ресивер. Когда возвращаюсь — состояние этих приборов восстанавливается как было до ухода.
На выход — например, [такие вот релейные модули](https://aliexpress.com/item/8-Channel-20A-Relay-Control-Module-for-Arduino-UNO-MEGA2560-R3-Raspberry-Pi/32763221083.html), DMX, Modbus переферия.
Контроллеры конфигурируются при помощи JSON файлов, которые при старте контроллера загружаются по http (далее, конфиг можно сохранить в NVRAM через Serial CLI). Ну и, конечно, все это управляется системой Openhab 2, через штатное мобильное приложение.
Задачи «малой автоматизации» решены как при помощи штатных openhab rules (не очень удобных), так и при помощи NodeRed. (По поводу NodeRed [вот статья](https://geektimes.ru/post/279814/), которая прекрасно описывает пример автоматизации.)
Исходники, вместе с примерами конфигов, выложены на [GIThub](https://github.com/anklimov/lighthub), описание понемногу выкладываю на [сайте проекта.](http://lazyhome.ru) Соответственно, более полная история под катом.
**UPDATE: Прошло полгода с момента публикации и так выглядит промышленный прототип устройства в процессе монтажа в электротехнический шкаф.**
Плата Arduino DUE установлена на материнскую плату.

Плата снята, видны оптические развязки, защиты входов, драйверы DMX, Modbus, 1-wire, мощная транзисторная сборка (например) для управления реле.

А вот так контроллер выглядит на DIN рейке (крышка снята), рядом с типовым релейным блоком. (Как я писал, сознательно не ставлю силовые элементы внутрь корпуса контроллера)
Началось все с ремонта в квартире, в процессе которого я решил сделать дом прилично умнее.
При этом, тратить серьезные деньги на «Брендовое» решение Умного Дома, откровенно, не хотелось. Тем более, что многие «Серьезные» решения использовали закрытые стандарты и интегрировались друг с другом при помощи откровенных костылей.
Соответственно, я поставил перед собой задачу собрать Умный Дом из максимально готовых и недорогих компонент.
В качестве Hardware для контроллера я выбрал Arduino Mega 2560+Ethernet shield.
Update: Прислушавшись к комментариям ниже, я портировал проект на Atmel SAM3X8E ARM Cortex-M3 (Arduino DUE), плата, которая при такой же копеечной стоимости, обладает на порядок большей производительностью, а что самое важное — RAM. С библиотекой DMX пришлось повозиться, но теперь и DMX-IN и DMX-OUT работают, используя один аппаратный USART, не занимая без дела ресурса процессора. Проект уже лежит на [github](https://github.com/anklimov/lighthub) и компилируется автоматически под нужную платформу.
Копеечная цена, огромное кол-во портов ввода вывода, 4 аппаратных UART, приличный размер NVRAM, который мне пока удалось только на 30% занять прошивкой и в который умещается с запасом весь конфиг, причем, прямо в формате JSON подтвердили разумность выбора.
После обновления Bootloader, и [корректировки библиотеки Ethernet](https://github.com/anklimov/Ethernet) удалось успешно задействовать аппаратный Watchdog процессора, что добавило решению «промышленности» а мне спокойствия, хотя, прошивка и без этого не была замечена в зависании.
Отсутствие на контроллере какой либо операционной системы позволяет считать его «системой реального времени», что позволяет, например, программно генерировать тот же сигнал DMX.
Узкое место — размер RAM. И это не позволяет использовать всю необъятную переферию контроллера. Хотя, более 30-ти разнообразных каналов (items, в терминах конфига) в память вполне умещаются. А подключить столько, сколько позволяет плата Arduino Mega — задача, все же, не имеющая отношение к реальности.
(на ARM — более этого узкого места нет)
Также, масштабируемость достигается увеличением числа устройств. У меня, например, задействованы два контроллера. Они разнесены по квартире (это, также, позволяет не тянуть все провода в одну точку). Для взаимодействия друг с другом, а также, с системами Openhab и NodeRed используется MQTT брокер Mosquitto.
В качестве драйвера шины 1-wire я использовал чип (I2C драйвер) [ds2482-100 с Aliexpress](https://aliexpress.com/item/DS2482-DS2482-100-DS2482S-100-Free-shipping/32285250088.html), который при цене в 60 руб обеспечивает устойчивую работу с шиной до 100М.
Для гибкого конфигурирования устройства я доработал библиотеку AJSON для Arduino, таким образом, что она имеет возможность как загружать объект по http так читать и записывать объект из/в NVRAM контроллера. Форк доступен [на Github](https://github.com/anklimov/aJson).
Serial CLI при создании нового контроллера надо прописать в NVRAM уникальный MAC адрес. Именно MAC является ключом, по которому изначально загружается конфигурация c http сервера.
В качестве управляющего ПО я взял Openhab 2, имеющий весь нужный мне функционал, плюс, мобильное приложение, плюс «Облако» — роль которого, правда, только в том, чтобы предоставлять доступ к домашней инфраструктуре извне, не прокидывая портов на роутере и не обладая фиксированным IP. Также, Openhab имеет интеграцию с HomeKit от Apple, что позволяет управлять устройствами дома с iPhone, вообще без установки аппликации. (Возможность интересная, но пользуюсь, в основном, «родным» приложением).
**Немного скриншотов Openhab**
Наличие в проекте квартиры большого кол-ва светодиодного освещения, также, требовало какого-то разумного управления.
**Подробности по LED освещению**Решения, обнаруженные на рынке были либо закрытыми «вещами в себе», либо стоили неадекватных денег, поддерживая при этом немного каналов. Часто, производители ограничивались тремя каналами (RGB), хотя, вариант RGBW позволяет использовать светодионые ленты в качестве основного освещения, а не просто для цветовой подсветки.
Подумав, я заказал на АliExpress [пару плат](https://aliexpress.com/item/30-channel-27channel-Easy-DMX-LED-controller-dmx-decoder-driver-rgb-led-controller/2015743918.html?spm=a2g0s.9042311.0.0.VkllL4), каждая из которых может управлять 30-ю каналами LED с номинальным током до 2А на канал.
Для того, чтобы увеличить максимальную мощность одного канала, я перешел со светодиодных лент на 12В на 24В ленты. При этом, полноценно осветить комнату около 16-18 кв. м оказалось возможным при помощи 4-х ключей. БОльшие по площади помещения пришлось зонировать — в гостиной подключил независимо 4 ленты по 5 м, задействовав при это 16 каналов.
Для синхронного управления всей комнатой, пришлось придумать тип канала «группа»
Вот как выглядит описание гостиной в JSON конфиге:
```
"kuh":[7,["kuhline","kuhfre","kuhwork","kuhwin"]],
"kuhwin":[1,5],
"kuhline":[1,13],
"kuhfre":[1,25],
"kuhwork":[1,1],
```
Первый элемент массива — тип канала, второй — параметр канала, который может являться массивом.
Для элемента типа 7 (группа) — аргументом является массив элементов, входящих в группу.
Рекурсия, конечно же, поддерживается.
Для элемента типа 1 (лента RGBW) — аргумент — базовый DMX адрес канала.
Со стандартной библиотекой EasyDMX платы не заработали сразу. Как оказалось, китайский LED контроллер не переваривал 2ms задержку между фреймами DMX (interframe delay). Несложная модификация кода библиотеки (сокращение цикла в два раза) помогла.
[Форк библиотеки](https://github.com/anklimov/DmxSimple) на GitHub-е
По просьбе читателей, добавил картинки на тему «LED освещение в действие»

Это альтернативный DMX декодер из категории «дорого и богато»
Далее, «фотосессия», на которой можно понять, насколько меняются помещения при изменении освещения, а также, то, что используя только белый цвет в RGBW лентах, можно получить приятное глазу рассеяное освещение.
Рекомендую ленты исключительно с теплым белым светом (2700К)








А далее, несколько примеров комбинирования точечных светильников и LED:




Обычное AC 220В освещение у меня получилось управлять китайскими диммерами с Aliexpress, имеющими поддержку Modbus RTU (стандартный промышленный протокол управления поверх RS-485). Эти диммеры прекрасно управляются локально (выключателями без фиксации), в то же время, контроллер имеет возможность считывать яркость и управлять ими по шине Modbus (реализовано пока для двухканального устройства).
На момент публикации статьи, диммеры пропали с Алиэкспресса, но я нашел китайского производителя по лейблу на печатной плате устройства. Привожу [ссылку на их аскетичный сайт](http://hadalzone.net). На вопросы по e-mail отвечают охотно, прислали даже куцую документацию.
Еще вариант управления 220В освещения — использовать DMX-512 AC диммер. На e-bay таких в ассортименте, любого формфактора — плата или на DIN рейку. От одного до восьми каналов.
Я, в начале, поостерегся этого варианта, так как контроллер был еще в очень эксперементальном виде и, для надежности, хотелось сохранить автономное локальное управление. Но сейчас бы уже использовал такой вариант.
Далее — я установил канальный кондиционер, который в состоянии как нагреть так и охладить всю квартиру. Чтобы как-то распределять холод и тепло по спальням, я установил сервоприводы с управлением сигналом 0-10В. Угол открытия задвижек регулируется автоматически при помощи NodeRed, в котором для этого нашелся [удобный PID регулятор](https://flows.nodered.org/node/node-red-contrib-pid).
**Подробности по кондиционированию**К сожалению, не удалось найти приводов воздушных заслонок с ШИМ или каким-то цифровым входом, поэтому на том же AliExpress были приобретены 4 преобразователя ШИМ в стандартный аналоговый сигнал 0..10В.
К сожалению, на Aliexpress этих устройств уже не вижу, но на e-bay — [пожалуйста](https://www.ebay.com/itm/XD-39-DC12V-30V-PWM-to-Voltage-Converter-Module-0-100-PWM-to-0-10V/291905165217?hash=item43f6e757a1:g:0ogAAOSwAuZX65DJ)
Преобразователи великолепно заработали сразу, пришлось только перепрограммировать таймер ШИМ выходов для того, чтобы задать подходящую частоту.
Ниже пример перепрограммирования таймеров 3 и 4 (отвечают за pin-ы 2, 3, 5, 6, 7, 8 Arduino Mega на частоту 4000Гц).
```
pinMode(iaddr,OUTPUT);
//timer 0 for pin 13 and 4
//timer 1 for pin 12 and 11
//timer 2 for pin 10 and 9
//timer 3 for pin 5 and 3 and 2
//timer 4 for pin 8 and 7 and 6
int tval = 7; // 111 in binary - used as an eraser
TCCR4B &= ~tval; // set the three bits in TCCR2B to 0
TCCR3B &= ~tval;
tval=2; //prescaler = 2 ---> PWM frequency is 4000 Hz
TCCR4B|=tval;
TCCR3B|=tval;
analogWrite(iaddr,k=map(Value,0,100,0,255));
```
Далее, я начал искать WiFi контроллеры теплых полов. Нашел, в целом, неплохое устройство стоимостью около 6 тыс руб от Теплолюкс, но оно имело некоторые существенные для меня недостатки.
Несмотря на наличие мобильного приложения, протокол управления был закрыт. Я провел некоторый реверс-инженеринг, который показал, что, теоретически, протокол можно расшифровать. Возможно, я бы этим и занялся, но обнаружил, что без переустановки подразетников сие устройство не устанавливается в один ряд с выключателями. Это определило судьбу устройства: продав его, я реализовал функционал простого термостата на своем контроллере, сэкономив почти 30 тыс руб на 5-ти теплых полах.
**Получилось следующее:*** Все управление — локально на контроллере и независимо от домашней ИТ инфраструктуры
* Используются измерения с 1-wire термодатчиков. Если датчик долгое время не может быть опрошен — нагреватель отключается.
* Через MQTT можно включить/выключить теплый пол и задать его температуру. Соответственно, полы управляемы через интерфейсы и мобильное приложение Openhab
* Я не стал реализовывать хитрые сценарии и расписания на контроллере. При желании, это легко реализуется правилами Openhab или Node-Red. Я ограничился только отключением устройств, когда люди покидают дом.
Вот пример конфига для одного теплого пола:
```
"ow":{
"2807FFD503000036":{"emit":"t_bath1","item":"h_bath1"}
},
"items":{
"h_bath1":[5,24,33],
},
```
Данные при опросе термометра OneWire с указанным адресом передаются на шину MQTT в топик t\_bath1, а также, внутри контроллера, объекту h\_bath, имеющему тип №5 (термостат), реле подключено к pin#24 контроллера, уставка — 33 градуса (можно корректировать по MQTT)
**Входы устройства**
В конфиге для каждого входа можно задать как передачу команды локальному объекту так и выдачу команды в MQTT топик. Причем, отдельно как на условное «нажатие» кнопки так и на «отпускание».
**Примеры:**
```
"in":{
"41":{"emit":"/myhome/in/all","scmd":"HALT","rcmd":"REST"},
"38":{"item":"spots_en"},
"37":{"emit":"/myhome/in/light","scmd":"ON","rcmd":"OFF"},
"40":{"emit":"/myhome/in/gstall","scmd":"TOGGLE","rcmd":"TOGGLE"},
"35":{"emit":"/myhome/s_out/water_leak"}
}
```
Pin 41: Геркон на замке входной двери — при запирании — выдаем в топик /myhome/in/all команду HALT, при отпирании — команду REST.
У меня это приводит к полному «засыпанию» и «просыпанию» дома. К слову — команды не входят в стандартный набор OpenHab, но получились крайне удобны — HALT — выключает устройство, REST — восстанавливает параметры устройства до последнего значения (цвет, яркость, температура), но только для того устройства, которое было выключено командой HALT а не OFF. Это позволяет не включать то, что было выключено на момент покидания дома.
Pin 38: Просто обычный выключатель света. При замыкании — выдает (по умолчанию) команду ON, при размыкании — команду OFF. Эти значения передаются объекту «spots\_en». Понятно, что состояние обьекта можно изменить с мобильного приложения. В этом случае, выключатель, как бы, остается, например, во включенном положении, но свет выключен.
Для любителей классических проходных выключателей, подойдет синтаксис Pin 40: И при включении и при выключении выдается команда TOGGLE (тоже, кстати, новая, относительно OpenHab), меняющая положение Вкл-Выкл устройства (в данном примере, лампа управляется не локально, а через MQTT другим контроллером).
Если это не перекидной выключатель а кнопка — достаточно просто скорректировать «rcmd»:"" — при этом команда на переключение будет выдаваться только при нажатии.
А, ну и почти забыл описать DMX-IN — вход, ради которого, можно сказать, я и начинал эту разработку.
На рынке масса удачных с дизайнерской точки зрения и, в целом, эргономичных DMX контроллеров светодиодных лент.
[Один из таких (сенсорную панель) я и купил](https://aliexpress.com/item/New-Touch-Panel-Led-DMX-Rgb-Strip-Controller-12-24v-86-Glass-Panel-DMX512-D8-Led/32487885735.html) в самом начале для экспериментов с DMX. Все хорошо, но архитектура DMX не предусматривает никакого управления из более чем одного места. Существует один Мастер, который постоянно транслирует в шину яркости каналов. Но в этом проекте данная проблема решена. Контроллер LightHub отслеживает изменения каналов DMX на входе, подключенном к сенсорной панели. Если они изменяются — транслирует изменения на выход (с маппингом на сконфигурированные устройства, в том числе, на группы светодиодных лент).
Пока ничего не меняется — устройства нормально управляются удаленно. Стоит сенсорной панели поменять значения яркости каналов — эти изменения транслируются на DMX выходы.
Как не странно, этот костыль получился вполне эргономичным. Хотя, как показал опыт, мы все реже используем сенсорную панель и все чаще смартфоны для управления устройствами.
**Заключение**
К сожалению, в одной статье невозможно описать все нюансы, заложенные в разработку.
Например, совсем за кадром осталась тема подключения Modbus устройств, их пуллинг и синхронизация локального состояния устройства с системой Умного Дома, интеграция с простой приточной установкой. Ну и, возможно, сравнение с существующими системами близких классов, такими, например, как MegaD-328, AMS и, даже, WirenBoard. Возможно, если будет заинтересованность — продолжу.
Также, пока за кадром то, что с использованием NodeRed удалось проинтегрировать систему с Telegram. Пока работает для получения оповещений, но можно создать полноценный Bot.
Относительно проекта LightHub — при всей дешевизне, контроллеры оказались вполне рабочим решением. Честно говоря, я сам не верил, что на основе Arduino можно создать стабильно работающую систему, но, по-моему, это удалось.
Конечно, надо многое еще доделать: полностью уйти от хардкода (осталось совсем чуть-чуть), немного и местами почистить и рефакторить код, тщательно документировать проект, развести печатную плату (сейчас интерфейсные Шилды спаяны просто на основе макетных плат и содержат три MAX-485 — (DMX-IN, DMX-OUT, Modbus) и 1-Wire мост) — и это станет, по сути, очень бюджетным готовым решением.
Warning: Напоминаю, что проект пока на уровне макетных плат. Открывая следующий спойлер, вы можете нанести урон своим эстетическим чувствам.
**Немного картинок**
Первый контроллер, управляющий LED (60 каналов DMX-512), Modbus (диммеры, приточка), заслонки ветиляции;

Это DMX-512 декодер, который удобно размещать там, где светодиодные ленты приходят к трансформаторам. У меня — под фальшпотолком в кладовке.

А это-второй контроллер, обслуживающий 1-wire, выключатели/датчики и релейный модуль. (Сам релейный модуль разместился прямо в распаечной коробке, где ему и место вместе с тремя фазами. Соседство 380В и слаботочки я искоренил везде, где возможно, после одного неудачного происшествия)
Понятно, что надо расширять функционал. Как минимум, в направлении беспроводных датчиков/устройств. (Хотя, например, ZWave и так сейчас можно использовать через стандартные биндинги Openhab).
Возможность подключения, например, бюджетного NooLight, вероятно, неплохая идея. Возможно, подумаю над миграцией на ESP-8266 для расширения RAM, хотя, уход на WiFi с проводного подключения к LAN мне не нравится с точки зрения надежности. Да и ESP не обладает такой богатой переферией как Arduino Mega. Еще планирую сделать учет электроэнергии через датчики тока и подключение Rotary Encoder на вход.
Также, полезно было бы сделать конфигурирование и запуск контроллера более User Friendly (визуальные конфигураторы и пр.). При этом, сознательно не хочется превращать контроллер в вебсервер с файлами/картинками, AJAX и пр. На мой взгляд, это уже должно являться прерогативой сервера. Хотя бы на основе Raspberry.
Но поскольку проект абсолютно Опенсорсный — возможны разные варианты, присоединяйтесь.
Также, с нетерпением ожидаю ваших отзывов.
### UPDATE:
После публикации статьи, объединив усилия вместе с одним из жителей Хабра и нарисовав принципиальную схему LighthHub Shield, приступили к разводке печатной платы, с учетом всего осмысленного опыта и комментариев
* Плата будет совместима как с Arduino Mega (5v) так и с Arduino DUE (ARM 3,3В)
* Встроенный интерфейс Ethernet на базе Wiznet5500
* 8 опторазвязанных дискретных входов, 8 дискретных входов/выходов с защитой по напряжению/току
* 8 аналоговых входов с защитой по напряжению/току. В дальнейшем, предполагаю использовать аналоговые входы для контроля потребляемой мощности (датчики тока) и для того, чтобы подключать внешние потенциометры (диммеры)
* 8 ШИМ выходов, 4 из них с мощными выходными ключами (до 500 мА/50В) + 4 дискретных мощных выхода. Позволят подключить локально к контроллеру, например, несколько пускателей или даже не сильно длинную RGBW LED ленту.
* Разьем формата [UEXT](https://www.olimex.com/Products/Modules/), который позволит, впоследствии, подключить к контроллеру совместимую переферию — например дополнительные радиомодули, для соединения с беспроводными устройствами.
* Остальные входы/выходы будут выведены без защит на разъемы RJ45 для подключения локальных устройств (релейные платы, ЦАП и пр)
* Конечно же, остаются интерфейсы 1-Wire для подключения термодатчиков, DMX-512 вход и выход для управления освещением, Modbus RTU для всего остального
Оставить комментарии по функциональности, а также, желание присоединиться к заказу первой партии плат, можно [тут](http://www.lazyhome.ru/index.php/featurerequest)
Следующим пунктом программы будет разработка платы контроллера со встроенным модулем ESP32 (это позволит уйти от формфактора Ардуино) | https://habr.com/ru/post/407975/ | null | ru | null |
# Google Chrome — убираем рутину с помощью кастомного поиска
**Disclaimer:** речь — о давно существующей функции, но, судя по комментам на Хабре, недооцененной, поэтому решил все-таки написать.
Google Chrome позволяет очень сильно ускорить рутинные задачи, связанные с различным поиском. используя адресную строку.
###### Например:
* "**`ru nightingale`**" показывает русский перевод [«nightingale» в Google Translate](http://translate.google.ru/#en/ru/nightingale)
* "**`ан соловей`**" или "**`fy соловей`**" переводит «соловей» на английский [там же](http://translate.google.ru/#ru/en/%D1%81%D0%BE%D0%BB%D0%BE%D0%B2%D0%B5%D0%B9)
* "**`j click`**" открывает документацию по [jQuery.click](http://api.jquery.com/click/)
* "**`m Лесная 6`**" открывает адрес [адрес «Лесная 6» на Яндекс.Картах](http://maps.yandex.ru/?text=%D0%9B%D0%B5%D1%81%D0%BD%D0%B0%D1%8F+6)
###### Настроить очень просто:
найдите на странице настроек Хрома кнопку «Управление поисковыми системами» и добавьте туда свой поиск:
* **Ключевое слово** — собственно «имя команды» для конкретного поиска
* **Ссылка с параметром** — URL, который вы хотите открыть; вместо конкретного текста запроса — `%s`
###### Для примеров выше:
* перевод на русский: `ru` `translate.google.ru/#en|ru|%s`
* перевод на английский: `ан` `translate.google.ru/#ru|en|%s` (полезно также забить и `fy`, чтобы не переключать раскладку)
* доки jQuery: `j` `api.jquery.com/%s`
* Яндекс.Карты: `m` `maps.yandex.ru/?text=%s`
В результате вы не только сэкономите кучу времени, но и гораздо больше узнаете — например, настроив так переводчик, я стал гораздо чаще им пользоваться. | https://habr.com/ru/post/218051/ | null | ru | null |
# Производительность Composer 2.0 с JIT PHP 8
> *Прежде чем перейти к статье, приглашаем всех желающих поучаствовать в* [*бесплатном вебинаре «PHP 8 — Что нового?»*](https://otus.pw/bw2y/)*.*
>
>

---
Последние несколько месяцев для PHP разработчиков выдались поистине захватывающими. С релизами Composer 2.0 и PHP 8.0 произошли значительные обновления кодовой базы DXP (Digital Experience Platform) Ibexa и множества других программных проектов, работающих на PHP. В рамках продолжения темы проведения [бенчмарков Composer 1.10 и 2.0](https://developers.ibexa.co/blog/benchmarks-of-composer-2.0-vs-1.10) и [Symfony 5.2 с PHP 7.1 и 8.0](https://developers.ibexa.co/blog/benchmarks-php-7.4-8.0-jit-opcache-preloading-symfony), сегодня мы рассмотрим производительность Composer 2.0 на PHP 8.0.
Как и в [предыдущих статьях](https://developers.ibexa.co/content-root/blog-authors/jani-tarvainen), я проводил бенчмарки на [Hetzner](https://hetzner.cloud/?ref=MsoNt9h6M6ak) CCX11 VPS с 2 выделенными виртуальными ЦП и 8 ГБ ОЗУ. Я протестировал три сценария с использования [Composer 2.0.7](https://github.com/composer/composer/releases/tag/2.0.7):
* PHP 7.4
* PHP 8.0
* PHP 8.0 [с JIT.](https://wiki.php.net/rfc/jit)
Я решил не [включать предварительную загрузку OPcache](https://developers.ibexa.co/content-root/blog/how-much-of-a-performance-boost-can-you-expect-for-a-symfony-5-app-with-php-opcache-preloading), потому что небольшое число запусков [Composer](https://getcomposer.org/) вряд ли что-нибудь от нее выиграет. Используемые конфигурации [OPCache](https://www.php.net/manual/en/opcache.configuration.php#ini.opcache.enable) и [JIT](https://www.php.net/manual/en/opcache.configuration.php#ini.opcache.jit):
```
opcache.preload_user=www-data
opcache.memory_consumption=1024
opcache.interned_strings_buffer=256
opcache.max_accelerated_files=30000
opcache.validate_timestamps=0
opcache.enable=1
opcache.enable_cli=1
opcache.file_cache="/tmp/php-file-cache"
opcache.file_cache_only=1
opcache.file_cache_consistency_checks=1
# only when JIT was enabled
#opcache.jit_buffer_size=512mb
#opcache.jit=1225
```
Контрольный прогон выполняется с установкой [Ibexa Experience](https://developers.ibexa.co/content-root/products/ibexa-experience) и включает следующее:
1. Установить без файла блокировки и очищенных кэшей
2. Потребовать новый пакет ([novactive/ezseobundle](https://packagist.org/packages/novactive/ezseobundle))
3. Установить с файлом блокировки, с очищенными кэшами
4. Установить с файлом блокировки, с заполненными кэшами
Я запускал этот набор три раза с [аналогичными скриптами из предыдущих бенчмарков](https://gist.github.com/janit/de5abba9fb109ae18c17ed673743a8c8) и выбирал лучшие показатели по каждому из пунктов. Для отчетности я измерял время и использование памяти.
По продолжительности установки особых различий нет. При полном разрешении зависимостей быстрее всего справляется PHP 7.4, а медленнее всего — PHP 8.0 с JIT. При установке с файлом блокировки, но с пустым кэшем самым медленным оказался PHP 8.0 без JIT. Для случаев с заполненным кэшем результаты идентичны — всего за 6 секунд, что является хорошим результатом для интегрированных [CI/CD конвейеров](https://developers.ibexa.co/content-root/products/ibexa-cloud).
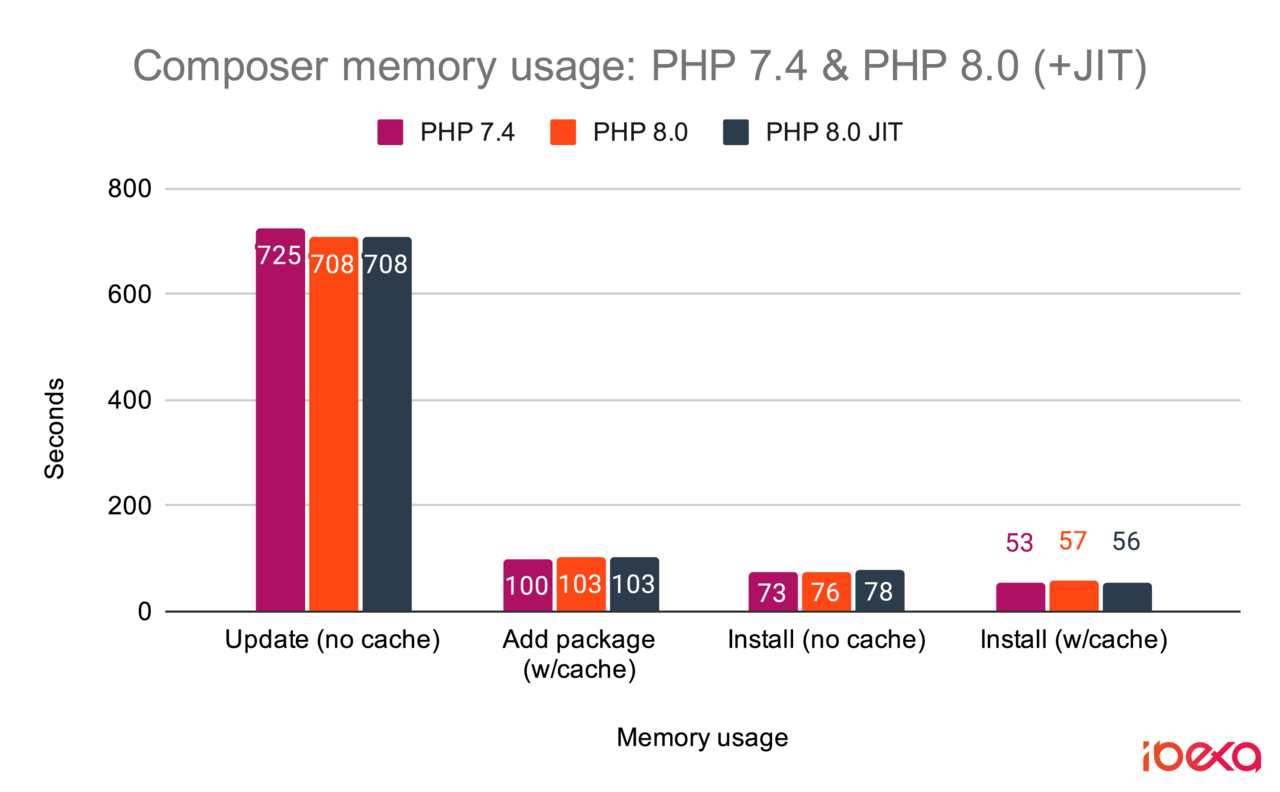По использованию памяти показатели еще ближе друг к другу. С полным разрешением зависимостей PHP 8 является наиболее экономным, но немного более расточительным в других сценариях. Различия здесь довольно малы и поэтому не имеют большого значения в реальных сценариях.
Судя по результатам бенчмарков, для Composer нет больших преимуществ от использования PHP 8.0 (с JIT или без него) вместо PHP 7.4. Для более ощутимых улучшений я бы порекомендовал просто [перейти с Composer 1 на Composer 2](https://getcomposer.org/upgrade/UPGRADE-2.0.md). Особенно учитывая значительное сокращение объема памяти, используемого для разрешения зависимостей.
---
> [Узнать подробнее о курсе](https://otus.pw/U33S/) «PHP-разработчик».
>
> [Зарегистрироваться на открытый вебинар](https://otus.pw/bw2y/) «PHP 8 — Что нового?».
>
> | https://habr.com/ru/post/536972/ | null | ru | null |
# Core Data + Repository pattern. Детали реализации
Всем привет! Данный пост рассчитан на людей, которые имеют представление о Core Data. Если вы не один из них, прочитайте краткую информацию [тут](https://habr.com/ru/post/436510/) и скорее присоединяйтесь. Прежде всего, мне хотелось бы поделиться своим взглядом на некоторые подходы к организации работы с данными в IOS приложениях, и в этом вопросе мне пришелся по душе паттерн репозиторий (далее - репозиторий). Поехали!
Немного про репозиторий
-----------------------
Основная идея репозитория заключается в том, чтобы абстрагироваться от источников данных, скрыть детали реализации, ведь, c точки зрения доступа к данным, эта самая реализация - не играет роли. Предоставить доступ к основным операциям над данными: сохранить, загрузить или удалить - главная задача репозитория.
Таким образом, к его преимуществам можно отнести:
* отсутствие зависимостей от реализации репозитория. Под капотом может быть все, что угодно: коллекция в оперативной памяти, UserDefaults, KeyChain, Core Data, Realm, URLCache, отдельный файл в tmp и т.п.;
* разделение зон ответственности. Репозиторий выступает прослойкой между бизнес-логикой и способом хранения данных, отделяя одно от другого;
* формирование единого, более структурированного подхода в работе с данными.
В конечном итоге, все это благоприятно сказывается на скорости разработки, возможностях масштабирования и тестируемости проектов.
Ближе к деталям
---------------
Рассмотрим самый неблагоприятный сценарий использования Core Data.
Для общего понимания будем использовать класс DataProvider (далее - DP) - его задача получать данные откуда - либо (сеть, UI) и класть их в Repository . Также, при необходимости, DP может достать данные из репозитория, выступая для него [фасадом](https://refactoring.guru/ru/design-patterns/facade). Под данными будем подразумевать массив доменных объектов. Именно ими оперирует репозиторий.
1. Core Data как один большой репозиторий с NSManagamentObject
--------------------------------------------------------------
Рисунок 1Идея оперировать [NSManagedObject](https://developer.apple.com/documentation/coredata/nsmanagedobject) в качестве доменного объекта самая простая, но не самая удачная. При таком подходе перед нами встают сразу несколько проблем:
1. Сore Data разрастается по всему проекту, вешая ненужные зависимости и нарушая зоны ответственности. Раскрываются детали реализации. Знать на чем завязана реализация репозитория - должен только репозиторий;
2. Используя единый репозиторий для всех Data Provider, он будет разрастаться с появлением новых доменных объектов;
3. В худшем случае, логика работы с объектами начнет пересекаться между собой и это может превратиться в один большой непредсказуемый magic.
2. Core Data + DB Client
------------------------
Первое, что приходит на ум, для решения проблем из предыдущего примера, это вынести логику работы с объектами в отдельный класс (назовем его DB Client), тогда наш Repository будет только сохранять и доставать объекты из хранилища, в то время, как вся логика по работе с объектами ляжет в DB Client. На выходе должно получиться что-то такое:
Рисунок 2Обе схемы решают проблему №1. (Core Data ограничивается DB Client и Repository), и частично могут решить проблему №2 и №3 на небольших проектах, но не исключают их полностью. Продолжая мысль дальше, возможно придти к следующей схеме:
Рисунок 31. Core Data можно ограничить только репозиторием. DB Client конвертирует доменные объекты в NSManagedObject и обратно;
2. Repository больше не единый и он не разрастается;
3. Логика работы с данными более структурирована и консолидирована
Здесь, стоит отметить, что вариантов композиции и декомпозиции классов, а также способов организации взаимодействия между ними - множество. Тем не менее, выше-описанная схема показывает еще одну, на мой взгляд, важную проблему: на каждый новый доменный объект, в лучшем случае, требуется заводить X2 объектов (DB Client и Repository). Поэтому, предлагаю рассмотреть еще один способ реализации. Для удобства, проект лежит [тут](https://github.com/ArturRuZ/CoreDataRepositoryPattern).
Подготовка к реализации
-----------------------
В первую очередь, таким я вижу репозиторий:
```
protocol AccessableRepository {
//1
associatedtype DomainModel
//2
var actualSearchedData: Observable<[DomainModel]>? {get}
//3
func save(_ objects: [DomainModel], completion: @escaping ((Result) -> Void))
//4
func save(\_ objects: [DomainModel], clearBeforeSaving: RepositorySearchRequest, completion: @escaping ((Result) -> Void))
//5
func present(by request: RepositorySearchRequest, completion: @escaping ((Result<[DomainModel]>) -> Void))
//6
func delete(by request: RepositorySearchRequest, completion: @escaping ((Result) -> Void))
//7
func eraseAllData(completion: @escaping ((Result) -> Void))
}
```
1. Доменный объект, которым оперирует репозиторий;
2. Возможность подписаться на отслеживание изменений в репозитории;
3. Сохранение объектов в репозиторий;
4. Сохранение объектов с возможностью очистки старых данных в рамках одного [контекста](https://developer.apple.com/documentation/coredata/nsmanagedobjectcontext);
5. Загрузка данных из репозитория;
6. Удаление объектов из репозитория;
7. Удаление всех данных из репозитория.
Возможно, ваш набор требований к репозиторияю будет отличаться, но концептуально ситуацию это не изменит.
К сожалению, возможность работать с репозиторием через AccessableRepository отсутствует, о чем свидетельствует ошибка на рисунке 4:
Рисунок 4В таком случае, хорошо подходит Generic-реализация репозитория, которая выглядит следующим образом:
```
class Repository: NSObject, AccessableRepository {
typealias DomainModel = DomainModel
var actualSearchedData: Observable<[DomainModel]>? {
fatalError("actualSearchedData must be overrided")
}
func save(\_ objects: [DomainModel], completion: @escaping ((Result) -> Void)) {
fatalError("save(\_ objects: must be overrided")
}
func save(\_ objects: [DomainModel], clearBeforeSaving: RepositorySearchRequest, completion: @escaping ((Result) -> Void)) {
fatalError("save(\_ objects vs clearBeforeSaving: must be overrided")
}
func present(by request: RepositorySearchRequest, completion: @escaping ((Result<[DomainModel]>) -> Void)) {
fatalError("present(by request: must be overrided")
}
func delete(by request: RepositorySearchRequest, completion: @escaping ((Result) -> Void)) {
fatalError("delete(by request: must be overrided")
}
func eraseAllData(completion: @escaping ((Result) -> Void)) {
fatalError("eraseAllData(completion: must be overrided")
}
}
```
2. NSObject нужен для взаимодействия с NSFetchResultController;
3. AccessableRepository - для наглядности, прозрачности и порядка;
4. FatalError играет роль предохранителя, чтобы всяк сюда входящий не использовал то, что не реализовано;
5. Данное решение позволяет не привязываться к конкретной реализации, а также обойти предыдущую проблему:
Рисунок 5Для работы с выборкой объектов потребуются объект с двумя свойствами:
```
protocol RepositorySearchRequest {
/* NSPredicate = nil, apply for all records
for deletion sortDescriptor is not Used
*/
//1
var predicate: NSPredicate? {get}
//2
var sortDescriptors: [NSSortDescriptor] {get}
}
```
1. Условие для выборки, если условие отсуствует - выборка применяется ко всему набору данных;
2. Условие для сортировки - может как отсуствтвоать так и присутствовать.
Поскольку, в дальнейшем может возникнуть необходимость использовать отдельный [NSPersistentContainer](https://developer.apple.com/documentation/coredata/nspersistentcontainer) (например для тестирования), который, в свою очередь, выступает источником контекста - нужно закрыть его протоколом:
```
protocol DBContextProviding {
//1
func mainQueueContext() -> NSManagedObjectContext
//2
func performBackgroundTask(_ block: @escaping (NSManagedObjectContext) -> Void)
}
```
1. Контекст, с которым работает main Queue, необходим для использования [NSFetchedResultsController](https://developer.apple.com/documentation/coredata/nsfetchedresultscontroller);
2. Требуется для выполнения операций с данными в фоновом потоке. Можно заменить на [newBackgroundContext()](https://developer.apple.com/documentation/coredata/nspersistentcontainer/1640581-newbackgroundcontext). Про различия в работе этих двух методов можно прочитать [тут](https://stackoverflow.com/questions/53633366/coredata-whats-the-difference-between-performbackgroundtask-and-newbackgroundc).
Также, потребуются объекты, которые будут осуществлять конвертацию (мапинг) доменных моделей в объекты репозитория (NSManagedObject) и обратно:
```
class DBEntityMapper {
//1
func convert(\_ entity: Entity) -> DomainModel? {
fatalError("convert(\_ entity: Entity: must be overrided")
}
//2
func update(\_ entity: Entity, by model: DomainModel) {
fatalError("supdate(\_ entity: Entity: must be overrided")
}
//3
func entityAccessorKey(\_ entity: Entity) -> String {
fatalError("entityAccessorKey must be overrided")
}
//4
func entityAccessorKey(\_ object: DomainModel) -> String {
fatalError("entityAccessorKey must be overrided")
}
}
```
1. Позволяет конвертировать NSManagedObject в доменную модель;
2. Позволяет обновить NSManagedObject с помощью доменной модели;
3. 4. - используется для связи между собой NSManagedObject и доменным объектом.
Когда-то, я использовал доменный объект, в качестве инициализатора NSManagedObject. С одной стороны, это было удобно, с другой стороны накладывало ряд ограничений. Например, когда использовались связи между объектами и один NSManagedObject создавал несколько других NSManagedObject. Такой подход размывал зоны ответственности и негативно сказывался на общей логике работы с данными.
Во время работы с репозиторием потребуется обрабатвать ошибки, для этого достаточно enum:
```
enum DBRepositoryErrors: Error {
case entityTypeError
case noChangesInRepository
}
```
Здесь абстрактная часть репозитория подходит к концу, осталось самои интересное - реализация.
Реализация
----------
Для данного примера, подойдет простая реализация DBContextProvider (без каких-либо дополнительных параметров):
```
final class DBContextProvider {
//1
private lazy var persistentContainer: NSPersistentContainer = {
let container = NSPersistentContainer(name: "DataStorageModel")
container.loadPersistentStores(completionHandler: { (_, error) in
if let error = error as NSError? {
fatalError("Unresolved error \(error),\(error.userInfo)")
}
container.viewContext.automaticallyMergesChangesFromParent = true
})
return container
}()
//2
private lazy var mainContext = persistentContainer.viewContext
}
//3
//MARK:- DBContextProviding implementation
extension DBContextProvider: DBContextProviding {
func performBackgroundTask(_ block: @escaping (NSManagedObjectContext) -> Void) {
persistentContainer.performBackgroundTask(block)
}
func mainQueueContext() -> NSManagedObjectContext {
self.mainContext
}
}
```
1. Инициализация NSPersistentContainer;
2. Раньше такой подход избавлял от утечек памяти;
3. Реализация DBContextProviding.
Основная составляющая репозитория выглядит следующим образом:
```
final class DBRepository: Repository, NSFetchedResultsControllerDelegate {
//1
private let associatedEntityName: String
//2
private let contextSource: DBContextProviding
//3
private var fetchedResultsController: NSFetchedResultsController?
//4
private var searchedData: Observable<[DomainModel]>?
//5
private let entityMapper: DBEntityMapper
//6
init(contextSource: DBContextProviding, autoUpdateSearchRequest: RepositorySearchRequest?, entityMapper: DBEntityMapper) {
self.contextSource = contextSource
self.associatedEntityName = String(describing: DBEntity.self)
self.entityMapper = entityMapper
super.init()
//7
guard let request = autoUpdateSearchRequest else { return }
self.searchedData = .init(value: [])
//self.fetchedResultsController = configureactualSearchedDataUpdating(request)
}
}
```
1. Cвойство, которое будет использовать при работе с [NSFetchRequest](https://developer.apple.com/documentation/coredata/nsfetchrequest);
2. DBContextProviding - для доступа к контексту, требуется для выполнения операций сохранения, загрузки, удаления;
3. fetchedResultsController - необходим, когда требуется отслеживать изменения в [NSPersistentStore](https://developer.apple.com/documentation/coredata/nspersistentstore) (проще говоря, изменение объектов в базе);
4. searchedData - зависит от fetchedResultsController и служит оберткой для fetchedResultsController, скрывая детали реализации и уведомляя подписчиков об изменениях в данных;
5. entityMapper - конвертирует доменные объекты в NSManagedObject и обратно;
6. Иницализатор;
7. В случае если autoUpdateSearchReques != nil, выполняем конфигурацию fetchedResultsController для отслеживания изменениы в базе ;
Чтобы не порождать однотипный код для работы с контекстом, потребуется вспомогательный метод:
```
private func applyChanges(context: NSManagedObjectContext, mergePolicy: Any = NSMergeByPropertyObjectTrumpMergePolicy, completion: ((Result) -> Void)? = nil) {
//1
context.mergePolicy = mergePolicy
switch context.hasChanges {
case true:
do {
//2
try context.save()
} catch {
ConsoleLog.logEvent(object: "DBRepository \(DBEntity.self)", method: "saveIn", "Error: \(error)")
completion?(Result.error(error))
}
ConsoleLog.logEvent(object: "DBRepository \(DBEntity.self)", method: "saveIn", "Saving Complete")
completion?(Result(value: ()))
case false:
//3
ConsoleLog.logEvent(object: "DBRepository \(DBEntity.self)", method: "saveIn", "No changes in context")
completion?(Result(error: DBRepositoryErrors.noChangesInRepository))
}
}
```
1. [mergePolicy](https://developer.apple.com/documentation/coredata/nsmergepolicy) - отвечает за то, как решаются конфликты при работе с контекстом. В данном случае, по умолчанию используется политика, которая отдает приоритет изменённым объектам, находящимся в памяти, а не в persistent store;
2. Сохранение изменений в persistent store;
3. Если изменения объектов отсутствуют, в completion-блок передается соответствующая ошибка.
Сохранение объектов реализовано следующим образом:
```
private func saveIn(data: [DomainModel], clearBeforeSaving: RepositorySearchRequest?, completion: @escaping ((Result) -> Void)) {
contextSource.performBackgroundTask() { context in
//1
if let clearBeforeSaving = clearBeforeSaving {
let clearFetchRequest = NSFetchRequest(entityName: self.associatedEntityName)
clearFetchRequest.predicate = clearBeforeSaving.predicate
clearFetchRequest.includesPropertyValues = false
(try? context.fetch(clearFetchRequest))?.forEach({ context.delete($0) })
}
//2
var existingObjects: [String: DBEntity] = [:]
let fetchRequest = NSFetchRequest(entityName: self.associatedEntityName)
(try? context.fetch(fetchRequest) as? [DBEntity])?.forEach({
let accessor = self.entityMapper.entityAccessorKey($0)
existingObjects[accessor] = $0
})
data.forEach({
let accessor = self.entityMapper.entityAccessorKey($0)
//3
let entityForUpdate: DBEntity? = existingObjects[accessor] ?? NSEntityDescription.insertNewObject(forEntityName: self.associatedEntityName, into: context) as? DBEntity
//4
guard let entity = entityForUpdate else { return }
self.entityMapper.update(entity, by: $0)
})
//5
self.applyChanges(context: context, completion: completion)
}
}
```
1. Используется при необходимости удалить объекты, перед сохранением новых (в рамках текущего контекста);
2. Выполняется выгрузка объектов, которые существуют в репозитории, для их дальнейшего изменения;
3. Если объект с нужным entityAccessorKey отсутствует, создается новый экземпляр NSManagedObject;
4. Выполнение мапинга свойств из доменного объекта в NSManagedObject;
5. Применение выполненных изменений.
***Важно:*** *Возможно вас смутил п.2., данное решение оптимально на небольших наборах данных. Я выполнял замеры (ExampleCase3 в демо-проекте) на 10 000 записей, iPhone 6s Plus IOS 12.4.1 и получил следующие результаты:*
* *время записи/перезаписи данных от 0,9 до 1.8 сек, cкачок потребления оперативной памяти в пике до 33 мб;*
* *если убрать код в п2 и оставить только вставку новых объектов, то время записи/перезаписи данных +- 20 сек, cкачок потребления оперативной памяти в пике до 50 мб.*
*Для больших наборов данных я бы рекомендовал разделять их на части, использовать* [*batchUpdate и batchDelete,*](https://developer.apple.com/library/archive/featuredarticles/CoreData_Batch_Guide/BatchUpdates/BatchUpdates.html) *а начиная с IOS 13 появился* [*batchInsert*](https://developer.apple.com/documentation/coredata/nsbatchinsertrequest)*.*
Таким образом, реализация методов ***save*** cводится к вызову метода ***saveIn***:
```
override func save(_ objects: [DomainModel], completion: @escaping ((Result) -> Void)) {
saveIn(data: objects, clearBeforeSaving: nil, completion: completion)
}
override func save(\_ objects: [DomainModel], clearBeforeSaving: RepositorySearchRequest, completion: @escaping ((Result) -> Void)) {
saveIn(data: objects, clearBeforeSaving: clearBeforeSaving, completion: completion)
}
```
Методы ***present, delete***, ***eraseAllData*** завязаны на работе с NSFetchRequest. В их реализации нет ничего особенного, поэтому не вижу смысла заострять на них внимание:
```
override func present(by request: RepositorySearchRequest, completion: @escaping ((Result<[DomainModel]>) -> Void)) {
//1
let fetchRequest = NSFetchRequest(entityName: associatedEntityName)
fetchRequest.predicate = request.predicate
fetchRequest.sortDescriptors = request.sortDescriptors
contextSource.performBackgroundTask() { context in
do {
//2
let rawData = try context.fetch(fetchRequest)
guard rawData.isEmpty == false else {return completion(Result(value: [])) }
guard let results = rawData as? [DBEntity] else {
completion(Result(value: []))
assertionFailure(DBRepositoryErrors.entityTypeError.localizedDescription)
return
}
//3
let converted = results.compactMap({ return self.entityMapper.convert($0) })
completion(Result(value: converted))
} catch {
completion(Result(error: error))
}
}
}
override func delete(by request: RepositorySearchRequest, completion: @escaping ((Result) -> Void)) {
//1
let fetchRequest = NSFetchRequest(entityName: associatedEntityName)
fetchRequest.predicate = request.predicate
fetchRequest.includesPropertyValues = false
contextSource.performBackgroundTask() { context in
//2
let results = try? context.fetch(fetchRequest)
results?.forEach({ context.delete($0) })
//3
self.applyChanges(context: context, completion: completion)
}
}
override func eraseAllData(completion: @escaping ((Result) -> Void)) {
//1
let fetchRequest = NSFetchRequest(entityName: associatedEntityName)
let batchDeleteRequest = NSBatchDeleteRequest(fetchRequest: fetchRequest)
batchDeleteRequest.resultType = .resultTypeObjectIDs
contextSource.performBackgroundTask({ context in
do {
//2
let result = try context.execute(batchDeleteRequest)
guard let deleteResult = result as? NSBatchDeleteResult,
let ids = deleteResult.result as? [NSManagedObjectID]
else {
completion(Result.error(DBRepositoryErrors.noChangesInRepository))
return
}
let changes = [NSDeletedObjectsKey: ids]
NSManagedObjectContext.mergeChanges(
fromRemoteContextSave: changes,
into: [self.contextSource.mainQueueContext()]
)
//3
completion(Result(value: ()))
return
} catch {
ConsoleLog.logEvent(object: "DBRepository \(DBEntity.self)", method: "eraseAllData", "Error: \(error)")
completion(Result.error(error))
}
})
```
1. Создание запроса;
2. Выборка объектов и их обработка;
3. Вовзрат результата операции.
Для реализации возможности отслеживания изменений данных в реальном времени, потребуется FetchedResultsController. Для его конфигурации используется следующий метод:
```
private func configureactualSearchedDataUpdating(_ request: RepositorySearchRequest) -> NSFetchedResultsController {
//1
let fetchRequest: NSFetchRequest = NSFetchRequest(entityName: associatedEntityName)
fetchRequest.predicate = request.predicate
fetchRequest.sortDescriptors = request.sortDescriptors
//2
let fetchedResultsController = NSFetchedResultsController(fetchRequest: fetchRequest,
managedObjectContext: contextSource.mainQueueContext(), sectionNameKeyPath: nil,
cacheName: nil)
//3
fetchedResultsController.delegate = self
try? fetchedResultsController.performFetch()
if let content = fetchedResultsController.fetchedObjects as? [DBEntity] {
updateObservableContent(content)
}
return fetchedResultsController
}
func updateObservableContent(\_ content: [DBEntity]) {
let converted = content.compactMap({ return self.entityMapper.convert($0) })
//4
searchedData?.value = converted
}
```
1. Формирование запроса, на основании которого будут отслеживаться изменения;
2. Создание экземпляра класса NSFetchedResultsController;
3. performFetch() позволяет выполнить запрос и получить данные, не дожидаясь изменений в базе. Например, это может быть полезно при реализации Ofline First;
4. Изменение свойства searchedData, в свою очередь уведомляет подписчиков (если такие имеются) об изменении.
Заключение
----------
На этом этапе реализация всех основных методов для работы с репозиторием подходит к концу. Для меня основными преимуществами данного подхода стало следующее:
* логика работы репозитория с Core Data стала везде единая;
* для добавления новых объектов в репозиторий, достаточно создать только EntityMapper (новое Entity требуется создать в любом случае). Вся логика по мапингу свойств также собрана в одном месте;
* Data слой стал более структурированным. Теперь можно точно гарантировать, что репозиторий не выполняет 100500 запросов в методе сохранения, чтобы проставить связи между объектами;
* репозиторий легко можно подменить, например для тестов, или для отладки.
Подобный подход может подойти не всем, и это основной его минус. Часто логика работы с данными зависит в т.ч и от бэк-энда. Основная задача этого поста - донести один из концептов по работе с Core Data. Смотрите демо-проект, допиливайте его под себя, пользуйтесь!
***Спасибо за внимание! Легкого кодинга, поменьше багов, побольше фич!*** | https://habr.com/ru/post/542752/ | null | ru | null |
# Лучшие практики безопасности Angular
Angular - это популярный front-end framework, созданный компанией Google. Как и другие популярные front-end фреймфорки, он использует архитектуру, основанную на компонентах для структурирования компонентов.
В этой статье будут рассмотрены существующие практики безопасности, которые следует использовать при написании Angular приложения.
Предотвращение межсайтового скриптинга (XSS)
--------------------------------------------
Межсайтовый скриптинг позволяет злоумышленнику внедрить вредоносный код в веб-страницу.
Чтобы это предотвратить, Angular создает переменные, которые интерполируются в шаблоны.
Angular шаблоны представляют собой исполняемый код, поэтому любые вредоносные куски кода необходимо "дезинфицировать".
Интерполяция очищена, но не *innerHtml.* Например:
> {{htmlSnippet}}
>
>
>
>
Очищена, но при этом:
>
>
>
- нет.
Следовательно, необходимо быть осторожным, при использовании *innerHtml*, чтобы предотвратить выполнение строк с тэгом *script*.
Прямое использование DOM API и явных вызовов очистки
----------------------------------------------------
Встроенные DOM API не защищают нас от уязвимостей безопасности.
*document, ElementRef* имеют небезопасные методы. Перед их использованием следует запустить метод *DomSanitizer.sanitize* и соответствующий *SecurityContext*.
Использование автономного компилятора шаблонов
----------------------------------------------
Возможно использование автономного компилятора шаблонов в продакшене для предотвращения внедрения шаблонов.
Доверие безопасным ценностям
----------------------------
Можно доверять безопасным значениям, используя DomSanitizer и вызывать один из следующий методов:
* `bypassSecurityTrustHtml`
* `bypassSecurityTrustScript`
* `bypassSecurityTrustStyle`
* `bypassSecurityTrustUrl`
* `bypassSecurityTrustResourceUrl`
Для того, чтобы доверять коду, устанавливаемому динамически.
Например, есть следующий код, который позволяет запустить JavaScript код в href атрибуте:
`app.component.ts` :
```
import { Component } from "@angular/core";
import { DomSanitizer } from "@angular/platform-browser";
@Component({
selector: "app-root",
templateUrl: "./app.component.html",
styleUrls: ["./app.component.css"]
})
export class AppComponent {
dangerousUrl;
trustedUrl;
constructor(private sanitizer: DomSanitizer) {
this.dangerousUrl = 'javascript:alert("Hi")';
this.trustedUrl = sanitizer.bypassSecurityTrustUrl(this.dangerousUrl);
}
}
```
`app.component.html` :
```
Click me
```
При передаче *this.dangerousUrl* в *sanitizer.bypassSecurityTrustUrl* мы верим, что код безопасен.
Уязвимости на HTTP уровне
-------------------------
Angular из коробки имеет поддержку, помогающую предотвратить распространённые уязвимости ( подделка межсайтовых запросов CSRF/XSRF или межсайтовый скриптинг XSS.
Подделка межсайтовых запросов — это атака, при которой злоумышленник выдает себя за законного пользователя и делает запрос от имени этого пользователя.
Распространенным методом защиты от CSRF является отправка случайно сгенерированного токена аутентификации в файле cookie. Клиент считывает файл cookie и добавляет настраиваемый заголовок запроса с токеном во все последующие запросы.
Сервер сравнивает полученное значение cookie со значением заголовка запроса и отклоняет запрос, если значения отсутствуют или не совпадают.
Все браузеры реализуют политику одного и того же источника. Только код с веб-сайта, на котором установлены файлы cookie, может прочитать файл cookie и установить пользовательские заголовки на сайте.
HTTP-клиент Angular`а может получить файл cookie с сервера и добавить настраиваемый заголовок запроса во все последующие запросы.
Включение межсайтового скрипта (XSSI)
-------------------------------------
Это уязвимость в старых браузерах, которая переопределяет собственные конструкторы объектов JavaScript и включающая URL-адрес API с использованием тега script.
Этот вид атак успешен только в том случае, если JSON имеет исполняемый JavaScript код.
Выводы
------
Атаки с использованием межсайтовых сценариев — это когда вредоносные скрипты внедряются в код приложения и запускаются.
Это предотвращается очисткой строк. Angular также предоставляет возможность пройти санитарную обработку.
Методы DOM небезопасны, поэтому мы должны помнить об этом при их использовании.
Подделка межсайтовых запросов - это когда злоумышленник отправляет запросы в качестве законного пользователя, выдавая себя за него.
HttpClient Angular`a может считывать пользовательские файлы cookie с сервера и отправлять заголовок запроса с уникальным идентификатором, который проверяется сервером, чтобы предотвратить эту атаку.
Мы можем предотвратить атаку с включением межсайтовых сценариев, очистив JSON, чтобы предотвратить выполнение исполняемой строки JSON.
Ссылка на оригинальную статью: [Angular Security Best Practices](https://javascript.plainenglish.io/angular-security-best-practices-54fadf8974a1) | https://habr.com/ru/post/675054/ | null | ru | null |
# Нарезка ресурсов – путь к оптимизации размера iOS-приложений
Нарезка приложения – это новая фича, которая появилась в iOS и tvOS версии 9.0. Теперь разработчики могут загружать на App Store несколько вариантов ресурсов для разных типов устройств. Это существенно уменьшает размер приложения, поскольку пользователь загружает пакет данных только для своего конкретного устройства.

[Нарезка приложения](https://developer.apple.com/library/tvos/documentation/IDEs/Conceptual/AppDistributionGuide/AppThinning/AppThinning.html#//apple_ref/doc/uid/TP40012582-CH35-SW1) пользуется популярностью у разработчиков, потому что позволяет упаковать больше ассетов в исходное приложение и при этом оставаться в пределах ограничения в 100 MБ на загрузку через мобильный интернет. Для достижения такого результата разработчики также могут обращаться к аналогичному методу использования ресурсов по запросу, о котором мы писали [ранее](http://blogs.unity3d.com/2015/11/26/mastering-on-demand-resources-for-apple-platforms/). Однако этот метод не всегда удобен и оптимален: приложение должно быть предварительно адаптировано для того, чтобы динамически загружать необходимые ресурсы. Использование ресурсов по запросу сложнее по всем параметрам, а при нарезке приложения эти сложности отсутствуют.
Нарезка приложения бывает двух типов: нарезка исполняемых файлов и нарезка ресурсов. Нарезка исполняемых файлов – это удаление неиспользуемого исполняемого кода из приложения. Этот тип применяется автоматически ко всем приложениям App Store для iOS/tvOS версии 9.0 и выше. Метод нарезки ресурсов, в свою очередь, требует больших усилий от разработчика, так как предполагает удаление неиспользуемых ассетов. Именно этот метод мы рассмотрим в данной статье.
Основная цель нарезки ресурсов приложения – задействовать неиспользуемую пропускную полосу и объем памяти при нескольких вариантах одного ассета. Зачастую необходимо применять различные варианты ассета, потому что возможности более старых, но всё еще широко используемых iOS-устройств сильно отличаются от новых версий. До выхода iOS 9.0 все ассеты должны были находиться в основном пакете приложения, что приводило к потере пропускной полосы и объема памяти на устройствах, поскольку из всех вариантов использовался только один. Применение метода нарезки ресурсов позволило исключить неиспользуемые ассеты из основного пакета приложения.
Нарезать ресурсы приложения удобнее всего через пакеты ассетов. Это самый простой способ структуризации. Более того, пакеты ассетов легко интегрировать в Unity, а их производительность прямо пропорциональна загрузке обычных массивов данных. Пакеты ассетов также можно использовать в качестве бэкэнда при использовании ресурсов по запросу, поэтому функцию нарезки легко добавить в приложение, которое уже использует ресурсы по запросу и наоборот. После настройки пакетов ассетов нужно будет сделать еще немного изменений, чтобы использовать нарезку ресурсов, как показано на примерах кода ниже. В этой статье мы не будем подробно рассматривать пакеты ассетов, поэтому если вы слышите о них впервые, рекомендуем ознакомиться с материалами [по ссылке.](http://unity3d.com/ru/learn/tutorials/topics/scripting/assetbundles-and-assetbundle-manager)
Чтобы нарезать ресурсы, разработчику необходимо указать, какие устройства подходят для всех вариантов ассетов, и загрузить необходимые ассеты при запуске приложения. В разработке приложений для оригинальной iOS нарезка ресурсов происходит так: внутри каталога ассетов создаются объекты данных или изображений и настраиваются варианты ресурсов для устройств, после чего ресурсы присваиваются плейсхолдерам в UI. В Unity разработчик сам настраивает варианты ресурсов, которые, по сути, являются пакетами с потенциально разным набором ассетов. Все варианты пакетов, задействованные в нарезке ресурсов приложения, должны быть зафиксированы в коде при помощи функции обратного вызова API: UnityEditor.iOS.BuildPipeline.collectResources. Затем точные требования к устройствам указываются в игровых настройках UI. И наконец разработчик должен вручную загрузить пакеты ассетов через AssetBundle.CreateFromFile API при запуске приложения.

Примеры кода, которые демонстрируют основные принципы использования нарезки ресурсов приложения:
**Скрипт регистрации ресурсов, участвующих в нарезке приложения:**
```
using UnityEditor.iOS;
#if ENABLE_IOS_APP_SLICING
public class BuildResources
{
[InitializeOnLoadMethod]
static void SetupResourcesBuild()
{
UnityEditor.iOS.BuildPipeline.collectResources += CollectResources;
}
static UnityEditor.iOS.Resource[] CollectResources()
{
return new Resource[] {
new Resource("asset-bundle-name").BindVariant("path/to/asset-bundle.hd"), "hd")
.BindVariant("path/to/asset-bundle.md"), "md")
.BindVariant("path/to/asset-bundle.sd"), "sd"),
};
}
```
**Загрузка пакетов ассетов при запуске:**
```
< ...>
var bundle = AssetBundle.LoadFromFile("res://asset-bundle-name");
// now use AssetBundle APIs to load assets
// or Application.LoadLevel to load scenes
var asset = bundle.LoadAsset("Asset");
< ...>
```
Изучение пакетов ассетов и нарезки ресурсов приложения лучше всего начать с нашего демопроекта Asset Bundle Manager («Менеджер пакетов ассетов») на [BitBucket](https://bitbucket.org/Unity-Technologies/assetbundledemo). По ссылке вы найдете подробное описание, как использовать и настраивать демопроект. | https://habr.com/ru/post/276069/ | null | ru | null |
# Медитация — древний хакинг реальности в современности

Супергерои — не современное изобретение. С древних времен люди мечтали о суперсилах и сверхспособностях, что было отражено в большом количестве эпосов и сказаний о героях, богах и о том, как обычные люди становились им равными.
И если в мифах Древней Греции обычно супер герои имели часть божественной крови, а в современных фильмах и мангах супергерои обычно становились таковыми при случайных обстоятельствах (укус паука, эксперимент ученых и т.п.), то в литературе и философии Азии это зачастую зависело только от самого человека.
Мало того, существовали различные структуры (их иногда называют традициями, линиями, системами и т.п.), которые копили знания и практиковали методы, которые приводили людей к тому, что сейчас мы бы назвали сверхспособностями.
Здесь мы прикоснемся к одному из базовых методов, который применялся с древности для хакинга реальности — медитации.
Хотя моя цель — написать все просто и понятно, но все равно будет немного терминов, исследований, быть может будет занудно. Однако те, кто хочет нормально понять что такое медитация и как с ее помощью можно хакать реальность — добро пожаловать под кат.
БОНУС — наверное мы все любим чудеса. Как насчет того, чтобы увеличить работоспособность мозга и продлить жизнь? В статье мы рассмотрим первый хак реальности для продления бодрой жизни, научим как его применять, приведем научные доказательства его эффективности и то, как самим проверить как он сработал на физическом уровне.
> Как день сменяется ночью, так постоянно по порядку человек появляется, изменяется, уничтожается, сотворяется.
>
> Ни страдания и ни удовольствия и никакие ощущения, ни появления и разрушения не постоянны для человека.
>
> Неуловимое время играет со всеми живыми существами в жестокую игру, где счастье внезапно проходит, оставляя всем печали.
>
> Философский текст индуизма “Йога Васиштхи”, примерно 6-10 века нашей эры.
Что такое медитация
-------------------
Для начала разберемся, что такое медитация. Вокруг термина накручено столько всего, что смысл теперь понять не так просто.
Сам термин пришел из Индии, но для его обозначения при переводе, использовали латинское слово meditatio — размышление. В оригинале, на санскрите, медитация называлась дхьяна. Это слово, например в википедии переводится как созерцание, «видение умом», «интуитивное видение», медитация, сосредоточение, размышление. Что дает нам намек на то, что это что-то относящееся к уму. Однако, для практического понимания это дает немного.
Если почитать в [буддийской вики про медитацию](http://vbuddisme.ru/wiki/%D0%9C%D0%B5%D0%B4%D0%B8%D1%82%D0%B0%D1%86%D0%B8%D1%8F), то можно увидеть, что там она определяется как метод трансформации ума.
Причем это не один какой-то застывший метод, а огромное количество практических методик, которые могут быть как жестко зафиксированными для всех, так и индивидуально применяемыми в зависимости от склада ума практикующего. Буддизм, который наиболее плотно использует методики медитации и очень много их изучает, возник примерно в 500 году до нашей эры и до нашего времени огромное количество практиков и ученых непрерывно применяли и улучшали эти методы для трансформации ума в выбранных ими направлениях.
Итак, попробуем дать определение для целей нашей статьи. Медитация, это метод для работы с умом, чаще всего (но не обязательно) состоящий из размышлений на заданную тему и сосредоточения ума каким-либо описанным образом, который направлен на трансформацию ума практикующего в выбранном контексте.
Например, мы можем чувствовать, что нас одолевает жадность и желать отрегулировать это состояние. Для этого мы можем начать ежедневную практику специально разработанной медитации, обычно от 10 до 30 минут в день и, спустя какое-то время, это состояние должно прийти в норму.
Конечно, можно менять ум по разному, модификации могут быть полезными, странными, бесполезными, вредными и т.п. Особенно в современности, когда в соц. сетях начинают постить на эту тему не пойми что. Это особенности современности работает во всех областях — для примера можно вспомнить битвы с прививками, гомеопатию и т.п.
И сама современная медицина, которая работает с телом, которое предположительно проще по устройству чем разум, часто “меняет показания” — сначала что-то вредно, потом по мере изучения оказывается не вредно, потом вообще полезно. Типовой пример из множества подобных — холестерин. Обзорная [статья про этот случай на гиктаймс](https://geektimes.ru/post/281784/).
Тоже самое вполне может случится и при работе с нашим умом, хотели, например понижение стресса, применяли какой-то метод, а получили вовсе другое, например нервность. Поэтому как всегда и везде, нужно применять наш развитый хорошим образованием мозг — подвергать все сомнению, не принимать ничего на веру, все проверять.
Про то, какой мы выбрали метод медитации и почему считаем его надежным — далее в статье.
Что такое хакинг реальности
---------------------------
> Хакер — человек, увлекающийся исследованием подробностей (деталей) программируемых систем, изучением вопроса повышения их возможностей, в противоположность большинству пользователей, которые предпочитают ограничиваться изучением необходимого минимума.
>
> Википедия
Каждый из нас живет в своей реальности — работа, дом, семьи, друзья, увлечения и т.п. И мало кто из нас не хотел бы хакнуть эту реальность. То есть не трудится до потери трудоспособности выполняя все положенные социальные обязательства до смерти, а как-то вот так взять и хакнуть реальность. При этом мы не рассматриваем химический хакинг — алкоголь и всякие более сильные вещества, про это достаточно литературы и так. При этом обычно, в перспективе многих лет, большая часть веществ (за редкими исключениями) приводит в реальность гораздо более худшую чем она была до того.
Как насчет того чтобы во снах попадать в в волшебные реальности и жить там вторую жизнь? Или умирая уносится в другие миры и осознанно там оставаться? Или прожить в этом мире не ~70 лет, постепенно затухая и глупея, а полноценно и бодро ~100 лет? Такой хакинг обычно вызывает у нас, гиков, интерес, что можно видеть по статьям тут и по популярности фантастической литературы.
Чтобы перейти к хакингу для начала разберемся в термине реальность. Что это такое? Даже обзорная статья в википедии дает множество определений и характеристик этого термина.
> Реальность (от лат. realis — вещественный, действительный) — философский термин, употребляющийся в разных значениях как существующее вообще; объективно явленный мир; фрагмент универсума, составляющий предметную область соответствующей науки; объективно существующие явления, факты, то есть существующие действительно. Различают объективную (материальную) реальность и субъективную (явления сознания) реальность.
>
> Википедия
Это определение одно из многих — в некоторых философских системах мы можем прочитать сильно от него отличающиеся, однако, примем его за основу, чтобы двигаться дальше.
Конечно можно схитрить и взять субъективную реальность, описать ее и рассказать, что вот — всё работает. Счастья больше, сны ярче, настроение лучше — ура.
Однако, мы усложним нашу задачу и возьмем hardware термин:
> Реальность — объективная реальность, то есть материя в совокупности различных её видов. Реальность противополагается здесь субъективной реальности, то есть явлениям сознания, и отождествляется с понятием материи.
И вот теперь мы можем идти дальше — как привести пример хакинга объективной реальности с помощью медитации? Для этого нам надо взять какой-то материальный объект и доказать, что мы можем его изменить просто медитируя какое то время ежедневно. Ну что, поехали?
Как медитация меняет объективную реальность
-------------------------------------------
Конечно круто было бы тут привести всякие ролики и фото того, как на медитационных ретритах возникают радуги, в черепе сами образуются отверстия для выхода сознания, как мы можем менять температуру своего тела и сидеть в простыне в Гималаях зимой, медитируя сутками, поедая чашку риса в день. Но у нас тут не The X-Files, поэтому пойдем куда обычно — на Pubmed.
[Источник](https://www.ncbi.nlm.nih.gov/pubmed/29016274)
По картинке можно видеть ажиотаж (хайп) вокруг медитации. Главная причина, с моей точки зрения, в том, что удовлетворив кучу потребностей люди обеспеченного мира оказались лицом к лицу с тем фактом, что это не решило проблем ума и уровень счастья, быть может, этот уровень даже стал ниже чем был в менее обеспеченные времена. Гениально про это написал Пелевин:
> — Справа — расстрел двенадцати сомалийских пиратов на барже «Алута», — сказала Софи. — Слева — основатель международных курсов омолаживания Элдер А. Заклинг понимает во время утреннего бритья, что уже не молод. То же самое, одинаковый выход агрегата «М5».
>
> — Правильно, — сказал я. — Аполло про это говорил. Что можно гуманным образом собирать больше баблоса, чем негуманным. Великая Частотная Революция…
>
> — Рама, агрегат «М5» — это страдание. Что значит «гуманный»? Который дает приличную картинку на экране? Без говна и крови? Это не гуманизм, Рама. Это умение заметать следы…”
>
> [Книга Бэтмен Аполло, Пелевин](https://libs.ru/book/197/)
Столкнувшись с тем, что удовлетворение материальных потребностей счастья не приносит, люди начали искать. Так как в эпоху 60-х движение нейросвободы проиграло потребительской правительственной политике, в которой исследования психоактивных веществ были сдвинуты в криминальную зону, то одной из новых областей изучения стала медитация.
С конца 1960-х в США открывалось много буддийских школ медитации, в которых учили буддийские мастера бежавшие из Тибета, а также множество мастеров остальных традиций буддизма. Это были хорошо образованные люди с огромным опытом медитации и работы с людьми.
Буддизм и его практики начали изучаться в университетах, начали проводится научные исследования, открываться все больше медитационных центров, что постепенно, привело к хайпу нашего времени. Как всегда во время хайпа возникло очень много мутных личностей и непонятных ответвлений.
Если набрать поиск `site:https://www.ncbi.nlm.nih.gov/pubmed/ meditation` то мы увидим, что всего доступно 6700 исследований, из них 276 за последний год.
В этих исследованиях есть то, что нам нужно, и наконец-то, после длинных введений мы переходим к чудесам. Как практика медитации может поменять что-то в объективной реальности.
Пример хакинга реальности с помощью медитации
---------------------------------------------
> — Ну и ладно, съем, — сказала Алиса. — Если я от него стану побольше, я смогу достать ключ, а если стану еще меньше, пролезу под дверь. Будь что будет — в сад я все равно заберусь! Больше или меньше? Больше или меньше? — озабоченно повторяла она, откусив кусочек пирожка, и даже положила себе руку на макушку, чтобы следить за своими превращениями.
>
> Как же она удивилась, когда оказалось, что ее размеры не изменились!
>
> Вообще-то обычно так и бывает с тем, кто ест пирожки, но Алиса так уже привыкла ждать одних только сюрпризов и чудес, что она даже немножко расстроилась — почему это вдруг опять все пошло, как обычно!
>
> Алиса в стране чудес.
Когда я начал изучать биохимию и генетику, то меня поразило то, как работают клетки — это целый микромир с огромным комплексом взаимосвязанных реакций, где чтобы получить какое то вещество запускаются каскады реакций. В воображении вставала картина планеты с океанами, озерами, лесами и тундрами. Если исчезнут волки, то олени станут больше болеть и вымрут. И все все взаимосвязано друг с другом таким же и гораздо более сложным образом.
Например, [диаграмма биосинтеза](http://www.genome.jp/kegg-bin/show_pathway?eco01230) аминокислот одной из самых изученных бактерий — кишечной палочки (E.coli)
[](http://www.genome.jp/kegg-bin/show_pathway?eco01230)
И это только одна операция из множества. А ведь внутри клеток еще происходит куча всего, например гликолиз, который вообще реализован на уровне компьютерной логики ([см. статью на Geektimes](https://geektimes.ru/post/282582/)).
Этот пример я привожу для того, чтобы показать то, как работает наш организм — это сложная взаимосвязанная система, где изменив что-то одно, мы влияем на кучу казалось бы не связанных с этим вещей. Например, выпив бокал вина мы запускаем каскад реакций одной из граней которых является ярко выраженный седативный (расслабляющий) эффект. Это повсеместно наблюдаемый результат влияния объективной реальности на субъективную (то есть вещества или воздействия на тело меняют наше внутреннее состояние).
В свою очередь выяснилось, что наше внутреннее состояние влияет на объективную реальность.
Исследования проводились на тему влияния медитации на наше тело.
**На заметку.** Мы публикуем все рассматриваемые исследования в нашем канале телеграм. В феврале, марте, апреле мы будем там подробно исследовать то, как влиять на наше здоровье и здоровье мозга при помощи добавок. Исследования будут не торопливые и подробные, только по научным статьям. Если вас это интересует вы можете [подписаться на наш канал](https://t.me/lifext).
### Влияние медитации на тело №1
Потенциальные защитные эффекты длительной медитации на атрофию серого вещества при старении. [Ссылка на исследование 1](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5447722/) [Ссылка 2](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4300906/)
Исследование от 2014 года, было обследовано 100 человек — 50 медитаторов и 50 обычных людей, средний возраст около 50 лет (от 24 до 77лет). Опыт медитации от 4 до 46 лет.
На приложенном рисунке суть исследования — по вертикальной оси объем серого вещества в мл., по горизонтальной возраст. Синяя линия — обычные люди, желтая — медитирующие.
Уже после 45 лет начинается разница в количестве серого вещества. (Примечание от нашего приложения — поэтому чем раньше начать медитировать, тем лучше.)
Далее авторы описывают предполагаемые механизмы, которые приводят к такому результату.
Предполагаемые варианты:
1. Образование новой материи — медитация стимулирует дендриды и синапсы, что приводит к росту серой материи и это восполняет ее потерю при старении.
2. Уменьшение возрастной потери — медитация приводит к уменьшению стресса, воспаления и т.п. (см. [статью](https://geektimes.ru/company/lifext/blog/296793/)), что приводит к уменьшению потери серого вещества
Заключение от авторов — данное исследование дает очередное подтверждение гипотезы того, что медитация может защищать наш мозг при старении.
### Влияние медитации на тело №2
Увеличение “связности мозга” ([читать что это такое](http://forum.lifext.ru/t/svyaznost-mozga-chto-eto-takoe/35)) у постоянно медитирующих людей.
[Ссылка на исследование](https://www.ncbi.nlm.nih.gov/pubmed/21664467)
В этом исследовании от 2011 года изучали структурную связность мозга у медитаторов. Утверждается, что практикующие медитацию идеально подходят для изучения пластичности мозга, так как они ежедневно его развивают.
Исследовали 27 человек практикующих медитацию + 27 контрольных. В результате было выявлено, что [фракционная анизотропия мозга](https://goo.gl/PxmkTQ) у медитирующих значительно выше.
Уровень фракционной анизотропии связан с когнитивным старением, каждые 10 лет он уменьшается на 3%. [Ссылка на исследование](http://www.ajnr.org/content/28/2/226.full)
Поэтому исследование о том, что медитация позволяет его повышать дает физическое подтверждение того, что с ее помощью мозг на физическом уровне замедляет старение.
### Вывод
Кроме этих двух исследований, есть еще огромное количество других, которые исследуют разные эффекты от медитации на тело и психологическое состояние человека. Например в обзорной статье ученых из США и Австралии <https://t.me/lifext/31> они делают вывод о том, что постоянная практика медитации уменьшает хроническое воспаление связанное со старением, которое приводит к ослаблению когнитивных функций с возрастом.
Получается, что просто сидя по 5-10-20 минут в день и делая практику медитации мы можем физически менять свой мозг и свое тело в сторону увеличения работоспособности. Практик медитации существует огромное количество, многие из них адаптированы к современной жизни, некоторые официально практикуются отдельными сотрудниками в технологических гигантах вроде гугла ([см.статью на хабре](https://habrahabr.ru/post/199272/))
Мы хотим предложить тем, кому интересно и кто готов пробовать делать медитацию по 5-10 минут два раза в день. В этой медитации внедрен хак, который должен сильно ускорить ее воздействие и эффект замедления старения.
Методика медитации + хак
------------------------
> Success! Wordpress have been installed! Were you expecting more steps? Sorry to disappoint.
>
> Wordpress developers
Пусть медитация это хакинг реальности, в том смысле, что мы изучаем реальность и самих себя глубже и с новых сторон, при этом что-то улучшая быстро и эффективно. Тогда хак внутри медитации должен этот эффект усиливать и ускорять действие.
К сожалению, медицинских исследований нашего хака не проводилось, но, мы надеемся, в ближайший год-два мы сможем провести их сами.
Однако к делу, классическая базовая медитация заключается в том, что мы садимся на стул или на пол со скрещенными ногами, спина прямая. Дышим носом, глаза полузакрыты или полностью закрыты. После этого мы обращаем внимание на свое дыхание и начинаем осознавать (направленно ощущать) как воздух выходит и выходит из наших ноздрей. при этом считаем вдохи-выдохи. Каждый цикл может быть, например 10, 20 и т.п. вдохов-выдохов.
При этом пока мы дышим и считаем, мы обращаем внимание на то, что удерживать внимание на дыхании не получается, в голову лезут разные мысли, не важно какие — о работе, доме, отношениях, хорошие, плохие, никакие и т.п. Мы не стараемся избавляться от мыслей и цель не в том, чтобы их отгонять.
Цель в том, чтобы ловить момент, когда мы отвлеклись, смотреть на последнюю мысль, не оценивать ее и возвращаться к сосредоточению на дыхании.
**Всё.** Знаменитая буддийская медитация меняющая реальность.
Смысл тут в том, что в жизни мы относимся к мыслям и эмоциям как к чему то, что дано. Например испытывая гнев, мы переживаем его до тех пор пока он сам не пройдет. При этом мы можем с ним бороться, подавлять (что не очень хорошо) или выплескивать (что тоже не очень), глушить алкоголем и т.п… Мы ощущаем его как бы своим, тем что дано и через что надо пройти, что надо проработать.
Эта простейшая медитация день за днем перепрошивает наши нейронные пути, показывая нам то, что мысли и эмоции просто некие концепции, к которым не обязательно цепляться. Это сразу и практика и теория. После какого-то времени практики мы вдруг можем заметить, что стали меньше нервничать или, если проблема была в вялости, то что мы стали более бодрыми. При этом в медитации происходит работа мозга, которая увеличивает его пластичность и физически сохраняет объем при старении.
Медитативный хак
----------------
Этот хак исходит из наблюдения (мнения), что люди, которые приносят общественную пользу, например профессора, видные ученые, преподаватели — стареют медленнее. А если они перестают работать, то быстро угасают.
**Гипотеза** — если человек значим для общества, приносит ему пользу и необходим для развития сообщества, то это что-то переключает в нашем организме. Человек начинает медленнее стареть, меньше болеть, мозг становится более ясным.
Техника медитации, которую я привел выше появилась около 500 года до нашей эры. После этого сообщество практикующих развивалось, строились монастыри, университеты, ученые изучали, практики практиковали и т.п. И, примерно около первого века до нашей эры, оформились дополнительные методики, в которых медитация становилась не только личной, но и распространялась на всех существ.
Поэтому можно считать, что данный хак был изобретен и применялся уже около 2000 лет, а мы его просто адаптируем под современные городские условия.
Смысл в том, что во время медитации мы визуализируем (данный термин в контексте медитаций означает — представляем, внутренне описываем, психологически воображаем и т.п.) группу людей и приносим им счастье и пользу. Это очень простая, базовая практика, проверенная веками, поэтому можно не боятся психологических косяков.
Мы предполагаем, что данный хак может запускать механизмы, которые помогают жить дольше и быть более здоровым.
Медитацию желательно делать ежедневно, это занимает всего восемь минут.
Ссылка на аудиотреки на двух языках <https://soundcloud.com/awaiking/sets/life-extension-meditation-for-daily-practice>
Вот и всё, тем кто дочитал спасибо!
Рекомендуемый комплекс для ежедневного приема
---------------------------------------------
* [Омега-3](https://ru.iherb.com/pr/Now-Foods-Omega-3-180-EPA-120-DHA-500-Softgels/18104?rcode=SAV8512) (если вы едите рыбу 2 или более раз в неделю, то эту добавку принимать НЕ НАДО)
* [Витамин Д](https://ru.iherb.com/pr/Now-Foods-Vitamin-D-3-High-Potency-1-000-IU-180-Softgels/543?rcode=SAV8512)
* [Комплект минералов](https://ru.iherb.com/pr/Now-Foods-Full-Spectrum-Minerals-Caps-240-Veg-Capsules/690?rcode=SAV8512)
* [Ежедневно 1 порцию белка, лучше утром](https://ru.iherb.com/pr/California-Gold-Nutrition-SPORT-Whey-Protein-Isolate-Unflavored-90-Protein-Fast-Absorption-Easy-to-Digest-Single-Source-Grade-A-Wisconsin-USA-Dairy-75-Servings-5-lbs-2270-g/76479?rcode=SAV8512) (это желательно заменить на 2 вареных яйца, идеально с авокадо или с оливковым маслом холодного отжима)
* [Пробиотики, которые выживают вне холодильника](http://www.iherb.com/pr/California-Gold-Nutrition-LactoBif-Probiotics-30-Billion-CFU-60-Veggie-Capsules/64009?rcode=SAV8512) — пробиотики очень важны для целостного здоровья, пить 1 раз в день, за автраком. Покупаем именно эти, так как в основном они могут портится вне холодильника и когда покупаем, то нет гарантий, что они выжили.
Рыбий жир и витамин D очень важны и для мозга и для тела, минералы и белок важны для долговременного здоровья тела. Желательно принимать тем, кому больше 30 лет.
После 35-40 лет также можно начать принимать пару добавок для молодости кожи и тканей и здоровья суставов:
* [Коллаген 1 и 2 типов"](https://www.iherb.com/pr/Lake-Avenue-Nutrition-Hydrolyzed-Collagen-Type-1-3-1-000-mg-365-Tablets/96303?rcode=SAV8512)
* [Коллаген UC-II](https://www.iherb.com/pr/Now-Foods-UC-II-Joint-Health-Undenatured-Type-II-Collagen-120-Veg-Capsules/64318?rcode=SAV8512) | https://habr.com/ru/post/374255/ | null | ru | null |
# Безопасность со вкусом Google

Отгремел Google I/O 2019 и пришла пора ~~переписывать проекты на новую архитектуру~~ изучать новинки. Так как я интересуюсь безопасностью мобильных приложений, то в первую очередь обратил внимание на новую библиотеку в семействе JetPack — **security-crypto**. Библиотека помогает правильно организовывать шифрование данных и при этом ограждает разработчиков от всех нюансов, которые сопровождают этот процесс.
Историческая справка
--------------------
Шифрование данных в Android всегда порождало много дискуссий. Какой алгоритм выбрать? Какой режим шифрования использовать? Что такое padding? Где хранить ключи? Для обычного разработчика изучать всё это и поддерживать знания в актуальном состоянии может быть трудно. Поэтому история чаще всего заканчивалась одним из трех сценариев:
* копипаст первого попавшегося решения со stackoverflow
* поиск «подходящего мануала» с последующей имплементацией и сбором граблей
* активация протокола «И так сойдет!»
По мере развития сообщества android-разработчиков начали появляться библиотеки, помогающие решать эту задачу. Качество этих решений было очень разным: из всего этого многообразия я могу выделить только [java-aes-crypto](https://github.com/tozny/java-aes-crypto), которую мы и использовали в Redmadrobot. Довольно качественная имплементация, но с ней была пара проблем.
Во-первых, это было просто шифрование строк. Само по себе это не плохо, но ведь эти строки нужно где-то хранить, в БД или SharedPreferences. А значит, нужно писать обертку над источником данных, чтобы все шифровалось на лету (что мы когда-то и делали). Но это код, который нужно поддерживать, таскать из проекта в проект или оформлять в библиотеку для удобства использования. В конечном итоге это тоже было сделано, но это не принесло успокоения пытливым умам.
Во-вторых, это решение ничего не предлагало для решения проблемы управления ключами. Их можно было сгенерить, но вот хранение полностью ложилось на плечи разработчика. Со всеми приседаниями вокруг AndroidKeystore на разных версиях ОС и устройствах, пришедших с Mainland China.
Этому городу нужен новый герой
------------------------------
Все шло своим чередом, пока летом 2018-го я не обнаружил, что есть такая замечательная библиотека от Google как [Tink](https://github.com/google/tink). Она достаточно проста в освоении и ограждает разработчика от огромного количества нюансов, касающихся криптографии. Используя эту библиотеку, практически невозможно сделать что-то неправильно. Более того, Tink полностью берет на себя управление ключами и абстрагирует все операции с AndroidKeystore от разработчика.
Но это все еще было просто шифрование строк. И тут очень удачно подвернулась [Binary Preferences](https://github.com/yandextaxitech/binaryprefs) — библиотека от отечественного производителя, на которую давно хотелось посмотреть. Она позволяет шифровать все сохраняемые данные любых алгоритмов — для этого было достаточно написать реализацию двух интерфейсов, [KeyEncryption](https://github.com/yandextaxitech/binaryprefs/blob/master/library/src/main/java/com/ironz/binaryprefs/encryption/KeyEncryption.java) и [ValueEncryption](https://github.com/yandextaxitech/binaryprefs/blob/master/library/src/main/java/com/ironz/binaryprefs/encryption/ValueEncryption.java) (для ключей и значений соответственно).
В итоге мы стали применять две этих библиотеки в связке и были счастливы, что наш код стал чище и проще для понимания.
security-crypto
---------------

Теперь Google в очередной раз решил пойти навстречу разработчикам и упростить их жизнь в области шифрования сохраняемых данных. Была анонсирована еще одна JetPack библиотека, которая призвана с этим помочь. Мне стало интересно, что же они такого революционного там написали, и я полез искать документацию (спойлер: ее нет). Нашел только [javadoc-и](https://devmir.teamusec.de/reference/kotlin/androidx/security/crypto/package-summary) по входящим в состав библиотеки классам, но и на том спасибо. Оказалось, что возможностей там негусто: шифрование файлов, SharedPreferences и работа с ключами.
Для проверки работоспособности библиотеки написал пару снипетов:
**Шифрование файлов**
```
val file = File(filesDir, "super_secure_file")
val encryptedFile = EncryptedFile.Builder(file, this, "my_secret_key", EncryptedFile.FileEncryptionScheme.AES256_GCM_HKDF_4KB)
.setKeysetAlias("my_test_keyset_alias")
.setKeysetPrefName("keyset_pref_file")
.build()
val outputStream = encryptedFile.openFileOutput()
outputStream.use {
it.write("secret info".toByteArray())
}
```
**Шифрование SharedPreferences**
```
val encryptedPreferences = EncryptedSharedPreferences.create(
"super_secret_preferences",
"prefrences_master_key",
this,
EncryptedSharedPreferences.PrefKeyEncryptionScheme.AES256_SIV,
EncryptedSharedPreferences.PrefValueEncryptionScheme.AES256_GCM
)
encryptedPreferences.edit().putString("secret", "super secret token")
```
К моему великому удивлению, все заработало с первого раза, и я полез смотреть, что за код они написали для этой библиотеки. Провалившись в исходники, я увидел, что это фактически обертка вокруг уже известной нам библиотеки Tink, а написанный код почти один в один как мы написали для шифрованных BinaryPreferences.
Меня очень обрадовало, что Google в этот раз не стал изобретать веломопед, а использовал свои же хорошо зарекомендовавшие себя наработки. Будем надеяться, что пришедший в JetPack пакет `security` не ограничится только этой библиотекой, а будет развиваться дальше.
[Демонстрация работы связки BinaryPreferences + Tink](https://github.com/Fi5t/advanced-tink)
[Исходный код библиотеки security-crypto](https://github.com/aosp-mirror/platform_frameworks_support/tree/androidx-master-dev/security/crypto)
[Демонстрация работы security-crypto](https://github.com/Fi5t/jetpack-security) | https://habr.com/ru/post/452252/ | null | ru | null |
# Алло, кто звонит или определение номера в Asterisk
Учитывая специфику телефонных сетей на территории России, проблемы с определением номера при настройке аналоговых линий ГТС на Asterisk возникают довольно часто. Разнообразие ГАТС и качество телефонных линий смонтированных еще во времена СССР всегда преподносят проблемы для интеграторов IP АТС.

Была установлена IP АТС Asterisk, и успешно использовалась. Через некоторое время появилась возможность подключить определитель номера, т.к. городские линии перевели на цифровую ГАТС с поддержкой CallerID, до этого линии были подключены к аналоговой ГАТС (да, аналоговые АТС еще живы), но определение номера не заработало.
Для начала рассмотрим небольшую теоретическую информацию, какие стандарты определения телефонного номера бывают.
**Теория определения номера**
АОН (также называют Русский АОН) — работа советских аналоговых ГАТС, был распространен в начале 90-х, но все еще встречается. Информация о номере вызывающего абонента передаётся в виде кода, носящего название «Безынтервальный Пакет». Не является услугой, как таковой, т. к. не предназначался для абонентов. Телефонный номер передается в виде 7 цифр. Телефонный аппарат, поддерживающий АОН при входящем звонке «снимает трубку» и считывает служебные сигналы телефонной станции, при этом для вызывающего абонента имитируется вызывной сигнал. На Asterisk данный вид определителя номера заставить заработать не удастся.
CallerID (он же Евро АОН) — услуга предоставляемая на цифровых ГАТС. Метод для отправки запроса и получения Caller ID информации в интервале между звонками. То есть, в отличии от АОН здесь не происходит «снятия трубки». В CallerID распространено несколько стандартов:
Bellcore-стандарт используется в США, Канаде, Австралии, Китае, Гонконге, Сингапуре, Италии и некоторыми телефонными компаниями Великобритании.
DTMF-стандарт: цифры номера передаются таким же способом, как и тональный набор номера — короткими двухчастотными посылками.
FSK-стандарт: Поток данных передаётся частотной модуляцией перед первым или перед вторым звонком на линии. Как показал опыт, большинство цифровых ГАТС Ростелекома работают по этому стандарту.
**Практика, или почему ничего не работает**
Для определения номера в каналах DAHDI в большинстве случаев достаточно добавления следующих строчек в chan\_dahdi.conf:
chan\_dahdi.conf
```
usecallerid=yes ; включаем CallerID
callerid=asreceived ; передаем callerid в неизменном виде
```
Если определение номера не заработало, рекомендую для начала подключить обычный телефонный аппарат с поддержкой CallerID и посмотреть работает ли на нем определение. В нашем случае, номер на ТА определялся без проблем, а на Asterisk никак не хотел. Более того, при подключении ТА параллельно астериску опеределение переставало работать и на телефоне.
Переходим к дальнейшему анализу. Запишем аудио канал линии и проанализируем в аудио редакторе запись. В нем попробуем найти данные CallerID.
Запись первого dahdi канала осуществляется следующей командой:
```
dahdi_monitor 1 -v -r streamrx.wav
```
Запускаем команду записи и звоним на нашу линию. После этого останавливаем выполнение dahdi\_monitor, в итоге у нас появится файл streamrx.wav. Копируем его себе и открываем его в аудиоредакторе (например Audacity).
Как видно никаких данных callerid нам не приходит. Поскольку обычный телефон номер определяет, то можно предположить что проблемы с оборудованием (платой или модулем FXO).
Ставим заведомо рабочий модуль FXO в плату и проверяем еще раз.
Теперь определение номера работает без проблем, на записи видим данные CallerID в стандарте FSK. Как видно, в этом случае была проблема с модулем.
**Ремонт FXO модуля**
FXO модули разных производителей для аналоговых карт построены практически по одной и той же схеме на базе двух микросхем: SI3019 и SI3050.
Пример схемы с даташита на Si3050 Si3018/19:
[](http://pbxnow.ru/sites/default/files/SI3019-KT-datasheetz_0.png)
На данной схеме линия подключается к контактам RING и TIP. На какие элементы следует обратить внимание при проблемах с работой модуля?
— Диодный мост D1 (также может быть выполнен в виде двух сборок по 2 диода). Иногда из строя на линиях аналоговых АТС и при превышении допустимого напряжения. При этом сам модуль может оставаться работоспособным, но часть диодов не работают. Проверяются после выпаивания со схемы.
— Динистор RV1 (275 V, 100 A). В нашем случае он оказался работоспособным.
— Резисторы R30, R32 (15 M?, 1/8 W, 5%), R31, R33 (5.1 M?, 1/8 W, 5%), R8, R7 (20 M?, 1/8 W). С ними тоже оказалось все в порядке.
Проблема оказалась в микросхеме Si3019. Сопротивление в точке подключения пина Ring1 было в два раза меньше, чем на рабочем модуле. После замены микросхемы Si3019 все заработало без проблем.
Также в грозовой период, при отсутствии внешней защиты, часто выходит из строя стабилитрон Z1 (43 V, 1/2 W). Симптомы при этом следующие: модуль не видит входящий вызов, при попытке позвонить через данный канал кроме тишины никаких действий. Решается заменой стабилитрона. | https://habr.com/ru/post/326600/ | null | ru | null |
# Как я пришел к формальной спецификации RISC-V процессора на F#
Томными зимними вечерами, когда солнце лениво пробегало сквозь пелену дней — я нашел в себе силы заняться реализацией давней мечты: разобраться как же устроены процессоры. Эта мечта привела меня к написанию формальной спецификации RISC-V процессора. [Проект на Github](https://github.com/mrLSD/riscv-fs)

Как это было
------------
Подобное желание у меня появилось достаточно давно, когда 20 лет назад я стал заниматься первыми своими проектами. По большей части это были научные исследования, математическое моделирование в рамках курсовых работ и научных статей. Это были времена Pascal и Delphi. Однако уже тогда мой интерес привлек Haskell и функциональное программирование. Прошло время, менялись языки проектов и технологии в которые я был вовлечен. Но с тех пор красной нитью проходил интерес к функциональным языкам программирования, и ими стали: Haskell, Idris, Agda. Однако в последнее время мои проекты были на языке Rust. Более глубокое погружение в Rust меня привело к изучению Embedded устройств.
### От Rust к Embedded
Возможности Rust настолько широки, а community настолько активно, что Embedded разработка стала поддерживать широкий спектр устройств. И это был мой первый шаг в более низкоуровневое понимание процессоров.
Первой моей платой стало: **STM32F407VET6**. Это было погружение в мир микроконтроллеров, от которого я на тот момент был очень далек, и достаточно приблизительно понимал как происходит работа на низком уровне.
Постепенно сюда добавились платы **esp32**, **ATmega328** (в лице платы [Ukraino UNO](https://www.mini-tech.com.ua/ukraino-uno)). Погружение в stm32 оказалось достаточно болезненным — информация достаточно обильная и часто не та, которая мне нужна. И оказалось, что разработка, к примеру, на Assembler — достаточно рутинная и неблагодарная задача, с их подмножеством более 1000 инструкций. Однако Rust с этим справлялся бодро, хотя порой возникали трудности с интеграцией для конкретных китайских плат.
Архитектура AVR оказалась заметно проще и прозрачнее. Обильные мануалы мне дали достаточное понимание как работать с таким достаточно ограниченным набором инструкций, и тем не менее иметь возможность создавать очень интересные решения. Тем не менее путь Arduino меня совсем не радовал, но вот написание на Asm/C/Rust оказалось куда увлекательнее.
А где же RISC-V?
----------------
И в этот момент возникает логичный вопрос — а где же **RISC-V CPU**?
Именно минималистичность AVR и достаточное его документирование, меня вернули к прежней мечте разобраться как же работает процессор. К этому времени у меня появилась FPGA плата и первые реализации для нее в виде взаимодействия с VGA устройствами, вывода графики, взаимодействия с периферией.
Моими проводниками в архитектуру процессоров стали книги:
* John L. Hennessy and David A. Patterson — Computer Architecture: A Quantitative Approach (The Morgan Kaufmann Series in Computer Architecture and Design)
* John L. Hennessy and David A. Patterson — Computer Organization and Design. The Hardware/Software Interface: RISC-V Edition
* Дэвид М. Хэррис и Сара Л. Хэррис — Цифровая схемотехника и архитектура компьютера
* The RISC-V Instruction Set Manual
### Зачем это нужно
Казалось бы — уже все давно написано и реализовано.
* [RISC-V Cores and SoC Overview](https://riscv.org/risc-v-cores/)
* [RISC-V Formal Verification](https://github.com/SymbioticEDA/riscv-formal)
разнообразные реализации на HDL, и языках программирования. Кстати достаточно интересная [реализация RISC-V на Rust](https://github.com/stephank/rvsim).
Однако что может быть интереснее, чем разобраться самому, и создать свое. Свой *велосипед*? Или внести свой вклад в *велосипедостроение*? Кроме личного глубокого интереса у меня возникла идея — а как попробовать популяризировать, заинтересовать. И найти свою форму, свой подход. А это значит представить достаточно скучную документацию по **RISC-V ISA** в виде [официальной спецификации](https://RISC.org/specifications/) в ином виде. И мне кажется путь *формализации* в этом смысле достаточно интересен.
Что я понимаю под формализацией? Достаточно обширное понятие. Представление определенного набора данных в формальном виде. В данном случае через описание структур и функционального описания. И в этом смысле функциональные языки программирования обладают своим очарованием. Также задача в том — чтобы человек который не сильно погружен в программирование мог прочитать код как спецификацию, по-возможности минимально вникая в специфику языка, на котором это описано.
Декларативный подход, так сказать. Есть высказывание, а как именно это работает — это уже не существенно. Главное читабельность, наглядность, и конечно же корректность. Соответствие *формальных высказываний* вкладываемому в них смыслу.

Итого — мне действительно любопытно передать свой интерес другим. Есть некая иллюзия того, что интерес — движущая сила к поступкам. Через что становится и проявляется индивидуальность. И в этом есть часть самореализации, воплощение творческого начала.
Амбициозно и немного лирики. Что же дальше?
### Существующие реализации
Они есть и на данный момент их агрегирует проект: [RISC-V Formal Verification](https://github.com/SymbioticEDA/riscv-formal).
Список формальных спецификаций (включая мою работу): <https://github.com/SymbioticEDA/riscv-formal/blob/master/docs/references.md>
Как видно — по большей части это формализации на языке Haskell. Это стало отправной идеей в выборе другого функционального языка. И мой выбор пал на **F#**.
### Почему `F#`
Так случилось, что про **F#** мне известно давно, но все как-то в суете повседневности не имел возможности познакомиться ближе. Еще одним фактором была **.NET** платформа. Беря во внимание что я под Linux-ом, долгое время меня не устраивали IDE, и `mono` выглядело достаточно сырым. А возвращение в Windows только ради MS Visual Studio — достаточно сомнительная идея.
Однако время не стоит на месте, а звезды на небе не спешат меняться. Но к этому времени [Jetbrains Rider](https://www.jetbrains.COM/rider/) — развился до полноценного и удобного инструмента, а `.NET Core` для Linux не приносит боль при одном взгляде на него.
Стал вопрос — какой функциональный язык выбрать. То что это должен быть именно функциональный язык — в несколько патетическом виде я аргументировал выше.
`Haskell, Idris, Agda`? `F#` — с ним я не знаком. Отличный повод узнать новые краски мира функциональных языков.
Да `F#` не чисто-функциональный. Но что мешает придерживаться "*чистоты*"? И тут оказалось — что [F# документация](https://docs.Microsoft.COM/en-us/dotnet/fsharp/) достаточно подробная и целостная. Читабельная, и я бы даже сказал интересная.
Чем сейчас для меня стал `F#`? Достаточно гибким языком, с очень удобными IDE (Rider, Visual Studio). Вполне развитыми типами (хотя конечно до `Idris` очень далеко). И в целом достаточно *милым* с точки зрения читабельности. Однако как оказалось его функциональная "*не чистота*" — может приводить код к совершенно невменяемому виду как с точки зрения читабельности, так и логики. Анализ пакетов в [Nuget](https://www.nuget.org/) это наглядно показывает.
Еще одной интересной и загадочной особенностью для меня стало открытие, что написать формализацию **RISC-V ISA** на **F#** ранее никого не интересовало (официально или в доступном для поиска виде). А это значит, что у меня есть шанс внести новую струю в это сообщество, язык, "*экосистему*".
### Подводные камни, с которыми я столкнулся
Самой сложной частью оказалось реализация Execution flow. Часто оказывалось, что не до конца понятно как инструкция должна работать. К сожалению надежного товарища, которому можно было бы позвонить в 3 часа ночи и взволнованным голосом с придыханием спросить: "А знаешь, `BLTU` инструкция наверное по-другому signextend-ится..." — у меня нет. В этом смысле иметь квалифицированных товарищей, которые добрым словом и уместным квалифицированным советом помогут — очень желанно.
Какие были трудности и подводные камни. Попробую тезисно:
* ELF — любопытной задачей стало разобраться как с ним работать, читать секции, инструкции. Скорее всего эта история в рамках текущего проекта не закончена.
* unsigned инструкции периодически меня приводили к ошибкам, которые я выявлял в процессе unit-тестирования
* реализация работы с памятью потребовала подумать над красивыми и читабельными алгоритмами компоновки байтов.
* годного пакета для работы с битами под `int32, int64` не оказалось. Потребовалось время на написание своего пакета и на его тестирование.
*Здесь хочу отметить, что работа с битами в F# таки в разы удобнее чем в Haskell с его [Data.Bits](http://hackage.haskell.org/package/base-4.12.0.0/docs/Data-Bits.html)*
* правильная поддержка битности регистров, с возможностью поддержки `x32` и `x64` одновременно. Невнимательность привела к тому, что я в некоторых местах использовал `int64`. Выявить это мне помогли unit-тесты. Но на это потребовалось время.
* простого, лаконичного, удобного лично мне CLI F# пакета я не нашел. Побочным эффектом стало написание минималистичного варианта в функциональном стиле
* на данный момент остается загадкой как правильно реализовать System Instructions: FENCE, ECALL, BREAK
* далеко не весь набор расширений (ISA extensions) из списка: `[A, M, C, F, D]` на данный момент очевидны. В особенности реализация `[F,D]` не через `soft float`.
* на данный момент ясного понимания Privileged Instructions, User Mod, работы с периферией — увы нет. И это путь исследований, проб и ошибок.
* нет *черного пояса* по написанию Assembler программ **под RISC-V.** Возможно далеко не часто в этом будет потребность, учитывая сколько языков уже портировано для написания под RISC-V.
* также существенным оказался фактор времени — его достаточно мало в водовороте основной работы, житейских потребностей и океана жизни вокруг. А работы достаточно много, и большая часть не столько в "*кодировании*" — написания самого кода, сколько в изучении, осваивания материалов.
### Как это работает и какие возможности
Теперь пожалуй наиболее *техническая* часть. Какие возможности на данный момент:
* выполнение набора инструкций `rv32i`
* возможность выполнения программы в качестве RISC-V симулятора — выполнения ELF-файлов.
* поддержка командной строки (CLI) — выбор выполняемой архитектуры, набора инструкций, исполняемых ELF-файлов, режима логирования, справки по командной строке.
* возможность вывода лога выполняемых инструкций, приближенного к `objdump` виду при дизассемблировании.
* возможность запуска тестов покрывающих весь реализованный набор инструкций.
Работа программы разделена на такие этапы и циклы:
* чтение командной строки
* чтение инструкций из ELF-файла
* чтение конкретной инструкции согласно текущему PC (Program Counter) — счетчику
* декодирование инструкции
* выполнение инструкции
* при наличии непредвиденных ситуаций расставлены ловушки (Trap), позволяющие завершить процесс выполнения, сигнализирующие о проблеме, и предоставляющие необходимые данные
* в случае если программа не в бесконечном цикле — вывод состояния регистров и завершение программы симулирования
Что входит в планы:
* Standard base 64i (почти завершено)
* Standard extension M (integer multiply/divide)
* Standard extension A (atomic memory ops)
* Standard extension C (Compressed 16-bit instructions)
* Standard extension F (Single-precision floating point)
* Standard extension D (Double-precision floating point\* Privilege Level M (Machine)
* Privilege Level U (User)
* Privilege Level S (Supervisor)
* Virtual Memory schemes SV32, SV39 and SV48
* host программы
* GPIO — работа с периферией
### Как запустить
Для того чтобы запустить программу необходимо наличие `.NET Core`. Если у вас не установлено, то к примеру, под `Ubuntu 16.04` необходимо выполнить такой набор команд:
```
$ wget -q https://packages.microsoft.com/config/ubuntu/16.04/packages-microsoft-prod.deb -O packages-microsoft-prod.deb
$ sudo dpkg -i packages-microsoft-prod.deb
$ sudo apt-get update
$ sudo apt-get install apt-transport-https
$ sudo apt-get update
$ sudo apt-get install dotnet-sdk-3.0
```
Чтобы проверить, что что-то в жизни изменилось — запустите:
```
$ dotnet --version
```
И жизнь должна заиграть новыми красками!
Теперь попробуем запустить. Для этого запаситесь любимым чаем или кофе, шоколадкой с плюшками, включите любимую музыку и выполните такой набор команд:
```
$ cd some/my/dev/dir
$ git clone https://github.com/mrLSD/riscv-fs
$ cd riscv-fs
$ dotnet build
$ dotnet run -- --help
```
и ваша консоль должна игриво подмигнуть вам справочным сообщением.
Запуск же:
```
$ dotnet run
```
Строгим тоном скажет — что нужны параметры. Поэтому запускаем:
```
$ dotnet run -- -A rv32i -v myapp.elf
```
Это тот самый неловкий момент, когда оказывается, что все-таки нам нужна уже готовая *ready for execution* программа под RISC-V. И тут есть мне чем вам помочь. Однако вам понадобится [GNU toolchain for RISC-V](https://github.com/riscv/riscv-gnu-toolchain). Его установка пусть будет домашним заданием — в описании к [репозиторию](https://github.com/riscv/riscv-gnu-toolchain) достаточно детально описано как это делать.
Далее, для получения заветного тестового ELF-файла, выполняем такие действия:
```
$ cd Tests/asm/
$ make build32
```
если у вас *RISC-V toolchain* есть в наличии то все должно пройти гладко. И файлики должны красоваться в директории:
```
$ ls Tests/asm/build/
add32 alu32 alui32 br32 j32 mem32 sys32 ui32
```
и теперь смело, без оглядки пробуем команду:
```
$ dotnet run -- -A rv32i -v Tests/asm/build/ui32
```
**Важно отметить**, что `Tests/asm` не является тестовыми программами, но их основная цель — это тестовые инструкции и их коды для написания тестов. Поэтому если вам что-то по душе более масштабное и героическое, то в вашей воле меняя мир — найти самостоятельно исполняемый 32-битный ELF файл с поддержкой только `rv32i` инструкций.
Однако набор инструкций и расширений будет пополняться, набирать обороты и приобретать вес.
Резюме и ссылки
---------------
Получилось немного патетическое, приправленное личной историей повествование. Временами техническое, порой субъективное. Однако воодушевленное и с легким налетом энтузиазма.
С моей же стороны мне интересно от вас услышать: отзывы, впечатления, добрые напутствия. А для самых смелых — помощь в поддержании проекта.
Интересен ли вам такой формат повествования и хотели бы вы продолжений?
* [сам проект](https://github.com/mrLSD/riscv-fs)
* [список RISC-V формальных спецификаций (включая мой проект)](https://github.com/SymbioticEDA/riscv-formal/blob/master/docs/references.md)
* [RISC-V specifications](https://riscv.org/specifications/)
* [RISC-V toolchain](https://github.com/riscv/riscv-gnu-toolchain)
* [Awesome F# (мой проект также включен)](https://github.com/fsprojects/awesome-fsharp)
* [Ariane — a 6-stage RISC-V CPU based on Verilog](https://github.com/pulp-platform/ariane) | https://habr.com/ru/post/473714/ | null | ru | null |
# А не козёл ли ты, пользователь?
В Android 4.2 (Jelly Bean) появился новый метод i**sUserAGoat ()**. Назначение этого метода достаточно туманно, в документации говорится «Used to determine whether the user making this call is subject to teleportations» — является ли пользователь, вызвавший данный метод, объектом для телепортации. Метод должен возвращать значение **true**, если пользователь — козёл. Но если взглянуть на исходники метода, то можно обнаружить, что метод всегда возвращал **false**.
Точнее, так было до недавнего времени. С появлением Android 5 Lollipop в документации была внесена поправка — As of LOLLIPOP, this method can now automatically identify goats using advanced goat recognition technology. — Начиная с LOLLIPOP, данный метод теперь может автоматически определять козлов, используя передовую технологию распознавания козлов. [Ссылка на документацию](http://developer.android.com/reference/android/os/UserManager.html#isUserAGoat()).
Любопытные программисты снова полезли в исходники и обнаружили код
```
public boolean isUserAGoat() {
return mContext.getPackageManager()
.isPackageAvailable("com.coffeestainstudios.goatsimulator");
}
```
Иными словами, теперь метод проверяет, установлено ли у пользователя приложение «Симулятор козла». По названию пакета обнаружилось приложение в Google Play — [Goat Simulator](https://play.google.com/store/apps/details?id=com.coffeestainstudios.goatsimulator). Приложение платное. Что-то мне не хочется проверять, являюсь ли я козлом, поэтому покупать не стал. | https://habr.com/ru/post/355448/ | null | ru | null |
# Как я перехватывал трафик покер рума или «Пишем свой MitM SSL прокси на C#»
Однажды у меня появилась навязчивая идея: посмотреть, а что же там такого покерный клиент отправляет на сервер. Как Вы понимаете, крупные покерные румы используют SSL для передачи данных. Протоколы, основанные на асимметричном шифровании, подвержены только одному известному мне виду атак — MitM (Man in the middle — человек посередине).
Помаявшись с тонной софта, предназначенного для реализации MitM на SSL соединение, я пришел к выводу, что руки растут не из того места либо у разработчиков данных инструментов, либо у меня. Но идея была жутко навязчивая, и было принято решение сделать всё вручную. Если интересно, что же из всего этого вышло, прошу под кат.
Данная статья просвещена написанию простого инструмента для реализации MitM-атаки. Те, кто не знакомы с тем, что такое MitM, могут почитать об этом [тут](http://ru.wikipedia.org/wiki/%D0%A7%D0%B5%D0%BB%D0%BE%D0%B2%D0%B5%D0%BA_%D0%BF%D0%BE%D1%81%D0%B5%D1%80%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5).
### Цель
В качестве подопытного был выбран клиент [Cake Poker](http://www.wincake.com/) по причине моего длительного знакомства с ним. Началось все с того, что я просто запустил покерный клиент и полез в старый добрый менеджер ресурсов, в котором нашел с десяток подключений от него.
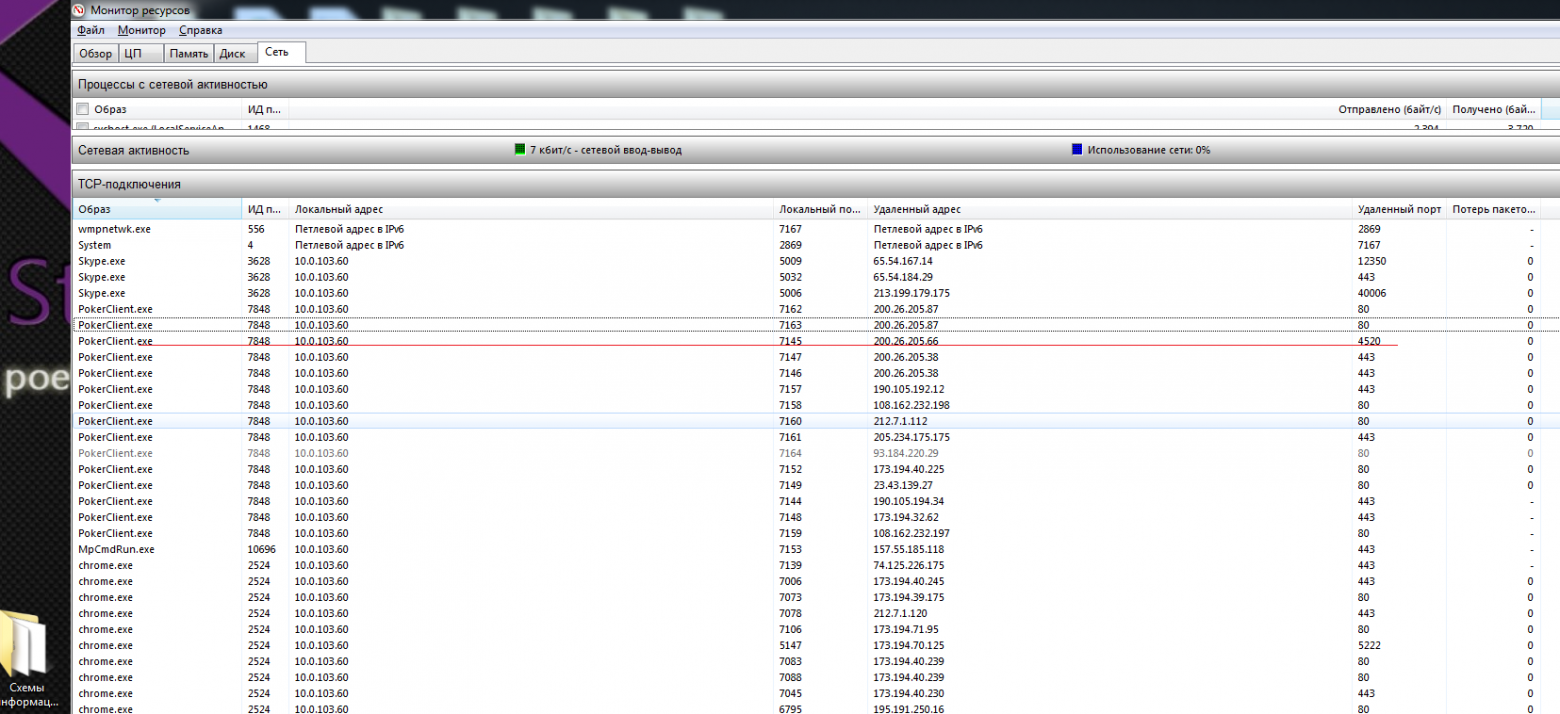
Поэкспериментировав, я смог выделить соединение, которое держится всегда. Его я и взял на прицел для проведение MitM атаки.
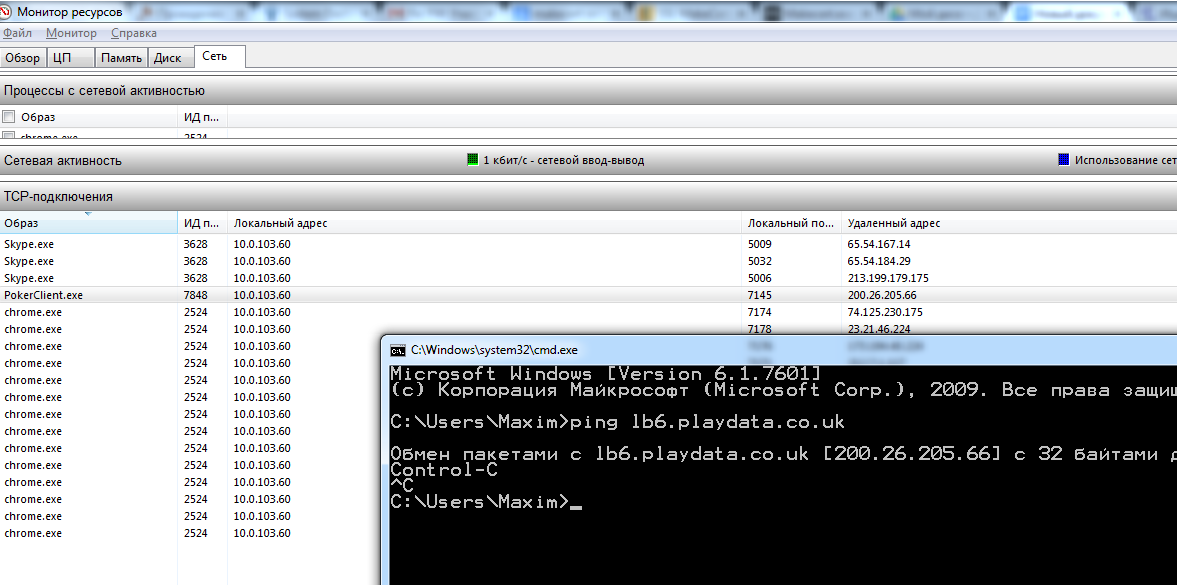
Источник соединения известен, конечная цель известна — lb6.playdata.co.uk.
### Перенаправление трафика
Теперь необходимо было вклиниться между клиентом и сервером. Нечего особо хитрого изобретать не стал, ибо незачем — просто добавил в host доменные имена, соотнесённые с 127.0.0.1. Не сложно догадаться, что если есть lb6.playdata.co.uk, то есть и lb1.playdata.co.uk, и lb8.playdata.co.uk. С ними поступил аналогично, занеся в host, т.к. конечные инстансы, как я понял, выбираются по расположению звёзд. При запуске покерного клиента он повисает в ожидании подключения. Замечательно. Это означает что трафик был перенаправлен на нашу машинку. Идём дальше.
### Прокси
Следующей задачей было написание прокси на C#. Да-да, простой прокси, для заготовки будущей программы. Чтобы не заниматься изобретением велосипеда, я по-быстрому нагуглил подходящее для меня решение: [TCP Proxy in C# using Task Parallel Library](http://loosexaml.wordpress.com/2011/04/27/tcp-proxy-in-c-using-tasks-parallel-library/).
Немного его отрефакторил (ненавижу, когда много вложенности), захардкодил конечную точку подключения и запустил. Запускаю покерного клиента — всё работает. В диспетчере ресурсов можем видеть, что трафик от покерного клиента идёт к моему прокси, а от него на сервер и обратно.
### MitM на SSL
Далее нам предстоит реализовать MitM-атаку на SSL. Разделим её на два этапа: первый — соединение клиента с прокси; второй — прокси с сервером.
Для реализации первого этапа, когда клиент подключится к прокси, мы не будем отправлять пришедшие данные дальше, а начнём, так называемую, процедуру рукопожатия. На C# это можно сделать с помощью экземпляра класса SslStream, построенного поверх уже созданного NetworkStream. В момент создания передаётся информация о протоколе и прочая специфическая информация.
После этого, передаём клиенту свой сертификат. Это делается с помощью метода AuthenticateAsServer класса SslStream, куда мы должны передать путь до файла сертификата.
Файл x509 сертификата был сгенерирована с помощью утилиты Makecert, которую можно вызвать из девелоперской консоли Visual Studio. Пришлось немного помучиться с параметрами, но всё получилось. Вот неплохое описание того, как ей можно пользоваться: [SSL communication in C#](http://ishare2learn.wordpress.com/tag/ssl/). В качестве имени укажем \*.playdata.co.uk. Это имя покрывает все домены, которые используются покерным клиентом.
```
makecert -n CN=MyCA -cy authority -a sha1 -sv “MyCA.pvk” -r “MyCA.cer” //Создаём сертификат ЦА
certmgr -add -all -c “MyCA.cer” -s -r LocalMachine Root //Добавляем в довереные коневые центры сертификаты
makecert -n CN=*.playdata.co.uk -ic MyCA.cer -iv MyCA.pvk -a sha1 -sky exchange -pe -sr currentuser -ss my SslServer.cer
//Создаём серверный сертификат
```
Мы сгенерировали серверный закрытый ключ и ключ УЦ (удостоверительного центра), которым подписан наш ключ. Ключ УЦ помещаем в «Доверенные корневые центры сертификации», и вуаля! Если посмотреть на наш серверный ключик средствами просмотра ключей Windows, то мы увидим, что система считает его валидным, как и покерный клиент, который запущен в нашей системе.
Путь до полученого сертификата мы передаём в метод AuthenticateAsServer. Если всё прошло хорошо, то у нас получится SSL соединение от клиента до прокси, в которое клиент будет посылать данные. Теперь необходимо давать клиенту адекватные ответы на его запросы. Для этого нам потребуется реализовать второй этап MitM-атаки, а именно построить SSL соединение от прокси до сервера. Так же строим SslStream поверх NetworkStream до сервера и авторизовываемся с помощью метода AuthenticateAsClient. Данные, приходящие из SSL соединения клиента и сервера отправляем друг другу.
**Процес рукопожатия C#**
```
var certificate = new X509Certificate("SslServer.cer", "123");
var clientStream = new SslStream(client.GetStream(), false);
clientStream.AuthenticateAsServer(certificate, false, System.Security.Authentication.SslProtocols.Default, false);
var server = new TcpClient("200.26.205.63", 4520);
var serverSslStream = new SslStream(server.GetStream(), false, SslValidationCallback, null);
serverSslStream.AuthenticateAsClient("lb3.playdata.co.uk");
```
Через некоторое время работы можно будет заметить в менеджере ресурсов расхождение количества отправленных байт на прокси и от него. Это обусловлено тем, что при шифровании разные ключи дают разный по размеру результат.
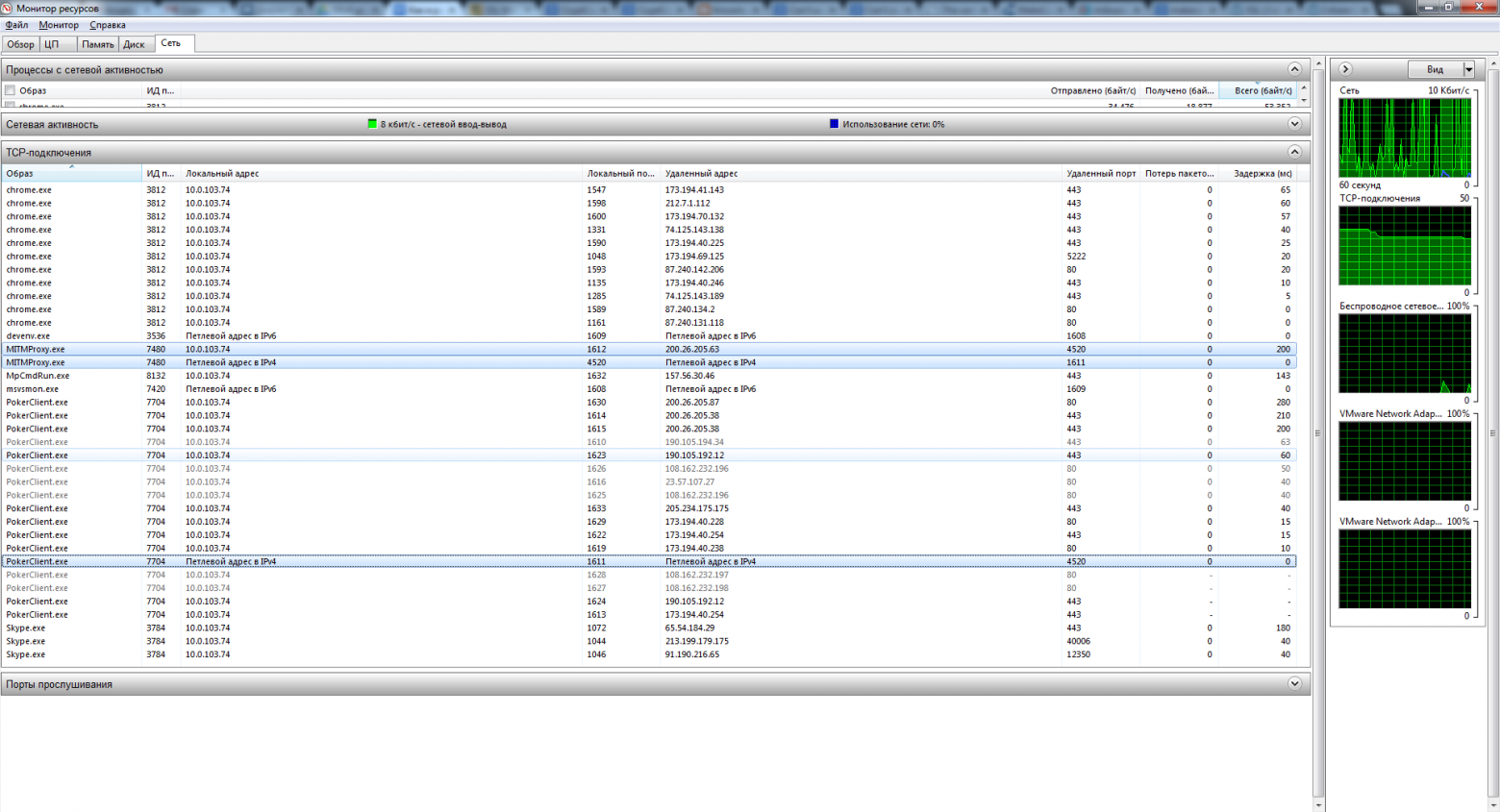
### Заключение
Что же дальше? А дальше мы добавим код для сохранения данных в текстовый файл, чтобы их можно было проанализировать то, что передаёт покерный клиент серверу. Собственно, всё, MitM Proxy написан.
Осталось добавить в него немного блекджека. Например, для разбора идущего через него трафика, выдирания карт пользователя и отправки нам и т. д…
Я написал разборщик трафика на лету, что бы можно было удобно мониторить, что отправляет клиент, и соотносить это с моими действиями. Демонстрация того, что получилось у меня:
**Исходники mitm proxy**
```
using System;
using System.Diagnostics;
using System.IO;
using System.Net;
using System.Net.Security;
using System.Net.Sockets;
using System.Security.Cryptography.X509Certificates;
using System.Threading.Tasks;
using ConnectionAnalizer;
namespace MITMProxy
{
class Program
{
static readonly TcpListener Listener = new TcpListener(IPAddress.Any, 4520);
const int BufferSize = 4096;
static void Main()
{
Listener.Start();
new Task(() =>
{
while (true)
{
var client = Listener.AcceptTcpClient();
new Task(() => AcceptConnection(client)).Start();
}
}).Start();
Debug.WriteLine("Server listening on port 4502. Press enter to exit.");
Console.ReadLine();
Listener.Stop();
}
private static void AcceptConnection(TcpClient client)
{
try
{
var certificate = new X509Certificate("SslServer.cer", "123");
var clientStream = new SslStream(client.GetStream(), false);
clientStream.AuthenticateAsServer(certificate, false, System.Security.Authentication.SslProtocols.Default, false);
var server = new TcpClient("200.26.205.63", 4520);
var serverSslStream = new SslStream(server.GetStream(), false, SslValidationCallback, null);
serverSslStream.AuthenticateAsClient("lb3.playdata.co.uk");
new Task(() => ReadFromClient(client, clientStream, serverSslStream)).Start();
new Task(() => ReadFromServer(serverSslStream, clientStream)).Start();
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
throw;
}
}
private static bool SslValidationCallback(object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors sslpolicyerrors)
{
return true;
}
private static void ReadFromServer(Stream serverStream, Stream clientStream)
{
var message = new byte[BufferSize];
while (true)
{
int serverBytes;
try
{
serverBytes = serverStream.Read(message, 0, BufferSize);
clientStream.Write(message, 0, serverBytes);
}
catch
{
break;
}
if (serverBytes == 0)
{
break;
}
}
}
private static void ReadFromClient(TcpClient client, Stream clientStream, Stream serverStream)
{
var message = new byte[BufferSize];
var fileInfo = new FileInfo("client");
if (!fileInfo.Exists)
fileInfo.Create().Dispose();
using (var stream = fileInfo.OpenWrite())
{
while (true)
{
int clientBytes;
try
{
clientBytes = clientStream.Read(message, 0, BufferSize);
}
catch
{
break;
}
if (clientBytes == 0)
{
break;
}
serverStream.Write(message, 0, clientBytes);
memoryStream.Write(message, 0, clientBytes);
stream.Write(message, 0, clientBytes);
}
client.Close();
}
}
}
}
``` | https://habr.com/ru/post/213397/ | null | ru | null |
# Утечка данных (которая могла произойти, но не произошла) из телемедицинской компании
Буквально пару дней назад я [писал](https://habr.com/ru/post/444114/) на Хабре про то, как российский медицинский онлайн-сервис DOC+ умудрился оставить в открытом доступе базу данных с детальными логами доступа, из которых можно было получить данные пациентов и сотрудников сервиса. И вот новый инцидент, с уже другим российским сервисом, предоставляющим пациентам онлайн-консультации врачей – «Доктор рядом» (www.drclinics.ru).
Напишу сразу, что благодаря адекватности сотрудников «Доктор рядом», уязвимость была быстро (2 часа с момента уведомления ночью!) устранена и скорее всего утечки персональных и медицинских данных не случилось. В отличии от инцидента с DOC+, где мне точно известно, что как минимум один json-файл с данными, размером 3.5 Гб попал в «открытый мир», а при этом официальная позиция выглядит так: "*В открытом доступе временно оказался незначительный объем данных, который не может привести к негативным последствиям для сотрудников и пользователей сервиса DOC+.*".

Со мной, как с владельцем Telegram-канала «[Утечки информации](http://tele.click/dataleak)», связался анонимный подписчик и сообщил о потенциальной уязвимости на сайте www.drclinics.ru.
Суть уязвимости заключалась в том, что, зная URL и находясь в системе под своей учетной записью, можно было просматривать данные других пациентов.
Для регистрации новой учетной записи в системе «Доктор рядом» фактически требуется только номер мобильного телефона, на который приходит подтверждающая СМС, поэтому проблем со входом в личный кабинет возникнуть ни у кого не могло.
После того как пользователь заходил в личный кабинет он мог сразу, меняя URL в адресной строке своего браузера, просматривать отчеты, содержащие персональные данные пациентов и даже медицинские диагнозы.
Существенная проблема заключалась в том, что сервис использует сквозную нумерацию отчетов и из этих номеров уже формирует URL:
`https://[адрес сайта]/…/…/40261/…`
Поэтому достаточно было установить минимальное допустимое число (7911) и максимальное (42926 — на момент наличия уязвимости), чтобы вычислить общее количество (35015) отчетов в системе и даже (при наличии злого умысла) выкачать их все простым скриптом.

Среди доступных для просмотра данных были: ФИО врача и пациента, даты рождения врача и пациента, телефоны врача и пациента, пол врача и пациента, адреса электронной почты врача и пациента, специализация врача, дата консультации, стоимость консультации и в некоторых случаях даже диагноз (в виде комментария к отчету).
Данная уязвимость по сути очень похожа на ту, что была [обнаружена в декабре 2017 года](https://www.devicelock.com/ru/blog/mikrofinansovaya-organizatsiya-ostavila-pasportnye-dannye-desyatkov-tysyach-svoih-klientov-v-otkrytom-dostupe.html) на сервере микрофинансовой организации «Займоград». Тогда перебором можно было получить 36763 договоров, содержащих полные паспортные данные клиентов организации.
Как я указал с самого начала, сотрудники «Доктор рядом» проявили реальный профессионализм и несмотря на то, что об уязвимости я им сообщил в 23:00 (Мск), доступ в личный кабинет был сразу закрыт для всех, а к 1:00 (Мск) данная уязвимость была устранена.
Не могу не пнуть еще раз PR-отдел все того же DOC+ (ООО «Новая Медицина»). Заявляя «*в открытом доступе временно оказался незначительный объем данных*», они упускают из вида, что в нашем распоряжении есть данные "объективного контроля", а именно поисковик Shodan. Как верно подметили в комментариях к той статье — согласно Shodan, дата первой фиксации открытого сервера ClickHouse на IP-адресе DOC+: 15.02.2019 03:08:00, дата последней фиксации: 17.03.2019 09:52:00. Размер базы данных около 40 Гб.
А всего было 15 фиксаций:
```
15.02.2019 03:08:00
16.02.2019 07:29:00
24.02.2019 02:03:00
24.02.2019 02:50:00
25.02.2019 20:39:00
27.02.2019 07:37:00
02.03.2019 14:08:00
06.03.2019 22:30:00
08.03.2019 00:23:00
08.03.2019 14:07:00
09.03.2019 05:27:00
09.03.2019 22:08:00
13.03.2019 03:58:00
15.03.2019 08:45:00
17.03.2019 09:52:00
```
Из заявления получается, что *временно* это чуть более месяца, а *незначительный объем данных* это примерно 40 гигабайт. Ну не знаю...
Но вернемся к «Доктор рядом».
На данный момент моя профессиональная паранойя не дает покоя только по одной оставшейся мелкой проблеме — по ответу сервера можно узнать количество отчетов в системе. Когда пытаешься получить отчет по URL, к которому нет доступа (но сам отчет при этом есть), то сервер возвращает *ACCESS\_DENIED*, а когда пытаешься получить отчет, которого нет, то возвращается *NOT\_FOUND*. Следя за увеличением количества отчетов в системе в динамике (раз в неделю, месяц и т.п.) можно оценить загруженность сервиса и объёмы предоставляемых услуг. Это конечно не нарушает персональных данных пациентов и врачей, но может быть нарушением коммерческой тайны компании. | https://habr.com/ru/post/444590/ | null | ru | null |
# Lightweight Tables или практические советы при проектировании БД…
 В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.
Тема не нова, но становится особенно актуальной, когда в базе наблюдается постоянный рост данных – таблицы становятся большими, а поиск и выборка по ним – медленной.
Как правило, это происходит из-за плохо спроектированной схемы – изначально не рассчитанной на оперирование большими объемами данных.
Чтобы рост данных в таблицах не приводил к падению производительности при работе с ними, рекомендуется взять на вооружение несколько правил при проектировании схемы.
**Первое и, наверное, самое важное.** Типы данных в таблицах должны иметь минимальную избыточность.
Все данные, которыми оперирует *SQL Server*, хранятся на, так называемых, страницах, которые имеют фиксированный размер в 8 Кб. При записи и чтении сервер оперирует именно страницами, а не отдельными строками.
Поэтому, чем более компактные типы данных используются в таблице, тем меньше страниц требуется для их хранения. Меньшее число страниц – меньшее количество дисковых операций.
Кроме очевидного снижения нагрузки на дисковую подсистему – в данном случае есть еще одно преимущество — при чтении с диска, любая страница вначале помещается в специальную область памяти (*Buffer Pool*), а потом уже используется по прямому назначению – для считывания или изменения данных.
При использовании компактных типов данных, в *Buffer Pool* можно поместить больше данных на том же количестве страниц – за счет этого мы не тратим впустую оперативную память и сокращаем количество логических операций.
Теперь рассмотрим небольшой пример – таблицу, в которой хранится информация о рабочих днях каждого сотрудника.
```
CREATE TABLE dbo.WorkOut1 (
DateOut DATETIME
, EmployeeID BIGINT
, WorkShiftCD NVARCHAR(10)
, WorkHours DECIMAL(24,2)
, CONSTRAINT PK_WorkOut1 PRIMARY KEY (DateOut, EmployeeID)
)
```
Правильно ли выбраны типы данных в этой таблице? По-видимому – нет.
Например, очень сомнительно что сотрудников на предприятии насколько много (2^63-1), что для покрытия такой ситуации был выбран тип данных *BIGINT*.
Уберем избыточность и посмотрим, будет ли запрос из такой таблицы более быстрым?
```
CREATE TABLE dbo.WorkOut2 (
DateOut SMALLDATETIME
, EmployeeID INT
, WorkShiftCD VARCHAR(10)
, WorkHours DECIMAL(8,2)
, CONSTRAINT PK_WorkOut2 PRIMARY KEY (DateOut, EmployeeID)
)
```
На плане выполнения можно увидеть разницу в стоимости, которое зависит от среднего размера строки и ожидаемого количество строк, которое вернет запрос:
Весьма логично, что чем меньший объем данных требуется прочитать – тем быстрее будет выполняться сам запрос:
*(3492294 row(s) affected)
SQL Server Execution Times:
CPU time = 1919 ms, elapsed time = 33606 ms.
(3492294 row(s) affected)
SQL Server Execution Times:
CPU time = 1420 ms, elapsed time = 29694 ms.*
Как Вы видите, использование менее избыточных типов данных зачастую положительно сказывается на производительности запросов и позволяет существенно снизить размер проблемных таблиц.
К слову, узнать размер таблицы можно посредством следующего запроса:
```
SELECT
table_name = SCHEMA_NAME(o.[schema_id]) + '.' + o.name
, data_size_mb = CAST(do.pages * 8. / 1024 AS DECIMAL(8,4))
FROM sys.objects o
JOIN (
SELECT
p.[object_id]
, total_rows = SUM(p.[rows])
, total_pages = SUM(a.total_pages)
, usedpages = SUM(a.used_pages)
, pages = SUM(
CASE
WHEN it.internal_type IN (202, 204, 207, 211, 212, 213, 214, 215, 216, 221, 222) THEN 0
WHEN a.[type] != 1 AND p.index_id < 2 THEN a.used_pages
WHEN p.index_id < 2 THEN a.data_pages ELSE 0
END
)
FROM sys.partitions p
JOIN sys.allocation_units a ON p.[partition_id] = a.container_id
LEFT JOIN sys.internal_tables it ON p.[object_id] = it.[object_id]
GROUP BY p.[object_id]
) do ON o.[object_id] = do.[object_id]
WHERE o.[type] = 'U'
```
Для рассматриваемых таблиц, запрос вернет следующие результаты:
```
table_name data_size_mb
-------------------- -------------------------------
dbo.WorkOut1 167.2578
dbo.WorkOut2 97.1250
```
**Правило второе.** Избегайте дублирования и применяйте нормализацию данных.
Собственно, недавно я анализировал базу данных одного [бесплатного веб-сервиса](http://sql-format.com/) для форматирования *T-SQL* кода. Серверная часть там очень простая и состояла из одной единственной таблицы:
```
CREATE TABLE dbo.format_history (
session_id BIGINT
, format_date DATETIME
, format_options XML
)
```
Каждый раз при форматировании сохранялся id текущей сессии, системное время сервера и настройки, с которыми пользователь отформатировал свой SQL код. Затем полученные данные использовались для выявления наиболее популярных стилей форматирования.
С ростом популярности сервиса, количество строк в таблице увеличилось, а обработка профилей форматирования занимала все большее количество времени. Причина заключалась в архитектуре сервиса – при каждой вставке в таблицу сохранялся полный набор настроек.
Настройки имели следующую XML структуру:
```
true
false
true
1
true
...
true
true
true
false
...
```
Всего 450 опций форматирования – каждая такая строка в таблице занимала примерно 33Кб. А ежедневный прирост данных составлял более 100Мб. С каждым днем база разрасталась, а делать аналитику по ней становилось делать дольше.
Исправить ситуацию оказалось просто – все уникальные профили были вынесены в отдельную таблицу, где для каждого набора опций был получен хеш. Начиная с *SQL Server 2008* для этого можно использовать функцию *sys.fn\_repl\_hash\_binary*.
В результате схема была нормализирована:
```
CREATE TABLE dbo.format_profile (
format_hash BINARY(16) PRIMARY KEY
, format_profile XML NOT NULL
)
CREATE TABLE dbo.format_history (
session_id BIGINT
, format_date SMALLDATETIME
, format_hash BINARY(16) NOT NULL
, CONSTRAINT PK_format_history PRIMARY KEY CLUSTERED (session_id, format_date)
)
```
И если запрос на вычитку раньше был таким:
```
SELECT fh.session_id, fh.format_date, fh.format_options
FROM SQLF.dbo.format_history fh
```
То на получение тех же данных в новой схеме потребовалось сделать JOIN:
```
SELECT fh.session_id, fh.format_date, fp.format_profile
FROM SQLF_v2.dbo.format_history fh
JOIN SQLF_v2.dbo.format_profile fp ON fh.format_hash = fp.format_hash
```
Если сравнить время выполнения запросов, то мы не увидим явного преимущества от изменения схемы.
*(3090 row(s) affected)
SQL Server Execution Times:
CPU time = 203 ms, elapsed time = 4698 ms.
(3090 row(s) affected)
SQL Server Execution Times:
CPU time = 125 ms, elapsed time = 4479 ms.*
Но цель в данном случае преследовалась другая – ускорить аналитику. И если раньше приходилось писать очень мудреный запрос для получения списка самых популярных профилей форматирования:
```
;WITH cte AS (
SELECT
fh.format_options
, hsh = sys.fn_repl_hash_binary(CAST(fh.format_options AS VARBINARY(MAX)))
, rn = ROW_NUMBER() OVER (ORDER BY 1/0)
FROM SQLF.dbo.format_history fh
)
SELECT c2.format_options, c1.cnt
FROM (
SELECT TOP (10) hsh, rn = MIN(rn), cnt = COUNT(1)
FROM cte
GROUP BY hsh
ORDER BY cnt DESC
) c1
JOIN cte c2 ON c1.rn = c2.rn
ORDER BY c1.cnt DESC
```
То за счет нормализации данных стало возможным существенно упростить не только сам запрос:
```
SELECT
fp.format_profile
, t.cnt
FROM (
SELECT TOP (10)
fh.format_hash
, cnt = COUNT(1)
FROM SQLF_v2.dbo.format_history fh
GROUP BY fh.format_hash
ORDER BY cnt DESC
) t
JOIN SQLF_v2.dbo.format_profile fp ON t.format_hash = fp.format_hash
```
Но и сократить время его выполнения:
*(10 row(s) affected)
SQL Server Execution Times:
CPU time = 2684 ms, elapsed time = 2774 ms.
(10 row(s) affected)
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 379 ms.*
Приятным дополнением также стало и снижение размера база данных на диске:
```
database_name row_size_mb
---------------- ---------------
SQLF 123.50
SQLF_v2 7.88
```
Вернуть размер файла данных для базы можно следующим запросом:
```
SELECT
database_name = DB_NAME(database_id)
, row_size_mb = CAST(SUM(CASE WHEN type_desc = 'ROWS' THEN size END) * 8. / 1024 AS DECIMAL(8,2))
FROM sys.master_files
WHERE database_id IN (DB_ID('SQLF'), DB_ID('SQLF_v2'))
GROUP BY database_id
```
Надеюсь, на этом примере, мне удалось показать важность нормализации данных и минимизации избыточности в базе.
**Третье.** Осторожно выбирайте столбцы, входящие в индексы.
Индексы позволяют существенно ускорить выборку из таблицы. Также как и данные из таблиц, индексы хранятся на страницах. Соотвественно. чем меньше страниц требуется для хранения индекса – тем быстрее по нему можно провести поиск.
Очень важно правильно выбрать поля, которые будут входить в кластерный индекс. Поскольку все столбцы кластерного индекса автоматически входят в каждый некластерный (по указателю).
**Четвертое.** Используйте промежуточные и консолидированные таблицы.
Здесь все достаточно просто – зачем каждый раз делать сложный запрос из большой таблицы, если есть возможность сделать простой запрос из маленькой.
Например, в наличии есть запрос по консолидации данных:
```
SELECT
WorkOutID
, CE = SUM(CASE WHEN WorkKeyCD = 'CE' THEN Value END)
, DE = SUM(CASE WHEN WorkKeyCD = 'DE' THEN Value END)
, RE = SUM(CASE WHEN WorkKeyCD = 'RE' THEN Value END)
, FD = SUM(CASE WHEN WorkKeyCD = 'FD' THEN Value END)
, TR = SUM(CASE WHEN WorkKeyCD = 'TR' THEN Value END)
, FF = SUM(CASE WHEN WorkKeyCD = 'FF' THEN Value END)
, PF = SUM(CASE WHEN WorkKeyCD = 'PF' THEN Value END)
, QW = SUM(CASE WHEN WorkKeyCD = 'QW' THEN Value END)
, FH = SUM(CASE WHEN WorkKeyCD = 'FH' THEN Value END)
, UH = SUM(CASE WHEN WorkKeyCD = 'UH' THEN Value END)
, NU = SUM(CASE WHEN WorkKeyCD = 'NU' THEN Value END)
, CS = SUM(CASE WHEN WorkKeyCD = 'CS' THEN Value END)
FROM dbo.WorkOutFactor
WHERE Value > 0
GROUP BY WorkOutID
```
Если данные в таблице изменяются не слишком часто, можно создать отдельную таблицу:
```
SELECT *
FROM dbo.WorkOutFactorCache
```
И не удивительно, что чтение из консолидированной таблицы будет проходить быстрее:
*(185916 row(s) affected)
SQL Server Execution Times:
CPU time = 3448 ms, elapsed time = 3116 ms.
(185916 row(s) affected)
SQL Server Execution Times:
CPU time = 1410 ms, elapsed time = 1202 ms.*
**Пятое.** В каждом правиле есть свои исключения.
Я показал пару примеров, когда изменение типов данных на менее избытоные позволяет сократить время выполнения запроса. Но это бывает не всегда.
Например, у типа данных *BIT* есть одна особенность – *SQL Server* оптимизирует хранение группы столбцов этакого типа на диске. Например, если в таблице имеется 8 или меньше столбцов типа *BIT*, они хранятся на странице как 1 байт, если до 16 столбцов типа *BIT*, они хранятся как 2 байта и т.д.
Хорошая новость – таблица будет занимать существенно меньше места и сократит количество дисковых операций.
Плохая новость – при выборке данных этого типа будет происходить неявное декодирование, которое очень требовательно к ресурсам процессора.
Покажу это на примере. Есть три идентичные таблицы, которые содержат информацию о календарном графике сотрудников (31 + 2 PK столбца). Все они отличаются только типом данных для консолидированных значений (1 — вышел на работу, 0 — отсутствовал):
```
SELECT * FROM dbo.E_51_INT
SELECT * FROM dbo.E_52_TINYINT
SELECT * FROM dbo.E_53_BIT
```
При использовании менее избыточных данных размер таблицы заметно уменьшился (особенно последняя таблица):
```
table_name data_size_mb
-------------------- --------------
dbo.E31_INT 150.2578
dbo.E32_TINYINT 50.4141
dbo.E33_BIT 24.1953
```
Но существенного выигрыша в скорости выполнения от использования типа *BIT* мы не получим:
```
(1000000 row(s) affected)
Table 'E31_INT'. Scan count 1, logical reads 19296, physical reads 1, read-ahead reads 19260, ...
SQL Server Execution Times:
CPU time = 1607 ms, elapsed time = 19962 ms.
(1000000 row(s) affected)
Table 'E32_TINYINT'. Scan count 1, logical reads 6471, physical reads 1, read-ahead reads 6477, ...
SQL Server Execution Times:
CPU time = 1029 ms, elapsed time = 16533 ms.
(1000000 row(s) affected)
Table 'E33_BIT'. Scan count 1, logical reads 3109, physical reads 1, read-ahead reads 3096, ...
SQL Server Execution Times:
CPU time = 1820 ms, elapsed time = 17121 ms.
```
Хотя план выполнения будет говорить об обратном:
В результате наблюдений было замечено, что негативный эффект от декодирования не будет проявятся если таблица содержит не более 8 *BIT* столбцов.
Попутно стоит отметить, что в метаданных *SQL Server* тип данных *BIT* используется очень редко – чаще применяют тип *BINARY* и вручную делают сдвиг для получения того или иного значения.
**И последнее о чем нужно упомянуть.** Удаляйте ненужные данные.
Собственно, зачем это делать?
При выборке данных, SQL Server поддерживает механизм оптимизации производительности, называемый упреждающим чтением, который пытается предугадать, какие именно страницы данных и индексов понадобятся для выполнения запроса, и помещает эти страницы в буферный кэш, прежде чем в них возникнет реальная необходимость.
Соответственно, если таблица содержит много лишних данных – это может привести к ненужным дисковым операциям.
Кроме того, удаление ненужных данных позволяет сократить количество логических операций при чтении данных из *Buffer Pool* – поиск и выборка данных будет проходить по меньшему объёму данных.
В заключение, что могу еще добавить – внимательно выбирайте типы данных для столбцов в Ваших таблицах и старайтесь учитывать будущие нагрузки на базу данных.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод:
[Practical Tips to Reduce SQL Server Database Table Size](http://blog.sqlauthority.com/2015/11/30/sql-server-practical-tips-to-reduce-sql-server-database-table-size-experts-opinion/) | https://habr.com/ru/post/211885/ | null | ru | null |
# Подсветка синтаксиса PostgreSQL
Спешу поделиться хорошей новостью: жизнь авторов статей про PostgreSQL и их читателей стала немного лучше.
Как знают все хаброписатели, для оформления исходного кода используется специальный тег , который подсвечивает синтаксис. Не секрет также, что подсветка не всегда получается идеальной, и тогда авторы (которым не все равно, как выглядят их статьи) вынуждены заниматься самодеятельностью — расцвечивать свой код с помощью .
Особенно печально все было с PostgreSQL, поскольку подсветка охватывала более или менее стандартный SQL и категорически не понимала специфики нашей СУБД. Шло время, Алексей [boomburum](https://habr.com/users/boomburum/) старательно исправлял мои font-ы на source (а я — обратно), пока не стало очевидно, что подсветку надо чинить. Наконец Далер [daleraliyorov](https://habr.com/users/daleraliyorov/) подсказал выход: добавить поддержку PostgreSQL в библиотеку [highlightjs](https://highlightjs.org/), которой пользуется Хабр. И вот — готово, встречайте.
### pgsql: SQL, PL/pgSQL и все-все-все
Итак, секрет правильной подсветки — в новом языке **pgsql**. Его можно выбрать в меню (кнопка «исходный код») или указать вручную. В html для этого надо написать
`мой код`
а в markdown — так:
````pgsql
мой код
````
В принципе, highlightjs умеет определять язык сама, но нормально это работает только для больших фрагментов кода; на маленьких кусочках автоопределение часто промахивается. Кроме того, автоопределение требует времени, так что если указать язык явно, код быстрее заиграет красками.
Например, чтобы получить
```
CREATE TABLE aircrafts_data (
aircraft_code character(3) NOT NULL,
model jsonb NOT NULL,
range integer NOT NULL,
CONSTRAINT aircrafts_range_check CHECK ((range > 0))
);
```
мы пишем
`CREATE TABLE aircrafts_data (
aircraft_code character(3) NOT NULL,
model jsonb NOT NULL,
range integer NOT NULL,
CONSTRAINT aircrafts_range_check CHECK ((range > 0))
);`
Тот же самый язык pgsql расцвечивает и код на PL/pgSQL. Например, чтобы получить
```
CREATE FUNCTION get_available_flightid(date) RETURNS SETOF integer AS $$
BEGIN
RETURN QUERY
SELECT flightid FROM flight WHERE flightdate >= $1 AND flightdate < ($1 + 1);
IF NOT FOUND THEN
RAISE EXCEPTION 'Нет рейсов на дату: %.', $1;
END IF;
RETURN;
END
$$ LANGUAGE plpgsql;
```
пишем
`CREATE FUNCTION get_available_flightid(date) RETURNS SETOF integer AS $$
...
$$ LANGUAGE plpgsql;`
Небольшая тонкость состоит в том, что символьные строки, заключенные в доллары, *всегда* подсвечиваются как код, а строки в апострофах не подсвечиваются *никогда*. Я рассматривал разные варианты, но именно этот показался наиболее адекватным.
Способность highlightjs автоматически определять язык фрагмента позволяет подсвечивать функции и на других языках. Например, все будет работать и для PL/Perl:
```
CREATE FUNCTION perl_max (integer, integer) RETURNS integer AS $$
my ($x, $y) = @_;
if (not defined $x) {
return undef if not defined $y;
return $y;
}
return $x if not defined $y;
return $x if $x > $y;
return $y;
$$ LANGUAGE plperl;
```
Для этого не нужно ничего специального, просто пишем
`CREATE FUNCTION perl_max (integer, integer) RETURNS integer AS $$
...
$$ LANGUAGE plperl;`
Конечно, выбранный язык зависит только от того, что написано внутри долларов, и никак не определяется тем, что написано после LANGUAGE.
В целом подсветка соответствует вышедшей недавно 11-й версии PostgreSQL.
Много сомнений было насчет подсветки функций. К сожалению, чтобы отличить имя функции от, например, имени таблицы, нужен полноценный синтаксический разбор, а в рамках подсветки синтаксиса это не решается. Можно составить длинный список стандартных функций и расцвечивать их, но как быть с функциями из многочисленных расширений? В итоге решил не расцвечивать вовсе — все равно все держится на ключевых словах, а пестроты поубавилось.
### plaintext: текст, просто текст
Иногда в статье требуется оформить результаты запроса. Конечно, никаких ключевых слов там нет, подсвечивать ничего не нужно, но хочется, чтобы текст смотрелся «консольно», так же, как код. Для этого теперь можно использовать специальный язык **plaintext**. Например, чтобы получить
```
WITH xmldata(data) AS (VALUES ($$
$$::xml)
)
SELECT xmltable.*
FROM XMLTABLE(XMLNAMESPACES('http://example.com/myns' AS x,
'http://example.com/b' AS "B"),
'/x:example/x:item'
PASSING (SELECT data FROM xmldata)
COLUMNS foo int PATH '@foo',
bar int PATH '@B:bar');
```
```
foo | bar
-----+-----
1 | 2
3 | 4
4 | 5
(3 rows)
```
пишем
`WITH xmldata(data) AS (VALUES ($$
...
foo | bar
-----+-----
1 | 2
3 | 4
4 | 5
(3 rows)`
Plaintext всегда надо указывать явно, автоматически он не определяется.
Надеюсь, что нововведение вам понравится и пригодится. Если найдете ошибку в том, как подсвечивается код (а ошибки неизбежны, слишком уж контекстно-зависимый синтаксис у SQL), создавайте задачу на [github проекта](https://github.com/highlightjs/highlight.js), а еще лучше — предлагайте решение.
*P. S. Не забывайте про конференцию [PGConf](https://pgconf.ru/2019), которая состоится 4–6 февраля в Москве. Заявки на доклады принимаются до 5 декабря!* | https://habr.com/ru/post/430040/ | null | ru | null |
# Frontend разработки порталов на СПО: делимся опытом
В [первой части](https://habr.com/ru/company/digdes/blog/492168/) статьи о том, как мы создаем портальные решения для крупнейших работодателей России, была описана архитектура со стороны backend-а. В данной статье мы перейдём к frontend-у.

Как уже отмечалось в первой части, основной нашей целью было разработать платформу, которую можно легко масштабировать и поддерживать.
**Переиспользуемость**
Фронт написан в большей части на Vue.js, и так как весь портал разбит на портлеты, каждый из них – это отдельный инстанс Vue со своим стором (Vuex), роутом (Vue Router) и компонентами. Каждый такой инстанс вынесен в свой репозиторий.
Так как портлет лежит в своем репозитории, встает вопрос о том, как не писать много однотипного кода для разных портлетов. Для решения этой проблемы мы выносим всё, что можно переиспользовать, в отдельный репозиторий, который потом подключается через .gitmodules. В данный момент таких сабмодулей два.
Один хранит общий функционал: это общие компоненты, сервисы, константы и т.д. У нас этот модуль называется Vue-common.
Во второй субмодуль вынесены настройки для сборки, он хранит конфиги для webpack-а, а также лоадеры и хелперы, необходимые при сборке. Этот модуль называется Vue-bundler.
Для удобства работы с API методы REST-а также были разделены на общие и локальные. Во Vue-common были вынесены методы для получения списка юзеров портала, методы администрирования, доступа к файловой системе портала и прочие. Все API endpoint-ы были вынесены в отдельные сервисы, которые регистрировались в точке входа и подключались к инстансу Vue. Затем они могли использоваться в любой точке приложения.
Каждый отдельный сервис регистрируется внутри плагина. Для подключения плагинов во Vue есть встроенная функция use. Подробнее о плагинах во Vue можно почитать [тут](https://ru.vuejs.org/v2/guide/plugins.html).
Сам плагин инициализируется вот так:
```
class Api {
constructor () {
// Инстанс http клиента, который формирует запросы
this.instance = instance
// Так происходит регистрация общих сервисов
// В каждый сервис прокидывается this, чтобы был доступ к инстансу http клиента
Object.keys(commonServices).forEach(name => commonServices[name](this))
// Так происходит регистрация локальных сервисов
requireService.keys().forEach(filename => requireService(filename).default(this))
}
install () {
Vue.prototype.$api= this
}
}
export default new Api()
```
Кроме инициализации:
1. Создается инстанс http клиента. В котором задается baseURL нашего backend-а и заголовки
```
const instance = axios.create({
baseURL: '/example/api',
responseType: 'json',
headers: {
'Content-Type': 'application/json',
'Cache-Control': 'no-cache',
'Pragma': 'no-cache',
}
})
Так как backend у нас рестовый, мы используем axios.
```
2. Создаются сервисы, хранящие сами запросы
```
// api - это наш http клиент
export default api => {
api.exampleService= {
exampleGetRequest(params) {
return api.instance.request({
method: 'get',
url: `example/get`,
params
})
},
examplePostRequest(data) {
return api.instance.request({
method: 'post',
url: `example/post`,
data
})
},
}
}
```
Во vue-common-е достаточно создать только такой сервис, а регистрируется он уже для каждого портлета в классе Api
3. Регистрируются общие и локальные сервисы
```
const requireService = require.context('./service', false, /.service.js$/)
```
В компонентах они используются очень просто. Например:
```
export default {
methods: {
someMethod() {
this.$api.exampleService.exampleGetRequest()
}
}
}
```
Если нужно делать запросы за пределами приложения, то можно сделать так:
```
// Импортировать апи класс (@ - это алиас прописанный в конфиге)
import api from ‘@/api’
// И потом просто из него дергать нужный метод
api.exampleService.exampleGetRequest()
```
**Маштабирование**
Как отмечалось выше, для каждого портала собирается отдельный бандл, а для каждого бандла есть свои entry point-ы. В каждом из них происходит регистрация компонентов и ассетов, настройка авторизации для локальной разработки и подключение плагинов.
Компоненты регистрируются глобально для каждого приложения как локальные, так и общие.
Регистрация компонентов выглядит так:
```
import _ from “lodash”
const requireComponent = require.context('@/components', true, /^[^_].+\.vue$/i)
requireComponent.keys().forEach(filename => {
const componentConfig = requireComponent(filename)
// Get PascalCase name of component
const componentName = _.upperFirst(
_.camelCase(/\/\w+\.vue/.exec(filename)[0].replace(/^\.\//, '').replace(/\.\w+$/, ''))
)
Vue.component(componentName, componentConfig.default || componentConfig)
})
```
Иногда возникает необходимость для разрабатываемого нами портала добавить уникальную функциональность и для этого приходится писать компоненты, свойственные только ему, или просто по-другому реализовать тот или иной компонент. Достаточно создать компонент в отдельной папке, например /components-portal/\*название портала\*/\*.vue, и зарегистрировать его в нужном entry point-е, добавив require.context не для одной папки, а для нескольких.
```
const contexts = [
require.context('@/components', true, /^[^_].+\.vue$/i),
require.context('@/components-portal/example', true, /^[^_].+\.vue$/i)
]
contexts.forEach(requireComponent => {
requireComponent.keys().forEach(filename => {
const componentConfig = requireComponent(filename)
// Get PascalCase name of component
const componentName = _.upperFirst(
_.camelCase(/\/\w+\.vue/.exec(filename)[0].replace(/^\.\//, '').replace(/\.\w+$/, ''))
)
Vue.component(componentName, componentConfig.default || componentConfig)
})
})
```
Если для компонента под определенный портал задать такое же имя, как из общей библиотеки компонентов, то он просто перепишется как свойство объекта и будет использован как компонент под данный портал.
Также глобально регистрируются ассеты, например svg иконки. Мы используем svg-sprite-loader, чтобы создать спрайт из svg иконок и потом использовать их через
Регистрируются они так:
```
const requireAll = (r) => r.keys().forEach(r)
const requireContext = require.context('@/assets/icons/', true, /\.svg$/)
requireAll(requireContext)
```
Чтобы масштабировать не только функционал, но и стили компонентов, у нас реализован механизм смены стилей для определенного портала. В однофайловых компонентах указываются стили в теге | https://habr.com/ru/post/492212/ | null | ru | null |
# Использование IPv6 в Advanced Direct Connect
Наблюдать за развитием файлообменной сети интересно, но ещё интереснее участвовать в нём.
На сегодняшний день, устанавливая и запуская современный [NMDC](http://mydc.ru/topic915.html) хаб, новоиспечённый администратор получает доступ практически ко всем наработкам и накопленному в этой области опыту его предшественников. Он имеет систему, готовую к расширению и кастомизации в том числе с помощью многочисленных скриптов.
С [ADC](https://adc.sourceforge.io/) хабами иначе. Структура этого протокола предполагает расширяемость. Хочешь новую фичу? Ну что ж – предлагай, продвигай, реализуй, внедряй, пользуйся.
[Translate to English](https://translate.google.com/translate?sl=ru&tl=en&u=https%3A%2F%2Fhabr.com%2Fru%2Fpost%2F522812%2F)
Как следствие, «из коробки» можно, конечно, получить готовый хаб, но просто запустить и забыть о нём будет нехорошо. Расширяемость в историческом контексте предполагает в том числе и наличие разного количества разных функций клиентского и серверного софта в зависимости от версии. И то, что будет работать без проблем у одного пользователя, может оказаться несовместимым с клиентом другого, и это нужно учитывать.
Так случилось и с IPv6. Старичок NMDC не умеет его в принципе, а вот ADC сам по себе к нему готов. Однако, не всё так просто.
### Совсем немного теории
«Активный» пользователь может принимать входящие соединения. Собственно, исходящий от него запрос на соединение на самом деле является приглашением.
«Пассивный» пользователь в общем случае может использовать только исходящие запросы. Посредством хаба он *просит* активного пользователя отослать приглашение – и соединение получается.
И да, этот механизм не зависит от версии используемого протокола IP.
### Лебедь, рак и щука
Поговорим о клиентском софте.
Поддержка IPv6 в **[DC++](https://dcplusplus.sourceforge.io/)** носит экспериментальный характер. Отдельных настроек для него нет, и тем удивительнее для меня было увидеть разные режимы работы для разных версий IP, причём пассивный как раз для шестой~~, но это неточно~~.
Получить активный режим при ручной настройке не удалось даже при явном использовании в качестве WAN IP домена с AAAA-записью, а вот в автоматическом режиме с использованием UPnP всё заработало как до́лжно.
**[AirDC++](https://airdcpp.net/)** также имеет поддержку IPv6-соединений, и реализована она вовсе отдельно от IPv4. Более того, этот клиент модифицирует тэги пользователей таким образом, чтобы отображать режимы работы для обоих IP протоколов одновременно. Сами хабы делать этого (пока) не умеют, а жаль.
Сразу должен оговориться: AirDC++ делает так один и для себя. В дальнейшем для удобства я буду использовать сочетания вроде **AP** или **AA** как указание на активный или пассивный режимы работы для IPv4 и IPv6 соответственно, а не их отображение в тэге реального клиента на реальном хабе. Это важно.
В нашем эксперименте мы будем использовать **FlylinkDC++** в качестве клиента, вовсе не знакомого с IPv6.
Следует также отметить, что поддержка [NATT](https://habr.com/ru/post/497944/) для этого протокола на момент написания статьи не была реализована ни в одном из клиентов.
### Начало
Первым делом мы рассмотрим заведомо невозможные соединения между пользователями разных версий протокола IP. Для теста будет использоваться [IPv6 ready хаб](https://www.uhub.org/) с ресурсными A- и AAAA-записями для доменного имени, выступающего в качестве его адреса.
Обратите внимание, при (фактической) попытке обращения к пользователю с IP-адресом шестой версии выводится ошибка.
```
Hub: [Outgoing][IPv4:412] DRCM AACX AACU ADCS/0.10 337151563
Hub: [Incoming][IPv4:412] DCTM AACU AACX ADCS/0.10 1988 337151563
Hub: [Outgoing][IPv4:412] DSTA AACX AACU 240 IP\sunknown
```
В переводе на человеческий это звучит как
> P4: – Можно я к тебе прицеплюсь?
>
> A6: – Цепляйся!
>
> P4: – Жизнь боль 0\_0
Краткий словарик, если что, [здесь](http://mydc.ru/topic2033.html).
А если наоборот, и соединение иницирует **A4**, то ошибка не выводится, и соединение просто «зависает».
```
Hub: [Outgoing][IPv4:412] DCTM AACX AACU ADCS/0.10 1993 3871342713
```
### Быть, а не казаться
Что важно, так это отображаемый на хабе режим соединения.
Клиенты без поддержки IPv6 должны будут видеть подключенных через него пользователей как однозначно пассивных просто потому, что для них хаб не заполняет **I4** или **I6** поле соответственно.

*FlylinkDC++ vs. IPv6*
На деле же ситуация проще и сложнее одновременно.
*AirDC++ vs. IPv6*
Проще, потому что IPv6 имеет приоритет над IPv4, и это понятно. Именно через него (хотя с помощью соответствующей опции доступно переопределение) будет установлено соединение с хабом, и его же активный клиент будет предлагать для соединения пассивному.
Сложнее, потому что если на хабе присутствуют пользователи с поддержкой IPv6, но подсоединены они строго через IPv4-адрес, то…
… то с ними можно соединиться (наобум) вообще не имея IPv4.
Обратите внимание, удалённый клиент обозначил себя как актива, но обрабатывается как пассив. Почему?
### Туды его в качель
Теперь попробуем соединять друг с другом клиенты с различными, но общими в части IPv4 наборами поддержки протокола IP.
Да, жаль, что пассивным пользователям приходится курить в сторонке. Но помочь этому нельзя, так как их видимый IP-адрес не имеет особого значения – на то они и пассивы.
Ба! Активный клиент отправляет [пассивную команду](https://adc.sourceforge.io/ADC.html#_rcm_2)?.. Логично было бы ожидать «зависшего» соединения, но нет, оно получается на условиях **A4**.
Почему так? Обращаемся к разработчику и получаем ответ:
> [CTM](https://adc.sourceforge.io/ADC.html#_ctm_2) isn't good if the other user doesn't support IPv6
И ведь не поспоришь! Но это требует уже внутренней, независимой от хаба логики (см. код [здесь](https://github.com/airdcpp/airgit/blob/7d18ea6d2a1dc98dde45e8c3d8d1a3c4aeeb5bb0/airdcpp/airdcpp/User.cpp#L281-L323) и [здесь](https://github.com/airdcpp/airgit/blob/master/airdcpp/airdcpp/OnlineUser.h#L61-L71)). Пассивам же по-прежнему помочь нельзя, потому что
> Active mode = [TCPx + IPx](https://dcpp.wordpress.com/2011/05/09/i4i6-should-be-broadcasted-regardless-of-tcp4tcp6/)
Попытки же соединения между клиентами с общими в части IPv6 наборами поддержки протокола IP выглядят следующим образом. Напомню, добиться **PA** для DC++ мне не удалось.
И снова сюрприз. Получается, пассивный режим для IPv6, который демонстрирует DC++, есть или намеренный фейк, или баг.
### Что дальше?
В настоящее время существует ровно два способа решения всех возможных проблем соединения пользователей в разных режимах и с разными наборами поддержки протокола IP.
Первый – приглушить IPv6 вовсе или, наоборот, создать хаб для работы только через него.
Второй – вот это [расширение](https://forum.dcbase.org/viewtopic.php?t=771), которое только-только подходит к стадии тестирования.
Ну и, ленясь настраивать активный режим для работы в DC, помните:
*Кто имеет, тому дано будет, а кто не имеет, у того отнимется и то, что он думает иметь.* Лк. 8:18 | https://habr.com/ru/post/522812/ | null | ru | null |
# Заметки о Unix: два сценария работы с конвейерами
Мне встречалось множество рекомендаций о повышении безопасности использования shell-скриптов в Bash путём включения опции `pipefail` (например — это рекомендуется в [данном](https://vaneyckt.io/posts/safer_bash_scripts_with_set_euxo_pipefail/) материале 2015 года). Это, с одной стороны, хорошая рекомендация. Но включение `pipefail` может привести к конфликту. В одном из двух сценариев использования конвейеров эта опция показывает себя замечательно, а вот в другом то, к чему приводит её включение, выглядит просто ужасно.
[](https://habr.com/ru/company/ruvds/blog/536968/)
Для того чтобы понять суть этой проблемы давайте сначала разберёмся с тем, за что именно отвечает опция Bash `pipefail`. Обратимся к [документации](https://www.gnu.org/savannah-checkouts/gnu/bash/manual/bash.html):
*Статусом выхода из конвейера, в том случае, если не включена опция `pipefail`, служит статус завершения последней команды конвейера. Если опция `pipefail` включена — статус выхода из конвейера является значением последней (самой правой) команды, завершённой с ненулевым статусом, или ноль — если работа всех команд завершена успешно.*
Причина использования `pipefail` заключается в том, что иначе команда, неожиданно завершившаяся с ошибкой и находящаяся где-нибудь в середине конвейера, обычно остаётся незамеченной. Она, если использовалась опция `set -e`, не приведёт к аварийному завершению скрипта. Можно пойти другим путём и тщательно проверять всё с использованием `$PIPESTATUS`, но это означает необходимость выполнения больших объёмов дополнительной работы.
К сожалению, именно тут на горизонте появляется наш старый друг [SIGPIPE](https://utcc.utoronto.ca/~cks/space/blog/linux/BashPipes). Роль `SIGPIPE` в конвейерах заключается в том, чтобы принуждать процессы к остановке в том случае, если они делают попытки записи в закрытый конвейер. Это происходит в том случае, если процесс, расположенный ближе к концу конвейера, не потребил все входные данные. Например, предположим, что нужно обработать первую тысячу строк выходных данных некоей сущности:
```
generate --thing | sed 1000q | gronkulate
```
Команда `sed`, после получения 1000 строк, завершит работу и закроет конвейер, в который пишет данные `generate`. А `generate` получит сигнал `SIGPIPE` и, по умолчанию, остановится. Статус выхода команды будет отличаться от нуля, а это значит, что с использованием `pipefail` работа всего конвейера «завершится с ошибкой» (а с использованием `set -e` скрипт нормально завершит работу).
(В некоторых случаях то, что происходит, может, от запуска к запуску, [меняться](https://utcc.utoronto.ca/~cks/space/blog/unix/ShellPipelineIndeterminate). Причина этого — в системе планирования выполнения процессов. Это может зависеть и от того, какой объём данных производят процессы, находящиеся ближе к началу конвейера, и как он соотносится с тем, что фильтруют процессы, расположенные ближе к концу конвейера. Так, если в нашем примере `generate` создаст 1000 строк или меньше — `sed` примет все эти данные.)
Это ведёт к двум шаблонам использования конвейеров командной оболочки. При использовании первого конвейер потребляет все входные данные, действуя так в тех случаях, если всё работает без сбоев. Так как подобным образом работают все процессы — ни у одного процесса никогда не должно возникнуть необходимости выполнять запись в закрытый конвейер. А значит — никогда не появится и сигнал `SIGPIPE`. Второй шаблон использования конвейеров предусматривает ситуацию, когда хотя бы один процесс завершает обработку входных данных раньше, чем обычно. Часто подобные процессы специально помещают в конвейер для остановки обработки данных в определённый момент (как `sed` в вышеприведённом примере). Подобные конвейеры иногда или даже всегда генерируют сигналы `SIGPIPE`, некоторые процессы в них завершаются с ненулевым кодом.
Конечно, пользоваться подобными конвейерами можно и в окружении, где применяется `pipefail`, и даже с `set -e`. Например, можно сделать так, чтобы один из шагов конвейера всегда сообщал бы об успешном завершении:
```
(generate --thing || true) | sed 1000q | gronkulate
```
Но об этой проблеме нужно помнить, нужно обращать внимание на то, какие команды могут окончить работу раньше, чем обычно, не читая всех входных данных. Если что-то упустить — то в «награду» за это, вероятно, можно получить ошибку из скрипта. Если автору скрипта будет сопутствовать успех, то это будет ошибка, возникающая регулярно. В противном случае ошибки будут возникать время от времени, случаясь тогда, когда одна из команд конвейера выдаёт необычно большой объём выходных данных, или тогда, когда другая команда завершает свою работу необычно рано или необычно быстро.
(Кроме того, очень хорошо было бы игнорировать только ошибки, связанные с `SIGPIPE`, но не другие ошибки. Если `generate` завершится с ошибкой по причинам, не связанным с `SIGPIPE`, то нам хотелось бы, чтобы весь конвейер выглядел бы так, как если бы он завершился с ошибкой.)
Чутьё подсказывает мне, что шаблон использования конвейеров, основанный на полном потреблении всех входных данных, распространён гораздо сильнее, чем шаблон, когда работа конвейера завершается раньше, чем обычно. Правда, я не пытался оценить свои скрипты на предмет особенностей использования в них конвейеров. Это, определённо, совершенно естественный шаблон использования конвейеров, когда в них выполняется фильтрация, трансформация или исследование всех сущностей из некоего набора (например — для того чтобы их посчитать или вывести некие сводные данные по ним).
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=ruvds&utm_content=zametkiounix#order) | https://habr.com/ru/post/536968/ | null | ru | null |
# 14 вещей, которые обязан знать iOS-разработчик
С разрешения автора выкладываю перевод статьи Norberto Gil Vasconcelos **«14 must knows for an iOS developer»** ([ссылка на оригинал](https://swiftsailing.net/14-must-knows-for-an-ios-developer-5ae502d7d87f)). На момент публикации статьи актуальной была версия Swift 3.
Как iOS-разработчик (в данный момент абсолютно зависимый от Swift), я создавал приложения с нуля, поддерживал приложения, работал в различных командах. За все время работы в этой индустрии я не раз слышал фразу: «Не можешь объяснить – значит не понимаешь». Так что, в попытке понять, чем именно я занимаюсь каждый день, я создаю список того, что, на мой взгляд, важно для любого iOS-разработчика. Я постараюсь максимально ясно объяснить каждый момент. [Пожалуйста, не стесняйтесь исправлять меня, высказывать свое мнение или предлагать свои дополнения в этот список.]
---
**Темы:** [ [контроль версий](#%D0%9A%D0%BE%D0%BD%D1%82%D1%80%D0%BE%D0%BB%D1%8C%20%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D0%B9) | [архитектурные паттерны](#%D0%90%D1%80%D1%85%D0%B8%D1%82%D0%B5%D0%BA%D1%82%D1%83%D1%80%D0%BD%D1%8B%D0%B5%20%D0%BF%D0%B0%D1%82%D1%82%D0%B5%D1%80%D0%BD%D1%8B) | [Objective-C против Swift](#Objective-C%20%D0%BF%D1%80%D0%BE%D1%82%D0%B8%D0%B2%20Swift) | [React](#React%20%D0%B8%D0%BB%D0%B8%20%D0%BD%D0%B5%20React?%20(%D0%B2%D0%BE%D1%82%20%D0%B2%20%D1%87%D0%B5%D0%BC%20%D0%B2%D0%BE%D0%BF%D1%80%D0%BE%D1%81)) | [менеджер зависимостей](#%D0%9C%D0%B5%D0%BD%D0%B5%D0%B4%D0%B6%D0%B5%D1%80%20%D0%B7%D0%B0%D0%B2%D0%B8%D1%81%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D0%B5%D0%B9) | [хранение информации](#%D0%A5%D1%80%D0%B0%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5%20%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%B8) | [CollectionViews & TableViews](#CollectionViews%20&%20TableViews) | [UI](#Storyboards%20VS%20Xibs%20VS%20%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D1%83%D0%B5%D0%BC%D1%8B%D0%B9%20UI) | [протоколы](#%D0%9F%D1%80%D0%BE%D1%82%D0%BE%D0%BA%D0%BE%D0%BB%D1%8B!) | [замыкания](#%D0%97%D0%B0%D0%BC%D1%8B%D0%BA%D0%B0%D0%BD%D0%B8%D1%8F) | [схемы](#%D0%A1%D1%85%D0%B5%D0%BC%D1%8B) | [тесты](#tests) | [геолокация](#%D0%93%D0%B5%D0%BE%D0%BB%D0%BE%D0%BA%D0%B0%D1%86%D0%B8%D1%8F) | [локализуемые строки](#%D0%9B%D0%BE%D0%BA%D0%B0%D0%BB%D0%B8%D0%B7%D1%83%D0%B5%D0%BC%D1%8B%D0%B5%20%D1%81%D1%82%D1%80%D0%BE%D0%BA%D0%B8) ]
---
Вот мой список, без лишних слов, в произвольном порядке.
#### 1 – Контроль версий
Поздравляю, вы приняты! Извлеките код из репозитория и приступайте к работе. Стоп, что?
Контроль версий необходим любому проекту, даже если вы только разработчик. Наиболее часто используемые системы – это Git и SVN.
**SVN** основан на централизованной системе управления версиями. Это репозиторий, где создаются рабочие копии, и для доступа к ним нужно соединение по сети. Авторизация изменений осуществляется по конкретному пути; система отслеживает изменения путем регистрации каждого файла, полную историю изменений можно посмотреть только в репозитории. Рабочие копии содержат лишь новейшую версию.
**Git** использует распределенную систему управления версиями. У вас будет локальный репозиторий, в котором вы сможете работать, сетевое подключение необходимо только для синхронизации. При изменении рабочей копии сохраняется состояние всего каталога, но регистрируются только внесенные изменения; и репозиторий, и рабочие копии имеют полную историю изменений.
#### 2 – Архитектурные паттерны
Ваши пальцы дрожат от волнения, вы разобрались с контролем версий! Или это из-за кофе? Неважно! Вы в ударе, и настал час программирования! Не-а. А чего еще ждать?
Прежде, чем вы сядете за клавиатуру, необходимо выбрать архитектурный паттерн, которого вы будете придерживаться. Если не вы начали проект, вы должны соответствовать уже существующему паттерну.
Существует широкий спектр паттернов, используемых при разработке мобильных приложений (MVC, MVP, MVVM, VIPER и т. д.). Дам краткий обзор наиболее часто используемых в разработке для iOS:
* **MVC** — сокращенно от Model, View, Controller. Controller создает мост между Model и View, которые не знают друг о друге. Связь между View и Controller очень тесная, поэтому Controller обрабатывает практически все. Что это значит? Проще говоря, если вы создаете сложный View, ваш контроллер (ViewController) будет безумно большим. Есть способы обойти это, однако они выходят за рамки MVC. Еще одним недостатком MVC является тестирование. Если вы используете тесты (так держать!), вы, вероятно, будете тестировать только Model, поскольку она является единственным слоем, отделенным от остальных. Плюс использования шаблона MVC в том, что он интуитивно понятен, и большинство разработчиков iOS привыкли к нему.
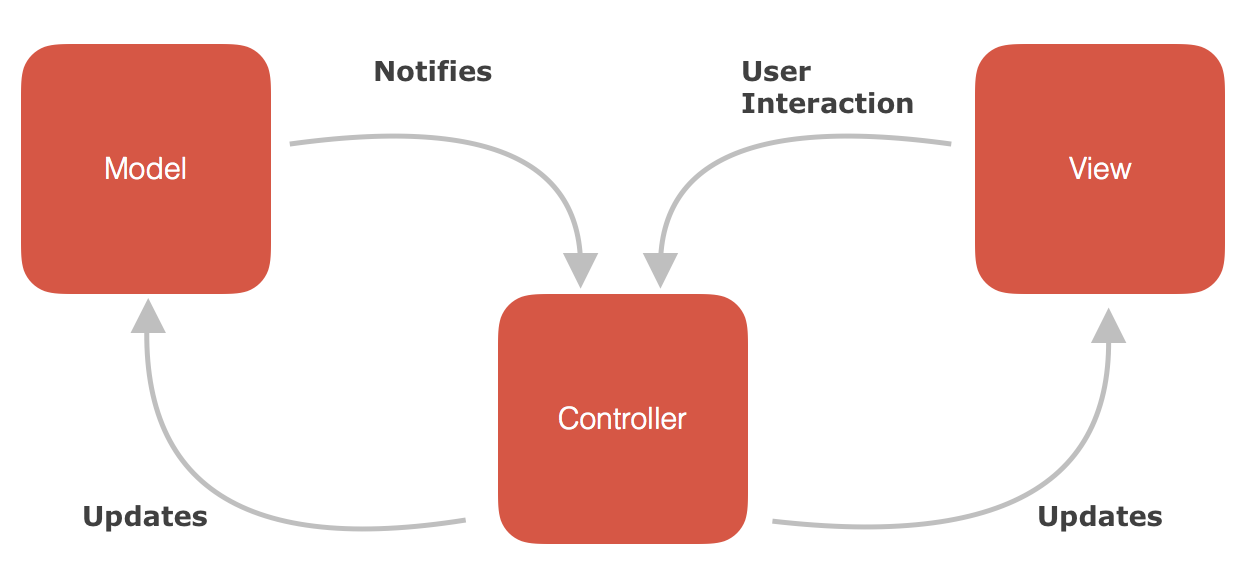
MVC – визуальное представление
* **MVVM** — сокращенно от **M**odel, **V**iew, **V**iew**M**odel. Привязки (в основном реактивное программирование) устанавливаются между View и ViewModel, это позволяет ViewModel вызывать изменения в модели, которая затем обновляет ViewModel, автоматически обновляя View из-за привязок. ViewModel ничего не знает о View, что облегчает тестирование, а привязки уменьшают объем кода.
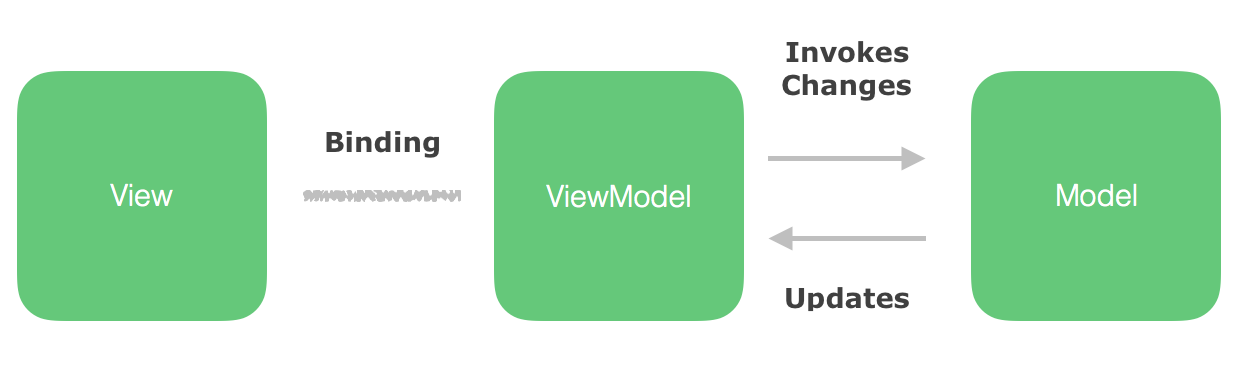
MVVM – визуальное представление
Для более глубокого понимания и получения информации о других паттернах я рекомендую прочесть [следующую статью](https://medium.com/ios-os-x-development/ios-architecture-patterns-ecba4c38de52).
Может показаться, что это не так уж и важно, но хорошо структурированный и организованный код может предотвратить много головной боли. Большая ошибка, которую каждый разработчик совершает в какой-то момент, состоит в том, чтобы просто получить желаемый результат и отказаться от организации кода, ошибочно полагая, что он экономит время. Если вы не согласны, послушайте старину Бенджи:
> Каждая минута, потраченная на организацию своей деятельности, экономит вам целый час
>
>
>
> *– Бенджамин Франклин*
>
>
Наша цель состоит в том, чтобы получить интуитивно понятный и простой для чтения код, который будет легко использовать и поддерживать.
#### 3 – Objective-C против Swift
Решая, на каком языке программирования писать свое приложение, вы должны знать, какими возможностями располагает каждый из них. Если есть возможность, я предпочитаю использовать Swift. Почему? Если честно, Objective-C имеет очень мало преимуществ по сравнению со Swift. Большинство примеров и учебных пособий написаны на Objective-C, а у Swift с каждым обновлением вносятся коррективы в парадигмы, что может приводить в уныние. Однако эти проблемы в конечном итоге исчезнут.
В сравнении с Objective-C, Swift делает скачок во многих отношениях. Его легко читать, он похож на естественный английский, и, поскольку он не построен на C, это позволяет отказаться от традиционных условностей. Для тех, кто знает Objective-C, это значит никаких больше точек с запятой, а вызовы методов и условия выражений не нужно будет заключать в скобки. Также легче поддерживать ваш код: Swift нужен только файл .swift вместо файлов .h и .m, потому что Xcode и компилятор LLVM могут определять зависимости и выполнять инкрементные сборки автоматически. В целом вам придется меньше беспокоиться о создании стандартизированного кода, и вы обнаружите, что можно достичь тех же результатов меньшим количеством строк.
Все еще сомневаетесь? Swift безопаснее, быстрее, и заботится об управлении памятью (большей ее частью!). Знаете, что происходит в Objective-C, когда вы вызываете метод с неинициализированной переменной-указателем? Ничего. Выражение становится неактивным и пропускается. Звучит здорово, потому что это не приводит к вылету приложения, однако вызывает ряд багов и нестабильное поведение, из-за которых вам захочется подумать о смене профессии. Серьезно. Идея стать профессиональным выгульщиком собак заиграла новыми красками. В это же время, счетчик Swift работает с optional-значениями. Вы не только получите лучшее представление о том, что может быть nil и поставите условия для предотвращения использования nil-значений, но и получите runtime crash, если nil optional все же будет использоваться, что упростит отладку. ARC (автоматический подсчет ссылок) помогает лучше распоряжаться памятью в Swift. В Objective-C ARC не работает с процедурным C или с API, наподобие Core Graphics.
#### 4 – React или не React? (вот в чем вопрос)
Функциональное реактивное программирование (FRP) – новый хит. Оно предназначено для упрощения составления асинхронных операций и потоков событий/данных. Для Swift это общая абстракция вычислений, выраженная через интерфейс Observable.
Проще всего проиллюстрировать это небольшим количеством кода. Скажем, малыш Тимми и его сестра Дженни хотят купить новую игровую приставку. Тимми получает от своих родителей 5 евро каждую неделю, то же самое касается Дженни. Однако Дженни зарабатывает еще 5 евро, доставляя газеты по выходным. Если оба экономят каждый цент, мы можем каждую неделю проверять, доступна ли консоль! Каждый раз, когда значение их сбережений меняется, рассчитывается их совокупная величина. Если этого достаточно, сообщение сохраняется в переменной isConsoleAttainable. В любой момент мы можем проверить сообщение, подписавшись на него.
```
// Сбережения
let timmySavings = Variable(5)
let jennySavings = Variable(10)
var isConsoleAttainable =
Observable
.combineLatest(timmy.asObservable(), jenny.asObservable()) { $0 + $1 }
.filter { $0 >= 300 }
.map { "\($0) достаточно для покупки приставки!" }
// Вторая неделя
timmySavings.value = 10
jennySavings.value = 20
isConsoleAttainable
.subscribe(onNext: { print($0) }) // Не выведет ничего
// Двадцатая неделя
timmySavings.value = 100
jennySavings.value = 200
isConsoleAttainable
.subscribe(onNext: { print($0) }) // 300 достаточно для покупки приставки!
```
Это лишь пример того, что можно сделать с FRP, как только вы освоите его, оно откроет целый новый мир возможностей, вплоть до принятия архитектуры, отличной от MVC… Да-да! MVVM!
Вы можете посмотреть на двух основных претендентов на звание главного Swift FRP:
* **[RxSwift](https://github.com/ReactiveX/RxSwift)**
* **[ReactiveCocoa](https://github.com/ReactiveCocoa/ReactiveCocoa)**
#### 5 – Менеджер зависимостей
CocoaPods и Carthage являются наиболее распространенными менеджерами зависимостей для проектов Cocoa Swift и Objective-C. Они упрощают процесс внедрения библиотеки и поддержания ее в актуальном состоянии.
**CocoaPods** имеет множество библиотек, собран с помощью Ruby и может быть установлен с помощью следующей команды:
```
$ sudo gem install cocoapods
```
После установки вы захотите создать Podfile для вашего проекта. Вы можете запустить следующую команду:
```
$ pod install
```
или создать пользовательский Podfile с такой структурой:
```
platform :ios, '8.0'
use_frameworks!
target 'MyApp' do
pod 'AFNetworking', '~> 2.6'
pod 'ORStackView', '~> 3.0'
pod 'SwiftyJSON', '~> 2.3'
end
```
После создания пришло время установить ваши новые модули:
```
$ pod install
```
Теперь вы можете открыть **.xcworkspace** вашего проекта, не забудьте импортировать ваши зависимости.
**Carthage** – децентрализованный менеджер зависимостей, в отличие от CocoaPods. Недостатком этого является то, что пользователям становится все труднее находить существующие библиотеки. С другой стороны, такой подход требует меньше работ по поддержке и позволяет избежать сбоев по причине централизованности хранилища.
Для получения дополнительной информации об установке и использовании загляните на [GitHub проекта](https://github.com/Carthage/Carthage).
#### 6 – Хранение информации
Начнем с простейшего способа сохранения данных для ваших приложений. **NSUserDefaults**, названный так, потому что он обычно используется для сохранения пользовательских данных по умолчанию, отображаемых при первой загрузке приложения. По этой причине он сделан простым и легким в использовании, однако это же подразумевает некоторые ограничения. Одним из них является тип объектов, которые принимает этот способ. Его поведение очень похоже на **Property List (Plist)**, который имеет такое же ограничение. Вот шесть типов объектов, которые они могут хранить:
* NSData
* NSDate
* NSNumber
* NSDictionary
* NSString
* NSArray
В целях совместимости со Swift, NSNumber может принять следующие типы:
* UInt
* Int
* Float
* Double
* Bool
Объекты могут быть сохранены в NSUserDefaults следующим образом (Сначала создайте константу, которая будет хранить ключ для сохраняемого объекта):
```
let keyConstant = "objectKey"
let defaults = NSUserDefaults.standardsUserDefaults()
defaults.setObject("Object to save", objectKey: keyConstant)
```
Чтобы прочитать объект из NSUserDefaults, мы можем сделать следующее:
```
if let name = defaults.stringForKey(keyConstant) {
print(name)
}
```
Есть несколько удобных методов для чтения и записи в NSUserDefaults, которые получают конкретные объекты вместо AnyObject.
**Keychain** представляет собой систему управления паролями и может содержать пароли, сертификаты, личные ключи или личные заметки. Keychain имеет два уровня шифрования устройства. Первый уровень использует код блокировки экрана блокировки в качестве ключа шифрования. Второй уровень использует ключ, сгенерированный и сохраненный на устройстве.
Что это значит? Это не совсем супер безопасно, особенно если вы не используете пароль на экране блокировки. Существуют также способы доступа к ключу, используемому на втором уровне, поскольку он сохранен на устройстве.
Лучшее решение — использовать собственное шифрование. (Не храните ключ на устройстве)
**CoreData** – это фреймворк, разработанный Apple, чтобы ваше приложение взаимодействовало с базой данных объектно-ориентированным образом. Это упрощает процесс, сокращая объем кода и избавляя от необходимости тестировать этот раздел.
Вы должны использовать CoreData, если вашему приложению требуются постоянные данные, это значительно упрощает процесс их сохранения и позволяет вам не создавать/тестировать свой собственный способ связи с БД.
#### 7 – CollectionViews & TableViews
Почти каждое приложение имеет одну или несколько CollectionViews и/или TableViews. Знание того, как они работают и когда использовать ту или иную, предотвратит сложные изменения в вашем приложении в будущем.
**TableViews** отображают список элементов в одном столбце по вертикали и ограничены только вертикальной прокруткой. Каждый элемент представлен UITableViewCell, который можно полностью настроить. Их можно отсортировать по разделам и строкам.
**CollectionViews** также отображают список элементов, однако они могут иметь несколько столбцов и строк (к примеру, сетка). Они могут прокручиваться по горизонтали и/или по вертикали, и каждый элемент представлен UICollectionViewCell. Как и UITableViewCells, они могут быть настроены по желанию и отсортированы по разделам и строкам.
Они обе имеют схожую функциональность и используют многоразовые ячейки для улучшения подвижности. Выбор того, что вам нужно, зависит от сложности, которую вы хотите иметь в списке. CollectionView может использоваться для представления любого списка и, на мой взгляд, всегда является лучшим выбором. Представьте, что вы хотите представить список контактов. Список простой, можно реализовать его одним столбцом, поэтому вы выбираете UITableView. Все работает! Через несколько месяцев ваш дизайнер решит, что контакты должны отображаться в формате сетки, а не в виде списка. Единственный способ сделать это — изменить реализацию UITableView на реализацию UICollectionView. Я пытаюсь сказать, что, хотя ваш список может быть простым и UITableView может быть достаточно, если есть большая вероятность изменения дизайна, вероятно, лучше всего реализовать этот список с помощью UICollectionView.
Какой бы выбор вы ни сделали, хорошей идеей будет создать общий TableView/CollectionView. Это облегчает реализацию и позволяет повторно использовать большой объем кода.
#### 8 – Storyboards VS Xibs VS программируемый UI
Каждый из этих методов может использоваться отдельно для создания пользовательского интерфейса, однако ничто не мешает вам объединить их.
**Storyboards** предоставляют более широкое представление о проекте, которое придется по вкусу дизайнерам, позволяя видеть поток приложения, а также его окна. Недостатком является то, что с добавлением большего количества окон соединения становятся более запутанными, а время загрузки Storyboard увеличивается. Проблемы слияния возникают гораздо чаще, потому что весь пользовательский интерфейс находится в одном файле. Их также становится гораздо сложнее решить.
**Xibs** обеспечивают визуальный просмотр окон или частей окна. Преимущества заключаются в простоте повторного использования, меньшем количестве конфликтов слияния, чем в Storyboards, и в простоте просмотра содержимого каждого из окон.
**Программирование** пользовательского интерфейса дает вам больший контроль над ним, снижает частоту конфликтов слияния, а если они и возникают, их проще устранить. Недостатком являются меньшая визуализация и дополнительное время, необходимое на написание.
Вышеуказанные подходы к созданию пользовательского интерфейса сильно разнятся. Но, по моему субъективному мнению, лучшим вариантом является сочетание всех трех. Несколько Storyboards (теперь мы можем переходить между Storyboard-ами!), с Xibs для любого визуального объекта, который не является основным окном, и, наконец, чуть-чуть программирования для дополнительного контроля, столь необходимого в определенных ситуациях.
#### 9 – Протоколы!
В быту протоколы существуют, чтобы в определенной ситуации мы знали, как реагировать. Допустим, вы пожарный, и возникла чрезвычайная ситуация. Каждый пожарный должен следовать протоколу, который устанавливает требования для успешного реагирования. То же самое относится и к протоколам в Swift/Objective-C.
Протокол определяет эскиз методов, свойств и других требований для заданных функций. Он может быть принят классом, структурой или перечислением, которые затем будут иметь фактическую реализацию этих требований.
Вот пример создания и использования протокола:
Для моего примера мне понадобится перечисление, в котором приведены различные типы материалов, используемые для тушения пожара.
```
enum ExtinguisherType: String {
case water, foam, sand
}
```
Далее я создам протокол реагирования на чрезвычайные ситуации.
```
protocol RespondEmergencyProtocol {
func putOutFire(with material: ExtinguisherType)
}
```
Теперь я создам класс пожарного, который подчиняется протоколу.
```
class Fireman: RespondEmergencyProtocol {
func putOutFire(with material: ExtinguisherType) {
print("Fire was put out using \(material.rawValue).")
}
}
```
Отлично! А теперь используем нашего пожарного.
```
var fireman: Fireman = Fireman()
fireman.putOutFire(with: .foam)
```
В результате должно получится следующее: *“Fire was put out using foam.”*
Протоколы также используются при Делегировании. Это позволяет классам или структурам делегировать определенные функции экземпляру другого типа. Протокол создается с делегируемыми обязанностями, чтобы гарантировать обеспечение их функциональности соответствующим типом.
Небольшой пример!
```
protocol FireStationDelegate: AnyObject {
func handleEmergency()
}
```
Пожарная служба делегирует пожарному меры по ликвидации чрезвычайной ситуации.
```
class FireStation {
weak var delegate: FireStationDelegate?
func emergencyCallReceived() {
delegate?.handleEmergency()
}
}
```
Это означает, что пожарный должен будет также соответствовать протоколу FireStationDelegate.
```
class Fireman: RespondEmergencyProtocol, FireStationDelegate {
func putOutFire(with material: ExtinguisherType) {
print("Fire was put out using \(material.rawValue).")
}
func handleEmergency() {
putOutFire(with: .water)
}
}
```
Все, что нужно сделать – чтобы пожарный на вызовах был назначен делегатом пожарной станции, и он будет обрабатывать принятые экстренные вызовы.
```
let firestation: FireStation = FireStation()
firestation.delegate = fireman
firestation.emergencyCallReceived()
```
В результате получим: *“Fire was put out using water.”*
#### 10 – Замыкания
Речь пойдет только о замыканиях Swift. В основном они используются для возврата завершающего блока или с функциями высокого порядка. Завершающие блоки используются, как понятно из названия, для выполнения блока кода после завершения задачи.
> Замыкания в Swift аналогичны блокам в C и Objective-C.
>
>
>
> Замыкания являются объектами первого класса\*, поэтому их можно вкладывать и передавать (как и блоки в Objective-C).
>
>
>
> В Swift функции – это частный случай замыканий.
>
>
>
> *Источник – fuckingswiftblocksyntax.com \*\**
Этот ресурс – отличное место для изучения синтаксиса замыканий.
\* Объекты первого класса (first-class objects) – объекты, которые можно использовать без ограничений: присвоить переменной, передать/вернуть из функции, создать/уничтожить во время выполнения программы и т.д. [Подробнее](https://stackoverflow.com/questions/245192/what-are-first-class-objects). (здесь и далее – прим. переводчика)
\*\* Сайт не работает, но остались снимки в waybackmachine, [пример](https://web.archive.org/web/20150311200453/http://fuckingswiftblocksyntax.com/).
#### 11 – Схемы
Если коротко, то схемы – это любой простой способ переключения между конфигурациями. Начнем с базовой информации. Рабочая область содержит различные связанные проекты. Проект может иметь различные таргеты — таргеты определяют продукт для сборки и способ сборки. Также, проект может иметь различные конфигурации. Схема в Xcode определяет коллекцию таргетов для сборки, конфигурацию, используемую при сборке, и коллекцию тестов для выполнения.
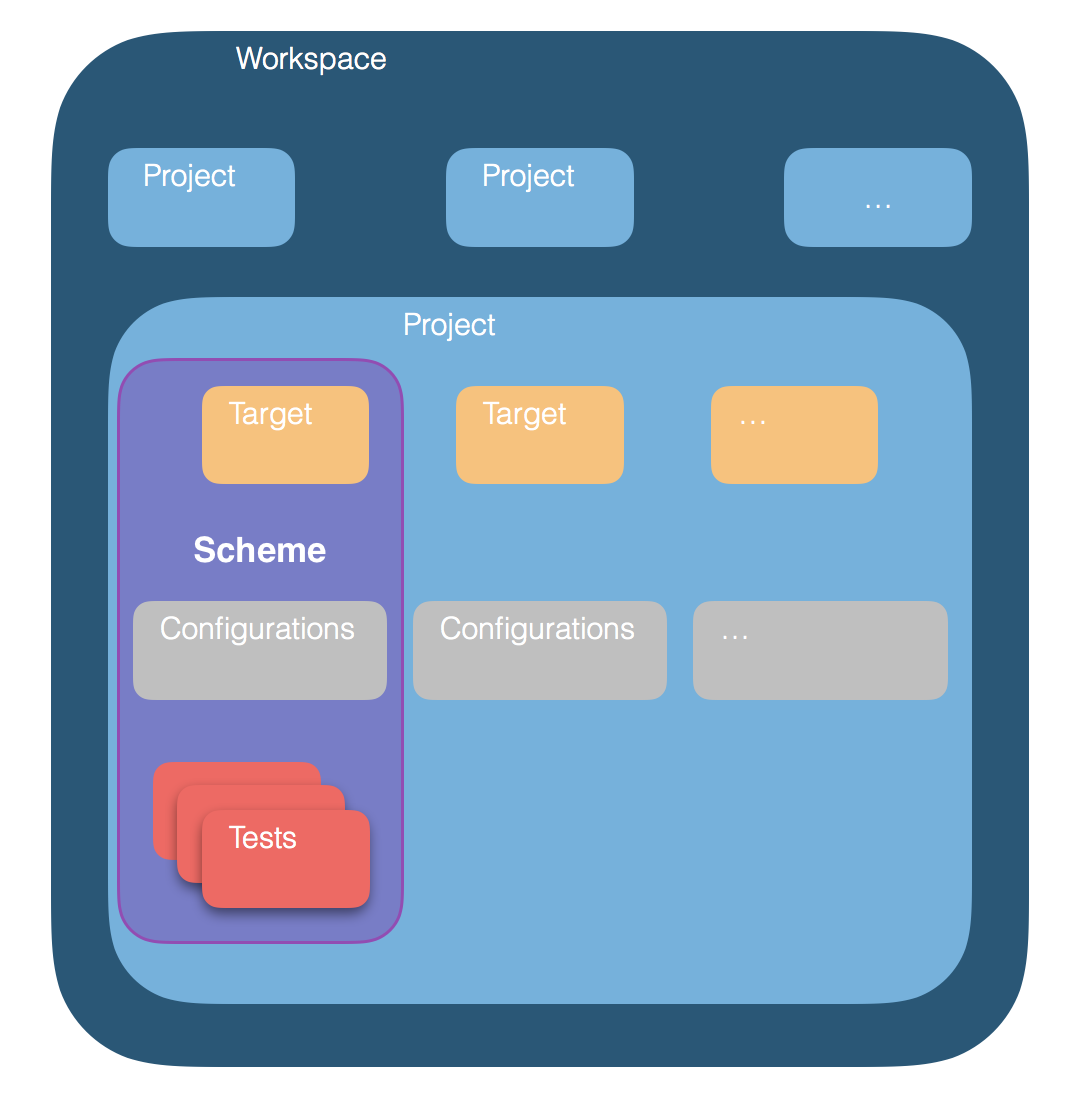
Фиолетовым показана одна из возможных схем
#### 12 – Тесты
Если вы выделяете время на тестирование своего приложения, вы на верном пути. Это, конечно, не панацея, вы не можете исправить каждый баг, равно как и гарантировать, что ваше приложение будет лишено каких-либо проблем; и все же я думаю, что плюсы перевешивают минусы.
Начнем с **минусов** модульного тестирования:
* Увеличение длительности разработки;
* Увеличение количества кода.
**Плюсы**:
* Необходимость создавать модульный код (для упрощения тестирования);
* Очевидно, обнаружение большинства ошибок до релиза;
* Упрощение поддержки.
В сочетании с утилитой **Инструменты** у вас будет все, чтобы приложение было гибким и работало без ошибок и сбоев.
Существует много инструментов, которые можно использовать для проверки работы приложения. В зависимости от того, что нужно отследить, вы можете выбрать один или несколько из них. Пожалуй, наиболее часто используемые инструменты – это **Leaks**, **Time Profiler** и **Allocations**.
### 13 - Геолокация
Во многих приложениях некоторые функции требуют определить местоположение пользователя. Так что неплохо бы иметь общее представление о том, как работает местоположение для iOS.
Существует фреймворк под названием Core Location, позволяющий получить доступ ко всему, что вам нужно:
> Фреймворк Core Location позволяет определить текущее местоположение или направление движения устройства. Фреймворк использует доступное аппаратное обеспечение для определения положения и направления пользователя. Вы можете использовать классы и протоколы этого фреймворка для настройки и планирования событий, связанных с местоположением и направлением. Вы также можете использовать Core Location для отслеживания перемещения по географическим регионам. В iOS вы также можете определить расстояние до Bluetooth-маячка\*.
>
>
>
> \* Как я понял, речь о технологии [iBeacon](https://ru.wikipedia.org/wiki/IBeacon)
Классно, не так ли? Ознакомьтесь с [документацией Apple](https://developer.apple.com/library/content/documentation/UserExperience/Conceptual/LocationAwarenessPG/Introduction/Introduction.html#//apple_ref/doc/uid/TP40009497) и приведенным там примером, чтобы лучше понять возможности фреймворка.
#### 14 – Локализуемые строки
То, что должно быть реализовано в любом приложении. Это позволяет менять язык в зависимости от региона, в котором находится устройство. Даже если ваше приложение только на одном языке, в будущем может возникнуть необходимость добавить новые. Если весь текст вводится с использованием локализуемых строк, все, что нужно сделать, это добавить переведенную версию файла Localizable.strings для нового языка.
Ресурс может быть добавлен в язык через инспектор файлов. Чтобы получить строку с NSLocalizedString, необходимо написать следующее:
```
NSLocalizedString(key:, comment:)
```
К сожалению, чтобы добавить новую строку в файл Localizable, это нужно сделать вручную. Вот пример структуры:
```
{
"APP_NAME" = "MyApp"
"LOGIN_LBL" = "Login"
...
}
```
Теперь другой язык (португальский), локализуемый файл:
```
{
"APP_NAME" = "MinhaApp"
"LOGIN_LBL" = "Entrar"
...
}
```
Есть даже способы реализации множественного числа.
> Всегда делись тем, чему ты научился.
>
>
>
> *– магистр Йода*
Надеюсь, эта статья была полезна! | https://habr.com/ru/post/501450/ | null | ru | null |
# Двумерные тестовые функции для оптимизации
Оптимизация функций — это область исследований, где поставлена задача найти некое входное значение [аргумент функции], результат которого — максимум или минимум данной функции. Алгоритмов оптимизации много, поэтому важно развивать алгоритмическое чутьё и исследовать алгоритмы на простых и легко визуализируемых тестовых функциях.
---
Двумерные функции принимают два входных значения (x и y) и выводят единожды вычисленное на основе входа значение. Эти функции — одни из самых простых для изучения оптимизации. Их преимущество в том, что они могут визуализироваться в виде контурного графика или графика поверхности, показывающего топографию проблемной области с оптимумом и уникальными элементами, которые отмечены точками. В этом туториале вы ознакомитесь со стандартными двумерными тестовыми функциями, которые можно использовать при изучении оптимизации функций. Давайте начнём.
### Обзор туториала
Двумерная функция — это функция, которая принимает две входные переменные и вычисляет целевое значение. Можно представить две входные переменные как две оси на графике, x и y. Каждый вход в функцию является единственной точкой на графике, а результат вычисления функции — некоторая высота на графике.
Такая визуализация позволяет концептуализировать функцию в виде поверхности, так мы сможем охарактеризовать функцию по структуре поверхности. Например, возвышенности указывают на большие значения целевой функции, а провалы — на небольшие.
Поверхность может иметь один основной оптимум или же много точек для оптимизации, в которых можно, говоря образно, застрять. Также она может быть гладкой, шумной, выпуклой, может иметь иные всевозможные свойства, которые важны в смысле алгоритмов оптимизации. Мы могли бы использовать множество других типов двумерных функций.
Вместе с тем, есть много стандартных тестовых функций, применяемых в области оптимизации, а также тестовые функции со специфическими свойствами, которые мы можем применять, когда тестируем различные алгоритмы. Рассмотрим несколько простых двумерных тестовых функций, разделив их на две группы согласно свойствам:
1. **Унимодальные функции.**
1. Унимодальная функция 1.
2. Унимодальная функция 2.
3. Унимодальная функция 3.
2. **Мультимодальные функции.**
1. Мультимодальная функция 1.
2. Мультимодальная функция 2.
3. Мультимодальная функция 3.
Реализация каждой целевой функции будет представлена на Python в выведена в виде поверхности.
Все целевые функции являются функциями минимизации, то есть задача — найти аргументы, при которых значение функции минимально. Любая максимизирующая функция может быть заменена функцией минимизации путем добавления минуса ко всем её значениям. Аналогичным образом минимизирующая функция заменяется максимизирующей. Кроме того, все функции взяты из литературы, их придумал не я. Ссылки смотрите в разделе «Дальнейшее чтение».
Вы можете выбрать, скопировать и вставить в код одну или несколько функций, чтобы использовать их в вашем собственном проекте, посвящённом изучению или сравнению поведения алгоритмов оптимизации.
### Унимодальные функции
Унимодальность означает, что функция имеет единственный глобальный оптимум.
Унимодальная функция может быть выпуклой и невыпуклой. Выпуклая функция — это функция, на графике которой между двумя любыми точками можно провести линию и эта линия останется в домене. В случае двумерной функции это означает, что поверхность имеет форму чаши, а линии между двумя точками проходят по чаше или внутри неё. Давайте рассмотрим несколько примеров унимодальных функций.
#### Унимодальная функция 1
Диапазон ограничен промежутком -5,0 и 5,0 и одним глобальным оптимумом в точке [0,0, 0,0].
```
# unimodal test function
from numpy import arange
from numpy import meshgrid
from matplotlib import pyplot
from mpl_toolkits.mplot3d import Axes3D
# objective function
def objective(x, y):
return x**2.0 + y**2.0
# define range for input
r_min, r_max = -5.0, 5.0
# sample input range uniformly at 0.1 increments
xaxis = arange(r_min, r_max, 0.1)
yaxis = arange(r_min, r_max, 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a surface plot with the jet color scheme
figure = pyplot.figure()
axis = figure.gca(projection='3d')
axis.plot_surface(x, y, results, cmap='jet')
# show the plot
pyplot.show()
```
Код создаёт поверхность согласно графику функции.
График поверхности на основе унимодальной функции оптимизации 1#### Унимодальная функция 2
Диапазон ограничен значениями -10,0 и 10,0 и одним глобальным оптимумом в точке [0,0, 0,0].
```
# unimodal test function
from numpy import arange
from numpy import meshgrid
from matplotlib import pyplot
from mpl_toolkits.mplot3d import Axes3D
# objective function
def objective(x, y):
return 0.26 * (x**2 + y**2) - 0.48 * x * y
# define range for input
r_min, r_max = -10.0, 10.0
# sample input range uniformly at 0.1 increments
xaxis = arange(r_min, r_max, 0.1)
yaxis = arange(r_min, r_max, 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a surface plot with the jet color scheme
figure = pyplot.figure()
axis = figure.gca(projection='3d')
axis.plot_surface(x, y, results, cmap='jet')
# show the plot
pyplot.show()
```
Код создаёт поверхность согласно графику функции.
График унимодальной функции оптимизации 2#### Унимодальная функция 3
Диапазон ограничен -10,0 и 10,0 и одним глобальным оптимумом при [0,0, 0,0], функция известна как функция Изома.
```
# unimodal test function
from numpy import cos
from numpy import exp
from numpy import pi
from numpy import arange
from numpy import meshgrid
from matplotlib import pyplot
from mpl_toolkits.mplot3d import Axes3D
# objective function
def objective(x, y):
return -cos(x) * cos(y) * exp(-((x - pi)**2 + (y - pi)**2))
# define range for input
r_min, r_max = -10, 10
# sample input range uniformly at 0.01 increments
xaxis = arange(r_min, r_max, 0.01)
yaxis = arange(r_min, r_max, 0.01)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a surface plot with the jet color scheme
figure = pyplot.figure()
axis = figure.gca(projection='3d')
axis.plot_surface(x, y, results, cmap='jet')
# show the plot
pyplot.show()
```
Код создаёт поверхность согласно графику функции.
График унимодальной функции оптимизации 3### Мультимодальные функции
[Мультимодальная функция](https://en.wikipedia.org/wiki/Multimodal_distribution) — это функция с более чем одной “*модой*” или оптимумом (например долиной на графике).
Мультимодальные функции являются невыпуклыми. Могут иметь место один или несколько ложных оптимумов. С другой стороны, может существовать и несколько глобальных оптимумов, например несколько различных значений аргументов функции, при которых она достигает минимума.
Вот несколько примеров мультимодальных функций.
#### Мультимодальная функция 1
Диапазон ограничен -5,0 и 5,0 и одним глобальным оптимумом при [0,0, 0,0]. Эта функция известна как [функция Экли](https://en.wikipedia.org/wiki/Ackley_function).
```
# multimodal test function
from numpy import arange
from numpy import exp
from numpy import sqrt
from numpy import cos
from numpy import e
from numpy import pi
from numpy import meshgrid
from matplotlib import pyplot
from mpl_toolkits.mplot3d import Axes3D
# objective function
def objective(x, y):
return -20.0 * exp(-0.2 * sqrt(0.5 * (x**2 + y**2))) - exp(0.5 * (cos(2 * pi * x) + cos(2 * pi * y))) + e + 20
# define range for input
r_min, r_max = -5.0, 5.0
# sample input range uniformly at 0.1 increments
xaxis = arange(r_min, r_max, 0.1)
yaxis = arange(r_min, r_max, 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a surface plot with the jet color scheme
figure = pyplot.figure()
axis = figure.gca(projection='3d')
axis.plot_surface(x, y, results, cmap='jet')
# show the plot
pyplot.show()
```
Код создаёт поверхность согласно графику функции.
Мультимодальная функция оптимизации 1#### Мультимодальная функция 2
Диапазон ограничен [-5,0 и 5,0], а функция имеет четыре глобальных оптимума при [3,0, 2,0], [-2,805118, 3,131312], [-3,779310, -3,283186], [3,584428, -1,848126]. Эта функция известна как [функция](https://en.wikipedia.org/wiki/Himmelblau%27s_function) [Химмельблау](https://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F_%D0%A5%D0%B8%D0%BC%D0%BC%D0%B5%D0%BB%D1%8C%D0%B1%D0%BB%D0%B0%D1%83).
```
# multimodal test function
from numpy import arange
from numpy import meshgrid
from matplotlib import pyplot
from mpl_toolkits.mplot3d import Axes3D
# objective function
def objective(x, y):
return (x**2 + y - 11)**2 + (x + y**2 -7)**2
# define range for input
r_min, r_max = -5.0, 5.0
# sample input range uniformly at 0.1 increments
xaxis = arange(r_min, r_max, 0.1)
yaxis = arange(r_min, r_max, 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a surface plot with the jet color scheme
figure = pyplot.figure()
axis = figure.gca(projection='3d')
axis.plot_surface(x, y, results, cmap='jet')
# show the plot
pyplot.show()
```
Код создаёт поверхность согласно графику функции.
Мультимодальная функция оптимизации 2#### Мультимодальная функция 3
Диапазон ограничен промежутком [-10,0 и 10,0] и функцией с четырьмя глобальными оптимумами в точках [8,05502, 9,66459], [-8,05502, 9,66459], [8,05502, -9,66459], [-8,05502, -9,66459]. Эта функция известна как табличная функция Хольдера.
```
# multimodal test function
from numpy import arange
from numpy import exp
from numpy import sqrt
from numpy import cos
from numpy import sin
from numpy import e
from numpy import pi
from numpy import absolute
from numpy import meshgrid
from matplotlib import pyplot
from mpl_toolkits.mplot3d import Axes3D
# objective function
def objective(x, y):
return -absolute(sin(x) * cos(y) * exp(absolute(1 - (sqrt(x**2 + y**2)/pi))))
# define range for input
r_min, r_max = -10.0, 10.0
# sample input range uniformly at 0.1 increments
xaxis = arange(r_min, r_max, 0.1)
yaxis = arange(r_min, r_max, 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a surface plot with the jet color scheme
figure = pyplot.figure()
axis = figure.gca(projection='3d')
axis.plot_surface(x, y, results, cmap='jet')
# show the plot
pyplot.show()
```
Код создаёт поверхность согласно графику функции.
График мультимодальной функции оптимизации 3### Резюме
Если вы хотите глубже погрузиться в тему — обратите внимание на сопутствующие материалы ниже.
* [Тестовые функции для оптимизации, Википедия](https://en.wikipedia.org/wiki/Test_functions_for_optimization).
* [Виртуальная библиотека имитационных экспериментов: функции тестирования и наборы данных](https://www.sfu.ca/~ssurjano/optimization.html).
* [Индекс тестовых функций](http://infinity77.net/global_optimization/test_functions.html).
* [GEA Toolbox — примеры целевых функций](http://www.geatbx.com/ver_3_3/fcnindex.html).
[Узнайте](https://skillfactory.ru/courses/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ALLCOURSES&utm_term=regular&utm_content=290321), как прокачаться в других специальностях или освоить их с нуля:
* [Профессия Data Scientist](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=290321)
* [Профессия Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=290321)
* [Курс по Data Engineering](https://skillfactory.ru/dataengineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEA&utm_term=regular&utm_content=290321)
Другие профессии и курсы**ПРОФЕССИИ**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FPW&utm_term=regular&utm_content=290321)
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=290321)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_QAJA&utm_term=regular&utm_content=290321)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=290321)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=290321)
* [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=290321)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=290321)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=290321)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=290321)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=290321)
**КУРСЫ**
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=290321)
* [Курс "Machine Learning и Deep Learning"](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=290321)
* [Курс "Математика для Data Science"](https://skillfactory.ru/math-stat-for-ds#syllabus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MAT&utm_term=regular&utm_content=290321)
* [Курс "Математика и Machine Learning для Data Science"](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=290321)
* [Курс "Python для веб-разработки"](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=290321)
* [Курс "Алгоритмы и структуры данных"](https://skillfactory.ru/algo?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_algo&utm_term=regular&utm_content=290321)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=290321)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=290321) | https://habr.com/ru/post/549472/ | null | ru | null |
# Iodide: интерактивный научный редактор от Mozilla
*Изучение аттрактора Лоренца, а затем редактирование кода в Iodide*
В последние десять лет произошёл настоящий взрыв интереса к «научным вычислениям» и «науке о данных», то есть применению вычислительных методов для поиска ответов на вопросы, анализа данных в естественных и социальных науках. Мы видим расцвет специализированных ЯП, инструментов и методов, которые помогают учёным исследовать и понимать данные и концепции, а также сообщать о своих выводах.
Но на сегодняшний день очень немногие научные инструменты используют полный коммуникационный потенциал современных браузеров. Результаты дата-майнинга не очень удобно просматривать в браузере. Поэтому сегодня Mozilla представляет [Iodide](http://iodide.io/) — экспериментальный инструмент, который помогает учёным составлять красивые интерактивные документы с использованием веб-технологий, всё в рамках итеративного рабочего процесса, который многим знаком.
Это не просто среда программирования для создания интерактивных документов в браузере. Iodide пытается помочь в рабочем процессе, связывая редактор и предпросмотр. Это отличается от стиля IDE, которая выдаёт презентационные документы типа pdf (они затем отделяются от исходного кода). И отличается от стиля блокнотов с ячейками, которые смешивают код и элементы презентации. В Iodide вы видите и документ, который выглядит так, как вы хотите, и лёгкий доступ к базовому коду и среде редактирования.
Iodide пока в альфа-версии, но в интернет-индустрии принято говорить: [«Если вас не смущает первая версия вашего продукта, вы опоздали с запуском»](https://www.linkedin.com/pulse/arent-any-typos-essay-we-launched-too-late-reid-hoffman/). Поэтому мы решили сделать очень ранний запуск в надежде получить отзывы от сообщества. У нас есть демо, которое [вы можете попробовать прямо сейчас](https://iodide.io/tryit), но там ещё много недоработок (пожалуйста, не используйте эту альфу для важной работы!). Надеемся, что вы закроете глаза на косяки и поймёте ценность самой концепции, а ваши отзывы помогут понять, в каком направлении нам двигаться дальше.
Как мы пришли к Iodide
======================
### Наука о данных в Mozilla
Наука о данных в Mozilla почти полностью основана на коммуникациях. Хотя мы иногда развёртываем дата-майнинговые модели непосредственно перед пользователями, такие как механизм рекомендаций расширений для браузера, но большую часть времени наши специалисты анализируют данные, чтобы выявить закономерности и поделиться информацией с инженерами, менеджерами продуктов и руководством.
Наука о данных предполагает написание большого количества кода, но в отличие от традиционной разработки ПО наша цель — отвечать на вопросы, а не создавать программное обеспечение. Это обычно сводится к созданию некоего отчёта — документа, диаграмм или интерактивной визуализации данных. Как и все, мы в Mozilla изучаем свои данные с помощью фантастических современных инструментов, таких как [Jupyter](https://jupyter.org/) и [R-Studio](https://www.rstudio.com/). Но когда приходит время делиться результатами, мы обычно не можем просто передать «заказчику» блокнот Jupyter или сценарий R, поэтому часто приходится копировать ключевые цифры и сводную статистику в документ Google.
Как выяснилось, довольно трудно перейти от изучения данных в коде к удобоваримому объяснению и обратно. Исследования показывают, что [это распространённая проблема](https://hal.archives-ouvertes.fr/hal-01676633/document). Когда один учёный читает чужой отчёт и хочет посмотреть соответствующий код, возникает много проблем: иногда отследить код легко, иногда нет. Если специалист хочет поэкспериментировать, изменив код, очевидно, всё ещё усложняется. У другого учёного может быть ваш код, но отличаться конфигурация на машине, а настройка требует времени.
*Полезный рабочий цикл в науке о данных*
### Почему в науке так мало веба?
На этом фоне в конце 2017 года я начал проект по интерактивной визуализации данных в Mozilla. В наши дни вы можете создавать такие визуализации с помощью отличных библиотек на Python, R и Julia, но для моего проекта требовалось перейти на Javascript. Это означало выход из привычного окружения науки о данных. Современные инструменты веб-разработки невероятно мощны, [но чрезвычайно сложные](https://hackernoon.com/how-it-feels-to-learn-javascript-in-2016-d3a717dd577f). Против своего желания мне пришлось создавать полноценную цепочку инструментов Javascript для сборки с горячей перезагрузкой модулей, но всё равно невозможно было найти нормальный редактор, который генерирует чистые, читаемые веб-документы в живом, итеративном рабочем процессе.
Я начал задаваться вопросом, почему нет такого инструмента — почему нет аналога Jupyter для интерактивных веб-документов — и пришёл к размышлениям, почему почти никто не использует Javascript для научных вычислений. Кажется, на это есть три важные причины:
1. Сам Javascript в научных кругах имеет противоречивую репутацию как медленный и неудобный язык.
2. Не так много библиотек научных вычислений работают в браузере или поддерживают Javascript.
3. Я обнаружил дефицит научных инструментов для программирования с поддержкой быстрых итераций и прямым доступом к презентационным возможностям браузера.
Это очень большие проблемы. Но работа в браузере имеет некоторые реальные преимущества для такой «коммуникативной» науки о данных, которой мы занимаемся в Mozilla. Конечно, самое большое преимущество в том, что у браузера самый передовой и хорошо поддерживаемый набор технологий визуализации данных: от [DOM](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model) до [WebGL](https://developer.mozilla.org/en-US/docs/Web/API/WebGL_API), [Canvas](https://developer.mozilla.org/en-US/docs/Web/API/Canvas_API) и [WebVR](https://developer.mozilla.org/en-US/docs/Web/API/WebVR_API).
Размышляя о трудностях в коммуникации, упомянутых выше, мне пришло в голову ещё одно потенциальное преимущество: в браузере конечный документ не обязательно отделять от инструмента, который его создал. Я хотел сделать инструмент для итеративной научной работы с веб-документами (веб-приложение с конкретной функциональностью)… и многие наши инструменты были по сути веб-приложениями. Для этих маленьких веб-приложений-документов, почему бы не связать документ с редактором?
Таким образом, читатели без технической подготовки могут просматривать красивый документ, а учёный мгновенно переключается в режим исходного кода. Более того, поскольку вычисления происходят в JS-движке браузера, учёный может сразу начать эксперименты с кодом. И всё это без подключения к удалённым вычислительным ресурсам или установки какого-либо программного обеспечения.
### Появление Iodide
Я начал обсуждать с коллегами потенциальные плюсы и минусы научных вычислений в браузере, и в ходе бесед мы отметили другие интересные тенденции.
Внутри Mozilla выходило много интересных демонстраций на [WebAssembly](https://webassembly.org/), новой платформе для запуска в браузере кода, написанного на языках, отличных от Javascript. WebAssembly позволяет запускать программы с невероятной скоростью, в некоторых случаях близко к нативным бинарникам. На WASM без проблем работают ресурсоёмкие процессы, даже [целые 3D-игровые движки](https://hacks.mozilla.org/2017/07/webassembly-for-native-games-on-the-web/). В принципе, можно скомпилировать лучшие в мире библиотеки численных вычислений C и C++ для WebAssembly, обернуть их в эргономичные API JS, как это делает проект SciPy для Python. В конце концов, [такие](https://github.com/likr/emlapack) [проекты](https://github.com/mljs/libsvm) [уже](https://github.com/stdlib-js/stdlib) [существуют](https://www.npmjs.com/package/cephes).
*WebAssembly позволяет запускать код в браузере почти без накладных расходов*
Мы также заметили, что сообщество Javascript готово вводить [новый синтаксис](https://reactjs.org/docs/introducing-jsx.html), если это помогает людям более эффективно [решать свои проблемы](https://flow.org/). Возможно, стоит попытаться эмулировать некоторые из ключевых синтаксических элементов, которые делают численное программирование более понятным и гибким в MATLAB, Julia и Python — это матричное умножение, многомерная нарезка, операции трансляции массива (broadcast array) и так далее. И снова мы обнаружили, что [многие согласны с нами](https://github.com/antimatter15/babel-experiments/tree/master/watlab).
Все эти предпосылки приводят к вопросу: насколько веб-платформа подходит для научных вычислений? Как минимум, она способна помочь в коммуникациях в тех процессах, с которыми мы сталкиваемся в Mozilla (и с которыми сталкиваются многие в индустрии и академических кругах). С [постоянно улучшающимся](https://github.com/tc39/proposals) ядром Javascript и возможностью добавления синтаксических расширений для численного программирования, возможно, сам JS станет более привлекательным для ученых. Казалось, WebAssembly позволяет использовать серьёзные научные библиотеки. Третья ножка стула — веб-окружение для создания научных документов. На этом последнем элементе мы сосредоточили свои эксперименты, которые привели нас к Iodide.
Анатомия Iodide
===============
Iodide — это инструмент, который обеспечивает учёным знакомый рабочий процесс для создания великолепных интерактивных документов, используя всю мощь веб-платформы. Работа построена в виде «отчётов» — по сути, это веб-страница, которую вы заполняете своим контентом. Плюс некоторые инструменты для итеративного изучения данных и изменения отчёта, чтобы создать финальный документ. Как только он готов, можете отправить ссылку непосредственно на него. Если коллеги и сотрудники хотят просмотреть код, то одним щелчком мыши переключаются в режим исследования. Если хотят поэкспериментировать с кодом и использовать его в качестве основы для своей работы, то ещё одним щелчком делается форк.
Дальше мы расскажем о некоторых экспериментальных идеях, как сделать этот рабочий процесс более гибким.
### Режим отчёта и режим исследования
Iodide стремится в одном месте увязать исследование, объяснение и сотрудничество. Центральное место здесь занимает способность перемещаться между красивым отчётом и полезной средой для итеративного исследования с научными вычислениями.
При [создании нового блокнота Iodide](https://iodide.io/tryit) вы попадаете в режим исследования (Explore View). Это набор панелей, включая редактор для написания кода, консоль для просмотра выходных данных, средство просмотра рабочей области для изучения переменных, созданных во время сеанса, и панель «Предварительный просмотр отчёта».
*Редактирование кода Markdown в режиме исследования Iodide*
Нажатием на кнопку *Report* в правом верхнем углу можно расширить содержимое панели предварительного просмотра на всё окно. Читатели, которые не заинтересованы в технических деталях, могут сосредоточиться на этом представлении документа, не углубляясь в код. Когда читатель заходит по ссылке на отчёт, код запускается автоматически. Для просмотра кода нужно нажать кнопку *Explore* в правом верхнем углу. Оттуда можно сделать и копию блокнота для собственных исследований.
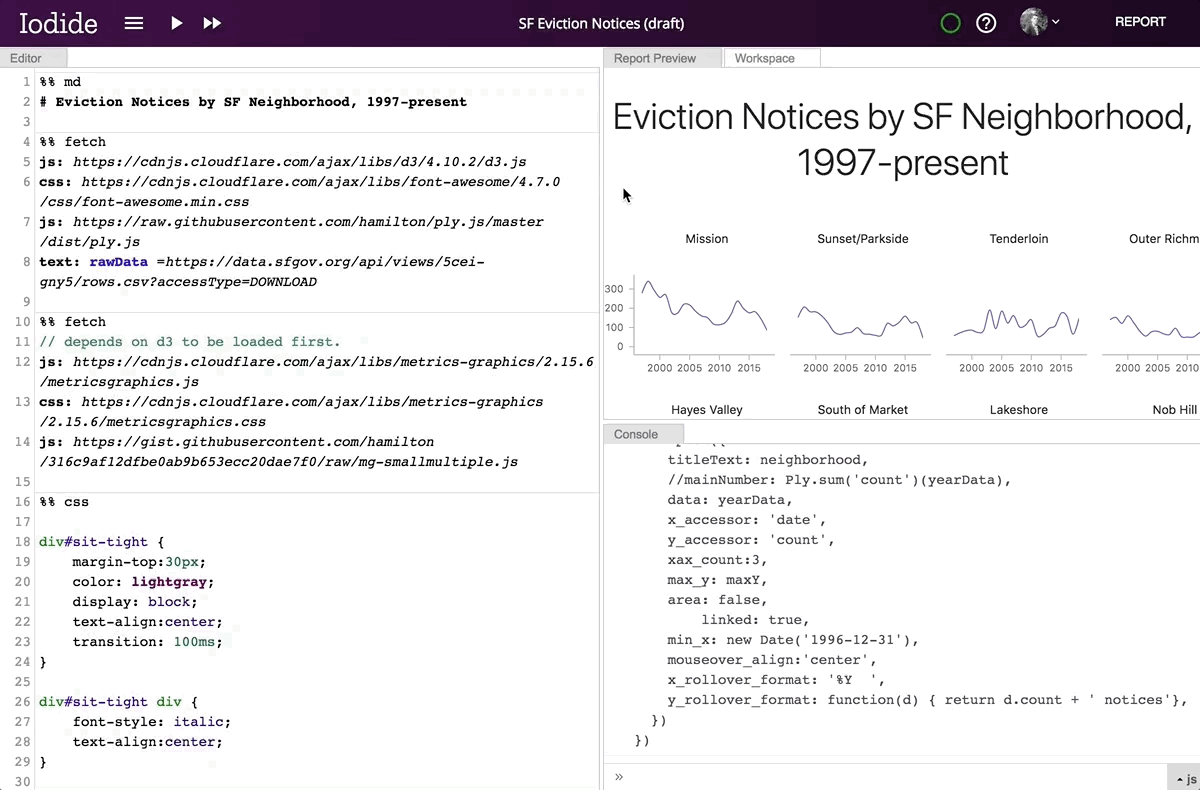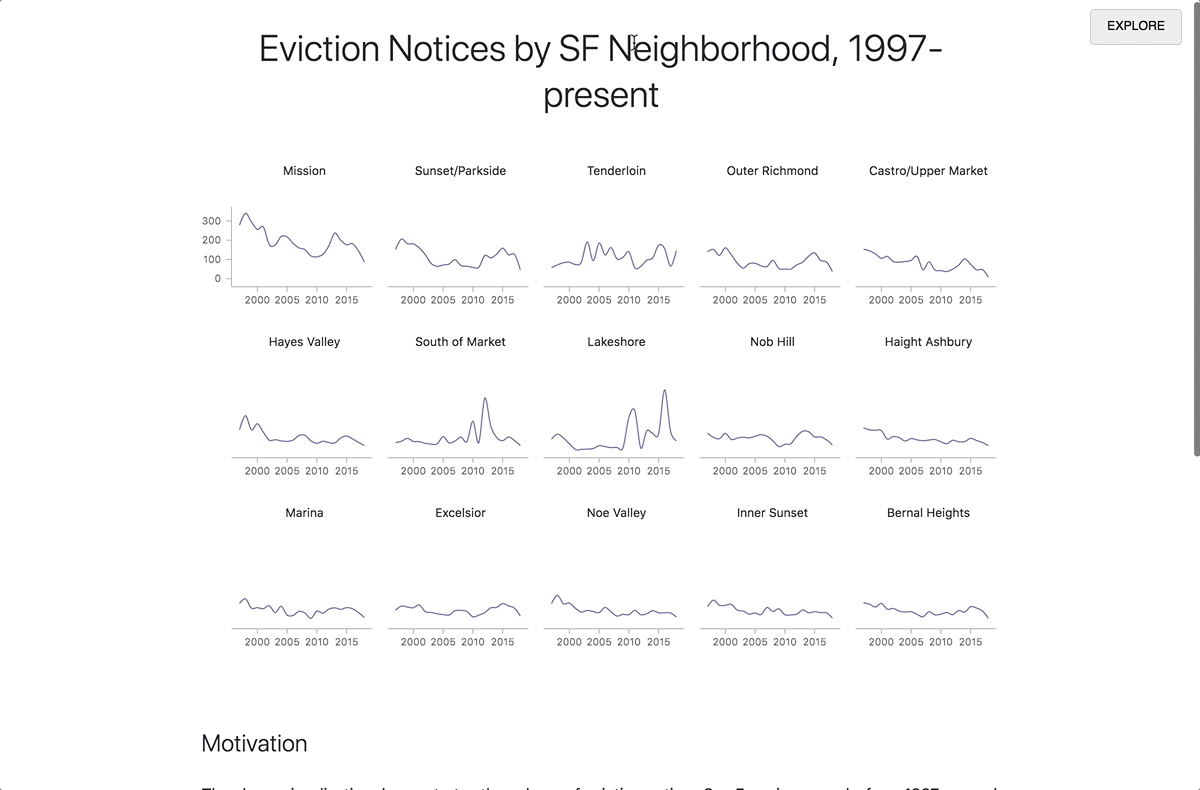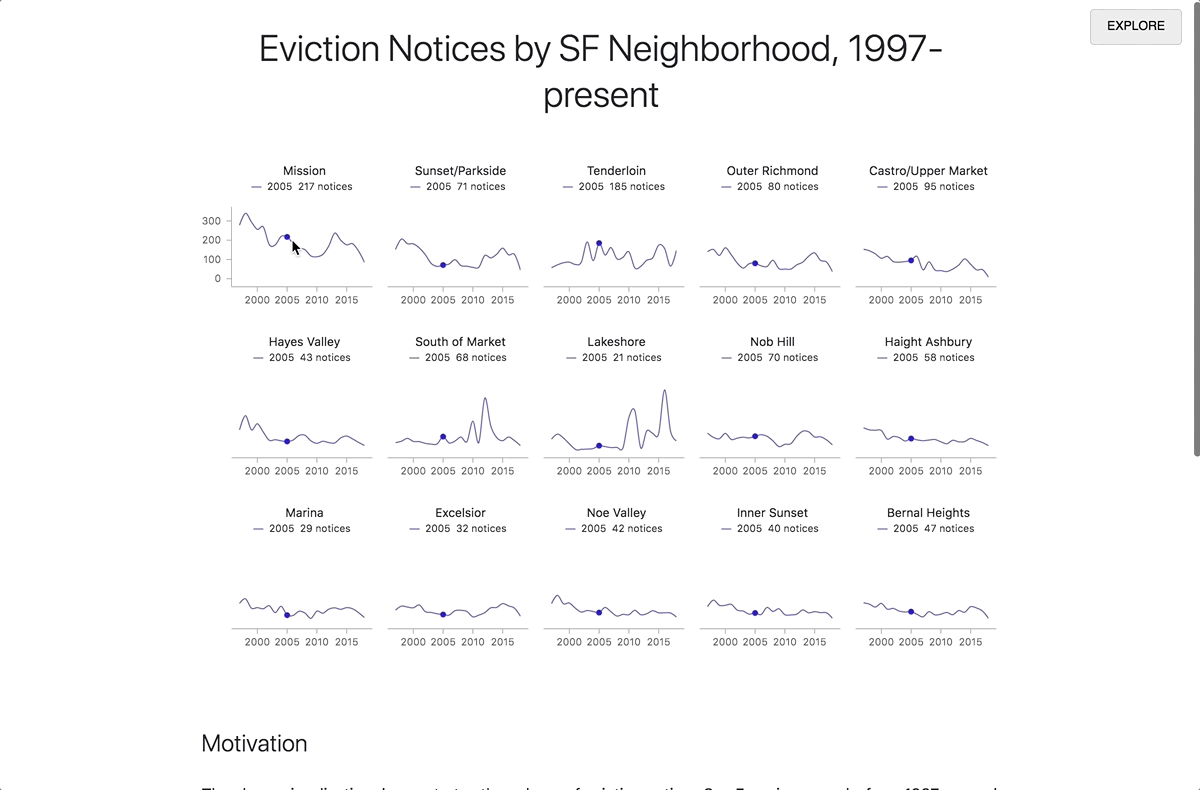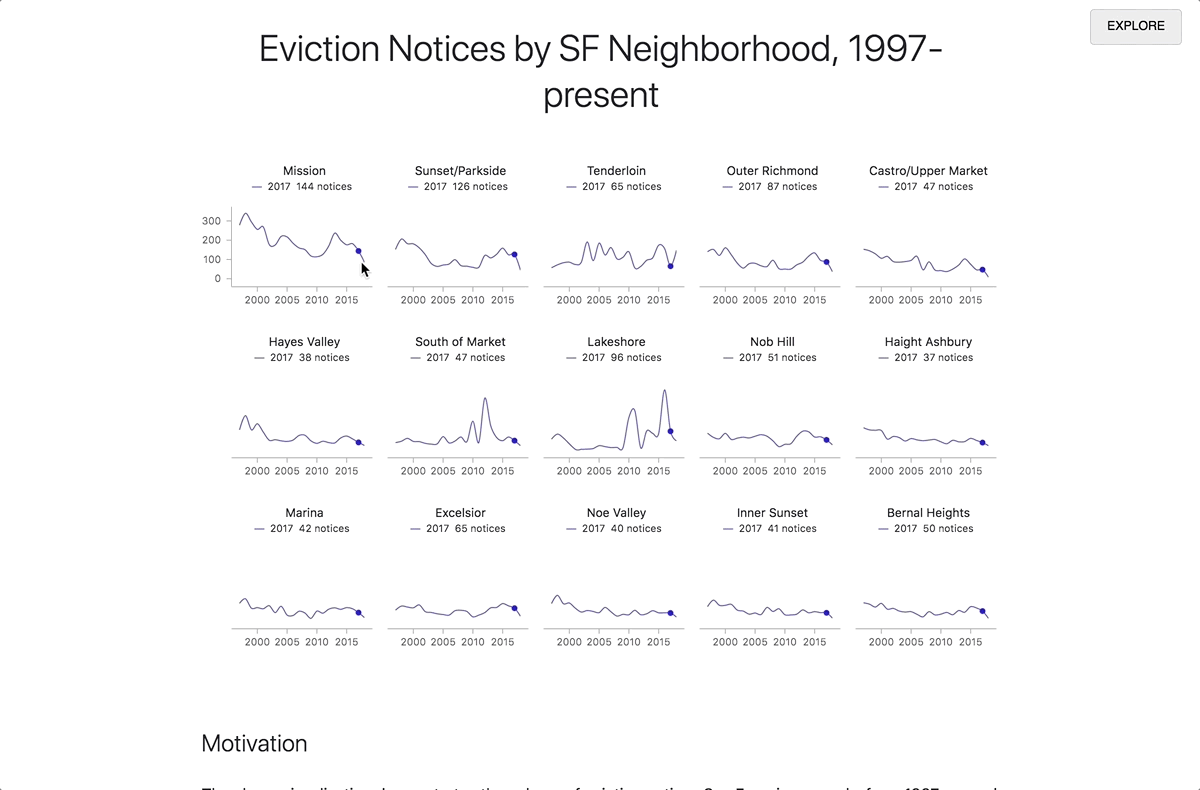
*Переход из режима исследования в режим отчёта*
Всякий раз, когда вы делитесь ссылкой на блокнот Iodide, ваш коллега всегда получает доступ к обоим этим представлениям. Чистый, читаемый документ никогда не отделяется от базового кода и среды редактирования.
### Живые, интерактивные документы с мощью веб-платформы
Документы Iodide живут в браузере. Это означает постоянную доступность вычислительного движка. Каждый документ — это живой интерактивный отчёт с запущенным кодом. Более того, поскольку вычисление происходит в браузере одновременно с презентацией, нет необходимости вызывать бэкенд языка в другом процессе. Таким образом, интерактивные документы обновляются в режиме реального времени, открывая возможность [плавных 3D-визуализаций](https://iodide.io/notebooks/34/?viewMode=report). Низкая задержка и высокая частота кадров [даже соответствуют требованиям VR](https://iodide.io/notebooks/337/?viewMode=report).
*Контрибутор Девин Бейли изучает данные МРТ своего мозга*
### Совместное использование и воспроизводимость
Опора на веб упрощает ряд элементов рабочего процесса, по сравнению с другими инструментами. Совместное использование реализовано нативно: документ и код доступны по одному URL и не нужно, скажем, вставлять ссылку на скрипт в сносках Google Docs. Вычислительное ядро — это браузер, а библиотеки подгружаются HTTP-запросом, как и любой скрипт — не требуется устанавливать никаких дополнительных языков, библиотек или инструментов. И поскольку браузеры обеспечивают совместимость, блокнот одинаково выглядит на всех компьютерах и ОС.
Для обеспечения совместной работы мы создали довольно простой сервер, где сохраняются блокноты. Есть публичный инстанс [iodide.io](http://iodide.io/), чтобы экспериментировать с Iodide и публиковать свои работы. Но можно создать и приватный инстанс за файрволом (мы в Mozilla так и делаем для некоторых внутренних документов). Но важно отметить, что сами блокноты не привязаны к одному серверу Iodide. Если возникнет необходимость, то легко перенести работу на другой сервер или экспортировать блокнот в виде пакета для совместного использования на других сервисах, таких как Netlify или GitHub Pages (подробнее об экспорте пакетов см. ниже в разделе «Что дальше?»). Передача вычислений на сторону клиента позволяет нам сосредоточиться на создании действительно отличной среды для обмена и сотрудничества, без необходимости выделять вычислительные ресурсы в облаке.
### Pyodide: научный стек Python в браузере
Когда мы начали думать о том, чтобы сделать веб лучше для учёных, то сосредоточились на способах, которые могут упростить работу с Javascript, таких как компиляция существующих научных библиотек в WebAssembly и их упаковка в простые JS API. Когда мы обрисовали идею [разработчикам WebAssembly в Mozilla](https://research.mozilla.org/webassembly/), они предложили более амбициозную идею: если многие учёные предпочитают Python, то ступите на их поле — скомпилируйте научный стек Python для запуска в WebAssembly.
Мы думали, что это звучит устрашающе, что это будет огромный проект и что он никогда не обеспечит удовлетворительную производительность… но *спустя две недели* у [Майка Дроэттбума](https://github.com/mdboom) была рабочая реализация Python, работающая внутри блокнота Iodide. В течение следующих нескольких месяцев мы добавили Numpy, Pandas и Matplotlib, [наиболее используемые модули](https://github.com/activityhistory/jupyter_on_github/blob/master/notebooks/9_notebook_clustering.ipynb) в научной экосистеме Python. Благодаря помощи Кирилла Смелкова и Романа Юрчака из [Nexedi](https://www.nexedi.com/) появилась поддержка Scipy и scikit-learn. С тех пор мы продолжаем потихоньку добавлять [другие библиотеки](https://github.com/iodide-project/pyodide/tree/master/packages).
Запуск интерпретатора Python внутри виртуальной машины Javascript добавляет накладные расходы к производительности, но они удивительно маленькие. По сравнению с нативным кодом, в наших тестах код выполняется в 1-12 раз медленнее в Firefox и в 1-16 раз медленнее в Chrome. Опыт показывает, что производительности вполне достаточно для комфортных интерактивных исследований.
*Matplotlib в браузере поддерживает интерактивные функции, недоступные в статических средах*
Перенос Python в браузер создаёт волшебные рабочие процессы. Например, вы можете импортировать и обработать данные в Python, а затем получить доступ к результирующим объектам из Javascript (в большинстве случаев преобразование происходит автоматически), чтобы отобразить их с помощью JS-библиотек, таких как [d3](https://d3js.org/). Ещё более волшебным образом вы получаете доступ к API браузера из кода Python, например, для [манипуляции DOM без использования Javascript](https://iodide.io/notebooks/300).
Конечно, о [Pyodide](https://github.com/iodide-project/pyodide) можно рассказать гораздо больше и он заслуживает отдельной статьи — мы рассмотрим его более подробно в следующем месяце.
### JSMD (JavaScript MarkDown)
Также как Jupyter и режим R-Markdown в R, редактор Iodide позволяет свободно чередовать код и заметки, разбивая код на куски, которые изменяются и запускаются как отдельные единицы. Наша реализация этой идеи соответствует реализации R Markdown и «режиму ячеек» в MATLAB: вместо явно основанного на ячейках интерфейса содержимое блокнота Iodide — это просто текстовый документ, который использует специальный синтаксис для разграничения определенных типов ячеек. Мы называем такой текстовый формат JSMD.
По образцу MATLAB, фрагменты кода начинаются знаками `%%`, за которыми следует строка, указывающая язык. В настоящее время мы поддерживаем фрагменты, содержащие Javascript, CSS, Markdown (и HTML), Python, специальный фрагмент 'fetch', который упрощает загрузку ресурсов, и плагины, расширяющие функциональность Iodide путём добавления новых типов ячеек.
Мы нашли этот формат весьма удобным. Он упрощает использование текстовых инструментов, таких как diff viewer и ваш собственный любимый текстовый редактор. Вы можете выполнять стандартные текстовые операции (вырезать/копировать/вставить) без необходимости изучать команды управления ячейками. Для более подробной информации см. [документацию по JSMD](https://iodide-project.github.io/docs/jsmd/).
Что дальше?
===========
Стоит повторить, что это лишь альфа-версия: мы продолжаем полировать интерфейс и устранять ошибки. Но в дополнение к этому есть ряд идей для следующих экспериментов. Если какая-то из этих идей кажется вам особенно полезной, дайте нам знать! А ещё лучше, помогите разработать!
### Расширенные функции совместной работы
Как уже упоминалось, мы создали очень простой бэкэнд, который позволяет просто сохранять работу, просматривать работы, выполненные другими, быстро форкать и расширять чужие блокноты. Но это только первые шаги в совместном рабочем процессе.
Теперь мы рассматриваем ещё три большие функции:
1. Треды комментариев в стиле Google Docs.
2. Возможность предлагать изменения в чужом блокноте через механизм fork/merge, как в GitHub.
3. Одновременное редактирование блокнотов, как в Google Docs.
На данный момент мы расставляем приоритеты примерно в таком порядке, но если вы решите их расставить иначе или у вас есть другие предложения, не стесняйтесь сообщить об этом!
### Больше языков!
Мы обсуждали с сообществами R и Julia возможность компиляции этих языков в WebAssembly, чтобы использовать их в Iodide и других браузерных проектах. На первый взгляд, это выполнимо, но реализация будет немного сложнее, чем для Python. Как и в Python, открываются некоторые интересные рабочие процессы: например, вы можете применить статистические модели в R или решить дифференциальные уравнения в Julia, а затем отобразить результаты с помощью API браузера. Если вы занимаетесь этими языками, пожалуйста, дайте знать — в частности, мы хотим получить помощь от экспертов по FORTRAN и LLVM.
### Экспорт блокнотов
Ранние версии Iodide были автономными запускаемыми HTML-файлами, которые включали как код JSMD, используемый в анализе, так и код JS для запуска самого Iodide, но мы отошли от этой архитектуры. Более поздние эксперименты убедили нас, что преимущества совместной работы с сервером Iodide перевешивают преимущества управления файлами в локальной системе. Тем не менее, эти эксперименты показали, что можно сделать автономный исполняемый блокнот Iodide, добавив код Iodide вместе с любыми данными и используемыми библиотеками в один большой HTML-файл. Он может получиться большим, но будет полезен как идеально воспроизводимый и архивируемый снимок.
### Браузерное расширение Iodide для текстовых редакторов
Хотя многие учёные привыкли работать в браузерных средах программирования, некоторые люди никогда не откажутся от любимого текстового редактора. Мы действительно хотим, чтобы Iodide пришёл туда, где людям удобно работать, включая тех, кто предпочитает вводить код в другом редакторе, но хочет получить доступ к интерактивным и итеративным функциям, которые предоставляет Iodide. Чтобы удовлетворить эту потребность, мы начали думать о создании лёгкого расширения браузера и некоторых простых API, чтобы позволить Iodide общаться с редакторами на стороне клиента.
Отзывы и помощь приветствуются!
===============================
Мы не пытаемся решить все проблемы научных данных и научных вычислений, а Iodide не универсальное решение. Если вам нужно обрабатывать терабайты данных на кластерах GPU, вряд ли Iodide вам чем-то поможет. Если вы публикуете статьи журнала и вам просто нужно написать документ в LaTeX, то есть лучшие инструменты. Если вам не нравится сама идея переносить всё в браузер, нет проблем — существует множество действительно удивительных инструментов, которые вы можете использовать для науки, и мы благодарны вам за это! Мы не хотим менять чьи-то привычки, а многим учёным не нужны веб-ориентированные коммуникации. Супер! Делайте, как вам удобно!
Но от учёных, которые делают или хотят делать контент для интернета, хотелось бы услышать, какие инструменты вам необходимы в работе!
Пожалуйста, зайдите на [iodide.io](https://extremely-alpha.iodide.io/), попробуйте этот инструмент и оставьте отзыв (но опять же: имейте в виду, что проект находится в альфа-версии — пожалуйста, не используйте его ни для какой критической работы, и помните, что в альфе всё может измениться). Можете [заполнить небольшую анкету](https://qsurvey.mozilla.com/s3/scientific-computing-survey), также приветствуются [тикеты и баг-репорты на Github](https://github.com/iodide-project/iodide/issues/new). Запросы функций и общие мысли оставляйте в нашей [группе Google](https://groups.google.com/forum/#!forum/iodide-dev) или в [Gitter](https://gitter.im/iodide-project/iodide).
Если хотите принять участие в создании Iodide, исходный код [опубликован на Github](https://github.com/iodide-project/iodide). Iodide затрагивает широкий спектр программных дисциплин: от разработки современных интерфейсов и научных вычислений до компиляции и транспиляции, поэтому здесь много интересного! | https://habr.com/ru/post/444596/ | null | ru | null |
# Danger. Автоматизируем ревью на CI и пишем свой плагин
Привет, я Татьяна Родионова, Android-разработчица в Lamoda. Как-то раз передо мной появилась задача упростить ревью пул-реквестов с помощью [Danger.](https://danger.systems/kotlin/) Я решила добавить автоматическую проверку кодстайла, используя [ktlint](https://github.com/pinterest/ktlint). Но оказалось, что Danger не поддерживает такое решение, поэтому я добавила такую проверку сама :)
Моя статья поможет разобраться в том, как настроить Danger и как заставить его выполнять задачи немного сложнее тех, которые есть в [официальном туториале](https://github.com/danger/kotlin).
Что такое Danger и как его установить
-------------------------------------
Danger — это система для автоматизации сообщений во время код-ревью, которая запускается на CI. Она позволяет избавиться от написания однотипных комментариев о кодстайле, ошибках в описании пул-реквеста, или, например, о его размере.
Для установки потребуется nix-система. На MacOS можно воспользоваться командой:
```
brew install danger/tap/danger-kotlin
```
А на Linux:
```
bash <(curl -s https://raw.githubusercontent.com/danger/kotlin/master/scripts/install.sh)
source ~/.bash_profile
```
Настройка контейнера с Danger
-----------------------------
Для настройки конфигурации Danger используется `Dangerfile.df.kts`, который лежит в корне проекта. Язык — Kotlin DSL, [с поддержкой автодополнения и подсветкой синтаксиса в Android Studio](https://github.com/danger/kotlin#autocomplete-and-syntax-highlighting-in-intellij-idea-or-android-studio).
Конфигурацию нужно написать самому и включить в нее те элементы, которые необходимы для конкретной задачи. Вот пример стандартной конфигурации с [Github](https://github.com/danger/kotlin):
```
import systems.danger.kotlin.*
danger(args) {
val allSourceFiles = git.modifiedFiles + git.createdFiles
val changelogChanged = allSourceFiles.contains("CHANGELOG.md")
val sourceChanges = allSourceFiles.firstOrNull { it.contains("src") }
onGitHub {
val isTrivial = pullRequest.title.contains("#trivial")
// Changelog
if (!isTrivial && !changelogChanged && sourceChanges != null) {
warn(WordUtils.capitalize("any changes to library code should be reflected in the Changelog."))
}
// Big PR Check
if ((pullRequest.additions ?: 0) - (pullRequest.deletions ?: 0) > 300) {
warn("Big PR, try to keep changes smaller if you can")
}
// Work in progress check
if (pullRequest.title.contains("WIP", false)) {
warn("PR is classed as Work in Progress")
}
}
}
```
Эта конфигурация для Github проверяет, нужно ли добавлять информацию в `changelog`, не слишком ли это большой пул-реквест (>300 изменений) и есть ли WIP (Work In Progress) в названии пул-реквеста.
В нашем проекте было решено запускать Danger изолированно, поэтому он настроен в Docker-контейнере. На это было несколько причин:
* **Это удобно**, так как docker-контейнер содержит только Danger, и необходимое окружение.
* **У Danger есть конфликтующие имплементации**. При запуске Danger вызывается команда `which danger`, которая определяет, какую вызвать имплементацию. На нашем CI была установлена ruby-имплементация Danger для iOS, вызываемая по умолчанию, поэтому для запуска Danger под Android пришлось бы ее удалять (Android требует JS-имплементацию). С docker таких проблем нет.
Для запуска необходима конфигурация в Dockerfile и скрипты запуска `build.sh` и `env.list` со списком переменных окружения.
Начнем с настройки конфигурации docker-файла. Устанавливаем `make`, `nodejs` и `danger js`:
```
RUN apt-get update \
&& apt-get install make \
&& apt-get install -y ca-certificates \
&& curl -sL https://deb.nodesource.com/setup_12.x | bash - \
&& apt-get install -y make zip nodejs \
&& npm install -g danger
```
Далее устанавливаем `kotlinc`, скачиваем `danger-kotlin` и собираем его из исходного кода из репозитория:
```
RUN curl -o kotlinc_inst.zip -L $KOTLINC_URL \
&& mkdir -p ${ANDROID_SDK_ROOT}/kotlinc/ \
&& unzip -q kotlinc_inst.zip -d /tmp/ \
&& mv /tmp/kotlinc/ ${ANDROID_SDK_ROOT}/kotlinc/ \
&& rm kotlinc_inst.zip \
&& git clone https://github.com/danger/kotlin.git --branch 1.0.0 --depth 1 _danger-kotlin \
&& cd _danger-kotlin \
&& sed -i 's/val emailAddress: String,/val emailAddress: String? = null,/g' $FILE \
&& make install
```
Тут можно заметить фикс в виде вызова `sed`. Это исправление кейса, когда у автора пул-реквеста нет email (например, он уже уволился). В таком случае пул-реквест не запустится из-за [бага](https://github.com/danger/kotlin/issues/210), который не починили разработчики.
Скрипт запуска `build.sh` выглядит следующим образом:
```
#!/bin/sh
set -e
echo "Running danger"
./gradlew ktlint
danger-kotlin $DANGER_ARG
echo "Build successfully finished"
exit 0
```
Кстати, перед запуском Danger нужно запустить ktlint. Сам по себе Danger не запускает gradle-таски, но может интерпретировать их результаты с помощью плагинов.
В файл с переменными `env.list` добавляем переменные окружения, необходимые для запуска контейнера. В нашем случае используются переменные для Bitbucket, но они с легкостью могут быть заменены на другие поддерживаемые веб-сервисы для хостинга — Github или Gitlab.
Для корректной работы в нужно указать `host`, `username` и `token` аккаунта, который будет постить сообщения. Дополнительно я добавила `DANGER_ARG`, чтобы была возможность менять тип команды и указывать дополнительные параметры: например, `pr` — отображает вывод Danger в консоль, а `ci` постит комментарий в пул-реквест:
```
DANGER_BITBUCKETSERVER_HOST=https://stash.lamoda.ru
DANGER_BITBUCKETSERVER_USERNAME=La Cat
DANGER_BITBUCKETSERVER_TOKEN=Заполнить перед сборкой
DANGER_ARG=pr ci
```
Все готово к запуску, теперь собираем наш контейнер! Для этого запускаем команду:
```
docker build -t mobile.docker.lamoda.ru/android/build/android-danger:1.0
```
`mobile.docker.lamoda.ru/android/build/android-danger:1.0` — имя образа Docker. Запускаем его:
```
docker run --name android-danger -it -v /path/to/project/source/files:/src -w /src --env-file env.list mobile.docker.lamoda.ru/android/build/android-danger:1.0
```
Чтобы залить образ в хранилище артефактов, исполняем эту команду:
```
docker push mobile.docker.lamoda.ru/android/build/android-danger:1.0
```
Теперь у нас есть готовый образ, который можно использовать на CI. Открываем готовый план (мы в Lamoda используем bamboo), идем в настройки и указываем образ для скачивания:
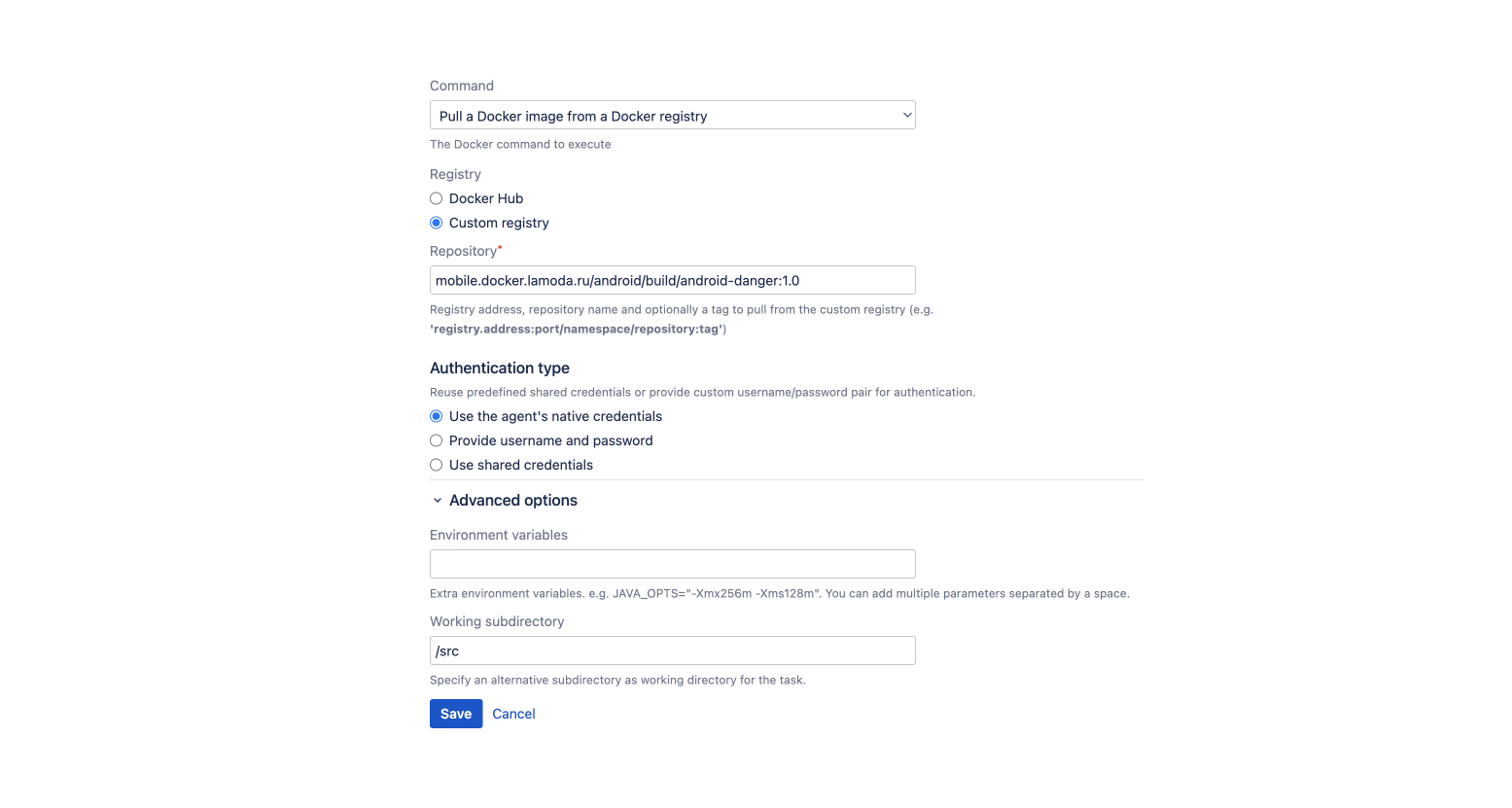Далее добавляем шаг для запуска контейнера со скаченным образом:
Дополнительно нужно указать в переменных окружения `bitbucket host`, `username` и `token`, чтобы была возможность быстро изменить их без пересборки контейнера. Также в переменные окружения контейнера нужно добавить номер пул-реквеста pr\_key, repositoryUrl и имя плана — без них Danger не увидит нужные ему параметры пул-реквеста при запуске.
```
bamboo_repository_pr_key=${bamboo.repository.pr.key} bamboo_planRepository_repositoryUrl=${bamboo.planRepository.repositoryUrl} bamboo_buildPlanName=${bamboo.buildPlanName}
```
Контейнер на CI настроен. По умолчанию установим триггер bamboo на создание и обновление пул-реквеста: Danger должен запускаться при создании пул-реквеста и его обновлении.
Теперь осталось разобраться с конфигурацией Danger.
Плагины Danger
--------------
Проверки Danger ограничиваются [встроенным API](https://github.com/danger/kotlin/tree/560131738e10096b34abd3f25e7e2bf220cd0d84/danger-kotlin-library/src/main/kotlin/systems/danger/kotlin). Используя его, можно проверять данные, которые касаются пул-реквеста: например, коммиты и их авторов. Но более сложные задачи реализуются [плагинами](https://github.com/danger/awesome-danger). Их написано немного, но с их помощью можно запустить Android Lint, Detect или получить отчет о запуске JUnit на вашем пул-реквесте.
Для подключения плагина перед написанием кода в `Dangerfile` нужно указать его зависимости – репозиторий, где лежит файл, а также его название, версию, и зарегистрировать используемый плагин. Например:
```
@file:Repository("https://repo.maven.apache.org")
@file:DependsOn("groupId:artifactId:version")
register plugin TestPlugin
```
Мне хотелось запустить ktlint, но нужного плагина не было. Поэтому я решила написать свой простой плагин для отображения результатов. Я создавала плагин отдельно от проекта, используя композитный билд.
Так как Danger не может запускать таски самостоятельно, а только интерпретирует результаты, то для начала нужно запустить ktlint, используя gradle в контейнере. Напомню, как выглядит скрипт запуска контейнера:
```
#!/bin/sh
set -e
echo "Running danger"
./gradlew ktlint
danger-kotlin $DANGER_ARG
echo "Build successfully finished"
exit 0
```
Так как отчет представляет из себя xml-файл, то основную работу будет выполнять парсер. Пример ktlint-отчета:
Подключим зависимость от Danger SDK в `build.gradle`:
```
dependencies {
implementation "systems.danger:danger-kotlin-sdk:1.2"
}
```
Создаем `kotlin-object` и наследуемся от `DangerPlugin`. Переопределяем обязательный `id`:
```
object DangerKtlintPlugin : DangerPlugin() {
override val id: String
get() = "systems.danger.ktlint.plugin"
}
```
Добавляем три функции — `print`, `parse` и `parseAll`. В `print` будем передавать путь (или список путей) к отчету, а `parse` будет вызывать парсер.
```
fun print(vararg lintFiles: String) {
report(parseAll(*lintFiles))
}
private fun parse(lintFilePath: String): ErrorType = LintParser.parse(lintFilePath).type
private fun parseAll(vararg lintFilePaths: String): List = lintFilePaths.map(::parse)
```
Теперь напишем сам парсер. Обходим все узлы в xml-файле, и собираем данные в модель:
```
internal object LintParser {
fun parse(filePath: String): KtlintStructure {
val factory = DocumentBuilderFactory.newInstance()
val builder = factory.newDocumentBuilder()
val document = builder.parse(java.io.File(filePath))
val rootElement = document.documentElement
val files = arrayListOf()
val type = rootElement.nodeName
rootElement.childNodes.forEach { file ->
val fileName = file.attributes.getNamedItem("name")
val lintErrors = arrayListOf()
file.childNodes.forEach { lintError ->
lintErrors.add(
LintError(
line = lintError.attributes.getNamedItem("line").nodeValue,
col = lintError.attributes.getNamedItem("column").nodeValue,
severity = lintError.attributes.getNamedItem("severity").nodeValue,
ruleId = lintError.attributes.getNamedItem("source").nodeValue,
detail = lintError.attributes.getNamedItem("message").nodeValue,
),
)
}
files.add(File(lintErrors = lintErrors, name = fileName.nodeValue))
}
return KtlintStructure(ErrorType(type = type, files = files))
}
```
Далее добавляем функцию для вывода сообщения:
```
private fun report(errors: List) {
errors.forEach { errorType ->
errorType.files.forEach { file ->
file.lintErrors.forEach { lintError ->
val message = "⚠️ ${errorType.type} ${lintError.severity}: " +
"line: ${lintError.line}, column: ${lintError.col}, " +
"message: ${lintError.detail}," + "\n" +
"path:${file.name} "
context.fail(
message,
)
}
}
}
}
```
Если есть ошибки в ktlint, то Danger выводит об этом сообщение. В таком случае помечаем сборку как неудачную.
Плагин написан, осталось собрать его. Настраиваем конфигурацию для `build.gradle`:
```
buildscript {
repositories {
// ссылка на ваше хранилище
}
dependencies {
classpath "systems.danger:danger-plugin-installer:0.1"
}
}
plugins {
id 'org.jetbrains.kotlin.jvm' version '1.5.0'
}
apply plugin: 'danger-kotlin-plugin-installer'
group 'systems.danger.ktlint'
version '1.0'
repositories {
// ссылка на ваше хранилище
}
dangerPlugin {
outputJar = "${buildDir}/libs/danger-ktlint-plugin.jar"
}
dependencies {
implementation "org.jetbrains.kotlin:kotlin-stdlib"
implementation "systems.danger:danger-kotlin-sdk:1.2"
}
```
Для сборки необходим jar-файл `danger-plugin-installer`. Его можно собрать в одноименном модуле [из официального репозитория](https://github.com/danger/kotlin/tree/master/danger-plugin-installer), вызвав `./gradlew jar`.
После необходимо указать этот jar в качестве зависимости для плагина и добавить его в репозиторий. Как только зависимость `danger-plugin-installer` будет установлена, нужно указать путь `outputJar` для написанного плагина, а также запустить команды `./gradlew build` и `./gradlew installDangerPlugin`.
Теперь в `/build/libs` появился jar библиотеки — `danger-ktlint-plugin-1.0.jar`. Для использования плагина его можно залить в приватное хранилище, подключить локально или можно опубликовать в opensource, используя [maven publish](https://docs.gradle.org/current/userguide/publishing_maven.html).
Результат
---------
В итоге Dangerfile выглядит следующим образом. Импортируем необходимые пакеты, регистрируем плагин — и все готово к использованию.
```
@file:Repository(*ссылка на ваше хранилище*)
@file:DependsOn("com.lamoda:danger-ktlint-plugin:1.0")
import com.lamoda.danger_ktlint_plugin.DangerKtlintPlugin
import systems.danger.kotlin.*
register plugin DangerKtlintPlugin
danger(args) {
DangerKtlintPlugin.print("lamoda/build/reports/ktlint.xml")
}
```
Теперь при запуске Danger плагин будет интерпретировать отчет ktlint и выводить в пул-реквесте в следующем виде:
Если вы исправите ошибки в следующем коммите, то сообщение обновится, и билд Danger можно считать успешным.
Надеюсь, моя статья была для вас полезной. Если остались вопросы, пишите их в комментариях! | https://habr.com/ru/post/681564/ | null | ru | null |
# Microsoft тестирует обновлённый диспетчер задач Windows 11 с возможностью поиска
Microsoft [анонсировала](https://blogs.windows.com/windows-insider/2022/11/10/announcing-windows-11-insider-preview-build-22621-891-and-22623-891/) обновление Windows 11, в которое войдёт переработанный диспетчер задач с возможностью поиска процессов. Это поможет пользователям лучше ориентироваться и быстрее находить необходимые процессы.
Только установленная и запущенная Windows 11 открывает вместе с собой больше сотни фоновых процессов, а если на машину установить основные приложение, то список вырастет до нескольких сотен. Для удобной навигации Microsoft анонсировала диспетчер задач с функциями поиска процессов.
Поиск можно будет осуществлять как по имени запущенного приложения, так и по названию издателя. Перейти к полю ввода можно кликом мыши по нему или сочетанием клавиш `Alt + F`. Пользователи, успевшие попробовать возможности нового диспетчера задач, рассказали, что поиск работает с небольшой задержкой после ввода запроса. Также некоторые отметили, что поле должно быть чуть больше.
Также стандартный диспетчер задач в Windows 11 получит поддержку тёмной темы. Пользователи в настройках смогут выбрать между тёмной, светлой или системной темой. Диалоговые окна диспетчера задач также повторяют тему основного окна.
Нововведения доступны в сборках Windows 11 Insider Preview версии 22621.891 и 22623.891. | https://habr.com/ru/post/698784/ | null | ru | null |
# TS-Serializable 2: с конвертации свойств из snake case и декоратором вместо наследования
Недавно мне повезло попасть на проект бэкенд которого написан на php. А как принято у php бекэндов json с ответом они отправляют в snake case стиле. И как следствие вся работа с данными на фронте происходила в перемешку в camel case и snake case стилях. Для решения этой проблемы была доработана [библиотека сериализации ts-serializable](https://github.com/LabEG/Serializable). Теперь при получении данных из json их можно приводить к принятому в js стилю camel case, а при отправке на сервер возвращать в snake case.

Так же после выхода первой версии у некоторых пользователей были пожелания по функционалу. Эти пожелания реализованы в новой версии.
Если вы не знакомы с библиотекой [ts-serializable](https://github.com/LabEG/Serializable), то рекомендуется сначала [прочитать эту статью](https://habr.com/ru/post/428812/).
### Конвертация имен свойств
По аналогии с Newtonsoft.Json были добавлены настройки сериализации. Их можно задать глобально, на один объект, или на один вызов десериализации.
Пример класса который будет десериализован из snake case в camel case, а при сериализации вернется в snake case.
```
import { Serializable, SnakeCaseNamingStrategy, jsonObject, jsonProperty, jsonName } from "ts-serializable";
const json = {
first_name: "Jack",
last_name: "Sparrow",
date_of_birth: "1690-05-05T21:29:43.000Z",
"very::strange::json:name": "I love jewelry"
};
@jsonObject({ namingStrategy: new SnakeCaseNamingStrategy() })
class User extends Serializable {
@jsonProperty(String, null)
public firstName: string | null = null;
@jsonProperty(String, null)
public lastName: string | null = null;
@jsonProperty(Date, null)
public dateOfBirth: Date | null = null;
@jsonName("very::strange::json:name")
@jsonProperty(String, null)
public veryStrangePropertyName: string | null = null;
}
const user = new User().fromJSON(json);
user.firstName === json.first_name; // true
user.lastName === json.last_name; // true
user.dateOfBirth?.toISOString() === json.date_of_birth; // true
user.veryStrangePropertyName === json["very::strange::json:name"]; // true
```
Здесь в декоратор jsonObject передаются настройки для работы сериализации и десериализации. Так же из коробки идут KebabCaseNamingStrategy и PascalCaseNamingStrategy. Если этого не достаточно, то можно написать свой конвертер имен свойств и передать его в параметрах.
Так же можно заметить декоратор jsonName, который можно использовать на совсем специфичных именах свойств.
### Указание настроек
Настройки можно задавать в разных местах:
* **Глобально.** Настройки будут применяться на всех объектах, если они не переопределены в объекте или методе.
* **На объект.** Настройки будут применяться на одном объекте, если они не переопределены в методе.
* **На один метод.** Настройки будут применяться на одном вызове десериализации и не работают при сериализации.
```
// Глобальные настройки
Serializable.defaultSettings: SerializationSettings = { ...options };
// Настройки для объекта
@jsonObject(settings?: Partial)
class User extends Serializable { ...code }
// Настройка для одной десериализации
new User().fromJSON(json: object, settings?: Partial);
```
### Декоратор вместо наследования
После выпуска первой версии библиотеки у некоторых пользователей возникла проблема с тем что наследование уже занято другим объектом. Реализовывать monkey patching не лучшая идея, к тому же расширения базового объекта в js ломает библиотеку react.
Но решение было найдено. Теперь объект можно расширить передав в декоратор jsonObject вторым параметром значение true:
```
@jsonObject(void 0, true) // расширит объект
class User {
public fromJSON!: (json: object) => this; // успокоит typescript
@jsonProperty(String, null)
public firstName: string | null = null;
@jsonProperty(String, null)
public lastName: string | null = null;
}
```
### Поддержка
Понравилась библиотека? Помоги сделать ее лучше и популярнее. [Присылайте issue, ставьте звезды](https://github.com/LabEG/Serializable). Не бойтесь экспериментировать! | https://habr.com/ru/post/502290/ | null | ru | null |
# Основные изменения React 18
Привет, меня зовут Кристина, я фронтенд-разработчик в Домклик. Хочу рассказать немного про основные изменения React 18.
Что нового:
* Новые возможности (`useId`, `useDeferredValue`, `useSyncExternalStore`, `useInsertionEffect`).
* Переходы (`startTransition`, `useTransition`).
* Suspense на сервере.
Улучшено:
* Конкурентный рендеринг.
* Автоматический батчинг.
Устарело:
* `ReactDOM.render` ⇒ `ReactDOM.createRoot`
* `ReactDOM.hydrate` ⇒ `ReactDOM.hydrateRoot`
* `ReactDOM.unmountComponentAtNode`
* `ReactDOM.renderSubtreeIntoContainer`
* `ReactDOMServer.renderToNodeStream`
Как обновиться?
1. `npm install react react-dom` или `yarn add react react-dom`.
2. Так как `ReactDOM.render` устарел, необходимо с помощью `ReactDOM.createRoot` создать root и отрендерить, применяя его. Без этого новые возможности React 18 будут недоступны.
```
import ReactDOM from 'react-dom';
import App from 'App';
const container = document.getElementById('app');
const root = ReactDOM.createRoot(container);
root.render();
```
### Конкурентный рендеринг (Concurrency)
Что такое *конкурентность*? Например, вам нужно позвонить Алисе и Бобу. В неконкурентном режиме вы сначала позвоните Алисе, и только после завершения разговора с ней позвоните Бобу. Если разговоры короткие, то всё в порядке, но если разговор с Алисой задержался, например из-за проблем на линии, то это может стать потерей времени.
В конкурентном режиме вы могли бы позвонить Алисе, затем поставить разговор на удержание и в это время позвонить Бобу. Но это не значит, что вы разговариваете с двумя людьми одновременно, просто из двух или более звонков вы можете выбирать наиболее важный для вас. Так же работает конкурентный рендеринг в React 18.
Рендеринг можно прерывать, приостанавливать, возобновлять или прекращать. Это позволяет React быстро реагировать на взаимодействия с пользователем. До React 18 рендеринг представлял собой одну непрерывную синхронную транзакцию, и после начала её нельзя было прервать.
### Автоматический батчинг (Automatic batching)
Что такое *батчинг*? Предлагаю рассмотреть ещё один пример из жизни. Допустим, вы решили приготовить салат. Составили список всех продуктов, которые вам нужно купить, идёте в магазин и покупаете всё за один раз — это батчинг.
Без батчинга вы начинаете готовить, потом оказывается, что у вас нет огурцов для салата, вы идёте в магазин, покупаете огурцы, возвращаетесь и продолжаете готовить, затем вы обнаруживаете, что у вас нет помидоров, вы идёте в магазин и… в этот момент вы уже выполнили свою дневную норму на фитнес-браслете.
В React батчинг помогает уменьшить количество повторных рендерингов, которые происходят при вызове `setState`.
```
setIsLoaded(true);
setError(true);
setModalStatus(‘error’);
```
В этом коде React будет заново рендерить после каждого из вызовов, но это не эффективно. Было бы лучше сначала записать все обновления состояния, а затем после них один раз отрендерить. Но как React может понять, что вы закончили обновлять состояния? А понять он может, например, с помощью обработчика событий:
```
// Такое поведение в React 17 и в React 18
function handleClick() {
setIsLoaded(true);
setError(true);
setModalStatus(‘error’);
}
```
Повторный рендеринг произойдёт после того, как будет выполнена функция.
Рассмотрим ещё один пример:
```
setTimeout(() => {
setIsLoaded(true);
setError(true);
setModalStatus(‘error’);
}, 1000);
```
До React 18 повторный рендеринг происходил бы при каждом обновлении состояния. Но теперь все обновления будут автоматически батчиться внутри таймаутов, промисов или нативных обработчиков событий.
### Переходы (Transitions)
Переходы можно использовать для обозначения срочных и несрочных обновлений. Например, при вводе текста в поле поиска появляется мигающий курсор, дающий визуальную обратную связь, и выполняется функция поиска данных. Визуальная обратная связь важнее для пользователя, а поиск менее важен и может быть помечен как несрочный. Такие несрочные обновления называются переходами (transitions). Проставляя их, вы даёте React знать, каким обновлениям отдавать приоритет. Это упрощает оптимизацию рендеринга.
Обновления можно пометить как несрочные с помощью `startTransition`:
```
import { startTransition } from 'react';
// Срочное обновление значения инпута
setInputValue(value);
// Несрочное обновления запроса поиска
startTransition(() => {
setSearchValue(value);
});
```
В чём отличие от `setTimeout`?
1. `setTimeout` имеет задержку в выполнении, а задержка `startTransition` зависит от устройства, на котором выполняется, и других срочных рендерингов.
2. Обновления `startTransition` могут быть прерваны.
3. Со `startTransition` можно отслеживать состояния ожидания с помощью нового хука `useTransition`.
```
function Counter() {
// Состояние ожидания
const [isPending, startTransition] = useTransition();
const [value, setValue] = useState(0);
const handleClick = () => {
startTransition(() => {
setValue(c => c + 1);
})
}
return (
<>
{ isPending && }
{ value }
);
}
```
### Suspense
В React 18 эта технология была архитектурно улучшена. Изменён рендеринг дочерних компонентов внутри Suspense. Также теперь есть возможность использования Suspense на сервере. Но что же это такое?
Представьте себе компонент, которому нужно выполнить асинхронную задачу, например, получение данных, прежде чем он сможет что-то отрендерить. Без Suspense такой компонент сохранял бы флаг `isFetching`/`isLoading` и в зависимости от него рендерил бы загрузчик, или скелет, или что-то ещё. А теперь с помощью Suspense компонент может дать понять, что он ещё «не готов», и приостановить рендеринг. В это время React пойдёт вверх по дереву до ближайшего Suspense, в котором будет установлен fallback, так называемый запасной вариант, который будет отображаться, пока компонент не будет «готов».
### Строгий режим
Строгий режим в React 18 будет имитировать unmount и повторный mount компонента с его предыдущим состоянием, когда mount происходит первый раз. Это закладывает основу для многократного использования состояния в будущем, когда React может немедленно смонтировать предыдущий экран
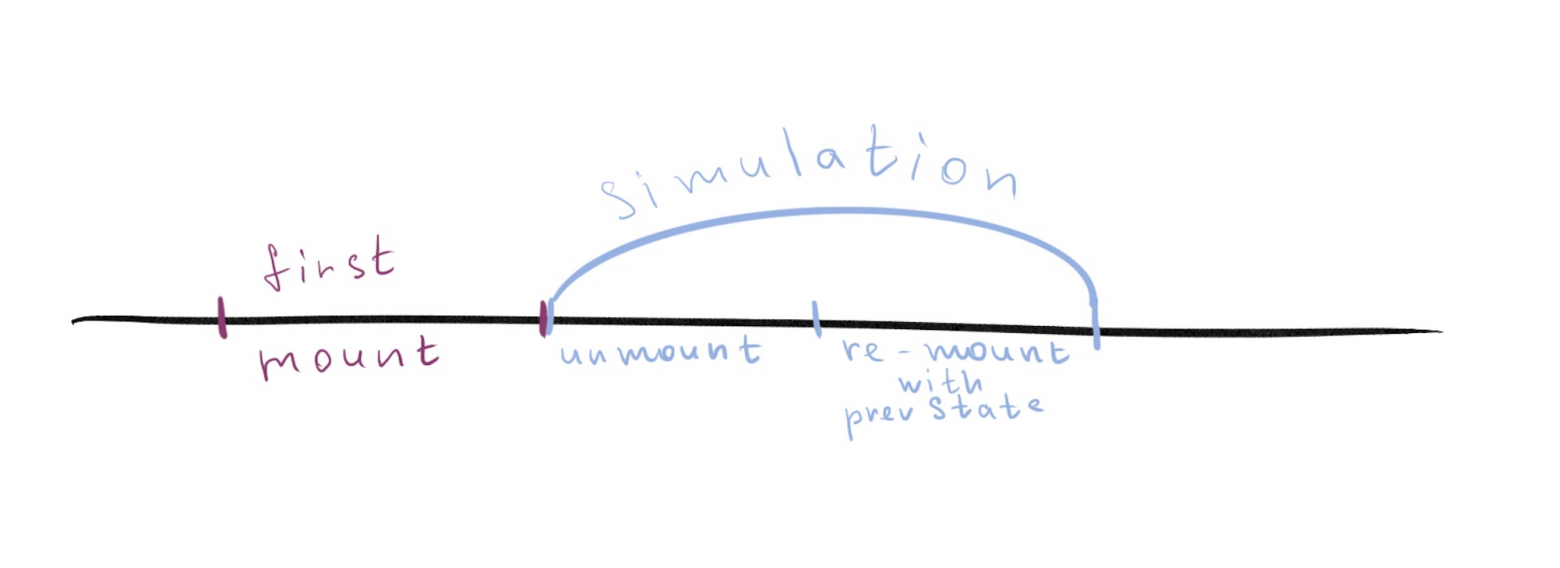Пожалуй это всё о чем я хотела рассказать в этой статье. Любые изменения ведут к новым возможностям. Удачи в обновлении! | https://habr.com/ru/post/689152/ | null | ru | null |
# Аналоги в Python и JavaScript. Часть третья
Продолжаем перевод серии статей про аналоги в Python и JavaScript
В прошлых выпусках мы опирались на синтаксис классических версий Питона (2.7) и JS на основе ECMAScript 5. В этот раз мы будем использовать новые функции которые появились в Питоне 3.6 и JS стандарта ECMAScript 6.
ECMAScript 6 — относительно новый стандарт [поддерживаемый большинством современных браузеров](https://kangax.github.io/compat-table/es6/). Для использования стандарта 6 в старых браузерах вам понадобиться [Babel](https://babeljs.io/) для перевода современных конструкций JS6 на кросс-браузерную поддержку.
В сегодняшней статье: переменные в строках, распаковка списков, лямбда-функции, итерирование без индексов, генераторы и множества (sets).
Содержание других выпусков:
1. [Первая часть](https://habr.com/post/416617/) — приведение к типу, тернарный оператор, доступ к свойству по имени свойства, словари, списки, строки, конкатенация строк
2. [Вторая часть](https://habr.com/post/417513/) — сериализация словарей, JSON, регулярки, ошибки и исключения.
3. Эта статья
4. [Четвертая часть](https://habr.com/post/419271/) — аргументы функций, создание и работа с классами, наследование, геттеры-сеттеры и свойства класса.
#### Переменные в строках
Традиционный способ построения строк с переменными использует конкатенацию строк и переменных:
```
name = 'World'
value = 'Hello, ' + name + '!\nWelcome!'
```
Такая запись может показаться разбросанной и плохочитаемой, также часто можно ошибиться в пробелах окружающих слова в строках.
Начиная с версии 3.6 в Питоне и в JS ECMAScrip6 вы можете использовать строковую интерполяцию, или, в терминах Питона — f-строки. Это строковые шаблоны в которых подставляются значения из переменных.
В Питоне f-строки помечаются символом f перед кавычками:
```
name = 'World'
value = f"""Hello, {name}!
Welcome!"""
price = 14.9
value = f'Price: {price:.2f} €' # 'Price: 14.90 €'
```
В JS [строковые шаблоны начинаются и кончаются обратной кавычкой](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/template_strings) (backtrick) `
```
name = 'World';
value = `Hello, ${name}!
Welcome!`;
price = 14.9;
value = `Price ${price.toFixed(2)} €`; // 'Price: 14.90 €'
```
Заметим, что шаблоны могут быть как одно- итак и многострочными.
В Питоне можно задать форматирование переменных.
#### Распаковка списков
В Питоне, а теперь уже и в JS существует интересная возможность присвоить элементы последовательности различным переменным. К примеру, мы можем присвоить трем переменным три значения из списка:
```
[a, b, c] = [1, 2, 3]
```
Для кортежей скобки могут быть опущены.
Следующий пример очень популярен в Питоне как способ обмена значений двух переменных:
```
a = 1
b = 2
a, b = b, a # поменяли значения
```
В JS6+ также возможно:
```
a = 1;
b = 2;
[a, b] = [b, a]; // поменяли значения
```
В Питоне, в случае если у нас есть неопределенное количество элементов в списке или кортеже, мы можем присвоить эти элементы кортежу из переменных в котором последние несколько значений вернуться как список:
```
first, second, *the_rest = [1, 2, 3, 4]
# first == 1
# second == 2
# the_rest == [3, 4]
```
Такое же можно сделать и в JS (ECMAScrip6):
```
[first, second, ...the_rest] = [1, 2, 3, 4];
// first === 1
// last === 2
// the_rest === [3, 4]
```
#### Лямбда-функции
И Питон и JS имеют довольно ясную функциональность для создания однострочных функций. Такие функции называются лямбда-функциями. Лямбды это такие функции которые принимают один или более аргументов и возвращают вычисленное значение. Обычно лямбда-функции используются когда нужно передать одну функцию в другую функцию в качестве колбека или в случае когда необходимо обработать каждый элемент последовательности.
В Питоне можно определить лямбда-функцию используя ключевое слово `lambda`:
```
sum = lambda x, y: x + y
square = lambda x: x ** 2
```
В JS используется `=>` нотация. Если аргументов больше одного, они помещаются в скобки:
```
sum = (x, y) => x + y;
square = x => Math.pow(x, 2);
```
#### Итерация без индексов
Многие ЯП позволяют обходить массивы только используя доступ к определенному элементу по номеру индекса и циклу с инкрементом этого индекса.
```
for (i=0; i
```
Это не слишком красивая запись, и немного сложная для новичков — такая запись не выглядит естественно. В Питоне есть красивый лаконичный способ обхода списка:
```
for item in ['A', 'B', 'C']:
print(item)
```
В современном JS такое реализуется при помощи оператора `for..of`:
```
for (let item of ['A', 'B', 'C']) {
console.log(item);
}
```
Также можно обойти строку посимвольно в Питоне:
```
for character in 'ABC':
print(character)
```
И в современном JavaScript:
```
for (let character of 'ABC') {
console.log(character);
}
```
#### Генераторы
И Питон и современный JS позволяют определить специальные функции которые будут выглядеть как итераторы. При каждом вызове (итерации) они будут возвращать следующее сгенерированное значение из последовательности. Такие функции называются генераторы.
Генераторы обычно используют чтобы получить: числа из диапазона, строки из файла, данные постранично из внешнего API, числа фибоначчи и другие динамически генерируемые последовательности.
Технически генераторы выглядят как обычные функции, но вместо того чтобы вернуть одно значение (и прекратить работу), они выдают одно значение и приостанавливают работу до следующего вызова. Они будут генерировать следующие значения из списка при каждом вызове пока не будет достигнут конец списка.
Рассмотрим пример на Питоне в котором создается генератор countdown() который возвращает числа от заданного числа до 1 в обратном порядке (10,9,8,...,1):
```
def countdown(counter):
while counter > 0:
yield counter
counter -= 1
for counter in countdown(10):
print(counter)
```
То же самое можно получить в современном JS, но обратите внимание на \* в описании функции. Это определяет ее как генератор:
```
function* countdown(counter) {
while (counter > 0) {
yield counter;
counter--;
}
}
for (let counter of countdown(10)) {
console.log(counter);
}
```
#### Множества (Sets)
Мы уже познакомились со списками (lists), кортежами (tuples), массивами (arrays). Но есть еще один тип данных — множества (sets). Множества это массивы данных в котором каждый уникальный элемент присутствует только в единственном экземпляре. Теория множеств определяет с множествами такие операции как объединение(union), пересечение(intersection), и разность(difference), но мы не будем сейчас их рассматривать.
Создаем множество, добавляем в него элемент, проверяем существование элемента, получаем общее количество элементов, обходим множество по элементам и удаляем один элемент используя Питон:
```
s = set(['A'])
s.add('B'); s.add('C')
'A' in s
len(s) == 3
for elem in s:
print(elem)
s.remove('C')
```
То же самое на JS:
```
s = new Set(['A']);
s.add('B').add('C');
s.has('A') === true;
s.size === 3;
for (let elem of s.values()) {
console.log(elem);
}
s.delete('C')
```
#### Подытожим
* Строковые шаблоны (f-строки) позволяют улучшить читаемость и упростить код, даже в случае многострочных объектов.
* Можно обходить массивы, группы или строки без использования индексов.
* Используя генераторы можно получить последовательности с практически неограниченным числом элементов.
* Использование множеств упрощает проверку уникальности элемента в массиве.
* Используйте лямбды когда вам нужны небольшие однострочные функции.
В следующей части поговорим об аргументах функций, классах, наследовании и свойствах. | https://habr.com/ru/post/418191/ | null | ru | null |
# Определяем порядок столбцов в составном индексе
Хочу поделиться простым эмпирическим методом, который я использую для определения того, в каком порядке должны идти столбцы в составном индексе. Этот способ подходит не только для MySQL, он также применим к любым СУБД, в которых используются b-tree индексы.
Давайте начнем с запроса, который возвращает пустой результат, но при этом делает полный скан таблицы. EXPLAIN покажет на нем, что нет доступных индексов (т.е. possible\_keys = NULL)
> `SELECT \* FROM tbl
>
> WHERE
>
> status='waiting' AND
>
> source='twitter' AND
>
> no\_send\_before <= '2009-05-28 03:17:50' AND
>
> tries <= 20
>
> ORDER BY date ASC LIMIT 1;`
Не пытайтесь понять смысл данного запроса, он приведен только в качестве примера. В простейшем случае мы хотим поместить самый избирательный столбец в индекс первым, так чтобы возможное количество совпадающих строк было минимальным, таким образом мы будем находить нужные строки быстро, насколько это возможно. Считая, что все столбцы имеют некоторое распределение значений, мы можем просто посчитать количество совпадений для каждого условия.
> `SELECT
>
> sum(status='waiting'),
>
> sum(source='twitter'),
>
> sum(no\_send\_before <= '2009-05-28 03:17:50'),
>
> sum(tries <= 20),
>
> count(\*)
>
> FROM tbl\G
>
>
>
> \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* 1. row \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
>
> sum(status ='waiting'): 550
>
> sum(source='twitter'): 37271
>
> sum(no\_send\_before <= '2009-05-28 03:17:50'): 36975
>
> sum(tries <= 20): 36569
>
> count(\*): 37271`
Всё просто — я обернул каждое условие функцией SUM(), которая для MySQL эквивалентна COUNT(число\_раз\_когда\_тру). Как видно, наиболее избирательным условием является «status=waiting». Давайте поместим этот столбец в индекс первым, после чего перенесем условие из SELECT в WHERE и снова выполним запрос, для подсчета совпадений в оставшемся наборе.
> `SELECT
>
> sum(source='twitter'),
>
> sum(no\_send\_before <= '2009-05-28 03:17:50'),
>
> sum(tries <= 20),
>
> count(\*)
>
> FROM tbl
>
> WHERE
>
> status='waiting'\G
>
> \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* 1. row \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
>
> sum(source='twitter'): 549
>
> sum(no\_send\_before <= '2009-05-28 03:17:50'): 255
>
> sum(tries <= 20): 294
>
> count(\*): 549`
Теперь мы опустились до приемлемого числа строк. Видно, что «source» совсем не обладает избирательностью, т.е. с помощью него ничего отфильтровать не получится, и добавление его в индекс не принесет никакой пользы. Можно отфильтровать оставшийся набор либо с помощью 'no\_send\_before', либо 'tries'. Выполнение запроса с любым из них в where уменьшит количество совпадений для другого условия до нуля.
> `SELECT
>
> sum(source='twitter'),
>
> sum(no\_send\_before <= '2009-05-28 03:17:50'),
>
> sum(tries <= 20),
>
> count(\*)
>
> FROM tbl
>
> WHERE
>
> status='waiting' AND
>
> no\_send\_before <= '2009-05-28 03:17:50'\G
>
> \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* 1. row \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
>
> sum(source='twitter'): 255
>
> sum(no\_send\_before <= '2009-05-28 03:17:50'): 255
>
> sum(tries <= 20): 0
>
> count(\*): 255
>
>
>
> \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
>
>
>
> SELECT
>
> sum(source='twitter'),
>
> sum(no\_send\_before <= '2009-05-28 03:17:50'),
>
> sum(tries <= 20),
>
> count(\*)
>
> FROM tbl
>
> WHERE
>
> status='waiting' AND
>
> tries <= 20\G
>
> \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* 1. row \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
>
> sum(source='twitter'): 294
>
> sum(no\_send\_before <= '2009-05-28 03:17:50'): 0
>
> sum(tries <= 20): 294
>
> count(\*): 294
>
> \* This source code was highlighted with Source Code Highlighter.`
Это значит, что мы можем сделать индекс с любым из них — (status,tries) или (status,no\_send\_before) и мы найдем наши ноль строк очень эффективно. Какой же из них лучше, зависит от того, для чего действительно используется эта таблица *(а также от наличия и структуры других запросов к этой таблице — прим. пер.)*. | https://habr.com/ru/post/61845/ | null | ru | null |
# Пишем плагин для Netbeans. Часть вторая
В [предыдущей части](http://habrahabr.ru/post/146788/) мы рассмотрели создание плагина для Pastebin, а также научились создавать действия для модулей и связывать их с определённой командой в меню. В этой статье мы расширим функционал плагина, добавив авторизацию и окно настроек.
#### Окно настроек
Начнём сразу с создания вкладки в окне настроек. В «New->Other->Module Development» выбираем «Options Panel» и нажимаем «Next >».

Нам предлагают выбрать создание первичной или вторичной панели в настройках. Первичная нам ни к чему, нас вполне устроит место в панели «Miscellaneous», ведь так? Выбираем «Create Secondary Panel», в поле «Primary Panel» ставим «Advanced», указываем заголовок и ключевые слова, например «Pastebin».
На следующем шаге проконтролируйте, чтобы правильно был указан «Package», а «Class Name Prefix» оставьте по умолчанию. Нажимаем «Finish» и получаем сгенерированный класс PastebinOptionsPanelController и форму PastebinPanel. Уже можно запустить модуль на проверку.
Как видно, вкладка создалась там, где надо, но она пока еще пустая. Давайте исправлять ситуацию.
Для успешной авторизации в pastebin нам потребуется логин и пароль. Перетягиваем в PastebinPanel JTextField и JPasswordField и располагаем поудобнее, назвав их loginTextField и passwordField.
Окно настроек мы создали.
#### Сохранение и восстановление настроек
Открыв код класса PastebinPanel можно легко догадаться, что методы store() / load() отвечают за сохранение и восстановление настроек. Netbeans даже нам показывает три возможных варианта совершения действий в закомментированных строчках. Первый вариант, это сохранение/загрузка посредством Preferences API, второй и третий — при помощи Netbeans Platform. Нам подойдёт второй предложенный способ, так как третий устарел. Пишем код:
```
public static final String LOGIN_KEY = "PastebinLogin", PASSWORD_KEY = "PastebinPassword";
void load() {
loginTextField.setText(NbPreferences.forModule(PastebinPanel.class).get(LOGIN_KEY, ""));
passwordField.setText(NbPreferences.forModule(PastebinPanel.class).get(PASSWORD_KEY, ""));
}
void store() {
NbPreferences.forModule(PastebinPanel.class).put(LOGIN_KEY, loginTextField.getText());
NbPreferences.forModule(PastebinPanel.class).put(PASSWORD_KEY, String.valueOf(passwordField.getPassword()));
}
```
Самое время проверить работоспособность. Запускаем, вводим значения, нажимаем Ok, заходим заново и видим, что всё успешно сохраняется. Отлично, с сохранением и загрузкой разобрались, это было не сложно.
#### Pastebin авторизация
В прошлой части мы уже писали отправку кода в pastebin, поэтому классы [PastebinRequest](http://pastebin.com/Fs6wMTxx) и [PastebinSender](http://pastebin.com/pgQSCxjJ) у нас остались. Удаляем из PastebinRequest строчку *append(«api\_user\_key», "")* и добавляем методы:
```
public void setUserKey(String key) {
append("api_user_key", key.trim());
}
public String getUserKeyRequest(String user, String pass) {
StringBuilder request = new StringBuilder();
request.append("api_dev_key=").append(API_DEV_KEY);
request.append("&api_user_name=").append(encode(user));
request.append("&api_user_password=").append(encode(pass));
return request.toString();
}
```
Класс PastebinSender придётся немного [переписать](http://pastebin.com/aUw98r1q).
Теперь в классе PastebinAction в конец метода setupRequest добавим следующие строки:
```
String user = NbPreferences.forModule(PastebinPanel.class).get(PastebinPanel.LOGIN_KEY, "");
String pass = NbPreferences.forModule(PastebinPanel.class).get(PastebinPanel.PASSWORD_KEY, "");
String userKey = PastebinSender.getUserKey(request.getUserKeyRequest(user, pass));
request.setUserKey(userKey);
```
Запускаем, вводим в настройках свои данные и пытаемся отправить код. Через несколько секунд появится окно со ссылкой. Видим, что отправитель кода уже не Guest, а мы. Ура, мы добились своего!
#### Локализация
Как и в прошлой статье, мы не будем останавливаться на английской версии плагина, поэтому добавим к нему и русский язык. Если в прошлый раз вы это не забыли сделать, то сейчас у вас должно быть два файла: Bundle.properties и Bundle\_ru\_RU.properties. Открыв первый файл, можно увидеть, что туда автоматически добавились строки:
*PastebinPanel.jLabel1.text=Login:
PastebinPanel.loginTextField.text=
PastebinPanel.jLabel2.text=Password:
PastebinPanel.passwordField.text=*
Вторая и последняя строки нам не нужны, поэтому удаляем их. Также нужно будет убрать привязку удалённых строчек к компонентам PastebinPanel. Открываем этот класс в Design режиме, выделяем loginTextField и в контекстном меню выбираем «Customize Code». Приводим код к такому виду:
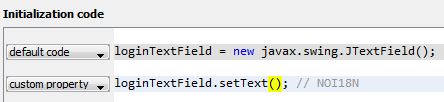
Аналогично следует поступить и с passwordField.
Теперь в Bundle\_ru\_RU.properties добавим строки:
*PastebinPanel.jLabel1.text=Логин:
PastebinPanel.jLabel2.text=Пароль:*
Запускаем, смотрим результат.
Остаётся только создать NBM-модуль. Как это делать, я описывал в прошлой статье.
#### Итоги
Мы научились создавать панель настроек для модуля, сохранять и восстанавливать настройки. Также мы улучшили клиент pastebin.com, добавив авторизацию.
Ссылка на полученный в этой части проект [здесь](https://docs.google.com/open?id=0B3TcatFyw2R-TUUtZU4wcFlfN0k)
Также может быть полезной [эта статья](http://platform.netbeans.org/tutorials/nbm-options.html). | https://habr.com/ru/post/149139/ | null | ru | null |
# Checking the Code of Zephyr Operating System

Some time ago we announced PVS-Studio's new feature that enabled it to integrate into PlatformIO. Naturally, our team kept in touch with the PlatformIO team while working on that feature, and they suggested that we check the real-time operating system Zephyr to see if we could find any interesting bugs in its code. We thought it was a good idea, and so here's this article about the check results.
PlatformIO
----------
Before proceeding with the main topic of this article, I'd like to mention [PlatformIO](https://platformio.org/) to the developers of embedded systems — it can make their life a bit easier. PlatformIO is a cross-platform tool for microcontroller programming. The core of PlatformIO is a command-line tool, however it is recommended to use it as a plugin for Visual Studio Code. It supports a large number of modern microchips, and boards based on them. It can automatically download suitable build systems. The site has a large collection of libraries for managing plug-in electronic components. There is support for several static code analyzers, including PVS-Studio.
PVS-Studio
----------
PVS-Studio is not much known in the world of embedded systems yet, so here's a brief overview of our tool in case you haven't heard of it. Our regular readers may skip over to the next section.
[PVS-Studio](https://www.viva64.com/en/pvs-studio/) is a static code analyzer that can detect bugs and potential vulnerabilities in the code of programs written in C, C++, C#, and Java. As for C and C++, the following compilers are supported:
* Windows. Visual Studio 2010-2019 C, C++, C++/CLI, C++/CX (WinRT)
* Windows. IAR Embedded Workbench, C/C++ Compiler for ARM C, C++
* Windows. QNX Momentics, QCC C, C++
* Windows/Linux. Keil µVision, DS-MDK, ARM Compiler 5/6 C, C++
* Windows/Linux. Texas Instruments Code Composer Studio, ARM Code Generation Tools C, C++
* Windows/Linux/macOS. GNU Arm Embedded Toolchain, Arm Embedded GCC compiler, C, C++
* Windows/Linux/macOS. Clang C, C++
* Linux/macOS. GCC C, C++
* Windows. MinGW C, C++
The analyzer uses its own [warning](https://www.viva64.com/en/w/) classification system, but you can also have warnings issued according to the coding standards [CWE](https://www.viva64.com/en/w/), [SEI CERT](https://www.viva64.com/en/cert/), and [MISRA](https://www.viva64.com/en/misra/).
PVS-Studio can be quickly adopted and put to regular use even in a large legacy project. This is achieved thanks to a special mechanism of mass [warning suppression](https://www.viva64.com/en/m/0032/). It makes the analyzer treat all existing warnings as technical debt and hide them, thus allowing you to focus on the warnings produced only on newly written or modified code. This enables the team to start using the analyzer in their everyday work, getting back every now and then to address the technical debt and gradually eliminate it.
PVS-Studio allows many other use scenarios. For instance, you can run it as a plugin for SonarQube. It can also integrate with such systems as Travis CI, CircleCI, GitLab CI/CD, and so on. A detailed description of PVS-Studio is outside the scope of this article, so please refer to the following article, which offers many useful links and answers to many questions: "[Why You Should Choose the PVS-Studio Static Analyzer to Integrate into Your Development Process](https://www.viva64.com/en/b/0687/)".
Zephyr
------
While working on [PVS-Studio's integration into PlatformIO](https://www.viva64.com/en/b/0714/), we kept in touch with the PlatformIO team, and they suggested that we check Zephyr, a project from the embedded software world. We liked the idea, and that's how this article appeared.
[Zephyr](http://www.zephyrproject.org/) is a small real-time operating system for connected, resource-constrained and embedded devices (with an emphasis on microcontrollers) supporting multiple architectures and released under the Apache License 2.0. Supported platforms: ARM (Cortex-M0, Cortex-M3, Cortex-M4, Cortex-M23, Cortex-M33, Cortex-R4, Cortex-R5, Cortex-A53), x86, x86-64, ARC, RISC-V, Nios II, Xtensa.
Here are some of its distinguishing features:
* Single address space. Combines application-specific code with a custom kernel to create a monolithic image that gets loaded and executed on a system's hardware.
* Highly configurable / Modular for flexibility. Allows an application to incorporate only the capabilities it needs as it needs them, and to specify their quantity and size.
* Compile-time resource definition. Reduces code size and increases performance for resource-limited systems.
* Minimal error checking. The same as the previous one, with complete debugging information provided during testing if needed.
* A number of services for development: multi-threading, interrupt, inter-thread synchronization, memory allocation, power management, and many other services.
One of the curious things about Zephyr is that [Synopsys](https://en.wikipedia.org/wiki/Synopsys) is involved into its development. In 2014, Synopsys bought Coverity, the creator of a static analyzer of the same name.
Hence it's only natural that Zephyr is being checked with [Coverity](https://en.wikipedia.org/wiki/Coverity) from the very beginning. This tool is a leader among analyzers, which helped guarantee the high quality of Zephyr's source code.
The quality of Zephyr's code
----------------------------
If you ask me, Zephyr is a high-quality project. These are the reasons why I think so:
* PVS-Studio produced 122 general-purpose warnings of the High level and 367 warnings of the Medium level. That's not much, considering the total number of C/C++ files checked – 560. The kernel is checked through samples checking. The total estimate I got for the project was 7810 C/C++ files and 10075 header files, which means the check covered only part of the project. But then again, I didn't aim at checking the entire code base, and the number of warnings I got still corresponds to a low warning density.
* Many of the warnings turned out to be false positives or «semi-false positives». What I mean by the latter is explained below.
* I used the [SourceMonitor](http://www.campwoodsw.com/sourcemonitor.html) utility to scan Zephyr's source code, and according to its statistics, comments make 48% of the code. That's quite a bit, and, as my practice proves, it means the developers really care about their code's quality and readability.
* The project is checked with the Coverity static analyzer. This must explain why PVS-Studio – while having found some bugs – still hasn't performed as impressively as it sometimes does when analyzing other projects.
Taking all this into account, I conclude that the project's authors care about their code's quality and reliability. Now let's look at some of the warnings issued by the PVS-Studio analyzer (version 7.06).
«Semi-false» warnings
---------------------
Since the project's code deals with low-level functionality, it's written in a specific way and uses a lot of conditional compilation (#ifdef). This leads to a large number of warnings that don't point at genuine bugs yet can't be viewed as outright false. This can be best explained with examples.
**«Semi-false» positives: example 1**
```
static struct char_framebuffer char_fb;
int cfb_framebuffer_invert(struct device *dev)
{
struct char_framebuffer *fb = &char_fb;
if (!fb || !fb->buf) {
return -1;
}
fb->inverted = !fb->inverted;
return 0;
}
```
PVS-Studio diagnostic message: [V560](https://www.viva64.com/en/w/v560/) A part of conditional expression is always false: !fb. cfb.c 188
Obtaining the address of a static variable always yields a non-null pointer, so the *fb* pointer is never equal to zero and, therefore, the check is not needed.
Yet it's obviously not a bug but simply a redundant, harmless check. Besides, the compiler will optimize it away when building a Release version, so this check wouldn't even cause any slowdown.
That's what I call «semi-false» positives. Technically, the analyzer is totally correct in pointing out that redundant check, and it's better to remove it. On the other hand, minor issues like that are too petty and plain even to mention here.
**«Semi-false» positives: example 2**
```
int hex2char(u8_t x, char *c)
{
if (x <= 9) {
*c = x + '0';
} else if (x >= 10 && x <= 15) {
*c = x - 10 + 'a';
} else {
return -EINVAL;
}
return 0;
}
```
PVS-Studio diagnostic message: [V560](https://www.viva64.com/en/w/v560/) A part of conditional expression is always true: x >= 10. hex.c 31
Again, the analyzer is technically correct by pointing out an always-true conditional subexpression. If the *x* variable is not less than or equal to 9, then it naturally will be always greater than or equal to 10. So the code can be simplified:
```
} else if (x <= 15) {
```
Again, the redundant check is not a true, harmful bug but just a decoration.
**«Semi-false» positives: example 3, more complicated case**
First let's look at the possible implementations of the *CHECKIF* macro:
```
#if defined(CONFIG_ASSERT_ON_ERRORS)
#define CHECKIF(expr) \
__ASSERT_NO_MSG(!(expr)); \
if (0)
#elif defined(CONFIG_NO_RUNTIME_CHECKS)
#define CHECKIF(...) \
if (0)
#else
#define CHECKIF(expr) \
if (expr)
#endif
```
Depending on the compilation mode, the check will be either executed or skipped. In our case, when analyzing the project with PVS-Studio, the following implementation was selected:
```
#define CHECKIF(expr) \
if (expr)
```
Let's see where we get from here.
```
int k_queue_append_list(struct k_queue *queue, void *head, void *tail)
{
CHECKIF(head == NULL || tail == NULL) {
return -EINVAL;
}
k_spinlock_key_t key = k_spin_lock(&queue->lock);
struct k_thread *thread = NULL;
if (head != NULL) {
thread = z_unpend_first_thread(&queue->wait_q);
}
....
}
```
PVS-Studio diagnostic message: [V547](https://www.viva64.com/en/w/v547/) [CWE-571] Expression 'head != NULL' is always true. queue.c 244
The analyzer believes the *(head != NULL)* check is always true. That's correct. If the *head* pointer is equal to NULL, the check at the beginning of the function will have it exit sooner:
```
CHECKIF(head == NULL || tail == NULL) {
return -EINVAL;
}
```
As a reminder, this is what the macro expands into in this implementation:
```
if (head == NULL || tail == NULL) {
return -EINVAL;
}
```
So again, PVS-Studio is technically right and its warning is to the point. But you can't just remove the check because it's still needed. Should the other scenario be selected, the macro would expand as follows:
```
if (0) {
return -EINVAL;
}
```
Now you want the redundant check. Sure, the analyzer wouldn't produce the warning in that case, but it does in this one, where we deal with the Debug version.
I hope it's clear now where «semi-false» positives come from. They aren't a problem, though. PVS-Studio provides a handful of false warning suppression mechanisms, which are described in detail in the documentation.
Relevant warnings
-----------------
Were there any interesting warnings then? Yes, there were, and we are going to take a look at some bugs of different types. But I'd like to make two statements first:
1. Static analysis is not about one-time checks like this. The correct use strategy is to regularly run the analyzer on the project, which is actually exactly how Coverity is used in the development of Zephyr. And that's how adopting PVS-Studio or any other analyzer allows you to detect even more bugs and thus make them cheaper to fix at earlier stages.
2. While writing this article, I didn't aim at finding as many bugs as possible and I could have well missed many of the bugs or erroneously discarded them as «semi-false» positives. If Zephyr's authors are reading this, I recommend that you check the project and study the analysis report on your own. Since the project is open-source and available on GitHub, you can use a [free PVS-Studio licensing](https://www.viva64.com/en/b/0614/) option.
**Fragment 1, typo**
```
static void gen_prov_ack(struct prov_rx *rx, struct net_buf_simple *buf)
{
....
if (link.tx.cb && link.tx.cb) {
link.tx.cb(0, link.tx.cb_data);
}
....
}
```
PVS-Studio diagnostic message: [V501](https://www.viva64.com/en/w/v501/) [CWE-571] There are identical sub-expressions to the left and to the right of the '&&' operator: link.tx.cb && link.tx.cb pb\_adv.c 377
The *link.tx.cb* variable is checked twice. This must be a typo, with *link.tx.cb\_data* being the second variable to be checked instead.
**Fragment 2, buffer overflow**
Let's take a look at the *net\_hostname\_get* function, which will be used further.
```
#if defined(CONFIG_NET_HOSTNAME_ENABLE)
const char *net_hostname_get(void);
#else
static inline const char *net_hostname_get(void)
{
return "zephyr";
}
#endif
```
In my case, the *#else* branch implementation was selected at the preprocessing stage, i.e. the preprocessed file will contain the following implementation of the function:
```
static inline const char *net_hostname_get(void)
{
return "zephyr";
}
```
The function returns a pointer to an array of 7 bytes (including the terminating null character at the end of the string).
Now, here's the code where the overflow occurs.
```
static int do_net_init(void)
{
....
(void)memcpy(hostname, net_hostname_get(), MAX_HOSTNAME_LEN);
....
}
```
PVS-Studio diagnostic message: [V512](https://www.viva64.com/en/w/v512/) [CWE-119] A call of the 'memcpy' function will lead to the 'net\_hostname\_get()' buffer becoming out of range. log\_backend\_net.c 114
After the preprocessing, *MAX\_HOSTNAME\_LEN* expands as follows:
```
(void)memcpy(hostname, net_hostname_get(),
sizeof("xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx"));
```
Therefore, when copying the data, the program will end up accessing memory beyond the string literal's bounds. How exactly it's going to affect the execution is hard to tell because this is undefined behavior.
**Fragment 3, potential buffer overflow**
```
int do_write_op_json(struct lwm2m_message *msg)
{
u8_t value[TOKEN_BUF_LEN];
u8_t base_name[MAX_RESOURCE_LEN];
u8_t full_name[MAX_RESOURCE_LEN];
....
/* combine base_name + name */
snprintf(full_name, TOKEN_BUF_LEN, "%s%s", base_name, value);
....
}
```
PVS-Studio diagnostic message: [V512](https://www.viva64.com/en/w/v512/) [CWE-119] A call of the 'snprintf' function will lead to overflow of the buffer 'full\_name'. lwm2m\_rw\_json.c 826
Substituting the macros' values leads us to the following:
```
u8_t value[64];
u8_t base_name[20];
u8_t full_name[20];
....
snprintf(full_name, 64, "%s%s", base_name, value);
```
Only 20 bytes are allocated for the *full\_name* buffer, which is where the string is formed, while the parts that the string is formed from are stored in two buffers 20 and 64 bytes long. In addition, the constant 64 passed to the *snprintf* function and intended to prevent the overflow is obviously a bit too large!
This code won't necessarily end up with a buffer overflow. Perhaps the developers always get away with it because the substrings are always too short. But overall, this code has no protection against an overflow, which is a classic security weakness [CWE-119](https://cwe.mitre.org/data/definitions/119.html).
**Fragment 4, expression is always true**
```
static int keys_set(const char *name, size_t len_rd, settings_read_cb read_cb,
void *cb_arg)
{
....
size_t len;
....
len = read_cb(cb_arg, val, sizeof(val));
if (len < 0) {
BT_ERR("Failed to read value (err %zu)", len);
return -EINVAL;
}
....
}
```
PVS-Studio diagnostic message: [V547](https://www.viva64.com/en/w/v547/) [CWE-570] Expression 'len < 0' is always false. Unsigned type value is never < 0. keys.c 312
The *len* variable is unsigned, which means it can't be less than 0. Therefore, the error state isn't handled in any way. Elsewhere, the value returned by the *read\_cb* function is stored in a variable of type *int* or *ssize\_t*. For example:
```
static inline int mesh_x_set(....)
{
ssize_t len;
len = read_cb(cb_arg, out, read_len);
if (len < 0) {
....
}
```
**Note.** Actually, the *read\_cb* function doesn't look fine at all. Look at its declaration:
```
static u8_t read_cb(const struct bt_gatt_attr *attr, void *user_data)
```
The type *u8\_t* is actually *unsigned char.*
The function always returns only positive values of type *unsigned char*. If we store such a value into a signed variable of type *int* or *ssize\_t*, it will still be a positive value. It means error state checks don't work in other cases either. But I didn't dig too deep into this issue.
**Fragment 5, something weird**
```
static char *mntpt_prepare(char *mntpt)
{
char *cpy_mntpt;
cpy_mntpt = k_malloc(strlen(mntpt) + 1);
if (cpy_mntpt) {
((u8_t *)mntpt)[strlen(mntpt)] = '\0';
memcpy(cpy_mntpt, mntpt, strlen(mntpt));
}
return cpy_mntpt;
}
```
PVS-Studio diagnostic message: [V575](https://www.viva64.com/en/w/v575/) [CWE-628] The 'memcpy' function doesn't copy the whole string. Use 'strcpy / strcpy\_s' function to preserve terminal null. shell.c 427

The developer was trying to make a function similar to *strdup* but failed.
The warning says the *memcpy* function copies a string but fails to copy the terminating null character, which is a very strange behavior.
You may think the copying of the terminating null takes place in the following line:
```
((u8_t *)mntpt)[strlen(mntpt)] = '\0';
```
But that's wrong! It's a typo that causes the terminating null to get copied into itself! Note that the target array is *mntpt*, not *cpy\_mntpt*. As a result, the *mntpt\_prepare* function returns a non-terminated string.
This is what should be written instead:
```
((u8_t *)cpy_mntpt)[strlen(mntpt)] = '\0';
```
But I still can't see the reason for such a complicated implementation! This code can be reduced to the following:
```
static char *mntpt_prepare(char *mntpt)
{
char *cpy_mntpt;
cpy_mntpt = k_malloc(strlen(mntpt) + 1);
if (cpy_mntpt) {
strcpy(cpy_mntpt, mntpt);
}
return cpy_mntpt;
}
```
**Fragment 6, pointer dereferencing before check**
```
int bt_mesh_model_publish(struct bt_mesh_model *model)
{
....
struct bt_mesh_model_pub *pub = model->pub;
....
struct bt_mesh_msg_ctx ctx = {
.send_rel = pub->send_rel,
};
....
if (!pub) {
return -ENOTSUP;
}
....
}
```
PVS-Studio diagnostic message: [V595](https://www.viva64.com/en/w/v595/) [CWE-476] The 'pub' pointer was utilized before it was verified against nullptr. Check lines: 708, 719. access.c 708
This is a [very common](https://www.viva64.com/en/examples/v595/) bug pattern. The pointer is first dereferenced to initialize a struct member:
```
.send_rel = pub->send_rel,
```
And only then is it checked for null.
**Fragments 7-9, pointer dereferencing before check**
```
int net_tcp_accept(struct net_context *context, net_tcp_accept_cb_t cb,
void *user_data)
{
....
struct tcp *conn = context->tcp;
....
conn->accept_cb = cb;
if (!conn || conn->state != TCP_LISTEN) {
return -EINVAL;
}
....
}
```
PVS-Studio diagnostic message: [V595](https://www.viva64.com/en/w/v595/) [CWE-476] The 'conn' pointer was utilized before it was verified against nullptr. Check lines: 1071, 1073. tcp2.c 1071
This case is the same as the previous one. No comments needed.
Two more errors like that:
* V595 [CWE-476] The 'context->tcp' pointer was utilized before it was verified against nullptr. Check lines: 1512, 1518. tcp.c 1512
* V595 [CWE-476] The 'fsm' pointer was utilized before it was verified against nullptr. Check lines: 365, 382. fsm.c 365
**Fragment 10, incorrect check**
```
static int x509_get_subject_alt_name( unsigned char **p,
const unsigned char *end,
mbedtls_x509_sequence *subject_alt_name)
{
....
while( *p < end )
{
if( ( end - *p ) < 1 )
return( MBEDTLS_ERR_X509_INVALID_EXTENSIONS +
MBEDTLS_ERR_ASN1_OUT_OF_DATA );
....
}
....
}
```
PVS-Studio diagnostic message: [V547](https://www.viva64.com/en/w/v547/) [CWE-570] Expression '(end — \* p) < 1' is always false. x509\_crt.c 635
Look closely at these conditions:
* \*p < end
* (end — \*p) < 1
They are mutually opposite.
If (\*p < end), then (end — \*p) will always yield the value 1 or larger. Something is wrong with this code, but I have no idea how it should be fixed.
**Fragment 11, unreachable code**
```
uint32_t lv_disp_get_inactive_time(const lv_disp_t * disp)
{
if(!disp) disp = lv_disp_get_default();
if(!disp) {
LV_LOG_WARN("lv_disp_get_inactive_time: no display registered");
return 0;
}
if(disp) return lv_tick_elaps(disp->last_activity_time);
lv_disp_t * d;
uint32_t t = UINT32_MAX;
d = lv_disp_get_next(NULL);
while(d) {
t = LV_MATH_MIN(t, lv_tick_elaps(d->last_activity_time));
d = lv_disp_get_next(d);
}
return t;
}
```
PVS-Studio diagnostic message: [V547](https://www.viva64.com/en/w/v547/) [CWE-571] Expression 'disp' is always true. lv\_disp.c 148
The function returns if *disp* is a null pointer. This is followed by an opposite check – whether the *disp* pointer is non-null (which is always true) – and the function returns all the same.
Because of this logic, part of the code in the function's body will never get control.
**Fragment 12, strange return value**
```
static size_t put_end_tlv(struct lwm2m_output_context *out, u16_t mark_pos,
u8_t *writer_flags, u8_t writer_flag,
int tlv_type, int tlv_id)
{
struct tlv_out_formatter_data *fd;
struct oma_tlv tlv;
u32_t len = 0U;
fd = engine_get_out_user_data(out);
if (!fd) {
return 0;
}
*writer_flags &= ~writer_flag;
len = out->out_cpkt->offset - mark_pos;
/* use stored location */
fd->mark_pos = mark_pos;
/* set instance length */
tlv_setup(&tlv, tlv_type, tlv_id, len);
len = oma_tlv_put(&tlv, out, NULL, true) - tlv.length;
return 0;
}
```
PVS-Studio diagnostic message: [V1001](https://www.viva64.com/en/w/v1001/) The 'len' variable is assigned but is not used by the end of the function. lwm2m\_rw\_oma\_tlv.c 338
The function has two *return* statements both of which return 0. It's strange for a function to return 0 in any case. And it's strange that the *len* variable is never used after it has been assigned a value. I strongly suspect that the programmer actually meant to write the following code:
```
len = oma_tlv_put(&tlv, out, NULL, true) - tlv.length;
return len;
}
```
**Fragments 13-16, synchronization error**
```
static int nvs_startup(struct nvs_fs *fs)
{
....
k_mutex_lock(&fs->nvs_lock, K_FOREVER);
....
if (fs->ate_wra == fs->data_wra && last_ate.len) {
return -ESPIPE;
}
....
end:
k_mutex_unlock(&fs->nvs_lock);
return rc;
}
```
PVS-Studio diagnostic message: [V1020](https://www.viva64.com/en/w/v1020/) The function exited without calling the 'k\_mutex\_unlock' function. Check lines: 620, 549. nvs.c 620
The function may return without unlocking the mutex. As far as I understand, the following should be written instead:
```
static int nvs_startup(struct nvs_fs *fs)
{
....
k_mutex_lock(&fs->nvs_lock, K_FOREVER);
....
if (fs->ate_wra == fs->data_wra && last_ate.len) {
rc = -ESPIPE;
goto end;
}
....
end:
k_mutex_unlock(&fs->nvs_lock);
return rc;
}
```
Three more bugs of this type:
* V1020 The function exited without calling the 'k\_mutex\_unlock' function. Check lines: 574, 549. nvs.c 574
* V1020 The function exited without calling the 'k\_mutex\_unlock' function. Check lines: 908, 890. net\_context.c 908
* V1020 The function exited without calling the 'k\_mutex\_unlock' function. Check lines: 1194, 1189. shell.c 1194
Conclusion
----------
I hope you enjoyed reading this article. Be sure to check our [blog](https://www.viva64.com/en/b/) for more project checks and other interesting articles.
Use static analyzers to eliminate tons of bugs and potential vulnerabilities at the earlier coding stage. Early bug detection is especially crucial to embedded systems, where updates are expensive and time-consuming.
I also encourage you to go and check your own projects with PVS-Studio. For detailed information about how to do that see the article "[How to quickly check out interesting warnings given by the PVS-Studio analyzer for C and C++ code?](https://www.viva64.com/en/b/0633/)". | https://habr.com/ru/post/495284/ | null | en | null |
# Получаем доменное имя, DNS и SSL сертификат нахаляву
Привет, Хабр. Данный пост предназначен для любителей халявы и содержит готовый рецепт по получению доменного имени, услуг DNS-сервера и SSL-сертификата с затратами 0 рублей 0 копеек. Бесплатный сыр бывает только в мышеловке и это правда, так что рецепт скорее для тех кто хочет красивую ссылку на свой личный небольшой проект с поддержкой https а не для серьёзных проектов.

Доменное имя
============
Идём на сайт [www.registry.cu.cc](http://www.registry.cu.cc/), там сразу же вбиваем нужное имя и нажимаем **check availability** => **checkout** если нужное имя доступно. После чего регистрируемся и идём в личный кабинет где видим свои доменные имена.
**img1**
**img2**
Находим нужное имя, идём в **Nameserver** и прописываем там DNS яндекса.
**img3**
**img4**
DNS-сервер
==========
Далее идём сюда [pdd.yandex.ru/domains\_add](https://pdd.yandex.ru/domains_add/) и добавляем только что созданное доменное имя.
**img5**
Видим что «Не удалось найти домен в DNS», ждём пока яндекс его найдёт.
**img6**
После чего подтверждаем владение доменом добавив соответствующую CNAME запись как написано в подробной инструкции яндекса. После чего ждём пока яндекс найдёт нужную ему запись и подтвердит владение доменом. Может потребоваться довольно много времени.
**img7**
**img8**
**img9**
После чего видим долгожданную надпись о том что домен подключён и делегирован на DNS яндекса.
**img10**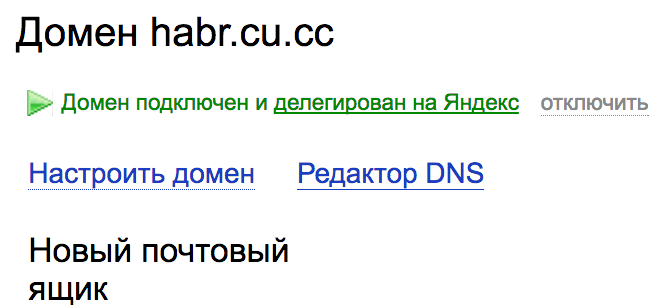
Далее идём в **Редактор DNS** и добавляем A — запись привязывая доменное имя к ip — адресу своего сервера.
**img11**
Может пройти довольно много времени пока эта A — запись вступит в силу. Запустим что-нибудь локально ( ведь мы прописали адрес сервера 127.0.0.1 ) и посмотрим как будет ресолвиться наш домен. Работает!
**ура!**
На этом с DNS-сервером всё, теперь займёмся получением ssl сертификата и обеспечим доступ к нашему серверу по https ( безопасность превыше всего ).
SSL-сертификат
==============
Идём на [www.startssl.com/Validate](https://www.startssl.com/Validate), регистрируемся, выбираем **Validations Wizard** => **Domain Validation (for SSL certificate)**, вводим наш домен
**img12**
И там нам предлагают доказать что мы владеем доменом при помощи e-mail, выбираем любой который нам нравится, создаём его в яндексе. Отправляем туда письмо, берём оттуда код и доказываем что домен принадлежит нам.
**img13**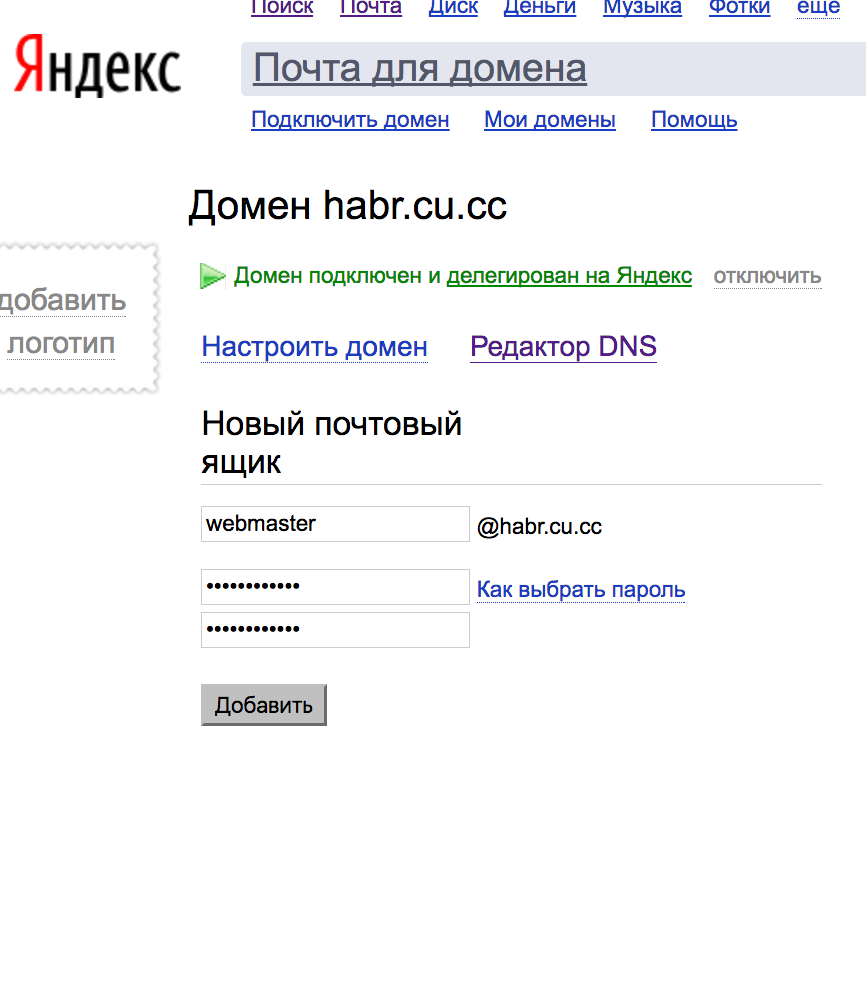
**img14**
**img15**
Затем идём в **Certificates Wizard** => **Web Server SSL/TLS Certificate**, указываем наш домен, генерим и вставляем ключ и нажимаем submit
**img16**
Ключ можно сгенерировать например так
```
mkdir ./certificates
mkdir ./certificates/habr.cu.cc
cd ./certificates/habr.cu.cc
openssl genrsa -out ./habr.cu.cc.key 2048
openssl req -new -sha256 -key ./habr.cu.cc.key -out ./habr.cu.cc.csr
cat ./habr.cu.cc.csr
```
Сертификат получен! Скачиваем себе архив
**img17**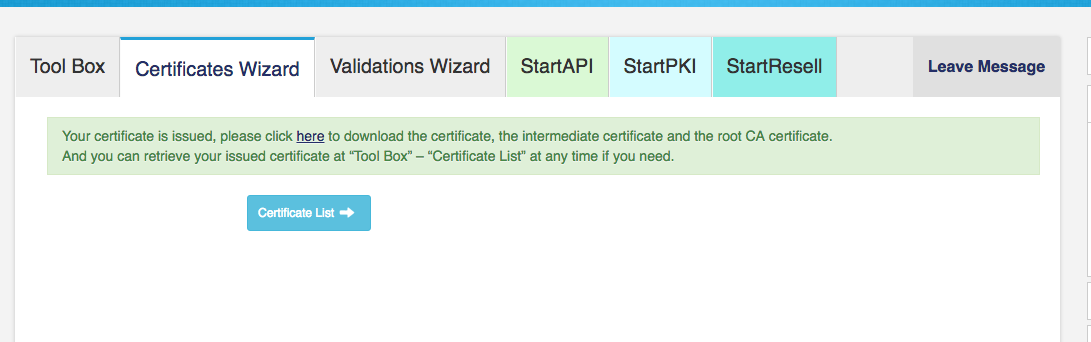
Распаковываем и копируем файлы ключей в директорию nginx
```
cp ~/Downloads/habr.cu.cc/1_habr.cu.cc_bundle.crt /usr/local/etc/nginx/1_habr.cu.cc_bundle.crt
cp ./habr.cu.cc.key /usr/local/etc/nginx/habr.cu.cc.key
nano /usr/local/etc/nginx/nginx.conf
```
Немного рихтуем конфиг
`server {
listen 8080;
ssl on;
server_name localhost;
ssl_certificate /usr/local/etc/nginx/1_habr.cu.cc_bundle.crt;
ssl_certificate_key /usr/local/etc/nginx/habr.cu.cc.key;`
Перезапускаем nginx
```
nginx -s stop
nginx
```
Открываем нашу страничку используя https… и всё работает!
**ура!**
Мы получили доменное имя, услуги DNS-сервера и подтверждённый SSL сертификат не заплатив никому ни копейки, и при этом совершенно легально. Для запуска нашего ультра-мега-гига сервиса осталось только поднять VPS и развернуть там нашу программу. Увы сегодня бесплатная ВПС-ка это слишком хорошо и нереально, за VPS-сервер всё-таки придётся платить кровавыми долларами из своего кармана. Но тем не менее всем хороших выходных и надеюсь заметка будет кому-нибудь полезной. | https://habr.com/ru/post/304600/ | null | ru | null |
# Service Locator — антипаттерн
Service Locator (или “локатор служб”) — хорошо всем нам известный паттерн. Поскольку он был [описан Мартином Фаулером](http://martinfowler.com/articles/injection.html), он должен быть хорошим, ведь так?
К сожалению нет, на практике это классический пример антипаттерна, который следует избегать.
Давайте разберемся, что с ним не так. Если отвечать коротко, то проблема с Service Locator заключается в том, что он скрывает зависимости класса, что вызывает ошибки времени выполнения вместо ошибок времени компиляции, а также усложняет сопровождение кода, потому что становится не совсем ясно, какие изменения окажутся критическими.
### Пример с OrderProcessor
Возьмем злободневный пример для всех, кто сталкивался с внедрением зависимостей: OrderProcessor. В рамках обработки заказа, OrderProcessor должен проверить заказ и, если все в порядке, отправить его на отгрузку. Вот пример реализации с использованием Service Locator:
```
public class OrderProcessor : IOrderProcessor
{
public void Process(Order order)
{
var validator = Locator.Resolve();
if (validator.Validate(order))
{
var shipper = Locator.Resolve();
shipper.Ship(order);
}
}
}
```
Service Locator используется в качестве альтернативы оператору new. Выглядит это следующим образом:
```
public static class Locator
{
private readonly static Dictionary>
services = new Dictionary>();
public static void Register(Func resolver)
{
Locator.services[typeof(T)] = () => resolver();
}
public static T Resolve()
{
return (T)Locator.services[typeof(T)]();
}
public static void Reset()
{
Locator.services.Clear();
}
}
```
Мы можем задать Locator с помощью метода Register. “Настоящая” реализация Service Locator была бы намного более усовершенствованной, чем эта, но этот пример вполне отражает суть паттерна.
Он гибок и расширяем, и даже поддерживает подмену сервисов тестовыми дублерами, как мы вскоре увидим.
Учитывая все это, в чем же подвох?
### Проблемы с API
Предположим на мгновение, что мы просто являемся пользователями класса OrderProcessor. Сами мы его не писали, а получили в сборке от третьих лиц, и нам еще даже не довелось взглянуть на него в Reflector.
Вот что мы получаем от IntelliSense в Visual Studio:
Итак, у класса есть конструктор по умолчанию. Это означает, что мы можем просто создать его новый инстанс и сразу же вызвать метод Process:
```
var order = new Order();
var sut = new OrderProcessor();
sut.Process(order);
```
Но не тут-то было, запуск этого кода внезапно вызывает KeyNotFoundException, потому что IOrderValidator не был зарегистрирован нами в Locator. Это не только неожиданно, это вполне может сбить нас с толку, если у нас нет доступа к исходному коду.
Просматривая исходный код (или используя Reflector) или копаясь в документации (фе!) мы можем, наконец, обнаружить, что нам нужно зарегистрировать инстанс IOrderValidator в Locator (совершенно несвязанным статическим классом), чтобы это все заработало.
В модульном тесте это можно сделать так:
```
var validatorStub = new Mock();
validatorStub.Setup(v => v.Validate(order)).Returns(false);
Locator.Register(() => validatorStub.Object);
```
Что еще более раздражает, так это то, что, поскольку внутреннее хранилище Locator статично, нам нужно вызывать метод Reset после каждого модульного теста. Но хотя бы это неудобство нас преследует в основном только в модульном тестировании.
В целом, однако, мы не можем обоснованно утверждать, что такое API способствует положительному опыту разработки.
### Проблемы с сопровождением
Хоть подобное использование Service Locator с точки зрения пользователя достаточно проблематично, но то, что кажется простым, вскоре становится проблемой и для разработчика, который должен сопровождать этот код.
Допустим, нам нужно расширить поведение OrderProcessor вызовом метода [IOrderCollector.Collect](https://blog.ploeh.dk/2010/02/02/RefactoringtoAggregateServices). Легко ли нам будет сделать это?
```
public void Process(Order order)
{
var validator = Locator.Resolve();
if (validator.Validate(order))
{
var collector = Locator.Resolve();
collector.Collect(order);
var shipper = Locator.Resolve();
shipper.Ship(order);
}
}
```
С чисто механистической точки зрения это легко — мы просто добавили новый вызов Locator.Resolve и вызвали IOrderCollector.Collect.
Является ли это изменение критическим?
Ответить на этот вопрос может быть на удивление трудно. Код, конечно, скомпилировался без ошибок, но один из моих модульных тестов демонстрирует ошибку. Что произойдет в рабочем приложении? Интерфейс IOrderCollector может быть уже зарегистрирован в Service Locator, поскольку он уже используется другими компонентами, и в этом случае он будет работать без сбоев. С другой стороны, дела могут обстоять немного по другому.
Суть в том, что становится намного сложнее сказать, вводите ли вы критическое изменение или нет. Вам нужно следить за всем приложением, в котором используется Service Locator, и компилятор вам в этом не поможет.
### Вариация паттерна: Concrete Service Locator
Можем ли мы как-то решить эти проблемы?
Одно из самых популярных решений — сделать Service Locator конкретным классом, который используется следующим образом:
```
public void Process(Order order)
{
var locator = new Locator();
var validator = locator.Resolve();
if (validator.Validate(order))
{
var shipper = locator.Resolve();
shipper.Ship(order);
}
}
```
Однако для работы ему все еще требуется статическое хранилище в памяти:
```
public class Locator
{
private readonly static Dictionary>
services = new Dictionary>();
public static void Register(Func resolver)
{
Locator.services[typeof(T)] = () => resolver();
}
public T Resolve()
{
return (T)Locator.services[typeof(T)]();
}
public static void Reset()
{
Locator.services.Clear();
}
}
```
Другими словами: нет никаких структурных различий между конкретным локатором служб и статическим локатором служб, который мы уже рассматривали. Он имеет те же проблемы и ничего не решает.
### Еще одна вариация: Abstract Service Locator #
Есть еще одна вариация, которая немного ближе к настоящему внедрению зависимостей: Service Locator представляет собой конкретный класс, реализующий интерфейс.
```
public interface IServiceLocator
{
T Resolve();
}
public class Locator : IServiceLocator
{
private readonly Dictionary> services;
public Locator()
{
this.services = new Dictionary>();
}
public void Register(Func resolver)
{
this.services[typeof(T)] = () => resolver();
}
public T Resolve()
{
return (T)this.services[typeof(T)]();
}
}
```
В этой вариации Service Locator необходимо внедрять в потребителя. Внедрение зависимостей через конструктор всегда является хорошим выбором для внедрения зависимостей, поэтому наш OrderProcessor трансформируется в следующую реализацию:
```
public class OrderProcessor : IOrderProcessor
{
private readonly IServiceLocator locator;
public OrderProcessor(IServiceLocator locator)
{
if (locator == null)
{
throw new ArgumentNullException("locator");
}
this.locator = locator;
}
public void Process(Order order)
{
var validator =
this.locator.Resolve();
if (validator.Validate(order))
{
var shipper =
this.locator.Resolve();
shipper.Ship(order);
}
}
}
```
Значит, теперь все хорошо?
Как разработчики, мы наконец получили небольшую помощь от IntelliSense:
Но что это нам говорит? По большому счету, не очень много чего. Итак, OrderProcessor нужен ServiceLocator — это немного больше информации, чем раньше, но мы по-прежнему не знаем, какие службы необходимы. Следующий код компилируется, но вылетает с тем же KeyNotFoundException, что и раньше:
```
var order = new Order();
var locator = new Locator();
var sut = new OrderProcessor(locator);
sut.Process(order);
```
С точки зрения разработчика, которому нужно будет сопровождать этот код, ситуация также не сильно улучшилась. Мы по-прежнему не получаем никакой помощи, если нам нужно добавить новую зависимость, окажется ли это изменение критическим или нет? Ответить на этот вопрос так же трудно, как и раньше.
### Заключение
Проблема с использованием Service Locator заключается не в том, что вы получаете зависимость от конкретной реализации Service Locator (хотя это тоже может быть проблемой), а в том, что это полноценный **антипаттерн**. Он становится причиной не самого приятного опыта разработки для пользователей вашего API и ухудшит вашу жизнь как разработчика, на котором лежит обязанность сопровождать код, потому что вам нужно будет подключать серьезные ментальные ресурсы, чтобы понять последствия каждого внесенного вами изменения.
Компилятор может предложить как пользователям, так и поставщикам немного помощи при **внедрении зависимостей через конструктор**, но эта помощь недоступна для API, которые полагаются на Service Locator.
Подробнее о паттернах и антипаттернах внедрения зависимостей можно прочитать [в моей книге](http://amzn.to/12p90MG).
Обновление от 20 мая 2014 г.: Еще один способ объяснить отрицательные аспекты Service Locator заключается в том, что он [нарушает SOLID](https://blog.ploeh.dk/2014/05/15/service-locator-violates-solid).
Обновление от 26 октября 2015 г.: Фундаментальная проблема с Service Locator заключается в том, что он [нарушает инкапсуляцию](https://blog.ploeh.dk/2015/10/26/service-locator-violates-encapsulation).
---
> Часто бывает, что реализация юнитов объектно-ориентированным подходом создает сложности при изменении/добавлении новых механик в игру. На конкретные классы завязываются компоненты системы, и код становится сильно связным.
>
> Недавно в OTUS в рамках онлайн-курса ["Unity Game Developer. Professional"](https://otus.pw/TGbB/) прошел открытый урок «Компоненты игровых объектов». На уроке мы рассмотрели, как при помощи компонентного подхода (не ECS) можно гибко изменять функциональность юнитов таким образом, чтобы система была слабо связной. Если интересно, запись вебинара можно [посмотреть по ссылке](https://otus.pw/Xy56/).
>
> | https://habr.com/ru/post/694458/ | null | ru | null |
# Как мы заняли 1-е место в задаче Matching в соревновании Data Fusion Contest 2022, или как нейронка обогнала бустинг
На платформе [ODS.ai](http://ods.ai) прошло соревнование по машинному обучению [Data Fusion Contest 2022](https://ods.ai/tracks/data-fusion-2022-competitions) от банка ВТБ.
Мы, команда Лаборатории ИИ Сбера и Института искусственного интеллекта AIRI, приняли решение поучаствовать в контесте, когда увидели, что тема соревнования сильно пересекалась с нашими исследованиями. Мы заняли первое место на private leaderboard в основной задаче Matching. Здесь я хотел бы описать решение, которое у нас получилось.
В рамках соревнования предлагались: датасет, содержащий транзакции, совершенные клиентами ВТБ по банковским картам, кликстрим (данные о посещении web-страниц) клиентов Ростелекома и разметка соответствия между клиентами из этих двух организаций. Соответствие устанавливается если два клиента – это один и тот же человек. Все данные были обезличены, а сами датасеты синтезированы на основе реальных данных таким образом, чтобы сохранить информацию о поведении пользователей.
В программу мероприятия входило пять задач разной сложности с разным призовым фондом. Мы решили сосредоточится на главной задаче [Matching](https://ods.ai/tracks/data-fusion-2022-competitions/competitions/data-fusion2022-main-challenge), как на самой сложной и самой интересной.
Про задачу
----------
В задаче необходимо было сделать решение, которое бы устанавливало соответствие между клиентами ВТБ и Ростелекома. В качестве ответа необходимо было для каждого клиента банка предоставить 100 наиболее вероятных клиентов Ростелекома. Оценка велась как для ранжирования, то есть, чем ближе правильный ответ был к началу списка, тем выше была оценка. Также в данных были случаи, когда для клиента ВТБ пары не находилось. Для таких клиентов в ответе нужно было выставить нулевой идентификатор пары (`rtk_id=0`).
Это было контейнерное соревнование: нужно было отправить код, который бы вычислял ответ для новых входных данных из тестового датасета, не использовавшихся при подготовке модели. Вследствие этого, требования к качеству кода были такими, что код должен корректно работать не только "на моем компьютере", а везде. Ресурсы контейнера были ограничены: на вычисления отводилось не больше часа, что требовало достаточной производительности от решения.
У нас уже был довольно большой опыт работы с событийными данными. Мы одними из первых предложили [метод](https://arxiv.org/abs/2002.08232) для контрастного обучения на неразмеченных транзакциях. Мы выложили в открытый доступ библиотеку [PyTorch-Lifestream](https://github.com/dllllb/pytorch-lifestream) для построения нейронных сетей для событийных данных. Но задача матчинга была для нас новой из-за необходимости одновременно работать с двумя разными доменами с событийными данными (транзакции и кликстрим).
Основной метрикой соревнования был R1, среднее гармоническое между Precision@100 и MRR@100. Precision равнялся 1 если правильный ответ попадал в top100 и 0, если не попадал. MRR (Mean Reciprocal Rank) равнялся "1 / position", где "position" – это позиция правильного ответа среди предложенных 100 кандидатов. То есть MRR = 1 если правильный ответ на первой позиции, 0.5 если на второй, 0.33 на третьей и 0.01 – если на последней. Если правильного ответа нет среди top100, то MRR = 0. Метрики усреднялись по всем клиентам. R1 считался по финальному среднему.
Локальная валидация
-------------------
Поскольку метрика считалась на top100, выбранных среди 3000 клиентов, нам необходимо было выбрать аналогичное количество клиентов для нашей собственной валидации. Действительно, гораздо легче получить правильный ответ, выбирая 100 кандидатов из 200, чем 100 из 3000. В данных было 17581 размеченных пар. Мы решили разбить данные на 6 фолдов по 2930 пар в каждом, что примерно соответствовало размеру public-private датасетов. Мы делали стратифицированное разбиение на основе длин последовательностей. Интуитивно кажется, что это позволило получить более сбалансированные фолды. А еще, это позволило поровну поделить клиентов без данных о сайтах, поскольку у них длина кликстрима равна 0, а разбиение стремится равномерно разложить эту группу по всем фолдам.
Про данные
----------
Всего в датасете было 15.4 млн транзакций для 17581 уникальных клиентов ВТБ и 94.8 млн событий кликстрима для 14671 уникальных клиентов Ростелекома. Итого, примерно 16.6% клиентов ВТБ были без матчинга. Еще были неразмеченные данные в виде 4952 клиентов ВТБ с 4.4 млн транзакций и столько же клиентов Ростелекома с 32.0 млн кликов. Неразмеченные данные хранились отдельно, мы их не включали ни в какой из фолдов.
Вот так выглядели сами данные.
Матчинг:
Здесь все просто, в строке прописано соответствие id банка и телекома. Там, где соответствия нет, указан 0.
Транзакции:
Здесь кроме id-клиента есть mcc код и два поля с его текстовым описанием, код валюты с расшифровкой, сумма транзакции (как с плюсом, так и с минусом) и дата-время транзакции.
Кликстрим:
Здесь кроме id клиента была указана категория страницы и три уровня иерархии с меньшей детализацией, дата-время клика и идентификатор устройства, с которого посещалась страница.
Базовое решение
---------------
Организаторами соревнования был предложен baseline, в котором в качестве фичей считались простые статистики (sum, mean, count) по сумме транзакции или количеству кликов в разрезе каждого mcc кода или категории. Фичи для транзакций и кликов объединялись и подавались в алгоритм бустинга. Алгоритм учился как задача бинарной классификации, где правильным ответом был 1, если транзакции и кликстрим соответствуют одному человеку (есть матч), и 0, если разным. На каждого клиента ВТБ был доступен один правильный клиент Ростелекома (соответствие из разметки) и несколько случайно выбранных из всей выборки неправильных примеров. На public leaderboard бейзлайн показывал R1 = 0.2217.
У нас получилось улучшить бейзлайн до R1 = 0.2757, но основные усилия хотелось приложить именно к решению задачи с помощью нейронных сетей. В качестве примера подхода основанного на генерации признаков для бустинга доступен код [решения](https://github.com/antklen/data_fusion_2022_solution), занявшего второе место в задаче Matching, опубликованный автором.
Схема нашего решения
--------------------
Мы решили использовать схему обучения похожую на сиамскую сеть, которая будет кодировать входную последовательность транзакций или кликстрим в вектор. Цель обучения нейросети – добиться, чтобы эти векторы, располагаясь в одном пространстве, были близкими по какой-либо метрике, если они принадлежат одному человеку, и далекими, если разным людям. То есть, вероятность матчинга объектов будет определяться расстоянием между их векторами. Такая схема часто применяется для установления соответствия между данными из разных доменов: например, картинок и подписей к ним. Была гипотеза, что этот подход сработает и для событийных данных разных типов. Тем более, что наши предыдущие исследования подтверждали, что методы, работающие для изображений, можно переложить на [транзакционные данные](https://arxiv.org/abs/2002.08232). Вот схема обучения:
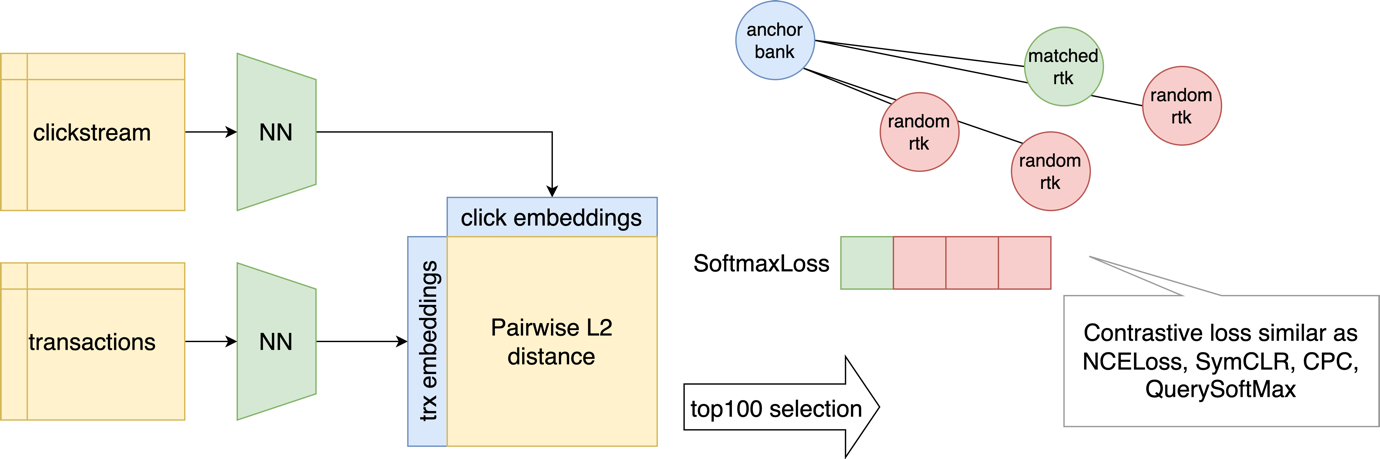Между векторами клиентов ВТБ и Ростелекома считаются попарные расстояния и используется функция потерь, штрафующая за неправильные расстояния между парами. Во время применения обученной сети мы просто отбираем для каждого клиента ВТБ top 100 самых близких клиентов Ростелекома. Мы использовали контрастную функцию потерь (Contrastive Loss, он же NCELoss, QuerySoftMax, …). При ее применении, цель обучения – сделать расстояние между правильной парой меньшим, чем между случайно выбранной неправильной парой. Более подробно на схеме:
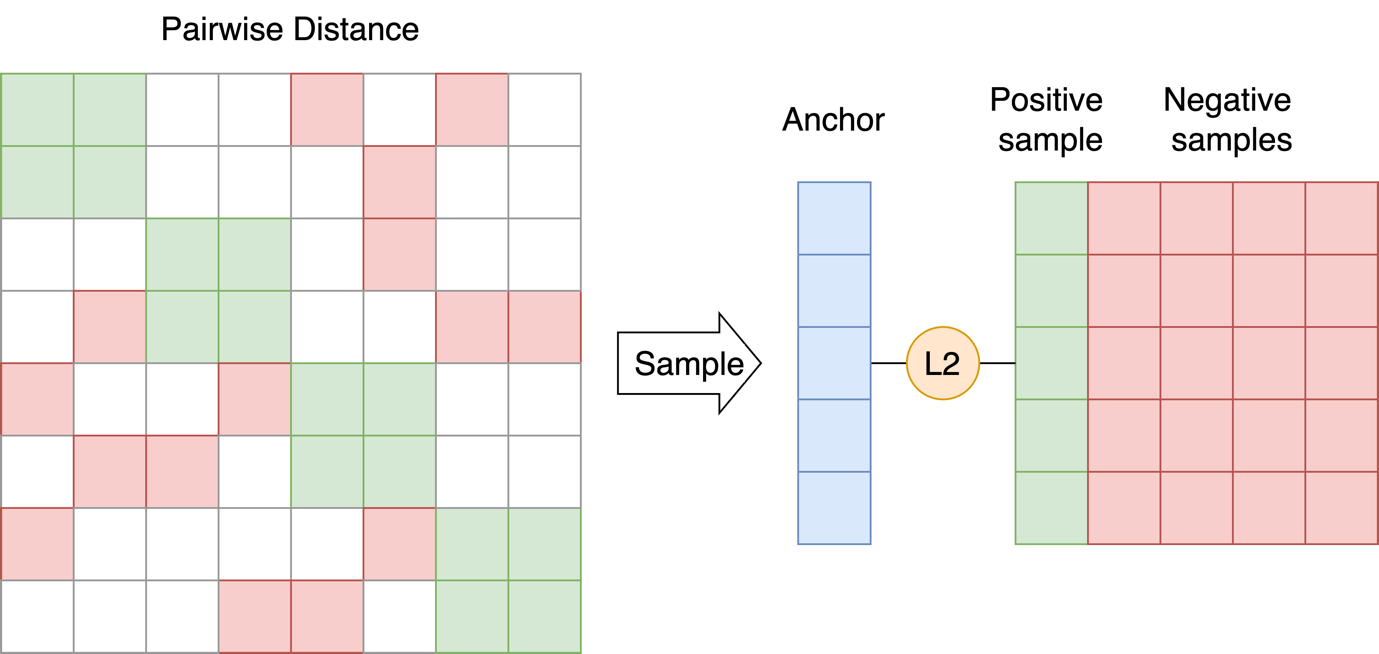Выбирается Anchor - клиент ВТБ, для него выбирается позитивный пример – правильный клиент Ростелекома и некоторое количество негативных примеров, неправильные пары, случайно выбранные из батча. Все примеры собираются в один тензор размера (число клиентов X 1 + число негативных примеров). По нему мы можем рассчитать контрастную функцию потерь. Точная формула:

Здесь *a* - выходной вектор нейросети, *sim* - мера близости двух векторов. Мы использовали квадрат расстояния Евклида между векторами в качестве мера близости. Добавление температуры *t* позволяет нормализовать значения степеней экспоненты и избежать слишком больших значений.
Мы использовали батч по 128 клиентов, и, для каждого клиента генерировали два подмножества из его транзакций или кликстрима. В этом случае матрица попарных расстояний будет иметь размер 256x256. Чем больше негативных примеров мы используем, тем большую разрешающую способность имеет функция потерь. Чтобы попасть в top 100 из 3000, надо быть в top 1 из 30, top 2 из 60 или top 4 из 120. В рамках top 4 правильный клиент может двигаться к первой позиции более плавно, чем в рамках top 1. Можно было бы еще увеличить число негативов, но тогда необходимо было бы также увеличить размер батча, а на его размер есть два ограничения: в рамках датасета у нас становится мало батчей, а сами батчи растут так, что не помещаются в память GPU. С теоретической точки зрения не так важно, сколько негативных примеров используется при расчете функции потерь – если брать меньше негативных примеров, то увеличится время обучения сети для достижения такого же качества. На практике оказалось, что количество негативных примеров в этой задаче имеет значение для сходимости обучения к приемлемому качеству за разумное время.
В качестве Anchor мы сначала брали только клиентов ВТБ, то есть, шли по матрице слева направо. Потом добавили такую же процедуру для клиентов Ростелекома (сверху вниз по матрице). Это позволило немного поднять качество и получить более сбалансированную матрицу, в которой нет сильных перекосов по популярности отдельных клиентов Ростелекома.
Архитектура нейросети
---------------------
Архитектура сети показана на схеме:
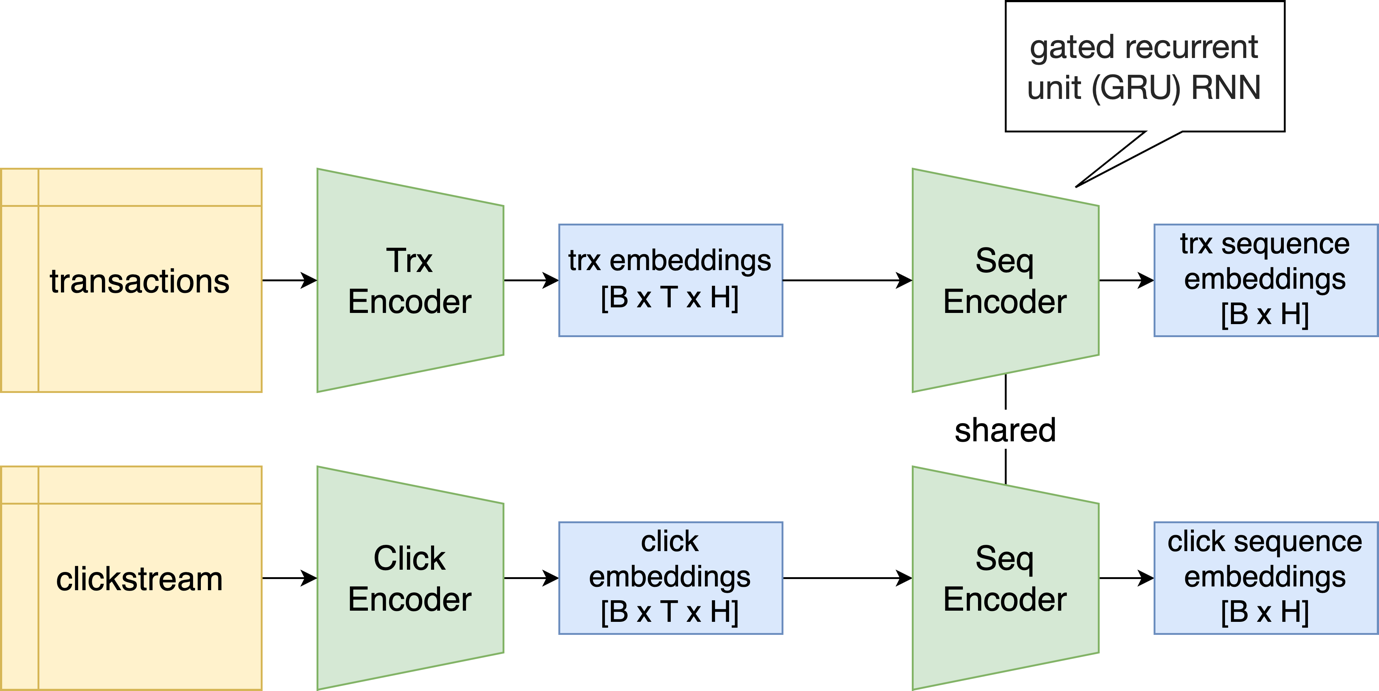Основных компонентов два: кодировщик, который сжимает каждую отдельную транзакцию или событие кликстрима в вектор, и кодировщик, который сжимает последовательность полученных векторов в один – итоговый вектор, описывающий клиента целиком. В качестве последнего использовалась стандартная [GRU RNN](https://pytorch.org/docs/stable/generated/torch.nn.GRU.html). Пробовали использовать здесь трансформер, но с ним качество получилось хуже. Поскольку финальные вектора находятся в одном векторном пространстве, возникла идея использовать общие веса для RNN слоя. Мы предполагали, что в этом случае общее векторное пространство будет также на входе в RNN, и что сеть сможет найти, например, похожие по смыслу mcc в транзакциях и категории в кликстриме. На практике оказалось, что вектора для транзакций и кликстрима получаются совсем разные, но это не мешает RNN с общими весами работать хорошо. В итоге использование общих весов позволило повысить качество, но немного не таким способом, как мы предполагали ранее.
В качестве кодировщика транзакций мы взяли готовый слой из нашей библиотеки TrxEncoder. Его работа показана на схеме:
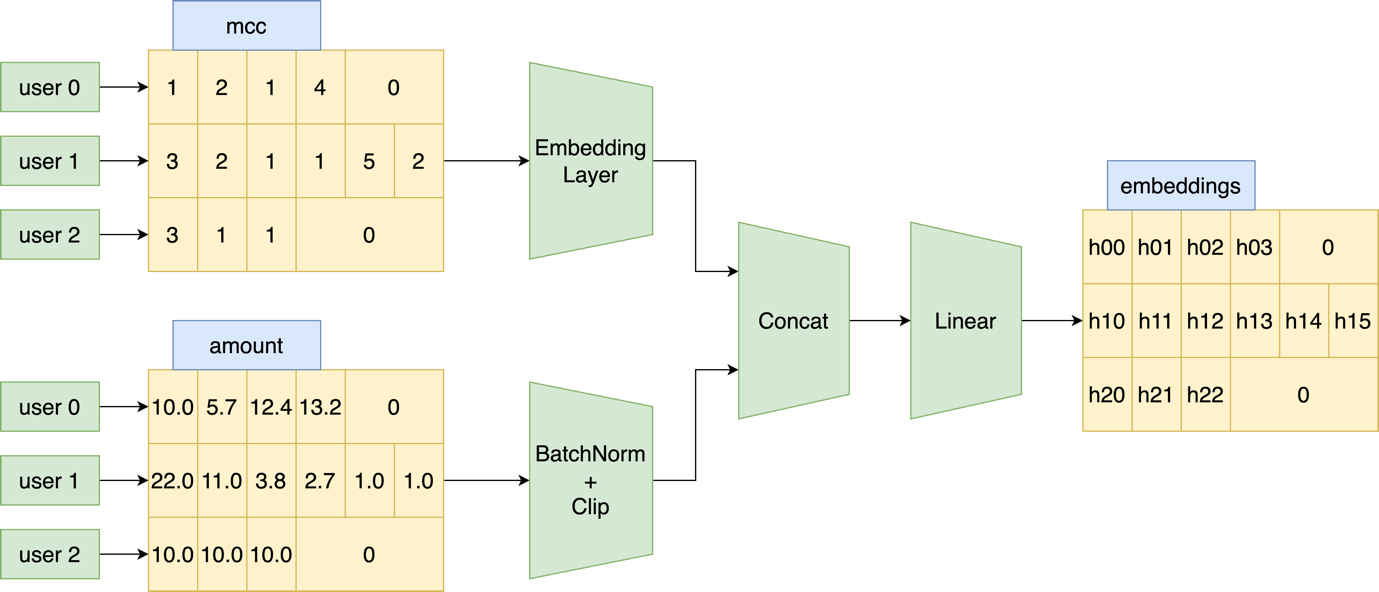Категориальные признаки подаются в embedding-слои. Числовые признаки нормируются и обрезаются выбросы. Результаты конкатенируются по всем признакам, и полученный вектор проходит через линейный слой, задача которого поменять размерность вектора. Это нужно для того, чтобы вектора для транзакций и кликстрима были одного размера, и можно было использовать RNN с общими весами.
Для того, чтобы подать данные в такой TrxEncoder, они специальным образом должны быть подготовлены. Нужно разбить транзакции на группы по клиентам, разделить колонки на отдельные вектора с признаками. Этот процесс показан на схеме:
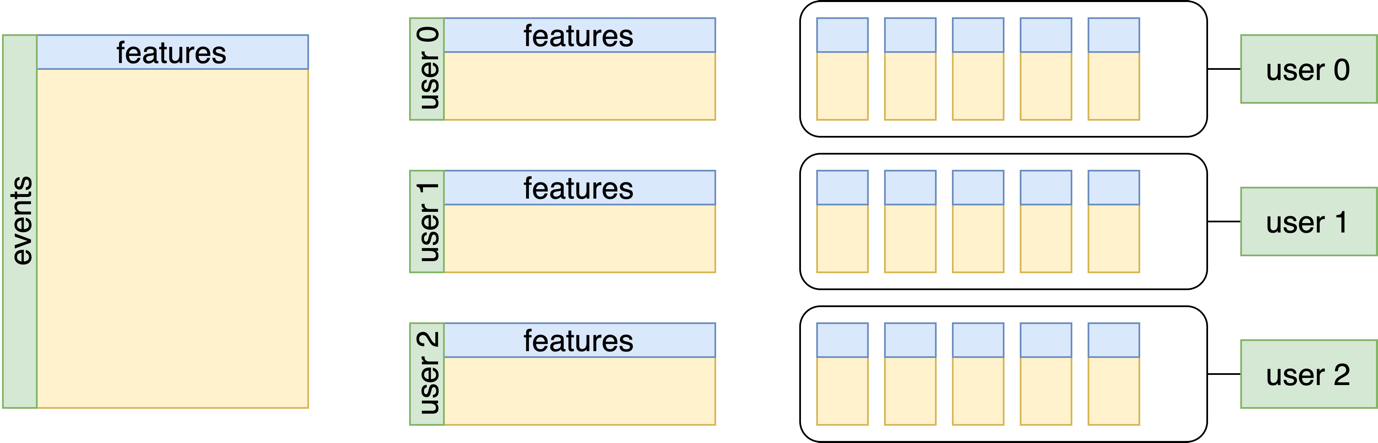Еще надо перевести тип данных в torch.Tensor и закодировать категориальные переменные. Мы использовали частотное кодирование. Чем чаще встречается значение категории, тем меньше значение соответствующего ей кода. Это удобно тем, что можно быстро регулировать размер используемого словаря и выбрасывать редкие категории. Например, чтобы оставить только 100 самых частых категорий в словаре, можно сделать `mcc_code.clamp(0, 100)`. Здесь все редкие категории, у которых код больше 100, будет объединены в одну.
Предобработка данных
--------------------
Теперь немного о признаках, которые мы использовали. Важное достоинство нейросетевого подхода, в отличие от, например, бустинга, в том, что признаки можно подавать почти в сыром виде. Сеть сама может обучиться получать полезные для правильного ответа промежуточные представления данных. И все же подобная обработка помогает повысить качество, особенно, на небольшом датасете.
Вот какие признаки мы использовали для карточных транзакций:
* Основной признак – это `mcc_code`. Как и для остальных категориальных признаков, мы применили частотное кодирование. Мы использовали почти все `mcc` из словаря, итого их получилось 350. Если брали меньше категорий, то итоговое качество падало.
* `сurrency_rk` – код валюты. Несмотря на то, что почти 99.8% значений приходятся на рубли, решили не выбрасывать остальные валюты (USD, EUR).
* `transaction_amt` – пробовали усложнить стандартный вариант, где поле просто нормируется. Разбили весь диапазон сумм на 100 бинов и закодировали сумму номером бина. Получился категориальный признак, для которого можно было обучить embedding-слой. Такой вариант позволяет более гибко строить признаки для суммы, сеть сможет выделить положительные, отрицательные, большие и маленькие диапазоны. Дополнительного прироста качества этот вариант разбиения не принес, но и хуже не стало. Этот признак мы оставили в финальном решении.
* `transaction_dttm` – во-первых, время использовалось для сортировки событий в хронологическом порядке. Во-вторых, из этого поля мы извлекли часы, минуты, секунды, день недели, номер дня в году, номер месяца. Больше всего пользы принесли часы: мы рассматривали номер часа как категориальный признак с обучаемым embedding-слоем для него, это дало большой прирост качества. Остальные признаки не помогли: минуты и секунды, вероятно, из-за слишком большой детализации; все, что относится к году, из-за того, что данных не так много, чтобы что-то выучить. Странно, но день недели тоже не дал прироста качества. Обычно какая-то недельная сезонность в данных присутствует.
* Пробовали использовать аналог позиционного эмбеддинга из трансформеров, переводили время в `timestamp` и считали от этого набор sin и cos с разной амплитудой и фазой. Получилось не лучше, чем было, и эти признаки не стали использовать.
* Наша RNN могла учитывать последовательность транзакций, но получала информации о расстоянии между ними по времени. Решили добавить признаки статистик вдоль временной оси: расстояние между соседними транзакциями в днях, количество транзакций в этот день, количество транзакций за последнюю неделю, считая от текущей транзакции. Из всего этого качество не падало только при использовании расстояния между транзакциями. Его мы оставили в финальном решении.
Для кликов использовали вот такие признаки:
* Категории, их также, как и `mcc` взяли почти все, в количестве 400 шт.
* Добавили все дополнительные иерархии `level_0` – `level_2`. Если событие имеет одно значение level, но разные категории, то это будет учитываться. Будет видна и похожесть по level, и разница по категориям. Без этих уровней было чуть похуже, чем с ними.
* Для поля `timestamp` посчитали те же временные признаки, что и для транзакций.
* Идентификатор устройства `new_uid` так и не смогли использовать. Считали количество уникальных id, в том числе и в разных временных окнах, пробовали делать отдельные последовательности для каждого устройства, пробовали закодировать устройство эмбеддингом по частоте его встречаемости у конкретного пользователя. Все это не сработало. Даже пробовали обучить отдельную сетку для кластеризации устройств. Сеть должна была посмотреть на всю последовательность кликов, и для каждого id выдать его класс. В итоге ответы сети схлопнулись, и для всех id предсказывался один и тот же класс.
Предобучение кодировщика транзакций с помощью Transfromer-модели
----------------------------------------------------------------
Можно заметить, что наряду с полезными признаками, мы добавили немного бесполезных, которые не повышали качество. Одна из причин, по которой это было сделано – предобучение кодировщика транзакций. Предполагалось, что во время предобучения сеть сформирует из мало полезных признаков какие-то их представления, которые потом сработают. Предобучение организовали по образу BERT. Использовалась промежуточная задача Masked Language Model. Отличие от NLP методов было в том, что мы маскировали и предсказывали не сам токен (транзакцию), а его вектор. Причина в том, что транзакция – сложный объект, и нет однозначного решения, как его маскировать и сравнивать потом с прогнозом. Вот схема предобучения:
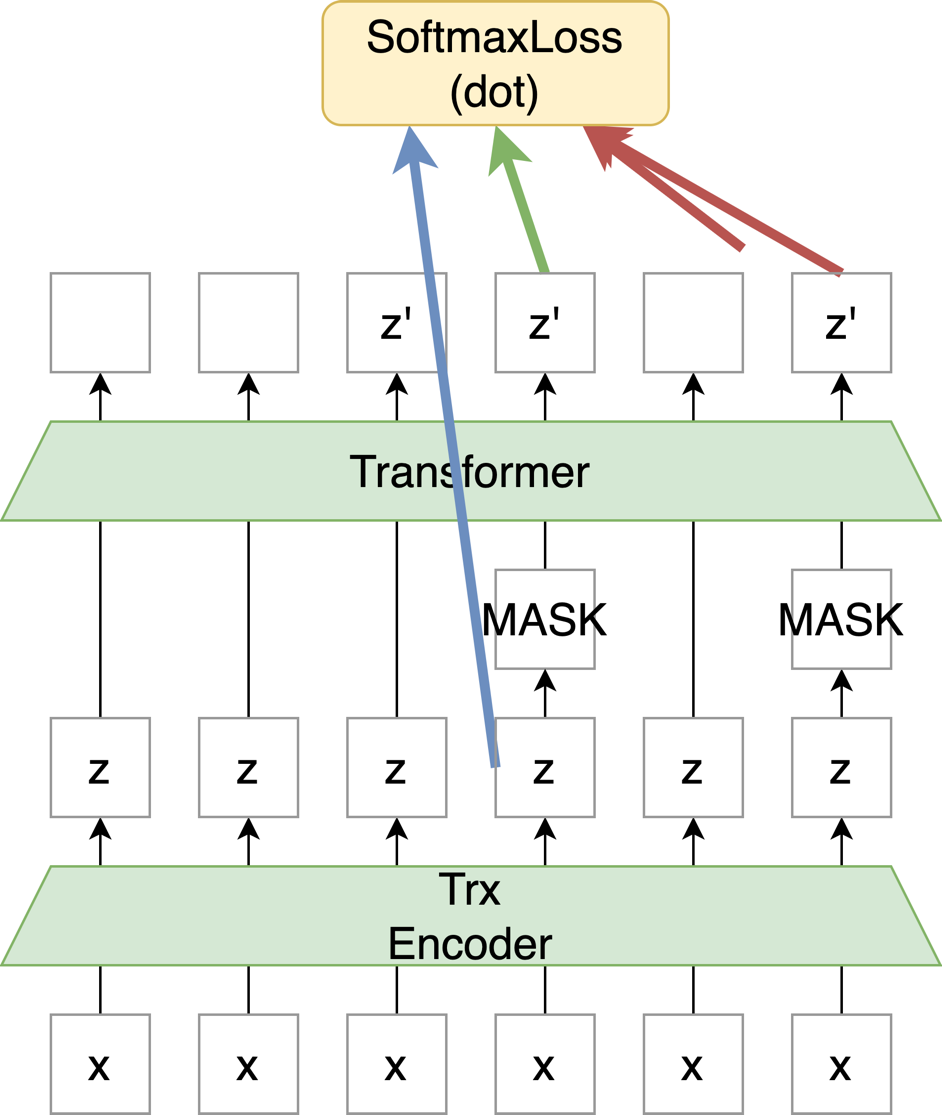Маскировались выходы TrxEncoder. Трансформер предсказывает значение вектора, которое было до маскирования. Используется уже упомянутый Contrastive Loss с негативными примерами. Негативные примеры нужны для того, чтобы сеть не смогла выучить тривиальное решение, например, все прогнозы делать нулями.
Предобучались TrxEncoder отдельно для транзакций и отдельно для кликов. Далее полученными весами инициировались соответствующие слои финальной модели и начиналось обучение под задачу матчинга. RNN слои при этом инициализировались случайными весами. Трансформер, который участвовал в предобучении, потом не использовался.
Аугментации
-----------
На всех этапах обучения сети мы использовали аугментации. Первая устраняла повторы в последовательностях. Повторяющиеся mcc или категории выбрасывались, а исходное количество транзакций записывалось в отдельное поля, как отдельный признак:
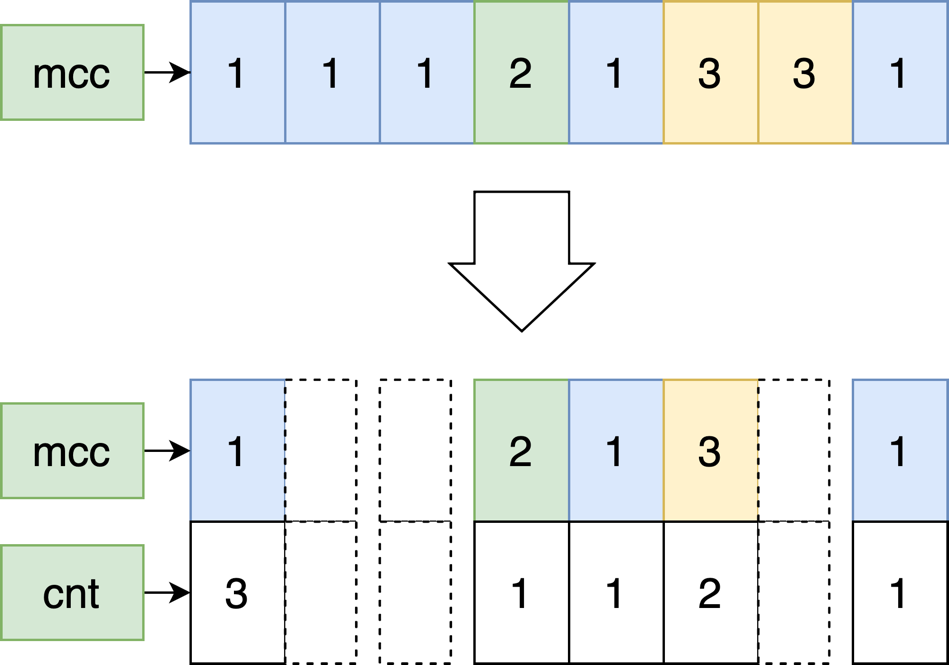Это позволило сократить длины последовательностей, особенно для кликстрима, где встречались очень длинные цепочки повторяющихся категорий.
Вторая – вырезала часть из всей последовательности. Длина и место начала семпла выбиралось случайно.
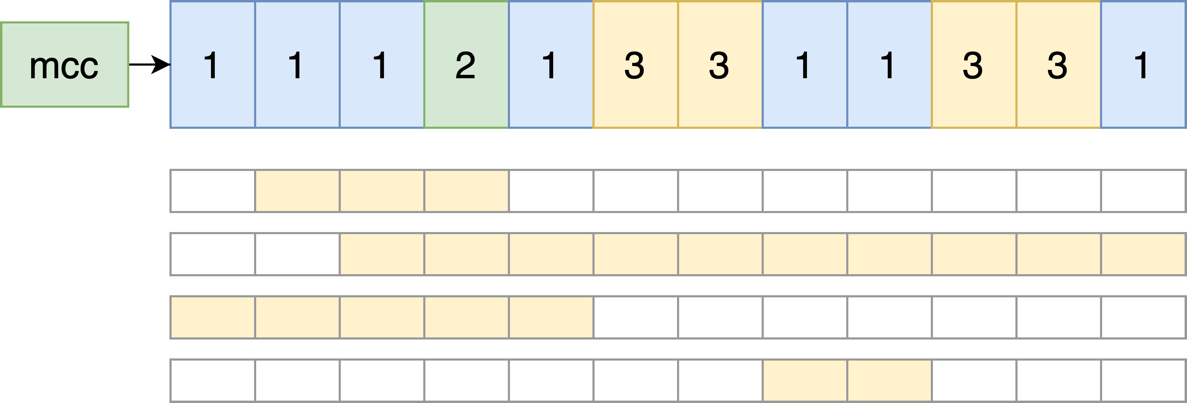Параметры семплирования были заданы так, что в обучение попадали и очень короткие последовательности (порядка 64 событий), и очень длинные (до 2000 событий, примерно половина всей последовательности). На коротких последовательностях сеть быстрее учится. На длинных получает больше информации.
Ансамблирование
---------------
В финальном варианте решения мы добавили использование ансамбля сетей. Несколько сетей учились с разными random seeds, каждая сеть выдавала матрицу попарных расстояний, а эти матрицы усреднялись по всем сетям ансамбля. В итоге это дало самый большой прирост качества, для ансамбля из пяти моделей R1 выросло с 0.2819 до 0.2949. Вот график зависимости качества от количества сетей в ансамбле:
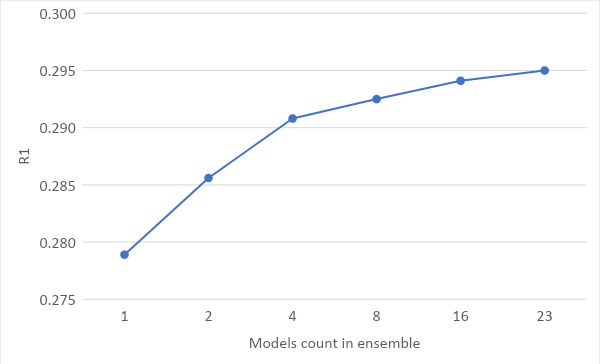В финальном решении мы смогли уместить 11 сетей, вычисление ответа для которых выполнялось почти за час. Можно было ускорить инференс и взять больше моделей в ансамбль, если бы мы вовремя заметили, что GPU в контейнер не подключилось. Позже мы делали точные замеры на локальной машине, и оказалось, что с GPU инференс с пятью моделями в ансамбле работает 2 минуты, из них полторы – это пребодработка данных.
Итоги
-----
Полученное решение заняло второе место на public leaderboard и первое – на private. Полный код финального решения можно посмотреть по [ссылке](https://github.com/ivkireev86/datafusion-contest-2022). Решение основано на нашей библиотеке для работы с событийными данными [PyTorch-Lifestream](https://github.com/dllllb/pytorch-lifestream).
Авторы текста: Иван Киреев и Дмитрий Бабаев | https://habr.com/ru/post/670572/ | null | ru | null |
# Тридцать лет С++. Интервью с Бьерном Страуструпом
[](https://habr.com/ru/company/skillfactory/blog/522400/)
Ранее мы делали материал про [использование C и C++ в Data Science](https://habr.com/ru/company/skillfactory/blog/509534/). А сегодня мы хотим поделиться с вами интервью с автором C++ Бьерном Страуструпом. Далее в посте вас ждет рассказ о профессиональном пути Бьерна, деталях создания собственного языка программирования и извлеченные им из этого уроки.
---
> Если вы держите хорошие идеи при себе, они бесполезны. Вы могли бы с таким же успехом разгадывать кроссворды. Только сформулированные в письменном виде и высказанные в беседах идеи становятся вкладом. (с) Бьерн Страуструп
>
>
**Основам объектно-ориентированного программирования вы научились у Кристена Нюгора, создавшего вместе с Оле-Йоханом Далем объектно-ориентированный язык программирования Simula. Кристен Нюгор часто посещал ваш университет в Дании. Как он повлиял на вашу карьеру?**
Кристен был интересным человеком со впечатляющим характером. Он был, конечно, очень творческой натурой и гигантом во всех отношениях. Для начала, рост его был около 6 футов и 6 дюймов и он был довольно широким. Вдохновившись чем-то, он мог обнять, как медведь. Обсуждение с ним любой темы — скажем, программирования, криминальной фантастики или трудовой политики всегда было интересным, иногда вдохновляющим.
Будучи молодым студентом магистратуры, я часто встречался с ним, потому что мой студенческий кабинет находился у начала лестницы, ведущей в гостевую квартиру. Каждый месяц он приезжал из Осло на неделю или около того. По прибытии он звал меня, чтобы (перефразируя) «доставить подозреваемых». Моей работой было привести полдюжины хороших учеников и ящик пива. Затем мы говорили — а это значит, что Кристен пару часов выдавал информацию на различные темы. Так я узнал много нового о проектировании и об основах [объектно-ориентированного программирования](https://en.wikipedia.org/wiki/Object-oriented_programming). Это была скандинавская школа ООП, где главную роль, конечно, играет проектирование и моделирование реального мира в коде.
**В 1979 году вы получили степень доктора философии *(прим. перев. российский аналог степени — кандидат наук)* по информатике в Кембриджском университете под руководством [Дэвида Уиллера](https://en.wikipedia.org/wiki/David_Wheeler_(computer_scientist)). Что вы узнали от Девида Уилера такого, что было полезно для вашей будущей работы?**
Дэвид Уиллер был мастером своего дела. О его умениях в проектировании ходили легенды. Интересен был стиль преподавания. Каждую неделю я приходил в его офис, чтобы рассказать, какие замечательные идеи у меня возникли или с какими я столкнулся за это время. Реакция была предсказуемой: «Да, Бьёрн, это неплохая идея; на самом деле, мы почти использовали ее для [EDSAC-2](https://en.wikipedia.org/wiki/EDSAC_2)». То есть у него была такая же идея, когда я поступил в начальную школу, и он отказался от нее в пользу чего-то лучше. Я слышал, что некоторым студентам было трудно справиться с такими ответами, но был очарован, потому что Девид затем приступил к разъяснению моих идей, оценивал их в контексте и подробно рассказывал об их сильных и слабых сторонах, возможных улучшениях и альтернативах. Я задавал вопросы, мы обсуждали проблемы, решения и компромиссы в течение часа или более. Он научил меня многому в том, как исследовать пространства проектирования и как объяснять идеи — всегда на конкретных примерах. При этом я нахожу его официальные лекции смертельно скучными. Не думаю, что ему нравилось их читать. У Дэвида были другие сильные стороны.
В мой первый день в Кембридже он спросил меня: «Какая разница между магистром и доктором?». Я не знал. «Если я должен сказать тебе, что делать, то ты магистр», — сказал он и продолжил (неизменно вежливо) указывать на то, что быть магистром Кембриджа — это судьба хуже смерти. Я не возражал, потому что, как он, наверное, забыл, я только что получил замечательную степень магистра математики в области вычислительной техники в Университете Орхеса.
За те годы, что он наблюдал за мной, не думаю, что он дал мне больше, чем один направляющий совет. В последний день перед отъездом из Кембриджа, после завершения диссертации, он пригласил меня на ланч и сказал: «Ты едешь в [Bell Labs](https://en.wikipedia.org/wiki/Bell_Labs). Это очень хорошее место со множеством прекрасных людей, но в то же время, это черная дыра. Хорошие люди приходят туда и о них больше никогда не слышат. Что бы ты ни делал, будь на виду». Здесь идеально подходит формулировка: если вы держите хорошие идеи при себе, они бесполезны. Вы могли бы с таким же успехом разгадывать кроссворды. Только сформулированные в письменном виде и высказанные в беседах идеи становятся вкладом.
> В Дэвиде Уиллере меня привлек его отличный послужной список как в аппаратном, так и в программном обеспечении. А Кристен Нюгор и Деннис Ритчи — честные, добрые и великодушные люди, которым можно доверять. Они усердно трудились ради того, что считали важным.
**Вы говорили, что спроектировали C++ ещё в 1979 году, чтобы ответить на вопрос «Как вы непосредственно манипулируете аппаратным обеспечением, а также поддерживаете эффективную высокоуровневую абстракцию?» Вы все ещё верите, что это была хорошая идея?**
Определенно! [Деннис Ритчи](https://en.wikipedia.org/wiki/Dennis_Ritchie) известен тем, что различает языки, призванные «решить проблему», и языки, призванные «доказать точку зрения». Подобно C, C++ относится к первой категории. Граница между программным и аппаратным обеспечением интересна, сложна, постоянно меняется и приобретает все большее значение. Фундаментальной идеей C++ было предоставить поддержку прямого доступа к оборудованию, основанную на модели языка C, а затем позволить людям «уйти» к уровням выражения выше, через так называемую абстракцию без накладных расходов. Похоже, что в этом пространстве проектирования есть бесконечная необходимость в коде. Я начал с С и [Simula](https://en.wikipedia.org/wiki/Simula)-подобных классов. С годами, улучшения (например, шаблоны) значительно расширили выразительные возможности и оптимизируемость С++.
**Почему вы выбрали C в качестве основы для своей работы?**
Я решил не начинать с нуля. Мне хотелось быть частью технического сообщества и не повторять все фундаментальные проектные решения. Я знал по меньшей мере десяток языков, которые мог бы использовать, гибких и с хорошим доступом к аппаратным средствам. Например, я знаком с [Algol 68](https://en.wikipedia.org/wiki/ALGOL_68) и мне понравилась его система типов. Но у языка не было большого индустриального сообщества. Вместе с этим, поддержка статической проверки типов в C была слабой. Но поддержка сообщества была превосходной: Деннис Ритчи и [Брайан Керниган](https://en.wikipedia.org/wiki/Brian_Kernighan) были прямо по коридору от меня! Кроме того, подход к работе с аппаратным обеспечением в C был отличным, поэтому в качестве основы я выбрал C и стал добавлять функциональность по мере необходимости, начиная с проверки аргументов функций и классов с конструкторами и деструкторами.
**Вы также писали, что на С++ можно смотреть как на результат трех десятилетий противоречивых требований. *Сделай язык проще! Добавь эти две важные особенности сейчас! Не ломай мой код!* Вы можете объяснить, что понимаете под этими требованиями?**
У многих людей есть очень разумные пожелания по улучшению. Но часто эти пожелания противоречат друг другу. Любой хороший дизайн должен включать в себя компромиссы.
* Очевидно, что у C++ есть нежелательная сложность и «бородавки», которые хотелось бы удалить. Я официально заявляю, что можно создать язык в 1/10 размера С++ (любой мерой) не в ущерб выразительности или мощности выполнения ([HOPL3](https://www.stroustrup.com/hopl-almost-final.pdf)). Это нелегко и я не думаю, что нынешние попытки увенчаются успехом. Но считаю это возможным и желательным.
* К сожалению, при достижении этой разумной цели порядка полутриллиона строк кода перестанет работать. Устареет огромное количество учебного материала и тяжело доставшийся опыт многих программистов. Многие, возможно, даже большинство организаций все ещё будут зависеть от С++ в течение многих лет или десятилетий. Автоматическое, гарантированное корректное преобразование исходного кода могло бы облегчить боль, но трансляция кода с грязного на чистый затруднена. При этом очень важный код на C++ управляет хитрыми аспектами аппаратного обеспечения.
* Наконец, мало кто хочет только упрощения. Люди хотят новые удобства, чисто выражающие что-то, что очень трудно выразить на C++. Им нужны новые возможности и эти возможности обязательно сделают язык больше.
* Мы просто не можем иметь все, что хотим. Но это не должно заставить нас унывать. Прогресс возможен, но он предполагает болезненные компромиссы и тщательную разработку. Стоит помнить, что каждый долгоживущий и широко используемый язык будет обладать особенностью, которая в ретроспективе может быть серьезно улучшена или заменена лучшими альтернативами. Язык также имеет большую кодовую базу, которая не соответствует современным стандартам проектирования и реализации. Это неизбежная цена успеха.
**Какие основные уроки вы извлекли за годы существования C++?**
Я извлек много уроков, так что трудно выбрать главный. Полагаю, вы имеете в виду уроки проектирования языка.
* Фундаментальные решения важны, и их трудно изменить, тем более, что в реальном мире основные языковые решения не могут изменяться.
* Мода соблазнительна и ей трудно сопротивляться, но она меняется куда быстрее, чем живет язык. Важно быть немного скромным и подозрительным к своим собственным убеждениям.
* Часто первое разумное решение не лучшее в долгосрочной перспективе.
* Стабильность на протяжении десятилетий — это особенность языка. Ты не знаешь, для чего и как люди будут использовать его.
* Ни один язык и ни один стиль программирования не будет хорошо служить всем пользователям.
Полная безопасность типов и управление ресурсами были идеалами для С++ с самого начала. Однако, учитывая необходимость обобщения и бескомпромиссности в производительности, к этим идеалам можно было подходить только поэтапно, по мере развития понимания и технологий. Произвольный код на C++ не может гарантировать безопасность типов и ресурсов. Мы не можем изменить язык так, чтобы предложить эти гарантии, не сломав при этом множество строк кода. Однако сегодня мы достигли той точки, когда можем гарантировать полную безопасность типов и ресурсов, используя комбинацию руководств, библиотечной поддержки и статического анализа: [The C++ Core Guidelines](https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md). Я изложил основные руководящие принципы в [работе 2015 года](https://www.stroustrup.com/resource-model.pdf). Сейчас статический анализатор, поддерживающий Core Guidelines, поставляется вместе с Microsoft Visual Studio. Я надеюсь на такую поддержку основных руководящих принципов, (которые не являются частью единой реализации), чтобы их использование стало повсеместным.
С годами я все больше ценю инструментальную поддержку. Мы пишем программы не просто на языке программирования, а в определенной цепочке инструментов и среде, состоящей из библиотек и конвенций. Мир C++ предлагает ошеломляющее разнообразие инструментов и библиотек. Многие из них превосходны, но нет доминирующих «неофициальных стандартов», поэтому очень трудно выбирать и сотрудничать с людьми разных предпочтений. Я надеюсь на сближение людей, которое существенно поможет разработчикам C++ и преподаванию C++. Это обсуждается в моей работе HOPL-4 и в [Thriving in a crowded and changing world: C++ 2006–2020](https://dl.acm.org/doi/abs/10.1145/3386320).
**Кто все ещё использует C++?**
Больше разработчиков, чем когда-либо. C++ — основа многих, многих систем и приложений, включая некоторые из наших наиболее широко используемых и известных систем. Это также обсуждается в [Thriving in a crowded and changing world: C++ 2006–2020](https://dl.acm.org/doi/abs/10.1145/3386320). Компании Google, Facebook — одни из основных пользователей. Полупроводниковая промышленность, игры, финансы, автомобильная и аэрокосмическая промышленность, медицина, биология, физика высоких энергий и астрономия — C++ используется во всех этих областях. Многое, однако, невидимо для конечных пользователей.
Разработчиков C++ трудно подсчитать, но опросы говорят о 4,5 миллионах пользователей и это число растет. Я даже слышал «5 миллионов». Нет хорошего подхода для подсчета. Многие индексы, такие как [Tiobe](https://en.wikipedia.org/wiki/TIOBE_index), считают «шум», то есть упоминания в сети. Но один увлеченный студент размещает гораздо больше упоминаний, чем 200 занятых разработчиков важных приложений.
**Во времена искусственного интеллекта С++ все ещё актуален?**
Конечно! C++ — основа большинства современных AI/ML. Большая часть нового автомобильного программного обеспечения — это C++, на C++ работает много высокопроизводительного программного обеспечения. Независимо от того, какой язык вы используете для AI/ML, реализация включает критическую часть на некоторых библиотеках C++. Пример — [Tensorflow](https://www.tensorflow.org/). Серьезный специалист по данным выразил это так: «Я трачу 97% своего времени на написание кода на Python и мой компьютер использует 98.5% циклов, работающих на C++, чтобы выполнить его».
**Какие из существующих сейчас языков наиболее интересны?**
Может быть C++. Многие идеи современных языков пришли из С++ или пошли в массы через С++. [RAII](https://en.wikipedia.org/wiki/Resource_acquisition_is_initialization) для управления ресурсами. Шаблоны для [обобщенного программирования](https://en.wikipedia.org/wiki/Generic_programming). Шаблоны и [`функции constexpr`](https://en.wikipedia.org/wiki/C%2B%2B11) для вычислений во время компиляции. Различные механизмы конкурентного выполнения. В свою очередь, С++, конечно же, во многом обязан более ранним языкам и исследованиям. В смысле будущих разработок, которые повлияют на методы программирования, я буду следить за статической рефлексией. Много интересной работы делается в [функциональных языках](https://en.wikipedia.org/wiki/Functional_programming) и в «скриптинге» (например, [TypeScript](https://en.wikipedia.org/wiki/TypeScript)).
**Почему вы решили оставить работу на полный рабочий день в академии и присоединиться к Morgan Stanley?**
Есть несколько связанных с этим причин. Больше десяти лет я делал большую часть того, что делал академик в смысле карьеры: преподавал студентам магистратуры, аспирантами, работал с будущими докторами философии, планировал учебные программы, писал учебники (например, [Programming — Principles and Practice Using C++ (Second Edition)](https://www.stroustrup.com/programming.html), научные работы на конференциях и в журналах (например, [Specifying C++ Concepts](https://www.stroustrup.com/popl06.pdf)), получал исследовательские гранты, заседал в университетских комитетах. Эта работа перестала быть новой, интересной и сложной.
Я чувствовал, что мне нужно вернуться «в шахту», в промышленность, чтобы убедиться, что мои работы и мнения все ещё актуальны. В академических кругах трудно было заниматься тем, что мне интересно: масштабированием, надежностью, производительностью и поддержкой. Кроме того, я почувствовал необходимость стать ближе к своей семье в Нью-Йорке и в Европе. Морган Стенли находился в Нью-Йорке, у него были очень интересные проблемы, связанные с надежностью и производительностью распределенных систем, большими базами кода на C++, и — что немного удивило меня, учитывая репутацию финансовой индустрии — было много приятных людей, с которыми можно работать.
**Вы приглашенный профессор информатики в Колумбийском университете. Какое главное послание вы хотите передать молодым студентам?**
Наша цивилизация в значительной степени зависит от программного обеспечения. Мы должны совершенствовать наши системы и для этого должны расти профессионально. То же самое я бы попытался передать опытным разработчикам, менеджерам и руководителям. Также я рассказываю о принципах проектирования С++ и показываю практические примеры того, как они воплощались на протяжении десятилетий. Нельзя преподавать проектирование абстрактно.
**Вы хотите что-нибудь добавить?**
Образование важно, но не все люди, которые хотят писать программное обеспечение, нуждаются в одинаковом образовании. Мы должны убедиться, что существует путь через лабиринт образования с хорошей поддержкой для людей, которые будут писать критически важные системы. Те системы, которым мы доверяем жизнь и средства к существованию. Мы должны стремиться к тому, чтобы уровень профессионализма был равен тому, который мы видим у лучших врачей и инженеров.
> [](https://skillfactory.ru/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_banner&utm_term=regular&utm_content=habr_banner)
>
>
>
> * [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=081020)
> * [Профессия Java-разработчик с нуля](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=081020)
> * [Курс по JavaScript](https://skillfactory.ru/javascript?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FJS&utm_term=regular&utm_content=081020)
> * [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=081020)
> * [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=081020)
>
>
>
>
> **Eще курсы**
> * [Обучение профессии Data Science с нуля](https://skillfactory.ru/data-scientist?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DST&utm_term=regular&utm_content=081020)
> * [Онлайн-буткемп по Data Science](https://skillfactory.ru/data-science-camp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSTCAMP&utm_term=regular&utm_content=081020)
> * [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=081020)
> * [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=081020)
> * [Продвинутый курс «Machine Learning Pro + Deep Learning»](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=081020)
> * [Онлайн-буткемп по Data Analytics](https://skillfactory.ru/business-analytics-camp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DACAMP&utm_term=regular&utm_content=081020)
> * [Профессия аналитика с любым стартовым уровнем](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=081020)
> * [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=081020)
> * [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=081020)
> * [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=081020)
> * [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=081020)
> * [Профессия UX-дизайнер с нуля](https://contented.ru/edu/uxdesigner?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_UXS&utm_term=regular&utm_content=081020)
> * [Профессия Web-дизайнер](https://contented.ru/edu/webdesigner?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WBDS&utm_term=regular&utm_content=081020)
>
>
>
>
>
>
> | https://habr.com/ru/post/522400/ | null | ru | null |
# Основы внутреннего устройства JavaScript

С ростом популярности JavaScript команды разработчиков начали использовать его поддержку на многих уровнях своего стека — во фронтенде, бэкенде, гибридных приложениях, встраиваемых устройствах и многом другом. В этой статье мы хотим более глубоко рассмотреть JavaScript и то, как он работает.
Введение
--------
Почти все уже слышали о концепции движка V8 и большинство людей знает, что язык JavaScript однопотоковый или что он использует очередь обратных вызовов.
В этом посте мы подробно разберём эти концепции и объясним, как же работает JavaScript. Благодаря знанию этих подробностей вы сможете писать более оптимальные приложения, надлежащим образом использующие API. Если вы работаете с JavaScript относительно недавно, этот пост поможет вам понять, почему JavaScript настолько «странный» по сравнению с другими языками. А если вы опытный разработчик на JavaScript, то он позволит вам по-новому взглянуть на внутреннее устройство JavaScript Runtime, с которым вы работаете каждый день.
В этой статье мы обсудим внутреннюю работу JavaScript в среде выполнения и в браузере. Это будет краткий обзор всех базовых компонентов, задействованных в исполнении кода на JavaScript. Мы рассмотрим следующие компоненты:
1. JavaScript Engine.
2. JavaScript Runtime Environment.
3. Стек вызовов.
4. Параллельность и цикл событий.
Давайте начнём с движка JavaScript.
JavaScript Engine
-----------------
Как вы, возможно, слышали ранее, JavaScript — это интерпретируемый язык программирования. Это означает, что перед исполнением исходный код не компилируется в двоичный код.
Как же компьютер может понять, что ему делать с простым тестовым скриптом? В этом и заключается работа движка JavaScript. Движок — это просто компьютерная программа, исполняющая код JavaScript. Движки JavaScript встроены во все современные браузеры. Когда файл скрипта загружается в браузер, движок исполняет каждую строку файла сверху вниз (чтобы упростить объяснение, мы не будем рассматривать поднятие (hoisting) в JS). Движок строка за строкой парсит код, преобразует его в машинный код, а затем исполняет.
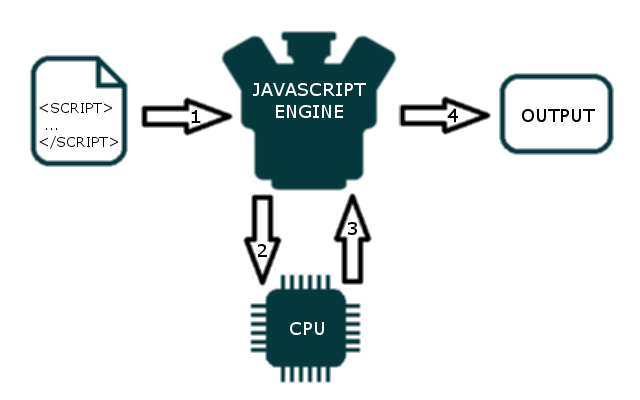
У каждого браузера есть собственный движок JavaScript, но самым известным является Google V8. Движок V8 лежит в основе Google Chrome, а также Node.js.

*Движки браузеров*
Движок состоит из двух основных компонентов:
* Куча памяти — здесь происходит распределение памяти.
* Стек вызовов — здесь находятся стековые кадры в процессе исполнения кода.

Любой движок JavaScript всегда содержит стек вызовов и кучу. Именно в стеке вызовов исполняется наш код. А куча — это пул неструктурированной памяти, хранящий все объекты, необходимые приложению.
Runtime
-------
Пока мы говорили только о движке JavaScript, но он не работает в изоляции. Он выполняется в среде под названием JavaScript Runtime Environment наряду со множеством других компонентов. JRE отвечает за обеспечение асинхронности JavaScript. Именно благодаря ей JavaScript способен добавлять события и выполнять HTTP-запросы асинхронно. JRE похожа на контейнер, состоящий из следующих компонентов:
* JS Engine;
* Web API;
* Очередь обратных вызовов или очередь сообщений;
* Таблица событий;
* Цикл событий.
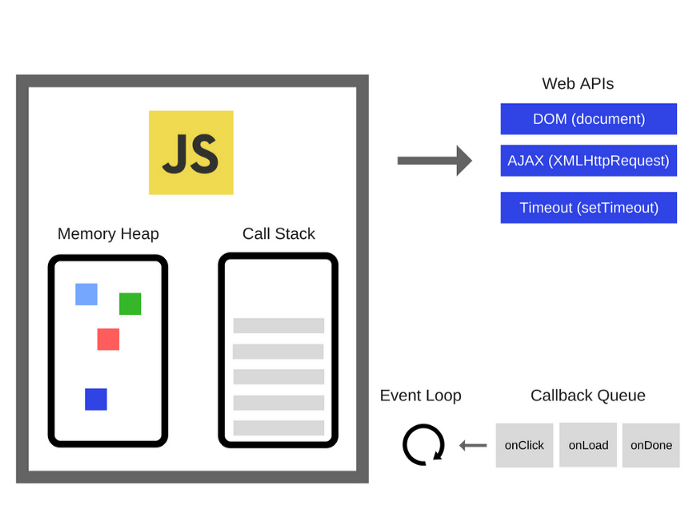
Стек вызовов
------------
JavaScript — это однопоточный язык программирования, то есть он имеет один стек вызовов. Следовательно, он может выполнять по одной задаче за раз.
Стек вызовов — это структура данных, по сути, записывающая, в каком месте программы мы находимся. Если мы заходим в функцию, то помещаем её в вершину стека. Если мы возвращаемся из функции, то извлекаем вершину стека. Вот и всё, что может делать стек. Давайте рассмотрим пример. Взгляните на следующий код:
```
function multiply(x, y) {
return x * y;
}function printSquare(x) {
var s = multiply(x, x);
console.log(s);
}printSquare(5);
```
Когда движок начинает исполнять код, стек вызовов будет пуст. Далее выполняются следующие шаги:
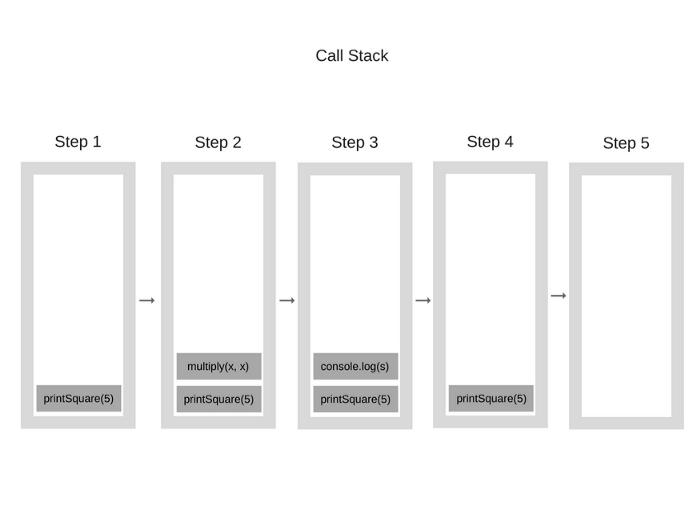
Каждая запись в стеке вызовов называется **стековым кадром**.
Выполнение кода в одном потоке может быть довольно простым процессом, потому что не приходится иметь дело со сложными ситуациями, возникающими в многопотоковых средах, например, с взаимными блокировками. Однако выполнение в одном потоке ещё и сильно ограничивает.
Параллельность и цикл событий
-----------------------------
Что произойдёт, когда в стеке вызовов есть вызовы функций, для обработки которых нужно огромное количество времени? Например, если нам нужно выполнить в браузере при помощи JavaScript какое-то сложное преобразование изображения.
Вы можете спросить: а почему это вообще проблема? Проблема в том, что пока в стеке вызовов есть функции, которые нужно исполнять, браузер не может делать ничего другого, он блокируется. Это значит, что браузер не может рендерить, не может выполнять любой другой код, он просто простаивает. И это создаёт проблемы, если UI в приложении должен быть отзывчивым.
Но это не единственная проблема. Как только браузер начинает обрабатывать такое количество задач в стеке вызовов, он может оказаться неотзывчивым на достаточно долгое время. И большинство браузеров предпринимают действия, выдавая ошибку, спрашивая пользователя, хочет ли он завершить выполнение веб-страницы.
Часть 2: внутреннее устройство движка
-------------------------------------

#### Компиляция и интерпретация
Для начала нам нужно рассказать о разнице между компиляцией и интерпретацией. Мы знаем, что процессор компьютера понимает только нули и единицы, поэтому в конечном итоге каждая компьютерная программа должна быть преобразована в машинный код, и это можно сделать при помощи компиляции или интерпретации.
При **компиляции** весь исходный код за раз преобразуется в машинный код. А затем этот машинный код записывается в портируемый файл, который может исполняться на любом совместимом компьютере. Здесь есть два этапа. Сначала машинный код собирается, а затем исполняется в процессоре. И исполнение может происходить намного позже компиляции.

При **интерпретации** используется интерпретатор, проходящий по исходному коду и исполняющий его строка за строкой. То есть двух описанных ранее этапов здесь нет. Вместо них код считывается и исполняется одновременно. Разумеется, исходный код всё равно нужно преобразовать в машинный код, но это просто происходит прямо перед исполнением, и не раньше.
JavaScript был полностью интерпретируемым языком, но проблема интерпретируемых языков заключается в том, что они гораздо медленнее скомпилированных языков. Раньше для JavaScript это было нормально, но для современного JavaScript и полнофункциональных приложений низкая производительность более неприемлема.
Многие люди по-прежнему считают, что JavaScript — это интерпретируемый язык, но это уже не так. Вместо простой интерпретации современные движки JavaScript используют комбинацию компиляции и интерпретации, называемую **компиляцией Just-in-time(JIT)**.

*Компиляция Just-in-time*
При таком подходе весь код компилируется в машинный код и сразу же исполняется. То есть присутствуют два этапа обычной предварительной компиляции, но портируемого исполняемого файла нет. И исполнение происходит сразу же после компиляции. Это идеально подходит для JavaScript, потому что это намного быстрее, чем просто исполнение строка за строкой.
#### Современная компиляция Just-in-time языка JavaScript
В дело вступает элемент кода JavaScript, называемый движком. Его первый этап — это парсинг кода, то есть, по сути, его чтение. В процессе парсинга код преобразуется в структуру данных под названием Abstract Syntax Tree (AST). Каждая строка кода разделяется на значимые для языка элементы, например, ключевые слова `const` или `function`, а затем все эти элементы структурированным образом сохраняются в дерево. На этом этапе также выполняются проверки синтаксических ошибок. Получившееся дерево позже будет использовано для генерации машинного кода.

Допустим, у нас есть очень простая программа, показанная на рисунке слева. Она лишь объявляет переменную, а справа показано, как выглядит дерево AST для этой одной строки кода. Итак, у нас есть объявление переменной, которая должна быть константой с именем «a» и значением «23». Как вы видите, кроме этого в дереве есть ещё много другого. Представьте, насколько объёмнее оно будет для реального большого приложения.
Следующий этап — это компиляция, при которой берётся сгенерированное AST и компилируется в машинный код. Этот машинный код исполняется сразу, так как в современном JavaScript используется компиляция Just-in-time. При этом стоит помнить, что исполнение происходит в стеке вызовов движка JavaScript. Подробнее об этом мы поговорим в следующей статье.

Отлично, наш код работает, так что на этом можно закончить, правда? Ну, не совсем, потому что в движках современного JavaScript есть продуманные стратегии оптимизации. Сначала они создают очень неоптимизированную версию машинного кода, чтобы он мог начать исполняться как можно быстрее. Затем в фоновом режиме этот код оптимизируется и рекомпилируется, пока программа уже исполняется. Это можно делать почти всегда и после каждой оптимизации. Неоптимизированный код просто заменяется новым, более оптимизированным кодом, даже без приостановки исполнения. И именно благодаря этому процессу современные движки наподобие V8 так быстры.
Все эти операции парсинга, компиляции и оптимизации выполняются в специальных потоках внутри движка, доступ к которым мы не можем получить из кода. То есть они отделены от основного потока, который управляет стеком вызовов, исполняющим наш код. В разных движках это реализовано немного по-разному, но в целом, именно так выглядит современная компиляция Just-in-time для JavaScript. | https://habr.com/ru/post/651005/ | null | ru | null |
# Перестановки. 9-й класс. Задача на четность
Май выдался холодным, отопление отключили, а вычислительные (и обогревательные) мощности какие-никакие, а простаивают. Так почему бы не загрузить их чем-нибудь ~~бесполезным~~, что и согреет, и развлечёт.
Но начну издалека. На днях попалась на глаза задачка для средней школы со следующей формулировкой: «Несколько последовательных натуральных чисел выписали в строку в таком порядке, что сумма каждых трёх подряд идущих чисел делится нацело на самое левое число этой тройки. Какое максимальное количество чисел могло быть выписано, если последнее число строки нечётно?»
При таком ограничении нетрудно доказать, что в каждой тройке нечётных чисел будет больше, чем чётных. И поскольку разница между ними не может быть больше единицы, максимальная длина последовательности ограничена пятью числами. А в качестве примера можно привести последовательность ***4 5 3 2 1***.
Подробное доказательство можно найти [здесь.](http://www.problems.ru/view_problem_details_new.php?id=98454)
Но что если убрать указанное ограничение на нечётность последнего числа? Тогда справа можно добавить числа ***7 6 8***, расширив последовательность до восьми чисел. Можно ещё и десятку добавить, а недостающую девятку присоединить слева. Ну и, наверное, это будет не единственная и не самая длинная перестановка.
Собственно, стараясь рассуждать логически, я не нашёл доказательства ограниченности таких последовательностей и решил привлечь к анализу домашний ~~обогреватель~~ вычислитель. Грубый полный перебор всех *N*! вариантов быстро показал несостоятельность метода, а вот направленный перебор позволил значительно продвинуться, и результат оказался и ожидаемым и неожиданным одновременно.
Выяснилось, что для всех *N* до 29 включительно такие перестановки чисел от 1 до *N* действительно находятся, правда, для длин 27 и 29 в единственном варианте. А вот дальше появляются пробелы. Для перестановок с размерами 30, 31, 32 и 33 решений нет, для числа 34 есть одно.
**такое**
***33 23 10 13 7 6 1 29 27 2 25 21 4 17 15 19 11 8 3 5 31 9 22 14 30 26 34 18 16 20 12 28 32 24***
Далее снова два пробела. Для значений 37 и 38 подобные последовательности есть и не единичные, а затем провал. Я даже было отчаялся, следующий десяток оказался полностью пустым, но удача улыбнулась, для *N*=51 таки находится нужная перестановка.
**вот она**
***46 45 1 44 49 39 10 29 21 37 5 32 23 41 51 31 20 11 9 2 43 35 8 27 13 14 25 3 47 40 7 33 16 17 15 19 26 50 28 22 6 38 34 4 30 18 42 48 36 12 24***
Их даже две, но они пересекаются по большей части.
Дальше снова намечается пустота, по крайней мере, для чисел 52 и 53 решений нет, а дальше не искал. Всё же с каждым шагом время ожидания растет по экспоненте, да и в доме уже заметно потеплело, решил пока на этом остановиться.
Если свести найденные количества возможных вариантов в одну таблицу, можно построить следующий график
Ну да, есть над чем помедитировать.
В исходной задаче не было требования начинать натуральный ряд с единицы. Главное чтобы в последовательности встречались все числа от *a* до *b*. Но я пробовал, становится только хуже, вариантов находится еще меньше. Что, собственно, объяснимо. Чем большее число стоит на левой позиции тройки, тем меньшую кратность можно получить суммой двух других, т.е. тем меньше доступных вариантов. Ну а вопрос верхнего предела длин таких последовательностей остается открытым. С ростом размерности вероятность успеха явно снижается, но вот обнуляется ли? Или дальше так и будут, пусть и редко, встречаться такие вот (не)интересные перестановки.
Напоследок, пожалуй, можно привести код программы-грелки,
**правда, он на Хаскеле**
вариант с учётом комментариев про наибольший общий делитель
```
import Data.IntSet (IntSet, notMember, insert, fromList)
import Control.Parallel.Strategies
import System.Environment
pvc :: Int -> Int -> Int -> Int -> IntSet -> [[Int]]
pvc _ 1 a b _ = [[a,b]]
pvc n k a b xs =
let c = a - mod b a
in [a:ys |
x <- [c, c+a .. n],
notMember x xs,
k * gcd b x <= n,
ys <- pvc n (k-1) b x (insert x xs)]
gen :: Int -> [[[Int]]]
gen n =
let ab = [(a, b) |
a <- [1..n], b <- [1..n],
gcd a b == 1, a /= b]
in map hlp ab `using` parList rseq
where
hlp (a,b) = pvc n (n-1) a b $ fromList [a, b]
main = do
[n] <- getArgs
print $ concat $ gen $ read n
``` | https://habr.com/ru/post/503790/ | null | ru | null |
# Как мы сделали хакатон в поезде и что из этого получилось
Всем привет! Я Миша Клюев, DevRel в Авито. В этой статье расскажем вам про наш опыт организации и проведения необычного хакатона. Внутри: рассказ о 56 часах кодинга в поезде, о том, что надо сделать, чтобы они состоялись, о том, какие проекты в итоге получились, и немного октябрьского моря.
Осторожно, трафик.

Идея
====
Идея сделать хакатон в поезде пришла ко мне достаточно спонтанно уже больше года назад. Поначалу мы с командой не воспринимали её слишком серьёзно. К тому времени мы уже провели несколько внутренних хакатонов (о которых писали в статьях: [1](https://habr.com/ru/company/avito/blog/334604/), [2](https://habr.com/ru/company/avito/blog/342466/)). Сразу скажу, что для нас процесс хакатона важнее результата: на выходе не ожидается новых бизнес-фич, которые уйдут в прод. Для нас главное, чтобы все участники получили удовольствие от участия (тем не менее, какое-то количество проектов действительно потом уходит в прод). Покодить для души — вот главный лозунг всех наших хакатонов, и каждый участник решает эту задачу по-своему. Вдохновлялся я примером фановых хакатонов wth.by, на одном из которых мне посчастливилось побывать в 2015 году.
Нам давно хотелось вынести хакатон из офиса, чтобы обстановка добавляла ещё больше драйва и веселья. Но просто смены декораций для полусотни разработчиков, которые большую часть времени проведут за ноутбуками, нам показалось мало. Тут то мы и поняли, что можно добавить движа в хакатон, если совместить его с путешествием, а поезд — самый очевидный для этого вид транспорта. Быстрый поиск показал, что хакатоны в поезде в мире [уже проводятся](https://tproger.ru/blogs/why-unusual-hackathons-are-held/), в том числе на постсоветском пространстве, но отечественных аналогов мы не нашли. Идея казалась несерьёзной и очень сложной в реализации: куда ехать, чтобы по пути была надежная связь, как заранее выкупить билеты в одном вагоне, пока не собраны паспортные данные участников, как проводить презентации проектов в поезде… Но летом этого года мы решили попробовать, и всё сложилось.
У РЖД можно арендовать вагоны разного класса и прицеплять их к поездам в нужных направлениях. Отсутствие стабильного интернета — не баг, а фича, дополнительный челендж, который влиял на выбор технологий и требовал более тщательной подготовки, решили мы. Город прибытия выбирали просто по времени движения поезда, одни сутки в одну сторону. Первым вариантом был Екатеринбург, но потом решили, что из осенней Москвы лучше выбираться куда-нибудь на юг.
В какой-то момент нам пришлось подвинуть даты проведения хакатона и чтобы поехать, мне пришлось бы в последний момент отказаться от выступлений на двух конференциях. Сам я очень люблю путешествовать на поездах, хакатон в поезде стал для меня мечтой, поэтому было крайне обидно его пропустить. Но теперь мне остаётся только передать слово моим коллегам, которые успешно организовали и провели этот уже легендарный (по крайней мере в Авито) хакатон и кусать локти, разглядывая фотки и читая отзывы участников. Ну и конечно думать о том, чем удивить в следующий раз!
Подготовка
==========
 **Валя Михно, event-менеджер**
Идея хакатона в поезде мне сразу понравилась. Круто вытащить коллег из офиса и вместе с ними отправиться в путешествие, да ещё и поработать по дороге. К тому же, мне всегда интересно браться за нестандартные задачи и проекты, которые до тебя никто не делал.
Хоть организовывать хакатон в поезде задача и интересная, но крайне непростая: трудно работать с железнодорожной монополией, получить гарантированное подтверждение регистрации от программистов, непонятно, как организовывать интернет в «слепых» зонах и составлять меню на два дня в плацкарте для пятидесяти незнакомых коллег.
Но, пожалуй, сложнее всего было выбрать направление нашего путешествия. Сначала мы планировали поездку в Екатеринбург по известной Транссибирской магистрали. Но в октябре в Екатеринбурге довольно холодно, да и варианты, как провести время пятидесяти уставшим программистам после суток в поезде с пользой, показались мне довольно банальными — всё это можно было и в Москве устроить. Тогда появилась идея поехать на юг, к морю. И тут моё внимание остановилось на маленьком курортном городе Анапа. Всё складывалось как нельзя лучше: отправление в пятницу утром, время в пути чуть меньше суток, семь часов на море (идеально, чтобы закрыть пляжный сезон), а прибытие в Москву в воскресенье вечером. В общем, бинго — едем в Анапу.
С менеджером РЖД мы выбрали нужные нам поезда туда и обратно, забронировали вагон-плацкарт (он атмосфернее и лучше помогает сплотить команды), обсудили все детали оформления поездки и запустили договор на согласование с нашими юристами. Все шло как по маслу и спокойно, но за месяц до поездки мне понадобилась информация по условиям вагона (количество и мощность розеток, наличие постельного белья и подстаканников и другие мелочи). И тут началось…
Я поехала на встречу с менеджером РЖД в депо, чтобы сделать фотки нашего вагона. Оказалось, что наш новый комфортный плацкарт с фоток на сайте превратился в вагон 2018 года старого формата. К тому же, даже его логисты РЖД не разрешили прицепить к изначально запланированному поезду «Москва – Анапа». Условие было ультимативное. Пришлось соглашаться на все условия и ехать другим поездом. Отказаться совсем мы не могли: вовсю шла регистрация на хакатон. Новый поезд едет до Анапы дольше, поэтому наше время в поезде увеличилось на шесть часов, а время на море сократилось до четырёх. Мы немного расстроились, но не отчаялись — мы ведь сами хотели устроить хардкор. Так и получилось.
*А как мы ездили в депо с работниками РЖД на служебной машине со всеми припасами, вскрывали наш вагон среди белого дня, останется в моей памяти надолго…*
### Анонс и тематика
 **Валя Михно, event-менеджер**
Как мы анонсировали хакатон и придумывали тематику достойно отдельной истории. Расскажу здесь об этом лишь вкратце. Мы почти сразу решили, что сделаем тематику «Безумного Макса» и описали это так: «Представьте, что мы мчимся в Анапу альтернативного будущего на футуристическом паровозе. Люди придумали мощные паровые компьютеры, мощный паровой lisp, fortran и прочие бейсики с паскалями, но забыли придумать интернет». В общем решили устроить коллегам настоящий челлендж — кодить в хардкорных условиях в поезде, без нормального интернета, душа и привычного комфорта, да к тому же провести свои выходные с коллегами, которых и так видишь целую неделю, плечом к плечу. Так себе перспектива. Одним словом, авантюра!
Мы разработали логотип, придумали дизайн всего мерча и постеров, сделали лендинг и открыли регистрацию. Регистрироваться нужно было сразу и наверняка, потому что на каждого выписывался именной билет. Если участник в последний момент откажется — его место пропадёт. Конечно, мы об этом сказали, но переживали, что никто не захочет регистрироваться: никому не хочется подставлять коллег, если вдруг в последний момент появятся какие-то важные дела. Но я верила, что авантюристы в нашей компании существуют. В первой волне регистрации вагон заполнился лишь наполовину. И какое-то время счётчик регистраций не двигался. Тогда нам пришлось применять смекалку.
Каждые пять дней мы постили новую информацию по этапу подготовки хакатона, что могло привлечь новых участников. Я сообщала о покупке высокоскоростных роутеров (интернет, всё-таки, будет), рассказывала о программе в Анапе с шашлыками от владельца гостиницы Акопа и постила оптимистичный прогноз погоды — шансы искупаться в октябре были высокие (и прогноз погоды меня не подвёл). Любителей поездной романтики я привлекала фотками дошираков и историями создания этого идеального блюда для поезда. Потом опубликовали номинации юбилейного хакатона. Среди них были наши традиционные, например, «Кубок хакатона» и «Самый эпичный фейл», и те, которые мы придумали под этот необычный хакатон: «Самый древний стиль программирования» и «Лучший фронтец». Наших инженеров номинации на участие вдохновили. Ну и в конце мы даже разрешили приглашать матёрых хакатонщиков, бывших сотрудников Авито. В сумме все сработало! Ровно за месяц до поездки наш вагон был полностью укомплектован, и все имена были внесены в договор.
### Интернет
 **Валя Михно, event-менеджер**
Несмотря на то, что тематика хакатона была хардкорной, я очень хотела, чтобы интернет, всё-таки, был. Выжать по полной возможности интернета на ходу и сделать его доступным для всех участников на всём пути — это стало для меня челленджем. Я несколько дней общалась с сетевиками в Авито, выбирала подходящие маршрутизаторы для нашего случая, рисовала план их размещения в вагоне, подбирала лучшего провайдера на пути «Москва – Анапа», изучала карты покрытия и мануалы роутеров. Интересный опыт! Что вышло из этого?
Мы закупили четыре 4G-роутера с высокоскоростным беспроводным соединением, которые позволяли использовать две сим-карты одновременно и переключаться на того провайдера, чей сигнал был сильнее. Закупили восемь сим-карт трёх главных российских операторов связи, шестнадцать Wi-Fi и GSM антенн. Всё протестировали и создали карту сети с помощью нашего лётчика-испытателя и разработчика, написавшего приложение, где эту карту можно было создать. Сил потратили много, но это стоило того. Конечно, на пути были мёртвые зоны в полях и лесах, но получилось лучше, чем мы ожидали. Скорости и покрытия хватало даже для того, чтобы наш фотограф мог закачать сотни фоток на облако и расшарить их хакатонщикам ещё в пути.

**Сережа Вертепов, senior QA engineer, лётчик-испытатель интернета**
Одним прекрасным утром я прочитал новость о том, что Авито планирует провести еще один хакатон. До этого я в хакатонах не участвовал, но давно планировал, и прочитав, что хакатон будет ещё и в поезде на пути в Анапу, я сразу понял, что такую возможность упускать нельзя. На сайте хакатона было сообщение о том, что нужен доброволец, который заранее проедет по маршруту «Москва — Анапа — Москва», чтобы составить карту покрытия сети ну и в целом разведать обстановку.
«Хм, неплохо», — подумал я и сразу же написал о своем желании стать первопроходцем. Меня сильно удивило, что никто не изъявил желания бесплатно съездить в Анапу, пусть и в не курортный сезон. Видимо, не все так любят курорты Краснодарского края, как я.
28 сентября я оказался в поезде. У меня было два айфона, приложение, которое трекает покрытие и координаты для построения дальнейшей карты (его написал наш lead iOS-engineer Влад Алексеев), а также Wi-Fi модем с двумя симками. Поездка прошла замечательно. Особенно радовало то, что за все время у меня практически не было попутчиков. Удивило то, что у меня не было какого-то информационного голода: интернет хоть какой-то, да был. На мессенджеры, соцсети хватало. Не всегда, конечно, но большую часть времени. По крайней мере мне так казалось, да и карта, которую построило наше приложение говорила плюс-минус о том же. Кстати, заметил, что первую половину пути более устойчивое соединение было у одного оператора, а вот ближе к Краснодарскому краю у другого. В общем, я проехался на поезде, пока один айфон трекал информацию с одной симки, а другой с модема с симками остальных операторов, провёл в Анапе одну ночь и вернулся. Всё «путешествие» заняло 4 дня.

### Условия для работы в поезде
 **Валя Михно, event-менеджер**
Хардкор хардкором, но угробить желудки пятидесяти инженеров или заразить их инфекцией не очень хотелось. Поэтому важным пунктом в организации хакатона было — создать комфортные условия для работы в плацкарте, чтобы разработчиков ничего не отвлекало творить и писать код. Мы подготовили вэлком пак со всем необходимым: футболка, тапки, набор для сна (маска и беруши), дорожный зубной набор, пачка активированного угля, санитайзер, бутылка воды, батончик и пару каш быстрого приготовления. Кроме этого, мы взяли с собой много разной еды (которая заняла целых две боковых полки вагона). Из еды было много разных закусок, но главным блюдом этой поездки был, конечно же, доширак. 75 пачек на 50 человек закончились быстро. Приз зрительских симпатий получил доширак с говядиной — ребята даже обменивали свои заначки на говяжий дошик. Это было гениально! Более здоровая еда тоже была: мы обедали вагоне-ресторане, еду в котором мы заказали заранее и даже прописали поштучно в договоре. Повторюсь, мы же не хотели испортить желудки коллег. Обед был комплексный и как полагается: «первое», «второе» и салат. Вместо компота — сок. Забавно получилось, что наш вагон прицепили дополнительно, и он был шестнадцатый по порядку. А вагон-ресторан был одиннадцатым. Каждый участник хакатона по пути на обед прошёл больше, чем через двадцать дверей, — проводники, отвечающие за свои вагоны, просили закрывать за собой двери. В сумме за два приема пищи в пятницу и в воскресенье мы открыли и закрыли больше ста двадцати дверей. Санитайзер положили не зря.
В итоге благодаря грамотным анонсам мы успешно закрыли регистрацию, донесли всю важную информацию до участников, в поезде все были сытые, никто не отравился, ни один инженер не потерялся, и мы благополучно доехали полным составом обратно в Москву. «Челлендж комплитед!». В наш телеграм чат «Поезднутые на AvitoHack RailRoad» после поездки ребята ещё долго писали свои впечатления и фотки с поездки. Все остались довольны, отзывы были отличные, а один коллега сказал, что это был самый яркий момент за все время работы в Авито. Я считаю, это и есть успех!
Статистика
==========
Хакатон в поезде — проект масштабный. Вот что у нас было с собой, чтобы его реализовать.
* 25 коробок с дошираками, молоком, чипсами и сухариками, кашами, фруктами и овощами, напитками, аптечкой и хакатономерчом.
* 144 бутылки воды.
* 134 банки разных газированных напитков.
И потратили почти 42 ГБ мобильного интернета.
Фотоотчёт
=========
Трудно писать об атмосфере, поэтому просто посмотрите фото.
**Смотреть фото**
.































Проекты
=======
Мы привезли с собой 19 проектов. Конечно, про все рассказать здесь не сможем, но вот немного подробностей.
```
Команда «Поездатые ребята» сделала навигатор для построения маршрута в дополненной реальности. Вдохновлялись проектом офисных карт, который был сделан на одном из предыдущих хакатонов. Сейчас навигатор может привести вас в любое место нашего плацкартного вагона.
```
```
Команда «4 туза» сделала приложение для аренды с механикой взаимного поиска. Как Тиндер, только для аренды. Объявления размещают и владельцы квартир, и арендаторы, а поиск происходит в обоих направлениях. Если оба полайкали, то открываются контакты.
```
```
У каждого есть ненужные вещи, от которых хочется избавиться, но даже их не получается продать на Авито. Коллеги из команды «Канапе» представили приложение Hlamingo, где можно обмениваться хламом.
```
```
Проект Super Blur — интеллектуальный блюр бэкграунда на фото автомобиля. В результате работы алгоритма сегментируется машина и её бэкграунд на фото, после этого применяется специальный градиентный блюр, для создания фото в стиле портрет.
```
```
Fratbots — игра на собственном игровом движке c ASCII-графикой и восьмибитной музыкой. Олды поймут! И графика, и музыка создавались на хакатоне.
```
А ещё мы сделали проект с [бесплатными облачными вычислениями на Go](https://github.com/scukonick/gocloud), cache для данных мониторинга в СlickHouse (для снижения нагрузки на базу данных при частых одинаковых запросах), проект с непрерывным профилированием Go-приложений, интерпретатор языка программирования Prolog, ускорили кодогенерацию для нашего Авито iOS проекта, написали приложение для подбора сочетаний опенсорс шрифтов на реальном контенте, а не на Lorem Ipsum и многое-многое другое.
Отзывы участников
=================
> * Вечеринки интровертов — это прекрасно! Я довольно замкнутый и опасался, что окажусь не в своей тарелке. Но я познакомился со всеми в вагоне и даже запомнил имена многих! Такое со мной впервые :-)
> * И отдохнул от работы, и в море искупался, и с коллегами потусил, и на свободную тему код написал. 12/10 GOTY НА КОНЧИКАХ ПАЛЬЦЕВ. В общем, просто бомбически, мегакрутой формат и реализация.
> * Идея поезда на первый взгляд казалась странной, но когда я принял участие, то время в поездке летело незаметно и даже не хотелось расставаться по окончанию поездки. Песни под гитару, выезд на автобусе под саундтрек из GTA, фотографии…
> * Это было чудесно! Познакомиться с отличными ребятами в неформальной обстановке. Отзываться и помогать друг другу — что может быть ценнее в этой жизни?! А для всего остального — MasterCard… Море шуток, веселья, по крайней мере, в нашей замечательной команде, и конечно же, хардкорной разработки на Rust!!! Впервые в жизни побывал на море и сделал, наконец, йога-фотки на пляже! А под гитарку б вечно играл в такой теплой атмосфере!
> * Только проведя двое суток в поезде, став сильнее, очистив свой разум и отбросив всякую шелуху в виде интернета и бесконечного гугления, богомерзких индусских мануалов и стековерфлоу, используя забытые древние практики медитации над кодоми чтения исходников, специальной диеты и алкоголя ты понимаешь, что главное — это люди с которыми ты работаешь, что только они могут поддержать тебя в трудную минуту и разделить радость победы или терпкий вкус самого дешевого вискаря, купленного в не сезон в Анапе!
> * Самое яркое впечатление — это когда ночью поезд остановился где-то в глуши на станции. Вагон не дотянули до перрона. И мы выскакивали под звездами в темноте и тусили возле вагона. Забирались по насыпи наверх. А вокруг — темнота, звёзды и тусклый свет от вагона… Невероятно просто.
> * Очень позитивный сюр. Куча кодеров в ночи на холме перед поездом, море в октябре, сама по себе ситуация: приехать в Анапу на несколько часов, искупаться и поехать обратно. Отличнейшая музыка от дуэта флейта-гитара, сибирские байки от наших соседей по плацкарту. Запах дошика, перед которым никто не устоял. Бескрайние поля, городки, романтика путешествия, скок-скок через рельсы, тутух-тутух, тутух-тутух…
>
>
>
>
Памятка хакатонщика от [pik4ez](https://habr.com/ru/users/pik4ez/)
==================================================================
Если вы или ваши друзья вдруг захотят повторить такой опыт, не лишним будет поделиться нашим опытом. Мы попросили самого опытного хакатонщика нашей команды, pik4ez’а, составить памятку для тех, кто решит покодить в поезде. Ему слово.
 **Дмитрий Белов, senior engineer, опытный хакатонщик**
* В поезде труднее найти абсолютно необитаемый уголок, в котором не будет никого, кроме вашей команды. Будьте хорошими соседями. В нашем случае в вагоне были и укулеле, и гитара, и флейта. Но ребята играли очень хорошо и не долго. Музыка не раздражала, а, наоборот, давала возможность собраться в музыкальном уголке, спеть пару песен и отдохнуть от программирования.
* Алкоголь снижает продуктивность. Не стоит включать его в меню.
* Вопрос с зарядом устройств стоит решить заранее. В нашем случае был современный вагон и достаточно розеток. Но на всякий случай многие брали с собой пауэр-банки.
* Приходится следить за таймингами. На поезд опаздывать нельзя, к пересадкам нужно быть готовым и заранее собрать необходимые вещи. Помогают сохранённые памятки с расписанием и организаторы, по счастливой случайности едущие в том же вагоне.
* Скоропорт не берём, разве что, на первый перекус. Из не скоропортящегося можно сконструировать вполне приличное питание.
* Но сколько кодера ни корми, а он всё равно дошик любит. В небольших количествах отлично заходят лапша быстрого приготовления и кофе три-в-одном. С утра хороша каша быстрого приготовления. Но полноценный обед очень нужен. Вагон-ресторан может помочь.
* Тапочки нужны.
* Кодить лёжа на полке особо не получается. Стараемся не заваливать стол, чтобы разместить на нём пару ноутов.
* Ночью желательно вовсе не шуметь. Хакатон на колёсах посложнее перенести без сна, поэтому к ночи многие ложатся отдыхать.
* Очень полезно на станциях выходить размяться.
* В поезде повышается вероятность услышать парочку новых историй даже от тех, с кем работаешь уже много лет.
* Если видите море — купайтесь.
Видео, как это было
===================
Мы хотим передать наши эмоции от хакатона как можно лучше, поэтому ещё сняли и видео в поезде. Мы спросили у ребят их впечатления от поездки и кодинга без интернета, какие программы пишут, где ещё можно проводить хакатоны и о чём мечтают программисты. А Дима Белов рассказал о своих первых хакатонах и в чём польза таких мероприятий.
Такими были наши впечатления и проекты. Надеемся, вдохновили вас на что-то новое и интересное. Если интересны детали — спрашивайте про них в комментариях. Обязательно ответим. | https://habr.com/ru/post/475974/ | null | ru | null |
# Сайт для программиста. Часть 2. Публикация

В [первой части](http://habrahabr.ru/post/159631/) я рассказал, как программисту относительно просто запустить с нуля свой личный сайт с использованием Github, Heroku и Twitter Bootstrap.
Но запустить сайт мало. Скорее всего, вам захочется на него периодически что-то выкладывать. Например, новые проекты в портфолио, или записи в блог.
В этой части я расскажу, как максимально просто создать механизм публикации для своего сайта, который при этом не будет ничего решать за вас (как большинство существующих сервисов), а позволит делать всё так, как вам захочется, позволяя автоматизировать то, что можно автоматизировать.
База данных — github
--------------------
СУБД мы использовать не будем. Контент сайта будет хранится в файлах, которые, в свою очередь, будут храниться на github.
Таким образом, вам не нужно заботиться о бэкапе, импорте и экспорте данных. С файлами работать просто и удобно.
Чтобы добавить на сайт страницу или опубликовать статью, вам достаточно будет просто создать файл и сохранить его в репозитории. Проще некуда.
Если вы читали [первую часть статьи](http://habrahabr.ru/post/159631/), то у вас уже есть репозиторий на github и больше пока делать ничего не нужно.
Система публикации — docpad
---------------------------
Писать блог в html-формате не самое большое удовольствие. К тому же, каждой странице и статье нужно как минимум задать URL и обернуть в общий шаблон.
К счастью, есть волшебная библиотека [docpad](http://docpad.org), которая возьмёт все эти скучные задачи на себя. Я не буду подробно описывать, что она умеет, проще перейти по ссылке и прочитать там.
Те, кто знает про jekyll или другие генераторы статических сайтов, могут спросить, почему docpad? Я выбрал его, потому что:
* Он не навязывает способ своего использования. Его можно использовать как генератор сайта, как движок, как часть движка, как шаблонизатор в конце концов. У него удобное API, позволяющее брать вам именно те функции, которых вам не хватает, при необходимости реализуя остальные самостоятельно.
* Он позволяет создавать динамические страницы, а не только статически их генерировать.
* Контент сайта организуется в удобную in-memory базу данных, с которой можно делать что захочется.
Если хотите обсудить плюсы и минусы — добро пожаловать в комментарии.
А пока попробуем всё это в деле.
Запускаем каркас сайта
----------------------
В [первой части статьи](http://habrahabr.ru/post/159631/) я уже описывал, как клонировать репозиторий на github и выкладывать его на heroku, не буду повторяться. В этот раз код лежит здесь: <http://github.com/daeq/docpad-sample>. Форкайте, клонируйте, выкладывайте на Heroku.
Для ленивых простейший набор команд, при условии уже установленного heroku-toolbelt.
```
git clone [email protected]:daeq/docpad-sample
cd docpad-sample
heroku apps:create docpad-sample
git push heroku master
```
После запуска этого кода, вы увидите такой сайт: <http://blog.programmer-site.tk>.
Публикуем
---------
Обратите внимание на три папки:
* src/layouts — здесь лежат шаблоны страниц. Они могут наследоваться друг от друга (см. шаблоны index и post)
* src/public — здесь лежат файлы, которые будут доступны из корня вашего сайта (т.е. файл src/public/favicon.ico будет доступен по адресу <http://<ваш> домен>/favicon.ico)
* src/documents — здесь лежат собственно страницы и тексты.
Любую папку можно сконфигурировать. Конфигурация находится в файле app.js.
Страницы и тексты docpad организует в удобные коллекции. Как работать с коллекцией, можно посмотреть в `src/documents/posts.html.eco`.
Чтобы добавить новый пост в блог, достаточно создать новый файл в папке src/documents/posts. В зависимости от расширения файла, он будет по-разному обработан. .html — для html-файлов, .md — для markdown-разметки. Поддерживаются и другие форматы. Если вам их не хватит — можно написать свой плагин.
Я лично предпочитаю писать в формате [Markdown](http://daringfireball.net/projects/markdown/). В нём легко писать, легко читать, его легко преобразовывать в другие форматы, для работы с ним есть куча инструментов.
Теперь добавьте новый файл в папку src/documents/posts, перезалейте/перезапустите приложение, и увидите, как в списке постов появился новый.
Вы могли заметить в начале файла блок, ограниченный символами `---`. Это метаданные документа. Обычно у документа есть как минимум одно поле метаданных — layout. Вы можете добавлять свои произвольные поля, которые потом использовать везде, где имеете дело с этим документом. Например:
* Переопределить поле date и сортировать посты в блоге по нему (а не по дате создания файла, как делается по умолчанию)
* Добавить поле tags, выводить теги в лейауте поста и сделать фильтрацию страниц/постов по тегам.
* Добавить поле series и в каждом из постов серии (например, как эта серия из двух постов про сайт прораммиста) выводить ссылки на остальные посты серии.
Комментарии
-----------
Мы не будем писать свою реализацию комментариев. Всё давно сделали за нас. Краткий список сервисов, которые позволят добавить комментарии на ваш сайт:
* <http://www.intensedebate.com/>
* <http://disqus.com/>
* <http://hypercomments.com/>
Я выбрал третий вариант, потому что он позволяет комментировать не только страницу целиком, но и отдельные фразы в тексте. Очень здорово для технических статей.
Выглядит это так:

Шаринг
------
Наверное, вы хотите, чтобы люди рассказывали друг другу о вашем сайте. Сервисов, которые позволяют вам добавить виджет шаринга, ещё больше, чем сервисов комментариев. Я выбрал <http://addthis.com>. Простой, красивый, и с неплохой аналитикой.
Виджет выглядит так:

Коллаборация
------------
На вашем сайте наверняка будут ошибки и неточности. К тому же, информация со временем устаревает. Очень удобно было бы дать вашим читателям возможность исправить что-то в ваших текстах.
К счастью, для этого не нужно делать ничего дополнительно. Github даёт вам отличную функциональность для этой задачи. Просто даём ссылку на файл со страницей в гитхабе и любой человек может предложить изменения к вашим файлам, а вы можете просмотреть их и принять или отклонить.
Это механизм [pull request](https://help.github.com/articles/using-pull-requests)-ов. Воспользоваться им можно прямо из веб-интерфейса.
Можете попробовать [предложить изменения к этой статье](https://github.com/daeq/daeq.ru/blob/master/src/documents/articles/programmer-site-2.html.md)
---
Похоже, теперь у нас есть минимальный набор функций для публикации на нашем сайте. Его можно дополнять и затачивать под ваши потребности. Удачи! | https://habr.com/ru/post/160431/ | null | ru | null |
# Разработка HTML5-игр в Intel XDK. Часть 5. Увеличиваем длину змеи и управляем ей

[Часть 1](https://habrahabr.ru/company/intel/blog/281380/) » [Часть 2](https://habrahabr.ru/company/intel/blog/281453/) » [Часть 3](https://habrahabr.ru/company/intel/blog/281523/) » [Часть 4](https://habrahabr.ru/company/intel/blog/281607/) » [Часть 5](https://habrahabr.ru/company/intel/blog/281639/) » [Часть 6](https://habrahabr.ru/company/intel/blog/281873/) » [Часть 7](https://habrahabr.ru/company/intel/blog/281981/) // Конец )

Сегодня займёмся тем, что увеличим длину тела змеи и создадим систему управления её перемещением.
[](https://habrahabr.ru/company/intel/blog/281639/)
Создаём тело змеи в виде цепочки фрагментов
-------------------------------------------
Змея состоит из множества частей. Это позволяет увеличивать её длину, но делает задачу перемещения игрового объекта непростой. Ведь нам нужно перемещать сущность, состоящую из множества частей, как единое целое. Сделаем это за несколько шагов. Для начала – создадим змею, которая может перемещаться как единое целое.
**1.** В коде слоя SnakeLayer замените переменную `snakeHead` на `snakeParts`.
**2.** Код `snakeHead: null` измените на такой:
```
snakeParts: null, // содержит части тела змеи
```
**3.** Замените метод `ctor` на нижеприведённый:
```
ctor: function () {
/* Получим размер окна */
var winSize = cc.view.getDesignResolutionSize();
/* Вызовем конструктор суперкласса */
this._super();
// Новый код расположен ниже
/* Инициализируем массив snakeParts */
this.snakeParts = [];
/* Создадим голову змеи */
var snakeHead = new SnakePart(asset.SnakeHead_png);
/* Установим координаты для головы змеи */
snakeHead.x = winSize.width / 2;
snakeHead.y = winSize.height / 2;
/* Добавим объект в качестве потомка слоя и добавим его в массив snakeParts */
this.addChild(snakeHead);
// Новая строка
this.snakeParts.push(snakeHead);
/* Запланируем обновления */
this.scheduleUpdate();
},
```
Здесь мы добавили в код возможность работы с телом змеи, состоящим из отдельных фрагментов. Сделано это с помощью массива, раньше мы рассматривали голову змеи как отдельный объект. Однако, это пока не решило проблему организации частей змеи в «единый организм». Для того, чтобы это сделать, будем назначать предыдущие позиции частей змеи тем частям, которые следуют за ними.
**4.** Переделайте код `SnakeParts` так, как показано ниже:
```
var SnakePart = cc.Sprite.extend({
// Добавьте строки ниже
prevX: this.x,
prevY: this.y,
ctor: function(sprite) {
/* Вызов конструктора суперкласса с передачей спрайта, символизирующего фрагмент тела змеи */
this._super(sprite);
},
move: function(posX, posY) {
// Добавьте строки ниже
/* Установим предыдущее расположение */
this.prevX = this.x;
this.prevY = this.y;
/* Обновим текущее расположения */
this.x = posX;
this.y = posY;
},
});
```
**5.** Добавьте в код `SnakeLayer` следующий метод:
```
addPart: function() {
var newPart = new SnakePart(asset.SnakeBody_png),
size = this.snakeParts.length,
tail = this.snakeParts[size - 1];
/* Изначально новая часть расположена в хвосте */
newPart.x = tail.x;
newPart.y = tail.y;
/* Добавляем объект в качестве потомка слоя */
this.addChild(newPart);
this.snakeParts.push(newPart);
},
```
По умолчанию позиция спрайта – (0, 0). Это означает, что объект `SnakePart`, до начала перемещения, появится в нижнем левом углу экрана. Мы эту проблему решаем, размещая новый спрайт в хвосте змеи.
**6.** Измените метод `moveSnake` в коде `SnakeLayer` для того, чтобы в нём использовался новый член класса `snakeParts` и с его помощью можно было перемещать все части змеи:
```
moveSnake: function(dir) {
/* Набор значений, задающих направление перемещения */
var up = 1, down = -1, left = -2, right = 2,
step = 20;
/* Запишем snakeHead в первый элемент массива */
var snakeHead = this.snakeParts[0];
/* Сопоставление направлений и реализующего перемещения кода */
var dirMap = {};
dirMap[up] = function() {snakeHead.move(snakeHead.x, snakeHead.y + step);};
dirMap[down] = function() {snakeHead.move(snakeHead.x, snakeHead.y - step);};
dirMap[left] = function() {snakeHead.move(snakeHead.x - step, snakeHead.y);};
dirMap[right] = function() {snakeHead.move(snakeHead.x + step, snakeHead.y);};
/* Перемещаем голову в заданном направлении */
if (dirMap[dir] !== undefined) {
dirMap[dir]();
}
// Добавьте код ниже
/* Сохраняем текущую позицию головы для следующего фрагмента змеи */
var prevX = snakeHead.prevX;
var prevY = snakeHead.prevY;
/* Перемещаем остальные части змеи */
for (var part = 1; part < this.snakeParts.length; part++) {
var curPart = this.snakeParts[part];
/* Перемещаем текущую часть, сохраняем её предыдущую позицию для следующей итерации */
curPart.move(prevX, prevY);
prevX = curPart.prevX;
prevY = curPart.prevY;
}
},
```
**7.** Добавьте следующий код в конструктор `SnakeLayer`. Это код **временный**, нужен он лишь для того, чтобы проверить, верно ли всё сделано на данном этапе разработки:
```
ctor: function () {
...
for (var parts = 0; parts < 10; parts++) {
this.addPart();
}
},
```
**8.** Запустите эмулятор. Если всё сделано правильно, вы увидите змею, которая медленно ползёт вверх, и, по мере движения, удлиняется, а потом уходит за пределы экрана.

*Движущаяся змея на игровом экране*
Теперь пришло время управлять этой змеёй.
События
-------
Стандартная система ввода данных в Cocos2d-JS основана на событиях. Здесь имеется централизованный менеджер событий ([Event Manager](http://www.cocos2d-x.org/reference/html5-js/V3.7/symbols/cc.eventManager.html)), который выполняет обработку всех событий в движке. Менеджер событий позволяет регистрировать функции обратного вызова, которые будут срабатывать в ответ на определённые события.
Для регистрации функции обратного вызова используется следующая конструкция:
```
cc.eventManager.addListener({
event: cc.EventListener.LISTENER, // прослушиватель
onEventType: callBackFunction // тип события и функция обратного вызова
}, this);
```
А вот – реальный пример реализации этой конструкции:
```
cc.eventManager.addListener({
event: cc.EventListener.KEYBOARD,
onKeyDown: callBackFunction1,
onKeyUp: callBackFunction2
}, this);
```
Функция обратного вызова
------------------------
Функция обратного вызова, которую передали при настройке прослушивателя, вызывается в другой области видимости. Это означает, что мы в ней не можем пользоваться ключевым словом «this». К счастью, Cocos2d-JS предоставляет некоторые вспомогательные механизмы для того, чтобы это обойти. Делается это с помощью объекта события.
Создавая функцию обратного вызова, можно указать несколько аргументов для неё. Второй аргумент – это всегда объект события. Он позволяет узнать тип события, которое представляет, и то, что является целью события. Это даёт нам доступ к узлу, который связан с событием.
Первый аргумент функции обратного вызова зависит от типа события. Например, если речь идёт об обработке событий клавиатуры, то первым аргументом будет код клавиши, задействованной в событии. В событии касания сенсорного экрана это будет объект касания, который несёт в себе сведения о координатах касания. Знание всего этого поможет нам наладить систему управления змейкой.
**1.** Добавьте в `SnakeLayer` следующий код:
```
curDir: 0, /* направление перемещения, соответствующее заданным ранее переменным */
```
**2.** Измените параметр «up», который использовался в `moveSnake` на «this.curDir» в методе `update`. Приведите его к такому виду:
```
this.moveSnake(this.curDir);
```
Теперь переменная curDir используется для изменения направления движения змеи.
**3.** Добавьте код для взаимодействия с менеджером событий в метод `ctor` слоя `SnakeLayer`:
```
/* Регистрируем прослушиватель событий клавиатуры */
cc.eventManager.addListener({
event: cc.EventListener.KEYBOARD,
onKeyPressed: function(keyCode, event) {
var targ = event.getCurrentTarget();
/* Набор значений, задающих направление перемещения */
var up = 1, down = -1, left = -2, right = 2;
/* Объект, в котором клавишам поставлены в соответствие направления */
var keyMap = {};
keyMap[87] = up; // w
keyMap[83] = down; // s
keyMap[65] = left; // a
keyMap[68] = right; // d
/* Обработка нажатий на клавиши */
if (keyMap[keyCode] !== undefined) {
targ.curDir = keyMap[keyCode];
}
}
}, this);
```
Этот код довольно прост. Когда обнаруживается, что нажата одна из интересующих нас клавиш, мы изменяем значение переменной `curDir` на то, которое соответствует нужному направлению. На следующей итерации игрового цикла змейка начнёт перемещаться в выбранном направлении до тех пор, пока не будет нажата одна из клавиш, задающих направление. Всё это хорошо, но на мобильном устройстве с сенсорным экраном работать не будет. Поэтому добавим в проект управление касаниями.
Добавьте в метод `ctor` следующий код для того, чтобы змейкой можно было управлять касаниями экрана:
```
/* Прослушиватель для организации сенсорного управления */
cc.eventManager.addListener({
event: cc.EventListener.TOUCH_ONE_BY_ONE,
onTouchBegan: function() {
/* Позволяет задействовать onTouchMoved, если возвращено true */
return true;
},
onTouchMoved: function(touch, event) {
var targ = event.getCurrentTarget();
var up = 1, down = -1, left = -2, right = 2;
/* Получаем расстояние перемещения */
var delta = touch.getDelta();
/* Если было касание с протягиванием */
if (delta.x !== 0 && delta.y !== 0) {
if (Math.abs(delta.x) > Math.abs(delta.y)) {
/* Определяем направление, получая знак */
targ.curDir = Math.sign(delta.x) * right;
} else if (Math.abs(delta.x) < Math.abs(delta.y)) {
/* Определяем направление, получая знак */
targ.curDir = Math.sign(delta.y) * up;
}
}
/* Если было простое касание, без протягивания, не делаем ничего */
}
}, this);
```
К несчастью, в Cocos2d-JS нет встроенной поддержки событий, вызываемых при жесте касания с протягиванием, поэтому нам понадобилось написать собственную реализацию подобного механизма. Мы смотрим на начальную и конечную точки жеста касания, и, если, например, расстояние перемещение вверх оказалось больше, чем в другие стороны, выполняем команду перемещения вверх. То же самое делается для перемещений вправо, влево, и вниз.
Теперь змейкой можно управлять! Однако, есть одна проблема. Игрок может неожиданно проиграть (с учётом той логики, которую мы ещё реализуем), если, например, змейка двигается вверх, а он нажмёт на клавишу «вниз». С этим мы справимся в продолжении.
Выводы
------
Подведём итоги сегодняшнего занятия:
* Части тела змеи движутся синхронно, так как при перемещении каждая из них передаёт следующей свою предыдущую позицию.
* При реализации управления игровым объектом задействована система событий.
Освоив сегодняшний материал, вы смогли следующее:
* Создать тело змеи и настроить его длину.
* Создать систему управления.
Змейка двигается по экрану, реагирует на нажатия клавиш на клавиатуре и на касания сенсорного экрана. Но пока в её перемещениях нет особого смысла. Поэтому в следующий раз мы добавим в игру угощение для неё и поговорим о распознавании и обработке столкновений.

[Часть 1](https://habrahabr.ru/company/intel/blog/281380/) » [Часть 2](https://habrahabr.ru/company/intel/blog/281453/) » [Часть 3](https://habrahabr.ru/company/intel/blog/281523/) » [Часть 4](https://habrahabr.ru/company/intel/blog/281607/) » [Часть 5](https://habrahabr.ru/company/intel/blog/281639/) » [Часть 6](https://habrahabr.ru/company/intel/blog/281873/) » [Часть 7](https://habrahabr.ru/company/intel/blog/281981/) // Конец )
 | https://habr.com/ru/post/281639/ | null | ru | null |
# Мое знакомство с ASP.NET MVC в Visual Studio 2015 на примере построения прототипа МИС
В этом году в качестве курсовой работы мне нужно было написать несложную медицинскую информационную систему (МИС) для небольшой частной клиники по лечению эпилепсии.
База данных пациентов в клинике уже была, написана она была еще в далеком 1998 году в Microsoft Access того времени (причем даже с красивым пользовательским интерфейсом), но вот работала она только в одном месте — на компьютере заведующего, да еще и поддерживать ее стало совершенно невозможно. Значит, давно назрела необходимость внедрять что-то новое!
Сказано — сделано. Работать надо было быстро (все-таки сдавать курсовую пора) и при этом хотелось сделать работу максимально интересной для себя. Я давно хотел разобраться с ASP.NET MVC, был немного знаком с C# и общими принципами MVC, поэтому скачал последнюю Visual Studio 2015 RC и принялся за работу.
Под катом — весь процесс знакомства с технологией и разработки такой системы со всеми встретившимися подводными камнями. Данная статья пригодится всем, кто знаком с программированием и когда-то делал блог по туториалу для любого MVC фреймфорка и хочет узнать, как же сделать что то более интересное.
Итак, начнем!
### Постановка задачи
Необходимо написать единую базу данных пациентов для небольшой клиники по лечению эпилепсии. После обсуждения с руководством центра были сформированы следующие требования:
* Интеграция в систему всех накопленных данных из предыдущей базы данных;
* Возможность доступа к системе со всех рабочих мест разных зданиях;
* Разделение прав;
* Наличие средства для составления расписания приемов;
* Возможность добавления в профиль пациента фотографий, видеофайлов и документов произвольного типа;
* Возможность редактирования встроенных словарей (диагнозы, назначения, исследования…);
* Простота поддержки и масштабирования;
* Возможность поиска по произвольным полям историй болезни всех пациентов.
### Реализация
Отправная точка для того, чтобы понять, как работает ASP.NET MVC — официальные учебные пособия на сайте <http://www.asp.net/mvc>. Для моей работы на первое время достаточно было вот этого [getting started](http://www.asp.net/mvc/overview/getting-started/introduction/getting-started). Я также попытался посмотреть [учебник на Хабре](http://habrahabr.ru/post/175999/), но лично мне он показался слишком специализированным.
Из [пособия на сайте Microsoft](http://www.asp.net/mvc/overview/getting-started/introduction/getting-started) (его лучше проделать руками, дабы лучше прочувствовать) отличная понятна общая механика процесса, работа контроллеров и представлений для одной модели, но не ясно, как делать более сложные приложения. Именно это я и собираюсь разобрать.
Разобравшись с основами, приступаем к работе.
Создаем новое ASP.NET приложение и запускаем его по Ctrl-F5:
**Создание проекта**
#### Написание моделей
Первая стадия нашей работы — описание используемых моделей. В моем случае все было просто. Необходимость быстрой интеграции старых данных Access продиктовала самое простое решение — в точности копировать старую схему данных, а уже потом, по необходимости, менять ее.
Если кратко, то есть пациент (персональные данные), связанный приемами (дата и врач). На каждом приеме врач может добавлять документы различных типов: анамнезы, диагнозы, назначения и т.д. А каждый такой анамнез, диагноз и другие документы и имеет тип из словаря — отдельной таблицы с перечислением.
Ну что ж, создаем новый файл Pacient.cs в папке Models и поочередно описываем каждую модель. Например:
**Добавление нескольких моделей**
```
public class DiagnosisType
{
public int ID { get; set; }
[DisplayName("Диагноз")]
public String name { get; set; }
[DisplayName("Описание")]
[DataType(DataType.MultilineText)]
public String description { get; set; }
}
public class Diagnosis
{
public int ID { get; set; }
[DisplayName("Диагноз")]
public DiagnosisType type { get; set; }
[DisplayName("Комментарий")]
[DataType(DataType.MultilineText)]
public String comments { get; set; }
}
public class VisitDate
{
public int ID { get; set; }
public int doctorID { get; set; }
[DisplayName("Дата приема")]
public DateTime date { get; set; }
public List anamnesis { get; set; }
public List debutes { get; set; }
public List diagnoses { get; set; }
public List researches { get; set; }
public List assigments { get; set; }
public List neurostatuses { get; set; }
public List reviews { get; set; }
public List syndromes { get; set; }
}
public enum Sex
{
[Display(Name = "Противоречивый")]
A,
[Display(Name = "Женский")]
F,
[Display(Name = "Мужской")]
M,
[Display(Name = "Не применимо")]
N,
[Display(Name = "Другой")]
O,
[Display(Name = "Неизвестный")]
U
}
public class Pacient
{
public int ID { get; set; }
[DisplayName("Лечащий врач")]
public Doctor doctor { get; set; }
[DisplayName("ФИО")]
public String name { get; set; }
[DisplayName("Номер карты")]
public String cart { get; set; }
[DisplayName("Телефон")]
[DataType(DataType.PhoneNumber)]
[Phone]
public String phone { get; set; }
[DisplayName("Дата регистрации в системе")]
[DataType(DataType.Date)]
public DateTime dateOfregistration { get; set; }
[DisplayName("Пол")]
public Sex sex { get; set; }
[DisplayName("Дата рождения")]
[DataType(DataType.Date)]
[DisplayFormat(DataFormatString = "{0:yyyy-MM-dd}", ApplyFormatInEditMode = true)]
public DateTime birthday { get; set; }
[DisplayName("Мать")]
public String mother { get; set; }
[DisplayName("Отец")]
public String father { get; set; }
[DisplayName("Адрес проживания")]
public String adress { get; set; }
[DisplayName("Коментарии")]
[DataType(DataType.Html)]
[AllowHtml]
public String comments { get; set; }
public List visits { get; set; }
}
```
Остальные классы из модели определяются по аналогии.
Замечания:
* **[DisplayName(«Диагноз»)]** — задает человеко-читаемое имя для поле, используется в представлениях;
* **[DataType(DataType.MultilineText)]** — в представлении для этого поля автоматически подставится textarea;
* **[AllowHtml]** — позволяет хранить в этом поле html, по-умолчанию это запрещено.
Общие идеи генерации таблиц базы данных из моделей в Entity Framework:
* Одна модель (один класс) – одна таблица;
* Переменные класса стандартных типов – поля таблицы в базе данных;
* Для создания поля стандартного типа, которое может содержать NULL, к имени типа необходимо добавить знак вопроса;
* Объект другого класса, тоже являющийся моделью приводит к созданию поля внешнего ключа, указывающего на запись в таблице, соответствующей этой модели;
* Включение в модель списка элементов приводит к созданию связи один ко многим. В модели элементов списка добавляется внешний ключ;
* Включение в два класса списков, содержащих объекты другого приводит к образованию связи многие-ко-многим и созданию дополнительной таблицы для этой связи.
Отлично, мы оформили все модели. Теперь необходимо сказать Entity Framework'у, что это именно модели для базы данных. Для этого создаем новый контекст соединения. **Один контекст — одна база данных**.
**Код создания контекста**
```
public class PacientDBContext : DbContext
{
public DbSet pacients { get; set; }
public DbSet anamnesisTypes { get; set; }
public DbSet anamneses { get; set; }
public DbSet debutes { get; set; }
public DbSet debuteTypes { get; set; }
public DbSet diagnoses { get; set; }
public DbSet diagnosisTypes { get; set; }
public DbSet researches { get; set; }
public DbSet researchTypes { get; set; }
public DbSet medicines { get; set; }
public DbSet medicineTypes { get; set; }
public DbSet neurostatuses { get; set; }
public DbSet neuroStatusTypes { get; set; }
public DbSet assigments { get; set; }
public DbSet assigmentTypes { get; set; }
public DbSet syndromes { get; set; }
public DbSet syndromeTypes { get; set; }
public DbSet reviews { get; set; }
public DbSet visits { get; set; }
public DbSet doctors { get; set; }
}
Работа, конечно, скучная, но времени экономится море. Осталась самая малость - написать об этом контексте в Web.config в корне проекта:
```
**Внимание! Подстава!** По умолчанию в Default Context написано *Data Source=(LocalDb)\MSLocalDB*, перед развертыванием оказалось, что это SQL Server Express 2014, а вот мой хостинг о нем совсем ничего не знал! Лучше сразу поставить Express 2012 (если его нету) и исправить на **v11.0**.
Теперь осталось только запустить приложение и система создаст новую базу данных… Или нет? У меня это происходило только при первом запросе доступа к этим данным. Но после обращения к данным слева в Обозревателе серверов можно наблюдать созданную для нас базу данных:
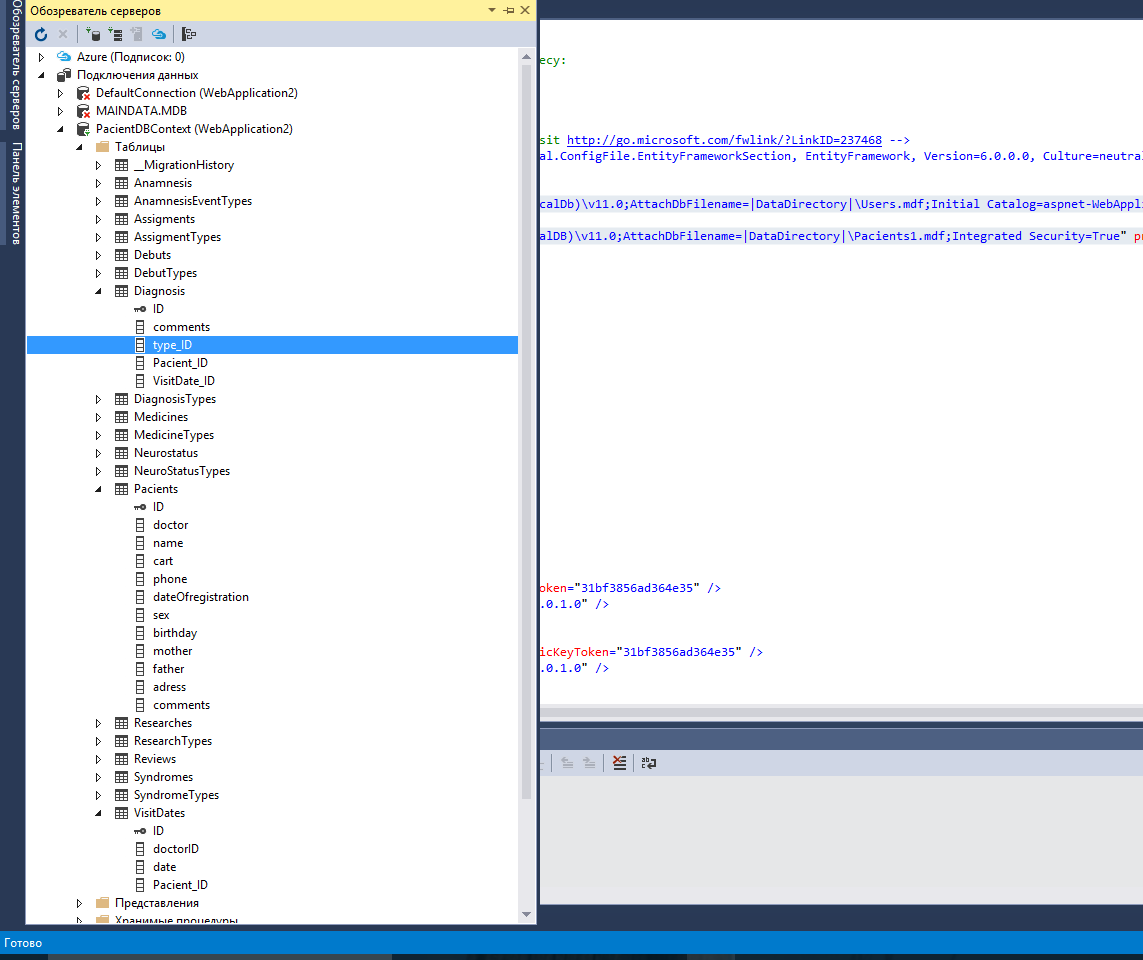
Кстати, если в последствии модели надо слегка поменять или что то добавить, необходимости пересоздавать базу нету. Для этого существуют автоматические миграции. Порядок работы: открываем консоль диспетчера пакетов, включаем миграции командой *Enable-Migrations –EnableAutomaticMigrations -ContextTypeName WebApplication2.Models.PacientDBContex*, для обновления базы в дальнейшем даем команду *update-database*. Подробнее — [тут](https://msdn.microsoft.com/ru-ru/data/jj554735.aspx).
#### Добавление контроллеров
Следующий шаг — добавление контроллеров для каждого типах данных в системе. Процесс автоматически-ручной. Нужно добавить контроллеры для каждого типа данных.
**Процесс добавления контроллера**
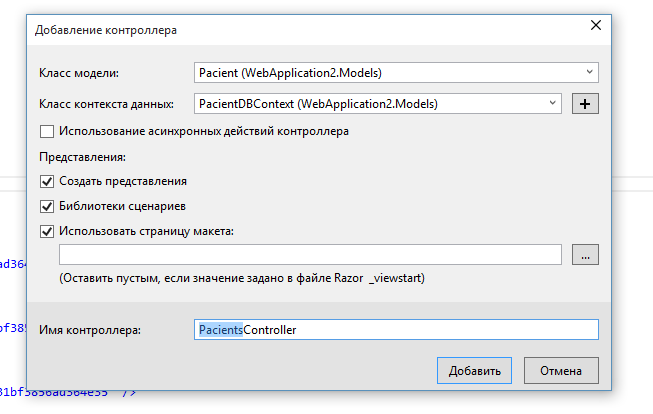
Отлично, теперь у нас есть контроллеры и стандартные представления для просмотра, добавления и изменения всех данных! Наверное и связывать их можно, как в админке Django… или нет?
А вот и нет! В стандартных никак нельзя связать пациента с датой приема, хотя на уровне моделей такая связь есть. С этого момента начинается самое интересное! Нам нужно сделать отображение страницы пациента со всеми его данными.
Для этого в PacientsContrtoller.cs меняем метод Details:
```
public ActionResult Details(int? id)
{
if (id == null)
{
return new HttpStatusCodeResult(HttpStatusCode.BadRequest);
}
//db.
Pacient pacient = db.pacients
.Include(p=>p.doctor)
.Include(p => p.visits.Select(w => w.anamnesis.Select(r=>r.type)))
.Include(p => p.visits.Select(w => w.debutes.Select(r => r.type)))
.Include(p => p.visits.Select(w => w.diagnoses.Select(r => r.type)))
.Include(p => p.visits.Select(w => w.researches.Select(r => r.type)))
.Include(p => p.visits.Select(w => w.anamnesis.Select(r => r.type)))
.Include(p => p.visits.Select(w => w.neurostatuses.Select(r => r.type)))
.Include(p => p.visits.Select(w => w.assigments.Select(r => r.type)))
.Include(p => p.visits.Select(w => w.syndromes.Select(r => r.type)))
.Include(p => p.visits.Select(w => w.reviews))
.Where(p=>p.ID == id).Single();
pacient.visits.Sort(delegate (VisitDate t1, VisitDate t2) { return t2.date.CompareTo(t1.date); });
return View(pacient);
}
```
В этом ужасно некрасивом LINQ запросе мы просим систему подгрузить абсолютно все данные о пациентах. Для этого используются Include, а для второго уровня вложенности — Select.
Для реализации поиска по имени или по слову в резюме приема тоже используем хитрый запрос:
```
public ActionResult SearchByName(String name = "", String mode = "name")
{
if (mode.Equals("name"))
return PartialView(db.pacients.Where(p => p.name.Contains(name)).ToList());
else
{
var results = db.pacients.Where(p => p.visits.Any(vd => vd.reviews.Any(r => r.comments.ToLower().Contains(name.ToLower()))));
return PartialView(results.ToList());
}
}
```
Напоминаю, что параметры для метода контроллера — это то, что приходит в GET запросе (в адресной строке после знака вопроса).
Остальные методы по сути остаются без изменений.
В каждом из контроллеров для документов (анамнезы, диагнозы, резюме...) я создал 4 новых метода в замен стандартных, они будут возвращать частичные (partial) представления по AJAX:
**Реализация**
```
public ActionResult pacientDetails(int? id)
{
if (id == null)
{
return new HttpStatusCodeResult(HttpStatusCode.BadRequest);
}
Anamnesis anamnesis = db.anamneses.Include(p => p.type).Where(p => p.ID == id).First();
if (anamnesis == null)
{
return HttpNotFound();
}
return PartialView("~/views/Anamnesis/pacientDetails.cshtml", anamnesis);
}
// GET: Anamnesis/Create
public ActionResult pacientCreate(int visitID, int num)
{
newAnamnesis na = new newAnamnesis();
na.visitID = visitID;
na.num = num;
na.anamnesis = new Anamnesis();
na.eventTypes = db.anamnesisTypes.ToList();
return PartialView(na);
}
public ActionResult Create(newAnamnesis data)
{
VisitDate visit = db.visits.Include(v => v.anamnesis).Where(v => v.ID == data.visitID).First();
if (visit == null)
return RedirectToAction("Index", "Pacients");
Pacient pacient = db.pacients.Where(p => p.visits.Any(v => v.ID == data.visitID)).First();
if (pacient == null)
return RedirectToAction("Index", "Pacients");
if (ModelState.IsValid)
{
AnamnesisEventType type = db.anamnesisTypes.Where(a => a.ID == data.anamnesis.type.ID).First();
data.anamnesis.type = type;
visit.anamnesis.Add(data.anamnesis);
db.SaveChanges();
return PartialView("/views/Anamnesis/pacientDetails.cshtml", data.anamnesis);
}
return PartialView("/views/Anamnesis/pacientCreate.cshtml", data);
}
// GET: Anamnesis/Edit/5
public ActionResult pacientEdit(int? id)
{
if (id == null)
{
return new HttpStatusCodeResult(HttpStatusCode.BadRequest);
}
Anamnesis anamnesis = db.anamneses.Include(p=>p.type).Where(p=>p.ID == id).First();
if (anamnesis == null)
{
return HttpNotFound();
}
return PartialView(anamnesis);
}
// POST: Anamnesis/Edit/5
[HttpPost]
[ValidateAntiForgeryToken]
public ActionResult pacientEdit([Bind(Include = "ID,comments")] Anamnesis anamnesis)
{
if (ModelState.IsValid)
{
db.Entry(anamnesis).State = EntityState.Modified;
db.SaveChanges();
return pacientDetails(anamnesis.ID);
}
return PartialView(anamnesis);
}
// GET: Anamnesis/Delete/5
public ActionResult pacientDelete(int? id)
{
if (id == null)
{
return new HttpStatusCodeResult(HttpStatusCode.BadRequest);
}
Anamnesis anamnesis = db.anamneses.Find(id);
if (anamnesis == null)
{
return HttpNotFound();
}
db.anamneses.Remove(anamnesis);
db.SaveChanges();
return PartialView();
}
```
#### Изменение стандартных представлений
Теперь наша задача изменить представления для пациента, чтобы они отображали всю информацию о нем и позволяли редактировать ее без обновления страницы.
На главной странице будем показывать форму поиска по двум параметрам на выбор и с помощью JQuery динамически подгружать результаты.
**Код страницы списка пациентов - Views/Pacient/Details.cshtml**
```
@{
ViewBag.Title = "Index";
}
Поиск пациентов
---------------
[Добавить](/Pacients/Create/)
Введите имя пациента
По имени
По резюме
$(document).ready(function () {
//$('#submit').cha
$('#submit').click(function (e) {
e.preventDefault();
var name = $('#search').val();
var mode = "name";
if ($("#reviewSearch").prop("checked"))
{
mode = "review"
}
name = name.replace(new RegExp(" ", 'g'), "%20");
$('#results').load("/Pacients/SearchByName?name=" + name + "&mode="+mode);
});
$('#search').keypress(function (event) {
if ($("#reviewSearch").prop("checked")) return;
if (event.which == 13) {
event.preventDefault();
}
var name = $('#search').val();
var mode = "name";
if ($("#reviewSearch").prop("checked")) {
mode = "review"
}
name = name.replace(new RegExp(" ", 'g'), "%20");
$('#results').load("/Pacients/SearchByName?name=" + name + "&mode=" + mode);
});
});
```
Шаблоны создания нового пациента и изменения оставим без изменений. А вот страницу подробной информации о пациенте пришлось разбить сразу на несколько представлений.
**Шапка страницы пациента**
```
@model WebApplication2.Models.Pacient
@{
ViewBag.Title = "Details";
}
[Назад](@Url.Action()
@Html.DisplayFor(model => model.name)
-------------------------------------
#### @Html.DisplayNameFor(model => model.doctor): @Html.DisplayFor(model => model.doctor.name)
@if (Model.visits.Count==0 || !(Model.visits.First().date.Equals(DateTime.Today)))
{
[Начать прием](@Url.Action()
}
---
@Html.Partial("~/Views/Pacients/visitsView.cshtml", Model)
```
Шапка командой *[Html](http://habrahabr.ru/users/html/).Partial("~/Views/Pacients/visitsView.cshtml", Model)* подгружает список всех документов. В начале списка документов находятся общие JS-функции для работы динамической подгрузки данных. VS2015 по-умолчанию поддерживает AngularJS, но в данном проекте я решил обойтись без него — проще, зато понятнее. Благо для этого понадобились всего четыре процедуры.
Во вкладке приемы находятся все данные упорядоченные по дате приема, в остальных вкладка — отдельные типы документов. Для упрощения все опять же разнесено по разным представлениям.
**Views/Pacients/visitsView.cshtml**
```
@model WebApplication2.Models.Pacient
@using WebApplication2.Models
function Delete(controller, id) {
if (confirm("Вы действительно хотите безвозвратно это удалить?")) {
$('#' + controller + 'Div' + id).load('/' + controller + '/pacientDelete/' + id);
$('.' + controller + 'Div' + id).load('/' + controller + '/pacientDelete/' + id);
}
}
function Cancel(controller, id) {
if (confirm("Лекарство будет отменено, но оно останется в истории приемов. Продолжаем?")) {
$("#" + controller + "Tab").find('#' + controller + 'Div' + id).load('/' + controller + '/pacientCancel/' + id);
$("#" + controller + "Tab").find('.' + controller + 'Div' + id).load('/' + controller + '/pacientCancel/' + id);
}
}
function CancelEdit(controller, id) {
$.get('/' + controller + '/pacientDetails/' + id, function (data) {
res = $.parseHTML('<div>' + data + '</div>');
if ($(res).find('.' + controller + 'Div' + id).html() != "") {
var content = $(res).find('.' + controller + 'Div' + id).html();
}
else {
var content = $(res).find('#' + controller + 'Div' + id).html();
}
$('#' + controller + 'Div' + id).html(content);
$('.' + controller + 'Div' + id).html(content);
});
}
function LoadEditForm(controller, id) {
if ($("#" + controller + "Tab").hasClass("active"))
{
$("#" + controller + "Tab").find('#' + controller + 'Div' + id).load('/' + controller + '/pacientEdit/' + id);
$("#" + controller + "Tab").find('.' + controller + 'Div' + id).load('/' + controller + '/pacientEdit/' + id);
}
else
{
$("#dateTab").find('#' + controller + 'Div' + id).load('/' + controller + '/pacientEdit/' + id);
$("#dateTab").find('.' + controller + 'Div' + id).load('/' + controller + '/pacientEdit/' + id);
}
}
function PostEditForm(controller, id, mce) {
if (mce == true) tinyMCE.triggerSave();
$.ajax({
type: "POST",
url: '/' + controller + '/pacientEdit/' + id,
data: $('.' + controller + 'Edit' + id).serialize() + $('#' + controller + 'Edit' + id).serialize(), // serializes the form's elements.
success: function (data) {
res = $.parseHTML('<div>' + data + '</div>');
if ($(res).find('.' + controller + 'Div' + id).html() != "")
{
var content = $(res).find('.' + controller + 'Div' + id).html();
}
else {
var content = $(res).find('#' + controller + 'Div' + id).html();
}
$('#' + controller + 'Div' + id).html(content);
$('.' + controller + 'Div' + id).html(content);
}
});
}
function PostCreateForm(controller, num, mce) {
if (mce == true) tinyMCE.triggerSave();
$.ajax({
type: "POST",
url: '/' + controller + '/Create/',
data: $('#' + controller + 'Create').serialize(), // serializes the form's elements.
success: function (data) {
res = $.parseHTML('<div><div>' + data + '</div></div>');
$('#documentData' + num).prepend($(res).find('div').first().html());
$('#' + controller + 'Tab').find('.tabContent').prepend($(res).find('div').first().html());
$('#' + controller + 'Create').trigger('reset');
}
});
}
* [Приемы](#dateTab)
* [Персональные данные](#InfoTab)
* [Анамнез](#AnamnesisTab)
* [Дебют](#DebutsTab)
* [Диагнозы](#DiagnosesTab)
* [Приступы](#SyndromesTab)
* [Исследования](#ResearchesTab)
* [Назначения](#AssigmentsTab)
* [Невростатус](#NeurostatusTab)
* [Резюме](#ReviewsTab)
@if (Model.visits.Count == 0)
{
Пациент еще не был на приеме.
}
@if (Model.visits.Count != 0 && Model.visits.First().date.Equals(DateTime.Today))
{
@Html.Partial("~/Views/Pacients/documentList.cshtml", new documentList { num = 1, add = true, visit = Model.visits.First() })
}
@{
int num = 9;
}
@foreach (var visit in Model.visits)
{
if (visit.date.Equals(DateTime.Today))
{
continue;
}
@Html.Partial("~/Views/Pacients/documentList.cshtml", new documentList { num = num, add = false, visit = visit })
num = num + 8;
}
@Html.Partial("~/Views/Pacients/PersonalData.cshtml", Model)
@Html.Partial("~/Views/Pacients/anamnesisList.cshtml", Model)
@Html.Partial("~/Views/Pacients/debutList.cshtml", Model)
@Html.Partial("~/Views/Pacients/diagnosisList.cshtml", Model)
@Html.Partial("~/Views/Pacients/syndromList.cshtml", Model)
@Html.Partial("~/Views/Pacients/researchList.cshtml", Model)
@Html.Partial("~/Views/Pacients/assigmentList.cshtml", Model)
@Html.Partial("~/Views/Pacients/neurostatusList.cshtml", Model)
@Html.Partial("~/Views/Pacients/reviewList.cshtml", Model)
```
Для примера рассмотрим одно из представлений для вкладки, например, с анамнезами.
**Views/Pacient/anamnesisList.cshtml**
```
@model WebApplication2.Models.Pacient
@using WebApplication2.Models
##### Сводный анамнез
@foreach (var visit in Model.visits)
{
foreach (var anamnes in visit.anamnesis)
{
@Html.Partial("~/Views/Anamnesis/pacientDetails.cshtml", anamnes)
}
}
```
Как вы помните, мы сделали в контроллерах документов по четыре новых метода: pacientDetails, pacientCreate, pacientEdit, pacientDelete. Надо из них ссылается представление выше. Значит нужно его создать!
**Добавление нового частичного представления**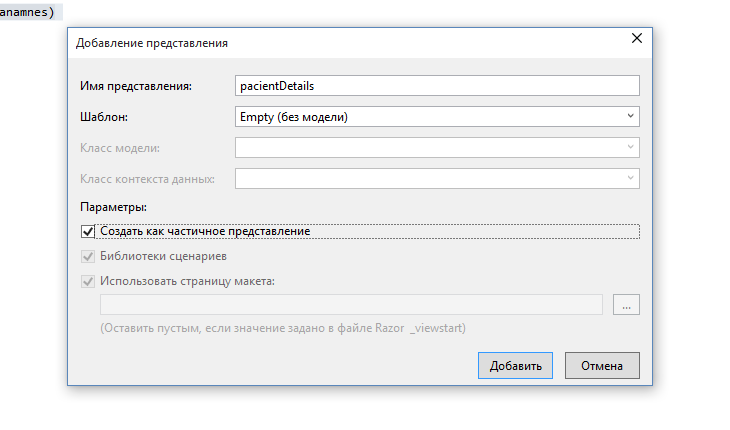
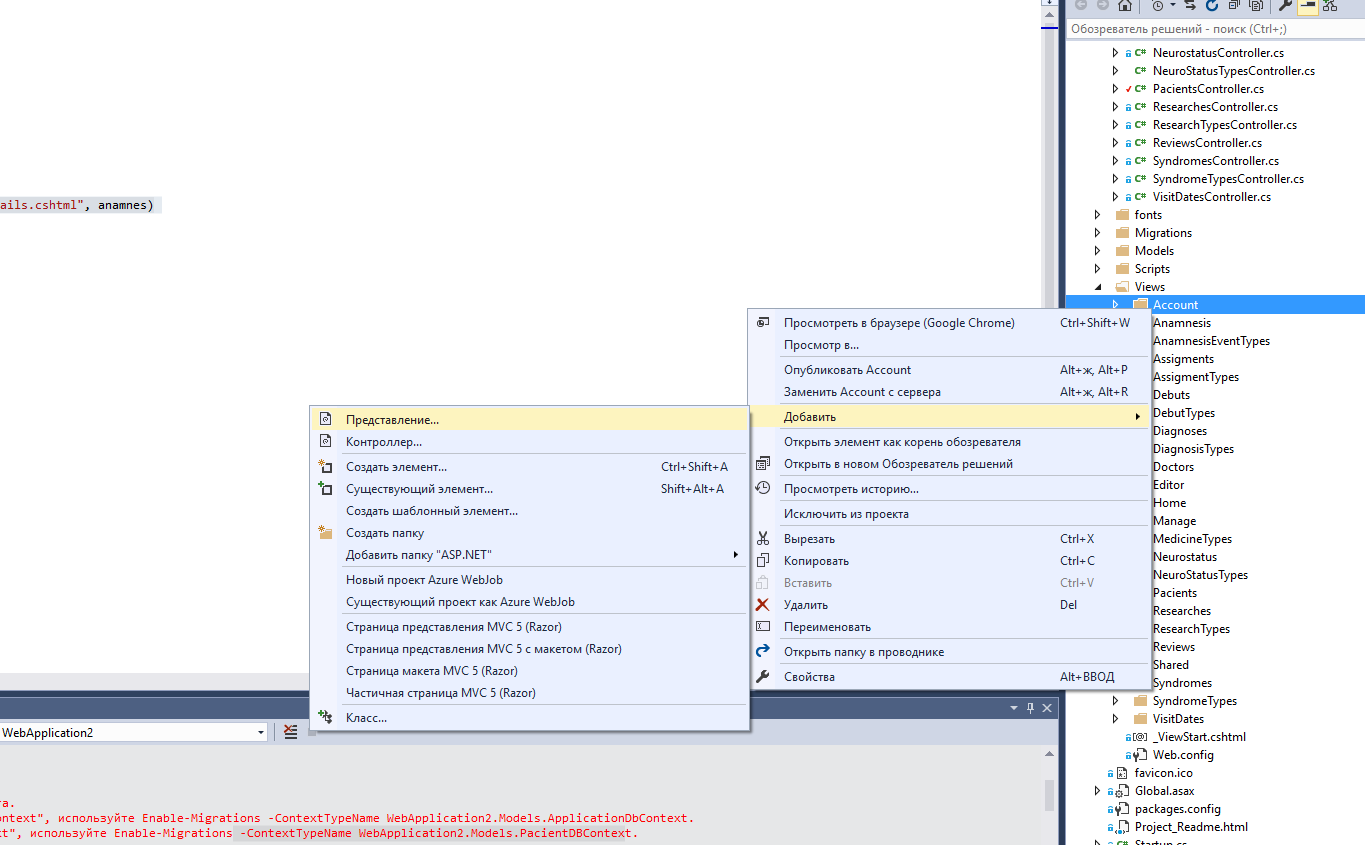
Создав представление, заполняем его:
**Views/Anamnesis/pacientDetails.cshtml**
```
@model WebApplication2.Models.Anamnesis
**@Html.DisplayFor(model => model.type.name)**
@Html.DisplayFor(model => model.comments)
---
```
Вместо обычных имен здесь используются [Html](http://habrahabr.ru/users/html/).DisplayFor(model => model.type.name) для отображения имени элемента. Это и позволяет задавать имена внутри моделей (как это сделано в начале поста).
Аналогично можно сделать с представлением для изменения анамнеза:
**Views/Anamnesis/pacientEdit.cshtml**
```
@model WebApplication2.Models.Anamnesis
@Html.AntiForgeryToken()
@Html.HiddenFor(model => model.ID)
@Html.HiddenFor(model => model.type.ID)
**@Html.DisplayFor(model => model.type.name)**
@Html.EditorFor(model => model.comments, new { htmlAttributes = new { @class = "form-control", @placeholder = Html.DisplayNameFor(model => model.comments) } })
@Html.ValidationMessageFor(model => model.comments, "", new { @class = "text-danger" })
```
Замечания:
* [Html](http://habrahabr.ru/users/html/).AntiForgeryToken() — добавляет уникальный ключ пользователя
* [Html](http://habrahabr.ru/users/html/).HiddenFor(model => model.ID) — добавляет для поля
* [Html](http://habrahabr.ru/users/html/).ValidationMessageFor(model => model.comments, "", new { [class](http://habrahabr.ru/users/class/) = «text-danger» }) — отображает сообщения валидатора
* [Html](http://habrahabr.ru/users/html/).EditorFor(model => model.comments) — отображает поле для ввода соотвественно типу поля (например, input или textarea)
* CancelEdit и PostEditForm — это описанные нами ранее JS процедуры
А вот с созданием новых объектов сложнее: нам надо связывать его с объектом из словаря, а это другая модель и другая таблица с данными. Надо тащить в форму создания список из всех возможных вариантов. Подгрузить их несложно, а вот передать в представление нельзя — она принимает только один параметр — модель. Придется создавать новую модель…
Создаем новый файл **Models\viewModels.cs** и добавляем туда код нашей модели для представления. В контекст его добавлять не надо.
**Код модели для добавления анамнеза**
```
public class newAnamnesis
{
public Anamnesis anamnesis { get; set; }
public int visitID { get; set; }
public int? num { get; set; }
public List eventTypes { get; set; }
}
```
Теперь вспомним нашу функцию pacientCreate в Controllers\AnamnesisController.cs:
**pacientCreate - метод добавления нового анамнеза**
```
// GET: Anamnesis/Create
public ActionResult pacientCreate(int visitID, int num)
{
newAnamnesis na = new newAnamnesis();
na.visitID = visitID;
na.num = num;
na.anamnesis = new Anamnesis();
na.eventTypes = db.anamnesisTypes.ToList();
return PartialView(na);
}
[HttpPost]
[ValidateAntiForgeryToken]
public ActionResult Create(newAnamnesis data)
{
VisitDate visit = db.visits.Include(v => v.anamnesis).Where(v => v.ID == data.visitID).First();
if (visit == null)
return RedirectToAction("Index", "Pacients");
Pacient pacient = db.pacients.Where(p => p.visits.Any(v => v.ID == data.visitID)).First();
if (pacient == null)
return RedirectToAction("Index", "Pacients");
if (ModelState.IsValid)
{
AnamnesisEventType type = db.anamnesisTypes.Where(a => a.ID == data.anamnesis.type.ID).First();
data.anamnesis.type = type;
visit.anamnesis.Add(data.anamnesis);
db.SaveChanges();
return PartialView("/views/Anamnesis/pacientDetails.cshtml", data.anamnesis);
}
return PartialView("/views/Anamnesis/pacientCreate.cshtml", data);
}
```
Фух, кажется теперь все готово. Осталось только проделать эти операции для всех остальных типов документов. К слову по идее этом можно автоматизировать, скажем создать шаблонное представление, но так в Razor делать нельзя. Поправьте, если я не прав.
Форма создания подгружается на вкладке приемы:
**Код представления documentList.cshtml для вкладки Приемы**
```
@model WebApplication2.Models.documentList
@using WebApplication2.Models
@{ var cl = "bs-callout-primary";
var ac = "";
}
@if (Model.add == false)
{
cl = "bs-callout-success";
ac = "";
}
@if (Model.add == false)
{
##### Прием @Model.visit.date
}
else
{
##### Текущий прием
}
@if (Model.visit.anamnesis.Count > 0 || Model.add == true)
{
####
[Анамнез@Model.visit.date](@String.Format()
@foreach (var anamnes in Model.visit.anamnesis)
{
@Html.Partial("~/Views/Anamnesis/pacientDetails.cshtml", anamnes);
}
@if (Model.add == true)
{
@Html.Action("pacientCreate", "Anamnesis", new { num = Model.num, visitID = Model.visit.ID})
}
Model.num = Model.num + 1;
}
@if (Model.visit.debutes.Count > 0 || Model.add == true)
{
####
[Дебют@Model.visit.date](@String.Format()
@foreach (var debut in Model.visit.debutes)
{
@Html.Partial("~/Views/Debuts/pacientDetails.cshtml", debut);
}
@if (Model.add == true)
{
@Html.Action("pacientCreate", "Debuts", new { num = Model.num, visitID = Model.visit.ID })
}
Model.num = Model.num + 1;
}
@if (Model.visit.diagnoses.Count > 0 || Model.add == true)
{
####
[Диагноз@Model.visit.date](@String.Format()
@foreach (var diagnosis in Model.visit.diagnoses)
{
@Html.Partial("~/Views/Diagnoses/pacientDetails.cshtml", diagnosis);
}
@if (Model.add == true)
{
@Html.Action("pacientCreate", "Diagnoses", new { num = Model.num, visitID = Model.visit.ID })
}
Model.num = Model.num + 1;
}
@if (Model.visit.syndromes.Count > 0 || Model.add == true)
{
####
[Приступы@Model.visit.date](@String.Format()
@foreach (var syndrome in Model.visit.syndromes)
{
@Html.Partial("~/Views/Syndromes/pacientDetails.cshtml", syndrome);
}
@if (Model.add == true)
{
@Html.Action("pacientCreate", "Syndromes", new { num = Model.num, visitID = Model.visit.ID })
}
Model.num = Model.num + 1;
}
@if (Model.visit.researches.Count > 0 || Model.add == true)
{
####
[Исследования@Model.visit.date](@String.Format()
@foreach (var research in Model.visit.researches)
{
@Html.Partial("~/Views/Researches/pacientDetails.cshtml", research);
}
@if (Model.add == true)
{
@Html.Action("pacientCreate", "Researches", new { num = Model.num, visitID = Model.visit.ID })
}
Model.num = Model.num + 1;
}
@if (Model.visit.assigments.Count > 0 || Model.add == true)
{
####
[Назначения@Model.visit.date](@String.Format()
@foreach (var assigment in Model.visit.assigments)
{
@Html.Partial("~/Views/Assigments/pacientDetails.cshtml", assigment);
}
@if (Model.add == true)
{
@Html.Action("pacientCreate", "Assigments", new { num = Model.num, visitID = Model.visit.ID })
}
Model.num = Model.num + 1;
}
@if (Model.visit.neurostatuses.Count > 0 || Model.add == true)
{
####
[Невростатус@Model.visit.date](@String.Format()
@foreach (var neurostatus in Model.visit.neurostatuses)
{
@Html.Partial("~/Views/Neurostatus/pacientDetails.cshtml", neurostatus);
}
@if (Model.add == true)
{
@Html.Action("pacientCreate", "Neurostatus", new { num = Model.num, visitID = Model.visit.ID })
}
Model.num = Model.num + 1;
}
@if (Model.visit.reviews.Count > 0 || Model.add == true)
{
####
[Резюме@Model.visit.date](@String.Format()
@foreach (var review in Model.visit.reviews)
{
@Html.Partial("~/Views/Reviews/pacientDetails.cshtml", review);
}
@if (Model.add == true)
{
@Html.Action("pacientCreate", "Reviews", new { num = Model.num, visitID = Model.visit.ID })
}
Model.num = Model.num + 1;
}
@Html.ActionLink("Очистить все сведения об этом приеме", "Delete", "VisitDates", new { id = Model.visit.ID }, new { @class = "btn btn-danger btn-sm pull-right", style = "margin-top: 10px;margin-right: 15px;" })
```
Для него, кстати, также потребовалось отдельно представление.
В итоге получилось вот так:
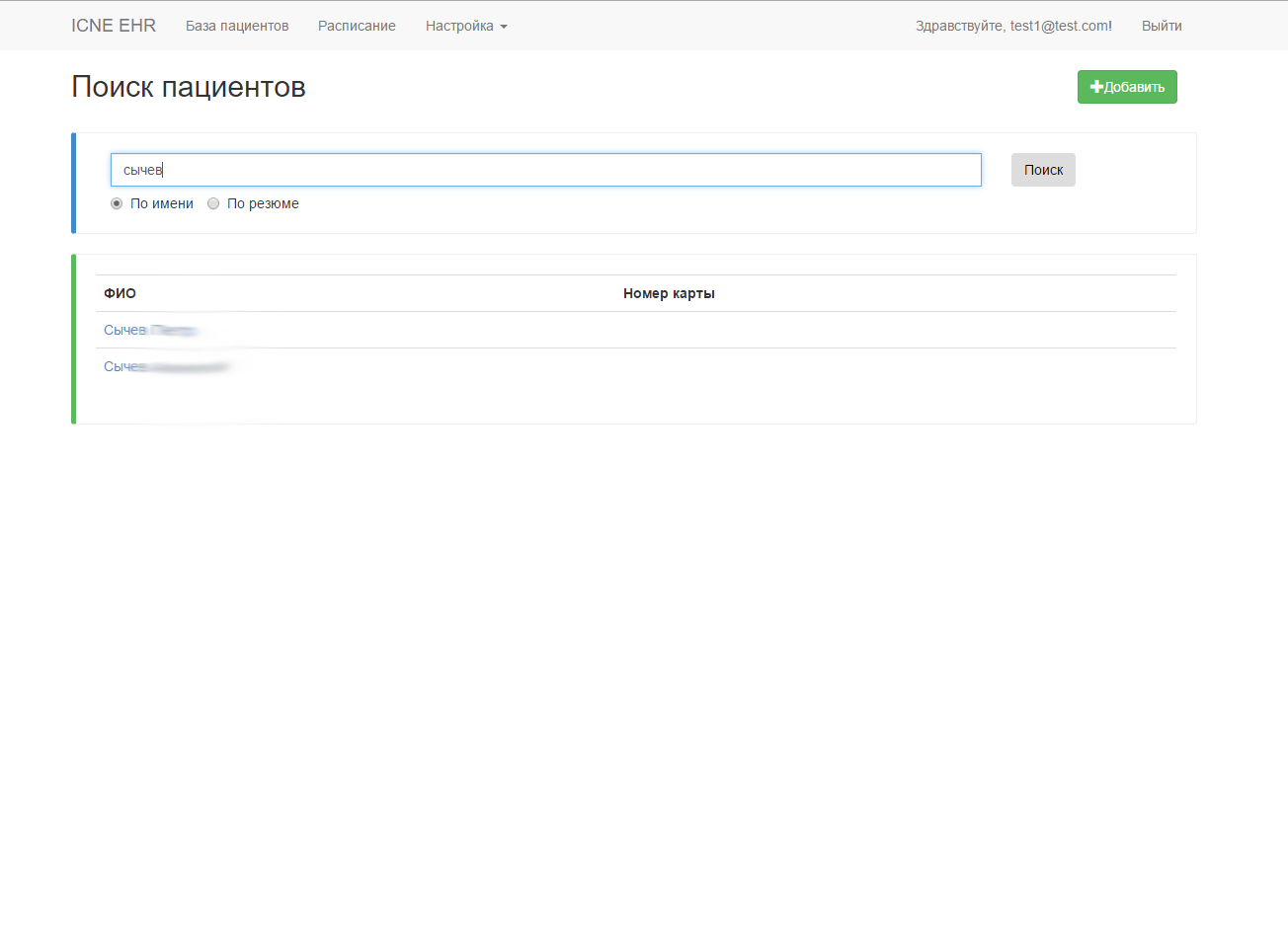

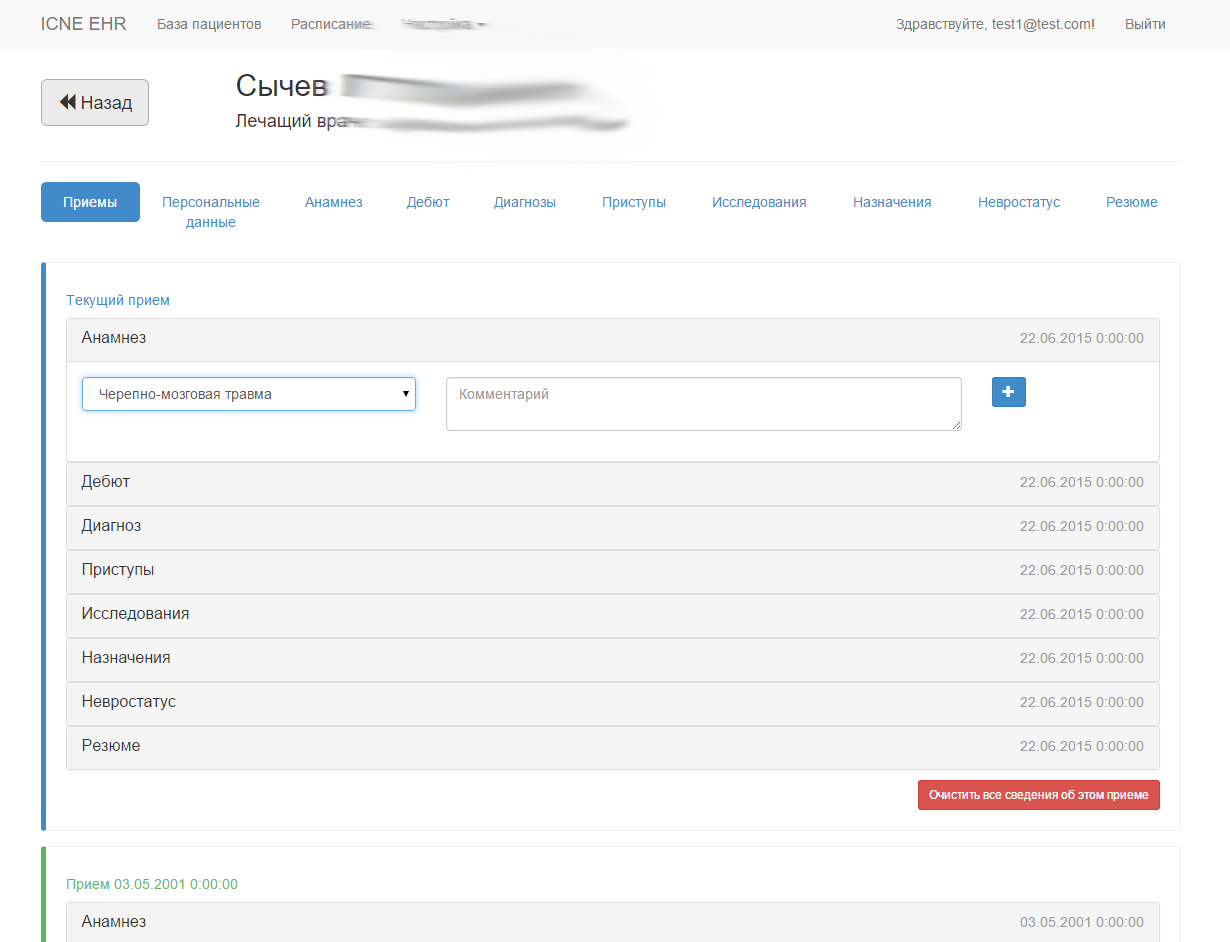
#### Публикация на сервер
Для развертывания на свой сервер по FTP необходимо развернуть проект и отдельно развернуть базу данных. Для этого щелкаем правой кнопкой по проекту и выбираем публикация.
Перед загрузкой нужно отредактировать Web.Release.Config в корне проекта, вписав в него connectionString для подключения к базе данных на сервере. Инструкции, как это сделать, заботливо предоставлены Microsoft прямо в самом файле.
Экспорт базы пришлось делать вручную через SQL Server Management Studio.
С Azure все должно быть еще проще — студия сама опубликует базу данных.
#### Заключение
К сожалению, все тонкости в одной статье описать крайне сложно, но общие моменты я постарался осветить. Полный код проекта доступен на GitHub: <https://github.com/roctbb/ICNE_EHR/>.
Догадываюсь, что некоторые вещи я сделал не совсем правильно, буду рад любым комментариям.
В качестве источников использовался сайт asp.net и бесчисленные вопросы на stackoverflow.com. | https://habr.com/ru/post/260867/ | null | ru | null |
# Как этот sidecar-контейнер оказался здесь [в Kubernetes]?
***Прим. перев.**: Этой статьёй, написанной Scott Rahner — инженером в Dow Jones, мы продолжаем цикл многочисленных материалов, доступно рассказывающих о том, как устроен Kubernetes, как работают, взаимосвязаны и используются его базовые компоненты. На сей раз это практическая заметка с примером кода для создания хука в Kubernetes, демонстрируемого автором «под предлогом» автоматического создания sidecar-контейнеров.*

*(Автор фото — Gordon A. Maxwell, найдено на просторах интернета.)*
Когда я начал изучать sidecar-контейнеры и service mesh'и, мне потребовалось разобраться в том, как работает ключевой механизм — автоматическая вставка sidecar-контейнера. Ведь в случае использования систем вроде Istio или Consul, при деплое контейнера с приложением внезапно в его pod'е появляется и уже настроенный контейнер Envoy *(схожая ситуация происходит и у Conduit, о котором мы [писали](https://habr.com/company/flant/blog/349496/) в начале года — прим. перев.)*. Что? Как? Так начались мои исследования…
Для тех, кто не знает, sidecar-контейнер — контейнер, который деплоится рядом с контейнерами приложения, чтобы каким-либо образом «помогать» этому приложению. Примером такого использования может служить прокси для управления трафиком и завершения TLS-сессий, контейнер для стриминга логов и метрик, контейнер для сканирования проблем в безопасности… Идея в том, чтобы изолировать различные аспекты всего приложения от бизнес-логики с помощью применения отдельных контейнеров для каждой функции.
Перед тем, как продолжить, обозначу свои ожидания. Цель этой статьи — не объяснить хитросплетения и сценарии использования Docker, Kubernetes, service mesh'ей и т.п., а наглядно показать один мощный подход к расширению возможностей этих технологий. Статья — для тех, кто уже знаком с применением данных технологий или, по крайней мере, немало о них прочитал. Чтобы попробовать практическую часть в действии, потребуется машина с уже настроенными Docker и Kubernetes. Простейший способ для этого — <https://docs.docker.com/docker-for-windows/kubernetes/> (инструкция для Windows, которая работает и в Docker for Mac). *(Прим. перев.: В качестве альтернативы пользователям Linux и \*nix-систем можем предложить [Minikube](https://habr.com/company/flant/blog/333470/).)*
Общая картина
-------------
Для начала давайте немного разберёмся с Kubernetes:

*[Kube Arch](https://kubernetes.io/docs/concepts/architecture/cloud-controller/), лицензированная под CC BY 4.0*
Когда вы собираетесь задеплоить что-либо в Kubernetes, необходимо отправить объект в kube-apiserver. Чаще всего это делают передачей аргументов или YAML-файла в kubectl. В таком случае сервер API перед тем, как непосредственно помещать данные в etcd и планировать соответствующие задания, проходит через несколько этапов:

Эта последовательность важна, чтобы разобраться, как работает вставка sidecar-контейнеров. В частности, нужно обратить внимание на [Admission Control](https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/), в рамках которого Kubernetes валидирует и, если необходимо, модифицирует объекты перед тем, как сохранять их *(подробнее об этом этапе см. в главе «Контроль допуска» [этой статьи](https://habr.com/company/flant/blog/342658/) — прим. перев.)*. Kubernetes также позволяет регистрировать [webhooks](https://kubernetes.io/docs/reference/access-authn-authz/extensible-admission-controllers/#admission-webhooks), которые могут выполнять определяемую пользователем валидацию и изменения *(mutations)*.
Однако процесс создания и регистрации своих хуков не так-то уж прост и хорошо документирован. Мне пришлось потратить несколько дней на чтение и перечитывание документации, а также на анализ кода Istio и Consul. А когда дело дошло до кода для некоторых из ответов API, я провёл не менее половины дня на выполнение случайных проб и ошибок.
После того, как результат был достигнут, думаю, что будет нечестно не поделиться им со всеми вами. Он простой и в то же время действенный.
Код
---
Название webhook говорит само за себя — это HTTP endpoint, реализующий API, определённый в Kubernetes. Вы создаёте API-сервер, который Kubernetes может вызывать перед тем, как разбираться с Deployment'ами. Здесь мне пришлось столкнуться со сложностями, поскольку доступны всего несколько примеров, некоторые из которых — просто unit-тесты Kubernetes, другие — спрятаны посреди огромной кодовой базы… и все написаны на Go. Но я выбрал более доступный вариант — Node.js:
```
const app = express();
app.use(bodyParser.json());
app.post('/mutate', (req, res) => {
console.log(req.body)
console.log(req.body.request.object)
let adminResp = {response:{
allowed: true,
patch: Buffer.from("[{ \"op\": \"add\", \"path\": \"/metadata/labels/foo\", \"value\": \"bar\" }]").toString('base64'),
patchType: "JSONPatch",
}}
console.log(adminResp)
res.send(adminResp)
})
const server = https.createServer(options, app);
```
*([index.js](https://github.com/dowjones/k8s-webhook/blob/master/docker/index.js))*
Путь к API — в данном случае это `/mutate` — может быть произвольным (должен лишь в дальнейшем соответствовать YAML, передаваемому в Kubernetes) . Для него важно видеть и понимать JSON, получаемый от API-сервера. В данном случае мы не вытаскиваем ничего из JSON, но это может пригодиться в других сценариях. В приведённом же выше коде мы обновляем JSON. Для этого нужно две вещи:
1. Изучить и понять [JSON Patch](http://jsonpatch.com/).
2. Правильно сконвертировать выражение JSON Patch в массив байтов, закодированный с base64.
Как только это сделано, достаточно лишь передать API-серверу ответ с очень простым объектом. В данном случае мы добавляем лейбл `foo=bar` любому попадающему к нам pod'у.
Deployment
----------
Хорошо, у нас есть код, который принимает запросы от API-сервера Kubernetes и отвечает на них, но как его задеплоить? И как заставить Kubernetes перенаправлять нам эти запросы? Развернуть такой endpoint можно везде, до чего может «достучаться» API-сервер Kubernetes. Простейшим способом является деплой кода в сам кластер Kubernetes, что мы и сделаем в данного примере. Я постарался сделать пример максимально простым, поэтому для всех действий использую лишь Docker и kubectl. Начнём с создания контейнера, в котором будет запускаться код:
```
FROM node:8
USER node
WORKDIR /home/node
COPY index.js .
COPY package.json .
RUN npm install
# позже сюда добавятся дополнительные команды для TLS
CMD node index.js
```
*([Dockerfile](https://github.com/dowjones/k8s-webhook/blob/master/docker/Dockerfile))*
Как видно, тут всё очень просто. Возьмите образ с node от сообщества и забросьте в него код. Теперь можно выполнить простую сборку:
```
docker build . -t localserver
```
Следующим шагом создадим Deployment в Kubernetes:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: webhook-server
spec:
replicas: 1
selector:
matchLabels:
component: webhook-server
template:
metadata:
labels:
component: webhook-server
spec:
containers:
- name: webhook-server
imagePullPolicy: Never
image: localserver
```
*([deployment.yaml](https://github.com/dowjones/k8s-webhook/blob/master/k8s/deployment.yaml))*
Заметили, как мы сослались на только что созданный образ? Так же просто тут мог быть и pod, и что-либо иное, к чему мы можем подключить сервис в Kubernetes. Теперь определим этот Service:
```
apiVersion: v1
kind: Service
metadata:
name: webhook-service
spec:
ports:
- port: 443
targetPort: 8443
selector:
component: webhook-server
```
Так в Kubernetes появится endpoint с внутренним именем, который указывает на наш контейнер. Финальный шаг — сообщить Kubernetes'у, что мы хотим, чтобы API-сервер вызывал этот сервис, когда он готов производить изменения *(mutations)*:
```
apiVersion: admissionregistration.k8s.io/v1beta1
kind: MutatingWebhookConfiguration
metadata:
name: webhook
webhooks:
- name: webhook-service.default.svc
failurePolicy: Fail
clientConfig:
service:
name: webhook-service
namespace: default
path: "/mutate"
# далее записан результат base64-кодирования файла rootCA.crt
# с помощью команды `cat rootCA.crt | base64 | tr -d '\n'`
# подробнее об этом см. ниже
caBundle: "LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUdHekNDQkFPZ0F3SUJBZ0lKQU1jcTN6UHZDQUd0TUEwR0NTcUdTSWIzRFFFQkN3VUFNSUdqTVFzd0NRWUQKVlFRR0V3SlZVekVUTUJFR0ExVUVDQXdLVG1WM0lFcGxjbk5sZVRFVE1CRUdBMVVFQnd3S1VISnBibU5sZEc5dQpJREVTTUJBR0ExVUVDZ3dKUkc5M0lFcHZibVZ6TVF3d0NnWURWUVFMREFOUVNVSXhIakFjQmdOVkJBTU1GWGRsClltaHZiMnN0S2k1a1pXWmhkV3gwTG5OMll6RW9NQ1lHQ1NxR1NJYjNEUUVKQVJZWmMyTnZkSFF1Y21Gb2JtVnkKUUdSdmQycHZibVZ6TG1OdmJUQWVGdzB4T0RFd016RXhOalU1TURWYUZ3MHlNVEE0TWpBeE5qVTVNRFZhTUlHagpNUXN3Q1FZRFZRUUdFd0pWVXpFVE1CRUdBMVVFQ0F3S1RtVjNJRXBsY25ObGVURVRNQkVHQTFVRUJ3d0tVSEpwCmJtTmxkRzl1SURFU01CQUdBMVVFQ2d3SlJHOTNJRXB2Ym1Wek1Rd3dDZ1lEVlFRTERBTlFTVUl4SGpBY0JnTlYKQkFNTUZYZGxZbWh2YjJzdEtpNWtaV1poZFd4MExuTjJZekVvTUNZR0NTcUdTSWIzRFFFSkFSWVpjMk52ZEhRdQpjbUZvYm1WeVFHUnZkMnB2Ym1WekxtTnZiVENDQWlJd0RRWUpLb1pJaHZjTkFRRUJCUUFEZ2dJUEFEQ0NBZ29DCmdnSUJBTHRpTU5mL1l3d0RkcHlPSUhja2FQK3J6NmdxYXBhWmZ2a0JndHVZK3BYQVZnNWc5M1RISmlPdlJYUnAKeG9UZ1o0RlA4N0V3R0NXRUZxZTRFRjh5UUxCK1NvWHBxUmRrWlVLYlM3eDVJNnNDb0h1dFJXaURpd3piV3lGawp3UnppeXpyMTQzN2wzYWxadU9VNkl5bU9mVDlETzdRaDNnY01HOEprQ09aVlVOelVIN3J4WmtieGg3M1lXNW5ZCjhSMU5tZDJ3cm1IWkVWc2JmS21GTlhvZjFueWtRcXMyMUQxT1FwQ3A1VDB5QU9penZlaW9OS3VsQVVpcjNVQ0EKSmNYYWpMMGZVS1ZIcGVTbGlhWXdKZmZNSDFqOElqSDZTdm5TdG9qQWlWdnJHb1ZKUlFqRXFLQkpYVGMyaHZCWQpCcjJqdGdQb25WWnBBTFphbktha0JTV1cyZ25oZVFKaHpKOGhkMXlEU0x6dFFKb2JkOHZUMEZ5bHZaQzY3aURnCmROb1NWbHBaQlpDSVIxTldaRVdGbTlTWWtKLzZ6emVqMFZpWnp2aFBYdm9GelZEVGZoMEwzQWljUTZlWTNzcEMKV0Fmb2VTcFUxaEVJeG92SmdwVkpMbnRaWkhyN1RJQ05CNlV5QnFVUzhEa0lTMkhnWkh2MTd1VjA3bTFzZDZDMApDUnV5YmZHQ0l2RGNwMCtzMjF6TENXemJuS3BzaFo5UkYvYWhXMW11cVN2dGt0WXlYOFVySlpKT1h3Z0NKenhLCmdwZGs3YlA4Y3ZkRWxUZDduQXRJbjZPcm42VWlVUnFpSXY1VSt0bmIvOVlrNDIxVzdlT2NxZ3JqTEY4eUo5ckIKN0hBYlhGRjM5OW5NMlBtYkZIV2FROG1xeWo0L0kxNm9tTHVsUGZvekVWK0xvMXVwQWdNQkFBR2pVREJPTUIwRwpBMVVkRGdRV0JCUnVKaTcyS0U5bWhpejZvYVhkSXlpbGpTeXhkVEFmQmdOVkhTTUVHREFXZ0JSdUppNzJLRTltCmhpejZvYVhkSXlpbGpTeXhkVEFNQmdOVkhSTUVCVEFEQVFIL01BMEdDU3FHU0liM0RRRUJDd1VBQTRJQ0FRQlQKS28wczJTTWZkSzdkRS9ZdFBwQ2lQNDVBK0xJSjVKd0l2dWdiUlNGeVRUSEU0akhVRTdQdWc3VHdGNC93YnJFZwpNN1F3OWUxbDA1M2lheWRFOS9sUlVDbzN4TnVVcU5jU2lCK3RIOE54dURHUUw5NHBuWTdTR3FuRjBDMlZ2d2x2CmxaYUQxNU41cVdvTVJrQU54VXRPRGFaWEdLcS94VVBSQWdNMHFtbXc5ZnIwaXAvQzFjVGMyVVhlejlGNTMvV2cKV1FNempWbUNTNGlnckR1a1FBNWxodFRlYUlzK3pxNk9ZeWNiN01KR1JBL0NhcnpDL1VuZExMbmhsdEtITkJhMwp0TDFVVUJCTzBMdmdMaE8zVk9nRENOazJYVmZzVHFueEUrTGp6R2dmUnRqYjE5L0p1d2V2OW00Y3ZzUlZESGVMCk9oQ0lvenorUHRLWHBwVDFWd1VRbFZlOG5ic2RiVnNZWmt4Q3llcGpMUTJ5TXNUUXdoa2NncGRiTnYzbTMvRC8Kc3N5ZS9iZnphUGFXVEE1R0d5emhXdXlENDZPT1lCUFlhZzd0aFFneXRvOWRpSWNDSHNMQ3BVZm1FQ1d6TERBYgozK2NadnZnYXZybFJCZjN2cVhrVlZxT1NLNGxna25iUEZJc0YvbnFIanM2WXI5Tktiai9sRGlBalRYaVdQdFRmClJzd0JodndveDJnK21zd0prQytId0cvckZ1RXFDdklTaFJGWlEvMDgyL0F5ekpYRlE3SlV3eHluL0dTQXlGZUsKL1Y3T01XTEhUeVd4Vkg4eVBCZ1JSVE1CK3NrOEVQQndveFRLSjZnLytTbmdkNXM1ZEx6ZDhpSTlsVHdxWDZBTApzNU1OY2NobFRWVU9RYnFGWXBKc3FTUTlIVlB2bjZDckRlTGlxTlNKQVE9PQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg=="
rules:
- operations: [ "CREATE" ]
apiGroups: [""]
apiVersions: ["v1"]
resources: ["pods"]
```
*([hook.yaml](https://github.com/dowjones/k8s-webhook/blob/master/k8s/hook.yaml))*
Название и путь здесь могут быть любыми, но я постарался сделать их настолько осмысленными, насколько возможно. Изменение пути будет означать необходимость модификации соответствующего кода в JavaScript. Важен и webhook `failurePolicy` — он определяет, должен ли объект сохраняться, если хук возвращает ошибку или не срабатывает. Мы в данном случае говорим Kubernetes'у не продолжать обработку. Наконец, правила (`rules`): они будут меняться в зависимости от того, на какие вызовы API вы ожидаете действий от Kubernetes. В данном случае, поскольку мы пытаемся эмулировать вставку sidecar-контейнера, нам требуется перехват запросов на создание pod'а.
Вот и всё! Так просто… но что насчёт безопасности? RBAC — это один из аспектов, который не затронут в статье. Я предполагаю, что вы запускаете пример в Minikube или же в Kubernetes, что идёт в поставке Docker for Windows/Mac. Однако расскажу ещё об одном необходимом элементе. API-сервер Kubernetes обращается только к endpoint'ам с HTTPS, поэтому для приложения потребуется наличие SSL-сертификатов. Также потребуется сообщить Kubernetes'у, кто является удостоверяющим центром корневого сертификата.
TLS
---
**Только для демонстрационных целей(!!!)** я добавил в `Dockerfile` немного кода, чтобы создать root CA и воспользоваться им для подписи сертификата:
```
RUN openssl genrsa -out rootCA.key 4096
RUN openssl req -x509 -new -nodes -key rootCA.key -sha256 -days 1024 -out rootCA.crt \
-subj "/C=US/ST=New Jersey/L=Princeton /O=Dow Jones/OU=PIB/CN=*.default.svc/[email protected]"
RUN openssl genrsa -out webhook.key 4096
RUN openssl req -new -key webhook.key -out webhook.csr \
-subj "/C=US/ST=New Jersey/L=Princeton /O=Dow Jones/OU=PIB/CN=webhook-service.default.svc/[email protected]"
RUN openssl x509 -req -in webhook.csr -CA rootCA.crt -CAkey rootCA.key -CAcreateserial -out webhook.crt -days 1024 -sha256
RUN cat rootCA.crt | base64 | tr -d '\n'
```
*([Dockerfile](https://gist.github.com/scott2449/fb874355b0708f175ab57c7a86be11a5#file-dockerfile))*
Обратите внимание: последний этап — выводит единственную строку с root CA, закодированным в base64. Именно это требуется для конфигурации хука, так что в своих дальнейших тестах убедитесь, что скопировали эту строку в поле `caBundle` файла `hook.yaml`. `Dockerfile` забрасывает сертификаты прямо в `WORKDIR`, так что JavaScript просто забирает их оттуда и использует для сервера:
```
const privateKey = fs.readFileSync('webhook.key').toString();
const certificate = fs.readFileSync('webhook.crt').toString();
//…
const options = {key: privateKey, cert: certificate};
const server = https.createServer(options, app);
```
Теперь код поддерживает запуск HTTPS, а также сообщил Kubernetes'у, где найти нас и какому удостоверяющему центру доверять. Осталось лишь задеплоить всё это в кластер:
```
kubectl create -f deployment.yaml
kubectl create -f service.yaml
kubectl create -f hook.yaml
```
### Резюмируем
* `Deployment.yaml` запускает контейнер, который обслуживает hook API по HTTPS и возвращает JSON Patch для изменения объекта.
* `Service.yaml` обеспечивает для контейнера endpoint — `webhook-service.default.svc`.
* `Hook.yaml` говорит API-серверу, где нас найти: `https://webhook-service.default.svc/mutate`.
Попробуем в деле!
-----------------
Всё развёрнуто в кластере — время попробовать код в действии, что мы сделаем добавлением нового pod/Deployment. Если всё работает правильно, хук должен будет добавить дополнительный лейбл `foo`:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
spec:
replicas: 1
selector:
matchLabels:
component: test
template:
metadata:
labels:
component: test
spec:
containers:
- name: test
image: node:8
command: [ "/bin/sh", "-c", "--" ]
args: [ "while true; do sleep 30; done;" ]
```
*([test.yaml](https://github.com/dowjones/k8s-webhook/blob/master/k8s/test.yaml))*
```
kubectl create -f test.yaml
```
Ок, мы увидели `deployment.apps test created`… но всё ли получилось?
```
kubectl describe pods test
Name: test-6f79f9f8bd-r7tbd
Namespace: default
Node: docker-for-desktop/192.168.65.3
Start Time: Sat, 10 Nov 2018 16:08:47 -0500
Labels: component=test
foo=bar
```
Замечательно! Хотя у `test.yaml` был задан единственный лейбл (`component`), результирующий pod получил два: `component` и `foo`.
Домашнее задание
----------------
Но подождите! Разве мы собирались использовать этот код, чтобы создать sidecar-контейнер? Я предупреждал, что покажу, **как** добавить sidecar… А теперь, с полученным знанием и кодом: <https://github.com/dowjones/k8s-webhook> — смело экспериментируйте и разбирайтесь в том, как сделать свой автоматически вставляемый sidecar. Это довольно просто: необходимо лишь подготовить правильный JSON Patch, который будет добавлять дополнительный контейнер в тестовом Deployment'е. Счастливой оркестровки!
P.S. от переводчика
-------------------
Читайте также в нашем блоге:
* «[Так что же такое pod в Kubernetes?](https://habr.com/company/flant/blog/415393/)»;
* «[Как обеспечивается высокая доступность в Kubernetes](https://habr.com/company/flant/blog/427283/)»;
* «[Как на самом деле работает планировщик Kubernetes?](https://habr.com/company/flant/blog/335552/)»;
* «Что происходит в Kubernetes при запуске kubectl run?» [Часть 1](https://habr.com/company/flant/blog/342658/) и [часть 2](https://habrahabr.ru/company/flant/blog/342822/);
* «[Понимаем RBAC в Kubernetes](https://habr.com/company/flant/blog/422801/)»;
* «[Наш опыт с Kubernetes в небольших проектах](https://habr.com/company/flant/blog/331188/)» *(видео доклада, включающего в себя знакомство с техническим устройством Kubernetes)*;
* «[Что такое service mesh и почему он мне нужен?](https://habr.com/company/flant/blog/327536/)». | https://habr.com/ru/post/431252/ | null | ru | null |
# Мощный Managed Kubernetes бесплатно и надолго (для экспериментов и не только)
Вступление
----------
Многие знают про аттракцион необычайной щедрости от Oracle. В своем облаке они дают Always Free не только пару небольших машинок на AMD, но и мощный сервер на ARM. 4 vCPU и целых 24GB RAM!
Поскольку с ARM я раньше дела практически не имел (только Raspberry, но это другое), мне было интересно погонять на нем Kubernetes, посмотреть отличия, сильно ли сложнее искать образы для ARM и т.п.
Так что в этой статье расскажу основные моменты, с которыми столкнулся, где ошибался. И в качестве примера свяжу его с домом через Wireguard, настрою Nginx ingress controller + basic auth + LetsEncrypt, а также мониторинг на Grafana + VictoriaMetrics.
Установка кластера
------------------
Общее понимание, что можно получить бесплатно: [Always Free Resources](https://docs.oracle.com/en-us/iaas/Content/FreeTier/freetier_topic-Always_Free_Resources.htm).
### Создание аккаунта
Часто бывают жалобы типа «не проходит карточка». Где-то видел подсказку, что адрес нужно вводить в американском формате: НомерДома, Улица, apt. НомерКв.
Не знаю, насколько правда, но у меня действительно принялась виртуальная кредитка Tinkoff (привязанная к основной, но с принудительно очень ограниченным лимитом), которая раньше не проходила. Полгода назад я несколько карт перепробовал прежде, чем нашел подходящую. Теперь же зарегистрировалось с первого раза. Может быть их антифрод менее подозрительно относится к правильно выглядящим адресам…
И да, вы не ослышались. У меня уже полгода работает такой бесплатный сервер просто с Docker, а сейчас вот завел второй аккаунт (другой номер телефона, карты и ФИО, но тот же самый домашний IP) для экспериментов с Kubernetes.
### Настройка сети
Не люблю предустановленные настройки, адреса по умолчанию… Первым делом удалил VCN и создал новый. А также две сети: Public (можно добавлять публичные IP) и Private (публичным такой ресурс уже не сделать, только через балансировщик и т.п.).
Для Public нужно создать Internet Gateway и настроить маршрут на него.
Для Private – создать NAT Gateway и для этой приватной сети указать маршрут в Интернет через него. В противном случае «внутри» все работать будет, виртуалка создастся, но даже apt update не пройдет. Даже нода хотя и создастся, на нее можно буджет зайти по ssh, но Ready она не станет.
### Создание кластера
Containers & Artifacts | Create cluster. Опять же, Quick Create мне не нравится, я шел через Custom. Хотя вполне можно и Quick. Система создаст VCN, сети, IGW, но названия ресурсов будут некрасивые.
Здесь важно определиться, какой доступ к кластеру вы хотите. Проще всего, конечно, и Kubernetes API endpoint, и будущие ноды размещать в Public subnet. Я же выбрал делать все приватным и только Load Balancer в Public.
Когда дело дошло до Node pool, выбрал VM.Standard.A1.Flex (тот самый ARM). Указал 4 CPU и 24GB RAM и что нужна только 1 нода. Можно и 2 по 2CPU/12GB, но для меня это менее эффективно и нецелесообразно. Выбор образов небогатый, взял Oracle Linux 8.
Здесь я сначала задал Availability Domain = EU-FRANKFURT-1-AD-2, но система очень долго висела в состоянии «кластер создан, node pool тоже, но ни одной ноды нет». Тупо не было требуемых ARM ресурсов. Через кнопку Scale поменял availability domain на AD-1, и все очень быстро создалось.
Размер Boot Volume сначала указал 100GB (вместо штатных 46GB), но в OS виделось все равно как 46GB. Расширил потом до 100G, но почему-то у ноды появились taint `node.kubernetes.io/unreachable:NoSchedule`. Удаление не помогало, перезагрузка тоже. Может временный сбой какой-то был (Scale до 2 создавал дополнительную ноду, но она оставлась NotReady), а может действительно нельзя так вмешиваться в работу managed кластера. Не стал разбираться, пересоздал со стандартным Boot volume.
Как расширял диск`fdisk /dev/sda` # удалил раздел 3, создал заново с того же места до максимума, Remove LVM2 signature – Нет, сохранил, вышел, перезгарузился на всякий случай.
`pvresize /dev/sda3`
`lvextend -l +100%FREE /dev/ocivolume/root
Size of logical volume ocivolume/root changed from 35.47 GiB (9081 extents) to <88.90 GiB (22758 extents)`
`xfs_growfs /dev/ocivolume/root`
Ах да, в Compute | Instances эта виртуалка будет видна без значка Always Free. Не пугайтесь, это нормально, потому что ограничивается общее количество CPU/RAM в месяц. При круглосуточной работе это те самые 4CPU/24GB. Мможно и несколькими маленькими набрать. Или наоборот, взять в 4 раза мощнее, но гонять только 1 неделю.
И на всякий случай про диск – в первом аккаунте был инцидент, что несмотря на общий объем менее 200GB, за один диск копеечку начислили (из бюджета **€** 250 которые даются на первые 30 дней). Оказалось, что я его создал, когда лимит был исчерпан, поэтому в Always Free он не попал. И не вернулся в него, когда потом я лишние удалил. Надо учитывать такую особенность.
Доступ
------
Поскольку извне никак в приватные сети не попасть, в Public subnet создал Compute | Instances. Ну а что, дают целых 2 штуки VM.Standard.E2.1.Micro (1 OCPU, 1GB RAM, 0.48Gbps). Тут я уже Ubuntu 20.04 заказал.
В Security group добавил полный доступ с публичных адресов домашней подсети, чтобы потом не заморачиваться отдельно с SSH, Wireguard и т.п.
### Сеть
Конечно, было бы красиво установить IPSEC прямо в облако. Но у меня дома не то что публичного IP нет, я еще и за парой Hide NAT. Поэтому для связи с внешними ресурсами (облаками, VPS) я использую Wireguard еще со времен, когда он появился на Mikrotik в виде беты.
Для Ubuntu`sudo -i
apt install wireguard
cd /etc/wireguard
umask 077`
`wg genkey | tee privatekey | wg pubkey > publickey`
`cat < wg0.conf
[Interface]
Address = 192.168.16.4/24
SaveConfig = true
PostUp = iptables -A FORWARD -i %i -j ACCEPT; iptables -t nat -A POSTROUTING -o ens3 -j MASQUERADE;
PostDown = iptables -D FORWARD -i %i -j ACCEPT; iptables -t nat -D POSTROUTING -o ens3 -j MASQUERADE
ListenPort = 51820
PrivateKey = XXX=
[Peer]
PublicKey = YYY=
AllowedIPs = 192.168.16.1/32, 192.168.4.0/22
EOF`
Разрешить форвардинг пакетов между интерфейсами
`echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
sysctl -p`
Важно: нужно поправить настройку VNIC у этой виртуальной машины.
И там Skip Source/Destination Check
Раньше нужно было перезагрузиться после установки. Сейчас вроде не обязательно, но не повредит.
`wg-quick up wg0
dmesg -wT | grep wireguard
[Sun Feb 6 07:13:57 2022] wireguard: WireGuard 1.0.0 loaded. See www.wireguard.com for information.
wg-quick down wg0`
Все работает, пусть будет автостарт
`systemctl enable [email protected]
systemctl daemon-reload
systemctl start wg-quick@wg0`
И нужно входящие UDP пакеты разрешить. И сохранить правила iptables.
`sudo iptables -I INPUT 1 -i ens3 -p udp --dport 51820 -j ACCEPT
sudo /sbin/iptables-save | sudo tee /etc/iptables/rules.v4`
После этого туннель поднимется (если «дома» все уже настроено), но только для этой VM. Чтобы стали доступны Kubernetes Endpoint и сама нода в этой приватной сети, нужно поправить таблицу маршрутизации. К «все в Интернет через NAT gateway» добавить «192.168 (которые я использую в примерах) на приватный адрес этой Ubuntu». Если забыли поправить Skip src check, на этом шаге вам напомнят.
Ну и нужно разрешить форвардинг между ens3 и wg0. Для разнообразия поправим непосредственно /etc/iptables/rules.v4, добавив пару правил
`:InstanceServices - [0:0]
-A INPUT -i ens3 -p udp -m udp --dport 51820 -j ACCEPT
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -p udp -m udp --sport 123 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited`
`# Add this
-A FORWARD -i ens3 -o wg0 -j ACCEPT
-A FORWARD -i wg0 -o ens3 -j ACCEPT`
`-A FORWARD -j REJECT --reject-with icmp-host-prohibited`
Теперь из дома можно подключаться к ARM ноде по ее приватному адресу. Равно как и к Kubernetes API endpoint.
### Управление Kubernetes
Ниже я покажу упрощенный вариант, но на этой виртуальной Ubuntu я делал все стандартно
#### Установка oci cli
`sudo apt install python3-pip
sudo pip install oci-cli`
Поскольку на Windows машине у меня уже был .oci/config с ключами, я его просто перенес на Ubuntu.
Поправил `key_file=C:\Users\user\.oci\sessions\DEFAULT\oci_api_key.pem` на `key_file=/home/ubuntu/.oci/sessions/DEFAULT/oci_api_key.pem` и пофиксил разрешения `oci setup repair-file-permissions --file /home/ubuntu/.oci/config`
Дальше стандартно
`ClusterID=ocid1.cluster.oc1.eu-frankfurt-1.aaa…….
oci ce cluster create-kubeconfig --cluster-id $ClusterID --file $HOME/.kube/config --region eu-frankfurt-1 --token-version 2.0.0 --kube-endpoint PRIVATE_ENDPOINT`
#### kubectl
kubectl можно стандартно через apt поставить. Я просто скачал для унификации с установкой на Oracle Linux ARM.
`RELEASE="v1.21.5"
ARCH="amd64" # "arm64" – для запуска на ноде
sudo curl -L --remote-name-all https://storage.googleapis.com/kubernetes-release/release/${RELEASE}/bin/linux/${ARCH}/kubectl`
`sudo chmod +x kubectl
sudo install -o root -g root -m 0755 kubectl /usr/bin/kubectl
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> $HOME/.bashrc`
Еще люблю смотреть поды с IP адресами и нодой, но не люблю лишние колонки READINESS GATES и т.п., поэтому в .bashrc обычно добавляю функцию (а не alias, который не принимает аргументы типа namespace)
`kgpod() { kubectl get po -o wide -o=custom-columns=NAMESPACE:.metadata.namespace,NAME:.metadata.name,READY:.status.containerStatuses[0].ready,RESTARTS:.status.containerStatuses[0].restartCount,IP:.status.podIP,NODE:.status.hostIP $*; }`
Итак, kubectl работает. На облачной Ubuntu вполне прилично, а вот с домашней винды довольно долго отвечает. И это понятно – по умолчанию аутентификация выполняется через плагин. Т.е. запускается нечто, меня аутентифицирует в облаке по ранее сохраненнм ключам… Прямо на глаз задержки видны. Да и на другие линуксовые машинки (а у меня в планах связать кластеры) не хочется ставить oci cli.
Поэтому я переключился на «по старинке» через токен. При том, что кластер доступен только изнутри через Wireguard, не считаю это существенным снижением безопасности.
ServiceAccountКак из bash сделать, и так понятно. Покажу, как это делал с Windows машины из powershell (в частности, для декодирования токена вместо base64 используется штатный certutil).
`kubectl -n kube-system create serviceaccount sa-user`
`kubectl create clusterrolebinding sa-user-bind --clusterrole=cluster-admin --serviceaccount=kube-system:sa-user`
`$TOKENNAME=kubectl -n kube-system get serviceaccount/sa-user -o jsonpath='{.secrets[0].name}'`
`kubectl -n kube-system get secret $TOKENNAME -o jsonpath='{.data.token}' > token.tmp`
`certutil -decode token.tmp token`
`$TOKEN=cat token`
`kubectl config set-credentials sa-user --token=$TOKEN`
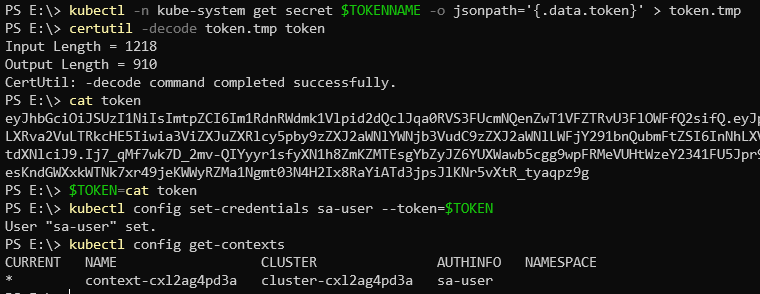`kubectl config set-context --current --user=sa-user`
Теперь и откликаться система стала намного быстрее, и на другие машины достаточно перенести .kube/config
Если файл с другим именем, просто указываем, какой именно нужен.
`export KUBECONFIG=~/.kube/ociK8s`
Monitoring
----------
Подготовку закончили, пора уже что-то полезное развернуть.
### Ingress Controller
Я, конечно, начал с Nginx Ingress Controller. При этом автоматически создался Network Load Balancer. Кстати, при большом желании на нем можно прокинуть TCP/6443 на kube-api и TCP/22 на ноду. Но это не спортивно.
Если захочется поработать непосредственно с ноды, можно helm и для ARM поставить
`https://github.com/helm/helm/releases
wget https://get.helm.sh/helm-v3.8.0-linux-arm64.tar.gz
sudo install -o root -g root -m 0755 kubectl /usr/bin/kubectl
sudo install -o root -g root -m 0755 linux-arm64/helm /usr/bin/helm
rm -rf linux-arm64`
Но я уже все дальше с домашней VM делал
`helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx`
`helm repo update`
`helm search repo ingress
NAME CHART VERSION APP VERSION DESCRIPTION
ingress-nginx/ingress-nginx 4.0.16 1.1.1 Ingress controller for Kubernetes using NGINX a...`
Для системных подов и мониторинга создам namespace, в него же установлю nginx
`kubectl create ns sysmon # to install system and monitoring tools`
`helm install -n sysmon ingress-nginx ingress-nginx/ingress-nginx`
Кстати, в результатах работы helm приводится не совсем корректный пример ingress. В нем отсутствует `pathType`, без него будут ругательства.
### Metrics-server
Без него даже kubectl top pod -A не покажет
`kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.0/components.yaml`
И нужно отредактировать конфигурацию (добавить выделенную строчку, у меня же все на самоподписанных сертифкатах)
`kubectl -n kube-system edit deployment metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls # ADD
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname`
### Victoria Metrics
#### Устанавливаем
Значительно быстрее Prometheus, поддерживает кучу всего другого. Например, принимает данные также и от telegraf / InfluxDB. В общем, очень нравится.
Тут уже нужно думать, где хранить данные. Я рассчитывал на встроенные провизионеры oracle.com/oci, blockvolume.csi.oraclecloud.com. Но при попытке запросить PVC 1Gi автоматически был создан том 50GB. Типа это минимум. Спасибо, не надо.
Можно поднять NFS на виртуалке вместе с Wireguard. Наверняка так и сделаю для других задач. Но если телеметрия пропадет, не страшно. свободные 30 гигов на ноде жальче :) Решил это хранить локально.
`sudo mkdir -p /mnt/LoSt/vicmet # Local Storage :)`
`cat <apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
---`
`apiVersion: v1
kind: PersistentVolume
metadata:
name: server-volume-vicmet-victoria-metrics-single-server-0
labels:
type: local
spec:
storageClassName: "local"
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/LoSt/vicmet"
EOF`
Для PV указал длинное имя в точности, как будет назван PVC при развертывании helm chart. При совпадении имен они автоматически свяжутся.
`helm repo add vm https://victoriametrics.github.io/helm-charts/
helm repo update
helm search repo vm/victoria-metrics-single -l | head -5`
`helm show values vm/victoria-metrics-single > vm_values_single.yaml`Это посмотреть параметры и указать ниже:
`cat <server:
persistentVolume:
# -- Persistent volume annotations
annotations:
volume.beta.kubernetes.io/storage-class: "local"
# -- Storage class name. Will be empty if not setted
storageClassName: local
size: 5Gi
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
scrape:
enabled: true
configMap: ""
extraLabels:
appname: victoriametrics
EOF`
Настройки скрапинга хранятся в configmap. Он создается автоматически, дополнить своими можно:
`kubectl edit configmaps -n sysmon vicmet-victoria-metrics-single-server-scrapeconfig
scrape_configs:
- job_name: victoriametrics
static_configs:
- targets:
- localhost:8428`
`# Свой фрагмент
- job_name: node-XXX
static_configs:
- targets: ['XXX.spec.antn.in:19100']`
`- job_name: kubernetes-apiservers`
#### Подключаемся
Временно опубликую через ingress. Только не простой, а с basic authentication.
`htpasswd -c auth vicmet`
и дважды указываю пароль
`kubectl create secret generic basic-auth-vicmet --from-file=auth -n sysmon`
`cat <apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: vicmet
namespace: sysmon
annotations:
# type of authentication
nginx.ingress.kubernetes.io/auth-type: basic
# name of the secret that contains the user/password definitions
nginx.ingress.kubernetes.io/auth-secret: basic-auth-vicmet
# message to display with an appropriate context why the authentication is required
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - Victoria Metrics'
spec:
ingressClassName: nginx
rules:
- host: vicmet.antn.in
http:
paths:
- backend:
service:
name: vicmet-victoria-metrics-single-server
port:
number: 8428
path: /
pathType: ImplementationSpecific
EOF`
После обновления DNS (CNAME на LoadBalancer IP, кучи IP не надо, бесплатно только 6 дают) <http://vicmet.antn.in> спрашивает пароль и потом позволяет посмотреть таргеты, метрики…
### Grafana
Еще немного осталось :)
Grafana я установлю не через helm, а просто подготовленным yaml.
Длинный, поэтому спойлер`sudo mkdir -p /mnt/LoSt/grafana
sudo chown 472 /mnt/LoSt/grafana`
Без этого grafana не сможет писать в директорию и не запустится.
`cat <apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana-pv
labels:
type: local
spec:
storageClassName: "local"
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/LoSt/grafana"
---`
`apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pv
namespace: sysmon
labels:
app: grafana
spec:
storageClassName: "local"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---`
`apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: grafana
name: grafana
namespace: sysmon
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
securityContext:
fsGroup: 472
supplementalGroups:
- 0
containers:
- name: grafana
image: grafana/grafana:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: http-grafana
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /robots.txt
port: 3000
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 2
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 3000
timeoutSeconds: 1
resources:
requests:
cpu: 250m
memory: 750Mi
limits:
cpu: 500m
memory: 1000Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-pv
volumes:
- name: grafana-pv
persistentVolumeClaim:
claimName: grafana-pv
---`
`apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: sysmon
spec:
ports:
- port: 3000
protocol: TCP
targetPort: http-grafana
selector:
app: grafana
sessionAffinity: None
type: ClusterIP
---`
`apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana
namespace: sysmon
spec:
ingressClassName: nginx
rules:
- host: grafana.antn.in
http:
paths:
- backend:
service:
name: grafana
port:
number: 3000
path: /
pathType: ImplementationSpecific
EOF`
### LetsEncrypt
И финальный аккорд – настроим https с валидными сертификатами.
`kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.7.1/cert-manager.yaml`
`cat <apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-staging # <--
spec:
acme:
# You must replace this email address with your own.
# Let's Encrypt will use this to contact you about expiring
# certificates, and issues related to your account.
email: [email protected]
server: https://acme-staging-v02.api.letsencrypt.org/directory
privateKeySecretRef:
# Secret resource that will be used to store the account's private key.
name: letsencrypt-staging
# Add a single challenge solver, HTTP01 using nginx
solvers:
- http01:
ingress:
class: nginx
---`
`apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-prod # <--
spec:
acme:
# You must replace this email address with your own.
# Let's Encrypt will use this to contact you about expiring
# certificates, and issues related to your account.
email: [email protected]
server: https://acme-v02.api.letsencrypt.org/directory # <--
privateKeySecretRef:
# Secret resource that will be used to store the account's private key.
name: letsencrypt-prod
# Add a single challenge solver, HTTP01 using nginx
solvers:
- http01:
ingress:
class: nginx
EOF`
Сначала проверил на staging, потом переключился на prod. Из-за кеширования в браузере удобнее проверять в incognito mode. Еще можен понадобиться удалить прежний сертифкат (kubectl delete secret -n sysmon grafana-tls)
Соответственно обновленный ingress, теперь с сертификатом. Просто помимо секции tls добавили аннотацию, «призывающую» cert-manager.
`cat <apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana
namespace: sysmon`
`annotations:
cert-manager.io/cluster-issuer: "letsencrypt-prod" # <--`
`spec:
ingressClassName: nginx`
`tls:
- hosts:
- grafana.antn.in
secretName: grafana-tls`
`rules:
- host: grafana.antn.in
http:
paths:
- backend:
service:
name: grafana
port:
number: 3000
path: /
pathType: ImplementationSpecific
EOF`
Все подключилось. Добавил источник данных (тип prometheus, адрес/URL с именем сервиса, который мне helm chart victoria-metrics выдал)
Добавил первую попавшуюся на сайте графаны Dashboard ID 747 и при импорте указал вышенастроенный источник данных. Сразу отобразились данные:
К VictoriaMetrics TLS не прикручивал, ибо не нужно это публиковать. Также терзает сомнение, не помешает ли basic authentication подтверждению сертифката. Не разбирался еще.
Заключение
-----------
Очень понравилось, что я вообще не задумавался, что нода на ARM. Ни в helm чартах, ни в обычных yaml. Только kubectl ставил под разные платформы (Windows, Oracle Linux8 arm64, Ubuntu 20.04 amd64), дальше все само.
Было бы интересно добавить в этот кластер еще и x86 ноду. Но выбрать бесплатную E1.Micrо в визарде невозможно. А развернуть на отдельной машинке и потом `kubeadm join` – вопрос, достойный разбирательства. Боюсь, Managed кластеру это не понравится.
Но какой-нибудь service mesh c домашним кубером со временем погоняю. Может, кстати, упростит решение давней проблемы – как публиковать «домашние» сервисы в Интернете (теперь через Ingress). | https://habr.com/ru/post/650017/ | null | ru | null |
# Разгони свой сайт – автоматическая СКЛЕЙКА + GZIP

Есть куча советов как убыстрить отдачу сайта – это и статика через nginx и кластеризация и куча еще всяческих хитрых технологий. Однако во всех книжках, советующих как можно повысить загрузку сайтов можно найти две постоянно повторяющиеся темы – «склеивание CSS/JS» и «включение сжатия».
**Склейка**
Все просто – если например у Вас на страничке 3 CSS файла и 5 JS, браузеру при загрузке придется создавать 8 соединений и выкачивать по ним данные, а как известно, лучше несколько больших файлов чем множество мелких. Связано это с тем, что на каждую установку соединения браузер тратит время и зачастую немаленькое – до 40% времени загрузки.
Стандартные методы написать некий командный файл, который пробегался бы по нужным файлам и склеивал их в один мне не нравились в принципе, ибо делать ручками вещи, которые можно сделать автоматически – в корне не верно, в данном случае хотя бы по тому, что это сказывается либо на разработке, либо на продакшене (дополнительные действия).
Как говорят «никогда не переписывайте то, что можно просто вырезать и наклеить» ;)
**Сжатие**
Чем меньше объем «прокачиваемых» файлов, тем соответственно меньше время тратится на загрузку. Даже если эти файлы сжаты и мы тратим некторое время на распаковку – при современных вычислительных мощностях на клиенте эта временная затрата практически не существенна.
Большинство современных браузеров поддерживают метод сжатия deflate, иногда называемый gzip по имени стандартной \*nix утилиты, осуществляющей это дело.
Что можно и нужно сжимать в веб? Любые текстовые запросы, как то: JS / CSS / JSON / HTML.
Есть замечательный модуль для Апача mod-deflate, которым можно прямо из .htaccess указать чего сжимать и чего не сжимать, очень прост в использовании, но увы и ах! – обычно запрещенный на стандартных хостингах по причине того, что они (хостеры) опасаются за свое процессорное время.
Доля разумного в этом конечно есть – этот модуль жмет все «на лету» и если не принять некоторых хитростей, каждый раз грузя страничку для нового пользователя он будет
заново пережимать все CSS / JS и т.д.
Если же у вас VDS и Вы – сам себе хозяин – используйте mod-deflate, ибо он хорошо отлажен и примеров применения в сети масса.
А мы вернемся к обычным хостигам – есть ли выход? Даже если Вас съели, у вас всегда есть два выхода — есть выход и здесь. Причем эта задача очень хорошо ложиться на предыдущую – сейчас объясню почему.
Большинство JS / CSS и других текстов – это статика, т.е. они не меняются в процессе функционирования сайта — есть смысл их объеденить, чтобы удовлетворить пункту о «склейке» + сразу же сжать.
Полученные файлы мы положим в некий кэш, откуда наш Апач будет их брать и отдавать. Причем процесс мы автоматизируем через mod-rewrite.
***Алгоритм получится примерно такой***:
1. запрашивается некий файл со специального URL
2. если клиент поддерживает сжатие и сжатый файл такого типа есть в нашем кэше – отдаем и завершаем обработку
3. если же сжатие не поддерживается и есть просто файл такого типа – отдаем его и заканчиваем обработку
4. иначе запускаем наш обработчик
*Условимся, что срабатывать наша модель при обращении к URLу вида «/glue/….»,
А файлы будут лежать в «/static/glue/…».*
В данном случае мы убиваем еще одного зайца — файлы будут отдаваться через PHP всего один раз — при формировании, а дальше будет все как у больших :) статику должен и будет отдавать веб-сервер.
В принципе можно сделать так, чтобы папка совпадала с URL-ом, тогда чуть упростится конфиг mod-rewrite но будет не так интересно, вобщем упростить всегда можно :)
Надеюсь, что в корне Вашего сайта уже живет файл .htaccess с содержанием типа такого:
> `RewriteEngine On
>
> RewriteBase /
>
> RewriteRule ^.\*$ index.php [QSA,L]`
Ну либо похожий. Основное условие, что если mod-rewrite не нашел чего сделать с пришедшим URL, он в конце концов вызовет какой-то скриптовый файл.
В данном случае – index.php
Для добавления нашего алгоритма пропишем в .htaccess следующее:
***Добавляем поддержку сжатых файлов .gz, а также .jz.gz и .css.gz***
> `AddEncoding gzip .gz
>
>
>
> <**FilesMatch** "\.js.gz$">
>
> *#для проксей*
>
> Header set Cache-control: private
>
> Header append Vary User-Agent
>
>
>
> ForceType "text/javascript"
>
> Header set Content-Encoding: gzip
>
> AddCharset windows-1251 .js.gz
>
> **FilesMatch**>
>
> <**FilesMatch** "\.css.gz$">
>
> *#для проксей*
>
> Header set Cache-control: private
>
> Header append Vary User-Agent
>
>
>
> ForceType "text/css"
>
> Header set Content-Encoding: gzip
>
> **FilesMatch**>`
***Добавляем правило отдачи наших файлов*** (разыменовывание URL в физическую папку)
> `RewriteCond %{ENV:REDIRECT\_GZ} =1
>
> RewriteCond %{REQUEST\_URI} ^/glue/(.+)$
>
> RewriteCond %{DOCUMENT\_ROOT}/static/glue/%1 -f
>
> RewriteRule . - [L]`
***Добавляем проверку на поддержку клиентом сжатия***
> `RewriteCond %{REQUEST\_URI} ^/glue/(.+)$
>
> RewriteCond %{DOCUMENT\_ROOT}/static/glue/%1.gz -f
>
> RewriteCond %{HTTP:Accept-Encoding} ^.\*?gzip.\*$ [NC]
>
> RewriteCond %{HTTP\_USER\_AGENT} !^konqueror [NC]
>
> RewriteRule ^siteglue/(.\*)$ /static/glue/$1.gz [L,E=GZ:1]`
***Если сжатие не поддерживается***
> `RewriteCond %{REQUEST\_URI} ^/glue/(.+)$
>
> RewriteCond %{DOCUMENT\_ROOT}/static/glue/%1 -f
>
> RewriteRule . static/glue/%1 [L,E=GZ:1]`
Теперь возьмемся за нашу самую главную магию – автоматическое формирование этих самых файлов.
Здесь еще одна есть хитрость, в данном случае скорее — еще одна условность – *в файлах html мы будем писать запросы к css или js в следующтим виде:
*«/glue/1.css—2.css—3-4-5.css»*, где «-» — это замена «/», а «--» – это разделитель файлов.*
Кроме того в именах могут быть только английские буквы, цифры и символ «\_», по мне — этого более, чем достаточно.
Конечно же, это условности и Вы можете выбрать себе другие правила и другие разделители. Например можно использовать «,» или что-либо еще.
Однако я выбрал «-» из-за того что это вполне нормальный и часто встречающийся символ URL и с ним врядли могут быть всякие дурацкие проблемы типа вырезания его кривыми скриптами на проксях по пути от Вас до клиента.
В файле в index.php (или что там у вас запускается согласно .htaccess?) добавляем обработчик, который проверяет URL на соответствие нашему «/glue/.\*» и в случе совпадения делает *echo( Glue::generate( $str ) )*, где *$str* — то, что у нас идет в URL после последнего слэша, т.е. для «/glue/a.js» это будет «a.js»
***Сам класс Glue вот такой***
> `**class** Glue {
>
> static $allowedExt = array(
>
> "js" => array( "check" => "/^js/.\*?.js$/", "delimeter" => ";n", "mime" => “text/javascript”),
>
> "css" => array( "check" => "/^css/.\*.css$/", "delimeter" => "n", "mime" => “text/css” ),
>
> );
>
>
>
> static **function** generate( $str ) {
>
> if ( !$str ) return **null**; *//не нашли URL*
>
>
>
> $files = array();
>
> preg\_replace( "/((?:[a-z0-9\_.]+-)+[a-z0-9\_.]+.([a-z0-9]+))(?:--|$)/ie", "**$files**[]=str\_replace( '-', '/', "1")", $str );
>
> if ( count( $files ) == 0 ) return **null**; *//не нашли ни одного файла в URL*
>
>
>
> $srcF = “/static”; *//наша папка, откуда берется статика*
>
> $dstF = “/glue”; *//папка, нашего кэша*
>
>
>
> $content = "";
>
>
>
> $cext = substr( strrchr( $files[0], '.' ), 1 );
>
> if ( $cext === **false** ) return **null**; *//не смогли определить расширение*
>
>
>
> $fd = **null**;
>
> foreach( **self**::$allowedExt as $k => $v ) {
>
> if ( $k == $cext ) {
>
> $fd = $v;
>
> break;
>
> }
>
> }
>
> if ( !$fd ) return **null**; *//не нашли среди доступных расширений*
>
>
>
> $usedNames = array();
>
> $fdC = &$fd["check"];
>
> $fdD = &$fd["delimeter"];
>
> foreach( $files as $name ) {
>
> $ext = substr( strrchr( $name, '.' ), 1 );
>
> if (
>
> $ext === **false** ||
>
> in\_array( $name, $usedNames ) ||
>
> $ext != $cext ||
>
> !preg\_match( $fdC, $name )
>
> ) return **null**; *//не смогли найти расширения, файл ч таким именем уже есть или расширение отличается от первоначального либо имя не удовлетваряет проверке*
>
>
>
> $usedNames[] = $name;
>
> $filec = file\_get\_contents( "**{$srcF}**/**{$name}**" );
>
> if ( !$filec ) return **null**; *//не смогли найти или прочитать файл*
>
> $content .= $content != "" ? $fdD . $filec : $filec;
>
> }
>
>
>
>
>
> *//сохранили файл*
>
> file\_put\_contents( "**{$dstF}**/**{$str}**", $content );
>
>
>
> *//сохранили сжатый файл*
>
> $gzip = gzencode( $content, 9 );; *//gzdeflate( $content, 9 );*
>
> if ( $gzip ) file\_put\_contents( "/**{$dstF}**/**{$str}**.gz",$gzip );
>
>
>
> *//мы должны отдать по данному запросу содержимое и mime-тип*
>
> header( "Content-type: " . $fd["mime"], **true** );
>
> return $content;
>
> }
>
> }`
Опять же, здесь лишь иллюстрируется один из способов КАК это сделать — не нравится статический класс — Вы можете выбрать любой другой способ — с блэкджеком и дамами не тяжелого поведения ;)
Вот в принципе все, осталось пробежаться по файлам проекта – все таки остался кусочек «ручной» работы :( — и прописать вместо кучи скриптов один, но по правилам, описанным чуть Выше.
Все – при первом запросе автоматически все соберется и начнет отдаваться.
***Еще одно маленькое дополнение – а что делать с контентом, отдаваемым PHP?***
Его тоже надо сжать!
Для этого в то месте где Вы отдаете файлы текстового вида, там где отдается сформированный контент – например так **echo( $content );**
Сделать следующее:
> `if ( isClientSupportGzip() ) {
>
> ob\_start("ob\_gzhandler");
>
> echo( $content );
>
> ob\_end\_flush();
>
> } else echo( $content );`
Это будет сжимать отдаваемый динамический контент, если клиент поддерживает сжатие. Функция, его проверяющая, взята с просторов интернета и выглядит так:
> `**function** isClientSupportGzip() {
>
> if ( headers\_sent() || connection\_aborted() ) return **false**;
>
> if ( stripos( getenv( "HTTP\_ACCEPT\_ENCODING" ), "gzip" ) === **false** ) return **false**;
>
> if ( stripos( getenv( "HTTP\_USER\_AGENT" ), "konqueror" ) !== **false** ) return **false**;
>
> return **true**;
>
> }`
Для девелоппинга рекомендую завести некую константу режима разработки и в случае установки ее в 1 просто не записывать файлы в кэш и не сжимать динамику – не придется при каждом изменении в каком-либо js файле лазить и очищать нашу директорию с кэшем.
**Вот и все – мы чуть-чуть разогнали свой сайт ) По моим наблюдениям прирост в скорости отдачи может составлять 30-40%.**
*Если есть какие-либо корректировки, предложения или критика – милости прошу в комменты – буду очень признателен, ибо как говорится – век учись )*
**Быстрых Вам сайтов, максимального сжатия и радостных клиентов ;) **
**P.S.**
Если вы используете какую либо библиотеку, например jquery, на всех страницах своего проекта с одним и тем же местом расположения, рекомендую все-таки вынести ее в отельный файл, то же касается единого css – т.о. она быстрее скэшируется, браузером.
При склейке JS помните особенность – склеивать надо через «;», т.к. в предыдущем файле после последней строчки может не оказаться «;»
При написании обработчика формирования кэша помните о хакерах – проверяйте все и вся, при неграмотном экранировании можно насклеивать и получить в качестве статики много чего интересного, на худой конец можно путем перебора насмерть засрать Вам дисковое пространство, так что даже мистер Пропер не поможет – аккуратней вобщем.
Если у Вас в сайт в самой непопулярной кодировке, чтобы все было шоколадно, замените
ForceType «text/javascript» на ForceType «text/javascript; content=windows-1251»
и добавьте: AddCharset windows-1251 .js и AddCharset windows-1251 .css
И еще маленький совет, придерживайтесь одинаковой очередности в указании склеиваемых файлов, ибо технически «/glue/a.js—b.js» и «/glue/b.js—a.js» это одно и тоже, а на практике вы получите два файла в кэше…
**Из комментариев**
**Imenem** и **TrueDrago** подсказали, что оптимальный уровень для deflate компрессии не 9, а 6 | https://habr.com/ru/post/134405/ | null | ru | null |
# Как обрабатывать спутниковые снимки с помощью Sen2Cor
Sen2Cor — программа для обработки снимков, сделанных со спутника Sentinel-2. В статье рассказывается, как установить, запустить и настроить её.

В магистратуре мне понадобилось сделать атмосферную коррекцию снимков со спутника Sentinel-2. Магистратура по экологии, поэтому можно было не углубляться в физику и математику, а использовать готовый инструмент. Такой инструмент нашёлся — Sen2Cor.
**Что такое Sentinel-2**
[Sentinel-2](https://sentinels.copernicus.eu/web/sentinel/missions/sentinel-2) — пара спутников, запущенных Европейским космическим агентством (ESA) в 2015 году. Снимают в 13 диапазонах, пролетают над одним и тем же местом примерно раз в неделю. Область съёмки — все континенты, прибрежные зоны и внутренние моря. Каждый снимок охватывает территорию 100 на 100 километров. Максимальное пространственное разрешение — 10 метров на пиксель. Снимки распространяются бесплатно — их можно скачать после регистрации через [Copernicus Open Access Hub](https://scihub.copernicus.eu/dhus/#/home) или [USGS Earth Explorer](https://earthexplorer.usgs.gov/).
Проблема в том, что понятной инструкции для Sen2Cor нет. Авторы учебников по геоинформатике не лезут в такие дебри, как работа с конкретными программами, а авторы научных статей, напротив, полагают, что коррекция снимков — слишком простая часть методики, поэтому не описывают её подробно. На сайтах «для чайников» (и не совсем для чайников) о Sen2Cor тоже не пишут. Официальная документация запутанная: достаточно сказать, что раздел «Установка» на 26-й странице «Руководства пользователя» сразу отсылает к 60-й странице Release Notes. Чтобы разобраться, мне потребовалось время.
Я решил написать понятное руководство по установке, запуску и настройке Sen2Cor. Руководство ориентировано на биологов, экологов, специалистов по сельскому хозяйству и всех тех, кому может понадобиться обработка спутниковых снимков, но для кого она не является основной задачей. По сути, я делюсь собственным опытом. Абсолютную правильность и полноту не гарантирую. Специалисты по геоинформатике, думаю, сами мне что-то посоветуют.
Строго говоря, Sen2Cor делает не только атмосферную коррекцию, но и поправку на угол восхождения Солнца и рельеф местности, а также тематическую классификацию (scene classification), но для меня важнее всего была атмосферная коррекция. Поэтому для простоты я иногда вместо «обработка» пишу «атмосферная коррекция», хотя это неточно.
Sen2Cor работает в трёх режимах: как отдельное консольное приложение, как плагин в составе Sentinel-2 Toolbox и как консольное приложение, используемое в PDGS (Payload Data Ground Segment). PDGS — это наземный центр обработки данных, получаемых со спутников. Находится он в Италии в исследовательском институте. Теоретически можно запустить Sen2Cor в том же режиме, в котором его запускают в центре обработки данных, но для запуска понадобятся данные, которые просто так в интернете не скачать, поэтому мы данный вариант рассматривать не будем. Sentinel-2 Tolobox тоже обойдём стороной, потому что с этой программой я не работал. Она с графическим интерфейсом, поэтому полагаю, что разобраться в её работе несложно. Итак, в данной статье описано, как использовать Sen2Cor в режиме консольной программы.
Sen2Cor работает в 64-битных Windows, MacOS и Linux. У меня Linux, поэтому команды буду показывать на примере Linux. Впрочем, разница только в установщиках и в путях к файлам.
Sen2Cor требует 4 Гб оперативной памяти. Если меньше, то он запустится, но может аварийно завершиться на середине обработки. Расход оперативной памяти зависит от разрешения производимых снимков, поэтому если памяти мало и программа из-за этого выдаёт ошибку, то можно запустить обработку с меньшим разрешением. О том, как это сделать, написано далее. Аналогичных жёстких требований к процессору нет, но чем слабее процессор, тем больше времени займёт обработка.
Установка
---------
Нужно скачать установщик и запустить его. Sen2Cor написан на Python, однако, интерпретатор и все необходимые пакеты находятся в установщике, поэтому самому устанавливать Python и настраивать окружение не нужно.
Предположим, что у нас есть пользователь user с домашним каталогом `/home/user`. Создадим в домашнем каталоге папку `spaceshots`, в которой будем работать со снимками. Полный путь к папке будет `/home/user/spaceshots`.
Далее загрузим и запустим установщик. Открываем [страницу Sen2Cor](https://step.esa.int/main/third-party-plugins-2/sen2cor/) на сайте инструментов Европейского космического агентства. Есть две версии программы: 2.5.5 и 2.8. Лучше устанавливать 2.8: она расходует меньше оперативной памяти и содержит меньше ошибок. Версия 2.5.5 может понадобиться, если нужно обработать снимки, сделанные по старым спецификациям. Нажмем на «Sen2Cor v2.8». В конце страницы в пункте «Standalone Installers» находятся ссылки для скачивания установщиков. Загружаем тот, который подходит для нашей операционной системы. В данном случае это «Linux installer: Sen2Cor-02.08.00-Linux64.run». Сохраняем файл в `/home/user/spaceshots`.
Далее открываем консоль, перемещаемся в каталог `spaceshots` и запускаем установщик.
```
$ cd ~/spaceshots
$ ./Sen2Cor-02.08.00-Linux64.run
```
По умолчанию программа устанавливается в текущий каталог. В нём создаётся папка `Sen2Cor-02.08.00-Linux64`, куда извлекаются все файлы программы. По большому счёту установка сводится к распаковке архива. Кроме того, в домашнем каталоге создаётся папка для конфигурационных файлов и логов: `/home/user/sen2cor/2.8`.
Если ошибок нет, то в консоли должна появиться надпись `«Congratulations, Installation successful...»` и предложение протестировать установку. Сделаем тестовый запуск:
```
$ /home/user/spaceshots/Sen2Cor-02.08.00-Linux64/bin/L2A_Process -h
```
В этой команде `/home/user/spaceshots/Sen2Cor-02.08.00-Linux64` — каталог, куда установился Sen2Cor. В папке `bin` находятся основные запускаемые файлы программы, в том числе главный файл `L2A_Process`. Опция `-h` говорит, что нужно показать справочную страницу. В результате выполнения команды в консоли должно появиться примерно следующее:
```
usage: L2A_Process.py [-h] [--mode MODE] [--resolution {10,20,60}]
[--datastrip DATASTRIP] [--tile TILE]
[--output_dir OUTPUT_DIR] [--work_dir WORK_DIR]
[--img_database_dir IMG_DATABASE_DIR]
[--res_database_dir RES_DATABASE_DIR]
[--processing_centre PROCESSING_CENTRE]
[--archiving_centre ARCHIVING_CENTRE]
[--processing_baseline PROCESSING_BASELINE] [--raw]
[--tif] [--sc_only] [--cr_only] [--debug]
[--GIP_L2A GIP_L2A] [--GIP_L2A_SC GIP_L2A_SC]
[--GIP_L2A_AC GIP_L2A_AC] [--GIP_L2A_PB GIP_L2A_PB]
input_dir
Sentinel-2 Level 2A Processor (Sen2Cor). Version: 2.8.0, created: 2019.02.20,
supporting Level-1C product version 14.2 - 14.5.
…
```
Если появилось, то установка прошла нормально и программа готова к использованию. Единственное, что ещё не помешает сделать — упростить запуск программы. Пока что нужно указывать полный путь к основному файлу: `/home/user/spaceshots/Sen2Cor-02.08.00-Linux64/bin/L2A_Process`. Это неудобно. Гораздо проще писать просто `L2A_Process`. Однако если сделать так прямо сейчас, то появится ошибка:
```
$ L2A_Process
bash: L2A_Process: команда не найдена
```
Чтобы исправить ошибку и запускать Sen2Cor по команде `L2A_Process`, нужно добавить одну команду в файл `.bashrc`, который находится в домашнем каталоге (в нашем случае — по адресу `/home/user/.bashrc`). Это скрытый файл, поэтому перед тем как открыть его, нужно включить в файловом менеджере показ скрытых файлов.
В конец файла `.bashrc` добавим следующие строки:
```
# Sen2Cor processor (v. 2.8.0)
source /home/user/spaceshots/Sen2Cor-02.08.00-Linux64/L2A_Bashrc
```
Первая строка — комментарий, чтобы помнить, зачем нужна вторая. Вторая строка при каждом запуске системы выполняет скрипт, содержащийся в файле `L2A_Bashrc`. Этот скрипт меняет некоторые переменные окружения так, что команда `L2A_Process` становится доступна отовсюду, и указывать полный путь к ней не нужно.
Чтобы изменения в `.bashrc` вступили в силу, нужно вернуться в консоль и выполнить команду
```
$ source ~/.bashrc
```
Ещё можно изменить место, куда будет установлена программа. Для этого нужно при запуске установщика указать опцию `--target`. Например, команда
```
# ./Sen2Cor-02.08.00-Linux64.run --target /usr/share/sen2cor
```
установит Sen2Cor в `/usr/share/sen2cor`. Мы запускаем команду от суперпользователя, потому что обычный пользователь, как правило, не может записывать файлы в `/usr`. Правда, в таком случае придётся потом запускать Sen2Cor с правами суперпользователя или менять права доступа к `/usr/share/sen2cor`.
**Как установить в MacOS и Windows**
В MacOS программа устанавливается так же, как в Linux.
В Windows установщик — это zip-архив, который нужно распаковать. При запуске вместо `L2A_Process` указывается `L2A_Process.bat`, и он находится не в папке `bin`, а сразу в той папке, в которую установлена программа:
```
C:\Users\user\spaceshots\Sen2Cor-02.08.00-Linux64/L2A_Process.bat -h
```
Папка с конфигурацией и логами в Windows тоже будет находиться в домашнем каталоге пользователя: `С:\Users\user\sen2cor\2.8`. Она создаётся при первом запуске программы.
Чтобы не указывать полный путь к запускаемому файлу, а писать просто `L2A_Process.bat`, в Windows нужно добавить путь к файлу `L2A_Bashrc.bat` в `PATH`.
Обработка снимка
----------------
Итак, мы установили Sen2Cor и сделали так, что он запускается по команде `L2A_Process`. Теперь сделаем атмосферную коррекцию. Предположим, что спутниковый снимок мы уже скачали и распаковали в `/home/user/spaceshots`. Я взял снимок местности к западу от Екатеринбурга, сделанный 27 июля 2018 года. Файл со снимком называется *L1C\_T40VFJ\_A016162\_20180727T071939.zip*. После распаковки появилась папка *S2A\_MSIL1C\_20180727T071621\_N0206\_R006\_T40VFJ\_20180727T092607.SAFE*. Тогда для атмосферной коррекции нужно выполнить такую команду:
```
$ L2A_Process S2A_MSIL1C_20180727T071621_N0206_R006_T40VFJ_20180727T092607.SAFE/
```
После нажатия на Enter можно отдохнуть, потому что обработка занимает довольно много времени (на Яндекс.Облаке с Intel Cascade Lake и гарантированной долей 5% CPU — около часа). Sen2Cor выводит в консоль информацию о ходе работы, так что вы будете примерно понимать, что в данный момент делает программа.
**Начало лога в консоли**
```
Sentinel-2 Level 2A Processor (Sen2Cor). Version: 2.8.0, created: 2019.02.20, supporting Level-1C product version 14.2 - 14.5 started ...
Product version: 14.5
Operation mode: TOOLBOX
Processing baseline: 99.99
Progress[%]: 0.00 : Generating datastrip metadata
L1C datastrip found, L2A datastrip successfully generated
Selected resolution: 60 m
Progress[%]: 1.13 : PID-4202, L2A_ProcessTile: processing with resolution 60 m, elapsed time[s]: 2.299, total: 0:00:10.789933
Progress[%]: 1.13 : PID-4202, L2A_ProcessTile: start of pre processing, elapsed time[s]: 0.000, total: 0:00:10.790432
Progress[%]: 1.27 : PID-4202, L2A_Tables: start import, elapsed time[s]: 0.278, total: 0:00:11.068694
Progress[%]: 1.69 : PID-4202, L2A_Tables: band B01 imported, elapsed time[s]: 0.851, total: 0:00:11.919562
Progress[%]: 9.39 : PID-4202, L2A_Tables: band B02 imported, elapsed time[s]: 15.618, total: 0:00:27.537532
Progress[%]: 17.16 : PID-4202, L2A_Tables: band B03 imported, elapsed time[s]: 15.743, total: 0:00:43.280800
…
```
Когда программа завершит работу, в `/home/user/spaceshots` рядом с *S2A\_MSIL1C\_20180727T071621\_N0206\_R006\_T40VFJ\_20180727T092607.SAFE/* должна появиться ещё одна папка с очень похожим названием — *S2A\_MSIL2A\_20180727T071621\_N9999\_R006\_T40VFJ\_20200507T083341.SAFE*
Теперь разберёмся, что делает программа и что за папку мы получили. Для этого нужно рассмотреть структуру снимков Sentinel-2.
Снимок со спутника Sentinel-2 — это zip-архив размером в несколько сотен мегабайт. В нашем случае архив называется *L1C\_T40VFJ\_A016162\_20180727T071939.zip*. В названии закодирована информация: уровень обработки (*L1C*), код, обозначающий территорию (*T40VFJ*), номер орбиты (*A016162*), дата и время съёмки. Внутри этого архива есть папка с длинным названием, которое заканчивается на .SAFE. В папке \*.SAFE есть папка GRANULE, в ней — ещё одна папка с длинным названием, внутри которой находится папка IMG\_DATA, а в ней — 14 изображений в формате jp2. Среди них есть 13 пронумерованных — их названия заканчиваются на B01-B12 (плюс ещё одно с номером B8A). Это тайлы — снимки земной поверхности, сделанные на определённых длинах волн. Например, B04 — это снимок в красном диапазоне, а B08 — в ближнем инфракрасном, и вместе эти два снимка можно использовать для расчёта такого известного индекса, как NDVI. Название 14-го изображения заканчивается на TCI, что означает True Color Image — это полноцветный снимок, то есть примерно такой, какой получился бы на обычный фотоаппарат.
Sen2Cor получает в качестве исходных данных папку \*.SAFE — именно она указывается в качестве единственного обязательного параметра при запуске программы. Если вместо папки \*.SAFE указать что-то другое, например, исходный архив со снимком или конкретный тайл, то программа не запустится.
```
$ L2A_Process T40VFJ_20180727T071621_B04.jp2
Product metadata file cannot be read.
```
Дело в том, что для атмосферной коррекции используются не только сами тайлы, но и метаданные, а они находятся в файлах внутри папки \*.SAFE, а не в тайлах.
Результатом работы программы также является папка \*.SAFE с похожей структурой: внутри есть папка GRANULE, внутри неё — ещё одна папка, в которой находится папка IMG\_DATA, а в ней скорректированные тайлы. Тайлы сгруппированы по пространственному разрешению: в папке R10m находятся те, у которых пространственное разрешение составляет 10 метров, в R20m — те, где разрешение 20 метров, в R60m — 60 метров. При определённых настройках какие-то разрешения не обрабатываются и соответствующие им папки не создаются — об этом чуть ниже.
Название папки \*.SAFE, получающейся в результате, отличается от названия исходной только одним: в начале вместо \_MSI**L1C**\_ указано \_MSI**L2A**\_. L1C и L2A — это коды уровня обработки. Уровень L1C означает, что снимок обработан до уровня Top-of-Atmosphere reflectance, то есть значения пикселей на снимке соответствуют отражению, зафиксированному у верхней границы атмосферы — там, где летает спутник. Уровень L2A — это обработка до уровня Bottom-of-Atmoshpere reflectance, то есть до значений отражения у поверхности Земли — так, как будто атмосфера абсолютно прозрачна. В реальности это, конечно, не так, и атмосферная коррекция позволяет убрать только часть искажений, возникающих при прохождении света через атмосферу, но в целом значения Bottom-of-Atmosphere reflectance больше соответствуют реальному отражению от земной поверхности, чем значения Top-of-Atmosphere reflectance.
Помимо скорректированных тайлов, Sen2Cor производит ещё несколько изображений: полноцветное (TCI), карты аэрозольной оптической плотности атмосферы (AOT — Aerosol Optical Thickness) и содержания водяного пара (WV — Water Vapour), карту тематической классификации типов поверхности (SC — Scene Classification). Они также находятся в папке IMG\_DATA в каталогах для соответствующего пространственного разрешения.
Если нужно, чтобы папка с результатом работы программы называлась не \*.SAFE, а по-другому, то можно самостоятельно указать название с помощью опции `--output_dir`. Предположим, что мы запускаем Sen2Cor три раза с разными настройками и хотим сохранить результаты в папки test1, test2 и test3. Тогда указываем `--output_dir` при запуске:
```
$ L2A_Process --output_dir /home/user/spaceshots/test1 S2A_MSIL1C_20180727T071621_N0206_R006_T40VFJ_20180727T092607.SAFE
```
— и скорректированный снимок окажется в каталоге `/home/user/spaceshots/test1`. При втором и третьем запуске указываем соответственно `--output_dir /home/user/spaceshots/test2` и `--output_dir /home/user/spaceshots/test3`.
Ещё одна полезная опция — это `--resolution`. Она позволяет установить пространственное разрешение тайлов, которые будут получены в результате работы программы. Sen2Cor может создавать изображения с разным пространственным разрешением — 10, 20 или 60 метров на пиксель. По умолчанию делаются 10 и 20 метров. Предположим, что нам для разведочного анализа достаточно тайлов с разрешением 60 метров на пиксель. Тогда можно указать целевое разрешение с помощью опции `--resolution`:
```
$ L2A_Process --resolution 60 S2A_MSIL1C_20180727T071621_N0206_R006_T40VFJ_20180727T092607.SAFE
```
При запуске с такими параметрами Sen2Cor обработает снимок и создаст скорректированные тайлы с разрешением 60 метров. В отличие от стандартного запуска, обработка занимает намного меньше времени — чуть больше четырёх минут. Расход памяти тоже меньше, поэтому если запуск со стандартным разрешением закончился ошибкой из-за нехватки памяти, то можно указать разрешение 60 метров. В папке IMG\_DATA будет находиться только папка R60m, а внутри неё — тайлы с разрешением 60 метров и некоторые другие изображения: полноцветное, тематическая карта и карта содержания водяного пара.
Конфигурационный файл
---------------------
Мы обработали спутниковый снимок с помощью Sen2Cor, используя настройки по умолчанию. Разрешение и папку для сохранения результатов работы можно поменять с помощью опций `--resolution` и `--output_dir`. Есть ещё несколько опций командной строки, однако, с их помощью можно настроить не всё. Есть множество других параметров, важных при обработке, например: учитывать ли рельеф, удалять ли облака, как оценивать состояние атмосферы. В Sen2Cor они настраиваются с помощью конфигурационного файла.
Если запустить Sen2Cor и не указать путь к конфигурационному файлу, как мы делали раньше, то будет использоваться стандартный конфигурационный файл. Стандартным конфигурационный файл находится в домашнем каталоге — в нашем случае в папке /`home/user/sen2cor/2.8/cfg`. Файл называется `L2A_GIPP.xml`. L2A означает уровень обработки, GIPP расшифровывается как Ground Image Processing Parameters — параметры наземной обработки изображения. Это обычный xml-файл, внутри которого есть несколько секций, а в секциях — элементы для разных настроек. Для каждой настройки прямо в файле написано пояснение. Кроме того, подробное описание настроек содержится в документации — правда, разобраться в ней непросто.
Можно отредактировать напрямую стандартный конфигурационный файл, но лучше скопировать его и явно указать при запуске программы, что нужно использовать другой конфигурационный файл. Скопируем L2A\_GIPP.xml в `/home/user/spaceshots`, переименуем в custom.xml и запустим программу с этим конфигурационным файлом:
```
$ L2A_Process --GIP_L2A /home/user/spaceshots/custom.xml --resolution 60 S2A_MSIL1C_20180727T071621_N0206_R006_T40VFJ_20180727T092607.SAFE
```
Обратите внимание, что опция для конфигурационного файла называется `--GIP_L2A` — с одной буквой «P». Поскольку мы не редактировали конфигурационный файл, то процесс и результат работы программы ничем не отличаются от запуска с конфигурацией по умолчанию.
В конфигурационном файле много разных параметров. Рассмотрим некоторые из них.
### Логи
`Log_Level` — параметр, который определяет, насколько подробным будет журнал работы программы. Лог отображается в консоли во время работы и дополнительно сохраняется в папке для логов (в нашем случае — `/home/user/sen2cor/2.8/log`). Значение по умолчанию — INFO. Обычно нет необходимости менять эту настройку, если вы не столкнулись с ошибками в работе программы.
### Учёт рельефа и угла восхождения Солнца
`DEM_Directory` — папка, в которой находится цифровая карта рельефа (DEM — Digital Elevetion Model). Результаты обработки с использованием цифровой карты рельефа обычно получаются более точными. По умолчанию — NONE, то есть рельеф не учитывается. Если у вас есть своя цифровая карта рельефа, то указываете путь к ней. Папка для DEM должна находиться там же, где и папки `cfg` и `log`, то есть в нашем случае — в каталоге `/home/user/sen2cor/2.8`. Следовательно, если у вас есть цифровая карта рельефа, то нужно поместить её в `/home/user/sen2cor/2.8/dem` и в DEM\_Directory указать dem. Если её нет, но все равно хочется использовать, то можно указать любой путь (например, тоже написать dem) и настроить следующий параметр.
`DEM_Reference` — URL, с которого нужно скачать цифровую модель рельефа, если её нет в папке, указанной в предыдущем пункте. Разработчики Sen2Cor предлагают использовать
```
http://data_public:[email protected]/srtm/tiles/GeoTIFF/
```
— это ссылка на STRM DEM, свободно распространяемую цифровую карту рельефа с 90-метровым пространственным разрешением. Учитывая, что масштаб ненамного мельче, чем у самих спутниковых снимков, эта модель должна давать хороший результат.
Если Sen2Cor увидит, что в `DEM_Directory` указано какое-то значение, помимо NONE, то он попытается открыть файлы с картой рельефа из указанного каталога. Если открыть файлы не получится, то он попытается скачать их по URL, указанному в `DEM_Reference`. Если не получится скачать, то в логе появится сообщение об ошибке и обработка продолжится без учёта рельефа. Файлы, скачанные с URL, сохраняются в `DEM_Directory` и не удаляются после завершения работы программы. Следовательно, если вы захотите ещё раз обработать тот же снимок с той же картой рельефа (например, изменив другие настройки коррекции), то Sen2Cor не будет повторно скачивать цифровую карту рельефа, а воспользуется её офлайн-копией.
Опция `Generate_DEM_Output` позволяет получить в результате работы программы отдельный тайл с цифровой картой рельефа. По умолчанию FALSE.
Опция `DEM_Terrain_Correction` частично отключает использование цифровой карты рельефа: рельеф по-прежнему будет учитываться при тематической классификации (SC) и построении карты AOT, но не при корректировке значений отражения от поверхности.
Если DEM не используется, то следует указать параметр `Altitude` — это средняя высота над уровнем моря в районе, запечатлённом на снимке. Высота указывается в километрах.
Ещё два параметра, имеющие отношение к учёту рельефа — это `BRDF_Correction` и `BRDF_Lower_Bound`. BRDF расшифровывается как [bidirectional reflectance distribution function](https://en.wikipedia.org/wiki/Bidirectional_reflectance_distribution_function) и означает уравнение, моделирующее отражение света от непрозрачной поверхности. Разные значения `BRDF_Correction` соответствует разным значениям одного из коэффициентов в этом уравнении. В официальной документации рекомендуют в большинстве случаев использовать 21. `BRDF_Lower_Bound` отвечает за ещё один коэффициент в уравнении, и его можно оставить по умолчанию, за исключением случаев, когда вы точно знаете, почему и зачем его нужно поменять.
### Красивая картинка
Параметр `Generate_TCI_Output` включает и выключает создание полноцветного изображения. По умолчанию TRUE, но если красивая картинка не нужна, то можно выбрать FALSE.
### Учёт состояния атмосферы
Параметры `Aerosol_Type`, `Mid_Latitude`, `Ozone_Content` указывают на состояние атмосферы в момент съёмки. `Aerosol_Type` можно установить по территории: если континент, то RURAL, если океан, то MARINE. `Mid_Latitude` аналогично определяется по времени года: если летом, то SUMMER, если зимой, то WINTER.
Параметр `Ozone_Content` указывает на содержание озона. Содержание озона можно поискать в [онлайн-архиве Всемирного центра данных по озону и ультрафиолетовому излучению](https://woudc.org/data/stations/?lang=en). На карте можно найти станцию, наиболее близкую к району съёмки, далее скачать набор с данными за нужное время и посмотреть результаты измерений в день съёмки. Однако установить реальный результат измерений в конфигурационном файле нельзя — нужно выбрать одно значение из списка для соответствующего времени года. Следовательно, нужно сначала узнать реально измеренное значение, а потом подобрать наиболее близкое из доступных. Например, по данным [станции в Екатеринбурге](https://woudc.org/data/stations/?id=122&lang=en), 27 июня 2018 года (время съёмки) содержание озона составляло 316 DU. В пояснении в конфигурационном файле указано: для лета в средних широтах доступные варианты — 250, 290, 331 (по умолчанию), 370, 410, 450. Наиболее близкое к 316 — это 331. Оно идёт по умолчанию, поэтому в данном случае можно ничего не менять. Если бы снимок был сделан несколькими днями раньше, когда содержание озона уменьшалось до 302 DU, следовало бы установить `Ozone_Content` в 290.
В принципе все три параметра — `Aerosol_Type`, `Mid_Latitude`, `Ozone_Content` — в большинстве случаев можно выставлять по умолчанию — AUTO для `Aerosol_Type` и `Mid_Latitude` и 0 для `Ozone_Content`. В таком случае Sen2Cor сам определит наиболее подходящие значения по метаданным снимка.
### Удаление облачности
Параметр `Cirrus_Correction` говорит, удалять или нет перистые облака со снимка. Работает в паре с `WV_Threshold_Cirrus` — это порог содержания водяного пара, ниже которого удаление облаков автоматически отключается, даже если `Cirrus_Correction` установлено в TRUE. Следовательно, если есть основания полагать, что содержание водяного пара в атмосфере в момент съёмки было низкое, но небольшие облака всё же есть, и их нужно удалить, то лучше уменьшить значение `WV_Threshold_Cirrus`. `WV_Threshold_Cirrus` может быть от 0.1 до 1.
Заключение
----------
Таким образом, в данной статье мы рассмотрели следующие вопросы: как установить Sen2Cor, как запустить его с настройками по умолчанию, как изменить некоторые параметры работы программы с помощью опций командной строки и конфигурационного файла. Для более глубокого изучения Sen2Cor можно обратиться к официальной документации, которая размещена на той же странице, что и установщики. Официальная документация включает четыре документа: более простые и понятные Release Note и Software User Manual и довольно сложные технические Product Definition и Input Output Data Definition. Последний файл также включает «The full reference of GIPP» в качестве вложенного pdf-файла. Полагаю, что технические специалисты найдут в этих документах ещё много полезного. | https://habr.com/ru/post/501188/ | null | ru | null |
# Как это работает: CAPTCHA
Сколько лет существует Хабр — столько лет на нём регулярно появляются посты про очередную капчу — будь то скрипт генерации картинки, новая идея капчи с котиками и тому подобное. Самый [свежий пример](http://habrahabr.ru/post/175079/) того, что человек не совсем понимает — как же всё таки должна работать капча (см. текст поста и последние комментарии), но при этом делится своими заблуждениями с сообществом. Складывается ощущение, что капча — это такая *terra incognita* для большинства разработчиков — как для тех, кто просто прикручивает её к очередной форме в надежде на то, что она будет работать «из коробки», так и для тех кто придумывает капчи вроде тех, на которых надо выбрать картинку с котиком из нескольких фото.
Статья содержит полезную информацию для тех, кто использует капчу на своём сервере, вместо того чтобы довериться стороннему сервису вроде reCaptcha.
А для затравки — если вы считаете, что такая проверка капчи будет работать:
`if($_POST['captcha'] == $_SESSION['captcha']) return true;` (пример из практики)
то вы глубоко заблуждаетесь.
### Captcha
Согласно своему определению, captcha — это автоматизированный публичный тест Тьюринга (тест который может пройти человек, но не компьютер). В статье я буду рассматривать свойтсва капчи на примере самого распространненого её вида — текста на картинке, хотя почти все написанное одинаково применимо к любому виду капчи.
### Два главных свойства капчи
Любая капча должна обладать двумя свойствами, без которых она не будет работать:
**Устойчивость к распознаванию** — свойство, защищающее капчу от распознавания алгоритмом — например системой распознавания текста. Гарантирует то, что человек сможет прочитать текст на картинке, а компьютер нет.
Антипример: стандартная капча форумов phpBB 2.x таким свойством не обладала — из-за относительной простоты распознавания появились скрипты, которые спамили все подряд форумы вынуждая веб-мастеров менять капчу на более стойкую.
**Устойчивость к угадыванию** — свойство капчи, не позволяющее угадать её значение за небольшое число попыток (менее 1000). Если набор возможных значений капчи невелик, программе не составит труда угадать её подбором вместо распознавания.
Антипример: арифметическая капча вроде «1+2» (перебор чисел от 1 до 20 в скором времени даст результат).
Антипример: выбрать из нескольких картинок ту, на которой изображён котик.
### Проверка капчи
**Значение для проверки должно храниться на сервере, а не передаваться вместе с картинкой в браузер.** Для сопоставления посетителя и правильного значения капчи необходимо использовать некий ключ, который передаётся вместе с капчей (идентификатор сессии, номер капчи и т.п.)
Антипример: если передавать саму капчу и значение для ее проверки (в том числе зашифрованное), то человеку достаточно один раз распознать такую капчу и далее использовать комбинацию «ответ»-«значение для проверки» в своём скрипте (по ссылке в начале поста как раз такой случай)
**Перед проверкой ответа — надо убедиться, что он не пустой.** В противном случае, злоумышленник может не загружая картинку или удалив идентификатор текущей сессии, передать пустое значение и пройти капчу, т.к. произойдёт сравнение двух пустых строк (в PHP несуществующее значение равно пустой строке).
Антипример: уже упомянутый мной код `if($_POST['captcha'] == $_SESSION['captcha']) return true;`
Причем этот код был написан опытным программистом.
**После проверки, сохраненное значение капчи необходимо удалить.** Если не сделать этого, злоумышленник сможет использовать данное значение снова неограниченное число раз. Да, при обновлении страницы с формой обновляется и капча (либо при генерации формы, либо при генерации картинки), вот только скрипт может не загружать форму снова (надо упомянуть, что это не актуально если на сайте используются одноразовые csrf-токены для форм).
Антипример: гипотетическая форма логина, в которой достаточно один раз ввести капчу правильно, и далее подбирать пароль скриптом, избегая перегенерации капчи на сервере.
### Пуленепробиваемая капча
**Защита от перебора.** Если ваша капча устойчива к распознаванию, но не очень устойчива к перебору (например на ней надо прочитать всего 3-4 цифры), желательно ограничить число неправильных ответов «с одного ip» / «для одного логина» / etc. Такие ограничения необходимо проверять ДО проверки самой капчи (то есть даже в случае правильно введенной капчи, при наличии ограничения она не должна считаться пройденной) иначе оно не будет препятствовать перебору.
**Защита от DoS.** При генерации капчи на своем сервере, надо понимать что это удобный вектор проведения DoS атак (которую, в отличие от DDoS, может устроить любой школьник). Для защиты можно ограничить число генерации капчи для одного ip, кэшированием капч и т.д. [Подробнее про это](http://habrahabr.ru/post/144427/)
**Защита от распознавания.** Если вы выбираете капчу, или вдруг собираетесь написать её сами, желательно понимать какая капча более защищена от распознавания. Существуют готовые универсальные скрипты распознавания капчи, работающие по принципу [OCR](http://ru.wikipedia.org/wiki/%D0%9E%D0%BF%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D1%80%D0%B0%D1%81%D0%BF%D0%BE%D0%B7%D0%BD%D0%B0%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D1%81%D0%B8%D0%BC%D0%B2%D0%BE%D0%BB%D0%BE%D0%B2), а в случае если ваш сайт заинтересует спамеров есть риск, что будут использовать / писать скрипт конкретно под вашу капчу. Последнее правда относится больше к сайтам уровня Яндекс или vk, а вот вариант с защитой от банальных OCR желательно предусмотреть.
**Защита от антигейтов.** Если говорить формально, то капча как тест Тьюринга не обязана защищать вас от антигейтов, так как в этом случае её будет распознавать человек. С практической же точки зрения, этот вопрос весьма актуален и защищаться как-то надо.
Тут нет и не может быть «золотого стандарта» (ибо в таком случае антигейты внедрят его поддержку), поэтому вы вольны дополнять капчу любыми ухищрениями, чтобы сделать её распознавание через антигейт невозможным. Например:
— нестандартная капча (сбор паззла, поворот изображения, клик по области на фото и т.п.);
— кириллическая капча — самое простое решение, но имеет ряд минусов: подходит только для проектов с русскоязычной аудиторией, есть антигейты с поддержкой кириллицы;
— использование виртуальной клавиатуры рядом с капчей для ввода нестандартных символов или фигур (может быть неудобно пользователям мобильных);
### Юзабилити
Не просите ввести капчу, если вы уже убедились, что перед вами человек. Тут однако, надо быть осторожным, чтобы форму нельзя было использовать скриптом неограниченное число раз после однократного ввода капчи человеком.
Пример: форма регистрации. Если я где-то регистрируюсь, и забыл ввести поле «почтовый индекс», но правильно ввёл капчу — не надо показывать мне новую. Потратьте 10 минут на то, чтобы сохранить где-то у себя, что вот эту конкретную форму сейчас пытается заполнить живой человек.
Для облегчения распознавания человеком: не используйте в капче одновременно буквы и цифры, не используйте одновременно прописные и строчные буквы, исключите похожие символы.
### Отказ от использования капчи
Лучшая капча — отсутствие капчи. Там где можно отказаться от её использования — это надо сделать. Возможно для этого придется реализовать дополнительные лимиты и проверки, но пользователи скажут вам спасибо.
Но тут надо быть очень осторожным. Например: форма регистрации без капчи, с полем email на который приходит письмо с активацией. Без дополнительных средств защиты такую форму могут завалить «левыми» адресами, и ваш сайт включат в черные списки почтовые службы. В таком случае можно обходиться без капчи, но только если у вас есть другой рубеж защиты, вроде лимита по ip.
Кому то информация в этом топике покажется очевидной, но если бы я не сталкивался с примерами непонимания этих простых принципов в жизни, в том числе у опытных коллег-разработчиков, я бы не стал тратить время на написание этого текста. | https://habr.com/ru/post/175461/ | null | ru | null |
# Рефакторинг платежного процесса Я.Денег — пробуждение силы

Для любого проекта с длинной историей однажды наступает момент, когда код начинает жить своей жизнью — просто не остается тех, кто хорошо ориентируется в логике и связях. Добавление новых функций порой похоже на выстрел наугад: может попасть в цель, а может — в зрителей.
И тогда приходит он, рефакторинг платежного процесса. Но мы решили сделать процесс еще интереснее, добавив к рефакторингу идеи **IDEF-0**.
Это все временно, потом поменяем
================================
Платежный процесс Яндекс.Денег развивался с 2002 года, и его фронтенд за эти годы оброс результатами труда многих поколений разработчиков. Оброс до того, что даже изменение алгоритма проверки баланса пользователя перед отправкой перевода превращалось в путешествие по поляне с капканами, — путешествие, незаметное пользователю, но увлекательное под капотом. В статье коснемся именно серверной части фронтенда.
Помимо трудностей с поддержкой, было сложно вводить в курс дела новых разработчиков, а это большой минус для компании, где инженеры регулярно мигрируют между проектами. Поэтому было решено провести глубокий рефакторинг кода. С учетом объемов работы это означало написать процесс заново.
Если начинать с нуля, то делать основательно, с использованием признанных методологий — теории конечных автоматов и [IDEF-0](https://ru.wikipedia.org/wiki/IDEF0). Принципы описания бизнес-процессов по этому стандарту знакомы с университетской скамьи как инженерам, так и управленцам — в этом они должны были найти общий язык. Заодно сбудется голубая мечта технаря об автоматическом построении диаграмм процесса, которые так любит руководство. Например, такая схема отображается на одном из дисплеев со статистикой, которые в изобилии развешаны в офисе Яндекс.Денег.
Мало просто причесать код — нужно сделать это с умом
====================================================
При переводе всего старого кода на новые рельсы появился набор модулей **Node.js**, в которых описаны все базовые методы-процессы. Причем описаны не просто набором процедур, а в соответствии с идеями IDEF-0: есть функциональные блоки, входные и выходные данные, связи процессов.
Вообще, в IDEF-0 описано много всего, что при разработке можно упростить, поэтому кальку со стандарта мы не делали и просто заимствовали идею и все релевантные принципы.
Функциональные блоки
--------------------
В IDEF-0 функциональный блок — это просто отдельная функция системы, которую графически изображают в виде прямоугольника. В платежном процессе Яндекс.Денег функциональные блоки содержат частички бизнес-логики того или иного процесса.
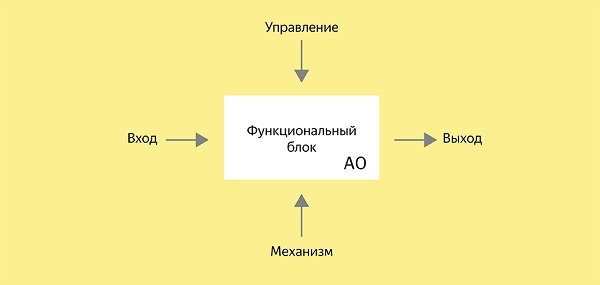
У каждой из четырех сторон функционального блока своя роль:
1. Верхняя сторона отвечает за управление;
2. Левая — входные данные (для кого операция, сколько перевести и прочее);
3. Правая сторона выводит результат;
4. Нижняя — это "Механизм", который обозначает используемые в процессе ресурсы.
В платежном фронтенде Яндекс.Денег используются только две стороны функционального блока — **вход** и **выход:** на вход передается набор данных для выполнения бизнес-логики, у выхода система ожидает результат выполнения этой логики.
Вот как это выглядит в коде:
```
/**
* Функциональный блок для проверки имени пользователя
* @param {Object} $flow служебный объект, экземпляр текущего процесса, позволяющий управлять переходами от блока к блоку
* @param {Object} inputData входящие данные
* @param {Object} inputData.userName имя пользователя
*/
const checkUserName($flow, inputData) {
if (inputData.userName) {
// Переходим к следующему функциональному блоку
const outputData = {
userName: inputData.userName
isUserNameValid: true
};
$flow.transition('doSomethingElse', outputData);
return;
}
$flow.transition('checkFailed', inputData);
}
```
Функция принимает в качестве аргументов два параметра:
1. $flow — служебный объект, экземпляр текущего процесса;
2. inputData — объект со входными данными для функционального блока. Отличие функционального блока от обычной функции заключается в способе передачи управления внешнему коду. Функциональный блок для этого использует отдельный метод transition.
При разработке функциональных блоков важно помнить о **принципе единой ответственности**, иначе не будет должной гибкости при добавлении новой бизнес-логики.
Интерфейсные дуги
-----------------
Интерфейсная дуга — просто стрелка функционального блока, которая ожидаемо обозначает передачу данных или влияние на функциональный блок.
В новом платежном процессе роль интерфейсной дуги исполняет функция **Transition** у объекта **$flow**, который является экземпляром отвечающего за предоставление API процесса.
Декомпозиция
------------
Хорошо всем известный принцип разбиения большого и сложного на много простых и понятных частей. В коде это означает упрощение и унификацию функций.
В IDEF-0 декомпозиция выглядит следующим образом:

Декомпозиция применялась в платежном процессе повсеместно, но рассмотрим на примере процесса проверки свойств пользователя.
Проверка свойств пользователя состоит из 5 функциональных блоков и двух выходов из процесса (отмечено синим), которые можно декомпозировать. Например, проверка номера телефона не относится только к пользователю и может пригодиться в других процессах. Если выделить это действие в отдельный процесс, то код станет проще и понятнее:

После декомпозиции проверки свойств пользователя часть функциональных блоков перемещается в новый процесс, который проверяет номер телефона. С помощью **BitBucket** разница видна более наглядно — за проверку телефона пользователя отвечают три функциональных блока:
1. **prepareToCheckPhone** —подготовка данных;
2. **requestBackendForCheckPhone** — запрос в бекенд;
3. **checkUserPhone** — анализ результатов.
До переноса вовне все эти блоки перегружали логику проверки свойств пользователя, а теперь процесс стал значительно проще и понятней даже очень молодому разработчику.
**Для любопытных оставлю исходный код под спойлером, чтобы вы могли самостоятельно оценить перегруженность логики.**
```
// check-phone.js
module.exports = new ProcessFlow({
initialStage: 'prepareInputData',
finalStages: [
'phoneValid',
'phoneInvalid'
],
stages: {
/**
* Функциональный блок для подготовки данных к проверке телефона
* @param {Object} $flow служебный объект, экземпляр текущего процесса
* @param {Object} inputData входящие данные
*/
prepareInputData($flow, inputData) {
/**
* Формат данных необходимый модулю провеки номера телефона, может отличаться от формата,
* которым оперирует конечный процесс, по этому данные нужно подготовить.
* Так же завязываться на структуру данных модуля проверки телефона в конечном процессе не стоит,
* модуль может поменяться, что может привести к серьезным изменениям всего процесса
*/
$flow.transition('checkPhone', {
phone: inputData
});
},
/**
* Функциональный блок проверки номера телефона
* @param {Object} $flow служебный объект, экземпляр текущего процесса
* @param {Object} inputData входящие данные
*/
checkPhone($flow, inputData) {
const someBackend = require('some-backend-module');
someBackend.checkPhone(inputData.phone)
.then((result) => {
$flow.transition('processCheckResult', result);
})
.catch((err) => {
$flow.transition('phoneInvalid', {
err: err
});
});
},
/**
* Функциональный блок анализа результатов проверки
* @param {Object} $flow служебный объект, экземпляр текущего процесса
* @param {Object} inputData входящие данные
*/
processCheckResult($flow, inputData) {
if (inputData.isPhoneValid) {
$flow.transition('phoneValid');
return;
}
$flow.transition('phoneInvalid');
}
}
});
// check-user.js
const checkPhoneProcess = require('./check-phone');
module.exports = new ProcessFlow({
// Указываем, какой функциональный блок отвечает за вход в процесс
initialStage: 'checkUserName',
// Описываем выходы из процесса
finalStages: [
'userCheckedSuccessful',
'userCheckFailed'
],
stages: {
/**
* Функциональный блок для проверки имени пользователя
* @param {Object} $flow служебный объект, экземпляр текущего процесса
* @param {Object} inputData входящие данные
*/
checkUserName($flow, inputData) {
if (inputData.userName) {
$flow.transition('checkUserBalance', inputData);
return;
}
$flow.transition('userCheckFailed', {
reason: 'invalid-user-name'
});
},
/**
* Функциональный блок для проверки баланса пользователя
* @param {Object} $flow служебный объект, экземпляр текущего процесса
* @param {Object} inputData входящие данные
*/
checkUserBalance($flow, inputData) {
if (inputData.balance > 0) {
$flow.transition('checkUserPhone', inputData);
return;
}
$flow.transition('userCheckFailed', {
reason: 'invalid-user-balance'
});
},
/**
* Функциональный блок проверки номера телефона
* @param {Object} $flow служебный объект, экземпляр текущего процесса
* @param {Object} inputData входящие данные
*/
checkUserPhone($flow, inputData) {
const phone = inputData.operatorCode + inputData.number;
checkPhoneProcess.start(phone, {
// описываем поведение в точках выхода процесса проверки телефона
phoneValid() {
$flow.transition('userCheckedSuccessful');
},
phoneInvalid() {
$flow.transition('userCheckFailed', {
reason: 'invalid-user-phone'
});
}
});
}
}
});
```
Каждый процесс платежа Яндекс.Денег является экземпляром класса **ProcessFlow**, который предоставляет API управления процессом. У него есть метод start, который вызывает функциональный блок, описанный в **initialStage**. В качестве аргументов метод start принимает входные данные и обработчики выходов процесса.
Принципы ограничения сложности
------------------------------
Процессы обычно содержат в себе сложную бизнес-логику, поэтому в коде приходится ограничивать их сложность в соответствии с рекомендациями IDEF-0:
* Не более 6 функциональных блоков на каждом уровне. Это ограничение подталкивает разработчика к использованию иерархии при описании сложной логики;
* Нижний предел в 3 блока гарантирует, что создание процесса оправданно;
* Количество выходящих из одного блока **интерфейсных дуг ограничено**.
На уже знакомой иллюстрации процесса "как было" видно 7 функциональных блоков, что увеличивает соблазн написать все плоско, не заморачиваясь с иерархией.

В следующем разделе покажу, как выглядит доработанный процесс после упрощения логики.
Пасхалка: автоматическая отрисовка схем
=======================================
В крупных компаниях бизнес-процессы порой устаревают быстрее, чем их успевают нарисовать аналитики. Увы, мы в этом плане не исключение, поэтому пришлось научиться рисовать быстрее.
Благодаря IDEF-0 и строгим правилам описания процессов в коде, мы можем с помощью статического анализа кода построить диаграмму связей как функциональных блоков, так и процессов между собой. Например, подойдет продукт [Esprima](http://esprima.org/). В результате анализа кода этим инструментом формируется объект со всеми функциональными блоками и переходами, а визуализация происходит в браузере с помощью библиотеки [GoJS](https://gojs.net/latest/index.html):

На схеме изображены процессы check-user и check-phone с указанием зависимости. Если их развернуть, получится следующее:
На схеме отлично видны начальные функциональные блоки, цветом помечены выходы процесса. Например, из этой схемы очевидно, что результат **userCheckFailed** может быть получен не только на этапе проверки номера телефона, но и на моменте проверки имени. Раньше это было до смешного не очевидно.
Так стоила ли овчинка выделки
=============================
Результатом рефакторинга платежного процесса стала целая платформа для описания процессов подготовки данных. Основной плюс от потраченного на рефакторинг времени — это правильный ход мыслей разработчиков, которые теперь придерживаются жестких правил при формировании логики новых процессов. Значит, в будущем рефакторинга будет меньше.
Кроме того, в суть процесса теперь может быстро вникнуть любой новичок. Это экономит массу времени на брифингах и позволяет внедрять новые фишки без опасений, что все развалится.
**Есть и побочный эффект — бизнес-аналитикам больше не приходится рисовать статические диаграммы, поэтому потребление кофе и чая с какао резко возросло.** | https://habr.com/ru/post/321824/ | null | ru | null |
# Хостинг сайта на Imgur
В интернете трудно найти нормальный хостинг для файлов, зато есть огромное количество бесплатных хостингов картинок вроде Imgur или Flickr. Поэтому давным-давно появилась идея размещать там произвольные файлы под видом картинок (есть масса плагинов, чтобы заливать на Flickr любые файлы или прятать произвольные файлы внутри настоящих фотографий). Сейчас эта концепция продвинулась ещё дальше.
Если вкратце, то экспериментальный инструмент [Web2img](https://github.com/etherdream/web2img) сначала перекодирует файлы вашего веб-сайта в формат изображений (для размещения на хостинге), а затем преобразует эту картинку в JS-скрипт для выполнения в браузере на лету (через service worker). Таким образом, контент сайта загружается с Imgur прямо в браузер.
На [демо-странице](https://etherdream.com/web2img/) можно посмотреть, как выглядит результат. Например, вот [исходные файлы](https://github.com/fanhtml5/test-site) тестового сайта (11 файлов, 1 738 978 байт). С помощью Web2img они преобразуются в картинку `6e69835a-3680-4c73-9940-d733464bddc3.png` размером 762х762 пикселя.
Сохраняем её на Imgur: `https://i.imgur.com/mGU3YV1.png`.
В демо-инструменте эта картинка преобразуется в скрипт [x.js](https://github.com/fanhtml5/fanhtml5.github.io) для запуска в браузере. Его можно минифицировать или не минифицировать. Вот код скрипта в обычном виде:
**Код скрипта**
```
var HASH = 'dXZrNL4q6Lr6KzN0ECHIW4RP8hQy9uL2W9uBP/CJ/4Y='
var URLS = ['https://i.imgur.com/mGU3YV1.png']
var PRIVACY = 2
var UPDATE_INTERVAL = 120
var IMG_TIMEOUT = 10
function pageEnv() {
var container = document.documentElement
function fallback(html) {
var noscripts = document.getElementsByTagName('noscript')
if (noscripts.length > 0) {
html = noscripts[0].innerHTML
}
container.innerHTML = html
}
var jsUrl = document.currentScript.src
var sw = navigator.serviceWorker
if (!sw) {
fallback('Service Worker is not supported')
return
}
var rootPath = getRootPath(jsUrl)
function unpackToCache(bytes, cache) {
var pendings = []
if (!sw.controller) {
var swPending = sw.register(jsUrl).catch(function(err) {
fallback(err.message)
})
pendings.push(swPending)
}
var info = JSON.stringify({
hash: HASH,
time: Date.now()
})
var res = new Response(info)
pendings.push([
cache.put(rootPath + '.cache-info', res),
])
var pathResMap = unpack(bytes)
for (var path in pathResMap) {
res = pathResMap[path]
pendings.push(
cache.put(rootPath + path, res)
)
}
Promise.all(pendings).then(function() {
location.reload()
})
}
function parseImgBuf(buf) {
if (!buf) {
loadNextUrl()
return
}
crypto.subtle.digest('SHA-256', buf).then(function(digest) {
var hashBin = new Uint8Array(digest)
var hashB64 = btoa(String.fromCharCode.apply(null, hashBin))
if (HASH && HASH !== hashB64) {
console.warn('[web2img] bad hash. exp:', HASH, 'but got:', hashB64)
loadNextUrl()
return
}
var bytes = decode1Px3Bytes(buf)
caches.delete('.web2img').then(function() {
caches.open('.web2img').then(function(cache) {
unpackToCache(bytes, cache)
})
})
})
}
// run in iframe
var loadImg = function(e) {
var opt = e.data
var img = new Image()
img.onload = function() {
clearInterval(tid)
var canvas = document.createElement('canvas')
canvas.width = img.width
canvas.height = img.height
var ctx = canvas.getContext('2d')
ctx.drawImage(img, 0, 0)
var imgData = ctx.getImageData(0, 0, img.width, img.height)
var buf = imgData.data.buffer
if (opt.privacy === 2) {
parent.postMessage(buf, '*', [buf])
} else {
parseImgBuf(buf)
}
}
img.onerror = function() {
clearInterval(tid)
if (opt.privacy === 2) {
parent.postMessage('', '*')
} else {
parseImgBuf()
}
}
if (opt.privacy === 1) {
img.referrerPolicy = 'no-referrer'
}
img.crossOrigin = 1
img.src = opt.url
var tid = setTimeout(function() {
console.log('[web2img] timeout:', opt.url)
img.onerror()
img.onerror = img.onload = null
img.src = ''
}, opt.timeout)
}
if (PRIVACY === 2) {
// hide `origin` header
var iframe = document.createElement('iframe')
if (typeof RELEASE !== 'undefined') {
iframe.src = 'data:text/html,onmessage=' + loadImg + ''
} else {
iframe.src = 'data:text/html;base64,' + btoa('onmessage=' + loadImg + '')
}
iframe.style.display = 'none'
iframe.onload = loadNextUrl
container.appendChild(iframe)
var iframeWin = iframe.contentWindow
self.onmessage = function(e) {
if (e.source === iframeWin) {
parseImgBuf(e.data)
}
}
} else {
loadNextUrl()
}
function loadNextUrl() {
var url = URLS.shift()
if (!url) {
fallback('failed to load resources')
return
}
var opt = {
url: url,
privacy: PRIVACY,
timeout: IMG_TIMEOUT * 1000
}
if (PRIVACY === 2) {
iframeWin.postMessage(opt, '*')
} else {
loadImg({data: opt})
}
}
function decode1Px3Bytes(pixelBuf) {
var u32 = new Uint32Array(pixelBuf)
var out = new Uint8Array(u32.length * 3)
var p = 0
u32.forEach(function(rgba) {
out[p++] = rgba
out[p++] = rgba >> 8
out[p++] = rgba >> 16
})
return out
}
function unpack(bytes) {
var confEnd = bytes.indexOf(13) // '\r'
var confBin = bytes.subarray(0, confEnd)
var confStr = new TextDecoder().decode(confBin)
var confObj = JSON.parse(confStr)
var offset = confEnd + 1
for (var path in confObj) {
var headers = confObj[path]
var expires = /\.html$/.test(path) ? 5 : UPDATE_INTERVAL
headers['cache-control'] = 'max-age=' + expires
var len = +headers['content-length']
var bin = bytes.subarray(offset, offset + len)
confObj[path] = new Response(bin, {
headers: headers
})
offset += len
}
return confObj
}
}
function swEnv() {
var jsUrl = location.href.split('?')[0]
var rootPath = getRootPath(jsUrl)
var isFirst = 1
var newJs
function openFile(path) {
return caches.open('.web2img').then(function(cache) {
return cache.match(path)
})
}
function checkUpdate() {
openFile(rootPath + '.cache-info').then(function(res) {
if (!res) {
return
}
res.json().then(function(info) {
if (Date.now() - info.time < 1000 * UPDATE_INTERVAL) {
return
}
var url, opt
if ('cache' in Request.prototype) {
url = jsUrl
opt = {cache: 'no-cache'}
} else {
url = jsUrl + '?t=' + Date.now()
}
fetch(url, opt).then(function(res) {
res.text().then(function(js) {
if (js.indexOf(info.hash) === -1) {
newJs = url
console.log('[web2img] new version found')
}
})
})
})
})
}
setInterval(checkUpdate, 1000 * UPDATE_INTERVAL)
function respondFile(url) {
var path = new URL(url).pathname
.replace(/\/{2,}/g, '/')
.replace(/\/$/, '/index.html')
return openFile(path).then(function(r1) {
return r1 || openFile(rootPath + '404.html').then(function(r2) {
return r2 || new Response('file not found: ' + path, {
status: 404
})
})
})
}
function respond(req) {
return caches.has('.web2img').then(function(existed) {
if (!existed) {
// fix cache
newJs = jsUrl
}
if (newJs && req.mode === 'navigate') {
var res = new Response('', {
headers: {
'content-type': 'text/html'
}
})
newJs = ''
console.log('[web2img] updating')
return res
}
return respondFile(req.url)
})
}
onfetch = function(e) {
if (isFirst) {
isFirst = 0
checkUpdate()
}
var req = e.request
if (req.url.indexOf(rootPath) === 0 && req.url.indexOf(jsUrl) !== 0) {
// url starts with rootPath (exclude x.js)
e.respondWith(respond(req))
}
}
oninstall = function() {
skipWaiting()
}
}
function getRootPath(url) {
// e.g.
// 'https://mysite.com/'
// 'https://xx.github.io/path/to/'
return url.split('?')[0].replace(/[^/]+$/, '')
}
if (self.document) {
pageEnv()
} else {
swEnv()
}
```
Осталось только запустить скрипт в браузере. Например, со странички `404.html`:
Таким образом, Imgur выполняет роль бесплатного CDN или бесплатного хостинга для загрузки файлов вашего сайта в браузер пользователя.
В принципе, это не новая идея. Наличие бесплатных хостингов картинок само собой наталкивает на мысль перекодировать файлы любого формата в картинки и использовать этот хостинг в качестве хранилища для файлов любого типа. Например, плагин [PngEncoder для Flickr](https://github.com/syncany/syncany-plugin-flickr/tree/develop/src/main/java/org/syncany/plugins/flickr) позволял гибридному облачному сервису [Syncany](https://www.syncany.org/) использовать в бэкенде хостинг фотографий Flickr, который бесплатно принимает до 1 ТБ файлов. С аналогичными целями можно использовать Google Photos и другие бесплатные хостинги фотографий, хотя подобный конвертация будет нарушать официальные правила использования этих сервисов (ToS).
Ещё одна экспериментальная программа [flickr-music-player](https://github.com/barosl/flickr-music-player) конвертирует музыкальные файлы в картинки — и размещает на Flickr, [пример](https://www.flickr.com/photos/barosl/albums/72157633839713560) (музыкальные файлы даже рендерятся как настоящие картинки, в соответствии с обложкой своего музыкального альбома).
Можно вспомнить также кодировщики [Flickr-FS](https://github.com/vgel/flickr-fuse) и [flickr-store](https://github.com/meltingice/flickr-store) для быстрого перекодирования файлов в картинки PNG, которые принимает Flickr.
В определённом смысле, такие интерфейсы превращают хостинги картинок в полноценные файловые системы, словно модуль FUSE под Linux, который позволяет разработчикам создавать новые типы файловых систем, доступные для монтирования пользователями без привилегий. | https://habr.com/ru/post/579422/ | null | ru | null |
# Обзор одной российской RTOS, часть 5. Первое приложение
Готова очередная публикация обзора особенностей ОСРВ МАКС. В предыдущей статье мы разбирались с теорией, а сегодня наступило время практики.
[Часть 1. Общие сведения](https://habrahabr.ru/post/336308/)
[Часть 2. Ядро ОСРВ МАКС](https://habrahabr.ru/post/336696/)
[Часть 3. Структура простейшей программы](https://habrahabr.ru/post/336944/)
[Часть 4. Полезная теория](https://habrahabr.ru/post/337476/)
Часть 5. Первое приложение (настоящая статья)
[Часть 6. Средства синхронизации потоков](https://habrahabr.ru/post/338682/)
[Часть 7. Средства обмена данными между задачами](https://habrahabr.ru/post/339498/)
[Часть 8. Работа с прерываниями](https://habrahabr.ru/post/340032/)
При начале работы с контроллерами, принято мигать светодиодами. Я нарушу эту традицию.
Во-первых, это банально надоело. Во-вторых, светодиоды потребляют слишком большой ток. Не спешите думать, что я экономлю каждый милливатт, просто по ходу работ, нам эта экономия будет крайне важна. Опять же, то, что мы увидим ниже — на светодиодах увидеть практически невозможно.
Итак, пока нет генератора проектов, берём проект по-умолчанию для своей макетной платы и своего любимого компилятора (я взял **...\maksRTOS\Compilers\STM32F4xx\MDK-ARM 5\Projects\Default)** и копируем его под иным именем (у меня получилось **...\maksRTOS\Compilers\STM32F4xx\MDK-ARM 5\Projects\Test1)** . Также следует снять со всех файлов атрибут «Только для чтения».
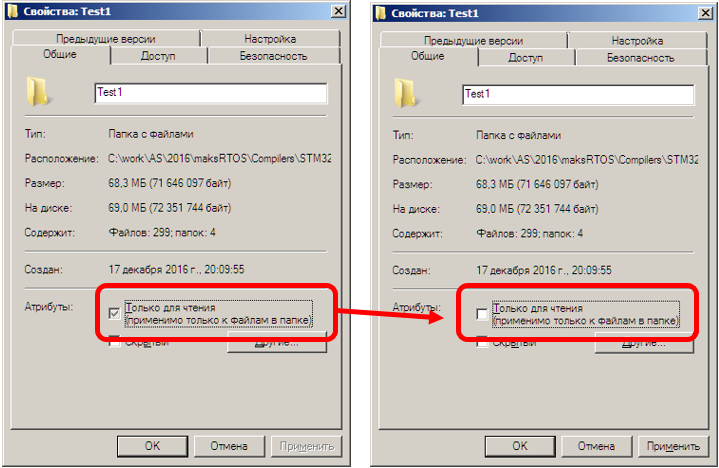
Каталог файлов проекта весьма спартанский.
DefaultApp.cpp
DefaultApp.h
main.cpp
MaksConfig.h
Файл main.cpp относится к каноническому примеру, файлы DefaultApp.cpp и DefaultApp.h описывают пустой класс-наследник от Application. Файл MaksConfig.h мы будем использовать для изменения опций системы.
Если открыть проект, то окажется, что к нему подключено огромное количество файлов операционной системы.
В свойствах проекта также имеется бешеное количество настроек.
Так что не стоит даже надеяться создать проект «с нуля». Придётся смириться с тем, что его надо или копировать из пустого проекта по умолчанию, или создавать при помощи автоматических утилит.
Для дальнейшего изложения, я разрываюсь между «правильно» и «читаемо». Дело в том, что правильно — это начать создавать файлы для задач, причём — отдельно заголовочный файл, отдельно — файл с кодом. Однако, читатель запутается в том, что автор натворит. Такой подход хорош при создании видеоуроков. Поэтому я пойду другим путём — начну добавлять новые классы в файл DefaultApp.h. Это в корне неверно при практической работе, но зато код получится более-менее читаемым в документе.
Итак. Мы не будем мигать светодиодами. Мы будем изменять состояние пары выводов контроллера, а результаты наблюдать — на осциллографе.
Сделаем класс задачи, которая занимается этим шевелением. Драйверы мы использовать пока не умеем, поэтому будем обращаться к портам по-старинке. Выберем пару свободных портов на плате. Пусть это будут PE2 и PE3. Что они свободны, я вывел из следующей таблицы, содержащейся в описании платы STM32F429-DISCO:
Сначала сделаем класс, шевелящий ножкой PE2, потом — переделаем его на шаблонный вид.
Идём в файл DefaultApp.h (как мы помним, это неправильно для реальной работы, но зато наглядно для текста) и создаём класс-наследник от Task. Что туда нужно добавить? Правильно, конструктор и функцию Execute(). Прекрасно, пишем (первая и последняя строки оставлены, как реперные, чтобы было ясно, куда именно пишем):
```
#include "maksRTOS.h"
class Blinker : public Task
{
public:
Blinker (const char * name = nullptr) : Task (name){}
virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<<2);
GPIOE->BSRR = (1<<(2+16));
}
}
};
class DefaultApp : public Application
```
Задача, дёргающая PE2 готов. Но теперь надо
* Включить тактирование порта E;
* Подключить задачу к планировщику.
Где это удобнее всего делать? Правильно, мы уже знаем, что это удобнее всего делать в функции
`void DefaultApp::Initialize()`
благо заготовка уже имеется. Пишем что-то, вроде этого:
```
void DefaultApp::Initialize()
{
/* Начните код приложения здесь */
// Включили тактирование порта E
RCC->AHB1ENR |= RCC_AHB1ENR_GPIOEEN;
// Линии PE2 и PE3 сделали выходами
GPIOE->MODER = GPIO_MODER_MODER2_0 | GPIO_MODER_MODER3_0;
// Подключили поток к планировщику
Task::Add (new Blinker ("Blink_PE2"));
}
```
Шьём в в пла… Ой, а в проекте по умолчанию используется симулятор.

Хорошо, переключаемся на JTAG адаптер (в случае платы STM32F429-DISCO — на ST-Link).
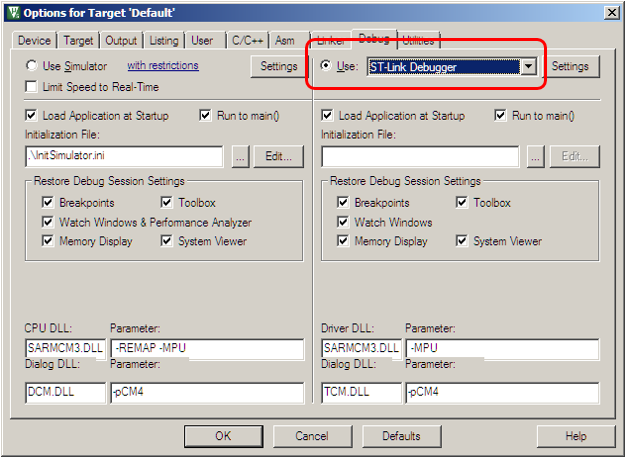
Теперь всё можно залить в плату. Заливаем, подключаем осциллограф к линии PE2, наблюдаем…
Красота! Только быстродействие какое-то низковатое.
Заменяем оптимизацию с уровня 0 на уровень 3
И… Всё перестаёт работать вообще
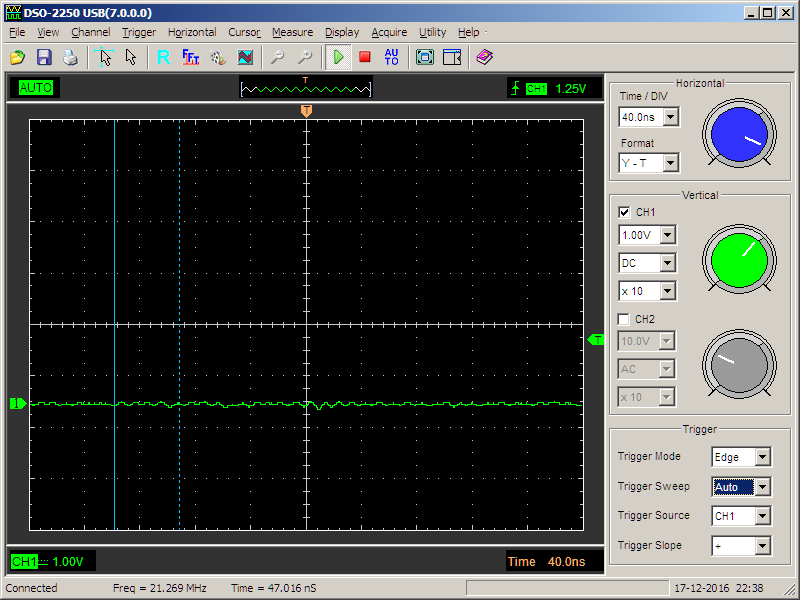
Пытаемя трассировать — по шагам прекрасно работает. Что за чудо? Ну, это не проблемы ОС, это проблемы микроконтроллера, ему не нравятся рядом стоящие команды записи в порт. Разгадка этого эффекта – в настройках тока выходных транзисторов. Выше ток – больше звон, но выше быстродействие. По умолчанию, все выходы настроены на минимальном быстродействии. А у нас оптимизатор всё хорошо умял:
`0x08004092 6182 STR r2,[r0,#0x18]
0x08004094 6181 STR r1,[r0,#0x18]
0x08004096 E7FC B 0x08004092`
Можно, конечно, поднять быстродействие выхода на этапе настройки порта
```
// Максимальный ток выходных транзисторов
GPIOE->OSPEEDR |= (3<<(2*2))|(3<<(3*2));
```
Но у сигнала будет явно неправильная скважность (Вверх, затем – вниз, затем – задержка на переход). Для улучшения сигнала поправим код основного цикла следующим образом:

**то же самое текстом**
```
virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<<2);
asm {nop}
GPIOE->BSRR = (1<<(2+16));
}
}
};
```
Здесь получается вверх, затем – задержка на NOP, затем – вниз, затем – задержка на переход, что обеспечивает скважность, близкую к 50% (в комментариях ниже было точно вычислено, что реально 3 такта в единице и 5 тактов в нуле, но это ближе к 50%, чем 1 к 5, да и на имеющемся осциллографе разницу в верхней и нижней частях импульсов всё равно практически невозможно заметить). И быстродействия выхода уже хватает даже в малошумящем режиме. Частота выходного сигнала стала 168/(3+5) = 21 МГц.
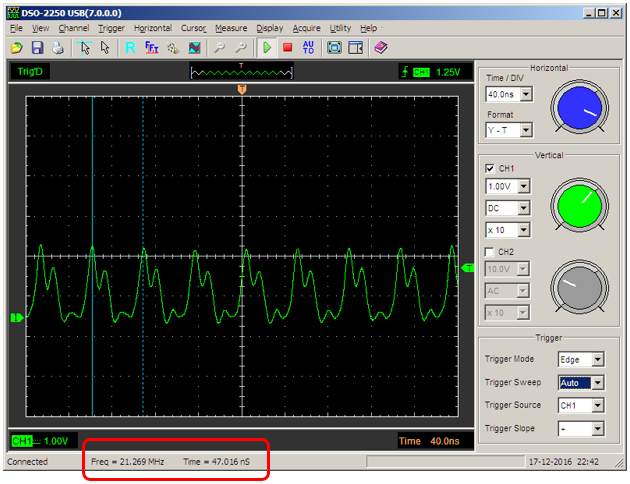
Правда, на другом масштабе нет-нет, да и проскочат вот такие чёрные провалы
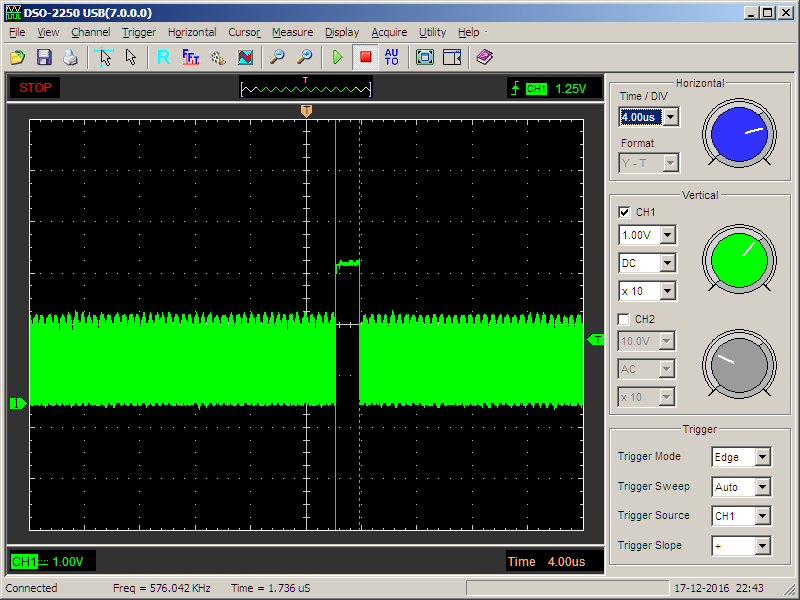
Это мы наблюдаем работу планировщика. Задача у нас одна, но периодически у неё отбирают управление, чтобы проверить, нельзя ли передать его кому-то другому. При наличии отсутствия других задач, управление возвращается той единственной, которая есть. Что ж, добавляем вторую задачу, которая будет дёргать PE3. Поместим номер бита в переменную-член класса, а настраивать его будем через конструктор

**Текстом**
```
class Blinker : public Task
{
int m_nBit;
public:
Blinker (int nBit,const char * name = nullptr) : Task (name),m_nBit(nBit){}
virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<BSRR = (1<<(m\_nBit+16));
}
}
};
```
А добавление задач в планировщик — вот так:
**Текстом**
```
void DefaultApp::Initialize()
{
/* Начните код приложения здесь */
// Включили тактирование порта E
RCC->AHB1ENR |= RCC_AHB1ENR_GPIOEEN;
// Линии PE2 и PE3 сделали выходами
GPIOE->MODER = GPIO_MODER_MODER2_0 | GPIO_MODER_MODER3_0;
// Подключили поток к планировщику
Task::Add (new Blinker (2,"Blink_PE2"));
Task::Add (new Blinker (3,"Blink_PE3"));
}
```
Подключаем второй канал осциллографа к выводу PE3. Теперь иногда идут импульсы на одном канале
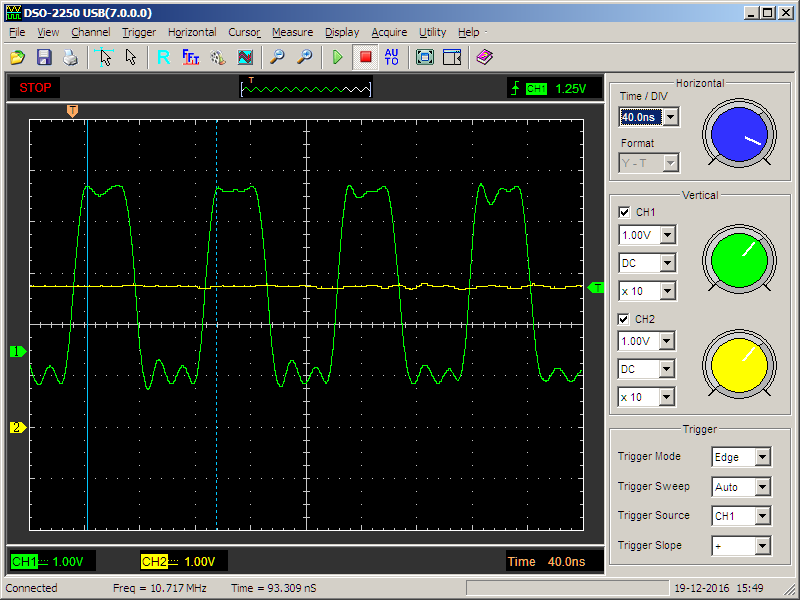
Ой какая частота низкая… Нет, фальстарт. Перепишем задачу на шаблонах…

**Текстом**
```
template
class Blinker : public Task
{
public:
Blinker (const char \* name = nullptr) : Task (name){}
virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<BSRR = (1<<(nBit+16));
}
}
};
```
И её постановку на планирование — вот так:

**Текстом**
```
Task::Add (new Blinker<2> ("Blink_PE2"));
Task::Add (new Blinker<3> ("Blink_PE3"));
```
Итак. Теперь иногда импульсы (с правильной частотой) идут на одном канале:
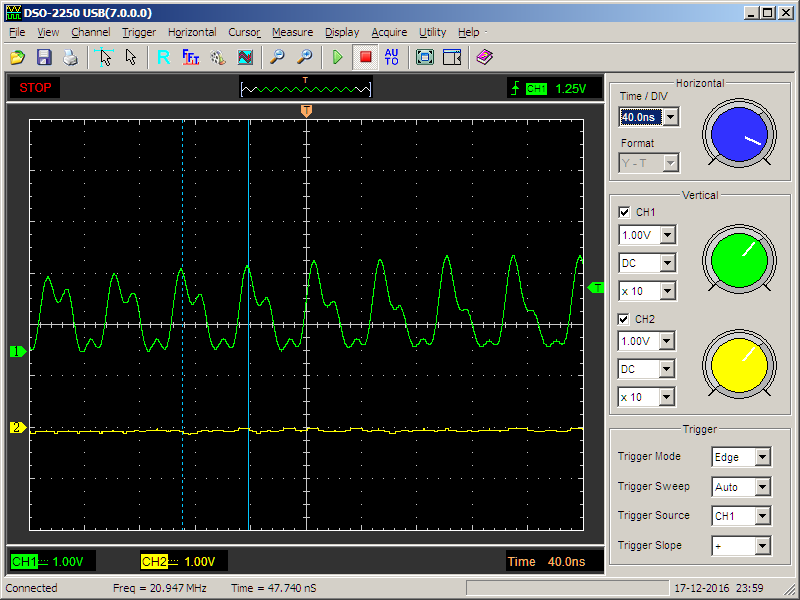
А иногда — на другом
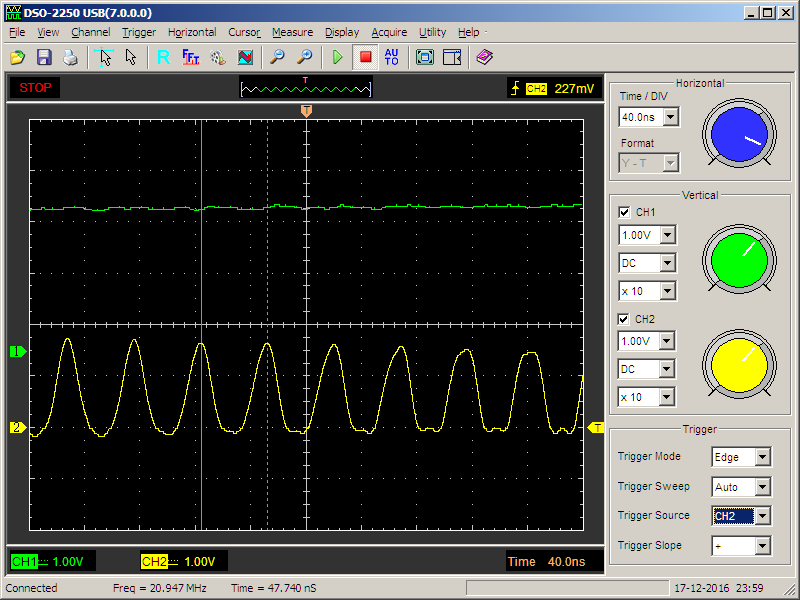
Можно выбрать масштаб, на котором видны кванты времени. Заодно произведём замер и убедимся, что один квант действительно равен одной миллисекунде (с точностью до масштаба экрана осциллографа)
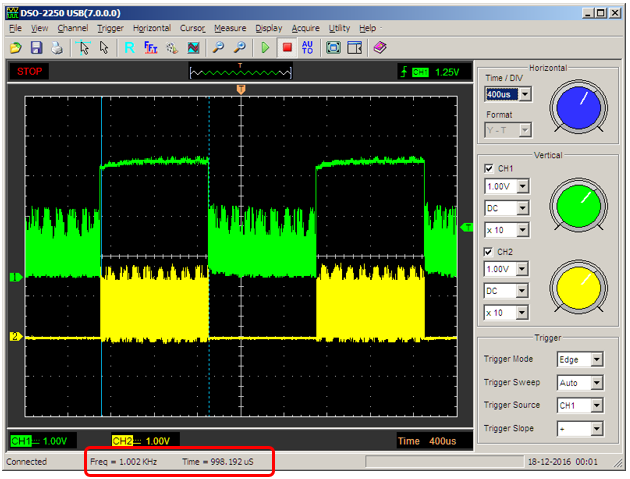
Можно убедиться, что планировщику всё так же нужно время для переключения задач (причём больше, чем в те времена, когда задача была одна)
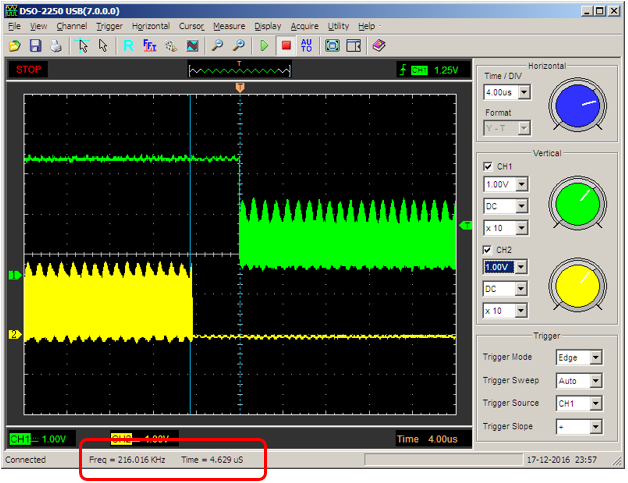
Теперь давайте рассмотрим работу потоков с разными приоритетами. Добавим забавную задачу, которая «то потухнет, то погаснет»
```
public:
Funny (const char * name = nullptr) : Task (name){}
virtual void Execute()
{
while (true)
{
Delay (5);
CpuDelay (5);
}
}
};
```
И добавим её в планировщик с более высоким приоритетом

**Текстом**
```
Task::Add (new Blinker<2> ("Blink_PE2"));
Task::Add (new Blinker<3> ("Blink_PE3"));
Task::Add (new Funny ("FunnyTask"),Task::PriorityHigh);
```
Эта задача половину времени выполняет задержку без переключения контекста. Так как её приоритет выше остальных, то управление не будет передано никому другому. Половину времени задача спит. То есть, находится в заблокированном состоянии. То есть, в это время будут работать потоки с нормальным приоритетом. Проверим?
Собственно, что и требовалось доказать. Пауза равна пяти миллисекундам (выделено курсорами), а во время работы нормальных задач, контекст успевает 5 раз переключиться между ними. Вот другой масштаб, чтобы было видно, что это не случайность, а статистика
Убираем работу этой ужасной задачи. Продолжать будем с двумя основными
Task::Add (new Blinker<2> («Blink\_PE2»));
Task::Add (new Blinker<3> («Blink\_PE3»));
Наконец, переведём дёрганье порта из режима «Совсем дёрганный» в более реальный. До светодиодного доводить не будем. Скажем, сделаем период величиной в 10 миллисекунд

**Текстом**
```
class Blinker : public Task
{
public:
Blinker (const char * name = nullptr) : Task (name){}
virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<BSRR = (1<<(nBit+16));
Delay (5);
}
}
};
```
Тепрерь подключаем амперметр. Для платы STM32F429-DISCO надо снять перемычку JP3 и включить прибор вместо неё, о чём сказано в документации:

Измеряем ток, потребляемый данным вариантом программы

Идём в файл MaksConfig.h и добавляем туда строку:
#define MAKS\_SLEEP\_ON\_IDLE 1

Собираем проект, «прошиваем» результат в плату, смотрим на амперметр:

Таааак, ещё одну теоретическую вещь проверили на практике. Тоже работает. А вот если бы мы мигали светодиодом, то он бы то потреблял, то не потреблял 10 мА, что на фоне измеренных значений — вполне существенно.
Ну, и напоследок заменим многозадачность на кооперативную. Для этого добавим конструктор к классу приложения

**Текстом**
```
class DefaultApp : public Application
{
public:
DefaultApp() : Application (false){}
private:
virtual void Initialize();
};
```
И сделаем так, чтобы задачи после трёх импульсов в порт передавали друг другу управление. Также добавим задержки, чтобы на осциллографе задержка планировщика не уводила бы изображение другой задачи за экран.
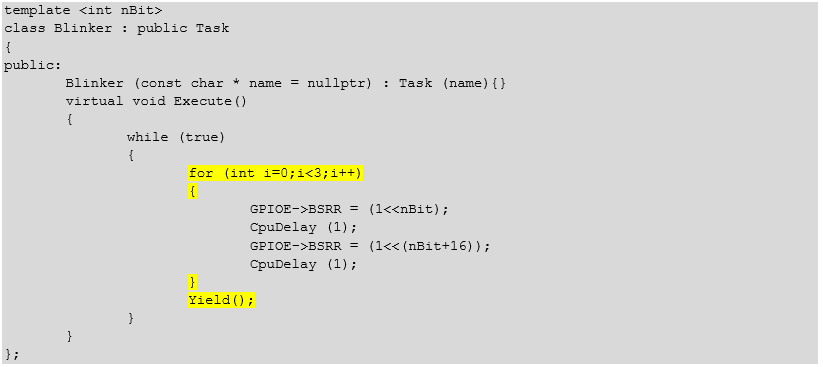
**Текстом**
```
template
class Blinker : public Task
{
public:
Blinker (const char \* name = nullptr) : Task (name){}
virtual void Execute()
{
while (true)
{
for (int i=0;i<3;i++)
{
GPIOE->BSRR = (1<BSRR = (1<<(nBit+16));
CpuDelay (1);
}
Yield();
}
}
};
```
Что там на осциллографе?
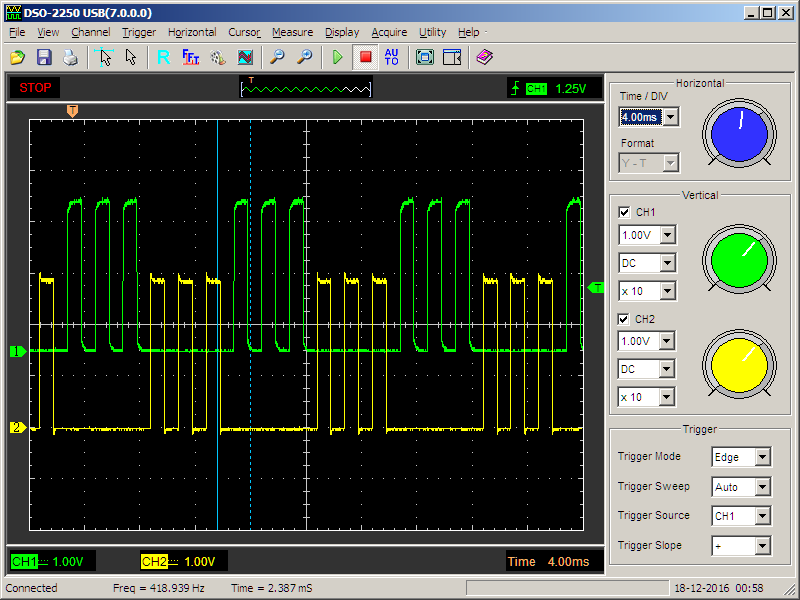
Собственно, мы хотели тройки импульсов — мы их получили.
Ну, и наконец, добавим виртуальную функцию

**Текстом**
```
class DefaultApp : public Application
{
public:
DefaultApp() : Application (true){}
virtual ALARM_ACTION OnAlarm(ALARM_REASON reason)
{
while (true)
{
volatile ALARM_REASON r = reason;
}
}
private:
virtual void Initialize();
};
```
и попробуем вызвать какую-либо проблему. Например, создадим критическую секцию в задаче с обычным уровнем привилегий.
```
Blinker (const char * name = nullptr) : Task (name){}
virtual void Execute()
{
CriticalSection cs;
while (true)
{
GPIOE->BSRR = (1<BSRR = (1<<(nBit+16));
Delay (5);
}
```
Запускаем проект на отладку, ставим точку останова на следующую строку
после чего запускаем на исполнение (F5). Моментально получаем останов (если не сработало — щёлкаем по пиктограмме «Stop»).
В строке, на которой произошёл останов, наводим курсор на переменную reason. Получаем следующий результат:
Ну что же, проверку первых основных теоретических выкладок мы завершили, можно переходить к следующему [большому сложному разделу](https://habrahabr.ru/post/338682/). | https://habr.com/ru/post/337974/ | null | ru | null |
# Отлаживаем Android-приложение с помощью браузера
Бывали ли у вас ситуации, когда ваше приложение работало некорректно у отдельно взятого тестировщика или на отдельно взятом устройстве? Кажется, что с такой ситуацией так или иначе знаком каждый разработчик. И найти причину проблемы порой может быть достаточно сложно из-за сложности получения информации: нет возможности снять логи, заглянуть в БД или Shared Preferences приложения и т.д. Некоторые из этих проблем можно решить просто попросив тестировщика зайти в браузер.
Именно для этого и была начата разработка [библиотеки Ultra Debugger](https://github.com/bartwell/ultra-debugger). На данный момент она позволяет:
* Отлеживать состояния приложения с помощью метода saveValue(Context context, String key, Object value). Можно посмотреть, работает ли прямо сейчас сервис, последнее высчитанное значение и т.д.
* Писать логи с помощью метода addLog(Context context, String text[, Throwable throwable]).
* Просматривать и редактировать Shared Preferences.
* Просматривать и редактировать записи в SQLite.
* Просматривать файлы, в том числе файлы в папке приложения.
* Просматривать значения полей в текущем активити.
* Вызывать методы в текущем активити.
Сама библиотека построена на модулях. За счет этого, при желании можно отключить ненужный функционал, а также расширять его путем добавления новых модулей.
**Разработчику**
Интеграция библиотеки очень проста:
1. Прописываем зависимости:
```
debugCompile 'ru.bartwell:ultradebugger:1.3'
compile 'ru.bartwell:ultradebugger.wrapper:1.3'
```
Как мы видим, основная зависимость подключается только для debug-сборок. При необходимости, можно подключать ее только для определенных flavor.
Отдельно подключаем wrapper. Это необязательно, мы можем вызывать методы библиотеки напрямую, но тогда могут возникнуть сложности при отключении библиотеки для релизных сборок. Он представляет собой обертку, которая вызывает методы библиотеки используя рефлексию. Да, рефлексия непроизводительна, но для debug-сборок это кажется не таким критичным.
2. В классе Application инициализируем библиотеку:
```
@Override
public void onCreate() {
super.onCreate();
// Wrapper будет работать только в debug-сборках
UltraDebuggerWrapper.setEnabled(BuildConfig.DEBUG);
// Необязательный второй параметр указывает порт для веб-интерфейса
UltraDebuggerWrapper.start(this, 8090);
}
```
*BuildConfig.DEBUG* может быть заменен например на *BuildConfig.FLAVOR.equals(«dev»)*.
3. При необходимости добавьте логи и сохраните нужные значения:
UltraDebuggerWrapper.saveValue(context, «SomeValue», 12345);
UltraDebuggerWrapper.addLog(context, «Some event»);
При запуске приложения в логи будет выведена строка содержащая ссылку на веб-интерфейс. Ссылка формируется из IP-адреса смартфона и номера порта указанного при вызове метода start(). При желании IP-адрес смартфона и номер порта можно получить с помощью методов UltraDebuggerWrapper.getIp() и UltraDebuggerWrapper.getPort() и вывести их в виде Toast или диалогового окна.
**Тестировщику**
Использовать библиотеку тестировщику тоже довольно просто. Нужно просто подключить смартфон и компьютер к одной WiFi-сети, набрать IP-адрес смартфона и порт в браузере (например, 192.168.0.33:8090). Может потребоваться разблокировать смартфон и запустить приложение. После этого откроется меню подключенных модулей и с помощью перехода по ссылкам можно будет получить необходимую информацию. Вот так выглядит например просмотр файлов:
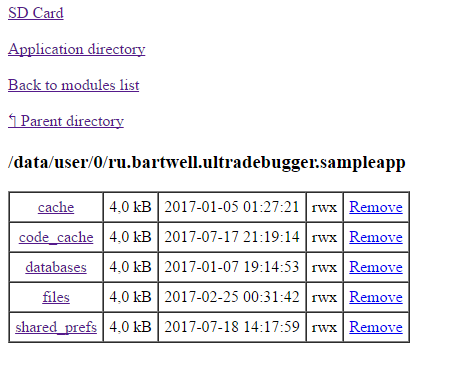
Да, WEB-интерфейс выглядит по-спартански :) Но нужную информацию при этом получить вполне позволяет.
**Заключение**
Определенно здесь есть плацдарм для доработок. Можно наращивать количество модулей, можно улучшить UI и UX веб-интерфейса, добавить тесты и поработать над качеством кода. Конечно, это все — прямая обязанность автора библиотеки. Но если вдруг Ultra Debugger покажется вам полезным и у вас возникнет желание добавить модуль или что-то доработать — смело создавайте Pull Request, приветствуется любая помощь по проекту. | https://habr.com/ru/post/333588/ | null | ru | null |
# QFont и размер шрифта не зависящий от устройства
Писал казуальную игру для Android, столкнулся со следующей проблемой. Надписи, на телефонах с экраном 5" и меньше, выглядят больше задуманного, а на планшетах, выглядят меньше задуманного.
Есть 2 типа надписей QLable и те, которые отрисовываются при помощи QPainter методом drawText.
Базовый размер игрового экрана 960х600, и в зависимости от запускаемого устройства он растягивается или сжимается.
Обратился к документации по классу QFont.
По методу [setPixelSize](http://doc.qt.io/qt-5/qfont.html#setPixelSize) написано следующее (сразу перевод):
```
Использование этой функции делает шрифт зависимым от устройства. Используйте setPointSize() или setPointSizeF(), что бы установить размер шрифта не зависимым от устройства.
```
В действительности, по крайней мере для Android устройств, это не правда.
А правда заключается в точности на оборот: setPointSize — зависит от устройства, setPixelSize — не зависит от устройства.
Может я не правильно понимаю смысл выражения — зависит/не зависит от устройства, но использоваине setPixelSize решило мою проблему.
Пишите, как справлялись с подобной проблемой на других ОС. | https://habr.com/ru/post/282499/ | null | ru | null |
# Что такое Prey и как он охотится за вашим компьютером

Доброго времени суток читатель.
В последнее время участились на хабре сообщения о том, как люди находят свой украденный компьютер с помощью неких волшебных сервисов, преподносящих всю информацию о злоумышленнике на блюдечке с золотой каемочкой.
Речь идет в первую очередь о событиях описанных [здесь](http://habrahabr.ru/blogs/infosecurity/120355/) и [здесь](http://habrahabr.ru/blogs/infosecurity/126581/), но для любителей все делать своими руками ~~(гентушников?)~~ есть еще информация [здесь](http://habrahabr.ru/blogs/infosecurity/110754/).
Мне почему-то казалось, что есть здесь обзоры таких программ, но поиск ничего не выдал, и я решил поведать общественности о замечательном сервисе [Prey](http://preyproject.com/). **Для тех кто о нем знает, пользуется им, либо каким-то другим предлагаю прочитать заключение статьи. Там есть несколько информации про верблюдов для всех пользователей подобных продуктов.**
Для тех кому интересны подробности — прошу под кат.
Коротко и четко о сервисе говорится на их сайте:
> Prey позволяет Вам следить за своим телефоном или ноутбуком все время и поможет найти, если они пропадут или их украдут. Это легкая open source разработка, кроме того абсолютно бесплатная. Она просто работает.
>
>
#### Что это такое
Prey — это программа, которая будучи запущенная на компьютере/телефоне сидит тихо и помалкивает, а в случае пропажи — по сигналу хозяина начинает втихую следить за действиями текущего пользователя (не будет уподобляться некоторым личностям и говорить «вор» — возможно это будет человек, который ищет как с вам связаться). Но обо всем по-порядку.
Немного общих слов:
* Prey — open source проект, расположенный на [Github](http://github.com/tomas/prey)
* Написано все в основном на Bash. Присутствуют Perl и Python
* Проекту 2.5 года (первый коммит состоялся 18 февраля 2009)
* Клиент кросплатформенный. На официальном сайте доступны для скачивания версии для Windows, Linux (отдельно пакет для Ubuntu), Mac OS, ссылка на Android Market
* Текущая версия 0.5.3
Далее, я буду делать обзор на основе версии для Mac, однако, для Windows и Linux все отличается только на уровне внешнего вида установщика.
#### Установка
При запуске установки будет предложено выбрать два варианта настройки — для работы через личный кабинет, либо слать отчеты напрямую в почту.
Про второй вариант стоит рассказать подробнее. Здесь необходимо указать URL который программа будет проверять на наличие с указанным интервалом, как только страницы не стало — запускает мониторинг. Ну и естественно указать реквизиты SMTP для отправки почты.
После выбора типа установки, ввода данных аккаунта или регистрации на preyproject.org (в версии Prey + Control Panel) и пароля администратора (для возможности запуска от root) происходит установка. Далее в Mac OS (и Linux наверняка) он поселяется в cron:
`*/20 * * * * /usr/share/prey/prey.sh > /var/log/prey.log`
На этом установка завершена. У Prey есть одно маленькое побочное явление, вызванное поселением в cron — его нет в списке установленных программ, но это скорее плюс. Удаление происходит не через корзину, а с помощью идущего в комплекте с установщиком деинсталлятора.
#### Панель управления
Я не использовал Standalone режим, поэтому тех кто с ним работает, пожалуйста, отпишитесь в комментариях как там все происходит.
Итак, войдя в панель управления, нам показывают общую информацию о привязанных девайсах, кнопку добавления нового (хотя при переходе по ней предлагают подключать устройство при установке) и ненавязчивая реклама pro-аккаунта. В общем ничего лишнего — все в меру, интуитивно понятно, а главное — только главное.
Далее при клике на имя открывается панель управления копией Prey на данном устройстве. Тут четыре вкладки, за которыми скрываются настройки и информация об устройстве. Слева тихо висит немного общей информациио, список отчетов и кнопка отвязки устройства.
К сожалению, у меня нет pro-аккаунта, и поэтому некоторые функции мне недоступны, но почитать о них можно. В конце статьи я дам краткий список того, что можно делать, если заплатить денюшку. Функции доступные в платной подписке я буду отмечать звездочкой.
##### Основные настройки
Основных настроек довольно немного, все скомпоновано по группам.
В самом верху расположены настройки текущего статуса, где можно «заявить» о пропаже, изменить интервал обновления, запросить отчет немедленно (\*).
Далее настройки делятся на две колонки: информация для сбора, и действия для выполнения.
Информация для сбора:
* Информацию о текущем местоположении. GeoIP или встроенный GPS
* Информация о сети: активные соединения, информация о Wi-Fi точке, трассировка
* Информация о текущей сессии: скриншот, запущенные процессы, информация о модифицированных файлах: период, папка для мониторинга
* Сномок с камеры
Действия для выполнения:
* Издавать звуки каждые 30 секунд
* Вывести текстовое сообщение (в котором можно указать координаты или ультиматум), проговорить это сообщение
* Заблокировать устройство до ввода указанного пароля
* Можно удалить или переместить (опционально) пароли, куки, профили Firefox, Safari, Chrome, Thunderbird
##### Конфигурация
Здесь располагается конфигурация для контрольной панели и самого скрипта.
Кроме того присутствуют настройки самого скрипта:
* \* Отчеты передаются по SSL
* \* Шифровать инструкции. Видимо для защиты при передаче от сервера
* \* Периодически сканировать железо компьютера.
* \* Автоматическое обновление
* Возможность работать по последней полученной конфигурации в автономном режиме
Отмечу, что Prey не заметил обновления до OS X Lion — пришлось ручками менять.
##### Железо
Тут не о чем много говорить, все предельно просто и понятно.

Вот мы и добрались до самого интересного места, ради которого все и затевалось!
##### Отчет
В отчете есть много разнообразной информации (хотя все зависит от того, что было выбрано в настройках), поэтому и разберем по частям все, что я получил.
При просмотре отчета информация слева заменяется информацией об IP (private, public, gateway) и MAC адресах.
В самом начале отчета, в части гордо именуемой **Location**, есть карта с нанесенным предполагаемым местонахождением устройства. Предполагаемым потому, что в данном случае он промахнулся на полкилометра.

Ниже приводятся в **Picture** и **Screenshot** фотография со встреной камеры (если таковая имеется) и скриншот. Не покажу здесь по двум причинам — я не получился на фото, а на экране личная информация.
Далее идут блоки информации уже для тех кто более-менее понимает что в них написано. По ним пробегусь быстро и приведу куски информации, потому как большинству хабражителей и так ясно, как оно выглядит.
Под заголовком **Uptime** ожидаемо находится данные об аптайме системы:
`11:20 up 4 days, 11:52, 2 users, load averages: 0.21 0.42 0.39`
Под заголовком **Running Programs** находится список всех запущенных программ:
`USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND
...
grigory 1212 0.0 0.9 2520340 19316 ?? S Sun02PM 0:04.65 .../MacOS/Terminal -psn_0_491640
...`
В части **Logged User** содержится список всех залогиненых пользователей:
`grigory`
Далее в **Logged User** содержится вывод комманды **netstat**:
`Active Internet connections (including servers)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
...
tcp4 0 0 grigorylaptop.im.56649 checkip-pao.dynd.http LAST_ACK
tcp4 0 0 grigorylaptop.im.56392 186-011.skype.qu.34051 ESTABLISHED
...`
Также присутствует информация о сети Wi-Fi (если к ней подключен, конечно):
`agrCtlRSSI: -57
agrExtRSSI: 0
agrCtlNoise: -91
agrExtNoise: 0
state: running
op mode: station
lastTxRate: 18
maxRate: 54
lastAssocStatus: 0
802.11 auth: open
link auth: wpa2-psk
BSSID: 00:**:**:**:**:**
SSID: ******
MCS: -1
channel: 11`
Блок **Complete Trace** содержит трассировку до google.com:
`traceroute: Warning: www.google.com has multiple addresses; using 74.125.232.18
traceroute to www.l.google.com (74.125.232.18), 64 hops max, 52 byte packets
1 .....
.....
6 *
7 msk-ix-gw1.google.com (193.232.244.232) 36.192 ms
8 *
9 74.125.232.18 (74.125.232.18) 33.950 ms`
На этом отчет заканчивается, хотя мне кажется, что этой информации тоже достаточно.
#### Плюсы
Относительно плюсов я думаю все понятно из вышесказанного, однако здесь есть один момент, который хотелось бы рассмотреть отдельно.
В обсуждениях новости об [эксперте по сетевой безопасности](http://habrahabr.ru/blogs/infosecurity/126581/#comment_4171411) высказывалось, что когда-нибудь создатели Prey начнут следить за самим пользователем без его ведома. На мой взгляд при открытых исходных кодах в купе со Standalone режимом такая ситуация становится маловероятной, но если уж паранойя совсем подступила — поправь исходники, убрав оттуда код общения с их сервером и будет счастье.
#### Минусы
Плюсы использования Prey описаны, а вот минусов кстати нет, то есть они конечно имеются, но мной были незамечены. Присутствуют один неприятный момент в бесплатной версии: Control Panel работатет по HTTP, но скорее всего я их со своим вниманием просто проглядел.
#### Pro-аккаунт
При наличии платной подписки становятся доступны все нижеперечисленные возможности:
* Отчет по запросу
* Отчеты передаются по SSL (на сайте написано «Full SSL encryption», видимо и Control Panel будет через HTTPS)
* Шифровать инструкции. Видимо для защиты при передаче от сервера
* Периодически сканировать железо компьютера.
* Автоматическое обновление
* Монитор активности устройства
* Интервал сбора отчетов можно уменьшить до двух минут
* Автоматическая установка на несколько устройств
#### А ты верблюд?
Какой верблюд? — спросите вы. Следить за своим компьютером это конечно хорошо, придти с заявлением на грабителя и парой-тройкой отчетов, конечно можно. Но все это там, за рубежем, а на нашей любимой Родине все могут понять с точностью до наоборот. Поэтому я предложил [glazkova](https://habrahabr.ru/users/glazkova/) обрисовать картину суровой действительности, рассмотренной через призму российского законодательства. На момент написания Мария сказала, что статья находится в работе. Так что спокойно ждем и НЕ ХОЛИВАРИМ по этому поводу.
#### О себе вместо заключения
Использовать данный сервис я начал около двух месяцев назад — установил сразу после покупки ноутбука, заодно закинул на HTC Desire. Сразу скажу, что вспомнил я про них когда читал о том [лондонском специалисте](http://habrahabr.ru/blogs/infosecurity/126581/). Про компьютеры все понятно — там он сидит в cron и спокойно делает свою работу, а вот про Android я не знаю как все устроено (нет времени ковырять исходники), но могу сказать главное — проблем с батареей и производительностью он не создает.
Из-за специфики работы сервиса трудно что-то говорить о комфорте использования. На мой непрофессиональный взгляд, работа сервиса не вызывает никаких нареканий кроме одного: панель управления иногда притормаживает — видимо пользователей у них уже достаточно много, и сервера начинают не справляться с нагрузкой. В остальном все замечательно.
**UPD 1.** Т.к. проскакивают комментарии в стиле «Дак они же отфарматируют диск и все.», «Пароль рута получается в три клика», я хочу сказать, что в начале поста неслучайно приведены ссылки на статьи из которых понятно, что такие люди были, есть, и, самое главное, будут. Поэтому смысл иметь такую программу в своем арсенале стоит.
**UPD 2.** Готова статья [glazkova](https://habrahabr.ru/users/glazkova/) о [правовых аспектах действий хозяев ноутбуков в случае их кражи](http://habrahabr.ru/company/pravo/blog/127241/). | https://habr.com/ru/post/126841/ | null | ru | null |
# Большой гайд по UTM-меткам: как узнать, откуда приходят пользователи

Способы разметки ссылок придуманы давно. Но как обычно, разные стандарты смешались и выбрать правильный формат не так просто. Оставим в стороне случаи, когда владелец площадки возражает против размеченных ссылок (а это не такой уж редкий случай). Разберемся в деталях — какие и когда UTM-метки ставить и что с ними делать дальше.
Системы аналитики (Яндекс.Метрика и Google Аналитика) без проблем определяют, откуда приходит трафик: из поиска, соцсетей, почтовой рассылки или по прямой ссылке. Но есть нюансы. Например, если трафик идет с внешнего сайта, вы узнаете об этом, но без детализации: с какой именно страницы или по какой именно ссылке — может остаться загадкой.
Хорошая новость в том, что есть универсальная система трекинга трафика — UTM-метки. Если рекламная ссылка размечена с помощью UTM, вы без проблем отследите источники переходов вплоть до конкретной ссылки на странице, объявления или ключевого слова.
Мы объяснили, что такое UTM метки, как их составлять для разных типов рекламы, как генерировать, как и где отслеживать, какие есть проблемы и как их избежать. Внутри — много примеров. Будет полезно и новичкам, и маркетологам с опытом.
**Содержание статьи**[UTM-метки: что это и для чего они нужны](#id1)
[Что такое UTM](#id2)
[Как выглядят UTM-метки](#id3)
[Из чего состоят UTM-метки](#id4)
[Сколько UTM-меток существует](#id5)
[Синтаксис UTM-меток](#id6)
[Какие есть способы трекинга трафика помимо UTM](#id7)
[gclid](#id8)
[yclid](#id9)
[from](#id10)
[Статические и динамические параметры UTM-меток](#id11)
[Динамические параметры в Яндекс.Директе](#id12)
[Динамические параметры в Google Рекламе](#id13)
[Как использовать UTM-метки в разных кампаниях: примеры](#id14)
[UTM-метки для SEO](#id15)
[Таргетированная реклама](#id16)
[Гостевые публикации, упоминания и другие способы размещения естественных ссылок](#id17)
[Разметка ссылок в email-рассылках](#id18)
[Как отследить эффективность офлайн-рекламы с помощью UTM-меток](#id19)
[Составляйте UTM-метки без ошибок: используйте генераторы](#id20)
[Campaign URL Builder](#id21)
[Генератор UTM от Tilda](#id22)
[Шаблоны в Google Таблицах для генерации UTM-меток](#id23)
[Нужно ли сокращать ссылки с UTM-метками?](#id24)
[Статистика по UTM-меткам: где смотреть](#id25)
[В Яндекс.Метрике](#id26)
[В Google Аналитике](#id27)
[Что может пойти не так при работе с UTM-метками: проблемы и их решение](#id28)
[Неправильный синтаксис](#id29)
[Используются только статические параметры](#id30)
[Дубли страниц в индексе: поисковики индексируют URL с разметкой](#id31)
[Полезные советы](#id32)
[Автоматизируйте работу с UTM-метками (и не только)](#id33)
UTM-метки: что это и для чего они нужны
---------------------------------------
UTM-метки — параметры, которые добавляются в URL-адреса для получения подробной информации о трафике.
**Пример**. Вы хотите разместить две рекламные ссылки на свой магазин на одном и том же сайте о новинках моды. Первая ссылка — сквозная в сайдбаре, вторая — нативная в статье о моде. В обоих случаях ссылка ведет на каталог: `https://clothingshop.ru/catalog`.
В чем недостаток простого размещения ссылок?
В системе аналитики вы увидите суммарное количество посещений, но не будете знать, по какой именно ссылке перешли посетители. Соответственно, не сможете понять, какой подход к рекламе на этом ресурсе более выгодный.
А если бы вы добавили UTM-метки в URL, то точно бы отследили трафик по каждой ссылке и оценили эффективность размещения.
Далее мы подробно расскажем, как это делать.
### Что такое UTM
UTM — это аббревиатура от Urchin Tracking Module. «Urchin» — название компании, которая создала и начала использовать эти метки. Кстати, компанию Urchin приобрел Google в 2005 году и создал на ее базе свою систему аналитики — Google Analytics.
UTM-метки оказались удобным и универсальным инструментом. Поэтому метки начали использовать в Яндекс.Метрике и других системах аналитики.
### Как выглядят UTM-метки
Обычный URL-адрес выглядит так:
```
https://bestbuyshop.ru/catalog
```
Такая ссылка понятна и привычна для всех. Но давайте добавим в нее UTM-метки, и посмотрим, как она будет выглядеть теперь:
```
https://bestbuyshop.ru/catalog?utm_source=facebook&utm_medium=cpc&utm_campaign={campaign_id}&utm_term={keyword}
```
URL стал громоздким и менее понятным, чем был изначально. Чтобы было проще воспринимать его, разобьем его на две части:
* первая часть — непосредственно адрес страницы, на которую нужно перейти;
* вторая часть (от знака ?) — те самые UTM-метки.
Наверняка со ссылками такого вида вы не раз сталкивались при клике по рекламным объявлениям:

Если вы еще не знакомы с UTM-метками, такой код может выглядеть шокирующе. Но все не так сложно, как кажется.
Из чего состоят UTM-метки
-------------------------
UTM-метки — это GET-параметры (передаются серверу с помощью ссылки).
GET-параметр очень просто определить: если вы видите в URL вопросительный знак, то все, что расположено после этого знака — GET-параметры.
В одном URL может быть несколько GET-параметров. Вот базовые правила синтаксиса:
* каждый GET-параметр состоит из двух элементов — ключа и значения. Между этими элементами — знак равенства (ключ=значение);
* GET-параметры разделяются знаком «&» (амперсанд).
Давайте еще раз посмотрим на пример ссылки с UTM-метками, которую мы приводили выше:
```
https://bestbuyshop.ru/catalog?utm_source=facebook&utm_medium=cpc&utm_campaign={campaign_id}&utm_term={keyword}
```
Все, что находится после знака «?» — это GET-параметры:
| Параметр | Значение |
| --- | --- |
| utm\_source | facebook |
| utm\_medium | cpc |
| utm\_campaign | {campaign\_id} |
| utm\_term | {keyword} |
### Сколько UTM-меток существует
Есть 5 универсальных UTM-меток, которые можно использовать для разметки любых ссылок. Эти метки распознают Google Аналитика и Яндекс.Метрика.
Три из пяти меток — обязательные, их нужно всегда размещать в URL:
* **utm\_source** — указывает на источник трафика. Например, сайт, на котором вы разместили гостевую статью со ссылкой на ваш ресурс. Или рекламная платформа (например, Facebook), в которой вы размещаете объявления со ссылкой для перехода на ваш сайт.
* **utm\_medium** — определяет тип трафика. Например, при размещении объявлений по модели оплаты за клик в этом параметре обычно прописывают значение «cpc» (cost per click — цена за клик). Для рекламного баннера — «banner», для ссылки в рассылке — «email».
* **utm\_campaign** — этот параметр нужен, чтобы указать к какой рекламной кампании относится ссылка. В некоторых случаях в этом параметре можно использовать динамические значения. Например, если вы размещаете таргетированную рекламу в Facebook, можно указать динамический параметр {campaign\_id}, и в ссылку автоматически подставится идентификатор вашей рекламной кампании.
Две метки можно использовать опционально:
* **utm\_term** — эта метка нужна для определения ключевого слова, по которому показывалось ваше рекламное объявление. Метка необязательная, но стоит использовать ее для разметки ссылок в поисковых кампаниях Яндекс.Директа или Google Ads. Для этого используйте динамический параметр {keyword}. Также параметр utm\_term подходит для указания другой информации (например, даты размещения рекламной ссылки).
* **utm\_content** — помогает различать объявления, если другие параметры идентичны. Например, если в одной статье вы используете две рекламные ссылки, то для отслеживания переходов по каждой из них используйте метку utm\_content с разными значениями для каждой ссылки.
Перечисленные метки используются наиболее часто. Их хватает для получения подробной статистики по трафику. Также есть дополнительные метки:
* **utm\_nooverride** — с помощью этой метки можно определить, где произошло первое касание с клиентом при отслеживании ассоциированных конверсий. Например, пользователь кликнул по объявлению таргетированной рекламы, перешел на сайт и подписался на рассылку. Затем перешел по ссылке из письма-подтверждения и зарегистрировался на сайте. В обычных условиях система аналитики засчитает в качестве источника email, хотя по сути пользователя привела таргетированная реклама. Чтобы правильно определить источник, в ссылке на сайте следует добавить метку utm\_nooverride со значением «1». Так система аналитики проигнорирует переход по этой ссылке, а учитывать будет предыдущий. *Обратите внимание! Метку utm\_nooverride понимает только Google Аналитика.*
* **utm\_referrer** — помогает корректно отслеживать и учитывать переходы при наличии Javascript-редиректа. Эта метка понятна только для Яндекс.Метрики.
> **Рекомендация**. Если вы запускаете рекламу для себя или работаете над проектом в одиночку, можете называть значения параметров UTM-меток как угодно. Главное, чтобы вы понимали, что обозначает каждое значение.
>
>
>
> Если же доступ к аналитике нужен вашим сотрудникам или коллегам — используйте понятные и стандартизированные названия, чтобы каждый человек четко понимал, что означает, к примеру, такое значение: `utm_campaign=derevyannie_stoly23_test_fb_wide`.
>
>
>
> Для удобства создайте документ в Google Таблицах (или Google Документах) и пропишите там правила разметки ссылок UTM-метками. Расшарьте доступ к файлу коллегам, и всем всё будет понятно.
>
>
Синтаксис UTM-меток
-------------------
Составим UTM-метки для рекламной кампании интернет-магазина мужской одежды и по ходу дела объясним, что и как делать.
Вот данные по кампании:
* целевая страница — `https://brandclothes.ru/winter_sale`;
* запускаем рекламу на поиске Google (рекламная система — Google Ads);
* название кампании — «Зимняя распродажа пальто»;
* для кампании создаем 2 объявления;
* ключевые слова: «зимние мужские пальто», «мужские пальто распродажа».
Пошагово составим UTM-разметку.
Первым делом нужно присвоить значение для каждой метки. Для этого пишем название самой метки, знак равенства («=»), а затем — значение параметра.
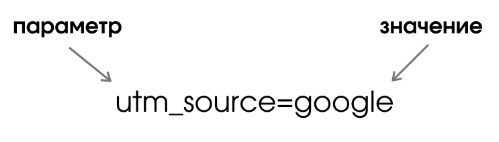
Здесь два важных момента:
1. Начинаем с обязательных меток.
2. Обязательные метки выстраиваем по принципе «от общего к частному» — сначала параметр самого высокого уровня (источник), затем вид рекламы, кампания, объявление и ключевое слово.
Присваиваем значения меткам:
* **utm\_source=google** — здесь мы можем указать любое другое значение, главное, чтобы потом было понятно, что трафик пришел именно из поиска Google. Например, можно указать значение google-search. Обратите внимание, если в значении параметра используете два и более слов, соединяйте их с помощью дефиса или подчеркивания. Если оставить пробел между словами, ссылка будет некорректной.
* **utm\_medium=search** — с помощью этого значения указываем, какой тип рекламы используется в кампании (поисковая).
* **utm\_campaign=muzhskie-palto** — название кампании, которое мы указали в Google Ads.
* **utm\_content=ad1** — с помощью этого параметра мы сможем отследить, какое из двух объявлений более эффективное. Предыдущие метки будут одинаковы для обоих объявлений, а в метке utm\_content мы указываем на конкретное объявление. Соответственно, для второго объявления будет значение utm\_content=ad2).
* **utm\_term=zimnie-muzhskie-palto** — указываем ключевое слово. Обратите внимание, для корректной работы UTM-меток лучше использовать латиницу. Для этого напишите русские слова транслитом (вручную или с помощью специальных сервисов).
У нас готовы все элементы, из которых будет состоять размеченная ссылка. Теперь составим ее по шагам.
1. Указываем URL целевой страницы (на которую будем вести трафик):
```
https://brandclothes.ru/winter_sale
```
2. В конце URL добавляем вопросительный знак:
```
https://brandclothes.ru/winter_sale?
```
3. Размещаем первую UTM-метку:
```
https://brandclothes.ru/winter_sale?utm_source=google
```
4. Помним, GET-параметры соединяются амперсандом. Ставим амперсанд:
```
https://brandclothes.ru/winter_sale?utm_source=google&
```
5. Далее — размещаем вторую метку:
```
https://brandclothes.ru/winter_sale?utm_source=google&utm_medium=search
```
6. Снова ставим амперсанд, затем третью метку и так далее. После последней метки амперсанд не нужен.
Для первого объявления у нас получилась такая ссылка:
```
https://brandclothes.ru/winter_sale?utm_source=google&utm_medium=search&utm_campaign=muzhskie-palto&utm_content=ad1&utm_term=zimnie-muzhskie-palto
```
Ссылка для второго объявления будет выглядеть практически идентичной. Отличаются только значения последних двух параметров — utm\_term и utm\_content:
```
https://brandclothes.ru/winter_sale?utm_source=google&utm_medium=search&utm_campaign=muzhskie-palto&utm_content=ad2&utm_term=muzhskie-palto-rasprodazha
```
**Обратите внимание!** Если вы запускаете рекламу только в Google и пользуетесь только Google Аналитикой, можете располагать метки в любом порядке. Google распознает их независимо от того, какая метка у вас идет в начале, а какая — в конце.
Для работы с Яндекс.Директом и Яндекс.Метрикой рекомендуется размещать метки последовательно: первой указывать utm\_source, затем — utm\_medium и так далее (как в нашем примере). Чтобы не запутаться, придерживайтесь этого правила при разметке ссылок UTM-метками для любой рекламной системы.
Какие есть способы трекинга трафика помимо UTM
----------------------------------------------
Для отслеживания переходов по ссылкам используют не только UTM-метки.
### gclid
Автоматическая разметка ссылок в объявлениях Google Рекламы. Так разметка выглядит в ссылке:

Нюансы gclid:
* Эта разметка используется только в Google Рекламе. Система автоматически генерирует идентификатор для отслеживания переходов по ссылке. Если вы размещаете рекламу также в Яндекс.Директе и других каналах, вам все равно нужно будет использовать другие метки (например, те же UTM).
* gclid-метки совместимы только с Google Аналитикой. Поэтому вы не сможете быстро и легко собрать в одном месте сводную статистику по эффективности рекламных кампаний в разных системах.
### yclid
Эта разметка аналогична gclid — только используется в Яндекс.Директе. Вот так выглядит ссылка с разметкой yclid:

Как и gclid, автоматическая разметка Яндекс.Директа имеет те же недостатки: метки совместимы с Яндекс.Директом и учитываются Яндекс.Метрикой. Другие системы аналитики (например, Google Аналитика) их не понимают.
Подобные метки есть и у других рекламных систем:
* у Facebook Рекламы — fbclid;
* у Яндекс.Маркета — ymclid;
* и т. д.
С ними все аналогично: их понимает только «родная» рекламная система.
### from
Это метка, с помощью которой можно определить источник перехода по рекламной ссылке. Распознается Яндекс.Метрикой.
Так выглядит URL с меткой from:
```
https://bestshop.ru/catalog/?from=ad-platform.
```
Метка from передает только один параметр (источник перехода), в то время как UTM-разметка позволяет получить пять параметров.
Статические и динамические параметры UTM-меток
----------------------------------------------
В UTM-разметке можно использовать статические или динамические параметры. Со статическими параметрами все просто: система аналитики зафиксирует те значения, которые вы укажете вручную.
Динамические параметры позволяют отслеживать расширенную статистику по кликам по рекламным объявлениям. Например, добавив к рекламной ссылке объявления Яндекс.Директа динамические параметры, вы сможете узнать:
* на какой позиции находилось объявление, когда по нему кликнули;
* по какому поисковому запросу было показано объявление;
* в каком регионе было показано объявление и т. д.
Динамические параметры в Яндекс.Директе
---------------------------------------
Ссылка, в которой указаны все доступные динамические параметры Яндекс.Директа, выглядит так:
```
http://www.site.ru/?type={source_type}&source={source}&added={addphrases}█={position_type}&pos={position}&key={keyword}&campaign={campaign_id}&name={campaign_name}&name_lat={campaign_name_lat}&retargeting={retargeting_id}&ad={ad_id}&phrase={phrase_id}&gbid={gbid}&device={device_type}®ion={region_id}®ion_name={region_name}
```
Полный список доступных параметров вы можете посмотреть [здесь](https://yandex.ru/support/direct/statistics/url-tags.html).

Мы же обратим внимание на несколько параметров:
* **{ad\_id}** — идентификатор объявления. Если этот параметр есть в ссылке, система аналитики получит данные, по какому именно объявлению кликнул пользователь. Если вы запускаете несколько вариантов объявлений для одной и той же целевой страницы (чтобы протестировать и найти наиболее эффективное объявление), используйте динамический параметр — это удобнее, чем прописывать идентификатор объявления для каждой ссылки вручную.
* **{campaign\_name}** — название кампании. Автоматически подставляет название рекламной кампании.
* **{position\_type}** — определяет тип блока, если объявление было показано на странице поисковой выдачи Яндекса. Здесь могут быть такие значения: premium — премиум-показы, other — блок справа или блок внизу, none — объявление показано в РСЯ или внешних сетях. Используйте вместе с этим параметром также параметр {position} — определяет точную позицию объявления в блоке.
### Динамические параметры в Google Рекламе
В рекламной системе Google есть свои динамические параметры — ValueTrack.
Так выглядит ссылка с динамическими параметрами Google:
```
http://mysite.ru/?utm_source=google&utm_medium=cpc&utm_campaign={network}&utm_content={creative}&utm_term={keyword}
```
Разберем параметры, которые здесь указаны:
* **{network}** — определяет рекламную сеть, из которой получен клик. По значению параметра система аналитики точно идентифицирует, откуда пришел клик: g — из поиска Google, s — из сайта поискового партнера, d — из контекстно-медийной сети (КМС).
* **{creative}** — уникальный идентификатор объявления.
* **{keyword}** — передает ключевое слово из аккаунта Google Рекламы, которое соответствует запросу пользователя (если объявление показывается на странице поисковой выдачи). Если объявление показывается в контекстно-медийной сети, параметр передает ключевое слово, которое соответствует содержанию сайта.
В [справке Google](https://support.google.com/google-ads/answer/6305348) вы найдете полный список параметров ValueTrack.
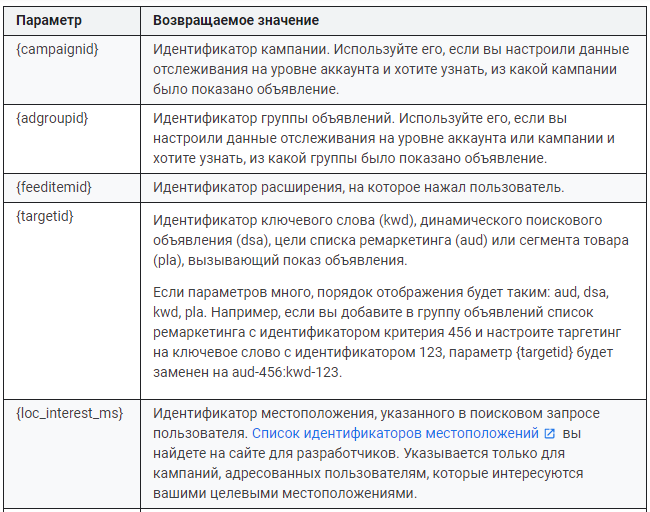
Как использовать UTM-метки в разных кампаниях: примеры
------------------------------------------------------
### UTM-метки для SEO
Они здесь вообще не нужны. Для анализа поискового трафика достаточно установить на сайт коды систем аналитики, а также подключить панели для вебмастеров Яндекса и Google. Этих действий хватит, чтобы отслеживать переходы из поиска и понимать, по каким запросам вы получаете клики.
### Контекстная реклама
Для кампаний контекстной рекламы важно отслеживать трафик и быть уверенным, что вы получаете точные и корректные данные. При этом необязательно использовать UTM-метки:
* Если вы запускаете кампании только в Google Рекламе, вам достаточно будет «родной» разметки gclid. Это даже лучше — разметка проставляется автоматически, вам ничего не нужно делать вручную.
* Если предпочитаете запускать кампании только в Яндекс.Директе, достаточно будет разметки yclid или Openstat.
UTM мы рекомендуем использовать в том случае, если вы одновременно используете несколько рекламных систем. UTM-метки универсальные и помогут отслеживать трафик в единой системе координат.
Структура UTM-меток для кампании выглядит так (пример):
**Для Яндекс.Директ**
| Параметр | Передаем данные | Значение параметра |
| --- | --- | --- |
| utm\_source | Рекламная система | yandex |
| utm\_medium | Канал трафика | {source\_type}\* |
| utm\_campaign | Идентификатор кампании | {campaign\_id}\* |
| utm\_content | Идентификатор объявления | {ad\_id}\* |
| utm\_term | Ключевое слово | {keyword}\* |
*\*здесь используем динамические параметры, чтобы не прописывать статические параметры для каждого объявления вручную.*
Пример URL с UTM-метками для Яндекс.Директа:
```
http://bestbuyshop.ru/catalog/?utm_source=yandex&utm_medium={source_type}&utm_campaign={campaign_id}&utm_content={ad_id}&utm_term={keyword}
```
**Для Google**
| Параметр | Передаем данные | Значение параметра |
| --- | --- | --- |
| utm\_source | Рекламная система | google |
| utm\_medium | Канал трафика | {network}\* |
| utm\_campaign | Идентификатор кампании | {campaignid}\* |
| utm\_content | Идентификатор объявления | {creative}\* |
| utm\_term | Ключевое слово | {keyword}\* |
*\*используем динамические параметры, которые «понимает» Google Аналитика.*
Пример URL с UTM-метками для Google Рекламы:
```
http://bestbuyshop.ru/catalog/?utm_source=google&utm_medium={network}&utm_campaign={campaignid}&utm_content={creative}&utm_term={keyword}
```
> Разметку рекламных ссылок UTM-метками можно автоматизировать. Равно как и подбор ключевиков, управление ставками и другие задачи, необходимые для запуска и ведения кампаний контекстной рекламы. Все это возможно в [модуле контекстной рекламы](https://promopult.ru/technology/ppc?utm_medium=paid_article&utm_source=habr&utm_campaign=blog&utm_term=2b16077d0129a574&utm_content=ppc) PromoPult. Система сделает за вас всю рутинную работу и сэкономит деньги и время.
>
>
### Таргетированная реклама
Если вы запускаете рекламу в соцсетях, вам также важно понимать, какие объявления лучше срабатывают, чтобы оптимизировать кампанию (отключить неэффективные и увеличивать бюджет для тех, которые приносят прибыль).
Рассмотрим несколько примеров UTM-разметки для объявлений в соцсетях.
**Для рекламных кампаний во ВКонтакте:**
| Параметр | Передаем данные | Значение |
| --- | --- | --- |
| utm\_source | Рекламная система | vkontakte |
| utm\_medium | Канал трафика | cpc |
| utm\_campaign | Идентификатор кампании | {campaign\_id}\* |
| utm\_content | Идентификатор объявления | {ad\_id}\* |
| utm\_term | Платформа, с которой шли переходы | {platform}\* |
*\*используем динамические параметры для автоматической подстановки нужных идентификаторов и значений.*
Готовый URL с разметкой для объявления ВКонтакте будет выглядеть так:
```
http://bestbuyshop.ru/catalog/?utm_source=vkontakte&utm_medium=cpc&utm_campaign={campaign_id}&utm_content={ad_id}&utm_term={platform}
```
**Для рекламных кампаний в myTarget:**
| Параметр | Передаем данные | Значение |
| --- | --- | --- |
| utm\_source | Рекламная система | mytarget |
| utm\_medium | Тип трафика | cpm |
| utm\_campaign | Идентификатор кампании | {{campaign\_id}}\* |
| utm\_content | Идентификатор объявления | {{ad\_id}}\* |
| utm\_term | ID региона, пол и возраст пользователя | {{geo}}.{{gender}}.{{age}}\* |
*\*используем динамические параметры.*
Так будет выглядеть полный URL с указанными UTM-метками для myTarget:
```
http://bestbuyshop.ru/catalog?utm_source=mytarget&utm_medium=cpm&utm_campaign={{campaign_id}}&utm_content={{ad_id}}&utm_term={{geo}}.{{gender}}.{{age}}
```
### Гостевые публикации, упоминания и другие способы размещения естественных ссылок
**UTM-разметка для ссылки в гостевой статье:**
| Параметр | Передаем данные | Значение |
| --- | --- | --- |
| utm\_source | Тип трафика | external\_paid |
| utm\_medium | Тип интеграции | guest\_publication |
| utm\_campaign | Название площадки | blog\_o\_mode |
| utm\_content | Название контента | article1 |
| utm\_term | Необязательный параметр. Можно использовать для дополнительной информации: например, указать размер площадки | medium |
Так будет выглядеть полный URL с метками:
```
http://bestbuyshop.ru/catalog/?utm_source=external_paid&utm_medium=guest_publication&utm_campaign=blog_o_mode&utm_content=article1&utm_term=medium
```
**UTM-разметка для ссылки в публикации в соцсетях:**
| Параметр | Передаем данные | Значение |
| --- | --- | --- |
| utm\_source | Тип трафика | external\_paid |
| utm\_medium | Тип интеграции | social\_post |
| utm\_campaign | Название площадки | public\_modashop |
| utm\_content | Название контента | post\_podborka |
| utm\_term | Необязательный параметр. Можно использовать для дополнительной информации: например, указать размер площадки | big |
Так будет выглядеть ссылка с разметкой:
```
http://bestbuyshop.ru/catalog?utm_source=external_paid&utm_medium=social_post&utm_campaign=public_modashop&utm_content=post_podborka&utm_term=big
```
**UTM-разметка для интеграции вашей рекламной ссылки в существующую статью**
| Параметр | Передаем данные | Значение |
| --- | --- | --- |
| utm\_source | Тип трафика | external\_paid |
| utm\_medium | Тип интеграции | url\_article |
| utm\_campaign | Название площадки | blog\_o\_stile |
| utm\_content | Название контента | article2 |
| utm\_term | Необязательный параметр. Можно использовать для дополнительной информации: например, указать размер площадки | medium |
Полный адрес ссылки:
```
http://bestbuyshop.ru/catalog/?utm_source=external_paid&utm_medium=url_article&utm_campaign=blog_o_stile&utm_content=article2&utm_term=medium
```
### Разметка ссылок в email-рассылках
Email-рассылки — отдельный канал трафика, который нужно отслеживать. Если вы используете этот инструмент, обязательно делайте разметку ссылок, чтобы понимать, из каких писем на ваш сайт приходят пользователи.
Вот пример структуры UTM-разметки для ссылок в письме для рассылки по базе клиентов:
| Параметр | Передаем данные | Значение |
| --- | --- | --- |
| utm\_source | Канал трафика | e-mail |
| utm\_medium | Тип рассылки | news |
| utm\_campaign | Название кампании | winter\_sale |
| utm\_content | Тип ccылки (к примеру, button — ссылка в кнопке, banner — на баннере, link — обычная ссылка в тексте) | button |
| utm\_term | Необязательный параметр | — |
Полный URL с разметкой будет выглядеть так:
```
http://bestbuyshop.ru/catalog/?utm_source=e-mail&utm_medium=news&utm_campaign=winter_sale&utm_content=button
```
### Как отследить эффективность офлайн-рекламы с помощью UTM-меток
Здесь помогут QR-коды. Например, вы можете напечатать рекламные плакаты или флаера и разместить на них QR-код со ссылкой на ваш сайт. Используйте UTM-метки для разметки ссылки, а затем сгенерируйте QR-код для размеченного URL. Все переходы по QR-коду вы сможете отслеживать в системах аналитики.
Вот пример разметки для офлайн-рекламы:
| Параметр | Передаем данные | Значение |
| --- | --- | --- |
| utm\_source | Канал трафика | qr\_code |
| utm\_medium | Рекламный носитель (плакат, флаер, ситилайт и т.д.) | flyer |
| utm\_campaign | Название кампании | winter\_sale |
| utm\_content | Место размещения рекламы | supermarket |
| utm\_term | Город/район | butovo |
Полный URL с метками будет выглядеть так:
```
http://bestbuyshop.ru/catalog/?utm_source=qr&utm_medium=flyer&utm_campaign=winter_sale&utm_content=supermarket&utm_term=butovo
```
Сгенерируйте для него QR-код и отправляйте в печать.
Составляйте UTM-метки без ошибок: используйте генераторы
--------------------------------------------------------
Теперь, когда мы подробно рассказали о UTM-метках, их назначении и синтаксисе, а также показали примеры использования, они уже не кажутся сложными. Но они все еще остаются достаточно громоздкими, а значит при ручном составлении меток возможны ошибки.
Чтобы свести вероятность ошибок к минимуму и ускорить процесс разметки ссылок, используйте генераторы UTM-меток.
### Campaign URL Builder
[Инструмент](https://ga-dev-tools.appspot.com/campaign-url-builder/) для генерации UTM-меток от Google. Работает просто:
* укажите адрес целевой страницы в поле «Website URL»;
* пропишите необходимые значения параметров в обязательных полях Campaign Source, Campaign Medium и Campaign Name. Дополнительно укажите значения параметров Term и Content.
* скопируйте сгенерированную ссылку и разместите ее в объявлении.
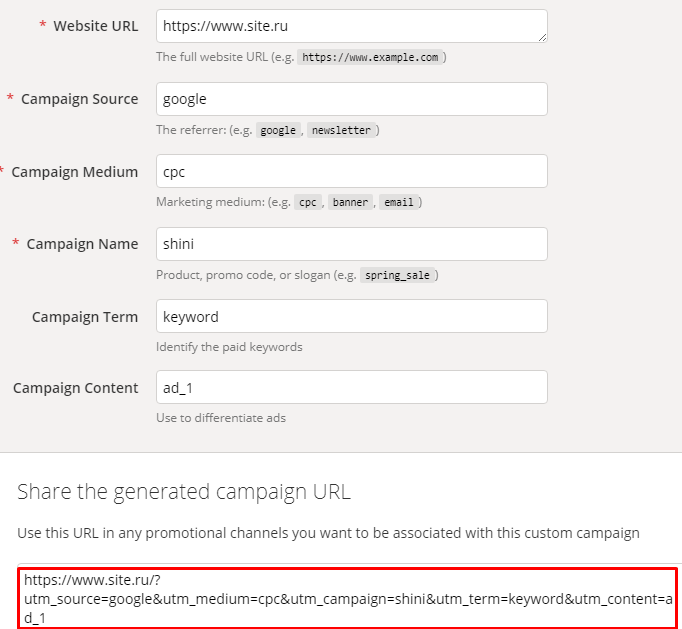
### Генератор UTM от Tilda
Простой [генератор UTM-меток](https://tilda.cc/ru/utm/) от одного из самых популярных конструкторов сайтов. С В генераторе UTM от Тильды можно создать метки для основных рекламных систем: Яндекс.Директ, Google Реклама, ВКонтакте, myTarget и Facebook.
Здесь также все просто:
* вставляете в поле «Адрес вашей страницы» URL страницы, на которую хотите вести трафик;
* выбираете источник трафика (рекламную систему). Например, Google Ads;
* указываете обязательные параметры и необязательные (если нужны);
* забираете готовую ссылку с UTM-метками.
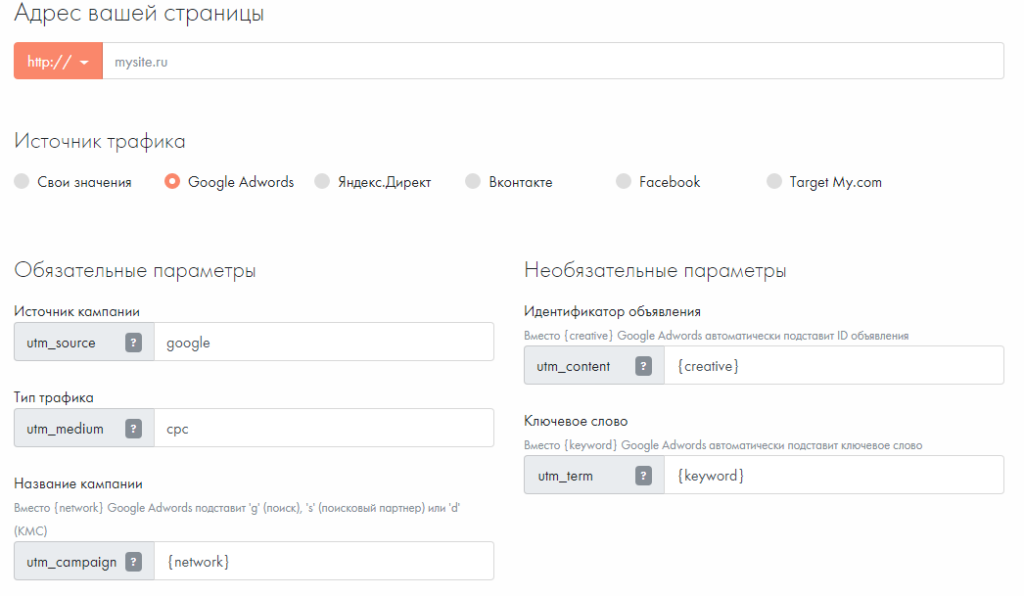
**Обратите внимание!** Генератор автоматически подставляет динамические параметры, подходящие для выбранной рекламной системы. Например, если вы выбрали Google Ads, в поле параметра utm\_content генератор подставит динамический параметр {creative}, который будет передавать идентификатор объявления. Вы можете использовать эти параметры или изменить их (для этого воспользуйтесь справкой по динамическим параметрам внизу страницы генератора):
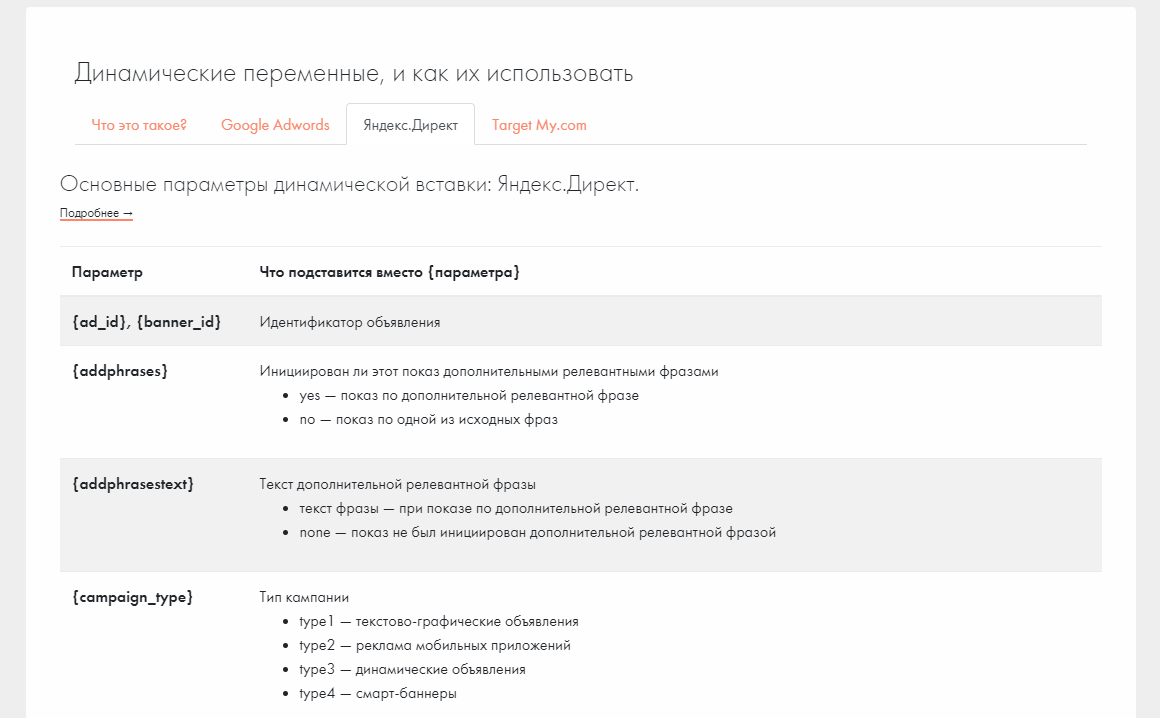
### Шаблоны в Google Таблицах для генерации UTM-меток
Такой шаблон легко создать самому с помощью формулы CONCATENATE. Но можно не создавать, а использовать готовый шаблон. Например, [этот](https://docs.google.com/spreadsheets/d/1ZmiH6jYiILVI1khH8NcsxOmOAmNAoDwO4QpwWAJF8P8/edit).
Откройте таблицу с шаблоном, создайте копию. В столбце «URL» укажите адрес целевой страницы, в столбцах параметров — необходимые значения. В столбце «Generated URL» появится готовая ссылка с корректной разметкой.

Нужно ли сокращать ссылки с UTM-метками?
----------------------------------------
URL-адрес страницы со всеми UTM-метками выглядит устрашающим для обычных пользователей. Но если вы размещаете их в объявлениях контекстной или таргетированной рекламы, это не имеет особого значения. Пользователи кликают по объявлениям, а саму ссылку видят разве что в адресной строке браузера.
То же самое относится и к ссылкам, которые имеют текстовый анкор.
Если же вы размещаете рекламную ссылку без анкора в статье или в комментарии, ее лучше сократить. Длинная ссылка с непонятными символами и словами будет выглядеть подозрительно, и вы получите меньше переходов.
Чтобы рекламная ссылка выглядела «нормально», используйте сервисы-сокращатели ссылок: [to.click](https://to.click/), [cutt.ly](https://cutt.ly/), [clck.ru](https://clck.ru/) или другие.

**Есть еще один способ скрытия ссылки, но его не стоит использовать**
Для реализации этого способа покупают отдельный домен, а затем настраивают с него 301-й редирект на ссылку с UTM. Таким образом пользователь кликает по обычной ссылке, а затем он перенаправляется на ссылку с разметкой.
Мы не рекомендуем пользоваться такими способами — можно попасть под санкции поисковиков.
Статистика по UTM-меткам: где смотреть
--------------------------------------
### В Яндекс.Метрике
В Яндекс.Метрике доступен специальный отчет, с помощью которого вы можете просмотреть детальную статистику по UTM-меткам. В интерфейсе Метрики отчет находится в Стандартных отчетах — **Источники → Метки UTM**.
Выберите этот отчет, затем проставьте галочки на тех метках, по которым хотите посмотреть статистику.

### В Google Аналитике
В Google Аналитике статистику по UTM-меткам можно посмотреть в отчете «Источник/канал» (находится в разделе **Источники трафика → Весь трафик**).
В столбце «Источник или канал» в каждой строке указаны два значения, разделенные слэшем:
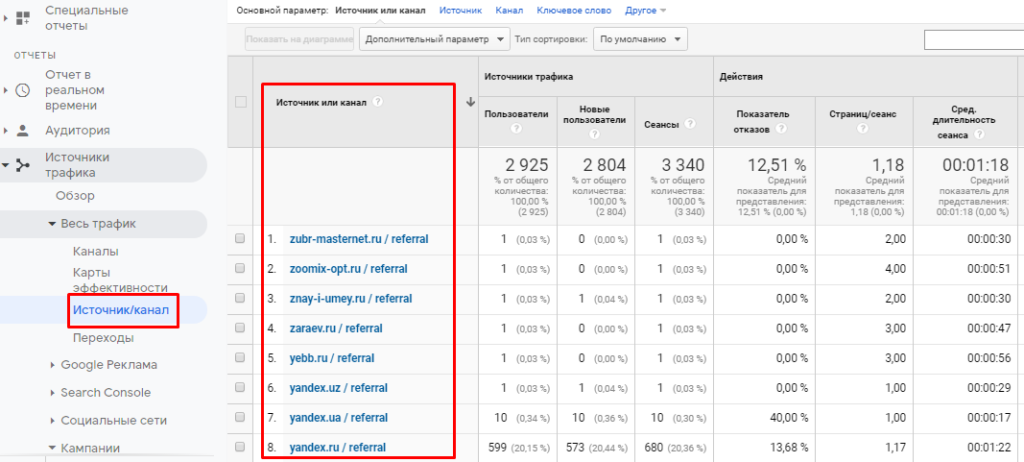
Первое значение (источник) — это параметр utm\_source. Второе значение (канал) — параметр utm\_medium.
Также в этом отчете можно посмотреть статистику по кампаниям (метка utm\_campaign). Для этого выберите соответствующий основной параметр: «Кампания».
Чтобы посмотреть статистику с разбивкой по объявлениям (метка utm\_content), выберите параметр «Содержание объявления».
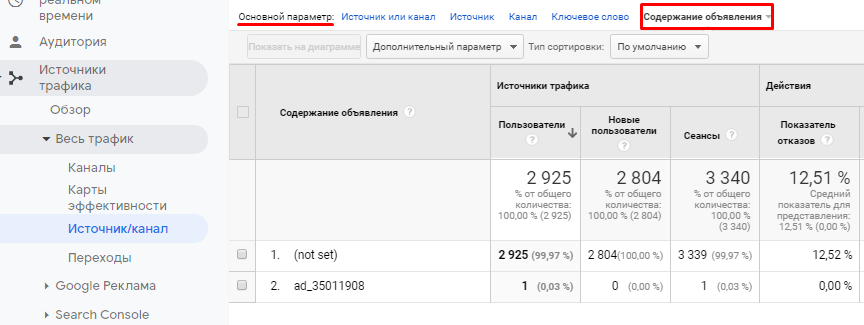
Также можно посмотреть данные по ключевым словам, по которым показывались ваши объявления и были получены клики. Для этого выберите параметр «Ключевое слово».
Что может пойти не так при работе с UTM-метками: проблемы и их решение
----------------------------------------------------------------------
### Неправильный синтаксис
Ссылки с UTM-метками достаточно длинные (особенно если вы используете все доступные параметры). Если прописывать параметры вручную, легко допустить ошибку.
UTM-метки чувствительны к синтаксису: достаточно пропустить один символ или поставить пробел вместо дефиса, и статистика не будет собираться.
Вместе с тем вы легко можете избежать ошибок: просто пользуйтесь генераторами UTM-меток.
### Используются только статические параметры
Если вы используете только статические параметры, вы усложняете себе работу и в итоге получаете меньше данных.
Например, вы хотите протестировать 20 разных объявлений и понять, какое из них эффективнее. Если использовать только статические параметры, вам придется вручную прописать название или идентификатор каждого объявления в параметре utm\_content.
Вместо этого вы могли бы использовать динамический параметр и прописать всего лишь одно значение: {ad\_id} (в Яндекс.Директе) или {creative} (в Google Рекламе).
### Дубли страниц в индексе: поисковики индексируют URL с разметкой
«Чистый» URL или URL с UTM-метками — одно и то же с точки зрения пользователей. При переходе по ним загрузится одна и та же целевая страница.
Но поисковые системы могут проиндексировать оба URL — в результатах поиска появятся дубли, что не очень хорошо.
Чтобы ссылки с UTM-метками не индексировались поисковиками и не было проблемы с дублями, используйте [атрибут rel="canonical"](https://blog.promopult.ru/seo/kak-i-kogda-ispolzovat-301-j-redirekt-i-canonical.html). Это универсальное решение.
Для робота Яндекса можно прописать в robots.txt следующий код:
```
User-agent: Yandex
Clean-param: utm_source&utm_medium&utm_campaign&utm_content&utm_term&sid&gclid&yclid
```
С помощью этого кода мы даем указание Яндексу не индексировать URL-адреса, содержащие GET-параметры.
Больше о дублях страниц [читайте](https://blog.promopult.ru/seo/chto-takoe-dubli-na-sajte-i-kak-s-nimi-borotsya.html) в блоге PromoPult.
### Полезные советы:
* Всегда заполняйте обязательные параметры (просто запомните их — utm\_source, utm\_medium и utm\_campaign). Они должны присутствовать в ссылке всегда. Если не заполнить хотя бы один из них, данные будут собираться некорректно.
* Используйте только латиницу (если прописывать кириллические значения параметров, могут быть проблемы с корректностью данных).
* Проверяйте, в каком регистре прописываете значения: google и Google в системе аналитики будут отображены как разные значения.
* Для разделения слов в метках используйте дефис («-») или нижнее подчеркивание («\_»). Следите за тем, чтобы между символами в ссылке не было пробелов (некоторые генераторы автоматически убирают пробелы, но на всякий случай проверяйте сгенерированные ссылки).
* В ссылке должен быть только один вопросительный знак — перед первой UTM-меткой.
* Если вы используете одновременно две разметки (например, gclid и UTM), проверьте ссылку перед публикацией объявления. Скопируйте ссылку в адресную строку браузера и перейдите по ней — страница сайта должна загружаться. Если страница не загружается, проверьте корректность разметки или отключите одну из них.
* Чтобы содержание меток распознавалось корректно, на вашем сайте должна использоваться кодировка UTF-8.
Автоматизируйте работу с UTM-метками (и не только)
--------------------------------------------------
Чтобы запустить кампанию контекстной или таргетированной рекламы, нужно проделать много работы: собрать ключевые слова, подготовить изображения и тексты, настроить таргетинги и многое другое. UTM-метки — одна из составляющих.
Автоматизируйте все эти задачи с помощью модулей [контекстной](https://promopult.ru/technology/ppc?utm_medium=paid_article&utm_source=habr&utm_campaign=blog&utm_term=2b16077d0129a574&utm_content=ppc) и [таргетированной](https://promopult.ru/technology/social?utm_medium=paid_article&utm_source=habr&utm_campaign=blog&utm_term=2b16077d0129a574&utm_content=social) рекламы PromoPult. Так вы сэкономите время и деньги, освободившись от рутинной работы. | https://habr.com/ru/post/478758/ | null | ru | null |
# Очистка поля типа file
вот такой странный, но ДЕЙСТВУЮЩИЙ способ :)
> `function clearFileInputField(Id) {
>
> document.getElementById(Id).innerHTML = document.getElementById(Id).innerHTML;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
пример работы — [designformasters.info/lab/clear-file-input/index.html](http://designformasters.info/lab/clear-file-input/index.html) (спасибо [Jenek](https://habrahabr.ru/users/jenek/) ) | https://habr.com/ru/post/65687/ | null | ru | null |
# Парсим Википедию, фильтруя, для задач NLP в 44 строки кода
В этой заметке я хотел бы дополнить эту [статью](https://habr.com/ru/post/425507/) и рассказать, как можно гибче использовать экстрактор Википедии WikiExtractor, фильтруя статьи по категориям.
Началось все с того, что мне нужны были определения для различных терминов. Термины и их определения, как правило, являются первым предложением на каждой странице Википедии. Пойдя по самому простому пути, я извлек все статьи и регулярками быстро выцепил все, что было нужно. Проблема в том, что объем определений перевалил за 500 Мб, причем, было слишком много лишнего, например, именованные сущности, города, годы и т.д. которые мне не нужны.
Я верно предположил, что у инструмента [WikiExtractor](https://github.com/attardi/wikiextractor) (я буду использовать другую версию, ссылка будет ниже) есть какой-то фильтр и это оказался фильтр по категориям. Категории являются тегами для статей, которые имеют иерархическую структуру для организации страниц. Я на радостях выставил категорию "Точные науки", очень наивно полагая, что все статьи, которые относятся к точным наукам будут включены в список, но чуда не случилось — у каждой страницы свой, крошечный, набор категорий и на отдельно взятой странице нет никакой информации о том, как эти категории соотносятся. Значит, если мне нужны страницы по точным наукам, я должен указать все категории, которые являются потомками для "Точных наук".
Ну не беда, сейчас найду сервис, подумал я, который запросто мне отгрузит все категории от заданного начала. К сожалению, я нашел только [это](https://ru.wikipedia.org/wiki/%D0%92%D0%B8%D0%BA%D0%B8%D0%BF%D0%B5%D0%B4%D0%B8%D1%8F:%D0%9F%D0%BE%D0%B8%D1%81%D0%BA_%D0%BF%D0%BE_%D0%BA%D0%B0%D1%82%D0%B5%D0%B3%D0%BE%D1%80%D0%B8%D1%8F%D0%BC), где можно просто посмотреть, как эти категории взаимосвязаны. Попытка в ручную перебрать категории тоже не увенчалась успехом, зато я "обрадовался" тому, что эти категории имеют структуру не дерева, как я думал все это время, а просто направленного графа, с циклами. Причем, сама иерархия очень сильно плывет — скажу наперед, что задав начальную точку "Математика", легко можно дойти до Александра I. В итоге, мне оставалось только восстановить этот граф локально и как-то получить список интересующих меня категорий.
Итак, задача ставится следующим образом: начиная с какой-то вершины, получить список всех категорий, которые связаны с это вершиной, имея возможность как-то ограничивать их.
Работа проводилась на машине с Ubuntu 16.04, но, полагаю, что для 18.04 следующие инструкции не вызовут проблем.
Скачиваем и развертываем данные
===============================
Первым делом, нам необходимо скачать все необходимые данные вот [отсюда](https://dumps.wikimedia.org/ruwiki/latest/), а именно
* ruwiki-latest-pages-articles.xml.bz2
* ruwiki-latest-categorylinks.sql.gz
* ruwiki-latest-category.sql.gz
* ruwiki-latest-page.sql.gz
Таблица categorylinks содержит связи между страницей, в смысле Википедии, и ссылкой на категорию вида [[Category:Title]] в любом месте этой страницы, [информация](https://www.mediawiki.org/wiki/Manual:Categorylinks_table). Нас интересуют столбцы cl\_from, которая содержит id страницы, и cl\_to, которая содержит название категории. Для того, чтобы связать id страницы, нам нужна таблица page ([информация](https://www.mediawiki.org/wiki/Manual:Page_table)) со столбцами page\_id и page\_title. Но нам не нужно знать взаимосвязь всех страниц, мы хотим только категории. Все категории, или их большинство, как я понял, имеют свою страницу, значит нам нужен перечень всех категорий, чтобы фильтровать названия страниц. Эта информацию содержится в таблице category([информация](category table)) в столбце cat\_title. Файл pages-articles.xml содержит текст самих статей.
Для работы с базами данных нам необходим mysql. Установить его можно, выполнив команду
```
sudo apt-get install mysql-server mysql-client
```
После этого, необходимо зайти в mysql и создать там базы данных, для того чтобы импортировать базы данных Википедии.
```
$ mysql -u username -p
mysql> create database category;
mysql> create database categorylinks;
mysql> create database page;
```
Создав базы данных, приступим к импорту. Он может занять весьма продолжительное время.
```
$ mysql -u username -p category < ruwiki-latest-category.sql
$ mysql -u username -p categorylinks < ruwiki-latest-categorylinks.sql
$ mysql -u username -p page < ruwiki-latest-page.sql
```
Формируем таблицу взаимосвязи категорий и восстанавливаем граф
==============================================================
Теперь нам нужно получить таблицу, в которой будет отражено как между собой связаны категории и для дальнейшей работы выгрузить таблицу в csv. Сделать это можно следующим запросом
```
mysql> select page_title, cl_to from categorylinks.categorylinks join page.page
on cl_from = page_id where page_title in (select cat_title from category) INTO outfile '/var/lib/mysql-files/category.csv' FIELDS terminated by ';' enclosed by '"' lines terminated by '\n';
```
Результат будет выглядеть следующим образом. Не забудьте вручную добавить название столбцов.

Стоит заметить, что слева у нас потомок, а справа — его предки, поэтому восстанавливать граф будем от потомков к предкам. Кроме того, есть еще очень много разных служебных категорий, которые мне лично не нужны, поэтому я их отфилтровал, сократив количество строк с примерно 1,6 миллионов до 1,1. Сделать все это можно при помощи следующего кода.
```
import pandas as pd
import networkx as nx
from tqdm.auto import tqdm, trange
#Filtering
df = pd.read_csv("category.csv", sep=";", error_bad_lines=False)
df = df.dropna()
df_filtered = df[df.parant.str.contains("[А-Яа-я]+:") != True]
df_filtered = df_filtered[df_filtered.parant.str.contains("Страницы,_") != True]
df_filtered = df_filtered[df_filtered.parant.str.contains("Статьи_проекта_") != True]
df_filtered = df_filtered[df_filtered.parant.str.contains("Хорошие_статьи") != True]
df_filtered = df_filtered[df_filtered.parant.str.contains("Перенаправления,_") != True]
df_filtered = df_filtered[df_filtered.parant.str.contains("Избранные_списки_") != True]
df_filtered = df_filtered[df_filtered.parant.str.contains("Избранные_статьи_") != True]
df_filtered = df_filtered[df_filtered.parant.str.contains("Списки_проекта") != True]
df_filtered = df_filtered[df_filtered.parant.str.contains("Добротные_статьи_") != True]
df_filtered = df_filtered[df_filtered.parant.str.contains("Статьи") != True]
# Graph recovering
G = nx.DiGraph()
c = 0
for i, gr in tqdm(df_filtered.groupby('child')):
vertex = set()
edges = []
for i, r in gr.iterrows():
G.add_node(r.parant, color="white")
G.add_node(r.child, color="white")
G.add_edge(r.parant, r.child)
```
Работаем с графом и извлекаем фильтрованные статьи
==================================================
Для того, чтобы пользоваться этим графом и решить поставленную в начале задачу, воспользуемся алгоритмом поиска в глубину с модификациями для обнаружения циклов, для чего мы пометили каждый узел белым цветом, и ограничения глубины поиска.
```
counter = 0
nodes = []
def dfs(G, node, max_depth):
global nodes, counter
G.nodes[node]['color'] = 'gray'
nodes.append(node)
counter += 1
if counter == max_depth:
counter -= 1
return
for v in G.successors(node):
if G.nodes[v]['color'] == 'white':
dfs(G, v, max_depth)
elif G.nodes[v]['color'] == 'gray':
continue
counter -= 1
```
В результате, в листе nodes у нас содержатся все категории начиная от указаной и до желаемой глубины от начала. Ниже представлен пример для начальной точки "Точные науки" с ограничением на глубину в 5 вершин. Всего их получилось около 2500 тысяч. Конечно, там содержатся категории, которые не относятся к точным наукам и, возможно, каких-то категорий, которые должны быть, там не окажутся, но с этим способом лучше не выйдет — либо больше покрытие и больше ненужных категорий, либо наоборот. Однако, это гораздо лучше, чем вручную отбирать эти категории.
Результат нужно сохранить построчно в файл, он нам понадобится для фильтарции.
**Подкатегории с вершины Точные науки**
```
Точные_науки
Информатика
CAM
Авторы_учебников_информатики
Архивное_дело
Археографические_комиссии
Археографические_комиссии_Украины
Виленская_археографическая_комиссия
Архивисты
Архивариусы
Архивисты_по_алфавиту
Архивисты_по_векам
Архивисты_по_странам
Архивное_дело_на_Украине
Архивисты_Украины
...
Терминология_телевидения
Терминология_японских_боевых_искусств
Термины_для_знаменитостей
Термины_и_понятия_аниме_и_манги
Технические_термины
Транспортная_терминология
Фантастические_термины_по_их_изобретателям
Филателистические_термины
Философские_термины
Цирковые_термины
Экономические_термины
Японские_исторические_термины
Экономика_знаний
Инкапсуляция_(программирование)
...
Бесконечность
Бесконечные_графы
Единое
Философы_математики
Прокл_Диадох
Функции
Арифметические_функции
Мультипликативные_функции
Большие_числа
Кусочно-линейные_функции
Преобразования
Дискретные_преобразования
Интегральные_преобразования
Преобразования_пространства
Теория_потенциала
Типы_функций
Числа
```
Для того, чтобы применить эти категории для фильтрации для русского языка, однако, нужно кое-что подправить в исходниках. Я использовал [эту](https://github.com/attardi/wikiextractor/tree/16186e290d9eb0eb3a3784c6c0635a9ed7e855c3) версию. Сейчас там что-то новое, возможно, исправления ниже уже не актуальны. В файле WikiExtractor.py нужно заменить "Category" на "Категория" в двух местах. Области с уже исправленным вариантом представлены ниже:
```
tagRE = re.compile(r'(.*?)<(/?\w+)[^>]*?>(?:([^<]*)(<.*?>)?)?')
# 1 2 3 4
keyRE = re.compile(r'key="(\d*)"')
catRE = re.compile(r'\[\[Категория:([^\|]+).*\]\].*') # capture the category name [[Category:Category name|Sortkey]]"
def load_templates(file, output_file=None):
...
```
```
if inText:
page.append(line)
# extract categories
if line.lstrip().startswith('[[Категория:'):
mCat = catRE.search(line)
if mCat:
catSet.add(mCat.group(1))
```
После этого нужно запустить команду
```
python WikiExtractor.py --filter_category categories --output wiki_filtered ruwiki-latest-pages-articles.xml
```
где categories — это файл с категориями. Отфильтрованные статьи будут лежать в wiki\_filtered.
На этом все. Спасибо за внимание. | https://habr.com/ru/post/513218/ | null | ru | null |
# JavaScript to TypeScript — трудности перевода
Наверно многие в курсе, что у JS достаточно ограниченно реализовано ООП. Одних уровень ООП в JS устраивает, другие не видят необходимости придерживаться правил ООП, другие без ООП не могут писать код. Тут мы попробуем без холивара разобраться в некоторых ньансах перехода с JS на TS.
О мотивации перехода мы поговорим в заключении статьи и скорее для тех, кто понимает важность качества кода. Но пару слов все же скажем вначале. Когда Вы делаете небольшой тестовый код, с неясным коммерческим статусом — то вряд ли вы будите этот код прилизывать. А ООП это хороший способ прилизать код, это не сколько не влияет на функциональность вашего кода, даже наоборот, часто задерживает быстрое написание тех фич, которые вы решили сделать. Иногда даже страдает производительность. Но наверное каждый знает тот уровень, когда ему самому уже сложно разобраться в своем коде, тогда вы начинаете его просматривать и время от времени подумывать о рефакторинге. Если ваш язык интерпретируемый, без строгой типизации и не достаточно хорошо поддерживает ООП, то вы этот момент будет оттягивать долго — но я рекоммендую все же об этом задуматься. Если ваш язык JS — хорошим вариантом будет его перевести на TS, вы ничего не потяряете это уж точно. Но есть некоторые сложности, из-за которых в процессе перевода вы можете засомневаться в правильности такого решения.
#### Глобальные переменные — зло
Если вы уж решили придерживаться ООП — откажитесь от глобальных переменных ВООБЩЕ. В JavaScript порой используют для этого директиву «use strict»;
В TypeScrip просто не объявляйте внешних переменных с помощью declare var. Делайте объявления только внутри классов, хотя бы так MyVar: any.
Наверное каждый может рассказать историю, почему глобальные переменные зло. Я расскажу свою. Можно сказать по ошибке я объявил одну переменную через declare var xmlhttp. Ну тогда мне показалось, что о ней как о классе TypeScript ничего не знает, а значит это кандидат на внешнию переменную. Генератор TypeScript это объявление при переводе на JavaScript проигнорировал и так она стала глобальной переменной. Ну, а так как в этой переменной содержалась ссылка на XMLHttpRequest, который обеспечивает асинхронное получение данных с сервера, то впоследствии, конечно, это приводит к багу как только вы одновременно будите получать через эту переменную разные типы данных. Причем некоторые браузеры будут это нивелировать, код даже сможет работать, но существенно замедлится и будут происходить отказы по ошибке синтаксиса JS. Вы ведь не всегда проверяете в коде перед использованием переменной, а задана ли она?
#### Порядок скриптов при наследовании
TypeScript поддерживает настоящие наследование, чем оно отличается от JS наследования поговорим позже. Объявляется оно так:
```
///
module CyberRise
{
export class Menu extends RequestData
{
}
}
```
Объявлен класс Menu наследуемый от RequestData в модуле CyberRise. В JS это генерируется зубодробительной конструкцией, которую я тут описывать не буду. По сути там трехуровневое вложение функций (и даже больше), целью чего является разграничение областей видимости. Используя модули мы можем не беспокоится о одинаковых названиях классов в разных библиотеках. А ведь действительно каждый разработчик любит использовать общеупотребительные название, даже такие как Window.
Еще Вы можете заметить конструкцию reference в начале файла. Дело в том, что TypeScript проверяет соответствие типов и ему еще на этапе компиляции (генерации JS) надо знать все о типах. Опять же преимущества строго типизированных языков я думаю все знают, отмечу самое прямое — проверка ошибок связанных с неправильным использованием объектов на этапе компиляции. Это сильно экономит время отладки в достаточно больших проектах.
Так вот кто знаком с Cи конструкция reference хоть и находится формально под комментарием является аналогом include. И самое главное, код перестанет работать если вы не в том порядке подключите скрипты. В таком варианте не работает:
script type=«text/javascript» src=«js/Menu.js»>
script type=«text/javascript» src=«js/RequestData.js»>
а так работает:
script type=«text/javascript» src=«js/RequestData.js»>
script type=«text/javascript» src=«js/Menu.js»>
Ну, собственно, это аналогично С++, там тоже include должны быть в определенном порядке. Только так как объявление скриптов делается не в TypeScript он не может это проверить на этапе компиляции и вы можете долго находится в прострации не понимая почему не выполняется ваш код. Хотя есть вариант когда весь код компилируется в один js файл, тогда компилятор TS гарантирует сам правильное расположение порядка кода. Но для серьезного проекта это может создать не удобства, т.к. пофайлово видеть код на JS все же удобнее. Придерживайтесь стиля «один файл — один класс».
upd. Если использовать проект студии HTML Application with TS — то это опять же не нужно, но я, например, использую проект ASP.NET — он ничего не знает о TS, кроме того, что я ему указываю как генерировать в post build. Поэтому думаю если у вас хоть более менее сложный проект (а зачем иначе вам переходить на TS?) или вообще вы не используете проект вы не будите использовать проект вида HTML Application with TS.
#### Калбэки, делегаты и прочие синонимы
С присвоением ссылки на функцию, т.е. с созданием калбэка тоже есть непонятки. Но они скорее дисциплириуют, но могут адептам JS показаться не естетвенными. Те кто привык к JS частенько, думаю, занимаются передачей ссылок на функцию, даже не думая о безопасности этого. К примеру, в .NET намеренно запретили прямую работу с ссылками, т.к. это приводит часто к багам. Но при ООП это часто не нужно, вместо этого передаются ссылки на объекты, и затем получающий объект использует public часть класса, используя нужные ему члены класса. Еще лучше если класс реализует интерфейс, и передается ссылка на интерфейсы. Увы, этого в JS нет, и поэтому часто пользуются не безопасной передачей ссылок на функцию.
Итак, код вида:
```
xmlhttp.onreadystatechange = this.OnDataProcessing;
```
Работать у вас больше не будет. Точнее будет, но не в том контексте, т.е. надо использовать костыль JS
```
xmlhttp.onreadystatechange = this.OnDataProcessing.bind(this);
```
Дело в том, что теперь на уровне класса вы больше не можете объявлять локальные переменные с помощью var. Теперь все, что вы объявляете на уровне класса = это свойства, используемые через this. Поэтому если раньше на такой костыль закрывали глаза, то теперь он выглядит еще более не естественно.
Поэтому лучше уж будет использовать аннонимные методы, чтобы устранить преследующую тень необъектного JS
```
this.xmlhttp.onreadystatechange = () =>
{
alert(this.xmlhttp.responseText);
}
```
#### Внешние вызовы
Частенько мы уже пользуемся теми бибилиотеками, которые разработаны в JS. И там часто предлагают использовать уже разработанные объекты-функции. Если они вызываются через new, как то
```
win = new Window({
className: "mac_os_x", title: locTitle, width: 1000, height: 600,
destroyOnClose: true, recenterAuto: false
});
```
компилятор TypeScript сообщит вам, что ничего не знает о таком классе Window (он то думает, что это класс :) ). Действительно мы наверняка еще словим, что класс Window уже объявлен. Но это будет не тот класс и не с той бибилиотеки, которую мы подразумеваем. Но если мы использовали модули, то все будет нормально. А чтобы компилятор понял, что это за класс нам надо описать сигнатуру, аналогично тому как мы это делаем используя методы из dll.
Написав:
```
declare var Window: new (a: any) => any;
```
компилятор от нас отстанет, поняв, что в качестве параметра мы передаем что угодно, и возвращаем что угодно. По хорошему можно типы прописать точнее.
#### Мотивация
Мотивация такого перехода с JS на TS у каждого может быть своя. И говоря о ней мы рискуем халиварить. Поэтому я ограничусь тем списком, который важен для меня, когда я начинаю структурировать код и мне нужны для этого инструменты (пусть многие это сочтут за синтаксический сахар, но за ним стоит не только синтаксис, но и глубинная реализация (или не до реализация) концепций в языке):
1. За всеми попытками разделить данные на модули, классы, объекты, наличие наследования — стоит простое желание разграничить области ответственности свойств и методов, а на уровень глубже разграничить области видимости переменных. Для этого TS выворачивается как только может, используя единственную для этого возможность в JS используя замыкания для инкапсуляции данных. Так он вводит понятие класса — как функции в функции, где одна функция это статические данные/методы/конструкторы на уровне класса, а во вложенной функции данные объекта.
2. Мы получаем строгую типизацию
3. Получаем такой бонус как полноценную поддержку конструкторов в классах. Без них надо изобретать т.н. фабрики с методами init()
4. Наследование становится не реализацией агрегации, как это по умолчанию в JS — а реальным наследованием, с контролем задания нужных конструкторов в наследниках. Чем наследование лучше агрегации? Да, не лучше, но часто нужно, когда ты разрабатываешь и перекрываешь поведение ряда базовых классов. Да и потом семантически это одношение вид чего-то (is a), а не часть чего-то (part of) — без разделения этой семантики все превращается в одну кашу, где отношения использования, агрегации, наследования становится одним и тем же.
5. Получаем еще один бонус — интерфейсы, как описательная часть классов. Объяснить их важность порой сложно, я и не буду пытаться. Те кто знает как их использовать оценят это, иные нет. Скажу лишь одно, с помощью интерфейсов реализуется множественное наследование, и легко можно сложный интерфейс public часть всего класса, поделить на ряд сваязанных интерфейсов, после чего передавать ссылки не на весь класс, а ссылки на выделенный интерфейс.
6. еще мелочь — есть enum`ы
7. а еще приятно, что есть т.н. необязательные параметры, т.е. те которые функции передавать не нужно, и что важнее те которые в интерфейсе можно не реализовывать. Это порой наверно даже лучше, чем в C# — где нужно отделаваться реализациями вида return null (на что мой шеф однажды пошутил, что если бы он знал как такие реализации делать в коммерческом смысле возвращая в качестве реализации [тут нечто не читаемое], то его клиенты были бы особенно рады :) ).
Пожалуй и все, если оцените через времечко напишу про трудности перевода баз данных — миграции с MySQL на MS SQL Server.
upd.
Люди, объясните некоторым ниже кто выступает с большим апломбом (тем более при этом выражая свои заблуждения), чем интерфейс отличается от этого
> Вы тоже самое получите просто помечая члены класса как public \ private
и аналогичный холивар/троллинг разводить мне не интересно, есть вопросы — напишите в личку отвечу.
> В данном случае, declare ничего не объявляет, а указывает компилятору, что во время выполнения будет такая переменная с таким типом, чтоб он не ругался на её использование.
И что? В статье явно написано, что это может привести к использованию глобальной переменной. Непонятно как — перечитайте статью. | https://habr.com/ru/post/232015/ | null | ru | null |
# Почему следует использовать RxJava в Android – краткое введение в RxJava
Здравствуйте все.
Мы продолжаем знакомить вас с нашим издательским поиском, и хотели прозондировать общественное мнение на тему RxJava.

В ближайшее время собираемся опубликовать более общий материал по реактивному программированию, которое нас также интересует не первый год, а сегодня предлагаем почитать о применении RxJava в Android, так как именно на этой платформе особенно важна динамичность и быстрота реагирования. Добро пожаловать под кат
В большинстве приложений Android мы реагируем на действия пользователя (щелчки, смахивание, т.д.), а тем временем в фоновом режиме идет какая-то другая работа (сетевая).
Оркестровка всех этих процессов – сложная задача, любой код рискует быстро превратиться в бесформенную кашу.
Например, не так просто послать по сети запрос к базе данных, а после его выполнения сразу начать одновременно выбирать и пользовательские сообщения, и настройки, а после завершения всей этой работы вывести приветственное сообщение.
Именно в таких случаях как нельзя кстати будет [RxJava](https://github.com/ReactiveX/RxJava) (ReactiveX) – библиотека, позволяющая соорганизовать множество действий, обусловленных определенными событиями в системе.
Работая с RxJava, можно будет забыть об обратных вызовах и адском управлении глобальным состоянием.
**Почему?**
Вернемся к нашему примеру:
> послать по сети запрос к базе данных, а после его выполнения сразу начать одновременно выбирать и пользовательские сообщения, и настройки, а после завершения всей этой работы вывести приветственное сообщение.
Если разобрать эту ситуацию подробнее, найдем в ней три основных этапа, причем **все три происходят в фоновом режиме**:
1. Выбрать пользователя из базы данных
2. **Одновременно** выбрать пользовательские настройки и сообщения
3. Скомбинировать результаты обоих запросов в один
Чтобы сделать то же самое в Java SE и Android, нам бы потребовалось:
1. Сделать 3-4 различные `AsyncTasks`
2. Создать семафор, который дождется завершения обоих запросов (по настройкам и по сообщениям)
3. Реализовать поля на уровне объектов для хранения результатов
Уже понятно, что для этого требуется управлять состоянием, а также задействовать некоторые механизмы блокировки, существующие в Java.
Всего этого можно избежать, работая с RxJava (см. примеры ниже) – весь код выглядит как поток, расположенный **в одном месте** и строится на базе **функциональной** парадигмы (см. [здесь](http://c2.com/cgi/wiki?AdvantagesOfFunctionalProgramming)).
**Быстрый запуск в Android**
Чтобы получить библиотеки, которые, скорее всего, понадобятся вам для проекта, вставьте в ваш файл build.gradle следующие строки:
compile 'io.reactivex:rxjava:1.1.0'
```
compile 'io.reactivex:rxjava-async-util:0.21.0'
compile 'io.reactivex:rxandroid:1.1.0'
compile 'com.jakewharton.rxbinding:rxbinding:0.3.0'
compile 'com.trello:rxlifecycle:0.4.0'
compile 'com.trello:rxlifecycle-components:0.4.0'
```
Таким образом будут включены:
* [RxJava](https://github.com/ReactiveX/RxJava) – основная библиотека ReactiveX для Java.
* [RxAndroid](https://github.com/ReactiveX/RxAndroid) — расширения RxJava для Android, которые помогут работать с потоками в Android и с Loopers.
* [RxBinding](https://github.com/JakeWharton/RxBinding) – привязки между RxJava и элементами пользовательского интерфейса Android, в частности, кнопками Buttons и текстовыми представлениями TextViews
* [RxJavaAsyncUtil](https://github.com/ReactiveX/RxJavaAsyncUtil) – помогает склеивать код [Callable](https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/Callable.html) и [Future](https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/Future.html).
**Пример**
Начнем с примера:
```
Observable.just("1", "2")
.subscribe(new Action1() {
@Override
public void call(String s) {
System.out.println(s);
}
});
```
Здесь мы создали [Observable](http://reactivex.io/documentation/observable.html), который сгенерирует два элемента — 1 и 2.
Мы подписались на observable, и теперь, как только элемент будет получен, мы выведем его на экран.
**Некоторые детали**
Объект *Observable* – такая сущность, на которую можно подписаться, а затем принимать генерируемые Observable элементы. Они могут создаваться самыми разными способами. Однако Observable обычно не начинает генерировать элементы, пока вы на них не подпишетесь.
После того, как вы подпишетесь на observable, вы получите Subscription (подписку). Подписка будет принимать объекты, поступающие от observable, пока он сам не просигнализирует, что завершил работу (не поставит такую отметку), либо (в очень редких случаях) прием будет продолжаться бесконечно.
Более того, все эти действия будут выполняться в главном потоке.
**Расширенный пример**
```
Observable.from(fetchHttpNetworkContentFuture())
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new Action1() {
@Override
public void call(String s) {
System.out.println(s);
}
}, new Action1() {
@Override
public void call(Throwable throwable) {
throwable.printStackTrace();
}
});
```
Здесь наблюдаем кое-что новое:
1. subscribeOn(Schedulers.io()) – благодаря этому методу Observable будет выполнять ожидание и вычисления в пуле потоков ThreadPool, предназначенном для ввода/вывода (Schedulers.io()).
2. observeOn(AndroidSchedulers.mainThread()) – благодаря этому методу, результат действия подписчика будет выполнен в главном потоке Android. Это требуется в случаях, когда вам нужно что-то изменить в пользовательском интерфейсе Android.
3. Во втором аргументе к .subscribe() появляется обработчик ошибок для операций с подпиской на случай, если что-то пойдет не так. Такая штука должна присутствовать почти всегда.
**Управление сложным потоком**
Помните сложный поток, описанный нами в самом начале?
Вот как он будет выглядеть с RxJava:
```
Observable.fromCallable(createNewUser())
.subscribeOn(Schedulers.io())
.flatMap(new Func1>>>() {
@Override
public Observable>> call(User user) {
return Observable.zip(
Observable.from(fetchUserSettings(user)),
Observable.from(fetchUserMessages(user))
, new Func2, Pair>>() {
@Override
public Pair> call(Settings settings, List messages) {
return Pair.create(settings, messages);
}
});
}
})
.doOnNext(new Action1>>() {
@Override
public void call(Pair> pair) {
System.out.println("Received settings" + pair.first);
}
})
.flatMap(new Func1>, Observable>() {
@Override
public Observable call(Pair> settingsListPair) {
return Observable.from(settingsListPair.second);
}
})
.subscribe(new Action1() {
@Override
public void call(Message message) {
System.out.println("New message " + message);
}
});
```
В таком случае будет создан новый пользователь (createNewUser()), и на этапе его создания и возвращения результата в то же самое время продолжится выбор пользовательских сообщений (fetchUserMessages()) и пользовательских настроек (fetchUserSettings). Мы дождемся завершения обоих действий и возвратим скомбинированный результат (Pair.create()).
Не забывайте – все это происходит в отдельном потоке (в фоновом режиме).
Затем программа выведет на экран полученные результаты. Наконец, список сообщений будет приспособлен еще в один observable, который будет выводить сообщения поодиночке, а не целым списком, причем каждое сообщение будет появляться в окне терминала.
**Функциональный подход**
Работать с RxJava будет гораздо проще, если вы знакомы с функциональным программированием, в частности, с концепциями map и zip. Кроме того, в RxJava и ФП очень похоже выстраивается обобщенная логика.
**Как создать собственный observable?**
Если код становится в значительной степени завязан на RxJava (например, [здесь](http://www.feedpresso.com/) ), то зачастую вам придется писать собственные observable, так, чтобы они укладывались в логику вашей программы.
Рассмотрим пример:
```
public Observable customObservable() {
return rx.Observable.create(new rx.Observable.OnSubscribe() {
@Override
public void call(final Subscriber super String subscriber) {
// Выполняется в фоновом режиме
Scheduler.Worker inner = Schedulers.io().createWorker();
subscriber.add(inner);
inner.schedule(new Action0() {
@Override
public void call() {
try {
String fancyText = getJson();
subscriber.onNext(fancyText);
} catch (Exception e) {
subscriber.onError(e);
} finally {
subscriber.onCompleted();
}
}
});
}
});
}
```
А вот похожий вариант, не требующий выполнять действие строго в конкретном потоке:
```
Observable observable = Observable.create(
new Observable.OnSubscribe() {
@Override
public void call(Subscriber super String subscriber) {
subscriber.onNext("Hi");
subscriber.onCompleted();
}
}
);
```
Здесь важно отметить три метода:
1. onNext(v) – отправляет подписчику новое значение
2. onError(e) – уведомляет наблюдателя о произошедшей ошибке
3. onCompleted() – уведомляет подписчика о том, что следует отписаться, поскольку от данного observable больше не поступит никакого контента
Кроме того, вероятно, будет удобно пользоваться RxJavaAsyncUtil.
Интеграция с другими библиотеками
По мере того, как RxJava становится все популярнее и де-факто превращается в стандарт асинхронного программирования в Android, все больше библиотек все в большей мере интегрируются с ней.
Всего несколько примеров:
[Retrofit](https://github.com/square/retrofit) — «Типобезопасный HTTP-клиент для Android и Java»
[SqlBrite](https://github.com/square/sqlbrite) — «Легкая обертка для SQLiteOpenHelper, обогащающая SQL-операции семантикой реактивных потоков.»
[StorIO](https://github.com/pushtorefresh/storio) — «Красивый API для SQLiteDatabase и ContentResolver»
Все эти библиотеки значительно упрощают работу с HTTP-запросами и базами данных.
**Интерактивность с Android UI**
Это введение было бы неполным, если бы мы не рассмотрели, как использовать нативные UI-элементы в Android.
```
TextView finalText;
EditText editText;
Button button;
...
RxView.clicks(button)
.subscribe(new Action1() {
@Override
public void call(Void aVoid) {
System.out.println("Click");
}
});
RxTextView.textChanges(editText)
.subscribe(new Action1() {
@Override
public void call(CharSequence charSequence) {
finalText.setText(charSequence);
}
});
...
```
Очевидно, можно просто положиться на setOnClickListener, но в долгосрочной перспективе RxBinding может подойти вам лучше, поскольку позволяет подключить UI к общему потоку RxJava.
**Советы**
Практика показывает, что при работе с RxJava следует придерживаться некоторых правил.
***Всегда использовать обработчик ошибок***
Пропускать обработчик ошибок таким образом
```
.subscribe(new Action1() {
@Override
public void call(Void aVoid) {
System.out.println("Click");
}
});
```
обычно не следует. Исключение, выбрасываемое в наблюдателе или в одном из действий будет выброшено исключение, которое, скорее всего, убьет вам все приложение.
Еще лучше было бы сделать обобщенный обработчик:
```
.subscribe(..., myErrorHandler);
```
**Извлекать методы действий**
Если у вас будет много внутренних классов, то через некоторое время удобочитаемость кода может испортиться (особенно если вы не работаете с RetroLambda).
Поэтому такой код:
```
.doOnNext(new Action1>>() {
@Override
public void call(Pair> pair) {
System.out.println("Received settings" + pair.first);
}
})
```
выглядел бы лучше после такого рефакторинга:
```
.doOnNext(logSettings())
@NonNull
private Action1>> logSettings() {
return new Action1>>() {
@Override
public void call(Pair> pair) {
System.out.println("Received settings" + pair.first);
}
};
}
```
***Использовать собственные классы или кортежи***
Бывают случаи, в которых некое значение определяется другим значением (например, пользователь и пользовательские настройки), и вы хотели бы получить оба этих значения при помощи двух асинхронных запросов.
В таких случаях рекомендую использовать [JavaTuples](http://www.javatuples.org/).
Пример:
```
Observable.fromCallable(createNewUser())
.subscribeOn(Schedulers.io())
.flatMap(new Func1>>() {
@Override
public Observable> call(final User user) {
return Observable.from(fetchUserSettings(user))
.map(new Func1>() {
@Override
public Pair call(Settings o) {
return Pair.create(user, o);
}
});
}
});
```
***Управление жизненным циклом***
Зачастую бывает так, что фоновый процесс (подписка) должен просуществовать дольше, чем активность или фрагмент, в котором (которой) он содержится. Но что если результат вас уже не интересует, как только пользователь покинет активность?
В таких случаях вам поможет проект [RxLifecycle](https://github.com/trello/RxLifecycle).
Оберните ваш observable вот так (взято из документации) и сразу после его разрушения выполнится отписка:
```
public class MyActivity extends RxActivity {
@Override
public void onResume() {
super.onResume();
myObservable
.compose(bindToLifecycle())
.subscribe();
}
}
```
**Заключение**
Конечно, это далеко не полное руководство об использовании RxJava в Android, но, надеюсь, смог вас убедить, что в некоторых отношениях RxJava лучше обычных AsyncTask. | https://habr.com/ru/post/307096/ | null | ru | null |
# Пишем UI авто тесты на TypeScript с использованием Page Object, Page Factory
### Вступление
В данной статье мы разберем, как писать UI автотесты с использованием паттернов Page Object, Page Factory на языке TypeScript. У меня уже была статья о том [Как правильно писать UI авто тесты на Python](https://habr.com/ru/post/708932/), тут мы разберем аналогичный пример.
### Requirements
Для примера написания UI авто тестов мы будем использовать:
* playwright - yarn add playwright/npm install playwright
* allure - yarn add allure-playwright/npm install allure-playwright
Вы можете использовать любой другой фреймворк и репортер, суть концепции работы с Page Object, Page Factory будет похожей на каждом фреймворке.
Обратите внимание, что все автотесты будут писаться через async, await, т.к. это единственный возможный способ для playwright. В других фреймворках может быть иначе.
Авто тесты будем писать на эту страницу <https://playwright.dev/>
Тест кейс:
1. Открываем страницу https://playwright.dev
2. Нажимаем на поиск
3. Проверяем, что модальное окно поиска успешно открылось
4. Вводим в поиск язык, в нашем случае будет python
5. Выбираем из результатов первый
6. Проверяем, что страница с Python открылась
Отмечу, что локаторы в примерах ниже не являются эталонными, а сайт для тестирования - это документация playwright, на фронтенд которой я никак не могу повлиять. В ваших проектах советую использовать кастомные data-qa-id, которые вы можете поставить в фронтенд приложении React/Vue/Angular или же попросить разработчиков сделать это.
Файл конфигурации playwright будет выглядеть стандартным образом, добавим лишь allure-report, headles, video, screenshot. Более подробно про конфигурацию playwright можно почитать [тут](https://playwright.dev/docs/test-configuration).
Playwright позволяет из коробки записывать видео и делать скриншоты + крепить их к отчету, для этого достаточно прописать `video: "on"`, `screenshot: "on"`, там есть и другие параметры. Если вам необходимо сохранять видео только на фейленный тест, то используйте `video: "retain-on-failure`, аналогично со скриншотом `screenshot: "only-on-failure"`. Конечно же вы можете сделать тоже самое и с Selenium. В конце статьи посмотрим на видео и скриншот в отчете.
playwright.config.ts
```
import type { PlaywrightTestConfig } from '@playwright/test';
import { devices } from '@playwright/test';
/**
* Read environment variables from file.
* https://github.com/motdotla/dotenv
*/
// require('dotenv').config();
/**
* See https://playwright.dev/docs/test-configuration.
*/
const config: PlaywrightTestConfig = {
testDir: './tests',
/* Maximum time one test can run for. */
timeout: 30 * 1000,
expect: {
/**
* Maximum time expect() should wait for the condition to be met.
* For example in `await expect(locator).toHaveText();`
*/
timeout: 5000
},
/* Run tests in files in parallel */
fullyParallel: true,
/* Fail the build on CI if you accidentally left test.only in the source code. */
forbidOnly: !!process.env.CI,
/* Retry on CI only */
retries: process.env.CI ? 2 : 0,
/* Opt out of parallel tests on CI. */
workers: process.env.CI ? 1 : undefined,
/* Reporter to use. See https://playwright.dev/docs/test-reporters */
reporter: [['html'], ['allure-playwright']],
/* Shared settings for all the projects below. See https://playwright.dev/docs/api/class-testoptions. */
use: {
/* Maximum time each action such as `click()` can take. Defaults to 0 (no limit). */
actionTimeout: 0,
baseURL: 'https://playwright.dev',
/* Base URL to use in actions like `await page.goto('/')`. */
// baseURL: 'http://localhost:3000',
/* Collect trace when retrying the failed test. See https://playwright.dev/docs/trace-viewer */
trace: 'on-first-retry',
headless: !!process.env.CI,
video: 'on',
screenshot: 'on'
},
/* Configure projects for major browsers */
projects: [
{
name: 'chromium',
use: {
...devices['Desktop Chrome']
}
}
]
};
export default config;
```
### Base Page
По сути Base Page - это основная страница, которая не описывает какую-то конкретную страницу или компонент. Сама по себе Base Page не должна использоваться в тестах и от нее мы наследуем наши страницы или компоненты.
pages\base-page.ts
```
import test, { Page } from '@playwright/test';
import { Navbar } from '../components/navigation/navbar';
export class BasePage {
readonly navbar: Navbar;
constructor(public page: Page) {
this.navbar = new Navbar(page);
}
async visit(url: string): Promise {
await test.step(`Opening the url "${url}"`, async () => {
await this.page.goto(url, { waitUntil: 'networkidle' });
});
}
async reload(): Promise {
const currentUrl = this.page.url();
await test.step(`Reloading page with url "${currentUrl}"`, async () => {
await this.page.reload({ waitUntil: 'domcontentloaded' });
});
}
}
```
Внутри BasePage описываем базовые методы. Это лишь образец того, как можно делать BasePage
Page Factory
------------
Теперь самое интересное. Мы определим несколько базовых компонентов для реализации работы паттерна. Но перед реализацией компонентов нам нужно добавить необходимые типы и вспомогательные методы.
utils\generic.ts
```
export const capitalizeFirstLetter = (string: string): string => string.charAt(0).toUpperCase() + string.slice(1);
```
utils\page-factory.ts
```
import { LocatorContext } from '../types/page-factory/component';
export const locatorTemplateFormat = (locator: string, { ...context }: LocatorContext): string => {
let template = locator;
for (const [key, value] of Object.entries(context)) {
template = template.replace(`{${key}}`, value.toString());
}
return template;
};
```
По сути функция `locatorTemplateFormat` будет брать строку локатора, например, `[data-qa-id="here-my-locator-with-index-{index}"]` и подставлять параметры и `context` внутрь строки локатора. Например:
```
const locator = '[data-qa-id="here-my-locator-with-index-{index}"]';
const context = {index: 5};
locatorTemplateFormat(locator, context) => '[data-qa-id="here-my-locator-with-index-5"]
```
Реализация `locatorTemplateFormat` может быть любая, я лишь привел пример, как это можно сделать. В своем фреймворке вы можете использовать другой форматер для шаблона локатора.
types\page-factory\component.ts
```
import { Page } from '@playwright/test';
export type LocatorContext = { [key: string]: string | boolean | number };
export type ComponentProps = {
page: Page;
name?: string;
locator: string;
};
export type LocatorProps = { locator?: string } & LocatorContext;
```
Базовый **Component**. Сам по себе Component не должен использоваться в тестах и от него мы будем наследовать другие компоненты и при необходимости переопределять методы, поэтому сделаем его абстрактным классом.
page-factory\component.ts
```
import { expect, Locator, Page, test } from '@playwright/test';
import { ComponentProps, LocatorProps } from '../types/page-factory/component';
import { capitalizeFirstLetter } from '../utils/generic';
import { locatorTemplateFormat } from '../utils/page-factory';
export abstract class Component {
page: Page;
locator: string;
private name: string | undefined;
constructor({ page, locator, name }: ComponentProps) {
this.page = page;
this.locator = locator;
this.name = name;
}
getLocator(props: LocatorProps = {}): Locator {
const { locator, ...context } = props;
const withTemplate = locatorTemplateFormat(locator || this.locator, context);
return this.page.locator(withTemplate);
}
get typeOf(): string {
return 'component';
}
get typeOfUpper(): string {
return capitalizeFirstLetter(this.typeOf);
}
get componentName(): string {
if (!this.name) {
throw Error('Provide "name" property to use "componentName"');
}
return this.name;
}
private getErrorMessage(action: string): string {
return `The ${this.typeOf} with name "${this.componentName}" and locator ${this.locator} ${action}`;
}
async shouldBeVisible(locatorProps: LocatorProps = {}): Promise {
await test.step(`${this.typeOfUpper} "${this.componentName}" should be visible on the page`, async () => {
const locator = this.getLocator(locatorProps);
await expect(locator, { message: this.getErrorMessage('is not visible') }).toBeVisible();
});
}
async shouldHaveText(text: string, locatorProps: LocatorProps = {}): Promise {
await test.step(`${this.typeOfUpper} "${this.componentName}" should have text "${text}"`, async () => {
const locator = this.getLocator(locatorProps);
await expect(locator, { message: this.getErrorMessage(`does not have text "${text}"`) }).toContainText(text);
});
}
async click(locatorProps: LocatorProps = {}): Promise {
await test.step(`Clicking the ${this.typeOf} with name "${this.componentName}"`, async () => {
const locator = this.getLocator(locatorProps);
await locator.click();
});
}
}
```
Выше приведена очень упрощенная реализация Component. В своем проекте вы можете добавить больше методов, больше настроек к ним, можете изменить названия шагов test.step, которые больше подходят вам.
Давайте сделаем еще несколько компонентов.
**Button** - кнопка. В данном компоненте будут базовые методы для работы с кнопками.
page-factory\button.ts
```
import test from '@playwright/test';
import { LocatorProps } from '../types/page-factory/component';
import { Component } from './component';
export class Button extends Component {
get typeOf(): string {
return 'button';
}
async hover(locatorProps: LocatorProps = {}): Promise {
await test.step(`Hovering the ${this.typeOf} with name "${this.componentName}"`, async () => {
const locator = this.getLocator(locatorProps);
await locator.hover();
});
}
async doubleClick(locatorProps: LocatorProps = {}) {
await test.step(`Double clicking ${this.typeOf} with name "${this.componentName}"`, async () => {
const locator = this.getLocator(locatorProps);
await locator.dblclick();
});
}
}
```
**Input** - поле ввода. В данном компоненте будут базовые методы для работы с инпутами.
page-factory\input.ts
```
import test, { expect } from '@playwright/test';
import { LocatorProps } from '../types/page-factory/component';
import { Component } from './component';
type FillProps = { validateValue?: boolean } & LocatorProps;
export class Input extends Component {
get typeOf(): string {
return 'input';
}
async fill(value: string, fillProps: FillProps = {}) {
const { validateValue, ...locatorProps } = fillProps;
await test.step(`Fill ${this.typeOf} "${this.componentName}" to value "${value}"`, async () => {
const locator = this.getLocator(locatorProps);
await locator.fill(value);
if (validateValue) {
await this.shouldHaveValue(value, locatorProps);
}
});
}
async shouldHaveValue(value: string, locatorProps: LocatorProps = {}) {
await test.step(`Checking that ${this.typeOf} "${this.componentName}" has a value "${value}"`, async () => {
const locator = this.getLocator(locatorProps);
await expect(locator).toHaveValue(value);
});
}
}
```
**Link** - ссылка. В данном компоненте будут базовые методы для работы со ссылками.
page-factory\link.ts
```
import { Component } from './component';
export class Link extends Component {
get typeOf(): string {
return 'link';
}
}
```
**ListItem** - любой элемент списка.
page-factory\list-item.ts
```
import { Component } from './component';
export class ListItem extends Component {
get typeOf(): string {
return 'list item';
}
}
```
**Title** - заголовок. Можно использовать просто Text, но я предпочитаю разделать все для понятности. Title, Text, Label, Subtitle...
page-factory\title.ts
```
import { Component } from './component';
export class Title extends Component {
get typeOf(): string {
return 'title';
}
}
```
**Лайфхак**. Если не знаете как называть компоненты, то можете использовать библиотеки для дизайна. К примеру дизайнеры вашего продукта используют [Material Design](https://m3.material.io/) для компонентов, тогда вы можете взять посмотреть <https://m3.material.io/components>, как называются те или иные компоненты в Material Desgin и по аналогии называть свои компоненты Page Factory. Но если вам и так понятно, как и почему называть компоненты, то этот лайфхак не для вас :)
Теперь вопрос: "Зачем все это?". Данный подход решает сразу тонну проблем и вопросов, которые возникают у любого QA Automation, который хоть раз писал UI авто тесты.
* Дает удобный и понятный интерфейс для работы с объектами на странице. То есть мы работаем не с каким-то там локатором, а с конкретным объектом, например, Button.
* Универсализирует все взаимодействия и проверки компонентов. Очень хорошо для команд, где над авто тестами работают два и более QA Automation, ну или если авто тесты пишут разработчики тоже. С таким подходом у вас не будет споров и проблем, то есть один QA Automation может писать так `expect(locator).toBeVisible()`, что является единственно правильным с точки зрения playwright. Второй QA Automation может писать так `expect(await locator.isVisible()).toBeTruthy()`, что тоже **по сути правильно**, но костыльно. На этой основе могут возникать бесполезные споры или еще хуже: каждый пишет так, как он хочет. По итогу получаем проект, в котором одни и те же проверки пишутся по разному. С данным подходом мы один раз устанавливаем, как делается проверка и забываем об этом, все работает прекрасно.
* Дает возможность универсализировать все шаги для отчета. В примере выше я использовал test.step из playwright, но на самом деле это не важно, вы можете использовать любой репортер. При объявлении нового компонента нам не нужно переписывать все шаги, они динамически формируются на основе параметров, name, typeOf. Конечно же, вы можете их изменить и расширить под ваши требования. Достаточно переопределить typeOf и мы получаем новый компонент с полностью уникальными шагами.
* Динамические локаторы - это вечная боль, но не с данным подходом. Механизм форматирования локатора до безобразия прост. Мы передаем `LocatorProps` в каждый метод, далее все это идет в сам локатор через функцию форматирования `locatorTemplateFormat`. То есть это позволяет писать нам локаторы `span#some-element-id-{userId}`, далее передавать `userId`через `LocatorProps` прямо в локатор, например так `this.myUserInput.fill('Hello World', { userId })` Механизм прост, но он избавляет нас от локаторов в методах, от дублирования или еще хуже хардкода локаторов.
* Появляется возможность создавать компоненты, работа с которыми специфична. Например, у вас в продукте есть какой-то хитрый автокомплит, который нужно как-то хитро кликать, возможно, печатать через клавиатуру. Вы можете создать компонент `MyCustomAutocomplete`, унаследовать его от `Input` и переопределить метод `fill`. Далее такой компонент можно будет использовать во всем проекте без дублирования логики ввода.
* Если у вас над автотестами работают сразу несколько QA Automation команд, например, одна тестирует админку, другая тестирует сайт, то вы можете вынести весь Page Factory внутрь библиотеки. Библиотеку можно запушить на pypi или на свой приватный nexus сервер. Далее библиотекой могут пользоваться все QA Automation команды, вы получите общий ентри поинт для написания UI авто тестов, общие шаги и проверки.
* Last but not least. Предложенный мною подход Page Factory максимально простой, а это очень важно для масштабирования в будущем. Хуже, когда в коде наблюдается "магия" и эта "магия" понятна только тому, кто ее создал. В решение выше та "магия" отсутствует, все максимально прозрачно и в рамках обычного ООП.
Возможно, данный подход не является классической реализацией Page Factory, но это единственное рабочее и адекватное решение, которое мне удалось выработать. Предложенное мною решение способно закрыть все вопросы и проблемы работы с компонентами.
Для меня главным образом закрывается две задачи:
* Фокус на тестировании бизнес логики, без вечных головоломок с кодом;
* Красивый и понятный отчет, который спокойно могут читать Manual QA, менеджеры и разработчики.
### Pages
Теперь опишем страницы, которые нам понадобятся, уже с использованием Page Factory.
Основная страница playwright [https://playwright.dev](https://playwright.dev/python/docs/languages)
pages\playwright-home-page.ts
```
import { BasePage } from './base-page';
export class PlaywrightHomePage extends BasePage {}
```
Страница с языками <https://playwright.dev/python/docs/languages>
pages\playwright-languages-page.ts
```
import { Page } from '@playwright/test';
import { Title } from '../page-factory/title';
import { capitalizeFirstLetter } from '../utils/generic';
import { BasePage } from './base-page';
export class PlaywrightLanguagesPage extends BasePage {
private readonly languageTitle: Title;
constructor(public page: Page) {
super(page);
this.languageTitle = new Title({ page, locator: 'h2#{language}', name: 'Language title' });
}
async languagePresent(language: string): Promise {
await this.languageTitle.shouldBeVisible({ language });
await this.languageTitle.shouldHaveText(capitalizeFirstLetter(language), { language });
}
}
```
### Components
Теперь опишем компоненты, которые нам будут нужны.
#### Navbar
components\navigation\navbar.ts
```
import { Page } from '@playwright/test';
import { Button } from '../../page-factory/button';
import { Link } from '../../page-factory/link';
import { SearchModal } from '../modals/search-modal';
export class Navbar {
readonly searchModal: SearchModal;
private readonly apiLink: Link;
private readonly docsLink: Link;
private readonly searchButton: Button;
constructor(public page: Page) {
this.searchModal = new SearchModal(page);
this.apiLink = new Link({ page, locator: "//a[text()='API']", name: 'API' });
this.docsLink = new Link({ page, locator: "//a[text()='Docs']", name: 'Docs' });
this.searchButton = new Button({ page, locator: 'button.DocSearch-Button', name: 'Search' });
}
async visitDocs(): Promise {
await this.docsLink.click();
}
async visitApi(): Promise {
await this.apiLink.click();
}
async openSearch(): Promise {
await this.searchButton.shouldBeVisible();
await this.searchButton.hover();
await this.searchButton.click();
await this.searchModal.modalIsOpened();
}
}
```
#### SearchModal
components\modals\search-modal.ts
```
import { Page } from '@playwright/test';
import { Input } from '../../page-factory/input';
import { ListItem } from '../../page-factory/list-item';
import { Title } from '../../page-factory/title';
type FindResult = {
keyword: string;
resultNumber: number;
};
export class SearchModal {
private readonly emptyResultsTitle: Title;
private readonly searchInput: Input;
private readonly searchResult: ListItem;
constructor(public page: Page) {
this.emptyResultsTitle = new Title({ page, locator: 'p.DocSearch-Help', name: 'Empty results' });
this.searchInput = new Input({ page, locator: '#docsearch-input', name: 'Search docs' });
this.searchResult = new ListItem({ page, locator: '#docsearch-item-{resultNumber}', name: 'Result item' });
}
async modalIsOpened(): Promise {
await this.searchInput.shouldBeVisible();
await this.emptyResultsTitle.shouldBeVisible();
}
async findResult({ keyword, resultNumber }: FindResult) {
await this.searchInput.fill(keyword, { validateValue: true });
await this.searchResult.click({ resultNumber });
}
}
```
**Лайфхак.** Если вы путаетесь и не знаете, как назвать какой-либо компонент, то можете посмотреть, как называются компоненты у разработчиков внутри React/Vue/Angular frontend приложения. Да, не всегда есть такая возможность, но если имеется доступ к frontend приложению, то советую брать названия и структуру компонентов именно от туда. Разработчики точно лучше знают структуру frontend приложения, чем любой QA Engineer, + вам будет легче в будущем повторно использовать компоненты и композицию. В нашем примере c <https://playwright.dev/> мы не имеем доступа к коду приложения, поэтому называем компоненты по смыслу.
### Testing
Теперь настало время теста. Тут все просто, у нас есть готовые страницы, тест соберем, как конструктор, но перед этим напишем фикстуры.
**Лайфхак.** Наверняка у вас в проекте есть много ресурсов, которые не влияют на основную бизнес-логику приложения. Например такие, как шрифты (woff,woff2), картинки (png, jpg, jpeg), иконки (ico, svg), музыкальные файлы (mp3), какие-то конфиги, которые фронт подгружает с бэка, можно отключить, это позволит сильно ускорить ваши тесты, проверьте. Конечно, не все ресурсы можно отключить, к этому тоже нужно относиться очень внимательно, посмотрите, что можно отключить или посоветуйтесь с разработчиками, например, отключать main.js/index.js/app.js или чанки точно не стоит :) Мы отключим загрузку статических файлов c помощью playwright:
utils\mocks\static-mock.ts
```
import { Page } from '@playwright/test';
export const mockStaticRecourses = async (page: Page): Promise => {
await page.route('\*\*/\*.{ico,png,jpg,mp3,woff,woff2}', (route) => route.abort());
};
```
fixtures\context-pages.ts
```
import { Fixtures, Page, PlaywrightTestArgs } from '@playwright/test';
import { mockStaticRecourses } from '../utils/mocks/static-mock';
export type ContextPagesFixture = {
contextPage: Page;
};
export const contextPagesFixture: Fixtures = {
contextPage: async ({ page }, use) => {
await mockStaticRecourses(page);
await use(page);
}
};
```
fixtures\playwright-pages.ts
```
import { Fixtures } from '@playwright/test';
import { PlaywrightHomePage } from '../pages/playwright-home-page';
import { PlaywrightLanguagesPage } from '../pages/playwright-languages-page';
import { ContextPagesFixture } from './context-pages';
export type PlaywrightPagesFixture = {
playwrightHomePage: PlaywrightHomePage;
playwrightLanguagesPage: PlaywrightLanguagesPage;
};
export const playwrightPagesFixture: Fixtures = {
playwrightHomePage: async ({ contextPage }, use) => {
const playwrightHomePage = new PlaywrightHomePage(contextPage);
await use(playwrightHomePage);
},
playwrightLanguagesPage: async ({ contextPage }, use) => {
const playwrightLanguagesPage = new PlaywrightLanguagesPage(contextPage);
await use(playwrightLanguagesPage);
}
};
```
Теперь сделаем extend стандартного test объекта из playwright и добавим в него свои фикстуры
tests\tests.ts
```
import { test as base } from '@playwright/test';
import { ContextPagesFixture, contextPagesFixture } from '../fixtures/context-pages';
import { PlaywrightPagesFixture, playwrightPagesFixture } from '../fixtures/playwright-pages';
import { combineFixtures } from '../utils/fixtures';
export const searchTest = base.extend(
combineFixtures(contextPagesFixture, playwrightPagesFixture)
);
```
В данном примере `combineFixtures` - это вспомогательный метод, который поможет нам собрать несколько объектов фикстур в один. В принципе можно обойтись и без него, но мне так удобнее:
utils\fixtures.ts
```
import { Fixtures } from '@playwright/test';
export const combineFixtures = (...args: Fixtures[]): Fixtures =>
args.reduce((acc, fixture) => ({ ...acc, ...fixture }), {});
```
tests\test-search.spec.ts
```
import { searchTest as test } from './tests';
test.beforeEach(async ({ playwrightHomePage }) => {
await playwrightHomePage.visit('/');
});
test('Testing search on playwright documentation page', async ({ playwrightHomePage, playwrightLanguagesPage }) => {
await playwrightHomePage.navbar.openSearch();
await playwrightHomePage.navbar.searchModal.findResult({ keyword: 'python', resultNumber: 0 });
await playwrightLanguagesPage.languagePresent('python');
});
```
При использовании Page Object, Page Factory, как описано выше, тесты пишутся легко и понятно. И, самое главное, это позволяет нам фокусироваться на тестировании бизнес логики продукта, а не на ерунде по типу, как написать test.step, как написать проверку или как мне динамически подставить параметр в локатор.
Report
------
Запустим тесты и посмотрим на отчет:
```
npx playwright test
```
Теперь запустим отчет:
```
allure serve
```
Либо можете собрать отчет и в папке allure-reports открыть файл index.html:
```
allure generate
```
Allure reportAllure report video
Получаем прекрасный отчет, в котором отображается вся нужная нам информация.
[Полную версию отчета посмотрите тут](https://nikita-filonov.github.io/playwright_typescript/).
### Заключение
Весь исходный код проекта [расположен на моем github](https://github.com/Nikita-Filonov/playwright_typescript). | https://habr.com/ru/post/712084/ | null | ru | null |
# Прогноз снятия наличных в банкомате при помощи простой нейронной сети

Возможно вы когда-нибудь встречали банкомат в режиме «Не обслуживается» (Out of service).
Одной из возможных причин такого состояния является отсутствие ~~электричества~~ денег в кассетах.
Чтобы этого не возникало, банкам интересно знать будущее — сколько наличности будет снято в банкоматах и когда деньги совсем закончатся.
Под катом решение этой задачи при помощи простой нейронной сети.
Для начала разберёмся, что такое нейронная сеть. С дилетантской точки зрения нейронную сеть можно представить как некий «чёрный ящик», который принимает на вход и выдаёт на выходе некий набор параметров. Обучить нейронную сеть — значит натренировать её на эталонном наборе входных и выходных данных, который называют обучающей выборкой.
**Рассмотрим простой пример.**
Научимся при помощи нейронной сети находить значение функции «Исключающее «ИЛИ».
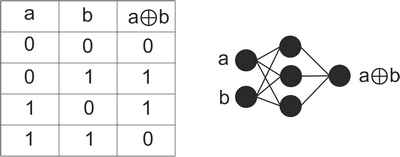
Здесь слева **a** и **b** — входные параметры, а справа **a⊕b** — выходной параметр. Обучив нейронную сеть на таблице истинности, мы сможем подавать на вход сети любые комбинации нулей и единиц и получать на выходе верный результат. Внимательный читатель заметил, что какое бы значение нулей и единиц мы не взяли после обучения, оно будет совпадать с одной из обучающих пар. В реальных задачах это обычно не так.
**Вернёмся к нашим банкоматам.**
Чтобы делать прогнозы, сначала необходимо ~~придумать~~ определить признаки, от которых зависит количество снятых средств. Это делается при помощи анализа статистики и применения здравого смысла. Так было обнаружено, что количество снятых денег в одни и те же дни недели обычно схоже. В результате получили следующую нейронную сеть:

Для прогноза на понедельник «Недели 3» на вход нейронной сети подаются данные за два предыдущих понедельника. Эта нейронная сеть хороша, но не способна предсказать пики снятия наличных в конкретные даты месяца (зарплата?). Их хорошо прогнозирует следующая нейронная сеть:
Для прогноза на 5 число «Месяца 3» на вход подаются данные за 4, 5, 6 числа двух предыдущих месяцев (это помогает улучшить прогноз, если «пиковый» день перенесётся на ±1 день из-за выходного или праздника).
В качестве результата можно было бы использовать среднее значение прогнозов двух предыдущих нейронных сетей. Но лучшим решением оказалось объединить их в одну большую нейронку:

Чтобы не ~~нарушать корпоративную тайну~~ раздувать статью, в ней были опущены некоторые важные технические детали (типы нейронов, виды обучения, нормализация данных и другие). Но надеюсь, что у непосвящённого читателя появилось представление, как эта штука работает.
**Хозяйке на заметку**Для реализации был использован [фреймворк машинного обучения Encog](http://www.heatonresearch.com/) (доступен под .Net, Java и C++). Он позволяет высокоуровнево создавать нейронные сети, указывая типы нейронов и их количество в каждом слое сети:
```
var network = new BasicNetwork();
network.AddLayer(new BasicLayer(null, true, 2));
network.AddLayer(new BasicLayer(new ActivationSigmoid(), true, 3));
network.AddLayer(new BasicLayer(new ActivationSigmoid(), true, 1));
network.Structure.FinalizeStructure();
network.Reset();
```
Если вы не хотите разбираться в достаточно сложной математике нейронов и методов обучения, рекомендую найти готовую библиотеку для своего языка. | https://habr.com/ru/post/265979/ | null | ru | null |
# PHP Дайджест № 220 (10 – 24 января 2022)
[](https://habr.com/ru/post/647491/) *Картинка [Vincent Pontier](https://twitter.com/Elroubio/status/1467434852840529925)*.
Подборка свежих новостей, инструментов и материалов из мира PHP.
Приятного чтения!
> Этот дайджест подготовлен совместно с [Insolita](https://twitter.com/DonnaInsolita). Если понравился выпуск, плюсаните пост, пожалуйста.
>
>
⚡️ Новости
----------
* **[The PHP Foundation Update, January 2022](https://opencollective.com/phpfoundation/updates/the-php-foundation-update)**
Фонд PHP стартовал свою работу в конце ноября и уже есть первые результаты. Получены и обрабатываются заявки на спонсорство от core-разработчиков, идет подготовка необходимых документов.
Обзоры по работе фонда будут публиковаться каждый месяц, можно подписаться на твиттер [@thephpf](https://twitter.com/thephpf), чтобы следить за новостями.
* **[PHP 8.0.15](https://www.php.net/ChangeLog-8.php#8.0.15), [PHP 8.1.2](https://www.php.net/ChangeLog-8.php#8.1.2)**
Багфиксы для актуальных веток PHP.
* **[Drupal покинули группу PHP-FIG](https://github.com/php-fig/fig-standards/pull/1263)**
Зато теперь используют [PHPStan в ядре](https://www.drupal.org/node/3258232).
* **❌ [[RFC] User Defined Operator Overloads](https://wiki.php.net/rfc/user_defined_operator_overloads)**
Предложение добавить перегрузку операторов в PHP ожидаемо не прошло голосование.
Автор RFC опубликовал довольно интересную инструкцию [Как сделать RFC для PHP](https://www.reddit.com/r/PHP/comments/s0pv1e/how_to_make_an_rfc_for_php/) с пачкой неочевидных советов.
* **[[Disussion] Trait expects interface](https://externals.io/message/116802)**
Интересное обсуждение поднял [SerafimArts](https://habr.com/ru/users/serafimarts/) с предложением добавить поддержку ключевого слова `expects` для трейтов, как указатель на то, что класс использующий трейт, должен имплементировать определенный интерфейс.
**Скрытый текст**
```
trait LoggerTrait expects LoggerInterface
{
// ...
}
class MyService
{
use LoggerTrait; // Fatal Error: Class MyService expects LoggerInterface to be implemented
}
class MyService2 implements LoggerInterface
{
use LoggerTrait; // OK
}
```
Это уже ~~было в симпсонах~~ [есть в Psalm](https://psalm.dev/docs/annotating_code/supported_annotations/#psalm-require-extends).
🛠 Инструменты
-------------
* [thephpleague/flysystem 3.0.0](https://github.com/thephpleague/flysystem) – Мажорное обновление популярной библиотеки для работы с файловыми системами. [Блогпост](https://blog.frankdejonge.nl/flysystem-3-0-0-is-released/) в поддержку
* [spatie/ignition](https://github.com/spatie/ignition) – Обновлена библиотека для отображения страниц ошибок для отладки, многим знакомая по Laravel, но теперь не зависит от фреймворка и может быть использована в любых приложениях. [Блогпост](https://freek.dev/2169-a-better-error-page-for-symfony-applications) с обзором изменений.
* [chevere/xr](https://github.com/chevere/xr) – Отладочный сервер на ReactPHP, вдохновлённый идеей [spatie/ray](https://github.com/spatie/ray), но вместо десктопного приложения просто cli-команда для запуска. [Видеодемо](https://vimeo.com/662391948).
* [marijnvanwezel/reflection-file](https://github.com/marijnvanwezel/reflection-file) — Небольшая библиотека позволяет получить рефлексию по пути файла, а не по классу. Но если нужно больше возможностей, стоит обратить внимание на [Roave/BetterReflection](https://github.com/Roave/BetterReflection)
* [Doctrine ORM 2.11](https://www.doctrine-project.org/2022/01/11/orm-2.11.html) — С подержкой перечислений, виртуальных столбцов, read-only свойств, вложенных атрибутов и другого.
* [viewi/viewi](https://github.com/viewi/viewi) — Мощный инструмент для создания реактивных приложений используя только PHP и HTML. Теперь есть [интеграция с Symfony](https://viewi.net/docs/integrations-symfony).
* [JustSteveKing/php-sdk](https://github.com/JustSteveKing/php-sdk), [Sammyjo20/Saloon](https://github.com/Sammyjo20/Saloon) — Две похожих библиотеки с одинаковой идеей: упростить создание SDK для сервисов или организовать доступ к разным API в едином стиле.
* [AliSaleem27/wordle-cl](https://github.com/AliSaleem27/wordle-cli) — CLI-версия популярной игры Wordle для отгадывания пятибуквенных слов.
* [flow-php/etl](https://github.com/flow-php/etl) — Реализация паттерна Extract Transform Load для PHP. [Тред](https://twitter.com/norbert_tech/status/1484863793280786439) от автора.
* [staabm/phpstan-dba](https://github.com/staabm/phpstan-dba) — Расширение для [PHPStan](https://github.com/phpstan/phpstan), которое проверяет валидность SQL-запросов в `PDO`, `mysqli` и `doctrine/dbal`. [Демо](https://github.com/staabm/phpstan-dba/pull/61/files#diff-98a3c43049f6a0c859c0303037d9773534396533d7890bad187d465d390d634e).
Symfony
--------
* [Новый способ для старта Symfony-проекта](https://symfony.com/blog/a-better-way-to-quickly-start-symfony-projects)
* [Доступна сертификация по Symfony 6](https://symfony.com/blog/introducing-the-symfony-6-certification) — 90 минут на 75 вопросов из 15 тем.
* [norberttech/static-content-generator-bundle](https://github.com/norberttech/static-content-generator-bundle) — Генерирует статическую html-версию из вашего приложения на Symfony.
* [Using custom PHP attributes for registering and configuring Symfony Messenger handlers](https://angelovdejan.me/2022/01/09/custom-php-attributes-for-symfony-messenger-handlers.html)
* [JSON Columns and Doctrine DBAL 3 Upgrade](https://dunglas.fr/2022/01/json-columns-and-doctrine-dbal-3-upgrade/)
* [Fast, Smart Flex Recipe Upgrades with recipes:update](https://symfony.com/blog/fast-smart-flex-recipe-upgrades-with-recipes-update)
* [Неделя Symfony #786 (17-23 января 2022)](https://symfony.com/blog/a-week-of-symfony-786-17-23-january-2022)
Laravel
--------
* 9 февраля пройдёт бесплатная онлайн-конференция **[Laracon Online](https://laracon.net)**
Конференция обычно платная, но ближайшая Laracon Online Winter будет бесплатной с трансляцией на [YouTube](https://www.youtube.com/watch?v=5ubDLFKKk54).
* 🇷🇺 [Laravel 9 — Что нового?](https://laravel.demiart.ru/laravel-9-whats-new/)
* [ajimoti/roles-and-permissions](https://github.com/ajimoti/roles-and-permissions) – Простая библиотека для управления ролями и полномочиями.
* [timothepearce/laravel-quasar](https://github.com/timothepearce/laravel-quasar/) – Библиотека предоставляет API для создания и управления проекциями данных (агрегаций, статистики, временных рядов).
* [LaravelDaily/Laravel-Roadmap-Learning-Path](https://github.com/LaravelDaily/Laravel-Roadmap-Learning-Path) — Систематизированная подборка материалов для изучения Laravel от простого к сложному.
* [Building an API using TDD in Laravel](https://laravel.io/articles/building-and-api-using-tdd-in-laravel)
* [Efficient Pagination Using Deferred Joins](https://aaronfrancis.com/2022/efficient-pagination-using-deferred-joins)
*  [Cоздание фабрик и seeders при связях между моделями](https://habr.com/ru/post/645055/)
📝 Статьи
--------
* [PHP in 2022](https://stitcher.io/blog/php-in-2022) — Традиционный обзор экосистемы от Brent Roose.
* [Как подменить один класс из vendor без форков](https://downing.tech/posts/overriding-vendor-classes) — В статье правится автозагрузка в composer.json. Как вариант, можно еще использовать патчи с помощью [cweagans/composer-patches](https://github.com/cweagans/composer-patches).
* [Как делать микросервисы на PHP](https://blog.ecotone.tech/how-to-integrate-microservices-in-php/) с помощью [ecotoneFramework/ecotone](https://github.com/ecotoneFramework/ecotone) и RabbitMQ.
* [Доступ к приватным свойствам в PHP](https://www.lambda-out-loud.com/posts/accessing-private-properties-php/) — Вместо рефлексии и доступа через `Closure::bind` еще можно преобразовать к массиву и это будет даже быстрее.
*  [PHP на стероидах: Swoole in production](https://habr.com/ru/post/647077/)
*  [Всё о fsync](https://habr.com/ru/company/otus/blog/646553/)
* 🇷🇺 Beer::PHP 🍺: [DateTimeImmutable vs DateTimeInterface](https://t.me/beerphp/97)
📣 Сообщество
------------
* 📺 [PHP in 7 minutes](https://www.youtube.com/watch?v=IfcFQxYPTxo)
*
---
> Подписывайтесь на Telegram-канал **[PHP Digest](https://t.me/phpdigest)**.
>
>
> Этот дайджест подготовлен совместно с [Insolita](https://twitter.com/DonnaInsolita). Если вам понравился выпуск, подпишитесь на Юлию [в твиттере](https://twitter.com/DonnaInsolita) и поставьте плюс в пост, пожалуйста.
>
>
Заметили ошибку или опечатку? Сообщите в [личку хабра](https://habrahabr.ru/conversations/pronskiy/) или [телеграм](https://t.me/pronskiy).
Прислать ссылку можно [через форму](https://bit.ly/php-digest-add-link) или просто напишите мне в [телеграм](https://t.me/pronskiy).
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 219](https://habr.com/ru/post/599935/) | https://habr.com/ru/post/647491/ | null | ru | null |
# Подсчет количества ссылок на запись в таблице через Foreign Keys
Потребовалось для собственных целей решить следующую задачку — для одной таблички (File) для каждой записи автоматом рассчитывать количество внешних записей, связанных через foreign key. Задача решалась для конкретной структуры таблички File, но при желании решение можно переделать на более универсальное.
Оговорюсь, что решение писалось для ненагруженной базы, без миллионов строк записей и ежеминутного обновления, поэтому вопрос просаживания производительности не стоял.
Основной причиной было то, что количество внешних связей до таблицы File может меняться в процессе разработки и постоянно переделывать запрос было бы просто неразумным. Планировалась некая модульность в самой системе, поэтому точно неизвестны все конечные таблицы.
Скрипт для создания двух табличек:
```
CREATE TABLE [dbo].[File](
[IdFile] [int] IDENTITY(1, 1) NOT NULL,
[NameFile] [nvarchar](max) NOT NULL,
[CountUsage] [int] NOT NULL,
PRIMARY KEY (IdFile)
)
SET identity_insert [dbo].[File] ON;
INSERT INTO [dbo].[File] ([IdFile], [NameFile],[CountUsage])
VALUES (1, 'test1', 0), (2, 'test2', 1000)
SET identity_insert [dbo].[File] OFF;
CREATE TABLE [dbo].[TestForFiles](
[IdTest] [int] IDENTITY(1, 1) NOT NULL,
[IdFileForTest] [int] NOT NULL,
PRIMARY KEY (IdTest)
)
ALTER TABLE [dbo].[TestForFiles] WITH CHECK ADD CONSTRAINT [FK_TestForFiles_File] FOREIGN KEY([IdFileForTest])
REFERENCES [dbo].[File] ([IdFile])
ALTER TABLE [dbo].[TestForFiles] CHECK CONSTRAINT [FK_TestForFiles_File]
INSERT INTO [dbo].[TestForFiles] ([IdFileForTest])
VALUES (1), (1), (1), (2)
```
Получаем таблицы File и TestForFiles. Таблица TestForFiles ссылается на File по полю IdFileForTest.
Получается следующий набор данных:
Следующий скрипт генерирует запрос для подсчета количества записей в таблице:
```
DECLARE @sql_tables nvarchar(max) = null;
SELECT @sql_tables = CASE WHEN @sql_tables IS NULL THEN '' ELSE @sql_tables + CHAR(13) + CHAR(10) + ' UNION ALL' + CHAR(13) + CHAR(10) END + ' SELECT ' + c.name + ' AS IdFile, count(*) AS FileCount FROM ' + t.name + ' GROUP BY ' + c.name
FROM sys.foreign_key_columns AS fk
INNER JOIN sys.tables AS t ON fk.parent_object_id = t.object_id
INNER JOIN sys.columns AS c ON fk.parent_object_id = c.object_id AND fk.parent_column_id = c.column_id
INNER JOIN sys.columns AS c2 ON fk.referenced_object_id = c2.object_id AND fk.referenced_column_id = c2.column_id
WHERE fk.referenced_object_id = (SELECT object_id FROM sys.tables WHERE name = 'File') AND c2.name = 'IdFile';
IF @sql_tables IS NOT NULL
BEGIN
DECLARE @sql nvarchar(max) = 'UPDATE dbo.[File]' + CHAR(13) + CHAR(10) +
'SET CountUsage = t2.FileCount' + CHAR(13) + CHAR(10) +
'FROM dbo.[File]' + CHAR(13) + CHAR(10) +
'INNER JOIN (' + CHAR(13) + CHAR(10) +
' SELECT IdFile, SUM(FileCount) AS FileCount ' + CHAR(13) + CHAR(10) +
' FROM (' + CHAR(13) + CHAR(10) +
@sql_tables + CHAR(13) + CHAR(10) +
' ) t' + CHAR(13) + CHAR(10) +
' GROUP BY IdFile' + CHAR(13) + CHAR(10) +
') t2 ON t2.IdFile = dbo.[File].IdFile';
print @sql;
EXEC sp_executesql @sql;
END;
```
Генерируется вот такой запрос:
```
UPDATE dbo.[File]
SET CountUsage = t2.FileCount
FROM dbo.[File]
INNER JOIN (
SELECT IdFile, SUM(FileCount) AS FileCount
FROM (
SELECT IdFileForTest AS IdFile, count(*) AS FileCount FROM TestForFiles GROUP BY IdFileForTest
) t
GROUP BY IdFile
) t2 ON t2.IdFile = dbo.[File].IdFile
```
В результате выполнения имеем следующее содержимое таблиц:
Еще раз повторюсь — задача решалась под конкретную таблицу File, подсчет работает только для случаев, когда есть foreign keys по полю IdFile.
Заранее благодарю за критику. | https://habr.com/ru/post/335882/ | null | ru | null |
# Профилирование в облаке и не только
Приложение, оптимально использующее вычислительные ресурсы, это всегда хорошо и приятно. А если такое приложение работает в облаке, то ещё и выгодно. Порой очень выгодно. Просто потому, что в один квант оплаченного облачного вычислительного ресурса влезает, например, больше показанных в браузере котиков вместе с рекламой или платёжных транзакций за подписки на тех же котиков. И если с профилированием Go приложений [всё более или менее понятно](https://blog.golang.org/pprof), то для приложений, написанных на C или C++, всё гораздо интереснее.
Так как большинство проблем с производительностью материализуются, как правило, в продакшене, то нас будут интересовать те инструменты, которые не требуют инструментализации кода и, следовательно, остановки и перезапуска рабочих процессов. Кроме того, я не буду упоминать профилировщики, которые анализируют работу кода на уровне микроархитектуры процессора типа vTune. Во-первых, на эту тему статей и так хватает. Во-вторых, я ошибочно полагаю, что вопросы микроархитектуры больше актуальны для разработчиков middleware типа серверов баз данных или библиотек, которые настолько круты, что Хабр не читают. Итак.
До недавнего времени одним из таких инструментов были [Google perftools](https://github.com/gperftools/gperftools). Они включают два профилировщика: для CPU и для оперативной памяти. Начнём с первого.
Чтобы ваша программа стала профилируемой, её необходимо слинковать вместе с профилировщиком. Можно статически, можно динамически или же вообще подгрузить при помощи `LD_PRELOAD`. Его размер составляет около 60k, и он более никак не нагружает систему, когда не используется. Так что всегда линковаться с ним на боевых серверах будет не слишком накладно. Активируется он установкой переменной окружения `CPUPROFILE`:
```
$ CPUPROFILE=/tmp/envoy.prof envoy --concurrency 1 -c /path/to/config.yaml
```
В этом случае статистика начинает собираться с момента запуска исполняемого файла. Если дополнительно установить `CPUPROFILESIGNAL=12`, то активация будет включаться и выключаться по пользовательскому сигналу 12 (SIGUSR2).
Принцип работы CPU-профилировщика заключается в том, что он периодически (период тоже можно изменить) делает снимок текущих стеков процесса и сохраняет их файл, который можно проанализировать утилитой pprof. Например, чтобы быстро оценить, какие функции больше других — или, точнее сказать, чаще других — нагружают процессор, достаточно ввести
```
$ pprof -text /tmp/envoy.prof
File: envoy-static
Type: cpu
Showing nodes accounting for 17.74s, 86.75% of 20.45s total
Dropped 900 nodes (cum <= 0.10s)
flat flat% sum% cum cum%
5.19s 25.38% 25.38% 17.02s 83.23% deflate_fast
4.04s 19.76% 45.13% 4.04s 19.76% longest_match
3.92s 19.17% 64.30% 3.92s 19.17% compress_block
3.04s 14.87% 79.17% 3.04s 14.87% slide_hash
0.62s 3.03% 82.20% 0.63s 3.08% crc32_z
0.18s 0.88% 83.08% 0.18s 0.88% writev
0.12s 0.59% 83.67% 0.12s 0.59% readv
0.11s 0.54% 84.21% 0.11s 0.54% close
0.08s 0.39% 84.60% 0.17s 0.83% std::__uniq_ptr_impl::_M_ptr
0.06s 0.29% 84.89% 0.16s 0.78% std::get
0.06s 0.29% 85.18% 0.18s 0.88% std::unique_ptr::get
0.04s 0.2% 85.38% 18.54s 90.66% http_parser_execute
0.03s 0.15% 85.53% 0.33s 1.61% Envoy::Router::Filter::decodeHeaders
0.03s 0.15% 85.67% 0.26s 1.27% absl::container_internal::raw_hash_set::find
0.02s 0.098% 85.77% 17.16s 83.91% Envoy::Http::Http1::ClientConnectionImpl::onBody
0.01s 0.049% 85.82% 0.12s 0.59% Envoy::Event::DispatcherImpl::clearDeferredDeleteList
0.01s 0.049% 85.87% 20.03s 97.95% Envoy::Event::FileEventImpl::mergeInjectedEventsAndRunCb
0.01s 0.049% 85.92% 17.06s 83.42% Envoy::Extensions::Compression::Gzip::Compressor::ZlibCompressorImpl::process
0.01s 0.049% 85.97% 0.13s 0.64% Envoy::Http::ConnectionManagerImpl::ActiveStream::encodeData
0.01s 0.049% 86.01% 0.11s 0.54% Envoy::Http::HeaderString::HeaderString
0.01s 0.049% 86.06% 0.32s 1.56% Envoy::Http::Http1::ClientConnectionImpl::onHeadersComplete
0.01s 0.049% 86.11% 17.18s 84.01% Envoy::Http::Http1::ConnectionImpl::dispatchBufferedBody
0.01s 0.049% 86.16% 19.14s 93.59% Envoy::Network::ConnectionImpl::onReadReady
0.01s 0.049% 86.21% 0.24s 1.17% Envoy::Network::ConnectionImpl::onWriteReady
0.01s 0.049% 86.26% 0.20s 0.98% Envoy::Network::IoSocketHandleImpl::read
0.01s 0.049% 86.31% 0.21s 1.03% Envoy::Network::RawBufferSocket::doRead
...
```
Для более детального анализа можно воспользоваться довольно удобным web-интерфейсом, который предоставляет тот же pprof:
```
$ pprof -http=localhost:8080 /tmp/envoy.prof
```
Теперь по адресу <http://localhost:8080> можно взглянуть на красивый граф вызовов функции (callgraph)
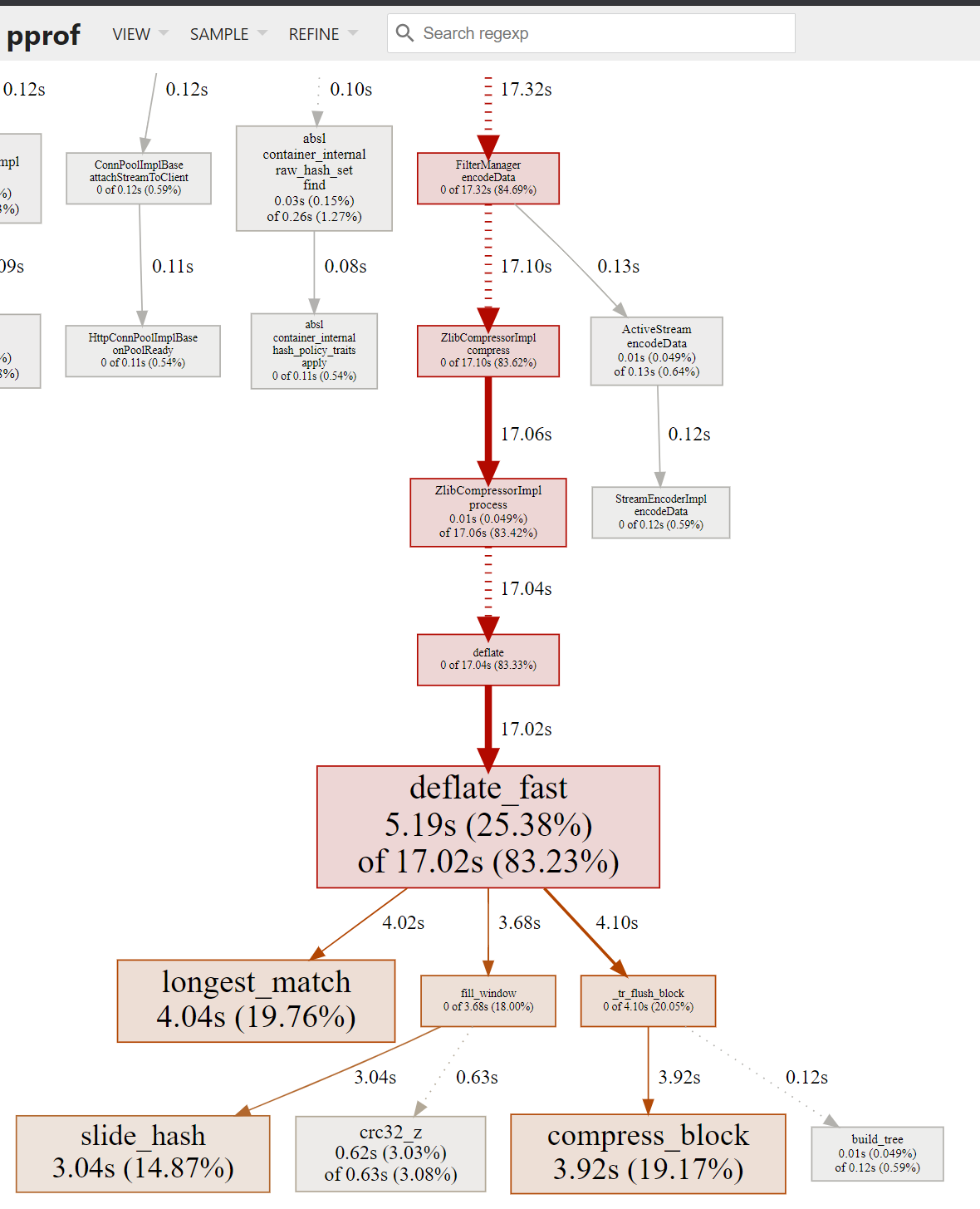
и на flamegraph
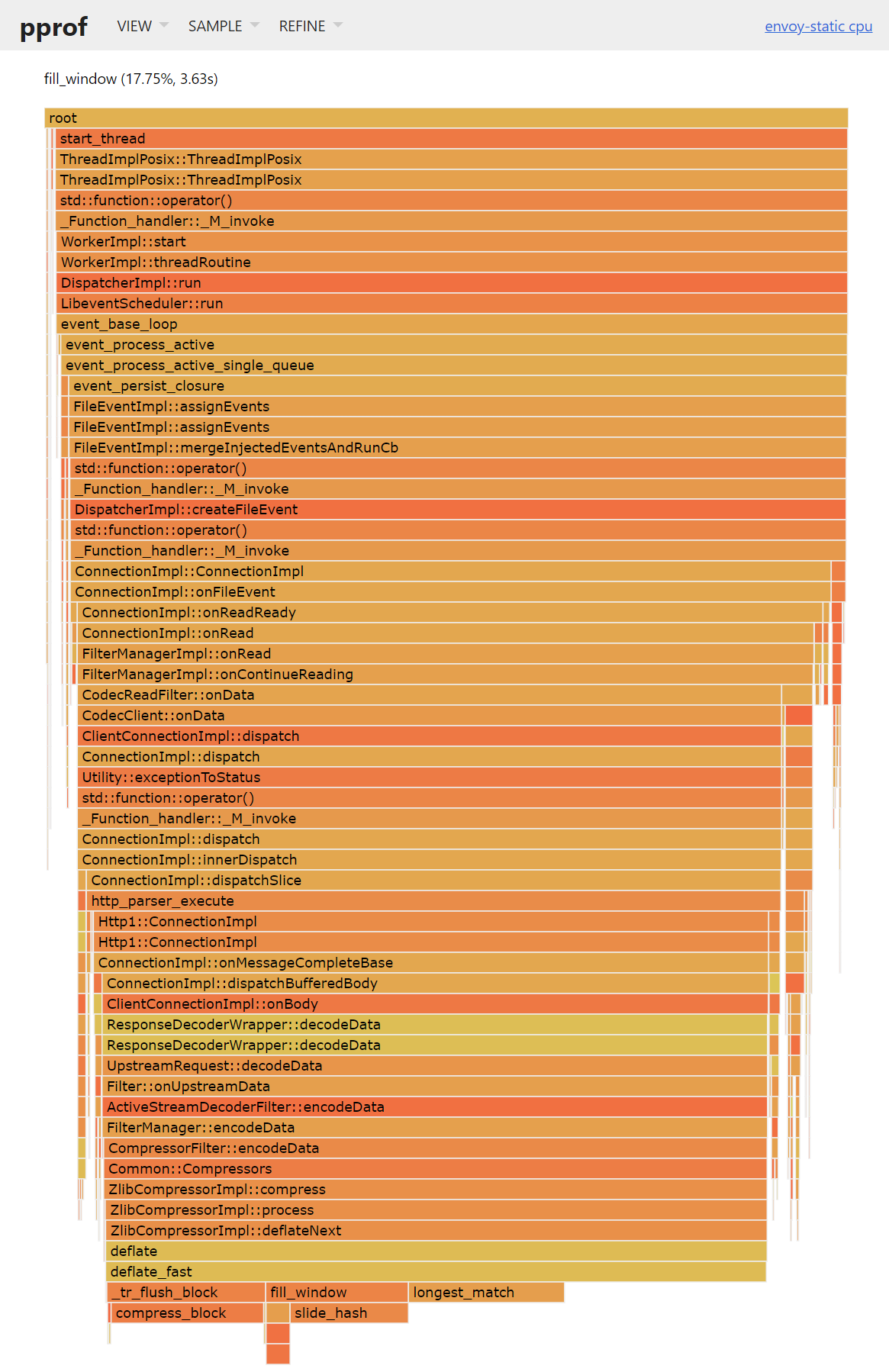
С анализом же расхода памяти всё несколько сложнее, покуда профилировщик кучи является органической частью tcmalloc (thread caching malloc) — альтернативного менеджера памяти от gperftools минимизирующего количество системных вызовов за счет предварительного выделения памяти сверх необходимого. То есть, чтобы иметь возможность профилировать память на боевой системе, необходимо отказаться от стандартных реализаций malloc() и new и всегда линковаться с tcmalloc. И хоть tcmalloc считается быстрее и эффективнее особенно в многопоточных программах, не все готовы его использовать хотя бы из-за немного большего расхода памяти. Тем не менее профилировать память с ним так же просто как и CPU:
```
$ HEAPPROFILE=/tmp/envoyhprof envoy --concurrency 1 -c /path/to/config.yaml
…
Dumping heap profile to /tmp/envoyhprof.0001.heap (1024 MB allocated cumulatively, 6 MB currently in use)
Dumping heap profile to /tmp/envoyhprof.0002.heap (2048 MB allocated cumulatively, 6 MB currently in use)
Dumping heap profile to /tmp/envoyhprof.0003.heap (3072 MB allocated cumulatively, 6 MB currently in use)
Dumping heap profile to /tmp/envoyhprof.0004.heap (4096 MB allocated cumulatively, 6 MB currently in use)
Dumping heap profile to /tmp/envoyhprof.0005.heap (5120 MB allocated cumulatively, 6 MB currently in use)
^C
Dumping heap profile to /tmp/envoyhprof.0006.heap (Exiting, 5 MB in use)
```
Теперь, чтобы узнать какие функции больше всего выделяли память на куче, надо снова воспользоваться pprof:
```
$ pprof -text -sample_index=alloc_space /tmp/envoyhprof.0005.heap
File: envoy-static
Type: alloc_space
Showing nodes accounting for 1558.99MB, 98.71% of 1579.32MB total
Dropped 1117 nodes (cum <= 7.90MB)
flat flat% sum% cum cum%
1043.23MB 66.06% 66.06% 1043.23MB 66.06% zcalloc
240.73MB 15.24% 81.30% 240.73MB 15.24% Envoy::Zlib::Base::Base
150.71MB 9.54% 90.84% 406.68MB 25.75% std::make_unique
79.15MB 5.01% 95.85% 79.15MB 5.01% std::allocator_traits::allocate
18.68MB 1.18% 97.04% 26.62MB 1.69% Envoy::Http::ConnectionManagerImpl::newStream
15.18MB 0.96% 98.00% 15.18MB 0.96% Envoy::InlineStorage::operator new
8.39MB 0.53% 98.53% 8.39MB 0.53% std::__cxx11::basic_string::basic_string
1.98MB 0.13% 98.65% 31.99MB 2.03% Envoy::Http::Http1::allocateConnPool(Envoy::Event::Dispatcher&, Envoy::Random::RandomGenerator&, std::shared_ptr, Envoy::Upstream::ResourcePriority, std::shared_ptr const&, std::shared_ptr const&, Envoy::Upstream::ClusterConnectivityState&)::$_1::operator()
0.93MB 0.059% 98.71% 38.29MB 2.42% Envoy::Server::ConnectionHandlerImpl::ActiveTcpListener::newConnection
0 0% 98.71% 59.54MB 3.77% Envoy::Buffer::WatermarkBufferFactory::create
0 0% 98.71% 73.55MB 4.66% Envoy::ConnectionPool::ConnPoolImplBase::newStream
...
```
Как следует из таблицы, больше всего памяти выделяла `zcalloc()` из zlib, что совсем не удивительно, поскольку во время профилирования приложение сжимало прокачиваемый через себя трафик.
Впрочем, это не самая интересная метрика. Обычно для нас важнее функции, которые используют больше всего памяти в настоящий момент:
```
$ pprof -text -sample_index=inuse_space /tmp/envoyhprof.0005.heap
File: envoy-static
Type: inuse_space
Showing nodes accounting for 6199.96kB, 96.84% of 6402.51kB total
Dropped 1016 nodes (cum <= 32.01kB)
flat flat% sum% cum cum%
2237.76kB 34.95% 34.95% 3232.51kB 50.49% std::make_unique
2041.45kB 31.89% 66.84% 2041.45kB 31.89% std::allocator_traits::allocate
375.03kB 5.86% 72.69% 753.26kB 11.77% google::protobuf::DescriptorPool::Tables::AllocateString[abi:cxx11]
267.78kB 4.18% 76.88% 267.78kB 4.18% std::__cxx11::basic_string::_M_mutate
201.61kB 3.15% 80.03% 201.61kB 3.15% zalloc_with_calloc
160.43kB 2.51% 82.53% 160.43kB 2.51% google::protobuf::Arena::CreateMessageInternal (inline)
146.74kB 2.29% 84.82% 146.74kB 2.29% std::__cxx11::basic_string::_M_construct
141.38kB 2.21% 87.03% 157.38kB 2.46% google::protobuf::DescriptorPool::Tables::AllocateMessage
139.88kB 2.18% 89.22% 139.88kB 2.18% google::protobuf::DescriptorPool::Tables::AllocateEmptyString[abi:cxx11]
88.04kB 1.38% 90.59% 113.12kB 1.77% google::protobuf::DescriptorPool::Tables::AllocateFileTables
72.52kB 1.13% 91.72% 72.90kB 1.14% ares_init_options
71kB 1.11% 92.83% 71kB 1.11% _GLOBAL__sub_I_eh_alloc.cc
69.81kB 1.09% 93.92% 69.81kB 1.09% zcalloc
51.16kB 0.8% 94.72% 51.16kB 0.8% google::protobuf::Arena::CreateArray (inline)
46.81kB 0.73% 95.45% 60.41kB 0.94% google::protobuf::Arena::CreateInternal (inline)
37.23kB 0.58% 96.03% 37.23kB 0.58% re2::PODArray::PODArray
33.53kB 0.52% 96.56% 33.53kB 0.52% std::__cxx11::basic_string::_M_assign
11.50kB 0.18% 96.74% 2213.77kB 34.58% Envoy::ConstSingleton::get
6.06kB 0.095% 96.83% 38.85kB 0.61% google::protobuf::internal::ArenaStringPtr::Set
0.24kB 0.0038% 96.84% 2590.71kB 40.46% Envoy::Server::InstanceImpl::InstanceImpl
0 0% 96.84% 79.56kB 1.24% Envoy::(anonymous namespace)::jsonConvertInternal
0 0% 96.84% 84.48kB 1.32% Envoy::(anonymous namespace)::tryWithApiBoosting
0 0% 96.84% 726.42kB 11.35% Envoy::Config::ApiTypeOracle::getEarlierVersionDescriptor
0 0% 96.84% 77.22kB 1.21% Envoy::Config::Utility::createTagProducer
0 0% 96.84% 706.72kB 11.04% Envoy::Config::Utility::getAndCheckFactory
0 0% 96.84% 707.38kB 11.05% Envoy::Config::Utility::getFactoryByType
...
```
Ожидаемо, большую часть памяти держит `std::make_unique()`. И вообще внутри кода Envoy оптимизировать особо нечего — главные потребители находятся в сторонних библиотеках. Однако если взглянуть на callgraph или flamegraph, то можно узнать, например, на какие функции обратить внимание, чтобы пореже звать `std::make_unique()`. Web-интерфейс в этом случае наиболее удобен
```
$ pprof -http=localhost:8080 /tmp/envoyhprof.0005.heap
```
В браузере вы увидите что-то вроде
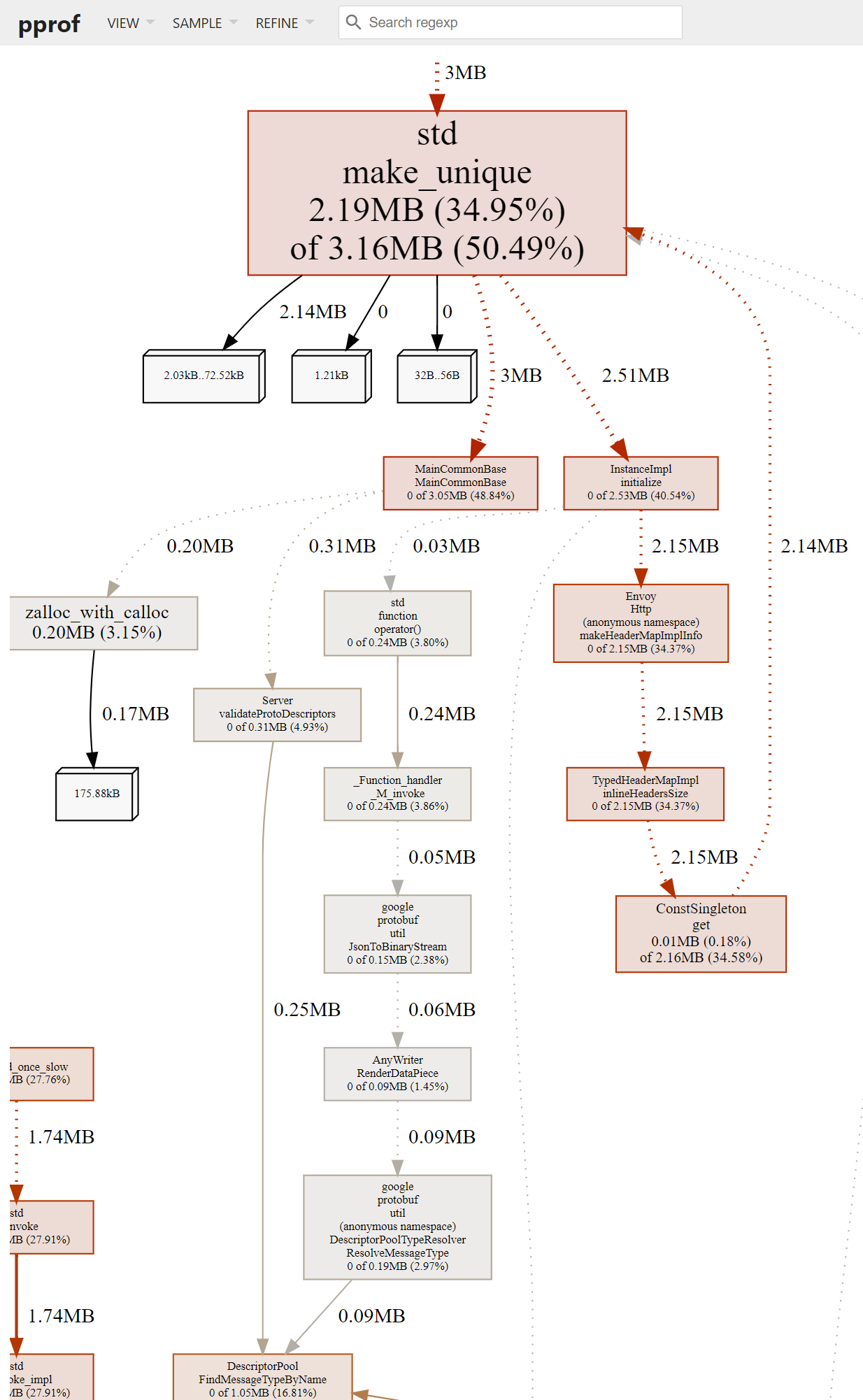
и

Можно также проверить, не течет ли память. Вычтем из результата самую первую часть дампа, где происходит инициализация программы:
```
$ pprof -text -sample_index=inuse_space --base=/tmp/envoyhprof.0001.heap /tmp/envoyhprof.0005.heap
File: envoy-static
Type: inuse_space
Showing nodes accounting for 1460B, 10.38% of 14060B total
flat flat% sum% cum cum%
1460B 10.38% 10.38% 1460B 10.38% hist_accumulate
0 0% 10.38% 1460B 10.38% Envoy::Event::DispatcherImpl::DispatcherImpl(std::__cxx11::basic_string const&, Envoy::Api::Api&, Envoy::Event::TimeSystem&, std::shared_ptr const&)::$_1::operator()
0 0% 10.38% 1460B 10.38% Envoy::Event::DispatcherImpl::run
0 0% 10.38% 1460B 10.38% Envoy::Event::DispatcherImpl::runPostCallbacks
0 0% 10.38% 1460B 10.38% Envoy::Event::LibeventScheduler::run
0 0% 10.38% 1460B 10.38% Envoy::Event::SchedulableCallbackImpl::SchedulableCallbackImpl(Envoy::CSmartPtr&, std::function)::$_0::__invoke
0 0% 10.38% 1460B 10.38% Envoy::Event::SchedulableCallbackImpl::SchedulableCallbackImpl(Envoy::CSmartPtr&, std::function)::$_0::operator()
0 0% 10.38% 1460B 10.38% Envoy::MainCommon::main
0 0% 10.38% 1460B 10.38% Envoy::MainCommon::run
0 0% 10.38% 1460B 10.38% Envoy::MainCommonBase::run
0 0% 10.38% 1460B 10.38% Envoy::Server::InstanceImpl::run
0 0% 10.38% 1460B 10.38% Envoy::Stats::ParentHistogramImpl::merge
0 0% 10.38% 730B 5.19% Envoy::Stats::ThreadLocalHistogramImpl::merge
0 0% 10.38% 1460B 10.38% Envoy::Stats::ThreadLocalStoreImpl::mergeHistograms(std::function)::$_2::operator()
0 0% 10.38% 1460B 10.38% Envoy::Stats::ThreadLocalStoreImpl::mergeInternal
0 0% 10.38% 1460B 10.38% __libc_start_main
0 0% 10.38% 1460B 10.38% event_base_loop
0 0% 10.38% 1460B 10.38% event_process_active
0 0% 10.38% 1460B 10.38% event_process_active_single_queue
0 0% 10.38% 1460B 10.38% main
0 0% 10.38% 1460B 10.38% std::_Function_handler::_M_invoke
0 0% 10.38% 1460B 10.38% std::function::operator()
```
Всё выглядит неплохо, память весьма умеренно тратится только на хранение накопленной статистики.
По закону жанра на этом месте должны начаться проблемы. Заключаются они в том, что не так давно Google выложил в своём аккаунте на GitHub новый, улучшенный tcmalloc. В котором, кэши памяти создаются не для потоков, как в оригинальной версии, а для ядер процессора. В задачах, создающих большое количество потоков, это может заметно улучшить производительность и снизить расход памяти.
Плохая же новость в том, что в новом tcmalloc отсутствует профилировщик. Однако же он теперь не особенно-то и нужен. В частности для профилирования CPU теперь вполне достаточно утилиты perf. Чтобы ею воспользоваться даже не нужно ни с чем линковаться. Всё нужное уже есть в ядре Linux:
```
$ perf record -g -F 99 -p `pgrep envoy`
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.694 MB perf.data (1532 samples) ]
```
Результат сохраняется в файл `perf.data`, формат которого понятен pprof (начиная с некоторой версии):
```
$ pprof -http=localhost:8080 perf.data
```
То есть результат совершенно идентичен варианту с использованием gperftools.
Однако имеются подозрения, что `perf.data` содержит даже больше полезных данных, чем pprof позволяет отобразить. В частности я не смог найти, как сделать разбивку стеков по потокам. Если кто-то знает, напишите, пожалуйста, в комментариях. Такая разбивка может быть полезна для обнаружения узких мест, когда несколько потоков делегируют какую-то работу одному единственному потоку и перегружают его. Пока что для меня незаменимым инструментом для таких случаев служит набор скриптов Брендана Грегга: <https://github.com/brendangregg/FlameGraph>. Если их применить к имеющемуся файлу `perf.data`, то получим flamegraph, в котором можно различить три потока — один главный и два рабочих.
```
$ perf script --input=perf.data | ./FlameGraph/stackcollapse-perf.pl > out.perf-folded
$ ./FlameGraph/flamegraph.pl out.perf-folded > perf.svg
```
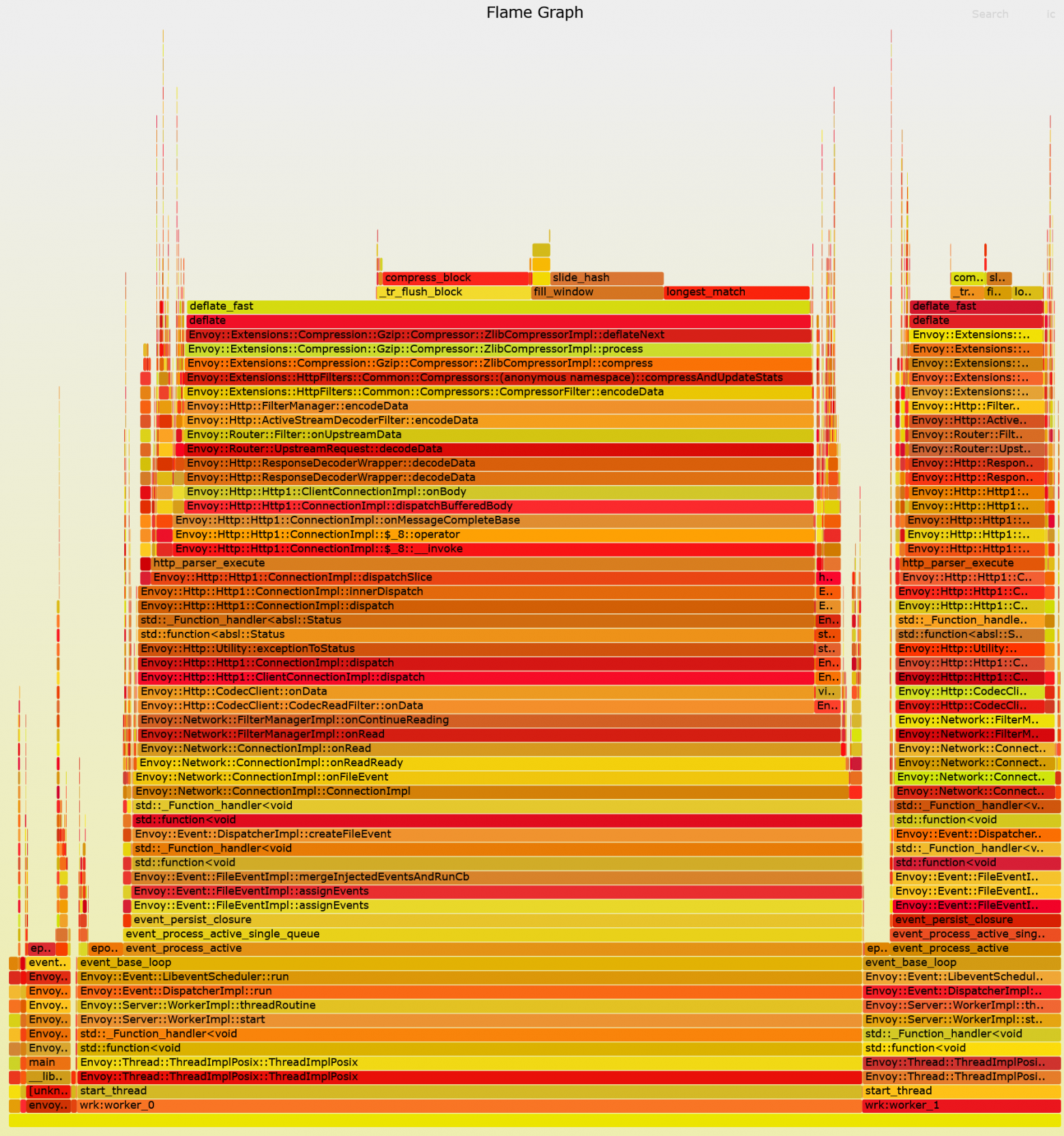
Впрочем, глядя на такой flamegraph, далеко не всегда мы можем догадаться, что имеем дело с блокировками на перегруженном потоке. Полезнее может оказаться картинка с неработающими потоками, то есть ожидающими снятия какой-нибудь блокировки. Опять же, всё нужное для этого есть в ядре Linux — речь идёт о eBPF. Инструментализация кода не требуется. Только убедитесь, что в вашей системе установлен пакет с инструментами для “BPF Compiler Collection”. В Fedora он называется bcc-tools.
```
$ /usr/share/bcc/tools/offcputime -df -p `pgrep envoy` 30 > out.stacks
$ ./FlameGraph/flamegraph.pl --color=io --title='Off-CPU Time Flame Graph' < out.stacks > off-cpu.svg
```
Для примера приведу два графика для Envoy под большой нагрузкой запущенного с четырьмя и девятью рабочими потоками.
Это 4 потока
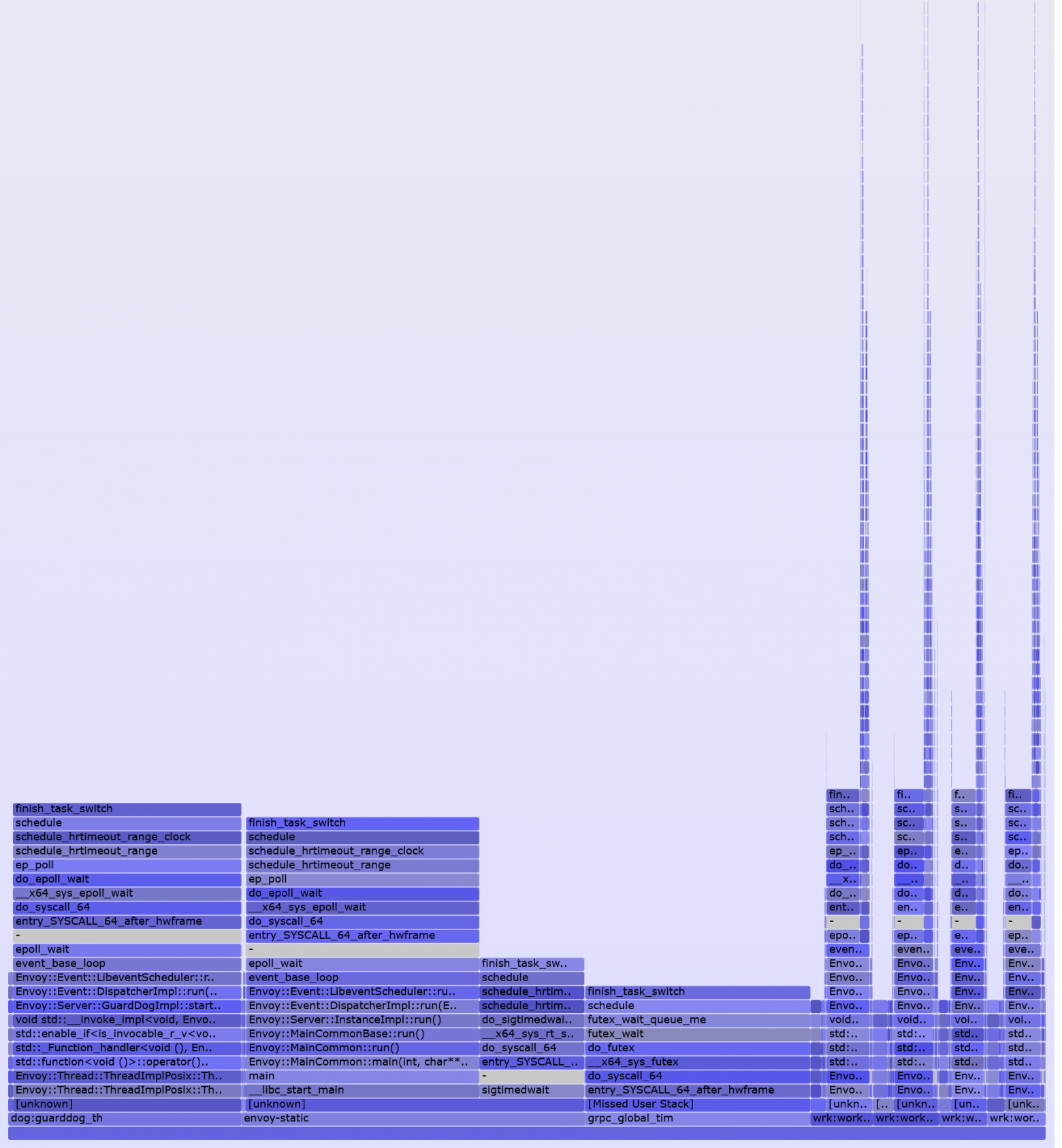
Это 9 потоков
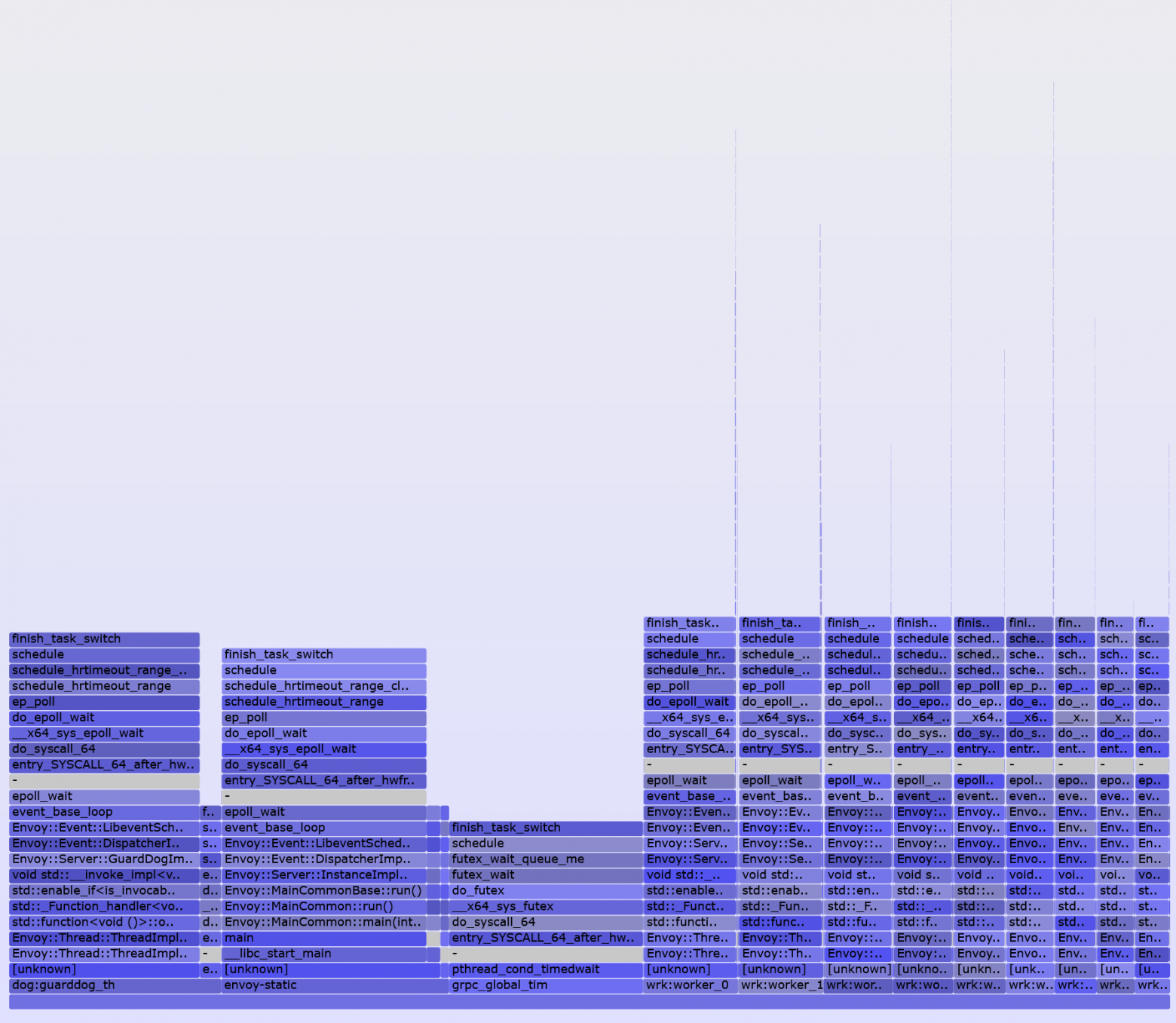
Можно заметить, что при большем количестве рабочих потоков оные всё большую часть времени ничегонеделания бесполезно ждут в цикле событий вместо того, чтобы с пользой ждать, например, возврата из других системных вызовов. При том, что запросы к серверу остаются необслуженными. Это как раз результат эксперимента по передаче части работы от рабочих потоков одному специализированному потоку — плохая идея в общем случае.
А вот с профилированием памяти не всё так радужно, хотя и тут можно кое-чего добиться полагаясь только на eBPF и на утилиту stackcount из bcc-tools. Для того, чтобы получить flamegraph в стиле pprof, надо сделать следующее
```
$ sudo /usr/share/bcc/tools/stackcount -p `pgrep envoy` -U "/full/path/to/envoy:_Znwm" > out.stack
$ ./FlameGraph/stackcollapse.pl < out.stacks | ./FlameGraph/flamegraph.pl --color=mem --title="operator new(std::size_t) Flame Graph" --countname="calls" > out.svg
```
stackcount группирует вызовы к некоторой функции по идентичным стекам вызовов к ней (stack traces) и суммирует их. Обратите внимание на странно выглядящий параметр `-U "/full/path/to/envoy:_Znwm"`. Он указывает на некоторую функцию в пространстве пользователя (в противоположность параметру -K, который может указать на функцию в пространстве ядра). В общем случае он задаётся как `-U lib:func`, где `lib` — это имя библиотеки, а `func` — имя функции в том виде, как оно выглядит выводе `objdump -tT /path/to/lib`. В нашем случае `_Znwm` — это не что иное как `void* operator new(std::size_t)`. А путь к исполняемому файлу вместо имени библиотеки указан потому, что есть нюанс — Envoy статически слинкован с tcmalloc. К сожалению, из документации вы не узнаете о таких мелочах.
Чтобы понять как C++ компилятор видоизменит (mangle) нужную вам функцию, воспользуйтесь вот таким однострочником
```
$ echo -e "#include \n void\* operator new(std::size\_t) {} " | g++ -x c++ -S - -o- 2> /dev/null
.file ""
.text
.globl \_Znwm
.type \_Znwm, @function
\_Znwm:
.LFB73:
.cfi\_startproc
pushq %rbp
.cfi\_def\_cfa\_offset 16
.cfi\_offset 6, -16
movq %rsp, %rbp
.cfi\_def\_cfa\_register 6
movq %rdi, -8(%rbp)
nop
popq %rbp
.cfi\_def\_cfa 7, 8
ret
.cfi\_endproc
.LFE73:
.size \_Znwm, .-\_Znwm
.ident "GCC: (GNU) 10.2.1 20201016 (Red Hat 10.2.1-6)"
.section .note.GNU-stack,"",@progbits
```
Обратите внимание, что имя функции будет разным на 32 и 64 разрядных платформах из-за разного размера `size_t`. Кроме того `void* operator new[](std::size_t)` — это отдельная функция. Как, впрочем, и `malloc()` с `calloc()`, которые будучи C-функциями свои имена не меняют.
Снова должен с сожалением констатировать, что stackcount покажет не сколько именно памяти выделялось в той или иной функции, а как часто. Но зато этот метод анализа применим даже в тех программах, которые не полагаются на готовые менеджеры памяти, а реализуют для работы с кучей свой, родной и ни на что не похожий, бесконечно оптимизированный “велосипед” (конечно же, с отсутствующими при этом средствами анализа расхода памяти).
Чтобы ответить на вопрос “сколько”, нужен инструмент, который будет суммировать аргументы вызовов malloc() или new, а лучше все сразу. То есть что-то вроде [этого](https://github.com/brendangregg/BPF-tools/blob/master/old/2017-12-23/mallocstacks.py). В идеале хотелось бы, чтобы во внимание принимались ещё free() и delete, но это уже из области магии. Если кто-то уже реализовал такое на eBPF, отпишитесь, пожалуйста, в комментариях.
В качестве заключения хочу порекомендовать всем, кого интересует тема производительности и оптимизации внимательно изучить [блог Брендана Грегга](http://www.brendangregg.com/). Там бездна полезной информации. | https://habr.com/ru/post/536100/ | null | ru | null |
# 3D Роза методом Монте-Карло
[](http://js1k.com/2012-love/demo/1022)
В этой статье Roman Cortes надеется вдохновить читателей, интересующихся компьютерной графикой, чтобы экспериментировать и весело провести время с различными методами визуализации.
[Roman Cortes](http://www.romancortes.com/blog/1k-rose/) для [конкурса любви 2012 js1k](http://js1k.com/2012-love/) сделал 3D розу на javascript (canvas), используя метод Монте-Карло.
#### Кратко о методе Монте-Карло
[Ме́тод Мо́нте-Ка́рло](http://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%9C%D0%BE%D0%BD%D1%82%D0%B5-%D0%9A%D0%B0%D1%80%D0%BB%D0%BE) — общее название группы численных методов, основанных на получении большого числа реализаций стохастического (случайного) процесса, который формируется таким образом, чтобы его вероятностные характеристики совпадали с аналогичными величинами решаемой задачи. Используется для решения задач в различных областях физики, химии, математики, экономики, оптимизации, теории управления и др.
#### Отрисовка поверхностей
Чтобы определить форму розы будем использовать несколько поверхностей. В общей сложности это 31 поверхность: 24 лепестка, 4 чашелистика (тонкие листья вокруг лепестков), 2 листа и 1 стебель розы.
2d пример функции определения поверхности:
```
function surface(a, b) { // I'm using a and b as parameters ranging from 0 to 1.
return {
x: a*50,
y: b*50
};
// this surface will be a square of 50x50 units of size
}
```
Код для отрисовки:
```
var canvas = document.body.appendChild(document.createElement("canvas")),
context = canvas.getContext("2d"),
a, b, position;
// Now I'm going to sample the surface at .1 intervals for a and b parameters:
for (a = 0; a < 1; a += .1) {
for (b = 0; b < 1; b += .1) {
position = surface(a, b);
context.fillRect(position.x, position.y, 1, 1);
}
}
```
Результат:

Сейчас мы уменьшим интервал этих пикселей для более плотной картинки

Это позволяет переопределить функцию поверхности для отрисовки круга. Есть несколько способов сделать это, но мы будем использовать следующую формулу: (x-x0)^2 + (y-y0)^2 < radius^2, где (x0, y0) является центром окружности:
```
function surface(a, b) {
var x = a * 100,
y = b * 100,
radius = 50,
x0 = 50,
y0 = 50;
if ((x - x0) * (x - x0) + (y - y0) * (y - y0) < radius * radius) {
// inside the circle
return {
x: x,
y: y
};
} else {
// outside the circle
return null;
}
}
```
Чтобы не зарисовывать точки вне круга добавим условие:
```
if (position = surface(a, b)) {
context.fillRect(position.x, position.y, 1, 1);
}
```
Получаем:

Как уже говорилось, существуют различные способы определения круга, а нам надо показать его только в одну сторону:
```
function surface(a, b) {
// Circle using polar coordinates
var angle = a * Math.PI * 2,
radius = 50,
x0 = 50,
y0 = 50;
return {
x: Math.cos(angle) * radius * b + x0,
y: Math.sin(angle) * radius * b + y0
};
}
```
Следующая функция позволяет нам деформировать круг, чтобы сделать его похожим на лепесток:
```
function surface(a, b) {
var x = a * 100,
y = b * 100,
radius = 50,
x0 = 50,
y0 = 50;
if ((x - x0) * (x - x0) + (y - y0) * (y - y0) < radius * radius) {
return {
x: x,
y: y * (1 + b) / 2 // deformation
};
} else {
return null;
}
}
```

Хочу добавить немного цвета:
```
function surface(a, b) {
var x = a * 100,
y = b * 100,
radius = 50,
x0 = 50,
y0 = 50;
if ((x - x0) * (x - x0) + (y - y0) * (y - y0) < radius * radius) {
return {
x: x,
y: y * (1 + b) / 2,
r: 100 + Math.floor((1 - b) * 155), // this will add a gradient
g: 50,
b: 50
};
} else {
return null;
}
}
for (a = 0; a < 1; a += .01) {
for (b = 0; b < 1; b += .001) {
if (point = surface(a, b)) {
context.fillStyle = "rgb(" + point.r + "," + point.g + "," + point.b + ")";
context.fillRect(point.x, point.y, 1, 1);
}
}
}
```

Лепестки готовы!
#### 3D-поверхность и перспективная проекция
Сделать 3D поверхность очень просто: просто добавьте a z свойства на поверхность. В качестве примера сделаем трубу/цилиндр:
```
function surface(a, b) {
var angle = a * Math.PI * 2,
radius = 100,
length = 400;
return {
x: Math.cos(angle) * radius,
y: Math.sin(angle) * radius,
z: b * length - length / 2, // by subtracting length/2 I have centered the tube at (0, 0, 0)
r: 0,
g: Math.floor(b * 255),
b: 0
};
}
```
Для добавления перспективы проекции надо определить положение камеры
Камеру будем делать в точке (0, 0, cameraZ), называться она будет «perspective» — расстояние от камеры к холсту. Центр будет в точке (0, 0, cameraZ + perspective). Теперь каждая точка будет проецироваться на холсте:
```
var pX, pY, // projected on canvas x and y coordinates
perspective = 350,
halfHeight = canvas.height / 2,
halfWidth = canvas.width / 2,
cameraZ = -700;
for (a = 0; a < 1; a += .001) {
for (b = 0; b < 1; b += .01) {
if (point = surface(a, b)) {
pX = (point.x * perspective) / (point.z - cameraZ) + halfWidth;
pY = (point.y * perspective) / (point.z - cameraZ) + halfHeight;
context.fillStyle = "rgb(" + point.r + "," + point.g + "," + point.b + ")";
context.fillRect(pX, pY, 1, 1);
}
}
}
```
Результат:

#### Z-buffer
Z-буфер является довольно распространенной технологией в области компьютерной графики для учета удаленности элементов изображения.

Это видно на Z-буфере розы: черный элемент далеко от камеры, белый близко к ней.
Реализация:
```
var zBuffer = [],
zBufferIndex;
for (a = 0; a < 1; a += .001) {
for (b = 0; b < 1; b += .01) {
if (point = surface(a, b)) {
pX = Math.floor((point.x * perspective) / (point.z - cameraZ) + halfWidth);
pY = Math.floor((point.y * perspective) / (point.z - cameraZ) + halfHeight);
zBufferIndex = pY * canvas.width + pX;
if ((typeof zBuffer[zBufferIndex] === "undefined") || (point.z < zBuffer[zBufferIndex])) {
zBuffer[zBufferIndex] = point.z;
context.fillStyle = "rgb(" + point.r + "," + point.g + "," + point.b + ")";
context.fillRect(pX, pY, 1, 1);
}
}
}
}
```
#### Вращение цилиндра
Вы можете использовать любой метод вектора вращения. В случае с розой, а здесь мы используем [теорему вращения Эйлера](http://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%B2%D1%80%D0%B0%D1%89%D0%B5%D0%BD%D0%B8%D1%8F_%D0%AD%D0%B9%D0%BB%D0%B5%D1%80%D0%B0). Давайте реализуем вращение вокруг оси Y:
```
function surface(a, b) {
var angle = a * Math.PI * 2,
radius = 100,
length = 400,
x = Math.cos(angle) * radius,
y = Math.sin(angle) * radius,
z = b * length - length / 2,
yAxisRotationAngle = -.4, // in radians!
rotatedX = x * Math.cos(yAxisRotationAngle) + z * Math.sin(yAxisRotationAngle),
rotatedZ = x * -Math.sin(yAxisRotationAngle) + z * Math.cos(yAxisRotationAngle);
return {
x: rotatedX,
y: y,
z: rotatedZ,
r: 0,
g: Math.floor(b * 255),
b: 0
};
}
```
Результат:

#### Метод Монте-Карло
```
var i;
window.setInterval(function () {
for (i = 0; i < 10000; i++) {
if (point = surface(Math.random(), Math.random())) {
pX = Math.floor((point.x * perspective) / (point.z - cameraZ) + halfWidth);
pY = Math.floor((point.y * perspective) / (point.z - cameraZ) + halfHeight);
zBufferIndex = pY * canvas.width + pX;
if ((typeof zBuffer[zBufferIndex] === "undefined") || (point.z < zBuffer[zBufferIndex])) {
zBuffer[zBufferIndex] = point.z;
context.fillStyle = "rgb(" + point.r + "," + point.g + "," + point.b + ")";
context.fillRect(pX, pY, 1, 1);
}
}
}
}, 0);
```
#### Заключение
Чтобы завершить розу, пришлось добавить третий параметр для функции которая выбирает часть розы. В случае c лепестками используем повороты и растяжки/деформации. Все это делается путем смешивания, которые описаны в этой статье.
Выбор на Монте-Карло/Z-буферизации пал для художественных целей. Не очень инновационный и не очень полезный скрипт, но очень хорошо вписывается в контекст js1k, где простота и минимальные размеры желательны.
Даже не верится что вся роза может находится в [этом](http://forum.xeksec.com/habr/rose/) коде:
```
JS1k, 1k demo submission [1022]
var b = document.body;
var c = document.getElementsByTagName('canvas')[0];
var a = c.getContext('2d');
document.body.clientWidth; // fix bug in webkit: http://qfox.nl/weblog/218
// start of submission //
with(m=Math)C=cos,S=sin,P=pow,R=random;c.width=c.height=f=500;h=-250;function p(a,b,c){if(c>60)return[S(a\*7)\*(13+5/(.2+P(b\*4,4)))-S(b)\*50,b\*f+50,625+C(a\*7)\*(13+5/(.2+P(b\*4,4)))+b\*400,a\*1-b/2,a];A=a\*2-1;B=b\*2-1;if(A\*A+B\*B<1){if(c>37){n=(j=c&1)?6:4;o=.5/(a+.01)+C(b\*125)\*3-a\*300;w=b\*h;return[o\*C(n)+w\*S(n)+j\*610-390,o\*S(n)-w\*C(n)+550-j\*350,1180+C(B+A)\*99-j\*300,.4-a\*.1+P(1-B\*B,-h\*6)\*.15-a\*b\*.4+C(a+b)/5+P(C((o\*(a+1)+(B>0?w:-w))/25),30)\*.1\*(1-B\*B),o/1e3+.7-o\*w\*3e-6]}if(c>32){c=c\*1.16-.15;o=a\*45-20;w=b\*b\*h;z=o\*S(c)+w\*C(c)+620;return[o\*C(c)-w\*S(c),28+C(B\*.5)\*99-b\*b\*b\*60-z/2-h,z,(b\*b\*.3+P((1-(A\*A)),7)\*.15+.3)\*b,b\*.7]}o=A\*(2-b)\*(80-c\*2);w=99-C(A)\*120-C(b)\*(-h-c\*4.9)+C(P(1-b,7))\*50+c\*2;z=o\*S(c)+w\*C(c)+700;return[o\*C(c)-w\*S(c),B\*99-C(P(b, 7))\*50-c/3-z/1.35+450,z,(1-b/1.2)\*.9+a\*.1, P((1-b),20)/4+.05]}}setInterval('for(i=0;i<1e4;i++)if(s=p(R(),R(),i%46/.74)){z=s[2];x=~~(s[0]\*f/z-h);y=~~(s[1]\*f/z-h);if(!m[q=y\*f+x]|m[q]>z)m[q]=z,a.fillStyle="rgb("+~(s[3]\*h)+","+~(s[4]\*h)+","+~(s[3]\*s[3]\*-80)+")",a.fillRect(x,y,1,1)}',0)
// end of submission //
``` | https://habr.com/ru/post/137762/ | null | ru | null |
# Хранение кода в бд или собираем код по кирпичикам
###### Данная статья написана [Napolsky](https://habrahabr.ru/users/napolsky/). По известным причина он не смог ее опубликовать. Если статья вам понравилась — поощрите автора известным способом.
В этом топике я расскажу об одном разрабатываемым мною подходе в веб программировании, сердцем которого является хранение кода в базе данных. Несколько замечаний по дальнейшему тексту:
* Под словосочетанием «код страницы» имеется ввиду исполняемый (php) код
* Во всех вопросах, касательно производительности, имеется ввиду чистое время генерации страницы, без использования акселлераторов, систем кеширования и т д
### Как все начиналось
Для того чтобы понять, а «зачем оно собственно надо» быстренько пройдем тот путь, который и привел меня к хранению кода в бд. Так сложилось, что свой путь в веб программировании я начинал не с написания каких-либо скриптов или модулей для существующих систем, а сразу с написания собственного движка сайта с абсолютного нуля. К этому моменту я имел двухлетний опыт программирования на C++ и, конечно же, по накатанной пытался строить свой веб движок на ООП (правда в то время в PHP от ООП было одно название :) ). В пределах разумного, я очень люблю свои «велосипеды». Особенно большие. И прежде чем воспользоваться готовым решением, всегда задаюсь вопросом «а нельзя ли написать получше?».
Вообще написание своих велосипедов очень полезно, особенно для начинающих разработчиков (когда на первом месте стоит поднятие профессионализма, а не написание кода в отведенный срок и бюджет). Только написание собственных решений дает понимание того, как что-то устроено изнутри на самом низком уровне. А это в свою очередь дает понимание сложности, ресурсоемкости, скорости тех или иных подходов, что, в конечном счете, выливается в выбор правильного инструментария для решения задачи. Например, в университете нас заставляли писать свои pushback'и для массивов, чтобы мы не забывали, что за казалось бы простыми и тривиальными вещами может скрываться что-то гораздо большее.
В итоге получился движок, построенной по довольно таки классической схеме: папки с классами, модулями, шаблонами и прочим. Ну и соответственно бесконечные инклуды всего этого при генерации страниц. А так как во мне, как и во многих программистах живет рационализатор, то меня стали беспокоить издержки такого подхода. В частности, больше всего мне не нравился тот факт, что **приходилось подключать много «ненужного» кода** («мертвого» кода, который заведомо не будет выполнен на странице) для страниц (например всю библиотеку, когда на данной странице нужна будет лишь одна функция из нее).
Не задумывались ли вы над количеством «мертвого» кода на странице? На самом деле его количество как правило в 7-15 раз превышает количество кода, который действительно будет выполнен при обращении к странице. Возьмите к примеру класс комментариев. В нем будут методы render(), delete(), edit(), add(), compress(), answer() и т д. При этом за 1 выполнение скрипта как правило будет вызван всего 1 из этих методов (delete — при удалении, edit — при редактировании и т д), а остальные заведомо не будут вызываться. Вот и считайте, сколько такого лишнего кода набежит на странице.
По началу я пытался проводить оптимизацию, «разрезая» и «склеивая» большие библиотеки или классы под нужды различных страниц, уменьшая таким образом количество инклудов и «мертвого» кода. Но это, конечно же, тупиковый путь. Шло время. Проекты, написанные на этом движке (царство им небесное :) ) становились все больше. Вместе с этим росло количество и размеры подключаемого кода, а вместе с ними и время генерации страниц. Я начал все чаще думать о том, как избавиться от «мертвого» кода. И тут меня посетила смелая, показавшайся даже бредовой мысль. А что если…
### Рождение идеи
**А что если разделить код на максимально мелкие независимые части, чтобы иметь возможность собирать на странице только то, что действительно нужно?** То есть разделить все функции, классы (в идеале и методы классов) и прочее. Таким образом, мы получим много много маленьких «кирпичиков», из которых потом будем складывать страницу. Тем самым появится возможность **полностью избавиться от «мертвого» кода и инклудов**. Меня по-настоящему взбудоражила эта идея, но вопросов было больше чем, ответов: как это сделать, будет ли это работать, какие подводные камни ожидают в реализации, насколько быстра такая система? Короче пока я не имел ни малейшего представления о том, как это реализовать и как оно будет работать. Но попробовать, конечно же, стоило.
### Путь воина
Идеология заключается в том, что разбив всё на максимально малые кусочки кода, мы сможем собрать из них что угодно.Вопроса о том, как хранить «кирпичики» кода не возникало — так как они уже были не кодом, а являлись по сути данными с набором атрибутов, то единственным возможным вариантом было использование бд. Постараюсь показать принцип работы подобной системы максимально просто и абстрактно, только передав суть.
###### 1 Хранение кирпичиков
Тут все просто и понятно: каждая отдельная функция, класс (а лучше даже метод класса), контроллер модуля, представление модуля и т д — это отдельная строка в бд. Например в простейшем случае таблица может иметь вид **id|code|name|componentType** (где **componentType** — тип кирпичика(функция, класс, модуль..))
###### 2 Хранение зависимостей
Так как код одного кирпичика может вызывать другой кирпичик (например зависимости типа функция-функция, модуль-функция или даже страница-модуль), то нужно хранить репликации. Сделать это можно с помощью таблицы репликаций, которая, в простейшем случае, имеет вид **id|parentId|childId**. Таким образом мы решаем проблему правильного сбора «кирпичиков» для вложенных конструкций:
> `function A()
>
> {
>
> B();
>
> }`
>
>
В этом случае в таблице репликаций будет запись, что **А** «нуждается» в **B**. Следовательно при подключении **А** автоматом будет подключена **B**.
###### 3 генерация кода страниц
Хорошо, у нас есть все кирпичики, но как из них собрать код страницы? Для этого, конечно же, нужен отдельный скрипт, который будет собирать из наших бесполезных самих по себе «кирпичиков» работоспособный код страницы. Назовем этот скрипт Codegen. Каким он будет зависит от того, что и как вы хотите собрать из своих «кирпичиков». В этом заключается одна из сильных сторон подхода: из одних и тех же кирпичиков вы можете собирать принципиально разные коды страниц. Можете даже собрать «классическую» архитектуру. Во избежание недопониманий: **генерация кода страницы годегеном происходит 1 раз, а не при каждом обращении к странице**.
На выходе получаем монолитный сгенерированный код для каждой страницы. При этом, в зависимости от Codegen, возможно как сразу получать весь необходимый код для страницы, так и подгружать некоторые части во время выполнения страницы (посредством eval из базы).
### Пожинаем плоды
Таким образом мы можем достичь следущих главных результатов:
**— полное отсутствие инклудов на странице
— сведение «мертвого» кода к нулю**
Вот что это дало в моем конкретном случае:
* количество кода сократилось с 12000-14000 до 1500-2000 строк на странице
* количество инклудов на странице сократилось с 16-22 до 0
* Время генерации страницы сократилось с 0.25-0.3 до 0.04-0.05 секунды (~600%. Напоминаю, что это без кеша в классике. с кешом цифра будет поменьше)
### За и против
Рассмотрим подробно плюсы и минусы идеологии хранения кода в бд.
**Минусы**
-**Невозможность полноценно использовать IDE**.Как следствие.Так как код хранится в бд, то для его редактирование/написание должен быть свой интерфейс(я например использую веб интерфейс). Как это примерно выглядит, можно посмотреть [здесь](http://dowith.ru/habr/1.jpg). Вообще для меня особых неудобств это никогда не представляло. Все необходимые мне инструменты (подсветка кода, горячие клавиши..) могу быть легко реализованы на веб интерфейсе. Для тех, кому нужно большее, полноценной замены IDE все же нет.
-**Сложность отладки**. Вытекает из первого пункта. Осложняется тем, что если вы захотите какой-то код динамически загружать из бд и выполнять его функцией eval, то найти ошибку может быть действительно непросто.
-**Поддержка**. Как и у всего, что не распространено поддержки вашего проекта другими разработчиками не будет никакой. Действительно проблема, которая решается только популяризацией.
В этом [топике](http://seniorbart.habrahabr.ru/blog/66204/) так же были указаны [еще](http://seniorbart.habrahabr.ru/blog/66204/#comment_1859551) [минусы](http://seniorbart.habrahabr.ru/blog/66204/#comment_1859827) с которыми я попробую поспорить:
> исходники это файлы, в итоге с ними можно делать любые файловые операции
Честно сказать, я не представляю что можно такого сделать с файлом, чего нельзя будет сделать со строкой в бд. Наоборот, строка в бд — куда более гибкая вещь чем файл.
> Распостранение/backup/update
… делается с дампом sql(один файл) намного проще и быстрее, чем с большим количеством файлов при классике.
> Безопасность, прямой код инжекшн в случае проблем
Проблема Тоже кажется надуманной. Сделайте разных пользователи для баз движка и баз сайта.
> Бекап, представляете, бывает так, что их не делают, и тогда любые ваши «кастомизации» on site коту под хвост если сломаеться база
Для работы движка (после того как сработает кодеген) бд уже не нужна. То есть сайт может работать и при выключенной бд.
**Плюсы**
— **Скорость**. Для меня это стало решающим фактором. Впервые, когда я сравнил скорость на старом «классическом» движке и на новом, я был потрясен результатом.
— **Гибкость на макроуровне**. Чем из наиболее мелких и простых частей состоит конструктор, тем более сложные вещи можно из него собрать.
— **Атрибуты у частей кода**. Так как наши кирпичики хранятся в таблице, то каждому из них мы можем задавать какие либо атрибуты, посредством добавления соответствующего поля. Это действительно очень важная особенность, открывающая новые просторы в разработке.
— **Возможность проводить любую обработку исполняемого кода перед его выполнением**. Как вы помните, весь код у нас проходит через codegen, а следовательно в нем мы можем его модифицировать произвольным образом. Например, применять языковые пакеты на стадии генерации кода страниц. Или еще таким образом: если в коде часто встречается какая-нибудь строка, например
> `if(!$user->isAdmin()) {ErrorLog('нехватает прав'); return;}`
>
>
Вы можете вместо нее писать везде коротко
> `_CHECKADMIN`
>
>
А на стадии генерации просто заменять его на нужный вам код. Так что предварительная обработка кода тоже дает простор для фантазии программиста.
### Заключение
В этой статье я хотел показать, что идеология хранения кода в бд не такая безнадежная, как может показаться на первый взгляд. На ряду с очевидными минусами, есть и уникальные плюсы, которые раздвигают рамки возможностей в веб программировании. И, что немаловажно, не только в теории, но и на практике: я использую этот подход уже на протяжении трех лет. А это по-моему, достаточный срок для проверки его «выживаемости» в реальных условиях. Я ни коим образом не утверждаю, что хранение кода в бд лучше, чем использование классического подхода. Но я верю, что это вполне конкурентоспособная концепция, и работа в этой области может дать толчок для появления принципиально новых фреймворков и CMS, с уникальными возможностями.
P.S. Если возникнет интерес, я могу продолжить эту тему описанием своей реализации предложенного подхода. | https://habr.com/ru/post/66309/ | null | ru | null |
# Организация виртуальной памяти
Привет, Хабрахабр!
В [предыдущей статье](http://habrahabr.ru/company/embox/blog/232605/) я рассказал про *vfork()* и пообещал рассказать о реализации вызова *fork()* как с поддержкой MMU, так и без неё (последняя, само собой, со значительными ограничениями). Но прежде, чем перейти к подробностям, будет логичнее начать с устройства виртуальной памяти.
Конечно, многие слышали про MMU, страничные таблицы и TLB. К сожалению, материалы на эту тему обычно рассматривают аппаратную сторону этого механизма, упоминая механизмы ОС только в общих чертах. Я же хочу разобрать конкретную программную реализацию в проекте [Embox](https://github.com/embox/embox). Это лишь один из возможных подходов, и он достаточно лёгок для понимания. Кроме того, это не музейный экспонат, и при желании можно залезть “под капот” ОС и попробовать что-нибудь поменять.
Введение
========
Любая программная система имеет логическую модель памяти. Самая простая из них — совпадающая с физической, когда все программы имеют прямой доступ ко всему адресному пространству.
При таком подходе программы имеют доступ ко всему адресному пространству, не только могут “мешать” друг другу, но и способны привести к сбою работы всей системы — для этого достаточно, например, затереть кусок памяти, в котором располагается код ОС. Кроме того, иногда физической памяти может просто не хватить для того, чтобы все нужные процессы могли работать одновременно. Виртуальная память — один из механизмов, позволяющих решить эти проблемы. В данной статье рассматривается работа с этим механизмом со стороны операционной системы на примере [ОС Embox](https://github.com/embox/embox). Все функции и типы данных, упомянутые в статье, вы можете найти в исходном коде нашего проекта.
Будет приведён ряд листингов, и некоторые из них слишком громоздки для размещения в статье в оригинальном виде, поэтому по возможности они будут сокращены и адаптированы. Также в тексте будут возникать отсылки к функциям и структурам, не имеющим прямого отношения к тематике статьи. Для них будет дано краткое описание, а более полную информацию о реализации можно найти на вики проекта.
Общие идеи
==========
Виртуальная память — это концепция, которая позволяет уйти от использования физических адресов, используя вместо них виртуальные, и это даёт ряд преимуществ:
* Расширение реального адресного пространства. Часть виртуальной памяти может быть вытеснена на жёсткий диск, и это позволяет программам использовать больше оперативной памяти, чем есть на самом деле.
* Создание изолированных адресных пространств для различных процессов, что повышает безопасность системы, а также решает проблему привязанности программы к определённым адресам памяти.
* Задание различных свойств для разных участков участков памяти. Например, может существовать неизменяемый участок памяти, видный нескольким процессам.
При этом вся виртуальная память делится на участки памяти постоянного размера, называемые страницами.
Аппаратная поддержка
--------------------
MMU — это компонент аппаратного обеспечения компьютера, через который “проходят” все запросы к памяти, совершаемые процессором. Задача этого устройства — трансляция адресов, управление кэшированием памяти и её защита.
Обращение к памяти хорошо описанно в [этой хабростатье](http://habrahabr.ru/post/211150/). Происходит оно следующим образом:
> Процессор подаёт на вход MMU виртуальный адрес
>
> Если MMU выключено или если виртуальный адрес попал в нетранслируемую область, то физический адрес просто приравнивается к виртуальному
>
> Если MMU включено и виртуальный адрес попал в транслируемую область, производится трансляция адреса, то есть замена номера виртуальной страницы на номер соответствующей ей физической страницы (смещение внутри страницы одинаковое):
>
> Если запись с нужным номером виртуальной страницы есть в TLB [Translation Lookaside Buffer], то номер физической страницы берётся из нее же
>
> Если нужной записи в TLB нет, то приходится искать ее в таблицах страниц, которые операционная система размещает в нетранслируемой области ОЗУ (чтобы не было промаха TLB при обработке предыдущего промаха). Поиск может быть реализован как аппаратно, так и программно — через обработчик исключения, называемого страничной ошибкой (page fault). Найденная запись добавляется в TLB, после чего команда, вызвавшая промах TLB, выполняется снова.
>
>
Таким образом, при обращении программы к тому или иному участку памяти трансляция адресов производится аппаратно. Программная часть работы с MMU — формирование таблиц страниц и работа с ними, распределение участков памяти, установка тех или иных флагов для страниц, а также обработка page fault, ошибки, которая происходит при отсутствии страницы в отображении.
В тексте статьи в основном будет рассматриваться трёхуровневая модель памяти, но это не является принципиальным ограничением: для получения модели с бóльшим количеством уровней можно действовать аналогичным образом, а особенности работы с меньшим количеством уровней (как, например, в архитектуре x86 — там всего два уровня) будут рассмотрены отдельно.
Программная поддержка
---------------------
Для приложений работа с виртуальной памятью незаметна. Это прозрачность обеспечивается наличием в ядре ОС соответствующей подсистемы, осуществляющей следующие действия:
* Выделение физических страниц из некоторого зарезервированного участка памяти
* Внесение соответствующих изменений в таблицы виртуальной памяти
* Сопоставление участков виртуальной памяти с процессами, выделившими их
* Проецирование региона физической памяти на виртуальный адрес
Данные механизмы будут рассмотрены подробно ниже, после введения нескольких базовых определений.
Виртуальный адрес
-----------------
*Page Global Directory* (далее — *PGD*) — таблица (здесь и далее — то же самое, что директория) самого высокого уровня, каждая запись в ней — ссылка на *Page Middle Directory* (*PMD*), записи которой, в свою очередь, ссылаются на таблицу *Page Table Entry* (*PTE*). Записи в *PTE* ссылаются на реальные физические адреса, а также хранят флаги состояния страницы.
То есть, при трёхуровневой иерархии памяти виртуальный адрес будет выглядеть так:

Значения полей *PGD*, *PMD* и *PTE* — это индексы в соответствующих таблицах (то есть сдвиги от начала этих таблиц), а *offset* — это смещение адреса от начала страницы.
В зависимости от архитектуры и режима страничной адресации, количество битов, выделяемых для каждого из полей, может отличаться. Кроме того, сама страничная иерархия может иметь число уровней, отличное от трёх: например, на x86 нет *PMD*.
Для обеспечения переносимости мы задали границы этих полей с помощью констант: *MMU\_PGD\_SHIFT*, *MMU\_PMD\_SHIFT*, *MMU\_PTE\_SHIFT*, которые в приведённой выше схеме равны 24, 18 и 12 соответственно их определение дано в заголовочном файле [src/include/hal/mmu.h](https://github.com/embox/embox/blob/master/src/include/hal/mmu.h). В дальнейшем будет рассматриваться именно этот пример.
На основании сдвигов *PGD*, *PMD* и *PTE* вычисляются соответствующие маски адресов.
```
#define MMU_PTE_ENTRIES (1UL << (MMU_PMD_SHIFT - MMU_PTE_SHIFT))
#define MMU_PTE_MASK ((MMU_PTE_ENTRIES - 1) << MMU_PTE_SHIFT)
#define MMU_PTE_SIZE (1UL << MMU_PTE_SHIFT)
#define MMU_PAGE_SIZE (1UL << MMU_PTE_SHIFT)
#define MMU_PAGE_MASK (MMU_PAGE_SIZE - 1)
```
Эти макросы даны в том же заголовочном файле.
Для работы с виртуальной таблицами виртуальной памяти в некоторой области памяти хранятся указатели на все *PGD*. При этом каждая задача хранит в себе контекст *struct mmu\_context*, который, по сути, является индексом в этой таблице. Таким образом, к каждой задаче относится одна таблица *PGD*, которую можно определить с помощью *mmu\_get\_root(ctx)*.
Страницы и работа с ними
------------------------
### Размер страницы
В реальных (то есть не в учебных) системах используются страницы от 512 байт до 64 килобайт. Чаще всего размер страницы определяется архитектурой и является фиксированным для всей системы, например — 4 KiB.
С одной стороны, при меньшем размере страницы память меньше фрагментируется. Ведь наименьшая единица виртуальной памяти, которая может быть выделена процессу — это одна страница, а программам очень редко требуется целое число страниц. А значит, в последней странице, которую запросил процесс, скорее всего останется неиспользуемая память, которая, тем не менее, будет выделена, а значит — использована неэффективно.
С другой стороны, чем меньше размер страницы, тем больше размер страничных таблиц. Более того, при отгрузке на HDD и при чтении страниц с HDD быстрее получится записать несколько больших страниц, чем много маленьких такого же суммарного размера.
Отдельного внимания заслуживают так называемые большие страницы: huge pages и large pages[[вики]](http://en.wikipedia.org/wiki/Page_%28computer_memory%29#Huge_pages).
| | | |
| --- | --- | --- |
| Платформа | Размер обычной страницы | Размер страницы максимально возможного размера |
| x86 | 4KB | 4MB |
| x86\_64 | 4KB | 1GB |
| IA-64 | 4KB | 256MB |
| PPC | 4KB | 16GB |
| SPARC | 8KB | 2GB |
| ARMv7 | 4KB | 16MB |
Действительно, при использовании таких страниц накладные расходы памяти повышаются. Тем не менее, прирост производительности программ в некоторых случаях может доходить до 10%[[ссылка](http://www.vmware.com/files/pdf/large_pg_performance.pdf)], что объясняется меньшим размером страничных директорий и более эффективной работой TLB.
В дальнейшем речь пойдёт о страницах обычного размера.
Устройство Page Table Entry
---------------------------
В реализации проекта Embox тип *mmu\_pte\_t* — это указатель.
Каждая запись *PTE* должна ссылаться на некоторую физическую страницу, а каждая физическая страница должна быть адресована какой-то записью *PTE*. Таким образом, в *mmu\_pte\_t* незанятыми остаются *MMU\_PTE\_SHIFT* бит, которые можно использовать для сохранения состояния страницы. Конкретный адрес бита, отвечающего за тот или иной флаг, как и набор флагов в целом, зависит от архитектуры.
Вот некоторые из флагов:
* MMU\_PAGE\_WRITABLE — Можно ли менять страницу
* MMU\_PAGE\_SUPERVISOR — Пространство супер-пользователя/пользователя
* MMU\_PAGE\_CACHEABLE — Нужно ли кэшировать
* MMU\_PAGE\_PRESENT — Используется ли данная запись директории
Снимать и устанавливать эти флаги можно с помощью следующих функций:
*mmu\_pte\_set\_writable(), mmu\_pte\_set\_usermode(), mmu\_pte\_set\_cacheable(), mmu\_pte\_set\_executable()*
Например: *mmu\_pte\_set\_writable(pte\_pointer, 0)*
Можно установить сразу несколько флагов:
```
void vmem_set_pte_flags(mmu_pte_t *pte, vmem_page_flags_t flags)
```
Здесь vmem\_page\_flags\_t — 32-битное значение, и соответствующие флаги берутся из первых *MMU\_PTE\_SHIFT* бит.
Трансляция виртуального адреса в физический
-------------------------------------------
Как уже писалось выше, при обращении к памяти трансляция адресов производится аппаратно, однако, явный доступ к физическим адресам может быть полезен в ряде случаев. Принцип поиска нужного участка памяти, конечно, такой же, как и в MMU.
Для того, чтобы получить из виртуального адреса физический, необходимо пройти по цепочке таблиц *PGD, PMD* и *PTE*. Функция *vmem\_translate()* и производит эти шаги.
Сначала проверяется, есть ли в *PGD* указатель на директорию *PMD*. Если это так, то вычисляется адрес *PMD*, а затем аналогичным образом находится *PTE*. После выделения физического адреса страницы из *PTE* необходимо добавить смещение, и после этого будет получен искомый физический адрес.
**Исходный код функции vmem\_translate**
```
mmu_paddr_t vmem_translate(mmu_ctx_t ctx, mmu_vaddr_t virt_addr) {
size_t pgd_idx, pmd_idx, pte_idx;
mmu_pgd_t *pgd;
mmu_pmd_t *pmd;
mmu_pte_t *pte;
pgd = mmu_get_root(ctx);
vmem_get_idx_from_vaddr(virt_addr, &pgd_idx, &pmd_idx, &pte_idx);
if (!mmu_pgd_present(pgd + pgd_idx)) {
return 0;
}
pmd = mmu_pgd_value(pgd + pgd_idx);
if (!mmu_pmd_present(pmd + pmd_idx)) {
return 0;
}
pte = mmu_pmd_value(pmd + pmd_idx);
if (!mmu_pte_present(pte + pte_idx)) {
return 0;
}
return mmu_pte_value(pte + pte_idx) + (virt_addr & MMU_PAGE_MASK);
}
```
Пояснения к коду функции.
*mmu\_paddr\_t* — это физический адрес страницы, назначение *mmu\_ctx\_t* уже обсуждалось выше в разделе “Виртуальный адрес”.
С помощью функции *vmem\_get\_idx\_from\_vaddr()* находятся сдвиги в таблицах *PGD, PMD* и *PTE*.
```
void vmem_get_idx_from_vaddr(mmu_vaddr_t virt_addr, size_t *pgd_idx, size_t *pmd_idx, size_t *pte_idx) {
*pgd_idx = ((uint32_t) virt_addr & MMU_PGD_MASK) >> MMU_PGD_SHIFT;
*pmd_idx = ((uint32_t) virt_addr & MMU_PMD_MASK) >> MMU_PMD_SHIFT;
*pte_idx = ((uint32_t) virt_addr & MMU_PTE_MASK) >> MMU_PTE_SHIFT;
}
```

Работа с Page Table Entry
-------------------------
Для работы с записей в таблице страниц, а так же с самими таблицами, есть ряд функций:
Эти функции возвращают 1, если у соответствующей структуры установлен бит *MMU\_PAGE\_PRESENT*
```
int mmu_pgd_present(mmu_pgd_t *pgd);
int mmu_pmd_present(mmu_pmd_t *pmd);
int mmu_pte_present(mmu_pte_t *pte);
```
Page Fault
----------
Page fault — это исключение, возникающее при обращении к странице, которая не загружена в физическую память — или потому, что она была вытеснена, или потому, что не была выделена.
В операционных системах общего назначения при обработке этого исключения происходит поиск нужной странице на внешнем носителе (жёстком диске, к примеру).
В нашей системе все страницы, к которым процесс имеет доступ, считаются присутствующими в оперативной памяти. Так, например, соответствующие сегменты .text, .data, .bss; куча; и так далее отображаются в таблицы при инициализации процесса. Данные, связанные с потоками (например, стэк), отображаются в таблицы процесса при создании потоков.
Выталкивание страниц во внешнюю память и их чтение в случае page fault не реализовано. С одной стороны, это лишает возможности использовать больше физической памяти, чем имеется на самом деле, а с другой — не является актуальной проблемой для встраиваемых систем. Нет никаких ограничений, делающих невозможной реализацию данного механизма, и при желании читатель может попробовать себя в этом деле :)
Выделение памяти
================
Для виртуальных страниц и для физических страниц, которые могут быть использованы при работе с виртуальной памятью, статически резервируется некоторое место в оперативной памяти. Тогда при выделении новых страниц и директорий они будут браться именно из этого места.
Исключением является набор указателей на PGD для каждого процесса (MMU-контексты процессов): этот массив хранится отдельно и используется при создании и разрушении процесса.
Выделение страниц
Итак, выделить физическую страницу можно с помощью *vmem\_alloc\_page*
```
void *vmem_alloc_page() {
return page_alloc(virt_page_allocator, 1);
}
```
Функция *page\_alloc()* ищет участок памяти из N незанятых страниц и возвращает физический адрес начала этого участка, помечая его как занятый. В приведённом коде virt\_page\_allocator ссылается на участок памяти, резервированной для выделения физических страниц, а 1 — количество необходимых страниц.
Выделение таблиц
Тип таблицы (*PGD, PMD, PTE*) не имеет значения при аллокации. Более того, выделение таблиц производится также с помощью функции page\_alloc(), только с другим аллокатором (*virt\_table\_allocator*).
Участки памяти (Memory Area)
============================
После добавления страниц в соответствующие таблицы нужно уметь сопоставлять участки памяти с процессами, к которым они относятся. У нас в системе процесс представлен структурой task, содержащей всю необходимую информацию для работы ОС с процессом. Все физически доступные участки адресного пространства процесса записываются в специальный репозиторий: task\_mmap. Он представляет из себя список дескрипторов этих участков (регионов), которые могут быть отображены на виртуальную память, если включена соответствующая поддержка.
```
struct emmap {
void *brk;
mmu_ctx_t ctx;
struct dlist_head marea_list;
};
```
*brk* — это самый большой из всех физических адресов репозитория, данное значение необходимо для ряда системных вызовов, которые не будут рассматриваться в данной статье.
*ctx* — это контекст задачи, использование которого обсуждалось в разделе “Виртуальный адрес”.
*struct dlist\_head* — это указатель на начало двусвязного списка, организация которого аналогична организации [*Linux Linked List*](http://isis.poly.edu/kulesh/stuff/src/klist/).
За каждый выделенный участок памяти отвечает структура marea
```
struct marea {
uintptr_t start;
uintptr_t end;
uint32_t flags;
uint32_t is_allocated;
struct dlist_head mmap_link;
};
```
Поля данной структуры имеют говорящие имена: адреса начала и конца данного участка памяти, флаги региона памяти. Поле mmap\_link нужно для поддержания двусвязного списка, о котором говорилось выше.
```
void mmap_add_marea(struct emmap *mmap, struct marea *marea) {
struct marea *ma_err;
if ((ma_err = mmap_find_marea(mmap, marea->start))
|| (ma_err = mmap_find_marea(mmap, marea->end))) {
/* Обработка ошибки */
}
dlist_add_prev(&marea->mmap_link, &mmap->marea_list);
}
```
Отображение виртуальных участков памяти на физические (Mapping)
===============================================================
Ранее уже рассказывалось о том, как происходит выделение физических страниц, какие данные о виртуальной памяти относятся к задаче, и теперь всё готово для того, чтобы говорить о непосредственном отображении виртуальных участков памяти на физические.
Отображение виртуальных участков памяти на физическую память подразумевает внесение соответствующих изменений в иерархию страничных директорий.
Подразумевается, что некоторый участок физической памяти уже выделен. Для того, чтобы выделить соответствующие виртуальные страницы и привязать их к физическим, используется функция vmem\_map\_region()
```
int vmem_map_region(mmu_ctx_t ctx, mmu_paddr_t phy_addr, mmu_vaddr_t virt_addr, size_t reg_size, vmem_page_flags_t flags) {
int res = do_map_region(ctx, phy_addr, virt_addr, reg_size, flags);
if (res) {
vmem_unmap_region(ctx, virt_addr, reg_size, 0);
}
return res;
}
```
В качестве параметров передаётся контекст задачи, адрес начала физического участка памяти, а также адрес начала виртуального участка. Переменная *flags* содержит флаги, которые будут установлены у соответствующих записей в *PTE*.
Основную работу на себя берёт *do\_map\_region()*. Она возвращает 0 при удачном выполнении и код ошибки — в ином случае. Если во время маппирования произошла ошибка, то часть страниц, которые успели выделиться, нужно откатить сделанные изменения с помощью функции vmem\_unmap\_region(), которая будет рассмотрена позднее.
Рассмотрим функцию *do\_map\_region()* подробнее.
**Исходный код функции do\_map\_region()**
```
static int do_map_region(mmu_ctx_t ctx, mmu_paddr_t phy_addr, mmu_vaddr_t virt_addr, size_t reg_size, vmem_page_flags_t flags) {
mmu_pgd_t *pgd;
mmu_pmd_t *pmd;
mmu_pte_t *pte;
mmu_paddr_t p_end = phy_addr + reg_size;
size_t pgd_idx, pmd_idx, pte_idx;
/* Considering that all boundaries are already aligned */
assert(!(virt_addr & MMU_PAGE_MASK));
assert(!(phy_addr & MMU_PAGE_MASK));
assert(!(reg_size & MMU_PAGE_MASK));
pgd = mmu_get_root(ctx);
vmem_get_idx_from_vaddr(virt_addr, &pgd_idx, &pmd_idx, &pte_idx);
for ( ; pgd_idx < MMU_PGD_ENTRIES; pgd_idx++) {
GET_PMD(pmd, pgd + pgd_idx);
for ( ; pmd_idx < MMU_PMD_ENTRIES; pmd_idx++) {
GET_PTE(pte, pmd + pmd_idx);
for ( ; pte_idx < MMU_PTE_ENTRIES; pte_idx++) {
/* Considering that address has not mapped yet */
assert(!mmu_pte_present(pte + pte_idx));
mmu_pte_set(pte + pte_idx, phy_addr);
vmem_set_pte_flags(pte + pte_idx, flags);
phy_addr += MMU_PAGE_SIZE;
if (phy_addr >= p_end) {
return ENOERR;
}
}
pte_idx = 0;
}
pmd_idx = 0;
}
return -EINVAL;
}
```
**Вспомогательные макросы**
```
#define GET_PMD(pmd, pgd) \
if (!mmu_pgd_present(pgd)) { \
pmd = vmem_alloc_pmd_table(); \
if (pmd == NULL) { \
return -ENOMEM; \
} \
mmu_pgd_set(pgd, pmd); \
} else { \
pmd = mmu_pgd_value(pgd); \
}
#define GET_PTE(pte, pmd) \
if (!mmu_pmd_present(pmd)) { \
pte = vmem_alloc_pte_table(); \
if (pte == NULL) { \
return -ENOMEM; \
} \
mmu_pmd_set(pmd, pte); \
} else { \
pte = mmu_pmd_value(pmd); \
}
```
Макросы *GET\_PTE* и *GET\_PMD* нужны для лучшей читаемости кода. Они делают следующее: если в таблице памяти нужный нам указатель не ссылается на существующую запись, нужно выделить её, если нет — то просто перейти по указателю к следующей записи.
В самом начале необходимо проверить, выровнены ли под размер страницы размер региона, физический и виртуальный адреса. После этого определяется *PGD*, соответствующая указанному контексту, и извлекаются сдвиги из виртуального адреса (более подробно это уже обсуждалось выше).
Затем последовательно перебираются виртуальные адреса, и в соответствующих записях *PTE* к ним привязывается нужный физический адрес. Если в таблицах отсутствуют какие-то записи, то они будут автоматически сгенерированы при вызове вышеупомянутых макросов *GET\_PTE* и *GET\_PMD*.
Освобождение виртуального участка памяти (Unmapping)
====================================================
После того, как участок виртуальной памяти был отображён на физическую, рано или поздно её придётся освободить: либо в случае ошибки, либо в случае завершения работы процесса.
Изменения, которые при этом необходимо внести в структуру страничной иерархии памяти, производятся с помощью функции *vmem\_unmap\_region()*.
**Исходный код функции vmem\_unmap\_region()**
```
void vmem_unmap_region(mmu_ctx_t ctx, mmu_vaddr_t virt_addr, size_t reg_size, int free_pages) {
mmu_pgd_t *pgd;
mmu_pmd_t *pmd;
mmu_pte_t *pte;
mmu_paddr_t v_end = virt_addr + reg_size;
size_t pgd_idx, pmd_idx, pte_idx;
void *addr;
/* Considering that all boundaries are already aligned */
assert(!(virt_addr & MMU_PAGE_MASK));
assert(!(reg_size & MMU_PAGE_MASK));
pgd = mmu_get_root(ctx);
vmem_get_idx_from_vaddr(virt_addr, &pgd_idx, &pmd_idx, &pte_idx);
for ( ; pgd_idx < MMU_PGD_ENTRIES; pgd_idx++) {
if (!mmu_pgd_present(pgd + pgd_idx)) {
virt_addr = binalign_bound(virt_addr, MMU_PGD_SIZE);
pte_idx = pmd_idx = 0;
continue;
}
pmd = mmu_pgd_value(pgd + pgd_idx);
for ( ; pmd_idx < MMU_PMD_ENTRIES; pmd_idx++) {
if (!mmu_pmd_present(pmd + pmd_idx)) {
virt_addr = binalign_bound(virt_addr, MMU_PMD_SIZE);
pte_idx = 0;
continue;
}
pte = mmu_pmd_value(pmd + pmd_idx);
for ( ; pte_idx < MMU_PTE_ENTRIES; pte_idx++) {
if (virt_addr >= v_end) {
// Try to free pte, pmd, pgd
if (try_free_pte(pte, pmd + pmd_idx) && try_free_pmd(pmd, pgd + pgd_idx)) {
try_free_pgd(pgd, ctx);
}
return;
}
if (mmu_pte_present(pte + pte_idx)) {
if (free_pages && mmu_pte_present(pte + pte_idx)) {
addr = (void *) mmu_pte_value(pte + pte_idx);
vmem_free_page(addr);
}
mmu_pte_unset(pte + pte_idx);
}
virt_addr += VMEM_PAGE_SIZE;
}
try_free_pte(pte, pmd + pmd_idx);
pte_idx = 0;
}
try_free_pmd(pmd, pgd + pgd_idx);
pmd_idx = 0;
}
try_free_pgd(pgd, ctx);
}
```
Все параметры функции, кроме последнего, должны быть уже знакомы. *free\_pages* отвечает за то, должны ли быть удалены страничные записи из таблиц.
*try\_free\_pte, try\_free\_pmd, try\_free\_pgd* — это вспомогательные функции. При удалении очередной страницы может выясниться, что директория, её содержащая, могла стать пустой, а значит, её нужно удалить из памяти.
**Исходный код функций try\_free\_pte, try\_free\_pmd, try\_free\_pgd**
```
static inline int try_free_pte(mmu_pte_t *pte, mmu_pmd_t *pmd) {
for (int pte_idx = 0 ; pte_idx < MMU_PTE_ENTRIES; pte_idx++) {
if (mmu_pte_present(pte + pte_idx)) {
return 0;
}
}
#if MMU_PTE_SHIFT != MMU_PMD_SHIFT
mmu_pmd_unset(pmd);
vmem_free_pte_table(pte);
#endif
return 1;
}
static inline int try_free_pmd(mmu_pmd_t *pmd, mmu_pgd_t *pgd) {
for (int pmd_idx = 0 ; pmd_idx < MMU_PMD_ENTRIES; pmd_idx++) {
if (mmu_pmd_present(pmd + pmd_idx)) {
return 0;
}
}
#if MMU_PMD_SHIFT != MMU_PGD_SHIFT
mmu_pgd_unset(pgd);
vmem_free_pmd_table(pmd);
#endif
return 1;
}
static inline int try_free_pgd(mmu_pgd_t *pgd, mmu_ctx_t ctx) {
for (int pgd_idx = 0 ; pgd_idx < MMU_PGD_ENTRIES; pgd_idx++) {
if (mmu_pgd_present(pgd + pgd_idx)) {
return 0;
}
}
// Something missing
vmem_free_pgd_table(pgd);
return 1;
}
```
Макросы вида
```
#if MMU_PTE_SHIFT != MMU_PMD_SHIFT
...
#endif
```
нужны как раз для случая двухуровневой иерархии памяти.
Заключение
==========
Конечно, данной статьи не достаточно, чтобы с нуля организовать работу с MMU, но, я надеюсь, она хоть немного поможет погрузиться в OSDev тем, кому он кажется слишком сложным.
P.S. Всех с началом [недели Мат-Меха](https://vk.com/mmweek) :) | https://habr.com/ru/post/256191/ | null | ru | null |
# ПЗС линейка: с чем ее едят

В этой статье я хочу представить свой опыт по использованию линейного ПЗС-фотоприемника. Такая ПЗС-линейка может быть использована в проекте самодельного спектрометра, считывателя штрих-кодов, датчика положения или отклонения лазерного луча, сканера для фото- или кинопленки и много где еще. В моем случае это был лазерный сканер, описывать который в сети мне не позволяет сфера его применения.
**Что такое прибор с зарядовой свзью**
Чаще всего, когда говорят о ПЗС, имеют в виду различные фотоприемники. Реже — это устройства памяти: регистры сдвига, линии задержки. По своей сути это устройство, чем-то напоминающее память на цилиндрических магнитных доменах, только на кремнии — с помощью создаваемой системой электродов бегущей волны электрического поля по полупроводнику перемещаются сгустки носителей заряда, каким-либо образом образовавшиеся в нем ранее. Таким образом, мы получаем регистр сдвига, имеющий предельно простую структуру и способный запоминать не только последовательность цифровых единиц и нулей, но и аналоговый сигнал.

В ПЗС-приемниках изображения используется как раз вот эта способность данной структуры — последовательно выводить один за другим заряды, накопленные под каждым из пикселов структуры. Кроме того, та же система затворов, что используется для перемещения зарядов, во время экспонирования создает потенциальные ямы, в которых эти заряды накапливаются (либо эти ямы создаются в процессе формирования структуры — подобно встроенному и индуцированному каналам МОП-транзистора). Более сложные структуры включают в себя резистивный затвор, вдоль которого формируется плавный потенциальный склон (так устроены ПЗС-линейки Hamamatsu S11155)., а также разделение зон накопления и переноса зарядов — накопленные заряды всей строки сначала переносятся в буферную строку, а затем уже последовательно выдвигаются на выход вдоль последней.
Простота внутренней структуры выливается в сложность управления ею. Даже простейший вариант ПЗС-линейки требует генерировать двух-или трехфазный сигнал сложной формы с различными уровнями напряжения с крутыми фронтами (при высокой входной емкости, составляющей 1000 и более пФ), сдвинутыми друг относительно друга. Линейки типа Hamamatsu S11155 требуют аж восьми разных сигналов с различными уровнями напряжений высокого и низкого уровня по обе стороны нуля.
К счастью, некоторые фирмы (например, Sony) выпускали линейки, в которых вся эта сложность формируется прямо на кристалле. И для их работы нужно сформировать всего два сигнала: открывающий электронный затвор на время экспозиции, и тактовый. В нашей конструкции именно такая линейка ILX554: ее (как правило, б/у, но вполне работоспособную) несложно приобрести у китайцев на Aliexpress.
**Заглянем в даташит**
И видим, что из 22 выводов корпуса задействованы лишь 6. Это питание +5В, входные сигналы ROG и CLK, выходной сигнал Vout, вход выбора режима SHSW и земля. И это все.
ROG — это управление электронным затвором (и запуском переноса заряда с фоточувствительной строки на непосредственно сдвиговый регистр). У него активный уровень — нулевой. Чтобы проэкспонировать матрицу, его надо прижать к нулю и подержать, сколько надо — от 5 мкс до нескольких секунд. А потом, отпустив, подождать не меньше 3 мкс (за это время отрабатывает схема переноса заряда). Все это время на входе CLK мы держим высокий уровень. А затем можно считывать линейку, подавая на вход CLK меандр частотой от нескольких десятков килогерц до 2 МГц. При этом при каждом перепаде с единицы в ноль очередной пиксел будет выталкиваться на выход. Таких пикселов в линейке 2088 штук, из них рабочих, светочувствительных — 2048 (реально — на несколько штук больше, но крайние пикселы частично затенены). Даташит рекомендует подавать на матрицу не менее 2090 импульсов CLK для корректной работы.
А как он будет выталкиваться, зависит от того, что на входе SHSW. Если на нем — логическая единица, то на выходе будет получаться довольно замысловатый сигнал:
Причем при переходе CLK из нуля в единицу происходит сброс, а из единицы в ноль — выдача полезного сигнала.
А при нуле на входе SHSW включается встроенная схема выборки-хранения, которая упрощает этот сигнал до простого ступенчатого видеосигнала, где с каждым новым переходом CLK в ноль просто появляется уровень сигнала очередного пиксела и удерживается в течение всего периода сигнала CLK.
Полезный диапазон выходного сигнала идет от некоего темнового уровня, который по данным даташита составляет 2,85 В, а в реальности он может быть различным (в моей линейке — около 3 В), а при насыщении уровень выходного сигнала падает до 1,5-2 В.
В общем-то и все, что нам нужно про эту линейку знать.
**Схема включения**

Она проста и очевидна. Сигналы CLK и ROG мы генерируем программно с помощью МК, а триггеры Шмитта на входе — простейший способ перейти от 3,3 В к 5 В. Дело в том, что по этим входам в линейке нет никаких буферов, и для корректной работы внутренних схем матрицы нужно подать на них меандр с полным размахом от нуля до пяти вольт и хорошей крутизной фронтов. Указанные на схеме NC7SZ14M5X — очень удобные одиночные инвертирующие триггеры Шмитта с крутыми фронтами и повышенной нагрузочной способностью, и я их часто использую в своих проектах.
С помощью DA1 уровень видеосигнала с линейки «разгоняется» до диапазона, в котором работает АЦП, одновременно убирается «подставка» величиной примерно 1,5 В, соответствующая уровню насыщения. Так как у разных экземпляров ПЗС-линеек достаточно сильно разнятся размах сигнала и величина «подставки», сопротивления R1 и R3 следует подобрать, «уложив» выходной сигнал в необходимый диапазон. При этом нужно учесть, что от сопротивления R1 зависит не только смещение, но и усиление, поэтому сначала нужно подбирать его.
L1 и L2 — ферритовые бусины или маленькие дроссели на 1-2 мкГ типоразмера 0805 или 0603. Резисторы и конденсаторы применены того же типоразмера. Схема собрана на двусторонней плате поверхностным монтажом. Разводку платы не привожу, так как у меня на ней еще много чего.
**Программная реализация на МК**
Задачей МК является формирование сигнала ROG высокого уровня (не забываем про инверторы!) нужной длительности, затем — небольшой (3-10 мкс) паузы, а после нее — последовательности из 2090 импульсов высокого уровня, разделенных равными им по длительности паузами. Во время этих импульсов (или пауз) через некоторое время после фронта значение освещенности пиксела снимается с помощью набортного или внешнего АЦП. После считывания кадра нужно также сделать паузу до нового импульса ROG — те же 3-10 мкс. После включения питания и, как выяснилось, после долгого (больше 100 мс) неиспользования линейки ее нужно «прочистить», подав вхолостую стандартную серию импульсов на CLK пару-тройку раз.
На STM32 это все разумно сделать на прерывании от таймера. Настроив таймер на генерацию прерываний частотой, соответствующей удвоенной частоте пикселов, мы каждое срабатывание таймера попадаем в прерывание, где попеременно выводим в порт ноль или единицу, и когда выводим ноль, после этого считываем показания с АЦП. И отсчитав 2090 циклов, мы останавливаем таймер. Чтобы считать очередной кадр, нужно сбросить счетчик циклов в ноль, запустить таймер и ждать, пока не считается все.
Примерно вот так, как приведено в данных фрагментах кода.
```
bool clkState = false;
bool frameOk = true;
uint16_t pixCount = 0;
uint16_t ccdFrame[2090];
inline uint16_t readADC1(void)
// Тут у нас зависящая от конкретного МК реализация чтения из АЦП
{
.
.
.
}
void Delay(unsigned int Val)
// Функция для небольших задержек
{
for( ; Val != 0; Val--)
__NOP();
}
void readCCD(void)
// Запуск считывания ПЗС-линейки
{
pixCount = 0; // Обнулили счетчик пикселов
frameOk = false; // Сбросили флаг
TIM_Cmd(TIM6, ENABLE); // Запустили таймер
while(frameOk == false); // Стоим, пока флаг не взведется
}
// ... всякий разный код ... //
void TIM6_IRQHandler(void)
/*
Здесь мы оказываемся раз в сколько-то микросекунд и
формируем меандр CLK и в нужные моменты запускаем АЦП
*/
{
if (TIM_GetITStatus(TIM4, TIM_IT_Update) != RESET)
{
if(clkState == true)
// Формируем паузу (лог.0) и здесь же запускаем АЦП
{
clkState = false;
GPIOB->ODR &= ~GPIO_ODR_ODR_1; // выводим в порт логический ноль
Delay(3); // Небольшая пауза, пока не закончатся помехи и переходные процессы
ccdFrame[pixCount] = readADC1();
}
else
// Формируем импульс (лог.1)
{
pixCount++;
clkState = true;
GPIOB->ODR |= GPIO_ODR_ODR_1; // Выводим в порт логическую едииницу
}
if(pixCount >= 2090)
// Дошли до конца линейки, выставили флаг и остановили таймер
{
pixCount = 0;
frameOk = true;
TIM_Cmd(TIM6, DISABLE);
}
TIM_ClearITPendingBit(TIM4, TIM_IT_Update);
}
}
```
**И вот результат**
Результат неплохой. Несмотря на то, что встроенный АЦП не блещет характеристиками, его шумовые характеристики вполне соответствуют шуму ПЗС-линейки. Размах шумовой дорожки темнового сигнала при времени накопления около 1 мс оказывается равен ~ 3-4 уровням квантования и при использовании внешнего 14-разрядного АЦП с прекрасными характеристиками результаты получаются лишь немногим лучше. С ростом же освещенности шумы растут по простой причине: количество фотоэлектронов в каждом из пикселов не так велико (по моим расчетам — около 30 тысяч при насыщении). У лучших приборов эта величина достигает 200 тысяч.
На графике ниже — пример зарегистрированного линейкой «изображения», на котором на фоне освещенной стены стоит темный стенд, на котором закреплен стеклянный полый шарик диаметром 1 см, залитый внутри черным раствором. Пик — это отражение от внешней поверхности этого шарика. Шум на светлых участках — это структура самой стены, усиленная спеклами от лазера, от кадра к кадру он остается неподвижным. Реальный шум линейки значительно меньше.

**Другие похожие линейки**
Совершенно аналогично работают и некоторые другие 2048-пиксельные черно-белые ПЗС-линейки фирмы SONY — ILX511, ILX551 (у последней отличается цоколевка и ей требуется два напряжения питания — 5 и 9 В), отличающиеся поперечным размером пиксела (от 14 до 200 мкм) и спектральной чувствительностью (ILX554A красно- и ИК-чувствительная, аналогичная с индексом B имеет пониженную чувствительность в ИК области и приближена по чувствительности к глазу, а ILX511B более синечувствительная). Разные у них и динамические характеристики: у ILX551B динамический диапазон за счет малых размеров пиксела достигает 6000 (наша линейка достигает такого ДД при коротких выдержках около 10 мкс).
\* \* \*
В данной статье рассмотрено подключение едва ли не самой простой в использовании ПЗС-линейки. Простота эта обусловлена тем, что вся сложность спрятана у нее под капотом. Если бы не встроенные драйвера, пришлось бы формировать множество разноуровневых сигналов.
К сожалению, по современным меркам, такие ПЗС-линейки со встроенными драйверами имеют не самые лучшие характеристики. Так, у данной линейки динамический диапазон, определенный, как соотношение сигнала насыщения к темновому сигналу, составляет 333:1, а определяемый, как отношение сигнала насыщения к минимальному обнаружимому на фоне шума сигналу — около 1000:1. Но такие приборы не только сложны в использовании, но часто и труднодоступны (та же Hamamatsu требует при покупке ее ПЗС-линеек и других фотоприемников сложных бюрократических формальностей в связи с двойным назначением этих изделий). Вместе с тем, далеко не всегда требуются столь высокие характеристики, и для многих целей параметры данных приборов вполне приемлемы. | https://habr.com/ru/post/457762/ | null | ru | null |
# Пишем приложение на Flutter в связке с Redux

Привет всем! В этой статье я хотел бы показать вам, как создать Flutter приложение, используя Redux. Если вы не знаете, что такое [Flutter](https://flutter.dev), то это — SDK с открытым исходным кодом для создания мобильных приложений от компании Google. Он используется для разработки приложений под Android и iOS, а также это пока единственный способ разработки приложений под Google Fuchsia.
Если вы знакомы с Flutter и хотите создать приложение, которое хорошо спроектировано, легко тестируется и имеет очень предсказуемое поведение, — продолжайте читать данную статью и вы скоро это узнаете!
Но перед тем как мы приступим к написанию самого приложения. Давайте немного познакомимся с теорией, давайте начнем с объяснения, что такое Redux.
### Что такое Redux?
[Redux](https://redux.js.org) — это архитектура, изначально созданная для языка JavaScript и используемая в приложениях, которые созданы с использованием ***reactive frameworks*** (таких как React Native или Flutter). Redux — это упрощенная версия архитектуры Flux, созданная Facebook. По сути, вам нужно знать три вещи:
1. Единственный источник правды/single source of truth - весь **state** вашего приложения хранится только в одном месте (называется **store**).
2. состояние доступно только для чтения/state is read-only — для изменения state приложения необходимо отправить actions(действие), после чего создастся новый state
3. изменения производятся с помощью чистых функций/pure functions — чистая функция (для простоты, это функция без side effects) принимает текущий state приложение и action и возвращает новый state приложения
**Примечание:** *Побочный эффект функции — возможность в процессе выполнения своих вычислений: читать и модифицировать значения глобальных переменных, осуществлять операции ввода-вывода, реагировать на исключительные ситуации, вызывать их обработчики. Если вызвать функцию с побочным эффектом дважды с одним и тем же набором значений входных аргументов, может случиться так, что в качестве результата будут возвращены разные значения. Такие функции называются недетерминированными функциями с побочными эффектами.*
Звучит круто, но каковы преимущества данного решения?
* у нас есть контроль над **state/состоянием** — это означает, что мы точно знаем, что вызвало изменение состояния, у нас нет дублированного состояния, и мы можем легко следить за потоком данных
* **Reducer** это чистые функции которые легко протестировать — мы можем передать state, action на вход и проверить, верность результата
* Приложение четко структурировано — у нас есть разные слои для actions, models, бизнес-логики и т. д. — так что вы точно знаете, куда добавить еще одну новую *фитчу*
* это отличная архитектура для более сложных приложений — вам не нужно передавать state по всему дереву вашего view от родителя к потомку
* и есть еще один ...
### Redux Time Travel
В Redux возможна одна интересная возможность — Путешествие во времени! С Redux и соответствующими инструментами вы можете отслеживать state вашего приложения с течением времени, проверять фактический state и воссоздавать его в любое время. Смотрите эту возможность в действии:

### Redux Widgets на простом примере
Все вышеперечисленные правила делают поток данных в Redux однонаправленным. Но что это значит? На практике все это делается с помощью **actions**, **reducers**, **store** и **states**. Давайте представим приложение, которое отображает счетчик:

1. Ваше приложение имеет определенный **state** при старте (количество кликов, которое равно 0)
2. На основании этого state/состояния отрисовывается **view**.
3. Если пользователь нажимает на кнопку, происходит отправка **action** (например, IncrementCounter)
4. После чего *action* получает **reducer**, который знает предыдущий *state* (счетчик 0), и получает *action* (IncrementCounter) и может вернуть новый **state** (счетчик теперь равен 1)
5. Наше приложение имеет новый **state/состояние** (счетчик равен 1)
6. На основании нового **state**, перерисовывается **view**, которое отобразит на экране текущий state/состояние
Итак, как вы можете видеть, как правило, это все о **state**. У вас есть один state всего приложения, **state** только *read-only*, и для создания нового **state** вам нужно отправить **action**. Отправка *actions* запускает **reducer**, который создает и вернет нам новый **state**. И история повторяется.

Давайте все же создадим небольшое приложение и более ближе познакомимся с реализацией подхода Redux в действий, приложение будет называться “*Список покупок/Shopping List*”
Мы посмотрим, как Redux работает на практике. Мы создадим простое приложение ShoppingCart. В приложении будут функциональные возможности, такие как:
* добавление покупок
* возможно будет пометить покупку как выполненную
* и это в основном все
Приложение будет выглядеть так:

Давайте начнем написания кода!
### Необходимое условие
В этой статье я не буду показывать создание пользовательского интерфейса для данного приложения. [Вы можете ознакомится с кодом который я подготовил для Вас, прежде чем продолжить погружение в Redux](https://github.com/pszklarska/flutter_shopping_cart). После чего мы продолжим написание кода и добавление *Redux* в текущее приложение.
**Примечание:** *Если вы никогда раньше не использовали Flutter, я советую вам попробовать [Flutter Codelabs от Google](https://codelabs.developers.google.com/codelabs/flutter/).*
### Предварительная подготовка
Чтобы начать использовать **Redux** для Flutter, нам необходимо добавить зависимости в файл *pubspec.yaml*:
```
flutter_redux: ^0.5.2
```
Вы также можете проверить текущую версию данной зависимости, перейдя на страничку [flutter\_redux](https://pub.dartlang.org/packages/flutter_redux).
*На момент написания статьи версия была, flutter\_redux 0.6.0*
### Model
Наше приложение должно уметь управлять добавлением и изменением элементов, поэтому мы будем использовать простую модель *CartItem* для хранения состояния одного элемента. Все наше состояние приложения будет просто списком CartItems. Как видите, CartItem — это просто объект.
```
class CartItem {
String name;
bool checked;
CartItem(this.name, this.checked);
}
```
Во-первых, нам нужно объявить actions. Action — это, по сути, любое намерение, которое может быть вызвано для изменения состояния приложения. По сути нас будет два actions для добавления и изменения элемента:
```
class AddItemAction {
final CartItem item;
AddItemAction(this.item);
}
class ToggleItemStateAction {
final CartItem item;
ToggleItemStateAction(this.item);
}
```
Затем нам нужно сообщить нашему приложению, что делать с этими *actions*. Вот почему используются *reducers* — они просто принимают текущее состояние приложения и действие (application state и action), затем создают и возвращают новый state. У нас будет два *reducer* метода:
```
List appReducers(List items, dynamic action) {
if (action is AddItemAction) {
return addItem(items, action);
} else if (action is ToggleItemStateAction) {
return toggleItemState(items, action);
}
return items;
}
List addItem(List items, AddItemAction action) {
return List.from(items)..add(action.item);
}
List toggleItemState(List items, ToggleItemStateAction action) {
return items.map((item) => item.name == action.item.name ?
action.item : item).toList();
}
```
Метод *appReducers()* делегирует action соответствующим методам. Оба метода *addItem()* и *toggleItemState()* возвращают новые списки — это наш новый state/ состояние. Как видите, вы **не должны изменять текущий список**. Вместо этого мы каждый раз создаем новый список.
### StoreProvider
Теперь, когда у нас есть *actions* и *reducers*, нам нужно предоставить место для хранения *состояния приложения*. В Redux он называется **store** и является единственным источником правды для приложения.
```
void main() {
final store = new Store>(
appReducers,
initialState: new List());
runApp(new FlutterReduxApp(store));
}
```
Чтобы создать **store**, нам нужно передать метод *reducers* и начальный **state**. Если мы создали **store**, мы должны передать его в *StoreProvider*, чтобы сообщить нашему приложению, что *store* может быть использован любым, кто захочет запросить текущий **state** приложения.
```
class FlutterReduxApp extends StatelessWidget {
final Store> store;
FlutterReduxApp(this.store);
@override
Widget build(BuildContext context) {
return new StoreProvider>(
store: store,
child: new ShoppingCartApp(),
);
}
}
```
В приведенном выше примере, *ShoppingCartApp(*) является основным виджетом нашего приложения.
### StoreConnector
В настоящее время у нас есть все, кроме… фактического добавления и изменения элементов для покупки. Как это сделать? Чтобы сделать это возможным, нам нужно использовать *StoreConnector*. Это способ получить **store** и отправить ему какие-то *action* или просто получить текущий **state**.
Во-первых, мы хотим получить текущие данные и отобразить их в виде списка на экране:
```
class ShoppingList extends StatelessWidget {
@override
Widget build(BuildContext context) {
return new StoreConnector, List>(
converter: (store) => store.state,
builder: (context, list) {
return new ListView.builder(
itemCount: list.length,
itemBuilder: (context, position) =>
new ShoppingListItem(list[position]));
},
);
}
}
```
Код выше оборачивает *ListView.builder* с *StoreConnector*. **StoreConnector** может принять текущий **state** (которое является списком элементов *) и с помощью функций *map* мы можем конвертировать его в что угодно. Но в нашем случае это будет один и тоже **state** (List ), потому что здесь нам нужен список покупок.
Далее, в функции *builder* мы получаем список — который в основном представляет собой список *CartItems* из **store**, который мы можем использовать для создания **ListView**.
Хорошо, круто — у нас есть данные. Теперь, как установить некоторые данные?
Для этого мы также будем использовать *StoreConnector*, но немного по-другому.
```
class AddItemDialog extends StatelessWidget {
@override
Widget build(BuildContext context) {
return new StoreConnector, OnItemAddedCallback>(
converter: (store) {
return (itemName) =>
store.dispatch(AddItemAction(CartItem(itemName, false)));
}, builder: (context, callback) {
return new AddItemDialogWidget(callback);
});
}
}typedef OnItemAddedCallback = Function(String itemName);
```
Давайте посмотрим на код. Мы использовали в *StoreConnector*, как и в предыдущем примере, но на этот раз вместо сопоставления списка *CartItems* с тем же списком, мы сделаем преобразование с помощью **map** в *OnItemAddedCallback*. Таким образом, мы можем передать [функцию обратного вызова](https://developer.mozilla.org/ru/docs/%D0%A1%D0%BB%D0%BE%D0%B2%D0%B0%D1%80%D1%8C/%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F_%D0%BE%D0%B1%D1%80%D0%B0%D1%82%D0%BD%D0%BE%D0%B3%D0%BE_%D0%B2%D1%8B%D0%B7%D0%BE%D0%B2%D0%B0) в *AddItemDialogWidget* и вызвать ее, когда пользователь будет добавлять новый элемент:
```
class AddItemDialogWidgetState extends State {
String itemName;
final OnItemAddedCallback callback;
AddItemDialogWidgetState(this.callback);
@override
Widget build(BuildContext context) {
return new AlertDialog(
...
actions: [
...
new FlatButton(
child: const Text('ADD'),
onPressed: () {
...
callback(itemName);
})
],
);
}
}
```
Теперь каждый раз, когда пользователь нажимает кнопку «ADD», функция обратного вызова отправляет **action** *AddItemAction()*.
Теперь мы можем сделать очень похожую реализацию для изменения состояния элемента.
```
class ShoppingListItem extends StatelessWidget {
final CartItem item;
ShoppingListItem(this.item);
@override
Widget build(BuildContext context) {
return new StoreConnector, OnStateChanged>(
converter: (store) {
return (item) => store.dispatch(ToggleItemStateAction(item));
}, builder: (context, callback) {
return new ListTile(
title: new Text(item.name),
leading: new Checkbox(
value: item.checked,
onChanged: (bool newValue) {
callback(CartItem(item.name, newValue));
}),
);
});
}
}
```
Как и в предыдущем примере, мы используем **StoreConnector** для отображения *List для функции обратного вызова *OnStateChanged*. Теперь каждый раз, когда флажок изменяется (в методе onChanged), функция обратного вызова запускает событие *ToggleItemStateAction*.
### Резюме
Это все! В этой статье мы создали простое приложение которое отображает список покупок и немного погрузились в использование архитектуры Redux. В нашем приложении мы можем добавить элементы и изменить их состояние. Добавление новых функций в это приложение так же просто, как добавление новых *actions* и *reducers*.
[Здесь](https://github.com/pszklarska/FlutterShoppingCart) вы можете ознакомится с исходный кодом этого приложения, включая виджет **Time Travel**:
Надеюсь, вам понравился этот пост!** | https://habr.com/ru/post/481624/ | null | ru | null |
# Функциональный DDS rенератор на ПЛИС
Недавно я увидел проект генератора сигналов на микроконтроллере AVR. Принцип генерации — [DDS](http://ra3ggi.qrz.ru/UZLY/dds.htm), на базе библиотеки [Jesper](http://www.myplace.nu/avr/minidds/) максимальная частота — 65534 Гц (и до 8 МГц HS выход с меандром). И тут я подумал, что генератор — отличная задача, где ПЛИС сможет показать себя в лучшем виде. В качестве спортивного интереса я решил повторить проект на ПЛИС, при этом по срокам уложиться в два выходных дня, а параметры получить не строго определенные, а максимально возможные. Что из этого получилось, можно узнать под катом
#### **День нулевой**
До того, как наступят выходные, у меня было немного времени подумать над реализацией. Чтобы упростить себе задачу, решил сделать генератор не в виде отдельного устройства с кнопками и LCD экраном, а в виде устройства, которое подключается к ПК через USB. Для этого у меня есть [плата USB2RS232](http://www.dx.com/p/pl2303hx-usb-to-rs232-ttl-converter-adapter-module-164590#.VYl73fntlBc). Плата драйверов не требует (CDC), поэтому, я думаю, что и под Linux будет работать (для кого-то это важно). Так же, не буду скрывать, что с приемом сообщений по RS232 я уже работал. [Модули для работы с RS232](http://opencores.org/project,uart2bus) буду брать готовые c [opencores.com](http://opencores.com/).
Для генерации синусоидального сигнала потребуется ЦАП. Тип ЦАП я выбрал, как и в исходном проекте — [R2R](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B7%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%BD%D1%8B%D0%B5_%D0%BC%D0%B0%D1%82%D1%80%D0%B8%D1%86%D1%8B) на 8 бит. Он позволит работать на высоких частотах, порядка мегагерц. Убежден, что ПЛИС с этим должна справиться
По поводу того, на чем написать программу для передачи данных через COM порт я задумался. С одной стороны, можно написать на Delphi7, опыт написания такой программы уже есть, к тому же размер исполняемого файла будет не большим. Еще попробовал набросать что-то для работы с Serial в виде java скрипта в html страничке, но более менее заработало только через Chrome serial API, но для этого надо устанавливать плагин… в общем тоже отпадает. В качестве новшества для себя попробовал PyQt5, но при распространении такого проекта, нужно тащить кучу библиотек. Попробовав собрать PyQt проект в exe файл, получилось больше 10 мб. То есть, будет ничем не лучше приложения, написанного на c++\Qt5. Стоит еще учесть, что опыта разработки на python у меня нет, а вот на Qt5 — есть. Поэтому выбор пал на Qt5. С пятой версии там появился модуль для работы с serial и я с ним уже работал. А еще приложение на Qt5 может быть перенесено на Linux и Mac (для кого-то это важно), а с 5.2 версии, приложения на QWidgets может быть перенесено даже на смартфон!
Что еще нужно? Естественно плата с ПЛИС. У меня их две (Cyclone iv EP4CE10E22C8N на 10 тыс. ячеек, и Cyclone ii EP2C5 на 5 тыс. ячеек). Я выберу ту, что слева, исключительно по причине более удобного разъема. В плане объема проект не предполагает быть большим, поэтому уместится в любую из двух. По скорости работы они не отличаются. Обе платы имеют «на борту» генераторы 50 МГц, а внутри ПЛИС есть [PLL](http://marsohod.org/index.php/11-blog/212-pll), с помощью которого я смогу увеличить частоту до запланированных 200 МГц.

#### **День первый**
В связи с тем, что модуль DDS я уже делал в своем синтезаторном проекте, то я сразу взялся за паяльник и начал паять ЦАП на резисторах. Плату взял макетную. Монтаж делал с применением [накрутки](http://habrahabr.ru/post/238675/). Единственное изменение, которое коснулось технологии — я отказался от кислоты [Ф38Н](http://habrastorage.org/files/9cb/2de/38d/9cb2de38d05a471babafc9b76d5f1022.jpg) для лужения стоек в пользу [индикаторного флюс-геля ТТ](https://habrastorage.org/files/bcd/8de/776/bcd8de7761954df4b730d351cc33f781.png). Суть технологии проста: в печатную плату впаиваю стойки, на них со стороны печатного монтажа припаиваю резисторы. Недостающие соединения выполняю накруткой. Еще, стойки удобны тем, что я их могу вставить прямо в плату ПЛИС.
К сожалению, дома в наличии не оказалось резисторов 1 и 2 килоома. Ехать в магазин было некогда. Пришлось поступиться одним из своих правил, и выпаять резисторы из старой не нужной платы. Там применялись резисторы 15К и 30К. Получился вот такой франкенштейн:

**Дальше я запустил Quartus, создал проект**После создания проекта нужно задать целевое устройство: Меню Assigments -> Device
Далее там же нажимаю кнопочку «Device and Pin options» потому что некоторые пины настроены так, что работать не будут. Настраиваю все, как «Use as regular I/O»
В проекте я «нахадркодил» неуправляемый главный модуль DDS на фиксированную частоту.
**Модуль генератора на 1000 Гц**
```
module signal_generator(clk50M, signal_out);
input wire clk50M;
output wire [7:0] signal_out;
wire clk200M;
osc osc_200M
reg [31:0] accumulator;
assign signal_out = accumulator[31:31-7];
//пробуем генерировать 1000 Гц
//50 000 000 Hz - тактовая частота внешнего генератора
//2^32 = 4 294 967 296 - разрядность DDS - 32 бита
//делим 1000Hz / 50 000 000 Hz / 2 * 4294967296 => 42949,67296
always @(posedge clk50M) begin
accumulator <= accumulator + 32'd42949;
end
endmodule
```
После этого нажал «Start Compilation», чтобы среда разработки задалась вопросом, какие у нас линии ввода вывода есть в главном модуле проекта и к каким физическим PIN's они подключены. Подключить можно практически к любому. После компиляции назначаем появившиеся линии к реальным PIN микросхемы ПЛИС:
**Пункт меню Assigments -> Pin Planner**На линии HS\_OUT, key0 и key1 прошу пока не обращать внимание, они появляются в проекте потом, но скрин в самом начале я сделать не успел.
В принципе, достаточно «прописать» только PIN\_nn в столбце Location, а остальные параметры (I/O standart, Current Strench и Slew Rate) можно оставить по умолчанию, либо выбрать такие же, что предлагаются по умолчанию (default), чтобы не было warning'ов.
**Как узнать какому PIN соответствует номер разъема на плате?**Номера контактов разъема подписаны на плате

А пины ПЛИС, к которым подключены контакты разъема, описаны в документации, которая идет в комплекте с платой ПЛИС.
После того, как пины назначены, компилирую проект еще раз и прошиваю с помощью USB программатора. Если у вас не установлены драйверы для программатора USB Byte blaster, то укажите Windows, что они находятся в папке, куда у вас установлен Quartus. Дальше она сама найдет.
Подключать программатор нужно к разъему JTAG. А пункт меню для программирования «Tools -> Programmer» (либо нажать значек на панели инструментов). Кнопка «Start», радостное «Success» и прошивка уже внутри ПЛИС и уже работает. Только не выключайте ПЛИС, а то она все забудет.
**Tools -> Programmer**
ЦАП подключен к разъему платы ПЛИС. К выходу ЦАП подключаю осциллограф С1-112А. В результате должна получиться «пила» потому что на выход 8 бит выводится старшая часть слова DDS аккумулятора фазы. А оно всегда увеличивается, пока не переполнится.
Каких-то 1.5 часа и для частоты в 1000 Гц я вижу следующую осциллограмму:
Хочу заметить, что «пила» по середине имеет небольшой перелом. Он связан с тем, что резисторы имеют разброс значений.
Еще один важный момент, который нужно было выяснить — это максимально возможная частота, с которой будет работать DDS генератор. При правильно настроенных параметрах TimeQuest, после компиляции в «Compilation Report» можно увидеть, что скорость работы схемы выше 200 МГц с запасом. А это значит, что частоту генератора 50 МГц я буду умножать с помощью PLL на 4. Увеличивать значение аккумулятора фазы DDS буду с частотой 200 МГц. Итоговый диапазон частот, который можно получить в наших условиях 0 — 100 МГц. Точность установки частоты:
```
200 000 000 Гц (clk) / 2^32 (DDS) = 0,047 Гц
```
То есть, это лучше, чем ~0.05 Гц. Точность в доли герца для генератора с таким диапазоном рабочих частот (0...100 МГц) считаю достаточной. Если кому-то потребуется повысить точность, то для этого можно увеличить разрядность DDS (при этом не забыть проверить TimeQuest Timing Analyzer, что скорость работы логической схемы укладывалась в CLK=200 МГц, ведь это сумматор), либо просто снизить тактовую частоту, если такой широкий диапазон частот не требуется.
**TimeQuest Timing Analyzer**
После того, как я увидел на экране «пилу», семейные дела заставили меня ехать на дачу (выходной же). Там я косил, варил, жарил шашлык и не подозревал о том сюрпризе, что ждал меня вечером. Уже ближе к ночи, перед сном, я решил посмотреть форму сигнала для других частот.
**Для частоты 100 КГц****Для частоты 250 КГц****Для частоты 500 КГц****Для частоты 1 МГц**
Не буду скрывать, что форма сигналов меня расстроила, особенно на 1МГц (жалкий, никчемный мегагерц!). Я планировал получить частоты несколько других порядков. Почитав про R2R ЦАП стала ясна причина проблемы — паразитные емкости. Поэтому в планах на следующий день было решено сделать ЦАП на резисторах 100 и 200 Ом, которые у меня есть в наличии, а этот ЦАП оставить для будущих разработок, не требующих работы на таких высоких частотах, ведь в гладкости пилы тоже есть свой плюс.
#### **День второй**
В связи с тем, что было интересно, как будет работать ЦАП на резисторах 100 и 200 Ом, я сразу взялся за паяльник. На этот раз ЦАП получился более аккуратным, а времени на его монтаж ушло меньше.

Ставим ЦАП на плату ПЛИС и подключаем к осциллографу

Проверяем 1 МГц — ВО! Совсем другое дело!

**Пила 10 МГц****Пила 25 МГц**
Форма пилы на 10 МГц еще похожа на правильную. Но на 25 МГц она уже совсем «не красивая». Однако, у С1-112а полоса пропускания — 10 МГц, так что в данном случае причина может быть уже в осциллографе.
В принципе, на этом вопрос с ЦАП можно считать закрытым. Теперь снимем осциллограммы высокоскоростного выхода. Для этого, выведем старший бит на отдельный PIN ПЛИС. Данные для этой линии будем брать со старшего бита аккумулятора DDS.
```
assign hs_out = accumulator[31];
```
**Меандр 1 МГц****Меандр 5 МГц****Меандр 25 МГц****Меандр 50 МГц уже практически не виден**
Но считаю, что выход ПЛИС стоило бы нагрузить на сопротивление. Возможно, фронты были бы круче.
Синус делается по таблице. Размер таблицы 256 значений по 8 бит. Можно было бы взять и больше, но у меня уже был готовый mif файл. С помощью мастера создаем элемент ROM с данными таблицы синуса из mif-файла.
**Создание ROM - Tools -> Mega Wizard Plugin manager**
Выбираем 1 портовую ROM и задаем название модулю
Соглашаемся
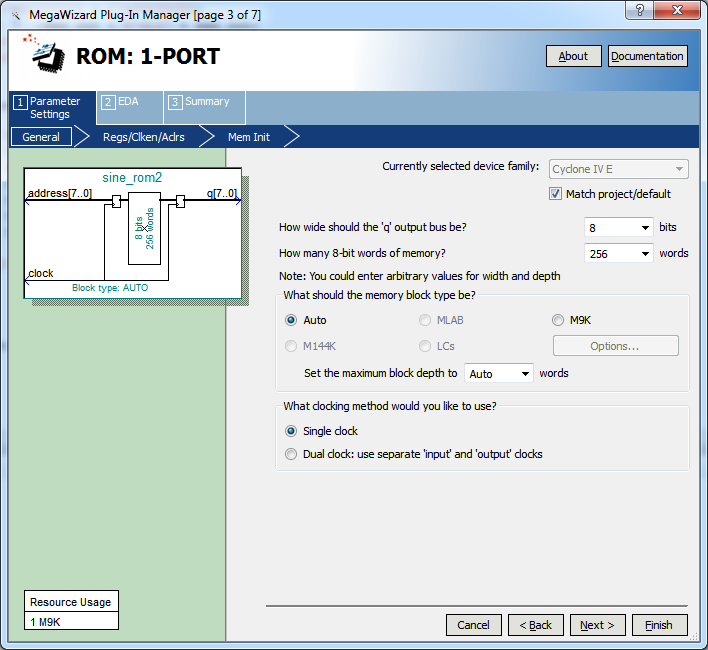
Тут тоже соглашаемся
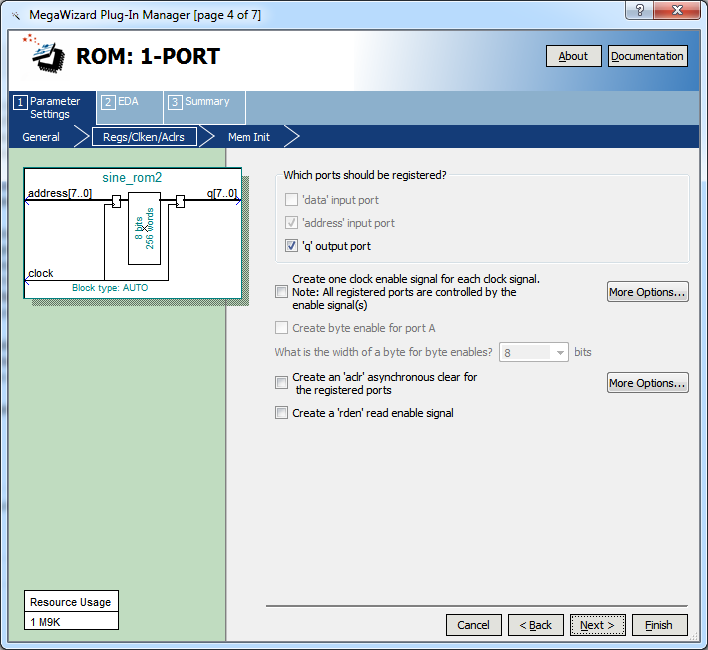
С помощью browse находим наш mif файл с таблицей синуса

Тут тоже ничего не меняем
Снимаем галочку с модуля sine\_rom\_bb.v — он не нужен. Дальше finish. Квартус спросит добавить модуль в проект — соглашаемся. После этого, модуль можно использовать так же, как любой другой модуль в Verilog.
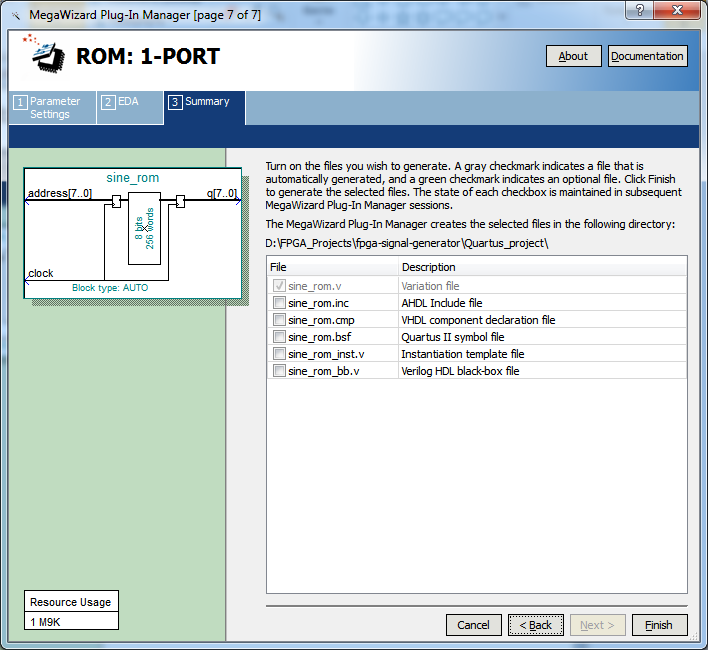
Старшие 8 бит слова аккумулятора DDS будут использоваться в качестве адреса ROM, а выход данных — значение синуса.
**Код**
```
//sine rom
wire [7:0] sine_out;
sine_rom sine1(.clock(clk200M), .address(accumulator[31:31-7]), .q(sine_out));
```
Осциллограмма синуса на разных частотах выглядит… одинаково.
При желании, можно рассмотреть проблемы ЦАП, связанные с разбросом резисторов:

Чтож, на этом выходные кончились. А ведь еще не написано ПО для управления с ПК. Вынужден констатировать факт, что в запланированные сроки я не уложился.
#### **День третий**
Времени совсем мало, поэтому программу пишем на скорую руку (в лучших традициях). Местами, чтобы сократить количество букв и удобство ввода информации с клавиатуры, применяется фильтр событий по имени виджета. Прошу понять и простить.
Интерфейс

Исходный код на [GitHub](https://github.com/UA3MQJ/fpga-signal-generator/tree/master/Qt_project/signal_generator). Там же есть уже собранное под windows приложение.
Код прост, как 5 копеек. В файл проекта .pro кроме всего прочего нужно добавить модуль serialport:
```
QT += core gui serialport
```
**Открытие COM порта**
```
QSerialPort serial;
...
serial.setPortName(ui->lbSerialPortInfo->currentText());
serial.setBaudRate(QSerialPort::Baud115200);
serial.setDataBits(QSerialPort::Data8);
serial.setParity(QSerialPort::NoParity);
serial.setStopBits(QSerialPort::OneStop);
serial.setFlowControl(QSerialPort::NoFlowControl);
serial.open(QIODevice::ReadWrite);
```
**Формирование и отправка сообщения**
```
QByteArray source;
QDataStream stream(&source, QIODevice::ReadWrite);
stream << (qint8)(01); // set freq msg
stream << waveform;
stream << adder32;
serial.write(source);
```
#### **День четвертый**
В спешном порядке доделываем прием данных по UART. Для приема сообщений по UART нужно поставить пару модулей. Один Baud генератор, второй — приемник. Для того, чтобы приемник работал на 115200, нужно произвести некоторые рассчеты, исходя, что основная тактовая частота у нас — 200 МГц.
**Модуль baud\_gen**
```
parameter global_clock_freq = 200000000;
parameter baud_rate = 115200;
//бодген - модуль для генерации клока UART
// first register:
// baud_freq = 16*baud_rate / gcd(global_clock_freq, 16*baud_rate)
//Greatest Common Divisor - наибольший общий делитель. http://www.alcula.com/calculators/math/gcd/
// second register:
// baud_limit = (global_clock_freq / gcd(global_clock_freq, 16*baud_rate)) - baud_freq
//можно добавить значения для других скоростей
parameter GCD = (baud_rate==115200) ? 12800 : 0;
parameter baud_freq = 16*baud_rate / GCD;
parameter baud_limit = (global_clock_freq / GCD) - baud_freq;
wire uart_clk;
baud_gen BG(.clock(clk), .reset(rst), .ce_16(uart_clk), .baud_freq(baud_freq), .baud_limit(baud_limit));
```
Ставлю модуль приема сообщений, на него подается uart\_clk и сигнал с физического входа ПЛИС.
**Модуль uart\_rx**
```
//RCV
wire [7:0] uart_command;
wire uart_data_ready;
uart_rx URX(.clock(clk),
.reset(rst),
.ce_16(uart_clk),
.ser_in(rx),
.rx_data(uart_command),
.new_rx_data(uart_data_ready) );
```
Дальше все это помещаю в отдельный модуль, который выдает только номер формы волны и значение приращения к регирстру аккумулятора фазы DDS.
**Модуль ctrl.v**
```
module ctrl(clk, rst, rx, wf, adder);
input wire clk, rst, rx;
output wire [7:0] wf; //wave form
output wire [31:0] adder;// adder value
reg [7:0] wf_reg;
initial wf_reg <= 8'd0;
reg [31:0] adder_reg;
initial adder_reg <= 32'd1073741;
```
Когда модуль uart\_rx принял байт информации, он на один такт ставит в единицу линию uart\_data\_ready. В это время на линии uart\_command находится принятый байт. Для приема сообщения пишу стейтмашину.
**Стейт-машина**
```
//rcv state machine
parameter SM_READY = 4'd0;
parameter SM_FRQ_WF = 4'd1;
parameter SM_FRQ_DDS1 = 4'd2;
parameter SM_FRQ_DDS2 = 4'd3;
parameter SM_FRQ_DDS3 = 4'd4;
parameter SM_FRQ_DDS4 = 4'd5;
//messages
parameter CMD_SETFREQ = 8'd1;
reg [3:0] rcv_state;
initial rcv_state <= SM_READY;
always @ (posedge clk) begin
if (uart_data_ready==1) begin
if (rcv_state==SM_READY) begin
rcv_state = (uart_command==CMD_SETFREQ) ? SM_FRQ_WF : rcv_state;
end else if (rcv_state==SM_FRQ_WF) begin
wf_reg <= uart_command;
rcv_state <= rcv_state + 1'b1;
end else if (rcv_state==SM_FRQ_DDS1) begin
adder_reg <= (adder_reg << 8) + uart_command;
rcv_state <= rcv_state + 1'b1;
end else if (rcv_state==SM_FRQ_DDS2) begin
adder_reg <= (adder_reg << 8) + uart_command;
rcv_state <= rcv_state + 1'b1;
end else if (rcv_state==SM_FRQ_DDS3) begin
adder_reg <= (adder_reg << 8) + uart_command;
rcv_state <= rcv_state + 1'b1;
end else if (rcv_state==SM_FRQ_DDS4) begin
adder_reg <= (adder_reg << 8) + uart_command;
rcv_state <= SM_READY;
end else begin
rcv_state <= SM_READY;
end
end //ucom_ready
end
```
Выводим данные на выходы модуля
**Вывод**
```
assign adder = adder_reg;
assign wf = wf_reg;
```
Добавляем модуль приема в главный модуль.
**Добавляем модуль ctrl в главный модуль**
```
//rs232 rcvr
wire [31:0] adder_value;
wire [7:0] waveform;
ctrl ctrl_0(.clk(clk200M), .rst(rst), .rx(RS232in), .wf(waveform), .adder(adder_value));
```
Значение приращения прибавляем к аккумулятору фазы
**Увеличиваем значение аккумулятора с каждым тактом**
```
always @(posedge clk200M) begin
accumulator <= accumulator + adder_value;
end
```
Из старшей части значения аккумулятора фазы получаем остальные волноформы. А в зависимости от выбранной формы — подключаем ее на выход.
**Волноформы**
```
// wave_forms
parameter SINE = 8'd0;
parameter SAW = 8'd1;
parameter RAMP = 8'd2;
parameter TRIA = 8'd3;
parameter SQUARE = 8'd4;
parameter SAWTRI = 8'd5;
parameter NOISE = 8'd6;
wire [7:0] saw_out = accumulator[31:31-7];
wire [7:0] noise_out = 8'd127; //!
wire [7:0] ramp_out = -saw_out;
wire [7:0] square_out = (saw_out > 127) ? 8'b11111111 : 1'b00000000;
wire [7:0] saw_tri_out = (saw_out > 7'd127) ? -saw_out : 8'd127 + saw_out;
wire [7:0] tri_out = (saw_out>8'd191) ? 7'd127 + ((saw_out << 1) - 9'd511) :
(saw_out>8'd063) ? 8'd255 - ((saw_out << 1) - 7'd127) : 7'd127 + (saw_out << 1);
//sine rom
wire [7:0] sine_out;
sine_rom sine1(.clock(clk200M), .address(saw_out), .q(sine_out));
wire [7:0] signal = (waveform == SINE) ? sine_out :
(waveform == SAW) ? saw_out :
(waveform == RAMP) ? ramp_out :
(waveform == TRIA) ? tri_out :
(waveform == SQUARE) ? square_out :
(waveform == SAWTRI) ? saw_tri_out :
(waveform == NOISE) ? noise_out : 8'd127; //TODO
```
Я был почти не удивлен, что оно сразу заработало. Единственная ошибка, которую я нашел — была в рассчетах: я делил искомую частоту на CLK, потом еще на два, потом умножал на разрядность аккумулятора. Но этого делать не нужно, потому что у нас получается 1 период при изменении значении аккумулятора от 0 до МАХ. Делить дополнительно на 2 нужно только если в качестве выхода меандра брать старший бит аккумулятора частоты (в этом случае частота получается ниже в 2 раза). Но получение меандра я переделал.
#### **День четвертый**
В него можно включить время, потраченное в каждый день на оформление статьи.
Приступим к проверке. Сначала осциллографом.
На радиочастотах от 28 и до 100 МГц я решил послушать генератор с помощью SDR приемника, поставив антенну рядом с платой.


#### **Выводы**
Как это часто бывает в ИТ — с оценкой сроков произошла ошибка в 2 — 2.5 раза. Цель достигнута: на коленке собран генератор до 100 МГц. Однако, чтобы эту поделку можно было назвать полноценным генератором, потребуется поработать еще. Поэтому есть большие перспективы для развития. Из за срыва сроков, я не добавил то, что в принципе мог: 1) генератор шума; 2) генератор волны, которую пользователь рисует сам; 3) генератор цифровой последовательности. Еще в генераторе нет регулировки амплитуды и смещения.
Использовано 227 ячеек из 10000. Список того, что еще можно добавить в проект:
* Расширить разрядность ЦАП
* Увеличить количество выходов с генерируемыми сигналами
* Применить микросхему ЦАП в большей разрядностью
* Реализовать управление амплитудой и смещением
* Добавить элементы управления, ЖК экран, для портативности
* Добавить генератор шума и других простых форм волн
* Добавить возможность загрузки произвольных форм волн
Я думаю, что любой желающий сможет это сделать самостоятельно, расширив проект нужным функционалом. Добавить проще, чем сделать с нуля. Формат команды управления очень простой, поэтому генератором можно управлять с микроконтроллера.
Исходные коды:<https://github.com/UA3MQJ/fpga-signal-generator>
#### **Ссылки с аналогами**
Далеко не полный список
[Функциональный DDS генератор.](http://cxem.net/izmer/izmer76.php) Создан базе AVR. Частоты 0… 65534 Гц.
[Обзор DDS-генератора GK101.](http://cxem.net/review/review15.php) Создан с применением ПЛИС Altera MAX240. Частоты до 10 МГц.
[Многофункциональный генератор на PIC16F870.](http://cxem.net/izmer/izmer88.php) Частотный диапазон: 11 Гц — 60 кГц.
[Аналоговый функциональный генератор.](http://cxem.net/izmer/izmer136.php) Частотный диапазон колеблется от 20 Гц до 300 кГц
[USB функциональный генератор на AD9833.](http://cxem.net/izmer/izmer112.php) На базе микросхемы DDS.
[Мини DDS — простейший передатчик на диапазон 137 кГц и не только.](http://qsl.net/ew6gb/mini_dds.html) Частота 136 КГц.
[DDS — функциональный генератор с «джамперным» управлением на ПЛМ.](http://www.cqham.ru/ddsfunc.html) | https://habr.com/ru/post/260999/ | null | ru | null |
# Идеальный бэкап за пять минут с ZFS

Приветствуем в блоге [компании «Маклауд»](https://habr.com/ru/company/macloud/)!
Сегодня мы поговорим о том, о чём должен помнить каждый — про бэкапы.
Программисты уже давно стараются использовать серьёзные production-ready решения для сохранения личных данных. Требования к инструментам растут, и если когда-то было принято держать домашние файлы на NAS и перекачивать снапшоты сервера через Rsync, то сейчас на передовой гораздо более сложные и функциональные проекты. Один из них — возможно, самый перспективный и мощный — файловая система ZFS. Оставив конкурента (btrfs) далеко позади и отстояв право на опен-сорс, она активно применяется как в хайлоаде, так и в личных системах хранения. Далее мы разберём её основные аспекты и за несколько минут поднимем рабочую систему бэкапа на удалённой VPSке. Поехали!
Кратко о ZFS
============
В ZFS заложена одна простая идея: должна существовать единая файловая система, заточенная под идеальное локальное хранение данных. Без лишних слоёв над LVM, без жёсткой привязки к железу, с максимальным покрытием задач прямо из коробки. И список возможностей у неё впечатляющий, вот самые базовые:
* Copy-on-write: данные никогда не перезаписываются, все старые версии доступны напрямую с диска, без необходимости использовать write-ahead log (и как следствие, сверять журналы). ZFS работает на дереве хэшей ([Merkle tree](https://en.wikipedia.org/wiki/Merkle_tree)), гарантирующее консистентность в обмен на затратные вычисления всего дерева. Таким образом, система прежде всего нацелена на максимальную сохранность всех данных.
* Так как любое сохранение состояния выполняется через атомарные транзакции, доступны «мгновенные снапшоты», которые действительно можно снимать с почти неограниченной частотой благодаря фиксированной стоимости. Не нужно проверять изменения всех данных, достаточно оперировать хэшами, за валидацию которых отвечает корневой блок дерева.
* Программный RAID через mirror или raidz — аналог RAID 5/6/7 — конфигурируется через виртуальные устройства (vdev). Нет зависимости от конкретного железа (не придётся бояться write-hole), можно выбрать между надёжностью и производительностью на одном и том же наборе дисков. А ещё при избыточности ZFS автоматически выполняет self-healing при случайных ошибках.
* Потоковое сжатие (LZ4/gzip) работает из коробки, не накладывая заметной задержки при записи. При этом слегка возрастающий расход процессорного времени компенсируется меньшей нагрузкой на диск, что полезно и для отказоустойчивости, и для вариативности в выборе дисков.
* Категория «прочее»: дедупликация данных (отключаемая), независимые вложенные файловые системы со своими настройками, недостижимый лимит на размер файлов (ZFS 128-битная), и самое главное для нас: встроенный трансфер снапшотов через команды send/receive с триггерами before и after.
[Здесь](https://habr.com/ru/company/mailru/blog/529516/), [здесь](https://habr.com/ru/post/504692/) и [здесь](https://openzfs.org/wiki/System_Administration) можно почитать подробнее про внутреннее устройство ZFS, её историю и нюансы администрирования.
Если сравнивать возможности Rsync и кастомных скриптов для синхронизации с ZFS, у них не будет ни шанса. Комбинируем плюсы выше: инкрементальные консистентные бэкапы + мгновенные снапшоты + программный RAID + отправка бэкапов из коробки = идеальный инструмент, объединяющий в себе мощный функционал и огромную производительность. Чтобы добиться подобного привычным инструментарием, понадобится оркестрировать кучу сервисов с многочисленными точками отказа.

Настраиваем бэкап за чашкой кофе
================================
Разнообразие возможных хост-систем огромно — ZFS поддерживается на FreeBSD, Linux, Windows и MacOS, и разобрать все возможные сценарии в рамках одной статьи невозможно, поэтому рассмотрим самый расхожий вариант. Дано: локальная машина или сервер на Ubuntu/CentOS с данными (скажем, веб или база данных), которые необходимо сохранить на удалённый сервер (VPS на тех же системах), с версионированием и быстрым откатом.
> Важный момент: за рокетсайнс под капотом ZFS расплачивается высокими требованиями к ресурсам при использовании raidz на обычных SSD (и при больших объёмах хранения, само собой). Поэтому для комфортной работы и на хост-машине, и на VPS потребуется как минимум двухъядерный процессор с 4гб памяти.
В последних версиях Ubuntu:
```
sudo apt install -y zfs
```
В версиях до 20.04:
```
sudo apt-get install zfsutils-linux
```
CentOS 8:
```
sudo dnf install https://zfsonlinux.org/epel/zfs-release.el8_3.noarch.rpm
gpg --import --import-options show-only /etc/pki/rpm-gpg/RPM-GPG-KEY-zfsonlinux
# в большинстве случаем также потребуется DKMS:
sudo dnf install epel-release
sudo dnf install kernel-devel zfs
```
Команда zfs без переданных аргументов откроет help:
```
missing command
usage: zfs command args ...
where 'command' is one of the following:
version
create [-p] [-o property=value] ...
create [-ps] [-b blocksize] [-o property=value] ... -V
destroy [-fnpRrv]
destroy [-dnpRrv] @[%][,...]
destroy #
snapshot [-r] [-o property=value] ... @ ...
rollback [-rRf]
clone [-p] [-o property=value] ...
...
```
Создадим пулы на хосте и на сервере командой zpool:
```
zpool create rpool
```
```
zpool create hotspare mirror sda sdb
```
Создадим в пулах файловые системы:
```
zfs create rpool/send-remote
```
```
zfs create hotspare/receive-remote
```
Запишем тестовый файл и создадим снапшот:
```
touch /rpool/send-remote/tmp
zfs snapshot rpool/send-remote@test0
```
Как видно, сохранение не заняло и секунды.
Теперь реплицируем данные на сервер (предполагается, что авторизация в ssh по ключу настроена, о том как это сделать, можно прочитать [здесь](https://www.digitalocean.com/community/tutorials/how-to-configure-ssh-key-based-authentication-on-a-linux-server)):
```
zfs send -R rpool/send-remote@test0 | ssh my-vps-host zfs receive -A hotspare/receive-remote
```
Теперь у нас есть реплика данных хоста. Обновим данные на хосте:
```
echo 123 > /rpool/send-remote/tmp
zfs snapshot rpool/send-remote@test1
```
Теперь нам не нужно делать модную реплику, достаточно инкрементальной записи:
```
zfs send -i rpool/send-remote@test1 | ssh my-vps-host zfs receive -A hotspare/receive-remote
```
Готово! Данные сохраняются на сервере, остаётся только настроить отправку по вашим триггерам (и/или регулярную синхронизацию). Для этого есть много готовых скриптов ([пример](https://habr.com/ru/post/491456/)), но лучше разобраться и написать свой, используя [документацию](https://openzfs.org/wiki/System_Administration)
Заключение
==========
Полностью разобраться в ZFS — огромный труд, освоив который, можно смело идти админить кровавый энтерпрайз. Но не всегда нужно идти на такие жертвы, достаточно изучить базовый функционал и написать пару скриптов, чтобы добиться результата, который потребовал бы куда более неудобного управления цепочкой более простых, но узкоспециализированных инструментов.
---
**Маклауд** размещает своё оборудование в надёжном дата-центре уровня TIER IV — *DataPro*. Мы предлагаем серверы для разных задач — в том числе, для хранения больших массивов данных, резервных копий. Зарегистрируйтесь [по ссылке](https://macloud.ru/?partner=fp22mrg62u) и получите 10% скидку на первый месяц аренды сервера любой конфигурации!
[](https://macloud.ru/?partner=habr_footer) | https://habr.com/ru/post/547056/ | null | ru | null |
# Тестирование в Openshift: Автоматизированное тестирование
Это заключительная часть серии из трех статей ([первая статья](https://habrahabr.ru/post/332994/), [вторая статья](https://habrahabr.ru/post/333012/)), которые посвящены автоматизированному тестированию программных продуктов в Openshift Origin. В данной статье будут рассмотрены аспекты тестирования в контейнерах и особенности выстраивания CI/CD при участии таких продуктов как:
1. Openshit Origin — как система для развертывания тестовых окружений.
2. Jenkins — как инструмент непрерывной интеграции.
3. Testlink — как система управления тестами.
4. Robot Framework — как framework для написания тестов.
Для лучшей репрезентативности я подготовил образ Vagrant, который содержит преднастроенную среду из вышеперечисленных продуктов (все перечисленные в данной статье объекты и механизмы могут быть легко проинспектированы). Чтобы повысить градус понимания материала я создал две задачи: задачу сборки, задачу тестирования. Обе задачи разбиты на этапы и детально описаны.
#### Быстрый старт:
1. [Загрузить Vagrant образ](https://drive.google.com/file/d/0B7eLip8tUY6ubk8wNE5vU2pmVWs/view?usp=sharing) и [Vagrantfile](https://raw.githubusercontent.com/livelace/openshift-testing/master/vagrant/Vagrantfile)
2. `vagrant box add --name viewshift viewshift-1.0.box && vagrant up`
**Описание окружения**
Создание полноценного окружения не входило в мои планы, но проиграв несколько сценариев со связыванием minishift c docker контейнерами пришло понимание, что это категорически неудобно и чревато ошибками. Тренировать воображение читателей с помощью одного текста считаю бесполезным занятием.
По умолчанию окружение стартует в графическом режиме. Сделано это для того, чтобы обойти проблему с доступом к продуктам извне. Настроен автоматический вход пользователя. Пользовательский Firefox содержит сохраненные закладки и учетные данные для доступа к продуктам.
Системные пользователи user и vagrant имеют неограниченный sudo доступ.
Задействованное ПО:
| Название | Версия | Учетные данные |
| --- | --- | --- |
| Openshift | 1.5.1 | admin:admin |
| Jenkins | 2.60.1 | admin:admin |
| Testlink | 1.9.16 | admin:admin |
| Gogs | 0.11.19.0609 | git:git |
| Mariadb | 5.5.52 | root:root |
| OpenShift Pipeline Jenkins Plugin | 1.0.47 | - |
| TestLink Plugin | 3.12 | - |
| Robot Framework plugin | 1.6.4 | - |
| Post-Build Script Plug-in | 0.17 | - |
| system | - | root:root |
| system | - | user:user |
| system | - | vagrant:vagrant |
SHA1:
0992d621809446e570be318067b70fe2b8e786b2 viewshift-1.0.box
#### Задача сборки:
Задача сборки подразумевает под собой сборку образа Docker с приложением "curl", которое в последующем будет участвовать в задаче тестирования.
*Примечание: в качестве корневого процесса (PID 1) в контейнере используется [supervisord](http://supervisord.org/). supervisord и другие похожие инструменты очень полезны в тех случаях, когда нужно завершить работу приложения полностью или управлять процессами удаленно.*
**Принципиальная схема:**

**Этапы**:
1. Определяем переменные, которые будут задействованы в задаче:
**PROJECT** — название проекта Openshift. Для данного проекта был создан ServiceAccount "jenkins", который обладает правами администратора в проекте. Данный ServiceAccount используется для доступа к проекту из Jenkins (данный аккаунт также используется в задаче тестирования).
**APP\_NAME** и **APP\_VERSION** — условное название и версия приложения, которые, тем не менее, фигурируют в нескольких местах: название и таг результирующего образа Docker, название запускаемого Build и т.д.
2. После того, как требуемые переменные были определены (продумана гранулярность/отличимость задач в проекте), требуется разнести их по всем YAML конфигурациям Openshift и другим шагам Jenkins.
3. На данном этапе создается объект BuildConfig, на базе которого будет создан и выполнен объект Build.
4. Происходит запуск процесс сборки на основе созданного BuildConfig. В случае успеха результирующий образ будет помещен во внутренний Docker регистр.
5. Все созданные объекты удаляются вне зависимости от успешности сборки.
#### Задача тестирования:
Под задачей тестирования подразумевается процесс тестирования приложения "curl", которое взаимодействует с сервисом "nginx" по протоколу HTTP. Мы хотим удостовериться, что приложение работает корректно и проходит заданные тесты.
**Принципиальная схема:**
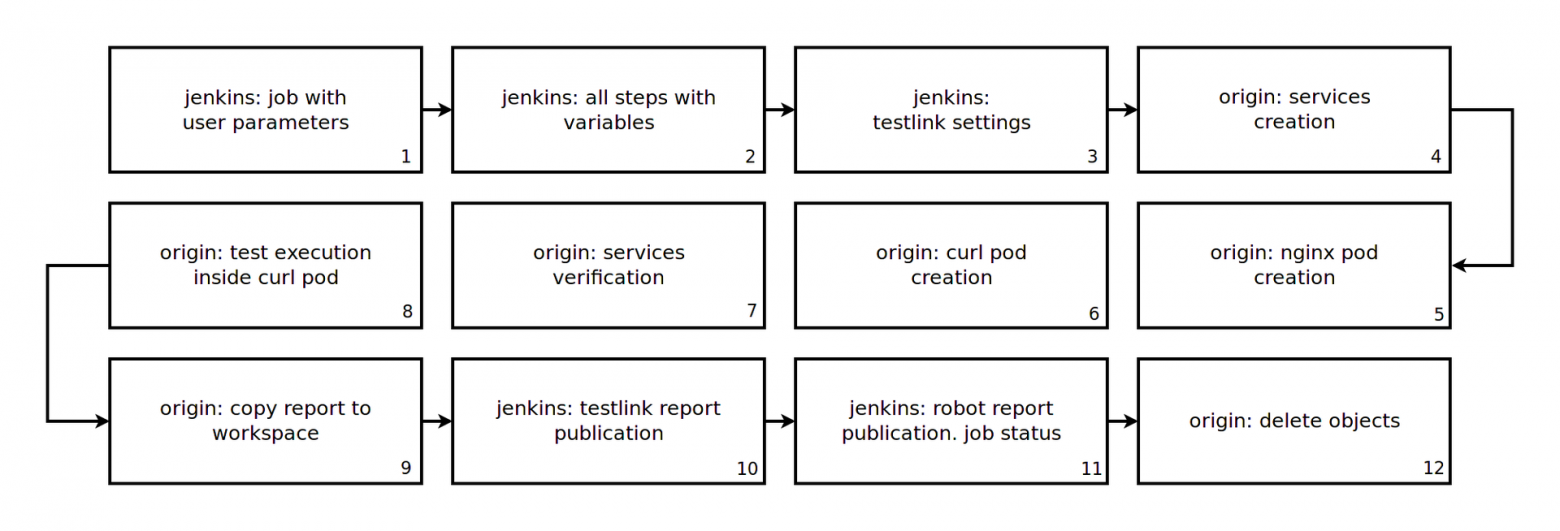
**Этапы**:
1. Определяем параметры, которые будут задействованы в задаче:
**PROJECT** — название проекта Openshift.
**TESTPLAN** — название тест-плана в Testlink. Задача завершится ошибкой, если указанный тест-план отсутствует в Testlink.
**APP\_NAME** и **APP\_VERSION** — условное название и версия приложения, которые аналогичным образом как и в задаче сборки.
**TEST\_CMD** — переменная, которая содержит название исполняемого файла, который будет запущен внутри контейнера. Аргументы командной строки указаываются в соотвествующем шаге Jenkins.
**TEST\_TIMEOUT** — численное выражение, которое задает время ожидания выполнения команды внутри контейнера. По истечении данного времени Jenkins задача завершает своё выполнение с ошибкой.
2. см. задачу сборки.
3. На данном этапе задается конфигурация Testlink, в которой указывается: с каким сервером будет установлена связь, какой тест-план будет использоваться (из тест-плана загружаются все назначенные данном тест-плану тесты для последующего сравнения), под какой платформой проводилось тестирование и т.д. Всё это требуется для последующей публикации пройденных тестов обратно в Testlink и отображения отчета тестирования непосредственно в Jenkins.
4. Данный этап предназначен для создания Service. Создаваемые сервисы будут указывать на приложения, которые будут запущены позднее. Через данные сервисы осуществляется проверка доступности приложений.
5. На данном этапе создается Pod для приложения "nginx".
6. На данном этапе создается Pod для приложения "curl". Образом для данного контейнера является образ, который создается в процессе задачи сборки. В отличии от "nginx", в данный образ добавлен том данных "share", который позволит контейнеру коммуницировать с файловой системой рабочего узла.
7. После того, как все Pod созданы, требуется проверка доступности приложений через опубликованные раннее сервисы.
8. На данном этапе происходит запуск команды тестирования в Pod с последующим ожиданием завершения выполнения данной команды.
9. После прохождения всех тестов происходит копирование отчета о тестировании в workspace задачи для последующего иморта в Testlink.
10. На данном этапе указывается стратегия (может быть не одна) сопоставления пройденных тестов с тем, что было получено из указанного раннее тест-плана. В данном случае идет простое сравнение названий тест-кейсов. После всех операции происходит публикация отчета о тестировании в Testlink.
11. Помимо отчета Teslink в формате Junit присутствует отчет о тестировании в формате Robot Framework, который установит статус выполненной задачи исходя из пороговых значений пройденных тестов.
12. На данном этапе происходит удаление всех созданных в процессе выполнения задачи объектов Openshift.
#### Всё вместе:
#### Преимущества и недостатки тестирования в контейнерах:
Недостатки:
1. Только Linux. Развивается так называемая ["легкая" виртуализация](https://clearlinux.org/features/intel%C2%AE-clear-containers) и стоит, наверное, ожидать [изменений в ситуациии](https://coreos.com/rkt/docs/latest/running-kvm-stage1.html), но пока только Linux.
2. Единая версия ядра для всех контейнеров. Возможно в п.1
3. Только x86\_64. Нет, безусловно, ваш образ может быть x86, но ядро будет x86\_64. Для кого-то это может стать препятствием.
4. Отсутствие вложенного SELinux ([вложенные CGroups существуют](https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt)).
5. Отсутствие полноценного видеоустройства и доступа к экрану. Возможно в п.1
Плюсы:
1. Скорость работы и гибкость запускаемых окружений, высокая плотность.
2. Унифицированный способ доставки, переносимости и повторяемости приложений.
#### Заключение:
Openshift Origin в связке с другими инструментами позволяет добиться впечатляющей гибкости и эффективности. Продуманная схема именования проектов/объектов позволяет избежать возникновения ошибок при массовых запусках задач тестирования.
#### Благодарность:
Хочу выразить благодарность сотрудникам компании Google за то, что сделали такую замечательную платформу.
Хочу выразить благодарность сотрудникам компании Red Hat, которые сделали из замечательной платформы законченный продукт.
#### Полезные ссылки:
1. [Minikube — быстрый способ познакомиться с Kubernetes](https://github.com/kubernetes/minikube)
2. [Minishift — быстрый способ познакомиться с Openshift](https://github.com/minishift/minishift)
3. [Почему для встроенного регистра используется IP-адрес вместо FQDN](https://github.com/openshift/origin/issues/6283) | https://habr.com/ru/post/333014/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.